
Search is not available for this dataset
pipeline_tag
stringclasses 48
values | library_name
stringclasses 205
values | text
stringlengths 0
18.3M
| metadata
stringlengths 2
1.07B
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
|
|---|---|---|---|---|---|---|---|---|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-XLS-R-300M-EN-15
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-300m`**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 15 `en` -> `{lang}` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from spoken `en` (Engish) to the following written languages `{lang}`:
`en` -> {`de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
For more information, please refer to Section *5.1.1* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-300m-EN-15).
You can select the target language, record some audio in English,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-300m-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## Results `en` -> `{lang}`
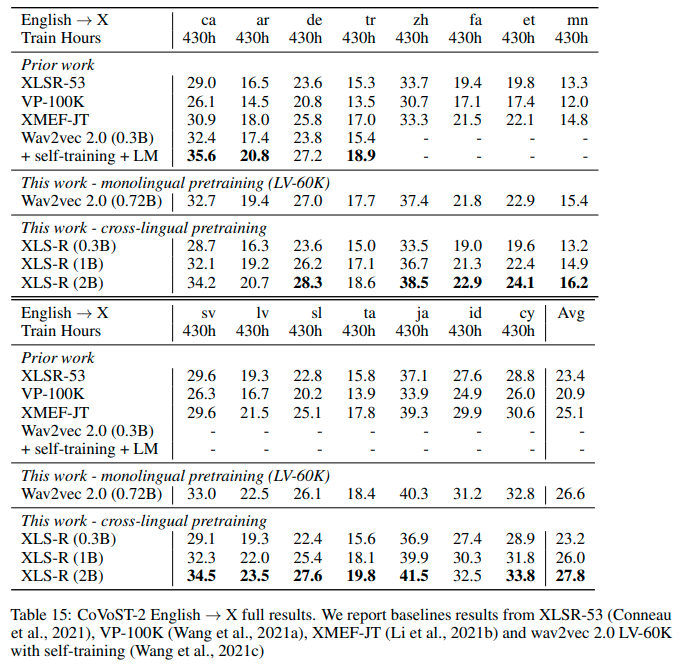
See the row of **XLS-R (0.3B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
{"language": ["multilingual", "en", "de", "tr", "fa", "sv", "mn", "zh", "cy", "ca", "sl", "et", "id", "ar", "ta", "lv", "ja"], "license": "apache-2.0", "tags": ["speech", "xls_r", "xls_r_translation", "automatic-speech-recognition"], "datasets": ["common_voice", "multilingual_librispeech", "covost2"], "pipeline_tag": "automatic-speech-recognition", "widget": [{"example_title": "English", "src": "https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3"}]}
|
facebook/wav2vec2-xls-r-300m-en-to-15
| null |
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"speech",
"xls_r",
"xls_r_translation",
"multilingual",
"en",
"de",
"tr",
"fa",
"sv",
"mn",
"zh",
"cy",
"ca",
"sl",
"et",
"id",
"ar",
"ta",
"lv",
"ja",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-XLS-R-300M
[Facebook's Wav2Vec2 XLS-R](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) counting **300 million** parameters.

XLS-R is Facebook AI's large-scale multilingual pretrained model for speech (the "XLM-R for Speech"). It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages. When using the model make sure that your speech input is sampled at 16kHz.
**Note**: This model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Translation, or Classification. Check out [**this blog**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for more information about ASR.
[XLS-R Paper](https://arxiv.org/abs/2111.09296)
Authors: Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli
**Abstract**
This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on 436K hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 20%-33% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this google colab](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb) for more information on how to fine-tune the model.
You can find other pretrained XLS-R models with different numbers of parameters:
* [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
* [1B version version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
* [2B version version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
|
{"language": ["multilingual", "ab", "af", "sq", "am", "ar", "hy", "as", "az", "ba", "eu", "be", "bn", "bs", "br", "bg", "my", "yue", "ca", "ceb", "km", "zh", "cv", "hr", "cs", "da", "dv", "nl", "en", "eo", "et", "fo", "fi", "fr", "gl", "lg", "ka", "de", "el", "gn", "gu", "ht", "cnh", "ha", "haw", "he", "hi", "hu", "is", "id", "ia", "ga", "it", "ja", "jv", "kb", "kn", "kk", "rw", "ky", "ko", "ku", "lo", "la", "lv", "ln", "lt", "lm", "mk", "mg", "ms", "ml", "mt", "gv", "mi", "mr", "mn", "ne", false, "nn", "oc", "or", "ps", "fa", "pl", "pt", "pa", "ro", "rm", "rm", "ru", "sah", "sa", "sco", "sr", "sn", "sd", "si", "sk", "sl", "so", "hsb", "es", "su", "sw", "sv", "tl", "tg", "ta", "tt", "te", "th", "bo", "tp", "tr", "tk", "uk", "ur", "uz", "vi", "vot", "war", "cy", "yi", "yo", "zu"], "license": "apache-2.0", "tags": ["speech", "xls_r", "xls_r_pretrained"], "datasets": ["common_voice", "multilingual_librispeech"], "language_bcp47": ["zh-HK", "zh-TW", "fy-NL"]}
|
facebook/wav2vec2-xls-r-300m
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"xls_r",
"xls_r_pretrained",
"multilingual",
"ab",
"af",
"sq",
"am",
"ar",
"hy",
"as",
"az",
"ba",
"eu",
"be",
"bn",
"bs",
"br",
"bg",
"my",
"yue",
"ca",
"ceb",
"km",
"zh",
"cv",
"hr",
"cs",
"da",
"dv",
"nl",
"en",
"eo",
"et",
"fo",
"fi",
"fr",
"gl",
"lg",
"ka",
"de",
"el",
"gn",
"gu",
"ht",
"cnh",
"ha",
"haw",
"he",
"hi",
"hu",
"is",
"id",
"ia",
"ga",
"it",
"ja",
"jv",
"kb",
"kn",
"kk",
"rw",
"ky",
"ko",
"ku",
"lo",
"la",
"lv",
"ln",
"lt",
"lm",
"mk",
"mg",
"ms",
"ml",
"mt",
"gv",
"mi",
"mr",
"mn",
"ne",
"no",
"nn",
"oc",
"or",
"ps",
"fa",
"pl",
"pt",
"pa",
"ro",
"rm",
"ru",
"sah",
"sa",
"sco",
"sr",
"sn",
"sd",
"si",
"sk",
"sl",
"so",
"hsb",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"ta",
"tt",
"te",
"th",
"bo",
"tp",
"tr",
"tk",
"uk",
"ur",
"uz",
"vi",
"vot",
"war",
"cy",
"yi",
"yo",
"zu",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53 finetuned on multi-lingual Common Voice
This checkpoint leverages the pretrained checkpoint [wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
and is fine-tuned on [CommonVoice](https://huggingface.co/datasets/common_voice) to recognize phonetic labels in multiple languages.
When using the model make sure that your speech input is sampled at 16kHz.
Note that the model outputs a string of phonetic labels. A dictionary mapping phonetic labels to words
has to be used to map the phonetic output labels to output words.
[Paper: Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
Authors: Qiantong Xu, Alexei Baevski, Michael Auli
**Abstract**
Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech recognition systems without any labeled data. However, in many cases there is labeled data available for related languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by mapping phonemes of the training languages to the target language using articulatory features. Experiments show that this simple method significantly outperforms prior work which introduced task-specific architectures and used only part of a monolingually pretrained model.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-xlsr-53-espeak-cv-ft")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-xlsr-53-espeak-cv-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['m ɪ s t ɚ k w ɪ l t ɚ ɪ z ð ɪ ɐ p ɑː s əl l ʌ v ð ə m ɪ d əl k l æ s ɪ z æ n d w iː aʊ ɡ l æ d t ə w ɛ l k ə m h ɪ z ɡ ɑː s p ə']
```
|
{"language": "multi-lingual", "license": "apache-2.0", "tags": ["speech", "audio", "automatic-speech-recognition", "phoneme-recognition"], "datasets": ["common_voice"], "widget": [{"example_title": "Librispeech sample 1", "src": "https://cdn-media.huggingface.co/speech_samples/sample1.flac"}, {"example_title": "Librispeech sample 2", "src": "https://cdn-media.huggingface.co/speech_samples/sample2.flac"}]}
|
facebook/wav2vec2-xlsr-53-espeak-cv-ft
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"phoneme-recognition",
"dataset:common_voice",
"arxiv:2109.11680",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
{}
|
facebook/wav2vec2-xlsr-53-phon-cv-babel-ft
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
automatic-speech-recognition
|
transformers
|
{}
|
facebook/wav2vec2-xlsr-53-phon-cv-ft
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
translation
|
transformers
|
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for de-en.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-de-en"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Maschinelles Lernen ist großartig, oder?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
de-en | [42.3](http://matrix.statmt.org/matrix/output/1902?run_id=6750) | 41.35
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
|
{"language": ["de", "en"], "license": "apache-2.0", "tags": ["translation", "wmt19", "facebook"], "datasets": ["wmt19"], "metrics": ["bleu"], "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png"}
|
facebook/wmt19-de-en
| null |
[
"transformers",
"pytorch",
"safetensors",
"fsmt",
"text2text-generation",
"translation",
"wmt19",
"facebook",
"de",
"en",
"dataset:wmt19",
"arxiv:1907.06616",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
translation
|
transformers
|
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for en-de.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-en-de"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, oder?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
en-de | [43.1](http://matrix.statmt.org/matrix/output/1909?run_id=6862) | 42.83
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
|
{"language": ["en", "de"], "license": "apache-2.0", "tags": ["translation", "wmt19", "facebook"], "datasets": ["wmt19"], "metrics": ["bleu"], "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png"}
|
facebook/wmt19-en-de
| null |
[
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt19",
"facebook",
"en",
"de",
"dataset:wmt19",
"arxiv:1907.06616",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
translation
|
transformers
|
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for en-ru.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-en-ru"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Машинное обучение - это здорово, не так ли?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
en-ru | [36.4](http://matrix.statmt.org/matrix/output/1914?run_id=6724) | 33.47
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-ru
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
|
{"language": ["en", "ru"], "license": "apache-2.0", "tags": ["translation", "wmt19", "facebook"], "datasets": ["wmt19"], "metrics": ["bleu"], "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png"}
|
facebook/wmt19-en-ru
| null |
[
"transformers",
"pytorch",
"fsmt",
"text2text-generation",
"translation",
"wmt19",
"facebook",
"en",
"ru",
"dataset:wmt19",
"arxiv:1907.06616",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
translation
|
transformers
|
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for ru-en.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-ru-en"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Машинное обучение - это здорово, не так ли?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
ru-en | [41.3](http://matrix.statmt.org/matrix/output/1907?run_id=6937) | 39.20
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=ru-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
|
{"language": ["ru", "en"], "license": "apache-2.0", "tags": ["translation", "wmt19", "facebook"], "datasets": ["wmt19"], "metrics": ["bleu"], "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png"}
|
facebook/wmt19-ru-en
| null |
[
"transformers",
"pytorch",
"safetensors",
"fsmt",
"text2text-generation",
"translation",
"wmt19",
"facebook",
"ru",
"en",
"dataset:wmt19",
"arxiv:1907.06616",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
translation
|
transformers
|
# WMT 21 En-X
WMT 21 En-X is a 4.7B multilingual encoder-decoder (seq-to-seq) model trained for one-to-many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2108.03265) and first released in [this](https://github.com/pytorch/fairseq/tree/main/examples/wmt21) repository.
The model can directly translate English text into 7 other languages: Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de).
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
Since the model was trained with domain tags, you should prepend them to the input as well.
* "wmtdata newsdomain": Use for sentences in the news domain
* "wmtdata otherdomain": Use for sentences in all other domain
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/wmt21-dense-24-wide-en-x")
tokenizer = AutoTokenizer.from_pretrained("facebook/wmt21-dense-24-wide-en-x")
inputs = tokenizer("wmtdata newsdomain One model for many languages.", return_tensors="pt")
# translate English to German
generated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.get_lang_id("de"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Ein Modell für viele Sprachen."
# translate English to Icelandic
generated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.get_lang_id("is"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Ein fyrirmynd fyrir mörg tungumál."
```
See the [model hub](https://huggingface.co/models?filter=wmt21) to look for more fine-tuned versions.
## Languages covered
English (en), Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de)
## BibTeX entry and citation info
```
@inproceedings{tran2021facebook
title={Facebook AI’s WMT21 News Translation Task Submission},
author={Chau Tran and Shruti Bhosale and James Cross and Philipp Koehn and Sergey Edunov and Angela Fan},
booktitle={Proc. of WMT},
year={2021},
}
```
|
{"language": ["multilingual", "ha", "is", "ja", "cs", "ru", "zh", "de", "en"], "license": "mit", "tags": ["translation", "wmt21"]}
|
facebook/wmt21-dense-24-wide-en-x
| null |
[
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"translation",
"wmt21",
"multilingual",
"ha",
"is",
"ja",
"cs",
"ru",
"zh",
"de",
"en",
"arxiv:2108.03265",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
translation
|
transformers
|
# WMT 21 X-En
WMT 21 X-En is a 4.7B multilingual encoder-decoder (seq-to-seq) model trained for one-to-many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2108.03265) and first released in [this](https://github.com/pytorch/fairseq/tree/main/examples/wmt21) repository.
The model can directly translate text from 7 languages: Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de) to English.
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
Since the model was trained with domain tags, you should prepend them to the input as well.
* "wmtdata newsdomain": Use for sentences in the news domain
* "wmtdata otherdomain": Use for sentences in all other domain
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/wmt21-dense-24-wide-x-en")
tokenizer = AutoTokenizer.from_pretrained("facebook/wmt21-dense-24-wide-x-en")
# translate German to English
tokenizer.src_lang = "de"
inputs = tokenizer("wmtdata newsdomain Ein Modell für viele Sprachen", return_tensors="pt")
generated_tokens = model.generate(**inputs)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "A model for many languages"
# translate Icelandic to English
tokenizer.src_lang = "is"
inputs = tokenizer("wmtdata newsdomain Ein fyrirmynd fyrir mörg tungumál", return_tensors="pt")
generated_tokens = model.generate(**inputs)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "One model for many languages"
```
See the [model hub](https://huggingface.co/models?filter=wmt21) to look for more fine-tuned versions.
## Languages covered
English (en), Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de)
## BibTeX entry and citation info
```
@inproceedings{tran2021facebook
title={Facebook AI’s WMT21 News Translation Task Submission},
author={Chau Tran and Shruti Bhosale and James Cross and Philipp Koehn and Sergey Edunov and Angela Fan},
booktitle={Proc. of WMT},
year={2021},
}
```
|
{"language": ["multilingual", "ha", "is", "ja", "cs", "ru", "zh", "de", "en"], "license": "mit", "tags": ["translation", "wmt21"]}
|
facebook/wmt21-dense-24-wide-x-en
| null |
[
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"translation",
"wmt21",
"multilingual",
"ha",
"is",
"ja",
"cs",
"ru",
"zh",
"de",
"en",
"arxiv:2108.03265",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# XGLM-1.7B
XGLM-1.7B is a multilingual autoregressive language model (with 1.7 billion parameters) trained on a balanced corpus of a diverse set of languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-1.7B is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-1.7B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-1.7B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-1.7B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
```
|
{"language": ["multilingual", "en", "ru", "zh", "de", "es", "fr", "ja", "it", "pt", "el", "ko", "fi", "id", "tr", "ar", "vi", "th", "bg", "ca", "hi", "et", "bn", "ta", "ur", "sw", "te", "eu", "my", "ht", "qu"], "license": "mit", "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png", "inference": false}
|
facebook/xglm-1.7B
| null |
[
"transformers",
"pytorch",
"tf",
"xglm",
"text-generation",
"multilingual",
"en",
"ru",
"zh",
"de",
"es",
"fr",
"ja",
"it",
"pt",
"el",
"ko",
"fi",
"id",
"tr",
"ar",
"vi",
"th",
"bg",
"ca",
"hi",
"et",
"bn",
"ta",
"ur",
"sw",
"te",
"eu",
"my",
"ht",
"qu",
"arxiv:2112.10668",
"license:mit",
"autotrain_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# XGLM-2.9B
XGLM-2.9B is a multilingual autoregressive language model (with 2.9 billion parameters) trained on a balanced corpus of a diverse set of languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-2.9B is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-2.9B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-2.9B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-2.9B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
```
|
{"language": ["multilingual", "en", "ru", "zh", "de", "es", "fr", "ja", "it", "pt", "el", "ko", "fi", "id", "tr", "ar", "vi", "th", "bg", "ca", "hi", "et", "bn", "ta", "ur", "sw", "te", "eu", "my", "ht", "qu"], "license": "mit", "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png", "inference": false}
|
facebook/xglm-2.9B
| null |
[
"transformers",
"pytorch",
"xglm",
"text-generation",
"multilingual",
"en",
"ru",
"zh",
"de",
"es",
"fr",
"ja",
"it",
"pt",
"el",
"ko",
"fi",
"id",
"tr",
"ar",
"vi",
"th",
"bg",
"ca",
"hi",
"et",
"bn",
"ta",
"ur",
"sw",
"te",
"eu",
"my",
"ht",
"qu",
"arxiv:2112.10668",
"license:mit",
"autotrain_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# XGLM-4.5B
XGLM-4.5B is a multilingual autoregressive language model (with 4.5 billion parameters) trained on a balanced corpus of a diverse set of 134 languages. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-4.5B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-4.5B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-4.5B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
```
|
{"language": ["multilingual", "en", "ru", "zh", "de", "es", "fr", "ja", "it", "pt", "el", "ko", "fi", "id", "tr", "ar", "vi", "th", "bg", "ca", "hi", "et", "bn", "ta", "ur", "sw", "te", "eu", "my", "ht", "qu"], "license": "mit", "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png", "inference": false}
|
facebook/xglm-4.5B
| null |
[
"transformers",
"pytorch",
"safetensors",
"xglm",
"text-generation",
"multilingual",
"en",
"ru",
"zh",
"de",
"es",
"fr",
"ja",
"it",
"pt",
"el",
"ko",
"fi",
"id",
"tr",
"ar",
"vi",
"th",
"bg",
"ca",
"hi",
"et",
"bn",
"ta",
"ur",
"sw",
"te",
"eu",
"my",
"ht",
"qu",
"arxiv:2112.10668",
"license:mit",
"autotrain_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# XGLM-564M
XGLM-564M is a multilingual autoregressive language model (with 564 million parameters) trained on a balanced corpus of a diverse set of 30 languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-564M is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-564M development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-564M")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-564M")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
```
|
{"language": ["multilingual", "en", "ru", "zh", "de", "es", "fr", "ja", "it", "pt", "el", "ko", "fi", "id", "tr", "ar", "vi", "th", "bg", "ca", "hi", "et", "bn", "ta", "ur", "sw", "te", "eu", "my", "ht", "qu"], "license": "mit", "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png", "inference": false}
|
facebook/xglm-564M
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"xglm",
"text-generation",
"multilingual",
"en",
"ru",
"zh",
"de",
"es",
"fr",
"ja",
"it",
"pt",
"el",
"ko",
"fi",
"id",
"tr",
"ar",
"vi",
"th",
"bg",
"ca",
"hi",
"et",
"bn",
"ta",
"ur",
"sw",
"te",
"eu",
"my",
"ht",
"qu",
"arxiv:2112.10668",
"license:mit",
"autotrain_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# XGLM-7.5B
XGLM-7.5B is a multilingual autoregressive language model (with 7.5 billion parameters) trained on a balanced corpus of a diverse set of languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-7.5B is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-7.5B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-7.5B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-7.5B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
```
|
{"language": ["multilingual", "en", "ru", "zh", "de", "es", "fr", "ja", "it", "pt", "el", "ko", "fi", "id", "tr", "ar", "vi", "th", "bg", "ca", "hi", "et", "bn", "ta", "ur", "sw", "te", "eu", "my", "ht", "qu"], "license": "mit", "thumbnail": "https://huggingface.co/front/thumbnails/facebook.png", "inference": false}
|
facebook/xglm-7.5B
| null |
[
"transformers",
"pytorch",
"xglm",
"text-generation",
"multilingual",
"en",
"ru",
"zh",
"de",
"es",
"fr",
"ja",
"it",
"pt",
"el",
"ko",
"fi",
"id",
"tr",
"ar",
"vi",
"th",
"bg",
"ca",
"hi",
"et",
"bn",
"ta",
"ur",
"sw",
"te",
"eu",
"my",
"ht",
"qu",
"arxiv:2112.10668",
"license:mit",
"autotrain_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# XLM-RoBERTa-XL (xlarge-sized model)
XLM-RoBERTa-XL model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
Disclaimer: The team releasing XLM-RoBERTa-XL did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLM-RoBERTa-XL is a extra large multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages.
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa-XL model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlm-roberta-xl) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='facebook/xlm-roberta-xl')
>>> unmasker("Europe is a <mask> continent.")
[{'score': 0.08562745153903961,
'token': 38043,
'token_str': 'living',
'sequence': 'Europe is a living continent.'},
{'score': 0.0799778401851654,
'token': 103494,
'token_str': 'dead',
'sequence': 'Europe is a dead continent.'},
{'score': 0.046154674142599106,
'token': 72856,
'token_str': 'lost',
'sequence': 'Europe is a lost continent.'},
{'score': 0.04358183592557907,
'token': 19336,
'token_str': 'small',
'sequence': 'Europe is a small continent.'},
{'score': 0.040570393204689026,
'token': 34923,
'token_str': 'beautiful',
'sequence': 'Europe is a beautiful continent.'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('facebook/xlm-roberta-xl')
model = AutoModelForMaskedLM.from_pretrained("facebook/xlm-roberta-xl")
# prepare input
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
# forward pass
output = model(**encoded_input)
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-00572,
author = {Naman Goyal and
Jingfei Du and
Myle Ott and
Giri Anantharaman and
Alexis Conneau},
title = {Larger-Scale Transformers for Multilingual Masked Language Modeling},
journal = {CoRR},
volume = {abs/2105.00572},
year = {2021},
url = {https://arxiv.org/abs/2105.00572},
eprinttype = {arXiv},
eprint = {2105.00572},
timestamp = {Wed, 12 May 2021 15:54:31 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-00572.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
{"language": ["multilingual", "af", "am", "ar", "as", "az", "be", "bg", "bn", "br", "bs", "ca", "cs", "cy", "da", "de", "el", "en", "eo", "es", "et", "eu", "fa", "fi", "fr", "fy", "ga", "gd", "gl", "gu", "ha", "he", "hi", "hr", "hu", "hy", "id", "is", "it", "ja", "jv", "ka", "kk", "km", "kn", "ko", "ku", "ky", "la", "lo", "lt", "lv", "mg", "mk", "ml", "mn", "mr", "ms", "my", "ne", "nl", false, "om", "or", "pa", "pl", "ps", "pt", "ro", "ru", "sa", "sd", "si", "sk", "sl", "so", "sq", "sr", "su", "sv", "sw", "ta", "te", "th", "tl", "tr", "ug", "uk", "ur", "uz", "vi", "xh", "yi", "zh"], "license": "mit"}
|
facebook/xlm-roberta-xl
| null |
[
"transformers",
"pytorch",
"xlm-roberta-xl",
"fill-mask",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2105.00572",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# XLM-RoBERTa-XL (xxlarge-sized model)
XLM-RoBERTa-XL model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
Disclaimer: The team releasing XLM-RoBERTa-XL did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLM-RoBERTa-XL is a extra large multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages.
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa-XL model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlm-roberta-xl) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='facebook/xlm-roberta-xxl')
>>> unmasker("Europe is a <mask> continent.")
[{'score': 0.22996895015239716,
'token': 28811,
'token_str': 'European',
'sequence': 'Europe is a European continent.'},
{'score': 0.14307449758052826,
'token': 21334,
'token_str': 'large',
'sequence': 'Europe is a large continent.'},
{'score': 0.12239163368940353,
'token': 19336,
'token_str': 'small',
'sequence': 'Europe is a small continent.'},
{'score': 0.07025063782930374,
'token': 18410,
'token_str': 'vast',
'sequence': 'Europe is a vast continent.'},
{'score': 0.032869212329387665,
'token': 6957,
'token_str': 'big',
'sequence': 'Europe is a big continent.'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('facebook/xlm-roberta-xxl')
model = AutoModelForMaskedLM.from_pretrained("facebook/xlm-roberta-xxl")
# prepare input
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
# forward pass
output = model(**encoded_input)
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-00572,
author = {Naman Goyal and
Jingfei Du and
Myle Ott and
Giri Anantharaman and
Alexis Conneau},
title = {Larger-Scale Transformers for Multilingual Masked Language Modeling},
journal = {CoRR},
volume = {abs/2105.00572},
year = {2021},
url = {https://arxiv.org/abs/2105.00572},
eprinttype = {arXiv},
eprint = {2105.00572},
timestamp = {Wed, 12 May 2021 15:54:31 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-00572.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
{"language": ["multilingual", "af", "am", "ar", "as", "az", "be", "bg", "bn", "br", "bs", "ca", "cs", "cy", "da", "de", "el", "en", "eo", "es", "et", "eu", "fa", "fi", "fr", "fy", "ga", "gd", "gl", "gu", "ha", "he", "hi", "hr", "hu", "hy", "id", "is", "it", "ja", "jv", "ka", "kk", "km", "kn", "ko", "ku", "ky", "la", "lo", "lt", "lv", "mg", "mk", "ml", "mn", "mr", "ms", "my", "ne", "nl", false, "om", "or", "pa", "pl", "ps", "pt", "ro", "ru", "sa", "sd", "si", "sk", "sl", "so", "sq", "sr", "su", "sv", "sw", "ta", "te", "th", "tl", "tr", "ug", "uk", "ur", "uz", "vi", "xh", "yi", "zh"], "license": "mit"}
|
facebook/xlm-roberta-xxl
| null |
[
"transformers",
"pytorch",
"xlm-roberta-xl",
"fill-mask",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2105.00572",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-en_ar-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Arabic
- Trained on MuST-C, CoVoST 2, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-ar-cv7](https://huggingface.co/facebook/tts_transformer-ar-cv7)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_ar-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-ar-cv7",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
{"language": "en-ar", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["must_c", "covost2"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3"}]}
|
facebook/xm_transformer_600m-en_ar-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:must_c",
"dataset:covost2",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-en_es-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Spanish
- Trained on MuST-C, EuroParl-ST, VoxPopuli, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-es-css10](https://huggingface.co/facebook/tts_transformer-es-css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_es-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-es-css10",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
{"language": "en-es", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["must_c", "europarl_st", "voxpopuli"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3"}]}
|
facebook/xm_transformer_600m-en_es-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:must_c",
"dataset:europarl_st",
"dataset:voxpopuli",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-en_fr-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-French
- Trained on MuST-C, EuroParl-ST, VoxPopuli, LibriTrans, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-fr-cv7_css10](https://huggingface.co/facebook/tts_transformer-fr-cv7_css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_fr-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-fr-cv7_css10",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
{"language": "en-fr", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["must_c", "europarl_st", "voxpopuli", "libritrans"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3"}]}
|
facebook/xm_transformer_600m-en_fr-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:must_c",
"dataset:europarl_st",
"dataset:voxpopuli",
"dataset:libritrans",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-en_ru-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Russian
- Trained on MuST-C, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-ru-cv7_css10](https://huggingface.co/facebook/tts_transformer-ru-cv7_css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_ru-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-ru-cv7_css10",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
{"language": "en-ru", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["must_c"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3"}]}
|
facebook/xm_transformer_600m-en_ru-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:must_c",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-en_tr-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Turkish
- Trained on MuST-C, CoVoST 2, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-tr-cv7](https://huggingface.co/facebook/tts_transformer-tr-cv7)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_tr-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-tr-cv7",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
{"language": "en-tr", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["must_c", "covost2"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3"}]}
|
facebook/xm_transformer_600m-en_tr-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:must_c",
"dataset:covost2",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-en_vi-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Vietnamese
- Trained on MuST-C, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-vi-cv7](https://huggingface.co/facebook/tts_transformer-vi-cv7)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_vi-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-vi-cv7",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
{"language": "en-vi", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["must_c"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3"}]}
|
facebook/xm_transformer_600m-en_vi-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:must_c",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-en_zh-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Chinese
- Trained on MuST-C, CoVoST 2, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-zh-cv7_css10](https://huggingface.co/facebook/tts_transformer-zh-cv7_css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_zh-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-zh-cv7_css10",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
{"language": "en-zh", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["must_c", "covost2"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3"}]}
|
facebook/xm_transformer_600m-en_zh-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:must_c",
"dataset:covost2",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-es_en-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- Spanish-English
- Trained on mTEDx, CoVoST 2, EuroParl-ST, VoxPopuli, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/fastspeech2-en-ljspeech](https://huggingface.co/facebook/fastspeech2-en-ljspeech)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-es_en-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/fastspeech2-en-ljspeech",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
{"language": "es-en", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["mtedx", "covost2", "europarl_st", "voxpopuli"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-es_en-multi_domain/resolve/main/common_voice_es_19966634.flac"}]}
|
facebook/xm_transformer_600m-es_en-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:mtedx",
"dataset:covost2",
"dataset:europarl_st",
"dataset:voxpopuli",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-fr_en-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- French-English
- Trained on mTEDx, CoVoST 2, EuroParl-ST, VoxPopuli, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/fastspeech2-en-ljspeech](https://huggingface.co/facebook/fastspeech2-en-ljspeech)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-fr_en-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/fastspeech2-en-ljspeech",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
{"language": "fr-en", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["mtedx", "covost2", "europarl_st", "voxpopuli"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-fr_en-multi_domain/resolve/main/common_voice_fr_19731305.mp3"}]}
|
facebook/xm_transformer_600m-fr_en-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:mtedx",
"dataset:covost2",
"dataset:europarl_st",
"dataset:voxpopuli",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
audio-to-audio
|
fairseq
|
# xm_transformer_600m-ru_en-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- Russian-English
- Trained on mTEDx, CoVoST 2, OpenSTT, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/fastspeech2-en-ljspeech](https://huggingface.co/facebook/fastspeech2-en-ljspeech)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-ru_en-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/fastspeech2-en-ljspeech",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
{"language": "ru-en", "library_name": "fairseq", "tags": ["fairseq", "audio", "audio-to-audio", "speech-to-speech-translation"], "datasets": ["mtedx", "covost2"], "task": "audio-to-audio", "widget": [{"example_title": "Common Voice sample 1", "src": "https://huggingface.co/facebook/xm_transformer_600m-ru_en-multi_domain/resolve/main/common_voice_ru_18945535.flac"}]}
|
facebook/xm_transformer_600m-ru_en-multi_domain
| null |
[
"fairseq",
"audio",
"audio-to-audio",
"speech-to-speech-translation",
"dataset:mtedx",
"dataset:covost2",
"arxiv:2010.05171",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola-3
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0002
- Matthews Correlation: 1.0
Label 0 : "AIMX"
Label 1 : "OWNX"
Label 2 : "CONT"
Label 3 : "BASE"
Label 4 : "MISC"
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 192 | 0.0060 | 1.0 |
| No log | 2.0 | 384 | 0.0019 | 1.0 |
| 0.0826 | 3.0 | 576 | 0.0010 | 1.0 |
| 0.0826 | 4.0 | 768 | 0.0006 | 1.0 |
| 0.0826 | 5.0 | 960 | 0.0005 | 1.0 |
| 0.001 | 6.0 | 1152 | 0.0004 | 1.0 |
| 0.001 | 7.0 | 1344 | 0.0003 | 1.0 |
| 0.0005 | 8.0 | 1536 | 0.0003 | 1.0 |
| 0.0005 | 9.0 | 1728 | 0.0002 | 1.0 |
| 0.0005 | 10.0 | 1920 | 0.0002 | 1.0 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["matthews_correlation"], "model-index": [{"name": "distilbert-base-uncased-finetuned-cola-3", "results": []}]}
|
fadhilarkan/distilbert-base-uncased-finetuned-cola-3
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola-4
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0011
- Matthews Correlation: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 104 | 0.0243 | 1.0 |
| No log | 2.0 | 208 | 0.0074 | 1.0 |
| No log | 3.0 | 312 | 0.0041 | 1.0 |
| No log | 4.0 | 416 | 0.0028 | 1.0 |
| 0.0929 | 5.0 | 520 | 0.0021 | 1.0 |
| 0.0929 | 6.0 | 624 | 0.0016 | 1.0 |
| 0.0929 | 7.0 | 728 | 0.0014 | 1.0 |
| 0.0929 | 8.0 | 832 | 0.0012 | 1.0 |
| 0.0929 | 9.0 | 936 | 0.0012 | 1.0 |
| 0.0021 | 10.0 | 1040 | 0.0011 | 1.0 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["matthews_correlation"], "model-index": [{"name": "distilbert-base-uncased-finetuned-cola-4", "results": []}]}
|
fadhilarkan/distilbert-base-uncased-finetuned-cola-4
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0008
- Matthews Correlation: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 130 | 0.0166 | 1.0 |
| No log | 2.0 | 260 | 0.0054 | 1.0 |
| No log | 3.0 | 390 | 0.0029 | 1.0 |
| 0.0968 | 4.0 | 520 | 0.0019 | 1.0 |
| 0.0968 | 5.0 | 650 | 0.0014 | 1.0 |
| 0.0968 | 6.0 | 780 | 0.0011 | 1.0 |
| 0.0968 | 7.0 | 910 | 0.0010 | 1.0 |
| 0.0018 | 8.0 | 1040 | 0.0008 | 1.0 |
| 0.0018 | 9.0 | 1170 | 0.0008 | 1.0 |
| 0.0018 | 10.0 | 1300 | 0.0008 | 1.0 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["matthews_correlation"], "model-index": [{"name": "distilbert-base-uncased-finetuned-cola", "results": []}]}
|
fadhilarkan/distilbert-base-uncased-finetuned-cola
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
question-answering
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1523
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2171 | 1.0 | 5533 | 1.1511 |
| 0.952 | 2.0 | 11066 | 1.1180 |
| 0.7707 | 3.0 | 16599 | 1.1523 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["squad"], "model_index": [{"name": "distilbert-base-uncased-finetuned-squad", "results": [{"task": {"name": "Question Answering", "type": "question-answering"}, "dataset": {"name": "squad", "type": "squad", "args": "plain_text"}}]}]}
|
fadhilarkan/distilbert-base-uncased-finetuned-squad
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gq-indo-k
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7905
- Rouge1: 22.5734
- Rouge2: 6.555
- Rougel: 20.9491
- Rougelsum: 20.9509
- Gen Len: 12.0767
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.9355 | 1.0 | 13032 | 2.8563 | 22.4828 | 6.5456 | 20.8782 | 20.8772 | 11.915 |
| 2.825 | 2.0 | 26064 | 2.7993 | 22.547 | 6.5815 | 20.8937 | 20.8973 | 12.0886 |
| 2.7631 | 3.0 | 39096 | 2.7905 | 22.5734 | 6.555 | 20.9491 | 20.9509 | 12.0767 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{"metrics": ["rouge"]}
|
fadhilarkan/gq-indo-k
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
question-answering
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qa-indo-k
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4984
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2537 | 1.0 | 8209 | 1.9642 |
| 0.943 | 2.0 | 16418 | 2.2143 |
| 0.6694 | 3.0 | 24627 | 2.4984 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{}
|
fadhilarkan/qa-indo-k
| null |
[
"transformers",
"pytorch",
"albert",
"question-answering",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qa-indo-math-k-v2
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9328
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 80 | 0.7969 |
| No log | 2.0 | 160 | 0.7612 |
| No log | 3.0 | 240 | 0.7624 |
| No log | 4.0 | 320 | 0.7424 |
| No log | 5.0 | 400 | 0.7634 |
| No log | 6.0 | 480 | 0.7415 |
| 0.9241 | 7.0 | 560 | 0.7219 |
| 0.9241 | 8.0 | 640 | 0.7792 |
| 0.9241 | 9.0 | 720 | 0.7803 |
| 0.9241 | 10.0 | 800 | 0.7666 |
| 0.9241 | 11.0 | 880 | 0.7614 |
| 0.9241 | 12.0 | 960 | 0.7616 |
| 0.6373 | 13.0 | 1040 | 0.7673 |
| 0.6373 | 14.0 | 1120 | 0.7818 |
| 0.6373 | 15.0 | 1200 | 0.8030 |
| 0.6373 | 16.0 | 1280 | 0.8021 |
| 0.6373 | 17.0 | 1360 | 0.8025 |
| 0.6373 | 18.0 | 1440 | 0.8628 |
| 0.5614 | 19.0 | 1520 | 0.8616 |
| 0.5614 | 20.0 | 1600 | 0.8739 |
| 0.5614 | 21.0 | 1680 | 0.8647 |
| 0.5614 | 22.0 | 1760 | 0.9006 |
| 0.5614 | 23.0 | 1840 | 0.9560 |
| 0.5614 | 24.0 | 1920 | 0.9395 |
| 0.486 | 25.0 | 2000 | 0.9453 |
| 0.486 | 26.0 | 2080 | 0.9569 |
| 0.486 | 27.0 | 2160 | 1.0208 |
| 0.486 | 28.0 | 2240 | 0.9860 |
| 0.486 | 29.0 | 2320 | 0.9806 |
| 0.486 | 30.0 | 2400 | 1.0681 |
| 0.486 | 31.0 | 2480 | 1.1085 |
| 0.4126 | 32.0 | 2560 | 1.1028 |
| 0.4126 | 33.0 | 2640 | 1.1110 |
| 0.4126 | 34.0 | 2720 | 1.1573 |
| 0.4126 | 35.0 | 2800 | 1.1387 |
| 0.4126 | 36.0 | 2880 | 1.2067 |
| 0.4126 | 37.0 | 2960 | 1.2079 |
| 0.3559 | 38.0 | 3040 | 1.2152 |
| 0.3559 | 39.0 | 3120 | 1.2418 |
| 0.3559 | 40.0 | 3200 | 1.2023 |
| 0.3559 | 41.0 | 3280 | 1.2679 |
| 0.3559 | 42.0 | 3360 | 1.3178 |
| 0.3559 | 43.0 | 3440 | 1.3419 |
| 0.3084 | 44.0 | 3520 | 1.4702 |
| 0.3084 | 45.0 | 3600 | 1.3824 |
| 0.3084 | 46.0 | 3680 | 1.4227 |
| 0.3084 | 47.0 | 3760 | 1.3925 |
| 0.3084 | 48.0 | 3840 | 1.4940 |
| 0.3084 | 49.0 | 3920 | 1.4110 |
| 0.2686 | 50.0 | 4000 | 1.4534 |
| 0.2686 | 51.0 | 4080 | 1.4749 |
| 0.2686 | 52.0 | 4160 | 1.5351 |
| 0.2686 | 53.0 | 4240 | 1.5479 |
| 0.2686 | 54.0 | 4320 | 1.4755 |
| 0.2686 | 55.0 | 4400 | 1.5207 |
| 0.2686 | 56.0 | 4480 | 1.5075 |
| 0.2388 | 57.0 | 4560 | 1.5470 |
| 0.2388 | 58.0 | 4640 | 1.5361 |
| 0.2388 | 59.0 | 4720 | 1.5914 |
| 0.2388 | 60.0 | 4800 | 1.6430 |
| 0.2388 | 61.0 | 4880 | 1.6249 |
| 0.2388 | 62.0 | 4960 | 1.5503 |
| 0.2046 | 63.0 | 5040 | 1.6441 |
| 0.2046 | 64.0 | 5120 | 1.6789 |
| 0.2046 | 65.0 | 5200 | 1.6174 |
| 0.2046 | 66.0 | 5280 | 1.6175 |
| 0.2046 | 67.0 | 5360 | 1.6947 |
| 0.2046 | 68.0 | 5440 | 1.6299 |
| 0.1891 | 69.0 | 5520 | 1.7419 |
| 0.1891 | 70.0 | 5600 | 1.8442 |
| 0.1891 | 71.0 | 5680 | 1.8802 |
| 0.1891 | 72.0 | 5760 | 1.8233 |
| 0.1891 | 73.0 | 5840 | 1.8172 |
| 0.1891 | 74.0 | 5920 | 1.8181 |
| 0.1664 | 75.0 | 6000 | 1.8399 |
| 0.1664 | 76.0 | 6080 | 1.8128 |
| 0.1664 | 77.0 | 6160 | 1.8423 |
| 0.1664 | 78.0 | 6240 | 1.8380 |
| 0.1664 | 79.0 | 6320 | 1.8941 |
| 0.1664 | 80.0 | 6400 | 1.8636 |
| 0.1664 | 81.0 | 6480 | 1.7949 |
| 0.1614 | 82.0 | 6560 | 1.8342 |
| 0.1614 | 83.0 | 6640 | 1.8123 |
| 0.1614 | 84.0 | 6720 | 1.8639 |
| 0.1614 | 85.0 | 6800 | 1.8580 |
| 0.1614 | 86.0 | 6880 | 1.8816 |
| 0.1614 | 87.0 | 6960 | 1.8579 |
| 0.1487 | 88.0 | 7040 | 1.8783 |
| 0.1487 | 89.0 | 7120 | 1.9175 |
| 0.1487 | 90.0 | 7200 | 1.9025 |
| 0.1487 | 91.0 | 7280 | 1.9207 |
| 0.1487 | 92.0 | 7360 | 1.9195 |
| 0.1487 | 93.0 | 7440 | 1.9142 |
| 0.1355 | 94.0 | 7520 | 1.9333 |
| 0.1355 | 95.0 | 7600 | 1.9238 |
| 0.1355 | 96.0 | 7680 | 1.9256 |
| 0.1355 | 97.0 | 7760 | 1.9305 |
| 0.1355 | 98.0 | 7840 | 1.9294 |
| 0.1355 | 99.0 | 7920 | 1.9301 |
| 0.1297 | 100.0 | 8000 | 1.9328 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{}
|
fadhilarkan/qa-indo-math-k-v2
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qa-indo-math-k
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8801
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 127 | 0.7652 |
| No log | 2.0 | 254 | 0.7520 |
| No log | 3.0 | 381 | 0.7681 |
| 0.9618 | 4.0 | 508 | 0.7337 |
| 0.9618 | 5.0 | 635 | 0.7560 |
| 0.9618 | 6.0 | 762 | 0.7397 |
| 0.9618 | 7.0 | 889 | 0.7298 |
| 0.6652 | 8.0 | 1016 | 0.7891 |
| 0.6652 | 9.0 | 1143 | 0.7874 |
| 0.6652 | 10.0 | 1270 | 0.7759 |
| 0.6652 | 11.0 | 1397 | 0.7505 |
| 0.6174 | 12.0 | 1524 | 0.7838 |
| 0.6174 | 13.0 | 1651 | 0.7878 |
| 0.6174 | 14.0 | 1778 | 0.8028 |
| 0.6174 | 15.0 | 1905 | 0.8154 |
| 0.5733 | 16.0 | 2032 | 0.8131 |
| 0.5733 | 17.0 | 2159 | 0.8278 |
| 0.5733 | 18.0 | 2286 | 0.8308 |
| 0.5733 | 19.0 | 2413 | 0.8433 |
| 0.5378 | 20.0 | 2540 | 0.8303 |
| 0.5378 | 21.0 | 2667 | 0.8352 |
| 0.5378 | 22.0 | 2794 | 0.8369 |
| 0.5378 | 23.0 | 2921 | 0.8518 |
| 0.5095 | 24.0 | 3048 | 0.8749 |
| 0.5095 | 25.0 | 3175 | 0.8533 |
| 0.5095 | 26.0 | 3302 | 0.8547 |
| 0.5095 | 27.0 | 3429 | 0.8844 |
| 0.4856 | 28.0 | 3556 | 0.8752 |
| 0.4856 | 29.0 | 3683 | 0.8804 |
| 0.4856 | 30.0 | 3810 | 0.8801 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{}
|
fadhilarkan/qa-indo-math-k
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9536
- Rouge1: 28.8137
- Rouge2: 9.1265
- Rougel: 26.0238
- Rougelsum: 26.0217
- Gen Len: 13.854
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.2142 | 1.0 | 8760 | 1.9994 | 29.007 | 9.2583 | 26.2377 | 26.2356 | 13.4546 |
| 2.1372 | 2.0 | 17520 | 1.9622 | 29.1077 | 9.445 | 26.3734 | 26.3687 | 13.6995 |
| 2.0755 | 3.0 | 26280 | 1.9536 | 28.8137 | 9.1265 | 26.0238 | 26.0217 | 13.854 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["squad"], "metrics": ["rouge"], "model_index": [{"name": "t5-small-finetuned-xsum-2", "results": [{"task": {"name": "Sequence-to-sequence Language Modeling", "type": "text2text-generation"}, "dataset": {"name": "squad", "type": "squad", "args": "plain_text"}, "metric": {"name": "Rouge1", "type": "rouge", "value": 28.8137}}]}]}
|
fadhilarkan/t5-small-finetuned-xsum-2
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["squad"], "model_index": [{"name": "t5-small-finetuned-xsum", "results": [{"task": {"name": "Sequence-to-sequence Language Modeling", "type": "text2text-generation"}, "dataset": {"name": "squad", "type": "squad", "args": "plain_text"}}]}]}
|
fadhilarkan/t5-small-finetuned-xsum
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
{}
|
fadhilarkan/t5_paw_global
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-summarization
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4740
- Rouge1: 28.3487
- Rouge2: 7.7836
- Rougel: 22.3307
- Rougelsum: 22.3357
- Gen Len: 18.8307
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 14
- eval_batch_size: 14
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.7042 | 1.0 | 14575 | 2.4740 | 28.3487 | 7.7836 | 22.3307 | 22.3357 | 18.8307 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{"metrics": ["rouge"]}
|
fadhilarkan/test-summarization
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
{}
|
fadhilarkan/tmpr60526f6
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
{}
|
fadhilarkan/tmpvqruuuz0
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
fagner/envoy
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
faizank2/bhand
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
faizank2/legal-ner
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
faizankhan29/distilbert-base-uncased-finetuned-squad
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
faizankhan29/distilbert-base-uncased
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
faizraza/temp1
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
faketermz/Bottest
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# test DialoGPT Model
|
{"tags": ["conversational"]}
|
faketermz/DialoGPT
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
token-classification
|
transformers
|
{}
|
famodde/optimizer-ner-fineTune-lst2021
| null |
[
"transformers",
"pytorch",
"camembert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
famodde/optimizer-ner-fineTune
| null |
[
"transformers",
"pytorch",
"camembert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
famodde/wangchanberta-ner-fineTune
| null |
[
"transformers",
"pytorch",
"camembert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
farazkh80/t5_base
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
farazkh80/text_summarizer
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
farheenomar/PlayGround
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
farianoor/faria
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
faroit/open-unmix
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
# Configuration
`title`: _string_
Display title for the Space
`emoji`: _string_
Space emoji (emoji-only character allowed)
`colorFrom`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`colorTo`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`sdk`: _string_
Can be either `gradio` or `streamlit`
`sdk_version` : _string_
Only applicable for `streamlit` SDK.
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
`app_file`: _string_
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
Path is relative to the root of the repository.
`pinned`: _boolean_
Whether the Space stays on top of your list.
|
{"title": "Test Space", "emoji": "\ud83d\udd25", "colorFrom": "indigo", "colorTo": "blue", "sdk": "gradio", "app_file": "app.py", "pinned": false}
|
omerXfaruq/test-space
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
image-classification
|
fastai
|
# Amazing!
Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (template below and [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using the 🤗Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join our fastai community on the Hugging Face Discord!
Greetings fellow fastlearner 🤝!
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
{"tags": ["fastai", "image-classification"]}
|
fastai/fastbook_04_mnist_basics
| null |
[
"fastai",
"image-classification",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
fastai
|
# Amazing!
Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (template below and [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using the 🤗Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join our fastai community on the Hugging Face Discord!
Greetings fellow fastlearner 🤝!
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
{"tags": ["fastai"]}
|
fastai/fastbook_06_multicat_Biwi_Kinect_Head_Pose
| null |
[
"fastai",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
fastai
|
# Amazing!
Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (template below and [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using the 🤗Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join our fastai community on the Hugging Face Discord!
Greetings fellow fastlearner 🤝!
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
{"tags": ["fastai"]}
|
fastai/fastbook_06_multicat_PASCAL
| null |
[
"fastai",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{"license": "afl-3.0"}
|
fastjt/cxcc
| null |
[
"license:afl-3.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{"license": "afl-3.0"}
|
fastjt/fastjtj
| null |
[
"license:afl-3.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{"license": "mit"}
|
fastyangmh/gradio_space_test
| null |
[
"license:mit",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# Hermione Granger DialoGPT Model
|
{"tags": ["conversational"]}
|
fatemaMeem98/DialoGPT-medium-HermioneGrangerBot
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
faten/test_model
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
fatsam/saved_model
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
fatvvs/model_name
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
faucetgm/my-test-bert0
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
{}
|
faust/broken_t5_squad2
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
# FERNET-C5
FERNET-C5 (**F**lexible **E**mbedding **R**epresentation **NET**work) is a monolingual Czech BERT-base model pre-trained from 93GB of Czech Colossal Clean Crawled Corpus (C5). See our paper for details.
## Paper
https://link.springer.com/chapter/10.1007/978-3-030-89579-2_3
The preprint of our paper is available at https://arxiv.org/abs/2107.10042.
## Citation
If you find this model useful, please cite our paper:
```
@inproceedings{FERNETC5,
title = {Comparison of Czech Transformers on Text Classification Tasks},
author = {Lehe{\v{c}}ka, Jan and {\v{S}}vec, Jan},
year = 2021,
booktitle = {Statistical Language and Speech Processing},
publisher = {Springer International Publishing},
address = {Cham},
pages = {27--37},
doi = {10.1007/978-3-030-89579-2_3},
isbn = {978-3-030-89579-2},
editor = {Espinosa-Anke, Luis and Mart{\'i}n-Vide, Carlos and Spasi{\'{c}}, Irena}
}
```
|
{"language": "cs", "license": "cc-by-nc-sa-4.0", "tags": ["Czech", "KKY", "FAV"]}
|
fav-kky/FERNET-C5
| null |
[
"transformers",
"pytorch",
"tf",
"safetensors",
"bert",
"fill-mask",
"Czech",
"KKY",
"FAV",
"cs",
"arxiv:2107.10042",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# FERNET-CC_sk
FERNET-CC_sk is a monolingual Slovak BERT-base model pre-trained from 29GB of filtered Slovak Common Crawl dataset.
It is a Slovak version of our Czech [FERNET-C5](https://huggingface.co/fav-kky/FERNET-C5) model.
Preprint of our paper is available at https://arxiv.org/abs/2107.10042.
|
{"language": "sk", "license": "cc-by-nc-sa-4.0", "tags": ["Slovak", "KKY", "FAV"]}
|
fav-kky/FERNET-CC_sk
| null |
[
"transformers",
"pytorch",
"tf",
"bert",
"fill-mask",
"Slovak",
"KKY",
"FAV",
"sk",
"arxiv:2107.10042",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# FERNET-News
FERNET-News is a monolingual Czech RoBERTa-base model pre-trained from 20.5GB of thoroughly cleaned Czech news corpus.
Preprint of our paper is available at https://arxiv.org/abs/2107.10042.
|
{"language": "cs", "license": "cc-by-nc-sa-4.0", "tags": ["Czech", "KKY", "FAV"]}
|
fav-kky/FERNET-News
| null |
[
"transformers",
"pytorch",
"tf",
"roberta",
"fill-mask",
"Czech",
"KKY",
"FAV",
"cs",
"arxiv:2107.10042",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# FERNET-News_sk
FERNET-News_sk is a monolingual Slovak RoBERTa-base model pre-trained from 4.5GB of thoroughly cleaned Slovak news corpus.
It is a Slovak version of our Czech [FERNET-News](https://huggingface.co/fav-kky/FERNET-News) model.
Preprint of our paper is available at https://arxiv.org/abs/2107.10042.
|
{"language": "sk", "license": "cc-by-nc-sa-4.0", "tags": ["Slovak", "KKY", "FAV"]}
|
fav-kky/FERNET-News_sk
| null |
[
"transformers",
"pytorch",
"tf",
"roberta",
"fill-mask",
"Slovak",
"KKY",
"FAV",
"sk",
"arxiv:2107.10042",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
feature-extraction
|
transformers
|
## Proc-RoBERTa
Proc-RoBERTa is a pre-trained language model for procedural text. It was built by fine-tuning the RoBERTa-based model on a procedural corpus (PubMed articles/chemical patents/cooking recipes), which contains 1.05B tokens. More details can be found in the following [paper](https://arxiv.org/abs/2109.04711):
```
@inproceedings{bai-etal-2021-pre,
title = "Pre-train or Annotate? Domain Adaptation with a Constrained Budget",
author = "Bai, Fan and
Ritter, Alan and
Xu, Wei",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
}
```
## Usage
```
from transformers import *
tokenizer = AutoTokenizer.from_pretrained("fbaigt/proc_roberta")
model = AutoModelForTokenClassification.from_pretrained("fbaigt/proc_roberta")
```
More usage details can be found [here](https://github.com/bflashcp3f/ProcBERT).
|
{"language": ["en"], "datasets": ["pubmed", "chemical patent", "cooking recipe"]}
|
fbaigt/proc_roberta
| null |
[
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"en",
"arxiv:2109.04711",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
feature-extraction
|
transformers
|
## ProcBERT
ProcBERT is a pre-trained language model specifically for procedural text. It was pre-trained on a large-scale procedural corpus (PubMed articles/chemical patents/cooking recipes) containing over 12B tokens and shows great performance on downstream tasks. More details can be found in the following [paper](https://arxiv.org/abs/2109.04711):
```
@inproceedings{bai-etal-2021-pre,
title = "Pre-train or Annotate? Domain Adaptation with a Constrained Budget",
author = "Bai, Fan and
Ritter, Alan and
Xu, Wei",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
}
```
## Usage
```
from transformers import *
tokenizer = AutoTokenizer.from_pretrained("fbaigt/procbert")
model = AutoModelForTokenClassification.from_pretrained("fbaigt/procbert")
```
More usage details can be found [here](https://github.com/bflashcp3f/ProcBERT).
|
{"language": ["en"], "datasets": ["pubmed", "chemical patent", "cooking recipe"]}
|
fbaigt/procbert
| null |
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:2109.04711",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
fbu63711/dfgdfgdf
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
fcivardi/xlm-roberta-base-finetuned-marc
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
This model is the fine-tuned model of "akdeniz27/bert-base-hungarian-cased-ner" using WikiANN-hu dataset.
|
{}
|
fdominik98/bert-base-hu-cased-ner
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
token-classification
|
transformers
|
Magyar nyelvű token classification feladatra felkészített BERT modell.
|
{}
|
fdominik98/ner-hu-model-2021
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7480
- Matthews Correlation: 0.5370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5292 | 1.0 | 535 | 0.5110 | 0.4239 |
| 0.3508 | 2.0 | 1070 | 0.4897 | 0.4993 |
| 0.2346 | 3.0 | 1605 | 0.6275 | 0.5029 |
| 0.1806 | 4.0 | 2140 | 0.7480 | 0.5370 |
| 0.1291 | 5.0 | 2675 | 0.8841 | 0.5200 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "distilbert-base-uncased-finetuned-cola", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "glue", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.5370037450559281, "name": "Matthews Correlation"}]}]}]}
|
federicopascual/distilbert-base-uncased-finetuned-cola
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
federicopascual/distilbert-base-uncased-finetuned-ner
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetune-sentiment-analysis-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4558
- Accuracy: 0.8867
- F1: 0.8944
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["imdb"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "finetune-sentiment-analysis-model-3000-samples", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "imdb", "type": "imdb", "args": "plain_text"}, "metrics": [{"type": "accuracy", "value": 0.8866666666666667, "name": "Accuracy"}, {"type": "f1", "value": 0.8944099378881988, "name": "F1"}]}]}]}
|
federicopascual/finetune-sentiment-analysis-model-3000-samples
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
federicopascual/finetune-sentiment-analysis-model-3000
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
federicopascual/finetune-sentiment-analysis-model
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-sentiment-analysis-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2868
- Accuracy: 0.909
- Precision: 0.8900
- Recall: 0.9283
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["imdb"], "metrics": ["accuracy", "precision", "recall"], "model-index": [{"name": "finetuned-sentiment-analysis-model", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "imdb", "type": "imdb", "args": "plain_text"}, "metrics": [{"type": "accuracy", "value": 0.909, "name": "Accuracy"}, {"type": "precision", "value": 0.8899803536345776, "name": "Precision"}, {"type": "recall", "value": 0.9282786885245902, "name": "Recall"}]}]}]}
|
federicopascual/finetuned-sentiment-analysis-model
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-analysis-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3130
- Accuracy: 0.8733
- F1: 0.8812
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["imdb"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "finetuning-sentiment-analysis-model-3000-samples", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "imdb", "type": "imdb", "args": "plain_text"}, "metrics": [{"type": "accuracy", "value": 0.8733333333333333, "name": "Accuracy"}, {"type": "f1", "value": 0.88125, "name": "F1"}]}]}]}
|
federicopascual/finetuning-sentiment-analysis-model-3000-samples
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples-testcopy
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3374
- Accuracy: 0.87
- F1: 0.8762
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["imdb"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "finetuning-sentiment-model-3000-samples-testcopy", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "imdb", "type": "imdb", "args": "plain_text"}, "metrics": [{"type": "accuracy", "value": 0.87, "name": "Accuracy"}, {"type": "f1", "value": 0.8761904761904761, "name": "F1"}]}]}]}
|
federicopascual/finetuning-sentiment-model-3000-samples-testcopy
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3404
- Accuracy: 0.8667
- F1: 0.8734
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["imdb"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "finetuning-sentiment-model-3000-samples", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "imdb", "type": "imdb", "args": "plain_text"}, "metrics": [{"type": "accuracy", "value": 0.8666666666666667, "name": "Accuracy"}, {"type": "f1", "value": 0.8734177215189873, "name": "F1"}]}]}]}
|
federicopascual/finetuning-sentiment-model-3000-samples
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
feidie/bert-base-uncased-finetuned-swag
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
feidie/distilgpt2-finetuned-wikitext2
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
feidie/distilroberta-base-finetuned-wikitext2
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
feifan/opus-mt-en-ro-finetuned-en-to-ro
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
felflare/TextFuseNet_weights
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
# ✨ bert-restore-punctuation
[]()
This a bert-base-uncased model finetuned for punctuation restoration on [Yelp Reviews](https://www.tensorflow.org/datasets/catalog/yelp_polarity_reviews).
The model predicts the punctuation and upper-casing of plain, lower-cased text. An example use case can be ASR output. Or other cases when text has lost punctuation.
This model is intended for direct use as a punctuation restoration model for the general English language. Alternatively, you can use this for further fine-tuning on domain-specific texts for punctuation restoration tasks.
Model restores the following punctuations -- **[! ? . , - : ; ' ]**
The model also restores the upper-casing of words.
-----------------------------------------------
## 🚋 Usage
**Below is a quick way to get up and running with the model.**
1. First, install the package.
```bash
pip install rpunct
```
2. Sample python code.
```python
from rpunct import RestorePuncts
# The default language is 'english'
rpunct = RestorePuncts()
rpunct.punctuate("""in 2018 cornell researchers built a high-powered detector that in combination with an algorithm-driven process called ptychography set a world record
by tripling the resolution of a state-of-the-art electron microscope as successful as it was that approach had a weakness it only worked with ultrathin samples that were
a few atoms thick anything thicker would cause the electrons to scatter in ways that could not be disentangled now a team again led by david muller the samuel b eckert
professor of engineering has bested its own record by a factor of two with an electron microscope pixel array detector empad that incorporates even more sophisticated
3d reconstruction algorithms the resolution is so fine-tuned the only blurring that remains is the thermal jiggling of the atoms themselves""")
# Outputs the following:
# In 2018, Cornell researchers built a high-powered detector that, in combination with an algorithm-driven process called Ptychography, set a world record by tripling the
# resolution of a state-of-the-art electron microscope. As successful as it was, that approach had a weakness. It only worked with ultrathin samples that were a few atoms
# thick. Anything thicker would cause the electrons to scatter in ways that could not be disentangled. Now, a team again led by David Muller, the Samuel B.
# Eckert Professor of Engineering, has bested its own record by a factor of two with an Electron microscope pixel array detector empad that incorporates even more
# sophisticated 3d reconstruction algorithms. The resolution is so fine-tuned the only blurring that remains is the thermal jiggling of the atoms themselves.
```
**This model works on arbitrarily large text in English language and uses GPU if available.**
-----------------------------------------------
## 📡 Training data
Here is the number of product reviews we used for finetuning the model:
| Language | Number of text samples|
| -------- | ----------------- |
| English | 560,000 |
We found the best convergence around _**3 epochs**_, which is what presented here and available via a download.
-----------------------------------------------
## 🎯 Accuracy
The fine-tuned model obtained the following accuracy on 45,990 held-out text samples:
| Accuracy | Overall F1 | Eval Support |
| -------- | ---------------------- | ------------------- |
| 91% | 90% | 45,990
Below is a breakdown of the performance of the model by each label:
| label | precision | recall | f1-score | support|
| --------- | -------------|-------- | ----------|--------|
| **!** | 0.45 | 0.17 | 0.24 | 424
| **!+Upper** | 0.43 | 0.34 | 0.38 | 98
| **'** | 0.60 | 0.27 | 0.37 | 11
| **,** | 0.59 | 0.51 | 0.55 | 1522
| **,+Upper** | 0.52 | 0.50 | 0.51 | 239
| **-** | 0.00 | 0.00 | 0.00 | 18
| **.** | 0.69 | 0.84 | 0.75 | 2488
| **.+Upper** | 0.65 | 0.52 | 0.57 | 274
| **:** | 0.52 | 0.31 | 0.39 | 39
| **:+Upper** | 0.36 | 0.62 | 0.45 | 16
| **;** | 0.00 | 0.00 | 0.00 | 17
| **?** | 0.54 | 0.48 | 0.51 | 46
| **?+Upper** | 0.40 | 0.50 | 0.44 | 4
| **none** | 0.96 | 0.96 | 0.96 |35352
| **Upper** | 0.84 | 0.82 | 0.83 | 5442
-----------------------------------------------
## ☕ Contact
Contact [Daulet Nurmanbetov]([email protected]) for questions, feedback and/or requests for similar models.
-----------------------------------------------
|
{"language": ["en"], "license": "mit", "tags": ["punctuation"], "datasets": ["yelp_polarity"], "metrics": ["f1"]}
|
felflare/bert-restore-punctuation
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"punctuation",
"en",
"dataset:yelp_polarity",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# DioloGPT KaeyaBot model
|
{"tags": ["conversational"]}
|
felinecity/DioloGPT-small-KaeyaBot
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# DioloGPT KaeyaBot model
|
{"tags": ["conversational"]}
|
felinecity/DioloGPT-small-KaeyaBot2
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# DioloGPT LisaBot model
|
{"tags": ["conversational"]}
|
felinecity/DioloGPT-small-LisaBot
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
felinecity/DioloGPT-small-harrypotter
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.