
Search is not available for this dataset
pipeline_tag
stringclasses 48
values | library_name
stringclasses 205
values | text
stringlengths 0
18.3M
| metadata
stringlengths 2
1.07B
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
|
|---|---|---|---|---|---|---|---|---|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Italian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Italian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "it", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import unicodedata
import jiwer
def chunked_wer(targets, predictions, chunk_size=None):
if chunk_size is None: return jiwer.wer(targets, predictions)
start = 0
end = chunk_size
H, S, D, I = 0, 0, 0, 0
while start < len(targets):
chunk_metrics = jiwer.compute_measures(targets[start:end], predictions[start:end])
H = H + chunk_metrics["hits"]
S = S + chunk_metrics["substitutions"]
D = D + chunk_metrics["deletions"]
I = I + chunk_metrics["insertions"]
start += chunk_size
end += chunk_size
return float(S + D + I) / float(H + S + D)
allowed_characters = [
" ",
"'",
'a',
'b',
'c',
'd',
'e',
'f',
'g',
'h',
'i',
'j',
'k',
'l',
'm',
'n',
'o',
'p',
'q',
'r',
's',
't',
'u',
'v',
'w',
'x',
'y',
'z',
'à',
'á',
'è',
'é',
'ì',
'í',
'ò',
'ó',
'ù',
'ú',
]
def remove_accents(input_str):
if input_str in allowed_characters:
return input_str
if input_str == 'ø':
return 'o'
elif input_str=='ß' or input_str =='ß':
return 'b'
elif input_str=='ё':
return 'e'
elif input_str=='đ':
return 'd'
nfkd_form = unicodedata.normalize('NFKD', input_str)
only_ascii = nfkd_form.encode('ASCII', 'ignore').decode()
if only_ascii is None or only_ascii=='':
return input_str
else:
return only_ascii
def fix_accents(sentence):
new_sentence=''
for char in sentence:
new_sentence+=remove_accents(char)
return new_sentence
test_dataset = load_dataset("common_voice", "it", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model.to("cuda")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
chars_to_remove= [",", "?", ".", "!", "-", ";", ":", '""', "%", '"', "�",'ʿ','“','”','(','=','`','_','+','«','<','>','~','…','«','»','–','\[','\]','°','̇','´','ʾ','„','̇','̇','̇','¡'] # All extra characters
chars_to_remove_regex = f'[{"".join(chars_to_remove)}]'
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower().replace('‘',"'").replace('ʻ',"'").replace('ʼ',"'").replace('’',"'").replace('ʹ',"''").replace('̇','')
batch["sentence"] = fix_accents(batch["sentence"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * chunked_wer(predictions=result["pred_strings"], targets=result["sentence"],chunk_size=5000)))
```
**Test Result**: 11.49 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://github.com/gchhablani/wav2vec2-week/blob/main/fine-tune-xlsr-wav2vec2-on-italian-asr-with-transformers_final.ipynb).
|
{"language": "it", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Italian by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice it", "type": "common_voice", "args": "it"}, "metrics": [{"type": "wer", "value": 11.49, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-it
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"it",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using a part of the [InterSpeech 2021 Marathi](https://navana-tech.github.io/IS21SS-indicASRchallenge/data.html) dataset. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `sentence` and `path` fields:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
resampler = torchaudio.transforms.Resample(8_000, 16_000) # The original data was with 8,000 sampling rate. You can change it according to your input.
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the test set of the Marathi data on InterSpeech-2021.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\'\�]'
resampler = torchaudio.transforms.Resample(8_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"),
attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 19.98 % (555 examples from test set were used for evaluation)
**Test Result on 10% of OpenSLR74 data**: 64.64 %
## Training
5000 examples of the InterSpeech Marathi dataset were used for training.
The colab notebook used for training can be found [here](https://colab.research.google.com/drive/1sIwGOLJPQqhKm_wVZDkzRuoJqAEgArFr?usp=sharing).
|
{"language": "mr", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["interspeech_2021_asr"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Marathi 2 by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "InterSpeech 2021 ASR mr", "type": "interspeech_2021_asr"}, "metrics": [{"type": "wer", "value": 14.53, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-mr-2
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"mr",
"dataset:interspeech_2021_asr",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using the [OpenSLR SLR64](http://openslr.org/64/) dataset and [InterSpeech 2021](https://navana-tech.github.io/IS21SS-indicASRchallenge/data.html) Marathi datasets. Note that this data OpenSLR contains only female voices. Please keep this in mind before using the model for your task. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `text` and `audio_path` fields:
```python
import torch
import torchaudio
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_data = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["audio_path"])
batch["speech"] = librosa.resample(speech_array[0].numpy(), sampling_rate, 16_000) # sampling_rate can vary
return batch
test_data= test_data.map(speech_file_to_array_fn)
inputs = processor(test_data["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_data["text"][:2])
```
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
```python
import torch
import torchaudio
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_data = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…]'
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
batch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["audio_path"])
batch["speech"] = librosa.resample(speech_array[0].numpy(), sampling_rate, 16_000)
return batch
test_data= test_data.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_data.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["text"])))
```
**Test Result**: 19.05 % (157+157 examples)
**Test Result on OpenSLR test**: 14.15 % (157 examples)
**Test Results on InterSpeech test**: 27.14 % (157 examples)
## Training
1412 examples of the OpenSLR Marathi dataset and 1412 examples of InterSpeech 2021 Marathi ASR dataset were used for training. For testing, 157 examples from each were used.
The colab notebook used for training and evaluation can be found [here](https://colab.research.google.com/drive/15fUhb4bUFFGJyNLr-_alvPxVX4w0YXRu?usp=sharing).
|
{"language": "mr", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["openslr", "interspeech_2021_asr"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Marathi by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "OpenSLR mr, InterSpeech 2021 ASR mr", "type": "openslr, interspeech_2021_asr"}, "metrics": [{"type": "wer", "value": 19.05, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-mr-3
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"mr",
"dataset:openslr",
"dataset:interspeech_2021_asr",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using the [OpenSLR SLR64](http://openslr.org/64/) dataset. Note that this data contains only female voices. Please keep this in mind before using the model for your task, although it works very well for male voice too. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `sentence` and `path` fields:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
resampler = torchaudio.transforms.Resample(48_000, 16_000) # The original data was with 48,000 sampling rate. You can change it according to your input.
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"),
attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 14.53 %
## Training
90% of the OpenSLR Marathi dataset was used for training.
The colab notebook used for training can be found [here](https://colab.research.google.com/drive/1_BbLyLqDUsXG3RpSULfLRjC6UY3RjwME?usp=sharing).
|
{"language": "mr", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["openslr"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Marathi by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "OpenSLR mr", "type": "openslr"}, "metrics": [{"type": "wer", "value": 14.53, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-mr
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"mr",
"dataset:openslr",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Odia
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Odia using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "or", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Odia test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "or", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…\'\_\’\।\|]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 52.64 %
## Training
The Common Voice `train` and `validation` datasets were used for training.The colab notebook used can be found [here](https://colab.research.google.com/drive/1s8DrwgB5y4Z7xXIrPXo1rQA5_1OZ8WD5?usp=sharing).
|
{"language": "or", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Odia by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice or", "type": "common_voice", "args": "or"}, "metrics": [{"type": "wer", "value": 52.64, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-or
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"or",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Portuguese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Portuguese using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "pt", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "pt", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\;\"\“\'\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 17.22 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The script used for training can be found [here](https://github.com/jqueguiner/wav2vec2-sprint/blob/main/run_common_voice.py).
The parameters passed were:
```bash
#!/usr/bin/env bash
python run_common_voice.py \
--model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
--dataset_config_name="pt" \
--output_dir=/workspace/output_models/pt/wav2vec2-large-xlsr-pt \
--cache_dir=/workspace/data \
--overwrite_output_dir \
--num_train_epochs="30" \
--per_device_train_batch_size="32" \
--per_device_eval_batch_size="32" \
--evaluation_strategy="steps" \
--learning_rate="3e-4" \
--warmup_steps="500" \
--fp16 \
--freeze_feature_extractor \
--save_steps="500" \
--eval_steps="500" \
--save_total_limit="1" \
--logging_steps="500" \
--group_by_length \
--feat_proj_dropout="0.0" \
--layerdrop="0.1" \
--gradient_checkpointing \
--do_train --do_eval \
```
Notebook containing the evaluation can be found [here](https://colab.research.google.com/drive/14e-zNK_5pm8EMY9EbeZerpHx7WsGycqG?usp=sharing).
|
{"language": "pt", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Portugese by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice pt", "type": "common_voice", "args": "pt"}, "metrics": [{"type": "wer", "value": 17.22, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-pt
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"pt",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Romansh-Sursilvan
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Romansh Sursilvan using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "rm-sursilv", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "rm-sursilv", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model.to("cuda")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”\\�\\…\\«\\»\\–]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 25.16 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://colab.research.google.com/drive/1dpZr_GzRowCciUbzM3GnW04TNKnB7vrP?usp=sharing).
|
{"language": "rm-sursilv", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Romansh Sursilvan by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice rm-sursilv", "type": "common_voice", "args": "rm-sursilv"}, "metrics": [{"type": "wer", "value": 25.16, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-rm-sursilv
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
gclb/test-names
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
gd2021/empathetic_chatbot
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
question-answering
|
transformers
|
{}
|
gdario/biobert_bioasq
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
gdber/esparanto
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{"license": "cc-by-4.0"}
|
gdber/model_card_test
| null |
[
"license:cc-by-4.0",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
automatic-speech-recognition
|
transformers
|
{}
|
gdimino/voxpopuli_base_it_2
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
# GreekSocialBERT
## Model description
A Greek language model based on [GreekBERT](https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1)
## Training data
The training data is a corpus of 458,293 documents collected from Greek social media accounts.
The training corpus has been collected and provided by [Palo LTD](http://www.paloservices.com/)
## Eval results
### BibTeX entry and citation info
```bibtex
@Article{info12080331,
AUTHOR = {Alexandridis, Georgios and Varlamis, Iraklis and Korovesis, Konstantinos and Caridakis, George and Tsantilas, Panagiotis},
TITLE = {A Survey on Sentiment Analysis and Opinion Mining in Greek Social Media},
JOURNAL = {Information},
VOLUME = {12},
YEAR = {2021},
NUMBER = {8},
ARTICLE-NUMBER = {331},
URL = {https://www.mdpi.com/2078-2489/12/8/331},
ISSN = {2078-2489},
DOI = {10.3390/info12080331}
}
```
|
{"language": "el"}
|
gealexandri/greeksocialbert-base-greek-uncased-v1
| null |
[
"transformers",
"pytorch",
"tf",
"bert",
"fill-mask",
"el",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# PaloBERT
## Model description
A Greek language model based on [RoBERTa](https://arxiv.org/abs/1907.11692)
## Training data
The training data is a corpus of 458,293 documents collected from Greek social media accounts. It also contains a GTP-2 tokenizer trained from scratch on the same corpus.
The training corpus has been collected and provided by [Palo LTD](http://www.paloservices.com/)
## Eval results
### BibTeX entry and citation info
```bibtex
@Article{info12080331,
AUTHOR = {Alexandridis, Georgios and Varlamis, Iraklis and Korovesis, Konstantinos and Caridakis, George and Tsantilas, Panagiotis},
TITLE = {A Survey on Sentiment Analysis and Opinion Mining in Greek Social Media},
JOURNAL = {Information},
VOLUME = {12},
YEAR = {2021},
NUMBER = {8},
ARTICLE-NUMBER = {331},
URL = {https://www.mdpi.com/2078-2489/12/8/331},
ISSN = {2078-2489},
DOI = {10.3390/info12080331}
}
```
|
{"language": "el"}
|
gealexandri/palobert-base-greek-uncased-v1
| null |
[
"transformers",
"pytorch",
"tf",
"roberta",
"fill-mask",
"el",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-classification
|
transformers
|
{}
|
geckos/bart-fined-tuned-on-entailment-classification
| null |
[
"transformers",
"pytorch",
"bart",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-classification
|
transformers
|
{}
|
geckos/bert-base-uncased-finetuned-glue-cola
| null |
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
{}
|
geckos/pegasus-fined-tuned-on-paraphrase
| null |
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
feature-extraction
|
transformers
|
hello
|
{}
|
geekfeed/gpt2_ja
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"feature-extraction",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
geekplusq/bert-base-cased-finetuned-ner
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
geekplusq/distilbert-base-uncased-finetuned-ner
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
geekydevu/distilbert-base-uncased-finetuned-cola
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
geekydevu/distilbert-base-uncased-finetuned-sst2
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
https://dl.fbaipublicfiles.com/avhubert/model/lrs3_vox/vsr/base_vox_433h.pt
|
{}
|
g30rv17ys/avhubert
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
gelayks/gel
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
genasix/test
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
fill-mask
|
transformers
|
# Please use 'Bert' related functions to load this model!
## Chinese BERT with Whole Word Masking Fix MLM Parameters
Init parameters by https://huggingface.co/hfl/chinese-roberta-wwm-ext-large
miss mlm parameters issue https://github.com/ymcui/Chinese-BERT-wwm/issues/98
Only train MLM parameters and freeze other parameters
More info in github https://github.com/genggui001/chinese_roberta_wwm_large_ext_fix_mlm
|
{"language": ["zh"], "license": "apache-2.0", "tags": ["bert"]}
|
genggui001/chinese_roberta_wwm_large_ext_fix_mlm
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
{}
|
geninhu/roberta_large_ITPT_FP
| null |
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
automatic-speech-recognition
|
transformers
|
# xls-asr-vi-40h-1B
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on 40 hours of FPT Open Speech Dataset (FOSD) and Common Voice 7.0.
### Benchmark WER result:
| | [VIVOS](https://huggingface.co/datasets/vivos) | [COMMON VOICE 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0) | [COMMON VOICE 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0)
|---|---|---|---|
|without LM| 25.93 | 34.21 |
|with 4-grams LM| 24.11 | 25.84 | 31.158 |
### Benchmark CER result:
| | [VIVOS](https://huggingface.co/datasets/vivos) | [COMMON VOICE 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0) | [COMMON VOICE 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0)
|---|---|---|---|
|without LM| 9.24 | 19.94 |
|with 4-grams LM| 10.37 | 12.96 | 16.179 |
## Evaluation
Please use the eval.py file to run the evaluation
```python
python eval.py --model_id geninhu/xls-asr-vi-40h-1B --dataset mozilla-foundation/common_voice_7_0 --config vi --split test --log_outputs
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 4.6222 | 1.85 | 1500 | 5.9479 | 0.5474 |
| 1.1362 | 3.7 | 3000 | 7.9799 | 0.5094 |
| 0.7814 | 5.56 | 4500 | 5.0330 | 0.4724 |
| 0.6281 | 7.41 | 6000 | 2.3484 | 0.5020 |
| 0.5472 | 9.26 | 7500 | 2.2495 | 0.4793 |
| 0.4827 | 11.11 | 9000 | 1.1530 | 0.4768 |
| 0.4327 | 12.96 | 10500 | 1.6160 | 0.4646 |
| 0.3989 | 14.81 | 12000 | 3.2633 | 0.4703 |
| 0.3522 | 16.67 | 13500 | 2.2337 | 0.4708 |
| 0.3201 | 18.52 | 15000 | 3.6879 | 0.4565 |
| 0.2899 | 20.37 | 16500 | 5.4389 | 0.4599 |
| 0.2776 | 22.22 | 18000 | 3.5284 | 0.4537 |
| 0.2574 | 24.07 | 19500 | 2.1759 | 0.4649 |
| 0.2378 | 25.93 | 21000 | 3.3901 | 0.4448 |
| 0.217 | 27.78 | 22500 | 1.1632 | 0.4565 |
| 0.2115 | 29.63 | 24000 | 1.7441 | 0.4232 |
| 0.1959 | 31.48 | 25500 | 3.4992 | 0.4304 |
| 0.187 | 33.33 | 27000 | 3.6163 | 0.4369 |
| 0.1748 | 35.19 | 28500 | 3.6038 | 0.4467 |
| 0.17 | 37.04 | 30000 | 2.9708 | 0.4362 |
| 0.159 | 38.89 | 31500 | 3.2045 | 0.4279 |
| 0.153 | 40.74 | 33000 | 3.2427 | 0.4287 |
| 0.1463 | 42.59 | 34500 | 3.5439 | 0.4270 |
| 0.139 | 44.44 | 36000 | 3.9381 | 0.4150 |
| 0.1352 | 46.3 | 37500 | 4.1744 | 0.4092 |
| 0.1369 | 48.15 | 39000 | 4.2279 | 0.4154 |
| 0.1273 | 50.0 | 40500 | 4.1691 | 0.4133 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
{"language": ["vi"], "license": "apache-2.0", "tags": ["automatic-speech-recognition", "common-voice", "hf-asr-leaderboard", "robust-speech-event"], "datasets": ["mozilla-foundation/common_voice_7_0"], "model-index": [{"name": "xls-asr-vi-40h-1B", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice 7.0", "type": "mozilla-foundation/common_voice_7_0", "args": "vi"}, "metrics": [{"type": "wer", "value": 25.846, "name": "Test WER (with LM)"}, {"type": "cer", "value": 12.961, "name": "Test CER (with LM)"}]}, {"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice 8.0", "type": "mozilla-foundation/common_voice_8_0", "args": "vi"}, "metrics": [{"type": "wer", "value": 31.158, "name": "Test WER (with LM)"}, {"type": "cer", "value": 16.179, "name": "Test CER (with LM)"}]}]}]}
|
geninhu/xls-asr-vi-40h-1B
| null |
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"common-voice",
"hf-asr-leaderboard",
"robust-speech-event",
"vi",
"dataset:mozilla-foundation/common_voice_7_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
automatic-speech-recognition
|
transformers
|
# xls-asr-vi-40h
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common voice 7.0 vi & private dataset.
It achieves the following results on the evaluation set (Without Language Model):
- Loss: 1.1177
- Wer: 60.58
## Evaluation
Please run the eval.py file
```bash
!python eval_custom.py --model_id geninhu/xls-asr-vi-40h --dataset mozilla-foundation/common_voice_7_0 --config vi --split test
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 23.3878 | 0.93 | 1500 | 21.9179 | 1.0 |
| 8.8862 | 1.85 | 3000 | 6.0599 | 1.0 |
| 4.3701 | 2.78 | 4500 | 4.3837 | 1.0 |
| 4.113 | 3.7 | 6000 | 4.2698 | 0.9982 |
| 3.9666 | 4.63 | 7500 | 3.9726 | 0.9989 |
| 3.5965 | 5.56 | 9000 | 3.7124 | 0.9975 |
| 3.3944 | 6.48 | 10500 | 3.5005 | 1.0057 |
| 3.304 | 7.41 | 12000 | 3.3710 | 1.0043 |
| 3.2482 | 8.33 | 13500 | 3.4201 | 1.0155 |
| 3.212 | 9.26 | 15000 | 3.3732 | 1.0151 |
| 3.1778 | 10.19 | 16500 | 3.2763 | 1.0009 |
| 3.1027 | 11.11 | 18000 | 3.1943 | 1.0025 |
| 2.9905 | 12.04 | 19500 | 2.8082 | 0.9703 |
| 2.7095 | 12.96 | 21000 | 2.4993 | 0.9302 |
| 2.4862 | 13.89 | 22500 | 2.3072 | 0.9140 |
| 2.3271 | 14.81 | 24000 | 2.1398 | 0.8949 |
| 2.1968 | 15.74 | 25500 | 2.0594 | 0.8817 |
| 2.111 | 16.67 | 27000 | 1.9404 | 0.8630 |
| 2.0387 | 17.59 | 28500 | 1.8895 | 0.8497 |
| 1.9504 | 18.52 | 30000 | 1.7961 | 0.8315 |
| 1.9039 | 19.44 | 31500 | 1.7433 | 0.8213 |
| 1.8342 | 20.37 | 33000 | 1.6790 | 0.7994 |
| 1.7824 | 21.3 | 34500 | 1.6291 | 0.7825 |
| 1.7359 | 22.22 | 36000 | 1.5783 | 0.7706 |
| 1.7053 | 23.15 | 37500 | 1.5248 | 0.7492 |
| 1.6504 | 24.07 | 39000 | 1.4930 | 0.7406 |
| 1.6263 | 25.0 | 40500 | 1.4572 | 0.7348 |
| 1.5893 | 25.93 | 42000 | 1.4202 | 0.7161 |
| 1.5669 | 26.85 | 43500 | 1.3987 | 0.7143 |
| 1.5277 | 27.78 | 45000 | 1.3512 | 0.6991 |
| 1.501 | 28.7 | 46500 | 1.3320 | 0.6879 |
| 1.4781 | 29.63 | 48000 | 1.3112 | 0.6788 |
| 1.4477 | 30.56 | 49500 | 1.2850 | 0.6657 |
| 1.4483 | 31.48 | 51000 | 1.2813 | 0.6633 |
| 1.4065 | 32.41 | 52500 | 1.2475 | 0.6541 |
| 1.3779 | 33.33 | 54000 | 1.2244 | 0.6503 |
| 1.3788 | 34.26 | 55500 | 1.2116 | 0.6407 |
| 1.3428 | 35.19 | 57000 | 1.1938 | 0.6352 |
| 1.3453 | 36.11 | 58500 | 1.1927 | 0.6340 |
| 1.3137 | 37.04 | 60000 | 1.1699 | 0.6252 |
| 1.2984 | 37.96 | 61500 | 1.1666 | 0.6229 |
| 1.2927 | 38.89 | 63000 | 1.1585 | 0.6188 |
| 1.2919 | 39.81 | 64500 | 1.1618 | 0.6190 |
| 1.293 | 40.74 | 66000 | 1.1479 | 0.6181 |
| 1.2853 | 41.67 | 67500 | 1.1423 | 0.6202 |
| 1.2687 | 42.59 | 69000 | 1.1315 | 0.6131 |
| 1.2603 | 43.52 | 70500 | 1.1333 | 0.6128 |
| 1.2577 | 44.44 | 72000 | 1.1191 | 0.6079 |
| 1.2435 | 45.37 | 73500 | 1.1177 | 0.6079 |
| 1.251 | 46.3 | 75000 | 1.1211 | 0.6092 |
| 1.2482 | 47.22 | 76500 | 1.1177 | 0.6060 |
| 1.2422 | 48.15 | 78000 | 1.1227 | 0.6097 |
| 1.2485 | 49.07 | 79500 | 1.1187 | 0.6071 |
| 1.2425 | 50.0 | 81000 | 1.1177 | 0.6058 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
{"language": ["vi"], "license": "apache-2.0", "tags": ["automatic-speech-recognition", "common-voice", "hf-asr-leaderboard", "robust-speech-event"], "datasets": ["mozilla-foundation/common_voice_7_0"], "model-index": [{"name": "xls-asr-vi-40h", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice 7.0", "type": "mozilla-foundation/common_voice_7_0", "args": "vi"}, "metrics": [{"type": "wer", "value": 56.57, "name": "Test WER (with Language model)"}]}]}]}
|
geninhu/xls-asr-vi-40h
| null |
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"common-voice",
"hf-asr-leaderboard",
"robust-speech-event",
"vi",
"dataset:mozilla-foundation/common_voice_7_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
genji/li
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# MechDistilGPT2
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Environmental Impact](#environmental-impact)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
## Model Details
- **Model Description:**
This model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.
- **Developed by:** [Ashwin](https://huggingface.co/geralt)
- **Model Type:** Causal Language modeling
- **Language(s):** English
- **License:** [More Information Needed]
- **Parent Model:** See the [DistilGPT2model](https://huggingface.co/distilgpt2) for more information about the Distilled-GPT2 base model.
- **Resources for more information:**
- [Research Paper](https://arxiv.org/abs/2105.09680)
- [GitHub Repo](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling.ipynb)
## Uses
#### Direct Use
The model can be used for tasks including topic classification, Causal Language modeling and text generation
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## Training
#### Training Data
This model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.
#### Training Procedure
###### Fine-Tuning
* Default Training Args
* Epochs = 3
* Training set = 200k sentences
* Validation set = 40k sentences
###### Framework versions
* Transformers 4.7.0.dev0
* Pytorch 1.8.1+cu111
* Datasets 1.6.2
* Tokenizers 0.10.2
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More information needed]
- **Hours used:** [More information needed]
- **Cloud Provider:** [More information needed]
- **Compute Region:** [More information needed"]
- **Carbon Emitted:** [More information needed]
## How to Get Started With the Model
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("geralt/MechDistilGPT2")
model = AutoModelForCausalLM.from_pretrained("geralt/MechDistilGPT2")
```
|
{"tags": ["Causal Language modeling", "text-generation", "CLM"], "model_index": [{"name": "MechDistilGPT2", "results": [{"task": {"name": "Causal Language modeling", "type": "Causal Language modeling"}}]}]}
|
geralt/MechDistilGPT2
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"Causal Language modeling",
"CLM",
"arxiv:2105.09680",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
gerardoalemanm/gpt-2-small-spanish
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
question-answering
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# biobert_v1.1_pubmed-finetuned-squad
This model is a fine-tuned version of [gerardozq/biobert_v1.1_pubmed-finetuned-squad](https://huggingface.co/gerardozq/biobert_v1.1_pubmed-finetuned-squad) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"tags": ["generated_from_trainer"], "datasets": ["squad_v2"], "model-index": [{"name": "biobert_v1.1_pubmed-finetuned-squad", "results": []}]}
|
gerardozq/biobert_v1.1_pubmed-finetuned-squad
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null |
transformers
|
# German Electra Uncased
<img width="300px" src="https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png">
[¹]
## Version 2 Release
We released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See "Evaluation of Version 2: GermEval18 Coarse" below for details.
## Model Info
This Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
It can be used as a drop-in replacement for **BERT** in most down-stream tasks (**ELECTRA** is even implemented as an extended **BERT** Class).
At the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
## Installation
This model has the special feature that it is **uncased** but does **not strip accents**.
This possibility was added by us with [PR #6280](https://github.com/huggingface/transformers/pull/6280).
To use it you have to use Transformers version 3.1.0 or newer.
```bash
pip install transformers -U
```
## Uncase and Umlauts ('Ö', 'Ä', 'Ü')
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
The special characters 'ö', 'ü', 'ä' are included through the `strip_accent=False` option, as this leads to an improved precision.
## Creators
This model was trained and open sourced in conjunction with the [**German NLP Group**](https://github.com/German-NLP-Group) in equal parts by:
- [**Philip May**](https://May.la) - [Deutsche Telekom](https://www.telekom.de/)
- [**Philipp Reißel**](https://www.linkedin.com/in/philipp-reissel/) - [ambeRoad](https://amberoad.de/)
## Evaluation of Version 2: GermEval18 Coarse
We evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.
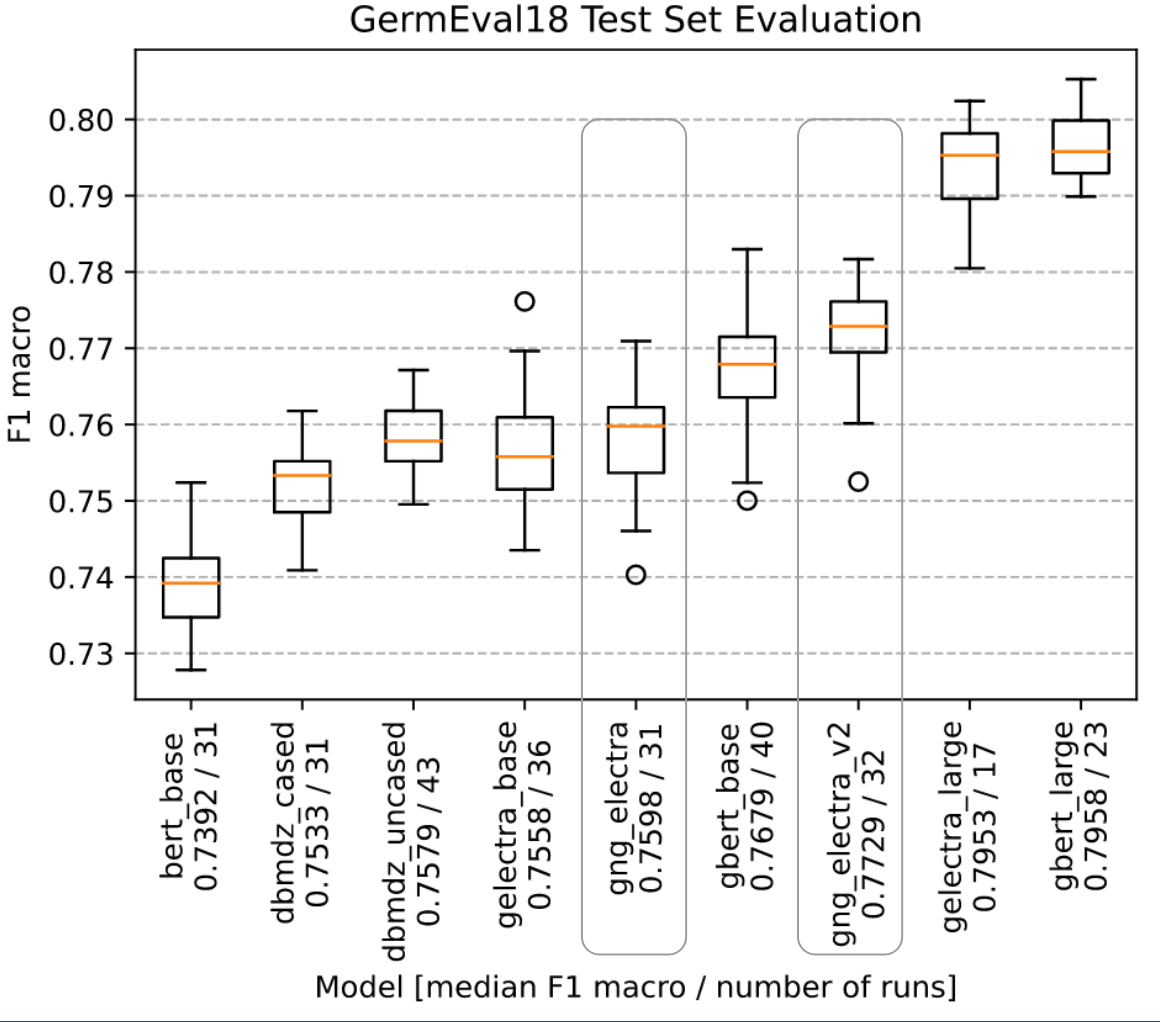
## Checkpoint evaluation
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.
## Pre-training details
### Data
- Cleaned Common Crawl Corpus 2019-09 German: [CC_net](https://github.com/facebookresearch/cc_net) (Only head coprus and filtered for language_score > 0.98) - 62 GB
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
- Subtitles - 823 MB
- News 2018 - 4.1 GB
The sentences were split with [SojaMo](https://github.com/tsproisl/SoMaJo). We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).
More Details can be found here [Preperaing Datasets for German Electra Github](https://github.com/German-NLP-Group/german-transformer-training)
### Electra Branch no_strip_accents
Because we do not want to stip accents in our training data we made a change to Electra and used this repo [Electra no_strip_accents](https://github.com/PhilipMay/electra/tree/no_strip_accents) (branch `no_strip_accents`). Then created the tf dataset with:
```bash
python build_pretraining_dataset.py --corpus-dir <corpus_dir> --vocab-file <dir>/vocab.txt --output-dir ./tf_data --max-seq-length 512 --num-processes 8 --do-lower-case --no-strip-accents
```
### The training
The training itself can be performed with the Original Electra Repo (No special case for this needed).
We run it with the following Config:
<details>
<summary>The exact Training Config</summary>
<br/>debug False
<br/>disallow_correct False
<br/>disc_weight 50.0
<br/>do_eval False
<br/>do_lower_case True
<br/>do_train True
<br/>electra_objective True
<br/>embedding_size 768
<br/>eval_batch_size 128
<br/>gcp_project None
<br/>gen_weight 1.0
<br/>generator_hidden_size 0.33333
<br/>generator_layers 1.0
<br/>iterations_per_loop 200
<br/>keep_checkpoint_max 0
<br/>learning_rate 0.0002
<br/>lr_decay_power 1.0
<br/>mask_prob 0.15
<br/>max_predictions_per_seq 79
<br/>max_seq_length 512
<br/>model_dir gs://XXX
<br/>model_hparam_overrides {}
<br/>model_name 02_Electra_Checkpoints_32k_766k_Combined
<br/>model_size base
<br/>num_eval_steps 100
<br/>num_tpu_cores 8
<br/>num_train_steps 766000
<br/>num_warmup_steps 10000
<br/>pretrain_tfrecords gs://XXX
<br/>results_pkl gs://XXX
<br/>results_txt gs://XXX
<br/>save_checkpoints_steps 5000
<br/>temperature 1.0
<br/>tpu_job_name None
<br/>tpu_name electrav5
<br/>tpu_zone None
<br/>train_batch_size 256
<br/>uniform_generator False
<br/>untied_generator True
<br/>untied_generator_embeddings False
<br/>use_tpu True
<br/>vocab_file gs://XXX
<br/>vocab_size 32767
<br/>weight_decay_rate 0.01
</details>
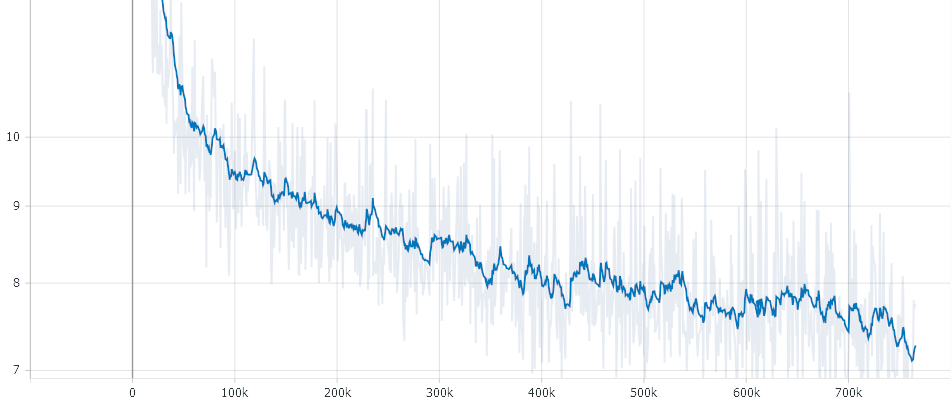
Please Note: *Due to the GAN like strucutre of Electra the loss is not that meaningful*
It took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used [tpunicorn](https://github.com/shawwn/tpunicorn). The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by [T-Systems on site services GmbH](https://www.t-systems-onsite.de/), [ambeRoad](https://amberoad.de/).
Special thanks to [Stefan Schweter](https://github.com/stefan-it) for your feedback and providing parts of the text corpus.
[¹]: Source for the picture [Pinterest](https://www.pinterest.cl/pin/371828512984142193/)
### Negative Results
We tried the following approaches which we found had no positive influence:
- **Increased Vocab Size**: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured
- **Decreased Batch-Size**: The original Electra was trained with a Batch Size per TPU Core of 16 whereas this Model was trained with 32 BS / TPU Core. We found out that 32 BS leads to better results when you compare metrics over computation time
## License - The MIT License
Copyright 2020-2021 Philip May<br>
Copyright 2020-2021 Philipp Reissel
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
{"language": "de", "license": "mit", "tags": ["electra", "commoncrawl", "uncased", "umlaute", "umlauts", "german", "deutsch"], "thumbnail": "https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png"}
|
german-nlp-group/electra-base-german-uncased
| null |
[
"transformers",
"pytorch",
"electra",
"pretraining",
"commoncrawl",
"uncased",
"umlaute",
"umlauts",
"german",
"deutsch",
"de",
"license:mit",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
fill-mask
|
transformers
|
# SlovakBERT (base-sized model)
SlovakBERT pretrained model on Slovak language using a masked language modeling (MLM) objective. This model is case-sensitive: it makes a difference between slovensko and Slovensko.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
**IMPORTANT**: The model was not trained on the “ and ” (direct quote) character -> so before tokenizing the text, it is advised to replace all “ and ” (direct quote marks) with a single "(double quote marks).
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='gerulata/slovakbert')
unmasker("Deti sa <mask> na ihrisku.")
[{'sequence': 'Deti sa hrali na ihrisku.',
'score': 0.6355380415916443,
'token': 5949,
'token_str': ' hrali'},
{'sequence': 'Deti sa hrajú na ihrisku.',
'score': 0.14731724560260773,
'token': 9081,
'token_str': ' hrajú'},
{'sequence': 'Deti sa zahrali na ihrisku.',
'score': 0.05016357824206352,
'token': 32553,
'token_str': ' zahrali'},
{'sequence': 'Deti sa stretli na ihrisku.',
'score': 0.041727423667907715,
'token': 5964,
'token_str': ' stretli'},
{'sequence': 'Deti sa učia na ihrisku.',
'score': 0.01886524073779583,
'token': 18099,
'token_str': ' učia'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import RobertaTokenizer, RobertaModel
tokenizer = RobertaTokenizer.from_pretrained('gerulata/slovakbert')
model = RobertaModel.from_pretrained('gerulata/slovakbert')
text = "Text ktorý sa má embedovať."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import RobertaTokenizer, TFRobertaModel
tokenizer = RobertaTokenizer.from_pretrained('gerulata/slovakbert')
model = TFRobertaModel.from_pretrained('gerulata/slovakbert')
text = "Text ktorý sa má embedovať."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
Or extract information from the model like this:
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='gerulata/slovakbert')
unmasker("Slovenské národne povstanie sa uskutočnilo v roku <mask>.")
[{'sequence': 'Slovenske narodne povstanie sa uskutočnilo v roku 1944.',
'score': 0.7383289933204651,
'token': 16621,
'token_str': ' 1944'},...]
```
# Training data
The SlovakBERT model was pretrained on these datasets:
- Wikipedia (326MB of text),
- OpenSubtitles (415MB of text),
- Oscar (4.6GB of text),
- Gerulata WebCrawl (12.7GB of text) ,
- Gerulata Monitoring (214 MB of text),
- blbec.online (4.5GB of text)
The text was then processed with the following steps:
- URL and email addresses were replaced with special tokens ("url", "email").
- Elongated interpunction was reduced (e.g. -- to -).
- Markdown syntax was deleted.
- All text content in braces f.g was eliminated to reduce the amount of markup and programming language text.
We segmented the resulting corpus into sentences and removed duplicates to get 181.6M unique sentences. In total, the final corpus has 19.35GB of text.
# Pretraining
The model was trained in **fairseq** on 4 x Nvidia A100 GPUs for 300K steps with a batch size of 512 and a sequence length of 512. The optimizer used is Adam with a learning rate of 5e-4, \\(\beta_{1} = 0.9\\), \\(\beta_{2} = 0.98\\) and \\(\epsilon = 1e-6\\), a weight decay of 0.01, dropout rate 0.1, learning rate warmup for 10k steps and linear decay of the learning rate after. We used 16-bit float precision.
## About us
<a href="https://www.gerulata.com/">
<img width="300px" src="https://www.gerulata.com/assets/images/Logo_Blue.svg">
</a>
Gerulata Technologies is a tech company on a mission to provide tools for fighting disinformation and hostile propaganda.
At Gerulata, we focus on providing state-of-the-art AI-powered tools that empower human analysts and provide them with the ability to make informed decisions.
Our tools allow for the monitoring and analysis of online activity, as well as the detection and tracking of disinformation and hostile propaganda campaigns. With our products, our clients are better equipped to identify and respond to threats in real-time.
### BibTeX entry and citation info
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2109.15254
```
@misc{pikuliak2021slovakbert,
title={SlovakBERT: Slovak Masked Language Model},
author={Matúš Pikuliak and Štefan Grivalský and Martin Konôpka and Miroslav Blšták and Martin Tamajka and Viktor Bachratý and Marián Šimko and Pavol Balážik and Michal Trnka and Filip Uhlárik},
year={2021},
eprint={2109.15254},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
{"language": "sk", "license": "mit", "tags": ["SlovakBERT"], "datasets": ["wikipedia", "opensubtitles", "oscar", "gerulatawebcrawl", "gerulatamonitoring", "blbec.online"]}
|
gerulata/slovakbert
| null |
[
"transformers",
"pytorch",
"tf",
"safetensors",
"roberta",
"fill-mask",
"SlovakBERT",
"sk",
"dataset:wikipedia",
"dataset:opensubtitles",
"dataset:oscar",
"dataset:gerulatawebcrawl",
"dataset:gerulatamonitoring",
"dataset:blbec.online",
"arxiv:2109.15254",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
geup/test
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
question-answering
|
transformers
|
{"language": ["ar"], "widget": [{"text": "\u0623\u064a\u0646 \u064a\u0639\u064a\u0634 \u0645\u062d\u0645\u062f \u061f", "context": "\u0627\u0633\u0645\u064a \u0645\u062d\u0645\u062f \u0648\u0623\u0646\u0627 \u0623\u0639\u064a\u0634 \u0641\u064a \u0633\u0648\u0631\u064a\u0627"}, {"text": "\u0645\u0627 \u0627\u0644\u0639\u062f\u062f \u0627\u0644\u0630\u0631\u064a \u0644\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u061f", "context": "\u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u0647\u0648 \u0639\u0646\u0635\u0631 \u0643\u064a\u0645\u064a\u0627\u0626\u064a \u0639\u062f\u062f\u0647 \u0627\u0644\u0630\u0631\u064a 1 \u060c \u0648\u0647\u0648 \u063a\u0627\u0632 \u0639\u062f\u064a\u0645 \u0627\u0644\u0631\u0627\u0626\u062d\u0629 \u0648\u0627\u0644\u0644\u0648\u0646 \u0648\u0647\u0648 \u0633\u0631\u064a\u0639 \u0627\u0644\u0627\u0634\u062a\u0639\u0627\u0644"}, {"text": "\u0645\u0627 \u062e\u0648\u0627\u0635 \u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u061f", "context": "\u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u0647\u0648 \u0639\u0646\u0635\u0631 \u0643\u064a\u0645\u064a\u0627\u0626\u064a \u0639\u062f\u062f\u0647 \u0627\u0644\u0630\u0631\u064a 1 \u060c \u0648\u0647\u0648 \u063a\u0627\u0632 \u0639\u062f\u064a\u0645 \u0627\u0644\u0631\u0627\u0626\u062d\u0629 \u0648\u0627\u0644\u0644\u0648\u0646 \u0648\u0647\u0648 \u0633\u0631\u064a\u0639 \u0627\u0644\u0627\u0634\u062a\u0639\u0627\u0644"}]}
|
gfdgdfgdg/arap_qa_bert
| null |
[
"transformers",
"pytorch",
"bert",
"question-answering",
"ar",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
question-answering
|
transformers
|
{"language": ["ar"], "widget": [{"text": "\u0623\u064a\u0646 \u064a\u0639\u064a\u0634 \u0645\u062d\u0645\u062f \u061f", "context": "\u0627\u0633\u0645\u064a \u0645\u062d\u0645\u062f \u0648\u0623\u0646\u0627 \u0623\u0639\u064a\u0634 \u0641\u064a \u0633\u0648\u0631\u064a\u0627"}, {"text": "\u0645\u0627 \u0627\u0644\u0639\u062f\u062f \u0627\u0644\u0630\u0631\u064a \u0644\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u061f", "context": "\u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u0647\u0648 \u0639\u0646\u0635\u0631 \u0643\u064a\u0645\u064a\u0627\u0626\u064a \u0639\u062f\u062f\u0647 \u0627\u0644\u0630\u0631\u064a 1 \u060c \u0648\u0647\u0648 \u063a\u0627\u0632 \u0639\u062f\u064a\u0645 \u0627\u0644\u0631\u0627\u0626\u062d\u0629 \u0648\u0627\u0644\u0644\u0648\u0646 \u0648\u0647\u0648 \u0633\u0631\u064a\u0639 \u0627\u0644\u0627\u0634\u062a\u0639\u0627\u0644"}, {"text": "\u0645\u0627 \u062e\u0648\u0627\u0635 \u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u061f", "context": "\u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u0647\u0648 \u0639\u0646\u0635\u0631 \u0643\u064a\u0645\u064a\u0627\u0626\u064a \u0639\u062f\u062f\u0647 \u0627\u0644\u0630\u0631\u064a 1 \u060c \u0648\u0647\u0648 \u063a\u0627\u0632 \u0639\u062f\u064a\u0645 \u0627\u0644\u0631\u0627\u0626\u062d\u0629 \u0648\u0627\u0644\u0644\u0648\u0646 \u0648\u0647\u0648 \u0633\u0631\u064a\u0639 \u0627\u0644\u0627\u0634\u062a\u0639\u0627\u0644"}]}
|
gfdgdfgdg/arap_qa_bert_large_v2
| null |
[
"transformers",
"pytorch",
"bert",
"question-answering",
"ar",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
question-answering
|
transformers
|
{"language": ["ar"], "widget": [{"text": "\u0623\u064a\u0646 \u064a\u0639\u064a\u0634 \u0645\u062d\u0645\u062f \u061f", "context": "\u0627\u0633\u0645\u064a \u0645\u062d\u0645\u062f \u0648\u0623\u0646\u0627 \u0623\u0639\u064a\u0634 \u0641\u064a \u0633\u0648\u0631\u064a\u0627"}, {"text": "\u0645\u0627 \u0627\u0644\u0639\u062f\u062f \u0627\u0644\u0630\u0631\u064a \u0644\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u061f", "context": "\u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u0647\u0648 \u0639\u0646\u0635\u0631 \u0643\u064a\u0645\u064a\u0627\u0626\u064a \u0639\u062f\u062f\u0647 \u0627\u0644\u0630\u0631\u064a 1 \u060c \u0648\u0647\u0648 \u063a\u0627\u0632 \u0639\u062f\u064a\u0645 \u0627\u0644\u0631\u0627\u0626\u062d\u0629 \u0648\u0627\u0644\u0644\u0648\u0646 \u0648\u0647\u0648 \u0633\u0631\u064a\u0639 \u0627\u0644\u0627\u0634\u062a\u0639\u0627\u0644"}, {"text": "\u0645\u0627 \u062e\u0648\u0627\u0635 \u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u061f", "context": "\u0627\u0644\u0647\u064a\u062f\u0631\u0648\u062c\u064a\u0646 \u0647\u0648 \u0639\u0646\u0635\u0631 \u0643\u064a\u0645\u064a\u0627\u0626\u064a \u0639\u062f\u062f\u0647 \u0627\u0644\u0630\u0631\u064a 1 \u060c \u0648\u0647\u0648 \u063a\u0627\u0632 \u0639\u062f\u064a\u0645 \u0627\u0644\u0631\u0627\u0626\u062d\u0629 \u0648\u0627\u0644\u0644\u0648\u0646 \u0648\u0647\u0648 \u0633\u0631\u064a\u0639 \u0627\u0644\u0627\u0634\u062a\u0639\u0627\u0644"}]}
|
gfdgdfgdg/arap_qa_bert_v2
| null |
[
"transformers",
"pytorch",
"bert",
"question-answering",
"ar",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
gfdream/DialoGPT-medium-harrypotter
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text-generation
|
transformers
|
# Family Guy (Peter) DialoGPT Model
|
{"tags": ["conversational"]}
|
gfdream/dialogpt-small-familyguy
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
text-generation
|
transformers
|
# Harry Potter DialoGPT Model
|
{"tags": ["conversational"]}
|
gfdream/dialogpt-small-harrypotter
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
gfoles/Poo
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ggggy/test
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ggosline/bart-base-herblabels
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-herblabels
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4823
- Rouge1: 3.0759
- Rouge2: 1.0495
- Rougel: 3.0758
- Rougelsum: 3.0431
- Gen Len: 18.9716
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 264 | 1.6010 | 2.4276 | 0.5658 | 2.3546 | 2.3099 | 18.9091 |
| 2.5052 | 2.0 | 528 | 1.0237 | 2.9016 | 0.3395 | 2.8221 | 2.783 | 18.9673 |
| 2.5052 | 3.0 | 792 | 0.7793 | 2.962 | 0.3091 | 2.9375 | 2.8786 | 18.9588 |
| 1.1552 | 4.0 | 1056 | 0.6530 | 2.98 | 0.4375 | 2.9584 | 2.8711 | 18.9588 |
| 1.1552 | 5.0 | 1320 | 0.5863 | 3.0023 | 0.5882 | 2.987 | 2.9155 | 18.9588 |
| 0.8659 | 6.0 | 1584 | 0.5428 | 3.0576 | 0.8019 | 3.0494 | 2.9989 | 18.9716 |
| 0.8659 | 7.0 | 1848 | 0.5145 | 3.0808 | 0.9476 | 3.0719 | 3.0237 | 18.9716 |
| 0.747 | 8.0 | 2112 | 0.4962 | 3.0748 | 1.0032 | 3.0683 | 3.0359 | 18.9716 |
| 0.747 | 9.0 | 2376 | 0.4856 | 3.0702 | 1.0196 | 3.0665 | 3.0328 | 18.9716 |
| 0.6987 | 10.0 | 2640 | 0.4823 | 3.0759 | 1.0495 | 3.0758 | 3.0431 | 18.9716 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["rouge"], "model-index": [{"name": "t5-small-herblabels", "results": []}]}
|
ggosline/t5-small-herblabels
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
null | null |
{}
|
ggosline/t5-small-herblables
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ggrunin/model_name
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC2GM-Gene-Modified_BioM-ELECTRA-Base-Discriminator
| null |
[
"transformers",
"pytorch",
"electra",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC2GM-Gene-Modified_PubMedBERT
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ghadeermobasher/BC2GM-Gene-Modified_biobert-large-cased-v1.1
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC2GM-Gene-Modified_scibert_scivocab_cased
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ghadeermobasher/BC2GM-Gene_Imbalanced-biobert-large-cased-v1.1
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC2GM-Gene_ImbalancedBioM-ELECTRA-Base-Discriminator
| null |
[
"transformers",
"pytorch",
"electra",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC2GM-Gene_ImbalancedPubMedBERT
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC2GM-Gene_Imbalancedscibert_scivocab_cased
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4-Original-biobert-v1.1
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4-Original-bluebert_pubmed_uncased_L-12_H-768_A-12
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4-Original-scibert_scivocab_uncased
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4-modified-PubmedBert
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4-modified-PubmedBert_small
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4-original-PubmedBert
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4-original-PubmedBert_small
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4CHEMD-Modified_BioM-ELECTRA-Base-Discriminator
| null |
[
"transformers",
"pytorch",
"electra",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4CHEMD-Modified_PubMedBERT
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4CHEMD-Modified_pubmed_clinical
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4CHEMD-Modified_scibert_scivocab_cased
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ghadeermobasher/BC4CHEMD_Imbalanced-biobert-large-cased-v1.1
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4CHEMD_ImbalancedBioM-ELECTRA-Base-Discriminator
| null |
[
"transformers",
"pytorch",
"electra",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4CHEMD_ImbalancedPubMedBERT
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4CHEMD_Imbalancedscibert_scivocab_cased
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4_CHEM_PubmedBERT
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4_Modified-biobert-v1.1
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4_Modified-bluebert_pubmed_uncased_L-12_H-768_A-12
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4_Modified-scibert_scivocab_uncased
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4_Modified_BiomedNLP-PubMedBERT-base-uncased-abstract
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC4_Original-BiomedNLP-PubMedBERT-base-uncased-abstract
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ghadeermobasher/BC5CDR-Chem-Modified-PubmedBert
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chem-Modified_biobert-large-cased
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chem-Modified_biobert-v1.1_latest
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chem-Modified_bluebert_pubmed_uncased_L-12_H-768_A-12_latest
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chem-Modified_pubmed_abstract_3
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chem-Modified_pubmed_abstract_latest
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chem-Modified_pubmed_full_3
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chem-Modified_scibert_scivocab_uncased_latest
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ghadeermobasher/BC5CDR-Chem-Original-PubmedBert
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ghadeermobasher/BC5CDR-Chem-Original-biobert-v1.1
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/WELT-PubMedBERT-BC5CDRChemical
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ghadeermobasher/BC5CDR-Chem2-Modified_bluebert_pubmed_uncased_L-12_H-768_A-12_latest
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/Original-PubMedBERT-BC5CDRChemical
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balanced-BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null |
adapter-transformers
|
# Adapter `ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR` for ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR
An [adapter](https://adapterhub.ml) for the `ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR` model that was trained on the [other](https://adapterhub.ml/explore/other/) dataset.
This adapter was created for usage with the **[adapter-transformers](https://github.com/Adapter-Hub/adapter-transformers)** library.
## Usage
First, install `adapter-transformers`:
```
pip install -U adapter-transformers
```
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. [More](https://docs.adapterhub.ml/installation.html)_
Now, the adapter can be loaded and activated like this:
```python
from transformers import AutoModelWithHeads
model = AutoModelWithHeads.from_pretrained("ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR")
adapter_name = model.load_adapter("ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here -->
|
{"tags": ["adapter-transformers", "adapterhub:other", "xlm-roberta"], "datasets": ["ghadeermobasher/BC5CDR-Chemical-Disease"]}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR
| null |
[
"adapter-transformers",
"pytorch",
"xlm-roberta",
"adapterhub:other",
"dataset:ghadeermobasher/BC5CDR-Chemical-Disease",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-from-PubMedBERT-fulltext
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balanced-biobert-base-cased-v1.2
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
null | null |
{}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balanced-biobert-large-cased-v1.1
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balanced-pubmedbert
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balanced-scibert_scivocab_cased
| null |
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balancedBioM-ELECTRA-Base-Discriminator
| null |
[
"transformers",
"pytorch",
"electra",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
|
token-classification
|
transformers
|
{}
|
ghadeermobasher/BC5CDR-Chemical-Disease_ImbalancedBioM-ELECTRA-Base-Discriminator
| null |
[
"transformers",
"pytorch",
"electra",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.