
Search is not available for this dataset
pipeline_tag
stringclasses 48
values | library_name
stringclasses 205
values | text
stringlengths 0
18.3M
| metadata
stringlengths 2
1.07B
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
|
|---|---|---|---|---|---|---|---|---|
text-generation
|
transformers
|
# GPT-Code-Clippy-125M-Code-Search-All
> **Please refer to our new [GitHub Wiki](https://github.com/ncoop57/gpt-code-clippy/wiki) which documents our efforts in detail in creating the open source version of GitHub Copilot**
## Model Description
GPT-CC-125M-Code-Search is a [GPT-Neo-125M model](https://huggingface.co/EleutherAI/gpt-neo-125M) finetuned using causal language modeling on all languages in the [CodeSearchNet Challenge dataset](https://huggingface.co/datasets/code_search_net). This model is specialized to autocomplete methods in multiple programming languages.
## Training data
[CodeSearchNet Challenge dataset](https://huggingface.co/datasets/code_search_net).
## Training procedure
The training script used to train this model can be found [here](https://github.com/ncoop57/gpt-code-clippy/blob/camera-ready/training/run_clm_flax.py).
```bash
./run_clm_flax.py \
--output_dir $HOME/gpt-neo-125M-code-search-all \
--model_name_or_path="EleutherAI/gpt-neo-125M" \
--dataset_name code_search_net \
--dataset_config_name="all" \
--do_train --do_eval \
--block_size="512" \
--per_device_train_batch_size="32" \
--per_device_eval_batch_size="64" \
--preprocessing_num_workers="8" \
--learning_rate="1.2e-4" \
--num_train_epochs 20 \
--warmup_steps 3000 \
--adam_beta1="0.9" \
--adam_beta2="0.95" \
--weight_decay="0.1" \
--overwrite_output_dir \
--logging_steps="25" \
--eval_steps="500" \
--push_to_hub="False" \
--report_to="all" \
--dtype="bfloat16" \
--skip_memory_metrics="True" \
--save_steps="500" \
--save_total_limit 10 \
--report_to="wandb" \
--run_name="gpt-neo-125M-code-search-all"
```
## Intended Use and Limitations
The model is finetuned methods from several languages and is intended to autocomplete methods given some prompt (method signature and docstring).
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, FlaxAutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-neo-125M-code-clippy-code-search-all")
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-neo-125M-code-clippy-code-search-all")
prompt = """def greet(name):
'''A function to greet user. Given a user name it should say hello'''
"""
input_ids = tokenizer(prompt, return_tensors='pt').input_ids.to(device)
start = input_ids.size(1)
out = model.generate(input_ids, do_sample=True, max_length=50, num_beams=2,
early_stopping=True, eos_token_id=tokenizer.eos_token_id, )
print(tokenizer.decode(out[0][start:]))
```
### Limitations and Biases
The model is intended to be used for research purposes and comes with no guarantees of quality of generated code.
GPT-CC is finetuned from GPT-Neo and might have inherited biases and limitations from it. See [GPT-Neo model card](https://huggingface.co/EleutherAI/gpt-neo-125M#limitations-and-biases) for details.
## Eval results
Coming soon...
|
{}
|
flax-community/gpt-neo-125M-code-search-all
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# GPT-Code-Clippy-125M-Code-Search-Py
> **Please refer to our new [GitHub Wiki](https://github.com/ncoop57/gpt-code-clippy/wiki) which documents our efforts in detail in creating the open source version of GitHub Copilot**
## Model Description
GPT-CC-125M-Code-Search is a [GPT-Neo-125M model](https://huggingface.co/EleutherAI/gpt-neo-125M) finetuned using causal language modeling on only the python language in the [CodeSearchNet Challenge dataset](https://huggingface.co/datasets/code_search_net). This model is specialized to autocomplete methods in the python language.
## Training data
[CodeSearchNet Challenge dataset](https://huggingface.co/datasets/code_search_net).
## Training procedure
The training script used to train this model can be found [here](https://github.com/ncoop57/gpt-code-clippy/blob/camera-ready/training/run_clm_flax.py).
```bash
./run_clm_flax.py \
--output_dir $HOME/gpt-neo-125M-code-search-py \
--model_name_or_path="EleutherAI/gpt-neo-125M" \
--dataset_name code_search_net \
--dataset_config_name="python" \
--do_train --do_eval \
--block_size="512" \
--per_device_train_batch_size="32" \
--per_device_eval_batch_size="64" \
--preprocessing_num_workers="8" \
--learning_rate="1.2e-4" \
--num_train_epochs 20 \
--warmup_steps 3000 \
--adam_beta1="0.9" \
--adam_beta2="0.95" \
--weight_decay="0.1" \
--overwrite_output_dir \
--logging_steps="25" \
--eval_steps="500" \
--push_to_hub="False" \
--report_to="all" \
--dtype="bfloat16" \
--skip_memory_metrics="True" \
--save_steps="500" \
--save_total_limit 10 \
--report_to="wandb" \
--run_name="gpt-neo-125M-code-search-py"
```
## Intended Use and Limitations
The model is finetuned methods from the python language and is intended to autocomplete python methods given some prompt (method signature and docstring).
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, FlaxAutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-neo-125M-code-clippy-code-search-py")
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-neo-125M-code-clippy-code-search-py")
prompt = """def greet(name):
'''A function to greet user. Given a user name it should say hello'''
"""
input_ids = tokenizer(prompt, return_tensors='pt').input_ids.to(device)
start = input_ids.size(1)
out = model.generate(input_ids, do_sample=True, max_length=50, num_beams=2,
early_stopping=True, eos_token_id=tokenizer.eos_token_id, )
print(tokenizer.decode(out[0][start:]))
```
### Limitations and Biases
The model is intended to be used for research purposes and comes with no guarantees of quality of generated code.
GPT-CC is finetuned from GPT-Neo and might have inherited biases and limitations from it. See [GPT-Neo model card](https://huggingface.co/EleutherAI/gpt-neo-125M#limitations-and-biases) for details.
## Eval results
Coming soon...
|
{}
|
flax-community/gpt-neo-125M-code-search-py
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
{}
|
flax-community/gpt-neo-125M-test
| null |
[
"transformers",
"jax",
"tensorboard",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
flax-community/gpt-neo-2.7B-code-clippy
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null |
transformers
|
# Cosmos QA (gpt2)
> This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/train-a-gpt2-model-for-contextual-common-sense-reasoning-using-the-cosmos-qa-dataset/7463), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team Members
-Rohan V Kashyap ([Rohan](https://huggingface.co/Rohan))
-Vivek V Kashyap ([Vivek](https://huggingface.co/Vivek))
## Dataset
[Cosmos QA: Machine Reading Comprehension with Contextual Commonsense Reasoning](https://huggingface.co/datasets/cosmos_qa).This dataset contains a set of 35,600 problems that require commonsense-based reading comprehension, formulated as multiple-choice questions.Understanding narratives requires reading between the lines, which in turn, requires interpreting the likely causes and effects of events, even when they are not mentioned explicitly.The questions focus on factual and literal understanding of the context paragraph, our dataset focuses on reading between the lines over a diverse collection of people's everyday narratives.
### Example
```json
{"Context":["It's a very humbling experience when you need someone
to dress you every morning, tie your shoes, and put your hair
up. Every menial task takes an unprecedented amount of effort.
It made me appreciate Dan even more. But anyway I shan't
dwell on this (I'm not dying after all) and not let it detract from
my lovely 5 days with my friends visiting from Jersey."],
"Question":["What's a possible reason the writer needed someone to
dress him every morning?"],
"Multiple Choice":["A: The writer doesn't like putting effort into these tasks.",
"B: The writer has a physical disability.",
"C: The writer is bad at doing his own hair.",
"D: None of the above choices."]
"link":"https://arxiv.org/pdf/1909.00277.pdf"
}
```
## How to use
```bash
# Installing requirements
pip install transformers
pip install datasets
```
```python
from model_file import FlaxGPT2ForMultipleChoice
from datasets import Dataset
model_path="flax-community/gpt2-Cosmos"
model = FlaxGPT2ForMultipleChoice.from_pretrained(model_path,input_shape=(1,4,1))
dataset=Dataset.from_csv('./')
def preprocess(example):
example['context&question']=example['context']+example['question']
example['first_sentence']=[example['context&question'],example['context&question'],example['context&question'],example['context&question']]
example['second_sentence']=example['answer0'],example['answer1'],example['answer2'],example['answer3']
return example
dataset=dataset.map(preprocess)
def tokenize(examples):
a=tokenizer(examples['first_sentence'],examples['second_sentence'],padding='max_length',truncation=True,max_length=256,return_tensors='jax')
a['labels']=examples['label']
return a
dataset=dataset.map(tokenize)
input_id=jnp.array(dataset['input_ids'])
att_mask=jnp.array(dataset['attention_mask'])
outputs=model(input_id,att_mask)
final_output=jnp.argmax(outputs,axis=-1)
print(f"the predction of the dataset : {final_output}")
```
```
The Correct answer:-Option 1
```
## Preprocessing
The texts are tokenized using the GPT2 tokenizer.To feed the inputs of multiple choice we concatenated context and question as first input and all the 4 possible choices as the second input to our tokenizer.
## Evaluation
The following tables summarize the scores obtained by the **GPT2-CosmosQA**.The ones marked as (^) are the baseline models.
| Model | Dev Acc | Test Acc |
|:---------------:|:-----:|:-----:|
| BERT-FT Multiway^| 68.3.| 68.4 |
| GPT-FT ^ | 54.0 | 54.4. |
| GPT2-CosmosQA | 60.3 | 59.7 |
## Inference
This project was mainly to test the common sense understanding of the GPT2-model.We finetuned on a Dataset known as CosmosQ requires reasoning beyond the exact text spans in the context.The above results shows that GPT2 model is doing better than most of the base line models given that it only used to predict the next word in the pre-training objective.
## Credits
Huge thanks to Huggingface 🤗 & Google Jax/Flax team for such a wonderful community week. Especially for providing such massive computing resource. Big thanks to [@patil-suraj](https://github.com/patil-suraj) & [@patrickvonplaten](https://github.com/patrickvonplaten) for mentoring during whole week.
|
{}
|
flax-community/gpt2-Cosmos
| null |
[
"transformers",
"jax",
"tensorboard",
"gpt2",
"arxiv:1909.00277",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
## GPT-2 Base Thai
GPT-2 Base Thai is a causal language model based on the [OpenAI GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) model. It was trained on the [OSCAR](https://huggingface.co/datasets/oscar) dataset, specifically the `unshuffled_deduplicated_th` subset. The model was trained from scratch and achieved an evaluation loss of 1.708 and an evaluation perplexity of 5.516.
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by HuggingFace. All training was done on a TPUv3-8 VM, sponsored by the Google Cloud team.
All necessary scripts used for training could be found in the [Files and versions](https://hf.co/flax-community/gpt2-base-thai/tree/main) tab, as well as the [Training metrics](https://hf.co/flax-community/gpt2-base-thai/tensorboard) logged via Tensorboard.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ---------------- | ------- | ----- | ------------------------------------ |
| `gpt2-base-thai` | 124M | GPT-2 | `unshuffled_deduplicated_th` Dataset |
## Evaluation Results
The model was trained for 3 epochs and the following is the final result once the training ended.
| train loss | valid loss | valid PPL | total time |
| ---------- | ---------- | --------- | ---------- |
| 1.638 | 1.708 | 5.516 | 6:12:34 |
## How to Use
### As Causal Language Model
```python
from transformers import pipeline
pretrained_name = "flax-community/gpt2-base-thai"
nlp = pipeline(
"text-generation",
model=pretrained_name,
tokenizer=pretrained_name
)
nlp("สวัสดีตอนเช้า")
```
### Feature Extraction in PyTorch
```python
from transformers import GPT2Model, GPT2TokenizerFast
pretrained_name = "flax-community/gpt2-base-thai"
model = GPT2Model.from_pretrained(pretrained_name)
tokenizer = GPT2TokenizerFast.from_pretrained(pretrained_name)
prompt = "สวัสดีตอนเช้า"
encoded_input = tokenizer(prompt, return_tensors='pt')
output = model(**encoded_input)
```
## Team Members
- Sakares Saengkaew ([@sakares](https://hf.co/sakares))
- Wilson Wongso ([@w11wo](https://hf.co/w11wo))
|
{"language": "th", "license": "mit", "tags": ["gpt2-base-thai"], "datasets": ["oscar"], "widget": [{"text": "\u0e2a\u0e27\u0e31\u0e2a\u0e14\u0e35\u0e15\u0e2d\u0e19\u0e40\u0e0a\u0e49\u0e32"}]}
|
flax-community/gpt2-base-thai
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"gpt2-base-thai",
"th",
"dataset:oscar",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# Bengali GPT-2
Bengali GPT-2 demo. Part of the [Huggingface JAX/Flax event](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/). Also features a [finetuned](https://huggingface.co/khalidsaifullaah/bengali-lyricist-gpt2?) model on bengali song lyrics.
# Model Description
OpenAI GPT-2 model was proposed in [Language Models are Unsupervised Multitask Learners](https://paperswithcode.com/paper/language-models-are-unsupervised-multitask) paper .Original GPT2 model was a causal (unidirectional) transformer pretrained using language modeling on a very large corpus of ~40 GB of text data. This model has same configuration but has been pretrained on bengali corpus of mC4(multilingual C4) dataset. The code for training the model has all been open-sourced [here](https://huggingface.co/flax-community/gpt2-bengali/tree/main).
# Training Details
Overall Result:
```Eval loss : 1.45, Eval Perplexity : 3.141```
Data: [mC4-bn](https://huggingface.co/datasets/mc4)
Train Steps: 250k steps
link 🤗 flax-community/gpt2-bengali
Demo : https://huggingface.co/spaces/flax-community/Gpt2-bengali
# Usage
For using the model there are multiple options available. For example using the pipeline directly we can try to generate sentences.
```
from transformers import pipeline
gpt2_bengali = pipeline('text-generation',model="flax-community/gpt2-bengali", tokenizer='flax-community/gpt2-bengali')
```
Similarly for using the finetuned model on bangla songs we can use following.
```
from transformers import pipeline
singer = pipeline('text-generation',model="khalidsaifullaah/bengali-lyricist-gpt2", tokenizer='khalidsaifullaah/bengali-lyricist-gpt2')
```
For using on other tasks the model needs to be fine-tuned on custom datasets. Details can be found in huggingface [documentation](https://huggingface.co/transformers/training.html)
# Contributors
* Khalid Saifullah
* Tasmiah Tahsin Mayeesha
* Ritobrata Ghosh
* Ibrahim Musa
* M Saiful Bari
### BibTeX entry and citation info
@misc {flax_community_2023,
author = { {Flax Community} },
title = { gpt2-bengali (Revision cb8fff6) },
year = 2023,
url = { https://huggingface.co/flax-community/gpt2-bengali },
doi = { 10.57967/hf/0938 },
publisher = { Hugging Face }
}
|
{"language": "bn", "license": "mit", "datasets": ["mc4"]}
|
flax-community/gpt2-bengali
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"bn",
"dataset:mc4",
"doi:10.57967/hf/0938",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# GPT2-large-indonesian
|
{}
|
flax-community/gpt2-large-indonesian
| null |
[
"transformers",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
flax-community/gpt2-layout-generation
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# GPT2-medium-indonesian
This is a pretrained model on Indonesian language using a causal language modeling (CLM) objective, which was first
introduced in [this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104)
organized by [HuggingFace](https://huggingface.co). All training was done on a TPUv3-8 VM sponsored by the Google Cloud team.
The demo can be found [here](https://huggingface.co/spaces/flax-community/gpt2-indonesian).
## How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='flax-community/gpt2-medium-indonesian')
>>> set_seed(42)
>>> generator("Sewindu sudah kita tak berjumpa,", max_length=30, num_return_sequences=5)
[{'generated_text': 'Sewindu sudah kita tak berjumpa, dua dekade lalu, saya hanya bertemu sekali. Entah mengapa, saya lebih nyaman berbicara dalam bahasa Indonesia, bahasa Indonesia'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, tapi dalam dua hari ini, kita bisa saja bertemu.”\
“Kau tau, bagaimana dulu kita bertemu?” aku'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, banyak kisah yang tersimpan. Tak mudah tuk kembali ke pelukan, di mana kini kita berada, sebuah tempat yang jauh'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, sejak aku lulus kampus di Bandung, aku sempat mencari kabar tentangmu. Ah, masih ada tempat di hatiku,'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, tapi Tuhan masih saja menyukarkan doa kita masing-masing.\
Tuhan akan memberi lebih dari apa yang kita'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('flax-community/gpt2-medium-indonesian')
model = GPT2Model.from_pretrained('flax-community/gpt2-medium-indonesian')
text = "Ubah dengan teks apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('flax-community/gpt2-medium-indonesian')
model = TFGPT2Model.from_pretrained('flax-community/gpt2-medium-indonesian')
text = "Ubah dengan teks apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Limitations and bias
The training data used for this model are Indonesian websites of [OSCAR](https://oscar-corpus.com/),
[mc4](https://huggingface.co/datasets/mc4) and [Wikipedia](https://huggingface.co/datasets/wikipedia). The datasets
contain a lot of unfiltered content from the internet, which is far from neutral. While we have done some filtering on
the dataset (see the **Training data** section), the filtering is by no means a thorough mitigation of biased content
that is eventually used by the training data. These biases might also affect models that are fine-tuned using this model.
As the openAI team themselves point out in their [model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we
> do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry
> out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender,
> race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with
> similar levels of caution around use cases that are sensitive to biases around human attributes.
We have done a basic bias analysis that you can find in this [notebook](https://huggingface.co/flax-community/gpt2-small-indonesian/blob/main/bias_analysis/gpt2_medium_indonesian_bias_analysis.ipynb), performed on [Indonesian GPT2 medium](https://huggingface.co/flax-community/gpt2-medium-indonesian), based on the bias analysis for [Polish GPT2](https://huggingface.co/flax-community/papuGaPT2) with modifications.
### Gender bias
We generated 50 texts starting with prompts "She/He works as". After doing some preprocessing (lowercase and stopwords removal) we obtain texts that are used to generate word clouds of female/male professions. The most salient terms for male professions are: driver, sopir (driver), ojek, tukang, online.

The most salient terms for female professions are: pegawai (employee), konsultan (consultant), asisten (assistant).

### Ethnicity bias
We generated 1,200 texts to assess bias across ethnicity and gender vectors. We will create prompts with the following scheme:
* Person - we will assess 5 ethnicities: Sunda, Batak, Minahasa, Dayak, Asmat, Neutral (no ethnicity)
* Topic - we will use 5 different topics:
* random act: *entered home*
* said: *said*
* works as: *works as*
* intent: *let [person] ...*
* define: *is*
Sample of generated prompt: "seorang perempuan sunda masuk ke rumah..." (a Sundanese woman enters the house...)
We used a [model](https://huggingface.co/Hate-speech-CNERG/dehatebert-mono-indonesian) trained on Indonesian hate speech corpus ([dataset 1](https://github.com/okkyibrohim/id-multi-label-hate-speech-and-abusive-language-detection), [dataset 2](https://github.com/ialfina/id-hatespeech-detection)) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the ethnicity and gender from the generated text before running the hate speech detector.
The following chart demonstrates the intensity of hate speech associated with the generated texts with outlier scores removed. Some ethnicities score higher than the neutral baseline.

### Religion bias
With the same methodology above, we generated 1,400 texts to assess bias across religion and gender vectors. We will assess 6 religions: Islam, Protestan (Protestant), Katolik (Catholic), Buddha (Buddhism), Hindu (Hinduism), and Khonghucu (Confucianism) with Neutral (no religion) as a baseline.
The following chart demonstrates the intensity of hate speech associated with the generated texts with outlier scores removed. Some religions score higher than the neutral baseline.

## Training data
The model was trained on a combined dataset of [OSCAR](https://oscar-corpus.com/), [mc4](https://huggingface.co/datasets/mc4)
and Wikipedia for the Indonesian language. We have filtered and reduced the mc4 dataset so that we end up with 29 GB
of data in total. The mc4 dataset was cleaned using [this filtering script](https://github.com/Wikidepia/indonesian_datasets/blob/master/dump/mc4/cleanup.py)
and we also only included links that have been cited by the Indonesian Wikipedia.
## Training procedure
The model was trained on a TPUv3-8 VM provided by the Google Cloud team. The training duration was `6d 3h 7m 26s`.
### Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| dataset | train loss | eval loss | eval perplexity |
| ---------- | ---------- | -------------- | ---------- |
| ID OSCAR+mc4+Wikipedia (29GB) | 2.79 | 2.696 | 14.826 |
### Tracking
The training process was tracked in [TensorBoard](https://huggingface.co/flax-community/gpt2-medium-indonesian/tensorboard) and [Weights and Biases](https://wandb.ai/wandb/hf-flax-gpt2-indonesian?workspace=user-cahya).
## Team members
- Akmal ([@Wikidepia](https://huggingface.co/Wikidepia))
- alvinwatner ([@alvinwatner](https://huggingface.co/alvinwatner))
- Cahya Wirawan ([@cahya](https://huggingface.co/cahya))
- Galuh Sahid ([@Galuh](https://huggingface.co/Galuh))
- Muhammad Agung Hambali ([@AyameRushia](https://huggingface.co/AyameRushia))
- Muhammad Fhadli ([@muhammadfhadli](https://huggingface.co/muhammadfhadli))
- Samsul Rahmadani ([@munggok](https://huggingface.co/munggok))
## Future work
We would like to pre-train further the models with larger and cleaner datasets and fine-tune it to specific domains
if we can get the necessary hardware resources.
|
{"language": "id", "widget": [{"text": "Sewindu sudah kita tak berjumpa, rinduku padamu sudah tak terkira."}]}
|
flax-community/gpt2-medium-indonesian
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"id",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# GPT2 Medium 4 Persian
> This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/pretrain-gpt2-from-scratch-in-persian/7560), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team Members
- [Mehrdad Farahani](huggingface.co/m3hrdadfi)
- [Saied Alimoradi](https://discuss.huggingface.co/u/saied)
- [M. Reza Zerehpoosh](huggingface.co/ironcladgeek)
- [Hooman Sedghamiz](https://discuss.huggingface.co/u/hooman650)
- [Mazeyar Moeini Feizabadi](https://discuss.huggingface.co/u/mazy1998)
## Dataset
We used [Oscar](https://huggingface.co/datasets/oscar) dataset, which is a huge multilingual corpus obtained by language classification and filtering of the Common Crawl corpus.
## How To Use
You can use this model directly with a pipeline for text generation.
```python
from transformers import pipeline, AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('flax-community/gpt2-medium-persian')
model = GPT2LMHeadModel.from_pretrained('flax-community/gpt2-medium-persian')
generator = pipeline('text-generation', model, tokenizer=tokenizer, config={'max_length':100})
generated_text = generator('در یک اتفاق شگفت انگیز، پژوهشگران')
```
For using Tensorflow import TFGPT2LMHeadModel instead of GPT2LMHeadModel.
## Demo
... SOON
## Evaluation
... SOON
|
{"language": "fa", "tags": ["text-generation"], "widget": [{"text": "\u062f\u0631 \u06cc\u06a9 \u0627\u062a\u0641\u0627\u0642 \u0634\u06af\u0641\u062a \u0627\u0646\u06af\u06cc\u0632\u060c \u067e\u0698\u0648\u0647\u0634\u06af\u0631\u0627\u0646"}, {"text": "\u06af\u0631\u0641\u062a\u06af\u06cc \u0628\u06cc\u0646\u06cc \u062f\u0631 \u06a9\u0648\u062f\u06a9\u0627\u0646 \u0648 \u0628\u0647\u200c\u062e\u0635\u0648\u0635 \u0646\u0648\u0632\u0627\u062f\u0627\u0646 \u0628\u0627\u0639\u062b \u0645\u06cc\u200c\u0634\u0648\u062f"}, {"text": "\u0627\u0645\u06cc\u062f\u0648\u0627\u0631\u06cc\u0645 \u0646\u0648\u0631\u0648\u0632 \u0627\u0645\u0633\u0627\u0644 \u0633\u0627\u0644\u06cc"}]}
|
flax-community/gpt2-medium-persian
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"fa",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# Question-Answering Using GPT2 - Persian
> This is a side project of this thread
[Flax/Jax Community Week - GPT2 4 Persian](https://discuss.huggingface.co/t/pretrain-gpt2-from-scratch-in-persian/7560), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team Members
- [Mehrdad Farahani](https://huggingface.co/m3hrdadfi)
## Dataset
We used [PersianQA](https://huggingface.co/datasets/SajjadAyoubi/persian_qa) dataset which is a reading comprehension dataset on Persian Wikipedia.
## How To Use TODO: Update
## Demo TODO: Update
## Evaluation TODO: Update
|
{"language": "fa", "tags": ["text-generation"], "datasets": ["persian_qa"], "widget": [{"text": "\u0646\u0627\u0641 \u062c\u0627\u06cc\u06cc \u0642\u0631\u0627\u0631 \u06af\u0631\u0641\u062a\u0647 \u06a9\u0647 \u062f\u0631 \u0648\u0627\u0642\u0639 \u0628\u0646\u062f\u0646\u0627\u0641 \u062f\u0631 \u062f\u0627\u062e\u0644 \u0631\u062d\u0645 \u062f\u0631 \u0622\u0646\u062c\u0627 \u0628\u0647 \u0634\u06a9\u0645 \u062c\u0646\u06cc\u0646 \u0648\u0635\u0644 \u0628\u0648\u062f\u0647\u200c\u0627\u0633\u062a. \u0628\u0646\u062f\u0646\u0627\u0641 \u06a9\u0647 \u062c\u0641\u062a \u0631\u0627 \u0628\u0647 \u062c\u0646\u06cc\u0646 \u0645\u062a\u0635\u0644 \u06a9\u0631\u062f\u0647 \u0628\u0639\u062f \u0627\u0632 \u062a\u0648\u0644\u062f \u0627\u0632 \u0646\u0648\u0632\u0627\u062f \u062c\u062f\u0627 \u0645\u06cc\u200c\u0634\u0648\u062f. \u0628\u0631\u0627\u06cc \u062c\u062f\u0627 \u06a9\u0631\u062f\u0646 \u0628\u0646\u062f \u0646\u0627\u0641 \u0627\u0632 \u062f\u0648 \u067e\u0646\u0633 \u0627\u0633\u062a\u0641\u0627\u062f\u0647 \u0645\u06cc\u200c\u06a9\u0646\u0646\u062f \u0648 \u0628\u06cc\u0646 \u0622\u0646 \u062f\u0648 \u0631\u0627 \u0645\u06cc\u0628\u0631\u0646\u062f. \u067e\u0646\u0633 \u062f\u06cc\u06af\u0631\u06cc \u0646\u0632\u062f\u06cc\u06a9 \u0634\u06a9\u0645 \u0646\u0648\u0632\u0627\u062f \u0642\u0631\u0627\u0631 \u062f\u0627\u062f\u0647 \u0645\u06cc\u200c\u0634\u0648\u062f \u06a9\u0647 \u0628\u0639\u062f \u0627\u0632 \u062f\u0648 \u0631\u0648\u0632 \u0628\u0631\u062f\u0627\u0634\u062a\u0647 \u062e\u0648\u0627\u0647\u062f \u0634\u062f. \u0628\u0646\u062f\u0646\u0627\u0641 \u0628\u0627\u0642\u06cc\u200c\u0645\u0627\u0646\u062f\u0647 \u0637\u06cc \u06f1\u06f5 \u0631\u0648\u0632 \u062e\u0634\u06a9 \u0634\u062f\u0647 \u0648 \u0645\u06cc\u200c\u0627\u0641\u062a\u062f \u0648 \u0628\u0647 \u062c\u0627\u06cc \u0622\u0646 \u0627\u0633\u06a9\u0627\u0631\u06cc \u0637\u0628\u06cc\u0639\u06cc \u0628\u0647 \u062c\u0627\u06cc \u0645\u06cc\u0645\u0627\u0646\u062f. \u0627\u0644\u0628\u062a\u0647 \u0628\u0631 \u062e\u0644\u0627\u0641 \u062a\u0635\u0648\u0631 \u0639\u0627\u0645\u0647 \u0645\u0631\u062f\u0645 \u0634\u06a9\u0644 \u0646\u0627\u0641 \u062f\u0631 \u0627\u062b\u0631 \u0628\u0631\u06cc\u062f\u0646 \u0628\u0646\u062f \u0646\u0627\u0641 \u0628\u0647 \u0648\u062c\u0648\u062f \u0646\u0645\u06cc\u200c\u0622\u06cc\u062f \u0648 \u067e\u06cc\u0634 \u0627\u0632 \u0627\u06cc\u0646 \u062f\u0631 \u0634\u06a9\u0645 \u0645\u0627\u062f\u0631 \u062d\u0627\u0644\u062a \u0646\u0627\u0641 \u0634\u06a9\u0644 \u06af\u0631\u0641\u062a\u0647\u200c\u0627\u0633\u062a. \u0634\u06a9\u0644 \u0646\u0627\u0641 \u062f\u0631 \u0645\u06cc\u0627\u0646 \u0645\u0631\u062f\u0645 \u0645\u062e\u062a\u0644\u0641 \u0645\u062a\u0641\u0627\u0648\u062a \u0627\u0633\u062a \u0648 \u0627\u0646\u062f\u0627\u0632\u0647 \u0622\u0646 \u0628\u06cc\u0646 \u06f1.\u06f5 \u062a\u0627 \u06f2 \u0633\u0627\u0646\u062a\u06cc\u200c\u0645\u062a\u0631 \u0627\u0633\u062a. \u062a\u0645\u0627\u0645 \u067e\u0633\u062a\u0627\u0646\u062f\u0627\u0631\u0627\u0646 \u062c\u0641\u062a\u200c\u0632\u06cc\u0633\u062a \u0646\u0627\u0641 \u062f\u0627\u0631\u0646\u062f. \u0646\u0627\u0641 \u062f\u0631 \u0627\u0646\u0633\u0627\u0646\u200c\u0647\u0627 \u0628\u0647 \u0633\u0627\u062f\u06af\u06cc \u0642\u0627\u0628\u0644 \u0645\u0634\u0627\u0647\u062f\u0647\u200c\u0627\u0633\u062a. \u067e\u0631\u0633\u0634: \u0628\u0646\u062f \u0646\u0627\u0641 \u0627\u0646\u0633\u0627\u0646 \u0628\u0647 \u06a9\u062c\u0627 \u0648\u0635\u0644 \u0627\u0633\u062a\u061f \u067e\u0627\u0633\u062e:"}, {"text": "\u062e\u0648\u0628\u060c \u0628\u062f\u060c \u0632\u0634\u062a \u06cc\u06a9 \u0641\u06cc\u0644\u0645 \u062f\u0631\u0698\u0627\u0646\u0631 \u0648\u0633\u062a\u0631\u0646 \u0627\u0633\u067e\u0627\u06af\u062a\u06cc \u062d\u0645\u0627\u0633\u06cc \u0627\u0633\u062a \u06a9\u0647 \u062a\u0648\u0633\u0637 \u0633\u0631\u062c\u0648 \u0644\u0626\u0648\u0646\u0647 \u062f\u0631 \u0633\u0627\u0644 \u06f1\u06f9\u06f6\u06f6 \u062f\u0631 \u0627\u06cc\u062a\u0627\u0644\u06cc\u0627 \u0633\u0627\u062e\u062a\u0647 \u0634\u062f. \u0632\u0628\u0627\u0646\u06cc \u06a9\u0647 \u0628\u0627\u0632\u06cc\u06af\u0631\u0627\u0646 \u0627\u06cc\u0646 \u0641\u06cc\u0644\u0645 \u0628\u0647 \u0622\u0646 \u062a\u06a9\u0644\u0645 \u0645\u06cc\u200c\u06a9\u0646\u0646\u062f \u0645\u062e\u0644\u0648\u0637\u06cc \u0627\u0632 \u0627\u06cc\u062a\u0627\u0644\u06cc\u0627\u06cc\u06cc \u0648 \u0627\u0646\u06af\u0644\u06cc\u0633\u06cc \u0627\u0633\u062a. \u0627\u06cc\u0646 \u0641\u06cc\u0644\u0645 \u0633\u0648\u0645\u06cc\u0646 (\u0648 \u0622\u062e\u0631\u06cc\u0646) \u0641\u06cc\u0644\u0645 \u0627\u0632 \u0633\u0647\u200c\u06af\u0627\u0646\u0647\u0654 \u062f\u0644\u0627\u0631 (Dollars Trilogy) \u0633\u0631\u062c\u0648 \u0644\u0626\u0648\u0646\u0647 \u0627\u0633\u062a. \u0627\u06cc\u0646 \u0641\u06cc\u0644\u0645 \u062f\u0631 \u062d\u0627\u0644 \u062d\u0627\u0636\u0631 \u062f\u0631 \u0641\u0647\u0631\u0633\u062a \u06f2\u06f5\u06f0 \u0641\u06cc\u0644\u0645 \u0628\u0631\u062a\u0631 \u062a\u0627\u0631\u06cc\u062e \u0633\u06cc\u0646\u0645\u0627 \u062f\u0631 \u0648\u0628\u200c\u06af\u0627\u0647 IMDB \u0628\u0627 \u0627\u0645\u062a\u06cc\u0627\u0632 \u06f8\u066b\u06f8 \u0627\u0632 \u06f1\u06f0\u060c \u0631\u062a\u0628\u0647\u0654 \u0647\u0634\u062a\u0645 \u0631\u0627 \u0628\u0647 \u062e\u0648\u062f \u0627\u062e\u062a\u0635\u0627\u0635 \u062f\u0627\u062f\u0647\u200c\u0627\u0633\u062a \u0648 \u0628\u0647 \u0639\u0646\u0648\u0627\u0646 \u0628\u0647\u062a\u0631\u06cc\u0646 \u0641\u06cc\u0644\u0645 \u0648\u0633\u062a\u0631\u0646 \u062a\u0627\u0631\u06cc\u062e \u0633\u06cc\u0646\u0645\u0627\u06cc \u062c\u0647\u0627\u0646 \u0634\u0646\u0627\u062e\u062a\u0647 \u0645\u06cc\u200c\u0634\u0648\u062f. \u00ab\u062e\u0648\u0628\u00bb (\u06a9\u0644\u06cc\u0646\u062a \u0627\u06cc\u0633\u062a\u0648\u0648\u062f\u060c \u062f\u0631 \u0641\u06cc\u0644\u0645\u060c \u0628\u0627 \u0646\u0627\u0645 \u00ab\u0628\u0644\u0648\u0646\u062f\u06cc\u00bb) \u0648 \u00ab\u0632\u0634\u062a\u00bb (\u0627\u06cc\u0644\u0627\u06cc \u0648\u0627\u0644\u0627\u06a9\u060c \u062f\u0631 \u0641\u06cc\u0644\u0645\u060c \u0628\u0627 \u0646\u0627\u0645 \u00ab\u062a\u0648\u06a9\u0648\u00bb) \u0628\u0627 \u0647\u0645 \u06a9\u0627\u0631 \u0645\u06cc\u200c\u06a9\u0646\u0646\u062f \u0648 \u0628\u0627 \u0634\u06af\u0631\u062f \u062e\u0627\u0635\u06cc\u060c \u0628\u0647 \u06af\u0648\u0644 \u0632\u062f\u0646 \u06a9\u0644\u0627\u0646\u062a\u0631\u0647\u0627\u06cc \u0645\u0646\u0627\u0637\u0642 \u0645\u062e\u062a\u0644\u0641 \u0648 \u067e\u0648\u0644 \u062f\u0631\u0622\u0648\u0631\u062f\u0646 \u0627\u0632 \u0627\u06cc\u0646 \u0631\u0627\u0647 \u0645\u06cc\u200c\u067e\u0631\u062f\u0627\u0632\u0646\u062f. \u00ab\u0628\u062f\u00bb (\u0644\u06cc \u0648\u0627\u0646 \u06a9\u0644\u06cc\u0641) \u0622\u062f\u0645\u06a9\u0634\u06cc \u062d\u0631\u0641\u0647\u200c\u0627\u06cc \u0627\u0633\u062a \u06a9\u0647 \u0628\u0647\u200c\u062e\u0627\u0637\u0631 \u067e\u0648\u0644 \u062d\u0627\u0636\u0631 \u0628\u0647 \u0627\u0646\u062c\u0627\u0645 \u0647\u0631 \u06a9\u0627\u0631\u06cc \u0627\u0633\u062a. \u00ab\u0628\u062f\u00bb\u060c \u06a9\u0647 \u062f\u0631 \u0641\u06cc\u0644\u0645 \u0627\u0648 \u0631\u0627 \u00ab\u0627\u0650\u0646\u062c\u0644 \u0622\u06cc\u0632 (\u0627\u0650\u06cc\u0646\u062c\u0644 \u0622\u06cc\u0632)\u00bb (\u0628\u0647 \u0627\u0646\u06af\u0644\u06cc\u0633\u06cc: Angel Eyes) \u0635\u062f\u0627 \u0645\u06cc\u200c\u06a9\u0646\u0646\u062f. \u0628\u0647\u200c\u062f\u0646\u0628\u0627\u0644 \u06af\u0646\u062c\u06cc \u0627\u0633\u062a \u06a9\u0647 \u062f\u0631 \u0637\u06cc \u062c\u0646\u06af\u200c\u0647\u0627\u06cc \u062f\u0627\u062e\u0644\u06cc \u0622\u0645\u0631\u06cc\u06a9\u0627\u060c \u0628\u0647 \u062f\u0633\u062a \u0633\u0631\u0628\u0627\u0632\u06cc \u0628\u0647 \u0646\u0627\u0645 \u00ab\u062c\u06a9\u0633\u0648\u0646\u00bb\u060c \u06a9\u0647 \u0628\u0639\u062f\u0647\u0627 \u0628\u0647 \u00ab\u06a9\u0627\u0631\u0633\u0648\u0646\u00bb \u0646\u0627\u0645\u0634 \u0631\u0627 \u062a\u063a\u06cc\u06cc\u0631 \u062f\u0627\u062f\u0647\u060c \u0645\u062e\u0641\u06cc \u0634\u062f\u0647\u200c\u0627\u0633\u062a. \u067e\u0631\u0633\u0634: \u062f\u0631 \u0641\u06cc\u0644\u0645 \u062e\u0648\u0628 \u0628\u062f \u0632\u0634\u062a \u0634\u062e\u0635\u06cc\u062a \u0647\u0627 \u06a9\u062c\u0627\u06cc\u06cc \u0635\u062d\u0628\u062a \u0645\u06cc \u06a9\u0646\u0646\u062f\u061f \u067e\u0627\u0633\u062e:"}, {"text": "\u0686\u0647\u0627\u0631\u0634\u0646\u0628\u0647\u200c\u0633\u0648\u0631\u06cc \u06cc\u06a9\u06cc \u0627\u0632 \u062c\u0634\u0646\u200c\u0647\u0627\u06cc \u0627\u06cc\u0631\u0627\u0646\u06cc \u0627\u0633\u062a \u06a9\u0647 \u0627\u0632 \u063a\u0631\u0648\u0628 \u0622\u062e\u0631\u06cc\u0646 \u0633\u0647\u200c\u0634\u0646\u0628\u0647 \u06cc \u0645\u0627\u0647 \u0627\u0633\u0641\u0646\u062f\u060c \u062a\u0627 \u067e\u0633 \u0627\u0632 \u0646\u06cc\u0645\u0647\u200c\u0634\u0628 \u062a\u0627 \u0622\u062e\u0631\u06cc\u0646 \u0686\u0647\u0627\u0631\u0634\u0646\u0628\u0647 \u06cc \u0633\u0627\u0644\u060c \u0628\u0631\u06af\u0632\u0627\u0631 \u0645\u06cc\u200c\u0634\u0648\u062f \u0648 \u0628\u0631\u0627\u0641\u0631\u0648\u062e\u062a\u0646 \u0648 \u067e\u0631\u06cc\u062f\u0646 \u0627\u0632 \u0631\u0648\u06cc \u0622\u062a\u0634 \u0645\u0634\u062e\u0635\u0647\u0654 \u0627\u0635\u0644\u06cc \u0622\u0646 \u0627\u0633\u062a. \u0627\u06cc\u0646 \u062c\u0634\u0646\u060c \u0646\u062e\u0633\u062a\u06cc\u0646 \u062c\u0634\u0646 \u0627\u0632 \u0645\u062c\u0645\u0648\u0639\u0647\u0654 \u062c\u0634\u0646\u200c\u0647\u0627 \u0648 \u0645\u0646\u0627\u0633\u0628\u062a\u200c\u0647\u0627\u06cc \u0646\u0648\u0631\u0648\u0632\u06cc \u0627\u0633\u062a \u06a9\u0647 \u0628\u0627 \u0628\u0631\u0627\u0641\u0631\u0648\u062e\u062a\u0646 \u0622\u062a\u0634 \u0648 \u0628\u0631\u062e\u06cc \u0631\u0641\u062a\u0627\u0631\u0647\u0627\u06cc \u0646\u0645\u0627\u062f\u06cc\u0646 \u062f\u06cc\u06af\u0631\u060c \u0628\u0647\u200c\u0635\u0648\u0631\u062a \u062c\u0645\u0639\u06cc \u062f\u0631 \u0641\u0636\u0627\u06cc \u0628\u0627\u0632 \u0628\u0631\u06af\u0632\u0627\u0631 \u0645\u06cc\u200c\u0634\u0648\u062f. \u0628\u0647\u200c\u06af\u0641\u062a\u0647\u0654 \u0627\u0628\u0631\u0627\u0647\u06cc\u0645 \u067e\u0648\u0631\u062f\u0627\u0648\u0648\u062f \u0686\u0647\u0627\u0631\u0634\u0646\u0628\u0647\u200c\u0633\u0648\u0631\u06cc \u0631\u06cc\u0634\u0647 \u062f\u0631 \u06af\u0627\u0647\u0646\u0628\u0627\u0631\u0650 \u0647\u064e\u0645\u064e\u0633\u0652\u067e\u064e\u062a\u0652\u0645\u064e\u062f\u064e\u0645 \u0632\u0631\u062a\u0634\u062a\u06cc\u0627\u0646 \u0648 \u0646\u06cc\u0632 \u062c\u0634\u0646 \u0646\u0632\u0648\u0644 \u0641\u0631\u0648\u0647\u0631\u0647\u0627 \u062f\u0627\u0631\u062f \u06a9\u0647 \u0634\u0634 \u0631\u0648\u0632 \u067e\u06cc\u0634 \u0627\u0632 \u0641\u0631\u0627\u0631\u0633\u06cc\u062f\u0646 \u0646\u0648\u0631\u0648\u0632 \u0628\u0631\u06af\u0632\u0627\u0631 \u0645\u06cc\u200c\u0634\u062f. \u0627\u062d\u062a\u0645\u0627\u0644 \u062f\u06cc\u06af\u0631 \u0627\u06cc\u0646 \u0627\u0633\u062a \u06a9\u0647 \u0686\u0647\u0627\u0631\u0634\u0646\u0628\u0647\u200c\u0633\u0648\u0631\u06cc \u0628\u0627\u0632\u0645\u0627\u0646\u062f\u0647 \u0648 \u0634\u06a9\u0644 \u062a\u062d\u0648\u0644\u200c\u06cc\u0627\u0641\u062a\u0647\u200c\u0627\u06cc \u0627\u0632 \u062c\u0634\u0646 \u0633\u062f\u0647 \u0628\u0627\u0634\u062f\u060c \u06a9\u0647 \u0627\u062d\u062a\u0645\u0627\u0644 \u0628\u0639\u06cc\u062f\u06cc \u0627\u0633\u062a. \u0639\u0644\u0627\u0648\u0647 \u0628\u0631\u0627\u0641\u0631\u0648\u062e\u062a\u0646 \u0622\u062a\u0634\u060c \u0622\u06cc\u06cc\u0646\u200c\u0647\u0627\u06cc \u0645\u062e\u062a\u0644\u0641 \u062f\u06cc\u06af\u0631\u06cc \u0646\u06cc\u0632 \u062f\u0631 \u0628\u062e\u0634\u200c\u0647\u0627\u06cc \u06af\u0648\u0646\u0627\u06af\u0648\u0646 \u0627\u06cc\u0631\u0627\u0646 \u062f\u0631 \u0632\u0645\u0627\u0646 \u0627\u06cc\u0646 \u062c\u0634\u0646 \u0627\u0646\u062c\u0627\u0645 \u0645\u06cc\u200c\u0634\u0648\u0646\u062f. \u0628\u0631\u0627\u06cc \u0646\u0645\u0648\u0646\u0647\u060c \u062f\u0631 \u062a\u0628\u0631\u06cc\u0632\u060c \u0645\u0631\u062f\u0645 \u0628\u0647 \u0686\u0647\u0627\u0631\u0634\u0646\u0628\u0647\u200c\u0628\u0627\u0632\u0627\u0631 \u0645\u06cc\u200c\u0631\u0648\u0646\u062f \u06a9\u0647 \u0628\u0627 \u0686\u0631\u0627\u063a \u0648 \u0634\u0645\u0639\u060c \u0628\u0647\u200c\u0637\u0631\u0632 \u0632\u06cc\u0628\u0627\u06cc\u06cc \u0686\u0631\u0627\u063a\u0627\u0646\u06cc \u0634\u062f\u0647\u200c\u0627\u0633\u062a. \u0647\u0631 \u062e\u0627\u0646\u0648\u0627\u062f\u0647 \u06cc\u06a9 \u0622\u06cc\u0646\u0647\u060c \u062f\u0627\u0646\u0647\u200c\u0647\u0627\u06cc \u0627\u0633\u0641\u0646\u062f\u060c \u0648 \u06cc\u06a9 \u06a9\u0648\u0632\u0647 \u0628\u0631\u0627\u06cc \u0633\u0627\u0644 \u0646\u0648 \u062e\u0631\u06cc\u062f\u0627\u0631\u06cc \u0645\u06cc\u200c\u06a9\u0646\u0646\u062f. \u0647\u0645\u0647\u200c\u0633\u0627\u0644\u0647 \u0634\u0647\u0631\u0648\u0646\u062f\u0627\u0646\u06cc \u0627\u0632 \u0627\u06cc\u0631\u0627\u0646 \u062f\u0631 \u0627\u062b\u0631 \u0627\u0646\u0641\u062c\u0627\u0631\u0647\u0627\u06cc \u0646\u0627\u062e\u0648\u0634\u0627\u06cc\u0646\u062f \u0645\u0631\u0628\u0648\u0637 \u0628\u0647 \u0627\u06cc\u0646 \u062c\u0634\u0646\u060c \u06a9\u0634\u062a\u0647 \u06cc\u0627 \u0645\u0635\u062f\u0648\u0645 \u0645\u06cc\u200c\u0634\u0648\u0646\u062f. \u067e\u0631\u0633\u0634: \u0646\u0627\u0645 \u062c\u0634\u0646 \u0627\u062e\u0631\u06cc\u0646 \u0634\u0646\u0628\u0647 \u06cc \u0633\u0627\u0644 \u0686\u06cc\u0633\u062a\u061f \u067e\u0627\u0633\u062e:"}]}
|
flax-community/gpt2-persian-question-answering
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"fa",
"dataset:persian_qa",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
Rap Lyric Generator <br/>
GPT-2 fine tuned using FLAX/JAX on over 10000 Rap Songs from over 50 rappers, the dataset was gathered from genius.com <br/>
Checkout the deployed version on hf-spaces :- [here](https://huggingface.co/spaces/Shankhdhar/Rap-Lyric-generator) <br/>
Colab for making predictions:- [here](https://colab.research.google.com/drive/1aibR06TrFGnt-TPmyIRDD2-8eT7PU5Kl#scrollTo=rgE3QbiTFIMQ)<br/>
The dataset we used: [dataset](https://huggingface.co/datasets/Cropinky/rap_lyrics_english)<br/>
Made by:-<br/>
[Anant Shankhdhar](https://huggingface.co/Shankhdhar)<br/>
[Jeronim Matijević](https://huggingface.co/Cropinky)<br/>
|
{}
|
flax-community/gpt2-rap-lyric-generator
| null |
[
"transformers",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# GPT2-small-indonesian
This is a pretrained model on Indonesian language using a causal language modeling (CLM) objective, which was first
introduced in [this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104)
organized by [HuggingFace](https://huggingface.co). All training was done on a TPUv3-8 VM sponsored by the Google Cloud team.
The demo can be found [here](https://huggingface.co/spaces/flax-community/gpt2-indonesian).
## How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness,
we set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='flax-community/gpt2-small-indonesian')
>>> set_seed(42)
>>> generator("Sewindu sudah kita tak berjumpa,", max_length=30, num_return_sequences=5)
[{'generated_text': 'Sewindu sudah kita tak berjumpa, dua dekade lalu, saya hanya bertemu sekali. Entah mengapa, saya lebih nyaman berbicara dalam bahasa Indonesia, bahasa Indonesia'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, tapi dalam dua hari ini, kita bisa saja bertemu.”\
“Kau tau, bagaimana dulu kita bertemu?” aku'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, banyak kisah yang tersimpan. Tak mudah tuk kembali ke pelukan, di mana kini kita berada, sebuah tempat yang jauh'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, sejak aku lulus kampus di Bandung, aku sempat mencari kabar tentangmu. Ah, masih ada tempat di hatiku,'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, tapi Tuhan masih saja menyukarkan doa kita masing-masing.\
Tuhan akan memberi lebih dari apa yang kita'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('flax-community/gpt2-small-indonesian')
model = GPT2Model.from_pretrained('flax-community/gpt2-small-indonesian')
text = "Ubah dengan teks apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('flax-community/gpt2-small-indonesian')
model = TFGPT2Model.from_pretrained('flax-community/gpt2-small-indonesian')
text = "Ubah dengan teks apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Limitations and bias
The training data used for this model are Indonesian websites of [OSCAR](https://oscar-corpus.com/),
[mc4](https://huggingface.co/datasets/mc4) and [Wikipedia](https://huggingface.co/datasets/wikipedia). The datasets
contain a lot of unfiltered content from the internet, which is far from neutral. While we have done some filtering on
the dataset (see the **Training data** section), the filtering is by no means a thorough mitigation of biased content
that is eventually used by the training data. These biases might also affect models that are fine-tuned using this model.
As the openAI team themselves point out in their [model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we
> do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry
> out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender,
> race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with
> similar levels of caution around use cases that are sensitive to biases around human attributes.
We have done a basic bias analysis that you can find in this [notebook](https://huggingface.co/flax-community/gpt2-small-indonesian/blob/main/bias_analysis/gpt2_medium_indonesian_bias_analysis.ipynb), performed on [Indonesian GPT2 medium](https://huggingface.co/flax-community/gpt2-medium-indonesian), based on the bias analysis for [Polish GPT2](https://huggingface.co/flax-community/papuGaPT2) with modifications.
### Gender bias
We generated 50 texts starting with prompts "She/He works as". After doing some preprocessing (lowercase and stopwords removal) we obtain texts that are used to generate word clouds of female/male professions. The most salient terms for male professions are: driver, sopir (driver), ojek, tukang, online.

The most salient terms for female professions are: pegawai (employee), konsultan (consultant), asisten (assistant).

### Ethnicity bias
We generated 1,200 texts to assess bias across ethnicity and gender vectors. We will create prompts with the following scheme:
* Person - we will assess 5 ethnicities: Sunda, Batak, Minahasa, Dayak, Asmat, Neutral (no ethnicity)
* Topic - we will use 5 different topics:
* random act: *entered home*
* said: *said*
* works as: *works as*
* intent: *let [person] ...*
* define: *is*
Sample of generated prompt: "seorang perempuan sunda masuk ke rumah..." (a Sundanese woman enters the house...)
We used a [model](https://huggingface.co/Hate-speech-CNERG/dehatebert-mono-indonesian) trained on Indonesian hate speech corpus ([dataset 1](https://github.com/okkyibrohim/id-multi-label-hate-speech-and-abusive-language-detection), [dataset 2](https://github.com/ialfina/id-hatespeech-detection)) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the ethnicity and gender from the generated text before running the hate speech detector.
The following chart demonstrates the intensity of hate speech associated with the generated texts with outlier scores removed. Some ethnicities score higher than the neutral baseline.

### Religion bias
With the same methodology above, we generated 1,400 texts to assess bias across religion and gender vectors. We will assess 6 religions: Islam, Protestan (Protestant), Katolik (Catholic), Buddha (Buddhism), Hindu (Hinduism), and Khonghucu (Confucianism) with Neutral (no religion) as a baseline.
The following chart demonstrates the intensity of hate speech associated with the generated texts with outlier scores removed. Some religions score higher than the neutral baseline.

## Training data
The model was trained on a combined dataset of [OSCAR](https://oscar-corpus.com/), [mc4](https://huggingface.co/datasets/mc4)
and Wikipedia for the Indonesian language. We have filtered and reduced the mc4 dataset so that we end up with 29 GB
of data in total. The mc4 dataset was cleaned using [this filtering script](https://github.com/Wikidepia/indonesian_datasets/blob/master/dump/mc4/cleanup.py)
and we also only included links that have been cited by the Indonesian Wikipedia.
## Training procedure
The model was trained on a TPUv3-8 VM provided by the Google Cloud team. The training duration was `4d 14h 50m 47s`.
### Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| dataset | train loss | eval loss | eval perplexity |
| ---------- | ---------- | -------------- | ---------- |
| ID OSCAR+mc4+wikipedia (29GB) | 3.046 | 2.926 | 18.66 |
### Tracking
The training process was tracked in [TensorBoard](https://huggingface.co/flax-community/gpt2-small-indonesian/tensorboard) and [Weights and Biases](https://wandb.ai/wandb/hf-flax-gpt2-indonesian?workspace=user-cahya).
## Team members
- Akmal ([@Wikidepia](https://huggingface.co/Wikidepia))
- alvinwatner ([@alvinwatner](https://huggingface.co/alvinwatner))
- Cahya Wirawan ([@cahya](https://huggingface.co/cahya))
- Galuh Sahid ([@Galuh](https://huggingface.co/Galuh))
- Muhammad Agung Hambali ([@AyameRushia](https://huggingface.co/AyameRushia))
- Muhammad Fhadli ([@muhammadfhadli](https://huggingface.co/muhammadfhadli))
- Samsul Rahmadani ([@munggok](https://huggingface.co/munggok))
## Future work
We would like to pre-train further the models with larger and cleaner datasets and fine-tune it to specific domains
if we can get the necessary hardware resources.
|
{"language": "id", "widget": [{"text": "Sewindu sudah kita tak berjumpa, rinduku padamu sudah tak terkira."}]}
|
flax-community/gpt2-small-indonesian
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"id",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
flax-community/gpt2-small-javanese
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
## GPT2 in Swahili
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by [HuggingFace](https://huggingface.co). All training was done on a TPUv3-8 VM sponsored by the Google Cloud team.
## How to use
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt2-swahili")
model = AutoModelWithLMHead.from_pretrained("flax-community/gpt2-swahili")
print(round((model.num_parameters())/(1000*1000)),"Million Parameters")
124 Million Parameters
```
#### **Training Data**:
This model was trained on [Swahili Safi](https://huggingface.co/datasets/flax-community/swahili-safi)
#### **More Details**:
For more details and Demo please check [HF Swahili Space](https://huggingface.co/spaces/flax-community/Swahili)
|
{"language": "sw", "datasets": ["flax-community/swahili-safi"], "widget": [{"text": "Ninitaka kukula"}]}
|
flax-community/gpt2-swahili
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"sw",
"dataset:flax-community/swahili-safi",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
feature-extraction
|
transformers
|
{}
|
flax-community/hubert-dementia-screening
| null |
[
"transformers",
"jax",
"hubert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
flax-community/hybrid-fnet-test
| null |
[
"transformers",
"jax",
"tensorboard",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
## Indonesian RoBERTa Base
Indonesian RoBERTa Base is a masked language model based on the [RoBERTa](https://arxiv.org/abs/1907.11692) model. It was trained on the [OSCAR](https://huggingface.co/datasets/oscar) dataset, specifically the `unshuffled_deduplicated_id` subset. The model was trained from scratch and achieved an evaluation loss of 1.798 and an evaluation accuracy of 62.45%.
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by HuggingFace. All training was done on a TPUv3-8 VM, sponsored by the Google Cloud team.
All necessary scripts used for training could be found in the [Files and versions](https://huggingface.co/flax-community/indonesian-roberta-base/tree/main) tab, as well as the [Training metrics](https://huggingface.co/flax-community/indonesian-roberta-base/tensorboard) logged via Tensorboard.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ------------------------- | ------- | ------- | ------------------------------------------ |
| `indonesian-roberta-base` | 124M | RoBERTa | OSCAR `unshuffled_deduplicated_id` Dataset |
## Evaluation Results
The model was trained for 8 epochs and the following is the final result once the training ended.
| train loss | valid loss | valid accuracy | total time |
| ---------- | ---------- | -------------- | ---------- |
| 1.870 | 1.798 | 0.6245 | 18:25:39 |
## How to Use
### As Masked Language Model
```python
from transformers import pipeline
pretrained_name = "flax-community/indonesian-roberta-base"
fill_mask = pipeline(
"fill-mask",
model=pretrained_name,
tokenizer=pretrained_name
)
fill_mask("Budi sedang <mask> di sekolah.")
```
### Feature Extraction in PyTorch
```python
from transformers import RobertaModel, RobertaTokenizerFast
pretrained_name = "flax-community/indonesian-roberta-base"
model = RobertaModel.from_pretrained(pretrained_name)
tokenizer = RobertaTokenizerFast.from_pretrained(pretrained_name)
prompt = "Budi sedang berada di sekolah."
encoded_input = tokenizer(prompt, return_tensors='pt')
output = model(**encoded_input)
```
## Team Members
- Wilson Wongso ([@w11wo](https://hf.co/w11wo))
- Steven Limcorn ([@stevenlimcorn](https://hf.co/stevenlimcorn))
- Samsul Rahmadani ([@munggok](https://hf.co/munggok))
- Chew Kok Wah ([@chewkokwah](https://hf.co/chewkokwah))
|
{"language": "id", "license": "mit", "tags": ["indonesian-roberta-base"], "datasets": ["oscar"], "widget": [{"text": "Budi telat ke sekolah karena ia <mask>."}]}
|
flax-community/indonesian-roberta-base
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"roberta",
"fill-mask",
"indonesian-roberta-base",
"id",
"dataset:oscar",
"arxiv:1907.11692",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
## Indonesian RoBERTa Large
Indonesian RoBERTa Large is a masked language model based on the [RoBERTa](https://arxiv.org/abs/1907.11692) model. It was trained on the [OSCAR](https://huggingface.co/datasets/oscar) dataset, specifically the `unshuffled_deduplicated_id` subset. The model was trained from scratch and achieved an evaluation loss of 4.801 and an evaluation accuracy of 29.8%.
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by HuggingFace. All training was done on a TPUv3-8 VM, sponsored by the Google Cloud team.
All necessary scripts used for training could be found in the [Files and versions](https://huggingface.co/flax-community/indonesian-roberta-large/tree/main) tab, as well as the [Training metrics](https://huggingface.co/flax-community/indonesian-roberta-large/tensorboard) logged via Tensorboard.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| -------------------------- | ------- | ------- | ------------------------------------------ |
| `indonesian-roberta-large` | 355M | RoBERTa | OSCAR `unshuffled_deduplicated_id` Dataset |
## Evaluation Results
The model was trained for 10 epochs and the following is the final result once the training ended.
| train loss | valid loss | valid accuracy | total time |
| ---------- | ---------- | -------------- | ---------- |
| 5.19 | 4.801 | 0.298 | 2:8:32:28 |
## How to Use
### As Masked Language Model
```python
from transformers import pipeline
pretrained_name = "flax-community/indonesian-roberta-large"
fill_mask = pipeline(
"fill-mask",
model=pretrained_name,
tokenizer=pretrained_name
)
fill_mask("Budi sedang <mask> di sekolah.")
```
### Feature Extraction in PyTorch
```python
from transformers import RobertaModel, RobertaTokenizerFast
pretrained_name = "flax-community/indonesian-roberta-large"
model = RobertaModel.from_pretrained(pretrained_name)
tokenizer = RobertaTokenizerFast.from_pretrained(pretrained_name)
prompt = "Budi sedang berada di sekolah."
encoded_input = tokenizer(prompt, return_tensors='pt')
output = model(**encoded_input)
```
## Team Members
- Wilson Wongso ([@w11wo](https://hf.co/w11wo))
- Steven Limcorn ([@stevenlimcorn](https://hf.co/stevenlimcorn))
- Samsul Rahmadani ([@munggok](https://hf.co/munggok))
- Chew Kok Wah ([@chewkokwah](https://hf.co/chewkokwah))
|
{"language": "id", "license": "mit", "tags": ["indonesian-roberta-large"], "datasets": ["oscar"], "widget": [{"text": "Budi telat ke sekolah karena ia <mask>."}]}
|
flax-community/indonesian-roberta-large
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"roberta",
"fill-mask",
"indonesian-roberta-large",
"id",
"dataset:oscar",
"arxiv:1907.11692",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
flax-community/koT5
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
# KoCLIP
This repository includes
## Installation
Create a virtual env and install `requirements.txt`.
```
pip install -r requirements.txt
```
For Google Cloud TPU VM please follow necessary installation steps here:
[Pytorch on TPU VM](https://cloud.google.com/tpu/docs/pytorch-xla-ug-tpu-vm)
[JAX/Flax on TPU VM](https://cloud.google.com/tpu/docs/jax-quickstart-tpu-vm)
|
{}
|
flax-community/koclip
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# MedCLIP: Fine-tuning a CLIP model on the ROCO medical dataset
<!--  -->
<h3 align="center">
<!-- <p>MedCLIP</p> -->
<img src="./assets/logo.png" alt="huggingface-medclip" width="250" height="250">
## Summary
This repository contains the code for fine-tuning a CLIP model on the [ROCO dataset](https://github.com/razorx89/roco-dataset), a dataset made of radiology images and a caption.
This work is done as a part of the [**Flax/Jax community week**](https://github.com/huggingface/transformers/blob/master/examples/research_projects/jax-projects/README.md#quickstart-flax-and-jax-in-transformers) organized by Hugging Face and Google.
### Demo
You can try a Streamlit demo app that uses this model on [🤗 Spaces](https://huggingface.co/spaces/kaushalya/medclip-roco). You may have to signup for 🤗 Spaces private beta to access this app (screenshot shown below).

🤗 Hub Model card: https://huggingface.co/flax-community/medclip-roco
## Dataset 🧩
Each image is accompanied by a textual caption. The caption length varies from a few characters (a single word) to 2,000 characters (multiple sentences). During preprocessing we remove all images that has a caption shorter than 10 characters.
Training set: 57,780 images with their caption.
Validation set: 7,200
Test set: 7,650
[ ] Give an example
## Installation 💽
This repo depends on the master branch of [Hugging Face - Transformers library](https://github.com/huggingface/transformers). First you need to clone the transformers repository and then install it locally (preferably inside a virtual environment) with `pip install -e ".[flax]"`.
## The Model ⚙️
You can load the pretrained model from the Hugging Face Hub with
```
from medclip.modeling_hybrid_clip import FlaxHybridCLIP
model = FlaxHybridCLIP.from_pretrained("flax-community/medclip-roco")
```
## Training
The model is trained using Flax/JAX on a cloud TPU-v3-8.
You can fine-tune a CLIP model implemented in Flax by simply running `sh run_medclip`.
This is the validation loss curve we observed when we trained the model using the `run_medclip.sh` script.

## Limitations 🚨
The current model is capable of identifying if a given radiology image is a PET scan or an ultrasound scan. However it fails at identifying a brain scan from a lung scan. ❗️This model **should not** be used in a medical setting without further evaluations❗️.
## Acknowledgements
Huge thanks to the Hugging Face 🤗 team and Google JAX/Flax team for organizing the community week and letting us use cloud compute for 2 weeks. We specially thank [@patil-suraj](https://github.com/patil-suraj) & [@patrickvonplaten](https://github.com/patrickvonplaten) for the continued support on Slack and the detailed feedback.
## TODO
[ ] Evaluation on down-stream tasks
[ ] Zero-shot learning performance
[ ] Merge the demo app
|
{}
|
kaushalya/medclip
| null |
[
"transformers",
"jax",
"tensorboard",
"hybrid-clip",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# MedCLIP
## Model description
## Intended uses & limitations
#### How to use
```python
# You can include sample code which will be formatted
```
#### Limitations and bias
Provide examples of latent issues and potential remediations.
## Training data
Describe the data you used to train the model.
If you initialized it with pre-trained weights, add a link to the pre-trained model card or repository with description of the pre-training data.
## Training procedure
Preprocessing, hardware used, hyperparameters...
## Eval results
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020}
}
```
|
{"language": ["en"], "license": "apache-2.0", "tags": ["vision"]}
|
flax-community/medclip
| null |
[
"transformers",
"jax",
"tensorboard",
"hybrid-clip",
"vision",
"en",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# Mongolian GPT2
Goal is to create a strong language generation model for Mongolian
Since initial code and data is pretty much written by @patrickvonplaten and other huggingface members, it should not be so hard to get the first sense.
## Model
Randomly initialized GPT2 model
## Datasets
We can use OSCAR which is available through datasets
## Datasets
A causal language modeling script for Flax is available here 1. It can be used pretty much without any required code changes.
If there is time left, I’d love to try some private crawling and integrate it datasets.
## Expected Outcome
Understandable Mongolian text generation model
## Challenges
Lack of data → OSCAR Mongolian is just 2.2G. Maybe we need to research ways to acquire more data with this.
|
{"language": "mn", "tags": ["gpt2"], "datasets": ["oscar"], "thumbnail": "https://avatars.githubusercontent.com/u/43239645?s=60&v=4"}
|
flax-community/mongolian-gpt2
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"mn",
"dataset:oscar",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# IndicNLP Marathi News Classifier
This model was fine-tuned using [Marathi RoBERTa](https://huggingface.co/flax-community/roberta-base-mr) on [IndicNLP Marathi News Dataset](https://github.com/AI4Bharat/indicnlp_corpus#indicnlp-news-article-classification-dataset)
## Dataset
IndicNLP Marathi news dataset consists 3 classes - `['lifestyle', 'entertainment', 'sports']` - with following docs distribution as per classes:
| train | eval | test |
| ----- | ---- | ---- |
| 9672 | 477 | 478 |
💯 Our **`mr-indicnlp-classifier`** model fine tuned from **roberta-base-mr** Pretrained Marathi RoBERTa model outperformed both classifier mentioned in [Arora, G. (2020). iNLTK](https://www.semanticscholar.org/paper/iNLTK%3A-Natural-Language-Toolkit-for-Indic-Languages-Arora/5039ed9e100d3a1cbbc25a02c82f6ee181609e83/figure/3) and [Kunchukuttan, Anoop et al. AI4Bharat-IndicNLP.](https://www.semanticscholar.org/paper/AI4Bharat-IndicNLP-Corpus%3A-Monolingual-Corpora-and-Kunchukuttan-Kakwani/7997d432925aff0ba05497d2893c09918298ca55/figure/4)
| Dataset | FT-W | FT-WC | INLP | iNLTK | **roberta-base-mr 🏆** |
| --------------- | ----- | ----- | ----- | ----- | --------------------- |
| iNLTK Headlines | 83.06 | 81.65 | 89.92 | 92.4 | **97.48** |
|
{}
|
flax-community/mr-indicnlp-classifier
| null |
[
"transformers",
"pytorch",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
{}
|
flax-community/mr-inltk-classifier
| null |
[
"transformers",
"pytorch",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
flax-community/multilingual-image-captioning-5M
| null |
[
"tensorboard",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
flax-community/multilingual-image-captioning
| null |
[
"tensorboard",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
{}
|
flax-community/multilingual-vqa-ft
| null |
[
"transformers",
"jax",
"tensorboard",
"clip-vision-bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
flax-community/multilingual-vqa-pt-45k-ft-adf
| null |
[
"tensorboard",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
{}
|
flax-community/multilingual-vqa-pt-45k-ft
| null |
[
"transformers",
"jax",
"tensorboard",
"clip-vision-bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
flax-community/multilingual-vqa-pt-60k-ft
| null |
[
"tensorboard",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
flax-community/multilingual-vqa-pt-70k-ft
| null |
[
"tensorboard",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
flax-community/multilingual-vqa-pt-ckpts
| null |
[
"tensorboard",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# Nordic GPT2--wikipedia
A Nordic GPT2 style model trained using Flax CLM pipeline on the Nordic parts
part of the wiki40b dataset.
https://huggingface.co/datasets/wiki40b
## Model series
This model is part of a series of models training on TPU with Flax Jax during Huggingface Flax/Jax challenge.
## Gpt models
## Swedish Gpt
https://huggingface.co/birgermoell/swedish-gpt/
## Swedish gpt wiki
https://huggingface.co/flax-community/swe-gpt-wiki
# Nordic gpt wiki
https://huggingface.co/flax-community/nordic-gpt-wiki
## Dansk gpt wiki
https://huggingface.co/flax-community/dansk-gpt-wiki
## Norsk gpt wiki
https://huggingface.co/flax-community/norsk-gpt-wiki
## Roberta models
## Nordic Roberta Wiki
https://huggingface.co/flax-community/nordic-roberta-wiki
## Swe Roberta Wiki Oscar
https://huggingface.co/flax-community/swe-roberta-wiki-oscar
## Roberta Swedish Scandi
https://huggingface.co/birgermoell/roberta-swedish-scandi
## Roberta Swedish
https://huggingface.co/birgermoell/roberta-swedish
## Swedish T5 model
https://huggingface.co/birgermoell/t5-base-swedish
## Data cleaning and preprocessing
The data was cleaned and preprocessed using the following script. Make sure to install depencies for beam_runner to make the dataset work.
```python
from datasets import load_dataset
def load_and_clean_wiki():
dataset = load_dataset('wiki40b', 'da', beam_runner='DirectRunner', split="train")
#dataset = load_dataset('wiki40b', 'sv', beam_runner='DirectRunner')
dataset = dataset.remove_columns(['wikidata_id', 'version_id'])
filtered_dataset = dataset.map(filter_wikipedia)
# filtered_dataset[:3]
# print(filtered_dataset[:3])
return filtered_dataset
def filter_wikipedia(batch):
batch["text"] = " ".join(batch["text"].split("\
_START_SECTION_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_ARTICLE_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_ARTICLE_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_PARAGRAPH_\
"))
batch["text"] = " ".join(batch["text"].split("_NEWLINE_"))
batch["text"] = " ".join(batch["text"].split("\xa0"))
return batch
```
## Training script
The following training script was used to train the model.
```bash
./run_clm_flax.py --output_dir="${MODEL_DIR}" --model_type="gpt2" --config_name="${MODEL_DIR}" --tokenizer_name="${MODEL_DIR}" --dataset_name="wiki40b" --dataset_config_name="da" --do_train --do_eval --block_size="512" --per_device_train_batch_size="64" --per_device_eval_batch_size="64" --learning_rate="5e-3" --warmup_steps="1000" --adam_beta1="0.9" --adam_beta2="0.98" --weight_decay="0.01" --overwrite_output_dir --num_train_epochs="20" --logging_steps="500" --save_steps="1000" --eval_steps="2500" --push_to_hub
```
|
{"language": "sv", "widget": [{"text": "Det var en g\u00e5ng"}]}
|
flax-community/nordic-gpt-wiki
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"sv",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# Nordic Roberta Wikipedia
## Description
Nord roberta model trainined on the swedish danish and norwegian wikipedia.
## Evaluation
Evaluation on Named Entity recognition in Danish.
I finetuned each model on 3 epochs on DaNE, repeated it 5 times for each model, and calculated 95% confidence intervals for the means. Here are the results:
xlm-roberta-base : 88.01 +- 0.43
flax-community/nordic-roberta-wiki: 85.75 +- 0.69 (this model)
Maltehb/danish-bert-botxo: 85.38 +- 0.55
flax-community/roberta-base-danish: 80.14 +- 1.47
flax-community/roberta-base-scandinavian : 78.03 +- 3.02
Maltehb/-l-ctra-danish-electra-small-cased: 57.87 +- 3.19
NbAiLab/nb-bert-base : 30.24 +- 1.21
Randomly initialised RoBERTa model: 19.79 +- 2.00
Evaluation on Sentiment analysis in Dansish
Here are the results on test set, where each model has been trained 5 times, and the “+-” refers to a 95% confidence interval of the mean score:
Maltehb/danish-bert-botxo: 65.19 +- 0.53
NbAiLab/nb-bert-base : 63.80 +- 0.77
xlm-roberta-base : 63.55 +- 1.59
flax-community/nordic-roberta-wiki : 56.46 +- 1.77
flax-community/roberta-base-danish : 54.73 +- 8.96
flax-community/roberta-base-scandinavian : 44.28 +- 9.21
Maltehb/-l-ctra-danish-electra-small-cased : 47.78 +- 12.65
Randomly initialised RoBERTa model: 36.96 +- 1.02
Maltehb/roberta-base-scandinavian : 33.65 +- 8.32
## Model series
This model is part of a series of models training on TPU with Flax Jax during Huggingface Flax/Jax challenge.
## Gpt models
## Swedish Gpt
https://huggingface.co/birgermoell/swedish-gpt/
## Swedish gpt wiki
https://huggingface.co/flax-community/swe-gpt-wiki
# Nordic gpt wiki
https://huggingface.co/flax-community/nordic-gpt-wiki
## Dansk gpt wiki
https://huggingface.co/flax-community/dansk-gpt-wiki
## Norsk gpt wiki
https://huggingface.co/flax-community/norsk-gpt-wiki
## Roberta models
## Nordic Roberta Wiki
https://huggingface.co/flax-community/nordic-roberta-wiki
## Swe Roberta Wiki Oscar
https://huggingface.co/flax-community/swe-roberta-wiki-oscar
## Roberta Swedish Scandi
https://huggingface.co/birgermoell/roberta-swedish-scandi
## Roberta Swedish
https://huggingface.co/birgermoell/roberta-swedish
## Swedish T5 model
https://huggingface.co/birgermoell/t5-base-swedish
|
{"language": "sv", "license": "cc-by-4.0", "tags": ["swedish", "roberta"], "pipeline_tag": "fill-mask", "widget": [{"text": "Meninged med livet \u00e4r <mask>."}]}
|
flax-community/nordic-roberta-wiki
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"feature-extraction",
"swedish",
"fill-mask",
"sv",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# GPT2-svenska-wikipedia
A norwegian GPT2 style model trained using Flax CLM pipeline on the Norwegian
part of the wiki40b dataset.
https://huggingface.co/datasets/wiki40b
## Model series
This model is part of a series of models training on TPU with Flax Jax during Huggingface Flax/Jax challenge.
## Gpt models
## Swedish Gpt
https://huggingface.co/birgermoell/swedish-gpt/
## Swedish gpt wiki
https://huggingface.co/flax-community/swe-gpt-wiki
# Nordic gpt wiki
https://huggingface.co/flax-community/nordic-gpt-wiki
## Dansk gpt wiki
https://huggingface.co/flax-community/dansk-gpt-wiki
## Norsk gpt wiki
https://huggingface.co/flax-community/norsk-gpt-wiki
## Roberta models
## Nordic Roberta Wiki
https://huggingface.co/flax-community/nordic-roberta-wiki
## Swe Roberta Wiki Oscar
https://huggingface.co/flax-community/swe-roberta-wiki-oscar
## Roberta Swedish Scandi
https://huggingface.co/birgermoell/roberta-swedish-scandi
## Roberta Swedish
https://huggingface.co/birgermoell/roberta-swedish
## Swedish T5 model
https://huggingface.co/birgermoell/t5-base-swedish
## Data cleaning and preprocessing
The data was cleaned and preprocessed using the following script. Make sure to install depencies for beam_runner to make the dataset work.
```python
from datasets import load_dataset
def load_and_clean_wiki():
dataset = load_dataset('wiki40b', 'no', beam_runner='DirectRunner', split="train")
#dataset = load_dataset('wiki40b', 'sv', beam_runner='DirectRunner')
dataset = dataset.remove_columns(['wikidata_id', 'version_id'])
filtered_dataset = dataset.map(filter_wikipedia)
# filtered_dataset[:3]
# print(filtered_dataset[:3])
return filtered_dataset
def filter_wikipedia(batch):
batch["text"] = " ".join(batch["text"].split("\
_START_SECTION_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_ARTICLE_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_ARTICLE_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_PARAGRAPH_\
"))
batch["text"] = " ".join(batch["text"].split("_NEWLINE_"))
batch["text"] = " ".join(batch["text"].split("\xa0"))
return batch
```
## Training script
The following training script was used to train the model.
```bash
./run_clm_flax.py --output_dir="${MODEL_DIR}" --model_type="gpt2" --config_name="${MODEL_DIR}" --tokenizer_name="${MODEL_DIR}" --dataset_name="wiki40b" --dataset_config_name="no" --do_train --do_eval --block_size="512" --per_device_train_batch_size="64" --per_device_eval_batch_size="64" --learning_rate="5e-3" --warmup_steps="1000" --adam_beta1="0.9" --adam_beta2="0.98" --weight_decay="0.01" --overwrite_output_dir --num_train_epochs="20" --logging_steps="500" --save_steps="1000" --eval_steps="2500" --push_to_hub
```
|
{"language": false, "widget": [{"text": "Det er flott"}]}
|
flax-community/norsk-gpt-wiki
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"no",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
{}
|
flax-community/papuGaPT2-large
| null |
[
"transformers",
"pytorch",
"jax",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# papuGaPT2 - Polish GPT2 language model
[GPT2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) was released in 2019 and surprised many with its text generation capability. However, up until very recently, we have not had a strong text generation model in Polish language, which limited the research opportunities for Polish NLP practitioners. With the release of this model, we hope to enable such research.
Our model follows the standard GPT2 architecture and training approach. We are using a causal language modeling (CLM) objective, which means that the model is trained to predict the next word (token) in a sequence of words (tokens).
## Datasets
We used the Polish subset of the [multilingual Oscar corpus](https://www.aclweb.org/anthology/2020.acl-main.156) to train the model in a self-supervised fashion.
```
from datasets import load_dataset
dataset = load_dataset('oscar', 'unshuffled_deduplicated_pl')
```
## Intended uses & limitations
The raw model can be used for text generation or fine-tuned for a downstream task. The model has been trained on data scraped from the web, and can generate text containing intense violence, sexual situations, coarse language and drug use. It also reflects the biases from the dataset (see below for more details). These limitations are likely to transfer to the fine-tuned models as well. At this stage, we do not recommend using the model beyond research.
## Bias Analysis
There are many sources of bias embedded in the model and we caution to be mindful of this while exploring the capabilities of this model. We have started a very basic analysis of bias that you can see in [this notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_bias_analysis.ipynb).
### Gender Bias
As an example, we generated 50 texts starting with prompts "She/He works as". The image below presents the resulting word clouds of female/male professions. The most salient terms for male professions are: teacher, sales representative, programmer. The most salient terms for female professions are: model, caregiver, receptionist, waitress.

### Ethnicity/Nationality/Gender Bias
We generated 1000 texts to assess bias across ethnicity, nationality and gender vectors. We created prompts with the following scheme:
* Person - in Polish this is a single word that differentiates both nationality/ethnicity and gender. We assessed the following 5 nationalities/ethnicities: German, Romani, Jewish, Ukrainian, Neutral. The neutral group used generic pronounts ("He/She").
* Topic - we used 5 different topics:
* random act: *entered home*
* said: *said*
* works as: *works as*
* intent: Polish *niech* which combined with *he* would roughly translate to *let him ...*
* define: *is*
Each combination of 5 nationalities x 2 genders x 5 topics had 20 generated texts.
We used a model trained on [Polish Hate Speech corpus](https://huggingface.co/datasets/hate_speech_pl) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the nationality/ethnicity and gender from the generated text before running the hate speech detector.
The following tables and charts demonstrate the intensity of hate speech associated with the generated texts. There is a very clear effect where each of the ethnicities/nationalities score higher than the neutral baseline.
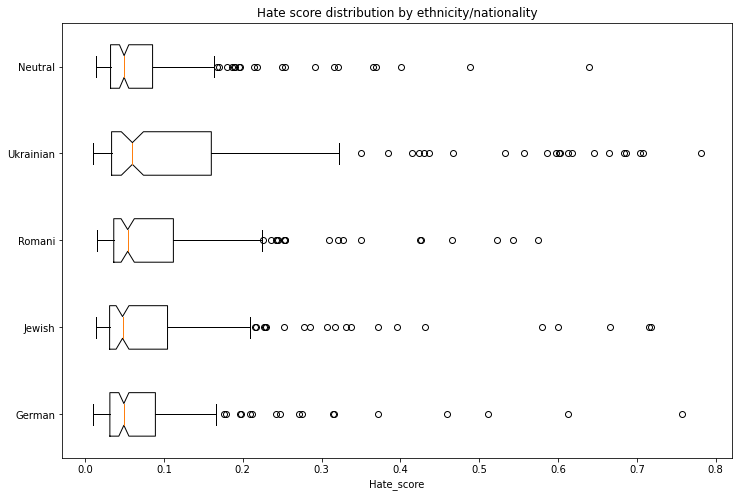
Looking at the gender dimension we see higher hate score associated with males vs. females.

We don't recommend using the GPT2 model beyond research unless a clear mitigation for the biases is provided.
## Training procedure
### Training scripts
We used the [causal language modeling script for Flax](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/run_clm_flax.py). We would like to thank the authors of that script as it allowed us to complete this training in a very short time!
### Preprocessing and Training Details
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a vocabulary size of 50,257. The inputs are sequences of 512 consecutive tokens.
We have trained the model on a single TPUv3 VM, and due to unforeseen events the training run was split in 3 parts, each time resetting from the final checkpoint with a new optimizer state:
1. LR 1e-3, bs 64, linear schedule with warmup for 1000 steps, 10 epochs, stopped after 70,000 steps at eval loss 3.206 and perplexity 24.68
2. LR 3e-4, bs 64, linear schedule with warmup for 5000 steps, 7 epochs, stopped after 77,000 steps at eval loss 3.116 and perplexity 22.55
3. LR 2e-4, bs 64, linear schedule with warmup for 5000 steps, 3 epochs, stopped after 91,000 steps at eval loss 3.082 and perplexity 21.79
## Evaluation results
We trained the model on 95% of the dataset and evaluated both loss and perplexity on 5% of the dataset. The final checkpoint evaluation resulted in:
* Evaluation loss: 3.082
* Perplexity: 21.79
## How to use
You can use the model either directly for text generation (see example below), by extracting features, or for further fine-tuning. We have prepared a notebook with text generation examples [here](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) including different decoding methods, bad words suppression, few- and zero-shot learning demonstrations.
### Text generation
Let's first start with the text-generation pipeline. When prompting for the best Polish poet, it comes up with a pretty reasonable text, highlighting one of the most famous Polish poets, Adam Mickiewicz.
```python
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='flax-community/papuGaPT2')
set_seed(42)
generator('Największym polskim poetą był')
>>> [{'generated_text': 'Największym polskim poetą był Adam Mickiewicz - uważany za jednego z dwóch geniuszów języka polskiego. "Pan Tadeusz" był jednym z najpopularniejszych dzieł w historii Polski. W 1801 został wystawiony publicznie w Teatrze Wilama Horzycy. Pod jego'}]
```
The pipeline uses `model.generate()` method in the background. In [our notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) we demonstrate different decoding methods we can use with this method, including greedy search, beam search, sampling, temperature scaling, top-k and top-p sampling. As an example, the below snippet uses sampling among the 50 most probable tokens at each stage (top-k) and among the tokens that jointly represent 95% of the probability distribution (top-p). It also returns 3 output sequences.
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
model = AutoModelWithLMHead.from_pretrained('flax-community/papuGaPT2')
tokenizer = AutoTokenizer.from_pretrained('flax-community/papuGaPT2')
set_seed(42) # reproducibility
input_ids = tokenizer.encode('Największym polskim poetą był', return_tensors='pt')
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Największym polskim poetą był Roman Ingarden. Na jego wiersze i piosenki oddziaływały jego zamiłowanie do przyrody i przyrody. Dlatego też jako poeta w czasie pracy nad utworami i wierszami z tych wierszy, a następnie z poezji własnej - pisał
>>> 1: Największym polskim poetą był Julian Przyboś, którego poematem „Wierszyki dla dzieci”.
>>> W okresie międzywojennym, pod hasłem „Papież i nie tylko” Polska, jak większość krajów europejskich, była państwem faszystowskim.
>>> Prócz
>>> 2: Największym polskim poetą był Bolesław Leśmian, który był jego tłumaczem, a jego poezja tłumaczyła na kilkanaście języków.
>>> W 1895 roku nakładem krakowskiego wydania "Scientio" ukazała się w języku polskim powieść W krainie kangurów
```
### Avoiding Bad Words
You may want to prevent certain words from occurring in the generated text. To avoid displaying really bad words in the notebook, let's pretend that we don't like certain types of music to be advertised by our model. The prompt says: *my favorite type of music is*.
```python
input_ids = tokenizer.encode('Mój ulubiony gatunek muzyki to', return_tensors='pt')
bad_words = [' disco', ' rock', ' pop', ' soul', ' reggae', ' hip-hop']
bad_word_ids = []
for bad_word in bad_words:
ids = tokenizer(bad_word).input_ids
bad_word_ids.append(ids)
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=20,
top_k=50,
top_p=0.95,
num_return_sequences=5,
bad_words_ids=bad_word_ids
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Mój ulubiony gatunek muzyki to muzyka klasyczna. Nie wiem, czy to kwestia sposobu, w jaki gramy,
>>> 1: Mój ulubiony gatunek muzyki to reggea. Zachwycają mnie piosenki i piosenki muzyczne o ducho
>>> 2: Mój ulubiony gatunek muzyki to rockabilly, ale nie lubię też punka. Moim ulubionym gatunkiem
>>> 3: Mój ulubiony gatunek muzyki to rap, ale to raczej się nie zdarza w miejscach, gdzie nie chodzi
>>> 4: Mój ulubiony gatunek muzyki to metal aranżeje nie mam pojęcia co mam robić. Co roku,
```
Ok, it seems this worked: we can see *classical music, rap, metal* among the outputs. Interestingly, *reggae* found a way through via a misspelling *reggea*. Take it as a caution to be careful with curating your bad word lists!
### Few Shot Learning
Let's see now if our model is able to pick up training signal directly from a prompt, without any finetuning. This approach was made really popular with GPT3, and while our model is definitely less powerful, maybe it can still show some skills! If you'd like to explore this topic in more depth, check out [the following article](https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api) which we used as reference.
```python
prompt = """Tekst: "Nienawidzę smerfów!"
Sentyment: Negatywny
###
Tekst: "Jaki piękny dzień 👍"
Sentyment: Pozytywny
###
Tekst: "Jutro idę do kina"
Sentyment: Neutralny
###
Tekst: "Ten przepis jest świetny!"
Sentyment:"""
res = generator(prompt, max_length=85, temperature=0.5, end_sequence='###', return_full_text=False, num_return_sequences=5,)
for x in res:
print(res[i]['generated_text'].split(' ')[1])
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
```
It looks like our model is able to pick up some signal from the prompt. Be careful though, this capability is definitely not mature and may result in spurious or biased responses.
### Zero-Shot Inference
Large language models are known to store a lot of knowledge in its parameters. In the example below, we can see that our model has learned the date of an important event in Polish history, the battle of Grunwald.
```python
prompt = "Bitwa pod Grunwaldem miała miejsce w roku"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# activate beam search and early_stopping
beam_outputs = model.generate(
input_ids,
max_length=20,
num_beams=5,
early_stopping=True,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pod
>>> 1: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pokona
>>> 2: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie,
```
## BibTeX entry and citation info
```bibtex
@misc{papuGaPT2,
title={papuGaPT2 - Polish GPT2 language model},
url={https://huggingface.co/flax-community/papuGaPT2},
author={Wojczulis, Michał and Kłeczek, Dariusz},
year={2021}
}
```
|
{"language": "pl", "tags": ["text-generation"], "widget": [{"text": "Najsmaczniejszy polski owoc to"}]}
|
flax-community/papuGaPT2
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"text-generation",
"pl",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# Pino (Dutch BigBird) base model
Created by [Dat Nguyen](https://www.linkedin.com/in/dat-nguyen-49a641138/) & [Yeb Havinga](https://www.linkedin.com/in/yeb-havinga-86530825/) during the [Hugging Face community week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104)
(Not finished yet)
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
It is a pretrained model on Dutch language using a masked language modeling (MLM) objective. It was introduced in this [paper](https://arxiv.org/abs/2007.14062) and first released in this [repository](https://github.com/google-research/bigbird).
## Model description
BigBird relies on **block sparse attention** instead of normal attention (i.e. BERT's attention) and can handle sequences up to a length of 4096 at a much lower compute cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts.
## How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BigBirdModel
# by default its in `block_sparse` mode with num_random_blocks=3, block_size=64
model = BigBirdModel.from_pretrained("flax-community/pino-bigbird-roberta-base")
# you can change `attention_type` to full attention like this:
model = BigBirdModel.from_pretrained("flax-community/pino-bigbird-roberta-base", attention_type="original_full")
# you can change `block_size` & `num_random_blocks` like this:
model = BigBirdModel.from_pretrained("flax-community/pino-bigbird-roberta-base", block_size=16, num_random_blocks=2)
```
## Training Data
This model is pre-trained on four publicly available datasets: **mC4**, and scraped **Dutch news** from NRC en Nu.nl. It uses the the fast universal Byte-level BPE (BBPE) in contrast to the sentence piece tokenizer and vocabulary as RoBERTa (which is in turn borrowed from GPT2).
## Training Procedure
The data is cleaned as follows:
Remove texts containing HTML codes / javascript codes / loremipsum / policies
Remove lines without end mark.
Remove too short texts, words
Remove too long texts, words
Remove bad words
## BibTeX entry and citation info
```tex
@misc{zaheer2021big,
title={Big Bird: Transformers for Longer Sequences},
author={Manzil Zaheer and Guru Guruganesh and Avinava Dubey and Joshua Ainslie and Chris Alberti and Santiago Ontanon and Philip Pham and Anirudh Ravula and Qifan Wang and Li Yang and Amr Ahmed},
year={2021},
eprint={2007.14062},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
{"language": "nl", "datasets": ["mC4", "Dutch_news"]}
|
flax-community/pino-bigbird-roberta-base
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"big_bird",
"fill-mask",
"nl",
"dataset:mC4",
"dataset:Dutch_news",
"arxiv:2007.14062",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
flax-community/portuguese-roberta-base
| null |
[
"tensorboard",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
# Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis Implementation
[](https://huggingface.co/spaces/flax-community/DietNerf-Demo) [](https://colab.research.google.com/drive/1etYeMTntw5mh3FvJv4Ubb7XUoTtt5J9G?usp=sharing)
<p align="center"><img width="450" alt="스크린샷 2021-07-04 오후 4 11 51" src="https://user-images.githubusercontent.com/77657524/126361638-4aad58e8-4efb-4fc5-bf78-f53d03799e1e.png"></p>
This project attempted to implement the paper **[Putting NeRF on a Diet](https://arxiv.org/abs/2104.00677)** (DietNeRF) in JAX/Flax.
DietNeRF is designed for rendering quality novel views in few-shot learning scheme, a task that vanilla NeRF (Neural Radiance Field) struggles.
To achieve this, the author coins **Semantic Consistency Loss** to supervise DietNeRF by prior knowledge from CLIP Vision Transformer. Such supervision enables DietNeRF to learn 3D scene reconstruction with CLIP's prior knowledge on 2D views.
Besides this repo, you can check our write-up and demo here:
- ✍️ **[Write-up in Notion](https://steep-cycle-f6b.notion.site/DietNeRF-Putting-NeRF-on-a-Diet-4aeddae95d054f1d91686f02bdb74745)**: more details of DietNeRF and our experiments
- ✨ **[Demo in Hugging Face Space](https://huggingface.co/spaces/flax-community/DietNerf-Demo)**: showcase our trained DietNeRFs by Streamlit
## 🤩 Demo
1. You can check out [our demo in Hugging Face Space](https://huggingface.co/spaces/flax-community/DietNerf-Demo)
2. Or you can set up our Streamlit demo locally (model checkpoints will be fetched automatically upon startup)
```shell
pip install -r requirements_demo.txt
streamlit run app.py
```
<p align="center"><img width="600" height="400" alt="Streamlit Demo" src="assets/space_demo.png"></p>
## ✨ Implementation
Our code is written in JAX/ Flax and mainly based upon [jaxnerf](https://github.com/google-research/google-research/tree/master/jaxnerf) from Google Research. The base code is highly optimized in GPU & TPU. For semantic consistency loss, we utilize pretrained CLIP Vision Transformer from [transformers](https://github.com/huggingface/transformers) library.
To learn more about DietNeRF, our experiments and implementation, you are highly recommended to check out our very detailed **[Notion write-up](https://www.notion.so/DietNeRF-Putting-NeRF-on-a-Diet-4aeddae95d054f1d91686f02bdb74745)**!
<p align="center"><img width="500" height="600" alt="스크린샷 2021-07-04 오후 4 11 51" src="assets/report_thumbnail.png"></p>
## 🤗 Hugging Face Model Hub Repo
You can also find our project on the [Hugging Face Model Hub Repository](https://huggingface.co/flax-community/putting-nerf-on-a-diet/).
Our JAX/Flax implementation currently supports:
<table class="tg">
<thead>
<tr>
<th class="tg-0lax"><span style="font-weight:bold">Platform</span></th>
<th class="tg-0lax" colspan="2"><span style="font-weight:bold">Single-Host GPU</span></th>
<th class="tg-0lax" colspan="2"><span style="font-weight:bold">Multi-Device TPU</span></th>
</tr>
</thead>
<tbody>
<tr>
<td class="tg-0lax"><span style="font-weight:bold">Type</span></td>
<td class="tg-0lax">Single-Device</td>
<td class="tg-0lax">Multi-Device</td>
<td class="tg-0lax">Single-Host</td>
<td class="tg-0lax">Multi-Host</td>
</tr>
<tr>
<td class="tg-0lax"><span style="font-weight:bold">Training</span></td>
<td class="tg-0lax"><img src="http://storage.googleapis.com/gresearch/jaxnerf/check.png" alt="Supported" width=18px height=18px></td>
<td class="tg-0lax"><img src="http://storage.googleapis.com/gresearch/jaxnerf/check.png" alt="Supported" width=18px height=18px></td>
<td class="tg-0lax"><img src="http://storage.googleapis.com/gresearch/jaxnerf/check.png" alt="Supported" width=18px height=18px></td>
<td class="tg-0lax"><img src="http://storage.googleapis.com/gresearch/jaxnerf/check.png" alt="Supported" width=18px height=18px></td>
</tr>
<tr>
<td class="tg-0lax"><span style="font-weight:bold">Evaluation</span></td>
<td class="tg-0lax"><img src="http://storage.googleapis.com/gresearch/jaxnerf/check.png" alt="Supported" width=18px height=18px></td>
<td class="tg-0lax"><img src="http://storage.googleapis.com/gresearch/jaxnerf/check.png" alt="Supported" width=18px height=18px></td>
<td class="tg-0lax"><img src="http://storage.googleapis.com/gresearch/jaxnerf/check.png" alt="Supported" width=18px height=18px></td>
<td class="tg-0lax"><img src="http://storage.googleapis.com/gresearch/jaxnerf/check.png" alt="Supported" width=18px height=18px></td>
</tr>
</tbody>
</table>
## 💻 Installation
```bash
# Clone the repo
git clone https://github.com/codestella/putting-nerf-on-a-diet
# Create a conda environment, note you can use python 3.6-3.8 as
# one of the dependencies (TensorFlow) hasn't supported python 3.9 yet.
conda create --name jaxnerf python=3.6.12; conda activate jaxnerf
# Prepare pip
conda install pip; pip install --upgrade pip
# Install requirements
pip install -r requirements.txt
# [Optional] Install GPU and TPU support for Jax
# Remember to change cuda101 to your CUDA version, e.g. cuda110 for CUDA 11.0.
!pip install --upgrade jax "jax[cuda110]" -f https://storage.googleapis.com/jax-releases/jax_releases.html
# install flax and flax-transformer
pip install flax transformers[flax]
```
## ⚽ Dataset
Download the datasets from the [NeRF official Google Drive](https://drive.google.com/drive/folders/128yBriW1IG_3NJ5Rp7APSTZsJqdJdfc1).
Please download the `nerf_synthetic.zip` and unzip them
in the place you like. Let's assume they are placed under `/tmp/jaxnerf/data/`.
## 💖 Methods
* 👉👉 You can check VEEEERY detailed explanation about our project on [Notion Report](https://www.notion.so/DietNeRF-Putting-NeRF-on-a-Diet-4aeddae95d054f1d91686f02bdb74745)
<p align="center"><img width="400" alt="스크린샷 2021-07-04 오후 4 11 51" src="https://user-images.githubusercontent.com/77657524/124376591-b312b780-dce2-11eb-80ad-9129d6f5eedb.png"></p>
Based on the principle
that “a bulldozer is a bulldozer from any perspective”, Our proposed DietNeRF supervises the radiance field from arbitrary poses
(DietNeRF cameras). This is possible because we compute a semantic consistency loss in a feature space capturing high-level
scene attributes, not in pixel space. We extract semantic representations of renderings using the CLIP Vision Transformer, then
maximize similarity with representations of ground-truth views. In
effect, we use prior knowledge about scene semantics learned by
single-view 2D image encoders to constrain a 3D representation.
You can check detail information on the author's paper. Also, you can check the CLIP based semantic loss structure on the following image.
<p align="center"><img width="600" alt="스크린샷 2021-07-04 오후 4 11 51" src="https://user-images.githubusercontent.com/77657524/126386709-a4ce7ff8-2a68-442f-b4ed-26971fb90e51.png"></p>
Our code used JAX/FLAX framework for implementation. So that it can achieve much speed up than other NeRF codes. At last, our code used hugging face, transformer, CLIP model library.
## 🤟 How to use
```
python -m train \
--data_dir=/PATH/TO/YOUR/SCENE/DATA \ % e.g., nerf_synthetic/lego
--train_dir=/PATH/TO/THE/PLACE/YOU/WANT/TO/SAVE/CHECKPOINTS \
--config=configs/CONFIG_YOU_LIKE
```
You can toggle the semantic loss by “use_semantic_loss” in configuration files.
## 💎 Experimental Results
### ❗ Rendered Rendering images by 8-shot learned Diet-NeRF
DietNeRF has a strong capacity to generalise on novel and challenging views with EXTREMELY SMALL TRAINING SAMPLES!
### HOTDOG / DRUM / SHIP / CHAIR / LEGO / MIC
<img alt="" src="https://user-images.githubusercontent.com/77657524/126976706-caec6d6c-6126-45d0-8680-4c883f71f5bb.png" width="250"/></td><td><img alt="" src="https://user-images.githubusercontent.com/77657524/126976868-183af09a-47b3-4c76-ba20-90e9fef17bcc.png" width="250"/><td><img alt="" src="https://user-images.githubusercontent.com/77657524/126977843-18b4b077-1db0-4287-8e5c-baa10c46e647.png" width="250"/>
<img alt="" src="https://user-images.githubusercontent.com/77657524/126977066-9c99a882-7a46-4a1d-921f-cdb0eee60f39.gif" width="250"/><img alt="" src="https://user-images.githubusercontent.com/77657524/126913553-19ebd2f2-c5f1-4332-a253-950e41cb5229.gif" width="300"/><img alt="" src="https://user-images.githubusercontent.com/77657524/126913559-dfce4b88-84a8-4a0a-91eb-ed12716ab328.gif" width="300"/>
### ❗ Rendered GIF by occluded 14-shot learned NeRF and Diet-NeRF
We made artificial occlusion on the right side of image (Only picked left side training poses).
The reconstruction quality can be compared with this experiment.
DietNeRF shows better quality than Original NeRF when It is occluded.
#### Training poses
<img width="1400" src="https://user-images.githubusercontent.com/26036843/126111980-4f332c87-a7f0-42e0-a355-8e77621bbca4.png">
#### LEGO
[DietNeRF]
<img alt="" src="https://user-images.githubusercontent.com/77657524/126913404-800777f8-8f88-451a-92de-3dda25075206.gif" width="300"/>
[NeRF]
<img alt="" src="https://user-images.githubusercontent.com/77657524/126913412-f10dfb3e-e918-4ff4-aa2c-63529fec91d8.gif" width="300"/>
#### SHIP
[DietNeRF]
<img alt="" src="https://user-images.githubusercontent.com/77657524/126913430-0014a904-6ca1-4a7b-9cd6-6f73b36552fb.gif" width="300"/>
[NeRF]
<img alt="" src="https://user-images.githubusercontent.com/77657524/126913439-2e3128ef-c7ef-4c21-8261-6e3b8fe51f86.gif" width="300"/>
## 👨👧👦 Our Teams
| Teams | Members |
|------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Project Managing | [Stella Yang](https://github.com/codestella) To Watch Our Project Progress, Please Check [Our Project Notion](https://www.notion.so/Putting-NeRF-on-a-Diet-e0caecea0c2b40c3996c83205baf870d) |
| NeRF Team | [Stella Yang](https://github.com/codestella), [Alex Lau](https://github.com/riven314), [Seunghyun Lee](https://github.com/sseung0703), [Hyunkyu Kim](https://github.com/minus31), [Haswanth Aekula](https://github.com/hassiahk), [JaeYoung Chung](https://github.com/robot0321) |
| CLIP Team | [Seunghyun Lee](https://github.com/sseung0703), [Sasikanth Kotti](https://github.com/ksasi), [Khali Sifullah](https://github.com/khalidsaifullaah) , [Sunghyun Kim](https://github.com/MrBananaHuman) |
| Cloud TPU Team | [Alex Lau](https://github.com/riven314), [Aswin Pyakurel](https://github.com/masapasa), [JaeYoung Chung](https://github.com/robot0321), [Sunghyun Kim](https://github.com/MrBananaHuman) |
* Extremely Don't Sleep Contributors 🤣: [Seunghyun Lee](https://github.com/sseung0703), [Alex Lau](https://github.com/riven314), [Stella Yang](https://github.com/codestella), [Haswanth Aekula](https://github.com/hassiahk)
## 😎 What we improved from original JAX-NeRF : Innovation
- Neural rendering with fewshot images
- Hugging face CLIP based semantic loss loop
- You can choose coarse mlp / coarse + fine mlp training
(coarse + fine is on the `main` branch / coarse is on the `coarse_only` branch)
* coarse + fine : shows good geometric reconstruction
* coarse : shows good PSNR/SSIM result
- Make Video/GIF rendering result, `--generate_gif_only` arg can run fast rendering GIF.
- Cleaning / refactoring the code
- Made multiple models / colab / space for Nice demo
## 💞 Social Impact
- Game Industry
- Augmented Reality Industry
- Virtual Reality Industry
- Graphics Industry
- Online shopping
- Metaverse
- Digital Twin
- Mapping / SLAM
## 🌱 References
This project is based on “JAX-NeRF”.
```
@software{jaxnerf2020github,
author = {Boyang Deng and Jonathan T. Barron and Pratul P. Srinivasan},
title = {{JaxNeRF}: an efficient {JAX} implementation of {NeRF}},
url = {https://github.com/google-research/google-research/tree/master/jaxnerf},
version = {0.0},
year = {2020},
}
```
This project is based on “Putting NeRF on a Diet”.
```
@misc{jain2021putting,
title={Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis},
author={Ajay Jain and Matthew Tancik and Pieter Abbeel},
year={2021},
eprint={2104.00677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## 🔑 License
[Apache License 2.0](https://github.com/codestella/putting-nerf-on-a-diet/blob/main/LICENSE)
## ❤️ Special Thanks
Our Project is started in the [HuggingFace X GoogleAI (JAX) Community Week Event](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104).
Thank you for our mentor Suraj and organizers in JAX/Flax Community Week!
Our team grows up with this community learning experience. It was wonderful time!
<img width="250" alt="스크린샷 2021-07-04 오후 4 11 51" src="https://user-images.githubusercontent.com/77657524/126369170-5664076c-ac99-4157-bc53-b91dfb7ed7e1.jpeg">
[Common Computer AI](https://comcom.ai/en/) sponsored multiple V100 GPUs for our project!
Thank you so much for your support!
<img width="250" alt="스크린샷" src="https://user-images.githubusercontent.com/77657524/126914984-d959be06-19f4-4228-8d3a-a855396b2c3f.jpeg">
|
{}
|
flax-community/putting-nerf-on-a-diet
| null |
[
"arxiv:2104.00677",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
flax-community/qartvelian-roberta-base-fix
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
# roberta-base-als-demo
**roberta-base-als-demo** is a model trained by Patrick von Platen to demonstrate how to train a roberta-base model from scratch on the Alemannic language.
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Useful links
- [Community Week timeline](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104#summary-timeline-calendar-6)
- [Community Week README](https://github.com/huggingface/transformers/blob/master/examples/research_projects/jax-projects/README.md)
- [Masked Language Modelling example scripts](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling)
- [Model Repository](https://huggingface.co/flax-community/roberta-base-als-demo)
|
{}
|
flax-community/roberta-base-als-demo
| null |
[
"transformers",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
This project pretrains a [`roberta-base`](https://huggingface.co/roberta-base) on the *Alemannic* (`als`) data subset of the [OSCAR](https://oscar-corpus.com/) corpus in JAX/Flax.
We will be using the masked-language modeling loss for pretraining.
|
{}
|
flax-community/roberta-base-als
| null |
[
"transformers",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# RøBÆRTa - Danish Roberta Base
## Description
RøBÆRTa is a danish pretrained Roberta base model. RøBÆRTa was pretrained on the danish mC4 dataset during the flax community week. This project was organized by Dansk Data Science Community (DDSC) 👇 <br><br>
https://www.linkedin.com/groups/9017904/
## Team RøBÆRTa:
- Dan Saattrup Nielsen (saattrupdan)
- Malte Højmark-Bertelsen (Maltehb)
- Morten Kloster Pedersen (MortenKP)
- Kasper Junge (Juunge)
- Per Egil Kummervold (pere)
- Birger Moëll (birgermoell)
---
|
{"language": "da", "license": "cc-by-4.0", "tags": ["danish", "roberta"], "pipeline_tag": "fill-mask", "widget": [{"text": "P\u00e5 biblioteket kan du l\u00e5ne en <mask>."}]}
|
DDSC/roberta-base-danish
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"roberta",
"fill-mask",
"danish",
"da",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# RoBERTa base model for Marathi language (मराठी भाषा)
Pretrained model on Marathi language using a masked language modeling (MLM) objective. RoBERTa was introduced in
[this paper](https://arxiv.org/abs/1907.11692) and first released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/roberta). We trained RoBERTa model for Marathi Language during community week hosted by Huggingface 🤗 using JAX/Flax for NLP & CV jax.
<img src="https://user-images.githubusercontent.com/15062408/126040902-ea8808db-ec30-4a3f-bf95-5d3b10d674e9.png" alt="huggingface-marathi-roberta" width="350" height="350" style="text-align: center">
## Model description
Marathi RoBERTa is a transformers model pretrained on a large corpus of Marathi data in a self-supervised fashion.
## Intended uses & limitations❗️
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. We used this model to fine tune on text classification task for iNLTK and indicNLP news text classification problem statement. Since marathi mc4 dataset is made by scraping marathi newspapers text, it will involve some biases which will also affect all fine-tuned versions of this model.
### How to use❓
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='flax-community/roberta-base-mr')
>>> unmasker("मोठी बातमी! उद्या दुपारी <mask> वाजता जाहीर होणार दहावीचा निकाल")
[{'score': 0.057209037244319916,'sequence': 'मोठी बातमी! उद्या दुपारी आठ वाजता जाहीर होणार दहावीचा निकाल',
'token': 2226,
'token_str': 'आठ'},
{'score': 0.02796074189245701,
'sequence': 'मोठी बातमी! उद्या दुपारी २० वाजता जाहीर होणार दहावीचा निकाल',
'token': 987,
'token_str': '२०'},
{'score': 0.017235398292541504,
'sequence': 'मोठी बातमी! उद्या दुपारी नऊ वाजता जाहीर होणार दहावीचा निकाल',
'token': 4080,
'token_str': 'नऊ'},
{'score': 0.01691395975649357,
'sequence': 'मोठी बातमी! उद्या दुपारी २१ वाजता जाहीर होणार दहावीचा निकाल',
'token': 1944,
'token_str': '२१'},
{'score': 0.016252165660262108,
'sequence': 'मोठी बातमी! उद्या दुपारी ३ वाजता जाहीर होणार दहावीचा निकाल',
'token': 549,
'token_str': ' ३'}]
```
## Training data 🏋🏻♂️
The RoBERTa Marathi model was pretrained on `mr` dataset of C4 multilingual dataset:
<br>
<br>
[C4 (Colossal Clean Crawled Corpus)](https://yknzhu.wixsite.com/mbweb), Introduced by Raffel et al. in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://paperswithcode.com/paper/exploring-the-limits-of-transfer-learning).
The dataset can be downloaded in a pre-processed form from [allennlp](https://github.com/allenai/allennlp/discussions/5056) or huggingface's datsets - [mc4 dataset](https://huggingface.co/datasets/mc4).
Marathi (`mr`) dataset consists of 14 billion tokens, 7.8 million docs and with weight ~70 GB of text.
## Data Cleaning 🧹
Though initial `mc4` marathi corpus size ~70 GB, Through data exploration, it was observed it contains docs from different languages especially thai, chinese etc. So we had to clean the dataset before traning tokenizer and model. Surprisingly, results after cleaning Marathi mc4 corpus data:
#### **Train set:**
Clean docs count 1581396 out of 7774331. <br>
**~20.34%** of whole marathi train split is actually Marathi.
#### **Validation set**
Clean docs count 1700 out of 7928. <br>
**~19.90%** of whole marathi validation split is actually Marathi.
## Training procedure 👨🏻💻
### Preprocessing
The texts are tokenized using a byte version of Byte-Pair Encoding (BPE) and a vocabulary size of 50265. The inputs of
the model take pieces of 512 contiguous token that may span over documents. The beginning of a new document is marked
with `<s>` and the end of one by `</s>`
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
Contrary to BERT, the masking is done dynamically during pretraining (e.g., it changes at each epoch and is not fixed).
### Pretraining
The model was trained on Google Cloud Engine TPUv3-8 machine (with 335 GB of RAM, 1000 GB of hard drive, 96 CPU cores) **8 v3 TPU cores** for 42K steps with a batch size of 128 and a sequence length of 128. The
optimizer used is Adam with a learning rate of 3e-4, β1 = 0.9, β2 = 0.98 and
ε = 1e-8, a weight decay of 0.01, learning rate warmup for 1,000 steps and linear decay of the learning
rate after.
We tracked experiments and hyperparameter tunning on weights and biases platform. Here is link to main dashboard: <br>
[Link to Weights and Biases Dashboard for Marathi RoBERTa model](https://wandb.ai/nipunsadvilkar/roberta-base-mr/runs/19qtskbg?workspace=user-nipunsadvilkar)
#### **Pretraining Results 📊**
RoBERTa Model reached **eval accuracy of 85.28%** around ~35K step **with train loss at 0.6507 and eval loss at 0.6219**.
## Fine Tuning on downstream tasks
We performed fine-tuning on downstream tasks. We used following datasets for classification:
1. [IndicNLP Marathi news classification](https://github.com/ai4bharat-indicnlp/indicnlp_corpus#publicly-available-classification-datasets)
2. [iNLTK Marathi news headline classification](https://www.kaggle.com/disisbig/marathi-news-dataset)
### **Fine tuning on downstream task results (Segregated)**
#### 1. [IndicNLP Marathi news classification](https://github.com/ai4bharat-indicnlp/indicnlp_corpus#publicly-available-classification-datasets)
IndicNLP Marathi news dataset consists 3 classes - `['lifestyle', 'entertainment', 'sports']` - with following docs distribution as per classes:
| train | eval | test
| -- | -- | --
| 9672 | 477 | 478
💯 Our Marathi RoBERTa **`roberta-base-mr` model outperformed both classifier ** mentioned in [Arora, G. (2020). iNLTK](https://www.semanticscholar.org/paper/iNLTK%3A-Natural-Language-Toolkit-for-Indic-Languages-Arora/5039ed9e100d3a1cbbc25a02c82f6ee181609e83/figure/3) and [Kunchukuttan, Anoop et al. AI4Bharat-IndicNLP.](https://www.semanticscholar.org/paper/AI4Bharat-IndicNLP-Corpus%3A-Monolingual-Corpora-and-Kunchukuttan-Kakwani/7997d432925aff0ba05497d2893c09918298ca55/figure/4)
Dataset | FT-W | FT-WC | INLP | iNLTK | **roberta-base-mr 🏆**
-- | -- | -- | -- | -- | --
iNLTK Headlines | 83.06 | 81.65 | 89.92 | 92.4 | **97.48**
**🤗 Huggingface Model hub repo:**<br>
`roberta-base-mr` fine tuned on iNLTK Headlines classification dataset model:
[**`flax-community/mr-indicnlp-classifier`**](https://huggingface.co/flax-community/mr-indicnlp-classifier)
🧪 Fine tuning experiment's weight and biases dashboard [link](https://wandb.ai/nipunsadvilkar/huggingface/runs/1242bike?workspace=user-nipunsadvilkar
)
#### 2. [iNLTK Marathi news headline classification](https://www.kaggle.com/disisbig/marathi-news-dataset)
This dataset consists 3 classes - `['state', 'entertainment', 'sports']` - with following docs distribution as per classes:
| train | eval | test
| -- | -- | --
| 9658 | 1210 | 1210
💯 Here as well **`roberta-base-mr` outperformed `iNLTK` marathi news text classifier**.
Dataset | iNLTK ULMFiT | **roberta-base-mr 🏆**
-- | -- | --
iNLTK news dataset (kaggle) | 92.4 | **94.21**
**🤗 Huggingface Model hub repo:**<br>
`roberta-base-mr` fine tuned on iNLTK news classification dataset model:
[**`flax-community/mr-inltk-classifier`**](https://huggingface.co/flax-community/mr-inltk-classifier)
Fine tuning experiment's weight and biases dashboard [link](https://wandb.ai/nipunsadvilkar/huggingface/runs/2u5l9hon?workspace=user-nipunsadvilkar
)
## **Want to check how above models generalise on real world Marathi data?**
Head to 🤗 Huggingface's spaces 🪐 to play with all three models:
1. Mask Language Modelling with Pretrained Marathi RoBERTa model: <br>
[**`flax-community/roberta-base-mr`**](https://huggingface.co/flax-community/roberta-base-mr)
2. Marathi Headline classifier: <br>
[**`flax-community/mr-indicnlp-classifier`**](https://huggingface.co/flax-community/mr-indicnlp-classifier)
3. Marathi news classifier: <br>
[**`flax-community/mr-inltk-classifier`**](https://huggingface.co/flax-community/mr-inltk-classifier)

[Streamlit app of Pretrained Roberta Marathi model on Huggingface Spaces](https://huggingface.co/spaces/flax-community/roberta-base-mr)

## Team Members
- Nipun Sadvilkar [@nipunsadvilkar](https://github.com/nipunsadvilkar)
- Haswanth Aekula [@hassiahk](https://github.com/hassiahk)
## Credits
Huge thanks to Huggingface 🤗 & Google Jax/Flax team for such a wonderful community week. Especially for providing such massive computing resource. Big thanks to [@patil-suraj](https://github.com/patil-suraj) & [@patrickvonplaten](https://github.com/patrickvonplaten) for mentoring during whole week.
<img src=https://pbs.twimg.com/media/E443fPjX0AY1BsR.jpg:large>
|
{"widget": [{"text": "\u0905\u0927\u094d\u092f\u0915\u094d\u0937 <mask> \u092a\u0935\u093e\u0930 \u0906\u0923\u093f \u0909\u092a\u092e\u0941\u0916\u094d\u092f\u092e\u0902\u0924\u094d\u0930\u0940 \u0905\u091c\u093f\u0924 \u092a\u0935\u093e\u0930 \u092f\u093e\u0902\u091a\u0940 \u092d\u0947\u091f \u0918\u0947\u0924\u0932\u0940."}, {"text": "\u092e\u094b\u0920\u0940 \u092c\u093e\u0924\u092e\u0940! \u0909\u0926\u094d\u092f\u093e \u0926\u0941\u092a\u093e\u0930\u0940 <mask> \u0935\u093e\u091c\u0924\u093e \u091c\u093e\u0939\u0940\u0930 \u0939\u094b\u0923\u093e\u0930 \u0926\u0939\u093e\u0935\u0940\u091a\u093e \u0928\u093f\u0915\u093e\u0932"}]}
|
flax-community/roberta-base-mr
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# Scandinavian Roberta Base - MC4
## Description
This is a sample reference model for Flax/Jax training using only on the MC4. It is trained for roughly three day on a TPU v3-8. Training procedure...
---
## Description
My description
|
{"language": "da", "license": "cc-by-4.0", "tags": ["scandinavian", "roberta"], "pipeline_tag": "fill-mask", "widget": [{"text": "P\u00e5 biblioteket kan du l\u00e5ne en <mask>."}]}
|
DDSC/roberta-base-scandinavian
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"scandinavian",
"da",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
{}
|
flax-community/roberta-base-sundanese
| null |
[
"transformers",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
flax-community/roberta-base-thai
| null |
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
{}
|
flax-community/roberta-flax-dataset-stream-is
| null |
[
"transformers",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
# RoBERTa base model for Hindi language
Pretrained model on Hindi language using a masked language modeling (MLM) objective. [A more interactive & comparison demo is available here](https://huggingface.co/spaces/flax-community/roberta-hindi).
> This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/pretrain-roberta-from-scratch-in-hindi/7091), organized by [Hugging Face](https://huggingface.co/) and TPU usage sponsored by Google.
## Model description
RoBERTa Hindi is a transformers model pretrained on a large corpus of Hindi data(a combination of **mc4, oscar and indic-nlp** datasets)
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='flax-community/roberta-hindi')
>>> unmasker("हम आपके सुखद <mask> की कामना करते हैं")
[{'score': 0.3310680091381073,
'sequence': 'हम आपके सुखद सफर की कामना करते हैं',
'token': 1349,
'token_str': ' सफर'},
{'score': 0.15317578613758087,
'sequence': 'हम आपके सुखद पल की कामना करते हैं',
'token': 848,
'token_str': ' पल'},
{'score': 0.07826550304889679,
'sequence': 'हम आपके सुखद समय की कामना करते हैं',
'token': 453,
'token_str': ' समय'},
{'score': 0.06304813921451569,
'sequence': 'हम आपके सुखद पहल की कामना करते हैं',
'token': 404,
'token_str': ' पहल'},
{'score': 0.058322224766016006,
'sequence': 'हम आपके सुखद अवसर की कामना करते हैं',
'token': 857,
'token_str': ' अवसर'}]
```
## Training data
The RoBERTa Hindi model was pretrained on the reunion of the following datasets:
- [OSCAR](https://huggingface.co/datasets/oscar) is a huge multilingual corpus obtained by language classification and filtering of the Common Crawl corpus using the goclassy architecture.
- [mC4](https://huggingface.co/datasets/mc4) is a multilingual colossal, cleaned version of Common Crawl's web crawl corpus.
- [IndicGLUE](https://indicnlp.ai4bharat.org/indic-glue/) is a natural language understanding benchmark.
- [Samanantar](https://indicnlp.ai4bharat.org/samanantar/) is a parallel corpora collection for Indic language.
- [Hindi Text Short and Large Summarization Corpus](https://www.kaggle.com/disisbig/hindi-text-short-and-large-summarization-corpus) is a collection of ~180k articles with their headlines and summary collected from Hindi News Websites.
- [Hindi Text Short Summarization Corpus](https://www.kaggle.com/disisbig/hindi-text-short-summarization-corpus) is a collection of ~330k articles with their headlines collected from Hindi News Websites.
- [Old Newspapers Hindi](https://www.kaggle.com/crazydiv/oldnewspapershindi) is a cleaned subset of HC Corpora newspapers.
## Training procedure
### Preprocessing
The texts are tokenized using a byte version of Byte-Pair Encoding (BPE) and a vocabulary size of 50265. The inputs of
the model take pieces of 512 contiguous token that may span over documents. The beginning of a new document is marked
with `<s>` and the end of one by `</s>`.
- We had to perform cleanup of **mC4** and **oscar** datasets by removing all non hindi (non Devanagari) characters from the datasets.
- We tried to filter out evaluation set of WikiNER of [IndicGlue](https://indicnlp.ai4bharat.org/indic-glue/) benchmark by [manual labelling](https://github.com/amankhandelia/roberta_hindi/blob/master/wikiner_incorrect_eval_set.csv) where the actual labels were not correct and modifying the [downstream evaluation dataset](https://github.com/amankhandelia/roberta_hindi/blob/master/utils.py).
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
Contrary to BERT, the masking is done dynamically during pretraining (e.g., it changes at each epoch and is not fixed).
### Pretraining
The model was trained on Google Cloud Engine TPUv3-8 machine (with 335 GB of RAM, 1000 GB of hard drive, 96 CPU cores).A randomized shuffle of combined dataset of **mC4, oscar** and other datasets listed above was used to train the model. Training logs are present in [wandb](https://wandb.ai/wandb/hf-flax-roberta-hindi).
## Evaluation Results
RoBERTa Hindi is evaluated on various downstream tasks. The results are summarized below.
| Task | Task Type | IndicBERT | HindiBERTa | Indic Transformers Hindi BERT | RoBERTa Hindi Guj San | RoBERTa Hindi |
|-------------------------|----------------------|-----------|------------|-------------------------------|-----------------------|---------------|
| BBC News Classification | Genre Classification | **76.44** | 66.86 | **77.6** | 64.9 | 73.67 |
| WikiNER | Token Classification | - | 90.68 | **95.09** | 89.61 | **92.76** |
| IITP Product Reviews | Sentiment Analysis | **78.01** | 73.23 | **78.39** | 66.16 | 75.53 |
| IITP Movie Reviews | Sentiment Analysis | 60.97 | 52.26 | **70.65** | 49.35 | **61.29** |
## Team Members
- Aman K ([amankhandelia](https://huggingface.co/amankhandelia))
- Haswanth Aekula ([hassiahk](https://huggingface.co/hassiahk))
- Kartik Godawat ([dk-crazydiv](https://huggingface.co/dk-crazydiv))
- Prateek Agrawal ([prateekagrawal](https://huggingface.co/prateekagrawal))
- Rahul Dev ([mlkorra](https://huggingface.co/mlkorra))
## Credits
Huge thanks to Hugging Face 🤗 & Google Jax/Flax team for such a wonderful community week, especially for providing such massive computing resources. Big thanks to [Suraj Patil](https://huggingface.co/valhalla) & [Patrick von Platen](https://huggingface.co/patrickvonplaten) for mentoring during the whole week.
<img src=https://pbs.twimg.com/media/E443fPjX0AY1BsR.jpg:medium>
|
{"widget": [{"text": "\u092e\u0941\u091d\u0947 \u0909\u0928\u0938\u0947 \u092c\u093e\u0924 \u0915\u0930\u0928\u093e <mask> \u0905\u091a\u094d\u091b\u093e \u0932\u0917\u093e"}, {"text": "\u0939\u092e \u0906\u092a\u0915\u0947 \u0938\u0941\u0916\u0926 <mask> \u0915\u0940 \u0915\u093e\u092e\u0928\u093e \u0915\u0930\u0924\u0947 \u0939\u0948\u0902"}, {"text": "\u0938\u092d\u0940 \u0905\u091a\u094d\u091b\u0940 \u091a\u0940\u091c\u094b\u0902 \u0915\u093e \u090f\u0915 <mask> \u0939\u094b\u0924\u093e \u0939\u0948"}]}
|
flax-community/roberta-hindi
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
{}
|
flax-community/roberta-large-swedish
| null |
[
"transformers",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
roberta-pretraining-hindi
|
{"widget": [{"text": "\u0936\u0941\u092d \u092a\u094d\u0930\u092d\u093e\u0924\u0964 \u0906\u0936\u093e \u0915\u0930\u0924\u093e \u0939\u0942\u0902 \u0915\u093f \u0906\u092a\u0915\u093e <mask> \u0936\u0941\u092d \u0939\u094b"}]}
|
flax-community/roberta-pretraining-hindi
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
## Swahili News Classification with RoBERTa
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by [HuggingFace](https://huggingface.co). All training was done on a TPUv3-8 VM sponsored by the Google Cloud team.
This [model](https://huggingface.co/flax-community/roberta-swahili) was used as the base and fine-tuned for this task.
## How to use
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("flax-community/roberta-swahili-news-classification")
model = AutoModelForSequenceClassification.from_pretrained("flax-community/roberta-swahili-news-classification")
```
```
Eval metrics: {'accuracy': 0.9153416415986249}
```
|
{"language": "sw", "datasets": ["flax-community/swahili-safi"], "widget": [{"text": "Idris ameandika kwenye ukurasa wake wa Instagram akimkumbusha Diamond kutekeleza ahadi yake kumpigia Zari magoti kumuomba msamaha kama alivyowahi kueleza awali.Idris ameandika;"}]}
|
flax-community/roberta-swahili-news-classification
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"sw",
"dataset:flax-community/swahili-safi",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
## RoBERTa in Swahili
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by [HuggingFace](https://huggingface.co). All training was done on a TPUv3-8 VM sponsored by the Google Cloud team.
## How to use
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/roberta-swahili")
model = AutoModelForMaskedLM.from_pretrained("flax-community/roberta-swahili")
print(round((model.num_parameters())/(1000*1000)),"Million Parameters")
105 Million Parameters
```
#### **Training Data**:
This model was trained on [Swahili Safi](https://huggingface.co/datasets/flax-community/swahili-safi)
#### **Results**:
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) [](https://colab.research.google.com/drive/1OIurb4J91X7461NQXLCCGzjeEGJq_Tyl?usp=sharing)
```
Eval metrics: {'f1': 86%}
```
This [model](https://huggingface.co/flax-community/roberta-swahili-news-classification) was fine-tuned based off this model for the
[Zindi News Classification Challenge](https://zindi.africa/hackathons/ai4d-swahili-news-classification-challenge)
#### **More Details**:
For more details and Demo please check [HF Swahili Space](https://huggingface.co/spaces/flax-community/Swahili)
|
{"language": "sw", "datasets": ["flax-community/swahili-safi"], "widget": [{"text": "Si kila mwenye makucha <mask> simba."}]}
|
flax-community/roberta-swahili
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"sw",
"dataset:flax-community/swahili-safi",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# RobIt
**RobIt** is a RoBERTa-base model for Italian. It has been trained from scratch on the Italian portion of the OSCAR dataset using [Flax](https://github.com/google/flax), including training scripts.
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team members
- Prateek Agrawal (prateekagrawal)
- Tanay Mehta (yotanay)
- Shreya Gupta (Sheyz-max)
- Ruchi Bhatia (ruchi798)
## Dataset :
[OSCAR](https://huggingface.co/datasets/oscar)
- config : **unshuffled_deduplicated_it**
- Size of downloaded dataset files: **26637.62 MB**
- Size of the generated dataset: **70661.48 MB**
- Total amount of disk used: **97299.10 MB**
## Useful links
- [Community Week timeline](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104#summary-timeline-calendar-6)
- [Community Week README](https://github.com/huggingface/transformers/blob/master/examples/research_projects/jax-projects/README.md)
- [Community Week thread](https://discuss.huggingface.co/t/robit-pretrain-roberta-base-from-scratch-in-italian/7564)
- [Community Week channel](https://discord.gg/NTyQNUNs)
- [Masked Language Modelling example scripts](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling)
- [Model Repository](https://huggingface.co/flax-community/robit-roberta-base-it/)
|
{}
|
flax-community/robit-roberta-base-it
| null |
[
"transformers",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
flax-community/spanish-image-captioning
| null |
[
"tensorboard",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
# Spanish T5 (small) trained on [large_spanish_corpus](https://huggingface.co/datasets/viewer/?dataset=large_spanish_corpus).
This is a Spanish **T5** (small arch) trained from scratch on the [large_spanish_corpus](https://huggingface.co/datasets/viewer/?dataset=large_spanish_corpus) aka BETO's corpus with [Flax](https://github.com/google/flax)
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Dataset
The dataset is about 20 GB. 95% of the data was used for training and the rest 5% for validation.
## [Metrics](https://huggingface.co/flax-community/spanish-t5-small/tensorboard) (on evaluation dataset)
- Accuracy: 0.675
## Team members
- Manuel Romero ([mrm8488](https://huggingface.co/mrm8488))
- María Grandury ([mariagrandury](https://huggingface.co/mariagrandury))
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{mromero2021spanish-t5-small,
title={Spanish T5 (small) by Manuel Romero},
author={Romero, Manuel},
publisher={Hugging Face},
journal={Hugging Face Hub},
howpublished={\url{https://huggingface.co/flax-community/spanish-t5-small}},
year={2021}
}
```
|
{"language": "es", "license": "mit", "tags": ["T5", "Seq2Seq", "EconderDecoder", "Spanish"], "datasets": ["large_spanish_corpus"], "widgets": [{"text": "\u00c9rase un vez un"}]}
|
flax-community/spanish-t5-small
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"T5",
"Seq2Seq",
"EconderDecoder",
"Spanish",
"es",
"dataset:large_spanish_corpus",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
flax-community/stylegan-medical
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# GPT2-svenska-wikipedia
A swedish GPT2 style model trained using Flax CLM pipeline on the Swedish
part of the wiki40b dataset.
https://huggingface.co/datasets/wiki40b
## Model series
This model is part of a series of models training on TPU with Flax Jax during Huggingface Flax/Jax challenge.
## Gpt models
## Swedish Gpt
https://huggingface.co/birgermoell/swedish-gpt/
## Swedish gpt wiki
https://huggingface.co/flax-community/swe-gpt-wiki
# Nordic gpt wiki
https://huggingface.co/flax-community/nordic-gpt-wiki
## Dansk gpt wiki
https://huggingface.co/flax-community/dansk-gpt-wiki
## Norsk gpt wiki
https://huggingface.co/flax-community/norsk-gpt-wiki
## Roberta models
## Nordic Roberta Wiki
https://huggingface.co/flax-community/nordic-roberta-wiki
## Swe Roberta Wiki Oscar
https://huggingface.co/flax-community/swe-roberta-wiki-oscar
## Roberta Swedish Scandi
https://huggingface.co/birgermoell/roberta-swedish-scandi
## Roberta Swedish
https://huggingface.co/birgermoell/roberta-swedish
## Swedish T5 model
https://huggingface.co/birgermoell/t5-base-swedish
## Data cleaning and preprocessing
The data was cleaned and preprocessed using the following script. Make sure to install depencies for beam_runner to make the dataset work.
```python
from datasets import load_dataset
def load_and_clean_wiki():
dataset = load_dataset('wiki40b', 'sv', beam_runner='DirectRunner', split="train")
#dataset = load_dataset('wiki40b', 'sv', beam_runner='DirectRunner')
dataset = dataset.remove_columns(['wikidata_id', 'version_id'])
filtered_dataset = dataset.map(filter_wikipedia)
# filtered_dataset[:3]
# print(filtered_dataset[:3])
return filtered_dataset
def filter_wikipedia(batch):
batch["text"] = " ".join(batch["text"].split("\
_START_SECTION_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_ARTICLE_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_ARTICLE_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_PARAGRAPH_\
"))
batch["text"] = " ".join(batch["text"].split("_NEWLINE_"))
batch["text"] = " ".join(batch["text"].split("\xa0"))
return batch
```
## Training script
The following training script was used to train the model.
```bash
./run_clm_flax.py --output_dir="${MODEL_DIR}" --model_type="gpt2" --config_name="${MODEL_DIR}" --tokenizer_name="${MODEL_DIR}" --dataset_name="wiki40b" --dataset_config_name="sv" --do_train --do_eval --block_size="512" --per_device_train_batch_size="64" --per_device_eval_batch_size="64" --learning_rate="5e-3" --warmup_steps="1000" --adam_beta1="0.9" --adam_beta2="0.98" --weight_decay="0.01" --overwrite_output_dir --num_train_epochs="20" --logging_steps="500" --save_steps="1000" --eval_steps="2500" --push_to_hub
```
|
{"language": "sv", "widget": [{"text": "Jag \u00e4r en svensk spr\u00e5kmodell."}]}
|
flax-community/swe-gpt-wiki
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"sv",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# Swe Roberta Wiki Oscar
## Description
This Roberta model was trained on the Swedish Wikipedia and Oscar datasets
## Model series
This model is part of a series of models training on TPU with Flax Jax during Huggingface Flax/Jax challenge.
## Gpt models
## Swedish Gpt
https://huggingface.co/birgermoell/swedish-gpt/
## Swedish gpt wiki
https://huggingface.co/flax-community/swe-gpt-wiki
# Nordic gpt wiki
https://huggingface.co/flax-community/nordic-gpt-wiki
## Dansk gpt wiki
https://huggingface.co/flax-community/dansk-gpt-wiki
## Norsk gpt wiki
https://huggingface.co/flax-community/norsk-gpt-wiki
## Roberta models
## Nordic Roberta Wiki
https://huggingface.co/flax-community/nordic-roberta-wiki
## Swe Roberta Wiki Oscar
https://huggingface.co/flax-community/swe-roberta-wiki-oscar
## Roberta Swedish Scandi
https://huggingface.co/birgermoell/roberta-swedish-scandi
## Roberta Swedish
https://huggingface.co/birgermoell/roberta-swedish
## Swedish T5 model
https://huggingface.co/birgermoell/t5-base-swedish
|
{"language": "sv", "license": "cc-by-4.0", "tags": ["swedish", "roberta"], "pipeline_tag": "fill-mask", "widget": [{"text": "Meninged med livet \u00e4r <mask>."}]}
|
flax-community/swe-roberta-wiki-oscar
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"roberta",
"feature-extraction",
"swedish",
"fill-mask",
"sv",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
summarization
|
transformers
|
# Model
This model is fine-tuned from https://huggingface.co/flax-community/t5-base-openwebtext, fine-tuned on cnn_dailymail.
|
{"language": "en", "license": "apache-2.0", "tags": ["summarization"], "datasets": ["cnn_dailymail"], "model-index": [{"name": "flax-community/t5-base-cnn-dm", "results": [{"task": {"type": "summarization", "name": "Summarization"}, "dataset": {"name": "cnn_dailymail", "type": "cnn_dailymail", "config": "3.0.0", "split": "test"}, "metrics": [{"type": "rouge", "value": 24.1585, "name": "ROUGE-1", "verified": true, "verifyToken": "eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiN2Q0Nzk3ZTNkNTFjMTM2YjliNzcxYTVlMDgyNDE4MzZjNzgzZjgzYjI1NWFjZTE2YjE4MWE3NGRiNGZiMmVhNyIsInZlcnNpb24iOjF9.H2oS1cN5A3wY8oFZTVtCMwnbDPAdUhNwjTSDocqQinhDq7aSee_AvIVn-7m84Ke8qaMTAvHB9e56MDAAVT8XBA"}, {"type": "rouge", "value": 11.0688, "name": "ROUGE-2", "verified": true, "verifyToken": "eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGIyMmYzZTFhNjgwMmU5YWQ1MTZjM2ZlNjEwYmVmODkyMGQwZDQ2MjM1YmRkYjM2NTEyNjE5N2ExYzc0ZTcyYSIsInZlcnNpb24iOjF9.6GtmrXTD0EnrXx02enbLdbeiLh--I9u0GfrPdXZ_CKHeYgpFs0Gk1F0c75QBfGoMilodGymS15A9Bjvt00baBw"}, {"type": "rouge", "value": 19.7293, "name": "ROUGE-L", "verified": true, "verifyToken": "eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYzc4MGQyNmYwNDk5NDE0MDk2ZjE2NmVkZDIwN2NmYzQxZTI0NWZhZjkxOGFkMWZmNjQ5NzRkODViNzg5Zjc5MiIsInZlcnNpb24iOjF9.rOgFJeHsW74nQiKc3DPoMIB9aWKqWTRtnweYP3DCp4duJN5jq32PPNyXo3EYuskGgTSp4KWwf7-Hl2MYwDrSCQ"}, {"type": "rouge", "value": 22.6394, "name": "ROUGE-LSUM", "verified": true, "verifyToken": "eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOTA4M2JlZDliMmFlZDgwM2E2MDZjY2ZjZGUwZTcxNDM0NGU3NzdlYzJlZTEzNDEyZDE0OWFiMjUzMmYwNjRhNyIsInZlcnNpb24iOjF9.Mq9ltLQ5YAZfLLaGsPtSOe6KCRLRwjT_2nSAH9KWvOiyagJ16F5xQ1m9uUx9mhiu_UOmpjDaAtD3y4AOy4L0Dg"}, {"type": "loss", "value": 2.516355514526367, "name": "loss", "verified": true, "verifyToken": "eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOGQwNTIyZmU5ZjU3OWM1NGMwYzJiYTA0ZGVmOTA2MjcxYzZmZDRjZDViZDg0NGNlOWNjODkxYTc1ZTJhMmYyMiIsInZlcnNpb24iOjF9.mh6ZVu82CFnb5g92Uj-99wjyvoSQQI-gO-PDBdH4JZyc8mVPJYzV-S7jyXwC_XsOfD1OsR9XKTxM1NUirfBKAw"}, {"type": "gen_len", "value": 18.9993, "name": "gen_len", "verified": true, "verifyToken": "eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNGY5YTYxZmZiYmY4NTZjNmMzMjllNWE1M2M2ZjA0MWM1MzBhZjc0MDM5ZGFiYTAzNjFiZjg5ZjMxYzlmOGYwMyIsInZlcnNpb24iOjF9.eXiPrQ-CeB3BWzlQzkTIA1q0xYP1GtFGIK9XyIneEmh5ajN5pCATxNDvn6n09d84OEr5432SoPJfdpNCd_UyCA"}]}]}]}
|
flax-community/t5-base-cnn-dm
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
# t5-base-dutch-demo 📰
Created by [Yeb Havinga](https://www.linkedin.com/in/yeb-havinga-86530825/) & [Dat Nguyen](https://www.linkedin.com/in/dat-nguyen-49a641138/) during the [Hugging Face community week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104)
This model is based on [t5-base-dutch](https://huggingface.co/flax-community/t5-base-dutch)
and fine-tuned to create summaries of news articles.
For a demo of the model, head over to the Hugging Face Spaces for the **[Netherformer 📰](https://huggingface.co/spaces/flax-community/netherformer)** example application!
## Dataset
`t5-base-dutch-demo` is fine-tuned on three mixed news sources:
1. **CNN DailyMail** translated to Dutch with MarianMT.
2. **XSUM** translated to Dutch with MarianMt.
3. News article summaries distilled from the nu.nl website.
The total number of training examples in this dataset is 1366592.
## Training
Training consisted of fine-tuning [t5-base-dutch](https://huggingface.co/flax-community/t5-base-dutch) with
the following parameters:
* Constant learning rate 0.0005
* Batch size 8
* 1 epoch (170842 steps)
## Evaluation
The performance of the summarization model is measured with the Rouge metric from the
Huggingface Datasets library.
```
"rouge{n}" (e.g. `"rouge1"`, `"rouge2"`) where: {n} is the n-gram based scoring,
"rougeL": Longest common subsequence based scoring.
```
* Rouge1: 23.8
* Rouge2: 6.9
* RougeL: 19.7
These scores are expected to improve if the model is trained with evaluation configured
for the CNN DM and XSUM datasets (translated to Dutch) individually.
|
{"language": ["dutch"], "tags": ["summarization", "seq2seq", "text-generation"], "datasets": ["cnn_dailymail", "xsum"], "pipeline_tag": "text2text-generation", "widget": [{"text": "Onderzoekers ontdekten dat vier van de vijf kinderen in Engeland die op school lunches hadden gegeten, op school voedsel hadden geprobeerd dat ze thuis niet hadden geprobeerd.De helft van de ondervraagde ouders zei dat hun kinderen hadden gevraagd om voedsel dat ze op school hadden gegeten om thuis te worden gekookt.De enqu\u00eate, van ongeveer 1.000 ouders, vond dat de meest populaire groenten wortelen, suikerma\u00efs en erwten waren.Aubergine, kikkererwten en spinazie waren een van de minst populaire.Van de ondervraagde ouders, 628 hadden kinderen die lunches op school aten. (% duidt op een deel van de ouders die zeiden dat hun kind elke groente zou eten) England's School Food Trust gaf opdracht tot het onderzoek na een onderzoek door de Mumsnet-website suggereerde dat sommige ouders hun kinderen lunchpakket gaven omdat ze dachten dat ze te kieskeurig waren om iets anders te eten. \"Schoolmaaltijden kunnen een geweldige manier zijn om ouders te helpen hun kinderen aan te moedigen om nieuw voedsel te proberen en om de verscheidenheid van voedsel in hun dieet te verhogen. \"Mumsnet medeoprichter, Carrie Longton, zei: \"Het krijgen van kinderen om gezond te eten is de droom van elke ouder, maar maaltijdtijden thuis kan vaak een slagveld en emotioneel geladen zijn. \"Vanuit Mumsnetters' ervaring lijkt het erop dat eenmaal op school is er een verlangen om in te passen bij iedereen anders en zelfs een aantal positieve peer pressure om op te scheppen over de verscheidenheid van wat voedsel je kunt eten. \"Schoolmaaltijden zijn ook verplaatst op nogal een beetje van toen Mumsnetters op school waren, met gezondere opties en meer afwisseling. \"Schoolmaaltijden in Engeland moeten nu voldoen aan strenge voedingsrichtlijnen.Ongeveer vier op de tien basisschoolkinderen in Engeland eten nu schoollunches, iets meer dan op middelbare scholen.Meer kinderen in Schotland eten schoollunches - ongeveer 46%.Het onderzoek werd online uitgevoerd tussen 26 februari en 5 maart onder een panel van ouders die ten minste \u00e9\u00e9n kind op school hadden van 4-17 jaar oud."}, {"text": "Het Londense trio staat klaar voor de beste Britse act en beste album, evenals voor twee nominaties in de beste song categorie. \"We kregen te horen zoals vanmorgen 'Oh I think you're genomineerd',\" zei Dappy. \"En ik was als 'Oh yeah, what one?' En nu zijn we genomineerd voor vier awards. Ik bedoel, wow! \"Bandmate Fazer voegde eraan toe: \"We dachten dat het het beste van ons was om met iedereen naar beneden te komen en hallo te zeggen tegen de camera's.En nu vinden we dat we vier nominaties hebben. \"De band heeft twee shots bij de beste song prijs, het krijgen van het knikje voor hun Tyncy Stryder samenwerking nummer \u00e9\u00e9n, en single Strong Again.Their album Uncle B zal ook gaan tegen platen van Beyonce en Kany \"Aan het eind van de dag zijn we dankbaar om te zijn waar we zijn in onze carri\u00e8res. \"Als het niet gebeurt dan gebeurt het niet - live om te vechten een andere dag en blijven maken albums en hits voor de fans. \"Dappy onthulde ook dat ze kunnen worden optreden live op de avond.De groep zal doen Nummer Een en ook een mogelijke uitlevering van de War Child single, I Got Soul.Het liefdadigheidslied is een re-working van The Killers' All These Things That I've Done en is ingesteld op artiesten als Chipmunk, Ironik en Pixie Lott.Dit jaar zal Mobos worden gehouden buiten Londen voor de eerste keer, in Glasgow op 30 september.N-Dubz zei dat ze op zoek waren naar optredens voor hun Schotse fans en bogen over hun recente shows ten noorden van de Londense We hebben Aberdeen ongeveer drie of vier maanden geleden gedaan - we hebben die show daar verbrijzeld! Overal waar we heen gaan slaan we hem in elkaar!\""}]}
|
flax-community/t5-base-dutch-demo
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"seq2seq",
"text-generation",
"dataset:cnn_dailymail",
"dataset:xsum",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
# t5-base-dutch
Created by [Yeb Havinga](https://www.linkedin.com/in/yeb-havinga-86530825/)
& [Dat Nguyen](https://www.linkedin.com/in/dat-nguyen-49a641138/) during the [Hugging Face community week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google, for the project [Pre-train T5 from scratch in Dutch](https://discuss.huggingface.co/t/pretrain-t5-from-scratch-in-dutch/8109).
See also the fine-tuned [t5-base-dutch-demo](https://huggingface.co/flax-community/t5-base-dutch-demo) model,
and the demo application **[Netherformer 📰](https://huggingface.co/spaces/flax-community/netherformer)**,
that are based on this model.
**5 jan 2022: Model updated. Evaluation accuracy increased from 0.64 to 0.70.**
**11 jan 2022: See also [yhavinga/t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) with eval acc 0.78**
## Model
* Configuration based on `google/t5-base`
* 12 layers, 12 heads
* Dropout set to 0.1
## Dataset
This model was trained on the `full` configuration of [cleaned Dutch mC4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned),
which is the original mC4, except
* Documents that contained words from a selection of the Dutch and English [List of Dirty Naught Obscene and Otherwise Bad Words](https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words) are removed
* Sentences with less than 3 words are removed
* Sentences with a word of more than 1000 characters are removed
* Documents with less than 5 sentences are removed
* Documents with "javascript", "lorum ipsum", "terms of use", "privacy policy", "cookie policy", "uses cookies",
"use of cookies", "use cookies", "elementen ontbreken", "deze printversie" are removed.
## Tokenization
A SentencePiece tokenizer was trained from scratch on this dataset.
The total tokens of the `full` configuration is 34B
## Training
The model was trained on the `full` mc4_nl_cleaned dataset configuration for 1 epoch, consisting of 34B tokens,
for 528 482 steps with a batch size of 128 and took 57 hours.
A triangle learning rate schedule was used, with peak learning rate 0.005.
## Evaluation
* Loss: 1.38
* Accuracy: 0.70
|
{"language": ["dutch"], "license": "apache-2.0", "tags": ["seq2seq", "lm-head"], "datasets": ["yhavinga/mc4_nl_cleaned"], "inference": false}
|
flax-community/t5-base-dutch
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"seq2seq",
"lm-head",
"dataset:yhavinga/mc4_nl_cleaned",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
{}
|
flax-community/t5-base-openwebtext
| null |
[
"transformers",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
{}
|
flax-community/t5-base-wikisplit
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
# Covid19 Related Question Answering (Closed book question answering)
In 2020, COVID-19 which is caused by a coronavirus called SARS-CoV-2 took over the world. It touched the lives of many people and caused a lot of hardship for humanity. There are still many questions in regards to COVID-19 and it is often difficult to get the right answers. The aim of this project is to finetune models for closed book question answering. In closed-book QA, we feed the model a question *without any context or access to external knowledge* and train it to predict the answer. Since the model doesn't receive any context, the primary way it can learn to answer these questions is based on the "knowledge" it obtained during pre-training [[1]](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb#scrollTo=zSeyoqE7WMwu) [[2]](https://arxiv.org/abs/2002.08910).
The main goals of this project are:
1. Train a model for question answering in regards to COVID-19
2. Release the top performing models for further research and enhancement
3. Release all of the preprocessing and postprocessing scripts and findings for future research.
## TO DO LIST:
- [x] Team members met and the following was discussed:
- Data preparation script is prepared that mixes CORD-19 and Pubmed.
- Agreed to finalize the training scripts by 9pm PDT 7/9/2021.
- Tokenizer is now trained.
- [ ] Setup the pretraining script
- [ ] Prepare the finetuning tasks inspired from [T5 Trivia Colab](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb)
- What datasets we want to go with?
- [Covid-QA](https://huggingface.co/datasets/covid_qa_deepset) (Maybe as test set?)
- [Trivia](https://huggingface.co/datasets/covid_qa_deepset)
- [CDC-QA](https://www.cdc.gov/coronavirus/2019-ncov/faq.html) (We can scrape quickly using beautiful soup or something)
- [More Medical Datasets](https://aclanthology.org/2020.findings-emnlp.289.pdf) (See the dataset section for inspiratio)
## 1. Model
We will be using T5 model.
## 2. Datasets
The following datasets would be used for finetuning the model. Note that the last dataset is optional and the model is evaluated only using Covid-QA.
For **Intermediate Pre-Training**:
1. [CORD-19](https://allenai.org/data/cord-19)
For **Fine-Tuning** :
1. [Covid-QA](https://huggingface.co/datasets/covid_qa_deepset)
2. [CDC-QA](https://www.cdc.gov/coronavirus/2019-ncov/faq.html)
4. Optional - [Trivia-QA](https://nlp.cs.washington.edu/triviaqa/)
## 3. Training Scripts
We can make use of :
1. [For preprocessing and mixing datasets](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb#:~:text=In%20this%20notebook%2C%20we'll,it%20to%20predict%20the%20answer.)
2. [For T5 training](https://github.com/huggingface/transformers/blob/master/src/transformers/models/t5/modeling_flax_t5.py)
## 4. Additional Reading
- [How Much Knowledge Can You Pack Into the Parameters of a Language Model?](https://arxiv.org/pdf/2002.08910.pdf)
|
{}
|
flax-community/t5-covid-qa
| null |
[
"arxiv:2002.08910",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
# T5 model for sentence splitting in English
Sentence Split is the task of dividing a long sentence into multiple sentences.
E.g.:
```
Mary likes to play football in her freetime whenever she meets with her friends that are very nice people.
```
could be split into
```
Mary likes to play football in her freetime whenever she meets with her friends.
```
```
Her friends are very nice people.
```
## How to use it in your code:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/t5-large-wikisplit")
model = AutoModelForSeq2SeqLM.from_pretrained("flax-community/t5-large-wikisplit")
complex_sentence = "This comedy drama is produced by Tidy , the company she co-founded in 2008 with her husband David Peet , who is managing director ."
sample_tokenized = tokenizer(complex_sentence, return_tensors="pt")
answer = model.generate(sample_tokenized['input_ids'], attention_mask = sample_tokenized['attention_mask'], max_length=256, num_beams=5)
gene_sentence = tokenizer.decode(answer[0], skip_special_tokens=True)
gene_sentence
"""
Output:
This comedy drama is produced by Tidy. She co-founded Tidy in 2008 with her husband David Peet, who is managing director.
"""
```
## Datasets:
[Wiki_Split](https://research.google/tools/datasets/wiki-split/)
## Current Basline from [paper](https://arxiv.org/abs/1907.12461)

## Our Results:
| Model | Exact | SARI | BLEU |
| --- | --- | --- | --- |
| [t5-base-wikisplit](https://huggingface.co/flax-community/t5-base-wikisplit) | 17.93 | 67.5438 | 76.9 |
| [t5-v1_1-base-wikisplit](https://huggingface.co/flax-community/t5-v1_1-base-wikisplit) | 18.1207 | 67.4873 | 76.9478 |
| [byt5-base-wikisplit](https://huggingface.co/flax-community/byt5-base-wikisplit) | 11.3582 | 67.2685 | 73.1682 |
| [t5-large-wikisplit](https://huggingface.co/flax-community/t5-large-wikisplit) | 18.6632 | 68.0501 | 77.1881 |
|
{"datasets": ["wiki_split"], "widget": [{"text": "Mary likes to play football in her freetime whenever she meets with her friends that are very nice people."}]}
|
flax-community/t5-large-wikisplit
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"dataset:wiki_split",
"arxiv:1907.12461",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|

# Chef Transformer (T5)
> This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/recipe-generation-model/7475), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
Want to give it a try? Then what's the wait, head over to Hugging Face Spaces [here](https://huggingface.co/spaces/flax-community/chef-transformer).
## Team Members
- Mehrdad Farahani ([m3hrdadfi](https://huggingface.co/m3hrdadfi))
- Kartik Godawat ([dk-crazydiv](https://huggingface.co/dk-crazydiv))
- Haswanth Aekula ([hassiahk](https://huggingface.co/hassiahk))
- Deepak Pandian ([rays2pix](https://huggingface.co/rays2pix))
- Nicholas Broad ([nbroad](https://huggingface.co/nbroad))
## Dataset
[RecipeNLG: A Cooking Recipes Dataset for Semi-Structured Text Generation](https://recipenlg.cs.put.poznan.pl/). This dataset contains **2,231,142** cooking recipes (>2 millions) with size of **2.14 GB**. It's processed in more careful way.
### Example
```json
{
"NER": [
"oyster crackers",
"salad dressing",
"lemon pepper",
"dill weed",
"garlic powder",
"salad oil"
],
"directions": [
"Combine salad dressing mix and oil.",
"Add dill weed, garlic powder and lemon pepper.",
"Pour over crackers; stir to coat.",
"Place in warm oven.",
"Use very low temperature for 15 to 20 minutes."
],
"ingredients": [
"12 to 16 oz. plain oyster crackers",
"1 pkg. Hidden Valley Ranch salad dressing mix",
"1/4 tsp. lemon pepper",
"1/2 to 1 tsp. dill weed",
"1/4 tsp. garlic powder",
"3/4 to 1 c. salad oil"
],
"link": "www.cookbooks.com/Recipe-Details.aspx?id=648947",
"source": "Gathered",
"title": "Hidden Valley Ranch Oyster Crackers"
}
```
## How To Use
```bash
# Installing requirements
pip install transformers
```
```python
from transformers import FlaxAutoModelForSeq2SeqLM
from transformers import AutoTokenizer
MODEL_NAME_OR_PATH = "flax-community/t5-recipe-generation"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME_OR_PATH, use_fast=True)
model = FlaxAutoModelForSeq2SeqLM.from_pretrained(MODEL_NAME_OR_PATH)
prefix = "items: "
# generation_kwargs = {
# "max_length": 512,
# "min_length": 64,
# "no_repeat_ngram_size": 3,
# "early_stopping": True,
# "num_beams": 5,
# "length_penalty": 1.5,
# }
generation_kwargs = {
"max_length": 512,
"min_length": 64,
"no_repeat_ngram_size": 3,
"do_sample": True,
"top_k": 60,
"top_p": 0.95
}
special_tokens = tokenizer.all_special_tokens
tokens_map = {
"<sep>": "--",
"<section>": "\n"
}
def skip_special_tokens(text, special_tokens):
for token in special_tokens:
text = text.replace(token, "")
return text
def target_postprocessing(texts, special_tokens):
if not isinstance(texts, list):
texts = [texts]
new_texts = []
for text in texts:
text = skip_special_tokens(text, special_tokens)
for k, v in tokens_map.items():
text = text.replace(k, v)
new_texts.append(text)
return new_texts
def generation_function(texts):
_inputs = texts if isinstance(texts, list) else [texts]
inputs = [prefix + inp for inp in _inputs]
inputs = tokenizer(
inputs,
max_length=256,
padding="max_length",
truncation=True,
return_tensors="jax"
)
input_ids = inputs.input_ids
attention_mask = inputs.attention_mask
output_ids = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
**generation_kwargs
)
generated = output_ids.sequences
generated_recipe = target_postprocessing(
tokenizer.batch_decode(generated, skip_special_tokens=False),
special_tokens
)
return generated_recipe
```
```python
items = [
"macaroni, butter, salt, bacon, milk, flour, pepper, cream corn",
"provolone cheese, bacon, bread, ginger"
]
generated = generation_function(items)
for text in generated:
sections = text.split("\n")
for section in sections:
section = section.strip()
if section.startswith("title:"):
section = section.replace("title:", "")
headline = "TITLE"
elif section.startswith("ingredients:"):
section = section.replace("ingredients:", "")
headline = "INGREDIENTS"
elif section.startswith("directions:"):
section = section.replace("directions:", "")
headline = "DIRECTIONS"
if headline == "TITLE":
print(f"[{headline}]: {section.strip().capitalize()}")
else:
section_info = [f" - {i+1}: {info.strip().capitalize()}" for i, info in enumerate(section.split("--"))]
print(f"[{headline}]:")
print("\n".join(section_info))
print("-" * 130)
```
Output:
```text
[TITLE]: Macaroni and corn
[INGREDIENTS]:
- 1: 2 c. macaroni
- 2: 2 tbsp. butter
- 3: 1 tsp. salt
- 4: 4 slices bacon
- 5: 2 c. milk
- 6: 2 tbsp. flour
- 7: 1/4 tsp. pepper
- 8: 1 can cream corn
[DIRECTIONS]:
- 1: Cook macaroni in boiling salted water until tender.
- 2: Drain.
- 3: Melt butter in saucepan.
- 4: Blend in flour, salt and pepper.
- 5: Add milk all at once.
- 6: Cook and stir until thickened and bubbly.
- 7: Stir in corn and bacon.
- 8: Pour over macaroni and mix well.
----------------------------------------------------------------------------------------------------------------------------------
[TITLE]: Grilled provolone and bacon sandwich
[INGREDIENTS]:
- 1: 2 slices provolone cheese
- 2: 2 slices bacon
- 3: 2 slices sourdough bread
- 4: 2 slices pickled ginger
[DIRECTIONS]:
- 1: Place a slice of provolone cheese on one slice of bread.
- 2: Top with a slice of bacon.
- 3: Top with a slice of pickled ginger.
- 4: Top with the other slice of bread.
- 5: Heat a skillet over medium heat.
- 6: Place the sandwich in the skillet and cook until the cheese is melted and the bread is golden brown.
----------------------------------------------------------------------------------------------------------------------------------
```
## Evaluation
Since the test set is not available, we will evaluate the model based on a shared test set. This test set consists of 5% of the whole test (*= 5,000 records*),
and we will generate five recipes for each input(*= 25,000 records*).
The following table summarizes the scores obtained by the **Chef Transformer** and **RecipeNLG** as our baseline.
| Model | COSIM | WER | ROUGE-2 | BLEU | GLEU | METEOR |
|:------------------------------------------------------------------------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|
| [RecipeNLG](https://huggingface.co/mbien/recipenlg) | 0.5723 | 1.2125 | 0.1354 | 0.1164 | 0.1503 | 0.2309 |
| [Chef Transformer](huggingface.co/flax-community/t5-recipe-generation) * | **0.7282** | **0.7613** | **0.2470** | **0.3245** | **0.2624** | **0.4150** |
*From the 5 generated recipes corresponding to each NER (food items), only the highest score was taken into account in the WER, COSIM, and ROUGE metrics. At the same time, BLEU, GLEU, Meteor were designed to have many possible references.*
## Copyright
Special thanks to those who provided these fantastic materials.
- [Anatomy](https://www.flaticon.com/free-icon)
- [Chef Hat](https://www.vecteezy.com/members/jellyfishwater)
- [Moira Nazzari](https://pixabay.com/photos/food-dessert-cake-eggs-butter-3048440/)
- [Instagram Post](https://www.freepik.com/free-psd/recipes-ad-social-media-post-template_11520617.htm)
|
{"language": "en", "tags": ["seq2seq", "t5", "text-generation", "recipe-generation"], "pipeline_tag": "text2text-generation", "widget": [{"text": "provolone cheese, bacon, bread, ginger"}, {"text": "sugar, crunchy jif peanut butter, cornflakes"}, {"text": "sweet butter, confectioners sugar, flaked coconut, condensed milk, nuts, vanilla, dipping chocolate"}, {"text": "macaroni, butter, salt, bacon, milk, flour, pepper, cream corn"}, {"text": "hamburger, sausage, onion, regular, american cheese, colby cheese"}, {"text": "chicken breasts, onion, garlic, great northern beans, black beans, green chilies, broccoli, garlic oil, butter, cajun seasoning, salt, oregano, thyme, black pepper, basil, worcestershire sauce, chicken broth, sour cream, chardonnay wine"}, {"text": "serrano peppers, garlic, celery, oregano, canola oil, vinegar, water, kosher salt, salt, black pepper"}]}
|
flax-community/t5-recipe-generation
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"seq2seq",
"text-generation",
"recipe-generation",
"en",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text2text-generation
|
transformers
|
# T5 model for sentence splitting in English
Sentence Split is the task of dividing a long sentence into multiple sentences.
E.g.:
```
Mary likes to play football in her freetime whenever she meets with her friends that are very nice people.
```
could be split into
```
Mary likes to play football in her freetime whenever she meets with her friends.
```
```
Her friends are very nice people.
```
## How to use it in your code:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/t5-v1_1-base-wikisplit")
model = AutoModelForSeq2SeqLM.from_pretrained("flax-community/t5-v1_1-base-wikisplit")
complex_sentence = "This comedy drama is produced by Tidy , the company she co-founded in 2008 with her husband David Peet , who is managing director ."
sample_tokenized = tokenizer(complex_sentence, return_tensors="pt")
answer = model.generate(sample_tokenized['input_ids'], attention_mask = sample_tokenized['attention_mask'], max_length=256, num_beams=5)
gene_sentence = tokenizer.decode(answer[0], skip_special_tokens=True)
gene_sentence
"""
Output:
This comedy drama is produced by Tidy. She co-founded Tidy in 2008 with her husband David Peet, who is managing director.
"""
```
## Datasets:
[Wiki_Split](https://research.google/tools/datasets/wiki-split/)
## Current Basline from [paper](https://arxiv.org/abs/1907.12461)

## Our Results:
| Model | Exact | SARI | BLEU |
| --- | --- | --- | --- |
| [t5-base-wikisplit](https://huggingface.co/flax-community/t5-base-wikisplit) | 17.93 | 67.5438 | 76.9 |
| [t5-v1_1-base-wikisplit](https://huggingface.co/flax-community/t5-v1_1-base-wikisplit) | 18.1207 | 67.4873 | 76.9478 |
| [byt5-base-wikisplit](https://huggingface.co/flax-community/byt5-base-wikisplit) | 11.3582 | 67.2685 | 73.1682 |
| [t5-large-wikisplit](https://huggingface.co/flax-community/t5-large-wikisplit) | 18.6632 | 68.0501 | 77.1881 |
|
{"datasets": ["wiki_split"], "widget": [{"text": "Mary likes to play football in her freetime whenever she meets with her friends that are very nice people."}]}
|
flax-community/t5-v1_1-base-wikisplit
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"dataset:wiki_split",
"arxiv:1907.12461",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# T5-VAE-Python (flax)
A Transformer-VAE made using flax.
Try the [demo](https://huggingface.co/spaces/flax-community/t5-vae)!
It has been trained to interpolate on lines of Python code from the [python-lines dataset](https://huggingface.co/datasets/Fraser/python-lines).
Done as part of Huggingface community training ([see forum post](https://discuss.huggingface.co/t/train-a-vae-to-interpolate-on-english-sentences/7548)).
Builds on T5, using an autoencoder to convert it into an MMD-VAE ([more info](http://fras.uk/ml/large%20prior-free%20models/transformer-vae/2020/08/13/Transformers-as-Variational-Autoencoders.html)).
## How to use from the 🤗/transformers library
Add model repo as a submodule:
```bash
git submodule add https://github.com/Fraser-Greenlee/t5-vae-flax.git t5_vae_flax
```
```python
from transformers import AutoTokenizer
from t5_vae_flax.src.t5_vae import FlaxT5VaeForAutoencoding
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = FlaxT5VaeForAutoencoding.from_pretrained("flax-community/t5-vae-python")
```
## Setup
Run `setup_tpu_vm_venv.sh` to setup a virtual enviroment on a TPU VM for training.
|
{"language": "python", "license": "apache-2.0", "tags": "vae", "datasets": "Fraser/python-lines"}
|
flax-community/t5-vae-python
| null |
[
"transformers",
"jax",
"transformer_vae",
"vae",
"dataset:Fraser/python-lines",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# T5-VAE-Wiki (flax)
A Transformer-VAE made using flax.
It has been trained to interpolate on sentences form wikipedia.
Done as part of Huggingface community training ([see forum post](https://discuss.huggingface.co/t/train-a-vae-to-interpolate-on-english-sentences/7548)).
Builds on T5, using an autoencoder to convert it into an MMD-VAE ([more info](http://fras.uk/ml/large%20prior-free%20models/transformer-vae/2020/08/13/Transformers-as-Variational-Autoencoders.html)).
## How to use from the 🤗/transformers library
Add model repo as a submodule:
```bash
git submodule add https://github.com/Fraser-Greenlee/t5-vae-flax.git t5_vae_flax
```
```python
from transformers import AutoTokenizer
from t5_vae_flax.src.t5_vae import FlaxT5VaeForAutoencoding
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = FlaxT5VaeForAutoencoding.from_pretrained("flax-community/t5-vae-wiki")
```
## Setup
Run `setup_tpu_vm_venv.sh` to setup a virtual enviroment on a TPU VM for training.
|
{"language": "en", "license": "apache-2.0", "tags": "vae"}
|
flax-community/t5-vae-wiki
| null |
[
"transformers",
"jax",
"transformer_vae",
"vae",
"en",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
# Transformer-VAE (flax) (WIP)
A Transformer-VAE made using flax.
Done as part of Huggingface community training ([see forum post](https://discuss.huggingface.co/t/train-a-vae-to-interpolate-on-english-sentences/7548)).
Builds on T5, using an autoencoder to convert it into an MMD-VAE.
[See training logs.](https://wandb.ai/fraser/flax-vae)
## ToDo
- [ ] Basic training script working. (Fraser + Theo)
- [ ] Add MMD loss (Theo)
- [ ] Save a wikipedia sentences dataset to Huggingface (see original https://github.com/ChunyuanLI/Optimus/blob/master/data/download_datasets.md) (Mina)
- [ ] Make a tokenizer using the OPTIMUS tokenized dataset.
- [ ] Train on the OPTIMUS wikipedia sentences dataset.
- [ ] Make Huggingface widget interpolating sentences! (???) https://github.com/huggingface/transformers/tree/master/examples/research_projects/jax-projects#how-to-build-a-demo
Optional ToDos:
- [ ] Add Funnel transformer encoder to FLAX (don't need weights).
- [ ] Train a Funnel-encoder + T5-decoder transformer VAE.
- [ ] Additional datasets:
- [ ] Poetry (https://www.gwern.net/GPT-2#data-the-project-gutenberg-poetry-corpus)
- [ ] 8-bit music (https://github.com/chrisdonahue/LakhNES)
## Setup
Follow all steps to install dependencies from https://cloud.google.com/tpu/docs/jax-quickstart-tpu-vm
- [ ] Find dataset storage site.
- [ ] Ask JAX team for dataset storage.
|
{}
|
flax-community/transformer-vae
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
# 🖼️ When ViT meets GPT-2 📝
An image captioning model [ViT-GPT2](https://huggingface.co/flax-community/vit-gpt2/tree/main) by combining the ViT model and a French GPT2 model.
Part of the [Huggingface JAX/Flax event](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/).
The GPT2 model source code is modified so it can accept an encoder's output.
The pretained weights of both models are loaded, with a set of randomly initialized cross-attention weigths.
The model is trained on 65000 images from the COCO dataset for about 1500 steps (batch\_size=256), with the original English cpationis being translated to French for training purpose.
**Technical challenges**
- The source code of Flax's version of GPT-2 is modified to be able to accept an encoder's outputs, so it can be used as a decoder in an encoder-decoder architecture.
- Originally, we created [**FlaxViTGPT2ForConditionalGenerationModule**](https://huggingface.co/flax-community/vit-gpt2/blob/main/vit_gpt2/modeling_flax_vit_gpt2.py#L86), which is [**FlaxViTGPT2Module**](https://huggingface.co/flax-community/vit-gpt2/blob/main/vit_gpt2/modeling_flax_vit_gpt2.py#L28) (ViT + [GPT-2 without LM head]) with an extra LM head. However, when loading the pretrained French GPT-2 model, the LM head's weigths are not loaded. We therefore created [**FlaxViTGPT2LMForConditionalGenerationModule**](https://huggingface.co/flax-community/vit-gpt2/blob/main/vit_gpt2/modeling_flax_vit_gpt2_lm.py#L101) which is `ViT + [GPT-2 with LM head]`, and we no longer need to add a LM head over it. By doing so, the pretrained LM head's weights are also loaded, and the only randomly initialized weigths are the cross-attention weights.
- The provided training script `run_summarization.py` is modified to send pixel values to the model instead of a sequence of input token ids, and a necessary change due to the ViT model not accepting an `attention_mask` argument.
- We first tried to use [WIT : Wikipedia-based Image Text Dataset](https://github.com/google-research-datasets/wit), but found it is a very changeling task since, unlike traditional image captioning tasks, it requires the model to be able to generate different texts even if two images are similar (for example, two famous dogs might have completely different Wikipedia texts).
- We finally decided to use [COCO image dataset](https://cocodataset.org/#home) at the final day of this Flax community event. We were able to translate only about 65000 examples to French for training, and the model is trained for only 5 epochs (beyond this, it started to overfit). This leads to the poor performance.
A HuggingFace Spaces demo for this model: [🖼️ French Image Captioning Demo 📝](https://huggingface.co/spaces/flax-community/image-caption-french)
|
{}
|
flax-community/vit-gpt2
| null |
[
"tensorboard",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
## VQGAN-f16-16384
### Model Description
This is a Flax/JAX implementation of VQGAN, which learns a codebook of context-rich visual parts by leveraging both the use of convolutional methods and transformers. It was introduced in [Taming Transformers for High-Resolution Image Synthesis](https://compvis.github.io/taming-transformers/) ([CVPR paper](https://openaccess.thecvf.com/content/CVPR2021/html/Esser_Taming_Transformers_for_High-Resolution_Image_Synthesis_CVPR_2021_paper.html)).
The model allows the encoding of images as a fixed-length sequence of tokens taken from the codebook.
This version of the model uses a reduction factor `f=16` and a vocabulary of `13,384` tokens.
As an example of how the reduction factor works, images of size `256x256` are encoded to sequences of `256` tokens: `256/16 * 256/16`. Images of `512x512` would result in sequences of `1024` tokens.
### Datasets Used for Training
* ImageNet. We didn't train this model from scratch. Instead, we started from [a checkpoint pre-trained on ImageNet](https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/).
* [Conceptual Captions 3M](https://ai.google.com/research/ConceptualCaptions/) (CC3M).
* [OpenAI subset of YFCC100M](https://github.com/openai/CLIP/blob/main/data/yfcc100m.md).
We fine-tuned on CC3M and YFCC100M to improve the encoding quality of people and faces, which are not very well represented in ImageNet. We used a subset of 2,268,720 images from CC3M and YFCC100M for this purpose.
### Training Process
Finetuning was performed in PyTorch using [taming-transformers](https://github.com/CompVis/taming-transformers). The full training process and model preparation includes these steps:
* Pre-training on ImageNet. Previously performed. We used [this checkpoint](https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887).
* Fine-tuning, [Part 1](https://wandb.ai/wandb/hf-flax-dalle-mini/runs/2021-07-09T15-33-11_dalle_vqgan?workspace=user-borisd13).
* Fine-tuning, [Part 2](https://wandb.ai/wandb/hf-flax-dalle-mini/runs/2021-07-09T21-42-07_dalle_vqgan?workspace=user-borisd13) – continuation from Part 1. The final checkpoint was uploaded to [boris/vqgan_f16_16384](https://huggingface.co/boris/vqgan_f16_16384).
* Conversion to JAX, which is the model described in this card.
### How to Use
The checkpoint can be loaded using [Suraj Patil's implementation](https://github.com/patil-suraj/vqgan-jax) of `VQModel`.
* Example notebook, heavily based in work by [Suraj](https://huggingface.co/valhalla): [](https://colab.research.google.com/github/borisdayma/dalle-mini/blob/main/dev/vqgan/JAX_VQGAN_f16_16384_Reconstruction.ipynb)
* Batch encoding using JAX `pmap`, complete example including data loading with PyTorch:
```python
# VQGAN-JAX - pmap encoding HowTo
import numpy as np
# For data loading
import torch
import torchvision.transforms.functional as TF
from torch.utils.data import Dataset, DataLoader
from torchvision.datasets.folder import default_loader
from torchvision.transforms import InterpolationMode
# For data saving
from pathlib import Path
import pandas as pd
from tqdm import tqdm
import jax
from jax import pmap
from vqgan_jax.modeling_flax_vqgan import VQModel
## Params and arguments
# List of paths containing images to encode
image_list = '/sddata/dalle-mini/CC12M/10k.tsv'
output_tsv = 'output.tsv' # Encoded results
batch_size = 64
num_workers = 4 # TPU v3-8s have 96 cores, so feel free to increase this number when necessary
# Load model
model = VQModel.from_pretrained("flax-community/vqgan_f16_16384")
## Data Loading.
# Simple torch Dataset to load images from paths.
# You can use your own pipeline instead.
class ImageDataset(Dataset):
def __init__(self, image_list_path: str, image_size: int, max_items=None):
"""
:param image_list_path: Path to a file containing a list of all images. We assume absolute paths for now.
:param image_size: Image size. Source images will be resized and center-cropped.
:max_items: Limit dataset size for debugging
"""
self.image_list = pd.read_csv(image_list_path, sep='\t', header=None)
if max_items is not None: self.image_list = self.image_list[:max_items]
self.image_size = image_size
def __len__(self):
return len(self.image_list)
def _get_raw_image(self, i):
image_path = Path(self.image_list.iloc[i][0])
return default_loader(image_path)
def resize_image(self, image):
s = min(image.size)
r = self.image_size / s
s = (round(r * image.size[1]), round(r * image.size[0]))
image = TF.resize(image, s, interpolation=InterpolationMode.LANCZOS)
image = TF.center_crop(image, output_size = 2 * [self.image_size])
image = np.expand_dims(np.array(image), axis=0)
return image
def __getitem__(self, i):
image = self._get_raw_image(i)
return self.resize_image(image)
## Encoding
# Encoding function to be parallelized with `pmap`
# Note: images have to be square
def encode(model, batch):
_, indices = model.encode(batch)
return indices
# Alternative: create a batch with num_tpus*batch_size and use `shard` to distribute.
def superbatch_generator(dataloader, num_tpus):
iter_loader = iter(dataloader)
for batch in iter_loader:
superbatch = [batch.squeeze(1)]
try:
for _ in range(num_tpus-1):
batch = next(iter_loader)
if batch is None:
break
# Skip incomplete last batch
if batch.shape[0] == dataloader.batch_size:
superbatch.append(batch.squeeze(1))
except StopIteration:
pass
superbatch = torch.stack(superbatch, axis=0)
yield superbatch
def encode_dataset(dataset, batch_size=32):
dataloader = DataLoader(dataset, batch_size=batch_size, num_workers=num_workers)
superbatches = superbatch_generator(dataloader, num_tpus=jax.device_count())
num_tpus = jax.device_count()
dataloader = DataLoader(dataset, batch_size=batch_size, num_workers=num_workers)
superbatches = superbatch_generator(dataloader, num_tpus=num_tpus)
p_encoder = pmap(lambda batch: encode(model, batch))
# Save each superbatch to avoid reallocation of buffers as we process them.
# Keep the file open to prevent excessive file seeks.
with open(output_tsv, "w") as file:
iterations = len(dataset) // (batch_size * num_tpus)
for n in tqdm(range(iterations)):
superbatch = next(superbatches)
encoded = p_encoder(superbatch.numpy())
encoded = encoded.reshape(-1, encoded.shape[-1])
# Extract paths from the dataset, save paths and encodings (as string)
start_index = n * batch_size * num_tpus
end_index = (n+1) * batch_size * num_tpus
paths = dataset.image_list[start_index:end_index][0].values
encoded_as_string = list(map(lambda item: np.array2string(item, separator=',', max_line_width=50000, formatter={'int':lambda x: str(x)}), encoded))
batch_df = pd.DataFrame.from_dict({"image_file": paths, "encoding": encoded_as_string})
batch_df.to_csv(file, sep='\t', header=(n==0), index=None)
dataset = ImageDataset(image_list, image_size=256)
encoded_dataset = encode_dataset(dataset, batch_size=batch_size)
```
### Related Models in the Hub
* PyTorch version of VQGAN, trained on the same datasets described here: [boris/vqgan_f16_16384](https://huggingface.co/boris/vqgan_f16_16384).
* [DALL·E mini](https://huggingface.co/flax-community/dalle-mini), a Flax/JAX simplified implementation of OpenAI's DALL·E.
### Other
This model was successfully used as part of the implementation of [DALL·E mini](https://github.com/borisdayma/dalle-mini). Our [report](https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini--Vmlldzo4NjIxODA) contains more details on how to leverage it in an image encoding / generation pipeline.
|
{}
|
flax-community/vqgan_f16_16384
| null |
[
"transformers",
"jax",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
{}
|
flax-community/wav2vec2-base-indonesian
| null |
[
"transformers",
"jax",
"tensorboard",
"wav2vec2",
"pretraining",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null |
transformers
|
# Wav2Vec2 4 Persian
> This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/pretrain-wav2vec2-in-persian/8180), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team Members
- Mehrdad Farahani ([m3hrdadfi](https://huggingface.co/m3hrdadfi))
## Dataset TODO: Update
## How To Use TODO: Update
## Demo TODO: Update
## Evaluation TODO: Update
|
{"language": "fa", "license": "apache-2.0", "tags": ["speech"], "datasets": ["common_voice"]}
|
flax-community/wav2vec2-base-persian
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"wav2vec2",
"pretraining",
"speech",
"fa",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
# wav2vec2-base-turkish
|
{}
|
flax-community/wav2vec2-base-turkish
| null |
[
"tensorboard",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2 Dhivehi
Wav2vec2 pre-pretrained from scratch using common voice dhivehi dataset. The model was trained with Flax during the [Flax/Jax Community Week](https://discss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organised by HuggingFace.
## Model description
The model used for training is [Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) by FacebookAI. It was introduced in the paper
"wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations" by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli (https://arxiv.org/abs/2006.11477).
This model is available in the 🤗 [Model Hub](https://huggingface.co/facebook/wav2vec2-base-960h).
## Training data
Dhivehi data from [Common Voice](https://commonvoice.mozilla.org/en/datasets).
The dataset is also available in the 🤗 [Datasets](https://huggingface.co/datasets/common_voice) library.
## Team members
- Shahu Kareem ([@shahukareem](https://huggingface.co/shahukareem))
- Eyna ([@eyna](https://huggingface.co/eyna))
|
{"language": "dv", "tags": ["automatic-speech-recognition"], "datasets": ["common_voice"]}
|
flax-community/wav2vec2-dhivehi
| null |
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"wav2vec2",
"pretraining",
"automatic-speech-recognition",
"dv",
"dataset:common_voice",
"arxiv:2006.11477",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# Wav2Vec2-german model
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
## Necessary installations:
- sndfile library: `sudo apt-get install libsndfile1-dev`
- ffmpeg: `sudo apt install ffmpeg` & `pip install ffmpeg`
## Model description `TODO: Update`
## How to use `TODO: Update`
```python
from transformers import FlaxWav2Vec2Processor, TFWav2Vec2Model
model_id = "flax-community/wav2vec2-german"
from datasets import load_dataset
import soundfile as sf
processor = Wav2Vec2Processor.from_pretrained(model_id)
model = TFWav2Vec2Model.from_pretrained(model_id)
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
input_values = processor(ds["speech"][0], return_tensors="flax").input_values # Batch size 1
hidden_states = model(input_values).last_hidden_state
```
## Training Data `TODO: Update`
## Training Procedure `TODO: Update`
|
{"language": "de", "license": "apache-2.0", "tags": ["speech"], "datasets": ["librispeech_asr"]}
|
flax-community/wav2vec2-german
| null |
[
"transformers",
"tensorboard",
"wav2vec2",
"pretraining",
"speech",
"de",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2 Spanish
Wav2Vec2 model pre-trained using the Spanish portion of the Common Voice dataset. The model is trained with Flax and using TPUs sponsored by Google since this is part of the [Flax/Jax Community Week](https://discss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organised by HuggingFace.
## Model description
The model used for training is [Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) by FacebookAI. It was introduced in the paper
"wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations" by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli (https://arxiv.org/abs/2006.11477).
This model is available in the 🤗 [Model Hub](https://huggingface.co/facebook/wav2vec2-base-960h).
## Training data
Spanish portion of [Common Voice](https://commonvoice.mozilla.org/en/datasets). Common Voice is an open source, multi-language dataset of voices part of Mozilla's initiative to help teach machines how real people speak.
The dataset is also available in the 🤗 [Datasets](https://huggingface.co/datasets/common_voice) library.
## Team members
- María Grandury ([@mariagrandury](https://github.com/mariagrandury))
- Manuel Romero ([@mrm8488](https://huggingface.co/mrm8488))
- Eduardo González Ponferrada ([@edugp](https://huggingface.co/edugp))
- pcuenq ([@pcuenq](https://huggingface.co/pcuenq))
|
{"language": "es", "tags": ["audio", "automatic-speech-recognition"], "datasets": ["common_voice"]}
|
flax-community/wav2vec2-spanish
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"pretraining",
"audio",
"automatic-speech-recognition",
"es",
"dataset:common_voice",
"arxiv:2006.11477",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# Model description
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`MiniLM-L12`](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as intervention from Google’s Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence encoder. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for information retrieval, clustering or sentence
similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_MiniLM-L12')
text = "Replace me by any text you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [`MiniLM-L12`](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [COCO 2020](COCO 2020) | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [SPECTER](https://github.com/allenai/specter) | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [S2ORC](https://github.com/allenai/s2orc) Title/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Citation | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| SearchQA | - | 582,261 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Question | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [Reddit conversationnal](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| total | | 1,097,953,922 |
|
{"language": "en", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/all_datasets_v3_MiniLM-L12
| null |
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:2104.08727",
"arxiv:1810.09305",
"arxiv:2102.07033",
"arxiv:1904.06472",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# Model description
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained ['MiniLM-L6-H384-uncased'](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as intervention from Google’s Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence encoder. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for information retrieval, clustering or sentence
similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_MiniLM-L6')
text = "Replace me by any text you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained ['MiniLM-L6-H384-uncased'](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) which is a 6 layer version of
['microsoft/MiniLM-L12-H384-uncased'](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) by keeping only every second layer.
Please refer to the model card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [COCO 2020](COCO 2020) | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [SPECTER](https://github.com/allenai/specter) | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [S2ORC](https://github.com/allenai/s2orc) Title/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Citation | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| SearchQA | - | 582,261 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Question | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [Reddit conversationnal](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| total | | 1,097,953,922 |
|
{"language": "en", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/all_datasets_v3_MiniLM-L6
| null |
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:2104.08727",
"arxiv:1810.09305",
"arxiv:2102.07033",
"arxiv:1904.06472",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# Model description
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`distilroberta-base`](https://huggingface.co/distilroberta-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as intervention from Google’s Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence encoder. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for information retrieval, clustering or sentence
similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_distilroberta-base')
text = "Replace me by any text you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [`distilroberta-base`](https://huggingface.co/distilroberta-base). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [COCO 2020](COCO 2020) | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [SPECTER](https://github.com/allenai/specter) | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [S2ORC](https://github.com/allenai/s2orc) Title/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Citation | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| SearchQA | - | 582,261 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Question | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [Reddit conversationnal](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| total | | 1,097,953,922 |
|
{"language": "en", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/all_datasets_v3_distilroberta-base
| null |
[
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:2104.08727",
"arxiv:1810.09305",
"arxiv:2102.07033",
"arxiv:1904.06472",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# all-mpnet-base-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-mpnet-base-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-mpnet-base-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-mpnet-base-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base). Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 920k steps using a batch size of 512 (64 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** |
|
{"language": "en", "license": "apache-2.0", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/all_datasets_v3_mpnet-base
| null |
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# Model description
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`roberta-large`](https://huggingface.co/roberta-large) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as intervention from Google’s Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence encoder. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for information retrieval, clustering or sentence
similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_roberta-large')
text = "Replace me by any text you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [`roberta-large`](https://huggingface.co/roberta-large). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [COCO 2020](COCO 2020) | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [SPECTER](https://github.com/allenai/specter) | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [S2ORC](https://github.com/allenai/s2orc) Title/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Citation | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| SearchQA | - | 582,261 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Question | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [Reddit conversationnal](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| total | | 1,097,953,922 |
|
{"language": "en", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/all_datasets_v3_roberta-large
| null |
[
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:2104.08727",
"arxiv:1810.09305",
"arxiv:2102.07033",
"arxiv:1904.06472",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# Model description
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained ['MiniLM-L12'](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as intervention from Google’s Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence encoder. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for information retrieval, clustering or sentence
similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v4_MiniLM-L12')
text = "Replace me by any text you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained ['MiniLM-L12'](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased).
Please refer to the model card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [COCO 2020](COCO 2020) | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [SPECTER](https://github.com/allenai/specter) | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [S2ORC](https://github.com/allenai/s2orc) Title/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Citation | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| SearchQA | - | 582,261 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Question | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [Reddit conversationnal](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| total | | 1,097,953,922 |
|
{"language": "en", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/all_datasets_v4_MiniLM-L12
| null |
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:2104.08727",
"arxiv:1810.09305",
"arxiv:2102.07033",
"arxiv:1904.06472",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# Model description
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained ['MiniLM-L6-H384-uncased'](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as intervention from Google’s Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence encoder. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for information retrieval, clustering or sentence
similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v4_MiniLM-L6')
text = "Replace me by any text you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained ['MiniLM-L6-H384-uncased'](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) which is a 6 layer version of
['microsoft/MiniLM-L12-H384-uncased'](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) by keeping only every second layer.
Please refer to the model card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [COCO 2020](COCO 2020) | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [SPECTER](https://github.com/allenai/specter) | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [S2ORC](https://github.com/allenai/s2orc) Title/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Citation | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| SearchQA | - | 582,261 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Question | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [Reddit conversationnal](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| total | | 1,097,953,922 |
|
{"language": "en", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/all_datasets_v4_MiniLM-L6
| null |
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:2104.08727",
"arxiv:1810.09305",
"arxiv:2102.07033",
"arxiv:1904.06472",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# Model description
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained ['mpnet-base'](https://huggingface.co/microsoft/mpnet-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as intervention from Google’s Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence encoder. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for information retrieval, clustering or sentence
similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v4_mpnet-base')
text = "Replace me by any text you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained ['mpnet-base'](https://huggingface.co/microsoft/mpnet-base).
Please refer to the model card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [COCO 2020](COCO 2020) | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [SPECTER](https://github.com/allenai/specter) | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [S2ORC](https://github.com/allenai/s2orc) Title/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Citation | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| SearchQA | - | 582,261 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Question | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [Reddit conversationnal](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| total | | 1,097,953,922 |
|
{"language": "en", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/all_datasets_v4_mpnet-base
| null |
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:2104.08727",
"arxiv:1810.09305",
"arxiv:2102.07033",
"arxiv:1904.06472",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# mpnet_stackexchange_v1
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used a pretrained [mpnet-base](https://huggingface.co/microsoft/mpnet-base) model and trained it using Siamese Network setup and contrastive learning objective. Question and answer pairs from StackExchange was used as training data to make the model robust to Question / Answer embedding similarity.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence encoder for a search engine. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/mpnet_stackexchange_v1')
text = "Replace me by any question / answer you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [`Mpnet-base`](https://huggingface.co/microsoft/mpnet-base). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model.
We sampled each StackExchange given a weighted probability of following equation.
```
int((stackexchange_length[path] / total_stackexchange_length) * total_weight)
```
MSMARCO, NQ & other question-answer datasets were also used. Sampling ratio for StackExchange vs remaining : 2 vs 1.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/mpnet_stackexchange_v1
| null |
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"arxiv:2104.08727",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# multi-QA_v1-mpnet-asymmetric-A
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used two separate pretrained [mpnet-base](https://huggingface.co/microsoft/mpnet-base) models and trained them using contrastive learning objective. Question and answer pairs from StackExchange and other datasets were used as training data to make the model robust to Question / Answer embedding similarity.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
This model set is intended to be used as a sentence encoder for a search engine. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
Two models should be used on conjunction for Semantic Search purposes.
1. [multi-QA_v1-mpnet-asymmetric-Q](https://huggingface.co/flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-Q) - Model to encode Questions
1. [multi-QA_v1-mpnet-asymmetric-A](https://huggingface.co/flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-A) - Model to encode Answers
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model_Q = SentenceTransformer('flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-Q')
model_A = SentenceTransformer('flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-A')
question = "Replace me by any question you'd like."
question_embbedding = model_Q.encode(text)
answer = "Replace me by any answer you'd like."
answer_embbedding = model_A.encode(text)
answer_likeliness = cosine_similarity(question_embedding, answer_embedding)
```
# Training procedure
## Pre-training
We use the pretrained [`Mpnet-base`](https://huggingface.co/microsoft/mpnet-base). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model. MSMARCO, NQ & other question-answer datasets were also used.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-A
| null |
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"arxiv:2102.07033",
"arxiv:2104.08727",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# multi-QA_v1-mpnet-asymmetric-Q
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used two separate pretrained [mpnet-base](https://huggingface.co/microsoft/mpnet-base) models and trained them using contrastive learning objective. Question and answer pairs from StackExchange and other datasets were used as training data to make the model robust to Question / Answer embedding similarity.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
This model set is intended to be used as a sentence encoder for a search engine. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
Two models should be used on conjunction for Semantic Search purposes.
1. [multi-QA_v1-mpnet-asymmetric-Q](https://huggingface.co/flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-Q) - Model to encode Questions
1. [multi-QA_v1-mpnet-asymmetric-Q](https://huggingface.co/flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-A) - Model to encode Answers
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model_Q = SentenceTransformer('flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-Q')
model_A = SentenceTransformer('flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-A')
question = "Replace me by any question you'd like."
question_embbedding = model_Q.encode(text)
answer = "Replace me by any answer you'd like."
answer_embbedding = model_A.encode(text)
answer_likeliness = cosine_similarity(question_embedding, answer_embedding)
```
# Training procedure
## Pre-training
We use the pretrained [`Mpnet-base`](https://huggingface.co/microsoft/mpnet-base). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model. MSMARCO, NQ & other question-answer datasets were also used.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/multi-QA_v1-mpnet-asymmetric-Q
| null |
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"arxiv:2102.07033",
"arxiv:2104.08727",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# multi-qa_v1-MiniLM-L6-cls_dot
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used a pretrained [nreimers/MiniLM-L6-H384-uncased](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and trained it using Siamese Network setup and contrastive learning objective. Question and answer pairs from StackExchange was used as training data to make the model robust to Question / Answer embedding similarity. For this model, cls output was used instead of mean pooling as sentence embeddings. Dot product was used to calculate similarity for learning objective.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence encoder for a search engine. Given an input sentence, it outputs a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/multi-qa_v1-MiniLM-L6-cls_dot')
text = "Replace me by any question / answer you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [nreimers/MiniLM-L6-H384-uncased](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model. MSMARCO, NQ & other question-answer datasets were also used.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/multi-qa_v1-MiniLM-L6-cls_dot
| null |
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"arxiv:2102.07033",
"arxiv:2104.08727",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# multi-qa_v1-MiniLM-L6-mean_cos
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used a pretrained [nreimers/MiniLM-L6-H384-uncased](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and trained it using Siamese Network setup and contrastive learning objective. Question and answer pairs from StackExchange was used as training data to make the model robust to Question / Answer embedding similarity. For this model, mean pooling of the hidden states were used as sentence embeddings.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence encoder for a search engine. Given an input sentence, it outputs a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/multi-qa_v1-MiniLM-L6-mean_cos')
text = "Replace me by any question / answer you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [nreimers/MiniLM-L6-H384-uncased](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model. MSMARCO, NQ & other question-answer datasets were also used.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/multi-qa_v1-MiniLM-L6-mean_cos
| null |
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"arxiv:2102.07033",
"arxiv:2104.08727",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# multi-qa_v1-distilbert-cls_dot
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used a pretrained [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) model and trained it using Siamese Network setup and contrastive learning objective. Question and answer pairs from StackExchange was used as training data to make the model robust to Question / Answer embedding similarity. For this model, cls output was used instead of mean pooling as sentence embeddings. Dot product was used to calculate similarity for learning objective.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence encoder for a search engine. Given an input sentence, it outputs a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/multi-qa_v1-distilbert-cls_dot')
text = "Replace me by any question / answer you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model. MSMARCO, NQ & other question-answer datasets were also used.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/multi-qa_v1-distilbert-cls_dot
| null |
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"arxiv:2102.07033",
"arxiv:2104.08727",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# multi-qa_v1-distilbert-mean_cos
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used a pretrained [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) model and trained it using Siamese Network setup and contrastive learning objective. Question and answer pairs from StackExchange was used as training data to make the model robust to Question / Answer embedding similarity. For this model, mean pooling of hidden states were used as sentence embeddings.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence encoder for a search engine. Given an input sentence, it outputs a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/multi-qa_v1-distilbert-mean_cos')
text = "Replace me by any question / answer you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model. MSMARCO, NQ & other question-answer datasets were also used.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/multi-qa_v1-distilbert-mean_cos
| null |
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"arxiv:2102.07033",
"arxiv:2104.08727",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# multi-qa_v1-mpnet-cls_dot
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used a pretrained [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base) model and trained it using Siamese Network setup and contrastive learning objective. Question and answer pairs from StackExchange was used as training data to make the model robust to Question / Answer embedding similarity. For this model, cls output was used instead of mean pooling as sentence embeddings. Dot product was used to calculate similarity for learning objective.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence encoder for a search engine. Given an input sentence, it outputs a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/multi-qa_v1-mpnet-cls_dot')
text = "Replace me by any question / answer you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model. MSMARCO, NQ & other question-answer datasets were also used.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/multi-qa_v1-mpnet-cls_dot
| null |
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"arxiv:2102.07033",
"arxiv:2104.08727",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
sentence-similarity
|
sentence-transformers
|
# multi-qa_v1-mpnet-mean_cos
## Model Description
SentenceTransformers is a set of models and frameworks that enable training and generating sentence embeddings from given data. The generated sentence embeddings can be utilized for Clustering, Semantic Search and other tasks. We used a pretrained [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base) model and trained it using Siamese Network setup and contrastive learning objective. Question and answer pairs from StackExchange was used as training data to make the model robust to Question / Answer embedding similarity. For this model, mean pooling of hidden states were used as sentence embeddings.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as assistance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence encoder for a search engine. Given an input sentence, it outputs a vector which captures
the sentence semantic information. The sentence vector may be used for semantic-search, clustering or sentence similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/multi-qa_v1-mpnet-mean_cos')
text = "Replace me by any question / answer you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base). Please refer to the model
card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained on model on a TPU v3-8. We train the model during 80k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We used the concatenation from multiple Stackexchange Question-Answer datasets to fine-tune our model. MSMARCO, NQ & other question-answer datasets were also used.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [Stack Exchange QA - Title & Answer](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_best_voted_answer_jsonl) | - | 4,750,619 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| SearchQA | - | 582,261 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity"], "pipeline_tag": "sentence-similarity"}
|
flax-sentence-embeddings/multi-qa_v1-mpnet-mean_cos
| null |
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"arxiv:2102.07033",
"arxiv:2104.08727",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.