
Search is not available for this dataset
pipeline_tag
stringclasses 48
values | library_name
stringclasses 205
values | text
stringlengths 0
18.3M
| metadata
stringlengths 2
1.07B
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
|
|---|---|---|---|---|---|---|---|---|
text-to-speech
|
fairseq
|
# tts_transformer-fr-cv7_css10
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- French
- Single-speaker male voice
- Pre-trained on [Common Voice v7](https://commonvoice.mozilla.org/en/datasets), fine-tuned on [CSS10](https://github.com/Kyubyong/css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-fr-cv7_css10",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Bonjour, ceci est un test."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
{"language": "fr", "library_name": "fairseq", "tags": ["fairseq", "audio", "text-to-speech"], "datasets": ["common_voice", "css10"], "task": "text-to-speech", "widget": [{"text": "Bonjour, ceci est un test.", "example_title": "Hello, this is a test run."}]}
|
facebook/tts_transformer-fr-cv7_css10
| null |
[
"fairseq",
"audio",
"text-to-speech",
"fr",
"dataset:common_voice",
"dataset:css10",
"arxiv:1809.08895",
"arxiv:2109.06912",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-to-speech
|
fairseq
|
# tts_transformer-ru-cv7_css10
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- Russian
- Single-speaker male voice
- Pre-trained on [Common Voice v7](https://commonvoice.mozilla.org/en/datasets), fine-tuned on [CSS10](https://github.com/Kyubyong/css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-ru-cv7_css10",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Здравствуйте, это пробный запуск."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
{"language": "ru", "library_name": "fairseq", "tags": ["fairseq", "audio", "text-to-speech"], "datasets": ["common_voice", "css10"], "task": "text-to-speech", "widget": [{"text": "\u0417\u0434\u0440\u0430\u0432\u0441\u0442\u0432\u0443\u0439\u0442\u0435, \u044d\u0442\u043e \u043f\u0440\u043e\u0431\u043d\u044b\u0439 \u0437\u0430\u043f\u0443\u0441\u043a.", "example_title": "Hello, this is a test run."}]}
|
facebook/tts_transformer-ru-cv7_css10
| null |
[
"fairseq",
"audio",
"text-to-speech",
"ru",
"dataset:common_voice",
"dataset:css10",
"arxiv:1809.08895",
"arxiv:2109.06912",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-to-speech
|
fairseq
|
# tts_transformer-tr-cv7
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- Turkish
- Single-speaker male voice
- Trained on [Common Voice v7](https://commonvoice.mozilla.org/en/datasets)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-tr-cv7",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Merhaba, bu bir deneme çalışmasıdır."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
{"language": "tr", "library_name": "fairseq", "tags": ["fairseq", "audio", "text-to-speech"], "datasets": ["common_voice"], "task": "text-to-speech", "widget": [{"text": "Merhaba, bu bir deneme \u00e7al\u0131\u015fmas\u0131d\u0131r.", "example_title": "Hello, this is a test run."}]}
|
facebook/tts_transformer-tr-cv7
| null |
[
"fairseq",
"audio",
"text-to-speech",
"tr",
"dataset:common_voice",
"arxiv:1809.08895",
"arxiv:2109.06912",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-to-speech
|
fairseq
|
# tts_transformer-vi-cv7
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- Vietnamese
- Single-speaker male voice
- Trained on [Common Voice v7](https://commonvoice.mozilla.org/en/datasets)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-vi-cv7",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Xin chào, đây là một cuộc chạy thử nghiệm."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
{"language": "vi", "library_name": "fairseq", "tags": ["fairseq", "audio", "text-to-speech"], "datasets": ["common_voice"], "task": "text-to-speech", "widget": [{"text": "Xin ch\u00e0o, \u0111\u00e2y l\u00e0 m\u1ed9t cu\u1ed9c ch\u1ea1y th\u1eed nghi\u1ec7m.", "example_title": "Hello, this is a test run."}]}
|
facebook/tts_transformer-vi-cv7
| null |
[
"fairseq",
"audio",
"text-to-speech",
"vi",
"dataset:common_voice",
"arxiv:1809.08895",
"arxiv:2109.06912",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-to-speech
|
fairseq
|
# tts_transformer-zh-cv7_css10
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- Simplified Chinese
- Single-speaker female voice
- Pre-trained on [Common Voice v7](https://commonvoice.mozilla.org/en/datasets), fine-tuned on [CSS10](https://github.com/Kyubyong/css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-zh-cv7_css10",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "您好,这是试运行。"
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
{"language": "zh", "library_name": "fairseq", "tags": ["fairseq", "audio", "text-to-speech"], "datasets": ["common_voice", "css10"], "task": "text-to-speech", "widget": [{"text": "\u60a8\u597d\uff0c\u8fd9\u662f\u8bd5\u8fd0\u884c\u3002", "example_title": "Hello, this is a test run."}]}
|
facebook/tts_transformer-zh-cv7_css10
| null |
[
"fairseq",
"audio",
"text-to-speech",
"zh",
"dataset:common_voice",
"dataset:css10",
"arxiv:1809.08895",
"arxiv:2109.06912",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Vision Transformer (base-sized model) pre-trained with MAE
Vision Transformer (ViT) model pre-trained using the MAE method. It was introduced in the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick and first released in [this repository](https://github.com/facebookresearch/mae).
Disclaimer: The team releasing MAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like). Images are presented to the model as a sequence of fixed-size patches.
During pre-training, one randomly masks out a high portion (75%) of the image patches. First, the encoder is used to encode the visual patches. Next, a learnable (shared) mask token is added at the positions of the masked patches. The decoder takes the encoded visual patches and mask tokens as input and reconstructs raw pixel values for the masked positions.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/vit-mae) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import AutoImageProcessor, ViTMAEForPreTraining
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained('facebook/vit-mae-base')
model = ViTMAEForPreTraining.from_pretrained('facebook/vit-mae-base')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
loss = outputs.loss
mask = outputs.mask
ids_restore = outputs.ids_restore
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2111-06377,
author = {Kaiming He and
Xinlei Chen and
Saining Xie and
Yanghao Li and
Piotr Doll{\'{a}}r and
Ross B. Girshick},
title = {Masked Autoencoders Are Scalable Vision Learners},
journal = {CoRR},
volume = {abs/2111.06377},
year = {2021},
url = {https://arxiv.org/abs/2111.06377},
eprinttype = {arXiv},
eprint = {2111.06377},
timestamp = {Tue, 16 Nov 2021 12:12:31 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-06377.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
{"license": "apache-2.0", "tags": ["vision"], "datasets": ["imagenet-1k"]}
|
facebook/vit-mae-base
| null |
[
"transformers",
"pytorch",
"tf",
"vit_mae",
"pretraining",
"vision",
"dataset:imagenet-1k",
"arxiv:2111.06377",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Vision Transformer (huge-sized model) pre-trained with MAE
Vision Transformer (ViT) model pre-trained using the MAE method. It was introduced in the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick and first released in [this repository](https://github.com/facebookresearch/mae).
Disclaimer: The team releasing MAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like). Images are presented to the model as a sequence of fixed-size patches.
During pre-training, one randomly masks out a high portion (75%) of the image patches. First, the encoder is used to encode the visual patches. Next, a learnable (shared) mask token is added at the positions of the masked patches. The decoder takes the encoded visual patches and mask tokens as input and reconstructs raw pixel values for the masked positions.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/vit-mae) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import AutoImageProcessor, ViTMAEForPreTraining
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained('facebook/vit-mae-huge')
model = ViTMAEForPreTraining.from_pretrained('facebook/vit-mae-huge')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
loss = outputs.loss
mask = outputs.mask
ids_restore = outputs.ids_restore
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2111-06377,
author = {Kaiming He and
Xinlei Chen and
Saining Xie and
Yanghao Li and
Piotr Doll{\'{a}}r and
Ross B. Girshick},
title = {Masked Autoencoders Are Scalable Vision Learners},
journal = {CoRR},
volume = {abs/2111.06377},
year = {2021},
url = {https://arxiv.org/abs/2111.06377},
eprinttype = {arXiv},
eprint = {2111.06377},
timestamp = {Tue, 16 Nov 2021 12:12:31 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-06377.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
{"license": "apache-2.0", "tags": ["vision"], "datasets": ["imagenet-1k"]}
|
facebook/vit-mae-huge
| null |
[
"transformers",
"pytorch",
"tf",
"vit_mae",
"pretraining",
"vision",
"dataset:imagenet-1k",
"arxiv:2111.06377",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Vision Transformer (large-sized model) pre-trained with MAE
Vision Transformer (ViT) model pre-trained using the MAE method. It was introduced in the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick and first released in [this repository](https://github.com/facebookresearch/mae).
Disclaimer: The team releasing MAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like). Images are presented to the model as a sequence of fixed-size patches.
During pre-training, one randomly masks out a high portion (75%) of the image patches. First, the encoder is used to encode the visual patches. Next, a learnable (shared) mask token is added at the positions of the masked patches. The decoder takes the encoded visual patches and mask tokens as input and reconstructs raw pixel values for the masked positions.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/vit-mae) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import AutoImageProcessor, ViTMAEForPreTraining
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained('facebook/vit-mae-large')
model = ViTMAEForPreTraining.from_pretrained('facebook/vit-mae-large')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
loss = outputs.loss
mask = outputs.mask
ids_restore = outputs.ids_restore
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2111-06377,
author = {Kaiming He and
Xinlei Chen and
Saining Xie and
Yanghao Li and
Piotr Doll{\'{a}}r and
Ross B. Girshick},
title = {Masked Autoencoders Are Scalable Vision Learners},
journal = {CoRR},
volume = {abs/2111.06377},
year = {2021},
url = {https://arxiv.org/abs/2111.06377},
eprinttype = {arXiv},
eprint = {2111.06377},
timestamp = {Tue, 16 Nov 2021 12:12:31 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-06377.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
{"license": "apache-2.0", "tags": ["vision"], "datasets": ["imagenet-1k"]}
|
facebook/vit-mae-large
| null |
[
"transformers",
"pytorch",
"tf",
"vit_mae",
"pretraining",
"vision",
"dataset:imagenet-1k",
"arxiv:2111.06377",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-100h
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained and fine-tuned on 100 hours of Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import soundfile as sf
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-100h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-100h")
# define function to read in sound file
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-base-100h** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import soundfile as sf
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-100h").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-100h")
def map_to_pred(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 6.1 | 13.5 |
|
{"language": "en", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition"], "datasets": ["librispeech_asr"]}
|
facebook/wav2vec2-base-100h
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 100k unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "multilingual", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-100k-voxpopuli
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"multilingual",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in cs (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-cs")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-cs")
# load dataset
ds = load_dataset("common_voice", "cs", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "cs", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-cs
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"cs",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in de (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-de")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-de")
# load dataset
ds = load_dataset("common_voice", "de", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "de", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-de
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"de",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in en (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-en")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-en")
# load dataset
ds = load_dataset("common_voice", "en", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "en", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-en
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"en",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in es (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-es")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-es")
# load dataset
ds = load_dataset("common_voice", "es", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "es", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-es
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"es",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
| null |
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in et (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-et")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-et")
# load dataset
ds = load_dataset("common_voice", "et", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "et", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-et
| null |
[
"audio",
"automatic-speech-recognition",
"voxpopuli",
"et",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in fi (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-fi")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-fi")
# load dataset
ds = load_dataset("common_voice", "fi", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "fi", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-fi
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"fi",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in fr (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-fr")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-fr")
# load dataset
ds = load_dataset("common_voice", "fr", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "fr", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-fr
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"fr",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in hr (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-hr")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-hr")
# load dataset
ds = load_dataset("common_voice", "hr", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "hr", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-hr
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"hr",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in hu (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-hu")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-hu")
# load dataset
ds = load_dataset("common_voice", "hu", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "hu", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-hu
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"hu",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in it (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-it")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-it")
# load dataset
ds = load_dataset("common_voice", "it", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "it", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-it
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"it",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
| null |
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in lt (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-lt")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-lt")
# load dataset
ds = load_dataset("common_voice", "lt", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "lt", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-lt
| null |
[
"audio",
"automatic-speech-recognition",
"voxpopuli",
"lt",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in nl (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-nl")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-nl")
# load dataset
ds = load_dataset("common_voice", "nl", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "nl", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-nl
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"nl",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in pl (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-pl")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-pl")
# load dataset
ds = load_dataset("common_voice", "pl", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "pl", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-pl
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"pl",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in ro (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-ro")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-ro")
# load dataset
ds = load_dataset("common_voice", "ro", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "ro", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-ro
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"ro",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in sk (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-sk")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-sk")
# load dataset
ds = load_dataset("common_voice", "sk", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "sk", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-sk
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"sk",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli-Finetuned
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10K unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390) and fine-tuned on the transcribed data in sl (refer to Table 1 of paper for more information).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Usage for inference
In the following it is shown how the model can be used in inference on a sample of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets)
```python
#!/usr/bin/env python3
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torchaudio
import torch
# resample audio
# load model & processor
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-sl")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-10k-voxpopuli-ft-sl")
# load dataset
ds = load_dataset("common_voice", "sl", split="validation[:1%]")
# common voice does not match target sampling rate
common_voice_sample_rate = 48000
target_sample_rate = 16000
resampler = torchaudio.transforms.Resample(common_voice_sample_rate, target_sample_rate)
# define mapping fn to read in sound file and resample
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
speech = resampler(speech)
batch["speech"] = speech[0]
return batch
# load all audio files
ds = ds.map(map_to_array)
# run inference on the first 5 data samples
inputs = processor(ds[:5]["speech"], sampling_rate=target_sample_rate, return_tensors="pt", padding=True)
# inference
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, axis=-1)
print(processor.batch_decode(predicted_ids))
```
|
{"language": "sl", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli-ft-sl
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"voxpopuli",
"sl",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10k unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "multilingual", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-10k-voxpopuli
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"multilingual",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-960h
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained and fine-tuned on 960 hours of Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and tokenizer
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-base-960h** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
def map_to_pred(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["audio"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 3.4 | 8.6 |
|
{"language": "en", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "hf-asr-leaderboard"], "datasets": ["librispeech_asr"], "widget": [{"example_title": "Librispeech sample 1", "src": "https://cdn-media.huggingface.co/speech_samples/sample1.flac"}, {"example_title": "Librispeech sample 2", "src": "https://cdn-media.huggingface.co/speech_samples/sample2.flac"}], "model-index": [{"name": "wav2vec2-base-960h", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "LibriSpeech (clean)", "type": "librispeech_asr", "config": "clean", "split": "test", "args": {"language": "en"}}, "metrics": [{"type": "wer", "value": 3.4, "name": "Test WER"}]}, {"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "LibriSpeech (other)", "type": "librispeech_asr", "config": "other", "split": "test", "args": {"language": "en"}}, "metrics": [{"type": "wer", "value": 8.6, "name": "Test WER"}]}]}]}
|
facebook/wav2vec2-base-960h
| null |
[
"transformers",
"pytorch",
"tf",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **bg** on **17.6k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **bg**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "bg", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-bg-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"bg",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **cs** on **18.7k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **cs**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "cs", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-cs-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"cs",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **da** on **13.6k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **da**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "da", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-da-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"da",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **de** on **23.2k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **de**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "de", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-de-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"de",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **el** on **17.7k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **el**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "el", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-el-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"el",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **en** on **24.1k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **en**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "en", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-en-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"en",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **es** on **21.4k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **es**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "es", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-es-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"es",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the es unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "es", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-es-voxpopuli
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"es",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **et** on **10.6k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **et**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "et", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-et-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"et",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **fi** on **14.2k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **fi**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "fi", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-fi-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"fi",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **fr** on **22.8k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **fr**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "fr", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-fr-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"fr",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the fr unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "fr", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-fr-voxpopuli
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"fr",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **hr** on **8.1k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **hr**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "hr", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-hr-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"hr",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **hu** on **17.7k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **hu**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "hu", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-hu-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"hu",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **it** on **21.9k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **it**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "it", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-it-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"it",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the it unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "it", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-it-voxpopuli
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"it",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **lt** on **14.4k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **lt**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "lt", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-lt-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"lt",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **lv** on **13.1k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **lv**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "lv", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-lv-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"lv",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **mt** on **9.1k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **mt**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "mt", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-mt-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"mt",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **nl** on **19.0k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **nl**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "nl", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-nl-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"nl",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the nl unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "nl", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-nl-voxpopuli
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"nl",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **pl** on **21.2k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **pl**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "pl", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-pl-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"pl",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **pt** on **17.5k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **pt**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "pt", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-pt-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"pt",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **ro** on **17.9k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **ro**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "ro", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-ro-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"ro",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **sk** on **12.1k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **sk**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "sk", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-sk-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"sk",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **sl** on **11.3k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **sl**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "sl", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-sl-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"sl",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-base-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained only in **sv** on **16.3k** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **sv**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "sv", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-base-sv-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"sv",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Base-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the sv unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "sv", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-base-sv-voxpopuli
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"sv",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-Base
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model.
|
{"language": "en", "license": "apache-2.0", "tags": ["speech"], "datasets": ["librispeech_asr"]}
|
facebook/wav2vec2-base
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained on the 100k unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "multilingual", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-large-100k-voxpopuli
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"multilingual",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained on the 10k unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "multilingual", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-large-10k-voxpopuli
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"multilingual",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-960h-Lv60 + Self-Training
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The large model pretrained and fine-tuned on 960 hours of Libri-Light and Librispeech on 16kHz sampled speech audio. Model was trained with [Self-Training objective](https://arxiv.org/abs/2010.11430). When using the model make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-large-960h-lv60-self** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60-self").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
def map_to_pred(batch):
inputs = processor(batch["audio"]["array"], return_tensors="pt", padding="longest")
input_values = inputs.input_values.to("cuda")
attention_mask = inputs.attention_mask.to("cuda")
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, remove_columns=["audio"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 1.9 | 3.9 |
|
{"language": "en", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition", "hf-asr-leaderboard"], "datasets": ["librispeech_asr"], "model-index": [{"name": "wav2vec2-large-960h-lv60", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "LibriSpeech (clean)", "type": "librispeech_asr", "config": "clean", "split": "test", "args": {"language": "en"}}, "metrics": [{"type": "wer", "value": 1.9, "name": "Test WER"}]}, {"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "LibriSpeech (other)", "type": "librispeech_asr", "config": "other", "split": "test", "args": {"language": "en"}}, "metrics": [{"type": "wer", "value": 3.9, "name": "Test WER"}]}]}]}
|
facebook/wav2vec2-large-960h-lv60-self
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"hf-asr-leaderboard",
"en",
"dataset:librispeech_asr",
"arxiv:2010.11430",
"arxiv:2006.11477",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-960h-Lv60
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The large model pretrained and fine-tuned on 960 hours of Libri-Light and Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-large-960h-lv60** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60")
def map_to_pred(batch):
inputs = processor(batch["audio"]["array"], return_tensors="pt", padding="longest")
input_values = inputs.input_values.to("cuda")
attention_mask = inputs.attention_mask.to("cuda")
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=16, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 2.2 | 4.5 |
|
{"language": "en", "license": "apache-2.0", "tags": ["speech"], "datasets": ["librispeech_asr"], "model-index": [{"name": "wav2vec2-large-960h-lv60", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "Librispeech (clean)", "type": "librispeech_asr", "args": "en"}, "metrics": [{"type": "wer", "value": 2.2, "name": "Test WER"}]}]}]}
|
facebook/wav2vec2-large-960h-lv60
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-960h
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The large model pretrained and fine-tuned on 960 hours of Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"],, return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-large-960h** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import soundfile as sf
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
def map_to_pred(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 2.8 | 6.3 |
|
{"language": "en", "license": "apache-2.0", "tags": ["speech"], "datasets": ["librispeech_asr"]}
|
facebook/wav2vec2-large-960h
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-large-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained only in **baltic** on **27.5** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **baltic**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "baltic", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-large-baltic-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-large-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained only in **el** on **17.7** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **el**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "el", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-large-el-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"el",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained on the es unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "es", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-large-es-voxpopuli
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"es",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
facebook/wav2vec2-large-fr-voxpopuli-v2
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained on the fr unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "fr", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-large-fr-voxpopuli
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"fr",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
facebook/wav2vec2-large-it-voxpopuli-v2
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained on the it unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "it", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-large-it-voxpopuli
| null |
[
"transformers",
"pytorch",
"jax",
"safetensors",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"it",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-Large-LV60
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model.
|
{"language": "en", "license": "apache-2.0", "tags": ["speech"], "datasets": ["librispeech_asr"]}
|
facebook/wav2vec2-large-lv60
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-large-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained only in **mt** on **9.1** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **mt**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "mt", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-large-mt-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"mt",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained on the nl unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "nl", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-large-nl-voxpopuli
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"nl",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-large-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained only in **north_germanic** on **29.9** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **north_germanic**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "north_germanic", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-large-north_germanic-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
facebook/wav2vec2-large-pt-voxpopuli-v2
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-Robust finetuned on Librispeech
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/).
This model is a fine-tuned version of the [wav2vec2-large-robust](https://huggingface.co/facebook/wav2vec2-large-robust) model.
It has been pretrained on:
- [Libri-Light](https://github.com/facebookresearch/libri-light): open-source audio books from the LibriVox project; clean, read-out audio data
- [CommonVoice](https://huggingface.co/datasets/common_voice): crowd-source collected audio data; read-out text snippets
- [Switchboard](https://catalog.ldc.upenn.edu/LDC97S62): telephone speech corpus; noisy telephone data
- [Fisher](https://catalog.ldc.upenn.edu/LDC2004T19): conversational telephone speech; noisy telephone data
and subsequently been finetuned on 960 hours of
- [Librispeech](https://huggingface.co/datasets/librispeech_asr): open-source read-out audio data.
When using the model make sure that your speech input is also sampled at 16Khz.
[Paper Robust Wav2Vec2](https://arxiv.org/abs/2104.01027)
Authors: Wei-Ning Hsu, Anuroop Sriram, Alexei Baevski, Tatiana Likhomanenko, Qiantong Xu, Vineel Pratap, Jacob Kahn, Ann Lee, Ronan Collobert, Gabriel Synnaeve, Michael Auli
**Abstract**
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at this https URL.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import soundfile as sf
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-robust-ft-libri-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-robust-ft-libri-960h")
# define function to read in sound file
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
# tokenize
input_values = processor(ds["speech"][:2], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
|
{"language": "en", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["libri_light", "common_voice", "switchboard", "fisher", "librispeech_asr"], "widget": [{"example_title": "Librispeech sample 1", "src": "https://cdn-media.huggingface.co/speech_samples/sample1.flac"}, {"example_title": "Librispeech sample 2", "src": "https://cdn-media.huggingface.co/speech_samples/sample2.flac"}]}
|
facebook/wav2vec2-large-robust-ft-libri-960h
| null |
[
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"en",
"dataset:libri_light",
"dataset:common_voice",
"dataset:switchboard",
"dataset:fisher",
"dataset:librispeech_asr",
"arxiv:2104.01027",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-Robust finetuned on Switchboard
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/).
This model is a fine-tuned version of the [wav2vec2-large-robust](https://huggingface.co/facebook/wav2vec2-large-robust) model.
It has been pretrained on:
- [Libri-Light](https://github.com/facebookresearch/libri-light): open-source audio books from the LibriVox project; clean, read-out audio data
- [CommonVoice](https://huggingface.co/datasets/common_voice): crowd-source collected audio data; read-out text snippets
- [Switchboard](https://catalog.ldc.upenn.edu/LDC97S62): telephone speech corpus; noisy telephone data
- [Fisher](https://catalog.ldc.upenn.edu/LDC2004T19): conversational telephone speech; noisy telephone data
and subsequently been finetuned on 300 hours of
- [Switchboard](https://catalog.ldc.upenn.edu/LDC97S62): telephone speech corpus; noisy telephone data
When using the model make sure that your speech input is also sampled at 16Khz.
[Paper Robust Wav2Vec2](https://arxiv.org/abs/2104.01027)
Authors: Wei-Ning Hsu, Anuroop Sriram, Alexei Baevski, Tatiana Likhomanenko, Qiantong Xu, Vineel Pratap, Jacob Kahn, Ann Lee, Ronan Collobert, Gabriel Synnaeve, Michael Auli
**Abstract**
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at this https URL.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-robust-ft-swbd-300h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-robust-ft-swbd-300h")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
|
{"language": "en", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["libri_light", "common_voice", "switchboard", "fisher"], "widget": [{"example_title": "Librispeech sample 1", "src": "https://cdn-media.huggingface.co/speech_samples/sample1.flac"}, {"example_title": "Librispeech sample 2", "src": "https://cdn-media.huggingface.co/speech_samples/sample2.flac"}]}
|
facebook/wav2vec2-large-robust-ft-swbd-300h
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"en",
"dataset:libri_light",
"dataset:common_voice",
"dataset:switchboard",
"dataset:fisher",
"arxiv:2104.01027",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-Large-Robust
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The large model pretrained on 16kHz sampled speech audio.
Speech datasets from multiple domains were used to pretrain the model:
- [Libri-Light](https://github.com/facebookresearch/libri-light): open-source audio books from the LibriVox project; clean, read-out audio data
- [CommonVoice](https://huggingface.co/datasets/common_voice): crowd-source collected audio data; read-out text snippets
- [Switchboard](https://catalog.ldc.upenn.edu/LDC97S62): telephone speech corpus; noisy telephone data
- [Fisher](https://catalog.ldc.upenn.edu/LDC2004T19): conversational telephone speech; noisy telephone data
When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
[Paper Robust Wav2Vec2](https://arxiv.org/abs/2104.01027)
Authors: Wei-Ning Hsu, Anuroop Sriram, Alexei Baevski, Tatiana Likhomanenko, Qiantong Xu, Vineel Pratap, Jacob Kahn, Ann Lee, Ronan Collobert, Gabriel Synnaeve, Michael Auli
**Abstract**
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at this https URL.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model.
|
{"language": "en", "license": "apache-2.0", "tags": ["speech"], "datasets": ["libri_light", "common_voice", "switchboard", "fisher"]}
|
facebook/wav2vec2-large-robust
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"en",
"dataset:libri_light",
"dataset:common_voice",
"dataset:switchboard",
"dataset:fisher",
"arxiv:2104.01027",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-large-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained only in **romance** on **101.5** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **romance**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "romance", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-large-romance-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-large-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained only in **slavic** on **88.99999999999999** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **slavic**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "slavic", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-large-slavic-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained on the sv unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
{"language": "sv", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli"]}
|
facebook/wav2vec2-large-sv-voxpopuli
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"sv",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-large-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained only in **uralic** on **42.5** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **uralic**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "uralic", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-large-uralic-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-large-VoxPopuli-V2
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) large model pretrained only in **west_germanic** on **66.3** unlabeled datat of the [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
The model is pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model for **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data in **west_germanic**. Check out [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for a more in-detail explanation of how to fine-tune the model.
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*.
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/).
|
{"language": "west_germanic", "license": "cc-by-nc-4.0", "tags": ["audio", "automatic-speech-recognition", "voxpopuli-v2"], "datasets": ["voxpopuli"], "inference": false}
|
facebook/wav2vec2-large-west_germanic-voxpopuli-v2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"voxpopuli-v2",
"dataset:voxpopuli",
"arxiv:2101.00390",
"license:cc-by-nc-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
## Evaluation on Common Voice NL Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-dutch"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "nl", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 21.1 %
|
{"language": "nl", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["common_voice"]}
|
facebook/wav2vec2-large-xlsr-53-dutch
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"nl",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
## Evaluation on Common Voice FR Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-french"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "fr", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 25.2 %
|
{"language": "fr", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["common_voice"]}
|
facebook/wav2vec2-large-xlsr-53-french
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"fr",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
## Evaluation on Common Voice DE Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-german"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "de", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 18.5 %
|
{"language": "de", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["common_voice"]}
|
facebook/wav2vec2-large-xlsr-53-german
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"de",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
## Evaluation on Common Voice IT Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-italian"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "it", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 22.1 %
|
{"language": "it", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["common_voice"]}
|
facebook/wav2vec2-large-xlsr-53-italian
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"it",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
## Evaluation on Common Voice PL Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-polish"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "pl", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 24.6 %
|
{"language": "nl", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["common_voice"]}
|
facebook/wav2vec2-large-xlsr-53-polish
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"nl",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
## Evaluation on Common Voice PT Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-portuguese"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "pt", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 27.1 %
|
{"language": "pt", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["common_voice"]}
|
facebook/wav2vec2-large-xlsr-53-portuguese
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"pt",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
## Evaluation on Common Voice ES Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-spanish"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "es", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 17.6 %
|
{"language": "es", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition"], "datasets": ["common_voice"]}
|
facebook/wav2vec2-large-xlsr-53-spanish
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"es",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-XLSR-53
[Facebook's XLSR-Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information.
[Paper](https://arxiv.org/abs/2006.13979)
Authors: Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli
**Abstract**
This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw waveform of speech in multiple languages. We build on wav2vec 2.0 which is trained by solving a contrastive task over masked latent speech representations and jointly learns a quantization of the latents shared across languages. The resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to a comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong individual models. Analysis shows that the latent discrete speech representations are shared across languages with increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing XLSR-53, a large model pretrained in 53 languages.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLSR_Wav2Vec2_on_Turkish_ASR_with_%F0%9F%A4%97_Transformers.ipynb) for more information on how to fine-tune the model.

|
{"language": "multilingual", "license": "apache-2.0", "tags": ["speech"], "datasets": ["common_voice"]}
|
facebook/wav2vec2-large-xlsr-53
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"speech",
"multilingual",
"dataset:common_voice",
"arxiv:2006.13979",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-Large
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model.
|
{"language": "en", "license": "apache-2.0", "tags": ["speech"], "datasets": ["librispeech_asr"]}
|
facebook/wav2vec2-large
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-LV60 finetuned on multi-lingual Common Voice
This checkpoint leverages the pretrained checkpoint [wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60)
and is fine-tuned on [CommonVoice](https://huggingface.co/datasets/common_voice) to recognize phonetic labels in multiple languages.
When using the model make sure that your speech input is sampled at 16kHz.
Note that the model outputs a string of phonetic labels. A dictionary mapping phonetic labels to words
has to be used to map the phonetic output labels to output words.
[Paper: Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
Authors: Qiantong Xu, Alexei Baevski, Michael Auli
**Abstract**
Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech recognition systems without any labeled data. However, in many cases there is labeled data available for related languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by mapping phonemes of the training languages to the target language using articulatory features. Experiments show that this simple method significantly outperforms prior work which introduced task-specific architectures and used only part of a monolingually pretrained model.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-lv-60-espeak-cv-ft")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-lv-60-espeak-cv-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['m ɪ s t ɚ k w ɪ l t ɚ ɹ ɪ z ð ɪ ɐ p ɑː s əl ʌ v ð ə m ɪ d əl k l æ s ᵻ z æ n d w iː ɑːɹ ɡ l æ d t ə w ɛ l k ə m h ɪ z ɡ ɑː s p əl']
```
|
{"language": "multilingual", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition", "phoneme-recognition"], "datasets": ["common_voice"], "widget": [{"example_title": "Librispeech sample 1", "src": "https://cdn-media.huggingface.co/speech_samples/sample1.flac"}, {"example_title": "Librispeech sample 2", "src": "https://cdn-media.huggingface.co/speech_samples/sample2.flac"}]}
|
facebook/wav2vec2-lv-60-espeak-cv-ft
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"phoneme-recognition",
"multilingual",
"dataset:common_voice",
"arxiv:2109.11680",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-XLS-R-2b-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-1b`**](https://huggingface.co/facebook/wav2vec2-xls-r-1b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-1b-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-1b-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-1b-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-1b-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (1B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
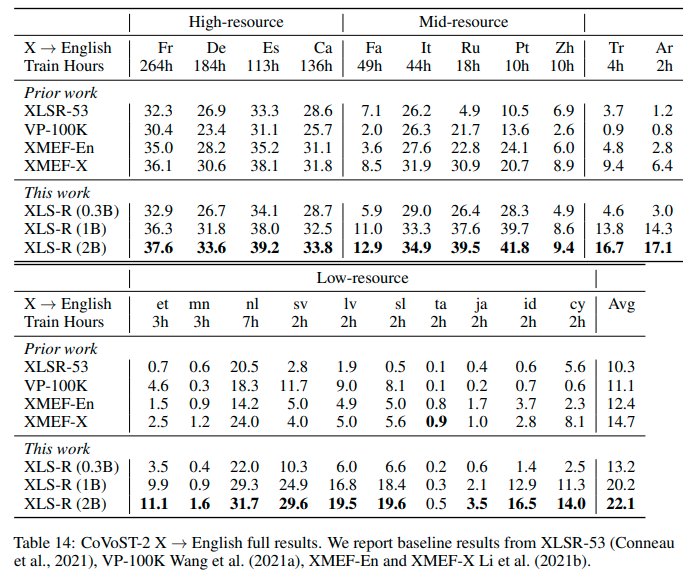
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
{"language": ["multilingual", "fr", "de", "es", "ca", "it", "ru", "zh", "pt", "fa", "et", "mn", "nl", "tr", "ar", "sv", "lv", "sl", "ta", "ja", "id", "cy", "en"], "license": "apache-2.0", "tags": ["speech", "xls_r", "automatic-speech-recognition", "xls_r_translation"], "datasets": ["common_voice", "multilingual_librispeech", "covost2"], "pipeline_tag": "automatic-speech-recognition", "widget": [{"example_title": "Swedish", "src": "https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3"}, {"example_title": "Arabic", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3"}, {"example_title": "Russian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3"}, {"example_title": "German", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3"}, {"example_title": "French", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3"}, {"example_title": "Indonesian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3"}, {"example_title": "Italian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3"}, {"example_title": "Japanese", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3"}, {"example_title": "Mongolian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3"}, {"example_title": "Dutch", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3"}, {"example_title": "Russian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3"}, {"example_title": "Turkish", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3"}, {"example_title": "Catalan", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3"}, {"example_title": "English", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3"}, {"example_title": "Dutch", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3"}]}
|
facebook/wav2vec2-xls-r-1b-21-to-en
| null |
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-XLS-R-1B-EN-15
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-1b`**](https://huggingface.co/facebook/wav2vec2-xls-r-1b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 15 `en` -> `{lang}` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from spoken `en` (Engish) to the following written languages `{lang}`:
`en` -> {`de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
For more information, please refer to Section *5.1.1* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-1B-EN-15).
You can select the target language, record some audio in English,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-1b-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-1b-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-1b-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-1b-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## Results `en` -> `{lang}`
See the row of **XLS-R (1B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
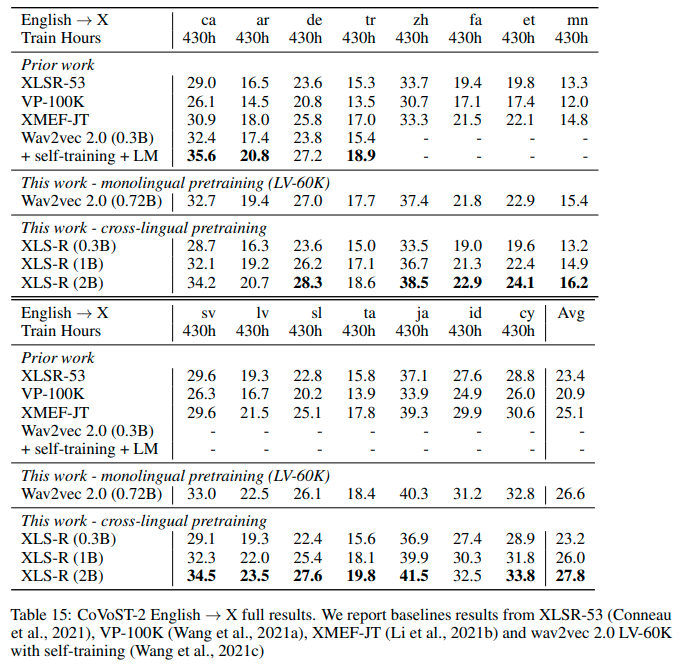
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
{"language": ["multilingual", "en", "de", "tr", "fa", "sv", "mn", "zh", "cy", "ca", "sl", "et", "id", "ar", "ta", "lv", "ja"], "license": "apache-2.0", "tags": ["speech", "xls_r", "automatic-speech-recognition", "xls_r_translation"], "datasets": ["common_voice", "multilingual_librispeech", "covost2"], "pipeline_tag": "automatic-speech-recognition", "widget": [{"example_title": "English", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3"}]}
|
facebook/wav2vec2-xls-r-1b-en-to-15
| null |
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"en",
"de",
"tr",
"fa",
"sv",
"mn",
"zh",
"cy",
"ca",
"sl",
"et",
"id",
"ar",
"ta",
"lv",
"ja",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-XLS-R-1B
[Facebook's Wav2Vec2 XLS-R](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages) counting **1 billion** parameters.

XLS-R is Facebook AI's large-scale multilingual pretrained model for speech (the "XLM-R for Speech"). It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages. When using the model make sure that your speech input is sampled at 16kHz.
**Note**: This model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Translation, or Classification. Check out [**this blog**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for more information about ASR.
[XLS-R Paper](https://arxiv.org/abs/2111.09296)
**Abstract**
This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on 436K hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 20%-33% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this google colab](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb) for more information on how to fine-tune the model.
You can find other pretrained XLS-R models with different numbers of parameters:
* [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
* [1B version version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
* [2B version version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
|
{"language": ["multilingual", "ab", "af", "sq", "am", "ar", "hy", "as", "az", "ba", "eu", "be", "bn", "bs", "br", "bg", "my", "yue", "ca", "ceb", "km", "zh", "cv", "hr", "cs", "da", "dv", "nl", "en", "eo", "et", "fo", "fi", "fr", "gl", "lg", "ka", "de", "el", "gn", "gu", "ht", "cnh", "ha", "haw", "he", "hi", "hu", "is", "id", "ia", "ga", "it", "ja", "jv", "kb", "kn", "kk", "rw", "ky", "ko", "ku", "lo", "la", "lv", "ln", "lt", "lm", "mk", "mg", "ms", "ml", "mt", "gv", "mi", "mr", "mn", "ne", false, "nn", "oc", "or", "ps", "fa", "pl", "pt", "pa", "ro", "rm", "rm", "ru", "sah", "sa", "sco", "sr", "sn", "sd", "si", "sk", "sl", "so", "hsb", "es", "su", "sw", "sv", "tl", "tg", "ta", "tt", "te", "th", "bo", "tp", "tr", "tk", "uk", "ur", "uz", "vi", "vot", "war", "cy", "yi", "yo", "zu"], "license": "apache-2.0", "tags": ["speech", "xls_r", "xls_r_pretrained"], "datasets": ["common_voice", "multilingual_librispeech"], "language_bcp47": ["zh-HK", "zh-TW", "fy-NL"]}
|
facebook/wav2vec2-xls-r-1b
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"xls_r",
"xls_r_pretrained",
"multilingual",
"ab",
"af",
"sq",
"am",
"ar",
"hy",
"as",
"az",
"ba",
"eu",
"be",
"bn",
"bs",
"br",
"bg",
"my",
"yue",
"ca",
"ceb",
"km",
"zh",
"cv",
"hr",
"cs",
"da",
"dv",
"nl",
"en",
"eo",
"et",
"fo",
"fi",
"fr",
"gl",
"lg",
"ka",
"de",
"el",
"gn",
"gu",
"ht",
"cnh",
"ha",
"haw",
"he",
"hi",
"hu",
"is",
"id",
"ia",
"ga",
"it",
"ja",
"jv",
"kb",
"kn",
"kk",
"rw",
"ky",
"ko",
"ku",
"lo",
"la",
"lv",
"ln",
"lt",
"lm",
"mk",
"mg",
"ms",
"ml",
"mt",
"gv",
"mi",
"mr",
"mn",
"ne",
"no",
"nn",
"oc",
"or",
"ps",
"fa",
"pl",
"pt",
"pa",
"ro",
"rm",
"ru",
"sah",
"sa",
"sco",
"sr",
"sn",
"sd",
"si",
"sk",
"sl",
"so",
"hsb",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"ta",
"tt",
"te",
"th",
"bo",
"tp",
"tr",
"tk",
"uk",
"ur",
"uz",
"vi",
"vot",
"war",
"cy",
"yi",
"yo",
"zu",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-XLS-R-2b-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-2b-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (2B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.

## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
{"language": ["multilingual", "fr", "de", "es", "ca", "it", "ru", "zh", "pt", "fa", "et", "mn", "nl", "tr", "ar", "sv", "lv", "sl", "ta", "ja", "id", "cy", "en"], "license": "apache-2.0", "tags": ["speech", "xls_r", "automatic-speech-recognition", "xls_r_translation"], "datasets": ["common_voice", "multilingual_librispeech", "covost2"], "pipeline_tag": "automatic-speech-recognition", "widget": [{"example_title": "Swedish", "src": "https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3"}, {"example_title": "Arabic", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3"}, {"example_title": "Russian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3"}, {"example_title": "German", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3"}, {"example_title": "French", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3"}, {"example_title": "Indonesian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3"}, {"example_title": "Italian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3"}, {"example_title": "Japanese", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3"}, {"example_title": "Mongolian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3"}, {"example_title": "Dutch", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3"}, {"example_title": "Russian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3"}, {"example_title": "Turkish", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3"}, {"example_title": "Catalan", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3"}, {"example_title": "English", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3"}, {"example_title": "Dutch", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3"}]}
|
facebook/wav2vec2-xls-r-2b-21-to-en
| null |
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-XLS-R-2B-22-16 (XLS-R-Any-to-Any)
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on `{input_lang}` -> `{output_lang}` translation pairs
of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{input_lang}` to the following written languages `{output_lang}`:
`{input_lang}` -> `{output_lang}`
with `{input_lang}` one of:
{`en`, `fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`}
and `{output_lang}`:
{`en`, `de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-2B-22-16).
You can select the target language, record some audio in any of the above mentioned input languages,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"en": 250004,
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-22-to-16", feature_extractor="facebook/wav2vec2-xls-r-2b-22-to-16")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-22-to-16")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-22-to-16")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
{"language": ["multilingual", "fr", "de", "es", "ca", "it", "ru", "zh", "pt", "fa", "et", "mn", "nl", "tr", "ar", "sv", "lv", "sl", "ta", "ja", "id", "cy", "en"], "license": "apache-2.0", "tags": ["speech", "xls_r", "automatic-speech-recognition", "xls_r_translation"], "datasets": ["common_voice", "multilingual_librispeech", "covost2"], "pipeline_tag": "automatic-speech-recognition", "widget": [{"example_title": "Swedish", "src": "https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3"}, {"example_title": "Arabic", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3"}, {"example_title": "Russian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3"}, {"example_title": "German", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3"}, {"example_title": "French", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3"}, {"example_title": "Indonesian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3"}, {"example_title": "Italian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3"}, {"example_title": "Japanese", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3"}, {"example_title": "Mongolian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3"}, {"example_title": "Dutch", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3"}, {"example_title": "Russian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3"}, {"example_title": "Turkish", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3"}, {"example_title": "Catalan", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3"}, {"example_title": "English", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3"}, {"example_title": "Dutch", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3"}]}
|
facebook/wav2vec2-xls-r-2b-22-to-16
| null |
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-XLS-R-2B-EN-15
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 15 `en` -> `{lang}` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from spoken `en` (Engish) to the following written languages `{lang}`:
`en` -> {`de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
For more information, please refer to Section *5.1.1* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-2B-EN-15).
You can select the target language, record some audio in English,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-2b-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## Results `en` -> `{lang}`
See the row of **XLS-R (2B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.

## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
{"language": ["multilingual", "en", "de", "tr", "fa", "sv", "mn", "zh", "cy", "ca", "sl", "et", "id", "ar", "ta", "lv", "ja"], "license": "apache-2.0", "tags": ["speech", "xls_r", "automatic-speech-recognition", "xls_r_translation"], "datasets": ["common_voice", "multilingual_librispeech", "covost2"], "pipeline_tag": "automatic-speech-recognition", "widget": [{"example_title": "English", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3"}]}
|
facebook/wav2vec2-xls-r-2b-en-to-15
| null |
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"en",
"de",
"tr",
"fa",
"sv",
"mn",
"zh",
"cy",
"ca",
"sl",
"et",
"id",
"ar",
"ta",
"lv",
"ja",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-XLS-R-2B
[Facebook's Wav2Vec2 XLS-R](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages) counting **2 billion** parameters.

XLS-R is Facebook AI's large-scale multilingual pretrained model for speech (the "XLM-R for Speech"). It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages. When using the model make sure that your speech input is sampled at 16kHz.
**Note**: This model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Translation, or Classification. Check out [**this blog**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for more information about ASR.
[XLS-R Paper](https://arxiv.org/abs/2111.09296)
Authors: Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli
**Abstract**
This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on 436K hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 20%-33% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this google colab](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb) for more information on how to fine-tune the model.
You can find other pretrained XLS-R models with different numbers of parameters:
* [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
* [1B version version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
* [2B version version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
|
{"language": ["multilingual", "ab", "af", "sq", "am", "ar", "hy", "as", "az", "ba", "eu", "be", "bn", "bs", "br", "bg", "my", "yue", "ca", "ceb", "km", "zh", "cv", "hr", "cs", "da", "dv", "nl", "en", "eo", "et", "fo", "fi", "fr", "gl", "lg", "ka", "de", "el", "gn", "gu", "ht", "cnh", "ha", "haw", "he", "hi", "hu", "is", "id", "ia", "ga", "it", "ja", "jv", "kb", "kn", "kk", "rw", "ky", "ko", "ku", "lo", "la", "lv", "ln", "lt", "lm", "mk", "mg", "ms", "ml", "mt", "gv", "mi", "mr", "mn", "ne", false, "nn", "oc", "or", "ps", "fa", "pl", "pt", "pa", "ro", "rm", "rm", "ru", "sah", "sa", "sco", "sr", "sn", "sd", "si", "sk", "sl", "so", "hsb", "es", "su", "sw", "sv", "tl", "tg", "ta", "tt", "te", "th", "bo", "tp", "tr", "tk", "uk", "ur", "uz", "vi", "vot", "war", "cy", "yi", "yo", "zu"], "license": "apache-2.0", "tags": ["speech", "xls_r", "xls_r_pretrained"], "datasets": ["common_voice", "multilingual_librispeech"], "language_bcp47": ["zh-HK", "zh-TW", "fy-NL"]}
|
facebook/wav2vec2-xls-r-2b
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"xls_r",
"xls_r_pretrained",
"multilingual",
"ab",
"af",
"sq",
"am",
"ar",
"hy",
"as",
"az",
"ba",
"eu",
"be",
"bn",
"bs",
"br",
"bg",
"my",
"yue",
"ca",
"ceb",
"km",
"zh",
"cv",
"hr",
"cs",
"da",
"dv",
"nl",
"en",
"eo",
"et",
"fo",
"fi",
"fr",
"gl",
"lg",
"ka",
"de",
"el",
"gn",
"gu",
"ht",
"cnh",
"ha",
"haw",
"he",
"hi",
"hu",
"is",
"id",
"ia",
"ga",
"it",
"ja",
"jv",
"kb",
"kn",
"kk",
"rw",
"ky",
"ko",
"ku",
"lo",
"la",
"lv",
"ln",
"lt",
"lm",
"mk",
"mg",
"ms",
"ml",
"mt",
"gv",
"mi",
"mr",
"mn",
"ne",
"no",
"nn",
"oc",
"or",
"ps",
"fa",
"pl",
"pt",
"pa",
"ro",
"rm",
"ru",
"sah",
"sa",
"sco",
"sr",
"sn",
"sd",
"si",
"sk",
"sl",
"so",
"hsb",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"ta",
"tt",
"te",
"th",
"bo",
"tp",
"tr",
"tk",
"uk",
"ur",
"uz",
"vi",
"vot",
"war",
"cy",
"yi",
"yo",
"zu",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-XLS-R-300M-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-300m`**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-300m-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (0.3B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.

## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
{"language": ["multilingual", "fr", "de", "es", "ca", "it", "ru", "zh", "pt", "fa", "et", "mn", "nl", "tr", "ar", "sv", "lv", "sl", "ta", "ja", "id", "cy", "en"], "license": "apache-2.0", "tags": ["speech", "xls_r", "automatic-speech-recognition", "xls_r_translation"], "datasets": ["common_voice", "multilingual_librispeech", "covost2"], "pipeline_tag": "automatic-speech-recognition", "widget": [{"example_title": "Swedish", "src": "https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3"}, {"example_title": "Arabic", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3"}, {"example_title": "Russian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3"}, {"example_title": "German", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3"}, {"example_title": "French", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3"}, {"example_title": "Indonesian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3"}, {"example_title": "Italian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3"}, {"example_title": "Japanese", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3"}, {"example_title": "Mongolian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3"}, {"example_title": "Dutch", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3"}, {"example_title": "Russian", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3"}, {"example_title": "Turkish", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3"}, {"example_title": "Catalan", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3"}, {"example_title": "English", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3"}, {"example_title": "Dutch", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3"}]}
|
facebook/wav2vec2-xls-r-300m-21-to-en
| null |
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.