
modelId
stringlengths 4
112
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 21
values | files
list | publishedBy
stringlengths 2
37
| downloads_last_month
int32 0
9.44M
| library
stringclasses 15
values | modelCard
large_stringlengths 0
100k
|
|---|---|---|---|---|---|---|---|---|
Salesforce/grappa_large_jnt | 2021-05-20T12:23:41.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"vocab.json"
]
| Salesforce | 5,537 | transformers | |
Salesforce/qaconv-bert-large-uncased-whole-word-masking-squad2 | 2021-05-27T19:15:05.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.txt"
]
| Salesforce | 37 | transformers | |
Salesforce/qaconv-roberta-large-squad2 | 2021-05-27T22:43:40.000Z | [
"pytorch",
"roberta",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| Salesforce | 26 | transformers | |
Salesforce/qaconv-unifiedqa-t5-3b | 2021-05-27T00:08:32.000Z | [
"pytorch",
"tf",
"t5",
"seq2seq",
"transformers",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"spiece.model",
"tf_model.h5",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin"
]
| Salesforce | 15 | transformers | |
Salesforce/qaconv-unifiedqa-t5-base | 2021-05-26T23:31:26.000Z | [
"pytorch",
"tf",
"t5",
"seq2seq",
"transformers",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"spiece.model",
"tf_model.h5",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin"
]
| Salesforce | 61 | transformers | |
Salesforce/qaconv-unifiedqa-t5-large | 2021-05-26T23:43:49.000Z | [
"pytorch",
"tf",
"t5",
"seq2seq",
"transformers",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"spiece.model",
"tf_model.h5",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin"
]
| Salesforce | 16 | transformers | |
SalmanMo/ALBERT_QA_1e | 2020-08-04T14:44:32.000Z | [
"pytorch",
"albert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"spiece.model",
"tokenizer_config.json"
]
| SalmanMo | 23 | transformers | |
Samsun121/model_name | 2021-01-29T14:24:10.000Z | []
| [
".gitattributes"
]
| Samsun121 | 0 | |||
SanayCo/model_output | 2021-05-18T22:31:51.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"nbest_predictions_.json",
"predictions_.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| SanayCo | 22 | transformers | |
Sandalfon/hugging_first_try | 2021-01-21T13:53:29.000Z | []
| [
".gitattributes"
]
| Sandalfon | 0 | |||
Sara/nlp | 2021-03-01T17:48:50.000Z | []
| [
".gitattributes"
]
| Sara | 0 | |||
Sarmad/d_base_qa | 2021-05-02T16:04:19.000Z | []
| [
".gitattributes",
"check"
]
| Sarmad | 0 | |||
Sarmad/emotion_all | 2021-03-26T10:24:26.000Z | []
| [
".gitattributes"
]
| Sarmad | 0 | |||
Sarmad/model1 | 2021-03-26T06:22:31.000Z | []
| [
".gitattributes"
]
| Sarmad | 0 | |||
Sarmad/model_all | 2021-03-26T07:09:35.000Z | []
| [
".gitattributes"
]
| Sarmad | 0 | |||
Sarmad/model_emotion_all | 2021-03-26T07:24:19.000Z | []
| [
".gitattributes"
]
| Sarmad | 0 | |||
Sarmad/projectmodel-bert | 2021-05-30T11:14:17.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| Sarmad | 17 | transformers | |
Sarmad/projectmodel | 2021-05-02T16:18:50.000Z | []
| [
".gitattributes"
]
| Sarmad | 0 | |||
Sarmad/your-model-name | 2021-03-26T20:01:59.000Z | []
| [
".gitattributes"
]
| Sarmad | 0 | |||
SaulLu/Test | 2021-05-17T16:52:00.000Z | []
| [
".gitattributes",
"tokenizer.json"
]
| SaulLu | 0 | |||
SaulLu/albert-bn-dev | 2021-04-25T09:27:39.000Z | [
"bn",
"dataset:oscar",
"dataset:wikipedia",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"special_tokens_map.json",
"spiece.model",
"tokenizer_config.json"
]
| SaulLu | 0 | ---
language:
- bn
thumbnail:
tags:
-
license: apache-2.0
datasets:
- oscar
- wikipedia
metrics:
-
---
# [WIP] Albert Bengali - dev version
## Model description
For the moment, only the tokenizer is available. The tokenizer is based on [SentencePiece](https://github.com/google/sentencepiece) with Unigram language model segmentation algorithm.
Taking into account certain characteristics of the language, we chose that:
- the tokenizer passes in lower case all the texts because the Bengali language is a monocameral scrip (no difference between capital and lower case);
- the sentence pieces can't go beyond the boundary of a word because the words are spaced by white spaces in the Bengali language.
## Intended uses & limitations
This tokenizer is adapted to the Bengali language. You can use it to pre-train an Albert model on the Bengali language.
#### How to use
To tokenize:
```python
from transformers import AlbertTokenizer
tokenizer = AlbertTokenizer.from_pretrained('SaulLu/albert-bn-dev')
text = "পোকেমন জাপানী ভিডিও গেম কোম্পানি নিনটেন্ডো কর্তৃক প্রকাশিত একটি মিডিয়া ফ্র্যাঞ্চাইজি।"
encoded_input = tokenizer(text, return_tensors='pt')
```
#### Limitations and bias
Provide examples of latent issues and potential remediations.
## Training data
The tokenizer was trained on a random subset of 4M sentences of Bengali Oscar and Bengali Wikipedia.
## Training procedure
### Tokenizer
The tokenizer was trained with the [SentencePiece](https://github.com/google/sentencepiece) on 8 x Intel(R) Core(TM) i7-10510U CPU @ 1.80GHz with 16GB RAM and 36GB SWAP.
```
import sentencepiece as spm
config = {
"input": "./dataset/oscar_bn.txt,./dataset/wikipedia_bn.txt",
"input_format": "text",
"model_type": "unigram",
"vocab_size": 32000,
"self_test_sample_size": 0,
"character_coverage": 0.9995,
"shuffle_input_sentence": true,
"seed_sentencepiece_size": 1000000,
"shrinking_factor": 0.75,
"num_threads": 8,
"num_sub_iterations": 2,
"max_sentencepiece_length": 16,
"max_sentence_length": 4192,
"split_by_unicode_script": true,
"split_by_number": true,
"split_digits": true,
"control_symbols": "[MASK]",
"byte_fallback": false,
"vocabulary_output_piece_score": true,
"normalization_rule_name": "nmt_nfkc_cf",
"add_dummy_prefix": true,
"remove_extra_whitespaces": true,
"hard_vocab_limit": true,
"unk_id": 1,
"bos_id": 2,
"eos_id": 3,
"pad_id": 0,
"bos_piece": "[CLS]",
"eos_piece": "[SEP]",
"train_extremely_large_corpus": true,
"split_by_whitespace": true,
"model_prefix": "./spiece",
"input_sentence_size": 4000000,
"user_defined_symbols": "(,),-,.,–,£,।",
}
spm.SentencePieceTrainer.train(**config)
```
<!-- ## Eval results
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020}
}
``` -->
|
||
SaulLu/bengali-tokenizer-v2 | 2021-05-20T15:06:39.000Z | []
| [
".gitattributes",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
]
| SaulLu | 0 | |||
SaulLu/bengali-tokenizer-v3 | 2021-05-19T17:04:29.000Z | []
| [
".gitattributes",
"tokenizer.json",
"tokenizer_config.json"
]
| SaulLu | 0 | |||
SaulLu/bengali-tokenizer | 2021-05-11T12:46:22.000Z | []
| [
".gitattributes",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
]
| SaulLu | 0 | |||
SaulLu/recreate-history | 2021-05-28T16:37:37.000Z | [
"pytorch",
"albert",
"token-classification",
"bn",
"dataset:xtreme",
"transformers",
"collaborative",
"bengali",
"NER",
"license:apache-2.0"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json"
]
| SaulLu | 42 | transformers |
---
language: bn
tags:
- collaborative
- bengali
- NER
license: apache-2.0
datasets: xtreme
metrics:
- Loss
- Accuracy
- Precision
- Recall
---
# sahajBERT Named Entity Recognition
## Model description
[sahajBERT](https://huggingface.co/neuropark/sahajBERT-NER) fine-tuned for NER using the bengali split of [WikiANN ](https://huggingface.co/datasets/wikiann).
Named Entities predicted by the model:
| Label id | Label |
|:--------:|:----:|
|0 |O|
|1 |B-PER|
|2 |I-PER|
|3 |B-ORG|
|4 |I-ORG|
|5 |B-LOC|
|6 |I-LOC|
## Intended uses & limitations
#### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
from transformers import AlbertForTokenClassification, TokenClassificationPipeline, PreTrainedTokenizerFast
# Initialize tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NER")
# Initialize model
model = AlbertForTokenClassification.from_pretrained("neuropark/sahajBERT-NER")
# Initialize pipeline
pipeline = TokenClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # Change me
output = pipeline(raw_text)
```
#### Limitations and bias
<!-- Provide examples of latent issues and potential remediations. -->
WIP
## Training data
The model was initialized it with pre-trained weights of [sahajBERT](https://huggingface.co/neuropark/sahajBERT-NER) at step 19519 and trained on the bengali of [WikiANN ](https://huggingface.co/datasets/wikiann)
## Training procedure
Coming soon!
<!-- ```bibtex
@inproceedings{...,
year={2020}
}
``` -->
## Eval results
loss: 0.11714419722557068
accuracy: 0.9772286821705426
precision: 0.9585365853658536
recall: 0.9651277013752456
f1 : 0.9618208516886931
### BibTeX entry and citation info
Coming soon!
<!-- ```bibtex
@inproceedings{...,
year={2020}
}
``` -->
|
SaulLu/test-model | 2021-05-28T12:28:31.000Z | [
"pytorch",
"albert",
"pretraining",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| SaulLu | 11 | transformers | ---
language:
-
-
thumbnail:
tags:
-
-
-
license:
datasets:
-
-
metrics:
-
-
---
# sahajBERT News Category Classification
## Model description
You can embed local or remote images using ``
## Intended uses & limitations
#### How to use
```python
# You can include sample code which will be formatted
```
#### Limitations and bias
Provide examples of latent issues and potential remediations.
## Training data
Describe the data you used to train the model.
If you initialized it with pre-trained weights, add a link to the pre-trained model card or repository with description of the pre-training data.
## Training procedure
### Collaborative training procedure
[here](https://huggingface.co/albertvillanova)
###
Preprocessing, hardware used, hyperparameters...
## Eval results
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020}
}
``` |
|
Scoops/SandalBot | 2021-06-04T01:12:20.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"conversational",
"text-generation"
]
| conversational | [
".gitattributes",
"README.md",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| Scoops | 115 | transformers | ---
tags:
- conversational
---
# Sandal Bot
Quick and dumb model for a discord chat bot. Based on DialoGPT-Medium |
ScottaStrong/DialogGPT-medium-Scott | 2021-06-17T03:59:06.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"conversational",
"license:mit",
"text-generation"
]
| conversational | [
".gitattributes",
"README.md",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| ScottaStrong | 19 | transformers | |
ScottaStrong/DialogGPT-medium-joshua | 2021-06-17T00:25:33.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"conversational",
"license:mit",
"text-generation"
]
| conversational | [
".gitattributes",
"README.md",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| ScottaStrong | 39 | transformers | |
ScottaStrong/DialogGPT-small-Scott | 2021-06-17T04:11:39.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"conversational",
"license:mit",
"text-generation"
]
| conversational | [
".gitattributes",
"README.md",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| ScottaStrong | 13 | transformers | |
ScottaStrong/DialogGPT-small-joshua | 2021-06-16T21:40:45.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"conversational",
"license:mit",
"text-generation"
]
| conversational | [
".gitattributes",
"HuggingFace-API-key.txt",
"README.md",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| ScottaStrong | 47 | transformers | |
Scrya/Wav2Vec2 | 2021-02-17T14:49:31.000Z | []
| [
".gitattributes",
"README.md"
]
| Scrya | 0 | Wav2Vec2 Model |
||
Semih/wav2vec2_Irish_Large | 2021-04-06T05:51:54.000Z | [
"pytorch",
"wav2vec2",
"ga-IE",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"optimizer-002.pt",
"preprocessor_config.json",
"pytorch_model.bin",
"scheduler.pt",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| Semih | 9 | transformers | ---
language: ga-IE
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Irish by Semih GULUM
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice gle
type: common_voice
args: ga-IE
metrics:
- name: Test WER
type: wer
---
# wav2vec2-irish-lite Speech to Text
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ga-IE", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("Semih/wav2vec2_Irish_Large")
model = Wav2Vec2ForCTC.from_pretrained("Semih/wav2vec2_Irish_Large")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
```
Test Result: 55.11 |
Senthil/Test | 2021-02-20T08:02:44.000Z | []
| [
".gitattributes"
]
| Senthil | 0 | |||
Sergey222/Aaa | 2021-02-05T18:00:06.000Z | []
| [
".gitattributes"
]
| Sergey222 | 0 | |||
Shah92/dspd-assignment-1 | 2021-03-16T21:22:32.000Z | []
| [
".gitattributes"
]
| Shah92 | 0 | |||
Shappey/roberta-base-QnA-squad2-trained | 2021-05-30T23:31:02.000Z | [
"pytorch",
"roberta",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| Shappey | 37 | transformers | |
Shauli/IE-metric-model-spike | 2021-05-18T22:33:59.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"flax_model.msgpack",
"linear.pt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| Shauli | 8 | transformers | ||
Shauli/RE-metric-model-siamese-spike | 2021-05-18T22:34:51.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"flax_model.msgpack",
"linear1.pt",
"linear2.pt",
"linear_rel_clf.pt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| Shauli | 8 | transformers | ||
Shauli/RE-metric-model-spike | 2021-05-18T22:36:05.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"flax_model.msgpack",
"linear.pt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| Shauli | 446 | transformers | ||
Shay77/Mine | 2021-04-06T10:22:57.000Z | []
| [
".gitattributes"
]
| Shay77 | 0 | |||
Shaya/POS_pretraining | 2021-01-09T16:06:01.000Z | []
| [
".gitattributes"
]
| Shaya | 0 | |||
ShenSeanchen/NLP | 2020-12-29T15:59:49.000Z | []
| [
".gitattributes",
"README.md"
]
| ShenSeanchen | 0 | This is a repo with gather thoughts and experiments on the state-of-the-art techniques in NLP. |
||
Shivaraj/ner | 2020-12-04T12:45:43.000Z | []
| [
".gitattributes"
]
| Shivaraj | 0 | |||
Shreesha/DialoGPT | 2021-06-14T02:55:56.000Z | []
| [
".gitattributes"
]
| Shreesha | 0 | |||
Shreesha/Discord-AI | 2021-06-12T15:47:08.000Z | []
| [
".gitattributes"
]
| Shreesha | 0 | |||
Shuvam/autonlp-college_classification-164469 | 2021-05-18T22:37:16.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"dataset:Shuvam/autonlp-data-college_classification",
"transformers",
"autonlp"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"sample_input.pkl",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| Shuvam | 13 | transformers | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- Shuvam/autonlp-data-college_classification
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 164469
## Validation Metrics
- Loss: 0.05527503043413162
- Accuracy: 0.9853049228508449
- Precision: 0.991044776119403
- Recall: 0.9793510324483776
- AUC: 0.9966895139869654
- F1: 0.9851632047477745
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/Shuvam/autonlp-college_classification-164469
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("Shuvam/autonlp-college_classification-164469", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Shuvam/autonlp-college_classification-164469", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
Sid51/CB | 2021-06-12T17:36:59.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| Sid51 | 9 | transformers | |
Sid51/Chan | 2021-06-10T20:30:33.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| Sid51 | 9 | transformers | |
Sid51/ChanBot | 2021-06-12T17:02:03.000Z | [
"pytorch",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| Sid51 | 5 | transformers | |
Sierra1669/DialoGPT-medium-Alice | 2021-06-06T00:44:54.000Z | []
| [
".gitattributes"
]
| Sierra1669 | 0 | |||
Sina/Persian-Digital-sentiments | 2021-03-05T11:27:55.000Z | []
| [
".gitattributes"
]
| Sina | 0 | |||
SkimBeeble41/user_sentiment | 2021-03-08T18:03:22.000Z | []
| [
".gitattributes"
]
| SkimBeeble41 | 0 | |||
Skoltech/russian-inappropriate-messages | 2021-05-18T22:39:46.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"ru",
"transformers",
"toxic comments classification"
]
| text-classification | [
".gitattributes",
"README.md",
"classifier_all_en.jpg",
"classifier_scheme_with_comments.jpg",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| Skoltech | 1,144 | transformers | ---
language:
- ru
tags:
- toxic comments classification
licenses:
- cc-by-nc-sa
---
## General concept of the model
#### Proposed usage
The **'inappropriateness'** substance we tried to collect in the dataset and detect with the model **is NOT a substitution of toxicity**, it is rather a derivative of toxicity. So the model based on our dataset could serve as **an additional layer of inappropriateness filtering after toxicity and obscenity filtration**. You can detect the exact sensitive topic by using [another model](https://huggingface.co/Skoltech/russian-sensitive-topics). The proposed pipeline is shown in the scheme below.
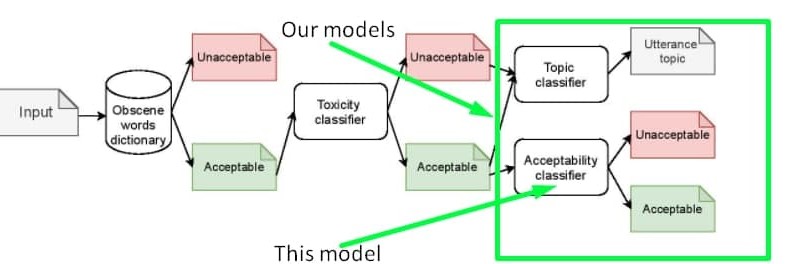
You can also train one classifier for both toxicity and inappropriateness detection. The data to be mixed with toxic labelled samples could be found on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages)
#### Inappropraiteness intuition
This model is trained on the dataset of inappropriate messages of the Russian language. Generally, an inappropriate utterance is an utterance that has not obscene words or any kind of toxic intent, but can still harm the reputation of the speaker. Find some sample for more intuition in the table below. Learn more about the concept of inappropriateness [in this article ](https://www.aclweb.org/anthology/2021.bsnlp-1.4/) presented at the workshop for Balto-Slavic NLP at the EACL-2021 conference. Please note that this article describes the first version of the dataset, while the model is trained on the extended version of the dataset open-sourced on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages). The properties of the dataset are the same as the one described in the article, the only difference is the size.
| Text | Inappropriate | Comment | Unsafe topic |
|------------------------------------------------------------------------------------------------------|---------------|----------------------------------------------------------------|---------------|
| Ладно бы видного деятеля завалили а тут какого то ноунейм нигру преступника | yes | Оправдание убийства | offline crime |
| Это нарушение УКРФ! | no | Осуждение нарушения закона | offline crime |
| Религия - это насилие высшего уровня. Верующего принуждают к вере еще в младенчестве. | yes | Оскорбление чувств верующих | religion |
| Христиане, как вы относитесь к иноверцам, в частности к Гамалиилу и к уверовавшим в Иисуса фарисеям? | no | Обычные вопросы к верующим без намека на оскорбление их чувств | religion |
| Хорошо что проституция запрещена | no | Осуждение простуитуции | prostitution |
| Возьму бабки и сниму шлюх на выходных | yes | Популяризация проституции | prostitution |
#### Metrics
The model was trained, validated, and tested only on the samples with 100% confidence, which allowed to get the following metrics on test set:
| | precision | recall | f1-score | support |
|--------------|----------|--------|----------|---------|
| 0 | 0.92 | 0.93 | 0.93 | 7839 |
| 1 | 0.80 | 0.76 | 0.78 | 2726 |
| accuracy | | | 0.89 | 10565 |
| macro avg | 0.86 | 0.85 | 0.85 | 10565 |
| weighted avg | 0.89 | 0.89 | 0.89 | 10565 |
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@inproceedings{babakov-etal-2021-detecting,
title = "Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company{'}s Reputation",
author = "Babakov, Nikolay and
Logacheva, Varvara and
Kozlova, Olga and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.4",
pages = "26--36",
abstract = "Not all topics are equally {``}flammable{''} in terms of toxicity: a calm discussion of turtles or fishing less often fuels inappropriate toxic dialogues than a discussion of politics or sexual minorities. We define a set of sensitive topics that can yield inappropriate and toxic messages and describe the methodology of collecting and labelling a dataset for appropriateness. While toxicity in user-generated data is well-studied, we aim at defining a more fine-grained notion of inappropriateness. The core of inappropriateness is that it can harm the reputation of a speaker. This is different from toxicity in two respects: (i) inappropriateness is topic-related, and (ii) inappropriate message is not toxic but still unacceptable. We collect and release two datasets for Russian: a topic-labelled dataset and an appropriateness-labelled dataset. We also release pre-trained classification models trained on this data.",
}
```
## Contacts
If you have any questions please contact [Nikolay](mailto:[email protected]) |
Skoltech/russian-sensitive-topics | 2021-05-18T22:41:20.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"ru",
"arxiv:2103.05345",
"transformers",
"toxic comments classification"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| Skoltech | 188 | transformers | ---
language:
- ru
tags:
- toxic comments classification
licenses:
- cc-by-nc-sa
---
## General concept of the model
This model is trained on the dataset of sensitive topics of the Russian language. The concept of sensitive topics is described [in this article ](https://www.aclweb.org/anthology/2021.bsnlp-1.4/) presented at the workshop for Balto-Slavic NLP at the EACL-2021 conference. Please note that this article describes the first version of the dataset, while the model is trained on the extended version of the dataset open-sourced on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/sensitive_topics/sensitive_topics.csv) or on [kaggle](https://www.kaggle.com/nigula/russian-sensitive-topics). The properties of the dataset is the same as the one described in the article, the only difference is the size.
## Instructions
The model predicts combinations of 18 sensitive topics described in the [article](https://arxiv.org/abs/2103.05345). You can find step-by-step instructions for using the model [here](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/sensitive_topics/Inference.ipynb)
## Metrics
The dataset partially manually labeled samples and partially semi-automatically labeled samples. Learn more in our article. We tested the performance of the classifier only on the part of manually labeled data that is why some topics are not well represented in the test set.
| | precision | recall | f1-score | support |
|-------------------|-----------|--------|----------|---------|
| offline_crime | 0.65 | 0.55 | 0.6 | 132 |
| online_crime | 0.5 | 0.46 | 0.48 | 37 |
| drugs | 0.87 | 0.9 | 0.88 | 87 |
| gambling | 0.5 | 0.67 | 0.57 | 6 |
| pornography | 0.73 | 0.59 | 0.65 | 204 |
| prostitution | 0.75 | 0.69 | 0.72 | 91 |
| slavery | 0.72 | 0.72 | 0.73 | 40 |
| suicide | 0.33 | 0.29 | 0.31 | 7 |
| terrorism | 0.68 | 0.57 | 0.62 | 47 |
| weapons | 0.89 | 0.83 | 0.86 | 138 |
| body_shaming | 0.9 | 0.67 | 0.77 | 109 |
| health_shaming | 0.84 | 0.55 | 0.66 | 108 |
| politics | 0.68 | 0.54 | 0.6 | 241 |
| racism | 0.81 | 0.59 | 0.68 | 204 |
| religion | 0.94 | 0.72 | 0.81 | 102 |
| sexual_minorities | 0.69 | 0.46 | 0.55 | 102 |
| sexism | 0.66 | 0.64 | 0.65 | 132 |
| social_injustice | 0.56 | 0.37 | 0.45 | 181 |
| none | 0.62 | 0.67 | 0.64 | 250 |
| micro avg | 0.72 | 0.61 | 0.66 | 2218 |
| macro avg | 0.7 | 0.6 | 0.64 | 2218 |
| weighted avg | 0.73 | 0.61 | 0.66 | 2218 |
| samples avg | 0.75 | 0.66 | 0.68 | 2218 |
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@inproceedings{babakov-etal-2021-detecting,
title = "Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company{'}s Reputation",
author = "Babakov, Nikolay and
Logacheva, Varvara and
Kozlova, Olga and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.4",
pages = "26--36",
abstract = "Not all topics are equally {``}flammable{''} in terms of toxicity: a calm discussion of turtles or fishing less often fuels inappropriate toxic dialogues than a discussion of politics or sexual minorities. We define a set of sensitive topics that can yield inappropriate and toxic messages and describe the methodology of collecting and labelling a dataset for appropriateness. While toxicity in user-generated data is well-studied, we aim at defining a more fine-grained notion of inappropriateness. The core of inappropriateness is that it can harm the reputation of a speaker. This is different from toxicity in two respects: (i) inappropriateness is topic-related, and (ii) inappropriate message is not toxic but still unacceptable. We collect and release two datasets for Russian: a topic-labelled dataset and an appropriateness-labelled dataset. We also release pre-trained classification models trained on this data.",
}
``` |
Sober/test | 2021-04-15T01:35:04.000Z | []
| [
".gitattributes"
]
| Sober | 0 | |||
Sora/Haechan | 2021-03-07T19:15:29.000Z | []
| [
".gitattributes"
]
| Sora | 0 | |||
SpanBERT/spanbert-base-cased | 2021-05-19T11:30:27.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"vocab.txt"
]
| SpanBERT | 42,194 | transformers | ||
SpanBERT/spanbert-large-cased | 2021-05-19T11:31:33.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"vocab.txt"
]
| SpanBERT | 31,522 | transformers | ||
SparkBeyond/roberta-large-sts-b | 2021-05-20T12:26:47.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json"
]
| SparkBeyond | 155 | transformers |
# Roberta Large STS-B
This model is a fine tuned RoBERTA model over STS-B.
It was trained with these params:
!python /content/transformers/examples/text-classification/run_glue.py \
--model_type roberta \
--model_name_or_path roberta-large \
--task_name STS-B \
--do_train \
--do_eval \
--do_lower_case \
--data_dir /content/glue_data/STS-B/ \
--max_seq_length 128 \
--per_gpu_eval_batch_size=8 \
--per_gpu_train_batch_size=8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir /content/roberta-sts-b
## How to run
```python
import toolz
import torch
batch_size = 6
def roberta_similarity_batches(to_predict):
batches = toolz.partition(batch_size, to_predict)
similarity_scores = []
for batch in batches:
sentences = [(sentence_similarity["sent1"], sentence_similarity["sent2"]) for sentence_similarity in batch]
batch_scores = similarity_roberta(model, tokenizer,sentences)
similarity_scores = similarity_scores + batch_scores[0].cpu().squeeze(axis=1).tolist()
return similarity_scores
def similarity_roberta(model, tokenizer, sent_pairs):
batch_token = tokenizer(sent_pairs, padding='max_length', truncation=True, max_length=500)
res = model(torch.tensor(batch_token['input_ids']).cuda(), attention_mask=torch.tensor(batch_token["attention_mask"]).cuda())
return res
similarity_roberta(model, tokenizer, [('NEW YORK--(BUSINESS WIRE)--Rosen Law Firm, a global investor rights law firm, announces it is investigating potential securities claims on behalf of shareholders of Vale S.A. ( VALE ) resulting from allegations that Vale may have issued materially misleading business information to the investing public',
'EQUITY ALERT: Rosen Law Firm Announces Investigation of Securities Claims Against Vale S.A. – VALE')])
```
|
Srulikbdd/Wav2Vec2-large-xlsr-welsh | 2021-03-29T19:09:41.000Z | [
"pytorch",
"wav2vec2",
"sv",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json"
]
| Srulikbdd | 18 | transformers | ---
language: sv
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Welsh by Srulik Ben David
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice cy
type: common_voice
args: cy
metrics:
- name: Test WER
type: wer
value: 29.4
---
Wav2Vec2-Large-XLSR-Welsh
Fine-tuned facebook/wav2vec2-large-xlsr-53 on the Welsh Common Voice dataset.
The data was augmented using standard augmentation approach.
When using this model, make sure that your speech input is sampled at 16kHz.
Test Result: 29.4%
Usage
The model can be used directly (without a language model) as follows:
```
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "cy", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("Srulikbdd/Wav2vec2-large-xlsr-welsh")
model = Wav2Vec2ForCTC.from_pretrained("Srulikbdd/Wav2vec2-large-xlsr-welsh")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
Evaluation
The model can be evaluated as follows on the Welsh test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "cy", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("Srulikbdd/Wav2Vec2-large-xlsr-welsh")
model = Wav2Vec2ForCTC.from_pretrained("Srulikbdd/Wav2Vec2-large-xlsr-welsh")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\?\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\.\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\!\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\-\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\u2013\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\u2014\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\;\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\:\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\%\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
``` |
SteveMama/pegasus-samsum | 2021-03-08T08:27:14.000Z | []
| [
".gitattributes"
]
| SteveMama | 0 | |||
StevenLimcorn/MelayuBERT | 2021-06-10T05:28:20.000Z | [
"pytorch",
"tf",
"bert",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| StevenLimcorn | 9 | transformers | |
StevenShoemakerNLP/pitchfork | 2021-05-21T11:15:10.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json"
]
| StevenShoemakerNLP | 8 | transformers | |
Storm-Breaker/NER-Test | 2020-12-16T02:57:56.000Z | []
| [
".gitattributes"
]
| Storm-Breaker | 0 | |||
Stu/bert | 2021-03-04T08:10:26.000Z | []
| [
".gitattributes"
]
| Stu | 0 | |||
Stu/model_name | 2021-03-04T08:10:08.000Z | []
| [
".gitattributes"
]
| Stu | 0 | |||
Suhan/indic-bert-v2 | 2021-04-05T15:51:14.000Z | []
| [
".gitattributes"
]
| Suhan | 0 | |||
Suhanshu/Movie-plot-generator | 2021-05-01T06:18:27.000Z | []
| [
".gitattributes"
]
| Suhanshu | 0 | |||
Sunbird/sunbert | 2021-02-08T05:14:29.000Z | []
| [
".gitattributes",
"README.md"
]
| Sunbird | 0 | ## SunBERT
Sunbert is a variant of bert trained on Ugandan text data for the tasks of ``Covid/Non Covid`` tweet classification as well as classification of Social Media news articles as either ``Organic, Promotional or Editorial``
Information has become more abundant with the internet. Specifically, people communicate in natural language over social media. Machine learning offers a good way to analyze natural language. We utilized methods from deep learning to analyze text from social media. We build models based on deep learning architectures - Bidirectional Encoder Representations from Transformers (BERT) to perform two downstream tasks:
1. Analyze posts from social media as promotional, editorial or Organic and
2. To identify tweets as either covid19 related or not. Both tasks show the ability of machine learning to be used to analyze large data and be used to support decision making.
We open source the dataset and source code of our model called SunBERT so that other people can utilize these techniques to their needs.
## Datasets:
We use data from Twitter and Facebook. The dataset contained tweets and posts from both social networks collected through CrowdTangle - a tool from facebook to help follow, analyze and report on what’s happening across social media.
## Models:
BERT (Bidirectional Encoder Representations from Transformers is a deep learning model published by researchers at Google AI. It presented state of the art performance in different Natural Language Processing tasks including Question Answering, Text Classification and Language Modelling. The key technical innovation is that BERT applies a bidirectional training of the Transformer - a popular Attention-based model to language processing.
## Use Cases:
We have shown the application of SunBERT to three use cases, Covid19 classification, News Classification and Language adaptation for Machine Learning research and development. However, SunBERT can be extended to perform other tasks; these include; Question Answering, Masked Language Modelling, Next Sentence Prediction.
Our code and datasets can be used as a starting point for any of these tasks, with minor modification to the model architecture.
|
||
SuperApril12/TEST | 2021-03-18T09:53:52.000Z | []
| [
".gitattributes"
]
| SuperApril12 | 0 | |||
SuperApril12/hello | 2021-03-18T09:51:02.000Z | []
| [
".gitattributes"
]
| SuperApril12 | 0 | |||
SuryA708/Eye-lid | 2021-05-25T22:50:31.000Z | []
| [
".gitattributes"
]
| SuryA708 | 0 | |||
T-Systems-onsite/bert-german-dbmdz-uncased-sentence-stsb | 2021-05-18T22:43:16.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"de",
"transformers",
"license:mit"
]
| [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"sentence_bert_config.json",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| T-Systems-onsite | 28 | transformers | ---
language: de
license: mit
---
# bert-german-dbmdz-uncased-sentence-stsb
**This model is outdated!**
The new [T-Systems-onsite/cross-en-de-roberta-sentence-transformer](https://huggingface.co/T-Systems-onsite/cross-en-de-roberta-sentence-transformer) model is better for German language. It is also the current best model for English language and works cross-lingually. Please consider using that model. |
|
T-Systems-onsite/cross-de-es-roberta-sentence-transformer | 2021-04-06T05:37:15.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 8 | transformers | ||
T-Systems-onsite/cross-de-fr-roberta-sentence-transformer | 2021-04-06T05:52:32.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 8 | transformers | ||
T-Systems-onsite/cross-de-it-roberta-sentence-transformer | 2021-04-06T06:06:02.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 9 | transformers | ||
T-Systems-onsite/cross-de-nl-roberta-sentence-transformer | 2021-04-06T06:23:39.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 8 | transformers | ||
T-Systems-onsite/cross-de-pl-roberta-sentence-transformer | 2021-04-06T06:38:22.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 9 | transformers | ||
T-Systems-onsite/cross-de-pt-roberta-sentence-transformer | 2021-04-06T07:08:02.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 6 | transformers | ||
T-Systems-onsite/cross-de-ru-roberta-sentence-transformer | 2021-04-06T07:24:44.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 12 | transformers | ||
T-Systems-onsite/cross-de-zh-roberta-sentence-transformer | 2021-04-06T11:09:56.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 7 | transformers | ||
T-Systems-onsite/cross-en-de-es-roberta-sentence-transformer | 2020-12-30T06:14:24.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 9 | transformers | ||
T-Systems-onsite/cross-en-de-fr-roberta-sentence-transformer | 2020-12-30T06:27:04.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 7 | transformers | ||
T-Systems-onsite/cross-en-de-it-roberta-sentence-transformer | 2020-12-30T06:39:57.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 10 | transformers | ||
T-Systems-onsite/cross-en-de-nl-roberta-sentence-transformer | 2020-12-30T07:03:00.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 10 | transformers | ||
T-Systems-onsite/cross-en-de-pl-roberta-sentence-transformer | 2020-12-29T06:50:44.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 8 | transformers | ||
T-Systems-onsite/cross-en-de-pt-roberta-sentence-transformer | 2021-01-01T08:48:16.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 10 | transformers | ||
T-Systems-onsite/cross-en-de-roberta-sentence-transformer | 2021-05-20T12:28:59.000Z | [
"pytorch",
"xlm-roberta",
"de",
"en",
"dataset:STSbenchmark",
"arxiv:1908.10084",
"transformers",
"license:mit",
"sentence_embedding",
"search",
"roberta",
"xlm-r-distilroberta-base-paraphrase-v1",
"paraphrase"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 3,635 | transformers | ---
language:
- de
- en
license: mit
tags:
- sentence_embedding
- search
- pytorch
- xlm-roberta
- roberta
- xlm-r-distilroberta-base-paraphrase-v1
- paraphrase
datasets:
- STSbenchmark
metrics:
- Spearman’s rank correlation
- cosine similarity
---
# Cross English & German RoBERTa for Sentence Embeddings
This model is intended to [compute sentence (text) embeddings](https://www.sbert.net/examples/applications/computing-embeddings/README.html) for English and German text. These embeddings can then be compared with [cosine-similarity](https://en.wikipedia.org/wiki/Cosine_similarity) to find sentences with a similar semantic meaning. For example this can be useful for [semantic textual similarity](https://www.sbert.net/docs/usage/semantic_textual_similarity.html), [semantic search](https://www.sbert.net/docs/usage/semantic_search.html), or [paraphrase mining](https://www.sbert.net/docs/usage/paraphrase_mining.html). To do this you have to use the [Sentence Transformers Python framework](https://github.com/UKPLab/sentence-transformers).
The speciality of this model is that it also works cross-lingually. Regardless of the language, the sentences are translated into very similar vectors according to their semantics. This means that you can, for example, enter a search in German and find results according to the semantics in German and also in English. Using a xlm model and _multilingual finetuning with language-crossing_ we reach performance that even exceeds the best current dedicated English large model (see Evaluation section below).
> Sentence-BERT (SBERT) is a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair from 65hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
Source: [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084)
This model is fine-tuned from [Philip May](https://may.la/) and open-sourced by [T-Systems-onsite](https://www.t-systems-onsite.de/). Special thanks to [Nils Reimers](https://www.nils-reimers.de/) for your awesome open-source work, the Sentence Transformers, the models and your help on GitHub.
## How to use
To use this model install the `sentence-transformers` package (see here: <https://github.com/UKPLab/sentence-transformers>).
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('T-Systems-onsite/cross-en-de-roberta-sentence-transformer')
```
For details of usage and examples see here:
- [Computing Sentence Embeddings](https://www.sbert.net/docs/usage/computing_sentence_embeddings.html)
- [Semantic Textual Similarity](https://www.sbert.net/docs/usage/semantic_textual_similarity.html)
- [Paraphrase Mining](https://www.sbert.net/docs/usage/paraphrase_mining.html)
- [Semantic Search](https://www.sbert.net/docs/usage/semantic_search.html)
- [Cross-Encoders](https://www.sbert.net/docs/usage/cross-encoder.html)
- [Examples on GitHub](https://github.com/UKPLab/sentence-transformers/tree/master/examples)
## Training
The base model is [xlm-roberta-base](https://huggingface.co/xlm-roberta-base). This model has been further trained by [Nils Reimers](https://www.nils-reimers.de/) on a large scale paraphrase dataset for 50+ languages. [Nils Reimers](https://www.nils-reimers.de/) about this [on GitHub](https://github.com/UKPLab/sentence-transformers/issues/509#issuecomment-712243280):
>A paper is upcoming for the paraphrase models.
>
>These models were trained on various datasets with Millions of examples for paraphrases, mainly derived from Wikipedia edit logs, paraphrases mined from Wikipedia and SimpleWiki, paraphrases from news reports, AllNLI-entailment pairs with in-batch-negative loss etc.
>
>In internal tests, they perform much better than the NLI+STSb models as they have see more and broader type of training data. NLI+STSb has the issue that they are rather narrow in their domain and do not contain any domain specific words / sentences (like from chemistry, computer science, math etc.). The paraphrase models has seen plenty of sentences from various domains.
>
>More details with the setup, all the datasets, and a wider evaluation will follow soon.
The resulting model called `xlm-r-distilroberta-base-paraphrase-v1` has been released here: <https://github.com/UKPLab/sentence-transformers/releases/tag/v0.3.8>
Building on this cross language model we fine-tuned it for English and German language on the [STSbenchmark](http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark) dataset. For German language we used the dataset of our [German STSbenchmark dataset](https://github.com/t-systems-on-site-services-gmbh/german-STSbenchmark) which has been translated with [deepl.com](https://www.deepl.com/translator). Additionally to the German and English training samples we generated samples of English and German crossed. We call this _multilingual finetuning with language-crossing_. It doubled the traing-datasize and tests show that it further improves performance.
We did an automatic hyperparameter search for 33 trials with [Optuna](https://github.com/optuna/optuna). Using 10-fold crossvalidation on the deepl.com test and dev dataset we found the following best hyperparameters:
- batch_size = 8
- num_epochs = 2
- lr = 1.026343323298136e-05,
- eps = 4.462251033010287e-06
- weight_decay = 0.04794438776350409
- warmup_steps_proportion = 0.1609010732760181
The final model was trained with these hyperparameters on the combination of the train and dev datasets from English, German and the crossings of them. The testset was left for testing.
# Evaluation
The evaluation has been done on English, German and both languages crossed with the STSbenchmark test data. The evaluation-code is available on [Colab](https://colab.research.google.com/drive/1gtGnKq_dYU_sDYqMohTYVMVpxMJjyH0M?usp=sharing). As the metric for evaluation we use the Spearman’s rank correlation between the cosine-similarity of the sentence embeddings and STSbenchmark labels.
| Model Name | Spearman<br/>German | Spearman<br/>English | Spearman<br/>EN-DE & DE-EN<br/>(cross) |
|---------------------------------------------------------------|-------------------|--------------------|------------------|
| xlm-r-distilroberta-base-paraphrase-v1 | 0.8079 | 0.8350 | 0.7983 |
| [xlm-r-100langs-bert-base-nli-stsb-mean-tokens](https://huggingface.co/sentence-transformers/xlm-r-100langs-bert-base-nli-stsb-mean-tokens) | 0.7877 | 0.8465 | 0.7908 |
| xlm-r-bert-base-nli-stsb-mean-tokens | 0.7877 | 0.8465 | 0.7908 |
| [roberta-large-nli-stsb-mean-tokens](https://huggingface.co/sentence-transformers/roberta-large-nli-stsb-mean-tokens) | 0.6371 | 0.8639 | 0.4109 |
| [T-Systems-onsite/<br/>german-roberta-sentence-transformer-v2](https://huggingface.co/T-Systems-onsite/german-roberta-sentence-transformer-v2) | 0.8529 | 0.8634 | 0.8415 |
| **T-Systems-onsite/<br/>cross-en-de-roberta-sentence-transformer** | **0.8550** | **0.8660** | **0.8525** |
|
|
T-Systems-onsite/cross-en-de-ru-roberta-sentence-transformer | 2021-01-01T10:26:38.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 10 | transformers | ||
T-Systems-onsite/cross-en-es-pt-roberta-sentence-transformer | 2020-12-29T07:03:36.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 8 | transformers | ||
T-Systems-onsite/cross-en-es-roberta-sentence-transformer | 2021-04-06T15:11:30.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 7 | transformers | ||
T-Systems-onsite/cross-en-fr-it-roberta-sentence-transformer | 2020-12-29T07:16:54.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 9 | transformers | ||
T-Systems-onsite/cross-en-fr-roberta-sentence-transformer | 2021-04-06T15:56:53.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 6 | transformers | ||
T-Systems-onsite/cross-en-it-roberta-sentence-transformer | 2021-04-06T16:08:36.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 6 | transformers | ||
T-Systems-onsite/cross-en-nl-fr-roberta-sentence-transformer | 2021-01-01T16:26:52.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 9 | transformers | ||
T-Systems-onsite/cross-en-nl-it-roberta-sentence-transformer | 2021-01-02T08:49:58.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 9 | transformers | ||
T-Systems-onsite/cross-en-nl-roberta-sentence-transformer | 2021-04-06T16:19:50.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 6 | transformers | ||
T-Systems-onsite/cross-en-pl-it-roberta-sentence-transformer | 2020-12-29T07:30:25.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 10 | transformers | ||
T-Systems-onsite/cross-en-pl-roberta-sentence-transformer | 2021-04-06T17:30:36.000Z | [
"pytorch",
"xlm-roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"sentence_bert_config.json",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"test_results.json",
"tokenizer_config.json"
]
| T-Systems-onsite | 7 | transformers |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.