
repoName
stringlengths 7
77
| tree
stringlengths 0
2.85M
| readme
stringlengths 0
4.9M
|
|---|---|---|
Near-Deluge_deluge | .vscode
settings.json
README.md
app
ui
README.md
craco.config.js
package.json
public
index.html
manifest.json
src
.env
accounts.json
assets
imgs
logos
discord.svg
components
navbar.css
products
product_card.css
stores
createStore.css
utils
dummy_data.ts
dummy_products.ts
config.ts
hooks
useGetAllStores.ts
useGetOrFetchProductCid.ts
useIsAUserProduct.ts
useLocalAddress.ts
useLocalStorageKey.ts
useProductIsInCart.ts
index.css
pages
home.css
react-app-env.d.ts
redux
slices
cart.slice.ts
contract.slice.ts
products.slice.ts
ratings.slice.ts
store.slice.ts
store.ts
theme.ts
utils
interface.ts
storage.ts
utils.ts
tailwind.config.js
tsconfig.json
webpack.config.js
contracts
marketplace
Cargo.toml
README.md
build.sh
neardev
dev-account.env
package-lock.json
src
internal_orders.rs
internal_products.rs
internal_storage.rs
internal_stores.rs
lib.rs
models.rs
utils.rs
project-notes
accounts.md
scripts
accounts.sh
deploy-marketplace.sh
deploy-rating.sh
distribute-funds.sh
kurtosis-new.md
launch-local-near-cluster.sh
sequence.sh
stablecoins.sh
testnet_scripts
accounts.json
deploy-accounts.js
deployment-on-testnet.md
funding_test_script.js
neardev
dev-account.env
package.json
sequence.sh
utils
apis
base.ts
models.ts
test_api.ts
config.ts
e2e-tests
create_store_test.ts
readme.md
ft_balance_of.ts
ft_transfer.ts
ft_transfer_call.ts
marketplace_cancel_order.ts
marketplace_complete_order.ts
marketplace_create_product.ts
marketplace_create_store.ts
marketplace_delete_product.ts
marketplace_delete_store.ts
marketplace_get_latest_codehash.ts
marketplace_initialize.ts
marketplace_list_customer_orders.ts
marketplace_list_store_orders.ts
marketplace_list_store_products.ts
marketplace_list_stores.ts
marketplace_order_intransit.ts
marketplace_retrieve_order.ts
marketplace_retrieve_product.ts
marketplace_retrieve_store.ts
marketplace_schedule_order.ts
marketplace_set_ft_contract_name.ts
marketplace_set_rating_contract_name.ts
marketplace_storage_deposit.ts
marketplace_storage_view.ts
marketplace_storage_withdraw.ts
marketplace_store_contract.ts
marketplace_update_product.ts
marketplace_update_store.ts
nft_tokens_of.ts
orders
order-1.json
order-1.testnet.json
order-2.json
order-2.testnet.json
order-3.json
package-lock.json
package.json
products
fabrics-delivery.test.near
product-1.json
product-2.json
update-product-1.json
prix.testnet
product-1.json
product-2.json
rating_create.ts
rating_get_owner.ts
rating_get_ratings.ts
rating_rate.ts
stores
fabrics-delivery.test.near.json
prix.testnet.json
update-fabrics-delivery.test.near.json
tsconfig.json
utils.md
| contract Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
# Deluge: An Ecommerce Platform on Blockchain
`powered by Near Blockchain and IPFS`
Deluge is a scam-proof, blockchain based ecommerce marketplace. It will be powered by the Deluge Token(DLG). Deluge provides a 2 way escrow service by utilizing the power of smart contracts on the Near Network. No hidden fees as all transactions are handled with private keys granting complete control of your fund.
## Codebase Guides
### Smart Contracts
Smart Contracts are Organised in `contracts/` folder.
Deluge Consists of follwing smart contracts:
- Marketplace Contract
+ This is the main contract for deluge which keep tracks for active orders, products and stores in the marketplace.
- Rating Contract
+ With each successful order, when a user recieves a product and completes and order it creates a rating on rating smart contract to which he/she can provide his honest feedback over the product.
- NFT Contract
+ Every Shop created on Deluge will have a NFT Contracts which generated a NFT Token on each successful order.
- FT Contract
+ Deluge is a marketplace and inorder to maintain stability of it's currency we need a coin to provide liquidity to the platform as well as have a common notion for product pricing. This will be updated soon.
| WIP |
### UI
User Interface for deluge is a react based web dApp.
App the code related to ui is in `app/` folder.
| WIP |
### Testing Scripts
All the testing scripts for localnet and setting up local development environment are in folders : `scripts\` and `utils\`
# Create React App example with TypeScript
## How to use
Download the example [or clone the repo](https://github.com/mui/material-ui):
<!-- #default-branch-switch -->
```sh
curl https://codeload.github.com/mui/material-ui/tar.gz/master | tar -xz --strip=2 material-ui-master/examples/create-react-app-with-typescript
cd create-react-app-with-typescript
```
Install it and run:
```sh
npm install
npm start
```
or:
<!-- #default-branch-switch -->
[](https://codesandbox.io/s/github/mui/material-ui/tree/master/examples/create-react-app-with-typescript)
<!-- #default-branch-switch -->
[](https://stackblitz.com/github/mui/material-ui/tree/master/examples/create-react-app-with-typescript)
## The idea behind the example
This example demonstrates how you can use [Create React App](https://github.com/facebookincubator/create-react-app) with [TypeScript](https://github.com/Microsoft/TypeScript).
It includes `@mui/material` and its peer dependencies, including `emotion`, the default style engine in MUI v5.
If you prefer, you can [use styled-components instead](https://mui.com/material-ui/guides/interoperability/#styled-components).
## What's next?
<!-- #default-branch-switch -->
You now have a working example project.
You can head back to the documentation, continuing browsing it from the [templates](https://mui.com/material-ui/getting-started/templates/) section.
|
Mycelium-Lab_crisp-lending | Cargo.toml
src
balance.rs
borrow.rs
deposit.rs
errors.rs
lib.rs
reserve.rs
token_receiver.rs
tests
collaterals.rs
common
mod.rs
utils.rs
| |
MuhammedNagm_ch4-near | .eslintrc.yml
.github
dependabot.yml
workflows
deploy.yml
tests.yml
.gitpod.yml
.travis.yml
README-Gitpod.md
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
guestbook.spec.ts
as_types.d.ts
main.ts
model.ts
tsconfig.json
babel.config.js
neardev
shared-test-staging
test.near.json
shared-test
test.near.json
package.json
src
App.js
config.js
index.html
index.js
tests
integration
App-integration.test.js
ui
App-ui.test.js
| Guest Book
==========
[](https://travis-ci.com/near-examples/guest-book)
[](https://gitpod.io/#https://github.com/near-examples/guest-book)
<!-- MAGIC COMMENT: DO NOT DELETE! Everything above this line is hidden on NEAR Examples page -->
Sign in with [NEAR] and add a message to the guest book! A starter app built with an [AssemblyScript] backend and a [React] frontend.
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you have Node.js ≥ 12 installed (https://nodejs.org), then use it to install [yarn]: `npm install --global yarn` (or just `npm i -g yarn`)
2. Run the local development server: `yarn && yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet! Running `yarn dev` will tell you the URL you can visit in your browser to see the app.
Exploring The Code
==================
1. The backend code lives in the `/assembly` folder. This code gets deployed to
the NEAR blockchain when you run `yarn deploy:contract`. This sort of
code-that-runs-on-a-blockchain is called a "smart contract" – [learn more
about NEAR smart contracts][smart contract docs].
2. The frontend code lives in the `/src` folder.
[/src/index.html](/src/index.html) is a great place to start exploring. Note
that it loads in `/src/index.js`, where you can learn how the frontend
connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and backend. The
backend code gets tested with the [asp] command for running the backend
AssemblyScript tests, and [jest] for running frontend tests. You can run
both of these at once with `yarn test`.
Both contract and client-side code will auto-reload as you change source files.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contracts get deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli
--------------------------
You need near-cli installed globally. Here's how:
npm install --global near-cli
This will give you the `near` [CLI] tool. Ensure that it's installed with:
near --version
Step 1: Create an account for the contract
------------------------------------------
Visit [NEAR Wallet] and make a new account. You'll be deploying these smart contracts to this new account.
Now authorize NEAR CLI for this new account, and follow the instructions it gives you:
near login
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'your-account-here!'
Step 3: change remote URL if you cloned this repo
-------------------------
Unless you forked this repository you will need to change the remote URL to a repo that you have commit access to. This will allow auto deployment to Github Pages from the command line.
1) go to GitHub and create a new repository for this project
2) open your terminal and in the root of this project enter the following:
$ `git remote set-url origin https://github.com/YOUR_USERNAME/YOUR_REPOSITORY.git`
Step 4: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contracts to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
[NEAR]: https://nearprotocol.com/
[yarn]: https://yarnpkg.com/
[AssemblyScript]: https://docs.assemblyscript.org/
[React]: https://reactjs.org
[smart contract docs]: https://docs.nearprotocol.com/docs/roles/developer/contracts/assemblyscript
[asp]: https://www.npmjs.com/package/@as-pect/cli
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.nearprotocol.com/docs/concepts/account
[NEAR Wallet]: https://wallet.nearprotocol.com
[near-cli]: https://github.com/nearprotocol/near-cli
[CLI]: https://www.w3schools.com/whatis/whatis_cli.asp
[create-near-app]: https://github.com/nearprotocol/create-near-app
[gh-pages]: https://github.com/tschaub/gh-pages
|
midou10_Near_Network_deployment | README.md
package-lock.json
package.json
src
config.js
kitProvider.js
| Near Network
====================
![Example Alert]()
## Usage
First, set the addresses you'd like in `addresses.<network>.yaml` and set your node and alerting envars in `.env-<network>`.
Then, develop this project locally with:
```shell
# Setup
yarn
# Test
yarn test
# Run locally
ENV_FILE=.env-template yarn dev
```
## Monitors
Monitors can be enabled or disabled by commenting out desired monitors in `src/monitor/monitor.ts`. Default monitors include:
<!-- * **Balance** - Monitor the CELO and cUSD balances of all addresses specified in the addresses yaml file
* **Electability Threshold** - Monitor the threshold of votes needed to get elected
* **Governance** - Monitor the network for governance activity
* **Key Rotation** - When validator keys are rotated, ensure that they are fully rotated
* **Network Participation** - Monitor overall network participation numbers
* **Node** - Monitor Celo node & network health
* **Pending Votes** - Monitor our addresses for pending votes. Remind us to activate them
* **Tobin Tax** - Remind us if/when the Tobin Tax is activated. Never send transactions when it is
* **Validator** - Monitor the health of our validators -->
## Deployment
The monitor can be containerized and readied for deploy like so. The container will listen on `$PORT` (default: 8080) and run anytime a request hits it. It's intended for deployment in a container management system with a job set to contact it every ~60 seconds to initiate a new run of the monitor.
```shell
docker build -t monitor .
docker run monitor
```
|
Learn-NEAR-Hispano_NCD2L1--nearbrary | README.md
as-pect.config.js
asconfig.json
package-lock.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
simple
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
models
book.ts
fragment.ts
user.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| # 📖 Nearbrary
Proyecto realizado para el NCD Bootcamp NEAR Hispano, edición de octubre 2021.
# Nearbrary es un plataforma donde puedes subir escritos y ganar dinero con ellos, sin editoriales de por medio.
# 📕 En Nearbrary, los usuarios podrán:
- Subir libros completos de su autoría con el fin de obtener ingresos o ponerlos públicos
- Comprar obras, ya sea un capítulo o de forma completa
- Revisar el catálogo de obras disponibles o próximas a publicar
Cada miembro dentro de la comunidad se identifica con su NEAR account ID
# ✎ Prerequisitos
1. Node.js _(Versión en la que se realizó: 16.11.1)_
2. Yarn instalado <code>npm install --global yarn</code>
3. instalar dependencias <code>yarn install</code>
4. Si es el caso, crear una cuenta de NEAR en [testnet](https://docs.near.org/docs/develop/basics/create-account#creating-a-testnet-account)
5. Instalar NEAR CLI <code>yarn install --global near-cli</code>
6. autorizar app para dar acceso a la cuenta de NEAR <code>near login</code>
## 🐑 Clonar el Repositorio
<code>git clone https://github.com/MiguelIslasH/nearbrary</code>
## 🥶 instalar y compilar el contrato
- <code>yarn install</code>
- <code>yarn build</code>
## 🚀 Deployar el contrato
- <code>yarn dev:deploy:contract</code>
## ☃ Correr comandos
Una vez en deploy el contrato, a partir de ahora [será utilizado como CONTRACT_ID en los ejemplos de comandos]
Utilizaremos [ACCOUNT_ID para identificar el account Id] que utilizamos para autorizar la app.
### Registrar usuario
near call _CONTRACT_ID_ registerUser '{"email": "[email protected]","name": "Carlitos"}' --accountId _ACCOUNT_ID_
### Publicar una obra: ejemplo que se usa en comprar libro
near call _CONTRACT_ID_ postBook '{"title": "La hacedora de viudas", "price": "20.20", "synopsis": "La noche es mi velo", "content": "Una vez un hombre me dijo que me pusiera ropa, así que me vestí con..."}' --accountId _ACCOUNT_ID_
### Consultar una obra
near view _CONTRACT_ID_ getBook '{"title": "La noche"}'
### Consultar todas las obras: regresa la instacia, pues se planea usar así para futuros avances
near view _CONTRACT_ID_ getBooks
### Comprar libro: ejemplo válido e inválido por la cantidad
near call _CONTRACT_ID_ buyBook '{"title": "La hacedora de viudas"}' --amount 20.20 --accountId _ACCOUNT_ID_
near call _CONTRACT_ID_ buyBook '{"title": "La hacedora de viudas"}' --amount 0 --accountId _ACCOUNT_ID_
### Consultar datos del usuario
near view _CONTRACT_ID_ getUserData '{"accountId": "_ACCOUNT_ID_"}'
# Caso de uso: Publicación y compra de obras.
Pensamos en un diseño que tuviera colores oscuros de forma predominante, la gente se desgasta menos su vista si la página cuenta con fondos oscuros, lo que el usuario haría sería:
* Consultar las obras publicadas y próximas a publicar
* Consultar las obras adquiridas
* Crear una cuenta usando tu cuenta de mainet.
* Iniciar sesión usando tu cuenta de mainet y tu contraseña.
* Ver el el detalle de alguna obra y:
* Comprarla completamente
* Comprarla parcialmente: por capítulos
* Los comentarios y reseñas sobre la obra
* Poder comentar y hacer una reseña
* Buscar obras por título, extensión, año y autor.
* Subir obras de su autoría
<br />
Estos diseños se pueden encontrar y navegar por ellos aquí: https://www.canva.com/design/DAEuDoppBm4/Ds8X480YRXE-LiZmxx1VOg/view?utm_content=DAEuDoppBm4&utm_campaign=designshare&utm_medium=link&utm_source=sharebutton

## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
|
Learn-NEAR_NCD--riddles | .gitpod.yml
README.md
babel.config.js
contract
Cargo.toml
README.md
compile.js
src
lib.rs
tests.rs
category
grade
add_riddle info
answer_riddle info
copy-dev-account.js
docs
css
app.246891c4.css
app.4a1a68b1.css
chunk-vendors.faef1ed3.css
img
logo-black.8d52ce32.svg
logo-white.951f686f.svg
index.html
js
app.095a4ca4.js
app.3c0bca8e.js
app.71deed67.js
chunk-vendors.61b62fee.js
jest.config.js
package.json
src
assets
logo-black.svg
logo-white.svg
config.js
global.css
main.js
utils.js
tests
unit
Notification.spec.js
SignedIn.spec.js
SignedOut.spec.js
| near-riddles Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
Test The Code
==================
```
cargo test -- --nocapture
```
[smart contract]: https://docs.near.org/docs/roles/developer/contracts/intro
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
near-riddles(NCD L1C2 Group G team project)
==================
This [Vue] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/main.js` is a great
place to start exploring.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-riddles.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-riddles.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-riddles.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-riddles.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[Vue]: https://vuejs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
Learn-NEAR-Club_Questionnaire | README.md
as-pect.config.js
asconfig.json
command.md
neardev
dev-account.env
package-lock.json
package.json
scripts
build.sh
full.sh
view_call.sh
src
as-pect.d.ts
as_types.d.ts
sample
__tests__
README.md
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| [Describe]: greeting
[Success]: ✔ should respond to sayHi()
[Success]: ✔ should respond to greetingUser()
[Success]: ✔ should respond to addToMyList()
[Success]: ✔ should respond to getNumTasks()
[Success]: ✔ should respond to showMyTasks()
[File]: src/sample/__tests__/index.unit.spec.ts
[Groups]: 2 pass, 2 total
[Result]: ✔ PASS
[Snapshot]: 0 total, 0 added, 0 removed, 0 different
[Summary]: 5 pass, 0 fail, 5 total
[Time]: 16.649ms
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[Result]: ✔ PASS
[Files]: 1 total
[Groups]: 2 count, 2 pass
[Tests]: 5 pass, 0 fail, 5 total
[Time]: 14260.268ms
$ cargo test -- --nocapture
Questionnaire on NEAR blockchain
Questionnaire is a smart contract deployed on Near.
User can save questions and answers to blockchain and retrieve data using VIEW and CHANGE methods.
Smart Contract lives here:
Questionnaire\src\sample\assembly\index.ts
Tests are here:
src\sample\__tests__\index.unit.spec.ts
1- yarn install
2- yarn dev
3- yarn build:release
4- near dev-deploy
or run ./scripts/build.sh instead of 3,4
near view dev-1645429298908-23414589644047 hello
near call dev-1645429298908-23414589644047 greetingUser --account_id tilek.testnet
near call dev-1645429298908-23414589644047 showMyQuestions --account_id tilek.testnet near call dev-1645429298908-23414589644047 showMyAnswers --account_id tilek.testnet
near call dev-1645429298908-23414589644047 addQuestion '{"question":"What is a sharding?"}' --account_id tilek.testnet near call dev-1645429298908-23414589644047 addQuestion '{"question":"What is WEB 3?"}' --account_id tilek.testnet near call dev-1645429298908-23414589644047 addAnswer '{"answer":"Sharding does a horizontal partition of your database and turns into smaller, more manageable tables."}' --account_id tilek.testnet near call dev-1645429298908-23414589644047 addAnswer '{"answer":"Web 3.0 is a general idea for a decentralized Internet based on public blockchains"}' --account_id tilek.testnet
near call dev-1645429298908-23414589644047 deleteQuestion '{"question":1}' --account_id tilek.testnet near call dev-1645429298908-23414589644047 deleteAnswer '{"answer":1}' --account_id tilek.testnet
near call dev-1645429298908-23414589644047 showMyQuestions --account_id tilek.testnet near call dev-1645429298908-23414589644047 showMyAnswers --account_id tilek.testnet
near call dev-1645429298908-23414589644047 getNumQuestions --account_id tilek.testnet near call dev-1645429298908-23414589644047 getNumAnswers --account_id tilek.testnet
yarn test:unit
|
ilerik_p2w | .gitpod.yml
DEVELOP.md
README.md
contract
Cargo.toml
README.md
build.sh
deploy.sh
deploy.testnet.js
src
lib.rs
views.rs
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| # P2W related NEAR contracts
NEAR contract designed to govern play2win game flow with dispute resolution and automatic rewards distribution.
To build and deploy contract run:
```bash
npm run install
npm run build
npm run deploy
```
## Deployment status:
- NEAR testnet: [p2w-v1.ilerik.testnet](https://explorer.testnet.near.org/accounts/p2w-v1.ilerik.testnet)
- NEAR mainnet: TBD
## Game flow
Game lifecycle diagram (italic for contract calls):
_create_game( reward, team_A, team_B )_
|
Ongoing // Game has started
|
_finish_game(outcome)_
|
// Captains declared same outcomes game is resolved automatically
Finished { outcome } --> _finish_game( result == outcome )_ --> Resolved { outcome }
|
_finish_game( result != outcome )_
|
// Captains declared different outcomes admins need to resolve manually
Disputed-->_resolve_game(outcome)_-->Resolved { outcome }
To run [integration tests](/integration-tests/src/main.ava.ts) covering the above flows:
```bash
npm run test:integration
```
## TO DO:
- ability to manage community of administrators responsible for dispute resolution
- implement reward distribution (either immediate on resolution or via claim mechanics or both)
## P2W smart contract
Testnet: p2w-v1.ilerik.testnet
|
mikedotexe_upgrade-player-example | Cargo.toml
README.md
build.sh
src
lib.rs
| # Rust contract upgrading a game player
Create a subaccount for this:
```bash
export NEAR_ACCT=YOUR_ACCOUNT_NAME.testnet
near create-account player.$NEAR_ACCT --masterAccount $NEAR_ACCT
```
Or remake if need be:
```bash
near delete player.$NEAR_ACCT $NEAR_ACCT
near create-account player.$NEAR_ACCT --masterAccount $NEAR_ACCT
```
Build and deploy:
```bash
./build.sh
near deploy player.$NEAR_ACCT --wasmFile res/upgrade_player_example.wasm
```
Add a player:
```bash
near call player.$NEAR_ACCT add_player '{"game_num": 1, "player": {"name": "Roshan", "hero_class": "NEARkat", "health": 100, "level": 1 }}' --accountId $NEAR_ACCT
near view player.$NEAR_ACCT get_game_players '{"game_num": 1}'
```
|
Peersyst_symbol-desktop-wallet | .eslintrc.js
.prettierrc.js
.travis.yml
CHANGELOG.md
CODE_OF_CONDUCT.md
CONTRIBUTING.md
README.md
Vue.config-back.js
__mocks__
Accounts.ts
Components.ts
MosaicConfigurations.ts
Store.ts
mosaics.ts
multisigGraphInfo.ts
profiles.ts
__tests__
components
AccountSelectorField.spec.ts
AmountInput.spec.ts
ButtonCopyToClipboard.spec.ts
FormLabel.spec.ts
FormRow.spec.ts
FormWrapper.spec.ts
MosaicInputManager.spec.ts
MultisigCosignatoriesDisplay.spec.ts
NavigationLinks
NavigationLinks.spec.ts
PeerSelector.spec.ts
Settings.spec.ts
TransactionList
TransactionListFilters
TransactionListFilter.spec.ts
core
validation
validators
UrlValidator.spec.ts
database
backends
NetworkBasedObjectStorage.spec.ts
SimpleObjectStorage.spec.ts
VersionedObjectStorage.spec.ts
e2e
MosaicServiceIntegrationTest.spec.ts
NetworkServiceIntegrationTest.spec.ts
NodeServiceIntegrationTest.spec.ts
services
AccountService.spec.ts
DerivationService.spec.ts
MosaicModel.spec.ts
MosaicService.spec.ts
MultisigService.spec.ts
ProfileService.spec.ts
RemoteAccountService.spec.ts
store
Diagnostic.spec.ts
Profile.spec.ts
Temporary.spec.ts
transactions
TransactionView.spec.ts
ViewAliasTransaction.spec.ts
ViewHashLockTransaction.spec.ts
ViewTransferTransaction.spec.ts
utils
FilterHelpers.spec.ts
Formatters.spec.ts
TimeHelpers.spec.ts
URLHelpers.spec.ts
views
forms
FormNodeEdit.spec.ts
babel.config.js
jest.config.js
package-lock.json
package.json
postcss.config.js
public
build.js
config
app.conf.js
fees.conf.js
network.conf.js
index.html
scripts
notarize.js
src
app
AppStore.ts
AppTs.ts
UIBootstrapper.ts
components
AccountActions
AccountActionsTs.ts
AccountAddressDisplay
AccountAddressDisplayTs.ts
AccountAliasDisplay
AccountAliasDisplayTs.ts
AccountBackupOptions
AccountBackupOptionsTs.ts
AccountContactQR
AccountContactQRTs.ts
AccountDetailsDisplay
AccountDetailsDisplayTs.ts
AccountLinks
AccountLinksTs.ts
AccountNameDisplay
AccountNameDisplayTs.ts
AccountPublicKeyDisplay
AccountPublicKeyDisplayTs.ts
AccountSelectorField
AccountSelectorFieldTs.ts
AccountSelectorPanel
AccountSelectorPanelTs.ts
ActionDisplay
ActionDisplayTs.ts
AddCosignatoryInput
AddCosignatoryInputTs.ts
AddressDisplay
AddressDisplayTs.ts
AmountDisplay
AmountDisplayTs.ts
AmountInput
AmountInputTs.ts
AppLogo
AppLogoTs.ts
ApprovalAndRemovalInput
ApprovalAndRemovalInputTs.ts
ButtonCopyToClipboard
ButtonCopyToClipboardTs.ts
ButtonRefresh
ButtonRefreshTs.ts
CosignatoryModificationsDisplay
CosignatoryModificationsDisplayTs.ts
DisabledUiOverlay
DisabledUiOverlayTs.ts
DivisibilityInput
DivisibilityInputTs.ts
DurationInput
DurationInputTs.ts
ErrorTooltip
ErrorTooltipTs.ts
ExplorerUrlSetter
ExplorerUrlSetterTs.ts
HardwareConfirmationButton
HardwareConfirmationButtonTs.ts
ImportanceScoreDisplay
ImportanceScoreDisplayTs.ts
LanguageSelector
LanguageSelectorTs.ts
LongTextDisplay
LongTextDisplayTs.ts
MaxFeeSelector
MaxFeeSelectorTs.ts
MessageInput
MessageInputTs.ts
MnemonicDisplay
MnemonicDisplayTs.ts
MnemonicInput
MnemonicInputTs.ts
MnemonicVerification
MnemonicVerificationTs.ts
MosaicAmountDisplay
MosaicAmountDisplayTs.ts
MosaicAttachmentInput
MosaicAttachmentInputTs.ts
MosaicBalanceList
MosaicBalanceListTs.ts
MosaicSelector
MosaicSelectorTs.ts
MultisigCosignatoriesDisplay
MultisigCosignatoriesDisplayTs.ts
NamespaceNameInput
NamespaceNameInputTs.ts
NamespaceSelector
NamespaceSelectorTs.ts
NavigationLinks
NavigationLinksTs.ts
NavigationTabs
NavigationTabsTs.ts
NetworkNodeSelector
NetworkNodeSelectorTs.ts
NetworkStatisticsPanel
NetworkStatisticsPanelTs.ts
PageNavigator
PageNavigatorTs.ts
PageTitle
PageTitleTs.ts
Pagination
PaginationTs.ts
PaidFeeDisplay
PaidFeeDisplayTs.ts
PeerSelector
PeerSelectorTs.ts
ProfileBalancesPanel
ProfileBalancesPanelTs.ts
ProtectedMnemonicDisplayButton
ProtectedMnemonicDisplayButtonTs.ts
ProtectedMnemonicQRButton
ProtectedMnemonicQRButtonTs.ts
ProtectedPrivateKeyDisplay
ProtectedPrivateKeyDisplayTs.ts
QRCode
ImportQRButton
ImportQRButtonTs.ts
QRCodeActions
ContactQRAction
ContactQRActionTs.ts
CosignatureQRAction
CosignatureQRActionTs.ts
MnemonicQRAction
MnemonicQRActionTs.ts
QRCodeActionsTs.ts
TemplateQRAction
TemplateQRActionTs.ts
TransactionQRAction
TransactionQRActionTs.ts
QRCodeDisplay
QRCodeDisplayTs.ts
QRCodePassword
QRCodePasswordTs.ts
UploadQRCode
UploadQRCodeTs.ts
RecipientInput
RecipientInputTs.ts
RemoveCosignatoryInput
RemoveCosignatoryInputTs.ts
RentalFees
RentalFeeTs.ts
Settings
SettingsTs.ts
SignerFilter
SignerFilterTs.ts
SignerSelector
SignerSelectorTs.ts
SplitButton
SplitButtonTs.ts
SupplyInput
SupplyInputTs.ts
TableDisplay
TableDisplayTs.ts
TableRow
TableRowTs.ts
TransactionDetails
TransactionDetailsTs.ts
TransactionDetailsHeader
TransactionDetailsHeaderTs.ts
TransactionList
TransactionListFilters
TransactionListFiltersTs.ts
TransactionStatusFilter
TransactionStatusFilterTs.ts
TransactionListTs.ts
TransactionRow
TransactionRowTs.ts
TransactionTable
TransactionTableTs.ts
TransactionUri
TransactionUriDisplay
TransactionUriDisplayTs.ts
WindowControls
WindowControlsTs.ts
config
AppConfig.ts
FeesConfig.ts
NetworkConfig.ts
index.ts
core
database
backends
INetworkBasedStorage.ts
IStorage.ts
IStorageBackend.ts
LocalStorageBackend.ts
NetworkBasedObjectStorage.ts
ObjectStorageBackend.ts
SimpleObjectStorage.ts
VersionedNetworkBasedObjectStorage.ts
VersionedObjectStorage.ts
entities
AccountModel.ts
BlockInfoModel.ts
MosaicConfigurationModel.ts
MosaicModel.ts
NamespaceModel.ts
NetworkBasedModel.ts
NetworkConfigurationModel.ts
NetworkCurrenciesModel.ts
NetworkCurrencyModel.ts
NetworkModel.ts
NodeModel.ts
ProfileModel.ts
SettingsModel.ts
VersionedModel.ts
storage
AccountModelStorage.ts
BlockInfoModelStorage.ts
MosaicConfigurationModelStorage.ts
MosaicModelStorage.ts
NamespaceModelStorage.ts
NetworkCurrenciesModelStorage.ts
NetworkModelStorage.ts
NodeModelStorage.ts
ProfileModelStorage.ts
SettingsModelStorage.ts
transactions
BroadcastResult.ts
TransactionDetailItem.ts
TransactionStatus.ts
TransactionView.ts
TransactionViewFactory.ts
ViewAccountKeyLinkTransaction.ts
ViewAliasTransaction.ts
ViewHashLockTransaction.ts
ViewMosaicDefinitionTransaction.ts
ViewMosaicSupplyChangeTransaction.ts
ViewMultisigAccountModificationTransaction.ts
ViewNamespaceRegistrationTransaction.ts
ViewTransferTransaction.ts
ViewUnknownTransaction.ts
ViewVotingKeyLinkTransaction.ts
ViewVrfKeyLinkTransaction.ts
utils
CSVHelpers.ts
Electron.ts
FilterHelpers.ts
Formatters.ts
LogLevels.ts
NetworkConfigurationHelpers.ts
NetworkTypeHelper.ts
NotificationType.ts
ObservableHelpers.ts
RESTDispatcher.ts
StorageHelpers.ts
TimeHelpers.ts
TrezorConnect.ts
UIHelpers.ts
URLHelpers.ts
URLInfo.ts
WebClient.ts
validation
CustomValidationRules.ts
ErrorMessages.ts
InitializeVeeValidate.ts
StandardValidationRules.ts
ValidationRuleset.ts
VeeValidateSetup.ts
validators
AddressValidator.ts
AliasValidator.ts
DerivationPathValidator.ts
MaxDecimalsValidator.ts
MosaicIdValidator.ts
NamespaceIdValidator.ts
PublicKeyValidator.ts
UrlValidator.ts
Validator.ts
index.ts
events.ts
language
en-US.json
index.ts
ja-JP.json
zh-CN.json
main.ts
router
AppRoute.ts
AppRouter.ts
RouteMeta.ts
TabEntry.ts
routes.ts
services
AccountService.ts
AssetTableService
AssetTableService.ts
MosaicTableService.ts
NamespaceTableService.ts
BlockService.ts
CommunityService.ts
DerivationService.ts
MosaicService.ts
MultisigService.ts
NamespaceService.ts
NetworkService.ts
NodeService.ts
ProfileService.ts
RESTService.ts
RemoteAccountService.ts
SettingService.ts
TransactionAnnouncerService.ts
TransactionCommand.ts
store
Account.ts
AppInfo.ts
AwaitLock.ts
Block.ts
Community.ts
Database.ts
Diagnostic.ts
Market.ts
Mosaic.ts
Namespace.ts
Network.ts
Notification.ts
Profile.ts
Statistics.ts
Temporary.ts
Transaction.ts
index.ts
plugins
onPeerConnection.ts
views
forms
FormAccountKeyLinkTransaction
FormAccountKeyLinkTransactionTs.ts
FormAccountNameUpdate
FormAccountNameUpdateTs.ts
FormAliasTransaction
FormAliasTransactionTs.ts
FormCreatePrivateKeyWallet
FormCreatePrivateKeyWalletTs.ts
FormExtendNamespaceDurationTransaction
FormExtendNamespaceDurationTransactionTs.ts
FormGeneralSettings
FormGeneralSettingsTs.ts
FormMosaicDefinitionTransaction
FormMosaicDefinitionTransactionTs.ts
FormMosaicSupplyChangeTransaction
FormMosaicSupplyChangeTransactionTs.ts
FormMultisigAccountModificationTransaction
FormMultisigAccountModificationTransactionTs.ts
FormNamespaceRegistrationTransaction
FormNamespaceRegistrationTransactionTs.ts
FormNodeEdit
FormNodeEditTs.ts
FormPersistentDelegationRequestTransaction
FormPersistentDelegationRequestTransactionTs.ts
FormProfileCreation
FormProfileCreationTs.ts
FormProfilePasswordUpdate
FormProfilePasswordUpdateTs.ts
FormProfileUnlock
FormProfileUnlockTs.ts
FormRemoteAccountCreation
FormRemoteAccountCreationTs.ts
FormSubAccountCreation
FormSubAccountCreationTs.ts
FormTransactionBase
FormTransactionBase.ts
FormTransactionConfirmation
FormTransactionConfirmationTs.ts
FormTransferTransaction
FormTransferTransactionTs.ts
MosaicInputsManager.ts
layout
PageLayout
PageLayoutTs.ts
modals
ModalFormAccountNameUpdate
ModalFormAccountNameUpdateTs.ts
ModalFormProfileUnlock
ModalFormProfileUnlockTs.ts
ModalFormSubAccountCreation
ModalFormSubAccountCreationTs.ts
ModalHarvestingWizard
ModalHarvestingWizardTs.ts
ModalImportQR
ModalImportQRTs.ts
ModalMnemonicBackupWizard
ModalMnemonicBackupWizardTs.ts
ModalMnemonicDisplay
ModalMnemonicDisplayTs.ts
ModalMnemonicExport
ModalMnemonicExportTs.ts
ModalNetworkNotMatchingProfile
ModalNetworkNotMatchingProfileTs.ts
ModalSettings
ModalSettingsTs.ts
ModalTransactionConfirmation
ModalTransactionConfirmationTs.ts
ModalTransactionCosignature
ModalTransactionCosignatureTs.ts
ModalTransactionDetails
ModalTransactionDetailsTs.ts
ModalTransactionExport
ModalTransactionExportTs.ts
ModalTransactionUriImport
ModalTransactionUriImportTs.ts
pages
accounts
AccountBackupPage
AccountBackupPageTs.ts
AccountDetailsPage
AccountDetailsPageTs.ts
AccountHarvestingPage
AccountHarvestingPageTs.ts
AccountsTs.ts
assets
AssetFormPageWrap
AssetFormPageWrapTs.ts
community
information
InformationTs.ts
dashboard
DashboardTs.ts
harvesting
DashboardHarvestingPageTs.ts
home
DashboardHomePageTs.ts
invoice
DashboardInvoicePageTs.ts
transfer
DashboardTransferPageTs.ts
multisig
MultisigDashboardPage
MultisigDashboardPageTs.ts
namespaces
createSubNamespace
CreateSubNamespaceTs.ts
profiles
LoginPageTs.ts
create-profile
CreateProfileTs.ts
finalize
FinalizeTs.ts
generate-mnemonic
GenerateMnemonicTs.ts
show-mnemonic
ShowMnemonicTs.ts
verify-mnemonic
VerifyMnemonicTs.ts
import-private-key
ImportPrivateKeyTs.ts
finalize
FinalizeTs.ts
input-private-key
InputPrivateKeyTs.ts
import-profile
ImportProfileTs.ts
account-selection
AccountSelectionTs.ts
finalize
FinalizeTs.ts
import-mnemonic
ImportMnemonicTs.ts
import-strategy
ImportStrategyTs.ts
settings
SettingsTs.ts
resources
Images.ts
fonts
fonts.css
img
icons
mosaic.svg
multisig.svg
namespace.svg
news.svg
qr.svg
wallet.svg
monitor
dash-board
dashboardConfirmed.svg
monitorAssetListPurple.svg
monitorCopyDocument.svg
travis
docker.sh
release.sh
tsconfig.json
vue.config.js
| # Symbol Desktop Wallet
[](https://travis-ci.com/nemgrouplimited/symbol-desktop-wallet)
[](https://opensource.org/licenses/Apache-2.0)
Cross-platform client for Symbol to manage accounts, mosaics, namespaces, and issue transactions.
## Installation
Symbol Desktop Wallet is available for Mac, Windows, and as a web application.
1. Download Symbol Desktop Wallet from the [releases section](https://github.com/nemgrouplimited/symbol-desktop-wallet/releases).
2. Launch the executable file and follow the installation instructions.
3. Create a profile. Remember to save the mnemonic somewhere safe (offline).
**NOTE**: This program is currently in development and only available for the Symbol test network. Do not use it for other purposes.
## Building instructions
Symbol CLI require **Node.js 10 or 12 LTS** to execute.
1. Clone the project.
```
git clone https://github.com/nemgrouplimited/symbol-desktop-wallet.git
```
2. Install the dependencies.
```
cd symbol-desktop-wallet
npm install
```
3. Start the development server.
```
npm run dev
```
4. Visit http://localhost:8080/#/ in your browser.
## Getting help
Use the following available resources to get help:
- [Symbol Documentation][docs]
- Join the community [slack group (#sig-client)][slack]
- If you found a bug, [open a new issue][issues]
## Contributing
Contributions are welcome and appreciated.
Check [CONTRIBUTING](CONTRIBUTING.md) for information on how to contribute.
## License
Copyright 2018-present NEM
Licensed under the [Apache License 2.0](LICENSE)
[self]: https://github.com/nemgrouplimited/symbol-desktop-wallet
[docs]: https://nemtech.github.io
[issues]: https://github.com/nemgrouplimited/symbol-desktop-wallet/issues
[slack]: https://join.slack.com/t/nem2/shared_invite/enQtMzY4MDc2NTg0ODgyLWZmZWRiMjViYTVhZjEzOTA0MzUyMTA1NTA5OWQ0MWUzNTA4NjM5OTJhOGViOTBhNjkxYWVhMWRiZDRkOTE0YmU
|
gabehamilton_nearby | .github
workflows
tests.yml
README.md
|
|
__tests__
test-template.ava.js
babel.config.json
commands.txt
jsconfig.json
neardev
dev-account.env
package.json
src
market-contract
index.ts
internal.ts
nft_callbacks.ts
sale.ts
sale_views.ts
nft-contract
approval.ts
enumeration.ts
index.ts
internal.ts
metadata.ts
mint.ts
nft_core.ts
royalty.ts
tsconfig.json
| # NEAR NFT-Tutorial JavaScript Edition
Welcome to NEAR's NFT tutorial, where we will help you parse the details around NEAR's [NEP-171 standard](https://nomicon.io/Standards/NonFungibleToken/Core.html) (Non-Fungible Token Standard), and show you how to build your own NFT smart contract from the ground up, improving your understanding about the NFT standard along the way.
## Prerequisites
* [Node.js](/develop/prerequisites#nodejs)
* [NEAR Wallet Account](wallet.testnet.near.org)
* [NEAR-CLI](https://docs.near.org/tools/near-cli#setup)
* [yarn](https://classic.yarnpkg.com/en/docs/install#mac-stable)
## Tutorial Stages
Each branch you will find in this repo corresponds to various stages of this tutorial with a partially completed contract at each stage. You are welcome to start from any stage you want to learn the most about.
| Branch | Docs Tutorial | Description |
| ------------- | ------------------------------------------------------------------------------------------------ | ----------- |
| 1.skeleton | [Contract Architecture](https://docs.near.org/docs/tutorials/contracts/nfts/js/skeleton) | You'll learn the basic architecture of the NFT smart contract. |
| 2.minting | [Minting](https://docs.near.org/docs/tutorials/contracts/nfts/js/minting) |Here you'll flesh out the skeleton so the smart contract can mint a non-fungible token |
| 3.enumeration | [Enumeration](https://docs.near.org/docs/tutorials/contracts/nfts/js/enumeration) | Here you'll find different enumeration methods that can be used to return the smart contract's states. |
| 4.core | [Core](https://docs.near.org/docs/tutorials/contracts/nfts/js/core) | In this tutorial you'll extend the NFT contract using the core standard, which will allow you to transfer non-fungible tokens. |
| 5.approval | [Approval](https://docs.near.org/docs/tutorials/contracts/nfts/js/approvals) | Here you'll expand the contract allowing other accounts to transfer NFTs on your behalf. |
| 6.royalty | [Royalty](https://docs.near.org/docs/tutorials/contracts/nfts/js/royalty) |Here you'll add the ability for non-fungible tokens to have royalties. This will allow people to get a percentage of the purchase price when an NFT is purchased. |
| 7.events | ----------- | This allows indexers to know what functions are being called and make it easier and more reliable to keep track of information that can be used to populate the collectibles tab in the wallet for example. (tutorial docs have yet to be implemented ) |
| 8.marketplace | ----------- | ----------- |
The tutorial series also contains a very helpful section on [**Upgrading Smart Contracts**](https://docs.near.org/docs/tutorials/contracts/nfts/js/upgrade-contract). Definitely go and check it out as this is a common pain point.
# Quick-Start
If you want to see the full completed contract go ahead and clone and build this repo using
```=bash
git clone https://github.com/near-examples/nft-tutorial-js.git
cd nft-tutorial-js
yarn && yarn build
```
Now that you've cloned and built the contract we can try a few things.
## Mint An NFT
Once you've created your near wallet go ahead and login to your wallet with your cli and follow the on-screen prompts
```=bash
near login
```
Once your logged in you have to deploy the contract. Make a subaccount with the name of your choosing
```=bash
near create-account nft-example.your-account.testnet --masterAccount your-account.testnet --initialBalance 10
```
After you've created your sub account deploy the contract to that sub account, set this variable to your sub account name
```=bash
NFT_CONTRACT_ID=nft-example.your-account.testnet
MAIN_ACCOUNT=your-account.testnet
```
Verify your new variable has the correct value
```=bash
echo $NFT_CONTRACT_ID
echo $MAIN_ACCOUNT
```
### Deploy Your Contract
```=bash
near deploy --accountId $NFT_CONTRACT_ID --wasmFile build/nft.wasm
```
### Initialize Your Contract
```=bash
near call $NFT_CONTRACT_ID init '{"owner_id": "'$NFT_CONTRACT_ID'"}' --accountId $NFT_CONTRACT_ID
```
### View Contracts Meta Data
```=bash
near view $NFT_CONTRACT_ID nft_metadata
```
### Minting Token
```bash=
near call $NFT_CONTRACT_ID nft_mint '{"token_id": "token-1", "metadata": {"title": "My Non Fungible Team Token", "description": "The Team Most Certainly Goes :)", "media": "https://bafybeiftczwrtyr3k7a2k4vutd3amkwsmaqyhrdzlhvpt33dyjivufqusq.ipfs.dweb.link/goteam-gif.gif"}, "receiver_id": "'$MAIN_ACCOUNT'"}' --accountId $MAIN_ACCOUNT --amount 0.1
```
After you've minted the token go to wallet.testnet.near.org to `your-account.testnet` and look in the collections tab and check out your new sample NFT!
## View NFT Information
After you've minted your NFT you can make a view call to get a response containing the `token_id` `owner_id` and the `metadata`
```bash=
near view $NFT_CONTRACT_ID nft_token '{"token_id": "token-1"}'
```
## Transfering NFTs
To transfer an NFT go ahead and make another [testnet wallet account](https://wallet.testnet.near.org).
Then run the following
```bash=
MAIN_ACCOUNT_2=your-second-wallet-account.testnet
```
Verify the correct variable names with this
```=bash
echo $NFT_CONTRACT_ID
echo $MAIN_ACCOUNT
echo $MAIN_ACCOUNT_2
```
To initiate the transfer..
```bash=
near call $NFT_CONTRACT_ID nft_transfer '{"receiver_id": "$MAIN_ACCOUNT_2", "token_id": "token-1", "memo": "Go Team :)"}' --accountId $MAIN_ACCOUNT --depositYocto 1
```
In this call you are depositing 1 yoctoNEAR for security and so that the user will be redirected to the NEAR wallet.
|
myasin786786_Helm3-k8s | README.md
db.js
docker-compose.yml
entrypoint.sh
frontity.settings.js
get_helm.sh
helm-antia-charts
templates
NOTES.txt
helm-chart
templates
NOTES.txt
jenkins
scripts
docker-build.sh
docker-push.sh
remote-deploy.sh
key.txt
mongo-setup
mongo-setup.js
mongo-setup.sh
wait-for-it.sh
package.json
packages
mars-theme
CHANGELOG.md
README.md
package.json
src
assets
antliaexplorer.svg
antliafaucet.svg
antliawallet.svg
color.svg
team
shakil.svg
white.svg
components
ANACoin
ANACoin.js
AboutUs
AboutUs.js
AntliaEcosystem
AntliaEcosystem.js
Blog
Blog.js
Consensus
Consensus.js
ContactUs
ContactUs.js
DevToolTabs
DevToolTabs.js
DevTools
DevTools.js
Events
Events.js
Footer
Footer.js
Interoperable
Interoperable.js
Investment
Investment.js
InvestmentForm
InvestmentForm.js
MainBanner
MainBanner.js
MediaPartners
MediaPartners.js
OurPartners
OurPartners.js
PrivacyPolicy
PrivacyPolicy.js
Sitemap
Sitemap.js
SmartContract
SmartContract.js
TechnicalRoadmap
TechnicalRoadmap.js
comingsoon.js
featured-media.js
header.js
index.css
index.js
link.js
list
index.js
list-item.js
list.js
pagination.js
loading.js
menu-icon.js
menu-modal.js
menu.js
nav.js
page-error.js
post.js
title.js
index.js
store
SEO
Blog
structuredData.js
Homepage
structuredData.js
config.js
types.ts
robots.txt
sitemap.xml
|
# `@frontity/mars-theme`
[](https://www.npmjs.com/package/@frontity/mars-theme) [](https://www.npmjs.com/package/@frontity/mars-theme) [](https://github.com/frontity/frontity/blob/master/LICENSE)
A starter theme for Frontity
Full info about this theme can be found in the [docs](https://docs.frontity.org/frontity-themes/frontity-mars-theme)

## Table of contents
<!-- toc -->
- [Install](#install)
- [Usage](#usage)
- [Feature Discussions](#feature-discussions)
- [Changelog](#changelog)
- [Open Source Community](#open-source-community)
- [Channels](#channels)
- [Get involved](#get-involved)
<!-- tocstop -->
## Install
```sh
npm i @frontity/mars-theme
```
## Usage
Once installed it should be included in your `frontity.settings.js`.
The theme options can be specified in the `state.theme` property.
```javascript
{
name: "@frontity/mars-theme",
state: {
theme: {
menu: [
["Home", "/"],
["Nature", "/category/nature/"],
["Travel", "/category/travel/"],
["Japan", "/tag/japan/"],
["About Us", "/about-us/"]
],
featured: {
showOnList: true,
showOnPost: true
}
}
}
},
```
Full info about this theme can be found in the [docs](https://docs.frontity.org/frontity-themes/frontity-mars-theme)
## Feature Discussions
[**Feature Discussions**](https://community.frontity.org/c/feature-discussions/33) about Frontity are public. You can join the discussions, vote for those you're interested in or create new ones.
These are the ones related to this package: https://community.frontity.org/tags/c/feature-discussions/33/mars-theme
## Changelog
Have a look at the latest updates of this package in the [CHANGELOG](CHANGELOG.md)
---
## Open Source Community
### Channels
[](https://community.frontity.org/) [](https://twitter.com/frontity) 
Frontity has a number of different channels at your disposal where you can find out more information about the project, join in discussions about it, and also get involved:
- **📖 [Docs](https://docs.frontity.org/):** Frontity's primary documentation resource - this is the place to learn how to build amazing sites with Frontity.
* **👨👩👧👦 [Community forum](https://community.frontity.org/):** join Frontity's forum and ask questions, share your knowledge, give feedback and meet other cool Frontity people. We'd love to know about what you're building with Frontity, so please do swing by the [forum](https://community.frontity.org/) and tell us about your projects.
* **🐞 Contribute:** Frontity uses [GitHub](https://github.com/frontity/frontity) for bugs and pull requests. Check out the [Contributing](../../CONTRIBUTING.md/) section to find out how you can help develop Frontity, or improve this documentation.
* **🗣 Social media**: interact with other Frontity users. Reach out to the Frontity team on [Twitter](https://twitter.com/frontity). Mention us in your tweets about Frontity and what you're building by using **`@frontity`**.
* 💌 **Newsletter:** do you want to receive the latest news about Frontity and find out as soon as there's an update to the framework? Subscribe to our [newsletter](https://frontity.org/newsletter).
### Get involved
[](https://github.com/frontity/frontity/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22)
Got questions or feedback about Frontity? We'd love to hear from you in our [community forum](https://community.frontity.org).
Frontity also welcomes contributions. There are many ways to support the project! If you don't know where to start then this guide might help: [How to contribute?](https://docs.frontity.org/contributing/how-to-contribute).
If you would like to start contributing to the code please open a pull request to address one of our [_good first issues_](https://github.com/frontity/frontity/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22).
|
noemk2_quickjs-wasm-near | .github
FUNDING.yml
workflows
main.yml
.gitpod.yml
README.md
cutils.c
cutils.h
dist
index.html
examples
fib.c
fib_module.js
hello.js
hello_module.js
pi_bigdecimal.js
pi_bigfloat.js
pi_bigint.js
point.c
test_fib.js
test_point.js
libbf.c
libbf.h
libregexp-opcode.h
libregexp.c
libregexp.h
libunicode-table.h
libunicode.c
libunicode.h
list.h
qjs.c
qjsc.c
qjscalc.js
quickjs-atom.h
quickjs-libc.c
quickjs-libc.h
quickjs-opcode.h
quickjs.h
readme.txt
release.sh
repl.js
run-test262.c
showcase
audioworkletprocessor.js
closeprotocol.component.html
closeprotocol.component.js
closeprotocol.html
contract.js
synth.js
test262_errors.txt
test262o_errors.txt
tests
bjson.c
microbench.js
test_bignum.js
test_bjson.js
test_builtin.js
test_closure.js
test_language.js
test_loop.js
test_op_overloading.js
test_qjscalc.js
test_std.js
test_worker.js
test_worker_module.js
unicode_download.sh
unicode_gen.c
unicode_gen_def.h
wasmlib
build.sh
libjseval.c
wasmlib.c
web
app.component.css
app.component.html
app.component.js
app.component.spec.js
callcontract
callcontract-page.component.css
callcontract-page.component.html
callcontract-page.component.js
code-editor
code-editor.component.js
code-page.component.css
code-page.component.html
code-page.component.js
common
progressindicator.js
compiler
compile.spec.js
nearenv.js
nearenv.spec.js
quickjs.js
wasi.js
importmap.js
importmapgenerator.js
index.html
near
near.component.html
near.component.js
near.js
near.spec.js
package-lock.json
package.json
rollup.config.js
| QuickJS for WebAssembly on NEAR protocol
========================================
QuickJS compiled to WebAssembly and a Web application for creating NEAR smart contracts in Javascript to run on smart contract VMs created with near-js-sdk.
[near-sdk-js](https://github.com/near/near-sdk-js>) makes it possible to deploy Javascript smart contracts on NEAR protocol.
This web application let you write, simulate, deploy and call your javascript smart contracts in the web browser.
Note: Currently you can only create low-level ( [see examples here](https://github.com/near/near-sdk-js/tree/master/examples/low-level) ) contracts from here.
# How to use?
Check out the deployment at https://petersalomonsen.github.io/quickjs-wasm-near/dist/index.html where you can choose between coding or calling contract in the left menu.
Choose `Code` and enter some source code in the code editor:
```
export function hello() {
env.log("Hello Near");
}
```
Now click `save` and you'll see that the `hello` method shows up in the method dropdown under `Simulation`. Click the `run` button to see the simulation output. You can also add arguments, deposits and storage to the simulation. If your code alters storage then that will affect the storage items after running.
Finally click `deploy` to upload your code on-chain. Note that deploying needs deposit, read more about it here: https://github.com/near/near-sdk-js#usage
After deploying you can call your contract, and test with arguments and deposit.
# Building
Building this projects involves compiling QuickJS as a static library using [emscripten](https://emscripten.org) and link to a Webassembly binary with the simple wrapper library in the [wasmlib](wasmlib) folder. This provides the in-browser simulation capacity.
The web application itself is in the [web](web) folder and is a pure web component app without any framework like React or Angular. For UI components [Material Design Web Components](https://github.com/material-components/material-web) is used, and for the code editor [CodeMirror 6](https://codemirror.net/6/). To be able to use these with "bare module imports" ( e.g. `import '@material/mwc-top-app-bar';` ), an [import map](https://github.com/WICG/import-maps) is needed, which is generated using the [JSPM Import Map Generator](https://github.com/jspm/generator). Given this it's possible to host the web app directly from the source files with static hosting, no development bundler like webpack is needed. Finally also a [rollup configuration](web/rollup.config.js) is provided for single js bundle production builds, which can be found in the [dist](dist) folder and is used for the hosted version.
Also see the [github actions pipeline](.github/workflows/main.yml) for commands to build and run the tests.
|
josefophe_nearmock | .github
dependabot.yml
workflows
tests.yml
.gitpod.yml
.travis.yml
Cargo.toml
README-Gitpod.md
README-Windows.md
README.md
borsh.js
frontend
App.js
config.js
index.html
index.js
package-lock.json
package.json
src
lib.rs
test.bat
test.js
test.sh
tests-ava
README.md
__tests__
main.ava.ts
package.json
tsconfig.json
| ## Inspiration
I have been in the education space for some years and I see the need for genuine community sharing between tutors and students for positive changes students performance using technology. This has been my personal project for some time now how tutors can share knowledge and earn token when student access their assessments within the Near Protocol ecosystem.
## What it does.
iMock is an decentralized app solution aimed to improve secondary school students(as a first case study), an Educational platform that enables learning at an easy pace, cost-effective and community based solution, providing seamless access to curated education assessment for students based on their curriculum. iMock is transparent in services and payment between authors/tutors and learners/students. User interface friendly, and on the blockchain (Near protocol).
- A tutor login with their near account and post their questions making a contract call and paying initial deposit of some near token(which covers gas fee and iMock storage fee)
- Students login with their near accounts, pay a token which in turns go back to the tutor (owner of the contract) they can practice the questions based on what they've learnt during the week at the end of each week making them conversant of what they learnt.
## How I built it
The contract was written in assembly script while the front was built with Typescript, chakra ui and firebase.
## Challenges I ran into
I had a learning challenge working with server side database storage with smart contracts or web3 as I cannot write to the database without a user token from firebase to authenticate the user writing to the database. This remain a big challenge for me storing data with a near account login model. I am yet to resolve this.
## Accomplishments that I am proud of
I was able to set up a login with near feature and authentication and smart contracts on assembly script.
## What I learned
Building with near protocol is quite an interesting journey as there is a lot to learn about web3 technology and how it works. With near I was able to full understand deployment and web3 accounts.
Status Message
==============
[](https://gitpod.io/#https://github.com/near-examples/rust-status-message)
<!-- MAGIC COMMENT: DO NOT DELETE! Everything above this line is hidden on NEAR Examples page -->
This smart contract saves and records the status messages of NEAR accounts that call it.
Windows users: please visit the [Windows-specific README file](README-Windows.md).
## Prerequisites
Ensure `near-cli` is installed by running:
```
near --version
```
If needed, install `near-cli`:
```
npm install near-cli -g
```
Ensure `Rust` is installed by running:
```
rustc --version
```
If needed, install `Rust`:
```
curl https://sh.rustup.rs -sSf | sh
```
Install dependencies
```
npm install
```
## Quick Start
To run this project locally:
1. Prerequisites: Make sure you have Node.js ≥ 12 installed (https://nodejs.org), then use it to install yarn: `npm install --global yarn` (or just `npm i -g yarn`)
2. Run the local development server: `yarn && yarn dev` (see package.json for a full list of scripts you can run with yarn)
Now you'll have a local development environment backed by the NEAR TestNet! Running yarn dev will tell you the URL you can visit in your browser to see the app.
## Building this contract
To make the build process compatible with multiple operating systems, the build process exists as a script in `package.json`.
There are a number of special flags used to compile the smart contract into the wasm file.
Run this command to build and place the wasm file in the `res` directory:
```bash
npm run build
```
**Note**: Instead of `npm`, users of [yarn](https://yarnpkg.com) may run:
```bash
yarn build
```
### Important
If you encounter an error similar to:
>note: the `wasm32-unknown-unknown` target may not be installed
Then run:
```bash
rustup target add wasm32-unknown-unknown
```
## Using this contract
### Web app
Deploy the smart contract to a specific account created with the NEAR Wallet. Then interact with the smart contract using near-api-js on the frontend.
If you do not have a NEAR account, please create one with [NEAR Wallet](https://wallet.testnet.near.org).
Make sure you have credentials saved locally for the account you want to deploy the contract to. To perform this run the following `near-cli` command:
```
near login
```
Deploy the contract to your NEAR account:
```bash
near deploy --wasmFile res/status_message.wasm --accountId YOUR_ACCOUNT_NAME
```
Build the frontend:
```bash
npm start
```
If all is successful the app should be live at `localhost:1234`!
### Quickest deploy
Build and deploy this smart contract to an development account. This development account will be created automatically and is not intended to be permanent. Please see the "Standard deploy" section for creating a more personalized account to deploy to.
```bash
near dev-deploy --wasmFile res/status_message.wasm --helperUrl https://near-contract-helper.onrender.com
```
Behind the scenes, this is creating an account and deploying a contract to it. On the console, notice a message like:
>Done deploying to dev-1234567890123
In this instance, the account is `dev-1234567890123`. A file has been created containing the key to the account, located at `neardev/dev-account`. To make the next few steps easier, we're going to set an environment variable containing this development account id and use that when copy/pasting commands.
Run this command to the environment variable:
```bash
source neardev/dev-account.env
```
You can tell if the environment variable is set correctly if your command line prints the account name after this command:
```bash
echo $CONTRACT_NAME
```
The next command will call the contract's `set_status` method:
```bash
near call $CONTRACT_NAME set_status '{"message": "aloha!"}' --accountId $CONTRACT_NAME
```
To retrieve the message from the contract, call `get_status` with the following:
```bash
near view $CONTRACT_NAME get_status '{"account_id": "'$CONTRACT_NAME'"}'
```
### Standard deploy
In this option, the smart contract will get deployed to a specific account created with the NEAR Wallet.
If you do not have a NEAR account, please create one with [NEAR Wallet](https://wallet.testnet.near.org).
Make sure you have credentials saved locally for the account you want to deploy the contract to. To perform this run the following `near-cli` command:
```
near login
```
Deploy the contract:
```bash
near deploy --wasmFile res/status_message.wasm --accountId YOUR_ACCOUNT_NAME
```
Set a status for your account:
```bash
near call YOUR_ACCOUNT_NAME set_status '{"message": "aloha friend"}' --accountId YOUR_ACCOUNT_NAME
```
Get the status:
```bash
near view YOUR_ACCOUNT_NAME get_status '{"account_id": "YOUR_ACCOUNT_NAME"}'
```
Note that these status messages are stored per account in a `HashMap`. See `src/lib.rs` for the code. We can try the same steps with another account to verify.
**Note**: we're adding `NEW_ACCOUNT_NAME` for the next couple steps.
There are two ways to create a new account:
- the NEAR Wallet (as we did before)
- `near create_account NEW_ACCOUNT_NAME --masterAccount YOUR_ACCOUNT_NAME`
Now call the contract on the first account (where it's deployed):
```bash
near call YOUR_ACCOUNT_NAME set_status '{"message": "bonjour"}' --accountId NEW_ACCOUNT_NAME
```
```bash
near view YOUR_ACCOUNT_NAME get_status '{"account_id": "NEW_ACCOUNT_NAME"}'
```
Returns `bonjour`.
Make sure the original status remains:
```bash
near view YOUR_ACCOUNT_NAME get_status '{"account_id": "YOUR_ACCOUNT_NAME"}'
```
## Testing
To test run:
```bash
cargo test --package status-message -- --nocapture
```
These tests use [near-workspaces-ava](https://github.com/near/workspaces-js/tree/main/packages/ava): delightful, deterministic local testing for NEAR smart contracts.
You will need to install [NodeJS](https://nodejs.dev/). Then you can use the `scripts` defined in [package.json](./package.json):
npm run test
If you want to run `near-workspaces-ava` or `ava` directly, you can use [npx](https://nodejs.dev/learn/the-npx-nodejs-package-runner):
npx near-workspaces-ava --help
npx ava --help
To run only one test file:
npm run test "**/main*" # matches test files starting with "main"
npm run test "**/whatever/**/*" # matches test files in the "whatever" directory
To run only one test:
npm run test -- -m "root sets*" # matches tests with titles starting with "root sets"
yarn test -m "root sets*" # same thing using yarn instead of npm, see https://yarnpkg.com/
# Rust Smart Contract Template
## Getting started
To get started with this template:
1. Click the "Use this template" button to create a new repo based on this template
2. Update line 2 of `Cargo.toml` with your project name
3. Update line 4 of `Cargo.toml` with your project author names
4. Set up the [prerequisites](https://github.com/near/near-sdk-rs#pre-requisites)
5. Begin writing your smart contract in `src/lib.rs`
6. Test the contract
`cargo test -- --nocapture`
8. Build the contract
`RUSTFLAGS='-C link-arg=-s' cargo build --target wasm32-unknown-unknown --release`
**Get more info at:**
* [Rust Smart Contract Quick Start](https://docs.near.org/docs/develop/contracts/rust/intro)
* [Rust SDK Book](https://www.near-sdk.io/)
# `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **simple** in the `src/simple` folder
- **singleton** in the `src/singleton` folder
### Simple
We say that an AssemblyScript contract is written in the "simple style" when the `index.ts` file (the contract entry point) includes a series of exported functions.
In this case, all exported functions become public contract methods.
```ts
// return the string 'hello world'
export function helloWorld(): string {}
// read the given key from account (contract) storage
export function read(key: string): string {}
// write the given value at the given key to account (contract) storage
export function write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
```
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
INSTALL `NEAR CLI` first like this: `npm i -g near-cli`
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── simple # Contract 1: "Simple example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 1
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 1
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
|
isikara_NearPaper-New_Name_of_the_Newspaper_Smart-Contract | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.dev-deploy.sh
2.health-check.sh
3.publish-news.sh
4.bring-news.sh
5.read-news.sh
6.delete-news.sh
7.send-gratitude.sh
README.md
src
as_types.d.ts
simple
asconfig.json
assembly
index.ts
model.ts
tsconfig.json
utils.ts
| ## Setting up your terminal
The scripts in this folder support a simple demonstration of the contract.
It uses the following setup:
```txt
┌───────────────────────────────────────┬───────────────────────────────────────┐
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
└───────────────────────────────────────┴───────────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export MY_ACC= # any account you control
export ID= # id of a specific news
export NEWS= # news
export AMOUNT= # donation amount
# for example
# export CONTRACT=dev-1651118992529-51112783772875
# export MY_ACC=alidev.testnet
# export ID=alidev.testnet
# export NEWS="What happened today?"
```
- Commands
_Public scripts_
```sh
1.dev-deploy.sh
2.health-check.sh
3.publish-news.sh
4.bring-news.sh
5.read-news.sh
6.delete-news.sh
7.send-gratitude.sh
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1651118992529-51112783772875
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
<div align="center">
<h3 align="center">NearPaper - Next Generation Newspaper Project</h3>
</div>

<details>
<summary>Table of Contents</summary>
<ol>
<li>
<a href="#intro">Introduction</a>
</li>
<li>
<a href="#infrastructure">Infrastructure</a>
</li>
<li>
<a href="#deploy-usage">Deploy and Usage</a>
</li>
<li><a href="#codereview">Code Review</a></li>
</ol>
</details>
### Intro
Next generation technologies continue to change the definition of many professions. Journalism is absolutely one of them and The NearPaper project is here to rewrite the codes of journalism. The main idea of the NearPaper project is to provide a fully decentralized and independent journalism infrastructure to the ecosystem. NearPaper users call themself pro-consumers that they can read and publish news without limitation of any central authority.
### Infrastructure
NearPaper is built on Near Blockchain. The web interface of the project is under development. Creating integrated applications for mobile users is also at the top of the list of near plans. The NearPaper project continues to be developed by following the nostalgic phenomena of its natural identity and by emporing destrucitive technologies. If you would like to be a part of the NearPaper project; you can clone, recode and play with the code. However, please don't hesitate to reach us. Remember! Legends don't die, they just change shape.
### Deploy-Usage
To deploy the contract for development, follow these steps:
1. clone this repo locally (`git clone https://github.com/isikara/NearPaper-New_Name_of_the_Newspaper_Smart-Contract.git`)
2. run `yarn` to install dependencies (`yarn`)
3. run `yarn build:release` to build your wasm file (`yarn build:release`)
3. run `./build/release/simple.wasm` to deploy the contract (`near dev-deploy ./build/release/simple.wasm`)
4. export `CONTRACT` to the deployed contract name (`export CONTRACT=<Contract-Name>`)
5. check `CONTRACT` veriable (`echo $CONTRACT`)
6. export `OWNER` (`export OWNER=<Your-Account-Name>`)
7. check `OWNER` (`echo $OWNER`)
To use the contract you can do any of the following:
|Name|Type|Details|Functionality|How to Call|
|---|---|---|---|---|
|allNews|PersistentUnorderedMap|public|This class is used to store all news with their id's.|-|
|News|Class|public|This class is state news with its id, newsman and publish date.|-|
|healthCheck|Function|public - view function|This function is used for general check.|`near call $CONTRACT healthCheck '{"req" : "<Your-Key>","rep" : "<Your-Value>"}' --accountId <Your-Account-Name>`|
|publishNews|Function|public - call function|This function is used to publish a news.|`near call $CONTRACT publishNews '{"text" : "<Your-News>"}' --accountId <Your-Account-Name>`|
|bringNews|Function|public - view function|This function is used to get a specific news by using its id.|`near view $CONTRACT bringNews '{"id" : <News-Id>}'`|
|readNews|Function|public - view function|This function is used to read all news on the contract.|`near view $CONTRACT readNews`|
|deleteNews|Function|public - call function|This function is used to delete a specific news by using its is. Only the account published the news can delete it.|`near call $CONTRACT deleteNews '{"id" : <News-Id>}' --accountId <Your-Account-Name>`|
|sendGratitude|Function|public - call function|This function is used to donate the Newsman by using it account name.|`near call $CONTRACT sendGratitude '{"newsman" : "<Newsman-Account-Name>"}' --amount <Donation-Amount> --accountId <Your-Account_name>`|
### CodeReview
model.ts
```ts
import {context, PersistentUnorderedMap, math, logging } from "near-sdk-as";
export const allNews = new PersistentUnorderedMap<u32, News>("allNews");
@nearBindgen
export class News {
id: u32;
sender: string;
date: u64;
constructor(public text: string) {
this.id = math.hash32<string>(text);
this.sender = context.sender;
this.date = context.blockTimestamp;
}
static publish(text: string): News {
const news = new News(text);
allNews.set(news.id, news);
return news;
}
static bringFromArchieve(id: u32): News {
return allNews.getSome(id);
}
static readANews(): News[] {
let start: u32 = 0;
logging.log("You can donate to a Newsman using 'sendGratitude' function!");
return allNews.values(start, allNews.length);
}
static deleteANews(id: u32): void {
const news = allNews.getSome(id);
assert(news.sender == context.sender, "It is not your news! First, you need to publish a News to delete it! Use 'publishNews' function");
allNews.delete(id);
}
}
```
index.ts
```ts
import { context, ContractPromiseBatch, logging, u128 } from "near-sdk-as";
import { AccountId } from "../../utils";
import { News, allNews } from "./model";
//Create and Publish a News
export function publishNews(text: string): News {
logging.log("A scratch to the history of the future!");
return News.publish(text);
}
//Take a Look to Archieve
export function bringNews(id: u32): News {
logging.log("You can send your thanks to the Newsman using 'sendGratitude' function!");
return News.bringFromArchieve(id);
}
//Read a News
export function readNews(): News[] {
assert(allNews.length > 0, "Nothing remarkable happens in these days.");
return News.readANews();
}
//Delete your News
export function deleteNews(id: u32): void {
logging.log("Looking forward to your new news!");
News.deleteANews(id);
}
//Donate the Newsman
export function sendGratitude(newsman: AccountId): void {
assert(context.accountBalance > context.attachedDeposit, "Your balance is not enough!");
logging.log(`Comolokko! ${context.attachedDeposit.toString()} yoktoNEAR sent`);
ContractPromiseBatch.create(newsman).transfer(context.attachedDeposit);
}
```
|
kuutamolabs_electrs | .hooks
install.sh
.travis.yml
Cargo.toml
README.md
RELEASE-NOTES.md
TODO.md
doc
schema.md
usage.md
scripts
run.sh
src
app.rs
bin
electrs.rs
popular-scripts.rs
tx-fingerprint-stats.rs
chain.rs
config.rs
daemon.rs
electrum
client.rs
discovery.rs
discovery
default_servers.rs
mod.rs
server.rs
elements
asset.rs
mod.rs
peg.rs
registry.rs
errors.rs
lib.rs
metrics.rs
new_index
db.rs
fetch.rs
mempool.rs
mod.rs
precache.rs
query.rs
schema.rs
rest.rs
signal.rs
util
block.rs
electrum_merkle.rs
fees.rs
mod.rs
script.rs
transaction.rs
tools
addr.py
client.py
mempool.py
xpub.py
| # Esplora - Electrs backend API
A block chain index engine and HTTP API written in Rust based on [romanz/electrs](https://github.com/romanz/electrs).
Used as the backend for the [Esplora block explorer](https://github.com/Blockstream/esplora) powering [blockstream.info](https://blockstream.info/).
API documentation [is available here](https://github.com/blockstream/esplora/blob/master/API.md).
Documentation for the database schema and indexing process [is available here](doc/schema.md).
### Installing & indexing
Install Rust, Bitcoin Core (no `txindex` needed) and the `clang` and `cmake` packages, then:
```bash
$ git clone https://github.com/blockstream/electrs && cd electrs
$ git checkout new-index
$ cargo run --release --bin electrs -- -vvvv --daemon-dir ~/.bitcoin
# Or for liquid:
$ cargo run --features liquid --release --bin electrs -- -vvvv --network liquid --daemon-dir ~/.liquid
```
See [electrs's original documentation](https://github.com/romanz/electrs/blob/master/doc/usage.md) for more detailed instructions.
Note that our indexes are incompatible with electrs's and has to be created separately.
The indexes require 610GB of storage after running compaction (as of June 2020), but you'll need to have
free space of about double that available during the index compaction process.
Creating the indexes should take a few hours on a beefy machine with SSD.
To deploy with Docker, follow the [instructions here](https://github.com/Blockstream/esplora#how-to-build-the-docker-image).
### Light mode
For personal or low-volume use, you may set `--lightmode` to reduce disk storage requirements
by roughly 50% at the cost of slower and more expensive lookups.
With this option set, raw transactions and metadata associated with blocks will not be kept in rocksdb
(the `T`, `X` and `M` indexes),
but instead queried from bitcoind on demand.
### Notable changes from Electrs:
- HTTP REST API in addition to the Electrum JSON-RPC protocol, with extended transaction information
(previous outputs, spending transactions, script asm and more).
- Extended indexes and database storage for improved performance under high load:
- A full transaction store mapping txids to raw transactions is kept in the database under the prefix `t`.
- An index of all spendable transaction outputs is kept under the prefix `O`.
- An index of all addresses (encoded as string) is kept under the prefix `a` to enable by-prefix address search.
- A map of blockhash to txids is kept in the database under the prefix `X`.
- Block stats metadata (number of transactions, size and weight) is kept in the database under the prefix `M`.
With these new indexes, bitcoind is no longer queried to serve user requests and is only polled
periodically for new blocks and for syncing the mempool.
- Support for Liquid and other Elements-based networks, including CT, peg-in/out and multi-asset.
(requires enabling the `liquid` feature flag using `--features liquid`)
### CLI options
In addition to electrs's original configuration options, a few new options are also available:
- `--http-addr <addr:port>` - HTTP server address/port to listen on (default: `127.0.0.1:3000`).
- `--lightmode` - enable light mode (see above)
- `--cors <origins>` - origins allowed to make cross-site request (optional, defaults to none).
- `--address-search` - enables the by-prefix address search index.
- `--index-unspendables` - enables indexing of provably unspendable outputs.
- `--utxos-limit <num>` - maximum number of utxos to return per address.
- `--electrum-txs-limit <num>` - maximum number of txs to return per address in the electrum server (does not apply for the http api).
- `--electrum-banner <text>` - welcome banner text for electrum server.
Additional options with the `liquid` feature:
- `--parent-network <network>` - the parent network this chain is pegged to.
Additional options with the `electrum-discovery` feature:
- `--electrum-hosts <json>` - a json map of the public hosts where the electrum server is reachable, in the [`server.features` format](https://electrumx.readthedocs.io/en/latest/protocol-methods.html#server.features).
- `--electrum-announce` - announce the electrum server on the electrum p2p server discovery network.
See `$ cargo run --release --bin electrs -- --help` for the full list of options.
## License
MIT
|
harshabakku_rainbow-bridge-ETH-XTZ | .buildkite
pipeline.yml
.pnp.js
.yarn
build-state.yml
unplugged
@web3-js-scrypt-shim-npm-0.1.0-863fdedab0
node_modules
@web3-js
scrypt-shim
LICENSE.md
README.md
package.json
scripts
postinstall.js
src
browser.js
index.js
@web3-js-websocket-npm-1.0.30-5f6c45434e
node_modules
@web3-js
websocket
CHANGELOG.md
README.md
gulpfile.js
index.js
lib
BufferUtil.fallback.js
BufferUtil.js
Deprecation.js
Validation.fallback.js
Validation.js
W3CWebSocket.js
WebSocketClient.js
WebSocketConnection.js
WebSocketFrame.js
WebSocketRequest.js
WebSocketRouter.js
WebSocketRouterRequest.js
WebSocketServer.js
browser.js
utils.js
version.js
websocket.js
package.json
vendor
FastBufferList.js
bufferutil-npm-4.0.2-6f283689b1
node_modules
bufferutil
README.md
fallback.js
index.js
package.json
src
bufferutil.c
fsevents-patch-dd91e7dab0
node_modules
fsevents
README.md
fsevents.d.ts
fsevents.js
package.json
vfs.js
keccak-npm-3.0.1-9f0a714d5c
node_modules
keccak
README.md
bindings.js
index.js
js.js
lib
api
index.js
keccak.js
shake.js
keccak-state-reference.js
keccak-state-unroll.js
keccak.js
package.json
src
README.md
libkeccak-32
KeccakP-1600-SnP.h
KeccakP-1600-inplace32BI.c
KeccakSponge-common.h
KeccakSpongeWidth1600.c
KeccakSpongeWidth1600.h
SnP-Relaned.h
align.h
brg_endian.h
libkeccak-64
KeccakP-1600-SnP.h
KeccakP-1600-opt64-config.h
KeccakP-1600-opt64.c
KeccakSponge-common.h
KeccakSpongeWidth1600.c
KeccakSpongeWidth1600.h
SnP-Relaned.h
align.h
brg_endian.h
nan-npm-2.14.2-e3ede8ce5d
node_modules
nan
CHANGELOG.md
LICENSE.md
README.md
doc
asyncworker.md
buffers.md
callback.md
converters.md
errors.md
json.md
maybe_types.md
methods.md
new.md
node_misc.md
object_wrappers.md
persistent.md
scopes.md
script.md
string_bytes.md
v8_internals.md
v8_misc.md
include_dirs.js
nan.h
nan_callbacks.h
nan_callbacks_12_inl.h
nan_callbacks_pre_12_inl.h
nan_converters.h
nan_converters_43_inl.h
nan_converters_pre_43_inl.h
nan_define_own_property_helper.h
nan_implementation_12_inl.h
nan_implementation_pre_12_inl.h
nan_json.h
nan_maybe_43_inl.h
nan_maybe_pre_43_inl.h
nan_new.h
nan_object_wrap.h
nan_persistent_12_inl.h
nan_persistent_pre_12_inl.h
nan_private.h
nan_string_bytes.h
nan_typedarray_contents.h
nan_weak.h
package.json
tools
1to2.js
README.md
package.json
node-addon-api-npm-2.0.2-8c2c1e9782
node_modules
node-addon-api
.travis.yml
CHANGELOG.md
CODE_OF_CONDUCT.md
CONTRIBUTING.md
LICENSE.md
README.md
appveyor.yml
doc
array_buffer.md
async_context.md
async_operations.md
async_progress_worker.md
async_worker.md
basic_types.md
bigint.md
boolean.md
buffer.md
callback_scope.md
callbackinfo.md
checker-tool.md
class_property_descriptor.md
cmake-js.md
conversion-tool.md
creating_a_release.md
dataview.md
date.md
env.md
error.md
error_handling.md
escapable_handle_scope.md
external.md
function.md
function_reference.md
generator.md
handle_scope.md
memory_management.md
node-gyp.md
number.md
object.md
object_lifetime_management.md
object_reference.md
object_wrap.md
prebuild_tools.md
promises.md
property_descriptor.md
range_error.md
reference.md
setup.md
string.md
symbol.md
threadsafe_function.md
type_error.md
typed_array.md
typed_array_of.md
value.md
version_management.md
working_with_javascript_values.md
external-napi
node_api.h
index.js
napi-inl.deprecated.h
napi-inl.h
napi.h
package.json
src
node_api.h
node_api_types.h
node_internals.h
nothing.c
util-inl.h
util.h
tools
README.md
check-napi.js
conversion.js
node-gyp-npm-7.1.2-002c5798eb
node_modules
node-gyp
.github
ISSUE_TEMPLATE.md
PULL_REQUEST_TEMPLATE.md
workflows
tests.yml
CHANGELOG.md
CONTRIBUTING.md
README.md
bin
node-gyp.js
gyp
.github
workflows
Python_tests.yml
node-gyp.yml
nodejs-windows.yml
release-please.yml
CHANGELOG.md
CODE_OF_CONDUCT.md
CONTRIBUTING.md
README.md
gyp.bat
gyp_main.py
pylib
gyp
MSVSNew.py
MSVSProject.py
MSVSSettings.py
MSVSSettings_test.py
MSVSToolFile.py
MSVSUserFile.py
MSVSUtil.py
MSVSVersion.py
__init__.py
common.py
common_test.py
easy_xml.py
easy_xml_test.py
flock_tool.py
generator
__init__.py
analyzer.py
android.py
cmake.py
compile_commands_json.py
dump_dependency_json.py
eclipse.py
gypd.py
gypsh.py
make.py
msvs.py
msvs_test.py
ninja.py
ninja_test.py
xcode.py
xcode_test.py
input.py
input_test.py
mac_tool.py
msvs_emulation.py
ninja_syntax.py
simple_copy.py
win_tool.py
xcode_emulation.py
xcode_ninja.py
xcodeproj_file.py
xml_fix.py
requirements_dev.txt
setup.py
test_gyp.py
tools
emacs
run-unit-tests.sh
graphviz.py
pretty_gyp.py
pretty_sln.py
pretty_vcproj.py
lib
Find-VisualStudio.cs
build.js
clean.js
configure.js
find-node-directory.js
find-python.js
find-visualstudio.js
install.js
list.js
node-gyp.js
process-release.js
proxy.js
rebuild.js
remove.js
util.js
macOS_Catalina.md
macOS_Catalina_acid_test.sh
package.json
test
common.js
fixtures
VS_2017_BuildTools_minimal.txt
VS_2017_Community_workload.txt
VS_2017_Express.txt
VS_2017_Unusable.txt
VS_2019_BuildTools_minimal.txt
VS_2019_Community_workload.txt
VS_2019_Preview.txt
test-charmap.py
process-exec-sync.js
simple-proxy.js
test-addon.js
test-configure-python.js
test-download.js
test-find-accessible-sync.js
test-find-node-directory.js
test-find-python.js
test-find-visualstudio.js
test-install.js
test-options.js
test-process-release.js
update-gyp.py
secp256k1-npm-4.0.2-80b0224eff
node_modules
secp256k1
API.md
README.md
bindings.js
elliptic.js
index.js
lib
elliptic.js
index.js
package.json
src
secp256k1.h
secp256k1
.travis.yml
README.md
SECURITY.md
autogen.sh
contrib
lax_der_parsing.c
lax_der_parsing.h
lax_der_privatekey_parsing.c
lax_der_privatekey_parsing.h
include
secp256k1.h
secp256k1_ecdh.h
secp256k1_preallocated.h
secp256k1_recovery.h
src
basic-config.h
bench.h
bench_ecdh.c
bench_ecmult.c
bench_internal.c
bench_recover.c
bench_sign.c
bench_verify.c
ecdsa.h
ecdsa_impl.h
eckey.h
eckey_impl.h
ecmult.h
ecmult_const.h
ecmult_const_impl.h
ecmult_gen.h
ecmult_gen_impl.h
ecmult_impl.h
field.h
field_10x26.h
field_10x26_impl.h
field_5x52.h
field_5x52_asm_impl.h
field_5x52_impl.h
field_5x52_int128_impl.h
field_impl.h
gen_context.c
group.h
group_impl.h
hash.h
hash_impl.h
java
org
bitcoin
NativeSecp256k1.java
NativeSecp256k1Test.java
NativeSecp256k1Util.java
Secp256k1Context.java
org_bitcoin_NativeSecp256k1.c
org_bitcoin_NativeSecp256k1.h
org_bitcoin_Secp256k1Context.c
org_bitcoin_Secp256k1Context.h
modules
ecdh
main_impl.h
tests_impl.h
recovery
main_impl.h
tests_impl.h
num.h
num_gmp.h
num_gmp_impl.h
num_impl.h
scalar.h
scalar_4x64.h
scalar_4x64_impl.h
scalar_8x32.h
scalar_8x32_impl.h
scalar_impl.h
scalar_low.h
scalar_low_impl.h
scratch.h
scratch_impl.h
secp256k1.c
testrand.h
testrand_impl.h
tests.c
tests_exhaustive.c
util.h
utf-8-validate-npm-5.0.3-70d3f814e3
node_modules
utf-8-validate
README.md
fallback.js
index.js
package.json
src
validation.c
web3-npm-1.2.6-4ec3c62f0f
node_modules
web3
README.md
angular-patch.js
package.json
src
index.js
types
index.d.ts
tests
web3-test.ts
tsconfig.json
tslint.json
web3-npm-1.3.0-685325b293
node_modules
web3
README.md
angular-patch.js
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
web3-test.ts
tsconfig.json
tslint.json
|
CHANGELOG.md
CODE_OF_CONDUCT.md
MIGRATION.md
README.md
SPEC.md
ci
e2e.sh
e2e_ci_prepare_env.sh
e2e_ci_prepare_log.sh
e2e_deploy_contract.sh
patch_contract_version.js
test_challenge.sh
test_ethrelay_catchup.sh
test_npm_package.sh
codechecks.yml
commands
clean.js
danger-deploy-myerc20.js
danger-submit-invalid-tezos-block.js
eth-dump.js
prepare.js
start
eth2tezos-relay.js
ganache.js
helpers.js
tezos.js
tezos2eth-relay.js
watchdog.js
status.js
stop
process.js
tezos-dump.js
config.json
docker-compose-dev.yml
docker-compose-prod.yml
docker-compose.yml
docs
README.md
workflows
eth2near-fun-transfer.md
index.js
lib
eth2tezos-relay.js
node_modules
.bin
sha.js
@ethersproject
abi
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
abi-coder.d.ts
abi-coder.js
coders
abstract-coder.d.ts
abstract-coder.js
address.d.ts
address.js
anonymous.d.ts
anonymous.js
array.d.ts
array.js
boolean.d.ts
boolean.js
bytes.d.ts
bytes.js
fixed-bytes.d.ts
fixed-bytes.js
null.d.ts
null.js
number.d.ts
number.js
string.d.ts
string.js
tuple.d.ts
tuple.js
fragments.d.ts
fragments.js
index.d.ts
index.js
interface.d.ts
interface.js
lib
_version.d.ts
_version.js
abi-coder.d.ts
abi-coder.js
coders
abstract-coder.d.ts
abstract-coder.js
address.d.ts
address.js
anonymous.d.ts
anonymous.js
array.d.ts
array.js
boolean.d.ts
boolean.js
bytes.d.ts
bytes.js
fixed-bytes.d.ts
fixed-bytes.js
null.d.ts
null.js
number.d.ts
number.js
string.d.ts
string.js
tuple.d.ts
tuple.js
fragments.d.ts
fragments.js
index.d.ts
index.js
interface.d.ts
interface.js
package.json
abstract-provider
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
abstract-signer
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
address
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
thirdparty.d.ts
base64
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
browser.d.ts
browser.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
browser.d.ts
browser.js
index.d.ts
index.js
package.json
bignumber
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
bignumber.d.ts
bignumber.js
fixednumber.d.ts
fixednumber.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
bignumber.d.ts
bignumber.js
fixednumber.d.ts
fixednumber.js
index.d.ts
index.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
thirdparty.d.ts
bytes
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
constants
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
hash
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
id.d.ts
id.js
index.d.ts
index.js
message.d.ts
message.js
namehash.d.ts
namehash.js
typed-data.d.ts
typed-data.js
lib
_version.d.ts
_version.js
id.d.ts
id.js
index.d.ts
index.js
message.d.ts
message.js
namehash.d.ts
namehash.js
typed-data.d.ts
typed-data.js
package.json
keccak256
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
node_modules
js-sha3
.travis.yml
CHANGELOG.md
LICENSE.txt
README.md
bower.json
build
sha3.min.js
index.d.ts
package.json
src
sha3.js
tests
index.html
node-test.js
test-shake.js
test.js
package.json
logger
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
networks
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
types.d.ts
types.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
types.d.ts
types.js
package.json
properties
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
rlp
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
signing-key
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
thirdparty.d.ts
strings
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
bytes32.d.ts
bytes32.js
idna.d.ts
idna.js
index.d.ts
index.js
utf8.d.ts
utf8.js
lib
_version.d.ts
_version.js
bytes32.d.ts
bytes32.js
idna.d.ts
idna.js
index.d.ts
index.js
utf8.d.ts
utf8.js
package.json
transactions
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
index.d.ts
index.js
lib
_version.d.ts
_version.js
index.d.ts
index.js
package.json
web
LICENSE.md
README.md
lib.esm
_version.d.ts
_version.js
browser-geturl.d.ts
browser-geturl.js
geturl.d.ts
geturl.js
index.d.ts
index.js
types.d.ts
types.js
lib
_version.d.ts
_version.js
browser-geturl.d.ts
browser-geturl.js
geturl.d.ts
geturl.js
index.d.ts
index.js
types.d.ts
types.js
package.json
thirdparty.d.ts
@jest
types
build
Circus.d.ts
Circus.js
Config.d.ts
Config.js
Global.d.ts
Global.js
index.d.ts
index.js
package.json
@opencensus
core
README.md
build
src
common
console-logger.d.ts
console-logger.js
time-util.d.ts
time-util.js
types.d.ts
types.js
validations.d.ts
validations.js
version.d.ts
version.js
exporters
console-exporter.d.ts
console-exporter.js
exporter-buffer.d.ts
exporter-buffer.js
types.d.ts
types.js
index.d.ts
index.js
internal
clock.d.ts
clock.js
cls-ah.d.ts
cls-ah.js
cls.d.ts
cls.js
string-utils.d.ts
string-utils.js
util.d.ts
util.js
metrics
export
base-metric-producer.d.ts
base-metric-producer.js
metric-producer-manager.d.ts
metric-producer-manager.js
types.d.ts
types.js
gauges
derived-gauge.d.ts
derived-gauge.js
gauge.d.ts
gauge.js
types.d.ts
types.js
metric-component.d.ts
metric-component.js
metric-registry.d.ts
metric-registry.js
metrics.d.ts
metrics.js
utils.d.ts
utils.js
resource
resource.d.ts
resource.js
types.d.ts
types.js
stats
bucket-boundaries.d.ts
bucket-boundaries.js
metric-producer.d.ts
metric-producer.js
metric-utils.d.ts
metric-utils.js
recorder.d.ts
recorder.js
stats.d.ts
stats.js
types.d.ts
types.js
view.d.ts
view.js
tags
tag-map.d.ts
tag-map.js
types.d.ts
types.js
validation.d.ts
validation.js
trace
config
types.d.ts
types.js
instrumentation
base-plugin.d.ts
base-plugin.js
types.d.ts
types.js
model
root-span.d.ts
root-span.js
span-base.d.ts
span-base.js
span.d.ts
span.js
tracer.d.ts
tracer.js
types.d.ts
types.js
propagation
types.d.ts
types.js
sampler
sampler.d.ts
sampler.js
types.d.ts
types.js
types.d.ts
types.js
node_modules
semver
CHANGELOG.md
README.md
package.json
semver.js
package.json
propagation-b3
README.md
build
src
b3-format.d.ts
b3-format.js
index.d.ts
index.js
node_modules
@opencensus
core
README.md
build
src
common
console-logger.d.ts
console-logger.js
types.d.ts
types.js
validations.d.ts
validations.js
version.d.ts
version.js
exporters
console-exporter.d.ts
console-exporter.js
exporter-buffer.d.ts
exporter-buffer.js
types.d.ts
types.js
index.d.ts
index.js
internal
clock.d.ts
clock.js
cls-ah.d.ts
cls-ah.js
cls.d.ts
cls.js
string-utils.d.ts
string-utils.js
util.d.ts
util.js
metrics
export
metric-producer.d.ts
metric-producer.js
types.d.ts
types.js
gauges
derived-gauge.d.ts
derived-gauge.js
gauge.d.ts
gauge.js
types.d.ts
types.js
metric-registry.d.ts
metric-registry.js
metrics.d.ts
metrics.js
utils.d.ts
utils.js
resource
resource.d.ts
resource.js
types.d.ts
types.js
stats
bucket-boundaries.d.ts
bucket-boundaries.js
metric-producer.d.ts
metric-producer.js
metric-utils.d.ts
metric-utils.js
recorder.d.ts
recorder.js
stats.d.ts
stats.js
types.d.ts
types.js
view.d.ts
view.js
trace
config
types.d.ts
types.js
instrumentation
base-plugin.d.ts
base-plugin.js
types.d.ts
types.js
model
root-span.d.ts
root-span.js
span-base.d.ts
span-base.js
span.d.ts
span.js
tracer.d.ts
tracer.js
types.d.ts
types.js
propagation
types.d.ts
types.js
sampler
sampler.d.ts
sampler.js
types.d.ts
types.js
types.d.ts
types.js
package.json
semver
CHANGELOG.md
README.md
package.json
semver.js
package.json
@pm2
agent-node
README.md
constants.js
index.js
node_modules
debug
CHANGELOG.md
README.md
dist
debug.js
node.js
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
ws
README.md
browser.js
index.js
lib
buffer-util.js
constants.js
event-target.js
extension.js
permessage-deflate.js
receiver.js
sender.js
validation.js
websocket-server.js
websocket.js
package.json
package.json
src
index.js
transport.js
utils
http.js
meta.js
agent
.mocharc.yml
.vscode
launch.json
README.md
config.js
constants.js
index.js
node_modules
debug
CHANGELOG.md
README.md
dist
debug.js
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
pm2-axon-rpc
.travis.yml
History.md
Readme.md
example.js
index.js
lib
client.js
server.js
node_modules
debug
CHANGELOG.md
README.md
dist
debug.js
node.js
package.json
src
browser.js
common.js
index.js
node.js
package.json
pm2-axon
.travis.yml
History.md
Readme.md
benchmark
pub.js
sub.js
index.js
lib
configurable
History.md
Readme.md
index.js
lib
configurable.js
package.json
index.js
plugins
queue.js
round-robin.js
sockets
pub-emitter.js
pub.js
pull.js
push.js
rep.js
req.js
sock.js
sub-emitter.js
sub.js
utils.js
node_modules
debug
CHANGELOG.md
README.md
dist
debug.js
node.js
package.json
src
browser.js
common.js
index.js
node.js
package.json
semver
CHANGELOG.md
README.md
bin
semver.js
classes
comparator.js
index.js
range.js
semver.js
functions
clean.js
cmp.js
coerce.js
compare-build.js
compare-loose.js
compare.js
diff.js
eq.js
gt.js
gte.js
inc.js
lt.js
lte.js
major.js
minor.js
neq.js
parse.js
patch.js
prerelease.js
rcompare.js
rsort.js
satisfies.js
sort.js
valid.js
index.js
internal
constants.js
debug.js
identifiers.js
re.js
package.json
preload.js
ranges
gtr.js
intersects.js
ltr.js
max-satisfying.js
min-satisfying.js
min-version.js
outside.js
simplify.js
to-comparators.js
valid.js
ws
README.md
browser.js
index.js
lib
buffer-util.js
constants.js
event-target.js
extension.js
limiter.js
permessage-deflate.js
receiver.js
sender.js
stream.js
validation.js
websocket-server.js
websocket.js
package.json
package.json
src
InteractorClient.js
InteractorDaemon.js
PM2Client.js
PM2Interface.js
TransporterInterface.js
Utility.js
WatchDog.js
push
DataRetriever.js
PushInteractor.js
TransactionAggregator.js
reverse
ReverseInteractor.js
transporters
AxonTransport.js
Transporter.js
WebsocketTransport.js
utils
BinaryHeap.js
EDS.js
probes
Histogram.js
units.js
io
.mocharc.js
.vscode
settings.json
CHANGELOG.md
LICENSE.md
NOTES.md
README.md
build
main
census
config
default-config.d.ts
default-config.js
constants.d.ts
constants.js
exporter.d.ts
exporter.js
instrumentation
ext-types.d.ts
ext-types.js
plugin-loader.d.ts
plugin-loader.js
plugins
express.d.ts
express.js
http.d.ts
http.js
http2.d.ts
http2.js
https.d.ts
https.js
ioredis.d.ts
ioredis.js
mongodb.d.ts
mongodb.js
mysql.d.ts
mysql.js
mysql2.d.ts
mysql2.js
net.d.ts
net.js
pg.d.ts
pg.js
redis.d.ts
redis.js
vue.d.ts
vue.js
tracer.d.ts
tracer.js
configuration.d.ts
configuration.js
constants.d.ts
constants.js
featureManager.d.ts
featureManager.js
features
dependencies.d.ts
dependencies.js
entrypoint.d.ts
entrypoint.js
events.d.ts
events.js
metrics.d.ts
metrics.js
notify.d.ts
notify.js
profiling.d.ts
profiling.js
tracing.d.ts
tracing.js
index.d.ts
index.js
metrics
eventLoopMetrics.d.ts
eventLoopMetrics.js
httpMetrics.d.ts
httpMetrics.js
network.d.ts
network.js
runtime.d.ts
runtime.js
v8.d.ts
v8.js
pmx.d.ts
pmx.js
profilers
addonProfiler.d.ts
addonProfiler.js
inspectorProfiler.d.ts
inspectorProfiler.js
serviceManager.d.ts
serviceManager.js
services
actions.d.ts
actions.js
inspector.d.ts
inspector.js
metrics.d.ts
metrics.js
runtimeStats.d.ts
runtimeStats.js
transport.d.ts
transport.js
transports
IPCTransport.d.ts
IPCTransport.js
WebsocketTransport.d.ts
WebsocketTransport.js
utils
BinaryHeap.d.ts
BinaryHeap.js
EDS.d.ts
EDS.js
EWMA.d.ts
EWMA.js
autocast.d.ts
autocast.js
metrics
counter.d.ts
counter.js
gauge.d.ts
gauge.js
histogram.d.ts
histogram.js
meter.d.ts
meter.js
miscellaneous.d.ts
miscellaneous.js
module.d.ts
module.js
stackParser.d.ts
stackParser.js
transactionAggregator.d.ts
transactionAggregator.js
units.d.ts
units.js
docker-compose.yml
docs
README.md
node_modules
async
CHANGELOG.md
README.md
all.js
allLimit.js
allSeries.js
any.js
anyLimit.js
anySeries.js
apply.js
applyEach.js
applyEachSeries.js
asyncify.js
auto.js
autoInject.js
bower.json
cargo.js
compose.js
concat.js
concatLimit.js
concatSeries.js
constant.js
detect.js
detectLimit.js
detectSeries.js
dir.js
dist
async.js
async.min.js
doDuring.js
doUntil.js
doWhilst.js
during.js
each.js
eachLimit.js
eachOf.js
eachOfLimit.js
eachOfSeries.js
eachSeries.js
ensureAsync.js
every.js
everyLimit.js
everySeries.js
filter.js
filterLimit.js
filterSeries.js
find.js
findLimit.js
findSeries.js
foldl.js
foldr.js
forEach.js
forEachLimit.js
forEachOf.js
forEachOfLimit.js
forEachOfSeries.js
forEachSeries.js
forever.js
groupBy.js
groupByLimit.js
groupBySeries.js
index.js
inject.js
internal
DoublyLinkedList.js
applyEach.js
breakLoop.js
consoleFunc.js
createTester.js
doLimit.js
doParallel.js
doParallelLimit.js
eachOfLimit.js
filter.js
findGetResult.js
getIterator.js
initialParams.js
iterator.js
map.js
notId.js
once.js
onlyOnce.js
parallel.js
queue.js
reject.js
setImmediate.js
slice.js
withoutIndex.js
wrapAsync.js
log.js
map.js
mapLimit.js
mapSeries.js
mapValues.js
mapValuesLimit.js
mapValuesSeries.js
memoize.js
nextTick.js
package.json
parallel.js
parallelLimit.js
priorityQueue.js
queue.js
race.js
reduce.js
reduceRight.js
reflect.js
reflectAll.js
reject.js
rejectLimit.js
rejectSeries.js
retry.js
retryable.js
select.js
selectLimit.js
selectSeries.js
seq.js
series.js
setImmediate.js
some.js
someLimit.js
someSeries.js
sortBy.js
timeout.js
times.js
timesLimit.js
timesSeries.js
transform.js
tryEach.js
unmemoize.js
until.js
waterfall.js
whilst.js
wrapSync.js
debug
CHANGELOG.md
README.md
dist
debug.js
package.json
src
browser.js
common.js
index.js
node.js
eventemitter2
CHANGELOG.md
LICENSE.txt
README.md
eventemitter2.d.ts
index.js
lib
eventemitter2.js
package.json
ms
index.js
license.md
package.json
readme.md
semver
CHANGELOG.md
README.md
bin
semver.js
package.json
semver.js
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
bower.json
docs
generator.md
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
test.sh
js-api
README.md
constants.js
dist
keymetrics.es5.js
keymetrics.es5.min.js
index.js
node_modules
async
CHANGELOG.md
README.md
all.js
allLimit.js
allSeries.js
any.js
anyLimit.js
anySeries.js
apply.js
applyEach.js
applyEachSeries.js
asyncify.js
auto.js
autoInject.js
bower.json
cargo.js
compose.js
concat.js
concatLimit.js
concatSeries.js
constant.js
detect.js
detectLimit.js
detectSeries.js
dir.js
dist
async.js
async.min.js
doDuring.js
doUntil.js
doWhilst.js
during.js
each.js
eachLimit.js
eachOf.js
eachOfLimit.js
eachOfSeries.js
eachSeries.js
ensureAsync.js
every.js
everyLimit.js
everySeries.js
filter.js
filterLimit.js
filterSeries.js
find.js
findLimit.js
findSeries.js
foldl.js
foldr.js
forEach.js
forEachLimit.js
forEachOf.js
forEachOfLimit.js
forEachOfSeries.js
forEachSeries.js
forever.js
groupBy.js
groupByLimit.js
groupBySeries.js
index.js
inject.js
internal
DoublyLinkedList.js
applyEach.js
breakLoop.js
consoleFunc.js
createTester.js
doLimit.js
doParallel.js
doParallelLimit.js
eachOfLimit.js
filter.js
findGetResult.js
getIterator.js
initialParams.js
iterator.js
map.js
notId.js
once.js
onlyOnce.js
parallel.js
queue.js
reject.js
setImmediate.js
slice.js
withoutIndex.js
wrapAsync.js
log.js
map.js
mapLimit.js
mapSeries.js
mapValues.js
mapValuesLimit.js
mapValuesSeries.js
memoize.js
nextTick.js
package.json
parallel.js
parallelLimit.js
priorityQueue.js
queue.js
race.js
reduce.js
reduceRight.js
reflect.js
reflectAll.js
reject.js
rejectLimit.js
rejectSeries.js
retry.js
retryable.js
select.js
selectLimit.js
selectSeries.js
seq.js
series.js
setImmediate.js
some.js
someLimit.js
someSeries.js
sortBy.js
timeout.js
times.js
timesLimit.js
timesSeries.js
transform.js
tryEach.js
unmemoize.js
until.js
waterfall.js
whilst.js
wrapSync.js
debug
CHANGELOG.md
README.md
dist
debug.js
node.js
package.json
src
browser.js
common.js
index.js
node.js
eventemitter2
CHANGELOG.md
LICENSE.txt
README.md
eventemitter2.d.ts
index.js
lib
eventemitter2.js
package.json
ms
index.js
license.md
package.json
readme.md
ws
README.md
browser.js
index.js
lib
buffer-util.js
constants.js
event-target.js
extension.js
limiter.js
permessage-deflate.js
receiver.js
sender.js
stream.js
validation.js
websocket-server.js
websocket.js
package.json
package.json
src
api_mappings.json
auth_strategies
browser_strategy.js
embed_strategy.js
standalone_strategy.js
strategy.js
endpoint.js
keymetrics.js
namespace.js
network.js
utils
validator.js
websocket.js
pm2-version-check
README.md
index.js
node_modules
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
@sindresorhus
is
dist
index.d.ts
index.js
package.json
readme.md
@szmarczak
http-timer
README.md
package.json
source
index.js
@taquito
http-utils
dist
lib
status_code.js
taquito-http-utils.js
taquito-http-utils.es5.js
taquito-http-utils.umd.js
types
status_code.d.ts
taquito-http-utils.d.ts
package.json
signature.json
michel-codec
README.md
dist
lib
macros.js
micheline-emitter.js
micheline-parser.js
micheline.js
michelson-validator.js
scan.js
taquito-michel-codec.js
utils.js
taquito-michel-codec.es5.js
taquito-michel-codec.umd.js
types
macros.d.ts
micheline-emitter.d.ts
micheline-parser.d.ts
micheline.d.ts
michelson-validator.d.ts
scan.d.ts
taquito-michel-codec.d.ts
utils.d.ts
package.json
signature.json
michelson-encoder
README.md
dist
lib
errors.js
michelson-map.js
schema
model.js
parameter.js
storage.js
types.js
taquito-michelson-encoder.js
tokens
bigmap.js
chain-id.js
comparable
address.js
bool.js
bytes.js
int.js
key_hash.js
mutez.js
nat.js
string.js
timestamp.js
contract.js
createToken.js
key.js
lambda.js
list.js
map.js
operation.js
option.js
or.js
pair.js
set.js
signature.js
token.js
tokens.js
unit.js
taquito-michelson-encoder.es5.js
taquito-michelson-encoder.umd.js
types
errors.d.ts
michelson-map.d.ts
schema
model.d.ts
parameter.d.ts
storage.d.ts
types.d.ts
taquito-michelson-encoder.d.ts
tokens
bigmap.d.ts
chain-id.d.ts
comparable
address.d.ts
bool.d.ts
bytes.d.ts
int.d.ts
key_hash.d.ts
mutez.d.ts
nat.d.ts
string.d.ts
timestamp.d.ts
contract.d.ts
createToken.d.ts
key.d.ts
lambda.d.ts
list.d.ts
map.d.ts
operation.d.ts
option.d.ts
or.d.ts
pair.d.ts
set.d.ts
signature.d.ts
token.d.ts
tokens.d.ts
unit.d.ts
package.json
signature.json
rpc
README.md
dist
lib
opkind.js
taquito-rpc.js
types.js
utils
utils.js
taquito-rpc.es5.js
taquito-rpc.umd.js
types
opkind.d.ts
taquito-rpc.d.ts
types.d.ts
utils
utils.d.ts
package.json
signature.json
signer
dist
lib
ec-key.js
ed-key.js
import-key.js
taquito-signer.js
taquito-signer.es5.js
taquito-signer.umd.js
types
ec-key.d.ts
ed-key.d.ts
import-key.d.ts
taquito-signer.d.ts
package.json
signature.json
taquito
README.md
dist
lib
batch
rpc-batch-provider.js
constants.js
context.js
contract
big-map.js
contract.js
errors.js
estimate.js
index.js
interface.js
manager-lambda.js
naive-estimate-provider.js
prepare.js
rpc-contract-provider.js
rpc-estimate-provider.js
semantic.js
forger
composite-forger.js
interface.js
rpc-forger.js
format.js
injector
interface.js
rpc-injector.js
operations
batch-operation.js
delegate-operation.js
operation-emitter.js
operation-errors.js
operations.js
origination-operation.js
transaction-operation.js
types.js
signer
interface.js
noop.js
subscribe
filters.js
interface.js
observable-subscription.js
polling-provider.js
taquito.js
tz
interface.js
rpc-tz-provider.js
wallet
delegation-operation.js
index.js
interface.js
legacy.js
operation.js
opreation-factory.js
origination-operation.js
receipt.js
transaction-operation.js
wallet.js
taquito.es5.js
taquito.min.js
taquito.min.js.LICENSE.txt
taquito.umd.js
types
batch
rpc-batch-provider.d.ts
constants.d.ts
context.d.ts
contract
big-map.d.ts
contract.d.ts
errors.d.ts
estimate.d.ts
index.d.ts
interface.d.ts
manager-lambda.d.ts
naive-estimate-provider.d.ts
prepare.d.ts
rpc-contract-provider.d.ts
rpc-estimate-provider.d.ts
semantic.d.ts
forger
composite-forger.d.ts
interface.d.ts
rpc-forger.d.ts
format.d.ts
injector
interface.d.ts
rpc-injector.d.ts
operations
batch-operation.d.ts
delegate-operation.d.ts
operation-emitter.d.ts
operation-errors.d.ts
operations.d.ts
origination-operation.d.ts
transaction-operation.d.ts
types.d.ts
signer
interface.d.ts
noop.d.ts
subscribe
filters.d.ts
interface.d.ts
observable-subscription.d.ts
polling-provider.d.ts
taquito.d.ts
tz
interface.d.ts
rpc-tz-provider.d.ts
wallet
delegation-operation.d.ts
index.d.ts
interface.d.ts
legacy.d.ts
operation.d.ts
opreation-factory.d.ts
origination-operation.d.ts
receipt.d.ts
transaction-operation.d.ts
wallet.d.ts
package.json
patch.js
signature.json
utils
README.md
dist
lib
constants.js
taquito-utils.js
validators.js
taquito-utils.es5.js
taquito-utils.umd.js
types
constants.d.ts
taquito-utils.d.ts
validators.d.ts
package.json
signature.json
@types
bn.js
README.md
index.d.ts
package.json
istanbul-lib-coverage
README.md
index.d.ts
package.json
istanbul-lib-report
README.md
index.d.ts
package.json
istanbul-reports
README.md
index.d.ts
package.json
node
README.md
assert.d.ts
async_hooks.d.ts
base.d.ts
buffer.d.ts
child_process.d.ts
cluster.d.ts
console.d.ts
constants.d.ts
crypto.d.ts
dgram.d.ts
dns.d.ts
domain.d.ts
events.d.ts
fs.d.ts
fs
promises.d.ts
globals.d.ts
globals.global.d.ts
http.d.ts
http2.d.ts
https.d.ts
index.d.ts
inspector.d.ts
module.d.ts
net.d.ts
os.d.ts
package.json
path.d.ts
perf_hooks.d.ts
process.d.ts
punycode.d.ts
querystring.d.ts
readline.d.ts
repl.d.ts
stream.d.ts
string_decoder.d.ts
timers.d.ts
tls.d.ts
trace_events.d.ts
ts3.4
assert.d.ts
base.d.ts
globals.global.d.ts
index.d.ts
ts3.6
base.d.ts
index.d.ts
tty.d.ts
url.d.ts
util.d.ts
v8.d.ts
vm.d.ts
wasi.d.ts
worker_threads.d.ts
zlib.d.ts
pbkdf2
README.md
index.d.ts
package.json
secp256k1
README.md
index.d.ts
package.json
yargs-parser
README.md
index.d.ts
package.json
yargs
README.md
index.d.ts
package.json
yargs.d.ts
@web3-js
scrypt-shim
LICENSE.md
README.md
node_modules
semver
CHANGELOG.md
README.md
bin
semver.js
package.json
semver.js
package.json
scripts
postinstall.js
src
browser.js
index.js
websocket
CHANGELOG.md
README.md
gulpfile.js
index.js
lib
BufferUtil.fallback.js
BufferUtil.js
Deprecation.js
Validation.fallback.js
Validation.js
W3CWebSocket.js
WebSocketClient.js
WebSocketConnection.js
WebSocketFrame.js
WebSocketRequest.js
WebSocketRouter.js
WebSocketRouterRequest.js
WebSocketServer.js
browser.js
utils.js
version.js
websocket.js
package.json
vendor
FastBufferList.js
abstract-leveldown
.travis.yml
CHANGELOG.md
LICENSE.md
README.md
abstract-chained-batch.js
abstract-iterator.js
abstract-leveldown.js
abstract
approximate-size-test.js
batch-test.js
chained-batch-test.js
close-test.js
del-test.js
get-test.js
iterator-test.js
leveldown-test.js
open-test.js
put-get-del-test.js
put-test.js
ranges-test.js
util.js
index.js
is-leveldown.js
package.json
test.js
testCommon.js
accepts
HISTORY.md
README.md
index.js
package.json
aes-js
LICENSE.txt
README.md
bower.json
generate-tests.py
index.js
package.json
run-readme.py
test
index.js
test-aes.js
test-buffer.js
test-counter.js
test-errors.js
test-padding.js
test.html
agent-base
.travis.yml
History.md
README.md
index.d.ts
index.js
package.json
patch-core.js
test
test.js
ajv
.tonic_example.js
README.md
dist
ajv.bundle.js
ajv.min.js
lib
ajv.d.ts
ajv.js
cache.js
compile
async.js
equal.js
error_classes.js
formats.js
index.js
resolve.js
rules.js
schema_obj.js
ucs2length.js
util.js
data.js
definition_schema.js
dotjs
README.md
_limit.js
_limitItems.js
_limitLength.js
_limitProperties.js
allOf.js
anyOf.js
comment.js
const.js
contains.js
custom.js
dependencies.js
enum.js
format.js
if.js
index.js
items.js
multipleOf.js
not.js
oneOf.js
pattern.js
properties.js
propertyNames.js
ref.js
required.js
uniqueItems.js
validate.js
keyword.js
refs
data.json
json-schema-draft-04.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
package.json
scripts
.eslintrc.yml
bundle.js
compile-dots.js
amp-message
Readme.md
index.js
package.json
amp
Readme.md
index.js
lib
decode.js
encode.js
stream.js
package.json
ansi-colors
README.md
index.js
package.json
symbols.js
types
index.d.ts
ansi-regex
index.js
package.json
readme.md
ansi-styles
index.d.ts
index.js
package.json
readme.md
any-promise
README.md
implementation.d.ts
implementation.js
index.d.ts
index.js
loader.js
optional.js
package.json
register-shim.js
register.d.ts
register.js
register
bluebird.d.ts
bluebird.js
es6-promise.d.ts
es6-promise.js
lie.d.ts
lie.js
native-promise-only.d.ts
native-promise-only.js
pinkie.d.ts
pinkie.js
promise.d.ts
promise.js
q.d.ts
q.js
rsvp.d.ts
rsvp.js
vow.d.ts
vow.js
when.d.ts
when.js
anymatch
README.md
index.d.ts
index.js
package.json
argparse
CHANGELOG.md
README.md
index.js
lib
action.js
action
append.js
append
constant.js
count.js
help.js
store.js
store
constant.js
false.js
true.js
subparsers.js
version.js
action_container.js
argparse.js
argument
error.js
exclusive.js
group.js
argument_parser.js
const.js
help
added_formatters.js
formatter.js
namespace.js
utils.js
node_modules
sprintf-js
README.md
bower.json
demo
angular.html
dist
angular-sprintf.min.js
sprintf.min.js
gruntfile.js
package.json
src
angular-sprintf.js
sprintf.js
test
test.js
package.json
arr-diff
README.md
index.js
package.json
arr-flatten
README.md
index.js
package.json
array-flatten
README.md
array-flatten.js
package.json
array-unique
README.md
index.js
package.json
asn1.js
.eslintrc.js
README.md
lib
asn1.js
asn1
api.js
base
buffer.js
index.js
node.js
reporter.js
constants
der.js
index.js
decoders
der.js
index.js
pem.js
encoders
der.js
index.js
pem.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
asn1
README.md
lib
ber
errors.js
index.js
reader.js
types.js
writer.js
index.js
package.json
assert-plus
CHANGES.md
README.md
assert.js
package.json
ast-types
.github
dependabot.yml
workflows
main.yml
README.md
def
babel-core.d.ts
babel-core.js
babel.d.ts
babel.js
core-operators.d.ts
core-operators.js
core.d.ts
core.js
es-proposals.d.ts
es-proposals.js
es2016.d.ts
es2016.js
es2017.d.ts
es2017.js
es2018.d.ts
es2018.js
es2019.d.ts
es2019.js
es2020.d.ts
es2020.js
es6.d.ts
es6.js
esprima.d.ts
esprima.js
flow.d.ts
flow.js
jsx.d.ts
jsx.js
type-annotations.d.ts
type-annotations.js
typescript.d.ts
typescript.js
fork.d.ts
fork.js
gen
builders.d.ts
builders.js
kinds.d.ts
kinds.js
namedTypes.d.ts
namedTypes.js
visitor.d.ts
visitor.js
lib
equiv.d.ts
equiv.js
node-path.d.ts
node-path.js
path-visitor.d.ts
path-visitor.js
path.d.ts
path.js
scope.d.ts
scope.js
shared.d.ts
shared.js
types.d.ts
types.js
main.d.ts
main.js
package.json
tsconfig.json
types.d.ts
types.js
async-limiter
.travis.yml
index.js
package.json
readme.md
async-listener
.travis.yml
README.md
es6-wrapped-promise.js
glue.js
index.js
node_modules
semver
CHANGELOG.md
README.md
package.json
semver.js
package.json
test
add-remove.tap.js
connection-handler-disconnects.tap.js
core-asynclistener-error-multiple-handled.simple.js
core-asynclistener-error-multiple-mix.simple.js
core-asynclistener-error-multiple-unhandled.simple.js
core-asynclistener-error-net.simple.js
core-asynclistener-error-throw-in-after.simple.js
core-asynclistener-error-throw-in-before-multiple.simple.js
core-asynclistener-error-throw-in-before.simple.js
core-asynclistener-error-throw-in-error.simple.js
core-asynclistener-error.simple.js
core-asynclistener-nexttick-remove.simple.js
core-asynclistener-only-add.simple.js
core-asynclistener-remove-before.simple.js
core-asynclistener-remove-inflight-error.simple.js
core-asynclistener-remove-inflight.simple.js
core-asynclistener.simple.js
core
core-asynclistener-add-inflight.js
core-asynclistener-error-throw-in-before-inflight.js
errors-this-tick.tap.js
fork-listen2-problem.tap.js
fork-listener.js
function-length-preserved.tap.js
handle.tap.js
http-request.tap.js
native-promises.tap.js
no-after-following-error.tap.js
overlapping-nexttick.tap.js
promise-subclass.js
simple-counter-with-io.tap.js
simple-counter.tap.js
simplified-error.simple.js
spawn.tap.js
timers.tap.js
zlib.tap.js
async
CHANGELOG.md
README.md
all.js
allLimit.js
allSeries.js
any.js
anyLimit.js
anySeries.js
apply.js
applyEach.js
applyEachSeries.js
asyncify.js
auto.js
autoInject.js
bower.json
cargo.js
cargoQueue.js
compose.js
concat.js
concatLimit.js
concatSeries.js
constant.js
detect.js
detectLimit.js
detectSeries.js
dir.js
dist
async.js
async.min.js
doDuring.js
doUntil.js
doWhilst.js
during.js
each.js
eachLimit.js
eachOf.js
eachOfLimit.js
eachOfSeries.js
eachSeries.js
ensureAsync.js
every.js
everyLimit.js
everySeries.js
filter.js
filterLimit.js
filterSeries.js
find.js
findLimit.js
findSeries.js
flatMap.js
flatMapLimit.js
flatMapSeries.js
foldl.js
foldr.js
forEach.js
forEachLimit.js
forEachOf.js
forEachOfLimit.js
forEachOfSeries.js
forEachSeries.js
forever.js
groupBy.js
groupByLimit.js
groupBySeries.js
index.js
inject.js
internal
DoublyLinkedList.js
Heap.js
applyEach.js
asyncEachOfLimit.js
awaitify.js
breakLoop.js
consoleFunc.js
createTester.js
eachOfLimit.js
filter.js
getIterator.js
initialParams.js
isArrayLike.js
iterator.js
map.js
once.js
onlyOnce.js
parallel.js
promiseCallback.js
queue.js
range.js
reject.js
setImmediate.js
withoutIndex.js
wrapAsync.js
log.js
map.js
mapLimit.js
mapSeries.js
mapValues.js
mapValuesLimit.js
mapValuesSeries.js
memoize.js
nextTick.js
package.json
parallel.js
parallelLimit.js
priorityQueue.js
queue.js
race.js
reduce.js
reduceRight.js
reflect.js
reflectAll.js
reject.js
rejectLimit.js
rejectSeries.js
retry.js
retryable.js
select.js
selectLimit.js
selectSeries.js
seq.js
series.js
setImmediate.js
some.js
someLimit.js
someSeries.js
sortBy.js
timeout.js
times.js
timesLimit.js
timesSeries.js
transform.js
tryEach.js
unmemoize.js
until.js
waterfall.js
whilst.js
wrapSync.js
asynckit
README.md
bench.js
index.js
lib
abort.js
async.js
defer.js
iterate.js
readable_asynckit.js
readable_parallel.js
readable_serial.js
readable_serial_ordered.js
state.js
streamify.js
terminator.js
package.json
parallel.js
serial.js
serialOrdered.js
stream.js
aws-sign2
README.md
index.js
package.json
aws4
.github
FUNDING.yml
.travis.yml
README.md
aws4.js
lru.js
package.json
axios
CHANGELOG.md
README.md
UPGRADE_GUIDE.md
dist
axios.js
axios.min.js
index.d.ts
index.js
lib
adapters
README.md
http.js
xhr.js
axios.js
cancel
Cancel.js
CancelToken.js
isCancel.js
core
Axios.js
InterceptorManager.js
README.md
buildFullPath.js
createError.js
dispatchRequest.js
enhanceError.js
mergeConfig.js
settle.js
transformData.js
defaults.js
helpers
README.md
bind.js
buildURL.js
combineURLs.js
cookies.js
deprecatedMethod.js
isAbsoluteURL.js
isURLSameOrigin.js
normalizeHeaderName.js
parseHeaders.js
spread.js
utils.js
package.json
balanced-match
LICENSE.md
README.md
index.js
package.json
base-x
LICENSE.md
README.md
package.json
src
index.d.ts
index.js
base64-js
README.md
base64js.min.js
index.js
package.json
bcrypt-pbkdf
CONTRIBUTING.md
README.md
index.js
package.json
bignumber.js
CHANGELOG.md
LICENCE.md
README.md
bignumber.d.ts
bignumber.js
bignumber.min.js
doc
API.html
package.json
binary-extensions
binary-extensions.json
binary-extensions.json.d.ts
index.d.ts
index.js
package.json
readme.md
bip39
CHANGELOG.md
README.md
node_modules
@types
node
README.md
assert.d.ts
async_hooks.d.ts
base.d.ts
buffer.d.ts
child_process.d.ts
cluster.d.ts
console.d.ts
constants.d.ts
crypto.d.ts
dgram.d.ts
dns.d.ts
domain.d.ts
events.d.ts
fs.d.ts
globals.d.ts
http.d.ts
http2.d.ts
https.d.ts
index.d.ts
inspector.d.ts
module.d.ts
net.d.ts
os.d.ts
package.json
path.d.ts
perf_hooks.d.ts
process.d.ts
punycode.d.ts
querystring.d.ts
readline.d.ts
repl.d.ts
stream.d.ts
string_decoder.d.ts
timers.d.ts
tls.d.ts
trace_events.d.ts
ts3.2
globals.d.ts
index.d.ts
util.d.ts
tty.d.ts
url.d.ts
util.d.ts
v8.d.ts
vm.d.ts
worker_threads.d.ts
zlib.d.ts
package.json
src
_wordlists.js
index.js
wordlists
chinese_simplified.json
chinese_traditional.json
english.json
french.json
italian.json
japanese.json
korean.json
spanish.json
types
_wordlists.d.ts
index.d.ts
wordlists.d.ts
bl
.travis.yml
LICENSE.md
README.md
bl.js
node_modules
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
readable-stream
.travis.yml
CONTRIBUTING.md
GOVERNANCE.md
README.md
doc
wg-meetings
2015-01-30.md
duplex-browser.js
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
internal
streams
BufferList.js
destroy.js
stream-browser.js
stream.js
node_modules
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
passthrough.js
readable-browser.js
readable.js
transform.js
writable-browser.js
writable.js
string_decoder
.travis.yml
README.md
lib
string_decoder.js
node_modules
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
package.json
test
test.js
blakejs
.travis.yml
README.md
blake2b.js
blake2s.js
generated_test_vectors.txt
index.js
package.json
test_blake2b.js
test_blake2s.js
util.js
blessed
CHANGELOG.md
README.md
bin
tput.js
browser
transform.js
example
ansi-viewer
README.md
index.js
package.json
singlebyte.js
blessed-telnet.js
index.js
multiplex.js
simple-form.js
time.js
widget.js
index.js
lib
alias.js
blessed.js
colors.js
events.js
gpmclient.js
helpers.js
keys.js
program.js
tput.js
unicode.js
widget.js
widgets
ansiimage.js
bigtext.js
box.js
button.js
checkbox.js
element.js
filemanager.js
form.js
image.js
input.js
layout.js
line.js
list.js
listbar.js
listtable.js
loading.js
log.js
message.js
node.js
overlayimage.js
progressbar.js
prompt.js
question.js
radiobutton.js
radioset.js
screen.js
scrollablebox.js
scrollabletext.js
table.js
terminal.js
text.js
textarea.js
textbox.js
video.js
package.json
usr
fonts
ter-u14b.json
ter-u14n.json
vendor
tng.js
bluebird
README.md
changelog.md
js
browser
bluebird.core.js
bluebird.core.min.js
bluebird.js
bluebird.min.js
release
any.js
assert.js
async.js
bind.js
bluebird.js
call_get.js
cancel.js
catch_filter.js
context.js
debuggability.js
direct_resolve.js
each.js
errors.js
es5.js
filter.js
finally.js
generators.js
join.js
map.js
method.js
nodeback.js
nodeify.js
promise.js
promise_array.js
promisify.js
props.js
queue.js
race.js
reduce.js
schedule.js
settle.js
some.js
synchronous_inspection.js
thenables.js
timers.js
using.js
util.js
package.json
bn.js
CHANGELOG.md
README.md
lib
bn.js
package.json
body-parser
HISTORY.md
README.md
index.js
lib
read.js
types
json.js
raw.js
text.js
urlencoded.js
package.json
brace-expansion
README.md
index.js
package.json
braces
CHANGELOG.md
README.md
index.js
lib
compile.js
constants.js
expand.js
parse.js
stringify.js
utils.js
package.json
brorand
README.md
index.js
package.json
test
api-test.js
browserify-aes
.travis.yml
README.md
aes.js
authCipher.js
browser.js
decrypter.js
encrypter.js
ghash.js
incr32.js
index.js
modes
cbc.js
cfb.js
cfb1.js
cfb8.js
ctr.js
ecb.js
index.js
list.json
ofb.js
package.json
streamCipher.js
browserify-cipher
.travis.yml
README.md
browser.js
index.js
package.json
test.js
browserify-des
.travis.yml
index.js
modes.js
package.json
readme.md
test.js
browserify-rsa
.travis.yml
index.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
readme.md
test.js
browserify-sign
README.md
algos.js
browser
algorithms.json
curves.json
index.js
sign.js
verify.js
index.js
package.json
bs58
CHANGELOG.md
README.md
index.js
package.json
bs58check
README.md
base.js
index.js
package.json
bsert
README.md
lib
assert.js
package.json
buffer-alloc-unsafe
index.js
package.json
readme.md
buffer-alloc
index.js
package.json
readme.md
buffer-crc32
README.md
index.js
package.json
buffer-fill
index.js
package.json
readme.md
buffer-from
index.js
package.json
readme.md
buffer-to-arraybuffer
CHANGELOG.md
LICENSE.md
README.md
bower.json
buffer-to-arraybuffer.js
package.json
test
buffer-to-arraybuffer.js
buffer-xor
.travis.yml
README.md
index.js
inline.js
inplace.js
package.json
test
fixtures.json
index.js
buffer
AUTHORS.md
README.md
index.d.ts
index.js
package.json
bufferutil
README.md
fallback.js
index.js
node_modules
node-gyp-build
README.md
bin.js
build-test.js
index.js
optional.js
package.json
package.json
src
bufferutil.c
bytes
History.md
Readme.md
index.js
package.json
cacheable-request
README.md
node_modules
get-stream
buffer-stream.js
index.d.ts
index.js
package.json
readme.md
lowercase-keys
index.d.ts
index.js
package.json
readme.md
package.json
src
index.js
camel-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
capability
Array.prototype.forEach.js
Array.prototype.map.js
Error.captureStackTrace.js
Error.prototype.stack.js
Function.prototype.bind.js
Object.create.js
Object.defineProperties.js
Object.defineProperty.js
Object.prototype.hasOwnProperty.js
README.md
arguments.callee.caller.js
es5.js
index.js
lib
CapabilityDetector.js
definitions.js
index.js
package.json
strict mode.js
capital-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
caseless
README.md
index.js
package.json
test.js
chalk
index.d.ts
package.json
readme.md
source
index.js
templates.js
util.js
change-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
charm
example
256.js
column.js
cursor.js
http_spin.js
lucky.js
position.js
progress.js
resize.js
spin.js
index.js
lib
encode.js
package.json
chokidar
README.md
index.js
lib
constants.js
fsevents-handler.js
nodefs-handler.js
package.json
types
index.d.ts
chownr
README.md
chownr.js
package.json
cids
.travis.yml
CHANGELOG.md
README.md
dist
index.js
index.min.js
docs
assets
anchor.js
bass-addons.css
bass.css
fonts
LICENSE.txt
source-code-pro.css
github.css
site.js
split.css
split.js
style.css
index.html
examples
cidv0-to-cidv1.js
node_modules
multicodec
.travis.yml
CHANGELOG.md
README.md
dist
index.min.js
index.min.js.LICENSE.txt
example.js
package.json
src
base-table.json
constants.js
index.js
int-table.js
print.js
util.js
varint-table.js
tools
update-table.js
package.json
src
cid-util.js
index.d.ts
index.js
cipher-base
.travis.yml
README.md
index.js
package.json
test.js
class-is
.eslintrc.json
.travis.yml
CHANGELOG.md
README.md
index.js
package.json
test
es5.test.js
es6.test.js
fixtures
es5
Algae.js
Animal.js
ExplicitWithoutNew.js
ImplicitExplicitWithoutNew.js
ImplicitWithoutNew.js
Mammal.js
Plant.js
index.js
es6
Algae.js
Animal.js
Mammal.js
Plant.js
index.js
cli-tableau
CHANGELOG.md
README.md
lib
index.js
utils.js
package.json
clone-response
README.md
package.json
src
index.js
co
History.md
Readme.md
index.js
package.json
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
README.md
index.js
package.json
combined-stream
Readme.md
lib
combined_stream.js
package.json
commander
CHANGELOG.md
Readme.md
index.js
package.json
typings
index.d.ts
concat-map
.travis.yml
example
map.js
index.js
package.json
test
map.js
configstore
index.js
package.json
readme.md
constant-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
content-disposition
HISTORY.md
README.md
index.js
node_modules
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
content-hash
.circleci
config.yml
.eslintrc.json
README.md
demo
index.html
main.js
dist
index.js
package.json
src
helpers.js
index.js
profiles.js
test
test.js
content-type
HISTORY.md
README.md
index.js
package.json
continuation-local-storage
.travis.yml
CHANGELOG.md
README.md
context.js
package.json
test
async-context.tap.js
async-no-run-queue-multiple.tap.js
bind-emitter.tap.js
bind.tap.js
crypto.tap.js
dns.tap.js
error-handling.tap.js
fs.tap.js
interleave-contexts.tap.js
monkeypatching.tap.js
namespaces.tap.js
nesting.tap.js
net-events.tap.js
promises.tap.js
proper-exit.tap.js
run-and-return.tap.js
simple.tap.js
timers.tap.js
tracer-scenarios.tap.js
zlib.tap.js
cookie-signature
History.md
Readme.md
index.js
package.json
cookie
HISTORY.md
README.md
index.js
package.json
cookiejar
cookiejar.js
package.json
readme.md
core-util-is
README.md
lib
util.js
package.json
test.js
cors
CONTRIBUTING.md
HISTORY.md
README.md
lib
index.js
package.json
create-ecdh
.travis.yml
browser.js
index.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
readme.md
create-hash
.travis.yml
README.md
browser.js
index.js
md5.js
package.json
test.js
create-hmac
README.md
browser.js
index.js
legacy.js
package.json
cron
.travis.yml
CHANGELOG.md
README.md
bower.json
examples
at_10_minutes.js
at_midnight.js
basic.js
complex_expr.js
every_10_minutes.js
every_30_minutes_between_9_and_5.js
get_next_runs.js
in_the_past.js
is_crontime_valid.js
is_job_running.js
long_running_on_tick.js
mon_to_fri_at_11_30.js
multiple_jobs.js
object_param.js
run_at_specific_date.js
time_dom_syntax_with_tz.js
lib
cron.js
package.json
tests
cron.test.js
crontime.test.js
crypto-browserify
.travis.yml
.zuul.yml
README.md
example
bundle.js
index.html
test.js
index.js
package.json
test
aes.js
create-hash.js
create-hmac.js
dh.js
ecdh.js
index.js
node
dh.js
pbkdf2.js
public-encrypt.js
random-bytes.js
random-fill.js
sign.js
crypto-random-string
index.d.ts
index.js
package.json
readme.md
d
.github
FUNDING.yml
CHANGELOG.md
README.md
auto-bind.js
index.js
lazy.js
package.json
test
auto-bind.js
index.js
lazy.js
dashdash
CHANGES.md
LICENSE.txt
README.md
lib
dashdash.js
package.json
data-uri-to-buffer
.travis.yml
History.md
README.md
index.js
package.json
test
test.js
dayjs
CHANGELOG.md
README.md
dayjs.min.js
esm
constant.js
index.d.ts
index.js
locale
af.js
am.js
ar-dz.js
ar-kw.js
ar-ly.js
ar-ma.js
ar-sa.js
ar-tn.js
ar.js
az.js
be.js
bg.js
bi.js
bm.js
bn.js
bo.js
br.js
bs.js
ca.js
cs.js
cv.js
cy.js
da.js
de-at.js
de-ch.js
de.js
dv.js
el.js
en-SG.js
en-au.js
en-ca.js
en-gb.js
en-ie.js
en-il.js
en-in.js
en-nz.js
en-tt.js
en.js
eo.js
es-do.js
es-pr.js
es-us.js
es.js
et.js
eu.js
fa.js
fi.js
fo.js
fr-ca.js
fr-ch.js
fr.js
fy.js
ga.js
gd.js
gl.js
gom-latn.js
gu.js
he.js
hi.js
hr.js
ht.js
hu.js
hy-am.js
id.js
index.d.ts
is.js
it-ch.js
it.js
ja.js
jv.js
ka.js
kk.js
km.js
kn.js
ko.js
ku.js
ky.js
lb.js
lo.js
lt.js
lv.js
me.js
mi.js
mk.js
ml.js
mn.js
mr.js
ms-my.js
ms.js
mt.js
my.js
nb.js
ne.js
nl-be.js
nl.js
nn.js
oc-lnc.js
pa-in.js
pl.js
pt-br.js
pt.js
ro.js
ru.js
rw.js
sd.js
se.js
si.js
sk.js
sl.js
sq.js
sr-cyrl.js
sr.js
ss.js
sv.js
sw.js
ta.js
te.js
tet.js
tg.js
th.js
tk.js
tl-ph.js
tlh.js
tr.js
types.d.ts
tzl.js
tzm-latn.js
tzm.js
ug-cn.js
uk.js
ur.js
uz-latn.js
uz.js
vi.js
x-pseudo.js
yo.js
zh-cn.js
zh-hk.js
zh-tw.js
zh.js
plugin
advancedFormat
index.d.ts
index.js
badMutable
index.d.ts
index.js
buddhistEra
index.d.ts
index.js
calendar
index.d.ts
index.js
customParseFormat
index.d.ts
index.js
dayOfYear
index.d.ts
index.js
duration
index.d.ts
index.js
isBetween
index.d.ts
index.js
isLeapYear
index.d.ts
index.js
isMoment
index.d.ts
index.js
isSameOrAfter
index.d.ts
index.js
isSameOrBefore
index.d.ts
index.js
isToday
index.d.ts
index.js
isTomorrow
index.d.ts
index.js
isYesterday
index.d.ts
index.js
isoWeek
index.d.ts
index.js
isoWeeksInYear
index.d.ts
index.js
localeData
index.d.ts
index.js
localizedFormat
index.d.ts
index.js
minMax
index.d.ts
index.js
objectSupport
index.d.ts
index.js
pluralGetSet
index.d.ts
index.js
quarterOfYear
index.d.ts
index.js
relativeTime
index.d.ts
index.js
timezone
index.d.ts
index.js
toArray
index.d.ts
index.js
toObject
index.d.ts
index.js
updateLocale
index.d.ts
index.js
utc
index.d.ts
index.js
weekOfYear
index.d.ts
index.js
weekYear
index.d.ts
index.js
weekday
index.d.ts
index.js
utils.js
index.d.ts
locale.json
locale
af.js
am.js
ar-dz.js
ar-kw.js
ar-ly.js
ar-ma.js
ar-sa.js
ar-tn.js
ar.js
az.js
be.js
bg.js
bi.js
bm.js
bn.js
bo.js
br.js
bs.js
ca.js
cs.js
cv.js
cy.js
da.js
de-at.js
de-ch.js
de.js
dv.js
el.js
en-SG.js
en-au.js
en-ca.js
en-gb.js
en-ie.js
en-il.js
en-in.js
en-nz.js
en-tt.js
en.js
eo.js
es-do.js
es-pr.js
es-us.js
es.js
et.js
eu.js
fa.js
fi.js
fo.js
fr-ca.js
fr-ch.js
fr.js
fy.js
ga.js
gd.js
gl.js
gom-latn.js
gu.js
he.js
hi.js
hr.js
ht.js
hu.js
hy-am.js
id.js
index.d.ts
is.js
it-ch.js
it.js
ja.js
jv.js
ka.js
kk.js
km.js
kn.js
ko.js
ku.js
ky.js
lb.js
lo.js
lt.js
lv.js
me.js
mi.js
mk.js
ml.js
mn.js
mr.js
ms-my.js
ms.js
mt.js
my.js
nb.js
ne.js
nl-be.js
nl.js
nn.js
oc-lnc.js
pa-in.js
pl.js
pt-br.js
pt.js
ro.js
ru.js
rw.js
sd.js
se.js
si.js
sk.js
sl.js
sq.js
sr-cyrl.js
sr.js
ss.js
sv.js
sw.js
ta.js
te.js
tet.js
tg.js
th.js
tk.js
tl-ph.js
tlh.js
tr.js
types.d.ts
tzl.js
tzm-latn.js
tzm.js
ug-cn.js
uk.js
ur.js
uz-latn.js
uz.js
vi.js
x-pseudo.js
yo.js
zh-cn.js
zh-hk.js
zh-tw.js
zh.js
package.json
plugin
advancedFormat.d.ts
advancedFormat.js
badMutable.d.ts
badMutable.js
buddhistEra.d.ts
buddhistEra.js
calendar.d.ts
calendar.js
customParseFormat.d.ts
customParseFormat.js
dayOfYear.d.ts
dayOfYear.js
duration.d.ts
duration.js
isBetween.d.ts
isBetween.js
isLeapYear.d.ts
isLeapYear.js
isMoment.d.ts
isMoment.js
isSameOrAfter.d.ts
isSameOrAfter.js
isSameOrBefore.d.ts
isSameOrBefore.js
isToday.d.ts
isToday.js
isTomorrow.d.ts
isTomorrow.js
isYesterday.d.ts
isYesterday.js
isoWeek.d.ts
isoWeek.js
isoWeeksInYear.d.ts
isoWeeksInYear.js
localeData.d.ts
localeData.js
localizedFormat.d.ts
localizedFormat.js
minMax.d.ts
minMax.js
objectSupport.d.ts
objectSupport.js
pluralGetSet.d.ts
pluralGetSet.js
quarterOfYear.d.ts
quarterOfYear.js
relativeTime.d.ts
relativeTime.js
timezone.d.ts
timezone.js
toArray.d.ts
toArray.js
toObject.d.ts
toObject.js
updateLocale.d.ts
updateLocale.js
utc.d.ts
utc.js
weekOfYear.d.ts
weekOfYear.js
weekYear.d.ts
weekYear.js
weekday.d.ts
weekday.js
debug
.coveralls.yml
.travis.yml
CHANGELOG.md
README.md
component.json
karma.conf.js
node.js
package.json
src
browser.js
debug.js
index.js
inspector-log.js
node.js
decode-uri-component
index.js
package.json
readme.md
decompress-response
index.js
package.json
readme.md
decompress-tar
index.js
package.json
readme.md
decompress-tarbz2
index.js
node_modules
file-type
index.js
package.json
readme.md
package.json
readme.md
decompress-targz
index.js
package.json
readme.md
decompress-unzip
index.js
node_modules
file-type
index.js
package.json
readme.md
get-stream
buffer-stream.js
index.js
package.json
readme.md
package.json
readme.md
decompress
index.js
node_modules
make-dir
index.js
node_modules
pify
index.js
package.json
readme.md
package.json
readme.md
package.json
readme.md
deep-is
.travis.yml
example
cmp.js
index.js
package.json
test
NaN.js
cmp.js
neg-vs-pos-0.js
defer-to-connect
README.md
dist
index.d.ts
index.js
package.json
deferred-leveldown
.travis.yml
LICENSE.md
README.md
deferred-iterator.js
deferred-leveldown.js
package.json
test.js
degenerator
.travis.yml
CHANGELOG.md
README.md
index.js
package.json
test
basic.expected.js
basic.js
get-example.expected.js
get-example.js
multiple.expected.js
multiple.js
pac-resolver-gh-16.expected.js
pac-resolver-gh-16.js
pac-resolver-gh-3.expected.js
pac-resolver-gh-3.js
test.js
delayed-stream
Readme.md
lib
delayed_stream.js
package.json
depd
History.md
Readme.md
index.js
lib
browser
index.js
compat
callsite-tostring.js
event-listener-count.js
index.js
package.json
des.js
README.md
lib
des.js
des
cbc.js
cipher.js
des.js
ede.js
utils.js
package.json
test
cbc-test.js
des-test.js
ede-test.js
fixtures.js
utils-test.js
destroy
README.md
index.js
package.json
diff-sequences
README.md
build
index.d.ts
index.js
package.json
perf
example.md
index.js
diff
CONTRIBUTING.md
README.md
dist
diff.js
diff.min.js
lib
convert
dmp.js
xml.js
diff
array.js
base.js
character.js
css.js
json.js
line.js
sentence.js
word.js
index.js
patch
apply.js
create.js
merge.js
parse.js
util
array.js
distance-iterator.js
params.js
package.json
release-notes.md
runtime.js
diffie-hellman
.travis.yml
browser.js
index.js
lib
dh.js
generatePrime.js
primes.json
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
readme.md
dom-walk
README.md
example
index.js
index.js
package.json
dot-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
dot-prop
index.d.ts
index.js
package.json
readme.md
duplexer3
LICENSE.md
README.md
index.js
package.json
ecc-jsbn
README.md
index.js
lib
ec.js
sec.js
package.json
test.js
ee-first
README.md
index.js
package.json
elliptic
README.md
lib
elliptic.js
elliptic
curve
base.js
edwards.js
index.js
mont.js
short.js
curves.js
ec
index.js
key.js
signature.js
eddsa
index.js
key.js
signature.js
precomputed
secp256k1.js
utils.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
emitter-listener
.travis.yml
README.md
listener.js
package.json
test
basic.tap.js
encodeurl
HISTORY.md
README.md
index.js
package.json
encoding-down
.travis.yml
CHANGELOG.md
CONTRIBUTORS.md
LICENSE.md
README.md
UPGRADING.md
index.js
node_modules
abstract-leveldown
.airtap.yml
.travis.yml
CHANGELOG.md
LICENSE.md
README.md
UPGRADING.md
abstract-chained-batch.js
abstract-iterator.js
abstract-leveldown.js
abstract
batch-test.js
chained-batch-test.js
close-test.js
del-test.js
get-test.js
iterator-range-test.js
iterator-test.js
leveldown-test.js
open-test.js
put-get-del-test.js
put-test.js
util.js
index.js
package.json
sauce-labs.svg
test.js
testCommon.js
level-codec
.travis.yml
CHANGELOG.md
CONTRIBUTORS.md
LICENSE.md
README.md
UPGRADING.md
index.js
lib
encodings.js
package.json
test
as-buffer.js
batch.js
codec.js
decoder.js
kv.js
ltgt.js
level-errors
.travis.yml
CHANGELOG.md
CONTRIBUTORS.md
LICENSE.md
README.md
UPGRADING.md
errors.js
package.json
test.js
package.json
test
index.js
end-of-stream
README.md
index.js
package.json
enquirer
CHANGELOG.md
README.md
index.d.ts
index.js
lib
ansi.js
combos.js
completer.js
interpolate.js
keypress.js
placeholder.js
prompt.js
prompts
autocomplete.js
basicauth.js
confirm.js
editable.js
form.js
index.js
input.js
invisible.js
list.js
multiselect.js
numeral.js
password.js
quiz.js
scale.js
select.js
snippet.js
sort.js
survey.js
text.js
toggle.js
render.js
roles.js
state.js
styles.js
symbols.js
theme.js
timer.js
types
array.js
auth.js
boolean.js
index.js
number.js
string.js
utils.js
package.json
errno
.travis.yml
README.md
build.js
cli.js
custom.js
errno.js
package.json
test.js
error-polyfill
README.md
index.js
lib
index.js
non-v8
Frame.js
FrameStringParser.js
FrameStringSource.js
index.js
prepareStackTrace.js
unsupported.js
v8.js
package.json
es5-ext
.github
FUNDING.yml
CHANGELOG.md
README.md
array
#
@@iterator
implement.js
index.js
is-implemented.js
shim.js
_compare-by-length.js
binary-search.js
clear.js
compact.js
concat
implement.js
index.js
is-implemented.js
shim.js
contains.js
copy-within
implement.js
index.js
is-implemented.js
shim.js
diff.js
e-index-of.js
e-last-index-of.js
entries
implement.js
index.js
is-implemented.js
shim.js
exclusion.js
fill
implement.js
index.js
is-implemented.js
shim.js
filter
implement.js
index.js
is-implemented.js
shim.js
find-index
implement.js
index.js
is-implemented.js
shim.js
find
implement.js
index.js
is-implemented.js
shim.js
first-index.js
first.js
flatten.js
for-each-right.js
group.js
index.js
indexes-of.js
intersection.js
is-copy.js
is-empty.js
is-uniq.js
keys
implement.js
index.js
is-implemented.js
shim.js
last-index.js
last.js
map
implement.js
index.js
is-implemented.js
shim.js
remove.js
separate.js
slice
implement.js
index.js
is-implemented.js
shim.js
some-right.js
splice
implement.js
index.js
is-implemented.js
shim.js
uniq.js
values
implement.js
index.js
is-implemented.js
shim.js
_is-extensible.js
_sub-array-dummy-safe.js
_sub-array-dummy.js
from
implement.js
index.js
is-implemented.js
shim.js
generate.js
index.js
is-plain-array.js
of
implement.js
index.js
is-implemented.js
shim.js
to-array.js
valid-array.js
boolean
index.js
is-boolean.js
date
#
copy.js
days-in-month.js
floor-day.js
floor-month.js
floor-year.js
format.js
index.js
ensure-time-value.js
index.js
is-date.js
is-time-value.js
valid-date.js
error
#
index.js
throw.js
custom.js
index.js
is-error.js
valid-error.js
function
#
compose.js
copy.js
curry.js
index.js
lock.js
microtask-delay.js
not.js
partial.js
spread.js
to-string-tokens.js
_define-length.js
constant.js
identity.js
index.js
invoke.js
is-arguments.js
is-function.js
noop.js
pluck.js
valid-function.js
global.js
index.js
iterable
for-each.js
index.js
is.js
validate-object.js
validate.js
json
index.js
safe-stringify.js
math
_decimal-adjust.js
_pack-ieee754.js
_unpack-ieee754.js
acosh
implement.js
index.js
is-implemented.js
shim.js
asinh
implement.js
index.js
is-implemented.js
shim.js
atanh
implement.js
index.js
is-implemented.js
shim.js
cbrt
implement.js
index.js
is-implemented.js
shim.js
ceil-10.js
clz32
implement.js
index.js
is-implemented.js
shim.js
cosh
implement.js
index.js
is-implemented.js
shim.js
expm1
implement.js
index.js
is-implemented.js
shim.js
floor-10.js
fround
implement.js
index.js
is-implemented.js
shim.js
hypot
implement.js
index.js
is-implemented.js
shim.js
imul
implement.js
index.js
is-implemented.js
shim.js
index.js
log10
implement.js
index.js
is-implemented.js
shim.js
log1p
implement.js
index.js
is-implemented.js
shim.js
log2
implement.js
index.js
is-implemented.js
shim.js
round-10.js
sign
implement.js
index.js
is-implemented.js
shim.js
sinh
implement.js
index.js
is-implemented.js
shim.js
tanh
implement.js
index.js
is-implemented.js
shim.js
trunc
implement.js
index.js
is-implemented.js
shim.js
number
#
index.js
pad.js
epsilon
implement.js
index.js
is-implemented.js
index.js
is-finite
implement.js
index.js
is-implemented.js
shim.js
is-integer
implement.js
index.js
is-implemented.js
shim.js
is-nan
implement.js
index.js
is-implemented.js
shim.js
is-natural.js
is-number.js
is-safe-integer
implement.js
index.js
is-implemented.js
shim.js
max-safe-integer
implement.js
index.js
is-implemented.js
min-safe-integer
implement.js
index.js
is-implemented.js
to-integer.js
to-pos-integer.js
to-uint32.js
object
_iterate.js
assign-deep.js
assign
implement.js
index.js
is-implemented.js
shim.js
clear.js
compact.js
compare.js
copy-deep.js
copy.js
count.js
create.js
ensure-array.js
ensure-finite-number.js
ensure-integer.js
ensure-natural-number-value.js
ensure-natural-number.js
ensure-plain-function.js
ensure-plain-object.js
ensure-promise.js
ensure-thenable.js
entries
implement.js
index.js
is-implemented.js
shim.js
eq.js
every.js
filter.js
find-key.js
find.js
first-key.js
flatten.js
for-each.js
get-property-names.js
index.js
is-array-like.js
is-callable.js
is-copy-deep.js
is-copy.js
is-empty.js
is-finite-number.js
is-integer.js
is-natural-number-value.js
is-natural-number.js
is-number-value.js
is-object.js
is-plain-function.js
is-plain-object.js
is-promise.js
is-thenable.js
is-value.js
is.js
key-of.js
keys
implement.js
index.js
is-implemented.js
shim.js
map-keys.js
map.js
mixin-prototypes.js
mixin.js
normalize-options.js
primitive-set.js
safe-traverse.js
serialize.js
set-prototype-of
implement.js
index.js
is-implemented.js
shim.js
some.js
to-array.js
unserialize.js
valid-callable.js
valid-object.js
valid-value.js
validate-array-like-object.js
validate-array-like.js
validate-stringifiable-value.js
validate-stringifiable.js
optional-chaining.js
package.json
promise
#
as-callback.js
finally
implement.js
index.js
is-implemented.js
shim.js
index.js
.eslintrc.json
index.js
lazy.js
reg-exp
#
index.js
is-sticky.js
is-unicode.js
match
implement.js
index.js
is-implemented.js
shim.js
replace
implement.js
index.js
is-implemented.js
shim.js
search
implement.js
index.js
is-implemented.js
shim.js
split
implement.js
index.js
is-implemented.js
shim.js
sticky
implement.js
is-implemented.js
unicode
implement.js
is-implemented.js
escape.js
index.js
is-reg-exp.js
valid-reg-exp.js
safe-to-string.js
string
#
@@iterator
implement.js
index.js
is-implemented.js
shim.js
at.js
camel-to-hyphen.js
capitalize.js
case-insensitive-compare.js
code-point-at
implement.js
index.js
is-implemented.js
shim.js
contains
implement.js
index.js
is-implemented.js
shim.js
count.js
ends-with
implement.js
index.js
is-implemented.js
shim.js
hyphen-to-camel.js
indent.js
index.js
last.js
normalize
_data.js
implement.js
index.js
is-implemented.js
shim.js
pad.js
plain-replace-all.js
plain-replace.js
repeat
implement.js
index.js
is-implemented.js
shim.js
starts-with
implement.js
index.js
is-implemented.js
shim.js
uncapitalize.js
format-method.js
from-code-point
implement.js
index.js
is-implemented.js
shim.js
index.js
is-string.js
random-uniq.js
random.js
raw
implement.js
index.js
is-implemented.js
shim.js
test
.eslintrc.json
__tad.js
array
#
@@iterator
implement.js
index.js
is-implemented.js
shim.js
_compare-by-length.js
binary-search.js
clear.js
compact.js
concat
implement.js
index.js
is-implemented.js
shim.js
contains.js
copy-within
implement.js
index.js
is-implemented.js
shim.js
diff.js
e-index-of.js
e-last-index-of.js
entries
implement.js
index.js
is-implemented.js
shim.js
exclusion.js
fill
implement.js
index.js
is-implemented.js
shim.js
filter
implement.js
index.js
is-implemented.js
shim.js
find-index
implement.js
index.js
is-implemented.js
shim.js
find
implement.js
index.js
is-implemented.js
shim.js
first-index.js
first.js
flatten.js
for-each-right.js
group.js
indexes-of.js
intersection.js
is-copy.js
is-empty.js
is-uniq.js
keys
implement.js
index.js
is-implemented.js
shim.js
last-index.js
last.js
map
implement.js
index.js
is-implemented.js
shim.js
remove.js
separate.js
slice
implement.js
index.js
is-implemented.js
shim.js
some-right.js
splice
implement.js
index.js
is-implemented.js
shim.js
uniq.js
values
implement.js
index.js
is-implemented.js
shim.js
__scopes.js
_is-extensible.js
_sub-array-dummy-safe.js
_sub-array-dummy.js
from
implement.js
index.js
is-implemented.js
shim.js
generate.js
is-plain-array.js
of
implement.js
index.js
is-implemented.js
shim.js
to-array.js
valid-array.js
boolean
is-boolean.js
date
#
copy.js
days-in-month.js
floor-day.js
floor-month.js
floor-year.js
format.js
ensure-time-value.js
is-date.js
is-time-value.js
valid-date.js
error
#
throw.js
custom.js
is-error.js
valid-error.js
function
#
compose.js
copy.js
curry.js
lock.js
microtask-delay.js
not.js
partial.js
spread.js
to-string-tokens.js
_define-length.js
constant.js
identity.js
invoke.js
is-arguments.js
is-function.js
noop.js
pluck.js
valid-function.js
global.js
iterable
for-each.js
is.js
validate-object.js
validate.js
json
safe-stringify.js
math
_decimal-adjust.js
_pack-ieee754.js
_unpack-ieee754.js
acosh
implement.js
index.js
is-implemented.js
shim.js
asinh
implement.js
index.js
is-implemented.js
shim.js
atanh
implement.js
index.js
is-implemented.js
shim.js
cbrt
implement.js
index.js
is-implemented.js
shim.js
ceil-10.js
clz32
implement.js
index.js
is-implemented.js
shim.js
cosh
implement.js
index.js
is-implemented.js
shim.js
expm1
implement.js
index.js
is-implemented.js
shim.js
floor-10.js
fround
implement.js
index.js
is-implemented.js
shim.js
hypot
implement.js
index.js
is-implemented.js
shim.js
imul
implement.js
index.js
is-implemented.js
shim.js
log10
implement.js
index.js
is-implemented.js
shim.js
log1p
implement.js
index.js
is-implemented.js
shim.js
log2
implement.js
index.js
is-implemented.js
shim.js
round-10.js
sign
implement.js
index.js
is-implemented.js
shim.js
sinh
implement.js
index.js
is-implemented.js
shim.js
tanh
implement.js
index.js
is-implemented.js
shim.js
trunc
implement.js
index.js
is-implemented.js
shim.js
number
#
pad.js
epsilon
implement.js
index.js
is-implemented.js
is-finite
implement.js
index.js
is-implemented.js
shim.js
is-integer
implement.js
index.js
is-implemented.js
shim.js
is-nan
implement.js
index.js
is-implemented.js
shim.js
is-natural.js
is-number.js
is-safe-integer
implement.js
index.js
is-implemented.js
shim.js
max-safe-integer
implement.js
index.js
is-implemented.js
min-safe-integer
implement.js
index.js
is-implemented.js
to-integer.js
to-pos-integer.js
to-uint32.js
object
_iterate.js
assign-deep.js
assign
implement.js
index.js
is-implemented.js
shim.js
clear.js
compact.js
compare.js
copy-deep.js
copy.js
count.js
create.js
ensure-array.js
ensure-finite-number.js
ensure-integer.js
ensure-natural-number-value.js
ensure-natural-number.js
ensure-plain-function.js
ensure-plain-object.js
ensure-promise.js
ensure-thenable.js
entries
implement.js
index.js
is-implemented.js
shim.js
eq.js
every.js
filter.js
find-key.js
find.js
first-key.js
flatten.js
for-each.js
get-property-names.js
is-array-like.js
is-callable.js
is-copy-deep.js
is-copy.js
is-empty.js
is-finite-number.js
is-integer.js
is-natural-number-value.js
is-natural-number.js
is-number-value.js
is-object.js
is-plain-function.js
is-plain-object.js
is-promise.js
is-thenable.js
is-value.js
is.js
key-of.js
keys
implement.js
index.js
is-implemented.js
shim.js
map-keys.js
map.js
mixin-prototypes.js
mixin.js
normalize-options.js
primitive-set.js
safe-traverse.js
serialize.js
set-prototype-of
implement.js
index.js
is-implemented.js
shim.js
some.js
to-array.js
unserialize.js
valid-callable.js
valid-object.js
valid-value.js
validate-array-like-object.js
validate-array-like.js
validate-stringifiable-value.js
validate-stringifiable.js
optional-chaining.js
promise
#
as-callback.js
finally
implement.js
index.js
is-implemented.js
shim.js
.eslintrc.json
lazy.js
reg-exp
#
index.js
is-sticky.js
is-unicode.js
match
implement.js
index.js
is-implemented.js
shim.js
replace
implement.js
index.js
is-implemented.js
shim.js
search
implement.js
index.js
is-implemented.js
shim.js
split
implement.js
index.js
is-implemented.js
shim.js
sticky
implement.js
is-implemented.js
unicode
implement.js
is-implemented.js
escape.js
is-reg-exp.js
valid-reg-exp.js
safe-to-string.js
string
#
@@iterator
implement.js
index.js
is-implemented.js
shim.js
at.js
camel-to-hyphen.js
capitalize.js
case-insensitive-compare.js
code-point-at
implement.js
index.js
is-implemented.js
shim.js
contains
implement.js
index.js
is-implemented.js
shim.js
count.js
ends-with
implement.js
index.js
is-implemented.js
shim.js
hyphen-to-camel.js
indent.js
last.js
normalize
_data.js
implement.js
index.js
is-implemented.js
shim.js
pad.js
plain-replace-all.js
plain-replace.js
repeat
implement.js
index.js
is-implemented.js
shim.js
starts-with
implement.js
index.js
is-implemented.js
shim.js
uncapitalize.js
format-method.js
from-code-point
implement.js
index.js
is-implemented.js
shim.js
is-string.js
random-uniq.js
random.js
raw
implement.js
index.js
is-implemented.js
shim.js
to-short-string-representation.js
to-short-string-representation.js
es6-iterator
#
chain.js
CHANGELOG.md
README.md
appveyor.yml
array.js
for-of.js
get.js
index.js
is-iterable.js
package.json
string.js
test
#
chain.js
.eslintrc.json
array.js
for-of.js
get.js
index.js
is-iterable.js
string.js
valid-iterable.js
valid-iterable.js
es6-promise
CHANGELOG.md
README.md
auto.js
dist
es6-promise.auto.js
es6-promise.auto.min.js
es6-promise.js
es6-promise.min.js
es6-promise.d.ts
lib
es6-promise.auto.js
es6-promise.js
es6-promise
-internal.js
asap.js
enumerator.js
polyfill.js
promise.js
promise
all.js
race.js
reject.js
resolve.js
then.js
utils.js
package.json
es6-promisify
README.md
dist
promise.js
promisify.js
package.json
es6-symbol
.github
FUNDING.yml
CHANGELOG.md
README.md
implement.js
index.js
is-implemented.js
is-native-implemented.js
is-symbol.js
lib
private
generate-name.js
setup
standard-symbols.js
symbol-registry.js
package.json
polyfill.js
test
implement.js
index.js
is-implemented.js
is-native-implemented.js
is-symbol.js
polyfill.js
validate-symbol.js
validate-symbol.js
escape-html
Readme.md
index.js
package.json
escape-regexp
Readme.md
component.json
index.js
package.json
escape-string-regexp
index.d.ts
index.js
package.json
readme.md
escodegen
README.md
bin
escodegen.js
esgenerate.js
escodegen.js
node_modules
esprima
README.md
bin
esparse.js
esvalidate.js
dist
esprima.js
package.json
package.json
esprima
README.md
bin
esparse.js
esvalidate.js
dist
esprima.js
package.json
estraverse
README.md
estraverse.js
gulpfile.js
package.json
esutils
README.md
lib
ast.js
code.js
keyword.js
utils.js
package.json
etag
HISTORY.md
README.md
index.js
package.json
eth-ens-namehash
README.md
circle.yml
dist
index.js
index.js
node_modules
js-sha3
.travis.yml
CHANGELOG.md
LICENSE.txt
README.md
bower.json
build
sha3.min.js
index.d.ts
package.json
src
sha3.js
tests
index.html
node-test.js
test-shake.js
test.js
package.json
test
index.js
eth-lib
README.md
lib
account.js
api.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
provider.js
rlp.js
types.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
src
account.js
api.js
array.js
bytes.js
desubits.js
hash.js
index.js
map.js
nat.js
passphrase.js
provider.js
rlp.js
types.js
test
lib
benchmark.js
randomData.js
test.js
eth-object
README.md
index.js
node_modules
ethereumjs-util
CHANGELOG.md
README.md
dist
@types
ethjs-util
index.d.ts
index.js
account.d.ts
account.js
address.d.ts
address.js
bytes.d.ts
bytes.js
constants.d.ts
constants.js
externals.d.ts
externals.js
hash.d.ts
hash.js
helpers.d.ts
helpers.js
index.d.ts
index.js
object.d.ts
object.js
signature.d.ts
signature.js
types.d.ts
types.js
package.json
web3
README.md
angular-patch.js
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
web3-test.ts
tsconfig.json
tslint.json
package.json
src
account.js
ethObject.js
header.js
log.js
proof.js
receipt.js
transaction.js
test
data
mainnet-block.json
zero_difficulty_header.json
test.js
eth-util-lite
README.md
index.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
ethereum-bloom-filters
README.md
dist
index.d.ts
index.js
utils.d.ts
utils.js
package.json
ethereum-cryptography
README.md
aes.d.ts
aes.js
bip39
index.d.ts
index.js
wordlists
czech.d.ts
czech.js
english.d.ts
english.js
french.d.ts
french.js
italian.d.ts
italian.js
japanese.d.ts
japanese.js
korean.d.ts
korean.js
simplified-chinese.d.ts
simplified-chinese.js
spanish.d.ts
spanish.js
traditional-chinese.d.ts
traditional-chinese.js
blake2b.d.ts
blake2b.js
hash-utils.d.ts
hash-utils.js
hdkey.d.ts
hdkey.js
index.d.ts
index.js
keccak.d.ts
keccak.js
package.json
pbkdf2.d.ts
pbkdf2.js
pure
hdkey.d.ts
hdkey.js
ripemd160.d.ts
ripemd160.js
sha256.d.ts
sha256.js
shims
hdkey-crypto.d.ts
hdkey-crypto.js
hdkey-secp256k1v3.d.ts
hdkey-secp256k1v3.js
vendor
hdkey-without-crypto.js
random.d.ts
random.js
ripemd160.d.ts
ripemd160.js
scrypt.d.ts
scrypt.js
secp256k1.d.ts
secp256k1.js
sha256.d.ts
sha256.js
shims
hdkey-crypto.d.ts
hdkey-crypto.js
hdkey-secp256k1v3.d.ts
hdkey-secp256k1v3.js
src
aes.ts
bip39
index.ts
wordlists
czech.ts
english.ts
french.ts
italian.ts
japanese.ts
korean.ts
simplified-chinese.ts
spanish.ts
traditional-chinese.ts
blake2b.ts
hash-utils.ts
hdkey.ts
index.ts
keccak.ts
pbkdf2.ts
pure
hdkey.ts
ripemd160.ts
sha256.ts
shims
hdkey-crypto.ts
hdkey-secp256k1v3.ts
vendor
hdkey-without-crypto.js
random.ts
ripemd160.ts
scrypt.ts
secp256k1.ts
sha256.ts
shims
hdkey-crypto.ts
hdkey-secp256k1v3.ts
vendor
bip39-without-wordlists.js
hdkey-without-crypto.js
vendor
bip39-without-wordlists.js
hdkey-without-crypto.js
ethereumjs-block
CHANGELOG.md
README.md
from-rpc.js
header-from-rpc.js
header.js
index.js
karma.conf.js
node_modules
async
CHANGELOG.md
README.md
all.js
allLimit.js
allSeries.js
any.js
anyLimit.js
anySeries.js
apply.js
applyEach.js
applyEachSeries.js
asyncify.js
auto.js
autoInject.js
bower.json
cargo.js
compose.js
concat.js
concatLimit.js
concatSeries.js
constant.js
detect.js
detectLimit.js
detectSeries.js
dir.js
dist
async.js
async.min.js
doDuring.js
doUntil.js
doWhilst.js
during.js
each.js
eachLimit.js
eachOf.js
eachOfLimit.js
eachOfSeries.js
eachSeries.js
ensureAsync.js
every.js
everyLimit.js
everySeries.js
filter.js
filterLimit.js
filterSeries.js
find.js
findLimit.js
findSeries.js
foldl.js
foldr.js
forEach.js
forEachLimit.js
forEachOf.js
forEachOfLimit.js
forEachOfSeries.js
forEachSeries.js
forever.js
groupBy.js
groupByLimit.js
groupBySeries.js
index.js
inject.js
internal
DoublyLinkedList.js
applyEach.js
breakLoop.js
consoleFunc.js
createTester.js
doLimit.js
doParallel.js
doParallelLimit.js
eachOfLimit.js
filter.js
findGetResult.js
getIterator.js
initialParams.js
iterator.js
map.js
notId.js
once.js
onlyOnce.js
parallel.js
queue.js
reject.js
setImmediate.js
slice.js
withoutIndex.js
wrapAsync.js
log.js
map.js
mapLimit.js
mapSeries.js
mapValues.js
mapValuesLimit.js
mapValuesSeries.js
memoize.js
nextTick.js
package.json
parallel.js
parallelLimit.js
priorityQueue.js
queue.js
race.js
reduce.js
reduceRight.js
reflect.js
reflectAll.js
reject.js
rejectLimit.js
rejectSeries.js
retry.js
retryable.js
select.js
selectLimit.js
selectSeries.js
seq.js
series.js
setImmediate.js
some.js
someLimit.js
someSeries.js
sortBy.js
timeout.js
times.js
timesLimit.js
timesSeries.js
transform.js
tryEach.js
unmemoize.js
until.js
waterfall.js
whilst.js
wrapSync.js
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
ethereumjs-util
CHANGELOG.md
README.md
dist
index.js
secp256k1-adapter.js
secp256k1-lib
der.js
index.js
package.json
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
merkle-patricia-tree
.travis.yml
CHANGELOG.md
README.md
baseTrie.js
benchmarks
checkpointing.js
random.js
checkpoint-interface.js
dist
trie.js
docs
index.md
index.js
karma.conf.js
node_modules
async
CHANGELOG.md
README.md
dist
async.js
async.min.js
lib
async.js
package.json
package.json
prioritizedTaskExecutor.js
proof.js
readStream.js
secure-interface.js
secure.js
test
encodeing.js
failingRefactorTests.js
index.js
offical.js
prioritizedTaskExecutor.js
proof.js
rawOPs.js
secure.js
streams.js
trieNode.js
util.js
readable-stream
.travis.yml
CONTRIBUTING.md
GOVERNANCE.md
README.md
doc
wg-meetings
2015-01-30.md
duplex-browser.js
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
internal
streams
BufferList.js
destroy.js
stream-browser.js
stream.js
node_modules
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
passthrough.js
readable-browser.js
readable.js
transform.js
writable-browser.js
writable.js
string_decoder
.travis.yml
README.md
lib
string_decoder.js
node_modules
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
package.json
ethereumjs-common
CHANGELOG.md
README.md
dist
chains
goerli.json
index.d.ts
index.js
kovan.json
mainnet.json
rinkeby.json
ropsten.json
genesisStates
goerli.json
index.d.ts
index.js
kovan.json
mainnet.json
rinkeby.json
ropsten.json
hardforks
byzantium.json
chainstart.json
constantinople.json
dao.json
homestead.json
index.d.ts
index.js
istanbul.json
muirGlacier.json
petersburg.json
spuriousDragon.json
tangerineWhistle.json
index.d.ts
index.js
types.d.ts
types.js
package.json
ethereumjs-tx
CHANGELOG.md
README.md
dist
fake.d.ts
fake.js
index.d.ts
index.js
transaction.d.ts
transaction.js
types.d.ts
types.js
package.json
ethereumjs-util
CHANGELOG.md
README.md
dist
account.d.ts
account.js
bytes.d.ts
bytes.js
constants.d.ts
constants.js
hash.d.ts
hash.js
index.d.ts
index.js
object.d.ts
object.js
secp256k1v3-adapter.d.ts
secp256k1v3-adapter.js
secp256k1v3-lib
der.d.ts
der.js
index.d.ts
index.js
signature.d.ts
signature.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
ethers
.eslintrc.js
.travis.yml
CODE_OF_CONDUCT.md
README.md
_version.js
contracts
contract.js
index.js
interface.js
dist
demo
index.html
style.css
ethers.js
ethers.min.js
ethers.types.txt
types
_version.d.ts
contracts
contract.d.ts
index.d.ts
interface.d.ts
ethers.d.ts
index.d.ts
providers
etherscan-provider.d.ts
fallback-provider.d.ts
index.d.ts
infura-provider.d.ts
ipc-provider.d.ts
json-rpc-provider.d.ts
provider.d.ts
web3-provider.d.ts
utils
abi-coder.d.ts
address.d.ts
base64.d.ts
bignumber.d.ts
bytes.d.ts
errors.d.ts
hash.d.ts
hmac.d.ts
index.d.ts
json-wallet.d.ts
keccak256.d.ts
networks.d.ts
pbkdf2.d.ts
properties.d.ts
random-bytes.d.ts
rlp.d.ts
secp256k1.d.ts
sha2.d.ts
shims.d.ts
solidity.d.ts
transaction.d.ts
types.d.ts
units.d.ts
utf8.d.ts
web.d.ts
wallet
hdnode.d.ts
index.d.ts
secret-storage.d.ts
signing-key.d.ts
wallet.d.ts
wordlists
index.d.ts
lang-en.d.ts
lang-it.d.ts
lang-ja.d.ts
lang-ko.d.ts
lang-zh.d.ts
wordlist.d.ts
wordlist-it.js
wordlist-ja.js
wordlist-ko.js
wordlist-zh.js
ethers.js
index.js
node_modules
@types
node
README.md
assert.d.ts
async_hooks.d.ts
base.d.ts
buffer.d.ts
child_process.d.ts
cluster.d.ts
console.d.ts
constants.d.ts
crypto.d.ts
dgram.d.ts
dns.d.ts
domain.d.ts
events.d.ts
fs.d.ts
globals.d.ts
http.d.ts
http2.d.ts
https.d.ts
index.d.ts
inspector.d.ts
module.d.ts
net.d.ts
os.d.ts
package.json
path.d.ts
perf_hooks.d.ts
process.d.ts
punycode.d.ts
querystring.d.ts
readline.d.ts
repl.d.ts
stream.d.ts
string_decoder.d.ts
timers.d.ts
tls.d.ts
trace_events.d.ts
ts3.6
assert.d.ts
base.d.ts
index.d.ts
tty.d.ts
url.d.ts
util.d.ts
v8.d.ts
vm.d.ts
worker_threads.d.ts
zlib.d.ts
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
elliptic
README.md
lib
elliptic.js
elliptic
curve
base.js
edwards.js
index.js
mont.js
short.js
curves.js
ec
index.js
key.js
signature.js
eddsa
index.js
key.js
signature.js
hmac-drbg.js
precomputed
secp256k1.js
utils.js
package.json
hash.js
.eslintrc.js
.travis.yml
README.md
lib
hash.d.ts
hash.js
hash
common.js
hmac.js
ripemd.js
sha.js
sha
1.js
224.js
256.js
384.js
512.js
common.js
utils.js
package.json
test
hash-test.js
hmac-test.js
js-sha3
.travis.yml
CHANGELOG.md
LICENSE.txt
README.md
bower.json
build
sha3.min.js
index.d.ts
package.json
src
sha3.js
tests
index.html
node-test.js
test-shake.js
test.js
scrypt-js
LICENSE.txt
README.md
index.html
package.json
scrypt.js
test
test-scrypt.js
test-vectors.json
thirdparty
buffer.js
setImmediate.js
unorm.js
setimmediate
LICENSE.txt
README.md
package.json
setImmediate.js
uuid
.travis.yml
LICENSE.md
README.md
benchmark
README.md
bench.sh
benchmark-native.c
benchmark.js
package.json
misc
compare.js
perf.js
package.json
rng-browser.js
rng.js
test
test.js
uuid.js
package.json
providers
etherscan-provider.js
fallback-provider.js
index.js
infura-provider.js
ipc-provider.js
json-rpc-provider.js
provider.js
web3-provider.js
shims
base64.js
empty.js
hmac.js
index.js
pbkdf2.js
random-bytes.js
shims.js
wordlists.js
xmlhttprequest.js
utils
abi-coder.js
address.js
base64.js
bignumber.js
bytes.js
errors.js
hash.js
hmac.js
index.js
json-wallet.js
keccak256.js
networks.js
pbkdf2.js
properties.js
random-bytes.js
rlp.js
secp256k1.js
sha2.js
shims.js
solidity.js
transaction.js
types.js
units.js
utf8.js
web.js
wallet
hdnode.js
index.js
secret-storage.js
signing-key.js
wallet.js
wordlists
index.js
lang-en.js
lang-it.js
lang-ja.js
lang-ko.js
lang-zh.js
wordlist.js
ethjs-unit
CHANGELOG.md
README.md
dist
ethjs-unit.js
ethjs-unit.min.js
internals
webpack
webpack.config.js
lib
index.js
index.txt
tests
test.index.js
node_modules
bn.js
.travis.yml
README.md
lib
bn.js
package.json
test
arithmetic-test.js
binary-test.js
constructor-test.js
fixtures.js
pummel
dh-group-test.js
red-test.js
utils-test.js
util
genCombMulTo.js
genCombMulTo10.js
package.json
src
index.js
tests
test.index.js
ethjs-util
CHANGELOG.md
README.md
dist
ethjs-util.js
ethjs-util.min.js
internals
webpack
webpack.config.js
lib
index.js
tests
test.index.js
package.json
src
index.js
tests
test.index.js
eventemitter2
CHANGELOG.md
LICENSE.txt
README.md
eventemitter2.d.ts
index.js
lib
eventemitter2.js
package.json
eventemitter3
README.md
index.d.ts
index.js
package.json
umd
eventemitter3.js
eventemitter3.min.js
evp_bytestokey
README.md
index.js
package.json
expand-brackets
README.md
index.js
package.json
expand-range
README.md
index.js
node_modules
fill-range
README.md
index.js
package.json
is-number
README.md
index.js
package.json
package.json
express
History.md
Readme.md
index.js
lib
application.js
express.js
middleware
init.js
query.js
request.js
response.js
router
index.js
layer.js
route.js
utils.js
view.js
node_modules
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
ext
CHANGELOG.md
README.md
docs
function
identity.md
global-this.md
math
ceil-10.md
floor-10.md
round-10.md
object
entries.md
string
random.md
string_
includes.md
thenable_
finally.md
function
identity.js
global-this
implementation.js
index.js
is-implemented.js
lib
private
decimal-adjust.js
math
ceil-10.js
floor-10.js
round-10.js
node_modules
type
CHANGELOG.md
README.md
array-length
coerce.js
ensure.js
array-like
ensure.js
is.js
array
ensure.js
is.js
date
ensure.js
is.js
docs
array-length.md
array-like.md
array.md
date.md
ensure.md
error.md
finite.md
function.md
integer.md
iterable.md
natural-number.md
number.md
object.md
plain-function.md
plain-object.md
promise.md
prototype.md
reg-exp.md
safe-integer.md
string.md
thenable.md
time-value.md
value.md
ensure.js
error
ensure.js
is.js
finite
coerce.js
ensure.js
function
ensure.js
is.js
integer
coerce.js
ensure.js
iterable
ensure.js
is.js
lib
ensure
min.js
is-to-string-tag-supported.js
resolve-error-message.js
resolve-exception.js
safe-to-string.js
to-short-string.js
natural-number
coerce.js
ensure.js
number
coerce.js
ensure.js
object
ensure.js
is.js
package.json
plain-function
ensure.js
is.js
plain-object
ensure.js
is.js
promise
ensure.js
is.js
prototype
is.js
reg-exp
ensure.js
is.js
safe-integer
coerce.js
ensure.js
string
coerce.js
ensure.js
test
_lib
arrow-function-if-supported.js
class-if-supported.js
array-length
coerce.js
ensure.js
array-like
ensure.js
is.js
array
ensure.js
is.js
date
ensure.js
is.js
ensure.js
error
ensure.js
is.js
finite
coerce.js
ensure.js
function
ensure.js
is.js
integer
coerce.js
ensure.js
iterable
ensure.js
is.js
lib
is-to-string-tag-supported.js
resolve-error-message.js
resolve-exception.js
safe-to-string.js
to-short-string.js
natural-number
coerce.js
ensure.js
number
coerce.js
ensure.js
object
ensure.js
is.js
plain-function
ensure.js
is.js
plain-object
ensure.js
is.js
promise
ensure.js
is.js
prototype
is.js
reg-exp
ensure.js
is.js
safe-integer
coerce.js
ensure.js
string
coerce.js
ensure.js
thenable
ensure.js
is.js
time-value
coerce.js
ensure.js
value
ensure.js
is.js
thenable
ensure.js
is.js
time-value
coerce.js
ensure.js
value
ensure.js
is.js
object
entries
implement.js
implementation.js
index.js
is-implemented.js
package.json
string
random.js
string_
includes
implementation.js
index.js
is-implemented.js
test
function
identity.js
global-this
implementation.js
index.js
is-implemented.js
math
ceil-10.js
floor-10.js
round-10.js
object
entries
_tests.js
implementation.js
index.js
is-implemented.js
string
random.js
string_
includes
_tests.js
implementation.js
index.js
is-implemented.js
thenable_
finally.js
thenable_
finally.js
extend
.jscs.json
.travis.yml
CHANGELOG.md
README.md
component.json
index.js
package.json
extglob
README.md
index.js
node_modules
is-extglob
README.md
index.js
package.json
package.json
extsprintf
README.md
lib
extsprintf.js
package.json
fast-deep-equal
README.md
es6
index.d.ts
index.js
react.d.ts
react.js
index.d.ts
index.js
package.json
react.d.ts
react.js
fast-json-stable-stringify
.eslintrc.yml
.github
FUNDING.yml
.travis.yml
README.md
benchmark
index.js
test.json
example
key_cmp.js
nested.js
str.js
value_cmp.js
index.d.ts
index.js
package.json
test
cmp.js
nested.js
str.js
to-json.js
fast-levenshtein
LICENSE.md
README.md
levenshtein.js
package.json
fclone
.travis.yml
README.md
bench
index.js
looparr.js
loopobj.js
package.json
bower.json
dist
fclone.d.ts
fclone.js
fclone.min.js
fclone.d.ts
package.json
src
fclone.js
fd-slicer
.travis.yml
CHANGELOG.md
README.md
index.js
package.json
test
test.js
file-type
index.js
package.json
readme.md
file-uri-to-path
.travis.yml
History.md
README.md
index.d.ts
index.js
package.json
test
test.js
tests.json
filename-regex
README.md
index.js
package.json
fill-range
README.md
index.js
package.json
finalhandler
HISTORY.md
README.md
index.js
package.json
follow-redirects
README.md
http.js
https.js
index.js
node_modules
debug
.coveralls.yml
.travis.yml
CHANGELOG.md
README.md
karma.conf.js
node.js
package.json
src
browser.js
debug.js
index.js
node.js
package.json
for-in
README.md
index.js
package.json
for-own
README.md
index.js
package.json
forever-agent
README.md
index.js
package.json
form-data
README.md
lib
browser.js
form_data.js
populate.js
package.json
forwarded
HISTORY.md
README.md
index.js
package.json
fresh
HISTORY.md
README.md
index.js
package.json
fs-constants
README.md
browser.js
index.js
package.json
fs-extra
CHANGELOG.md
README.md
docs
copy-sync.md
copy.md
emptyDir-sync.md
emptyDir.md
ensureDir-sync.md
ensureDir.md
ensureFile-sync.md
ensureFile.md
ensureLink-sync.md
ensureLink.md
ensureSymlink-sync.md
ensureSymlink.md
fs-read-write.md
move-sync.md
move.md
outputFile-sync.md
outputFile.md
outputJson-sync.md
outputJson.md
pathExists-sync.md
pathExists.md
readJson-sync.md
readJson.md
remove-sync.md
remove.md
writeJson-sync.md
writeJson.md
lib
copy-sync
copy-file-sync.js
copy-sync.js
index.js
copy
copy.js
index.js
ncp.js
empty
index.js
ensure
file.js
index.js
link.js
symlink-paths.js
symlink-type.js
symlink.js
fs
index.js
index.js
json
index.js
jsonfile.js
output-json-sync.js
output-json.js
mkdirs
index.js
mkdirs-sync.js
mkdirs.js
win32.js
move-sync
index.js
move
index.js
output
index.js
path-exists
index.js
remove
index.js
rimraf.js
util
assign.js
buffer.js
utimes.js
package.json
fs-minipass
README.md
index.js
package.json
fs.realpath
README.md
index.js
old.js
package.json
ftp
README.md
lib
connection.js
parser.js
node_modules
readable-stream
README.md
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
package.json
passthrough.js
readable.js
transform.js
writable.js
string_decoder
README.md
index.js
package.json
package.json
test
test-parser.js
test.js
function-bind
.jscs.json
.travis.yml
README.md
implementation.js
index.js
package.json
test
index.js
functional-red-black-tree
README.md
bench
test.js
package.json
rbtree.js
test
test.js
get-stream
buffer-stream.js
index.js
package.json
readme.md
get-uri
.github
workflows
test.yml
History.md
README.md
data.js
file.js
ftp.js
http.js
https.js
index.js
node_modules
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
readable-stream
.travis.yml
CONTRIBUTING.md
GOVERNANCE.md
README.md
doc
wg-meetings
2015-01-30.md
duplex-browser.js
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
internal
streams
BufferList.js
destroy.js
stream-browser.js
stream.js
package.json
passthrough.js
readable-browser.js
readable.js
transform.js
writable-browser.js
writable.js
safe-buffer
README.md
index.d.ts
index.js
package.json
string_decoder
.travis.yml
README.md
lib
string_decoder.js
package.json
notfound.js
notmodified.js
package.json
test
data.js
file.js
ftp.js
http.js
https.js
redirect.js
test.js
getpass
.travis.yml
README.md
lib
index.js
package.json
glob-base
README.md
index.js
node_modules
glob-parent
.travis.yml
README.md
index.js
package.json
test.js
is-extglob
README.md
index.js
package.json
is-glob
README.md
index.js
package.json
package.json
glob-parent
README.md
index.js
package.json
glob
README.md
changelog.md
common.js
glob.js
package.json
sync.js
global
.travis.yml
README.md
console.js
document.js
package.json
process.js
window.js
got
package.json
readme.md
source
as-promise.js
as-stream.js
create.js
errors.js
get-response.js
index.js
known-hook-events.js
merge.js
normalize-arguments.js
progress.js
request-as-event-emitter.js
utils
deep-freeze.js
get-body-size.js
is-form-data.js
timed-out.js
url-to-options.js
graceful-fs
README.md
clone.js
graceful-fs.js
legacy-streams.js
package.json
polyfills.js
har-schema
README.md
lib
afterRequest.json
beforeRequest.json
browser.json
cache.json
content.json
cookie.json
creator.json
entry.json
har.json
header.json
index.js
log.json
page.json
pageTimings.json
postData.json
query.json
request.json
response.json
timings.json
package.json
har-validator
README.md
lib
async.js
error.js
promise.js
package.json
has-ansi
index.js
node_modules
ansi-regex
index.js
package.json
readme.md
package.json
readme.md
has-flag
index.d.ts
index.js
package.json
readme.md
has-symbol-support-x
.eslintrc.json
.travis.yml
.uglifyjsrc.json
README.md
badges.html
index.js
lib
has-symbol-support-x.js
has-symbol-support-x.min.js
package.json
tests
index.html
run.js
spec
test.js
has-to-string-tag-x
.eslintrc.json
.travis.yml
.uglifyjsrc.json
README.md
badges.html
index.js
lib
has-to-string-tag-x.js
has-to-string-tag-x.min.js
package.json
has
README.md
package.json
src
index.js
test
index.js
hash-base
README.md
index.js
package.json
hash.js
.eslintrc.js
.travis.yml
README.md
lib
hash.d.ts
hash.js
hash
common.js
hmac.js
ripemd.js
sha.js
sha
1.js
224.js
256.js
384.js
512.js
common.js
utils.js
package.json
test
hash-test.js
hmac-test.js
header-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
hmac-drbg
.travis.yml
README.md
lib
hmac-drbg.js
package.json
test
drbg-test.js
fixtures
hmac-drbg-nist.json
http-cache-semantics
README.md
index.js
package.json
http-errors
HISTORY.md
README.md
index.js
node_modules
inherits
README.md
inherits.js
inherits_browser.js
package.json
package.json
http-https
README.md
http-https.js
package.json
test.js
http-proxy-agent
.travis.yml
History.md
README.md
index.js
node_modules
debug
.coveralls.yml
.travis.yml
CHANGELOG.md
README.md
karma.conf.js
node.js
package.json
src
browser.js
debug.js
index.js
node.js
package.json
test
test.js
http-signature
CHANGES.md
README.md
http_signing.md
lib
index.js
parser.js
signer.js
utils.js
verify.js
package.json
https-proxy-agent
.eslintrc.js
.github
workflows
test.yml
README.md
index.d.ts
index.js
node_modules
debug
CHANGELOG.md
README.md
dist
debug.js
node.js
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
iconv-lite
Changelog.md
README.md
encodings
dbcs-codec.js
dbcs-data.js
index.js
internal.js
sbcs-codec.js
sbcs-data-generated.js
sbcs-data.js
tables
big5-added.json
cp936.json
cp949.json
cp950.json
eucjp.json
gb18030-ranges.json
gbk-added.json
shiftjis.json
utf16.js
utf7.js
lib
bom-handling.js
extend-node.js
index.d.ts
index.js
streams.js
package.json
idna-uts46-hx
HISTORY.md
LICENSE.txt
README.md
build-unicode-tables.py
idna-map.js
node_modules
punycode
LICENSE-MIT.txt
README.md
package.json
punycode.es6.js
punycode.js
package.json
test
node_fs_shim.js
test-amd.html
test-idna-vector.spec.js
test-uts46.spec.js
uts46.js
ieee754
README.md
index.d.ts
index.js
package.json
immediate
.travis.yml
LICENSE.txt
README.md
bower.json
component.json
dist
immediate.js
immediate.min.js
lib
index.js
messageChannel.js
mutation.js
nextTick.js
queueMicrotask.js
stateChange.js
timeout.js
package.json
imurmurhash
README.md
imurmurhash.js
imurmurhash.min.js
package.json
inflight
README.md
inflight.js
package.json
inherits
README.md
inherits.js
inherits_browser.js
package.json
ip
.travis.yml
README.md
lib
ip.js
package.json
test
api-test.js
ipaddr.js
README.md
ipaddr.min.js
lib
ipaddr.js
ipaddr.js.d.ts
package.json
is-binary-path
index.d.ts
index.js
package.json
readme.md
is-buffer
README.md
index.js
package.json
test
basic.js
is-core-module
.github
FUNDING.yml
workflows
rebase.yml
require-allow-edits.yml
.travis.yml
CHANGELOG.md
README.md
core.json
index.js
package.json
test
index.js
is-dotfile
README.md
index.js
package.json
is-equal-shallow
README.md
index.js
package.json
is-extendable
README.md
index.js
package.json
is-extglob
README.md
index.js
package.json
is-function
README.md
index.js
package.json
test.js
is-glob
README.md
index.js
package.json
is-hex-prefixed
.travis.yml
CHANGELOG.md
README.md
package.json
src
index.js
tests
test.index.js
is-natural-number
README.md
index.js
index.jsnext.js
package.json
is-number
README.md
index.js
package.json
is-obj
index.d.ts
index.js
package.json
readme.md
is-object
.jscs.json
.testem.json
.travis.yml
README.md
index.js
package.json
test
index.js
is-plain-obj
index.js
package.json
readme.md
is-posix-bracket
README.md
index.js
package.json
is-primitive
README.md
index.js
package.json
is-retry-allowed
index.js
package.json
readme.md
is-stream
index.js
package.json
readme.md
is-typedarray
LICENSE.md
README.md
index.js
package.json
test.js
isarray
README.md
build
build.js
component.json
index.js
package.json
isobject
README.md
index.js
node_modules
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
package.json
isstream
.travis.yml
LICENSE.md
README.md
isstream.js
package.json
test.js
isurl
README.md
index.js
package.json
jest-diff
build
cleanupSemantic.d.ts
cleanupSemantic.js
constants.d.ts
constants.js
diffLines.d.ts
diffLines.js
diffStrings.d.ts
diffStrings.js
getAlignedDiffs.d.ts
getAlignedDiffs.js
index.d.ts
index.js
joinAlignedDiffs.d.ts
joinAlignedDiffs.js
printDiffs.d.ts
printDiffs.js
types.d.ts
types.js
node_modules
ansi-styles
index.js
package.json
readme.md
chalk
index.js
package.json
readme.md
templates.js
types
index.d.ts
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
.eslintrc.json
README.md
index.js
package.json
test.js
escape-string-regexp
index.js
package.json
readme.md
has-flag
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
package.json
jest-get-type
build
index.d.ts
index.js
package.json
jest-matcher-utils
build
index.d.ts
index.js
node_modules
ansi-styles
index.js
package.json
readme.md
chalk
index.js
package.json
readme.md
templates.js
types
index.d.ts
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
.eslintrc.json
README.md
index.js
package.json
test.js
escape-string-regexp
index.js
package.json
readme.md
has-flag
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
package.json
jest-matchers
build-es5
asymmetric-matchers.js
index.js
jasmine-utils.js
matchers.js
spyMatchers.js
toThrowMatchers.js
utils.js
build
asymmetric-matchers.js
index.js
jasmine-utils.js
matchers.js
spyMatchers.js
toThrowMatchers.js
utils.js
node_modules
ansi-regex
index.js
package.json
readme.md
ansi-styles
index.js
package.json
readme.md
chalk
index.js
package.json
readme.md
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
.eslintrc.json
README.md
index.js
package.json
test.js
escape-string-regexp
index.js
package.json
readme.md
jest-diff
build-es5
constants.js
diffStrings.js
index.js
build
constants.js
diffStrings.js
index.js
package.json
jest-matcher-utils
build-es5
index.js
build
index.js
package.json
pretty-format
README.md
build-es5
index.js
plugins
AsymmetricMatcher.js
ConvertAnsi.js
HTMLElement.js
ImmutableList.js
ImmutableMap.js
ImmutableOrderedMap.js
ImmutableOrderedSet.js
ImmutablePlugins.js
ImmutableSet.js
ImmutableStack.js
ReactElement.js
ReactTestComponent.js
lib
escapeHTML.js
printImmutable.js
build
index.js
plugins
AsymmetricMatcher.js
ConvertAnsi.js
HTMLElement.js
ImmutableList.js
ImmutableMap.js
ImmutableOrderedMap.js
ImmutableOrderedSet.js
ImmutablePlugins.js
ImmutableSet.js
ImmutableStack.js
ReactElement.js
ReactTestComponent.js
lib
escapeHTML.js
printImmutable.js
node_modules
ansi-styles
index.js
package.json
readme.md
package.json
perf
test.js
world.geo.json
supports-color
index.js
package.json
readme.md
package.json
jest-message-util
build-es5
index.js
build
index.js
node_modules
ansi-styles
index.js
package.json
readme.md
chalk
index.js
package.json
readme.md
escape-string-regexp
index.js
package.json
readme.md
supports-color
index.js
package.json
readme.md
package.json
jest-regex-util
build-es5
index.js
build
index.js
package.json
js-sha256
CHANGELOG.md
LICENSE.txt
README.md
build
sha256.min.js
index.d.ts
package.json
src
sha256.js
js-sha3
CHANGELOG.md
LICENSE.txt
README.md
build
sha3.min.js
index.d.ts
package.json
src
sha3.js
jsbn
README.md
example.html
example.js
index.js
package.json
json-buffer
.travis.yml
README.md
index.js
package.json
test
index.js
json-schema-traverse
.eslintrc.yml
.travis.yml
README.md
index.js
package.json
spec
.eslintrc.yml
fixtures
schema.js
index.spec.js
json-schema
README.md
draft-zyp-json-schema-03.xml
draft-zyp-json-schema-04.xml
lib
links.js
validate.js
package.json
test
tests.js
json-stringify-safe
CHANGELOG.md
README.md
package.json
stringify.js
test
stringify_test.js
jsonfile
CHANGELOG.md
README.md
index.js
package.json
jsprim
CHANGES.md
CONTRIBUTING.md
README.md
lib
jsprim.js
package.json
keccak
README.md
bindings.js
index.js
js.js
lib
api
index.js
keccak.js
shake.js
keccak-state-reference.js
keccak-state-unroll.js
keccak.js
package.json
src
README.md
libkeccak-32
KeccakP-1600-SnP.h
KeccakP-1600-inplace32BI.c
KeccakSponge-common.h
KeccakSpongeWidth1600.c
KeccakSpongeWidth1600.h
SnP-Relaned.h
align.h
brg_endian.h
libkeccak-64
KeccakP-1600-SnP.h
KeccakP-1600-opt64-config.h
KeccakP-1600-opt64.c
KeccakSponge-common.h
KeccakSpongeWidth1600.c
KeccakSpongeWidth1600.h
SnP-Relaned.h
align.h
brg_endian.h
keyv
README.md
package.json
src
index.js
kind-of
README.md
index.js
package.json
lazy
README.md
lazy.js
package.json
test
bucket.js
complex.js
custom.js
em.js
filter.js
foldr.js
forEach.js
head.js
join.js
lines.js
map.js
pipe.js
product.js
range.js
skip.js
sum.js
tail.js
take.js
takeWhile.js
level-codec
.travis.yml
LICENSE.md
README.md
index.js
lib
encodings.js
package.json
test
as-buffer.js
batch.js
codec.js
decoder.js
kv.js
ltgt.js
level-errors
.travis.yml
LICENSE.md
README.md
errors.js
package.json
test.js
level-iterator-stream
.travis.yml
LICENSE.md
README.md
example.js
index.js
node_modules
readable-stream
README.md
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
package.json
passthrough.js
readable.js
transform.js
writable.js
string_decoder
README.md
index.js
package.json
package.json
test.js
level-mem
.travis.yml
CHANGELOG.md
CONTRIBUTING.md
LICENSE.md
README.md
UPGRADING.md
level-mem.js
node_modules
abstract-leveldown
.airtap.yml
.travis.yml
CHANGELOG.md
LICENSE.md
README.md
UPGRADING.md
abstract-chained-batch.js
abstract-iterator.js
abstract-leveldown.js
abstract
batch-test.js
chained-batch-test.js
close-test.js
del-test.js
get-test.js
iterator-range-test.js
iterator-test.js
leveldown-test.js
open-test.js
put-get-del-test.js
put-test.js
util.js
index.js
package.json
sauce-labs.svg
test.js
testCommon.js
immediate
.travis.yml
LICENSE.txt
README.md
bench.js
bower.json
component.json
dist
immediate.js
immediate.min.js
lib
index.js
messageChannel.js
mutation.js
nextTick.js
stateChange.js
timeout.js
package.json
memdown
CHANGELOG.md
LICENSE.md
README.md
UPGRADING.md
immediate-browser.js
immediate.js
memdown.js
package.json
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
test.js
level-packager
.travis.yml
CHANGELOG.md
CONTRIBUTORS.md
LICENSE.md
README.md
UPGRADING.md
abstract
base-test.js
db-values-test.js
destroy-test.js
error-if-exists-test.js
location.js
repair-test.js
test.js
level-packager.js
node_modules
abstract-leveldown
.airtap.yml
.travis.yml
CHANGELOG.md
LICENSE.md
README.md
UPGRADING.md
abstract-chained-batch.js
abstract-iterator.js
abstract-leveldown.js
abstract
batch-test.js
chained-batch-test.js
close-test.js
del-test.js
get-test.js
iterator-range-test.js
iterator-test.js
leveldown-test.js
open-test.js
put-get-del-test.js
put-test.js
util.js
index.js
package.json
sauce-labs.svg
test.js
testCommon.js
deferred-leveldown
.travis.yml
CHANGELOG.md
LICENSE.md
README.md
UPGRADING.md
deferred-iterator.js
deferred-leveldown.js
package.json
test.js
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
level-errors
.travis.yml
CHANGELOG.md
CONTRIBUTORS.md
LICENSE.md
README.md
UPGRADING.md
errors.js
package.json
test.js
level-iterator-stream
.travis.yml
CHANGELOG.md
LICENSE.md
README.md
UPGRADING.md
example.js
index.js
package.json
test.js
levelup
CHANGELOG.md
CONTRIBUTORS.md
LICENSE.md
README.md
UPGRADING.md
lib
batch.js
common.js
levelup.js
promisify.js
package.json
sauce-labs.svg
readable-stream
.travis.yml
CONTRIBUTING.md
GOVERNANCE.md
README.md
doc
wg-meetings
2015-01-30.md
duplex-browser.js
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
internal
streams
BufferList.js
destroy.js
stream-browser.js
stream.js
package.json
passthrough.js
readable-browser.js
readable.js
transform.js
writable-browser.js
writable.js
safe-buffer
README.md
index.d.ts
index.js
package.json
string_decoder
.travis.yml
README.md
lib
string_decoder.js
package.json
package.json
test.js
level-ws
README.md
level-ws.js
node_modules
readable-stream
README.md
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
package.json
passthrough.js
readable.js
transform.js
writable.js
string_decoder
README.md
index.js
package.json
xtend
README.md
has-keys.js
index.js
mutable.js
package.json
test.js
package.json
test.js
levelup
.travis.yml
CHANGELOG.md
LICENSE.md
README.md
buster.js
lib
batch.js
leveldown.js
levelup.js
util.js
node_modules
semver
README.md
package.json
semver.js
package.json
test
approximate-size-test.js
argument-checking-test.js
batch-test.js
binary-test.js
browserify-test.js
common.js
create-stream-vs-put-racecondition.js
data
browser-throws.js
browser-works.js
deferred-open-test.js
destroy-repair-test.js
encoding-test.js
get-put-del-test.js
idempotent-test.js
init-test.js
inject-encoding-test.js
json-test.js
key-value-streams-test.js
leveldown-substitution-test.js
null-and-undefined-test.js
open-patchsafe-test.js
optional-leveldown-test.js
read-stream-test.js
snapshot-test.js
test-10k-times.sh
levn
README.md
lib
cast.js
coerce.js
index.js
parse-string.js
parse.js
package.json
libsodium-wrappers
README.md
dist
modules
libsodium-wrappers.js
package.json
libsodium
README.md
dist
modules
libsodium.js
package.json
lodash
README.md
_DataView.js
_Hash.js
_LazyWrapper.js
_ListCache.js
_LodashWrapper.js
_Map.js
_MapCache.js
_Promise.js
_Set.js
_SetCache.js
_Stack.js
_Symbol.js
_Uint8Array.js
_WeakMap.js
_apply.js
_arrayAggregator.js
_arrayEach.js
_arrayEachRight.js
_arrayEvery.js
_arrayFilter.js
_arrayIncludes.js
_arrayIncludesWith.js
_arrayLikeKeys.js
_arrayMap.js
_arrayPush.js
_arrayReduce.js
_arrayReduceRight.js
_arraySample.js
_arraySampleSize.js
_arrayShuffle.js
_arraySome.js
_asciiSize.js
_asciiToArray.js
_asciiWords.js
_assignMergeValue.js
_assignValue.js
_assocIndexOf.js
_baseAggregator.js
_baseAssign.js
_baseAssignIn.js
_baseAssignValue.js
_baseAt.js
_baseClamp.js
_baseClone.js
_baseConforms.js
_baseConformsTo.js
_baseCreate.js
_baseDelay.js
_baseDifference.js
_baseEach.js
_baseEachRight.js
_baseEvery.js
_baseExtremum.js
_baseFill.js
_baseFilter.js
_baseFindIndex.js
_baseFindKey.js
_baseFlatten.js
_baseFor.js
_baseForOwn.js
_baseForOwnRight.js
_baseForRight.js
_baseFunctions.js
_baseGet.js
_baseGetAllKeys.js
_baseGetTag.js
_baseGt.js
_baseHas.js
_baseHasIn.js
_baseInRange.js
_baseIndexOf.js
_baseIndexOfWith.js
_baseIntersection.js
_baseInverter.js
_baseInvoke.js
_baseIsArguments.js
_baseIsArrayBuffer.js
_baseIsDate.js
_baseIsEqual.js
_baseIsEqualDeep.js
_baseIsMap.js
_baseIsMatch.js
_baseIsNaN.js
_baseIsNative.js
_baseIsRegExp.js
_baseIsSet.js
_baseIsTypedArray.js
_baseIteratee.js
_baseKeys.js
_baseKeysIn.js
_baseLodash.js
_baseLt.js
_baseMap.js
_baseMatches.js
_baseMatchesProperty.js
_baseMean.js
_baseMerge.js
_baseMergeDeep.js
_baseNth.js
_baseOrderBy.js
_basePick.js
_basePickBy.js
_baseProperty.js
_basePropertyDeep.js
_basePropertyOf.js
_basePullAll.js
_basePullAt.js
_baseRandom.js
_baseRange.js
_baseReduce.js
_baseRepeat.js
_baseRest.js
_baseSample.js
_baseSampleSize.js
_baseSet.js
_baseSetData.js
_baseSetToString.js
_baseShuffle.js
_baseSlice.js
_baseSome.js
_baseSortBy.js
_baseSortedIndex.js
_baseSortedIndexBy.js
_baseSortedUniq.js
_baseSum.js
_baseTimes.js
_baseToNumber.js
_baseToPairs.js
_baseToString.js
_baseUnary.js
_baseUniq.js
_baseUnset.js
_baseUpdate.js
_baseValues.js
_baseWhile.js
_baseWrapperValue.js
_baseXor.js
_baseZipObject.js
_cacheHas.js
_castArrayLikeObject.js
_castFunction.js
_castPath.js
_castRest.js
_castSlice.js
_charsEndIndex.js
_charsStartIndex.js
_cloneArrayBuffer.js
_cloneBuffer.js
_cloneDataView.js
_cloneRegExp.js
_cloneSymbol.js
_cloneTypedArray.js
_compareAscending.js
_compareMultiple.js
_composeArgs.js
_composeArgsRight.js
_copyArray.js
_copyObject.js
_copySymbols.js
_copySymbolsIn.js
_coreJsData.js
_countHolders.js
_createAggregator.js
_createAssigner.js
_createBaseEach.js
_createBaseFor.js
_createBind.js
_createCaseFirst.js
_createCompounder.js
_createCtor.js
_createCurry.js
_createFind.js
_createFlow.js
_createHybrid.js
_createInverter.js
_createMathOperation.js
_createOver.js
_createPadding.js
_createPartial.js
_createRange.js
_createRecurry.js
_createRelationalOperation.js
_createRound.js
_createSet.js
_createToPairs.js
_createWrap.js
_customDefaultsAssignIn.js
_customDefaultsMerge.js
_customOmitClone.js
_deburrLetter.js
_defineProperty.js
_equalArrays.js
_equalByTag.js
_equalObjects.js
_escapeHtmlChar.js
_escapeStringChar.js
_flatRest.js
_freeGlobal.js
_getAllKeys.js
_getAllKeysIn.js
_getData.js
_getFuncName.js
_getHolder.js
_getMapData.js
_getMatchData.js
_getNative.js
_getPrototype.js
_getRawTag.js
_getSymbols.js
_getSymbolsIn.js
_getTag.js
_getValue.js
_getView.js
_getWrapDetails.js
_hasPath.js
_hasUnicode.js
_hasUnicodeWord.js
_hashClear.js
_hashDelete.js
_hashGet.js
_hashHas.js
_hashSet.js
_initCloneArray.js
_initCloneByTag.js
_initCloneObject.js
_insertWrapDetails.js
_isFlattenable.js
_isIndex.js
_isIterateeCall.js
_isKey.js
_isKeyable.js
_isLaziable.js
_isMaskable.js
_isMasked.js
_isPrototype.js
_isStrictComparable.js
_iteratorToArray.js
_lazyClone.js
_lazyReverse.js
_lazyValue.js
_listCacheClear.js
_listCacheDelete.js
_listCacheGet.js
_listCacheHas.js
_listCacheSet.js
_mapCacheClear.js
_mapCacheDelete.js
_mapCacheGet.js
_mapCacheHas.js
_mapCacheSet.js
_mapToArray.js
_matchesStrictComparable.js
_memoizeCapped.js
_mergeData.js
_metaMap.js
_nativeCreate.js
_nativeKeys.js
_nativeKeysIn.js
_nodeUtil.js
_objectToString.js
_overArg.js
_overRest.js
_parent.js
_reEscape.js
_reEvaluate.js
_reInterpolate.js
_realNames.js
_reorder.js
_replaceHolders.js
_root.js
_safeGet.js
_setCacheAdd.js
_setCacheHas.js
_setData.js
_setToArray.js
_setToPairs.js
_setToString.js
_setWrapToString.js
_shortOut.js
_shuffleSelf.js
_stackClear.js
_stackDelete.js
_stackGet.js
_stackHas.js
_stackSet.js
_strictIndexOf.js
_strictLastIndexOf.js
_stringSize.js
_stringToArray.js
_stringToPath.js
_toKey.js
_toSource.js
_unescapeHtmlChar.js
_unicodeSize.js
_unicodeToArray.js
_unicodeWords.js
_updateWrapDetails.js
_wrapperClone.js
add.js
after.js
array.js
ary.js
assign.js
assignIn.js
assignInWith.js
assignWith.js
at.js
attempt.js
before.js
bind.js
bindAll.js
bindKey.js
camelCase.js
capitalize.js
castArray.js
ceil.js
chain.js
chunk.js
clamp.js
clone.js
cloneDeep.js
cloneDeepWith.js
cloneWith.js
collection.js
commit.js
compact.js
concat.js
cond.js
conforms.js
conformsTo.js
constant.js
core.js
core.min.js
countBy.js
create.js
curry.js
curryRight.js
date.js
debounce.js
deburr.js
defaultTo.js
defaults.js
defaultsDeep.js
defer.js
delay.js
difference.js
differenceBy.js
differenceWith.js
divide.js
drop.js
dropRight.js
dropRightWhile.js
dropWhile.js
each.js
eachRight.js
endsWith.js
entries.js
entriesIn.js
eq.js
escape.js
escapeRegExp.js
every.js
extend.js
extendWith.js
fill.js
filter.js
find.js
findIndex.js
findKey.js
findLast.js
findLastIndex.js
findLastKey.js
first.js
flatMap.js
flatMapDeep.js
flatMapDepth.js
flatten.js
flattenDeep.js
flattenDepth.js
flip.js
floor.js
flow.js
flowRight.js
forEach.js
forEachRight.js
forIn.js
forInRight.js
forOwn.js
forOwnRight.js
fp.js
fp
F.js
T.js
__.js
_baseConvert.js
_convertBrowser.js
_falseOptions.js
_mapping.js
_util.js
add.js
after.js
all.js
allPass.js
always.js
any.js
anyPass.js
apply.js
array.js
ary.js
assign.js
assignAll.js
assignAllWith.js
assignIn.js
assignInAll.js
assignInAllWith.js
assignInWith.js
assignWith.js
assoc.js
assocPath.js
at.js
attempt.js
before.js
bind.js
bindAll.js
bindKey.js
camelCase.js
capitalize.js
castArray.js
ceil.js
chain.js
chunk.js
clamp.js
clone.js
cloneDeep.js
cloneDeepWith.js
cloneWith.js
collection.js
commit.js
compact.js
complement.js
compose.js
concat.js
cond.js
conforms.js
conformsTo.js
constant.js
contains.js
convert.js
countBy.js
create.js
curry.js
curryN.js
curryRight.js
curryRightN.js
date.js
debounce.js
deburr.js
defaultTo.js
defaults.js
defaultsAll.js
defaultsDeep.js
defaultsDeepAll.js
defer.js
delay.js
difference.js
differenceBy.js
differenceWith.js
dissoc.js
dissocPath.js
divide.js
drop.js
dropLast.js
dropLastWhile.js
dropRight.js
dropRightWhile.js
dropWhile.js
each.js
eachRight.js
endsWith.js
entries.js
entriesIn.js
eq.js
equals.js
escape.js
escapeRegExp.js
every.js
extend.js
extendAll.js
extendAllWith.js
extendWith.js
fill.js
filter.js
find.js
findFrom.js
findIndex.js
findIndexFrom.js
findKey.js
findLast.js
findLastFrom.js
findLastIndex.js
findLastIndexFrom.js
findLastKey.js
first.js
flatMap.js
flatMapDeep.js
flatMapDepth.js
flatten.js
flattenDeep.js
flattenDepth.js
flip.js
floor.js
flow.js
flowRight.js
forEach.js
forEachRight.js
forIn.js
forInRight.js
forOwn.js
forOwnRight.js
fromPairs.js
function.js
functions.js
functionsIn.js
get.js
getOr.js
groupBy.js
gt.js
gte.js
has.js
hasIn.js
head.js
identical.js
identity.js
inRange.js
includes.js
includesFrom.js
indexBy.js
indexOf.js
indexOfFrom.js
init.js
initial.js
intersection.js
intersectionBy.js
intersectionWith.js
invert.js
invertBy.js
invertObj.js
invoke.js
invokeArgs.js
invokeArgsMap.js
invokeMap.js
isArguments.js
isArray.js
isArrayBuffer.js
isArrayLike.js
isArrayLikeObject.js
isBoolean.js
isBuffer.js
isDate.js
isElement.js
isEmpty.js
isEqual.js
isEqualWith.js
isError.js
isFinite.js
isFunction.js
isInteger.js
isLength.js
isMap.js
isMatch.js
isMatchWith.js
isNaN.js
isNative.js
isNil.js
isNull.js
isNumber.js
isObject.js
isObjectLike.js
isPlainObject.js
isRegExp.js
isSafeInteger.js
isSet.js
isString.js
isSymbol.js
isTypedArray.js
isUndefined.js
isWeakMap.js
isWeakSet.js
iteratee.js
join.js
juxt.js
kebabCase.js
keyBy.js
keys.js
keysIn.js
lang.js
last.js
lastIndexOf.js
lastIndexOfFrom.js
lowerCase.js
lowerFirst.js
lt.js
lte.js
map.js
mapKeys.js
mapValues.js
matches.js
matchesProperty.js
math.js
max.js
maxBy.js
mean.js
meanBy.js
memoize.js
merge.js
mergeAll.js
mergeAllWith.js
mergeWith.js
method.js
methodOf.js
min.js
minBy.js
mixin.js
multiply.js
nAry.js
negate.js
next.js
noop.js
now.js
nth.js
nthArg.js
number.js
object.js
omit.js
omitAll.js
omitBy.js
once.js
orderBy.js
over.js
overArgs.js
overEvery.js
overSome.js
pad.js
padChars.js
padCharsEnd.js
padCharsStart.js
padEnd.js
padStart.js
parseInt.js
partial.js
partialRight.js
partition.js
path.js
pathEq.js
pathOr.js
paths.js
pick.js
pickAll.js
pickBy.js
pipe.js
placeholder.js
plant.js
pluck.js
prop.js
propEq.js
propOr.js
property.js
propertyOf.js
props.js
pull.js
pullAll.js
pullAllBy.js
pullAllWith.js
pullAt.js
random.js
range.js
rangeRight.js
rangeStep.js
rangeStepRight.js
rearg.js
reduce.js
reduceRight.js
reject.js
remove.js
repeat.js
replace.js
rest.js
restFrom.js
result.js
reverse.js
round.js
sample.js
sampleSize.js
seq.js
set.js
setWith.js
shuffle.js
size.js
slice.js
snakeCase.js
some.js
sortBy.js
sortedIndex.js
sortedIndexBy.js
sortedIndexOf.js
sortedLastIndex.js
sortedLastIndexBy.js
sortedLastIndexOf.js
sortedUniq.js
sortedUniqBy.js
split.js
spread.js
spreadFrom.js
startCase.js
startsWith.js
string.js
stubArray.js
stubFalse.js
stubObject.js
stubString.js
stubTrue.js
subtract.js
sum.js
sumBy.js
symmetricDifference.js
symmetricDifferenceBy.js
symmetricDifferenceWith.js
tail.js
take.js
takeLast.js
takeLastWhile.js
takeRight.js
takeRightWhile.js
takeWhile.js
tap.js
template.js
templateSettings.js
throttle.js
thru.js
times.js
toArray.js
toFinite.js
toInteger.js
toIterator.js
toJSON.js
toLength.js
toLower.js
toNumber.js
toPairs.js
toPairsIn.js
toPath.js
toPlainObject.js
toSafeInteger.js
toString.js
toUpper.js
transform.js
trim.js
trimChars.js
trimCharsEnd.js
trimCharsStart.js
trimEnd.js
trimStart.js
truncate.js
unapply.js
unary.js
unescape.js
union.js
unionBy.js
unionWith.js
uniq.js
uniqBy.js
uniqWith.js
uniqueId.js
unnest.js
unset.js
unzip.js
unzipWith.js
update.js
updateWith.js
upperCase.js
upperFirst.js
useWith.js
util.js
value.js
valueOf.js
values.js
valuesIn.js
where.js
whereEq.js
without.js
words.js
wrap.js
wrapperAt.js
wrapperChain.js
wrapperLodash.js
wrapperReverse.js
wrapperValue.js
xor.js
xorBy.js
xorWith.js
zip.js
zipAll.js
zipObj.js
zipObject.js
zipObjectDeep.js
zipWith.js
fromPairs.js
function.js
functions.js
functionsIn.js
get.js
groupBy.js
gt.js
gte.js
has.js
hasIn.js
head.js
identity.js
inRange.js
includes.js
index.js
indexOf.js
initial.js
intersection.js
intersectionBy.js
intersectionWith.js
invert.js
invertBy.js
invoke.js
invokeMap.js
isArguments.js
isArray.js
isArrayBuffer.js
isArrayLike.js
isArrayLikeObject.js
isBoolean.js
isBuffer.js
isDate.js
isElement.js
isEmpty.js
isEqual.js
isEqualWith.js
isError.js
isFinite.js
isFunction.js
isInteger.js
isLength.js
isMap.js
isMatch.js
isMatchWith.js
isNaN.js
isNative.js
isNil.js
isNull.js
isNumber.js
isObject.js
isObjectLike.js
isPlainObject.js
isRegExp.js
isSafeInteger.js
isSet.js
isString.js
isSymbol.js
isTypedArray.js
isUndefined.js
isWeakMap.js
isWeakSet.js
iteratee.js
join.js
kebabCase.js
keyBy.js
keys.js
keysIn.js
lang.js
last.js
lastIndexOf.js
lodash.js
lodash.min.js
lowerCase.js
lowerFirst.js
lt.js
lte.js
map.js
mapKeys.js
mapValues.js
matches.js
matchesProperty.js
math.js
max.js
maxBy.js
mean.js
meanBy.js
memoize.js
merge.js
mergeWith.js
method.js
methodOf.js
min.js
minBy.js
mixin.js
multiply.js
negate.js
next.js
noop.js
now.js
nth.js
nthArg.js
number.js
object.js
omit.js
omitBy.js
once.js
orderBy.js
over.js
overArgs.js
overEvery.js
overSome.js
package.json
pad.js
padEnd.js
padStart.js
parseInt.js
partial.js
partialRight.js
partition.js
pick.js
pickBy.js
plant.js
property.js
propertyOf.js
pull.js
pullAll.js
pullAllBy.js
pullAllWith.js
pullAt.js
random.js
range.js
rangeRight.js
rearg.js
reduce.js
reduceRight.js
reject.js
remove.js
repeat.js
replace.js
rest.js
result.js
reverse.js
round.js
sample.js
sampleSize.js
seq.js
set.js
setWith.js
shuffle.js
size.js
slice.js
snakeCase.js
some.js
sortBy.js
sortedIndex.js
sortedIndexBy.js
sortedIndexOf.js
sortedLastIndex.js
sortedLastIndexBy.js
sortedLastIndexOf.js
sortedUniq.js
sortedUniqBy.js
split.js
spread.js
startCase.js
startsWith.js
string.js
stubArray.js
stubFalse.js
stubObject.js
stubString.js
stubTrue.js
subtract.js
sum.js
sumBy.js
tail.js
take.js
takeRight.js
takeRightWhile.js
takeWhile.js
tap.js
template.js
templateSettings.js
throttle.js
thru.js
times.js
toArray.js
toFinite.js
toInteger.js
toIterator.js
toJSON.js
toLength.js
toLower.js
toNumber.js
toPairs.js
toPairsIn.js
toPath.js
toPlainObject.js
toSafeInteger.js
toString.js
toUpper.js
transform.js
trim.js
trimEnd.js
trimStart.js
truncate.js
unary.js
unescape.js
union.js
unionBy.js
unionWith.js
uniq.js
uniqBy.js
uniqWith.js
uniqueId.js
unset.js
unzip.js
unzipWith.js
update.js
updateWith.js
upperCase.js
upperFirst.js
util.js
value.js
valueOf.js
values.js
valuesIn.js
without.js
words.js
wrap.js
wrapperAt.js
wrapperChain.js
wrapperLodash.js
wrapperReverse.js
wrapperValue.js
xor.js
xorBy.js
xorWith.js
zip.js
zipObject.js
zipObjectDeep.js
zipWith.js
log-driver
.travis.yml
README.md
index.js
package.json
lower-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
lowercase-keys
index.js
package.json
readme.md
lru-cache
README.md
index.js
package.json
ltgt
.travis.yml
README.md
index.js
package.json
test.js
make-dir
index.d.ts
index.js
node_modules
semver
CHANGELOG.md
README.md
bin
semver.js
package.json
semver.js
package.json
readme.md
math-random
.travis.yml
browser.js
node.js
package.json
readme.md
test.js
md5.js
README.md
index.js
package.json
media-typer
HISTORY.md
README.md
index.js
package.json
memdown
README.md
immediate-browser.js
immediate.js
memdown.d.ts
memdown.js
node_modules
abstract-leveldown
.travis.yml
CHANGELOG.md
LICENSE.md
README.md
abstract-chained-batch.js
abstract-iterator.js
abstract-leveldown.js
abstract
approximate-size-test.js
batch-test.js
chained-batch-test.js
close-test.js
del-test.js
get-test.js
iterator-test.js
leveldown-test.js
open-test.js
put-get-del-test.js
put-test.js
ranges-test.js
util.js
index.d.ts
index.js
is-leveldown.js
package.json
test.js
testCommon.js
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
merge-descriptors
HISTORY.md
README.md
index.js
package.json
merkle-patricia-tree
CHANGELOG.md
README.md
baseTrie.js
benchmarks
checkpointing.js
random.js
checkpoint-interface.js
dist
trie.js
docs
index.md
documentation.yml
index.js
karma.conf.js
node_modules
async
CHANGELOG.md
README.md
all.js
allLimit.js
allSeries.js
any.js
anyLimit.js
anySeries.js
apply.js
applyEach.js
applyEachSeries.js
asyncify.js
auto.js
autoInject.js
bower.json
cargo.js
compose.js
concat.js
concatLimit.js
concatSeries.js
constant.js
detect.js
detectLimit.js
detectSeries.js
dir.js
dist
async.js
async.min.js
doDuring.js
doUntil.js
doWhilst.js
during.js
each.js
eachLimit.js
eachOf.js
eachOfLimit.js
eachOfSeries.js
eachSeries.js
ensureAsync.js
every.js
everyLimit.js
everySeries.js
filter.js
filterLimit.js
filterSeries.js
find.js
findLimit.js
findSeries.js
foldl.js
foldr.js
forEach.js
forEachLimit.js
forEachOf.js
forEachOfLimit.js
forEachOfSeries.js
forEachSeries.js
forever.js
groupBy.js
groupByLimit.js
groupBySeries.js
index.js
inject.js
internal
DoublyLinkedList.js
applyEach.js
breakLoop.js
consoleFunc.js
createTester.js
doLimit.js
doParallel.js
doParallelLimit.js
eachOfLimit.js
filter.js
findGetResult.js
getIterator.js
initialParams.js
iterator.js
map.js
notId.js
once.js
onlyOnce.js
parallel.js
queue.js
reject.js
setImmediate.js
slice.js
withoutIndex.js
wrapAsync.js
log.js
map.js
mapLimit.js
mapSeries.js
mapValues.js
mapValuesLimit.js
mapValuesSeries.js
memoize.js
nextTick.js
package.json
parallel.js
parallelLimit.js
priorityQueue.js
queue.js
race.js
reduce.js
reduceRight.js
reflect.js
reflectAll.js
reject.js
rejectLimit.js
rejectSeries.js
retry.js
retryable.js
select.js
selectLimit.js
selectSeries.js
seq.js
series.js
setImmediate.js
some.js
someLimit.js
someSeries.js
sortBy.js
timeout.js
times.js
timesLimit.js
timesSeries.js
transform.js
tryEach.js
unmemoize.js
until.js
waterfall.js
whilst.js
wrapSync.js
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
ethereumjs-util
CHANGELOG.md
README.md
dist
index.js
secp256k1-adapter.js
secp256k1-lib
der.js
index.js
package.json
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
level-ws
.travis.yml
CHANGELOG.md
CONTRIBUTORS.md
LICENSE.md
README.md
UPGRADING.md
level-ws.js
node_modules
readable-stream
.travis.yml
CONTRIBUTING.md
GOVERNANCE.md
README.md
doc
wg-meetings
2015-01-30.md
duplex-browser.js
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
internal
streams
BufferList.js
destroy.js
stream-browser.js
stream.js
package.json
passthrough.js
readable-browser.js
readable.js
transform.js
writable-browser.js
writable.js
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
test.js
string_decoder
.travis.yml
README.md
lib
string_decoder.js
node_modules
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
package.json
prioritizedTaskExecutor.js
proof.js
readStream.js
scratchReadStream.js
secure-interface.js
secure.js
trieNode.js
util.js
methods
HISTORY.md
README.md
index.js
package.json
micromatch
README.md
index.js
lib
chars.js
expand.js
glob.js
utils.js
node_modules
braces
README.md
index.js
package.json
is-extglob
README.md
index.js
package.json
is-glob
README.md
index.js
package.json
normalize-path
README.md
index.js
package.json
package.json
miller-rabin
1.js
README.md
lib
mr.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
test.js
test
api-test.js
mime-db
HISTORY.md
README.md
db.json
index.js
package.json
mime-types
HISTORY.md
README.md
index.js
package.json
mime
CHANGELOG.md
README.md
cli.js
mime.js
package.json
src
build.js
test.js
types.json
mimic-response
index.js
package.json
readme.md
min-document
.testem.json
.travis.yml
CONTRIBUTION.md
README.md
document.js
dom-comment.js
dom-element.js
dom-fragment.js
dom-text.js
event.js
event
add-event-listener.js
dispatch-event.js
remove-event-listener.js
index.js
package.json
serialize.js
test
cleanup.js
index.js
static
index.html
test-adapter.js
test-document.js
test-dom-comment.js
test-dom-element.js
minimalistic-assert
index.js
package.json
readme.md
minimalistic-crypto-utils
.travis.yml
README.md
lib
utils.js
package.json
test
utils-test.js
minimatch
README.md
minimatch.js
package.json
minimist
.travis.yml
example
parse.js
index.js
package.json
test
all_bool.js
bool.js
dash.js
default_bool.js
dotted.js
kv_short.js
long.js
num.js
parse.js
parse_modified.js
proto.js
short.js
stop_early.js
unknown.js
whitespace.js
minipass
README.md
index.js
package.json
minizlib
README.md
constants.js
index.js
package.json
mkdirp-promise
README.md
lib
index.js
package.json
mkdirp
CHANGELOG.md
bin
cmd.js
index.js
lib
find-made.js
mkdirp-manual.js
mkdirp-native.js
opts-arg.js
path-arg.js
use-native.js
package.json
mock-fs
changelog.md
lib
binding.js
buffer.js
bypass.js
descriptor.js
directory.js
error.js
file.js
filesystem.js
index.js
item.js
loader.js
symlink.js
license.md
package.json
readme.md
module-details-from-path
.travis.yml
README.md
index.js
package.json
test.js
moment-timezone
README.md
builds
moment-timezone-with-data-10-year-range.js
moment-timezone-with-data-10-year-range.min.js
moment-timezone-with-data-1970-2030.js
moment-timezone-with-data-1970-2030.min.js
moment-timezone-with-data-2012-2022.js
moment-timezone-with-data-2012-2022.min.js
moment-timezone-with-data.js
moment-timezone-with-data.min.js
moment-timezone.min.js
changelog.md
composer.json
data
meta
latest.json
packed
latest.json
index.d.ts
index.js
moment-timezone-utils.d.ts
moment-timezone-utils.js
moment-timezone.js
package-lock.json
package.json
moment
CHANGELOG.md
README.md
dist
locale
af.js
ar-dz.js
ar-kw.js
ar-ly.js
ar-ma.js
ar-sa.js
ar-tn.js
ar.js
az.js
be.js
bg.js
bm.js
bn-bd.js
bn.js
bo.js
br.js
bs.js
ca.js
cs.js
cv.js
cy.js
da.js
de-at.js
de-ch.js
de.js
dv.js
el.js
en-au.js
en-ca.js
en-gb.js
en-ie.js
en-il.js
en-in.js
en-nz.js
en-sg.js
eo.js
es-do.js
es-mx.js
es-us.js
es.js
et.js
eu.js
fa.js
fi.js
fil.js
fo.js
fr-ca.js
fr-ch.js
fr.js
fy.js
ga.js
gd.js
gl.js
gom-deva.js
gom-latn.js
gu.js
he.js
hi.js
hr.js
hu.js
hy-am.js
id.js
is.js
it-ch.js
it.js
ja.js
jv.js
ka.js
kk.js
km.js
kn.js
ko.js
ku.js
ky.js
lb.js
lo.js
lt.js
lv.js
me.js
mi.js
mk.js
ml.js
mn.js
mr.js
ms-my.js
ms.js
mt.js
my.js
nb.js
ne.js
nl-be.js
nl.js
nn.js
oc-lnc.js
pa-in.js
pl.js
pt-br.js
pt.js
ro.js
ru.js
sd.js
se.js
si.js
sk.js
sl.js
sq.js
sr-cyrl.js
sr.js
ss.js
sv.js
sw.js
ta.js
te.js
tet.js
tg.js
th.js
tk.js
tl-ph.js
tlh.js
tr.js
tzl.js
tzm-latn.js
tzm.js
ug-cn.js
uk.js
ur.js
uz-latn.js
uz.js
vi.js
x-pseudo.js
yo.js
zh-cn.js
zh-hk.js
zh-mo.js
zh-tw.js
moment.js
ender.js
locale
af.js
ar-dz.js
ar-kw.js
ar-ly.js
ar-ma.js
ar-sa.js
ar-tn.js
ar.js
az.js
be.js
bg.js
bm.js
bn-bd.js
bn.js
bo.js
br.js
bs.js
ca.js
cs.js
cv.js
cy.js
da.js
de-at.js
de-ch.js
de.js
dv.js
el.js
en-au.js
en-ca.js
en-gb.js
en-ie.js
en-il.js
en-in.js
en-nz.js
en-sg.js
eo.js
es-do.js
es-mx.js
es-us.js
es.js
et.js
eu.js
fa.js
fi.js
fil.js
fo.js
fr-ca.js
fr-ch.js
fr.js
fy.js
ga.js
gd.js
gl.js
gom-deva.js
gom-latn.js
gu.js
he.js
hi.js
hr.js
hu.js
hy-am.js
id.js
is.js
it-ch.js
it.js
ja.js
jv.js
ka.js
kk.js
km.js
kn.js
ko.js
ku.js
ky.js
lb.js
lo.js
lt.js
lv.js
me.js
mi.js
mk.js
ml.js
mn.js
mr.js
ms-my.js
ms.js
mt.js
my.js
nb.js
ne.js
nl-be.js
nl.js
nn.js
oc-lnc.js
pa-in.js
pl.js
pt-br.js
pt.js
ro.js
ru.js
sd.js
se.js
si.js
sk.js
sl.js
sq.js
sr-cyrl.js
sr.js
ss.js
sv.js
sw.js
ta.js
te.js
tet.js
tg.js
th.js
tk.js
tl-ph.js
tlh.js
tr.js
tzl.js
tzm-latn.js
tzm.js
ug-cn.js
uk.js
ur.js
uz-latn.js
uz.js
vi.js
x-pseudo.js
yo.js
zh-cn.js
zh-hk.js
zh-mo.js
zh-tw.js
min
locales.js
locales.min.js
moment-with-locales.js
moment-with-locales.min.js
moment.min.js
moment.d.ts
moment.js
package.js
package.json
src
lib
create
check-overflow.js
date-from-array.js
from-anything.js
from-array.js
from-object.js
from-string-and-array.js
from-string-and-format.js
from-string.js
local.js
parsing-flags.js
utc.js
valid.js
duration
abs.js
add-subtract.js
as.js
bubble.js
clone.js
constructor.js
create.js
duration.js
get.js
humanize.js
iso-string.js
prototype.js
valid.js
format
format.js
locale
base-config.js
calendar.js
constructor.js
en.js
formats.js
invalid.js
lists.js
locale.js
locales.js
ordinal.js
pre-post-format.js
prototype.js
relative.js
set.js
moment
add-subtract.js
calendar.js
clone.js
compare.js
constructor.js
creation-data.js
diff.js
format.js
from.js
get-set.js
locale.js
min-max.js
moment.js
now.js
prototype.js
start-end-of.js
to-type.js
to.js
valid.js
parse
regex.js
token.js
units
aliases.js
constants.js
day-of-month.js
day-of-week.js
day-of-year.js
era.js
hour.js
millisecond.js
minute.js
month.js
offset.js
priorities.js
quarter.js
second.js
timestamp.js
timezone.js
units.js
week-calendar-utils.js
week-year.js
week.js
year.js
utils
abs-ceil.js
abs-floor.js
abs-round.js
compare-arrays.js
defaults.js
deprecate.js
extend.js
has-own-prop.js
hooks.js
index-of.js
is-array.js
is-calendar-spec.js
is-date.js
is-function.js
is-leap-year.js
is-moment-input.js
is-number.js
is-object-empty.js
is-object.js
is-string.js
is-undefined.js
keys.js
map.js
mod.js
some.js
to-int.js
zero-fill.js
locale
af.js
ar-dz.js
ar-kw.js
ar-ly.js
ar-ma.js
ar-sa.js
ar-tn.js
ar.js
az.js
be.js
bg.js
bm.js
bn-bd.js
bn.js
bo.js
br.js
bs.js
ca.js
cs.js
cv.js
cy.js
da.js
de-at.js
de-ch.js
de.js
dv.js
el.js
en-au.js
en-ca.js
en-gb.js
en-ie.js
en-il.js
en-in.js
en-nz.js
en-sg.js
eo.js
es-do.js
es-mx.js
es-us.js
es.js
et.js
eu.js
fa.js
fi.js
fil.js
fo.js
fr-ca.js
fr-ch.js
fr.js
fy.js
ga.js
gd.js
gl.js
gom-deva.js
gom-latn.js
gu.js
he.js
hi.js
hr.js
hu.js
hy-am.js
id.js
is.js
it-ch.js
it.js
ja.js
jv.js
ka.js
kk.js
km.js
kn.js
ko.js
ku.js
ky.js
lb.js
lo.js
lt.js
lv.js
me.js
mi.js
mk.js
ml.js
mn.js
mr.js
ms-my.js
ms.js
mt.js
my.js
nb.js
ne.js
nl-be.js
nl.js
nn.js
oc-lnc.js
pa-in.js
pl.js
pt-br.js
pt.js
ro.js
ru.js
sd.js
se.js
si.js
sk.js
sl.js
sq.js
sr-cyrl.js
sr.js
ss.js
sv.js
sw.js
ta.js
te.js
tet.js
tg.js
th.js
tk.js
tl-ph.js
tlh.js
tr.js
tzl.js
tzm-latn.js
tzm.js
ug-cn.js
uk.js
ur.js
uz-latn.js
uz.js
vi.js
x-pseudo.js
yo.js
zh-cn.js
zh-hk.js
zh-mo.js
zh-tw.js
moment.js
ts3.1-typings
moment.d.ts
ms
index.js
license.md
package.json
readme.md
multibase
CHANGELOG.md
README.md
dist
index.js
index.min.js
index.min.js.LICENSE.txt
package.json
src
base.js
base16.js
base32.js
base64.js
constants.js
index.js
multicodec
.travis.yml
CHANGELOG.md
README.md
dist
index.js
index.min.js
example.js
package.json
src
base-table.json
constants.js
index.js
int-table.js
print.js
util.js
varint-table.js
tools
update-table.js
multihashes
CHANGELOG.md
README.md
dist
index.js
index.min.js
index.min.js.LICENSE.txt
node_modules
multibase
CHANGELOG.md
README.md
dist
index.js
index.min.js
index.min.js.LICENSE.txt
package.json
src
base.js
base16.js
base32.js
base64.js
constants.js
index.js
package.json
src
constants.js
index.js
mustache
CHANGELOG.md
README.md
mustache.js
mustache.min.js
package.json
mute-stream
README.md
mute.js
package.json
nan
CHANGELOG.md
LICENSE.md
README.md
doc
asyncworker.md
buffers.md
callback.md
converters.md
errors.md
json.md
maybe_types.md
methods.md
new.md
node_misc.md
object_wrappers.md
persistent.md
scopes.md
script.md
string_bytes.md
v8_internals.md
v8_misc.md
include_dirs.js
nan.h
nan_callbacks.h
nan_callbacks_12_inl.h
nan_callbacks_pre_12_inl.h
nan_converters.h
nan_converters_43_inl.h
nan_converters_pre_43_inl.h
nan_define_own_property_helper.h
nan_implementation_12_inl.h
nan_implementation_pre_12_inl.h
nan_json.h
nan_maybe_43_inl.h
nan_maybe_pre_43_inl.h
nan_new.h
nan_object_wrap.h
nan_persistent_12_inl.h
nan_persistent_pre_12_inl.h
nan_private.h
nan_string_bytes.h
nan_typedarray_contents.h
nan_weak.h
package.json
tools
1to2.js
README.md
package.json
nano-json-stream-parser
README.md
dist
index.js
example
a.js
package.json
src
index.js
near-api-js
.eslintrc.yml
.github
ISSUE_TEMPLATE
bug_report.md
feature_request.md
workflows
docs.yml
.gitpod.yml
.nyc_output
cov.json
.travis.yml
CODE_OF_CONDUCT.md
CONTRIBUTING.md
README.md
browser-exports.js
dist
near-api-js.js
near-api-js.min.js
gen_error_types.js
lib
account.d.ts
account.js
account_creator.d.ts
account_creator.js
browser-index.d.ts
browser-index.js
common-index.d.ts
common-index.js
connection.d.ts
connection.js
contract.d.ts
contract.js
generated
rpc_error_schema.d.ts
rpc_error_schema.json
rpc_error_types.d.ts
rpc_error_types.js
index.d.ts
index.js
key_stores
browser-index.d.ts
browser-index.js
browser_local_storage_key_store.d.ts
browser_local_storage_key_store.js
in_memory_key_store.d.ts
in_memory_key_store.js
index.d.ts
index.js
keystore.d.ts
keystore.js
merge_key_store.d.ts
merge_key_store.js
unencrypted_file_system_keystore.d.ts
unencrypted_file_system_keystore.js
near.d.ts
near.js
providers
index.d.ts
index.js
json-rpc-provider.d.ts
json-rpc-provider.js
provider.d.ts
provider.js
res
error_messages.d.ts
error_messages.json
signer.d.ts
signer.js
transaction.d.ts
transaction.js
utils
enums.d.ts
enums.js
errors.d.ts
errors.js
format.d.ts
format.js
index.d.ts
index.js
key_pair.d.ts
key_pair.js
network.d.ts
network.js
rpc_errors.d.ts
rpc_errors.js
serialize.d.ts
serialize.js
web.d.ts
web.js
validators.d.ts
validators.js
wallet-account.d.ts
wallet-account.js
node_modules
depd
History.md
Readme.md
index.js
lib
browser
index.js
package.json
tweetnacl
AUTHORS.md
CHANGELOG.md
PULL_REQUEST_TEMPLATE.md
README.md
nacl-fast.js
nacl-fast.min.js
nacl.d.ts
nacl.js
nacl.min.js
package.json
package.json
src
.eslintrc.yml
account.ts
account_creator.ts
browser-index.ts
common-index.ts
connection.ts
contract.ts
generated
rpc_error_schema.json
rpc_error_types.ts
index.ts
key_stores
browser-index.ts
browser_local_storage_key_store.ts
in_memory_key_store.ts
index.ts
keystore.ts
merge_key_store.ts
unencrypted_file_system_keystore.ts
near.ts
providers
index.ts
json-rpc-provider.ts
provider.ts
res
error_messages.json
signer.ts
transaction.ts
utils
enums.ts
errors.ts
format.ts
index.ts
key_pair.ts
network.ts
rpc_errors.ts
serialize.ts
web.ts
validators.ts
wallet-account.ts
test
.eslintrc.yml
account.access_key.test.js
account.test.js
config.js
contract.test.js
data
signed_transaction1.json
transaction1.json
fuzz
borsh-roundtrip.js
key_pair.test.js
key_stores
browser_keystore.test.js
in_memory_keystore.test.js
keystore_common.js
merge_keystore.test.js
unencrypted_file_system_keystore.test.js
promise.test.js
providers.test.js
serialize.test.js
signer.test.js
test-utils.js
utils
format.test.js
rpc-errors.test.js
validator.test.js
wallet-account.test.js
tsconfig.json
needle
README.md
examples
deflated-stream.js
digest-auth.js
download-to-file.js
multipart-stream.js
parsed-stream.js
parsed-stream2.js
stream-events.js
stream-to-file.js
upload-image.js
lib
auth.js
cookies.js
decoder.js
multipart.js
needle.js
parsers.js
querystring.js
license.txt
node_modules
debug
CHANGELOG.md
README.md
dist
debug.js
node.js
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
test
basic_auth_spec.js
compression_spec.js
cookies_spec.js
decoder_spec.js
errors_spec.js
headers_spec.js
helpers.js
long_string_spec.js
output_spec.js
parsing_spec.js
post_data_spec.js
proxy_spec.js
querystring_spec.js
redirect_spec.js
redirect_with_timeout.js
request_stream_spec.js
response_stream_spec.js
socket_pool_spec.js
url_spec.js
utils
formidable.js
proxy.js
test.js
negotiator
HISTORY.md
README.md
index.js
lib
charset.js
encoding.js
language.js
mediaType.js
package.json
netmask
README.md
example
ipcalc.coffee
lib
netmask.coffee
netmask.js
package.json
test
badnets.coffee
netmasks.coffee
tests
netmask.js
next-tick
.travis.yml
README.md
index.js
package.json
test
index.js
no-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
node-addon-api
.travis.yml
CHANGELOG.md
CODE_OF_CONDUCT.md
CONTRIBUTING.md
LICENSE.md
README.md
appveyor.yml
doc
array_buffer.md
async_context.md
async_operations.md
async_progress_worker.md
async_worker.md
basic_types.md
bigint.md
boolean.md
buffer.md
callback_scope.md
callbackinfo.md
checker-tool.md
class_property_descriptor.md
cmake-js.md
conversion-tool.md
creating_a_release.md
dataview.md
date.md
env.md
error.md
error_handling.md
escapable_handle_scope.md
external.md
function.md
function_reference.md
generator.md
handle_scope.md
memory_management.md
node-gyp.md
number.md
object.md
object_lifetime_management.md
object_reference.md
object_wrap.md
prebuild_tools.md
promises.md
property_descriptor.md
range_error.md
reference.md
setup.md
string.md
symbol.md
threadsafe_function.md
type_error.md
typed_array.md
typed_array_of.md
value.md
version_management.md
working_with_javascript_values.md
external-napi
node_api.h
index.js
napi-inl.deprecated.h
napi-inl.h
napi.h
package.json
src
node_api.h
node_api_types.h
node_internals.h
nothing.c
util-inl.h
util.h
tools
README.md
check-napi.js
conversion.js
node-fetch
CHANGELOG.md
LICENSE.md
README.md
browser.js
lib
index.es.js
index.js
package.json
node-gyp-build
README.md
bin.js
build-test.js
index.js
optional.js
package.json
normalize-path
README.md
index.js
package.json
normalize-url
index.d.ts
index.js
package.json
readme.md
nssocket
.travis.yml
README.md
examples
bla.js
foo.js
reconnect.js
simple-protocol.js
verbose-protocol.js
lib
common.js
nssocket.js
node_modules
eventemitter2
README.md
index.js
lib
eventemitter2.js
package.json
package.json
test
create-server-test.js
msgpack-tcp-test.js
tcp-reconnect-test.js
tcp-test.js
tls-test.js
number-to-bn
.travis.yml
.zuul.yml
CHANGELOG.md
README.md
dist
number-to-bn.js
number-to-bn.min.js
internals
webpack
webpack.config.js
node_modules
bn.js
.travis.yml
README.md
lib
bn.js
package.json
test
arithmetic-test.js
binary-test.js
constructor-test.js
fixtures.js
pummel
dh-group-test.js
red-test.js
utils-test.js
util
genCombMulTo.js
genCombMulTo10.js
package.json
src
index.js
tests
test.index.js
o3
README.md
index.js
lib
Class.js
abstractMethod.js
index.js
package.json
oauth-sign
README.md
index.js
package.json
object-assign
index.js
package.json
readme.md
object-keys
.travis.yml
README.md
foreach.js
index.js
isArguments.js
package.json
shim.js
test
foreach.js
index.js
isArguments.js
shim.js
object.omit
README.md
index.js
package.json
oboe
.travis.yml
CONTRIBUTING.md
Gruntfile.js
README.md
component.json
dist
oboe-browser.js
oboe-browser.min.js
oboe-node.js
index.js
jasmine.json
package.json
webpack.config.js
webpack.config.node.js
on-finished
HISTORY.md
README.md
index.js
package.json
once
README.md
once.js
package.json
optionator
CHANGELOG.md
README.md
lib
help.js
index.js
util.js
package.json
p-cancelable
index.d.ts
index.js
package.json
readme.md
p-finally
index.js
package.json
readme.md
p-timeout
index.js
package.json
readme.md
pac-proxy-agent
.github
workflows
test.yml
History.md
README.md
index.js
node_modules
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
test
test.js
pac-resolver
.travis.yml
CHANGELOG.md
README.md
dateRange.js
dnsDomainIs.js
dnsDomainLevels.js
dnsResolve.js
index.js
isInNet.js
isPlainHostName.js
isResolvable.js
localHostOrDomainIs.js
myIpAddress.js
package.json
shExpMatch.js
test
dnsDomainIs.js
dnsDomainLevels.js
dnsResolve.js
isInNet.js
isPlainHostName.js
isResolvable.js
localHostOrDomainIs.js
myIpAddress.js
shExpMatch.js
test.js
timeRange.js
weekdayRange.js
timeRange.js
weekdayRange.js
param-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
parse-asn1
README.md
aesid.json
asn1.js
certificate.js
fixProc.js
index.js
package.json
parse-glob
README.md
index.js
node_modules
is-extglob
README.md
index.js
package.json
is-glob
README.md
index.js
package.json
package.json
parse-headers
.travis.yml
example.js
package.json
parse-headers.js
readme.md
test.js
parseurl
HISTORY.md
README.md
index.js
package.json
pascal-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
path-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
path-is-absolute
index.js
package.json
readme.md
path-parse
.travis.yml
README.md
index.js
package.json
test.js
path-to-regexp
History.md
Readme.md
index.js
package.json
pbkdf2
README.md
browser.js
index.js
lib
async.js
default-encoding.js
precondition.js
sync-browser.js
sync.js
to-buffer.js
package.json
pend
README.md
index.js
package.json
test.js
performance-now
.travis.yml
README.md
lib
performance-now.js
license.txt
package.json
src
index.d.ts
performance-now.coffee
test
performance-now.coffee
scripts.coffee
scripts
delayed-call.coffee
delayed-require.coffee
difference.coffee
initial-value.coffee
picomatch
CHANGELOG.md
README.md
index.js
lib
constants.js
parse.js
picomatch.js
scan.js
utils.js
package.json
pidusage
CHANGELOG.md
README.md
index.js
lib
bin.js
helpers
cpu.js
parallel.js
history.js
procfile.js
ps.js
stats.js
wmic.js
package.json
pify
index.js
package.json
readme.md
pinkie-promise
index.js
package.json
readme.md
pinkie
index.js
package.json
readme.md
pm2-axon-rpc
.travis.yml
History.md
Readme.md
example.js
index.js
lib
client.js
server.js
node_modules
debug
CHANGELOG.md
README.md
dist
debug.js
node.js
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
pm2-axon
History.md
Readme.md
index.js
lib
configurable
History.md
Readme.md
index.js
lib
configurable.js
package.json
index.js
plugins
queue.js
round-robin.js
sockets
pub-emitter.js
pub.js
pull.js
push.js
rep.js
req.js
sock.js
sub-emitter.js
sub.js
utils.js
node_modules
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
pm2-deploy
README.md
deploy.js
package.json
pm2-multimeter
example
drop.js
multibar.js
multirel.js
single.js
sum.js
web_multibar.js
web_multirel.js
web_sum.js
index.js
lib
bar.js
package.json
pm2-promise
.travis.yml
README.md
__tests__
index.js
index.js
package.json
pm2
.mocharc.js
.travis.yml
CHANGELOG.md
CONTRIBUTING.md
GNU-AGPL-3.0.txt
README.md
constants.js
index.js
lib
API.js
API
Configuration.js
Containerizer.js
Dashboard.js
Deploy.js
Extra.js
ExtraMgmt
Docker.js
Log.js
LogManagement.js
Modules
LOCAL.js
Modularizer.js
NPM.js
TAR.js
flagExt.js
index.js
Monit.js
Serve.js
Startup.js
UX
helpers.js
index.js
pm2-describe.js
pm2-ls-minimal.js
pm2-ls.js
Version.js
interpreter.json
pm2-plus
PM2IO.js
auth-strategies
CliAuth.js
WebAuth.js
helpers.js
link.js
process-selector.js
schema.json
Client.js
Common.js
Configuration.js
Daemon.js
Event.js
God.js
God
ActionMethods.js
ClusterMode.js
ForkMode.js
Methods.js
Reload.js
HttpInterface.js
ProcessContainer.js
ProcessContainerFork.js
ProcessContainerForkLegacy.js
ProcessContainerLegacy.js
ProcessUtils.js
Sysinfo
MeanCalc.js
ServiceDetection
ServiceDetection.js
SystemInfo.js
psList.js
test.js
TreeKill.js
Utility.js
VersionCheck.js
Watcher.js
Worker.js
binaries
CLI.js
DevCLI.js
Runtime.js
Runtime4Docker.js
completion.js
completion.sh
templates
init-scripts
pm2-init-amazon.sh
sample-apps
http-server
README.md
api.js
ecosystem.config.js
package.json
pm2-plus-metrics-actions
README.md
custom-metrics.js
ecosystem.config.js
package.json
python-app
README.md
echo.py
ecosystem.config.js
package.json
tools
Config.js
IsAbsolute.js
copydirSync.js
deleteFolderRecursive.js
find-package-json.js
fmt.js
isbinaryfile.js
json5.js
open.js
passwd.js
promise.min.js
removeFolderRecursive.js
sexec.js
treeify.js
which.js
node_modules
commander
CHANGELOG.md
Readme.md
index.js
package.json
typings
index.d.ts
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
paths.js
types
index.d.ts
tsconfig.json
prelude-ls
CHANGELOG.md
README.md
lib
Func.js
List.js
Num.js
Obj.js
Str.js
index.js
package.json
prepend-http
index.js
package.json
readme.md
preserve
.travis.yml
.verb.md
README.md
index.js
package.json
test.js
pretty-format
README.md
build-es5
index.js
build
collections.d.ts
collections.js
index.d.ts
index.js
plugins
AsymmetricMatcher.d.ts
AsymmetricMatcher.js
ConvertAnsi.d.ts
ConvertAnsi.js
DOMCollection.d.ts
DOMCollection.js
DOMElement.d.ts
DOMElement.js
Immutable.d.ts
Immutable.js
ReactElement.d.ts
ReactElement.js
ReactTestComponent.d.ts
ReactTestComponent.js
lib
escapeHTML.d.ts
escapeHTML.js
markup.d.ts
markup.js
types.d.ts
types.js
node_modules
ansi-styles
index.js
package.json
readme.md
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
.eslintrc.json
README.md
index.js
package.json
test.js
package.json
perf
test.js
world.geo.json
process-nextick-args
index.js
license.md
package.json
readme.md
process
README.md
browser.js
index.js
package.json
promisfy
README.md
index.js
package.json
promptly
.travis.yml
README.md
index.js
package.json
test
test.js
proxy-addr
HISTORY.md
README.md
index.js
package.json
proxy-agent
.github
workflows
test.yml
History.md
README.md
index.d.ts
index.js
node_modules
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
test
test.js
proxy-from-env
.travis.yml
README.md
index.js
package.json
test.js
prr
.travis.yml
LICENSE.md
README.md
package.json
prr.js
test.js
ps-list
index.d.ts
index.js
package.json
readme.md
psl
README.md
browserstack-logo.svg
data
rules.json
dist
psl.js
psl.min.js
index.js
package.json
public-encrypt
.travis.yml
browser.js
index.js
mgf.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
privateDecrypt.js
publicEncrypt.js
readme.md
test
index.js
nodeTests.js
withPublic.js
xor.js
pump
.travis.yml
README.md
index.js
package.json
test-browser.js
test-node.js
punycode
LICENSE-MIT.txt
README.md
package.json
punycode.es6.js
punycode.js
qs
CHANGELOG.md
README.md
dist
qs.js
lib
formats.js
index.js
parse.js
stringify.js
utils.js
package.json
test
index.js
parse.js
stringify.js
utils.js
query-string
index.js
package.json
readme.md
rainbow-bridge-rs
package.json
rainbow-bridge-sol
.buildkite
pipeline.yml
build_all.sh
ci
test_verify_near_headers.sh
test_verify_near_proofs.sh
dist.sh
nearbridge
.solcover.js
.soliumrc.json
README.md
codechecks.yml
dist.sh
migrations
1_initial_migration.js
package.json
scripts
coverage.sh
test.sh
test
181.json
244.json
304.json
308.json
368.json
369.json
NearBridge.js
NearBridge2.js
block_120998.json
block_121498.json
block_121998.json
block_12640118.json
block_12640218.json
block_15178713.json
block_15178760.json
block_15204402.json
block_15248583.json
block_9580503.json
block_9580534.json
block_9580624.json
block_9605.json
block_9610.json
ed25519-test-cases.json
ed25519-test.js
init_validators_12640118.json
init_validators_15178713.json
truffle-config.js
nearprover
.solcover.js
.soliumrc.json
README.md
codechecks.yml
dist.sh
migrations
1_initial_migration.js
package.json
scripts
coverage.sh
test.sh
test
NearProver.js
proof2.json
proof3.json
proof4.json
proof5.json
proof6.json
truffle-config.js
package.json
randomatic
README.md
index.js
node_modules
is-number
README.md
index.js
package.json
kind-of
CHANGELOG.md
README.md
index.js
package.json
package.json
randombytes
.travis.yml
.zuul.yml
README.md
browser.js
index.js
package.json
test.js
randomfill
.travis.yml
.zuul.yml
README.md
browser.js
index.js
package.json
test.js
range-parser
HISTORY.md
README.md
index.js
package.json
raw-body
HISTORY.md
README.md
index.d.ts
index.js
package.json
react-is
README.md
build-info.json
cjs
react-is.development.js
react-is.production.min.js
index.js
package.json
umd
react-is.development.js
react-is.production.min.js
read
README.md
lib
read.js
package.json
readable-stream
CONTRIBUTING.md
GOVERNANCE.md
README.md
errors-browser.js
errors.js
experimentalWarning.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
internal
streams
async_iterator.js
buffer_list.js
destroy.js
end-of-stream.js
from-browser.js
from.js
pipeline.js
state.js
stream-browser.js
stream.js
package.json
readable-browser.js
readable.js
readdirp
README.md
index.d.ts
index.js
package.json
regex-cache
README.md
index.js
package.json
remove-trailing-separator
history.md
index.js
package.json
readme.md
repeat-element
README.md
index.js
package.json
repeat-string
README.md
index.js
package.json
request
CHANGELOG.md
README.md
index.js
lib
auth.js
cookies.js
getProxyFromURI.js
har.js
hawk.js
helpers.js
multipart.js
oauth.js
querystring.js
redirect.js
tunnel.js
node_modules
qs
CHANGELOG.md
README.md
dist
qs.js
lib
formats.js
index.js
parse.js
stringify.js
utils.js
package.json
test
index.js
parse.js
stringify.js
utils.js
package.json
request.js
require-in-the-middle
README.md
index.js
node_modules
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
resolve
.travis.yml
appveyor.yml
example
async.js
sync.js
index.js
lib
async.js
caller.js
core.js
core.json
is-core.js
node-modules-paths.js
normalize-options.js
sync.js
package.json
test
core.js
dotdot.js
dotdot
abc
index.js
index.js
faulty_basedir.js
filter.js
filter_sync.js
mock.js
mock_sync.js
module_dir.js
module_dir
xmodules
aaa
index.js
ymodules
aaa
index.js
zmodules
bbb
main.js
package.json
node-modules-paths.js
node_path.js
node_path
x
aaa
index.js
ccc
index.js
y
bbb
index.js
ccc
index.js
nonstring.js
pathfilter.js
pathfilter
deep_ref
main.js
precedence.js
precedence
aaa.js
aaa
index.js
main.js
bbb.js
bbb
main.js
resolver.js
resolver
baz
doom.js
package.json
quux.js
browser_field
a.js
b.js
package.json
cup.coffee
dot_main
index.js
package.json
dot_slash_main
index.js
package.json
foo.js
incorrect_main
index.js
package.json
invalid_main
package.json
mug.coffee
mug.js
multirepo
lerna.json
package.json
packages
package-a
index.js
package.json
package-b
index.js
package.json
nested_symlinks
mylib
async.js
package.json
sync.js
other_path
lib
other-lib.js
root.js
quux
foo
index.js
same_names
foo.js
foo
index.js
symlinked
_
node_modules
foo.js
package
bar.js
package.json
without_basedir
main.js
resolver_sync.js
shadowed_core.js
shadowed_core
node_modules
util
index.js
subdirs.js
symlinks.js
responselike
README.md
package.json
src
index.js
ripemd160
CHANGELOG.md
README.md
index.js
package.json
rlp
CHANGELOG.md
README.md
dist
index.d.ts
index.js
types.d.ts
types.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
run-series
README.md
index.js
package.json
rx-sandbox
CHANGELOG.md
README.md
dist
src
RxSandbox.d.ts
RxSandbox.js
RxSandboxInstance.d.ts
RxSandboxInstance.js
assert
constructObservableMarble.d.ts
constructObservableMarble.js
constructSubscriptionMarble.d.ts
constructSubscriptionMarble.js
marbleAssert.d.ts
marbleAssert.js
index.d.ts
index.js
marbles
ObservableMarbleToken.d.ts
ObservableMarbleToken.js
SubscriptionMarbleToken.d.ts
SubscriptionMarbleToken.js
parseObservableMarble.d.ts
parseObservableMarble.js
parseSubscriptionMarble.d.ts
parseSubscriptionMarble.js
tokenParseReducer.d.ts
tokenParseReducer.js
message
TestMessage.d.ts
TestMessage.js
scheduler
TestScheduler.d.ts
TestScheduler.js
calculateSubscriptionFrame.d.ts
calculateSubscriptionFrame.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
rxjs
AsyncSubject.d.ts
AsyncSubject.js
BehaviorSubject.d.ts
BehaviorSubject.js
InnerSubscriber.d.ts
InnerSubscriber.js
LICENSE.txt
Notification.d.ts
Notification.js
Observable.d.ts
Observable.js
Observer.d.ts
Observer.js
Operator.d.ts
Operator.js
OuterSubscriber.d.ts
OuterSubscriber.js
README.md
ReplaySubject.d.ts
ReplaySubject.js
Rx.d.ts
Rx.js
Scheduler.d.ts
Scheduler.js
Subject.d.ts
Subject.js
SubjectSubscription.d.ts
SubjectSubscription.js
Subscriber.d.ts
Subscriber.js
Subscription.d.ts
Subscription.js
_esm2015
LICENSE.txt
README.md
ajax
index.js
fetch
index.js
index.js
internal-compatibility
index.js
internal
AsyncSubject.js
BehaviorSubject.js
InnerSubscriber.js
Notification.js
Observable.js
Observer.js
Operator.js
OuterSubscriber.js
ReplaySubject.js
Rx.js
Scheduler.js
Subject.js
SubjectSubscription.js
Subscriber.js
Subscription.js
config.js
innerSubscribe.js
observable
ConnectableObservable.js
SubscribeOnObservable.js
bindCallback.js
bindNodeCallback.js
combineLatest.js
concat.js
defer.js
dom
AjaxObservable.js
WebSocketSubject.js
ajax.js
fetch.js
webSocket.js
empty.js
forkJoin.js
from.js
fromArray.js
fromEvent.js
fromEventPattern.js
fromIterable.js
fromPromise.js
generate.js
iif.js
interval.js
merge.js
never.js
of.js
onErrorResumeNext.js
pairs.js
partition.js
race.js
range.js
throwError.js
timer.js
using.js
zip.js
operators
audit.js
auditTime.js
buffer.js
bufferCount.js
bufferTime.js
bufferToggle.js
bufferWhen.js
catchError.js
combineAll.js
combineLatest.js
concat.js
concatAll.js
concatMap.js
concatMapTo.js
count.js
debounce.js
debounceTime.js
defaultIfEmpty.js
delay.js
delayWhen.js
dematerialize.js
distinct.js
distinctUntilChanged.js
distinctUntilKeyChanged.js
elementAt.js
endWith.js
every.js
exhaust.js
exhaustMap.js
expand.js
filter.js
finalize.js
find.js
findIndex.js
first.js
groupBy.js
ignoreElements.js
index.js
isEmpty.js
last.js
map.js
mapTo.js
materialize.js
max.js
merge.js
mergeAll.js
mergeMap.js
mergeMapTo.js
mergeScan.js
min.js
multicast.js
observeOn.js
onErrorResumeNext.js
pairwise.js
partition.js
pluck.js
publish.js
publishBehavior.js
publishLast.js
publishReplay.js
race.js
reduce.js
refCount.js
repeat.js
repeatWhen.js
retry.js
retryWhen.js
sample.js
sampleTime.js
scan.js
sequenceEqual.js
share.js
shareReplay.js
single.js
skip.js
skipLast.js
skipUntil.js
skipWhile.js
startWith.js
subscribeOn.js
switchAll.js
switchMap.js
switchMapTo.js
take.js
takeLast.js
takeUntil.js
takeWhile.js
tap.js
throttle.js
throttleTime.js
throwIfEmpty.js
timeInterval.js
timeout.js
timeoutWith.js
timestamp.js
toArray.js
window.js
windowCount.js
windowTime.js
windowToggle.js
windowWhen.js
withLatestFrom.js
zip.js
zipAll.js
scheduled
scheduleArray.js
scheduleIterable.js
scheduleObservable.js
schedulePromise.js
scheduled.js
scheduler
Action.js
AnimationFrameAction.js
AnimationFrameScheduler.js
AsapAction.js
AsapScheduler.js
AsyncAction.js
AsyncScheduler.js
QueueAction.js
QueueScheduler.js
VirtualTimeScheduler.js
animationFrame.js
asap.js
async.js
queue.js
symbol
iterator.js
observable.js
rxSubscriber.js
testing
ColdObservable.js
HotObservable.js
SubscriptionLog.js
SubscriptionLoggable.js
TestMessage.js
TestScheduler.js
types.js
util
ArgumentOutOfRangeError.js
EmptyError.js
Immediate.js
ObjectUnsubscribedError.js
TimeoutError.js
UnsubscriptionError.js
applyMixins.js
canReportError.js
errorObject.js
hostReportError.js
identity.js
isArray.js
isArrayLike.js
isDate.js
isFunction.js
isInteropObservable.js
isIterable.js
isNumeric.js
isObject.js
isObservable.js
isPromise.js
isScheduler.js
noop.js
not.js
pipe.js
root.js
subscribeTo.js
subscribeToArray.js
subscribeToIterable.js
subscribeToObservable.js
subscribeToPromise.js
subscribeToResult.js
toSubscriber.js
tryCatch.js
operators
index.js
path-mapping.js
testing
index.js
webSocket
index.js
_esm5
LICENSE.txt
README.md
ajax
index.js
fetch
index.js
index.js
internal-compatibility
index.js
internal
AsyncSubject.js
BehaviorSubject.js
InnerSubscriber.js
Notification.js
Observable.js
Observer.js
Operator.js
OuterSubscriber.js
ReplaySubject.js
Rx.js
Scheduler.js
Subject.js
SubjectSubscription.js
Subscriber.js
Subscription.js
config.js
innerSubscribe.js
observable
ConnectableObservable.js
SubscribeOnObservable.js
bindCallback.js
bindNodeCallback.js
combineLatest.js
concat.js
defer.js
dom
AjaxObservable.js
WebSocketSubject.js
ajax.js
fetch.js
webSocket.js
empty.js
forkJoin.js
from.js
fromArray.js
fromEvent.js
fromEventPattern.js
fromIterable.js
fromPromise.js
generate.js
iif.js
interval.js
merge.js
never.js
of.js
onErrorResumeNext.js
pairs.js
partition.js
race.js
range.js
throwError.js
timer.js
using.js
zip.js
operators
audit.js
auditTime.js
buffer.js
bufferCount.js
bufferTime.js
bufferToggle.js
bufferWhen.js
catchError.js
combineAll.js
combineLatest.js
concat.js
concatAll.js
concatMap.js
concatMapTo.js
count.js
debounce.js
debounceTime.js
defaultIfEmpty.js
delay.js
delayWhen.js
dematerialize.js
distinct.js
distinctUntilChanged.js
distinctUntilKeyChanged.js
elementAt.js
endWith.js
every.js
exhaust.js
exhaustMap.js
expand.js
filter.js
finalize.js
find.js
findIndex.js
first.js
groupBy.js
ignoreElements.js
index.js
isEmpty.js
last.js
map.js
mapTo.js
materialize.js
max.js
merge.js
mergeAll.js
mergeMap.js
mergeMapTo.js
mergeScan.js
min.js
multicast.js
observeOn.js
onErrorResumeNext.js
pairwise.js
partition.js
pluck.js
publish.js
publishBehavior.js
publishLast.js
publishReplay.js
race.js
reduce.js
refCount.js
repeat.js
repeatWhen.js
retry.js
retryWhen.js
sample.js
sampleTime.js
scan.js
sequenceEqual.js
share.js
shareReplay.js
single.js
skip.js
skipLast.js
skipUntil.js
skipWhile.js
startWith.js
subscribeOn.js
switchAll.js
switchMap.js
switchMapTo.js
take.js
takeLast.js
takeUntil.js
takeWhile.js
tap.js
throttle.js
throttleTime.js
throwIfEmpty.js
timeInterval.js
timeout.js
timeoutWith.js
timestamp.js
toArray.js
window.js
windowCount.js
windowTime.js
windowToggle.js
windowWhen.js
withLatestFrom.js
zip.js
zipAll.js
scheduled
scheduleArray.js
scheduleIterable.js
scheduleObservable.js
schedulePromise.js
scheduled.js
scheduler
Action.js
AnimationFrameAction.js
AnimationFrameScheduler.js
AsapAction.js
AsapScheduler.js
AsyncAction.js
AsyncScheduler.js
QueueAction.js
QueueScheduler.js
VirtualTimeScheduler.js
animationFrame.js
asap.js
async.js
queue.js
symbol
iterator.js
observable.js
rxSubscriber.js
testing
ColdObservable.js
HotObservable.js
SubscriptionLog.js
SubscriptionLoggable.js
TestMessage.js
TestScheduler.js
types.js
util
ArgumentOutOfRangeError.js
EmptyError.js
Immediate.js
ObjectUnsubscribedError.js
TimeoutError.js
UnsubscriptionError.js
applyMixins.js
canReportError.js
errorObject.js
hostReportError.js
identity.js
isArray.js
isArrayLike.js
isDate.js
isFunction.js
isInteropObservable.js
isIterable.js
isNumeric.js
isObject.js
isObservable.js
isPromise.js
isScheduler.js
noop.js
not.js
pipe.js
root.js
subscribeTo.js
subscribeToArray.js
subscribeToIterable.js
subscribeToObservable.js
subscribeToPromise.js
subscribeToResult.js
toSubscriber.js
tryCatch.js
operators
index.js
path-mapping.js
testing
index.js
webSocket
index.js
add
observable
bindCallback.d.ts
bindCallback.js
bindNodeCallback.d.ts
bindNodeCallback.js
combineLatest.d.ts
combineLatest.js
concat.d.ts
concat.js
defer.d.ts
defer.js
dom
ajax.d.ts
ajax.js
webSocket.d.ts
webSocket.js
empty.d.ts
empty.js
forkJoin.d.ts
forkJoin.js
from.d.ts
from.js
fromEvent.d.ts
fromEvent.js
fromEventPattern.d.ts
fromEventPattern.js
fromPromise.d.ts
fromPromise.js
generate.d.ts
generate.js
if.d.ts
if.js
interval.d.ts
interval.js
merge.d.ts
merge.js
never.d.ts
never.js
of.d.ts
of.js
onErrorResumeNext.d.ts
onErrorResumeNext.js
pairs.d.ts
pairs.js
race.d.ts
race.js
range.d.ts
range.js
throw.d.ts
throw.js
timer.d.ts
timer.js
using.d.ts
using.js
zip.d.ts
zip.js
operator
audit.d.ts
audit.js
auditTime.d.ts
auditTime.js
buffer.d.ts
buffer.js
bufferCount.d.ts
bufferCount.js
bufferTime.d.ts
bufferTime.js
bufferToggle.d.ts
bufferToggle.js
bufferWhen.d.ts
bufferWhen.js
catch.d.ts
catch.js
combineAll.d.ts
combineAll.js
combineLatest.d.ts
combineLatest.js
concat.d.ts
concat.js
concatAll.d.ts
concatAll.js
concatMap.d.ts
concatMap.js
concatMapTo.d.ts
concatMapTo.js
count.d.ts
count.js
debounce.d.ts
debounce.js
debounceTime.d.ts
debounceTime.js
defaultIfEmpty.d.ts
defaultIfEmpty.js
delay.d.ts
delay.js
delayWhen.d.ts
delayWhen.js
dematerialize.d.ts
dematerialize.js
distinct.d.ts
distinct.js
distinctUntilChanged.d.ts
distinctUntilChanged.js
distinctUntilKeyChanged.d.ts
distinctUntilKeyChanged.js
do.d.ts
do.js
elementAt.d.ts
elementAt.js
every.d.ts
every.js
exhaust.d.ts
exhaust.js
exhaustMap.d.ts
exhaustMap.js
expand.d.ts
expand.js
filter.d.ts
filter.js
finally.d.ts
finally.js
find.d.ts
find.js
findIndex.d.ts
findIndex.js
first.d.ts
first.js
groupBy.d.ts
groupBy.js
ignoreElements.d.ts
ignoreElements.js
isEmpty.d.ts
isEmpty.js
last.d.ts
last.js
let.d.ts
let.js
map.d.ts
map.js
mapTo.d.ts
mapTo.js
materialize.d.ts
materialize.js
max.d.ts
max.js
merge.d.ts
merge.js
mergeAll.d.ts
mergeAll.js
mergeMap.d.ts
mergeMap.js
mergeMapTo.d.ts
mergeMapTo.js
mergeScan.d.ts
mergeScan.js
min.d.ts
min.js
multicast.d.ts
multicast.js
observeOn.d.ts
observeOn.js
onErrorResumeNext.d.ts
onErrorResumeNext.js
pairwise.d.ts
pairwise.js
partition.d.ts
partition.js
pluck.d.ts
pluck.js
publish.d.ts
publish.js
publishBehavior.d.ts
publishBehavior.js
publishLast.d.ts
publishLast.js
publishReplay.d.ts
publishReplay.js
race.d.ts
race.js
reduce.d.ts
reduce.js
repeat.d.ts
repeat.js
repeatWhen.d.ts
repeatWhen.js
retry.d.ts
retry.js
retryWhen.d.ts
retryWhen.js
sample.d.ts
sample.js
sampleTime.d.ts
sampleTime.js
scan.d.ts
scan.js
sequenceEqual.d.ts
sequenceEqual.js
share.d.ts
share.js
shareReplay.d.ts
shareReplay.js
single.d.ts
single.js
skip.d.ts
skip.js
skipLast.d.ts
skipLast.js
skipUntil.d.ts
skipUntil.js
skipWhile.d.ts
skipWhile.js
startWith.d.ts
startWith.js
subscribeOn.d.ts
subscribeOn.js
switch.d.ts
switch.js
switchMap.d.ts
switchMap.js
switchMapTo.d.ts
switchMapTo.js
take.d.ts
take.js
takeLast.d.ts
takeLast.js
takeUntil.d.ts
takeUntil.js
takeWhile.d.ts
takeWhile.js
throttle.d.ts
throttle.js
throttleTime.d.ts
throttleTime.js
timeInterval.d.ts
timeInterval.js
timeout.d.ts
timeout.js
timeoutWith.d.ts
timeoutWith.js
timestamp.d.ts
timestamp.js
toArray.d.ts
toArray.js
toPromise.d.ts
toPromise.js
window.d.ts
window.js
windowCount.d.ts
windowCount.js
windowTime.d.ts
windowTime.js
windowToggle.d.ts
windowToggle.js
windowWhen.d.ts
windowWhen.js
withLatestFrom.d.ts
withLatestFrom.js
zip.d.ts
zip.js
zipAll.d.ts
zipAll.js
ajax
index.d.ts
index.js
package.json
bundles
rxjs.umd.js
rxjs.umd.min.js
fetch
index.d.ts
index.js
package.json
index.d.ts
index.js
interfaces.d.ts
interfaces.js
internal-compatibility
index.d.ts
index.js
package.json
internal
AsyncSubject.d.ts
AsyncSubject.js
BehaviorSubject.d.ts
BehaviorSubject.js
InnerSubscriber.d.ts
InnerSubscriber.js
Notification.d.ts
Notification.js
Observable.d.ts
Observable.js
Observer.d.ts
Observer.js
Operator.d.ts
Operator.js
OuterSubscriber.d.ts
OuterSubscriber.js
ReplaySubject.d.ts
ReplaySubject.js
Rx.d.ts
Rx.js
Scheduler.d.ts
Scheduler.js
Subject.d.ts
Subject.js
SubjectSubscription.d.ts
SubjectSubscription.js
Subscriber.d.ts
Subscriber.js
Subscription.d.ts
Subscription.js
config.d.ts
config.js
innerSubscribe.d.ts
innerSubscribe.js
observable
ConnectableObservable.d.ts
ConnectableObservable.js
SubscribeOnObservable.d.ts
SubscribeOnObservable.js
bindCallback.d.ts
bindCallback.js
bindNodeCallback.d.ts
bindNodeCallback.js
combineLatest.d.ts
combineLatest.js
concat.d.ts
concat.js
defer.d.ts
defer.js
dom
AjaxObservable.d.ts
AjaxObservable.js
WebSocketSubject.d.ts
WebSocketSubject.js
ajax.d.ts
ajax.js
fetch.d.ts
fetch.js
webSocket.d.ts
webSocket.js
empty.d.ts
empty.js
forkJoin.d.ts
forkJoin.js
from.d.ts
from.js
fromArray.d.ts
fromArray.js
fromEvent.d.ts
fromEvent.js
fromEventPattern.d.ts
fromEventPattern.js
fromIterable.d.ts
fromIterable.js
fromPromise.d.ts
fromPromise.js
generate.d.ts
generate.js
iif.d.ts
iif.js
interval.d.ts
interval.js
merge.d.ts
merge.js
never.d.ts
never.js
of.d.ts
of.js
onErrorResumeNext.d.ts
onErrorResumeNext.js
pairs.d.ts
pairs.js
partition.d.ts
partition.js
race.d.ts
race.js
range.d.ts
range.js
throwError.d.ts
throwError.js
timer.d.ts
timer.js
using.d.ts
using.js
zip.d.ts
zip.js
operators
audit.d.ts
audit.js
auditTime.d.ts
auditTime.js
buffer.d.ts
buffer.js
bufferCount.d.ts
bufferCount.js
bufferTime.d.ts
bufferTime.js
bufferToggle.d.ts
bufferToggle.js
bufferWhen.d.ts
bufferWhen.js
catchError.d.ts
catchError.js
combineAll.d.ts
combineAll.js
combineLatest.d.ts
combineLatest.js
concat.d.ts
concat.js
concatAll.d.ts
concatAll.js
concatMap.d.ts
concatMap.js
concatMapTo.d.ts
concatMapTo.js
count.d.ts
count.js
debounce.d.ts
debounce.js
debounceTime.d.ts
debounceTime.js
defaultIfEmpty.d.ts
defaultIfEmpty.js
delay.d.ts
delay.js
delayWhen.d.ts
delayWhen.js
dematerialize.d.ts
dematerialize.js
distinct.d.ts
distinct.js
distinctUntilChanged.d.ts
distinctUntilChanged.js
distinctUntilKeyChanged.d.ts
distinctUntilKeyChanged.js
elementAt.d.ts
elementAt.js
endWith.d.ts
endWith.js
every.d.ts
every.js
exhaust.d.ts
exhaust.js
exhaustMap.d.ts
exhaustMap.js
expand.d.ts
expand.js
filter.d.ts
filter.js
finalize.d.ts
finalize.js
find.d.ts
find.js
findIndex.d.ts
findIndex.js
first.d.ts
first.js
groupBy.d.ts
groupBy.js
ignoreElements.d.ts
ignoreElements.js
index.d.ts
index.js
isEmpty.d.ts
isEmpty.js
last.d.ts
last.js
map.d.ts
map.js
mapTo.d.ts
mapTo.js
materialize.d.ts
materialize.js
max.d.ts
max.js
merge.d.ts
merge.js
mergeAll.d.ts
mergeAll.js
mergeMap.d.ts
mergeMap.js
mergeMapTo.d.ts
mergeMapTo.js
mergeScan.d.ts
mergeScan.js
min.d.ts
min.js
multicast.d.ts
multicast.js
observeOn.d.ts
observeOn.js
onErrorResumeNext.d.ts
onErrorResumeNext.js
pairwise.d.ts
pairwise.js
partition.d.ts
partition.js
pluck.d.ts
pluck.js
publish.d.ts
publish.js
publishBehavior.d.ts
publishBehavior.js
publishLast.d.ts
publishLast.js
publishReplay.d.ts
publishReplay.js
race.d.ts
race.js
reduce.d.ts
reduce.js
refCount.d.ts
refCount.js
repeat.d.ts
repeat.js
repeatWhen.d.ts
repeatWhen.js
retry.d.ts
retry.js
retryWhen.d.ts
retryWhen.js
sample.d.ts
sample.js
sampleTime.d.ts
sampleTime.js
scan.d.ts
scan.js
sequenceEqual.d.ts
sequenceEqual.js
share.d.ts
share.js
shareReplay.d.ts
shareReplay.js
single.d.ts
single.js
skip.d.ts
skip.js
skipLast.d.ts
skipLast.js
skipUntil.d.ts
skipUntil.js
skipWhile.d.ts
skipWhile.js
startWith.d.ts
startWith.js
subscribeOn.d.ts
subscribeOn.js
switchAll.d.ts
switchAll.js
switchMap.d.ts
switchMap.js
switchMapTo.d.ts
switchMapTo.js
take.d.ts
take.js
takeLast.d.ts
takeLast.js
takeUntil.d.ts
takeUntil.js
takeWhile.d.ts
takeWhile.js
tap.d.ts
tap.js
throttle.d.ts
throttle.js
throttleTime.d.ts
throttleTime.js
throwIfEmpty.d.ts
throwIfEmpty.js
timeInterval.d.ts
timeInterval.js
timeout.d.ts
timeout.js
timeoutWith.d.ts
timeoutWith.js
timestamp.d.ts
timestamp.js
toArray.d.ts
toArray.js
window.d.ts
window.js
windowCount.d.ts
windowCount.js
windowTime.d.ts
windowTime.js
windowToggle.d.ts
windowToggle.js
windowWhen.d.ts
windowWhen.js
withLatestFrom.d.ts
withLatestFrom.js
zip.d.ts
zip.js
zipAll.d.ts
zipAll.js
scheduled
scheduleArray.d.ts
scheduleArray.js
scheduleIterable.d.ts
scheduleIterable.js
scheduleObservable.d.ts
scheduleObservable.js
schedulePromise.d.ts
schedulePromise.js
scheduled.d.ts
scheduled.js
scheduler
Action.d.ts
Action.js
AnimationFrameAction.d.ts
AnimationFrameAction.js
AnimationFrameScheduler.d.ts
AnimationFrameScheduler.js
AsapAction.d.ts
AsapAction.js
AsapScheduler.d.ts
AsapScheduler.js
AsyncAction.d.ts
AsyncAction.js
AsyncScheduler.d.ts
AsyncScheduler.js
QueueAction.d.ts
QueueAction.js
QueueScheduler.d.ts
QueueScheduler.js
VirtualTimeScheduler.d.ts
VirtualTimeScheduler.js
animationFrame.d.ts
animationFrame.js
asap.d.ts
asap.js
async.d.ts
async.js
queue.d.ts
queue.js
symbol
iterator.d.ts
iterator.js
observable.d.ts
observable.js
rxSubscriber.d.ts
rxSubscriber.js
testing
ColdObservable.d.ts
ColdObservable.js
HotObservable.d.ts
HotObservable.js
SubscriptionLog.d.ts
SubscriptionLog.js
SubscriptionLoggable.d.ts
SubscriptionLoggable.js
TestMessage.d.ts
TestMessage.js
TestScheduler.d.ts
TestScheduler.js
types.d.ts
types.js
util
ArgumentOutOfRangeError.d.ts
ArgumentOutOfRangeError.js
EmptyError.d.ts
EmptyError.js
Immediate.d.ts
Immediate.js
ObjectUnsubscribedError.d.ts
ObjectUnsubscribedError.js
TimeoutError.d.ts
TimeoutError.js
UnsubscriptionError.d.ts
UnsubscriptionError.js
applyMixins.d.ts
applyMixins.js
canReportError.d.ts
canReportError.js
errorObject.d.ts
errorObject.js
hostReportError.d.ts
hostReportError.js
identity.d.ts
identity.js
isArray.d.ts
isArray.js
isArrayLike.d.ts
isArrayLike.js
isDate.d.ts
isDate.js
isFunction.d.ts
isFunction.js
isInteropObservable.d.ts
isInteropObservable.js
isIterable.d.ts
isIterable.js
isNumeric.d.ts
isNumeric.js
isObject.d.ts
isObject.js
isObservable.d.ts
isObservable.js
isPromise.d.ts
isPromise.js
isScheduler.d.ts
isScheduler.js
noop.d.ts
noop.js
not.d.ts
not.js
pipe.d.ts
pipe.js
root.d.ts
root.js
subscribeTo.d.ts
subscribeTo.js
subscribeToArray.d.ts
subscribeToArray.js
subscribeToIterable.d.ts
subscribeToIterable.js
subscribeToObservable.d.ts
subscribeToObservable.js
subscribeToPromise.d.ts
subscribeToPromise.js
subscribeToResult.d.ts
subscribeToResult.js
toSubscriber.d.ts
toSubscriber.js
tryCatch.d.ts
tryCatch.js
migrations
collection.json
update-6_0_0
index.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
observable
ArrayLikeObservable.d.ts
ArrayLikeObservable.js
ArrayObservable.d.ts
ArrayObservable.js
BoundCallbackObservable.d.ts
BoundCallbackObservable.js
BoundNodeCallbackObservable.d.ts
BoundNodeCallbackObservable.js
ConnectableObservable.d.ts
ConnectableObservable.js
DeferObservable.d.ts
DeferObservable.js
EmptyObservable.d.ts
EmptyObservable.js
ErrorObservable.d.ts
ErrorObservable.js
ForkJoinObservable.d.ts
ForkJoinObservable.js
FromEventObservable.d.ts
FromEventObservable.js
FromEventPatternObservable.d.ts
FromEventPatternObservable.js
FromObservable.d.ts
FromObservable.js
GenerateObservable.d.ts
GenerateObservable.js
IfObservable.d.ts
IfObservable.js
IntervalObservable.d.ts
IntervalObservable.js
IteratorObservable.d.ts
IteratorObservable.js
NeverObservable.d.ts
NeverObservable.js
PairsObservable.d.ts
PairsObservable.js
PromiseObservable.d.ts
PromiseObservable.js
RangeObservable.d.ts
RangeObservable.js
ScalarObservable.d.ts
ScalarObservable.js
SubscribeOnObservable.d.ts
SubscribeOnObservable.js
TimerObservable.d.ts
TimerObservable.js
UsingObservable.d.ts
UsingObservable.js
bindCallback.d.ts
bindCallback.js
bindNodeCallback.d.ts
bindNodeCallback.js
combineLatest.d.ts
combineLatest.js
concat.d.ts
concat.js
defer.d.ts
defer.js
dom
AjaxObservable.d.ts
AjaxObservable.js
WebSocketSubject.d.ts
WebSocketSubject.js
ajax.d.ts
ajax.js
webSocket.d.ts
webSocket.js
empty.d.ts
empty.js
forkJoin.d.ts
forkJoin.js
from.d.ts
from.js
fromArray.d.ts
fromArray.js
fromEvent.d.ts
fromEvent.js
fromEventPattern.d.ts
fromEventPattern.js
fromIterable.d.ts
fromIterable.js
fromPromise.d.ts
fromPromise.js
generate.d.ts
generate.js
if.d.ts
if.js
interval.d.ts
interval.js
merge.d.ts
merge.js
never.d.ts
never.js
of.d.ts
of.js
onErrorResumeNext.d.ts
onErrorResumeNext.js
pairs.d.ts
pairs.js
race.d.ts
race.js
range.d.ts
range.js
throw.d.ts
throw.js
timer.d.ts
timer.js
using.d.ts
using.js
zip.d.ts
zip.js
operator
audit.d.ts
audit.js
auditTime.d.ts
auditTime.js
buffer.d.ts
buffer.js
bufferCount.d.ts
bufferCount.js
bufferTime.d.ts
bufferTime.js
bufferToggle.d.ts
bufferToggle.js
bufferWhen.d.ts
bufferWhen.js
catch.d.ts
catch.js
combineAll.d.ts
combineAll.js
combineLatest.d.ts
combineLatest.js
concat.d.ts
concat.js
concatAll.d.ts
concatAll.js
concatMap.d.ts
concatMap.js
concatMapTo.d.ts
concatMapTo.js
count.d.ts
count.js
debounce.d.ts
debounce.js
debounceTime.d.ts
debounceTime.js
defaultIfEmpty.d.ts
defaultIfEmpty.js
delay.d.ts
delay.js
delayWhen.d.ts
delayWhen.js
dematerialize.d.ts
dematerialize.js
distinct.d.ts
distinct.js
distinctUntilChanged.d.ts
distinctUntilChanged.js
distinctUntilKeyChanged.d.ts
distinctUntilKeyChanged.js
do.d.ts
do.js
elementAt.d.ts
elementAt.js
every.d.ts
every.js
exhaust.d.ts
exhaust.js
exhaustMap.d.ts
exhaustMap.js
expand.d.ts
expand.js
filter.d.ts
filter.js
finally.d.ts
finally.js
find.d.ts
find.js
findIndex.d.ts
findIndex.js
first.d.ts
first.js
groupBy.d.ts
groupBy.js
ignoreElements.d.ts
ignoreElements.js
isEmpty.d.ts
isEmpty.js
last.d.ts
last.js
let.d.ts
let.js
map.d.ts
map.js
mapTo.d.ts
mapTo.js
materialize.d.ts
materialize.js
max.d.ts
max.js
merge.d.ts
merge.js
mergeAll.d.ts
mergeAll.js
mergeMap.d.ts
mergeMap.js
mergeMapTo.d.ts
mergeMapTo.js
mergeScan.d.ts
mergeScan.js
min.d.ts
min.js
multicast.d.ts
multicast.js
observeOn.d.ts
observeOn.js
onErrorResumeNext.d.ts
onErrorResumeNext.js
pairwise.d.ts
pairwise.js
partition.d.ts
partition.js
pluck.d.ts
pluck.js
publish.d.ts
publish.js
publishBehavior.d.ts
publishBehavior.js
publishLast.d.ts
publishLast.js
publishReplay.d.ts
publishReplay.js
race.d.ts
race.js
reduce.d.ts
reduce.js
repeat.d.ts
repeat.js
repeatWhen.d.ts
repeatWhen.js
retry.d.ts
retry.js
retryWhen.d.ts
retryWhen.js
sample.d.ts
sample.js
sampleTime.d.ts
sampleTime.js
scan.d.ts
scan.js
sequenceEqual.d.ts
sequenceEqual.js
share.d.ts
share.js
shareReplay.d.ts
shareReplay.js
single.d.ts
single.js
skip.d.ts
skip.js
skipLast.d.ts
skipLast.js
skipUntil.d.ts
skipUntil.js
skipWhile.d.ts
skipWhile.js
startWith.d.ts
startWith.js
subscribeOn.d.ts
subscribeOn.js
switch.d.ts
switch.js
switchMap.d.ts
switchMap.js
switchMapTo.d.ts
switchMapTo.js
take.d.ts
take.js
takeLast.d.ts
takeLast.js
takeUntil.d.ts
takeUntil.js
takeWhile.d.ts
takeWhile.js
throttle.d.ts
throttle.js
throttleTime.d.ts
throttleTime.js
timeInterval.d.ts
timeInterval.js
timeout.d.ts
timeout.js
timeoutWith.d.ts
timeoutWith.js
timestamp.d.ts
timestamp.js
toArray.d.ts
toArray.js
toPromise.d.ts
toPromise.js
window.d.ts
window.js
windowCount.d.ts
windowCount.js
windowTime.d.ts
windowTime.js
windowToggle.d.ts
windowToggle.js
windowWhen.d.ts
windowWhen.js
withLatestFrom.d.ts
withLatestFrom.js
zip.d.ts
zip.js
zipAll.d.ts
zipAll.js
operators
audit.d.ts
audit.js
auditTime.d.ts
auditTime.js
buffer.d.ts
buffer.js
bufferCount.d.ts
bufferCount.js
bufferTime.d.ts
bufferTime.js
bufferToggle.d.ts
bufferToggle.js
bufferWhen.d.ts
bufferWhen.js
catchError.d.ts
catchError.js
combineAll.d.ts
combineAll.js
combineLatest.d.ts
combineLatest.js
concat.d.ts
concat.js
concatAll.d.ts
concatAll.js
concatMap.d.ts
concatMap.js
concatMapTo.d.ts
concatMapTo.js
count.d.ts
count.js
debounce.d.ts
debounce.js
debounceTime.d.ts
debounceTime.js
defaultIfEmpty.d.ts
defaultIfEmpty.js
delay.d.ts
delay.js
delayWhen.d.ts
delayWhen.js
dematerialize.d.ts
dematerialize.js
distinct.d.ts
distinct.js
distinctUntilChanged.d.ts
distinctUntilChanged.js
distinctUntilKeyChanged.d.ts
distinctUntilKeyChanged.js
elementAt.d.ts
elementAt.js
every.d.ts
every.js
exhaust.d.ts
exhaust.js
exhaustMap.d.ts
exhaustMap.js
expand.d.ts
expand.js
filter.d.ts
filter.js
finalize.d.ts
finalize.js
find.d.ts
find.js
findIndex.d.ts
findIndex.js
first.d.ts
first.js
groupBy.d.ts
groupBy.js
ignoreElements.d.ts
ignoreElements.js
index.d.ts
index.js
isEmpty.d.ts
isEmpty.js
last.d.ts
last.js
map.d.ts
map.js
mapTo.d.ts
mapTo.js
materialize.d.ts
materialize.js
max.d.ts
max.js
merge.d.ts
merge.js
mergeAll.d.ts
mergeAll.js
mergeMap.d.ts
mergeMap.js
mergeMapTo.d.ts
mergeMapTo.js
mergeScan.d.ts
mergeScan.js
min.d.ts
min.js
multicast.d.ts
multicast.js
observeOn.d.ts
observeOn.js
onErrorResumeNext.d.ts
onErrorResumeNext.js
package.json
pairwise.d.ts
pairwise.js
partition.d.ts
partition.js
pluck.d.ts
pluck.js
publish.d.ts
publish.js
publishBehavior.d.ts
publishBehavior.js
publishLast.d.ts
publishLast.js
publishReplay.d.ts
publishReplay.js
race.d.ts
race.js
reduce.d.ts
reduce.js
refCount.d.ts
refCount.js
repeat.d.ts
repeat.js
repeatWhen.d.ts
repeatWhen.js
retry.d.ts
retry.js
retryWhen.d.ts
retryWhen.js
sample.d.ts
sample.js
sampleTime.d.ts
sampleTime.js
scan.d.ts
scan.js
sequenceEqual.d.ts
sequenceEqual.js
share.d.ts
share.js
shareReplay.d.ts
shareReplay.js
single.d.ts
single.js
skip.d.ts
skip.js
skipLast.d.ts
skipLast.js
skipUntil.d.ts
skipUntil.js
skipWhile.d.ts
skipWhile.js
startWith.d.ts
startWith.js
subscribeOn.d.ts
subscribeOn.js
switchAll.d.ts
switchAll.js
switchMap.d.ts
switchMap.js
switchMapTo.d.ts
switchMapTo.js
take.d.ts
take.js
takeLast.d.ts
takeLast.js
takeUntil.d.ts
takeUntil.js
takeWhile.d.ts
takeWhile.js
tap.d.ts
tap.js
throttle.d.ts
throttle.js
throttleTime.d.ts
throttleTime.js
throwIfEmpty.d.ts
throwIfEmpty.js
timeInterval.d.ts
timeInterval.js
timeout.d.ts
timeout.js
timeoutWith.d.ts
timeoutWith.js
timestamp.d.ts
timestamp.js
toArray.d.ts
toArray.js
window.d.ts
window.js
windowCount.d.ts
windowCount.js
windowTime.d.ts
windowTime.js
windowToggle.d.ts
windowToggle.js
windowWhen.d.ts
windowWhen.js
withLatestFrom.d.ts
withLatestFrom.js
zip.d.ts
zip.js
zipAll.d.ts
zipAll.js
package.json
scheduler
animationFrame.d.ts
animationFrame.js
asap.d.ts
asap.js
async.d.ts
async.js
queue.d.ts
queue.js
src
AsyncSubject.ts
BehaviorSubject.ts
InnerSubscriber.ts
LICENSE.txt
MiscJSDoc.ts
Notification.ts
Observable.ts
Observer.ts
Operator.ts
OuterSubscriber.ts
README.md
ReplaySubject.ts
Rx.global.js
Rx.ts
Scheduler.ts
Subject.ts
SubjectSubscription.ts
Subscriber.ts
Subscription.ts
add
observable
bindCallback.ts
bindNodeCallback.ts
combineLatest.ts
concat.ts
defer.ts
dom
ajax.ts
webSocket.ts
empty.ts
forkJoin.ts
from.ts
fromEvent.ts
fromEventPattern.ts
fromPromise.ts
generate.ts
if.ts
interval.ts
merge.ts
never.ts
of.ts
onErrorResumeNext.ts
pairs.ts
race.ts
range.ts
throw.ts
timer.ts
using.ts
zip.ts
operator
audit.ts
auditTime.ts
buffer.ts
bufferCount.ts
bufferTime.ts
bufferToggle.ts
bufferWhen.ts
catch.ts
combineAll.ts
combineLatest.ts
concat.ts
concatAll.ts
concatMap.ts
concatMapTo.ts
count.ts
debounce.ts
debounceTime.ts
defaultIfEmpty.ts
delay.ts
delayWhen.ts
dematerialize.ts
distinct.ts
distinctUntilChanged.ts
distinctUntilKeyChanged.ts
do.ts
elementAt.ts
every.ts
exhaust.ts
exhaustMap.ts
expand.ts
filter.ts
finally.ts
find.ts
findIndex.ts
first.ts
groupBy.ts
ignoreElements.ts
isEmpty.ts
last.ts
let.ts
map.ts
mapTo.ts
materialize.ts
max.ts
merge.ts
mergeAll.ts
mergeMap.ts
mergeMapTo.ts
mergeScan.ts
min.ts
multicast.ts
observeOn.ts
onErrorResumeNext.ts
pairwise.ts
partition.ts
pluck.ts
publish.ts
publishBehavior.ts
publishLast.ts
publishReplay.ts
race.ts
reduce.ts
repeat.ts
repeatWhen.ts
retry.ts
retryWhen.ts
sample.ts
sampleTime.ts
scan.ts
sequenceEqual.ts
share.ts
shareReplay.ts
single.ts
skip.ts
skipLast.ts
skipUntil.ts
skipWhile.ts
startWith.ts
subscribeOn.ts
switch.ts
switchMap.ts
switchMapTo.ts
take.ts
takeLast.ts
takeUntil.ts
takeWhile.ts
throttle.ts
throttleTime.ts
timeInterval.ts
timeout.ts
timeoutWith.ts
timestamp.ts
toArray.ts
toPromise.ts
window.ts
windowCount.ts
windowTime.ts
windowToggle.ts
windowWhen.ts
withLatestFrom.ts
zip.ts
zipAll.ts
ajax
index.ts
package.json
fetch
index.ts
package.json
index.ts
interfaces.ts
internal-compatibility
index.ts
package.json
internal
AsyncSubject.ts
BehaviorSubject.ts
InnerSubscriber.ts
Notification.ts
Observable.ts
Observer.ts
Operator.ts
OuterSubscriber.ts
ReplaySubject.ts
Rx.ts
Scheduler.ts
Subject.ts
SubjectSubscription.ts
Subscriber.ts
Subscription.ts
config.ts
innerSubscribe.ts
observable
ConnectableObservable.ts
SubscribeOnObservable.ts
bindCallback.ts
bindNodeCallback.ts
combineLatest.ts
concat.ts
defer.ts
dom
AjaxObservable.ts
MiscJSDoc.ts
WebSocketSubject.ts
ajax.ts
fetch.ts
webSocket.ts
empty.ts
forkJoin.ts
from.ts
fromArray.ts
fromEvent.ts
fromEventPattern.ts
fromIterable.ts
fromObservable.ts
fromPromise.ts
generate.ts
iif.ts
interval.ts
merge.ts
never.ts
of.ts
onErrorResumeNext.ts
pairs.ts
partition.ts
race.ts
range.ts
throwError.ts
timer.ts
using.ts
zip.ts
operators
audit.ts
auditTime.ts
buffer.ts
bufferCount.ts
bufferTime.ts
bufferToggle.ts
bufferWhen.ts
catchError.ts
combineAll.ts
combineLatest.ts
concat.ts
concatAll.ts
concatMap.ts
concatMapTo.ts
count.ts
debounce.ts
debounceTime.ts
defaultIfEmpty.ts
delay.ts
delayWhen.ts
dematerialize.ts
distinct.ts
distinctUntilChanged.ts
distinctUntilKeyChanged.ts
elementAt.ts
endWith.ts
every.ts
exhaust.ts
exhaustMap.ts
expand.ts
filter.ts
finalize.ts
find.ts
findIndex.ts
first.ts
groupBy.ts
ignoreElements.ts
index.ts
isEmpty.ts
last.ts
map.ts
mapTo.ts
materialize.ts
max.ts
merge.ts
mergeAll.ts
mergeMap.ts
mergeMapTo.ts
mergeScan.ts
min.ts
multicast.ts
observeOn.ts
onErrorResumeNext.ts
pairwise.ts
partition.ts
pluck.ts
publish.ts
publishBehavior.ts
publishLast.ts
publishReplay.ts
race.ts
reduce.ts
refCount.ts
repeat.ts
repeatWhen.ts
retry.ts
retryWhen.ts
sample.ts
sampleTime.ts
scan.ts
sequenceEqual.ts
share.ts
shareReplay.ts
single.ts
skip.ts
skipLast.ts
skipUntil.ts
skipWhile.ts
startWith.ts
subscribeOn.ts
switchAll.ts
switchMap.ts
switchMapTo.ts
take.ts
takeLast.ts
takeUntil.ts
takeWhile.ts
tap.ts
throttle.ts
throttleTime.ts
throwIfEmpty.ts
timeInterval.ts
timeout.ts
timeoutWith.ts
timestamp.ts
toArray.ts
window.ts
windowCount.ts
windowTime.ts
windowToggle.ts
windowWhen.ts
withLatestFrom.ts
zip.ts
zipAll.ts
scheduled
scheduleArray.ts
scheduleIterable.ts
scheduleObservable.ts
schedulePromise.ts
scheduled.ts
scheduler
Action.ts
AnimationFrameAction.ts
AnimationFrameScheduler.ts
AsapAction.ts
AsapScheduler.ts
AsyncAction.ts
AsyncScheduler.ts
QueueAction.ts
QueueScheduler.ts
VirtualTimeScheduler.ts
animationFrame.ts
asap.ts
async.ts
queue.ts
symbol
iterator.ts
observable.ts
rxSubscriber.ts
testing
ColdObservable.ts
HotObservable.ts
SubscriptionLog.ts
SubscriptionLoggable.ts
TestMessage.ts
TestScheduler.ts
types.ts
umd.ts
util
ArgumentOutOfRangeError.ts
EmptyError.ts
Immediate.ts
ObjectUnsubscribedError.ts
TimeoutError.ts
UnsubscriptionError.ts
applyMixins.ts
canReportError.ts
errorObject.ts
hostReportError.ts
identity.ts
isArray.ts
isArrayLike.ts
isDate.ts
isFunction.ts
isInteropObservable.ts
isIterable.ts
isNumeric.ts
isObject.ts
isObservable.ts
isPromise.ts
isScheduler.ts
noop.ts
not.ts
pipe.ts
root.ts
subscribeTo.ts
subscribeToArray.ts
subscribeToIterable.ts
subscribeToObservable.ts
subscribeToPromise.ts
subscribeToResult.ts
toSubscriber.ts
tryCatch.ts
observable
ArrayLikeObservable.ts
ArrayObservable.ts
BoundCallbackObservable.ts
BoundNodeCallbackObservable.ts
ConnectableObservable.ts
DeferObservable.ts
EmptyObservable.ts
ErrorObservable.ts
ForkJoinObservable.ts
FromEventObservable.ts
FromEventPatternObservable.ts
FromObservable.ts
GenerateObservable.ts
IfObservable.ts
IntervalObservable.ts
IteratorObservable.ts
NeverObservable.ts
PairsObservable.ts
PromiseObservable.ts
RangeObservable.ts
ScalarObservable.ts
SubscribeOnObservable.ts
TimerObservable.ts
UsingObservable.ts
bindCallback.ts
bindNodeCallback.ts
combineLatest.ts
concat.ts
defer.ts
dom
AjaxObservable.ts
WebSocketSubject.ts
ajax.ts
webSocket.ts
empty.ts
forkJoin.ts
from.ts
fromArray.ts
fromEvent.ts
fromEventPattern.ts
fromIterable.ts
fromPromise.ts
generate.ts
if.ts
interval.ts
merge.ts
never.ts
of.ts
onErrorResumeNext.ts
pairs.ts
race.ts
range.ts
throw.ts
timer.ts
using.ts
zip.ts
operator
audit.ts
auditTime.ts
buffer.ts
bufferCount.ts
bufferTime.ts
bufferToggle.ts
bufferWhen.ts
catch.ts
combineAll.ts
combineLatest.ts
concat.ts
concatAll.ts
concatMap.ts
concatMapTo.ts
count.ts
debounce.ts
debounceTime.ts
defaultIfEmpty.ts
delay.ts
delayWhen.ts
dematerialize.ts
distinct.ts
distinctUntilChanged.ts
distinctUntilKeyChanged.ts
do.ts
elementAt.ts
every.ts
exhaust.ts
exhaustMap.ts
expand.ts
filter.ts
finally.ts
find.ts
findIndex.ts
first.ts
groupBy.ts
ignoreElements.ts
isEmpty.ts
last.ts
let.ts
map.ts
mapTo.ts
materialize.ts
max.ts
merge.ts
mergeAll.ts
mergeMap.ts
mergeMapTo.ts
mergeScan.ts
min.ts
multicast.ts
observeOn.ts
onErrorResumeNext.ts
pairwise.ts
partition.ts
pluck.ts
publish.ts
publishBehavior.ts
publishLast.ts
publishReplay.ts
race.ts
reduce.ts
repeat.ts
repeatWhen.ts
retry.ts
retryWhen.ts
sample.ts
sampleTime.ts
scan.ts
sequenceEqual.ts
share.ts
shareReplay.ts
single.ts
skip.ts
skipLast.ts
skipUntil.ts
skipWhile.ts
startWith.ts
subscribeOn.ts
switch.ts
switchMap.ts
switchMapTo.ts
take.ts
takeLast.ts
takeUntil.ts
takeWhile.ts
throttle.ts
throttleTime.ts
timeInterval.ts
timeout.ts
timeoutWith.ts
timestamp.ts
toArray.ts
toPromise.ts
window.ts
windowCount.ts
windowTime.ts
windowToggle.ts
windowWhen.ts
withLatestFrom.ts
zip.ts
zipAll.ts
operators
audit.ts
auditTime.ts
buffer.ts
bufferCount.ts
bufferTime.ts
bufferToggle.ts
bufferWhen.ts
catchError.ts
combineAll.ts
combineLatest.ts
concat.ts
concatAll.ts
concatMap.ts
concatMapTo.ts
count.ts
debounce.ts
debounceTime.ts
defaultIfEmpty.ts
delay.ts
delayWhen.ts
dematerialize.ts
distinct.ts
distinctUntilChanged.ts
distinctUntilKeyChanged.ts
elementAt.ts
every.ts
exhaust.ts
exhaustMap.ts
expand.ts
filter.ts
finalize.ts
find.ts
findIndex.ts
first.ts
groupBy.ts
ignoreElements.ts
index.ts
isEmpty.ts
last.ts
map.ts
mapTo.ts
materialize.ts
max.ts
merge.ts
mergeAll.ts
mergeMap.ts
mergeMapTo.ts
mergeScan.ts
min.ts
multicast.ts
observeOn.ts
onErrorResumeNext.ts
package.json
pairwise.ts
partition.ts
pluck.ts
publish.ts
publishBehavior.ts
publishLast.ts
publishReplay.ts
race.ts
reduce.ts
refCount.ts
repeat.ts
repeatWhen.ts
retry.ts
retryWhen.ts
sample.ts
sampleTime.ts
scan.ts
sequenceEqual.ts
share.ts
shareReplay.ts
single.ts
skip.ts
skipLast.ts
skipUntil.ts
skipWhile.ts
startWith.ts
subscribeOn.ts
switchAll.ts
switchMap.ts
switchMapTo.ts
take.ts
takeLast.ts
takeUntil.ts
takeWhile.ts
tap.ts
throttle.ts
throttleTime.ts
throwIfEmpty.ts
timeInterval.ts
timeout.ts
timeoutWith.ts
timestamp.ts
toArray.ts
window.ts
windowCount.ts
windowTime.ts
windowToggle.ts
windowWhen.ts
withLatestFrom.ts
zip.ts
zipAll.ts
scheduler
animationFrame.ts
asap.ts
async.ts
queue.ts
symbol
iterator.ts
observable.ts
rxSubscriber.ts
testing
index.ts
package.json
tsconfig.json
util
ArgumentOutOfRangeError.ts
EmptyError.ts
Immediate.ts
ObjectUnsubscribedError.ts
TimeoutError.ts
UnsubscriptionError.ts
applyMixins.ts
errorObject.ts
hostReportError.ts
identity.ts
isArray.ts
isArrayLike.ts
isDate.ts
isFunction.ts
isIterable.ts
isNumeric.ts
isObject.ts
isObservable.ts
isPromise.ts
isScheduler.ts
noop.ts
not.ts
pipe.ts
root.ts
subscribeTo.ts
subscribeToArray.ts
subscribeToIterable.ts
subscribeToObservable.ts
subscribeToPromise.ts
subscribeToResult.ts
toSubscriber.ts
tryCatch.ts
webSocket
index.ts
package.json
symbol
iterator.d.ts
iterator.js
observable.d.ts
observable.js
rxSubscriber.d.ts
rxSubscriber.js
testing
index.d.ts
index.js
package.json
util
ArgumentOutOfRangeError.d.ts
ArgumentOutOfRangeError.js
EmptyError.d.ts
EmptyError.js
Immediate.d.ts
Immediate.js
ObjectUnsubscribedError.d.ts
ObjectUnsubscribedError.js
TimeoutError.d.ts
TimeoutError.js
UnsubscriptionError.d.ts
UnsubscriptionError.js
applyMixins.d.ts
applyMixins.js
errorObject.d.ts
errorObject.js
hostReportError.d.ts
hostReportError.js
identity.d.ts
identity.js
isArray.d.ts
isArray.js
isArrayLike.d.ts
isArrayLike.js
isDate.d.ts
isDate.js
isFunction.d.ts
isFunction.js
isIterable.d.ts
isIterable.js
isNumeric.d.ts
isNumeric.js
isObject.d.ts
isObject.js
isObservable.d.ts
isObservable.js
isPromise.d.ts
isPromise.js
isScheduler.d.ts
isScheduler.js
noop.d.ts
noop.js
not.d.ts
not.js
pipe.d.ts
pipe.js
root.d.ts
root.js
subscribeTo.d.ts
subscribeTo.js
subscribeToArray.d.ts
subscribeToArray.js
subscribeToIterable.d.ts
subscribeToIterable.js
subscribeToObservable.d.ts
subscribeToObservable.js
subscribeToPromise.d.ts
subscribeToPromise.js
subscribeToResult.d.ts
subscribeToResult.js
toSubscriber.d.ts
toSubscriber.js
tryCatch.d.ts
tryCatch.js
webSocket
index.d.ts
index.js
package.json
safe-buffer
README.md
index.d.ts
index.js
package.json
safer-buffer
Porting-Buffer.md
Readme.md
dangerous.js
package.json
safer.js
tests.js
sax
README.md
lib
sax.js
package.json
scrypt-js
LICENSE.txt
README.md
index.html
package.json
scrypt.d.ts
scrypt.js
thirdparty
buffer.js
setImmediate.js
unorm.js
scryptsy
CHANGELOG.md
README.md
lib
index.js
scrypt.js
scryptSync.js
utils.js
package.json
secp256k1
API.md
README.md
bindings.js
elliptic.js
index.js
lib
elliptic.js
index.js
package.json
src
secp256k1.h
secp256k1
.travis.yml
README.md
SECURITY.md
autogen.sh
contrib
lax_der_parsing.c
lax_der_parsing.h
lax_der_privatekey_parsing.c
lax_der_privatekey_parsing.h
include
secp256k1.h
secp256k1_ecdh.h
secp256k1_preallocated.h
secp256k1_recovery.h
src
basic-config.h
bench.h
bench_ecdh.c
bench_ecmult.c
bench_internal.c
bench_recover.c
bench_sign.c
bench_verify.c
ecdsa.h
ecdsa_impl.h
eckey.h
eckey_impl.h
ecmult.h
ecmult_const.h
ecmult_const_impl.h
ecmult_gen.h
ecmult_gen_impl.h
ecmult_impl.h
field.h
field_10x26.h
field_10x26_impl.h
field_5x52.h
field_5x52_asm_impl.h
field_5x52_impl.h
field_5x52_int128_impl.h
field_impl.h
gen_context.c
group.h
group_impl.h
hash.h
hash_impl.h
java
org
bitcoin
NativeSecp256k1.java
NativeSecp256k1Test.java
NativeSecp256k1Util.java
Secp256k1Context.java
org_bitcoin_NativeSecp256k1.c
org_bitcoin_NativeSecp256k1.h
org_bitcoin_Secp256k1Context.c
org_bitcoin_Secp256k1Context.h
modules
ecdh
main_impl.h
tests_impl.h
recovery
main_impl.h
tests_impl.h
num.h
num_gmp.h
num_gmp_impl.h
num_impl.h
scalar.h
scalar_4x64.h
scalar_4x64_impl.h
scalar_8x32.h
scalar_8x32_impl.h
scalar_impl.h
scalar_low.h
scalar_low_impl.h
scratch.h
scratch_impl.h
secp256k1.c
testrand.h
testrand_impl.h
tests.c
tests_exhaustive.c
util.h
seek-bzip
README.md
lib
bitreader.js
crc32.js
index.js
stream.js
node_modules
commander
CHANGELOG.md
Readme.md
index.js
package.json
typings
index.d.ts
package.json
semaphore
.travis.yml
README.md
bower.json
lib
semaphore.js
package.json
test
semaphore.js
semver
CHANGELOG.md
README.md
bin
semver.js
classes
comparator.js
index.js
range.js
semver.js
functions
clean.js
cmp.js
coerce.js
compare-build.js
compare-loose.js
compare.js
diff.js
eq.js
gt.js
gte.js
inc.js
lt.js
lte.js
major.js
minor.js
neq.js
parse.js
patch.js
prerelease.js
rcompare.js
rsort.js
satisfies.js
sort.js
valid.js
index.js
internal
constants.js
debug.js
identifiers.js
re.js
package.json
preload.js
ranges
gtr.js
intersects.js
ltr.js
max-satisfying.js
min-satisfying.js
min-version.js
outside.js
simplify.js
subset.js
to-comparators.js
valid.js
send
HISTORY.md
README.md
index.js
node_modules
ms
index.js
license.md
package.json
readme.md
package.json
sentence-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
serve-static
HISTORY.md
README.md
index.js
package.json
servify
README.md
dist
servify.min.js
package.json
servify-browser.js
servify-node.js
servify.js
test
test.js
setimmediate
LICENSE.txt
package.json
setImmediate.js
setprototypeof
README.md
index.d.ts
index.js
package.json
test
index.js
sha.js
.travis.yml
README.md
bin.js
hash.js
index.js
package.json
sha.js
sha1.js
sha224.js
sha256.js
sha384.js
sha512.js
test
hash.js
test.js
vectors.js
shimmer
.travis.yml
README.md
index.js
package.json
test
init.tap.js
massUnwrap.tap.js
massWrap.tap.js
unwrap.tap.js
wrap.tap.js
signal-exit
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
signals.js
simple-concat
.travis.yml
README.md
index.js
package.json
test
basic.js
simple-get
README.md
index.js
package.json
slash
index.js
package.json
readme.md
smart-buffer
.travis.yml
README.md
build
smartbuffer.js
utils.js
docs
CHANGELOG.md
README_v3.md
ROADMAP.md
package.json
typings
smartbuffer.d.ts
utils.d.ts
snake-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
socks-proxy-agent
.travis.yml
History.md
README.md
index.js
node_modules
agent-base
.travis.yml
History.md
README.md
index.js
package.json
patch-core.js
test
test.js
package.json
test
test.js
socks
.travis.yml
README.md
build
client
socksclient.js
common
constants.js
helpers.js
receivebuffer.js
util.js
index.js
docs
examples
index.md
javascript
associateExample.md
bindExample.md
connectExample.md
typescript
associateExample.md
bindExample.md
connectExample.md
index.md
migratingFromV1.md
package.json
typings
client
socksclient.d.ts
common
constants.d.ts
helpers.d.ts
receiveBuffer.d.ts
util.d.ts
index.d.ts
source-map-support
LICENSE.md
README.md
browser-source-map-support.js
package.json
register.js
source-map-support.js
source-map
CHANGELOG.md
README.md
dist
source-map.debug.js
source-map.js
source-map.min.js
lib
array-set.js
base64-vlq.js
base64.js
binary-search.js
mapping-list.js
quick-sort.js
source-map-consumer.js
source-map-generator.js
source-node.js
util.js
package.json
source-map.d.ts
source-map.js
sprintf-js
CHANGELOG.md
CONTRIBUTORS.md
README.md
dist
angular-sprintf.min.js
sprintf.min.js
package.json
src
angular-sprintf.js
sprintf.js
sshpk
.travis.yml
README.md
lib
algs.js
certificate.js
dhe.js
ed-compat.js
errors.js
fingerprint.js
formats
auto.js
dnssec.js
openssh-cert.js
pem.js
pkcs1.js
pkcs8.js
putty.js
rfc4253.js
ssh-private.js
ssh.js
x509-pem.js
x509.js
identity.js
index.js
key.js
private-key.js
signature.js
ssh-buffer.js
utils.js
package.json
statuses
HISTORY.md
README.md
codes.json
index.js
package.json
strict-uri-encode
index.js
package.json
readme.md
string_decoder
README.md
lib
string_decoder.js
package.json
strip-ansi
index.js
node_modules
ansi-regex
index.js
package.json
readme.md
package.json
readme.md
strip-dirs
README.md
index.js
package.json
strip-hex-prefix
.travis.yml
CHANGELOG.md
README.md
package.json
src
index.js
tests
test.index.js
supports-color
browser.js
index.js
package.json
readme.md
swarm-js
README.md
archives
archives.json
deps.txt
examples
dapp_upload.js
example_dapp_uploader
swarm.min.js
run_node.js
simple_usage.js
uploader_dapp
index.html
index.js
swarm.min.js
lib
api-browser.js
api-node.js
files.js
pick.js
swarm-hash.js
swarm.js
node_modules
get-stream
buffer-stream.js
index.js
package.json
readme.md
got
index.js
package.json
readme.md
p-cancelable
index.js
package.json
readme.md
prepend-http
index.js
package.json
readme.md
url-parse-lax
index.js
package.json
readme.md
package.json
scripts
archives
archives.json
prepareArchives.js
src
api-browser.js
api-node.js
files.js
pick.js
swarm-hash.js
swarm.js
systeminformation
CHANGELOG.md
README.md
lib
battery.js
cli.js
cpu.js
docker.js
dockerSocket.js
filesystem.js
graphics.js
index.d.ts
index.js
internet.js
memory.js
network.js
osinfo.js
processes.js
system.js
users.js
util.js
virtualbox.js
wifi.js
package.json
tar-stream
README.md
extract.js
headers.js
index.js
node_modules
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
readable-stream
.travis.yml
CONTRIBUTING.md
GOVERNANCE.md
README.md
doc
wg-meetings
2015-01-30.md
duplex-browser.js
duplex.js
lib
_stream_duplex.js
_stream_passthrough.js
_stream_readable.js
_stream_transform.js
_stream_writable.js
internal
streams
BufferList.js
destroy.js
stream-browser.js
stream.js
package.json
passthrough.js
readable-browser.js
readable.js
transform.js
writable-browser.js
writable.js
safe-buffer
README.md
index.d.ts
index.js
package.json
string_decoder
.travis.yml
README.md
lib
string_decoder.js
package.json
pack.js
package.json
tar
README.md
index.js
lib
buffer.js
create.js
extract.js
header.js
high-level-opt.js
large-numbers.js
list.js
mkdir.js
mode-fix.js
pack.js
parse.js
pax.js
read-entry.js
replace.js
types.js
unpack.js
update.js
warn-mixin.js
winchars.js
write-entry.js
node_modules
mkdirp
bin
cmd.js
usage.txt
index.js
package.json
package.json
text-encoding-utf-8
LICENSE.md
README.md
lib
encoding.js
encoding.lib.js
package.json
src
encoding.js
polyfill.js
tez-bridge-lib
.buildkite
pipeline.yml
CHANGELOG.md
README.md
config
index.js
contracts
eth
.buildkite
pipeline.yml
CHANGELOG.md
build_all.sh
ci
test_verify_near_headers.sh
test_verify_near_proofs.sh
dist.sh
nearbridge
.solcover.js
.soliumrc.json
README.md
codechecks.yml
dist.sh
migrations
1_initial_migration.js
package.json
scripts
coverage.sh
test.sh
test
181.json
244.json
304.json
308.json
368.json
369.json
NearBridge.js
NearBridge2.js
block_120998.json
block_121498.json
block_121998.json
block_12640118.json
block_12640218.json
block_15178713.json
block_15178760.json
block_15204402.json
block_15248583.json
block_9580503.json
block_9580534.json
block_9580624.json
block_9605.json
block_9610.json
ed25519-test-cases.json
ed25519-test.js
init_validators_12640118.json
init_validators_15178713.json
truffle-config.js
nearprover
.solcover.js
.soliumrc.json
README.md
codechecks.yml
dist.sh
migrations
1_initial_migration.js
package.json
scripts
coverage.sh
test.sh
test
NearProver.js
proof2.json
proof3.json
proof4.json
proof5.json
proof6.json
truffle-config.js
package.json
near
.buildkite
pipeline.yml
Cargo.toml
build_all.sh
ci
test_verify_eth_headers.sh
test_verify_eth_proofs.sh
eth-client
Cargo.toml
README.md
build.sh
src
data
10234001.json
10234002.json
10234003.json
10234004.json
10234005.json
10234006.json
10234007.json
10234008.json
10234009.json
10234010.json
10234011.json
2.json
3.json
400000.json
400001.json
8996776.json
8996777.json
dag_merkle_roots.json
lib.rs
tests.rs
test.sh
eth-prover
Cargo.toml
build.sh
src
lib.rs
tests.rs
test.sh
tests
spec.rs
utils.rs
eth-types
Cargo.toml
src
lib.rs
mintable-fungible-token
Cargo.toml
build.sh
data
proof.json
src
lib.rs
package.json
tezos
EthClientOnTezos.py
FA2TezToken.py
eth-on-tezos-client
dag_merkle_roots.json
index.js
eth-on-tezos-prover
index.js
eth-proof-extractor
index.js
eth2tezos-relay
index.js
index.js
init
eth-contracts.js
index.js
tezos-contracts.js
tezos-token-factory.js
node_modules
tweetnacl
AUTHORS.md
CHANGELOG.md
PULL_REQUEST_TEMPLATE.md
README.md
nacl-fast.js
nacl-fast.min.js
nacl.d.ts
nacl.js
nacl.min.js
package.json
package.json
src
get-config.js
utils.js
tezbridge
borsh.js
borshify-proof.js
helpers.js
robust.js
tezos-dump.js
tezos-mintable-token
index.js
tezos2eth-relay
index.js
transfer-eth-erc20
deploy-token.js
from-tezos.js
index.js
to-tezos.js
watchdog
index.js
tezbridge-token-connector
README.md
bridge-token-factory
Cargo.toml
build.sh
src
lib.rs
lock_event.rs
prover.rs
unlock_event.rs
tests
token_transfer.rs
bridge-token
Cargo.toml
build.sh
src
lib.rs
erc20-connector
dist.sh
migrations
1_initial_migration.js
package.json
scripts
coverage.sh
test.sh
test
TokenLocker.js
proof_template.json
truffle-config.js
mock-prover
Cargo.toml
build.sh
src
lib.rs
package.json
through
.travis.yml
index.js
package.json
test
async.js
auto-destroy.js
buffering.js
end.js
index.js
thunkify
History.md
Readme.md
index.js
package.json
test
index.js
timed-out
index.js
package.json
readme.md
to-buffer
.travis.yml
README.md
index.js
package.json
test.js
to-readable-stream
index.js
package.json
readme.md
to-regex-range
README.md
index.js
package.json
toidentifier
README.md
index.js
package.json
tough-cookie
README.md
lib
cookie.js
memstore.js
pathMatch.js
permuteDomain.js
pubsuffix-psl.js
store.js
version.js
package.json
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
tunnel-agent
README.md
index.js
package.json
tv4
LICENSE.txt
README.md
lang
de.js
es.js
fr.js
nb.js
pl-PL.js
pt-PT.js
sv-SE.js
zh-CN.js
package.json
tv4.async-jquery.js
tv4.js
tweetnacl
AUTHORS.md
CHANGELOG.md
PULL_REQUEST_TEMPLATE.md
README.md
nacl-fast.js
nacl-fast.min.js
nacl.d.ts
nacl.js
nacl.min.js
package.json
type-check
README.md
lib
check.js
index.js
parse-type.js
package.json
type-is
HISTORY.md
README.md
index.js
package.json
type
CHANGELOG.md
README.md
array-length
coerce.js
ensure.js
array-like
ensure.js
is.js
array
ensure.js
is.js
date
ensure.js
is.js
error
ensure.js
is.js
finite
coerce.js
ensure.js
function
ensure.js
is.js
integer
coerce.js
ensure.js
iterable
ensure.js
is.js
lib
is-to-string-tag-supported.js
resolve-exception.js
safe-to-string.js
to-short-string.js
natural-number
coerce.js
ensure.js
number
coerce.js
ensure.js
object
ensure.js
is.js
package.json
plain-function
ensure.js
is.js
plain-object
ensure.js
is.js
promise
ensure.js
is.js
prototype
is.js
reg-exp
ensure.js
is.js
safe-integer
coerce.js
ensure.js
string
coerce.js
ensure.js
test
_lib
arrow-function-if-supported.js
class-if-supported.js
array-length
coerce.js
ensure.js
array-like
ensure.js
is.js
array
ensure.js
is.js
date
ensure.js
is.js
error
ensure.js
is.js
finite
coerce.js
ensure.js
function
ensure.js
is.js
integer
coerce.js
ensure.js
iterable
ensure.js
is.js
lib
is-to-string-tag-supported.js
resolve-exception.js
safe-to-string.js
to-short-string.js
natural-number
coerce.js
ensure.js
number
coerce.js
ensure.js
object
ensure.js
is.js
plain-function
ensure.js
is.js
plain-object
ensure.js
is.js
promise
ensure.js
is.js
prototype
is.js
reg-exp
ensure.js
is.js
safe-integer
coerce.js
ensure.js
string
coerce.js
ensure.js
thenable
ensure.js
is.js
time-value
coerce.js
ensure.js
value
ensure.js
is.js
thenable
ensure.js
is.js
time-value
coerce.js
ensure.js
value
ensure.js
is.js
typedarray-to-buffer
.airtap.yml
.travis.yml
README.md
index.js
package.json
test
basic.js
u3
README.md
index.js
lib
cache.js
eachCombination.js
index.js
package.json
ultron
README.md
index.js
package.json
unbzip2-stream
README.md
dist
unbzip2-stream.min.js
index.js
lib
bit_iterator.js
bzip2.js
package.json
underscore
README.md
package.json
underscore-min.js
underscore.js
unique-string
index.d.ts
index.js
package.json
readme.md
universalify
README.md
index.js
package.json
unpipe
HISTORY.md
README.md
index.js
package.json
upper-case-first
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
upper-case
README.md
dist.es2015
index.d.ts
index.js
index.spec.d.ts
index.spec.js
dist
index.d.ts
index.js
index.spec.d.ts
index.spec.js
node_modules
tslib
CopyrightNotice.txt
LICENSE.txt
README.md
modules
index.js
package.json
package.json
test
validateModuleExportsMatchCommonJS
index.js
package.json
tslib.d.ts
tslib.es6.html
tslib.es6.js
tslib.html
tslib.js
package.json
uri-js
README.md
dist
es5
uri.all.d.ts
uri.all.js
uri.all.min.d.ts
uri.all.min.js
esnext
index.d.ts
index.js
regexps-iri.d.ts
regexps-iri.js
regexps-uri.d.ts
regexps-uri.js
schemes
http.d.ts
http.js
https.d.ts
https.js
mailto.d.ts
mailto.js
urn-uuid.d.ts
urn-uuid.js
urn.d.ts
urn.js
ws.d.ts
ws.js
wss.d.ts
wss.js
uri.d.ts
uri.js
util.d.ts
util.js
package.json
url-parse-lax
index.js
package.json
readme.md
url-set-query
LICENSE.md
README.md
index.js
package.json
url-to-options
README.md
index.js
package.json
utf-8-validate
README.md
fallback.js
index.js
node_modules
node-gyp-build
README.md
bin.js
build-test.js
index.js
optional.js
package.json
package.json
src
validation.c
utf8
LICENSE-MIT.txt
README.md
package.json
utf8.js
util-deprecate
History.md
README.md
browser.js
node.js
package.json
utils-merge
README.md
index.js
package.json
uuid
CHANGELOG.md
LICENSE.md
README.md
index.js
lib
bytesToUuid.js
md5-browser.js
md5.js
rng-browser.js
rng.js
sha1-browser.js
sha1.js
v35.js
package.json
v1.js
v3.js
v4.js
v5.js
varint
README.md
bench.js
decode.js
encode.js
index.js
length.js
package.json
test.js
vary
HISTORY.md
README.md
index.js
package.json
verror
CHANGES.md
CONTRIBUTING.md
README.md
lib
verror.js
package.json
vizion
.travis.yml
CHANGELOG.md
README.md
index.js
lib
git.js
hg.js
identify.js
svn.js
vizion.js
node_modules
async
CHANGELOG.md
README.md
dist
async.js
async.min.js
lib
async.js
package.json
package.json
test
all.mocha.js
fixtures
test_hg
contributors.txt
test_svn
branches
development
README.md
trunk
README.md
git_scenario.mocha.js
support
env.js
web3-bzz
README.md
lib
index.js
node_modules
@types
node
README.md
assert.d.ts
async_hooks.d.ts
base.d.ts
buffer.d.ts
child_process.d.ts
cluster.d.ts
console.d.ts
constants.d.ts
crypto.d.ts
dgram.d.ts
dns.d.ts
domain.d.ts
events.d.ts
fs.d.ts
globals.d.ts
globals.global.d.ts
http.d.ts
http2.d.ts
https.d.ts
index.d.ts
inspector.d.ts
module.d.ts
net.d.ts
os.d.ts
package.json
path.d.ts
perf_hooks.d.ts
process.d.ts
punycode.d.ts
querystring.d.ts
readline.d.ts
repl.d.ts
stream.d.ts
string_decoder.d.ts
timers.d.ts
tls.d.ts
trace_events.d.ts
ts3.3
assert.d.ts
base.d.ts
globals.global.d.ts
index.d.ts
ts3.6
base.d.ts
index.d.ts
tty.d.ts
url.d.ts
util.d.ts
v8.d.ts
vm.d.ts
wasi.d.ts
worker_threads.d.ts
zlib.d.ts
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
bzz-test.ts
tsconfig.json
tslint.json
web3-core-helpers
README.md
lib
errors.js
formatters.js
index.js
package.json
src
errors.js
formatters.js
index.js
tsconfig.json
types
index.d.ts
tests
errors-test.ts
formatters-test.ts
tsconfig.json
tslint.json
web3-core-method
README.md
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tsconfig.json
tslint.json
web3-core-promievent
README.md
lib
index.js
package.json
src
index.js
tsconfig.json
web3-core-requestmanager
README.md
lib
batch.js
givenProvider.js
index.js
jsonrpc.js
package.json
src
batch.js
givenProvider.js
index.js
jsonrpc.js
tsconfig.json
web3-core-subscriptions
README.md
lib
index.js
subscription.js
package.json
src
index.js
subscription.js
tsconfig.json
types
index.d.ts
tests
subscriptions.tests.ts
tsconfig.json
tslint.json
web3-core
README.md
lib
extend.js
index.js
node_modules
@types
node
README.md
assert.d.ts
async_hooks.d.ts
base.d.ts
buffer.d.ts
child_process.d.ts
cluster.d.ts
console.d.ts
constants.d.ts
crypto.d.ts
dgram.d.ts
dns.d.ts
domain.d.ts
events.d.ts
fs.d.ts
globals.d.ts
globals.global.d.ts
http.d.ts
http2.d.ts
https.d.ts
index.d.ts
inspector.d.ts
module.d.ts
net.d.ts
os.d.ts
package.json
path.d.ts
perf_hooks.d.ts
process.d.ts
punycode.d.ts
querystring.d.ts
readline.d.ts
repl.d.ts
stream.d.ts
string_decoder.d.ts
timers.d.ts
tls.d.ts
trace_events.d.ts
ts3.3
assert.d.ts
base.d.ts
globals.global.d.ts
index.d.ts
ts3.6
base.d.ts
index.d.ts
tty.d.ts
url.d.ts
util.d.ts
v8.d.ts
vm.d.ts
wasi.d.ts
worker_threads.d.ts
zlib.d.ts
package.json
src
extend.js
index.js
tsconfig.json
types
index.d.ts
tsconfig.json
tslint.json
web3-eth-abi
README.md
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
abi-coder-test.ts
tsconfig.json
tslint.json
web3-eth-accounts
README.md
lib
index.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
eth-lib
README.md
lib
abi.js
account.js
api.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
provider.js
rlp.js
rpc.js
transaction.js
types.js
package.json
src
abi.js
account.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
rlp.js
rpc.js
transaction.js
test
lib
benchmark.js
randomData.js
test.js
uuid
.eslintrc.json
CHANGELOG.md
LICENSE.md
README.md
README_js.md
index.js
lib
bytesToUuid.js
md5-browser.js
md5.js
rng-browser.js
rng.js
sha1-browser.js
sha1.js
v35.js
package.json
v1.js
v3.js
v4.js
v5.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
accounts-tests.ts
tsconfig.json
tslint.json
web3-eth-contract
README.md
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
contract-test.ts
tsconfig.json
tslint.json
web3-eth-ens
README.md
lib
ENS.js
config.js
contracts
Registry.js
index.js
lib
ResolverMethodHandler.js
contentHash.js
resources
ABI
Registry.js
Resolver.js
package.json
src
ENS.js
config.js
contracts
Registry.js
index.js
lib
ResolverMethodHandler.js
contentHash.js
resources
ABI
Registry.js
Resolver.js
tsconfig.json
types
index.d.ts
tests
ens-test.ts
tsconfig.json
tslint.json
web3-eth-iban
README.md
lib
index.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
iban-tests.ts
tsconfig.json
tslint.json
web3-eth-personal
README.md
lib
index.js
node_modules
@types
node
README.md
assert.d.ts
async_hooks.d.ts
base.d.ts
buffer.d.ts
child_process.d.ts
cluster.d.ts
console.d.ts
constants.d.ts
crypto.d.ts
dgram.d.ts
dns.d.ts
domain.d.ts
events.d.ts
fs.d.ts
globals.d.ts
globals.global.d.ts
http.d.ts
http2.d.ts
https.d.ts
index.d.ts
inspector.d.ts
module.d.ts
net.d.ts
os.d.ts
package.json
path.d.ts
perf_hooks.d.ts
process.d.ts
punycode.d.ts
querystring.d.ts
readline.d.ts
repl.d.ts
stream.d.ts
string_decoder.d.ts
timers.d.ts
tls.d.ts
trace_events.d.ts
ts3.3
assert.d.ts
base.d.ts
globals.global.d.ts
index.d.ts
ts3.6
base.d.ts
index.d.ts
tty.d.ts
url.d.ts
util.d.ts
v8.d.ts
vm.d.ts
wasi.d.ts
worker_threads.d.ts
zlib.d.ts
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
personal-tests.ts
tsconfig.json
tslint.json
web3-eth
README.md
lib
getNetworkType.js
index.js
package.json
src
getNetworkType.js
index.js
tsconfig.json
types
index.d.ts
tests
eth.tests.ts
tsconfig.json
tslint.json
web3-net
README.md
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
network-test.ts
tsconfig.json
tslint.json
web3-providers-http
README.md
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
web3-provider-http-tests.ts
tsconfig.json
tslint.json
web3-providers-ipc
README.md
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
web3-provider-ipc-tests.ts
tsconfig.json
tslint.json
web3-providers-ws
README.md
lib
helpers.js
index.js
package.json
src
helpers.js
index.js
tsconfig.json
types
index.d.ts
tests
web3-provider-ws-tests.ts
tsconfig.json
tslint.json
web3-shh
README.md
lib
index.js
package.json
src
index.js
tsconfig.json
types
index.d.ts
tests
shh-test.ts
tsconfig.json
tslint.json
web3-utils
README.md
lib
index.js
soliditySha3.js
utils.js
node_modules
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
eth-lib
README.md
lib
abi.js
account.js
api.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
provider.js
rlp.js
rpc.js
transaction.js
types.js
package.json
src
abi.js
account.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
rlp.js
rpc.js
transaction.js
test
lib
benchmark.js
randomData.js
test.js
package.json
src
index.js
soliditySha3.js
utils.js
tsconfig.json
types
index.d.ts
tests
ascii-to-hex-test.ts
bytes-to-hex-test.ts
check-address-checksum-test.ts
encode-packed.ts
from-ascii-test.ts
from-decimal-test.ts
from-utf8-test.ts
from-wei-test.ts
get-signature-params-test.ts
get-unit-value-test.ts
hex-to-ascii-test.ts
hex-to-bytes-test.ts
hex-to-number-string-test.ts
hex-to-number-test.ts
hex-to-string-test.ts
hex-to-utf8-test.ts
is-address-test.ts
is-big-number-test.ts
is-bloom-test.ts
is-bn-test.ts
is-contract-address-in-bloom.ts
is-hex-strict-test.ts
is-hex-test.ts
is-in-bloom.ts
is-topic-in-bloom.ts
is-topic-test.ts
is-topic.ts
is-user-ethereum-address-in-bloom.ts
json-interface-method-to-string-test.ts
keccak256-test.ts
left-pad-test.ts
number-to-hex-test.ts
pad-left-test.ts
pad-right-test.ts
random-hex-test.ts
right-pad-test.ts
sha3-raw-test.ts
sha3-test.ts
solidity-sha3-raw-test.ts
solidity-sha3-test.ts
string-to-hex-test.ts
strip-hex-prefix-test.ts
test-address-test.ts
test-topic-test.ts
to-ascii-test.ts
to-bn-test.ts
to-check-sum-address-test.ts
to-decimal-test.ts
to-hex-test.ts
to-twos-compement-test.ts
to-utf8-test.ts
to-wei-test.ts
unit-map-test.ts
utf8-to-hex-test.ts
tsconfig.json
tslint.json
web3
README.md
angular-patch.js
node_modules
@types
node
README.md
assert.d.ts
async_hooks.d.ts
base.d.ts
buffer.d.ts
child_process.d.ts
cluster.d.ts
console.d.ts
constants.d.ts
crypto.d.ts
dgram.d.ts
dns.d.ts
domain.d.ts
events.d.ts
fs.d.ts
globals.d.ts
globals.global.d.ts
http.d.ts
http2.d.ts
https.d.ts
index.d.ts
inspector.d.ts
module.d.ts
net.d.ts
os.d.ts
package.json
path.d.ts
perf_hooks.d.ts
process.d.ts
punycode.d.ts
querystring.d.ts
readline.d.ts
repl.d.ts
stream.d.ts
string_decoder.d.ts
timers.d.ts
tls.d.ts
trace_events.d.ts
ts3.3
assert.d.ts
base.d.ts
globals.global.d.ts
index.d.ts
ts3.6
base.d.ts
index.d.ts
tty.d.ts
url.d.ts
util.d.ts
v8.d.ts
vm.d.ts
wasi.d.ts
worker_threads.d.ts
zlib.d.ts
bn.js
README.md
lib
bn.js
package.json
util
genCombMulTo.js
genCombMulTo10.js
eventemitter3
README.md
index.d.ts
index.js
package.json
umd
eventemitter3.js
eventemitter3.min.js
get-stream
buffer-stream.js
index.js
package.json
readme.md
oboe
.travis.yml
CONTRIBUTING.md
Gruntfile.js
README.md
component.json
dist
oboe-browser.js
oboe-browser.min.js
oboe-node.js
index.js
jasmine.json
package.json
test
README.md
amd.conf.js
concat.conf.js
http.conf.js
json
allTypes.json
emptyKey.json
firstTenNaturalNumbers.json
incomplete.json
oneHundredRecords.json
smallestPossible.json
tenRecords.json
libs
ascentFrom.js
calledLikeMatcher.js
es5-sham.js
es5-shim.js
listMatcher.js
oboeAsserter.js
platform.js
prettyPrintEvents.js
sinon-ie.js
sinon.js
spiedPubSub.js
testUrl.js
testVars.js
toString.js
min.conf.js
require
require.js
specs
amd.integration.spec.js
clarinet.unit.spec.js
defaults.unit.spec.js
detectCrossOrigin.unit.spec.js
errorReport.unit.spec.js
functional.unit.spec.js
incrementalContentBuilder.unit.spec.js
instanceApi.component.spec.js
instanceApi.unit.spec.js
instanceController.unit.spec.js
jsonPath.unit.spec.js
jsonPathTokens.unit.spec.js
lists.unit.spec.js
oboe.component.spec.js
oboe.integration.spec.js
oboe.performance.spec.js
parseResponseHeaders.unit.spec.js
patternAdaptor.unit.spec.js
publicApi.unit.spec.js
pubsub.unit.spec.js
singleEventPubSub.unit.spec.js
streamingHttp.integration.spec.js
streamingHttp.unit.spec.js
streamingXhr.unit.spec.js
streamsource.js
unit.conf.js
p-cancelable
index.js
package.json
readme.md
prepend-http
index.js
package.json
readme.md
swarm-js
README.md
archives
archives.json
examples
dapp_upload.js
run_node.js
simple_usage.js
uploader_dapp
index.html
index.js
swarm.min.js
lib
api-browser.js
api-node.js
files.js
pick.js
swarm-hash.js
swarm.js
node_modules
got
index.js
package.json
readme.md
package.json
scripts
archives
archives.json
prepareArchives.js
src
api-browser.js
api-node.js
files.js
pick.js
swarm-hash.js
swarm.js
url-parse-lax
index.js
package.json
readme.md
uuid
.eslintrc.json
CHANGELOG.md
LICENSE.md
README.md
README_js.md
index.js
lib
bytesToUuid.js
md5-browser.js
md5.js
rng-browser.js
rng.js
sha1-browser.js
sha1.js
v35.js
package.json
v1.js
v3.js
v4.js
v5.js
web3-bzz
README.md
node_modules
@types
node
README.md
assert.d.ts
async_hooks.d.ts
base.d.ts
buffer.d.ts
child_process.d.ts
cluster.d.ts
console.d.ts
constants.d.ts
crypto.d.ts
dgram.d.ts
dns.d.ts
domain.d.ts
events.d.ts
fs.d.ts
globals.d.ts
http.d.ts
http2.d.ts
https.d.ts
index.d.ts
inspector.d.ts
module.d.ts
net.d.ts
os.d.ts
package.json
path.d.ts
perf_hooks.d.ts
process.d.ts
punycode.d.ts
querystring.d.ts
readline.d.ts
repl.d.ts
stream.d.ts
string_decoder.d.ts
timers.d.ts
tls.d.ts
trace_events.d.ts
ts3.6
assert.d.ts
base.d.ts
index.d.ts
tty.d.ts
url.d.ts
util.d.ts
v8.d.ts
vm.d.ts
worker_threads.d.ts
zlib.d.ts
package.json
src
index.js
types
index.d.ts
tests
bzz-test.ts
tsconfig.json
tslint.json
web3-core-helpers
README.md
package.json
src
errors.js
formatters.js
index.js
types
index.d.ts
tests
errors-test.ts
formatters-test.ts
tsconfig.json
tslint.json
web3-core-method
README.md
package.json
src
index.js
types
index.d.ts
tsconfig.json
tslint.json
web3-core-promievent
README.md
package.json
src
index.js
web3-core-requestmanager
README.md
package.json
src
batch.js
givenProvider.js
index.js
jsonrpc.js
web3-core-subscriptions
README.md
package.json
src
index.js
subscription.js
types
index.d.ts
tests
subscriptions.tests.ts
tsconfig.json
tslint.json
web3-core
README.md
package.json
src
extend.js
index.js
types
index.d.ts
tsconfig.json
tslint.json
web3-eth-abi
README.md
package.json
src
index.js
types
index.d.ts
tests
abi-coder-test.ts
tsconfig.json
tslint.json
web3-eth-accounts
README.md
node_modules
eth-lib
README.md
lib
abi.js
account.js
api.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
provider.js
rlp.js
rpc.js
transaction.js
types.js
package.json
src
abi.js
account.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
rlp.js
rpc.js
transaction.js
test
lib
benchmark.js
randomData.js
test.js
package.json
src
index.js
types
index.d.ts
tests
accounts-tests.ts
tsconfig.json
tslint.json
web3-eth-contract
README.md
package.json
src
index.js
types
index.d.ts
tests
contract-test.ts
tsconfig.json
tslint.json
web3-eth-ens
README.md
package.json
src
ENS.js
config.js
contracts
Registry.js
index.js
lib
ResolverMethodHandler.js
ressources
ABI
Registry.js
Resolver.js
types
index.d.ts
tests
ens-test.ts
tsconfig.json
tslint.json
web3-eth-iban
README.md
package.json
src
index.js
types
index.d.ts
tests
iban-tests.ts
tsconfig.json
tslint.json
web3-eth-personal
README.md
package.json
src
index.js
types
index.d.ts
tests
personal-tests.ts
tsconfig.json
tslint.json
web3-eth
README.md
package.json
src
getNetworkType.js
index.js
types
index.d.ts
tests
eth.tests.ts
tsconfig.json
tslint.json
web3-net
README.md
package.json
src
index.js
types
index.d.ts
tests
network-test.ts
tsconfig.json
tslint.json
web3-providers-http
README.md
package.json
src
index.js
types
index.d.ts
tests
web3-provider-http-tests.ts
tsconfig.json
tslint.json
web3-providers-ipc
README.md
package.json
src
index.js
types
index.d.ts
tests
web3-provider-ipc-tests.ts
tsconfig.json
tslint.json
web3-providers-ws
README.md
package.json
src
index.js
types
index.d.ts
tests
web3-provider-ws-tests.ts
tsconfig.json
tslint.json
web3-shh
README.md
package.json
src
index.js
types
index.d.ts
tests
shh-test.ts
tsconfig.json
tslint.json
web3-utils
README.md
node_modules
eth-lib
README.md
lib
abi.js
account.js
api.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
provider.js
rlp.js
rpc.js
transaction.js
types.js
package.json
src
abi.js
account.js
array.js
bytes.js
desubits.js
fn.js
hash.js
index.js
map.js
nat.js
passphrase.js
rlp.js
rpc.js
transaction.js
test
lib
benchmark.js
randomData.js
test.js
package.json
src
index.js
soliditySha3.js
utils.js
types
index.d.ts
tests
ascii-to-hex-test.ts
bytes-to-hex-test.ts
check-address-checksum-test.ts
from-ascii-test.ts
from-decimal-test.ts
from-utf8-test.ts
from-wei-test.ts
get-signature-params-test.ts
get-unit-value-test.ts
hex-to-ascii-test.ts
hex-to-bytes-test.ts
hex-to-number-string-test.ts
hex-to-number-test.ts
hex-to-string-test.ts
hex-to-utf8-test.ts
is-address-test.ts
is-big-number-test.ts
is-bloom-test.ts
is-bn-test.ts
is-contract-address-in-bloom.ts
is-hex-strict-test.ts
is-hex-test.ts
is-in-bloom.ts
is-topic-in-bloom.ts
is-topic-test.ts
is-topic.ts
is-user-ethereum-address-in-bloom.ts
json-interface-method-to-string-test.ts
keccak256-test.ts
left-pad-test.ts
number-to-hex-test.ts
pad-left-test.ts
pad-right-test.ts
random-hex-test.ts
right-pad-test.ts
sha3-raw-test.ts
sha3-test.ts
solidity-sha3-raw-test.ts
solidity-sha3-test.ts
string-to-hex-test.ts
strip-hex-prefix-test.ts
test-address-test.ts
test-topic-test.ts
to-ascii-test.ts
to-bn-test.ts
to-check-sum-address-test.ts
to-decimal-test.ts
to-hex-test.ts
to-twos-compement-test.ts
to-utf8-test.ts
to-wei-test.ts
unit-map-test.ts
utf8-to-hex-test.ts
tsconfig.json
tslint.json
package.json
src
index.js
types
index.d.ts
tests
web3-test.ts
tsconfig.json
tslint.json
websocket
.github
workflows
websocket-tests.yml
CHANGELOG.md
README.md
gulpfile.js
index.js
lib
Deprecation.js
W3CWebSocket.js
WebSocketClient.js
WebSocketConnection.js
WebSocketFrame.js
WebSocketRequest.js
WebSocketRouter.js
WebSocketRouterRequest.js
WebSocketServer.js
browser.js
utils.js
version.js
websocket.js
package.json
vendor
FastBufferList.js
word-wrap
README.md
index.d.ts
index.js
package.json
wrappy
README.md
package.json
wrappy.js
write-file-atomic
CHANGELOG.md
README.md
index.js
package.json
ws
README.md
index.js
lib
BufferUtil.js
Constants.js
ErrorCodes.js
EventTarget.js
Extensions.js
PerMessageDeflate.js
Receiver.js
Sender.js
Validation.js
WebSocket.js
WebSocketServer.js
node_modules
safe-buffer
README.md
index.d.ts
index.js
package.json
package.json
xdg-basedir
index.d.ts
index.js
package.json
readme.md
xhr-request-promise
README.md
index.js
package.json
test
fixtures
error.json
photo.json
index.spec.js
xhr-request
LICENSE.md
README.md
index.js
lib
ensure-header.js
normalize-response.js
request-browser.js
request.js
package.json
xhr
CONTRIBUTING.md
README.md
index.d.ts
index.js
package.json
xhr2-cookies
README.md
dist
errors.d.ts
errors.js
index.d.ts
index.js
progress-event.d.ts
progress-event.js
xml-http-request-event-target.d.ts
xml-http-request-event-target.js
xml-http-request-upload.d.ts
xml-http-request-upload.js
xml-http-request.d.ts
xml-http-request.js
package.json
xmlhttprequest
README.md
lib
XMLHttpRequest.js
package.json
xregexp
MIT-LICENSE.txt
README.md
package.json
tests
node-qunit.js
tests.js
xregexp-all.js
xtend
README.md
immutable.js
mutable.js
package.json
test.js
yaeti
README.md
gulpfile.js
index.js
lib
Event.browser.js
Event.js
EventTarget.js
package.json
yallist
README.md
iterator.js
package.json
yallist.js
yamljs
.travis.yml
README.md
bower.json
cli
json2yaml.js
yaml2json.js
demo
demo.html
dist
yaml.debug.js
yaml.js
yaml.legacy.js
yaml.min.js
index.js
lib
Dumper.js
Escaper.js
Exception
DumpException.js
ParseException.js
ParseMore.js
Inline.js
Parser.js
Pattern.js
Unescaper.js
Utils.js
Yaml.js
package.json
src
Dumper.coffee
Escaper.coffee
Exception
DumpException.coffee
ParseException.coffee
ParseMore.coffee
Inline.coffee
Parser.coffee
Pattern.coffee
Unescaper.coffee
Utils.coffee
Yaml.coffee
test
SpecRunner.html
lib
jasmine-2.0.0
boot.js
console.js
jasmine-html.js
jasmine.css
jasmine.js
spec
YamlSpec.coffee
YamlSpec.js
example.yml
yauzl
README.md
index.js
package.json
Inspector mode only
Begin Testing
EDITABLE CONFIG DEFAULTS
|
|
| :--------- |
| :-------- |
| :--- |
|
|
|
|
Welcome to debugging React
end of tests
package-lock.json
package.json
scripts
prepare.sh
start_ganache.sh
test
run_test.sh
test-deploy-token-sanity.js
test-init-token-factory.js
vendor
ethashproof
Readme.md
build.sh
cache.go
cmd
cache
main.go
epoch
main.go
relayer
main.go
dag_merkle_proof.go
dag_merkle_root.go
ethash
algorithm.go
algorithm_test.go
api.go
consensus.go
consensus_test.go
ethash.go
ethash_test.go
ethashproof_ext.go
sealer.go
sealer_test.go
mtree
branch.go
branch_tree.go
constants.go
dag_mt.go
merkle_tree.go
util.go
ganache
package.json
| # Elliptic [](http://travis-ci.org/indutny/elliptic) [](https://coveralls.io/github/indutny/elliptic?branch=master) [](https://codeclimate.com/github/indutny/elliptic)
[](https://saucelabs.com/u/gh-indutny-elliptic)
Fast elliptic-curve cryptography in a plain javascript implementation.
NOTE: Please take a look at http://safecurves.cr.yp.to/ before choosing a curve
for your cryptography operations.
## Incentive
ECC is much slower than regular RSA cryptography, the JS implementations are
even more slower.
## Benchmarks
```bash
$ node benchmarks/index.js
Benchmarking: sign
elliptic#sign x 262 ops/sec ±0.51% (177 runs sampled)
eccjs#sign x 55.91 ops/sec ±0.90% (144 runs sampled)
------------------------
Fastest is elliptic#sign
========================
Benchmarking: verify
elliptic#verify x 113 ops/sec ±0.50% (166 runs sampled)
eccjs#verify x 48.56 ops/sec ±0.36% (125 runs sampled)
------------------------
Fastest is elliptic#verify
========================
Benchmarking: gen
elliptic#gen x 294 ops/sec ±0.43% (176 runs sampled)
eccjs#gen x 62.25 ops/sec ±0.63% (129 runs sampled)
------------------------
Fastest is elliptic#gen
========================
Benchmarking: ecdh
elliptic#ecdh x 136 ops/sec ±0.85% (156 runs sampled)
------------------------
Fastest is elliptic#ecdh
========================
```
## API
### ECDSA
```javascript
var EC = require('elliptic').ec;
// Create and initialize EC context
// (better do it once and reuse it)
var ec = new EC('secp256k1');
// Generate keys
var key = ec.genKeyPair();
// Sign the message's hash (input must be an array, or a hex-string)
var msgHash = [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ];
var signature = key.sign(msgHash);
// Export DER encoded signature in Array
var derSign = signature.toDER();
// Verify signature
console.log(key.verify(msgHash, derSign));
// CHECK WITH NO PRIVATE KEY
var pubPoint = key.getPublic();
var x = pubPoint.getX();
var y = pubPoint.getY();
// Public Key MUST be either:
// 1) '04' + hex string of x + hex string of y; or
// 2) object with two hex string properties (x and y); or
// 3) object with two buffer properties (x and y)
var pub = pubPoint.encode('hex'); // case 1
var pub = { x: x.toString('hex'), y: y.toString('hex') }; // case 2
var pub = { x: x.toBuffer(), y: y.toBuffer() }; // case 3
var pub = { x: x.toArrayLike(Buffer), y: y.toArrayLike(Buffer) }; // case 3
// Import public key
var key = ec.keyFromPublic(pub, 'hex');
// Signature MUST be either:
// 1) DER-encoded signature as hex-string; or
// 2) DER-encoded signature as buffer; or
// 3) object with two hex-string properties (r and s); or
// 4) object with two buffer properties (r and s)
var signature = '3046022100...'; // case 1
var signature = new Buffer('...'); // case 2
var signature = { r: 'b1fc...', s: '9c42...' }; // case 3
// Verify signature
console.log(key.verify(msgHash, signature));
```
### EdDSA
```javascript
var EdDSA = require('elliptic').eddsa;
// Create and initialize EdDSA context
// (better do it once and reuse it)
var ec = new EdDSA('ed25519');
// Create key pair from secret
var key = ec.keyFromSecret('693e3c...'); // hex string, array or Buffer
// Sign the message's hash (input must be an array, or a hex-string)
var msgHash = [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ];
var signature = key.sign(msgHash).toHex();
// Verify signature
console.log(key.verify(msgHash, signature));
// CHECK WITH NO PRIVATE KEY
// Import public key
var pub = '0a1af638...';
var key = ec.keyFromPublic(pub, 'hex');
// Verify signature
var signature = '70bed1...';
console.log(key.verify(msgHash, signature));
```
### ECDH
```javascript
var EC = require('elliptic').ec;
var ec = new EC('curve25519');
// Generate keys
var key1 = ec.genKeyPair();
var key2 = ec.genKeyPair();
var shared1 = key1.derive(key2.getPublic());
var shared2 = key2.derive(key1.getPublic());
console.log('Both shared secrets are BN instances');
console.log(shared1.toString(16));
console.log(shared2.toString(16));
```
three and more members:
```javascript
var EC = require('elliptic').ec;
var ec = new EC('curve25519');
var A = ec.genKeyPair();
var B = ec.genKeyPair();
var C = ec.genKeyPair();
var AB = A.getPublic().mul(B.getPrivate())
var BC = B.getPublic().mul(C.getPrivate())
var CA = C.getPublic().mul(A.getPrivate())
var ABC = AB.mul(C.getPrivate())
var BCA = BC.mul(A.getPrivate())
var CAB = CA.mul(B.getPrivate())
console.log(ABC.getX().toString(16))
console.log(BCA.getX().toString(16))
console.log(CAB.getX().toString(16))
```
NOTE: `.derive()` returns a [BN][1] instance.
## Supported curves
Elliptic.js support following curve types:
* Short Weierstrass
* Montgomery
* Edwards
* Twisted Edwards
Following curve 'presets' are embedded into the library:
* `secp256k1`
* `p192`
* `p224`
* `p256`
* `p384`
* `p521`
* `curve25519`
* `ed25519`
NOTE: That `curve25519` could not be used for ECDSA, use `ed25519` instead.
### Implementation details
ECDSA is using deterministic `k` value generation as per [RFC6979][0]. Most of
the curve operations are performed on non-affine coordinates (either projective
or extended), various windowing techniques are used for different cases.
All operations are performed in reduction context using [bn.js][1], hashing is
provided by [hash.js][2]
### Related projects
* [eccrypto][3]: isomorphic implementation of ECDSA, ECDH and ECIES for both
browserify and node (uses `elliptic` for browser and [secp256k1-node][4] for
node)
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2014.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: http://tools.ietf.org/html/rfc6979
[1]: https://github.com/indutny/bn.js
[2]: https://github.com/indutny/hash.js
[3]: https://github.com/bitchan/eccrypto
[4]: https://github.com/wanderer/secp256k1-node
# Merge Descriptors
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Merge objects using descriptors.
```js
var thing = {
get name() {
return 'jon'
}
}
var animal = {
}
merge(animal, thing)
animal.name === 'jon'
```
## API
### merge(destination, source)
Redefines `destination`'s descriptors with `source`'s.
### merge(destination, source, false)
Defines `source`'s descriptors on `destination` if `destination` does not have
a descriptor by the same name.
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/merge-descriptors.svg
[npm-url]: https://npmjs.org/package/merge-descriptors
[travis-image]: https://img.shields.io/travis/component/merge-descriptors/master.svg
[travis-url]: https://travis-ci.org/component/merge-descriptors
[coveralls-image]: https://img.shields.io/coveralls/component/merge-descriptors/master.svg
[coveralls-url]: https://coveralls.io/r/component/merge-descriptors?branch=master
[downloads-image]: https://img.shields.io/npm/dm/merge-descriptors.svg
[downloads-url]: https://npmjs.org/package/merge-descriptors
# mime
Comprehensive MIME type mapping API based on mime-db module.
## Install
Install with [npm](http://github.com/isaacs/npm):
npm install mime
## Contributing / Testing
npm run test
## Command Line
mime [path_string]
E.g.
> mime scripts/jquery.js
application/javascript
## API - Queries
### mime.lookup(path)
Get the mime type associated with a file, if no mime type is found `application/octet-stream` is returned. Performs a case-insensitive lookup using the extension in `path` (the substring after the last '/' or '.'). E.g.
```js
var mime = require('mime');
mime.lookup('/path/to/file.txt'); // => 'text/plain'
mime.lookup('file.txt'); // => 'text/plain'
mime.lookup('.TXT'); // => 'text/plain'
mime.lookup('htm'); // => 'text/html'
```
### mime.default_type
Sets the mime type returned when `mime.lookup` fails to find the extension searched for. (Default is `application/octet-stream`.)
### mime.extension(type)
Get the default extension for `type`
```js
mime.extension('text/html'); // => 'html'
mime.extension('application/octet-stream'); // => 'bin'
```
### mime.charsets.lookup()
Map mime-type to charset
```js
mime.charsets.lookup('text/plain'); // => 'UTF-8'
```
(The logic for charset lookups is pretty rudimentary. Feel free to suggest improvements.)
## API - Defining Custom Types
Custom type mappings can be added on a per-project basis via the following APIs.
### mime.define()
Add custom mime/extension mappings
```js
mime.define({
'text/x-some-format': ['x-sf', 'x-sft', 'x-sfml'],
'application/x-my-type': ['x-mt', 'x-mtt'],
// etc ...
});
mime.lookup('x-sft'); // => 'text/x-some-format'
```
The first entry in the extensions array is returned by `mime.extension()`. E.g.
```js
mime.extension('text/x-some-format'); // => 'x-sf'
```
### mime.load(filepath)
Load mappings from an Apache ".types" format file
```js
mime.load('./my_project.types');
```
The .types file format is simple - See the `types` dir for examples.
# min-document
[![build status][1]][2] [![dependency status][3]][4]
<!-- [![browser support][5]][6] -->
A minimal DOM implementation
## Example
```js
var document = require("min-document")
var div = document.createElement("div")
div.className = "foo bar"
var span = document.createElement("span")
div.appendChild(span)
span.textContent = "Hello!"
/* <div class="foo bar">
<span>Hello!</span>
</div>
*/
var html = String(div)
```
## Installation
`npm install min-document`
## Contributors
- Raynos
## MIT Licenced
[1]: https://secure.travis-ci.org/Raynos/min-document.png
[2]: https://travis-ci.org/Raynos/min-document
[3]: https://david-dm.org/Raynos/min-document.png
[4]: https://david-dm.org/Raynos/min-document
[5]: https://ci.testling.com/Raynos/min-document.png
[6]: https://ci.testling.com/Raynos/min-document
## Add dynamic instrumentation to emitters
`shimmer` does a bunch of the work necessary to wrap other methods in
a wrapper you provide:
```javascript
var EventEmitter = require('events').EventEmitter;
var wrapEmitter = require('emitter-listener');
var ee = new EventEmitter();
var id = 0;
wrapEmitter(
ee,
function mark(listener) {
listener.id = id++;
},
function prepare(listener) {
console.log('listener id is %d', listener.id);
}
);
```
### Mandatory disclaimer
There are times when it's necessary to monkeypatch default behavior in
JavaScript and Node. However, changing the behavior of the runtime on the fly
is rarely a good idea, and you should be using this module because you need to,
not because it seems like fun.
#### wrapEmitter(emitter, mark, prepare)
Wrap an EventEmitter's event listeners. Each listener will be passed to
`mark` when it is registered with `.addListener()` or `.on()`, and then
each listener is passed to `prepare` to be wrapped before it's called
by the `.emit()` call. `wrapListener` deals with the single listener
vs array of listeners logic, and also ensures that edge cases like
`.removeListener()` being called from within an `.emit()` for the same
event type is handled properly.
The wrapped EE can be restored to its pristine state by using
emitter.__unwrap(), but this should only be used if you *really* know
what you're doing.
data-uri-to-buffer
==================
### Generate a Buffer instance from a [Data URI][rfc] string
[](https://travis-ci.org/TooTallNate/node-data-uri-to-buffer)
This module accepts a ["data" URI][rfc] String of data, and returns a
node.js `Buffer` instance with the decoded data.
Installation
------------
Install with `npm`:
``` bash
$ npm install data-uri-to-buffer
```
Example
-------
``` js
var dataUriToBuffer = require('data-uri-to-buffer');
// plain-text data is supported
var uri = 'data:,Hello%2C%20World!';
var decoded = dataUriToBuffer(uri);
console.log(decoded.toString());
// 'Hello, World!'
// base64-encoded data is supported
uri = 'data:text/plain;base64,SGVsbG8sIFdvcmxkIQ%3D%3D';
decoded = dataUriToBuffer(uri);
console.log(decoded.toString());
// 'Hello, World!'
```
API
---
### dataUriToBuffer(String uri) → Buffer
The `type` property on the Buffer instance gets set to the Content-Type portion of
the "mediatype" portion of the "data" URI, or defaults to `"text/plain"` if not
specified.
The `charset` property on the Buffer instance gets set to the Charset portion of
the "mediatype" portion of the "data" URI, or defaults to `"US-ASCII"` if not
specified.
License
-------
(The MIT License)
Copyright (c) 2014 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[rfc]: http://tools.ietf.org/html/rfc2397
# fs-minipass
Filesystem streams based on [minipass](http://npm.im/minipass).
4 classes are exported:
- ReadStream
- ReadStreamSync
- WriteStream
- WriteStreamSync
When using `ReadStreamSync`, all of the data is made available
immediately upon consuming the stream. Nothing is buffered in memory
when the stream is constructed. If the stream is piped to a writer,
then it will synchronously `read()` and emit data into the writer as
fast as the writer can consume it. (That is, it will respect
backpressure.) If you call `stream.read()` then it will read the
entire file and return the contents.
When using `WriteStreamSync`, every write is flushed to the file
synchronously. If your writes all come in a single tick, then it'll
write it all out in a single tick. It's as synchronous as you are.
The async versions work much like their node builtin counterparts,
with the exception of introducing significantly less Stream machinery
overhead.
## USAGE
It's just streams, you pipe them or read() them or write() to them.
```js
const fsm = require('fs-minipass')
const readStream = new fsm.ReadStream('file.txt')
const writeStream = new fsm.WriteStream('output.txt')
writeStream.write('some file header or whatever\n')
readStream.pipe(writeStream)
```
## ReadStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `readSize` The size of reads to do, defaults to 16MB
- `size` The size of the file, if known. Prevents zero-byte read()
call at the end.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the file is done being read.
## WriteStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `mode` The mode to create the file with. Defaults to `0o666`.
- `start` The position in the file to start reading. If not
specified, then the file will start writing at position zero, and be
truncated by default.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the stream is ended.
- `flags` Flags to use when opening the file. Irrelevant if `fd` is
passed in, since file won't be opened in that case. Defaults to
`'a'` if a `pos` is specified, or `'w'` otherwise.
# http-https
A wrapper that chooses http or https for requests
## USAGE
```javascript
var hh = require('http-https')
var req = hh.request('http://example.com/bar')
var secureReq = hh.request('https://secure.example.com/foo')
// or with a parsed object...
var opt = url.parse(someUrlMaybeHttpMaybeHttps)
opt.headers = {
'user-agent': 'flergy mc flerg'
}
opt.method = 'HEAD'
var req = hh.request(opt, function (res) {
console.log('got response!', res.statusCode, res.headers)
})
req.end()
```
# is-extglob [](http://badge.fury.io/js/is-extglob) [](https://travis-ci.org/jonschlinkert/is-extglob)
> Returns true if a string has an extglob.
## Install with [npm](npmjs.org)
```bash
npm i is-extglob --save
```
## Usage
```js
var isExtglob = require('is-extglob');
```
**True**
```js
isExtglob('?(abc)');
isExtglob('@(abc)');
isExtglob('!(abc)');
isExtglob('*(abc)');
isExtglob('+(abc)');
```
**False**
Everything else...
```js
isExtglob('foo.js');
isExtglob('!foo.js');
isExtglob('*.js');
isExtglob('**/abc.js');
isExtglob('abc/*.js');
isExtglob('abc/(aaa|bbb).js');
isExtglob('abc/[a-z].js');
isExtglob('abc/{a,b}.js');
isExtglob('abc/?.js');
isExtglob('abc.js');
isExtglob('abc/def/ghi.js');
```
## Related
* [extglob](https://github.com/jonschlinkert/extglob): Extended globs. extglobs add the expressive power of regular expressions to glob patterns.
* [micromatch](https://github.com/jonschlinkert/micromatch): Glob matching for javascript/node.js. A faster alternative to minimatch (10-45x faster on avg), with all the features you're used to using in your Grunt and gulp tasks.
* [parse-glob](https://github.com/jonschlinkert/parse-glob): Parse a glob pattern into an object of tokens.
## Run tests
Install dev dependencies.
```bash
npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-extglob/issues)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright (c) 2015 Jon Schlinkert
Released under the MIT license
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on March 06, 2015._
# Statuses
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
HTTP status utility for node.
This module provides a list of status codes and messages sourced from
a few different projects:
* The [IANA Status Code Registry](https://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml)
* The [Node.js project](https://nodejs.org/)
* The [NGINX project](https://www.nginx.com/)
* The [Apache HTTP Server project](https://httpd.apache.org/)
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install statuses
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var status = require('statuses')
```
### var code = status(Integer || String)
If `Integer` or `String` is a valid HTTP code or status message, then the
appropriate `code` will be returned. Otherwise, an error will be thrown.
<!-- eslint-disable no-undef -->
```js
status(403) // => 403
status('403') // => 403
status('forbidden') // => 403
status('Forbidden') // => 403
status(306) // throws, as it's not supported by node.js
```
### status.STATUS_CODES
Returns an object which maps status codes to status messages, in
the same format as the
[Node.js http module](https://nodejs.org/dist/latest/docs/api/http.html#http_http_status_codes).
### status.codes
Returns an array of all the status codes as `Integer`s.
### var msg = status[code]
Map of `code` to `status message`. `undefined` for invalid `code`s.
<!-- eslint-disable no-undef, no-unused-expressions -->
```js
status[404] // => 'Not Found'
```
### var code = status[msg]
Map of `status message` to `code`. `msg` can either be title-cased or
lower-cased. `undefined` for invalid `status message`s.
<!-- eslint-disable no-undef, no-unused-expressions -->
```js
status['not found'] // => 404
status['Not Found'] // => 404
```
### status.redirect[code]
Returns `true` if a status code is a valid redirect status.
<!-- eslint-disable no-undef, no-unused-expressions -->
```js
status.redirect[200] // => undefined
status.redirect[301] // => true
```
### status.empty[code]
Returns `true` if a status code expects an empty body.
<!-- eslint-disable no-undef, no-unused-expressions -->
```js
status.empty[200] // => undefined
status.empty[204] // => true
status.empty[304] // => true
```
### status.retry[code]
Returns `true` if you should retry the rest.
<!-- eslint-disable no-undef, no-unused-expressions -->
```js
status.retry[501] // => undefined
status.retry[503] // => true
```
[npm-image]: https://img.shields.io/npm/v/statuses.svg
[npm-url]: https://npmjs.org/package/statuses
[node-version-image]: https://img.shields.io/node/v/statuses.svg
[node-version-url]: https://nodejs.org/en/download
[travis-image]: https://img.shields.io/travis/jshttp/statuses.svg
[travis-url]: https://travis-ci.org/jshttp/statuses
[coveralls-image]: https://img.shields.io/coveralls/jshttp/statuses.svg
[coveralls-url]: https://coveralls.io/r/jshttp/statuses?branch=master
[downloads-image]: https://img.shields.io/npm/dm/statuses.svg
[downloads-url]: https://npmjs.org/package/statuses
# range-parser
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Node.js Version][node-image]][node-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Range header field parser.
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install range-parser
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var parseRange = require('range-parser')
```
### parseRange(size, header, options)
Parse the given `header` string where `size` is the maximum size of the resource.
An array of ranges will be returned or negative numbers indicating an error parsing.
* `-2` signals a malformed header string
* `-1` signals an unsatisfiable range
<!-- eslint-disable no-undef -->
```js
// parse header from request
var range = parseRange(size, req.headers.range)
// the type of the range
if (range.type === 'bytes') {
// the ranges
range.forEach(function (r) {
// do something with r.start and r.end
})
}
```
#### Options
These properties are accepted in the options object.
##### combine
Specifies if overlapping & adjacent ranges should be combined, defaults to `false`.
When `true`, ranges will be combined and returned as if they were specified that
way in the header.
<!-- eslint-disable no-undef -->
```js
parseRange(100, 'bytes=50-55,0-10,5-10,56-60', { combine: true })
// => [
// { start: 0, end: 10 },
// { start: 50, end: 60 }
// ]
```
## License
[MIT](LICENSE)
[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/range-parser/master
[coveralls-url]: https://coveralls.io/r/jshttp/range-parser?branch=master
[node-image]: https://badgen.net/npm/node/range-parser
[node-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/range-parser
[npm-url]: https://npmjs.org/package/range-parser
[npm-version-image]: https://badgen.net/npm/v/range-parser
[travis-image]: https://badgen.net/travis/jshttp/range-parser/master
[travis-url]: https://travis-ci.org/jshttp/range-parser
# Migration Script
The migration tool is designed to reduce repetitive work in the migration process. However, the script is not aiming to convert every thing for you. There are usually some small fixes and major reconstruction required.
### How To Use
To run the conversion script, first make sure you have the latest `node-addon-api` in your `node_modules` directory.
```
npm install node-addon-api
```
Then run the script passing your project directory
```
node ./node_modules/node-addon-api/tools/conversion.js ./
```
After finish, recompile and debug things that are missed by the script.
### Quick Fixes
Here is the list of things that can be fixed easily.
1. Change your methods' return value to void if it doesn't return value to JavaScript.
2. Use `.` to access attribute or to invoke member function in Napi::Object instead of `->`.
3. `Napi::New(env, value);` to `Napi::[Type]::New(env, value);
### Major Reconstructions
The implementation of `Napi::ObjectWrap` is significantly different from NAN's. `Napi::ObjectWrap` takes a pointer to the wrapped object and creates a reference to the wrapped object inside ObjectWrap constructor. `Napi::ObjectWrap` also associates wrapped object's instance methods to Javascript module instead of static methods like NAN.
So if you use Nan::ObjectWrap in your module, you will need to execute the following steps.
1. Convert your [ClassName]::New function to a constructor function that takes a `Napi::CallbackInfo`. Declare it as
```
[ClassName](const Napi::CallbackInfo& info);
```
and define it as
```
[ClassName]::[ClassName](const Napi::CallbackInfo& info) : Napi::ObjectWrap<[ClassName]>(info){
...
}
```
This way, the `Napi::ObjectWrap` constructor will be invoked after the object has been instantiated and `Napi::ObjectWrap` can use the `this` pointer to create a reference to the wrapped object.
2. Move your original constructor code into the new constructor. Delete your original constructor.
3. In your class initialization function, associate native methods in the following way. The `&` character before methods is required because they are not static methods but instance methods.
```
Napi::FunctionReference constructor;
void [ClassName]::Init(Napi::Env env, Napi::Object exports, Napi::Object module) {
Napi::HandleScope scope(env);
Napi::Function ctor = DefineClass(env, "Canvas", {
InstanceMethod("Func1", &[ClassName]::Func1),
InstanceMethod("Func2", &[ClassName]::Func2),
InstanceAccessor("Value", &[ClassName]::ValueGetter),
StaticMethod("MethodName", &[ClassName]::StaticMethod),
InstanceValue("Value", Napi::[Type]::New(env, value)),
});
constructor = Napi::Persistent(ctor);
constructor .SuppressDestruct();
exports.Set("[ClassName]", ctor);
}
```
4. In function where you need to Unwrap the ObjectWrap in NAN like `[ClassName]* native = Nan::ObjectWrap::Unwrap<[ClassName]>(info.This());`, use `this` pointer directly as the unwrapped object as each ObjectWrap instance is associated with a unique object instance.
If you still find issues after following this guide, please leave us an issue describing your problem and we will try to resolve it.
semaphore.js
============
[](https://travis-ci.org/abrkn/semaphore.js)
Install:
npm install semaphore
Limit simultaneous access to a resource.
```javascript
// Create
var sem = require('semaphore')(capacity);
// Take
sem.take(fn[, n=1])
sem.take(n, fn)
// Leave
sem.leave([n])
// Available
sem.available([n])
```
```javascript
// Limit concurrent db access
var sem = require('semaphore')(1);
var server = require('http').createServer(req, res) {
sem.take(function() {
expensive_database_operation(function(err, res) {
sem.leave();
if (err) return res.end("Error");
return res.end(res);
});
});
});
```
```javascript
// 2 clients at a time
var sem = require('semaphore')(2);
var server = require('http').createServer(req, res) {
res.write("Then good day, madam!");
sem.take(function() {
res.end("We hope to see you soon for tea.");
sem.leave();
});
});
```
```javascript
// Rate limit
var sem = require('semaphore')(10);
var server = require('http').createServer(req, res) {
sem.take(function() {
res.end(".");
setTimeout(sem.leave, 500)
});
});
```
License
===
MIT
# level-ws
> A basic WriteStream implementation for [levelup](https://github.com/level/levelup)
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/level-ws)

[](http://travis-ci.org/Level/level-ws)
[](https://david-dm.org/level/level-ws)
[](https://www.npmjs.com/package/level-ws)
[](https://coveralls.io/github/Level/level-ws)
[](https://standardjs.com)
`level-ws` provides the most basic general-case WriteStream for `levelup`. It was extracted from the core `levelup` at version 0.18.0.
`level-ws` is not a high-performance WriteStream. If your benchmarking shows that your particular usage pattern and data types do not perform well with this WriteStream then you should try one of the alternative WriteStreams available for `levelup` that are optimised for different use-cases.
**If you are upgrading:** please see [`UPGRADING.md`](UPGRADING.md).
## Usage
```js
var level = require('level')
var WriteStream = require('level-ws')
var db = level('/path/to/db')
var ws = WriteStream(db) // ...
```
## API
### `ws = WriteStream(db[, options])`
Creates a [Writable](https://nodejs.org/dist/latest-v8.x/docs/api/stream.html#stream_class_stream_writable) stream which operates in **objectMode**, accepting objects with `'key'` and `'value'` pairs on its `write()` method.
The optional `options` argument may contain:
* `type` *(string, default: `'put'`)*: Default batch operation for missing `type` property during `ws.write()`.
The WriteStream will buffer writes and submit them as a `batch()` operations where writes occur *within the same tick*.
```js
var ws = WriteStream(db)
ws.on('error', function (err) {
console.log('Oh my!', err)
})
ws.on('close', function () {
console.log('Stream closed')
})
ws.write({ key: 'name', value: 'Yuri Irsenovich Kim' })
ws.write({ key: 'dob', value: '16 February 1941' })
ws.write({ key: 'spouse', value: 'Kim Young-sook' })
ws.write({ key: 'occupation', value: 'Clown' })
ws.end()
```
The standard `write()`, `end()` and `destroy()` methods are implemented on the WriteStream. `'drain'`, `'error'`, `'close'` and `'pipe'` events are emitted.
You can specify encodings for individual entries by setting `.keyEncoding` and/or `.valueEncoding`:
```js
writeStream.write({
key: new Buffer([1, 2, 3]),
value: { some: 'json' },
keyEncoding: 'binary',
valueEncoding : 'json'
})
```
If individual `write()` operations are performed with a `'type'` property of `'del'`, they will be passed on as `'del'` operations to the batch.
```js
var ws = WriteStream(db)
ws.on('error', function (err) {
console.log('Oh my!', err)
})
ws.on('close', function () {
console.log('Stream closed')
})
ws.write({ type: 'del', key: 'name' })
ws.write({ type: 'del', key: 'dob' })
ws.write({ type: 'put', key: 'spouse' })
ws.write({ type: 'del', key: 'occupation' })
ws.end()
```
If the *WriteStream* is created with a `'type'` option of `'del'`, all `write()` operations will be interpreted as `'del'`, unless explicitly specified as `'put'`.
```js
var ws = WriteStream(db, { type: 'del' })
ws.on('error', function (err) {
console.log('Oh my!', err)
})
ws.on('close', function () {
console.log('Stream closed')
})
ws.write({ key: 'name' })
ws.write({ key: 'dob' })
// but it can be overridden
ws.write({ type: 'put', key: 'spouse', value: 'Ri Sol-ju' })
ws.write({ key: 'occupation' })
ws.end()
```
## License
[MIT](./LICENSE.md) © 2012-present `level-ws` [Contributors](./CONTRIBUTORS.md).
[level-badge]: http://leveldb.org/img/badge.svg
# bsert
Minimal assert with type checking.
## Usage
``` js
const assert = require('bsert');
```
## Contribution and License Agreement
If you contribute code to this project, you are implicitly allowing your code
to be distributed under the MIT license. You are also implicitly verifying that
all code is your original work. `</legalese>`
## License
- Copyright (c) 2018, Christopher Jeffrey (MIT License).
See LICENSE for more info.
# Basic HTTP Server and Cluster mode
In this boilerplate it will start an http server in cluster mode.
You can check the content of the ecosystem.config.js on how to start mutliple instances of the same HTTP application in order to get the most from your working system.
## Via CLI
Via CLI you can start any HTTP/TCP application in cluster mode with:
```bash
$ pm2 start api.js -i max
```
# ripemd160
[](https://www.npmjs.org/package/ripemd160)
[](https://travis-ci.org/crypto-browserify/ripemd160)
[](https://david-dm.org/crypto-browserify/ripemd160#info=dependencies)
[](https://github.com/feross/standard)
Node style `ripemd160` on pure JavaScript.
## Example
```js
var RIPEMD160 = require('ripemd160')
console.log(new RIPEMD160().update('42').digest('hex'))
// => 0df020ba32aa9b8b904471ff582ce6b579bf8bc8
var ripemd160stream = new RIPEMD160()
ripemd160stream.end('42')
console.log(ripemd160stream.read().toString('hex'))
// => 0df020ba32aa9b8b904471ff582ce6b579bf8bc8
```
## LICENSE
MIT
# send
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Linux Build][travis-image]][travis-url]
[![Windows Build][appveyor-image]][appveyor-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Send is a library for streaming files from the file system as a http response
supporting partial responses (Ranges), conditional-GET negotiation (If-Match,
If-Unmodified-Since, If-None-Match, If-Modified-Since), high test coverage,
and granular events which may be leveraged to take appropriate actions in your
application or framework.
Looking to serve up entire folders mapped to URLs? Try [serve-static](https://www.npmjs.org/package/serve-static).
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```bash
$ npm install send
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var send = require('send')
```
### send(req, path, [options])
Create a new `SendStream` for the given path to send to a `res`. The `req` is
the Node.js HTTP request and the `path` is a urlencoded path to send (urlencoded,
not the actual file-system path).
#### Options
##### acceptRanges
Enable or disable accepting ranged requests, defaults to true.
Disabling this will not send `Accept-Ranges` and ignore the contents
of the `Range` request header.
##### cacheControl
Enable or disable setting `Cache-Control` response header, defaults to
true. Disabling this will ignore the `immutable` and `maxAge` options.
##### dotfiles
Set how "dotfiles" are treated when encountered. A dotfile is a file
or directory that begins with a dot ("."). Note this check is done on
the path itself without checking if the path actually exists on the
disk. If `root` is specified, only the dotfiles above the root are
checked (i.e. the root itself can be within a dotfile when when set
to "deny").
- `'allow'` No special treatment for dotfiles.
- `'deny'` Send a 403 for any request for a dotfile.
- `'ignore'` Pretend like the dotfile does not exist and 404.
The default value is _similar_ to `'ignore'`, with the exception that
this default will not ignore the files within a directory that begins
with a dot, for backward-compatibility.
##### end
Byte offset at which the stream ends, defaults to the length of the file
minus 1. The end is inclusive in the stream, meaning `end: 3` will include
the 4th byte in the stream.
##### etag
Enable or disable etag generation, defaults to true.
##### extensions
If a given file doesn't exist, try appending one of the given extensions,
in the given order. By default, this is disabled (set to `false`). An
example value that will serve extension-less HTML files: `['html', 'htm']`.
This is skipped if the requested file already has an extension.
##### immutable
Enable or diable the `immutable` directive in the `Cache-Control` response
header, defaults to `false`. If set to `true`, the `maxAge` option should
also be specified to enable caching. The `immutable` directive will prevent
supported clients from making conditional requests during the life of the
`maxAge` option to check if the file has changed.
##### index
By default send supports "index.html" files, to disable this
set `false` or to supply a new index pass a string or an array
in preferred order.
##### lastModified
Enable or disable `Last-Modified` header, defaults to true. Uses the file
system's last modified value.
##### maxAge
Provide a max-age in milliseconds for http caching, defaults to 0.
This can also be a string accepted by the
[ms](https://www.npmjs.org/package/ms#readme) module.
##### root
Serve files relative to `path`.
##### start
Byte offset at which the stream starts, defaults to 0. The start is inclusive,
meaning `start: 2` will include the 3rd byte in the stream.
#### Events
The `SendStream` is an event emitter and will emit the following events:
- `error` an error occurred `(err)`
- `directory` a directory was requested `(res, path)`
- `file` a file was requested `(path, stat)`
- `headers` the headers are about to be set on a file `(res, path, stat)`
- `stream` file streaming has started `(stream)`
- `end` streaming has completed
#### .pipe
The `pipe` method is used to pipe the response into the Node.js HTTP response
object, typically `send(req, path, options).pipe(res)`.
### .mime
The `mime` export is the global instance of of the
[`mime` npm module](https://www.npmjs.com/package/mime).
This is used to configure the MIME types that are associated with file extensions
as well as other options for how to resolve the MIME type of a file (like the
default type to use for an unknown file extension).
## Error-handling
By default when no `error` listeners are present an automatic response will be
made, otherwise you have full control over the response, aka you may show a 5xx
page etc.
## Caching
It does _not_ perform internal caching, you should use a reverse proxy cache
such as Varnish for this, or those fancy things called CDNs. If your
application is small enough that it would benefit from single-node memory
caching, it's small enough that it does not need caching at all ;).
## Debugging
To enable `debug()` instrumentation output export __DEBUG__:
```
$ DEBUG=send node app
```
## Running tests
```
$ npm install
$ npm test
```
## Examples
### Serve a specific file
This simple example will send a specific file to all requests.
```js
var http = require('http')
var send = require('send')
var server = http.createServer(function onRequest (req, res) {
send(req, '/path/to/index.html')
.pipe(res)
})
server.listen(3000)
```
### Serve all files from a directory
This simple example will just serve up all the files in a
given directory as the top-level. For example, a request
`GET /foo.txt` will send back `/www/public/foo.txt`.
```js
var http = require('http')
var parseUrl = require('parseurl')
var send = require('send')
var server = http.createServer(function onRequest (req, res) {
send(req, parseUrl(req).pathname, { root: '/www/public' })
.pipe(res)
})
server.listen(3000)
```
### Custom file types
```js
var http = require('http')
var parseUrl = require('parseurl')
var send = require('send')
// Default unknown types to text/plain
send.mime.default_type = 'text/plain'
// Add a custom type
send.mime.define({
'application/x-my-type': ['x-mt', 'x-mtt']
})
var server = http.createServer(function onRequest (req, res) {
send(req, parseUrl(req).pathname, { root: '/www/public' })
.pipe(res)
})
server.listen(3000)
```
### Custom directory index view
This is a example of serving up a structure of directories with a
custom function to render a listing of a directory.
```js
var http = require('http')
var fs = require('fs')
var parseUrl = require('parseurl')
var send = require('send')
// Transfer arbitrary files from within /www/example.com/public/*
// with a custom handler for directory listing
var server = http.createServer(function onRequest (req, res) {
send(req, parseUrl(req).pathname, { index: false, root: '/www/public' })
.once('directory', directory)
.pipe(res)
})
server.listen(3000)
// Custom directory handler
function directory (res, path) {
var stream = this
// redirect to trailing slash for consistent url
if (!stream.hasTrailingSlash()) {
return stream.redirect(path)
}
// get directory list
fs.readdir(path, function onReaddir (err, list) {
if (err) return stream.error(err)
// render an index for the directory
res.setHeader('Content-Type', 'text/plain; charset=UTF-8')
res.end(list.join('\n') + '\n')
})
}
```
### Serving from a root directory with custom error-handling
```js
var http = require('http')
var parseUrl = require('parseurl')
var send = require('send')
var server = http.createServer(function onRequest (req, res) {
// your custom error-handling logic:
function error (err) {
res.statusCode = err.status || 500
res.end(err.message)
}
// your custom headers
function headers (res, path, stat) {
// serve all files for download
res.setHeader('Content-Disposition', 'attachment')
}
// your custom directory handling logic:
function redirect () {
res.statusCode = 301
res.setHeader('Location', req.url + '/')
res.end('Redirecting to ' + req.url + '/')
}
// transfer arbitrary files from within
// /www/example.com/public/*
send(req, parseUrl(req).pathname, { root: '/www/public' })
.on('error', error)
.on('directory', redirect)
.on('headers', headers)
.pipe(res)
})
server.listen(3000)
```
## License
[MIT](LICENSE)
[appveyor-image]: https://badgen.net/appveyor/ci/dougwilson/send/master?label=windows
[appveyor-url]: https://ci.appveyor.com/project/dougwilson/send
[coveralls-image]: https://badgen.net/coveralls/c/github/pillarjs/send/master
[coveralls-url]: https://coveralls.io/r/pillarjs/send?branch=master
[node-image]: https://badgen.net/npm/node/send
[node-url]: https://nodejs.org/en/download/
[npm-downloads-image]: https://badgen.net/npm/dm/send
[npm-url]: https://npmjs.org/package/send
[npm-version-image]: https://badgen.net/npm/v/send
[travis-image]: https://badgen.net/travis/pillarjs/send/master?label=linux
[travis-url]: https://travis-ci.org/pillarjs/send
BLAKE.js
====
[](https://travis-ci.org/dcposch/blakejs)
[](https://badge.fury.io/js/blakejs)
**blake.js is a pure Javascript implementation of the BLAKE2b and BLAKE2s hash functions.**

---
[RFC 7693: The BLAKE Cryptographic Hash and MAC](https://tools.ietf.org/html/rfc7693)
BLAKE is the default family of hash functions in the venerable NaCl crypto library. Like SHA2 and SHA3 but unlike MD5 and SHA1, BLAKE offers solid security. With an optimized assembly implementation, BLAKE can be faster than all of those other hash functions.
Of course, this implementation is in Javascript, so it won't be winning any speed records. More under Performance below. It's short and sweet, less than 500 LOC.
**As far as I know, this is the only package available today to compute BLAKE in a browser.**
Quick Start
---
```js
var blake = require('blakejs')
console.log(blake.blake2bHex('abc'))
// prints ba80a53f981c4d0d6a2797b69f12f6e94c212f14685ac4b74b12bb6fdbffa2d17d87c5392aab792dc252d5de4533cc9518d38aa8dbf1925ab92386edd4009923
console.log(blake.blake2sHex('abc'))
// prints 508c5e8c327c14e2e1a72ba34eeb452f37458b209ed63a294d999b4c86675982
```
API
---
### 1. Use `blake2b` to compute a BLAKE2b hash
Pass it a string, `Buffer`, or `Uint8Array` containing bytes to hash, and it will return a `Uint8Array` containing the hash.
```js
// Computes the BLAKE2B hash of a string or byte array, and returns a Uint8Array
//
// Returns a n-byte Uint8Array
//
// Parameters:
// - input - the input bytes, as a string, Buffer, or Uint8Array
// Strings are converted to UTF8 bytes
// - key - optional key Uint8Array, up to 64 bytes
// - outlen - optional output length in bytes, default 64
function blake2b(input, key, outlen) {
[...]
}
```
For convenience, `blake2bHex` takes the same arguments and works the same way, but returns a hex string.
### 2. Use `blake2b[Init,Update,Final]` to compute a streaming hash
```js
var KEY = null // optional key
var OUTPUT_LENGTH = 64 // bytes
var context = blake2bInit(OUTPUT_LENGTH, KEY)
...
// each time you get a byte array from the stream:
blake2bUpdate(context, bytes)
...
// finally, once the stream has been exhausted
var hash = blake2bFinal(context)
// returns a 64-byte hash, as a Uint8Array
```
### 3. All `blake2b*` functions have `blake2s*` equivalents
BLAKE2b: `blake2b`, `blake2bHex`, `blake2bInit`, `blake2bUpdate`, and `blake2bFinal`
BLAKE2s: `blake2s`, `blake2sHex`, `blake2sInit`, `blake2sUpdate`, and `blake2sFinal`
The inputs are identical except that maximum key size and maximum output size are 32 bytes instead of 64.
Limitations
---
* Can only handle up to 2**53 bytes of input
If your webapp is hashing more than 8 petabytes, you may have other problems :)
Testing
---
* Examples from the RFC
* BLAKE2s self-test from the RFC
* Examples from http://pythonhosted.org/pyblake2/examples.html
* A longer set of test vectors generated by https://github.com/jedisct1/crypto-test-vectors/tree/master/crypto/hash/blake2/blake2b/nosalt-nopersonalization/generators/libsodium
Performance
---
```
BLAKE2b: 15.2 MB / second on a 2.2GHz i7-4770HQ
BLAKE2s: 20.4 MB / second
¯\_(ツ)_/¯
```
If you're using BLAKE2b in server side node.js code, you probably want the [native wrapper](https://www.npmjs.com/package/blake2) which should be able to do several hundred MB / second on the same processor.
If you're using BLAKE2b in a web app, 15 MB/sec might be fine.
Javascript doesn't have 64-bit integers, and BLAKE2b is a 64-bit integer algorithm. Writing it with`Uint32Array` is not that fast. BLAKE2s is a 32-bit algorithm, so it's a bit faster.
If we want better machine code at the expense of gross-looking Javascript, we could use asm.js
License
---
Creative Commons CC0. Ported from the reference C implementation in
[RFC 7693](https://tools.ietf.org/html/rfc7693).
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# Managing a Python Application
On this boilerlate you will see how you can start a Python application with PM2.
## Eth-Lib
Lightweight Ethereum libraries. This is a temporary repository which will be used as the basis of an implementation on Idris (or similar).
# web3-eth-abi
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This is the abi package used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-abi
```
## Usage
```js
const Web3EthAbi = require('web3-eth-abi');
Web3EthAbi.encodeFunctionSignature('myMethod(uint256,string)');
> '0x24ee0097'
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-eth-abi.svg
[npm-url]: https://npmjs.org/package/web3-eth-abi
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-eth-abi
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-eth-abi
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-eth-abi
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-eth-abi
# No Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a lower cased string with spaces between words.
## Installation
```
npm install no-case --save
```
## Usage
```js
import { noCase } from "no-case";
noCase("string"); //=> "string"
noCase("dot.case"); //=> "dot case"
noCase("PascalCase"); //=> "pascal case"
noCase("version 1.2.10"); //=> "version 1 2 10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/no-case.svg?style=flat
[npm-url]: https://npmjs.org/package/no-case
[downloads-image]: https://img.shields.io/npm/dm/no-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/no-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/no-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=no-case
scrypt
======
The [scrypt](https://en.wikipedia.org/wiki/Scrypt) password-base key derivation function (pkbdf) is an algorithm designed to be brute-force resistant that converts human readable passwords into fixed length arrays of bytes, which can then be used as a key for symetric block ciphers, private keys, et cetera.
### Features:
- **Non-blocking** - Gives other events in the event loop opportunities to run (asynchrorous)
- **Cancellable** - If the key is not longer required, the computation can be cancelled
- **Progress Callback** - Provides the current progress of key derivation as a percentage complete
Tuning
------
The scrypt algorithm is, by design, expensive to execute, which increases the amount of time an attacker requires in order to brute force guess a password, adjustable by several parameters which can be tuned:
- **N** - The general work factor; increasing this increases the difficulty of the overall derivation
- **p** - The memory cost; increasing this increases the memory required during derivation
- **r** - The parallelization factor; increasing the computation required during derivation
Installing
----------
**node.js**
You should likely not use this module for *node.js* as there are many faster [alternatives](https://www.npmjs.com/package/scrypt), but if you so wish to do so:
```
npm install scrypt-js
```
**browser**
```html
<script src="https://raw.githubusercontent.com/ricmoo/scrypt-js/master/scrypt.js" type="text/javascript"></script>
```
API
---
```html
<html>
<body>
<!-- These two libraries are highly recommended for encoding password/salt -->
<script src="libs/buffer.js" type="text/javascript"></script>
<script src="libs/unorm.js" type="text/javascript"></script>
<!-- This shim library greatly improves performance of the scrypt algorithm -->
<script src="libs/setImmediate.js" type="text/javascript"></script>
<script src="index.js" type="text/javascript"></script>
<script type="text/javascript">
// See the section below: "Encoding Notes"
var password = new buffer.SlowBuffer("anyPassword".normalize('NFKC'));
var salt = new buffer.SlowBuffer("someSalt".normalize('NFKC'));
var N = 1024, r = 8, p = 1;
var dkLen = 32;
scrypt(password, salt, N, r, p, dkLen, function(error, progress, key) {
if (error) {
console.log("Error: " + error);
} else if (key) {
console.log("Found: " + key);
} else {
// update UI with progress complete
updateInterface(progress);
}
});
</script>
</body>
</html>
```
Encoding Notes
--------------
```
TL;DR - either only allow ASCII characters in passwords, or use
String.prototype.normalize('NFKC') on any password
```
It is *HIGHLY* recommended that you do **NOT** pass strings into this (or any password-base key derivation function) library without careful consideration; you should convert your strings to a canonical format that you will use consistently across all platforms.
When encoding passowrds with UTF-8, it is important to realize that there may be multiple UTF-8 representations of a given string. Since the key generated by a password-base key derivation function is *dependant on the specific bytes*, this matters a great deal.
**Composed vs. Decomposed**
Certain UTF-8 code points can be combined with other characters to create composed characters. For example, the letter *a with the umlaut diacritic mark* (two dots over it) can be expressed two ways; as its composed form, U+00FC; or its decomposed form, which is the letter "u" followed by U+0308 (which basically means modify the previous character by adding an umlaut to it).
```javascript
// In the following two cases, a "u" with an umlaut would be seen
> '\u00fc'
> 'u\u0308'
// In its composed form, it is 2 bytes long
> new Buffer('u\u0308'.normalize('NFKC'))
<Buffer c3 bc>
> new Buffer('\u00fc')
<Buffer c3 bc>
// Whereas the decomposed form is 3 bytes, the letter u followed by U+0308
> new Buffer('\u00fc'.normalize('NFKD'))
<Buffer 75 cc 88>
> new Buffer('u\u0308')
<Buffer 75 cc 88>
```
**Compatibility equivalence mode**
Certain strings are often displayed the same, even though they may have different semantic means. For example, UTF-8 provides a code point for the roman number for one, which appears as the letter I, in most fonts identically. Compatibility equivalence will fold these two cases into simply the capital letter I.
```
> '\u2160'
'I'
> 'I'
'I'
> '\u2160' === 'I'
false
> '\u2160'.normalize('NFKC') === 'I'
true
```
**Normalizing**
The `normalize()` method of a string can be used to convert a string to a specific form. Without going into too much detail, I generally recommend `NFKC`, however if you wish to dive deeper into this, a nice short summary can be found in Pythons [unicodedata module](https://docs.python.org/2/library/unicodedata.html#unicodedata.normalize)'s documentation.
For browsers without `normalize()` support, the [npm unorm module](https://www.npmjs.com/package/unorm) can be used to polyfill strings.
**Another example of encoding woes**
One quick story I will share is a project which used the `SHA256(encodeURI(password))` as a key, which (ignorig [raindbow table attacks](https://en.wikipedia.org/wiki/Rainbow_table)) had an unfortunate consequence of old web browsers replacing spaces with `+` while on new web browsers, replacing it with a `%20`, causing issues for anyone who used spaces in their password.
### Suggestions
- While it may be inconvenient to many international users, one option is to restrict passwords to a safe subset of ASCII, for example: `/^[A-Za-z0-9!@#$%^&*()]+$/`.
- My personal recommendation is to normalize to the NFKC form, however, one could imagine setting their password to a Chinese phrase on one computer, and then one day using a computer that does not have Chinese input capabilites and therefore be unable to log in.
**See:** [Unicode Equivalence](https://en.wikipedia.org/wiki/Unicode_equivalence)
Tests
-----
The test cases from the [scrypt whitepaper](http://www.tarsnap.com/scrypt/scrypt.pdf) are included in `test/test-vectors.json` and can be run using:
```javascript
npm test
```
Special Thanks
--------------
I would like to thank @dchest for his [scrypt-async](https://github.com/dchest/scrypt-async-js) library and for his assistance providing feedback and optimization suggestions.
License
-------
MIT license.
References
----------
- [scrypt white paper](http://www.tarsnap.com/scrypt/scrypt.pdf)
- [wikipedia](https://en.wikipedia.org/wiki/Scrypt)
- [scrypt-async npm module](https://www.npmjs.com/package/scrypt-async)
- [scryptsy npm module](https://www.npmjs.com/package/scryptsy)
- [Unicode Equivalence](https://en.wikipedia.org/wiki/Unicode_equivalence)
Donations
---------
Obviously, it's all licensed under the MIT license, so use it as you wish; but if you'd like to buy me a coffee, I won't complain. =)
- Bitcoin - `1LsxZkCZpQXyiGsoAnAW9nRRfck3Nvv7QS`
- Dogecoin - `DF1VMTgyPsew619hwq5tT2RP8BNh2ZpzWA`
- Testnet3 - `muf7Vak4ZCVgtYZCnGStDXuoEdmZuo2nhA`
js-multihash
============
[](http://ipn.io)
[](https://github.com/multiformats/multiformats)
[](https://webchat.freenode.net/?channels=%23ipfs)
[](https://coveralls.io/github/multiformats/js-multihash?branch=master)
[](https://travis-ci.org/multiformats/js-multihash)
[](https://david-dm.org/multiformats/js-multihash)
[](https://github.com/feross/standard)
[](https://github.com/RichardLitt/standard-readme)
> multihash implementation in node.js
This is the [multihash](//github.com/multiformats/multihash) implementation in Node.
It is extended by [js-multihashing](https://github.com/multiformats/js-multihashing)
and [js-multihashing-async](https://github.com/multiformats/js-multihashing-async),
so give those a look as well.
## Lead Maintainer
[David Dias](http://github.com/diasdavid/)
## Table of Contents
- [Install](#install)
- [In Node.js through npm](#in-nodejs-through-npm)
- [Browser: Browserify, Webpack, other bundlers](#browser-browserify-webpack-other-bundlers)
- [In the Browser through `<script>` tag](#in-the-browser-through-script-tag)
- [Gotchas](#gotchas)
- [Usage](#usage)
- [API](#api)
- [Contribute](#contribute)
- [License](#license)
## Install
### Using npm
```bash
> npm install --save multihashes # node the name of the module is multihashes
```
Once the install is complete, you can require it as a normal dependency
```js
const multihashes = require('multihashes')
```
You can require it and use with your favourite bundler to bundle this package in a browser compatible code.
### Using a `<script>` tag
Loading this module through a script tag will make the ```Multihashes``` obj available in the global namespace.
```
<script src="https://unpkg.com/multihashes/dist/index.min.js"></script>
<!-- OR -->
<script src="https://unpkg.com/multihashes/dist/index.js"></script>
```
#### Gotchas
You will need to use Node.js `Buffer` API compatible, if you are running inside the browser, you can access it by `multihash.Buffer` or you can install Feross's [Buffer](https://github.com/feross/buffer).
## Usage
```js
> var multihash = require('multihashes')
> var buf = new Buffer('0beec7b5ea3f0fdbc95d0dd47f3c5bc275da8a33', 'hex')
> var encoded = multihash.encode(buf, 'sha1')
> console.log(encoded)
<Buffer 11 14 0b ee c7 b5 ea 3f 0f db c9 5d 0d d4 7f 3c 5b c2 75 da 8a 33>
> multihash.decode(encoded)
{ code: 17,
name: 'sha1',
length: 20,
digest: <Buffer 0b ee c7 b5 ea 3f 0f db c9 5d 0d d4 7f 3c 5b c2 75 da 8a 33> }
```
## API
https://multiformats.github.io/js-multihash/
## Contribute
Contributions welcome. Please check out [the issues](https://github.com/multiformats/js-multihash/issues).
Check out our [contributing document](https://github.com/multiformats/multiformats/blob/master/contributing.md) for more information on how we work, and about contributing in general. Please be aware that all interactions related to multiformats are subject to the IPFS [Code of Conduct](https://github.com/ipfs/community/blob/master/code-of-conduct.md).
Small note: If editing the README, please conform to the [standard-readme](https://github.com/RichardLitt/standard-readme) specification.
## License
[MIT](LICENSE) © 2016 Protocol Labs Inc.
# Methods
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
HTTP verbs that Node.js core's HTTP parser supports.
This module provides an export that is just like `http.METHODS` from Node.js core,
with the following differences:
* All method names are lower-cased.
* Contains a fallback list of methods for Node.js versions that do not have a
`http.METHODS` export (0.10 and lower).
* Provides the fallback list when using tools like `browserify` without pulling
in the `http` shim module.
## Install
```bash
$ npm install methods
```
## API
```js
var methods = require('methods')
```
### methods
This is an array of lower-cased method names that Node.js supports. If Node.js
provides the `http.METHODS` export, then this is the same array lower-cased,
otherwise it is a snapshot of the verbs from Node.js 0.10.
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/methods.svg?style=flat
[npm-url]: https://npmjs.org/package/methods
[node-version-image]: https://img.shields.io/node/v/methods.svg?style=flat
[node-version-url]: https://nodejs.org/en/download/
[travis-image]: https://img.shields.io/travis/jshttp/methods.svg?style=flat
[travis-url]: https://travis-ci.org/jshttp/methods
[coveralls-image]: https://img.shields.io/coveralls/jshttp/methods.svg?style=flat
[coveralls-url]: https://coveralls.io/r/jshttp/methods?branch=master
[downloads-image]: https://img.shields.io/npm/dm/methods.svg?style=flat
[downloads-url]: https://npmjs.org/package/methods
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# levelup
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/levelup)

[](http://travis-ci.org/Level/levelup)
[](https://david-dm.org/level/levelup)
[](https://www.npmjs.com/package/levelup)
[](https://coveralls.io/github/Level/levelup)
[](https://standardjs.com)
## Table of Contents
<details><summary>Click to expand</summary>
- [Introduction](#introduction)
- [Supported Platforms](#supported-platforms)
- [Usage](#usage)
- [API](#api)
- [Promise Support](#promise-support)
- [Events](#events)
- [Extending](#extending)
- [Multi-process Access](#multi-process-access)
- [Support](#support)
- [Contributing](#contributing)
- [Big Thanks](#big-thanks)
- [License](#license)
</details>
## Introduction
**Fast and simple storage. A Node.js wrapper for `abstract-leveldown` compliant stores, which follow the characteristics of [LevelDB](https://github.com/google/leveldb).**
LevelDB is a simple key-value store built by Google. It's used in Google Chrome and many other products. LevelDB supports arbitrary byte arrays as both keys and values, singular _get_, _put_ and _delete_ operations, _batched put and delete_, bi-directional iterators and simple compression using the very fast [Snappy](http://google.github.io/snappy/) algorithm.
LevelDB stores entries sorted lexicographically by keys. This makes the [streaming interface](#createReadStream) of `levelup` - which exposes LevelDB iterators as [Readable Streams](https://nodejs.org/docs/latest/api/stream.html#stream_readable_streams) - a very powerful query mechanism.
The most common store is [`leveldown`](https://github.com/level/leveldown/) which provides a pure C++ binding to LevelDB. [Many alternative stores are available](https://github.com/Level/awesome/#stores) such as [`level.js`](https://github.com/level/level.js) in the browser or [`memdown`](https://github.com/level/memdown) for an in-memory store. They typically support strings and Buffers for both keys and values. For a richer set of data types you can wrap the store with [`encoding-down`](https://github.com/level/encoding-down).
**The [`level`](https://github.com/level/level) package is the recommended way to get started.** It conveniently bundles `levelup`, [`leveldown`](https://github.com/level/leveldown/) and [`encoding-down`](https://github.com/level/encoding-down). Its main export is `levelup` - i.e. you can do `var db = require('level')`.
## Supported Platforms
We aim to support Active LTS and Current Node.js releases as well as browsers. For support of the underlying store, please see the respective documentation.
[](https://saucelabs.com/u/levelup)
## Usage
**If you are upgrading:** please see [`UPGRADING.md`](UPGRADING.md).
First you need to install `levelup`! No stores are included so you must also install `leveldown` (for example).
```sh
$ npm install levelup leveldown
```
All operations are asynchronous. If you do not provide a callback, [a Promise is returned](#promise-support).
```js
var levelup = require('levelup')
var leveldown = require('leveldown')
// 1) Create our store
var db = levelup(leveldown('./mydb'))
// 2) Put a key & value
db.put('name', 'levelup', function (err) {
if (err) return console.log('Ooops!', err) // some kind of I/O error
// 3) Fetch by key
db.get('name', function (err, value) {
if (err) return console.log('Ooops!', err) // likely the key was not found
// Ta da!
console.log('name=' + value)
})
})
```
## API
- [<code><b>levelup()</b></code>](#ctor)
- [<code>db.<b>open()</b></code>](#open)
- [<code>db.<b>close()</b></code>](#close)
- [<code>db.<b>put()</b></code>](#put)
- [<code>db.<b>get()</b></code>](#get)
- [<code>db.<b>del()</b></code>](#del)
- [<code>db.<b>batch()</b></code> _(array form)_](#batch)
- [<code>db.<b>batch()</b></code> _(chained form)_](#batch_chained)
- [<code>db.<b>isOpen()</b></code>](#isOpen)
- [<code>db.<b>isClosed()</b></code>](#isClosed)
- [<code>db.<b>createReadStream()</b></code>](#createReadStream)
- [<code>db.<b>createKeyStream()</b></code>](#createKeyStream)
- [<code>db.<b>createValueStream()</b></code>](#createValueStream)
- [<code>db.<b>iterator()</b></code>](#iterator)
### Special Notes
- <a href="#writeStreams">What happened to <code><b>db.createWriteStream()</b></code></a>
<a name="ctor"></a>
### `levelup(db[, options[, callback]])`
The main entry point for creating a new `levelup` instance.
- `db` must be an [`abstract-leveldown`](https://github.com/level/abstract-leveldown) compliant store.
- `options` is passed on to the underlying store when opened and is specific to the type of store being used
Calling `levelup(db)` will also open the underlying store. This is an asynchronous operation which will trigger your callback if you provide one. The callback should take the form `function (err, db) {}` where `db` is the `levelup` instance. If you don't provide a callback, any read & write operations are simply queued internally until the store is fully opened.
This leads to two alternative ways of managing a `levelup` instance:
```js
levelup(leveldown(location), options, function (err, db) {
if (err) throw err
db.get('foo', function (err, value) {
if (err) return console.log('foo does not exist')
console.log('got foo =', value)
})
})
```
Versus the equivalent:
```js
// Will throw if an error occurs
var db = levelup(leveldown(location), options)
db.get('foo', function (err, value) {
if (err) return console.log('foo does not exist')
console.log('got foo =', value)
})
```
<a name="open"></a>
### `db.open([callback])`
Opens the underlying store. In general you should never need to call this method directly as it's automatically called by <a href="#ctor"><code>levelup()</code></a>.
However, it is possible to _reopen_ the store after it has been closed with <a href="#close"><code>close()</code></a>, although this is not generally advised.
If no callback is passed, a promise is returned.
<a name="close"></a>
### `db.close([callback])`
<code>close()</code> closes the underlying store. The callback will receive any error encountered during closing as the first argument.
You should always clean up your `levelup` instance by calling `close()` when you no longer need it to free up resources. A store cannot be opened by multiple instances of `levelup` simultaneously.
If no callback is passed, a promise is returned.
<a name="put"></a>
### `db.put(key, value[, options][, callback])`
<code>put()</code> is the primary method for inserting data into the store. Both `key` and `value` can be of any type as far as `levelup` is concerned.
`options` is passed on to the underlying store.
If no callback is passed, a promise is returned.
<a name="get"></a>
### `db.get(key[, options][, callback])`
<code>get()</code> is the primary method for fetching data from the store. The `key` can be of any type. If it doesn't exist in the store then the callback or promise will receive an error. A not-found err object will be of type `'NotFoundError'` so you can `err.type == 'NotFoundError'` or you can perform a truthy test on the property `err.notFound`.
```js
db.get('foo', function (err, value) {
if (err) {
if (err.notFound) {
// handle a 'NotFoundError' here
return
}
// I/O or other error, pass it up the callback chain
return callback(err)
}
// .. handle `value` here
})
```
`options` is passed on to the underlying store.
If no callback is passed, a promise is returned.
<a name="del"></a>
### `db.del(key[, options][, callback])`
<code>del()</code> is the primary method for removing data from the store.
```js
db.del('foo', function (err) {
if (err)
// handle I/O or other error
});
```
`options` is passed on to the underlying store.
If no callback is passed, a promise is returned.
<a name="batch"></a>
### `db.batch(array[, options][, callback])` _(array form)_
<code>batch()</code> can be used for very fast bulk-write operations (both _put_ and _delete_). The `array` argument should contain a list of operations to be executed sequentially, although as a whole they are performed as an atomic operation inside the underlying store.
Each operation is contained in an object having the following properties: `type`, `key`, `value`, where the _type_ is either `'put'` or `'del'`. In the case of `'del'` the `value` property is ignored. Any entries with a `key` of `null` or `undefined` will cause an error to be returned on the `callback` and any `type: 'put'` entry with a `value` of `null` or `undefined` will return an error.
```js
var ops = [
{ type: 'del', key: 'father' },
{ type: 'put', key: 'name', value: 'Yuri Irsenovich Kim' },
{ type: 'put', key: 'dob', value: '16 February 1941' },
{ type: 'put', key: 'spouse', value: 'Kim Young-sook' },
{ type: 'put', key: 'occupation', value: 'Clown' }
]
db.batch(ops, function (err) {
if (err) return console.log('Ooops!', err)
console.log('Great success dear leader!')
})
```
`options` is passed on to the underlying store.
If no callback is passed, a promise is returned.
<a name="batch_chained"></a>
### `db.batch()` _(chained form)_
<code>batch()</code>, when called with no arguments will return a `Batch` object which can be used to build, and eventually commit, an atomic batch operation. Depending on how it's used, it is possible to obtain greater performance when using the chained form of `batch()` over the array form.
```js
db.batch()
.del('father')
.put('name', 'Yuri Irsenovich Kim')
.put('dob', '16 February 1941')
.put('spouse', 'Kim Young-sook')
.put('occupation', 'Clown')
.write(function () { console.log('Done!') })
```
<b><code>batch.put(key, value)</code></b>
Queue a _put_ operation on the current batch, not committed until a `write()` is called on the batch.
This method may `throw` a `WriteError` if there is a problem with your put (such as the `value` being `null` or `undefined`).
<b><code>batch.del(key)</code></b>
Queue a _del_ operation on the current batch, not committed until a `write()` is called on the batch.
This method may `throw` a `WriteError` if there is a problem with your delete.
<b><code>batch.clear()</code></b>
Clear all queued operations on the current batch, any previous operations will be discarded.
<b><code>batch.length</code></b>
The number of queued operations on the current batch.
<b><code>batch.write(\[options][, callback])</code></b>
Commit the queued operations for this batch. All operations not _cleared_ will be written to the underlying store atomically, that is, they will either all succeed or fail with no partial commits.
The optional `options` object is passed to the `.write()` operation of the underlying batch object.
If no callback is passed, a promise is returned.
<a name="isOpen"></a>
### `db.isOpen()`
A `levelup` instance can be in one of the following states:
- _"new"_ - newly created, not opened or closed
- _"opening"_ - waiting for the underlying store to be opened
- _"open"_ - successfully opened the store, available for use
- _"closing"_ - waiting for the store to be closed
- _"closed"_ - store has been successfully closed, should not be used
`isOpen()` will return `true` only when the state is "open".
<a name="isClosed"></a>
### `db.isClosed()`
_See <a href="#put"><code>isOpen()</code></a>_
`isClosed()` will return `true` only when the state is "closing" _or_ "closed", it can be useful for determining if read and write operations are permissible.
<a name="createReadStream"></a>
### `db.createReadStream([options])`
Returns a [Readable Stream](https://nodejs.org/docs/latest/api/stream.html#stream_readable_streams) of key-value pairs. A pair is an object with `key` and `value` properties. By default it will stream all entries in the underlying store from start to end. Use the options described below to control the range, direction and results.
```js
db.createReadStream()
.on('data', function (data) {
console.log(data.key, '=', data.value)
})
.on('error', function (err) {
console.log('Oh my!', err)
})
.on('close', function () {
console.log('Stream closed')
})
.on('end', function () {
console.log('Stream ended')
})
```
You can supply an options object as the first parameter to `createReadStream()` with the following properties:
- `gt` (greater than), `gte` (greater than or equal) define the lower bound of the range to be streamed. Only entries where the key is greater than (or equal to) this option will be included in the range. When `reverse=true` the order will be reversed, but the entries streamed will be the same.
- `lt` (less than), `lte` (less than or equal) define the higher bound of the range to be streamed. Only entries where the key is less than (or equal to) this option will be included in the range. When `reverse=true` the order will be reversed, but the entries streamed will be the same.
- `reverse` _(boolean, default: `false`)_: stream entries in reverse order. Beware that due to the way that stores like LevelDB work, a reverse seek can be slower than a forward seek.
- `limit` _(number, default: `-1`)_: limit the number of entries collected by this stream. This number represents a _maximum_ number of entries and may not be reached if you get to the end of the range first. A value of `-1` means there is no limit. When `reverse=true` the entries with the highest keys will be returned instead of the lowest keys.
- `keys` _(boolean, default: `true`)_: whether the results should contain keys. If set to `true` and `values` set to `false` then results will simply be keys, rather than objects with a `key` property. Used internally by the `createKeyStream()` method.
- `values` _(boolean, default: `true`)_: whether the results should contain values. If set to `true` and `keys` set to `false` then results will simply be values, rather than objects with a `value` property. Used internally by the `createValueStream()` method.
Legacy options:
- `start`: instead use `gte`
- `end`: instead use `lte`
<a name="createKeyStream"></a>
### `db.createKeyStream([options])`
Returns a [Readable Stream](https://nodejs.org/docs/latest/api/stream.html#stream_readable_streams) of keys rather than key-value pairs. Use the same options as described for [`createReadStream`](#createReadStream) to control the range and direction.
You can also obtain this stream by passing an options object to `createReadStream()` with `keys` set to `true` and `values` set to `false`. The result is equivalent; both streams operate in [object mode](https://nodejs.org/docs/latest/api/stream.html#stream_object_mode).
```js
db.createKeyStream()
.on('data', function (data) {
console.log('key=', data)
})
// same as:
db.createReadStream({ keys: true, values: false })
.on('data', function (data) {
console.log('key=', data)
})
```
<a name="createValueStream"></a>
### `db.createValueStream([options])`
Returns a [Readable Stream](https://nodejs.org/docs/latest/api/stream.html#stream_readable_streams) of values rather than key-value pairs. Use the same options as described for [`createReadStream`](#createReadStream) to control the range and direction.
You can also obtain this stream by passing an options object to `createReadStream()` with `values` set to `true` and `keys` set to `false`. The result is equivalent; both streams operate in [object mode](https://nodejs.org/docs/latest/api/stream.html#stream_object_mode).
```js
db.createValueStream()
.on('data', function (data) {
console.log('value=', data)
})
// same as:
db.createReadStream({ keys: false, values: true })
.on('data', function (data) {
console.log('value=', data)
})
```
<a name="iterator"></a>
### `db.iterator([options])`
Returns an [`abstract-leveldown` iterator](https://github.com/Level/abstract-leveldown/#abstractleveldown_iteratoroptions), which is what powers the readable streams above. Options are the same as the range options of [`createReadStream()`](#createReadStream) and are passed to the underlying store.
<a name="writeStreams"></a>
#### What happened to `db.createWriteStream`?
`db.createWriteStream()` has been removed in order to provide a smaller and more maintainable core. It primarily existed to create symmetry with `db.createReadStream()` but through much [discussion](https://github.com/level/levelup/issues/199), removing it was the best course of action.
The main driver for this was performance. While `db.createReadStream()` performs well under most use cases, `db.createWriteStream()` was highly dependent on the application keys and values. Thus we can't provide a standard implementation and encourage more `write-stream` implementations to be created to solve the broad spectrum of use cases.
Check out the implementations that the community has already produced [here](https://github.com/level/levelup/wiki/Modules#write-streams).
## Promise Support
`levelup` ships with native `Promise` support out of the box.
Each function accepting a callback returns a promise if the callback is omitted. This applies for:
- `db.get(key[, options])`
- `db.put(key, value[, options])`
- `db.del(key[, options])`
- `db.batch(ops[, options])`
- `db.batch().write()`
The only exception is the `levelup` constructor itself, which if no callback is passed will lazily open the underlying store in the background.
Example:
```js
var db = levelup(leveldown('./my-db'))
db.put('foo', 'bar')
.then(function () { return db.get('foo') })
.then(function (value) { console.log(value) })
.catch(function (err) { console.error(err) })
```
Or using `async/await`:
```js
const main = async () => {
const db = levelup(leveldown('./my-db'))
await db.put('foo', 'bar')
console.log(await db.get('foo'))
}
```
## Events
`levelup` is an [`EventEmitter`](https://nodejs.org/api/events.html) and emits the following events.
| Event | Description | Arguments |
| :-------- | :-------------------------- | :------------------- |
| `put` | Key has been updated | `key, value` (any) |
| `del` | Key has been deleted | `key` (any) |
| `batch` | Batch has executed | `operations` (array) |
| `opening` | Underlying store is opening | - |
| `open` | Store has opened | - |
| `ready` | Alias of `open` | - |
| `closing` | Store is closing | - |
| `closed` | Store has closed. | - |
For example you can do:
```js
db.on('put', function (key, value) {
console.log('inserted', { key, value })
})
```
## Extending
A list of <a href="https://github.com/level/levelup/wiki/Modules"><b>Level modules and projects</b></a> can be found in the wiki. We are in the process of moving all this to [`awesome`](https://github.com/Level/awesome/).
## Multi-process Access
Stores like LevelDB are thread-safe but they are **not** suitable for accessing with multiple processes. You should only ever have a store open from a single Node.js process. Node.js clusters are made up of multiple processes so a `levelup` instance cannot be shared between them either.
See the aformentioned <a href="https://github.com/level/levelup/wiki/Modules"><b>wiki</b></a> for modules like [multilevel](https://github.com/juliangruber/multilevel), that may help if you require a single store to be shared across processes.
## Support
There are multiple ways you can find help in using Level in Node.js:
- **IRC:** you'll find an active group of `levelup` users in the **##leveldb** channel on Freenode, including most of the contributors to this project.
- **Mailing list:** there is an active [Node.js LevelDB](https://groups.google.com/forum/#!forum/node-levelup) Google Group.
- **GitHub:** you're welcome to open an issue here on this GitHub repository if you have a question.
## Contributing
`levelup` is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [contribution guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
## Big Thanks
Cross-browser Testing Platform and Open Source ♥ Provided by [Sauce Labs](https://saucelabs.com).
[](https://saucelabs.com)
## License
[MIT](LICENSE.md) © 2012-present `levelup` [Contributors](CONTRIBUTORS.md).
[level-badge]: http://leveldb.org/img/badge.svg
# Upper Case First
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transforms the string with the first character in upper cased.
## Installation
```
npm install upper-case-first --save
```
## Usage
```js
import { upperCaseFirst } from "upper-case-first";
upperCaseFirst("test"); //=> "Test"
```
## License
MIT
[npm-image]: https://img.shields.io/npm/v/upper-case-first.svg?style=flat
[npm-url]: https://npmjs.org/package/upper-case-first
[downloads-image]: https://img.shields.io/npm/dm/upper-case-first.svg?style=flat
[downloads-url]: https://npmjs.org/package/upper-case-first
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/upper-case-first.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=upper-case-first
# pm2-promise
[![NPM version][npm-image]][npm-url]
[![Downloads][downloads-image]][npm-url]
[![Build Status][travis-image]][travis-url]
pm2-promise is a tiny library that adds promise awareness to pm2
## Installation
```sh
npm install pm2-promise
```
[downloads-image]: https://img.shields.io/npm/dm/pm2-promise.svg
[npm-url]: https://www.npmjs.com/package/pm2-promise
[npm-image]: https://img.shields.io/npm/v/pm2-promise.svg
[travis-url]: https://travis-ci.org/3axap4eHko/pm2-promise
[travis-image]: https://img.shields.io/travis/3axap4eHko/pm2-promise/master.svg
# encoding-down
> An [`abstract-leveldown`] implementation that wraps another store to encode keys and values.
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/encoding-down)

[](https://travis-ci.org/Level/encoding-down)
[](https://david-dm.org/level/encoding-down)
[](https://standardjs.com)
[](https://www.npmjs.com/package/encoding-down)
## Introduction
Stores like [`leveldown`] can only store strings and Buffers. For a richer set of data types you can wrap such a store with `encoding-down`. It allows you to specify an _encoding_ to use for keys and values independently. This not only widens the range of input types, but also limits the range of output types. The encoding is applied to all read and write operations: it encodes writes and decodes reads.
[Many encodings are builtin][builtin-encodings] courtesy of [`level-codec`]. The default encoding is `utf8` which ensures you'll always get back a string. You can also provide a custom encoding like `bytewise` - [or your own](#custom-encodings)!
## Usage
Without any options, `encoding-down` defaults to the `utf8` encoding.
```js
const levelup = require('levelup')
const leveldown = require('leveldown')
const encode = require('encoding-down')
const db = levelup(encode(leveldown('./db1')))
db.put('example', Buffer.from('encoding-down'), function (err) {
db.get('example', function (err, value) {
console.log(typeof value, value) // 'string encoding-down'
})
})
```
Can we store objects? Yes!
```js
const db = levelup(encode(leveldown('./db2'), { valueEncoding: 'json' }))
db.put('example', { awesome: true }, function (err) {
db.get('example', function (err, value) {
console.log(value) // { awesome: true }
console.log(typeof value) // 'object'
})
})
```
How about storing Buffers, but getting back a hex-encoded string?
```js
const db = levelup(encode(leveldown('./db3'), { valueEncoding: 'hex' }))
db.put('example', Buffer.from([0, 255]), function (err) {
db.get('example', function (err, value) {
console.log(typeof value, value) // 'string 00ff'
})
})
```
What if we previously stored binary data?
```js
const db = levelup(encode(leveldown('./db4'), { valueEncoding: 'binary' }))
db.put('example', Buffer.from([0, 255]), function (err) {
db.get('example', function (err, value) {
console.log(typeof value, value) // 'object <Buffer 00 ff>'
})
// Override the encoding for this operation
db.get('example', { valueEncoding: 'base64' }, function (err, value) {
console.log(typeof value, value) // 'string AP8='
})
})
```
And what about keys?
```js
const db = levelup(encode(leveldown('./db5'), { keyEncoding: 'json' }))
db.put({ awesome: true }, 'example', function (err) {
db.get({ awesome: true }, function (err, value) {
console.log(value) // 'example'
})
})
```
```js
const db = levelup(encode(leveldown('./db6'), { keyEncoding: 'binary' }))
db.put(Buffer.from([0, 255]), 'example', function (err) {
db.get('00ff', { keyEncoding: 'hex' }, function (err, value) {
console.log(value) // 'example'
})
})
```
## Usage with [`level`]
The [`level`] module conveniently bundles `encoding-down` and passes its `options` to `encoding-down`. This means you can simply do:
```js
const level = require('level')
const db = level('./db7', { valueEncoding: 'json' })
db.put('example', 42, function (err) {
db.get('example', function (err, value) {
console.log(value) // 42
console.log(typeof value) // 'number'
})
})
```
## API
### `const db = require('encoding-down')(db[, options])`
- `db` must be an [`abstract-leveldown`] compliant store
- `options` are passed to [`level-codec`]:
- `keyEncoding`: encoding to use for keys
- `valueEncoding`: encoding to use for values
Both encodings default to `'utf8'`. They can be a string (builtin `level-codec` encoding) or an object (custom encoding).
## Custom encodings
Please refer to [`level-codec` documentation][encoding-format] for a precise description of the format. Here's a quick example with `level` and `async/await` just for fun:
```js
const level = require('level')
const lexint = require('lexicographic-integer')
async function main () {
const db = level('./db8', {
keyEncoding: {
type: 'lexicographic-integer',
encode: (n) => lexint.pack(n, 'hex'),
decode: lexint.unpack,
buffer: false
}
})
await db.put(2, 'example')
await db.put(10, 'example')
// Without our encoding, the keys would sort as 10, 2.
db.createKeyStream().on('data', console.log) // 2, 10
}
main()
```
With an npm-installed encoding (modularity ftw!) we can reduce the above to:
```js
const level = require('level')
const lexint = require('lexicographic-integer-encoding')('hex')
const db = level('./db8', {
keyEncoding: lexint
})
```
## License
[MIT](./LICENSE.md) © 2017-present `encoding-down` [Contributors](./CONTRIBUTORS.md).
[level-badge]: http://leveldb.org/img/badge.svg
[`abstract-leveldown`]: https://github.com/level/abstract-leveldown
[`leveldown`]: https://github.com/level/leveldown
[`level`]: https://github.com/level/level
[`level-codec`]: https://github.com/level/codec
[builtin-encodings]: https://github.com/level/codec#builtin-encodings
[encoding-format]: https://github.com/level/codec#encoding-format
# SYNOPSIS
[](https://www.npmjs.org/package/rlp)
[](https://github.com/ethereumjs/rlp/actions)
[](https://coveralls.io/r/ethereumjs/rlp)
[](https://gitter.im/ethereum/ethereumjs-lib)
[Recursive Length](https://github.com/ethereum/wiki/wiki/RLP) Prefix Encoding for node.js.
## INSTALL
`npm install rlp`
install with `-g` if you want to use the cli.
## USAGE
```javascript
var RLP = require('rlp')
var assert = require('assert')
var nestedList = [[], [[]], [[], [[]]]]
var encoded = RLP.encode(nestedList)
var decoded = RLP.decode(encoded)
assert.deepEqual(nestedList, decoded)
```
## API
`rlp.encode(plain)` - RLP encodes an `Array`, `Buffer` or `String` and returns a `Buffer`.
`rlp.decode(encoded, [skipRemainderCheck=false])` - Decodes an RLP encoded `Buffer`, `Array` or `String` and returns a `Buffer` or an `Array` of `Buffers`. If `skipRemainderCheck` is enabled, `rlp` will just decode the first rlp sequence in the buffer. By default, it would throw an error if there are more bytes in Buffer than used by rlp sequence.
## CLI
`rlp decode <hex string>`
`rlp encode <json String>`
## TESTS
Test uses mocha. To run tests and linting: `npm test`. To auto fix linting problems use: `npm run test:fix`.
## CODE COVERAGE
Install dev dependencies
`npm install`
Run
`npm run coverage`
The results are at
`coverage/lcov-report/index.html`
# EthereumJS
See our organizational [documentation](https://ethereumjs.readthedocs.io) for an introduction to `EthereumJS` as well as information on current standards and best practices.
If you want to join for work or do improvements on the libraries have a look at our [contribution guidelines](https://ethereumjs.readthedocs.io/en/latest/contributing.html).
# content-hash
[](https://www.npmjs.com/package/content-hash)[](https://circleci.com/gh/pldespaigne/content-hash)[](https://gitter.im/content-hash/lobby)[](https://beerpay.io/pldespaigne/content-hash)
>This is a simple package made for encoding and decoding content hashes as specified in the [EIP 1577](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-1577.md).
This package will be useful for every [Ethereum](https://www.ethereum.org/) developer wanting to interact with [EIP 1577](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-1577.md) compliant [ENS resolvers](http://docs.ens.domains/en/latest/introduction.html).
Here you can find a [live demo](https://content-hash.surge.sh/) of this package.
* link to [npm](https://www.npmjs.com/package/content-hash)
* link to [Github](https://github.com/pldespaigne/content-hash)
## 🔠 Supported Codec
- `swarm-ns`
- `ipfs-ns`
- `ipns-ns`
- Every other codec supported by [multicodec](https://github.com/multiformats/multicodec) will be encoded by default in `utf-8`.
> You can see the full list of codec supported [here](https://github.com/multiformats/multicodec/blob/master/table.csv)
## 📥 Install
* via **npm** :
```bash
$> npm install content-hash
```
* via **Github** : Download or clone this repo, then install the dependencies.
```bash
$> git clone https://github.com/pldespaigne/content-hash.git
$> cd content-hash
$> npm install
```
> For browser only usage, installation is not required.
## 🛠 Usage
Import the module in order to use it :
* **NodeJS** :
```javascript
const contentHash = require('content-hash')
```
* **Browser** :
```html
<!--From CDN-->
<script type="text/javascript" src="https://unpkg.com/content-hash/dist/index.js"></script>
<!--From local module-->
<script type="text/javascript" src="path/to/dist/index.js"></script>
```
> To rebuild the browser version of the package run `npm run build` into the root folder. Don't forget to also run `npm run lint` and `npm test` before building !
## 📕 API
> All hex string **inputs** can be prefixed with `0x`, but it's **not mandatory**.
> ⚠️ All **outputs** are **NOT** prefixed with `0x`
### contentHash.decode( contentHash ) -> string
This function takes a content hash as a hex **string** and returns the decoded content as a **string**.
```javascript
const encoded = 'e3010170122029f2d17be6139079dc48696d1f582a8530eb9805b561eda517e22a892c7e3f1f'
const content = contentHash.decode(encoded)
// 'QmRAQB6YaCyidP37UdDnjFY5vQuiBrcqdyoW1CuDgwxkD4'
```
### contentHash.fromIpfs( ipfsHash ) -> string
This function takes an IPFS address as a base58 encoded **string** and returns the encoded content hash as a hex **string**.
> this function just call `contentHash.encode()` under the hood
```javascript
const ipfsHash = 'QmRAQB6YaCyidP37UdDnjFY5vQuiBrcqdyoW1CuDgwxkD4'
const contentH = contentHash.fromIpfs(ipfsHash)
// 'e3010170122029f2d17be6139079dc48696d1f582a8530eb9805b561eda517e22a892c7e3f1f'
```
### contentHash.fromSwarm( swarmHash ) -> string
This function takes a Swarm address as a hex **string** and returns the encoded content hash as a hex **string**.
> this function just call `contentHash.encode()` under the hood
```javascript
const swarmHash = 'd1de9994b4d039f6548d191eb26786769f580809256b4685ef316805265ea162'
const contentH = contentHash.fromSwarm(swarmHash)
// 'e40101701b20d1de9994b4d039f6548d191eb26786769f580809256b4685ef316805265ea162'
```
### contentHash.encode( codec, value) -> string
This function takes a [supported codec](#-supported-codec) as a **string** and a value as a **string** and returns coresponding content hash as a hex **string**.
```javascript
const onion = 'zqktlwi4fecvo6ri'
contentHash.encode('onion', onion);
// 'bc037a716b746c776934666563766f367269'
```
### contentHash.getCodec( contentHash ) -> string
This function takes a content hash as a hex **string** and returns the codec as a hex **string**.
```javascript
const encoded = 'e40101701b20d1de9994b4d039f6548d191eb26786769f580809256b4685ef316805265ea162'
const codec = contentHash.getCodec(encoded) // 'swarm-ns'
codec === 'ipfs-ns' // false
```
### contentHash.helpers
This object contain the following helpers functions :
- #### cidV0ToV1Base32( ipfsHash ) -> string
This function takes an ipfsHash and convert it to a CID v1 encoded in base32.
```javascript
const ipfs = 'QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG'
const cidV1 = contentHash.helpers.cidV0ToV1Base32(ipfs)
// 'bafybeibj6lixxzqtsb45ysdjnupvqkufgdvzqbnvmhw2kf7cfkesy7r7d4'
```
## 👨💻 Maintainer
* pldespaigne : [github](https://github.com/pldespaigne), [twitter](https://twitter.com/pldespaigne)
## 🙌 Contributing
For any questions, discussions, bug report, or whatever I will be happy to answer through the [issues](https://github.com/pldespaigne/content-hash/issues) or on my [twitter](https://twitter.com/pldespaigne) 😁. PR (with tests) are also welcome !
## 📝 License
This project is licensed under the **ISC License**, you can find it [here](https://github.com/pldespaigne/content-hash/blob/master/LICENSE).
> Note that the dependencies may have a different License
# pretty-format
> Stringify any JavaScript value.
- Supports [all built-in JavaScript types](#type-support)
- [Blazingly fast](https://gist.github.com/thejameskyle/2b04ffe4941aafa8f970de077843a8fd) (similar performance to v8's `JSON.stringify` and significantly faster than Node's `util.format`)
- Plugin system for extending with custom types (i.e. [`ReactTestComponent`](#reacttestcomponent-plugin))
## Installation
```sh
$ yarn add pretty-format
```
## Usage
```js
const prettyFormat = require('pretty-format');
var obj = { property: {} };
obj.circularReference = obj;
obj[Symbol('foo')] = 'foo';
obj.map = new Map();
obj.map.set('prop', 'value');
obj.array = [1, NaN, Infinity];
console.log(prettyFormat(obj));
```
**Result:**
```js
Object {
"property": Object {},
"circularReference": [Circular],
"map": Map {
"prop" => "value"
},
"array": Array [
1,
NaN,
Infinity
],
Symbol(foo): "foo"
}
```
#### Type Support
`Object`, `Array`, `ArrayBuffer`, `DataView`, `Float32Array`, `Float64Array`, `Int8Array`, `Int16Array`, `Int32Array`, `Uint8Array`, `Uint8ClampedArray`, `Uint16Array`, `Uint32Array`, `arguments`, `Boolean`, `Date`, `Error`, `Function`, `Infinity`, `Map`, `NaN`, `null`, `Number`, `RegExp`, `Set`, `String`, `Symbol`, `undefined`, `WeakMap`, `WeakSet`
### API
```js
console.log(prettyFormat(object));
console.log(prettyFormat(object, options));
```
Options:
* **`callToJSON`**<br>
Type: `boolean`, default: `true`<br>
Call `toJSON()` on passed object.
* **`indent`**<br>
Type: `number`, default: `2`<br>
Number of spaces for indentation.
* **`maxDepth`**<br>
Type: `number`, default: `Infinity`<br>
Print only this number of levels.
* **`min`**<br>
Type: `boolean`, default: `false`<br>
Print without whitespace.
* **`plugins`**<br>
Type: `array`, default: `[]`<br>
Plugins (see the next section).
* **`printFunctionName`**<br>
Type: `boolean`, default: `true`<br>
Print function names or just `[Function]`.
* **`escapeRegex`**<br>
Type: `boolean`, default: `false`<br>
Escape special characters in regular expressions.
* **`highlight`**<br>
Type: `boolean`, default: `false`<br>
Highlight syntax for terminal (works only with `ReactTestComponent` and `ReactElement` plugins.
* **`theme`**<br>
Type: `object`, default: `{tag: 'cyan', content: 'reset'...}`<br>
Syntax highlight theme.<br>
Uses [ansi-styles colors](https://github.com/chalk/ansi-styles#colors) + `reset` for no color.<br>
Available types: `tag`, `content`, `prop` and `value`.
### Plugins
Pretty format also supports adding plugins:
```js
const fooPlugin = {
test(val) {
return val && val.hasOwnProperty('foo');
},
print(val, print, indent) {
return 'Foo: ' + print(val.foo);
}
};
const obj = {foo: {bar: {}}};
prettyFormat(obj, {
plugins: [fooPlugin]
});
// Foo: Object {
// "bar": Object {}
// }
```
#### `ReactTestComponent` and `ReactElement` plugins
```js
const prettyFormat = require('pretty-format');
const reactTestPlugin = require('pretty-format').plugins.ReactTestComponent;
const reactElementPlugin = require('pretty-format').plugins.ReactElement;
const React = require('react');
const renderer = require('react-test-renderer');
const element = React.createElement('h1', null, 'Hello World');
prettyFormat(renderer.create(element).toJSON(), {
plugins: [reactTestPlugin, reactElementPlugin]
});
// <h1>
// Hello World
// </h1>
```
# fast-levenshtein - Levenshtein algorithm in Javascript
[](http://travis-ci.org/hiddentao/fast-levenshtein)
[](https://badge.fury.io/js/fast-levenshtein)
[](https://www.npmjs.com/package/fast-levenshtein)
[](https://twitter.com/hiddentao)
An efficient Javascript implementation of the [Levenshtein algorithm](http://en.wikipedia.org/wiki/Levenshtein_distance) with locale-specific collator support.
## Features
* Works in node.js and in the browser.
* Better performance than other implementations by not needing to store the whole matrix ([more info](http://www.codeproject.com/Articles/13525/Fast-memory-efficient-Levenshtein-algorithm)).
* Locale-sensitive string comparisions if needed.
* Comprehensive test suite and performance benchmark.
* Small: <1 KB minified and gzipped
## Installation
### node.js
Install using [npm](http://npmjs.org/):
```bash
$ npm install fast-levenshtein
```
### Browser
Using bower:
```bash
$ bower install fast-levenshtein
```
If you are not using any module loader system then the API will then be accessible via the `window.Levenshtein` object.
## Examples
**Default usage**
```javascript
var levenshtein = require('fast-levenshtein');
var distance = levenshtein.get('back', 'book'); // 2
var distance = levenshtein.get('我愛你', '我叫你'); // 1
```
**Locale-sensitive string comparisons**
It supports using [Intl.Collator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Collator) for locale-sensitive string comparisons:
```javascript
var levenshtein = require('fast-levenshtein');
levenshtein.get('mikailovitch', 'Mikhaïlovitch', { useCollator: true});
// 1
```
## Building and Testing
To build the code and run the tests:
```bash
$ npm install -g grunt-cli
$ npm install
$ npm run build
```
## Performance
_Thanks to [Titus Wormer](https://github.com/wooorm) for [encouraging me](https://github.com/hiddentao/fast-levenshtein/issues/1) to do this._
Benchmarked against other node.js levenshtein distance modules (on Macbook Air 2012, Core i7, 8GB RAM):
```bash
Running suite Implementation comparison [benchmark/speed.js]...
>> levenshtein-edit-distance x 234 ops/sec ±3.02% (73 runs sampled)
>> levenshtein-component x 422 ops/sec ±4.38% (83 runs sampled)
>> levenshtein-deltas x 283 ops/sec ±3.83% (78 runs sampled)
>> natural x 255 ops/sec ±0.76% (88 runs sampled)
>> levenshtein x 180 ops/sec ±3.55% (86 runs sampled)
>> fast-levenshtein x 1,792 ops/sec ±2.72% (95 runs sampled)
Benchmark done.
Fastest test is fast-levenshtein at 4.2x faster than levenshtein-component
```
You can run this benchmark yourself by doing:
```bash
$ npm install
$ npm run build
$ npm run benchmark
```
## Contributing
If you wish to submit a pull request please update and/or create new tests for any changes you make and ensure the grunt build passes.
See [CONTRIBUTING.md](https://github.com/hiddentao/fast-levenshtein/blob/master/CONTRIBUTING.md) for details.
## License
MIT - see [LICENSE.md](https://github.com/hiddentao/fast-levenshtein/blob/master/LICENSE.md)
# lru cache
A cache object that deletes the least-recently-used items.
[](https://travis-ci.org/isaacs/node-lru-cache) [](https://coveralls.io/github/isaacs/node-lru-cache)
## Installation:
```javascript
npm install lru-cache --save
```
## Usage:
```javascript
var LRU = require("lru-cache")
, options = { max: 500
, length: function (n, key) { return n * 2 + key.length }
, dispose: function (key, n) { n.close() }
, maxAge: 1000 * 60 * 60 }
, cache = new LRU(options)
, otherCache = new LRU(50) // sets just the max size
cache.set("key", "value")
cache.get("key") // "value"
// non-string keys ARE fully supported
// but note that it must be THE SAME object, not
// just a JSON-equivalent object.
var someObject = { a: 1 }
cache.set(someObject, 'a value')
// Object keys are not toString()-ed
cache.set('[object Object]', 'a different value')
assert.equal(cache.get(someObject), 'a value')
// A similar object with same keys/values won't work,
// because it's a different object identity
assert.equal(cache.get({ a: 1 }), undefined)
cache.reset() // empty the cache
```
If you put more stuff in it, then items will fall out.
If you try to put an oversized thing in it, then it'll fall out right
away.
## Options
* `max` The maximum size of the cache, checked by applying the length
function to all values in the cache. Not setting this is kind of
silly, since that's the whole purpose of this lib, but it defaults
to `Infinity`. Setting it to a non-number or negative number will
throw a `TypeError`. Setting it to 0 makes it be `Infinity`.
* `maxAge` Maximum age in ms. Items are not pro-actively pruned out
as they age, but if you try to get an item that is too old, it'll
drop it and return undefined instead of giving it to you.
Setting this to a negative value will make everything seem old!
Setting it to a non-number will throw a `TypeError`.
* `length` Function that is used to calculate the length of stored
items. If you're storing strings or buffers, then you probably want
to do something like `function(n, key){return n.length}`. The default is
`function(){return 1}`, which is fine if you want to store `max`
like-sized things. The item is passed as the first argument, and
the key is passed as the second argumnet.
* `dispose` Function that is called on items when they are dropped
from the cache. This can be handy if you want to close file
descriptors or do other cleanup tasks when items are no longer
accessible. Called with `key, value`. It's called *before*
actually removing the item from the internal cache, so if you want
to immediately put it back in, you'll have to do that in a
`nextTick` or `setTimeout` callback or it won't do anything.
* `stale` By default, if you set a `maxAge`, it'll only actually pull
stale items out of the cache when you `get(key)`. (That is, it's
not pre-emptively doing a `setTimeout` or anything.) If you set
`stale:true`, it'll return the stale value before deleting it. If
you don't set this, then it'll return `undefined` when you try to
get a stale entry, as if it had already been deleted.
* `noDisposeOnSet` By default, if you set a `dispose()` method, then
it'll be called whenever a `set()` operation overwrites an existing
key. If you set this option, `dispose()` will only be called when a
key falls out of the cache, not when it is overwritten.
* `updateAgeOnGet` When using time-expiring entries with `maxAge`,
setting this to `true` will make each item's effective time update
to the current time whenever it is retrieved from cache, causing it
to not expire. (It can still fall out of cache based on recency of
use, of course.)
## API
* `set(key, value, maxAge)`
* `get(key) => value`
Both of these will update the "recently used"-ness of the key.
They do what you think. `maxAge` is optional and overrides the
cache `maxAge` option if provided.
If the key is not found, `get()` will return `undefined`.
The key and val can be any value.
* `peek(key)`
Returns the key value (or `undefined` if not found) without
updating the "recently used"-ness of the key.
(If you find yourself using this a lot, you *might* be using the
wrong sort of data structure, but there are some use cases where
it's handy.)
* `del(key)`
Deletes a key out of the cache.
* `reset()`
Clear the cache entirely, throwing away all values.
* `has(key)`
Check if a key is in the cache, without updating the recent-ness
or deleting it for being stale.
* `forEach(function(value,key,cache), [thisp])`
Just like `Array.prototype.forEach`. Iterates over all the keys
in the cache, in order of recent-ness. (Ie, more recently used
items are iterated over first.)
* `rforEach(function(value,key,cache), [thisp])`
The same as `cache.forEach(...)` but items are iterated over in
reverse order. (ie, less recently used items are iterated over
first.)
* `keys()`
Return an array of the keys in the cache.
* `values()`
Return an array of the values in the cache.
* `length`
Return total length of objects in cache taking into account
`length` options function.
* `itemCount`
Return total quantity of objects currently in cache. Note, that
`stale` (see options) items are returned as part of this item
count.
* `dump()`
Return an array of the cache entries ready for serialization and usage
with 'destinationCache.load(arr)`.
* `load(cacheEntriesArray)`
Loads another cache entries array, obtained with `sourceCache.dump()`,
into the cache. The destination cache is reset before loading new entries
* `prune()`
Manually iterates over the entire cache proactively pruning old entries
# XMLHttpRequest polyfill for node.js
Based on [https://github.com/pwnall/node-xhr2](https://github.com/pwnall/node-xhr2)
* Adds support for cookies
* Adds in-project TypeScript type definitions
* Switched to TypeScript
### Cookies
* saved in `XMLHttpRequest.cookieJar`
* saved between redirects
* saved between requests
* can be cleared by doing:
```typescript
import * as Cookie from 'cookiejar';
XMLHttpRequest.cookieJar = Cookie.CookieJar();
```
### Aims
* Provide full XMLHttpRequest features to Angular Universal HttpClient &
`node-angular-http-client`
### Changelog
#### `1.1.0`
* added saving of cookies between requests, not just redirects
* bug fixes
* most tests from `xhr2` ported over and passing
# [Moment Timezone](http://momentjs.com/timezone)
[](https://gitter.im/moment/moment-timezone?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
[![NPM version][npm-version-image]][npm-url] [![NPM downloads][npm-downloads-image]][npm-url] [![MIT License][license-image]][license-url] [![Build Status][travis-image]][travis-url]
IANA Time Zone Database + [Moment.js](http://momentjs.com).
```js
var june = moment("2014-06-01T12:00:00Z");
june.tz('America/Los_Angeles').format('ha z'); // 5am PDT
june.tz('America/New_York').format('ha z'); // 8am EDT
june.tz('Asia/Tokyo').format('ha z'); // 9pm JST
june.tz('Australia/Sydney').format('ha z'); // 10pm EST
var dec = moment("2014-12-01T12:00:00Z");
dec.tz('America/Los_Angeles').format('ha z'); // 4am PST
dec.tz('America/New_York').format('ha z'); // 7am EST
dec.tz('Asia/Tokyo').format('ha z'); // 9pm JST
dec.tz('Australia/Sydney').format('ha z'); // 11pm EST
```
#### [Contribute code or compile time zone data](contributing.md)
#### [Read the changelog](changelog.md)
[license-image]: http://img.shields.io/badge/license-MIT-blue.svg?style=flat
[license-url]: LICENSE
[npm-url]: https://npmjs.org/package/moment-timezone
[npm-version-image]: http://img.shields.io/npm/v/moment-timezone.svg?style=flat
[npm-downloads-image]: http://img.shields.io/npm/dm/moment-timezone.svg?style=flat
[travis-url]: http://travis-ci.org/moment/moment-timezone
[travis-image]: http://img.shields.io/travis/moment/moment-timezone/develop.svg?style=flat
# bl *(BufferList)*
[](https://travis-ci.org/rvagg/bl)
**A Node.js Buffer list collector, reader and streamer thingy.**
[](https://nodei.co/npm/bl/)
[](https://nodei.co/npm/bl/)
**bl** is a storage object for collections of Node Buffers, exposing them with the main Buffer readable API. Also works as a duplex stream so you can collect buffers from a stream that emits them and emit buffers to a stream that consumes them!
The original buffers are kept intact and copies are only done as necessary. Any reads that require the use of a single original buffer will return a slice of that buffer only (which references the same memory as the original buffer). Reads that span buffers perform concatenation as required and return the results transparently.
```js
const BufferList = require('bl')
var bl = new BufferList()
bl.append(new Buffer('abcd'))
bl.append(new Buffer('efg'))
bl.append('hi') // bl will also accept & convert Strings
bl.append(new Buffer('j'))
bl.append(new Buffer([ 0x3, 0x4 ]))
console.log(bl.length) // 12
console.log(bl.slice(0, 10).toString('ascii')) // 'abcdefghij'
console.log(bl.slice(3, 10).toString('ascii')) // 'defghij'
console.log(bl.slice(3, 6).toString('ascii')) // 'def'
console.log(bl.slice(3, 8).toString('ascii')) // 'defgh'
console.log(bl.slice(5, 10).toString('ascii')) // 'fghij'
// or just use toString!
console.log(bl.toString()) // 'abcdefghij\u0003\u0004'
console.log(bl.toString('ascii', 3, 8)) // 'defgh'
console.log(bl.toString('ascii', 5, 10)) // 'fghij'
// other standard Buffer readables
console.log(bl.readUInt16BE(10)) // 0x0304
console.log(bl.readUInt16LE(10)) // 0x0403
```
Give it a callback in the constructor and use it just like **[concat-stream](https://github.com/maxogden/node-concat-stream)**:
```js
const bl = require('bl')
, fs = require('fs')
fs.createReadStream('README.md')
.pipe(bl(function (err, data) { // note 'new' isn't strictly required
// `data` is a complete Buffer object containing the full data
console.log(data.toString())
}))
```
Note that when you use the *callback* method like this, the resulting `data` parameter is a concatenation of all `Buffer` objects in the list. If you want to avoid the overhead of this concatenation (in cases of extreme performance consciousness), then avoid the *callback* method and just listen to `'end'` instead, like a standard Stream.
Or to fetch a URL using [hyperquest](https://github.com/substack/hyperquest) (should work with [request](http://github.com/mikeal/request) and even plain Node http too!):
```js
const hyperquest = require('hyperquest')
, bl = require('bl')
, url = 'https://raw.github.com/rvagg/bl/master/README.md'
hyperquest(url).pipe(bl(function (err, data) {
console.log(data.toString())
}))
```
Or, use it as a readable stream to recompose a list of Buffers to an output source:
```js
const BufferList = require('bl')
, fs = require('fs')
var bl = new BufferList()
bl.append(new Buffer('abcd'))
bl.append(new Buffer('efg'))
bl.append(new Buffer('hi'))
bl.append(new Buffer('j'))
bl.pipe(fs.createWriteStream('gibberish.txt'))
```
## API
* <a href="#ctor"><code><b>new BufferList([ callback ])</b></code></a>
* <a href="#length"><code>bl.<b>length</b></code></a>
* <a href="#append"><code>bl.<b>append(buffer)</b></code></a>
* <a href="#get"><code>bl.<b>get(index)</b></code></a>
* <a href="#slice"><code>bl.<b>slice([ start[, end ] ])</b></code></a>
* <a href="#shallowSlice"><code>bl.<b>shallowSlice([ start[, end ] ])</b></code></a>
* <a href="#copy"><code>bl.<b>copy(dest, [ destStart, [ srcStart [, srcEnd ] ] ])</b></code></a>
* <a href="#duplicate"><code>bl.<b>duplicate()</b></code></a>
* <a href="#consume"><code>bl.<b>consume(bytes)</b></code></a>
* <a href="#toString"><code>bl.<b>toString([encoding, [ start, [ end ]]])</b></code></a>
* <a href="#readXX"><code>bl.<b>readDoubleBE()</b></code>, <code>bl.<b>readDoubleLE()</b></code>, <code>bl.<b>readFloatBE()</b></code>, <code>bl.<b>readFloatLE()</b></code>, <code>bl.<b>readInt32BE()</b></code>, <code>bl.<b>readInt32LE()</b></code>, <code>bl.<b>readUInt32BE()</b></code>, <code>bl.<b>readUInt32LE()</b></code>, <code>bl.<b>readInt16BE()</b></code>, <code>bl.<b>readInt16LE()</b></code>, <code>bl.<b>readUInt16BE()</b></code>, <code>bl.<b>readUInt16LE()</b></code>, <code>bl.<b>readInt8()</b></code>, <code>bl.<b>readUInt8()</b></code></a>
* <a href="#streams">Streams</a>
--------------------------------------------------------
<a name="ctor"></a>
### new BufferList([ callback | Buffer | Buffer array | BufferList | BufferList array | String ])
The constructor takes an optional callback, if supplied, the callback will be called with an error argument followed by a reference to the **bl** instance, when `bl.end()` is called (i.e. from a piped stream). This is a convenient method of collecting the entire contents of a stream, particularly when the stream is *chunky*, such as a network stream.
Normally, no arguments are required for the constructor, but you can initialise the list by passing in a single `Buffer` object or an array of `Buffer` object.
`new` is not strictly required, if you don't instantiate a new object, it will be done automatically for you so you can create a new instance simply with:
```js
var bl = require('bl')
var myinstance = bl()
// equivalent to:
var BufferList = require('bl')
var myinstance = new BufferList()
```
--------------------------------------------------------
<a name="length"></a>
### bl.length
Get the length of the list in bytes. This is the sum of the lengths of all of the buffers contained in the list, minus any initial offset for a semi-consumed buffer at the beginning. Should accurately represent the total number of bytes that can be read from the list.
--------------------------------------------------------
<a name="append"></a>
### bl.append(Buffer | Buffer array | BufferList | BufferList array | String)
`append(buffer)` adds an additional buffer or BufferList to the internal list. `this` is returned so it can be chained.
--------------------------------------------------------
<a name="get"></a>
### bl.get(index)
`get()` will return the byte at the specified index.
--------------------------------------------------------
<a name="slice"></a>
### bl.slice([ start, [ end ] ])
`slice()` returns a new `Buffer` object containing the bytes within the range specified. Both `start` and `end` are optional and will default to the beginning and end of the list respectively.
If the requested range spans a single internal buffer then a slice of that buffer will be returned which shares the original memory range of that Buffer. If the range spans multiple buffers then copy operations will likely occur to give you a uniform Buffer.
--------------------------------------------------------
<a name="shallowSlice"></a>
### bl.shallowSlice([ start, [ end ] ])
`shallowSlice()` returns a new `BufferList` object containing the bytes within the range specified. Both `start` and `end` are optional and will default to the beginning and end of the list respectively.
No copies will be performed. All buffers in the result share memory with the original list.
--------------------------------------------------------
<a name="copy"></a>
### bl.copy(dest, [ destStart, [ srcStart [, srcEnd ] ] ])
`copy()` copies the content of the list in the `dest` buffer, starting from `destStart` and containing the bytes within the range specified with `srcStart` to `srcEnd`. `destStart`, `start` and `end` are optional and will default to the beginning of the `dest` buffer, and the beginning and end of the list respectively.
--------------------------------------------------------
<a name="duplicate"></a>
### bl.duplicate()
`duplicate()` performs a **shallow-copy** of the list. The internal Buffers remains the same, so if you change the underlying Buffers, the change will be reflected in both the original and the duplicate. This method is needed if you want to call `consume()` or `pipe()` and still keep the original list.Example:
```js
var bl = new BufferList()
bl.append('hello')
bl.append(' world')
bl.append('\n')
bl.duplicate().pipe(process.stdout, { end: false })
console.log(bl.toString())
```
--------------------------------------------------------
<a name="consume"></a>
### bl.consume(bytes)
`consume()` will shift bytes *off the start of the list*. The number of bytes consumed don't need to line up with the sizes of the internal Buffers—initial offsets will be calculated accordingly in order to give you a consistent view of the data.
--------------------------------------------------------
<a name="toString"></a>
### bl.toString([encoding, [ start, [ end ]]])
`toString()` will return a string representation of the buffer. The optional `start` and `end` arguments are passed on to `slice()`, while the `encoding` is passed on to `toString()` of the resulting Buffer. See the [Buffer#toString()](http://nodejs.org/docs/latest/api/buffer.html#buffer_buf_tostring_encoding_start_end) documentation for more information.
--------------------------------------------------------
<a name="readXX"></a>
### bl.readDoubleBE(), bl.readDoubleLE(), bl.readFloatBE(), bl.readFloatLE(), bl.readInt32BE(), bl.readInt32LE(), bl.readUInt32BE(), bl.readUInt32LE(), bl.readInt16BE(), bl.readInt16LE(), bl.readUInt16BE(), bl.readUInt16LE(), bl.readInt8(), bl.readUInt8()
All of the standard byte-reading methods of the `Buffer` interface are implemented and will operate across internal Buffer boundaries transparently.
See the <b><code>[Buffer](http://nodejs.org/docs/latest/api/buffer.html)</code></b> documentation for how these work.
--------------------------------------------------------
<a name="streams"></a>
### Streams
**bl** is a Node **[Duplex Stream](http://nodejs.org/docs/latest/api/stream.html#stream_class_stream_duplex)**, so it can be read from and written to like a standard Node stream. You can also `pipe()` to and from a **bl** instance.
--------------------------------------------------------
## Contributors
**bl** is brought to you by the following hackers:
* [Rod Vagg](https://github.com/rvagg)
* [Matteo Collina](https://github.com/mcollina)
* [Jarett Cruger](https://github.com/jcrugzz)
=======
<a name="license"></a>
## License & copyright
Copyright (c) 2013-2016 bl contributors (listed above).
bl is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE.md file for more details.
# prr [](http://travis-ci.org/rvagg/prr)
An sensible alternative to `Object.defineProperty()`. Available in npm and Ender as **prr**.
## Usage
Set the property `'foo'` (`obj.foo`) to have the value `'bar'` with default options (`'enumerable'`, `'configurable'` and `'writable'` are all `false`):
```js
prr(obj, 'foo', 'bar')
```
Adjust the default options:
```js
prr(obj, 'foo', 'bar', { enumerable: true, writable: true })
```
Do the same operation for multiple properties:
```js
prr(obj, { one: 'one', two: 'two' })
// or with options:
prr(obj, { one: 'one', two: 'two' }, { enumerable: true, writable: true })
```
### Simplify!
But obviously, having to write out the full options object makes it nearly as bad as the original `Object.defineProperty()` so we can simplify.
As an alternative method we can use an options string where each character represents a option: `'e'=='enumerable'`, `'c'=='configurable'` and `'w'=='writable'`:
```js
prr(obj, 'foo', 'bar', 'ew') // enumerable and writable but not configurable
// muliple properties:
prr(obj, { one: 'one', two: 'two' }, 'ewc') // configurable too
```
## Where can I use it?
Anywhere! For pre-ES5 environments *prr* will simply fall-back to an `object[property] = value` so you can get close to what you want.
*prr* is Ender-compatible so you can include it in your Ender build and `$.prr(...)` or `var prr = require('prr'); prr(...)`.
## Licence
prr is Copyright (c) 2013 Rod Vagg [@rvagg](https://twitter.com/rvagg) and licensed under the MIT licence. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE.md file for more details.
# simple-get [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/simple-get/master.svg
[travis-url]: https://travis-ci.org/feross/simple-get
[npm-image]: https://img.shields.io/npm/v/simple-get.svg
[npm-url]: https://npmjs.org/package/simple-get
[downloads-image]: https://img.shields.io/npm/dm/simple-get.svg
[downloads-url]: https://npmjs.org/package/simple-get
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
### Simplest way to make http get requests
## features
This module is the lightest possible wrapper on top of node.js `http`, but supporting these essential features:
- follows redirects
- automatically handles gzip/deflate responses
- supports HTTPS
- supports specifying a timeout
- supports convenience `url` key so there's no need to use `url.parse` on the url when specifying options
- composes well with npm packages for features like cookies, proxies, form data, & OAuth
All this in < 120 lines of code.
## install
```
npm install simple-get
```
## usage
Note, all these examples also work in the browser with [browserify](http://browserify.org/).
### simple GET request
Doesn't get easier than this:
```js
const get = require('simple-get')
get('http://example.com', function (err, res) {
if (err) throw err
console.log(res.statusCode) // 200
res.pipe(process.stdout) // `res` is a stream
})
```
### even simpler GET request
If you just want the data, and don't want to deal with streams:
```js
const get = require('simple-get')
get.concat('http://example.com', function (err, res, data) {
if (err) throw err
console.log(res.statusCode) // 200
console.log(data) // Buffer('this is the server response')
})
```
### POST, PUT, PATCH, HEAD, DELETE support
For `POST`, call `get.post` or use option `{ method: 'POST' }`.
```js
const get = require('simple-get')
const opts = {
url: 'http://example.com',
body: 'this is the POST body'
}
get.post(opts, function (err, res) {
if (err) throw err
res.pipe(process.stdout) // `res` is a stream
})
```
#### A more complex example:
```js
const get = require('simple-get')
get({
url: 'http://example.com',
method: 'POST',
body: 'this is the POST body',
// simple-get accepts all options that node.js `http` accepts
// See: http://nodejs.org/api/http.html#http_http_request_options_callback
headers: {
'user-agent': 'my cool app'
}
}, function (err, res) {
if (err) throw err
// All properties/methods from http.IncomingResponse are available,
// even if a gunzip/inflate transform stream was returned.
// See: http://nodejs.org/api/http.html#http_http_incomingmessage
res.setTimeout(10000)
console.log(res.headers)
res.on('data', function (chunk) {
// `chunk` is the decoded response, after it's been gunzipped or inflated
// (if applicable)
console.log('got a chunk of the response: ' + chunk)
}))
})
```
### JSON
You can serialize/deserialize request and response with JSON:
```js
const get = require('simple-get')
const opts = {
method: 'POST',
url: 'http://example.com',
body: {
key: 'value'
},
json: true
}
get.concat(opts, function (err, res, data) {
if (err) throw err
console.log(data.key) // `data` is an object
})
```
### Timeout
You can set a timeout (in milliseconds) on the request with the `timeout` option.
If the request takes longer than `timeout` to complete, then the entire request
will fail with an `Error`.
```js
const get = require('simple-get')
const opts = {
url: 'http://example.com',
timeout: 2000 // 2 second timeout
}
get(opts, function (err, res) {})
```
### One Quick Tip
It's a good idea to set the `'user-agent'` header so the provider can more easily
see how their resource is used.
```js
const get = require('simple-get')
const pkg = require('./package.json')
get('http://example.com', {
headers: {
'user-agent': `my-module/${pkg.version} (https://github.com/username/my-module)`
}
})
```
### Proxies
You can use the [`tunnel`](https://github.com/koichik/node-tunnel) module with the
`agent` option to work with proxies:
```js
const get = require('simple-get')
const tunnel = require('tunnel')
const opts = {
url: 'http://example.com',
agent: tunnel.httpOverHttp({
proxy: {
host: 'localhost'
}
})
}
get(opts, function (err, res) {})
```
### Cookies
You can use the [`cookie`](https://github.com/jshttp/cookie) module to include
cookies in a request:
```js
const get = require('simple-get')
const cookie = require('cookie')
const opts = {
url: 'http://example.com',
headers: {
cookie: cookie.serialize('foo', 'bar')
}
}
get(opts, function (err, res) {})
```
### Form data
You can use the [`form-data`](https://github.com/form-data/form-data) module to
create POST request with form data:
```js
const fs = require('fs')
const get = require('simple-get')
const FormData = require('form-data')
const form = new FormData()
form.append('my_file', fs.createReadStream('/foo/bar.jpg'))
const opts = {
url: 'http://example.com',
body: form
}
get.post(opts, function (err, res) {})
```
#### Or, include `application/x-www-form-urlencoded` form data manually:
```js
const get = require('simple-get')
const opts = {
url: 'http://example.com',
form: {
key: 'value'
}
}
get.post(opts, function (err, res) {})
```
### OAuth
You can use the [`oauth-1.0a`](https://github.com/ddo/oauth-1.0a) module to create
a signed OAuth request:
```js
const get = require('simple-get')
const crypto = require('crypto')
const OAuth = require('oauth-1.0a')
const oauth = OAuth({
consumer: {
key: process.env.CONSUMER_KEY,
secret: process.env.CONSUMER_SECRET
},
signature_method: 'HMAC-SHA1',
hash_function: (baseString, key) => crypto.createHmac('sha1', key).update(baseString).digest('base64')
})
const token = {
key: process.env.ACCESS_TOKEN,
secret: process.env.ACCESS_TOKEN_SECRET
}
const url = 'https://api.twitter.com/1.1/statuses/home_timeline.json'
const opts = {
url: url,
headers: oauth.toHeader(oauth.authorize({url, method: 'GET'}, token)),
json: true
}
get(opts, function (err, res) {})
```
### Throttle requests
You can use [limiter](https://github.com/jhurliman/node-rate-limiter) to throttle requests. This is useful when calling an API that is rate limited.
```js
const simpleGet = require('simple-get')
const RateLimiter = require('limiter').RateLimiter
const limiter = new RateLimiter(1, 'second')
const get = (opts, cb) => limiter.removeTokens(1, () => simpleGet(opts, cb))
get.concat = (opts, cb) => limiter.removeTokens(1, () => simpleGet.concat(opts, cb))
var opts = {
url: 'http://example.com'
}
get.concat(opts, processResult)
get.concat(opts, processResult)
function processResult (err, res, data) {
if (err) throw err
console.log(data.toString())
}
```
## license
MIT. Copyright (c) [Feross Aboukhadijeh](http://feross.org).
# u3 - Utility Functions
This lib contains utility functions for e3, dataflower and other projects.
## Documentation
### Installation
```bash
npm install u3
```
```bash
bower install u3
```
#### Usage
In this documentation I used the lib as follows:
```js
var u3 = require("u3"),
cache = u3.cache,
eachCombination = u3.eachCombination;
```
### Function wrappers
#### cache
The `cache(fn)` function caches the fn results, so by the next calls it will return the result of the first call.
You can use different arguments, but they won't affect the return value.
```js
var a = cache(function fn(x, y, z){
return x + y + z;
});
console.log(a(1, 2, 3)); // 6
console.log(a()); // 6
console.log(a()); // 6
```
### Math
#### eachCombination
The `eachCombination(alternativesByDimension, callback)` calls the `callback(a,b,c,...)` on each combination of the `alternatives[a[],b[],c[],...]`.
```js
eachCombination([
[1, 2, 3],
["a", "b"],
], console.log);
/*
1, "a"
1, "b"
2, "a"
2, "b"
3, "a"
3, "b"
*/
```
You can use any dimension and number of alternatives. In the current example we used 2 dimensions. By the first dimension we used 3 alternatives: `[1, 2, 3]` and by the second dimension we used 2 alternatives: `["a", "b"]`.
## License
MIT - 2016 Jánszky László Lajos
# axios // adapters
The modules under `adapters/` are modules that handle dispatching a request and settling a returned `Promise` once a response is received.
## Example
```js
var settle = require('./../core/settle');
module.exports = function myAdapter(config) {
// At this point:
// - config has been merged with defaults
// - request transformers have already run
// - request interceptors have already run
// Make the request using config provided
// Upon response settle the Promise
return new Promise(function(resolve, reject) {
var response = {
data: responseData,
status: request.status,
statusText: request.statusText,
headers: responseHeaders,
config: config,
request: request
};
settle(resolve, reject, response);
// From here:
// - response transformers will run
// - response interceptors will run
});
}
```
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# is-glob [](http://badge.fury.io/js/is-glob) [](https://travis-ci.org/jonschlinkert/is-glob)
> Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a better user experience.
Also take a look at [is-valid-glob](https://github.com/jonschlinkert/is-valid-glob) and [has-glob](https://github.com/jonschlinkert/has-glob).
## Install
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i is-glob --save
```
## Usage
```js
var isGlob = require('is-glob');
```
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js');
isGlob('*.js');
isGlob('**/abc.js');
isGlob('abc/*.js');
isGlob('abc/(aaa|bbb).js');
isGlob('abc/[a-z].js');
isGlob('abc/{a,b}.js');
isGlob('abc/?.js');
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js');
isGlob('abc/!(a).js');
isGlob('abc/+(a).js');
isGlob('abc/*(a).js');
isGlob('abc/?(a).js');
//=> true
```
**False**
Patterns that do not have glob patterns return `false`:
```js
isGlob('abc.js');
isGlob('abc/def/ghi.js');
isGlob('foo.js');
isGlob('abc/@.js');
isGlob('abc/+.js');
isGlob();
isGlob(null);
//=> false
```
Arrays are also `false` (If you want to check if an array has a glob pattern, use [has-glob](https://github.com/jonschlinkert/has-glob)):
```js
isGlob(['**/*.js']);
isGlob(['foo.js']);
//=> false
```
## Related
* [has-glob](https://www.npmjs.com/package/has-glob): Returns `true` if an array has a glob pattern. | [homepage](https://github.com/jonschlinkert/has-glob)
* [is-extglob](https://www.npmjs.com/package/is-extglob): Returns true if a string has an extglob. | [homepage](https://github.com/jonschlinkert/is-extglob)
* [is-posix-bracket](https://www.npmjs.com/package/is-posix-bracket): Returns true if the given string is a POSIX bracket expression (POSIX character class). | [homepage](https://github.com/jonschlinkert/is-posix-bracket)
* [is-valid-glob](https://www.npmjs.com/package/is-valid-glob): Return true if a value is a valid glob pattern or patterns. | [homepage](https://github.com/jonschlinkert/is-valid-glob)
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. Just… [more](https://www.npmjs.com/package/micromatch) | [homepage](https://github.com/jonschlinkert/micromatch)
## Run tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-glob/issues/new).
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2015 Jon Schlinkert
Released under the MIT license.
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on October 02, 2015._
<div align="center">
<br/>
<a href="http://pm2.keymetrics.io/" title="PM2 Keymetrics link">
<img width=710px src="https://raw.githubusercontent.com/Unitech/pm2/development/pres/pm2-v4.png" alt="pm2 logo">
</a>
<br/>
<br/>
<b>P</b>(rocess) <b>M</b>(anager) <b>2</b><br/>
<i>Runtime Edition</i>
<br/><br/>
<a href="https://img.shields.io/npm/dm/pm2" title="PM2 Tests">
<img src="https://img.shields.io/npm/dm/pm2" alt="Downloads per Month"/>
</a>
<a href="https://badge.fury.io/js/pm2" title="NPM Version Badge">
<img src="https://badge.fury.io/js/pm2.svg" alt="npm version">
</a>
<a href="https://img.shields.io/node/v/pm2.svg" title="Node Limitation">
<img src="https://img.shields.io/node/v/pm2.svg" alt="node version">
</a>
<a href="https://travis-ci.org/Unitech/pm2" title="PM2 Tests">
<img src="https://travis-ci.org/Unitech/pm2.svg?branch=master" alt="Build Status"/>
</a>
<br/>
<br/>
<br/>
</div>
PM2 is a production process manager for Node.js applications with a built-in load balancer. It allows you to keep applications alive forever, to reload them without downtime and to facilitate common system admin tasks.
Starting an application in production mode is as easy as:
```bash
$ pm2 start app.js
```
PM2 is constantly assailed by [more than 1800 tests](https://travis-ci.org/Unitech/pm2).
Official website: [https://pm2.keymetrics.io/](https://pm2.keymetrics.io/)
Works on Linux (stable) & macOS (stable) & Windows (stable). All Node.js versions are supported starting Node.js 8.X.
### Installing PM2
With NPM:
```bash
$ npm install pm2 -g
```
Or if you don't have Node.js installed:
```bash
wget -qO- https://getpm2.com/install.sh | bash
```
### Start an application
You can start any application (Node.js, Python, Ruby, binaries in $PATH...) like that:
```bash
$ pm2 start app.js
```
Your app is now daemonized, monitored and kept alive forever.
### Managing Applications
Once applications are started you can manage them easily:

To list all running applications:
```bash
$ pm2 list
```
Managing apps is straightforward:
```bash
$ pm2 stop <app_name|namespace|id|'all'|json_conf>
$ pm2 restart <app_name|namespace|id|'all'|json_conf>
$ pm2 delete <app_name|namespace|id|'all'|json_conf>
```
To have more details on a specific application:
```bash
$ pm2 describe <id|app_name>
```
To monitor logs, custom metrics, application information:
```bash
$ pm2 monit
```
[More about Process Management](https://pm2.keymetrics.io/docs/usage/process-management/)
### Cluster Mode: Node.js Load Balancing & Zero Downtime Reload
The Cluster mode is a special mode when starting a Node.js application, it starts multiple processes and load-balance HTTP/TCP/UDP queries between them. This increase overall performance (by a factor of x10 on 16 cores machines) and reliability (faster socket re-balancing in case of unhandled errors).
Starting a Node.js application in cluster mode that will leverage all CPUs available:
```bash
$ pm2 start api.js -i <processes>
```
`<processes>` can be `'max'`, `-1` (all cpu minus 1) or a specified number of instances to start.
**Zero Downtime Reload**
Hot Reload allows to update an application without any downtime:
```bash
$ pm2 reload all
```
Seamlessly supported by all major Node.js frameworks and any Node.js applications without any code change:

[More informations about how PM2 make clustering easy](https://pm2.keymetrics.io/docs/usage/cluster-mode/)
### Container Support
With the drop-in replacement command for `node`, called `pm2-runtime`, run your Node.js application in a hardened production environment.
Using it is seamless:
```
RUN npm install pm2 -g
CMD [ "pm2-runtime", "npm", "--", "start" ]
```
[Read More about the dedicated integration](https://pm2.keymetrics.io/docs/usage/docker-pm2-nodejs/)
### Terminal Based Monitoring

Monitor all processes launched straight from the command line:
```bash
$ pm2 monit
```
### Log Management
To consult logs just type the command:
```bash
$ pm2 logs
```
Standard, Raw, JSON and formated output are available.
Examples:
```bash
$ pm2 logs APP-NAME # Display APP-NAME logs
$ pm2 logs --json # JSON output
$ pm2 logs --format # Formated output
$ pm2 flush # Flush all logs
$ pm2 reloadLogs # Reload all logs
```
[More about log management](https://pm2.keymetrics.io/docs/usage/log-management/)
### Startup Scripts Generation
PM2 can generates and configure a Startup Script to keep PM2 and your processes alive at every server restart.
Init Systems Supported: **systemd**, **upstart**, **launchd**, **rc.d**
```bash
# Generate Startup Script
$ pm2 startup
# Freeze your process list across server restart
$ pm2 save
# Remove Startup Script
$ pm2 unstartup
```
[More about Startup Scripts Generation](https://pm2.keymetrics.io/docs/usage/startup/)
### PM2 Modules
PM2 embeds a simple and powerful module system. Installing a module is straightforward:
```bash
$ pm2 install <module_name>
```
Here are some PM2 compatible modules (standalone Node.js applications managed by PM2):
[**pm2-logrotate**](https://www.npmjs.com/package/pm2-logrotate) automatically rotate logs and limit logs size<br/>
[**pm2-server-monit**](https://www.npmjs.com/package/pm2-server-monit) monitor the current server with more than 20+ metrics and 8 actions<br/>
### Updating PM2
```bash
# Install latest PM2 version
$ npm install pm2@latest -g
# Save process list, exit old PM2 & restore all processes
$ pm2 update
```
*PM2 updates are seamless*
## PM2+ Monitoring
If you manage your apps with PM2, PM2+ makes it easy to monitor and manage apps across servers.
Feel free to try it:
[Discover the monitoring dashboard for PM2](https://app.pm2.io/)
Thanks in advance and we hope that you like PM2!
## CHANGELOG
[CHANGELOG](https://github.com/Unitech/PM2/blob/master/CHANGELOG.md)
## Contributors
[Contributors](http://pm2.keymetrics.io/hall-of-fame/)
## License
PM2 is made available under the terms of the GNU Affero General Public License 3.0 (AGPL 3.0).
For other licenses [contact us](mailto:[email protected]).
# diff-sequences
Compare items in two sequences to find a **longest common subsequence**.
The items not in common are the items to delete or insert in a **shortest edit script**.
To maximize flexibility and minimize memory, you write **callback** functions as configuration:
**Input** function `isCommon(aIndex, bIndex)` compares items at indexes in the sequences and returns a truthy/falsey value. This package might call your function more than once for some pairs of indexes.
- Because your function encapsulates **comparison**, this package can compare items according to `===` operator, `Object.is` method, or other criterion.
- Because your function encapsulates **sequences**, this package can find differences in arrays, strings, or other data.
**Output** function `foundSubsequence(nCommon, aCommon, bCommon)` receives the number of adjacent items and starting indexes of each common subsequence. If sequences do not have common items, then this package does not call your function.
If N is the sum of lengths of sequences and L is length of a longest common subsequence, then D = N – 2L is the number of **differences** in the corresponding shortest edit script.
[_An O(ND) Difference Algorithm and Its Variations_](http://xmailserver.org/diff2.pdf) by Eugene W. Myers is fast when sequences have **few** differences.
This package implements the **linear space** variation with optimizations so it is fast even when sequences have **many** differences.
## Usage
To add this package as a dependency of a project, do either of the following:
- `npm install diff-sequences`
- `yarn add diff-sequences`
To use `diff` as the name of the default export from this package, do either of the following:
- `var diff = require('diff-sequences'); // CommonJS modules`
- `import diff from 'diff-sequences'; // ECMAScript modules`
Call `diff` with the **lengths** of sequences and your **callback** functions:
```js
/* eslint-disable no-var */
var a = ['a', 'b', 'c', 'a', 'b', 'b', 'a'];
var b = ['c', 'b', 'a', 'b', 'a', 'c'];
function isCommon(aIndex, bIndex) {
return a[aIndex] === b[bIndex];
}
function foundSubsequence(nCommon, aCommon, bCommon) {
// see examples
}
diff(a.length, b.length, isCommon, foundSubsequence);
```
## Example of longest common subsequence
Some sequences (for example, `a` and `b` in the example of usage) have more than one longest common subsequence.
This package finds the following common items:
| comparisons of common items | values | output arguments |
| :------------------------------- | :--------- | --------------------------: |
| `a[2] === b[0]` | `'c'` | `foundSubsequence(1, 2, 0)` |
| `a[4] === b[1]` | `'b'` | `foundSubsequence(1, 4, 1)` |
| `a[5] === b[3] && a[6] === b[4]` | `'b', 'a'` | `foundSubsequence(2, 5, 3)` |
The “edit graph” analogy in the Myers paper shows the following common items:
| comparisons of common items | values |
| :------------------------------- | :--------- |
| `a[2] === b[0]` | `'c'` |
| `a[3] === b[2] && a[4] === b[3]` | `'a', 'b'` |
| `a[6] === b[4]` | `'a'` |
Various packages which implement the Myers algorithm will **always agree** on the **length** of a longest common subsequence, but might **sometimes disagree** on which **items** are in it.
## Example of callback functions to count common items
```js
/* eslint-disable no-var */
// Return length of longest common subsequence according to === operator.
function countCommonItems(a, b) {
var n = 0;
function isCommon(aIndex, bIndex) {
return a[aIndex] === b[bIndex];
}
function foundSubsequence(nCommon) {
n += nCommon;
}
diff(a.length, b.length, isCommon, foundSubsequence);
return n;
}
var commonLength = countCommonItems(
['a', 'b', 'c', 'a', 'b', 'b', 'a'],
['c', 'b', 'a', 'b', 'a', 'c'],
);
```
| category of items | expression | value |
| :----------------- | ------------------------: | ----: |
| in common | `commonLength` | `4` |
| to delete from `a` | `a.length - commonLength` | `3` |
| to insert from `b` | `b.length - commonLength` | `2` |
If the length difference `b.length - a.length` is:
- negative: its absolute value is the minimum number of items to **delete** from `a`
- positive: it is the minimum number of items to **insert** from `b`
- zero: there is an **equal** number of items to delete from `a` and insert from `b`
- non-zero: there is an equal number of **additional** items to delete from `a` and insert from `b`
In this example, `6 - 7` is:
- negative: `1` is the minimum number of items to **delete** from `a`
- non-zero: `2` is the number of **additional** items to delete from `a` and insert from `b`
## Example of callback functions to find common items
```js
// Return array of items in longest common subsequence according to Object.is method.
const findCommonItems = (a, b) => {
const array = [];
diff(
a.length,
b.length,
(aIndex, bIndex) => Object.is(a[aIndex], b[bIndex]),
(nCommon, aCommon) => {
for (; nCommon !== 0; nCommon -= 1, aCommon += 1) {
array.push(a[aCommon]);
}
},
);
return array;
};
const commonItems = findCommonItems(
['a', 'b', 'c', 'a', 'b', 'b', 'a'],
['c', 'b', 'a', 'b', 'a', 'c'],
);
```
| `i` | `commonItems[i]` | `aIndex` |
| --: | :--------------- | -------: |
| `0` | `'c'` | `2` |
| `1` | `'b'` | `4` |
| `2` | `'b'` | `5` |
| `3` | `'a'` | `6` |
## Example of callback functions to diff index intervals
Instead of slicing array-like objects, you can adjust indexes in your callback functions.
```js
// Diff index intervals that are half open [start, end) like array slice method.
const diffIndexIntervals = (a, aStart, aEnd, b, bStart, bEnd) => {
// Validate: 0 <= aStart and aStart <= aEnd and aEnd <= a.length
// Validate: 0 <= bStart and bStart <= bEnd and bEnd <= b.length
diff(
aEnd - aStart,
bEnd - bStart,
(aIndex, bIndex) => Object.is(a[aStart + aIndex], b[bStart + bIndex]),
(nCommon, aCommon, bCommon) => {
// aStart + aCommon, bStart + bCommon
},
);
// After the last common subsequence, do any remaining work.
};
```
## Example of callback functions to emulate diff command
Linux or Unix has a `diff` command to compare files line by line. Its output is a **shortest edit script**:
- **c**hange adjacent lines from the first file to lines from the second file
- **d**elete lines from the first file
- **a**ppend or insert lines from the second file
```js
// Given zero-based half-open range [start, end) of array indexes,
// return one-based closed range [start + 1, end] as string.
const getRange = (start, end) =>
start + 1 === end ? `${start + 1}` : `${start + 1},${end}`;
// Given index intervals of lines to delete or insert, or both, or neither,
// push formatted diff lines onto array.
const pushDelIns = (aLines, aIndex, aEnd, bLines, bIndex, bEnd, array) => {
const deleteLines = aIndex !== aEnd;
const insertLines = bIndex !== bEnd;
const changeLines = deleteLines && insertLines;
if (changeLines) {
array.push(getRange(aIndex, aEnd) + 'c' + getRange(bIndex, bEnd));
} else if (deleteLines) {
array.push(getRange(aIndex, aEnd) + 'd' + String(bIndex));
} else if (insertLines) {
array.push(String(aIndex) + 'a' + getRange(bIndex, bEnd));
} else {
return;
}
for (; aIndex !== aEnd; aIndex += 1) {
array.push('< ' + aLines[aIndex]); // delete is less than
}
if (changeLines) {
array.push('---');
}
for (; bIndex !== bEnd; bIndex += 1) {
array.push('> ' + bLines[bIndex]); // insert is greater than
}
};
// Given content of two files, return emulated output of diff utility.
const findShortestEditScript = (a, b) => {
const aLines = a.split('\n');
const bLines = b.split('\n');
const aLength = aLines.length;
const bLength = bLines.length;
const isCommon = (aIndex, bIndex) => aLines[aIndex] === bLines[bIndex];
let aIndex = 0;
let bIndex = 0;
const array = [];
const foundSubsequence = (nCommon, aCommon, bCommon) => {
pushDelIns(aLines, aIndex, aCommon, bLines, bIndex, bCommon, array);
aIndex = aCommon + nCommon; // number of lines compared in a
bIndex = bCommon + nCommon; // number of lines compared in b
};
diff(aLength, bLength, isCommon, foundSubsequence);
// After the last common subsequence, push remaining change lines.
pushDelIns(aLines, aIndex, aLength, bLines, bIndex, bLength, array);
return array.length === 0 ? '' : array.join('\n') + '\n';
};
```
## Example of callback functions to format diff lines
Here is simplified code to format **changed and unchanged lines** in expected and received values after a test fails in Jest:
```js
// Format diff with minus or plus for change lines and space for common lines.
const formatDiffLines = (a, b) => {
// Jest depends on pretty-format package to serialize objects as strings.
// Unindented for comparison to avoid distracting differences:
const aLinesUn = format(a, {indent: 0 /*, other options*/}).split('\n');
const bLinesUn = format(b, {indent: 0 /*, other options*/}).split('\n');
// Indented to display changed and unchanged lines:
const aLinesIn = format(a, {indent: 2 /*, other options*/}).split('\n');
const bLinesIn = format(b, {indent: 2 /*, other options*/}).split('\n');
const aLength = aLinesIn.length; // Validate: aLinesUn.length === aLength
const bLength = bLinesIn.length; // Validate: bLinesUn.length === bLength
const isCommon = (aIndex, bIndex) => aLinesUn[aIndex] === bLinesUn[bIndex];
// Only because the GitHub Flavored Markdown doc collapses adjacent spaces,
// this example code and the following table represent spaces as middle dots.
let aIndex = 0;
let bIndex = 0;
const array = [];
const foundSubsequence = (nCommon, aCommon, bCommon) => {
for (; aIndex !== aCommon; aIndex += 1) {
array.push('-·' + aLinesIn[aIndex]); // delete is minus
}
for (; bIndex !== bCommon; bIndex += 1) {
array.push('+·' + bLinesIn[bIndex]); // insert is plus
}
for (; nCommon !== 0; nCommon -= 1, aIndex += 1, bIndex += 1) {
// For common lines, received indentation seems more intuitive.
array.push('··' + bLinesIn[bIndex]); // common is space
}
};
diff(aLength, bLength, isCommon, foundSubsequence);
// After the last common subsequence, push remaining change lines.
for (; aIndex !== aLength; aIndex += 1) {
array.push('-·' + aLinesIn[aIndex]);
}
for (; bIndex !== bLength; bIndex += 1) {
array.push('+·' + bLinesIn[bIndex]);
}
return array;
};
const expected = {
searching: '',
sorting: {
ascending: true,
fieldKey: 'what',
},
};
const received = {
searching: '',
sorting: [
{
descending: false,
fieldKey: 'what',
},
],
};
const diffLines = formatDiffLines(expected, received);
```
If N is the sum of lengths of sequences and L is length of a longest common subsequence, then N – L is length of an array of diff lines. In this example, N is 7 + 9, L is 5, and N – L is 11.
| `i` | `diffLines[i]` | `aIndex` | `bIndex` |
| ---: | :--------------------------------- | -------: | -------: |
| `0` | `'··Object {'` | `0` | `0` |
| `1` | `'····"searching": "",'` | `1` | `1` |
| `2` | `'-···"sorting": Object {'` | `2` | |
| `3` | `'-·····"ascending": true,'` | `3` | |
| `4` | `'+·····"sorting": Array ['` | | `2` |
| `5` | `'+·······Object {'` | | `3` |
| `6` | `'+·········"descending": false,'` | | `4` |
| `7` | `'··········"fieldKey": "what",'` | `4` | `5` |
| `8` | `'········},'` | `5` | `6` |
| `9` | `'+·····],'` | | `7` |
| `10` | `'··}'` | `6` | `8` |
## Example of callback functions to find diff items
Here is simplified code to find changed and unchanged substrings **within adjacent changed lines** in expected and received values after a test fails in Jest:
```js
// Return diff items for strings (compatible with diff-match-patch package).
const findDiffItems = (a, b) => {
const isCommon = (aIndex, bIndex) => a[aIndex] === b[bIndex];
let aIndex = 0;
let bIndex = 0;
const array = [];
const foundSubsequence = (nCommon, aCommon, bCommon) => {
if (aIndex !== aCommon) {
array.push([-1, a.slice(aIndex, aCommon)]); // delete is -1
}
if (bIndex !== bCommon) {
array.push([1, b.slice(bIndex, bCommon)]); // insert is 1
}
aIndex = aCommon + nCommon; // number of characters compared in a
bIndex = bCommon + nCommon; // number of characters compared in b
array.push([0, a.slice(aCommon, aIndex)]); // common is 0
};
diff(a.length, b.length, isCommon, foundSubsequence);
// After the last common subsequence, push remaining change items.
if (aIndex !== a.length) {
array.push([-1, a.slice(aIndex)]);
}
if (bIndex !== b.length) {
array.push([1, b.slice(bIndex)]);
}
return array;
};
const expectedDeleted = ['"sorting": Object {', '"ascending": true,'].join(
'\n',
);
const receivedInserted = [
'"sorting": Array [',
'Object {',
'"descending": false,',
].join('\n');
const diffItems = findDiffItems(expectedDeleted, receivedInserted);
```
| `i` | `diffItems[i][0]` | `diffItems[i][1]` |
| --: | ----------------: | :---------------- |
| `0` | `0` | `'"sorting": '` |
| `1` | `1` | `'Array [\n'` |
| `2` | `0` | `'Object {\n"'` |
| `3` | `-1` | `'a'` |
| `4` | `1` | `'de'` |
| `5` | `0` | `'scending": '` |
| `6` | `-1` | `'tru'` |
| `7` | `1` | `'fals'` |
| `8` | `0` | `'e,'` |
The length difference `b.length - a.length` is equal to the sum of `diffItems[i][0]` values times `diffItems[i][1]` lengths. In this example, the difference `48 - 38` is equal to the sum `10`.
| category of diff item | `[0]` | `[1]` lengths | subtotal |
| :-------------------- | ----: | -----------------: | -------: |
| in common | `0` | `11 + 10 + 11 + 2` | `0` |
| to delete from `a` | `–1` | `1 + 3` | `-4` |
| to insert from `b` | `1` | `8 + 2 + 4` | `14` |
Instead of formatting the changed substrings with escape codes for colors in the `foundSubsequence` function to save memory, this example spends memory to **gain flexibility** before formatting, so a separate heuristic algorithm might modify the generic array of diff items to show changes more clearly:
| `i` | `diffItems[i][0]` | `diffItems[i][1]` |
| --: | ----------------: | :---------------- |
| `6` | `-1` | `'true'` |
| `7` | `1` | `'false'` |
| `8` | `0` | `','` |
For expected and received strings of serialized data, the result of finding changed **lines**, and then finding changed **substrings** within adjacent changed lines (as in the preceding two examples) sometimes displays the changes in a more intuitive way than the result of finding changed substrings, and then splitting them into changed and unchanged lines.
# bufferutil
[](https://www.npmjs.com/package/bufferutil)
[](https://travis-ci.org/websockets/bufferutil)
[](https://ci.appveyor.com/project/lpinca/bufferutil)
`bufferutil` is what makes `ws` fast. It provides some utilities to efficiently
perform some operations such as masking and unmasking the data payload of
WebSocket frames.
## Installation
```
npm install bufferutil --save-optional
```
The `--save-optional` flag tells npm to save the package in your package.json
under the [`optionalDependencies`](https://docs.npmjs.com/files/package.json#optionaldependencies)
key.
## API
The module exports two functions.
### `bufferUtil.mask(source, mask, output, offset, length)`
Masks a buffer using the given masking-key as specified by the WebSocket
protocol.
#### Arguments
- `source` - The buffer to mask.
- `mask` - A buffer representing the masking-key.
- `output` - The buffer where to store the result.
- `offset` - The offset at which to start writing.
- `length` - The number of bytes to mask.
#### Example
```js
'use strict';
const bufferUtil = require('bufferutil');
const crypto = require('crypto');
const source = crypto.randomBytes(10);
const mask = crypto.randomBytes(4);
bufferUtil.mask(source, mask, source, 0, source.length);
```
### `bufferUtil.unmask(buffer, mask)`
Unmasks a buffer using the given masking-key as specified by the WebSocket
protocol.
#### Arguments
- `buffer` - The buffer to unmask.
- `mask` - A buffer representing the masking-key.
#### Example
```js
'use strict';
const bufferUtil = require('bufferutil');
const crypto = require('crypto');
const buffer = crypto.randomBytes(10);
const mask = crypto.randomBytes(4);
bufferUtil.unmask(buffer, mask);
```
## License
[MIT](LICENSE)
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# is-function
[](https://ci.testling.com/grncdr/js-is-function)
Is that thing a function? Use this module to find out.
## API
### module.exports = function isFunction(fn) -> Boolean
Return `true` if `fn` is a function, otherwise `false`.
## Why not typeof fn === 'function'
Because certain old browsers misreport the type of `RegExp` objects as functions.
## Acknowledgements
I stole this from https://github.com/ljharb/object-keys
## License
MIT
# serve-static
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Linux Build][travis-image]][travis-url]
[![Windows Build][appveyor-image]][appveyor-url]
[![Test Coverage][coveralls-image]][coveralls-url]
## Install
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install serve-static
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var serveStatic = require('serve-static')
```
### serveStatic(root, options)
Create a new middleware function to serve files from within a given root
directory. The file to serve will be determined by combining `req.url`
with the provided root directory. When a file is not found, instead of
sending a 404 response, this module will instead call `next()` to move on
to the next middleware, allowing for stacking and fall-backs.
#### Options
##### acceptRanges
Enable or disable accepting ranged requests, defaults to true.
Disabling this will not send `Accept-Ranges` and ignore the contents
of the `Range` request header.
##### cacheControl
Enable or disable setting `Cache-Control` response header, defaults to
true. Disabling this will ignore the `immutable` and `maxAge` options.
##### dotfiles
Set how "dotfiles" are treated when encountered. A dotfile is a file
or directory that begins with a dot ("."). Note this check is done on
the path itself without checking if the path actually exists on the
disk. If `root` is specified, only the dotfiles above the root are
checked (i.e. the root itself can be within a dotfile when set
to "deny").
- `'allow'` No special treatment for dotfiles.
- `'deny'` Deny a request for a dotfile and 403/`next()`.
- `'ignore'` Pretend like the dotfile does not exist and 404/`next()`.
The default value is similar to `'ignore'`, with the exception that this
default will not ignore the files within a directory that begins with a dot.
##### etag
Enable or disable etag generation, defaults to true.
##### extensions
Set file extension fallbacks. When set, if a file is not found, the given
extensions will be added to the file name and search for. The first that
exists will be served. Example: `['html', 'htm']`.
The default value is `false`.
##### fallthrough
Set the middleware to have client errors fall-through as just unhandled
requests, otherwise forward a client error. The difference is that client
errors like a bad request or a request to a non-existent file will cause
this middleware to simply `next()` to your next middleware when this value
is `true`. When this value is `false`, these errors (even 404s), will invoke
`next(err)`.
Typically `true` is desired such that multiple physical directories can be
mapped to the same web address or for routes to fill in non-existent files.
The value `false` can be used if this middleware is mounted at a path that
is designed to be strictly a single file system directory, which allows for
short-circuiting 404s for less overhead. This middleware will also reply to
all methods.
The default value is `true`.
##### immutable
Enable or disable the `immutable` directive in the `Cache-Control` response
header, defaults to `false`. If set to `true`, the `maxAge` option should
also be specified to enable caching. The `immutable` directive will prevent
supported clients from making conditional requests during the life of the
`maxAge` option to check if the file has changed.
##### index
By default this module will send "index.html" files in response to a request
on a directory. To disable this set `false` or to supply a new index pass a
string or an array in preferred order.
##### lastModified
Enable or disable `Last-Modified` header, defaults to true. Uses the file
system's last modified value.
##### maxAge
Provide a max-age in milliseconds for http caching, defaults to 0. This
can also be a string accepted by the [ms](https://www.npmjs.org/package/ms#readme)
module.
##### redirect
Redirect to trailing "/" when the pathname is a dir. Defaults to `true`.
##### setHeaders
Function to set custom headers on response. Alterations to the headers need to
occur synchronously. The function is called as `fn(res, path, stat)`, where
the arguments are:
- `res` the response object
- `path` the file path that is being sent
- `stat` the stat object of the file that is being sent
## Examples
### Serve files with vanilla node.js http server
```js
var finalhandler = require('finalhandler')
var http = require('http')
var serveStatic = require('serve-static')
// Serve up public/ftp folder
var serve = serveStatic('public/ftp', { 'index': ['index.html', 'index.htm'] })
// Create server
var server = http.createServer(function onRequest (req, res) {
serve(req, res, finalhandler(req, res))
})
// Listen
server.listen(3000)
```
### Serve all files as downloads
```js
var contentDisposition = require('content-disposition')
var finalhandler = require('finalhandler')
var http = require('http')
var serveStatic = require('serve-static')
// Serve up public/ftp folder
var serve = serveStatic('public/ftp', {
'index': false,
'setHeaders': setHeaders
})
// Set header to force download
function setHeaders (res, path) {
res.setHeader('Content-Disposition', contentDisposition(path))
}
// Create server
var server = http.createServer(function onRequest (req, res) {
serve(req, res, finalhandler(req, res))
})
// Listen
server.listen(3000)
```
### Serving using express
#### Simple
This is a simple example of using Express.
```js
var express = require('express')
var serveStatic = require('serve-static')
var app = express()
app.use(serveStatic('public/ftp', { 'index': ['default.html', 'default.htm'] }))
app.listen(3000)
```
#### Multiple roots
This example shows a simple way to search through multiple directories.
Files are look for in `public-optimized/` first, then `public/` second as
a fallback.
```js
var express = require('express')
var path = require('path')
var serveStatic = require('serve-static')
var app = express()
app.use(serveStatic(path.join(__dirname, 'public-optimized')))
app.use(serveStatic(path.join(__dirname, 'public')))
app.listen(3000)
```
#### Different settings for paths
This example shows how to set a different max age depending on the served
file type. In this example, HTML files are not cached, while everything else
is for 1 day.
```js
var express = require('express')
var path = require('path')
var serveStatic = require('serve-static')
var app = express()
app.use(serveStatic(path.join(__dirname, 'public'), {
maxAge: '1d',
setHeaders: setCustomCacheControl
}))
app.listen(3000)
function setCustomCacheControl (res, path) {
if (serveStatic.mime.lookup(path) === 'text/html') {
// Custom Cache-Control for HTML files
res.setHeader('Cache-Control', 'public, max-age=0')
}
}
```
## License
[MIT](LICENSE)
[appveyor-image]: https://badgen.net/appveyor/ci/dougwilson/serve-static/master?label=windows
[appveyor-url]: https://ci.appveyor.com/project/dougwilson/serve-static
[coveralls-image]: https://badgen.net/coveralls/c/github/expressjs/serve-static/master
[coveralls-url]: https://coveralls.io/r/expressjs/serve-static?branch=master
[node-image]: https://badgen.net/npm/node/serve-static
[node-url]: https://nodejs.org/en/download/
[npm-downloads-image]: https://badgen.net/npm/dm/serve-static
[npm-url]: https://npmjs.org/package/serve-static
[npm-version-image]: https://badgen.net/npm/v/serve-static
[travis-image]: https://badgen.net/travis/expressjs/serve-static/master?label=linux
[travis-url]: https://travis-ci.org/expressjs/serve-static
# is-glob [](http://badge.fury.io/js/is-glob) [](https://travis-ci.org/jonschlinkert/is-glob)
> Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a better user experience.
Also take a look at [is-valid-glob](https://github.com/jonschlinkert/is-valid-glob) and [has-glob](https://github.com/jonschlinkert/has-glob).
## Install
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i is-glob --save
```
## Usage
```js
var isGlob = require('is-glob');
```
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js');
isGlob('*.js');
isGlob('**/abc.js');
isGlob('abc/*.js');
isGlob('abc/(aaa|bbb).js');
isGlob('abc/[a-z].js');
isGlob('abc/{a,b}.js');
isGlob('abc/?.js');
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js');
isGlob('abc/!(a).js');
isGlob('abc/+(a).js');
isGlob('abc/*(a).js');
isGlob('abc/?(a).js');
//=> true
```
**False**
Patterns that do not have glob patterns return `false`:
```js
isGlob('abc.js');
isGlob('abc/def/ghi.js');
isGlob('foo.js');
isGlob('abc/@.js');
isGlob('abc/+.js');
isGlob();
isGlob(null);
//=> false
```
Arrays are also `false` (If you want to check if an array has a glob pattern, use [has-glob](https://github.com/jonschlinkert/has-glob)):
```js
isGlob(['**/*.js']);
isGlob(['foo.js']);
//=> false
```
## Related
* [has-glob](https://www.npmjs.com/package/has-glob): Returns `true` if an array has a glob pattern. | [homepage](https://github.com/jonschlinkert/has-glob)
* [is-extglob](https://www.npmjs.com/package/is-extglob): Returns true if a string has an extglob. | [homepage](https://github.com/jonschlinkert/is-extglob)
* [is-posix-bracket](https://www.npmjs.com/package/is-posix-bracket): Returns true if the given string is a POSIX bracket expression (POSIX character class). | [homepage](https://github.com/jonschlinkert/is-posix-bracket)
* [is-valid-glob](https://www.npmjs.com/package/is-valid-glob): Return true if a value is a valid glob pattern or patterns. | [homepage](https://github.com/jonschlinkert/is-valid-glob)
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. Just… [more](https://www.npmjs.com/package/micromatch) | [homepage](https://github.com/jonschlinkert/micromatch)
## Run tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-glob/issues/new).
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2015 Jon Schlinkert
Released under the MIT license.
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on October 02, 2015._
node-fetch
==========
[![npm version][npm-image]][npm-url]
[![build status][travis-image]][travis-url]
[![coverage status][codecov-image]][codecov-url]
[![install size][install-size-image]][install-size-url]
[![Discord][discord-image]][discord-url]
A light-weight module that brings `window.fetch` to Node.js
(We are looking for [v2 maintainers and collaborators](https://github.com/bitinn/node-fetch/issues/567))
[![Backers][opencollective-image]][opencollective-url]
<!-- TOC -->
- [Motivation](#motivation)
- [Features](#features)
- [Difference from client-side fetch](#difference-from-client-side-fetch)
- [Installation](#installation)
- [Loading and configuring the module](#loading-and-configuring-the-module)
- [Common Usage](#common-usage)
- [Plain text or HTML](#plain-text-or-html)
- [JSON](#json)
- [Simple Post](#simple-post)
- [Post with JSON](#post-with-json)
- [Post with form parameters](#post-with-form-parameters)
- [Handling exceptions](#handling-exceptions)
- [Handling client and server errors](#handling-client-and-server-errors)
- [Advanced Usage](#advanced-usage)
- [Streams](#streams)
- [Buffer](#buffer)
- [Accessing Headers and other Meta data](#accessing-headers-and-other-meta-data)
- [Extract Set-Cookie Header](#extract-set-cookie-header)
- [Post data using a file stream](#post-data-using-a-file-stream)
- [Post with form-data (detect multipart)](#post-with-form-data-detect-multipart)
- [Request cancellation with AbortSignal](#request-cancellation-with-abortsignal)
- [API](#api)
- [fetch(url[, options])](#fetchurl-options)
- [Options](#options)
- [Class: Request](#class-request)
- [Class: Response](#class-response)
- [Class: Headers](#class-headers)
- [Interface: Body](#interface-body)
- [Class: FetchError](#class-fetcherror)
- [License](#license)
- [Acknowledgement](#acknowledgement)
<!-- /TOC -->
## Motivation
Instead of implementing `XMLHttpRequest` in Node.js to run browser-specific [Fetch polyfill](https://github.com/github/fetch), why not go from native `http` to `fetch` API directly? Hence, `node-fetch`, minimal code for a `window.fetch` compatible API on Node.js runtime.
See Matt Andrews' [isomorphic-fetch](https://github.com/matthew-andrews/isomorphic-fetch) or Leonardo Quixada's [cross-fetch](https://github.com/lquixada/cross-fetch) for isomorphic usage (exports `node-fetch` for server-side, `whatwg-fetch` for client-side).
## Features
- Stay consistent with `window.fetch` API.
- Make conscious trade-off when following [WHATWG fetch spec][whatwg-fetch] and [stream spec](https://streams.spec.whatwg.org/) implementation details, document known differences.
- Use native promise but allow substituting it with [insert your favorite promise library].
- Use native Node streams for body on both request and response.
- Decode content encoding (gzip/deflate) properly and convert string output (such as `res.text()` and `res.json()`) to UTF-8 automatically.
- Useful extensions such as timeout, redirect limit, response size limit, [explicit errors](ERROR-HANDLING.md) for troubleshooting.
## Difference from client-side fetch
- See [Known Differences](LIMITS.md) for details.
- If you happen to use a missing feature that `window.fetch` offers, feel free to open an issue.
- Pull requests are welcomed too!
## Installation
Current stable release (`2.x`)
```sh
$ npm install node-fetch
```
## Loading and configuring the module
We suggest you load the module via `require` until the stabilization of ES modules in node:
```js
const fetch = require('node-fetch');
```
If you are using a Promise library other than native, set it through `fetch.Promise`:
```js
const Bluebird = require('bluebird');
fetch.Promise = Bluebird;
```
## Common Usage
NOTE: The documentation below is up-to-date with `2.x` releases; see the [`1.x` readme](https://github.com/bitinn/node-fetch/blob/1.x/README.md), [changelog](https://github.com/bitinn/node-fetch/blob/1.x/CHANGELOG.md) and [2.x upgrade guide](UPGRADE-GUIDE.md) for the differences.
#### Plain text or HTML
```js
fetch('https://github.com/')
.then(res => res.text())
.then(body => console.log(body));
```
#### JSON
```js
fetch('https://api.github.com/users/github')
.then(res => res.json())
.then(json => console.log(json));
```
#### Simple Post
```js
fetch('https://httpbin.org/post', { method: 'POST', body: 'a=1' })
.then(res => res.json()) // expecting a json response
.then(json => console.log(json));
```
#### Post with JSON
```js
const body = { a: 1 };
fetch('https://httpbin.org/post', {
method: 'post',
body: JSON.stringify(body),
headers: { 'Content-Type': 'application/json' },
})
.then(res => res.json())
.then(json => console.log(json));
```
#### Post with form parameters
`URLSearchParams` is available in Node.js as of v7.5.0. See [official documentation](https://nodejs.org/api/url.html#url_class_urlsearchparams) for more usage methods.
NOTE: The `Content-Type` header is only set automatically to `x-www-form-urlencoded` when an instance of `URLSearchParams` is given as such:
```js
const { URLSearchParams } = require('url');
const params = new URLSearchParams();
params.append('a', 1);
fetch('https://httpbin.org/post', { method: 'POST', body: params })
.then(res => res.json())
.then(json => console.log(json));
```
#### Handling exceptions
NOTE: 3xx-5xx responses are *NOT* exceptions and should be handled in `then()`; see the next section for more information.
Adding a catch to the fetch promise chain will catch *all* exceptions, such as errors originating from node core libraries, network errors and operational errors, which are instances of FetchError. See the [error handling document](ERROR-HANDLING.md) for more details.
```js
fetch('https://domain.invalid/')
.catch(err => console.error(err));
```
#### Handling client and server errors
It is common to create a helper function to check that the response contains no client (4xx) or server (5xx) error responses:
```js
function checkStatus(res) {
if (res.ok) { // res.status >= 200 && res.status < 300
return res;
} else {
throw MyCustomError(res.statusText);
}
}
fetch('https://httpbin.org/status/400')
.then(checkStatus)
.then(res => console.log('will not get here...'))
```
## Advanced Usage
#### Streams
The "Node.js way" is to use streams when possible:
```js
fetch('https://assets-cdn.github.com/images/modules/logos_page/Octocat.png')
.then(res => {
const dest = fs.createWriteStream('./octocat.png');
res.body.pipe(dest);
});
```
#### Buffer
If you prefer to cache binary data in full, use buffer(). (NOTE: `buffer()` is a `node-fetch`-only API)
```js
const fileType = require('file-type');
fetch('https://assets-cdn.github.com/images/modules/logos_page/Octocat.png')
.then(res => res.buffer())
.then(buffer => fileType(buffer))
.then(type => { /* ... */ });
```
#### Accessing Headers and other Meta data
```js
fetch('https://github.com/')
.then(res => {
console.log(res.ok);
console.log(res.status);
console.log(res.statusText);
console.log(res.headers.raw());
console.log(res.headers.get('content-type'));
});
```
#### Extract Set-Cookie Header
Unlike browsers, you can access raw `Set-Cookie` headers manually using `Headers.raw()`. This is a `node-fetch` only API.
```js
fetch(url).then(res => {
// returns an array of values, instead of a string of comma-separated values
console.log(res.headers.raw()['set-cookie']);
});
```
#### Post data using a file stream
```js
const { createReadStream } = require('fs');
const stream = createReadStream('input.txt');
fetch('https://httpbin.org/post', { method: 'POST', body: stream })
.then(res => res.json())
.then(json => console.log(json));
```
#### Post with form-data (detect multipart)
```js
const FormData = require('form-data');
const form = new FormData();
form.append('a', 1);
fetch('https://httpbin.org/post', { method: 'POST', body: form })
.then(res => res.json())
.then(json => console.log(json));
// OR, using custom headers
// NOTE: getHeaders() is non-standard API
const form = new FormData();
form.append('a', 1);
const options = {
method: 'POST',
body: form,
headers: form.getHeaders()
}
fetch('https://httpbin.org/post', options)
.then(res => res.json())
.then(json => console.log(json));
```
#### Request cancellation with AbortSignal
> NOTE: You may cancel streamed requests only on Node >= v8.0.0
You may cancel requests with `AbortController`. A suggested implementation is [`abort-controller`](https://www.npmjs.com/package/abort-controller).
An example of timing out a request after 150ms could be achieved as the following:
```js
import AbortController from 'abort-controller';
const controller = new AbortController();
const timeout = setTimeout(
() => { controller.abort(); },
150,
);
fetch(url, { signal: controller.signal })
.then(res => res.json())
.then(
data => {
useData(data)
},
err => {
if (err.name === 'AbortError') {
// request was aborted
}
},
)
.finally(() => {
clearTimeout(timeout);
});
```
See [test cases](https://github.com/bitinn/node-fetch/blob/master/test/test.js) for more examples.
## API
### fetch(url[, options])
- `url` A string representing the URL for fetching
- `options` [Options](#fetch-options) for the HTTP(S) request
- Returns: <code>Promise<[Response](#class-response)></code>
Perform an HTTP(S) fetch.
`url` should be an absolute url, such as `https://example.com/`. A path-relative URL (`/file/under/root`) or protocol-relative URL (`//can-be-http-or-https.com/`) will result in a rejected `Promise`.
<a id="fetch-options"></a>
### Options
The default values are shown after each option key.
```js
{
// These properties are part of the Fetch Standard
method: 'GET',
headers: {}, // request headers. format is the identical to that accepted by the Headers constructor (see below)
body: null, // request body. can be null, a string, a Buffer, a Blob, or a Node.js Readable stream
redirect: 'follow', // set to `manual` to extract redirect headers, `error` to reject redirect
signal: null, // pass an instance of AbortSignal to optionally abort requests
// The following properties are node-fetch extensions
follow: 20, // maximum redirect count. 0 to not follow redirect
timeout: 0, // req/res timeout in ms, it resets on redirect. 0 to disable (OS limit applies). Signal is recommended instead.
compress: true, // support gzip/deflate content encoding. false to disable
size: 0, // maximum response body size in bytes. 0 to disable
agent: null // http(s).Agent instance or function that returns an instance (see below)
}
```
##### Default Headers
If no values are set, the following request headers will be sent automatically:
Header | Value
------------------- | --------------------------------------------------------
`Accept-Encoding` | `gzip,deflate` _(when `options.compress === true`)_
`Accept` | `*/*`
`Connection` | `close` _(when no `options.agent` is present)_
`Content-Length` | _(automatically calculated, if possible)_
`Transfer-Encoding` | `chunked` _(when `req.body` is a stream)_
`User-Agent` | `node-fetch/1.0 (+https://github.com/bitinn/node-fetch)`
Note: when `body` is a `Stream`, `Content-Length` is not set automatically.
##### Custom Agent
The `agent` option allows you to specify networking related options which are out of the scope of Fetch, including and not limited to the following:
- Support self-signed certificate
- Use only IPv4 or IPv6
- Custom DNS Lookup
See [`http.Agent`](https://nodejs.org/api/http.html#http_new_agent_options) for more information.
In addition, the `agent` option accepts a function that returns `http`(s)`.Agent` instance given current [URL](https://nodejs.org/api/url.html), this is useful during a redirection chain across HTTP and HTTPS protocol.
```js
const httpAgent = new http.Agent({
keepAlive: true
});
const httpsAgent = new https.Agent({
keepAlive: true
});
const options = {
agent: function (_parsedURL) {
if (_parsedURL.protocol == 'http:') {
return httpAgent;
} else {
return httpsAgent;
}
}
}
```
<a id="class-request"></a>
### Class: Request
An HTTP(S) request containing information about URL, method, headers, and the body. This class implements the [Body](#iface-body) interface.
Due to the nature of Node.js, the following properties are not implemented at this moment:
- `type`
- `destination`
- `referrer`
- `referrerPolicy`
- `mode`
- `credentials`
- `cache`
- `integrity`
- `keepalive`
The following node-fetch extension properties are provided:
- `follow`
- `compress`
- `counter`
- `agent`
See [options](#fetch-options) for exact meaning of these extensions.
#### new Request(input[, options])
<small>*(spec-compliant)*</small>
- `input` A string representing a URL, or another `Request` (which will be cloned)
- `options` [Options][#fetch-options] for the HTTP(S) request
Constructs a new `Request` object. The constructor is identical to that in the [browser](https://developer.mozilla.org/en-US/docs/Web/API/Request/Request).
In most cases, directly `fetch(url, options)` is simpler than creating a `Request` object.
<a id="class-response"></a>
### Class: Response
An HTTP(S) response. This class implements the [Body](#iface-body) interface.
The following properties are not implemented in node-fetch at this moment:
- `Response.error()`
- `Response.redirect()`
- `type`
- `trailer`
#### new Response([body[, options]])
<small>*(spec-compliant)*</small>
- `body` A `String` or [`Readable` stream][node-readable]
- `options` A [`ResponseInit`][response-init] options dictionary
Constructs a new `Response` object. The constructor is identical to that in the [browser](https://developer.mozilla.org/en-US/docs/Web/API/Response/Response).
Because Node.js does not implement service workers (for which this class was designed), one rarely has to construct a `Response` directly.
#### response.ok
<small>*(spec-compliant)*</small>
Convenience property representing if the request ended normally. Will evaluate to true if the response status was greater than or equal to 200 but smaller than 300.
#### response.redirected
<small>*(spec-compliant)*</small>
Convenience property representing if the request has been redirected at least once. Will evaluate to true if the internal redirect counter is greater than 0.
<a id="class-headers"></a>
### Class: Headers
This class allows manipulating and iterating over a set of HTTP headers. All methods specified in the [Fetch Standard][whatwg-fetch] are implemented.
#### new Headers([init])
<small>*(spec-compliant)*</small>
- `init` Optional argument to pre-fill the `Headers` object
Construct a new `Headers` object. `init` can be either `null`, a `Headers` object, an key-value map object or any iterable object.
```js
// Example adapted from https://fetch.spec.whatwg.org/#example-headers-class
const meta = {
'Content-Type': 'text/xml',
'Breaking-Bad': '<3'
};
const headers = new Headers(meta);
// The above is equivalent to
const meta = [
[ 'Content-Type', 'text/xml' ],
[ 'Breaking-Bad', '<3' ]
];
const headers = new Headers(meta);
// You can in fact use any iterable objects, like a Map or even another Headers
const meta = new Map();
meta.set('Content-Type', 'text/xml');
meta.set('Breaking-Bad', '<3');
const headers = new Headers(meta);
const copyOfHeaders = new Headers(headers);
```
<a id="iface-body"></a>
### Interface: Body
`Body` is an abstract interface with methods that are applicable to both `Request` and `Response` classes.
The following methods are not yet implemented in node-fetch at this moment:
- `formData()`
#### body.body
<small>*(deviation from spec)*</small>
* Node.js [`Readable` stream][node-readable]
Data are encapsulated in the `Body` object. Note that while the [Fetch Standard][whatwg-fetch] requires the property to always be a WHATWG `ReadableStream`, in node-fetch it is a Node.js [`Readable` stream][node-readable].
#### body.bodyUsed
<small>*(spec-compliant)*</small>
* `Boolean`
A boolean property for if this body has been consumed. Per the specs, a consumed body cannot be used again.
#### body.arrayBuffer()
#### body.blob()
#### body.json()
#### body.text()
<small>*(spec-compliant)*</small>
* Returns: <code>Promise</code>
Consume the body and return a promise that will resolve to one of these formats.
#### body.buffer()
<small>*(node-fetch extension)*</small>
* Returns: <code>Promise<Buffer></code>
Consume the body and return a promise that will resolve to a Buffer.
#### body.textConverted()
<small>*(node-fetch extension)*</small>
* Returns: <code>Promise<String></code>
Identical to `body.text()`, except instead of always converting to UTF-8, encoding sniffing will be performed and text converted to UTF-8 if possible.
(This API requires an optional dependency of the npm package [encoding](https://www.npmjs.com/package/encoding), which you need to install manually. `webpack` users may see [a warning message](https://github.com/bitinn/node-fetch/issues/412#issuecomment-379007792) due to this optional dependency.)
<a id="class-fetcherror"></a>
### Class: FetchError
<small>*(node-fetch extension)*</small>
An operational error in the fetching process. See [ERROR-HANDLING.md][] for more info.
<a id="class-aborterror"></a>
### Class: AbortError
<small>*(node-fetch extension)*</small>
An Error thrown when the request is aborted in response to an `AbortSignal`'s `abort` event. It has a `name` property of `AbortError`. See [ERROR-HANDLING.MD][] for more info.
## Acknowledgement
Thanks to [github/fetch](https://github.com/github/fetch) for providing a solid implementation reference.
`node-fetch` v1 was maintained by [@bitinn](https://github.com/bitinn); v2 was maintained by [@TimothyGu](https://github.com/timothygu), [@bitinn](https://github.com/bitinn) and [@jimmywarting](https://github.com/jimmywarting); v2 readme is written by [@jkantr](https://github.com/jkantr).
## License
MIT
[npm-image]: https://flat.badgen.net/npm/v/node-fetch
[npm-url]: https://www.npmjs.com/package/node-fetch
[travis-image]: https://flat.badgen.net/travis/bitinn/node-fetch
[travis-url]: https://travis-ci.org/bitinn/node-fetch
[codecov-image]: https://flat.badgen.net/codecov/c/github/bitinn/node-fetch/master
[codecov-url]: https://codecov.io/gh/bitinn/node-fetch
[install-size-image]: https://flat.badgen.net/packagephobia/install/node-fetch
[install-size-url]: https://packagephobia.now.sh/result?p=node-fetch
[discord-image]: https://img.shields.io/discord/619915844268326952?color=%237289DA&label=Discord&style=flat-square
[discord-url]: https://discord.gg/Zxbndcm
[opencollective-image]: https://opencollective.com/node-fetch/backers.svg
[opencollective-url]: https://opencollective.com/node-fetch
[whatwg-fetch]: https://fetch.spec.whatwg.org/
[response-init]: https://fetch.spec.whatwg.org/#responseinit
[node-readable]: https://nodejs.org/api/stream.html#stream_readable_streams
[mdn-headers]: https://developer.mozilla.org/en-US/docs/Web/API/Headers
[LIMITS.md]: https://github.com/bitinn/node-fetch/blob/master/LIMITS.md
[ERROR-HANDLING.md]: https://github.com/bitinn/node-fetch/blob/master/ERROR-HANDLING.md
[UPGRADE-GUIDE.md]: https://github.com/bitinn/node-fetch/blob/master/UPGRADE-GUIDE.md
# accepts
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Higher level content negotiation based on [negotiator](https://www.npmjs.com/package/negotiator).
Extracted from [koa](https://www.npmjs.com/package/koa) for general use.
In addition to negotiator, it allows:
- Allows types as an array or arguments list, ie `(['text/html', 'application/json'])`
as well as `('text/html', 'application/json')`.
- Allows type shorthands such as `json`.
- Returns `false` when no types match
- Treats non-existent headers as `*`
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install accepts
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var accepts = require('accepts')
```
### accepts(req)
Create a new `Accepts` object for the given `req`.
#### .charset(charsets)
Return the first accepted charset. If nothing in `charsets` is accepted,
then `false` is returned.
#### .charsets()
Return the charsets that the request accepts, in the order of the client's
preference (most preferred first).
#### .encoding(encodings)
Return the first accepted encoding. If nothing in `encodings` is accepted,
then `false` is returned.
#### .encodings()
Return the encodings that the request accepts, in the order of the client's
preference (most preferred first).
#### .language(languages)
Return the first accepted language. If nothing in `languages` is accepted,
then `false` is returned.
#### .languages()
Return the languages that the request accepts, in the order of the client's
preference (most preferred first).
#### .type(types)
Return the first accepted type (and it is returned as the same text as what
appears in the `types` array). If nothing in `types` is accepted, then `false`
is returned.
The `types` array can contain full MIME types or file extensions. Any value
that is not a full MIME types is passed to `require('mime-types').lookup`.
#### .types()
Return the types that the request accepts, in the order of the client's
preference (most preferred first).
## Examples
### Simple type negotiation
This simple example shows how to use `accepts` to return a different typed
respond body based on what the client wants to accept. The server lists it's
preferences in order and will get back the best match between the client and
server.
```js
var accepts = require('accepts')
var http = require('http')
function app (req, res) {
var accept = accepts(req)
// the order of this list is significant; should be server preferred order
switch (accept.type(['json', 'html'])) {
case 'json':
res.setHeader('Content-Type', 'application/json')
res.write('{"hello":"world!"}')
break
case 'html':
res.setHeader('Content-Type', 'text/html')
res.write('<b>hello, world!</b>')
break
default:
// the fallback is text/plain, so no need to specify it above
res.setHeader('Content-Type', 'text/plain')
res.write('hello, world!')
break
}
res.end()
}
http.createServer(app).listen(3000)
```
You can test this out with the cURL program:
```sh
curl -I -H'Accept: text/html' http://localhost:3000/
```
## License
[MIT](LICENSE)
[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/accepts/master
[coveralls-url]: https://coveralls.io/r/jshttp/accepts?branch=master
[node-version-image]: https://badgen.net/npm/node/accepts
[node-version-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/accepts
[npm-url]: https://npmjs.org/package/accepts
[npm-version-image]: https://badgen.net/npm/v/accepts
[travis-image]: https://badgen.net/travis/jshttp/accepts/master
[travis-url]: https://travis-ci.org/jshttp/accepts
# run-series [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/run-series/master.svg
[travis-url]: https://travis-ci.org/feross/run-series
[npm-image]: https://img.shields.io/npm/v/run-series.svg
[npm-url]: https://npmjs.org/package/run-series
[downloads-image]: https://img.shields.io/npm/dm/run-series.svg
[downloads-url]: https://npmjs.org/package/run-series
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
### Run an array of functions in series
 [](https://saucelabs.com/u/run-series)
### install
```
npm install run-series
```
### usage
#### series(tasks, [callback])
Run the functions in the `tasks` array in series, each one running once the previous
function has completed. If any functions in the series pass an error to its callback, no
more functions are run, and `callback` is immediately called with the value of the error.
Otherwise, `callback` receives an array of results when `tasks` have completed.
##### arguments
- `tasks` - An array containing functions to run, each function is passed a
`callback(err, result)` which it must call on completion with an error `err` (which can
be `null`) and an optional result value.
- `callback(err, results)` - An optional callback to run once all the functions have
completed. This function gets a results array containing all the result arguments passed
to the task callbacks.
##### example
```js
var series = require('run-series')
series([
function (callback) {
// do some stuff ...
callback(null, 'one')
},
function (callback) {
// do some stuff ...
callback(null, 'two')
}
],
// optional callback
function (err, results) {
// the results array will equal ['one','two']
})
```
This module is basically equavalent to
[`async.series`](https://github.com/caolan/async#seriestasks-callback), but it's
handy to just have the functions you need instead of the kitchen sink. Modularity!
Especially handy if you're serving to the browser and need to reduce your javascript
bundle size.
Works great in the browser with [browserify](http://browserify.org/)!
### see also
- [run-auto](https://github.com/feross/run-auto)
- [run-parallel](https://github.com/feross/run-parallel)
- [run-parallel-limit](https://github.com/feross/run-parallel-limit)
- [run-waterfall](https://github.com/feross/run-waterfall)
### license
MIT. Copyright (c) [Feross Aboukhadijeh](http://feross.org).
# minimalistic-crypto-utils
[](http://travis-ci.org/indutny/minimalistic-crypto-utils)
[](http://badge.fury.io/js/minimalistic-crypto-utils)
Very minimal utils that are required in order to write reasonable JS-only
crypto module.
## Usage
```js
const utils = require('minimalistic-crypto-utils');
utils.toArray('abcd', 'hex');
utils.encode([ 1, 2, 3, 4 ], 'hex');
utils.toHex([ 1, 2, 3, 4 ]);
```
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2017.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: http://tools.ietf.org/html/rfc6979
[1]: https://github.com/indutny/bn.js
[2]: https://github.com/indutny/hash.js
[3]: https://github.com/bitchan/eccrypto
[4]: https://github.com/wanderer/secp256k1-node
# xhr-request
[](http://github.com/badges/stability-badges)
An extremely tiny HTTP/HTTPS request client for Node and the browser. Uses [xhr](https://www.npmjs.com/package/xhr) in the browser and [simple-get](https://www.npmjs.com/package/simple-get) in Node.
Supported response types: JSON, ArrayBuffer, and text (default).
For streaming requests, you can just use [simple-get](https://www.npmjs.com/package/simple-get) directly. It works in Node/browser and supports true streaming in new versions of Chrome/FireFox.
## Install
```sh
npm install xhr-request --save
```
## Example
A simple example, loading JSON:
```js
var request = require('xhr-request')
request('http://foo.com/some/api', {
json: true
}, function (err, data) {
if (err) throw err
// the JSON result
console.log(data.foo.bar)
})
```
Another example, sending a JSON `body` with a `query` parameter. Receives binary data as the response.
```js
var request = require('xhr-request')
request('http://foo.com/some/api', {
method: 'PUT',
json: true,
body: { foo: 'bar' },
responseType: 'arraybuffer',
query: {
sort: 'name'
}
}, function (err, data) {
if (err) throw err
console.log('got ArrayBuffer result: ', data)
})
```
## Motivation
There are a lot of HTTP clients, but most of them are Node-centric and lead to large browser bundles with builtins like `url`, `buffer`, `http`, `zlib`, streams, etc.
With browserify, this bundles to 7kb minified. Compare to 742kb for [request](https://www.npmjs.com/package/request), 153kb for [got](https://www.npmjs.com/package/got), 74kb for [simple-get](https://www.npmjs.com/package/simple-get), and 25kb for [nets](https://www.npmjs.com/package/nets).
## Usage
#### `req = xhrRequest(url, [opt], [callback])`
Sends a request to the given `url` with optional `opt` settings, triggering `callback` on complete.
Options:
- `query` (String|Object)
- the query parameters to use for the URL
- `headers` (Object)
- the headers for the request
- `json` (Boolean)
- if true, `responseType` defaults to `'json`' and `body` will be sent as JSON
- `responseType` (String)
- can be `'text'`, `'arraybuffer'` or `'json'`
- defaults to `'text'` unless `json` is true
- `body` (String|JSON)
- an optional body to send with request
- sent as text unless `json` is true
- `method` (String)
- an optional method to use, defaults to `'GET'`
- `timeout` (Number)
- milliseconds to use as a timeout, defaults to 0 (no timeout)
The `callback` is called with the arguments `(error, data, response)`
- `error` on success will be null/undefined
- `data` the result of the request, either a JSON object, string, or `ArrayBuffer`
- `response` the request response, see below
The response object has the following form:
```js
{
statusCode: Number,
method: String,
headers: {},
url: String,
rawRequest: {}
}
```
The `rawRequest` is the XMLHttpRequest in the browser, and the `http` response in Node.
Since `opt` is optional, you can specify `callback` as the second argument.
#### `req.abort()`
The returned `req` (the [ClientRequest](https://nodejs.org/api/http.html#http_class_http_clientrequest) or XMLHttpRequest) has an `abort()` method which can be used to cancel the request and send an Error to the callback.
## See Also
- [simple-get](https://www.npmjs.com/package/simple-get)
- [xhr](https://www.npmjs.com/package/xhr)
- [got](https://www.npmjs.com/package/got)
- [nets](https://www.npmjs.com/package/nets)
- [superagent](https://www.npmjs.com/package/nets)
- [axios](https://www.npmjs.com/package/axios)
## License
MIT, see [LICENSE.md](http://github.com/Jam3/xhr-request/blob/master/LICENSE.md) for details.
### Estraverse [](http://travis-ci.org/estools/estraverse)
Estraverse ([estraverse](http://github.com/estools/estraverse)) is
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
traversal functions from [esmangle project](http://github.com/estools/esmangle).
### Documentation
You can find usage docs at [wiki page](https://github.com/estools/estraverse/wiki/Usage).
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
estraverse.traverse(ast, {
enter: function (node, parent) {
if (node.type == 'FunctionExpression' || node.type == 'FunctionDeclaration')
return estraverse.VisitorOption.Skip;
},
leave: function (node, parent) {
if (node.type == 'VariableDeclarator')
console.log(node.id.name);
}
});
```
We can use `this.skip`, `this.remove` and `this.break` functions instead of using Skip, Remove and Break.
```javascript
estraverse.traverse(ast, {
enter: function (node) {
this.break();
}
});
```
And estraverse provides `estraverse.replace` function. When returning node from `enter`/`leave`, current node is replaced with it.
```javascript
result = estraverse.replace(tree, {
enter: function (node) {
// Replace it with replaced.
if (node.type === 'Literal')
return replaced;
}
});
```
By passing `visitor.keys` mapping, we can extend estraverse traversing functionality.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Extending the existing traversing rules.
keys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
});
```
By passing `visitor.fallback` option, we can control the behavior when encountering unknown nodes.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Iterating the child **nodes** of unknown nodes.
fallback: 'iteration'
});
```
When `visitor.fallback` is a function, we can determine which keys to visit on each node.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Skip the `argument` property of each node
fallback: function(node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument';
});
}
});
```
### License
Copyright (C) 2012-2016 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# Synposis
An elegant way to define lightweight protocols on-top of TCP/TLS sockets in node.js
# Motivation
Working within node.js it is very easy to write lightweight network protocols that communicate over TCP or TLS. The definition of such protocols often requires repeated (and tedious) parsing of individual TCP/TLS packets into a message header and some JSON body.
# Build Status
[](http://travis-ci.org/nodejitsu/nssocket)
# Installation
```
[sudo] npm install nssocket
```
# How it works
With `nssocket` this tedious bookkeeping work is done automatically for you in two ways:
1. Leverages wildcard and namespaced events from [EventEmitter2][0]
2. Automatically serializes messages passed to `.send()` and deserializes messages from `data` events.
3. Implements default reconnect logic for potentially faulty connections.
4. Automatically wraps TCP connections with TLS using [a known workaround][1]
## Messages
Messages in `nssocket` are serialized JSON arrays of the following form:
``` js
["namespace", "to", "event", { "this": "is", "the": "payload" }]
```
Although this is not as optimal as other message formats (pure binary, msgpack) most of your applications are probably IO-bound, and not by the computation time needed for serialization / deserialization. When working with `NsSocket` instances, all events are namespaced under `data` to avoid collision with other events.
## Simple Example
``` js
var nssocket = require('nssocket');
//
// Create an `nssocket` TCP server
//
var server = nssocket.createServer(function (socket) {
//
// Here `socket` will be an instance of `nssocket.NsSocket`.
//
socket.send(['you', 'there']);
socket.data(['iam', 'here'], function (data) {
//
// Good! The socket speaks our language
// (i.e. simple 'you::there', 'iam::here' protocol)
//
// { iam: true, indeedHere: true }
//
console.dir(data);
})
});
//
// Tell the server to listen on port `6785` and then connect to it
// using another NsSocket instance.
//
server.listen(6785);
var outbound = new nssocket.NsSocket();
outbound.data(['you', 'there'], function () {
outbound.send(['iam', 'here'], { iam: true, indeedHere: true });
});
outbound.connect(6785);
```
## Reconnect Example
`nssocket` exposes simple options for enabling reconnection of the underlying socket. By default, these options are disabled. Lets look at a simple example:
``` js
var net = require('net'),
nssocket = require('nssocket');
net.createServer(function (socket) {
//
// Close the underlying socket after `1000ms`
//
setTimeout(function () {
socket.destroy();
}, 1000);
}).listen(8345);
//
// Create an NsSocket instance with reconnect enabled
//
var socket = new nssocket.NsSocket({
reconnect: true,
type: 'tcp4',
});
socket.on('start', function () {
//
// The socket will emit this event periodically
// as it attempts to reconnect
//
console.dir('start');
});
socket.connect(8345);
```
# API
### socket.send(event, data)
Writes `data` to the socket with the specified `event`, on the receiving end it will look like: `JSON.stringify([event, data])`.
### socket.on(event, callback)
Equivalent to the underlying `.addListener()` or `.on()` function on the underlying socket except that it will permit all `EventEmitter2` wildcards and namespaces.
### socket.data(event, callback)
Helper function for performing shorthand listeners namespaced under the `data` event. For example:
``` js
//
// These two statements are equivalent
//
someSocket.on(['data', 'some', 'event'], function (data) { });
someSocket.data(['some', 'event'], function (data) { });
```
### socket.end()
Closes the current socket, emits `close` event, possibly also `error`
### socket.destroy()
Remove all listeners, destroys socket, clears buffer. It is recommended that you use `socket.end()`.
## Tests
All tests are written with [vows][2] and should be run through [npm][3]:
``` bash
$ npm test
```
### Author: [Nodejitsu](http://www.nodejitsu.com)
### Contributors: [Paolo Fragomeni](http://github.com/hij1nx), [Charlie Robbins](http://github.com/indexzero), [Jameson Lee](http://github.com/drjackal), [Gene Diaz Jr.](http://github.com/genediazjr)
[0]: http://github.com/hij1nx/eventemitter2
[1]: https://gist.github.com/848444
[2]: http://vowsjs.org
[3]: http://npmjs.org
# js-multicodec
[](https://protocol.ai)
[](https://github.com/multiformats/multiformats)
[](https://webchat.freenode.net/?channels=%23ipfs)
[](https://github.com/RichardLitt/standard-readme)
[](https://travis-ci.com/multiformats/js-multicodec)
[](https://coveralls.io/github/multiformats/js-multiformats?branch=master)
> JavaScript implementation of the multicodec specification
## Lead Maintainer
[Henrique Dias](http://github.com/hacdias)
## Table of Contents
- [Install](#install)
- [Usage](#usage)
- [Updating the lookup table](#updating-the-lookup-table)
- [Contribute](#contribute)
- [License](#license)
## Install
```sh
> npm install multicodec
```
```JavaScript
const multicodec = require('multicodec')
```
## Usage
### Example
```JavaScript
const multicodec = require('multicodec')
const prefixedProtobuf = multicodec.addPrefix('protobuf', protobufBuffer)
// prefixedProtobuf 0x50...
// The multicodec codec values can be accessed directly:
console.log(multicodec.DAG_CBOR)
// 113
// To get the string representation of a codec, e.g. for error messages:
console.log(multicodec.print[113])
// dag-cbor
```
### API
https://multiformats.github.io/js-multicodec/
[multicodec default table](https://github.com/multiformats/multicodec/blob/master/table.csv)
## Updating the lookup table
Updating the lookup table is done with a script. The source of truth is the
[multicodec default table](https://github.com/multiformats/multicodec/blob/master/table.csv).
Update the table with running:
node ./tools/update-table.js
## Contribute
Contributions welcome. Please check out [the issues](https://github.com/multiformats/js-multicodec/issues).
Check out our [contributing document](https://github.com/multiformats/multiformats/blob/master/contributing.md) for more information on how we work, and about contributing in general. Please be aware that all interactions related to multiformats are subject to the IPFS [Code of Conduct](https://github.com/ipfs/community/blob/master/code-of-conduct.md).
Small note: If editing the README, please conform to the [standard-readme](https://github.com/RichardLitt/standard-readme) specification.
## License
[MIT](LICENSE) © 2016 Protocol Labs Inc.
# responselike
> A response-like object for mocking a Node.js HTTP response stream
[](https://travis-ci.org/lukechilds/responselike)
[](https://coveralls.io/github/lukechilds/responselike?branch=master)
[](https://www.npmjs.com/package/responselike)
[](https://www.npmjs.com/package/responselike)
Returns a streamable response object similar to a [Node.js HTTP response stream](https://nodejs.org/api/http.html#http_class_http_incomingmessage). Useful for formatting cached responses so they can be consumed by code expecting a real response.
## Install
```shell
npm install --save responselike
```
Or if you're just using for testing you'll want:
```shell
npm install --save-dev responselike
```
## Usage
```js
const Response = require('responselike');
const response = new Response(200, { foo: 'bar' }, Buffer.from('Hi!'), 'https://example.com');
response.statusCode;
// 200
response.headers;
// { foo: 'bar' }
response.body;
// <Buffer 48 69 21>
response.url;
// 'https://example.com'
response.pipe(process.stdout);
// Hi!
```
## API
### new Response(statusCode, headers, body, url)
Returns a streamable response object similar to a [Node.js HTTP response stream](https://nodejs.org/api/http.html#http_class_http_incomingmessage).
#### statusCode
Type: `number`
HTTP response status code.
#### headers
Type: `object`
HTTP headers object. Keys will be automatically lowercased.
#### body
Type: `buffer`
A Buffer containing the response body. The Buffer contents will be streamable but is also exposed directly as `response.body`.
#### url
Type: `string`
Request URL string.
## License
MIT © Luke Childs
# Eth ENS Namehash [](https://circleci.com/gh/danfinlay/eth-ens-namehash)
A javascript library for generating Ethereum Name Service (ENS) namehashes per [spec](https://github.com/ethereum/EIPs/issues/137).
[Available on NPM](https://www.npmjs.com/package/eth-ens-namehash)
## Installation
`npm install eth-ens-namehash -S`
## Usage
```javascript
var namehash = require('eth-ens-namehash')
var hash = namehash.hash('foo.eth')
// '0xde9b09fd7c5f901e23a3f19fecc54828e9c848539801e86591bd9801b019f84f'
// Also supports normalizing strings to ENS compatibility:
var input = getUserInput()
var normalized = namehash.normalize(input)
```
## Security Warning
ENS Supports UTF-8 characters, and so many duplicate names are possible. For example:
- faceboоk.eth
- facebook.eth
The first one has non-ascii chars. (control+F on this page and search for facebook, only the second one will match).
namehash.normalize() doesn't automagically remap those, and so other precautions should be taken to avoid user phishing.
## Development
This module supports advanced JavaScript syntax, but exports an ES5-compatible module. To re-build the exported module after making changes, run `npm run bundle` (must have [browserify](http://browserify.org/) installed).
# isurl [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url]
> Checks whether a value is a WHATWG [`URL`](https://developer.mozilla.org/en/docs/Web/API/URL).
Works cross-realm/iframe and despite @@toStringTag.
## Installation
[Node.js](http://nodejs.org/) `>= 4` is required. To install, type this at the command line:
```shell
npm install isurl
```
## Usage
```js
const isURL = require('isurl');
isURL('http://domain/'); //-> false
isURL(new URL('http://domain/')); //-> true
```
Optionally, acceptance can be extended to incomplete `URL` implementations that lack `searchParams` (which are common in many modern web browsers):
```js
const url = new URL('http://domain/?query');
console.log(url.searchParams); //-> undefined
isURL.lenient(url); //-> true
```
[npm-image]: https://img.shields.io/npm/v/isurl.svg
[npm-url]: https://npmjs.org/package/isurl
[travis-image]: https://img.shields.io/travis/stevenvachon/isurl.svg
[travis-url]: https://travis-ci.org/stevenvachon/isurl
# tar-stream
tar-stream is a streaming tar parser and generator and nothing else. It is streams2 and operates purely using streams which means you can easily extract/parse tarballs without ever hitting the file system.
Note that you still need to gunzip your data if you have a `.tar.gz`. We recommend using [gunzip-maybe](https://github.com/mafintosh/gunzip-maybe) in conjunction with this.
```
npm install tar-stream
```
[](http://travis-ci.org/mafintosh/tar-stream)
[](http://opensource.org/licenses/MIT)
## Usage
tar-stream exposes two streams, [pack](https://github.com/mafintosh/tar-stream#packing) which creates tarballs and [extract](https://github.com/mafintosh/tar-stream#extracting) which extracts tarballs. To [modify an existing tarball](https://github.com/mafintosh/tar-stream#modifying-existing-tarballs) use both.
It implementes USTAR with additional support for pax extended headers. It should be compatible with all popular tar distributions out there (gnutar, bsdtar etc)
## Related
If you want to pack/unpack directories on the file system check out [tar-fs](https://github.com/mafintosh/tar-fs) which provides file system bindings to this module.
## Packing
To create a pack stream use `tar.pack()` and call `pack.entry(header, [callback])` to add tar entries.
``` js
var tar = require('tar-stream')
var pack = tar.pack() // pack is a streams2 stream
// add a file called my-test.txt with the content "Hello World!"
pack.entry({ name: 'my-test.txt' }, 'Hello World!')
// add a file called my-stream-test.txt from a stream
var entry = pack.entry({ name: 'my-stream-test.txt', size: 11 }, function(err) {
// the stream was added
// no more entries
pack.finalize()
})
entry.write('hello')
entry.write(' ')
entry.write('world')
entry.end()
// pipe the pack stream somewhere
pack.pipe(process.stdout)
```
## Extracting
To extract a stream use `tar.extract()` and listen for `extract.on('entry', (header, stream, next) )`
``` js
var extract = tar.extract()
extract.on('entry', function(header, stream, next) {
// header is the tar header
// stream is the content body (might be an empty stream)
// call next when you are done with this entry
stream.on('end', function() {
next() // ready for next entry
})
stream.resume() // just auto drain the stream
})
extract.on('finish', function() {
// all entries read
})
pack.pipe(extract)
```
The tar archive is streamed sequentially, meaning you **must** drain each entry's stream as you get them or else the main extract stream will receive backpressure and stop reading.
## Headers
The header object using in `entry` should contain the following properties.
Most of these values can be found by stat'ing a file.
``` js
{
name: 'path/to/this/entry.txt',
size: 1314, // entry size. defaults to 0
mode: 0644, // entry mode. defaults to to 0755 for dirs and 0644 otherwise
mtime: new Date(), // last modified date for entry. defaults to now.
type: 'file', // type of entry. defaults to file. can be:
// file | link | symlink | directory | block-device
// character-device | fifo | contiguous-file
linkname: 'path', // linked file name
uid: 0, // uid of entry owner. defaults to 0
gid: 0, // gid of entry owner. defaults to 0
uname: 'maf', // uname of entry owner. defaults to null
gname: 'staff', // gname of entry owner. defaults to null
devmajor: 0, // device major version. defaults to 0
devminor: 0 // device minor version. defaults to 0
}
```
## Modifying existing tarballs
Using tar-stream it is easy to rewrite paths / change modes etc in an existing tarball.
``` js
var extract = tar.extract()
var pack = tar.pack()
var path = require('path')
extract.on('entry', function(header, stream, callback) {
// let's prefix all names with 'tmp'
header.name = path.join('tmp', header.name)
// write the new entry to the pack stream
stream.pipe(pack.entry(header, callback))
})
extract.on('finish', function() {
// all entries done - lets finalize it
pack.finalize()
})
// pipe the old tarball to the extractor
oldTarballStream.pipe(extract)
// pipe the new tarball the another stream
pack.pipe(newTarballStream)
```
## Saving tarball to fs
``` js
var fs = require('fs')
var tar = require('tar-stream')
var pack = tar.pack() // pack is a streams2 stream
var path = 'YourTarBall.tar'
var yourTarball = fs.createWriteStream(path)
// add a file called YourFile.txt with the content "Hello World!"
pack.entry({name: 'YourFile.txt'}, 'Hello World!', function (err) {
if (err) throw err
pack.finalize()
})
// pipe the pack stream to your file
pack.pipe(yourTarball)
yourTarball.on('close', function () {
console.log(path + ' has been written')
fs.stat(path, function(err, stats) {
if (err) throw err
console.log(stats)
console.log('Got file info successfully!')
})
})
```
## Performance
[See tar-fs for a performance comparison with node-tar](https://github.com/mafintosh/tar-fs/blob/master/README.md#performance)
# License
MIT
Node.js - jsonfile
================
Easily read/write JSON files.
[](https://www.npmjs.org/package/jsonfile)
[](http://travis-ci.org/jprichardson/node-jsonfile)
[](https://ci.appveyor.com/project/jprichardson/node-jsonfile/branch/master)
<a href="https://github.com/feross/standard"><img src="https://cdn.rawgit.com/feross/standard/master/sticker.svg" alt="Standard JavaScript" width="100"></a>
Why?
----
Writing `JSON.stringify()` and then `fs.writeFile()` and `JSON.parse()` with `fs.readFile()` enclosed in `try/catch` blocks became annoying.
Installation
------------
npm install --save jsonfile
API
---
### readFile(filename, [options], callback)
`options` (`object`, default `undefined`): Pass in any `fs.readFile` options or set `reviver` for a [JSON reviver](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse).
- `throws` (`boolean`, default: `true`). If `JSON.parse` throws an error, pass this error to the callback.
If `false`, returns `null` for the object.
```js
var jsonfile = require('jsonfile')
var file = '/tmp/data.json'
jsonfile.readFile(file, function(err, obj) {
console.dir(obj)
})
```
### readFileSync(filename, [options])
`options` (`object`, default `undefined`): Pass in any `fs.readFileSync` options or set `reviver` for a [JSON reviver](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse).
- `throws` (`boolean`, default: `true`). If an error is encountered reading or parsing the file, throw the error. If `false`, returns `null` for the object.
```js
var jsonfile = require('jsonfile')
var file = '/tmp/data.json'
console.dir(jsonfile.readFileSync(file))
```
### writeFile(filename, obj, [options], callback)
`options`: Pass in any `fs.writeFile` options or set `replacer` for a [JSON replacer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify). Can also pass in `spaces` and override `EOL` string.
```js
var jsonfile = require('jsonfile')
var file = '/tmp/data.json'
var obj = {name: 'JP'}
jsonfile.writeFile(file, obj, function (err) {
console.error(err)
})
```
**formatting with spaces:**
```js
var jsonfile = require('jsonfile')
var file = '/tmp/data.json'
var obj = {name: 'JP'}
jsonfile.writeFile(file, obj, {spaces: 2}, function(err) {
console.error(err)
})
```
**overriding EOL:**
```js
var jsonfile = require('jsonfile')
var file = '/tmp/data.json'
var obj = {name: 'JP'}
jsonfile.writeFile(file, obj, {spaces: 2, EOL: '\r\n'}, function(err) {
console.error(err)
})
```
**appending to an existing JSON file:**
You can use `fs.writeFile` option `{flag: 'a'}` to achieve this.
```js
var jsonfile = require('jsonfile')
var file = '/tmp/mayAlreadyExistedData.json'
var obj = {name: 'JP'}
jsonfile.writeFile(file, obj, {flag: 'a'}, function (err) {
console.error(err)
})
```
### writeFileSync(filename, obj, [options])
`options`: Pass in any `fs.writeFileSync` options or set `replacer` for a [JSON replacer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify). Can also pass in `spaces` and override `EOL` string.
```js
var jsonfile = require('jsonfile')
var file = '/tmp/data.json'
var obj = {name: 'JP'}
jsonfile.writeFileSync(file, obj)
```
**formatting with spaces:**
```js
var jsonfile = require('jsonfile')
var file = '/tmp/data.json'
var obj = {name: 'JP'}
jsonfile.writeFileSync(file, obj, {spaces: 2})
```
**overriding EOL:**
```js
var jsonfile = require('jsonfile')
var file = '/tmp/data.json'
var obj = {name: 'JP'}
jsonfile.writeFileSync(file, obj, {spaces: 2, EOL: '\r\n'})
```
**appending to an existing JSON file:**
You can use `fs.writeFileSync` option `{flag: 'a'}` to achieve this.
```js
var jsonfile = require('jsonfile')
var file = '/tmp/mayAlreadyExistedData.json'
var obj = {name: 'JP'}
jsonfile.writeFileSync(file, obj, {flag: 'a'})
```
License
-------
(MIT License)
Copyright 2012-2016, JP Richardson <[email protected]>
# buffer-xor
[](http://travis-ci.org/crypto-browserify/buffer-xor)
[](https://www.npmjs.org/package/buffer-xor)
[](https://github.com/feross/standard)
A simple module for bitwise-xor on buffers.
## Examples
``` javascript
var xor = require("buffer-xor")
var a = new Buffer('00ff0f', 'hex')
var b = new Buffer('f0f0', 'hex')
console.log(xor(a, b))
// => <Buffer f0 0f>
```
Or for those seeking those few extra cycles, perform the operation in place:
``` javascript
var xorInplace = require("buffer-xor/inplace")
var a = new Buffer('00ff0f', 'hex')
var b = new Buffer('f0f0', 'hex')
console.log(xorInplace(a, b))
// => <Buffer f0 0f>
// NOTE: xorInplace will return the shorter slice of its parameters
// See that a has been mutated
console.log(a)
// => <Buffer f0 0f 0f>
```
## License [MIT](LICENSE)
# SYNOPSIS
[](https://www.npmjs.org/package/ethereumjs-util)
[](https://github.com/ethereumjs/ethereumjs-util/actions)
[](https://coveralls.io/r/ethereumjs/ethereumjs-util)
[![Discord][discord-badge]][discord-link]
A collection of utility functions for Ethereum. It can be used in Node.js and in the browser with [browserify](http://browserify.org/).
# INSTALL
`npm install ethereumjs-util`
# USAGE
```js
import assert from 'assert'
import { isValidChecksumAddress, unpadBuffer, BN } from 'ethereumjs-util'
const address = '0x2F015C60E0be116B1f0CD534704Db9c92118FB6A'
assert.ok(isValidChecksumAddress(address))
assert.equal(unpadBuffer(Buffer.from('000000006600', 'hex')), Buffer.from('6600', 'hex'))
assert.equal(new BN('dead', 16).add(new BN('101010', 2)), 57047)
```
# API
## Documentation
### Modules
- [account](docs/modules/_account_.md)
- Account class
- Private/public key and address-related functionality (creation, validation, conversion)
- [address](docs/modules/_address_.md)
- Address class and type
- [bytes](docs/modules/_bytes_.md)
- Byte-related helper and conversion functions
- [constants](docs/modules/_constants_.md)
- Exposed constants
- e.g. KECCAK256_NULL_S for string representation of Keccak-256 hash of null
- [hash](docs/modules/_hash_.md)
- Hash functions
- [object](docs/modules/_object_.md)
- Helper function for creating a binary object (`DEPRECATED`)
- [signature](docs/modules/_signature_.md)
- Signing, signature validation, conversion, recovery
- [types](docs/modules/_types_.md)
- Helpful TypeScript types
- [externals](docs/modules/_externals_.md)
- Helper methods from `ethjs-util`
- Re-exports of `BN`, `rlp`
### ethjs-util methods
The following methods are available provided by [ethjs-util](https://github.com/ethjs/ethjs-util):
- arrayContainsArray
- toBuffer
- getBinarySize
- stripHexPrefix
- isHexPrefixed
- isHexString
- padToEven
- intToHex
- fromAscii
- fromUtf8
- toUtf8
- toAscii
- getKeys
Import can be done directly by function name analogous to the build-in function import:
```js
import { intToHex, stripHexPrefix } from 'ethereumjs-util'
```
### Re-Exports
Additionally `ethereumjs-util` re-exports a few commonly-used libraries. These include:
- [BN.js](https://github.com/indutny/bn.js) (version `5.x`)
- [rlp](https://github.com/ethereumjs/rlp) (version `2.x`)
# EthereumJS
See our organizational [documentation](https://ethereumjs.readthedocs.io) for an introduction to `EthereumJS` as well as information on current standards and best practices.
If you want to join for work or do improvements on the libraries have a look at our [contribution guidelines](https://ethereumjs.readthedocs.io/en/latest/contributing.html).
# LICENSE
MPL-2.0
[discord-badge]: https://img.shields.io/static/v1?logo=discord&label=discord&message=Join&color=blue
[discord-link]: https://discord.gg/TNwARpR
smart-buffer [](https://travis-ci.org/JoshGlazebrook/smart-buffer) [](https://coveralls.io/github/JoshGlazebrook/smart-buffer?branch=master)
=============
smart-buffer is a Buffer wrapper that adds automatic read & write offset tracking, string operations, data insertions, and more.

**Key Features**:
* Proxies all of the Buffer write and read functions
* Keeps track of read and write offsets automatically
* Grows the internal Buffer as needed
* Useful string operations. (Null terminating strings)
* Allows for inserting values at specific points in the Buffer
* Built in TypeScript
* Type Definitions Provided
* Browser Support (using Webpack/Browserify)
* Full test coverage
**Requirements**:
* Node v4.0+ is supported at this time. (Versions prior to 2.0 will work on node 0.10)
## Breaking Changes in v4.0
* Old constructor patterns have been completely removed. It's now required to use the SmartBuffer.fromXXX() factory constructors.
* rewind(), skip(), moveTo() have been removed. (see [offsets](#offsets))
* Internal private properties are now prefixed with underscores (_)
* **All** writeXXX() methods that are given an offset will now **overwrite data** instead of insert. (see [write vs insert](#write-vs-insert))
* insertXXX() methods have been added for when you want to insert data at a specific offset (this replaces the old behavior of writeXXX() when an offset was provided)
## Looking for v3 docs?
Legacy documentation for version 3 and prior can be found [here](https://github.com/JoshGlazebrook/smart-buffer/blob/master/docs/README_v3.md).
## Installing:
`yarn add smart-buffer`
or
`npm install smart-buffer`
Note: The published NPM package includes the built javascript library.
If you cloned this repo and wish to build the library manually use:
`npm run build`
## Using smart-buffer
```javascript
// Javascript
const SmartBuffer = require('smart-buffer').SmartBuffer;
// Typescript
import { SmartBuffer, SmartBufferOptions} from 'smart-buffer';
```
### Simple Example
Building a packet that uses the following protocol specification:
`[PacketType:2][PacketLength:2][Data:XX]`
To build this packet using the vanilla Buffer class, you would have to count up the length of the data payload beforehand. You would also need to keep track of the current "cursor" position in your Buffer so you write everything in the right places. With smart-buffer you don't have to do either of those things.
```javascript
function createLoginPacket(username, password, age, country) {
const packet = new SmartBuffer();
packet.writeUInt16LE(0x0060); // Some packet type
packet.writeStringNT(username);
packet.writeStringNT(password);
packet.writeUInt8(age);
packet.writeStringNT(country);
packet.insertUInt16LE(packet.length - 2, 2);
return packet.toBuffer();
}
```
With the above function, you now can do this:
```javascript
const login = createLoginPacket("Josh", "secret123", 22, "United States");
// <Buffer 60 00 1e 00 4a 6f 73 68 00 73 65 63 72 65 74 31 32 33 00 16 55 6e 69 74 65 64 20 53 74 61 74 65 73 00>
```
Notice that the `[PacketLength:2]` value (1e 00) was inserted at position 2.
Reading back the packet we created above is just as easy:
```javascript
const reader = SmartBuffer.fromBuffer(login);
const logininfo = {
packetType: reader.readUInt16LE(),
packetLength: reader.readUInt16LE(),
username: reader.readStringNT(),
password: reader.readStringNT(),
age: reader.readUInt8(),
country: reader.readStringNT()
};
/*
{
packetType: 96, (0x0060)
packetLength: 30,
username: 'Josh',
password: 'secret123',
age: 22,
country: 'United States'
}
*/
```
## Write vs Insert
In prior versions of SmartBuffer, .writeXXX(value, offset) calls would insert data when an offset was provided. In version 4, this will now overwrite the data at the offset position. To insert data there are now corresponding .insertXXX(value, offset) methods.
**SmartBuffer v3**:
```javascript
const buff = SmartBuffer.fromBuffer(new Buffer([1,2,3,4,5,6]));
buff.writeInt8(7, 2);
console.log(buff.toBuffer())
// <Buffer 01 02 07 03 04 05 06>
```
**SmartBuffer v4**:
```javascript
const buff = SmartBuffer.fromBuffer(new Buffer([1,2,3,4,5,6]));
buff.writeInt8(7, 2);
console.log(buff.toBuffer());
// <Buffer 01 02 07 04 05 06>
```
To insert you instead should use:
```javascript
const buff = SmartBuffer.fromBuffer(new Buffer([1,2,3,4,5,6]));
buff.insertInt8(7, 2);
console.log(buff.toBuffer());
// <Buffer 01 02 07 03 04 05 06>
```
**Note:** Insert/Writing to a position beyond the currently tracked internal Buffer will zero pad to your offset.
## Constructing a smart-buffer
There are a few different ways to construct a SmartBuffer instance.
```javascript
// Creating SmartBuffer from existing Buffer
const buff = SmartBuffer.fromBuffer(buffer); // Creates instance from buffer. (Uses default utf8 encoding)
const buff = SmartBuffer.fromBuffer(buffer, 'ascii'); // Creates instance from buffer with ascii encoding for strings.
// Creating SmartBuffer with specified internal Buffer size. (Note: this is not a hard cap, the internal buffer will grow as needed).
const buff = SmartBuffer.fromSize(1024); // Creates instance with internal Buffer size of 1024.
const buff = SmartBuffer.fromSize(1024, 'utf8'); // Creates instance with internal Buffer size of 1024, and utf8 encoding for strings.
// Creating SmartBuffer with options object. This one specifies size and encoding.
const buff = SmartBuffer.fromOptions({
size: 1024,
encoding: 'ascii'
});
// Creating SmartBuffer with options object. This one specified an existing Buffer.
const buff = SmartBuffer.fromOptions({
buff: buffer
});
// Creating SmartBuffer from a string.
const buff = SmartBuffer.fromBuffer(Buffer.from('some string', 'utf8'));
// Just want a regular SmartBuffer with all default options?
const buff = new SmartBuffer();
```
# Api Reference:
**Note:** SmartBuffer is fully documented with Typescript definitions as well as jsdocs so your favorite editor/IDE will have intellisense.
**Table of Contents**
1. [Constructing](#constructing)
2. **Numbers**
1. [Integers](#integers)
2. [Floating Points](#floating-point-numbers)
3. **Strings**
1. [Strings](#strings)
2. [Null Terminated Strings](#null-terminated-strings)
4. [Buffers](#buffers)
5. [Offsets](#offsets)
6. [Other](#other)
## Constructing
### constructor()
### constructor([options])
- ```options``` *{SmartBufferOptions}* An optional options object to construct a SmartBuffer with.
Examples:
```javascript
const buff = new SmartBuffer();
const buff = new SmartBuffer({
size: 1024,
encoding: 'ascii'
});
```
### Class Method: fromBuffer(buffer[, encoding])
- ```buffer``` *{Buffer}* The Buffer instance to wrap.
- ```encoding``` *{string}* The string encoding to use. ```Default: 'utf8'```
Examples:
```javascript
const someBuffer = Buffer.from('some string');
const buff = SmartBuffer.fromBuffer(someBuffer); // Defaults to utf8
const buff = SmartBuffer.fromBuffer(someBuffer, 'ascii');
```
### Class Method: fromSize(size[, encoding])
- ```size``` *{number}* The size to initialize the internal Buffer.
- ```encoding``` *{string}* The string encoding to use. ```Default: 'utf8'```
Examples:
```javascript
const buff = SmartBuffer.fromSize(1024); // Defaults to utf8
const buff = SmartBuffer.fromSize(1024, 'ascii');
```
### Class Method: fromOptions(options)
- ```options``` *{SmartBufferOptions}* The Buffer instance to wrap.
```typescript
interface SmartBufferOptions {
encoding?: BufferEncoding; // Defaults to utf8
size?: number; // Defaults to 4096
buff?: Buffer;
}
```
Examples:
```javascript
const buff = SmartBuffer.fromOptions({
size: 1024
};
const buff = SmartBuffer.fromOptions({
size: 1024,
encoding: 'utf8'
});
const buff = SmartBuffer.fromOptions({
encoding: 'utf8'
});
const someBuff = Buffer.from('some string', 'utf8');
const buff = SmartBuffer.fromOptions({
buffer: someBuff,
encoding: 'utf8'
});
```
## Integers
### readInt8([offset])
- ```offset``` *{number}* Optional position to start reading data from. **Default**: ```Auto managed offset```
- Returns *{number}*
Read a Int8 value.
### buff.readInt16BE([offset])
### buff.readInt16LE([offset])
### buff.readUInt16BE([offset])
### buff.readUInt16LE([offset])
- ```offset``` *{number}* Optional position to start reading data from. **Default**: ```Auto managed offset```
- Returns *{number}*
Read a 16 bit integer value.
### buff.readInt32BE([offset])
### buff.readInt32LE([offset])
### buff.readUInt32BE([offset])
### buff.readUInt32LE([offset])
- ```offset``` *{number}* Optional position to start reading data from. **Default**: ```Auto managed offset```
- Returns *{number}*
Read a 32 bit integer value.
### buff.writeInt8(value[, offset])
### buff.writeUInt8(value[, offset])
- ```value``` *{number}* The value to write.
- ```offset``` *{number}* An optional offset to write this value to. **Default:** ```Auto managed offset```
- Returns *{this}*
Write a Int8 value.
### buff.insertInt8(value, offset)
### buff.insertUInt8(value, offset)
- ```value``` *{number}* The value to insert.
- ```offset``` *{number}* The offset to insert this data at.
- Returns *{this}*
Insert a Int8 value.
### buff.writeInt16BE(value[, offset])
### buff.writeInt16LE(value[, offset])
### buff.writeUInt16BE(value[, offset])
### buff.writeUInt16LE(value[, offset])
- ```value``` *{number}* The value to write.
- ```offset``` *{number}* An optional offset to write this value to. **Default:** ```Auto managed offset```
- Returns *{this}*
Write a 16 bit integer value.
### buff.insertInt16BE(value, offset)
### buff.insertInt16LE(value, offset)
### buff.insertUInt16BE(value, offset)
### buff.insertUInt16LE(value, offset)
- ```value``` *{number}* The value to insert.
- ```offset``` *{number}* The offset to insert this data at.
- Returns *{this}*
Insert a 16 bit integer value.
### buff.writeInt32BE(value[, offset])
### buff.writeInt32LE(value[, offset])
### buff.writeUInt32BE(value[, offset])
### buff.writeUInt32LE(value[, offset])
- ```value``` *{number}* The value to write.
- ```offset``` *{number}* An optional offset to write this value to. **Default:** ```Auto managed offset```
- Returns *{this}*
Write a 32 bit integer value.
### buff.insertInt32BE(value, offset)
### buff.insertInt32LE(value, offset)
### buff.insertUInt32BE(value, offset)
### buff.nsertUInt32LE(value, offset)
- ```value``` *{number}* The value to insert.
- ```offset``` *{number}* The offset to insert this data at.
- Returns *{this}*
Insert a 32 bit integer value.
## Floating Point Numbers
### buff.readFloatBE([offset])
### buff.readFloatLE([offset])
- ```offset``` *{number}* Optional position to start reading data from. **Default**: ```Auto managed offset```
- Returns *{number}*
Read a Float value.
### buff.eadDoubleBE([offset])
### buff.readDoubleLE([offset])
- ```offset``` *{number}* Optional position to start reading data from. **Default**: ```Auto managed offset```
- Returns *{number}*
Read a Double value.
### buff.writeFloatBE(value[, offset])
### buff.writeFloatLE(value[, offset])
- ```value``` *{number}* The value to write.
- ```offset``` *{number}* An optional offset to write this value to. **Default:** ```Auto managed offset```
- Returns *{this}*
Write a Float value.
### buff.insertFloatBE(value, offset)
### buff.insertFloatLE(value, offset)
- ```value``` *{number}* The value to insert.
- ```offset``` *{number}* The offset to insert this data at.
- Returns *{this}*
Insert a Float value.
### buff.writeDoubleBE(value[, offset])
### buff.writeDoubleLE(value[, offset])
- ```value``` *{number}* The value to write.
- ```offset``` *{number}* An optional offset to write this value to. **Default:** ```Auto managed offset```
- Returns *{this}*
Write a Double value.
### buff.insertDoubleBE(value, offset)
### buff.insertDoubleLE(value, offset)
- ```value``` *{number}* The value to insert.
- ```offset``` *{number}* The offset to insert this data at.
- Returns *{this}*
Insert a Double value.
## Strings
### buff.readString()
### buff.readString(size[, encoding])
### buff.readString(encoding)
- ```size``` *{number}* The number of bytes to read. **Default:** ```Reads to the end of the Buffer.```
- ```encoding``` *{string}* The string encoding to use. **Default:** ```utf8```.
Read a string value.
Examples:
```javascript
const buff = SmartBuffer.fromBuffer(Buffer.from('hello there', 'utf8'));
buff.readString(); // 'hello there'
buff.readString(2); // 'he'
buff.readString(2, 'utf8'); // 'he'
buff.readString('utf8'); // 'hello there'
```
### buff.writeString(value)
### buff.writeString(value[, offset])
### buff.writeString(value[, encoding])
### buff.writeString(value[, offset[, encoding]])
- ```value``` *{string}* The string value to write.
- ```offset``` *{number}* The offset to write this value to. **Default:** ```Auto managed offset```
- ```encoding``` *{string}* An optional string encoding to use. **Default:** ```utf8```
Write a string value.
Examples:
```javascript
buff.writeString('hello'); // Auto managed offset
buff.writeString('hello', 2);
buff.writeString('hello', 'utf8') // Auto managed offset
buff.writeString('hello', 2, 'utf8');
```
### buff.insertString(value, offset[, encoding])
- ```value``` *{string}* The string value to write.
- ```offset``` *{number}* The offset to write this value to.
- ```encoding``` *{string}* An optional string encoding to use. **Default:** ```utf8```
Insert a string value.
Examples:
```javascript
buff.insertString('hello', 2);
buff.insertString('hello', 2, 'utf8');
```
## Null Terminated Strings
### buff.readStringNT()
### buff.readStringNT(encoding)
- ```encoding``` *{string}* The string encoding to use. **Default:** ```utf8```.
Read a null terminated string value. (If a null is not found, it will read to the end of the Buffer).
Examples:
```javascript
const buff = SmartBuffer.fromBuffer(Buffer.from('hello\0 there', 'utf8'));
buff.readStringNT(); // 'hello'
// If we called this again:
buff.readStringNT(); // ' there'
```
### buff.writeStringNT(value)
### buff.writeStringNT(value[, offset])
### buff.writeStringNT(value[, encoding])
### buff.writeStringNT(value[, offset[, encoding]])
- ```value``` *{string}* The string value to write.
- ```offset``` *{number}* The offset to write this value to. **Default:** ```Auto managed offset```
- ```encoding``` *{string}* An optional string encoding to use. **Default:** ```utf8```
Write a null terminated string value.
Examples:
```javascript
buff.writeStringNT('hello'); // Auto managed offset <Buffer 68 65 6c 6c 6f 00>
buff.writeStringNT('hello', 2); // <Buffer 00 00 68 65 6c 6c 6f 00>
buff.writeStringNT('hello', 'utf8') // Auto managed offset
buff.writeStringNT('hello', 2, 'utf8');
```
### buff.insertStringNT(value, offset[, encoding])
- ```value``` *{string}* The string value to write.
- ```offset``` *{number}* The offset to write this value to.
- ```encoding``` *{string}* An optional string encoding to use. **Default:** ```utf8```
Insert a null terminated string value.
Examples:
```javascript
buff.insertStringNT('hello', 2);
buff.insertStringNT('hello', 2, 'utf8');
```
## Buffers
### buff.readBuffer([length])
- ```length``` *{number}* The number of bytes to read into a Buffer. **Default:** ```Reads to the end of the Buffer```
Read a Buffer of a specified size.
### buff.writeBuffer(value[, offset])
- ```value``` *{Buffer}* The buffer value to write.
- ```offset``` *{number}* An optional offset to write the value to. **Default:** ```Auto managed offset```
### buff.insertBuffer(value, offset)
- ```value``` *{Buffer}* The buffer value to write.
- ```offset``` *{number}* The offset to write the value to.
### buff.readBufferNT()
Read a null terminated Buffer.
### buff.writeBufferNT(value[, offset])
- ```value``` *{Buffer}* The buffer value to write.
- ```offset``` *{number}* An optional offset to write the value to. **Default:** ```Auto managed offset```
Write a null terminated Buffer.
### buff.insertBufferNT(value, offset)
- ```value``` *{Buffer}* The buffer value to write.
- ```offset``` *{number}* The offset to write the value to.
Insert a null terminated Buffer.
## Offsets
### buff.readOffset
### buff.readOffset(offset)
- ```offset``` *{number}* The new read offset value to set.
- Returns: ```The current read offset```
Gets or sets the current read offset.
Examples:
```javascript
const currentOffset = buff.readOffset; // 5
buff.readOffset = 10;
console.log(buff.readOffset) // 10
```
### buff.writeOffset
### buff.writeOffset(offset)
- ```offset``` *{number}* The new write offset value to set.
- Returns: ```The current write offset```
Gets or sets the current write offset.
Examples:
```javascript
const currentOffset = buff.writeOffset; // 5
buff.writeOffset = 10;
console.log(buff.writeOffset) // 10
```
### buff.encoding
### buff.encoding(encoding)
- ```encoding``` *{string}* The new string encoding to set.
- Returns: ```The current string encoding```
Gets or sets the current string encoding.
Examples:
```javascript
const currentEncoding = buff.encoding; // 'utf8'
buff.encoding = 'ascii';
console.log(buff.encoding) // 'ascii'
```
## Other
### buff.clear()
Clear and resets the SmartBuffer instance.
### buff.remaining()
- Returns ```Remaining data left to be read```
Gets the number of remaining bytes to be read.
### buff.internalBuffer
- Returns: *{Buffer}*
Gets the internally managed Buffer (Includes unmanaged data).
Examples:
```javascript
const buff = SmartBuffer.fromSize(16);
buff.writeString('hello');
console.log(buff.InternalBuffer); // <Buffer 68 65 6c 6c 6f 00 00 00 00 00 00 00 00 00 00 00>
```
### buff.toBuffer()
- Returns: *{Buffer}*
Gets a sliced Buffer instance of the internally managed Buffer. (Only includes managed data)
Examples:
```javascript
const buff = SmartBuffer.fromSize(16);
buff.writeString('hello');
console.log(buff.toBuffer()); // <Buffer 68 65 6c 6c 6f>
```
### buff.toString([encoding])
- ```encoding``` *{string}* The string encoding to use when converting to a string. **Default:** ```utf8```
- Returns *{string}*
Gets a string representation of all data in the SmartBuffer.
### buff.destroy()
Destroys the SmartBuffer instance.
## License
This work is licensed under the [MIT license](http://en.wikipedia.org/wiki/MIT_License).
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# web3-utils
This is a sub package of [web3.js][repo]
This contains useful utility functions for Dapp developers.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-utils
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-utils.js` in your html file.
This will expose the `Web3Utils` object on the window object.
## Usage
```js
// in node.js
var Web3Utils = require('web3-utils');
console.log(Web3Utils);
{
sha3: function(){},
soliditySha3: function(){},
isAddress: function(){},
...
}
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
## getpass
Get a password from the terminal. Sounds simple? Sounds like the `readline`
module should be able to do it? NOPE.
## Install and use it
```bash
npm install --save getpass
```
```javascript
const mod_getpass = require('getpass');
```
## API
### `mod_getpass.getPass([options, ]callback)`
Gets a password from the terminal. If available, this uses `/dev/tty` to avoid
interfering with any data being piped in or out of stdio.
This function prints a prompt (by default `Password:`) and then accepts input
without echoing.
Parameters:
* `options`, an Object, with properties:
* `prompt`, an optional String
* `callback`, a `Func(error, password)`, with arguments:
* `error`, either `null` (no error) or an `Error` instance
* `password`, a String
# <img src="docs_app/assets/Rx_Logo_S.png" alt="RxJS Logo" width="86" height="86"> RxJS: Reactive Extensions For JavaScript
[](https://circleci.com/gh/ReactiveX/rxjs/tree/6.x)
[](http://badge.fury.io/js/%40reactivex%2Frxjs)
[](https://gitter.im/Reactive-Extensions/RxJS?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
# RxJS 6 Stable
### MIGRATION AND RELEASE INFORMATION:
Find out how to update to v6, **automatically update your TypeScript code**, and more!
- [Current home is MIGRATION.md](./docs_app/content/guide/v6/migration.md)
### FOR V 5.X PLEASE GO TO [THE 5.0 BRANCH](https://github.com/ReactiveX/rxjs/tree/5.x)
Reactive Extensions Library for JavaScript. This is a rewrite of [Reactive-Extensions/RxJS](https://github.com/Reactive-Extensions/RxJS) and is the latest production-ready version of RxJS. This rewrite is meant to have better performance, better modularity, better debuggable call stacks, while staying mostly backwards compatible, with some breaking changes that reduce the API surface.
[Apache 2.0 License](LICENSE.txt)
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [Contribution Guidelines](CONTRIBUTING.md)
- [Maintainer Guidelines](doc_app/content/maintainer-guidelines.md)
- [API Documentation](https://rxjs.dev/)
## Versions In This Repository
- [master](https://github.com/ReactiveX/rxjs/commits/master) - This is all of the current, unreleased work, which is against v6 of RxJS right now
- [stable](https://github.com/ReactiveX/rxjs/commits/stable) - This is the branch for the latest version you'd get if you do `npm install rxjs`
## Important
By contributing or commenting on issues in this repository, whether you've read them or not, you're agreeing to the [Contributor Code of Conduct](CODE_OF_CONDUCT.md). Much like traffic laws, ignorance doesn't grant you immunity.
## Installation and Usage
### ES6 via npm
```sh
npm install rxjs
```
It's recommended to pull in the Observable creation methods you need directly from `'rxjs'` as shown below with `range`. And you can pull in any operator you need from one spot, under `'rxjs/operators'`.
```ts
import { range } from "rxjs";
import { map, filter } from "rxjs/operators";
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
```
Here, we're using the built-in `pipe` method on Observables to combine operators. See [pipeable operators](https://github.com/ReactiveX/rxjs/blob/master/doc/pipeable-operators.md) for more information.
### CommonJS via npm
To install this library for CommonJS (CJS) usage, use the following command:
```sh
npm install rxjs
```
(Note: destructuring available in Node 8+)
```js
const { range } = require('rxjs');
const { map, filter } = require('rxjs/operators');
range(1, 200).pipe(
filter(x => x % 2 === 1),
map(x => x + x)
).subscribe(x => console.log(x));
```
### CDN
For CDN, you can use [unpkg](https://unpkg.com/):
https://unpkg.com/rxjs/bundles/rxjs.umd.min.js
The global namespace for rxjs is `rxjs`:
```js
const { range } = rxjs;
const { map, filter } = rxjs.operators;
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
```
## Goals
- Smaller overall bundles sizes
- Provide better performance than preceding versions of RxJS
- To model/follow the [Observable Spec Proposal](https://github.com/zenparsing/es-observable) to the observable
- Provide more modular file structure in a variety of formats
- Provide more debuggable call stacks than preceding versions of RxJS
## Building/Testing
- `npm run build_all` - builds everything
- `npm test` - runs tests
- `npm run test_no_cache` - run test with `ts-node` set to false
## Performance Tests
Run `npm run build_perf` or `npm run perf` to run the performance tests with `protractor`.
Run `npm run perf_micro [operator]` to run micro performance test benchmarking operator.
## Adding documentation
We appreciate all contributions to the documentation of any type. All of the information needed to get the docs app up and running locally as well as how to contribute can be found in the [documentation directory](./docs_app).
## Generating PNG marble diagrams
The script `npm run tests2png` requires some native packages installed locally: `imagemagick`, `graphicsmagick`, and `ghostscript`.
For Mac OS X with [Homebrew](http://brew.sh/):
- `brew install imagemagick`
- `brew install graphicsmagick`
- `brew install ghostscript`
- You may need to install the Ghostscript fonts manually:
- Download the tarball from the [gs-fonts project](https://sourceforge.net/projects/gs-fonts)
- `mkdir -p /usr/local/share/ghostscript && tar zxvf /path/to/ghostscript-fonts.tar.gz -C /usr/local/share/ghostscript`
For Debian Linux:
- `sudo add-apt-repository ppa:dhor/myway`
- `apt-get install imagemagick`
- `apt-get install graphicsmagick`
- `apt-get install ghostscript`
For Windows and other Operating Systems, check the download instructions here:
- http://imagemagick.org
- http://www.graphicsmagick.org
- http://www.ghostscript.com/
Node.js: fs-extra
=================
`fs-extra` adds file system methods that aren't included in the native `fs` module and adds promise support to the `fs` methods. It should be a drop in replacement for `fs`.
[](https://www.npmjs.org/package/fs-extra)
[](http://travis-ci.org/jprichardson/node-fs-extra)
[](https://ci.appveyor.com/project/jprichardson/node-fs-extra/branch/master)
[](https://www.npmjs.org/package/fs-extra)
[](https://coveralls.io/r/jprichardson/node-fs-extra)
<a href="https://github.com/feross/standard"><img src="https://cdn.rawgit.com/feross/standard/master/sticker.svg" alt="Standard JavaScript" width="100"></a>
Why?
----
I got tired of including `mkdirp`, `rimraf`, and `ncp` in most of my projects.
Installation
------------
npm install --save fs-extra
Usage
-----
`fs-extra` is a drop in replacement for native `fs`. All methods in `fs` are attached to `fs-extra`. All `fs` methods return promises if the callback isn't passed.
You don't ever need to include the original `fs` module again:
```js
const fs = require('fs') // this is no longer necessary
```
you can now do this:
```js
const fs = require('fs-extra')
```
or if you prefer to make it clear that you're using `fs-extra` and not `fs`, you may want
to name your `fs` variable `fse` like so:
```js
const fse = require('fs-extra')
```
you can also keep both, but it's redundant:
```js
const fs = require('fs')
const fse = require('fs-extra')
```
Sync vs Async
-------------
Most methods are async by default. All async methods will return a promise if the callback isn't passed.
Sync methods on the other hand will throw if an error occurs.
Example:
```js
const fs = require('fs-extra')
// Async with promises:
fs.copy('/tmp/myfile', '/tmp/mynewfile')
.then(() => console.log('success!'))
.catch(err => console.error(err))
// Async with callbacks:
fs.copy('/tmp/myfile', '/tmp/mynewfile', err => {
if (err) return console.error(err)
console.log('success!')
})
// Sync:
try {
fs.copySync('/tmp/myfile', '/tmp/mynewfile')
console.log('success!')
} catch (err) {
console.error(err)
}
```
Methods
-------
### Async
- [copy](docs/copy.md)
- [emptyDir](docs/emptyDir.md)
- [ensureFile](docs/ensureFile.md)
- [ensureDir](docs/ensureDir.md)
- [ensureLink](docs/ensureLink.md)
- [ensureSymlink](docs/ensureSymlink.md)
- [mkdirs](docs/ensureDir.md)
- [move](docs/move.md)
- [outputFile](docs/outputFile.md)
- [outputJson](docs/outputJson.md)
- [pathExists](docs/pathExists.md)
- [readJson](docs/readJson.md)
- [remove](docs/remove.md)
- [writeJson](docs/writeJson.md)
### Sync
- [copySync](docs/copy-sync.md)
- [emptyDirSync](docs/emptyDir-sync.md)
- [ensureFileSync](docs/ensureFile-sync.md)
- [ensureDirSync](docs/ensureDir-sync.md)
- [ensureLinkSync](docs/ensureLink-sync.md)
- [ensureSymlinkSync](docs/ensureSymlink-sync.md)
- [mkdirsSync](docs/ensureDir-sync.md)
- [moveSync](docs/move-sync.md)
- [outputFileSync](docs/outputFile-sync.md)
- [outputJsonSync](docs/outputJson-sync.md)
- [pathExistsSync](docs/pathExists-sync.md)
- [readJsonSync](docs/readJson-sync.md)
- [removeSync](docs/remove-sync.md)
- [writeJsonSync](docs/writeJson-sync.md)
**NOTE:** You can still use the native Node.js methods. They are promisified and copied over to `fs-extra`. See [notes on `fs.read()` & `fs.write()`](docs/fs-read-write.md)
### What happened to `walk()` and `walkSync()`?
They were removed from `fs-extra` in v2.0.0. If you need the functionality, `walk` and `walkSync` are available as separate packages, [`klaw`](https://github.com/jprichardson/node-klaw) and [`klaw-sync`](https://github.com/manidlou/node-klaw-sync).
Third Party
-----------
### TypeScript
If you like TypeScript, you can use `fs-extra` with it: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/fs-extra
### File / Directory Watching
If you want to watch for changes to files or directories, then you should use [chokidar](https://github.com/paulmillr/chokidar).
### Misc.
- [mfs](https://github.com/cadorn/mfs) - Monitor your fs-extra calls.
Hacking on fs-extra
-------------------
Wanna hack on `fs-extra`? Great! Your help is needed! [fs-extra is one of the most depended upon Node.js packages](http://nodei.co/npm/fs-extra.png?downloads=true&downloadRank=true&stars=true). This project
uses [JavaScript Standard Style](https://github.com/feross/standard) - if the name or style choices bother you,
you're gonna have to get over it :) If `standard` is good enough for `npm`, it's good enough for `fs-extra`.
[](https://github.com/feross/standard)
What's needed?
- First, take a look at existing issues. Those are probably going to be where the priority lies.
- More tests for edge cases. Specifically on different platforms. There can never be enough tests.
- Improve test coverage. See coveralls output for more info.
Note: If you make any big changes, **you should definitely file an issue for discussion first.**
### Running the Test Suite
fs-extra contains hundreds of tests.
- `npm run lint`: runs the linter ([standard](http://standardjs.com/))
- `npm run unit`: runs the unit tests
- `npm test`: runs both the linter and the tests
### Windows
If you run the tests on the Windows and receive a lot of symbolic link `EPERM` permission errors, it's
because on Windows you need elevated privilege to create symbolic links. You can add this to your Windows's
account by following the instructions here: http://superuser.com/questions/104845/permission-to-make-symbolic-links-in-windows-7
However, I didn't have much luck doing this.
Since I develop on Mac OS X, I use VMWare Fusion for Windows testing. I create a shared folder that I map to a drive on Windows.
I open the `Node.js command prompt` and run as `Administrator`. I then map the network drive running the following command:
net use z: "\\vmware-host\Shared Folders"
I can then navigate to my `fs-extra` directory and run the tests.
Naming
------
I put a lot of thought into the naming of these functions. Inspired by @coolaj86's request. So he deserves much of the credit for raising the issue. See discussion(s) here:
* https://github.com/jprichardson/node-fs-extra/issues/2
* https://github.com/flatiron/utile/issues/11
* https://github.com/ryanmcgrath/wrench-js/issues/29
* https://github.com/substack/node-mkdirp/issues/17
First, I believe that in as many cases as possible, the [Node.js naming schemes](http://nodejs.org/api/fs.html) should be chosen. However, there are problems with the Node.js own naming schemes.
For example, `fs.readFile()` and `fs.readdir()`: the **F** is capitalized in *File* and the **d** is not capitalized in *dir*. Perhaps a bit pedantic, but they should still be consistent. Also, Node.js has chosen a lot of POSIX naming schemes, which I believe is great. See: `fs.mkdir()`, `fs.rmdir()`, `fs.chown()`, etc.
We have a dilemma though. How do you consistently name methods that perform the following POSIX commands: `cp`, `cp -r`, `mkdir -p`, and `rm -rf`?
My perspective: when in doubt, err on the side of simplicity. A directory is just a hierarchical grouping of directories and files. Consider that for a moment. So when you want to copy it or remove it, in most cases you'll want to copy or remove all of its contents. When you want to create a directory, if the directory that it's suppose to be contained in does not exist, then in most cases you'll want to create that too.
So, if you want to remove a file or a directory regardless of whether it has contents, just call `fs.remove(path)`. If you want to copy a file or a directory whether it has contents, just call `fs.copy(source, destination)`. If you want to create a directory regardless of whether its parent directories exist, just call `fs.mkdirs(path)` or `fs.mkdirp(path)`.
Credit
------
`fs-extra` wouldn't be possible without using the modules from the following authors:
- [Isaac Shlueter](https://github.com/isaacs)
- [Charlie McConnel](https://github.com/avianflu)
- [James Halliday](https://github.com/substack)
- [Andrew Kelley](https://github.com/andrewrk)
License
-------
Licensed under MIT
Copyright (c) 2011-2017 [JP Richardson](https://github.com/jprichardson)
[1]: http://nodejs.org/docs/latest/api/fs.html
[jsonfile]: https://github.com/jprichardson/node-jsonfile
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
`disable()`
Will disable all namespaces. The functions returns the namespaces currently
enabled (and skipped). This can be useful if you want to disable debugging
temporarily without knowing what was enabled to begin with.
For example:
```js
let debug = require('debug');
debug.enable('foo:*,-foo:bar');
let namespaces = debug.disable();
debug.enable(namespaces);
```
Note: There is no guarantee that the string will be identical to the initial
enable string, but semantically they will be identical.
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# minimatch
A minimal matching utility.
[](http://travis-ci.org/isaacs/minimatch)
This is the matching library used internally by npm.
It works by converting glob expressions into JavaScript `RegExp`
objects.
## Usage
```javascript
var minimatch = require("minimatch")
minimatch("bar.foo", "*.foo") // true!
minimatch("bar.foo", "*.bar") // false!
minimatch("bar.foo", "*.+(bar|foo)", { debug: true }) // true, and noisy!
```
## Features
Supports these glob features:
* Brace Expansion
* Extended glob matching
* "Globstar" `**` matching
See:
* `man sh`
* `man bash`
* `man 3 fnmatch`
* `man 5 gitignore`
## Minimatch Class
Create a minimatch object by instantiating the `minimatch.Minimatch` class.
```javascript
var Minimatch = require("minimatch").Minimatch
var mm = new Minimatch(pattern, options)
```
### Properties
* `pattern` The original pattern the minimatch object represents.
* `options` The options supplied to the constructor.
* `set` A 2-dimensional array of regexp or string expressions.
Each row in the
array corresponds to a brace-expanded pattern. Each item in the row
corresponds to a single path-part. For example, the pattern
`{a,b/c}/d` would expand to a set of patterns like:
[ [ a, d ]
, [ b, c, d ] ]
If a portion of the pattern doesn't have any "magic" in it
(that is, it's something like `"foo"` rather than `fo*o?`), then it
will be left as a string rather than converted to a regular
expression.
* `regexp` Created by the `makeRe` method. A single regular expression
expressing the entire pattern. This is useful in cases where you wish
to use the pattern somewhat like `fnmatch(3)` with `FNM_PATH` enabled.
* `negate` True if the pattern is negated.
* `comment` True if the pattern is a comment.
* `empty` True if the pattern is `""`.
### Methods
* `makeRe` Generate the `regexp` member if necessary, and return it.
Will return `false` if the pattern is invalid.
* `match(fname)` Return true if the filename matches the pattern, or
false otherwise.
* `matchOne(fileArray, patternArray, partial)` Take a `/`-split
filename, and match it against a single row in the `regExpSet`. This
method is mainly for internal use, but is exposed so that it can be
used by a glob-walker that needs to avoid excessive filesystem calls.
All other methods are internal, and will be called as necessary.
### minimatch(path, pattern, options)
Main export. Tests a path against the pattern using the options.
```javascript
var isJS = minimatch(file, "*.js", { matchBase: true })
```
### minimatch.filter(pattern, options)
Returns a function that tests its
supplied argument, suitable for use with `Array.filter`. Example:
```javascript
var javascripts = fileList.filter(minimatch.filter("*.js", {matchBase: true}))
```
### minimatch.match(list, pattern, options)
Match against the list of
files, in the style of fnmatch or glob. If nothing is matched, and
options.nonull is set, then return a list containing the pattern itself.
```javascript
var javascripts = minimatch.match(fileList, "*.js", {matchBase: true}))
```
### minimatch.makeRe(pattern, options)
Make a regular expression object from the pattern.
## Options
All options are `false` by default.
### debug
Dump a ton of stuff to stderr.
### nobrace
Do not expand `{a,b}` and `{1..3}` brace sets.
### noglobstar
Disable `**` matching against multiple folder names.
### dot
Allow patterns to match filenames starting with a period, even if
the pattern does not explicitly have a period in that spot.
Note that by default, `a/**/b` will **not** match `a/.d/b`, unless `dot`
is set.
### noext
Disable "extglob" style patterns like `+(a|b)`.
### nocase
Perform a case-insensitive match.
### nonull
When a match is not found by `minimatch.match`, return a list containing
the pattern itself if this option is set. When not set, an empty list
is returned if there are no matches.
### matchBase
If set, then patterns without slashes will be matched
against the basename of the path if it contains slashes. For example,
`a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`.
### nocomment
Suppress the behavior of treating `#` at the start of a pattern as a
comment.
### nonegate
Suppress the behavior of treating a leading `!` character as negation.
### flipNegate
Returns from negate expressions the same as if they were not negated.
(Ie, true on a hit, false on a miss.)
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between minimatch and other
implementations, and are intentional.
If the pattern starts with a `!` character, then it is negated. Set the
`nonegate` flag to suppress this behavior, and treat leading `!`
characters normally. This is perhaps relevant if you wish to start the
pattern with a negative extglob pattern like `!(a|B)`. Multiple `!`
characters at the start of a pattern will negate the pattern multiple
times.
If a pattern starts with `#`, then it is treated as a comment, and
will not match anything. Use `\#` to match a literal `#` at the
start of a line, or set the `nocomment` flag to suppress this behavior.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.1, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
If an escaped pattern has no matches, and the `nonull` flag is set,
then minimatch.match returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`minimatch.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
# Deploy system for PM2
This is the module that allows to do `pm2 deploy`.
Documentation: http://pm2.keymetrics.io/docs/usage/deployment/
[](https://travis-ci.org/Unitech/pm2-deploy) [](https://npm.im/pm2-deploy) [](https://packagephobia.now.sh/result?p=pm2-deploy) [](https://github.com/Unitech/pm2-deploy/blob/master/LICENSE) [](https://github.com/Flet/semistandard)
## Instalation
$ npm install pm2-deploy
## Programmatic Usage
```js
var deployForEnv = require('pm2-deploy').deployForEnv;
// Define deploy configuration with target environments
var deployConfig = {
prod: {
user: 'node',
host: '212.83.163.168',
ref: 'origin/master',
repo: '[email protected]:Unitech/eip-vitrine.git',
path: '/var/www/test-deploy'
},
dev: {
user: 'node',
host: '212.83.163.168',
ref: 'origin/master',
repo: '[email protected]:Unitech/eip-vitrine.git',
path: '/var/www/test-dev'
}
};
// Invoke deployment for `dev` environment
deployForEnv(deployConfig, 'dev', [], function (err, args) {
if (err) {
console.error('Deploy failed:', err.message);
return console.error(err.stack);
}
console.log('Success!');
});
// Rollback `prod` environment
deployForEnv(deployConfig, 'prod', ['revert', 1], function (err, args) {
if (err) {
console.error('Rollback failed:', err.message);
return console.error(err.stack);
}
console.log('Success!');
});
```
## API
<!-- Generated by documentation.js. Update this documentation by updating the source code. -->
#### Table of Contents
- [deployForEnv](#deployforenv)
- [Parameters](#parameters)
- [DeployCallback](#deploycallback)
- [Parameters](#parameters-1)
### deployForEnv
Deploy to a single environment
#### Parameters
- `deployConfig` **[object](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/Object)** object containing deploy configs for all environments
- `env` **[string](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/String)** the name of the environment to deploy to
- `args` **[array](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/Array)** custom deploy command-line arguments
- `cb` **[DeployCallback](#deploycallback)** done callback
Returns **[boolean](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/Boolean)** return value is always `false`
### DeployCallback
Type: [Function](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Statements/function)
#### Parameters
- `error` **[Error](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/Error)** deployment error
- `args` **[array](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Global_Objects/Array)** custom command-line arguments provided to deploy
# content-type
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Create and parse HTTP Content-Type header according to RFC 7231
## Installation
```sh
$ npm install content-type
```
## API
```js
var contentType = require('content-type')
```
### contentType.parse(string)
```js
var obj = contentType.parse('image/svg+xml; charset=utf-8')
```
Parse a content type string. This will return an object with the following
properties (examples are shown for the string `'image/svg+xml; charset=utf-8'`):
- `type`: The media type (the type and subtype, always lower case).
Example: `'image/svg+xml'`
- `parameters`: An object of the parameters in the media type (name of parameter
always lower case). Example: `{charset: 'utf-8'}`
Throws a `TypeError` if the string is missing or invalid.
### contentType.parse(req)
```js
var obj = contentType.parse(req)
```
Parse the `content-type` header from the given `req`. Short-cut for
`contentType.parse(req.headers['content-type'])`.
Throws a `TypeError` if the `Content-Type` header is missing or invalid.
### contentType.parse(res)
```js
var obj = contentType.parse(res)
```
Parse the `content-type` header set on the given `res`. Short-cut for
`contentType.parse(res.getHeader('content-type'))`.
Throws a `TypeError` if the `Content-Type` header is missing or invalid.
### contentType.format(obj)
```js
var str = contentType.format({type: 'image/svg+xml'})
```
Format an object into a content type string. This will return a string of the
content type for the given object with the following properties (examples are
shown that produce the string `'image/svg+xml; charset=utf-8'`):
- `type`: The media type (will be lower-cased). Example: `'image/svg+xml'`
- `parameters`: An object of the parameters in the media type (name of the
parameter will be lower-cased). Example: `{charset: 'utf-8'}`
Throws a `TypeError` if the object contains an invalid type or parameter names.
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/content-type.svg
[npm-url]: https://npmjs.org/package/content-type
[node-version-image]: https://img.shields.io/node/v/content-type.svg
[node-version-url]: http://nodejs.org/download/
[travis-image]: https://img.shields.io/travis/jshttp/content-type/master.svg
[travis-url]: https://travis-ci.org/jshttp/content-type
[coveralls-image]: https://img.shields.io/coveralls/jshttp/content-type/master.svg
[coveralls-url]: https://coveralls.io/r/jshttp/content-type
[downloads-image]: https://img.shields.io/npm/dm/content-type.svg
[downloads-url]: https://npmjs.org/package/content-type
# mime-db
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Node.js Version][node-image]][node-url]
[![Build Status][travis-image]][travis-url]
[![Coverage Status][coveralls-image]][coveralls-url]
This is a database of all mime types.
It consists of a single, public JSON file and does not include any logic,
allowing it to remain as un-opinionated as possible with an API.
It aggregates data from the following sources:
- http://www.iana.org/assignments/media-types/media-types.xhtml
- http://svn.apache.org/repos/asf/httpd/httpd/trunk/docs/conf/mime.types
- http://hg.nginx.org/nginx/raw-file/default/conf/mime.types
## Installation
```bash
npm install mime-db
```
### Database Download
If you're crazy enough to use this in the browser, you can just grab the
JSON file using [jsDelivr](https://www.jsdelivr.com/). It is recommended to
replace `master` with [a release tag](https://github.com/jshttp/mime-db/tags)
as the JSON format may change in the future.
```
https://cdn.jsdelivr.net/gh/jshttp/mime-db@master/db.json
```
## Usage
<!-- eslint-disable no-unused-vars -->
```js
var db = require('mime-db')
// grab data on .js files
var data = db['application/javascript']
```
## Data Structure
The JSON file is a map lookup for lowercased mime types.
Each mime type has the following properties:
- `.source` - where the mime type is defined.
If not set, it's probably a custom media type.
- `apache` - [Apache common media types](http://svn.apache.org/repos/asf/httpd/httpd/trunk/docs/conf/mime.types)
- `iana` - [IANA-defined media types](http://www.iana.org/assignments/media-types/media-types.xhtml)
- `nginx` - [nginx media types](http://hg.nginx.org/nginx/raw-file/default/conf/mime.types)
- `.extensions[]` - known extensions associated with this mime type.
- `.compressible` - whether a file of this type can be gzipped.
- `.charset` - the default charset associated with this type, if any.
If unknown, every property could be `undefined`.
## Contributing
To edit the database, only make PRs against `src/custom.json` or
`src/custom-suffix.json`.
The `src/custom.json` file is a JSON object with the MIME type as the keys
and the values being an object with the following keys:
- `compressible` - leave out if you don't know, otherwise `true`/`false` to
indicate whether the data represented by the type is typically compressible.
- `extensions` - include an array of file extensions that are associated with
the type.
- `notes` - human-readable notes about the type, typically what the type is.
- `sources` - include an array of URLs of where the MIME type and the associated
extensions are sourced from. This needs to be a [primary source](https://en.wikipedia.org/wiki/Primary_source);
links to type aggregating sites and Wikipedia are _not acceptable_.
To update the build, run `npm run build`.
### Adding Custom Media Types
The best way to get new media types included in this library is to register
them with the IANA. The community registration procedure is outlined in
[RFC 6838 section 5](http://tools.ietf.org/html/rfc6838#section-5). Types
registered with the IANA are automatically pulled into this library.
If that is not possible / feasible, they can be added directly here as a
"custom" type. To do this, it is required to have a primary source that
definitively lists the media type. If an extension is going to be listed as
associateed with this media type, the source must definitively link the
media type and extension as well.
[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/mime-db/master
[coveralls-url]: https://coveralls.io/r/jshttp/mime-db?branch=master
[node-image]: https://badgen.net/npm/node/mime-db
[node-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/mime-db
[npm-url]: https://npmjs.org/package/mime-db
[npm-version-image]: https://badgen.net/npm/v/mime-db
[travis-image]: https://badgen.net/travis/jshttp/mime-db/master
[travis-url]: https://travis-ci.org/jshttp/mime-db
# string_decoder
***Node-core v8.9.4 string_decoder for userland***
[](https://nodei.co/npm/string_decoder/)
[](https://nodei.co/npm/string_decoder/)
```bash
npm install --save string_decoder
```
***Node-core string_decoder for userland***
This package is a mirror of the string_decoder implementation in Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.9.4/docs/api/).
As of version 1.0.0 **string_decoder** uses semantic versioning.
## Previous versions
Previous version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10.
## Update
The *build/* directory contains a build script that will scrape the source from the [nodejs/node](https://github.com/nodejs/node) repo given a specific Node version.
## Streams Working Group
`string_decoder` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
See [readable-stream](https://github.com/nodejs/readable-stream) for
more details.
![Log Driver][logdriver-logo]
=========
[![Build Status][travis-image]][travis-url] [![NPM Version][npm-image]][npm-url] [](https://codecov.io/github/cainus/logdriver?branch=master)
Logdriver is a node.js logger that only logs to stdout.
#### You're going to want to log the output of stdout and stderr anyway, so you might as well put all your logging through stdout. Logging libraries that don't write to stdout or stderr are missing absolutely critical output like the stack trace if/when your app dies.
## There are some other nice advantages:
* When working on your app locally, logs just show up in stdout just like if you'd used console.log(). That's a heck of a lot simpler than tailing a log file.
* Logging transports can be externalized from your app entirely, and completely decoupled. This means if you want to log to irc, you write an irc client script that reads from stdin, and you just pipe your app's output to that script.
```console
node yourapp.js 2>&1 | node ircloggerbot.js
```
* You can still easily log to a file on a production server by piping your stdout and stderr to a file like so when you initialize your app:
```console
node yourapp.js 2>&1 >> somefile.log
```
NB: If you're logging to a file, [Logrotate](http://linuxcommand.org/man_pages/logrotate8.html) is probably going to be your best friend.
* You can still easily log to syslog by piping your stdout and stderr to the 'logger' command like so:
```console
node yourapp.js 2>&1 | logger
```
## Usage:
Getting the default logger:
```javascript
var logger = require('log-driver').logger;
```
This logger has levels 'error', 'warn', 'info', 'debug', and 'trace'.
If you don't like those levels, change the default:
```javascript
var logger = require('log-driver')({
levels: ['superimportant', 'checkthisout', 'whocares' ]
});
logger.whocares("brangelina in lover's quarrel!");
```
Specifying what log level to log at to make logs less chatty:
```javascript
var logger = require('log-driver')({ level: "info" });
logger.info("info test");
logger.warn("warn test");
logger.error("error test");
logger.trace("trace test");
```
output:
```console
[info] "2013-03-26T18:30:14.570Z" 'info test'
[warn] "2013-03-26T18:30:14.573Z" 'warn test'
[error] "2013-03-26T18:30:14.574Z" 'error test'
```
(notice the trace() call was omitted because it's less than the info
level.
Turning off all log output (sometimes nice for automated tests to keep
output clean):
```javascript
var logger = require('log-driver')({ level: false });
```
Using the same logger everywhere:
The last logger you created is always available this way:
```javascript
var logger = require('log-driver').logger;
```
This way, if you use only one logger in your application (like most
applications), you can just configure it once, and get it this way
everywhere else.
Don't like the logging format? Just change it by passing a new
formatting function like so:
```javascript
var logger = require('log-driver')({
format: function() {
// let's do pure JSON:
return JSON.stringify(arguments);
}
});
```
[logdriver-logo]: https://raw.github.com/cainus/logdriver/master/logo.png
[travis-image]: https://travis-ci.org/cainus/logdriver.png?branch=master
[travis-url]: https://travis-ci.org/cainus/logdriver
[coveralls-image]: https://coveralls.io/repos/cainus/logdriver/badge.png?branch=master
[coveralls-url]: https://coveralls.io/repos/cainus/logdriver
[npm-image]: https://badge.fury.io/js/log-driver.png
[npm-url]: https://badge.fury.io/js/log-driver
# jsprim: utilities for primitive JavaScript types
This module provides miscellaneous facilities for working with strings,
numbers, dates, and objects and arrays of these basic types.
### deepCopy(obj)
Creates a deep copy of a primitive type, object, or array of primitive types.
### deepEqual(obj1, obj2)
Returns whether two objects are equal.
### isEmpty(obj)
Returns true if the given object has no properties and false otherwise. This
is O(1) (unlike `Object.keys(obj).length === 0`, which is O(N)).
### hasKey(obj, key)
Returns true if the given object has an enumerable, non-inherited property
called `key`. [For information on enumerability and ownership of properties, see
the MDN
documentation.](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Enumerability_and_ownership_of_properties)
### forEachKey(obj, callback)
Like Array.forEach, but iterates enumerable, owned properties of an object
rather than elements of an array. Equivalent to:
for (var key in obj) {
if (Object.prototype.hasOwnProperty.call(obj, key)) {
callback(key, obj[key]);
}
}
### flattenObject(obj, depth)
Flattens an object up to a given level of nesting, returning an array of arrays
of length "depth + 1", where the first "depth" elements correspond to flattened
columns and the last element contains the remaining object . For example:
flattenObject({
'I': {
'A': {
'i': {
'datum1': [ 1, 2 ],
'datum2': [ 3, 4 ]
},
'ii': {
'datum1': [ 3, 4 ]
}
},
'B': {
'i': {
'datum1': [ 5, 6 ]
},
'ii': {
'datum1': [ 7, 8 ],
'datum2': [ 3, 4 ],
},
'iii': {
}
}
},
'II': {
'A': {
'i': {
'datum1': [ 1, 2 ],
'datum2': [ 3, 4 ]
}
}
}
}, 3)
becomes:
[
[ 'I', 'A', 'i', { 'datum1': [ 1, 2 ], 'datum2': [ 3, 4 ] } ],
[ 'I', 'A', 'ii', { 'datum1': [ 3, 4 ] } ],
[ 'I', 'B', 'i', { 'datum1': [ 5, 6 ] } ],
[ 'I', 'B', 'ii', { 'datum1': [ 7, 8 ], 'datum2': [ 3, 4 ] } ],
[ 'I', 'B', 'iii', {} ],
[ 'II', 'A', 'i', { 'datum1': [ 1, 2 ], 'datum2': [ 3, 4 ] } ]
]
This function is strict: "depth" must be a non-negative integer and "obj" must
be a non-null object with at least "depth" levels of nesting under all keys.
### flattenIter(obj, depth, func)
This is similar to `flattenObject` except that instead of returning an array,
this function invokes `func(entry)` for each `entry` in the array that
`flattenObject` would return. `flattenIter(obj, depth, func)` is logically
equivalent to `flattenObject(obj, depth).forEach(func)`. Importantly, this
version never constructs the full array. Its memory usage is O(depth) rather
than O(n) (where `n` is the number of flattened elements).
There's another difference between `flattenObject` and `flattenIter` that's
related to the special case where `depth === 0`. In this case, `flattenObject`
omits the array wrapping `obj` (which is regrettable).
### pluck(obj, key)
Fetch nested property "key" from object "obj", traversing objects as needed.
For example, `pluck(obj, "foo.bar.baz")` is roughly equivalent to
`obj.foo.bar.baz`, except that:
1. If traversal fails, the resulting value is undefined, and no error is
thrown. For example, `pluck({}, "foo.bar")` is just undefined.
2. If "obj" has property "key" directly (without traversing), the
corresponding property is returned. For example,
`pluck({ 'foo.bar': 1 }, 'foo.bar')` is 1, not undefined. This is also
true recursively, so `pluck({ 'a': { 'foo.bar': 1 } }, 'a.foo.bar')` is
also 1, not undefined.
### randElt(array)
Returns an element from "array" selected uniformly at random. If "array" is
empty, throws an Error.
### startsWith(str, prefix)
Returns true if the given string starts with the given prefix and false
otherwise.
### endsWith(str, suffix)
Returns true if the given string ends with the given suffix and false
otherwise.
### parseInteger(str, options)
Parses the contents of `str` (a string) as an integer. On success, the integer
value is returned (as a number). On failure, an error is **returned** describing
why parsing failed.
By default, leading and trailing whitespace characters are not allowed, nor are
trailing characters that are not part of the numeric representation. This
behaviour can be toggled by using the options below. The empty string (`''`) is
not considered valid input. If the return value cannot be precisely represented
as a number (i.e., is smaller than `Number.MIN_SAFE_INTEGER` or larger than
`Number.MAX_SAFE_INTEGER`), an error is returned. Additionally, the string
`'-0'` will be parsed as the integer `0`, instead of as the IEEE floating point
value `-0`.
This function accepts both upper and lowercase characters for digits, similar to
`parseInt()`, `Number()`, and [strtol(3C)](https://illumos.org/man/3C/strtol).
The following may be specified in `options`:
Option | Type | Default | Meaning
------------------ | ------- | ------- | ---------------------------
base | number | 10 | numeric base (radix) to use, in the range 2 to 36
allowSign | boolean | true | whether to interpret any leading `+` (positive) and `-` (negative) characters
allowImprecise | boolean | false | whether to accept values that may have lost precision (past `MAX_SAFE_INTEGER` or below `MIN_SAFE_INTEGER`)
allowPrefix | boolean | false | whether to interpret the prefixes `0b` (base 2), `0o` (base 8), `0t` (base 10), or `0x` (base 16)
allowTrailing | boolean | false | whether to ignore trailing characters
trimWhitespace | boolean | false | whether to trim any leading or trailing whitespace/line terminators
leadingZeroIsOctal | boolean | false | whether a leading zero indicates octal
Note that if `base` is unspecified, and `allowPrefix` or `leadingZeroIsOctal`
are, then the leading characters can change the default base from 10. If `base`
is explicitly specified and `allowPrefix` is true, then the prefix will only be
accepted if it matches the specified base. `base` and `leadingZeroIsOctal`
cannot be used together.
**Context:** It's tricky to parse integers with JavaScript's built-in facilities
for several reasons:
- `parseInt()` and `Number()` by default allow the base to be specified in the
input string by a prefix (e.g., `0x` for hex).
- `parseInt()` allows trailing nonnumeric characters.
- `Number(str)` returns 0 when `str` is the empty string (`''`).
- Both functions return incorrect values when the input string represents a
valid integer outside the range of integers that can be represented precisely.
Specifically, `parseInt('9007199254740993')` returns 9007199254740992.
- Both functions always accept `-` and `+` signs before the digit.
- Some older JavaScript engines always interpret a leading 0 as indicating
octal, which can be surprising when parsing input from users who expect a
leading zero to be insignificant.
While each of these may be desirable in some contexts, there are also times when
none of them are wanted. `parseInteger()` grants greater control over what
input's permissible.
### iso8601(date)
Converts a Date object to an ISO8601 date string of the form
"YYYY-MM-DDTHH:MM:SS.sssZ". This format is not customizable.
### parseDateTime(str)
Parses a date expressed as a string, as either a number of milliseconds since
the epoch or any string format that Date accepts, giving preference to the
former where these two sets overlap (e.g., strings containing small numbers).
### hrtimeDiff(timeA, timeB)
Given two hrtime readings (as from Node's `process.hrtime()`), where timeA is
later than timeB, compute the difference and return that as an hrtime. It is
illegal to invoke this for a pair of times where timeB is newer than timeA.
### hrtimeAdd(timeA, timeB)
Add two hrtime intervals (as from Node's `process.hrtime()`), returning a new
hrtime interval array. This function does not modify either input argument.
### hrtimeAccum(timeA, timeB)
Add two hrtime intervals (as from Node's `process.hrtime()`), storing the
result in `timeA`. This function overwrites (and returns) the first argument
passed in.
### hrtimeNanosec(timeA), hrtimeMicrosec(timeA), hrtimeMillisec(timeA)
This suite of functions converts a hrtime interval (as from Node's
`process.hrtime()`) into a scalar number of nanoseconds, microseconds or
milliseconds. Results are truncated, as with `Math.floor()`.
### validateJsonObject(schema, object)
Uses JSON validation (via JSV) to validate the given object against the given
schema. On success, returns null. On failure, *returns* (does not throw) a
useful Error object.
### extraProperties(object, allowed)
Check an object for unexpected properties. Accepts the object to check, and an
array of allowed property name strings. If extra properties are detected, an
array of extra property names is returned. If no properties other than those
in the allowed list are present on the object, the returned array will be of
zero length.
### mergeObjects(provided, overrides, defaults)
Merge properties from objects "provided", "overrides", and "defaults". The
intended use case is for functions that accept named arguments in an "args"
object, but want to provide some default values and override other values. In
that case, "provided" is what the caller specified, "overrides" are what the
function wants to override, and "defaults" contains default values.
The function starts with the values in "defaults", overrides them with the
values in "provided", and then overrides those with the values in "overrides".
For convenience, any of these objects may be falsey, in which case they will be
ignored. The input objects are never modified, but properties in the returned
object are not deep-copied.
For example:
mergeObjects(undefined, { 'objectMode': true }, { 'highWaterMark': 0 })
returns:
{ 'objectMode': true, 'highWaterMark': 0 }
For another example:
mergeObjects(
{ 'highWaterMark': 16, 'objectMode': 7 }, /* from caller */
{ 'objectMode': true }, /* overrides */
{ 'highWaterMark': 0 }); /* default */
returns:
{ 'objectMode': true, 'highWaterMark': 16 }
# Contributing
See separate [contribution guidelines](CONTRIBUTING.md).
# Abstract LevelDOWN
<img alt="LevelDB Logo" height="100" src="http://leveldb.org/img/logo.svg">
[](http://travis-ci.org/Level/abstract-leveldown)
[](https://david-dm.org/level/abstract-leveldown)
[](https://greenkeeper.io/)
[](https://nodei.co/npm/abstract-leveldown/)
[](https://nodei.co/npm/abstract-leveldown/)
An abstract prototype matching the **[LevelDOWN](https://github.com/level/leveldown/)** API. Useful for extending **[LevelUP](https://github.com/level/levelup)** functionality by providing a replacement to LevelDOWN.
As of version 0.7, LevelUP allows you to pass a `'db'` option when you create a new instance. This will override the default LevelDOWN store with a LevelDOWN API compatible object.
**Abstract LevelDOWN** provides a simple, operational *noop* base prototype that's ready for extending. By default, all operations have sensible "noops" (operations that essentially do nothing). For example, simple operations such as `.open(callback)` and `.close(callback)` will simply invoke the callback (on a *next tick*). More complex operations perform sensible actions, for example: `.get(key, callback)` will always return a `'NotFound'` `Error` on the callback.
You add functionality by implementing the underscore versions of the operations. For example, to implement a `put()` operation you add a `_put()` method to your object. Each of these underscore methods override the default *noop* operations and are always provided with **consistent arguments**, regardless of what is passed in by the client.
Additionally, all methods provide argument checking and sensible defaults for optional arguments. All bad-argument errors are compatible with LevelDOWN (they pass the LevelDOWN method arguments tests). For example, if you call `.open()` without a callback argument you'll get an `Error('open() requires a callback argument')`. Where optional arguments are involved, your underscore methods will receive sensible defaults. A `.get(key, callback)` will pass through to a `._get(key, options, callback)` where the `options` argument is an empty object.
## Example
A simplistic in-memory LevelDOWN replacement
```js
var util = require('util')
, AbstractLevelDOWN = require('./').AbstractLevelDOWN
// constructor, passes through the 'location' argument to the AbstractLevelDOWN constructor
function FakeLevelDOWN (location) {
AbstractLevelDOWN.call(this, location)
}
// our new prototype inherits from AbstractLevelDOWN
util.inherits(FakeLevelDOWN, AbstractLevelDOWN)
// implement some methods
FakeLevelDOWN.prototype._open = function (options, callback) {
// initialise a memory storage object
this._store = {}
// optional use of nextTick to be a nice async citizen
process.nextTick(function () { callback(null, this) }.bind(this))
}
FakeLevelDOWN.prototype._put = function (key, value, options, callback) {
key = '_' + key // safety, to avoid key='__proto__'-type skullduggery
this._store[key] = value
process.nextTick(callback)
}
FakeLevelDOWN.prototype._get = function (key, options, callback) {
var value = this._store['_' + key]
if (value === undefined) {
// 'NotFound' error, consistent with LevelDOWN API
return process.nextTick(function () { callback(new Error('NotFound')) })
}
process.nextTick(function () {
callback(null, value)
})
}
FakeLevelDOWN.prototype._del = function (key, options, callback) {
delete this._store['_' + key]
process.nextTick(callback)
}
// now use it in LevelUP
var levelup = require('levelup')
var db = levelup('/who/cares/', {
// the 'db' option replaces LevelDOWN
db: function (location) { return new FakeLevelDOWN(location) }
})
db.put('foo', 'bar', function (err) {
if (err) throw err
db.get('foo', function (err, value) {
if (err) throw err
console.log('Got foo =', value)
})
})
```
See [MemDOWN](https://github.com/Level/memdown/) if you are looking for a complete in-memory replacement for LevelDOWN.
## Extensible API
Remember that each of these methods, if you implement them, will receive exactly the number and order of arguments described. Optional arguments will be converted to sensible defaults.
### AbstractLevelDOWN(location)
### AbstractLevelDOWN#status
An `AbstractLevelDOWN` based database can be in one of the following states:
* `'new'` - newly created, not opened or closed
* `'opening'` - waiting for the database to be opened
* `'open'` - successfully opened the database, available for use
* `'closing'` - waiting for the database to be closed
* `'closed'` - database has been successfully closed, should not be used
### AbstractLevelDOWN#_open(options, callback)
### AbstractLevelDOWN#_close(callback)
### AbstractLevelDOWN#_get(key, options, callback)
### AbstractLevelDOWN#_put(key, value, options, callback)
### AbstractLevelDOWN#_del(key, options, callback)
### AbstractLevelDOWN#_batch(array, options, callback)
If `batch()` is called without arguments or with only an options object then it should return a `Batch` object with chainable methods. Otherwise it will invoke a classic batch operation.
### AbstractLevelDOWN#_chainedBatch()
By default a `batch()` operation without arguments returns a blank `AbstractChainedBatch` object. The prototype is available on the main exports for you to extend. If you want to implement chainable batch operations then you should extend the `AbstractChaindBatch` and return your object in the `_chainedBatch()` method.
### AbstractLevelDOWN#_approximateSize(start, end, callback)
### AbstractLevelDOWN#_serializeKey(key)
### AbstractLevelDOWN#_serializeValue(value)
### AbstractLevelDOWN#_iterator(options)
By default an `iterator()` operation returns a blank `AbstractIterator` object. The prototype is available on the main exports for you to extend. If you want to implement iterator operations then you should extend the `AbstractIterator` and return your object in the `_iterator(options)` method.
`AbstractIterator` implements the basic state management found in LevelDOWN. It keeps track of when a `next()` is in progress and when an `end()` has been called so it doesn't allow concurrent `next()` calls, it does allow `end()` while a `next()` is in progress and it doesn't allow either `next()` or `end()` after `end()` has been called.
### AbstractIterator(db)
Provided with the current instance of `AbstractLevelDOWN` by default.
### AbstractIterator#_next(callback)
### AbstractIterator#_end(callback)
### AbstractChainedBatch
Provided with the current instance of `AbstractLevelDOWN` by default.
### AbstractChainedBatch#_put(key, value)
### AbstractChainedBatch#_del(key)
### AbstractChainedBatch#_clear()
### AbstractChainedBatch#_write(options, callback)
### AbstractChainedBatch#_serializeKey(key)
### AbstractChainedBatch#_serializeValue(value)
### isLevelDown(db)
Returns `true` if `db` has the same public api as `AbstractLevelDOWN`, otherwise `false`. This is a utility function and it's not part of the extensible api.
<a name="contributing"></a>
Contributing
------------
AbstractLevelDOWN is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [contribution guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
<a name="license"></a>
License & Copyright
-------------------
Copyright © 2013-2017 **AbstractLevelDOWN** [contributors](https://github.com/level/community#contributors).
**AbstractLevelDOWN** is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included `LICENSE.md` file for more details.
# Pascal Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a string of capitalized words without separators.
## Installation
```
npm install pascal-case --save
```
## Usage
```js
import { pascalCase } from "pascal-case";
pascalCase("string"); //=> "String"
pascalCase("dot.case"); //=> "DotCase"
pascalCase("PascalCase"); //=> "PascalCase"
pascalCase("version 1.2.10"); //=> "Version_1_2_10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
### Merge Numbers
If you'd like to remove the behavior prefixing `_` before numbers, you can use `pascalCaseTransformMerge`:
```js
import { pascalCaseTransformMerge } from "pascal-case";
pascalCase("version 12", { transform: pascalCaseTransformMerge }); //=> "Version12"
```
## License
MIT
[npm-image]: https://img.shields.io/npm/v/pascal-case.svg?style=flat
[npm-url]: https://npmjs.org/package/pascal-case
[downloads-image]: https://img.shields.io/npm/dm/pascal-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/pascal-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/pascal-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=pascal-case
A light, featureful and explicit option parsing library for node.js.
[Why another one? See below](#why). tl;dr: The others I've tried are one of
too loosey goosey (not explicit), too big/too many deps, or ill specified.
YMMV.
Follow <a href="https://twitter.com/intent/user?screen_name=trentmick" target="_blank">@trentmick</a>
for updates to node-dashdash.
# Install
npm install dashdash
# Usage
```javascript
var dashdash = require('dashdash');
// Specify the options. Minimally `name` (or `names`) and `type`
// must be given for each.
var options = [
{
// `names` or a single `name`. First element is the `opts.KEY`.
names: ['help', 'h'],
// See "Option specs" below for types.
type: 'bool',
help: 'Print this help and exit.'
}
];
// Shortcut form. As called it infers `process.argv`. See below for
// the longer form to use methods like `.help()` on the Parser object.
var opts = dashdash.parse({options: options});
console.log("opts:", opts);
console.log("args:", opts._args);
```
# Longer Example
A more realistic [starter script "foo.js"](./examples/foo.js) is as follows.
This also shows using `parser.help()` for formatted option help.
```javascript
var dashdash = require('./lib/dashdash');
var options = [
{
name: 'version',
type: 'bool',
help: 'Print tool version and exit.'
},
{
names: ['help', 'h'],
type: 'bool',
help: 'Print this help and exit.'
},
{
names: ['verbose', 'v'],
type: 'arrayOfBool',
help: 'Verbose output. Use multiple times for more verbose.'
},
{
names: ['file', 'f'],
type: 'string',
help: 'File to process',
helpArg: 'FILE'
}
];
var parser = dashdash.createParser({options: options});
try {
var opts = parser.parse(process.argv);
} catch (e) {
console.error('foo: error: %s', e.message);
process.exit(1);
}
console.log("# opts:", opts);
console.log("# args:", opts._args);
// Use `parser.help()` for formatted options help.
if (opts.help) {
var help = parser.help({includeEnv: true}).trimRight();
console.log('usage: node foo.js [OPTIONS]\n'
+ 'options:\n'
+ help);
process.exit(0);
}
// ...
```
Some example output from this script (foo.js):
```
$ node foo.js -h
# opts: { help: true,
_order: [ { name: 'help', value: true, from: 'argv' } ],
_args: [] }
# args: []
usage: node foo.js [OPTIONS]
options:
--version Print tool version and exit.
-h, --help Print this help and exit.
-v, --verbose Verbose output. Use multiple times for more verbose.
-f FILE, --file=FILE File to process
$ node foo.js -v
# opts: { verbose: [ true ],
_order: [ { name: 'verbose', value: true, from: 'argv' } ],
_args: [] }
# args: []
$ node foo.js --version arg1
# opts: { version: true,
_order: [ { name: 'version', value: true, from: 'argv' } ],
_args: [ 'arg1' ] }
# args: [ 'arg1' ]
$ node foo.js -f bar.txt
# opts: { file: 'bar.txt',
_order: [ { name: 'file', value: 'bar.txt', from: 'argv' } ],
_args: [] }
# args: []
$ node foo.js -vvv --file=blah
# opts: { verbose: [ true, true, true ],
file: 'blah',
_order:
[ { name: 'verbose', value: true, from: 'argv' },
{ name: 'verbose', value: true, from: 'argv' },
{ name: 'verbose', value: true, from: 'argv' },
{ name: 'file', value: 'blah', from: 'argv' } ],
_args: [] }
# args: []
```
See the ["examples"](examples/) dir for a number of starter examples using
some of dashdash's features.
# Environment variable integration
If you want to allow environment variables to specify options to your tool,
dashdash makes this easy. We can change the 'verbose' option in the example
above to include an 'env' field:
```javascript
{
names: ['verbose', 'v'],
type: 'arrayOfBool',
env: 'FOO_VERBOSE', // <--- add this line
help: 'Verbose output. Use multiple times for more verbose.'
},
```
then the **"FOO_VERBOSE" environment variable** can be used to set this
option:
```shell
$ FOO_VERBOSE=1 node foo.js
# opts: { verbose: [ true ],
_order: [ { name: 'verbose', value: true, from: 'env' } ],
_args: [] }
# args: []
```
Boolean options will interpret the empty string as unset, '0' as false
and anything else as true.
```shell
$ FOO_VERBOSE= node examples/foo.js # not set
# opts: { _order: [], _args: [] }
# args: []
$ FOO_VERBOSE=0 node examples/foo.js # '0' is false
# opts: { verbose: [ false ],
_order: [ { key: 'verbose', value: false, from: 'env' } ],
_args: [] }
# args: []
$ FOO_VERBOSE=1 node examples/foo.js # true
# opts: { verbose: [ true ],
_order: [ { key: 'verbose', value: true, from: 'env' } ],
_args: [] }
# args: []
$ FOO_VERBOSE=boogabooga node examples/foo.js # true
# opts: { verbose: [ true ],
_order: [ { key: 'verbose', value: true, from: 'env' } ],
_args: [] }
# args: []
```
Non-booleans can be used as well. Strings:
```shell
$ FOO_FILE=data.txt node examples/foo.js
# opts: { file: 'data.txt',
_order: [ { key: 'file', value: 'data.txt', from: 'env' } ],
_args: [] }
# args: []
```
Numbers:
```shell
$ FOO_TIMEOUT=5000 node examples/foo.js
# opts: { timeout: 5000,
_order: [ { key: 'timeout', value: 5000, from: 'env' } ],
_args: [] }
# args: []
$ FOO_TIMEOUT=blarg node examples/foo.js
foo: error: arg for "FOO_TIMEOUT" is not a positive integer: "blarg"
```
With the `includeEnv: true` config to `parser.help()` the environment
variable can also be included in **help output**:
usage: node foo.js [OPTIONS]
options:
--version Print tool version and exit.
-h, --help Print this help and exit.
-v, --verbose Verbose output. Use multiple times for more verbose.
Environment: FOO_VERBOSE=1
-f FILE, --file=FILE File to process
# Bash completion
Dashdash provides a simple way to create a Bash completion file that you
can place in your "bash_completion.d" directory -- sometimes that is
"/usr/local/etc/bash_completion.d/"). Features:
- Support for short and long opts
- Support for knowing which options take arguments
- Support for subcommands (e.g. 'git log <TAB>' to show just options for the
log subcommand). See
[node-cmdln](https://github.com/trentm/node-cmdln#bash-completion) for
how to integrate that.
- Does the right thing with "--" to stop options.
- Custom optarg and arg types for custom completions.
Dashdash will return bash completion file content given a parser instance:
var parser = dashdash.createParser({options: options});
console.log( parser.bashCompletion({name: 'mycli'}) );
or directly from a `options` array of options specs:
var code = dashdash.bashCompletionFromOptions({
name: 'mycli',
options: OPTIONS
});
Write that content to "/usr/local/etc/bash_completion.d/mycli" and you will
have Bash completions for `mycli`. Alternatively you can write it to
any file (e.g. "~/.bashrc") and source it.
You could add a `--completion` hidden option to your tool that emits the
completion content and document for your users to call that to install
Bash completions.
See [examples/ddcompletion.js](examples/ddcompletion.js) for a complete
example, including how one can define bash functions for completion of custom
option types. Also see [node-cmdln](https://github.com/trentm/node-cmdln) for
how it uses this for Bash completion for full multi-subcommand tools.
- TODO: document specExtra
- TODO: document includeHidden
- TODO: document custom types, `function complete\_FOO` guide, completionType
- TODO: document argtypes
# Parser config
Parser construction (i.e. `dashdash.createParser(CONFIG)`) takes the
following fields:
- `options` (Array of option specs). Required. See the
[Option specs](#option-specs) section below.
- `interspersed` (Boolean). Optional. Default is true. If true this allows
interspersed arguments and options. I.e.:
node ./tool.js -v arg1 arg2 -h # '-h' is after interspersed args
Set it to false to have '-h' **not** get parsed as an option in the above
example.
- `allowUnknown` (Boolean). Optional. Default is false. If false, this causes
unknown arguments to throw an error. I.e.:
node ./tool.js -v arg1 --afe8asefksjefhas
Set it to true to treat the unknown option as a positional
argument.
**Caveat**: When a shortopt group, such as `-xaz` contains a mix of
known and unknown options, the *entire* group is passed through
unmolested as a positional argument.
Consider if you have a known short option `-a`, and parse the
following command line:
node ./tool.js -xaz
where `-x` and `-z` are unknown. There are multiple ways to
interpret this:
1. `-x` takes a value: `{x: 'az'}`
2. `-x` and `-z` are both booleans: `{x:true,a:true,z:true}`
Since dashdash does not know what `-x` and `-z` are, it can't know
if you'd prefer to receive `{a:true,_args:['-x','-z']}` or
`{x:'az'}`, or `{_args:['-xaz']}`. Leaving the positional arg unprocessed
is the easiest mistake for the user to recover from.
# Option specs
Example using all fields (required fields are noted):
```javascript
{
names: ['file', 'f'], // Required (one of `names` or `name`).
type: 'string', // Required.
completionType: 'filename',
env: 'MYTOOL_FILE',
help: 'Config file to load before running "mytool"',
helpArg: 'PATH',
helpWrap: false,
default: path.resolve(process.env.HOME, '.mytoolrc')
}
```
Each option spec in the `options` array must/can have the following fields:
- `name` (String) or `names` (Array). Required. These give the option name
and aliases. The first name (if more than one given) is the key for the
parsed `opts` object.
- `type` (String). Required. One of:
- bool
- string
- number
- integer
- positiveInteger
- date (epoch seconds, e.g. 1396031701, or ISO 8601 format
`YYYY-MM-DD[THH:MM:SS[.sss][Z]]`, e.g. "2014-03-28T18:35:01.489Z")
- arrayOfBool
- arrayOfString
- arrayOfNumber
- arrayOfInteger
- arrayOfPositiveInteger
- arrayOfDate
FWIW, these names attempt to match with asserts on
[assert-plus](https://github.com/mcavage/node-assert-plus).
You can add your own custom option types with `dashdash.addOptionType`.
See below.
- `completionType` (String). Optional. This is used for [Bash
completion](#bash-completion) for an option argument. If not specified,
then the value of `type` is used. Any string may be specified, but only the
following values have meaning:
- `none`: Provide no completions.
- `file`: Bash's default completion (i.e. `complete -o default`), which
includes filenames.
- *Any string FOO for which a `function complete_FOO` Bash function is
defined.* This is for custom completions for a given tool. Typically
these custom functions are provided in the `specExtra` argument to
`dashdash.bashCompletionFromOptions()`. See
["examples/ddcompletion.js"](examples/ddcompletion.js) for an example.
- `env` (String or Array of String). Optional. An environment variable name
(or names) that can be used as a fallback for this option. For example,
given a "foo.js" like this:
var options = [{names: ['dry-run', 'n'], env: 'FOO_DRY_RUN'}];
var opts = dashdash.parse({options: options});
Both `node foo.js --dry-run` and `FOO_DRY_RUN=1 node foo.js` would result
in `opts.dry_run = true`.
An environment variable is only used as a fallback, i.e. it is ignored if
the associated option is given in `argv`.
- `help` (String). Optional. Used for `parser.help()` output.
- `helpArg` (String). Optional. Used in help output as the placeholder for
the option argument, e.g. the "PATH" in:
...
-f PATH, --file=PATH File to process
...
- `helpWrap` (Boolean). Optional, default true. Set this to `false` to have
that option's `help` *not* be text wrapped in `<parser>.help()` output.
- `default`. Optional. A default value used for this option, if the
option isn't specified in argv.
- `hidden` (Boolean). Optional, default false. If true, help output will not
include this option. See also the `includeHidden` option to
`bashCompletionFromOptions()` for [Bash completion](#bash-completion).
# Option group headings
You can add headings between option specs in the `options` array. To do so,
simply add an object with only a `group` property -- the string to print as
the heading for the subsequent options in the array. For example:
```javascript
var options = [
{
group: 'Armament Options'
},
{
names: [ 'weapon', 'w' ],
type: 'string'
},
{
group: 'General Options'
},
{
names: [ 'help', 'h' ],
type: 'bool'
}
];
...
```
Note: You can use an empty string, `{group: ''}`, to get a blank line in help
output between groups of options.
# Help config
The `parser.help(...)` function is configurable as follows:
Options:
Armament Options:
^^ -w WEAPON, --weapon=WEAPON Weapon with which to crush. One of: |
/ sword, spear, maul |
/ General Options: |
/ -h, --help Print this help and exit. |
/ ^^^^ ^ |
\ `-- indent `-- helpCol maxCol ---'
`-- headingIndent
- `indent` (Number or String). Default 4. Set to a number (for that many
spaces) or a string for the literal indent.
- `headingIndent` (Number or String). Default half length of `indent`. Set to
a number (for that many spaces) or a string for the literal indent. This
indent applies to group heading lines, between normal option lines.
- `nameSort` (String). Default is 'length'. By default the names are
sorted to put the short opts first (i.e. '-h, --help' preferred
to '--help, -h'). Set to 'none' to not do this sorting.
- `maxCol` (Number). Default 80. Note that reflow is just done on whitespace
so a long token in the option help can overflow maxCol.
- `helpCol` (Number). If not set a reasonable value will be determined
between `minHelpCol` and `maxHelpCol`.
- `minHelpCol` (Number). Default 20.
- `maxHelpCol` (Number). Default 40.
- `helpWrap` (Boolean). Default true. Set to `false` to have option `help`
strings *not* be textwrapped to the helpCol..maxCol range.
- `includeEnv` (Boolean). Default false. If the option has associated
environment variables (via the `env` option spec attribute), then
append mentioned of those envvars to the help string.
- `includeDefault` (Boolean). Default false. If the option has a default value
(via the `default` option spec attribute, or a default on the option's type),
then a "Default: VALUE" string will be appended to the help string.
# Custom option types
Dashdash includes a good starter set of option types that it will parse for
you. However, you can add your own via:
var dashdash = require('dashdash');
dashdash.addOptionType({
name: '...',
takesArg: true,
helpArg: '...',
parseArg: function (option, optstr, arg) {
...
},
array: false, // optional
arrayFlatten: false, // optional
default: ..., // optional
completionType: ... // optional
});
For example, a simple option type that accepts 'yes', 'y', 'no' or 'n' as
a boolean argument would look like:
var dashdash = require('dashdash');
function parseYesNo(option, optstr, arg) {
var argLower = arg.toLowerCase()
if (~['yes', 'y'].indexOf(argLower)) {
return true;
} else if (~['no', 'n'].indexOf(argLower)) {
return false;
} else {
throw new Error(format(
'arg for "%s" is not "yes" or "no": "%s"',
optstr, arg));
}
}
dashdash.addOptionType({
name: 'yesno'
takesArg: true,
helpArg: '<yes|no>',
parseArg: parseYesNo
});
var options = {
{names: ['answer', 'a'], type: 'yesno'}
};
var opts = dashdash.parse({options: options});
See "examples/custom-option-\*.js" for other examples.
See the `addOptionType` block comment in "lib/dashdash.js" for more details.
Please let me know [with an
issue](https://github.com/trentm/node-dashdash/issues/new) if you write a
generally useful one.
# Why
Why another node.js option parsing lib?
- `nopt` really is just for "tools like npm". Implicit opts (e.g. '--no-foo'
works for every '--foo'). Can't disable abbreviated opts. Can't do multiple
usages of same opt, e.g. '-vvv' (I think). Can't do grouped short opts.
- `optimist` has surprise interpretation of options (at least to me).
Implicit opts mean ambiguities and poor error handling for fat-fingering.
`process.exit` calls makes it hard to use as a libary.
- `optparse` Incomplete docs. Is this an attempted clone of Python's `optparse`.
Not clear. Some divergence. `parser.on("name", ...)` API is weird.
- `argparse` Dep on underscore. No thanks just for option processing.
`find lib | wc -l` -> `26`. Overkill.
Argparse is a bit different anyway. Not sure I want that.
- `posix-getopt` No type validation. Though that isn't a killer. AFAIK can't
have a long opt without a short alias. I.e. no `getopt_long` semantics.
Also, no whizbang features like generated help output.
- ["commander.js"](https://github.com/visionmedia/commander.js): I wrote
[a critique](http://trentm.com/2014/01/a-critique-of-commander-for-nodejs.html)
a while back. It seems fine, but last I checked had
[an outstanding bug](https://github.com/visionmedia/commander.js/pull/121)
that would prevent me from using it.
# License
MIT. See LICENSE.txt.
<div align="center">
<h1><code>Rainbow Bridge CLI</code></h1>
<p>
<strong>OPS tool to Rainbow Bridge, an Ethereum to Tezos trustless, fully decentralized, bidirectional bridge</strong>
</p>
<p>
<a href="https://buildkite.com/tezosprotocol/tez-bridge-cli"><img src=" https://badge.buildkite.com/93478642b0ddf8e3548c16d2e60c4adbca4fd853520b6a5bca.svg?branch=master" alt="Buildkite Build" /></a>
<a href="https://npmjs.com/tez-bridge-cli"><img alt="npm" src="https://img.shields.io/npm/v/tez-bridge-cli.svg?style=flat-square"></a>
</p>
</div>
## Table of Contents
- [Pre-requisites](#pre-requisites)
- [Usage](#usage)
- [Security](#security)
- [Gas costs](#gas-costs)
- [Using Bridge on Testnet](#using-bridge-on-testnet)
- [Deploying and Using Locally](#deploying-and-using-locally)
- [Contract Development Workflow](#contract-development-workflow)
## Pre-requisites
The current version of CLI is all-in-one package -- it is used both for production and testing. As a result, even if you
need CLI only for the token transfer you need to install all testing dependencies. This will be changed in the future.
- Install golang, [see](https://golang.org/dl/).
- Make sure you are using Node with version <=13. We recommend using [nvm](https://github.com/nvm-sh/nvm) for installing node and npm, if you already don't have one. This constraint will be removed soon;
- yarn
- docker, for deterministic compile rust contracts
### If you want to test with a local tezos node:
- You would also need to install resources needed to compile tezoscore (in the future this will only be required for the testing CLI):
```bash
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source $HOME/.cargo/env
rustup default stable
rustup target add wasm32-unknown-unknown
```
- Then install dependencies needed for the compilation of tezoscore, [see](https://docs.tezos.org/docs/local-setup/running-testnet#compiling-and-running-official-node-without-docker).
- python3, for tezosup
## Usage
You can install `tez-bridge-cli` from npm
```
npm i -g tez-bridge-cli
```
To learn the commands that you can use with the tezbridge bridge run
```
tezbridge --help
```
Alternatively, clone this repo, `yarn install`, then you can see what commands you can use with:
```
./index.js --help
```
Parameters of each command can be specified through environment variables, command line arguments, entries in the `~/.tezbridge/config.json` config file, or the default value will be used -- in that priority.
If argument is not provided and there is no default value the program will not execute.
If script successfully executes a command then each parameter provided through the command line argument will be
written into the config file. Additionally, if scripts generates new parameters (e.g. it deploys a contract to Ethereum
and obtains its address) will also be written into the config file. Arguments should not be specified multiple times.
Note, you can use environment variables to pass sensitive data which will not lead to it being written into the config file.
## Security
Bridge is secure as long as majority (1/2) of Etherem mining power is honest and supermajority (2/3) of TEZOS stake is honest.
There are no additional security requirements, except that Ethereum should be able to accept 1 transaction within 4 hour period even in the worst congestion scenario.
## Gas costs
TEZOS fees are negligible, both for bridge maintenance and for token transfer.
Ethereum fees are the following:
- To transfer ERC20 token from ETH to TEZOS: Approx 43,989 gas to set allowance and approx 37,407 gas to lock it;
- To transfer ERC20 token back from TEZOS to ETH: Approx 240,531 gas to unlock the token;
- To submit a TEZOS block header: approx 697,140 gas;
- To challenge a TEZOS block header: approx 700k gas.
As of 2020-07-14 (gas price is 40 gwei) the cost of running bridge on TEZOS mainnnet and Ethereum mainnet is approx 42 USD/day. The cost of ETH->TEZOS transfer of ERC20 token is 1 USD. The cost of TEZOS->ETH transfer of ERC20 token is 2 USD.
## Using Bridge on Testnet
### PoA vs PoW Ethereum networks
Rainbow bridge can be deployed either on PoW or PoA networks. However, the main use case of the bridge is Ethereum Mainnet, which makes its design very PoW-centric and it is only trustless and decentralized for PoW networks. Unfortunately, the only popular PoW testnet is Ropsten, which frequently undergoes huge reorgs of more than [16k blocks](https://github.com/tezos/tez-bridge-cli/issues/329), because people test 51% attacks on it. 16k reorgs can wipe out entire contracts and revert days of computations. Overall, Ropsten has the following unfortunate specifics that does not exist with Ethereum Mainnet:
* Extremely long re-orgs;
* Gas price volatility -- Ropsten blocks might have orders of magnitude different median gas price;
* Slow block production -- sometimes Ropsten blocks are produced once per several minutes;
* [Infura is unreliable on Ropsten](https://github.com/tezos/tez-bridge-cli/issues/330)
Therefore we advise users to not use Ropsten for bridge testing. Instead, we recommend using one of Ethereum's PoA testnet. Unfortunately, PoA networks have a differen header format and are also centralized by nature. Therefore when deploying bridge on PoA network please use `--tezos-client-trusted-signer` parameter. This will force `EthOnTezosClient` to not validate Ethereum headers (since PoA headers are not valid PoW headers) and accept them only from the provided authority.
The documenation below assumes Rinkeby testnet.
### Using existing bridge on Rinkeby
This section explains how to use existing bridge with mock ERC20 token that was already deployed. You would need to have some amount of this token on Rinkeby, so reach out to [email protected] if you want to give it a try.
We assume you have two accounts:
* One TEZOS account on TEZOS testnet with at least 1 TEZOS token. We denote it as `<tezos_token_holder_account>` and its secret key as `<tezos_token_holder_sk>`;
* One Ethereum account on Rinkeby testnet with at least 1 ETH and 100 ERC20 tokens (this example uses ERC20 deployed to `0x8151a8F90267bFf183E06921841C5dE774499388` as an example. If you want some of these ERC20 tokens please contact [email protected]). We denote it as `<eth_token_holder_address>` and its private key as `<eth_token_holder_sk>`;
Make sure you have tezbridge cli installed:
```bash
npm i -g tez-bridge-cli
```
If you have already used the bridge on this machine run a cleanup:
```bash
tezbridge clean
```
If you're using tez-bridge-cli 1.x, create `~/.tezbridge/config.json` file with the following content:
```json
{
"tezosNetworkId": "testnet",
"tezosNodeUrl": "https://rpc.testnet.tezos.org/",
"ethNodeUrl": "https://rinkeby.infura.io/v3/<project_id>",
"tezosMasterAccount": "<tezos_token_holder_account>",
"tezosMasterSk": "<tezos_token_holder_sk>",
"tezosClientAccount": "ethontezosclient10",
"tezosProverAccount": "ethontezosprover10",
"tezosClientTrustedSigner": "eth2tezosrelay10.testnet",
"ethMasterSk": "<eth_token_holder_sk>",
"ethEd25519Address": "0x9003342d15B21b4C42e1702447fE2f39FfAF55C2",
"ethClientAddress": "0xF721c979db97413AA9D0F91ad531FaBF769bb09C",
"ethProverAddress": "0xc5D62d66B8650E6242D9936c7e50E959BA0F9E37",
"ethErc20Address": "0x8151a8F90267bFf183E06921841C5dE774499388",
"ethLockerAddress": "0x5f7Cc23F90b5264a083dcB3b171c7111Dc32dD00",
"tezosFunTokenAccount": "mintablefuntoken11"
}
```
If you are using tez-bridge-cli 2.x, create `~/.tezbridge/config.json` file with the following content:
```json
{
"tezosNetworkId": "testnet",
"tezosNodeUrl": "https://rpc.testnet.tezos.org/",
"ethNodeUrl": "https://rinkeby.infura.io/v3/<project_id>",
"tezosMasterAccount": "<tezos_token_holder_account>",
"tezosMasterSk": "<tezos_token_holder_sk>",
"tezosClientAccount": "ethontezosclient10",
"tezosProverAccount": "ethontezosprover10",
"tezosClientTrustedSigner": "eth2tezosrelay10.testnet",
"ethMasterSk": "<eth_token_holder_sk>",
"ethEd25519Address": "0x9003342d15B21b4C42e1702447fE2f39FfAF55C2",
"ethClientAddress": "0xF721c979db97413AA9D0F91ad531FaBF769bb09C",
"ethProverAddress": "0xc5D62d66B8650E6242D9936c7e50E959BA0F9E37",
"tezosTokenFactoryAccount": "ntf4.bridge2.testnet",
"ethErc20Address": "0x21e7381368baa3f3e9640fe19780c4271ad96f37",
"ethLockerAddress": "0x7f66c116a4f51e43e7c1c33d3714a4acfa9c40fb",
"tezosErc20Account": "21e7381368baa3f3e9640fe19780c4271ad96f37.ntf4.bridge2.testnet"
}
```
You can get infura project id, by registering at [infura.io](http://infura.io/).
To transfer ERC20 from ETH to TEZOS run:
```bash
tezbridge transfer-eth-erc20-to-tezos --amount 10 --eth-sender-sk <eth_token_holder_address> --tezos-receiver-account <tezos_token_holder_account>
```
(If the command interrupts in the middle re-run it and it will resume the transfer. PoA RPC sometimes has issues)
Wait for the transfer to finish. You should see:
```
Transferred
Balance of <tezos_token_holder_account> after the transfer is 10
```
To transfer ERC20 back from TEZOS to ETH run:
```bash
tezbridge transfer-eth-erc20-from-tezos --amount 1 --tezos-sender-account <tezos_token_holder_account> --tezos-sender-sk <tezos_token_holder_sk> --eth-receiver-address <eth_token_holder_address>
```
You should see:
```
ERC20 balance of <eth_token_holder_address> after the transfer: 91
```
Congratulations, you have achieved a roundtrip of ERC20 token through the bridge!
<!---
### Deploying new bridge
If you used bridge before from your machine, then clean up the setup. We recommend using cloud instance for deploying and running the bridge. Go to a cloud instance and install dependencies from [Pre-requisites](#pre-requisites).
Then run:
```bash
tezbridge clean
tezbridge prepare
```
Then initialize `EthOnTezosClient` and `EthOnTezosProver`:
```bash
tezbridge init-tezos-contracts --tezos-network-id testnet --tezos-node-url <testnet_nodes_url> --eth-node-url https://ropsten.infura.io/v3/<infura_project_id> --tezos-master-account <tezos_master_account> --tezos-master-sk <tezos_master_sk> --tezos-client-account ethontezosclient01 --tezos-client-init-balance 2000000000000000000000000000 --tezos-prover-account ethontezosprover01
```
* Make sure `ethontezosclient01` and `ethontezosprover01` do not exist yet. You can check it by going to https://explorer.testnet.tezos.org/accounts/ethontezosclient01 and https://explorer.testnet.tezos.org/accounts/ethontezosprover01 . If they exist, pick different names;
* You can get `<infura_project_id>` by creating a free [infura](http://infura.io/) account. If you are working in TEZOS organization please ask [email protected];
* For `<testnet_nodes_url>` you can use `http://rpc.testnet.tezos.org/`. If you are working in TEZOS organization please ask [email protected];
Then start `eth2tezos-relay`:
```bash
node index.js start eth2tezos-relay --tezos-master-account <eth2tezosrelay_account> --tezos-master-sk <eth2tezosrelay_sk>
```
Now initialize `TezosOnEthClient` and `TezosOnEthProver`:
```bash
node index.js init-eth-ed25519 --eth-master-sk <eth_master_sk>
node index.js init-eth-client --eth-client-lock-eth-amount 100000000000000000 --eth-client-lock-duration 600
node index.js init-eth-prover
```
This will set the bond to 0.1 ETH and challenge period to 10 minutes. **Do not use these settings on Mainnet!** Mainnet should be using 20ETH bond and 4 hour challenge period.
Then start the `tezos2eth-relay` and watchdog:
```bash
node index.js start tezos2eth-relay --eth-master-sk <tezos2ethrelay_sk>
node index.js start bride-watchdog --eth-master-sk <watchdog_sk>
```
-->
## Deploying and Using Locally
To locally test the bridge run:
```bash
tezbridge clean
tezbridge prepare
tezbridge start tezos-node
tezbridge start ganache
```
### Initializing the contracts
First let's initialize the contracts that bridge needs to function:
```bash
tezbridge init-tezos-contracts
tezbridge init-eth-ed25519
tezbridge init-eth-client --eth-client-lock-eth-amount 1000 --eth-client-lock-duration 10
tezbridge init-eth-prover
```
Now, let's set up token on Ethereum blockchain that we can transfer to TEZOS blockchain (this can be your own token).
```bash
tezbridge init-eth-erc20
tezbridge init-eth-locker
```
Now, let's initialize token factory on TEZOS blockchain.
```bash
tezbridge init-tezos-token-factory
```
### Starting the services
Now start the services that will relay the information between the chains:
```bash
tezbridge start eth2tezos-relay
tezbridge start tezos2eth-relay --eth-master-sk 0x2bdd21761a483f71054e14f5b827213567971c676928d9a1808cbfa4b7501201
tezbridge start bridge-watchdog --eth-master-sk 0x2bdd21761a483f71054e14f5b827213567971c676928d9a1808cbfa4b7501202
```
Note, you can observe the logs of the relays by running:
```bash
pm2 logs
```
### Transferring tokens
Finally, let's transfer some tokens
```bash
tezbridge transfer-eth-erc20-to-tezos --amount 1000 --eth-sender-sk 0x2bdd21761a483f71054e14f5b827213567971c676928d9a1808cbfa4b7501200 --tezos-receiver-account tez_bridge_eth_on_tezos_prover --tezos-master-account tezostokenfactory
```
Note, when we deployed ERC20 to the Ethereum blockchain we have minted a large number of tokens to the default master
key of Ganache, so we have transferred ERC20 tokens from it to `alice.test.tezos`.
Notice that we are using `tezostokenfactory` account here to pay for the TEZOS gas fees, any account for which we know a secret key would've worked too.
You must observe blocks being submitted.
Now let's try to transfer one token back to Ethereum
```bash
tezbridge transfer-eth-erc20-from-tezos --amount 1 --tezos-sender-account tez_bridge_eth_on_tezos_prover --tezos-sender-sk ed25519:3D4YudUQRE39Lc4JHghuB5WM8kbgDDa34mnrEP5DdTApVH81af7e2dWgNPEaiQfdJnZq1CNPp5im4Rg5b733oiMP --eth-receiver-address 0xEC8bE1A5630364292E56D01129E8ee8A9578d7D8
```
You should observe the change of the ERC20 balance as reported by the CLI.
## Contract Development Workflow
Above steps are ways to run a local bridge and development workflows you need if make any changes to tez-bridge-cli. If you want to update any of solidity or rust contracts, they're not in this repo now and workflow is as following.
- Install dependencies:
```bash
tezbridge clean
tezbridge prepare
```
- Start local TEZOS network and Ganache
```bash
tezbridge tezos-node
tezbridge ganache
```
- If you want to modify solidity contracts, go to `node_modules/tez-bridge-sol`, make changes there and run `./build_all.sh` to recompile solidity contracts.
- If you want to modify rust contracts, go to `node_modules/ranbow-bridge-rs`, make changes there and run `./build_all.sh` to recompile rust contracts.
- If you want to modify tezbridge bridge lib, go to `node_modules/tez-bridge-lib` and make changes there
- Follow instructions above to init eth contracts and tezos contracts, start services and start testing with bridge
- For changes to Solidity contract, Rust contract, and tez-bridge-lib, please submit PRs to: https://github.com/tezos/tez-bridge-sol , https://github.com/tezos/tez-bridge-rs , and https://github.com/tezos/tez-bridge-lib respectively.
- After PR merged in contract repos and tez-bridge-lib repo, we will periodically publish them as new version of npm packages. And tez-bridge-cli will adopt new version of them.
<!---
The following is outdated.
# Docker:
## Currently we have the following docker options:
1. Rainbow Docker image containing tezbridge ready for running
- run the tezbridge docker image with a custom command
2. A development docker compose setup (docker-compose-dev.yml)
- ganache
- local tezos node
- eth2tezos-relay
3. A production docker compose setup (docker-compose-prod.yml)
- eth2tezos-relay
## Running the docker setup:
1. One options is to adapt the current config.json specified in the root folder of the project and build a new image.
2. Specifying the configuration flags through environment variables.
We recommend a usage of both, encouraging using the config.json for common configurations, while passing the secrets through environment variables.
Examples:
```
# Creating a docker image
docker build .
# Running the development env with config setup
docker-compose up
# Running the development env with ENV overrides
docker-compose -f docker-compose-dev.yml up -e MASTER_SK=<key> -e ...
# Running the production env just use:
docker-compose -f docker-compose-prod.yml instead
```
-->
# url-to-options [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url]
Convert a WHATWG [URL](https://developer.mozilla.org/en/docs/Web/API/URL) to an `http.request`/`https.request` options object.
## Installation
[Node.js](http://nodejs.org/) `>= 4` is required. To install, type this at the command line:
```shell
npm install url-to-options
```
## Usage
```js
const urlToOptions = require('url-to-options');
const url = new URL('http://user:pass@hostname:8080/');
const opts = urlToOptions(url);
//-> { auth:'user:pass', port:8080, … }
```
[npm-image]: https://img.shields.io/npm/v/url-to-options.svg
[npm-url]: https://npmjs.org/package/url-to-options
[travis-image]: https://img.shields.io/travis/stevenvachon/url-to-options.svg
[travis-url]: https://travis-ci.org/stevenvachon/url-to-options
# ltgt
implement correct ranges for level-*
[](http://travis-ci.org/dominictarr/ltgt)
[](https://ci.testling.com/dominictarr/ltgt)
# example
``` js
var ltgt = require('ltgt')
ltgt.start(range) //the start of the range
ltgt.end(range) //the end of the range
//returns the lower/upper bound, whether it's inclusive or not.
ltgt.lowerBound(range)
ltgt.upperBound(range)
ltgt.lt(range)
ltgt.gt(range)
ltgt.lte(range)
ltgt.gte(range)
//return wether this is a reversed order
//(this is significant for start/end ranges
ltgt.reverse(range)
var filter = ltgt.filter(range)
filter(key) == true //if key contained in range.
ltgt.contains(range, key)
```
# ways to specify ranges
there have been a variety of ways to specify ranges in level-*.
this module supports them all.
# gt/gte, lt/lte
specify a range between a lower bound (gt, gte) and an upper bound (lt, lte)
if `gte` and `gt` is undefined, read from the start of the database,
if `lte` and `lt` is undefined, read until the end of the database,
# min, max
legacy level-sublevel style,
synonym for `gte`, `lte`.
# start, end, reverse
legacy levelup style.
The range is from `start` -> `end`, `start` does not specify the lowest
record, instead it specifies the first record to be read. However,
`reverse` must also be passed correctly. This is way to specify a range is
confusing if you need to read in reverse,
so it's strongly recommended to use `gt/gte,lt/lte`.
If `reverse` is `true`,
`start` *must* be `undefined` or less than `end`,
unless `end` is `undefined`.
if `reverse` is `false`
`end` *must* be `undefined` or greater than `start`,
unless `start` is `undefined`.
if start is undefined, read from the first record in the database
if end is undefined read until the last record in the database.
# api
## ltgt.contains(range, key, compare)
using the provided compare method, return `true` if `key`
is within `range`. compare defaults to `ltgt.compare`
## ltgt.filter(range, compare)
return a function that returns true if it's argument is within range.
can be passed to `Array.filter`
``` js
[1,2,3,4,5].filter(ltgt.filter({gt: 2, lte: 4})
// => [3, 4]
```
## ltgt.lowerBound(range)
return the lower bound of `range`.
Incase the lower bound is specified with `gt`,
check `ltgt.lowerBoundExclusive`
## ltgt.upperBound(range)
return the upperBound of `range`.
Incase the upper bound is specified with `gt`,
check `ltgt.upperBoundExclusive`
## ltgt.lowerBoundExclusive(range)
return true if upper bound is exclusive.
## ltgt.upperBoundExclusive(range)
return true if lower bound is exclusive.
## ltgt.start(range, default)
The start of the range. This takes into account direction (reverse)
If a `start` is not provided, `default` is used.
## ltgt.end(range, default)
The end of the range. This takes into account direction (reverse)
If a `end` is not provided, `default` is used.
## ltgt.startInclusive(range)
returns true if the range should start at the exact value returned
by `start(range)` otherwise, it should skip one input.
## ltgt.endInclusive(range)
returns true if the range should include the exact value returned
by `end(range)` otherwise, it should end on that value.
## ltgt.toLtgt(range, _range, map, lowerBound, upperBound)
convert a range to a new ltgt range. `_range`
is the object to return - if you want to mutate `range`
call `ltgt.toLtgt(range, range, map)`
`map` gets called on each key in the range, and wether it's an upper or lower bound -
so can be used as an encode function.
`map(value, isUpperBound)` if `isUpperBound` is false, this is the lower bound.
## License
MIT
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
number
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.pmod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available)
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `a.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][1]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# Glob
Match files using the patterns the shell uses, like stars and stuff.
[](https://travis-ci.org/isaacs/node-glob/) [](https://ci.appveyor.com/project/isaacs/node-glob) [](https://coveralls.io/github/isaacs/node-glob?branch=master)
This is a glob implementation in JavaScript. It uses the `minimatch`
library to do its matching.

## Usage
Install with npm
```
npm i glob
```
```javascript
var glob = require("glob")
// options is optional
glob("**/*.js", options, function (er, files) {
// files is an array of filenames.
// If the `nonull` option is set, and nothing
// was found, then files is ["**/*.js"]
// er is an error object or null.
})
```
## Glob Primer
"Globs" are the patterns you type when you do stuff like `ls *.js` on
the command line, or put `build/*` in a `.gitignore` file.
Before parsing the path part patterns, braced sections are expanded
into a set. Braced sections start with `{` and end with `}`, with any
number of comma-delimited sections within. Braced sections may contain
slash characters, so `a{/b/c,bcd}` would expand into `a/b/c` and `abcd`.
The following characters have special magic meaning when used in a
path portion:
* `*` Matches 0 or more characters in a single path portion
* `?` Matches 1 character
* `[...]` Matches a range of characters, similar to a RegExp range.
If the first character of the range is `!` or `^` then it matches
any character not in the range.
* `!(pattern|pattern|pattern)` Matches anything that does not match
any of the patterns provided.
* `?(pattern|pattern|pattern)` Matches zero or one occurrence of the
patterns provided.
* `+(pattern|pattern|pattern)` Matches one or more occurrences of the
patterns provided.
* `*(a|b|c)` Matches zero or more occurrences of the patterns provided
* `@(pattern|pat*|pat?erN)` Matches exactly one of the patterns
provided
* `**` If a "globstar" is alone in a path portion, then it matches
zero or more directories and subdirectories searching for matches.
It does not crawl symlinked directories.
### Dots
If a file or directory path portion has a `.` as the first character,
then it will not match any glob pattern unless that pattern's
corresponding path part also has a `.` as its first character.
For example, the pattern `a/.*/c` would match the file at `a/.b/c`.
However the pattern `a/*/c` would not, because `*` does not start with
a dot character.
You can make glob treat dots as normal characters by setting
`dot:true` in the options.
### Basename Matching
If you set `matchBase:true` in the options, and the pattern has no
slashes in it, then it will seek for any file anywhere in the tree
with a matching basename. For example, `*.js` would match
`test/simple/basic.js`.
### Empty Sets
If no matching files are found, then an empty array is returned. This
differs from the shell, where the pattern itself is returned. For
example:
$ echo a*s*d*f
a*s*d*f
To get the bash-style behavior, set the `nonull:true` in the options.
### See Also:
* `man sh`
* `man bash` (Search for "Pattern Matching")
* `man 3 fnmatch`
* `man 5 gitignore`
* [minimatch documentation](https://github.com/isaacs/minimatch)
## glob.hasMagic(pattern, [options])
Returns `true` if there are any special characters in the pattern, and
`false` otherwise.
Note that the options affect the results. If `noext:true` is set in
the options object, then `+(a|b)` will not be considered a magic
pattern. If the pattern has a brace expansion, like `a/{b/c,x/y}`
then that is considered magical, unless `nobrace:true` is set in the
options.
## glob(pattern, [options], cb)
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* `cb` `{Function}`
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Perform an asynchronous glob search.
## glob.sync(pattern, [options])
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* return: `{Array<String>}` filenames found matching the pattern
Perform a synchronous glob search.
## Class: glob.Glob
Create a Glob object by instantiating the `glob.Glob` class.
```javascript
var Glob = require("glob").Glob
var mg = new Glob(pattern, options, cb)
```
It's an EventEmitter, and starts walking the filesystem to find matches
immediately.
### new glob.Glob(pattern, [options], [cb])
* `pattern` `{String}` pattern to search for
* `options` `{Object}`
* `cb` `{Function}` Called when an error occurs, or matches are found
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Note that if the `sync` flag is set in the options, then matches will
be immediately available on the `g.found` member.
### Properties
* `minimatch` The minimatch object that the glob uses.
* `options` The options object passed in.
* `aborted` Boolean which is set to true when calling `abort()`. There
is no way at this time to continue a glob search after aborting, but
you can re-use the statCache to avoid having to duplicate syscalls.
* `cache` Convenience object. Each field has the following possible
values:
* `false` - Path does not exist
* `true` - Path exists
* `'FILE'` - Path exists, and is not a directory
* `'DIR'` - Path exists, and is a directory
* `[file, entries, ...]` - Path exists, is a directory, and the
array value is the results of `fs.readdir`
* `statCache` Cache of `fs.stat` results, to prevent statting the same
path multiple times.
* `symlinks` A record of which paths are symbolic links, which is
relevant in resolving `**` patterns.
* `realpathCache` An optional object which is passed to `fs.realpath`
to minimize unnecessary syscalls. It is stored on the instantiated
Glob object, and may be re-used.
### Events
* `end` When the matching is finished, this is emitted with all the
matches found. If the `nonull` option is set, and no match was found,
then the `matches` list contains the original pattern. The matches
are sorted, unless the `nosort` flag is set.
* `match` Every time a match is found, this is emitted with the specific
thing that matched. It is not deduplicated or resolved to a realpath.
* `error` Emitted when an unexpected error is encountered, or whenever
any fs error occurs if `options.strict` is set.
* `abort` When `abort()` is called, this event is raised.
### Methods
* `pause` Temporarily stop the search
* `resume` Resume the search
* `abort` Stop the search forever
### Options
All the options that can be passed to Minimatch can also be passed to
Glob to change pattern matching behavior. Also, some have been added,
or have glob-specific ramifications.
All options are false by default, unless otherwise noted.
All options are added to the Glob object, as well.
If you are running many `glob` operations, you can pass a Glob object
as the `options` argument to a subsequent operation to shortcut some
`stat` and `readdir` calls. At the very least, you may pass in shared
`symlinks`, `statCache`, `realpathCache`, and `cache` options, so that
parallel glob operations will be sped up by sharing information about
the filesystem.
* `cwd` The current working directory in which to search. Defaults
to `process.cwd()`.
* `root` The place where patterns starting with `/` will be mounted
onto. Defaults to `path.resolve(options.cwd, "/")` (`/` on Unix
systems, and `C:\` or some such on Windows.)
* `dot` Include `.dot` files in normal matches and `globstar` matches.
Note that an explicit dot in a portion of the pattern will always
match dot files.
* `nomount` By default, a pattern starting with a forward-slash will be
"mounted" onto the root setting, so that a valid filesystem path is
returned. Set this flag to disable that behavior.
* `mark` Add a `/` character to directory matches. Note that this
requires additional stat calls.
* `nosort` Don't sort the results.
* `stat` Set to true to stat *all* results. This reduces performance
somewhat, and is completely unnecessary, unless `readdir` is presumed
to be an untrustworthy indicator of file existence.
* `silent` When an unusual error is encountered when attempting to
read a directory, a warning will be printed to stderr. Set the
`silent` option to true to suppress these warnings.
* `strict` When an unusual error is encountered when attempting to
read a directory, the process will just continue on in search of
other matches. Set the `strict` option to raise an error in these
cases.
* `cache` See `cache` property above. Pass in a previously generated
cache object to save some fs calls.
* `statCache` A cache of results of filesystem information, to prevent
unnecessary stat calls. While it should not normally be necessary
to set this, you may pass the statCache from one glob() call to the
options object of another, if you know that the filesystem will not
change between calls. (See "Race Conditions" below.)
* `symlinks` A cache of known symbolic links. You may pass in a
previously generated `symlinks` object to save `lstat` calls when
resolving `**` matches.
* `sync` DEPRECATED: use `glob.sync(pattern, opts)` instead.
* `nounique` In some cases, brace-expanded patterns can result in the
same file showing up multiple times in the result set. By default,
this implementation prevents duplicates in the result set. Set this
flag to disable that behavior.
* `nonull` Set to never return an empty set, instead returning a set
containing the pattern itself. This is the default in glob(3).
* `debug` Set to enable debug logging in minimatch and glob.
* `nobrace` Do not expand `{a,b}` and `{1..3}` brace sets.
* `noglobstar` Do not match `**` against multiple filenames. (Ie,
treat it as a normal `*` instead.)
* `noext` Do not match `+(a|b)` "extglob" patterns.
* `nocase` Perform a case-insensitive match. Note: on
case-insensitive filesystems, non-magic patterns will match by
default, since `stat` and `readdir` will not raise errors.
* `matchBase` Perform a basename-only match if the pattern does not
contain any slash characters. That is, `*.js` would be treated as
equivalent to `**/*.js`, matching all js files in all directories.
* `nodir` Do not match directories, only files. (Note: to match
*only* directories, simply put a `/` at the end of the pattern.)
* `ignore` Add a pattern or an array of glob patterns to exclude matches.
Note: `ignore` patterns are *always* in `dot:true` mode, regardless
of any other settings.
* `follow` Follow symlinked directories when expanding `**` patterns.
Note that this can result in a lot of duplicate references in the
presence of cyclic links.
* `realpath` Set to true to call `fs.realpath` on all of the results.
In the case of a symlink that cannot be resolved, the full absolute
path to the matched entry is returned (though it will usually be a
broken symlink)
* `absolute` Set to true to always receive absolute paths for matched
files. Unlike `realpath`, this also affects the values returned in
the `match` event.
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between node-glob and other
implementations, and are intentional.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.3, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
Note that symlinked directories are not crawled as part of a `**`,
though their contents may match against subsequent portions of the
pattern. This prevents infinite loops and duplicates and the like.
If an escaped pattern has no matches, and the `nonull` flag is set,
then glob returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`glob.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
### Comments and Negation
Previously, this module let you mark a pattern as a "comment" if it
started with a `#` character, or a "negated" pattern if it started
with a `!` character.
These options were deprecated in version 5, and removed in version 6.
To specify things that should not match, use the `ignore` option.
## Windows
**Please only use forward-slashes in glob expressions.**
Though windows uses either `/` or `\` as its path separator, only `/`
characters are used by this glob implementation. You must use
forward-slashes **only** in glob expressions. Back-slashes will always
be interpreted as escape characters, not path separators.
Results from absolute patterns such as `/foo/*` are mounted onto the
root setting using `path.join`. On windows, this will by default result
in `/foo/*` matching `C:\foo\bar.txt`.
## Race Conditions
Glob searching, by its very nature, is susceptible to race conditions,
since it relies on directory walking and such.
As a result, it is possible that a file that exists when glob looks for
it may have been deleted or modified by the time it returns the result.
As part of its internal implementation, this program caches all stat
and readdir calls that it makes, in order to cut down on system
overhead. However, this also makes it even more susceptible to races,
especially if the cache or statCache objects are reused between glob
calls.
Users are thus advised not to use a glob result as a guarantee of
filesystem state in the face of rapid changes. For the vast majority
of operations, this is never a problem.
## Glob Logo
Glob's logo was created by [Tanya Brassie](http://tanyabrassie.com/). Logo files can be found [here](https://github.com/isaacs/node-glob/tree/master/logo).
The logo is licensed under a [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/).
## Contributing
Any change to behavior (including bugfixes) must come with a test.
Patches that fail tests or reduce performance will be rejected.
```
# to run tests
npm test
# to re-generate test fixtures
npm run test-regen
# to benchmark against bash/zsh
npm run bench
# to profile javascript
npm run prof
```

# json-buffer
JSON functions that can convert buffers!
[](http://travis-ci.org/dominictarr/json-buffer)
[](https://ci.testling.com/dominictarr/json-buffer)
JSON mangles buffers by converting to an array...
which isn't helpful. json-buffers converts to base64 instead,
and deconverts base64 to a buffer.
``` js
var JSONB = require('json-buffer')
var Buffer = require('buffer').Buffer
var str = JSONB.stringify(new Buffer('hello there!'))
console.log(JSONB.parse(str)) //GET a BUFFER back
```
## License
MIT
# abstract-leveldown
> An abstract prototype matching the [`leveldown`](https://github.com/level/leveldown/) API. Useful for extending [`levelup`](https://github.com/level/levelup) functionality by providing a replacement to `leveldown`.
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/abstract-leveldown)

[](http://travis-ci.org/Level/abstract-leveldown)
[](https://david-dm.org/level/abstract-leveldown)
[](https://standardjs.com)
[](https://www.npmjs.com/package/abstract-leveldown)
`abstract-leveldown` provides a simple, operational *noop* base prototype that's ready for extending. By default, all operations have sensible "noops" (operations that essentially do nothing). For example, simple operations such as `.open(callback)` and `.close(callback)` will simply invoke the callback (on a *next tick*). More complex operations perform sensible actions, for example: `.get(key, callback)` will always return a `'NotFound'` `Error` on the callback.
You add functionality by implementing the underscore versions of the operations. For example, to implement a `put()` operation you add a `_put()` method to your object. Each of these underscore methods override the default *noop* operations and are always provided with **consistent arguments**, regardless of what is passed in by the client.
Additionally, all methods provide argument checking and sensible defaults for optional arguments. All bad-argument errors are compatible with `leveldown` (they pass the `leveldown` method arguments tests). For example, if you call `.open()` without a callback argument you'll get an `Error('open() requires a callback argument')`. Where optional arguments are involved, your underscore methods will receive sensible defaults. A `.get(key, callback)` will pass through to a `._get(key, options, callback)` where the `options` argument is an empty object.
**If you are upgrading:** please see [UPGRADING.md](UPGRADING.md).
## Example
A simplistic in-memory `leveldown` replacement
```js
var util = require('util')
var AbstractLevelDOWN = require('./').AbstractLevelDOWN
// constructor, passes through the 'location' argument to the AbstractLevelDOWN constructor
function FakeLevelDOWN (location) {
AbstractLevelDOWN.call(this, location)
}
// our new prototype inherits from AbstractLevelDOWN
util.inherits(FakeLevelDOWN, AbstractLevelDOWN)
// implement some methods
FakeLevelDOWN.prototype._open = function (options, callback) {
// initialise a memory storage object
this._store = {}
// optional use of nextTick to be a nice async citizen
process.nextTick(function () { callback(null, this) }.bind(this))
}
FakeLevelDOWN.prototype._put = function (key, value, options, callback) {
key = '_' + key // safety, to avoid key='__proto__'-type skullduggery
this._store[key] = value
process.nextTick(callback)
}
FakeLevelDOWN.prototype._get = function (key, options, callback) {
var value = this._store['_' + key]
if (value === undefined) {
// 'NotFound' error, consistent with LevelDOWN API
return process.nextTick(function () { callback(new Error('NotFound')) })
}
process.nextTick(function () {
callback(null, value)
})
}
FakeLevelDOWN.prototype._del = function (key, options, callback) {
delete this._store['_' + key]
process.nextTick(callback)
}
// Now use it with levelup
var levelup = require('levelup')
var db = levelup(new FakeLevelDOWN('/who/cares'))
db.put('foo', 'bar', function (err) {
if (err) throw err
db.get('foo', function (err, value) {
if (err) throw err
console.log('Got foo =', value)
})
})
```
See [`memdown`](https://github.com/Level/memdown/) if you are looking for a complete in-memory replacement for `leveldown`.
## Browser support
[](https://saucelabs.com/u/abstract-leveldown)
## Extensible API
Remember that each of these methods, if you implement them, will receive exactly the number and order of arguments described. Optional arguments will be converted to sensible defaults.
### `AbstractLevelDOWN(location)`
### `AbstractLevelDOWN#status`
An `AbstractLevelDOWN` based database can be in one of the following states:
* `'new'` - newly created, not opened or closed
* `'opening'` - waiting for the database to be opened
* `'open'` - successfully opened the database, available for use
* `'closing'` - waiting for the database to be closed
* `'closed'` - database has been successfully closed, should not be used
### `AbstractLevelDOWN#_open(options, callback)`
### `AbstractLevelDOWN#_close(callback)`
### `AbstractLevelDOWN#_get(key, options, callback)`
### `AbstractLevelDOWN#_put(key, value, options, callback)`
### `AbstractLevelDOWN#_del(key, options, callback)`
### `AbstractLevelDOWN#_batch(array, options, callback)`
If `batch()` is called without arguments or with only an options object then it should return a `Batch` object with chainable methods. Otherwise it will invoke a classic batch operation.
### `AbstractLevelDOWN#_chainedBatch()`
By default a `batch()` operation without arguments returns a blank `AbstractChainedBatch` object. The prototype is available on the main exports for you to extend. If you want to implement chainable batch operations then you should extend the `AbstractChaindBatch` and return your object in the `_chainedBatch()` method.
### `AbstractLevelDOWN#_serializeKey(key)`
### `AbstractLevelDOWN#_serializeValue(value)`
### `AbstractLevelDOWN#_iterator(options)`
By default an `iterator()` operation returns a blank `AbstractIterator` object. The prototype is available on the main exports for you to extend. If you want to implement iterator operations then you should extend the `AbstractIterator` and return your object in the `_iterator(options)` method.
The `iterator()` operation accepts the following range options:
* `gt`
* `gte`
* `lt`
* `lte`
* `start` (legacy)
* `end` (legacy)
A range option that is either an empty buffer, an empty string or `null` will be ignored.
`AbstractIterator` implements the basic state management found in LevelDOWN. It keeps track of when a `next()` is in progress and when an `end()` has been called so it doesn't allow concurrent `next()` calls, it does allow `end()` while a `next()` is in progress and it doesn't allow either `next()` or `end()` after `end()` has been called.
### `AbstractIterator(db)`
Provided with the current instance of `AbstractLevelDOWN` by default.
### `AbstractIterator#_next(callback)`
### `AbstractIterator#_end(callback)`
### `AbstractChainedBatch`
Provided with the current instance of `AbstractLevelDOWN` by default.
### `AbstractChainedBatch#_put(key, value)`
### `AbstractChainedBatch#_del(key)`
### `AbstractChainedBatch#_clear()`
### `AbstractChainedBatch#_write(options, callback)`
### `AbstractChainedBatch#_serializeKey(key)`
### `AbstractChainedBatch#_serializeValue(value)`
<a name="contributing"></a>
## Contributing
`abstract-leveldown` is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [contribution guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
## Big Thanks
Cross-browser Testing Platform and Open Source ♥ Provided by [Sauce Labs](https://saucelabs.com).
[](https://saucelabs.com)
<a name="license"></a>
## License
Copyright © 2013-2018 `abstract-leveldown` [contributors](https://github.com/level/community#contributors).
`abstract-leveldown` is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included `LICENSE.md` file for more details.
[level-badge]: http://leveldb.org/img/badge.svg
# expand-brackets [](https://www.npmjs.com/package/expand-brackets) [](https://npmjs.org/package/expand-brackets) [](https://travis-ci.org/jonschlinkert/expand-brackets)
> Expand POSIX bracket expressions (character classes) in glob patterns.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install expand-brackets --save
```
## Usage
```js
var brackets = require('expand-brackets');
brackets('[![:lower:]]');
//=> '[^a-z]'
```
## .isMatch
Return true if the given string matches the bracket expression:
```js
brackets.isMatch('A', '[![:lower:]]');
//=> true
brackets.isMatch('a', '[![:lower:]]');
//=> false
```
## .makeRe
Make a regular expression from a bracket expression:
```js
brackets.makeRe('[![:lower:]]');
//=> /[^a-z]/
```
The following named POSIX bracket expressions are supported:
* `[:alnum:]`: Alphanumeric characters (`a-zA-Z0-9]`)
* `[:alpha:]`: Alphabetic characters (`a-zA-Z]`)
* `[:blank:]`: Space and tab (`[ t]`)
* `[:digit:]`: Digits (`[0-9]`)
* `[:lower:]`: Lowercase letters (`[a-z]`)
* `[:punct:]`: Punctuation and symbols. (`[!"#$%&'()*+, -./:;<=>?@ [\]^_``{|}~]`)
* `[:upper:]`: Uppercase letters (`[A-Z]`)
* `[:word:]`: Word characters (letters, numbers and underscores) (`[A-Za-z0-9_]`)
* `[:xdigit:]`: Hexadecimal digits (`[A-Fa-f0-9]`)
Collating sequences are not supported.
## Related projects
You might also be interested in these projects:
* [extglob](https://www.npmjs.com/package/extglob): Convert extended globs to regex-compatible strings. Add (almost) the expressive power of regular expressions to… [more](https://www.npmjs.com/package/extglob) | [homepage](https://github.com/jonschlinkert/extglob)
* [is-extglob](https://www.npmjs.com/package/is-extglob): Returns true if a string has an extglob. | [homepage](https://github.com/jonschlinkert/is-extglob)
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern.… [more](https://www.npmjs.com/package/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob)
* [is-posix-bracket](https://www.npmjs.com/package/is-posix-bracket): Returns true if the given string is a POSIX bracket expression (POSIX character class). | [homepage](https://github.com/jonschlinkert/is-posix-bracket)
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. Just… [more](https://www.npmjs.com/package/micromatch) | [homepage](https://github.com/jonschlinkert/micromatch)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/expand-brackets/issues/new).
## Building docs
Generate readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install verb && npm run docs
```
Or, if [verb](https://github.com/verbose/verb) is installed globally:
```sh
$ verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
verb © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/expand-brackets/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v, on April 01, 2016._
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
ecc-jsbn
========
ECC package based on [jsbn](https://github.com/andyperlitch/jsbn) from [Tom Wu](http://www-cs-students.stanford.edu/~tjw/).
This is a subset of the same interface as the [node compiled module](https://github.com/quartzjer/ecc), but works in the browser too.
Also uses point compression now from [https://github.com/kaielvin](https://github.com/kaielvin/jsbn-ec-point-compression).
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# TezosBridge
TruffleFramework template with travis-ci.org and coveralls.io configured
[](https://travis-ci.org/tezosprotocol/bridge)
[](https://coveralls.io/github/tezosprotocol/bridge?branch=master)
scrypt
======
The [scrypt](https://en.wikipedia.org/wiki/Scrypt) password-base key derivation
function (pbkdf) is an algorithm designed to be brute-force resistant that
converts human readable passwords into fixed length arrays of bytes, which can
then be used as a key for symmetric block ciphers, private keys, et cetera.
### Features:
- **Non-blocking** - Gives other events in the event loop opportunities to run (asynchronous)
- **Cancellable** - If the key is no longer required, the computation can be cancelled
- **Progress Callback** - Provides the current progress of key derivation as a percentage complete
Tuning
------
The scrypt algorithm is, by design, expensive to execute, which increases the amount of time an attacker requires in order to brute force guess a password, adjustable by several parameters which can be tuned:
- **N** - The CPU/memory cost; increasing this increases the overall difficulty
- **r** - The block size; increasing this increases the dependency on memory latency and bandwidth
- **p** - The parallelization cost; increasing this increases the dependency on multi-processing
Installing
----------
**node.js**
If you do not require the progress callback or cancellable features, and your application
is specific to *node.js*, you should likely use the
[built-in crypto package](https://nodejs.org/api/crypto.html#crypto_crypto_scrypt_password_salt_keylen_options_callback).
Otherwise, to install in node.js, use:
```
npm install scrypt-js
```
**browser**
```html
<script src="https://raw.githubusercontent.com/ricmoo/scrypt-js/master/scrypt.js" type="text/javascript"></script>
```
API
---
**scrypt . scrypt ( password , salt , N , r , p , dkLen [ , progressCallback ] )** *=> Promise<Uint8Array>*
Compute the scrypt PBKDF asynchronously using a Promise. If *progressCallback* is
provided, it is periodically called with a single parameter, a number between 0 and
1 (inclusive) indicating the completion progress; it will **always** emit 0 at the
beginning and 1 at the end, and numbers between may repeat.
**scrypt . syncScrypt ( password , salt , N , r , p , dkLen )** *=> Uint8Array*
Compute the scrypt PBKDF synchronously. Keep in mind this may stall UI and other tasks and the
asynchronous version is highly preferred.
Example
-------
```html
<html>
<body>
<div><span id="progress"></span>% complete...</div>
<!-- These two libraries are highly recommended for encoding password/salt -->
<script src="libs/buffer.js" type="text/javascript"></script>
<!-- This shim library greatly improves performance of the scrypt algorithm -->
<script src="libs/setImmediate.js" type="text/javascript"></script>
<script src="index.js" type="text/javascript"></script>
<script type="text/javascript">
// See the section below: "Encoding Notes"
const password = new buffer.SlowBuffer("anyPassword".normalize('NFKC'));
const salt = new buffer.SlowBuffer("someSalt".normalize('NFKC'));
const N = 1024, r = 8, p = 1;
const dkLen = 32;
function updateInterface(progress) {
document.getElementById("progress").textContent = Math.trunc(100 * progress);
}
// Async
const keyPromise = scrypt.scrypt(password, salt, N, r, p, dkLen, updateInterface);
keyPromise.then(function(key) {
console.log("Derived Key (async): ", key);
});
// Sync
const key = scrypt.syncScrypt(password, salt, N, r, p, dkLen);
console.log("Derived Key (sync): ", key);
</script>
</body>
</html>
```
Encoding Notes
--------------
```
TL;DR - either only allow ASCII characters in passwords, or use
String.prototype.normalize('NFKC') on any password
```
It is *HIGHLY* recommended that you do **NOT** pass strings into this (or any password-base key derivation function) library without careful consideration; you should convert your strings to a canonical format that you will use consistently across all platforms.
When encoding passwords with UTF-8, it is important to realize that there may be multiple UTF-8 representations of a given string. Since the key generated by a password-base key derivation function is *dependent on the specific bytes*, this matters a great deal.
**Composed vs. Decomposed**
Certain UTF-8 code points can be combined with other characters to create composed characters. For example, the letter *a with the umlaut diacritic mark* (two dots over it) can be expressed two ways; as its composed form, U+00FC; or its decomposed form, which is the letter "u" followed by U+0308 (which basically means modify the previous character by adding an umlaut to it).
```javascript
// In the following two cases, a "u" with an umlaut would be seen
> '\u00fc'
> 'u\u0308'
// In its composed form, it is 2 bytes long
> new Buffer('u\u0308'.normalize('NFKC'))
<Buffer c3 bc>
> new Buffer('\u00fc')
<Buffer c3 bc>
// Whereas the decomposed form is 3 bytes, the letter u followed by U+0308
> new Buffer('\u00fc'.normalize('NFKD'))
<Buffer 75 cc 88>
> new Buffer('u\u0308')
<Buffer 75 cc 88>
```
**Compatibility equivalence mode**
Certain strings are often displayed the same, even though they may have different semantic means. For example, UTF-8 provides a code point for the roman number for one, which appears as the letter I, in most fonts identically. Compatibility equivalence will fold these two cases into simply the capital letter I.
```
> '\u2160'
'I'
> 'I'
'I'
> '\u2160' === 'I'
false
> '\u2160'.normalize('NFKC') === 'I'
true
```
**Normalizing**
The `normalize()` method of a string can be used to convert a string to a
specific form. Without going into too much detail, I generally recommend
`NFKC`, however if you wish to dive deeper into this, a nice short summary
can be found in Pythons [unicodedata module](https://docs.python.org/2/library/unicodedata.html#unicodedata.normalize)'s
documentation.
For browsers without `normalize()` support, the [npm unorm module](https://www.npmjs.com/package/unorm)
can be used to polyfill strings.
**Another example of encoding woes**
One quick story I will share is a project which used the `SHA256(encodeURI(password))` as
a key, which (ignoring [rainbow table attacks](https://en.wikipedia.org/wiki/Rainbow_table))
had an unfortunate consequence of old web browsers replacing spaces with `+` while on new web
browsers, replacing it with a `%20`, causing issues for anyone who used spaces in their password.
### Suggestions
- While it may be inconvenient to many international users, one option is to restrict passwords to a safe subset of ASCII, for example: `/^[A-Za-z0-9!@#$%^&*()]+$/`.
- My personal recommendation is to normalize to the NFKC form, however, one could imagine setting their password to a Chinese phrase on one computer, and then one day using a computer that does not have Chinese input capabilities and therefore be unable to log in.
**See:** [Unicode Equivalence](https://en.wikipedia.org/wiki/Unicode_equivalence)
Tests
-----
The test cases from the [scrypt whitepaper](http://www.tarsnap.com/scrypt/scrypt.pdf) are included in `test/test-vectors.json` and can be run using:
```javascript
npm test
```
Special Thanks
--------------
I would like to thank @dchest for his [scrypt-async](https://github.com/dchest/scrypt-async-js)
library and for his assistance providing feedback and optimization suggestions.
License
-------
MIT license.
References
----------
- [scrypt white paper](http://www.tarsnap.com/scrypt/scrypt.pdf)
- [Wikipedia](https://en.wikipedia.org/wiki/Scrypt)
- [scrypt-async npm module](https://www.npmjs.com/package/scrypt-async)
- [scryptsy npm module](https://www.npmjs.com/package/scryptsy)
- [Unicode Equivalence](https://en.wikipedia.org/wiki/Unicode_equivalence)
Donations
---------
Obviously, it's all licensed under the MIT license, so use it as you wish;
but if you'd like to buy me a coffee, I won't complain. =)
- Ethereum - `ricmoo.eth`
# es6-iterator
## ECMAScript 6 Iterator interface
### Installation
$ npm install es6-iterator
To port it to Browser or any other (non CJS) environment, use your favorite CJS bundler. No favorite yet? Try: [Browserify](http://browserify.org/), [Webmake](https://github.com/medikoo/modules-webmake) or [Webpack](http://webpack.github.io/)
## API
### Constructors
#### Iterator(list) _(es6-iterator)_
Abstract Iterator interface. Meant for extensions and not to be used on its own.
Accepts any _list_ object (technically object with numeric _length_ property).
_Mind it doesn't iterate strings properly, for that use dedicated [StringIterator](#string-iterator)_
```javascript
var Iterator = require('es6-iterator')
var iterator = new Iterator([1, 2, 3]);
iterator.next(); // { value: 1, done: false }
iterator.next(); // { value: 2, done: false }
iterator.next(); // { value: 3, done: false }
iterator.next(); // { value: undefined, done: true }
```
#### ArrayIterator(arrayLike[, kind]) _(es6-iterator/array)_
Dedicated for arrays and array-likes. Supports three iteration kinds:
* __value__ _(default)_ - Iterates values
* __key__ - Iterates indexes
* __key+value__ - Iterates keys and indexes, each iteration value is in _[key, value]_ form.
```javascript
var ArrayIterator = require('es6-iterator/array')
var iterator = new ArrayIterator([1, 2, 3], 'key+value');
iterator.next(); // { value: [0, 1], done: false }
iterator.next(); // { value: [1, 2], done: false }
iterator.next(); // { value: [2, 3], done: false }
iterator.next(); // { value: undefined, done: true }
```
May also be used for _arguments_ objects:
```javascript
(function () {
var iterator = new ArrayIterator(arguments);
iterator.next(); // { value: 1, done: false }
iterator.next(); // { value: 2, done: false }
iterator.next(); // { value: 3, done: false }
iterator.next(); // { value: undefined, done: true }
}(1, 2, 3));
```
#### StringIterator(str) _(es6-iterator/string)_
Assures proper iteration over unicode symbols.
See: http://mathiasbynens.be/notes/javascript-unicode
```javascript
var StringIterator = require('es6-iterator/string');
var iterator = new StringIterator('f🙈o🙉o🙊');
iterator.next(); // { value: 'f', done: false }
iterator.next(); // { value: '🙈', done: false }
iterator.next(); // { value: 'o', done: false }
iterator.next(); // { value: '🙉', done: false }
iterator.next(); // { value: 'o', done: false }
iterator.next(); // { value: '🙊', done: false }
iterator.next(); // { value: undefined, done: true }
```
### Function utilities
#### forOf(iterable, callback[, thisArg]) _(es6-iterator/for-of)_
Polyfill for ECMAScript 6 [`for...of`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for...of) statement.
```
var forOf = require('es6-iterator/for-of');
var result = [];
forOf('🙈🙉🙊', function (monkey) { result.push(monkey); });
console.log(result); // ['🙈', '🙉', '🙊'];
```
Optionally you can break iteration at any point:
```javascript
var result = [];
forOf([1,2,3,4]', function (val, doBreak) {
result.push(monkey);
if (val >= 3) doBreak();
});
console.log(result); // [1, 2, 3];
```
#### get(obj) _(es6-iterator/get)_
Return iterator for any iterable object.
```javascript
var getIterator = require('es6-iterator/get');
var iterator = get([1,2,3]);
iterator.next(); // { value: 1, done: false }
iterator.next(); // { value: 2, done: false }
iterator.next(); // { value: 3, done: false }
iterator.next(); // { value: undefined, done: true }
```
#### isIterable(obj) _(es6-iterator/is-iterable)_
Whether _obj_ is iterable
```javascript
var isIterable = require('es6-iterator/is-iterable');
isIterable(null); // false
isIterable(true); // false
isIterable('str'); // true
isIterable(['a', 'r', 'r']); // true
isIterable(new ArrayIterator([])); // true
```
#### validIterable(obj) _(es6-iterator/valid-iterable)_
If _obj_ is an iterable it is returned. Otherwise _TypeError_ is thrown.
### Method extensions
#### iterator.chain(iterator1[, …iteratorn]) _(es6-iterator/#/chain)_
Chain multiple iterators into one.
### Tests [](https://travis-ci.org/medikoo/es6-iterator)
$ npm test
# web3-providers-http
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a HTTP provider sub-package for [web3.js][repo].
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-providers-http
```
## Usage
```js
const http = require('http');
const Web3HttpProvider = require('web3-providers-http');
const options = {
keepAlive: true,
timeout: 20000, // milliseconds,
headers: [{name: 'Access-Control-Allow-Origin', value: '*'},{...}],
withCredentials: false,
agent: {http: http.Agent(...), baseUrl: ''}
};
const provider = new Web3HttpProvider('http://localhost:8545', options);
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/dm/web3-providers-http.svg
[npm-url]: https://npmjs.org/package/web3-providers-http
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-providers-http
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-providers-http
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-providers-http
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-providers-http
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# readable-stream
***Node-core v8.11.1 streams for userland*** [](https://travis-ci.org/nodejs/readable-stream)
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
[](https://saucelabs.com/u/readable-stream)
```bash
npm install --save readable-stream
```
***Node-core streams for userland***
This package is a mirror of the Streams2 and Streams3 implementations in
Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.11.1/docs/api/stream.html).
If you want to guarantee a stable streams base, regardless of what version of
Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core, for background see [this blogpost](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).
As of version 2.0.0 **readable-stream** uses semantic versioning.
# Streams Working Group
`readable-stream` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
<a name="members"></a>
## Team Members
* **Chris Dickinson** ([@chrisdickinson](https://github.com/chrisdickinson)) <[email protected]>
- Release GPG key: 9554F04D7259F04124DE6B476D5A82AC7E37093B
* **Calvin Metcalf** ([@calvinmetcalf](https://github.com/calvinmetcalf)) <[email protected]>
- Release GPG key: F3EF5F62A87FC27A22E643F714CE4FF5015AA242
* **Rod Vagg** ([@rvagg](https://github.com/rvagg)) <[email protected]>
- Release GPG key: DD8F2338BAE7501E3DD5AC78C273792F7D83545D
* **Sam Newman** ([@sonewman](https://github.com/sonewman)) <[email protected]>
* **Mathias Buus** ([@mafintosh](https://github.com/mafintosh)) <[email protected]>
* **Domenic Denicola** ([@domenic](https://github.com/domenic)) <[email protected]>
* **Matteo Collina** ([@mcollina](https://github.com/mcollina)) <[email protected]>
- Release GPG key: 3ABC01543F22DD2239285CDD818674489FBC127E
* **Irina Shestak** ([@lrlna](https://github.com/lrlna)) <[email protected]>
Oboe.js is an [open source](LICENCE) Javascript library
for loading JSON using streaming, combining the convenience of DOM with
the speed and fluidity of SAX.
It can parse any JSON as a stream, is small enough to be a [micro-library](http://microjs.com/#),
doesn't have dependencies, and doesn't care which other libraries you need it to speak to.
We can load trees [larger than the available memory](http://oboejs.com/examples#loading-json-trees-larger-than-the-available-ram).
Or we can [instantiate classical OOP models from JSON](http://oboejs.com/examples#demarshalling-json-to-an-oop-model),
or [completely transform your JSON](http://oboejs.com/examples#transforming-json-while-it-is-streaming) while it is being read.
Oboe makes it really easy to start using json from a response before the ajax request completes.
Or even if it never completes.
Where next?
-----------
- [The website](http://oboejs.com)
- Visualise [faster web applications through streaming](http://oboejs.com/why)
- Visit the [project homepage](http://oboejs.com)
- Browse [code examples](http://oboejs.com/examples)
- Learn the Oboe.js [API](http://oboejs.com/api)
- [Download](http://oboejs.com/download) the library
- [Discuss](http://oboejs.com/discuss) Oboe.js
# Param Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a lower cased string with dashes between words.
## Installation
```
npm install param-case --save
```
## Usage
```js
import { paramCase } from "param-case";
paramCase("string"); //=> "string"
paramCase("dot.case"); //=> "dot-case"
paramCase("PascalCase"); //=> "pascal-case"
paramCase("version 1.2.10"); //=> "version-1-2-10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/param-case.svg?style=flat
[npm-url]: https://npmjs.org/package/param-case
[downloads-image]: https://img.shields.io/npm/dm/param-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/param-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/param-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=param-case
# SYNOPSIS
[](https://www.npmjs.org/package/ethereumjs-util)
[](https://travis-ci.org/ethereumjs/ethereumjs-util)
[](https://coveralls.io/r/ethereumjs/ethereumjs-util)
[](https://gitter.im/ethereum/ethereumjs-lib) or #ethereumjs on freenode
[](https://github.com/feross/standard)
A collection of utility functions for ethereum. It can be used in node.js or can be in the browser with browserify.
# API
[./docs/](./docs/index.md)
Most of the string manipulation methods are provided by [ethjs-util](https://github.com/ethjs/ethjs-util)
# LICENSE
MPL-2.0
# browserify-sign
[](https://www.npmjs.org/package/browserify-sign)
[](https://travis-ci.org/crypto-browserify/browserify-sign)
[](https://david-dm.org/crypto-browserify/browserify-sign#info=dependencies)
[](https://github.com/feross/standard)
A package to duplicate the functionality of node's crypto public key functions, much of this is based on [Fedor Indutny's](https://github.com/indutny) work on [indutny/tls.js](https://github.com/indutny/tls.js).
## LICENSE
ISC
# Polyfill for `Object.setPrototypeOf`
[](https://npmjs.org/package/setprototypeof)
[](https://npmjs.org/package/setprototypeof)
[](https://github.com/standard/standard)
A simple cross platform implementation to set the prototype of an instianted object. Supports all modern browsers and at least back to IE8.
## Usage:
```
$ npm install --save setprototypeof
```
```javascript
var setPrototypeOf = require('setprototypeof')
var obj = {}
setPrototypeOf(obj, {
foo: function () {
return 'bar'
}
})
obj.foo() // bar
```
TypeScript is also supported:
```typescript
import setPrototypeOf = require('setprototypeof')
```
# node-http-signature
node-http-signature is a node.js library that has client and server components
for Joyent's [HTTP Signature Scheme](http_signing.md).
## Usage
Note the example below signs a request with the same key/cert used to start an
HTTP server. This is almost certainly not what you actually want, but is just
used to illustrate the API calls; you will need to provide your own key
management in addition to this library.
### Client
```js
var fs = require('fs');
var https = require('https');
var httpSignature = require('http-signature');
var key = fs.readFileSync('./key.pem', 'ascii');
var options = {
host: 'localhost',
port: 8443,
path: '/',
method: 'GET',
headers: {}
};
// Adds a 'Date' header in, signs it, and adds the
// 'Authorization' header in.
var req = https.request(options, function(res) {
console.log(res.statusCode);
});
httpSignature.sign(req, {
key: key,
keyId: './cert.pem'
});
req.end();
```
### Server
```js
var fs = require('fs');
var https = require('https');
var httpSignature = require('http-signature');
var options = {
key: fs.readFileSync('./key.pem'),
cert: fs.readFileSync('./cert.pem')
};
https.createServer(options, function (req, res) {
var rc = 200;
var parsed = httpSignature.parseRequest(req);
var pub = fs.readFileSync(parsed.keyId, 'ascii');
if (!httpSignature.verifySignature(parsed, pub))
rc = 401;
res.writeHead(rc);
res.end();
}).listen(8443);
```
## Installation
npm install http-signature
## License
MIT.
## Bugs
See <https://github.com/joyent/node-http-signature/issues>.
cipher-base
===
[](https://travis-ci.org/crypto-browserify/cipher-base)
Abstract base class to inherit from if you want to create streams implementing
the same api as node crypto streams.
Requires you to implement 2 methods `_final` and `_update`. `_update` takes a
buffer and should return a buffer, `_final` takes no arguments and should return
a buffer.
The constructor takes one argument and that is a string which if present switches
it into hash mode, i.e. the object you get from crypto.createHash or
crypto.createSign, this switches the name of the final method to be the string
you passed instead of `final` and returns `this` from update.
# normalize-path [](https://www.npmjs.com/package/normalize-path) [](https://npmjs.org/package/normalize-path) [](https://npmjs.org/package/normalize-path) [](https://travis-ci.org/jonschlinkert/normalize-path)
> Normalize slashes in a file path to be posix/unix-like forward slashes. Also condenses repeat slashes to a single slash and removes and trailing slashes, unless disabled.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save normalize-path
```
## Usage
```js
const normalize = require('normalize-path');
console.log(normalize('\\foo\\bar\\baz\\'));
//=> '/foo/bar/baz'
```
**win32 namespaces**
```js
console.log(normalize('\\\\?\\UNC\\Server01\\user\\docs\\Letter.txt'));
//=> '//?/UNC/Server01/user/docs/Letter.txt'
console.log(normalize('\\\\.\\CdRomX'));
//=> '//./CdRomX'
```
**Consecutive slashes**
Condenses multiple consecutive forward slashes (except for leading slashes in win32 namespaces) to a single slash.
```js
console.log(normalize('.//foo//bar///////baz/'));
//=> './foo/bar/baz'
```
### Trailing slashes
By default trailing slashes are removed. Pass `false` as the last argument to disable this behavior and _**keep** trailing slashes_:
```js
console.log(normalize('foo\\bar\\baz\\', false)); //=> 'foo/bar/baz/'
console.log(normalize('./foo/bar/baz/', false)); //=> './foo/bar/baz/'
```
## Release history
### v3.0
No breaking changes in this release.
* a check was added to ensure that [win32 namespaces](https://msdn.microsoft.com/library/windows/desktop/aa365247(v=vs.85).aspx#namespaces) are handled properly by win32 `path.parse()` after a path has been normalized by this library.
* a minor optimization was made to simplify how the trailing separator was handled
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
Other useful path-related libraries:
* [contains-path](https://www.npmjs.com/package/contains-path): Return true if a file path contains the given path. | [homepage](https://github.com/jonschlinkert/contains-path "Return true if a file path contains the given path.")
* [is-absolute](https://www.npmjs.com/package/is-absolute): Returns true if a file path is absolute. Does not rely on the path module… [more](https://github.com/jonschlinkert/is-absolute) | [homepage](https://github.com/jonschlinkert/is-absolute "Returns true if a file path is absolute. Does not rely on the path module and can be used as a polyfill for node.js native `path.isAbolute`.")
* [is-relative](https://www.npmjs.com/package/is-relative): Returns `true` if the path appears to be relative. | [homepage](https://github.com/jonschlinkert/is-relative "Returns `true` if the path appears to be relative.")
* [parse-filepath](https://www.npmjs.com/package/parse-filepath): Pollyfill for node.js `path.parse`, parses a filepath into an object. | [homepage](https://github.com/jonschlinkert/parse-filepath "Pollyfill for node.js `path.parse`, parses a filepath into an object.")
* [path-ends-with](https://www.npmjs.com/package/path-ends-with): Return `true` if a file path ends with the given string/suffix. | [homepage](https://github.com/jonschlinkert/path-ends-with "Return `true` if a file path ends with the given string/suffix.")
* [unixify](https://www.npmjs.com/package/unixify): Convert Windows file paths to unix paths. | [homepage](https://github.com/jonschlinkert/unixify "Convert Windows file paths to unix paths.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 35 | [jonschlinkert](https://github.com/jonschlinkert) |
| 1 | [phated](https://github.com/phated) |
### Author
**Jon Schlinkert**
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
### License
Copyright © 2018, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on April 19, 2018._
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# media-typer
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Simple RFC 6838 media type parser
## Installation
```sh
$ npm install media-typer
```
## API
```js
var typer = require('media-typer')
```
### typer.parse(string)
```js
var obj = typer.parse('image/svg+xml; charset=utf-8')
```
Parse a media type string. This will return an object with the following
properties (examples are shown for the string `'image/svg+xml; charset=utf-8'`):
- `type`: The type of the media type (always lower case). Example: `'image'`
- `subtype`: The subtype of the media type (always lower case). Example: `'svg'`
- `suffix`: The suffix of the media type (always lower case). Example: `'xml'`
- `parameters`: An object of the parameters in the media type (name of parameter always lower case). Example: `{charset: 'utf-8'}`
### typer.parse(req)
```js
var obj = typer.parse(req)
```
Parse the `content-type` header from the given `req`. Short-cut for
`typer.parse(req.headers['content-type'])`.
### typer.parse(res)
```js
var obj = typer.parse(res)
```
Parse the `content-type` header set on the given `res`. Short-cut for
`typer.parse(res.getHeader('content-type'))`.
### typer.format(obj)
```js
var obj = typer.format({type: 'image', subtype: 'svg', suffix: 'xml'})
```
Format an object into a media type string. This will return a string of the
mime type for the given object. For the properties of the object, see the
documentation for `typer.parse(string)`.
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/media-typer.svg?style=flat
[npm-url]: https://npmjs.org/package/media-typer
[node-version-image]: https://img.shields.io/badge/node.js-%3E%3D_0.6-brightgreen.svg?style=flat
[node-version-url]: http://nodejs.org/download/
[travis-image]: https://img.shields.io/travis/jshttp/media-typer.svg?style=flat
[travis-url]: https://travis-ci.org/jshttp/media-typer
[coveralls-image]: https://img.shields.io/coveralls/jshttp/media-typer.svg?style=flat
[coveralls-url]: https://coveralls.io/r/jshttp/media-typer
[downloads-image]: https://img.shields.io/npm/dm/media-typer.svg?style=flat
[downloads-url]: https://npmjs.org/package/media-typer
# proxy-addr
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Node.js Version][node-image]][node-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Determine address of proxied request
## Install
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install proxy-addr
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var proxyaddr = require('proxy-addr')
```
### proxyaddr(req, trust)
Return the address of the request, using the given `trust` parameter.
The `trust` argument is a function that returns `true` if you trust
the address, `false` if you don't. The closest untrusted address is
returned.
<!-- eslint-disable no-undef -->
```js
proxyaddr(req, function (addr) { return addr === '127.0.0.1' })
proxyaddr(req, function (addr, i) { return i < 1 })
```
The `trust` arugment may also be a single IP address string or an
array of trusted addresses, as plain IP addresses, CIDR-formatted
strings, or IP/netmask strings.
<!-- eslint-disable no-undef -->
```js
proxyaddr(req, '127.0.0.1')
proxyaddr(req, ['127.0.0.0/8', '10.0.0.0/8'])
proxyaddr(req, ['127.0.0.0/255.0.0.0', '192.168.0.0/255.255.0.0'])
```
This module also supports IPv6. Your IPv6 addresses will be normalized
automatically (i.e. `fe80::00ed:1` equals `fe80:0:0:0:0:0:ed:1`).
<!-- eslint-disable no-undef -->
```js
proxyaddr(req, '::1')
proxyaddr(req, ['::1/128', 'fe80::/10'])
```
This module will automatically work with IPv4-mapped IPv6 addresses
as well to support node.js in IPv6-only mode. This means that you do
not have to specify both `::ffff:a00:1` and `10.0.0.1`.
As a convenience, this module also takes certain pre-defined names
in addition to IP addresses, which expand into IP addresses:
<!-- eslint-disable no-undef -->
```js
proxyaddr(req, 'loopback')
proxyaddr(req, ['loopback', 'fc00:ac:1ab5:fff::1/64'])
```
* `loopback`: IPv4 and IPv6 loopback addresses (like `::1` and
`127.0.0.1`).
* `linklocal`: IPv4 and IPv6 link-local addresses (like
`fe80::1:1:1:1` and `169.254.0.1`).
* `uniquelocal`: IPv4 private addresses and IPv6 unique-local
addresses (like `fc00:ac:1ab5:fff::1` and `192.168.0.1`).
When `trust` is specified as a function, it will be called for each
address to determine if it is a trusted address. The function is
given two arguments: `addr` and `i`, where `addr` is a string of
the address to check and `i` is a number that represents the distance
from the socket address.
### proxyaddr.all(req, [trust])
Return all the addresses of the request, optionally stopping at the
first untrusted. This array is ordered from closest to furthest
(i.e. `arr[0] === req.connection.remoteAddress`).
<!-- eslint-disable no-undef -->
```js
proxyaddr.all(req)
```
The optional `trust` argument takes the same arguments as `trust`
does in `proxyaddr(req, trust)`.
<!-- eslint-disable no-undef -->
```js
proxyaddr.all(req, 'loopback')
```
### proxyaddr.compile(val)
Compiles argument `val` into a `trust` function. This function takes
the same arguments as `trust` does in `proxyaddr(req, trust)` and
returns a function suitable for `proxyaddr(req, trust)`.
<!-- eslint-disable no-undef, no-unused-vars -->
```js
var trust = proxyaddr.compile('loopback')
var addr = proxyaddr(req, trust)
```
This function is meant to be optimized for use against every request.
It is recommend to compile a trust function up-front for the trusted
configuration and pass that to `proxyaddr(req, trust)` for each request.
## Testing
```sh
$ npm test
```
## Benchmarks
```sh
$ npm run-script bench
```
## License
[MIT](LICENSE)
[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/proxy-addr/master
[coveralls-url]: https://coveralls.io/r/jshttp/proxy-addr?branch=master
[node-image]: https://badgen.net/npm/node/proxy-addr
[node-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/proxy-addr
[npm-url]: https://npmjs.org/package/proxy-addr
[npm-version-image]: https://badgen.net/npm/v/proxy-addr
[travis-image]: https://badgen.net/travis/jshttp/proxy-addr/master
[travis-url]: https://travis-ci.org/jshttp/proxy-addr
# Ozone - Javascript Class Framework
[](https://travis-ci.org/inf3rno/o3)
The Ozone class framework contains enhanced class support to ease the development of object-oriented javascript applications in an ES5 environment.
Another alternative to get a better class support to use ES6 classes and compilers like Babel, Traceur or TypeScript until native ES6 support arrives.
## Documentation
### Installation
```bash
npm install o3
```
```bash
bower install o3
```
#### Environment compatibility
The framework succeeded the tests on
- node v4.2 and v5.x
- chrome 51.0
- firefox 47.0 and 48.0
- internet explorer 11.0
- phantomjs 2.1
by the usage of npm scripts under win7 x64.
I wasn't able to test the framework by Opera since the Karma launcher is buggy, so I decided not to support Opera.
I used [Yadda](https://github.com/acuminous/yadda) to write BDD tests.
I used [Karma](https://github.com/karma-runner/karma) with [Browserify](https://github.com/substack/node-browserify) to test the framework in browsers.
On pre-ES5 environments there will be bugs in the Class module due to pre-ES5 enumeration and the lack of some ES5 methods, so pre-ES5 environments are not supported.
#### Requirements
An ES5 capable environment is required with
- `Object.create`
- ES5 compatible property enumeration: `Object.defineProperty`, `Object.getOwnPropertyDescriptor`, `Object.prototype.hasOwnProperty`, etc.
- `Array.prototype.forEach`
#### Usage
In this documentation I used the framework as follows:
```js
var o3 = require("o3"),
Class = o3.Class;
```
### Inheritance
#### Inheriting from native classes (from the Error class in these examples)
You can extend native classes by calling the Class() function.
```js
var UserError = Class(Error, {
prototype: {
message: "blah",
constructor: function UserError() {
Error.captureStackTrace(this, this.constructor);
}
}
});
```
An alternative to call Class.extend() with the Ancestor as the context. The Class() function uses this in the background.
```js
var UserError = Class.extend.call(Error, {
prototype: {
message: "blah",
constructor: function UserError() {
Error.captureStackTrace(this, this.constructor);
}
}
});
```
#### Inheriting from custom classes
You can use Class.extend() by any other class, not just by native classes.
```js
var Ancestor = Class(Object, {
prototype: {
a: 1,
b: 2
}
});
var Descendant = Class.extend.call(Ancestor, {
prototype: {
c: 3
}
});
```
Or you can simply add it as a static method, so you don't have to pass context any time you want to use it. The only drawback, that this static method will be inherited as well.
```js
var Ancestor = Class(Object, {
extend: Class.extend,
prototype: {
a: 1,
b: 2
}
});
var Descendant = Ancestor.extend({
prototype: {
c: 3
}
});
```
#### Inheriting from the Class class
You can inherit the extend() method and other utility methods from the Class class. Probably this is the simplest solution if you need the Class API and you don't need to inherit from special native classes like Error.
```js
var Ancestor = Class.extend({
prototype: {
a: 1,
b: 2
}
});
var Descendant = Ancestor.extend({
prototype: {
c: 3
}
});
```
#### Inheritance with clone and merge
The static extend() method uses the clone() and merge() utility methods to inherit from the ancestor and add properties from the config.
```js
var MyClass = Class.clone.call(Object, function MyClass(){
// ...
});
Class.merge.call(MyClass, {
prototype: {
x: 1,
y: 2
}
});
```
Or with utility methods.
```js
var MyClass = Class.clone(function MyClass() {
// ...
}).merge({
prototype: {
x: 1,
y: 2
}
});
```
#### Inheritance with clone and absorb
You can fill in missing properties with the usage of absorb.
```js
var MyClass = Class(SomeAncestor, {...});
Class.absorb.call(MyClass, Class);
MyClass.merge({...});
```
For example if you don't have Class methods and your class already has an ancestor, then you can use absorb() to add Class methods.
#### Abstract classes
Using abstract classes with instantiation verification won't be implemented in this lib, however we provide an `abstractMethod`, which you can put to not implemented parts of your abstract class.
```js
var AbstractA = Class({
prototype: {
doA: function (){
// ...
var b = this.getB();
// ...
// do something with b
// ...
},
getB: abstractMethod
}
});
var AB1 = Class(AbstractA, {
prototype: {
getB: function (){
return new B1();
}
}
});
var ab1 = new AB1();
```
I strongly support the composition over inheritance principle and I think you should use dependency injection instead of abstract classes.
```js
var A = Class({
prototype: {
init: function (b){
this.b = b;
},
doA: function (){
// ...
// do something with this.b
// ...
}
}
});
var b = new B1();
var ab1 = new A(b);
```
### Constructors
#### Using a custom constructor
You can pass your custom constructor as a config option by creating the class.
```js
var MyClass = Class(Object, {
prototype: {
constructor: function () {
// ...
}
}
});
```
#### Using a custom factory to create the constructor
Or you can pass a static factory method to create your custom constructor.
```js
var MyClass = Class(Object, {
factory: function () {
return function () {
// ...
}
}
});
```
#### Using an inherited factory to create the constructor
By inheritance the constructors of the descendant classes will be automatically created as well.
```js
var Ancestor = Class(Object, {
factory: function () {
return function () {
// ...
}
}
});
var Descendant = Class(Ancestor, {});
```
#### Using the default factory to create the constructor
You don't need to pass anything if you need a noop function as constructor. The Class.factory() will create a noop constructor by default.
```js
var MyClass = Class(Object, {});
```
In fact you don't need to pass any arguments to the Class function if you need an empty class inheriting from the Object native class.
```js
var MyClass = Class();
```
The default factory calls the build() and init() methods if they are given.
```js
var MyClass = Class({
prototype: {
build: function (options) {
console.log("build", options);
},
init: function (options) {
console.log("init", options);
}
}
});
var my = new MyClass({a: 1, b: 2});
// build {a: 1, b: 2}
// init {a: 1, b: 2}
var my2 = my.clone({c: 3});
// build {c: 3}
var MyClass2 = MyClass.extend({}, [{d: 4}]);
// build {d: 4}
```
### Instantiation
#### Creating new instance with the new operator
Ofc. you can create a new instance in the javascript way.
```js
var MyClass = Class();
var my = new MyClass();
```
#### Creating a new instance with the static newInstance method
If you want to pass an array of arguments then you can do it the following way.
```js
var MyClass = Class.extend({
prototype: {
constructor: function () {
for (var i in arguments)
console.log(arguments[i]);
}
}
});
var my = MyClass.newInstance.apply(MyClass, ["a", "b", "c"]);
// a
// b
// c
```
#### Creating new instance with clone
You can create a new instance by cloning the prototype of the class.
```js
var MyClass = Class();
var my = Class.prototype.clone.call(MyClass.prototype);
```
Or you can inherit the utility methods to make this easier.
```js
var MyClass = Class.extend();
var my = MyClass.prototype.clone();
```
Just be aware that by default cloning calls only the `build()` method, so the `init()` method won't be called by the new instance.
#### Cloning instances
You can clone an existing instance with the clone method.
```js
var MyClass = Class.extend();
var my = MyClass.prototype.clone();
var my2 = my.clone();
```
Be aware that this is prototypal inheritance with Object.create(), so the inherited properties won't be enumerable.
The clone() method calls the build() method on the new instance if it is given.
#### Using clone in the constructor
You can use the same behavior both by cloning and by creating a new instance using the constructor
```js
var MyClass = Class.extend({
lastIndex: 0,
prototype: {
index: undefined,
constructor: function MyClass() {
return MyClass.prototype.clone();
},
clone: function () {
var instance = Class.prototype.clone.call(this);
instance.index = ++MyClass.lastIndex;
return instance;
}
}
});
var my1 = new MyClass();
var my2 = MyClass.prototype.clone();
var my3 = my1.clone();
var my4 = my2.clone();
```
Be aware that this way the constructor will drop the instance created with the `new` operator.
Be aware that the clone() method is used by inheritance, so creating the prototype of a descendant class will use the clone() method as well.
```js
var Descendant = MyClass.clone(function Descendant() {
return Descendant.prototype.clone();
});
var my5 = Descendant.prototype;
var my6 = new Descendant();
// ...
```
#### Using absorb(), merge() or inheritance to set the defaults values on properties
You can use absorb() to set default values after configuration.
```js
var MyClass = Class.extend({
prototype: {
constructor: function (config) {
var theDefaults = {
// ...
};
this.merge(config);
this.absorb(theDefaults);
}
}
});
```
You can use merge() to set default values before configuration.
```js
var MyClass = Class.extend({
prototype: {
constructor: function (config) {
var theDefaults = {
// ...
};
this.merge(theDefaults);
this.merge(config);
}
}
});
```
You can use inheritance to set default values on class level.
```js
var MyClass = Class.extend({
prototype: {
aProperty: defaultValue,
// ...
constructor: function (config) {
this.merge(config);
}
}
});
```
## License
MIT - 2015 Jánszky László Lajos
# **node-addon-api module**
This module contains **header-only C++ wrapper classes** which simplify
the use of the C based [N-API](https://nodejs.org/dist/latest/docs/api/n-api.html)
provided by Node.js when using C++. It provides a C++ object model
and exception handling semantics with low overhead.
N-API is an ABI stable C interface provided by Node.js for building native
addons. It is independent from the underlying JavaScript runtime (e.g. V8 or ChakraCore)
and is maintained as part of Node.js itself. It is intended to insulate
native addons from changes in the underlying JavaScript engine and allow
modules compiled for one version to run on later versions of Node.js without
recompilation.
The `node-addon-api` module, which is not part of Node.js, preserves the benefits
of the N-API as it consists only of inline code that depends only on the stable API
provided by N-API. As such, modules built against one version of Node.js
using node-addon-api should run without having to be rebuilt with newer versions
of Node.js.
It is important to remember that *other* Node.js interfaces such as
`libuv` (included in a project via `#include <uv.h>`) are not ABI-stable across
Node.js major versions. Thus, an addon must use N-API and/or `node-addon-api`
exclusively and build against a version of Node.js that includes an
implementation of N-API (meaning a version of Node.js newer than 6.14.2) in
order to benefit from ABI stability across Node.js major versions. Node.js
provides an [ABI stability guide][] containing a detailed explanation of ABI
stability in general, and the N-API ABI stability guarantee in particular.
As new APIs are added to N-API, node-addon-api must be updated to provide
wrappers for those new APIs. For this reason node-addon-api provides
methods that allow callers to obtain the underlying N-API handles so
direct calls to N-API and the use of the objects/methods provided by
node-addon-api can be used together. For example, in order to be able
to use an API for which the node-addon-api does not yet provide a wrapper.
APIs exposed by node-addon-api are generally used to create and
manipulate JavaScript values. Concepts and operations generally map
to ideas specified in the **ECMA262 Language Specification**.
- **[Setup](#setup)**
- **[API Documentation](#api)**
- **[Examples](#examples)**
- **[Tests](#tests)**
- **[More resource and info about native Addons](#resources)**
- **[Code of Conduct](CODE_OF_CONDUCT.md)**
- **[Contributors](#contributors)**
- **[License](#license)**
## **Current version: 2.0.2**
(See [CHANGELOG.md](CHANGELOG.md) for complete Changelog)
[](https://nodei.co/npm/node-addon-api/) [](https://nodei.co/npm/node-addon-api/)
<a name="setup"></a>
## Setup
- [Installation and usage](doc/setup.md)
- [node-gyp](doc/node-gyp.md)
- [cmake-js](doc/cmake-js.md)
- [Conversion tool](doc/conversion-tool.md)
- [Checker tool](doc/checker-tool.md)
- [Generator](doc/generator.md)
- [Prebuild tools](doc/prebuild_tools.md)
<a name="api"></a>
### **API Documentation**
The following is the documentation for node-addon-api.
- [Basic Types](doc/basic_types.md)
- [Array](doc/basic_types.md#array)
- [Symbol](doc/symbol.md)
- [String](doc/string.md)
- [Name](doc/basic_types.md#name)
- [Number](doc/number.md)
- [Date](doc/date.md)
- [BigInt](doc/bigint.md)
- [Boolean](doc/boolean.md)
- [Env](doc/env.md)
- [Value](doc/value.md)
- [CallbackInfo](doc/callbackinfo.md)
- [Reference](doc/reference.md)
- [External](doc/external.md)
- [Object](doc/object.md)
- [ObjectReference](doc/object_reference.md)
- [PropertyDescriptor](doc/property_descriptor.md)
- [Error Handling](doc/error_handling.md)
- [Error](doc/error.md)
- [TypeError](doc/type_error.md)
- [RangeError](doc/range_error.md)
- [Object Lifetime Management](doc/object_lifetime_management.md)
- [HandleScope](doc/handle_scope.md)
- [EscapableHandleScope](doc/escapable_handle_scope.md)
- [Working with JavaScript Values](doc/working_with_javascript_values.md)
- [Function](doc/function.md)
- [FunctionReference](doc/function_reference.md)
- [ObjectWrap](doc/object_wrap.md)
- [ClassPropertyDescriptor](doc/class_property_descriptor.md)
- [Buffer](doc/buffer.md)
- [ArrayBuffer](doc/array_buffer.md)
- [TypedArray](doc/typed_array.md)
- [TypedArrayOf](doc/typed_array_of.md)
- [DataView](doc/dataview.md)
- [Memory Management](doc/memory_management.md)
- [Async Operations](doc/async_operations.md)
- [AsyncWorker](doc/async_worker.md)
- [AsyncContext](doc/async_context.md)
- [AsyncProgressWorker](doc/async_progress_worker.md)
- [Thread-safe Functions](doc/threadsafe_function.md)
- [Promises](doc/promises.md)
- [Version management](doc/version_management.md)
<a name="examples"></a>
### **Examples**
Are you new to **node-addon-api**? Take a look at our **[examples](https://github.com/nodejs/node-addon-examples)**
- **[Hello World](https://github.com/nodejs/node-addon-examples/tree/master/1_hello_world/node-addon-api)**
- **[Pass arguments to a function](https://github.com/nodejs/node-addon-examples/tree/master/2_function_arguments/node-addon-api)**
- **[Callbacks](https://github.com/nodejs/node-addon-examples/tree/master/3_callbacks/node-addon-api)**
- **[Object factory](https://github.com/nodejs/node-addon-examples/tree/master/4_object_factory/node-addon-api)**
- **[Function factory](https://github.com/nodejs/node-addon-examples/tree/master/5_function_factory/node-addon-api)**
- **[Wrapping C++ Object](https://github.com/nodejs/node-addon-examples/tree/master/6_object_wrap/node-addon-api)**
- **[Factory of wrapped object](https://github.com/nodejs/node-addon-examples/tree/master/7_factory_wrap/node-addon-api)**
- **[Passing wrapped object around](https://github.com/nodejs/node-addon-examples/tree/master/8_passing_wrapped/node-addon-api)**
<a name="tests"></a>
### **Tests**
To run the **node-addon-api** tests do:
```
npm install
npm test
```
To avoid testing the deprecated portions of the API run
```
npm install
npm test --disable-deprecated
```
### **Debug**
To run the **node-addon-api** tests with `--debug` option:
```
npm run-script dev
```
If you want faster build, you might use the following option:
```
npm run-script dev:incremental
```
Take a look and get inspired by our **[test suite](https://github.com/nodejs/node-addon-api/tree/master/test)**
<a name="resources"></a>
## **Contributing**
We love contributions from the community to **node-addon-api**.
See [CONTRIBUTING.md](CONTRIBUTING.md) for more details on our philosophy around extending this module.
### **More resource and info about native Addons**
- **[C++ Addons](https://nodejs.org/dist/latest/docs/api/addons.html)**
- **[N-API](https://nodejs.org/dist/latest/docs/api/n-api.html)**
- **[N-API - Next Generation Node API for Native Modules](https://youtu.be/-Oniup60Afs)**
<a name="contributors"></a>
## WG Members / Collaborators
### Active
| Name | GitHub Link |
| ------------------- | ----------------------------------------------------- |
| Anna Henningsen | [addaleax](https://github.com/addaleax) |
| Gabriel Schulhof | [gabrielschulhof](https://github.com/gabrielschulhof) |
| Hitesh Kanwathirtha | [digitalinfinity](https://github.com/digitalinfinity) |
| Jim Schlight | [jschlight](https://github.com/jschlight) |
| Michael Dawson | [mhdawson](https://github.com/mhdawson) |
| Kevin Eady | [KevinEady](https://github.com/KevinEady)
| Nicola Del Gobbo | [NickNaso](https://github.com/NickNaso) |
### Emeritus
| Name | GitHub Link |
| ------------------- | ----------------------------------------------------- |
| Arunesh Chandra | [aruneshchandra](https://github.com/aruneshchandra) |
| Benjamin Byholm | [kkoopa](https://github.com/kkoopa) |
| Jason Ginchereau | [jasongin](https://github.com/jasongin) |
| Sampson Gao | [sampsongao](https://github.com/sampsongao) |
| Taylor Woll | [boingoing](https://github.com/boingoing) |
<a name="license"></a>
Licensed under [MIT](./LICENSE.md)
[ABI stability guide]: https://nodejs.org/en/docs/guides/abi-stability/
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# level-errors
> Error types for [levelup][levelup].
[![level badge][level-badge]](https://github.com/Level/awesome)
[](https://www.npmjs.com/package/level-errors)
[](https://www.npmjs.com/package/level-errors)
[](https://travis-ci.org/Level/errors)
[](https://coveralls.io/github/Level/errors)
[](https://standardjs.com)
[](https://www.npmjs.com/package/level-errors)
[](#backers)
[](#sponsors)
## API
**If you are upgrading:** please see [`UPGRADING.md`](UPGRADING.md).
### `.LevelUPError()`
Generic error base class.
### `.InitializationError()`
Error initializing the database, like when the database's location argument is missing.
### `.OpenError()`
Error opening the database.
### `.ReadError()`
Error reading from the database.
### `.WriteError()`
Error writing to the database.
### `.NotFoundError()`
Data not found error.
Has extra properties:
- `notFound`: `true`
- `status`: 404
### `.EncodingError()`
Error encoding data.
## Contributing
[`Level/errors`](https://github.com/Level/errors) is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [Contribution Guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
## Donate
To sustain [`Level`](https://github.com/Level) and its activities, become a backer or sponsor on [Open Collective](https://opencollective.com/level). Your logo or avatar will be displayed on our 28+ [GitHub repositories](https://github.com/Level), [npm](https://www.npmjs.com/) packages and (soon) [our website](http://leveldb.org). 💖
### Backers
[](https://opencollective.com/level)
### Sponsors
[](https://opencollective.com/level)
## License
[MIT](LICENSE.md) © 2012-present [Contributors](CONTRIBUTORS.md).
[level-badge]: http://leveldb.org/img/badge.svg
[levelup]: https://github.com/Level/levelup
# extglob [](http://badge.fury.io/js/extglob) [](https://travis-ci.org/jonschlinkert/extglob)
> Convert extended globs to regex-compatible strings. Add (almost) the expressive power of regular expressions to glob patterns.
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i extglob --save
```
Used by [micromatch](https://github.com/jonschlinkert/micromatch).
**Features**
* Convert an extglob string to a regex-compatible string. **Only converts extglobs**, to handle full globs use [micromatch](https://github.com/jonschlinkert/micromatch).
* Pass `{regex: true}` to return a regex
* Handles nested patterns
* More complete (and correct) support than [minimatch](https://github.com/isaacs/minimatch)
## Usage
```js
var extglob = require('extglob');
extglob('?(z)');
//=> '(?:z)?'
extglob('*(z)');
//=> '(?:z)*'
extglob('+(z)');
//=> '(?:z)+'
extglob('@(z)');
//=> '(?:z)'
extglob('!(z)');
//=> '(?!^(?:(?!z)[^/]*?)).*$'
```
**Optionally return regex**
```js
extglob('!(z)', {regex: true});
//=> /(?!^(?:(?!z)[^/]*?)).*$/
```
## Extglob patterns
To learn more about how extglobs work, see the docs for [Bash pattern matching](https://www.gnu.org/software/bash/manual/html_node/Pattern-Matching.html):
* `?(pattern)`: Match zero or one occurrence of the given pattern.
* `*(pattern)`: Match zero or more occurrences of the given pattern.
* `+(pattern)`: Match one or more occurrences of the given pattern.
* `@(pattern)`: Match one of the given pattern.
* `!(pattern)`: Match anything except one of the given pattern.
## Related
* [braces](https://github.com/jonschlinkert/braces): Fastest brace expansion for node.js, with the most complete support for the Bash 4.3 braces… [more](https://github.com/jonschlinkert/braces)
* [expand-brackets](https://github.com/jonschlinkert/expand-brackets): Expand POSIX bracket expressions (character classes) in glob patterns.
* [expand-range](https://github.com/jonschlinkert/expand-range): Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. See… [more](https://github.com/jonschlinkert/expand-range)
* [fill-range](https://github.com/jonschlinkert/fill-range): Fill in a range of numbers or letters, optionally passing an increment or multiplier to… [more](https://github.com/jonschlinkert/fill-range)
* [micromatch](https://github.com/jonschlinkert/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. Just… [more](https://github.com/jonschlinkert/micromatch)
## Run tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/extglob/issues/new)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2015 Jon Schlinkert
Released under the MIT license.
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on August 01, 2015._
JSON Schema is a repository for the JSON Schema specification, reference schemas and a CommonJS implementation of JSON Schema (not the only JavaScript implementation of JSON Schema, JSV is another excellent JavaScript validator).
Code is licensed under the AFL or BSD license as part of the Persevere
project which is administered under the Dojo foundation,
and all contributions require a Dojo CLA.
# level-iterator-stream
> Turn a leveldown iterator into a readable stream
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/level-iterator-stream)

[](https://travis-ci.org/Level/iterator-stream)
[](https://david-dm.org/level/iterator-stream)
[](https://standardjs.com)
[](https://www.npmjs.com/package/level-iterator-stream)
## Usage
**If you are upgrading:** please see [UPGRADING.md](UPGRADING.md).
```js
var iteratorStream = require('level-iterator-stream')
var leveldown = require('leveldown')
var db = leveldown(__dirname + '/db')
db.open(function (err) {
if (err) throw err
var stream = iteratorStream(db.iterator())
stream.on('data', function (kv) {
console.log('%s -> %s', kv.key, kv.value)
})
})
```
## Installation
```bash
$ npm install level-iterator-stream
```
## API
### `stream = iteratorStream(iterator[, options])`
Create a readable stream from `iterator`. `options` are passed down to the `require('readable-stream').Readable` constructor, with `objectMode` forced to `true`.
Set `options.keys` or `options.values` to `false` to only get values / keys. Otherwise receive `{ key, value }` objects.
When the stream ends, the `iterator` will be closed and afterwards a `"close"` event emitted.
`.destroy()` will force close the underlying iterator.
## License
Copyright © 2012-present `level-iterator-stream` contributors.
`level-iterator-stream` is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included `LICENSE.md` file for more details.
[level-badge]: http://leveldb.org/img/badge.svg
# fd-slicer
[](https://travis-ci.org/andrewrk/node-fd-slicer)
Safe `fs.ReadStream` and `fs.WriteStream` using the same fd.
Let's say that you want to perform a parallel upload of a file to a remote
server. To do this, we want to create multiple read streams. The first thing
you might think of is to use the `{start: 0, end: 0}` API of
`fs.createReadStream`. This gives you two choices:
0. Use the same file descriptor for all `fs.ReadStream` objects.
0. Open the file multiple times, resulting in a separate file descriptor
for each read stream.
Neither of these are acceptable options. The first one is a severe bug,
because the API docs for `fs.write` state:
> Note that it is unsafe to use `fs.write` multiple times on the same file
> without waiting for the callback. For this scenario, `fs.createWriteStream`
> is strongly recommended.
`fs.createWriteStream` will solve the problem if you only create one of them
for the file descriptor, but it will exhibit this unsafety if you create
multiple write streams per file descriptor.
The second option suffers from a race condition. For each additional time the
file is opened after the first, it is possible that the file is modified. So
in our parallel uploading example, we might upload a corrupt file that never
existed on the client's computer.
This module solves this problem by providing `createReadStream` and
`createWriteStream` that operate on a shared file descriptor and provides
the convenient stream API while still allowing slicing and dicing.
This module also gives you some additional power that the builtin
`fs.createWriteStream` do not give you. These features are:
* Emitting a 'progress' event on write.
* Ability to set a maximum size and emit an error if this size is exceeded.
* Ability to create an `FdSlicer` instance from a `Buffer`. This enables you
to provide API for handling files as well as buffers using the same API.
## Usage
```js
var fdSlicer = require('fd-slicer');
var fs = require('fs');
fs.open("file.txt", 'r', function(err, fd) {
if (err) throw err;
var slicer = fdSlicer.createFromFd(fd);
var firstPart = slicer.createReadStream({start: 0, end: 100});
var secondPart = slicer.createReadStream({start: 100});
var firstOut = fs.createWriteStream("first.txt");
var secondOut = fs.createWriteStream("second.txt");
firstPart.pipe(firstOut);
secondPart.pipe(secondOut);
});
```
You can also create from a buffer:
```js
var fdSlicer = require('fd-slicer');
var slicer = FdSlicer.createFromBuffer(someBuffer);
var firstPart = slicer.createReadStream({start: 0, end: 100});
var secondPart = slicer.createReadStream({start: 100});
var firstOut = fs.createWriteStream("first.txt");
var secondOut = fs.createWriteStream("second.txt");
firstPart.pipe(firstOut);
secondPart.pipe(secondOut);
```
## API Documentation
### fdSlicer.createFromFd(fd, [options])
```js
var fdSlicer = require('fd-slicer');
fs.open("file.txt", 'r', function(err, fd) {
if (err) throw err;
var slicer = fdSlicer.createFromFd(fd);
// ...
});
```
Make sure `fd` is a properly initialized file descriptor. If you want to
use `createReadStream` make sure you open it for reading and if you want
to use `createWriteStream` make sure you open it for writing.
`options` is an optional object which can contain:
* `autoClose` - if set to `true`, the file descriptor will be automatically
closed once the last stream that references it is closed. Defaults to
`false`. `ref()` and `unref()` can be used to increase or decrease the
reference count, respectively.
### fdSlicer.createFromBuffer(buffer, [options])
```js
var fdSlicer = require('fd-slicer');
var slicer = fdSlicer.createFromBuffer(someBuffer);
// ...
```
`options` is an optional object which can contain:
* `maxChunkSize` - A `Number` of bytes. see `createReadStream()`.
If falsey, defaults to unlimited.
#### Properties
##### fd
The file descriptor passed in. `undefined` if created from a buffer.
#### Methods
##### createReadStream(options)
Available `options`:
* `start` - Number. The offset into the file to start reading from. Defaults
to 0.
* `end` - Number. Exclusive upper bound offset into the file to stop reading
from.
* `highWaterMark` - Number. The maximum number of bytes to store in the
internal buffer before ceasing to read from the underlying resource.
Defaults to 16 KB.
* `encoding` - String. If specified, then buffers will be decoded to strings
using the specified encoding. Defaults to `null`.
The ReadableStream that this returns has these additional methods:
* `destroy(err)` - stop streaming. `err` is optional and is the error that
will be emitted in order to cause the streaming to stop. Defaults to
`new Error("stream destroyed")`.
If `maxChunkSize` was specified (see `createFromBuffer()`), the read stream
will provide chunks of at most that size. Normally, the read stream provides
the entire range requested in a single chunk, but this can cause performance
problems in some circumstances.
See [thejoshwolfe/yauzl#87](https://github.com/thejoshwolfe/yauzl/issues/87).
##### createWriteStream(options)
Available `options`:
* `start` - Number. The offset into the file to start writing to. Defaults to
0.
* `end` - Number. Exclusive upper bound offset into the file. If this offset
is reached, the write stream will emit an 'error' event and stop functioning.
In this situation, `err.code === 'ETOOBIG'`. Defaults to `Infinity`.
* `highWaterMark` - Number. Buffer level when `write()` starts returning
false. Defaults to 16KB.
* `decodeStrings` - Boolean. Whether or not to decode strings into Buffers
before passing them to` _write()`. Defaults to `true`.
The WritableStream that this returns has these additional methods:
* `destroy()` - stop streaming
And these additional properties:
* `bytesWritten` - number of bytes written to the stream
And these additional events:
* 'progress' - emitted when `bytesWritten` changes.
##### read(buffer, offset, length, position, callback)
Equivalent to `fs.read`, but with concurrency protection.
`callback` must be defined.
##### write(buffer, offset, length, position, callback)
Equivalent to `fs.write`, but with concurrency protection.
`callback` must be defined.
##### ref()
Increase the `autoClose` reference count by 1.
##### unref()
Decrease the `autoClose` reference count by 1.
#### Events
##### 'error'
Emitted if `fs.close` returns an error when auto closing.
##### 'close'
Emitted when fd-slicer closes the file descriptor due to `autoClose`. Never
emitted if created from a buffer.
[](https://www.npmjs.com/package/esprima)
[](https://www.npmjs.com/package/esprima)
[](https://travis-ci.org/jquery/esprima)
[](https://codecov.io/github/jquery/esprima)
**Esprima** ([esprima.org](http://esprima.org), BSD license) is a high performance,
standard-compliant [ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
parser written in ECMAScript (also popularly known as
[JavaScript](https://en.wikipedia.org/wiki/JavaScript)).
Esprima is created and maintained by [Ariya Hidayat](https://twitter.com/ariyahidayat),
with the help of [many contributors](https://github.com/jquery/esprima/contributors).
### Features
- Full support for ECMAScript 2016 ([ECMA-262 7th Edition](http://www.ecma-international.org/publications/standards/Ecma-262.htm))
- Sensible [syntax tree format](https://github.com/estree/estree/blob/master/es5.md) as standardized by [ESTree project](https://github.com/estree/estree)
- Experimental support for [JSX](https://facebook.github.io/jsx/), a syntax extension for [React](https://facebook.github.io/react/)
- Optional tracking of syntax node location (index-based and line-column)
- [Heavily tested](http://esprima.org/test/ci.html) (~1300 [unit tests](https://github.com/jquery/esprima/tree/master/test/fixtures) with [full code coverage](https://codecov.io/github/jquery/esprima))
### API
Esprima can be used to perform [lexical analysis](https://en.wikipedia.org/wiki/Lexical_analysis) (tokenization) or [syntactic analysis](https://en.wikipedia.org/wiki/Parsing) (parsing) of a JavaScript program.
A simple example on Node.js REPL:
```javascript
> var esprima = require('esprima');
> var program = 'const answer = 42';
> esprima.tokenize(program);
[ { type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'answer' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '42' } ]
> esprima.parse(program);
{ type: 'Program',
body:
[ { type: 'VariableDeclaration',
declarations: [Object],
kind: 'const' } ],
sourceType: 'script' }
```
vizionar_test
=============
Empty repo for testing purposes
# varint
encode whole numbers to an array of [protobuf-style varint bytes](https://developers.google.com/protocol-buffers/docs/encoding#varints) and also decode them.
```javascript
var varint = require('varint')
var bytes = varint.encode(300) // === [0xAC, 0x02]
varint.decode(bytes) // 300
varint.decode.bytes // 2 (the last decode() call required 2 bytes)
```
## api
### varint = require('varint')
### varint.encode(num[, buffer=[], offset=0]) -> buffer
Encodes `num` into `buffer` starting at `offset`. returns `buffer`, with the encoded varint written into it. If `buffer` is not provided, it will default to a new array.
`varint.encode.bytes` will now be set to the number of bytes
modified.
### varint.decode(data[, offset=0]) -> number
decodes `data`, which can be either a buffer or array of integers, from position `offset` or default 0 and returns the decoded original integer.
Throws a `RangeError` when `data` does not represent a valid encoding.
### varint.decode.bytes
if you also require the length (number of bytes) that were required to decode the integer you can access it via `varint.decode.bytes`. this is an integer property that will tell you the number of bytes that the last .decode() call had to use to decode.
### varint.encode.bytes
similar to `decode.bytes` when encoding a number it can be useful to know how many bytes where written (especially if you pass an output array). you can access this via `varint.encode.bytes` which holds the number of bytes written in the last encode.
### varint.encodingLength(num)
returns the number of bytes this number will be encoded as, up to a maximum of 8.
## usage notes
If varint is passed a buffer that does not contain a valid end
byte, then `decode` will throw `RangeError`, and `decode.bytes`
will be set to 0. If you are reading from a streaming source,
it's okay to pass an incomplete buffer into `decode`, detect this
case, and then concatenate the next buffer.
# License
MIT
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# is-typedarray [](http://github.com/badges/stability-badges)
Detect whether or not an object is a
[Typed Array](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Typed_arrays).
## Usage
[](https://nodei.co/npm/is-typedarray/)
### isTypedArray(array)
Returns `true` when array is a Typed Array, and `false` when it is not.
## License
MIT. See [LICENSE.md](http://github.com/hughsk/is-typedarray/blob/master/LICENSE.md) for details.
# http-errors
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][node-url]
[![Node.js Version][node-image]][node-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Create HTTP errors for Express, Koa, Connect, etc. with ease.
## Install
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```bash
$ npm install http-errors
```
## Example
```js
var createError = require('http-errors')
var express = require('express')
var app = express()
app.use(function (req, res, next) {
if (!req.user) return next(createError(401, 'Please login to view this page.'))
next()
})
```
## API
This is the current API, currently extracted from Koa and subject to change.
### Error Properties
- `expose` - can be used to signal if `message` should be sent to the client,
defaulting to `false` when `status` >= 500
- `headers` - can be an object of header names to values to be sent to the
client, defaulting to `undefined`. When defined, the key names should all
be lower-cased
- `message` - the traditional error message, which should be kept short and all
single line
- `status` - the status code of the error, mirroring `statusCode` for general
compatibility
- `statusCode` - the status code of the error, defaulting to `500`
### createError([status], [message], [properties])
Create a new error object with the given message `msg`.
The error object inherits from `createError.HttpError`.
<!-- eslint-disable no-undef, no-unused-vars -->
```js
var err = createError(404, 'This video does not exist!')
```
- `status: 500` - the status code as a number
- `message` - the message of the error, defaulting to node's text for that status code.
- `properties` - custom properties to attach to the object
### createError([status], [error], [properties])
Extend the given `error` object with `createError.HttpError`
properties. This will not alter the inheritance of the given
`error` object, and the modified `error` object is the
return value.
<!-- eslint-disable no-redeclare, no-undef, no-unused-vars -->
```js
fs.readFile('foo.txt', function (err, buf) {
if (err) {
if (err.code === 'ENOENT') {
var httpError = createError(404, err, { expose: false })
} else {
var httpError = createError(500, err)
}
}
})
```
- `status` - the status code as a number
- `error` - the error object to extend
- `properties` - custom properties to attach to the object
### new createError\[code || name\](\[msg]\))
Create a new error object with the given message `msg`.
The error object inherits from `createError.HttpError`.
<!-- eslint-disable no-undef, no-unused-vars -->
```js
var err = new createError.NotFound()
```
- `code` - the status code as a number
- `name` - the name of the error as a "bumpy case", i.e. `NotFound` or `InternalServerError`.
#### List of all constructors
|Status Code|Constructor Name |
|-----------|-----------------------------|
|400 |BadRequest |
|401 |Unauthorized |
|402 |PaymentRequired |
|403 |Forbidden |
|404 |NotFound |
|405 |MethodNotAllowed |
|406 |NotAcceptable |
|407 |ProxyAuthenticationRequired |
|408 |RequestTimeout |
|409 |Conflict |
|410 |Gone |
|411 |LengthRequired |
|412 |PreconditionFailed |
|413 |PayloadTooLarge |
|414 |URITooLong |
|415 |UnsupportedMediaType |
|416 |RangeNotSatisfiable |
|417 |ExpectationFailed |
|418 |ImATeapot |
|421 |MisdirectedRequest |
|422 |UnprocessableEntity |
|423 |Locked |
|424 |FailedDependency |
|425 |UnorderedCollection |
|426 |UpgradeRequired |
|428 |PreconditionRequired |
|429 |TooManyRequests |
|431 |RequestHeaderFieldsTooLarge |
|451 |UnavailableForLegalReasons |
|500 |InternalServerError |
|501 |NotImplemented |
|502 |BadGateway |
|503 |ServiceUnavailable |
|504 |GatewayTimeout |
|505 |HTTPVersionNotSupported |
|506 |VariantAlsoNegotiates |
|507 |InsufficientStorage |
|508 |LoopDetected |
|509 |BandwidthLimitExceeded |
|510 |NotExtended |
|511 |NetworkAuthenticationRequired|
## License
[MIT](LICENSE)
[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/http-errors/master
[coveralls-url]: https://coveralls.io/r/jshttp/http-errors?branch=master
[node-image]: https://badgen.net/npm/node/http-errors
[node-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/http-errors
[npm-url]: https://npmjs.org/package/http-errors
[npm-version-image]: https://badgen.net/npm/v/http-errors
[travis-image]: https://badgen.net/travis/jshttp/http-errors/master
[travis-url]: https://travis-ci.org/jshttp/http-errors
# inflight
Add callbacks to requests in flight to avoid async duplication
## USAGE
```javascript
var inflight = require('inflight')
// some request that does some stuff
function req(key, callback) {
// key is any random string. like a url or filename or whatever.
//
// will return either a falsey value, indicating that the
// request for this key is already in flight, or a new callback
// which when called will call all callbacks passed to inflightk
// with the same key
callback = inflight(key, callback)
// If we got a falsey value back, then there's already a req going
if (!callback) return
// this is where you'd fetch the url or whatever
// callback is also once()-ified, so it can safely be assigned
// to multiple events etc. First call wins.
setTimeout(function() {
callback(null, key)
}, 100)
}
// only assigns a single setTimeout
// when it dings, all cbs get called
req('foo', cb1)
req('foo', cb2)
req('foo', cb3)
req('foo', cb4)
```
## Disclaimer
**This library isn't activelly maintained as I moved on to other things. If you'd like to maintain it, please let me know. For now, I think I can point to Erebos: https://erebos.js.org/**
## Swarm.js
This library allows you to interact with the Swarm network from JavaScript.
### Getting started
1. Install
```bash
npm install swarm-js
```
2. Import
```javascript
// Loads the Swarm API pointing to the official gateway
const swarm = require("swarm-js").at("http://swarm-gateways.net");
```
### Examples
#### Uploads
- With JSON:
- Raw data:
```javascript
const file = "test file"; // could also be an Uint8Array of binary data
swarm.upload(file).then(hash => {
console.log("Uploaded file. Address:", hash);
})
```
- Directory:
To upload a directory, just call `swarm.upload(directory)`, where directory is an object mapping paths to entries, those containing a mime-type and the data (Uint8Array or UTF-8 String).
```javascript
const dir = {
"/foo.txt": {type: "text/plain", data: "file 0"},
"/bar.txt": {type: "text/plain", data: "file 1"}
};
swarm.upload(dir).then(hash => {
console.log("Uploaded directory. Address:", hash);
});
```
- From disk:
- On Node.js:
```javascript
swarm.upload({
path: "/path/to/thing", // path to data / file / directory
kind: "directory", // could also be "file" or "data"
defaultFile: "/index.html"}) // optional, and only for kind === "directory"
.then(console.log)
.catch(console.log);
```
- On browsers:
```javascript
// only works inside an event
document.onClick = function() {
swarm.upload({pick: "file"}) // could also be "directory" or "data"
.then(alert);
};
```
#### Downloads
- With JSON:
- Raw data:
```javascript
const fileHash = "a5c10851ef054c268a2438f10a21f6efe3dc3dcdcc2ea0e6a1a7a38bf8c91e23";
swarm.download(fileHash).then(array => {
console.log("Downloaded file:", swarm.toString(array));
});
```
- Directory:
```javascript
const dirHash = "7e980476df218c05ecfcb0a2ca73597193a34c5a9d6da84d54e295ecd8e0c641";
swarm.download(dirHash).then(dir => {
console.log("Downloaded directory:");
for (let path in dir) {
console.log("-", path, ":", dir[path].data.toString());
}
});
```
- To disk:
- On Node.js:
```javascript
swarm.download("DAPP_HASH", "/target/dir")
.then(path => console.log(`Downloaded DApp to ${path}.`))
.catch(console.log);
```
- On browser:
(Just link the Swarm URL.)
#### SwarmHash
```javascript
console.log(swarm.hash("unicode string áéíóú λ"));
console.log(swarm.hash("0x41414141"));
console.log(swarm.hash([65, 65, 65, 65]));
console.log(swarm.hash(new Uint8Array([65, 65, 65, 65])));
```
### More
For more examples, check out [examples](/examples).

[](https://travis-ci.org/caolan/async)
[](https://www.npmjs.com/package/async)
[](https://coveralls.io/r/caolan/async?branch=master)
[](https://gitter.im/caolan/async?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
[](https://www.libhive.com/providers/npm/packages/async)
[](https://www.jsdelivr.com/package/npm/async)
Async is a utility module which provides straight-forward, powerful functions for working with [asynchronous JavaScript](http://caolan.github.io/async/global.html). Although originally designed for use with [Node.js](https://nodejs.org/) and installable via `npm install --save async`, it can also be used directly in the browser.
This version of the package is optimized for the Node.js environment. If you use Async with webpack, install [`async-es`](https://www.npmjs.com/package/async-es) instead.
For Documentation, visit <https://caolan.github.io/async/>
*For Async v1.5.x documentation, go [HERE](https://github.com/caolan/async/blob/v1.5.2/README.md)*
```javascript
// for use with Node-style callbacks...
var async = require("async");
var obj = {dev: "/dev.json", test: "/test.json", prod: "/prod.json"};
var configs = {};
async.forEachOf(obj, (value, key, callback) => {
fs.readFile(__dirname + value, "utf8", (err, data) => {
if (err) return callback(err);
try {
configs[key] = JSON.parse(data);
} catch (e) {
return callback(e);
}
callback();
});
}, err => {
if (err) console.error(err.message);
// configs is now a map of JSON data
doSomethingWith(configs);
});
```
```javascript
var async = require("async");
// ...or ES2017 async functions
async.mapLimit(urls, 5, async function(url) {
const response = await fetch(url)
return response.body
}, (err, results) => {
if (err) throw err
// results is now an array of the response bodies
console.log(results)
})
```
# Pend
Dead-simple optimistic async helper.
## Usage
```js
var Pend = require('pend');
var pend = new Pend();
pend.max = 10; // defaults to Infinity
setTimeout(pend.hold(), 1000); // pend.wait will have to wait for this hold to finish
pend.go(function(cb) {
console.log("this function is immediately executed");
setTimeout(function() {
console.log("calling cb 1");
cb();
}, 500);
});
pend.go(function(cb) {
console.log("this function is also immediately executed");
setTimeout(function() {
console.log("calling cb 2");
cb();
}, 1000);
});
pend.wait(function(err) {
console.log("this is excuted when the first 2 have returned.");
console.log("err is a possible error in the standard callback style.");
});
```
Output:
```
this function is immediately executed
this function is also immediately executed
calling cb 1
calling cb 2
this is excuted when the first 2 have returned.
err is a possible error in the standard callback style.
```
# is-glob [](http://badge.fury.io/js/is-glob) [](https://travis-ci.org/jonschlinkert/is-glob)
> Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a better user experience.
Also take a look at [is-valid-glob](https://github.com/jonschlinkert/is-valid-glob) and [has-glob](https://github.com/jonschlinkert/has-glob).
## Install
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i is-glob --save
```
## Usage
```js
var isGlob = require('is-glob');
```
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js');
isGlob('*.js');
isGlob('**/abc.js');
isGlob('abc/*.js');
isGlob('abc/(aaa|bbb).js');
isGlob('abc/[a-z].js');
isGlob('abc/{a,b}.js');
isGlob('abc/?.js');
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js');
isGlob('abc/!(a).js');
isGlob('abc/+(a).js');
isGlob('abc/*(a).js');
isGlob('abc/?(a).js');
//=> true
```
**False**
Patterns that do not have glob patterns return `false`:
```js
isGlob('abc.js');
isGlob('abc/def/ghi.js');
isGlob('foo.js');
isGlob('abc/@.js');
isGlob('abc/+.js');
isGlob();
isGlob(null);
//=> false
```
Arrays are also `false` (If you want to check if an array has a glob pattern, use [has-glob](https://github.com/jonschlinkert/has-glob)):
```js
isGlob(['**/*.js']);
isGlob(['foo.js']);
//=> false
```
## Related
* [has-glob](https://www.npmjs.com/package/has-glob): Returns `true` if an array has a glob pattern. | [homepage](https://github.com/jonschlinkert/has-glob)
* [is-extglob](https://www.npmjs.com/package/is-extglob): Returns true if a string has an extglob. | [homepage](https://github.com/jonschlinkert/is-extglob)
* [is-posix-bracket](https://www.npmjs.com/package/is-posix-bracket): Returns true if the given string is a POSIX bracket expression (POSIX character class). | [homepage](https://github.com/jonschlinkert/is-posix-bracket)
* [is-valid-glob](https://www.npmjs.com/package/is-valid-glob): Return true if a value is a valid glob pattern or patterns. | [homepage](https://github.com/jonschlinkert/is-valid-glob)
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. Just… [more](https://www.npmjs.com/package/micromatch) | [homepage](https://github.com/jonschlinkert/micromatch)
## Run tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-glob/issues/new).
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2015 Jon Schlinkert
Released under the MIT license.
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on October 02, 2015._
**string_decoder.js** (`require('string_decoder')`) from Node.js core
Copyright Joyent, Inc. and other Node contributors. See LICENCE file for details.
Version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10. **Prefer the stable version over the unstable.**
The *build/* directory contains a build script that will scrape the source from the [joyent/node](https://github.com/joyent/node) repo given a specific Node version.
# on-finished
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Execute a callback when a HTTP request closes, finishes, or errors.
## Install
```sh
$ npm install on-finished
```
## API
```js
var onFinished = require('on-finished')
```
### onFinished(res, listener)
Attach a listener to listen for the response to finish. The listener will
be invoked only once when the response finished. If the response finished
to an error, the first argument will contain the error. If the response
has already finished, the listener will be invoked.
Listening to the end of a response would be used to close things associated
with the response, like open files.
Listener is invoked as `listener(err, res)`.
```js
onFinished(res, function (err, res) {
// clean up open fds, etc.
// err contains the error is request error'd
})
```
### onFinished(req, listener)
Attach a listener to listen for the request to finish. The listener will
be invoked only once when the request finished. If the request finished
to an error, the first argument will contain the error. If the request
has already finished, the listener will be invoked.
Listening to the end of a request would be used to know when to continue
after reading the data.
Listener is invoked as `listener(err, req)`.
```js
var data = ''
req.setEncoding('utf8')
res.on('data', function (str) {
data += str
})
onFinished(req, function (err, req) {
// data is read unless there is err
})
```
### onFinished.isFinished(res)
Determine if `res` is already finished. This would be useful to check and
not even start certain operations if the response has already finished.
### onFinished.isFinished(req)
Determine if `req` is already finished. This would be useful to check and
not even start certain operations if the request has already finished.
## Special Node.js requests
### HTTP CONNECT method
The meaning of the `CONNECT` method from RFC 7231, section 4.3.6:
> The CONNECT method requests that the recipient establish a tunnel to
> the destination origin server identified by the request-target and,
> if successful, thereafter restrict its behavior to blind forwarding
> of packets, in both directions, until the tunnel is closed. Tunnels
> are commonly used to create an end-to-end virtual connection, through
> one or more proxies, which can then be secured using TLS (Transport
> Layer Security, [RFC5246]).
In Node.js, these request objects come from the `'connect'` event on
the HTTP server.
When this module is used on a HTTP `CONNECT` request, the request is
considered "finished" immediately, **due to limitations in the Node.js
interface**. This means if the `CONNECT` request contains a request entity,
the request will be considered "finished" even before it has been read.
There is no such thing as a response object to a `CONNECT` request in
Node.js, so there is no support for for one.
### HTTP Upgrade request
The meaning of the `Upgrade` header from RFC 7230, section 6.1:
> The "Upgrade" header field is intended to provide a simple mechanism
> for transitioning from HTTP/1.1 to some other protocol on the same
> connection.
In Node.js, these request objects come from the `'upgrade'` event on
the HTTP server.
When this module is used on a HTTP request with an `Upgrade` header, the
request is considered "finished" immediately, **due to limitations in the
Node.js interface**. This means if the `Upgrade` request contains a request
entity, the request will be considered "finished" even before it has been
read.
There is no such thing as a response object to a `Upgrade` request in
Node.js, so there is no support for for one.
## Example
The following code ensures that file descriptors are always closed
once the response finishes.
```js
var destroy = require('destroy')
var http = require('http')
var onFinished = require('on-finished')
http.createServer(function onRequest(req, res) {
var stream = fs.createReadStream('package.json')
stream.pipe(res)
onFinished(res, function (err) {
destroy(stream)
})
})
```
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/on-finished.svg
[npm-url]: https://npmjs.org/package/on-finished
[node-version-image]: https://img.shields.io/node/v/on-finished.svg
[node-version-url]: http://nodejs.org/download/
[travis-image]: https://img.shields.io/travis/jshttp/on-finished/master.svg
[travis-url]: https://travis-ci.org/jshttp/on-finished
[coveralls-image]: https://img.shields.io/coveralls/jshttp/on-finished/master.svg
[coveralls-url]: https://coveralls.io/r/jshttp/on-finished?branch=master
[downloads-image]: https://img.shields.io/npm/dm/on-finished.svg
[downloads-url]: https://npmjs.org/package/on-finished
randomfill
===
[](https://www.npmjs.org/package/randomfill)
randomfill from node that works in the browser. In node you just get crypto.randomBytes, but in the browser it uses .crypto/msCrypto.getRandomValues
```js
var randomFill = require('randomfill');
var buf
randomFill.randomFillSync(16);//get 16 random bytes
randomFill.randomFill(16, function (err, resp) {
// resp is 16 random bytes
});
```
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
`disable()`
Will disable all namespaces. The functions returns the namespaces currently
enabled (and skipped). This can be useful if you want to disable debugging
temporarily without knowing what was enabled to begin with.
For example:
```js
let debug = require('debug');
debug.enable('foo:*,-foo:bar');
let namespaces = debug.disable();
debug.enable(namespaces);
```
Note: There is no guarantee that the string will be identical to the initial
enable string, but semantically they will be identical.
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# Punycode.js [](https://travis-ci.org/bestiejs/punycode.js) [](https://codecov.io/gh/bestiejs/punycode.js) [](https://gemnasium.com/bestiejs/punycode.js)
Punycode.js is a robust Punycode converter that fully complies to [RFC 3492](https://tools.ietf.org/html/rfc3492) and [RFC 5891](https://tools.ietf.org/html/rfc5891).
This JavaScript library is the result of comparing, optimizing and documenting different open-source implementations of the Punycode algorithm:
* [The C example code from RFC 3492](https://tools.ietf.org/html/rfc3492#appendix-C)
* [`punycode.c` by _Markus W. Scherer_ (IBM)](http://opensource.apple.com/source/ICU/ICU-400.42/icuSources/common/punycode.c)
* [`punycode.c` by _Ben Noordhuis_](https://github.com/bnoordhuis/punycode/blob/master/punycode.c)
* [JavaScript implementation by _some_](http://stackoverflow.com/questions/183485/can-anyone-recommend-a-good-free-javascript-for-punycode-to-unicode-conversion/301287#301287)
* [`punycode.js` by _Ben Noordhuis_](https://github.com/joyent/node/blob/426298c8c1c0d5b5224ac3658c41e7c2a3fe9377/lib/punycode.js) (note: [not fully compliant](https://github.com/joyent/node/issues/2072))
This project was [bundled](https://github.com/joyent/node/blob/master/lib/punycode.js) with Node.js from [v0.6.2+](https://github.com/joyent/node/compare/975f1930b1...61e796decc) until [v7](https://github.com/nodejs/node/pull/7941) (soft-deprecated).
The current version supports recent versions of Node.js only. It provides a CommonJS module and an ES6 module. For the old version that offers the same functionality with broader support, including Rhino, Ringo, Narwhal, and web browsers, see [v1.4.1](https://github.com/bestiejs/punycode.js/releases/tag/v1.4.1).
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install punycode --save
```
In [Node.js](https://nodejs.org/):
```js
const punycode = require('punycode');
```
## API
### `punycode.decode(string)`
Converts a Punycode string of ASCII symbols to a string of Unicode symbols.
```js
// decode domain name parts
punycode.decode('maana-pta'); // 'mañana'
punycode.decode('--dqo34k'); // '☃-⌘'
```
### `punycode.encode(string)`
Converts a string of Unicode symbols to a Punycode string of ASCII symbols.
```js
// encode domain name parts
punycode.encode('mañana'); // 'maana-pta'
punycode.encode('☃-⌘'); // '--dqo34k'
```
### `punycode.toUnicode(input)`
Converts a Punycode string representing a domain name or an email address to Unicode. Only the Punycoded parts of the input will be converted, i.e. it doesn’t matter if you call it on a string that has already been converted to Unicode.
```js
// decode domain names
punycode.toUnicode('xn--maana-pta.com');
// → 'mañana.com'
punycode.toUnicode('xn----dqo34k.com');
// → '☃-⌘.com'
// decode email addresses
punycode.toUnicode('джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq');
// → 'джумла@джpумлатест.bрфa'
```
### `punycode.toASCII(input)`
Converts a lowercased Unicode string representing a domain name or an email address to Punycode. Only the non-ASCII parts of the input will be converted, i.e. it doesn’t matter if you call it with a domain that’s already in ASCII.
```js
// encode domain names
punycode.toASCII('mañana.com');
// → 'xn--maana-pta.com'
punycode.toASCII('☃-⌘.com');
// → 'xn----dqo34k.com'
// encode email addresses
punycode.toASCII('джумла@джpумлатест.bрфa');
// → 'джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq'
```
### `punycode.ucs2`
#### `punycode.ucs2.decode(string)`
Creates an array containing the numeric code point values of each Unicode symbol in the string. While [JavaScript uses UCS-2 internally](https://mathiasbynens.be/notes/javascript-encoding), this function will convert a pair of surrogate halves (each of which UCS-2 exposes as separate characters) into a single code point, matching UTF-16.
```js
punycode.ucs2.decode('abc');
// → [0x61, 0x62, 0x63]
// surrogate pair for U+1D306 TETRAGRAM FOR CENTRE:
punycode.ucs2.decode('\uD834\uDF06');
// → [0x1D306]
```
#### `punycode.ucs2.encode(codePoints)`
Creates a string based on an array of numeric code point values.
```js
punycode.ucs2.encode([0x61, 0x62, 0x63]);
// → 'abc'
punycode.ucs2.encode([0x1D306]);
// → '\uD834\uDF06'
```
### `punycode.version`
A string representing the current Punycode.js version number.
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
Punycode.js is available under the [MIT](https://mths.be/mit) license.
# near-api-js
[](https://travis-ci.com/near/near-api-js)
[](https://gitpod.io/#https://github.com/near/near-api-js)
A JavaScript/TypeScript library for development of DApps on the NEAR platform
# Contribute to this library
1. Install dependencies
yarn
2. Run continuous build with:
yarn build -- -w
# Publish
Prepare `dist` version by running:
yarn dist
When publishing to npm use [np](https://github.com/sindresorhus/np).
# Integration Test
Start the node by following instructions from [nearcore](https://github.com/nearprotocol/nearcore), then
yarn test
Tests use sample contract from `near-hello` npm package, see https://github.com/nearprotocol/near-hello
# Update error messages
Follow next steps:
1. [Change hash for the commit with errors in the nearcore](https://github.com/near/near-api-js/blob/master/gen_error_types.js#L7-L9)
2. Generate new types for errors: `node gen_error_types.js`
3. `yarn fix` fix any issues with linter.
4. `yarn build` to update `lib/**.js` files
# License
This repository is distributed under the terms of both the MIT license and the Apache License (Version 2.0).
See [LICENSE](LICENSE) and [LICENSE-APACHE](LICENSE-APACHE) for details.
# body-parser
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Node.js body parsing middleware.
Parse incoming request bodies in a middleware before your handlers, available
under the `req.body` property.
**Note** As `req.body`'s shape is based on user-controlled input, all
properties and values in this object are untrusted and should be validated
before trusting. For example, `req.body.foo.toString()` may fail in multiple
ways, for example the `foo` property may not be there or may not be a string,
and `toString` may not be a function and instead a string or other user input.
[Learn about the anatomy of an HTTP transaction in Node.js](https://nodejs.org/en/docs/guides/anatomy-of-an-http-transaction/).
_This does not handle multipart bodies_, due to their complex and typically
large nature. For multipart bodies, you may be interested in the following
modules:
* [busboy](https://www.npmjs.org/package/busboy#readme) and
[connect-busboy](https://www.npmjs.org/package/connect-busboy#readme)
* [multiparty](https://www.npmjs.org/package/multiparty#readme) and
[connect-multiparty](https://www.npmjs.org/package/connect-multiparty#readme)
* [formidable](https://www.npmjs.org/package/formidable#readme)
* [multer](https://www.npmjs.org/package/multer#readme)
This module provides the following parsers:
* [JSON body parser](#bodyparserjsonoptions)
* [Raw body parser](#bodyparserrawoptions)
* [Text body parser](#bodyparsertextoptions)
* [URL-encoded form body parser](#bodyparserurlencodedoptions)
Other body parsers you might be interested in:
- [body](https://www.npmjs.org/package/body#readme)
- [co-body](https://www.npmjs.org/package/co-body#readme)
## Installation
```sh
$ npm install body-parser
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var bodyParser = require('body-parser')
```
The `bodyParser` object exposes various factories to create middlewares. All
middlewares will populate the `req.body` property with the parsed body when
the `Content-Type` request header matches the `type` option, or an empty
object (`{}`) if there was no body to parse, the `Content-Type` was not matched,
or an error occurred.
The various errors returned by this module are described in the
[errors section](#errors).
### bodyParser.json([options])
Returns middleware that only parses `json` and only looks at requests where
the `Content-Type` header matches the `type` option. This parser accepts any
Unicode encoding of the body and supports automatic inflation of `gzip` and
`deflate` encodings.
A new `body` object containing the parsed data is populated on the `request`
object after the middleware (i.e. `req.body`).
#### Options
The `json` function takes an optional `options` object that may contain any of
the following keys:
##### inflate
When set to `true`, then deflated (compressed) bodies will be inflated; when
`false`, deflated bodies are rejected. Defaults to `true`.
##### limit
Controls the maximum request body size. If this is a number, then the value
specifies the number of bytes; if it is a string, the value is passed to the
[bytes](https://www.npmjs.com/package/bytes) library for parsing. Defaults
to `'100kb'`.
##### reviver
The `reviver` option is passed directly to `JSON.parse` as the second
argument. You can find more information on this argument
[in the MDN documentation about JSON.parse](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse#Example.3A_Using_the_reviver_parameter).
##### strict
When set to `true`, will only accept arrays and objects; when `false` will
accept anything `JSON.parse` accepts. Defaults to `true`.
##### type
The `type` option is used to determine what media type the middleware will
parse. This option can be a string, array of strings, or a function. If not a
function, `type` option is passed directly to the
[type-is](https://www.npmjs.org/package/type-is#readme) library and this can
be an extension name (like `json`), a mime type (like `application/json`), or
a mime type with a wildcard (like `*/*` or `*/json`). If a function, the `type`
option is called as `fn(req)` and the request is parsed if it returns a truthy
value. Defaults to `application/json`.
##### verify
The `verify` option, if supplied, is called as `verify(req, res, buf, encoding)`,
where `buf` is a `Buffer` of the raw request body and `encoding` is the
encoding of the request. The parsing can be aborted by throwing an error.
### bodyParser.raw([options])
Returns middleware that parses all bodies as a `Buffer` and only looks at
requests where the `Content-Type` header matches the `type` option. This
parser supports automatic inflation of `gzip` and `deflate` encodings.
A new `body` object containing the parsed data is populated on the `request`
object after the middleware (i.e. `req.body`). This will be a `Buffer` object
of the body.
#### Options
The `raw` function takes an optional `options` object that may contain any of
the following keys:
##### inflate
When set to `true`, then deflated (compressed) bodies will be inflated; when
`false`, deflated bodies are rejected. Defaults to `true`.
##### limit
Controls the maximum request body size. If this is a number, then the value
specifies the number of bytes; if it is a string, the value is passed to the
[bytes](https://www.npmjs.com/package/bytes) library for parsing. Defaults
to `'100kb'`.
##### type
The `type` option is used to determine what media type the middleware will
parse. This option can be a string, array of strings, or a function.
If not a function, `type` option is passed directly to the
[type-is](https://www.npmjs.org/package/type-is#readme) library and this
can be an extension name (like `bin`), a mime type (like
`application/octet-stream`), or a mime type with a wildcard (like `*/*` or
`application/*`). If a function, the `type` option is called as `fn(req)`
and the request is parsed if it returns a truthy value. Defaults to
`application/octet-stream`.
##### verify
The `verify` option, if supplied, is called as `verify(req, res, buf, encoding)`,
where `buf` is a `Buffer` of the raw request body and `encoding` is the
encoding of the request. The parsing can be aborted by throwing an error.
### bodyParser.text([options])
Returns middleware that parses all bodies as a string and only looks at
requests where the `Content-Type` header matches the `type` option. This
parser supports automatic inflation of `gzip` and `deflate` encodings.
A new `body` string containing the parsed data is populated on the `request`
object after the middleware (i.e. `req.body`). This will be a string of the
body.
#### Options
The `text` function takes an optional `options` object that may contain any of
the following keys:
##### defaultCharset
Specify the default character set for the text content if the charset is not
specified in the `Content-Type` header of the request. Defaults to `utf-8`.
##### inflate
When set to `true`, then deflated (compressed) bodies will be inflated; when
`false`, deflated bodies are rejected. Defaults to `true`.
##### limit
Controls the maximum request body size. If this is a number, then the value
specifies the number of bytes; if it is a string, the value is passed to the
[bytes](https://www.npmjs.com/package/bytes) library for parsing. Defaults
to `'100kb'`.
##### type
The `type` option is used to determine what media type the middleware will
parse. This option can be a string, array of strings, or a function. If not
a function, `type` option is passed directly to the
[type-is](https://www.npmjs.org/package/type-is#readme) library and this can
be an extension name (like `txt`), a mime type (like `text/plain`), or a mime
type with a wildcard (like `*/*` or `text/*`). If a function, the `type`
option is called as `fn(req)` and the request is parsed if it returns a
truthy value. Defaults to `text/plain`.
##### verify
The `verify` option, if supplied, is called as `verify(req, res, buf, encoding)`,
where `buf` is a `Buffer` of the raw request body and `encoding` is the
encoding of the request. The parsing can be aborted by throwing an error.
### bodyParser.urlencoded([options])
Returns middleware that only parses `urlencoded` bodies and only looks at
requests where the `Content-Type` header matches the `type` option. This
parser accepts only UTF-8 encoding of the body and supports automatic
inflation of `gzip` and `deflate` encodings.
A new `body` object containing the parsed data is populated on the `request`
object after the middleware (i.e. `req.body`). This object will contain
key-value pairs, where the value can be a string or array (when `extended` is
`false`), or any type (when `extended` is `true`).
#### Options
The `urlencoded` function takes an optional `options` object that may contain
any of the following keys:
##### extended
The `extended` option allows to choose between parsing the URL-encoded data
with the `querystring` library (when `false`) or the `qs` library (when
`true`). The "extended" syntax allows for rich objects and arrays to be
encoded into the URL-encoded format, allowing for a JSON-like experience
with URL-encoded. For more information, please
[see the qs library](https://www.npmjs.org/package/qs#readme).
Defaults to `true`, but using the default has been deprecated. Please
research into the difference between `qs` and `querystring` and choose the
appropriate setting.
##### inflate
When set to `true`, then deflated (compressed) bodies will be inflated; when
`false`, deflated bodies are rejected. Defaults to `true`.
##### limit
Controls the maximum request body size. If this is a number, then the value
specifies the number of bytes; if it is a string, the value is passed to the
[bytes](https://www.npmjs.com/package/bytes) library for parsing. Defaults
to `'100kb'`.
##### parameterLimit
The `parameterLimit` option controls the maximum number of parameters that
are allowed in the URL-encoded data. If a request contains more parameters
than this value, a 413 will be returned to the client. Defaults to `1000`.
##### type
The `type` option is used to determine what media type the middleware will
parse. This option can be a string, array of strings, or a function. If not
a function, `type` option is passed directly to the
[type-is](https://www.npmjs.org/package/type-is#readme) library and this can
be an extension name (like `urlencoded`), a mime type (like
`application/x-www-form-urlencoded`), or a mime type with a wildcard (like
`*/x-www-form-urlencoded`). If a function, the `type` option is called as
`fn(req)` and the request is parsed if it returns a truthy value. Defaults
to `application/x-www-form-urlencoded`.
##### verify
The `verify` option, if supplied, is called as `verify(req, res, buf, encoding)`,
where `buf` is a `Buffer` of the raw request body and `encoding` is the
encoding of the request. The parsing can be aborted by throwing an error.
## Errors
The middlewares provided by this module create errors depending on the error
condition during parsing. The errors will typically have a `status`/`statusCode`
property that contains the suggested HTTP response code, an `expose` property
to determine if the `message` property should be displayed to the client, a
`type` property to determine the type of error without matching against the
`message`, and a `body` property containing the read body, if available.
The following are the common errors emitted, though any error can come through
for various reasons.
### content encoding unsupported
This error will occur when the request had a `Content-Encoding` header that
contained an encoding but the "inflation" option was set to `false`. The
`status` property is set to `415`, the `type` property is set to
`'encoding.unsupported'`, and the `charset` property will be set to the
encoding that is unsupported.
### request aborted
This error will occur when the request is aborted by the client before reading
the body has finished. The `received` property will be set to the number of
bytes received before the request was aborted and the `expected` property is
set to the number of expected bytes. The `status` property is set to `400`
and `type` property is set to `'request.aborted'`.
### request entity too large
This error will occur when the request body's size is larger than the "limit"
option. The `limit` property will be set to the byte limit and the `length`
property will be set to the request body's length. The `status` property is
set to `413` and the `type` property is set to `'entity.too.large'`.
### request size did not match content length
This error will occur when the request's length did not match the length from
the `Content-Length` header. This typically occurs when the request is malformed,
typically when the `Content-Length` header was calculated based on characters
instead of bytes. The `status` property is set to `400` and the `type` property
is set to `'request.size.invalid'`.
### stream encoding should not be set
This error will occur when something called the `req.setEncoding` method prior
to this middleware. This module operates directly on bytes only and you cannot
call `req.setEncoding` when using this module. The `status` property is set to
`500` and the `type` property is set to `'stream.encoding.set'`.
### too many parameters
This error will occur when the content of the request exceeds the configured
`parameterLimit` for the `urlencoded` parser. The `status` property is set to
`413` and the `type` property is set to `'parameters.too.many'`.
### unsupported charset "BOGUS"
This error will occur when the request had a charset parameter in the
`Content-Type` header, but the `iconv-lite` module does not support it OR the
parser does not support it. The charset is contained in the message as well
as in the `charset` property. The `status` property is set to `415`, the
`type` property is set to `'charset.unsupported'`, and the `charset` property
is set to the charset that is unsupported.
### unsupported content encoding "bogus"
This error will occur when the request had a `Content-Encoding` header that
contained an unsupported encoding. The encoding is contained in the message
as well as in the `encoding` property. The `status` property is set to `415`,
the `type` property is set to `'encoding.unsupported'`, and the `encoding`
property is set to the encoding that is unsupported.
## Examples
### Express/Connect top-level generic
This example demonstrates adding a generic JSON and URL-encoded parser as a
top-level middleware, which will parse the bodies of all incoming requests.
This is the simplest setup.
```js
var express = require('express')
var bodyParser = require('body-parser')
var app = express()
// parse application/x-www-form-urlencoded
app.use(bodyParser.urlencoded({ extended: false }))
// parse application/json
app.use(bodyParser.json())
app.use(function (req, res) {
res.setHeader('Content-Type', 'text/plain')
res.write('you posted:\n')
res.end(JSON.stringify(req.body, null, 2))
})
```
### Express route-specific
This example demonstrates adding body parsers specifically to the routes that
need them. In general, this is the most recommended way to use body-parser with
Express.
```js
var express = require('express')
var bodyParser = require('body-parser')
var app = express()
// create application/json parser
var jsonParser = bodyParser.json()
// create application/x-www-form-urlencoded parser
var urlencodedParser = bodyParser.urlencoded({ extended: false })
// POST /login gets urlencoded bodies
app.post('/login', urlencodedParser, function (req, res) {
res.send('welcome, ' + req.body.username)
})
// POST /api/users gets JSON bodies
app.post('/api/users', jsonParser, function (req, res) {
// create user in req.body
})
```
### Change accepted type for parsers
All the parsers accept a `type` option which allows you to change the
`Content-Type` that the middleware will parse.
```js
var express = require('express')
var bodyParser = require('body-parser')
var app = express()
// parse various different custom JSON types as JSON
app.use(bodyParser.json({ type: 'application/*+json' }))
// parse some custom thing into a Buffer
app.use(bodyParser.raw({ type: 'application/vnd.custom-type' }))
// parse an HTML body into a string
app.use(bodyParser.text({ type: 'text/html' }))
```
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/body-parser.svg
[npm-url]: https://npmjs.org/package/body-parser
[travis-image]: https://img.shields.io/travis/expressjs/body-parser/master.svg
[travis-url]: https://travis-ci.org/expressjs/body-parser
[coveralls-image]: https://img.shields.io/coveralls/expressjs/body-parser/master.svg
[coveralls-url]: https://coveralls.io/r/expressjs/body-parser?branch=master
[downloads-image]: https://img.shields.io/npm/dm/body-parser.svg
[downloads-url]: https://npmjs.org/package/body-parser
# is-natural-number.js
[](https://www.npmjs.com/package/is-natural-number)
[](https://github.com/shinnn/is-natural-number.js/releases)
[](https://travis-ci.org/shinnn/is-natural-number.js)
[](https://coveralls.io/r/shinnn/is-natural-number.js?branch=master)
[](https://david-dm.org/shinnn/is-natural-number.js#info=devDependencies)
Check if a value is a [natural number](https://wikipedia.org/wiki/Natural_number)
## Installation
### Package managers
#### [npm](https://www.npmjs.com/)
```
npm install is-natural-number
```
#### [Bower](http://bower.io/)
```
bower install is-natural-number
```
#### [Duo](http://duojs.org/)
```javascript
var isNaturalNumber = require('shinnn/is-natural-number.js');
```
### Standalone
[Download the script file directly.](https://raw.githubusercontent.com/shinnn/is-natural-number.js/master/is-natural-number.js)
## API
### isNaturalNumber(*number*, *option*)
*number*: `Number`
*option*: `Object`
Return: `Boolean`
It returns `true` if the first argument is one of the natural numbers. If not, or the argument is not a number, it returns `false`.
```javascript
isNaturalNumber(10); //=> true
isNaturalNumber(-10); //=> false
isNaturalNumber(10.5); //=> false
isNaturalNumber(Infinity); //=> false
isNaturalNumber('10'); //=> false
```
*Check [the test](./test.js) for more detailed specifications.*
#### option.includeZero
Type: `Boolean`
Default: `false`
By default the number `0` is not regarded as a natural number.
Setting this option `true` makes `0` regarded as a natural number.
```javascript
isNaturalNumber(0); //=> false
isNaturalNumber(0, {includeZero: true}); //=> true
```
## License
Copyright (c) 2014 - 2016 [Shinnosuke Watanabe](https://github.com/shinnn)
Licensed under [the MIT License](./LICENSE).
# fill-range [](https://www.npmjs.com/package/fill-range) [](https://npmjs.org/package/fill-range) [](https://npmjs.org/package/fill-range) [](https://travis-ci.org/jonschlinkert/fill-range)
> Fill in a range of numbers or letters, optionally passing an increment or multiplier to use.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
- [Install](#install)
- [Usage](#usage)
* [Invalid ranges](#invalid-ranges)
* [Custom function](#custom-function)
* [Special characters](#special-characters)
+ [plus](#plus)
+ [pipe and tilde](#pipe-and-tilde)
+ [angle bracket](#angle-bracket)
+ [question mark](#question-mark)
- [About](#about)
_(TOC generated by [verb](https://github.com/verbose/verb) using [markdown-toc](https://github.com/jonschlinkert/markdown-toc))_
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save fill-range
```
## Usage
```js
var range = require('fill-range');
range('a', 'e');
//=> ['a', 'b', 'c', 'd', 'e']
```
**Params**
```js
range(start, stop, step, options, fn);
```
* `start`: **{String|Number}** the number or letter to start with
* `end`: **{String|Number}** the number or letter to end with
* `step`: **{String|Number}** optionally pass the step to use. works for letters or numbers.
* `options`: **{Object}**:
- `makeRe`: return a regex-compatible string (still returned as an array for consistency)
- `step`: pass the step on the options as an alternative to passing it as an argument
- `silent`: `true` by default, set to false to throw errors for invalid ranges.
* `fn`: **{Function}** optionally [pass a function](#custom-function) to modify each character
**Examples**
```js
range(1, 3)
//=> ['1', '2', '3']
range('1', '3')
//=> ['1', '2', '3']
range('0', '-5')
//=> [ '0', '-1', '-2', '-3', '-4', '-5' ]
range(-9, 9, 3)
//=> [ '-9', '-6', '-3', '0', '3', '6', '9' ])
range('-1', '-10', '-2')
//=> [ '-1', '-3', '-5', '-7', '-9' ]
range('1', '10', '2')
//=> [ '1', '3', '5', '7', '9' ]
range('a', 'e')
//=> ['a', 'b', 'c', 'd', 'e']
range('a', 'e', 2)
//=> ['a', 'c', 'e']
range('A', 'E', 2)
//=> ['A', 'C', 'E']
```
### Invalid ranges
When an invalid range is passed, `null` is returned.
```js
range('1.1', '2');
//=> null
range('a', '2');
//=> null
range(1, 10, 'foo');
//=> null
```
If you want errors to be throw, pass `silent: false` on the options:
### Custom function
Optionally pass a custom function as the third or fourth argument:
```js
range('a', 'e', function (val, isNumber, pad, i) {
if (!isNumber) {
return String.fromCharCode(val) + i;
}
return val;
});
//=> ['a0', 'b1', 'c2', 'd3', 'e4']
```
### Special characters
A special character may be passed as the third arg instead of a step increment. These characters can be pretty useful for brace expansion, creating file paths, test fixtures and similar use case.
```js
range('a', 'z', SPECIAL_CHARACTER_HERE);
```
**Supported characters**
* `+`: repeat the given string `n` times
* `|`: create a regex-ready string, instead of an array
* `>`: join values to single array element
* `?`: randomize the given pattern using [randomatic]
#### plus
Character: _(`+`)_
Repeat the first argument the number of times passed on the second argument.
**Examples:**
```js
range('a', 3, '+');
//=> ['a', 'a', 'a']
range('abc', 2, '+');
//=> ['abc', 'abc']
```
#### pipe and tilde
Characters: _(`|` and `~`)_
Creates a regex-capable string (either a logical `or` or a character class) from the expanded arguments.
**Examples:**
```js
range('a', 'c', '|');
//=> ['(a|b|c)'
range('a', 'c', '~');
//=> ['[a-c]'
range('a', 'z', '|5');
//=> ['(a|f|k|p|u|z)'
```
**Automatic separator correction**
To avoid this error:
> `Range out of order in character class`
Fill-range detects invalid sequences and uses the correct syntax. For example:
**invalid** (regex)
If you pass these:
```js
range('a', 'z', '~5');
// which would result in this
//=> ['[a-f-k-p-u-z]']
range('10', '20', '~');
// which would result in this
//=> ['[10-20]']
```
**valid** (regex)
fill-range corrects them to this:
```js
range('a', 'z', '~5');
//=> ['(a|f|k|p|u|z)'
range('10', '20', '~');
//=> ['(10-20)'
```
#### angle bracket
Character: _(`>`)_
Joins all values in the returned array to a single value.
**Examples:**
```js
range('a', 'e', '>');
//=> ['abcde']
range('5', '8', '>');
//=> ['5678']
range('2', '20', '2>');
//=> ['2468101214161820']
```
#### question mark
Character: _(`?`)_
Uses [randomatic] to generate randomized alpha, numeric, or alpha-numeric patterns based on the provided arguments.
**Examples:**
_(actual results would obviously be randomized)_
Generate a 5-character, uppercase, alphabetical string:
```js
range('A', 5, '?');
//=> ['NSHAK']
```
Generate a 5-digit random number:
```js
range('0', 5, '?');
//=> ['36583']
```
Generate a 10-character alpha-numeric string:
```js
range('A0', 10, '?');
//=> ['5YJD60VQNN']
```
See the [randomatic] repo for all available options and or to create issues or feature requests related to randomization.
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [braces](https://www.npmjs.com/package/braces): Bash-like brace expansion, implemented in JavaScript. Safer than other brace expansion libs, with complete support… [more](https://github.com/micromatch/braces) | [homepage](https://github.com/micromatch/braces "Bash-like brace expansion, implemented in JavaScript. Safer than other brace expansion libs, with complete support for the Bash 4.3 braces specification, without sacrificing speed.")
* [expand-range](https://www.npmjs.com/package/expand-range): Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. Used… [more](https://github.com/jonschlinkert/expand-range) | [homepage](https://github.com/jonschlinkert/expand-range "Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. Used by [micromatch].")
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/jonschlinkert/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. | [homepage](https://github.com/micromatch/micromatch "Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 111 | [jonschlinkert](https://github.com/jonschlinkert) |
| 2 | [paulmillr](https://github.com/paulmillr) |
| 1 | [edorivai](https://github.com/edorivai) |
| 1 | [realityking](https://github.com/realityking) |
| 1 | [wtgtybhertgeghgtwtg](https://github.com/wtgtybhertgeghgtwtg) |
### Author
**Jon Schlinkert**
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
### License
Copyright © 2018, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on May 08, 2018._
# strip-dirs
[](https://www.npmjs.com/package/strip-dirs)
[](https://travis-ci.org/shinnn/node-strip-dirs)
[](https://ci.appveyor.com/project/ShinnosukeWatanabe/node-strip-dirs)
[](https://coveralls.io/r/shinnn/node-strip-dirs)
[](https://david-dm.org/shinnn/node-strip-dirs)
[](https://david-dm.org/shinnn/node-strip-dirs#info=devDependencies)
Remove leading directory components from a path, like [tar(1)](http://linuxcommand.org/man_pages/tar1.html)'s `--strip-components` option
```javascript
const stripDirs = require('strip-dirs');
stripDirs('foo/bar/baz', 1); //=> 'bar/baz'
stripDirs('foo/bar/baz', 2); //=> 'baz'
stripDirs('foo/bar/baz', 999); //=> 'baz'
```
## Installation
[Use npm](https://docs.npmjs.com/cli/install).
```
npm install --save strip-dirs
```
## API
```javascript
const stripDirs = require('strip-dirs');
```
### stripDirs(*path*, *count* [, *option*])
*path*: `String` (A relative path)
*count*: `Number` (0, 1, 2, ...)
*option*: `Object`
Return: `String`
It removes directory components from the beginning of the *path* by *count*.
```javascript
const stripDirs = require('strip-dirs');
stripDirs('foo/bar', 1); //=> 'bar'
stripDirs('foo/bar/baz', 2); //=> 'bar'
stripDirs('foo/././/bar/./', 1); //=> 'bar'
stripDirs('foo/bar', 0); //=> 'foo/bar'
stripDirs('/foo/bar', 1) // throw an error because the path is an absolute path
```
If you want to remove all directory components certainly, use [`path.basename`](https://nodejs.org/api/path.html#path_path_basename_path_ext) instead of this module.
#### option.disallowOverflow
Type: `Boolean`
Default: `false`
By default, it keeps the last path component when path components are fewer than the *count*.
If this option is enabled, it throws an error in this situation.
```javascript
stripDirs('foo/bar/baz', 9999); //=> 'baz'
stripDirs('foo/bar/baz', 9999, {disallowOverflow: true}); // throws an range error
```
## License
Copyright (c) 2014 - 2016 [Shinnosuke Watanabe](https://github.com/shinnn)
Licensed under [the MIT License](./LICENSE).
## number-to-bn
<div>
<!-- Dependency Status -->
<a href="https://david-dm.org/silentcicero/number-to-bn">
<img src="https://david-dm.org/silentcicero/number-to-bn.svg"
alt="Dependency Status" />
</a>
<!-- devDependency Status -->
<a href="https://david-dm.org/silentcicero/number-to-bn#info=devDependencies">
<img src="https://david-dm.org/silentcicero/number-to-bn/dev-status.svg" alt="devDependency Status" />
</a>
<!-- Build Status -->
<a href="https://travis-ci.org/SilentCicero/number-to-bn">
<img src="https://travis-ci.org/SilentCicero/number-to-bn.svg"
alt="Build Status" />
</a>
<!-- NPM Version -->
<a href="https://www.npmjs.org/package/number-to-bn">
<img src="http://img.shields.io/npm/v/number-to-bn.svg"
alt="NPM version" />
</a>
<a href="https://coveralls.io/r/SilentCicero/number-to-bn">
<img src="https://coveralls.io/repos/github/SilentCicero/number-to-bn/badge.svg" alt="Test Coverage" />
</a>
<!-- Javascript Style -->
<a href="http://airbnb.io/javascript/">
<img src="https://img.shields.io/badge/code%20style-airbnb-brightgreen.svg" alt="js-airbnb-style" />
</a>
</div>
<br />
A simple method to convert integer or hex integer numbers to BN.js object instances. Does not supprot decimal numbers.
## Install
```
npm install --save number-to-bn
```
## Usage
```js
const numberToBN = require('number-to-bn');
console.log(numberToBN('-1'));
// result <BN ...> -1
console.log(numberToBN(1));
// result <BN ...> 1
console.log(numberToBN(new BN(100)));
// result <BN ...> 100
console.log(numberToBN(new BigNumber(10000)));
// result <BN ...> 10000
console.log(numberToBN('0x0a'));
// result <BN ...> 10
console.log(numberToBN('-0x0a'));
// result <BN ...> -10
console.log(numberToBN('0.9')); // or {}, [], undefined, 9.9
// throws new Error(...)
console.log(numberToBN(null)); // or {}, [], undefined, 9.9
// throws new Error(...)
```
## Important documents
- [Changelog](CHANGELOG.md)
- [License](https://raw.githubusercontent.com/silentcicero/number-to-bn/master/LICENSE)
## Licence
This project is licensed under the MIT license, Copyright (c) 2016 Nick Dodson. For more information see LICENSE.md.
```
The MIT License
Copyright (c) 2016 Nick Dodson. nickdodson.com
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
```
# SYNOPSIS
[](https://www.npmjs.org/package/ethereumjs-block)
[](https://travis-ci.org/ethereumjs/ethereumjs-block)
[](https://coveralls.io/r/ethereumjs/ethereumjs-block)
[]() or #ethereumjs on freenode
[](https://github.com/feross/standard)
Implements schema and functions related to Ethereum's block.
# INSTALL
`npm install ethereumjs-block`
# BROWSER
This module work with `browserify`.
# API
[./docs](./docs/index.md)
# TESTING
Tests in the ``tests`` directory are partly outdated and testing is primarily done by running the ``BlockchainTests`` from within the [ethereumjs-vm](https://github.com/ethereumjs/ethereumjs-vm) repository.
Relevant test folders:
- ``bcTotalDifficultyTest``
- TODO
# LICENSE
[MPL-2.0](https://tldrlegal.com/license/mozilla-public-license-2.0-(mpl-2))
# normalize-path [](https://www.npmjs.com/package/normalize-path) [](https://npmjs.org/package/normalize-path) [](https://npmjs.org/package/normalize-path) [](https://travis-ci.org/jonschlinkert/normalize-path)
> Normalize file path slashes to be unix-like forward slashes. Also condenses repeat slashes to a single slash and removes and trailing slashes unless disabled.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save normalize-path
```
## Usage
```js
var normalize = require('normalize-path');
normalize('\\foo\\bar\\baz\\');
//=> '/foo/bar/baz'
normalize('./foo/bar/baz/');
//=> './foo/bar/baz'
```
Pass `false` as the last argument to **keep** trailing slashes:
```js
normalize('./foo/bar/baz/', false);
//=> './foo/bar/baz/'
normalize('foo\\bar\\baz\\', false);
//=> 'foo/bar/baz/'
```
## About
### Related projects
* [contains-path](https://www.npmjs.com/package/contains-path): Return true if a file path contains the given path. | [homepage](https://github.com/jonschlinkert/contains-path "Return true if a file path contains the given path.")
* [ends-with](https://www.npmjs.com/package/ends-with): Returns `true` if the given `string` or `array` ends with `suffix` using strict equality for… [more](https://github.com/jonschlinkert/ends-with) | [homepage](https://github.com/jonschlinkert/ends-with "Returns `true` if the given `string` or `array` ends with `suffix` using strict equality for comparisons.")
* [is-absolute](https://www.npmjs.com/package/is-absolute): Polyfill for node.js `path.isAbolute`. Returns true if a file path is absolute. | [homepage](https://github.com/jonschlinkert/is-absolute "Polyfill for node.js `path.isAbolute`. Returns true if a file path is absolute.")
* [is-relative](https://www.npmjs.com/package/is-relative): Returns `true` if the path appears to be relative. | [homepage](https://github.com/jonschlinkert/is-relative "Returns `true` if the path appears to be relative.")
* [parse-filepath](https://www.npmjs.com/package/parse-filepath): Pollyfill for node.js `path.parse`, parses a filepath into an object. | [homepage](https://github.com/jonschlinkert/parse-filepath "Pollyfill for node.js `path.parse`, parses a filepath into an object.")
* [path-ends-with](https://www.npmjs.com/package/path-ends-with): Return `true` if a file path ends with the given string/suffix. | [homepage](https://github.com/jonschlinkert/path-ends-with "Return `true` if a file path ends with the given string/suffix.")
* [path-segments](https://www.npmjs.com/package/path-segments): Get n specific segments of a file path, e.g. first 2, last 3, etc. | [homepage](https://github.com/jonschlinkert/path-segments "Get n specific segments of a file path, e.g. first 2, last 3, etc.")
* [rewrite-ext](https://www.npmjs.com/package/rewrite-ext): Automatically re-write the destination extension of a filepath based on the source extension. e.g… [more](https://github.com/jonschlinkert/rewrite-ext) | [homepage](https://github.com/jonschlinkert/rewrite-ext "Automatically re-write the destination extension of a filepath based on the source extension. e.g `.coffee` => `.js`. This will only rename the ext, no other path parts are modified.")
* [unixify](https://www.npmjs.com/package/unixify): Convert Windows file paths to unix paths. | [homepage](https://github.com/jonschlinkert/unixify "Convert Windows file paths to unix paths.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 31 | [jonschlinkert](https://github.com/jonschlinkert) |
| 1 | [phated](https://github.com/phated) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.4.3, on March 29, 2017._
# pm2 custom metrics boilerplate
In this boilerplate you will discover a working example of custom metrics feature.
Metrics covered are:
- io.metric
- io.counter
- io.meter
- io.histogram
## What is Custom Metrics?
Custom metrics is a powerfull way to get more visibility from a running application. It will allow you to monitor in realtime the current value of variables, know the number of actions being processed, measure latency and much more.
Once you have plugged in some custom metrics you will be able to monitor their value in realtime with
`pm2 monit`
Or
`pm2 describe`
Or on the PM2+ Web interface
`pm2 open`
## Example
```javascript
const io = require('@pm2/io')
const currentReq = io.counter({
name: 'CM: Current Processing',
type: 'counter'
})
setInterval(() => {
currentReq.inc()
}, 1000)
```
## Documentation
https://doc.pm2.io/en/plus/guide/custom-metrics/
# utils-merge
[](https://www.npmjs.com/package/utils-merge)
[](https://travis-ci.org/jaredhanson/utils-merge)
[](https://codeclimate.com/github/jaredhanson/utils-merge)
[](https://coveralls.io/r/jaredhanson/utils-merge)
[](https://david-dm.org/jaredhanson/utils-merge)
Merges the properties from a source object into a destination object.
## Install
```bash
$ npm install utils-merge
```
## Usage
```javascript
var a = { foo: 'bar' }
, b = { bar: 'baz' };
merge(a, b);
// => { foo: 'bar', bar: 'baz' }
```
## License
[The MIT License](http://opensource.org/licenses/MIT)
Copyright (c) 2013-2017 Jared Hanson <[http://jaredhanson.net/](http://jaredhanson.net/)>
<a target='_blank' rel='nofollow' href='https://app.codesponsor.io/link/vK9dyjRnnWsMzzJTQ57fRJpH/jaredhanson/utils-merge'> <img alt='Sponsor' width='888' height='68' src='https://app.codesponsor.io/embed/vK9dyjRnnWsMzzJTQ57fRJpH/jaredhanson/utils-merge.svg' /></a>
# etag
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Create simple HTTP ETags
This module generates HTTP ETags (as defined in RFC 7232) for use in
HTTP responses.
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install etag
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var etag = require('etag')
```
### etag(entity, [options])
Generate a strong ETag for the given entity. This should be the complete
body of the entity. Strings, `Buffer`s, and `fs.Stats` are accepted. By
default, a strong ETag is generated except for `fs.Stats`, which will
generate a weak ETag (this can be overwritten by `options.weak`).
<!-- eslint-disable no-undef -->
```js
res.setHeader('ETag', etag(body))
```
#### Options
`etag` accepts these properties in the options object.
##### weak
Specifies if the generated ETag will include the weak validator mark (that
is, the leading `W/`). The actual entity tag is the same. The default value
is `false`, unless the `entity` is `fs.Stats`, in which case it is `true`.
## Testing
```sh
$ npm test
```
## Benchmark
```bash
$ npm run-script bench
> [email protected] bench nodejs-etag
> node benchmark/index.js
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
modules@48
[email protected]
> node benchmark/body0-100b.js
100B body
4 tests completed.
buffer - strong x 258,647 ops/sec ±1.07% (180 runs sampled)
buffer - weak x 263,812 ops/sec ±0.61% (184 runs sampled)
string - strong x 259,955 ops/sec ±1.19% (185 runs sampled)
string - weak x 264,356 ops/sec ±1.09% (184 runs sampled)
> node benchmark/body1-1kb.js
1KB body
4 tests completed.
buffer - strong x 189,018 ops/sec ±1.12% (182 runs sampled)
buffer - weak x 190,586 ops/sec ±0.81% (186 runs sampled)
string - strong x 144,272 ops/sec ±0.96% (188 runs sampled)
string - weak x 145,380 ops/sec ±1.43% (187 runs sampled)
> node benchmark/body2-5kb.js
5KB body
4 tests completed.
buffer - strong x 92,435 ops/sec ±0.42% (188 runs sampled)
buffer - weak x 92,373 ops/sec ±0.58% (189 runs sampled)
string - strong x 48,850 ops/sec ±0.56% (186 runs sampled)
string - weak x 49,380 ops/sec ±0.56% (190 runs sampled)
> node benchmark/body3-10kb.js
10KB body
4 tests completed.
buffer - strong x 55,989 ops/sec ±0.93% (188 runs sampled)
buffer - weak x 56,148 ops/sec ±0.55% (190 runs sampled)
string - strong x 27,345 ops/sec ±0.43% (188 runs sampled)
string - weak x 27,496 ops/sec ±0.45% (190 runs sampled)
> node benchmark/body4-100kb.js
100KB body
4 tests completed.
buffer - strong x 7,083 ops/sec ±0.22% (190 runs sampled)
buffer - weak x 7,115 ops/sec ±0.26% (191 runs sampled)
string - strong x 3,068 ops/sec ±0.34% (190 runs sampled)
string - weak x 3,096 ops/sec ±0.35% (190 runs sampled)
> node benchmark/stats.js
stat
4 tests completed.
real - strong x 871,642 ops/sec ±0.34% (189 runs sampled)
real - weak x 867,613 ops/sec ±0.39% (190 runs sampled)
fake - strong x 401,051 ops/sec ±0.40% (189 runs sampled)
fake - weak x 400,100 ops/sec ±0.47% (188 runs sampled)
```
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/etag.svg
[npm-url]: https://npmjs.org/package/etag
[node-version-image]: https://img.shields.io/node/v/etag.svg
[node-version-url]: https://nodejs.org/en/download/
[travis-image]: https://img.shields.io/travis/jshttp/etag/master.svg
[travis-url]: https://travis-ci.org/jshttp/etag
[coveralls-image]: https://img.shields.io/coveralls/jshttp/etag/master.svg
[coveralls-url]: https://coveralls.io/r/jshttp/etag?branch=master
[downloads-image]: https://img.shields.io/npm/dm/etag.svg
[downloads-url]: https://npmjs.org/package/etag
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
number
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.pmod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available)
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `a.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][1]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
`disable()`
Will disable all namespaces. The functions returns the namespaces currently
enabled (and skipped). This can be useful if you want to disable debugging
temporarily without knowing what was enabled to begin with.
For example:
```js
let debug = require('debug');
debug.enable('foo:*,-foo:bar');
let namespaces = debug.disable();
debug.enable(namespaces);
```
Note: There is no guarantee that the string will be identical to the initial
enable string, but semantically they will be identical.
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# once
Only call a function once.
## usage
```javascript
var once = require('once')
function load (file, cb) {
cb = once(cb)
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Or add to the Function.prototype in a responsible way:
```javascript
// only has to be done once
require('once').proto()
function load (file, cb) {
cb = cb.once()
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Ironically, the prototype feature makes this module twice as
complicated as necessary.
To check whether you function has been called, use `fn.called`. Once the
function is called for the first time the return value of the original
function is saved in `fn.value` and subsequent calls will continue to
return this value.
```javascript
var once = require('once')
function load (cb) {
cb = once(cb)
var stream = createStream()
stream.once('data', cb)
stream.once('end', function () {
if (!cb.called) cb(new Error('not found'))
})
}
```
## `once.strict(func)`
Throw an error if the function is called twice.
Some functions are expected to be called only once. Using `once` for them would
potentially hide logical errors.
In the example below, the `greet` function has to call the callback only once:
```javascript
function greet (name, cb) {
// return is missing from the if statement
// when no name is passed, the callback is called twice
if (!name) cb('Hello anonymous')
cb('Hello ' + name)
}
function log (msg) {
console.log(msg)
}
// this will print 'Hello anonymous' but the logical error will be missed
greet(null, once(msg))
// once.strict will print 'Hello anonymous' and throw an error when the callback will be called the second time
greet(null, once.strict(msg))
```
# yauzl
[](https://travis-ci.org/thejoshwolfe/yauzl)
[](https://coveralls.io/r/thejoshwolfe/yauzl)
yet another unzip library for node. For zipping, see
[yazl](https://github.com/thejoshwolfe/yazl).
Design principles:
* Follow the spec.
Don't scan for local file headers.
Read the central directory for file metadata.
(see [No Streaming Unzip API](#no-streaming-unzip-api)).
* Don't block the JavaScript thread.
Use and provide async APIs.
* Keep memory usage under control.
Don't attempt to buffer entire files in RAM at once.
* Never crash (if used properly).
Don't let malformed zip files bring down client applications who are trying to catch errors.
* Catch unsafe file names.
See `validateFileName()`.
## Usage
```js
var yauzl = require("yauzl");
yauzl.open("path/to/file.zip", {lazyEntries: true}, function(err, zipfile) {
if (err) throw err;
zipfile.readEntry();
zipfile.on("entry", function(entry) {
if (/\/$/.test(entry.fileName)) {
// Directory file names end with '/'.
// Note that entires for directories themselves are optional.
// An entry's fileName implicitly requires its parent directories to exist.
zipfile.readEntry();
} else {
// file entry
zipfile.openReadStream(entry, function(err, readStream) {
if (err) throw err;
readStream.on("end", function() {
zipfile.readEntry();
});
readStream.pipe(somewhere);
});
}
});
});
```
See also `examples/` for more usage examples.
## API
The default for every optional `callback` parameter is:
```js
function defaultCallback(err) {
if (err) throw err;
}
```
### open(path, [options], [callback])
Calls `fs.open(path, "r")` and reads the `fd` effectively the same as `fromFd()` would.
`options` may be omitted or `null`. The defaults are `{autoClose: true, lazyEntries: false, decodeStrings: true, validateEntrySizes: true, strictFileNames: false}`.
`autoClose` is effectively equivalent to:
```js
zipfile.once("end", function() {
zipfile.close();
});
```
`lazyEntries` indicates that entries should be read only when `readEntry()` is called.
If `lazyEntries` is `false`, `entry` events will be emitted as fast as possible to allow `pipe()`ing
file data from all entries in parallel.
This is not recommended, as it can lead to out of control memory usage for zip files with many entries.
See [issue #22](https://github.com/thejoshwolfe/yauzl/issues/22).
If `lazyEntries` is `true`, an `entry` or `end` event will be emitted in response to each call to `readEntry()`.
This allows processing of one entry at a time, and will keep memory usage under control for zip files with many entries.
`decodeStrings` is the default and causes yauzl to decode strings with `CP437` or `UTF-8` as required by the spec.
The exact effects of turning this option off are:
* `zipfile.comment`, `entry.fileName`, and `entry.fileComment` will be `Buffer` objects instead of `String`s.
* Any Info-ZIP Unicode Path Extra Field will be ignored. See `extraFields`.
* Automatic file name validation will not be performed. See `validateFileName()`.
`validateEntrySizes` is the default and ensures that an entry's reported uncompressed size matches its actual uncompressed size.
This check happens as early as possible, which is either before emitting each `"entry"` event (for entries with no compression),
or during the `readStream` piping after calling `openReadStream()`.
See `openReadStream()` for more information on defending against zip bomb attacks.
When `strictFileNames` is `false` (the default) and `decodeStrings` is `true`,
all backslash (`\`) characters in each `entry.fileName` are replaced with forward slashes (`/`).
The spec forbids file names with backslashes,
but Microsoft's `System.IO.Compression.ZipFile` class in .NET versions 4.5.0 until 4.6.1
creates non-conformant zipfiles with backslashes in file names.
`strictFileNames` is `false` by default so that clients can read these
non-conformant zipfiles without knowing about this Microsoft-specific bug.
When `strictFileNames` is `true` and `decodeStrings` is `true`,
entries with backslashes in their file names will result in an error. See `validateFileName()`.
When `decodeStrings` is `false`, `strictFileNames` has no effect.
The `callback` is given the arguments `(err, zipfile)`.
An `err` is provided if the End of Central Directory Record cannot be found, or if its metadata appears malformed.
This kind of error usually indicates that this is not a zip file.
Otherwise, `zipfile` is an instance of `ZipFile`.
### fromFd(fd, [options], [callback])
Reads from the fd, which is presumed to be an open .zip file.
Note that random access is required by the zip file specification,
so the fd cannot be an open socket or any other fd that does not support random access.
`options` may be omitted or `null`. The defaults are `{autoClose: false, lazyEntries: false, decodeStrings: true, validateEntrySizes: true, strictFileNames: false}`.
See `open()` for the meaning of the options and callback.
### fromBuffer(buffer, [options], [callback])
Like `fromFd()`, but reads from a RAM buffer instead of an open file.
`buffer` is a `Buffer`.
If a `ZipFile` is acquired from this method,
it will never emit the `close` event,
and calling `close()` is not necessary.
`options` may be omitted or `null`. The defaults are `{lazyEntries: false, decodeStrings: true, validateEntrySizes: true, strictFileNames: false}`.
See `open()` for the meaning of the options and callback.
The `autoClose` option is ignored for this method.
### fromRandomAccessReader(reader, totalSize, [options], [callback])
This method of reading a zip file allows clients to implement their own back-end file system.
For example, a client might translate read calls into network requests.
The `reader` parameter must be of a type that is a subclass of
[RandomAccessReader](#class-randomaccessreader) that implements the required methods.
The `totalSize` is a Number and indicates the total file size of the zip file.
`options` may be omitted or `null`. The defaults are `{autoClose: true, lazyEntries: false, decodeStrings: true, validateEntrySizes: true, strictFileNames: false}`.
See `open()` for the meaning of the options and callback.
### dosDateTimeToDate(date, time)
Converts MS-DOS `date` and `time` data into a JavaScript `Date` object.
Each parameter is a `Number` treated as an unsigned 16-bit integer.
Note that this format does not support timezones,
so the returned object will use the local timezone.
### validateFileName(fileName)
Returns `null` or a `String` error message depending on the validity of `fileName`.
If `fileName` starts with `"/"` or `/[A-Za-z]:\//` or if it contains `".."` path segments or `"\\"`,
this function returns an error message appropriate for use like this:
```js
var errorMessage = yauzl.validateFileName(fileName);
if (errorMessage != null) throw new Error(errorMessage);
```
This function is automatically run for each entry, as long as `decodeStrings` is `true`.
See `open()`, `strictFileNames`, and `Event: "entry"` for more information.
### Class: ZipFile
The constructor for the class is not part of the public API.
Use `open()`, `fromFd()`, `fromBuffer()`, or `fromRandomAccessReader()` instead.
#### Event: "entry"
Callback gets `(entry)`, which is an `Entry`.
See `open()` and `readEntry()` for when this event is emitted.
If `decodeStrings` is `true`, entries emitted via this event have already passed file name validation.
See `validateFileName()` and `open()` for more information.
If `validateEntrySizes` is `true` and this entry's `compressionMethod` is `0` (stored without compression),
this entry has already passed entry size validation.
See `open()` for more information.
#### Event: "end"
Emitted after the last `entry` event has been emitted.
See `open()` and `readEntry()` for more info on when this event is emitted.
#### Event: "close"
Emitted after the fd is actually closed.
This is after calling `close()` (or after the `end` event when `autoClose` is `true`),
and after all stream pipelines created from `openReadStream()` have finished reading data from the fd.
If this `ZipFile` was acquired from `fromRandomAccessReader()`,
the "fd" in the previous paragraph refers to the `RandomAccessReader` implemented by the client.
If this `ZipFile` was acquired from `fromBuffer()`, this event is never emitted.
#### Event: "error"
Emitted in the case of errors with reading the zip file.
(Note that other errors can be emitted from the streams created from `openReadStream()` as well.)
After this event has been emitted, no further `entry`, `end`, or `error` events will be emitted,
but the `close` event may still be emitted.
#### readEntry()
Causes this `ZipFile` to emit an `entry` or `end` event (or an `error` event).
This method must only be called when this `ZipFile` was created with the `lazyEntries` option set to `true` (see `open()`).
When this `ZipFile` was created with the `lazyEntries` option set to `true`,
`entry` and `end` events are only ever emitted in response to this method call.
The event that is emitted in response to this method will not be emitted until after this method has returned,
so it is safe to call this method before attaching event listeners.
After calling this method, calling this method again before the response event has been emitted will cause undefined behavior.
Calling this method after the `end` event has been emitted will cause undefined behavior.
Calling this method after calling `close()` will cause undefined behavior.
#### openReadStream(entry, [options], callback)
`entry` must be an `Entry` object from this `ZipFile`.
`callback` gets `(err, readStream)`, where `readStream` is a `Readable Stream` that provides the file data for this entry.
If this zipfile is already closed (see `close()`), the `callback` will receive an `err`.
`options` may be omitted or `null`, and has the following defaults:
```js
{
decompress: entry.isCompressed() ? true : null,
decrypt: null,
start: 0, // actually the default is null, see below
end: entry.compressedSize, // actually the default is null, see below
}
```
If the entry is compressed (with a supported compression method),
and the `decompress` option is `true` (or omitted),
the read stream provides the decompressed data.
Omitting the `decompress` option is what most clients should do.
The `decompress` option must be `null` (or omitted) when the entry is not compressed (see `isCompressed()`),
and either `true` (or omitted) or `false` when the entry is compressed.
Specifying `decompress: false` for a compressed entry causes the read stream
to provide the raw compressed file data without going through a zlib inflate transform.
If the entry is encrypted (see `isEncrypted()`), clients may want to avoid calling `openReadStream()` on the entry entirely.
Alternatively, clients may call `openReadStream()` for encrypted entries and specify `decrypt: false`.
If the entry is also compressed, clients must *also* specify `decompress: false`.
Specifying `decrypt: false` for an encrypted entry causes the read stream to provide the raw, still-encrypted file data.
(This data includes the 12-byte header described in the spec.)
The `decrypt` option must be `null` (or omitted) for non-encrypted entries, and `false` for encrypted entries.
Omitting the `decrypt` option (or specifying it as `null`) for an encrypted entry
will result in the `callback` receiving an `err`.
This default behavior is so that clients not accounting for encrypted files aren't surprised by bogus file data.
The `start` (inclusive) and `end` (exclusive) options are byte offsets into this entry's file data,
and can be used to obtain part of an entry's file data rather than the whole thing.
If either of these options are specified and non-`null`,
then the above options must be used to obain the file's raw data.
Speficying `{start: 0, end: entry.compressedSize}` will result in the complete file,
which is effectively the default values for these options,
but note that unlike omitting the options, when you specify `start` or `end` as any non-`null` value,
the above requirement is still enforced that you must also pass the appropriate options to get the file's raw data.
It's possible for the `readStream` provided to the `callback` to emit errors for several reasons.
For example, if zlib cannot decompress the data, the zlib error will be emitted from the `readStream`.
Two more error cases (when `validateEntrySizes` is `true`) are if the decompressed data has too many
or too few actual bytes compared to the reported byte count from the entry's `uncompressedSize` field.
yauzl notices this false information and emits an error from the `readStream`
after some number of bytes have already been piped through the stream.
This check allows clients to trust the `uncompressedSize` field in `Entry` objects.
Guarding against [zip bomb](http://en.wikipedia.org/wiki/Zip_bomb) attacks can be accomplished by
doing some heuristic checks on the size metadata and then watching out for the above errors.
Such heuristics are outside the scope of this library,
but enforcing the `uncompressedSize` is implemented here as a security feature.
It is possible to destroy the `readStream` before it has piped all of its data.
To do this, call `readStream.destroy()`.
You must `unpipe()` the `readStream` from any destination before calling `readStream.destroy()`.
If this zipfile was created using `fromRandomAccessReader()`, the `RandomAccessReader` implementation
must provide readable streams that implement a `.destroy()` method (see `randomAccessReader._readStreamForRange()`)
in order for calls to `readStream.destroy()` to work in this context.
#### close()
Causes all future calls to `openReadStream()` to fail,
and closes the fd, if any, after all streams created by `openReadStream()` have emitted their `end` events.
If the `autoClose` option is set to `true` (see `open()`),
this function will be called automatically effectively in response to this object's `end` event.
If the `lazyEntries` option is set to `false` (see `open()`) and this object's `end` event has not been emitted yet,
this function causes undefined behavior.
If the `lazyEntries` option is set to `true`,
you can call this function instead of calling `readEntry()` to abort reading the entries of a zipfile.
It is safe to call this function multiple times; after the first call, successive calls have no effect.
This includes situations where the `autoClose` option effectively calls this function for you.
If `close()` is never called, then the zipfile is "kept open".
For zipfiles created with `fromFd()`, this will leave the `fd` open, which may be desirable.
For zipfiles created with `open()`, this will leave the underlying `fd` open, thereby "leaking" it, which is probably undesirable.
For zipfiles created with `fromRandomAccessReader()`, the reader's `close()` method will never be called.
For zipfiles created with `fromBuffer()`, the `close()` function has no effect whether called or not.
Regardless of how this `ZipFile` was created, there are no resources other than those listed above that require cleanup from this function.
This means it may be desirable to never call `close()` in some usecases.
#### isOpen
`Boolean`. `true` until `close()` is called; then it's `false`.
#### entryCount
`Number`. Total number of central directory records.
#### comment
`String`. Always decoded with `CP437` per the spec.
If `decodeStrings` is `false` (see `open()`), this field is the undecoded `Buffer` instead of a decoded `String`.
### Class: Entry
Objects of this class represent Central Directory Records.
Refer to the zipfile specification for more details about these fields.
These fields are of type `Number`:
* `versionMadeBy`
* `versionNeededToExtract`
* `generalPurposeBitFlag`
* `compressionMethod`
* `lastModFileTime` (MS-DOS format, see `getLastModDateTime`)
* `lastModFileDate` (MS-DOS format, see `getLastModDateTime`)
* `crc32`
* `compressedSize`
* `uncompressedSize`
* `fileNameLength` (bytes)
* `extraFieldLength` (bytes)
* `fileCommentLength` (bytes)
* `internalFileAttributes`
* `externalFileAttributes`
* `relativeOffsetOfLocalHeader`
#### fileName
`String`.
Following the spec, the bytes for the file name are decoded with
`UTF-8` if `generalPurposeBitFlag & 0x800`, otherwise with `CP437`.
Alternatively, this field may be populated from the Info-ZIP Unicode Path Extra Field
(see `extraFields`).
This field is automatically validated by `validateFileName()` before yauzl emits an "entry" event.
If this field would contain unsafe characters, yauzl emits an error instead of an entry.
If `decodeStrings` is `false` (see `open()`), this field is the undecoded `Buffer` instead of a decoded `String`.
Therefore, `generalPurposeBitFlag` and any Info-ZIP Unicode Path Extra Field are ignored.
Furthermore, no automatic file name validation is performed for this file name.
#### extraFields
`Array` with each entry in the form `{id: id, data: data}`,
where `id` is a `Number` and `data` is a `Buffer`.
This library looks for and reads the ZIP64 Extended Information Extra Field (0x0001)
in order to support ZIP64 format zip files.
This library also looks for and reads the Info-ZIP Unicode Path Extra Field (0x7075)
in order to support some zipfiles that use it instead of General Purpose Bit 11
to convey `UTF-8` file names.
When the field is identified and verified to be reliable (see the zipfile spec),
the the file name in this field is stored in the `fileName` property,
and the file name in the central directory record for this entry is ignored.
Note that when `decodeStrings` is false, all Info-ZIP Unicode Path Extra Fields are ignored.
None of the other fields are considered significant by this library.
Fields that this library reads are left unalterned in the `extraFields` array.
#### fileComment
`String` decoded with the charset indicated by `generalPurposeBitFlag & 0x800` as with the `fileName`.
(The Info-ZIP Unicode Path Extra Field has no effect on the charset used for this field.)
If `decodeStrings` is `false` (see `open()`), this field is the undecoded `Buffer` instead of a decoded `String`.
Prior to yauzl version 2.7.0, this field was erroneously documented as `comment` instead of `fileComment`.
For compatibility with any code that uses the field name `comment`,
yauzl creates an alias field named `comment` which is identical to `fileComment`.
#### getLastModDate()
Effectively implemented as:
```js
return dosDateTimeToDate(this.lastModFileDate, this.lastModFileTime);
```
#### isEncrypted()
Returns is this entry encrypted with "Traditional Encryption".
Effectively implemented as:
```js
return (this.generalPurposeBitFlag & 0x1) !== 0;
```
See `openReadStream()` for the implications of this value.
Note that "Strong Encryption" is not supported, and will result in an `"error"` event emitted from the `ZipFile`.
#### isCompressed()
Effectively implemented as:
```js
return this.compressionMethod === 8;
```
See `openReadStream()` for the implications of this value.
### Class: RandomAccessReader
This class is meant to be subclassed by clients and instantiated for the `fromRandomAccessReader()` function.
An example implementation can be found in `test/test.js`.
#### randomAccessReader._readStreamForRange(start, end)
Subclasses *must* implement this method.
`start` and `end` are Numbers and indicate byte offsets from the start of the file.
`end` is exclusive, so `_readStreamForRange(0x1000, 0x2000)` would indicate to read `0x1000` bytes.
`end - start` will always be at least `1`.
This method should return a readable stream which will be `pipe()`ed into another stream.
It is expected that the readable stream will provide data in several chunks if necessary.
If the readable stream provides too many or too few bytes, an error will be emitted.
(Note that `validateEntrySizes` has no effect on this check,
because this is a low-level API that should behave correctly regardless of the contents of the file.)
Any errors emitted on the readable stream will be handled and re-emitted on the client-visible stream
(returned from `zipfile.openReadStream()`) or provided as the `err` argument to the appropriate callback
(for example, for `fromRandomAccessReader()`).
The returned stream *must* implement a method `.destroy()`
if you call `readStream.destroy()` on streams you get from `openReadStream()`.
If you never call `readStream.destroy()`, then streams returned from this method do not need to implement a method `.destroy()`.
`.destroy()` should abort any streaming that is in progress and clean up any associated resources.
`.destroy()` will only be called after the stream has been `unpipe()`d from its destination.
Note that the stream returned from this method might not be the same object that is provided by `openReadStream()`.
The stream returned from this method might be `pipe()`d through one or more filter streams (for example, a zlib inflate stream).
#### randomAccessReader.read(buffer, offset, length, position, callback)
Subclasses may implement this method.
The default implementation uses `createReadStream()` to fill the `buffer`.
This method should behave like `fs.read()`.
#### randomAccessReader.close(callback)
Subclasses may implement this method.
The default implementation is effectively `setImmediate(callback);`.
`callback` takes parameters `(err)`.
This method is called once the all streams returned from `_readStreamForRange()` have ended,
and no more `_readStreamForRange()` or `read()` requests will be issued to this object.
## How to Avoid Crashing
When a malformed zipfile is encountered, the default behavior is to crash (throw an exception).
If you want to handle errors more gracefully than this,
be sure to do the following:
* Provide `callback` parameters where they are allowed, and check the `err` parameter.
* Attach a listener for the `error` event on any `ZipFile` object you get from `open()`, `fromFd()`, `fromBuffer()`, or `fromRandomAccessReader()`.
* Attach a listener for the `error` event on any stream you get from `openReadStream()`.
Minor version updates to yauzl will not add any additional requirements to this list.
## Limitations
### No Streaming Unzip API
Due to the design of the .zip file format, it's impossible to interpret a .zip file from start to finish
(such as from a readable stream) without sacrificing correctness.
The Central Directory, which is the authority on the contents of the .zip file, is at the end of a .zip file, not the beginning.
A streaming API would need to either buffer the entire .zip file to get to the Central Directory before interpreting anything
(defeating the purpose of a streaming interface), or rely on the Local File Headers which are interspersed through the .zip file.
However, the Local File Headers are explicitly denounced in the spec as being unreliable copies of the Central Directory,
so trusting them would be a violation of the spec.
Any library that offers a streaming unzip API must make one of the above two compromises,
which makes the library either dishonest or nonconformant (usually the latter).
This library insists on correctness and adherence to the spec, and so does not offer a streaming API.
Here is a way to create a spec-conformant .zip file using the `zip` command line program (Info-ZIP)
available in most unix-like environments, that is (nearly) impossible to parse correctly with a streaming parser:
```
$ echo -ne '\x50\x4b\x07\x08\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' > file.txt
$ zip -q0 - file.txt | cat > out.zip
```
This .zip file contains a single file entry that uses General Purpose Bit 3,
which means the Local File Header doesn't know the size of the file.
Any streaming parser that encounters this situation will either immediately fail,
or attempt to search for the Data Descriptor after the file's contents.
The file's contents is a sequence of 16-bytes crafted to exactly mimic a valid Data Descriptor for an empty file,
which will fool any parser that gets this far into thinking that the file is empty rather than containing 16-bytes.
What follows the file's real contents is the file's real Data Descriptor,
which will likely cause some kind of signature mismatch error for a streaming parser (if one hasn't occurred already).
By using General Purpose Bit 3 (and compression method 0),
it's possible to create arbitrarily ambiguous .zip files that
distract parsers with file contents that contain apparently valid .zip file metadata.
### Limitted ZIP64 Support
For ZIP64, only zip files smaller than `8PiB` are supported,
not the full `16EiB` range that a 64-bit integer should be able to index.
This is due to the JavaScript Number type being an IEEE 754 double precision float.
The Node.js `fs` module probably has this same limitation.
### ZIP64 Extensible Data Sector Is Ignored
The spec does not allow zip file creators to put arbitrary data here,
but rather reserves its use for PKWARE and mentions something about Z390.
This doesn't seem useful to expose in this library, so it is ignored.
### No Multi-Disk Archive Support
This library does not support multi-disk zip files.
The multi-disk fields in the zipfile spec were intended for a zip file to span multiple floppy disks,
which probably never happens now.
If the "number of this disk" field in the End of Central Directory Record is not `0`,
the `open()`, `fromFd()`, `fromBuffer()`, or `fromRandomAccessReader()` `callback` will receive an `err`.
By extension the following zip file fields are ignored by this library and not provided to clients:
* Disk where central directory starts
* Number of central directory records on this disk
* Disk number where file starts
### Limited Encryption Handling
You can detect when a file entry is encrypted with "Traditional Encryption" via `isEncrypted()`,
but yauzl will not help you decrypt it.
See `openReadStream()`.
If a zip file contains file entries encrypted with "Strong Encryption", yauzl emits an error.
If the central directory is encrypted or compressed, yauzl emits an error.
### Local File Headers Are Ignored
Many unzip libraries mistakenly read the Local File Header data in zip files.
This data is officially defined to be redundant with the Central Directory information,
and is not to be trusted.
Aside from checking the signature, yauzl ignores the content of the Local File Header.
### No CRC-32 Checking
This library provides the `crc32` field of `Entry` objects read from the Central Directory.
However, this field is not used for anything in this library.
### versionNeededToExtract Is Ignored
The field `versionNeededToExtract` is ignored,
because this library doesn't support the complete zip file spec at any version,
### No Support For Obscure Compression Methods
Regarding the `compressionMethod` field of `Entry` objects,
only method `0` (stored with no compression)
and method `8` (deflated) are supported.
Any of the other 15 official methods will cause the `openReadStream()` `callback` to receive an `err`.
### Data Descriptors Are Ignored
There may or may not be Data Descriptor sections in a zip file.
This library provides no support for finding or interpreting them.
### Archive Extra Data Record Is Ignored
There may or may not be an Archive Extra Data Record section in a zip file.
This library provides no support for finding or interpreting it.
### No Language Encoding Flag Support
Zip files officially support charset encodings other than CP437 and UTF-8,
but the zip file spec does not specify how it works.
This library makes no attempt to interpret the Language Encoding Flag.
## Change History
* 2.10.0
* Added support for non-conformant zipfiles created by Microsoft, and added option `strictFileNames` to disable the workaround. [issue #66](https://github.com/thejoshwolfe/yauzl/issues/66), [issue #88](https://github.com/thejoshwolfe/yauzl/issues/88)
* 2.9.2
* Removed `tools/hexdump-zip.js` and `tools/hex2bin.js`. Those tools are now located here: [thejoshwolfe/hexdump-zip](https://github.com/thejoshwolfe/hexdump-zip) and [thejoshwolfe/hex2bin](https://github.com/thejoshwolfe/hex2bin)
* Worked around performance problem with zlib when using `fromBuffer()` and `readStream.destroy()` for large compressed files. [issue #87](https://github.com/thejoshwolfe/yauzl/issues/87)
* 2.9.1
* Removed `console.log()` accidentally introduced in 2.9.0. [issue #64](https://github.com/thejoshwolfe/yauzl/issues/64)
* 2.9.0
* Throw an exception if `readEntry()` is called without `lazyEntries:true`. Previously this caused undefined behavior. [issue #63](https://github.com/thejoshwolfe/yauzl/issues/63)
* 2.8.0
* Added option `validateEntrySizes`. [issue #53](https://github.com/thejoshwolfe/yauzl/issues/53)
* Added `examples/promises.js`
* Added ability to read raw file data via `decompress` and `decrypt` options. [issue #11](https://github.com/thejoshwolfe/yauzl/issues/11), [issue #38](https://github.com/thejoshwolfe/yauzl/issues/38), [pull #39](https://github.com/thejoshwolfe/yauzl/pull/39)
* Added `start` and `end` options to `openReadStream()`. [issue #38](https://github.com/thejoshwolfe/yauzl/issues/38)
* 2.7.0
* Added option `decodeStrings`. [issue #42](https://github.com/thejoshwolfe/yauzl/issues/42)
* Fixed documentation for `entry.fileComment` and added compatibility alias. [issue #47](https://github.com/thejoshwolfe/yauzl/issues/47)
* 2.6.0
* Support Info-ZIP Unicode Path Extra Field, used by WinRAR for Chinese file names. [issue #33](https://github.com/thejoshwolfe/yauzl/issues/33)
* 2.5.0
* Ignore malformed Extra Field that is common in Android .apk files. [issue #31](https://github.com/thejoshwolfe/yauzl/issues/31)
* 2.4.3
* Fix crash when parsing malformed Extra Field buffers. [issue #31](https://github.com/thejoshwolfe/yauzl/issues/31)
* 2.4.2
* Remove .npmignore and .travis.yml from npm package.
* 2.4.1
* Fix error handling.
* 2.4.0
* Add ZIP64 support. [issue #6](https://github.com/thejoshwolfe/yauzl/issues/6)
* Add `lazyEntries` option. [issue #22](https://github.com/thejoshwolfe/yauzl/issues/22)
* Add `readStream.destroy()` method. [issue #26](https://github.com/thejoshwolfe/yauzl/issues/26)
* Add `fromRandomAccessReader()`. [issue #14](https://github.com/thejoshwolfe/yauzl/issues/14)
* Add `examples/unzip.js`.
* 2.3.1
* Documentation updates.
* 2.3.0
* Check that `uncompressedSize` is correct, or else emit an error. [issue #13](https://github.com/thejoshwolfe/yauzl/issues/13)
* 2.2.1
* Update dependencies.
* 2.2.0
* Update dependencies.
* 2.1.0
* Remove dependency on `iconv`.
* 2.0.3
* Fix crash when trying to read a 0-byte file.
* 2.0.2
* Fix event behavior after errors.
* 2.0.1
* Fix bug with using `iconv`.
* 2.0.0
* Initial release.
# is-dotfile [](https://www.npmjs.com/package/is-dotfile) [](https://npmjs.org/package/is-dotfile) [](https://npmjs.org/package/is-dotfile) [](https://travis-ci.org/jonschlinkert/is-dotfile)
> Return true if a file path is (or has) a dotfile. Returns false if the path is a dot directory.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-dotfile
```
## Usage
To be considered a dotfile, it must be the last filename in the path, like `.gitignore`. Otherwise it's a [dot directory](https://github.com/jonschlinkert/is-dotdir), like `.git/` and `.github/`.
```js
var isDotfile = require('is-dotfile');
```
**false**
All of the following return `false`:
```js
isDotfile('a/b/c.js');
isDotfile('/.git/foo');
isDotfile('a/b/c/.git/foo');
//=> false
```
**true**
All of the following return `true`:
```js
isDotfile('a/b/.gitignore');
isDotfile('.gitignore');
isDotfile('/.gitignore');
//=> true
```
## About
### Related projects
* [dotdir-regex](https://www.npmjs.com/package/dotdir-regex): Regex for matching dot-directories, like `.git/` | [homepage](https://github.com/regexps/dotdir-regex "Regex for matching dot-directories, like `.git/`")
* [dotfile-regex](https://www.npmjs.com/package/dotfile-regex): Regular expresson for matching dotfiles. | [homepage](https://github.com/regexps/dotfile-regex "Regular expresson for matching dotfiles.")
* [is-dotdir](https://www.npmjs.com/package/is-dotdir): Returns true if a path is a dot-directory. | [homepage](https://github.com/jonschlinkert/is-dotdir "Returns true if a path is a dot-directory.")
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/jonschlinkert/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 13 | [jonschlinkert](https://github.com/jonschlinkert) |
| 1 | [Lykathia](https://github.com/Lykathia) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on May 30, 2017._
# lodash v4.17.20
The [Lodash](https://lodash.com/) library exported as [Node.js](https://nodejs.org/) modules.
## Installation
Using npm:
```shell
$ npm i -g npm
$ npm i --save lodash
```
In Node.js:
```js
// Load the full build.
var _ = require('lodash');
// Load the core build.
var _ = require('lodash/core');
// Load the FP build for immutable auto-curried iteratee-first data-last methods.
var fp = require('lodash/fp');
// Load method categories.
var array = require('lodash/array');
var object = require('lodash/fp/object');
// Cherry-pick methods for smaller browserify/rollup/webpack bundles.
var at = require('lodash/at');
var curryN = require('lodash/fp/curryN');
```
See the [package source](https://github.com/lodash/lodash/tree/4.17.20-npm) for more details.
**Note:**<br>
Install [n_](https://www.npmjs.com/package/n_) for Lodash use in the Node.js < 6 REPL.
## Support
Tested in Chrome 74-75, Firefox 66-67, IE 11, Edge 18, Safari 11-12, & Node.js 8-12.<br>
Automated [browser](https://saucelabs.com/u/lodash) & [CI](https://travis-ci.org/lodash/lodash/) test runs are available.
# axios
[](https://www.npmjs.org/package/axios)
[](https://travis-ci.org/axios/axios)
[](https://coveralls.io/r/mzabriskie/axios)
[](https://packagephobia.now.sh/result?p=axios)
[](http://npm-stat.com/charts.html?package=axios)
[](https://gitter.im/mzabriskie/axios)
[](https://www.codetriage.com/axios/axios)
Promise based HTTP client for the browser and node.js
## Features
- Make [XMLHttpRequests](https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest) from the browser
- Make [http](http://nodejs.org/api/http.html) requests from node.js
- Supports the [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) API
- Intercept request and response
- Transform request and response data
- Cancel requests
- Automatic transforms for JSON data
- Client side support for protecting against [XSRF](http://en.wikipedia.org/wiki/Cross-site_request_forgery)
## Browser Support
 |  |  |  |  |  |
--- | --- | --- | --- | --- | --- |
Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | 11 ✔ |
[](https://saucelabs.com/u/axios)
## Installing
Using npm:
```bash
$ npm install axios
```
Using bower:
```bash
$ bower install axios
```
Using yarn:
```bash
$ yarn add axios
```
Using cdn:
```html
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
```
## Example
### note: CommonJS usage
In order to gain the TypeScript typings (for intellisense / autocomplete) while using CommonJS imports with `require()` use the following approach:
```js
const axios = require('axios').default;
// axios.<method> will now provide autocomplete and parameter typings
```
Performing a `GET` request
```js
const axios = require('axios');
// Make a request for a user with a given ID
axios.get('/user?ID=12345')
.then(function (response) {
// handle success
console.log(response);
})
.catch(function (error) {
// handle error
console.log(error);
})
.finally(function () {
// always executed
});
// Optionally the request above could also be done as
axios.get('/user', {
params: {
ID: 12345
}
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
})
.finally(function () {
// always executed
});
// Want to use async/await? Add the `async` keyword to your outer function/method.
async function getUser() {
try {
const response = await axios.get('/user?ID=12345');
console.log(response);
} catch (error) {
console.error(error);
}
}
```
> **NOTE:** `async/await` is part of ECMAScript 2017 and is not supported in Internet
> Explorer and older browsers, so use with caution.
Performing a `POST` request
```js
axios.post('/user', {
firstName: 'Fred',
lastName: 'Flintstone'
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
```
Performing multiple concurrent requests
```js
function getUserAccount() {
return axios.get('/user/12345');
}
function getUserPermissions() {
return axios.get('/user/12345/permissions');
}
axios.all([getUserAccount(), getUserPermissions()])
.then(axios.spread(function (acct, perms) {
// Both requests are now complete
}));
```
## axios API
Requests can be made by passing the relevant config to `axios`.
##### axios(config)
```js
// Send a POST request
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
});
```
```js
// GET request for remote image
axios({
method: 'get',
url: 'http://bit.ly/2mTM3nY',
responseType: 'stream'
})
.then(function (response) {
response.data.pipe(fs.createWriteStream('ada_lovelace.jpg'))
});
```
##### axios(url[, config])
```js
// Send a GET request (default method)
axios('/user/12345');
```
### Request method aliases
For convenience aliases have been provided for all supported request methods.
##### axios.request(config)
##### axios.get(url[, config])
##### axios.delete(url[, config])
##### axios.head(url[, config])
##### axios.options(url[, config])
##### axios.post(url[, data[, config]])
##### axios.put(url[, data[, config]])
##### axios.patch(url[, data[, config]])
###### NOTE
When using the alias methods `url`, `method`, and `data` properties don't need to be specified in config.
### Concurrency
Helper functions for dealing with concurrent requests.
##### axios.all(iterable)
##### axios.spread(callback)
### Creating an instance
You can create a new instance of axios with a custom config.
##### axios.create([config])
```js
const instance = axios.create({
baseURL: 'https://some-domain.com/api/',
timeout: 1000,
headers: {'X-Custom-Header': 'foobar'}
});
```
### Instance methods
The available instance methods are listed below. The specified config will be merged with the instance config.
##### axios#request(config)
##### axios#get(url[, config])
##### axios#delete(url[, config])
##### axios#head(url[, config])
##### axios#options(url[, config])
##### axios#post(url[, data[, config]])
##### axios#put(url[, data[, config]])
##### axios#patch(url[, data[, config]])
##### axios#getUri([config])
## Request Config
These are the available config options for making requests. Only the `url` is required. Requests will default to `GET` if `method` is not specified.
```js
{
// `url` is the server URL that will be used for the request
url: '/user',
// `method` is the request method to be used when making the request
method: 'get', // default
// `baseURL` will be prepended to `url` unless `url` is absolute.
// It can be convenient to set `baseURL` for an instance of axios to pass relative URLs
// to methods of that instance.
baseURL: 'https://some-domain.com/api/',
// `transformRequest` allows changes to the request data before it is sent to the server
// This is only applicable for request methods 'PUT', 'POST', 'PATCH' and 'DELETE'
// The last function in the array must return a string or an instance of Buffer, ArrayBuffer,
// FormData or Stream
// You may modify the headers object.
transformRequest: [function (data, headers) {
// Do whatever you want to transform the data
return data;
}],
// `transformResponse` allows changes to the response data to be made before
// it is passed to then/catch
transformResponse: [function (data) {
// Do whatever you want to transform the data
return data;
}],
// `headers` are custom headers to be sent
headers: {'X-Requested-With': 'XMLHttpRequest'},
// `params` are the URL parameters to be sent with the request
// Must be a plain object or a URLSearchParams object
params: {
ID: 12345
},
// `paramsSerializer` is an optional function in charge of serializing `params`
// (e.g. https://www.npmjs.com/package/qs, http://api.jquery.com/jquery.param/)
paramsSerializer: function (params) {
return Qs.stringify(params, {arrayFormat: 'brackets'})
},
// `data` is the data to be sent as the request body
// Only applicable for request methods 'PUT', 'POST', and 'PATCH'
// When no `transformRequest` is set, must be of one of the following types:
// - string, plain object, ArrayBuffer, ArrayBufferView, URLSearchParams
// - Browser only: FormData, File, Blob
// - Node only: Stream, Buffer
data: {
firstName: 'Fred'
},
// syntax alternative to send data into the body
// method post
// only the value is sent, not the key
data: 'Country=Brasil&City=Belo Horizonte',
// `timeout` specifies the number of milliseconds before the request times out.
// If the request takes longer than `timeout`, the request will be aborted.
timeout: 1000, // default is `0` (no timeout)
// `withCredentials` indicates whether or not cross-site Access-Control requests
// should be made using credentials
withCredentials: false, // default
// `adapter` allows custom handling of requests which makes testing easier.
// Return a promise and supply a valid response (see lib/adapters/README.md).
adapter: function (config) {
/* ... */
},
// `auth` indicates that HTTP Basic auth should be used, and supplies credentials.
// This will set an `Authorization` header, overwriting any existing
// `Authorization` custom headers you have set using `headers`.
// Please note that only HTTP Basic auth is configurable through this parameter.
// For Bearer tokens and such, use `Authorization` custom headers instead.
auth: {
username: 'janedoe',
password: 's00pers3cret'
},
// `responseType` indicates the type of data that the server will respond with
// options are: 'arraybuffer', 'document', 'json', 'text', 'stream'
// browser only: 'blob'
responseType: 'json', // default
// `responseEncoding` indicates encoding to use for decoding responses
// Note: Ignored for `responseType` of 'stream' or client-side requests
responseEncoding: 'utf8', // default
// `xsrfCookieName` is the name of the cookie to use as a value for xsrf token
xsrfCookieName: 'XSRF-TOKEN', // default
// `xsrfHeaderName` is the name of the http header that carries the xsrf token value
xsrfHeaderName: 'X-XSRF-TOKEN', // default
// `onUploadProgress` allows handling of progress events for uploads
onUploadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `onDownloadProgress` allows handling of progress events for downloads
onDownloadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `maxContentLength` defines the max size of the http response content in bytes allowed
maxContentLength: 2000,
// `validateStatus` defines whether to resolve or reject the promise for a given
// HTTP response status code. If `validateStatus` returns `true` (or is set to `null`
// or `undefined`), the promise will be resolved; otherwise, the promise will be
// rejected.
validateStatus: function (status) {
return status >= 200 && status < 300; // default
},
// `maxRedirects` defines the maximum number of redirects to follow in node.js.
// If set to 0, no redirects will be followed.
maxRedirects: 5, // default
// `socketPath` defines a UNIX Socket to be used in node.js.
// e.g. '/var/run/docker.sock' to send requests to the docker daemon.
// Only either `socketPath` or `proxy` can be specified.
// If both are specified, `socketPath` is used.
socketPath: null, // default
// `httpAgent` and `httpsAgent` define a custom agent to be used when performing http
// and https requests, respectively, in node.js. This allows options to be added like
// `keepAlive` that are not enabled by default.
httpAgent: new http.Agent({ keepAlive: true }),
httpsAgent: new https.Agent({ keepAlive: true }),
// 'proxy' defines the hostname and port of the proxy server.
// You can also define your proxy using the conventional `http_proxy` and
// `https_proxy` environment variables. If you are using environment variables
// for your proxy configuration, you can also define a `no_proxy` environment
// variable as a comma-separated list of domains that should not be proxied.
// Use `false` to disable proxies, ignoring environment variables.
// `auth` indicates that HTTP Basic auth should be used to connect to the proxy, and
// supplies credentials.
// This will set an `Proxy-Authorization` header, overwriting any existing
// `Proxy-Authorization` custom headers you have set using `headers`.
proxy: {
host: '127.0.0.1',
port: 9000,
auth: {
username: 'mikeymike',
password: 'rapunz3l'
}
},
// `cancelToken` specifies a cancel token that can be used to cancel the request
// (see Cancellation section below for details)
cancelToken: new CancelToken(function (cancel) {
})
}
```
## Response Schema
The response for a request contains the following information.
```js
{
// `data` is the response that was provided by the server
data: {},
// `status` is the HTTP status code from the server response
status: 200,
// `statusText` is the HTTP status message from the server response
statusText: 'OK',
// `headers` the headers that the server responded with
// All header names are lower cased
headers: {},
// `config` is the config that was provided to `axios` for the request
config: {},
// `request` is the request that generated this response
// It is the last ClientRequest instance in node.js (in redirects)
// and an XMLHttpRequest instance in the browser
request: {}
}
```
When using `then`, you will receive the response as follows:
```js
axios.get('/user/12345')
.then(function (response) {
console.log(response.data);
console.log(response.status);
console.log(response.statusText);
console.log(response.headers);
console.log(response.config);
});
```
When using `catch`, or passing a [rejection callback](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise/then) as second parameter of `then`, the response will be available through the `error` object as explained in the [Handling Errors](#handling-errors) section.
## Config Defaults
You can specify config defaults that will be applied to every request.
### Global axios defaults
```js
axios.defaults.baseURL = 'https://api.example.com';
axios.defaults.headers.common['Authorization'] = AUTH_TOKEN;
axios.defaults.headers.post['Content-Type'] = 'application/x-www-form-urlencoded';
```
### Custom instance defaults
```js
// Set config defaults when creating the instance
const instance = axios.create({
baseURL: 'https://api.example.com'
});
// Alter defaults after instance has been created
instance.defaults.headers.common['Authorization'] = AUTH_TOKEN;
```
### Config order of precedence
Config will be merged with an order of precedence. The order is library defaults found in [lib/defaults.js](https://github.com/axios/axios/blob/master/lib/defaults.js#L28), then `defaults` property of the instance, and finally `config` argument for the request. The latter will take precedence over the former. Here's an example.
```js
// Create an instance using the config defaults provided by the library
// At this point the timeout config value is `0` as is the default for the library
const instance = axios.create();
// Override timeout default for the library
// Now all requests using this instance will wait 2.5 seconds before timing out
instance.defaults.timeout = 2500;
// Override timeout for this request as it's known to take a long time
instance.get('/longRequest', {
timeout: 5000
});
```
## Interceptors
You can intercept requests or responses before they are handled by `then` or `catch`.
```js
// Add a request interceptor
axios.interceptors.request.use(function (config) {
// Do something before request is sent
return config;
}, function (error) {
// Do something with request error
return Promise.reject(error);
});
// Add a response interceptor
axios.interceptors.response.use(function (response) {
// Any status code that lie within the range of 2xx cause this function to trigger
// Do something with response data
return response;
}, function (error) {
// Any status codes that falls outside the range of 2xx cause this function to trigger
// Do something with response error
return Promise.reject(error);
});
```
If you need to remove an interceptor later you can.
```js
const myInterceptor = axios.interceptors.request.use(function () {/*...*/});
axios.interceptors.request.eject(myInterceptor);
```
You can add interceptors to a custom instance of axios.
```js
const instance = axios.create();
instance.interceptors.request.use(function () {/*...*/});
```
## Handling Errors
```js
axios.get('/user/12345')
.catch(function (error) {
if (error.response) {
// The request was made and the server responded with a status code
// that falls out of the range of 2xx
console.log(error.response.data);
console.log(error.response.status);
console.log(error.response.headers);
} else if (error.request) {
// The request was made but no response was received
// `error.request` is an instance of XMLHttpRequest in the browser and an instance of
// http.ClientRequest in node.js
console.log(error.request);
} else {
// Something happened in setting up the request that triggered an Error
console.log('Error', error.message);
}
console.log(error.config);
});
```
Using the `validateStatus` config option, you can define HTTP code(s) that should throw an error.
```js
axios.get('/user/12345', {
validateStatus: function (status) {
return status < 500; // Reject only if the status code is greater than or equal to 500
}
})
```
Using `toJSON` you get an object with more information about the HTTP error.
```js
axios.get('/user/12345')
.catch(function (error) {
console.log(error.toJSON());
});
```
## Cancellation
You can cancel a request using a *cancel token*.
> The axios cancel token API is based on the withdrawn [cancelable promises proposal](https://github.com/tc39/proposal-cancelable-promises).
You can create a cancel token using the `CancelToken.source` factory as shown below:
```js
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// handle error
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// cancel the request (the message parameter is optional)
source.cancel('Operation canceled by the user.');
```
You can also create a cancel token by passing an executor function to the `CancelToken` constructor:
```js
const CancelToken = axios.CancelToken;
let cancel;
axios.get('/user/12345', {
cancelToken: new CancelToken(function executor(c) {
// An executor function receives a cancel function as a parameter
cancel = c;
})
});
// cancel the request
cancel();
```
> Note: you can cancel several requests with the same cancel token.
## Using application/x-www-form-urlencoded format
By default, axios serializes JavaScript objects to `JSON`. To send data in the `application/x-www-form-urlencoded` format instead, you can use one of the following options.
### Browser
In a browser, you can use the [`URLSearchParams`](https://developer.mozilla.org/en-US/docs/Web/API/URLSearchParams) API as follows:
```js
const params = new URLSearchParams();
params.append('param1', 'value1');
params.append('param2', 'value2');
axios.post('/foo', params);
```
> Note that `URLSearchParams` is not supported by all browsers (see [caniuse.com](http://www.caniuse.com/#feat=urlsearchparams)), but there is a [polyfill](https://github.com/WebReflection/url-search-params) available (make sure to polyfill the global environment).
Alternatively, you can encode data using the [`qs`](https://github.com/ljharb/qs) library:
```js
const qs = require('qs');
axios.post('/foo', qs.stringify({ 'bar': 123 }));
```
Or in another way (ES6),
```js
import qs from 'qs';
const data = { 'bar': 123 };
const options = {
method: 'POST',
headers: { 'content-type': 'application/x-www-form-urlencoded' },
data: qs.stringify(data),
url,
};
axios(options);
```
### Node.js
In node.js, you can use the [`querystring`](https://nodejs.org/api/querystring.html) module as follows:
```js
const querystring = require('querystring');
axios.post('http://something.com/', querystring.stringify({ foo: 'bar' }));
```
You can also use the [`qs`](https://github.com/ljharb/qs) library.
###### NOTE
The `qs` library is preferable if you need to stringify nested objects, as the `querystring` method has known issues with that use case (https://github.com/nodejs/node-v0.x-archive/issues/1665).
## Semver
Until axios reaches a `1.0` release, breaking changes will be released with a new minor version. For example `0.5.1`, and `0.5.4` will have the same API, but `0.6.0` will have breaking changes.
## Promises
axios depends on a native ES6 Promise implementation to be [supported](http://caniuse.com/promises).
If your environment doesn't support ES6 Promises, you can [polyfill](https://github.com/jakearchibald/es6-promise).
## TypeScript
axios includes [TypeScript](http://typescriptlang.org) definitions.
```typescript
import axios from 'axios';
axios.get('/user?ID=12345');
```
## Resources
* [Changelog](https://github.com/axios/axios/blob/master/CHANGELOG.md)
* [Upgrade Guide](https://github.com/axios/axios/blob/master/UPGRADE_GUIDE.md)
* [Ecosystem](https://github.com/axios/axios/blob/master/ECOSYSTEM.md)
* [Contributing Guide](https://github.com/axios/axios/blob/master/CONTRIBUTING.md)
* [Code of Conduct](https://github.com/axios/axios/blob/master/CODE_OF_CONDUCT.md)
## Credits
axios is heavily inspired by the [$http service](https://docs.angularjs.org/api/ng/service/$http) provided in [Angular](https://angularjs.org/). Ultimately axios is an effort to provide a standalone `$http`-like service for use outside of Angular.
## License
[MIT](LICENSE)
DeferredLevelDOWN
=================
**A mock LevelDOWN implementation that queues operations while a real LevelDOWN instance is being opened.**
<img alt="LevelDB Logo" height="100" src="http://leveldb.org/img/logo.svg">
[](http://travis-ci.org/Level/deferred-leveldown)
[](https://nodei.co/npm/deferred-leveldown/)
**DeferredLevelDOWN** implements the basic [AbstractLevelDOWN](https://github.com/rvagg/node-abstract-leveldown) API so it can be used as a drop-in replacement where LevelDOWN is needed.
`put()`, `get()`, `del()` and `batch()` operations are all queued and kept in memory until a new LevelDOWN-compatible object can be supplied.
The `setDb(db)` method is used to supply a new LevelDOWN object. Once received, all queued operations are replayed against that object, in order.
`batch()` operations will all be replayed as the array form. Chained-batch operations are converted before being stored.
Contributing
------------
DeferredLevelDOWN is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [CONTRIBUTING.md](https://github.com/rvagg/node-levelup/blob/master/CONTRIBUTING.md) file for more details.
### Contributors
DeferredLevelDOWN is only possible due to the excellent work of the following contributors:
<table><tbody>
<tr><th align="left">Rod Vagg</th><td><a href="https://github.com/rvagg">GitHub/rvagg</a></td><td><a href="http://twitter.com/rvagg">Twitter/@rvagg</a></td></tr>
<tr><th align="left">John Chesley</th><td><a href="https://github.com/chesles/">GitHub/chesles</a></td><td><a href="http://twitter.com/chesles">Twitter/@chesles</a></td></tr>
<tr><th align="left">Jake Verbaten</th><td><a href="https://github.com/raynos">GitHub/raynos</a></td><td><a href="http://twitter.com/raynos2">Twitter/@raynos2</a></td></tr>
<tr><th align="left">Dominic Tarr</th><td><a href="https://github.com/dominictarr">GitHub/dominictarr</a></td><td><a href="http://twitter.com/dominictarr">Twitter/@dominictarr</a></td></tr>
<tr><th align="left">Max Ogden</th><td><a href="https://github.com/maxogden">GitHub/maxogden</a></td><td><a href="http://twitter.com/maxogden">Twitter/@maxogden</a></td></tr>
<tr><th align="left">Lars-Magnus Skog</th><td><a href="https://github.com/ralphtheninja">GitHub/ralphtheninja</a></td><td><a href="http://twitter.com/ralphtheninja">Twitter/@ralphtheninja</a></td></tr>
<tr><th align="left">David Björklund</th><td><a href="https://github.com/kesla">GitHub/kesla</a></td><td><a href="http://twitter.com/david_bjorklund">Twitter/@david_bjorklund</a></td></tr>
<tr><th align="left">Julian Gruber</th><td><a href="https://github.com/juliangruber">GitHub/juliangruber</a></td><td><a href="http://twitter.com/juliangruber">Twitter/@juliangruber</a></td></tr>
<tr><th align="left">Paolo Fragomeni</th><td><a href="https://github.com/hij1nx">GitHub/hij1nx</a></td><td><a href="http://twitter.com/hij1nx">Twitter/@hij1nx</a></td></tr>
<tr><th align="left">Anton Whalley</th><td><a href="https://github.com/No9">GitHub/No9</a></td><td><a href="https://twitter.com/antonwhalley">Twitter/@antonwhalley</a></td></tr>
<tr><th align="left">Matteo Collina</th><td><a href="https://github.com/mcollina">GitHub/mcollina</a></td><td><a href="https://twitter.com/matteocollina">Twitter/@matteocollina</a></td></tr>
<tr><th align="left">Pedro Teixeira</th><td><a href="https://github.com/pgte">GitHub/pgte</a></td><td><a href="https://twitter.com/pgte">Twitter/@pgte</a></td></tr>
<tr><th align="left">James Halliday</th><td><a href="https://github.com/substack">GitHub/substack</a></td><td><a href="https://twitter.com/substack">Twitter/@substack</a></td></tr>
</tbody></table>
<a name="license"></a>
License & copyright
-------------------
Copyright (c) 2013-2015 DeferredLevelDOWN contributors (listed above).
DeferredLevelDOWN is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE.md file for more details.
# sprintf.js
**sprintf.js** is a complete open source JavaScript sprintf implementation for the *browser* and *node.js*.
Its prototype is simple:
string sprintf(string format , [mixed arg1 [, mixed arg2 [ ,...]]])
The placeholders in the format string are marked by `%` and are followed by one or more of these elements, in this order:
* An optional number followed by a `$` sign that selects which argument index to use for the value. If not specified, arguments will be placed in the same order as the placeholders in the input string.
* An optional `+` sign that forces to preceed the result with a plus or minus sign on numeric values. By default, only the `-` sign is used on negative numbers.
* An optional padding specifier that says what character to use for padding (if specified). Possible values are `0` or any other character precedeed by a `'` (single quote). The default is to pad with *spaces*.
* An optional `-` sign, that causes sprintf to left-align the result of this placeholder. The default is to right-align the result.
* An optional number, that says how many characters the result should have. If the value to be returned is shorter than this number, the result will be padded. When used with the `j` (JSON) type specifier, the padding length specifies the tab size used for indentation.
* An optional precision modifier, consisting of a `.` (dot) followed by a number, that says how many digits should be displayed for floating point numbers. When used with the `g` type specifier, it specifies the number of significant digits. When used on a string, it causes the result to be truncated.
* A type specifier that can be any of:
* `%` — yields a literal `%` character
* `b` — yields an integer as a binary number
* `c` — yields an integer as the character with that ASCII value
* `d` or `i` — yields an integer as a signed decimal number
* `e` — yields a float using scientific notation
* `u` — yields an integer as an unsigned decimal number
* `f` — yields a float as is; see notes on precision above
* `g` — yields a float as is; see notes on precision above
* `o` — yields an integer as an octal number
* `s` — yields a string as is
* `x` — yields an integer as a hexadecimal number (lower-case)
* `X` — yields an integer as a hexadecimal number (upper-case)
* `j` — yields a JavaScript object or array as a JSON encoded string
## JavaScript `vsprintf`
`vsprintf` is the same as `sprintf` except that it accepts an array of arguments, rather than a variable number of arguments:
vsprintf("The first 4 letters of the english alphabet are: %s, %s, %s and %s", ["a", "b", "c", "d"])
## Argument swapping
You can also swap the arguments. That is, the order of the placeholders doesn't have to match the order of the arguments. You can do that by simply indicating in the format string which arguments the placeholders refer to:
sprintf("%2$s %3$s a %1$s", "cracker", "Polly", "wants")
And, of course, you can repeat the placeholders without having to increase the number of arguments.
## Named arguments
Format strings may contain replacement fields rather than positional placeholders. Instead of referring to a certain argument, you can now refer to a certain key within an object. Replacement fields are surrounded by rounded parentheses - `(` and `)` - and begin with a keyword that refers to a key:
var user = {
name: "Dolly"
}
sprintf("Hello %(name)s", user) // Hello Dolly
Keywords in replacement fields can be optionally followed by any number of keywords or indexes:
var users = [
{name: "Dolly"},
{name: "Molly"},
{name: "Polly"}
]
sprintf("Hello %(users[0].name)s, %(users[1].name)s and %(users[2].name)s", {users: users}) // Hello Dolly, Molly and Polly
Note: mixing positional and named placeholders is not (yet) supported
## Computed values
You can pass in a function as a dynamic value and it will be invoked (with no arguments) in order to compute the value on-the-fly.
sprintf("Current timestamp: %d", Date.now) // Current timestamp: 1398005382890
sprintf("Current date and time: %s", function() { return new Date().toString() })
# AngularJS
You can now use `sprintf` and `vsprintf` (also aliased as `fmt` and `vfmt` respectively) in your AngularJS projects. See `demo/`.
# Installation
## Via Bower
bower install sprintf
## Or as a node.js module
npm install sprintf-js
### Usage
var sprintf = require("sprintf-js").sprintf,
vsprintf = require("sprintf-js").vsprintf
sprintf("%2$s %3$s a %1$s", "cracker", "Polly", "wants")
vsprintf("The first 4 letters of the english alphabet are: %s, %s, %s and %s", ["a", "b", "c", "d"])
# License
**sprintf.js** is licensed under the terms of the 3-clause BSD license.
# braces [](https://www.npmjs.com/package/braces) [](https://npmjs.org/package/braces) [](https://travis-ci.org/jonschlinkert/braces)
Fastest brace expansion for node.js, with the most complete support for the Bash 4.3 braces specification.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install braces --save
```
## Features
* Complete support for the braces part of the [Bash 4.3 Brace Expansion](www.gnu.org/software/bash/). Braces passes [all of the relevant unit tests](#bash-4-3-support) from the spec.
* Expands comma-separated values: `a/{b,c}/d` => `['a/b/d', 'a/c/d']`
* Expands alphabetical or numerical ranges: `{1..3}` => `['1', '2', '3']`
* [Very fast](#benchmarks)
* [Special characters](./patterns.md) can be used to generate interesting patterns.
## Example usage
```js
var braces = require('braces');
braces('a/{x,y}/c{d}e')
//=> ['a/x/cde', 'a/y/cde']
braces('a/b/c/{x,y}')
//=> ['a/b/c/x', 'a/b/c/y']
braces('a/{x,{1..5},y}/c{d}e')
//=> ['a/x/cde', 'a/1/cde', 'a/y/cde', 'a/2/cde', 'a/3/cde', 'a/4/cde', 'a/5/cde']
```
### Use case: fixtures
> Use braces to generate test fixtures!
**Example**
```js
var braces = require('./');
var path = require('path');
var fs = require('fs');
braces('blah/{a..z}.js').forEach(function(fp) {
if (!fs.existsSync(path.dirname(fp))) {
fs.mkdirSync(path.dirname(fp));
}
fs.writeFileSync(fp, '');
});
```
See the [tests](./test/test.js) for more examples and use cases (also see the [bash spec tests](./test/bash-mm-adjusted.js));
### Range expansion
Uses [expand-range](https://github.com/jonschlinkert/expand-range) for range expansion.
```js
braces('a{1..3}b')
//=> ['a1b', 'a2b', 'a3b']
braces('a{5..8}b')
//=> ['a5b', 'a6b', 'a7b', 'a8b']
braces('a{00..05}b')
//=> ['a00b', 'a01b', 'a02b', 'a03b', 'a04b', 'a05b']
braces('a{01..03}b')
//=> ['a01b', 'a02b', 'a03b']
braces('a{000..005}b')
//=> ['a000b', 'a001b', 'a002b', 'a003b', 'a004b', 'a005b']
braces('a{a..e}b')
//=> ['aab', 'abb', 'acb', 'adb', 'aeb']
braces('a{A..E}b')
//=> ['aAb', 'aBb', 'aCb', 'aDb', 'aEb']
```
Pass a function as the last argument to customize range expansions:
```js
var range = braces('x{a..e}y', function (str, i) {
return String.fromCharCode(str) + i;
});
console.log(range);
//=> ['xa0y', 'xb1y', 'xc2y', 'xd3y', 'xe4y']
```
See [expand-range](https://github.com/jonschlinkert/expand-range) for benchmarks, tests and the full list of range expansion features.
## Options
### options.makeRe
Type: `Boolean`
Deafault: `false`
Return a regex-optimal string. If you're using braces to generate regex, this will result in dramatically faster performance.
**Examples**
With the default settings (`{makeRe: false}`):
```js
braces('{1..5}');
//=> ['1', '2', '3', '4', '5']
```
With `{makeRe: true}`:
```js
braces('{1..5}', {makeRe: true});
//=> ['[1-5]']
braces('{3..9..3}', {makeRe: true});
//=> ['(3|6|9)']
```
### options.bash
Type: `Boolean`
Default: `false`
Enables complete support for the Bash specification. The downside is a 20-25% speed decrease.
**Example**
Using the default setting (`{bash: false}`):
```js
braces('a{b}c');
//=> ['abc']
```
In bash (and minimatch), braces with one item are not expanded. To get the same result with braces, set `{bash: true}`:
```js
braces('a{b}c', {bash: true});
//=> ['a{b}c']
```
### options.nodupes
Type: `Boolean`
Deafault: `true`
Duplicates are removed by default. To keep duplicates, pass `{nodupes: false}` on the options
## Bash 4.3 Support
> Better support for Bash 4.3 than minimatch
This project has comprehensive unit tests, including tests coverted from [Bash 4.3](www.gnu.org/software/bash/). Currently only 8 of 102 unit tests fail, and
## Run benchmarks
Install dev dependencies:
```bash
npm i -d && npm benchmark
```
### Latest results
```bash
#1: escape.js
brace-expansion.js x 114,934 ops/sec ±1.24% (93 runs sampled)
braces.js x 342,254 ops/sec ±0.84% (90 runs sampled)
#2: exponent.js
brace-expansion.js x 12,359 ops/sec ±0.86% (96 runs sampled)
braces.js x 20,389 ops/sec ±0.71% (97 runs sampled)
#3: multiple.js
brace-expansion.js x 114,469 ops/sec ±1.44% (94 runs sampled)
braces.js x 401,621 ops/sec ±0.87% (91 runs sampled)
#4: nested.js
brace-expansion.js x 102,769 ops/sec ±1.55% (92 runs sampled)
braces.js x 314,088 ops/sec ±0.71% (98 runs sampled)
#5: normal.js
brace-expansion.js x 157,577 ops/sec ±1.65% (91 runs sampled)
braces.js x 1,115,950 ops/sec ±0.74% (94 runs sampled)
#6: range.js
brace-expansion.js x 138,822 ops/sec ±1.71% (91 runs sampled)
braces.js x 1,108,353 ops/sec ±0.85% (94 runs sampled)
```
## Related projects
You might also be interested in these projects:
* [expand-range](https://www.npmjs.com/package/expand-range): Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. See… [more](https://www.npmjs.com/package/expand-range) | [homepage](https://github.com/jonschlinkert/expand-range)
* [fill-range](https://www.npmjs.com/package/fill-range): Fill in a range of numbers or letters, optionally passing an increment or multiplier to… [more](https://www.npmjs.com/package/fill-range) | [homepage](https://github.com/jonschlinkert/fill-range)
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. | [homepage](https://github.com/jonschlinkert/micromatch)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/braces/issues/new).
## Building docs
Generate readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install verb && npm run docs
```
Or, if [verb](https://github.com/verbose/verb) is installed globally:
```sh
$ verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/braces/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v0.9.0, on May 21, 2016._
# utf-8-validate
[](https://www.npmjs.com/package/utf-8-validate)
[](https://travis-ci.com/websockets/utf-8-validate)
[](https://ci.appveyor.com/project/lpinca/utf-8-validate)
Check if a buffer contains valid UTF-8 encoded text.
## Installation
```
npm install utf-8-validate --save-optional
```
The `--save-optional` flag tells npm to save the package in your package.json
under the [`optionalDependencies`](https://docs.npmjs.com/files/package.json#optionaldependencies)
key.
## API
The module exports a single function which takes one argument.
### `isValidUTF8(buffer)`
Checks whether a buffer contains valid UTF-8.
#### Arguments
- `buffer` - The buffer to check.
#### Return value
`true` if the buffer contains only correct UTF-8, else `false`.
#### Example
```js
'use strict';
const isValidUTF8 = require('utf-8-validate');
const buf = Buffer.from([0xf0, 0x90, 0x80, 0x80]);
console.log(isValidUTF8(buf));
// => true
```
## License
[MIT](LICENSE)
## Swarm.js
This library allows you to interact with the Swarm network from JavaScript.
### Getting started
1. Install
```bash
npm install swarm-js
```
2. Import
```javascript
// Loads the Swarm API pointing to the official gateway
const swarm = require("swarm-js").at("http://swarm-gateways.net");
```
### Examples
#### Uploads
- With JSON:
- Raw data:
```javascript
const file = "test file"; // could also be an Uint8Array of binary data
swarm.upload(file).then(hash => {
console.log("Uploaded file. Address:", hash);
})
```
- Directory:
To upload a directory, just call `swarm.upload(directory)`, where directory is an object mapping paths to entries, those containing a mime-type and the data (Uint8Array or UTF-8 String).
```javascript
const dir = {
"/foo.txt": {type: "text/plain", data: "file 0"},
"/bar.txt": {type: "text/plain", data: "file 1"}
};
swarm.upload(dir).then(hash => {
console.log("Uploaded directory. Address:", hash);
});
```
- From disk:
- On Node.js:
```javascript
swarm.upload({
path: "/path/to/thing", // path to data / file / directory
kind: "directory", // could also be "file" or "data"
defaultFile: "/index.html"}) // optional, and only for kind === "directory"
.then(console.log)
.catch(console.log);
```
- On browsers:
```javascript
// only works inside an event
document.onClick = function() {
swarm.upload({pick: "file"}) // could also be "directory" or "data"
.then(alert);
};
```
#### Downloads
- With JSON:
- Raw data:
```javascript
const fileHash = "a5c10851ef054c268a2438f10a21f6efe3dc3dcdcc2ea0e6a1a7a38bf8c91e23";
swarm.download(fileHash).then(array => {
console.log("Downloaded file:", swarm.toString(array));
});
```
- Directory:
```javascript
const dirHash = "7e980476df218c05ecfcb0a2ca73597193a34c5a9d6da84d54e295ecd8e0c641";
swarm.download(dirHash).then(dir => {
console.log("Downloaded directory:");
for (let path in dir) {
console.log("-", path, ":", dir[path].data.toString());
}
});
```
- To disk:
- On Node.js:
```javascript
swarm.download("DAPP_HASH", "/target/dir")
.then(path => console.log(`Downloaded DApp to ${path}.`))
.catch(console.log);
```
- On browser:
(Just link the Swarm URL.)
#### SwarmHash
```javascript
console.log(swarm.hash("unicode string áéíóú λ"));
console.log(swarm.hash("0x41414141"));
console.log(swarm.hash([65, 65, 65, 65]));
console.log(swarm.hash(new Uint8Array([65, 65, 65, 65])));
```
### More
For more examples, check out [examples](/examples).
# node-errno
> Better [libuv](https://github.com/libuv/libuv)/[Node.js](https://nodejs.org)/[io.js](https://iojs.org) error handling & reporting. Available in npm as *errno*.
[](https://www.npmjs.com/package/errno)
[](http://travis-ci.org/rvagg/node-errno)
[](https://www.npmjs.com/package/errno)
* [errno exposed](#errnoexposed)
* [Custom errors](#customerrors)
<a name="errnoexposed"></a>
## errno exposed
Ever find yourself needing more details about Node.js errors? Me too, so *node-errno* contains the errno mappings direct from libuv so you can use them in your code.
**By errno:**
```js
require('errno').errno[3]
// → {
// "errno": 3,
// "code": "EACCES",
// "description": "permission denied"
// }
```
**By code:**
```js
require('errno').code.ENOTEMPTY
// → {
// "errno": 53,
// "code": "ENOTEMPTY",
// "description": "directory not empty"
// }
```
**Make your errors more descriptive:**
```js
var errno = require('errno')
function errmsg(err) {
var str = 'Error: '
// if it's a libuv error then get the description from errno
if (errno.errno[err.errno])
str += errno.errno[err.errno].description
else
str += err.message
// if it's a `fs` error then it'll have a 'path' property
if (err.path)
str += ' [' + err.path + ']'
return str
}
var fs = require('fs')
fs.readFile('thisisnotarealfile.txt', function (err, data) {
if (err)
console.log(errmsg(err))
})
```
**Use as a command line tool:**
```
~ $ errno 53
{
"errno": 53,
"code": "ENOTEMPTY",
"description": "directory not empty"
}
~ $ errno EROFS
{
"errno": 56,
"code": "EROFS",
"description": "read-only file system"
}
~ $ errno foo
No such errno/code: "foo"
```
Supply no arguments for the full list. Error codes are processed case-insensitive.
You will need to install with `npm install errno -g` if you want the `errno` command to be available without supplying a full path to the node_modules installation.
<a name="customerrors"></a>
## Custom errors
Use `errno.custom.createError()` to create custom `Error` objects to throw around in your Node.js library. Create error hierarchies so `instanceof` becomes a useful tool in tracking errors. Call-stack is correctly captured at the time you create an instance of the error object, plus a `cause` property will make available the original error object if you pass one in to the constructor.
```js
var create = require('errno').custom.createError
var MyError = create('MyError') // inherits from Error
var SpecificError = create('SpecificError', MyError) // inherits from MyError
var OtherError = create('OtherError', MyError)
// use them!
if (condition) throw new SpecificError('Eeek! Something bad happened')
if (err) return callback(new OtherError(err))
```
Also available is a `errno.custom.FilesystemError` with in-built access to errno properties:
```js
fs.readFile('foo', function (err, data) {
if (err) return callback(new errno.custom.FilesystemError(err))
// do something else
})
```
The resulting error object passed through the callback will have the following properties: `code`, `errno`, `path` and `message` will contain a descriptive human-readable message.
## Contributors
* [bahamas10](https://github.com/bahamas10) (Dave Eddy) - Added CLI
* [ralphtheninja](https://github.com/ralphtheninja) (Lars-Magnus Skog)
## Copyright & Licence
*Copyright (c) 2012-2015 [Rod Vagg](https://github.com/rvagg) ([@rvagg](https://twitter.com/rvagg))*
Made available under the MIT licence:
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is furnished
to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# Dot Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a lower case string with a period between words.
## Installation
```
npm install dot-case --save
```
## Usage
```js
import { dotCase } from "dot-case";
dotCase("string"); //=> "string"
dotCase("dot.case"); //=> "dot.case"
dotCase("PascalCase"); //=> "pascal.case"
dotCase("version 1.2.10"); //=> "version.1.2.10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/dot-case.svg?style=flat
[npm-url]: https://npmjs.org/package/dot-case
[downloads-image]: https://img.shields.io/npm/dm/dot-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/dot-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/dot-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=dot-case
# sha.js
[](https://www.npmjs.org/package/sha.js)
[](https://travis-ci.org/crypto-browserify/sha.js)
[](https://david-dm.org/crypto-browserify/sha.js#info=dependencies)
[](https://github.com/feross/standard)
Node style `SHA` on pure JavaScript.
```js
var shajs = require('sha.js')
console.log(shajs('sha256').update('42').digest('hex'))
// => 73475cb40a568e8da8a045ced110137e159f890ac4da883b6b17dc651b3a8049
console.log(new shajs.sha256().update('42').digest('hex'))
// => 73475cb40a568e8da8a045ced110137e159f890ac4da883b6b17dc651b3a8049
var sha256stream = shajs('sha256')
sha256stream.end('42')
console.log(sha256stream.read().toString('hex'))
// => 73475cb40a568e8da8a045ced110137e159f890ac4da883b6b17dc651b3a8049
```
## supported hashes
`sha.js` currently implements:
- SHA (SHA-0) -- **legacy, do not use in new systems**
- SHA-1 -- **legacy, do not use in new systems**
- SHA-224
- SHA-256
- SHA-384
- SHA-512
## Not an actual stream
Note, this doesn't actually implement a stream, but wrapping this in a stream is trivial.
It does update incrementally, so you can hash things larger than RAM, as it uses a constant amount of memory (except when using base64 or utf8 encoding, see code comments).
## Acknowledgements
This work is derived from Paul Johnston's [A JavaScript implementation of the Secure Hash Algorithm](http://pajhome.org.uk/crypt/md5/sha1.html).
## LICENSE [MIT](LICENSE)
# Capital Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a space separated string with each word capitalized.
## Installation
```
npm install capital-case --save
```
## Usage
```js
import { capitalCase } from "capital-case";
capitalCase("string"); //=> "String"
capitalCase("dot.case"); //=> "Dot Case"
capitalCase("PascalCase"); //=> "Pascal Case"
capitalCase("version 1.2.10"); //=> "Version 1 2 10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/capital-case.svg?style=flat
[npm-url]: https://npmjs.org/package/capital-case
[downloads-image]: https://img.shields.io/npm/dm/capital-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/capital-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/capital-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=capital-case
# type-check [](https://travis-ci.org/gkz/type-check)
<a name="type-check" />
`type-check` is a library which allows you to check the types of JavaScript values at runtime with a Haskell like type syntax. It is great for checking external input, for testing, or even for adding a bit of safety to your internal code. It is a major component of [levn](https://github.com/gkz/levn). MIT license. Version 0.3.2. Check out the [demo](http://gkz.github.io/type-check/).
For updates on `type-check`, [follow me on twitter](https://twitter.com/gkzahariev).
npm install type-check
## Quick Examples
```js
// Basic types:
var typeCheck = require('type-check').typeCheck;
typeCheck('Number', 1); // true
typeCheck('Number', 'str'); // false
typeCheck('Error', new Error); // true
typeCheck('Undefined', undefined); // true
// Comment
typeCheck('count::Number', 1); // true
// One type OR another type:
typeCheck('Number | String', 2); // true
typeCheck('Number | String', 'str'); // true
// Wildcard, matches all types:
typeCheck('*', 2) // true
// Array, all elements of a single type:
typeCheck('[Number]', [1, 2, 3]); // true
typeCheck('[Number]', [1, 'str', 3]); // false
// Tuples, or fixed length arrays with elements of different types:
typeCheck('(String, Number)', ['str', 2]); // true
typeCheck('(String, Number)', ['str']); // false
typeCheck('(String, Number)', ['str', 2, 5]); // false
// Object properties:
typeCheck('{x: Number, y: Boolean}', {x: 2, y: false}); // true
typeCheck('{x: Number, y: Boolean}', {x: 2}); // false
typeCheck('{x: Number, y: Maybe Boolean}', {x: 2}); // true
typeCheck('{x: Number, y: Boolean}', {x: 2, y: false, z: 3}); // false
typeCheck('{x: Number, y: Boolean, ...}', {x: 2, y: false, z: 3}); // true
// A particular type AND object properties:
typeCheck('RegExp{source: String, ...}', /re/i); // true
typeCheck('RegExp{source: String, ...}', {source: 're'}); // false
// Custom types:
var opt = {customTypes:
{Even: { typeOf: 'Number', validate: function(x) { return x % 2 === 0; }}}};
typeCheck('Even', 2, opt); // true
// Nested:
var type = '{a: (String, [Number], {y: Array, ...}), b: Error{message: String, ...}}'
typeCheck(type, {a: ['hi', [1, 2, 3], {y: [1, 'ms']}], b: new Error('oh no')}); // true
```
Check out the [type syntax format](#syntax) and [guide](#guide).
## Usage
`require('type-check');` returns an object that exposes four properties. `VERSION` is the current version of the library as a string. `typeCheck`, `parseType`, and `parsedTypeCheck` are functions.
```js
// typeCheck(type, input, options);
typeCheck('Number', 2); // true
// parseType(type);
var parsedType = parseType('Number'); // object
// parsedTypeCheck(parsedType, input, options);
parsedTypeCheck(parsedType, 2); // true
```
### typeCheck(type, input, options)
`typeCheck` checks a JavaScript value `input` against `type` written in the [type format](#type-format) (and taking account the optional `options`) and returns whether the `input` matches the `type`.
##### arguments
* type - `String` - the type written in the [type format](#type-format) which to check against
* input - `*` - any JavaScript value, which is to be checked against the type
* options - `Maybe Object` - an optional parameter specifying additional options, currently the only available option is specifying [custom types](#custom-types)
##### returns
`Boolean` - whether the input matches the type
##### example
```js
typeCheck('Number', 2); // true
```
### parseType(type)
`parseType` parses string `type` written in the [type format](#type-format) into an object representing the parsed type.
##### arguments
* type - `String` - the type written in the [type format](#type-format) which to parse
##### returns
`Object` - an object in the parsed type format representing the parsed type
##### example
```js
parseType('Number'); // [{type: 'Number'}]
```
### parsedTypeCheck(parsedType, input, options)
`parsedTypeCheck` checks a JavaScript value `input` against parsed `type` in the parsed type format (and taking account the optional `options`) and returns whether the `input` matches the `type`. Use this in conjunction with `parseType` if you are going to use a type more than once.
##### arguments
* type - `Object` - the type in the parsed type format which to check against
* input - `*` - any JavaScript value, which is to be checked against the type
* options - `Maybe Object` - an optional parameter specifying additional options, currently the only available option is specifying [custom types](#custom-types)
##### returns
`Boolean` - whether the input matches the type
##### example
```js
parsedTypeCheck([{type: 'Number'}], 2); // true
var parsedType = parseType('String');
parsedTypeCheck(parsedType, 'str'); // true
```
<a name="type-format" />
## Type Format
### Syntax
White space is ignored. The root node is a __Types__.
* __Identifier__ = `[\$\w]+` - a group of any lower or upper case letters, numbers, underscores, or dollar signs - eg. `String`
* __Type__ = an `Identifier`, an `Identifier` followed by a `Structure`, just a `Structure`, or a wildcard `*` - eg. `String`, `Object{x: Number}`, `{x: Number}`, `Array{0: String, 1: Boolean, length: Number}`, `*`
* __Types__ = optionally a comment (an `Indentifier` followed by a `::`), optionally the identifier `Maybe`, one or more `Type`, separated by `|` - eg. `Number`, `String | Date`, `Maybe Number`, `Maybe Boolean | String`
* __Structure__ = `Fields`, or a `Tuple`, or an `Array` - eg. `{x: Number}`, `(String, Number)`, `[Date]`
* __Fields__ = a `{`, followed one or more `Field` separated by a comma `,` (trailing comma `,` is permitted), optionally an `...` (always preceded by a comma `,`), followed by a `}` - eg. `{x: Number, y: String}`, `{k: Function, ...}`
* __Field__ = an `Identifier`, followed by a colon `:`, followed by `Types` - eg. `x: Date | String`, `y: Boolean`
* __Tuple__ = a `(`, followed by one or more `Types` separated by a comma `,` (trailing comma `,` is permitted), followed by a `)` - eg `(Date)`, `(Number, Date)`
* __Array__ = a `[` followed by exactly one `Types` followed by a `]` - eg. `[Boolean]`, `[Boolean | Null]`
### Guide
`type-check` uses `Object.toString` to find out the basic type of a value. Specifically,
```js
{}.toString.call(VALUE).slice(8, -1)
{}.toString.call(true).slice(8, -1) // 'Boolean'
```
A basic type, eg. `Number`, uses this check. This is much more versatile than using `typeof` - for example, with `document`, `typeof` produces `'object'` which isn't that useful, and our technique produces `'HTMLDocument'`.
You may check for multiple types by separating types with a `|`. The checker proceeds from left to right, and passes if the value is any of the types - eg. `String | Boolean` first checks if the value is a string, and then if it is a boolean. If it is none of those, then it returns false.
Adding a `Maybe` in front of a list of multiple types is the same as also checking for `Null` and `Undefined` - eg. `Maybe String` is equivalent to `Undefined | Null | String`.
You may add a comment to remind you of what the type is for by following an identifier with a `::` before a type (or multiple types). The comment is simply thrown out.
The wildcard `*` matches all types.
There are three types of structures for checking the contents of a value: 'fields', 'tuple', and 'array'.
If used by itself, a 'fields' structure will pass with any type of object as long as it is an instance of `Object` and the properties pass - this allows for duck typing - eg. `{x: Boolean}`.
To check if the properties pass, and the value is of a certain type, you can specify the type - eg. `Error{message: String}`.
If you want to make a field optional, you can simply use `Maybe` - eg. `{x: Boolean, y: Maybe String}` will still pass if `y` is undefined (or null).
If you don't care if the value has properties beyond what you have specified, you can use the 'etc' operator `...` - eg. `{x: Boolean, ...}` will match an object with an `x` property that is a boolean, and with zero or more other properties.
For an array, you must specify one or more types (separated by `|`) - it will pass for something of any length as long as each element passes the types provided - eg. `[Number]`, `[Number | String]`.
A tuple checks for a fixed number of elements, each of a potentially different type. Each element is separated by a comma - eg. `(String, Number)`.
An array and tuple structure check that the value is of type `Array` by default, but if another type is specified, they will check for that instead - eg. `Int32Array[Number]`. You can use the wildcard `*` to search for any type at all.
Check out the [type precedence](https://github.com/zaboco/type-precedence) library for type-check.
## Options
Options is an object. It is an optional parameter to the `typeCheck` and `parsedTypeCheck` functions. The only current option is `customTypes`.
<a name="custom-types" />
### Custom Types
__Example:__
```js
var options = {
customTypes: {
Even: {
typeOf: 'Number',
validate: function(x) {
return x % 2 === 0;
}
}
}
};
typeCheck('Even', 2, options); // true
typeCheck('Even', 3, options); // false
```
`customTypes` allows you to set up custom types for validation. The value of this is an object. The keys of the object are the types you will be matching. Each value of the object will be an object having a `typeOf` property - a string, and `validate` property - a function.
The `typeOf` property is the type the value should be, and `validate` is a function which should return true if the value is of that type. `validate` receives one parameter, which is the value that we are checking.
## Technical About
`type-check` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It also uses the [prelude.ls](http://preludels.com/) library.
[](https://nodei.co/npm/continuation-local-storage/)
# Continuation-Local Storage
Continuation-local storage works like thread-local storage in threaded
programming, but is based on chains of Node-style callbacks instead of threads.
The standard Node convention of functions calling functions is very similar to
something called ["continuation-passing style"][cps] in functional programming,
and the name comes from the way this module allows you to set and get values
that are scoped to the lifetime of these chains of function calls.
Suppose you're writing a module that fetches a user and adds it to a session
before calling a function passed in by a user to continue execution:
```javascript
// setup.js
var createNamespace = require('continuation-local-storage').createNamespace;
var session = createNamespace('my session');
var db = require('./lib/db.js');
function start(options, next) {
db.fetchUserById(options.id, function (error, user) {
if (error) return next(error);
session.set('user', user);
next();
});
}
```
Later on in the process of turning that user's data into an HTML page, you call
another function (maybe defined in another module entirely) that wants to fetch
the value you set earlier:
```javascript
// send_response.js
var getNamespace = require('continuation-local-storage').getNamespace;
var session = getNamespace('my session');
var render = require('./lib/render.js')
function finish(response) {
var user = session.get('user');
render({user: user}).pipe(response);
}
```
When you set values in continuation-local storage, those values are accessible
until all functions called from the original function – synchronously or
asynchronously – have finished executing. This includes callbacks passed to
`process.nextTick` and the [timer functions][] ([setImmediate][],
[setTimeout][], and [setInterval][]), as well as callbacks passed to
asynchronous functions that call native functions (such as those exported from
the `fs`, `dns`, `zlib` and `crypto` modules).
A simple rule of thumb is anywhere where you might have set a property on the
`request` or `response` objects in an HTTP handler, you can (and should) now
use continuation-local storage. This API is designed to allow you extend the
scope of a variable across a sequence of function calls, but with values
specific to each sequence of calls.
Values are grouped into namespaces, created with `createNamespace()`. Sets of
function calls are grouped together by calling them within the function passed
to `.run()` on the namespace object. Calls to `.run()` can be nested, and each
nested context this creates has its own copy of the set of values from the
parent context. When a function is making multiple asynchronous calls, this
allows each child call to get, set, and pass along its own context without
overwriting the parent's.
A simple, annotated example of how this nesting behaves:
```javascript
var createNamespace = require('continuation-local-storage').createNamespace;
var writer = createNamespace('writer');
writer.run(function () {
writer.set('value', 0);
requestHandler();
});
function requestHandler() {
writer.run(function(outer) {
// writer.get('value') returns 0
// outer.value is 0
writer.set('value', 1);
// writer.get('value') returns 1
// outer.value is 1
process.nextTick(function() {
// writer.get('value') returns 1
// outer.value is 1
writer.run(function(inner) {
// writer.get('value') returns 1
// outer.value is 1
// inner.value is 1
writer.set('value', 2);
// writer.get('value') returns 2
// outer.value is 1
// inner.value is 2
});
});
});
setTimeout(function() {
// runs with the default context, because nested contexts have ended
console.log(writer.get('value')); // prints 0
}, 1000);
}
```
## cls.createNamespace(name)
* return: {Namespace}
Each application wanting to use continuation-local values should create its own
namespace. Reading from (or, more significantly, writing to) namespaces that
don't belong to you is a faux pas.
## cls.getNamespace(name)
* return: {Namespace}
Look up an existing namespace.
## cls.destroyNamespace(name)
Dispose of an existing namespace. WARNING: be sure to dispose of any references
to destroyed namespaces in your old code, as contexts associated with them will
no longer be propagated.
## cls.reset()
Completely reset all continuation-local storage namespaces. WARNING: while this
will stop the propagation of values in any existing namespaces, if there are
remaining references to those namespaces in code, the associated storage will
still be reachable, even though the associated state is no longer being updated.
Make sure you clean up any references to destroyed namespaces yourself.
## process.namespaces
* return: dictionary of {Namespace} objects
Continuation-local storage has a performance cost, and so it isn't enabled
until the module is loaded for the first time. Once the module is loaded, the
current set of namespaces is available in `process.namespaces`, so library code
that wants to use continuation-local storage only when it's active should test
for the existence of `process.namespaces`.
## Class: Namespace
Application-specific namespaces group values local to the set of functions
whose calls originate from a callback passed to `namespace.run()` or
`namespace.bind()`.
### namespace.active
* return: the currently active context on a namespace
### namespace.set(key, value)
* return: `value`
Set a value on the current continuation context. Must be set within an active
continuation chain started with `namespace.run()` or `namespace.bind()`.
### namespace.get(key)
* return: the requested value, or `undefined`
Look up a value on the current continuation context. Recursively searches from
the innermost to outermost nested continuation context for a value associated
with a given key. Must be set within an active continuation chain started with
`namespace.run()` or `namespace.bind()`.
### namespace.run(callback)
* return: the context associated with that callback
Create a new context on which values can be set or read. Run all the functions
that are called (either directly, or indirectly through asynchronous functions
that take callbacks themselves) from the provided callback within the scope of
that namespace. The new context is passed as an argument to the callback
when it's called.
### namespace.runAndReturn(callback)
* return: the return value of the callback
Create a new context on which values can be set or read. Run all the functions
that are called (either directly, or indirectly through asynchronous functions
that take callbacks themselves) from the provided callback within the scope of
that namespace. The new context is passed as an argument to the callback
when it's called.
Same as `namespace.run()` but returns the return value of the callback rather
than the context.
### namespace.bind(callback, [context])
* return: a callback wrapped up in a context closure
Bind a function to the specified namespace. Works analogously to
`Function.bind()` or `domain.bind()`. If context is omitted, it will default to
the currently active context in the namespace, or create a new context if none
is currently defined.
### namespace.bindEmitter(emitter)
Bind an EventEmitter to a namespace. Operates similarly to `domain.add`, with a
less generic name and the additional caveat that unlike domains, namespaces
never implicitly bind EventEmitters to themselves when they're created within
the context of an active namespace.
The most likely time you'd want to use this is when you're using Express or
Connect and want to make sure your middleware execution plays nice with CLS, or
are doing other things with HTTP listeners:
```javascript
http.createServer(function (req, res) {
writer.bindEmitter(req);
writer.bindEmitter(res);
// do other stuff, some of which is asynchronous
});
```
### namespace.createContext()
* return: a context cloned from the currently active context
Use this with `namespace.bind()`, if you want to have a fresh context at invocation time,
as opposed to binding time:
```javascript
function doSomething(p) {
console.log("%s = %s", p, ns.get(p));
}
function bindLater(callback) {
return writer.bind(callback, writer.createContext());
}
setInterval(function () {
var bound = bindLater(doSomething);
bound('test');
}, 100);
```
## context
A context is a plain object created using the enclosing context as its prototype.
# copyright & license
See [LICENSE](https://github.com/othiym23/node-continuation-local-storage/blob/master/LICENSE)
for the details of the BSD 2-clause "simplified" license used by
`continuation-local-storage`. This package was developed in 2012-2013 (and is
maintained now) by Forrest L Norvell, [@othiym23](https://github.com/othiym23),
with considerable help from Timothy Caswell,
[@creationix](https://github.com/creationix), working for The Node Firm. This
work was underwritten by New Relic for use in their Node.js instrumentation
agent, so maybe give that a look if you have some Node.js
performance-monitoring needs.
[timer functions]: https://nodejs.org/api/timers.html
[setImmediate]: https://nodejs.org/api/timers.html#timers_setimmediate_callback_arg
[setTimeout]: https://nodejs.org/api/timers.html#timers_settimeout_callback_delay_arg
[setInterval]: https://nodejs.org/api/timers.html#timers_setinterval_callback_delay_arg
[cps]: http://en.wikipedia.org/wiki/Continuation-passing_style
1to2 naively converts source code files from NAN 1 to NAN 2. There will be erroneous conversions,
false positives and missed opportunities. The input files are rewritten in place. Make sure that
you have backups. You will have to manually review the changes afterwards and do some touchups.
```sh
$ tools/1to2.js
Usage: 1to2 [options] <file ...>
Options:
-h, --help output usage information
-V, --version output the version number
```
**string_decoder.js** (`require('string_decoder')`) from Node.js core
Copyright Joyent, Inc. and other Node contributors. See LICENCE file for details.
Version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10. **Prefer the stable version over the unstable.**
The *build/* directory contains a build script that will scrape the source from the [joyent/node](https://github.com/joyent/node) repo given a specific Node version.
# ethereum-cryptography
[![npm version][1]][2]
[![Travis CI][3]][4]
[![license][5]][6]
[![Types][7]][8]
This npm package contains all the cryptographic primitives normally used when
developing Javascript/TypeScript applications and tools for Ethereum.
Pure Javascript implementations of all the primitives are included, so it can
be used out of the box for web applications and libraries.
In Node, it takes advantage of the built-in and N-API based implementations
whenever possible.
The cryptographic primitives included are:
* [Pseudorandom number generation](#pseudorandom-number-generation-submodule)
* [Keccak](#keccak-submodule)
* [Scrypt](#scrypt-submodule)
* [PBKDF2](#pbkdf2-submodule)
* [SHA-256](#sha-256-submodule)
* [RIPEMD-160](#ripemd-160-submodule)
* [BLAKE2b](#blake2b-submodule)
* [AES](#aes-submodule)
* [Secp256k1](#secp256k1-submodule)
* [Hierarchical Deterministic keys derivation](#hierarchical-deterministic-keys-submodule)
* [Seed recovery phrases](#seed-recovery-phrases)
## Installation
Via `npm`:
```bash
$ npm install ethereum-cryptography
```
Via `yarn`:
```bash
$ yarn add ethereum-cryptography
```
## Usage
This package has no single entry-point, but submodule for each cryptographic
primitive. Read each primitive's section of this document to learn how to use
them.
The reason for this is that importing everything from a single file will lead to
huge bundles when using this package for the web. This could be avoided through
tree-shaking, but the possibility of it not working properly on one of
[the supported bundlers](#browser-usage) is too high.
## Pseudorandom number generation submodule
The `random` submodule has functions to generate cryptographically strong
pseudo-random data in synchronous and asynchronous ways.
In Node, this functions are backed by [`crypto.randomBytes`](https://nodejs.org/api/crypto.html#crypto_crypto_randombytes_size_callback).
In the browser, [`crypto.getRandomValues`](https://developer.mozilla.org/en-US/docs/Web/API/Crypto/getRandomValues)
is used. If not available, this module won't work, as that would be insecure.
### Function types
```ts
function getRandomBytes(bytes: number): Promise<Buffer>;
function getRandomBytesSync(bytes: number): Buffer;
```
### Example usage
```js
const { getRandomBytesSync } = require("ethereum-cryptography/random");
console.log(getRandomBytesSync(32).toString("hex"));
```
## Keccak submodule
The `keccak` submodule has four functions that implement different variations of
the Keccak hashing algorithm. These are `keccak224`, `keccak256`, `keccak384`,
and `keccak512`.
### Function types
```ts
function keccak224(msg: Buffer): Buffer;
function keccak256(msg: Buffer): Buffer;
function keccak384(msg: Buffer): Buffer;
function keccak512(msg: Buffer): Buffer;
```
### Example usage
```js
const { keccak256 } = require("ethereum-cryptography/keccak");
console.log(keccak256(Buffer.from("Hello, world!", "ascii")).toString("hex"));
```
## Scrypt submodule
The `scrypt` submodule has two functions implementing the Scrypt key
derivation algorithm in synchronous and asynchronous ways. This algorithm is
very slow, and using the synchronous version in the browser is not recommended,
as it will block its main thread and hang your UI.
### Password encoding
Encoding passwords is a frequent source of errors. Please read
[these notes](https://github.com/ricmoo/scrypt-js/tree/0eb70873ddf3d24e34b53e0d9a99a0cef06a79c0#encoding-notes)
before using this submodule.
### Function types
```ts
function scrypt(password: Buffer, salt: Buffer, n: number, p: number, r: number, dklen: number): Promise<Buffer>;
function scryptSync(password: Buffer, salt: Buffer, n: number, p: number, r: number, dklen: number): Buffer;
```
### Example usage
```js
const { scryptSync } = require("ethereum-cryptography/scrypt");
console.log(
scryptSync(
Buffer.from("ascii password", "ascii"),
Buffer.from("salt", "hex"),
16,
1,
1,
64
).toString("hex")
);
```
## PBKDF2 submodule
The `pbkdf2` submodule has two functions implementing the PBKDF2 key
derivation algorithm in synchronous and asynchronous ways. This algorithm is
very slow, and using the synchronous version in the browser is not recommended,
as it will block its main thread and hang your UI.
### Password encoding
Encoding passwords is a frequent source of errors. Please read
[these notes](https://github.com/ricmoo/scrypt-js/tree/0eb70873ddf3d24e34b53e0d9a99a0cef06a79c0#encoding-notes)
before using this submodule.
### Supported digests
In Node this submodule uses the built-in implementation and supports any digest
returned by [`crypto.getHashes`](https://nodejs.org/api/crypto.html#crypto_crypto_gethashes).
In the browser, it is tested to support at least `sha256`, the only digest
normally used with `pbkdf2` in Ethereum. It may support more.
### Function types
```ts
function pbkdf2(password: Buffer, salt: Buffer, iterations: number, keylen: number, digest: string): Promise<Buffer>;
function pbkdf2Sync(password: Buffer, salt: Buffer, iterations: number, keylen: number, digest: string): Buffer;
```
### Example usage
```js
const { pbkdf2Sync } = require("ethereum-cryptography/pbkdf2");
console.log(
pbkdf2Sync(
Buffer.from("ascii password", "ascii"),
Buffer.from("salt", "hex"),
4096,
32,
'sha256'
).toString("hex")
);
```
## SHA-256 submodule
The `sha256` submodule contains a single function implementing the SHA-256
hashing algorithm.
### Function types
```ts
function sha256(msg: Buffer): Buffer;
```
### Example usage
```js
const { sha256 } = require("ethereum-cryptography/sha256");
console.log(sha256(Buffer.from("message", "ascii")).toString("hex"));
```
## RIPEMD-160 submodule
The `ripemd160` submodule contains a single function implementing the
RIPEMD-160 hashing algorithm.
### Function types
```ts
function ripemd160(msg: Buffer): Buffer;
```
### Example usage
```js
const { ripemd160 } = require("ethereum-cryptography/ripemd160");
console.log(ripemd160(Buffer.from("message", "ascii")).toString("hex"));
```
## BLAKE2b submodule
The `blake2b` submodule contains a single function implementing the
BLAKE2b non-keyed hashing algorithm.
### Function types
```ts
function blake2b(input: Buffer, outputLength = 64): Buffer;
```
### Example usage
```js
const { blake2b } = require("ethereum-cryptography/blake2b");
console.log(blake2b(Buffer.from("message", "ascii")).toString("hex"));
```
## AES submodule
The `aes` submodule contains encryption and decryption functions implementing
the [Advanced Encryption Standard](https://en.wikipedia.org/wiki/Advanced_Encryption_Standard)
algorithm.
### Encrypting with passwords
AES is not supposed to be used directly with a password. Doing that will
compromise your users' security.
The `key` parameters in this submodule are meant to be strong cryptographic
keys. If you want to obtain such a key from a password, please use a
[key derivation function](https://en.wikipedia.org/wiki/Key_derivation_function)
like [pbkdf2](#pbkdf2-submodule) or [scrypt](#scrypt-submodule).
### Operation modes
This submodule works with different [block cipher modes of operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation). If you are using this module in a new
application, we recommend using the default.
While this module may work with any mode supported by OpenSSL, we only test it
with `aes-128-ctr`, `aes-128-cbc`, and `aes-256-cbc`. If you use another module
a warning will be printed in the console.
We only recommend using `aes-128-cbc` and `aes-256-cbc` to decrypt already
encrypted data.
### Padding plaintext messages
Some operation modes require the plaintext message to be a multiple of `16`. If
that isn't the case, your message has to be padded.
By default, this module automatically pads your messages according to [PKCS#7](https://tools.ietf.org/html/rfc2315).
Note that this padding scheme always adds at least 1 byte of padding. If you
are unsure what anything of this means, we **strongly** recommend you to use
the defaults.
If you need to encrypt without padding or want to use another padding scheme,
you can disable PKCS#7 padding by passing `false` as the last argument and
handling padding yourself. Note that if you do this and your operation mode
requires padding, `encrypt` will throw if your plaintext message isn't a
multiple of `16`.
This option is only present to enable the decryption of already encrypted data.
To encrypt new data, we recommend using the default.
### How to use the IV parameter
The `iv` parameter of the `encrypt` function must be unique, or the security
of the encryption algorithm can be compromissed.
You can generate a new `iv` using the `random` module.
Note that to decrypt a value, you have to provide the same `iv` used to encrypt
it.
### How to handle errors with this module
Sensitive information can be leaked via error messages when using this module.
To avoid this, you should make sure that the errors you return don't
contain the exact reason for the error. Instead, errors must report general
encryption/decryption failures.
Note that implementing this can mean catching all errors that can be thrown
when calling on of this module's functions, and just throwing a new generic
exception.
### Function types
```ts
function encrypt(msg: Buffer, key: Buffer, iv: Buffer, mode = "aes-128-ctr", pkcs7PaddingEnabled = true): Buffer;
function decrypt(cypherText: Buffer, key: Buffer, iv: Buffer, mode = "aes-128-ctr", pkcs7PaddingEnabled = true): Buffer
```
### Example usage
```js
const { encrypt } = require("ethereum-cryptography/aes");
console.log(
encrypt(
Buffer.from("message", "ascii"),
Buffer.from("2b7e151628aed2a6abf7158809cf4f3c", "hex"),
Buffer.from("f0f1f2f3f4f5f6f7f8f9fafbfcfdfeff", "hex")
).toString("hex")
);
```
## Secp256k1 submodule
The `secp256k1` submodule provides a library for elliptic curve operations on
the curve Secp256k1.
It has the exact same API than the version `4.x` of the [`secp256k1`](https://github.com/cryptocoinjs/secp256k1-node)
module from cryptocoinjs, with two added function to create private keys.
### Creating private keys
Secp256k1 private keys need to be cryptographycally secure random numbers with
certain caracteristics. If this is not the case, the security of Secp256k1 is
compromissed.
We strongly recommend to use this module to create new private keys.
### Function types
Functions to create private keys:
```ts
function createPrivateKey(): Promise<Uint8Array>;
function function createPrivateKeySync(): Uint8Array;
```
For the rest of the functions, pleasse read [`secp256k1`'s documentation](https://github.com/cryptocoinjs/secp256k1-node).
### Example usage
```js
const { createPrivateKeySync, ecdsaSign } = require("ethereum-cryptography/secp256k1");
const msgHash = Buffer.from(
"82ff40c0a986c6a5cfad4ddf4c3aa6996f1a7837f9c398e17e5de5cbd5a12b28",
"hex"
);
const privateKey = createPrivateKeySync();
console.log(Buffer.from(ecdsaSign(msgHash, privateKey).signature).toString("hex"));
```
## Hierarchical Deterministic keys submodule
The `hdkey` submodule provides a library for keys derivation according to
[BIP32](https://github.com/bitcoin/bips/blob/master/bip-0032.mediawiki).
It has almost the exact same API than the version `1.x` of
[`hdkey` from cryptocoinjs](https://github.com/cryptocoinjs/hdkey),
but it's backed by this package's primitives, and has built-in TypeScript types.
Its only difference is that it has to be be used with a named import.
### Function types
This module exports a single class whose type is
```ts
class HDKey {
public static HARDENED_OFFSET: number;
public static fromMasterSeed(seed: Buffer, versions: Versions): HDKey;
public static fromExtendedKey(base58key: string, versions: Versions): HDKey;
public static fromJSON(json: { xpriv: string }): HDKey;
public versions: Versions;
public depth: number;
public index: number;
public chainCode: Buffer | null;
public privateKey: Buffer | null;
public publicKey: Buffer | null;
public fingerprint: number;
public parentFingerprint: number;
public pubKeyHash: Buffer | undefined;
public identifier: Buffer | undefined;
public privateExtendedKey: string;
public publicExtendedKey: string;
private constructor(versios: Versions);
public derive(path: string): HDKey;
public deriveChild(index: number): HDKey;
public sign(hash: Buffer): Buffer;
public verify(hash: Buffer, signature: Buffer): boolean;
public wipePrivateData(): this;
public toJSON(): { xpriv: string; xpub: string };
}
interface Versions {
private: number;
public: number;
}
```
### Example usage
```js
const { HDKey } = require("ethereum-cryptography/hdkey");
const seed = "fffcf9f6f3f0edeae7e4e1dedbd8d5d2cfccc9c6c3c0bdbab7b4b1aeaba8a5a29f9c999693908d8a8784817e7b7875726f6c696663605d5a5754514e4b484542";
const hdkey = HDKey.fromMasterSeed(Buffer.from(seed, "hex"));
const childkey = hdkey.derive("m/0/2147483647'/1");
console.log(childkey.privateExtendedKey);
```
## Seed recovery phrases
The `bip39` submodule provides functions to generate, validate and use seed
recovery phrases according to [BIP39](https://github.com/bitcoin/bips/blob/master/bip-0039.mediawiki).
### Function types
```ts
function generateMnemonic(wordlist: string[], strength: number = 128): string;
function mnemonicToEntropy(mnemonic: string, wordlist: string[]): Buffer;
function entropyToMnemonic(entropy: Buffer, wordlist: string[]): string;
function validateMnemonic(mnemonic: string, wordlist: string[]): boolean;
async function mnemonicToSeed(mnemonic: string, passphrase: string = ""): Promise<Buffer>;
function mnemonicToSeedSync(mnemonic: string, passphrase: string = ""): Buffer;
```
### Word lists
This submodule also contains the word lists defined by BIP39 for Czech, English,
French, Italian, Japanese, Korean, Simplified and Traditional Chinese, and
Spanish. These are not imported by default, as that would increase bundle sizes
too much. Instead, you should import and use them explicitly.
The word lists are exported as a `wordlist` variable in each of these submodules:
* `ethereum-cryptography/bip39/wordlists/czech.js`
* `ethereum-cryptography/bip39/wordlists/english.js`
* `ethereum-cryptography/bip39/wordlists/french.js`
* `ethereum-cryptography/bip39/wordlists/italian.js`
* `ethereum-cryptography/bip39/wordlists/japanese.js`
* `ethereum-cryptography/bip39/wordlists/korean.js`
* `ethereum-cryptography/bip39/wordlists/simplified-chinese.js`
* `ethereum-cryptography/bip39/wordlists/spanish.js`
* `ethereum-cryptography/bip39/wordlists/traditional-chinese.js`
### Example usage
```js
const { generateMnemonic } = require("ethereum-cryptography/bip39");
const { wordlist } = require("ethereum-cryptography/bip39/wordlists/english");
console.log(generateMnemonic(wordlist));
```
## Browser usage
This package works with all the major Javascript bundlers. It is
tested with `webpack`, `Rollup`, `Parcel`, and `Browserify`.
### Rollup setup
Using this library with Rollup requires the following plugins:
[`@rollup/plugin-commonjs`](https://www.npmjs.com/package/@rollup/plugin-commonjs)
[`@rollup/plugin-json`](https://www.npmjs.com/package/@rollup/plugin-json)
[`@rollup/plugin-node-resolve`](https://www.npmjs.com/package/@rollup/plugin-node-resolve)
[`rollup-plugin-node-builtins`](https://www.npmjs.com/package/rollup-plugin-node-builtins)
[`rollup-plugin-node-globals`](https://www.npmjs.com/package/rollup-plugin-node-globals)
These can be used by setting your `plugins` array like this:
```js
plugins: [
commonjs(),
json(),
nodeGlobals(),
nodeBuiltins(),
resolve({
browser: true,
preferBuiltins: false,
}),
]
```
## Missing cryptographic primitives
This package intentionally excludes the the cryptographic primitives necessary
to implement the following EIPs:
* [EIP 196: Precompiled contracts for addition and scalar multiplication on the elliptic curve alt_bn128](https://eips.ethereum.org/EIPS/eip-196)
* [EIP 197: Precompiled contracts for optimal ate pairing check on the elliptic curve alt_bn128](https://eips.ethereum.org/EIPS/eip-197)
* [EIP 198: Big integer modular exponentiation](https://eips.ethereum.org/EIPS/eip-198)
* [EIP 152: Add Blake2 compression function `F` precompile](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-152.md)
Feel free to open an issue if you want this decision to be reconsidered, or if
you found another primitive that is missing.
## Security audit
This library has been audited by [Trail of Bits](https://www.trailofbits.com/).
You can see the results of the audit and the changes implemented as a result of
it in [`audit/`](./audit).
## License
`ethereum-cryptography` is released under [the MIT License](./LICENSE).
[1]: https://img.shields.io/npm/v/ethereum-cryptography.svg
[2]: https://www.npmjs.com/package/ethereum-cryptography
[3]: https://img.shields.io/travis/ethereum/js-ethereum-cryptography/master.svg?label=Travis%20CI
[4]: https://travis-ci.org/ethereum/js-ethereum-cryptography
[5]: https://img.shields.io/npm/l/ethereum-cryptography
[6]: https://github.com/ethereum/js-ethereum-cryptography/blob/master/packages/ethereum-cryptography/LICENSE
[7]: https://img.shields.io/npm/types/ethereum-cryptography.svg
[8]: https://www.npmjs.com/package/ethereum-cryptography
# is-equal-shallow [](http://badge.fury.io/js/is-equal-shallow) [](https://travis-ci.org/jonschlinkert/is-equal-shallow)
> Does a shallow comparison of two objects, returning false if the keys or values differ.
The purpose of this lib is to do the fastest comparison possible of two objects when the values will predictably be primitives.
* only compares objects.
* only compares the first level of each object
* values must be primitives. If a value is not a primitive, even if the values are the same, `false` is returned.
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i is-equal-shallow --save
```
## Usage
```js
var equals = require('is-equal-shallow');
equals(object_a, object_b);
```
**Examples**
```js
equals({a: true, b: true}, {a: true, b: true});
//=> 'true'
equals({a: true, b: false}, {c: false, b: false});
//=> 'false'
equals({a: true, b: false}, {a: false, b: false});
//=> 'false'
```
Strict comparison for equality:
```js
equals({a: true, b: true}, {a: true, b: 'true'});
//=> 'false'
```
When values are not primitives, `false` is always returned:
```js
equals({ b: {}}, { b: {}});
//=> 'false'
equals({ b: []}, { b: []});
//=> 'false'
```
## Related projects
Other object utils:
* [clone-deep](https://github.com/jonschlinkert/clone-deep): Recursively (deep) clone JavaScript native types, like Object, Array, RegExp, Date as well as primitives.
* [for-in](https://github.com/jonschlinkert/for-in): Iterate over the own and inherited enumerable properties of an objecte, and return an object… [more](https://github.com/jonschlinkert/for-in)
* [for-own](https://github.com/jonschlinkert/for-own): Iterate over the own enumerable properties of an object, and return an object with properties… [more](https://github.com/jonschlinkert/for-own)
* [is-plain-object](https://github.com/jonschlinkert/is-plain-object): Returns true if an object was created by the `Object` constructor.
* [isobject](https://github.com/jonschlinkert/isobject): Returns true if the value is an object and not an array or null.
## Running tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-equal-shallow/issues/new)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2015 Jon Schlinkert
Released under the MIT license.
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on June 22, 2015._
# web3-shh
This is a sub package of [web3.js][repo]
This is the whisper v5 package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-shh
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-shh.js` in your html file.
This will expose the `Web3Personal` object on the window object.
## Usage
```js
// in node.js
var Web3Personal = require('web3-shh');
var shh = new Web3Personal('ws://localhost:8546');
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
<h1 align="center">
<img width="250" src="https://rawgit.com/lukechilds/keyv/master/media/logo.svg" alt="keyv">
<br>
<br>
</h1>
> Simple key-value storage with support for multiple backends
[](https://travis-ci.org/lukechilds/keyv)
[](https://coveralls.io/github/lukechilds/keyv?branch=master)
[](https://www.npmjs.com/package/keyv)
[](https://www.npmjs.com/package/keyv)
Keyv provides a consistent interface for key-value storage across multiple backends via storage adapters. It supports TTL based expiry, making it suitable as a cache or a persistent key-value store.
## Features
There are a few existing modules similar to Keyv, however Keyv is different because it:
- Isn't bloated
- Has a simple Promise based API
- Suitable as a TTL based cache or persistent key-value store
- [Easily embeddable](#add-cache-support-to-your-module) inside another module
- Works with any storage that implements the [`Map`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) API
- Handles all JSON types plus `Buffer`
- Supports namespaces
- Wide range of [**efficient, well tested**](#official-storage-adapters) storage adapters
- Connection errors are passed through (db failures won't kill your app)
- Supports the current active LTS version of Node.js or higher
## Usage
Install Keyv.
```
npm install --save keyv
```
By default everything is stored in memory, you can optionally also install a storage adapter.
```
npm install --save @keyv/redis
npm install --save @keyv/mongo
npm install --save @keyv/sqlite
npm install --save @keyv/postgres
npm install --save @keyv/mysql
```
Create a new Keyv instance, passing your connection string if applicable. Keyv will automatically load the correct storage adapter.
```js
const Keyv = require('keyv');
// One of the following
const keyv = new Keyv();
const keyv = new Keyv('redis://user:pass@localhost:6379');
const keyv = new Keyv('mongodb://user:pass@localhost:27017/dbname');
const keyv = new Keyv('sqlite://path/to/database.sqlite');
const keyv = new Keyv('postgresql://user:pass@localhost:5432/dbname');
const keyv = new Keyv('mysql://user:pass@localhost:3306/dbname');
// Handle DB connection errors
keyv.on('error', err => console.log('Connection Error', err));
await keyv.set('foo', 'expires in 1 second', 1000); // true
await keyv.set('foo', 'never expires'); // true
await keyv.get('foo'); // 'never expires'
await keyv.delete('foo'); // true
await keyv.clear(); // undefined
```
### Namespaces
You can namespace your Keyv instance to avoid key collisions and allow you to clear only a certain namespace while using the same database.
```js
const users = new Keyv('redis://user:pass@localhost:6379', { namespace: 'users' });
const cache = new Keyv('redis://user:pass@localhost:6379', { namespace: 'cache' });
await users.set('foo', 'users'); // true
await cache.set('foo', 'cache'); // true
await users.get('foo'); // 'users'
await cache.get('foo'); // 'cache'
await users.clear(); // undefined
await users.get('foo'); // undefined
await cache.get('foo'); // 'cache'
```
### Custom Serializers
Keyv uses [`json-buffer`](https://github.com/dominictarr/json-buffer) for data serialization to ensure consistency across different backends.
You can optionally provide your own serialization functions to support extra data types or to serialize to something other than JSON.
```js
const keyv = new Keyv({ serialize: JSON.stringify, deserialize: JSON.parse });
```
**Warning:** Using custom serializers means you lose any guarantee of data consistency. You should do extensive testing with your serialisation functions and chosen storage engine.
## Official Storage Adapters
The official storage adapters are covered by [over 150 integration tests](https://travis-ci.org/lukechilds/keyv/jobs/260418145) to guarantee consistent behaviour. They are lightweight, efficient wrappers over the DB clients making use of indexes and native TTLs where available.
Database | Adapter | Native TTL | Status
---|---|---|---
Redis | [@keyv/redis](https://github.com/lukechilds/keyv-redis) | Yes | [](https://travis-ci.org/lukechilds/keyv-redis) [](https://coveralls.io/github/lukechilds/keyv-redis?branch=master)
MongoDB | [@keyv/mongo](https://github.com/lukechilds/keyv-mongo) | Yes | [](https://travis-ci.org/lukechilds/keyv-mongo) [](https://coveralls.io/github/lukechilds/keyv-mongo?branch=master)
SQLite | [@keyv/sqlite](https://github.com/lukechilds/keyv-sqlite) | No | [](https://travis-ci.org/lukechilds/keyv-sqlite) [](https://coveralls.io/github/lukechilds/keyv-sqlite?branch=master)
PostgreSQL | [@keyv/postgres](https://github.com/lukechilds/keyv-postgres) | No | [](https://travis-ci.org/lukechildskeyv-postgreskeyv) [](https://coveralls.io/github/lukechilds/keyv-postgres?branch=master)
MySQL | [@keyv/mysql](https://github.com/lukechilds/keyv-mysql) | No | [](https://travis-ci.org/lukechilds/keyv-mysql) [](https://coveralls.io/github/lukechilds/keyv-mysql?branch=master)
## Third-party Storage Adapters
You can also use third-party storage adapters or build your own. Keyv will wrap these storage adapters in TTL functionality and handle complex types internally.
```js
const Keyv = require('keyv');
const myAdapter = require('./my-storage-adapter');
const keyv = new Keyv({ store: myAdapter });
```
Any store that follows the [`Map`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) api will work.
```js
new Keyv({ store: new Map() });
```
For example, [`quick-lru`](https://github.com/sindresorhus/quick-lru) is a completely unrelated module that implements the Map API.
```js
const Keyv = require('keyv');
const QuickLRU = require('quick-lru');
const lru = new QuickLRU({ maxSize: 1000 });
const keyv = new Keyv({ store: lru });
```
The following are third-party storage adapters compatible with Keyv:
- [quick-lru](https://github.com/sindresorhus/quick-lru) - Simple "Least Recently Used" (LRU) cache
- [keyv-file](https://github.com/zaaack/keyv-file) - File system storage adapter for Keyv
- [keyv-dynamodb](https://www.npmjs.com/package/keyv-dynamodb) - DynamoDB storage adapter for Keyv
## Add Cache Support to your Module
Keyv is designed to be easily embedded into other modules to add cache support. The recommended pattern is to expose a `cache` option in your modules options which is passed through to Keyv. Caching will work in memory by default and users have the option to also install a Keyv storage adapter and pass in a connection string, or any other storage that implements the `Map` API.
You should also set a namespace for your module so you can safely call `.clear()` without clearing unrelated app data.
Inside your module:
```js
class AwesomeModule {
constructor(opts) {
this.cache = new Keyv({
uri: typeof opts.cache === 'string' && opts.cache,
store: typeof opts.cache !== 'string' && opts.cache,
namespace: 'awesome-module'
});
}
}
```
Now it can be consumed like this:
```js
const AwesomeModule = require('awesome-module');
// Caches stuff in memory by default
const awesomeModule = new AwesomeModule();
// After npm install --save keyv-redis
const awesomeModule = new AwesomeModule({ cache: 'redis://localhost' });
// Some third-party module that implements the Map API
const awesomeModule = new AwesomeModule({ cache: some3rdPartyStore });
```
## API
### new Keyv([uri], [options])
Returns a new Keyv instance.
The Keyv instance is also an `EventEmitter` that will emit an `'error'` event if the storage adapter connection fails.
### uri
Type: `String`<br>
Default: `undefined`
The connection string URI.
Merged into the options object as options.uri.
### options
Type: `Object`
The options object is also passed through to the storage adapter. Check your storage adapter docs for any extra options.
#### options.namespace
Type: `String`<br>
Default: `'keyv'`
Namespace for the current instance.
#### options.ttl
Type: `Number`<br>
Default: `undefined`
Default TTL. Can be overridden by specififying a TTL on `.set()`.
#### options.serialize
Type: `Function`<br>
Default: `JSONB.stringify`
A custom serialization function.
#### options.deserialize
Type: `Function`<br>
Default: `JSONB.parse`
A custom deserialization function.
#### options.store
Type: `Storage adapter instance`<br>
Default: `new Map()`
The storage adapter instance to be used by Keyv.
#### options.adapter
Type: `String`<br>
Default: `undefined`
Specify an adapter to use. e.g `'redis'` or `'mongodb'`.
### Instance
Keys must always be strings. Values can be of any type.
#### .set(key, value, [ttl])
Set a value.
By default keys are persistent. You can set an expiry TTL in milliseconds.
Returns `true`.
#### .get(key)
Returns the value.
#### .delete(key)
Deletes an entry.
Returns `true` if the key existed, `false` if not.
#### .clear()
Delete all entries in the current namespace.
Returns `undefined`.
## License
MIT © Luke Childs
# web3-eth-contract
This is a sub package of [web3.js][repo]
This is the contract package to be used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-contract
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-eth-contract.js` in your html file.
This will expose the `Web3EthContract` object on the window object.
## Usage
```js
// in node.js
var Web3EthContract = require('web3-eth-contract');
// set provider for all later instances to use
Web3EthContract.setProvider('ws://localhost:8546');
var contract = new Web3EthContract(jsonInterface, address);
contract.methods.somFunc().send({from: ....})
.on('receipt', function(){
...
});
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
Native Abstractions for Node.js
===============================
**A header file filled with macro and utility goodness for making add-on development for Node.js easier across versions 0.8, 0.10, 0.12, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 and 14.**
***Current version: 2.14.2***
*(See [CHANGELOG.md](https://github.com/nodejs/nan/blob/master/CHANGELOG.md) for complete ChangeLog)*
[](https://nodei.co/npm/nan/) [](https://nodei.co/npm/nan/)
[](https://travis-ci.org/nodejs/nan)
[](https://ci.appveyor.com/project/RodVagg/nan)
Thanks to the crazy changes in V8 (and some in Node core), keeping native addons compiling happily across versions, particularly 0.10 to 0.12 to 4.0, is a minor nightmare. The goal of this project is to store all logic necessary to develop native Node.js addons without having to inspect `NODE_MODULE_VERSION` and get yourself into a macro-tangle.
This project also contains some helper utilities that make addon development a bit more pleasant.
* **[News & Updates](#news)**
* **[Usage](#usage)**
* **[Example](#example)**
* **[API](#api)**
* **[Tests](#tests)**
* **[Known issues](#issues)**
* **[Governance & Contributing](#governance)**
<a name="news"></a>
## News & Updates
<a name="usage"></a>
## Usage
Simply add **NAN** as a dependency in the *package.json* of your Node addon:
``` bash
$ npm install --save nan
```
Pull in the path to **NAN** in your *binding.gyp* so that you can use `#include <nan.h>` in your *.cpp* files:
``` python
"include_dirs" : [
"<!(node -e \"require('nan')\")"
]
```
This works like a `-I<path-to-NAN>` when compiling your addon.
<a name="example"></a>
## Example
Just getting started with Nan? Take a look at the **[Node Add-on Examples](https://github.com/nodejs/node-addon-examples)**.
Refer to a [quick-start **Nan** Boilerplate](https://github.com/fcanas/node-native-boilerplate) for a ready-to-go project that utilizes basic Nan functionality.
For a simpler example, see the **[async pi estimation example](https://github.com/nodejs/nan/tree/master/examples/async_pi_estimate)** in the examples directory for full code and an explanation of what this Monte Carlo Pi estimation example does. Below are just some parts of the full example that illustrate the use of **NAN**.
Yet another example is **[nan-example-eol](https://github.com/CodeCharmLtd/nan-example-eol)**. It shows newline detection implemented as a native addon.
Also take a look at our comprehensive **[C++ test suite](https://github.com/nodejs/nan/tree/master/test/cpp)** which has a plethora of code snippets for your pasting pleasure.
<a name="api"></a>
## API
Additional to the NAN documentation below, please consult:
* [The V8 Getting Started * Guide](https://v8.dev/docs/embed)
* [V8 API Documentation](https://v8docs.nodesource.com/)
* [Node Add-on Documentation](https://nodejs.org/api/addons.html)
<!-- START API -->
### JavaScript-accessible methods
A _template_ is a blueprint for JavaScript functions and objects in a context. You can use a template to wrap C++ functions and data structures within JavaScript objects so that they can be manipulated from JavaScript. See the V8 Embedders Guide section on [Templates](https://github.com/v8/v8/wiki/Embedder%27s-Guide#templates) for further information.
In order to expose functionality to JavaScript via a template, you must provide it to V8 in a form that it understands. Across the versions of V8 supported by NAN, JavaScript-accessible method signatures vary widely, NAN fully abstracts method declaration and provides you with an interface that is similar to the most recent V8 API but is backward-compatible with older versions that still use the now-deceased `v8::Argument` type.
* **Method argument types**
- <a href="doc/methods.md#api_nan_function_callback_info"><b><code>Nan::FunctionCallbackInfo</code></b></a>
- <a href="doc/methods.md#api_nan_property_callback_info"><b><code>Nan::PropertyCallbackInfo</code></b></a>
- <a href="doc/methods.md#api_nan_return_value"><b><code>Nan::ReturnValue</code></b></a>
* **Method declarations**
- <a href="doc/methods.md#api_nan_method"><b>Method declaration</b></a>
- <a href="doc/methods.md#api_nan_getter"><b>Getter declaration</b></a>
- <a href="doc/methods.md#api_nan_setter"><b>Setter declaration</b></a>
- <a href="doc/methods.md#api_nan_property_getter"><b>Property getter declaration</b></a>
- <a href="doc/methods.md#api_nan_property_setter"><b>Property setter declaration</b></a>
- <a href="doc/methods.md#api_nan_property_enumerator"><b>Property enumerator declaration</b></a>
- <a href="doc/methods.md#api_nan_property_deleter"><b>Property deleter declaration</b></a>
- <a href="doc/methods.md#api_nan_property_query"><b>Property query declaration</b></a>
- <a href="doc/methods.md#api_nan_index_getter"><b>Index getter declaration</b></a>
- <a href="doc/methods.md#api_nan_index_setter"><b>Index setter declaration</b></a>
- <a href="doc/methods.md#api_nan_index_enumerator"><b>Index enumerator declaration</b></a>
- <a href="doc/methods.md#api_nan_index_deleter"><b>Index deleter declaration</b></a>
- <a href="doc/methods.md#api_nan_index_query"><b>Index query declaration</b></a>
* Method and template helpers
- <a href="doc/methods.md#api_nan_set_method"><b><code>Nan::SetMethod()</code></b></a>
- <a href="doc/methods.md#api_nan_set_prototype_method"><b><code>Nan::SetPrototypeMethod()</code></b></a>
- <a href="doc/methods.md#api_nan_set_accessor"><b><code>Nan::SetAccessor()</code></b></a>
- <a href="doc/methods.md#api_nan_set_named_property_handler"><b><code>Nan::SetNamedPropertyHandler()</code></b></a>
- <a href="doc/methods.md#api_nan_set_indexed_property_handler"><b><code>Nan::SetIndexedPropertyHandler()</code></b></a>
- <a href="doc/methods.md#api_nan_set_template"><b><code>Nan::SetTemplate()</code></b></a>
- <a href="doc/methods.md#api_nan_set_prototype_template"><b><code>Nan::SetPrototypeTemplate()</code></b></a>
- <a href="doc/methods.md#api_nan_set_instance_template"><b><code>Nan::SetInstanceTemplate()</code></b></a>
- <a href="doc/methods.md#api_nan_set_call_handler"><b><code>Nan::SetCallHandler()</code></b></a>
- <a href="doc/methods.md#api_nan_set_call_as_function_handler"><b><code>Nan::SetCallAsFunctionHandler()</code></b></a>
### Scopes
A _local handle_ is a pointer to an object. All V8 objects are accessed using handles, they are necessary because of the way the V8 garbage collector works.
A handle scope can be thought of as a container for any number of handles. When you've finished with your handles, instead of deleting each one individually you can simply delete their scope.
The creation of `HandleScope` objects is different across the supported versions of V8. Therefore, NAN provides its own implementations that can be used safely across these.
- <a href="doc/scopes.md#api_nan_handle_scope"><b><code>Nan::HandleScope</code></b></a>
- <a href="doc/scopes.md#api_nan_escapable_handle_scope"><b><code>Nan::EscapableHandleScope</code></b></a>
Also see the V8 Embedders Guide section on [Handles and Garbage Collection](https://github.com/v8/v8/wiki/Embedder%27s%20Guide#handles-and-garbage-collection).
### Persistent references
An object reference that is independent of any `HandleScope` is a _persistent_ reference. Where a `Local` handle only lives as long as the `HandleScope` in which it was allocated, a `Persistent` handle remains valid until it is explicitly disposed.
Due to the evolution of the V8 API, it is necessary for NAN to provide a wrapper implementation of the `Persistent` classes to supply compatibility across the V8 versions supported.
- <a href="doc/persistent.md#api_nan_persistent_base"><b><code>Nan::PersistentBase & v8::PersistentBase</code></b></a>
- <a href="doc/persistent.md#api_nan_non_copyable_persistent_traits"><b><code>Nan::NonCopyablePersistentTraits & v8::NonCopyablePersistentTraits</code></b></a>
- <a href="doc/persistent.md#api_nan_copyable_persistent_traits"><b><code>Nan::CopyablePersistentTraits & v8::CopyablePersistentTraits</code></b></a>
- <a href="doc/persistent.md#api_nan_persistent"><b><code>Nan::Persistent</code></b></a>
- <a href="doc/persistent.md#api_nan_global"><b><code>Nan::Global</code></b></a>
- <a href="doc/persistent.md#api_nan_weak_callback_info"><b><code>Nan::WeakCallbackInfo</code></b></a>
- <a href="doc/persistent.md#api_nan_weak_callback_type"><b><code>Nan::WeakCallbackType</code></b></a>
Also see the V8 Embedders Guide section on [Handles and Garbage Collection](https://developers.google.com/v8/embed#handles).
### New
NAN provides a `Nan::New()` helper for the creation of new JavaScript objects in a way that's compatible across the supported versions of V8.
- <a href="doc/new.md#api_nan_new"><b><code>Nan::New()</code></b></a>
- <a href="doc/new.md#api_nan_undefined"><b><code>Nan::Undefined()</code></b></a>
- <a href="doc/new.md#api_nan_null"><b><code>Nan::Null()</code></b></a>
- <a href="doc/new.md#api_nan_true"><b><code>Nan::True()</code></b></a>
- <a href="doc/new.md#api_nan_false"><b><code>Nan::False()</code></b></a>
- <a href="doc/new.md#api_nan_empty_string"><b><code>Nan::EmptyString()</code></b></a>
### Converters
NAN contains functions that convert `v8::Value`s to other `v8::Value` types and native types. Since type conversion is not guaranteed to succeed, they return `Nan::Maybe` types. These converters can be used in place of `value->ToX()` and `value->XValue()` (where `X` is one of the types, e.g. `Boolean`) in a way that provides a consistent interface across V8 versions. Newer versions of V8 use the new `v8::Maybe` and `v8::MaybeLocal` types for these conversions, older versions don't have this functionality so it is provided by NAN.
- <a href="doc/converters.md#api_nan_to"><b><code>Nan::To()</code></b></a>
### Maybe Types
The `Nan::MaybeLocal` and `Nan::Maybe` types are monads that encapsulate `v8::Local` handles that _may be empty_.
* **Maybe Types**
- <a href="doc/maybe_types.md#api_nan_maybe_local"><b><code>Nan::MaybeLocal</code></b></a>
- <a href="doc/maybe_types.md#api_nan_maybe"><b><code>Nan::Maybe</code></b></a>
- <a href="doc/maybe_types.md#api_nan_nothing"><b><code>Nan::Nothing</code></b></a>
- <a href="doc/maybe_types.md#api_nan_just"><b><code>Nan::Just</code></b></a>
* **Maybe Helpers**
- <a href="doc/maybe_types.md#api_nan_call"><b><code>Nan::Call()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_to_detail_string"><b><code>Nan::ToDetailString()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_to_array_index"><b><code>Nan::ToArrayIndex()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_equals"><b><code>Nan::Equals()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_new_instance"><b><code>Nan::NewInstance()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_function"><b><code>Nan::GetFunction()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_set"><b><code>Nan::Set()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_define_own_property"><b><code>Nan::DefineOwnProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_force_set"><del><b><code>Nan::ForceSet()</code></b></del></a>
- <a href="doc/maybe_types.md#api_nan_get"><b><code>Nan::Get()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_property_attribute"><b><code>Nan::GetPropertyAttributes()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has"><b><code>Nan::Has()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_delete"><b><code>Nan::Delete()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_property_names"><b><code>Nan::GetPropertyNames()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_own_property_names"><b><code>Nan::GetOwnPropertyNames()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_set_prototype"><b><code>Nan::SetPrototype()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_object_proto_to_string"><b><code>Nan::ObjectProtoToString()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_own_property"><b><code>Nan::HasOwnProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_real_named_property"><b><code>Nan::HasRealNamedProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_real_indexed_property"><b><code>Nan::HasRealIndexedProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_real_named_callback_property"><b><code>Nan::HasRealNamedCallbackProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_real_named_property_in_prototype_chain"><b><code>Nan::GetRealNamedPropertyInPrototypeChain()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_real_named_property"><b><code>Nan::GetRealNamedProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_call_as_function"><b><code>Nan::CallAsFunction()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_call_as_constructor"><b><code>Nan::CallAsConstructor()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_source_line"><b><code>Nan::GetSourceLine()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_line_number"><b><code>Nan::GetLineNumber()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_start_column"><b><code>Nan::GetStartColumn()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_end_column"><b><code>Nan::GetEndColumn()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_clone_element_at"><b><code>Nan::CloneElementAt()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_private"><b><code>Nan::HasPrivate()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_private"><b><code>Nan::GetPrivate()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_set_private"><b><code>Nan::SetPrivate()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_delete_private"><b><code>Nan::DeletePrivate()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_make_maybe"><b><code>Nan::MakeMaybe()</code></b></a>
### Script
NAN provides a `v8::Script` helpers as the API has changed over the supported versions of V8.
- <a href="doc/script.md#api_nan_compile_script"><b><code>Nan::CompileScript()</code></b></a>
- <a href="doc/script.md#api_nan_run_script"><b><code>Nan::RunScript()</code></b></a>
### JSON
The _JSON_ object provides the C++ versions of the methods offered by the `JSON` object in javascript. V8 exposes these methods via the `v8::JSON` object.
- <a href="doc/json.md#api_nan_json_parse"><b><code>Nan::JSON.Parse</code></b></a>
- <a href="doc/json.md#api_nan_json_stringify"><b><code>Nan::JSON.Stringify</code></b></a>
Refer to the V8 JSON object in the [V8 documentation](https://v8docs.nodesource.com/node-8.16/da/d6f/classv8_1_1_j_s_o_n.html) for more information about these methods and their arguments.
### Errors
NAN includes helpers for creating, throwing and catching Errors as much of this functionality varies across the supported versions of V8 and must be abstracted.
Note that an Error object is simply a specialized form of `v8::Value`.
Also consult the V8 Embedders Guide section on [Exceptions](https://developers.google.com/v8/embed#exceptions) for more information.
- <a href="doc/errors.md#api_nan_error"><b><code>Nan::Error()</code></b></a>
- <a href="doc/errors.md#api_nan_range_error"><b><code>Nan::RangeError()</code></b></a>
- <a href="doc/errors.md#api_nan_reference_error"><b><code>Nan::ReferenceError()</code></b></a>
- <a href="doc/errors.md#api_nan_syntax_error"><b><code>Nan::SyntaxError()</code></b></a>
- <a href="doc/errors.md#api_nan_type_error"><b><code>Nan::TypeError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_error"><b><code>Nan::ThrowError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_range_error"><b><code>Nan::ThrowRangeError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_reference_error"><b><code>Nan::ThrowReferenceError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_syntax_error"><b><code>Nan::ThrowSyntaxError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_type_error"><b><code>Nan::ThrowTypeError()</code></b></a>
- <a href="doc/errors.md#api_nan_fatal_exception"><b><code>Nan::FatalException()</code></b></a>
- <a href="doc/errors.md#api_nan_errno_exception"><b><code>Nan::ErrnoException()</code></b></a>
- <a href="doc/errors.md#api_nan_try_catch"><b><code>Nan::TryCatch</code></b></a>
### Buffers
NAN's `node::Buffer` helpers exist as the API has changed across supported Node versions. Use these methods to ensure compatibility.
- <a href="doc/buffers.md#api_nan_new_buffer"><b><code>Nan::NewBuffer()</code></b></a>
- <a href="doc/buffers.md#api_nan_copy_buffer"><b><code>Nan::CopyBuffer()</code></b></a>
- <a href="doc/buffers.md#api_nan_free_callback"><b><code>Nan::FreeCallback()</code></b></a>
### Nan::Callback
`Nan::Callback` makes it easier to use `v8::Function` handles as callbacks. A class that wraps a `v8::Function` handle, protecting it from garbage collection and making it particularly useful for storage and use across asynchronous execution.
- <a href="doc/callback.md#api_nan_callback"><b><code>Nan::Callback</code></b></a>
### Asynchronous work helpers
`Nan::AsyncWorker`, `Nan::AsyncProgressWorker` and `Nan::AsyncProgressQueueWorker` are helper classes that make working with asynchronous code easier.
- <a href="doc/asyncworker.md#api_nan_async_worker"><b><code>Nan::AsyncWorker</code></b></a>
- <a href="doc/asyncworker.md#api_nan_async_progress_worker"><b><code>Nan::AsyncProgressWorkerBase & Nan::AsyncProgressWorker</code></b></a>
- <a href="doc/asyncworker.md#api_nan_async_progress_queue_worker"><b><code>Nan::AsyncProgressQueueWorker</code></b></a>
- <a href="doc/asyncworker.md#api_nan_async_queue_worker"><b><code>Nan::AsyncQueueWorker</code></b></a>
### Strings & Bytes
Miscellaneous string & byte encoding and decoding functionality provided for compatibility across supported versions of V8 and Node. Implemented by NAN to ensure that all encoding types are supported, even for older versions of Node where they are missing.
- <a href="doc/string_bytes.md#api_nan_encoding"><b><code>Nan::Encoding</code></b></a>
- <a href="doc/string_bytes.md#api_nan_encode"><b><code>Nan::Encode()</code></b></a>
- <a href="doc/string_bytes.md#api_nan_decode_bytes"><b><code>Nan::DecodeBytes()</code></b></a>
- <a href="doc/string_bytes.md#api_nan_decode_write"><b><code>Nan::DecodeWrite()</code></b></a>
### Object Wrappers
The `ObjectWrap` class can be used to make wrapped C++ objects and a factory of wrapped objects.
- <a href="doc/object_wrappers.md#api_nan_object_wrap"><b><code>Nan::ObjectWrap</code></b></a>
### V8 internals
The hooks to access V8 internals—including GC and statistics—are different across the supported versions of V8, therefore NAN provides its own hooks that call the appropriate V8 methods.
- <a href="doc/v8_internals.md#api_nan_gc_callback"><b><code>NAN_GC_CALLBACK()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_add_gc_epilogue_callback"><b><code>Nan::AddGCEpilogueCallback()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_remove_gc_epilogue_callback"><b><code>Nan::RemoveGCEpilogueCallback()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_add_gc_prologue_callback"><b><code>Nan::AddGCPrologueCallback()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_remove_gc_prologue_callback"><b><code>Nan::RemoveGCPrologueCallback()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_get_heap_statistics"><b><code>Nan::GetHeapStatistics()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_set_counter_function"><b><code>Nan::SetCounterFunction()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_set_create_histogram_function"><b><code>Nan::SetCreateHistogramFunction()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_set_add_histogram_sample_function"><b><code>Nan::SetAddHistogramSampleFunction()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_idle_notification"><b><code>Nan::IdleNotification()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_low_memory_notification"><b><code>Nan::LowMemoryNotification()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_context_disposed_notification"><b><code>Nan::ContextDisposedNotification()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_get_internal_field_pointer"><b><code>Nan::GetInternalFieldPointer()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_set_internal_field_pointer"><b><code>Nan::SetInternalFieldPointer()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_adjust_external_memory"><b><code>Nan::AdjustExternalMemory()</code></b></a>
### Miscellaneous V8 Helpers
- <a href="doc/v8_misc.md#api_nan_utf8_string"><b><code>Nan::Utf8String</code></b></a>
- <a href="doc/v8_misc.md#api_nan_get_current_context"><b><code>Nan::GetCurrentContext()</code></b></a>
- <a href="doc/v8_misc.md#api_nan_set_isolate_data"><b><code>Nan::SetIsolateData()</code></b></a>
- <a href="doc/v8_misc.md#api_nan_get_isolate_data"><b><code>Nan::GetIsolateData()</code></b></a>
- <a href="doc/v8_misc.md#api_nan_typedarray_contents"><b><code>Nan::TypedArrayContents</code></b></a>
### Miscellaneous Node Helpers
- <a href="doc/node_misc.md#api_nan_asyncresource"><b><code>Nan::AsyncResource</code></b></a>
- <a href="doc/node_misc.md#api_nan_make_callback"><b><code>Nan::MakeCallback()</code></b></a>
- <a href="doc/node_misc.md#api_nan_module_init"><b><code>NAN_MODULE_INIT()</code></b></a>
- <a href="doc/node_misc.md#api_nan_export"><b><code>Nan::Export()</code></b></a>
<!-- END API -->
<a name="tests"></a>
### Tests
To run the NAN tests do:
``` sh
npm install
npm run-script rebuild-tests
npm test
```
Or just:
``` sh
npm install
make test
```
<a name="issues"></a>
## Known issues
### Compiling against Node.js 0.12 on OSX
With new enough compilers available on OSX, the versions of V8 headers corresponding to Node.js 0.12
do not compile anymore. The error looks something like:
```
❯ CXX(target) Release/obj.target/accessors/cpp/accessors.o
In file included from ../cpp/accessors.cpp:9:
In file included from ../../nan.h:51:
In file included from /Users/ofrobots/.node-gyp/0.12.18/include/node/node.h:61:
/Users/ofrobots/.node-gyp/0.12.18/include/node/v8.h:5800:54: error: 'CreateHandle' is a protected member of 'v8::HandleScope'
return Handle<T>(reinterpret_cast<T*>(HandleScope::CreateHandle(
~~~~~~~~~~~~~^~~~~~~~~~~~
```
This can be worked around by patching your local versions of v8.h corresponding to Node 0.12 to make
`v8::Handle` a friend of `v8::HandleScope`. Since neither Node.js not V8 support this release line anymore
this patch cannot be released by either project in an official release.
For this reason, we do not test against Node.js 0.12 on OSX in this project's CI. If you need to support
that configuration, you will need to either get an older compiler, or apply a source patch to the version
of V8 headers as a workaround.
<a name="governance"></a>
## Governance & Contributing
NAN is governed by the [Node.js Addon API Working Group](https://github.com/nodejs/CTC/blob/master/WORKING_GROUPS.md#addon-api)
### Addon API Working Group (WG)
The NAN project is jointly governed by a Working Group which is responsible for high-level guidance of the project.
Members of the WG are also known as Collaborators, there is no distinction between the two, unlike other Node.js projects.
The WG has final authority over this project including:
* Technical direction
* Project governance and process (including this policy)
* Contribution policy
* GitHub repository hosting
* Maintaining the list of additional Collaborators
For the current list of WG members, see the project [README.md](./README.md#collaborators).
Individuals making significant and valuable contributions are made members of the WG and given commit-access to the project. These individuals are identified by the WG and their addition to the WG is discussed via GitHub and requires unanimous consensus amongst those WG members participating in the discussion with a quorum of 50% of WG members required for acceptance of the vote.
_Note:_ If you make a significant contribution and are not considered for commit-access log an issue or contact a WG member directly.
For the current list of WG members / Collaborators, see the project [README.md](./README.md#collaborators).
### Consensus Seeking Process
The WG follows a [Consensus Seeking](https://en.wikipedia.org/wiki/Consensus-seeking_decision-making) decision making model.
Modifications of the contents of the NAN repository are made on a collaborative basis. Anybody with a GitHub account may propose a modification via pull request and it will be considered by the WG. All pull requests must be reviewed and accepted by a WG member with sufficient expertise who is able to take full responsibility for the change. In the case of pull requests proposed by an existing WG member, an additional WG member is required for sign-off. Consensus should be sought if additional WG members participate and there is disagreement around a particular modification.
If a change proposal cannot reach a consensus, a WG member can call for a vote amongst the members of the WG. Simple majority wins.
<a id="developers-certificate-of-origin"></a>
## Developer's Certificate of Origin 1.1
By making a contribution to this project, I certify that:
* (a) The contribution was created in whole or in part by me and I
have the right to submit it under the open source license
indicated in the file; or
* (b) The contribution is based upon previous work that, to the best
of my knowledge, is covered under an appropriate open source
license and I have the right under that license to submit that
work with modifications, whether created in whole or in part
by me, under the same open source license (unless I am
permitted to submit under a different license), as indicated
in the file; or
* (c) The contribution was provided directly to me by some other
person who certified (a), (b) or (c) and I have not modified
it.
* (d) I understand and agree that this project and the contribution
are public and that a record of the contribution (including all
personal information I submit with it, including my sign-off) is
maintained indefinitely and may be redistributed consistent with
this project or the open source license(s) involved.
<a name="collaborators"></a>
### WG Members / Collaborators
<table><tbody>
<tr><th align="left">Rod Vagg</th><td><a href="https://github.com/rvagg">GitHub/rvagg</a></td><td><a href="http://twitter.com/rvagg">Twitter/@rvagg</a></td></tr>
<tr><th align="left">Benjamin Byholm</th><td><a href="https://github.com/kkoopa/">GitHub/kkoopa</a></td><td>-</td></tr>
<tr><th align="left">Trevor Norris</th><td><a href="https://github.com/trevnorris">GitHub/trevnorris</a></td><td><a href="http://twitter.com/trevnorris">Twitter/@trevnorris</a></td></tr>
<tr><th align="left">Nathan Rajlich</th><td><a href="https://github.com/TooTallNate">GitHub/TooTallNate</a></td><td><a href="http://twitter.com/TooTallNate">Twitter/@TooTallNate</a></td></tr>
<tr><th align="left">Brett Lawson</th><td><a href="https://github.com/brett19">GitHub/brett19</a></td><td><a href="http://twitter.com/brett19x">Twitter/@brett19x</a></td></tr>
<tr><th align="left">Ben Noordhuis</th><td><a href="https://github.com/bnoordhuis">GitHub/bnoordhuis</a></td><td><a href="http://twitter.com/bnoordhuis">Twitter/@bnoordhuis</a></td></tr>
<tr><th align="left">David Siegel</th><td><a href="https://github.com/agnat">GitHub/agnat</a></td><td><a href="http://twitter.com/agnat">Twitter/@agnat</a></td></tr>
<tr><th align="left">Michael Ira Krufky</th><td><a href="https://github.com/mkrufky">GitHub/mkrufky</a></td><td><a href="http://twitter.com/mkrufky">Twitter/@mkrufky</a></td></tr>
</tbody></table>
## Licence & copyright
Copyright (c) 2018 NAN WG Members / Collaborators (listed above).
Native Abstractions for Node.js is licensed under an MIT license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE file for more details.
# Camel Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a string with the separator denoted by the next word capitalized.
## Installation
```
npm install camel-case --save
```
## Usage
```js
import { camelCase } from "camel-case";
camelCase("string"); //=> "string"
camelCase("dot.case"); //=> "dotCase"
camelCase("PascalCase"); //=> "pascalCase"
camelCase("version 1.2.10"); //=> "version_1_2_10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
### Merge Numbers
If you'd like to remove the behavior prefixing `_` before numbers, you can use `camelCaseTransformMerge`:
```js
import { camelCaseTransformMerge } from "camel-case";
camelCase("version 12", { transform: camelCaseTransformMerge }); //=> "version12"
```
## License
MIT
[npm-image]: https://img.shields.io/npm/v/camel-case.svg?style=flat
[npm-url]: https://npmjs.org/package/camel-case
[downloads-image]: https://img.shields.io/npm/dm/camel-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/camel-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/camel-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=camel-case
# level-errors
> Error types for [levelup][levelup].
[![level badge][level-badge]](https://github.com/Level/awesome)
[](https://www.npmjs.com/package/level-errors)
[](https://www.npmjs.com/package/level-errors)
[](https://travis-ci.org/Level/errors)
[](https://coveralls.io/github/Level/errors)
[](https://standardjs.com)
[](https://www.npmjs.com/package/level-errors)
[](#backers)
[](#sponsors)
## API
**If you are upgrading:** please see [`UPGRADING.md`](UPGRADING.md).
### `.LevelUPError()`
Generic error base class.
### `.InitializationError()`
Error initializing the database, like when the database's location argument is missing.
### `.OpenError()`
Error opening the database.
### `.ReadError()`
Error reading from the database.
### `.WriteError()`
Error writing to the database.
### `.NotFoundError()`
Data not found error.
Has extra properties:
- `notFound`: `true`
- `status`: 404
### `.EncodingError()`
Error encoding data.
## Contributing
[`Level/errors`](https://github.com/Level/errors) is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [Contribution Guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
## Donate
To sustain [`Level`](https://github.com/Level) and its activities, become a backer or sponsor on [Open Collective](https://opencollective.com/level). Your logo or avatar will be displayed on our 28+ [GitHub repositories](https://github.com/Level), [npm](https://www.npmjs.com/) packages and (soon) [our website](http://leveldb.org). 💖
### Backers
[](https://opencollective.com/level)
### Sponsors
[](https://opencollective.com/level)
## License
[MIT](LICENSE.md) © 2012-present [Contributors](CONTRIBUTORS.md).
[level-badge]: http://leveldb.org/img/badge.svg
[levelup]: https://github.com/Level/levelup
# `node-gyp` - Node.js native addon build tool
[](https://github.com/nodejs/node-gyp/actions?query=workflow%3ATests+branch%3Amaster)
`node-gyp` is a cross-platform command-line tool written in Node.js for
compiling native addon modules for Node.js. It contains a vendored copy of the
[gyp-next](https://github.com/nodejs/gyp-next) project that was previously used
by the Chromium team, extended to support the development of Node.js native addons.
Note that `node-gyp` is _not_ used to build Node.js itself.
Multiple target versions of Node.js are supported (i.e. `0.8`, ..., `4`, `5`, `6`,
etc.), regardless of what version of Node.js is actually installed on your system
(`node-gyp` downloads the necessary development files or headers for the target version).
## Features
* The same build commands work on any of the supported platforms
* Supports the targeting of different versions of Node.js
## Installation
You can install `node-gyp` using `npm`:
``` bash
$ npm install -g node-gyp
```
Depending on your operating system, you will need to install:
### On Unix
* Python v2.7, v3.5, v3.6, v3.7, or v3.8
* `make`
* A proper C/C++ compiler toolchain, like [GCC](https://gcc.gnu.org)
### On macOS
**ATTENTION**: If your Mac has been _upgraded_ to macOS Catalina (10.15), please read [macOS_Catalina.md](macOS_Catalina.md).
* Python v2.7, v3.5, v3.6, v3.7, or v3.8
* [Xcode](https://developer.apple.com/xcode/download/)
* You also need to install the `XCode Command Line Tools` by running `xcode-select --install`. Alternatively, if you already have the full Xcode installed, you can find them under the menu `Xcode -> Open Developer Tool -> More Developer Tools...`. This step will install `clang`, `clang++`, and `make`.
### On Windows
Install the current version of Python from the [Microsoft Store package](https://docs.python.org/3/using/windows.html#the-microsoft-store-package).
#### Option 1
Install all the required tools and configurations using Microsoft's [windows-build-tools](https://github.com/felixrieseberg/windows-build-tools) using `npm install --global windows-build-tools` from an elevated PowerShell or CMD.exe (run as Administrator).
#### Option 2
Install tools and configuration manually:
* Install Visual C++ Build Environment: [Visual Studio Build Tools](https://visualstudio.microsoft.com/thank-you-downloading-visual-studio/?sku=BuildTools)
(using "Visual C++ build tools" workload) or [Visual Studio 2017 Community](https://visualstudio.microsoft.com/pl/thank-you-downloading-visual-studio/?sku=Community)
(using the "Desktop development with C++" workload)
* Launch cmd, `npm config set msvs_version 2017`
If the above steps didn't work for you, please visit [Microsoft's Node.js Guidelines for Windows](https://github.com/Microsoft/nodejs-guidelines/blob/master/windows-environment.md#compiling-native-addon-modules) for additional tips.
To target native ARM64 Node.js on Windows 10 on ARM, add the components "Visual C++ compilers and libraries for ARM64" and "Visual C++ ATL for ARM64".
### Configuring Python Dependency
`node-gyp` requires that you have installed a compatible version of Python, one of: v2.7, v3.5, v3.6,
v3.7, or v3.8. If you have multiple Python versions installed, you can identify which Python
version `node-gyp` should use in one of the following ways:
1. by setting the `--python` command-line option, e.g.:
``` bash
$ node-gyp <command> --python /path/to/executable/python
```
2. If `node-gyp` is called by way of `npm`, *and* you have multiple versions of
Python installed, then you can set `npm`'s 'python' config key to the appropriate
value:
``` bash
$ npm config set python /path/to/executable/python
```
3. If the `PYTHON` environment variable is set to the path of a Python executable,
then that version will be used, if it is a compatible version.
4. If the `NODE_GYP_FORCE_PYTHON` environment variable is set to the path of a
Python executable, it will be used instead of any of the other configured or
builtin Python search paths. If it's not a compatible version, no further
searching will be done.
## How to Use
To compile your native addon, first go to its root directory:
``` bash
$ cd my_node_addon
```
The next step is to generate the appropriate project build files for the current
platform. Use `configure` for that:
``` bash
$ node-gyp configure
```
Auto-detection fails for Visual C++ Build Tools 2015, so `--msvs_version=2015`
needs to be added (not needed when run by npm as configured above):
``` bash
$ node-gyp configure --msvs_version=2015
```
__Note__: The `configure` step looks for a `binding.gyp` file in the current
directory to process. See below for instructions on creating a `binding.gyp` file.
Now you will have either a `Makefile` (on Unix platforms) or a `vcxproj` file
(on Windows) in the `build/` directory. Next, invoke the `build` command:
``` bash
$ node-gyp build
```
Now you have your compiled `.node` bindings file! The compiled bindings end up
in `build/Debug/` or `build/Release/`, depending on the build mode. At this point,
you can require the `.node` file with Node.js and run your tests!
__Note:__ To create a _Debug_ build of the bindings file, pass the `--debug` (or
`-d`) switch when running either the `configure`, `build` or `rebuild` commands.
## The `binding.gyp` file
A `binding.gyp` file describes the configuration to build your module, in a
JSON-like format. This file gets placed in the root of your package, alongside
`package.json`.
A barebones `gyp` file appropriate for building a Node.js addon could look like:
```python
{
"targets": [
{
"target_name": "binding",
"sources": [ "src/binding.cc" ]
}
]
}
```
## Further reading
Some additional resources for Node.js native addons and writing `gyp` configuration files:
* ["Going Native" a nodeschool.io tutorial](http://nodeschool.io/#goingnative)
* ["Hello World" node addon example](https://github.com/nodejs/node/tree/master/test/addons/hello-world)
* [gyp user documentation](https://gyp.gsrc.io/docs/UserDocumentation.md)
* [gyp input format reference](https://gyp.gsrc.io/docs/InputFormatReference.md)
* [*"binding.gyp" files out in the wild* wiki page](https://github.com/nodejs/node-gyp/wiki/%22binding.gyp%22-files-out-in-the-wild)
## Commands
`node-gyp` responds to the following commands:
| **Command** | **Description**
|:--------------|:---------------------------------------------------------------
| `help` | Shows the help dialog
| `build` | Invokes `make`/`msbuild.exe` and builds the native addon
| `clean` | Removes the `build` directory if it exists
| `configure` | Generates project build files for the current platform
| `rebuild` | Runs `clean`, `configure` and `build` all in a row
| `install` | Installs Node.js header files for the given version
| `list` | Lists the currently installed Node.js header versions
| `remove` | Removes the Node.js header files for the given version
## Command Options
`node-gyp` accepts the following command options:
| **Command** | **Description**
|:----------------------------------|:------------------------------------------
| `-j n`, `--jobs n` | Run `make` in parallel. The value `max` will use all available CPU cores
| `--target=v6.2.1` | Node.js version to build for (default is `process.version`)
| `--silly`, `--loglevel=silly` | Log all progress to console
| `--verbose`, `--loglevel=verbose` | Log most progress to console
| `--silent`, `--loglevel=silent` | Don't log anything to console
| `debug`, `--debug` | Make Debug build (default is `Release`)
| `--release`, `--no-debug` | Make Release build
| `-C $dir`, `--directory=$dir` | Run command in different directory
| `--make=$make` | Override `make` command (e.g. `gmake`)
| `--thin=yes` | Enable thin static libraries
| `--arch=$arch` | Set target architecture (e.g. ia32)
| `--tarball=$path` | Get headers from a local tarball
| `--devdir=$path` | SDK download directory (default is OS cache directory)
| `--ensure` | Don't reinstall headers if already present
| `--dist-url=$url` | Download header tarball from custom URL
| `--proxy=$url` | Set HTTP(S) proxy for downloading header tarball
| `--noproxy=$urls` | Set urls to ignore proxies when downloading header tarball
| `--cafile=$cafile` | Override default CA chain (to download tarball)
| `--nodedir=$path` | Set the path to the node source code
| `--python=$path` | Set path to the Python binary
| `--msvs_version=$version` | Set Visual Studio version (Windows only)
| `--solution=$solution` | Set Visual Studio Solution version (Windows only)
## Configuration
### Environment variables
Use the form `npm_config_OPTION_NAME` for any of the command options listed
above (dashes in option names should be replaced by underscores).
For example, to set `devdir` equal to `/tmp/.gyp`, you would:
Run this on Unix:
```bash
$ export npm_config_devdir=/tmp/.gyp
```
Or this on Windows:
```console
> set npm_config_devdir=c:\temp\.gyp
```
### `npm` configuration
Use the form `OPTION_NAME` for any of the command options listed above.
For example, to set `devdir` equal to `/tmp/.gyp`, you would run:
```bash
$ npm config set [--global] devdir /tmp/.gyp
```
**Note:** Configuration set via `npm` will only be used when `node-gyp`
is run via `npm`, not when `node-gyp` is run directly.
## License
`node-gyp` is available under the MIT license. See the [LICENSE
file](LICENSE) for details.
# Optionator
<a name="optionator" />
Optionator is a JavaScript/Node.js option parsing and help generation library used by [eslint](http://eslint.org), [Grasp](http://graspjs.com), [LiveScript](http://livescript.net), [esmangle](https://github.com/estools/esmangle), [escodegen](https://github.com/estools/escodegen), and [many more](https://www.npmjs.com/browse/depended/optionator).
For an online demo, check out the [Grasp online demo](http://www.graspjs.com/#demo).
[About](#about) · [Usage](#usage) · [Settings Format](#settings-format) · [Argument Format](#argument-format)
## Why?
The problem with other option parsers, such as `yargs` or `minimist`, is they just accept all input, valid or not.
With Optionator, if you mistype an option, it will give you an error (with a suggestion for what you meant).
If you give the wrong type of argument for an option, it will give you an error rather than supplying the wrong input to your application.
$ cmd --halp
Invalid option '--halp' - perhaps you meant '--help'?
$ cmd --count str
Invalid value for option 'count' - expected type Int, received value: str.
Other helpful features include reformatting the help text based on the size of the console, so that it fits even if the console is narrow, and accepting not just an array (eg. process.argv), but a string or object as well, making things like testing much easier.
## About
Optionator uses [type-check](https://github.com/gkz/type-check) and [levn](https://github.com/gkz/levn) behind the scenes to cast and verify input according the specified types.
MIT license. Version 0.8.3
npm install optionator
For updates on Optionator, [follow me on twitter](https://twitter.com/gkzahariev).
Optionator is a Node.js module, but can be used in the browser as well if packed with webpack/browserify.
## Usage
`require('optionator');` returns a function. It has one property, `VERSION`, the current version of the library as a string. This function is called with an object specifying your options and other information, see the [settings format section](#settings-format). This in turn returns an object with three properties, `parse`, `parseArgv`, `generateHelp`, and `generateHelpForOption`, which are all functions.
```js
var optionator = require('optionator')({
prepend: 'Usage: cmd [options]',
append: 'Version 1.0.0',
options: [{
option: 'help',
alias: 'h',
type: 'Boolean',
description: 'displays help'
}, {
option: 'count',
alias: 'c',
type: 'Int',
description: 'number of things',
example: 'cmd --count 2'
}]
});
var options = optionator.parseArgv(process.argv);
if (options.help) {
console.log(optionator.generateHelp());
}
...
```
### parse(input, parseOptions)
`parse` processes the `input` according to your settings, and returns an object with the results.
##### arguments
* input - `[String] | Object | String` - the input you wish to parse
* parseOptions - `{slice: Int}` - all options optional
- `slice` specifies how much to slice away from the beginning if the input is an array or string - by default `0` for string, `2` for array (works with `process.argv`)
##### returns
`Object` - the parsed options, each key is a camelCase version of the option name (specified in dash-case), and each value is the processed value for that option. Positional values are in an array under the `_` key.
##### example
```js
parse(['node', 't.js', '--count', '2', 'positional']); // {count: 2, _: ['positional']}
parse('--count 2 positional'); // {count: 2, _: ['positional']}
parse({count: 2, _:['positional']}); // {count: 2, _: ['positional']}
```
### parseArgv(input)
`parseArgv` works exactly like `parse`, but only for array input and it slices off the first two elements.
##### arguments
* input - `[String]` - the input you wish to parse
##### returns
See "returns" section in "parse"
##### example
```js
parseArgv(process.argv);
```
### generateHelp(helpOptions)
`generateHelp` produces help text based on your settings.
##### arguments
* helpOptions - `{showHidden: Boolean, interpolate: Object}` - all options optional
- `showHidden` specifies whether to show options with `hidden: true` specified, by default it is `false`
- `interpolate` specify data to be interpolated in `prepend` and `append` text, `{{key}}` is the format - eg. `generateHelp({interpolate:{version: '0.4.2'}})`, will change this `append` text: `Version {{version}}` to `Version 0.4.2`
##### returns
`String` - the generated help text
##### example
```js
generateHelp(); /*
"Usage: cmd [options] positional
-h, --help displays help
-c, --count Int number of things
Version 1.0.0
"*/
```
### generateHelpForOption(optionName)
`generateHelpForOption` produces expanded help text for the specified with `optionName` option. If an `example` was specified for the option, it will be displayed, and if a `longDescription` was specified, it will display that instead of the `description`.
##### arguments
* optionName - `String` - the name of the option to display
##### returns
`String` - the generated help text for the option
##### example
```js
generateHelpForOption('count'); /*
"-c, --count Int
description: number of things
example: cmd --count 2
"*/
```
## Settings Format
When your `require('optionator')`, you get a function that takes in a settings object. This object has the type:
{
prepend: String,
append: String,
options: [{heading: String} | {
option: String,
alias: [String] | String,
type: String,
enum: [String],
default: String,
restPositional: Boolean,
required: Boolean,
overrideRequired: Boolean,
dependsOn: [String] | String,
concatRepeatedArrays: Boolean | (Boolean, Object),
mergeRepeatedObjects: Boolean,
description: String,
longDescription: String,
example: [String] | String
}],
helpStyle: {
aliasSeparator: String,
typeSeparator: String,
descriptionSeparator: String,
initialIndent: Int,
secondaryIndent: Int,
maxPadFactor: Number
},
mutuallyExclusive: [[String | [String]]],
concatRepeatedArrays: Boolean | (Boolean, Object), // deprecated, set in defaults object
mergeRepeatedObjects: Boolean, // deprecated, set in defaults object
positionalAnywhere: Boolean,
typeAliases: Object,
defaults: Object
}
All of the properties are optional (the `Maybe` has been excluded for brevities sake), except for having either `heading: String` or `option: String` in each object in the `options` array.
### Top Level Properties
* `prepend` is an optional string to be placed before the options in the help text
* `append` is an optional string to be placed after the options in the help text
* `options` is a required array specifying your options and headings, the options and headings will be displayed in the order specified
* `helpStyle` is an optional object which enables you to change the default appearance of some aspects of the help text
* `mutuallyExclusive` is an optional array of arrays of either strings or arrays of strings. The top level array is a list of rules, each rule is a list of elements - each element can be either a string (the name of an option), or a list of strings (a group of option names) - there will be an error if more than one element is present
* `concatRepeatedArrays` see description under the "Option Properties" heading - use at the top level is deprecated, if you want to set this for all options, use the `defaults` property
* `mergeRepeatedObjects` see description under the "Option Properties" heading - use at the top level is deprecated, if you want to set this for all options, use the `defaults` property
* `positionalAnywhere` is an optional boolean (defaults to `true`) - when `true` it allows positional arguments anywhere, when `false`, all arguments after the first positional one are taken to be positional as well, even if they look like a flag. For example, with `positionalAnywhere: false`, the arguments `--flag --boom 12 --crack` would have two positional arguments: `12` and `--crack`
* `typeAliases` is an optional object, it allows you to set aliases for types, eg. `{Path: 'String'}` would allow you to use the type `Path` as an alias for the type `String`
* `defaults` is an optional object following the option properties format, which specifies default values for all options. A default will be overridden if manually set. For example, you can do `default: { type: "String" }` to set the default type of all options to `String`, and then override that default in an individual option by setting the `type` property
#### Heading Properties
* `heading` a required string, the name of the heading
#### Option Properties
* `option` the required name of the option - use dash-case, without the leading dashes
* `alias` is an optional string or array of strings which specify any aliases for the option
* `type` is a required string in the [type check](https://github.com/gkz/type-check) [format](https://github.com/gkz/type-check#type-format), this will be used to cast the inputted value and validate it
* `enum` is an optional array of strings, each string will be parsed by [levn](https://github.com/gkz/levn) - the argument value must be one of the resulting values - each potential value must validate against the specified `type`
* `default` is a optional string, which will be parsed by [levn](https://github.com/gkz/levn) and used as the default value if none is set - the value must validate against the specified `type`
* `restPositional` is an optional boolean - if set to `true`, everything after the option will be taken to be a positional argument, even if it looks like a named argument
* `required` is an optional boolean - if set to `true`, the option parsing will fail if the option is not defined
* `overrideRequired` is a optional boolean - if set to `true` and the option is used, and there is another option which is required but not set, it will override the need for the required option and there will be no error - this is useful if you have required options and want to use `--help` or `--version` flags
* `concatRepeatedArrays` is an optional boolean or tuple with boolean and options object (defaults to `false`) - when set to `true` and an option contains an array value and is repeated, the subsequent values for the flag will be appended rather than overwriting the original value - eg. option `g` of type `[String]`: `-g a -g b -g c,d` will result in `['a','b','c','d']`
You can supply an options object by giving the following value: `[true, options]`. The one currently supported option is `oneValuePerFlag`, this only allows one array value per flag. This is useful if your potential values contain a comma.
* `mergeRepeatedObjects` is an optional boolean (defaults to `false`) - when set to `true` and an option contains an object value and is repeated, the subsequent values for the flag will be merged rather than overwriting the original value - eg. option `g` of type `Object`: `-g a:1 -g b:2 -g c:3,d:4` will result in `{a: 1, b: 2, c: 3, d: 4}`
* `dependsOn` is an optional string or array of strings - if simply a string (the name of another option), it will make sure that that other option is set, if an array of strings, depending on whether `'and'` or `'or'` is first, it will either check whether all (`['and', 'option-a', 'option-b']`), or at least one (`['or', 'option-a', 'option-b']`) other options are set
* `description` is an optional string, which will be displayed next to the option in the help text
* `longDescription` is an optional string, it will be displayed instead of the `description` when `generateHelpForOption` is used
* `example` is an optional string or array of strings with example(s) for the option - these will be displayed when `generateHelpForOption` is used
#### Help Style Properties
* `aliasSeparator` is an optional string, separates multiple names from each other - default: ' ,'
* `typeSeparator` is an optional string, separates the type from the names - default: ' '
* `descriptionSeparator` is an optional string , separates the description from the padded name and type - default: ' '
* `initialIndent` is an optional int - the amount of indent for options - default: 2
* `secondaryIndent` is an optional int - the amount of indent if wrapped fully (in addition to the initial indent) - default: 4
* `maxPadFactor` is an optional number - affects the default level of padding for the names/type, it is multiplied by the average of the length of the names/type - default: 1.5
## Argument Format
At the highest level there are two types of arguments: named, and positional.
Name arguments of any length are prefixed with `--` (eg. `--go`), and those of one character may be prefixed with either `--` or `-` (eg. `-g`).
There are two types of named arguments: boolean flags (eg. `--problemo`, `-p`) which take no value and result in a `true` if they are present, the falsey `undefined` if they are not present, or `false` if present and explicitly prefixed with `no` (eg. `--no-problemo`). Named arguments with values (eg. `--tseries 800`, `-t 800`) are the other type. If the option has a type `Boolean` it will automatically be made into a boolean flag. Any other type results in a named argument that takes a value.
For more information about how to properly set types to get the value you want, take a look at the [type check](https://github.com/gkz/type-check) and [levn](https://github.com/gkz/levn) pages.
You can group single character arguments that use a single `-`, however all except the last must be boolean flags (which take no value). The last may be a boolean flag, or an argument which takes a value - eg. `-ba 2` is equivalent to `-b -a 2`.
Positional arguments are all those values which do not fall under the above - they can be anywhere, not just at the end. For example, in `cmd -b one -a 2 two` where `b` is a boolean flag, and `a` has the type `Number`, there are two positional arguments, `one` and `two`.
Everything after an `--` is positional, even if it looks like a named argument.
You may optionally use `=` to separate option names from values, for example: `--count=2`.
If you specify the option `NUM`, then any argument using a single `-` followed by a number will be valid and will set the value of `NUM`. Eg. `-2` will be parsed into `NUM: 2`.
If duplicate named arguments are present, the last one will be taken.
## Technical About
`optionator` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It uses [levn](https://github.com/gkz/levn) to cast arguments to their specified type, and uses [type-check](https://github.com/gkz/type-check) to validate values. It also uses the [prelude.ls](http://preludels.com/) library.
# glob-base [](http://badge.fury.io/js/glob-base) [](https://travis-ci.org/jonschlinkert/glob-base)
> Returns an object with the (non-glob) base path and the actual pattern.
Use [glob-parent](https://github.com/es128/glob-parent) if you just want the base path.
## Install with [npm](npmjs.org)
```bash
npm i glob-base --save
```
## Related projects
* [glob-parent](https://github.com/es128/glob-parent): Strips glob magic from a string to provide the parent path
* [micromatch](https://github.com/jonschlinkert/micromatch): Glob matching for javascript/node.js. A faster alternative to minimatch (10-45x faster on avg), with all the features you're used to using in your Grunt and gulp tasks.
* [parse-glob](https://github.com/jonschlinkert/parse-glob): Parse a glob pattern into an object of tokens.
* [is-glob](https://github.com/jonschlinkert/is-glob): Returns `true` if the given string looks like a glob pattern.
* [braces](https://github.com/jonschlinkert/braces): Fastest brace expansion for node.js, with the most complete support for the Bash 4.3 braces specification.
* [fill-range](https://github.com/jonschlinkert/fill-range): Fill in a range of numbers or letters, optionally passing an increment or multiplier to use.
* [expand-range](https://github.com/jonschlinkert/expand-range): Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. See the benchmarks. Used by micromatch.
## Usage
```js
var globBase = require('glob-base');
globBase('a/b/.git/');
//=> { base: 'a/b/.git/', isGlob: false, glob: '' })
globBase('a/b/**/e');
//=> { base: 'a/b', isGlob: true, glob: '**/e' }
globBase('a/b/*.{foo,bar}');
//=> { base: 'a/b', isGlob: true, glob: '*.{foo,bar}' }
globBase('a/b/.git/**');
//=> { base: 'a/b/.git', isGlob: true, glob: '**' }
globBase('a/b/c/*.md');
//=> { base: 'a/b/c', isGlob: true, glob: '*.md' }
globBase('a/b/c/.*.md');
//=> { base: 'a/b/c', isGlob: true, glob: '.*.md' }
globBase('a/b/{c,d}');
//=> { base: 'a/b', isGlob: true, glob: '{c,d}' }
globBase('!*.min.js');
//=> { base: '.', isGlob: true, glob: '!*.min.js' }
globBase('!foo');
//=> { base: '.', isGlob: true, glob: '!foo' }
globBase('!foo/(a|b).min.js');
//=> { base: '.', isGlob: true, glob: '!foo/(a|b).min.js' }
globBase('');
//=> { base: '.', isGlob: false, glob: '' }
globBase('**/*.md');
//=> { base: '.', isGlob: true, glob: '**/*.md' }
globBase('**/*.min.js');
//=> { base: '.', isGlob: true, glob: '**/*.min.js' }
globBase('**/.*');
//=> { base: '.', isGlob: true, glob: '**/.*' }
globBase('**/d');
//=> { base: '.', isGlob: true, glob: '**/d' }
globBase('*.*');
//=> { base: '.', isGlob: true, glob: '*.*' }
globBase('*.min.js');
//=> { base: '.', isGlob: true, glob: '*.min.js' }
globBase('*/*');
//=> { base: '.', isGlob: true, glob: '*/*' }
globBase('*b');
//=> { base: '.', isGlob: true, glob: '*b' }
globBase('.');
//=> { base: '.', isGlob: false, glob: '.' }
globBase('.*');
//=> { base: '.', isGlob: true, glob: '.*' }
globBase('./*');
//=> { base: '.', isGlob: true, glob: '*' }
globBase('/a');
//=> { base: '/', isGlob: false, glob: 'a' }
globBase('@(a|b)/e.f.g/');
//=> { base: '.', isGlob: true, glob: '@(a|b)/e.f.g/' }
globBase('[a-c]b*');
//=> { base: '.', isGlob: true, glob: '[a-c]b*' }
globBase('a');
//=> { base: '.', isGlob: false, glob: 'a' }
globBase('a.min.js');
//=> { base: '.', isGlob: false, glob: 'a.min.js' }
globBase('a/');
//=> { base: 'a/', isGlob: false, glob: '' }
globBase('a/**/j/**/z/*.md');
//=> { base: 'a', isGlob: true, glob: '**/j/**/z/*.md' }
globBase('a/*/c/*.md');
//=> { base: 'a', isGlob: true, glob: '*/c/*.md' }
globBase('a/?/c.md');
//=> { base: 'a', isGlob: true, glob: '?/c.md' }
globBase('a/??/c.js');
//=> { base: 'a', isGlob: true, glob: '??/c.js' }
globBase('a?b');
//=> { base: '.', isGlob: true, glob: 'a?b' }
globBase('bb');
//=> { base: '.', isGlob: false, glob: 'bb' }
globBase('c.md');
//=> { base: '.', isGlob: false, glob: 'c.md' }
```
## Running tests
Install dev dependencies.
```bash
npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/glob-base/issues)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright (c) 2015 Jon Schlinkert
Released under the MIT license
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on March 08, 2015._
# web3
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is the main package of [web3.js][repo].
Please read the main [README][repo-readme] and [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[repo-readme]: https://github.com/ethereum/web3.js/blob/1.x/README.md
[npm-image]: https://img.shields.io/npm/v/web3.svg
[npm-url]: https://npmjs.org/package/web3
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3
# Importing Keccak C code
The XKCP project contains various implementations of Keccak-related algorithms. These are the steps to select a specific implementation and import the code into our project.
First, generate the source bundles in XKCP:
```
git clone https://github.com/XKCP/XKCP.git
cd XKCP
git checkout 58b20ec
# Edit "Makefile.build". After all the <fragment> tags, add the following two <target> tags:
<target name="node32" inherits="KeccakSpongeWidth1600 inplace1600bi"/>
<target name="node64" inherits="KeccakSpongeWidth1600 optimized1600ufull"/>
make node32.pack node64.pack
```
The source files we need are now under XKCP's "bin/.pack/npm32/" and "bin/.pack/npm64/".
- Copy those to our repo under "src/libkeccak-32" and "src/libkeccak-64".
- Update our "binding.gyp" to point to the correct ".c" files.
- Run `npm run rebuild`.
## Implementation Choice
Currently, we're using two of XKCP KeccakP[1600] implementations -- the generic 32-bit-optimized one and the generic 64-bit-optimized one.
XKCP has implementations that use CPU-specific instructions (e.g. Intel AVR) and are likely much faster. It might be worth using those.
# web3-eth-contract
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This is the contract package used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-contract
```
## Usage
```js
const Web3EthContract = require('web3-eth-contract');
// Set provider for all later instances to use
Web3EthContract.setProvider('ws://localhost:8546');
const contract = new Web3EthContract(jsonInterface, address);
contract.methods.somFunc().send({from: ....})
.on('receipt', function(){
...
});
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-eth-contract.svg
[npm-url]: https://npmjs.org/package/web3-eth-contract
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-eth-contract
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-eth-contract
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-eth-contract
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-eth-contract

[](https://travis-ci.org/caolan/async)
[](https://www.npmjs.com/package/async)
[](https://coveralls.io/r/caolan/async?branch=master)
[](https://gitter.im/caolan/async?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
[](https://www.libhive.com/providers/npm/packages/async)
[](https://www.jsdelivr.com/package/npm/async)
Async is a utility module which provides straight-forward, powerful functions for working with [asynchronous JavaScript](http://caolan.github.io/async/global.html). Although originally designed for use with [Node.js](https://nodejs.org/) and installable via `npm install --save async`, it can also be used directly in the browser.
This version of the package is optimized for the Node.js environment. If you use Async with webpack, install [`async-es`](https://www.npmjs.com/package/async-es) instead.
For Documentation, visit <https://caolan.github.io/async/>
*For Async v1.5.x documentation, go [HERE](https://github.com/caolan/async/blob/v1.5.2/README.md)*
```javascript
// for use with Node-style callbacks...
var async = require("async");
var obj = {dev: "/dev.json", test: "/test.json", prod: "/prod.json"};
var configs = {};
async.forEachOf(obj, (value, key, callback) => {
fs.readFile(__dirname + value, "utf8", (err, data) => {
if (err) return callback(err);
try {
configs[key] = JSON.parse(data);
} catch (e) {
return callback(e);
}
callback();
});
}, err => {
if (err) console.error(err.message);
// configs is now a map of JSON data
doSomethingWith(configs);
});
```
```javascript
var async = require("async");
// ...or ES2017 async functions
async.mapLimit(urls, 5, async function(url) {
const response = await fetch(url)
return response.body
}, (err, results) => {
if (err) throw err
// results is now an array of the response bodies
console.log(results)
})
```
# ansi-colors [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=W8YFZ425KND68) [](https://www.npmjs.com/package/ansi-colors) [](https://npmjs.org/package/ansi-colors) [](https://npmjs.org/package/ansi-colors) [](https://travis-ci.org/doowb/ansi-colors)
> Easily add ANSI colors to your text and symbols in the terminal. A faster drop-in replacement for chalk, kleur and turbocolor (without the dependencies and rendering bugs).
Please consider following this project's author, [Brian Woodward](https://github.com/doowb), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save ansi-colors
```

## Why use this?
ansi-colors is _the fastest Node.js library for terminal styling_. A more performant drop-in replacement for chalk, with no dependencies.
* _Blazing fast_ - Fastest terminal styling library in node.js, 10-20x faster than chalk!
* _Drop-in replacement_ for [chalk](https://github.com/chalk/chalk).
* _No dependencies_ (Chalk has 7 dependencies in its tree!)
* _Safe_ - Does not modify the `String.prototype` like [colors](https://github.com/Marak/colors.js).
* Supports [nested colors](#nested-colors), **and does not have the [nested styling bug](#nested-styling-bug) that is present in [colorette](https://github.com/jorgebucaran/colorette), [chalk](https://github.com/chalk/chalk), and [kleur](https://github.com/lukeed/kleur)**.
* Supports [chained colors](#chained-colors).
* [Toggle color support](#toggle-color-support) on or off.
## Usage
```js
const c = require('ansi-colors');
console.log(c.red('This is a red string!'));
console.log(c.green('This is a red string!'));
console.log(c.cyan('This is a cyan string!'));
console.log(c.yellow('This is a yellow string!'));
```

## Chained colors
```js
console.log(c.bold.red('this is a bold red message'));
console.log(c.bold.yellow.italic('this is a bold yellow italicized message'));
console.log(c.green.bold.underline('this is a bold green underlined message'));
```

## Nested colors
```js
console.log(c.yellow(`foo ${c.red.bold('red')} bar ${c.cyan('cyan')} baz`));
```

### Nested styling bug
`ansi-colors` does not have the nested styling bug found in [colorette](https://github.com/jorgebucaran/colorette), [chalk](https://github.com/chalk/chalk), and [kleur](https://github.com/lukeed/kleur).
```js
const { bold, red } = require('ansi-styles');
console.log(bold(`foo ${red.dim('bar')} baz`));
const colorette = require('colorette');
console.log(colorette.bold(`foo ${colorette.red(colorette.dim('bar'))} baz`));
const kleur = require('kleur');
console.log(kleur.bold(`foo ${kleur.red.dim('bar')} baz`));
const chalk = require('chalk');
console.log(chalk.bold(`foo ${chalk.red.dim('bar')} baz`));
```
**Results in the following**
(sans icons and labels)

## Toggle color support
Easily enable/disable colors.
```js
const c = require('ansi-colors');
// disable colors manually
c.enabled = false;
// or use a library to automatically detect support
c.enabled = require('color-support').hasBasic;
console.log(c.red('I will only be colored red if the terminal supports colors'));
```
## Strip ANSI codes
Use the `.unstyle` method to strip ANSI codes from a string.
```js
console.log(c.unstyle(c.blue.bold('foo bar baz')));
//=> 'foo bar baz'
```
## Available styles
**Note** that bright and bright-background colors are not always supported.
| Colors | Background Colors | Bright Colors | Bright Background Colors |
| ------- | ----------------- | ------------- | ------------------------ |
| black | bgBlack | blackBright | bgBlackBright |
| red | bgRed | redBright | bgRedBright |
| green | bgGreen | greenBright | bgGreenBright |
| yellow | bgYellow | yellowBright | bgYellowBright |
| blue | bgBlue | blueBright | bgBlueBright |
| magenta | bgMagenta | magentaBright | bgMagentaBright |
| cyan | bgCyan | cyanBright | bgCyanBright |
| white | bgWhite | whiteBright | bgWhiteBright |
| gray | | | |
| grey | | | |
_(`gray` is the U.S. spelling, `grey` is more commonly used in the Canada and U.K.)_
### Style modifiers
* dim
* **bold**
* hidden
* _italic_
* underline
* inverse
* ~~strikethrough~~
* reset
## Aliases
Create custom aliases for styles.
```js
const colors = require('ansi-colors');
colors.alias('primary', colors.yellow);
colors.alias('secondary', colors.bold);
console.log(colors.primary.secondary('Foo'));
```
## Themes
A theme is an object of custom aliases.
```js
const colors = require('ansi-colors');
colors.theme({
danger: colors.red,
dark: colors.dim.gray,
disabled: colors.gray,
em: colors.italic,
heading: colors.bold.underline,
info: colors.cyan,
muted: colors.dim,
primary: colors.blue,
strong: colors.bold,
success: colors.green,
underline: colors.underline,
warning: colors.yellow
});
// Now, we can use our custom styles alongside the built-in styles!
console.log(colors.danger.strong.em('Error!'));
console.log(colors.warning('Heads up!'));
console.log(colors.info('Did you know...'));
console.log(colors.success.bold('It worked!'));
```
## Performance
**Libraries tested**
* ansi-colors v3.0.4
* chalk v2.4.1
### Mac
> MacBook Pro, Intel Core i7, 2.3 GHz, 16 GB.
**Load time**
Time it takes to load the first time `require()` is called:
* ansi-colors - `1.915ms`
* chalk - `12.437ms`
**Benchmarks**
```
# All Colors
ansi-colors x 173,851 ops/sec ±0.42% (91 runs sampled)
chalk x 9,944 ops/sec ±2.53% (81 runs sampled)))
# Chained colors
ansi-colors x 20,791 ops/sec ±0.60% (88 runs sampled)
chalk x 2,111 ops/sec ±2.34% (83 runs sampled)
# Nested colors
ansi-colors x 59,304 ops/sec ±0.98% (92 runs sampled)
chalk x 4,590 ops/sec ±2.08% (82 runs sampled)
```
### Windows
> Windows 10, Intel Core i7-7700k CPU @ 4.2 GHz, 32 GB
**Load time**
Time it takes to load the first time `require()` is called:
* ansi-colors - `1.494ms`
* chalk - `11.523ms`
**Benchmarks**
```
# All Colors
ansi-colors x 193,088 ops/sec ±0.51% (95 runs sampled))
chalk x 9,612 ops/sec ±3.31% (77 runs sampled)))
# Chained colors
ansi-colors x 26,093 ops/sec ±1.13% (94 runs sampled)
chalk x 2,267 ops/sec ±2.88% (80 runs sampled))
# Nested colors
ansi-colors x 67,747 ops/sec ±0.49% (93 runs sampled)
chalk x 4,446 ops/sec ±3.01% (82 runs sampled))
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [ansi-wrap](https://www.npmjs.com/package/ansi-wrap): Create ansi colors by passing the open and close codes. | [homepage](https://github.com/jonschlinkert/ansi-wrap "Create ansi colors by passing the open and close codes.")
* [strip-color](https://www.npmjs.com/package/strip-color): Strip ANSI color codes from a string. No dependencies. | [homepage](https://github.com/jonschlinkert/strip-color "Strip ANSI color codes from a string. No dependencies.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 48 | [jonschlinkert](https://github.com/jonschlinkert) |
| 42 | [doowb](https://github.com/doowb) |
| 6 | [lukeed](https://github.com/lukeed) |
| 2 | [Silic0nS0ldier](https://github.com/Silic0nS0ldier) |
| 1 | [dwieeb](https://github.com/dwieeb) |
| 1 | [jorgebucaran](https://github.com/jorgebucaran) |
| 1 | [madhavarshney](https://github.com/madhavarshney) |
| 1 | [chapterjason](https://github.com/chapterjason) |
### Author
**Brian Woodward**
* [GitHub Profile](https://github.com/doowb)
* [Twitter Profile](https://twitter.com/doowb)
* [LinkedIn Profile](https://linkedin.com/in/woodwardbrian)
### License
Copyright © 2019, [Brian Woodward](https://github.com/doowb).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on July 01, 2019._
# ethereumjs-common
[![NPM Package][common-npm-badge]][common-npm-link]
[![GitHub Issues][common-issues-badge]][common-issues-link]
[![Actions Status][common-actions-badge]][common-actions-link]
[![Code Coverage][common-coverage-badge]][common-coverage-link]
[![Gitter][gitter-badge]][gitter-link]
[![js-standard-style][js-standard-style-badge]][js-standard-style-link]
Resources common to all Ethereum implementations.
Succeeds the old [ethereum/common](https://github.com/ethereumjs/common/) library.
# INSTALL
`npm install ethereumjs-common`
# USAGE
All parameters can be accessed through the `Common` class which can be required through the
main package and instantiated either with just the `chain` (e.g. 'mainnet') or the `chain`
together with a specific `hardfork` provided.
Here are some simple usage examples:
```javascript
const Common = require('ethereumjs-common')
// Instantiate with only the chain
let c = new Common('ropsten')
c.param('gasPrices', 'ecAddGas', 'byzantium') // 500
// Chain and hardfork provided
c = new Common('ropsten', 'byzantium')
c.param('pow', 'minerReward') // 3000000000000000000
// Access genesis data for Ropsten network
c.genesis().hash // 0x41941023680923e0fe4d74a34bdac8141f2540e3ae90623718e47d66d1ca4a2d
// Get bootstrap nodes for chain/network
c.bootstrapNodes() // Array with current nodes
```
It is encouraged to also explicitly set the `supportedHardforks` if the initializing library
only supports a certain range of `hardforks`:
```javascript
let c = new Common('ropsten', null, ['byzantium', 'constantinople', 'petersburg'])
```
This will e.g. throw an error when a param is requested for an unsupported hardfork and
like this prevents unpredicted behaviour.
# API
See the API documentation for a full list of functions for accessing specific chain and
depending hardfork parameters. There are also additional helper functions like
`paramByBlock (topic, name, blockNumber)` or `hardforkIsActiveOnBlock (hardfork, blockNumber)`
to ease `blockNumber` based access to parameters.
- [API Docs](./docs/README.md)
# Hardfork Params
## Active Hardforks
There are currently parameter changes by the following past and future hardfork by the
library supported:
- `chainstart`
- `homestead`
- `dao`
- `tangerineWhistle`
- `spuriousDragon`
- `byzantium`
- `constantinople`
- `petersburg` (aka `constantinopleFix`, apply together with `constantinople`)
- `istanbul`
- `muirGlacier`
## Future Hardforks
The `muirGlacier` HF delaying the difficulty bomb and scheduled for January 2020
is supported by the library since `v1.5.0`.
## Parameter Access
For hardfork-specific parameter access with the `param()` and `paramByBlock()` functions
you can use the following `topics`:
- `gasConfig`
- `gasPrices`
- `vm`
- `pow`
- `casper`
- `sharding`
See one of the hardfork files like `byzantium.json` in the `hardforks` directory
for an overview. For consistency, the chain start (`chainstart`) is considered an own
hardfork.
The hardfork-specific json files only contain the deltas from `chainstart` and
shouldn't be accessed directly until you have a specific reason for it.
Note: The list of `gasPrices` and gas price changes on hardforks is consistent
but not complete, so there are currently gas price values missing (PRs welcome!).
# Chain Params
Supported chains:
- `mainnet`
- `ropsten`
- `rinkeby`
- `kovan`
- `goerli` (final configuration since `v1.1.0`)
- Private/custom chain parameters
The following chain-specific parameters are provided:
- `name`
- `chainId`
- `networkId`
- `genesis` block header values
- `hardforks` block numbers
- `bootstrapNodes` list
To get an overview of the different parameters have a look at one of the chain-specifc
files like `mainnet.json` in the `chains` directory, or to the `Chain` type in [./src/types.ts](./src/types.ts).
## Working with private/custom chains
There are two ways to set up a common instance with parameters for a private/custom chain:
1. You can pass a dictionary - conforming to the parameter format described above - with your custom values in
the constructor or the `setChain()` method for the `chain` parameter.
2. You can base your custom chain's config in a standard one, using the `Common.forCustomChain` method.
# Bootstrap Nodes
There is no separate config file for bootstrap nodes like in the old `ethereum-common` library.
Instead use the `common.bootstrapNodes()` function to get nodes for a specific chain/network.
# Genesis States
Network-specific genesis files are located in the `genesisStates` folder.
Due to the large file sizes genesis states are not directly included in the `index.js` file
but have to be accessed directly, e.g.:
```javascript
const mainnetGenesisState = require('ethereumjs-common/dist/genesisStates/mainnet')
```
Or by accessing dynamically:
```javascript
const genesisStates = require('ethereumjs-common/dist/genesisStates')
const mainnetGenesisState = genesisStates.genesisStateByName('mainnet')
const mainnetGenesisState = genesisStates.genesisStateById(1) // alternative via network Id
```
# EthereumJS
See our organizational [documentation](https://ethereumjs.readthedocs.io) for an introduction to `EthereumJS` as well as information on current standards and best practices.
If you want to join for work or do improvements on the libraries have a look at our [contribution guidelines](https://ethereumjs.readthedocs.io/en/latest/contributing.html).
# LICENSE
[MIT](https://opensource.org/licenses/MIT)
[gitter-badge]: https://img.shields.io/gitter/room/ethereum/ethereumjs.svg
[gitter-link]: https://gitter.im/ethereum/ethereumjs
[js-standard-style-badge]: https://cdn.rawgit.com/feross/standard/master/badge.svg
[js-standard-style-link]: https://github.com/feross/standard
[common-npm-badge]: https://img.shields.io/npm/v/ethereumjs-common.svg
[common-npm-link]: https://www.npmjs.org/package/ethereumjs-common
[common-issues-badge]: https://img.shields.io/github/issues/ethereumjs/ethereumjs-vm/package:%20common?label=issues
[common-issues-link]: https://github.com/ethereumjs/ethereumjs-vm/issues?q=is%3Aopen+is%3Aissue+label%3A"package%3A+common"
[common-actions-badge]: https://github.com/ethereumjs/ethereumjs-vm/workflows/Common%20Test/badge.svg
[common-actions-link]: https://github.com/ethereumjs/ethereumjs-vm/actions?query=workflow%3A%22Common+Test%22
[common-coverage-badge]: https://codecov.io/gh/ethereumjs/ethereumjs-vm/branch/master/graph/badge.svg?flag=common
[common-coverage-link]: https://codecov.io/gh/ethereumjs/ethereumjs-vm/tree/master/packages/common
# micromatch [](https://www.npmjs.com/package/micromatch) [](https://npmjs.org/package/micromatch) [](https://travis-ci.org/jonschlinkert/micromatch)
> Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch.
Micromatch supports all of the same matching features as [minimatch](https://github.com/isaacs/minimatch) and [multimatch](https://github.com/sindresorhus/multimatch).
* [mm()](#usage) is the same as [multimatch()](https://github.com/sindresorhus/multimatch)
* [mm.match()](#match) is the same as [minimatch.match()](https://github.com/isaacs/minimatch)
* use [mm.isMatch()](#ismatch) instead of [minimatch()](https://github.com/isaacs/minimatch)
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save micromatch
```
## Start matching!
```js
var mm = require('micromatch');
console.log(mm(['']))
```
***
### Features
* [Drop-in replacement](#switch-from-minimatch) for [minimatch](https://github.com/isaacs/minimatch) and [multimatch](https://github.com/sindresorhus/multimatch)
* Built-in support for multiple glob patterns, like `['foo/*.js', '!bar.js']`
* [Brace Expansion](https://github.com/jonschlinkert/braces) (`foo/bar-{1..5}.md`, `one/{two,three}/four.md`)
* Typical glob patterns, like `**/*`, `a/b/*.js`, or `['foo/*.js', '!bar.js']`
* Methods like `.isMatch()`, `.contains()` and `.any()`
**Extended globbing features:**
* Logical `OR` (`foo/bar/(abc|xyz).js`)
* Regex character classes (`foo/bar/baz-[1-5].js`)
* POSIX [bracket expressions](https://github.com/jonschlinkert/expand-brackets) (`**/[[:alpha:][:digit:]]/`)
* [extglobs](https://github.com/jonschlinkert/extglob) (`**/+(x|y)`, `!(a|b)`, etc).
You can combine these to create whatever matching patterns you need.
**Example**
```js
// double-negation!
mm(['fa', 'fb', 'f', 'fo'], '!(f!(o))');
//=> ['fo']
```
## Why switch to micromatch?
* Native support for multiple glob patterns, no need for wrappers like [multimatch](https://github.com/sindresorhus/multimatch)
* [10-55x faster](#benchmarks) and more performant than [minimatch](https://github.com/isaacs/minimatch) and [multimatch](https://github.com/sindresorhus/multimatch). This is achieved through a combination of caching and regex optimization strategies, a fundamentally different approach than minimatch.
* More extensive support for the Bash 4.3 specification
* More complete extglob support
* Extensive [unit tests](./test) (approx. 1,300 tests). Minimatch fails many of the tests.
### Switch from minimatch
Use `mm.isMatch()` instead of `minimatch()`:
```js
mm.isMatch('foo', 'b*');
//=> false
```
Use `mm.match()` instead of `minimatch.match()`:
```js
mm.match(['foo', 'bar'], 'b*');
//=> 'bar'
```
### Switch from multimatch
Same signature:
```js
mm(['foo', 'bar', 'baz'], ['f*', '*z']);
//=> ['foo', 'baz']
```
***
## Usage
Add micromatch to your node.js project:
```js
var mm = require('micromatch');
```
**Signature**
```js
mm(array_of_strings, glob_patterns[, options]);
```
**Example**
```js
mm(['foo', 'bar', 'baz'], 'b*');
//=> ['bar', 'baz']
```
### Usage examples
**Brace expansion**
Match files with `.js` or `.txt` extensions.
```js
mm(['a.js', 'b.md', 'c.txt'], '*.{js,txt}');
//=> ['a.js', 'c.txt']
```
**Extglobs**
Match anything except for files with the `.md` extension.
```js
mm(files, '**/*.!(md)');
//=> ['a.js', 'c.txt']
```
**Multiple patterns**
Match using an array of patterns.
```js
mm(['a.md', 'b.js', 'c.txt', 'd.json'], ['*.md', '*.txt']);
//=> ['a.md', 'c.txt']
```
**Negation patterns:**
Behavior is designed to be what users would expect, based on conventions that are already well-established.
* [minimatch](https://github.com/isaacs/minimatch) behavior is used when the pattern is a string, so patterns are **inclusive by default**.
* [multimatch](https://github.com/sindresorhus/multimatch) behavior is used when an array of patterns is passed, so patterns are **exclusive by default**.
```js
mm(['a.js', 'b.md', 'c.txt'], '!*.{js,txt}');
//=> ['b.md']
mm(['a.md', 'b.js', 'c.txt', 'd.json'], ['*.*', '!*.{js,txt}']);
//=> ['a.md', 'd.json']
```
***
## API methods
```js
var mm = require('micromatch');
```
### .match
```js
mm.match(array, globString);
```
Return an array of files that match the given glob pattern. Useful if you only need to use a single glob pattern.
**Example**
```js
mm.match(['ab', 'a/b', 'bb', 'b/c'], '?b');
//=> ['ab', 'bb']
mm.match(['ab', 'a/b', 'bb', 'b/c'], '*/b');
//=> ['a/b']
```
### .isMatch
```js
mm.isMatch(filepath, globString);
```
Returns true if a file path matches the given glob pattern.
**Example**
```js
mm.isMatch('.verb.md', '*.md');
//=> false
mm.isMatch('.verb.md', '*.md', {dot: true});
//=> true
```
### .contains
Returns true if any part of a file path matches the given glob pattern. Think of this is "has path" versus "is path".
**Example**
`.isMatch()` would return false for both of the following:
```js
mm.contains('a/b/c', 'a/b');
//=> true
mm.contains('a/b/c', 'a/*');
//=> true
```
### .matcher
Returns a function for matching using the supplied pattern. e.g. create your own "matcher". The advantage of this method is that the pattern can be compiled outside of a loop.
**Pattern**
Can be any of the following:
* `glob/string`
* `regex`
* `function`
**Example**
```js
var isMatch = mm.matcher('*.md');
var files = [];
['a.md', 'b.txt', 'c.md'].forEach(function(fp) {
if (isMatch(fp)) {
files.push(fp);
}
});
```
### .filter
Returns a function that can be passed to `Array#filter()`.
**Params**
* `patterns` **{String|Array}**:
**Examples**
Single glob:
```js
var fn = mm.filter('*.md');
['a.js', 'b.txt', 'c.md'].filter(fn);
//=> ['c.md']
var fn = mm.filter('[a-c]');
['a', 'b', 'c', 'd', 'e'].filter(fn);
//=> ['a', 'b', 'c']
```
Array of glob patterns:
```js
var arr = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15];
var fn = mm.filter(['{1..10}', '![7-9]', '!{3..4}']);
arr.filter(fn);
//=> [1, 2, 5, 6, 10]
```
_(Internally this function generates the matching function by using the [matcher](#matcher) method. You can use the [matcher](#matcher) method directly to create your own filter function)_
### .any
Returns true if a file path matches any of the given patterns.
```js
mm.any(filepath, patterns, options);
```
**Params**
* filepath `{String}`: The file path to test.
* patterns `{String|Array}`: One or more glob patterns
* options: `{Object}`: options to pass to the `.matcher()` method.
**Example**
```js
mm.any('abc', ['!*z']);
//=> true
mm.any('abc', ['a*', 'z*']);
//=> true
mm.any('abc', 'a*');
//=> true
mm.any('abc', ['z*']);
//=> false
```
### .expand
Returns an object with a regex-compatible string and tokens.
```js
mm.expand('*.js');
// when `track` is enabled (for debugging), the `history` array is used
// to record each mutation to the glob pattern as it's converted to regex
{ options: { track: false, dot: undefined, makeRe: true, negated: false },
pattern: '(.*\\/|^)bar\\/(?:(?!(?:^|\\/)\\.).)*?',
history: [],
tokens:
{ path:
{ whole: '**/bar/**',
dirname: '**/bar/',
filename: '**',
basename: '**',
extname: '',
ext: '' },
is:
{ glob: true,
negated: false,
globstar: true,
dotfile: false,
dotdir: false },
match: {},
original: '**/bar/**',
pattern: '**/bar/**',
base: '' } }
```
### .makeRe
Create a regular expression for matching file paths based on the given pattern:
```js
mm.makeRe('*.js');
//=> /^(?:(?!\.)(?=.)[^/]*?\.js)$/
```
## Options
### options.unixify
Normalize slashes in file paths and glob patterns to forward slashes.
Type: `{Boolean}`
Default: `undefined` on non-windows, `true` on windows.
### options.dot
Match dotfiles. Same behavior as [minimatch](https://github.com/isaacs/minimatch).
Type: `{Boolean}`
Default: `false`
### options.unescape
Unescape slashes in glob patterns. Use cautiously, especially on windows.
Type: `{Boolean}`
Default: `undefined`
**Example**
```js
mm.isMatch('abc', '\\a\\b\\c', {unescape: true});
//=> true
```
### options.nodupes
Remove duplicate elements from the result array.
Type: `{Boolean}`
Default: `undefined`
**Example**
Example of using the `unescape` and `nodupes` options together:
```js
mm.match(['abc', '\\a\\b\\c'], '\\a\\b\\c', {unescape: true});
//=> ['abc', 'abc']
mm.match(['abc', '\\a\\b\\c'], '\\a\\b\\c', {unescape: true, nodupes: true});
//=> ['abc']
```
### options.matchBase
Allow glob patterns without slashes to match a file path based on its basename. . Same behavior as [minimatch](https://github.com/isaacs/minimatch).
Type: `{Boolean}`
Default: `false`
**Example**
```js
mm(['a/b.js', 'a/c.md'], '*.js');
//=> []
mm(['a/b.js', 'a/c.md'], '*.js', {matchBase: true});
//=> ['a/b.js']
```
### options.nobraces
Don't expand braces in glob patterns. Same behavior as [minimatch](https://github.com/isaacs/minimatch) `nobrace`.
Type: `{Boolean}`
Default: `undefined`
See [braces](https://github.com/jonschlinkert/braces) for more information about extended brace expansion.
### options.nobrackets
Don't expand POSIX bracket expressions.
Type: `{Boolean}`
Default: `undefined`
See [expand-brackets](https://github.com/jonschlinkert/expand-brackets) for more information about extended bracket expressions.
### options.noextglob
Don't expand extended globs.
Type: `{Boolean}`
Default: `undefined`
See [extglob](https://github.com/jonschlinkert/extglob) for more information about extended globs.
### options.nocase
Use a case-insensitive regex for matching files. Same behavior as [minimatch](https://github.com/isaacs/minimatch).
Type: `{Boolean}`
Default: `false`
### options.nonegate
Disallow negation (`!`) patterns.
Type: `{Boolean}`
Default: `false`
### options.nonull
If `true`, when no matches are found the actual (array-ified) glob pattern is returned instead of an empty array. Same behavior as [minimatch](https://github.com/isaacs/minimatch).
Type: `{Boolean}`
Default: `false`
### options.cache
Cache the platform (e.g. `win32`) to prevent this from being looked up for every filepath.
Type: `{Boolean}`
Default: `true`
***
## Other features
Micromatch also supports the following.
### Extended globbing
#### extglobs
Extended globbing, as described by the bash man page:
| **pattern** | **regex equivalent** | **description** |
| --- | --- | --- |
| `?(pattern-list)` | `(... | ...)?` | Matches zero or one occurrence of the given patterns |
| `*(pattern-list)` | `(... | ...)*` | Matches zero or more occurrences of the given patterns |
| `+(pattern-list)` | `(... | ...)+` | Matches one or more occurrences of the given patterns |
| `@(pattern-list)` | `(... | ...)` <sup>*</sup> | Matches one of the given patterns |
| `!(pattern-list)` | N/A | Matches anything except one of the given patterns |
<sup><strong>*</strong></sup> `@` isn't a RegEx character.
Powered by [extglob](https://github.com/jonschlinkert/extglob). Visit that library for the full range of options or to report extglob related issues.
See [extglob](https://github.com/jonschlinkert/extglob) for more information about extended globs.
#### brace expansion
In simple cases, brace expansion appears to work the same way as the logical `OR` operator. For example, `(a|b)` will achieve the same result as `{a,b}`.
Here are some powerful features unique to brace expansion (versus character classes):
* range expansion: `a{1..3}b/*.js` expands to: `['a1b/*.js', 'a2b/*.js', 'a3b/*.js']`
* nesting: `a{c,{d,e}}b/*.js` expands to: `['acb/*.js', 'adb/*.js', 'aeb/*.js']`
Visit [braces](https://github.com/jonschlinkert/braces) to ask questions and create an issue related to brace-expansion, or to see the full range of features and options related to brace expansion.
#### regex character classes
With the exception of brace expansion (`{a,b}`, `{1..5}`, etc), most of the special characters convert directly to regex, so you can expect them to follow the same rules and produce the same results as regex.
For example, given the list: `['a.js', 'b.js', 'c.js', 'd.js', 'E.js']`:
* `[ac].js`: matches both `a` and `c`, returning `['a.js', 'c.js']`
* `[b-d].js`: matches from `b` to `d`, returning `['b.js', 'c.js', 'd.js']`
* `[b-d].js`: matches from `b` to `d`, returning `['b.js', 'c.js', 'd.js']`
* `a/[A-Z].js`: matches and uppercase letter, returning `['a/E.md']`
Learn about [regex character classes](http://www.regular-expressions.info/charclass.html).
#### regex groups
Given `['a.js', 'b.js', 'c.js', 'd.js', 'E.js']`:
* `(a|c).js`: would match either `a` or `c`, returning `['a.js', 'c.js']`
* `(b|d).js`: would match either `b` or `d`, returning `['b.js', 'd.js']`
* `(b|[A-Z]).js`: would match either `b` or an uppercase letter, returning `['b.js', 'E.js']`
As with regex, parenthese can be nested, so patterns like `((a|b)|c)/b` will work. But it might be easier to achieve your goal using brace expansion.
#### POSIX bracket expressions
**Example**
```js
mm.isMatch('a1', '[[:alpha:][:digit:]]');
//=> true
```
See [expand-brackets](https://github.com/jonschlinkert/expand-brackets) for more information about extended bracket expressions.
***
## Notes
Whenever possible parsing behavior for patterns is based on globbing specifications in Bash 4.3. Patterns that aren't described by Bash follow wildmatch spec (used by git).
## Benchmarks
Run the [benchmarks](./benchmark):
```bash
node benchmark
```
As of July 15, 2016:
```bash
#1: basename-braces
micromatch x 26,420 ops/sec ±0.89% (91 runs sampled)
minimatch x 3,507 ops/sec ±0.64% (97 runs sampled)
#2: basename
micromatch x 25,315 ops/sec ±0.82% (93 runs sampled)
minimatch x 4,398 ops/sec ±0.86% (94 runs sampled)
#3: braces-no-glob
micromatch x 341,254 ops/sec ±0.78% (93 runs sampled)
minimatch x 30,197 ops/sec ±1.12% (91 runs sampled)
#4: braces
micromatch x 54,649 ops/sec ±0.74% (94 runs sampled)
minimatch x 3,095 ops/sec ±0.82% (95 runs sampled)
#5: immediate
micromatch x 16,719 ops/sec ±0.79% (95 runs sampled)
minimatch x 4,348 ops/sec ±0.86% (96 runs sampled)
#6: large
micromatch x 721 ops/sec ±0.77% (94 runs sampled)
minimatch x 17.73 ops/sec ±1.08% (50 runs sampled)
#7: long
micromatch x 5,051 ops/sec ±0.87% (97 runs sampled)
minimatch x 628 ops/sec ±0.83% (94 runs sampled)
#8: mid
micromatch x 51,280 ops/sec ±0.80% (95 runs sampled)
minimatch x 1,923 ops/sec ±0.84% (95 runs sampled)
#9: multi-patterns
micromatch x 22,440 ops/sec ±0.97% (94 runs sampled)
minimatch x 2,481 ops/sec ±1.10% (94 runs sampled)
#10: no-glob
micromatch x 722,823 ops/sec ±1.30% (87 runs sampled)
minimatch x 52,967 ops/sec ±1.09% (94 runs sampled)
#11: range
micromatch x 243,471 ops/sec ±0.79% (94 runs sampled)
minimatch x 11,736 ops/sec ±0.82% (96 runs sampled)
#12: shallow
micromatch x 190,874 ops/sec ±0.98% (95 runs sampled)
minimatch x 21,699 ops/sec ±0.81% (97 runs sampled)
#13: short
micromatch x 496,393 ops/sec ±3.86% (90 runs sampled)
minimatch x 53,765 ops/sec ±0.75% (95 runs sampled)
```
## Tests
### Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
### Coverage
As of July 15, 2016:
```sh
Statements : 100% (441/441)
Branches : 100% (270/270)
Functions : 100% (54/54)
Lines : 100% (429/429)
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
Please be sure to run the benchmarks before/after any code changes to judge the impact before you do a PR. thanks!
## Related
* [braces](https://www.npmjs.com/package/braces): Fastest brace expansion for node.js, with the most complete support for the Bash 4.3 braces… [more](https://github.com/jonschlinkert/braces) | [homepage](https://github.com/jonschlinkert/braces "Fastest brace expansion for node.js, with the most complete support for the Bash 4.3 braces specification.")
* [expand-brackets](https://www.npmjs.com/package/expand-brackets): Expand POSIX bracket expressions (character classes) in glob patterns. | [homepage](https://github.com/jonschlinkert/expand-brackets "Expand POSIX bracket expressions (character classes) in glob patterns.")
* [expand-range](https://www.npmjs.com/package/expand-range): Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. See… [more](https://github.com/jonschlinkert/expand-range) | [homepage](https://github.com/jonschlinkert/expand-range "Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. See the benchmarks. Used by micromatch.")
* [extglob](https://www.npmjs.com/package/extglob): Convert extended globs to regex-compatible strings. Add (almost) the expressive power of regular expressions to… [more](https://github.com/jonschlinkert/extglob) | [homepage](https://github.com/jonschlinkert/extglob "Convert extended globs to regex-compatible strings. Add (almost) the expressive power of regular expressions to glob patterns.")
* [fill-range](https://www.npmjs.com/package/fill-range): Fill in a range of numbers or letters, optionally passing an increment or multiplier to… [more](https://github.com/jonschlinkert/fill-range) | [homepage](https://github.com/jonschlinkert/fill-range "Fill in a range of numbers or letters, optionally passing an increment or multiplier to use.")
* [gulp-micromatch](https://www.npmjs.com/package/gulp-micromatch): Filter vinyl files with glob patterns, string, regexp, array, object or matcher function. micromatch stream. | [homepage](https://github.com/tunnckocore/gulp-micromatch#readme "Filter vinyl files with glob patterns, string, regexp, array, object or matcher function. micromatch stream.")
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/jonschlinkert/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
* [parse-glob](https://www.npmjs.com/package/parse-glob): Parse a glob pattern into an object of tokens. | [homepage](https://github.com/jonschlinkert/parse-glob "Parse a glob pattern into an object of tokens.")
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
## Building docs
_(This document was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme) (a [verb](https://github.com/verbose/verb) generator), please don't edit the readme directly. Any changes to the readme must be made in [.verb.md](.verb.md).)_
To generate the readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install -g verb verb-generate-readme && verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/micromatch/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v0.9.0, on July 15, 2016._
## Caseless -- wrap an object to set and get property with caseless semantics but also preserve caseing.
This library is incredibly useful when working with HTTP headers. It allows you to get/set/check for headers in a caseless manner while also preserving the caseing of headers the first time they are set.
## Usage
```javascript
var headers = {}
, c = caseless(headers)
;
c.set('a-Header', 'asdf')
c.get('a-header') === 'asdf'
```
## has(key)
Has takes a name and if it finds a matching header will return that header name with the preserved caseing it was set with.
```javascript
c.has('a-header') === 'a-Header'
```
## set(key, value[, clobber=true])
Set is fairly straight forward except that if the header exists and clobber is disabled it will add `','+value` to the existing header.
```javascript
c.set('a-Header', 'fdas')
c.set('a-HEADER', 'more', false)
c.get('a-header') === 'fdsa,more'
```
## swap(key)
Swaps the casing of a header with the new one that is passed in.
```javascript
var headers = {}
, c = caseless(headers)
;
c.set('a-Header', 'fdas')
c.swap('a-HEADER')
c.has('a-header') === 'a-HEADER'
headers === {'a-HEADER': 'fdas'}
```
# web3-shh
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo]
This is the whisper v5 package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-shh
```
## Usage
```js
const Web3Personal = require('web3-shh');
const shh = new Web3Personal('ws://localhost:8546');
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-shh.svg
[npm-url]: https://npmjs.org/package/web3-shh
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-shh
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-shh
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-shh
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-shh
# js-multicodec
[](https://protocol.ai)
[](https://github.com/multiformats/multiformats)
[](https://webchat.freenode.net/?channels=%23ipfs)
[](https://github.com/RichardLitt/standard-readme)
[](https://travis-ci.com/multiformats/js-multicodec)
[](https://coveralls.io/github/multiformats/js-multiformats?branch=master)
> JavaScript implementation of the multicodec specification
## Lead Maintainer
[Henrique Dias](http://github.com/hacdias)
## Table of Contents
- [Install](#install)
- [Usage](#usage)
- [Updating the lookup table](#updating-the-lookup-table)
- [Contribute](#contribute)
- [License](#license)
## Install
```sh
> npm install multicodec
```
The type definitions for this package are available on http://definitelytyped.org/. To install just use:
```sh
$ npm install -D @types/multicodec
```
## Usage
### Example
```JavaScript
const multicodec = require('multicodec')
const prefixedProtobuf = multicodec.addPrefix('protobuf', protobufBuffer)
// prefixedProtobuf 0x50...
// The multicodec codec values can be accessed directly:
console.log(multicodec.DAG_CBOR)
// 113
// To get the string representation of a codec, e.g. for error messages:
console.log(multicodec.print[113])
// dag-cbor
```
### API
https://multiformats.github.io/js-multicodec/
[multicodec default table](https://github.com/multiformats/multicodec/blob/master/table.csv)
## Updating the lookup table
Updating the lookup table is done with a script. The source of truth is the
[multicodec default table](https://github.com/multiformats/multicodec/blob/master/table.csv).
Update the table with running:
npm run update-table
## Contribute
Contributions welcome. Please check out [the issues](https://github.com/multiformats/js-multicodec/issues).
Check out our [contributing document](https://github.com/multiformats/multiformats/blob/master/contributing.md) for more information on how we work, and about contributing in general. Please be aware that all interactions related to multiformats are subject to the IPFS [Code of Conduct](https://github.com/ipfs/community/blob/master/code-of-conduct.md).
Small note: If editing the README, please conform to the [standard-readme](https://github.com/RichardLitt/standard-readme) specification.
## License
[MIT](LICENSE) © 2016 Protocol Labs Inc.
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows note
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Note that PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Then, run the program to be debugged as usual.
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# fast-json-stable-stringify
Deterministic `JSON.stringify()` - a faster version of [@substack](https://github.com/substack)'s json-stable-strigify without [jsonify](https://github.com/substack/jsonify).
You can also pass in a custom comparison function.
[](https://travis-ci.org/epoberezkin/fast-json-stable-stringify)
[](https://coveralls.io/github/epoberezkin/fast-json-stable-stringify?branch=master)
# example
``` js
var stringify = require('fast-json-stable-stringify');
var obj = { c: 8, b: [{z:6,y:5,x:4},7], a: 3 };
console.log(stringify(obj));
```
output:
```
{"a":3,"b":[{"x":4,"y":5,"z":6},7],"c":8}
```
# methods
``` js
var stringify = require('fast-json-stable-stringify')
```
## var str = stringify(obj, opts)
Return a deterministic stringified string `str` from the object `obj`.
## options
### cmp
If `opts` is given, you can supply an `opts.cmp` to have a custom comparison
function for object keys. Your function `opts.cmp` is called with these
parameters:
``` js
opts.cmp({ key: akey, value: avalue }, { key: bkey, value: bvalue })
```
For example, to sort on the object key names in reverse order you could write:
``` js
var stringify = require('fast-json-stable-stringify');
var obj = { c: 8, b: [{z:6,y:5,x:4},7], a: 3 };
var s = stringify(obj, function (a, b) {
return a.key < b.key ? 1 : -1;
});
console.log(s);
```
which results in the output string:
```
{"c":8,"b":[{"z":6,"y":5,"x":4},7],"a":3}
```
Or if you wanted to sort on the object values in reverse order, you could write:
```
var stringify = require('fast-json-stable-stringify');
var obj = { d: 6, c: 5, b: [{z:3,y:2,x:1},9], a: 10 };
var s = stringify(obj, function (a, b) {
return a.value < b.value ? 1 : -1;
});
console.log(s);
```
which outputs:
```
{"d":6,"c":5,"b":[{"z":3,"y":2,"x":1},9],"a":10}
```
### cycles
Pass `true` in `opts.cycles` to stringify circular property as `__cycle__` - the result will not be a valid JSON string in this case.
TypeError will be thrown in case of circular object without this option.
# install
With [npm](https://npmjs.org) do:
```
npm install fast-json-stable-stringify
```
# benchmark
To run benchmark (requires Node.js 6+):
```
node benchmark
```
Results:
```
fast-json-stable-stringify x 17,189 ops/sec ±1.43% (83 runs sampled)
json-stable-stringify x 13,634 ops/sec ±1.39% (85 runs sampled)
fast-stable-stringify x 20,212 ops/sec ±1.20% (84 runs sampled)
faster-stable-stringify x 15,549 ops/sec ±1.12% (84 runs sampled)
The fastest is fast-stable-stringify
```
## Enterprise support
fast-json-stable-stringify package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-fast-json-stable-stringify?utm_source=npm-fast-json-stable-stringify&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
# license
[MIT](https://github.com/epoberezkin/fast-json-stable-stringify/blob/master/LICENSE)
# fresh
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
HTTP response freshness testing
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```
$ npm install fresh
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var fresh = require('fresh')
```
### fresh(reqHeaders, resHeaders)
Check freshness of the response using request and response headers.
When the response is still "fresh" in the client's cache `true` is
returned, otherwise `false` is returned to indicate that the client
cache is now stale and the full response should be sent.
When a client sends the `Cache-Control: no-cache` request header to
indicate an end-to-end reload request, this module will return `false`
to make handling these requests transparent.
## Known Issues
This module is designed to only follow the HTTP specifications, not
to work-around all kinda of client bugs (especially since this module
typically does not recieve enough information to understand what the
client actually is).
There is a known issue that in certain versions of Safari, Safari
will incorrectly make a request that allows this module to validate
freshness of the resource even when Safari does not have a
representation of the resource in the cache. The module
[jumanji](https://www.npmjs.com/package/jumanji) can be used in
an Express application to work-around this issue and also provides
links to further reading on this Safari bug.
## Example
### API usage
<!-- eslint-disable no-redeclare, no-undef -->
```js
var reqHeaders = { 'if-none-match': '"foo"' }
var resHeaders = { 'etag': '"bar"' }
fresh(reqHeaders, resHeaders)
// => false
var reqHeaders = { 'if-none-match': '"foo"' }
var resHeaders = { 'etag': '"foo"' }
fresh(reqHeaders, resHeaders)
// => true
```
### Using with Node.js http server
```js
var fresh = require('fresh')
var http = require('http')
var server = http.createServer(function (req, res) {
// perform server logic
// ... including adding ETag / Last-Modified response headers
if (isFresh(req, res)) {
// client has a fresh copy of resource
res.statusCode = 304
res.end()
return
}
// send the resource
res.statusCode = 200
res.end('hello, world!')
})
function isFresh (req, res) {
return fresh(req.headers, {
'etag': res.getHeader('ETag'),
'last-modified': res.getHeader('Last-Modified')
})
}
server.listen(3000)
```
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/fresh.svg
[npm-url]: https://npmjs.org/package/fresh
[node-version-image]: https://img.shields.io/node/v/fresh.svg
[node-version-url]: https://nodejs.org/en/
[travis-image]: https://img.shields.io/travis/jshttp/fresh/master.svg
[travis-url]: https://travis-ci.org/jshttp/fresh
[coveralls-image]: https://img.shields.io/coveralls/jshttp/fresh/master.svg
[coveralls-url]: https://coveralls.io/r/jshttp/fresh?branch=master
[downloads-image]: https://img.shields.io/npm/dm/fresh.svg
[downloads-url]: https://npmjs.org/package/fresh
Oboe.js is an [open source](LICENCE) Javascript library
for loading JSON using streaming, combining the convenience of DOM with
the speed and fluidity of SAX.
It can parse any JSON as a stream, is small enough to be a [micro-library](http://microjs.com/#),
doesn't have dependencies, and doesn't care which other libraries you need it to speak to.
We can load trees [larger than the available memory](http://oboejs.com/examples#loading-json-trees-larger-than-the-available-ram).
Or we can [instantiate classical OOP models from JSON](http://oboejs.com/examples#demarshalling-json-to-an-oop-model),
or [completely transform your JSON](http://oboejs.com/examples#transforming-json-while-it-is-streaming) while it is being read.
Oboe makes it really easy to start using json from a response before the ajax request completes.
Or even if it never completes.
Where next?
-----------
- [The website](http://oboejs.com)
- Visualise [faster web applications through streaming](http://oboejs.com/why)
- Visit the [project homepage](http://oboejs.com)
- Browse [code examples](http://oboejs.com/examples)
- Learn the Oboe.js [API](http://oboejs.com/api)
- [Download](http://oboejs.com/download) the library
- [Discuss](http://oboejs.com/discuss) Oboe.js
# axios // helpers
The modules found in `helpers/` should be generic modules that are _not_ specific to the domain logic of axios. These modules could theoretically be published to npm on their own and consumed by other modules or apps. Some examples of generic modules are things like:
- Browser polyfills
- Managing cookies
- Parsing HTTP headers
# FClone
Clone objects by dropping circular references
[](https://travis-ci.org/soyuka/fclone)
This module clones a Javascript object in safe mode (eg: drops circular values) recursively. Circular values are replaced with a string: `'[Circular]'`.
Ideas from [tracker1/safe-clone-deep](https://github.com/tracker1/safe-clone-deep). I improved the workflow a bit by:
- refactoring the code (complete rewrite)
- fixing node 6+
- micro optimizations
- use of `Array.isArray` and `Buffer.isBuffer`
Node 0.10 compatible, distributed files are translated to es2015.
## Installation
```bash
npm install fclone
# or
bower install fclone
```
## Usage
```javascript
const fclone = require('fclone');
let a = {c: 'hello'};
a.b = a;
let o = fclone(a);
console.log(o);
// outputs: { c: 'hello', b: '[Circular]' }
//JSON.stringify is now safe
console.log(JSON.stringify(o));
```
## Benchmarks
Some benchs:
```
fclone x 17,081 ops/sec ±0.71% (79 runs sampled)
fclone + json.stringify x 9,433 ops/sec ±0.91% (81 runs sampled)
util.inspect (outputs a string) x 2,498 ops/sec ±0.77% (90 runs sampled)
jsan x 5,379 ops/sec ±0.82% (91 runs sampled)
circularjson x 4,719 ops/sec ±1.16% (91 runs sampled)
deepcopy x 5,478 ops/sec ±0.77% (86 runs sampled)
json-stringify-safe x 5,828 ops/sec ±1.30% (84 runs sampled)
clone x 8,713 ops/sec ±0.68% (88 runs sampled)
Fastest is util.format (outputs a string)
```
iMurmurHash.js
==============
An incremental implementation of the MurmurHash3 (32-bit) hashing algorithm for JavaScript based on [Gary Court's implementation](https://github.com/garycourt/murmurhash-js) with [kazuyukitanimura's modifications](https://github.com/kazuyukitanimura/murmurhash-js).
This version works significantly faster than the non-incremental version if you need to hash many small strings into a single hash, since string concatenation (to build the single string to pass the non-incremental version) is fairly costly. In one case tested, using the incremental version was about 50% faster than concatenating 5-10 strings and then hashing.
Installation
------------
To use iMurmurHash in the browser, [download the latest version](https://raw.github.com/jensyt/imurmurhash-js/master/imurmurhash.min.js) and include it as a script on your site.
```html
<script type="text/javascript" src="/scripts/imurmurhash.min.js"></script>
<script>
// Your code here, access iMurmurHash using the global object MurmurHash3
</script>
```
---
To use iMurmurHash in Node.js, install the module using NPM:
```bash
npm install imurmurhash
```
Then simply include it in your scripts:
```javascript
MurmurHash3 = require('imurmurhash');
```
Quick Example
-------------
```javascript
// Create the initial hash
var hashState = MurmurHash3('string');
// Incrementally add text
hashState.hash('more strings');
hashState.hash('even more strings');
// All calls can be chained if desired
hashState.hash('and').hash('some').hash('more');
// Get a result
hashState.result();
// returns 0xe4ccfe6b
```
Functions
---------
### MurmurHash3 ([string], [seed])
Get a hash state object, optionally initialized with the given _string_ and _seed_. _Seed_ must be a positive integer if provided. Calling this function without the `new` keyword will return a cached state object that has been reset. This is safe to use as long as the object is only used from a single thread and no other hashes are created while operating on this one. If this constraint cannot be met, you can use `new` to create a new state object. For example:
```javascript
// Use the cached object, calling the function again will return the same
// object (but reset, so the current state would be lost)
hashState = MurmurHash3();
...
// Create a new object that can be safely used however you wish. Calling the
// function again will simply return a new state object, and no state loss
// will occur, at the cost of creating more objects.
hashState = new MurmurHash3();
```
Both methods can be mixed however you like if you have different use cases.
---
### MurmurHash3.prototype.hash (string)
Incrementally add _string_ to the hash. This can be called as many times as you want for the hash state object, including after a call to `result()`. Returns `this` so calls can be chained.
---
### MurmurHash3.prototype.result ()
Get the result of the hash as a 32-bit positive integer. This performs the tail and finalizer portions of the algorithm, but does not store the result in the state object. This means that it is perfectly safe to get results and then continue adding strings via `hash`.
```javascript
// Do the whole string at once
MurmurHash3('this is a test string').result();
// 0x70529328
// Do part of the string, get a result, then the other part
var m = MurmurHash3('this is a');
m.result();
// 0xbfc4f834
m.hash(' test string').result();
// 0x70529328 (same as above)
```
---
### MurmurHash3.prototype.reset ([seed])
Reset the state object for reuse, optionally using the given _seed_ (defaults to 0 like the constructor). Returns `this` so calls can be chained.
---
License (MIT)
-------------
Copyright (c) 2013 Gary Court, Jens Taylor
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
node-asn1 is a library for encoding and decoding ASN.1 datatypes in pure JS.
Currently BER encoding is supported; at some point I'll likely have to do DER.
## Usage
Mostly, if you're *actually* needing to read and write ASN.1, you probably don't
need this readme to explain what and why. If you have no idea what ASN.1 is,
see this: ftp://ftp.rsa.com/pub/pkcs/ascii/layman.asc
The source is pretty much self-explanatory, and has read/write methods for the
common types out there.
### Decoding
The following reads an ASN.1 sequence with a boolean.
var Ber = require('asn1').Ber;
var reader = new Ber.Reader(Buffer.from([0x30, 0x03, 0x01, 0x01, 0xff]));
reader.readSequence();
console.log('Sequence len: ' + reader.length);
if (reader.peek() === Ber.Boolean)
console.log(reader.readBoolean());
### Encoding
The following generates the same payload as above.
var Ber = require('asn1').Ber;
var writer = new Ber.Writer();
writer.startSequence();
writer.writeBoolean(true);
writer.endSequence();
console.log(writer.buffer);
## Installation
npm install asn1
## License
MIT.
## Bugs
See <https://github.com/joyent/node-asn1/issues>.
# js-cid
[](http://protocol.ai/)
[](http://webchat.freenode.net/?channels=%23ipfs)
[](https://travis-ci.com/multiformats/js-cid)
[](https://coveralls.io/github/multiformats/js-cid?branch=master)
[](https://david-dm.org/multiformats/js-cid)
[](https://github.com/feross/standard)
[](https://greenkeeper.io/)
> [CID](https://github.com/multiformats/cid) implementation in JavaScript.
## Lead Maintainer
[Volker Mische](https://github.com/vmx)
## Table of Contents
- [Install](#install)
- [Usage](#usage)
- [API](#api)
- [Contribute](#contribute)
- [License](#license)
## Install
### In Node.js through npm
```bash
$ npm install --save cids
```
### Browser: Browserify, Webpack, other bundlers
The code published to npm that gets loaded on require is in fact an ES5 transpiled version with the right shims added. This means that you can require it and use with your favourite bundler without having to adjust asset management process.
```js
const CID = require('cids')
```
### In the Browser through `<script>` tag
Loading this module through a script tag will make the ```Cids``` obj available in the global namespace.
```
<script src="https://unpkg.com/cids/dist/index.min.js"></script>
<!-- OR -->
<script src="https://unpkg.com/cids/dist/index.js"></script>
```
#### Gotchas
You will need to use Node.js `Buffer` API compatible, if you are running inside the browser, you can access it by `multihash.Buffer` or you can install Feross's [Buffer](https://github.com/feross/buffer).
## Usage
You can create an instance from a CID string or CID Buffer
```js
const CID = require('cids')
const cid = new CID('bafybeig6xv5nwphfmvcnektpnojts33jqcuam7bmye2pb54adnrtccjlsu')
cid.version // 1
cid.codec // 'dag-pb'
cid.multibaseName // 'base32'
cid.toString()
// 'bafybeig6xv5nwphfmvcnektpnojts33jqcuam7bmye2pb54adnrtccjlsu'
```
or by specifying the [cid version](https://github.com/multiformats/cid#versions), [multicodec name](https://github.com/multiformats/multicodec/blob/master/table.csv) and [multihash](https://github.com/multiformats/multihash):
```js
const CID = require('cids')
const multihashing = require('multihashing-async')
const hash = await multihashing(Buffer.from('OMG!'), 'sha2-256')
const cid = new CID(1, 'dag-pb', hash)
console.log(cid.toString())
// bafybeig6xv5nwphfmvcnektpnojts33jqcuam7bmye2pb54adnrtccjlsu
```
The string form of v1 CIDs defaults to `base32` encoding (v0 CIDs are always `base58btc` encoded). When creating a new instance you can optionally specify the default multibase to use when calling `toBaseEncodedString()` or `toString()`
```js
const cid = new CID(1, 'raw', hash, 'base64')
console.log(cid.toString())
// mAXASIN69ets85WVE0ipva5M5b2mAqAZ8LME08PeAG2MxCSuV
```
If you construct an instance from a valid CID string, the base you provided will be preserved as the default.
```js
// e.g. a base64url encoded CID
const cid = new CID('uAXASIHJSUj5lkfuP5VPWf_VahvhARLRqPkF24QxY-lKaSqvV')
cid.toString()
// uAXASIHJSUj5lkfuP5VPWf_VahvhARLRqPkF24QxY-lKaSqvV
```
## API
### CID.isCID(cid)
Returns true if object is a valid CID instance, false if not valid.
It's important to use this method rather than `instanceof` checks in
order to handle CID objects from different versions of this module.
### CID.validateCID(cid)
Validates the different components (version, codec, multihash, multibaseName) of the CID
instance. Throws an `Error` if not valid.
### new CID(version, codec, multihash, [multibaseName])
`version` must be [either 0 or 1](https://github.com/multiformats/cid#versions).
`codec` must be a string of a valid [registered codec](https://github.com/multiformats/multicodec/blob/master/table.csv).
`multihash` must be a `Buffer` instance of a valid [multihash](https://github.com/multiformats/multihash).
`multibaseName` optional string. Must be a valid [multibase](https://github.com/multiformats/multibase/blob/master/multibase.csv) name. Default is `base58btc` for v0 CIDs or `base32` for v1 CIDs.
### new CID(baseEncodedString)
Additionally, you can instantiate an instance from a base encoded
string.
### new CID(Buffer)
Additionally, you can instantiate an instance from a buffer.
#### cid.codec
Property containing the codec string.
#### cid.version
Property containing the CID version integer.
#### cid.multihash
Property containing the multihash buffer.
#### cid.multibaseName
Property containing the default base to use when calling `.toString`
#### cid.buffer
Property containing the full CID encoded as a `Buffer`.
#### cid.prefix
Proprety containing a buffer of the CID version, codec, and the prefix
section of the multihash.
#### cid.toV0()
Returns the CID encoded in version 0. Only works for `dag-pb` codecs.
Throws if codec is not `dag-pb`.
#### cid.toV1()
Returns the CID encoded in version 1.
#### cid.toBaseEncodedString(base=this.multibaseName)
Returns a base encoded string of the CID. Defaults to the base encoding in `this.multibaseName`.
The value of `this.multibaseName` depends on how the instance was constructed:
1. If the CID was constructed from an object that already had a multibase (a string or an existing CID) then it retains that base.
2. If the CID was constructed from an object that _did not_ have a multibase (a buffer, or by passing only version + codec + multihash to the constructor), then `multibaseName` will be `base58btc` for a v0 CID or `base32` for a v1 CID.
#### cid.toString(base=this.multibaseName)
Shorthand for `cid.toBaseEncodedString` described above.
#### cid.equals(cid)
Compare cid instance. Returns true if CID's are identical, false if
otherwise.
## Contribute
[](https://github.com/ipfs/community/blob/master/contributing.md)
Contributions welcome. Please check out [the issues](https://github.com/multiformats/js-cid/issues).
Check out our [contributing document](https://github.com/ipfs/community/blob/master/CONTRIBUTING_JS.md) for more information on how we work, and about contributing in general. Please be aware that all interactions related to multiformats are subject to the IPFS [Code of Conduct](https://github.com/ipfs/community/blob/master/code-of-conduct.md).
Small note: If editing the Readme, please conform to the [standard-readme](https://github.com/RichardLitt/standard-readme) specification.
## License
MIT
anymatch [](https://travis-ci.org/micromatch/anymatch) [](https://coveralls.io/r/micromatch/anymatch?branch=master)
======
Javascript module to match a string against a regular expression, glob, string,
or function that takes the string as an argument and returns a truthy or falsy
value. The matcher can also be an array of any or all of these. Useful for
allowing a very flexible user-defined config to define things like file paths.
__Note: This module has Bash-parity, please be aware that Windows-style backslashes are not supported as separators. See https://github.com/micromatch/micromatch#backslashes for more information.__
Usage
-----
```sh
npm install anymatch
```
#### anymatch(matchers, testString, [returnIndex], [options])
* __matchers__: (_Array|String|RegExp|Function_)
String to be directly matched, string with glob patterns, regular expression
test, function that takes the testString as an argument and returns a truthy
value if it should be matched, or an array of any number and mix of these types.
* __testString__: (_String|Array_) The string to test against the matchers. If
passed as an array, the first element of the array will be used as the
`testString` for non-function matchers, while the entire array will be applied
as the arguments for function matchers.
* __options__: (_Object_ [optional]_) Any of the [picomatch](https://github.com/micromatch/picomatch#options) options.
* __returnIndex__: (_Boolean [optional]_) If true, return the array index of
the first matcher that that testString matched, or -1 if no match, instead of a
boolean result.
```js
const anymatch = require('anymatch');
const matchers = [ 'path/to/file.js', 'path/anyjs/**/*.js', /foo.js$/, string => string.includes('bar') && string.length > 10 ] ;
anymatch(matchers, 'path/to/file.js'); // true
anymatch(matchers, 'path/anyjs/baz.js'); // true
anymatch(matchers, 'path/to/foo.js'); // true
anymatch(matchers, 'path/to/bar.js'); // true
anymatch(matchers, 'bar.js'); // false
// returnIndex = true
anymatch(matchers, 'foo.js', {returnIndex: true}); // 2
anymatch(matchers, 'path/anyjs/foo.js', {returnIndex: true}); // 1
// any picomatc
// using globs to match directories and their children
anymatch('node_modules', 'node_modules'); // true
anymatch('node_modules', 'node_modules/somelib/index.js'); // false
anymatch('node_modules/**', 'node_modules/somelib/index.js'); // true
anymatch('node_modules/**', '/absolute/path/to/node_modules/somelib/index.js'); // false
anymatch('**/node_modules/**', '/absolute/path/to/node_modules/somelib/index.js'); // true
const matcher = anymatch(matchers);
['foo.js', 'bar.js'].filter(matcher); // [ 'foo.js' ]
anymatch master* ❯
```
#### anymatch(matchers)
You can also pass in only your matcher(s) to get a curried function that has
already been bound to the provided matching criteria. This can be used as an
`Array#filter` callback.
```js
var matcher = anymatch(matchers);
matcher('path/to/file.js'); // true
matcher('path/anyjs/baz.js', true); // 1
['foo.js', 'bar.js'].filter(matcher); // ['foo.js']
```
Changelog
----------
[See release notes page on GitHub](https://github.com/micromatch/anymatch/releases)
- **v3.0:** Removed `startIndex` and `endIndex` arguments. Node 8.x-only.
- **v2.0:** [micromatch](https://github.com/jonschlinkert/micromatch) moves away from minimatch-parity and inline with Bash. This includes handling backslashes differently (see https://github.com/micromatch/micromatch#backslashes for more information).
- **v1.2:** anymatch uses [micromatch](https://github.com/jonschlinkert/micromatch)
for glob pattern matching. Issues with glob pattern matching should be
reported directly to the [micromatch issue tracker](https://github.com/jonschlinkert/micromatch/issues).
License
-------
[ISC](https://raw.github.com/micromatch/anymatch/master/LICENSE)
## xhr-request-promise
Thin wrapper on top of [this](https://www.npmjs.com/package/xhr-request) to use Promise instead of callbacks.
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
## Eth-Lib
Lightweight Ethereum libraries. This is a temporary repository which will be used as the basis of an implementation on Idris (or similar).
[](https://nodei.co/npm/async-listener/)
[](https://travis-ci.org/othiym23/async-listener)
# process.addAsyncListener polyfill
This is an implementation of Trevor Norris's
process.{addAsyncListener,removeAsyncListener} API for adding behavior to async
calls. You can see his implementation (currently a work in progress) on
[Node.js core pull request #6011](https://github.com/joyent/node/pull/6011).
This polyfill / shim is intended for use in versions of Node prior to whatever
version of Node in which Trevor's changes finally land (anticipated at the time
of this writing as 0.11.7).
Here's his documentation of the intended API, which will probably get cleaned up
here later:
## createAsyncListener(callbacks[, initialStorage])
* `callbacks` {Object}
* `initialStorage` {Value}
Returns a constructed `AsyncListener` object. Which can then be passed to
`process.addAsyncListener()` and `process.removeAsyncListener()`. Each
function parameter is as follows:
1. `callbacks`: An `Object` which may contain four optional fields:
* `create`: A `function (storage)` that is called when an asynchronous event
is queued. Recives the `storage` attached to the listener. `storage` can be
created by passing an `initialStorage` argument during construction, or by
returning a `Value` from `create` which will be attached to the listener
and overwrite the `initialStorage`.
* `before`: A `function (context, storage)` that is called immediately
before the asynchronous callback is about to run. It will be passed both
the `context` (i.e. `this`) of the calling function and the `storage`.
* `after`: A `function (context, storage)` called immediately after the
asynchronous event's callback is run. Note that if the event's callback
throws during execution this will not be called.
* `error`: A `function (storage, error)` called if the event's callback
threw. If `error` returns `true` then Node will assume the error has been
properly handled and resume execution normally.
1. `initialStorage`: A `Value` (i.e. anything) that will be, by default,
attached to all new event instances. This will be overwritten if a `Value`
is returned by `create()`.
## addAsyncListener(callbacks[, initialStorage])
## addAsyncListener(asyncListener)
Returns a constructed `AsyncListener` object and immediately adds it to the
listening queue.
## removeAsyncListener(asyncListener)
Removes the `asyncListener` from the listening queue.
# web3-core
This is a sub package of [web3.js][repo]
The core package contains core functions for [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core
```
## Usage
```js
// in node.js
var core = require('web3-core');
var CoolLib = function CoolLib() {
// sets _requestmanager and adds basic functions
core.packageInit(this, arguments);
};
CoolLib.providers;
CoolLib.givenProvider;
CoolLib.setProvider();
CoolLib.BatchRequest();
CoolLib.extend();
...
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# ASN1.js
ASN.1 DER Encoder/Decoder and DSL.
## Example
Define model:
```javascript
var asn = require('asn1.js');
var Human = asn.define('Human', function() {
this.seq().obj(
this.key('firstName').octstr(),
this.key('lastName').octstr(),
this.key('age').int(),
this.key('gender').enum({ 0: 'male', 1: 'female' }),
this.key('bio').seqof(Bio)
);
});
var Bio = asn.define('Bio', function() {
this.seq().obj(
this.key('time').gentime(),
this.key('description').octstr()
);
});
```
Encode data:
```javascript
var output = Human.encode({
firstName: 'Thomas',
lastName: 'Anderson',
age: 28,
gender: 'male',
bio: [
{
time: +new Date('31 March 1999'),
description: 'freedom of mind'
}
]
}, 'der');
```
Decode data:
```javascript
var human = Human.decode(output, 'der');
console.log(human);
/*
{ firstName: <Buffer 54 68 6f 6d 61 73>,
lastName: <Buffer 41 6e 64 65 72 73 6f 6e>,
age: 28,
gender: 'male',
bio:
[ { time: 922820400000,
description: <Buffer 66 72 65 65 64 6f 6d 20 6f 66 20 6d 69 6e 64> } ] }
*/
```
### Partial decode
Its possible to parse data without stopping on first error. In order to do it,
you should call:
```javascript
var human = Human.decode(output, 'der', { partial: true });
console.log(human);
/*
{ result: { ... },
errors: [ ... ] }
*/
```
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2017.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
## Any Promise
[](http://travis-ci.org/kevinbeaty/any-promise)
Let your library support any ES 2015 (ES6) compatible `Promise` and leave the choice to application authors. The application can *optionally* register its preferred `Promise` implementation and it will be exported when requiring `any-promise` from library code.
If no preference is registered, defaults to the global `Promise` for newer Node.js versions. The browser version defaults to the window `Promise`, so polyfill or register as necessary.
### Usage with global Promise:
Assuming the global `Promise` is the desired implementation:
```bash
# Install any libraries depending on any-promise
$ npm install mz
```
The installed libraries will use global Promise by default.
```js
// in library
var Promise = require('any-promise') // the global Promise
function promiseReturningFunction(){
return new Promise(function(resolve, reject){...})
}
```
### Usage with registration:
Assuming `bluebird` is the desired Promise implementation:
```bash
# Install preferred promise library
$ npm install bluebird
# Install any-promise to allow registration
$ npm install any-promise
# Install any libraries you would like to use depending on any-promise
$ npm install mz
```
Register your preference in the application entry point before any other `require` of packages that load `any-promise`:
```javascript
// top of application index.js or other entry point
require('any-promise/register/bluebird')
// -or- Equivalent to above, but allows customization of Promise library
require('any-promise/register')('bluebird', {Promise: require('bluebird')})
```
Now that the implementation is registered, you can use any package depending on `any-promise`:
```javascript
var fsp = require('mz/fs') // mz/fs will use registered bluebird promises
var Promise = require('any-promise') // the registered bluebird promise
```
It is safe to call `register` multiple times, but it must always be with the same implementation.
Again, registration is *optional*. It should only be called by the application user if overriding the global `Promise` implementation is desired.
### Optional Application Registration
As an application author, you can *optionally* register a preferred `Promise` implementation on application startup (before any call to `require('any-promise')`:
You must register your preference before any call to `require('any-promise')` (by you or required packages), and only one implementation can be registered. Typically, this registration would occur at the top of the application entry point.
#### Registration shortcuts
If you are using a known `Promise` implementation, you can register your preference with a shortcut:
```js
require('any-promise/register/bluebird')
// -or-
import 'any-promise/register/q';
```
Shortcut registration is the preferred registration method as it works in the browser and Node.js. It is also convenient for using with `import` and many test runners, that offer a `--require` flag:
```
$ ava --require=any-promise/register/bluebird test.js
```
Current known implementations include `bluebird`, `q`, `when`, `rsvp`, `es6-promise`, `promise`, `native-promise-only`, `pinkie`, `vow` and `lie`. If you are not using a known implementation, you can use another registration method described below.
#### Basic Registration
As an alternative to registration shortcuts, you can call the `register` function with the preferred `Promise` implementation. The benefit of this approach is that a `Promise` library can be required by name without being a known implementation. This approach does NOT work in the browser. To use `any-promise` in the browser use either registration shortcuts or specify the `Promise` constructor using advanced registration (see below).
```javascript
require('any-promise/register')('when')
// -or- require('any-promise/register')('any other ES6 compatible library (known or otherwise)')
```
This registration method will try to detect the `Promise` constructor from requiring the specified implementation. If you would like to specify your own constructor, see advanced registration.
#### Advanced Registration
To use the browser version, you should either install a polyfill or explicitly register the `Promise` constructor:
```javascript
require('any-promise/register')('bluebird', {Promise: require('bluebird')})
```
This could also be used for registering a custom `Promise` implementation or subclass.
Your preference will be registered globally, allowing a single registration even if multiple versions of `any-promise` are installed in the NPM dependency tree or are using multiple bundled JavaScript files in the browser. You can bypass this global registration in options:
```javascript
require('../register')('es6-promise', {Promise: require('es6-promise').Promise, global: false})
```
### Library Usage
To use any `Promise` constructor, simply require it:
```javascript
var Promise = require('any-promise');
return Promise
.all([xf, f, init, coll])
.then(fn);
return new Promise(function(resolve, reject){
try {
resolve(item);
} catch(e){
reject(e);
}
});
```
Except noted below, libraries using `any-promise` should only use [documented](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) functions as there is no guarantee which implementation will be chosen by the application author. Libraries should never call `register`, only the application user should call if desired.
#### Advanced Library Usage
If your library needs to branch code based on the registered implementation, you can retrieve it using `var impl = require('any-promise/implementation')`, where `impl` will be the package name (`"bluebird"`, `"when"`, etc.) if registered, `"global.Promise"` if using the global version on Node.js, or `"window.Promise"` if using the browser version. You should always include a default case, as there is no guarantee what package may be registered.
### Support for old Node.js versions
Node.js versions prior to `v0.12` may have contained buggy versions of the global `Promise`. For this reason, the global `Promise` is not loaded automatically for these old versions. If using `any-promise` in Node.js versions versions `<= v0.12`, the user should register a desired implementation.
If an implementation is not registered, `any-promise` will attempt to discover an installed `Promise` implementation. If no implementation can be found, an error will be thrown on `require('any-promise')`. While the auto-discovery usually avoids errors, it is non-deterministic. It is recommended that the user always register a preferred implementation for older Node.js versions.
This auto-discovery is only available for Node.jS versions prior to `v0.12`. Any newer versions will always default to the global `Promise` implementation.
### Related
- [any-observable](https://github.com/sindresorhus/any-observable) - `any-promise` for Observables.
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# readable-stream
***Node-core streams for userland***
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
This package is a mirror of the Streams2 and Streams3 implementations in Node-core.
If you want to guarantee a stable streams base, regardless of what version of Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core.
**readable-stream** comes in two major versions, v1.0.x and v1.1.x. The former tracks the Streams2 implementation in Node 0.10, including bug-fixes and minor improvements as they are added. The latter tracks Streams3 as it develops in Node 0.11; we will likely see a v1.2.x branch for Node 0.12.
**readable-stream** uses proper patch-level versioning so if you pin to `"~1.0.0"` you’ll get the latest Node 0.10 Streams2 implementation, including any fixes and minor non-breaking improvements. The patch-level versions of 1.0.x and 1.1.x should mirror the patch-level versions of Node-core releases. You should prefer the **1.0.x** releases for now and when you’re ready to start using Streams3, pin to `"~1.1.0"`
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# readdirp [](https://github.com/paulmillr/readdirp)
Recursive version of [fs.readdir](https://nodejs.org/api/fs.html#fs_fs_readdir_path_options_callback). Exposes a **stream API** and a **promise API**.
```sh
npm install readdirp
```
```javascript
const readdirp = require('readdirp');
// Use streams to achieve small RAM & CPU footprint.
// 1) Streams example with for-await.
for await (const entry of readdirp('.')) {
const {path} = entry;
console.log(`${JSON.stringify({path})}`);
}
// 2) Streams example, non for-await.
// Print out all JS files along with their size within the current folder & subfolders.
readdirp('.', {fileFilter: '*.js', alwaysStat: true})
.on('data', (entry) => {
const {path, stats: {size}} = entry;
console.log(`${JSON.stringify({path, size})}`);
})
// Optionally call stream.destroy() in `warn()` in order to abort and cause 'close' to be emitted
.on('warn', error => console.error('non-fatal error', error))
.on('error', error => console.error('fatal error', error))
.on('end', () => console.log('done'));
// 3) Promise example. More RAM and CPU than streams / for-await.
const files = await readdirp.promise('.');
console.log(files.map(file => file.path));
// Other options.
readdirp('test', {
fileFilter: '*.js',
directoryFilter: ['!.git', '!*modules']
// directoryFilter: (di) => di.basename.length === 9
type: 'files_directories',
depth: 1
});
```
For more examples, check out `examples` directory.
## API
`const stream = readdirp(root[, options])` — **Stream API**
- Reads given root recursively and returns a `stream` of [entry infos](#entryinfo)
- Optionally can be used like `for await (const entry of stream)` with node.js 10+ (`asyncIterator`).
- `on('data', (entry) => {})` [entry info](#entryinfo) for every file / dir.
- `on('warn', (error) => {})` non-fatal `Error` that prevents a file / dir from being processed. Example: inaccessible to the user.
- `on('error', (error) => {})` fatal `Error` which also ends the stream. Example: illegal options where passed.
- `on('end')` — we are done. Called when all entries were found and no more will be emitted.
- `on('close')` — stream is destroyed via `stream.destroy()`.
Could be useful if you want to manually abort even on a non fatal error.
At that point the stream is no longer `readable` and no more entries, warning or errors are emitted
- To learn more about streams, consult the very detailed [nodejs streams documentation](https://nodejs.org/api/stream.html)
or the [stream-handbook](https://github.com/substack/stream-handbook)
`const entries = await readdirp.promise(root[, options])` — **Promise API**. Returns a list of [entry infos](#entryinfo).
First argument is awalys `root`, path in which to start reading and recursing into subdirectories.
### options
- `fileFilter: ["*.js"]`: filter to include or exclude files. A `Function`, Glob string or Array of glob strings.
- **Function**: a function that takes an entry info as a parameter and returns true to include or false to exclude the entry
- **Glob string**: a string (e.g., `*.js`) which is matched using [picomatch](https://github.com/micromatch/picomatch), so go there for more
information. Globstars (`**`) are not supported since specifying a recursive pattern for an already recursive function doesn't make sense. Negated globs (as explained in the minimatch documentation) are allowed, e.g., `!*.txt` matches everything but text files.
- **Array of glob strings**: either need to be all inclusive or all exclusive (negated) patterns otherwise an error is thrown.
`['*.json', '*.js']` includes all JavaScript and Json files.
`['!.git', '!node_modules']` includes all directories except the '.git' and 'node_modules'.
- Directories that do not pass a filter will not be recursed into.
- `directoryFilter: ['!.git']`: filter to include/exclude directories found and to recurse into. Directories that do not pass a filter will not be recursed into.
- `depth: 5`: depth at which to stop recursing even if more subdirectories are found
- `type: 'files'`: determines if data events on the stream should be emitted for `'files'` (default), `'directories'`, `'files_directories'`, or `'all'`. Setting to `'all'` will also include entries for other types of file descriptors like character devices, unix sockets and named pipes.
- `alwaysStat: false`: always return `stats` property for every file. Default is `false`, readdirp will return `Dirent` entries. Setting it to `true` can double readdir execution time - use it only when you need file `size`, `mtime` etc. Cannot be enabled on node <10.10.0.
- `lstat: false`: include symlink entries in the stream along with files. When `true`, `fs.lstat` would be used instead of `fs.stat`
### `EntryInfo`
Has the following properties:
- `path: 'assets/javascripts/react.js'`: path to the file/directory (relative to given root)
- `fullPath: '/Users/dev/projects/app/assets/javascripts/react.js'`: full path to the file/directory found
- `basename: 'react.js'`: name of the file/directory
- `dirent: fs.Dirent`: built-in [dir entry object](https://nodejs.org/api/fs.html#fs_class_fs_dirent) - only with `alwaysStat: false`
- `stats: fs.Stats`: built in [stat object](https://nodejs.org/api/fs.html#fs_class_fs_stats) - only with `alwaysStat: true`
## Changelog
- 3.5 (Oct 13, 2020) disallows recursive directory-based symlinks.
Before, it could have entered infinite loop.
- 3.4 (Mar 19, 2020) adds support for directory-based symlinks.
- 3.3 (Dec 6, 2019) stabilizes RAM consumption and enables perf management with `highWaterMark` option. Fixes race conditions related to `for-await` looping.
- 3.2 (Oct 14, 2019) improves performance by 250% and makes streams implementation more idiomatic.
- 3.1 (Jul 7, 2019) brings `bigint` support to `stat` output on Windows. This is backwards-incompatible for some cases. Be careful. It you use it incorrectly, you'll see "TypeError: Cannot mix BigInt and other types, use explicit conversions".
- 3.0 brings huge performance improvements and stream backpressure support.
- Upgrading 2.x to 3.x:
- Signature changed from `readdirp(options)` to `readdirp(root, options)`
- Replaced callback API with promise API.
- Renamed `entryType` option to `type`
- Renamed `entryType: 'both'` to `'files_directories'`
- `EntryInfo`
- Renamed `stat` to `stats`
- Emitted only when `alwaysStat: true`
- `dirent` is emitted instead of `stats` by default with `alwaysStat: false`
- Renamed `name` to `basename`
- Removed `parentDir` and `fullParentDir` properties
- Supported node.js versions:
- 3.x: node 8+
- 2.x: node 0.6+
## License
Copyright (c) 2012-2019 Thorsten Lorenz, Paul Miller (<https://paulmillr.com>)
MIT License, see [LICENSE](LICENSE) file.
# Async.js
[](https://travis-ci.org/caolan/async)
[](https://www.npmjs.org/package/async)
[](https://coveralls.io/r/caolan/async?branch=master)
[](https://gitter.im/caolan/async?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
Async is a utility module which provides straight-forward, powerful functions
for working with asynchronous JavaScript. Although originally designed for
use with [Node.js](http://nodejs.org) and installable via `npm install async`,
it can also be used directly in the browser.
Async is also installable via:
- [bower](http://bower.io/): `bower install async`
- [component](https://github.com/component/component): `component install
caolan/async`
- [jam](http://jamjs.org/): `jam install async`
- [spm](http://spmjs.io/): `spm install async`
Async provides around 20 functions that include the usual 'functional'
suspects (`map`, `reduce`, `filter`, `each`…) as well as some common patterns
for asynchronous control flow (`parallel`, `series`, `waterfall`…). All these
functions assume you follow the Node.js convention of providing a single
callback as the last argument of your `async` function.
## Quick Examples
```javascript
async.map(['file1','file2','file3'], fs.stat, function(err, results){
// results is now an array of stats for each file
});
async.filter(['file1','file2','file3'], fs.exists, function(results){
// results now equals an array of the existing files
});
async.parallel([
function(){ ... },
function(){ ... }
], callback);
async.series([
function(){ ... },
function(){ ... }
]);
```
There are many more functions available so take a look at the docs below for a
full list. This module aims to be comprehensive, so if you feel anything is
missing please create a GitHub issue for it.
## Common Pitfalls <sub>[(StackOverflow)](http://stackoverflow.com/questions/tagged/async.js)</sub>
### Synchronous iteration functions
If you get an error like `RangeError: Maximum call stack size exceeded.` or other stack overflow issues when using async, you are likely using a synchronous iterator. By *synchronous* we mean a function that calls its callback on the same tick in the javascript event loop, without doing any I/O or using any timers. Calling many callbacks iteratively will quickly overflow the stack. If you run into this issue, just defer your callback with `async.setImmediate` to start a new call stack on the next tick of the event loop.
This can also arise by accident if you callback early in certain cases:
```js
async.eachSeries(hugeArray, function iterator(item, callback) {
if (inCache(item)) {
callback(null, cache[item]); // if many items are cached, you'll overflow
} else {
doSomeIO(item, callback);
}
}, function done() {
//...
});
```
Just change it to:
```js
async.eachSeries(hugeArray, function iterator(item, callback) {
if (inCache(item)) {
async.setImmediate(function () {
callback(null, cache[item]);
});
} else {
doSomeIO(item, callback);
//...
```
Async guards against synchronous functions in some, but not all, cases. If you are still running into stack overflows, you can defer as suggested above, or wrap functions with [`async.ensureAsync`](#ensureAsync) Functions that are asynchronous by their nature do not have this problem and don't need the extra callback deferral.
If JavaScript's event loop is still a bit nebulous, check out [this article](http://blog.carbonfive.com/2013/10/27/the-javascript-event-loop-explained/) or [this talk](http://2014.jsconf.eu/speakers/philip-roberts-what-the-heck-is-the-event-loop-anyway.html) for more detailed information about how it works.
### Multiple callbacks
Make sure to always `return` when calling a callback early, otherwise you will cause multiple callbacks and unpredictable behavior in many cases.
```js
async.waterfall([
function (callback) {
getSomething(options, function (err, result) {
if (err) {
callback(new Error("failed getting something:" + err.message));
// we should return here
}
// since we did not return, this callback still will be called and
// `processData` will be called twice
callback(null, result);
});
},
processData
], done)
```
It is always good practice to `return callback(err, result)` whenever a callback call is not the last statement of a function.
### Binding a context to an iterator
This section is really about `bind`, not about `async`. If you are wondering how to
make `async` execute your iterators in a given context, or are confused as to why
a method of another library isn't working as an iterator, study this example:
```js
// Here is a simple object with an (unnecessarily roundabout) squaring method
var AsyncSquaringLibrary = {
squareExponent: 2,
square: function(number, callback){
var result = Math.pow(number, this.squareExponent);
setTimeout(function(){
callback(null, result);
}, 200);
}
};
async.map([1, 2, 3], AsyncSquaringLibrary.square, function(err, result){
// result is [NaN, NaN, NaN]
// This fails because the `this.squareExponent` expression in the square
// function is not evaluated in the context of AsyncSquaringLibrary, and is
// therefore undefined.
});
async.map([1, 2, 3], AsyncSquaringLibrary.square.bind(AsyncSquaringLibrary), function(err, result){
// result is [1, 4, 9]
// With the help of bind we can attach a context to the iterator before
// passing it to async. Now the square function will be executed in its
// 'home' AsyncSquaringLibrary context and the value of `this.squareExponent`
// will be as expected.
});
```
## Download
The source is available for download from
[GitHub](https://github.com/caolan/async/blob/master/lib/async.js).
Alternatively, you can install using Node Package Manager (`npm`):
npm install async
As well as using Bower:
bower install async
__Development:__ [async.js](https://github.com/caolan/async/raw/master/lib/async.js) - 29.6kb Uncompressed
## In the Browser
So far it's been tested in IE6, IE7, IE8, FF3.6 and Chrome 5.
Usage:
```html
<script type="text/javascript" src="async.js"></script>
<script type="text/javascript">
async.map(data, asyncProcess, function(err, results){
alert(results);
});
</script>
```
## Documentation
Some functions are also available in the following forms:
* `<name>Series` - the same as `<name>` but runs only a single async operation at a time
* `<name>Limit` - the same as `<name>` but runs a maximum of `limit` async operations at a time
### Collections
* [`each`](#each), `eachSeries`, `eachLimit`
* [`forEachOf`](#forEachOf), `forEachOfSeries`, `forEachOfLimit`
* [`map`](#map), `mapSeries`, `mapLimit`
* [`filter`](#filter), `filterSeries`, `filterLimit`
* [`reject`](#reject), `rejectSeries`, `rejectLimit`
* [`reduce`](#reduce), [`reduceRight`](#reduceRight)
* [`detect`](#detect), `detectSeries`, `detectLimit`
* [`sortBy`](#sortBy)
* [`some`](#some), `someLimit`
* [`every`](#every), `everyLimit`
* [`concat`](#concat), `concatSeries`
### Control Flow
* [`series`](#seriestasks-callback)
* [`parallel`](#parallel), `parallelLimit`
* [`whilst`](#whilst), [`doWhilst`](#doWhilst)
* [`until`](#until), [`doUntil`](#doUntil)
* [`during`](#during), [`doDuring`](#doDuring)
* [`forever`](#forever)
* [`waterfall`](#waterfall)
* [`compose`](#compose)
* [`seq`](#seq)
* [`applyEach`](#applyEach), `applyEachSeries`
* [`queue`](#queue), [`priorityQueue`](#priorityQueue)
* [`cargo`](#cargo)
* [`auto`](#auto)
* [`retry`](#retry)
* [`iterator`](#iterator)
* [`times`](#times), `timesSeries`, `timesLimit`
### Utils
* [`apply`](#apply)
* [`nextTick`](#nextTick)
* [`memoize`](#memoize)
* [`unmemoize`](#unmemoize)
* [`ensureAsync`](#ensureAsync)
* [`constant`](#constant)
* [`asyncify`](#asyncify)
* [`wrapSync`](#wrapSync)
* [`log`](#log)
* [`dir`](#dir)
* [`noConflict`](#noConflict)
## Collections
<a name="forEach" />
<a name="each" />
### each(arr, iterator, [callback])
Applies the function `iterator` to each item in `arr`, in parallel.
The `iterator` is called with an item from the list, and a callback for when it
has finished. If the `iterator` passes an error to its `callback`, the main
`callback` (for the `each` function) is immediately called with the error.
Note, that since this function applies `iterator` to each item in parallel,
there is no guarantee that the iterator functions will complete in order.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A function to apply to each item in `arr`.
The iterator is passed a `callback(err)` which must be called once it has
completed. If no error has occurred, the `callback` should be run without
arguments or with an explicit `null` argument. The array index is not passed
to the iterator. If you need the index, use [`forEachOf`](#forEachOf).
* `callback(err)` - *Optional* A callback which is called when all `iterator` functions
have finished, or an error occurs.
__Examples__
```js
// assuming openFiles is an array of file names and saveFile is a function
// to save the modified contents of that file:
async.each(openFiles, saveFile, function(err){
// if any of the saves produced an error, err would equal that error
});
```
```js
// assuming openFiles is an array of file names
async.each(openFiles, function(file, callback) {
// Perform operation on file here.
console.log('Processing file ' + file);
if( file.length > 32 ) {
console.log('This file name is too long');
callback('File name too long');
} else {
// Do work to process file here
console.log('File processed');
callback();
}
}, function(err){
// if any of the file processing produced an error, err would equal that error
if( err ) {
// One of the iterations produced an error.
// All processing will now stop.
console.log('A file failed to process');
} else {
console.log('All files have been processed successfully');
}
});
```
__Related__
* eachSeries(arr, iterator, [callback])
* eachLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="forEachOf" />
<a name="eachOf" />
### forEachOf(obj, iterator, [callback])
Like `each`, except that it iterates over objects, and passes the key as the second argument to the iterator.
__Arguments__
* `obj` - An object or array to iterate over.
* `iterator(item, key, callback)` - A function to apply to each item in `obj`.
The `key` is the item's key, or index in the case of an array. The iterator is
passed a `callback(err)` which must be called once it has completed. If no
error has occurred, the callback should be run without arguments or with an
explicit `null` argument.
* `callback(err)` - *Optional* A callback which is called when all `iterator` functions have finished, or an error occurs.
__Example__
```js
var obj = {dev: "/dev.json", test: "/test.json", prod: "/prod.json"};
var configs = {};
async.forEachOf(obj, function (value, key, callback) {
fs.readFile(__dirname + value, "utf8", function (err, data) {
if (err) return callback(err);
try {
configs[key] = JSON.parse(data);
} catch (e) {
return callback(e);
}
callback();
})
}, function (err) {
if (err) console.error(err.message);
// configs is now a map of JSON data
doSomethingWith(configs);
})
```
__Related__
* forEachOfSeries(obj, iterator, [callback])
* forEachOfLimit(obj, limit, iterator, [callback])
---------------------------------------
<a name="map" />
### map(arr, iterator, [callback])
Produces a new array of values by mapping each value in `arr` through
the `iterator` function. The `iterator` is called with an item from `arr` and a
callback for when it has finished processing. Each of these callback takes 2 arguments:
an `error`, and the transformed item from `arr`. If `iterator` passes an error to its
callback, the main `callback` (for the `map` function) is immediately called with the error.
Note, that since this function applies the `iterator` to each item in parallel,
there is no guarantee that the `iterator` functions will complete in order.
However, the results array will be in the same order as the original `arr`.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A function to apply to each item in `arr`.
The iterator is passed a `callback(err, transformed)` which must be called once
it has completed with an error (which can be `null`) and a transformed item.
* `callback(err, results)` - *Optional* A callback which is called when all `iterator`
functions have finished, or an error occurs. Results is an array of the
transformed items from the `arr`.
__Example__
```js
async.map(['file1','file2','file3'], fs.stat, function(err, results){
// results is now an array of stats for each file
});
```
__Related__
* mapSeries(arr, iterator, [callback])
* mapLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="select" />
<a name="filter" />
### filter(arr, iterator, [callback])
__Alias:__ `select`
Returns a new array of all the values in `arr` which pass an async truth test.
_The callback for each `iterator` call only accepts a single argument of `true` or
`false`; it does not accept an error argument first!_ This is in-line with the
way node libraries work with truth tests like `fs.exists`. This operation is
performed in parallel, but the results array will be in the same order as the
original.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A truth test to apply to each item in `arr`.
The `iterator` is passed a `callback(truthValue)`, which must be called with a
boolean argument once it has completed.
* `callback(results)` - *Optional* A callback which is called after all the `iterator`
functions have finished.
__Example__
```js
async.filter(['file1','file2','file3'], fs.exists, function(results){
// results now equals an array of the existing files
});
```
__Related__
* filterSeries(arr, iterator, [callback])
* filterLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="reject" />
### reject(arr, iterator, [callback])
The opposite of [`filter`](#filter). Removes values that pass an `async` truth test.
__Related__
* rejectSeries(arr, iterator, [callback])
* rejectLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="reduce" />
### reduce(arr, memo, iterator, [callback])
__Aliases:__ `inject`, `foldl`
Reduces `arr` into a single value using an async `iterator` to return
each successive step. `memo` is the initial state of the reduction.
This function only operates in series.
For performance reasons, it may make sense to split a call to this function into
a parallel map, and then use the normal `Array.prototype.reduce` on the results.
This function is for situations where each step in the reduction needs to be async;
if you can get the data before reducing it, then it's probably a good idea to do so.
__Arguments__
* `arr` - An array to iterate over.
* `memo` - The initial state of the reduction.
* `iterator(memo, item, callback)` - A function applied to each item in the
array to produce the next step in the reduction. The `iterator` is passed a
`callback(err, reduction)` which accepts an optional error as its first
argument, and the state of the reduction as the second. If an error is
passed to the callback, the reduction is stopped and the main `callback` is
immediately called with the error.
* `callback(err, result)` - *Optional* A callback which is called after all the `iterator`
functions have finished. Result is the reduced value.
__Example__
```js
async.reduce([1,2,3], 0, function(memo, item, callback){
// pointless async:
process.nextTick(function(){
callback(null, memo + item)
});
}, function(err, result){
// result is now equal to the last value of memo, which is 6
});
```
---------------------------------------
<a name="reduceRight" />
### reduceRight(arr, memo, iterator, [callback])
__Alias:__ `foldr`
Same as [`reduce`](#reduce), only operates on `arr` in reverse order.
---------------------------------------
<a name="detect" />
### detect(arr, iterator, [callback])
Returns the first value in `arr` that passes an async truth test. The
`iterator` is applied in parallel, meaning the first iterator to return `true` will
fire the detect `callback` with that result. That means the result might not be
the first item in the original `arr` (in terms of order) that passes the test.
If order within the original `arr` is important, then look at [`detectSeries`](#detectSeries).
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A truth test to apply to each item in `arr`.
The iterator is passed a `callback(truthValue)` which must be called with a
boolean argument once it has completed. **Note: this callback does not take an error as its first argument.**
* `callback(result)` - *Optional* A callback which is called as soon as any iterator returns
`true`, or after all the `iterator` functions have finished. Result will be
the first item in the array that passes the truth test (iterator) or the
value `undefined` if none passed. **Note: this callback does not take an error as its first argument.**
__Example__
```js
async.detect(['file1','file2','file3'], fs.exists, function(result){
// result now equals the first file in the list that exists
});
```
__Related__
* detectSeries(arr, iterator, [callback])
* detectLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="sortBy" />
### sortBy(arr, iterator, [callback])
Sorts a list by the results of running each `arr` value through an async `iterator`.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A function to apply to each item in `arr`.
The iterator is passed a `callback(err, sortValue)` which must be called once it
has completed with an error (which can be `null`) and a value to use as the sort
criteria.
* `callback(err, results)` - *Optional* A callback which is called after all the `iterator`
functions have finished, or an error occurs. Results is the items from
the original `arr` sorted by the values returned by the `iterator` calls.
__Example__
```js
async.sortBy(['file1','file2','file3'], function(file, callback){
fs.stat(file, function(err, stats){
callback(err, stats.mtime);
});
}, function(err, results){
// results is now the original array of files sorted by
// modified date
});
```
__Sort Order__
By modifying the callback parameter the sorting order can be influenced:
```js
//ascending order
async.sortBy([1,9,3,5], function(x, callback){
callback(null, x);
}, function(err,result){
//result callback
} );
//descending order
async.sortBy([1,9,3,5], function(x, callback){
callback(null, x*-1); //<- x*-1 instead of x, turns the order around
}, function(err,result){
//result callback
} );
```
---------------------------------------
<a name="some" />
### some(arr, iterator, [callback])
__Alias:__ `any`
Returns `true` if at least one element in the `arr` satisfies an async test.
_The callback for each iterator call only accepts a single argument of `true` or
`false`; it does not accept an error argument first!_ This is in-line with the
way node libraries work with truth tests like `fs.exists`. Once any iterator
call returns `true`, the main `callback` is immediately called.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A truth test to apply to each item in the array
in parallel. The iterator is passed a `callback(truthValue)`` which must be
called with a boolean argument once it has completed.
* `callback(result)` - *Optional* A callback which is called as soon as any iterator returns
`true`, or after all the iterator functions have finished. Result will be
either `true` or `false` depending on the values of the async tests.
**Note: the callbacks do not take an error as their first argument.**
__Example__
```js
async.some(['file1','file2','file3'], fs.exists, function(result){
// if result is true then at least one of the files exists
});
```
__Related__
* someLimit(arr, limit, iterator, callback)
---------------------------------------
<a name="every" />
### every(arr, iterator, [callback])
__Alias:__ `all`
Returns `true` if every element in `arr` satisfies an async test.
_The callback for each `iterator` call only accepts a single argument of `true` or
`false`; it does not accept an error argument first!_ This is in-line with the
way node libraries work with truth tests like `fs.exists`.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A truth test to apply to each item in the array
in parallel. The iterator is passed a `callback(truthValue)` which must be
called with a boolean argument once it has completed.
* `callback(result)` - *Optional* A callback which is called as soon as any iterator returns
`false`, or after all the iterator functions have finished. Result will be
either `true` or `false` depending on the values of the async tests.
**Note: the callbacks do not take an error as their first argument.**
__Example__
```js
async.every(['file1','file2','file3'], fs.exists, function(result){
// if result is true then every file exists
});
```
__Related__
* everyLimit(arr, limit, iterator, callback)
---------------------------------------
<a name="concat" />
### concat(arr, iterator, [callback])
Applies `iterator` to each item in `arr`, concatenating the results. Returns the
concatenated list. The `iterator`s are called in parallel, and the results are
concatenated as they return. There is no guarantee that the results array will
be returned in the original order of `arr` passed to the `iterator` function.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A function to apply to each item in `arr`.
The iterator is passed a `callback(err, results)` which must be called once it
has completed with an error (which can be `null`) and an array of results.
* `callback(err, results)` - *Optional* A callback which is called after all the `iterator`
functions have finished, or an error occurs. Results is an array containing
the concatenated results of the `iterator` function.
__Example__
```js
async.concat(['dir1','dir2','dir3'], fs.readdir, function(err, files){
// files is now a list of filenames that exist in the 3 directories
});
```
__Related__
* concatSeries(arr, iterator, [callback])
## Control Flow
<a name="series" />
### series(tasks, [callback])
Run the functions in the `tasks` array in series, each one running once the previous
function has completed. If any functions in the series pass an error to its
callback, no more functions are run, and `callback` is immediately called with the value of the error.
Otherwise, `callback` receives an array of results when `tasks` have completed.
It is also possible to use an object instead of an array. Each property will be
run as a function, and the results will be passed to the final `callback` as an object
instead of an array. This can be a more readable way of handling results from
[`series`](#series).
**Note** that while many implementations preserve the order of object properties, the
[ECMAScript Language Specification](http://www.ecma-international.org/ecma-262/5.1/#sec-8.6)
explicitly states that
> The mechanics and order of enumerating the properties is not specified.
So if you rely on the order in which your series of functions are executed, and want
this to work on all platforms, consider using an array.
__Arguments__
* `tasks` - An array or object containing functions to run, each function is passed
a `callback(err, result)` it must call on completion with an error `err` (which can
be `null`) and an optional `result` value.
* `callback(err, results)` - An optional callback to run once all the functions
have completed. This function gets a results array (or object) containing all
the result arguments passed to the `task` callbacks.
__Example__
```js
async.series([
function(callback){
// do some stuff ...
callback(null, 'one');
},
function(callback){
// do some more stuff ...
callback(null, 'two');
}
],
// optional callback
function(err, results){
// results is now equal to ['one', 'two']
});
// an example using an object instead of an array
async.series({
one: function(callback){
setTimeout(function(){
callback(null, 1);
}, 200);
},
two: function(callback){
setTimeout(function(){
callback(null, 2);
}, 100);
}
},
function(err, results) {
// results is now equal to: {one: 1, two: 2}
});
```
---------------------------------------
<a name="parallel" />
### parallel(tasks, [callback])
Run the `tasks` array of functions in parallel, without waiting until the previous
function has completed. If any of the functions pass an error to its
callback, the main `callback` is immediately called with the value of the error.
Once the `tasks` have completed, the results are passed to the final `callback` as an
array.
**Note:** `parallel` is about kicking-off I/O tasks in parallel, not about parallel execution of code. If your tasks do not use any timers or perform any I/O, they will actually be executed in series. Any synchronous setup sections for each task will happen one after the other. JavaScript remains single-threaded.
It is also possible to use an object instead of an array. Each property will be
run as a function and the results will be passed to the final `callback` as an object
instead of an array. This can be a more readable way of handling results from
[`parallel`](#parallel).
__Arguments__
* `tasks` - An array or object containing functions to run. Each function is passed
a `callback(err, result)` which it must call on completion with an error `err`
(which can be `null`) and an optional `result` value.
* `callback(err, results)` - An optional callback to run once all the functions
have completed successfully. This function gets a results array (or object) containing all
the result arguments passed to the task callbacks.
__Example__
```js
async.parallel([
function(callback){
setTimeout(function(){
callback(null, 'one');
}, 200);
},
function(callback){
setTimeout(function(){
callback(null, 'two');
}, 100);
}
],
// optional callback
function(err, results){
// the results array will equal ['one','two'] even though
// the second function had a shorter timeout.
});
// an example using an object instead of an array
async.parallel({
one: function(callback){
setTimeout(function(){
callback(null, 1);
}, 200);
},
two: function(callback){
setTimeout(function(){
callback(null, 2);
}, 100);
}
},
function(err, results) {
// results is now equals to: {one: 1, two: 2}
});
```
__Related__
* parallelLimit(tasks, limit, [callback])
---------------------------------------
<a name="whilst" />
### whilst(test, fn, callback)
Repeatedly call `fn`, while `test` returns `true`. Calls `callback` when stopped,
or an error occurs.
__Arguments__
* `test()` - synchronous truth test to perform before each execution of `fn`.
* `fn(callback)` - A function which is called each time `test` passes. The function is
passed a `callback(err)`, which must be called once it has completed with an
optional `err` argument.
* `callback(err, [results])` - A callback which is called after the test
function has failed and repeated execution of `fn` has stopped. `callback`
will be passed an error and any arguments passed to the final `fn`'s callback.
__Example__
```js
var count = 0;
async.whilst(
function () { return count < 5; },
function (callback) {
count++;
setTimeout(function () {
callback(null, count);
}, 1000);
},
function (err, n) {
// 5 seconds have passed, n = 5
}
);
```
---------------------------------------
<a name="doWhilst" />
### doWhilst(fn, test, callback)
The post-check version of [`whilst`](#whilst). To reflect the difference in
the order of operations, the arguments `test` and `fn` are switched.
`doWhilst` is to `whilst` as `do while` is to `while` in plain JavaScript.
---------------------------------------
<a name="until" />
### until(test, fn, callback)
Repeatedly call `fn` until `test` returns `true`. Calls `callback` when stopped,
or an error occurs. `callback` will be passed an error and any arguments passed
to the final `fn`'s callback.
The inverse of [`whilst`](#whilst).
---------------------------------------
<a name="doUntil" />
### doUntil(fn, test, callback)
Like [`doWhilst`](#doWhilst), except the `test` is inverted. Note the argument ordering differs from `until`.
---------------------------------------
<a name="during" />
### during(test, fn, callback)
Like [`whilst`](#whilst), except the `test` is an asynchronous function that is passed a callback in the form of `function (err, truth)`. If error is passed to `test` or `fn`, the main callback is immediately called with the value of the error.
__Example__
```js
var count = 0;
async.during(
function (callback) {
return callback(null, count < 5);
},
function (callback) {
count++;
setTimeout(callback, 1000);
},
function (err) {
// 5 seconds have passed
}
);
```
---------------------------------------
<a name="doDuring" />
### doDuring(fn, test, callback)
The post-check version of [`during`](#during). To reflect the difference in
the order of operations, the arguments `test` and `fn` are switched.
Also a version of [`doWhilst`](#doWhilst) with asynchronous `test` function.
---------------------------------------
<a name="forever" />
### forever(fn, [errback])
Calls the asynchronous function `fn` with a callback parameter that allows it to
call itself again, in series, indefinitely.
If an error is passed to the callback then `errback` is called with the
error, and execution stops, otherwise it will never be called.
```js
async.forever(
function(next) {
// next is suitable for passing to things that need a callback(err [, whatever]);
// it will result in this function being called again.
},
function(err) {
// if next is called with a value in its first parameter, it will appear
// in here as 'err', and execution will stop.
}
);
```
---------------------------------------
<a name="waterfall" />
### waterfall(tasks, [callback])
Runs the `tasks` array of functions in series, each passing their results to the next in
the array. However, if any of the `tasks` pass an error to their own callback, the
next function is not executed, and the main `callback` is immediately called with
the error.
__Arguments__
* `tasks` - An array of functions to run, each function is passed a
`callback(err, result1, result2, ...)` it must call on completion. The first
argument is an error (which can be `null`) and any further arguments will be
passed as arguments in order to the next task.
* `callback(err, [results])` - An optional callback to run once all the functions
have completed. This will be passed the results of the last task's callback.
__Example__
```js
async.waterfall([
function(callback) {
callback(null, 'one', 'two');
},
function(arg1, arg2, callback) {
// arg1 now equals 'one' and arg2 now equals 'two'
callback(null, 'three');
},
function(arg1, callback) {
// arg1 now equals 'three'
callback(null, 'done');
}
], function (err, result) {
// result now equals 'done'
});
```
Or, with named functions:
```js
async.waterfall([
myFirstFunction,
mySecondFunction,
myLastFunction,
], function (err, result) {
// result now equals 'done'
});
function myFirstFunction(callback) {
callback(null, 'one', 'two');
}
function mySecondFunction(arg1, arg2, callback) {
// arg1 now equals 'one' and arg2 now equals 'two'
callback(null, 'three');
}
function myLastFunction(arg1, callback) {
// arg1 now equals 'three'
callback(null, 'done');
}
```
Or, if you need to pass any argument to the first function:
```js
async.waterfall([
async.apply(myFirstFunction, 'zero'),
mySecondFunction,
myLastFunction,
], function (err, result) {
// result now equals 'done'
});
function myFirstFunction(arg1, callback) {
// arg1 now equals 'zero'
callback(null, 'one', 'two');
}
function mySecondFunction(arg1, arg2, callback) {
// arg1 now equals 'one' and arg2 now equals 'two'
callback(null, 'three');
}
function myLastFunction(arg1, callback) {
// arg1 now equals 'three'
callback(null, 'done');
}
```
---------------------------------------
<a name="compose" />
### compose(fn1, fn2...)
Creates a function which is a composition of the passed asynchronous
functions. Each function consumes the return value of the function that
follows. Composing functions `f()`, `g()`, and `h()` would produce the result of
`f(g(h()))`, only this version uses callbacks to obtain the return values.
Each function is executed with the `this` binding of the composed function.
__Arguments__
* `functions...` - the asynchronous functions to compose
__Example__
```js
function add1(n, callback) {
setTimeout(function () {
callback(null, n + 1);
}, 10);
}
function mul3(n, callback) {
setTimeout(function () {
callback(null, n * 3);
}, 10);
}
var add1mul3 = async.compose(mul3, add1);
add1mul3(4, function (err, result) {
// result now equals 15
});
```
---------------------------------------
<a name="seq" />
### seq(fn1, fn2...)
Version of the compose function that is more natural to read.
Each function consumes the return value of the previous function.
It is the equivalent of [`compose`](#compose) with the arguments reversed.
Each function is executed with the `this` binding of the composed function.
__Arguments__
* `functions...` - the asynchronous functions to compose
__Example__
```js
// Requires lodash (or underscore), express3 and dresende's orm2.
// Part of an app, that fetches cats of the logged user.
// This example uses `seq` function to avoid overnesting and error
// handling clutter.
app.get('/cats', function(request, response) {
var User = request.models.User;
async.seq(
_.bind(User.get, User), // 'User.get' has signature (id, callback(err, data))
function(user, fn) {
user.getCats(fn); // 'getCats' has signature (callback(err, data))
}
)(req.session.user_id, function (err, cats) {
if (err) {
console.error(err);
response.json({ status: 'error', message: err.message });
} else {
response.json({ status: 'ok', message: 'Cats found', data: cats });
}
});
});
```
---------------------------------------
<a name="applyEach" />
### applyEach(fns, args..., callback)
Applies the provided arguments to each function in the array, calling
`callback` after all functions have completed. If you only provide the first
argument, then it will return a function which lets you pass in the
arguments as if it were a single function call.
__Arguments__
* `fns` - the asynchronous functions to all call with the same arguments
* `args...` - any number of separate arguments to pass to the function
* `callback` - the final argument should be the callback, called when all
functions have completed processing
__Example__
```js
async.applyEach([enableSearch, updateSchema], 'bucket', callback);
// partial application example:
async.each(
buckets,
async.applyEach([enableSearch, updateSchema]),
callback
);
```
__Related__
* applyEachSeries(tasks, args..., [callback])
---------------------------------------
<a name="queue" />
### queue(worker, [concurrency])
Creates a `queue` object with the specified `concurrency`. Tasks added to the
`queue` are processed in parallel (up to the `concurrency` limit). If all
`worker`s are in progress, the task is queued until one becomes available.
Once a `worker` completes a `task`, that `task`'s callback is called.
__Arguments__
* `worker(task, callback)` - An asynchronous function for processing a queued
task, which must call its `callback(err)` argument when finished, with an
optional `error` as an argument. If you want to handle errors from an individual task, pass a callback to `q.push()`.
* `concurrency` - An `integer` for determining how many `worker` functions should be
run in parallel. If omitted, the concurrency defaults to `1`. If the concurrency is `0`, an error is thrown.
__Queue objects__
The `queue` object returned by this function has the following properties and
methods:
* `length()` - a function returning the number of items waiting to be processed.
* `started` - a function returning whether or not any items have been pushed and processed by the queue
* `running()` - a function returning the number of items currently being processed.
* `workersList()` - a function returning the array of items currently being processed.
* `idle()` - a function returning false if there are items waiting or being processed, or true if not.
* `concurrency` - an integer for determining how many `worker` functions should be
run in parallel. This property can be changed after a `queue` is created to
alter the concurrency on-the-fly.
* `push(task, [callback])` - add a new task to the `queue`. Calls `callback` once
the `worker` has finished processing the task. Instead of a single task, a `tasks` array
can be submitted. The respective callback is used for every task in the list.
* `unshift(task, [callback])` - add a new task to the front of the `queue`.
* `saturated` - a callback that is called when the `queue` length hits the `concurrency` limit,
and further tasks will be queued.
* `empty` - a callback that is called when the last item from the `queue` is given to a `worker`.
* `drain` - a callback that is called when the last item from the `queue` has returned from the `worker`.
* `paused` - a boolean for determining whether the queue is in a paused state
* `pause()` - a function that pauses the processing of tasks until `resume()` is called.
* `resume()` - a function that resumes the processing of queued tasks when the queue is paused.
* `kill()` - a function that removes the `drain` callback and empties remaining tasks from the queue forcing it to go idle.
__Example__
```js
// create a queue object with concurrency 2
var q = async.queue(function (task, callback) {
console.log('hello ' + task.name);
callback();
}, 2);
// assign a callback
q.drain = function() {
console.log('all items have been processed');
}
// add some items to the queue
q.push({name: 'foo'}, function (err) {
console.log('finished processing foo');
});
q.push({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
// add some items to the queue (batch-wise)
q.push([{name: 'baz'},{name: 'bay'},{name: 'bax'}], function (err) {
console.log('finished processing item');
});
// add some items to the front of the queue
q.unshift({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
```
---------------------------------------
<a name="priorityQueue" />
### priorityQueue(worker, concurrency)
The same as [`queue`](#queue) only tasks are assigned a priority and completed in ascending priority order. There are two differences between `queue` and `priorityQueue` objects:
* `push(task, priority, [callback])` - `priority` should be a number. If an array of
`tasks` is given, all tasks will be assigned the same priority.
* The `unshift` method was removed.
---------------------------------------
<a name="cargo" />
### cargo(worker, [payload])
Creates a `cargo` object with the specified payload. Tasks added to the
cargo will be processed altogether (up to the `payload` limit). If the
`worker` is in progress, the task is queued until it becomes available. Once
the `worker` has completed some tasks, each callback of those tasks is called.
Check out [these](https://camo.githubusercontent.com/6bbd36f4cf5b35a0f11a96dcd2e97711ffc2fb37/68747470733a2f2f662e636c6f75642e6769746875622e636f6d2f6173736574732f313637363837312f36383130382f62626330636662302d356632392d313165322d393734662d3333393763363464633835382e676966) [animations](https://camo.githubusercontent.com/f4810e00e1c5f5f8addbe3e9f49064fd5d102699/68747470733a2f2f662e636c6f75642e6769746875622e636f6d2f6173736574732f313637363837312f36383130312f38346339323036362d356632392d313165322d383134662d3964336430323431336266642e676966) for how `cargo` and `queue` work.
While [queue](#queue) passes only one task to one of a group of workers
at a time, cargo passes an array of tasks to a single worker, repeating
when the worker is finished.
__Arguments__
* `worker(tasks, callback)` - An asynchronous function for processing an array of
queued tasks, which must call its `callback(err)` argument when finished, with
an optional `err` argument.
* `payload` - An optional `integer` for determining how many tasks should be
processed per round; if omitted, the default is unlimited.
__Cargo objects__
The `cargo` object returned by this function has the following properties and
methods:
* `length()` - A function returning the number of items waiting to be processed.
* `payload` - An `integer` for determining how many tasks should be
process per round. This property can be changed after a `cargo` is created to
alter the payload on-the-fly.
* `push(task, [callback])` - Adds `task` to the `queue`. The callback is called
once the `worker` has finished processing the task. Instead of a single task, an array of `tasks`
can be submitted. The respective callback is used for every task in the list.
* `saturated` - A callback that is called when the `queue.length()` hits the concurrency and further tasks will be queued.
* `empty` - A callback that is called when the last item from the `queue` is given to a `worker`.
* `drain` - A callback that is called when the last item from the `queue` has returned from the `worker`.
* `idle()`, `pause()`, `resume()`, `kill()` - cargo inherits all of the same methods and event calbacks as [`queue`](#queue)
__Example__
```js
// create a cargo object with payload 2
var cargo = async.cargo(function (tasks, callback) {
for(var i=0; i<tasks.length; i++){
console.log('hello ' + tasks[i].name);
}
callback();
}, 2);
// add some items
cargo.push({name: 'foo'}, function (err) {
console.log('finished processing foo');
});
cargo.push({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
cargo.push({name: 'baz'}, function (err) {
console.log('finished processing baz');
});
```
---------------------------------------
<a name="auto" />
### auto(tasks, [concurrency], [callback])
Determines the best order for running the functions in `tasks`, based on their requirements. Each function can optionally depend on other functions being completed first, and each function is run as soon as its requirements are satisfied.
If any of the functions pass an error to their callback, the `auto` sequence will stop. Further tasks will not execute (so any other functions depending on it will not run), and the main `callback` is immediately called with the error. Functions also receive an object containing the results of functions which have completed so far.
Note, all functions are called with a `results` object as a second argument,
so it is unsafe to pass functions in the `tasks` object which cannot handle the
extra argument.
For example, this snippet of code:
```js
async.auto({
readData: async.apply(fs.readFile, 'data.txt', 'utf-8')
}, callback);
```
will have the effect of calling `readFile` with the results object as the last
argument, which will fail:
```js
fs.readFile('data.txt', 'utf-8', cb, {});
```
Instead, wrap the call to `readFile` in a function which does not forward the
`results` object:
```js
async.auto({
readData: function(cb, results){
fs.readFile('data.txt', 'utf-8', cb);
}
}, callback);
```
__Arguments__
* `tasks` - An object. Each of its properties is either a function or an array of
requirements, with the function itself the last item in the array. The object's key
of a property serves as the name of the task defined by that property,
i.e. can be used when specifying requirements for other tasks.
The function receives two arguments: (1) a `callback(err, result)` which must be
called when finished, passing an `error` (which can be `null`) and the result of
the function's execution, and (2) a `results` object, containing the results of
the previously executed functions.
* `concurrency` - An optional `integer` for determining the maximum number of tasks that can be run in parallel. By default, as many as possible.
* `callback(err, results)` - An optional callback which is called when all the
tasks have been completed. It receives the `err` argument if any `tasks`
pass an error to their callback. Results are always returned; however, if
an error occurs, no further `tasks` will be performed, and the results
object will only contain partial results.
__Example__
```js
async.auto({
get_data: function(callback){
console.log('in get_data');
// async code to get some data
callback(null, 'data', 'converted to array');
},
make_folder: function(callback){
console.log('in make_folder');
// async code to create a directory to store a file in
// this is run at the same time as getting the data
callback(null, 'folder');
},
write_file: ['get_data', 'make_folder', function(callback, results){
console.log('in write_file', JSON.stringify(results));
// once there is some data and the directory exists,
// write the data to a file in the directory
callback(null, 'filename');
}],
email_link: ['write_file', function(callback, results){
console.log('in email_link', JSON.stringify(results));
// once the file is written let's email a link to it...
// results.write_file contains the filename returned by write_file.
callback(null, {'file':results.write_file, 'email':'[email protected]'});
}]
}, function(err, results) {
console.log('err = ', err);
console.log('results = ', results);
});
```
This is a fairly trivial example, but to do this using the basic parallel and
series functions would look like this:
```js
async.parallel([
function(callback){
console.log('in get_data');
// async code to get some data
callback(null, 'data', 'converted to array');
},
function(callback){
console.log('in make_folder');
// async code to create a directory to store a file in
// this is run at the same time as getting the data
callback(null, 'folder');
}
],
function(err, results){
async.series([
function(callback){
console.log('in write_file', JSON.stringify(results));
// once there is some data and the directory exists,
// write the data to a file in the directory
results.push('filename');
callback(null);
},
function(callback){
console.log('in email_link', JSON.stringify(results));
// once the file is written let's email a link to it...
callback(null, {'file':results.pop(), 'email':'[email protected]'});
}
]);
});
```
For a complicated series of `async` tasks, using the [`auto`](#auto) function makes adding
new tasks much easier (and the code more readable).
---------------------------------------
<a name="retry" />
### retry([opts = {times: 5, interval: 0}| 5], task, [callback])
Attempts to get a successful response from `task` no more than `times` times before
returning an error. If the task is successful, the `callback` will be passed the result
of the successful task. If all attempts fail, the callback will be passed the error and
result (if any) of the final attempt.
__Arguments__
* `opts` - Can be either an object with `times` and `interval` or a number.
* `times` - The number of attempts to make before giving up. The default is `5`.
* `interval` - The time to wait between retries, in milliseconds. The default is `0`.
* If `opts` is a number, the number specifies the number of times to retry, with the default interval of `0`.
* `task(callback, results)` - A function which receives two arguments: (1) a `callback(err, result)`
which must be called when finished, passing `err` (which can be `null`) and the `result` of
the function's execution, and (2) a `results` object, containing the results of
the previously executed functions (if nested inside another control flow).
* `callback(err, results)` - An optional callback which is called when the
task has succeeded, or after the final failed attempt. It receives the `err` and `result` arguments of the last attempt at completing the `task`.
The [`retry`](#retry) function can be used as a stand-alone control flow by passing a callback, as shown below:
```js
// try calling apiMethod 3 times
async.retry(3, apiMethod, function(err, result) {
// do something with the result
});
```
```js
// try calling apiMethod 3 times, waiting 200 ms between each retry
async.retry({times: 3, interval: 200}, apiMethod, function(err, result) {
// do something with the result
});
```
```js
// try calling apiMethod the default 5 times no delay between each retry
async.retry(apiMethod, function(err, result) {
// do something with the result
});
```
It can also be embedded within other control flow functions to retry individual methods
that are not as reliable, like this:
```js
async.auto({
users: api.getUsers.bind(api),
payments: async.retry(3, api.getPayments.bind(api))
}, function(err, results) {
// do something with the results
});
```
---------------------------------------
<a name="iterator" />
### iterator(tasks)
Creates an iterator function which calls the next function in the `tasks` array,
returning a continuation to call the next one after that. It's also possible to
“peek” at the next iterator with `iterator.next()`.
This function is used internally by the `async` module, but can be useful when
you want to manually control the flow of functions in series.
__Arguments__
* `tasks` - An array of functions to run.
__Example__
```js
var iterator = async.iterator([
function(){ sys.p('one'); },
function(){ sys.p('two'); },
function(){ sys.p('three'); }
]);
node> var iterator2 = iterator();
'one'
node> var iterator3 = iterator2();
'two'
node> iterator3();
'three'
node> var nextfn = iterator2.next();
node> nextfn();
'three'
```
---------------------------------------
<a name="apply" />
### apply(function, arguments..)
Creates a continuation function with some arguments already applied.
Useful as a shorthand when combined with other control flow functions. Any arguments
passed to the returned function are added to the arguments originally passed
to apply.
__Arguments__
* `function` - The function you want to eventually apply all arguments to.
* `arguments...` - Any number of arguments to automatically apply when the
continuation is called.
__Example__
```js
// using apply
async.parallel([
async.apply(fs.writeFile, 'testfile1', 'test1'),
async.apply(fs.writeFile, 'testfile2', 'test2'),
]);
// the same process without using apply
async.parallel([
function(callback){
fs.writeFile('testfile1', 'test1', callback);
},
function(callback){
fs.writeFile('testfile2', 'test2', callback);
}
]);
```
It's possible to pass any number of additional arguments when calling the
continuation:
```js
node> var fn = async.apply(sys.puts, 'one');
node> fn('two', 'three');
one
two
three
```
---------------------------------------
<a name="nextTick" />
### nextTick(callback), setImmediate(callback)
Calls `callback` on a later loop around the event loop. In Node.js this just
calls `process.nextTick`; in the browser it falls back to `setImmediate(callback)`
if available, otherwise `setTimeout(callback, 0)`, which means other higher priority
events may precede the execution of `callback`.
This is used internally for browser-compatibility purposes.
__Arguments__
* `callback` - The function to call on a later loop around the event loop.
__Example__
```js
var call_order = [];
async.nextTick(function(){
call_order.push('two');
// call_order now equals ['one','two']
});
call_order.push('one')
```
<a name="times" />
### times(n, iterator, [callback])
Calls the `iterator` function `n` times, and accumulates results in the same manner
you would use with [`map`](#map).
__Arguments__
* `n` - The number of times to run the function.
* `iterator` - The function to call `n` times.
* `callback` - see [`map`](#map)
__Example__
```js
// Pretend this is some complicated async factory
var createUser = function(id, callback) {
callback(null, {
id: 'user' + id
})
}
// generate 5 users
async.times(5, function(n, next){
createUser(n, function(err, user) {
next(err, user)
})
}, function(err, users) {
// we should now have 5 users
});
```
__Related__
* timesSeries(n, iterator, [callback])
* timesLimit(n, limit, iterator, [callback])
## Utils
<a name="memoize" />
### memoize(fn, [hasher])
Caches the results of an `async` function. When creating a hash to store function
results against, the callback is omitted from the hash and an optional hash
function can be used.
If no hash function is specified, the first argument is used as a hash key, which may work reasonably if it is a string or a data type that converts to a distinct string. Note that objects and arrays will not behave reasonably. Neither will cases where the other arguments are significant. In such cases, specify your own hash function.
The cache of results is exposed as the `memo` property of the function returned
by `memoize`.
__Arguments__
* `fn` - The function to proxy and cache results from.
* `hasher` - An optional function for generating a custom hash for storing
results. It has all the arguments applied to it apart from the callback, and
must be synchronous.
__Example__
```js
var slow_fn = function (name, callback) {
// do something
callback(null, result);
};
var fn = async.memoize(slow_fn);
// fn can now be used as if it were slow_fn
fn('some name', function () {
// callback
});
```
<a name="unmemoize" />
### unmemoize(fn)
Undoes a [`memoize`](#memoize)d function, reverting it to the original, unmemoized
form. Handy for testing.
__Arguments__
* `fn` - the memoized function
---------------------------------------
<a name="ensureAsync" />
### ensureAsync(fn)
Wrap an async function and ensure it calls its callback on a later tick of the event loop. If the function already calls its callback on a next tick, no extra deferral is added. This is useful for preventing stack overflows (`RangeError: Maximum call stack size exceeded`) and generally keeping [Zalgo](http://blog.izs.me/post/59142742143/designing-apis-for-asynchrony) contained.
__Arguments__
* `fn` - an async function, one that expects a node-style callback as its last argument
Returns a wrapped function with the exact same call signature as the function passed in.
__Example__
```js
function sometimesAsync(arg, callback) {
if (cache[arg]) {
return callback(null, cache[arg]); // this would be synchronous!!
} else {
doSomeIO(arg, callback); // this IO would be asynchronous
}
}
// this has a risk of stack overflows if many results are cached in a row
async.mapSeries(args, sometimesAsync, done);
// this will defer sometimesAsync's callback if necessary,
// preventing stack overflows
async.mapSeries(args, async.ensureAsync(sometimesAsync), done);
```
---------------------------------------
<a name="constant">
### constant(values...)
Returns a function that when called, calls-back with the values provided. Useful as the first function in a `waterfall`, or for plugging values in to `auto`.
__Example__
```js
async.waterfall([
async.constant(42),
function (value, next) {
// value === 42
},
//...
], callback);
async.waterfall([
async.constant(filename, "utf8"),
fs.readFile,
function (fileData, next) {
//...
}
//...
], callback);
async.auto({
hostname: async.constant("https://server.net/"),
port: findFreePort,
launchServer: ["hostname", "port", function (cb, options) {
startServer(options, cb);
}],
//...
}, callback);
```
---------------------------------------
<a name="asyncify">
<a name="wrapSync">
### asyncify(func)
__Alias:__ `wrapSync`
Take a sync function and make it async, passing its return value to a callback. This is useful for plugging sync functions into a waterfall, series, or other async functions. Any arguments passed to the generated function will be passed to the wrapped function (except for the final callback argument). Errors thrown will be passed to the callback.
__Example__
```js
async.waterfall([
async.apply(fs.readFile, filename, "utf8"),
async.asyncify(JSON.parse),
function (data, next) {
// data is the result of parsing the text.
// If there was a parsing error, it would have been caught.
}
], callback)
```
If the function passed to `asyncify` returns a Promise, that promises's resolved/rejected state will be used to call the callback, rather than simply the synchronous return value. Example:
```js
async.waterfall([
async.apply(fs.readFile, filename, "utf8"),
async.asyncify(function (contents) {
return db.model.create(contents);
}),
function (model, next) {
// `model` is the instantiated model object.
// If there was an error, this function would be skipped.
}
], callback)
```
This also means you can asyncify ES2016 `async` functions.
```js
var q = async.queue(async.asyncify(async function (file) {
var intermediateStep = await processFile(file);
return await somePromise(intermediateStep)
}));
q.push(files);
```
---------------------------------------
<a name="log" />
### log(function, arguments)
Logs the result of an `async` function to the `console`. Only works in Node.js or
in browsers that support `console.log` and `console.error` (such as FF and Chrome).
If multiple arguments are returned from the async function, `console.log` is
called on each argument in order.
__Arguments__
* `function` - The function you want to eventually apply all arguments to.
* `arguments...` - Any number of arguments to apply to the function.
__Example__
```js
var hello = function(name, callback){
setTimeout(function(){
callback(null, 'hello ' + name);
}, 1000);
};
```
```js
node> async.log(hello, 'world');
'hello world'
```
---------------------------------------
<a name="dir" />
### dir(function, arguments)
Logs the result of an `async` function to the `console` using `console.dir` to
display the properties of the resulting object. Only works in Node.js or
in browsers that support `console.dir` and `console.error` (such as FF and Chrome).
If multiple arguments are returned from the async function, `console.dir` is
called on each argument in order.
__Arguments__
* `function` - The function you want to eventually apply all arguments to.
* `arguments...` - Any number of arguments to apply to the function.
__Example__
```js
var hello = function(name, callback){
setTimeout(function(){
callback(null, {hello: name});
}, 1000);
};
```
```js
node> async.dir(hello, 'world');
{hello: 'world'}
```
---------------------------------------
<a name="noConflict" />
### noConflict()
Changes the value of `async` back to its original value, returning a reference to the
`async` object.
English | [简体中文](./docs/zh-cn/README.zh-CN.md) | [日本語](./docs/ja/README-ja.md) | [Português Brasileiro](./docs/pt-br/README-pt-br.md) | [한국어](./docs/ko/README-ko.md) | [Español (España)](./docs/es-es/README-es-es.md) | [Русский](./docs/ru/README-ru.md)
<p align="center"><a href="https://day.js.org/" target="_blank" rel="noopener noreferrer"><img width="550"
src="https://user-images.githubusercontent.com/17680888/39081119-3057bbe2-456e-11e8-862c-646133ad4b43.png"
alt="Day.js"></a></p>
<p align="center">Fast <b>2kB</b> alternative to Moment.js with the same modern API</p>
<br>
<p align="center">
<a href="https://unpkg.com/dayjs/dayjs.min.js"><img
src="http://img.badgesize.io/https://unpkg.com/dayjs/dayjs.min.js?compression=gzip&style=flat-square"
alt="Gzip Size"></a>
<a href="https://www.npmjs.com/package/dayjs"><img src="https://img.shields.io/npm/v/dayjs.svg?style=flat-square&colorB=51C838"
alt="NPM Version"></a>
<a href="https://travis-ci.org/iamkun/dayjs"><img
src="https://img.shields.io/travis/iamkun/dayjs/master.svg?style=flat-square" alt="Build Status"></a>
<a href="https://codecov.io/gh/iamkun/dayjs"><img
src="https://img.shields.io/codecov/c/github/iamkun/dayjs/master.svg?style=flat-square" alt="Codecov"></a>
<a href="https://github.com/iamkun/dayjs/blob/master/LICENSE"><img
src="https://img.shields.io/badge/license-MIT-brightgreen.svg?style=flat-square" alt="License"></a>
<br>
<a href="https://saucelabs.com/u/dayjs">
<img width="750" src="https://user-images.githubusercontent.com/17680888/40040137-8e3323a6-584b-11e8-9dba-bbe577ee8a7b.png" alt="Sauce Test Status">
</a>
</p>
> Day.js is a minimalist JavaScript library that parses, validates, manipulates, and displays dates and times for modern browsers with a largely Moment.js-compatible API. If you use Moment.js, you already know how to use Day.js.
```js
dayjs().startOf('month').add(1, 'day').set('year', 2018).format('YYYY-MM-DD HH:mm:ss');
```
* 🕒 Familiar Moment.js API & patterns
* 💪 Immutable
* 🔥 Chainable
* 🌐 I18n support
* 📦 2kb mini library
* 👫 All browsers supported
---
## Getting Started
### Documentation
You can find for more details, API, and other docs on [day.js.org](https://day.js.org/) website.
### Installation
```console
npm install dayjs --save
```
📚[Installation Guide](https://day.js.org/docs/en/installation/installation)
### API
It's easy to use Day.js APIs to parse, validate, manipulate, and display dates and times.
```javascript
dayjs('2018-08-08') // parse
dayjs().format('{YYYY} MM-DDTHH:mm:ss SSS [Z] A') // display
dayjs().set('month', 3).month() // get & set
dayjs().add(1, 'year') // manipulate
dayjs().isBefore(dayjs()) // query
```
📚[API Reference](https://day.js.org/docs/en/parse/parse)
### I18n
Day.js has great support for internationalization.
But none of them will be included in your build unless you use it.
```javascript
import 'dayjs/locale/es' // load on demand
dayjs.locale('es') // use Spanish locale globally
dayjs('2018-05-05').locale('zh-cn').format() // use Chinese Simplified locale in a specific instance
```
📚[Internationalization](https://day.js.org/docs/en/i18n/i18n)
### Plugin
A plugin is an independent module that can be added to Day.js to extend functionality or add new features.
```javascript
import advancedFormat from 'dayjs/plugin/advancedFormat' // load on demand
dayjs.extend(advancedFormat) // use plugin
dayjs().format('Q Do k kk X x') // more available formats
```
📚[Plugin List](https://day.js.org/docs/en/plugin/plugin)
## Sponsors
Support this project by becoming a sponsor. Your logo will show up here with a link to your website. [[Become a sponsor](https://opencollective.com/dayjs#sponsor)]
<a href="https://opencollective.com/dayjs/sponsor/0/website" target="_blank"><img src="https://opencollective.com/dayjs/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/dayjs/sponsor/1/website" target="_blank"><img src="https://opencollective.com/dayjs/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/dayjs/sponsor/2/website" target="_blank"><img src="https://opencollective.com/dayjs/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/dayjs/sponsor/3/website" target="_blank"><img src="https://opencollective.com/dayjs/sponsor/3/avatar.svg"></a>
## Contributors
This project exists thanks to all the people who contribute.
Please give us a 💖 star 💖 to support us. Thank you.
And thank you to all our backers! 🙏
<a href="https://opencollective.com/dayjs/backer/0/website?requireActive=false" target="_blank"><img src="https://opencollective.com/dayjs/backer/0/avatar.svg?requireActive=false"></a>
<a href="https://opencollective.com/dayjs/backer/1/website?requireActive=false" target="_blank"><img src="https://opencollective.com/dayjs/backer/1/avatar.svg?requireActive=false"></a>
<a href="https://opencollective.com/dayjs/backer/2/website?requireActive=false" target="_blank"><img src="https://opencollective.com/dayjs/backer/2/avatar.svg?requireActive=false"></a>
<a href="https://opencollective.com/dayjs/backer/3/website?requireActive=false" target="_blank"><img src="https://opencollective.com/dayjs/backer/3/avatar.svg?requireActive=false"></a>
<a href="https://opencollective.com/dayjs#backers" target="_blank"><img src="https://opencollective.com/dayjs/contributors.svg?width=890" /></a>
## License
Day.js is licensed under a [MIT License](./LICENSE).
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
write-file-atomic
-----------------
This is an extension for node's `fs.writeFile` that makes its operation
atomic and allows you set ownership (uid/gid of the file).
### var writeFileAtomic = require('write-file-atomic')<br>writeFileAtomic(filename, data, [options], [callback])
* filename **String**
* data **String** | **Buffer**
* options **Object** | **String**
* chown **Object** default, uid & gid of existing file, if any
* uid **Number**
* gid **Number**
* encoding **String** | **Null** default = 'utf8'
* fsync **Boolean** default = true
* mode **Number** default, from existing file, if any
* tmpfileCreated **Function** called when the tmpfile is created
* callback **Function**
Atomically and asynchronously writes data to a file, replacing the file if it already
exists. data can be a string or a buffer.
The file is initially named `filename + "." + murmurhex(__filename, process.pid, ++invocations)`.
Note that `require('worker_threads').threadId` is used in addition to `process.pid` if running inside of a worker thread.
If writeFile completes successfully then, if passed the **chown** option it will change
the ownership of the file. Finally it renames the file back to the filename you specified. If
it encounters errors at any of these steps it will attempt to unlink the temporary file and then
pass the error back to the caller.
If multiple writes are concurrently issued to the same file, the write operations are put into a queue and serialized in the order they were called, using Promises. Writes to different files are still executed in parallel.
If provided, the **chown** option requires both **uid** and **gid** properties or else
you'll get an error. If **chown** is not specified it will default to using
the owner of the previous file. To prevent chown from being ran you can
also pass `false`, in which case the file will be created with the current user's credentials.
If **mode** is not specified, it will default to using the permissions from
an existing file, if any. Expicitly setting this to `false` remove this default, resulting
in a file created with the system default permissions.
If options is a String, it's assumed to be the **encoding** option. The **encoding** option is ignored if **data** is a buffer. It defaults to 'utf8'.
If the **fsync** option is **false**, writeFile will skip the final fsync call.
If the **tmpfileCreated** option is specified it will be called with the name of the tmpfile when created.
Example:
```javascript
writeFileAtomic('message.txt', 'Hello Node', {chown:{uid:100,gid:50}}, function (err) {
if (err) throw err;
console.log('It\'s saved!');
});
```
This function also supports async/await:
```javascript
(async () => {
try {
await writeFileAtomic('message.txt', 'Hello Node', {chown:{uid:100,gid:50}});
console.log('It\'s saved!');
} catch (err) {
console.error(err);
process.exit(1);
}
})();
```
### var writeFileAtomicSync = require('write-file-atomic').sync<br>writeFileAtomicSync(filename, data, [options])
The synchronous version of **writeFileAtomic**.
# libsodium.js
## Overview
The [sodium](https://github.com/jedisct1/libsodium) crypto library
compiled to WebAssembly and pure JavaScript using
[Emscripten](https://github.com/kripken/emscripten), with
automatically generated wrappers to make it easy to use in web
applications.
The complete library weighs 188 KB (minified, gzipped, includes pure JS +
WebAssembly versions) and can run in a web browser as well as server-side.
### Compatibility
Supported browsers/JS engines:
* Chrome >= 16
* Edge >= 0.11
* Firefox >= 21
* Mobile Safari on iOS >= 8.0 (older versions produce incorrect results)
* NodeJS
* Opera >= 15
* Safari >= 6 (older versions produce incorrect results)
This is comparable to the WebCrypto API, which is compatible with a
similar number of browsers.
Signatures and other Edwards25519-based operations are compatible with
[WasmCrypto](https://github.com/jedisct1/wasm-crypto).
## Installation
The [dist](https://github.com/jedisct1/libsodium.js/tree/master/dist)
directory contains pre-built scripts. Copy the files from one of its
subdirectories to your application:
- [browsers](https://github.com/jedisct1/libsodium.js/tree/master/dist/browsers)
includes a single-file script that can be included in web pages.
It contains code for commonly used functions.
- [browsers-sumo](https://github.com/jedisct1/libsodium.js/tree/master/dist/browsers-sumo)
is a superset of the previous script, that contains all functions,
including rarely used ones and undocumented ones.
- [modules](https://github.com/jedisct1/libsodium.js/tree/master/dist/modules)
includes commonly used functions, and is designed to be loaded as a module.
`libsodium-wrappers` is the module your application should load, which
will in turn automatically load `libsodium` as a dependency.
- [modules-sumo](https://github.com/jedisct1/libsodium.js/tree/master/dist/modules-sumo)
contains sumo variants of the previous modules.
The modules are also available on npm:
- [libsodium-wrappers](https://www.npmjs.com/package/libsodium-wrappers)
- [libsodium-wrappers-sumo](https://www.npmjs.com/package/libsodium-wrappers-sumo)
If you prefer Bower:
```sh
bower install libsodium.js
```
### Usage (as a module)
Load the `sodium-wrappers` module. The returned object contains a `.ready`
property: a promise that must be resolve before the sodium functions
can be used.
Example:
```js
const _sodium = require('libsodium-wrappers');
(async() => {
await _sodium.ready;
const sodium = _sodium;
let key = sodium.crypto_secretstream_xchacha20poly1305_keygen();
let res = sodium.crypto_secretstream_xchacha20poly1305_init_push(key);
let [state_out, header] = [res.state, res.header];
let c1 = sodium.crypto_secretstream_xchacha20poly1305_push(state_out,
sodium.from_string('message 1'), null,
sodium.crypto_secretstream_xchacha20poly1305_TAG_MESSAGE);
let c2 = sodium.crypto_secretstream_xchacha20poly1305_push(state_out,
sodium.from_string('message 2'), null,
sodium.crypto_secretstream_xchacha20poly1305_TAG_FINAL);
let state_in = sodium.crypto_secretstream_xchacha20poly1305_init_pull(header, key);
let r1 = sodium.crypto_secretstream_xchacha20poly1305_pull(state_in, c1);
let [m1, tag1] = [sodium.to_string(r1.message), r1.tag];
let r2 = sodium.crypto_secretstream_xchacha20poly1305_pull(state_in, c2);
let [m2, tag2] = [sodium.to_string(r2.message), r2.tag];
console.log(m1);
console.log(m2);
})();
```
### Usage (in a web browser, via a callback)
The `sodium.js` file includes both the core libsodium functions, as
well as the higher-level JavaScript wrappers. It can be loaded
asynchronusly.
A `sodium` object should be defined in the global namespace, with the
following property:
- `onload`: the function to call after the wrapper is initialized.
Example:
```html
<script>
window.sodium = {
onload: function (sodium) {
let h = sodium.crypto_generichash(64, sodium.from_string('test'));
console.log(sodium.to_hex(h));
}
};
</script>
<script src="sodium.js" async></script>
```
## Additional helpers
* `from_base64()`, `to_base64()` with an optional second parameter
whose value is one of: `base64_variants.ORIGINAL`, `base64_variants.ORIGINAL_NO_PADDING`,
`base64_variants.URLSAFE` or `base64_variants.URLSAFE_NO_PADDING`. Default is `base64_variants.URLSAFE_NO_PADDING`.
* `from_hex()`, `to_hex()`
* `from_string()`, `to_string()`
* `pad(<buffer>, <block size>)`, `unpad(<buffer>, <block size>)`
* `memcmp()` (constant-time check for equality, returns `true` or `false`)
* `compare()` (constant-time comparison. Values must have the same
size. Returns `-1`, `0` or `1`)
* `memzero()` (applies to `Uint8Array` objects)
* `increment()` (increments an arbitrary-long number stored as a
little-endian `Uint8Array` - typically to increment nonces)
* `add()` (adds two arbitrary-long numbers stored as little-endian
`Uint8Array` vectors)
* `is_zero()` (constant-time, checks `Uint8Array` objects for all zeros)
## API
The API exposed by the wrappers is identical to the one of the C
library, except that buffer lengths never need to be explicitly given.
Binary input buffers should be `Uint8Array` objects. However, if a string
is given instead, the wrappers will automatically convert the string
to an array containing a UTF-8 representation of the string.
Example:
```javascript
var key = sodium.randombytes_buf(sodium.crypto_shorthash_KEYBYTES),
hash1 = sodium.crypto_shorthash(new Uint8Array([1, 2, 3, 4]), key),
hash2 = sodium.crypto_shorthash('test', key);
```
If the output is a unique binary buffer, it is returned as a
`Uint8Array` object.
Example (secretbox):
```javascript
let key = sodium.from_hex('724b092810ec86d7e35c9d067702b31ef90bc43a7b598626749914d6a3e033ed');
function encrypt_and_prepend_nonce(message) {
let nonce = sodium.randombytes_buf(sodium.crypto_secretbox_NONCEBYTES);
return nonce.concat(sodium.crypto_secretbox_easy(message, nonce, key));
}
function decrypt_after_extracting_nonce(nonce_and_ciphertext) {
if (nonce_and_ciphertext.length < sodium.crypto_secretbox_NONCEBYTES + sodium.crypto_secretbox_MACBYTES) {
throw "Short message";
}
let nonce = nonce_and_ciphertext.slice(0, sodium.crypto_secretbox_NONCEBYTES),
ciphertext = nonce_and_ciphertext.slice(sodium.crypto_secretbox_NONCEBYTES);
return sodium.crypto_secretbox_open_easy(ciphertext, nonce, key);
}
```
In addition, the `from_hex`, `to_hex`, `from_string`, and `to_string`
functions are available to explicitly convert hexadecimal, and
arbitrary string representations from/to `Uint8Array` objects.
Functions returning more than one output buffer are returning them as
an object. For example, the `sodium.crypto_box_keypair()` function
returns the following object:
```javascript
{ keyType: 'curve25519', privateKey: (Uint8Array), publicKey: (Uint8Array) }
```
### Standard vs Sumo version
The standard version (in the `dist/browsers` and `dist/modules`
directories) contains the high-level functions, and is the recommended
one for most projects.
Alternatively, the "sumo" version, available in the
`dist/browsers-sumo` and `dist/modules-sumo` directories contains all
the symbols from the original library. This includes undocumented,
untested, deprecated, low-level and easy to misuse functions.
The `crypto_pwhash_*` function set is included in both versions.
The sumo version is slightly larger than the standard version, and
should be used only if you really need the extra symbols it provides.
### Compilation
If you want to compile the files yourself, the following dependencies
need to be installed on your system:
* Emscripten
* binaryen
* git
* NodeJS
* make
Running `make` will install the dev dependencies, clone libsodium,
build it, test it, build the wrapper, and create the modules and
minified distribution files.
## Authors
Built by Ahmad Ben Mrad, Frank Denis and Ryan Lester.
## License
This wrapper is distributed under the
[ISC License](https://en.wikipedia.org/wiki/ISC_license).
Like `chown -R`.
Takes the same arguments as `fs.chown()`
# readable-stream
***Node-core streams for userland***
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
This package is a mirror of the Streams2 and Streams3 implementations in Node-core.
If you want to guarantee a stable streams base, regardless of what version of Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core.
**readable-stream** comes in two major versions, v1.0.x and v1.1.x. The former tracks the Streams2 implementation in Node 0.10, including bug-fixes and minor improvements as they are added. The latter tracks Streams3 as it develops in Node 0.11; we will likely see a v1.2.x branch for Node 0.12.
**readable-stream** uses proper patch-level versioning so if you pin to `"~1.0.0"` you’ll get the latest Node 0.10 Streams2 implementation, including any fixes and minor non-breaking improvements. The patch-level versions of 1.0.x and 1.1.x should mirror the patch-level versions of Node-core releases. You should prefer the **1.0.x** releases for now and when you’re ready to start using Streams3, pin to `"~1.1.0"`
# Chokidar [](https://github.com/paulmillr/chokidar) [](https://github.com/paulmillr/chokidar)
> A neat wrapper around Node.js fs.watch / fs.watchFile / FSEvents.
[](https://www.npmjs.com/package/chokidar)
Version 3 is out! Check out our blog post about it: [Chokidar 3: How to save 32TB of traffic every week](https://paulmillr.com/posts/chokidar-3-save-32tb-of-traffic/)
## Why?
Node.js `fs.watch`:
* Doesn't report filenames on MacOS.
* Doesn't report events at all when using editors like Sublime on MacOS.
* Often reports events twice.
* Emits most changes as `rename`.
* Does not provide an easy way to recursively watch file trees.
Node.js `fs.watchFile`:
* Almost as bad at event handling.
* Also does not provide any recursive watching.
* Results in high CPU utilization.
Chokidar resolves these problems.
Initially made for **[Brunch](https://brunch.io/)** (an ultra-swift web app build tool), it is now used in
[Microsoft's Visual Studio Code](https://github.com/microsoft/vscode),
[gulp](https://github.com/gulpjs/gulp/),
[karma](https://karma-runner.github.io/),
[PM2](https://github.com/Unitech/PM2),
[browserify](http://browserify.org/),
[webpack](https://webpack.github.io/),
[BrowserSync](https://www.browsersync.io/),
and [many others](https://www.npmjs.com/browse/depended/chokidar).
It has proven itself in production environments.
## How?
Chokidar does still rely on the Node.js core `fs` module, but when using
`fs.watch` and `fs.watchFile` for watching, it normalizes the events it
receives, often checking for truth by getting file stats and/or dir contents.
On MacOS, chokidar by default uses a native extension exposing the Darwin
`FSEvents` API. This provides very efficient recursive watching compared with
implementations like `kqueue` available on most \*nix platforms. Chokidar still
does have to do some work to normalize the events received that way as well.
On other platforms, the `fs.watch`-based implementation is the default, which
avoids polling and keeps CPU usage down. Be advised that chokidar will initiate
watchers recursively for everything within scope of the paths that have been
specified, so be judicious about not wasting system resources by watching much
more than needed.
## Getting started
Install with npm:
```sh
npm install chokidar
```
Then `require` and use it in your code:
```javascript
const chokidar = require('chokidar');
// One-liner for current directory
chokidar.watch('.').on('all', (event, path) => {
console.log(event, path);
});
```
## API
```javascript
// Example of a more typical implementation structure:
// Initialize watcher.
const watcher = chokidar.watch('file, dir, glob, or array', {
ignored: /(^|[\/\\])\../, // ignore dotfiles
persistent: true
});
// Something to use when events are received.
const log = console.log.bind(console);
// Add event listeners.
watcher
.on('add', path => log(`File ${path} has been added`))
.on('change', path => log(`File ${path} has been changed`))
.on('unlink', path => log(`File ${path} has been removed`));
// More possible events.
watcher
.on('addDir', path => log(`Directory ${path} has been added`))
.on('unlinkDir', path => log(`Directory ${path} has been removed`))
.on('error', error => log(`Watcher error: ${error}`))
.on('ready', () => log('Initial scan complete. Ready for changes'))
.on('raw', (event, path, details) => { // internal
log('Raw event info:', event, path, details);
});
// 'add', 'addDir' and 'change' events also receive stat() results as second
// argument when available: https://nodejs.org/api/fs.html#fs_class_fs_stats
watcher.on('change', (path, stats) => {
if (stats) console.log(`File ${path} changed size to ${stats.size}`);
});
// Watch new files.
watcher.add('new-file');
watcher.add(['new-file-2', 'new-file-3', '**/other-file*']);
// Get list of actual paths being watched on the filesystem
var watchedPaths = watcher.getWatched();
// Un-watch some files.
await watcher.unwatch('new-file*');
// Stop watching.
// The method is async!
watcher.close().then(() => console.log('closed'));
// Full list of options. See below for descriptions.
// Do not use this example!
chokidar.watch('file', {
persistent: true,
ignored: '*.txt',
ignoreInitial: false,
followSymlinks: true,
cwd: '.',
disableGlobbing: false,
usePolling: false,
interval: 100,
binaryInterval: 300,
alwaysStat: false,
depth: 99,
awaitWriteFinish: {
stabilityThreshold: 2000,
pollInterval: 100
},
ignorePermissionErrors: false,
atomic: true // or a custom 'atomicity delay', in milliseconds (default 100)
});
```
`chokidar.watch(paths, [options])`
* `paths` (string or array of strings). Paths to files, dirs to be watched
recursively, or glob patterns.
- Note: globs must not contain windows separators (`\`),
because that's how they work by the standard —
you'll need to replace them with forward slashes (`/`).
- Note 2: for additional glob documentation, check out low-level
library: [picomatch](https://github.com/micromatch/picomatch).
* `options` (object) Options object as defined below:
#### Persistence
* `persistent` (default: `true`). Indicates whether the process
should continue to run as long as files are being watched. If set to
`false` when using `fsevents` to watch, no more events will be emitted
after `ready`, even if the process continues to run.
#### Path filtering
* `ignored` ([anymatch](https://github.com/es128/anymatch)-compatible definition)
Defines files/paths to be ignored. The whole relative or absolute path is
tested, not just filename. If a function with two arguments is provided, it
gets called twice per path - once with a single argument (the path), second
time with two arguments (the path and the
[`fs.Stats`](https://nodejs.org/api/fs.html#fs_class_fs_stats)
object of that path).
* `ignoreInitial` (default: `false`). If set to `false` then `add`/`addDir` events are also emitted for matching paths while
instantiating the watching as chokidar discovers these file paths (before the `ready` event).
* `followSymlinks` (default: `true`). When `false`, only the
symlinks themselves will be watched for changes instead of following
the link references and bubbling events through the link's path.
* `cwd` (no default). The base directory from which watch `paths` are to be
derived. Paths emitted with events will be relative to this.
* `disableGlobbing` (default: `false`). If set to `true` then the strings passed to `.watch()` and `.add()` are treated as
literal path names, even if they look like globs.
#### Performance
* `usePolling` (default: `false`).
Whether to use fs.watchFile (backed by polling), or fs.watch. If polling
leads to high CPU utilization, consider setting this to `false`. It is
typically necessary to **set this to `true` to successfully watch files over
a network**, and it may be necessary to successfully watch files in other
non-standard situations. Setting to `true` explicitly on MacOS overrides the
`useFsEvents` default. You may also set the CHOKIDAR_USEPOLLING env variable
to true (1) or false (0) in order to override this option.
* _Polling-specific settings_ (effective when `usePolling: true`)
* `interval` (default: `100`). Interval of file system polling, in milliseconds. You may also
set the CHOKIDAR_INTERVAL env variable to override this option.
* `binaryInterval` (default: `300`). Interval of file system
polling for binary files.
([see list of binary extensions](https://github.com/sindresorhus/binary-extensions/blob/master/binary-extensions.json))
* `useFsEvents` (default: `true` on MacOS). Whether to use the
`fsevents` watching interface if available. When set to `true` explicitly
and `fsevents` is available this supercedes the `usePolling` setting. When
set to `false` on MacOS, `usePolling: true` becomes the default.
* `alwaysStat` (default: `false`). If relying upon the
[`fs.Stats`](https://nodejs.org/api/fs.html#fs_class_fs_stats)
object that may get passed with `add`, `addDir`, and `change` events, set
this to `true` to ensure it is provided even in cases where it wasn't
already available from the underlying watch events.
* `depth` (default: `undefined`). If set, limits how many levels of
subdirectories will be traversed.
* `awaitWriteFinish` (default: `false`).
By default, the `add` event will fire when a file first appears on disk, before
the entire file has been written. Furthermore, in some cases some `change`
events will be emitted while the file is being written. In some cases,
especially when watching for large files there will be a need to wait for the
write operation to finish before responding to a file creation or modification.
Setting `awaitWriteFinish` to `true` (or a truthy value) will poll file size,
holding its `add` and `change` events until the size does not change for a
configurable amount of time. The appropriate duration setting is heavily
dependent on the OS and hardware. For accurate detection this parameter should
be relatively high, making file watching much less responsive.
Use with caution.
* *`options.awaitWriteFinish` can be set to an object in order to adjust
timing params:*
* `awaitWriteFinish.stabilityThreshold` (default: 2000). Amount of time in
milliseconds for a file size to remain constant before emitting its event.
* `awaitWriteFinish.pollInterval` (default: 100). File size polling interval, in milliseconds.
#### Errors
* `ignorePermissionErrors` (default: `false`). Indicates whether to watch files
that don't have read permissions if possible. If watching fails due to `EPERM`
or `EACCES` with this set to `true`, the errors will be suppressed silently.
* `atomic` (default: `true` if `useFsEvents` and `usePolling` are `false`).
Automatically filters out artifacts that occur when using editors that use
"atomic writes" instead of writing directly to the source file. If a file is
re-added within 100 ms of being deleted, Chokidar emits a `change` event
rather than `unlink` then `add`. If the default of 100 ms does not work well
for you, you can override it by setting `atomic` to a custom value, in
milliseconds.
### Methods & Events
`chokidar.watch()` produces an instance of `FSWatcher`. Methods of `FSWatcher`:
* `.add(path / paths)`: Add files, directories, or glob patterns for tracking.
Takes an array of strings or just one string.
* `.on(event, callback)`: Listen for an FS event.
Available events: `add`, `addDir`, `change`, `unlink`, `unlinkDir`, `ready`,
`raw`, `error`.
Additionally `all` is available which gets emitted with the underlying event
name and path for every event other than `ready`, `raw`, and `error`. `raw` is internal, use it carefully.
* `.unwatch(path / paths)`: Stop watching files, directories, or glob patterns.
Takes an array of strings or just one string. Use with `await` to ensure bugs don't happen.
* `.close()`: **async** Removes all listeners from watched files. Asynchronous, returns Promise.
* `.getWatched()`: Returns an object representing all the paths on the file
system being watched by this `FSWatcher` instance. The object's keys are all the
directories (using absolute paths unless the `cwd` option was used), and the
values are arrays of the names of the items contained in each directory.
## CLI
If you need a CLI interface for your file watching, check out
[chokidar-cli](https://github.com/kimmobrunfeldt/chokidar-cli), allowing you to
execute a command on each change, or get a stdio stream of change events.
## Install Troubleshooting
* `npm WARN optional dep failed, continuing [email protected]`
* This message is normal part of how `npm` handles optional dependencies and is
not indicative of a problem. Even if accompanied by other related error messages,
Chokidar should function properly.
* `TypeError: fsevents is not a constructor`
* Update chokidar by doing `rm -rf node_modules package-lock.json yarn.lock && npm install`, or update your dependency that uses chokidar.
* Chokidar is producing `ENOSP` error on Linux, like this:
* `bash: cannot set terminal process group (-1): Inappropriate ioctl for device bash: no job control in this shell`
`Error: watch /home/ ENOSPC`
* This means Chokidar ran out of file handles and you'll need to increase their count by executing the following command in Terminal:
`echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p`
## Changelog
For more detailed changelog, see [`full_changelog.md`](.github/full_changelog.md).
- **v3.4 (Apr 26, 2020):** Support for directory-based symlinks. Macos file replacement fixes.
- **v3.3 (Nov 2, 2019):** `FSWatcher#close()` method became async. That fixes IO race conditions related to close method.
- **v3.2 (Oct 1, 2019):** Improve Linux RAM usage by 50%. Race condition fixes. Windows glob fixes. Improve stability by using tight range of dependency versions.
- **v3.1 (Sep 16, 2019):** dotfiles are no longer filtered out by default. Use `ignored` option if needed. Improve initial Linux scan time by 50%.
- **v3 (Apr 30, 2019):** massive CPU & RAM consumption improvements; reduces deps / package size by a factor of 17x and bumps Node.js requirement to v8.16 and higher.
- **v2 (Dec 29, 2017):** Globs are now posix-style-only; without windows support. Tons of bugfixes.
- **v1 (Apr 7, 2015):** Glob support, symlink support, tons of bugfixes. Node 0.8+ is supported
- **v0.1 (Apr 20, 2012):** Initial release, extracted from [Brunch](https://github.com/brunch/brunch/blob/9847a065aea300da99bd0753f90354cde9de1261/src/helpers.coffee#L66)
## Also
Why was chokidar named this way? What's the meaning behind it?
>Chowkidar is a transliteration of a Hindi word meaning 'watchman, gatekeeper', चौकीदार. This ultimately comes from Sanskrit _ चतुष्क_ (crossway, quadrangle, consisting-of-four).
## License
MIT (c) Paul Miller (<https://paulmillr.com>), see [LICENSE](LICENSE) file.
# Snake Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a lower case string with underscores between words.
## Installation
```
npm install snake-case --save
```
## Usage
```js
import { snakeCase } from "snake-case";
snakeCase("string"); //=> "string"
snakeCase("dot.case"); //=> "dot_case"
snakeCase("PascalCase"); //=> "pascal_case"
snakeCase("version 1.2.10"); //=> "version_1_2_10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/snake-case.svg?style=flat
[npm-url]: https://npmjs.org/package/snake-case
[downloads-image]: https://img.shields.io/npm/dm/snake-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/snake-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/snake-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=snake-case
# [Moment.js](http://momentjs.com/)
[![NPM version][npm-version-image]][npm-url]
[![NPM downloads][npm-downloads-image]][npm-downloads-url]
[![MIT License][license-image]][license-url]
[![Build Status][travis-image]][travis-url]
[![Coverage Status][coveralls-image]][coveralls-url]
[![FOSSA Status][fossa-badge-image]][fossa-badge-url]
[![SemVer compatibility][semver-image]][semver-url]
A JavaScript date library for parsing, validating, manipulating, and formatting dates.
## Project Status
Moment.js is a legacy project, now in maintenance mode. In most cases, you should choose a different library.
For more details and recommendations, please see [Project Status](https://momentjs.com/docs/#/-project-status/) in the docs.
*Thank you.*
## Resources
- [Documentation](https://momentjs.com/docs/)
- [Changelog](CHANGELOG.md)
- [Stack Overflow](https://stackoverflow.com/questions/tagged/momentjs)
## License
Moment.js is freely distributable under the terms of the [MIT license][license-url].
[![FOSSA Status][fossa-large-image]][fossa-large-url]
[license-image]: https://img.shields.io/badge/license-MIT-blue.svg?style=flat
[license-url]: LICENSE
[npm-url]: https://npmjs.org/package/moment
[npm-version-image]: https://img.shields.io/npm/v/moment.svg?style=flat
[npm-downloads-image]: https://img.shields.io/npm/dm/moment.svg?style=flat
[npm-downloads-url]: https://npmcharts.com/compare/moment?minimal=true
[travis-url]: https://travis-ci.org/moment/moment
[travis-image]: https://img.shields.io/travis/moment/moment/develop.svg?style=flat
[coveralls-image]: https://coveralls.io/repos/moment/moment/badge.svg?branch=develop
[coveralls-url]: https://coveralls.io/r/moment/moment?branch=develop
[fossa-badge-image]: https://app.fossa.io/api/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Fmoment%2Fmoment.svg?type=shield
[fossa-badge-url]: https://app.fossa.io/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Fmoment%2Fmoment?ref=badge_shield
[fossa-large-image]: https://app.fossa.io/api/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Fmoment%2Fmoment.svg?type=large
[fossa-large-url]: https://app.fossa.io/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Fmoment%2Fmoment?ref=badge_large
[semver-image]: https://api.dependabot.com/badges/compatibility_score?dependency-name=moment&package-manager=npm_and_yarn&version-scheme=semver
[semver-url]: https://dependabot.com/compatibility-score.html?dependency-name=moment&package-manager=npm_and_yarn&version-scheme=semver
# to-regex-range [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=W8YFZ425KND68) [](https://www.npmjs.com/package/to-regex-range) [](https://npmjs.org/package/to-regex-range) [](https://npmjs.org/package/to-regex-range) [](https://travis-ci.org/micromatch/to-regex-range)
> Pass two numbers, get a regex-compatible source string for matching ranges. Validated against more than 2.78 million test assertions.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save to-regex-range
```
<details>
<summary><strong>What does this do?</strong></summary>
<br>
This libary generates the `source` string to be passed to `new RegExp()` for matching a range of numbers.
**Example**
```js
const toRegexRange = require('to-regex-range');
const regex = new RegExp(toRegexRange('15', '95'));
```
A string is returned so that you can do whatever you need with it before passing it to `new RegExp()` (like adding `^` or `$` boundaries, defining flags, or combining it another string).
<br>
</details>
<details>
<summary><strong>Why use this library?</strong></summary>
<br>
### Convenience
Creating regular expressions for matching numbers gets deceptively complicated pretty fast.
For example, let's say you need a validation regex for matching part of a user-id, postal code, social security number, tax id, etc:
* regex for matching `1` => `/1/` (easy enough)
* regex for matching `1` through `5` => `/[1-5]/` (not bad...)
* regex for matching `1` or `5` => `/(1|5)/` (still easy...)
* regex for matching `1` through `50` => `/([1-9]|[1-4][0-9]|50)/` (uh-oh...)
* regex for matching `1` through `55` => `/([1-9]|[1-4][0-9]|5[0-5])/` (no prob, I can do this...)
* regex for matching `1` through `555` => `/([1-9]|[1-9][0-9]|[1-4][0-9]{2}|5[0-4][0-9]|55[0-5])/` (maybe not...)
* regex for matching `0001` through `5555` => `/(0{3}[1-9]|0{2}[1-9][0-9]|0[1-9][0-9]{2}|[1-4][0-9]{3}|5[0-4][0-9]{2}|55[0-4][0-9]|555[0-5])/` (okay, I get the point!)
The numbers are contrived, but they're also really basic. In the real world you might need to generate a regex on-the-fly for validation.
**Learn more**
If you're interested in learning more about [character classes](http://www.regular-expressions.info/charclass.html) and other regex features, I personally have always found [regular-expressions.info](http://www.regular-expressions.info/charclass.html) to be pretty useful.
### Heavily tested
As of April 07, 2019, this library runs [>1m test assertions](./test/test.js) against generated regex-ranges to provide brute-force verification that results are correct.
Tests run in ~280ms on my MacBook Pro, 2.5 GHz Intel Core i7.
### Optimized
Generated regular expressions are optimized:
* duplicate sequences and character classes are reduced using quantifiers
* smart enough to use `?` conditionals when number(s) or range(s) can be positive or negative
* uses fragment caching to avoid processing the same exact string more than once
<br>
</details>
## Usage
Add this library to your javascript application with the following line of code
```js
const toRegexRange = require('to-regex-range');
```
The main export is a function that takes two integers: the `min` value and `max` value (formatted as strings or numbers).
```js
const source = toRegexRange('15', '95');
//=> 1[5-9]|[2-8][0-9]|9[0-5]
const regex = new RegExp(`^${source}$`);
console.log(regex.test('14')); //=> false
console.log(regex.test('50')); //=> true
console.log(regex.test('94')); //=> true
console.log(regex.test('96')); //=> false
```
## Options
### options.capture
**Type**: `boolean`
**Deafault**: `undefined`
Wrap the returned value in parentheses when there is more than one regex condition. Useful when you're dynamically generating ranges.
```js
console.log(toRegexRange('-10', '10'));
//=> -[1-9]|-?10|[0-9]
console.log(toRegexRange('-10', '10', { capture: true }));
//=> (-[1-9]|-?10|[0-9])
```
### options.shorthand
**Type**: `boolean`
**Deafault**: `undefined`
Use the regex shorthand for `[0-9]`:
```js
console.log(toRegexRange('0', '999999'));
//=> [0-9]|[1-9][0-9]{1,5}
console.log(toRegexRange('0', '999999', { shorthand: true }));
//=> \d|[1-9]\d{1,5}
```
### options.relaxZeros
**Type**: `boolean`
**Default**: `true`
This option relaxes matching for leading zeros when when ranges are zero-padded.
```js
const source = toRegexRange('-0010', '0010');
const regex = new RegExp(`^${source}$`);
console.log(regex.test('-10')); //=> true
console.log(regex.test('-010')); //=> true
console.log(regex.test('-0010')); //=> true
console.log(regex.test('10')); //=> true
console.log(regex.test('010')); //=> true
console.log(regex.test('0010')); //=> true
```
When `relaxZeros` is false, matching is strict:
```js
const source = toRegexRange('-0010', '0010', { relaxZeros: false });
const regex = new RegExp(`^${source}$`);
console.log(regex.test('-10')); //=> false
console.log(regex.test('-010')); //=> false
console.log(regex.test('-0010')); //=> true
console.log(regex.test('10')); //=> false
console.log(regex.test('010')); //=> false
console.log(regex.test('0010')); //=> true
```
## Examples
| **Range** | **Result** | **Compile time** |
| --- | --- | --- |
| `toRegexRange(-10, 10)` | `-[1-9]\|-?10\|[0-9]` | _132μs_ |
| `toRegexRange(-100, -10)` | `-1[0-9]\|-[2-9][0-9]\|-100` | _50μs_ |
| `toRegexRange(-100, 100)` | `-[1-9]\|-?[1-9][0-9]\|-?100\|[0-9]` | _42μs_ |
| `toRegexRange(001, 100)` | `0{0,2}[1-9]\|0?[1-9][0-9]\|100` | _109μs_ |
| `toRegexRange(001, 555)` | `0{0,2}[1-9]\|0?[1-9][0-9]\|[1-4][0-9]{2}\|5[0-4][0-9]\|55[0-5]` | _51μs_ |
| `toRegexRange(0010, 1000)` | `0{0,2}1[0-9]\|0{0,2}[2-9][0-9]\|0?[1-9][0-9]{2}\|1000` | _31μs_ |
| `toRegexRange(1, 50)` | `[1-9]\|[1-4][0-9]\|50` | _24μs_ |
| `toRegexRange(1, 55)` | `[1-9]\|[1-4][0-9]\|5[0-5]` | _23μs_ |
| `toRegexRange(1, 555)` | `[1-9]\|[1-9][0-9]\|[1-4][0-9]{2}\|5[0-4][0-9]\|55[0-5]` | _30μs_ |
| `toRegexRange(1, 5555)` | `[1-9]\|[1-9][0-9]{1,2}\|[1-4][0-9]{3}\|5[0-4][0-9]{2}\|55[0-4][0-9]\|555[0-5]` | _43μs_ |
| `toRegexRange(111, 555)` | `11[1-9]\|1[2-9][0-9]\|[2-4][0-9]{2}\|5[0-4][0-9]\|55[0-5]` | _38μs_ |
| `toRegexRange(29, 51)` | `29\|[34][0-9]\|5[01]` | _24μs_ |
| `toRegexRange(31, 877)` | `3[1-9]\|[4-9][0-9]\|[1-7][0-9]{2}\|8[0-6][0-9]\|87[0-7]` | _32μs_ |
| `toRegexRange(5, 5)` | `5` | _8μs_ |
| `toRegexRange(5, 6)` | `5\|6` | _11μs_ |
| `toRegexRange(1, 2)` | `1\|2` | _6μs_ |
| `toRegexRange(1, 5)` | `[1-5]` | _15μs_ |
| `toRegexRange(1, 10)` | `[1-9]\|10` | _22μs_ |
| `toRegexRange(1, 100)` | `[1-9]\|[1-9][0-9]\|100` | _25μs_ |
| `toRegexRange(1, 1000)` | `[1-9]\|[1-9][0-9]{1,2}\|1000` | _31μs_ |
| `toRegexRange(1, 10000)` | `[1-9]\|[1-9][0-9]{1,3}\|10000` | _34μs_ |
| `toRegexRange(1, 100000)` | `[1-9]\|[1-9][0-9]{1,4}\|100000` | _36μs_ |
| `toRegexRange(1, 1000000)` | `[1-9]\|[1-9][0-9]{1,5}\|1000000` | _42μs_ |
| `toRegexRange(1, 10000000)` | `[1-9]\|[1-9][0-9]{1,6}\|10000000` | _42μs_ |
## Heads up!
**Order of arguments**
When the `min` is larger than the `max`, values will be flipped to create a valid range:
```js
toRegexRange('51', '29');
```
Is effectively flipped to:
```js
toRegexRange('29', '51');
//=> 29|[3-4][0-9]|5[0-1]
```
**Steps / increments**
This library does not support steps (increments). A pr to add support would be welcome.
## History
### v2.0.0 - 2017-04-21
**New features**
Adds support for zero-padding!
### v1.0.0
**Optimizations**
Repeating ranges are now grouped using quantifiers. rocessing time is roughly the same, but the generated regex is much smaller, which should result in faster matching.
## Attribution
Inspired by the python library [range-regex](https://github.com/dimka665/range-regex).
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [expand-range](https://www.npmjs.com/package/expand-range): Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. Used… [more](https://github.com/jonschlinkert/expand-range) | [homepage](https://github.com/jonschlinkert/expand-range "Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. Used by micromatch.")
* [fill-range](https://www.npmjs.com/package/fill-range): Fill in a range of numbers or letters, optionally passing an increment or `step` to… [more](https://github.com/jonschlinkert/fill-range) | [homepage](https://github.com/jonschlinkert/fill-range "Fill in a range of numbers or letters, optionally passing an increment or `step` to use, or create a regex-compatible range with `options.toRegex`")
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. | [homepage](https://github.com/micromatch/micromatch "Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch.")
* [repeat-element](https://www.npmjs.com/package/repeat-element): Create an array by repeating the given value n times. | [homepage](https://github.com/jonschlinkert/repeat-element "Create an array by repeating the given value n times.")
* [repeat-string](https://www.npmjs.com/package/repeat-string): Repeat the given string n times. Fastest implementation for repeating a string. | [homepage](https://github.com/jonschlinkert/repeat-string "Repeat the given string n times. Fastest implementation for repeating a string.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 63 | [jonschlinkert](https://github.com/jonschlinkert) |
| 3 | [doowb](https://github.com/doowb) |
| 2 | [realityking](https://github.com/realityking) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
Please consider supporting me on Patreon, or [start your own Patreon page](https://patreon.com/invite/bxpbvm)!
<a href="https://www.patreon.com/jonschlinkert">
<img src="https://c5.patreon.com/external/logo/[email protected]" height="50">
</a>
### License
Copyright © 2019, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on April 07, 2019._
__
/\ \ __
__ __ ___ \_\ \ __ _ __ ____ ___ ___ _ __ __ /\_\ ____
/\ \/\ \ /' _ `\ /'_ \ /'__`\/\ __\/ ,__\ / ___\ / __`\/\ __\/'__`\ \/\ \ /',__\
\ \ \_\ \/\ \/\ \/\ \ \ \/\ __/\ \ \//\__, `\/\ \__//\ \ \ \ \ \//\ __/ __ \ \ \/\__, `\
\ \____/\ \_\ \_\ \___,_\ \____\\ \_\\/\____/\ \____\ \____/\ \_\\ \____\/\_\ _\ \ \/\____/
\/___/ \/_/\/_/\/__,_ /\/____/ \/_/ \/___/ \/____/\/___/ \/_/ \/____/\/_//\ \_\ \/___/
\ \____/
\/___/
Underscore.js is a utility-belt library for JavaScript that provides
support for the usual functional suspects (each, map, reduce, filter...)
without extending any core JavaScript objects.
For Docs, License, Tests, and pre-packed downloads, see:
http://underscorejs.org
For support and questions, please use
[the gitter channel](https://gitter.im/jashkenas/underscore)
or [stackoverflow](http://stackoverflow.com/search?q=underscore.js)
Underscore is an open-sourced component of DocumentCloud:
https://github.com/documentcloud
Many thanks to our contributors:
https://github.com/jashkenas/underscore/contributors
This project adheres to a [code of conduct](CODE_OF_CONDUCT.md). By participating, you are expected to uphold this code.
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# performance-now [](https://travis-ci.org/braveg1rl/performance-now) [](https://david-dm.org/braveg1rl/performance-now)
Implements a function similar to `performance.now` (based on `process.hrtime`).
Modern browsers have a `window.performance` object with - among others - a `now` method which gives time in milliseconds, but with sub-millisecond precision. This module offers the same function based on the Node.js native `process.hrtime` function.
Using `process.hrtime` means that the reported time will be monotonically increasing, and not subject to clock-drift.
According to the [High Resolution Time specification](http://www.w3.org/TR/hr-time/), the number of milliseconds reported by `performance.now` should be relative to the value of `performance.timing.navigationStart`.
In the current version of the module (2.0) the reported time is relative to the time the current Node process has started (inferred from `process.uptime()`).
Version 1.0 reported a different time. The reported time was relative to the time the module was loaded (i.e. the time it was first `require`d). If you need this functionality, version 1.0 is still available on NPM.
## Example usage
```javascript
var now = require("performance-now")
var start = now()
var end = now()
console.log(start.toFixed(3)) // the number of milliseconds the current node process is running
console.log((start-end).toFixed(3)) // ~ 0.002 on my system
```
Running the now function two times right after each other yields a time difference of a few microseconds. Given this overhead, I think it's best to assume that the precision of intervals computed with this method is not higher than 10 microseconds, if you don't know the exact overhead on your own system.
## License
performance-now is released under the [MIT License](http://opensource.org/licenses/MIT).
Copyright (c) 2017 Braveg1rl
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# abstract-leveldown
> An abstract prototype matching the [`leveldown`](https://github.com/level/leveldown/) API. Useful for extending [`levelup`](https://github.com/level/levelup) functionality by providing a replacement to `leveldown`.
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/abstract-leveldown)
[](http://travis-ci.org/Level/abstract-leveldown)
[](https://david-dm.org/level/abstract-leveldown)
[](https://www.npmjs.com/package/abstract-leveldown)
`abstract-leveldown` provides a simple, operational *noop* base prototype that's ready for extending. By default, all operations have sensible "noops" (operations that essentially do nothing). For example, simple operations such as `.open(callback)` and `.close(callback)` will simply invoke the callback (on a *next tick*). More complex operations perform sensible actions, for example: `.get(key, callback)` will always return a `'NotFound'` `Error` on the callback.
You add functionality by implementing the underscore versions of the operations. For example, to implement a `put()` operation you add a `_put()` method to your object. Each of these underscore methods override the default *noop* operations and are always provided with **consistent arguments**, regardless of what is passed in by the client.
Additionally, all methods provide argument checking and sensible defaults for optional arguments. All bad-argument errors are compatible with `leveldown` (they pass the `leveldown` method arguments tests). For example, if you call `.open()` without a callback argument you'll get an `Error('open() requires a callback argument')`. Where optional arguments are involved, your underscore methods will receive sensible defaults. A `.get(key, callback)` will pass through to a `._get(key, options, callback)` where the `options` argument is an empty object.
## Example
A simplistic in-memory `leveldown` replacement
```js
var util = require('util')
var AbstractLevelDOWN = require('./').AbstractLevelDOWN
// constructor, passes through the 'location' argument to the AbstractLevelDOWN constructor
function FakeLevelDOWN (location) {
AbstractLevelDOWN.call(this, location)
}
// our new prototype inherits from AbstractLevelDOWN
util.inherits(FakeLevelDOWN, AbstractLevelDOWN)
// implement some methods
FakeLevelDOWN.prototype._open = function (options, callback) {
// initialise a memory storage object
this._store = {}
// optional use of nextTick to be a nice async citizen
process.nextTick(function () { callback(null, this) }.bind(this))
}
FakeLevelDOWN.prototype._put = function (key, value, options, callback) {
key = '_' + key // safety, to avoid key='__proto__'-type skullduggery
this._store[key] = value
process.nextTick(callback)
}
FakeLevelDOWN.prototype._get = function (key, options, callback) {
var value = this._store['_' + key]
if (value === undefined) {
// 'NotFound' error, consistent with LevelDOWN API
return process.nextTick(function () { callback(new Error('NotFound')) })
}
process.nextTick(function () {
callback(null, value)
})
}
FakeLevelDOWN.prototype._del = function (key, options, callback) {
delete this._store['_' + key]
process.nextTick(callback)
}
// Now use it with levelup
var levelup = require('levelup')
var db = levelup(new FakeLevelDOWN('/who/cares'))
db.put('foo', 'bar', function (err) {
if (err) throw err
db.get('foo', function (err, value) {
if (err) throw err
console.log('Got foo =', value)
})
})
```
See [`memdown`](https://github.com/Level/memdown/) if you are looking for a complete in-memory replacement for `leveldown`.
## Extensible API
Remember that each of these methods, if you implement them, will receive exactly the number and order of arguments described. Optional arguments will be converted to sensible defaults.
### AbstractLevelDOWN(location)
### AbstractLevelDOWN#status
An `AbstractLevelDOWN` based database can be in one of the following states:
* `'new'` - newly created, not opened or closed
* `'opening'` - waiting for the database to be opened
* `'open'` - successfully opened the database, available for use
* `'closing'` - waiting for the database to be closed
* `'closed'` - database has been successfully closed, should not be used
### AbstractLevelDOWN#_open(options, callback)
### AbstractLevelDOWN#_close(callback)
### AbstractLevelDOWN#_get(key, options, callback)
### AbstractLevelDOWN#_put(key, value, options, callback)
### AbstractLevelDOWN#_del(key, options, callback)
### AbstractLevelDOWN#_batch(array, options, callback)
If `batch()` is called without arguments or with only an options object then it should return a `Batch` object with chainable methods. Otherwise it will invoke a classic batch operation.
### AbstractLevelDOWN#_chainedBatch()
By default a `batch()` operation without arguments returns a blank `AbstractChainedBatch` object. The prototype is available on the main exports for you to extend. If you want to implement chainable batch operations then you should extend the `AbstractChaindBatch` and return your object in the `_chainedBatch()` method.
### AbstractLevelDOWN#_approximateSize(start, end, callback)
### AbstractLevelDOWN#_serializeKey(key)
### AbstractLevelDOWN#_serializeValue(value)
### AbstractLevelDOWN#_iterator(options)
By default an `iterator()` operation returns a blank `AbstractIterator` object. The prototype is available on the main exports for you to extend. If you want to implement iterator operations then you should extend the `AbstractIterator` and return your object in the `_iterator(options)` method.
`AbstractIterator` implements the basic state management found in LevelDOWN. It keeps track of when a `next()` is in progress and when an `end()` has been called so it doesn't allow concurrent `next()` calls, it does allow `end()` while a `next()` is in progress and it doesn't allow either `next()` or `end()` after `end()` has been called.
### AbstractIterator(db)
Provided with the current instance of `AbstractLevelDOWN` by default.
### AbstractIterator#_next(callback)
### AbstractIterator#_end(callback)
### AbstractChainedBatch
Provided with the current instance of `AbstractLevelDOWN` by default.
### AbstractChainedBatch#_put(key, value)
### AbstractChainedBatch#_del(key)
### AbstractChainedBatch#_clear()
### AbstractChainedBatch#_write(options, callback)
### AbstractChainedBatch#_serializeKey(key)
### AbstractChainedBatch#_serializeValue(value)
### isLevelDown(db)
Returns `true` if `db` has the same public api as `abstract-leveldown`, otherwise `false`. This is a utility function and it's not part of the extensible api.
<a name="contributing"></a>
Contributing
------------
`abstract-leveldown` is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [contribution guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
<a name="license"></a>
License & Copyright
-------------------
Copyright © 2013-2017 `abstract-leveldown` [contributors](https://github.com/level/community#contributors).
`abstract-leveldown` is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included `LICENSE.md` file for more details.
[level-badge]: http://leveldb.org/img/badge.svg
# universalify
[](https://travis-ci.org/RyanZim/universalify)



Make a callback- or promise-based function support both promises and callbacks.
Uses the native promise implementation.
## Installation
```bash
npm install universalify
```
## API
### `universalify.fromCallback(fn)`
Takes a callback-based function to universalify, and returns the universalified function.
Function must take a callback as the last parameter that will be called with the signature `(error, result)`. `universalify` does not support calling the callback with more than three arguments, and does not ensure that the callback is only called once.
```js
function callbackFn (n, cb) {
setTimeout(() => cb(null, n), 15)
}
const fn = universalify.fromCallback(callbackFn)
// Works with Promises:
fn('Hello World!')
.then(result => console.log(result)) // -> Hello World!
.catch(error => console.error(error))
// Works with Callbacks:
fn('Hi!', (error, result) => {
if (error) return console.error(error)
console.log(result)
// -> Hi!
})
```
### `universalify.fromPromise(fn)`
Takes a promise-based function to universalify, and returns the universalified function.
Function must return a valid JS promise. `universalify` does not ensure that a valid promise is returned.
```js
function promiseFn (n) {
return new Promise(resolve => {
setTimeout(() => resolve(n), 15)
})
}
const fn = universalify.fromPromise(promiseFn)
// Works with Promises:
fn('Hello World!')
.then(result => console.log(result)) // -> Hello World!
.catch(error => console.error(error))
// Works with Callbacks:
fn('Hi!', (error, result) => {
if (error) return console.error(error)
console.log(result)
// -> Hi!
})
```
## License
MIT
text-encoding-utf-8
==============
This is a **partial** polyfill for the [Encoding Living Standard](https://encoding.spec.whatwg.org/)
API for the Web, allowing encoding and decoding of textual data to and from Typed Array
buffers for binary data in JavaScript.
This is fork of [text-encoding](https://github.com/inexorabletash/text-encoding)
that **only** support **UTF-8**.
Basic examples and tests are included.
### Install ###
There are a few ways you can get the `text-encoding-utf-8` library.
#### Node ####
`text-encoding-utf-8` is on `npm`. Simply run:
```js
npm install text-encoding-utf-8
```
Or add it to your `package.json` dependencies.
### HTML Page Usage ###
```html
<script src="encoding.js"></script>
```
### API Overview ###
Basic Usage
```js
var uint8array = TextEncoder(encoding).encode(string);
var string = TextDecoder(encoding).decode(uint8array);
```
Streaming Decode
```js
var string = "", decoder = TextDecoder(encoding), buffer;
while (buffer = next_chunk()) {
string += decoder.decode(buffer, {stream:true});
}
string += decoder.decode(); // finish the stream
```
### Encodings ###
Only `utf-8` and `UTF-8` are supported.
### Non-Standard Behavior ###
Only `utf-8` and `UTF-8` are supported.
### Motivation
Binary size matters, especially on a mobile phone. Safari on iOS does not
support TextDecoder or TextEncoder.
# mute-stream
Bytes go in, but they don't come out (when muted).
This is a basic pass-through stream, but when muted, the bytes are
silently dropped, rather than being passed through.
## Usage
```javascript
var MuteStream = require('mute-stream')
var ms = new MuteStream(options)
ms.pipe(process.stdout)
ms.write('foo') // writes 'foo' to stdout
ms.mute()
ms.write('bar') // does not write 'bar'
ms.unmute()
ms.write('baz') // writes 'baz' to stdout
// can also be used to mute incoming data
var ms = new MuteStream
input.pipe(ms)
ms.on('data', function (c) {
console.log('data: ' + c)
})
input.emit('data', 'foo') // logs 'foo'
ms.mute()
input.emit('data', 'bar') // does not log 'bar'
ms.unmute()
input.emit('data', 'baz') // logs 'baz'
```
## Options
All options are optional.
* `replace` Set to a string to replace each character with the
specified string when muted. (So you can show `****` instead of the
password, for example.)
* `prompt` If you are using a replacement char, and also using a
prompt with a readline stream (as for a `Password: *****` input),
then specify what the prompt is so that backspace will work
properly. Otherwise, pressing backspace will overwrite the prompt
with the replacement character, which is weird.
## ms.mute()
Set `muted` to `true`. Turns `.write()` into a no-op.
## ms.unmute()
Set `muted` to `false`
## ms.isTTY
True if the pipe destination is a TTY, or if the incoming pipe source is
a TTY.
## Other stream methods...
The other standard readable and writable stream methods are all
available. The MuteStream object acts as a facade to its pipe source
and destination.
pac-proxy-agent
===============
### A [PAC file][pac-wikipedia] proxy `http.Agent` implementation for HTTP and HTTPS
[](https://travis-ci.org/TooTallNate/node-pac-proxy-agent)
This module provides an `http.Agent` implementation that retreives the specified
[PAC proxy file][pac-wikipedia] and uses it to resolve which HTTP, HTTPS, or
SOCKS proxy, or if a direct connection should be used to connect to the
HTTP endpoint.
It is designed to be be used with the built-in `http` and `https` modules.
Installation
------------
Install with `npm`:
``` bash
$ npm install pac-proxy-agent
```
Example
-------
``` js
var url = require('url');
var http = require('http');
var PacProxyAgent = require('pac-proxy-agent');
// URI to a PAC proxy file to use (the "pac+" prefix is stripped)
var proxy = 'pac+https://cloudup.com/ceGH2yZ0Bjp+';
console.log('using PAC proxy proxy file at %j', proxy);
// HTTP endpoint for the proxy to connect to
var endpoint = 'http://nodejs.org/api/';
console.log('attempting to GET %j', endpoint);
var opts = url.parse(endpoint);
// create an instance of the `PacProxyAgent` class with the PAC file location
var agent = new PacProxyAgent(proxy);
opts.agent = agent;
http.get(opts, function (res) {
console.log('"response" event!', res.headers);
res.pipe(process.stdout);
});
```
License
-------
(The MIT License)
Copyright (c) 2014 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[pac-wikipedia]: http://wikipedia.org/wiki/Proxy_auto-config
[](https://travis-ci.org/othiym23/shimmer)
[](https://coveralls.io/r/othiym23/shimmer?branch=master)
## Safer monkeypatching for Node.js
`shimmer` does a bunch of the work necessary to wrap other methods in
a wrapper you provide:
```javascript
var http = require('http');
var shimmer = require('shimmer');
shimmer.wrap(http, 'request', function (original) {
return function () {
console.log("Starting request!");
var returned = original.apply(this, arguments)
console.log("Done setting up request -- OH YEAH!");
return returned;
};
});
```
### Mandatory disclaimer
There are times when it's necessary to monkeypatch default behavior in
JavaScript and Node. However, changing the behavior of the runtime on the fly
is rarely a good idea, and you should be using this module because you need to,
not because it seems like fun.
### API
All monkeypatched functions have an attribute, `__wrapped`, set to true on
them.
#### shimmer(options)
If you pass in an options object containing a function labeled `logger`,
`shimmer` will use it instead of the logger, which defaults to `console.error`.
`shimmer` is built to be as unobtrusive as possible and has no need to run
asynchronously, so it defaults to logging when things fail, instead of
throwing.
#### shimmer.wrap(nodule, name, wrapper)
`shimmer` monkeypatches in place, so it expects to be passed an object.
It accepts either instances, prototypes, or the results of calling
`require`. `name` must be the string key for the field's name on the
object.
`wrapper` is a function that takes a single parameter, which is the original
function to be monkeypatched. `shimmer` assumes that you're adding behavior
to the original method, and not replacing it outright. If you *are* replacing
the original function, feel free to ignore the passed-in function.
If you *aren't* discarding the original, remember these tips:
* call the original with something like `original.apply(this, arguments)`,
unless your reason for monkeypatching is to transform the arguments.
* always capture and return the return value coming from the original function.
Today's null-returning callback is tomorrow's error-code returning callback.
* Don't make an asynchronous function synchronous and vice versa.
#### shimmer.massWrap(nodules, names, wrapper)
Just like `wrap`, with the addition that you can wrap multiple methods on
multiple modules. Note that this function expects the list of functions to be
monkeypatched on all of the modules to be the same.
#### shimmer.unwrap(nodule, name)
A convenience function for restoring the function back the way it was before
you started. Won't unwrap if somebody else has monkeypatched the function after
you (but will log in that case). Won't throw if you try to double-unwrap a
function (but will log).
#### shimmer.massUnwrap(nodules, names)
Just like `unwrap`, with the addition that you can unwrap multiple methods on
multiple modules. Note that this function expects the list of functions to be
unwrapped on all of the modules to be the same.
# array-unique [](http://badge.fury.io/js/array-unique) [](https://travis-ci.org/jonschlinkert/array-unique)
> Return an array free of duplicate values. Fastest ES5 implementation.
## Install with [npm](npmjs.org)
```bash
npm i array-unique --save
```
## Usage
```js
var unique = require('array-unique');
unique(['a', 'b', 'c', 'c']);
//=> ['a', 'b', 'c']
```
## Related
* [arr-diff](https://github.com/jonschlinkert/arr-diff): Returns an array with only the unique values from the first array, by excluding all values from additional arrays using strict equality for comparisons.
* [arr-union](https://github.com/jonschlinkert/arr-union): Returns an array of unique values using strict equality for comparisons.
* [arr-flatten](https://github.com/jonschlinkert/arr-flatten): Recursively flatten an array or arrays. This is the fastest implementation of array flatten.
* [arr-reduce](https://github.com/jonschlinkert/arr-reduce): Fast array reduce that also loops over sparse elements.
* [arr-map](https://github.com/jonschlinkert/arr-map): Faster, node.js focused alternative to JavaScript's native array map.
* [arr-pluck](https://github.com/jonschlinkert/arr-pluck): Retrieves the value of a specified property from all elements in the collection.
## Run tests
Install dev dependencies.
```bash
npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/array-unique/issues)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright (c) 2015 Jon Schlinkert
Released under the MIT license
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on March 24, 2015._
1to2 naively converts source code files from NAN 1 to NAN 2. There will be erroneous conversions,
false positives and missed opportunities. The input files are rewritten in place. Make sure that
you have backups. You will have to manually review the changes afterwards and do some touchups.
```sh
$ tools/1to2.js
Usage: 1to2 [options] <file ...>
Options:
-h, --help output usage information
-V, --version output the version number
```
# jsbn: javascript big number
[Tom Wu's Original Website](http://www-cs-students.stanford.edu/~tjw/jsbn/)
I felt compelled to put this on github and publish to npm. I haven't tested every other big integer library out there, but the few that I have tested in comparison to this one have not even come close in performance. I am aware of the `bi` module on npm, however it has been modified and I wanted to publish the original without modifications. This is jsbn and jsbn2 from Tom Wu's original website above, with the modular pattern applied to prevent global leaks and to allow for use with node.js on the server side.
## usage
var BigInteger = require('jsbn');
var a = new BigInteger('91823918239182398123');
alert(a.bitLength()); // 67
## API
### bi.toString()
returns the base-10 number as a string
### bi.negate()
returns a new BigInteger equal to the negation of `bi`
### bi.abs
returns new BI of absolute value
### bi.compareTo
### bi.bitLength
### bi.mod
### bi.modPowInt
### bi.clone
### bi.intValue
### bi.byteValue
### bi.shortValue
### bi.signum
### bi.toByteArray
### bi.equals
### bi.min
### bi.max
### bi.and
### bi.or
### bi.xor
### bi.andNot
### bi.not
### bi.shiftLeft
### bi.shiftRight
### bi.getLowestSetBit
### bi.bitCount
### bi.testBit
### bi.setBit
### bi.clearBit
### bi.flipBit
### bi.add
### bi.subtract
### bi.multiply
### bi.divide
### bi.remainder
### bi.divideAndRemainder
### bi.modPow
### bi.modInverse
### bi.pow
### bi.gcd
### bi.isProbablePrime
# string_decoder
***Node-core v8.9.4 string_decoder for userland***
[](https://nodei.co/npm/string_decoder/)
[](https://nodei.co/npm/string_decoder/)
```bash
npm install --save string_decoder
```
***Node-core string_decoder for userland***
This package is a mirror of the string_decoder implementation in Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.9.4/docs/api/).
As of version 1.0.0 **string_decoder** uses semantic versioning.
## Previous versions
Previous version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10.
## Update
The *build/* directory contains a build script that will scrape the source from the [nodejs/node](https://github.com/nodejs/node) repo given a specific Node version.
## Streams Working Group
`string_decoder` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
See [readable-stream](https://github.com/nodejs/readable-stream) for
more details.
# Async.js
[](https://travis-ci.org/caolan/async)
[](https://www.npmjs.org/package/async)
[](https://coveralls.io/r/caolan/async?branch=master)
[](https://gitter.im/caolan/async?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
Async is a utility module which provides straight-forward, powerful functions
for working with asynchronous JavaScript. Although originally designed for
use with [Node.js](http://nodejs.org) and installable via `npm install async`,
it can also be used directly in the browser.
Async is also installable via:
- [bower](http://bower.io/): `bower install async`
- [component](https://github.com/component/component): `component install
caolan/async`
- [jam](http://jamjs.org/): `jam install async`
- [spm](http://spmjs.io/): `spm install async`
Async provides around 20 functions that include the usual 'functional'
suspects (`map`, `reduce`, `filter`, `each`…) as well as some common patterns
for asynchronous control flow (`parallel`, `series`, `waterfall`…). All these
functions assume you follow the Node.js convention of providing a single
callback as the last argument of your `async` function.
## Quick Examples
```javascript
async.map(['file1','file2','file3'], fs.stat, function(err, results){
// results is now an array of stats for each file
});
async.filter(['file1','file2','file3'], fs.exists, function(results){
// results now equals an array of the existing files
});
async.parallel([
function(){ ... },
function(){ ... }
], callback);
async.series([
function(){ ... },
function(){ ... }
]);
```
There are many more functions available so take a look at the docs below for a
full list. This module aims to be comprehensive, so if you feel anything is
missing please create a GitHub issue for it.
## Common Pitfalls <sub>[(StackOverflow)](http://stackoverflow.com/questions/tagged/async.js)</sub>
### Synchronous iteration functions
If you get an error like `RangeError: Maximum call stack size exceeded.` or other stack overflow issues when using async, you are likely using a synchronous iterator. By *synchronous* we mean a function that calls its callback on the same tick in the javascript event loop, without doing any I/O or using any timers. Calling many callbacks iteratively will quickly overflow the stack. If you run into this issue, just defer your callback with `async.setImmediate` to start a new call stack on the next tick of the event loop.
This can also arise by accident if you callback early in certain cases:
```js
async.eachSeries(hugeArray, function iterator(item, callback) {
if (inCache(item)) {
callback(null, cache[item]); // if many items are cached, you'll overflow
} else {
doSomeIO(item, callback);
}
}, function done() {
//...
});
```
Just change it to:
```js
async.eachSeries(hugeArray, function iterator(item, callback) {
if (inCache(item)) {
async.setImmediate(function () {
callback(null, cache[item]);
});
} else {
doSomeIO(item, callback);
//...
```
Async guards against synchronous functions in some, but not all, cases. If you are still running into stack overflows, you can defer as suggested above, or wrap functions with [`async.ensureAsync`](#ensureAsync) Functions that are asynchronous by their nature do not have this problem and don't need the extra callback deferral.
If JavaScript's event loop is still a bit nebulous, check out [this article](http://blog.carbonfive.com/2013/10/27/the-javascript-event-loop-explained/) or [this talk](http://2014.jsconf.eu/speakers/philip-roberts-what-the-heck-is-the-event-loop-anyway.html) for more detailed information about how it works.
### Multiple callbacks
Make sure to always `return` when calling a callback early, otherwise you will cause multiple callbacks and unpredictable behavior in many cases.
```js
async.waterfall([
function (callback) {
getSomething(options, function (err, result) {
if (err) {
callback(new Error("failed getting something:" + err.message));
// we should return here
}
// since we did not return, this callback still will be called and
// `processData` will be called twice
callback(null, result);
});
},
processData
], done)
```
It is always good practice to `return callback(err, result)` whenever a callback call is not the last statement of a function.
### Binding a context to an iterator
This section is really about `bind`, not about `async`. If you are wondering how to
make `async` execute your iterators in a given context, or are confused as to why
a method of another library isn't working as an iterator, study this example:
```js
// Here is a simple object with an (unnecessarily roundabout) squaring method
var AsyncSquaringLibrary = {
squareExponent: 2,
square: function(number, callback){
var result = Math.pow(number, this.squareExponent);
setTimeout(function(){
callback(null, result);
}, 200);
}
};
async.map([1, 2, 3], AsyncSquaringLibrary.square, function(err, result){
// result is [NaN, NaN, NaN]
// This fails because the `this.squareExponent` expression in the square
// function is not evaluated in the context of AsyncSquaringLibrary, and is
// therefore undefined.
});
async.map([1, 2, 3], AsyncSquaringLibrary.square.bind(AsyncSquaringLibrary), function(err, result){
// result is [1, 4, 9]
// With the help of bind we can attach a context to the iterator before
// passing it to async. Now the square function will be executed in its
// 'home' AsyncSquaringLibrary context and the value of `this.squareExponent`
// will be as expected.
});
```
## Download
The source is available for download from
[GitHub](https://github.com/caolan/async/blob/master/lib/async.js).
Alternatively, you can install using Node Package Manager (`npm`):
npm install async
As well as using Bower:
bower install async
__Development:__ [async.js](https://github.com/caolan/async/raw/master/lib/async.js) - 29.6kb Uncompressed
## In the Browser
So far it's been tested in IE6, IE7, IE8, FF3.6 and Chrome 5.
Usage:
```html
<script type="text/javascript" src="async.js"></script>
<script type="text/javascript">
async.map(data, asyncProcess, function(err, results){
alert(results);
});
</script>
```
## Documentation
Some functions are also available in the following forms:
* `<name>Series` - the same as `<name>` but runs only a single async operation at a time
* `<name>Limit` - the same as `<name>` but runs a maximum of `limit` async operations at a time
### Collections
* [`each`](#each), `eachSeries`, `eachLimit`
* [`forEachOf`](#forEachOf), `forEachOfSeries`, `forEachOfLimit`
* [`map`](#map), `mapSeries`, `mapLimit`
* [`filter`](#filter), `filterSeries`, `filterLimit`
* [`reject`](#reject), `rejectSeries`, `rejectLimit`
* [`reduce`](#reduce), [`reduceRight`](#reduceRight)
* [`detect`](#detect), `detectSeries`, `detectLimit`
* [`sortBy`](#sortBy)
* [`some`](#some), `someLimit`
* [`every`](#every), `everyLimit`
* [`concat`](#concat), `concatSeries`
### Control Flow
* [`series`](#seriestasks-callback)
* [`parallel`](#parallel), `parallelLimit`
* [`whilst`](#whilst), [`doWhilst`](#doWhilst)
* [`until`](#until), [`doUntil`](#doUntil)
* [`during`](#during), [`doDuring`](#doDuring)
* [`forever`](#forever)
* [`waterfall`](#waterfall)
* [`compose`](#compose)
* [`seq`](#seq)
* [`applyEach`](#applyEach), `applyEachSeries`
* [`queue`](#queue), [`priorityQueue`](#priorityQueue)
* [`cargo`](#cargo)
* [`auto`](#auto)
* [`retry`](#retry)
* [`iterator`](#iterator)
* [`times`](#times), `timesSeries`, `timesLimit`
### Utils
* [`apply`](#apply)
* [`nextTick`](#nextTick)
* [`memoize`](#memoize)
* [`unmemoize`](#unmemoize)
* [`ensureAsync`](#ensureAsync)
* [`constant`](#constant)
* [`asyncify`](#asyncify)
* [`wrapSync`](#wrapSync)
* [`log`](#log)
* [`dir`](#dir)
* [`noConflict`](#noConflict)
## Collections
<a name="forEach" />
<a name="each" />
### each(arr, iterator, [callback])
Applies the function `iterator` to each item in `arr`, in parallel.
The `iterator` is called with an item from the list, and a callback for when it
has finished. If the `iterator` passes an error to its `callback`, the main
`callback` (for the `each` function) is immediately called with the error.
Note, that since this function applies `iterator` to each item in parallel,
there is no guarantee that the iterator functions will complete in order.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A function to apply to each item in `arr`.
The iterator is passed a `callback(err)` which must be called once it has
completed. If no error has occurred, the `callback` should be run without
arguments or with an explicit `null` argument. The array index is not passed
to the iterator. If you need the index, use [`forEachOf`](#forEachOf).
* `callback(err)` - *Optional* A callback which is called when all `iterator` functions
have finished, or an error occurs.
__Examples__
```js
// assuming openFiles is an array of file names and saveFile is a function
// to save the modified contents of that file:
async.each(openFiles, saveFile, function(err){
// if any of the saves produced an error, err would equal that error
});
```
```js
// assuming openFiles is an array of file names
async.each(openFiles, function(file, callback) {
// Perform operation on file here.
console.log('Processing file ' + file);
if( file.length > 32 ) {
console.log('This file name is too long');
callback('File name too long');
} else {
// Do work to process file here
console.log('File processed');
callback();
}
}, function(err){
// if any of the file processing produced an error, err would equal that error
if( err ) {
// One of the iterations produced an error.
// All processing will now stop.
console.log('A file failed to process');
} else {
console.log('All files have been processed successfully');
}
});
```
__Related__
* eachSeries(arr, iterator, [callback])
* eachLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="forEachOf" />
<a name="eachOf" />
### forEachOf(obj, iterator, [callback])
Like `each`, except that it iterates over objects, and passes the key as the second argument to the iterator.
__Arguments__
* `obj` - An object or array to iterate over.
* `iterator(item, key, callback)` - A function to apply to each item in `obj`.
The `key` is the item's key, or index in the case of an array. The iterator is
passed a `callback(err)` which must be called once it has completed. If no
error has occurred, the callback should be run without arguments or with an
explicit `null` argument.
* `callback(err)` - *Optional* A callback which is called when all `iterator` functions have finished, or an error occurs.
__Example__
```js
var obj = {dev: "/dev.json", test: "/test.json", prod: "/prod.json"};
var configs = {};
async.forEachOf(obj, function (value, key, callback) {
fs.readFile(__dirname + value, "utf8", function (err, data) {
if (err) return callback(err);
try {
configs[key] = JSON.parse(data);
} catch (e) {
return callback(e);
}
callback();
})
}, function (err) {
if (err) console.error(err.message);
// configs is now a map of JSON data
doSomethingWith(configs);
})
```
__Related__
* forEachOfSeries(obj, iterator, [callback])
* forEachOfLimit(obj, limit, iterator, [callback])
---------------------------------------
<a name="map" />
### map(arr, iterator, [callback])
Produces a new array of values by mapping each value in `arr` through
the `iterator` function. The `iterator` is called with an item from `arr` and a
callback for when it has finished processing. Each of these callback takes 2 arguments:
an `error`, and the transformed item from `arr`. If `iterator` passes an error to its
callback, the main `callback` (for the `map` function) is immediately called with the error.
Note, that since this function applies the `iterator` to each item in parallel,
there is no guarantee that the `iterator` functions will complete in order.
However, the results array will be in the same order as the original `arr`.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A function to apply to each item in `arr`.
The iterator is passed a `callback(err, transformed)` which must be called once
it has completed with an error (which can be `null`) and a transformed item.
* `callback(err, results)` - *Optional* A callback which is called when all `iterator`
functions have finished, or an error occurs. Results is an array of the
transformed items from the `arr`.
__Example__
```js
async.map(['file1','file2','file3'], fs.stat, function(err, results){
// results is now an array of stats for each file
});
```
__Related__
* mapSeries(arr, iterator, [callback])
* mapLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="select" />
<a name="filter" />
### filter(arr, iterator, [callback])
__Alias:__ `select`
Returns a new array of all the values in `arr` which pass an async truth test.
_The callback for each `iterator` call only accepts a single argument of `true` or
`false`; it does not accept an error argument first!_ This is in-line with the
way node libraries work with truth tests like `fs.exists`. This operation is
performed in parallel, but the results array will be in the same order as the
original.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A truth test to apply to each item in `arr`.
The `iterator` is passed a `callback(truthValue)`, which must be called with a
boolean argument once it has completed.
* `callback(results)` - *Optional* A callback which is called after all the `iterator`
functions have finished.
__Example__
```js
async.filter(['file1','file2','file3'], fs.exists, function(results){
// results now equals an array of the existing files
});
```
__Related__
* filterSeries(arr, iterator, [callback])
* filterLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="reject" />
### reject(arr, iterator, [callback])
The opposite of [`filter`](#filter). Removes values that pass an `async` truth test.
__Related__
* rejectSeries(arr, iterator, [callback])
* rejectLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="reduce" />
### reduce(arr, memo, iterator, [callback])
__Aliases:__ `inject`, `foldl`
Reduces `arr` into a single value using an async `iterator` to return
each successive step. `memo` is the initial state of the reduction.
This function only operates in series.
For performance reasons, it may make sense to split a call to this function into
a parallel map, and then use the normal `Array.prototype.reduce` on the results.
This function is for situations where each step in the reduction needs to be async;
if you can get the data before reducing it, then it's probably a good idea to do so.
__Arguments__
* `arr` - An array to iterate over.
* `memo` - The initial state of the reduction.
* `iterator(memo, item, callback)` - A function applied to each item in the
array to produce the next step in the reduction. The `iterator` is passed a
`callback(err, reduction)` which accepts an optional error as its first
argument, and the state of the reduction as the second. If an error is
passed to the callback, the reduction is stopped and the main `callback` is
immediately called with the error.
* `callback(err, result)` - *Optional* A callback which is called after all the `iterator`
functions have finished. Result is the reduced value.
__Example__
```js
async.reduce([1,2,3], 0, function(memo, item, callback){
// pointless async:
process.nextTick(function(){
callback(null, memo + item)
});
}, function(err, result){
// result is now equal to the last value of memo, which is 6
});
```
---------------------------------------
<a name="reduceRight" />
### reduceRight(arr, memo, iterator, [callback])
__Alias:__ `foldr`
Same as [`reduce`](#reduce), only operates on `arr` in reverse order.
---------------------------------------
<a name="detect" />
### detect(arr, iterator, [callback])
Returns the first value in `arr` that passes an async truth test. The
`iterator` is applied in parallel, meaning the first iterator to return `true` will
fire the detect `callback` with that result. That means the result might not be
the first item in the original `arr` (in terms of order) that passes the test.
If order within the original `arr` is important, then look at [`detectSeries`](#detectSeries).
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A truth test to apply to each item in `arr`.
The iterator is passed a `callback(truthValue)` which must be called with a
boolean argument once it has completed. **Note: this callback does not take an error as its first argument.**
* `callback(result)` - *Optional* A callback which is called as soon as any iterator returns
`true`, or after all the `iterator` functions have finished. Result will be
the first item in the array that passes the truth test (iterator) or the
value `undefined` if none passed. **Note: this callback does not take an error as its first argument.**
__Example__
```js
async.detect(['file1','file2','file3'], fs.exists, function(result){
// result now equals the first file in the list that exists
});
```
__Related__
* detectSeries(arr, iterator, [callback])
* detectLimit(arr, limit, iterator, [callback])
---------------------------------------
<a name="sortBy" />
### sortBy(arr, iterator, [callback])
Sorts a list by the results of running each `arr` value through an async `iterator`.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A function to apply to each item in `arr`.
The iterator is passed a `callback(err, sortValue)` which must be called once it
has completed with an error (which can be `null`) and a value to use as the sort
criteria.
* `callback(err, results)` - *Optional* A callback which is called after all the `iterator`
functions have finished, or an error occurs. Results is the items from
the original `arr` sorted by the values returned by the `iterator` calls.
__Example__
```js
async.sortBy(['file1','file2','file3'], function(file, callback){
fs.stat(file, function(err, stats){
callback(err, stats.mtime);
});
}, function(err, results){
// results is now the original array of files sorted by
// modified date
});
```
__Sort Order__
By modifying the callback parameter the sorting order can be influenced:
```js
//ascending order
async.sortBy([1,9,3,5], function(x, callback){
callback(null, x);
}, function(err,result){
//result callback
} );
//descending order
async.sortBy([1,9,3,5], function(x, callback){
callback(null, x*-1); //<- x*-1 instead of x, turns the order around
}, function(err,result){
//result callback
} );
```
---------------------------------------
<a name="some" />
### some(arr, iterator, [callback])
__Alias:__ `any`
Returns `true` if at least one element in the `arr` satisfies an async test.
_The callback for each iterator call only accepts a single argument of `true` or
`false`; it does not accept an error argument first!_ This is in-line with the
way node libraries work with truth tests like `fs.exists`. Once any iterator
call returns `true`, the main `callback` is immediately called.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A truth test to apply to each item in the array
in parallel. The iterator is passed a `callback(truthValue)`` which must be
called with a boolean argument once it has completed.
* `callback(result)` - *Optional* A callback which is called as soon as any iterator returns
`true`, or after all the iterator functions have finished. Result will be
either `true` or `false` depending on the values of the async tests.
**Note: the callbacks do not take an error as their first argument.**
__Example__
```js
async.some(['file1','file2','file3'], fs.exists, function(result){
// if result is true then at least one of the files exists
});
```
__Related__
* someLimit(arr, limit, iterator, callback)
---------------------------------------
<a name="every" />
### every(arr, iterator, [callback])
__Alias:__ `all`
Returns `true` if every element in `arr` satisfies an async test.
_The callback for each `iterator` call only accepts a single argument of `true` or
`false`; it does not accept an error argument first!_ This is in-line with the
way node libraries work with truth tests like `fs.exists`.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A truth test to apply to each item in the array
in parallel. The iterator is passed a `callback(truthValue)` which must be
called with a boolean argument once it has completed.
* `callback(result)` - *Optional* A callback which is called as soon as any iterator returns
`false`, or after all the iterator functions have finished. Result will be
either `true` or `false` depending on the values of the async tests.
**Note: the callbacks do not take an error as their first argument.**
__Example__
```js
async.every(['file1','file2','file3'], fs.exists, function(result){
// if result is true then every file exists
});
```
__Related__
* everyLimit(arr, limit, iterator, callback)
---------------------------------------
<a name="concat" />
### concat(arr, iterator, [callback])
Applies `iterator` to each item in `arr`, concatenating the results. Returns the
concatenated list. The `iterator`s are called in parallel, and the results are
concatenated as they return. There is no guarantee that the results array will
be returned in the original order of `arr` passed to the `iterator` function.
__Arguments__
* `arr` - An array to iterate over.
* `iterator(item, callback)` - A function to apply to each item in `arr`.
The iterator is passed a `callback(err, results)` which must be called once it
has completed with an error (which can be `null`) and an array of results.
* `callback(err, results)` - *Optional* A callback which is called after all the `iterator`
functions have finished, or an error occurs. Results is an array containing
the concatenated results of the `iterator` function.
__Example__
```js
async.concat(['dir1','dir2','dir3'], fs.readdir, function(err, files){
// files is now a list of filenames that exist in the 3 directories
});
```
__Related__
* concatSeries(arr, iterator, [callback])
## Control Flow
<a name="series" />
### series(tasks, [callback])
Run the functions in the `tasks` array in series, each one running once the previous
function has completed. If any functions in the series pass an error to its
callback, no more functions are run, and `callback` is immediately called with the value of the error.
Otherwise, `callback` receives an array of results when `tasks` have completed.
It is also possible to use an object instead of an array. Each property will be
run as a function, and the results will be passed to the final `callback` as an object
instead of an array. This can be a more readable way of handling results from
[`series`](#series).
**Note** that while many implementations preserve the order of object properties, the
[ECMAScript Language Specification](http://www.ecma-international.org/ecma-262/5.1/#sec-8.6)
explicitly states that
> The mechanics and order of enumerating the properties is not specified.
So if you rely on the order in which your series of functions are executed, and want
this to work on all platforms, consider using an array.
__Arguments__
* `tasks` - An array or object containing functions to run, each function is passed
a `callback(err, result)` it must call on completion with an error `err` (which can
be `null`) and an optional `result` value.
* `callback(err, results)` - An optional callback to run once all the functions
have completed. This function gets a results array (or object) containing all
the result arguments passed to the `task` callbacks.
__Example__
```js
async.series([
function(callback){
// do some stuff ...
callback(null, 'one');
},
function(callback){
// do some more stuff ...
callback(null, 'two');
}
],
// optional callback
function(err, results){
// results is now equal to ['one', 'two']
});
// an example using an object instead of an array
async.series({
one: function(callback){
setTimeout(function(){
callback(null, 1);
}, 200);
},
two: function(callback){
setTimeout(function(){
callback(null, 2);
}, 100);
}
},
function(err, results) {
// results is now equal to: {one: 1, two: 2}
});
```
---------------------------------------
<a name="parallel" />
### parallel(tasks, [callback])
Run the `tasks` array of functions in parallel, without waiting until the previous
function has completed. If any of the functions pass an error to its
callback, the main `callback` is immediately called with the value of the error.
Once the `tasks` have completed, the results are passed to the final `callback` as an
array.
**Note:** `parallel` is about kicking-off I/O tasks in parallel, not about parallel execution of code. If your tasks do not use any timers or perform any I/O, they will actually be executed in series. Any synchronous setup sections for each task will happen one after the other. JavaScript remains single-threaded.
It is also possible to use an object instead of an array. Each property will be
run as a function and the results will be passed to the final `callback` as an object
instead of an array. This can be a more readable way of handling results from
[`parallel`](#parallel).
__Arguments__
* `tasks` - An array or object containing functions to run. Each function is passed
a `callback(err, result)` which it must call on completion with an error `err`
(which can be `null`) and an optional `result` value.
* `callback(err, results)` - An optional callback to run once all the functions
have completed successfully. This function gets a results array (or object) containing all
the result arguments passed to the task callbacks.
__Example__
```js
async.parallel([
function(callback){
setTimeout(function(){
callback(null, 'one');
}, 200);
},
function(callback){
setTimeout(function(){
callback(null, 'two');
}, 100);
}
],
// optional callback
function(err, results){
// the results array will equal ['one','two'] even though
// the second function had a shorter timeout.
});
// an example using an object instead of an array
async.parallel({
one: function(callback){
setTimeout(function(){
callback(null, 1);
}, 200);
},
two: function(callback){
setTimeout(function(){
callback(null, 2);
}, 100);
}
},
function(err, results) {
// results is now equals to: {one: 1, two: 2}
});
```
__Related__
* parallelLimit(tasks, limit, [callback])
---------------------------------------
<a name="whilst" />
### whilst(test, fn, callback)
Repeatedly call `fn`, while `test` returns `true`. Calls `callback` when stopped,
or an error occurs.
__Arguments__
* `test()` - synchronous truth test to perform before each execution of `fn`.
* `fn(callback)` - A function which is called each time `test` passes. The function is
passed a `callback(err)`, which must be called once it has completed with an
optional `err` argument.
* `callback(err, [results])` - A callback which is called after the test
function has failed and repeated execution of `fn` has stopped. `callback`
will be passed an error and any arguments passed to the final `fn`'s callback.
__Example__
```js
var count = 0;
async.whilst(
function () { return count < 5; },
function (callback) {
count++;
setTimeout(function () {
callback(null, count);
}, 1000);
},
function (err, n) {
// 5 seconds have passed, n = 5
}
);
```
---------------------------------------
<a name="doWhilst" />
### doWhilst(fn, test, callback)
The post-check version of [`whilst`](#whilst). To reflect the difference in
the order of operations, the arguments `test` and `fn` are switched.
`doWhilst` is to `whilst` as `do while` is to `while` in plain JavaScript.
---------------------------------------
<a name="until" />
### until(test, fn, callback)
Repeatedly call `fn` until `test` returns `true`. Calls `callback` when stopped,
or an error occurs. `callback` will be passed an error and any arguments passed
to the final `fn`'s callback.
The inverse of [`whilst`](#whilst).
---------------------------------------
<a name="doUntil" />
### doUntil(fn, test, callback)
Like [`doWhilst`](#doWhilst), except the `test` is inverted. Note the argument ordering differs from `until`.
---------------------------------------
<a name="during" />
### during(test, fn, callback)
Like [`whilst`](#whilst), except the `test` is an asynchronous function that is passed a callback in the form of `function (err, truth)`. If error is passed to `test` or `fn`, the main callback is immediately called with the value of the error.
__Example__
```js
var count = 0;
async.during(
function (callback) {
return callback(null, count < 5);
},
function (callback) {
count++;
setTimeout(callback, 1000);
},
function (err) {
// 5 seconds have passed
}
);
```
---------------------------------------
<a name="doDuring" />
### doDuring(fn, test, callback)
The post-check version of [`during`](#during). To reflect the difference in
the order of operations, the arguments `test` and `fn` are switched.
Also a version of [`doWhilst`](#doWhilst) with asynchronous `test` function.
---------------------------------------
<a name="forever" />
### forever(fn, [errback])
Calls the asynchronous function `fn` with a callback parameter that allows it to
call itself again, in series, indefinitely.
If an error is passed to the callback then `errback` is called with the
error, and execution stops, otherwise it will never be called.
```js
async.forever(
function(next) {
// next is suitable for passing to things that need a callback(err [, whatever]);
// it will result in this function being called again.
},
function(err) {
// if next is called with a value in its first parameter, it will appear
// in here as 'err', and execution will stop.
}
);
```
---------------------------------------
<a name="waterfall" />
### waterfall(tasks, [callback])
Runs the `tasks` array of functions in series, each passing their results to the next in
the array. However, if any of the `tasks` pass an error to their own callback, the
next function is not executed, and the main `callback` is immediately called with
the error.
__Arguments__
* `tasks` - An array of functions to run, each function is passed a
`callback(err, result1, result2, ...)` it must call on completion. The first
argument is an error (which can be `null`) and any further arguments will be
passed as arguments in order to the next task.
* `callback(err, [results])` - An optional callback to run once all the functions
have completed. This will be passed the results of the last task's callback.
__Example__
```js
async.waterfall([
function(callback) {
callback(null, 'one', 'two');
},
function(arg1, arg2, callback) {
// arg1 now equals 'one' and arg2 now equals 'two'
callback(null, 'three');
},
function(arg1, callback) {
// arg1 now equals 'three'
callback(null, 'done');
}
], function (err, result) {
// result now equals 'done'
});
```
Or, with named functions:
```js
async.waterfall([
myFirstFunction,
mySecondFunction,
myLastFunction,
], function (err, result) {
// result now equals 'done'
});
function myFirstFunction(callback) {
callback(null, 'one', 'two');
}
function mySecondFunction(arg1, arg2, callback) {
// arg1 now equals 'one' and arg2 now equals 'two'
callback(null, 'three');
}
function myLastFunction(arg1, callback) {
// arg1 now equals 'three'
callback(null, 'done');
}
```
Or, if you need to pass any argument to the first function:
```js
async.waterfall([
async.apply(myFirstFunction, 'zero'),
mySecondFunction,
myLastFunction,
], function (err, result) {
// result now equals 'done'
});
function myFirstFunction(arg1, callback) {
// arg1 now equals 'zero'
callback(null, 'one', 'two');
}
function mySecondFunction(arg1, arg2, callback) {
// arg1 now equals 'one' and arg2 now equals 'two'
callback(null, 'three');
}
function myLastFunction(arg1, callback) {
// arg1 now equals 'three'
callback(null, 'done');
}
```
---------------------------------------
<a name="compose" />
### compose(fn1, fn2...)
Creates a function which is a composition of the passed asynchronous
functions. Each function consumes the return value of the function that
follows. Composing functions `f()`, `g()`, and `h()` would produce the result of
`f(g(h()))`, only this version uses callbacks to obtain the return values.
Each function is executed with the `this` binding of the composed function.
__Arguments__
* `functions...` - the asynchronous functions to compose
__Example__
```js
function add1(n, callback) {
setTimeout(function () {
callback(null, n + 1);
}, 10);
}
function mul3(n, callback) {
setTimeout(function () {
callback(null, n * 3);
}, 10);
}
var add1mul3 = async.compose(mul3, add1);
add1mul3(4, function (err, result) {
// result now equals 15
});
```
---------------------------------------
<a name="seq" />
### seq(fn1, fn2...)
Version of the compose function that is more natural to read.
Each function consumes the return value of the previous function.
It is the equivalent of [`compose`](#compose) with the arguments reversed.
Each function is executed with the `this` binding of the composed function.
__Arguments__
* `functions...` - the asynchronous functions to compose
__Example__
```js
// Requires lodash (or underscore), express3 and dresende's orm2.
// Part of an app, that fetches cats of the logged user.
// This example uses `seq` function to avoid overnesting and error
// handling clutter.
app.get('/cats', function(request, response) {
var User = request.models.User;
async.seq(
_.bind(User.get, User), // 'User.get' has signature (id, callback(err, data))
function(user, fn) {
user.getCats(fn); // 'getCats' has signature (callback(err, data))
}
)(req.session.user_id, function (err, cats) {
if (err) {
console.error(err);
response.json({ status: 'error', message: err.message });
} else {
response.json({ status: 'ok', message: 'Cats found', data: cats });
}
});
});
```
---------------------------------------
<a name="applyEach" />
### applyEach(fns, args..., callback)
Applies the provided arguments to each function in the array, calling
`callback` after all functions have completed. If you only provide the first
argument, then it will return a function which lets you pass in the
arguments as if it were a single function call.
__Arguments__
* `fns` - the asynchronous functions to all call with the same arguments
* `args...` - any number of separate arguments to pass to the function
* `callback` - the final argument should be the callback, called when all
functions have completed processing
__Example__
```js
async.applyEach([enableSearch, updateSchema], 'bucket', callback);
// partial application example:
async.each(
buckets,
async.applyEach([enableSearch, updateSchema]),
callback
);
```
__Related__
* applyEachSeries(tasks, args..., [callback])
---------------------------------------
<a name="queue" />
### queue(worker, [concurrency])
Creates a `queue` object with the specified `concurrency`. Tasks added to the
`queue` are processed in parallel (up to the `concurrency` limit). If all
`worker`s are in progress, the task is queued until one becomes available.
Once a `worker` completes a `task`, that `task`'s callback is called.
__Arguments__
* `worker(task, callback)` - An asynchronous function for processing a queued
task, which must call its `callback(err)` argument when finished, with an
optional `error` as an argument. If you want to handle errors from an individual task, pass a callback to `q.push()`.
* `concurrency` - An `integer` for determining how many `worker` functions should be
run in parallel. If omitted, the concurrency defaults to `1`. If the concurrency is `0`, an error is thrown.
__Queue objects__
The `queue` object returned by this function has the following properties and
methods:
* `length()` - a function returning the number of items waiting to be processed.
* `started` - a function returning whether or not any items have been pushed and processed by the queue
* `running()` - a function returning the number of items currently being processed.
* `workersList()` - a function returning the array of items currently being processed.
* `idle()` - a function returning false if there are items waiting or being processed, or true if not.
* `concurrency` - an integer for determining how many `worker` functions should be
run in parallel. This property can be changed after a `queue` is created to
alter the concurrency on-the-fly.
* `push(task, [callback])` - add a new task to the `queue`. Calls `callback` once
the `worker` has finished processing the task. Instead of a single task, a `tasks` array
can be submitted. The respective callback is used for every task in the list.
* `unshift(task, [callback])` - add a new task to the front of the `queue`.
* `saturated` - a callback that is called when the `queue` length hits the `concurrency` limit,
and further tasks will be queued.
* `empty` - a callback that is called when the last item from the `queue` is given to a `worker`.
* `drain` - a callback that is called when the last item from the `queue` has returned from the `worker`.
* `paused` - a boolean for determining whether the queue is in a paused state
* `pause()` - a function that pauses the processing of tasks until `resume()` is called.
* `resume()` - a function that resumes the processing of queued tasks when the queue is paused.
* `kill()` - a function that removes the `drain` callback and empties remaining tasks from the queue forcing it to go idle.
__Example__
```js
// create a queue object with concurrency 2
var q = async.queue(function (task, callback) {
console.log('hello ' + task.name);
callback();
}, 2);
// assign a callback
q.drain = function() {
console.log('all items have been processed');
}
// add some items to the queue
q.push({name: 'foo'}, function (err) {
console.log('finished processing foo');
});
q.push({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
// add some items to the queue (batch-wise)
q.push([{name: 'baz'},{name: 'bay'},{name: 'bax'}], function (err) {
console.log('finished processing item');
});
// add some items to the front of the queue
q.unshift({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
```
---------------------------------------
<a name="priorityQueue" />
### priorityQueue(worker, concurrency)
The same as [`queue`](#queue) only tasks are assigned a priority and completed in ascending priority order. There are two differences between `queue` and `priorityQueue` objects:
* `push(task, priority, [callback])` - `priority` should be a number. If an array of
`tasks` is given, all tasks will be assigned the same priority.
* The `unshift` method was removed.
---------------------------------------
<a name="cargo" />
### cargo(worker, [payload])
Creates a `cargo` object with the specified payload. Tasks added to the
cargo will be processed altogether (up to the `payload` limit). If the
`worker` is in progress, the task is queued until it becomes available. Once
the `worker` has completed some tasks, each callback of those tasks is called.
Check out [these](https://camo.githubusercontent.com/6bbd36f4cf5b35a0f11a96dcd2e97711ffc2fb37/68747470733a2f2f662e636c6f75642e6769746875622e636f6d2f6173736574732f313637363837312f36383130382f62626330636662302d356632392d313165322d393734662d3333393763363464633835382e676966) [animations](https://camo.githubusercontent.com/f4810e00e1c5f5f8addbe3e9f49064fd5d102699/68747470733a2f2f662e636c6f75642e6769746875622e636f6d2f6173736574732f313637363837312f36383130312f38346339323036362d356632392d313165322d383134662d3964336430323431336266642e676966) for how `cargo` and `queue` work.
While [queue](#queue) passes only one task to one of a group of workers
at a time, cargo passes an array of tasks to a single worker, repeating
when the worker is finished.
__Arguments__
* `worker(tasks, callback)` - An asynchronous function for processing an array of
queued tasks, which must call its `callback(err)` argument when finished, with
an optional `err` argument.
* `payload` - An optional `integer` for determining how many tasks should be
processed per round; if omitted, the default is unlimited.
__Cargo objects__
The `cargo` object returned by this function has the following properties and
methods:
* `length()` - A function returning the number of items waiting to be processed.
* `payload` - An `integer` for determining how many tasks should be
process per round. This property can be changed after a `cargo` is created to
alter the payload on-the-fly.
* `push(task, [callback])` - Adds `task` to the `queue`. The callback is called
once the `worker` has finished processing the task. Instead of a single task, an array of `tasks`
can be submitted. The respective callback is used for every task in the list.
* `saturated` - A callback that is called when the `queue.length()` hits the concurrency and further tasks will be queued.
* `empty` - A callback that is called when the last item from the `queue` is given to a `worker`.
* `drain` - A callback that is called when the last item from the `queue` has returned from the `worker`.
* `idle()`, `pause()`, `resume()`, `kill()` - cargo inherits all of the same methods and event calbacks as [`queue`](#queue)
__Example__
```js
// create a cargo object with payload 2
var cargo = async.cargo(function (tasks, callback) {
for(var i=0; i<tasks.length; i++){
console.log('hello ' + tasks[i].name);
}
callback();
}, 2);
// add some items
cargo.push({name: 'foo'}, function (err) {
console.log('finished processing foo');
});
cargo.push({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
cargo.push({name: 'baz'}, function (err) {
console.log('finished processing baz');
});
```
---------------------------------------
<a name="auto" />
### auto(tasks, [concurrency], [callback])
Determines the best order for running the functions in `tasks`, based on their requirements. Each function can optionally depend on other functions being completed first, and each function is run as soon as its requirements are satisfied.
If any of the functions pass an error to their callback, the `auto` sequence will stop. Further tasks will not execute (so any other functions depending on it will not run), and the main `callback` is immediately called with the error. Functions also receive an object containing the results of functions which have completed so far.
Note, all functions are called with a `results` object as a second argument,
so it is unsafe to pass functions in the `tasks` object which cannot handle the
extra argument.
For example, this snippet of code:
```js
async.auto({
readData: async.apply(fs.readFile, 'data.txt', 'utf-8')
}, callback);
```
will have the effect of calling `readFile` with the results object as the last
argument, which will fail:
```js
fs.readFile('data.txt', 'utf-8', cb, {});
```
Instead, wrap the call to `readFile` in a function which does not forward the
`results` object:
```js
async.auto({
readData: function(cb, results){
fs.readFile('data.txt', 'utf-8', cb);
}
}, callback);
```
__Arguments__
* `tasks` - An object. Each of its properties is either a function or an array of
requirements, with the function itself the last item in the array. The object's key
of a property serves as the name of the task defined by that property,
i.e. can be used when specifying requirements for other tasks.
The function receives two arguments: (1) a `callback(err, result)` which must be
called when finished, passing an `error` (which can be `null`) and the result of
the function's execution, and (2) a `results` object, containing the results of
the previously executed functions.
* `concurrency` - An optional `integer` for determining the maximum number of tasks that can be run in parallel. By default, as many as possible.
* `callback(err, results)` - An optional callback which is called when all the
tasks have been completed. It receives the `err` argument if any `tasks`
pass an error to their callback. Results are always returned; however, if
an error occurs, no further `tasks` will be performed, and the results
object will only contain partial results.
__Example__
```js
async.auto({
get_data: function(callback){
console.log('in get_data');
// async code to get some data
callback(null, 'data', 'converted to array');
},
make_folder: function(callback){
console.log('in make_folder');
// async code to create a directory to store a file in
// this is run at the same time as getting the data
callback(null, 'folder');
},
write_file: ['get_data', 'make_folder', function(callback, results){
console.log('in write_file', JSON.stringify(results));
// once there is some data and the directory exists,
// write the data to a file in the directory
callback(null, 'filename');
}],
email_link: ['write_file', function(callback, results){
console.log('in email_link', JSON.stringify(results));
// once the file is written let's email a link to it...
// results.write_file contains the filename returned by write_file.
callback(null, {'file':results.write_file, 'email':'[email protected]'});
}]
}, function(err, results) {
console.log('err = ', err);
console.log('results = ', results);
});
```
This is a fairly trivial example, but to do this using the basic parallel and
series functions would look like this:
```js
async.parallel([
function(callback){
console.log('in get_data');
// async code to get some data
callback(null, 'data', 'converted to array');
},
function(callback){
console.log('in make_folder');
// async code to create a directory to store a file in
// this is run at the same time as getting the data
callback(null, 'folder');
}
],
function(err, results){
async.series([
function(callback){
console.log('in write_file', JSON.stringify(results));
// once there is some data and the directory exists,
// write the data to a file in the directory
results.push('filename');
callback(null);
},
function(callback){
console.log('in email_link', JSON.stringify(results));
// once the file is written let's email a link to it...
callback(null, {'file':results.pop(), 'email':'[email protected]'});
}
]);
});
```
For a complicated series of `async` tasks, using the [`auto`](#auto) function makes adding
new tasks much easier (and the code more readable).
---------------------------------------
<a name="retry" />
### retry([opts = {times: 5, interval: 0}| 5], task, [callback])
Attempts to get a successful response from `task` no more than `times` times before
returning an error. If the task is successful, the `callback` will be passed the result
of the successful task. If all attempts fail, the callback will be passed the error and
result (if any) of the final attempt.
__Arguments__
* `opts` - Can be either an object with `times` and `interval` or a number.
* `times` - The number of attempts to make before giving up. The default is `5`.
* `interval` - The time to wait between retries, in milliseconds. The default is `0`.
* If `opts` is a number, the number specifies the number of times to retry, with the default interval of `0`.
* `task(callback, results)` - A function which receives two arguments: (1) a `callback(err, result)`
which must be called when finished, passing `err` (which can be `null`) and the `result` of
the function's execution, and (2) a `results` object, containing the results of
the previously executed functions (if nested inside another control flow).
* `callback(err, results)` - An optional callback which is called when the
task has succeeded, or after the final failed attempt. It receives the `err` and `result` arguments of the last attempt at completing the `task`.
The [`retry`](#retry) function can be used as a stand-alone control flow by passing a callback, as shown below:
```js
// try calling apiMethod 3 times
async.retry(3, apiMethod, function(err, result) {
// do something with the result
});
```
```js
// try calling apiMethod 3 times, waiting 200 ms between each retry
async.retry({times: 3, interval: 200}, apiMethod, function(err, result) {
// do something with the result
});
```
```js
// try calling apiMethod the default 5 times no delay between each retry
async.retry(apiMethod, function(err, result) {
// do something with the result
});
```
It can also be embedded within other control flow functions to retry individual methods
that are not as reliable, like this:
```js
async.auto({
users: api.getUsers.bind(api),
payments: async.retry(3, api.getPayments.bind(api))
}, function(err, results) {
// do something with the results
});
```
---------------------------------------
<a name="iterator" />
### iterator(tasks)
Creates an iterator function which calls the next function in the `tasks` array,
returning a continuation to call the next one after that. It's also possible to
“peek” at the next iterator with `iterator.next()`.
This function is used internally by the `async` module, but can be useful when
you want to manually control the flow of functions in series.
__Arguments__
* `tasks` - An array of functions to run.
__Example__
```js
var iterator = async.iterator([
function(){ sys.p('one'); },
function(){ sys.p('two'); },
function(){ sys.p('three'); }
]);
node> var iterator2 = iterator();
'one'
node> var iterator3 = iterator2();
'two'
node> iterator3();
'three'
node> var nextfn = iterator2.next();
node> nextfn();
'three'
```
---------------------------------------
<a name="apply" />
### apply(function, arguments..)
Creates a continuation function with some arguments already applied.
Useful as a shorthand when combined with other control flow functions. Any arguments
passed to the returned function are added to the arguments originally passed
to apply.
__Arguments__
* `function` - The function you want to eventually apply all arguments to.
* `arguments...` - Any number of arguments to automatically apply when the
continuation is called.
__Example__
```js
// using apply
async.parallel([
async.apply(fs.writeFile, 'testfile1', 'test1'),
async.apply(fs.writeFile, 'testfile2', 'test2'),
]);
// the same process without using apply
async.parallel([
function(callback){
fs.writeFile('testfile1', 'test1', callback);
},
function(callback){
fs.writeFile('testfile2', 'test2', callback);
}
]);
```
It's possible to pass any number of additional arguments when calling the
continuation:
```js
node> var fn = async.apply(sys.puts, 'one');
node> fn('two', 'three');
one
two
three
```
---------------------------------------
<a name="nextTick" />
### nextTick(callback), setImmediate(callback)
Calls `callback` on a later loop around the event loop. In Node.js this just
calls `process.nextTick`; in the browser it falls back to `setImmediate(callback)`
if available, otherwise `setTimeout(callback, 0)`, which means other higher priority
events may precede the execution of `callback`.
This is used internally for browser-compatibility purposes.
__Arguments__
* `callback` - The function to call on a later loop around the event loop.
__Example__
```js
var call_order = [];
async.nextTick(function(){
call_order.push('two');
// call_order now equals ['one','two']
});
call_order.push('one')
```
<a name="times" />
### times(n, iterator, [callback])
Calls the `iterator` function `n` times, and accumulates results in the same manner
you would use with [`map`](#map).
__Arguments__
* `n` - The number of times to run the function.
* `iterator` - The function to call `n` times.
* `callback` - see [`map`](#map)
__Example__
```js
// Pretend this is some complicated async factory
var createUser = function(id, callback) {
callback(null, {
id: 'user' + id
})
}
// generate 5 users
async.times(5, function(n, next){
createUser(n, function(err, user) {
next(err, user)
})
}, function(err, users) {
// we should now have 5 users
});
```
__Related__
* timesSeries(n, iterator, [callback])
* timesLimit(n, limit, iterator, [callback])
## Utils
<a name="memoize" />
### memoize(fn, [hasher])
Caches the results of an `async` function. When creating a hash to store function
results against, the callback is omitted from the hash and an optional hash
function can be used.
If no hash function is specified, the first argument is used as a hash key, which may work reasonably if it is a string or a data type that converts to a distinct string. Note that objects and arrays will not behave reasonably. Neither will cases where the other arguments are significant. In such cases, specify your own hash function.
The cache of results is exposed as the `memo` property of the function returned
by `memoize`.
__Arguments__
* `fn` - The function to proxy and cache results from.
* `hasher` - An optional function for generating a custom hash for storing
results. It has all the arguments applied to it apart from the callback, and
must be synchronous.
__Example__
```js
var slow_fn = function (name, callback) {
// do something
callback(null, result);
};
var fn = async.memoize(slow_fn);
// fn can now be used as if it were slow_fn
fn('some name', function () {
// callback
});
```
<a name="unmemoize" />
### unmemoize(fn)
Undoes a [`memoize`](#memoize)d function, reverting it to the original, unmemoized
form. Handy for testing.
__Arguments__
* `fn` - the memoized function
---------------------------------------
<a name="ensureAsync" />
### ensureAsync(fn)
Wrap an async function and ensure it calls its callback on a later tick of the event loop. If the function already calls its callback on a next tick, no extra deferral is added. This is useful for preventing stack overflows (`RangeError: Maximum call stack size exceeded`) and generally keeping [Zalgo](http://blog.izs.me/post/59142742143/designing-apis-for-asynchrony) contained.
__Arguments__
* `fn` - an async function, one that expects a node-style callback as its last argument
Returns a wrapped function with the exact same call signature as the function passed in.
__Example__
```js
function sometimesAsync(arg, callback) {
if (cache[arg]) {
return callback(null, cache[arg]); // this would be synchronous!!
} else {
doSomeIO(arg, callback); // this IO would be asynchronous
}
}
// this has a risk of stack overflows if many results are cached in a row
async.mapSeries(args, sometimesAsync, done);
// this will defer sometimesAsync's callback if necessary,
// preventing stack overflows
async.mapSeries(args, async.ensureAsync(sometimesAsync), done);
```
---------------------------------------
<a name="constant">
### constant(values...)
Returns a function that when called, calls-back with the values provided. Useful as the first function in a `waterfall`, or for plugging values in to `auto`.
__Example__
```js
async.waterfall([
async.constant(42),
function (value, next) {
// value === 42
},
//...
], callback);
async.waterfall([
async.constant(filename, "utf8"),
fs.readFile,
function (fileData, next) {
//...
}
//...
], callback);
async.auto({
hostname: async.constant("https://server.net/"),
port: findFreePort,
launchServer: ["hostname", "port", function (cb, options) {
startServer(options, cb);
}],
//...
}, callback);
```
---------------------------------------
<a name="asyncify">
<a name="wrapSync">
### asyncify(func)
__Alias:__ `wrapSync`
Take a sync function and make it async, passing its return value to a callback. This is useful for plugging sync functions into a waterfall, series, or other async functions. Any arguments passed to the generated function will be passed to the wrapped function (except for the final callback argument). Errors thrown will be passed to the callback.
__Example__
```js
async.waterfall([
async.apply(fs.readFile, filename, "utf8"),
async.asyncify(JSON.parse),
function (data, next) {
// data is the result of parsing the text.
// If there was a parsing error, it would have been caught.
}
], callback)
```
If the function passed to `asyncify` returns a Promise, that promises's resolved/rejected state will be used to call the callback, rather than simply the synchronous return value. Example:
```js
async.waterfall([
async.apply(fs.readFile, filename, "utf8"),
async.asyncify(function (contents) {
return db.model.create(contents);
}),
function (model, next) {
// `model` is the instantiated model object.
// If there was an error, this function would be skipped.
}
], callback)
```
This also means you can asyncify ES2016 `async` functions.
```js
var q = async.queue(async.asyncify(async function (file) {
var intermediateStep = await processFile(file);
return await somePromise(intermediateStep)
}));
q.push(files);
```
---------------------------------------
<a name="log" />
### log(function, arguments)
Logs the result of an `async` function to the `console`. Only works in Node.js or
in browsers that support `console.log` and `console.error` (such as FF and Chrome).
If multiple arguments are returned from the async function, `console.log` is
called on each argument in order.
__Arguments__
* `function` - The function you want to eventually apply all arguments to.
* `arguments...` - Any number of arguments to apply to the function.
__Example__
```js
var hello = function(name, callback){
setTimeout(function(){
callback(null, 'hello ' + name);
}, 1000);
};
```
```js
node> async.log(hello, 'world');
'hello world'
```
---------------------------------------
<a name="dir" />
### dir(function, arguments)
Logs the result of an `async` function to the `console` using `console.dir` to
display the properties of the resulting object. Only works in Node.js or
in browsers that support `console.dir` and `console.error` (such as FF and Chrome).
If multiple arguments are returned from the async function, `console.dir` is
called on each argument in order.
__Arguments__
* `function` - The function you want to eventually apply all arguments to.
* `arguments...` - Any number of arguments to apply to the function.
__Example__
```js
var hello = function(name, callback){
setTimeout(function(){
callback(null, {hello: name});
}, 1000);
};
```
```js
node> async.dir(hello, 'world');
{hello: 'world'}
```
---------------------------------------
<a name="noConflict" />
### noConflict()
Changes the value of `async` back to its original value, returning a reference to the
`async` object.
# SYNOPSIS
[](https://www.npmjs.org/package/merkle-patricia-tree)
[](https://travis-ci.org/ethereumjs/merkle-patricia-tree)
[](https://coveralls.io/r/ethereumjs/merkle-patricia-tree)
[](https://gitter.im/ethereum/ethereumjs-lib) or #ethereumjs on freenode
[](https://github.com/feross/standard)
This is an implementation of the modified merkle patricia tree as specified in the [Ethereum's yellow paper](http://gavwood.com/Paper.pdf).
> The modified Merkle Patricia tree (trie) provides a persistent data structure to map between arbitrary-length binary data (byte arrays). It is defined in terms of a mutable data structure to map between 256-bit binary fragments and arbitrary-length binary data. The core of the trie, and its sole requirement in terms of the protocol specification is to provide a single 32-byte value that identifies a given set of key-value pairs.
\- Ethereum's yellow paper
The only backing store supported is LevelDB through the ```levelup``` module.
# INSTALL
`npm install merkle-patricia-tree`
# USAGE
## Initialization and Basic Usage
```javascript
var Trie = require('merkle-patricia-tree'),
level = require('level'),
db = level('./testdb'),
trie = new Trie(db);
trie.put('test', 'one', function () {
trie.get('test', function (err, value) {
if(value) console.log(value.toString())
});
});
```
## Merkle Proofs
```javascript
Trie.prove(trie, 'test', function (err, prove) {
if (err) return cb(err)
Trie.verifyProof(trie.root, 'test', prove, function (err, value) {
if (err) return cb(err)
console.log(value.toString())
cb()
})
})
```
## Read stream on Geth DB
```javascript
var level = require('level')
var Trie = require('./secure')
var stateRoot = "0xd7f8974fb5ac78d9ac099b9ad5018bedc2ce0a72dad1827a1709da30580f0544" // Block #222
var db = level('YOUR_PATH_TO_THE_GETH_CHAIN_DB')
var trie = new Trie(db, stateRoot)
trie.createReadStream()
.on('data', function (data) {
console.log(data)
})
.on('end', function() {
console.log('End.')
})
```
# API
[./docs/](./docs/index.md)
# TESTING
`npm test`
# REFERENCES
- ["Exploring Ethereum's state trie with Node.js"](https://wanderer.github.io/ethereum/nodejs/code/2014/05/21/using-ethereums-tries-with-node/) blog post
- ["Merkling in Ethereum"](https://blog.ethereum.org/2015/11/15/merkling-in-ethereum/) blog post
- [Ethereum Trie Specification](https://github.com/ethereum/wiki/wiki/Patricia-Tree) Wiki
- ["Understanding the ethereum trie"](https://easythereentropy.wordpress.com/2014/06/04/understanding-the-ethereum-trie/) blog post
- ["Trie and Patricia Trie Overview"](https://www.youtube.com/watch?v=jXAHLqQthKw&t=26s) Video Talk on Youtube
# LICENSE
MPL-2.0
# fs.realpath
A backwards-compatible fs.realpath for Node v6 and above
In Node v6, the JavaScript implementation of fs.realpath was replaced
with a faster (but less resilient) native implementation. That raises
new and platform-specific errors and cannot handle long or excessively
symlink-looping paths.
This module handles those cases by detecting the new errors and
falling back to the JavaScript implementation. On versions of Node
prior to v6, it has no effect.
## USAGE
```js
var rp = require('fs.realpath')
// async version
rp.realpath(someLongAndLoopingPath, function (er, real) {
// the ELOOP was handled, but it was a bit slower
})
// sync version
var real = rp.realpathSync(someLongAndLoopingPath)
// monkeypatch at your own risk!
// This replaces the fs.realpath/fs.realpathSync builtins
rp.monkeypatch()
// un-do the monkeypatching
rp.unmonkeypatch()
```
# md5.js
[](https://www.npmjs.org/package/md5.js)
[](https://travis-ci.org/crypto-browserify/md5.js)
[](https://david-dm.org/crypto-browserify/md5.js#info=dependencies)
[](https://github.com/feross/standard)
Node style `md5` on pure JavaScript.
From [NIST SP 800-131A][1]: *md5 is no longer acceptable where collision resistance is required such as digital signatures.*
## Example
```js
var MD5 = require('md5.js')
console.log(new MD5().update('42').digest('hex'))
// => a1d0c6e83f027327d8461063f4ac58a6
var md5stream = new MD5()
md5stream.end('42')
console.log(md5stream.read().toString('hex'))
// => a1d0c6e83f027327d8461063f4ac58a6
```
## LICENSE [MIT](LICENSE)
[1]: http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-131Ar1.pdf
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
[![Build status][nix-build-image]][nix-build-url]
[![Windows status][win-build-image]][win-build-url]
![Transpilation status][transpilation-image]
[![npm version][npm-image]][npm-url]
# es6-symbol
## ECMAScript 6 Symbol polyfill
For more information about symbols see following links
- [Symbols in ECMAScript 6 by Axel Rauschmayer](http://www.2ality.com/2014/12/es6-symbols.html)
- [MDN Documentation](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol)
- [Specification](https://tc39.github.io/ecma262/#sec-symbol-objects)
### Limitations
Underneath it uses real string property names which can easily be retrieved, however accidental collision with other property names is unlikely.
### Usage
If you'd like to use native version when it exists and fallback to [ponyfill](https://ponyfill.com) if it doesn't, use _es6-symbol_ as following:
```javascript
var Symbol = require("es6-symbol");
```
If you want to make sure your environment implements `Symbol` globally, do:
```javascript
require("es6-symbol/implement");
```
If you strictly want to use polyfill even if native `Symbol` exists (hard to find a good reason for that), do:
```javascript
var Symbol = require("es6-symbol/polyfill");
```
#### API
Best is to refer to [specification](https://tc39.github.io/ecma262/#sec-symbol-objects). Still if you want quick look, follow examples:
```javascript
var Symbol = require("es6-symbol");
var symbol = Symbol("My custom symbol");
var x = {};
x[symbol] = "foo";
console.log(x[symbol]);
("foo");
// Detect iterable:
var iterator, result;
if (possiblyIterable[Symbol.iterator]) {
iterator = possiblyIterable[Symbol.iterator]();
result = iterator.next();
while (!result.done) {
console.log(result.value);
result = iterator.next();
}
}
```
### Installation
#### NPM
In your project path:
$ npm install es6-symbol
##### Browser
To port it to Browser or any other (non CJS) environment, use your favorite CJS bundler. No favorite yet? Try: [Browserify](http://browserify.org/), [Webmake](https://github.com/medikoo/modules-webmake) or [Webpack](http://webpack.github.io/)
## Tests
$ npm test
## Security contact information
To report a security vulnerability, please use the [Tidelift security contact](https://tidelift.com/security). Tidelift will coordinate the fix and disclosure.
---
<div align="center">
<b>
<a href="https://tidelift.com/subscription/pkg/npm-es6-symbol?utm_source=npm-es6-symbol&utm_medium=referral&utm_campaign=readme">Get professional support for d with a Tidelift subscription</a>
</b>
<br>
<sub>
Tidelift helps make open source sustainable for maintainers while giving companies<br>assurances about security, maintenance, and licensing for their dependencies.
</sub>
</div>
[nix-build-image]: https://semaphoreci.com/api/v1/medikoo-org/es6-symbol/branches/master/shields_badge.svg
[nix-build-url]: https://semaphoreci.com/medikoo-org/es6-symbol
[win-build-image]: https://ci.appveyor.com/api/projects/status/1s743lt3el278anj?svg=true
[win-build-url]: https://ci.appveyor.com/project/medikoo/es6-symbol
[transpilation-image]: https://img.shields.io/badge/transpilation-free-brightgreen.svg
[npm-image]: https://img.shields.io/npm/v/es6-symbol.svg
[npm-url]: https://www.npmjs.com/package/es6-symbol
yaml.js
=======

Standalone JavaScript YAML 1.2 Parser & Encoder. Works under node.js and all major browsers. Also brings command line YAML/JSON conversion tools.
Mainly inspired from [Symfony Yaml Component](https://github.com/symfony/Yaml).
How to use
----------
Import yaml.js in your html page:
``` html
<script type="text/javascript" src="yaml.js"></script>
```
Parse yaml string:
``` js
nativeObject = YAML.parse(yamlString);
```
Dump native object into yaml string:
``` js
yamlString = YAML.stringify(nativeObject[, inline /* @integer depth to start using inline notation at */[, spaces /* @integer number of spaces to use for indentation */] ]);
```
Load yaml file:
``` js
nativeObject = YAML.load('file.yml');
```
Load yaml file:
``` js
YAML.load('file.yml', function(result)
{
nativeObject = result;
});
```
Use with node.js
----------------
Install module:
``` bash
npm install yamljs
```
Use it:
``` js
YAML = require('yamljs');
// parse YAML string
nativeObject = YAML.parse(yamlString);
// Generate YAML
yamlString = YAML.stringify(nativeObject, 4);
// Load yaml file using YAML.load
nativeObject = YAML.load('myfile.yml');
```
Command line tools
------------------
You can enable the command line tools by installing yamljs as a global module:
``` bash
npm install -g yamljs
```
Then, two cli commands should become available: **yaml2json** and **json2yaml**. They let you convert YAML to JSON and JSON to YAML very easily.
**yaml2json**
```
usage: yaml2json [-h] [-v] [-p] [-i INDENTATION] [-s] [-r] [-w] input
Positional arguments:
input YAML file or directory containing YAML files.
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-p, --pretty Output pretty (indented) JSON.
-i INDENTATION, --indentation INDENTATION
Number of space characters used to indent code (use
with --pretty, default: 2).
-s, --save Save output inside JSON file(s) with the same name.
-r, --recursive If the input is a directory, also find YAML files in
sub-directories recursively.
-w, --watch Watch for changes.
```
**json2yaml**
```
usage: json2yaml [-h] [-v] [-d DEPTH] [-i INDENTATION] [-s] [-r] [-w] input
Positional arguments:
input JSON file or directory containing JSON files.
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-d DEPTH, --depth DEPTH
Set minimum level of depth before generating inline
YAML (default: 2).
-i INDENTATION, --indentation INDENTATION
Number of space characters used to indent code
(default: 2).
-s, --save Save output inside YML file(s) with the same name.
-r, --recursive If the input is a directory, also find JSON files in
sub-directories recursively.
-w, --watch Watch for changes.
```
**examples**
``` bash
# Convert YAML to JSON and output resulting JSON on the console
yaml2json myfile.yml
# Store output inside a JSON file
yaml2json myfile.yml > output.json
# Output "pretty" (indented) JSON
yaml2json myfile.yml --pretty
# Save the output inside a file called myfile.json
yaml2json myfile.yml --pretty --save
# Watch a full directory and convert any YAML file into its JSON equivalent
yaml2json mydirectory --pretty --save --recursive
# Convert JSON to YAML and store output inside a JSON file
json2yaml myfile.json > output.yml
# Output YAML that will be inlined only after 8 levels of indentation
json2yaml myfile.json --depth 8
# Save the output inside a file called myfile.json with 4 spaces for each indentation
json2yaml myfile.json --indentation 4
# Watch a full directory and convert any JSON file into its YAML equivalent
json2yaml mydirectory --pretty --save --recursive
<!--
-- This file is auto-generated from README_js.md. Changes should be made there.
-->
# uuid [](http://travis-ci.org/kelektiv/node-uuid) #
Simple, fast generation of [RFC4122](http://www.ietf.org/rfc/rfc4122.txt) UUIDS.
Features:
* Support for version 1, 3, 4 and 5 UUIDs
* Cross-platform
* Uses cryptographically-strong random number APIs (when available)
* Zero-dependency, small footprint (... but not [this small](https://gist.github.com/982883))
[**Deprecation warning**: The use of `require('uuid')` is deprecated and will not be
supported after version 3.x of this module. Instead, use `require('uuid/[v1|v3|v4|v5]')` as shown in the examples below.]
## Quickstart - CommonJS (Recommended)
```shell
npm install uuid
```
Then generate your uuid version of choice ...
Version 1 (timestamp):
```javascript
const uuidv1 = require('uuid/v1');
uuidv1(); // ⇨ '45745c60-7b1a-11e8-9c9c-2d42b21b1a3e'
```
Version 3 (namespace):
```javascript
const uuidv3 = require('uuid/v3');
// ... using predefined DNS namespace (for domain names)
uuidv3('hello.example.com', uuidv3.DNS); // ⇨ '9125a8dc-52ee-365b-a5aa-81b0b3681cf6'
// ... using predefined URL namespace (for, well, URLs)
uuidv3('http://example.com/hello', uuidv3.URL); // ⇨ 'c6235813-3ba4-3801-ae84-e0a6ebb7d138'
// ... using a custom namespace
//
// Note: Custom namespaces should be a UUID string specific to your application!
// E.g. the one here was generated using this modules `uuid` CLI.
const MY_NAMESPACE = '1b671a64-40d5-491e-99b0-da01ff1f3341';
uuidv3('Hello, World!', MY_NAMESPACE); // ⇨ 'e8b5a51d-11c8-3310-a6ab-367563f20686'
```
Version 4 (random):
```javascript
const uuidv4 = require('uuid/v4');
uuidv4(); // ⇨ '10ba038e-48da-487b-96e8-8d3b99b6d18a'
```
Version 5 (namespace):
```javascript
const uuidv5 = require('uuid/v5');
// ... using predefined DNS namespace (for domain names)
uuidv5('hello.example.com', uuidv5.DNS); // ⇨ 'fdda765f-fc57-5604-a269-52a7df8164ec'
// ... using predefined URL namespace (for, well, URLs)
uuidv5('http://example.com/hello', uuidv5.URL); // ⇨ '3bbcee75-cecc-5b56-8031-b6641c1ed1f1'
// ... using a custom namespace
//
// Note: Custom namespaces should be a UUID string specific to your application!
// E.g. the one here was generated using this modules `uuid` CLI.
const MY_NAMESPACE = '1b671a64-40d5-491e-99b0-da01ff1f3341';
uuidv5('Hello, World!', MY_NAMESPACE); // ⇨ '630eb68f-e0fa-5ecc-887a-7c7a62614681'
```
## Quickstart - Browser-ready Versions
Browser-ready versions of this module are available via [wzrd.in](https://github.com/jfhbrook/wzrd.in).
For version 1 uuids:
```html
<script src="http://wzrd.in/standalone/uuid%2Fv1@latest"></script>
<script>
uuidv1(); // -> v1 UUID
</script>
```
For version 3 uuids:
```html
<script src="http://wzrd.in/standalone/uuid%2Fv3@latest"></script>
<script>
uuidv3('http://example.com/hello', uuidv3.URL); // -> v3 UUID
</script>
```
For version 4 uuids:
```html
<script src="http://wzrd.in/standalone/uuid%2Fv4@latest"></script>
<script>
uuidv4(); // -> v4 UUID
</script>
```
For version 5 uuids:
```html
<script src="http://wzrd.in/standalone/uuid%2Fv5@latest"></script>
<script>
uuidv5('http://example.com/hello', uuidv5.URL); // -> v5 UUID
</script>
```
## API
### Version 1
```javascript
const uuidv1 = require('uuid/v1');
// Incantations
uuidv1();
uuidv1(options);
uuidv1(options, buffer, offset);
```
Generate and return a RFC4122 v1 (timestamp-based) UUID.
* `options` - (Object) Optional uuid state to apply. Properties may include:
* `node` - (Array) Node id as Array of 6 bytes (per 4.1.6). Default: Randomly generated ID. See note 1.
* `clockseq` - (Number between 0 - 0x3fff) RFC clock sequence. Default: An internally maintained clockseq is used.
* `msecs` - (Number) Time in milliseconds since unix Epoch. Default: The current time is used.
* `nsecs` - (Number between 0-9999) additional time, in 100-nanosecond units. Ignored if `msecs` is unspecified. Default: internal uuid counter is used, as per 4.2.1.2.
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing.
Returns `buffer`, if specified, otherwise the string form of the UUID
Note: The <node> id is generated guaranteed to stay constant for the lifetime of the current JS runtime. (Future versions of this module may use persistent storage mechanisms to extend this guarantee.)
Example: Generate string UUID with fully-specified options
```javascript
const v1options = {
node: [0x01, 0x23, 0x45, 0x67, 0x89, 0xab],
clockseq: 0x1234,
msecs: new Date('2011-11-01').getTime(),
nsecs: 5678
};
uuidv1(v1options); // ⇨ '710b962e-041c-11e1-9234-0123456789ab'
```
Example: In-place generation of two binary IDs
```javascript
// Generate two ids in an array
const arr = new Array();
uuidv1(null, arr, 0); // ⇨ [ 69, 117, 109, 208, 123, 26, 17, 232, 146, 52, 45, 66, 178, 27, 26, 62 ]
uuidv1(null, arr, 16); // ⇨ [ 69, 117, 109, 208, 123, 26, 17, 232, 146, 52, 45, 66, 178, 27, 26, 62, 69, 117, 109, 209, 123, 26, 17, 232, 146, 52, 45, 66, 178, 27, 26, 62 ]
```
### Version 3
```javascript
const uuidv3 = require('uuid/v3');
// Incantations
uuidv3(name, namespace);
uuidv3(name, namespace, buffer);
uuidv3(name, namespace, buffer, offset);
```
Generate and return a RFC4122 v3 UUID.
* `name` - (String | Array[]) "name" to create UUID with
* `namespace` - (String | Array[]) "namespace" UUID either as a String or Array[16] of byte values
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing. Default = 0
Returns `buffer`, if specified, otherwise the string form of the UUID
Example:
```javascript
uuidv3('hello world', MY_NAMESPACE); // ⇨ '042ffd34-d989-321c-ad06-f60826172424'
```
### Version 4
```javascript
const uuidv4 = require('uuid/v4')
// Incantations
uuidv4();
uuidv4(options);
uuidv4(options, buffer, offset);
```
Generate and return a RFC4122 v4 UUID.
* `options` - (Object) Optional uuid state to apply. Properties may include:
* `random` - (Number[16]) Array of 16 numbers (0-255) to use in place of randomly generated values
* `rng` - (Function) Random # generator function that returns an Array[16] of byte values (0-255)
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing.
Returns `buffer`, if specified, otherwise the string form of the UUID
Example: Generate string UUID with predefined `random` values
```javascript
const v4options = {
random: [
0x10, 0x91, 0x56, 0xbe, 0xc4, 0xfb, 0xc1, 0xea,
0x71, 0xb4, 0xef, 0xe1, 0x67, 0x1c, 0x58, 0x36
]
};
uuidv4(v4options); // ⇨ '109156be-c4fb-41ea-b1b4-efe1671c5836'
```
Example: Generate two IDs in a single buffer
```javascript
const buffer = new Array();
uuidv4(null, buffer, 0); // ⇨ [ 54, 122, 218, 70, 45, 70, 65, 24, 171, 53, 95, 130, 83, 195, 242, 45 ]
uuidv4(null, buffer, 16); // ⇨ [ 54, 122, 218, 70, 45, 70, 65, 24, 171, 53, 95, 130, 83, 195, 242, 45, 108, 204, 255, 103, 171, 86, 76, 94, 178, 225, 188, 236, 150, 20, 151, 87 ]
```
### Version 5
```javascript
const uuidv5 = require('uuid/v5');
// Incantations
uuidv5(name, namespace);
uuidv5(name, namespace, buffer);
uuidv5(name, namespace, buffer, offset);
```
Generate and return a RFC4122 v5 UUID.
* `name` - (String | Array[]) "name" to create UUID with
* `namespace` - (String | Array[]) "namespace" UUID either as a String or Array[16] of byte values
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing. Default = 0
Returns `buffer`, if specified, otherwise the string form of the UUID
Example:
```javascript
uuidv5('hello world', MY_NAMESPACE); // ⇨ '9f282611-e0fd-5650-8953-89c8e342da0b'
```
## Command Line
UUIDs can be generated from the command line with the `uuid` command.
```shell
$ uuid
ddeb27fb-d9a0-4624-be4d-4615062daed4
$ uuid v1
02d37060-d446-11e7-a9fa-7bdae751ebe1
```
Type `uuid --help` for usage details
## Testing
```shell
npm test
```
----
Markdown generated from [README_js.md](README_js.md) by [](https://github.com/broofa/runmd)
# kind-of [](https://www.npmjs.com/package/kind-of) [](https://npmjs.org/package/kind-of) [](https://npmjs.org/package/kind-of) [](https://travis-ci.org/jonschlinkert/kind-of)
> Get the native type of a value.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save kind-of
```
## Install
Install with [bower](https://bower.io/)
```sh
$ bower install kind-of --save
```
## Usage
> es5, browser and es6 ready
```js
var kindOf = require('kind-of');
kindOf(undefined);
//=> 'undefined'
kindOf(null);
//=> 'null'
kindOf(true);
//=> 'boolean'
kindOf(false);
//=> 'boolean'
kindOf(new Boolean(true));
//=> 'boolean'
kindOf(new Buffer(''));
//=> 'buffer'
kindOf(42);
//=> 'number'
kindOf(new Number(42));
//=> 'number'
kindOf('str');
//=> 'string'
kindOf(new String('str'));
//=> 'string'
kindOf(arguments);
//=> 'arguments'
kindOf({});
//=> 'object'
kindOf(Object.create(null));
//=> 'object'
kindOf(new Test());
//=> 'object'
kindOf(new Date());
//=> 'date'
kindOf([]);
//=> 'array'
kindOf([1, 2, 3]);
//=> 'array'
kindOf(new Array());
//=> 'array'
kindOf(/foo/);
//=> 'regexp'
kindOf(new RegExp('foo'));
//=> 'regexp'
kindOf(function () {});
//=> 'function'
kindOf(function * () {});
//=> 'function'
kindOf(new Function());
//=> 'function'
kindOf(new Map());
//=> 'map'
kindOf(new WeakMap());
//=> 'weakmap'
kindOf(new Set());
//=> 'set'
kindOf(new WeakSet());
//=> 'weakset'
kindOf(Symbol('str'));
//=> 'symbol'
kindOf(new Int8Array());
//=> 'int8array'
kindOf(new Uint8Array());
//=> 'uint8array'
kindOf(new Uint8ClampedArray());
//=> 'uint8clampedarray'
kindOf(new Int16Array());
//=> 'int16array'
kindOf(new Uint16Array());
//=> 'uint16array'
kindOf(new Int32Array());
//=> 'int32array'
kindOf(new Uint32Array());
//=> 'uint32array'
kindOf(new Float32Array());
//=> 'float32array'
kindOf(new Float64Array());
//=> 'float64array'
```
## Benchmarks
Benchmarked against [typeof](http://github.com/CodingFu/typeof) and [type-of](https://github.com/ForbesLindesay/type-of).
Note that performaces is slower for es6 features `Map`, `WeakMap`, `Set` and `WeakSet`.
```bash
#1: array
current x 23,329,397 ops/sec ±0.82% (94 runs sampled)
lib-type-of x 4,170,273 ops/sec ±0.55% (94 runs sampled)
lib-typeof x 9,686,935 ops/sec ±0.59% (98 runs sampled)
#2: boolean
current x 27,197,115 ops/sec ±0.85% (94 runs sampled)
lib-type-of x 3,145,791 ops/sec ±0.73% (97 runs sampled)
lib-typeof x 9,199,562 ops/sec ±0.44% (99 runs sampled)
#3: date
current x 20,190,117 ops/sec ±0.86% (92 runs sampled)
lib-type-of x 5,166,970 ops/sec ±0.74% (94 runs sampled)
lib-typeof x 9,610,821 ops/sec ±0.50% (96 runs sampled)
#4: function
current x 23,855,460 ops/sec ±0.60% (97 runs sampled)
lib-type-of x 5,667,740 ops/sec ±0.54% (100 runs sampled)
lib-typeof x 10,010,644 ops/sec ±0.44% (100 runs sampled)
#5: null
current x 27,061,047 ops/sec ±0.97% (96 runs sampled)
lib-type-of x 13,965,573 ops/sec ±0.62% (97 runs sampled)
lib-typeof x 8,460,194 ops/sec ±0.61% (97 runs sampled)
#6: number
current x 25,075,682 ops/sec ±0.53% (99 runs sampled)
lib-type-of x 2,266,405 ops/sec ±0.41% (98 runs sampled)
lib-typeof x 9,821,481 ops/sec ±0.45% (99 runs sampled)
#7: object
current x 3,348,980 ops/sec ±0.49% (99 runs sampled)
lib-type-of x 3,245,138 ops/sec ±0.60% (94 runs sampled)
lib-typeof x 9,262,952 ops/sec ±0.59% (99 runs sampled)
#8: regex
current x 21,284,827 ops/sec ±0.72% (96 runs sampled)
lib-type-of x 4,689,241 ops/sec ±0.43% (100 runs sampled)
lib-typeof x 8,957,593 ops/sec ±0.62% (98 runs sampled)
#9: string
current x 25,379,234 ops/sec ±0.58% (96 runs sampled)
lib-type-of x 3,635,148 ops/sec ±0.76% (93 runs sampled)
lib-typeof x 9,494,134 ops/sec ±0.49% (98 runs sampled)
#10: undef
current x 27,459,221 ops/sec ±1.01% (93 runs sampled)
lib-type-of x 14,360,433 ops/sec ±0.52% (99 runs sampled)
lib-typeof x 23,202,868 ops/sec ±0.59% (94 runs sampled)
```
## Optimizations
In 7 out of 8 cases, this library is 2x-10x faster than other top libraries included in the benchmarks. There are a few things that lead to this performance advantage, none of them hard and fast rules, but all of them simple and repeatable in almost any code library:
1. Optimize around the fastest and most common use cases first. Of course, this will change from project-to-project, but I took some time to understand how and why `typeof` checks were being used in my own libraries and other libraries I use a lot.
2. Optimize around bottlenecks - In other words, the order in which conditionals are implemented is significant, because each check is only as fast as the failing checks that came before it. Here, the biggest bottleneck by far is checking for plain objects (an object that was created by the `Object` constructor). I opted to make this check happen by process of elimination rather than brute force up front (e.g. by using something like `val.constructor.name`), so that every other type check would not be penalized it.
3. Don't do uneccessary processing - why do `.slice(8, -1).toLowerCase();` just to get the word `regex`? It's much faster to do `if (type === '[object RegExp]') return 'regex'`
## About
### Related projects
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/jonschlinkert/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
* [is-number](https://www.npmjs.com/package/is-number): Returns true if the value is a number. comprehensive tests. | [homepage](https://github.com/jonschlinkert/is-number "Returns true if the value is a number. comprehensive tests.")
* [is-primitive](https://www.npmjs.com/package/is-primitive): Returns `true` if the value is a primitive. | [homepage](https://github.com/jonschlinkert/is-primitive "Returns `true` if the value is a primitive. ")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 59 | [jonschlinkert](https://github.com/jonschlinkert) |
| 2 | [miguelmota](https://github.com/miguelmota) |
| 1 | [dtothefp](https://github.com/dtothefp) |
| 1 | [ksheedlo](https://github.com/ksheedlo) |
| 1 | [pdehaan](https://github.com/pdehaan) |
| 1 | [laggingreflex](https://github.com/laggingreflex) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on May 16, 2017._
# Header Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a dash separated string of capitalized words.
## Installation
```
npm install header-case --save
```
## Usage
```js
import { headerCase } from "header-case";
headerCase("string"); //=> "String"
headerCase("dot.case"); //=> "Dot-Case"
headerCase("PascalCase"); //=> "Pascal-Case"
headerCase("version 1.2.10"); //=> "Version-1-2-10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/header-case.svg?style=flat
[npm-url]: https://npmjs.org/package/header-case
[downloads-image]: https://img.shields.io/npm/dm/header-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/header-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/header-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=header-case
# yaeti
Yet Another [EventTarget](https://developer.mozilla.org/es/docs/Web/API/EventTarget) Implementation.
The library exposes both the [EventTarget](https://developer.mozilla.org/es/docs/Web/API/EventTarget) interface and the [Event](https://developer.mozilla.org/en-US/docs/Web/API/Event) interface.
## Installation
```bash
$ npm install yaeti --save
```
## Usage
```javascript
var yaeti = require('yaeti');
// Custom class we want to make an EventTarget.
function Foo() {
// Make Foo an EventTarget.
yaeti.EventTarget.call(this);
}
// Create an instance.
var foo = new Foo();
function listener1() {
console.log('listener1');
}
function listener2() {
console.log('listener2');
}
foo.addEventListener('bar', listener1);
foo.addEventListener('bar', listener2);
foo.removeEventListener('bar', listener1);
var event = new yaeti.Event('bar');
foo.dispatchEvent(event);
// Output:
// => "listener2"
```
## API
#### `yaeti.EventTarget` interface
Implementation of the [EventTarget](https://developer.mozilla.org/es/docs/Web/API/EventTarget) interface.
* Make a custom class inherit from `EventTarget`:
```javascript
function Foo() {
yaeti.EventTarget.call(this);
}
```
* Make an existing object an `EventTarget`:
```javascript
yaeti.EventTarget.call(obj);
```
The interface implements the `addEventListener`, `removeEventListener` and `dispatchEvent` methods as defined by the W3C.
##### `listeners` read-only property
Returns an object whose keys are configured event types (String) and whose values are an array of listeners (functions) for those event types.
#### `yaeti.Event` interface
Implementation of the [Event](https://developer.mozilla.org/en-US/docs/Web/API/Event) interface.
*NOTE:* Just useful in Node (the browser already exposes the native `Event` interface).
```javascript
var event = new yaeti.Event('bar');
```
## Author
[Iñaki Baz Castillo](https://github.com/ibc)
## License
[MIT](./LICENSE)
# web3-net
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This is the net package used in other [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-net
```
## Usage
```js
const Web3Net = require('web3-net');
const net = new Web3Net('ws://localhost:8546');
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-net.svg
[npm-url]: https://npmjs.org/package/web3-net
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-net
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-net
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-net
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-net
# word-wrap [](https://www.npmjs.com/package/word-wrap) [](https://npmjs.org/package/word-wrap) [](https://npmjs.org/package/word-wrap) [](https://travis-ci.org/jonschlinkert/word-wrap)
> Wrap words to a specified length.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save word-wrap
```
## Usage
```js
var wrap = require('word-wrap');
wrap('Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.');
```
Results in:
```
Lorem ipsum dolor sit amet, consectetur adipiscing
elit, sed do eiusmod tempor incididunt ut labore
et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut
aliquip ex ea commodo consequat.
```
## Options

### options.width
Type: `Number`
Default: `50`
The width of the text before wrapping to a new line.
**Example:**
```js
wrap(str, {width: 60});
```
### options.indent
Type: `String`
Default: `` (two spaces)
The string to use at the beginning of each line.
**Example:**
```js
wrap(str, {indent: ' '});
```
### options.newline
Type: `String`
Default: `\n`
The string to use at the end of each line.
**Example:**
```js
wrap(str, {newline: '\n\n'});
```
### options.escape
Type: `function`
Default: `function(str){return str;}`
An escape function to run on each line after splitting them.
**Example:**
```js
var xmlescape = require('xml-escape');
wrap(str, {
escape: function(string){
return xmlescape(string);
}
});
```
### options.trim
Type: `Boolean`
Default: `false`
Trim trailing whitespace from the returned string. This option is included since `.trim()` would also strip the leading indentation from the first line.
**Example:**
```js
wrap(str, {trim: true});
```
### options.cut
Type: `Boolean`
Default: `false`
Break a word between any two letters when the word is longer than the specified width.
**Example:**
```js
wrap(str, {cut: true});
```
## About
### Related projects
* [common-words](https://www.npmjs.com/package/common-words): Updated list (JSON) of the 100 most common words in the English language. Useful for… [more](https://github.com/jonschlinkert/common-words) | [homepage](https://github.com/jonschlinkert/common-words "Updated list (JSON) of the 100 most common words in the English language. Useful for excluding these words from arrays.")
* [shuffle-words](https://www.npmjs.com/package/shuffle-words): Shuffle the words in a string and optionally the letters in each word using the… [more](https://github.com/jonschlinkert/shuffle-words) | [homepage](https://github.com/jonschlinkert/shuffle-words "Shuffle the words in a string and optionally the letters in each word using the Fisher-Yates algorithm. Useful for creating test fixtures, benchmarking samples, etc.")
* [unique-words](https://www.npmjs.com/package/unique-words): Return the unique words in a string or array. | [homepage](https://github.com/jonschlinkert/unique-words "Return the unique words in a string or array.")
* [wordcount](https://www.npmjs.com/package/wordcount): Count the words in a string. Support for english, CJK and Cyrillic. | [homepage](https://github.com/jonschlinkert/wordcount "Count the words in a string. Support for english, CJK and Cyrillic.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 43 | [jonschlinkert](https://github.com/jonschlinkert) |
| 2 | [lordvlad](https://github.com/lordvlad) |
| 2 | [hildjj](https://github.com/hildjj) |
| 1 | [danilosampaio](https://github.com/danilosampaio) |
| 1 | [2fd](https://github.com/2fd) |
| 1 | [toddself](https://github.com/toddself) |
| 1 | [wolfgang42](https://github.com/wolfgang42) |
| 1 | [zachhale](https://github.com/zachhale) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on June 02, 2017._
[](https://circleci.com/gh/kwonoj/rx-sandbox/tree/master)
[](https://codecov.io/gh/kwonoj/rx-sandbox)
[](https://www.npmjs.com/package/rx-sandbox)
[](https://greenkeeper.io/)
# RxSandbox
`RxSandbox` is test suite for RxJS, based on marble diagram DSL for easier assertion around Observables.
For RxJS 5 support, check pre-1.x versions. 1.x supports latest RxJS 6.x.
## What's difference with `TestScheduler` in RxJS?
`RxJS` 5's test cases are written via its own [`TestScheduler`](https://github.com/ReactiveX/rxjs/blob/9267b30ebc982e1845843f85866906496b3aaa8f/src/testing/TestScheduler.ts) implementation. While it still can be used for testing any other Observable based codes its ergonomics are not user code friendly, reason why core repo tracks [issue](https://github.com/ReactiveX/rxjs/issues/1775) to provide separate package for general usage. RxSandbox aims to resolve those ergonomics with few design goals
- Provides feature parity to `TestScheduler`
- Support extended marble diagram DSL
- Near-zero configuration, works out of box
- No dependencies to specific test framework
# Install
This has a peer dependencies of `rxjs@5.*.*`, which will have to be installed as well
```sh
npm install rx-sandbox
```
# Usage
## Observable marble diagram token description
In `RxSandbox`, `Observable` is represented via `marble` diagram. Marble syntax is a string represents events happening over `virtual` time so called as `frame`.
- `-` : Single `frame` of time passage, by default `1`.
- `|` : Successful completion of an observable signaling `complete()`.
- `#` : An error terminating the observable signaling `error()`.
- ` `(whitespace) : Noop, whitespace does nothing but allows align marbles for readability.
- `a` : Any other character than predefined token represents a value being emitted by `next()`
- `()` : When multiple events need to single in the same frame synchronously, parenthesis are used to group those events. You can group nexted values, a completion or an error in this manner. The position of the initial `(`determines the time at which its values are emitted.
- `^` : (hot observables only) Shows the point at which the tested observables will be subscribed to the hot observable. This is the "zero frame" for that observable, every frame before the `^` will be negative.
- `!` : (for subscription testing) Shows the point at which the tested observables will be unsubscribed.
- `...n...` : (`n` is number) Expanding timeframe. For cases of testing long time period in observable, can shorten marble diagram instead of repeating `-`.
The first character of marble string always represents `0` frame.
### Few examples
```js
const never = `------`; // Observable.never() regardless of number of `-`
const empty = `|`; // Observable.empty();
const error = `#`; // Observable.throw(`#`);
const obs1 = `----a----`;
//` 01234 `, emits `a` on frame 4
const obs2 = `----a---|`;
//` 012345678`, emits `a` on frame 4, completes on 8
const obs2 = `-a-^-b--|`;
//` 012345`, emits `b` on frame 2, completes on 5 - hot observable only
const obs3 = `--(abc)-|`;
//` 012222234, emits `a`,`b`,`c` on frame 2, completes on 4
const obs4 = `----(a|)`;
//` 01234444, emits `a` and complets on frame 4
const obs5 = ` - --a- -|`;
//` 0 1234 56, emits `a` on frame 3, completes on frame 6
const obs6 = `--...4...--|`
//` 01......5678, completes on 8
```
## Subscription marble diagram token description
The subscription marble syntax is slightly different to conventional marble syntax. It represents the **subscription** and an **unsubscription** points happening over time. There should be no other type of event represented in such diagram.
- `-` : Single `frame` of time passage, by default `1`.
- `^` : Shows the point in time at which a subscription happen.
- `!` : Shows the point in time at which a subscription is unsubscribed.
- (whitespace) : Noop, whitespace does nothing but allows align marbles for readability.
- `...n...` : (`n` is number) Expanding timeframe. For cases of testing long time period in observable, can shorten marble diagram instead of repeating `-`.
There should be **at most one** `^` point in a subscription marble diagram, and **at most one** `!` point. Other than that, the `-` character is the only one allowed in a subscription marble diagram.
### Few examples
```js
const sub1 = `-----`; // no subscription
const sub2 = `--^--`;
//` 012`, subscription happend on frame 2, not unsubscribed
const sub3 = `--^--!-`;
//` 012345, subscription happend on frame 2, unsubscribed on frame 5
```
## Anatomy of test interface
You can import `rxSandbox`, and create instance using `create()`.
```js
import { expect } from 'chai';
import { rxSandbox } from 'rx-sandbox';
it('testcase', () => {
const { hot, cold, flush, getMessages, e, s } = rxSandbox.create();
const e1 = hot(' --^--a--b--|');
const e2 = cold(' ---x--y--|', {x: 1, y: 2});
const expected = e(' ---q--r--|');
const sub = s(' ^ !');
const messages = getMessages(e1.merge(e2));
flush();
//assertion
expect(messages).to.deep.equal(expected);
expect(e1.subscriptions).to.deep.equal(sub);
});
```
### Creating sandbox
```typescript
rxSandbox.create(autoFlush?: boolean, frameTimeFactor?: number, maxFrameValue?: number): RxSandboxInstance
```
`frameTimeFactor` allows to override default frame passage `1` to given value.
`maxFrameValue` allows to override maximum frame number testscheduler will accept. (`1000` by default). Maxframevalue is relavant to frameTimeFactor. (i.e if `frameTimeFactor = 2` and `maxFrameValue = 4`, `--` will represent max frame)
Refer below for `autoFlush` option.
### Using RxSandboxInstance
`RxSandboxInstance` exposes below interfaces.
#### Creating hot, cold observable
```typescript
hot<T = string>(marble: string, value?: { [key: string]: T } | null, error?: any): HotObservable<T>;
hot<T = string>(messages: Array<TestMessage<T>>): HotObservable<T>;
cold<T = string>(marble: string, value?: { [key: string]: T } | null, error?: any): ColdObservable<T>;
cold<T = string>(messages: Array<TestMessage<T>>): ColdObservable<T>;
```
Both interfaces accepts marble diagram string, and optionally accepts custom values for marble values or errors. Otherwise, you can create `Array<TestMessage<T>>` directly instead of marble diagram.
#### Creating expected value, subscriptions
To compare observable's result, we can use marble diagram as well wrapped by utility function to generate values to be asserted.
```typescript
e<T = string>(marble: string, value?: { [key: string]: T } | null, error?: any): Array<TestMessage<T>>;
//const expected = e(`----a---b--|`);
```
It accepts same parameter to hot / cold observable creation but instead of returning observable, returns array of metadata for marble diagram.
Subscription metadata also need to be generated via wrapped function.
```typescript
s(marble: string): SubscriptionLog;
//const subs = s('--^---!');
```
#### Getting values from observable
Once we have hot, cold observables we can get metadata from those observables as well to assert with expected metadata values.
```typescript
getMessages<T = string>(observable: Observable<any>, unsubscriptionMarbls: string = null): Array<TestMessage<T>>>;
const e1 = hot('--a--b--|');
const messages = getMessages(e1.mapTo('x'));
//at this moment, messages are empty!
assert(messages.length === 0);
```
It is important to note at the moment of getting metadata array, it is not filled with actual value but just empty array. Scheduler should be flushed to fill in values.
```typescript
const e1 = hot(' --a--b--|');
const expected = e('--x--x--|')
const subs = s(` ^ !`);
const messages = getMessages(e1.mapTo('x'));
//at this moment, messages are empty!
expect(messages).to.be.empty;
flush();
//now values are available
expect(messages).to.deep.equal(expected);
//subscriptions are also available too
expect(e1.subscriptions).to.deep.equal(subs);
```
Or if you need to control timeframe instead of flush out whole at once, you can use `advanceTo` as well.
```typescript
const e1 = hot(' --a--b--|');
const subs = s(` ^ !`);
const messages = getMessages(e1.mapTo('x'));
//at this moment, messages are empty!
expect(messages).to.be.empty;
advanceTo(3);
const expected = e('--x------'); // we're flushing to frame 3 only, so rest of marbles are not constructed
//now values are available
expect(messages).to.deep.equal(expected);
//subscriptions are also available too
expect(e1.subscriptions).to.deep.equal(subs);
```
#### Flushing scheduler automatically
By default sandbox instance requires to `flush()` explicitly to execute observables. For cases each test case doesn't require to schedule multiple observables but only need to test single, we can create sandbox instance to flush automatically. Since it flushes scheduler as soon as `getMessages` being called, subsequent `getMessages` call will raise errors.
```typescript
const { hot, e } = rxSandbox.create(true);
const e1 = hot(' --a--b--|');
const expected = e('--x--x--|')
const messages = getMessages(e1.mapTo('x'));
//without flushing, observable immeditealy executes and values are available.
expect(messages).to.deep.equal(expected);
//subsequent attempt will throw
expect(() => getMessages(e1.mapTo('y'))).to.throw();
```
#### Custom frame time factor
Each timeframe `-` is predefined to `1`, can be overridden.
```typescript
const { e } = rxSandbox.create(false, 10);
const expected = e('--x--x--|');
// now each frame takes 10
expect(expected[0].frame).to.equal(20);
```
#### Custom assertion for marble diagram
Messages generated by `rxSandbox` is plain object array, so any kind of assertion can be used. In addition to those, `rxSandbox` provides own custom assertion method `marbleAssert` for easier marble diagram diff.
```typescript
marbleAssert<T = string>(source: Array<SubscriptionLog | TestMessage<T>>): { to: { equal(expected: Array<SubscriptionLog | TestMessage<T>>): void } }
```
It accepts array of test messages generated by `getMessages` and `e`, or subscription log by `Hot/ColdObservable.subscriptions` or `s` (in case of utility method `s` it returns single subscription, so need to be constructed as array).
```typescript
import { rxSandbox } from 'rx-sandbox';
const { marbleAssert } = rxSandbox;
const {hot, e, s, getMessages, flush} = rxSandbox.create();
const source = hot('---a--b--|');
const expected = e('---x--x---|');
const sub = s('^-----!');
const messages = getMessages(source.mapTo('x'));
flush();
marbleAssert(messages).to.equal(expected);
marbleAssert(source.subscriptions).to.equal([sub]);
```
When assertion fails, it'll display visual / object diff with raw object values for easier debugging.
**Assert Observable marble diagram**
<img src="https://user-images.githubusercontent.com/1210596/29504109-186ac83a-85f2-11e7-8fd1-b65cef4a7803.png" width="600">
**Assert subscription log marble diagram**
<img src="https://user-images.githubusercontent.com/1210596/29504117-291c5ebe-85f2-11e7-939f-986f2d400b4f.png" width="600">
# Building / Testing
Few npm scripts are supported for build / test code.
- `build`: Transpiles code to ES5 commonjs to `dist`.
- `build:clean`: Clean up existing build
- `test`: Run unit test. Does not require `build` before execute test.
- `lint`: Run lint over all codebases
- `lint:staged`: Run lint only for staged changes. This'll be executed automatically with precommit hook.
- `commit`: Commit wizard to write commit message
# Deprecated!
As of Feb 11th 2020, request is fully deprecated. No new changes are expected land. In fact, none have landed for some time.
For more information about why request is deprecated and possible alternatives refer to
[this issue](https://github.com/request/request/issues/3142).
# Request - Simplified HTTP client
[](https://nodei.co/npm/request/)
[](https://travis-ci.org/request/request)
[](https://codecov.io/github/request/request?branch=master)
[](https://coveralls.io/r/request/request)
[](https://david-dm.org/request/request)
[](https://snyk.io/test/npm/request)
[](https://gitter.im/request/request?utm_source=badge)
## Super simple to use
Request is designed to be the simplest way possible to make http calls. It supports HTTPS and follows redirects by default.
```js
const request = require('request');
request('http://www.google.com', function (error, response, body) {
console.error('error:', error); // Print the error if one occurred
console.log('statusCode:', response && response.statusCode); // Print the response status code if a response was received
console.log('body:', body); // Print the HTML for the Google homepage.
});
```
## Table of contents
- [Streaming](#streaming)
- [Promises & Async/Await](#promises--asyncawait)
- [Forms](#forms)
- [HTTP Authentication](#http-authentication)
- [Custom HTTP Headers](#custom-http-headers)
- [OAuth Signing](#oauth-signing)
- [Proxies](#proxies)
- [Unix Domain Sockets](#unix-domain-sockets)
- [TLS/SSL Protocol](#tlsssl-protocol)
- [Support for HAR 1.2](#support-for-har-12)
- [**All Available Options**](#requestoptions-callback)
Request also offers [convenience methods](#convenience-methods) like
`request.defaults` and `request.post`, and there are
lots of [usage examples](#examples) and several
[debugging techniques](#debugging).
---
## Streaming
You can stream any response to a file stream.
```js
request('http://google.com/doodle.png').pipe(fs.createWriteStream('doodle.png'))
```
You can also stream a file to a PUT or POST request. This method will also check the file extension against a mapping of file extensions to content-types (in this case `application/json`) and use the proper `content-type` in the PUT request (if the headers don’t already provide one).
```js
fs.createReadStream('file.json').pipe(request.put('http://mysite.com/obj.json'))
```
Request can also `pipe` to itself. When doing so, `content-type` and `content-length` are preserved in the PUT headers.
```js
request.get('http://google.com/img.png').pipe(request.put('http://mysite.com/img.png'))
```
Request emits a "response" event when a response is received. The `response` argument will be an instance of [http.IncomingMessage](https://nodejs.org/api/http.html#http_class_http_incomingmessage).
```js
request
.get('http://google.com/img.png')
.on('response', function(response) {
console.log(response.statusCode) // 200
console.log(response.headers['content-type']) // 'image/png'
})
.pipe(request.put('http://mysite.com/img.png'))
```
To easily handle errors when streaming requests, listen to the `error` event before piping:
```js
request
.get('http://mysite.com/doodle.png')
.on('error', function(err) {
console.error(err)
})
.pipe(fs.createWriteStream('doodle.png'))
```
Now let’s get fancy.
```js
http.createServer(function (req, resp) {
if (req.url === '/doodle.png') {
if (req.method === 'PUT') {
req.pipe(request.put('http://mysite.com/doodle.png'))
} else if (req.method === 'GET' || req.method === 'HEAD') {
request.get('http://mysite.com/doodle.png').pipe(resp)
}
}
})
```
You can also `pipe()` from `http.ServerRequest` instances, as well as to `http.ServerResponse` instances. The HTTP method, headers, and entity-body data will be sent. Which means that, if you don't really care about security, you can do:
```js
http.createServer(function (req, resp) {
if (req.url === '/doodle.png') {
const x = request('http://mysite.com/doodle.png')
req.pipe(x)
x.pipe(resp)
}
})
```
And since `pipe()` returns the destination stream in ≥ Node 0.5.x you can do one line proxying. :)
```js
req.pipe(request('http://mysite.com/doodle.png')).pipe(resp)
```
Also, none of this new functionality conflicts with requests previous features, it just expands them.
```js
const r = request.defaults({'proxy':'http://localproxy.com'})
http.createServer(function (req, resp) {
if (req.url === '/doodle.png') {
r.get('http://google.com/doodle.png').pipe(resp)
}
})
```
You can still use intermediate proxies, the requests will still follow HTTP forwards, etc.
[back to top](#table-of-contents)
---
## Promises & Async/Await
`request` supports both streaming and callback interfaces natively. If you'd like `request` to return a Promise instead, you can use an alternative interface wrapper for `request`. These wrappers can be useful if you prefer to work with Promises, or if you'd like to use `async`/`await` in ES2017.
Several alternative interfaces are provided by the request team, including:
- [`request-promise`](https://github.com/request/request-promise) (uses [Bluebird](https://github.com/petkaantonov/bluebird) Promises)
- [`request-promise-native`](https://github.com/request/request-promise-native) (uses native Promises)
- [`request-promise-any`](https://github.com/request/request-promise-any) (uses [any-promise](https://www.npmjs.com/package/any-promise) Promises)
Also, [`util.promisify`](https://nodejs.org/api/util.html#util_util_promisify_original), which is available from Node.js v8.0 can be used to convert a regular function that takes a callback to return a promise instead.
[back to top](#table-of-contents)
---
## Forms
`request` supports `application/x-www-form-urlencoded` and `multipart/form-data` form uploads. For `multipart/related` refer to the `multipart` API.
#### application/x-www-form-urlencoded (URL-Encoded Forms)
URL-encoded forms are simple.
```js
request.post('http://service.com/upload', {form:{key:'value'}})
// or
request.post('http://service.com/upload').form({key:'value'})
// or
request.post({url:'http://service.com/upload', form: {key:'value'}}, function(err,httpResponse,body){ /* ... */ })
```
#### multipart/form-data (Multipart Form Uploads)
For `multipart/form-data` we use the [form-data](https://github.com/form-data/form-data) library by [@felixge](https://github.com/felixge). For the most cases, you can pass your upload form data via the `formData` option.
```js
const formData = {
// Pass a simple key-value pair
my_field: 'my_value',
// Pass data via Buffers
my_buffer: Buffer.from([1, 2, 3]),
// Pass data via Streams
my_file: fs.createReadStream(__dirname + '/unicycle.jpg'),
// Pass multiple values /w an Array
attachments: [
fs.createReadStream(__dirname + '/attachment1.jpg'),
fs.createReadStream(__dirname + '/attachment2.jpg')
],
// Pass optional meta-data with an 'options' object with style: {value: DATA, options: OPTIONS}
// Use case: for some types of streams, you'll need to provide "file"-related information manually.
// See the `form-data` README for more information about options: https://github.com/form-data/form-data
custom_file: {
value: fs.createReadStream('/dev/urandom'),
options: {
filename: 'topsecret.jpg',
contentType: 'image/jpeg'
}
}
};
request.post({url:'http://service.com/upload', formData: formData}, function optionalCallback(err, httpResponse, body) {
if (err) {
return console.error('upload failed:', err);
}
console.log('Upload successful! Server responded with:', body);
});
```
For advanced cases, you can access the form-data object itself via `r.form()`. This can be modified until the request is fired on the next cycle of the event-loop. (Note that this calling `form()` will clear the currently set form data for that request.)
```js
// NOTE: Advanced use-case, for normal use see 'formData' usage above
const r = request.post('http://service.com/upload', function optionalCallback(err, httpResponse, body) {...})
const form = r.form();
form.append('my_field', 'my_value');
form.append('my_buffer', Buffer.from([1, 2, 3]));
form.append('custom_file', fs.createReadStream(__dirname + '/unicycle.jpg'), {filename: 'unicycle.jpg'});
```
See the [form-data README](https://github.com/form-data/form-data) for more information & examples.
#### multipart/related
Some variations in different HTTP implementations require a newline/CRLF before, after, or both before and after the boundary of a `multipart/related` request (using the multipart option). This has been observed in the .NET WebAPI version 4.0. You can turn on a boundary preambleCRLF or postamble by passing them as `true` to your request options.
```js
request({
method: 'PUT',
preambleCRLF: true,
postambleCRLF: true,
uri: 'http://service.com/upload',
multipart: [
{
'content-type': 'application/json',
body: JSON.stringify({foo: 'bar', _attachments: {'message.txt': {follows: true, length: 18, 'content_type': 'text/plain' }}})
},
{ body: 'I am an attachment' },
{ body: fs.createReadStream('image.png') }
],
// alternatively pass an object containing additional options
multipart: {
chunked: false,
data: [
{
'content-type': 'application/json',
body: JSON.stringify({foo: 'bar', _attachments: {'message.txt': {follows: true, length: 18, 'content_type': 'text/plain' }}})
},
{ body: 'I am an attachment' }
]
}
},
function (error, response, body) {
if (error) {
return console.error('upload failed:', error);
}
console.log('Upload successful! Server responded with:', body);
})
```
[back to top](#table-of-contents)
---
## HTTP Authentication
```js
request.get('http://some.server.com/').auth('username', 'password', false);
// or
request.get('http://some.server.com/', {
'auth': {
'user': 'username',
'pass': 'password',
'sendImmediately': false
}
});
// or
request.get('http://some.server.com/').auth(null, null, true, 'bearerToken');
// or
request.get('http://some.server.com/', {
'auth': {
'bearer': 'bearerToken'
}
});
```
If passed as an option, `auth` should be a hash containing values:
- `user` || `username`
- `pass` || `password`
- `sendImmediately` (optional)
- `bearer` (optional)
The method form takes parameters
`auth(username, password, sendImmediately, bearer)`.
`sendImmediately` defaults to `true`, which causes a basic or bearer
authentication header to be sent. If `sendImmediately` is `false`, then
`request` will retry with a proper authentication header after receiving a
`401` response from the server (which must contain a `WWW-Authenticate` header
indicating the required authentication method).
Note that you can also specify basic authentication using the URL itself, as
detailed in [RFC 1738](http://www.ietf.org/rfc/rfc1738.txt). Simply pass the
`user:password` before the host with an `@` sign:
```js
const username = 'username',
password = 'password',
url = 'http://' + username + ':' + password + '@some.server.com';
request({url}, function (error, response, body) {
// Do more stuff with 'body' here
});
```
Digest authentication is supported, but it only works with `sendImmediately`
set to `false`; otherwise `request` will send basic authentication on the
initial request, which will probably cause the request to fail.
Bearer authentication is supported, and is activated when the `bearer` value is
available. The value may be either a `String` or a `Function` returning a
`String`. Using a function to supply the bearer token is particularly useful if
used in conjunction with `defaults` to allow a single function to supply the
last known token at the time of sending a request, or to compute one on the fly.
[back to top](#table-of-contents)
---
## Custom HTTP Headers
HTTP Headers, such as `User-Agent`, can be set in the `options` object.
In the example below, we call the github API to find out the number
of stars and forks for the request repository. This requires a
custom `User-Agent` header as well as https.
```js
const request = require('request');
const options = {
url: 'https://api.github.com/repos/request/request',
headers: {
'User-Agent': 'request'
}
};
function callback(error, response, body) {
if (!error && response.statusCode == 200) {
const info = JSON.parse(body);
console.log(info.stargazers_count + " Stars");
console.log(info.forks_count + " Forks");
}
}
request(options, callback);
```
[back to top](#table-of-contents)
---
## OAuth Signing
[OAuth version 1.0](https://tools.ietf.org/html/rfc5849) is supported. The
default signing algorithm is
[HMAC-SHA1](https://tools.ietf.org/html/rfc5849#section-3.4.2):
```js
// OAuth1.0 - 3-legged server side flow (Twitter example)
// step 1
const qs = require('querystring')
, oauth =
{ callback: 'http://mysite.com/callback/'
, consumer_key: CONSUMER_KEY
, consumer_secret: CONSUMER_SECRET
}
, url = 'https://api.twitter.com/oauth/request_token'
;
request.post({url:url, oauth:oauth}, function (e, r, body) {
// Ideally, you would take the body in the response
// and construct a URL that a user clicks on (like a sign in button).
// The verifier is only available in the response after a user has
// verified with twitter that they are authorizing your app.
// step 2
const req_data = qs.parse(body)
const uri = 'https://api.twitter.com/oauth/authenticate'
+ '?' + qs.stringify({oauth_token: req_data.oauth_token})
// redirect the user to the authorize uri
// step 3
// after the user is redirected back to your server
const auth_data = qs.parse(body)
, oauth =
{ consumer_key: CONSUMER_KEY
, consumer_secret: CONSUMER_SECRET
, token: auth_data.oauth_token
, token_secret: req_data.oauth_token_secret
, verifier: auth_data.oauth_verifier
}
, url = 'https://api.twitter.com/oauth/access_token'
;
request.post({url:url, oauth:oauth}, function (e, r, body) {
// ready to make signed requests on behalf of the user
const perm_data = qs.parse(body)
, oauth =
{ consumer_key: CONSUMER_KEY
, consumer_secret: CONSUMER_SECRET
, token: perm_data.oauth_token
, token_secret: perm_data.oauth_token_secret
}
, url = 'https://api.twitter.com/1.1/users/show.json'
, qs =
{ screen_name: perm_data.screen_name
, user_id: perm_data.user_id
}
;
request.get({url:url, oauth:oauth, qs:qs, json:true}, function (e, r, user) {
console.log(user)
})
})
})
```
For [RSA-SHA1 signing](https://tools.ietf.org/html/rfc5849#section-3.4.3), make
the following changes to the OAuth options object:
* Pass `signature_method : 'RSA-SHA1'`
* Instead of `consumer_secret`, specify a `private_key` string in
[PEM format](http://how2ssl.com/articles/working_with_pem_files/)
For [PLAINTEXT signing](http://oauth.net/core/1.0/#anchor22), make
the following changes to the OAuth options object:
* Pass `signature_method : 'PLAINTEXT'`
To send OAuth parameters via query params or in a post body as described in The
[Consumer Request Parameters](http://oauth.net/core/1.0/#consumer_req_param)
section of the oauth1 spec:
* Pass `transport_method : 'query'` or `transport_method : 'body'` in the OAuth
options object.
* `transport_method` defaults to `'header'`
To use [Request Body Hash](https://oauth.googlecode.com/svn/spec/ext/body_hash/1.0/oauth-bodyhash.html) you can either
* Manually generate the body hash and pass it as a string `body_hash: '...'`
* Automatically generate the body hash by passing `body_hash: true`
[back to top](#table-of-contents)
---
## Proxies
If you specify a `proxy` option, then the request (and any subsequent
redirects) will be sent via a connection to the proxy server.
If your endpoint is an `https` url, and you are using a proxy, then
request will send a `CONNECT` request to the proxy server *first*, and
then use the supplied connection to connect to the endpoint.
That is, first it will make a request like:
```
HTTP/1.1 CONNECT endpoint-server.com:80
Host: proxy-server.com
User-Agent: whatever user agent you specify
```
and then the proxy server make a TCP connection to `endpoint-server`
on port `80`, and return a response that looks like:
```
HTTP/1.1 200 OK
```
At this point, the connection is left open, and the client is
communicating directly with the `endpoint-server.com` machine.
See [the wikipedia page on HTTP Tunneling](https://en.wikipedia.org/wiki/HTTP_tunnel)
for more information.
By default, when proxying `http` traffic, request will simply make a
standard proxied `http` request. This is done by making the `url`
section of the initial line of the request a fully qualified url to
the endpoint.
For example, it will make a single request that looks like:
```
HTTP/1.1 GET http://endpoint-server.com/some-url
Host: proxy-server.com
Other-Headers: all go here
request body or whatever
```
Because a pure "http over http" tunnel offers no additional security
or other features, it is generally simpler to go with a
straightforward HTTP proxy in this case. However, if you would like
to force a tunneling proxy, you may set the `tunnel` option to `true`.
You can also make a standard proxied `http` request by explicitly setting
`tunnel : false`, but **note that this will allow the proxy to see the traffic
to/from the destination server**.
If you are using a tunneling proxy, you may set the
`proxyHeaderWhiteList` to share certain headers with the proxy.
You can also set the `proxyHeaderExclusiveList` to share certain
headers only with the proxy and not with destination host.
By default, this set is:
```
accept
accept-charset
accept-encoding
accept-language
accept-ranges
cache-control
content-encoding
content-language
content-length
content-location
content-md5
content-range
content-type
connection
date
expect
max-forwards
pragma
proxy-authorization
referer
te
transfer-encoding
user-agent
via
```
Note that, when using a tunneling proxy, the `proxy-authorization`
header and any headers from custom `proxyHeaderExclusiveList` are
*never* sent to the endpoint server, but only to the proxy server.
### Controlling proxy behaviour using environment variables
The following environment variables are respected by `request`:
* `HTTP_PROXY` / `http_proxy`
* `HTTPS_PROXY` / `https_proxy`
* `NO_PROXY` / `no_proxy`
When `HTTP_PROXY` / `http_proxy` are set, they will be used to proxy non-SSL requests that do not have an explicit `proxy` configuration option present. Similarly, `HTTPS_PROXY` / `https_proxy` will be respected for SSL requests that do not have an explicit `proxy` configuration option. It is valid to define a proxy in one of the environment variables, but then override it for a specific request, using the `proxy` configuration option. Furthermore, the `proxy` configuration option can be explicitly set to false / null to opt out of proxying altogether for that request.
`request` is also aware of the `NO_PROXY`/`no_proxy` environment variables. These variables provide a granular way to opt out of proxying, on a per-host basis. It should contain a comma separated list of hosts to opt out of proxying. It is also possible to opt of proxying when a particular destination port is used. Finally, the variable may be set to `*` to opt out of the implicit proxy configuration of the other environment variables.
Here's some examples of valid `no_proxy` values:
* `google.com` - don't proxy HTTP/HTTPS requests to Google.
* `google.com:443` - don't proxy HTTPS requests to Google, but *do* proxy HTTP requests to Google.
* `google.com:443, yahoo.com:80` - don't proxy HTTPS requests to Google, and don't proxy HTTP requests to Yahoo!
* `*` - ignore `https_proxy`/`http_proxy` environment variables altogether.
[back to top](#table-of-contents)
---
## UNIX Domain Sockets
`request` supports making requests to [UNIX Domain Sockets](https://en.wikipedia.org/wiki/Unix_domain_socket). To make one, use the following URL scheme:
```js
/* Pattern */ 'http://unix:SOCKET:PATH'
/* Example */ request.get('http://unix:/absolute/path/to/unix.socket:/request/path')
```
Note: The `SOCKET` path is assumed to be absolute to the root of the host file system.
[back to top](#table-of-contents)
---
## TLS/SSL Protocol
TLS/SSL Protocol options, such as `cert`, `key` and `passphrase`, can be
set directly in `options` object, in the `agentOptions` property of the `options` object, or even in `https.globalAgent.options`. Keep in mind that, although `agentOptions` allows for a slightly wider range of configurations, the recommended way is via `options` object directly, as using `agentOptions` or `https.globalAgent.options` would not be applied in the same way in proxied environments (as data travels through a TLS connection instead of an http/https agent).
```js
const fs = require('fs')
, path = require('path')
, certFile = path.resolve(__dirname, 'ssl/client.crt')
, keyFile = path.resolve(__dirname, 'ssl/client.key')
, caFile = path.resolve(__dirname, 'ssl/ca.cert.pem')
, request = require('request');
const options = {
url: 'https://api.some-server.com/',
cert: fs.readFileSync(certFile),
key: fs.readFileSync(keyFile),
passphrase: 'password',
ca: fs.readFileSync(caFile)
};
request.get(options);
```
### Using `options.agentOptions`
In the example below, we call an API that requires client side SSL certificate
(in PEM format) with passphrase protected private key (in PEM format) and disable the SSLv3 protocol:
```js
const fs = require('fs')
, path = require('path')
, certFile = path.resolve(__dirname, 'ssl/client.crt')
, keyFile = path.resolve(__dirname, 'ssl/client.key')
, request = require('request');
const options = {
url: 'https://api.some-server.com/',
agentOptions: {
cert: fs.readFileSync(certFile),
key: fs.readFileSync(keyFile),
// Or use `pfx` property replacing `cert` and `key` when using private key, certificate and CA certs in PFX or PKCS12 format:
// pfx: fs.readFileSync(pfxFilePath),
passphrase: 'password',
securityOptions: 'SSL_OP_NO_SSLv3'
}
};
request.get(options);
```
It is able to force using SSLv3 only by specifying `secureProtocol`:
```js
request.get({
url: 'https://api.some-server.com/',
agentOptions: {
secureProtocol: 'SSLv3_method'
}
});
```
It is possible to accept other certificates than those signed by generally allowed Certificate Authorities (CAs).
This can be useful, for example, when using self-signed certificates.
To require a different root certificate, you can specify the signing CA by adding the contents of the CA's certificate file to the `agentOptions`.
The certificate the domain presents must be signed by the root certificate specified:
```js
request.get({
url: 'https://api.some-server.com/',
agentOptions: {
ca: fs.readFileSync('ca.cert.pem')
}
});
```
The `ca` value can be an array of certificates, in the event you have a private or internal corporate public-key infrastructure hierarchy. For example, if you want to connect to https://api.some-server.com which presents a key chain consisting of:
1. its own public key, which is signed by:
2. an intermediate "Corp Issuing Server", that is in turn signed by:
3. a root CA "Corp Root CA";
you can configure your request as follows:
```js
request.get({
url: 'https://api.some-server.com/',
agentOptions: {
ca: [
fs.readFileSync('Corp Issuing Server.pem'),
fs.readFileSync('Corp Root CA.pem')
]
}
});
```
[back to top](#table-of-contents)
---
## Support for HAR 1.2
The `options.har` property will override the values: `url`, `method`, `qs`, `headers`, `form`, `formData`, `body`, `json`, as well as construct multipart data and read files from disk when `request.postData.params[].fileName` is present without a matching `value`.
A validation step will check if the HAR Request format matches the latest spec (v1.2) and will skip parsing if not matching.
```js
const request = require('request')
request({
// will be ignored
method: 'GET',
uri: 'http://www.google.com',
// HTTP Archive Request Object
har: {
url: 'http://www.mockbin.com/har',
method: 'POST',
headers: [
{
name: 'content-type',
value: 'application/x-www-form-urlencoded'
}
],
postData: {
mimeType: 'application/x-www-form-urlencoded',
params: [
{
name: 'foo',
value: 'bar'
},
{
name: 'hello',
value: 'world'
}
]
}
}
})
// a POST request will be sent to http://www.mockbin.com
// with body an application/x-www-form-urlencoded body:
// foo=bar&hello=world
```
[back to top](#table-of-contents)
---
## request(options, callback)
The first argument can be either a `url` or an `options` object. The only required option is `uri`; all others are optional.
- `uri` || `url` - fully qualified uri or a parsed url object from `url.parse()`
- `baseUrl` - fully qualified uri string used as the base url. Most useful with `request.defaults`, for example when you want to do many requests to the same domain. If `baseUrl` is `https://example.com/api/`, then requesting `/end/point?test=true` will fetch `https://example.com/api/end/point?test=true`. When `baseUrl` is given, `uri` must also be a string.
- `method` - http method (default: `"GET"`)
- `headers` - http headers (default: `{}`)
---
- `qs` - object containing querystring values to be appended to the `uri`
- `qsParseOptions` - object containing options to pass to the [qs.parse](https://github.com/hapijs/qs#parsing-objects) method. Alternatively pass options to the [querystring.parse](https://nodejs.org/docs/v0.12.0/api/querystring.html#querystring_querystring_parse_str_sep_eq_options) method using this format `{sep:';', eq:':', options:{}}`
- `qsStringifyOptions` - object containing options to pass to the [qs.stringify](https://github.com/hapijs/qs#stringifying) method. Alternatively pass options to the [querystring.stringify](https://nodejs.org/docs/v0.12.0/api/querystring.html#querystring_querystring_stringify_obj_sep_eq_options) method using this format `{sep:';', eq:':', options:{}}`. For example, to change the way arrays are converted to query strings using the `qs` module pass the `arrayFormat` option with one of `indices|brackets|repeat`
- `useQuerystring` - if true, use `querystring` to stringify and parse
querystrings, otherwise use `qs` (default: `false`). Set this option to
`true` if you need arrays to be serialized as `foo=bar&foo=baz` instead of the
default `foo[0]=bar&foo[1]=baz`.
---
- `body` - entity body for PATCH, POST and PUT requests. Must be a `Buffer`, `String` or `ReadStream`. If `json` is `true`, then `body` must be a JSON-serializable object.
- `form` - when passed an object or a querystring, this sets `body` to a querystring representation of value, and adds `Content-type: application/x-www-form-urlencoded` header. When passed no options, a `FormData` instance is returned (and is piped to request). See "Forms" section above.
- `formData` - data to pass for a `multipart/form-data` request. See
[Forms](#forms) section above.
- `multipart` - array of objects which contain their own headers and `body`
attributes. Sends a `multipart/related` request. See [Forms](#forms) section
above.
- Alternatively you can pass in an object `{chunked: false, data: []}` where
`chunked` is used to specify whether the request is sent in
[chunked transfer encoding](https://en.wikipedia.org/wiki/Chunked_transfer_encoding)
In non-chunked requests, data items with body streams are not allowed.
- `preambleCRLF` - append a newline/CRLF before the boundary of your `multipart/form-data` request.
- `postambleCRLF` - append a newline/CRLF at the end of the boundary of your `multipart/form-data` request.
- `json` - sets `body` to JSON representation of value and adds `Content-type: application/json` header. Additionally, parses the response body as JSON.
- `jsonReviver` - a [reviver function](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse) that will be passed to `JSON.parse()` when parsing a JSON response body.
- `jsonReplacer` - a [replacer function](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify) that will be passed to `JSON.stringify()` when stringifying a JSON request body.
---
- `auth` - a hash containing values `user` || `username`, `pass` || `password`, and `sendImmediately` (optional). See documentation above.
- `oauth` - options for OAuth HMAC-SHA1 signing. See documentation above.
- `hawk` - options for [Hawk signing](https://github.com/hueniverse/hawk). The `credentials` key must contain the necessary signing info, [see hawk docs for details](https://github.com/hueniverse/hawk#usage-example).
- `aws` - `object` containing AWS signing information. Should have the properties `key`, `secret`, and optionally `session` (note that this only works for services that require session as part of the canonical string). Also requires the property `bucket`, unless you’re specifying your `bucket` as part of the path, or the request doesn’t use a bucket (i.e. GET Services). If you want to use AWS sign version 4 use the parameter `sign_version` with value `4` otherwise the default is version 2. If you are using SigV4, you can also include a `service` property that specifies the service name. **Note:** you need to `npm install aws4` first.
- `httpSignature` - options for the [HTTP Signature Scheme](https://github.com/joyent/node-http-signature/blob/master/http_signing.md) using [Joyent's library](https://github.com/joyent/node-http-signature). The `keyId` and `key` properties must be specified. See the docs for other options.
---
- `followRedirect` - follow HTTP 3xx responses as redirects (default: `true`). This property can also be implemented as function which gets `response` object as a single argument and should return `true` if redirects should continue or `false` otherwise.
- `followAllRedirects` - follow non-GET HTTP 3xx responses as redirects (default: `false`)
- `followOriginalHttpMethod` - by default we redirect to HTTP method GET. you can enable this property to redirect to the original HTTP method (default: `false`)
- `maxRedirects` - the maximum number of redirects to follow (default: `10`)
- `removeRefererHeader` - removes the referer header when a redirect happens (default: `false`). **Note:** if true, referer header set in the initial request is preserved during redirect chain.
---
- `encoding` - encoding to be used on `setEncoding` of response data. If `null`, the `body` is returned as a `Buffer`. Anything else **(including the default value of `undefined`)** will be passed as the [encoding](http://nodejs.org/api/buffer.html#buffer_buffer) parameter to `toString()` (meaning this is effectively `utf8` by default). (**Note:** if you expect binary data, you should set `encoding: null`.)
- `gzip` - if `true`, add an `Accept-Encoding` header to request compressed content encodings from the server (if not already present) and decode supported content encodings in the response. **Note:** Automatic decoding of the response content is performed on the body data returned through `request` (both through the `request` stream and passed to the callback function) but is not performed on the `response` stream (available from the `response` event) which is the unmodified `http.IncomingMessage` object which may contain compressed data. See example below.
- `jar` - if `true`, remember cookies for future use (or define your custom cookie jar; see examples section)
---
- `agent` - `http(s).Agent` instance to use
- `agentClass` - alternatively specify your agent's class name
- `agentOptions` - and pass its options. **Note:** for HTTPS see [tls API doc for TLS/SSL options](http://nodejs.org/api/tls.html#tls_tls_connect_options_callback) and the [documentation above](#using-optionsagentoptions).
- `forever` - set to `true` to use the [forever-agent](https://github.com/request/forever-agent) **Note:** Defaults to `http(s).Agent({keepAlive:true})` in node 0.12+
- `pool` - an object describing which agents to use for the request. If this option is omitted the request will use the global agent (as long as your options allow for it). Otherwise, request will search the pool for your custom agent. If no custom agent is found, a new agent will be created and added to the pool. **Note:** `pool` is used only when the `agent` option is not specified.
- A `maxSockets` property can also be provided on the `pool` object to set the max number of sockets for all agents created (ex: `pool: {maxSockets: Infinity}`).
- Note that if you are sending multiple requests in a loop and creating
multiple new `pool` objects, `maxSockets` will not work as intended. To
work around this, either use [`request.defaults`](#requestdefaultsoptions)
with your pool options or create the pool object with the `maxSockets`
property outside of the loop.
- `timeout` - integer containing number of milliseconds, controls two timeouts.
- **Read timeout**: Time to wait for a server to send response headers (and start the response body) before aborting the request.
- **Connection timeout**: Sets the socket to timeout after `timeout` milliseconds of inactivity. Note that increasing the timeout beyond the OS-wide TCP connection timeout will not have any effect ([the default in Linux can be anywhere from 20-120 seconds][linux-timeout])
[linux-timeout]: http://www.sekuda.com/overriding_the_default_linux_kernel_20_second_tcp_socket_connect_timeout
---
- `localAddress` - local interface to bind for network connections.
- `proxy` - an HTTP proxy to be used. Supports proxy Auth with Basic Auth, identical to support for the `url` parameter (by embedding the auth info in the `uri`)
- `strictSSL` - if `true`, requires SSL certificates be valid. **Note:** to use your own certificate authority, you need to specify an agent that was created with that CA as an option.
- `tunnel` - controls the behavior of
[HTTP `CONNECT` tunneling](https://en.wikipedia.org/wiki/HTTP_tunnel#HTTP_CONNECT_tunneling)
as follows:
- `undefined` (default) - `true` if the destination is `https`, `false` otherwise
- `true` - always tunnel to the destination by making a `CONNECT` request to
the proxy
- `false` - request the destination as a `GET` request.
- `proxyHeaderWhiteList` - a whitelist of headers to send to a
tunneling proxy.
- `proxyHeaderExclusiveList` - a whitelist of headers to send
exclusively to a tunneling proxy and not to destination.
---
- `time` - if `true`, the request-response cycle (including all redirects) is timed at millisecond resolution. When set, the following properties are added to the response object:
- `elapsedTime` Duration of the entire request/response in milliseconds (*deprecated*).
- `responseStartTime` Timestamp when the response began (in Unix Epoch milliseconds) (*deprecated*).
- `timingStart` Timestamp of the start of the request (in Unix Epoch milliseconds).
- `timings` Contains event timestamps in millisecond resolution relative to `timingStart`. If there were redirects, the properties reflect the timings of the final request in the redirect chain:
- `socket` Relative timestamp when the [`http`](https://nodejs.org/api/http.html#http_event_socket) module's `socket` event fires. This happens when the socket is assigned to the request.
- `lookup` Relative timestamp when the [`net`](https://nodejs.org/api/net.html#net_event_lookup) module's `lookup` event fires. This happens when the DNS has been resolved.
- `connect`: Relative timestamp when the [`net`](https://nodejs.org/api/net.html#net_event_connect) module's `connect` event fires. This happens when the server acknowledges the TCP connection.
- `response`: Relative timestamp when the [`http`](https://nodejs.org/api/http.html#http_event_response) module's `response` event fires. This happens when the first bytes are received from the server.
- `end`: Relative timestamp when the last bytes of the response are received.
- `timingPhases` Contains the durations of each request phase. If there were redirects, the properties reflect the timings of the final request in the redirect chain:
- `wait`: Duration of socket initialization (`timings.socket`)
- `dns`: Duration of DNS lookup (`timings.lookup` - `timings.socket`)
- `tcp`: Duration of TCP connection (`timings.connect` - `timings.socket`)
- `firstByte`: Duration of HTTP server response (`timings.response` - `timings.connect`)
- `download`: Duration of HTTP download (`timings.end` - `timings.response`)
- `total`: Duration entire HTTP round-trip (`timings.end`)
- `har` - a [HAR 1.2 Request Object](http://www.softwareishard.com/blog/har-12-spec/#request), will be processed from HAR format into options overwriting matching values *(see the [HAR 1.2 section](#support-for-har-12) for details)*
- `callback` - alternatively pass the request's callback in the options object
The callback argument gets 3 arguments:
1. An `error` when applicable (usually from [`http.ClientRequest`](http://nodejs.org/api/http.html#http_class_http_clientrequest) object)
2. An [`http.IncomingMessage`](https://nodejs.org/api/http.html#http_class_http_incomingmessage) object (Response object)
3. The third is the `response` body (`String` or `Buffer`, or JSON object if the `json` option is supplied)
[back to top](#table-of-contents)
---
## Convenience methods
There are also shorthand methods for different HTTP METHODs and some other conveniences.
### request.defaults(options)
This method **returns a wrapper** around the normal request API that defaults
to whatever options you pass to it.
**Note:** `request.defaults()` **does not** modify the global request API;
instead, it **returns a wrapper** that has your default settings applied to it.
**Note:** You can call `.defaults()` on the wrapper that is returned from
`request.defaults` to add/override defaults that were previously defaulted.
For example:
```js
//requests using baseRequest() will set the 'x-token' header
const baseRequest = request.defaults({
headers: {'x-token': 'my-token'}
})
//requests using specialRequest() will include the 'x-token' header set in
//baseRequest and will also include the 'special' header
const specialRequest = baseRequest.defaults({
headers: {special: 'special value'}
})
```
### request.METHOD()
These HTTP method convenience functions act just like `request()` but with a default method already set for you:
- *request.get()*: Defaults to `method: "GET"`.
- *request.post()*: Defaults to `method: "POST"`.
- *request.put()*: Defaults to `method: "PUT"`.
- *request.patch()*: Defaults to `method: "PATCH"`.
- *request.del() / request.delete()*: Defaults to `method: "DELETE"`.
- *request.head()*: Defaults to `method: "HEAD"`.
- *request.options()*: Defaults to `method: "OPTIONS"`.
### request.cookie()
Function that creates a new cookie.
```js
request.cookie('key1=value1')
```
### request.jar()
Function that creates a new cookie jar.
```js
request.jar()
```
### response.caseless.get('header-name')
Function that returns the specified response header field using a [case-insensitive match](https://tools.ietf.org/html/rfc7230#section-3.2)
```js
request('http://www.google.com', function (error, response, body) {
// print the Content-Type header even if the server returned it as 'content-type' (lowercase)
console.log('Content-Type is:', response.caseless.get('Content-Type'));
});
```
[back to top](#table-of-contents)
---
## Debugging
There are at least three ways to debug the operation of `request`:
1. Launch the node process like `NODE_DEBUG=request node script.js`
(`lib,request,otherlib` works too).
2. Set `require('request').debug = true` at any time (this does the same thing
as #1).
3. Use the [request-debug module](https://github.com/request/request-debug) to
view request and response headers and bodies.
[back to top](#table-of-contents)
---
## Timeouts
Most requests to external servers should have a timeout attached, in case the
server is not responding in a timely manner. Without a timeout, your code may
have a socket open/consume resources for minutes or more.
There are two main types of timeouts: **connection timeouts** and **read
timeouts**. A connect timeout occurs if the timeout is hit while your client is
attempting to establish a connection to a remote machine (corresponding to the
[connect() call][connect] on the socket). A read timeout occurs any time the
server is too slow to send back a part of the response.
These two situations have widely different implications for what went wrong
with the request, so it's useful to be able to distinguish them. You can detect
timeout errors by checking `err.code` for an 'ETIMEDOUT' value. Further, you
can detect whether the timeout was a connection timeout by checking if the
`err.connect` property is set to `true`.
```js
request.get('http://10.255.255.1', {timeout: 1500}, function(err) {
console.log(err.code === 'ETIMEDOUT');
// Set to `true` if the timeout was a connection timeout, `false` or
// `undefined` otherwise.
console.log(err.connect === true);
process.exit(0);
});
```
[connect]: http://linux.die.net/man/2/connect
## Examples:
```js
const request = require('request')
, rand = Math.floor(Math.random()*100000000).toString()
;
request(
{ method: 'PUT'
, uri: 'http://mikeal.iriscouch.com/testjs/' + rand
, multipart:
[ { 'content-type': 'application/json'
, body: JSON.stringify({foo: 'bar', _attachments: {'message.txt': {follows: true, length: 18, 'content_type': 'text/plain' }}})
}
, { body: 'I am an attachment' }
]
}
, function (error, response, body) {
if(response.statusCode == 201){
console.log('document saved as: http://mikeal.iriscouch.com/testjs/'+ rand)
} else {
console.log('error: '+ response.statusCode)
console.log(body)
}
}
)
```
For backwards-compatibility, response compression is not supported by default.
To accept gzip-compressed responses, set the `gzip` option to `true`. Note
that the body data passed through `request` is automatically decompressed
while the response object is unmodified and will contain compressed data if
the server sent a compressed response.
```js
const request = require('request')
request(
{ method: 'GET'
, uri: 'http://www.google.com'
, gzip: true
}
, function (error, response, body) {
// body is the decompressed response body
console.log('server encoded the data as: ' + (response.headers['content-encoding'] || 'identity'))
console.log('the decoded data is: ' + body)
}
)
.on('data', function(data) {
// decompressed data as it is received
console.log('decoded chunk: ' + data)
})
.on('response', function(response) {
// unmodified http.IncomingMessage object
response.on('data', function(data) {
// compressed data as it is received
console.log('received ' + data.length + ' bytes of compressed data')
})
})
```
Cookies are disabled by default (else, they would be used in subsequent requests). To enable cookies, set `jar` to `true` (either in `defaults` or `options`).
```js
const request = request.defaults({jar: true})
request('http://www.google.com', function () {
request('http://images.google.com')
})
```
To use a custom cookie jar (instead of `request`’s global cookie jar), set `jar` to an instance of `request.jar()` (either in `defaults` or `options`)
```js
const j = request.jar()
const request = request.defaults({jar:j})
request('http://www.google.com', function () {
request('http://images.google.com')
})
```
OR
```js
const j = request.jar();
const cookie = request.cookie('key1=value1');
const url = 'http://www.google.com';
j.setCookie(cookie, url);
request({url: url, jar: j}, function () {
request('http://images.google.com')
})
```
To use a custom cookie store (such as a
[`FileCookieStore`](https://github.com/mitsuru/tough-cookie-filestore)
which supports saving to and restoring from JSON files), pass it as a parameter
to `request.jar()`:
```js
const FileCookieStore = require('tough-cookie-filestore');
// NOTE - currently the 'cookies.json' file must already exist!
const j = request.jar(new FileCookieStore('cookies.json'));
request = request.defaults({ jar : j })
request('http://www.google.com', function() {
request('http://images.google.com')
})
```
The cookie store must be a
[`tough-cookie`](https://github.com/SalesforceEng/tough-cookie)
store and it must support synchronous operations; see the
[`CookieStore` API docs](https://github.com/SalesforceEng/tough-cookie#api)
for details.
To inspect your cookie jar after a request:
```js
const j = request.jar()
request({url: 'http://www.google.com', jar: j}, function () {
const cookie_string = j.getCookieString(url); // "key1=value1; key2=value2; ..."
const cookies = j.getCookies(url);
// [{key: 'key1', value: 'value1', domain: "www.google.com", ...}, ...]
})
```
[back to top](#table-of-contents)
# EventEmitter3
[](https://www.npmjs.com/package/eventemitter3)[](https://travis-ci.org/primus/eventemitter3)[](https://david-dm.org/primus/eventemitter3)[](https://coveralls.io/r/primus/eventemitter3?branch=master)[](https://webchat.freenode.net/?channels=primus)
[](https://saucelabs.com/u/eventemitter3)
EventEmitter3 is a high performance EventEmitter. It has been micro-optimized
for various of code paths making this, one of, if not the fastest EventEmitter
available for Node.js and browsers. The module is API compatible with the
EventEmitter that ships by default with Node.js but there are some slight
differences:
- Domain support has been removed.
- We do not `throw` an error when you emit an `error` event and nobody is
listening.
- The `newListener` and `removeListener` events have been removed as they
are useful only in some uncommon use-cases.
- The `setMaxListeners`, `getMaxListeners`, `prependListener` and
`prependOnceListener` methods are not available.
- Support for custom context for events so there is no need to use `fn.bind`.
- The `removeListener` method removes all matching listeners, not only the
first.
It's a drop in replacement for existing EventEmitters, but just faster. Free
performance, who wouldn't want that? The EventEmitter is written in EcmaScript 3
so it will work in the oldest browsers and node versions that you need to
support.
## Installation
```bash
$ npm install --save eventemitter3
```
## CDN
Recommended CDN:
```text
https://unpkg.com/eventemitter3@latest/umd/eventemitter3.min.js
```
## Usage
After installation the only thing you need to do is require the module:
```js
var EventEmitter = require('eventemitter3');
```
And you're ready to create your own EventEmitter instances. For the API
documentation, please follow the official Node.js documentation:
http://nodejs.org/api/events.html
### Contextual emits
We've upgraded the API of the `EventEmitter.on`, `EventEmitter.once` and
`EventEmitter.removeListener` to accept an extra argument which is the `context`
or `this` value that should be set for the emitted events. This means you no
longer have the overhead of an event that required `fn.bind` in order to get a
custom `this` value.
```js
var EE = new EventEmitter()
, context = { foo: 'bar' };
function emitted() {
console.log(this === context); // true
}
EE.once('event-name', emitted, context);
EE.on('another-event', emitted, context);
EE.removeListener('another-event', emitted, context);
```
### Tests and benchmarks
This module is well tested. You can run:
- `npm test` to run the tests under Node.js.
- `npm run test-browser` to run the tests in real browsers via Sauce Labs.
We also have a set of benchmarks to compare EventEmitter3 with some available
alternatives. To run the benchmarks run `npm run benchmark`.
Tests and benchmarks are not included in the npm package. If you want to play
with them you have to clone the GitHub repository.
Note that you will have to run an additional `npm i` in the benchmarks folder
before `npm run benchmark`.
## License
[MIT](LICENSE)
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# js-sha3
[](https://travis-ci.org/emn178/js-sha3)
[](https://coveralls.io/r/emn178/js-sha3?branch=master)
[](https://nodei.co/npm/js-sha3/)
A simple SHA-3 / Keccak / Shake hash function for JavaScript supports UTF-8 encoding.
## Notice
* Sha3 methods has been renamed to keccak since v0.2.0. It means that sha3 methods of v0.1.x are equal to keccak methods of v0.2.x and later.
* `buffer` method is deprecated. This maybe confuse with Buffer in node.js. Please use `arrayBuffer` instead.
## Demo
[SHA3-512 Online](http://emn178.github.io/online-tools/sha3_512.html)
[SHA3-384 Online](http://emn178.github.io/online-tools/sha3_384.html)
[SHA3-256 Online](http://emn178.github.io/online-tools/sha3_256.html)
[SHA3-224 Online](http://emn178.github.io/online-tools/sha3_224.html)
[Keccak-512 Online](http://emn178.github.io/online-tools/keccak_512.html)
[Keccak-384 Online](http://emn178.github.io/online-tools/keccak_384.html)
[Keccak-256 Online](http://emn178.github.io/online-tools/keccak_256.html)
[Keccak-224 Online](http://emn178.github.io/online-tools/keccak_224.html)
[Shake-128 Online](http://emn178.github.io/online-tools/shake_128.html)
[Shake-256 Online](http://emn178.github.io/online-tools/shake_256.html)
## Download
[Compress](https://raw.github.com/emn178/js-sha3/master/build/sha3.min.js)
[Uncompress](https://raw.github.com/emn178/js-sha3/master/src/sha3.js)
## Installation
You can also install js-sha3 by using Bower.
bower install js-sha3
For node.js, you can use this command to install:
npm install js-sha3
## Usage
You could use like this:
```JavaScript
sha3_512('Message to hash');
sha3_384('Message to hash');
sha3_256('Message to hash');
sha3_224('Message to hash');
keccak_512('Message to hash');
keccak_384('Message to hash');
keccak_256('Message to hash');
keccak_224('Message to hash');
shake_128('Message to hash', 256);
shake_256('Message to hash', 512);
// Support ArrayBuffer output
var buffer = keccak_224.buffer('Message to hash');
// Support Array output
var buffer = keccak_224.array('Message to hash');
// update hash
sha3_512.update('Message ').update('to ').update('hash').hex();
// specify shake output bits at first update
shake_128.update('Message ', 256).update('to ').update('hash').hex();
// or to use create
var hash = sha3_512.create();
hash.update('...');
hash.update('...');
hash.hex();
// specify shake output bits when creating
var hash = shake_128.create(256);
hash.update('...');
hash.update('...');
hash.hex();
```
If you use node.js, you should require the module first:
```JavaScript
sha3_512 = require('js-sha3').sha3_512;
sha3_384 = require('js-sha3').sha3_384;
sha3_256 = require('js-sha3').sha3_256;
sha3_224 = require('js-sha3').sha3_224;
keccak_512 = require('js-sha3').keccak_512;
keccak_384 = require('js-sha3').keccak_384;
keccak_256 = require('js-sha3').keccak_256;
keccak_224 = require('js-sha3').keccak_224;
shake_128 = require('js-sha3').shake_128;
shake_256 = require('js-sha3').shake_256;
```
If you use TypeScript, you can import like this:
```TypeScript
import { sha3_512 } from 'js-sha3';
```
## Example
Code
```JavaScript
sha3_512('');
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
sha3_512('The quick brown fox jumps over the lazy dog');
// 01dedd5de4ef14642445ba5f5b97c15e47b9ad931326e4b0727cd94cefc44fff23f07bf543139939b49128caf436dc1bdee54fcb24023a08d9403f9b4bf0d450
sha3_512('The quick brown fox jumps over the lazy dog.');
// 18f4f4bd419603f95538837003d9d254c26c23765565162247483f65c50303597bc9ce4d289f21d1c2f1f458828e33dc442100331b35e7eb031b5d38ba6460f8
sha3_384('');
// 0c63a75b845e4f7d01107d852e4c2485c51a50aaaa94fc61995e71bbee983a2ac3713831264adb47fb6bd1e058d5f004
sha3_384('The quick brown fox jumps over the lazy dog');
// 7063465e08a93bce31cd89d2e3ca8f602498696e253592ed26f07bf7e703cf328581e1471a7ba7ab119b1a9ebdf8be41
sha3_384('The quick brown fox jumps over the lazy dog.');
// 1a34d81695b622df178bc74df7124fe12fac0f64ba5250b78b99c1273d4b080168e10652894ecad5f1f4d5b965437fb9
sha3_256('');
// a7ffc6f8bf1ed76651c14756a061d662f580ff4de43b49fa82d80a4b80f8434a
sha3_256('The quick brown fox jumps over the lazy dog');
// 69070dda01975c8c120c3aada1b282394e7f032fa9cf32f4cb2259a0897dfc04
sha3_256('The quick brown fox jumps over the lazy dog.');
// a80f839cd4f83f6c3dafc87feae470045e4eb0d366397d5c6ce34ba1739f734d
sha3_224('');
// 6b4e03423667dbb73b6e15454f0eb1abd4597f9a1b078e3f5b5a6bc7
sha3_224('The quick brown fox jumps over the lazy dog');
// d15dadceaa4d5d7bb3b48f446421d542e08ad8887305e28d58335795
sha3_224('The quick brown fox jumps over the lazy dog.');
// 2d0708903833afabdd232a20201176e8b58c5be8a6fe74265ac54db0
keccak_512('');
// 0eab42de4c3ceb9235fc91acffe746b29c29a8c366b7c60e4e67c466f36a4304c00fa9caf9d87976ba469bcbe06713b435f091ef2769fb160cdab33d3670680e
keccak_512('The quick brown fox jumps over the lazy dog');
// d135bb84d0439dbac432247ee573a23ea7d3c9deb2a968eb31d47c4fb45f1ef4422d6c531b5b9bd6f449ebcc449ea94d0a8f05f62130fda612da53c79659f609
keccak_512('The quick brown fox jumps over the lazy dog.');
// ab7192d2b11f51c7dd744e7b3441febf397ca07bf812cceae122ca4ded6387889064f8db9230f173f6d1ab6e24b6e50f065b039f799f5592360a6558eb52d760
keccak_384('');
// 2c23146a63a29acf99e73b88f8c24eaa7dc60aa771780ccc006afbfa8fe2479b2dd2b21362337441ac12b515911957ff
keccak_384('The quick brown fox jumps over the lazy dog');
// 283990fa9d5fb731d786c5bbee94ea4db4910f18c62c03d173fc0a5e494422e8a0b3da7574dae7fa0baf005e504063b3
keccak_384('The quick brown fox jumps over the lazy dog.');
// 9ad8e17325408eddb6edee6147f13856ad819bb7532668b605a24a2d958f88bd5c169e56dc4b2f89ffd325f6006d820b
keccak_256('');
// c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470
keccak_256('The quick brown fox jumps over the lazy dog');
// 4d741b6f1eb29cb2a9b9911c82f56fa8d73b04959d3d9d222895df6c0b28aa15
keccak_256('The quick brown fox jumps over the lazy dog.');
// 578951e24efd62a3d63a86f7cd19aaa53c898fe287d2552133220370240b572d
keccak_224('');
// f71837502ba8e10837bdd8d365adb85591895602fc552b48b7390abd
keccak_224('The quick brown fox jumps over the lazy dog');
// 310aee6b30c47350576ac2873fa89fd190cdc488442f3ef654cf23fe
keccak_224('The quick brown fox jumps over the lazy dog.');
// c59d4eaeac728671c635ff645014e2afa935bebffdb5fbd207ffdeab
shake_128('', 256);
// 7f9c2ba4e88f827d616045507605853ed73b8093f6efbc88eb1a6eacfa66ef26
shake_256('', 512);
// 46b9dd2b0ba88d13233b3feb743eeb243fcd52ea62b81b82b50c27646ed5762fd75dc4ddd8c0f200cb05019d67b592f6fc821c49479ab48640292eacb3b7c4be
```
It also supports UTF-8 encoding:
Code
```JavaScript
sha3_512('中文');
// 059bbe2efc50cc30e4d8ec5a96be697e2108fcbf9193e1296192eddabc13b143c0120d059399a13d0d42651efe23a6c1ce2d1efb576c5b207fa2516050505af7
sha3_384('中文');
// 9fb5b99e3c546f2738dcd50a14e9aef9c313800c1bf8cf76bc9b2c3a23307841364c5a2d0794702662c5796fb72f5432
sha3_256('中文');
// ac5305da3d18be1aed44aa7c70ea548da243a59a5fd546f489348fd5718fb1a0
sha3_224('中文');
// 106d169e10b61c2a2a05554d3e631ec94467f8316640f29545d163ee
keccak_512('中文');
// 2f6a1bd50562230229af34b0ccf46b8754b89d23ae2c5bf7840b4acfcef86f87395edc0a00b2bfef53bafebe3b79de2e3e01cbd8169ddbb08bde888dcc893524
keccak_384('中文');
// 743f64bb7544c6ed923be4741b738dde18b7cee384a3a09c4e01acaaac9f19222cdee137702bd3aa05dc198373d87d6c
keccak_256('中文');
// 70a2b6579047f0a977fcb5e9120a4e07067bea9abb6916fbc2d13ffb9a4e4eee
keccak_224('中文');
// f71837502ba8e10837bdd8d365adb85591895602fc552b48b7390abd
```
It also supports byte `Array`, `Uint8Array`, `ArrayBuffer` input:
Code
```JavaScript
sha3_512([]);
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
sha3_512(new Uint8Array([]));
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
// ...
```
## Benchmark
[UTF8](http://jsperf.com/sha3/5)
[ASCII](http://jsperf.com/sha3/4)
## License
The project is released under the [MIT license](http://www.opensource.org/licenses/MIT).
## Contact
The project's website is located at https://github.com/emn178/js-sha3
Author: Chen, Yi-Cyuan ([email protected])
# deferred-leveldown
> A mock `abstract-leveldown` implementation that queues operations while a real `abstract-leveldown` instance is being opened.
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/deferred-leveldown)

[](https://travis-ci.org/Level/deferred-leveldown)
[](https://david-dm.org/level/deferred-leveldown)
[](https://standardjs.com)
[](https://www.npmjs.com/package/deferred-leveldown)
`deferred-leveldown` implements the basic [abstract-leveldown](https://github.com/Level/abstract-leveldown) API so it can be used as a drop-in replacement where `leveldown` is needed.
`put()`, `get()`, `del()` and `batch()` operations are all queued and kept in memory until the `abstract-leveldown`-compatible object has been opened through `deferred-leveldown`'s `open()` method.
`batch()` operations will all be replayed as the array form. Chained-batch operations are converted before being stored.
```js
const deferred = require('deferred-leveldown')
const leveldown = require('leveldown')
const db = deferred(leveldown('location'))
db.put('foo', 'bar', function (err) {
})
db.open(function (err) {
// ...
})
```
**If you are upgrading:** please see [UPGRADING.md](UPGRADING.md).
## Contributing
`deferred-leveldown` is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [CONTRIBUTING.md](https://github.com/Level/community/blob/master/CONTRIBUTING.md) file for more details.
### Contributors
`deferred-leveldown` is only possible due to the excellent work of the following contributors:
<table><tbody>
<tr><th align="left">Rod Vagg</th><td><a href="https://github.com/rvagg">GitHub/rvagg</a></td><td><a href="http://twitter.com/rvagg">Twitter/@rvagg</a></td></tr>
<tr><th align="left">John Chesley</th><td><a href="https://github.com/chesles/">GitHub/chesles</a></td><td><a href="http://twitter.com/chesles">Twitter/@chesles</a></td></tr>
<tr><th align="left">Jake Verbaten</th><td><a href="https://github.com/raynos">GitHub/raynos</a></td><td><a href="http://twitter.com/raynos2">Twitter/@raynos2</a></td></tr>
<tr><th align="left">Dominic Tarr</th><td><a href="https://github.com/dominictarr">GitHub/dominictarr</a></td><td><a href="http://twitter.com/dominictarr">Twitter/@dominictarr</a></td></tr>
<tr><th align="left">Max Ogden</th><td><a href="https://github.com/maxogden">GitHub/maxogden</a></td><td><a href="http://twitter.com/maxogden">Twitter/@maxogden</a></td></tr>
<tr><th align="left">Lars-Magnus Skog</th><td><a href="https://github.com/ralphtheninja">GitHub/ralphtheninja</a></td><td><a href="http://twitter.com/ralphtheninja">Twitter/@ralphtheninja</a></td></tr>
<tr><th align="left">David Björklund</th><td><a href="https://github.com/kesla">GitHub/kesla</a></td><td><a href="http://twitter.com/david_bjorklund">Twitter/@david_bjorklund</a></td></tr>
<tr><th align="left">Julian Gruber</th><td><a href="https://github.com/juliangruber">GitHub/juliangruber</a></td><td><a href="http://twitter.com/juliangruber">Twitter/@juliangruber</a></td></tr>
<tr><th align="left">Paolo Fragomeni</th><td><a href="https://github.com/hij1nx">GitHub/hij1nx</a></td><td><a href="http://twitter.com/hij1nx">Twitter/@hij1nx</a></td></tr>
<tr><th align="left">Anton Whalley</th><td><a href="https://github.com/No9">GitHub/No9</a></td><td><a href="https://twitter.com/antonwhalley">Twitter/@antonwhalley</a></td></tr>
<tr><th align="left">Matteo Collina</th><td><a href="https://github.com/mcollina">GitHub/mcollina</a></td><td><a href="https://twitter.com/matteocollina">Twitter/@matteocollina</a></td></tr>
<tr><th align="left">Pedro Teixeira</th><td><a href="https://github.com/pgte">GitHub/pgte</a></td><td><a href="https://twitter.com/pgte">Twitter/@pgte</a></td></tr>
<tr><th align="left">James Halliday</th><td><a href="https://github.com/substack">GitHub/substack</a></td><td><a href="https://twitter.com/substack">Twitter/@substack</a></td></tr>
</tbody></table>
## License
Copyright (c) 2013-2018 `deferred-leveldown` contributors (listed above).
`deferred-leveldown` is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included [LICENSE.md](LICENSE.md) file for more details.
[level-badge]: http://leveldb.org/img/badge.svg
# is-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/is-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/is-buffer
[npm-image]: https://img.shields.io/npm/v/is-buffer.svg
[npm-url]: https://npmjs.org/package/is-buffer
[downloads-image]: https://img.shields.io/npm/dm/is-buffer.svg
[downloads-url]: https://npmjs.org/package/is-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Determine if an object is a [`Buffer`](http://nodejs.org/api/buffer.html) (including the [browserify Buffer](https://github.com/feross/buffer))
[![saucelabs][saucelabs-image]][saucelabs-url]
[saucelabs-image]: https://saucelabs.com/browser-matrix/is-buffer.svg
[saucelabs-url]: https://saucelabs.com/u/is-buffer
## Why not use `Buffer.isBuffer`?
This module lets you check if an object is a `Buffer` without using `Buffer.isBuffer` (which includes the whole [buffer](https://github.com/feross/buffer) module in [browserify](http://browserify.org/)).
It's future-proof and works in node too!
## install
```bash
npm install is-buffer
```
## usage
```js
var isBuffer = require('is-buffer')
isBuffer(new Buffer(4)) // true
isBuffer(undefined) // false
isBuffer(null) // false
isBuffer('') // false
isBuffer(true) // false
isBuffer(false) // false
isBuffer(0) // false
isBuffer(1) // false
isBuffer(1.0) // false
isBuffer('string') // false
isBuffer({}) // false
isBuffer(function foo () {}) // false
```
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org).
# require-in-the-middle
Hook into the Node.js `require` function. This allows you to modify
modules on-the-fly as they are being required.
[](https://www.npmjs.com/package/require-in-the-middle)
[](https://travis-ci.org/elastic/require-in-the-middle)
[](https://github.com/feross/standard)
## Installation
```
npm install require-in-the-middle --save
```
## Usage
```js
const path = require('path')
const Hook = require('require-in-the-middle')
// Hook into the express and mongodb module
Hook(['express', 'mongodb'], function (exports, name, basedir) {
const version = require(path.join(basedir, 'package.json')).version
console.log('loading %s@%s', name, version)
// expose the module version as a property on its exports object
exports._version = version
// whatever you return will be returned by `require`
return exports
})
```
## API
The require-in-the-middle module exposes a single function:
### `hook = Hook([modules][, options], onrequire)`
When called a `hook` object is returned.
Arguments:
- `modules` <string[]> An optional array of module names to limit which modules
trigger a call of the `onrequire` callback. If specified, this must be the
first argument. Both regular modules (e.g. `react-dom`) and
sub-modules (e.g. `react-dom/server`) can be specified in the array.
- `options` <Object> An optional object containing fields that change when the
`onrequire` callback is called. If specified, this must be the second
argument.
- `options.internals` <boolean> Specifies whether `onrequire` should be called
when module-internal files are loaded; defaults to `false`.
- `onrequire` <Function> The function to call when a module is required.
The `onrequire` callback will be called the first time a module is
required. The function is called with three arguments:
- `exports` <Object> The value of the `module.exports` property that would
normally be exposed by the required module.
- `name` <string> The name of the module being required. If `options.internals`
was set to `true`, the path of module-internal files that are loaded
(relative to `basedir`) will be appended to the module name, separated by
`path.sep`.
- `basedir` <string> The directory where the module is located, or `undefined`
for core modules.
Return the value you want the module to expose (normally the `exports`
argument).
### `hook.unhook()`
Removes the `onrequire` callback so that it will not be triggerd by
subsequent calls to `require()`.
## License
[MIT](https://github.com/elastic/require-in-the-middle/blob/master/LICENSE)
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# promisfy
## description
this package is used for transform a node-style asynchronous function to a promise-style function. It's very handy if you are using async/await. After `v1.1.0`, you can also use it for a event callback.
a node-style asynchronous function should be like this:
```javascript
function asycFunction(arg1, arg2, callback) {
// do something
}
// callback should be like this
function callback(err, result) {
// do something
}
```
The first argument `err` represents whether the asynchronous call is failed(`null` while it's successful), and the second argument is the result of this call.
## install
```shell
npm install --save promisfy
```
## usage
very simple to use:
```javascript
const fs = require('fs');
const http = require('http');
const {promisfy, waitFor} = require('promisfy');
// using promisfy
// if you are using some some callbacks without error as its first argument,
// try promisfyNoError()
const readFile = promisfy(fs.readFile);
async function main() {
let content = await readFile('myfile.txt', {encoding:'utf8'});
return content;
}
main().then(function(content) {
console.log('myfile:');
console.log(content);
})
// using waitFor
// receive post data
http.createServer(80, function(req, res) {
async function handleRequest(req, res) {
if (req.method === 'POST') {
req.body = await waitFor(req.sock, 'data');
}
// now you can do something with req.body
}
})
```
Be attention, `waitFor` the `data` or `stream` event will make this function add listener to `data`, `end` and `error` events. All data will be returned only if there is no `error` event triggered and the `end` event is triggered. As for other event, only the second argument will be passed to the Promise
After v1.1.4, you can pass a context to the `promisfy` as its second argument. Context will be used as the context of `fn`, for example:
```javascript
function callback() {
console.log(this)
}
promisfy(fs.readFile, fs);
```
If your callback function expects more than just 2 arguments, the 2nd through nth arguments will be automatically bundled in an array when the promise resolves.
```javascript
foo(inputArg1, (error,responseArg1,responseArg2,responseArg3) => {})
```
can be promisfied like this:
```javascript
var [responseArg1,responseArg2,responseArg3] = await promisfy(foo)(inputArg1)
```
# web3
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is the main package of [web3.js][repo].
Please read the main [README][repo-readme] and [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[repo-readme]: https://github.com/ethereum/web3.js/blob/1.x/README.md
[npm-image]: https://img.shields.io/npm/v/web3.svg
[npm-url]: https://npmjs.org/package/web3
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3
# type-is
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Infer the content-type of a request.
### Install
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install type-is
```
## API
```js
var http = require('http')
var typeis = require('type-is')
http.createServer(function (req, res) {
var istext = typeis(req, ['text/*'])
res.end('you ' + (istext ? 'sent' : 'did not send') + ' me text')
})
```
### typeis(request, types)
Checks if the `request` is one of the `types`. If the request has no body,
even if there is a `Content-Type` header, then `null` is returned. If the
`Content-Type` header is invalid or does not matches any of the `types`, then
`false` is returned. Otherwise, a string of the type that matched is returned.
The `request` argument is expected to be a Node.js HTTP request. The `types`
argument is an array of type strings.
Each type in the `types` array can be one of the following:
- A file extension name such as `json`. This name will be returned if matched.
- A mime type such as `application/json`.
- A mime type with a wildcard such as `*/*` or `*/json` or `application/*`.
The full mime type will be returned if matched.
- A suffix such as `+json`. This can be combined with a wildcard such as
`*/vnd+json` or `application/*+json`. The full mime type will be returned
if matched.
Some examples to illustrate the inputs and returned value:
<!-- eslint-disable no-undef -->
```js
// req.headers.content-type = 'application/json'
typeis(req, ['json']) // => 'json'
typeis(req, ['html', 'json']) // => 'json'
typeis(req, ['application/*']) // => 'application/json'
typeis(req, ['application/json']) // => 'application/json'
typeis(req, ['html']) // => false
```
### typeis.hasBody(request)
Returns a Boolean if the given `request` has a body, regardless of the
`Content-Type` header.
Having a body has no relation to how large the body is (it may be 0 bytes).
This is similar to how file existence works. If a body does exist, then this
indicates that there is data to read from the Node.js request stream.
<!-- eslint-disable no-undef -->
```js
if (typeis.hasBody(req)) {
// read the body, since there is one
req.on('data', function (chunk) {
// ...
})
}
```
### typeis.is(mediaType, types)
Checks if the `mediaType` is one of the `types`. If the `mediaType` is invalid
or does not matches any of the `types`, then `false` is returned. Otherwise, a
string of the type that matched is returned.
The `mediaType` argument is expected to be a
[media type](https://tools.ietf.org/html/rfc6838) string. The `types` argument
is an array of type strings.
Each type in the `types` array can be one of the following:
- A file extension name such as `json`. This name will be returned if matched.
- A mime type such as `application/json`.
- A mime type with a wildcard such as `*/*` or `*/json` or `application/*`.
The full mime type will be returned if matched.
- A suffix such as `+json`. This can be combined with a wildcard such as
`*/vnd+json` or `application/*+json`. The full mime type will be returned
if matched.
Some examples to illustrate the inputs and returned value:
<!-- eslint-disable no-undef -->
```js
var mediaType = 'application/json'
typeis.is(mediaType, ['json']) // => 'json'
typeis.is(mediaType, ['html', 'json']) // => 'json'
typeis.is(mediaType, ['application/*']) // => 'application/json'
typeis.is(mediaType, ['application/json']) // => 'application/json'
typeis.is(mediaType, ['html']) // => false
```
## Examples
### Example body parser
```js
var express = require('express')
var typeis = require('type-is')
var app = express()
app.use(function bodyParser (req, res, next) {
if (!typeis.hasBody(req)) {
return next()
}
switch (typeis(req, ['urlencoded', 'json', 'multipart'])) {
case 'urlencoded':
// parse urlencoded body
throw new Error('implement urlencoded body parsing')
case 'json':
// parse json body
throw new Error('implement json body parsing')
case 'multipart':
// parse multipart body
throw new Error('implement multipart body parsing')
default:
// 415 error code
res.statusCode = 415
res.end()
break
}
})
```
## License
[MIT](LICENSE)
[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/type-is/master
[coveralls-url]: https://coveralls.io/r/jshttp/type-is?branch=master
[node-version-image]: https://badgen.net/npm/node/type-is
[node-version-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/type-is
[npm-url]: https://npmjs.org/package/type-is
[npm-version-image]: https://badgen.net/npm/v/type-is
[travis-image]: https://badgen.net/travis/jshttp/type-is/master
[travis-url]: https://travis-ci.org/jshttp/type-is
# web3-core-subscriptions
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]tus][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo]
This subscriptions package is used within some [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-subscriptions
```
## Usage
```js
const Web3Subscriptions = require('web3-core-subscriptions');
const sub = new Web3Subscriptions({
name: 'subscribe',
type: 'eth',
subscriptions: {
'newBlockHeaders': {
subscriptionName: 'newHeads',
params: 0,
outputFormatter: formatters.outputBlockFormatter
},
'pendingTransactions': {
params: 0,
outputFormatter: formatters.outputTransactionFormatter
}
}
});
sub.attachToObject(myCoolLib);
myCoolLib.subscribe('newBlockHeaders', function(){ ... });
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-core-subscriptions.svg
[npm-url]: https://npmjs.org/package/web3-core-subscriptions
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-core-subscriptions
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-core-subscriptions
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-core-subscriptions
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-core-subscriptions
# string_decoder
***Node-core v8.9.4 string_decoder for userland***
[](https://nodei.co/npm/string_decoder/)
[](https://nodei.co/npm/string_decoder/)
```bash
npm install --save string_decoder
```
***Node-core string_decoder for userland***
This package is a mirror of the string_decoder implementation in Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.9.4/docs/api/).
As of version 1.0.0 **string_decoder** uses semantic versioning.
## Previous versions
Previous version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10.
## Update
The *build/* directory contains a build script that will scrape the source from the [nodejs/node](https://github.com/nodejs/node) repo given a specific Node version.
## Streams Working Group
`string_decoder` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
See [readable-stream](https://github.com/nodejs/readable-stream) for
more details.
## Follow Redirects
Drop-in replacement for Nodes `http` and `https` that automatically follows redirects.
[](https://www.npmjs.com/package/follow-redirects)
[](https://travis-ci.org/follow-redirects/follow-redirects)
[](https://coveralls.io/r/follow-redirects/follow-redirects?branch=master)
[](https://david-dm.org/follow-redirects/follow-redirects)
[](https://www.npmjs.com/package/follow-redirects)
`follow-redirects` provides [request](https://nodejs.org/api/http.html#http_http_request_options_callback) and [get](https://nodejs.org/api/http.html#http_http_get_options_callback)
methods that behave identically to those found on the native [http](https://nodejs.org/api/http.html#http_http_request_options_callback) and [https](https://nodejs.org/api/https.html#https_https_request_options_callback)
modules, with the exception that they will seamlessly follow redirects.
```javascript
var http = require('follow-redirects').http;
var https = require('follow-redirects').https;
http.get('http://bit.ly/900913', function (response) {
response.on('data', function (chunk) {
console.log(chunk);
});
}).on('error', function (err) {
console.error(err);
});
```
You can inspect the final redirected URL through the `responseUrl` property on the `response`.
If no redirection happened, `responseUrl` is the original request URL.
```javascript
https.request({
host: 'bitly.com',
path: '/UHfDGO',
}, function (response) {
console.log(response.responseUrl);
// 'http://duckduckgo.com/robots.txt'
});
```
## Options
### Global options
Global options are set directly on the `follow-redirects` module:
```javascript
var followRedirects = require('follow-redirects');
followRedirects.maxRedirects = 10;
followRedirects.maxBodyLength = 20 * 1024 * 1024; // 20 MB
```
The following global options are supported:
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
### Per-request options
Per-request options are set by passing an `options` object:
```javascript
var url = require('url');
var followRedirects = require('follow-redirects');
var options = url.parse('http://bit.ly/900913');
options.maxRedirects = 10;
http.request(options);
```
In addition to the [standard HTTP](https://nodejs.org/api/http.html#http_http_request_options_callback) and [HTTPS options](https://nodejs.org/api/https.html#https_https_request_options_callback),
the following per-request options are supported:
- `followRedirects` (default: `true`) – whether redirects should be followed.
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
- `agents` (default: `undefined`) – sets the `agent` option per protocol, since HTTP and HTTPS use different agents. Example value: `{ http: new http.Agent(), https: new https.Agent() }`
- `trackRedirects` (default: `false`) – whether to store the redirected response details into the `redirects` array on the response object.
### Advanced usage
By default, `follow-redirects` will use the Node.js default implementations
of [`http`](https://nodejs.org/api/http.html)
and [`https`](https://nodejs.org/api/https.html).
To enable features such as caching and/or intermediate request tracking,
you might instead want to wrap `follow-redirects` around custom protocol implementations:
```javascript
var followRedirects = require('follow-redirects').wrap({
http: require('your-custom-http'),
https: require('your-custom-https'),
});
```
Such custom protocols only need an implementation of the `request` method.
## Browserify Usage
Due to the way `XMLHttpRequest` works, the `browserify` versions of `http` and `https` already follow redirects.
If you are *only* targeting the browser, then this library has little value for you. If you want to write cross
platform code for node and the browser, `follow-redirects` provides a great solution for making the native node
modules behave the same as they do in browserified builds in the browser. To avoid bundling unnecessary code
you should tell browserify to swap out `follow-redirects` with the standard modules when bundling.
To make this easier, you need to change how you require the modules:
```javascript
var http = require('follow-redirects/http');
var https = require('follow-redirects/https');
```
You can then replace `follow-redirects` in your browserify configuration like so:
```javascript
"browser": {
"follow-redirects/http" : "http",
"follow-redirects/https" : "https"
}
```
The `browserify-http` module has not kept pace with node development, and no long behaves identically to the native
module when running in the browser. If you are experiencing problems, you may want to check out
[browserify-http-2](https://www.npmjs.com/package/http-browserify-2). It is more actively maintained and
attempts to address a few of the shortcomings of `browserify-http`. In that case, your browserify config should
look something like this:
```javascript
"browser": {
"follow-redirects/http" : "browserify-http-2/http",
"follow-redirects/https" : "browserify-http-2/https"
}
```
## Contributing
Pull Requests are always welcome. Please [file an issue](https://github.com/follow-redirects/follow-redirects/issues)
detailing your proposal before you invest your valuable time. Additional features and bug fixes should be accompanied
by tests. You can run the test suite locally with a simple `npm test` command.
## Debug Logging
`follow-redirects` uses the excellent [debug](https://www.npmjs.com/package/debug) for logging. To turn on logging
set the environment variable `DEBUG=follow-redirects` for debug output from just this module. When running the test
suite it is sometimes advantageous to set `DEBUG=*` to see output from the express server as well.
## Authors
- Olivier Lalonde ([email protected])
- James Talmage ([email protected])
- [Ruben Verborgh](https://ruben.verborgh.org/)
## License
[https://github.com/follow-redirects/follow-redirects/blob/master/LICENSE](MIT License)
semver(1) -- The semantic versioner for npm
===========================================
## Install
```bash
npm install --save semver
````
## Usage
As a node module:
```js
const semver = require('semver')
semver.valid('1.2.3') // '1.2.3'
semver.valid('a.b.c') // null
semver.clean(' =v1.2.3 ') // '1.2.3'
semver.satisfies('1.2.3', '1.x || >=2.5.0 || 5.0.0 - 7.2.3') // true
semver.gt('1.2.3', '9.8.7') // false
semver.lt('1.2.3', '9.8.7') // true
```
As a command-line utility:
```
$ semver -h
SemVer 5.3.0
A JavaScript implementation of the http://semver.org/ specification
Copyright Isaac Z. Schlueter
Usage: semver [options] <version> [<version> [...]]
Prints valid versions sorted by SemVer precedence
Options:
-r --range <range>
Print versions that match the specified range.
-i --increment [<level>]
Increment a version by the specified level. Level can
be one of: major, minor, patch, premajor, preminor,
prepatch, or prerelease. Default level is 'patch'.
Only one version may be specified.
--preid <identifier>
Identifier to be used to prefix premajor, preminor,
prepatch or prerelease version increments.
-l --loose
Interpret versions and ranges loosely
Program exits successfully if any valid version satisfies
all supplied ranges, and prints all satisfying versions.
If no satisfying versions are found, then exits failure.
Versions are printed in ascending order, so supplying
multiple versions to the utility will just sort them.
```
## Versions
A "version" is described by the `v2.0.0` specification found at
<http://semver.org/>.
A leading `"="` or `"v"` character is stripped off and ignored.
## Ranges
A `version range` is a set of `comparators` which specify versions
that satisfy the range.
A `comparator` is composed of an `operator` and a `version`. The set
of primitive `operators` is:
* `<` Less than
* `<=` Less than or equal to
* `>` Greater than
* `>=` Greater than or equal to
* `=` Equal. If no operator is specified, then equality is assumed,
so this operator is optional, but MAY be included.
For example, the comparator `>=1.2.7` would match the versions
`1.2.7`, `1.2.8`, `2.5.3`, and `1.3.9`, but not the versions `1.2.6`
or `1.1.0`.
Comparators can be joined by whitespace to form a `comparator set`,
which is satisfied by the **intersection** of all of the comparators
it includes.
A range is composed of one or more comparator sets, joined by `||`. A
version matches a range if and only if every comparator in at least
one of the `||`-separated comparator sets is satisfied by the version.
For example, the range `>=1.2.7 <1.3.0` would match the versions
`1.2.7`, `1.2.8`, and `1.2.99`, but not the versions `1.2.6`, `1.3.0`,
or `1.1.0`.
The range `1.2.7 || >=1.2.9 <2.0.0` would match the versions `1.2.7`,
`1.2.9`, and `1.4.6`, but not the versions `1.2.8` or `2.0.0`.
### Prerelease Tags
If a version has a prerelease tag (for example, `1.2.3-alpha.3`) then
it will only be allowed to satisfy comparator sets if at least one
comparator with the same `[major, minor, patch]` tuple also has a
prerelease tag.
For example, the range `>1.2.3-alpha.3` would be allowed to match the
version `1.2.3-alpha.7`, but it would *not* be satisfied by
`3.4.5-alpha.9`, even though `3.4.5-alpha.9` is technically "greater
than" `1.2.3-alpha.3` according to the SemVer sort rules. The version
range only accepts prerelease tags on the `1.2.3` version. The
version `3.4.5` *would* satisfy the range, because it does not have a
prerelease flag, and `3.4.5` is greater than `1.2.3-alpha.7`.
The purpose for this behavior is twofold. First, prerelease versions
frequently are updated very quickly, and contain many breaking changes
that are (by the author's design) not yet fit for public consumption.
Therefore, by default, they are excluded from range matching
semantics.
Second, a user who has opted into using a prerelease version has
clearly indicated the intent to use *that specific* set of
alpha/beta/rc versions. By including a prerelease tag in the range,
the user is indicating that they are aware of the risk. However, it
is still not appropriate to assume that they have opted into taking a
similar risk on the *next* set of prerelease versions.
#### Prerelease Identifiers
The method `.inc` takes an additional `identifier` string argument that
will append the value of the string as a prerelease identifier:
```javascript
semver.inc('1.2.3', 'prerelease', 'beta')
// '1.2.4-beta.0'
```
command-line example:
```bash
$ semver 1.2.3 -i prerelease --preid beta
1.2.4-beta.0
```
Which then can be used to increment further:
```bash
$ semver 1.2.4-beta.0 -i prerelease
1.2.4-beta.1
```
### Advanced Range Syntax
Advanced range syntax desugars to primitive comparators in
deterministic ways.
Advanced ranges may be combined in the same way as primitive
comparators using white space or `||`.
#### Hyphen Ranges `X.Y.Z - A.B.C`
Specifies an inclusive set.
* `1.2.3 - 2.3.4` := `>=1.2.3 <=2.3.4`
If a partial version is provided as the first version in the inclusive
range, then the missing pieces are replaced with zeroes.
* `1.2 - 2.3.4` := `>=1.2.0 <=2.3.4`
If a partial version is provided as the second version in the
inclusive range, then all versions that start with the supplied parts
of the tuple are accepted, but nothing that would be greater than the
provided tuple parts.
* `1.2.3 - 2.3` := `>=1.2.3 <2.4.0`
* `1.2.3 - 2` := `>=1.2.3 <3.0.0`
#### X-Ranges `1.2.x` `1.X` `1.2.*` `*`
Any of `X`, `x`, or `*` may be used to "stand in" for one of the
numeric values in the `[major, minor, patch]` tuple.
* `*` := `>=0.0.0` (Any version satisfies)
* `1.x` := `>=1.0.0 <2.0.0` (Matching major version)
* `1.2.x` := `>=1.2.0 <1.3.0` (Matching major and minor versions)
A partial version range is treated as an X-Range, so the special
character is in fact optional.
* `""` (empty string) := `*` := `>=0.0.0`
* `1` := `1.x.x` := `>=1.0.0 <2.0.0`
* `1.2` := `1.2.x` := `>=1.2.0 <1.3.0`
#### Tilde Ranges `~1.2.3` `~1.2` `~1`
Allows patch-level changes if a minor version is specified on the
comparator. Allows minor-level changes if not.
* `~1.2.3` := `>=1.2.3 <1.(2+1).0` := `>=1.2.3 <1.3.0`
* `~1.2` := `>=1.2.0 <1.(2+1).0` := `>=1.2.0 <1.3.0` (Same as `1.2.x`)
* `~1` := `>=1.0.0 <(1+1).0.0` := `>=1.0.0 <2.0.0` (Same as `1.x`)
* `~0.2.3` := `>=0.2.3 <0.(2+1).0` := `>=0.2.3 <0.3.0`
* `~0.2` := `>=0.2.0 <0.(2+1).0` := `>=0.2.0 <0.3.0` (Same as `0.2.x`)
* `~0` := `>=0.0.0 <(0+1).0.0` := `>=0.0.0 <1.0.0` (Same as `0.x`)
* `~1.2.3-beta.2` := `>=1.2.3-beta.2 <1.3.0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
#### Caret Ranges `^1.2.3` `^0.2.5` `^0.0.4`
Allows changes that do not modify the left-most non-zero digit in the
`[major, minor, patch]` tuple. In other words, this allows patch and
minor updates for versions `1.0.0` and above, patch updates for
versions `0.X >=0.1.0`, and *no* updates for versions `0.0.X`.
Many authors treat a `0.x` version as if the `x` were the major
"breaking-change" indicator.
Caret ranges are ideal when an author may make breaking changes
between `0.2.4` and `0.3.0` releases, which is a common practice.
However, it presumes that there will *not* be breaking changes between
`0.2.4` and `0.2.5`. It allows for changes that are presumed to be
additive (but non-breaking), according to commonly observed practices.
* `^1.2.3` := `>=1.2.3 <2.0.0`
* `^0.2.3` := `>=0.2.3 <0.3.0`
* `^0.0.3` := `>=0.0.3 <0.0.4`
* `^1.2.3-beta.2` := `>=1.2.3-beta.2 <2.0.0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
* `^0.0.3-beta` := `>=0.0.3-beta <0.0.4` Note that prereleases in the
`0.0.3` version *only* will be allowed, if they are greater than or
equal to `beta`. So, `0.0.3-pr.2` would be allowed.
When parsing caret ranges, a missing `patch` value desugars to the
number `0`, but will allow flexibility within that value, even if the
major and minor versions are both `0`.
* `^1.2.x` := `>=1.2.0 <2.0.0`
* `^0.0.x` := `>=0.0.0 <0.1.0`
* `^0.0` := `>=0.0.0 <0.1.0`
A missing `minor` and `patch` values will desugar to zero, but also
allow flexibility within those values, even if the major version is
zero.
* `^1.x` := `>=1.0.0 <2.0.0`
* `^0.x` := `>=0.0.0 <1.0.0`
### Range Grammar
Putting all this together, here is a Backus-Naur grammar for ranges,
for the benefit of parser authors:
```bnf
range-set ::= range ( logical-or range ) *
logical-or ::= ( ' ' ) * '||' ( ' ' ) *
range ::= hyphen | simple ( ' ' simple ) * | ''
hyphen ::= partial ' - ' partial
simple ::= primitive | partial | tilde | caret
primitive ::= ( '<' | '>' | '>=' | '<=' | '=' | ) partial
partial ::= xr ( '.' xr ( '.' xr qualifier ? )? )?
xr ::= 'x' | 'X' | '*' | nr
nr ::= '0' | ['1'-'9'] ( ['0'-'9'] ) *
tilde ::= '~' partial
caret ::= '^' partial
qualifier ::= ( '-' pre )? ( '+' build )?
pre ::= parts
build ::= parts
parts ::= part ( '.' part ) *
part ::= nr | [-0-9A-Za-z]+
```
## Functions
All methods and classes take a final `loose` boolean argument that, if
true, will be more forgiving about not-quite-valid semver strings.
The resulting output will always be 100% strict, of course.
Strict-mode Comparators and Ranges will be strict about the SemVer
strings that they parse.
* `valid(v)`: Return the parsed version, or null if it's not valid.
* `inc(v, release)`: Return the version incremented by the release
type (`major`, `premajor`, `minor`, `preminor`, `patch`,
`prepatch`, or `prerelease`), or null if it's not valid
* `premajor` in one call will bump the version up to the next major
version and down to a prerelease of that major version.
`preminor`, and `prepatch` work the same way.
* If called from a non-prerelease version, the `prerelease` will work the
same as `prepatch`. It increments the patch version, then makes a
prerelease. If the input version is already a prerelease it simply
increments it.
* `prerelease(v)`: Returns an array of prerelease components, or null
if none exist. Example: `prerelease('1.2.3-alpha.1') -> ['alpha', 1]`
* `major(v)`: Return the major version number.
* `minor(v)`: Return the minor version number.
* `patch(v)`: Return the patch version number.
* `intersects(r1, r2, loose)`: Return true if the two supplied ranges
or comparators intersect.
### Comparison
* `gt(v1, v2)`: `v1 > v2`
* `gte(v1, v2)`: `v1 >= v2`
* `lt(v1, v2)`: `v1 < v2`
* `lte(v1, v2)`: `v1 <= v2`
* `eq(v1, v2)`: `v1 == v2` This is true if they're logically equivalent,
even if they're not the exact same string. You already know how to
compare strings.
* `neq(v1, v2)`: `v1 != v2` The opposite of `eq`.
* `cmp(v1, comparator, v2)`: Pass in a comparison string, and it'll call
the corresponding function above. `"==="` and `"!=="` do simple
string comparison, but are included for completeness. Throws if an
invalid comparison string is provided.
* `compare(v1, v2)`: Return `0` if `v1 == v2`, or `1` if `v1` is greater, or `-1` if
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `rcompare(v1, v2)`: The reverse of compare. Sorts an array of versions
in descending order when passed to `Array.sort()`.
* `diff(v1, v2)`: Returns difference between two versions by the release type
(`major`, `premajor`, `minor`, `preminor`, `patch`, `prepatch`, or `prerelease`),
or null if the versions are the same.
### Comparators
* `intersects(comparator)`: Return true if the comparators intersect
### Ranges
* `validRange(range)`: Return the valid range or null if it's not valid
* `satisfies(version, range)`: Return true if the version satisfies the
range.
* `maxSatisfying(versions, range)`: Return the highest version in the list
that satisfies the range, or `null` if none of them do.
* `minSatisfying(versions, range)`: Return the lowest version in the list
that satisfies the range, or `null` if none of them do.
* `gtr(version, range)`: Return `true` if version is greater than all the
versions possible in the range.
* `ltr(version, range)`: Return `true` if version is less than all the
versions possible in the range.
* `outside(version, range, hilo)`: Return true if the version is outside
the bounds of the range in either the high or low direction. The
`hilo` argument must be either the string `'>'` or `'<'`. (This is
the function called by `gtr` and `ltr`.)
* `intersects(range)`: Return true if any of the ranges comparators intersect
Note that, since ranges may be non-contiguous, a version might not be
greater than a range, less than a range, *or* satisfy a range! For
example, the range `1.2 <1.2.9 || >2.0.0` would have a hole from `1.2.9`
until `2.0.0`, so the version `1.2.10` would not be greater than the
range (because `2.0.1` satisfies, which is higher), nor less than the
range (since `1.2.8` satisfies, which is lower), and it also does not
satisfy the range.
If you want to know if a version satisfies or does not satisfy a
range, use the `satisfies(version, range)` function.
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# xtend
[![browser support][3]][4]
[](http://github.com/badges/stability-badges)
Extend like a boss
xtend is a basic utility library which allows you to extend an object by appending all of the properties from each object in a list. When there are identical properties, the right-most property takes precedence.
## Examples
```js
var extend = require("xtend")
// extend returns a new object. Does not mutate arguments
var combination = extend({
a: "a",
b: "c"
}, {
b: "b"
})
// { a: "a", b: "b" }
```
## Stability status: Locked
## MIT Licensed
[3]: http://ci.testling.com/Raynos/xtend.png
[4]: http://ci.testling.com/Raynos/xtend
# web3-net
This is a sub package of [web3.js][repo]
This is the net package to be used in other web3.js packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-net
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-net.js` in your html file.
This will expose the `Web3Net` object on the window object.
## Usage
```js
// in node.js
var Web3Net = require('web3-net');
var net = new Web3Net('ws://localhost:8546');
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# web3-core-requestmanager
This is a sub package of [web3.js][repo]
The requestmanager package is used by most [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-requestmanager
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-core-requestmanager.js` in your html file.
This will expose the `Web3RequestManager` object on the window object.
## Usage
```js
// in node.js
var Web3WsProvider = require('web3-providers-ws');
var Web3RequestManager = require('web3-core-requestmanager');
var requestManager = new Web3RequestManager(new Web3WsProvider('ws://localhost:8546'));
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
## Pure JS character encoding conversion [](https://travis-ci.org/ashtuchkin/iconv-lite)
* Doesn't need native code compilation. Works on Windows and in sandboxed environments like [Cloud9](http://c9.io).
* Used in popular projects like [Express.js (body_parser)](https://github.com/expressjs/body-parser),
[Grunt](http://gruntjs.com/), [Nodemailer](http://www.nodemailer.com/), [Yeoman](http://yeoman.io/) and others.
* Faster than [node-iconv](https://github.com/bnoordhuis/node-iconv) (see below for performance comparison).
* Intuitive encode/decode API
* Streaming support for Node v0.10+
* [Deprecated] Can extend Node.js primitives (buffers, streams) to support all iconv-lite encodings.
* In-browser usage via [Browserify](https://github.com/substack/node-browserify) (~180k gzip compressed with Buffer shim included).
* Typescript [type definition file](https://github.com/ashtuchkin/iconv-lite/blob/master/lib/index.d.ts) included.
* React Native is supported (need to explicitly `npm install` two more modules: `buffer` and `stream`).
* License: MIT.
[](https://npmjs.org/packages/iconv-lite/)
## Usage
### Basic API
```javascript
var iconv = require('iconv-lite');
// Convert from an encoded buffer to js string.
str = iconv.decode(Buffer.from([0x68, 0x65, 0x6c, 0x6c, 0x6f]), 'win1251');
// Convert from js string to an encoded buffer.
buf = iconv.encode("Sample input string", 'win1251');
// Check if encoding is supported
iconv.encodingExists("us-ascii")
```
### Streaming API (Node v0.10+)
```javascript
// Decode stream (from binary stream to js strings)
http.createServer(function(req, res) {
var converterStream = iconv.decodeStream('win1251');
req.pipe(converterStream);
converterStream.on('data', function(str) {
console.log(str); // Do something with decoded strings, chunk-by-chunk.
});
});
// Convert encoding streaming example
fs.createReadStream('file-in-win1251.txt')
.pipe(iconv.decodeStream('win1251'))
.pipe(iconv.encodeStream('ucs2'))
.pipe(fs.createWriteStream('file-in-ucs2.txt'));
// Sugar: all encode/decode streams have .collect(cb) method to accumulate data.
http.createServer(function(req, res) {
req.pipe(iconv.decodeStream('win1251')).collect(function(err, body) {
assert(typeof body == 'string');
console.log(body); // full request body string
});
});
```
### [Deprecated] Extend Node.js own encodings
> NOTE: This doesn't work on latest Node versions. See [details](https://github.com/ashtuchkin/iconv-lite/wiki/Node-v4-compatibility).
```javascript
// After this call all Node basic primitives will understand iconv-lite encodings.
iconv.extendNodeEncodings();
// Examples:
buf = new Buffer(str, 'win1251');
buf.write(str, 'gbk');
str = buf.toString('latin1');
assert(Buffer.isEncoding('iso-8859-15'));
Buffer.byteLength(str, 'us-ascii');
http.createServer(function(req, res) {
req.setEncoding('big5');
req.collect(function(err, body) {
console.log(body);
});
});
fs.createReadStream("file.txt", "shift_jis");
// External modules are also supported (if they use Node primitives, which they probably do).
request = require('request');
request({
url: "http://github.com/",
encoding: "cp932"
});
// To remove extensions
iconv.undoExtendNodeEncodings();
```
## Supported encodings
* All node.js native encodings: utf8, ucs2 / utf16-le, ascii, binary, base64, hex.
* Additional unicode encodings: utf16, utf16-be, utf-7, utf-7-imap.
* All widespread singlebyte encodings: Windows 125x family, ISO-8859 family,
IBM/DOS codepages, Macintosh family, KOI8 family, all others supported by iconv library.
Aliases like 'latin1', 'us-ascii' also supported.
* All widespread multibyte encodings: CP932, CP936, CP949, CP950, GB2312, GBK, GB18030, Big5, Shift_JIS, EUC-JP.
See [all supported encodings on wiki](https://github.com/ashtuchkin/iconv-lite/wiki/Supported-Encodings).
Most singlebyte encodings are generated automatically from [node-iconv](https://github.com/bnoordhuis/node-iconv). Thank you Ben Noordhuis and libiconv authors!
Multibyte encodings are generated from [Unicode.org mappings](http://www.unicode.org/Public/MAPPINGS/) and [WHATWG Encoding Standard mappings](http://encoding.spec.whatwg.org/). Thank you, respective authors!
## Encoding/decoding speed
Comparison with node-iconv module (1000x256kb, on MacBook Pro, Core i5/2.6 GHz, Node v0.12.0).
Note: your results may vary, so please always check on your hardware.
operation [email protected] [email protected]
----------------------------------------------------------
encode('win1251') ~96 Mb/s ~320 Mb/s
decode('win1251') ~95 Mb/s ~246 Mb/s
## BOM handling
* Decoding: BOM is stripped by default, unless overridden by passing `stripBOM: false` in options
(f.ex. `iconv.decode(buf, enc, {stripBOM: false})`).
A callback might also be given as a `stripBOM` parameter - it'll be called if BOM character was actually found.
* If you want to detect UTF-8 BOM when decoding other encodings, use [node-autodetect-decoder-stream](https://github.com/danielgindi/node-autodetect-decoder-stream) module.
* Encoding: No BOM added, unless overridden by `addBOM: true` option.
## UTF-16 Encodings
This library supports UTF-16LE, UTF-16BE and UTF-16 encodings. First two are straightforward, but UTF-16 is trying to be
smart about endianness in the following ways:
* Decoding: uses BOM and 'spaces heuristic' to determine input endianness. Default is UTF-16LE, but can be
overridden with `defaultEncoding: 'utf-16be'` option. Strips BOM unless `stripBOM: false`.
* Encoding: uses UTF-16LE and writes BOM by default. Use `addBOM: false` to override.
## Other notes
When decoding, be sure to supply a Buffer to decode() method, otherwise [bad things usually happen](https://github.com/ashtuchkin/iconv-lite/wiki/Use-Buffers-when-decoding).
Untranslatable characters are set to � or ?. No transliteration is currently supported.
Node versions 0.10.31 and 0.11.13 are buggy, don't use them (see #65, #77).
## Testing
```bash
$ git clone [email protected]:ashtuchkin/iconv-lite.git
$ cd iconv-lite
$ npm install
$ npm test
$ # To view performance:
$ node test/performance.js
$ # To view test coverage:
$ npm run coverage
$ open coverage/lcov-report/index.html
```
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# level-codec
> Encode keys, values and range options, with built-in or custom encodings.
[![level badge][level-badge]](https://github.com/Level/awesome)
[](https://www.npmjs.com/package/level-codec)
[](https://www.npmjs.com/package/level-codec)
[](https://travis-ci.com/Level/codec)
[](https://www.npmjs.com/package/level-codec)
[](https://coveralls.io/github/Level/codec)
[](https://standardjs.com)
[](#backers)
[](#sponsors)
## Usage
**If you are upgrading:** please see [`UPGRADING.md`](UPGRADING.md).
```js
const Codec = require('level-codec')
const codec = Codec({ keyEncoding: 'json' })
const key = codec.encodeKey({ foo: 'bar' })
console.log(key) // -> '{"foo":"bar"}'
console.log(codec.decodeKey(key)) // -> { foo: 'bar' }
```
## API
### `codec = Codec([opts])`
Create a new codec, with a global options object.
### `codec.encodeKey(key[, opts])`
Encode `key` with given `opts`.
### `codec.encodeValue(value[, opts])`
Encode `value` with given `opts`.
### `codec.encodeBatch(batch[, opts])`
Encode `batch` ops with given `opts`.
### `codec.encodeLtgt(ltgt)`
Encode the ltgt values of option object `ltgt`.
### `codec.decodeKey(key[, opts])`
Decode `key` with given `opts`.
### `codec.decodeValue(value[, opts])`
Decode `value` with given `opts`.
### `codec.createStreamDecoder([opts])`
Create a function with signature `(key, value)`, that for each key-value pair returned from a levelup read stream returns the decoded value to be emitted.
### `codec.keyAsBuffer([opts])`
Check whether `opts` and the global `opts` call for a binary key encoding.
### `codec.valueAsBuffer([opts])`
Check whether `opts` and the global `opts` call for a binary value encoding.
### `codec.encodings`
The builtin encodings as object of form
```js
{
[type]: encoding
}
```
See below for a list and the format of `encoding`.
## Builtin Encodings
| Type | Input | Stored as | Output |
| :---------------------------------------------------------------- | :--------------------------- | :--------------- | :-------- |
| `utf8` | String or Buffer | String or Buffer | String |
| `json` | Any JSON type | JSON string | Input |
| `binary` | Buffer, string or byte array | Buffer | As stored |
| `hex`<br>`ascii`<br>`base64`<br>`ucs2`<br>`utf16le`<br>`utf-16le` | String or Buffer | Buffer | String |
| `none` a.k.a. `id` | Any type (bypass encoding) | Input\* | As stored |
<sup>\*</sup> Stores may have their own type coercion. Whether type information is preserved depends on the [`abstract-leveldown`] implementation as well as the underlying storage (`LevelDB`, `IndexedDB`, etc).
## Encoding Format
An encoding is an object of the form:
```js
{
encode: function (data) {
return data
},
decode: function (data) {
return data
},
buffer: Boolean,
type: 'example'
}
```
All of these properties are required.
The `buffer` boolean tells consumers whether to fetch data as a Buffer, before calling your `decode()` function on that data. If `buffer` is true, it is assumed that `decode()` takes a Buffer. If false, it is assumed that `decode` takes any other type (usually a string).
To explain this in the grand scheme of things, consider a store like [`leveldown`] which has the ability to return either a Buffer or string, both sourced from the same byte array. Wrap this store with [`encoding-down`] and it'll select the most optimal data type based on the `buffer` property of the active encoding. If your `decode()` function needs a string (and the data can legitimately become a UTF8 string), you should set `buffer` to `false`. This avoids the cost of having to convert a Buffer to a string.
The `type` string should be a unique name.
## Contributing
[`Level/codec`](https://github.com/Level/codec) is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [Contribution Guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
## Donate
To sustain [`Level`](https://github.com/Level) and its activities, become a backer or sponsor on [Open Collective](https://opencollective.com/level). Your logo or avatar will be displayed on our 28+ [GitHub repositories](https://github.com/Level) and [npm](https://www.npmjs.com/) packages. 💖
### Backers
[](https://opencollective.com/level)
### Sponsors
[](https://opencollective.com/level)
## License
[MIT](LICENSE.md) © 2012-present [Contributors](CONTRIBUTORS.md).
[level-badge]: https://leveljs.org/img/badge.svg
[`encoding-down`]: https://github.com/Level/encoding-down
[`abstract-leveldown`]: https://github.com/Level/abstract-leveldown
[`leveldown`]: https://github.com/Level/leveldown
# is-number [](https://www.npmjs.com/package/is-number) [](https://npmjs.org/package/is-number) [](https://npmjs.org/package/is-number) [](https://travis-ci.org/jonschlinkert/is-number)
> Returns true if the value is a number. comprehensive tests.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-number
```
## Usage
To understand some of the rationale behind the decisions made in this library (and to learn about some oddities of number evaluation in JavaScript), [see this gist](https://gist.github.com/jonschlinkert/e30c70c713da325d0e81).
```js
var isNumber = require('is-number');
```
### true
See the [tests](./test.js) for more examples.
```js
isNumber(5e3) //=> 'true'
isNumber(0xff) //=> 'true'
isNumber(-1.1) //=> 'true'
isNumber(0) //=> 'true'
isNumber(1) //=> 'true'
isNumber(1.1) //=> 'true'
isNumber(10) //=> 'true'
isNumber(10.10) //=> 'true'
isNumber(100) //=> 'true'
isNumber('-1.1') //=> 'true'
isNumber('0') //=> 'true'
isNumber('012') //=> 'true'
isNumber('0xff') //=> 'true'
isNumber('1') //=> 'true'
isNumber('1.1') //=> 'true'
isNumber('10') //=> 'true'
isNumber('10.10') //=> 'true'
isNumber('100') //=> 'true'
isNumber('5e3') //=> 'true'
isNumber(parseInt('012')) //=> 'true'
isNumber(parseFloat('012')) //=> 'true'
```
### False
See the [tests](./test.js) for more examples.
```js
isNumber('foo') //=> 'false'
isNumber([1]) //=> 'false'
isNumber([]) //=> 'false'
isNumber(function () {}) //=> 'false'
isNumber(Infinity) //=> 'false'
isNumber(NaN) //=> 'false'
isNumber(new Array('abc')) //=> 'false'
isNumber(new Array(2)) //=> 'false'
isNumber(new Buffer('abc')) //=> 'false'
isNumber(null) //=> 'false'
isNumber(undefined) //=> 'false'
isNumber({abc: 'abc'}) //=> 'false'
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [even](https://www.npmjs.com/package/even): Get the even numbered items from an array. | [homepage](https://github.com/jonschlinkert/even "Get the even numbered items from an array.")
* [is-even](https://www.npmjs.com/package/is-even): Return true if the given number is even. | [homepage](https://github.com/jonschlinkert/is-even "Return true if the given number is even.")
* [is-odd](https://www.npmjs.com/package/is-odd): Returns true if the given number is odd. | [homepage](https://github.com/jonschlinkert/is-odd "Returns true if the given number is odd.")
* [is-primitive](https://www.npmjs.com/package/is-primitive): Returns `true` if the value is a primitive. | [homepage](https://github.com/jonschlinkert/is-primitive "Returns `true` if the value is a primitive. ")
* [kind-of](https://www.npmjs.com/package/kind-of): Get the native type of a value. | [homepage](https://github.com/jonschlinkert/kind-of "Get the native type of a value.")
* [odd](https://www.npmjs.com/package/odd): Get the odd numbered items from an array. | [homepage](https://github.com/jonschlinkert/odd "Get the odd numbered items from an array.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 38 | [jonschlinkert](https://github.com/jonschlinkert) |
| 5 | [charlike](https://github.com/charlike) |
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on October 17, 2017._
# color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
# asynckit [](https://www.npmjs.com/package/asynckit)
Minimal async jobs utility library, with streams support.
[](https://travis-ci.org/alexindigo/asynckit)
[](https://travis-ci.org/alexindigo/asynckit)
[](https://ci.appveyor.com/project/alexindigo/asynckit)
[](https://coveralls.io/github/alexindigo/asynckit?branch=master)
[](https://david-dm.org/alexindigo/asynckit)
[](https://www.bithound.io/github/alexindigo/asynckit)
<!-- [](https://www.npmjs.com/package/reamde) -->
AsyncKit provides harness for `parallel` and `serial` iterators over list of items represented by arrays or objects.
Optionally it accepts abort function (should be synchronously return by iterator for each item), and terminates left over jobs upon an error event. For specific iteration order built-in (`ascending` and `descending`) and custom sort helpers also supported, via `asynckit.serialOrdered` method.
It ensures async operations to keep behavior more stable and prevent `Maximum call stack size exceeded` errors, from sync iterators.
| compression | size |
| :----------------- | -------: |
| asynckit.js | 12.34 kB |
| asynckit.min.js | 4.11 kB |
| asynckit.min.js.gz | 1.47 kB |
## Install
```sh
$ npm install --save asynckit
```
## Examples
### Parallel Jobs
Runs iterator over provided array in parallel. Stores output in the `result` array,
on the matching positions. In unlikely event of an error from one of the jobs,
will terminate rest of the active jobs (if abort function is provided)
and return error along with salvaged data to the main callback function.
#### Input Array
```javascript
var parallel = require('asynckit').parallel
, assert = require('assert')
;
var source = [ 1, 1, 4, 16, 64, 32, 8, 2 ]
, expectedResult = [ 2, 2, 8, 32, 128, 64, 16, 4 ]
, expectedTarget = [ 1, 1, 2, 4, 8, 16, 32, 64 ]
, target = []
;
parallel(source, asyncJob, function(err, result)
{
assert.deepEqual(result, expectedResult);
assert.deepEqual(target, expectedTarget);
});
// async job accepts one element from the array
// and a callback function
function asyncJob(item, cb)
{
// different delays (in ms) per item
var delay = item * 25;
// pretend different jobs take different time to finish
// and not in consequential order
var timeoutId = setTimeout(function() {
target.push(item);
cb(null, item * 2);
}, delay);
// allow to cancel "leftover" jobs upon error
// return function, invoking of which will abort this job
return clearTimeout.bind(null, timeoutId);
}
```
More examples could be found in [test/test-parallel-array.js](test/test-parallel-array.js).
#### Input Object
Also it supports named jobs, listed via object.
```javascript
var parallel = require('asynckit/parallel')
, assert = require('assert')
;
var source = { first: 1, one: 1, four: 4, sixteen: 16, sixtyFour: 64, thirtyTwo: 32, eight: 8, two: 2 }
, expectedResult = { first: 2, one: 2, four: 8, sixteen: 32, sixtyFour: 128, thirtyTwo: 64, eight: 16, two: 4 }
, expectedTarget = [ 1, 1, 2, 4, 8, 16, 32, 64 ]
, expectedKeys = [ 'first', 'one', 'two', 'four', 'eight', 'sixteen', 'thirtyTwo', 'sixtyFour' ]
, target = []
, keys = []
;
parallel(source, asyncJob, function(err, result)
{
assert.deepEqual(result, expectedResult);
assert.deepEqual(target, expectedTarget);
assert.deepEqual(keys, expectedKeys);
});
// supports full value, key, callback (shortcut) interface
function asyncJob(item, key, cb)
{
// different delays (in ms) per item
var delay = item * 25;
// pretend different jobs take different time to finish
// and not in consequential order
var timeoutId = setTimeout(function() {
keys.push(key);
target.push(item);
cb(null, item * 2);
}, delay);
// allow to cancel "leftover" jobs upon error
// return function, invoking of which will abort this job
return clearTimeout.bind(null, timeoutId);
}
```
More examples could be found in [test/test-parallel-object.js](test/test-parallel-object.js).
### Serial Jobs
Runs iterator over provided array sequentially. Stores output in the `result` array,
on the matching positions. In unlikely event of an error from one of the jobs,
will not proceed to the rest of the items in the list
and return error along with salvaged data to the main callback function.
#### Input Array
```javascript
var serial = require('asynckit/serial')
, assert = require('assert')
;
var source = [ 1, 1, 4, 16, 64, 32, 8, 2 ]
, expectedResult = [ 2, 2, 8, 32, 128, 64, 16, 4 ]
, expectedTarget = [ 0, 1, 2, 3, 4, 5, 6, 7 ]
, target = []
;
serial(source, asyncJob, function(err, result)
{
assert.deepEqual(result, expectedResult);
assert.deepEqual(target, expectedTarget);
});
// extended interface (item, key, callback)
// also supported for arrays
function asyncJob(item, key, cb)
{
target.push(key);
// it will be automatically made async
// even it iterator "returns" in the same event loop
cb(null, item * 2);
}
```
More examples could be found in [test/test-serial-array.js](test/test-serial-array.js).
#### Input Object
Also it supports named jobs, listed via object.
```javascript
var serial = require('asynckit').serial
, assert = require('assert')
;
var source = [ 1, 1, 4, 16, 64, 32, 8, 2 ]
, expectedResult = [ 2, 2, 8, 32, 128, 64, 16, 4 ]
, expectedTarget = [ 0, 1, 2, 3, 4, 5, 6, 7 ]
, target = []
;
var source = { first: 1, one: 1, four: 4, sixteen: 16, sixtyFour: 64, thirtyTwo: 32, eight: 8, two: 2 }
, expectedResult = { first: 2, one: 2, four: 8, sixteen: 32, sixtyFour: 128, thirtyTwo: 64, eight: 16, two: 4 }
, expectedTarget = [ 1, 1, 4, 16, 64, 32, 8, 2 ]
, target = []
;
serial(source, asyncJob, function(err, result)
{
assert.deepEqual(result, expectedResult);
assert.deepEqual(target, expectedTarget);
});
// shortcut interface (item, callback)
// works for object as well as for the arrays
function asyncJob(item, cb)
{
target.push(item);
// it will be automatically made async
// even it iterator "returns" in the same event loop
cb(null, item * 2);
}
```
More examples could be found in [test/test-serial-object.js](test/test-serial-object.js).
_Note: Since _object_ is an _unordered_ collection of properties,
it may produce unexpected results with sequential iterations.
Whenever order of the jobs' execution is important please use `serialOrdered` method._
### Ordered Serial Iterations
TBD
For example [compare-property](compare-property) package.
### Streaming interface
TBD
## Want to Know More?
More examples can be found in [test folder](test/).
Or open an [issue](https://github.com/alexindigo/asynckit/issues) with questions and/or suggestions.
## License
AsyncKit is licensed under the MIT license.
## Escodegen
[](http://badge.fury.io/js/escodegen)
[](http://travis-ci.org/estools/escodegen)
[](https://david-dm.org/estools/escodegen)
[](https://david-dm.org/estools/escodegen#info=devDependencies)
Escodegen ([escodegen](http://github.com/estools/escodegen)) is an
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
(also popularly known as [JavaScript](http://en.wikipedia.org/wiki/JavaScript))
code generator from [Mozilla's Parser API](https://developer.mozilla.org/en/SpiderMonkey/Parser_API)
AST. See the [online generator](https://estools.github.io/escodegen/demo/index.html)
for a demo.
### Install
Escodegen can be used in a web browser:
<script src="escodegen.browser.js"></script>
escodegen.browser.js can be found in tagged revisions on GitHub.
Or in a Node.js application via npm:
npm install escodegen
### Usage
A simple example: the program
escodegen.generate({
type: 'BinaryExpression',
operator: '+',
left: { type: 'Literal', value: 40 },
right: { type: 'Literal', value: 2 }
});
produces the string `'40 + 2'`.
See the [API page](https://github.com/estools/escodegen/wiki/API) for
options. To run the tests, execute `npm test` in the root directory.
### Building browser bundle / minified browser bundle
At first, execute `npm install` to install the all dev dependencies.
After that,
npm run-script build
will generate `escodegen.browser.js`, which can be used in browser environments.
And,
npm run-script build-min
will generate the minified file `escodegen.browser.min.js`.
### License
#### Escodegen
Copyright (C) 2012 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# axios // core
The modules found in `core/` should be modules that are specific to the domain logic of axios. These modules would most likely not make sense to be consumed outside of the axios module, as their logic is too specific. Some examples of core modules are:
- Dispatching requests
- Managing interceptors
- Handling config
# ieee754 [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/ieee754/master.svg
[travis-url]: https://travis-ci.org/feross/ieee754
[npm-image]: https://img.shields.io/npm/v/ieee754.svg
[npm-url]: https://npmjs.org/package/ieee754
[downloads-image]: https://img.shields.io/npm/dm/ieee754.svg
[downloads-url]: https://npmjs.org/package/ieee754
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
[![saucelabs][saucelabs-image]][saucelabs-url]
[saucelabs-image]: https://saucelabs.com/browser-matrix/ieee754.svg
[saucelabs-url]: https://saucelabs.com/u/ieee754
### Read/write IEEE754 floating point numbers from/to a Buffer or array-like object.
## install
```
npm install ieee754
```
## methods
`var ieee754 = require('ieee754')`
The `ieee754` object has the following functions:
```
ieee754.read = function (buffer, offset, isLE, mLen, nBytes)
ieee754.write = function (buffer, value, offset, isLE, mLen, nBytes)
```
The arguments mean the following:
- buffer = the buffer
- offset = offset into the buffer
- value = value to set (only for `write`)
- isLe = is little endian?
- mLen = mantissa length
- nBytes = number of bytes
## what is ieee754?
The IEEE Standard for Floating-Point Arithmetic (IEEE 754) is a technical standard for floating-point computation. [Read more](http://en.wikipedia.org/wiki/IEEE_floating_point).
## license
BSD 3 Clause. Copyright (c) 2008, Fair Oaks Labs, Inc.

[](https://travis-ci.org/caolan/async)
[](https://dev.azure.com/caolanmcmahon/async/_build/latest?definitionId=1&branchName=master)
[](https://www.npmjs.com/package/async)
[](https://coveralls.io/r/caolan/async?branch=master)
[](https://gitter.im/caolan/async?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
[](https://www.jsdelivr.com/package/npm/async)
<!--
|Linux|Windows|MacOS|
|-|-|-|
|[](https://dev.azure.com/caolanmcmahon/async/_build/latest?definitionId=1&branchName=master) | [](https://dev.azure.com/caolanmcmahon/async/_build/latest?definitionId=1&branchName=master) | [](https://dev.azure.com/caolanmcmahon/async/_build/latest?definitionId=1&branchName=master)| -->
Async is a utility module which provides straight-forward, powerful functions for working with [asynchronous JavaScript](http://caolan.github.io/async/v3/global.html). Although originally designed for use with [Node.js](https://nodejs.org/) and installable via `npm i async`, it can also be used directly in the browser. A ESM/MJS version is included in the main `async` package that should automatically be used with compatible bundlers such as Webpack and Rollup.
A pure ESM version of Async is available as [`async-es`](https://www.npmjs.com/package/async-es).
For Documentation, visit <https://caolan.github.io/async/>
*For Async v1.5.x documentation, go [HERE](https://github.com/caolan/async/blob/v1.5.2/README.md)*
```javascript
// for use with Node-style callbacks...
var async = require("async");
var obj = {dev: "/dev.json", test: "/test.json", prod: "/prod.json"};
var configs = {};
async.forEachOf(obj, (value, key, callback) => {
fs.readFile(__dirname + value, "utf8", (err, data) => {
if (err) return callback(err);
try {
configs[key] = JSON.parse(data);
} catch (e) {
return callback(e);
}
callback();
});
}, err => {
if (err) console.error(err.message);
// configs is now a map of JSON data
doSomethingWith(configs);
});
```
```javascript
var async = require("async");
// ...or ES2017 async functions
async.mapLimit(urls, 5, async function(url) {
const response = await fetch(url)
return response.body
}, (err, results) => {
if (err) throw err
// results is now an array of the response bodies
console.log(results)
})
```
[XRegExp](http://xregexp.com/)
==============================
XRegExp provides augmented, extensible, cross-browser JavaScript regular expressions. You get new syntax and flags beyond what browsers support natively, along with a collection of utils to make your client-side grepping and parsing easier. XRegExp also frees you from worrying about pesky inconsistencies in cross-browser regex handling and the dubious `lastIndex` property.
XRegExp supports all native ES5 regular expression syntax. It's about 3.5 KB when minified and gzipped. It works with Internet Explorer 5.5+, Firefox 1.5+, Chrome, Safari 3+, and Opera 9.5+.
## Performance
XRegExp regular expressions compile to native RegExp objects, thus there is no performance difference when using XRegExp objects with native methods. There is a small performance cost when *compiling* XRegExps. If you want, however, you can use `XRegExp.cache` to avoid ever incurring the compilation cost for a given pattern more than once. Doing so can even lead to XRegExp being faster than native regexes in synthetic tests that repeatedly compile the same regex.
## Usage examples
~~~ js
// Using named capture and flag x (free-spacing and line comments)
var date = XRegExp('(?<year> [0-9]{4}) -? # year \n\
(?<month> [0-9]{2}) -? # month \n\
(?<day> [0-9]{2}) # day ', 'x');
// XRegExp.exec gives you named backreferences on the match result
var match = XRegExp.exec('2012-02-22', date);
match.day; // -> '22'
// It also includes optional pos and sticky arguments
var pos = 3, result = [];
while (match = XRegExp.exec('<1><2><3><4>5<6>', /<(\d+)>/, pos, 'sticky')) {
result.push(match[1]);
pos = match.index + match[0].length;
} // result -> ['2', '3', '4']
// XRegExp.replace allows named backreferences in replacements
XRegExp.replace('2012-02-22', date, '${month}/${day}/${year}'); // -> '02/22/2012'
XRegExp.replace('2012-02-22', date, function (match) {
return match.month + '/' + match.day + '/' + match.year;
}); // -> '02/22/2012'
// In fact, all XRegExps are RegExps and work perfectly with native methods
date.test('2012-02-22'); // -> true
// The *only* caveat is that named captures must be referred to using numbered backreferences
'2012-02-22'.replace(date, '$2/$3/$1'); // -> '02/22/2012'
// If you want, you can extend native methods so you don't have to worry about this
// Doing so also fixes numerous browser bugs in the native methods
XRegExp.install('natives');
'2012-02-22'.replace(date, '${month}/${day}/${year}'); // -> '02/22/2012'
'2012-02-22'.replace(date, function (match) {
return match.month + '/' + match.day + '/' + match.year;
}); // -> '02/22/2012'
date.exec('2012-02-22').day; // -> '22'
// Extract every other digit from a string using XRegExp.forEach
XRegExp.forEach('1a2345', /\d/, function (match, i) {
if (i % 2) this.push(+match[0]);
}, []); // -> [2, 4]
// Get numbers within <b> tags using XRegExp.matchChain
XRegExp.matchChain('1 <b>2</b> 3 <b>4 a 56</b>', [
XRegExp('(?is)<b>.*?</b>'),
/\d+/
]); // -> ['2', '4', '56']
// You can also pass forward and return specific backreferences
var html = '<a href="http://xregexp.com/">XRegExp</a>\
<a href="http://www.google.com/">Google</a>';
XRegExp.matchChain(html, [
{regex: /<a href="([^"]+)">/i, backref: 1},
{regex: XRegExp('(?i)^https?://(?<domain>[^/?#]+)'), backref: 'domain'}
]); // -> ['xregexp.com', 'www.google.com']
// XRegExp.union safely merges strings and regexes into a single pattern
XRegExp.union(['a+b*c', /(dogs)\1/, /(cats)\1/], 'i');
// -> /a\+b\*c|(dogs)\1|(cats)\2/i
~~~
These examples should give you the flavor of what's possible, but XRegExp has more syntax, flags, utils, options, and browser fixes that aren't shown here. You can even augment XRegExp's regular expression syntax with addons (see below) or write your own. See [xregexp.com](http://xregexp.com/) for more details.
## Addons
In browsers, you can either load addons individually, or bundle all addons together with XRegExp by loading `xregexp-all.js`. XRegExp's [npm](http://npmjs.org/) package uses `xregexp-all.js`, which means that the addons are always available when XRegExp is installed on the server using npm.
### XRegExp Unicode Base
In browsers, first include the Unicode Base script:
~~~ html
<script src="xregexp.js"></script>
<script src="addons/unicode/unicode-base.js"></script>
~~~
Then you can do this:
~~~ js
var unicodeWord = XRegExp('^\\p{L}+$');
unicodeWord.test('Русский'); // -> true
unicodeWord.test('日本語'); // -> true
unicodeWord.test('العربية'); // -> true
~~~
The base script adds `\p{Letter}` and its alias `\p{L}`, but other Unicode categories, scripts, blocks, and properties require addon packages. Try these next examples after additionally including `unicode-scripts.js`:
~~~ js
XRegExp('^\\p{Hiragana}+$').test('ひらがな'); // -> true
XRegExp('^[\\p{Latin}\\p{Common}]+$').test('Über Café.'); // -> true
~~~
XRegExp uses the Unicode 6.1 Basic Multilingual Plane.
### XRegExp.build
In browsers, first include the script:
~~~ html
<script src="xregexp.js"></script>
<script src="addons/build.js"></script>
~~~
You can then build regular expressions using named subpatterns, for readability and pattern reuse:
~~~ js
var time = XRegExp.build('(?x)^ {{hours}} ({{minutes}}) $', {
hours: XRegExp.build('{{h12}} : | {{h24}}', {
h12: /1[0-2]|0?[1-9]/,
h24: /2[0-3]|[01][0-9]/
}, 'x'),
minutes: /^[0-5][0-9]$/
});
time.test('10:59'); // -> true
XRegExp.exec('10:59', time).minutes; // -> '59'
~~~
Named subpatterns can be provided as strings or regex objects. A leading `^` and trailing unescaped `$` are stripped from subpatterns if both are present, which allows embedding independently useful anchored patterns. `{{…}}` tokens can be quantified as a single unit. Backreferences in the outer pattern and provided subpatterns are automatically renumbered to work correctly within the larger combined pattern. The syntax `({{name}})` works as shorthand for named capture via `(?<name>{{name}})`. Named subpatterns cannot be embedded within character classes.
See also: *[Creating Grammatical Regexes Using XRegExp.build](http://blog.stevenlevithan.com/archives/grammatical-patterns-xregexp-build)*.
### XRegExp.matchRecursive
In browsers, first include the script:
~~~ html
<script src="xregexp.js"></script>
<script src="addons/matchrecursive.js"></script>
~~~
You can then match recursive constructs using XRegExp pattern strings as left and right delimiters:
~~~ js
var str = '(t((e))s)t()(ing)';
XRegExp.matchRecursive(str, '\\(', '\\)', 'g');
// -> ['t((e))s', '', 'ing']
// Extended information mode with valueNames
str = 'Here is <div> <div>an</div></div> example';
XRegExp.matchRecursive(str, '<div\\s*>', '</div>', 'gi', {
valueNames: ['between', 'left', 'match', 'right']
});
/* -> [
{name: 'between', value: 'Here is ', start: 0, end: 8},
{name: 'left', value: '<div>', start: 8, end: 13},
{name: 'match', value: ' <div>an</div>', start: 13, end: 27},
{name: 'right', value: '</div>', start: 27, end: 33},
{name: 'between', value: ' example', start: 33, end: 41}
] */
// Omitting unneeded parts with null valueNames, and using escapeChar
str = '...{1}\\{{function(x,y){return y+x;}}';
XRegExp.matchRecursive(str, '{', '}', 'g', {
valueNames: ['literal', null, 'value', null],
escapeChar: '\\'
});
/* -> [
{name: 'literal', value: '...', start: 0, end: 3},
{name: 'value', value: '1', start: 4, end: 5},
{name: 'literal', value: '\\{', start: 6, end: 8},
{name: 'value', value: 'function(x,y){return y+x;}', start: 9, end: 35}
] */
// Sticky mode via flag y
str = '<1><<<2>>><3>4<5>';
XRegExp.matchRecursive(str, '<', '>', 'gy');
// -> ['1', '<<2>>', '3']
~~~
`XRegExp.matchRecursive` throws an error if it sees an unbalanced delimiter in the target string.
### XRegExp Prototype Methods
In browsers, first include the script:
~~~ html
<script src="xregexp.js"></script>
<script src="addons/prototypes.js"></script>
~~~
New XRegExp regexes then gain a collection of useful methods: `apply`, `call`, `forEach`, `globalize`, `xexec`, and `xtest`.
~~~ js
// To demonstrate the call method, let's first create the function we'll be using...
function filter(array, fn) {
var res = [];
array.forEach(function (el) {if (fn.call(null, el)) res.push(el);});
return res;
}
// Now we can filter arrays using functions and regexes
filter(['a', 'ba', 'ab', 'b'], XRegExp('^a')); // -> ['a', 'ab']
~~~
Native `RegExp` objects copied by `XRegExp` are augmented with any `XRegExp.prototype` methods. The following lines therefore work equivalently:
~~~ js
XRegExp('[a-z]', 'ig').xexec('abc');
XRegExp(/[a-z]/ig).xexec('abc');
XRegExp.globalize(/[a-z]/i).xexec('abc');
~~~
## Installation and usage
In browsers:
~~~ html
<script src="xregexp-min.js"></script>
~~~
Or, to bundle XRegExp with all of its addons:
~~~ html
<script src="xregexp-all-min.js"></script>
~~~
Using [npm](http://npmjs.org/):
~~~ bash
npm install xregexp
~~~
In [Node.js](http://nodejs.org/) and [CommonJS module](http://wiki.commonjs.org/wiki/Modules) loaders:
~~~ js
var XRegExp = require('xregexp').XRegExp;
~~~
### Running tests on the server with npm
~~~ bash
npm install -g qunit # needed to run the tests
npm test # in the xregexp root
~~~
If XRegExp was not installed using npm, just open `tests/index.html` in your browser.
## &c
**Lookbehind:** A [collection of short functions](https://gist.github.com/2387872) is available that makes it easy to simulate infinite-length leading lookbehind.
## Changelog
* Releases: [Version history](http://xregexp.com/history/).
* Upcoming: [Milestones](https://github.com/slevithan/XRegExp/issues/milestones), [Roadmap](https://github.com/slevithan/XRegExp/wiki/Roadmap).
## About
XRegExp and addons copyright 2007-2012 by [Steven Levithan](http://stevenlevithan.com/).
Tools: Unicode range generators by [Mathias Bynens](http://mathiasbynens.be/). Source file concatenator by [Bjarke Walling](http://twitter.com/walling).
Prior art: `XRegExp.build` inspired by [Lea Verou](http://lea.verou.me/)'s [RegExp.create](http://lea.verou.me/2011/03/create-complex-regexps-more-easily/). `XRegExp.union` inspired by [Ruby](http://www.ruby-lang.org/). XRegExp's syntax extensions come from Perl, .NET, etc.
All code released under the [MIT License](http://mit-license.org/).
Fork me to show support, fix, and extend.
## Eth-Lib
Lightweight Ethereum libraries. This is a temporary repository which will be used as the basis of an implementation on Idris (or similar).
# NearBridge
TruffleFramework template with travis-ci.org and coveralls.io configured
[](https://travis-ci.org/nearprotocol/bridge)
[](https://coveralls.io/github/nearprotocol/bridge?branch=master)
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows note
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Note that PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Then, run the program to be debugged as usual.
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
<h1 align="center">Picomatch</h1>
<p align="center">
<a href="https://npmjs.org/package/picomatch">
<img src="https://img.shields.io/npm/v/picomatch.svg" alt="version">
</a>
<a href="https://github.com/micromatch/picomatch/actions?workflow=Tests">
<img src="https://github.com/micromatch/picomatch/workflows/Tests/badge.svg" alt="test status">
</a>
<a href="https://coveralls.io/github/micromatch/picomatch">
<img src="https://img.shields.io/coveralls/github/micromatch/picomatch/master.svg" alt="coverage status">
</a>
<a href="https://npmjs.org/package/picomatch">
<img src="https://img.shields.io/npm/dm/picomatch.svg" alt="downloads">
</a>
</p>
<br>
<br>
<p align="center">
<strong>Blazing fast and accurate glob matcher written in JavaScript.</strong></br>
<em>No dependencies and full support for standard and extended Bash glob features, including braces, extglobs, POSIX brackets, and regular expressions.</em>
</p>
<br>
<br>
## Why picomatch?
* **Lightweight** - No dependencies
* **Minimal** - Tiny API surface. Main export is a function that takes a glob pattern and returns a matcher function.
* **Fast** - Loads in about 2ms (that's several times faster than a [single frame of a HD movie](http://www.endmemo.com/sconvert/framespersecondframespermillisecond.php) at 60fps)
* **Performant** - Use the returned matcher function to speed up repeat matching (like when watching files)
* **Accurate matching** - Using wildcards (`*` and `?`), globstars (`**`) for nested directories, [advanced globbing](#advanced-globbing) with extglobs, braces, and POSIX brackets, and support for escaping special characters with `\` or quotes.
* **Well tested** - Thousands of unit tests
See the [library comparison](#library-comparisons) to other libraries.
<br>
<br>
## Table of Contents
<details><summary> Click to expand </summary>
- [Install](#install)
- [Usage](#usage)
- [API](#api)
* [picomatch](#picomatch)
* [.test](#test)
* [.matchBase](#matchbase)
* [.isMatch](#ismatch)
* [.parse](#parse)
* [.scan](#scan)
* [.compileRe](#compilere)
* [.toRegex](#toregex)
- [Options](#options)
* [Picomatch options](#picomatch-options)
* [Scan Options](#scan-options)
* [Options Examples](#options-examples)
- [Globbing features](#globbing-features)
* [Basic globbing](#basic-globbing)
* [Advanced globbing](#advanced-globbing)
* [Braces](#braces)
* [Matching special characters as literals](#matching-special-characters-as-literals)
- [Library Comparisons](#library-comparisons)
- [Benchmarks](#benchmarks)
- [Philosophies](#philosophies)
- [About](#about)
* [Author](#author)
* [License](#license)
_(TOC generated by [verb](https://github.com/verbose/verb) using [markdown-toc](https://github.com/jonschlinkert/markdown-toc))_
</details>
<br>
<br>
## Install
Install with [npm](https://www.npmjs.com/):
```sh
npm install --save picomatch
```
<br>
## Usage
The main export is a function that takes a glob pattern and an options object and returns a function for matching strings.
```js
const pm = require('picomatch');
const isMatch = pm('*.js');
console.log(isMatch('abcd')); //=> false
console.log(isMatch('a.js')); //=> true
console.log(isMatch('a.md')); //=> false
console.log(isMatch('a/b.js')); //=> false
```
<br>
## API
### [picomatch](lib/picomatch.js#L32)
Creates a matcher function from one or more glob patterns. The returned function takes a string to match as its first argument, and returns true if the string is a match. The returned matcher function also takes a boolean as the second argument that, when true, returns an object with additional information.
**Params**
* `globs` **{String|Array}**: One or more glob patterns.
* `options` **{Object=}**
* `returns` **{Function=}**: Returns a matcher function.
**Example**
```js
const picomatch = require('picomatch');
// picomatch(glob[, options]);
const isMatch = picomatch('*.!(*a)');
console.log(isMatch('a.a')); //=> false
console.log(isMatch('a.b')); //=> true
```
### [.test](lib/picomatch.js#L117)
Test `input` with the given `regex`. This is used by the main `picomatch()` function to test the input string.
**Params**
* `input` **{String}**: String to test.
* `regex` **{RegExp}**
* `returns` **{Object}**: Returns an object with matching info.
**Example**
```js
const picomatch = require('picomatch');
// picomatch.test(input, regex[, options]);
console.log(picomatch.test('foo/bar', /^(?:([^/]*?)\/([^/]*?))$/));
// { isMatch: true, match: [ 'foo/', 'foo', 'bar' ], output: 'foo/bar' }
```
### [.matchBase](lib/picomatch.js#L161)
Match the basename of a filepath.
**Params**
* `input` **{String}**: String to test.
* `glob` **{RegExp|String}**: Glob pattern or regex created by [.makeRe](#makeRe).
* `returns` **{Boolean}**
**Example**
```js
const picomatch = require('picomatch');
// picomatch.matchBase(input, glob[, options]);
console.log(picomatch.matchBase('foo/bar.js', '*.js'); // true
```
### [.isMatch](lib/picomatch.js#L183)
Returns true if **any** of the given glob `patterns` match the specified `string`.
**Params**
* **{String|Array}**: str The string to test.
* **{String|Array}**: patterns One or more glob patterns to use for matching.
* **{Object}**: See available [options](#options).
* `returns` **{Boolean}**: Returns true if any patterns match `str`
**Example**
```js
const picomatch = require('picomatch');
// picomatch.isMatch(string, patterns[, options]);
console.log(picomatch.isMatch('a.a', ['b.*', '*.a'])); //=> true
console.log(picomatch.isMatch('a.a', 'b.*')); //=> false
```
### [.parse](lib/picomatch.js#L199)
Parse a glob pattern to create the source string for a regular expression.
**Params**
* `pattern` **{String}**
* `options` **{Object}**
* `returns` **{Object}**: Returns an object with useful properties and output to be used as a regex source string.
**Example**
```js
const picomatch = require('picomatch');
const result = picomatch.parse(pattern[, options]);
```
### [.scan](lib/picomatch.js#L231)
Scan a glob pattern to separate the pattern into segments.
**Params**
* `input` **{String}**: Glob pattern to scan.
* `options` **{Object}**
* `returns` **{Object}**: Returns an object with
**Example**
```js
const picomatch = require('picomatch');
// picomatch.scan(input[, options]);
const result = picomatch.scan('!./foo/*.js');
console.log(result);
{ prefix: '!./',
input: '!./foo/*.js',
start: 3,
base: 'foo',
glob: '*.js',
isBrace: false,
isBracket: false,
isGlob: true,
isExtglob: false,
isGlobstar: false,
negated: true }
```
### [.compileRe](lib/picomatch.js#L250)
Create a regular expression from a parsed glob pattern.
**Params**
* `state` **{String}**: The object returned from the `.parse` method.
* `options` **{Object}**
* `returns` **{RegExp}**: Returns a regex created from the given pattern.
**Example**
```js
const picomatch = require('picomatch');
const state = picomatch.parse('*.js');
// picomatch.compileRe(state[, options]);
console.log(picomatch.compileRe(state));
//=> /^(?:(?!\.)(?=.)[^/]*?\.js)$/
```
### [.toRegex](lib/picomatch.js#L318)
Create a regular expression from the given regex source string.
**Params**
* `source` **{String}**: Regular expression source string.
* `options` **{Object}**
* `returns` **{RegExp}**
**Example**
```js
const picomatch = require('picomatch');
// picomatch.toRegex(source[, options]);
const { output } = picomatch.parse('*.js');
console.log(picomatch.toRegex(output));
//=> /^(?:(?!\.)(?=.)[^/]*?\.js)$/
```
<br>
## Options
### Picomatch options
The following options may be used with the main `picomatch()` function or any of the methods on the picomatch API.
| **Option** | **Type** | **Default value** | **Description** |
| --- | --- | --- | --- |
| `basename` | `boolean` | `false` | If set, then patterns without slashes will be matched against the basename of the path if it contains slashes. For example, `a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`. |
| `bash` | `boolean` | `false` | Follow bash matching rules more strictly - disallows backslashes as escape characters, and treats single stars as globstars (`**`). |
| `capture` | `boolean` | `undefined` | Return regex matches in supporting methods. |
| `contains` | `boolean` | `undefined` | Allows glob to match any part of the given string(s). |
| `cwd` | `string` | `process.cwd()` | Current working directory. Used by `picomatch.split()` |
| `debug` | `boolean` | `undefined` | Debug regular expressions when an error is thrown. |
| `dot` | `boolean` | `false` | Enable dotfile matching. By default, dotfiles are ignored unless a `.` is explicitly defined in the pattern, or `options.dot` is true |
| `expandRange` | `function` | `undefined` | Custom function for expanding ranges in brace patterns, such as `{a..z}`. The function receives the range values as two arguments, and it must return a string to be used in the generated regex. It's recommended that returned strings be wrapped in parentheses. |
| `failglob` | `boolean` | `false` | Throws an error if no matches are found. Based on the bash option of the same name. |
| `fastpaths` | `boolean` | `true` | To speed up processing, full parsing is skipped for a handful common glob patterns. Disable this behavior by setting this option to `false`. |
| `flags` | `boolean` | `undefined` | Regex flags to use in the generated regex. If defined, the `nocase` option will be overridden. |
| [format](#optionsformat) | `function` | `undefined` | Custom function for formatting the returned string. This is useful for removing leading slashes, converting Windows paths to Posix paths, etc. |
| `ignore` | `array\|string` | `undefined` | One or more glob patterns for excluding strings that should not be matched from the result. |
| `keepQuotes` | `boolean` | `false` | Retain quotes in the generated regex, since quotes may also be used as an alternative to backslashes. |
| `literalBrackets` | `boolean` | `undefined` | When `true`, brackets in the glob pattern will be escaped so that only literal brackets will be matched. |
| `lookbehinds` | `boolean` | `true` | Support regex positive and negative lookbehinds. Note that you must be using Node 8.1.10 or higher to enable regex lookbehinds. |
| `matchBase` | `boolean` | `false` | Alias for `basename` |
| `maxLength` | `boolean` | `65536` | Limit the max length of the input string. An error is thrown if the input string is longer than this value. |
| `nobrace` | `boolean` | `false` | Disable brace matching, so that `{a,b}` and `{1..3}` would be treated as literal characters. |
| `nobracket` | `boolean` | `undefined` | Disable matching with regex brackets. |
| `nocase` | `boolean` | `false` | Make matching case-insensitive. Equivalent to the regex `i` flag. Note that this option is overridden by the `flags` option. |
| `nodupes` | `boolean` | `true` | Deprecated, use `nounique` instead. This option will be removed in a future major release. By default duplicates are removed. Disable uniquification by setting this option to false. |
| `noext` | `boolean` | `false` | Alias for `noextglob` |
| `noextglob` | `boolean` | `false` | Disable support for matching with extglobs (like `+(a\|b)`) |
| `noglobstar` | `boolean` | `false` | Disable support for matching nested directories with globstars (`**`) |
| `nonegate` | `boolean` | `false` | Disable support for negating with leading `!` |
| `noquantifiers` | `boolean` | `false` | Disable support for regex quantifiers (like `a{1,2}`) and treat them as brace patterns to be expanded. |
| [onIgnore](#optionsonIgnore) | `function` | `undefined` | Function to be called on ignored items. |
| [onMatch](#optionsonMatch) | `function` | `undefined` | Function to be called on matched items. |
| [onResult](#optionsonResult) | `function` | `undefined` | Function to be called on all items, regardless of whether or not they are matched or ignored. |
| `posix` | `boolean` | `false` | Support POSIX character classes ("posix brackets"). |
| `posixSlashes` | `boolean` | `undefined` | Convert all slashes in file paths to forward slashes. This does not convert slashes in the glob pattern itself |
| `prepend` | `boolean` | `undefined` | String to prepend to the generated regex used for matching. |
| `regex` | `boolean` | `false` | Use regular expression rules for `+` (instead of matching literal `+`), and for stars that follow closing parentheses or brackets (as in `)*` and `]*`). |
| `strictBrackets` | `boolean` | `undefined` | Throw an error if brackets, braces, or parens are imbalanced. |
| `strictSlashes` | `boolean` | `undefined` | When true, picomatch won't match trailing slashes with single stars. |
| `unescape` | `boolean` | `undefined` | Remove backslashes preceding escaped characters in the glob pattern. By default, backslashes are retained. |
| `unixify` | `boolean` | `undefined` | Alias for `posixSlashes`, for backwards compatibility. |
### Scan Options
In addition to the main [picomatch options](#picomatch-options), the following options may also be used with the [.scan](#scan) method.
| **Option** | **Type** | **Default value** | **Description** |
| --- | --- | --- | --- |
| `tokens` | `boolean` | `false` | When `true`, the returned object will include an array of tokens (objects), representing each path "segment" in the scanned glob pattern |
| `parts` | `boolean` | `false` | When `true`, the returned object will include an array of strings representing each path "segment" in the scanned glob pattern. This is automatically enabled when `options.tokens` is true |
**Example**
```js
const picomatch = require('picomatch');
const result = picomatch.scan('!./foo/*.js', { tokens: true });
console.log(result);
// {
// prefix: '!./',
// input: '!./foo/*.js',
// start: 3,
// base: 'foo',
// glob: '*.js',
// isBrace: false,
// isBracket: false,
// isGlob: true,
// isExtglob: false,
// isGlobstar: false,
// negated: true,
// maxDepth: 2,
// tokens: [
// { value: '!./', depth: 0, isGlob: false, negated: true, isPrefix: true },
// { value: 'foo', depth: 1, isGlob: false },
// { value: '*.js', depth: 1, isGlob: true }
// ],
// slashes: [ 2, 6 ],
// parts: [ 'foo', '*.js' ]
// }
```
<br>
### Options Examples
#### options.expandRange
**Type**: `function`
**Default**: `undefined`
Custom function for expanding ranges in brace patterns. The [fill-range](https://github.com/jonschlinkert/fill-range) library is ideal for this purpose, or you can use custom code to do whatever you need.
**Example**
The following example shows how to create a glob that matches a folder
```js
const fill = require('fill-range');
const regex = pm.makeRe('foo/{01..25}/bar', {
expandRange(a, b) {
return `(${fill(a, b, { toRegex: true })})`;
}
});
console.log(regex);
//=> /^(?:foo\/((?:0[1-9]|1[0-9]|2[0-5]))\/bar)$/
console.log(regex.test('foo/00/bar')) // false
console.log(regex.test('foo/01/bar')) // true
console.log(regex.test('foo/10/bar')) // true
console.log(regex.test('foo/22/bar')) // true
console.log(regex.test('foo/25/bar')) // true
console.log(regex.test('foo/26/bar')) // false
```
#### options.format
**Type**: `function`
**Default**: `undefined`
Custom function for formatting strings before they're matched.
**Example**
```js
// strip leading './' from strings
const format = str => str.replace(/^\.\//, '');
const isMatch = picomatch('foo/*.js', { format });
console.log(isMatch('./foo/bar.js')); //=> true
```
#### options.onMatch
```js
const onMatch = ({ glob, regex, input, output }) => {
console.log({ glob, regex, input, output });
};
const isMatch = picomatch('*', { onMatch });
isMatch('foo');
isMatch('bar');
isMatch('baz');
```
#### options.onIgnore
```js
const onIgnore = ({ glob, regex, input, output }) => {
console.log({ glob, regex, input, output });
};
const isMatch = picomatch('*', { onIgnore, ignore: 'f*' });
isMatch('foo');
isMatch('bar');
isMatch('baz');
```
#### options.onResult
```js
const onResult = ({ glob, regex, input, output }) => {
console.log({ glob, regex, input, output });
};
const isMatch = picomatch('*', { onResult, ignore: 'f*' });
isMatch('foo');
isMatch('bar');
isMatch('baz');
```
<br>
<br>
## Globbing features
* [Basic globbing](#basic-globbing) (Wildcard matching)
* [Advanced globbing](#advanced-globbing) (extglobs, posix brackets, brace matching)
### Basic globbing
| **Character** | **Description** |
| --- | --- |
| `*` | Matches any character zero or more times, excluding path separators. Does _not match_ path separators or hidden files or directories ("dotfiles"), unless explicitly enabled by setting the `dot` option to `true`. |
| `**` | Matches any character zero or more times, including path separators. Note that `**` will only match path separators (`/`, and `\\` on Windows) when they are the only characters in a path segment. Thus, `foo**/bar` is equivalent to `foo*/bar`, and `foo/a**b/bar` is equivalent to `foo/a*b/bar`, and _more than two_ consecutive stars in a glob path segment are regarded as _a single star_. Thus, `foo/***/bar` is equivalent to `foo/*/bar`. |
| `?` | Matches any character excluding path separators one time. Does _not match_ path separators or leading dots. |
| `[abc]` | Matches any characters inside the brackets. For example, `[abc]` would match the characters `a`, `b` or `c`, and nothing else. |
#### Matching behavior vs. Bash
Picomatch's matching features and expected results in unit tests are based on Bash's unit tests and the Bash 4.3 specification, with the following exceptions:
* Bash will match `foo/bar/baz` with `*`. Picomatch only matches nested directories with `**`.
* Bash greedily matches with negated extglobs. For example, Bash 4.3 says that `!(foo)*` should match `foo` and `foobar`, since the trailing `*` bracktracks to match the preceding pattern. This is very memory-inefficient, and IMHO, also incorrect. Picomatch would return `false` for both `foo` and `foobar`.
<br>
### Advanced globbing
* [extglobs](#extglobs)
* [POSIX brackets](#posix-brackets)
* [Braces](#brace-expansion)
#### Extglobs
| **Pattern** | **Description** |
| --- | --- |
| `@(pattern)` | Match _only one_ consecutive occurrence of `pattern` |
| `*(pattern)` | Match _zero or more_ consecutive occurrences of `pattern` |
| `+(pattern)` | Match _one or more_ consecutive occurrences of `pattern` |
| `?(pattern)` | Match _zero or **one**_ consecutive occurrences of `pattern` |
| `!(pattern)` | Match _anything but_ `pattern` |
**Examples**
```js
const pm = require('picomatch');
// *(pattern) matches ZERO or more of "pattern"
console.log(pm.isMatch('a', 'a*(z)')); // true
console.log(pm.isMatch('az', 'a*(z)')); // true
console.log(pm.isMatch('azzz', 'a*(z)')); // true
// +(pattern) matches ONE or more of "pattern"
console.log(pm.isMatch('a', 'a*(z)')); // true
console.log(pm.isMatch('az', 'a*(z)')); // true
console.log(pm.isMatch('azzz', 'a*(z)')); // true
// supports multiple extglobs
console.log(pm.isMatch('foo.bar', '!(foo).!(bar)')); // false
// supports nested extglobs
console.log(pm.isMatch('foo.bar', '!(!(foo)).!(!(bar))')); // true
```
#### POSIX brackets
POSIX classes are disabled by default. Enable this feature by setting the `posix` option to true.
**Enable POSIX bracket support**
```js
console.log(pm.makeRe('[[:word:]]+', { posix: true }));
//=> /^(?:(?=.)[A-Za-z0-9_]+\/?)$/
```
**Supported POSIX classes**
The following named POSIX bracket expressions are supported:
* `[:alnum:]` - Alphanumeric characters, equ `[a-zA-Z0-9]`
* `[:alpha:]` - Alphabetical characters, equivalent to `[a-zA-Z]`.
* `[:ascii:]` - ASCII characters, equivalent to `[\\x00-\\x7F]`.
* `[:blank:]` - Space and tab characters, equivalent to `[ \\t]`.
* `[:cntrl:]` - Control characters, equivalent to `[\\x00-\\x1F\\x7F]`.
* `[:digit:]` - Numerical digits, equivalent to `[0-9]`.
* `[:graph:]` - Graph characters, equivalent to `[\\x21-\\x7E]`.
* `[:lower:]` - Lowercase letters, equivalent to `[a-z]`.
* `[:print:]` - Print characters, equivalent to `[\\x20-\\x7E ]`.
* `[:punct:]` - Punctuation and symbols, equivalent to `[\\-!"#$%&\'()\\*+,./:;<=>?@[\\]^_`{|}~]`.
* `[:space:]` - Extended space characters, equivalent to `[ \\t\\r\\n\\v\\f]`.
* `[:upper:]` - Uppercase letters, equivalent to `[A-Z]`.
* `[:word:]` - Word characters (letters, numbers and underscores), equivalent to `[A-Za-z0-9_]`.
* `[:xdigit:]` - Hexadecimal digits, equivalent to `[A-Fa-f0-9]`.
See the [Bash Reference Manual](https://www.gnu.org/software/bash/manual/html_node/Pattern-Matching.html) for more information.
### Braces
Picomatch does not do brace expansion. For [brace expansion](https://www.gnu.org/software/bash/manual/html_node/Brace-Expansion.html) and advanced matching with braces, use [micromatch](https://github.com/micromatch/micromatch) instead. Picomatch has very basic support for braces.
### Matching special characters as literals
If you wish to match the following special characters in a filepath, and you want to use these characters in your glob pattern, they must be escaped with backslashes or quotes:
**Special Characters**
Some characters that are used for matching in regular expressions are also regarded as valid file path characters on some platforms.
To match any of the following characters as literals: `$^*+?()[]
Examples:
```js
console.log(pm.makeRe('foo/bar \\(1\\)'));
console.log(pm.makeRe('foo/bar \\(1\\)'));
```
<br>
<br>
## Library Comparisons
The following table shows which features are supported by [minimatch](https://github.com/isaacs/minimatch), [micromatch](https://github.com/micromatch/micromatch), [picomatch](https://github.com/micromatch/picomatch), [nanomatch](https://github.com/micromatch/nanomatch), [extglob](https://github.com/micromatch/extglob), [braces](https://github.com/micromatch/braces), and [expand-brackets](https://github.com/micromatch/expand-brackets).
| **Feature** | `minimatch` | `micromatch` | `picomatch` | `nanomatch` | `extglob` | `braces` | `expand-brackets` |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Wildcard matching (`*?+`) | ✔ | ✔ | ✔ | ✔ | - | - | - |
| Advancing globbing | ✔ | ✔ | ✔ | - | - | - | - |
| Brace _matching_ | ✔ | ✔ | ✔ | - | - | ✔ | - |
| Brace _expansion_ | ✔ | ✔ | - | - | - | ✔ | - |
| Extglobs | partial | ✔ | ✔ | - | ✔ | - | - |
| Posix brackets | - | ✔ | ✔ | - | - | - | ✔ |
| Regular expression syntax | - | ✔ | ✔ | ✔ | ✔ | - | ✔ |
| File system operations | - | - | - | - | - | - | - |
<br>
<br>
## Benchmarks
Performance comparison of picomatch and minimatch.
```
# .makeRe star
picomatch x 1,993,050 ops/sec ±0.51% (91 runs sampled)
minimatch x 627,206 ops/sec ±1.96% (87 runs sampled))
# .makeRe star; dot=true
picomatch x 1,436,640 ops/sec ±0.62% (91 runs sampled)
minimatch x 525,876 ops/sec ±0.60% (88 runs sampled)
# .makeRe globstar
picomatch x 1,592,742 ops/sec ±0.42% (90 runs sampled)
minimatch x 962,043 ops/sec ±1.76% (91 runs sampled)d)
# .makeRe globstars
picomatch x 1,615,199 ops/sec ±0.35% (94 runs sampled)
minimatch x 477,179 ops/sec ±1.33% (91 runs sampled)
# .makeRe with leading star
picomatch x 1,220,856 ops/sec ±0.40% (92 runs sampled)
minimatch x 453,564 ops/sec ±1.43% (94 runs sampled)
# .makeRe - basic braces
picomatch x 392,067 ops/sec ±0.70% (90 runs sampled)
minimatch x 99,532 ops/sec ±2.03% (87 runs sampled))
```
<br>
<br>
## Philosophies
The goal of this library is to be blazing fast, without compromising on accuracy.
**Accuracy**
The number one of goal of this library is accuracy. However, it's not unusual for different glob implementations to have different rules for matching behavior, even with simple wildcard matching. It gets increasingly more complicated when combinations of different features are combined, like when extglobs are combined with globstars, braces, slashes, and so on: `!(**/{a,b,*/c})`.
Thus, given that there is no canonical glob specification to use as a single source of truth when differences of opinion arise regarding behavior, sometimes we have to implement our best judgement and rely on feedback from users to make improvements.
**Performance**
Although this library performs well in benchmarks, and in most cases it's faster than other popular libraries we benchmarked against, we will always choose accuracy over performance. It's not helpful to anyone if our library is faster at returning the wrong answer.
<br>
<br>
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
Please read the [contributing guide](.github/contributing.md) for advice on opening issues, pull requests, and coding standards.
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2017-present, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
# jsdiff
[](http://travis-ci.org/kpdecker/jsdiff)
[](https://saucelabs.com/u/jsdiff)
A javascript text differencing implementation.
Based on the algorithm proposed in
["An O(ND) Difference Algorithm and its Variations" (Myers, 1986)](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.4.6927).
## Installation
```bash
npm install diff --save
```
or
```bash
bower install jsdiff --save
```
## API
* `JsDiff.diffChars(oldStr, newStr[, options])` - diffs two blocks of text, comparing character by character.
Returns a list of change objects (See below).
Options
* `ignoreCase`: `true` to ignore casing difference. Defaults to `false`.
* `JsDiff.diffWords(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, ignoring whitespace.
Returns a list of change objects (See below).
Options
* `ignoreCase`: Same as in `diffChars`.
* `JsDiff.diffWordsWithSpace(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, treating whitespace as significant.
Returns a list of change objects (See below).
* `JsDiff.diffLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line.
Options
* `ignoreWhitespace`: `true` to ignore leading and trailing whitespace. This is the same as `diffTrimmedLines`
* `newlineIsToken`: `true` to treat newline characters as separate tokens. This allows for changes to the newline structure to occur independently of the line content and to be treated as such. In general this is the more human friendly form of `diffLines` and `diffLines` is better suited for patches and other computer friendly output.
Returns a list of change objects (See below).
* `JsDiff.diffTrimmedLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line, ignoring leading and trailing whitespace.
Returns a list of change objects (See below).
* `JsDiff.diffSentences(oldStr, newStr[, options])` - diffs two blocks of text, comparing sentence by sentence.
Returns a list of change objects (See below).
* `JsDiff.diffCss(oldStr, newStr[, options])` - diffs two blocks of text, comparing CSS tokens.
Returns a list of change objects (See below).
* `JsDiff.diffJson(oldObj, newObj[, options])` - diffs two JSON objects, comparing the fields defined on each. The order of fields, etc does not matter in this comparison.
Returns a list of change objects (See below).
* `JsDiff.diffArrays(oldArr, newArr[, options])` - diffs two arrays, comparing each item for strict equality (===).
Options
* `comparator`: `function(left, right)` for custom equality checks
Returns a list of change objects (See below).
* `JsDiff.createTwoFilesPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Parameters:
* `oldFileName` : String to be output in the filename section of the patch for the removals
* `newFileName` : String to be output in the filename section of the patch for the additions
* `oldStr` : Original string value
* `newStr` : New string value
* `oldHeader` : Additional information to include in the old file header
* `newHeader` : Additional information to include in the new file header
* `options` : An object with options. Currently, only `context` is supported and describes how many lines of context should be included.
* `JsDiff.createPatch(fileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Just like JsDiff.createTwoFilesPatch, but with oldFileName being equal to newFileName.
* `JsDiff.structuredPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader, options)` - returns an object with an array of hunk objects.
This method is similar to createTwoFilesPatch, but returns a data structure
suitable for further processing. Parameters are the same as createTwoFilesPatch. The data structure returned may look like this:
```js
{
oldFileName: 'oldfile', newFileName: 'newfile',
oldHeader: 'header1', newHeader: 'header2',
hunks: [{
oldStart: 1, oldLines: 3, newStart: 1, newLines: 3,
lines: [' line2', ' line3', '-line4', '+line5', '\\ No newline at end of file'],
}]
}
```
* `JsDiff.applyPatch(source, patch[, options])` - applies a unified diff patch.
Return a string containing new version of provided data. `patch` may be a string diff or the output from the `parsePatch` or `structuredPatch` methods.
The optional `options` object may have the following keys:
- `fuzzFactor`: Number of lines that are allowed to differ before rejecting a patch. Defaults to 0.
- `compareLine(lineNumber, line, operation, patchContent)`: Callback used to compare to given lines to determine if they should be considered equal when patching. Defaults to strict equality but may be overridden to provide fuzzier comparison. Should return false if the lines should be rejected.
* `JsDiff.applyPatches(patch, options)` - applies one or more patches.
This method will iterate over the contents of the patch and apply to data provided through callbacks. The general flow for each patch index is:
- `options.loadFile(index, callback)` is called. The caller should then load the contents of the file and then pass that to the `callback(err, data)` callback. Passing an `err` will terminate further patch execution.
- `options.patched(index, content, callback)` is called once the patch has been applied. `content` will be the return value from `applyPatch`. When it's ready, the caller should call `callback(err)` callback. Passing an `err` will terminate further patch execution.
Once all patches have been applied or an error occurs, the `options.complete(err)` callback is made.
* `JsDiff.parsePatch(diffStr)` - Parses a patch into structured data
Return a JSON object representation of the a patch, suitable for use with the `applyPatch` method. This parses to the same structure returned by `JsDiff.structuredPatch`.
* `convertChangesToXML(changes)` - converts a list of changes to a serialized XML format
All methods above which accept the optional `callback` method will run in sync mode when that parameter is omitted and in async mode when supplied. This allows for larger diffs without blocking the event loop. This may be passed either directly as the final parameter or as the `callback` field in the `options` object.
### Change Objects
Many of the methods above return change objects. These objects consist of the following fields:
* `value`: Text content
* `added`: True if the value was inserted into the new string
* `removed`: True of the value was removed from the old string
Note that some cases may omit a particular flag field. Comparison on the flag fields should always be done in a truthy or falsy manner.
## Examples
Basic example in Node
```js
require('colors');
var jsdiff = require('diff');
var one = 'beep boop';
var other = 'beep boob blah';
var diff = jsdiff.diffChars(one, other);
diff.forEach(function(part){
// green for additions, red for deletions
// grey for common parts
var color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
process.stderr.write(part.value[color]);
});
console.log();
```
Running the above program should yield
<img src="images/node_example.png" alt="Node Example">
Basic example in a web page
```html
<pre id="display"></pre>
<script src="diff.js"></script>
<script>
var one = 'beep boop',
other = 'beep boob blah',
color = '',
span = null;
var diff = JsDiff.diffChars(one, other),
display = document.getElementById('display'),
fragment = document.createDocumentFragment();
diff.forEach(function(part){
// green for additions, red for deletions
// grey for common parts
color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
span = document.createElement('span');
span.style.color = color;
span.appendChild(document
.createTextNode(part.value));
fragment.appendChild(span);
});
display.appendChild(fragment);
</script>
```
Open the above .html file in a browser and you should see
<img src="images/web_example.png" alt="Node Example">
**[Full online demo](http://kpdecker.github.com/jsdiff)**
## Compatibility
[](https://saucelabs.com/u/jsdiff)
jsdiff supports all ES3 environments with some known issues on IE8 and below. Under these browsers some diff algorithms such as word diff and others may fail due to lack of support for capturing groups in the `split` operation.
## License
See [LICENSE](https://github.com/kpdecker/jsdiff/blob/master/LICENSE).
# blessed
A curses-like library with a high level terminal interface API for node.js.

Blessed is over 16,000 lines of code and terminal goodness. It's completely
implemented in javascript, and its goal consists of two things:
1. Reimplement ncurses entirely by parsing and compiling terminfo and termcap,
and exposing a `Program` object which can output escape sequences compatible
with _any_ terminal.
2. Implement a widget API which is heavily optimized for terminals.
The blessed renderer makes use of CSR (change-scroll-region), and BCE
(back-color-erase). It draws the screen using the painter's algorithm and is
sped up with smart cursor movements and a screen damage buffer. This means
rendering of your application will be extremely efficient: blessed only draws
the changes (damage) to the screen.
Blessed is arguably as accurate as ncurses, but even more optimized in some
ways. The widget library gives you an API which is reminiscent of the DOM.
Anyone is able to make an awesome terminal application with blessed. There are
terminal widget libraries for other platforms (primarily [python][urwid] and
[perl][curses-ui]), but blessed is possibly the most DOM-like (dare I say the
most user-friendly?).
Blessed has been used to implement other popular libraries and programs.
Examples include: the [slap text editor][slap] and [blessed-contrib][contrib].
The blessed API itself has gone on to inspire [termui][termui] for Go.
## Install
``` bash
$ npm install blessed
```
## Example
This will render a box with line borders containing the text `'Hello world!'`,
perfectly centered horizontally and vertically.
__NOTE__: It is recommend you use either `smartCSR` or `fastCSR` as a
`blessed.screen` option. This will enable CSR when scrolling text in elements
or when manipulating lines.
``` js
var blessed = require('blessed');
// Create a screen object.
var screen = blessed.screen({
smartCSR: true
});
screen.title = 'my window title';
// Create a box perfectly centered horizontally and vertically.
var box = blessed.box({
top: 'center',
left: 'center',
width: '50%',
height: '50%',
content: 'Hello {bold}world{/bold}!',
tags: true,
border: {
type: 'line'
},
style: {
fg: 'white',
bg: 'magenta',
border: {
fg: '#f0f0f0'
},
hover: {
bg: 'green'
}
}
});
// Append our box to the screen.
screen.append(box);
// Add a png icon to the box
var icon = blessed.image({
parent: box,
top: 0,
left: 0,
type: 'overlay',
width: 'shrink',
height: 'shrink',
file: __dirname + '/my-program-icon.png',
search: false
});
// If our box is clicked, change the content.
box.on('click', function(data) {
box.setContent('{center}Some different {red-fg}content{/red-fg}.{/center}');
screen.render();
});
// If box is focused, handle `enter`/`return` and give us some more content.
box.key('enter', function(ch, key) {
box.setContent('{right}Even different {black-fg}content{/black-fg}.{/right}\n');
box.setLine(1, 'bar');
box.insertLine(1, 'foo');
screen.render();
});
// Quit on Escape, q, or Control-C.
screen.key(['escape', 'q', 'C-c'], function(ch, key) {
return process.exit(0);
});
// Focus our element.
box.focus();
// Render the screen.
screen.render();
```
## Documentation
### Widgets
- [Base Nodes](#base-nodes)
- [Node](#node-from-eventemitter) (abstract)
- [Screen](#screen-from-node)
- [Element](#element-from-node) (abstract)
- [Boxes](#boxes)
- [Box](#box-from-element)
- [Text](#text-from-element)
- [Line](#line-from-box)
- [ScrollableBox](#scrollablebox-from-box) (deprecated)
- [ScrollableText](#scrollabletext-from-scrollablebox) (deprecated)
- [BigText](#bigtext-from-box)
- [Lists](#lists)
- [List](#list-from-box)
- [FileManager](#filemanager-from-list)
- [ListTable](#listtable-from-list)
- [Listbar](#listbar-from-box)
- [Forms](#forms)
- [Form](#form-from-box)
- [Input](#input-from-box) (abstract)
- [Textarea](#textarea-from-input)
- [Textbox](#textbox-from-textarea)
- [Button](#button-from-input)
- [Checkbox](#checkbox-from-input)
- [RadioSet](#radioset-from-box)
- [RadioButton](#radiobutton-from-checkbox)
- [Prompts](#prompts)
- [Prompt](#prompt-from-box)
- [Question](#question-from-box)
- [Message](#message-from-box)
- [Loading](#loading-from-box)
- [Data Display](#data-display)
- [ProgressBar](#progressbar-from-input)
- [Log](#log-from-scrollabletext)
- [Table](#table-from-box)
- [Special Elements](#special-elements)
- [Terminal](#terminal-from-box)
- [Image](#image-from-box)
- [ANSIImage](#ansiimage-from-box)
- [OverlayImage](#overlayimage-from-box)
- [Video](#video-from-box)
- [Layout](#layout-from-element)
### Other
- [Helpers](#helpers)
### Mechanics
- [Content & Tags](#content--tags)
- [Colors](#colors)
- [Attributes](#attributes)
- [Alignment](#alignment)
- [Escaping](#escaping)
- [SGR Sequences](#sgr-sequences)
- [Style](#style)
- [Colors](#colors-1)
- [Attributes](#attributes-1)
- [Transparency](#transparency)
- [Shadow](#shadow)
- [Effects](#effects)
- [Events](#events)
- [Event Bubbling](#event-bubbling)
- [Poisitioning](#positioning)
- [Rendering](#rendering)
- [Artificial Cursors](#artificial-cursors)
- [Multiple Screens](#multiple-screens)
- [Server Side Usage](#server-side-usage)
### Notes
- [Windows Compatibility](#windows-compatibility)
- [Low-level Usage](#low-level-usage)
- [Testing](#testing)
- [Examples](#examples)
- [FAQ](#faq)
## Widgets
Blessed comes with a number of high-level widgets so you can avoid all the
nasty low-level terminal stuff.
### Base Nodes
#### Node (from EventEmitter)
The base node which everything inherits from.
##### Options:
- __screen__ - The screen to be associated with.
- __parent__ - The desired parent.
- __children__ - An arrray of children.
##### Properties:
- Inherits all from EventEmitter.
- __type__ - Type of the node (e.g. `box`).
- __options__ - Original options object.
- __parent__ - Parent node.
- __screen__ - Parent screen.
- __children__ - Array of node's children.
- __data, _, $__ - An object for any miscellanous user data.
- __index__ - Render index (document order index) of the last render call.
##### Events:
- Inherits all from EventEmitter.
- __adopt__ - Received when node is added to a parent.
- __remove__ - Received when node is removed from it's current parent.
- __reparent__ - Received when node gains a new parent.
- __attach__ - Received when node is attached to the screen directly or
somewhere in its ancestry.
- __detach__ - Received when node is detached from the screen directly or
somewhere in its ancestry.
##### Methods:
- Inherits all from EventEmitter.
- __prepend(node)__ - Prepend a node to this node's children.
- __append(node)__ - Append a node to this node's children.
- __remove(node)__ - Remove child node from node.
- __insert(node, i)__ - Insert a node to this node's children at index `i`.
- __insertBefore(node, refNode)__ - Insert a node to this node's children
before the reference node.
- __insertAfter(node, refNode)__ - Insert a node from node after the reference
node.
- __detach()__ - Remove node from its parent.
- __emitDescendants(type, args..., [iterator])__ - Emit event for element, and
recursively emit same event for all descendants.
- __get(name, [default])__ - Get user property with a potential default value.
- __set(name, value)__ - Set user property to value.
#### Screen (from Node)
The screen on which every other node renders.
##### Options:
- __program__ - The blessed `Program` to be associated with. Will be
automatically instantiated if none is provided.
- __smartCSR__ - Attempt to perform CSR optimization on all possible elements
(not just full-width ones, elements with uniform cells to their sides).
This is known to cause flickering with elements that are not full-width,
however, it is more optimal for terminal rendering.
- __fastCSR__ - Do CSR on any element within 20 cols of the screen edge on
either side. Faster than `smartCSR`, but may cause flickering depending on
what is on each side of the element.
- __useBCE__ - Attempt to perform `back_color_erase` optimizations for terminals
that support it. It will also work with terminals that don't support it, but
only on lines with the default background color. As it stands with the current
implementation, it's uncertain how much terminal performance this adds at the
cost of overhead within node.
- __resizeTimeout__ - Amount of time (in ms) to redraw the screen after the
terminal is resized (Default: 300).
- __tabSize__ - The width of tabs within an element's content.
- __autoPadding__ - Automatically position child elements with border and
padding in mind (__NOTE__: this is a recommended option. It may become
default in the future).
- __cursor.artificial__ - Have blessed draw a custom cursor and hide the
terminal cursor (__experimental__).
- __cursor.shape__ - Shape of the cursor. Can be: block, underline, or line.
- __cursor.blink__ - Whether the cursor blinks.
- __cursor.color__ - Color of the color. Accepts any valid color value (`null`
is default).
- __log__ - Create a log file. See `log` method.
- __dump__ - Dump all output and input to desired file. Can be used together
with `log` option if set as a boolean.
- __debug__ - Debug mode. Enables usage of the `debug` method. Also creates a
debug console which will display when pressing F12. It will display all log
and debug messages.
- __ignoreLocked__ - Array of keys in their full format (e.g. `C-c`) to ignore
when keys are locked or grabbed. Useful for creating a key that will _always_
exit no matter whether the keys are locked.
- __dockBorders__ - Automatically "dock" borders with other elements instead of
overlapping, depending on position (__experimental__). For example:
These border-overlapped elements:
```
┌─────────┌─────────┐
│ box1 │ box2 │
└─────────└─────────┘
```
Become:
```
┌─────────┬─────────┐
│ box1 │ box2 │
└─────────┴─────────┘
```
- __ignoreDockContrast__ - Normally, dockable borders will not dock if the
colors or attributes are different. This option will allow them to dock
regardless. It may produce some odd looking multi-colored borders though.
- __fullUnicode__ - Allow for rendering of East Asian double-width characters,
utf-16 surrogate pairs, and unicode combining characters. This allows you to
display text above the basic multilingual plane. This is behind an option
because it may affect performance slightly negatively. Without this option
enabled, all double-width, surrogate pair, and combining characters will be
replaced by `'??'`, `'?'`, `''` respectively. (NOTE: iTerm2 cannot display
combining characters properly. Blessed simply removes them from an element's
content if iTerm2 is detected).
- __sendFocus__ - Send focus events after mouse is enabled.
- __warnings__ - Display warnings (such as the output not being a TTY, similar
to ncurses).
- __forceUnicode__ - Force blessed to use unicode even if it is not detected
via terminfo, env variables, or windows code page. If value is `true` unicode
is forced. If value is `false` non-unicode is forced (default: `null`).
- __input/output__ - Input and output streams. `process.stdin`/`process.stdout`
by default, however, it could be a `net.Socket` if you want to make a program
that runs over telnet or something of that nature.
- __terminal__ - `TERM` name used for terminfo parsing. The `$TERM` env variable is
used by default.
- __title__ - Set the terminal window title if possible.
##### Properties:
- Inherits all from Node.
- __program__ - The blessed Program object.
- __tput__ - The blessed Tput object (only available if you passed `tput: true`
to the Program constructor.)
- __focused__ - Top of the focus history stack.
- __width__ - Width of the screen (same as `program.cols`).
- __height__ - Height of the screen (same as `program.rows`).
- __cols__ - Same as `screen.width`.
- __rows__ - Same as `screen.height`.
- __left__ - Relative left offset, always zero.
- __right__ - Relative right offset, always zero.
- __top__ - Relative top offset, always zero.
- __bottom__ - Relative bottom offset, always zero.
- __aleft__ - Absolute left offset, always zero.
- __aright__ - Absolute right offset, always zero.
- __atop__ - Absolute top offset, always zero.
- __abottom__ - Absolute bottom offset, always zero.
- __grabKeys__ - Whether the focused element grabs all keypresses.
- __lockKeys__ - Prevent keypresses from being received by any element.
- __hover__ - The currently hovered element. Only set if mouse events are bound.
- __terminal__ - Set or get terminal name. `Set` calls `screen.setTerminal()`
internally.
- __title__ - Set or get window title.
##### Events:
- Inherits all from Node.
- __resize__ - Received on screen resize.
- __mouse__ - Received on mouse events.
- __keypress__ - Received on key events.
- __element [name]__ - Global events received for all elements.
- __key [name]__ - Received on key event for [name].
- __focus, blur__ - Received when the terminal window focuses/blurs. Requires a
terminal supporting the focus protocol and focus needs to be passed to
program.enableMouse().
- __prerender__ - Received before render.
- __render__ - Received on render.
- __warning__ - Received when blessed notices something untoward (output is not
a tty, terminfo not found, etc).
- __destroy__ - Received when the screen is destroyed (only useful when using
multiple screens).
##### Methods:
- Inherits all from Node.
- __log(msg, ...)__ - Write string to the log file if one was created.
- __debug(msg, ...)__ - Same as the log method, but only gets called if the
`debug` option was set.
- __alloc()__ - Allocate a new pending screen buffer and a new output screen
buffer.
- __realloc()__ - Reallocate the screen buffers and clear the screen.
- __draw(start, end)__ - Draw the screen based on the contents of the screen
buffer.
- __render()__ - Render all child elements, writing all data to the screen
buffer and drawing the screen.
- __clearRegion(x1, x2, y1, y2)__ - Clear any region on the screen.
- __fillRegion(attr, ch, x1, x2, y1, y2)__ - Fill any region with a character
of a certain attribute.
- __focusOffset(offset)__ - Focus element by offset of focusable elements.
- __focusPrevious()__ - Focus previous element in the index.
- __focusNext()__ - Focus next element in the index.
- __focusPush(element)__ - Push element on the focus stack (equivalent to
`screen.focused = el`).
- __focusPop()__ - Pop element off the focus stack.
- __saveFocus()__ - Save the focused element.
- __restoreFocus()__ - Restore the saved focused element.
- __rewindFocus()__ - "Rewind" focus to the last visible and attached element.
- __key(name, listener)__ - Bind a keypress listener for a specific key.
- __onceKey(name, listener)__ - Bind a keypress listener for a specific key
once.
- __unkey(name, listener)__ - Remove a keypress listener for a specific key.
- __spawn(file, args, options)__ - Spawn a process in the foreground, return to
blessed app after exit.
- __exec(file, args, options, callback)__ - Spawn a process in the foreground,
return to blessed app after exit. Executes callback on error or exit.
- __readEditor([options], callback)__ - Read data from text editor.
- __setEffects(el, fel, over, out, effects, temp)__ - Set effects based on
two events and attributes.
- __insertLine(n, y, top, bottom)__ - Insert a line into the screen (using csr:
this bypasses the output buffer).
- __deleteLine(n, y, top, bottom)__ - Delete a line from the screen (using csr:
this bypasses the output buffer).
- __insertBottom(top, bottom)__ - Insert a line at the bottom of the screen.
- __insertTop(top, bottom)__ - Insert a line at the top of the screen.
- __deleteBottom(top, bottom)__ - Delete a line at the bottom of the screen.
- __deleteTop(top, bottom)__ - Delete a line at the top of the screen.
- __enableMouse([el])__ - Enable mouse events for the screen and optionally an
element (automatically called when a form of on('mouse') is bound).
- __enableKeys([el])__ - Enable keypress events for the screen and optionally
an element (automatically called when a form of on('keypress') is bound).
- __enableInput([el])__ - Enable key and mouse events. Calls bot enableMouse
and enableKeys.
- __copyToClipboard(text)__ - Attempt to copy text to clipboard using iTerm2's
proprietary sequence. Returns true if successful.
- __cursorShape(shape, blink)__ - Attempt to change cursor shape. Will not work
in all terminals (see artificial cursors for a solution to this). Returns
true if successful.
- __cursorColor(color)__ - Attempt to change cursor color. Returns true if
successful.
- __cursorReset()__ - Attempt to reset cursor. Returns true if successful.
- __screenshot([xi, xl, yi, yl])__ - Take an SGR screenshot of the screen
within the region. Returns a string containing only characters and SGR codes.
Can be displayed by simply echoing it in a terminal.
- __destroy()__ - Destroy the screen object and remove it from the global list.
Also remove all global events relevant to the screen object. If all screen
objects are destroyed, the node process is essentially reset to its initial
state.
- __setTerminal(term)__ - Reset the terminal to `term`. Reloads terminfo.
#### Element (from Node)
The base element.
##### Options:
- __fg, bg, bold, underline__ - Attributes.
- __style__ - May contain attributes in the format of:
``` js
{
fg: 'blue',
bg: 'black',
border: {
fg: 'blue'
},
scrollbar: {
bg: 'blue'
},
focus: {
bg: 'red'
},
hover: {
bg: 'red'
}
}
```
- __border__ - Border object, see below.
- __content__ - Element's text content.
- __clickable__ - Element is clickable.
- __input, keyable__ - Element is focusable and can receive key input.
- __focused__ - Element is focused.
- __hidden__ - Whether the element is hidden.
- __label__ - A simple text label for the element.
- __hoverText__ - A floating text label for the element which appears on mouseover.
- __align__ - Text alignment: `left`, `center`, or `right`.
- __valign__ - Vertical text alignment: `top`, `middle`, or `bottom`.
- __shrink__ - Shrink/flex/grow to content and child elements. Width/height
during render.
- __padding__ - Amount of padding on the inside of the element. Can be a number
or an object containing the properties: `left`, `right`, `top`, and `bottom`.
- __width, height__ - Width/height of the element, can be a number, percentage
(`0-100%`), or keyword (`half` or `shrink`). Percentages can also have
offsets (`50%+1`, `50%-1`).
- __left, right, top, bottom__ - Offsets of the element __relative to its
parent__. Can be a number, percentage (`0-100%`), or keyword (`center`).
`right` and `bottom` do not accept keywords. Percentages can also have
offsets (`50%+1`, `50%-1`).
- __position__ - Can contain the above options.
- __scrollable__ - Whether the element is scrollable or not.
- __ch__ - Background character (default is whitespace ` `).
- __draggable__ - Allow the element to be dragged with the mouse.
- __shadow__ - Draw a translucent offset shadow behind the element.
##### Properties:
- Inherits all from Node.
- __name__ - Name of the element. Useful for form submission.
- __border__ - Border object.
- __type__ - Type of border (`line` or `bg`). `bg` by default.
- __ch__ - Character to use if `bg` type, default is space.
- __bg, fg__ - Border foreground and background, must be numbers (-1 for
default).
- __bold, underline__ - Border attributes.
- __style__ - Contains attributes (e.g. `fg/bg/underline`). See above.
- __position__ - Raw width, height, and offsets.
- __content__ - Raw text content.
- __hidden__ - Whether the element is hidden or not.
- __visible__ - Whether the element is visible or not.
- __detached__ - Whether the element is attached to a screen in its ancestry
somewhere.
- __fg, bg__ - Foreground and background, must be numbers (-1 for default).
- __bold, underline__ - Attributes.
- __width__ - Calculated width.
- __height__ - Calculated height.
- __left__ - Calculated relative left offset.
- __right__ - Calculated relative right offset.
- __top__ - Calculated relative top offset.
- __bottom__ - Calculated relative bottom offset.
- __aleft__ - Calculated absolute left offset.
- __aright__ - Calculated absolute right offset.
- __atop__ - Calculated absolute top offset.
- __abottom__ - Calculated absolute bottom offset.
- __draggable__ - Whether the element is draggable. Set to true to allow
dragging.
##### Events:
- Inherits all from Node.
- __blur, focus__ - Received when an element is focused or unfocused.
- __mouse__ - Received on mouse events for this element.
- __mousedown, mouseup__ - Mouse button was pressed or released.
- __wheeldown, wheelup__ - Wheel was scrolled down or up.
- __mouseover, mouseout__ - Element was hovered or unhovered.
- __mousemove__ - Mouse was moved somewhere on this element.
- __click__ - Element was clicked (slightly smarter than mouseup).
- __keypress__ - Received on key events for this element.
- __move__ - Received when the element is moved.
- __resize__ - Received when the element is resized.
- __key [name]__ - Received on key event for [name].
- __prerender__ - Received before a call to render.
- __render__ - Received after a call to render.
- __hide__ - Received when element becomes hidden.
- __show__ - Received when element is shown.
- __destroy__ - Received when element is destroyed.
##### Methods:
- Inherits all from Node.
- Note: If the `scrollable` option is enabled, Element inherits all methods
from ScrollableBox.
- __render()__ - Write content and children to the screen buffer.
- __hide()__ - Hide element.
- __show()__ - Show element.
- __toggle()__ - Toggle hidden/shown.
- __focus()__ - Focus element.
- __key(name, listener)__ - Bind a keypress listener for a specific key.
- __onceKey(name, listener)__ - Bind a keypress listener for a specific key
once.
- __unkey(name, listener)__ - Remove a keypress listener for a specific key.
- __onScreenEvent(type, handler)__ - Same as`el.on('screen', ...)` except this
will automatically keep track of which listeners are bound to the screen
object. For use with `removeScreenEvent()`, `free()`, and `destroy()`.
- __removeScreenEvent(type, handler)__ - Same as`el.removeListener('screen',
...)` except this will automatically keep track of which listeners are bound
to the screen object. For use with `onScreenEvent()`, `free()`, and
`destroy()`.
- __free()__ - Free up the element. Automatically unbind all events that may
have been bound to the screen object. This prevents memory leaks. For use
with `onScreenEvent()`, `removeScreenEvent()`, and `destroy()`.
- __destroy()__ - Same as the `detach()` method, except this will automatically
call `free()` and unbind any screen events to prevent memory leaks. for use
with `onScreenEvent()`, `removeScreenEvent()`, and `free()`.
- __setIndex(z)__ - Set the z-index of the element (changes rendering order).
- __setFront()__ - Put the element in front of its siblings.
- __setBack()__ - Put the element in back of its siblings.
- __setLabel(text/options)__ - Set the label text for the top-left corner.
Example options: `{text:'foo',side:'left'}`
- __removeLabel()__ - Remove the label completely.
- __setHover(text/options)__ - Set a hover text box to follow the cursor.
Similar to the "title" DOM attribute in the browser.
Example options: `{text:'foo'}`
- __removeHover()__ - Remove the hover label completely.
- __enableMouse()__ - Enable mouse events for the element (automatically called
when a form of on('mouse') is bound).
- __enableKeys()__ - Enable keypress events for the element (automatically
called when a form of on('keypress') is bound).
- __enableInput()__ - Enable key and mouse events. Calls bot enableMouse and
enableKeys.
- __enableDrag()__ - Enable dragging of the element.
- __disableDrag()__ - Disable dragging of the element.
- __screenshot([xi, xl, yi, yl])__ - Take an SGR screenshot of the element
within the region. Returns a string containing only characters and SGR codes.
Can be displayed by simply echoing it in a terminal.
###### Content Methods
Methods for dealing with text content, line by line. Useful for writing a
text editor, irc client, etc.
Note: All of these methods deal with pre-aligned, pre-wrapped text. If you use
deleteTop() on a box with a wrapped line at the top, it may remove 3-4 "real"
lines (rows) depending on how long the original line was.
The `lines` parameter can be a string or an array of strings. The `line`
parameter must be a string.
- __setContent(text)__ - Set the content. Note: When text is input, it will be
stripped of all non-SGR escape codes, tabs will be replaced with 8 spaces,
and tags will be replaced with SGR codes (if enabled).
- __getContent()__ - Return content, slightly different from `el.content`.
Assume the above formatting.
- __setText(text)__ - Similar to `setContent`, but ignore tags and remove escape
codes.
- __getText()__ - Similar to `getContent`, but return content with tags and
escape codes removed.
- __insertLine(i, lines)__ - Insert a line into the box's content.
- __deleteLine(i)__ - Delete a line from the box's content.
- __getLine(i)__ - Get a line from the box's content.
- __getBaseLine(i)__ - Get a line from the box's content from the visible top.
- __setLine(i, line)__ - Set a line in the box's content.
- __setBaseLine(i, line)__ - Set a line in the box's content from the visible
top.
- __clearLine(i)__ - Clear a line from the box's content.
- __clearBaseLine(i)__ - Clear a line from the box's content from the visible
top.
- __insertTop(lines)__ - Insert a line at the top of the box.
- __insertBottom(lines)__ - Insert a line at the bottom of the box.
- __deleteTop()__ - Delete a line at the top of the box.
- __deleteBottom()__ - Delete a line at the bottom of the box.
- __unshiftLine(lines)__ - Unshift a line onto the top of the content.
- __shiftLine(i)__ - Shift a line off the top of the content.
- __pushLine(lines)__ - Push a line onto the bottom of the content.
- __popLine(i)__ - Pop a line off the bottom of the content.
- __getLines()__ - An array containing the content lines.
- __getScreenLines()__ - An array containing the lines as they are displayed on
the screen.
- __strWidth(text)__ - Get a string's displayed width, taking into account
double-width, surrogate pairs, combining characters, tags, and SGR escape
codes.
### Boxes
#### Box (from Element)
A box element which draws a simple box containing `content` or other elements.
##### Options:
- Inherits all from Element.
##### Properties:
- Inherits all from Element.
##### Events:
- Inherits all from Element.
##### Methods:
- Inherits all from Element.
#### Text (from Element)
An element similar to Box, but geared towards rendering simple text elements.
##### Options:
- Inherits all from Element.
- __fill__ - Fill the entire line with chosen bg until parent bg ends, even if
there is not enough text to fill the entire width. __(deprecated)__
- __align__ - Text alignment: `left`, `center`, or `right`.
Inherits all options, properties, events, and methods from Element.
#### Line (from Box)
A simple line which can be `line` or `bg` styled.
##### Options:
- Inherits all from Box.
- __orientation__ - Can be `vertical` or `horizontal`.
- __type, bg, fg, ch__ - Treated the same as a border object.
(attributes can be contained in `style`).
Inherits all options, properties, events, and methods from Box.
#### ScrollableBox (from Box)
__DEPRECATED__ - Use Box with the `scrollable` option instead.
A box with scrollable content.
##### Options:
- Inherits all from Box.
- __baseLimit__ - A limit to the childBase. Default is `Infinity`.
- __alwaysScroll__ - A option which causes the ignoring of `childOffset`. This
in turn causes the childBase to change every time the element is scrolled.
- __scrollbar__ - Object enabling a scrollbar.
- __scrollbar.style__ - Style of the scrollbar.
- __scrollbar.track__ - Style of the scrollbar track if present (takes regular
style options).
##### Properties:
- Inherits all from Box.
- __childBase__ - The offset of the top of the scroll content.
- __childOffset__ - The offset of the chosen item/line.
##### Events:
- Inherits all from Box.
- __scroll__ - Received when the element is scrolled.
##### Methods:
- __scroll(offset)__ - Scroll the content by a relative offset.
- __scrollTo(index)__ - Scroll the content to an absolute index.
- __setScroll(index)__ - Same as `scrollTo`.
- __setScrollPerc(perc)__ - Set the current scroll index in percentage (0-100).
- __getScroll()__ - Get the current scroll index in lines.
- __getScrollHeight()__ - Get the actual height of the scrolling area.
- __getScrollPerc()__ - Get the current scroll index in percentage.
- __resetScroll()__ - Reset the scroll index to its initial state.
#### ScrollableText (from ScrollableBox)
__DEPRECATED__ - Use Box with the `scrollable` and `alwaysScroll` options
instead.
A scrollable text box which can display and scroll text, as well as handle
pre-existing newlines and escape codes.
##### Options:
- Inherits all from ScrollableBox.
- __mouse__ - Whether to enable automatic mouse support for this element.
- __keys__ - Use predefined keys for navigating the text.
- __vi__ - Use vi keys with the `keys` option.
##### Properties:
- Inherits all from ScrollableBox.
##### Events:
- Inherits all from ScrollableBox.
##### Methods:
- Inherits all from ScrollableBox.
#### BigText (from Box)
A box which can render content drawn as 8x14 cell characters using the terminus
font.
##### Options:
- Inherits all from Box.
- __font__ - bdf->json font file to use (see [ttystudio][ttystudio] for
instructions on compiling BDFs to JSON).
- __fontBold__ - bdf->json bold font file to use (see [ttystudio][ttystudio]
for instructions on compiling BDFs to JSON).
- __fch__ - foreground character. (default: `' '`)
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
### Lists
#### List (from Box)
A scrollable list which can display selectable items.
##### Options:
- Inherits all from Box.
- __style.selected__ - Style for a selected item.
- __style.item__ - Style for an unselected item.
- __mouse__ - Whether to automatically enable mouse support for this list
(allows clicking items).
- __keys__ - Use predefined keys for navigating the list.
- __vi__ - Use vi keys with the `keys` option.
- __items__ - An array of strings which become the list's items.
- __search__ - A function that is called when `vi` mode is enabled and the key
`/` is pressed. This function accepts a callback function which should be
called with the search string. The search string is then used to jump to an
item that is found in `items`.
- __interactive__ - Whether the list is interactive and can have items selected
(Default: true).
- __invertSelected__ - Whether to automatically override tags and invert fg of
item when selected (Default: `true`).
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
- __select__ - Received when an item is selected.
- __cancel__ - List was canceled (when `esc` is pressed with the `keys` option).
- __action__ - Either a select or a cancel event was received.
##### Methods:
- Inherits all from Box.
- __add/addItem(text)__ - Add an item based on a string.
- __removeItem(child)__ - Removes an item from the list. Child can be an
element, index, or string.
- __pushItem(child)__ - Push an item onto the list.
- __popItem()__ - Pop an item off the list.
- __unshiftItem(child)__ - Unshift an item onto the list.
- __shiftItem()__ - Shift an item off the list.
- __insertItem(i, child)__ - Inserts an item to the list. Child can be an
element, index, or string.
- __getItem(child)__ - Returns the item element. Child can be an element,
index, or string.
- __setItem(child, content)__ - Set item to content.
- __spliceItem(i, n, item1, ...)__ - Remove and insert items to the list.
- __clearItems()__ - Clears all items from the list.
- __setItems(items)__ - Sets the list items to multiple strings.
- __getItemIndex(child)__ - Returns the item index from the list. Child can be
an element, index, or string.
- __select(index)__ - Select an index of an item.
- __move(offset)__ - Select item based on current offset.
- __up(amount)__ - Select item above selected.
- __down(amount)__ - Select item below selected.
- __pick(callback)__ - Show/focus list and pick an item. The callback is
executed with the result.
- __fuzzyFind([string/regex/callback])__ - Find an item based on its text
content.
#### FileManager (from List)
A very simple file manager for selecting files.
##### Options:
- Inherits all from List.
- __cwd__ - Current working directory.
##### Properties:
- Inherits all from List.
- __cwd__ - Current working directory.
##### Events:
- Inherits all from List.
- __cd__ - Directory was selected and navigated to.
- __file__ - File was selected.
##### Methods:
- Inherits all from List.
- __refresh([cwd], [callback])__ - Refresh the file list (perform a `readdir` on `cwd`
and update the list items).
- __pick([cwd], callback)__ - Pick a single file and return the path in the callback.
- __reset([cwd], [callback])__ - Reset back to original cwd.
#### ListTable (from List)
A stylized table of text elements with a list.
##### Options:
- Inherits all from List.
- __rows/data__ - Array of array of strings representing rows.
- __pad__ - Spaces to attempt to pad on the sides of each cell. `2` by default:
one space on each side (only useful if the width is shrunken).
- __noCellBorders__ - Do not draw inner cells.
- __style.header__ - Header style.
- __style.cell__ - Cell style.
##### Properties:
- Inherits all from List.
##### Events:
- Inherits all from List.
##### Methods:
- Inherits all from List.
- __setRows/setData(rows)__ - Set rows in table. Array of arrays of strings.
``` js
table.setData([
[ 'Animals', 'Foods' ],
[ 'Elephant', 'Apple' ],
[ 'Bird', 'Orange' ]
]);
```
#### Listbar (from Box)
A horizontal list. Useful for a main menu bar.
##### Options:
- Inherits all from Box.
- __style.selected__ - Style for a selected item.
- __style.item__ - Style for an unselected item.
- __commands/items__ - Set buttons using an object with keys as titles of
buttons, containing of objects containing keys of `keys` and `callback`.
- __autoCommandKeys__ - Automatically bind list buttons to keys 0-9.
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
- __setItems(commands)__ - Set commands (see `commands` option above).
- __add/addItem/appendItem(item, callback)__ - Append an item to the bar.
- __select(offset)__ - Select an item on the bar.
- __removeItem(child)__ - Remove item from the bar.
- __move(offset)__ - Move relatively across the bar.
- __moveLeft(offset)__ - Move left relatively across the bar.
- __moveRight(offset)__ - Move right relatively across the bar.
- __selectTab(index)__ - Select button and execute its callback.
### Forms
#### Form (from Box)
A form which can contain form elements.
##### Options:
- Inherits all from Box.
- __keys__ - Allow default keys (tab, vi keys, enter).
- __vi__ - Allow vi keys.
##### Properties:
- Inherits all from Box.
- __submission__ - Last submitted data.
##### Events:
- Inherits all from Box.
- __submit__ - Form is submitted. Receives a data object.
- __cancel__ - Form is discarded.
- __reset__ - Form is cleared.
##### Methods:
- Inherits all from Box.
- __focusNext()__ - Focus next form element.
- __focusPrevious()__ - Focus previous form element.
- __submit()__ - Submit the form.
- __cancel()__ - Discard the form.
- __reset()__ - Clear the form.
#### Input (from Box)
A form input.
#### Textarea (from Input)
A box which allows multiline text input.
##### Options:
- Inherits all from Input.
- __keys__ - Use pre-defined keys (`i` or `enter` for insert, `e` for editor,
`C-e` for editor while inserting).
- __mouse__ - Use pre-defined mouse events (right-click for editor).
- __inputOnFocus__ - Call `readInput()` when the element is focused.
Automatically unfocus.
##### Properties:
- Inherits all from Input.
- __value__ - The input text. __read-only__.
##### Events:
- Inherits all from Input.
- __submit__ - Value is submitted (enter).
- __cancel__ - Value is discared (escape).
- __action__ - Either submit or cancel.
##### Methods:
- Inherits all from Input.
- __submit__ - Submit the textarea (emits `submit`).
- __cancel__ - Cancel the textarea (emits `cancel`).
- __readInput(callback)__ - Grab key events and start reading text from the
keyboard. Takes a callback which receives the final value.
- __readEditor(callback)__ - Open text editor in `$EDITOR`, read the output from
the resulting file. Takes a callback which receives the final value.
- __getValue()__ - The same as `this.value`, for now.
- __clearValue()__ - Clear input.
- __setValue(text)__ - Set value.
#### Textbox (from Textarea)
A box which allows text input.
##### Options:
- Inherits all from Textarea.
- __secret__ - Completely hide text.
- __censor__ - Replace text with asterisks (`*`).
##### Properties:
- Inherits all from Textarea.
- __secret__ - Completely hide text.
- __censor__ - Replace text with asterisks (`*`).
##### Events:
- Inherits all from Textarea.
##### Methods:
- Inherits all from Textarea.
#### Button (from Input)
A button which can be focused and allows key and mouse input.
##### Options:
- Inherits all from Input.
##### Properties:
- Inherits all from Input.
##### Events:
- Inherits all from Input.
- __press__ - Received when the button is clicked/pressed.
##### Methods:
- Inherits all from Input.
- __press()__ - Press button. Emits `press`.
#### Checkbox (from Input)
A checkbox which can be used in a form element.
##### Options:
- Inherits all from Input.
- __checked__ - Whether the element is checked or not.
- __mouse__ - Enable mouse support.
##### Properties:
- Inherits all from Input.
- __text__ - The text next to the checkbox (do not use setContent, use
`check.text = ''`).
- __checked__ - Whether the element is checked or not.
- __value__ - Same as `checked`.
##### Events:
- Inherits all from Input.
- __check__ - Received when element is checked.
- __uncheck__ received when element is unchecked.
##### Methods:
- Inherits all from Input.
- __check()__ - Check the element.
- __uncheck()__ - Uncheck the element.
- __toggle()__ - Toggle checked state.
#### RadioSet (from Box)
An element wrapping RadioButtons. RadioButtons within this element will be
mutually exclusive with each other.
##### Options:
- Inherits all from Box.
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
#### RadioButton (from Checkbox)
A radio button which can be used in a form element.
##### Options:
- Inherits all from Checkbox.
##### Properties:
- Inherits all from Checkbox.
##### Events:
- Inherits all from Checkbox.
##### Methods:
- Inherits all from Checkbox.
### Prompts
#### Prompt (from Box)
A prompt box containing a text input, okay, and cancel buttons (automatically
hidden).
##### Options:
- Inherits all from Box.
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
- __input/setInput/readInput(text, value, callback)__ - Show the prompt and
wait for the result of the textbox. Set text and initial value.
#### Question (from Box)
A question box containing okay and cancel buttons (automatically hidden).
##### Options:
- Inherits all from Box.
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
- __ask(question, callback)__ - Ask a `question`. `callback` will yield the
result.
#### Message (from Box)
A box containing a message to be displayed (automatically hidden).
##### Options:
- Inherits all from Box.
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
- __log/display(text, [time], callback)__ - Display a message for a time
(default is 3 seconds). Set time to 0 for a perpetual message that is
dismissed on keypress.
- __error(text, [time], callback)__ - Display an error in the same way.
#### Loading (from Box)
A box with a spinning line to denote loading (automatically hidden).
##### Options:
- Inherits all from Box.
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
- __load(text)__ - Display the loading box with a message. Will lock keys until
`stop` is called.
- __stop()__ - Hide loading box. Unlock keys.
### Data Display
#### ProgressBar (from Input)
A progress bar allowing various styles. This can also be used as a form input.
##### Options:
- Inherits all from Input.
- __orientation__ - Can be `horizontal` or `vertical`.
- __style.bar__ - Style of the bar contents itself.
- __pch__ - The character to fill the bar with (default is space).
- __filled__ - The amount filled (0 - 100).
- __value__ - Same as `filled`.
- __keys__ - Enable key support.
- __mouse__ - Enable mouse support.
##### Properties:
- Inherits all from Input.
##### Events:
- Inherits all from Input.
- __reset__ - Bar was reset.
- __complete__ - Bar has completely filled.
##### Methods:
- Inherits all from Input.
- __progress(amount)__ - Progress the bar by a fill amount.
- __setProgress(amount)__ - Set progress to specific amount.
- __reset()__ - Reset the bar.
#### Log (from ScrollableText)
A log permanently scrolled to the bottom.
##### Options:
- Inherits all from ScrollableText.
- __scrollback__ - Amount of scrollback allowed. Default: Infinity.
- __scrollOnInput__ - Scroll to bottom on input even if the user has scrolled
up. Default: false.
##### Properties:
- Inherits all from ScrollableText.
- __scrollback__ - Amount of scrollback allowed. Default: Infinity.
- __scrollOnInput__ - Scroll to bottom on input even if the user has scrolled
up. Default: false.
##### Events:
- Inherits all from ScrollableText.
- __log__ - Emitted on a log line. Passes in line.
##### Methods:
- Inherits all from ScrollableText.
- __log/add(text)__ - Add a log line.
#### Table (from Box)
A stylized table of text elements.
##### Options:
- Inherits all from Box.
- __rows/data__ - Array of array of strings representing rows.
- __pad__ - Spaces to attempt to pad on the sides of each cell. `2` by default:
one space on each side (only useful if the width is shrunken).
- __noCellBorders__ - Do not draw inner cells.
- __fillCellBorders__ - Fill cell borders with the adjacent background color.
- __style.header__ - Header style.
- __style.cell__ - Cell style.
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
- __setRows/setData(rows)__ - Set rows in table. Array of arrays of strings.
``` js
table.setData([
[ 'Animals', 'Foods' ],
[ 'Elephant', 'Apple' ],
[ 'Bird', 'Orange' ]
]);
```
### Special Elements
#### Terminal (from Box)
A box which spins up a pseudo terminal and renders the output. Useful for
writing a terminal multiplexer, or something similar to an mc-like file
manager. Requires term.js and pty.js to be installed. See
`example/multiplex.js` for an example terminal multiplexer.
##### Options:
- Inherits all from Box.
- __handler__ - Handler for input data.
- __shell__ - Name of shell. `$SHELL` by default.
- __args__ - Args for shell.
- __cursor__ - Can be `line`, `underline`, and `block`.
- __terminal__ - Terminal name (Default: `xterm`).
- __env__ - Object for process env.
- Other options similar to term.js'.
##### Properties:
- Inherits all from Box.
- __term__ - Reference to the headless term.js terminal.
- __pty__ - Reference to the pty.js pseudo terminal.
##### Events:
- Inherits all from Box.
- __title__ - Window title from terminal.
- Other events similar to ScrollableBox.
##### Methods:
- Inherits all from Box.
- __write(data)__ - Write data to the terminal.
- __screenshot([xi, xl, yi, xl])__ - Nearly identical to `element.screenshot`,
however, the specified region includes the terminal's _entire_ scrollback,
rather than just what is visible on the screen.
- Other methods similar to ScrollableBox.
#### Image (from Box)
Display an image in the terminal (jpeg, png, gif) using either blessed's
internal png/gif-to-terminal renderer (using a [ANSIImage element](#ansiimage-from-box)) or
using `w3mimgdisplay` (using a [OverlayImage element](#overlayimage-from-box)).
##### Options:
- Inherits all from Box.
- __file__ - Path to image.
- __type__ - `ansi` or `overlay`. Whether to render the file as ANSI art or
using `w3m` to overlay. See the [ANSIImage element](#ansiimage-from-box) for
more information/options. (__default__: `ansi`).
##### Properties:
- Inherits all from Box.
- See [ANSIImage element](#ansiimage-from-box)
- See [OverlayImage element](#overlayimage-from-box)
##### Events:
- Inherits all from Box.
- See [ANSIImage element](#ansiimage-from-box)
- See [OverlayImage element](#overlayimage-from-box)
##### Methods:
- Inherits all from Box.
- See [ANSIImage element](#ansiimage-from-box)
- See [OverlayImage element](#overlayimage-from-box)
#### ANSIImage (from Box)
Convert any `.png` file (or `.gif`, see below) to an ANSI image and display it
as an element. This differs from the `OverlayImage` element in that it uses
blessed's internal PNG/GIF parser and does not require external dependencies.
Blessed uses an internal from-scratch PNG/GIF reader because no other javascript
PNG reader supports Adam7 interlaced images (much less pass the png test
suite).
The blessed PNG reader supports adam7 deinterlacing, animation (APNG), all
color types, bit depths 1-32, alpha, alpha palettes, and outputs scaled bitmaps
(cellmaps) in blessed for efficient rendering to the screen buffer. It also
uses some code from libcaca/libcucul to add density ASCII characters in order
to give the image more detail in the terminal.
If a corrupt PNG or a non-PNG is passed in, blessed will display error text in
the element.
`.gif` files are also supported via a javascript implementation (they are
internally converted to bitmaps and fed to the PNG renderer). Any other image
format is support only if the user has imagemagick (`convert` and `identify`)
installed.
##### Options:
- Inherits all from Box.
- __file__ - URL or path to PNG/GIF file. Can also be a buffer.
- __scale__ - Scale cellmap down (`0-1.0`) from its original pixel width/height
(Default: `1.0`).
- __width/height__ - This differs from other element's `width` or `height` in
that only one of them is needed: blessed will maintain the aspect ratio of
the image as it scales down to the proper number of cells. __NOTE__: PNG/GIF's
are always automatically shrunken to size (based on scale) if a `width` or
`height` is not given.
- __ascii__ - Add various "density" ASCII characters over the rendering to give
the image more detail, similar to libcaca/libcucul (the library mplayer uses
to display videos in the terminal).
- __animate__ - Whether to animate if the image is an APNG/animating GIF. If
false, only display the first frame or IDAT (Default: `true`).
- __speed__ - Set the speed of animation. Slower: `0.0-1.0`. Faster: `1-1000`.
It cannot go faster than 1 frame per millisecond, so 1000 is the fastest.
(Default: 1.0)
- __optimization__ - `mem` or `cpu`. If optimizing for memory, animation frames
will be rendered to bitmaps _as the animation plays_, using less memory.
Optimizing for cpu will precompile all bitmaps beforehand, which may be
faster, but might also OOM the process on large images. (Default: `mem`).
##### Properties:
- Inherits all from Box.
- __img__ - Image object from the png reader.
- __img.width__ - Pixel width.
- __img.height__ - Pixel height.
- __img.bmp__ - Image bitmap.
- __img.cellmap__ - Image cellmap (bitmap scaled down to cell size).
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
- __setImage(file)__ - Set the image in the box to a new path. File can be a
path, url, or buffer.
- __clearImage()__ - Clear the image.
- __play()__ - Play animation if it has been paused or stopped.
- __pause()__ - Pause animation.
- __stop()__ - Stop animation.
#### OverlayImage (from Box)
Display an image in the terminal (jpeg, png, gif) using w3mimgdisplay. Requires
w3m to be installed. X11 required: works in xterm, urxvt, and possibly other
terminals.
##### Options:
- Inherits all from Box.
- __file__ - Path to image.
- __ansi__ - Render the file as ANSI art instead of using `w3m` to overlay
Internally uses the ANSIImage element. See the [ANSIImage element](#ansiimage-from-box) for
more information/options. (Default: `true`).
- __w3m__ - Path to w3mimgdisplay. If a proper `w3mimgdisplay` path is not
given, blessed will search the entire disk for the binary.
- __search__ - Whether to search `/usr`, `/bin`, and `/lib` for
`w3mimgdisplay` (Default: `true`).
##### Properties:
- Inherits all from Box.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
- __setImage(img, [callback])__ - Set the image in the box to a new path.
- __clearImage([callback])__ - Clear the current image.
- __imageSize(img, [callback])__ - Get the size of an image file in pixels.
- __termSize([callback])__ - Get the size of the terminal in pixels.
- __getPixelRatio([callback])__ - Get the pixel to cell ratio for the terminal.
- _Note:_ All methods above can be synchronous as long as the host version of
node supports `spawnSync`.
#### Video (from Box)
A box which spins up a pseudo terminal in order to render a video via `mplayer
-vo caca` or `mpv --vo caca`. Requires `mplayer` or `mpv` to be installed with
libcaca support.
##### Options:
- Inherits all from Box.
- __file__ - Video to play.
- __start__ - Start time in seconds.
##### Properties:
- Inherits all from Box.
- __tty__ - The terminal element running `mplayer` or `mpv`.
##### Events:
- Inherits all from Box.
##### Methods:
- Inherits all from Box.
#### Layout (from Element)
A layout which can position children automatically based on a `renderer` method
(__experimental__ - the mechanics of this element may be changed in the
future!).
By default, the Layout element automatically positions children as if they were
`display: inline-block;` in CSS.
##### Options:
- Inherits all from Element.
- __renderer__ - A callback which is called right before the children are
iterated over to be rendered. Should return an iterator callback which is
called on each child element: __iterator(el, i)__.
- __layout__ - Using the default renderer, it provides two layouts: inline, and
grid. `inline` is the default and will render akin to `inline-block`. `grid`
will create an automatic grid based on element dimensions. The grid cells'
width and height are always determined by the largest children in the layout.
##### Properties:
- Inherits all from Element.
##### Events:
- Inherits all from Element.
##### Methods:
- Inherits all from Element.
- __renderer(coords)__ - A callback which is called right before the children
are iterated over to be rendered. Should return an iterator callback which is
called on each child element: __iterator(el, i)__.
- __isRendered(el)__ - Check to see if a previous child element has been
rendered and is visible on screen. This is __only__ useful for checking child
elements that have already been attempted to be rendered! see the example
below.
- __getLast(i)__ - Get the last rendered and visible child element based on an
index. This is useful for basing the position of the current child element on
the position of the last child element.
- __getLastCoords(i)__ - Get the last rendered and visible child element coords
based on an index. This is useful for basing the position of the current
child element on the position of the last child element. See the example
below.
##### Rendering a Layout for child elements
###### Notes
You must __always__ give `Layout` a width and height. This is a chicken-and-egg
problem: blessed cannot calculate the width and height dynamically _before_ the
children are positioned.
`border` and `padding` are already calculated into the `coords` object the
`renderer` receives, so there is no need to account for it in your renderer.
Try to set position for children using `el.position`. `el.position` is the most
primitive "to-be-rendered" way to set coordinates. Setting `el.left` directly
has more dynamic behavior which may interfere with rendering.
Some definitions for `coords` (otherwise known as `el.lpos`):
- `coords.xi` - the absolute x coordinate of the __left__ side of a rendered
element. It is absolute: relative to the screen itself.
- `coords.xl` - the absolute x coordinate of the __right__ side of a rendered
element. It is absolute: relative to the screen itself.
- `coords.yi` - the absolute y coordinate of the __top__ side of a rendered
element. It is absolute: relative to the screen itself.
- `coords.yl` - the absolute y coordinate of the __bottom__ side of a rendered
element. It is absolute: relative to the screen itself.
Note again: the `coords` the renderer receives for the Layout already has
border and padding subtracted, so you do not have to account for these. The
children do not.
###### Example
Here is an example of how to provide a renderer. Note that this is also the
default renderer if none is provided. This renderer will render each child as
though they were `display: inline-block;` in CSS, as if there were a
dynamically sized horizontal grid from left to right.
``` js
var layout = blessed.layout({
parent: screen,
top: 'center',
left: 'center',
width: '50%',
height: '50%',
border: 'line',
style: {
bg: 'red',
border: {
fg: 'blue'
}
},
// NOTE: This is already the default renderer if none is provided!
renderer: function(coords) {
var self = this;
// The coordinates of the layout element
var width = coords.xl - coords.xi
, height = coords.yl - coords.yi
, xi = coords.xi
, xl = coords.xl
, yi = coords.yi
, yl = coords.yl;
// The current row offset in cells (which row are we on?)
var rowOffset = 0;
// The index of the first child in the row
var rowIndex = 0;
return function iterator(el, i) {
// Make our children shrinkable. If they don't have a height, for
// example, calculate it for them.
el.shrink = true;
// Find the previous rendered child's coordinates
var last = self.getLastCoords(i);
// If there is no previously rendered element, we are on the first child.
if (!last) {
el.position.left = 0;
el.position.top = 0;
} else {
// Otherwise, figure out where to place this child. We'll start by
// setting it's `left`/`x` coordinate to right after the previous
// rendered element. This child will end up directly to the right of it.
el.position.left = last.xl - xi;
// If our child does not overlap the right side of the Layout, set it's
// `top`/`y` to the current `rowOffset` (the coordinate for the current
// row).
if (el.position.left + el.width <= width) {
el.position.top = rowOffset;
} else {
// Otherwise we need to start a new row and calculate a new
// `rowOffset` and `rowIndex` (the index of the child on the current
// row).
rowOffset += self.children.slice(rowIndex, i).reduce(function(out, el) {
if (!self.isRendered(el)) return out;
out = Math.max(out, el.lpos.yl - el.lpos.yi);
return out;
}, 0);
rowIndex = i;
el.position.left = 0;
el.position.top = rowOffset;
}
}
// If our child overflows the Layout, do not render it!
// Disable this feature for now.
if (el.position.top + el.height > height) {
// Returning false tells blessed to ignore this child.
// return false;
}
};
}
});
for (var i = 0; i < 10; i++) {
blessed.box({
parent: layout,
width: i % 2 === 0 ? 10 : 20,
height: i % 2 === 0 ? 5 : 10,
border: 'line'
});
}
```
### Other
#### Helpers
All helpers reside on `blessed.helpers` or `blessed`.
- __merge(a, b)__ - Merge objects `a` and `b` into object `a`.
- __asort(obj)__ - Sort array alphabetically by `name` prop.
- __hsort(obj)__ - Sort array numerically by `index` prop.
- __findFile(start, target)__ - Find a file at `start` directory with name
`target`.
- __escape(text)__ - Escape content's tags to be passed into `el.setContent()`.
Example: `box.setContent('escaped tag: ' + blessed.escape('{bold}{/bold}'));`
- __parseTags(text)__ - Parse tags into SGR escape codes.
- __generateTags(style, text)__ - Generate text tags based on `style` object.
- __attrToBinary(style, element)__ - Convert `style` attributes to binary
format.
- __stripTags(text)__ - Strip text of tags and SGR sequences.
- __cleanTags(text)__ - Strip text of tags, SGR escape code, and
leading/trailing whitespace.
- __dropUnicode(text)__ - Drop text of any >U+FFFF characters.
### Mechanics
#### Content & Tags
Every element can have text content via `setContent`. If `tags: true` was
passed to the element's constructor, the content can contain tags. For example:
``` js
box.setContent('hello {red-fg}{green-bg}{bold}world{/bold}{/green-bg}{/red-fg}');
```
To make this more concise `{/}` cancels all character attributes.
``` js
box.setContent('hello {red-fg}{green-bg}{bold}world{/}');
```
##### Colors
Blessed tags support the basic 16 colors for colors, as well as up to 256
colors.
``` js
box.setContent('hello {red-fg}{green-bg}world{/}');
```
Tags can also use hex colors (which will be reduced to the most accurate
terminal color):
``` js
box.setContent('hello {#ff0000-fg}{#00ff00-bg}world{/}');
```
##### Attributes
Blessed supports all terminal attributes, including `bold`, `underline`,
`blink`, `inverse`, and `invisible`.
``` js
box.setContent('hello {bold}world{/bold}');
```
##### Alignment
Newlines and alignment are also possible in content.
``` js
box.setContent('hello\n'
+ '{right}world{/right}\n'
+ '{center}foo{/center}\n');
+ 'left{|}right');
```
This will produce a box that looks like:
```
| hello |
| world |
| foo |
| left right |
```
##### Escaping
Escaping can either be done using `blessed.escape()`
```
box.setContent('here is an escaped tag: ' + blessed.escape('{bold}{/bold}'));
```
Or with the special `{open}` and `{close}` tags:
```
box.setContent('here is an escaped tag: {open}bold{close}{open}/bold{close}');
```
Either will produce:
```
here is an escaped tag: {bold}{/bold}
```
##### SGR Sequences
Content can also handle SGR escape codes. This means if you got output from a
program, say `git log` for example, you can feed it directly to an element's
content and the colors will be parsed appropriately.
This means that while `{red-fg}foo{/red-fg}` produces `^[[31mfoo^[[39m`, you
could just feed `^[[31mfoo^[[39m` directly to the content.
#### Style
The style option controls most of the visual aspects of an element.
``` js
style: {
fg: 'blue',
bg: 'black',
bold: true,
underline: false,
blink: false,
inverse: false,
invisible: false,
transparent: false,
border: {
fg: 'blue',
bg: 'red'
},
scrollbar: {
bg: 'blue'
},
focus: {
bg: 'red'
},
hover: {
bg: 'red'
}
}
```
##### Colors
Colors can be the names of any of the 16 basic terminal colors, along with hex
values (e.g. `#ff0000`) for 256 color terminals. If 256 or 88 colors is not
supported. Blessed with reduce the color to whatever is available.
##### Attributes
Blessed supports all terminal attributes, including `bold`, `underline`,
`blink`, `inverse`, and `invisible`. Attributes are represented as bools in the
`style` object.
##### Transparency
Blessed can set the opacity of an element to 50% using `style.transparent =
true;`. While this seems like it normally shouldn't be possible in a terminal,
blessed will use a color blending algorithm to blend the element of the
foremost element with the background behind it. Obviously characters cannot be
blended, but background colors can.
##### Shadow
Translucent shadows are also an option when it comes to styling an element.
This option will create a 50% opacity 2-cell wide, 1-cell high shadow offset to
the bottom-right.
``` js
shadow: true
```
##### Effects
Blessed supports hover and focus styles. (Hover is only useful is mouse input
is enabled).
``` js
style: {
hover: {
bg: 'red'
},
focus: {
border: {
fg: 'blue'
}
}
}
```
##### Scrollbar
On scrollable elements, blessed will support style options for the scrollbar,
such as:
``` js
style: {
scrollbar: {
bg: 'red',
fg: 'blue'
}
}
```
As a main option, scrollbar will either take a bool or an object:
``` js
scrollbar: {
ch: ' '
}
```
Or:
``` js
scrollbar: true
```
#### Events
Events in Blessed work similar to the traditional node.js model, with one
important difference: they have a concept of a tree and event bubbling.
##### Event Bubbling
Events can bubble in blessed. For example:
Receiving all click events for `box` (a normal event listener):
``` js
box.on('click', function(mouse) {
box.setContent('You clicked ' + mouse.x + ', ' + mouse.y + '.');
screen.render();
});
```
Receiving all click events for `box`, as well as all of its children:
``` js
box.on('element click', function(el, mouse) {
box.setContent('You clicked '
+ el.type + ' at ' + mouse.x + ', ' + mouse.y + '.');
screen.render();
if (el === box) {
return false; // Cancel propagation.
}
});
```
`el` gets passed in as the first argument. It refers to the target element the
event occurred on. Returning `false` will cancel propagation up the tree.
#### Positioning
Offsets may be a number, a percentage (e.g. `50%`), or a keyword (e.g.
`center`).
Dimensions may be a number, or a percentage (e.g. `50%`).
Positions are treated almost _exactly_ the same as they are in CSS/CSSOM when
an element has the `position: absolute` CSS property.
When an element is created, it can be given coordinates in its constructor:
``` js
var box = blessed.box({
left: 'center',
top: 'center',
bg: 'yellow',
width: '50%',
height: '50%'
});
```
This tells blessed to create a box, perfectly centered __relative to its
parent__, 50% as wide and 50% as tall as its parent.
Percentages can also have offsets applied to them:
``` js
...
height: '50%-1',
left: '45%+1',
...
```
To access the calculated offsets, relative to the parent:
``` js
console.log(box.left);
console.log(box.top);
```
To access the calculated offsets, absolute (relative to the screen):
``` js
console.log(box.aleft);
console.log(box.atop);
```
##### Overlapping offsets and dimensions greater than parents'
This still needs to be tested a bit, but it should work.
#### Rendering
To actually render the screen buffer, you must call `render`.
``` js
box.setContent('Hello {#0fe1ab-fg}world{/}.');
screen.render();
```
Elements are rendered with the lower elements in the children array being
painted first. In terms of the painter's algorithm, the lowest indicies in the
array are the furthest away, just like in the DOM.
#### Artificial Cursors
Terminal cursors can be tricky. They all have different custom escape codes to
alter. As an _experimental_ alternative, blessed can draw a cursor for you,
allowing you to have a custom cursor that you control.
``` js
var screen = blessed.screen({
cursor: {
artificial: true,
shape: 'line',
blink: true,
color: null // null for default
}
});
```
That's it. It's controlled the same way as the regular cursor.
To create a custom cursor:
``` js
var screen = blessed.screen({
cursor: {
artificial: true,
shape: {
bg: 'red',
fg: 'white',
bold: true,
ch: '#'
},
blink: true
}
});
```
#### Multiple Screens
Blessed supports the ability to create multiple screens. This may not seem
useful at first, but if you're writing a program that serves terminal
interfaces over http, telnet, or any other protocol, this can be very useful.
##### Server Side Usage
A simple telnet server might look like this (see examples/blessed-telnet.js for
a full example):
``` js
var blessed = require('blessed');
var telnet = require('telnet');
telnet.createServer(function(client) {
client.do.transmit_binary();
client.do.terminal_type();
client.do.window_size();
client.on('terminal type', function(data) {
if (data.command === 'sb' && data.name) {
screen.terminal = data.name;
screen.render();
}
});
client.on('window size', function(data) {
if (data.command === 'sb') {
client.columns = data.columns;
client.rows = data.rows;
client.emit('resize');
}
});
// Make the client look like a tty:
client.setRawMode = function(mode) {
client.isRaw = mode;
if (!client.writable) return;
if (mode) {
client.do.suppress_go_ahead();
client.will.suppress_go_ahead();
client.will.echo();
} else {
client.dont.suppress_go_ahead();
client.wont.suppress_go_ahead();
client.wont.echo();
}
};
client.isTTY = true;
client.isRaw = false;
client.columns = 80;
client.rows = 24;
var screen = blessed.screen({
smartCSR: true,
input: client,
output: client,
terminal: 'xterm-256color',
fullUnicode: true
});
client.on('close', function() {
if (!screen.destroyed) {
screen.destroy();
}
});
screen.key(['C-c', 'q'], function(ch, key) {
screen.destroy();
});
screen.on('destroy', function() {
if (client.writable) {
client.destroy();
}
});
screen.data.main = blessed.box({
parent: screen,
left: 'center',
top: 'center',
width: '80%',
height: '90%',
border: 'line',
content: 'Welcome to my server. Here is your own private session.'
});
screen.render();
}).listen(2300);
```
Once you've written something similar and started it, you can simply telnet
into your blessed app:
``` bash
$ telnet localhost 2300
```
Creating a netcat server would also work as long as you disable line buffering
and terminal echo on the commandline via `stty`:
`$ stty -icanon -echo; ncat localhost 2300; stty icanon echo`
Or by using netcat's `-t` option: `$ ncat -t localhost 2300`
Creating a streaming http 1.1 server than runs in the terminal is possible by
curling it with special arguments: `$ curl -sSNT. localhost:8080`.
There are currently no examples of netcat/nc/ncat or http->curl servers yet.
---
The `blessed.screen` constructor can accept `input`, `output`, and `term`
arguments to aid with this. The multiple screens will be managed internally by
blessed. The programmer just has to keep track of the references, however, to
avoid ambiguity, it's possible to explicitly dictate which screen a node is
part of by using the `screen` option when creating an element.
The `screen.destroy()` method is also crucial: this will clean up all event
listeners the screen has bound and make sure it stops listening on the event
loop. Make absolutely certain to remember to clean up your screens once you're
done with them.
A tricky part is making sure to include the ability for the client to send the
TERM which is reset on the serverside, and the terminal size, which is should
also be reset on the serverside. Both of these capabilities are demonstrated
above.
For a working example of a blessed telnet server, see
`examples/blessed-telnet.js`.
### Notes
#### Windows Compatibility
Currently there is no `mouse` or `resize` event support on Windows.
Windows users will need to explicitly set `term` when creating a screen like so
(__NOTE__: This is no longer necessary as of the latest versions of blessed.
This is now handled automatically):
``` js
var screen = blessed.screen({ terminal: 'windows-ansi' });
```
#### Low-level Usage
This will actually parse the xterm terminfo and compile every
string capability to a javascript function:
``` js
var blessed = require('blessed');
var tput = blessed.tput({
terminal: 'xterm-256color',
extended: true
});
process.stdout.write(tput.setaf(4) + 'Hello' + tput.sgr0() + '\n');
```
To play around with it on the command line, it works just like tput:
``` bash
$ tput.js setaf 2
$ tput.js sgr0
$ echo "$(tput.js setaf 2)Hello World$(tput.js sgr0)"
```
The main functionality is exposed in the main `blessed` module:
``` js
var blessed = require('blessed')
, program = blessed.program();
program.key('q', function(ch, key) {
program.clear();
program.disableMouse();
program.showCursor();
program.normalBuffer();
process.exit(0);
});
program.on('mouse', function(data) {
if (data.action === 'mousemove') {
program.move(data.x, data.y);
program.bg('red');
program.write('x');
program.bg('!red');
}
});
program.alternateBuffer();
program.enableMouse();
program.hideCursor();
program.clear();
program.move(1, 1);
program.bg('black');
program.write('Hello world', 'blue fg');
program.setx((program.cols / 2 | 0) - 4);
program.down(5);
program.write('Hi again!');
program.bg('!black');
program.feed();
```
#### Testing
Most tests contained in the `test/` directory are interactive. It's up to the
programmer to determine whether the test is properly displayed. In the future
it might be better to do something similar to vttest.
#### Examples
Examples can be found in `examples/`.
#### FAQ
1. Why doesn't the Linux console render lines correctly on Ubuntu?
- You need to install the `ncurses-base` package __and__ the `ncurses-term`
package. (#98)
2. Why do vertical lines look chopped up in iTerm2?
- All ACS vertical lines look this way in iTerm2 with the default font.
3. Why can't I use my mouse in Terminal.app?
- Terminal.app does not support mouse events.
4. Why doesn't the OverlayImage element appear in my terminal?
- The OverlayImage element uses w3m to display images. This generally only
works on X11+xterm/urxvt, but it _may_ work on other unix terminals.
5. Why can't my mouse clicks register beyond 255 cells?
- Older versions of VTE do not support any modern mouse protocol. On top of
that, the old X10 protocol it _does_ implement is bugged. Through several
workarounds we've managed to get the cell limit from `127` to `255`. If
you're not happy with this, you may want to look into using xterm or urxvt,
or a terminal which uses a modern VTE, like gnome-terminal.
6. Is blessed efficient?
- Yes. Blessed implements CSR and uses the painter's algorithm to render the
screen. It maintains two screen buffers so it only needs to render what
has changed on the terminal screen.
7. Will blessed work with all terminals?
- Yes. Blessed has a terminfo/termcap parser and compiler that was written
from scratch. It should work with every terminal as long as a terminfo
file is provided. If you notice any compatibility issues in your termial,
do not hesitate to post an issue.
8. What is "curses" and "ncurses"?
- ["curses"][curses] was an old library written in the early days of unix
which allowed a programmer to easily manipulate the cursor in order to
render the screen. ["ncurses"][ncurses] is a free reimplementation of
curses. It improved upon it quite a bit by focusing more on terminal
compatibility and is now the standard library for implementing terminal
programs. Blessed uses neither of these, and instead handles terminal
compatibility itself.
9. What is the difference between blessed and blessed-contrib?
- blessed is a major piece of code which reimplements curses from the ground
up. A UI API is then layered on top of this. [blessed-contrib][contrib] is
a popular library built on top of blessed which makes clever use of modules
to implement useful widgets like graphs, ascii art, and so on.
10. Are there blessed-like solutions for non-javascript platforms?
- Yes. There are some fantastic solutions out there.
- Perl: [Curses::UI][curses-ui]
- Python: [Urwid][urwid]
- Go: [termui][termui] & [termbox-go][termbox]
## Contribution and License Agreement
If you contribute code to this project, you are implicitly allowing your code
to be distributed under the MIT license. You are also implicitly verifying that
all code is your original work. `</legalese>`
## License
Copyright (c) 2013-2015, Christopher Jeffrey. (MIT License)
See LICENSE for more info.
[slap]: https://github.com/slap-editor/slap
[contrib]: https://github.com/yaronn/blessed-contrib
[termui]: https://github.com/gizak/termui
[curses]: https://en.wikipedia.org/wiki/Curses_(programming_library)
[ncurses]: https://en.wikipedia.org/wiki/Ncurses
[urwid]: http://urwid.org/reference/index.html
[curses-ui]: http://search.cpan.org/~mdxi/Curses-UI-0.9609/lib/Curses/UI.pm
[termbox]: https://github.com/nsf/termbox-go
[ttystudio]: https://github.com/chjj/ttystudio#choosing-a-new-font-for-your-terminal-recording
# fsevents [](https://nodei.co/npm/fsevents/)
Native access to MacOS FSEvents in [Node.js](https://nodejs.org/)
The FSEvents API in MacOS allows applications to register for notifications of
changes to a given directory tree. It is a very fast and lightweight alternative
to kqueue.
This is a low-level library. For a cross-platform file watching module that
uses fsevents, check out [Chokidar](https://github.com/paulmillr/chokidar).
## Installation
Supports only **Node.js v8.16 and higher**.
```sh
npm install fsevents
```
## Usage
```js
const fsevents = require('fsevents');
const stop = fsevents.watch(__dirname, (path, flags, id) => {
const info = fsevents.getInfo(path, flags, id);
}); // To start observation
stop(); // To end observation
```
The callback passed as the second parameter to `.watch` get's called whenever the operating system detects a
a change in the file system. It takes three arguments:
###### `fsevents.watch(dirname: string, (path: string, flags: number, id: string) => void): () => Promise<undefined>`
* `path: string` - the item in the filesystem that have been changed
* `flags: number` - a numeric value describing what the change was
* `id: string` - an unique-id identifying this specific event
Returns closer callback which when called returns a Promise resolving when the watcher process has been shut down.
###### `fsevents.getInfo(path: string, flags: number, id: string): FsEventInfo`
The `getInfo` function takes the `path`, `flags` and `id` arguments and converts those parameters into a structure
that is easier to digest to determine what the change was.
The `FsEventsInfo` has the following shape:
```js
/**
* @typedef {'created'|'modified'|'deleted'|'moved'|'root-changed'|'cloned'|'unknown'} FsEventsEvent
* @typedef {'file'|'directory'|'symlink'} FsEventsType
*/
{
"event": "created", // {FsEventsEvent}
"path": "file.txt",
"type": "file", // {FsEventsType}
"changes": {
"inode": true, // Had iNode Meta-Information changed
"finder": false, // Had Finder Meta-Data changed
"access": false, // Had access permissions changed
"xattrs": false // Had xAttributes changed
},
"flags": 0x100000000
}
```
## Engine compatibility
- v2 supports node 8.16+
- v1.2.8 supports node 6+
- v1.2.7 supports node 4+
## License
The MIT License Copyright (C) 2010-2020 by Philipp Dunkel, Ben Noordhuis, Elan Shankar, Paul Miller — see LICENSE file.
Visit our [GitHub page](https://github.com/fsevents/fsevents) and [NPM Page](https://npmjs.org/package/fsevents)
# isarray
`Array#isArray` for older browsers.
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
ethers.js
=========
[](https://badge.fury.io/js/ethers)
Complete Ethereum wallet implementation and utilities in JavaScript (and TypeScript).
**Features:**
- Keep your private keys in your client, **safe** and sound
- Import and export **JSON wallets** (Geth, Parity and crowdsale) and brain wallets
- Import and export BIP 39 **mnemonic phrases** (12 word backup phrases) and **HD Wallets** (English, Italian, Japanese, Korean, Simplified Chinese, Traditional Chinese; more coming soon)
- Meta-classes create JavaScript objects from any contract ABI
- Connect to Ethereum nodes over [JSON-RPC](https://github.com/ethereum/wiki/wiki/JSON-RPC), [INFURA](https://infura.io), [Etherscan](https://etherscan.io), or [MetaMask](https://metamask.io)
- ENS names are first-class citizens; they can be used anywhere an Ethereum addresses can be
- **Tiny** (~84kb compressed; 270kb uncompressed)
- **Complete** functionality for all your Ethereum needs
- Extensive [documentation](https://docs.ethers.io/ethers.js/html/)
- Large collection of test cases which are maintained and added to
- Fully TypeScript ready, with definition files and full TypeScript source
- **MIT License** (including ALL dependencies); completely open source to do with as you please
Installing
----------
To use in a browser:
```html
<script charset="utf-8"
src="https://cdn.ethers.io/scripts/ethers-v4.min.js"
type="text/javascript">
</script>
```
To use in [node.js](https://nodejs.org/):
```
/Users/ethers/my-app> npm install --save ethers
```
Documentation
-------------
Browse the [API Documentation](https://docs.ethers.io/ethers.js/html/) online.
Documentation is generated using [Sphinx](http://www.sphinx-doc.org) and can be browsed locally from the /docs/build/html directory.
Hacking and Contributing
------------------------
The JavaScript code is now generated from TypeScript, so make sure you modify the
TypeScript and compile it, rather than modifying the JavaScript directly. To start
auto-compiling the TypeScript code, you may use:
```
/home/ethers> npm run auto-build
```
A very important part of ethers is its exhaustive test cases, so before making any
bug fix, please add a test case that fails prior to the fix, and succeeds after the
fix. All regression tests must pass.
Pull requests are always welcome, but please keep a few points in mind:
- Compatibility-breaking changes will not be accepted; they may be considered for the next major version
- Security is important; adding dependencies require fairly convincing arguments
- The library aims to be lean, so keep an eye on the `dist/ethers.min.js` filesize before and after your changes
- Add test cases for both expected and unexpected input
- Any new features need to be supported by us (issues, documentation, testing), so anything that is overly complicated or specific may not be accepted
If in doubt, please start an issue, and we can have a nice public discussion. :)
Donations
---------
I do this because I love it, but if you want to buy me a coffee, I won't say no. **:o)**
Ethereum: `0xEA517D5a070e6705Cc5467858681Ed953d285Eb9`
License
-------
Completely MIT Licensed. Including ALL dependencies.
# AST Types 
This module provides an efficient, modular,
[Esprima](https://github.com/ariya/esprima)-compatible implementation of
the [abstract syntax
tree](http://en.wikipedia.org/wiki/Abstract_syntax_tree) type hierarchy
pioneered by the [Mozilla Parser
API](https://developer.mozilla.org/en-US/docs/SpiderMonkey/Parser_API).
Installation
---
From NPM:
npm install ast-types
From GitHub:
cd path/to/node_modules
git clone git://github.com/benjamn/ast-types.git
cd ast-types
npm install .
Basic Usage
---
```js
import assert from "assert";
import {
namedTypes as n,
builders as b,
} from "ast-types";
var fooId = b.identifier("foo");
var ifFoo = b.ifStatement(fooId, b.blockStatement([
b.expressionStatement(b.callExpression(fooId, []))
]));
assert.ok(n.IfStatement.check(ifFoo));
assert.ok(n.Statement.check(ifFoo));
assert.ok(n.Node.check(ifFoo));
assert.ok(n.BlockStatement.check(ifFoo.consequent));
assert.strictEqual(
ifFoo.consequent.body[0].expression.arguments.length,
0,
);
assert.strictEqual(ifFoo.test, fooId);
assert.ok(n.Expression.check(ifFoo.test));
assert.ok(n.Identifier.check(ifFoo.test));
assert.ok(!n.Statement.check(ifFoo.test));
```
AST Traversal
---
Because it understands the AST type system so thoroughly, this library
is able to provide excellent node iteration and traversal mechanisms.
If you want complete control over the traversal, and all you need is a way
of enumerating the known fields of your AST nodes and getting their
values, you may be interested in the primitives `getFieldNames` and
`getFieldValue`:
```js
import {
getFieldNames,
getFieldValue,
} from "ast-types";
const partialFunExpr = { type: "FunctionExpression" };
// Even though partialFunExpr doesn't actually contain all the fields that
// are expected for a FunctionExpression, types.getFieldNames knows:
console.log(getFieldNames(partialFunExpr));
// [ 'type', 'id', 'params', 'body', 'generator', 'expression',
// 'defaults', 'rest', 'async' ]
// For fields that have default values, types.getFieldValue will return
// the default if the field is not actually defined.
console.log(getFieldValue(partialFunExpr, "generator"));
// false
```
Two more low-level helper functions, `eachField` and `someField`, are
defined in terms of `getFieldNames` and `getFieldValue`:
```js
// Iterate over all defined fields of an object, including those missing
// or undefined, passing each field name and effective value (as returned
// by getFieldValue) to the callback. If the object has no corresponding
// Def, the callback will never be called.
export function eachField(object, callback, context) {
getFieldNames(object).forEach(function(name) {
callback.call(this, name, getFieldValue(object, name));
}, context);
}
// Similar to eachField, except that iteration stops as soon as the
// callback returns a truthy value. Like Array.prototype.some, the final
// result is either true or false to indicates whether the callback
// returned true for any element or not.
export function someField(object, callback, context) {
return getFieldNames(object).some(function(name) {
return callback.call(this, name, getFieldValue(object, name));
}, context);
}
```
So here's how you might make a copy of an AST node:
```js
import { eachField } from "ast-types";
const copy = {};
eachField(node, function(name, value) {
// Note that undefined fields will be visited too, according to
// the rules associated with node.type, and default field values
// will be substituted if appropriate.
copy[name] = value;
})
```
But that's not all! You can also easily visit entire syntax trees using
the powerful `types.visit` abstraction.
Here's a trivial example of how you might assert that `arguments.callee`
is never used in `ast`:
```js
import assert from "assert";
import {
visit,
namedTypes as n,
} from "ast-types";
visit(ast, {
// This method will be called for any node with .type "MemberExpression":
visitMemberExpression(path) {
// Visitor methods receive a single argument, a NodePath object
// wrapping the node of interest.
var node = path.node;
if (
n.Identifier.check(node.object) &&
node.object.name === "arguments" &&
n.Identifier.check(node.property)
) {
assert.notStrictEqual(node.property.name, "callee");
}
// It's your responsibility to call this.traverse with some
// NodePath object (usually the one passed into the visitor
// method) before the visitor method returns, or return false to
// indicate that the traversal need not continue any further down
// this subtree.
this.traverse(path);
}
});
```
Here's a slightly more involved example of transforming `...rest`
parameters into browser-runnable ES5 JavaScript:
```js
import { builders as b, visit } from "ast-types";
// Reuse the same AST structure for Array.prototype.slice.call.
var sliceExpr = b.memberExpression(
b.memberExpression(
b.memberExpression(
b.identifier("Array"),
b.identifier("prototype"),
false
),
b.identifier("slice"),
false
),
b.identifier("call"),
false
);
visit(ast, {
// This method will be called for any node whose type is a subtype of
// Function (e.g., FunctionDeclaration, FunctionExpression, and
// ArrowFunctionExpression). Note that types.visit precomputes a
// lookup table from every known type to the appropriate visitor
// method to call for nodes of that type, so the dispatch takes
// constant time.
visitFunction(path) {
// Visitor methods receive a single argument, a NodePath object
// wrapping the node of interest.
const node = path.node;
// It's your responsibility to call this.traverse with some
// NodePath object (usually the one passed into the visitor
// method) before the visitor method returns, or return false to
// indicate that the traversal need not continue any further down
// this subtree. An assertion will fail if you forget, which is
// awesome, because it means you will never again make the
// disastrous mistake of forgetting to traverse a subtree. Also
// cool: because you can call this method at any point in the
// visitor method, it's up to you whether your traversal is
// pre-order, post-order, or both!
this.traverse(path);
// This traversal is only concerned with Function nodes that have
// rest parameters.
if (!node.rest) {
return;
}
// For the purposes of this example, we won't worry about functions
// with Expression bodies.
n.BlockStatement.assert(node.body);
// Use types.builders to build a variable declaration of the form
//
// var rest = Array.prototype.slice.call(arguments, n);
//
// where `rest` is the name of the rest parameter, and `n` is a
// numeric literal specifying the number of named parameters the
// function takes.
const restVarDecl = b.variableDeclaration("var", [
b.variableDeclarator(
node.rest,
b.callExpression(sliceExpr, [
b.identifier("arguments"),
b.literal(node.params.length)
])
)
]);
// Similar to doing node.body.body.unshift(restVarDecl), except
// that the other NodePath objects wrapping body statements will
// have their indexes updated to accommodate the new statement.
path.get("body", "body").unshift(restVarDecl);
// Nullify node.rest now that we have simulated the behavior of
// the rest parameter using ordinary JavaScript.
path.get("rest").replace(null);
// There's nothing wrong with doing node.rest = null, but I wanted
// to point out that the above statement has the same effect.
assert.strictEqual(node.rest, null);
}
});
```
Here's how you might use `types.visit` to implement a function that
determines if a given function node refers to `this`:
```js
function usesThis(funcNode) {
n.Function.assert(funcNode);
var result = false;
visit(funcNode, {
visitThisExpression(path) {
result = true;
// The quickest way to terminate the traversal is to call
// this.abort(), which throws a special exception (instanceof
// this.AbortRequest) that will be caught in the top-level
// types.visit method, so you don't have to worry about
// catching the exception yourself.
this.abort();
},
visitFunction(path) {
// ThisExpression nodes in nested scopes don't count as `this`
// references for the original function node, so we can safely
// avoid traversing this subtree.
return false;
},
visitCallExpression(path) {
const node = path.node;
// If the function contains CallExpression nodes involving
// super, those expressions will implicitly depend on the
// value of `this`, even though they do not explicitly contain
// any ThisExpression nodes.
if (this.isSuperCallExpression(node)) {
result = true;
this.abort(); // Throws AbortRequest exception.
}
this.traverse(path);
},
// Yes, you can define arbitrary helper methods.
isSuperCallExpression(callExpr) {
n.CallExpression.assert(callExpr);
return this.isSuperIdentifier(callExpr.callee)
|| this.isSuperMemberExpression(callExpr.callee);
},
// And even helper helper methods!
isSuperIdentifier(node) {
return n.Identifier.check(node.callee)
&& node.callee.name === "super";
},
isSuperMemberExpression(node) {
return n.MemberExpression.check(node.callee)
&& n.Identifier.check(node.callee.object)
&& node.callee.object.name === "super";
}
});
return result;
}
```
As you might guess, when an `AbortRequest` is thrown from a subtree, the
exception will propagate from the corresponding calls to `this.traverse`
in the ancestor visitor methods. If you decide you want to cancel the
request, simply catch the exception and call its `.cancel()` method. The
rest of the subtree beneath the `try`-`catch` block will be abandoned, but
the remaining siblings of the ancestor node will still be visited.
NodePath
---
The `NodePath` object passed to visitor methods is a wrapper around an AST
node, and it serves to provide access to the chain of ancestor objects
(all the way back to the root of the AST) and scope information.
In general, `path.node` refers to the wrapped node, `path.parent.node`
refers to the nearest `Node` ancestor, `path.parent.parent.node` to the
grandparent, and so on.
Note that `path.node` may not be a direct property value of
`path.parent.node`; for instance, it might be the case that `path.node` is
an element of an array that is a direct child of the parent node:
```js
path.node === path.parent.node.elements[3]
```
in which case you should know that `path.parentPath` provides
finer-grained access to the complete path of objects (not just the `Node`
ones) from the root of the AST:
```js
// In reality, path.parent is the grandparent of path:
path.parentPath.parentPath === path.parent
// The path.parentPath object wraps the elements array (note that we use
// .value because the elements array is not a Node):
path.parentPath.value === path.parent.node.elements
// The path.node object is the fourth element in that array:
path.parentPath.value[3] === path.node
// Unlike path.node and path.value, which are synonyms because path.node
// is a Node object, path.parentPath.node is distinct from
// path.parentPath.value, because the elements array is not a
// Node. Instead, path.parentPath.node refers to the closest ancestor
// Node, which happens to be the same as path.parent.node:
path.parentPath.node === path.parent.node
// The path is named for its index in the elements array:
path.name === 3
// Likewise, path.parentPath is named for the property by which
// path.parent.node refers to it:
path.parentPath.name === "elements"
// Putting it all together, we can follow the chain of object references
// from path.parent.node all the way to path.node by accessing each
// property by name:
path.parent.node[path.parentPath.name][path.name] === path.node
```
These `NodePath` objects are created during the traversal without
modifying the AST nodes themselves, so it's not a problem if the same node
appears more than once in the AST (like `Array.prototype.slice.call` in
the example above), because it will be visited with a distict `NodePath`
each time it appears.
Child `NodePath` objects are created lazily, by calling the `.get` method
of a parent `NodePath` object:
```js
// If a NodePath object for the elements array has never been created
// before, it will be created here and cached in the future:
path.get("elements").get(3).value === path.value.elements[3]
// Alternatively, you can pass multiple property names to .get instead of
// chaining multiple .get calls:
path.get("elements", 0).value === path.value.elements[0]
```
`NodePath` objects support a number of useful methods:
```js
// Replace one node with another node:
var fifth = path.get("elements", 4);
fifth.replace(newNode);
// Now do some stuff that might rearrange the list, and this replacement
// remains safe:
fifth.replace(newerNode);
// Replace the third element in an array with two new nodes:
path.get("elements", 2).replace(
b.identifier("foo"),
b.thisExpression()
);
// Remove a node and its parent if it would leave a redundant AST node:
//e.g. var t = 1, y =2; removing the `t` and `y` declarators results in `var undefined`.
path.prune(); //returns the closest parent `NodePath`.
// Remove a node from a list of nodes:
path.get("elements", 3).replace();
// Add three new nodes to the beginning of a list of nodes:
path.get("elements").unshift(a, b, c);
// Remove and return the first node in a list of nodes:
path.get("elements").shift();
// Push two new nodes onto the end of a list of nodes:
path.get("elements").push(d, e);
// Remove and return the last node in a list of nodes:
path.get("elements").pop();
// Insert a new node before/after the seventh node in a list of nodes:
var seventh = path.get("elements", 6);
seventh.insertBefore(newNode);
seventh.insertAfter(newNode);
// Insert a new element at index 5 in a list of nodes:
path.get("elements").insertAt(5, newNode);
```
Scope
---
The object exposed as `path.scope` during AST traversals provides
information about variable and function declarations in the scope that
contains `path.node`. See [scope.ts](lib/scope.ts) for its public
interface, which currently includes `.isGlobal`, `.getGlobalScope()`,
`.depth`, `.declares(name)`, `.lookup(name)`, and `.getBindings()`.
Custom AST Node Types
---
The `ast-types` module was designed to be extended. To that end, it
provides a readable, declarative syntax for specifying new AST node types,
based primarily upon the `require("ast-types").Type.def` function:
```js
import {
Type,
builtInTypes,
builders as b,
finalize,
} from "ast-types";
const { def } = Type;
const { string } = builtInTypes;
// Suppose you need a named File type to wrap your Programs.
def("File")
.bases("Node")
.build("name", "program")
.field("name", string)
.field("program", def("Program"));
// Prevent further modifications to the File type (and any other
// types newly introduced by def(...)).
finalize();
// The b.file builder function is now available. It expects two
// arguments, as named by .build("name", "program") above.
const main = b.file("main.js", b.program([
// Pointless program contents included for extra color.
b.functionDeclaration(b.identifier("succ"), [
b.identifier("x")
], b.blockStatement([
b.returnStatement(
b.binaryExpression(
"+", b.identifier("x"), b.literal(1)
)
)
]))
]));
assert.strictEqual(main.name, "main.js");
assert.strictEqual(main.program.body[0].params[0].name, "x");
// etc.
// If you pass the wrong type of arguments, or fail to pass enough
// arguments, an AssertionError will be thrown.
b.file(b.blockStatement([]));
// ==> AssertionError: {"body":[],"type":"BlockStatement","loc":null} does not match type string
b.file("lib/types.js", b.thisExpression());
// ==> AssertionError: {"type":"ThisExpression","loc":null} does not match type Program
```
The `def` syntax is used to define all the default AST node types found in
[babel-core.ts](def/babel-core.ts),
[babel.ts](def/babel.ts),
[core.ts](def/core.ts),
[es-proposals.ts](def/es-proposals.ts),
[es6.ts](def/es6.ts),
[es7.ts](def/es7.ts),
[es2020.ts](def/es2020.ts),
[esprima.ts](def/esprima.ts),
[flow.ts](def/flow.ts),
[jsx.ts](def/jsx.ts),
[type-annotations.ts](def/type-annotations.ts),
and
[typescripts.ts](def/typescripts.ts),
so you have
no shortage of examples to learn from.
A JavaScript library for arbitrary-precision decimal and non-decimal arithmetic.
[](https://www.npmjs.com/package/bignumber.js)
[](https://www.npmjs.com/package/bignumber.js)
[](https://travis-ci.org/MikeMcl/bignumber.js)
<br />
## Features
- Integers and decimals
- Simple API but full-featured
- Faster, smaller, and perhaps easier to use than JavaScript versions of Java's BigDecimal
- 8 KB minified and gzipped
- Replicates the `toExponential`, `toFixed`, `toPrecision` and `toString` methods of JavaScript's Number type
- Includes a `toFraction` and a correctly-rounded `squareRoot` method
- Supports cryptographically-secure pseudo-random number generation
- No dependencies
- Wide platform compatibility: uses JavaScript 1.5 (ECMAScript 3) features only
- Comprehensive [documentation](http://mikemcl.github.io/bignumber.js/) and test set
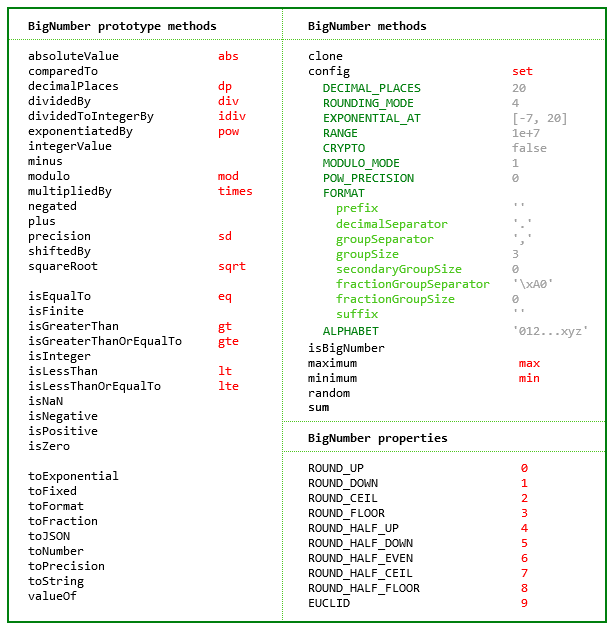
If a smaller and simpler library is required see [big.js](https://github.com/MikeMcl/big.js/).
It's less than half the size but only works with decimal numbers and only has half the methods.
It also does not allow `NaN` or `Infinity`, or have the configuration options of this library.
See also [decimal.js](https://github.com/MikeMcl/decimal.js/), which among other things adds support for non-integer powers, and performs all operations to a specified number of significant digits.
## Load
The library is the single JavaScript file *bignumber.js* or ES module *bignumber.mjs*.
### Browser:
```html
<script src='path/to/bignumber.js'></script>
```
> ES module
```html
<script type="module">
import BigNumber from './path/to/bignumber.mjs';
...
</script>
```
### [Node.js](http://nodejs.org):
```bash
$ npm install bignumber.js
```
```javascript
const BigNumber = require('bignumber.js');
```
> ES module
```javascript
import BigNumber from "bignumber.js";
// or
import { BigNumber } from "bignumber.js";
```
## Use
The library exports a single constructor function, [`BigNumber`](http://mikemcl.github.io/bignumber.js/#bignumber), which accepts a value of type Number, String or BigNumber,
```javascript
let x = new BigNumber(123.4567);
let y = BigNumber('123456.7e-3');
let z = new BigNumber(x);
x.isEqualTo(y) && y.isEqualTo(z) && x.isEqualTo(z); // true
```
To get the string value of a BigNumber use [`toString()`](http://mikemcl.github.io/bignumber.js/#toS) or [`toFixed()`](http://mikemcl.github.io/bignumber.js/#toFix). Using `toFixed()` prevents exponential notation being returned, no matter how large or small the value.
```javascript
let x = new BigNumber('1111222233334444555566');
x.toString(); // "1.111222233334444555566e+21"
x.toFixed(); // "1111222233334444555566"
```
If the limited precision of Number values is not well understood, it is recommended to create BigNumbers from String values rather than Number values to avoid a potential loss of precision.
*In all further examples below, `let`, semicolons and `toString` calls are not shown. If a commented-out value is in quotes it means `toString` has been called on the preceding expression.*
```javascript
// Precision loss from using numeric literals with more than 15 significant digits.
new BigNumber(1.0000000000000001) // '1'
new BigNumber(88259496234518.57) // '88259496234518.56'
new BigNumber(99999999999999999999) // '100000000000000000000'
// Precision loss from using numeric literals outside the range of Number values.
new BigNumber(2e+308) // 'Infinity'
new BigNumber(1e-324) // '0'
// Precision loss from the unexpected result of arithmetic with Number values.
new BigNumber(0.7 + 0.1) // '0.7999999999999999'
```
When creating a BigNumber from a Number, note that a BigNumber is created from a Number's decimal `toString()` value not from its underlying binary value. If the latter is required, then pass the Number's `toString(2)` value and specify base 2.
```javascript
new BigNumber(Number.MAX_VALUE.toString(2), 2)
```
BigNumbers can be created from values in bases from 2 to 36. See [`ALPHABET`](http://mikemcl.github.io/bignumber.js/#alphabet) to extend this range.
```javascript
a = new BigNumber(1011, 2) // "11"
b = new BigNumber('zz.9', 36) // "1295.25"
c = a.plus(b) // "1306.25"
```
*Performance is better if base 10 is NOT specified for decimal values. Only specify base 10 when it is desired that the number of decimal places of the input value be limited to the current [`DECIMAL_PLACES`](http://mikemcl.github.io/bignumber.js/#decimal-places) setting.*
A BigNumber is immutable in the sense that it is not changed by its methods.
```javascript
0.3 - 0.1 // 0.19999999999999998
x = new BigNumber(0.3)
x.minus(0.1) // "0.2"
x // "0.3"
```
The methods that return a BigNumber can be chained.
```javascript
x.dividedBy(y).plus(z).times(9)
x.times('1.23456780123456789e+9').plus(9876.5432321).dividedBy('4444562598.111772').integerValue()
```
Some of the longer method names have a shorter alias.
```javascript
x.squareRoot().dividedBy(y).exponentiatedBy(3).isEqualTo(x.sqrt().div(y).pow(3)) // true
x.modulo(y).multipliedBy(z).eq(x.mod(y).times(z)) // true
```
As with JavaScript's Number type, there are [`toExponential`](http://mikemcl.github.io/bignumber.js/#toE), [`toFixed`](http://mikemcl.github.io/bignumber.js/#toFix) and [`toPrecision`](http://mikemcl.github.io/bignumber.js/#toP) methods.
```javascript
x = new BigNumber(255.5)
x.toExponential(5) // "2.55500e+2"
x.toFixed(5) // "255.50000"
x.toPrecision(5) // "255.50"
x.toNumber() // 255.5
```
A base can be specified for [`toString`](http://mikemcl.github.io/bignumber.js/#toS).
*Performance is better if base 10 is NOT specified, i.e. use `toString()` not `toString(10)`. Only specify base 10 when it is desired that the number of decimal places be limited to the current [`DECIMAL_PLACES`](http://mikemcl.github.io/bignumber.js/#decimal-places) setting.*
```javascript
x.toString(16) // "ff.8"
```
There is a [`toFormat`](http://mikemcl.github.io/bignumber.js/#toFor) method which may be useful for internationalisation.
```javascript
y = new BigNumber('1234567.898765')
y.toFormat(2) // "1,234,567.90"
```
The maximum number of decimal places of the result of an operation involving division (i.e. a division, square root, base conversion or negative power operation) is set using the `set` or `config` method of the `BigNumber` constructor.
The other arithmetic operations always give the exact result.
```javascript
BigNumber.set({ DECIMAL_PLACES: 10, ROUNDING_MODE: 4 })
x = new BigNumber(2)
y = new BigNumber(3)
z = x.dividedBy(y) // "0.6666666667"
z.squareRoot() // "0.8164965809"
z.exponentiatedBy(-3) // "3.3749999995"
z.toString(2) // "0.1010101011"
z.multipliedBy(z) // "0.44444444448888888889"
z.multipliedBy(z).decimalPlaces(10) // "0.4444444445"
```
There is a [`toFraction`](http://mikemcl.github.io/bignumber.js/#toFr) method with an optional *maximum denominator* argument
```javascript
y = new BigNumber(355)
pi = y.dividedBy(113) // "3.1415929204"
pi.toFraction() // [ "7853982301", "2500000000" ]
pi.toFraction(1000) // [ "355", "113" ]
```
and [`isNaN`](http://mikemcl.github.io/bignumber.js/#isNaN) and [`isFinite`](http://mikemcl.github.io/bignumber.js/#isF) methods, as `NaN` and `Infinity` are valid `BigNumber` values.
```javascript
x = new BigNumber(NaN) // "NaN"
y = new BigNumber(Infinity) // "Infinity"
x.isNaN() && !y.isNaN() && !x.isFinite() && !y.isFinite() // true
```
The value of a BigNumber is stored in a decimal floating point format in terms of a coefficient, exponent and sign.
```javascript
x = new BigNumber(-123.456);
x.c // [ 123, 45600000000000 ] coefficient (i.e. significand)
x.e // 2 exponent
x.s // -1 sign
```
For advanced usage, multiple BigNumber constructors can be created, each with their own independent configuration.
```javascript
// Set DECIMAL_PLACES for the original BigNumber constructor
BigNumber.set({ DECIMAL_PLACES: 10 })
// Create another BigNumber constructor, optionally passing in a configuration object
BN = BigNumber.clone({ DECIMAL_PLACES: 5 })
x = new BigNumber(1)
y = new BN(1)
x.div(3) // '0.3333333333'
y.div(3) // '0.33333'
```
To avoid having to call `toString` or `valueOf` on a BigNumber to get its value in the Node.js REPL or when using `console.log` use
```javascript
BigNumber.prototype[require('util').inspect.custom] = BigNumber.prototype.valueOf;
```
For further information see the [API](http://mikemcl.github.io/bignumber.js/) reference in the *doc* directory.
## Test
The *test/modules* directory contains the test scripts for each method.
The tests can be run with Node.js or a browser. For Node.js use
$ npm test
or
$ node test/test
To test a single method, use, for example
$ node test/methods/toFraction
For the browser, open *test/test.html*.
## Build
For Node, if [uglify-js](https://github.com/mishoo/UglifyJS2) is installed
npm install uglify-js -g
then
npm run build
will create *bignumber.min.js*.
A source map will also be created in the root directory.
## Licence
The MIT Licence.
See [LICENCE](https://github.com/MikeMcl/bignumber.js/blob/master/LICENCE).
# pidusage
[](https://travis-ci.org/soyuka/pidusage)
[](https://ci.appveyor.com/project/soyuka/pidusage)
[](https://codecov.io/gh/soyuka/pidusage)
[](https://www.npmjs.com/package/pidusage)
[](https://github.com/soyuka/pidusage/tree/master/license)
Cross-platform process cpu % and memory usage of a PID.
## Synopsis
Ideas from https://github.com/arunoda/node-usage but with no C-bindings.
Please note that if you need to check a Node.JS script process cpu and memory usage, you can use [`process.cpuUsage`][node:cpuUsage] and [`process.memoryUsage`][node:memUsage] since node v6.1.0. This script remain useful when you have no control over the remote script, or if the process is not a Node.JS process.
## Usage
```js
var pidusage = require('pidusage')
pidusage(process.pid, function (err, stats) {
console.log(stats)
// => {
// cpu: 10.0, // percentage (from 0 to 100*vcore)
// memory: 357306368, // bytes
// ppid: 312, // PPID
// pid: 727, // PID
// ctime: 867000, // ms user + system time
// elapsed: 6650000, // ms since the start of the process
// timestamp: 864000000 // ms since epoch
// }
cb()
})
// It supports also multiple pids
pidusage([727, 1234], function (err, stats) {
console.log(stats)
// => {
// 727: {
// cpu: 10.0, // percentage (from 0 to 100*vcore)
// memory: 357306368, // bytes
// ppid: 312, // PPID
// pid: 727, // PID
// ctime: 867000, // ms user + system time
// elapsed: 6650000, // ms since the start of the process
// timestamp: 864000000 // ms since epoch
// },
// 1234: {
// cpu: 0.1, // percentage (from 0 to 100*vcore)
// memory: 3846144, // bytes
// ppid: 727, // PPID
// pid: 1234, // PID
// ctime: 0, // ms user + system time
// elapsed: 20000, // ms since the start of the process
// timestamp: 864000000 // ms since epoch
// }
// }
})
// If no callback is given it returns a promise instead
const stats = await pidusage(process.pid)
console.log(stats)
// => {
// cpu: 10.0, // percentage (from 0 to 100*vcore)
// memory: 357306368, // bytes
// ppid: 312, // PPID
// pid: 727, // PID
// ctime: 867000, // ms user + system time
// elapsed: 6650000, // ms since the start of the process
// timestamp: 864000000 // ms since epoch
// }
// Avoid using setInterval as they could overlap with asynchronous processing
function compute(cb) {
pidusage(process.pid, function (err, stats) {
console.log(stats)
// => {
// cpu: 10.0, // percentage (from 0 to 100*vcore)
// memory: 357306368, // bytes
// ppid: 312, // PPID
// pid: 727, // PID
// ctime: 867000, // ms user + system time
// elapsed: 6650000, // ms since the start of the process
// timestamp: 864000000 // ms since epoch
// }
cb()
})
}
function interval(time) {
setTimeout(function() {
compute(function() {
interval(time)
})
}, time)
}
// Compute statistics every second:
interval(1000)
// Above example using async/await
const compute = async () => {
const stats = await pidusage(process.pid)
// do something
}
// Compute statistics every second:
const interval = async (time) => {
setTimeout(async () => {
await compute()
interval(time)
}, time)
}
interval(1000)
```
## Compatibility
| Property | Linux | FreeBSD | NetBSD | SunOS | macOS | Win | AIX | Alpine
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| `cpu` | ✅ | ❓ | ❓ | ❓ | ✅ | ℹ️ | ❓ | ✅ |
| `memory` | ✅ | ❓ | ❓ | ❓ | ✅ | ✅ | ❓ | ✅ |
| `pid` | ✅ | ❓ | ❓ | ❓ | ✅ | ✅ | ❓ | ✅ |
| `ctime` | ✅ | ❓ | ❓ | ❓ | ✅ | ✅ | ❓ | ✅ |
| `elapsed` | ✅ | ❓ | ❓ | ❓ | ✅ | ✅ | ❓ | ✅ |
| `timestamp` | ✅ | ❓ | ❓ | ❓ | ✅ | ✅ | ❓ | ✅ |
✅ = Working
ℹ️ = Not Accurate
❓ = Should Work
❌ = Not Working
Please if your platform is not supported or if you have reported wrong readings
[file an issue][new issue].
By default, pidusage will use `procfile` parsing on most unix systems. If you want to use `ps` instead use the `usePs` option:
```
pidusage(pid, {usePs: true})
```
## API
<a name="pidusage"></a>
### pidusage(pids, [options = {}], [callback]) ⇒ <code>[Promise.<Object>]</code>
Get pid informations.
**Kind**: global function
**Returns**: <code>Promise.<Object></code> - Only when the callback is not provided.
**Access**: public
| Param | Type | Description |
| --- | --- | --- |
| pids | <code>Number</code> \| <code>Array.<Number></code> \| <code>String</code> \| <code>Array.<String></code> | A pid or a list of pids. |
| [callback] | <code>function</code> | Called when the statistics are ready. If not provided a promise is returned instead. |
### pidusage.clear()
If needed this function can be used to delete all in-memory metrics and clear the event loop. This is not necessary before exiting as the interval we're registring does not hold up the event loop.
## Related
- [pidusage-tree][gh:pidusage-tree] -
Compute a pidusage tree
## Authors
- **Antoine Bluchet** - [soyuka][github:soyuka]
- **Simone Primarosa** - [simonepri][github:simonepri]
See also the list of [contributors][contributors] who participated in this project.
## License
This project is licensed under the MIT License - see the [LICENSE][license] file for details.
<!-- Links -->
[new issue]: https://github.com/soyuka/pidusage/issues/new
[license]: https://github.com/soyuka/pidusage/tree/master/LICENSE
[contributors]: https://github.com/soyuka/pidusage/contributors
[github:soyuka]: https://github.com/soyuka
[github:simonepri]: https://github.com/simonepri
[gh:pidusage-tree]: https://github.com/soyuka/pidusage-tree
[node:cpuUsage]: https://nodejs.org/api/process.html#process_process_cpuusage_previousvalue
[node:memUsage]: https://nodejs.org/api/process.html#process_process_memoryusage
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# prelude.ls [](https://travis-ci.org/gkz/prelude-ls)
is a functionally oriented utility library. It is powerful and flexible. Almost all of its functions are curried. It is written in, and is the recommended base library for, <a href="http://livescript.net">LiveScript</a>.
See **[the prelude.ls site](http://preludels.com)** for examples, a reference, and more.
You can install via npm `npm install prelude-ls`
### Development
`make test` to test
`make build` to build `lib` from `src`
`make build-browser` to build browser versions
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# core-util-is
The `util.is*` functions introduced in Node v0.12.
## Servify
Microservices the simplest way conceivable.
## Usage
### Create a microservice:
```javascript
const servify = require("servify");
// The service state
let count = 0;
// Starts a microservice with 3 API methods
servify.api(3000, {
// Squares a number
square: (x) => x * x,
// Concats two arrays
concat: (a, b) => a.concat(b),
// Increments and returns the counter
count: () => count++
}).then(() => console.log("servified port 3000"))
```
### Call a microservice from code:
```javascript
const servify = require("servify");
// Builds the API interface from an URL
const api = servify.at("http://localhost:3000");
// Calls API methods like normal lib functions
api.square(2)
.then(x => console.log(x));
api.concat([1,2], [3,4])
.then(arr => console.log(arr));
api.count()
.then(i => console.log(i));
```
### Call a microservice from the browser / request:
```javascript
Just access the url followed by a function call:
http://localhost:3000/square(2)
http://localhost:3000/concat([1,2], [3,4])
http://localhost:3000/count()
```
## Support
This requires ES6 Proxy support, so you need node.js 6 and up. Proxies cannot be polyfilled in earlier versions.
## Why
When all you want is to create a microservice, [Express.js](http://expressjs.com) becomes annoyingly verbose. You have to worry about things like serializing/deserializing JSON, chosing how to format query/param inputs, picking a XHR lib on the client and so on. Servify is a ridiculously thin (50 LOC) lib that just standardizes that boring stuff. To create a microservice, all you need is an object of functions specifying your API. To interact with a service, all you need is its URL. You can then call its functions exactly like you would call a normal lib (except it returns a Promise, obviously).
TweetNaCl.js
============
Port of [TweetNaCl](http://tweetnacl.cr.yp.to) / [NaCl](http://nacl.cr.yp.to/)
to JavaScript for modern browsers and Node.js. Public domain.
[
](https://travis-ci.org/dchest/tweetnacl-js)
Demo: <https://tweetnacl.js.org>
**:warning: The library is stable and API is frozen, however it has not been
independently reviewed. If you can help reviewing it, please [contact
me](mailto:[email protected]).**
Documentation
=============
* [Overview](#overview)
* [Installation](#installation)
* [Usage](#usage)
* [Public-key authenticated encryption (box)](#public-key-authenticated-encryption-box)
* [Secret-key authenticated encryption (secretbox)](#secret-key-authenticated-encryption-secretbox)
* [Scalar multiplication](#scalar-multiplication)
* [Signatures](#signatures)
* [Hashing](#hashing)
* [Random bytes generation](#random-bytes-generation)
* [Constant-time comparison](#constant-time-comparison)
* [System requirements](#system-requirements)
* [Development and testing](#development-and-testing)
* [Benchmarks](#benchmarks)
* [Contributors](#contributors)
* [Who uses it](#who-uses-it)
Overview
--------
The primary goal of this project is to produce a translation of TweetNaCl to
JavaScript which is as close as possible to the original C implementation, plus
a thin layer of idiomatic high-level API on top of it.
There are two versions, you can use either of them:
* `nacl.js` is the port of TweetNaCl with minimum differences from the
original + high-level API.
* `nacl-fast.js` is like `nacl.js`, but with some functions replaced with
faster versions.
Installation
------------
You can install TweetNaCl.js via a package manager:
[Bower](http://bower.io):
$ bower install tweetnacl
[NPM](https://www.npmjs.org/):
$ npm install tweetnacl
or [download source code](https://github.com/dchest/tweetnacl-js/releases).
Usage
-----
All API functions accept and return bytes as `Uint8Array`s. If you need to
encode or decode strings, use functions from
<https://github.com/dchest/tweetnacl-util-js> or one of the more robust codec
packages.
In Node.js v4 and later `Buffer` objects are backed by `Uint8Array`s, so you
can freely pass them to TweetNaCl.js functions as arguments. The returned
objects are still `Uint8Array`s, so if you need `Buffer`s, you'll have to
convert them manually; make sure to convert using copying: `new Buffer(array)`,
instead of sharing: `new Buffer(array.buffer)`, because some functions return
subarrays of their buffers.
### Public-key authenticated encryption (box)
Implements *curve25519-xsalsa20-poly1305*.
#### nacl.box.keyPair()
Generates a new random key pair for box and returns it as an object with
`publicKey` and `secretKey` members:
{
publicKey: ..., // Uint8Array with 32-byte public key
secretKey: ... // Uint8Array with 32-byte secret key
}
#### nacl.box.keyPair.fromSecretKey(secretKey)
Returns a key pair for box with public key corresponding to the given secret
key.
#### nacl.box(message, nonce, theirPublicKey, mySecretKey)
Encrypt and authenticates message using peer's public key, our secret key, and
the given nonce, which must be unique for each distinct message for a key pair.
Returns an encrypted and authenticated message, which is
`nacl.box.overheadLength` longer than the original message.
#### nacl.box.open(box, nonce, theirPublicKey, mySecretKey)
Authenticates and decrypts the given box with peer's public key, our secret
key, and the given nonce.
Returns the original message, or `false` if authentication fails.
#### nacl.box.before(theirPublicKey, mySecretKey)
Returns a precomputed shared key which can be used in `nacl.box.after` and
`nacl.box.open.after`.
#### nacl.box.after(message, nonce, sharedKey)
Same as `nacl.box`, but uses a shared key precomputed with `nacl.box.before`.
#### nacl.box.open.after(box, nonce, sharedKey)
Same as `nacl.box.open`, but uses a shared key precomputed with `nacl.box.before`.
#### nacl.box.publicKeyLength = 32
Length of public key in bytes.
#### nacl.box.secretKeyLength = 32
Length of secret key in bytes.
#### nacl.box.sharedKeyLength = 32
Length of precomputed shared key in bytes.
#### nacl.box.nonceLength = 24
Length of nonce in bytes.
#### nacl.box.overheadLength = 16
Length of overhead added to box compared to original message.
### Secret-key authenticated encryption (secretbox)
Implements *xsalsa20-poly1305*.
#### nacl.secretbox(message, nonce, key)
Encrypt and authenticates message using the key and the nonce. The nonce must
be unique for each distinct message for this key.
Returns an encrypted and authenticated message, which is
`nacl.secretbox.overheadLength` longer than the original message.
#### nacl.secretbox.open(box, nonce, key)
Authenticates and decrypts the given secret box using the key and the nonce.
Returns the original message, or `false` if authentication fails.
#### nacl.secretbox.keyLength = 32
Length of key in bytes.
#### nacl.secretbox.nonceLength = 24
Length of nonce in bytes.
#### nacl.secretbox.overheadLength = 16
Length of overhead added to secret box compared to original message.
### Scalar multiplication
Implements *curve25519*.
#### nacl.scalarMult(n, p)
Multiplies an integer `n` by a group element `p` and returns the resulting
group element.
#### nacl.scalarMult.base(n)
Multiplies an integer `n` by a standard group element and returns the resulting
group element.
#### nacl.scalarMult.scalarLength = 32
Length of scalar in bytes.
#### nacl.scalarMult.groupElementLength = 32
Length of group element in bytes.
### Signatures
Implements [ed25519](http://ed25519.cr.yp.to).
#### nacl.sign.keyPair()
Generates new random key pair for signing and returns it as an object with
`publicKey` and `secretKey` members:
{
publicKey: ..., // Uint8Array with 32-byte public key
secretKey: ... // Uint8Array with 64-byte secret key
}
#### nacl.sign.keyPair.fromSecretKey(secretKey)
Returns a signing key pair with public key corresponding to the given
64-byte secret key. The secret key must have been generated by
`nacl.sign.keyPair` or `nacl.sign.keyPair.fromSeed`.
#### nacl.sign.keyPair.fromSeed(seed)
Returns a new signing key pair generated deterministically from a 32-byte seed.
The seed must contain enough entropy to be secure. This method is not
recommended for general use: instead, use `nacl.sign.keyPair` to generate a new
key pair from a random seed.
#### nacl.sign(message, secretKey)
Signs the message using the secret key and returns a signed message.
#### nacl.sign.open(signedMessage, publicKey)
Verifies the signed message and returns the message without signature.
Returns `null` if verification failed.
#### nacl.sign.detached(message, secretKey)
Signs the message using the secret key and returns a signature.
#### nacl.sign.detached.verify(message, signature, publicKey)
Verifies the signature for the message and returns `true` if verification
succeeded or `false` if it failed.
#### nacl.sign.publicKeyLength = 32
Length of signing public key in bytes.
#### nacl.sign.secretKeyLength = 64
Length of signing secret key in bytes.
#### nacl.sign.seedLength = 32
Length of seed for `nacl.sign.keyPair.fromSeed` in bytes.
#### nacl.sign.signatureLength = 64
Length of signature in bytes.
### Hashing
Implements *SHA-512*.
#### nacl.hash(message)
Returns SHA-512 hash of the message.
#### nacl.hash.hashLength = 64
Length of hash in bytes.
### Random bytes generation
#### nacl.randomBytes(length)
Returns a `Uint8Array` of the given length containing random bytes of
cryptographic quality.
**Implementation note**
TweetNaCl.js uses the following methods to generate random bytes,
depending on the platform it runs on:
* `window.crypto.getRandomValues` (WebCrypto standard)
* `window.msCrypto.getRandomValues` (Internet Explorer 11)
* `crypto.randomBytes` (Node.js)
If the platform doesn't provide a suitable PRNG, the following functions,
which require random numbers, will throw exception:
* `nacl.randomBytes`
* `nacl.box.keyPair`
* `nacl.sign.keyPair`
Other functions are deterministic and will continue working.
If a platform you are targeting doesn't implement secure random number
generator, but you somehow have a cryptographically-strong source of entropy
(not `Math.random`!), and you know what you are doing, you can plug it into
TweetNaCl.js like this:
nacl.setPRNG(function(x, n) {
// ... copy n random bytes into x ...
});
Note that `nacl.setPRNG` *completely replaces* internal random byte generator
with the one provided.
### Constant-time comparison
#### nacl.verify(x, y)
Compares `x` and `y` in constant time and returns `true` if their lengths are
non-zero and equal, and their contents are equal.
Returns `false` if either of the arguments has zero length, or arguments have
different lengths, or their contents differ.
System requirements
-------------------
TweetNaCl.js supports modern browsers that have a cryptographically secure
pseudorandom number generator and typed arrays, including the latest versions
of:
* Chrome
* Firefox
* Safari (Mac, iOS)
* Internet Explorer 11
Other systems:
* Node.js
Development and testing
------------------------
Install NPM modules needed for development:
$ npm install
To build minified versions:
$ npm run build
Tests use minified version, so make sure to rebuild it every time you change
`nacl.js` or `nacl-fast.js`.
### Testing
To run tests in Node.js:
$ npm run test-node
By default all tests described here work on `nacl.min.js`. To test other
versions, set environment variable `NACL_SRC` to the file name you want to test.
For example, the following command will test fast minified version:
$ NACL_SRC=nacl-fast.min.js npm run test-node
To run full suite of tests in Node.js, including comparing outputs of
JavaScript port to outputs of the original C version:
$ npm run test-node-all
To prepare tests for browsers:
$ npm run build-test-browser
and then open `test/browser/test.html` (or `test/browser/test-fast.html`) to
run them.
To run headless browser tests with `tape-run` (powered by Electron):
$ npm run test-browser
(If you get `Error: spawn ENOENT`, install *xvfb*: `sudo apt-get install xvfb`.)
To run tests in both Node and Electron:
$ npm test
### Benchmarking
To run benchmarks in Node.js:
$ npm run bench
$ NACL_SRC=nacl-fast.min.js npm run bench
To run benchmarks in a browser, open `test/benchmark/bench.html` (or
`test/benchmark/bench-fast.html`).
Benchmarks
----------
For reference, here are benchmarks from MacBook Pro (Retina, 13-inch, Mid 2014)
laptop with 2.6 GHz Intel Core i5 CPU (Intel) in Chrome 53/OS X and Xiaomi Redmi
Note 3 smartphone with 1.8 GHz Qualcomm Snapdragon 650 64-bit CPU (ARM) in
Chrome 52/Android:
| | nacl.js Intel | nacl-fast.js Intel | nacl.js ARM | nacl-fast.js ARM |
| ------------- |:-------------:|:-------------------:|:-------------:|:-----------------:|
| salsa20 | 1.3 MB/s | 128 MB/s | 0.4 MB/s | 43 MB/s |
| poly1305 | 13 MB/s | 171 MB/s | 4 MB/s | 52 MB/s |
| hash | 4 MB/s | 34 MB/s | 0.9 MB/s | 12 MB/s |
| secretbox 1K | 1113 op/s | 57583 op/s | 334 op/s | 14227 op/s |
| box 1K | 145 op/s | 718 op/s | 37 op/s | 368 op/s |
| scalarMult | 171 op/s | 733 op/s | 56 op/s | 380 op/s |
| sign | 77 op/s | 200 op/s | 20 op/s | 61 op/s |
| sign.open | 39 op/s | 102 op/s | 11 op/s | 31 op/s |
(You can run benchmarks on your devices by clicking on the links at the bottom
of the [home page](https://tweetnacl.js.org)).
In short, with *nacl-fast.js* and 1024-byte messages you can expect to encrypt and
authenticate more than 57000 messages per second on a typical laptop or more than
14000 messages per second on a $170 smartphone, sign about 200 and verify 100
messages per second on a laptop or 60 and 30 messages per second on a smartphone,
per CPU core (with Web Workers you can do these operations in parallel),
which is good enough for most applications.
Contributors
------------
See AUTHORS.md file.
Third-party libraries based on TweetNaCl.js
-------------------------------------------
* [forward-secrecy](https://github.com/alax/forward-secrecy) — Axolotl ratchet implementation
* [nacl-stream](https://github.com/dchest/nacl-stream-js) - streaming encryption
* [tweetnacl-auth-js](https://github.com/dchest/tweetnacl-auth-js) — implementation of [`crypto_auth`](http://nacl.cr.yp.to/auth.html)
* [chloride](https://github.com/dominictarr/chloride) - unified API for various NaCl modules
Who uses it
-----------
Some notable users of TweetNaCl.js:
* [miniLock](http://minilock.io/)
* [Stellar](https://www.stellar.org/)
util-deprecate
==============
### The Node.js `util.deprecate()` function with browser support
In Node.js, this module simply re-exports the `util.deprecate()` function.
In the web browser (i.e. via browserify), a browser-specific implementation
of the `util.deprecate()` function is used.
## API
A `deprecate()` function is the only thing exposed by this module.
``` javascript
// setup:
exports.foo = deprecate(foo, 'foo() is deprecated, use bar() instead');
// users see:
foo();
// foo() is deprecated, use bar() instead
foo();
foo();
```
## License
(The MIT License)
Copyright (c) 2014 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person
obtaining a copy of this software and associated documentation
files (the "Software"), to deal in the Software without
restriction, including without limitation the rights to use,
copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the
Software is furnished to do so, subject to the following
conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES
OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
OTHER DEALINGS IN THE SOFTWARE.
#object-keys <sup>[![Version Badge][2]][1]</sup>
[![Build Status][3]][4] [![dependency status][5]][6]
[![browser support][7]][8]
An Object.keys shim. Uses Object.keys if available.
## Example
```js
var keys = require('object-keys');
var assert = require('assert');
var obj = {
a: true,
b: true,
c: true
};
assert.equal(keys(obj), ['a', 'b', 'c']);
```
## Source
Implementation taken directly from [es5-shim]([9]), with modifications, including from [lodash]([10]).
## Tests
Simply clone the repo, `npm install`, and run `npm test`
[1]: https://npmjs.org/package/object-keys
[2]: http://vb.teelaun.ch/ljharb/object-keys.svg
[3]: https://travis-ci.org/ljharb/object-keys.png
[4]: https://travis-ci.org/ljharb/object-keys
[5]: https://david-dm.org/ljharb/object-keys.png
[6]: https://david-dm.org/ljharb/object-keys
[7]: https://ci.testling.com/ljharb/object-keys.png
[8]: https://ci.testling.com/ljharb/object-keys
[9]: https://github.com/kriskowal/es5-shim/blob/master/es5-shim.js#L542-589
[10]: https://github.com/bestiejs/lodash
# eth-util-lite
This is a low-dependency utility for Ethereum. It replaces a small subset of the [ethereumjs-util](https://github.com/ethereumjs/ethereumjs-util) and [ethjs-util](https://github.com/ethjs/ethjs-util) APIs.
Ethereum to Tezos trustless, fully decentralized, bidirectional bridge
See https://github.com/tezos/tezos-bridge for Installation, Usage, Documentation and Examples.
base64-js
=========
`base64-js` does basic base64 encoding/decoding in pure JS.
[](http://travis-ci.org/beatgammit/base64-js)
Many browsers already have base64 encoding/decoding functionality, but it is for text data, not all-purpose binary data.
Sometimes encoding/decoding binary data in the browser is useful, and that is what this module does.
## install
With [npm](https://npmjs.org) do:
`npm install base64-js` and `var base64js = require('base64-js')`
For use in web browsers do:
`<script src="base64js.min.js"></script>`
## methods
`base64js` has three exposed functions, `byteLength`, `toByteArray` and `fromByteArray`, which both take a single argument.
* `byteLength` - Takes a base64 string and returns length of byte array
* `toByteArray` - Takes a base64 string and returns a byte array
* `fromByteArray` - Takes a byte array and returns a base64 string
## license
MIT
aws4
----
[](https://travis-ci.org/github/mhart/aws4)
A small utility to sign vanilla Node.js http(s) request options using Amazon's
[AWS Signature Version 4](https://docs.aws.amazon.com/general/latest/gr/signature-version-4.html).
If you want to sign and send AWS requests in a modern browser, or an environment like [Cloudflare Workers](https://developers.cloudflare.com/workers/), then check out [aws4fetch](https://github.com/mhart/aws4fetch) – otherwise you can also bundle this library for use [in older browsers](./browser).
The only AWS service that *doesn't* support v4 as of 2020-05-22 is
[SimpleDB](https://docs.aws.amazon.com/AmazonSimpleDB/latest/DeveloperGuide/SDB_API.html)
(it only supports [AWS Signature Version 2](https://github.com/mhart/aws2)).
It also provides defaults for a number of core AWS headers and
request parameters, making it very easy to query AWS services, or
build out a fully-featured AWS library.
Example
-------
```javascript
var https = require('https')
var aws4 = require('aws4')
// to illustrate usage, we'll create a utility function to request and pipe to stdout
function request(opts) { https.request(opts, function(res) { res.pipe(process.stdout) }).end(opts.body || '') }
// aws4 will sign an options object as you'd pass to http.request, with an AWS service and region
var opts = { host: 'my-bucket.s3.us-west-1.amazonaws.com', path: '/my-object', service: 's3', region: 'us-west-1' }
// aws4.sign() will sign and modify these options, ready to pass to http.request
aws4.sign(opts, { accessKeyId: '', secretAccessKey: '' })
// or it can get credentials from process.env.AWS_ACCESS_KEY_ID, etc
aws4.sign(opts)
// for most AWS services, aws4 can figure out the service and region if you pass a host
opts = { host: 'my-bucket.s3.us-west-1.amazonaws.com', path: '/my-object' }
// usually it will add/modify request headers, but you can also sign the query:
opts = { host: 'my-bucket.s3.amazonaws.com', path: '/?X-Amz-Expires=12345', signQuery: true }
// and for services with simple hosts, aws4 can infer the host from service and region:
opts = { service: 'sqs', region: 'us-east-1', path: '/?Action=ListQueues' }
// and if you're using us-east-1, it's the default:
opts = { service: 'sqs', path: '/?Action=ListQueues' }
aws4.sign(opts)
console.log(opts)
/*
{
host: 'sqs.us-east-1.amazonaws.com',
path: '/?Action=ListQueues',
headers: {
Host: 'sqs.us-east-1.amazonaws.com',
'X-Amz-Date': '20121226T061030Z',
Authorization: 'AWS4-HMAC-SHA256 Credential=ABCDEF/20121226/us-east-1/sqs/aws4_request, ...'
}
}
*/
// we can now use this to query AWS
request(opts)
/*
<?xml version="1.0"?>
<ListQueuesResponse xmlns="https://queue.amazonaws.com/doc/2012-11-05/">
...
*/
// aws4 can infer the HTTP method if a body is passed in
// method will be POST and Content-Type: 'application/x-www-form-urlencoded; charset=utf-8'
request(aws4.sign({ service: 'iam', body: 'Action=ListGroups&Version=2010-05-08' }))
/*
<ListGroupsResponse xmlns="https://iam.amazonaws.com/doc/2010-05-08/">
...
*/
// you can specify any custom option or header as per usual
request(aws4.sign({
service: 'dynamodb',
region: 'ap-southeast-2',
method: 'POST',
path: '/',
headers: {
'Content-Type': 'application/x-amz-json-1.0',
'X-Amz-Target': 'DynamoDB_20120810.ListTables'
},
body: '{}'
}))
/*
{"TableNames":[]}
...
*/
// The raw RequestSigner can be used to generate CodeCommit Git passwords
var signer = new aws4.RequestSigner({
service: 'codecommit',
host: 'git-codecommit.us-east-1.amazonaws.com',
method: 'GIT',
path: '/v1/repos/MyAwesomeRepo',
})
var password = signer.getDateTime() + 'Z' + signer.signature()
// see example.js for examples with other services
```
API
---
### aws4.sign(requestOptions, [credentials])
Calculates and populates any necessary AWS headers and/or request
options on `requestOptions`. Returns `requestOptions` as a convenience for chaining.
`requestOptions` is an object holding the same options that the Node.js
[http.request](https://nodejs.org/docs/latest/api/http.html#http_http_request_options_callback)
function takes.
The following properties of `requestOptions` are used in the signing or
populated if they don't already exist:
- `hostname` or `host` (will try to be determined from `service` and `region` if not given)
- `method` (will use `'GET'` if not given or `'POST'` if there is a `body`)
- `path` (will use `'/'` if not given)
- `body` (will use `''` if not given)
- `service` (will try to be calculated from `hostname` or `host` if not given)
- `region` (will try to be calculated from `hostname` or `host` or use `'us-east-1'` if not given)
- `signQuery` (to sign the query instead of adding an `Authorization` header, defaults to false)
- `headers['Host']` (will use `hostname` or `host` or be calculated if not given)
- `headers['Content-Type']` (will use `'application/x-www-form-urlencoded; charset=utf-8'`
if not given and there is a `body`)
- `headers['Date']` (used to calculate the signature date if given, otherwise `new Date` is used)
Your AWS credentials (which can be found in your
[AWS console](https://portal.aws.amazon.com/gp/aws/securityCredentials))
can be specified in one of two ways:
- As the second argument, like this:
```javascript
aws4.sign(requestOptions, {
secretAccessKey: "<your-secret-access-key>",
accessKeyId: "<your-access-key-id>",
sessionToken: "<your-session-token>"
})
```
- From `process.env`, such as this:
```
export AWS_ACCESS_KEY_ID="<your-access-key-id>"
export AWS_SECRET_ACCESS_KEY="<your-secret-access-key>"
export AWS_SESSION_TOKEN="<your-session-token>"
```
(will also use `AWS_ACCESS_KEY` and `AWS_SECRET_KEY` if available)
The `sessionToken` property and `AWS_SESSION_TOKEN` environment variable are optional for signing
with [IAM STS temporary credentials](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_temp_use-resources.html).
Installation
------------
With [npm](https://www.npmjs.com/) do:
```
npm install aws4
```
Can also be used [in the browser](./browser).
Thanks
------
Thanks to [@jed](https://github.com/jed) for his
[dynamo-client](https://github.com/jed/dynamo-client) lib where I first
committed and subsequently extracted this code.
Also thanks to the
[official Node.js AWS SDK](https://github.com/aws/aws-sdk-js) for giving
me a start on implementing the v4 signature.
# abstract-leveldown
> An abstract prototype matching the [`leveldown`](https://github.com/level/leveldown/) API. Useful for extending [`levelup`](https://github.com/level/levelup) functionality by providing a replacement to `leveldown`.
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/abstract-leveldown)

[](http://travis-ci.org/Level/abstract-leveldown)
[](https://david-dm.org/level/abstract-leveldown)
[](https://standardjs.com)
[](https://www.npmjs.com/package/abstract-leveldown)
`abstract-leveldown` provides a simple, operational *noop* base prototype that's ready for extending. By default, all operations have sensible "noops" (operations that essentially do nothing). For example, simple operations such as `.open(callback)` and `.close(callback)` will simply invoke the callback (on a *next tick*). More complex operations perform sensible actions, for example: `.get(key, callback)` will always return a `'NotFound'` `Error` on the callback.
You add functionality by implementing the underscore versions of the operations. For example, to implement a `put()` operation you add a `_put()` method to your object. Each of these underscore methods override the default *noop* operations and are always provided with **consistent arguments**, regardless of what is passed in by the client.
Additionally, all methods provide argument checking and sensible defaults for optional arguments. All bad-argument errors are compatible with `leveldown` (they pass the `leveldown` method arguments tests). For example, if you call `.open()` without a callback argument you'll get an `Error('open() requires a callback argument')`. Where optional arguments are involved, your underscore methods will receive sensible defaults. A `.get(key, callback)` will pass through to a `._get(key, options, callback)` where the `options` argument is an empty object.
**If you are upgrading:** please see [UPGRADING.md](UPGRADING.md).
## Example
A simplistic in-memory `leveldown` replacement
```js
var util = require('util')
var AbstractLevelDOWN = require('./').AbstractLevelDOWN
// constructor, passes through the 'location' argument to the AbstractLevelDOWN constructor
function FakeLevelDOWN (location) {
AbstractLevelDOWN.call(this, location)
}
// our new prototype inherits from AbstractLevelDOWN
util.inherits(FakeLevelDOWN, AbstractLevelDOWN)
// implement some methods
FakeLevelDOWN.prototype._open = function (options, callback) {
// initialise a memory storage object
this._store = {}
// optional use of nextTick to be a nice async citizen
process.nextTick(function () { callback(null, this) }.bind(this))
}
FakeLevelDOWN.prototype._put = function (key, value, options, callback) {
key = '_' + key // safety, to avoid key='__proto__'-type skullduggery
this._store[key] = value
process.nextTick(callback)
}
FakeLevelDOWN.prototype._get = function (key, options, callback) {
var value = this._store['_' + key]
if (value === undefined) {
// 'NotFound' error, consistent with LevelDOWN API
return process.nextTick(function () { callback(new Error('NotFound')) })
}
process.nextTick(function () {
callback(null, value)
})
}
FakeLevelDOWN.prototype._del = function (key, options, callback) {
delete this._store['_' + key]
process.nextTick(callback)
}
// Now use it with levelup
var levelup = require('levelup')
var db = levelup(new FakeLevelDOWN('/who/cares'))
db.put('foo', 'bar', function (err) {
if (err) throw err
db.get('foo', function (err, value) {
if (err) throw err
console.log('Got foo =', value)
})
})
```
See [`memdown`](https://github.com/Level/memdown/) if you are looking for a complete in-memory replacement for `leveldown`.
## Browser support
[](https://saucelabs.com/u/abstract-leveldown)
## Extensible API
Remember that each of these methods, if you implement them, will receive exactly the number and order of arguments described. Optional arguments will be converted to sensible defaults.
### `AbstractLevelDOWN(location)`
### `AbstractLevelDOWN#status`
An `AbstractLevelDOWN` based database can be in one of the following states:
* `'new'` - newly created, not opened or closed
* `'opening'` - waiting for the database to be opened
* `'open'` - successfully opened the database, available for use
* `'closing'` - waiting for the database to be closed
* `'closed'` - database has been successfully closed, should not be used
### `AbstractLevelDOWN#_open(options, callback)`
### `AbstractLevelDOWN#_close(callback)`
### `AbstractLevelDOWN#_get(key, options, callback)`
### `AbstractLevelDOWN#_put(key, value, options, callback)`
### `AbstractLevelDOWN#_del(key, options, callback)`
### `AbstractLevelDOWN#_batch(array, options, callback)`
If `batch()` is called without arguments or with only an options object then it should return a `Batch` object with chainable methods. Otherwise it will invoke a classic batch operation.
### `AbstractLevelDOWN#_chainedBatch()`
By default a `batch()` operation without arguments returns a blank `AbstractChainedBatch` object. The prototype is available on the main exports for you to extend. If you want to implement chainable batch operations then you should extend the `AbstractChaindBatch` and return your object in the `_chainedBatch()` method.
### `AbstractLevelDOWN#_serializeKey(key)`
### `AbstractLevelDOWN#_serializeValue(value)`
### `AbstractLevelDOWN#_iterator(options)`
By default an `iterator()` operation returns a blank `AbstractIterator` object. The prototype is available on the main exports for you to extend. If you want to implement iterator operations then you should extend the `AbstractIterator` and return your object in the `_iterator(options)` method.
The `iterator()` operation accepts the following range options:
* `gt`
* `gte`
* `lt`
* `lte`
* `start` (legacy)
* `end` (legacy)
A range option that is either an empty buffer, an empty string or `null` will be ignored.
`AbstractIterator` implements the basic state management found in LevelDOWN. It keeps track of when a `next()` is in progress and when an `end()` has been called so it doesn't allow concurrent `next()` calls, it does allow `end()` while a `next()` is in progress and it doesn't allow either `next()` or `end()` after `end()` has been called.
### `AbstractIterator(db)`
Provided with the current instance of `AbstractLevelDOWN` by default.
### `AbstractIterator#_next(callback)`
### `AbstractIterator#_end(callback)`
### `AbstractChainedBatch`
Provided with the current instance of `AbstractLevelDOWN` by default.
### `AbstractChainedBatch#_put(key, value)`
### `AbstractChainedBatch#_del(key)`
### `AbstractChainedBatch#_clear()`
### `AbstractChainedBatch#_write(options, callback)`
### `AbstractChainedBatch#_serializeKey(key)`
### `AbstractChainedBatch#_serializeValue(value)`
<a name="contributing"></a>
## Contributing
`abstract-leveldown` is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [contribution guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
## Big Thanks
Cross-browser Testing Platform and Open Source ♥ Provided by [Sauce Labs](https://saucelabs.com).
[](https://saucelabs.com)
<a name="license"></a>
## License
Copyright © 2013-2018 `abstract-leveldown` [contributors](https://github.com/level/community#contributors).
`abstract-leveldown` is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included `LICENSE.md` file for more details.
[level-badge]: http://leveldb.org/img/badge.svg
# cacheable-request
> Wrap native HTTP requests with RFC compliant cache support
[](https://travis-ci.org/lukechilds/cacheable-request)
[](https://coveralls.io/github/lukechilds/cacheable-request?branch=master)
[](https://www.npmjs.com/package/cacheable-request)
[](https://www.npmjs.com/package/cacheable-request)
[RFC 7234](http://httpwg.org/specs/rfc7234.html) compliant HTTP caching for native Node.js HTTP/HTTPS requests. Caching works out of the box in memory or is easily pluggable with a wide range of storage adapters.
**Note:** This is a low level wrapper around the core HTTP modules, it's not a high level request library.
## Features
- Only stores cacheable responses as defined by RFC 7234
- Fresh cache entries are served directly from cache
- Stale cache entries are revalidated with `If-None-Match`/`If-Modified-Since` headers
- 304 responses from revalidation requests use cached body
- Updates `Age` header on cached responses
- Can completely bypass cache on a per request basis
- In memory cache by default
- Official support for Redis, MongoDB, SQLite, PostgreSQL and MySQL storage adapters
- Easily plug in your own or third-party storage adapters
- If DB connection fails, cache is automatically bypassed ([disabled by default](#optsautomaticfailover))
- Adds cache support to any existing HTTP code with minimal changes
- Uses [http-cache-semantics](https://github.com/pornel/http-cache-semantics) internally for HTTP RFC 7234 compliance
## Install
```shell
npm install cacheable-request
```
## Usage
```js
const http = require('http');
const CacheableRequest = require('cacheable-request');
// Then instead of
const req = http.request('http://example.com', cb);
req.end();
// You can do
const cacheableRequest = new CacheableRequest(http.request);
const cacheReq = cacheableRequest('http://example.com', cb);
cacheReq.on('request', req => req.end());
// Future requests to 'example.com' will be returned from cache if still valid
// You pass in any other http.request API compatible method to be wrapped with cache support:
const cacheableRequest = new CacheableRequest(https.request);
const cacheableRequest = new CacheableRequest(electron.net);
```
## Storage Adapters
`cacheable-request` uses [Keyv](https://github.com/lukechilds/keyv) to support a wide range of storage adapters.
For example, to use Redis as a cache backend, you just need to install the official Redis Keyv storage adapter:
```
npm install @keyv/redis
```
And then you can pass `CacheableRequest` your connection string:
```js
const cacheableRequest = new CacheableRequest(http.request, 'redis://user:pass@localhost:6379');
```
[View all official Keyv storage adapters.](https://github.com/lukechilds/keyv#official-storage-adapters)
Keyv also supports anything that follows the Map API so it's easy to write your own storage adapter or use a third-party solution.
e.g The following are all valid storage adapters
```js
const storageAdapter = new Map();
// or
const storageAdapter = require('./my-storage-adapter');
// or
const QuickLRU = require('quick-lru');
const storageAdapter = new QuickLRU({ maxSize: 1000 });
const cacheableRequest = new CacheableRequest(http.request, storageAdapter);
```
View the [Keyv docs](https://github.com/lukechilds/keyv) for more information on how to use storage adapters.
## API
### new cacheableRequest(request, [storageAdapter])
Returns the provided request function wrapped with cache support.
#### request
Type: `function`
Request function to wrap with cache support. Should be [`http.request`](https://nodejs.org/api/http.html#http_http_request_options_callback) or a similar API compatible request function.
#### storageAdapter
Type: `Keyv storage adapter`<br>
Default: `new Map()`
A [Keyv](https://github.com/lukechilds/keyv) storage adapter instance, or connection string if using with an official Keyv storage adapter.
### Instance
#### cacheableRequest(opts, [cb])
Returns an event emitter.
##### opts
Type: `object`, `string`
- Any of the default request functions options.
- Any [`http-cache-semantics`](https://github.com/kornelski/http-cache-semantics#constructor-options) options.
- Any of the following:
###### opts.cache
Type: `boolean`<br>
Default: `true`
If the cache should be used. Setting this to false will completely bypass the cache for the current request.
###### opts.strictTtl
Type: `boolean`<br>
Default: `false`
If set to `true` once a cached resource has expired it is deleted and will have to be re-requested.
If set to `false` (default), after a cached resource's TTL expires it is kept in the cache and will be revalidated on the next request with `If-None-Match`/`If-Modified-Since` headers.
###### opts.maxTtl
Type: `number`<br>
Default: `undefined`
Limits TTL. The `number` represents milliseconds.
###### opts.automaticFailover
Type: `boolean`<br>
Default: `false`
When set to `true`, if the DB connection fails we will automatically fallback to a network request. DB errors will still be emitted to notify you of the problem even though the request callback may succeed.
###### opts.forceRefresh
Type: `boolean`<br>
Default: `false`
Forces refreshing the cache. If the response could be retrieved from the cache, it will perform a new request and override the cache instead.
##### cb
Type: `function`
The callback function which will receive the response as an argument.
The response can be either a [Node.js HTTP response stream](https://nodejs.org/api/http.html#http_class_http_incomingmessage) or a [responselike object](https://github.com/lukechilds/responselike). The response will also have a `fromCache` property set with a boolean value.
##### .on('request', request)
`request` event to get the request object of the request.
**Note:** This event will only fire if an HTTP request is actually made, not when a response is retrieved from cache. However, you should always handle the `request` event to end the request and handle any potential request errors.
##### .on('response', response)
`response` event to get the response object from the HTTP request or cache.
##### .on('error', error)
`error` event emitted in case of an error with the cache.
Errors emitted here will be an instance of `CacheableRequest.RequestError` or `CacheableRequest.CacheError`. You will only ever receive a `RequestError` if the request function throws (normally caused by invalid user input). Normal request errors should be handled inside the `request` event.
To properly handle all error scenarios you should use the following pattern:
```js
cacheableRequest('example.com', cb)
.on('error', err => {
if (err instanceof CacheableRequest.CacheError) {
handleCacheError(err); // Cache error
} else if (err instanceof CacheableRequest.RequestError) {
handleRequestError(err); // Request function thrown
}
})
.on('request', req => {
req.on('error', handleRequestError); // Request error emitted
req.end();
});
```
**Note:** Database connection errors are emitted here, however `cacheable-request` will attempt to re-request the resource and bypass the cache on a connection error. Therefore a database connection error doesn't necessarily mean the request won't be fulfilled.
## License
MIT © Luke Childs
**string_decoder.js** (`require('string_decoder')`) from Node.js core
Copyright Joyent, Inc. and other Node contributors. See LICENCE file for details.
Version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10. **Prefer the stable version over the unstable.**
The *build/* directory contains a build script that will scrape the source from the [joyent/node](https://github.com/joyent/node) repo given a specific Node version.
# utf-8-validate
[](https://www.npmjs.com/package/utf-8-validate)
[](https://travis-ci.org/websockets/utf-8-validate)
[](https://ci.appveyor.com/project/lpinca/utf-8-validate)
Check if a buffer contains valid UTF-8 encoded text.
## Installation
```
npm install utf-8-validate --save-optional
```
The `--save-optional` flag tells npm to save the package in your package.json
under the [`optionalDependencies`](https://docs.npmjs.com/files/package.json#optionaldependencies)
key.
## API
The module exports a single function which takes one argument.
### `isValidUTF8(buffer)`
Checks whether a buffer contains valid UTF-8.
#### Arguments
- `buffer` - The buffer to check.
#### Return value
`true` if the buffer contains only correct UTF-8, else `false`.
#### Example
```js
'use strict';
const isValidUTF8 = require('utf-8-validate');
const buf = Buffer.from([0xf0, 0x90, 0x80, 0x80]);
console.log(isValidUTF8(buf));
// => true
```
## License
[MIT](LICENSE)
js-multibase
============
[](https://protocol.ai)
[](https://github.com/multiformats/multiformats)
[](https://webchat.freenode.net/?channels=%23ipfs)
[](https://david-dm.org/multiformats/js-multibase)
[](https://codecov.io/gh/multiformats/js-multibase)
[](https://travis-ci.com/multiformats/js-multibase)
> JavaScript implementation of the [multibase](https://github.com/multiformats/multibase) specification
## Lead Maintainer
[Oli Evans](https://github.com/olizilla)
## Table of Contents
- [Install](#install)
- [In Node.js through npm](#in-nodejs-through-npm)
- [Browser: Browserify, Webpack, other bundlers](#browser-browserify-webpack-other-bundlers)
- [In the Browser through `<script>` tag](#in-the-browser-through-script-tag)
- [Gotchas](#gotchas)
- [Usage](#usage)
- [Example](#example)
- [API](#api)
- [`multibase` - Prefixes an encoded buffer with its multibase code](#multibase---prefixes-an-encoded-buffer-with-its-multibase-code)
- [`multibase.encode` - Encodes a buffer into one of the supported encodings, prefixing it with the multibase code](#multibaseencode---encodes-a-buffer-into-one-of-the-supported-encodings-prefixing-it-with-the-multibase-code)
- [`multibase.decode` - Decodes a buffer or string](#multibasedecode---decodes-a-buffer-or-string)
- [`multibase.isEncoded` - Checks if buffer or string is encoded](#multibaseisencoded---checks-if-buffer-or-string-is-encoded)
- [`multibase.names` - Supported base encoding names](#multibasenames)
- [`multibase.codes` - Supported base encoding codes](#multibasecodes)
- [Supported Encodings, see `src/constants.js`](#supported-encodings-see-srcconstantsjs)
- [Architecture and Encoding/Decoding](#architecture-and-encodingdecoding)
- [Adding additional bases](#adding-additional-bases)
- [License](#license)
## Install
### In Node.js through npm
```bash
> npm install --save multibase
```
### Browser: Browserify, Webpack, other bundlers
The code published to npm that gets loaded on require is in fact an ES5 transpiled version with the right shims added. This means that you can require it and use with your favourite bundler without having to adjust asset management process.
```js
const multibase = require('multibase')
```
### In the Browser through `<script>` tag
Loading this module through a script tag will make the ```Multibase``` obj available in the global namespace.
```html
<script src="https://unpkg.com/multibase/dist/index.min.js"></script>
<!-- OR -->
<script src="https://unpkg.com/multibase/dist/index.js"></script>
```
## Usage
### Example
```JavaScript
const { Buffer } = require('buffer')
const multibase = require('multibase')
const encodedBuf = multibase.encode('base58btc', new Buffer('hey, how is it going'))
const decodedBuf = multibase.decode(encodedBuf)
console.log(decodedBuf.toString())
// hey, how is it going
```
## API
https://multiformats.github.io/js-multibase/
### `multibase` - Prefixes an encoded buffer with its multibase code
```
const multibased = multibase(<nameOrCode>, encodedBuf)
```
### `multibase.encode` - Encodes a buffer into one of the supported encodings, prefixing it with the multibase code
```JavaScript
const encodedBuf = multibase.encode(<nameOrCode>, <buf>)
```
### `multibase.decode` - Decodes a buffer or string
```JavaScript
const decodedBuf = multibase.decode(bufOrString)
```
### `multibase.isEncoded` - Checks if buffer or string is encoded
```JavaScript
const value = multibase.isEncoded(bufOrString)
// value is the name of the encoding if it is encoded, false otherwise
```
### `multibase.names`
A frozen `Array` of supported base encoding names.
### `multibase.codes`
A frozen `Array` of supported base encoding codes.
### Supported Encodings, see [`src/constants.js`](/src/constants.js)
## Architecture and Encoding/Decoding
Multibase package defines all the supported bases and the location of their implementation in the constants.js file. A base is a class with a name, a code, an implementation and an alphabet.
```js
class Base {
constructor (name, code, implementation, alphabet) {
//...
}
// ...
}
```
The ```implementation``` is an object where the encoding/decoding functions are implemented. It must take one argument, (the alphabet) following the [base-x module](https://github.com/cryptocoinjs/base-x) architecture.
The ```alphabet``` is the **ordered** set of defined symbols for a given base.
The idea behind this is that several bases may have implementations from different locations/modules so it's useful to have an object (and a summary) of all of them in one location (hence the constants.js).
All the supported bases are currently using the npm [base-x](https://github.com/cryptocoinjs/base-x) module as their implementation. It is using bitwise maipulation to go from one base to another, so this module does not support padding at the moment.
## Adding additional bases
If the base you are looking for is not supported yet in js-multibase and you know a good encoding/decoding algorithm, you can add support for this base easily by editing the constants.js file
(**you'll need to create an issue about that beforehand since a code and a canonical name have to be defined**):
```js
const baseX = require('base-x')
//const newPackage = require('your-package-name')
const constants = [
['base2', '0', baseX, '01'],
['base8', '7', baseX, '01234567'],
// ... [ 'your-base-name', 'code-to-be-defined', newPackage, 'alphabet']
]
```
The required package defines the implementation of the encoding/decoding process. **It must comply by these rules** :
- `encode` and `decode` functions with to-be-encoded buffer as the only expected argument
- the require call use the `alphabet` given as an argument for the encoding/decoding process
*If no package is specified , it means the base is not implemented yet*
Adding a new base requires the tests to be updated. Test files to be updated are :
- constants.spec.js
```js
describe('constants', () => {
it('constants indexed by name', () => {
const names = constants.names
expect(Object.keys(names).length).to.equal(constants-count) // currently 12
})
it('constants indexed by code', () => {
const codes = constants.codes
expect(Object.keys(codes).length).to.equal(constants-count)
})
})
```
- multibase.spec.js
- if the base is implemented
```js
const supportedBases = [
['base2', 'yes mani !', '01111001011001010111001100100000011011010110000101101110011010010010000000100001'],
['base8', 'yes mani !', '7171312714403326055632220041'],
['base10', 'yes mani !', '9573277761329450583662625'],
// ... ['your-base-name', 'what you want', 'expected output']
```
- if the base is not implemented yet
```js
const supportedBases = [
// ... ['your-base-name']
```
## Contribute
Contributions welcome. Please check out [the issues](https://github.com/multiformats/js-multibase/issues).
Check out our [contributing document](https://github.com/multiformats/multiformats/blob/master/contributing.md) for more information on how we work, and about contributing in general. Please be aware that all interactions related to multiformats are subject to the IPFS [Code of Conduct](https://github.com/ipfs/community/blob/master/code-of-conduct.md).
Small note: If editing the README, please conform to the [standard-readme](https://github.com/RichardLitt/standard-readme) specification.
## License
[MIT](LICENSE) © Protocol Labs Inc.
scryptsy
========
[](http://travis-ci.org/cryptocoinjs/scryptsy)
[](https://coveralls.io/r/cryptocoinjs/scryptsy)
[](https://www.npmjs.org/package/scryptsy)
`scryptsy` is a pure Javascript implementation of the [scrypt][wiki] key derivation function that is fully compatible with Node.js and the browser (via Browserify).
Why?
----
`Scrypt` is an integral part of many crypto currencies. It's a part of the [BIP38](https://github.com/bitcoin/bips/blob/master/bip-0038.mediawiki) standard for encrypting private Bitcoin keys. It also serves as the [proof-of-work system](http://en.wikipedia.org/wiki/Proof-of-work_system) for many crypto currencies, most notably: Litecoin and Dogecoin.
Installation
------------
npm install --save scryptsy
Browserify Note
------------
When using a browserified bundle, be sure to add `setImmediate` as a shim.
Example
-------
```js
const scrypt = require('scryptsy')
async function main () {
var key = "pleaseletmein"
var salt = "SodiumChloride"
var data1 = scrypt(key, salt, 16384, 8, 1, 64)
console.log(data1.toString('hex'))
// => 7023bdcb3afd7348461c06cd81fd38ebfda8fbba904f8e3ea9b543f6545da1f2d5432955613f0fcf62d49705242a9af9e61e85dc0d651e40dfcf017b45575887
// async is actually slower, but it will free up the event loop occasionally
// which will allow for front end GUI elements to update and cause it to not
// freeze up.
// See benchmarks below
// Passing 300 below means every 300 iterations internally will call setImmediate once
var data2 = await scrypt.async(key, salt, 16384, 8, 1, 64, undefined, 300)
console.log(data2.toString('hex'))
// => 7023bdcb3afd7348461c06cd81fd38ebfda8fbba904f8e3ea9b543f6545da1f2d5432955613f0fcf62d49705242a9af9e61e85dc0d651e40dfcf017b45575887
}
main().catch(console.error)
```
Benchmarks
-------
Internal iterations are N * p, so changing r doesn't affect the number of calls to setImmediate.
Decreasing pI decreases performance in exchange for more frequently freeing the event loop.
(pI Default is 5000 loops per setImmediate call)
Note: these benchmarks were done on node v10 on a CPU with good single thread performance.
browsers show a much larger difference. Please tinker with the pI setting to balance between
performance and GUI responsiveness.
If `pI >= N`, setImmediate will only be called `p * 2` times total (on the i = 0 of each for loop).
```
---------------------------
time : type : (N,r,p,pI) (pI = promiseInterval)
---------------------------
2266 ms : sync (2^16,16,1)
2548 ms : async (2^16,16,1,5000)
12.44% increase
---------------------------
2616 ms : sync (2^16,1,16)
2995 ms : async (2^16,1,16,5000)
14.49% increase
---------------------------
2685 ms : sync (2^20,1,1)
3090 ms : async (2^20,1,1,5000)
15.08% increase
---------------------------
2235 ms : sync (2^16,16,1)
2627 ms : async (2^16,16,1,10)
17.54% increase
---------------------------
2592 ms : sync (2^16,1,16)
3305 ms : async (2^16,1,16,10)
27.51% increase
---------------------------
2705 ms : sync (2^20,1,1)
3363 ms : async (2^20,1,1,10)
24.33% increase
---------------------------
2278 ms : sync (2^16,16,1)
2773 ms : async (2^16,16,1,1)
21.73% increase
---------------------------
2617 ms : sync (2^16,1,16)
5632 ms : async (2^16,1,16,1)
115.21% increase
---------------------------
2727 ms : sync (2^20,1,1)
5723 ms : async (2^20,1,1,1)
109.86% increase
---------------------------
```
API
---
### scrypt(key, salt, N, r, p, keyLenBytes, [progressCallback])
- **key**: The key. Either `Buffer` or `string`.
- **salt**: The salt. Either `Buffer` or `string`.
- **N**: The number of iterations. `number` (integer)
- **r**: Memory factor. `number` (integer)
- **p**: Parallelization factor. `number` (integer)
- **keyLenBytes**: The number of bytes to return. `number` (integer)
- **progressCallback**: Call callback on every `1000` ops. Passes in `{current, total, percent}` as first parameter to `progressCallback()`.
Returns `Buffer`.
### scrypt.async(key, salt, N, r, p, keyLenBytes, [progressCallback, promiseInterval])
- **key**: The key. Either `Buffer` or `string`.
- **salt**: The salt. Either `Buffer` or `string`.
- **N**: The number of iterations. `number` (integer)
- **r**: Memory factor. `number` (integer)
- **p**: Parallelization factor. `number` (integer)
- **keyLenBytes**: The number of bytes to return. `number` (integer)
- **progressCallback**: Call callback on every `1000` ops. Passes in `{current, total, percent}` as first parameter to `progressCallback()`.
- **promiseInterval**: The number of internal iterations before calling setImmediate once to free the event loop.
Returns `Promise<Buffer>`.
Resources
---------
- [Tarsnap Blurb on Scrypt][tarsnap]
- [Scrypt Whitepaper](http://www.tarsnap.com/scrypt/scrypt.pdf)
- [IETF Scrypt](https://tools.ietf.org/html/draft-josefsson-scrypt-kdf-00) (Test vector params are [incorrect](https://twitter.com/dchest/status/247734446881640448).)
License
-------
MIT
[wiki]: http://en.wikipedia.org/wiki/Scrypt
[tarsnap]: http://www.tarsnap.com/scrypt.html
# next-tick
## Environment agnostic nextTick polyfill
To be used in environment agnostic modules that need nextTick functionality.
- When run in Node.js `process.nextTick` is used
- In modern browsers microtask resolution is guaranteed by `MutationObserver`
- In other engines `setImmediate` or `setTimeout(fn, 0)` is used as fallback.
- If none of the above is supported module resolves to `null`
## Installation
### NPM
In your project path:
$ npm install next-tick
#### Browser
You can easily bundle `next-tick` for browser with any CJS bundler, e.g. [modules-webmake](https://github.com/medikoo/modules-webmake)
## Tests [](https://travis-ci.org/medikoo/next-tick)
$ npm test
# web3-eth-ens
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This is the contract package to be used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-ens
```
## Usage
```js
const eth = new Web3Eth(web3.currentProvider);
const ens = new EthEns(eth);
ens.getAddress('ethereum.eth').then(function(result) {
console.log(result);
});
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-eth-ens.svg
[npm-url]: https://npmjs.org/package/web3-eth-ens
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-eth-ens
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-eth-ens
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-eth-ens
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-eth-ens
# class-is
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Coverage Status][codecov-image]][codecov-url] [![Dependency status][david-dm-image]][david-dm-url] [![Dev Dependency status][david-dm-dev-image]][david-dm-dev-url] [![Greenkeeper badge][greenkeeper-image]][greenkeeper-url]
[npm-url]:https://npmjs.org/package/class-is
[downloads-image]:http://img.shields.io/npm/dm/class-is.svg
[npm-image]:http://img.shields.io/npm/v/class-is.svg
[travis-url]:https://travis-ci.org/moxystudio/js-class-is
[travis-image]:http://img.shields.io/travis/moxystudio/js-class-is/master.svg
[codecov-url]:https://codecov.io/gh/moxystudio/js-class-is
[codecov-image]:https://img.shields.io/codecov/c/github/moxystudio/js-class-is/master.svg
[david-dm-url]:https://david-dm.org/moxystudio/js-class-is
[david-dm-image]:https://img.shields.io/david/moxystudio/js-class-is.svg
[david-dm-dev-url]:https://david-dm.org/moxystudio/js-class-is?type=dev
[david-dm-dev-image]:https://img.shields.io/david/dev/moxystudio/js-class-is.svg
[greenkeeper-image]:https://badges.greenkeeper.io/moxystudio/js-class-is.svg
[greenkeeper-url]:https://greenkeeper.io/
Enhances a JavaScript class by adding an `is<Class>` property to compare types between realms.
## Motivation
Checking if a value is an instance of a class in JavaScript is not an easy task.
You can use `instanceof`, but that doesn't work between different realms or different versions. Comparing with `constructor.name` could be a solution but if you need to Uglify the module it doesn't work, as it creates different names for the same module.
[Symbols](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol) to the rescue!
## Installation
`$ npm install class-is`
If you want to use this module in the browser you have to compile it yourself to your desired target.
## Usage
### ES6 classes:
```js
// Package X
const withIs = require('class-is');
class Person {
constructor(name, city) {
this.name = name;
this.city = city;
}
}
module.exports = withIs(Person, {
className: 'Person',
symbolName: '@org/package-x/Person',
});
```
```js
// Package Y
const withIs = require('class-is');
class Animal {
constructor(species) {
this.species = species;
}
}
module.exports = withIs(Animal, {
className: 'Animal',
symbolName: '@org/package-y/Animal',
});
```
```js
const Person = require('package-x');
const Animal = require('package-y');
const diogo = new Person('Diogo', 'Porto');
const wolf = new Animal('Gray Wolf');
console.log(Person.isPerson(diogo));
console.log(Person.isPerson(wolf));
```
Running the example above will print:
```
true
false
```
### ES5 and below classes:
In ES5 it's not unusual to see constructors like the one below, so you can call it without using the `new` keyword.
```js
function Circle(radius) {
if (!(this instanceof Circle)) {
return new Circle();
}
this.radius = radius;
}
```
In such cases you can use the `withIs.proto` method:
```js
const withIs = require('class-is');
const Circle = withIs.proto(function (radius) {
if (!(this instanceof Circle)) {
return new Circle();
}
this.radius = radius;
}, {
className: 'Circle',
symbolName: '@org/package/Circle',
});
```
...or even better:
```js
const withIs = require('class-is');
function Circle(radius) {
this.radius = radius;
}
module.exports = withIs.proto(Circle, {
className: 'Circle',
symbolName: '@org/package/Circle',
withoutNew: true,
});
```
## API
### withIs(Class, { className, symbolName })
###### class
Type: `class`
The class to be enhanced.
###### className
Type: `String`
The name of the class your passing.
###### symbolName
Type: `String`
Unique *id* for the class. This should be namespaced so different classes from different modules do not collide and give false positives.
Example: `@organization/package/Class`
### withIs.proto(Class, { className, symbolName, withoutNew })
The `className` and `symbolName` parameters are the same as above.
###### withoutNew
Type: `Boolean`
Default: `false`
Allow creating an instance without the `new` operator.
## Tests
`$ npm test`
`$ npm test -- --watch` during development
## License
[MIT](http://www.opensource.org/licenses/mit-license.php)
# cors
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
CORS is a node.js package for providing a [Connect](http://www.senchalabs.org/connect/)/[Express](http://expressjs.com/) middleware that can be used to enable [CORS](http://en.wikipedia.org/wiki/Cross-origin_resource_sharing) with various options.
**[Follow me (@troygoode) on Twitter!](https://twitter.com/intent/user?screen_name=troygoode)**
* [Installation](#installation)
* [Usage](#usage)
* [Simple Usage](#simple-usage-enable-all-cors-requests)
* [Enable CORS for a Single Route](#enable-cors-for-a-single-route)
* [Configuring CORS](#configuring-cors)
* [Configuring CORS Asynchronously](#configuring-cors-asynchronously)
* [Enabling CORS Pre-Flight](#enabling-cors-pre-flight)
* [Configuration Options](#configuration-options)
* [Demo](#demo)
* [License](#license)
* [Author](#author)
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install cors
```
## Usage
### Simple Usage (Enable *All* CORS Requests)
```javascript
var express = require('express')
var cors = require('cors')
var app = express()
app.use(cors())
app.get('/products/:id', function (req, res, next) {
res.json({msg: 'This is CORS-enabled for all origins!'})
})
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80')
})
```
### Enable CORS for a Single Route
```javascript
var express = require('express')
var cors = require('cors')
var app = express()
app.get('/products/:id', cors(), function (req, res, next) {
res.json({msg: 'This is CORS-enabled for a Single Route'})
})
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80')
})
```
### Configuring CORS
```javascript
var express = require('express')
var cors = require('cors')
var app = express()
var corsOptions = {
origin: 'http://example.com',
optionsSuccessStatus: 200 // some legacy browsers (IE11, various SmartTVs) choke on 204
}
app.get('/products/:id', cors(corsOptions), function (req, res, next) {
res.json({msg: 'This is CORS-enabled for only example.com.'})
})
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80')
})
```
### Configuring CORS w/ Dynamic Origin
```javascript
var express = require('express')
var cors = require('cors')
var app = express()
var whitelist = ['http://example1.com', 'http://example2.com']
var corsOptions = {
origin: function (origin, callback) {
if (whitelist.indexOf(origin) !== -1) {
callback(null, true)
} else {
callback(new Error('Not allowed by CORS'))
}
}
}
app.get('/products/:id', cors(corsOptions), function (req, res, next) {
res.json({msg: 'This is CORS-enabled for a whitelisted domain.'})
})
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80')
})
```
If you do not want to block REST tools or server-to-server requests,
add a `!origin` check in the origin function like so:
```javascript
var corsOptions = {
origin: function (origin, callback) {
if (whitelist.indexOf(origin) !== -1 || !origin) {
callback(null, true)
} else {
callback(new Error('Not allowed by CORS'))
}
}
}
```
### Enabling CORS Pre-Flight
Certain CORS requests are considered 'complex' and require an initial
`OPTIONS` request (called the "pre-flight request"). An example of a
'complex' CORS request is one that uses an HTTP verb other than
GET/HEAD/POST (such as DELETE) or that uses custom headers. To enable
pre-flighting, you must add a new OPTIONS handler for the route you want
to support:
```javascript
var express = require('express')
var cors = require('cors')
var app = express()
app.options('/products/:id', cors()) // enable pre-flight request for DELETE request
app.del('/products/:id', cors(), function (req, res, next) {
res.json({msg: 'This is CORS-enabled for all origins!'})
})
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80')
})
```
You can also enable pre-flight across-the-board like so:
```javascript
app.options('*', cors()) // include before other routes
```
### Configuring CORS Asynchronously
```javascript
var express = require('express')
var cors = require('cors')
var app = express()
var whitelist = ['http://example1.com', 'http://example2.com']
var corsOptionsDelegate = function (req, callback) {
var corsOptions;
if (whitelist.indexOf(req.header('Origin')) !== -1) {
corsOptions = { origin: true } // reflect (enable) the requested origin in the CORS response
} else {
corsOptions = { origin: false } // disable CORS for this request
}
callback(null, corsOptions) // callback expects two parameters: error and options
}
app.get('/products/:id', cors(corsOptionsDelegate), function (req, res, next) {
res.json({msg: 'This is CORS-enabled for a whitelisted domain.'})
})
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80')
})
```
## Configuration Options
* `origin`: Configures the **Access-Control-Allow-Origin** CORS header. Possible values:
- `Boolean` - set `origin` to `true` to reflect the [request origin](http://tools.ietf.org/html/draft-abarth-origin-09), as defined by `req.header('Origin')`, or set it to `false` to disable CORS.
- `String` - set `origin` to a specific origin. For example if you set it to `"http://example.com"` only requests from "http://example.com" will be allowed.
- `RegExp` - set `origin` to a regular expression pattern which will be used to test the request origin. If it's a match, the request origin will be reflected. For example the pattern `/example\.com$/` will reflect any request that is coming from an origin ending with "example.com".
- `Array` - set `origin` to an array of valid origins. Each origin can be a `String` or a `RegExp`. For example `["http://example1.com", /\.example2\.com$/]` will accept any request from "http://example1.com" or from a subdomain of "example2.com".
- `Function` - set `origin` to a function implementing some custom logic. The function takes the request origin as the first parameter and a callback (which expects the signature `err [object], allow [bool]`) as the second.
* `methods`: Configures the **Access-Control-Allow-Methods** CORS header. Expects a comma-delimited string (ex: 'GET,PUT,POST') or an array (ex: `['GET', 'PUT', 'POST']`).
* `allowedHeaders`: Configures the **Access-Control-Allow-Headers** CORS header. Expects a comma-delimited string (ex: 'Content-Type,Authorization') or an array (ex: `['Content-Type', 'Authorization']`). If not specified, defaults to reflecting the headers specified in the request's **Access-Control-Request-Headers** header.
* `exposedHeaders`: Configures the **Access-Control-Expose-Headers** CORS header. Expects a comma-delimited string (ex: 'Content-Range,X-Content-Range') or an array (ex: `['Content-Range', 'X-Content-Range']`). If not specified, no custom headers are exposed.
* `credentials`: Configures the **Access-Control-Allow-Credentials** CORS header. Set to `true` to pass the header, otherwise it is omitted.
* `maxAge`: Configures the **Access-Control-Max-Age** CORS header. Set to an integer to pass the header, otherwise it is omitted.
* `preflightContinue`: Pass the CORS preflight response to the next handler.
* `optionsSuccessStatus`: Provides a status code to use for successful `OPTIONS` requests, since some legacy browsers (IE11, various SmartTVs) choke on `204`.
The default configuration is the equivalent of:
```json
{
"origin": "*",
"methods": "GET,HEAD,PUT,PATCH,POST,DELETE",
"preflightContinue": false,
"optionsSuccessStatus": 204
}
```
For details on the effect of each CORS header, read [this](http://www.html5rocks.com/en/tutorials/cors/) article on HTML5 Rocks.
## Demo
A demo that illustrates CORS working (and not working) using jQuery is available here: [http://node-cors-client.herokuapp.com/](http://node-cors-client.herokuapp.com/)
Code for that demo can be found here:
* Client: [https://github.com/TroyGoode/node-cors-client](https://github.com/TroyGoode/node-cors-client)
* Server: [https://github.com/TroyGoode/node-cors-server](https://github.com/TroyGoode/node-cors-server)
## License
[MIT License](http://www.opensource.org/licenses/mit-license.php)
## Author
[Troy Goode](https://github.com/TroyGoode) ([[email protected]](mailto:[email protected]))
[coveralls-image]: https://img.shields.io/coveralls/expressjs/cors/master.svg
[coveralls-url]: https://coveralls.io/r/expressjs/cors?branch=master
[downloads-image]: https://img.shields.io/npm/dm/cors.svg
[downloads-url]: https://npmjs.org/package/cors
[npm-image]: https://img.shields.io/npm/v/cors.svg
[npm-url]: https://npmjs.org/package/cors
[travis-image]: https://img.shields.io/travis/expressjs/cors/master.svg
[travis-url]: https://travis-ci.org/expressjs/cors
# EventEmitter3
[](https://www.npmjs.com/package/eventemitter3)[](https://travis-ci.org/primus/eventemitter3)[](https://david-dm.org/primus/eventemitter3)[](https://coveralls.io/r/primus/eventemitter3?branch=master)[](https://webchat.freenode.net/?channels=primus)
[](https://saucelabs.com/u/eventemitter3)
EventEmitter3 is a high performance EventEmitter. It has been micro-optimized
for various of code paths making this, one of, if not the fastest EventEmitter
available for Node.js and browsers. The module is API compatible with the
EventEmitter that ships by default with Node.js but there are some slight
differences:
- Domain support has been removed.
- We do not `throw` an error when you emit an `error` event and nobody is
listening.
- The `newListener` and `removeListener` events have been removed as they
are useful only in some uncommon use-cases.
- The `setMaxListeners`, `getMaxListeners`, `prependListener` and
`prependOnceListener` methods are not available.
- Support for custom context for events so there is no need to use `fn.bind`.
- The `removeListener` method removes all matching listeners, not only the
first.
It's a drop in replacement for existing EventEmitters, but just faster. Free
performance, who wouldn't want that? The EventEmitter is written in EcmaScript 3
so it will work in the oldest browsers and node versions that you need to
support.
## Installation
```bash
$ npm install --save eventemitter3
```
## CDN
Recommended CDN:
```text
https://unpkg.com/eventemitter3@latest/umd/eventemitter3.min.js
```
## Usage
After installation the only thing you need to do is require the module:
```js
var EventEmitter = require('eventemitter3');
```
And you're ready to create your own EventEmitter instances. For the API
documentation, please follow the official Node.js documentation:
http://nodejs.org/api/events.html
### Contextual emits
We've upgraded the API of the `EventEmitter.on`, `EventEmitter.once` and
`EventEmitter.removeListener` to accept an extra argument which is the `context`
or `this` value that should be set for the emitted events. This means you no
longer have the overhead of an event that required `fn.bind` in order to get a
custom `this` value.
```js
var EE = new EventEmitter()
, context = { foo: 'bar' };
function emitted() {
console.log(this === context); // true
}
EE.once('event-name', emitted, context);
EE.on('another-event', emitted, context);
EE.removeListener('another-event', emitted, context);
```
### Tests and benchmarks
This module is well tested. You can run:
- `npm test` to run the tests under Node.js.
- `npm run test-browser` to run the tests in real browsers via Sauce Labs.
We also have a set of benchmarks to compare EventEmitter3 with some available
alternatives. To run the benchmarks run `npm run benchmark`.
Tests and benchmarks are not included in the npm package. If you want to play
with them you have to clone the GitHub repository.
## License
[MIT](LICENSE)
# node-gyp-build
> Build tool and bindings loader for [`node-gyp`][node-gyp] that supports prebuilds.
```
npm install node-gyp-build
```
[](https://travis-ci.org/prebuild/node-gyp-build)
Use together with [`prebuildify`][prebuildify] to easily support prebuilds for your native modules.
## Usage
> **Note.** Prebuild names have changed in [`prebuildify@3`][prebuildify] and `node-gyp-build@4`. Please see the documentation below.
`node-gyp-build` works similar to [`node-gyp build`][node-gyp] except that it will check if a build or prebuild is present before rebuilding your project.
It's main intended use is as an npm install script and bindings loader for native modules that bundle prebuilds using [`prebuildify`][prebuildify].
First add `node-gyp-build` as an install script to your native project
``` js
{
...
"scripts": {
"install": "node-gyp-build"
}
}
```
Then in your `index.js`, instead of using the [`bindings`](https://www.npmjs.com/package/bindings) module use `node-gyp-build` to load your binding.
``` js
var binding = require('node-gyp-build')(__dirname)
```
If you do these two things and bundle prebuilds with [`prebuildify`][prebuildify] your native module will work for most platforms
without having to compile on install time AND will work in both node and electron without the need to recompile between usage.
Users can override `node-gyp-build` and force compiling by doing `npm install --build-from-source`.
Prebuilds will be attempted loaded from `MODULE_PATH/prebuilds/...` and then next `EXEC_PATH/prebuilds/...` (the latter allowing use with `zeit/pkg`)
## Supported prebuild names
If so desired you can bundle more specific flavors, for example `musl` builds to support Alpine, or targeting a numbered ARM architecture version.
These prebuilds can be bundled in addition to generic prebuilds; `node-gyp-build` will try to find the most specific flavor first. Prebuild filenames are composed of _tags_. The runtime tag takes precedence, as does an `abi` tag over `napi`. For more details on tags, please see [`prebuildify`][prebuildify].
Values for the `libc` and `armv` tags are auto-detected but can be overridden through the `LIBC` and `ARM_VERSION` environment variables, respectively.
## License
MIT
[prebuildify]: https://github.com/prebuild/prebuildify
[node-gyp]: https://www.npmjs.com/package/node-gyp
# json-stringify-safe
Like JSON.stringify, but doesn't throw on circular references.
## Usage
Takes the same arguments as `JSON.stringify`.
```javascript
var stringify = require('json-stringify-safe');
var circularObj = {};
circularObj.circularRef = circularObj;
circularObj.list = [ circularObj, circularObj ];
console.log(stringify(circularObj, null, 2));
```
Output:
```json
{
"circularRef": "[Circular]",
"list": [
"[Circular]",
"[Circular]"
]
}
```
## Details
```
stringify(obj, serializer, indent, decycler)
```
The first three arguments are the same as to JSON.stringify. The last
is an argument that's only used when the object has been seen already.
The default `decycler` function returns the string `'[Circular]'`.
If, for example, you pass in `function(k,v){}` (return nothing) then it
will prune cycles. If you pass in `function(k,v){ return {foo: 'bar'}}`,
then cyclical objects will always be represented as `{"foo":"bar"}` in
the result.
```
stringify.getSerialize(serializer, decycler)
```
Returns a serializer that can be used elsewhere. This is the actual
function that's passed to JSON.stringify.
**Note** that the function returned from `getSerialize` is stateful for now, so
do **not** use it more than once.
# hash-base
[](https://www.npmjs.org/package/hash-base)
[](https://travis-ci.org/crypto-browserify/hash-base)
[](https://david-dm.org/crypto-browserify/hash-base#info=dependencies)
[](https://github.com/feross/standard)
Abstract base class to inherit from if you want to create streams implementing the same API as node crypto [Hash][1] (for [Cipher][2] / [Decipher][3] check [crypto-browserify/cipher-base][4]).
## Example
```js
const HashBase = require('hash-base')
const inherits = require('inherits')
// our hash function is XOR sum of all bytes
function MyHash () {
HashBase.call(this, 1) // in bytes
this._sum = 0x00
}
inherits(MyHash, HashBase)
MyHash.prototype._update = function () {
for (let i = 0; i < this._block.length; ++i) this._sum ^= this._block[i]
}
MyHash.prototype._digest = function () {
return this._sum
}
const data = Buffer.from([ 0x00, 0x42, 0x01 ])
const hash = new MyHash().update(data).digest()
console.log(hash) // => 67
```
You also can check [source code](index.js) or [crypto-browserify/md5.js][5]
## LICENSE
MIT
[1]: https://nodejs.org/api/crypto.html#crypto_class_hash
[2]: https://nodejs.org/api/crypto.html#crypto_class_cipher
[3]: https://nodejs.org/api/crypto.html#crypto_class_decipher
[4]: https://github.com/crypto-browserify/cipher-base
[5]: https://github.com/crypto-browserify/md5.js
# web3-core-promievent
This is a sub package of [web3.js][repo]
This is the PromiEvent package is used to return a EventEmitter mixed with a Promise to allow multiple final states as well as chaining.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-promievent
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-core-promievent.js` in your html file.
This will expose the `Web3PromiEvent` object on the window object.
## Usage
```js
// in node.js
var Web3PromiEvent = require('web3-core-promievent');
var myFunc = function(){
var promiEvent = Web3PromiEvent();
setTimeout(function() {
promiEvent.eventEmitter.emit('done', 'Hello!');
promiEvent.resolve('Hello!');
}, 10);
return promiEvent.eventEmitter;
};
// and run it
myFunc()
.then(console.log);
.on('done', console.log);
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
pac-resolver
============
### Generates an asynchronous resolver function from a [PAC file][pac-wikipedia]
[](https://travis-ci.org/TooTallNate/node-pac-resolver)
This module accepts a JavaScript String of code, which is meant to be a
[PAC proxy file][pac-wikipedia], and returns a generated asynchronous
`FindProxyForURL()` function.
Installation
------------
Install with `npm`:
``` bash
$ npm install pac-resolver
```
Example
-------
Given the PAC proxy file named `proxy.pac`:
``` js
function FindProxyForURL(url, host) {
if (isInNet(myIpAddress(), "10.1.10.0", "255.255.255.0")) {
return "PROXY 1.2.3.4:8080";
} else {
return "DIRECT";
}
}
```
You can consume this PAC file with `pac-resolver` like so:
``` js
var fs = require('fs');
var pac = require('pac-resolver');
var FindProxyForURL = pac(fs.readFileSync('proxy.pac'));
FindProxyForURL('http://foo.com/').then((res) => {
console.log(res);
// "DIRECT"
});
```
API
---
### pac(String jsStr[, Object options]) → Function
Returns an asynchronous `FindProxyForURL()` function based off of the given JS
string `jsStr` PAC proxy file. An optional `options` object may be passed in which
respects the following options:
* `filename` - String - the filename to use in error stack traces. Defaults to `proxy.pac`.
* `sandbox` - Object - a map of functions to include in the sandbox of the
JavaScript environment where the JS code will be executed. i.e. if you wanted to
include the common `alert` function you could pass `alert: console.log`. For
async functions, you must set the `async = true` property on the function
instance, and the JS code will be able to invoke the function as if it were
synchronous.
License
-------
(The MIT License)
Copyright (c) 2013 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[pac-file-docs]: https://web.archive.org/web/20070602031929/http://wp.netscape.com/eng/mozilla/2.0/relnotes/demo/proxy-live.html
[pac-wikipedia]: http://wikipedia.org/wiki/Proxy_auto-config
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
# Generic ERC20/NEP21 connector for Rainbow Bridge
## Specification
## Ethereum's side
```solidity
contract ERC20Locker {
constructor(bytes memory nearTokenFactory, INearProver prover) public;
function lockToken(IERC20 token, uint256 amount, string memory accountId) public;
function unlockToken(bytes memory proofData, uint64 proofBlockHeader) public;
}
```
## NEAR's side
```rust
struct BridgeTokenFactory {
/// The account of the prover that we can use to prove
pub prover_account: AccountId,
/// Address of the Ethereum locker contract.
pub locker_address: [u8; 20],
/// Hashes of the events that were already used.
pub used_events: UnorderedSet<Vec<u8>>,
/// Mapping from Ethereum tokens to NEAR tokens.
pub tokens: UnorderedMap<EvmAddress, AccountId>;
}
impl BridgeTokenFactory {
/// Initializes the contract.
/// `prover_account`: NEAR account of the Near Prover contract;
/// `locker_address`: Ethereum address of the locker contract, in hex.
#[init]
pub fn new(prover_account: AccountId, locker_address: String) -> Self;
/// Relays the lock event from Ethereum.
/// Uses prover to validate that proof is correct and relies on a canonical Ethereum chain.
/// Send `mint` action to the token that is specified in the proof.
#[payable]
pub fn deposit(&mut self, proof: Proof);
/// A callback from BridgeToken contract deployed under this factory.
/// Is called after tokens are burned there to create an receipt result `(amount, token_address, recipient_address)` for Ethereum to unlock the token.
pub fn finish_withdraw(token_account: AccountId, amount: Balance, recipient: EvmAddress);
/// Transfers given NEP-21 token from `predecessor_id` to factory to lock.
/// On success, leaves a receipt result `(amount, token_address, recipient_address)`.
#[payable]
pub fn lock(&mut self, token: AccountId, amount: Balance, recipient: String);
/// Relays the unlock event from Ethereum.
/// Uses prover to validate that proof is correct and relies on a canonical Ethereum chain.
/// Uses NEP-21 `transfer` action to move funds to `recipient` account.
#[payable]
pub fn unlock(&mut self, proof: Proof);
/// Deploys BridgeToken contract for the given EVM address in hex code.
/// The name of new NEP21 compatible contract will be <hex(evm_address)>.<current_id>.
/// Expects ~35N attached to cover storage for BridgeToken.
#[payable]
pub fn deploy_bridge_token(address: String);
}
struct BridgeToken {
controller: AccountId,
token: Token, // uses https://github.com/ilblackdragon/balancer-near/tree/master/near-lib-rs
}
impl BridgeToken {
/// Setup the Token contract with given factory/controller.
pub fn new(controller: AccountId) -> Self;
/// Mint tokens to given user. Only can be called by the controller.
pub fn mint(&mut self, account_id: AccountId, amount: Balance);
/// Withdraw tokens from this contract.
/// Burns sender's tokens and calls controller to create event for relaying.
pub fn withdraw(&mut self, amount: U128, recipient: String) -> Promise;
}
impl FungibleToken for BridgeToken {
// see example https://github.com/ilblackdragon/balancer-near/blob/master/balancer-pool/src/lib.rs#L329
}
```
## Setup new ERC20 on NEAR
To setup token contract on NEAR side, anyone can call `<bridge_token_factory>.deploy_bridge_token(<erc20>)` where `<erc20>` is the address of the token.
With this call must attach the amount of $NEAR to cover storage for (at least 30 $NEAR currently).
This will create `<<hex(erc20)>.<bridge_token_factory>>` NEP21-compatible contract.
## Setup new NEP21 on Ethereum
TODO
## Usage flow Ethereum -> NEAR
1. User sends `<erc20>.approve(<erc20locker>, <amount>)` Ethereum transaction.
2. User sends `<erc20locker>.lock(<erc20>, <amount>, <destination>)` Ethereum transaction. This transaction will create `Locked` event.
3. Relayers will be sending Ethereum blocks to the `EthClient` on NEAR side.
4. After sufficient number of confirmations on top of the mined Ethereum block that contain the `lock` transaction, user or relayer can call `BridgeTokenFactory.mint(proof)`. Proof is the extracted information from the event on Ethereum side.
5. `BridgeTokenFactory.mint` function will call `EthProver` and verify that proof is correct and relies on a block with sufficient number of confirmations.
6. `EthProver` will return callback to `BridgeTokenFactory` confirming that proof is correct.
7. `BridgeTokenFactory` will call `<<hex(erc20)>.<bridge_token_factory>>.mint(<near_account_id>, <amount>)`.
8. User can use `<<hex(erc20)>.<bridge_token_factory>>` token in other applications now on NEAR.
## Usage flow NEAR -> Ethereum
TODO
## Testing
### Testing Ethereum side
```
cd erc20-locker
yarn
npm run test?
truffle rpctest
truffle test
```
### Testing NEAR side
```
cd bridge-token-factory
./build.sh
cargo test --all
```
# ansi-viewer
A terminal app to view ANSI art from http://artscene.textfiles.com/ansi/.

## Contribution and License Agreement
If you contribute code to this project, you are implicitly allowing your code
to be distributed under the MIT license. You are also implicitly verifying that
all code is your original work. `</legalese>`
## License
Copyright (c) 2015, Christopher Jeffrey. (MIT License)
See LICENSE for more info.
# uuid [](http://travis-ci.org/defunctzombie/node-uuid) #
[](https://ci.testling.com/defunctzombie/node-uuid)
Simple, fast generation of [RFC4122](http://www.ietf.org/rfc/rfc4122.txt) UUIDS.
Features:
* Generate RFC4122 version 1 or version 4 UUIDs
* Runs in node.js and all browsers.
* Cryptographically strong random # generation on supporting platforms
* 1185 bytes minified and gzip'ed (Want something smaller? Check this [crazy shit](https://gist.github.com/982883) out! )
* [Annotated source code](http://broofa.github.com/node-uuid/docs/uuid.html)
## Getting Started
Install it in your browser:
```html
<script src="uuid.js"></script>
```
Or in node.js:
```
npm install uuid
```
```javascript
var uuid = require('uuid');
// Generate a v1 (time-based) id
uuid.v1(); // -> '6c84fb90-12c4-11e1-840d-7b25c5ee775a'
// Generate a v4 (random) id
uuid.v4(); // -> '110ec58a-a0f2-4ac4-8393-c866d813b8d1'
```
## API
### uuid.v1([`options` [, `buffer` [, `offset`]]])
Generate and return a RFC4122 v1 (timestamp-based) UUID.
* `options` - (Object) Optional uuid state to apply. Properties may include:
* `node` - (Array) Node id as Array of 6 bytes (per 4.1.6). Default: Randomly generated ID. See note 1.
* `clockseq` - (Number between 0 - 0x3fff) RFC clock sequence. Default: An internally maintained clockseq is used.
* `msecs` - (Number | Date) Time in milliseconds since unix Epoch. Default: The current time is used.
* `nsecs` - (Number between 0-9999) additional time, in 100-nanosecond units. Ignored if `msecs` is unspecified. Default: internal uuid counter is used, as per 4.2.1.2.
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing.
Returns `buffer`, if specified, otherwise the string form of the UUID
Notes:
1. The randomly generated node id is only guaranteed to stay constant for the lifetime of the current JS runtime. (Future versions of this module may use persistent storage mechanisms to extend this guarantee.)
Example: Generate string UUID with fully-specified options
```javascript
uuid.v1({
node: [0x01, 0x23, 0x45, 0x67, 0x89, 0xab],
clockseq: 0x1234,
msecs: new Date('2011-11-01').getTime(),
nsecs: 5678
}); // -> "710b962e-041c-11e1-9234-0123456789ab"
```
Example: In-place generation of two binary IDs
```javascript
// Generate two ids in an array
var arr = new Array(32); // -> []
uuid.v1(null, arr, 0); // -> [02 a2 ce 90 14 32 11 e1 85 58 0b 48 8e 4f c1 15]
uuid.v1(null, arr, 16); // -> [02 a2 ce 90 14 32 11 e1 85 58 0b 48 8e 4f c1 15 02 a3 1c b0 14 32 11 e1 85 58 0b 48 8e 4f c1 15]
// Optionally use uuid.unparse() to get stringify the ids
uuid.unparse(buffer); // -> '02a2ce90-1432-11e1-8558-0b488e4fc115'
uuid.unparse(buffer, 16) // -> '02a31cb0-1432-11e1-8558-0b488e4fc115'
```
### uuid.v4([`options` [, `buffer` [, `offset`]]])
Generate and return a RFC4122 v4 UUID.
* `options` - (Object) Optional uuid state to apply. Properties may include:
* `random` - (Number[16]) Array of 16 numbers (0-255) to use in place of randomly generated values
* `rng` - (Function) Random # generator to use. Set to one of the built-in generators - `uuid.mathRNG` (all platforms), `uuid.nodeRNG` (node.js only), `uuid.whatwgRNG` (WebKit only) - or a custom function that returns an array[16] of byte values.
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing.
Returns `buffer`, if specified, otherwise the string form of the UUID
Example: Generate string UUID with fully-specified options
```javascript
uuid.v4({
random: [
0x10, 0x91, 0x56, 0xbe, 0xc4, 0xfb, 0xc1, 0xea,
0x71, 0xb4, 0xef, 0xe1, 0x67, 0x1c, 0x58, 0x36
]
});
// -> "109156be-c4fb-41ea-b1b4-efe1671c5836"
```
Example: Generate two IDs in a single buffer
```javascript
var buffer = new Array(32); // (or 'new Buffer' in node.js)
uuid.v4(null, buffer, 0);
uuid.v4(null, buffer, 16);
```
### uuid.parse(id[, buffer[, offset]])
### uuid.unparse(buffer[, offset])
Parse and unparse UUIDs
* `id` - (String) UUID(-like) string
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written. Default: A new Array or Buffer is used
* `offset` - (Number) Starting index in `buffer` at which to begin writing. Default: 0
Example parsing and unparsing a UUID string
```javascript
var bytes = uuid.parse('797ff043-11eb-11e1-80d6-510998755d10'); // -> <Buffer 79 7f f0 43 11 eb 11 e1 80 d6 51 09 98 75 5d 10>
var string = uuid.unparse(bytes); // -> '797ff043-11eb-11e1-80d6-510998755d10'
```
### uuid.noConflict()
(Browsers only) Set `uuid` property back to it's previous value.
Returns the uuid object.
Example:
```javascript
var myUuid = uuid.noConflict();
myUuid.v1(); // -> '6c84fb90-12c4-11e1-840d-7b25c5ee775a'
```
## Deprecated APIs
Support for the following v1.2 APIs is available in v1.3, but is deprecated and will be removed in the next major version.
### uuid([format [, buffer [, offset]]])
uuid() has become uuid.v4(), and the `format` argument is now implicit in the `buffer` argument. (i.e. if you specify a buffer, the format is assumed to be binary).
### uuid.BufferClass
The class of container created when generating binary uuid data if no buffer argument is specified. This is expected to go away, with no replacement API.
## Testing
In node.js
```
> cd test
> node test.js
```
In Browser
```
open test/test.html
```
### Benchmarking
Requires node.js
```
cd benchmark/
npm install
node benchmark.js
```
For a more complete discussion of uuid performance, please see the `benchmark/README.md` file, and the [benchmark wiki](https://github.com/broofa/uuid/wiki/Benchmark)
For browser performance [checkout the JSPerf tests](http://jsperf.com/node-uuid-performance).
## Release notes
### 1.4.0
* Improved module context detection
* Removed public RNG functions
### 1.3.2
* Improve tests and handling of v1() options (Issue #24)
* Expose RNG option to allow for perf testing with different generators
### 1.3.0
* Support for version 1 ids, thanks to [@ctavan](https://github.com/ctavan)!
* Support for node.js crypto API
* De-emphasizing performance in favor of a) cryptographic quality PRNGs where available and b) more manageable code
# IP
[](https://www.npmjs.com/package/ip)
IP address utilities for node.js
## Installation
### npm
```shell
npm install ip
```
### git
```shell
git clone https://github.com/indutny/node-ip.git
```
## Usage
Get your ip address, compare ip addresses, validate ip addresses, etc.
```js
var ip = require('ip');
ip.address() // my ip address
ip.isEqual('::1', '::0:1'); // true
ip.toBuffer('127.0.0.1') // Buffer([127, 0, 0, 1])
ip.toString(new Buffer([127, 0, 0, 1])) // 127.0.0.1
ip.fromPrefixLen(24) // 255.255.255.0
ip.mask('192.168.1.134', '255.255.255.0') // 192.168.1.0
ip.cidr('192.168.1.134/26') // 192.168.1.128
ip.not('255.255.255.0') // 0.0.0.255
ip.or('192.168.1.134', '0.0.0.255') // 192.168.1.255
ip.isPrivate('127.0.0.1') // true
ip.isV4Format('127.0.0.1'); // true
ip.isV6Format('::ffff:127.0.0.1'); // true
// operate on buffers in-place
var buf = new Buffer(128);
var offset = 64;
ip.toBuffer('127.0.0.1', buf, offset); // [127, 0, 0, 1] at offset 64
ip.toString(buf, offset, 4); // '127.0.0.1'
// subnet information
ip.subnet('192.168.1.134', '255.255.255.192')
// { networkAddress: '192.168.1.128',
// firstAddress: '192.168.1.129',
// lastAddress: '192.168.1.190',
// broadcastAddress: '192.168.1.191',
// subnetMask: '255.255.255.192',
// subnetMaskLength: 26,
// numHosts: 62,
// length: 64,
// contains: function(addr){...} }
ip.cidrSubnet('192.168.1.134/26')
// Same as previous.
// range checking
ip.cidrSubnet('192.168.1.134/26').contains('192.168.1.190') // true
// ipv4 long conversion
ip.toLong('127.0.0.1'); // 2130706433
ip.fromLong(2130706433); // '127.0.0.1'
```
### License
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2012.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# object.omit [](https://www.npmjs.com/package/object.omit) [](https://npmjs.org/package/object.omit) [](https://npmjs.org/package/object.omit) [](https://travis-ci.org/jonschlinkert/object.omit)
> Return a copy of an object excluding the given key, or array of keys. Also accepts an optional filter function as the last argument.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save object.omit
```
## Usage
```js
var omit = require('object.omit');
```
Pass a string `key` to omit:
```js
omit({a: 'a', b: 'b', c: 'c'}, 'a')
//=> { b: 'b', c: 'c' }
```
Pass an array of `keys` to omit:
```js
omit({a: 'a', b: 'b', c: 'c'}, ['a', 'c'])
//=> { b: 'b' }
```
Returns the object if no keys are passed:
```js
omit({a: 'a', b: 'b', c: 'c'})
//=> {a: 'a', b: 'b', c: 'c'}
```
Returns an empty object if no value is passed.
```js
omit()
//=> {}
```
### Filter function
An optional filter function may be passed as the last argument, with or without keys passed on the arguments:
**filter on keys**
```js
var res = omit({a: 'a', b: 'b', c: 'c'}, function (val, key) {
return key === 'a';
});
//=> {a: 'a'}
```
**filter on values**
```js
var fn = function() {};
var obj = {a: 'a', b: 'b', c: fn};
var res = omit(obj, ['a'], function (val, key) {
return typeof val !== 'function';
});
//=> {b: 'b'}
```
## About
### Related projects
* [object.defaults](https://www.npmjs.com/package/object.defaults): Like `extend` but only copies missing properties/values to the target object. | [homepage](https://github.com/jonschlinkert/object.defaults "Like `extend` but only copies missing properties/values to the target object.")
* [object.filter](https://www.npmjs.com/package/object.filter): Create a new object filtered to have only properties for which the callback returns true. | [homepage](https://github.com/jonschlinkert/object.filter "Create a new object filtered to have only properties for which the callback returns true.")
* [object.pick](https://www.npmjs.com/package/object.pick): Returns a filtered copy of an object with only the specified keys, similar to `_.pick… [more](https://github.com/jonschlinkert/object.pick) | [homepage](https://github.com/jonschlinkert/object.pick "Returns a filtered copy of an object with only the specified keys, similar to`_.pick` from lodash / underscore.")
* [object.pluck](https://www.npmjs.com/package/object.pluck): Like pluck from underscore / lo-dash, but returns an object composed of specified properties, with… [more](https://github.com/jonschlinkert/object.pluck) | [homepage](https://github.com/jonschlinkert/object.pluck "Like pluck from underscore / lo-dash, but returns an object composed of specified properties, with values unmodified from those of the original object.")
* [object.reduce](https://www.npmjs.com/package/object.reduce): Reduces an object to a value that is the accumulated result of running each property… [more](https://github.com/jonschlinkert/object.reduce) | [homepage](https://github.com/jonschlinkert/object.reduce "Reduces an object to a value that is the accumulated result of running each property in the object through a callback.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Building docs
_(This document was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme) (a [verb](https://github.com/verbose/verb) generator), please don't edit the readme directly. Any changes to the readme must be made in [.verb.md](.verb.md).)_
To generate the readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install -g verb verb-generate-readme && verb
```
### Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
### License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/object.omit/blob/master/LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.2.0, on October 27, 2016._
# string_decoder
***Node-core v8.9.4 string_decoder for userland***
[](https://nodei.co/npm/string_decoder/)
[](https://nodei.co/npm/string_decoder/)
```bash
npm install --save string_decoder
```
***Node-core string_decoder for userland***
This package is a mirror of the string_decoder implementation in Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.9.4/docs/api/).
As of version 1.0.0 **string_decoder** uses semantic versioning.
## Previous versions
Previous version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10.
## Update
The *build/* directory contains a build script that will scrape the source from the [nodejs/node](https://github.com/nodejs/node) repo given a specific Node version.
## Streams Working Group
`string_decoder` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
See [readable-stream](https://github.com/nodejs/readable-stream) for
more details.
# web3-providers-ipc
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is an IPC provider sub-package for [web3.js][repo].
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-providers-ipc
```
## Usage
```js
const Web3IpcProvider = require('web3-providers-ipc');
const net = require(net);
const ipc = new Web3IpcProvider('/Users/me/Library/Ethereum/geth.ipc', net);
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-providers-ipc.svg
[npm-url]: https://npmjs.org/package/web3-providers-ipc
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-providers-ipc
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-providers-ipc
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-providers-ipc
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-providers-ipc
# Tiny Validator (for v4 JSON Schema)
[](http://travis-ci.org/geraintluff/tv4) [](https://gemnasium.com/geraintluff/tv4) [](http://badge.fury.io/js/tv4)
Use [json-schema](http://json-schema.org/) [draft v4](http://json-schema.org/latest/json-schema-core.html) to validate simple values and complex objects using a rich [validation vocabulary](http://json-schema.org/latest/json-schema-validation.html) ([examples](http://json-schema.org/examples.html)).
There is support for `$ref` with JSON Pointer fragment paths (```other-schema.json#/properties/myKey```).
## Usage 1: Simple validation
```javascript
var valid = tv4.validate(data, schema);
```
If validation returns ```false```, then an explanation of why validation failed can be found in ```tv4.error```.
The error object will look something like:
```json
{
"code": 0,
"message": "Invalid type: string",
"dataPath": "/intKey",
"schemaPath": "/properties/intKey/type"
}
```
The `"code"` property will refer to one of the values in `tv4.errorCodes` - in this case, `tv4.errorCodes.INVALID_TYPE`.
To enable external schema to be referenced, you use:
```javascript
tv4.addSchema(url, schema);
```
If schemas are referenced (```$ref```) but not known, then validation will return ```true``` and the missing schema(s) will be listed in ```tv4.missing```. For more info see the API documentation below.
## Usage 2: Multi-threaded validation
Storing the error and missing schemas does not work well in multi-threaded environments, so there is an alternative syntax:
```javascript
var result = tv4.validateResult(data, schema);
```
The result will look something like:
```json
{
"valid": false,
"error": {...},
"missing": [...]
}
```
## Usage 3: Multiple errors
Normally, `tv4` stops when it encounters the first validation error. However, you can collect an array of validation errors using:
```javascript
var result = tv4.validateMultiple(data, schema);
```
The result will look something like:
```json
{
"valid": false,
"errors": [
{...},
...
],
"missing": [...]
}
```
## Asynchronous validation
Support for asynchronous validation (where missing schemas are fetched) can be added by including an extra JavaScript file. Currently, the only version requires jQuery (`tv4.async-jquery.js`), but the code is very short and should be fairly easy to modify for other libraries (such as MooTools).
Usage:
```javascript
tv4.validate(data, schema, function (isValid, validationError) { ... });
```
`validationError` is simply taken from `tv4.error`.
## Cyclical JavaScript objects
While they don't occur in proper JSON, JavaScript does support self-referencing objects. Any of the above calls support an optional third argument: `checkRecursive`. If true, tv4 will handle self-referencing objects properly - this slows down validation slightly, but that's better than a hanging script.
Consider this data, notice how both `a` and `b` refer to each other:
```javascript
var a = {};
var b = { a: a };
a.b = b;
var aSchema = { properties: { b: { $ref: 'bSchema' }}};
var bSchema = { properties: { a: { $ref: 'aSchema' }}};
tv4.addSchema('aSchema', aSchema);
tv4.addSchema('bSchema', bSchema);
```
If the `checkRecursive` argument were missing, this would throw a "too much recursion" error.
To enable support for this, pass `true` as additional argument to any of the regular validation methods:
```javascript
tv4.validate(a, aSchema, true);
tv4.validateResult(data, aSchema, true);
tv4.validateMultiple(data, aSchema, true);
```
## The `banUnknownProperties` flag
Sometimes, it is desirable to flag all unknown properties as an error. This is especially useful during development, to catch typos and the like, even when extra custom-defined properties are allowed.
As such, tv4 implements ["ban unknown properties" mode](https://github.com/json-schema/json-schema/wiki/ban-unknown-properties-mode-\(v5-proposal\)), enabled by a fourth-argument flag:
```javascript
tv4.validate(data, schema, checkRecursive, true);
tv4.validateResult(data, schema, checkRecursive, true);
tv4.validateMultiple(data, schema, checkRecursive, true);
```
## API
There are additional api commands available for more complex use-cases:
##### addSchema(uri, schema)
Pre-register a schema for reference by other schema and synchronous validation.
````js
tv4.addSchema('http://example.com/schema', { ... });
````
* `uri` the uri to identify this schema.
* `schema` the schema object.
Schemas that have their `id` property set can be added directly.
````js
tv4.addSchema({ ... });
````
##### getSchema(uri)
Return a schema from the cache.
* `uri` the uri of the schema (may contain a `#` fragment)
````js
var schema = tv4.getSchema('http://example.com/schema');
````
##### getSchemaMap()
Return a shallow copy of the schema cache, mapping schema document URIs to schema objects.
````
var map = tv4.getSchemaMap();
var schema = map[uri];
````
##### getSchemaUris(filter)
Return an Array with known schema document URIs.
* `filter` optional RegExp to filter URIs
````
var arr = tv4.getSchemaUris();
// optional filter using a RegExp
var arr = tv4.getSchemaUris(/^https?://example.com/);
````
##### getMissingUris(filter)
Return an Array with schema document URIs that are used as `$ref` in known schemas but which currently have no associated schema data.
Use this in combination with `tv4.addSchema(uri, schema)` to preload the cache for complete synchronous validation with.
* `filter` optional RegExp to filter URIs
````
var arr = tv4.getMissingUris();
// optional filter using a RegExp
var arr = tv4.getMissingUris(/^https?://example.com/);
````
##### dropSchemas()
Drop all known schema document URIs from the cache.
````
tv4.dropSchemas();
````
##### freshApi()
Return a new tv4 instance with no shared state.
````
var otherTV4 = tv4.freshApi();
````
##### reset()
Manually reset validation status from the simple `tv4.validate(data, schema)`. Although tv4 will self reset on each validation there are some implementation scenarios where this is useful.
````
tv4.reset();
````
##### setErrorReporter(reporter)
Sets a custom error reporter. This is a function that accepts three arguments, and returns an error message (string):
```
tv4.setErrorReporter(function (error, data, schema) {
return "Error code: " + error.code;
});
```
The `error` object already has everything aside from the `.message` property filled in (so you can use `error.params`, `error.dataPath`, `error.schemaPath` etc.).
If nothing is returned (or the empty string), then it falls back to the default error reporter. To remove a custom error reporter, call `tv4.setErrorReporter(null)`.
##### language(code)
Sets the language used by the default error reporter.
* `code` is a language code, like `'en'` or `'en-gb'`
````
tv4.language('en-gb');
````
If you specify a multi-level language code (e.g. `fr-CH`), then it will fall back to the generic version (`fr`) if needed.
##### addLanguage(code, map)
Add a new template-based language map for the default error reporter (used by `tv4.language(code)`)
* `code` is new language code
* `map` is an object mapping error IDs or constant names (e.g. `103` or `"NUMBER_MAXIMUM"`) to language strings.
````
tv4.addLanguage('fr', { ... });
// select for use
tv4.language('fr')
````
If you register a multi-level language code (e.g. `fr-FR`), then it will also be registered for plain `fr` if that does not already exist.
##### addFormat(format, validationFunction)
Add a custom format validator. (There are no built-in format validators. Several common ones can be found [here](https://github.com/ikr/tv4-formats) though)
* `format` is a string, corresponding to the `"format"` value in schemas.
* `validationFunction` is a function that either returns:
* `null` (meaning no error)
* an error string (explaining the reason for failure)
````
tv4.addFormat('decimal-digits', function (data, schema) {
if (typeof data === 'string' && !/^[0-9]+$/.test(data)) {
return null;
}
return "must be string of decimal digits";
});
````
Alternatively, multiple formats can be added at the same time using an object:
````
tv4.addFormat({
'my-format': function () {...},
'other-format': function () {...}
});
````
##### defineKeyword(keyword, validationFunction)
Add a custom keyword validator.
* `keyword` is a string, corresponding to a schema keyword
* `validationFunction` is a function that either returns:
* `null` (meaning no error)
* an error string (explaining the reason for failure)
* an error object (containing some of: `code`/`message`/`dataPath`/`schemaPath`)
````
tv4.defineKeyword('my-custom-keyword', function (data, value, schema) {
if (simpleFailure()) {
return "Failure";
} else if (detailedFailure()) {
return {code: tv4.errorCodes.MY_CUSTOM_CODE, message: {param1: 'a', param2: 'b'}};
} else {
return null;
}
});
````
`schema` is the schema upon which the keyword is defined. In the above example, `value === schema['my-custom-keyword']`.
If an object is returned from the custom validator, and its `message` is a string, then that is used as the message result. If `message` is an object, then that is used to populate the (localisable) error template.
##### defineError(codeName, codeNumber, defaultMessage)
Defines a custom error code.
* `codeName` is a string, all-caps underscore separated, e.g. `"MY_CUSTOM_ERROR"`
* `codeNumber` is an integer > 10000, which will be stored in `tv4.errorCodes` (e.g. `tv4.errorCodes.MY_CUSTOM_ERROR`)
* `defaultMessage` is an error message template to use (assuming translations have not been provided for this code)
An example of `defaultMessage` might be: `"Incorrect moon (expected {expected}, got {actual}"`). This is filled out if a custom keyword returns a object `message` (see above). Translations will be used, if associated with the correct code name/number.
## Demos
### Basic usage
<div class="content inline-demo" markdown="1" data-demo="demo1">
<pre class="code" id="demo1">
var schema = {
"items": {
"type": "boolean"
}
};
var data1 = [true, false];
var data2 = [true, 123];
alert("data 1: " + tv4.validate(data1, schema)); // true
alert("data 2: " + tv4.validate(data2, schema)); // false
alert("data 2 error: " + JSON.stringify(tv4.error, null, 4));
</pre>
</div>
### Use of <code>$ref</code>
<div class="content inline-demo" markdown="1" data-demo="demo2">
<pre class="code" id="demo2">
var schema = {
"type": "array",
"items": {"$ref": "#"}
};
var data1 = [[], [[]]];
var data2 = [[], [true, []]];
alert("data 1: " + tv4.validate(data1, schema)); // true
alert("data 2: " + tv4.validate(data2, schema)); // false
</pre>
</div>
### Missing schema
<div class="content inline-demo" markdown="1" data-demo="demo3">
<pre class="code" id="demo3">
var schema = {
"type": "array",
"items": {"$ref": "http://example.com/schema" }
};
var data = [1, 2, 3];
alert("Valid: " + tv4.validate(data, schema)); // true
alert("Missing schemas: " + JSON.stringify(tv4.missing));
</pre>
</div>
### Referencing remote schema
<div class="content inline-demo" markdown="1" data-demo="demo4">
<pre class="code" id="demo4">
tv4.addSchema("http://example.com/schema", {
"definitions": {
"arrayItem": {"type": "boolean"}
}
});
var schema = {
"type": "array",
"items": {"$ref": "http://example.com/schema#/definitions/arrayItem" }
};
var data1 = [true, false, true];
var data2 = [1, 2, 3];
alert("data 1: " + tv4.validate(data1, schema)); // true
alert("data 2: " + tv4.validate(data2, schema)); // false
</pre>
</div>
## Supported platforms
* Node.js
* All modern browsers
* IE >= 7
## Installation
You can manually download [`tv4.js`](https://raw.github.com/geraintluff/tv4/master/tv4.js) or the minified [`tv4.min.js`](https://raw.github.com/geraintluff/tv4/master/tv4.min.js) and include it in your html to create the global `tv4` variable.
Alternately use it as a CommonJS module:
````js
var tv4 = require('tv4');
````
or as an AMD module (e.g. with requirejs):
```js
require('tv4', function(tv4){
//use tv4 here
});
```
There is a command-line tool that wraps this library: [tv4-cmd](https://www.npmjs.com/package/tv4-cmd).
#### npm
````
$ npm install tv4
````
#### bower
````
$ bower install tv4
````
#### component.io
````
$ component install geraintluff/tv4
````
## Build and test
You can rebuild and run the node and browser tests using node.js and [grunt](http://http://gruntjs.com/):
Make sure you have the global grunt cli command:
````
$ npm install grunt-cli -g
````
Clone the git repos, open a shell in the root folder and install the development dependencies:
````
$ npm install
````
Rebuild and run the tests:
````
$ grunt
````
It will run a build and display one Spec-style report for the node.js and two Dot-style reports for both the plain and minified browser tests (via phantomJS). You can also use your own browser to manually run the suites by opening [`test/index.html`](http://geraintluff.github.io/tv4/test/index.html) and [`test/index-min.html`](http://geraintluff.github.io/tv4/test/index-min.html).
## Contributing
Pull-requests for fixes and expansions are welcome. Edit the partial files in `/source` and add your tests in a suitable suite or folder under `/test/tests` and run `grunt` to rebuild and run the test suite. Try to maintain an idiomatic coding style and add tests for any new features. It is recommend to discuss big changes in an Issue.
Do you speak another language? `tv4` needs internationalisation - please contribute language files to `/lang`!
## Packages using tv4
* [chai-json-schema](http://chaijs.com/plugins/chai-json-schema) is a [Chai Assertion Library](http://chaijs.com) plugin to assert values against json-schema.
* [grunt-tv4](http://www.github.com/Bartvds/grunt-tv4) is a plugin for [Grunt](http://http://gruntjs.com/) that uses tv4 to bulk validate json files.
## License
The code is available as "public domain", meaning that it is completely free to use, without any restrictions at all. Read the full license [here](http://geraintluff.github.com/tv4/LICENSE.txt).
It's also available under an [MIT license](http://jsonary.com/LICENSE.txt).
# dom-walk
iteratively walk a DOM node
## Example
``` js
var walk = require("dom-walk")
walk(document.body.childNodes, function (node) {
console.log("node", node)
})
```
## Installation
`npm install dom-walk`
## Contributors
- Raynos
## MIT Licenced
# hmac-drbg
[](http://travis-ci.org/indutny/hmac-drbg)
[](http://badge.fury.io/js/hmac-drbg)
JS-only implementation of [HMAC DRBG][0].
## Usage
```js
const DRBG = require('hmac-drbg');
const hash = require('hash.js');
const d = new DRBG({
hash: hash.sha256,
entropy: '0123456789abcdef',
nonce: '0123456789abcdef',
pers: '0123456789abcdef' /* or `null` */
});
d.generate(32, 'hex');
```
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2017.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: http://csrc.nist.gov/groups/ST/toolkit/documents/rng/HashBlockCipherDRBG.pdf
get-uri
=======
### Returns a `stream.Readable` from a URI string
[](https://travis-ci.org/TooTallNate/node-get-uri)
This high-level module accepts a URI string and returns a `Readable` stream
instance. There is built-in support for a variety of "protocols", and it's
easily extensible with more:
| Protocol | Description | Example
|:---------:|:-------------------------------:|:---------------------------------:
| `data` | [Data URIs][data] | `data:text/plain;base64,SGVsbG8sIFdvcmxkIQ%3D%3D`
| `file` | [File URIs][file] | `file:///c:/windows/example.ini`
| `ftp` | [FTP URIs][ftp] | `ftp://ftp.kernel.org/pub/site/README`
| `http` | [HTTP URIs][http] | `http://www.example.com/path/to/name`
| `https` | [HTTPS URIs][https] | `https://www.example.com/path/to/name`
Installation
------------
Install with `npm`:
``` bash
$ npm install get-uri
```
Example
-------
To simply get a `stream.Readable` instance from a `file:` URI, try something like:
``` js
var getUri = require('get-uri');
// `file:` maps to a `fs.ReadStream` instance…
getUri('file:///Users/nrajlich/wat.json', function (err, rs) {
if (err) throw err;
rs.pipe(process.stdout);
});
```
Missing Endpoints
-----------------
When you pass in a URI in which the resource referenced does not exist on the
destination server, then a `NotFoundError` will be returned. The `code` of the
error instance is set to `"ENOTFOUND"`, so you can special-case that in your code
to detect when a bad filename is requested:
``` js
getUri('http://example.com/resource.json', function (err, rs) {
if (err) {
if ('ENOTFOUND' == err.code) {
// bad file path requested
} else {
// something else bad happened...
throw err;
}
}
// your app code…
});
```
Cacheability
------------
When calling `getUri()` with the same URI multiple times, the `get-uri` module
supports sending an indicator that the remote resource has not been modified
since the last time it has been retreived from that node process.
To do this, pass in a `cache` option to the "options object" argument
with the value set to the `stream.Readable` instance that was previously
returned. If the remote resource has not been changed since the last call for
that same URI, then a `NotModifiedError` instance will be returned with it's
`code` property set to `"ENOTMODIFIED"`.
When the `"ENOTMODIFIED"` error occurs, then you can safely re-use the
results from the previous `getUri()` call for that same URI:
``` js
// maps to a `fs.ReadStream` instance
getUri('http://example.com/resource.json', function (err, rs) {
if (err) throw err;
// … some time later, if you need to get this same URI again, pass in the
// previous `stream.Readable` instance as `cache` option to potentially
// receive an "ENOTMODIFIED" response:
var opts = { cache: rs };
getUri('http://example.com/resource.json', opts, function (err, rs2) {
if (err) {
if ('ENOTFOUND' == err.code) {
// bad file path requested
} else if ('ENOTMODIFIED' == err.code) {
// source file has not been modified since last time it was requested,
// so `rs2` is undefined and you are expected to re-use results from
// a previous call to `getUri()`
} else {
// something else bad happened...
throw err;
}
}
});
});
```
API
---
### getUri(String uri[, Object options,] Function callback)
A `uri` String is required. An optional `options` object may be passed in:
- `cache` - A `stream.Readable` instance from a previous call to `getUri()` with the same URI. If this option is passed in, and the destination endpoint has not been modified, then an `ENOTMODIFIED` error is returned
Any other options passed in to the `options` object will be passed through
to the low-level connection creation functions (`http.get()`, `ftp.connect()`,
etc).
Invokes the given `callback` function with a `stream.Readable` instance to
read the resource at the given `uri`.
License
-------
(The MIT License)
Copyright (c) 2014 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[data]: http://tools.ietf.org/html/rfc2397
[file]: http://tools.ietf.org/html/draft-hoffman-file-uri-03
[ftp]: http://www.w3.org/Protocols/rfc959/
[http]: http://www.w3.org/Protocols/rfc2616/rfc2616.html
[https]: http://wikipedia.org/wiki/HTTP_Secure
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# Rainbow Bridge
This documentation is about design, usage, maintenance, and testing of the TEZOS-ETH bridge.
* [Overview of the components](./components.md)
* [Standard workflows](./workflows/README.md)
* [Transferring Ethereum ERC20 to Tezos](./workflows/eth2tezos-fun-transfer.md)
To see the explanation of each individual CLI please use `--help`.
# web3-core-requestmanager
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This requestmanager package is used by most [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-requestmanager
```
## Usage
```js
const Web3WsProvider = require('web3-providers-ws');
const Web3RequestManager = require('web3-core-requestmanager');
const requestManager = new Web3RequestManager(new Web3WsProvider('ws://localhost:8546'));
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-core-requestmanager.svg
[npm-url]: https://npmjs.org/package/web3-core-requestmanager
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-core-requestmanager
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-core-requestmanager
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-core-requestmanager
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-core-requestmanager
# assert-plus
This library is a super small wrapper over node's assert module that has two
things: (1) the ability to disable assertions with the environment variable
NODE\_NDEBUG, and (2) some API wrappers for argument testing. Like
`assert.string(myArg, 'myArg')`. As a simple example, most of my code looks
like this:
```javascript
var assert = require('assert-plus');
function fooAccount(options, callback) {
assert.object(options, 'options');
assert.number(options.id, 'options.id');
assert.bool(options.isManager, 'options.isManager');
assert.string(options.name, 'options.name');
assert.arrayOfString(options.email, 'options.email');
assert.func(callback, 'callback');
// Do stuff
callback(null, {});
}
```
# API
All methods that *aren't* part of node's core assert API are simply assumed to
take an argument, and then a string 'name' that's not a message; `AssertionError`
will be thrown if the assertion fails with a message like:
AssertionError: foo (string) is required
at test (/home/mark/work/foo/foo.js:3:9)
at Object.<anonymous> (/home/mark/work/foo/foo.js:15:1)
at Module._compile (module.js:446:26)
at Object..js (module.js:464:10)
at Module.load (module.js:353:31)
at Function._load (module.js:311:12)
at Array.0 (module.js:484:10)
at EventEmitter._tickCallback (node.js:190:38)
from:
```javascript
function test(foo) {
assert.string(foo, 'foo');
}
```
There you go. You can check that arrays are of a homogeneous type with `Arrayof$Type`:
```javascript
function test(foo) {
assert.arrayOfString(foo, 'foo');
}
```
You can assert IFF an argument is not `undefined` (i.e., an optional arg):
```javascript
assert.optionalString(foo, 'foo');
```
Lastly, you can opt-out of assertion checking altogether by setting the
environment variable `NODE_NDEBUG=1`. This is pseudo-useful if you have
lots of assertions, and don't want to pay `typeof ()` taxes to v8 in
production. Be advised: The standard functions re-exported from `assert` are
also disabled in assert-plus if NDEBUG is specified. Using them directly from
the `assert` module avoids this behavior.
The complete list of APIs is:
* assert.array
* assert.bool
* assert.buffer
* assert.func
* assert.number
* assert.finite
* assert.object
* assert.string
* assert.stream
* assert.date
* assert.regexp
* assert.uuid
* assert.arrayOfArray
* assert.arrayOfBool
* assert.arrayOfBuffer
* assert.arrayOfFunc
* assert.arrayOfNumber
* assert.arrayOfFinite
* assert.arrayOfObject
* assert.arrayOfString
* assert.arrayOfStream
* assert.arrayOfDate
* assert.arrayOfRegexp
* assert.arrayOfUuid
* assert.optionalArray
* assert.optionalBool
* assert.optionalBuffer
* assert.optionalFunc
* assert.optionalNumber
* assert.optionalFinite
* assert.optionalObject
* assert.optionalString
* assert.optionalStream
* assert.optionalDate
* assert.optionalRegexp
* assert.optionalUuid
* assert.optionalArrayOfArray
* assert.optionalArrayOfBool
* assert.optionalArrayOfBuffer
* assert.optionalArrayOfFunc
* assert.optionalArrayOfNumber
* assert.optionalArrayOfFinite
* assert.optionalArrayOfObject
* assert.optionalArrayOfString
* assert.optionalArrayOfStream
* assert.optionalArrayOfDate
* assert.optionalArrayOfRegexp
* assert.optionalArrayOfUuid
* assert.AssertionError
* assert.fail
* assert.ok
* assert.equal
* assert.notEqual
* assert.deepEqual
* assert.notDeepEqual
* assert.strictEqual
* assert.notStrictEqual
* assert.throws
* assert.doesNotThrow
* assert.ifError
# Installation
npm install assert-plus
## License
The MIT License (MIT)
Copyright (c) 2012 Mark Cavage
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
## Bugs
See <https://github.com/mcavage/node-assert-plus/issues>.
# encodeurl
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Encode a URL to a percent-encoded form, excluding already-encoded sequences
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install encodeurl
```
## API
```js
var encodeUrl = require('encodeurl')
```
### encodeUrl(url)
Encode a URL to a percent-encoded form, excluding already-encoded sequences.
This function will take an already-encoded URL and encode all the non-URL
code points (as UTF-8 byte sequences). This function will not encode the
"%" character unless it is not part of a valid sequence (`%20` will be
left as-is, but `%foo` will be encoded as `%25foo`).
This encode is meant to be "safe" and does not throw errors. It will try as
hard as it can to properly encode the given URL, including replacing any raw,
unpaired surrogate pairs with the Unicode replacement character prior to
encoding.
This function is _similar_ to the intrinsic function `encodeURI`, except it
will not encode the `%` character if that is part of a valid sequence, will
not encode `[` and `]` (for IPv6 hostnames) and will replace raw, unpaired
surrogate pairs with the Unicode replacement character (instead of throwing).
## Examples
### Encode a URL containing user-controled data
```js
var encodeUrl = require('encodeurl')
var escapeHtml = require('escape-html')
http.createServer(function onRequest (req, res) {
// get encoded form of inbound url
var url = encodeUrl(req.url)
// create html message
var body = '<p>Location ' + escapeHtml(url) + ' not found</p>'
// send a 404
res.statusCode = 404
res.setHeader('Content-Type', 'text/html; charset=UTF-8')
res.setHeader('Content-Length', String(Buffer.byteLength(body, 'utf-8')))
res.end(body, 'utf-8')
})
```
### Encode a URL for use in a header field
```js
var encodeUrl = require('encodeurl')
var escapeHtml = require('escape-html')
var url = require('url')
http.createServer(function onRequest (req, res) {
// parse inbound url
var href = url.parse(req)
// set new host for redirect
href.host = 'localhost'
href.protocol = 'https:'
href.slashes = true
// create location header
var location = encodeUrl(url.format(href))
// create html message
var body = '<p>Redirecting to new site: ' + escapeHtml(location) + '</p>'
// send a 301
res.statusCode = 301
res.setHeader('Content-Type', 'text/html; charset=UTF-8')
res.setHeader('Content-Length', String(Buffer.byteLength(body, 'utf-8')))
res.setHeader('Location', location)
res.end(body, 'utf-8')
})
```
## Testing
```sh
$ npm test
$ npm run lint
```
## References
- [RFC 3986: Uniform Resource Identifier (URI): Generic Syntax][rfc-3986]
- [WHATWG URL Living Standard][whatwg-url]
[rfc-3986]: https://tools.ietf.org/html/rfc3986
[whatwg-url]: https://url.spec.whatwg.org/
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/encodeurl.svg
[npm-url]: https://npmjs.org/package/encodeurl
[node-version-image]: https://img.shields.io/node/v/encodeurl.svg
[node-version-url]: https://nodejs.org/en/download
[travis-image]: https://img.shields.io/travis/pillarjs/encodeurl.svg
[travis-url]: https://travis-ci.org/pillarjs/encodeurl
[coveralls-image]: https://img.shields.io/coveralls/pillarjs/encodeurl.svg
[coveralls-url]: https://coveralls.io/r/pillarjs/encodeurl?branch=master
[downloads-image]: https://img.shields.io/npm/dm/encodeurl.svg
[downloads-url]: https://npmjs.org/package/encodeurl
### esutils [](http://travis-ci.org/estools/esutils)
esutils ([esutils](http://github.com/estools/esutils)) is
utility box for ECMAScript language tools.
### API
### ast
#### ast.isExpression(node)
Returns true if `node` is an Expression as defined in ECMA262 edition 5.1 section
[11](https://es5.github.io/#x11).
#### ast.isStatement(node)
Returns true if `node` is a Statement as defined in ECMA262 edition 5.1 section
[12](https://es5.github.io/#x12).
#### ast.isIterationStatement(node)
Returns true if `node` is an IterationStatement as defined in ECMA262 edition
5.1 section [12.6](https://es5.github.io/#x12.6).
#### ast.isSourceElement(node)
Returns true if `node` is a SourceElement as defined in ECMA262 edition 5.1
section [14](https://es5.github.io/#x14).
#### ast.trailingStatement(node)
Returns `Statement?` if `node` has trailing `Statement`.
```js
if (cond)
consequent;
```
When taking this `IfStatement`, returns `consequent;` statement.
#### ast.isProblematicIfStatement(node)
Returns true if `node` is a problematic IfStatement. If `node` is a problematic `IfStatement`, `node` cannot be represented as an one on one JavaScript code.
```js
{
type: 'IfStatement',
consequent: {
type: 'WithStatement',
body: {
type: 'IfStatement',
consequent: {type: 'EmptyStatement'}
}
},
alternate: {type: 'EmptyStatement'}
}
```
The above node cannot be represented as a JavaScript code, since the top level `else` alternate belongs to an inner `IfStatement`.
### code
#### code.isDecimalDigit(code)
Return true if provided code is decimal digit.
#### code.isHexDigit(code)
Return true if provided code is hexadecimal digit.
#### code.isOctalDigit(code)
Return true if provided code is octal digit.
#### code.isWhiteSpace(code)
Return true if provided code is white space. White space characters are formally defined in ECMA262.
#### code.isLineTerminator(code)
Return true if provided code is line terminator. Line terminator characters are formally defined in ECMA262.
#### code.isIdentifierStart(code)
Return true if provided code can be the first character of ECMA262 Identifier. They are formally defined in ECMA262.
#### code.isIdentifierPart(code)
Return true if provided code can be the trailing character of ECMA262 Identifier. They are formally defined in ECMA262.
### keyword
#### keyword.isKeywordES5(id, strict)
Returns `true` if provided identifier string is a Keyword or Future Reserved Word
in ECMA262 edition 5.1. They are formally defined in ECMA262 sections
[7.6.1.1](http://es5.github.io/#x7.6.1.1) and [7.6.1.2](http://es5.github.io/#x7.6.1.2),
respectively. If the `strict` flag is truthy, this function additionally checks whether
`id` is a Keyword or Future Reserved Word under strict mode.
#### keyword.isKeywordES6(id, strict)
Returns `true` if provided identifier string is a Keyword or Future Reserved Word
in ECMA262 edition 6. They are formally defined in ECMA262 sections
[11.6.2.1](http://ecma-international.org/ecma-262/6.0/#sec-keywords) and
[11.6.2.2](http://ecma-international.org/ecma-262/6.0/#sec-future-reserved-words),
respectively. If the `strict` flag is truthy, this function additionally checks whether
`id` is a Keyword or Future Reserved Word under strict mode.
#### keyword.isReservedWordES5(id, strict)
Returns `true` if provided identifier string is a Reserved Word in ECMA262 edition 5.1.
They are formally defined in ECMA262 section [7.6.1](http://es5.github.io/#x7.6.1).
If the `strict` flag is truthy, this function additionally checks whether `id`
is a Reserved Word under strict mode.
#### keyword.isReservedWordES6(id, strict)
Returns `true` if provided identifier string is a Reserved Word in ECMA262 edition 6.
They are formally defined in ECMA262 section [11.6.2](http://ecma-international.org/ecma-262/6.0/#sec-reserved-words).
If the `strict` flag is truthy, this function additionally checks whether `id`
is a Reserved Word under strict mode.
#### keyword.isRestrictedWord(id)
Returns `true` if provided identifier string is one of `eval` or `arguments`.
They are restricted in strict mode code throughout ECMA262 edition 5.1 and
in ECMA262 edition 6 section [12.1.1](http://ecma-international.org/ecma-262/6.0/#sec-identifiers-static-semantics-early-errors).
#### keyword.isIdentifierNameES5(id)
Return true if provided identifier string is an IdentifierName as specified in
ECMA262 edition 5.1 section [7.6](https://es5.github.io/#x7.6).
#### keyword.isIdentifierNameES6(id)
Return true if provided identifier string is an IdentifierName as specified in
ECMA262 edition 6 section [11.6](http://ecma-international.org/ecma-262/6.0/#sec-names-and-keywords).
#### keyword.isIdentifierES5(id, strict)
Return true if provided identifier string is an Identifier as specified in
ECMA262 edition 5.1 section [7.6](https://es5.github.io/#x7.6). If the `strict`
flag is truthy, this function additionally checks whether `id` is an Identifier
under strict mode.
#### keyword.isIdentifierES6(id, strict)
Return true if provided identifier string is an Identifier as specified in
ECMA262 edition 6 section [12.1](http://ecma-international.org/ecma-262/6.0/#sec-identifiers).
If the `strict` flag is truthy, this function additionally checks whether `id`
is an Identifier under strict mode.
### License
Copyright (C) 2013 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# js-sha3
[](https://travis-ci.org/emn178/js-sha3)
[](https://coveralls.io/r/emn178/js-sha3?branch=master)
[](https://nodei.co/npm/js-sha3/)
A simple SHA-3 / Keccak / Shake hash function for JavaScript supports UTF-8 encoding.
## Notice
* v0.8.0+ will throw an error if try to update hash after finalize.
* Sha3 methods has been renamed to keccak since v0.2.0. It means that sha3 methods of v0.1.x are equal to keccak methods of v0.2.x and later.
* `buffer` method is deprecated. This maybe confuse with Buffer in node.js. Please use `arrayBuffer` instead.
## Demo
[SHA3-512 Online](http://emn178.github.io/online-tools/sha3_512.html)
[SHA3-384 Online](http://emn178.github.io/online-tools/sha3_384.html)
[SHA3-256 Online](http://emn178.github.io/online-tools/sha3_256.html)
[SHA3-224 Online](http://emn178.github.io/online-tools/sha3_224.html)
[Keccak-512 Online](http://emn178.github.io/online-tools/keccak_512.html)
[Keccak-384 Online](http://emn178.github.io/online-tools/keccak_384.html)
[Keccak-256 Online](http://emn178.github.io/online-tools/keccak_256.html)
[Keccak-224 Online](http://emn178.github.io/online-tools/keccak_224.html)
[Shake128 Online](http://emn178.github.io/online-tools/shake_128.html)
[Shake256 Online](http://emn178.github.io/online-tools/shake_256.html)
## Download
[Compress](https://raw.github.com/emn178/js-sha3/master/build/sha3.min.js)
[Uncompress](https://raw.github.com/emn178/js-sha3/master/src/sha3.js)
## Installation
You can also install js-sha3 by using Bower.
bower install js-sha3
For node.js, you can use this command to install:
npm install js-sha3
## Usage
You could use like this:
```JavaScript
sha3_512('Message to hash');
sha3_384('Message to hash');
sha3_256('Message to hash');
sha3_224('Message to hash');
keccak512('Message to hash');
keccak384('Message to hash');
keccak256('Message to hash');
keccak224('Message to hash');
shake128('Message to hash', 256);
shake256('Message to hash', 512);
cshake128('Message to hash', 256, 'function name', 'customization');
cshake256('Message to hash', 512, 'function name', 'customization');
kmac128('key', 'Message to hash', 256, 'customization');
kmac256('key', 'Message to hash', 512, 'customization');
// Support ArrayBuffer output
var arrayBuffer = keccak224.arrayBuffer('Message to hash');
// Support Array output
var bytes = keccak224.digest('Message to hash');
var bytes = keccak224.array('Message to hash');
// update hash
sha3_512.update('Message ').update('to ').update('hash').hex();
// specify shake output bits at first update
shake128.update('Message ', 256).update('to ').update('hash').hex();
// or to use create
var hash = sha3_512.create();
hash.update('...');
hash.update('...');
hash.hex();
// specify shake output bits when creating
var hash = shake128.create(256);
hash.update('...');
hash.update('...');
hash.hex();
// specify cshake output bits, function name and customization when creating
var hash = cshake128.create(256, 'function name', 'customization');
// specify kmac key, output bits and customization when creating
var hash = kmac128.create('key', 256, 'customization');
```
If you use node.js, you should require the module first:
```JavaScript
sha3_512 = require('js-sha3').sha3_512;
sha3_384 = require('js-sha3').sha3_384;
sha3_256 = require('js-sha3').sha3_256;
sha3_224 = require('js-sha3').sha3_224;
keccak512 = require('js-sha3').keccak512;
keccak384 = require('js-sha3').keccak384;
keccak256 = require('js-sha3').keccak256;
keccak224 = require('js-sha3').keccak224;
shake128 = require('js-sha3').shake128;
shake256 = require('js-sha3').shake256;
cshake128 = require('js-sha3').cshake128;
cshake256 = require('js-sha3').cshake256;
kmac128 = require('js-sha3').kmac128;
kmac256 = require('js-sha3').kmac256;
```
If you use TypeScript, you can import like this:
```TypeScript
import { sha3_512 } from 'js-sha3';
```
## Example
Code
```JavaScript
sha3_512('');
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
sha3_512('The quick brown fox jumps over the lazy dog');
// 01dedd5de4ef14642445ba5f5b97c15e47b9ad931326e4b0727cd94cefc44fff23f07bf543139939b49128caf436dc1bdee54fcb24023a08d9403f9b4bf0d450
sha3_512('The quick brown fox jumps over the lazy dog.');
// 18f4f4bd419603f95538837003d9d254c26c23765565162247483f65c50303597bc9ce4d289f21d1c2f1f458828e33dc442100331b35e7eb031b5d38ba6460f8
sha3_384('');
// 0c63a75b845e4f7d01107d852e4c2485c51a50aaaa94fc61995e71bbee983a2ac3713831264adb47fb6bd1e058d5f004
sha3_384('The quick brown fox jumps over the lazy dog');
// 7063465e08a93bce31cd89d2e3ca8f602498696e253592ed26f07bf7e703cf328581e1471a7ba7ab119b1a9ebdf8be41
sha3_384('The quick brown fox jumps over the lazy dog.');
// 1a34d81695b622df178bc74df7124fe12fac0f64ba5250b78b99c1273d4b080168e10652894ecad5f1f4d5b965437fb9
sha3_256('');
// a7ffc6f8bf1ed76651c14756a061d662f580ff4de43b49fa82d80a4b80f8434a
sha3_256('The quick brown fox jumps over the lazy dog');
// 69070dda01975c8c120c3aada1b282394e7f032fa9cf32f4cb2259a0897dfc04
sha3_256('The quick brown fox jumps over the lazy dog.');
// a80f839cd4f83f6c3dafc87feae470045e4eb0d366397d5c6ce34ba1739f734d
sha3_224('');
// 6b4e03423667dbb73b6e15454f0eb1abd4597f9a1b078e3f5b5a6bc7
sha3_224('The quick brown fox jumps over the lazy dog');
// d15dadceaa4d5d7bb3b48f446421d542e08ad8887305e28d58335795
sha3_224('The quick brown fox jumps over the lazy dog.');
// 2d0708903833afabdd232a20201176e8b58c5be8a6fe74265ac54db0
keccak512('');
// 0eab42de4c3ceb9235fc91acffe746b29c29a8c366b7c60e4e67c466f36a4304c00fa9caf9d87976ba469bcbe06713b435f091ef2769fb160cdab33d3670680e
keccak512('The quick brown fox jumps over the lazy dog');
// d135bb84d0439dbac432247ee573a23ea7d3c9deb2a968eb31d47c4fb45f1ef4422d6c531b5b9bd6f449ebcc449ea94d0a8f05f62130fda612da53c79659f609
keccak512('The quick brown fox jumps over the lazy dog.');
// ab7192d2b11f51c7dd744e7b3441febf397ca07bf812cceae122ca4ded6387889064f8db9230f173f6d1ab6e24b6e50f065b039f799f5592360a6558eb52d760
keccak384('');
// 2c23146a63a29acf99e73b88f8c24eaa7dc60aa771780ccc006afbfa8fe2479b2dd2b21362337441ac12b515911957ff
keccak384('The quick brown fox jumps over the lazy dog');
// 283990fa9d5fb731d786c5bbee94ea4db4910f18c62c03d173fc0a5e494422e8a0b3da7574dae7fa0baf005e504063b3
keccak384('The quick brown fox jumps over the lazy dog.');
// 9ad8e17325408eddb6edee6147f13856ad819bb7532668b605a24a2d958f88bd5c169e56dc4b2f89ffd325f6006d820b
keccak256('');
// c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470
keccak256('The quick brown fox jumps over the lazy dog');
// 4d741b6f1eb29cb2a9b9911c82f56fa8d73b04959d3d9d222895df6c0b28aa15
keccak256('The quick brown fox jumps over the lazy dog.');
// 578951e24efd62a3d63a86f7cd19aaa53c898fe287d2552133220370240b572d
keccak224('');
// f71837502ba8e10837bdd8d365adb85591895602fc552b48b7390abd
keccak224('The quick brown fox jumps over the lazy dog');
// 310aee6b30c47350576ac2873fa89fd190cdc488442f3ef654cf23fe
keccak224('The quick brown fox jumps over the lazy dog.');
// c59d4eaeac728671c635ff645014e2afa935bebffdb5fbd207ffdeab
shake128('', 256);
// 7f9c2ba4e88f827d616045507605853ed73b8093f6efbc88eb1a6eacfa66ef26
shake256('', 512);
// 46b9dd2b0ba88d13233b3feb743eeb243fcd52ea62b81b82b50c27646ed5762fd75dc4ddd8c0f200cb05019d67b592f6fc821c49479ab48640292eacb3b7c4be
```
It also supports UTF-8 encoding:
Code
```JavaScript
sha3_512('中文');
// 059bbe2efc50cc30e4d8ec5a96be697e2108fcbf9193e1296192eddabc13b143c0120d059399a13d0d42651efe23a6c1ce2d1efb576c5b207fa2516050505af7
sha3_384('中文');
// 9fb5b99e3c546f2738dcd50a14e9aef9c313800c1bf8cf76bc9b2c3a23307841364c5a2d0794702662c5796fb72f5432
sha3_256('中文');
// ac5305da3d18be1aed44aa7c70ea548da243a59a5fd546f489348fd5718fb1a0
sha3_224('中文');
// 106d169e10b61c2a2a05554d3e631ec94467f8316640f29545d163ee
keccak512('中文');
// 2f6a1bd50562230229af34b0ccf46b8754b89d23ae2c5bf7840b4acfcef86f87395edc0a00b2bfef53bafebe3b79de2e3e01cbd8169ddbb08bde888dcc893524
keccak384('中文');
// 743f64bb7544c6ed923be4741b738dde18b7cee384a3a09c4e01acaaac9f19222cdee137702bd3aa05dc198373d87d6c
keccak256('中文');
// 70a2b6579047f0a977fcb5e9120a4e07067bea9abb6916fbc2d13ffb9a4e4eee
keccak224('中文');
// f71837502ba8e10837bdd8d365adb85591895602fc552b48b7390abd
```
It also supports byte `Array`, `Uint8Array`, `ArrayBuffer` input:
Code
```JavaScript
sha3_512([]);
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
sha3_512(new Uint8Array([]));
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
// ...
```
## Benchmark
[UTF8](http://jsperf.com/sha3/5)
[ASCII](http://jsperf.com/sha3/4)
## License
The project is released under the [MIT license](http://www.opensource.org/licenses/MIT).
## Contact
The project's website is located at https://github.com/emn178/js-sha3
Author: Chen, Yi-Cyuan ([email protected])
sshpk
=========
Parse, convert, fingerprint and use SSH keys (both public and private) in pure
node -- no `ssh-keygen` or other external dependencies.
Supports RSA, DSA, ECDSA (nistp-\*) and ED25519 key types, in PEM (PKCS#1,
PKCS#8) and OpenSSH formats.
This library has been extracted from
[`node-http-signature`](https://github.com/joyent/node-http-signature)
(work by [Mark Cavage](https://github.com/mcavage) and
[Dave Eddy](https://github.com/bahamas10)) and
[`node-ssh-fingerprint`](https://github.com/bahamas10/node-ssh-fingerprint)
(work by Dave Eddy), with additions (including ECDSA support) by
[Alex Wilson](https://github.com/arekinath).
Install
-------
```
npm install sshpk
```
Examples
--------
```js
var sshpk = require('sshpk');
var fs = require('fs');
/* Read in an OpenSSH-format public key */
var keyPub = fs.readFileSync('id_rsa.pub');
var key = sshpk.parseKey(keyPub, 'ssh');
/* Get metadata about the key */
console.log('type => %s', key.type);
console.log('size => %d bits', key.size);
console.log('comment => %s', key.comment);
/* Compute key fingerprints, in new OpenSSH (>6.7) format, and old MD5 */
console.log('fingerprint => %s', key.fingerprint().toString());
console.log('old-style fingerprint => %s', key.fingerprint('md5').toString());
```
Example output:
```
type => rsa
size => 2048 bits
comment => [email protected]
fingerprint => SHA256:PYC9kPVC6J873CSIbfp0LwYeczP/W4ffObNCuDJ1u5w
old-style fingerprint => a0:c8:ad:6c:32:9a:32:fa:59:cc:a9:8c:0a:0d:6e:bd
```
More examples: converting between formats:
```js
/* Read in a PEM public key */
var keyPem = fs.readFileSync('id_rsa.pem');
var key = sshpk.parseKey(keyPem, 'pem');
/* Convert to PEM PKCS#8 public key format */
var pemBuf = key.toBuffer('pkcs8');
/* Convert to SSH public key format (and return as a string) */
var sshKey = key.toString('ssh');
```
Signing and verifying:
```js
/* Read in an OpenSSH/PEM *private* key */
var keyPriv = fs.readFileSync('id_ecdsa');
var key = sshpk.parsePrivateKey(keyPriv, 'pem');
var data = 'some data';
/* Sign some data with the key */
var s = key.createSign('sha1');
s.update(data);
var signature = s.sign();
/* Now load the public key (could also use just key.toPublic()) */
var keyPub = fs.readFileSync('id_ecdsa.pub');
key = sshpk.parseKey(keyPub, 'ssh');
/* Make a crypto.Verifier with this key */
var v = key.createVerify('sha1');
v.update(data);
var valid = v.verify(signature);
/* => true! */
```
Matching fingerprints with keys:
```js
var fp = sshpk.parseFingerprint('SHA256:PYC9kPVC6J873CSIbfp0LwYeczP/W4ffObNCuDJ1u5w');
var keys = [sshpk.parseKey(...), sshpk.parseKey(...), ...];
keys.forEach(function (key) {
if (fp.matches(key))
console.log('found it!');
});
```
Usage
-----
## Public keys
### `parseKey(data[, format = 'auto'[, options]])`
Parses a key from a given data format and returns a new `Key` object.
Parameters
- `data` -- Either a Buffer or String, containing the key
- `format` -- String name of format to use, valid options are:
- `auto`: choose automatically from all below
- `pem`: supports both PKCS#1 and PKCS#8
- `ssh`: standard OpenSSH format,
- `pkcs1`, `pkcs8`: variants of `pem`
- `rfc4253`: raw OpenSSH wire format
- `openssh`: new post-OpenSSH 6.5 internal format, produced by
`ssh-keygen -o`
- `dnssec`: `.key` file format output by `dnssec-keygen` etc
- `putty`: the PuTTY `.ppk` file format (supports truncated variant without
all the lines from `Private-Lines:` onwards)
- `options` -- Optional Object, extra options, with keys:
- `filename` -- Optional String, name for the key being parsed
(eg. the filename that was opened). Used to generate
Error messages
- `passphrase` -- Optional String, encryption passphrase used to decrypt an
encrypted PEM file
### `Key.isKey(obj)`
Returns `true` if the given object is a valid `Key` object created by a version
of `sshpk` compatible with this one.
Parameters
- `obj` -- Object to identify
### `Key#type`
String, the type of key. Valid options are `rsa`, `dsa`, `ecdsa`.
### `Key#size`
Integer, "size" of the key in bits. For RSA/DSA this is the size of the modulus;
for ECDSA this is the bit size of the curve in use.
### `Key#comment`
Optional string, a key comment used by some formats (eg the `ssh` format).
### `Key#curve`
Only present if `this.type === 'ecdsa'`, string containing the name of the
named curve used with this key. Possible values include `nistp256`, `nistp384`
and `nistp521`.
### `Key#toBuffer([format = 'ssh'])`
Convert the key into a given data format and return the serialized key as
a Buffer.
Parameters
- `format` -- String name of format to use, for valid options see `parseKey()`
### `Key#toString([format = 'ssh])`
Same as `this.toBuffer(format).toString()`.
### `Key#fingerprint([algorithm = 'sha256'[, hashType = 'ssh']])`
Creates a new `Fingerprint` object representing this Key's fingerprint.
Parameters
- `algorithm` -- String name of hash algorithm to use, valid options are `md5`,
`sha1`, `sha256`, `sha384`, `sha512`
- `hashType` -- String name of fingerprint hash type to use, valid options are
`ssh` (the type of fingerprint used by OpenSSH, e.g. in
`ssh-keygen`), `spki` (used by HPKP, some OpenSSL applications)
### `Key#createVerify([hashAlgorithm])`
Creates a `crypto.Verifier` specialized to use this Key (and the correct public
key algorithm to match it). The returned Verifier has the same API as a regular
one, except that the `verify()` function takes only the target signature as an
argument.
Parameters
- `hashAlgorithm` -- optional String name of hash algorithm to use, any
supported by OpenSSL are valid, usually including
`sha1`, `sha256`.
`v.verify(signature[, format])` Parameters
- `signature` -- either a Signature object, or a Buffer or String
- `format` -- optional String, name of format to interpret given String with.
Not valid if `signature` is a Signature or Buffer.
### `Key#createDiffieHellman()`
### `Key#createDH()`
Creates a Diffie-Hellman key exchange object initialized with this key and all
necessary parameters. This has the same API as a `crypto.DiffieHellman`
instance, except that functions take `Key` and `PrivateKey` objects as
arguments, and return them where indicated for.
This is only valid for keys belonging to a cryptosystem that supports DHE
or a close analogue (i.e. `dsa`, `ecdsa` and `curve25519` keys). An attempt
to call this function on other keys will yield an `Error`.
## Private keys
### `parsePrivateKey(data[, format = 'auto'[, options]])`
Parses a private key from a given data format and returns a new
`PrivateKey` object.
Parameters
- `data` -- Either a Buffer or String, containing the key
- `format` -- String name of format to use, valid options are:
- `auto`: choose automatically from all below
- `pem`: supports both PKCS#1 and PKCS#8
- `ssh`, `openssh`: new post-OpenSSH 6.5 internal format, produced by
`ssh-keygen -o`
- `pkcs1`, `pkcs8`: variants of `pem`
- `rfc4253`: raw OpenSSH wire format
- `dnssec`: `.private` format output by `dnssec-keygen` etc.
- `options` -- Optional Object, extra options, with keys:
- `filename` -- Optional String, name for the key being parsed
(eg. the filename that was opened). Used to generate
Error messages
- `passphrase` -- Optional String, encryption passphrase used to decrypt an
encrypted PEM file
### `generatePrivateKey(type[, options])`
Generates a new private key of a certain key type, from random data.
Parameters
- `type` -- String, type of key to generate. Currently supported are `'ecdsa'`
and `'ed25519'`
- `options` -- optional Object, with keys:
- `curve` -- optional String, for `'ecdsa'` keys, specifies the curve to use.
If ECDSA is specified and this option is not given, defaults to
using `'nistp256'`.
### `PrivateKey.isPrivateKey(obj)`
Returns `true` if the given object is a valid `PrivateKey` object created by a
version of `sshpk` compatible with this one.
Parameters
- `obj` -- Object to identify
### `PrivateKey#type`
String, the type of key. Valid options are `rsa`, `dsa`, `ecdsa`.
### `PrivateKey#size`
Integer, "size" of the key in bits. For RSA/DSA this is the size of the modulus;
for ECDSA this is the bit size of the curve in use.
### `PrivateKey#curve`
Only present if `this.type === 'ecdsa'`, string containing the name of the
named curve used with this key. Possible values include `nistp256`, `nistp384`
and `nistp521`.
### `PrivateKey#toBuffer([format = 'pkcs1'])`
Convert the key into a given data format and return the serialized key as
a Buffer.
Parameters
- `format` -- String name of format to use, valid options are listed under
`parsePrivateKey`. Note that ED25519 keys default to `openssh`
format instead (as they have no `pkcs1` representation).
### `PrivateKey#toString([format = 'pkcs1'])`
Same as `this.toBuffer(format).toString()`.
### `PrivateKey#toPublic()`
Extract just the public part of this private key, and return it as a `Key`
object.
### `PrivateKey#fingerprint([algorithm = 'sha256'])`
Same as `this.toPublic().fingerprint()`.
### `PrivateKey#createVerify([hashAlgorithm])`
Same as `this.toPublic().createVerify()`.
### `PrivateKey#createSign([hashAlgorithm])`
Creates a `crypto.Sign` specialized to use this PrivateKey (and the correct
key algorithm to match it). The returned Signer has the same API as a regular
one, except that the `sign()` function takes no arguments, and returns a
`Signature` object.
Parameters
- `hashAlgorithm` -- optional String name of hash algorithm to use, any
supported by OpenSSL are valid, usually including
`sha1`, `sha256`.
`v.sign()` Parameters
- none
### `PrivateKey#derive(newType)`
Derives a related key of type `newType` from this key. Currently this is
only supported to change between `ed25519` and `curve25519` keys which are
stored with the same private key (but usually distinct public keys in order
to avoid degenerate keys that lead to a weak Diffie-Hellman exchange).
Parameters
- `newType` -- String, type of key to derive, either `ed25519` or `curve25519`
## Fingerprints
### `parseFingerprint(fingerprint[, options])`
Pre-parses a fingerprint, creating a `Fingerprint` object that can be used to
quickly locate a key by using the `Fingerprint#matches` function.
Parameters
- `fingerprint` -- String, the fingerprint value, in any supported format
- `options` -- Optional Object, with properties:
- `algorithms` -- Array of strings, names of hash algorithms to limit
support to. If `fingerprint` uses a hash algorithm not on
this list, throws `InvalidAlgorithmError`.
- `hashType` -- String, the type of hash the fingerprint uses, either `ssh`
or `spki` (normally auto-detected based on the format, but
can be overridden)
- `type` -- String, the entity this fingerprint identifies, either `key` or
`certificate`
### `Fingerprint.isFingerprint(obj)`
Returns `true` if the given object is a valid `Fingerprint` object created by a
version of `sshpk` compatible with this one.
Parameters
- `obj` -- Object to identify
### `Fingerprint#toString([format])`
Returns a fingerprint as a string, in the given format.
Parameters
- `format` -- Optional String, format to use, valid options are `hex` and
`base64`. If this `Fingerprint` uses the `md5` algorithm, the
default format is `hex`. Otherwise, the default is `base64`.
### `Fingerprint#matches(keyOrCertificate)`
Verifies whether or not this `Fingerprint` matches a given `Key` or
`Certificate`. This function uses double-hashing to avoid leaking timing
information. Returns a boolean.
Note that a `Key`-type Fingerprint will always return `false` if asked to match
a `Certificate` and vice versa.
Parameters
- `keyOrCertificate` -- a `Key` object or `Certificate` object, the entity to
match this fingerprint against
## Signatures
### `parseSignature(signature, algorithm, format)`
Parses a signature in a given format, creating a `Signature` object. Useful
for converting between the SSH and ASN.1 (PKCS/OpenSSL) signature formats, and
also returned as output from `PrivateKey#createSign().sign()`.
A Signature object can also be passed to a verifier produced by
`Key#createVerify()` and it will automatically be converted internally into the
correct format for verification.
Parameters
- `signature` -- a Buffer (binary) or String (base64), data of the actual
signature in the given format
- `algorithm` -- a String, name of the algorithm to be used, possible values
are `rsa`, `dsa`, `ecdsa`
- `format` -- a String, either `asn1` or `ssh`
### `Signature.isSignature(obj)`
Returns `true` if the given object is a valid `Signature` object created by a
version of `sshpk` compatible with this one.
Parameters
- `obj` -- Object to identify
### `Signature#toBuffer([format = 'asn1'])`
Converts a Signature to the given format and returns it as a Buffer.
Parameters
- `format` -- a String, either `asn1` or `ssh`
### `Signature#toString([format = 'asn1'])`
Same as `this.toBuffer(format).toString('base64')`.
## Certificates
`sshpk` includes basic support for parsing certificates in X.509 (PEM) format
and the OpenSSH certificate format. This feature is intended to be used mainly
to access basic metadata about certificates, extract public keys from them, and
also to generate simple self-signed certificates from an existing key.
Notably, there is no implementation of CA chain-of-trust verification, and only
very minimal support for key usage restrictions. Please do the security world
a favour, and DO NOT use this code for certificate verification in the
traditional X.509 CA chain style.
### `parseCertificate(data, format)`
Parameters
- `data` -- a Buffer or String
- `format` -- a String, format to use, one of `'openssh'`, `'pem'` (X.509 in a
PEM wrapper), or `'x509'` (raw DER encoded)
### `createSelfSignedCertificate(subject, privateKey[, options])`
Parameters
- `subject` -- an Identity, the subject of the certificate
- `privateKey` -- a PrivateKey, the key of the subject: will be used both to be
placed in the certificate and also to sign it (since this is
a self-signed certificate)
- `options` -- optional Object, with keys:
- `lifetime` -- optional Number, lifetime of the certificate from now in
seconds
- `validFrom`, `validUntil` -- optional Dates, beginning and end of
certificate validity period. If given
`lifetime` will be ignored
- `serial` -- optional Buffer, the serial number of the certificate
- `purposes` -- optional Array of String, X.509 key usage restrictions
### `createCertificate(subject, key, issuer, issuerKey[, options])`
Parameters
- `subject` -- an Identity, the subject of the certificate
- `key` -- a Key, the public key of the subject
- `issuer` -- an Identity, the issuer of the certificate who will sign it
- `issuerKey` -- a PrivateKey, the issuer's private key for signing
- `options` -- optional Object, with keys:
- `lifetime` -- optional Number, lifetime of the certificate from now in
seconds
- `validFrom`, `validUntil` -- optional Dates, beginning and end of
certificate validity period. If given
`lifetime` will be ignored
- `serial` -- optional Buffer, the serial number of the certificate
- `purposes` -- optional Array of String, X.509 key usage restrictions
### `Certificate#subjects`
Array of `Identity` instances describing the subject of this certificate.
### `Certificate#issuer`
The `Identity` of the Certificate's issuer (signer).
### `Certificate#subjectKey`
The public key of the subject of the certificate, as a `Key` instance.
### `Certificate#issuerKey`
The public key of the signing issuer of this certificate, as a `Key` instance.
May be `undefined` if the issuer's key is unknown (e.g. on an X509 certificate).
### `Certificate#serial`
The serial number of the certificate. As this is normally a 64-bit or wider
integer, it is returned as a Buffer.
### `Certificate#purposes`
Array of Strings indicating the X.509 key usage purposes that this certificate
is valid for. The possible strings at the moment are:
* `'signature'` -- key can be used for digital signatures
* `'identity'` -- key can be used to attest about the identity of the signer
(X.509 calls this `nonRepudiation`)
* `'codeSigning'` -- key can be used to sign executable code
* `'keyEncryption'` -- key can be used to encrypt other keys
* `'encryption'` -- key can be used to encrypt data (only applies for RSA)
* `'keyAgreement'` -- key can be used for key exchange protocols such as
Diffie-Hellman
* `'ca'` -- key can be used to sign other certificates (is a Certificate
Authority)
* `'crl'` -- key can be used to sign Certificate Revocation Lists (CRLs)
### `Certificate#getExtension(nameOrOid)`
Retrieves information about a certificate extension, if present, or returns
`undefined` if not. The string argument `nameOrOid` should be either the OID
(for X509 extensions) or the name (for OpenSSH extensions) of the extension
to retrieve.
The object returned will have the following properties:
* `format` -- String, set to either `'x509'` or `'openssh'`
* `name` or `oid` -- String, only one set based on value of `format`
* `data` -- Buffer, the raw data inside the extension
### `Certificate#getExtensions()`
Returns an Array of all present certificate extensions, in the same manner and
format as `getExtension()`.
### `Certificate#isExpired([when])`
Tests whether the Certificate is currently expired (i.e. the `validFrom` and
`validUntil` dates specify a range of time that does not include the current
time).
Parameters
- `when` -- optional Date, if specified, tests whether the Certificate was or
will be expired at the specified time instead of now
Returns a Boolean.
### `Certificate#isSignedByKey(key)`
Tests whether the Certificate was validly signed by the given (public) Key.
Parameters
- `key` -- a Key instance
Returns a Boolean.
### `Certificate#isSignedBy(certificate)`
Tests whether this Certificate was validly signed by the subject of the given
certificate. Also tests that the issuer Identity of this Certificate and the
subject Identity of the other Certificate are equivalent.
Parameters
- `certificate` -- another Certificate instance
Returns a Boolean.
### `Certificate#fingerprint([hashAlgo])`
Returns the X509-style fingerprint of the entire certificate (as a Fingerprint
instance). This matches what a web-browser or similar would display as the
certificate fingerprint and should not be confused with the fingerprint of the
subject's public key.
Parameters
- `hashAlgo` -- an optional String, any hash function name
### `Certificate#toBuffer([format])`
Serializes the Certificate to a Buffer and returns it.
Parameters
- `format` -- an optional String, output format, one of `'openssh'`, `'pem'` or
`'x509'`. Defaults to `'x509'`.
Returns a Buffer.
### `Certificate#toString([format])`
- `format` -- an optional String, output format, one of `'openssh'`, `'pem'` or
`'x509'`. Defaults to `'pem'`.
Returns a String.
## Certificate identities
### `identityForHost(hostname)`
Constructs a host-type Identity for a given hostname.
Parameters
- `hostname` -- the fully qualified DNS name of the host
Returns an Identity instance.
### `identityForUser(uid)`
Constructs a user-type Identity for a given UID.
Parameters
- `uid` -- a String, user identifier (login name)
Returns an Identity instance.
### `identityForEmail(email)`
Constructs an email-type Identity for a given email address.
Parameters
- `email` -- a String, email address
Returns an Identity instance.
### `identityFromDN(dn)`
Parses an LDAP-style DN string (e.g. `'CN=foo, C=US'`) and turns it into an
Identity instance.
Parameters
- `dn` -- a String
Returns an Identity instance.
### `identityFromArray(arr)`
Constructs an Identity from an array of DN components (see `Identity#toArray()`
for the format).
Parameters
- `arr` -- an Array of Objects, DN components with `name` and `value`
Returns an Identity instance.
Supported attributes in DNs:
| Attribute name | OID |
| -------------- | --- |
| `cn` | `2.5.4.3` |
| `o` | `2.5.4.10` |
| `ou` | `2.5.4.11` |
| `l` | `2.5.4.7` |
| `s` | `2.5.4.8` |
| `c` | `2.5.4.6` |
| `sn` | `2.5.4.4` |
| `postalCode` | `2.5.4.17` |
| `serialNumber` | `2.5.4.5` |
| `street` | `2.5.4.9` |
| `x500UniqueIdentifier` | `2.5.4.45` |
| `role` | `2.5.4.72` |
| `telephoneNumber` | `2.5.4.20` |
| `description` | `2.5.4.13` |
| `dc` | `0.9.2342.19200300.100.1.25` |
| `uid` | `0.9.2342.19200300.100.1.1` |
| `mail` | `0.9.2342.19200300.100.1.3` |
| `title` | `2.5.4.12` |
| `gn` | `2.5.4.42` |
| `initials` | `2.5.4.43` |
| `pseudonym` | `2.5.4.65` |
### `Identity#toString()`
Returns the identity as an LDAP-style DN string.
e.g. `'CN=foo, O=bar corp, C=us'`
### `Identity#type`
The type of identity. One of `'host'`, `'user'`, `'email'` or `'unknown'`
### `Identity#hostname`
### `Identity#uid`
### `Identity#email`
Set when `type` is `'host'`, `'user'`, or `'email'`, respectively. Strings.
### `Identity#cn`
The value of the first `CN=` in the DN, if any. It's probably better to use
the `#get()` method instead of this property.
### `Identity#get(name[, asArray])`
Returns the value of a named attribute in the Identity DN. If there is no
attribute of the given name, returns `undefined`. If multiple components
of the DN contain an attribute of this name, an exception is thrown unless
the `asArray` argument is given as `true` -- then they will be returned as
an Array in the same order they appear in the DN.
Parameters
- `name` -- a String
- `asArray` -- an optional Boolean
### `Identity#toArray()`
Returns the Identity as an Array of DN component objects. This looks like:
```js
[ {
"name": "cn",
"value": "Joe Bloggs"
},
{
"name": "o",
"value": "Organisation Ltd"
} ]
```
Each object has a `name` and a `value` property. The returned objects may be
safely modified.
Errors
------
### `InvalidAlgorithmError`
The specified algorithm is not valid, either because it is not supported, or
because it was not included on a list of allowed algorithms.
Thrown by `Fingerprint.parse`, `Key#fingerprint`.
Properties
- `algorithm` -- the algorithm that could not be validated
### `FingerprintFormatError`
The fingerprint string given could not be parsed as a supported fingerprint
format, or the specified fingerprint format is invalid.
Thrown by `Fingerprint.parse`, `Fingerprint#toString`.
Properties
- `fingerprint` -- if caused by a fingerprint, the string value given
- `format` -- if caused by an invalid format specification, the string value given
### `KeyParseError`
The key data given could not be parsed as a valid key.
Properties
- `keyName` -- `filename` that was given to `parseKey`
- `format` -- the `format` that was trying to parse the key (see `parseKey`)
- `innerErr` -- the inner Error thrown by the format parser
### `KeyEncryptedError`
The key is encrypted with a symmetric key (ie, it is password protected). The
parsing operation would succeed if it was given the `passphrase` option.
Properties
- `keyName` -- `filename` that was given to `parseKey`
- `format` -- the `format` that was trying to parse the key (currently can only
be `"pem"`)
### `CertificateParseError`
The certificate data given could not be parsed as a valid certificate.
Properties
- `certName` -- `filename` that was given to `parseCertificate`
- `format` -- the `format` that was trying to parse the key
(see `parseCertificate`)
- `innerErr` -- the inner Error thrown by the format parser
Friends of sshpk
----------------
* [`sshpk-agent`](https://github.com/arekinath/node-sshpk-agent) is a library
for speaking the `ssh-agent` protocol from node.js, which uses `sshpk`
file-uri-to-path
================
### Convert a `file:` URI to a file path
[](https://travis-ci.org/TooTallNate/file-uri-to-path)
Accepts a `file:` URI and returns a regular file path suitable for use with the
`fs` module functions.
Installation
------------
Install with `npm`:
``` bash
$ npm install file-uri-to-path
```
Example
-------
``` js
var uri2path = require('file-uri-to-path');
uri2path('file://localhost/c|/WINDOWS/clock.avi');
// "c:\\WINDOWS\\clock.avi"
uri2path('file:///c|/WINDOWS/clock.avi');
// "c:\\WINDOWS\\clock.avi"
uri2path('file://localhost/c:/WINDOWS/clock.avi');
// "c:\\WINDOWS\\clock.avi"
uri2path('file://hostname/path/to/the%20file.txt');
// "\\\\hostname\\path\\to\\the file.txt"
uri2path('file:///c:/path/to/the%20file.txt');
// "c:\\path\\to\\the file.txt"
```
API
---
### fileUriToPath(String uri) → String
License
-------
(The MIT License)
Copyright (c) 2014 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# keccak
This module provides native bindings to [Keccak sponge function family][1] from [Keccak Code Package][2]. In browser pure JavaScript implementation will be used.
## Usage
You can use this package as [node Hash][3].
```js
const createKeccakHash = require('keccak')
console.log(createKeccakHash('keccak256').digest().toString('hex'))
// => c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470
console.log(createKeccakHash('keccak256').update('Hello world!').digest('hex'))
// => ecd0e108a98e192af1d2c25055f4e3bed784b5c877204e73219a5203251feaab
```
Also object has two useful methods: `_resetState` and `_clone`
```js
const createKeccakHash = require('keccak')
console.log(createKeccakHash('keccak256').update('Hello World!')._resetState().digest('hex'))
// => c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470
const hash1 = createKeccakHash('keccak256').update('Hello')
const hash2 = hash1._clone()
console.log(hash1.digest('hex'))
// => 06b3dfaec148fb1bb2b066f10ec285e7c9bf402ab32aa78a5d38e34566810cd2
console.log(hash1.update(' world!').digest('hex'))
// => throw Error: Digest already called
console.log(hash2.update(' world!').digest('hex'))
// => ecd0e108a98e192af1d2c25055f4e3bed784b5c877204e73219a5203251feaab
```
### Why I should use this package?
I thought it will be popular question, so I decide write explanation in readme.
I know a few popular packages on [npm][4] related with [Keccak][1]:
- [sha3][5] ([phusion/node-sha3][6] on github) — not actual because support _only keccak_.
- [js-sha3][7] ([emn178/js-sha3][8] on github) — brilliant package which support keccak, sha3, shake. But not implement [node Hash][3] interface unfortunately!
- [browserify-sha3][9] ([wanderer/browserify-sha3][10] on github) — based on [js-sha3][7] (but not support shake!). Support [node Hash][3] interface, but without [streams][11].
- [keccakjs][12] ([axic/keccakjs][13] on github) — uses [sha3][5] and [browserify-sha3][9] as fallback. As result _keccak only_ with [node Hash][3] interface without [streams][11].
## LICENSE
This library is free and open-source software released under the MIT license.
[1]: http://keccak.noekeon.org/
[2]: https://github.com/gvanas/KeccakCodePackage
[3]: https://nodejs.org/api/crypto.html#crypto_class_hash
[4]: http://npmjs.com/
[5]: https://www.npmjs.com/package/sha3
[6]: https://github.com/phusion/node-sha3
[7]: https://www.npmjs.com/package/js-sha3
[8]: https://github.com/emn178/js-sha3
[9]: https://www.npmjs.com/package/browserify-sha3
[10]: https://github.com/wanderer/browserify-sha3
[11]: http://nodejs.org/api/stream.html
[12]: https://www.npmjs.com/package/keccakjs
[13]: https://github.com/axic/keccakjs
# web3-core-method
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This method package is used within most [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-method
```
## Usage
```js
const Web3Method = require('web3-core-method');
const method = new Web3Method({
name: 'sendTransaction',
call: 'eth_sendTransaction',
params: 1,
inputFormatter: [inputTransactionFormatter]
});
method.attachToObject(myCoolLib);
myCoolLib.sendTransaction({...}, function(){ ... });
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-core-method.svg
[npm-url]: https://npmjs.org/package/web3-core-method
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-core-method
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-core-method
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-core-method
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-core-method
AES-JS
======
[](https://badge.fury.io/js/aes-js)
A pure JavaScript implementation of the AES block cipher algorithm and all common modes of operation (CBC, CFB, CTR, ECB and OFB).
Features
--------
- Pure JavaScript (with no dependencies)
- Supports all key sizes (128-bit, 192-bit and 256-bit)
- Supports all common modes of operation (CBC, CFB, CTR, ECB and OFB)
- Works in either node.js or web browsers
Migrating from 2.x to 3.x
-------------------------
The utility functions have been renamed in the 3.x branch, since they were causing a great deal of confusion converting between bytes and string.
The examples have also been updated to encode binary data as printable hex strings.
**Strings and Bytes**
Strings should **NOT** be used as keys. UTF-8 allows variable length, multi-byte characters, so a string that is 16 *characters* long may not be 16 *bytes* long.
Also, UTF8 should **NOT** be used to store arbitrary binary data as it is a *string* encoding format, not a *binary* encoding format.
```javascript
// aesjs.util.convertStringToBytes(aString)
// Becomes:
aesjs.utils.utf8.toBytes(aString)
// aesjs.util.convertBytesToString(aString)
// Becomes:
aesjs.utils.utf8.fromBytes(aString)
```
**Bytes and Hex strings**
Binary data, such as encrypted bytes, can safely be stored and printed as hexidecimal strings.
```javascript
// aesjs.util.convertStringToBytes(aString, 'hex')
// Becomes:
aesjs.utils.hex.toBytes(aString)
// aesjs.util.convertBytesToString(aString, 'hex')
// Becomes:
aesjs.utils.hex.fromBytes(aString)
```
**Typed Arrays**
The 3.x and above versions of aes-js use [Uint8Array](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Uint8Array) instead of Array, which reduces code size when used with Browserify (it no longer pulls in Buffer) and is also about **twice** the speed.
However, if you need to support browsers older than IE 10, you should continue using version 2.x.
API
===
#### Node.js
To install `aes-js` in your node.js project:
```
npm install aes-js
```
And to access it from within node, simply add:
```javascript
var aesjs = require('aes-js');
```
#### Web Browser
To use `aes-js` in a web page, add the following:
```html
<script type="text/javascript" src="https://cdn.rawgit.com/ricmoo/aes-js/e27b99df/index.js"></script>
```
Keys
----
All keys must be 128 bits (16 bytes), 192 bits (24 bytes) or 256 bits (32 bytes) long.
The library work with `Array`, `Uint8Array` and `Buffer` objects as well as any *array-like* object (i.e. must have a `length` property, and have a valid byte value for each entry).
```javascript
// 128-bit, 192-bit and 256-bit keys
var key_128 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15];
var key_192 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23];
var key_256 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28,
29, 30, 31];
// or, you may use Uint8Array:
var key_128_array = new Uint8Array(key_128);
var key_192_array = new Uint8Array(key_192);
var key_258_array = new Uint8Array(key_256);
// or, you may use Buffer in node.js:
var key_128_buffer = new Buffer(key_128);
var key_192_buffer = new Buffer(key_192);
var key_258_buffer = new Buffer(key_256);
```
To generate keys from simple-to-remember passwords, consider using a password-based key-derivation function such as [scrypt](https://www.npmjs.com/package/scrypt-js) or [bcrypt](https://www.npmjs.com/search?q=bcrypt).
Common Modes of Operation
-------------------------
There are several modes of operations, each with various pros and cons. In general though, the **CBC** and **CTR** modes are recommended. The **ECB is NOT recommended.**, and is included primarily for completeness.
### CTR - Counter (recommended)
```javascript
// An example 128-bit key (16 bytes * 8 bits/byte = 128 bits)
var key = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 ];
// Convert text to bytes
var text = 'Text may be any length you wish, no padding is required.';
var textBytes = aesjs.utils.utf8.toBytes(text);
// The counter is optional, and if omitted will begin at 1
var aesCtr = new aesjs.ModeOfOperation.ctr(key, new aesjs.Counter(5));
var encryptedBytes = aesCtr.encrypt(textBytes);
// To print or store the binary data, you may convert it to hex
var encryptedHex = aesjs.utils.hex.fromBytes(encryptedBytes);
console.log(encryptedHex);
// "a338eda3874ed884b6199150d36f49988c90f5c47fe7792b0cf8c7f77eeffd87
// ea145b73e82aefcf2076f881c88879e4e25b1d7b24ba2788"
// When ready to decrypt the hex string, convert it back to bytes
var encryptedBytes = aesjs.utils.hex.toBytes(encryptedHex);
// The counter mode of operation maintains internal state, so to
// decrypt a new instance must be instantiated.
var aesCtr = new aesjs.ModeOfOperation.ctr(key, new aesjs.Counter(5));
var decryptedBytes = aesCtr.decrypt(encryptedBytes);
// Convert our bytes back into text
var decryptedText = aesjs.utils.utf8.fromBytes(decryptedBytes);
console.log(decryptedText);
// "Text may be any length you wish, no padding is required."
```
### CBC - Cipher-Block Chaining (recommended)
```javascript
// An example 128-bit key
var key = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 ];
// The initialization vector (must be 16 bytes)
var iv = [ 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,35, 36 ];
// Convert text to bytes (text must be a multiple of 16 bytes)
var text = 'TextMustBe16Byte';
var textBytes = aesjs.utils.utf8.toBytes(text);
var aesCbc = new aesjs.ModeOfOperation.cbc(key, iv);
var encryptedBytes = aesCbc.encrypt(textBytes);
// To print or store the binary data, you may convert it to hex
var encryptedHex = aesjs.utils.hex.fromBytes(encryptedBytes);
console.log(encryptedHex);
// "104fb073f9a131f2cab49184bb864ca2"
// When ready to decrypt the hex string, convert it back to bytes
var encryptedBytes = aesjs.utils.hex.toBytes(encryptedHex);
// The cipher-block chaining mode of operation maintains internal
// state, so to decrypt a new instance must be instantiated.
var aesCbc = new aesjs.ModeOfOperation.cbc(key, iv);
var decryptedBytes = aesCbc.decrypt(encryptedBytes);
// Convert our bytes back into text
var decryptedText = aesjs.utils.utf8.fromBytes(decryptedBytes);
console.log(decryptedText);
// "TextMustBe16Byte"
```
### CFB - Cipher Feedback
```javascript
// An example 128-bit key
var key = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 ];
// The initialization vector (must be 16 bytes)
var iv = [ 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,35, 36 ];
// Convert text to bytes (must be a multiple of the segment size you choose below)
var text = 'TextMustBeAMultipleOfSegmentSize';
var textBytes = aesjs.utils.utf8.toBytes(text);
// The segment size is optional, and defaults to 1
var segmentSize = 8;
var aesCfb = new aesjs.ModeOfOperation.cfb(key, iv, segmentSize);
var encryptedBytes = aesCfb.encrypt(textBytes);
// To print or store the binary data, you may convert it to hex
var encryptedHex = aesjs.utils.hex.fromBytes(encryptedBytes);
console.log(encryptedHex);
// "55e3af2638c560b4fdb9d26a630733ea60197ec23deb85b1f60f71f10409ce27"
// When ready to decrypt the hex string, convert it back to bytes
var encryptedBytes = aesjs.utils.hex.toBytes(encryptedHex);
// The cipher feedback mode of operation maintains internal state,
// so to decrypt a new instance must be instantiated.
var aesCfb = new aesjs.ModeOfOperation.cfb(key, iv, 8);
var decryptedBytes = aesCfb.decrypt(encryptedBytes);
// Convert our bytes back into text
var decryptedText = aesjs.utils.utf8.fromBytes(decryptedBytes);
console.log(decryptedText);
// "TextMustBeAMultipleOfSegmentSize"
```
### OFB - Output Feedback
```javascript
// An example 128-bit key
var key = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 ];
// The initialization vector (must be 16 bytes)
var iv = [ 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,35, 36 ];
// Convert text to bytes
var text = 'Text may be any length you wish, no padding is required.';
var textBytes = aesjs.utils.utf8.toBytes(text);
var aesOfb = new aesjs.ModeOfOperation.ofb(key, iv);
var encryptedBytes = aesOfb.encrypt(textBytes);
// To print or store the binary data, you may convert it to hex
var encryptedHex = aesjs.utils.hex.fromBytes(encryptedBytes);
console.log(encryptedHex);
// "55e3af2655dd72b9f32456042f39bae9accff6259159e608be55a1aa313c598d
// b4b18406d89c83841c9d1af13b56de8eda8fcfe9ec8e75e8"
// When ready to decrypt the hex string, convert it back to bytes
var encryptedBytes = aesjs.utils.hex.toBytes(encryptedHex);
// The output feedback mode of operation maintains internal state,
// so to decrypt a new instance must be instantiated.
var aesOfb = new aesjs.ModeOfOperation.ofb(key, iv);
var decryptedBytes = aesOfb.decrypt(encryptedBytes);
// Convert our bytes back into text
var decryptedText = aesjs.utils.utf8.fromBytes(decryptedBytes);
console.log(decryptedText);
// "Text may be any length you wish, no padding is required."
```
### ECB - Electronic Codebook (NOT recommended)
This mode is **not** recommended. Since, for a given key, the same plaintext block in produces the same ciphertext block out, this mode of operation can leak data, such as patterns. For more details and examples, see the Wikipedia article, [Electronic Codebook](http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#Electronic_Codebook_.28ECB.29).
```javascript
// An example 128-bit key
var key = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 ];
// Convert text to bytes
var text = 'TextMustBe16Byte';
var textBytes = aesjs.utils.utf8.toBytes(text);
var aesEcb = new aesjs.ModeOfOperation.ecb(key);
var encryptedBytes = aesEcb.encrypt(textBytes);
// To print or store the binary data, you may convert it to hex
var encryptedHex = aesjs.utils.hex.fromBytes(encryptedBytes);
console.log(encryptedHex);
// "a7d93b35368519fac347498dec18b458"
// When ready to decrypt the hex string, convert it back to bytes
var encryptedBytes = aesjs.utils.hex.toBytes(encryptedHex);
// Since electronic codebook does not store state, we can
// reuse the same instance.
//var aesEcb = new aesjs.ModeOfOperation.ecb(key);
var decryptedBytes = aesEcb.decrypt(encryptedBytes);
// Convert our bytes back into text
var decryptedText = aesjs.utils.utf8.fromBytes(decryptedBytes);
console.log(decryptedText);
// "TextMustBe16Byte"
```
Block Cipher
------------
You should usually use one of the above common modes of operation. Using the block cipher algorithm directly is also possible using **ECB** as that mode of operation is merely a thin wrapper.
But this might be useful to experiment with custom modes of operation or play with block cipher algorithms.
```javascript
// the AES block cipher algorithm works on 16 byte bloca ks, no more, no less
var text = "ABlockIs16Bytes!";
var textAsBytes = aesjs.utils.utf8.toBytes(text)
console.log(textAsBytes);
// [65, 66, 108, 111, 99, 107, 73, 115, 49, 54, 66, 121, 116, 101, 115, 33]
// create an instance of the block cipher algorithm
var key = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 9, 3];
var aes = new aesjs.AES(key);
// encrypt...
var encryptedBytes = aes.encrypt(textAsBytes);
console.log(encryptedBytes);
// [136, 15, 199, 174, 118, 133, 233, 177, 143, 47, 42, 211, 96, 55, 107, 109]
// To print or store the binary data, you may convert it to hex
var encryptedHex = aesjs.utils.hex.fromBytes(encryptedBytes);
console.log(encryptedHex);
// "880fc7ae7685e9b18f2f2ad360376b6d"
// When ready to decrypt the hex string, convert it back to bytes
var encryptedBytes = aesjs.utils.hex.toBytes(encryptedHex);
// decrypt...
var decryptedBytes = aes.decrypt(encryptedBytes);
console.log(decryptedBytes);
// [65, 66, 108, 111, 99, 107, 73, 115, 49, 54, 66, 121, 116, 101, 115, 33]
// decode the bytes back into our original text
var decryptedText = aesjs.utils.utf8.fromBytes(decryptedBytes);
console.log(decryptedText);
// "ABlockIs16Bytes!"
```
Notes
=====
What is a Key
-------------
This seems to be a point of confusion for many people new to using encryption. You can think of the key as the *"password"*. However, these algorithms require the *"password"* to be a specific length.
With AES, there are three possible key lengths, 128-bit (16 bytes), 192-bit (24 bytes) or 256-bit (32 bytes). When you create an AES object, the key size is automatically detected, so it is important to pass in a key of the correct length.
Often, you wish to provide a password of arbitrary length, for example, something easy to remember or write down. In these cases, you must come up with a way to transform the password into a key of a specific length. A **Password-Based Key Derivation Function** (PBKDF) is an algorithm designed for this exact purpose.
Here is an example, using the popular (possibly obsolete?) pbkdf2:
```javascript
var pbkdf2 = require('pbkdf2');
var key_128 = pbkdf2.pbkdf2Sync('password', 'salt', 1, 128 / 8, 'sha512');
var key_192 = pbkdf2.pbkdf2Sync('password', 'salt', 1, 192 / 8, 'sha512');
var key_256 = pbkdf2.pbkdf2Sync('password', 'salt', 1, 256 / 8, 'sha512');
```
Another possibility, is to use a hashing function, such as SHA256 to hash the password, but this method is vulnerable to [Rainbow Attacks](http://en.wikipedia.org/wiki/Rainbow_table), unless you use a [salt](http://en.wikipedia.org/wiki/Salt_(cryptography)).
Performance
-----------
Todo...
Tests
-----
A test suite has been generated (`test/test-vectors.json`) from a known correct implementation, [pycrypto](https://www.dlitz.net/software/pycrypto/). To generate new test vectors, run `python generate-tests.py`.
To run the node.js test suite:
```
npm test
```
To run the web browser tests, open the `test/test.html` file in your browser.
FAQ
---
#### How do I get a question I have added?
E-mail me at [email protected] with any questions, suggestions, comments, et cetera.
Donations
---------
Obviously, it's all licensed under the MIT license, so use it as you wish; but if you'd like to buy me a coffee, I won't complain. =)
- Bitcoin - `1K1Ax9t6uJmjE4X5xcoVuyVTsiLrYRqe2P`
- Ethereum - `0x70bDC274028F3f391E398dF8e3977De64FEcBf04`
# abstract-leveldown
> An abstract prototype matching the [`leveldown`](https://github.com/level/leveldown/) API. Useful for extending [`levelup`](https://github.com/level/levelup) functionality by providing a replacement to `leveldown`.
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/abstract-leveldown)

[](http://travis-ci.org/Level/abstract-leveldown)
[](https://david-dm.org/level/abstract-leveldown)
[](https://standardjs.com)
[](https://www.npmjs.com/package/abstract-leveldown)
`abstract-leveldown` provides a simple, operational *noop* base prototype that's ready for extending. By default, all operations have sensible "noops" (operations that essentially do nothing). For example, simple operations such as `.open(callback)` and `.close(callback)` will simply invoke the callback (on a *next tick*). More complex operations perform sensible actions, for example: `.get(key, callback)` will always return a `'NotFound'` `Error` on the callback.
You add functionality by implementing the underscore versions of the operations. For example, to implement a `put()` operation you add a `_put()` method to your object. Each of these underscore methods override the default *noop* operations and are always provided with **consistent arguments**, regardless of what is passed in by the client.
Additionally, all methods provide argument checking and sensible defaults for optional arguments. All bad-argument errors are compatible with `leveldown` (they pass the `leveldown` method arguments tests). For example, if you call `.open()` without a callback argument you'll get an `Error('open() requires a callback argument')`. Where optional arguments are involved, your underscore methods will receive sensible defaults. A `.get(key, callback)` will pass through to a `._get(key, options, callback)` where the `options` argument is an empty object.
**If you are upgrading:** please see [UPGRADING.md](UPGRADING.md).
## Example
A simplistic in-memory `leveldown` replacement
```js
var util = require('util')
var AbstractLevelDOWN = require('./').AbstractLevelDOWN
// constructor, passes through the 'location' argument to the AbstractLevelDOWN constructor
function FakeLevelDOWN (location) {
AbstractLevelDOWN.call(this, location)
}
// our new prototype inherits from AbstractLevelDOWN
util.inherits(FakeLevelDOWN, AbstractLevelDOWN)
// implement some methods
FakeLevelDOWN.prototype._open = function (options, callback) {
// initialise a memory storage object
this._store = {}
// optional use of nextTick to be a nice async citizen
process.nextTick(function () { callback(null, this) }.bind(this))
}
FakeLevelDOWN.prototype._put = function (key, value, options, callback) {
key = '_' + key // safety, to avoid key='__proto__'-type skullduggery
this._store[key] = value
process.nextTick(callback)
}
FakeLevelDOWN.prototype._get = function (key, options, callback) {
var value = this._store['_' + key]
if (value === undefined) {
// 'NotFound' error, consistent with LevelDOWN API
return process.nextTick(function () { callback(new Error('NotFound')) })
}
process.nextTick(function () {
callback(null, value)
})
}
FakeLevelDOWN.prototype._del = function (key, options, callback) {
delete this._store['_' + key]
process.nextTick(callback)
}
// Now use it with levelup
var levelup = require('levelup')
var db = levelup(new FakeLevelDOWN('/who/cares'))
db.put('foo', 'bar', function (err) {
if (err) throw err
db.get('foo', function (err, value) {
if (err) throw err
console.log('Got foo =', value)
})
})
```
See [`memdown`](https://github.com/Level/memdown/) if you are looking for a complete in-memory replacement for `leveldown`.
## Browser support
[](https://saucelabs.com/u/abstract-leveldown)
## Extensible API
Remember that each of these methods, if you implement them, will receive exactly the number and order of arguments described. Optional arguments will be converted to sensible defaults.
### `AbstractLevelDOWN(location)`
### `AbstractLevelDOWN#status`
An `AbstractLevelDOWN` based database can be in one of the following states:
* `'new'` - newly created, not opened or closed
* `'opening'` - waiting for the database to be opened
* `'open'` - successfully opened the database, available for use
* `'closing'` - waiting for the database to be closed
* `'closed'` - database has been successfully closed, should not be used
### `AbstractLevelDOWN#_open(options, callback)`
### `AbstractLevelDOWN#_close(callback)`
### `AbstractLevelDOWN#_get(key, options, callback)`
### `AbstractLevelDOWN#_put(key, value, options, callback)`
### `AbstractLevelDOWN#_del(key, options, callback)`
### `AbstractLevelDOWN#_batch(array, options, callback)`
If `batch()` is called without arguments or with only an options object then it should return a `Batch` object with chainable methods. Otherwise it will invoke a classic batch operation.
### `AbstractLevelDOWN#_chainedBatch()`
By default a `batch()` operation without arguments returns a blank `AbstractChainedBatch` object. The prototype is available on the main exports for you to extend. If you want to implement chainable batch operations then you should extend the `AbstractChaindBatch` and return your object in the `_chainedBatch()` method.
### `AbstractLevelDOWN#_serializeKey(key)`
### `AbstractLevelDOWN#_serializeValue(value)`
### `AbstractLevelDOWN#_iterator(options)`
By default an `iterator()` operation returns a blank `AbstractIterator` object. The prototype is available on the main exports for you to extend. If you want to implement iterator operations then you should extend the `AbstractIterator` and return your object in the `_iterator(options)` method.
The `iterator()` operation accepts the following range options:
* `gt`
* `gte`
* `lt`
* `lte`
* `start` (legacy)
* `end` (legacy)
A range option that is either an empty buffer, an empty string or `null` will be ignored.
`AbstractIterator` implements the basic state management found in LevelDOWN. It keeps track of when a `next()` is in progress and when an `end()` has been called so it doesn't allow concurrent `next()` calls, it does allow `end()` while a `next()` is in progress and it doesn't allow either `next()` or `end()` after `end()` has been called.
### `AbstractIterator(db)`
Provided with the current instance of `AbstractLevelDOWN` by default.
### `AbstractIterator#_next(callback)`
### `AbstractIterator#_end(callback)`
### `AbstractChainedBatch`
Provided with the current instance of `AbstractLevelDOWN` by default.
### `AbstractChainedBatch#_put(key, value)`
### `AbstractChainedBatch#_del(key)`
### `AbstractChainedBatch#_clear()`
### `AbstractChainedBatch#_write(options, callback)`
### `AbstractChainedBatch#_serializeKey(key)`
### `AbstractChainedBatch#_serializeValue(value)`
<a name="contributing"></a>
## Contributing
`abstract-leveldown` is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [contribution guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
## Big Thanks
Cross-browser Testing Platform and Open Source ♥ Provided by [Sauce Labs](https://saucelabs.com).
[](https://saucelabs.com)
<a name="license"></a>
## License
Copyright © 2013-2018 `abstract-leveldown` [contributors](https://github.com/level/community#contributors).
`abstract-leveldown` is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included `LICENSE.md` file for more details.
[level-badge]: http://leveldb.org/img/badge.svg
# is-number [](https://www.npmjs.com/package/is-number) [](https://npmjs.org/package/is-number) [](https://npmjs.org/package/is-number) [](https://travis-ci.org/jonschlinkert/is-number)
> Returns true if the value is a finite number.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-number
```
## Why is this needed?
In JavaScript, it's not always as straightforward as it should be to reliably check if a value is a number. It's common for devs to use `+`, `-`, or `Number()` to cast a string value to a number (for example, when values are returned from user input, regex matches, parsers, etc). But there are many non-intuitive edge cases that yield unexpected results:
```js
console.log(+[]); //=> 0
console.log(+''); //=> 0
console.log(+' '); //=> 0
console.log(typeof NaN); //=> 'number'
```
This library offers a performant way to smooth out edge cases like these.
## Usage
```js
const isNumber = require('is-number');
```
See the [tests](./test.js) for more examples.
### true
```js
isNumber(5e3); // true
isNumber(0xff); // true
isNumber(-1.1); // true
isNumber(0); // true
isNumber(1); // true
isNumber(1.1); // true
isNumber(10); // true
isNumber(10.10); // true
isNumber(100); // true
isNumber('-1.1'); // true
isNumber('0'); // true
isNumber('012'); // true
isNumber('0xff'); // true
isNumber('1'); // true
isNumber('1.1'); // true
isNumber('10'); // true
isNumber('10.10'); // true
isNumber('100'); // true
isNumber('5e3'); // true
isNumber(parseInt('012')); // true
isNumber(parseFloat('012')); // true
```
### False
Everything else is false, as you would expect:
```js
isNumber(Infinity); // false
isNumber(NaN); // false
isNumber(null); // false
isNumber(undefined); // false
isNumber(''); // false
isNumber(' '); // false
isNumber('foo'); // false
isNumber([1]); // false
isNumber([]); // false
isNumber(function () {}); // false
isNumber({}); // false
```
## Release history
### 7.0.0
* Refactor. Now uses `.isFinite` if it exists.
* Performance is about the same as v6.0 when the value is a string or number. But it's now 3x-4x faster when the value is not a string or number.
### 6.0.0
* Optimizations, thanks to @benaadams.
### 5.0.0
**Breaking changes**
* removed support for `instanceof Number` and `instanceof String`
## Benchmarks
As with all benchmarks, take these with a grain of salt. See the [benchmarks](./benchmark/index.js) for more detail.
```
# all
v7.0 x 413,222 ops/sec ±2.02% (86 runs sampled)
v6.0 x 111,061 ops/sec ±1.29% (85 runs sampled)
parseFloat x 317,596 ops/sec ±1.36% (86 runs sampled)
fastest is 'v7.0'
# string
v7.0 x 3,054,496 ops/sec ±1.05% (89 runs sampled)
v6.0 x 2,957,781 ops/sec ±0.98% (88 runs sampled)
parseFloat x 3,071,060 ops/sec ±1.13% (88 runs sampled)
fastest is 'parseFloat,v7.0'
# number
v7.0 x 3,146,895 ops/sec ±0.89% (89 runs sampled)
v6.0 x 3,214,038 ops/sec ±1.07% (89 runs sampled)
parseFloat x 3,077,588 ops/sec ±1.07% (87 runs sampled)
fastest is 'v6.0'
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [is-plain-object](https://www.npmjs.com/package/is-plain-object): Returns true if an object was created by the `Object` constructor. | [homepage](https://github.com/jonschlinkert/is-plain-object "Returns true if an object was created by the `Object` constructor.")
* [is-primitive](https://www.npmjs.com/package/is-primitive): Returns `true` if the value is a primitive. | [homepage](https://github.com/jonschlinkert/is-primitive "Returns `true` if the value is a primitive. ")
* [isobject](https://www.npmjs.com/package/isobject): Returns true if the value is an object and not an array or null. | [homepage](https://github.com/jonschlinkert/isobject "Returns true if the value is an object and not an array or null.")
* [kind-of](https://www.npmjs.com/package/kind-of): Get the native type of a value. | [homepage](https://github.com/jonschlinkert/kind-of "Get the native type of a value.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 49 | [jonschlinkert](https://github.com/jonschlinkert) |
| 5 | [charlike-old](https://github.com/charlike-old) |
| 1 | [benaadams](https://github.com/benaadams) |
| 1 | [realityking](https://github.com/realityking) |
### Author
**Jon Schlinkert**
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
### License
Copyright © 2018, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on June 15, 2018._
# extsprintf: extended POSIX-style sprintf
Stripped down version of s[n]printf(3c). We make a best effort to throw an
exception when given a format string we don't understand, rather than ignoring
it, so that we won't break existing programs if/when we go implement the rest
of this.
This implementation currently supports specifying
* field alignment ('-' flag),
* zero-pad ('0' flag)
* always show numeric sign ('+' flag),
* field width
* conversions for strings, decimal integers, and floats (numbers).
* argument size specifiers. These are all accepted but ignored, since
Javascript has no notion of the physical size of an argument.
Everything else is currently unsupported, most notably: precision, unsigned
numbers, non-decimal numbers, and characters.
Besides the usual POSIX conversions, this implementation supports:
* `%j`: pretty-print a JSON object (using node's "inspect")
* `%r`: pretty-print an Error object
# Example
First, install it:
# npm install extsprintf
Now, use it:
var mod_extsprintf = require('extsprintf');
console.log(mod_extsprintf.sprintf('hello %25s', 'world'));
outputs:
hello world
# Also supported
**printf**: same args as sprintf, but prints the result to stdout
**fprintf**: same args as sprintf, preceded by a Node stream. Prints the result
to the given stream.
# function-bind
<!--
[![build status][travis-svg]][travis-url]
[![NPM version][npm-badge-svg]][npm-url]
[![Coverage Status][5]][6]
[![gemnasium Dependency Status][7]][8]
[![Dependency status][deps-svg]][deps-url]
[![Dev Dependency status][dev-deps-svg]][dev-deps-url]
-->
<!-- [![browser support][11]][12] -->
Implementation of function.prototype.bind
## Example
I mainly do this for unit tests I run on phantomjs.
PhantomJS does not have Function.prototype.bind :(
```js
Function.prototype.bind = require("function-bind")
```
## Installation
`npm install function-bind`
## Contributors
- Raynos
## MIT Licenced
[travis-svg]: https://travis-ci.org/Raynos/function-bind.svg
[travis-url]: https://travis-ci.org/Raynos/function-bind
[npm-badge-svg]: https://badge.fury.io/js/function-bind.svg
[npm-url]: https://npmjs.org/package/function-bind
[5]: https://coveralls.io/repos/Raynos/function-bind/badge.png
[6]: https://coveralls.io/r/Raynos/function-bind
[7]: https://gemnasium.com/Raynos/function-bind.png
[8]: https://gemnasium.com/Raynos/function-bind
[deps-svg]: https://david-dm.org/Raynos/function-bind.svg
[deps-url]: https://david-dm.org/Raynos/function-bind
[dev-deps-svg]: https://david-dm.org/Raynos/function-bind/dev-status.svg
[dev-deps-url]: https://david-dm.org/Raynos/function-bind#info=devDependencies
[11]: https://ci.testling.com/Raynos/function-bind.png
[12]: https://ci.testling.com/Raynos/function-bind
randombytes
===
[](https://www.npmjs.org/package/randombytes) [](https://travis-ci.org/crypto-browserify/randombytes)
randombytes from node that works in the browser. In node you just get crypto.randomBytes, but in the browser it uses .crypto/msCrypto.getRandomValues
```js
var randomBytes = require('randombytes');
randomBytes(16);//get 16 random bytes
randomBytes(16, function (err, resp) {
// resp is 16 random bytes
});
```
[![Build status][nix-build-image]][nix-build-url]
[![Windows status][win-build-image]][win-build-url]
![Transpilation status][transpilation-image]
[![npm version][npm-image]][npm-url]
# es5-ext
## ECMAScript 5 extensions
### (with respect to ECMAScript 6 standard)
Shims for upcoming ES6 standard and other goodies implemented strictly with ECMAScript conventions in mind.
It's designed to be used in compliant ECMAScript 5 or ECMAScript 6 environments. Older environments are not supported, although most of the features should work with correct ECMAScript 5 shim on board.
When used in ECMAScript 6 environment, native implementation (if valid) takes precedence over shims.
### Installation
$ npm install es5-ext
To port it to Browser or any other (non CJS) environment, use your favorite CJS bundler. No favorite yet? Try: [Browserify](http://browserify.org/), [Webmake](https://github.com/medikoo/modules-webmake) or [Webpack](http://webpack.github.io/)
### Usage
#### ECMAScript 6 features
You can force ES6 features to be implemented in your environment, e.g. following will assign `from` function to `Array` (only if it's not implemented already).
```javascript
require("es5-ext/array/from/implement");
Array.from("foo"); // ['f', 'o', 'o']
```
You can also access shims directly, without fixing native objects. Following will return native `Array.from` if it's available and fallback to shim if it's not.
```javascript
var aFrom = require("es5-ext/array/from");
aFrom("foo"); // ['f', 'o', 'o']
```
If you want to use shim unconditionally (even if native implementation exists) do:
```javascript
var aFrom = require("es5-ext/array/from/shim");
aFrom("foo"); // ['f', 'o', 'o']
```
##### List of ES6 shims
It's about properties introduced with ES6 and those that have been updated in new spec.
- `Array.from` -> `require('es5-ext/array/from')`
- `Array.of` -> `require('es5-ext/array/of')`
- `Array.prototype.concat` -> `require('es5-ext/array/#/concat')`
- `Array.prototype.copyWithin` -> `require('es5-ext/array/#/copy-within')`
- `Array.prototype.entries` -> `require('es5-ext/array/#/entries')`
- `Array.prototype.fill` -> `require('es5-ext/array/#/fill')`
- `Array.prototype.filter` -> `require('es5-ext/array/#/filter')`
- `Array.prototype.find` -> `require('es5-ext/array/#/find')`
- `Array.prototype.findIndex` -> `require('es5-ext/array/#/find-index')`
- `Array.prototype.keys` -> `require('es5-ext/array/#/keys')`
- `Array.prototype.map` -> `require('es5-ext/array/#/map')`
- `Array.prototype.slice` -> `require('es5-ext/array/#/slice')`
- `Array.prototype.splice` -> `require('es5-ext/array/#/splice')`
- `Array.prototype.values` -> `require('es5-ext/array/#/values')`
- `Array.prototype[@@iterator]` -> `require('es5-ext/array/#/@@iterator')`
- `Math.acosh` -> `require('es5-ext/math/acosh')`
- `Math.asinh` -> `require('es5-ext/math/asinh')`
- `Math.atanh` -> `require('es5-ext/math/atanh')`
- `Math.cbrt` -> `require('es5-ext/math/cbrt')`
- `Math.clz32` -> `require('es5-ext/math/clz32')`
- `Math.cosh` -> `require('es5-ext/math/cosh')`
- `Math.exmp1` -> `require('es5-ext/math/expm1')`
- `Math.fround` -> `require('es5-ext/math/fround')`
- `Math.hypot` -> `require('es5-ext/math/hypot')`
- `Math.imul` -> `require('es5-ext/math/imul')`
- `Math.log1p` -> `require('es5-ext/math/log1p')`
- `Math.log2` -> `require('es5-ext/math/log2')`
- `Math.log10` -> `require('es5-ext/math/log10')`
- `Math.sign` -> `require('es5-ext/math/sign')`
- `Math.signh` -> `require('es5-ext/math/signh')`
- `Math.tanh` -> `require('es5-ext/math/tanh')`
- `Math.trunc` -> `require('es5-ext/math/trunc')`
- `Number.EPSILON` -> `require('es5-ext/number/epsilon')`
- `Number.MAX_SAFE_INTEGER` -> `require('es5-ext/number/max-safe-integer')`
- `Number.MIN_SAFE_INTEGER` -> `require('es5-ext/number/min-safe-integer')`
- `Number.isFinite` -> `require('es5-ext/number/is-finite')`
- `Number.isInteger` -> `require('es5-ext/number/is-integer')`
- `Number.isNaN` -> `require('es5-ext/number/is-nan')`
- `Number.isSafeInteger` -> `require('es5-ext/number/is-safe-integer')`
- `Object.assign` -> `require('es5-ext/object/assign')`
- `Object.keys` -> `require('es5-ext/object/keys')`
- `Object.setPrototypeOf` -> `require('es5-ext/object/set-prototype-of')`
- `Promise.prototype.finally` -> `require('es5-ext/promise/#/finally')`
- `RegExp.prototype.match` -> `require('es5-ext/reg-exp/#/match')`
- `RegExp.prototype.replace` -> `require('es5-ext/reg-exp/#/replace')`
- `RegExp.prototype.search` -> `require('es5-ext/reg-exp/#/search')`
- `RegExp.prototype.split` -> `require('es5-ext/reg-exp/#/split')`
- `RegExp.prototype.sticky` -> Implement with `require('es5-ext/reg-exp/#/sticky/implement')`, use as function with `require('es5-ext/reg-exp/#/is-sticky')`
- `RegExp.prototype.unicode` -> Implement with `require('es5-ext/reg-exp/#/unicode/implement')`, use as function with `require('es5-ext/reg-exp/#/is-unicode')`
- `String.fromCodePoint` -> `require('es5-ext/string/from-code-point')`
- `String.raw` -> `require('es5-ext/string/raw')`
- `String.prototype.codePointAt` -> `require('es5-ext/string/#/code-point-at')`
- `String.prototype.contains` -> `require('es5-ext/string/#/contains')`
- `String.prototype.endsWith` -> `require('es5-ext/string/#/ends-with')`
- `String.prototype.normalize` -> `require('es5-ext/string/#/normalize')`
- `String.prototype.repeat` -> `require('es5-ext/string/#/repeat')`
- `String.prototype.startsWith` -> `require('es5-ext/string/#/starts-with')`
- `String.prototype[@@iterator]` -> `require('es5-ext/string/#/@@iterator')`
#### Non ECMAScript standard features
**es5-ext** provides also other utils, and implements them as if they were proposed for a standard. It mostly offers methods (not functions) which can directly be assigned to native prototypes:
```javascript
Object.defineProperty(Function.prototype, "partial", {
value: require("es5-ext/function/#/partial"),
configurable: true,
enumerable: false,
writable: true
});
Object.defineProperty(Array.prototype, "flatten", {
value: require("es5-ext/array/#/flatten"),
configurable: true,
enumerable: false,
writable: true
});
Object.defineProperty(String.prototype, "capitalize", {
value: require("es5-ext/string/#/capitalize"),
configurable: true,
enumerable: false,
writable: true
});
```
See [es5-extend](https://github.com/wookieb/es5-extend#es5-extend), a great utility that automatically will extend natives for you.
**Important:** Remember to **not** extend natives in scope of generic reusable packages (e.g. ones you intend to publish to npm). Extending natives is fine **only** if you're the _owner_ of the global scope, so e.g. in final project you lead development of.
When you're in situation when native extensions are not good idea, then you should use methods indirectly:
```javascript
var flatten = require("es5-ext/array/#/flatten");
flatten.call([1, [2, [3, 4]]]); // [1, 2, 3, 4]
```
for better convenience you can turn methods into functions:
```javascript
var call = Function.prototype.call;
var flatten = call.bind(require("es5-ext/array/#/flatten"));
flatten([1, [2, [3, 4]]]); // [1, 2, 3, 4]
```
You can configure custom toolkit (like [underscorejs](http://underscorejs.org/)), and use it throughout your application
```javascript
var util = {};
util.partial = call.bind(require("es5-ext/function/#/partial"));
util.flatten = call.bind(require("es5-ext/array/#/flatten"));
util.startsWith = call.bind(require("es5-ext/string/#/starts-with"));
util.flatten([1, [2, [3, 4]]]); // [1, 2, 3, 4]
```
As with native ones most methods are generic and can be run on any type of object.
## API
### Global extensions
#### global _(es5-ext/global)_
Object that represents global scope
### Array Constructor extensions
#### from(arrayLike[, mapFn[, thisArg]]) _(es5-ext/array/from)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.from).
Returns array representation of _iterable_ or _arrayLike_. If _arrayLike_ is an instance of array, its copy is returned.
#### generate([length[, …fill]]) _(es5-ext/array/generate)_
Generate an array of pre-given _length_ built of repeated arguments.
#### isPlainArray(x) _(es5-ext/array/is-plain-array)_
Returns true if object is plain array (not instance of one of the Array's extensions).
#### of([…items]) _(es5-ext/array/of)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.of).
Create an array from given arguments.
#### toArray(obj) _(es5-ext/array/to-array)_
Returns array representation of `obj`. If `obj` is already an array, `obj` is returned back.
#### validArray(obj) _(es5-ext/array/valid-array)_
Returns `obj` if it's an array, otherwise throws `TypeError`
### Array Prototype extensions
#### arr.binarySearch(compareFn) _(es5-ext/array/#/binary-search)_
In **sorted** list search for index of item for which _compareFn_ returns value closest to _0_.
It's variant of binary search algorithm
#### arr.clear() _(es5-ext/array/#/clear)_
Clears the array
#### arr.compact() _(es5-ext/array/#/compact)_
Returns a copy of the context with all non-values (`null` or `undefined`) removed.
#### arr.concat() _(es5-ext/array/#/concat)_
[_Updated with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.prototype.concat).
ES6's version of `concat`. Supports `isConcatSpreadable` symbol, and returns array of same type as the context.
#### arr.contains(searchElement[, position]) _(es5-ext/array/#/contains)_
Whether list contains the given value.
#### arr.copyWithin(target, start[, end]) _(es5-ext/array/#/copy-within)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.copywithin).
#### arr.diff(other) _(es5-ext/array/#/diff)_
Returns the array of elements that are present in context list but not present in other list.
#### arr.eIndexOf(searchElement[, fromIndex]) _(es5-ext/array/#/e-index-of)_
_egal_ version of `indexOf` method. [_SameValueZero_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-samevaluezero) logic is used for comparision
#### arr.eLastIndexOf(searchElement[, fromIndex]) _(es5-ext/array/#/e-last-index-of)_
_egal_ version of `lastIndexOf` method. [_SameValueZero_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-samevaluezero) logic is used for comparision
#### arr.entries() _(es5-ext/array/#/entries)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.prototype.entries).
Returns iterator object, which traverses the array. Each value is represented with an array, where first value is an index and second is corresponding to index value.
#### arr.exclusion([…lists]]) _(es5-ext/array/#/exclusion)_
Returns the array of elements that are found only in one of the lists (either context list or list provided in arguments).
#### arr.fill(value[, start, end]) _(es5-ext/array/#/fill)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.fill).
#### arr.filter(callback[, thisArg]) _(es5-ext/array/#/filter)_
[_Updated with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.filter).
ES6's version of `filter`, returns array of same type as the context.
#### arr.find(predicate[, thisArg]) _(es5-ext/array/#/find)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.find).
Return first element for which given function returns true
#### arr.findIndex(predicate[, thisArg]) _(es5-ext/array/#/find-index)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.findindex).
Return first index for which given function returns true
#### arr.first() _(es5-ext/array/#/first)_
Returns value for first defined index
#### arr.firstIndex() _(es5-ext/array/#/first-index)_
Returns first declared index of the array
#### arr.flatten() _(es5-ext/array/#/flatten)_
Returns flattened version of the array
#### arr.forEachRight(cb[, thisArg]) _(es5-ext/array/#/for-each-right)_
`forEach` starting from last element
#### arr.group(cb[, thisArg]) _(es5-ext/array/#/group)_
Group list elements by value returned by _cb_ function
#### arr.indexesOf(searchElement[, fromIndex]) _(es5-ext/array/#/indexes-of)_
Returns array of all indexes of given value
#### arr.intersection([…lists]) _(es5-ext/array/#/intersection)_
Computes the array of values that are the intersection of all lists (context list and lists given in arguments)
#### arr.isCopy(other) _(es5-ext/array/#/is-copy)_
Returns true if both context and _other_ lists have same content
#### arr.isUniq() _(es5-ext/array/#/is-uniq)_
Returns true if all values in array are unique
#### arr.keys() _(es5-ext/array/#/keys)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.prototype.keys).
Returns iterator object, which traverses all array indexes.
#### arr.last() _(es5-ext/array/#/last)_
Returns value of last defined index
#### arr.lastIndex() _(es5-ext/array/#/last)_
Returns last defined index of the array
#### arr.map(callback[, thisArg]) _(es5-ext/array/#/map)_
[_Updated with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.map).
ES6's version of `map`, returns array of same type as the context.
#### arr.remove(value[, …valuen]) _(es5-ext/array/#/remove)_
Remove values from the array
#### arr.separate(sep) _(es5-ext/array/#/separate)_
Returns array with items separated with `sep` value
#### arr.slice(callback[, thisArg]) _(es5-ext/array/#/slice)_
[_Updated with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.slice).
ES6's version of `slice`, returns array of same type as the context.
#### arr.someRight(cb[, thisArg]) _(es5-ext/array/#/someRight)_
`some` starting from last element
#### arr.splice(callback[, thisArg]) _(es5-ext/array/#/splice)_
[_Updated with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.splice).
ES6's version of `splice`, returns array of same type as the context.
#### arr.uniq() _(es5-ext/array/#/uniq)_
Returns duplicate-free version of the array
#### arr.values() _(es5-ext/array/#/values)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.prototype.values).
Returns iterator object which traverses all array values.
#### arr[@@iterator] _(es5-ext/array/#/@@iterator)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-array.prototype-@@iterator).
Returns iterator object which traverses all array values.
### Boolean Constructor extensions
#### isBoolean(x) _(es5-ext/boolean/is-boolean)_
Whether value is boolean
### Date Constructor extensions
#### isDate(x) _(es5-ext/date/is-date)_
Whether value is date instance
#### validDate(x) _(es5-ext/date/valid-date)_
If given object is not date throw TypeError in other case return it.
### Date Prototype extensions
#### date.copy(date) _(es5-ext/date/#/copy)_
Returns a copy of the date object
#### date.daysInMonth() _(es5-ext/date/#/days-in-month)_
Returns number of days of date's month
#### date.floorDay() _(es5-ext/date/#/floor-day)_
Sets the date time to 00:00:00.000
#### date.floorMonth() _(es5-ext/date/#/floor-month)_
Sets date day to 1 and date time to 00:00:00.000
#### date.floorYear() _(es5-ext/date/#/floor-year)_
Sets date month to 0, day to 1 and date time to 00:00:00.000
#### date.format(pattern) _(es5-ext/date/#/format)_
Formats date up to given string. Supported patterns:
- `%Y` - Year with century, 1999, 2003
- `%y` - Year without century, 99, 03
- `%m` - Month, 01..12
- `%d` - Day of the month 01..31
- `%H` - Hour (24-hour clock), 00..23
- `%M` - Minute, 00..59
- `%S` - Second, 00..59
- `%L` - Milliseconds, 000..999
### Error Constructor extensions
#### custom(message/_, code, ext_/) _(es5-ext/error/custom)_
Creates custom error object, optinally extended with `code` and other extension properties (provided with `ext` object)
#### isError(x) _(es5-ext/error/is-error)_
Whether value is an error (instance of `Error`).
#### validError(x) _(es5-ext/error/valid-error)_
If given object is not error throw TypeError in other case return it.
### Error Prototype extensions
#### err.throw() _(es5-ext/error/#/throw)_
Throws error
### Function Constructor extensions
Some of the functions were inspired by [Functional JavaScript](http://osteele.com/sources/javascript/functional/) project by Olivier Steele
#### constant(x) _(es5-ext/function/constant)_
Returns a constant function that returns pregiven argument
_k(x)(y) =def x_
#### identity(x) _(es5-ext/function/identity)_
Identity function. Returns first argument
_i(x) =def x_
#### invoke(name[, …args]) _(es5-ext/function/invoke)_
Returns a function that takes an object as an argument, and applies object's
_name_ method to arguments.
_name_ can be name of the method or method itself.
_invoke(name, …args)(object, …args2) =def object\[name\]\(…args, …args2\)_
#### isArguments(x) _(es5-ext/function/is-arguments)_
Whether value is arguments object
#### isFunction(arg) _(es5-ext/function/is-function)_
Whether value is instance of function
#### noop() _(es5-ext/function/noop)_
No operation function
#### pluck(name) _(es5-ext/function/pluck)_
Returns a function that takes an object, and returns the value of its _name_
property
_pluck(name)(obj) =def obj[name]_
#### validFunction(arg) _(es5-ext/function/valid-function)_
If given object is not function throw TypeError in other case return it.
### Function Prototype extensions
Some of the methods were inspired by [Functional JavaScript](http://osteele.com/sources/javascript/functional/) project by Olivier Steele
#### fn.compose([…fns]) _(es5-ext/function/#/compose)_
Applies the functions in reverse argument-list order.
_f1.compose(f2, f3, f4)(…args) =def f1(f2(f3(f4(…arg))))_
`compose` can also be used in plain function form as:
_compose(f1, f2, f3, f4)(…args) =def f1(f2(f3(f4(…arg))))_
#### fn.copy() _(es5-ext/function/#/copy)_
Produces copy of given function
#### fn.curry([n]) _(es5-ext/function/#/curry)_
Invoking the function returned by this function only _n_ arguments are passed to the underlying function. If the underlying function is not saturated, the result is a function that passes all its arguments to the underlying function.
If _n_ is not provided then it defaults to context function length
_f.curry(4)(arg1, arg2)(arg3)(arg4) =def f(arg1, args2, arg3, arg4)_
#### fn.lock([…args]) _(es5-ext/function/#/lock)_
Returns a function that applies the underlying function to _args_, and ignores its own arguments.
_f.lock(…args)(…args2) =def f(…args)_
_Named after it's counterpart in Google Closure_
#### fn.not() _(es5-ext/function/#/not)_
Returns a function that returns boolean negation of value returned by underlying function.
_f.not()(…args) =def !f(…args)_
#### fn.partial([…args]) _(es5-ext/function/#/partial)_
Returns a function that when called will behave like context function called with initially passed arguments. If more arguments are suplilied, they are appended to initial args.
_f.partial(…args1)(…args2) =def f(…args1, …args2)_
#### fn.spread() _(es5-ext/function/#/spread)_
Returns a function that applies underlying function with first list argument
_f.match()(args) =def f.apply(null, args)_
#### fn.toStringTokens() _(es5-ext/function/#/to-string-tokens)_
Serializes function into two (arguments and body) string tokens. Result is plain object with `args` and `body` properties.
### Math extensions
#### acosh(x) _(es5-ext/math/acosh)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.acosh).
#### asinh(x) _(es5-ext/math/asinh)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.asinh).
#### atanh(x) _(es5-ext/math/atanh)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.atanh).
#### cbrt(x) _(es5-ext/math/cbrt)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.cbrt).
#### clz32(x) _(es5-ext/math/clz32)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.clz32).
#### cosh(x) _(es5-ext/math/cosh)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.cosh).
#### expm1(x) _(es5-ext/math/expm1)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.expm1).
#### fround(x) _(es5-ext/math/fround)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.fround).
#### hypot([…values]) _(es5-ext/math/hypot)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.hypot).
#### imul(x, y) _(es5-ext/math/imul)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.imul).
#### log1p(x) _(es5-ext/math/log1p)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.log1p).
#### log2(x) _(es5-ext/math/log2)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.log2).
#### log10(x) _(es5-ext/math/log10)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.log10).
#### sign(x) _(es5-ext/math/sign)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.sign).
#### sinh(x) _(es5-ext/math/sinh)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.sinh).
#### tanh(x) _(es5-ext/math/tanh)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.tanh).
#### trunc(x) _(es5-ext/math/trunc)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-math.trunc).
### Number Constructor extensions
#### EPSILON _(es5-ext/number/epsilon)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-number.epsilon).
The difference between 1 and the smallest value greater than 1 that is representable as a Number value, which is approximately 2.2204460492503130808472633361816 x 10-16.
#### isFinite(x) _(es5-ext/number/is-finite)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-number.isfinite).
Whether value is finite. Differs from global isNaN that it doesn't do type coercion.
#### isInteger(x) _(es5-ext/number/is-integer)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-number.isinteger).
Whether value is integer.
#### isNaN(x) _(es5-ext/number/is-nan)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-number.isnan).
Whether value is NaN. Differs from global isNaN that it doesn't do type coercion.
#### isNumber(x) _(es5-ext/number/is-number)_
Whether given value is number
#### isSafeInteger(x) _(es5-ext/number/is-safe-integer)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-number.issafeinteger).
#### MAX*SAFE_INTEGER *(es5-ext/number/max-safe-integer)\_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-number.maxsafeinteger).
The value of Number.MAX_SAFE_INTEGER is 9007199254740991.
#### MIN*SAFE_INTEGER *(es5-ext/number/min-safe-integer)\_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-number.minsafeinteger).
The value of Number.MIN_SAFE_INTEGER is -9007199254740991 (253-1).
#### toInteger(x) _(es5-ext/number/to-integer)_
Converts value to integer
#### toPosInteger(x) _(es5-ext/number/to-pos-integer)_
Converts value to positive integer. If provided value is less than 0, then 0 is returned
#### toUint32(x) _(es5-ext/number/to-uint32)_
Converts value to unsigned 32 bit integer. This type is used for array lengths.
See: http://www.2ality.com/2012/02/js-integers.html
### Number Prototype extensions
#### num.pad(length[, precision]) _(es5-ext/number/#/pad)_
Pad given number with zeros. Returns string
### Object Constructor extensions
#### assign(target, source[, …sourcen]) _(es5-ext/object/assign)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-object.assign).
Extend _target_ by enumerable own properties of other objects. If properties are already set on target object, they will be overwritten.
#### clear(obj) _(es5-ext/object/clear)_
Remove all enumerable own properties of the object
#### compact(obj) _(es5-ext/object/compact)_
Returns copy of the object with all enumerable properties that have no falsy values
#### compare(obj1, obj2) _(es5-ext/object/compare)_
Universal cross-type compare function. To be used for e.g. array sort.
#### copy(obj) _(es5-ext/object/copy)_
Returns copy of the object with all enumerable properties.
#### copyDeep(obj) _(es5-ext/object/copy-deep)_
Returns deep copy of the object with all enumerable properties.
#### count(obj) _(es5-ext/object/count)_
Counts number of enumerable own properties on object
#### create(obj[, properties]) _(es5-ext/object/create)_
`Object.create` alternative that provides workaround for [V8 issue](http://code.google.com/p/v8/issues/detail?id=2804).
When `null` is provided as a prototype, it's substituted with specially prepared object that derives from Object.prototype but has all Object.prototype properties shadowed with undefined.
It's quirky solution that allows us to have plain objects with no truthy properties but with turnable prototype.
Use only for objects that you plan to switch prototypes of and be aware of limitations of this workaround.
#### eq(x, y) _(es5-ext/object/eq)_
Whether two values are equal, using [_SameValueZero_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-samevaluezero) algorithm.
#### every(obj, cb[, thisArg[, compareFn]]) _(es5-ext/object/every)_
Analogous to Array.prototype.every. Returns true if every key-value pair in this object satisfies the provided testing function.
Optionally _compareFn_ can be provided which assures that keys are tested in given order. If provided _compareFn_ is equal to `true`, then order is alphabetical (by key).
#### filter(obj, cb[, thisArg]) _(es5-ext/object/filter)_
Analogous to Array.prototype.filter. Returns new object with properites for which _cb_ function returned truthy value.
#### firstKey(obj) _(es5-ext/object/first-key)_
Returns first enumerable key of the object, as keys are unordered by specification, it can be any key of an object.
#### flatten(obj) _(es5-ext/object/flatten)_
Returns new object, with flatten properties of input object
_flatten({ a: { b: 1 }, c: { d: 1 } }) =def { b: 1, d: 1 }_
#### forEach(obj, cb[, thisArg[, compareFn]]) _(es5-ext/object/for-each)_
Analogous to Array.prototype.forEach. Calls a function for each key-value pair found in object
Optionally _compareFn_ can be provided which assures that properties are iterated in given order. If provided _compareFn_ is equal to `true`, then order is alphabetical (by key).
#### getPropertyNames() _(es5-ext/object/get-property-names)_
Get all (not just own) property names of the object
#### is(x, y) _(es5-ext/object/is)_
Whether two values are equal, using [_SameValue_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-samevaluezero) algorithm.
#### isArrayLike(x) _(es5-ext/object/is-array-like)_
Whether object is array-like object
#### isCopy(x, y) _(es5-ext/object/is-copy)_
Two values are considered a copy of same value when all of their own enumerable properties have same values.
#### isCopyDeep(x, y) _(es5-ext/object/is-copy-deep)_
Deep comparision of objects
#### isEmpty(obj) _(es5-ext/object/is-empty)_
True if object doesn't have any own enumerable property
#### isObject(arg) _(es5-ext/object/is-object)_
Whether value is not primitive
#### isPlainObject(arg) _(es5-ext/object/is-plain-object)_
Whether object is plain object, its protototype should be Object.prototype and it cannot be host object.
#### keyOf(obj, searchValue) _(es5-ext/object/key-of)_
Search object for value
#### keys(obj) _(es5-ext/object/keys)_
[_Updated with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-object.keys).
ES6's version of `keys`, doesn't throw on primitive input
#### map(obj, cb[, thisArg]) _(es5-ext/object/map)_
Analogous to Array.prototype.map. Creates a new object with properties which values are results of calling a provided function on every key-value pair in this object.
#### mapKeys(obj, cb[, thisArg]) _(es5-ext/object/map-keys)_
Create new object with same values, but remapped keys
#### mixin(target, source) _(es5-ext/object/mixin)_
Extend _target_ by all own properties of other objects. Properties found in both objects will be overwritten (unless they're not configurable and cannot be overwritten).
_It was for a moment part of ECMAScript 6 draft._
#### mixinPrototypes(target, …source]) _(es5-ext/object/mixin-prototypes)_
Extends _target_, with all source and source's prototype properties.
Useful as an alternative for `setPrototypeOf` in environments in which it cannot be shimmed (no `__proto__` support).
#### normalizeOptions(options) _(es5-ext/object/normalize-options)_
Normalizes options object into flat plain object.
Useful for functions in which we either need to keep options object for future reference or need to modify it for internal use.
- It never returns input `options` object back (always a copy is created)
- `options` can be undefined in such case empty plain object is returned.
- Copies all enumerable properties found down prototype chain.
#### primitiveSet([…names]) _(es5-ext/object/primitive-set)_
Creates `null` prototype based plain object, and sets on it all property names provided in arguments to true.
#### safeTraverse(obj[, …names]) _(es5-ext/object/safe-traverse)_
Safe navigation of object properties. See http://wiki.ecmascript.org/doku.php?id=strawman:existential_operator
#### serialize(value) _(es5-ext/object/serialize)_
Serialize value into string. Differs from [JSON.stringify](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify) that it serializes also dates, functions and regular expresssions.
#### setPrototypeOf(object, proto) _(es5-ext/object/set-prototype-of)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-object.setprototypeof).
If native version is not provided, it depends on existence of `__proto__` functionality, if it's missing, `null` instead of function is exposed.
#### some(obj, cb[, thisArg[, compareFn]]) _(es5-ext/object/some)_
Analogous to Array.prototype.some Returns true if any key-value pair satisfies the provided
testing function.
Optionally _compareFn_ can be provided which assures that keys are tested in given order. If provided _compareFn_ is equal to `true`, then order is alphabetical (by key).
#### toArray(obj[, cb[, thisArg[, compareFn]]]) _(es5-ext/object/to-array)_
Creates an array of results of calling a provided function on every key-value pair in this object.
Optionally _compareFn_ can be provided which assures that results are added in given order. If provided _compareFn_ is equal to `true`, then order is alphabetical (by key).
#### unserialize(str) _(es5-ext/object/unserialize)_
Userializes value previously serialized with [serialize](#serializevalue-es5-extobjectserialize)
#### validCallable(x) _(es5-ext/object/valid-callable)_
If given object is not callable throw TypeError in other case return it.
#### validObject(x) _(es5-ext/object/valid-object)_
Throws error if given value is not an object, otherwise it is returned.
#### validValue(x) _(es5-ext/object/valid-value)_
Throws error if given value is `null` or `undefined`, otherwise returns value.
### Promise Prototype extensions
#### promise.finally(onFinally) _(es5-ext/promise/#/finally)_
[_Introduced with ECMAScript 2018_](https://tc39.github.io/ecma262/#sec-promise.prototype.finally).
### RegExp Constructor extensions
#### escape(str) _(es5-ext/reg-exp/escape)_
Escapes string to be used in regular expression
#### isRegExp(x) _(es5-ext/reg-exp/is-reg-exp)_
Whether object is regular expression
#### validRegExp(x) _(es5-ext/reg-exp/valid-reg-exp)_
If object is regular expression it is returned, otherwise TypeError is thrown.
### RegExp Prototype extensions
#### re.isSticky(x) _(es5-ext/reg-exp/#/is-sticky)_
Whether regular expression has `sticky` flag.
It's to be used as counterpart to [regExp.sticky](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-get-regexp.prototype.sticky) if it's not implemented.
#### re.isUnicode(x) _(es5-ext/reg-exp/#/is-unicode)_
Whether regular expression has `unicode` flag.
It's to be used as counterpart to [regExp.unicode](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-get-regexp.prototype.unicode) if it's not implemented.
#### re.match(string) _(es5-ext/reg-exp/#/match)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-regexp.prototype.match).
#### re.replace(string, replaceValue) _(es5-ext/reg-exp/#/replace)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-regexp.prototype.replace).
#### re.search(string) _(es5-ext/reg-exp/#/search)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-regexp.prototype.search).
#### re.split(string) _(es5-ext/reg-exp/#/search)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-regexp.prototype.split).
#### re.sticky _(es5-ext/reg-exp/#/sticky/implement)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-regexp.prototype.sticky).
It's a getter, so only `implement` and `is-implemented` modules are provided.
#### re.unicode _(es5-ext/reg-exp/#/unicode/implement)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-regexp.prototype.unicode).
It's a getter, so only `implement` and `is-implemented` modules are provided.
### String Constructor extensions
#### formatMethod(fMap) _(es5-ext/string/format-method)_
Creates format method. It's used e.g. to create `Date.prototype.format` method
#### fromCodePoint([…codePoints]) _(es5-ext/string/from-code-point)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-string.fromcodepoint)
#### isString(x) _(es5-ext/string/is-string)_
Whether object is string
#### randomUniq() _(es5-ext/string/random-uniq)_
Returns randomly generated id, with guarantee of local uniqueness (no same id will be returned twice)
#### raw(callSite[, …substitutions]) _(es5-ext/string/raw)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-string.raw)
### String Prototype extensions
#### str.at(pos) _(es5-ext/string/#/at)_
_Proposed for ECMAScript 6/7 standard, but not (yet) in a draft_
Returns a string at given position in Unicode-safe manner.
Based on [implementation by Mathias Bynens](https://github.com/mathiasbynens/String.prototype.at).
#### str.camelToHyphen() _(es5-ext/string/#/camel-to-hyphen)_
Convert camelCase string to hyphen separated, e.g. one-two-three -> oneTwoThree.
Useful when converting names from js property convention into filename convention.
#### str.capitalize() _(es5-ext/string/#/capitalize)_
Capitalize first character of a string
#### str.caseInsensitiveCompare(str) _(es5-ext/string/#/case-insensitive-compare)_
Case insensitive compare
#### str.codePointAt(pos) _(es5-ext/string/#/code-point-at)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-string.prototype.codepointat)
Based on [implementation by Mathias Bynens](https://github.com/mathiasbynens/String.prototype.codePointAt).
#### str.contains(searchString[, position]) _(es5-ext/string/#/contains)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-string.prototype.contains)
Whether string contains given string.
#### str.endsWith(searchString[, endPosition]) _(es5-ext/string/#/ends-with)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-string.prototype.endswith).
Whether strings ends with given string
#### str.hyphenToCamel() _(es5-ext/string/#/hyphen-to-camel)_
Convert hyphen separated string to camelCase, e.g. one-two-three -> oneTwoThree.
Useful when converting names from filename convention to js property name convention.
#### str.indent(str[, count]) _(es5-ext/string/#/indent)_
Indents each line with provided _str_ (if _count_ given then _str_ is repeated _count_ times).
#### str.last() _(es5-ext/string/#/last)_
Return last character
#### str.normalize([form]) _(es5-ext/string/#/normalize)_
[_Introduced with ECMAScript 6_](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/normalize).
Returns the Unicode Normalization Form of a given string.
Based on Matsuza's version. Code used for integrated shim can be found at [github.com/walling/unorm](https://github.com/walling/unorm/blob/master/lib/unorm.js)
#### str.pad(fill[, length]) _(es5-ext/string/#/pad)_
Pad string with _fill_.
If _length_ si given than _fill_ is reapated _length_ times.
If _length_ is negative then pad is applied from right.
#### str.repeat(n) _(es5-ext/string/#/repeat)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-string.prototype.repeat).
Repeat given string _n_ times
#### str.plainReplace(search, replace) _(es5-ext/string/#/plain-replace)_
Simple `replace` version. Doesn't support regular expressions. Replaces just first occurrence of search string. Doesn't support insert patterns, therefore it is safe to replace text with text obtained programmatically (there's no need for additional _\$_ characters escape in such case).
#### str.plainReplaceAll(search, replace) _(es5-ext/string/#/plain-replace-all)_
Simple `replace` version. Doesn't support regular expressions. Replaces all occurrences of search string. Doesn't support insert patterns, therefore it is safe to replace text with text obtained programmatically (there's no need for additional _\$_ characters escape in such case).
#### str.startsWith(searchString[, position]) _(es5-ext/string/#/starts-with)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-string.prototype.startswith).
Whether strings starts with given string
#### str[@@iterator] _(es5-ext/string/#/@@iterator)_
[_Introduced with ECMAScript 6_](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-string.prototype-@@iterator).
Returns iterator object which traverses all string characters (with respect to unicode symbols)
### Tests
$ npm test
## Security contact information
To report a security vulnerability, please use the [Tidelift security contact](https://tidelift.com/security). Tidelift will coordinate the fix and disclosure.
## es5-ext for enterprise
Available as part of the Tidelift Subscription
The maintainers of es5-ext and thousands of other packages are working with Tidelift to deliver commercial support and maintenance for the open source dependencies you use to build your applications. Save time, reduce risk, and improve code health, while paying the maintainers of the exact dependencies you use. [Learn more.](https://tidelift.com/subscription/pkg/npm-es5-ext?utm_source=npm-es5-ext&utm_medium=referral&utm_campaign=enterprise&utm_term=repo)
[nix-build-image]: https://semaphoreci.com/api/v1/medikoo-org/es5-ext/branches/master/shields_badge.svg
[nix-build-url]: https://semaphoreci.com/medikoo-org/es5-ext
[win-build-image]: https://ci.appveyor.com/api/projects/status/3jox67ksw3p8hkwh/branch/master?svg=true
[win-build-url]: https://ci.appveyor.com/project/medikoo/es5-ext
[transpilation-image]: https://img.shields.io/badge/transpilation-free-brightgreen.svg
[npm-image]: https://img.shields.io/npm/v/es5-ext.svg
[npm-url]: https://www.npmjs.com/package/es5-ext
tunnel-agent
============
HTTP proxy tunneling agent. Formerly part of mikeal/request, now a standalone module.
# web3-core-subscriptions
This is a sub package of [web3.js][repo]
The subscriptions package used within some [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-subscriptions
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-core-subscriptions.js` in your html file.
This will expose the `Web3Subscriptions` object on the window object.
## Usage
```js
// in node.js
var Web3Subscriptions = require('web3-core-subscriptions');
var sub = new Web3Subscriptions({
name: 'subscribe',
type: 'eth',
subscriptions: {
'newBlockHeaders': {
subscriptionName: 'newHeads',
params: 0,
outputFormatter: formatters.outputBlockFormatter
},
'pendingTransactions': {
params: 0,
outputFormatter: formatters.outputTransactionFormatter
}
}
});
sub.attachToObject(myCoolLib);
myCoolLib.subscribe('newBlockHeaders', function(){ ... });
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
## ethjs-util
<div>
<!-- Dependency Status -->
<a href="https://david-dm.org/ethjs/ethjs-util">
<img src="https://david-dm.org/ethjs/ethjs-util.svg"
alt="Dependency Status" />
</a>
<!-- devDependency Status -->
<a href="https://david-dm.org/ethjs/ethjs-util#info=devDependencies">
<img src="https://david-dm.org/ethjs/ethjs-util/dev-status.svg" alt="devDependency Status" />
</a>
<!-- Build Status -->
<a href="https://travis-ci.org/ethjs/ethjs-util">
<img src="https://travis-ci.org/ethjs/ethjs-util.svg"
alt="Build Status" />
</a>
<!-- NPM Version -->
<a href="https://www.npmjs.org/package/ethjs-util">
<img src="http://img.shields.io/npm/v/ethjs-util.svg"
alt="NPM version" />
</a>
<!-- Test Coverage -->
<a href="https://coveralls.io/r/ethjs/ethjs-util">
<img src="https://coveralls.io/repos/github/ethjs/ethjs-util/badge.svg" alt="Test Coverage" />
</a>
<!-- Javascript Style -->
<a href="http://airbnb.io/javascript/">
<img src="https://img.shields.io/badge/code%20style-airbnb-brightgreen.svg" alt="js-airbnb-style" />
</a>
</div>
<br />
A simple set of Ethereum JS utilities such as `toBuffer` and `isHexPrefixed`.
## Install
```
npm install --save ethjs-util
```
## Usage
```js
const util = require('ethjs-util');
const value = util.intToBuffer(38272);
// returns <Buffer ...>
```
## About
A simple set of Ethereum JS utilties, mainly for frontend dApps.
## Available Methods
```
getBinarySize <Function (String) : (Number)>
intToBuffer <Function (Number) : (Buffer)>
intToHex <Function (Number) : (String)>
padToEven <Function (String) : (String)>
isHexPrefixed <Function (String) : (Boolean)>
isHexString <Function (Value, Length) : (Boolean)>
stripHexPrefix <Function (String) : (String)>
addHexPrefix <Function (String) : (String)>
getKeys <Function (Params, Key, Empty) : (Array)>
arrayContainsArray <Function (Array, Array) : (Boolean)>
fromAscii <Function (String) : (String)>
fromUtf8 <Function (String) : (String)>
toAscii <Function (String) : (String)>
toUtf8 <Function (String) : (String)>
```
## Contributing
Please help better the ecosystem by submitting issues and pull requests to default. We need all the help we can get to build the absolute best linting standards and utilities. We follow the AirBNB linting standard and the unix philosophy.
## Guides
You'll find more detailed information on using `ethjs-util` and tailoring it to your needs in our guides:
- [User guide](docs/user-guide.md) - Usage, configuration, FAQ and complementary tools.
- [Developer guide](docs/developer-guide.md) - Contributing to `ethjs-util` and writing your own code and coverage.
## Help out
There is always a lot of work to do, and will have many rules to maintain. So please help out in any way that you can:
- Create, enhance, and debug ethjs rules (see our guide to ["Working on rules"](./github/CONTRIBUTING.md)).
- Improve documentation.
- Chime in on any open issue or pull request.
- Open new issues about your ideas for making `ethjs-util` better, and pull requests to show us how your idea works.
- Add new tests to *absolutely anything*.
- Create or contribute to ecosystem tools, like modules for encoding or contracts.
- Spread the word.
Please consult our [Code of Conduct](CODE_OF_CONDUCT.md) docs before helping out.
We communicate via [issues](https://github.com/ethjs/ethjs-util/issues) and [pull requests](https://github.com/ethjs/ethjs-util/pulls).
## Important documents
- [Changelog](CHANGELOG.md)
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [License](https://raw.githubusercontent.com/ethjs/ethjs-util/master/LICENSE)
## Licence
This project is licensed under the MIT license, Copyright (c) 2016 Nick Dodson. For more information see LICENSE.md.
```
The MIT License
Copyright (c) 2016 Nick Dodson. nickdodson.com
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
```
socks-proxy-agent
================
### A SOCKS proxy `http.Agent` implementation for HTTP and HTTPS
[](https://travis-ci.org/TooTallNate/node-socks-proxy-agent)
This module provides an `http.Agent` implementation that connects to a
specified SOCKS proxy server, and can be used with the built-in `http`
or `https` modules.
It can also be used in conjunction with the `ws` module to establish a WebSocket
connection over a SOCKS proxy. See the "Examples" section below.
Installation
------------
Install with `npm`:
``` bash
$ npm install socks-proxy-agent
```
Examples
--------
#### `http` module example
``` js
var url = require('url');
var http = require('http');
var SocksProxyAgent = require('socks-proxy-agent');
// SOCKS proxy to connect to
var proxy = process.env.socks_proxy || 'socks://127.0.0.1:9050';
console.log('using proxy server %j', proxy);
// HTTP endpoint for the proxy to connect to
var endpoint = process.argv[2] || 'http://nodejs.org/api/';
console.log('attempting to GET %j', endpoint);
var opts = url.parse(endpoint);
// create an instance of the `SocksProxyAgent` class with the proxy server information
var agent = new SocksProxyAgent(proxy);
opts.agent = agent;
http.get(opts, function (res) {
console.log('"response" event!', res.headers);
res.pipe(process.stdout);
});
```
#### `https` module example
``` js
var url = require('url');
var https = require('https');
var SocksProxyAgent = require('socks-proxy-agent');
// SOCKS proxy to connect to
var proxy = process.env.socks_proxy || 'socks://127.0.0.1:9050';
console.log('using proxy server %j', proxy);
// HTTP endpoint for the proxy to connect to
var endpoint = process.argv[2] || 'https://encrypted.google.com/';
console.log('attempting to GET %j', endpoint);
var opts = url.parse(endpoint);
// create an instance of the `SocksProxyAgent` class with the proxy server information
var agent = new SocksProxyAgent(proxy);
opts.agent = agent;
https.get(opts, function (res) {
console.log('"response" event!', res.headers);
res.pipe(process.stdout);
});
```
#### `ws` WebSocket connection example
``` js
var WebSocket = require('ws');
var SocksProxyAgent = require('socks-proxy-agent');
// SOCKS proxy to connect to
var proxy = process.env.socks_proxy || 'socks://127.0.0.1:9050';
console.log('using proxy server %j', proxy);
// WebSocket endpoint for the proxy to connect to
var endpoint = process.argv[2] || 'ws://echo.websocket.org';
console.log('attempting to connect to WebSocket %j', endpoint);
// create an instance of the `SocksProxyAgent` class with the proxy server information
var agent = new SocksProxyAgent(proxy);
// initiate the WebSocket connection
var socket = new WebSocket(endpoint, { agent: agent });
socket.on('open', function () {
console.log('"open" event!');
socket.send('hello world');
});
socket.on('message', function (data, flags) {
console.log('"message" event! %j %j', data, flags);
socket.close();
});
```
License
-------
(The MIT License)
Copyright (c) 2013 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
bs58
====
[](https://travis-ci.org/cryptocoinjs/bs58)
JavaScript component to compute base 58 encoding. This encoding is typically used for crypto currencies such as Bitcoin.
**Note:** If you're looking for **base 58 check** encoding, see: [https://github.com/bitcoinjs/bs58check](https://github.com/bitcoinjs/bs58check), which depends upon this library.
Install
-------
npm i --save bs58
API
---
### encode(input)
`input` must be a [Buffer](https://nodejs.org/api/buffer.html) or an `Array`. It returns a `string`.
**example**:
```js
const bs58 = require('bs58')
const bytes = Buffer.from('003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187', 'hex')
const address = bs58.encode(bytes)
console.log(address)
// => 16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS
```
### decode(input)
`input` must be a base 58 encoded string. Returns a [Buffer](https://nodejs.org/api/buffer.html).
**example**:
```js
const bs58 = require('bs58')
const address = '16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS'
const bytes = bs58.decode(address)
console.log(out.toString('hex'))
// => 003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187
```
Hack / Test
-----------
Uses JavaScript standard style. Read more:
[](https://github.com/feross/standard)
Credits
-------
- [Mike Hearn](https://github.com/mikehearn) for original Java implementation
- [Stefan Thomas](https://github.com/justmoon) for porting to JavaScript
- [Stephan Pair](https://github.com/gasteve) for buffer improvements
- [Daniel Cousens](https://github.com/dcousens) for cleanup and merging improvements from bitcoinjs-lib
- [Jared Deckard](https://github.com/deckar01) for killing `bigi` as a dependency
License
-------
MIT
# pretty-format
Stringify any JavaScript value.
- Serialize built-in JavaScript types.
- Serialize application-specific data types with built-in or user-defined plugins.
## Installation
```sh
$ yarn add pretty-format
```
## Usage
```js
const prettyFormat = require('pretty-format'); // CommonJS
```
```js
import prettyFormat from 'pretty-format'; // ES2015 modules
```
```js
const val = {object: {}};
val.circularReference = val;
val[Symbol('foo')] = 'foo';
val.map = new Map([['prop', 'value']]);
val.array = [-0, Infinity, NaN];
console.log(prettyFormat(val));
/*
Object {
"array": Array [
-0,
Infinity,
NaN,
],
"circularReference": [Circular],
"map": Map {
"prop" => "value",
},
"object": Object {},
Symbol(foo): "foo",
}
*/
```
## Usage with options
```js
function onClick() {}
console.log(prettyFormat(onClick));
/*
[Function onClick]
*/
const options = {
printFunctionName: false,
};
console.log(prettyFormat(onClick, options));
/*
[Function]
*/
```
<!-- prettier-ignore -->
| key | type | default | description |
| :------------------ | :-------- | :--------- | :------------------------------------------------------ |
| `callToJSON` | `boolean` | `true` | call `toJSON` method (if it exists) on objects |
| `escapeRegex` | `boolean` | `false` | escape special characters in regular expressions |
| `escapeString` | `boolean` | `true` | escape special characters in strings |
| `highlight` | `boolean` | `false` | highlight syntax with colors in terminal (some plugins) |
| `indent` | `number` | `2` | spaces in each level of indentation |
| `maxDepth` | `number` | `Infinity` | levels to print in arrays, objects, elements, and so on |
| `min` | `boolean` | `false` | minimize added space: no indentation nor line breaks |
| `plugins` | `array` | `[]` | plugins to serialize application-specific data types |
| `printFunctionName` | `boolean` | `true` | include or omit the name of a function |
| `theme` | `object` | | colors to highlight syntax in terminal |
Property values of `theme` are from [ansi-styles colors](https://github.com/chalk/ansi-styles#colors)
```js
const DEFAULT_THEME = {
comment: 'gray',
content: 'reset',
prop: 'yellow',
tag: 'cyan',
value: 'green',
};
```
## Usage with plugins
The `pretty-format` package provides some built-in plugins, including:
- `ReactElement` for elements from `react`
- `ReactTestComponent` for test objects from `react-test-renderer`
```js
// CommonJS
const prettyFormat = require('pretty-format');
const ReactElement = prettyFormat.plugins.ReactElement;
const ReactTestComponent = prettyFormat.plugins.ReactTestComponent;
const React = require('react');
const renderer = require('react-test-renderer');
```
```js
// ES2015 modules and destructuring assignment
import prettyFormat from 'pretty-format';
const {ReactElement, ReactTestComponent} = prettyFormat.plugins;
import React from 'react';
import renderer from 'react-test-renderer';
```
```js
const onClick = () => {};
const element = React.createElement('button', {onClick}, 'Hello World');
const formatted1 = prettyFormat(element, {
plugins: [ReactElement],
printFunctionName: false,
});
const formatted2 = prettyFormat(renderer.create(element).toJSON(), {
plugins: [ReactTestComponent],
printFunctionName: false,
});
/*
<button
onClick=[Function]
>
Hello World
</button>
*/
```
## Usage in Jest
For snapshot tests, Jest uses `pretty-format` with options that include some of its built-in plugins. For this purpose, plugins are also known as **snapshot serializers**.
To serialize application-specific data types, you can add modules to `devDependencies` of a project, and then:
In an **individual** test file, you can add a module as follows. It precedes any modules from Jest configuration.
```js
import serializer from 'my-serializer-module';
expect.addSnapshotSerializer(serializer);
// tests which have `expect(value).toMatchSnapshot()` assertions
```
For **all** test files, you can specify modules in Jest configuration. They precede built-in plugins for React, HTML, and Immutable.js data types. For example, in a `package.json` file:
```json
{
"jest": {
"snapshotSerializers": ["my-serializer-module"]
}
}
```
## Writing plugins
A plugin is a JavaScript object.
If `options` has a `plugins` array: for the first plugin whose `test(val)` method returns a truthy value, then `prettyFormat(val, options)` returns the result from either:
- `serialize(val, …)` method of the **improved** interface (available in **version 21** or later)
- `print(val, …)` method of the **original** interface (if plugin does not have `serialize` method)
### test
Write `test` so it can receive `val` argument of any type. To serialize **objects** which have certain properties, then a guarded expression like `val != null && …` or more concise `val && …` prevents the following errors:
- `TypeError: Cannot read property 'whatever' of null`
- `TypeError: Cannot read property 'whatever' of undefined`
For example, `test` method of built-in `ReactElement` plugin:
```js
const elementSymbol = Symbol.for('react.element');
const test = val => val && val.$$typeof === elementSymbol;
```
Pay attention to efficiency in `test` because `pretty-format` calls it often.
### serialize
The **improved** interface is available in **version 21** or later.
Write `serialize` to return a string, given the arguments:
- `val` which “passed the test”
- unchanging `config` object: derived from `options`
- current `indentation` string: concatenate to `indent` from `config`
- current `depth` number: compare to `maxDepth` from `config`
- current `refs` array: find circular references in objects
- `printer` callback function: serialize children
### config
<!-- prettier-ignore -->
| key | type | description |
| :------------------ | :-------- | :------------------------------------------------------ |
| `callToJSON` | `boolean` | call `toJSON` method (if it exists) on objects |
| `colors` | `Object` | escape codes for colors to highlight syntax |
| `escapeRegex` | `boolean` | escape special characters in regular expressions |
| `escapeString` | `boolean` | escape special characters in strings |
| `indent` | `string` | spaces in each level of indentation |
| `maxDepth` | `number` | levels to print in arrays, objects, elements, and so on |
| `min` | `boolean` | minimize added space: no indentation nor line breaks |
| `plugins` | `array` | plugins to serialize application-specific data types |
| `printFunctionName` | `boolean` | include or omit the name of a function |
| `spacingInner` | `strong` | spacing to separate items in a list |
| `spacingOuter` | `strong` | spacing to enclose a list of items |
Each property of `colors` in `config` corresponds to a property of `theme` in `options`:
- the key is the same (for example, `tag`)
- the value in `colors` is a object with `open` and `close` properties whose values are escape codes from [ansi-styles](https://github.com/chalk/ansi-styles) for the color value in `theme` (for example, `'cyan'`)
Some properties in `config` are derived from `min` in `options`:
- `spacingInner` and `spacingOuter` are **newline** if `min` is `false`
- `spacingInner` is **space** and `spacingOuter` is **empty string** if `min` is `true`
### Example of serialize and test
This plugin is a pattern you can apply to serialize composite data types. Of course, `pretty-format` does not need a plugin to serialize arrays :)
```js
// We reused more code when we factored out a function for child items
// that is independent of depth, name, and enclosing punctuation (see below).
const SEPARATOR = ',';
function serializeItems(items, config, indentation, depth, refs, printer) {
if (items.length === 0) {
return '';
}
const indentationItems = indentation + config.indent;
return (
config.spacingOuter +
items
.map(
item =>
indentationItems +
printer(item, config, indentationItems, depth, refs), // callback
)
.join(SEPARATOR + config.spacingInner) +
(config.min ? '' : SEPARATOR) + // following the last item
config.spacingOuter +
indentation
);
}
const plugin = {
test(val) {
return Array.isArray(val);
},
serialize(array, config, indentation, depth, refs, printer) {
const name = array.constructor.name;
return ++depth > config.maxDepth
? '[' + name + ']'
: (config.min ? '' : name + ' ') +
'[' +
serializeItems(array, config, indentation, depth, refs, printer) +
']';
},
};
```
```js
const val = {
filter: 'completed',
items: [
{
text: 'Write test',
completed: true,
},
{
text: 'Write serialize',
completed: true,
},
],
};
```
```js
console.log(
prettyFormat(val, {
plugins: [plugin],
}),
);
/*
Object {
"filter": "completed",
"items": Array [
Object {
"completed": true,
"text": "Write test",
},
Object {
"completed": true,
"text": "Write serialize",
},
],
}
*/
```
```js
console.log(
prettyFormat(val, {
indent: 4,
plugins: [plugin],
}),
);
/*
Object {
"filter": "completed",
"items": Array [
Object {
"completed": true,
"text": "Write test",
},
Object {
"completed": true,
"text": "Write serialize",
},
],
}
*/
```
```js
console.log(
prettyFormat(val, {
maxDepth: 1,
plugins: [plugin],
}),
);
/*
Object {
"filter": "completed",
"items": [Array],
}
*/
```
```js
console.log(
prettyFormat(val, {
min: true,
plugins: [plugin],
}),
);
/*
{"filter": "completed", "items": [{"completed": true, "text": "Write test"}, {"completed": true, "text": "Write serialize"}]}
*/
```
### print
The **original** interface is adequate for plugins:
- that **do not** depend on options other than `highlight` or `min`
- that **do not** depend on `depth` or `refs` in recursive traversal, and
- if values either
- do **not** require indentation, or
- do **not** occur as children of JavaScript data structures (for example, array)
Write `print` to return a string, given the arguments:
- `val` which “passed the test”
- current `printer(valChild)` callback function: serialize children
- current `indenter(lines)` callback function: indent lines at the next level
- unchanging `config` object: derived from `options`
- unchanging `colors` object: derived from `options`
The 3 properties of `config` are `min` in `options` and:
- `spacing` and `edgeSpacing` are **newline** if `min` is `false`
- `spacing` is **space** and `edgeSpacing` is **empty string** if `min` is `true`
Each property of `colors` corresponds to a property of `theme` in `options`:
- the key is the same (for example, `tag`)
- the value in `colors` is a object with `open` and `close` properties whose values are escape codes from [ansi-styles](https://github.com/chalk/ansi-styles) for the color value in `theme` (for example, `'cyan'`)
### Example of print and test
This plugin prints functions with the **number of named arguments** excluding rest argument.
```js
const plugin = {
print(val) {
return `[Function ${val.name || 'anonymous'} ${val.length}]`;
},
test(val) {
return typeof val === 'function';
},
};
```
```js
const val = {
onClick(event) {},
render() {},
};
prettyFormat(val, {
plugins: [plugin],
});
/*
Object {
"onClick": [Function onClick 1],
"render": [Function render 0],
}
*/
prettyFormat(val);
/*
Object {
"onClick": [Function onClick],
"render": [Function render],
}
*/
```
This plugin **ignores** the `printFunctionName` option. That limitation of the original `print` interface is a reason to use the improved `serialize` interface, described above.
```js
prettyFormat(val, {
plugins: [pluginOld],
printFunctionName: false,
});
/*
Object {
"onClick": [Function onClick 1],
"render": [Function render 0],
}
*/
prettyFormat(val, {
printFunctionName: false,
});
/*
Object {
"onClick": [Function],
"render": [Function],
}
*/
```
# Destroy
[![NPM version][npm-image]][npm-url]
[![Build status][travis-image]][travis-url]
[![Test coverage][coveralls-image]][coveralls-url]
[![License][license-image]][license-url]
[![Downloads][downloads-image]][downloads-url]
[![Gittip][gittip-image]][gittip-url]
Destroy a stream.
This module is meant to ensure a stream gets destroyed, handling different APIs
and Node.js bugs.
## API
```js
var destroy = require('destroy')
```
### destroy(stream)
Destroy the given stream. In most cases, this is identical to a simple
`stream.destroy()` call. The rules are as follows for a given stream:
1. If the `stream` is an instance of `ReadStream`, then call `stream.destroy()`
and add a listener to the `open` event to call `stream.close()` if it is
fired. This is for a Node.js bug that will leak a file descriptor if
`.destroy()` is called before `open`.
2. If the `stream` is not an instance of `Stream`, then nothing happens.
3. If the `stream` has a `.destroy()` method, then call it.
The function returns the `stream` passed in as the argument.
## Example
```js
var destroy = require('destroy')
var fs = require('fs')
var stream = fs.createReadStream('package.json')
// ... and later
destroy(stream)
```
[npm-image]: https://img.shields.io/npm/v/destroy.svg?style=flat-square
[npm-url]: https://npmjs.org/package/destroy
[github-tag]: http://img.shields.io/github/tag/stream-utils/destroy.svg?style=flat-square
[github-url]: https://github.com/stream-utils/destroy/tags
[travis-image]: https://img.shields.io/travis/stream-utils/destroy.svg?style=flat-square
[travis-url]: https://travis-ci.org/stream-utils/destroy
[coveralls-image]: https://img.shields.io/coveralls/stream-utils/destroy.svg?style=flat-square
[coveralls-url]: https://coveralls.io/r/stream-utils/destroy?branch=master
[license-image]: http://img.shields.io/npm/l/destroy.svg?style=flat-square
[license-url]: LICENSE.md
[downloads-image]: http://img.shields.io/npm/dm/destroy.svg?style=flat-square
[downloads-url]: https://npmjs.org/package/destroy
[gittip-image]: https://img.shields.io/gittip/jonathanong.svg?style=flat-square
[gittip-url]: https://www.gittip.com/jonathanong/
# has
> Object.prototype.hasOwnProperty.call shortcut
## Installation
```sh
npm install --save has
```
## Usage
```js
var has = require('has');
has({}, 'hasOwnProperty'); // false
has(Object.prototype, 'hasOwnProperty'); // true
```
# buffer-crc32
[](http://travis-ci.org/brianloveswords/buffer-crc32)
crc32 that works with binary data and fancy character sets, outputs
buffer, signed or unsigned data and has tests.
Derived from the sample CRC implementation in the PNG specification: http://www.w3.org/TR/PNG/#D-CRCAppendix
# install
```
npm install buffer-crc32
```
# example
```js
var crc32 = require('buffer-crc32');
// works with buffers
var buf = Buffer([0x00, 0x73, 0x75, 0x70, 0x20, 0x62, 0x72, 0x6f, 0x00])
crc32(buf) // -> <Buffer 94 5a ab 4a>
// has convenience methods for getting signed or unsigned ints
crc32.signed(buf) // -> -1805997238
crc32.unsigned(buf) // -> 2488970058
// will cast to buffer if given a string, so you can
// directly use foreign characters safely
crc32('自動販売機') // -> <Buffer cb 03 1a c5>
// and works in append mode too
var partialCrc = crc32('hey');
var partialCrc = crc32(' ', partialCrc);
var partialCrc = crc32('sup', partialCrc);
var partialCrc = crc32(' ', partialCrc);
var finalCrc = crc32('bros', partialCrc); // -> <Buffer 47 fa 55 70>
```
# tests
This was tested against the output of zlib's crc32 method. You can run
the tests with`npm test` (requires tap)
# see also
https://github.com/alexgorbatchev/node-crc, `crc.buffer.crc32` also
supports buffer inputs and return unsigned ints (thanks @tjholowaychuk).
# license
MIT/X11
# capability.js - javascript environment capability detection
[](https://travis-ci.org/inf3rno/capability)
The capability.js library provides capability detection for different javascript environments.
## Documentation
This project is empty yet.
### Installation
```bash
npm install capability
```
```bash
bower install capability
```
#### Environment compatibility
The lib requires only basic javascript features, so it will run in every js environments.
#### Requirements
If you want to use the lib in browser, you'll need a node module loader, e.g. browserify, webpack, etc...
#### Usage
In this documentation I used the lib as follows:
```js
var capability = require("capability");
```
### Capabilities API
#### Defining a capability
You can define a capability by using the `define(name, test)` function.
```js
capability.define("Object.create", function () {
return Object.create;
});
```
The `name` parameter should contain the identifier of the capability and the `test` parameter should contain a function, which can detect the capability.
If the capability is supported by the environment, then the `test()` should return `true`, otherwise it should return `false`.
You don't have to convert the return value into a `Boolean`, the library will do that for you, so you won't have memory leaks because of this.
#### Testing a capability
The `test(name)` function will return a `Boolean` about whether the capability is supported by the actual environment.
```js
console.log(capability.test("Object.create"));
// true - in recent environments
// false - by pre ES5 environments without Object.create
```
You can use `capability(name)` instead of `capability.test(name)` if you want a short code by optional requirements.
#### Checking a capability
The `check(name)` function will throw an Error when the capability is not supported by the actual environment.
```js
capability.check("Object.create");
// this will throw an Error by pre ES5 environments without Object.create
```
#### Checking capability with require and modules
It is possible to check the environments with `require()` by adding a module, which calls the `check(name)` function.
By the capability definitions in this lib I added such modules by each definition, so you can do for example `require("capability/es5")`.
Ofc. you can do fun stuff if you want, e.g. you can call multiple `check`s from a single `requirements.js` file in your lib, etc...
### Definitions
Currently the following definitions are supported by the lib:
- strict mode
- `arguments.callee.caller`
- es5
- `Array.prototype.forEach`
- `Array.prototype.map`
- `Function.prototype.bind`
- `Object.create`
- `Object.defineProperties`
- `Object.defineProperty`
- `Object.prototype.hasOwnProperty`
- `Error.captureStackTrace`
- `Error.prototype.stack`
## License
MIT - 2016 Jánszky László Lajos
# web3-eth-iban
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub package of [web3.js][repo]
This is the IBAN package to be used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-iban
```
## Usage
```js
const Web3EthIban = require('web3-eth-iban');
const iban = new Web3EthIban('XE75JRZCTTLBSYEQBGAS7GID8DKR7QY0QA3');
iban.toAddress() > '0xa94f5374Fce5edBC8E2a8697C15331677e6EbF0B';
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-eth-iban.svg
[npm-url]: https://npmjs.org/package/web3-eth-iban
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-eth-iban
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-eth-iban
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-eth-iban
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=web3-eth-iban
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
`disable()`
Will disable all namespaces. The functions returns the namespaces currently
enabled (and skipped). This can be useful if you want to disable debugging
temporarily without knowing what was enabled to begin with.
For example:
```js
let debug = require('debug');
debug.enable('foo:*,-foo:bar');
let namespaces = debug.disable();
debug.enable(namespaces);
```
Note: There is no guarantee that the string will be identical to the initial
enable string, but semantically they will be identical.
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# web3-eth-ens
This is a sub package of [web3.js][repo]
This is the contract package to be used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-ens
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-eth-ens.js` and `dist/web3-eth.js` in your html file.
This will expose the `EthEns` object on the window object.
## Usage
```js
var eth = new Web3Eth(web3.currentProvider);
var ens = new EthEns(eth);
ens.getAddress('ethereum.eth').then(function(result) {
console.log(result);
});
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[![Build Status][travis-svg]][travis-url]
[![dependency status][deps-svg]][deps-url]
[![dev dependency status][dev-deps-svg]][dev-deps-url]
# extend() for Node.js <sup>[![Version Badge][npm-version-png]][npm-url]</sup>
`node-extend` is a port of the classic extend() method from jQuery. It behaves as you expect. It is simple, tried and true.
Notes:
* Since Node.js >= 4,
[`Object.assign`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/assign)
now offers the same functionality natively (but without the "deep copy" option).
See [ECMAScript 2015 (ES6) in Node.js](https://nodejs.org/en/docs/es6).
* Some native implementations of `Object.assign` in both Node.js and many
browsers (since NPM modules are for the browser too) may not be fully
spec-compliant.
Check [`object.assign`](https://www.npmjs.com/package/object.assign) module for
a compliant candidate.
## Installation
This package is available on [npm][npm-url] as: `extend`
``` sh
npm install extend
```
## Usage
**Syntax:** extend **(** [`deep`], `target`, `object1`, [`objectN`] **)**
*Extend one object with one or more others, returning the modified object.*
**Example:**
``` js
var extend = require('extend');
extend(targetObject, object1, object2);
```
Keep in mind that the target object will be modified, and will be returned from extend().
If a boolean true is specified as the first argument, extend performs a deep copy, recursively copying any objects it finds. Otherwise, the copy will share structure with the original object(s).
Undefined properties are not copied. However, properties inherited from the object's prototype will be copied over.
Warning: passing `false` as the first argument is not supported.
### Arguments
* `deep` *Boolean* (optional)
If set, the merge becomes recursive (i.e. deep copy).
* `target` *Object*
The object to extend.
* `object1` *Object*
The object that will be merged into the first.
* `objectN` *Object* (Optional)
More objects to merge into the first.
## License
`node-extend` is licensed under the [MIT License][mit-license-url].
## Acknowledgements
All credit to the jQuery authors for perfecting this amazing utility.
Ported to Node.js by [Stefan Thomas][github-justmoon] with contributions by [Jonathan Buchanan][github-insin] and [Jordan Harband][github-ljharb].
[travis-svg]: https://travis-ci.org/justmoon/node-extend.svg
[travis-url]: https://travis-ci.org/justmoon/node-extend
[npm-url]: https://npmjs.org/package/extend
[mit-license-url]: http://opensource.org/licenses/MIT
[github-justmoon]: https://github.com/justmoon
[github-insin]: https://github.com/insin
[github-ljharb]: https://github.com/ljharb
[npm-version-png]: http://versionbadg.es/justmoon/node-extend.svg
[deps-svg]: https://david-dm.org/justmoon/node-extend.svg
[deps-url]: https://david-dm.org/justmoon/node-extend
[dev-deps-svg]: https://david-dm.org/justmoon/node-extend/dev-status.svg
[dev-deps-url]: https://david-dm.org/justmoon/node-extend#info=devDependencies
# preserve [](http://badge.fury.io/js/preserve)
> Temporarily substitute tokens in the given `string` with placeholders, then put them back after transforming the string.
Useful for protecting tokens, like templates in HTML, from being mutated when the string is transformed in some way, like from a formatter/beautifier.
**Example without `preserve`**
Let's say you want to use [js-beautify] on a string of html with Lo-Dash/Underscore templates, such as: `<ul><li><%= name %></li></ul>`:
js-beautify will render the template unusable (and apply incorrect formatting because of the unfamiliar syntax from the Lo-Dash template):
```html
<ul>
<li>
<%=n ame %>
</li>
</ul>
```
**Example with `preserve`**
Correct.
```html
<ul>
<li><%= name %></li>
</ul>
```
For the record, this is just a random example, I've had very few issues with js-beautify in general. But with or without js-beautify, this kind of token mangling does happen sometimes when you use formatters, beautifiers or similar tools.
## Install
## Install with [npm](npmjs.org)
```bash
npm i preserve --save
```
## Run tests
```bash
npm test
```
## API
### [.before](index.js#L23)
Replace tokens in `str` with a temporary, heuristic placeholder.
* `str` **{String}**
* `returns` **{String}**: String with placeholders.
```js
tokens.before('{a\\,b}');
//=> '{__ID1__}'
```
### [.after](index.js#L44)
Replace placeholders in `str` with original tokens.
* `str` **{String}**: String with placeholders
* `returns` **{String}** `str`: String with original tokens.
```js
tokens.after('{__ID1__}');
//=> '{a\\,b}'
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/preserve/issues)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright (c) 2015-2015, Jon Schlinkert.
Released under the MIT license
***
_This file was generated by [verb](https://github.com/assemble/verb) on January 10, 2015._
[js-beautify]: https://github.com/beautify-web/js-beautify
Browser-friendly inheritance fully compatible with standard node.js
[inherits](http://nodejs.org/api/util.html#util_util_inherits_constructor_superconstructor).
This package exports standard `inherits` from node.js `util` module in
node environment, but also provides alternative browser-friendly
implementation through [browser
field](https://gist.github.com/shtylman/4339901). Alternative
implementation is a literal copy of standard one located in standalone
module to avoid requiring of `util`. It also has a shim for old
browsers with no `Object.create` support.
While keeping you sure you are using standard `inherits`
implementation in node.js environment, it allows bundlers such as
[browserify](https://github.com/substack/node-browserify) to not
include full `util` package to your client code if all you need is
just `inherits` function. It worth, because browser shim for `util`
package is large and `inherits` is often the single function you need
from it.
It's recommended to use this package instead of
`require('util').inherits` for any code that has chances to be used
not only in node.js but in browser too.
## usage
```js
var inherits = require('inherits');
// then use exactly as the standard one
```
## note on version ~1.0
Version ~1.0 had completely different motivation and is not compatible
neither with 2.0 nor with standard node.js `inherits`.
If you are using version ~1.0 and planning to switch to ~2.0, be
careful:
* new version uses `super_` instead of `super` for referencing
superclass
* new version overwrites current prototype while old one preserves any
existing fields on it
# <img src="docs_app/assets/Rx_Logo_S.png" alt="RxJS Logo" width="86" height="86"> RxJS: Reactive Extensions For JavaScript
[](https://circleci.com/gh/ReactiveX/rxjs/tree/6.x)
[](http://badge.fury.io/js/%40reactivex%2Frxjs)
[](https://gitter.im/Reactive-Extensions/RxJS?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
# RxJS 6 Stable
### MIGRATION AND RELEASE INFORMATION:
Find out how to update to v6, **automatically update your TypeScript code**, and more!
- [Current home is MIGRATION.md](./docs_app/content/guide/v6/migration.md)
### FOR V 5.X PLEASE GO TO [THE 5.0 BRANCH](https://github.com/ReactiveX/rxjs/tree/5.x)
Reactive Extensions Library for JavaScript. This is a rewrite of [Reactive-Extensions/RxJS](https://github.com/Reactive-Extensions/RxJS) and is the latest production-ready version of RxJS. This rewrite is meant to have better performance, better modularity, better debuggable call stacks, while staying mostly backwards compatible, with some breaking changes that reduce the API surface.
[Apache 2.0 License](LICENSE.txt)
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [Contribution Guidelines](CONTRIBUTING.md)
- [Maintainer Guidelines](doc_app/content/maintainer-guidelines.md)
- [API Documentation](https://rxjs.dev/)
## Versions In This Repository
- [master](https://github.com/ReactiveX/rxjs/commits/master) - This is all of the current, unreleased work, which is against v6 of RxJS right now
- [stable](https://github.com/ReactiveX/rxjs/commits/stable) - This is the branch for the latest version you'd get if you do `npm install rxjs`
## Important
By contributing or commenting on issues in this repository, whether you've read them or not, you're agreeing to the [Contributor Code of Conduct](CODE_OF_CONDUCT.md). Much like traffic laws, ignorance doesn't grant you immunity.
## Installation and Usage
### ES6 via npm
```sh
npm install rxjs
```
It's recommended to pull in the Observable creation methods you need directly from `'rxjs'` as shown below with `range`. And you can pull in any operator you need from one spot, under `'rxjs/operators'`.
```ts
import { range } from "rxjs";
import { map, filter } from "rxjs/operators";
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
```
Here, we're using the built-in `pipe` method on Observables to combine operators. See [pipeable operators](https://github.com/ReactiveX/rxjs/blob/master/doc/pipeable-operators.md) for more information.
### CommonJS via npm
To install this library for CommonJS (CJS) usage, use the following command:
```sh
npm install rxjs
```
(Note: destructuring available in Node 8+)
```js
const { range } = require('rxjs');
const { map, filter } = require('rxjs/operators');
range(1, 200).pipe(
filter(x => x % 2 === 1),
map(x => x + x)
).subscribe(x => console.log(x));
```
### CDN
For CDN, you can use [unpkg](https://unpkg.com/):
https://unpkg.com/rxjs/bundles/rxjs.umd.min.js
The global namespace for rxjs is `rxjs`:
```js
const { range } = rxjs;
const { map, filter } = rxjs.operators;
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
```
## Goals
- Smaller overall bundles sizes
- Provide better performance than preceding versions of RxJS
- To model/follow the [Observable Spec Proposal](https://github.com/zenparsing/es-observable) to the observable
- Provide more modular file structure in a variety of formats
- Provide more debuggable call stacks than preceding versions of RxJS
## Building/Testing
- `npm run build_all` - builds everything
- `npm test` - runs tests
- `npm run test_no_cache` - run test with `ts-node` set to false
## Performance Tests
Run `npm run build_perf` or `npm run perf` to run the performance tests with `protractor`.
Run `npm run perf_micro [operator]` to run micro performance test benchmarking operator.
## Adding documentation
We appreciate all contributions to the documentation of any type. All of the information needed to get the docs app up and running locally as well as how to contribute can be found in the [documentation directory](./docs_app).
## Generating PNG marble diagrams
The script `npm run tests2png` requires some native packages installed locally: `imagemagick`, `graphicsmagick`, and `ghostscript`.
For Mac OS X with [Homebrew](http://brew.sh/):
- `brew install imagemagick`
- `brew install graphicsmagick`
- `brew install ghostscript`
- You may need to install the Ghostscript fonts manually:
- Download the tarball from the [gs-fonts project](https://sourceforge.net/projects/gs-fonts)
- `mkdir -p /usr/local/share/ghostscript && tar zxvf /path/to/ghostscript-fonts.tar.gz -C /usr/local/share/ghostscript`
For Debian Linux:
- `sudo add-apt-repository ppa:dhor/myway`
- `apt-get install imagemagick`
- `apt-get install graphicsmagick`
- `apt-get install ghostscript`
For Windows and other Operating Systems, check the download instructions here:
- http://imagemagick.org
- http://www.graphicsmagick.org
- http://www.ghostscript.com/
# sprintf-js
[![Build Status][travisci-image]][travisci-url] [![NPM Version][npm-image]][npm-url] [![Dependency Status][dependencies-image]][dependencies-url] [![devDependency Status][dev-dependencies-image]][dev-dependencies-url]
[travisci-image]: https://travis-ci.org/alexei/sprintf.js.svg?branch=master
[travisci-url]: https://travis-ci.org/alexei/sprintf.js
[npm-image]: https://badge.fury.io/js/sprintf-js.svg
[npm-url]: https://badge.fury.io/js/sprintf-js
[dependencies-image]: https://david-dm.org/alexei/sprintf.js.svg
[dependencies-url]: https://david-dm.org/alexei/sprintf.js
[dev-dependencies-image]: https://david-dm.org/alexei/sprintf.js/dev-status.svg
[dev-dependencies-url]: https://david-dm.org/alexei/sprintf.js#info=devDependencies
**sprintf-js** is a complete open source JavaScript `sprintf` implementation for the **browser** and **Node.js**.
**Note: as of v1.1.1 you might need some polyfills for older environments. See [Support](#support) section below.**
## Usage
var sprintf = require('sprintf-js').sprintf,
vsprintf = require('sprintf-js').vsprintf
sprintf('%2$s %3$s a %1$s', 'cracker', 'Polly', 'wants')
vsprintf('The first 4 letters of the english alphabet are: %s, %s, %s and %s', ['a', 'b', 'c', 'd'])
## Installation
### NPM
npm install sprintf-js
### Bower
bower install sprintf
## API
### `sprintf`
Returns a formatted string:
string sprintf(string format, mixed arg1?, mixed arg2?, ...)
### `vsprintf`
Same as `sprintf` except it takes an array of arguments, rather than a variable number of arguments:
string vsprintf(string format, array arguments?)
## Format specification
The placeholders in the format string are marked by `%` and are followed by one or more of these elements, in this order:
* An optional number followed by a `$` sign that selects which argument index to use for the value. If not specified, arguments will be placed in the same order as the placeholders in the input string.
* An optional `+` sign that forces to preceed the result with a plus or minus sign on numeric values. By default, only the `-` sign is used on negative numbers.
* An optional padding specifier that says what character to use for padding (if specified). Possible values are `0` or any other character precedeed by a `'` (single quote). The default is to pad with *spaces*.
* An optional `-` sign, that causes `sprintf` to left-align the result of this placeholder. The default is to right-align the result.
* An optional number, that says how many characters the result should have. If the value to be returned is shorter than this number, the result will be padded. When used with the `j` (JSON) type specifier, the padding length specifies the tab size used for indentation.
* An optional precision modifier, consisting of a `.` (dot) followed by a number, that says how many digits should be displayed for floating point numbers. When used with the `g` type specifier, it specifies the number of significant digits. When used on a string, it causes the result to be truncated.
* A type specifier that can be any of:
* `%` — yields a literal `%` character
* `b` — yields an integer as a binary number
* `c` — yields an integer as the character with that ASCII value
* `d` or `i` — yields an integer as a signed decimal number
* `e` — yields a float using scientific notation
* `u` — yields an integer as an unsigned decimal number
* `f` — yields a float as is; see notes on precision above
* `g` — yields a float as is; see notes on precision above
* `o` — yields an integer as an octal number
* `s` — yields a string as is
* `t` — yields `true` or `false`
* `T` — yields the type of the argument<sup><a href="#fn-1" name="fn-ref-1">1</a></sup>
* `v` — yields the primitive value of the specified argument
* `x` — yields an integer as a hexadecimal number (lower-case)
* `X` — yields an integer as a hexadecimal number (upper-case)
* `j` — yields a JavaScript object or array as a JSON encoded string
## Features
### Argument swapping
You can also swap the arguments. That is, the order of the placeholders doesn't have to match the order of the arguments. You can do that by simply indicating in the format string which arguments the placeholders refer to:
sprintf('%2$s %3$s a %1$s', 'cracker', 'Polly', 'wants')
And, of course, you can repeat the placeholders without having to increase the number of arguments.
### Named arguments
Format strings may contain replacement fields rather than positional placeholders. Instead of referring to a certain argument, you can now refer to a certain key within an object. Replacement fields are surrounded by rounded parentheses - `(` and `)` - and begin with a keyword that refers to a key:
var user = {
name: 'Dolly',
}
sprintf('Hello %(name)s', user) // Hello Dolly
Keywords in replacement fields can be optionally followed by any number of keywords or indexes:
var users = [
{name: 'Dolly'},
{name: 'Molly'},
{name: 'Polly'},
]
sprintf('Hello %(users[0].name)s, %(users[1].name)s and %(users[2].name)s', {users: users}) // Hello Dolly, Molly and Polly
Note: mixing positional and named placeholders is not (yet) supported
### Computed values
You can pass in a function as a dynamic value and it will be invoked (with no arguments) in order to compute the value on the fly.
sprintf('Current date and time: %s', function() { return new Date().toString() })
### AngularJS
You can use `sprintf` and `vsprintf` (also aliased as `fmt` and `vfmt` respectively) in your AngularJS projects. See `demo/`.
## Support
### Node.js
`sprintf-js` runs in all active Node versions (4.x+).
### Browser
`sprintf-js` should work in all modern browsers. As of v1.1.1, you might need polyfills for the following:
- `String.prototype.repeat()` (any IE)
- `Array.isArray()` (IE < 9)
- `Object.create()` (IE < 9)
YMMV
## License
**sprintf-js** is licensed under the terms of the 3-clause BSD license.
## Notes
<small><sup><a href="#fn-ref-1" name="fn-1">1</a></sup> `sprintf` doesn't use the `typeof` operator. As such, the value `null` is a `null`, an array is an `array` (not an `object`), a date value is a `date` etc.</small>
# pbkdf2
[](https://www.npmjs.org/package/pbkdf2)
[](https://travis-ci.org/crypto-browserify/pbkdf2)
[](https://david-dm.org/crypto-browserify/pbkdf2#info=dependencies)
[](https://github.com/feross/standard)
This library provides the functionality of PBKDF2 with the ability to use any supported hashing algorithm returned from `crypto.getHashes()`
## Usage
```js
var pbkdf2 = require('pbkdf2')
var derivedKey = pbkdf2.pbkdf2Sync('password', 'salt', 1, 32, 'sha512')
...
```
For more information on the API, please see the relevant [Node documentation](https://nodejs.org/api/crypto.html#crypto_crypto_pbkdf2_password_salt_iterations_keylen_digest_callback).
For high performance, use the `async` variant (`pbkdf2.pbkdf2`), not `pbkdf2.pbkdf2Sync`, this variant has the oppurtunity to use `window.crypto.subtle` when browserified.
## Credits
This module is a derivative of [cryptocoinjs/pbkdf2-sha256](https://github.com/cryptocoinjs/pbkdf2-sha256/), so thanks to [JP Richardson](https://github.com/jprichardson/) for laying the ground work.
Thank you to [FangDun Cai](https://github.com/fundon) for donating the package name on npm, if you're looking for his previous module it is located at [fundon/pbkdf2](https://github.com/fundon/pbkdf2).
# defer-to-connect
> The safe way to handle the `connect` socket event
[](https://coveralls.io/github/szmarczak/defer-to-connect?branch=master)
Once you receive the socket, it may be already connected (or disconnected).<br>
To avoid checking that, use `defer-to-connect`. It'll do that for you.
## Usage
```js
const deferToConnect = require('defer-to-connect');
deferToConnect(socket, () => {
console.log('Connected!');
});
```
## API
### deferToConnect(socket, connectListener)
Calls `connectListener()` when connected.
### deferToConnect(socket, listeners)
#### listeners
An object representing `connect`, `secureConnect` and `close` properties.
Calls `connect()` when the socket is connected.<br>
Calls `secureConnect()` when the socket is securely connected.<br>
Calls `close()` when the socket is destroyed.
## License
MIT
# Change Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform a string between `camelCase`, `PascalCase`, `Capital Case`, `snake_case`, `param-case`, `CONSTANT_CASE` and others.
## Installation
```
npm install change-case --save
```
## Usage
```js
import {
camelCase,
capitalCase,
constantCase,
dotCase,
headerCase,
noCase,
paramCase,
pascalCase,
pathCase,
sentenceCase,
snakeCase
} from "change-case";
```
Methods can also be installed [independently](https://github.com/blakeembrey/change-case). All functions also accept [`options`](https://github.com/blakeembrey/change-case#options) as the second argument.
## License
MIT
[npm-image]: https://img.shields.io/npm/v/change-case.svg?style=flat
[npm-url]: https://npmjs.org/package/change-case
[downloads-image]: https://img.shields.io/npm/dm/change-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/change-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/change-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=change-case
# nano-json-stream-parser
A complete, pure JavaScript, streamed JSON parser in about `750 bytes` (gzipped). It is similar to [Oboe.js](https://github.com/jimhigson/oboe.js/), a streaming JSON micro-library with a size of `4.8kb` (gzipped). While that alone isn't much, sizes add up quickly when you stack many libs. This lib achieves a 85% size reduction, while still offering the same main functionality. Uses ES6 arrows.
## Install
npm i nano-json-stream-parser
## Usage
Usage is self explanatory:
```javascript
const njsp = require("nano-json-stream-parser");
// Callback is called when there is a complete JSON
const parse = njsp((json) => console.log(json));
parse('[1,2,3,4]');
parse('[1,2');
parse(',3,4]');
parse("[::invalid_json_is_ignored::]");
parse('{"pos": {"x":');
parse('1.70, "y": 2.');
parse('49, "z": 2e3}}');
parse('[ "aaaa\\"abcd\\u0123\\\\aa\\/aa" ]')
```
Output:
```
[ 1, 2, 3, 4 ]
[ 1, 2, 3, 4 ]
{ pos: { x: 1.7, y: 2.49, z: 2000 } }
[ 'aaaa"abcdģ\\aa/aa' ]
```
## Disclaimer
This library has no tests yet and could contain buggy edge-cases.
# string_decoder
***Node-core v8.9.4 string_decoder for userland***
[](https://nodei.co/npm/string_decoder/)
[](https://nodei.co/npm/string_decoder/)
```bash
npm install --save string_decoder
```
***Node-core string_decoder for userland***
This package is a mirror of the string_decoder implementation in Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.9.4/docs/api/).
As of version 1.0.0 **string_decoder** uses semantic versioning.
## Previous versions
Previous version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10.
## Update
The *build/* directory contains a build script that will scrape the source from the [nodejs/node](https://github.com/nodejs/node) repo given a specific Node version.
## Streams Working Group
`string_decoder` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
See [readable-stream](https://github.com/nodejs/readable-stream) for
more details.
# simple-concat [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/simple-concat/master.svg
[travis-url]: https://travis-ci.org/feross/simple-concat
[npm-image]: https://img.shields.io/npm/v/simple-concat.svg
[npm-url]: https://npmjs.org/package/simple-concat
[downloads-image]: https://img.shields.io/npm/dm/simple-concat.svg
[downloads-url]: https://npmjs.org/package/simple-concat
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
### Super-minimalist version of [`concat-stream`](https://github.com/maxogden/concat-stream). Less than 15 lines!
## install
```
npm install simple-concat
```
## usage
This example is longer than the implementation.
```js
var s = new stream.PassThrough()
concat(s, function (err, buf) {
if (err) throw err
console.error(buf)
})
s.write('abc')
setTimeout(function () {
s.write('123')
}, 10)
setTimeout(function () {
s.write('456')
}, 20)
setTimeout(function () {
s.end('789')
}, 30)
```
## license
MIT. Copyright (c) [Feross Aboukhadijeh](http://feross.org).
<a href="http://promisesaplus.com/">
<img src="http://promisesaplus.com/assets/logo-small.png" alt="Promises/A+ logo"
title="Promises/A+ 1.1 compliant" align="right" />
</a>
[](https://travis-ci.org/petkaantonov/bluebird)
[](http://petkaantonov.github.io/bluebird/coverage/debug/index.html)
**Got a question?** Join us on [stackoverflow](http://stackoverflow.com/questions/tagged/bluebird), the [mailing list](https://groups.google.com/forum/#!forum/bluebird-js) or chat on [IRC](https://webchat.freenode.net/?channels=#promises)
# Introduction
Bluebird is a fully featured promise library with focus on innovative features and performance
See the [**bluebird website**](http://bluebirdjs.com/docs/getting-started.html) for further documentation, references and instructions. See the [**API reference**](http://bluebirdjs.com/docs/api-reference.html) here.
For bluebird 2.x documentation and files, see the [2.x tree](https://github.com/petkaantonov/bluebird/tree/2.x).
### Note
Promises in Node.js 10 are significantly faster than before. Bluebird still includes a lot of features like cancellation, iteration methods and warnings that native promises don't. If you are using Bluebird for performance rather than for those - please consider giving native promises a shot and running the benchmarks yourself.
# Questions and issues
The [github issue tracker](https://github.com/petkaantonov/bluebird/issues) is **_only_** for bug reports and feature requests. Anything else, such as questions for help in using the library, should be posted in [StackOverflow](http://stackoverflow.com/questions/tagged/bluebird) under tags `promise` and `bluebird`.
## Thanks
Thanks to BrowserStack for providing us with a free account which lets us support old browsers like IE8.
# License
The MIT License (MIT)
Copyright (c) 2013-2019 Petka Antonov
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# web3-eth-iban
This is a sub package of [web3.js][repo]
This is the IBAN package to be used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-iban
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-eth-iban.js` in your html file.
This will expose the `Web3EthIban` object on the window object.
## Usage
```js
// in node.js
var Web3EthIban = require('web3-eth-iban');
var iban = new Web3EthIban('XE75JRZCTTLBSYEQBGAS7GID8DKR7QY0QA3');
iban.toAddress() > '0xa94f5374Fce5edBC8E2a8697C15331677e6EbF0B';
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
agent-base
==========
### Turn a function into an [`http.Agent`][http.Agent] instance
[](https://travis-ci.org/TooTallNate/node-agent-base)
This module provides an `http.Agent` generator. That is, you pass it an async
callback function, and it returns a new `http.Agent` instance that will invoke the
given callback function when sending outbound HTTP requests.
#### Some subclasses:
Here's some more interesting uses of `agent-base`.
Send a pull request to list yours!
* [`http-proxy-agent`][http-proxy-agent]: An HTTP(s) proxy `http.Agent` implementation for HTTP endpoints
* [`https-proxy-agent`][https-proxy-agent]: An HTTP(s) proxy `http.Agent` implementation for HTTPS endpoints
* [`pac-proxy-agent`][pac-proxy-agent]: A PAC file proxy `http.Agent` implementation for HTTP and HTTPS
* [`socks-proxy-agent`][socks-proxy-agent]: A SOCKS (v4a) proxy `http.Agent` implementation for HTTP and HTTPS
Installation
------------
Install with `npm`:
``` bash
$ npm install agent-base
```
Example
-------
Here's a minimal example that creates a new `net.Socket` connection to the server
for every HTTP request (i.e. the equivalent of `agent: false` option):
```js
var net = require('net');
var tls = require('tls');
var url = require('url');
var http = require('http');
var agent = require('agent-base');
var endpoint = 'http://nodejs.org/api/';
var parsed = url.parse(endpoint);
// This is the important part!
parsed.agent = agent(function (req, opts) {
var socket;
// `secureEndpoint` is true when using the https module
if (opts.secureEndpoint) {
socket = tls.connect(opts);
} else {
socket = net.connect(opts);
}
return socket;
});
// Everything else works just like normal...
http.get(parsed, function (res) {
console.log('"response" event!', res.headers);
res.pipe(process.stdout);
});
```
Returning a Promise or using an `async` function is also supported:
```js
agent(async function (req, opts) {
await sleep(1000);
// etc…
});
```
Return another `http.Agent` instance to "pass through" the responsibility
for that HTTP request to that agent:
```js
agent(function (req, opts) {
return opts.secureEndpoint ? https.globalAgent : http.globalAgent;
});
```
API
---
## Agent(Function callback[, Object options]) → [http.Agent][]
Creates a base `http.Agent` that will execute the callback function `callback`
for every HTTP request that it is used as the `agent` for. The callback function
is responsible for creating a `stream.Duplex` instance of some kind that will be
used as the underlying socket in the HTTP request.
The `options` object accepts the following properties:
* `timeout` - Number - Timeout for the `callback()` function in milliseconds. Defaults to Infinity (optional).
The callback function should have the following signature:
### callback(http.ClientRequest req, Object options, Function cb) → undefined
The ClientRequest `req` can be accessed to read request headers and
and the path, etc. The `options` object contains the options passed
to the `http.request()`/`https.request()` function call, and is formatted
to be directly passed to `net.connect()`/`tls.connect()`, or however
else you want a Socket to be created. Pass the created socket to
the callback function `cb` once created, and the HTTP request will
continue to proceed.
If the `https` module is used to invoke the HTTP request, then the
`secureEndpoint` property on `options` _will be set to `true`_.
License
-------
(The MIT License)
Copyright (c) 2013 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[http-proxy-agent]: https://github.com/TooTallNate/node-http-proxy-agent
[https-proxy-agent]: https://github.com/TooTallNate/node-https-proxy-agent
[pac-proxy-agent]: https://github.com/TooTallNate/node-pac-proxy-agent
[socks-proxy-agent]: https://github.com/TooTallNate/node-socks-proxy-agent
[http.Agent]: https://nodejs.org/api/http.html#http_class_http_agent
# readable-stream
***Node-core v8.11.1 streams for userland*** [](https://travis-ci.org/nodejs/readable-stream)
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
[](https://saucelabs.com/u/readable-stream)
```bash
npm install --save readable-stream
```
***Node-core streams for userland***
This package is a mirror of the Streams2 and Streams3 implementations in
Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.11.1/docs/api/stream.html).
If you want to guarantee a stable streams base, regardless of what version of
Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core, for background see [this blogpost](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).
As of version 2.0.0 **readable-stream** uses semantic versioning.
# Streams Working Group
`readable-stream` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
<a name="members"></a>
## Team Members
* **Chris Dickinson** ([@chrisdickinson](https://github.com/chrisdickinson)) <[email protected]>
- Release GPG key: 9554F04D7259F04124DE6B476D5A82AC7E37093B
* **Calvin Metcalf** ([@calvinmetcalf](https://github.com/calvinmetcalf)) <[email protected]>
- Release GPG key: F3EF5F62A87FC27A22E643F714CE4FF5015AA242
* **Rod Vagg** ([@rvagg](https://github.com/rvagg)) <[email protected]>
- Release GPG key: DD8F2338BAE7501E3DD5AC78C273792F7D83545D
* **Sam Newman** ([@sonewman](https://github.com/sonewman)) <[email protected]>
* **Mathias Buus** ([@mafintosh](https://github.com/mafintosh)) <[email protected]>
* **Domenic Denicola** ([@domenic](https://github.com/domenic)) <[email protected]>
* **Matteo Collina** ([@mcollina](https://github.com/mcollina)) <[email protected]>
- Release GPG key: 3ABC01543F22DD2239285CDD818674489FBC127E
* **Irina Shestak** ([@lrlna](https://github.com/lrlna)) <[email protected]>
# proxy-from-env
[](https://travis-ci.org/Rob--W/proxy-from-env)
[](https://coveralls.io/github/Rob--W/proxy-from-env?branch=master)
`proxy-from-env` is a Node.js package that exports a function (`getProxyForUrl`)
that takes an input URL (a string or
[`url.parse`](https://nodejs.org/docs/latest/api/url.html#url_url_parsing)'s
return value) and returns the desired proxy URL (also a string) based on
standard proxy environment variables. If no proxy is set, an empty string is
returned.
It is your responsibility to actually proxy the request using the given URL.
Installation:
```sh
npm install proxy-from-env
```
## Example
This example shows how the data for a URL can be fetched via the
[`http` module](https://nodejs.org/api/http.html), in a proxy-aware way.
```javascript
var http = require('http');
var parseUrl = require('url').parse;
var getProxyForUrl = require('proxy-from-env').getProxyForUrl;
var some_url = 'http://example.com/something';
// // Example, if there is a proxy server at 10.0.0.1:1234, then setting the
// // http_proxy environment variable causes the request to go through a proxy.
// process.env.http_proxy = 'http://10.0.0.1:1234';
//
// // But if the host to be proxied is listed in NO_PROXY, then the request is
// // not proxied (but a direct request is made).
// process.env.no_proxy = 'example.com';
var proxy_url = getProxyForUrl(some_url); // <-- Our magic.
if (proxy_url) {
// Should be proxied through proxy_url.
var parsed_some_url = parseUrl(some_url);
var parsed_proxy_url = parseUrl(proxy_url);
// A HTTP proxy is quite simple. It is similar to a normal request, except the
// path is an absolute URL, and the proxied URL's host is put in the header
// instead of the server's actual host.
httpOptions = {
protocol: parsed_proxy_url.protocol,
hostname: parsed_proxy_url.hostname,
port: parsed_proxy_url.port,
path: parsed_some_url.href,
headers: {
Host: parsed_some_url.host, // = host name + optional port.
},
};
} else {
// Direct request.
httpOptions = some_url;
}
http.get(httpOptions, function(res) {
var responses = [];
res.on('data', function(chunk) { responses.push(chunk); });
res.on('end', function() { console.log(responses.join('')); });
});
```
## Environment variables
The environment variables can be specified in lowercase or uppercase, with the
lowercase name having precedence over the uppercase variant. A variable that is
not set has the same meaning as a variable that is set but has no value.
### NO\_PROXY
`NO_PROXY` is a list of host names (optionally with a port). If the input URL
matches any of the entries in `NO_PROXY`, then the input URL should be fetched
by a direct request (i.e. without a proxy).
Matching follows the following rules:
- `NO_PROXY=*` disables all proxies.
- Space and commas may be used to separate the entries in the `NO_PROXY` list.
- If `NO_PROXY` does not contain any entries, then proxies are never disabled.
- If a port is added after the host name, then the ports must match. If the URL
does not have an explicit port name, the protocol's default port is used.
- Generally, the proxy is only disabled if the host name is an exact match for
an entry in the `NO_PROXY` list. The only exceptions are entries that start
with a dot or with a wildcard; then the proxy is disabled if the host name
ends with the entry.
See `test.js` for examples of what should match and what does not.
### \*\_PROXY
The environment variable used for the proxy depends on the protocol of the URL.
For example, `https://example.com` uses the "https" protocol, and therefore the
proxy to be used is `HTTPS_PROXY` (_NOT_ `HTTP_PROXY`, which is _only_ used for
http:-URLs).
The library is not limited to http(s), other schemes such as
`FTP_PROXY` (ftp:),
`WSS_PROXY` (wss:),
`WS_PROXY` (ws:)
are also supported.
If present, `ALL_PROXY` is used as fallback if there is no other match.
## External resources
The exact way of parsing the environment variables is not codified in any
standard. This library is designed to be compatible with formats as expected by
existing software.
The following resources were used to determine the desired behavior:
- cURL:
https://curl.haxx.se/docs/manpage.html#ENVIRONMENT
https://github.com/curl/curl/blob/4af40b3646d3b09f68e419f7ca866ff395d1f897/lib/url.c#L4446-L4514
https://github.com/curl/curl/blob/4af40b3646d3b09f68e419f7ca866ff395d1f897/lib/url.c#L4608-L4638
- wget:
https://www.gnu.org/software/wget/manual/wget.html#Proxies
http://git.savannah.gnu.org/cgit/wget.git/tree/src/init.c?id=636a5f9a1c508aa39e35a3a8e9e54520a284d93d#n383
http://git.savannah.gnu.org/cgit/wget.git/tree/src/retr.c?id=93c1517c4071c4288ba5a4b038e7634e4c6b5482#n1278
- W3:
https://www.w3.org/Daemon/User/Proxies/ProxyClients.html
- Python's urllib:
https://github.com/python/cpython/blob/936135bb97fe04223aa30ca6e98eac8f3ed6b349/Lib/urllib/request.py#L755-L782
https://github.com/python/cpython/blob/936135bb97fe04223aa30ca6e98eac8f3ed6b349/Lib/urllib/request.py#L2444-L2479
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# raw-body
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build status][travis-image]][travis-url]
[![Test coverage][coveralls-image]][coveralls-url]
Gets the entire buffer of a stream either as a `Buffer` or a string.
Validates the stream's length against an expected length and maximum limit.
Ideal for parsing request bodies.
## Install
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install raw-body
```
### TypeScript
This module includes a [TypeScript](https://www.typescriptlang.org/)
declaration file to enable auto complete in compatible editors and type
information for TypeScript projects. This module depends on the Node.js
types, so install `@types/node`:
```sh
$ npm install @types/node
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var getRawBody = require('raw-body')
```
### getRawBody(stream, [options], [callback])
**Returns a promise if no callback specified and global `Promise` exists.**
Options:
- `length` - The length of the stream.
If the contents of the stream do not add up to this length,
an `400` error code is returned.
- `limit` - The byte limit of the body.
This is the number of bytes or any string format supported by
[bytes](https://www.npmjs.com/package/bytes),
for example `1000`, `'500kb'` or `'3mb'`.
If the body ends up being larger than this limit,
a `413` error code is returned.
- `encoding` - The encoding to use to decode the body into a string.
By default, a `Buffer` instance will be returned when no encoding is specified.
Most likely, you want `utf-8`, so setting `encoding` to `true` will decode as `utf-8`.
You can use any type of encoding supported by [iconv-lite](https://www.npmjs.org/package/iconv-lite#readme).
You can also pass a string in place of options to just specify the encoding.
If an error occurs, the stream will be paused, everything unpiped,
and you are responsible for correctly disposing the stream.
For HTTP requests, no handling is required if you send a response.
For streams that use file descriptors, you should `stream.destroy()` or `stream.close()` to prevent leaks.
## Errors
This module creates errors depending on the error condition during reading.
The error may be an error from the underlying Node.js implementation, but is
otherwise an error created by this module, which has the following attributes:
* `limit` - the limit in bytes
* `length` and `expected` - the expected length of the stream
* `received` - the received bytes
* `encoding` - the invalid encoding
* `status` and `statusCode` - the corresponding status code for the error
* `type` - the error type
### Types
The errors from this module have a `type` property which allows for the progamatic
determination of the type of error returned.
#### encoding.unsupported
This error will occur when the `encoding` option is specified, but the value does
not map to an encoding supported by the [iconv-lite](https://www.npmjs.org/package/iconv-lite#readme)
module.
#### entity.too.large
This error will occur when the `limit` option is specified, but the stream has
an entity that is larger.
#### request.aborted
This error will occur when the request stream is aborted by the client before
reading the body has finished.
#### request.size.invalid
This error will occur when the `length` option is specified, but the stream has
emitted more bytes.
#### stream.encoding.set
This error will occur when the given stream has an encoding set on it, making it
a decoded stream. The stream should not have an encoding set and is expected to
emit `Buffer` objects.
## Examples
### Simple Express example
```js
var contentType = require('content-type')
var express = require('express')
var getRawBody = require('raw-body')
var app = express()
app.use(function (req, res, next) {
getRawBody(req, {
length: req.headers['content-length'],
limit: '1mb',
encoding: contentType.parse(req).parameters.charset
}, function (err, string) {
if (err) return next(err)
req.text = string
next()
})
})
// now access req.text
```
### Simple Koa example
```js
var contentType = require('content-type')
var getRawBody = require('raw-body')
var koa = require('koa')
var app = koa()
app.use(function * (next) {
this.text = yield getRawBody(this.req, {
length: this.req.headers['content-length'],
limit: '1mb',
encoding: contentType.parse(this.req).parameters.charset
})
yield next
})
// now access this.text
```
### Using as a promise
To use this library as a promise, simply omit the `callback` and a promise is
returned, provided that a global `Promise` is defined.
```js
var getRawBody = require('raw-body')
var http = require('http')
var server = http.createServer(function (req, res) {
getRawBody(req)
.then(function (buf) {
res.statusCode = 200
res.end(buf.length + ' bytes submitted')
})
.catch(function (err) {
res.statusCode = 500
res.end(err.message)
})
})
server.listen(3000)
```
### Using with TypeScript
```ts
import * as getRawBody from 'raw-body';
import * as http from 'http';
const server = http.createServer((req, res) => {
getRawBody(req)
.then((buf) => {
res.statusCode = 200;
res.end(buf.length + ' bytes submitted');
})
.catch((err) => {
res.statusCode = err.statusCode;
res.end(err.message);
});
});
server.listen(3000);
```
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/raw-body.svg
[npm-url]: https://npmjs.org/package/raw-body
[node-version-image]: https://img.shields.io/node/v/raw-body.svg
[node-version-url]: https://nodejs.org/en/download/
[travis-image]: https://img.shields.io/travis/stream-utils/raw-body/master.svg
[travis-url]: https://travis-ci.org/stream-utils/raw-body
[coveralls-image]: https://img.shields.io/coveralls/stream-utils/raw-body/master.svg
[coveralls-url]: https://coveralls.io/r/stream-utils/raw-body?branch=master
[downloads-image]: https://img.shields.io/npm/dm/raw-body.svg
[downloads-url]: https://npmjs.org/package/raw-body
# qs <sup>[![Version Badge][2]][1]</sup>
[![Build Status][3]][4]
[![dependency status][5]][6]
[![dev dependency status][7]][8]
[![License][license-image]][license-url]
[![Downloads][downloads-image]][downloads-url]
[![npm badge][11]][1]
A querystring parsing and stringifying library with some added security.
Lead Maintainer: [Jordan Harband](https://github.com/ljharb)
The **qs** module was originally created and maintained by [TJ Holowaychuk](https://github.com/visionmedia/node-querystring).
## Usage
```javascript
var qs = require('qs');
var assert = require('assert');
var obj = qs.parse('a=c');
assert.deepEqual(obj, { a: 'c' });
var str = qs.stringify(obj);
assert.equal(str, 'a=c');
```
### Parsing Objects
[](#preventEval)
```javascript
qs.parse(string, [options]);
```
**qs** allows you to create nested objects within your query strings, by surrounding the name of sub-keys with square brackets `[]`.
For example, the string `'foo[bar]=baz'` converts to:
```javascript
assert.deepEqual(qs.parse('foo[bar]=baz'), {
foo: {
bar: 'baz'
}
});
```
When using the `plainObjects` option the parsed value is returned as a null object, created via `Object.create(null)` and as such you should be aware that prototype methods will not exist on it and a user may set those names to whatever value they like:
```javascript
var nullObject = qs.parse('a[hasOwnProperty]=b', { plainObjects: true });
assert.deepEqual(nullObject, { a: { hasOwnProperty: 'b' } });
```
By default parameters that would overwrite properties on the object prototype are ignored, if you wish to keep the data from those fields either use `plainObjects` as mentioned above, or set `allowPrototypes` to `true` which will allow user input to overwrite those properties. *WARNING* It is generally a bad idea to enable this option as it can cause problems when attempting to use the properties that have been overwritten. Always be careful with this option.
```javascript
var protoObject = qs.parse('a[hasOwnProperty]=b', { allowPrototypes: true });
assert.deepEqual(protoObject, { a: { hasOwnProperty: 'b' } });
```
URI encoded strings work too:
```javascript
assert.deepEqual(qs.parse('a%5Bb%5D=c'), {
a: { b: 'c' }
});
```
You can also nest your objects, like `'foo[bar][baz]=foobarbaz'`:
```javascript
assert.deepEqual(qs.parse('foo[bar][baz]=foobarbaz'), {
foo: {
bar: {
baz: 'foobarbaz'
}
}
});
```
By default, when nesting objects **qs** will only parse up to 5 children deep. This means if you attempt to parse a string like
`'a[b][c][d][e][f][g][h][i]=j'` your resulting object will be:
```javascript
var expected = {
a: {
b: {
c: {
d: {
e: {
f: {
'[g][h][i]': 'j'
}
}
}
}
}
}
};
var string = 'a[b][c][d][e][f][g][h][i]=j';
assert.deepEqual(qs.parse(string), expected);
```
This depth can be overridden by passing a `depth` option to `qs.parse(string, [options])`:
```javascript
var deep = qs.parse('a[b][c][d][e][f][g][h][i]=j', { depth: 1 });
assert.deepEqual(deep, { a: { b: { '[c][d][e][f][g][h][i]': 'j' } } });
```
The depth limit helps mitigate abuse when **qs** is used to parse user input, and it is recommended to keep it a reasonably small number.
For similar reasons, by default **qs** will only parse up to 1000 parameters. This can be overridden by passing a `parameterLimit` option:
```javascript
var limited = qs.parse('a=b&c=d', { parameterLimit: 1 });
assert.deepEqual(limited, { a: 'b' });
```
To bypass the leading question mark, use `ignoreQueryPrefix`:
```javascript
var prefixed = qs.parse('?a=b&c=d', { ignoreQueryPrefix: true });
assert.deepEqual(prefixed, { a: 'b', c: 'd' });
```
An optional delimiter can also be passed:
```javascript
var delimited = qs.parse('a=b;c=d', { delimiter: ';' });
assert.deepEqual(delimited, { a: 'b', c: 'd' });
```
Delimiters can be a regular expression too:
```javascript
var regexed = qs.parse('a=b;c=d,e=f', { delimiter: /[;,]/ });
assert.deepEqual(regexed, { a: 'b', c: 'd', e: 'f' });
```
Option `allowDots` can be used to enable dot notation:
```javascript
var withDots = qs.parse('a.b=c', { allowDots: true });
assert.deepEqual(withDots, { a: { b: 'c' } });
```
If you have to deal with legacy browsers or services, there's
also support for decoding percent-encoded octets as iso-8859-1:
```javascript
var oldCharset = qs.parse('a=%A7', { charset: 'iso-8859-1' });
assert.deepEqual(oldCharset, { a: '§' });
```
Some services add an initial `utf8=✓` value to forms so that old
Internet Explorer versions are more likely to submit the form as
utf-8. Additionally, the server can check the value against wrong
encodings of the checkmark character and detect that a query string
or `application/x-www-form-urlencoded` body was *not* sent as
utf-8, eg. if the form had an `accept-charset` parameter or the
containing page had a different character set.
**qs** supports this mechanism via the `charsetSentinel` option.
If specified, the `utf8` parameter will be omitted from the
returned object. It will be used to switch to `iso-8859-1`/`utf-8`
mode depending on how the checkmark is encoded.
**Important**: When you specify both the `charset` option and the
`charsetSentinel` option, the `charset` will be overridden when
the request contains a `utf8` parameter from which the actual
charset can be deduced. In that sense the `charset` will behave
as the default charset rather than the authoritative charset.
```javascript
var detectedAsUtf8 = qs.parse('utf8=%E2%9C%93&a=%C3%B8', {
charset: 'iso-8859-1',
charsetSentinel: true
});
assert.deepEqual(detectedAsUtf8, { a: 'ø' });
// Browsers encode the checkmark as ✓ when submitting as iso-8859-1:
var detectedAsIso8859_1 = qs.parse('utf8=%26%2310003%3B&a=%F8', {
charset: 'utf-8',
charsetSentinel: true
});
assert.deepEqual(detectedAsIso8859_1, { a: 'ø' });
```
If you want to decode the `&#...;` syntax to the actual character,
you can specify the `interpretNumericEntities` option as well:
```javascript
var detectedAsIso8859_1 = qs.parse('a=%26%239786%3B', {
charset: 'iso-8859-1',
interpretNumericEntities: true
});
assert.deepEqual(detectedAsIso8859_1, { a: '☺' });
```
It also works when the charset has been detected in `charsetSentinel`
mode.
### Parsing Arrays
**qs** can also parse arrays using a similar `[]` notation:
```javascript
var withArray = qs.parse('a[]=b&a[]=c');
assert.deepEqual(withArray, { a: ['b', 'c'] });
```
You may specify an index as well:
```javascript
var withIndexes = qs.parse('a[1]=c&a[0]=b');
assert.deepEqual(withIndexes, { a: ['b', 'c'] });
```
Note that the only difference between an index in an array and a key in an object is that the value between the brackets must be a number
to create an array. When creating arrays with specific indices, **qs** will compact a sparse array to only the existing values preserving
their order:
```javascript
var noSparse = qs.parse('a[1]=b&a[15]=c');
assert.deepEqual(noSparse, { a: ['b', 'c'] });
```
Note that an empty string is also a value, and will be preserved:
```javascript
var withEmptyString = qs.parse('a[]=&a[]=b');
assert.deepEqual(withEmptyString, { a: ['', 'b'] });
var withIndexedEmptyString = qs.parse('a[0]=b&a[1]=&a[2]=c');
assert.deepEqual(withIndexedEmptyString, { a: ['b', '', 'c'] });
```
**qs** will also limit specifying indices in an array to a maximum index of `20`. Any array members with an index of greater than `20` will
instead be converted to an object with the index as the key. This is needed to handle cases when someone sent, for example, `a[999999999]` and it will take significant time to iterate over this huge array.
```javascript
var withMaxIndex = qs.parse('a[100]=b');
assert.deepEqual(withMaxIndex, { a: { '100': 'b' } });
```
This limit can be overridden by passing an `arrayLimit` option:
```javascript
var withArrayLimit = qs.parse('a[1]=b', { arrayLimit: 0 });
assert.deepEqual(withArrayLimit, { a: { '1': 'b' } });
```
To disable array parsing entirely, set `parseArrays` to `false`.
```javascript
var noParsingArrays = qs.parse('a[]=b', { parseArrays: false });
assert.deepEqual(noParsingArrays, { a: { '0': 'b' } });
```
If you mix notations, **qs** will merge the two items into an object:
```javascript
var mixedNotation = qs.parse('a[0]=b&a[b]=c');
assert.deepEqual(mixedNotation, { a: { '0': 'b', b: 'c' } });
```
You can also create arrays of objects:
```javascript
var arraysOfObjects = qs.parse('a[][b]=c');
assert.deepEqual(arraysOfObjects, { a: [{ b: 'c' }] });
```
Some people use comma to join array, **qs** can parse it:
```javascript
var arraysOfObjects = qs.parse('a=b,c', { comma: true })
assert.deepEqual(arraysOfObjects, { a: ['b', 'c'] })
```
(_this cannot convert nested objects, such as `a={b:1},{c:d}`_)
### Stringifying
[](#preventEval)
```javascript
qs.stringify(object, [options]);
```
When stringifying, **qs** by default URI encodes output. Objects are stringified as you would expect:
```javascript
assert.equal(qs.stringify({ a: 'b' }), 'a=b');
assert.equal(qs.stringify({ a: { b: 'c' } }), 'a%5Bb%5D=c');
```
This encoding can be disabled by setting the `encode` option to `false`:
```javascript
var unencoded = qs.stringify({ a: { b: 'c' } }, { encode: false });
assert.equal(unencoded, 'a[b]=c');
```
Encoding can be disabled for keys by setting the `encodeValuesOnly` option to `true`:
```javascript
var encodedValues = qs.stringify(
{ a: 'b', c: ['d', 'e=f'], f: [['g'], ['h']] },
{ encodeValuesOnly: true }
);
assert.equal(encodedValues,'a=b&c[0]=d&c[1]=e%3Df&f[0][0]=g&f[1][0]=h');
```
This encoding can also be replaced by a custom encoding method set as `encoder` option:
```javascript
var encoded = qs.stringify({ a: { b: 'c' } }, { encoder: function (str) {
// Passed in values `a`, `b`, `c`
return // Return encoded string
}})
```
_(Note: the `encoder` option does not apply if `encode` is `false`)_
Analogue to the `encoder` there is a `decoder` option for `parse` to override decoding of properties and values:
```javascript
var decoded = qs.parse('x=z', { decoder: function (str) {
// Passed in values `x`, `z`
return // Return decoded string
}})
```
Examples beyond this point will be shown as though the output is not URI encoded for clarity. Please note that the return values in these cases *will* be URI encoded during real usage.
When arrays are stringified, by default they are given explicit indices:
```javascript
qs.stringify({ a: ['b', 'c', 'd'] });
// 'a[0]=b&a[1]=c&a[2]=d'
```
You may override this by setting the `indices` option to `false`:
```javascript
qs.stringify({ a: ['b', 'c', 'd'] }, { indices: false });
// 'a=b&a=c&a=d'
```
You may use the `arrayFormat` option to specify the format of the output array:
```javascript
qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'indices' })
// 'a[0]=b&a[1]=c'
qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'brackets' })
// 'a[]=b&a[]=c'
qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'repeat' })
// 'a=b&a=c'
qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'comma' })
// 'a=b,c'
```
When objects are stringified, by default they use bracket notation:
```javascript
qs.stringify({ a: { b: { c: 'd', e: 'f' } } });
// 'a[b][c]=d&a[b][e]=f'
```
You may override this to use dot notation by setting the `allowDots` option to `true`:
```javascript
qs.stringify({ a: { b: { c: 'd', e: 'f' } } }, { allowDots: true });
// 'a.b.c=d&a.b.e=f'
```
Empty strings and null values will omit the value, but the equals sign (=) remains in place:
```javascript
assert.equal(qs.stringify({ a: '' }), 'a=');
```
Key with no values (such as an empty object or array) will return nothing:
```javascript
assert.equal(qs.stringify({ a: [] }), '');
assert.equal(qs.stringify({ a: {} }), '');
assert.equal(qs.stringify({ a: [{}] }), '');
assert.equal(qs.stringify({ a: { b: []} }), '');
assert.equal(qs.stringify({ a: { b: {}} }), '');
```
Properties that are set to `undefined` will be omitted entirely:
```javascript
assert.equal(qs.stringify({ a: null, b: undefined }), 'a=');
```
The query string may optionally be prepended with a question mark:
```javascript
assert.equal(qs.stringify({ a: 'b', c: 'd' }, { addQueryPrefix: true }), '?a=b&c=d');
```
The delimiter may be overridden with stringify as well:
```javascript
assert.equal(qs.stringify({ a: 'b', c: 'd' }, { delimiter: ';' }), 'a=b;c=d');
```
If you only want to override the serialization of `Date` objects, you can provide a `serializeDate` option:
```javascript
var date = new Date(7);
assert.equal(qs.stringify({ a: date }), 'a=1970-01-01T00:00:00.007Z'.replace(/:/g, '%3A'));
assert.equal(
qs.stringify({ a: date }, { serializeDate: function (d) { return d.getTime(); } }),
'a=7'
);
```
You may use the `sort` option to affect the order of parameter keys:
```javascript
function alphabeticalSort(a, b) {
return a.localeCompare(b);
}
assert.equal(qs.stringify({ a: 'c', z: 'y', b : 'f' }, { sort: alphabeticalSort }), 'a=c&b=f&z=y');
```
Finally, you can use the `filter` option to restrict which keys will be included in the stringified output.
If you pass a function, it will be called for each key to obtain the replacement value. Otherwise, if you
pass an array, it will be used to select properties and array indices for stringification:
```javascript
function filterFunc(prefix, value) {
if (prefix == 'b') {
// Return an `undefined` value to omit a property.
return;
}
if (prefix == 'e[f]') {
return value.getTime();
}
if (prefix == 'e[g][0]') {
return value * 2;
}
return value;
}
qs.stringify({ a: 'b', c: 'd', e: { f: new Date(123), g: [2] } }, { filter: filterFunc });
// 'a=b&c=d&e[f]=123&e[g][0]=4'
qs.stringify({ a: 'b', c: 'd', e: 'f' }, { filter: ['a', 'e'] });
// 'a=b&e=f'
qs.stringify({ a: ['b', 'c', 'd'], e: 'f' }, { filter: ['a', 0, 2] });
// 'a[0]=b&a[2]=d'
```
### Handling of `null` values
By default, `null` values are treated like empty strings:
```javascript
var withNull = qs.stringify({ a: null, b: '' });
assert.equal(withNull, 'a=&b=');
```
Parsing does not distinguish between parameters with and without equal signs. Both are converted to empty strings.
```javascript
var equalsInsensitive = qs.parse('a&b=');
assert.deepEqual(equalsInsensitive, { a: '', b: '' });
```
To distinguish between `null` values and empty strings use the `strictNullHandling` flag. In the result string the `null`
values have no `=` sign:
```javascript
var strictNull = qs.stringify({ a: null, b: '' }, { strictNullHandling: true });
assert.equal(strictNull, 'a&b=');
```
To parse values without `=` back to `null` use the `strictNullHandling` flag:
```javascript
var parsedStrictNull = qs.parse('a&b=', { strictNullHandling: true });
assert.deepEqual(parsedStrictNull, { a: null, b: '' });
```
To completely skip rendering keys with `null` values, use the `skipNulls` flag:
```javascript
var nullsSkipped = qs.stringify({ a: 'b', c: null}, { skipNulls: true });
assert.equal(nullsSkipped, 'a=b');
```
If you're communicating with legacy systems, you can switch to `iso-8859-1`
using the `charset` option:
```javascript
var iso = qs.stringify({ æ: 'æ' }, { charset: 'iso-8859-1' });
assert.equal(iso, '%E6=%E6');
```
Characters that don't exist in `iso-8859-1` will be converted to numeric
entities, similar to what browsers do:
```javascript
var numeric = qs.stringify({ a: '☺' }, { charset: 'iso-8859-1' });
assert.equal(numeric, 'a=%26%239786%3B');
```
You can use the `charsetSentinel` option to announce the character by
including an `utf8=✓` parameter with the proper encoding if the checkmark,
similar to what Ruby on Rails and others do when submitting forms.
```javascript
var sentinel = qs.stringify({ a: '☺' }, { charsetSentinel: true });
assert.equal(sentinel, 'utf8=%E2%9C%93&a=%E2%98%BA');
var isoSentinel = qs.stringify({ a: 'æ' }, { charsetSentinel: true, charset: 'iso-8859-1' });
assert.equal(isoSentinel, 'utf8=%26%2310003%3B&a=%E6');
```
### Dealing with special character sets
By default the encoding and decoding of characters is done in `utf-8`,
and `iso-8859-1` support is also built in via the `charset` parameter.
If you wish to encode querystrings to a different character set (i.e.
[Shift JIS](https://en.wikipedia.org/wiki/Shift_JIS)) you can use the
[`qs-iconv`](https://github.com/martinheidegger/qs-iconv) library:
```javascript
var encoder = require('qs-iconv/encoder')('shift_jis');
var shiftJISEncoded = qs.stringify({ a: 'こんにちは!' }, { encoder: encoder });
assert.equal(shiftJISEncoded, 'a=%82%B1%82%F1%82%C9%82%BF%82%CD%81I');
```
This also works for decoding of query strings:
```javascript
var decoder = require('qs-iconv/decoder')('shift_jis');
var obj = qs.parse('a=%82%B1%82%F1%82%C9%82%BF%82%CD%81I', { decoder: decoder });
assert.deepEqual(obj, { a: 'こんにちは!' });
```
### RFC 3986 and RFC 1738 space encoding
RFC3986 used as default option and encodes ' ' to *%20* which is backward compatible.
In the same time, output can be stringified as per RFC1738 with ' ' equal to '+'.
```
assert.equal(qs.stringify({ a: 'b c' }), 'a=b%20c');
assert.equal(qs.stringify({ a: 'b c' }, { format : 'RFC3986' }), 'a=b%20c');
assert.equal(qs.stringify({ a: 'b c' }, { format : 'RFC1738' }), 'a=b+c');
```
[1]: https://npmjs.org/package/qs
[2]: http://versionbadg.es/ljharb/qs.svg
[3]: https://api.travis-ci.org/ljharb/qs.svg
[4]: https://travis-ci.org/ljharb/qs
[5]: https://david-dm.org/ljharb/qs.svg
[6]: https://david-dm.org/ljharb/qs
[7]: https://david-dm.org/ljharb/qs/dev-status.svg
[8]: https://david-dm.org/ljharb/qs?type=dev
[9]: https://ci.testling.com/ljharb/qs.png
[10]: https://ci.testling.com/ljharb/qs
[11]: https://nodei.co/npm/qs.png?downloads=true&stars=true
[license-image]: http://img.shields.io/npm/l/qs.svg
[license-url]: LICENSE
[downloads-image]: http://img.shields.io/npm/dm/qs.svg
[downloads-url]: http://npm-stat.com/charts.html?package=qs
# create-hash
[](https://travis-ci.org/crypto-browserify/createHash)
Node style hashes for use in the browser, with native hash functions in node.
API is the same as hashes in node:
```js
var createHash = require('create-hash')
var hash = createHash('sha224')
hash.update('synchronous write') // optional encoding parameter
hash.digest() // synchronously get result with optional encoding parameter
hash.write('write to it as a stream')
hash.end() // remember it's a stream
hash.read() // only if you ended it as a stream though
```
To get the JavaScript version even in node do `require('create-hash/browser')`
# filename-regex [](https://www.npmjs.com/package/filename-regex) [](https://npmjs.org/package/filename-regex) [](https://npmjs.org/package/filename-regex) [](https://travis-ci.org/regexhq/filename-regex)
> Regular expression for matching file names, with or without extension.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save filename-regex
```
## Usage
```js
var regex = require('filename-regex');
'a/b/c/d.min.js'.match(regex());
//=> match[0] = 'd.min.js'
'a/b/c/.dotfile'.match(regex());
//=> match[0] = '.dotfile'
```
## About
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.4.3, on April 28, 2017._
https-proxy-agent
================
### An HTTP(s) proxy `http.Agent` implementation for HTTPS
[](https://github.com/TooTallNate/node-https-proxy-agent/actions?workflow=Node+CI)
This module provides an `http.Agent` implementation that connects to a specified
HTTP or HTTPS proxy server, and can be used with the built-in `https` module.
Specifically, this `Agent` implementation connects to an intermediary "proxy"
server and issues the [CONNECT HTTP method][CONNECT], which tells the proxy to
open a direct TCP connection to the destination server.
Since this agent implements the CONNECT HTTP method, it also works with other
protocols that use this method when connecting over proxies (i.e. WebSockets).
See the "Examples" section below for more.
Installation
------------
Install with `npm`:
``` bash
$ npm install https-proxy-agent
```
Examples
--------
#### `https` module example
``` js
var url = require('url');
var https = require('https');
var HttpsProxyAgent = require('https-proxy-agent');
// HTTP/HTTPS proxy to connect to
var proxy = process.env.http_proxy || 'http://168.63.76.32:3128';
console.log('using proxy server %j', proxy);
// HTTPS endpoint for the proxy to connect to
var endpoint = process.argv[2] || 'https://graph.facebook.com/tootallnate';
console.log('attempting to GET %j', endpoint);
var options = url.parse(endpoint);
// create an instance of the `HttpsProxyAgent` class with the proxy server information
var agent = new HttpsProxyAgent(proxy);
options.agent = agent;
https.get(options, function (res) {
console.log('"response" event!', res.headers);
res.pipe(process.stdout);
});
```
#### `ws` WebSocket connection example
``` js
var url = require('url');
var WebSocket = require('ws');
var HttpsProxyAgent = require('https-proxy-agent');
// HTTP/HTTPS proxy to connect to
var proxy = process.env.http_proxy || 'http://168.63.76.32:3128';
console.log('using proxy server %j', proxy);
// WebSocket endpoint for the proxy to connect to
var endpoint = process.argv[2] || 'ws://echo.websocket.org';
var parsed = url.parse(endpoint);
console.log('attempting to connect to WebSocket %j', endpoint);
// create an instance of the `HttpsProxyAgent` class with the proxy server information
var options = url.parse(proxy);
var agent = new HttpsProxyAgent(options);
// finally, initiate the WebSocket connection
var socket = new WebSocket(endpoint, { agent: agent });
socket.on('open', function () {
console.log('"open" event!');
socket.send('hello world');
});
socket.on('message', function (data, flags) {
console.log('"message" event! %j %j', data, flags);
socket.close();
});
```
API
---
### new HttpsProxyAgent(Object options)
The `HttpsProxyAgent` class implements an `http.Agent` subclass that connects
to the specified "HTTP(s) proxy server" in order to proxy HTTPS and/or WebSocket
requests. This is achieved by using the [HTTP `CONNECT` method][CONNECT].
The `options` argument may either be a string URI of the proxy server to use, or an
"options" object with more specific properties:
* `host` - String - Proxy host to connect to (may use `hostname` as well). Required.
* `port` - Number - Proxy port to connect to. Required.
* `protocol` - String - If `https:`, then use TLS to connect to the proxy.
* `headers` - Object - Additional HTTP headers to be sent on the HTTP CONNECT method.
* Any other options given are passed to the `net.connect()`/`tls.connect()` functions.
License
-------
(The MIT License)
Copyright (c) 2013 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[CONNECT]: http://en.wikipedia.org/wiki/HTTP_tunnel#HTTP_CONNECT_Tunneling
# end-of-stream
A node module that calls a callback when a readable/writable/duplex stream has completed or failed.
npm install end-of-stream
[](https://travis-ci.org/mafintosh/end-of-stream)
## Usage
Simply pass a stream and a callback to the `eos`.
Both legacy streams, streams2 and stream3 are supported.
``` js
var eos = require('end-of-stream');
eos(readableStream, function(err) {
// this will be set to the stream instance
if (err) return console.log('stream had an error or closed early');
console.log('stream has ended', this === readableStream);
});
eos(writableStream, function(err) {
if (err) return console.log('stream had an error or closed early');
console.log('stream has finished', this === writableStream);
});
eos(duplexStream, function(err) {
if (err) return console.log('stream had an error or closed early');
console.log('stream has ended and finished', this === duplexStream);
});
eos(duplexStream, {readable:false}, function(err) {
if (err) return console.log('stream had an error or closed early');
console.log('stream has finished but might still be readable');
});
eos(duplexStream, {writable:false}, function(err) {
if (err) return console.log('stream had an error or closed early');
console.log('stream has ended but might still be writable');
});
eos(readableStream, {error:false}, function(err) {
// do not treat emit('error', err) as a end-of-stream
});
```
## License
MIT
## Related
`end-of-stream` is part of the [mississippi stream utility collection](https://github.com/maxogden/mississippi) which includes more useful stream modules similar to this one.
Lazy lists for node
===================
# Table of contents:
[Introduction](#Introduction)
[Documentation](#Documentation)
<a name="Introduction" />
# Introduction
Lazy comes really handy when you need to treat a stream of events like a list.
The best use case currently is returning a lazy list from an asynchronous
function, and having data pumped into it via events. In asynchronous
programming you can't just return a regular list because you don't yet have
data for it. The usual solution so far has been to provide a callback that gets
called when the data is available. But doing it this way you lose the power of
chaining functions and creating pipes, which leads to not that nice interfaces.
(See the 2nd example below to see how it improved the interface in one of my
modules.)
Check out this toy example, first you create a Lazy object:
```javascript
var Lazy = require('lazy');
var lazy = new Lazy;
lazy
.filter(function (item) {
return item % 2 == 0
})
.take(5)
.map(function (item) {
return item*2;
})
.join(function (xs) {
console.log(xs);
});
```
This code says that 'lazy' is going to be a lazy list that filters even
numbers, takes first five of them, then multiplies all of them by 2, and then
calls the join function (think of join as in threads) on the final list.
And now you can emit 'data' events with data in them at some point later,
```javascript
[0,1,2,3,4,5,6,7,8,9,10].forEach(function (x) {
lazy.emit('data', x);
});
```
The output will be produced by the 'join' function, which will output the
expected [0, 4, 8, 12, 16].
And here is a real-world example. Some time ago I wrote a hash database for
node.js called node-supermarket (think of key-value store except greater). Now
it had a similar interface as a list, you could .forEach on the stored
elements, .filter them, etc. But being asynchronous in nature it lead to the
following code, littered with callbacks and temporary lists:
```javascript
var Store = require('supermarket');
var db = new Store({ filename : 'users.db', json : true });
var users_over_20 = [];
db.filter(
function (user, meta) {
// predicate function
return meta.age > 20;
},
function (err, user, meta) {
// function that gets executed when predicate is true
if (users_over_20.length < 5)
users_over_20.push(meta);
},
function () {
// done function, called when all records have been filtered
// now do something with users_over_20
}
)
```
This code selects first five users who are over 20 years old and stores them
in users_over_20.
But now we changed the node-supermarket interface to return lazy lists, and
the code became:
```javascript
var Store = require('supermarket');
var db = new Store({ filename : 'users.db', json : true });
db.filter(function (user, meta) {
return meta.age > 20;
})
.take(5)
.join(function (xs) {
// xs contains the first 5 users who are over 20!
});
```
This is so much nicer!
Here is the latest feature: .lines. Given a stream of data that has \n's in it,
.lines converts that into a list of lines.
Here is an example from node-iptables that I wrote the other week,
```javascript
var Lazy = require('lazy');
var spawn = require('child_process').spawn;
var iptables = spawn('iptables', ['-L', '-n', '-v']);
Lazy(iptables.stdout)
.lines
.map(String)
.skip(2) // skips the two lines that are iptables header
.map(function (line) {
// packets, bytes, target, pro, opt, in, out, src, dst, opts
var fields = line.trim().split(/\s+/, 9);
return {
parsed : {
packets : fields[0],
bytes : fields[1],
target : fields[2],
protocol : fields[3],
opt : fields[4],
in : fields[5],
out : fields[6],
src : fields[7],
dst : fields[8]
},
raw : line.trim()
};
});
```
This example takes the `iptables -L -n -v` command and uses .lines on its output.
Then it .skip's two lines from input and maps a function on all other lines that
creates a data structure from the output.
<a name="Documentation" />
# Documentation
Supports the following operations:
* lazy.filter(f)
* lazy.forEach(f)
* lazy.map(f)
* lazy.take(n)
* lazy.takeWhile(f)
* lazy.bucket(init, f)
* lazy.lines
* lazy.sum(f)
* lazy.product(f)
* lazy.foldr(op, i, f)
* lazy.skip(n)
* lazy.head(f)
* lazy.tail(f)
* lazy.join(f)
The Lazy object itself has a .range property for generating all the possible ranges.
Here are several examples:
* Lazy.range('10..') - infinite range starting from 10
* Lazy.range('(10..') - infinite range starting from 11
* Lazy.range(10) - range from 0 to 9
* Lazy.range(-10, 10) - range from -10 to 9 (-10, -9, ... 0, 1, ... 9)
* Lazy.range(-10, 10, 2) - range from -10 to 8, skipping every 2nd element (-10, -8, ... 0, 2, 4, 6, 8)
* Lazy.range(10, 0, 2) - reverse range from 10 to 1, skipping every 2nd element (10, 8, 6, 4, 2)
* Lazy.range(10, 0) - reverse range from 10 to 1
* Lazy.range('5..50') - range from 5 to 49
* Lazy.range('50..44') - range from 50 to 45
* Lazy.range('1,1.1..4') - range from 1 to 4 with increment of 0.1 (1, 1.1, 1.2, ... 3.9)
* Lazy.range('4,3.9..1') - reverse range from 4 to 1 with decerement of 0.1
* Lazy.range('[1..10]') - range from 1 to 10 (all inclusive)
* Lazy.range('[10..1]') - range from 10 to 1 (all inclusive)
* Lazy.range('[1..10)') - range grom 1 to 9
* Lazy.range('[10..1)') - range from 10 to 2
* Lazy.range('(1..10]') - range from 2 to 10
* Lazy.range('(10..1]') - range from 9 to 1
* Lazy.range('(1..10)') - range from 2 to 9
* Lazy.range('[5,10..50]') - range from 5 to 50 with a step of 5 (all inclusive)
Then you can use other lazy functions on these ranges.
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# web3-eth
This is a sub package of [web3.js][repo]
This is the Eth package to be used [web3.js][repo].
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-eth.js` in your html file.
This will expose the `Web3Eth` object on the window object.
## Usage
```js
// in node.js
var Web3Eth = require('web3-eth');
var eth = new Web3Eth('ws://localhost:8546');
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# negotiator
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
An HTTP content negotiator for Node.js
## Installation
```sh
$ npm install negotiator
```
## API
```js
var Negotiator = require('negotiator')
```
### Accept Negotiation
```js
availableMediaTypes = ['text/html', 'text/plain', 'application/json']
// The negotiator constructor receives a request object
negotiator = new Negotiator(request)
// Let's say Accept header is 'text/html, application/*;q=0.2, image/jpeg;q=0.8'
negotiator.mediaTypes()
// -> ['text/html', 'image/jpeg', 'application/*']
negotiator.mediaTypes(availableMediaTypes)
// -> ['text/html', 'application/json']
negotiator.mediaType(availableMediaTypes)
// -> 'text/html'
```
You can check a working example at `examples/accept.js`.
#### Methods
##### mediaType()
Returns the most preferred media type from the client.
##### mediaType(availableMediaType)
Returns the most preferred media type from a list of available media types.
##### mediaTypes()
Returns an array of preferred media types ordered by the client preference.
##### mediaTypes(availableMediaTypes)
Returns an array of preferred media types ordered by priority from a list of
available media types.
### Accept-Language Negotiation
```js
negotiator = new Negotiator(request)
availableLanguages = ['en', 'es', 'fr']
// Let's say Accept-Language header is 'en;q=0.8, es, pt'
negotiator.languages()
// -> ['es', 'pt', 'en']
negotiator.languages(availableLanguages)
// -> ['es', 'en']
language = negotiator.language(availableLanguages)
// -> 'es'
```
You can check a working example at `examples/language.js`.
#### Methods
##### language()
Returns the most preferred language from the client.
##### language(availableLanguages)
Returns the most preferred language from a list of available languages.
##### languages()
Returns an array of preferred languages ordered by the client preference.
##### languages(availableLanguages)
Returns an array of preferred languages ordered by priority from a list of
available languages.
### Accept-Charset Negotiation
```js
availableCharsets = ['utf-8', 'iso-8859-1', 'iso-8859-5']
negotiator = new Negotiator(request)
// Let's say Accept-Charset header is 'utf-8, iso-8859-1;q=0.8, utf-7;q=0.2'
negotiator.charsets()
// -> ['utf-8', 'iso-8859-1', 'utf-7']
negotiator.charsets(availableCharsets)
// -> ['utf-8', 'iso-8859-1']
negotiator.charset(availableCharsets)
// -> 'utf-8'
```
You can check a working example at `examples/charset.js`.
#### Methods
##### charset()
Returns the most preferred charset from the client.
##### charset(availableCharsets)
Returns the most preferred charset from a list of available charsets.
##### charsets()
Returns an array of preferred charsets ordered by the client preference.
##### charsets(availableCharsets)
Returns an array of preferred charsets ordered by priority from a list of
available charsets.
### Accept-Encoding Negotiation
```js
availableEncodings = ['identity', 'gzip']
negotiator = new Negotiator(request)
// Let's say Accept-Encoding header is 'gzip, compress;q=0.2, identity;q=0.5'
negotiator.encodings()
// -> ['gzip', 'identity', 'compress']
negotiator.encodings(availableEncodings)
// -> ['gzip', 'identity']
negotiator.encoding(availableEncodings)
// -> 'gzip'
```
You can check a working example at `examples/encoding.js`.
#### Methods
##### encoding()
Returns the most preferred encoding from the client.
##### encoding(availableEncodings)
Returns the most preferred encoding from a list of available encodings.
##### encodings()
Returns an array of preferred encodings ordered by the client preference.
##### encodings(availableEncodings)
Returns an array of preferred encodings ordered by priority from a list of
available encodings.
## See Also
The [accepts](https://npmjs.org/package/accepts#readme) module builds on
this module and provides an alternative interface, mime type validation,
and more.
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/negotiator.svg
[npm-url]: https://npmjs.org/package/negotiator
[node-version-image]: https://img.shields.io/node/v/negotiator.svg
[node-version-url]: https://nodejs.org/en/download/
[travis-image]: https://img.shields.io/travis/jshttp/negotiator/master.svg
[travis-url]: https://travis-ci.org/jshttp/negotiator
[coveralls-image]: https://img.shields.io/coveralls/jshttp/negotiator/master.svg
[coveralls-url]: https://coveralls.io/r/jshttp/negotiator?branch=master
[downloads-image]: https://img.shields.io/npm/dm/negotiator.svg
[downloads-url]: https://npmjs.org/package/negotiator
# utf8.js [](https://travis-ci.org/mathiasbynens/utf8.js) [](https://coveralls.io/r/mathiasbynens/utf8.js) [](https://gemnasium.com/mathiasbynens/utf8.js)
_utf8.js_ is a well-tested UTF-8 encoder/decoder written in JavaScript. Unlike many other JavaScript solutions, it is designed to be a _proper_ UTF-8 encoder/decoder: it can encode/decode any scalar Unicode code point values, as per [the Encoding Standard](https://encoding.spec.whatwg.org/#utf-8). [Here’s an online demo.](https://mothereff.in/utf-8)
Feel free to fork if you see possible improvements!
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install utf8
```
In a browser:
```html
<script src="utf8.js"></script>
```
In [Node.js](https://nodejs.org/):
```js
const utf8 = require('utf8');
```
## API
### `utf8.encode(string)`
Encodes any given JavaScript string (`string`) as UTF-8, and returns the UTF-8-encoded version of the string. It throws an error if the input string contains a non-scalar value, i.e. a lone surrogate. (If you need to be able to encode non-scalar values as well, use [WTF-8](https://mths.be/wtf8) instead.)
```js
// U+00A9 COPYRIGHT SIGN; see http://codepoints.net/U+00A9
utf8.encode('\xA9');
// → '\xC2\xA9'
// U+10001 LINEAR B SYLLABLE B038 E; see http://codepoints.net/U+10001
utf8.encode('\uD800\uDC01');
// → '\xF0\x90\x80\x81'
```
### `utf8.decode(byteString)`
Decodes any given UTF-8-encoded string (`byteString`) as UTF-8, and returns the UTF-8-decoded version of the string. It throws an error when malformed UTF-8 is detected. (If you need to be able to decode encoded non-scalar values as well, use [WTF-8](https://mths.be/wtf8) instead.)
```js
utf8.decode('\xC2\xA9');
// → '\xA9'
utf8.decode('\xF0\x90\x80\x81');
// → '\uD800\uDC01'
// → U+10001 LINEAR B SYLLABLE B038 E
```
### `utf8.version`
A string representing the semantic version number.
## Support
utf8.js has been tested in at least Chrome 27-39, Firefox 3-34, Safari 4-8, Opera 10-28, IE 6-11, Node.js v0.10.0, Narwhal 0.3.2, RingoJS 0.8-0.11, PhantomJS 1.9.0, and Rhino 1.7RC4.
## Unit tests & code coverage
After cloning this repository, run `npm install` to install the dependencies needed for development and testing. You may want to install Istanbul _globally_ using `npm install istanbul -g`.
Once that’s done, you can run the unit tests in Node using `npm test` or `node tests/tests.js`. To run the tests in Rhino, Ringo, Narwhal, PhantomJS, and web browsers as well, use `grunt test`.
To generate the code coverage report, use `grunt cover`.
## FAQ
### Why is the first release named v2.0.0? Haven’t you heard of [semantic versioning](http://semver.org/)?
Long before utf8.js was created, the `utf8` module on npm was registered and used by another (slightly buggy) library. @ryanmcgrath was kind enough to give me access to the `utf8` package on npm when I told him about utf8.js. Since there has already been a v1.0.0 release of the old library, and to avoid breaking backwards compatibility with projects that rely on the `utf8` npm package, I decided the tag the first release of utf8.js as v2.0.0 and take it from there.
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
utf8.js is available under the [MIT](https://mths.be/mit) license.
# randomatic [](https://www.npmjs.com/package/randomatic) [](https://npmjs.org/package/randomatic) [](https://npmjs.org/package/randomatic) [](https://travis-ci.org/jonschlinkert/randomatic)
> Generate randomized strings of a specified length using simple character sequences. The original generate-password.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save randomatic
```
## Usage
```js
var randomize = require('randomatic');
```
## API
```js
randomize(pattern, length, options);
randomize.isCrypto;
```
* `pattern` **{String}**: (required) The pattern to use for randomizing
* `length` **{Number}**: (optional) The length of the string to generate
* `options` **{Object}**: (optional) See available [options](#options)
* `randomize.isCrypto` will be `true` when a cryptographically secure function is being used to generate random numbers. The value will be `false` when the function in use is `Math.random`.
### pattern
> The pattern to use for randomizing
Patterns can contain any combination of the below characters, specified in any order.
**Example:**
To generate a 10-character randomized string using all available characters:
```js
randomize('*', 10);
//=> 'x2_^-5_T[$'
randomize('Aa0!', 10);
//=> 'LV3u~BSGhw'
```
* `a`: Lowercase alpha characters (`abcdefghijklmnopqrstuvwxyz'`)
* `A`: Uppercase alpha characters (`ABCDEFGHIJKLMNOPQRSTUVWXYZ'`)
* `0`: Numeric characters (`0123456789'`)
* `!`: Special characters (`~!@#$%^&()_+-={}[];\',.`)
* `*`: All characters (all of the above combined)
* `?`: Custom characters (pass a string of custom characters to the options)
### length
> The length of the string to generate
**Examples:**
* `randomize('A', 5)` will generate a 5-character, uppercase, alphabetical, randomized string, e.g. `KDJWJ`.
* `randomize('0', 2)` will generate a 2-digit random number
* `randomize('0', 3)` will generate a 3-digit random number
* `randomize('0', 12)` will generate a 12-digit random number
* `randomize('A0', 16)` will generate a 16-character, alpha-numeric randomized string
If `length` is left undefined, the length of the pattern in the first parameter will be used. For example:
* `randomize('00')` will generate a 2-digit random number
* `randomize('000')` will generate a 3-digit random number
* `randomize('0000')` will generate a 4-digit random number...
* `randomize('AAAAA')` will generate a 5-character, uppercase alphabetical random string...
These are just examples, [see the tests](./test.js) for more use cases and examples.
## options
> These are options that can be passed as the third argument.
#### chars
Type: `String`
Default: `undefined`
Define a custom string to be randomized.
**Example:**
* `randomize('?', 20, {chars: 'jonschlinkert'})` will generate a 20-character randomized string from the letters contained in `jonschlinkert`.
* `randomize('?', {chars: 'jonschlinkert'})` will generate a 13-character randomized string from the letters contained in `jonschlinkert`.
#### exclude
Type: `String|Array`
Default: `undefined`
Specify a string or array of characters can are excluded from the possible characters used to generate the randomized string.
**Example:**
* `randomize('*', 20, { exclude: '0oOiIlL1' })` will generate a 20-character randomized string using all of possible characters except for `0oOiIlL1`.
## Usage Examples
* `randomize('A', 4)` (_whitespace insenstive_) would result in randomized 4-digit uppercase letters, like, `ZAKH`, `UJSL`... etc.
* `randomize('AAAA')` is equivelant to `randomize('A', 4)`
* `randomize('AAA0')` and `randomize('AA00')` and `randomize('A0A0')` are equivelant to `randomize('A0', 4)`
* `randomize('aa')`: results in double-digit, randomized, lower-case letters (`abcdefghijklmnopqrstuvwxyz`)
* `randomize('AAA')`: results in triple-digit, randomized, upper-case letters (`ABCDEFGHIJKLMNOPQRSTUVWXYZ`)
* `randomize('0', 6)`: results in six-digit, randomized numbers (`0123456789`)
* `randomize('!', 5)`: results in single-digit randomized, _valid_ non-letter characters (`~!@#$%^&()_+-={}[]
* `randomize('A!a0', 9)`: results in nine-digit, randomized characters (any of the above)
_The order in which the characters are defined is insignificant._
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [pad-left](https://www.npmjs.com/package/pad-left): Left pad a string with zeros or a specified string. Fastest implementation. | [homepage](https://github.com/jonschlinkert/pad-left "Left pad a string with zeros or a specified string. Fastest implementation.")
* [pad-right](https://www.npmjs.com/package/pad-right): Right pad a string with zeros or a specified string. Fastest implementation. | [homepage](https://github.com/jonschlinkert/pad-right "Right pad a string with zeros or a specified string. Fastest implementation.")
* [repeat-string](https://www.npmjs.com/package/repeat-string): Repeat the given string n times. Fastest implementation for repeating a string. | [homepage](https://github.com/jonschlinkert/repeat-string "Repeat the given string n times. Fastest implementation for repeating a string.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 56 | [jonschlinkert](https://github.com/jonschlinkert) |
| 6 | [doowb](https://github.com/doowb) |
| 4 | [kivlor](https://github.com/kivlor) |
| 2 | [realityking](https://github.com/realityking) |
| 2 | [ywpark1](https://github.com/ywpark1) |
| 1 | [TrySound](https://github.com/TrySound) |
| 1 | [drag0s](https://github.com/drag0s) |
| 1 | [paulmillr](https://github.com/paulmillr) |
| 1 | [sunknudsen](https://github.com/sunknudsen) |
| 1 | [faizulhaque-tp](https://github.com/faizulhaque-tp) |
| 1 | [michaelrhodes](https://github.com/michaelrhodes) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2018, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on October 23, 2018._
# EVP\_BytesToKey
[](https://www.npmjs.org/package/evp_bytestokey)
[](https://travis-ci.org/crypto-browserify/EVP_BytesToKey)
[](https://david-dm.org/crypto-browserify/EVP_BytesToKey#info=dependencies)
[](https://github.com/feross/standard)
The insecure [key derivation algorithm from OpenSSL.][1]
**WARNING: DO NOT USE, except for compatibility reasons.**
MD5 is insecure.
Use at least `scrypt` or `pbkdf2-hmac-sha256` instead.
## API
`EVP_BytesToKey(password, salt, keyLen, ivLen)`
* `password` - `Buffer`, password used to derive the key data.
* `salt` - 8 byte `Buffer` or `null`, salt is used as a salt in the derivation.
* `keyBits` - `number`, key length in **bits**.
* `ivLen` - `number`, iv length in bytes.
*Returns*: `{ key: Buffer, iv: Buffer }`
## Examples
MD5 with `aes-256-cbc`:
```js
const crypto = require('crypto')
const EVP_BytesToKey = require('evp_bytestokey')
const result = EVP_BytesToKey(
'my-secret-password',
null,
32,
16
)
// =>
// { key: <Buffer e3 4f 96 f3 86 24 82 7c c2 5d ff 23 18 6f 77 72 54 45 7f 49 d4 be 4b dd 4f 6e 1b cc 92 a4 27 33>,
// iv: <Buffer 85 71 9a bf ae f4 1e 74 dd 46 b6 13 79 56 f5 5b> }
const cipher = crypto.createCipheriv('aes-256-cbc', result.key, result.iv)
```
## LICENSE [MIT](LICENSE)
[1]: https://wiki.openssl.org/index.php/Manual:EVP_BytesToKey(3)
[2]: https://nodejs.org/api/crypto.html#crypto_class_hash
## Eth-Lib
Lightweight Ethereum libraries. This is a temporary repository which will be used as the basis of an implementation on Idris (or similar).
# web3-core-helpers
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo] with useful helper functions.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-helpers
```
## Usage
```js
const helpers = require('web3-core-helpers');
helpers.formatters;
helpers.errors;
...
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-core-helpers.svg
[npm-url]: https://npmjs.org/package/web3-core-helpers
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-core-helpers
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-core-helpers
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-core-helpers
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-core-helpers
Needle
======
[](https://nodei.co/npm/needle/)
The leanest and most handsome HTTP client in the Nodelands.
```js
var needle = require('needle');
needle.get('http://www.google.com', function(error, response) {
if (!error && response.statusCode == 200)
console.log(response.body);
});
```
Callbacks not floating your boat? Needle got your back.
``` js
var data = {
file: '/home/johnlennon/walrus.png',
content_type: 'image/png'
};
// the callback is optional, and needle returns a `readableStream` object
// that triggers a 'done' event when the request/response process is complete.
needle
.post('https://my.server.com/foo', data, { multipart: true })
.on('readable', function() { /* eat your chunks */ })
.on('done', function(err, resp) {
console.log('Ready-o!');
})
```
From version 2.0.x up, Promises are also supported. Just call `needle()` directly and you'll get a native Promise object.
```js
needle('put', 'https://hacking.the.gibson/login', { password: 'god' }, { json: true })
.then(function(response) {
return doSomethingWith(response)
})
.catch(function(err) {
console.log('Call the locksmith!')
})
```
With only two real dependencies, Needle supports:
- HTTP/HTTPS requests, with the usual verbs you would expect
- All of Node's native TLS options, such as 'rejectUnauthorized' (see below)
- Basic & Digest authentication with auto-detection
- Multipart form-data (e.g. file uploads)
- HTTP Proxy forwarding, optionally with authentication
- Streaming gzip or deflate decompression
- Automatic XML & JSON parsing
- 301/302/303 redirect following, with fine-grained tuning, and
- Streaming non-UTF-8 charset decoding, via `iconv-lite`
And yes, Mr. Wayne, it does come in black.
This makes Needle an ideal alternative for performing quick HTTP requests in Node, either for API interaction, downloading or uploading streams of data, and so on. If you need OAuth, AWS support or anything fancier, you should check out mikeal's request module.
Install
-------
```
$ npm install needle
```
Usage
-----
```js
// using promises
needle('get', 'https://server.com/posts/12')
.then(function(resp) {
// ...
})
.catch(function(err) {
// ...
});
// with callback
needle.get('ifconfig.me/all.json', function(error, response, body) {
if (error) throw error;
// body is an alias for `response.body`,
// that in this case holds a JSON-decoded object.
console.log(body.ip_addr);
});
// no callback, using streams
var out = fs.createWriteStream('logo.png');
needle.get('https://google.com/images/logo.png').pipe(out).on('finish', function() {
console.log('Pipe finished!');
});
```
As you can see, you can use Needle with Promises or without them. When using Promises or when a callback is passed, the response's body will be buffered and written to `response.body`, and the callback will be fired when all of the data has been collected and processed (e.g. decompressed, decoded and/or parsed).
When no callback is passed, however, the buffering logic will be skipped but the response stream will still go through Needle's processing pipeline, so you get all the benefits of post-processing while keeping the streamishness we all love from Node.
Response pipeline
-----------------
Depending on the response's Content-Type, Needle will either attempt to parse JSON or XML streams, or, if a text response was received, will ensure that the final encoding you get is UTF-8.
You can also request a gzip/deflated response, which, if sent by the server, will be processed before parsing or decoding is performed.
```js
needle.get('http://stackoverflow.com/feeds', { compressed: true }, function(err, resp) {
console.log(resp.body); // this little guy won't be a Gzipped binary blob
// but a nice object containing all the latest entries
});
```
Or in anti-callback mode, using a few other options:
```js
var options = {
compressed : true, // sets 'Accept-Encoding' to 'gzip,deflate'
follow_max : 5, // follow up to five redirects
rejectUnauthorized : true // verify SSL certificate
}
var stream = needle.get('https://backend.server.com/everything.html', options);
// read the chunks from the 'readable' event, so the stream gets consumed.
stream.on('readable', function() {
while (data = this.read()) {
console.log(data.toString());
}
})
stream.on('done', function(err) {
// if our request had an error, our 'done' event will tell us.
if (!err) console.log('Great success!');
})
```
API
---
### needle(method, url[, data][, options][, callback]) `(> 2.0.x)`
Calling `needle()` directly returns a Promise. Besides `method` and `url`, all parameters are optional, although when sending a `post`, `put` or `patch` request you will get an error if `data` is not present.
```js
needle('get', 'http://some.url.com')
.then(function(resp) { console.log(resp.body) })
.catch(function(err) { console.error(err) })
})
```
Except from the above, all of Needle's request methods return a Readable stream, and both `options` and `callback` are optional. If passed, the callback will return three arguments: `error`, `response` and `body`, which is basically an alias for `response.body`.
### needle.head(url[, options][, callback])
```js
needle.head('https://my.backend.server.com', {
open_timeout: 5000 // if we're not able to open a connection in 5 seconds, boom.
}, function(err, resp) {
if (err)
console.log('Shoot! Something is wrong: ' + err.message)
else
console.log('Yup, still alive.')
})
```
### needle.get(url[, options][, callback])
```js
needle.get('google.com/search?q=syd+barrett', function(err, resp) {
// if no http:// is found, Needle will automagically prepend it.
});
```
### needle.post(url, data[, options][, callback])
```js
var options = {
headers: { 'X-Custom-Header': 'Bumbaway atuna' }
}
needle.post('https://my.app.com/endpoint', 'foo=bar', options, function(err, resp) {
// you can pass params as a string or as an object.
});
```
### needle.put(url, data[, options][, callback])
```js
var nested = {
params: {
are: {
also: 'supported'
}
}
}
needle.put('https://api.app.com/v2', nested, function(err, resp) {
console.log('Got ' + resp.bytes + ' bytes.') // another nice treat from this handsome fella.
});
```
### needle.patch(url, data[, options][, callback])
Same behaviour as PUT.
### needle.delete(url, data[, options][, callback])
```js
var options = {
username: 'fidelio',
password: 'x'
}
needle.delete('https://api.app.com/messages/123', null, options, function(err, resp) {
// in this case, data may be null, but you need to explicity pass it.
});
```
### needle.request(method, url, data[, options][, callback])
Generic request. This not only allows for flexibility, but also lets you perform a GET request with data, in which case will be appended to the request as a query string, unless you pass a `json: true` option (read below).
```js
var params = {
q : 'a very smart query',
page : 2
}
needle.request('get', 'forum.com/search', params, function(err, resp) {
if (!err && resp.statusCode == 200)
console.log(resp.body); // here you go, mister.
});
```
Now, if you set pass `json: true` among the options, Needle won't set your params as a querystring but instead send a JSON representation of your data through the request's body, as well as set the `Content-Type` and `Accept` headers to `application/json`.
```js
needle.request('get', 'forum.com/search', params, { json: true }, function(err, resp) {
if (resp.statusCode == 200) console.log('It worked!');
});
```
Events
------
The [Readable stream](https://nodejs.org/api/stream.html#stream_class_stream_readable) object returned by the above request methods emits the following events, in addition to the regular ones (e.g. `end`, `close`, `data`, `pipe`, `readable`).
### Event: `'response'`
- `response <http.IncomingMessage>`
Emitted when the underlying [http.ClientRequest](https://nodejs.org/api/http.html#http_class_http_clientrequest) emits a response event. This is after the connection is established and the header received, but before any of it is processed (e.g. authorization required or redirect to be followed). No data has been consumed at this point.
### Event: `'redirect'`
- `location <String>`
Indicates that the a redirect is being followed. This means that the response code was a redirect (`301`, `302`, `303`, `307`) and the given [redirect options](#redirect-options) allowed following the URL received in the `Location` header.
### Event: `'header'`
- `statusCode <Integer>`
- `headers <Object>`
Triggered after the header has been processed, and just before the data is to be consumed. This implies that no redirect was followed and/or authentication header was received. In other words, we got a "valid" response.
### Event: `'done'` (previously 'end')
- `exception <Error>` (optional)
Emitted when the request/response process has finished, either because all data was consumed or an error ocurred somewhere in between. Unlike a regular stream's `end` event, Needle's `done` will be fired either on success or on failure, which is why the first argument may be an Error object. In other words:
```js
var resp = needle.get('something.worthy/of/being/streamed/by/needle');
resp.pipe(someWritableStream);
resp.on('done', function(err) {
if (err) console.log('An error ocurred: ' + err.message);
else console.log('Great success!');
})
```
### Event: `'err'`
- `exception <Error>`
Emitted when an error ocurrs. This should only happen once in the lifecycle of a Needle request.
### Event: `'timeout'`
- `type <String>`
Emitted when an timeout error occurs. Type can be either 'open', 'response', or 'read'. This will called right before aborting the request, which will also trigger an `err` event, a described above, with an `ECONNRESET` (Socket hang up) exception.
Request options
---------------
For information about options that've changed, there's always [the changelog](https://github.com/tomas/needle/releases).
- `agent` : Uses an [http.Agent](https://nodejs.org/api/http.html#http_class_http_agent) of your choice, instead of the global, default one. Useful for tweaking the behaviour at the connection level, such as when doing tunneling (see below for an example).
- `json` : When `true`, sets content type to `application/json` and sends request body as JSON string, instead of a query string.
- `open_timeout`: (or `timeout`) Returns error if connection takes longer than X milisecs to establish. Defaults to `10000` (10 secs). `0` means no timeout.
- `response_timeout`: Returns error if no response headers are received in X milisecs, counting from when the connection is opened. Defaults to `0` (no response timeout).
- `read_timeout`: Returns error if data transfer takes longer than X milisecs, once response headers are received. Defaults to `0` (no timeout).
- `follow_max` : (or `follow`) Number of redirects to follow. Defaults to `0`. See below for more redirect options.
- `multipart` : Enables multipart/form-data encoding. Defaults to `false`. Use it when uploading files.
- `proxy` : Forwards request through HTTP(s) proxy. Eg. `proxy: 'http://user:[email protected]:3128'`. For more advanced proxying/tunneling use a custom `agent`, as described below.
- `headers` : Object containing custom HTTP headers for request. Overrides defaults described below.
- `auth` : Determines what to do with provided username/password. Options are `auto`, `digest` or `basic` (default). `auto` will detect the type of authentication depending on the response headers.
- `stream_length`: When sending streams, this lets you manually set the Content-Length header --if the stream's bytecount is known beforehand--, preventing ECONNRESET (socket hang up) errors on some servers that misbehave when receiving payloads of unknown size. Set it to `0` and Needle will get and set the stream's length for you, or leave unset for the default behaviour, which is no Content-Length header for stream payloads.
- `localAddress` : <string>, IP address. Passed to http/https request. Local interface from witch the request should be emitted.
Response options
----------------
- `decode_response` : (or `decode`) Whether to decode the text responses to UTF-8, if Content-Type header shows a different charset. Defaults to `true`.
- `parse_response` : (or `parse`) Whether to parse XML or JSON response bodies automagically. Defaults to `true`. You can also set this to 'xml' or 'json' in which case Needle will *only* parse the response if the content type matches.
- `output` : Dump response output to file. This occurs after parsing and charset decoding is done.
- `parse_cookies` : Whether to parse response’s `Set-Cookie` header. Defaults to `true`. If parsed, response cookies will be available at `resp.cookies`.
HTTP Header options
-------------------
These are basically shortcuts to the `headers` option described above.
- `cookies` : Builds and sets a Cookie header from a `{ key: 'value' }` object.
- `compressed`: If `true`, sets 'Accept-Encoding' header to 'gzip,deflate', and inflates content if zipped. Defaults to `false`.
- `username` : For HTTP basic auth.
- `password` : For HTTP basic auth. Requires username to be passed, but is optional.
- `accept` : Sets 'Accept' HTTP header. Defaults to `*/*`.
- `connection`: Sets 'Connection' HTTP header. Not set by default, unless running Node < 0.11.4 in which case it defaults to `close`. More info about this below.
- `user_agent`: Sets the 'User-Agent' HTTP header. Defaults to `Needle/{version} (Node.js {node_version})`.
- `content_type`: Sets the 'Content-Type' header. Unset by default, unless you're sending data in which case it's set accordingly to whatever is being sent (`application/x-www-form-urlencoded`, `application/json` or `multipart/form-data`). That is, of course, unless the option is passed, either here or through `options.headers`. You're the boss.
Node.js TLS Options
-------------------
These options are passed directly to `https.request` if present. Taken from the [original documentation](http://nodejs.org/docs/latest/api/https.html):
- `pfx` : Certificate, Private key and CA certificates to use for SSL.
- `key` : Private key to use for SSL.
- `passphrase` : A string of passphrase for the private key or pfx.
- `cert` : Public x509 certificate to use.
- `ca` : An authority certificate or array of authority certificates to check the remote host against.
- `ciphers` : A string describing the ciphers to use or exclude.
- `rejectUnauthorized` : If true, the server certificate is verified against the list of supplied CAs. An 'error' event is emitted if verification fails. Verification happens at the connection level, before the HTTP request is sent.
- `secureProtocol` : The SSL method to use, e.g. SSLv3_method to force SSL version 3.
Redirect options
----------------
These options only apply if the `follow_max` (or `follow`) option is higher than 0.
- `follow_set_cookies` : Sends the cookies received in the `set-cookie` header as part of the following request. `false` by default.
- `follow_set_referer` : Sets the 'Referer' header to the requested URI when following a redirect. `false` by default.
- `follow_keep_method` : If enabled, resends the request using the original verb instead of being rewritten to `get` with no data. `false` by default.
- `follow_if_same_host` : When true, Needle will only follow redirects that point to the same host as the original request. `false` by default.
- `follow_if_same_protocol` : When true, Needle will only follow redirects that point to the same protocol as the original request. `false` by default.
Overriding Defaults
-------------------
Yes sir, we have it. Needle includes a `defaults()` method, that lets you override some of the defaults for all future requests. Like this:
```js
needle.defaults({
open_timeout: 60000,
user_agent: 'MyApp/1.2.3',
parse_response: false });
```
This will override Needle's default user agent and 10-second timeout, and disable response parsing, so you don't need to pass those options in every other request.
More advanced Proxy support
---------------------------
Since you can pass a custom HTTPAgent to Needle you can do all sorts of neat stuff. For example, if you want to use the [`tunnel`](https://github.com/koichik/node-tunnel) module for HTTPS proxying, you can do this:
```js
var tunnel = require('tunnel');
var myAgent = tunnel.httpOverHttp({
proxy: { host: 'localhost' }
});
needle.get('foobar.com', { agent: myAgent });
```
Regarding the 'Connection' header
---------------------------------
Unless you're running an old version of Node (< 0.11.4), by default Needle won't set the Connection header on requests, yielding Node's default behaviour of keeping the connection alive with the target server. This speeds up inmensely the process of sending several requests to the same host.
On older versions, however, this has the unwanted behaviour of preventing the runtime from exiting, either because of a bug or 'feature' that was changed on 0.11.4. To overcome this Needle does set the 'Connection' header to 'close' on those versions, however this also means that making new requests to the same host doesn't benefit from Keep-Alive.
So if you're stuck on 0.10 or even lower and want full speed, you can simply set the Connection header to 'Keep-Alive' by using `{ connection: 'Keep-Alive' }`. Please note, though, that an event loop handler will prevent the runtime from exiting so you'll need to manually call `process.exit()` or the universe will collapse.
Examples Galore
---------------
### HTTPS GET with Basic Auth
```js
needle.get('https://api.server.com', { username: 'you', password: 'secret' },
function(err, resp) {
// used HTTP auth
});
```
Or use [RFC-1738](http://tools.ietf.org/html/rfc1738#section-3.1) basic auth URL syntax:
```js
needle.get('https://username:[email protected]', function(err, resp) {
// used HTTP auth from URL
});
```
### Digest Auth
```js
needle.get('other.server.com', { username: 'you', password: 'secret', auth: 'digest' },
function(err, resp, body) {
// needle prepends 'http://' to your URL, if missing
});
```
### Custom Accept header, deflate
```js
var options = {
compressed : true,
follow : 10,
accept : 'application/vnd.github.full+json'
}
needle.get('api.github.com/users/tomas', options, function(err, resp, body) {
// body will contain a JSON.parse(d) object
// if parsing fails, you'll simply get the original body
});
```
### GET XML object
```js
needle.get('https://news.ycombinator.com/rss', function(err, resp, body) {
// you'll get a nice object containing the nodes in the RSS
});
```
### GET binary, output to file
```js
needle.get('http://upload.server.com/tux.png', { output: '/tmp/tux.png' }, function(err, resp, body) {
// you can dump any response to a file, not only binaries.
});
```
### GET through proxy
```js
needle.get('http://search.npmjs.org', { proxy: 'http://localhost:1234' }, function(err, resp, body) {
// request passed through proxy
});
```
### GET a very large document in a stream (from 0.7+)
```js
var stream = needle.get('http://www.as35662.net/100.log');
stream.on('readable', function() {
var chunk;
while (chunk = this.read()) {
console.log('got data: ', chunk);
}
});
```
### GET JSON object in a stream (from 0.7+)
```js
var stream = needle.get('http://jsonplaceholder.typicode.com/db', { parse: true });
stream.on('readable', function() {
var node;
// our stream will only emit a single JSON root node.
while (node = this.read()) {
console.log('got data: ', node);
}
});
```
### GET JSONStream flexible parser with search query (from 0.7+)
```js
// The 'data' element of this stream will be the string representation
// of the titles of all posts.
needle.get('http://jsonplaceholder.typicode.com/db', { parse: true })
.pipe(new JSONStream.parse('posts.*.title'));
.on('data', function (obj) {
console.log('got post title: %s', obj);
});
```
### File upload using multipart, passing file path
```js
var data = {
foo: 'bar',
image: { file: '/home/tomas/linux.png', content_type: 'image/png' }
}
needle.post('http://my.other.app.com', data, { multipart: true }, function(err, resp, body) {
// needle will read the file and include it in the form-data as binary
});
```
### Stream upload, PUT or POST
``` js
needle.put('https://api.app.com/v2', fs.createReadStream('myfile.txt'), function(err, resp, body) {
// stream content is uploaded verbatim
});
```
### Multipart POST, passing data buffer
```js
var buffer = fs.readFileSync('/path/to/package.zip');
var data = {
zip_file: {
buffer : buffer,
filename : 'mypackage.zip',
content_type : 'application/octet-stream'
}
}
needle.post('http://somewhere.com/over/the/rainbow', data, { multipart: true }, function(err, resp, body) {
// if you see, when using buffers we need to pass the filename for the multipart body.
// you can also pass a filename when using the file path method, in case you want to override
// the default filename to be received on the other end.
});
```
### Multipart with custom Content-Type
```js
var data = {
token: 'verysecret',
payload: {
value: JSON.stringify({ title: 'test', version: 1 }),
content_type: 'application/json'
}
}
needle.post('http://test.com/', data, { timeout: 5000, multipart: true }, function(err, resp, body) {
// in this case, if the request takes more than 5 seconds
// the callback will return a [Socket closed] error
});
```
For even more examples, check out the examples directory in the repo.
### Testing
To run tests, you need to generate a self-signed SSL certificate in the `test` directory. After cloning the repository, run the following commands:
$ mkdir -p test/keys
$ openssl genrsa -out test/keys/ssl.key 2048
$ openssl req -new -key test/keys/ssl.key -x509 -days 999 -out test/keys/ssl.cert
Then you should be able to run `npm test` once you have the dependencies in place.
> Note: Tests currently only work on linux-based environments that have `/proc/self/fd`. They *do not* work on MacOS environments.
> You can use Docker to run tests by creating a container and mounting the needle project directory on `/app`
> `docker create --name Needle -v /app -w /app -v /app/node_modules -i node:argon`
Credits
-------
Written by Tomás Pollak, with the help of contributors.
Copyright
---------
(c) Fork Ltd. Licensed under the MIT license.
# Punycode.js [](https://travis-ci.org/bestiejs/punycode.js) [](https://codecov.io/gh/bestiejs/punycode.js) [](https://gemnasium.com/bestiejs/punycode.js)
Punycode.js is a robust Punycode converter that fully complies to [RFC 3492](https://tools.ietf.org/html/rfc3492) and [RFC 5891](https://tools.ietf.org/html/rfc5891).
This JavaScript library is the result of comparing, optimizing and documenting different open-source implementations of the Punycode algorithm:
* [The C example code from RFC 3492](https://tools.ietf.org/html/rfc3492#appendix-C)
* [`punycode.c` by _Markus W. Scherer_ (IBM)](http://opensource.apple.com/source/ICU/ICU-400.42/icuSources/common/punycode.c)
* [`punycode.c` by _Ben Noordhuis_](https://github.com/bnoordhuis/punycode/blob/master/punycode.c)
* [JavaScript implementation by _some_](http://stackoverflow.com/questions/183485/can-anyone-recommend-a-good-free-javascript-for-punycode-to-unicode-conversion/301287#301287)
* [`punycode.js` by _Ben Noordhuis_](https://github.com/joyent/node/blob/426298c8c1c0d5b5224ac3658c41e7c2a3fe9377/lib/punycode.js) (note: [not fully compliant](https://github.com/joyent/node/issues/2072))
This project was [bundled](https://github.com/joyent/node/blob/master/lib/punycode.js) with Node.js from [v0.6.2+](https://github.com/joyent/node/compare/975f1930b1...61e796decc) until [v7](https://github.com/nodejs/node/pull/7941) (soft-deprecated).
The current version supports recent versions of Node.js only. It provides a CommonJS module and an ES6 module. For the old version that offers the same functionality with broader support, including Rhino, Ringo, Narwhal, and web browsers, see [v1.4.1](https://github.com/bestiejs/punycode.js/releases/tag/v1.4.1).
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install punycode --save
```
In [Node.js](https://nodejs.org/):
```js
const punycode = require('punycode');
```
## API
### `punycode.decode(string)`
Converts a Punycode string of ASCII symbols to a string of Unicode symbols.
```js
// decode domain name parts
punycode.decode('maana-pta'); // 'mañana'
punycode.decode('--dqo34k'); // '☃-⌘'
```
### `punycode.encode(string)`
Converts a string of Unicode symbols to a Punycode string of ASCII symbols.
```js
// encode domain name parts
punycode.encode('mañana'); // 'maana-pta'
punycode.encode('☃-⌘'); // '--dqo34k'
```
### `punycode.toUnicode(input)`
Converts a Punycode string representing a domain name or an email address to Unicode. Only the Punycoded parts of the input will be converted, i.e. it doesn’t matter if you call it on a string that has already been converted to Unicode.
```js
// decode domain names
punycode.toUnicode('xn--maana-pta.com');
// → 'mañana.com'
punycode.toUnicode('xn----dqo34k.com');
// → '☃-⌘.com'
// decode email addresses
punycode.toUnicode('джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq');
// → 'джумла@джpумлатест.bрфa'
```
### `punycode.toASCII(input)`
Converts a lowercased Unicode string representing a domain name or an email address to Punycode. Only the non-ASCII parts of the input will be converted, i.e. it doesn’t matter if you call it with a domain that’s already in ASCII.
```js
// encode domain names
punycode.toASCII('mañana.com');
// → 'xn--maana-pta.com'
punycode.toASCII('☃-⌘.com');
// → 'xn----dqo34k.com'
// encode email addresses
punycode.toASCII('джумла@джpумлатест.bрфa');
// → 'джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq'
```
### `punycode.ucs2`
#### `punycode.ucs2.decode(string)`
Creates an array containing the numeric code point values of each Unicode symbol in the string. While [JavaScript uses UCS-2 internally](https://mathiasbynens.be/notes/javascript-encoding), this function will convert a pair of surrogate halves (each of which UCS-2 exposes as separate characters) into a single code point, matching UTF-16.
```js
punycode.ucs2.decode('abc');
// → [0x61, 0x62, 0x63]
// surrogate pair for U+1D306 TETRAGRAM FOR CENTRE:
punycode.ucs2.decode('\uD834\uDF06');
// → [0x1D306]
```
#### `punycode.ucs2.encode(codePoints)`
Creates a string based on an array of numeric code point values.
```js
punycode.ucs2.encode([0x61, 0x62, 0x63]);
// → 'abc'
punycode.ucs2.encode([0x1D306]);
// → '\uD834\uDF06'
```
### `punycode.version`
A string representing the current Punycode.js version number.
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
Punycode.js is available under the [MIT](https://mths.be/mit) license.
# sax js
A sax-style parser for XML and HTML.
Designed with [node](http://nodejs.org/) in mind, but should work fine in
the browser or other CommonJS implementations.
## What This Is
* A very simple tool to parse through an XML string.
* A stepping stone to a streaming HTML parser.
* A handy way to deal with RSS and other mostly-ok-but-kinda-broken XML
docs.
## What This Is (probably) Not
* An HTML Parser - That's a fine goal, but this isn't it. It's just
XML.
* A DOM Builder - You can use it to build an object model out of XML,
but it doesn't do that out of the box.
* XSLT - No DOM = no querying.
* 100% Compliant with (some other SAX implementation) - Most SAX
implementations are in Java and do a lot more than this does.
* An XML Validator - It does a little validation when in strict mode, but
not much.
* A Schema-Aware XSD Thing - Schemas are an exercise in fetishistic
masochism.
* A DTD-aware Thing - Fetching DTDs is a much bigger job.
## Regarding `<!DOCTYPE`s and `<!ENTITY`s
The parser will handle the basic XML entities in text nodes and attribute
values: `& < > ' "`. It's possible to define additional
entities in XML by putting them in the DTD. This parser doesn't do anything
with that. If you want to listen to the `ondoctype` event, and then fetch
the doctypes, and read the entities and add them to `parser.ENTITIES`, then
be my guest.
Unknown entities will fail in strict mode, and in loose mode, will pass
through unmolested.
## Usage
```javascript
var sax = require("./lib/sax"),
strict = true, // set to false for html-mode
parser = sax.parser(strict);
parser.onerror = function (e) {
// an error happened.
};
parser.ontext = function (t) {
// got some text. t is the string of text.
};
parser.onopentag = function (node) {
// opened a tag. node has "name" and "attributes"
};
parser.onattribute = function (attr) {
// an attribute. attr has "name" and "value"
};
parser.onend = function () {
// parser stream is done, and ready to have more stuff written to it.
};
parser.write('<xml>Hello, <who name="world">world</who>!</xml>').close();
// stream usage
// takes the same options as the parser
var saxStream = require("sax").createStream(strict, options)
saxStream.on("error", function (e) {
// unhandled errors will throw, since this is a proper node
// event emitter.
console.error("error!", e)
// clear the error
this._parser.error = null
this._parser.resume()
})
saxStream.on("opentag", function (node) {
// same object as above
})
// pipe is supported, and it's readable/writable
// same chunks coming in also go out.
fs.createReadStream("file.xml")
.pipe(saxStream)
.pipe(fs.createWriteStream("file-copy.xml"))
```
## Arguments
Pass the following arguments to the parser function. All are optional.
`strict` - Boolean. Whether or not to be a jerk. Default: `false`.
`opt` - Object bag of settings regarding string formatting. All default to `false`.
Settings supported:
* `trim` - Boolean. Whether or not to trim text and comment nodes.
* `normalize` - Boolean. If true, then turn any whitespace into a single
space.
* `lowercase` - Boolean. If true, then lowercase tag names and attribute names
in loose mode, rather than uppercasing them.
* `xmlns` - Boolean. If true, then namespaces are supported.
* `position` - Boolean. If false, then don't track line/col/position.
* `strictEntities` - Boolean. If true, only parse [predefined XML
entities](http://www.w3.org/TR/REC-xml/#sec-predefined-ent)
(`&`, `'`, `>`, `<`, and `"`)
## Methods
`write` - Write bytes onto the stream. You don't have to do this all at
once. You can keep writing as much as you want.
`close` - Close the stream. Once closed, no more data may be written until
it is done processing the buffer, which is signaled by the `end` event.
`resume` - To gracefully handle errors, assign a listener to the `error`
event. Then, when the error is taken care of, you can call `resume` to
continue parsing. Otherwise, the parser will not continue while in an error
state.
## Members
At all times, the parser object will have the following members:
`line`, `column`, `position` - Indications of the position in the XML
document where the parser currently is looking.
`startTagPosition` - Indicates the position where the current tag starts.
`closed` - Boolean indicating whether or not the parser can be written to.
If it's `true`, then wait for the `ready` event to write again.
`strict` - Boolean indicating whether or not the parser is a jerk.
`opt` - Any options passed into the constructor.
`tag` - The current tag being dealt with.
And a bunch of other stuff that you probably shouldn't touch.
## Events
All events emit with a single argument. To listen to an event, assign a
function to `on<eventname>`. Functions get executed in the this-context of
the parser object. The list of supported events are also in the exported
`EVENTS` array.
When using the stream interface, assign handlers using the EventEmitter
`on` function in the normal fashion.
`error` - Indication that something bad happened. The error will be hanging
out on `parser.error`, and must be deleted before parsing can continue. By
listening to this event, you can keep an eye on that kind of stuff. Note:
this happens *much* more in strict mode. Argument: instance of `Error`.
`text` - Text node. Argument: string of text.
`doctype` - The `<!DOCTYPE` declaration. Argument: doctype string.
`processinginstruction` - Stuff like `<?xml foo="blerg" ?>`. Argument:
object with `name` and `body` members. Attributes are not parsed, as
processing instructions have implementation dependent semantics.
`sgmldeclaration` - Random SGML declarations. Stuff like `<!ENTITY p>`
would trigger this kind of event. This is a weird thing to support, so it
might go away at some point. SAX isn't intended to be used to parse SGML,
after all.
`opentagstart` - Emitted immediately when the tag name is available,
but before any attributes are encountered. Argument: object with a
`name` field and an empty `attributes` set. Note that this is the
same object that will later be emitted in the `opentag` event.
`opentag` - An opening tag. Argument: object with `name` and `attributes`.
In non-strict mode, tag names are uppercased, unless the `lowercase`
option is set. If the `xmlns` option is set, then it will contain
namespace binding information on the `ns` member, and will have a
`local`, `prefix`, and `uri` member.
`closetag` - A closing tag. In loose mode, tags are auto-closed if their
parent closes. In strict mode, well-formedness is enforced. Note that
self-closing tags will have `closeTag` emitted immediately after `openTag`.
Argument: tag name.
`attribute` - An attribute node. Argument: object with `name` and `value`.
In non-strict mode, attribute names are uppercased, unless the `lowercase`
option is set. If the `xmlns` option is set, it will also contains namespace
information.
`comment` - A comment node. Argument: the string of the comment.
`opencdata` - The opening tag of a `<![CDATA[` block.
`cdata` - The text of a `<![CDATA[` block. Since `<![CDATA[` blocks can get
quite large, this event may fire multiple times for a single block, if it
is broken up into multiple `write()`s. Argument: the string of random
character data.
`closecdata` - The closing tag (`]]>`) of a `<. In browser [elliptic](https://github.com/indutny/elliptic) will be used as fallback.
Works on node version 10.0.0 or greater, because use [N-API](https://nodejs.org/api/n-api.html).
## Installation
##### from npm
`npm install secp256k1`
##### from git
```
git clone [email protected]:cryptocoinjs/secp256k1-node.git
cd secp256k1-node
git submodule update --init
npm install
```
##### Windows
The easiest way to build the package on windows is to install [windows-build-tools](https://github.com/felixrieseberg/windows-build-tools).
Or install the following software:
* Git: https://git-scm.com/download/win
* nvm: https://github.com/coreybutler/nvm-windows
* Python 2.7: https://www.python.org/downloads/release/python-2712/
* Visual C++ Build Tools: http://landinghub.visualstudio.com/visual-cpp-build-tools (Custom Install, and select both Windows 8.1 and Windows 10 SDKs)
And run commands:
```
npm config set msvs_version 2015 --global
npm install npm@next -g
```
Based on:
* https://github.com/nodejs/node-gyp/issues/629#issuecomment-153196245
* https://github.com/nodejs/node-gyp/issues/972
## Usage
* [API Reference (v4.x)](API.md) (current version)
* [API Reference (v3.x)](https://github.com/cryptocoinjs/secp256k1-node/blob/v3.x/API.md)
* [API Reference (v2.x)](https://github.com/cryptocoinjs/secp256k1-node/blob/v2.x/API.md)
##### Private Key generation, Public Key creation, signature creation, signature verification
```js
const { randomBytes } = require('crypto')
const secp256k1 = require('secp256k1')
// or require('secp256k1/elliptic')
// if you want to use pure js implementation in node
// generate message to sign
// message should have 32-byte length, if you have some other length you can hash message
// for example `msg = sha256(rawMessage)`
const msg = randomBytes(32)
// generate privKey
let privKey
do {
privKey = randomBytes(32)
} while (!secp256k1.privateKeyVerify(privKey))
// get the public key in a compressed format
const pubKey = secp256k1.publicKeyCreate(privKey)
// sign the message
const sigObj = secp256k1.ecdsaSign(msg, privKey)
// verify the signature
console.log(secp256k1.ecdsaVerify(sigObj.signature, msg, pubKey))
// => true
```
\* **.verify return false for high signatures**
##### Get X point of ECDH
```js
const { randomBytes } = require('crypto')
// const secp256k1 = require('./elliptic')
const secp256k1 = require('./')
// generate privKey
function getPrivateKey () {
while (true) {
const privKey = randomBytes(32)
if (secp256k1.privateKeyVerify(privKey)) return privKey
}
}
// generate private and public keys
const privKey = getPrivateKey()
const pubKey = secp256k1.publicKeyCreate(getPrivateKey())
// compressed public key from X and Y
function hashfn (x, y) {
const pubKey = new Uint8Array(33)
pubKey[0] = (y[31] & 1) === 0 ? 0x02 : 0x03
pubKey.set(x, 1)
return pubKey
}
// get X point of ecdh
const ecdhPointX = secp256k1.ecdh(pubKey, privKey, { hashfn }, Buffer.alloc(33))
console.log(ecdhPointX.toString('hex'))
```
## LICENSE
This library is free and open-source software released under the MIT license.
# typedarray-to-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/typedarray-to-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/typedarray-to-buffer
[npm-image]: https://img.shields.io/npm/v/typedarray-to-buffer.svg
[npm-url]: https://npmjs.org/package/typedarray-to-buffer
[downloads-image]: https://img.shields.io/npm/dm/typedarray-to-buffer.svg
[downloads-url]: https://npmjs.org/package/typedarray-to-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Convert a typed array to a [Buffer](https://github.com/feross/buffer) without a copy.
[![saucelabs][saucelabs-image]][saucelabs-url]
[saucelabs-image]: https://saucelabs.com/browser-matrix/typedarray-to-buffer.svg
[saucelabs-url]: https://saucelabs.com/u/typedarray-to-buffer
Say you're using the ['buffer'](https://github.com/feross/buffer) module on npm, or
[browserify](http://browserify.org/) and you're working with lots of binary data.
Unfortunately, sometimes the browser or someone else's API gives you a typed array like
`Uint8Array` to work with and you need to convert it to a `Buffer`. What do you do?
Of course: `Buffer.from(uint8array)`
But, alas, every time you do `Buffer.from(uint8array)` **the entire array gets copied**.
The `Buffer` constructor does a copy; this is
defined by the [node docs](http://nodejs.org/api/buffer.html) and the 'buffer' module
matches the node API exactly.
So, how can we avoid this expensive copy in
[performance critical applications](https://github.com/feross/buffer/issues/22)?
***Simply use this module, of course!***
If you have an `ArrayBuffer`, you don't need this module, because
`Buffer.from(arrayBuffer)`
[is already efficient](https://nodejs.org/api/buffer.html#buffer_class_method_buffer_from_arraybuffer_byteoffset_length).
## install
```bash
npm install typedarray-to-buffer
```
## usage
To convert a typed array to a `Buffer` **without a copy**, do this:
```js
var toBuffer = require('typedarray-to-buffer')
var arr = new Uint8Array([1, 2, 3])
arr = toBuffer(arr)
// arr is a buffer now!
arr.toString() // '\u0001\u0002\u0003'
arr.readUInt16BE(0) // 258
```
## how it works
If the browser supports typed arrays, then `toBuffer` will **augment the typed array** you
pass in with the `Buffer` methods and return it. See [how does Buffer
work?](https://github.com/feross/buffer#how-does-it-work) for more about how augmentation
works.
This module uses the typed array's underlying `ArrayBuffer` to back the new `Buffer`. This
respects the "view" on the `ArrayBuffer`, i.e. `byteOffset` and `byteLength`. In other
words, if you do `toBuffer(new Uint32Array([1, 2, 3]))`, then the new `Buffer` will
contain `[1, 0, 0, 0, 2, 0, 0, 0, 3, 0, 0, 0]`, **not** `[1, 2, 3]`. And it still doesn't
require a copy.
If the browser doesn't support typed arrays, then `toBuffer` will create a new `Buffer`
object, copy the data into it, and return it. There's no simple performance optimization
we can do for old browsers. Oh well.
If this module is used in node, then it will just call `Buffer.from`. This is just for
the convenience of modules that work in both node and the browser.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org).
# hash.js [](http://travis-ci.org/indutny/hash.js)
Just a bike-shed.
## Install
```sh
npm install hash.js
```
## Usage
```js
var hash = require('hash.js')
hash.sha256().update('abc').digest('hex')
```
## Selective hash usage
```js
var sha512 = require('hash.js/lib/hash/sha/512');
sha512().update('abc').digest('hex');
```
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2014.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
# duplexer3 [](https://travis-ci.org/floatdrop/duplexer3) [](https://coveralls.io/github/floatdrop/duplexer3?branch=master)
Like [duplexer2](https://github.com/deoxxa/duplexer2) but using Streams3 without readable-stream dependency
```javascript
var stream = require("stream");
var duplexer3 = require("duplexer3");
var writable = new stream.Writable({objectMode: true}),
readable = new stream.Readable({objectMode: true});
writable._write = function _write(input, encoding, done) {
if (readable.push(input)) {
return done();
} else {
readable.once("drain", done);
}
};
readable._read = function _read(n) {
// no-op
};
// simulate the readable thing closing after a bit
writable.once("finish", function() {
setTimeout(function() {
readable.push(null);
}, 500);
});
var duplex = duplexer3(writable, readable);
duplex.on("data", function(e) {
console.log("got data", JSON.stringify(e));
});
duplex.on("finish", function() {
console.log("got finish event");
});
duplex.on("end", function() {
console.log("got end event");
});
duplex.write("oh, hi there", function() {
console.log("finished writing");
});
duplex.end(function() {
console.log("finished ending");
});
```
```
got data "oh, hi there"
finished writing
got finish event
finished ending
got end event
```
## Overview
This is a reimplementation of [duplexer](https://www.npmjs.com/package/duplexer) using the
Streams3 API which is standard in Node as of v4. Everything largely
works the same.
## Installation
[Available via `npm`](https://docs.npmjs.com/cli/install):
```
$ npm i duplexer3
```
## API
### duplexer3
Creates a new `DuplexWrapper` object, which is the actual class that implements
most of the fun stuff. All that fun stuff is hidden. DON'T LOOK.
```javascript
duplexer3([options], writable, readable)
```
```javascript
const duplex = duplexer3(new stream.Writable(), new stream.Readable());
```
Arguments
* __options__ - an object specifying the regular `stream.Duplex` options, as
well as the properties described below.
* __writable__ - a writable stream
* __readable__ - a readable stream
Options
* __bubbleErrors__ - a boolean value that specifies whether to bubble errors
from the underlying readable/writable streams. Default is `true`.
## License
3-clause BSD. [A copy](./LICENSE) is included with the source.
## Contact
* GitHub ([deoxxa](http://github.com/deoxxa))
* Twitter ([@deoxxa](http://twitter.com/deoxxa))
* Email ([[email protected]](mailto:[email protected]))
# regex-cache [](https://www.npmjs.com/package/regex-cache) [](https://npmjs.org/package/regex-cache) [](https://npmjs.org/package/regex-cache) [](https://travis-ci.org/jonschlinkert/regex-cache) [](https://ci.appveyor.com/project/jonschlinkert/regex-cache)
> Memoize the results of a call to the RegExp constructor, avoiding repetitious runtime compilation of the same string and options, resulting in surprising performance improvements.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save regex-cache
```
* Read [what this does](#what-this-does).
* See [the benchmarks](#benchmarks)
## Usage
Wrap a function like this:
```js
var cache = require('regex-cache');
var someRegex = cache(require('some-regex-lib'));
```
**Caching a regex**
If you want to cache a regex after calling `new RegExp()`, or you're requiring a module that returns a regex, wrap it with a function first:
```js
var cache = require('regex-cache');
function yourRegex(str, opts) {
// do stuff to str and opts
return new RegExp(str, opts.flags);
}
var regex = cache(yourRegex);
```
## Recommendations
### Use this when...
* **No options are passed** to the function that creates the regex. Regardless of how big or small the regex is, when zero options are passed, caching will be faster than not.
* **A few options are passed**, and the values are primitives. The limited benchmarks I did show that caching is beneficial when up to 8 or 9 options are passed.
### Do not use this when...
* **The values of options are not primitives**. When non-primitives must be compared for equality, the time to compare the options is most likely as long or longer than the time to just create a new regex.
### Example benchmarks
Performance results, with and without regex-cache:
```bash
# no args passed (defaults)
with-cache x 8,699,231 ops/sec ±0.86% (93 runs sampled)
without-cache x 2,777,551 ops/sec ±0.63% (95 runs sampled)
# string and six options passed
with-cache x 1,885,934 ops/sec ±0.80% (93 runs sampled)
without-cache x 1,256,893 ops/sec ±0.65% (97 runs sampled)
# string only
with-cache x 7,723,256 ops/sec ±0.87% (92 runs sampled)
without-cache x 2,303,060 ops/sec ±0.47% (99 runs sampled)
# one option passed
with-cache x 4,179,877 ops/sec ±0.53% (100 runs sampled)
without-cache x 2,198,422 ops/sec ±0.47% (95 runs sampled)
# two options passed
with-cache x 3,256,222 ops/sec ±0.51% (99 runs sampled)
without-cache x 2,121,401 ops/sec ±0.79% (97 runs sampled)
# six options passed
with-cache x 1,816,018 ops/sec ±1.08% (96 runs sampled)
without-cache x 1,157,176 ops/sec ±0.53% (100 runs sampled)
#
# diminishing returns happen about here
#
# ten options passed
with-cache x 1,210,598 ops/sec ±0.56% (92 runs sampled)
without-cache x 1,665,588 ops/sec ±1.07% (100 runs sampled)
# twelve options passed
with-cache x 1,042,096 ops/sec ±0.68% (92 runs sampled)
without-cache x 1,389,414 ops/sec ±0.68% (97 runs sampled)
# twenty options passed
with-cache x 661,125 ops/sec ±0.80% (93 runs sampled)
without-cache x 1,208,757 ops/sec ±0.65% (97 runs sampled)
#
# when non-primitive values are compared
#
# single value on the options is an object
with-cache x 1,398,313 ops/sec ±1.05% (95 runs sampled)
without-cache x 2,228,281 ops/sec ±0.56% (99 runs sampled)
```
## Run benchmarks
Install dev dependencies:
```bash
npm i -d && npm run benchmarks
```
## What this does
If you're using `new RegExp('foo')` instead of a regex literal, it's probably because you need to dyamically generate a regex based on user options or some other potentially changing factors.
When your function creates a string based on user inputs and passes it to the `RegExp` constructor, regex-cache caches the results. The next time the function is called if the key of a cached regex matches the user input (or no input was given), the cached regex is returned, avoiding unnecessary runtime compilation.
Using the RegExp constructor offers a lot of flexibility, but the runtime compilation comes at a price - it's slow. Not specifically because of the call to the RegExp constructor, but **because you have to build up the string before `new RegExp()` is even called**.
## About
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 31 | [jonschlinkert](https://github.com/jonschlinkert) |
| 1 | [MartinKolarik](https://github.com/MartinKolarik) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on September 01, 2017._
# web3-core-helpers
This is a sub package of [web3.js][repo]
Helper functions used in [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-helpers
```
## Usage
```js
// in node.js
var helpers = require('web3-core-helpers');
helpers.formatters;
helpers.errors;
...
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
* `n` - the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
* `rn` - both argument and return value of the function are plain JavaScript
Numbers. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
* `BN.max(a, b)` - return `a` if `a` bigger than `b`
* `BN.min(a, b)` - return `a` if `a` less than `b`
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
### Number Size
Optimized for elliptic curves that work with 256-bit numbers.
There is no limitation on the size of the numbers.
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# web3-eth
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This Eth package is used within some [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth
```
## Usage
```js
const Web3Eth = require('web3-eth');
const eth = new Web3Eth('ws://localhost:8546');
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3-eth.js
[npm-image]: https://img.shields.io/npm/v/web3-eth.svg
[npm-url]: https://npmjs.org/package/web3-eth
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-eth
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-eth
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-eth
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-eth
# create-hmac
[](https://www.npmjs.org/package/create-hmac)
[](https://travis-ci.org/crypto-browserify/createHmac)
[](https://david-dm.org/crypto-browserify/createHmac#info=dependencies)
[](https://github.com/feross/standard)
Node style HMACs for use in the browser, with native HMAC functions in node. API is the same as HMACs in node:
```js
var createHmac = require('create-hmac')
var hmac = createHmac('sha224', Buffer.from('secret key'))
hmac.update('synchronous write') //optional encoding parameter
hmac.digest() // synchronously get result with optional encoding parameter
hmac.write('write to it as a stream')
hmac.end() //remember it's a stream
hmac.read() //only if you ended it as a stream though
```
# is-number [](http://badge.fury.io/js/is-number) [](https://travis-ci.org/jonschlinkert/is-number)
> Returns true if the value is a number. comprehensive tests.
To understand some of the rationale behind the decisions made in this library (and to learn about some oddities of number evaluation in JavaScript), [see this gist](https://gist.github.com/jonschlinkert/e30c70c713da325d0e81).
## Install
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i is-number --save
```
## Usage
```js
var isNumber = require('is-number');
```
### true
See the [tests](./test.js) for more examples.
```js
isNumber(5e3) //=> 'true'
isNumber(0xff) //=> 'true'
isNumber(-1.1) //=> 'true'
isNumber(0) //=> 'true'
isNumber(1) //=> 'true'
isNumber(1.1) //=> 'true'
isNumber(10) //=> 'true'
isNumber(10.10) //=> 'true'
isNumber(100) //=> 'true'
isNumber('-1.1') //=> 'true'
isNumber('0') //=> 'true'
isNumber('012') //=> 'true'
isNumber('0xff') //=> 'true'
isNumber('1') //=> 'true'
isNumber('1.1') //=> 'true'
isNumber('10') //=> 'true'
isNumber('10.10') //=> 'true'
isNumber('100') //=> 'true'
isNumber('5e3') //=> 'true'
isNumber(parseInt('012')) //=> 'true'
isNumber(parseFloat('012')) //=> 'true'
```
### False
See the [tests](./test.js) for more examples.
```js
isNumber('foo') //=> 'false'
isNumber([1]) //=> 'false'
isNumber([]) //=> 'false'
isNumber(function () {}) //=> 'false'
isNumber(Infinity) //=> 'false'
isNumber(NaN) //=> 'false'
isNumber(new Array('abc')) //=> 'false'
isNumber(new Array(2)) //=> 'false'
isNumber(new Buffer('abc')) //=> 'false'
isNumber(null) //=> 'false'
isNumber(undefined) //=> 'false'
isNumber({abc: 'abc'}) //=> 'false'
```
## Other projects
* [even](https://www.npmjs.com/package/even): Get the even numbered items from an array. | [homepage](https://github.com/jonschlinkert/even)
* [is-even](https://www.npmjs.com/package/is-even): Return true if the given number is even. | [homepage](https://github.com/jonschlinkert/is-even)
* [is-odd](https://www.npmjs.com/package/is-odd): Returns true if the given number is odd. | [homepage](https://github.com/jonschlinkert/is-odd)
* [is-primitive](https://www.npmjs.com/package/is-primitive): Returns `true` if the value is a primitive. | [homepage](https://github.com/jonschlinkert/is-primitive)
* [kind-of](https://www.npmjs.com/package/kind-of): Get the native type of a value. | [homepage](https://github.com/jonschlinkert/kind-of)
* [odd](https://www.npmjs.com/package/odd): Get the odd numbered items from an array. | [homepage](https://github.com/jonschlinkert/odd)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-number/issues/new).
## Run tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2015 Jon Schlinkert
Released under the MIT license.
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on November 22, 2015._
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 3.9.2 or later
npm install tslib
# TypeScript 3.8.4 or earlier
npm install tslib@^1
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 3.9.2 or later
yarn add tslib
# TypeScript 3.8.4 or earlier
yarn add tslib@^1
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 3.9.2 or later
bower install tslib
# TypeScript 3.8.4 or earlier
bower install tslib@^1
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 3.9.2 or later
jspm install tslib
# TypeScript 3.8.4 or earlier
jspm install tslib@^1
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/[email protected]/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# is-posix-bracket [](https://www.npmjs.com/package/is-posix-bracket) [](https://npmjs.org/package/is-posix-bracket) [](https://travis-ci.org/jonschlinkert/is-posix-bracket)
> Returns true if the given string is a POSIX bracket expression (POSIX character class).
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install is-posix-bracket --save
```
## Usage
```js
var isPosixBracket = require('is-posix-bracket');
isPosixBracket('[foo:]]');
//=> false
isPosixBracket('[xdigit:]]');
//=> false
isPosixBracket('[[:xdigit:]]');
//=> true
isPosixBracket('[[:xdigit:]]');
//=> true
isPosixBracket('[[:alpha:]123]');
//=> true
isPosixBracket('[[:alpha:]123]');
//=> true
isPosixBracket('[a-c[:digit:]x-z]');
//=> true
isPosixBracket('[:al:]');
//=> true
isPosixBracket('[abc[:punct:][0-9]');
//=> true
```
## Related projects
You might also be interested in these projects:
* [braces](https://www.npmjs.com/package/braces): Fastest brace expansion for node.js, with the most complete support for the Bash 4.3 braces… [more](https://www.npmjs.com/package/braces) | [homepage](https://github.com/jonschlinkert/braces)
* [expand-brackets](https://www.npmjs.com/package/expand-brackets): Expand POSIX bracket expressions (character classes) in glob patterns. | [homepage](https://github.com/jonschlinkert/expand-brackets)
* [is-extglob](https://www.npmjs.com/package/is-extglob): Returns true if a string has an extglob. | [homepage](https://github.com/jonschlinkert/is-extglob)
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern.… [more](https://www.npmjs.com/package/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob)
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. Just… [more](https://www.npmjs.com/package/micromatch) | [homepage](https://github.com/jonschlinkert/micromatch)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-posix-bracket/issues/new).
## Building docs
Generate readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install verb && npm run docs
```
Or, if [verb](https://github.com/verbose/verb) is installed globally:
```sh
$ verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/is-posix-bracket/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v, on April 05, 2016._
# node-uuid Benchmarks
### Results
To see the results of our benchmarks visit https://github.com/broofa/node-uuid/wiki/Benchmark
### Run them yourself
node-uuid comes with some benchmarks to measure performance of generating UUIDs. These can be run using node.js. node-uuid is being benchmarked against some other uuid modules, that are available through npm namely `uuid` and `uuid-js`.
To prepare and run the benchmark issue;
```
npm install uuid uuid-js
node benchmark/benchmark.js
```
You'll see an output like this one:
```
# v4
nodeuuid.v4(): 854700 uuids/second
nodeuuid.v4('binary'): 788643 uuids/second
nodeuuid.v4('binary', buffer): 1336898 uuids/second
uuid(): 479386 uuids/second
uuid('binary'): 582072 uuids/second
uuidjs.create(4): 312304 uuids/second
# v1
nodeuuid.v1(): 938086 uuids/second
nodeuuid.v1('binary'): 683060 uuids/second
nodeuuid.v1('binary', buffer): 1644736 uuids/second
uuidjs.create(1): 190621 uuids/second
```
* The `uuid()` entries are for Nikhil Marathe's [uuid module](https://bitbucket.org/nikhilm/uuidjs) which is a wrapper around the native libuuid library.
* The `uuidjs()` entries are for Patrick Negri's [uuid-js module](https://github.com/pnegri/uuid-js) which is a pure javascript implementation based on [UUID.js](https://github.com/LiosK/UUID.js) by LiosK.
If you want to get more reliable results you can run the benchmark multiple times and write the output into a log file:
```
for i in {0..9}; do node benchmark/benchmark.js >> benchmark/bench_0.4.12.log; done;
```
If you're interested in how performance varies between different node versions, you can issue the above command multiple times.
You can then use the shell script `bench.sh` provided in this directory to calculate the averages over all benchmark runs and draw a nice plot:
```
(cd benchmark/ && ./bench.sh)
```
This assumes you have [gnuplot](http://www.gnuplot.info/) and [ImageMagick](http://www.imagemagick.org/) installed. You'll find a nice `bench.png` graph in the `benchmark/` directory then.
node-cron
=
[](https://travis-ci.org/kelektiv/node-cron)
[](https://david-dm.org/ncb000gt/node-cron)
Cron is a tool that allows you to execute _something_ on a schedule. This is
typically done using the cron syntax. We allow you to execute a function
whenever your scheduled job triggers. We also allow you to execute a job
external to the javascript process using `child_process`. Additionally, this
library goes beyond the basic cron syntax and allows you to
supply a Date object. This will be used as the trigger for your callback. Cron
syntax is still an acceptable CronTime format. Although the Cron patterns
supported here extend on the standard Unix format to support seconds digits,
leaving it off will default to 0 and match the Unix behavior.
Installation
==
npm install cron
If You Are Submitting Bugs/Issues
==
Because we can't magically know what you are doing to expose an issue, it is
best if you provide a snippet of code. This snippet need not include your secret
sauce, but it must replicate the issue you are describing. The issues that get
closed without resolution tend to be the ones without code examples. Thanks.
Versions and Backwards compatibility breaks:
==
As goes with semver, breaking backwards compatibility should be explicit in the
versioning of your library. As such, we'll upgrade the version of this module
in accordance with breaking changes (I'm not always great about doing it this
way so if you notice that there are breaking changes that haven't been bumped
appropriately please let me know).
Usage (basic cron usage):
==
```javascript
var CronJob = require('cron').CronJob;
var job = new CronJob('* * * * * *', function() {
console.log('You will see this message every second');
}, null, true, 'America/Los_Angeles');
job.start();
```
Note - You need to explicitly start a job in order to make it run. This gives a
little more control over running your jobs.
There are more examples available in this repository at:
[/examples](https://github.com/kelektiv/node-cron/tree/master/examples)
Available Cron patterns:
==
Asterisk. E.g. *
Ranges. E.g. 1-3,5
Steps. E.g. */2
[Read up on cron patterns here](http://crontab.org). Note the examples in the
link have five fields, and 1 minute as the finest granularity, but this library
has six fields, with 1 second as the finest granularity.
There are tools that help when constructing your cronjobs. You might find
something like https://crontab.guru/ or https://cronjob.xyz/ helpful. But,
note that these don't necessarily accept the exact same syntax as this
library, for instance, it doesn't accept the `seconds` field, so keep that in
mind.
Cron Ranges
==
When specifying your cron values you'll need to make sure that your values fall
within the ranges. For instance, some cron's use a 0-7 range for the day of
week where both 0 and 7 represent Sunday. We do not. And that is an optimisation.
* Seconds: 0-59
* Minutes: 0-59
* Hours: 0-23
* Day of Month: 1-31
* Months: 0-11 (Jan-Dec)
* Day of Week: 0-6 (Sun-Sat)
Gotchas
==
* Millisecond level granularity in JS or moment date objects.
Because computers take time to do things, there may be some delay in execution.
This should be on the order of milliseconds. This module doesn't allow MS level
granularity for the regular cron syntax, but _does_ allow you to specify a real
date of execution in either a javascript date object or a moment object.
When this happens you may find that you aren't able to execute a job that
_should_ run in the future like with `new Date().setMilliseconds(new
Date().getMilliseconds() + 1)`. This is due to those cycles of execution
above. This wont be the same for everyone because of compute speed. When I
tried it locally I saw that somewhere around the 4-5 ms mark was where I got
consistent ticks using real dates, but anything less than that would result
in an exception. This could be really confusing. We could restrict the
granularity for all dates to seconds, but felt that it wasn't a huge problem
so long as you were made aware. If this becomes more of an issue, We can
revisit it.
* Arrow Functions for `onTick`
Arrow functions get their `this` context from their parent scope. Thus, if you use them, you will not get
the `this` context of the cronjob. You can read a little more in this ticket [GH-40](https://github.com/kelektiv/node-cron/issues/47#issuecomment-459762775)
API
==
Parameter Based
* `job` - shortcut to `new cron.CronJob()`.
* `time` - shortcut to `new cron.CronTime()`.
* `sendAt` - tells you when a `CronTime` will be run.
* `timeout` - tells you when the next timeout is.
* `CronJob`
* `constructor(cronTime, onTick, onComplete, start, timezone, context,
runOnInit, unrefTimeout)` - Of note, the first parameter here can be a JSON object that
has the below names and associated types (see examples above).
* `cronTime` - [REQUIRED] - The time to fire off your job. This can be in
the form of cron syntax or a JS
[Date](https://developer.mozilla.org/en/JavaScript/Reference/Global_Objects/Date) object.
* `onTick` - [REQUIRED] - The function to fire at the specified time. If an
`onComplete` callback was provided, `onTick` will receive it as an argument.
`onTick` may call `onComplete` when it has finished its work.
* `onComplete` - [OPTIONAL] - A function that will fire when the job is
stopped with `job.stop()`, and may also be called by `onTick` at the end of each run.
* `start` - [OPTIONAL] - Specifies whether to start the job just before
exiting the constructor. By default this is set to false. If left at default
you will need to call `job.start()` in order to start the job (assuming
`job` is the variable you set the cronjob to). This does not immediately
fire your `onTick` function, it just gives you more control over the
behavior of your jobs.
* `timeZone` - [OPTIONAL] - Specify the timezone for the execution. This
will modify the actual time relative to your timezone. If the timezone is
invalid, an error is thrown. You can check all timezones available at
[Moment Timezone Website](http://momentjs.com/timezone/). Probably don't use
both.
`timeZone` and `utcOffset` together or weird things may happen.
* `context` - [OPTIONAL] - The context within which to execute the onTick
method. This defaults to the cronjob itself allowing you to call
`this.stop()`. However, if you change this you'll have access to the
functions and values within your context object.
* `runOnInit` - [OPTIONAL] - This will immediately fire your `onTick`
function as soon as the requisite initialization has happened. This option
is set to `false` by default for backwards compatibility.
* `utcOffset` - [OPTIONAL] - This allows you to specify the offset of your
timezone rather than using the `timeZone` param. Probably don't use both
`timeZone` and `utcOffset` together or weird things may happen.
* `unrefTimeout` - [OPTIONAL] - If you have code that keeps the event loop
running and want to stop the node process when that finishes regardless of
the state of your cronjob, you can do so making use of this parameter. This
is off by default and cron will run as if it needs to control the event
loop. For more information take a look at
[timers#timers_timeout_unref](https://nodejs.org/api/timers.html#timers_timeout_unref)
from the NodeJS docs.
* `start` - Runs your job.
* `stop` - Stops your job.
* `setTime` - Stops and changes the time for the `CronJob`. Param must be a `CronTime`.
* `lastDate` - Tells you the last execution date.
* `nextDates` - Provides an array of the next set of dates that will trigger an `onTick`.
* `fireOnTick` - Allows you to override the `onTick` calling behavior. This
matters so only do this if you have a really good reason to do so.
* `addCallback` - Allows you to add `onTick` callbacks.
* `CronTime`
* `constructor(time)`
* `time` - [REQUIRED] - The time to fire off your job. This can be in the
form of cron syntax or a JS
[Date](https://developer.mozilla.org/en/JavaScript/Reference/Global_Objects/Date)
object.
Contributions
==
This is a community effort project. In the truest sense, this project started as
an open source project from [cron.js](http://github.com/padolsey/cron.js) and
grew into something else. Other people have contributed code, time, and
oversight to the project. At this point there are too many to name here so I'll
just say thanks.
License
==
MIT
argparse
========
[](http://travis-ci.org/nodeca/argparse)
[](https://www.npmjs.org/package/argparse)
CLI arguments parser for node.js. Javascript port of python's
[argparse](http://docs.python.org/dev/library/argparse.html) module
(original version 3.2). That's a full port, except some very rare options,
recorded in issue tracker.
**NB. Difference with original.**
- Method names changed to camelCase. See [generated docs](http://nodeca.github.com/argparse/).
- Use `defaultValue` instead of `default`.
- Use `argparse.Const.REMAINDER` instead of `argparse.REMAINDER`, and
similarly for constant values `OPTIONAL`, `ZERO_OR_MORE`, and `ONE_OR_MORE`
(aliases for `nargs` values `'?'`, `'*'`, `'+'`, respectively), and
`SUPPRESS`.
Example
=======
test.js file:
```javascript
#!/usr/bin/env node
'use strict';
var ArgumentParser = require('../lib/argparse').ArgumentParser;
var parser = new ArgumentParser({
version: '0.0.1',
addHelp:true,
description: 'Argparse example'
});
parser.addArgument(
[ '-f', '--foo' ],
{
help: 'foo bar'
}
);
parser.addArgument(
[ '-b', '--bar' ],
{
help: 'bar foo'
}
);
parser.addArgument(
'--baz',
{
help: 'baz bar'
}
);
var args = parser.parseArgs();
console.dir(args);
```
Display help:
```
$ ./test.js -h
usage: example.js [-h] [-v] [-f FOO] [-b BAR] [--baz BAZ]
Argparse example
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-f FOO, --foo FOO foo bar
-b BAR, --bar BAR bar foo
--baz BAZ baz bar
```
Parse arguments:
```
$ ./test.js -f=3 --bar=4 --baz 5
{ foo: '3', bar: '4', baz: '5' }
```
More [examples](https://github.com/nodeca/argparse/tree/master/examples).
ArgumentParser objects
======================
```
new ArgumentParser({parameters hash});
```
Creates a new ArgumentParser object.
**Supported params:**
- ```description``` - Text to display before the argument help.
- ```epilog``` - Text to display after the argument help.
- ```addHelp``` - Add a -h/–help option to the parser. (default: true)
- ```argumentDefault``` - Set the global default value for arguments. (default: null)
- ```parents``` - A list of ArgumentParser objects whose arguments should also be included.
- ```prefixChars``` - The set of characters that prefix optional arguments. (default: ‘-‘)
- ```formatterClass``` - A class for customizing the help output.
- ```prog``` - The name of the program (default: `path.basename(process.argv[1])`)
- ```usage``` - The string describing the program usage (default: generated)
- ```conflictHandler``` - Usually unnecessary, defines strategy for resolving conflicting optionals.
**Not supported yet**
- ```fromfilePrefixChars``` - The set of characters that prefix files from which additional arguments should be read.
Details in [original ArgumentParser guide](http://docs.python.org/dev/library/argparse.html#argumentparser-objects)
addArgument() method
====================
```
ArgumentParser.addArgument(name or flag or [name] or [flags...], {options})
```
Defines how a single command-line argument should be parsed.
- ```name or flag or [name] or [flags...]``` - Either a positional name
(e.g., `'foo'`), a single option (e.g., `'-f'` or `'--foo'`), an array
of a single positional name (e.g., `['foo']`), or an array of options
(e.g., `['-f', '--foo']`).
Options:
- ```action``` - The basic type of action to be taken when this argument is encountered at the command line.
- ```nargs```- The number of command-line arguments that should be consumed.
- ```constant``` - A constant value required by some action and nargs selections.
- ```defaultValue``` - The value produced if the argument is absent from the command line.
- ```type``` - The type to which the command-line argument should be converted.
- ```choices``` - A container of the allowable values for the argument.
- ```required``` - Whether or not the command-line option may be omitted (optionals only).
- ```help``` - A brief description of what the argument does.
- ```metavar``` - A name for the argument in usage messages.
- ```dest``` - The name of the attribute to be added to the object returned by parseArgs().
Details in [original add_argument guide](http://docs.python.org/dev/library/argparse.html#the-add-argument-method)
Action (some details)
================
ArgumentParser objects associate command-line arguments with actions.
These actions can do just about anything with the command-line arguments associated
with them, though most actions simply add an attribute to the object returned by
parseArgs(). The action keyword argument specifies how the command-line arguments
should be handled. The supported actions are:
- ```store``` - Just stores the argument’s value. This is the default action.
- ```storeConst``` - Stores value, specified by the const keyword argument.
(Note that the const keyword argument defaults to the rather unhelpful None.)
The 'storeConst' action is most commonly used with optional arguments, that
specify some sort of flag.
- ```storeTrue``` and ```storeFalse``` - Stores values True and False
respectively. These are special cases of 'storeConst'.
- ```append``` - Stores a list, and appends each argument value to the list.
This is useful to allow an option to be specified multiple times.
- ```appendConst``` - Stores a list, and appends value, specified by the
const keyword argument to the list. (Note, that the const keyword argument defaults
is None.) The 'appendConst' action is typically used when multiple arguments need
to store constants to the same list.
- ```count``` - Counts the number of times a keyword argument occurs. For example,
used for increasing verbosity levels.
- ```help``` - Prints a complete help message for all the options in the current
parser and then exits. By default a help action is automatically added to the parser.
See ArgumentParser for details of how the output is created.
- ```version``` - Prints version information and exit. Expects a `version=`
keyword argument in the addArgument() call.
Details in [original action guide](http://docs.python.org/dev/library/argparse.html#action)
Sub-commands
============
ArgumentParser.addSubparsers()
Many programs split their functionality into a number of sub-commands, for
example, the svn program can invoke sub-commands like `svn checkout`, `svn update`,
and `svn commit`. Splitting up functionality this way can be a particularly good
idea when a program performs several different functions which require different
kinds of command-line arguments. `ArgumentParser` supports creation of such
sub-commands with `addSubparsers()` method. The `addSubparsers()` method is
normally called with no arguments and returns an special action object.
This object has a single method `addParser()`, which takes a command name and
any `ArgumentParser` constructor arguments, and returns an `ArgumentParser` object
that can be modified as usual.
Example:
sub_commands.js
```javascript
#!/usr/bin/env node
'use strict';
var ArgumentParser = require('../lib/argparse').ArgumentParser;
var parser = new ArgumentParser({
version: '0.0.1',
addHelp:true,
description: 'Argparse examples: sub-commands',
});
var subparsers = parser.addSubparsers({
title:'subcommands',
dest:"subcommand_name"
});
var bar = subparsers.addParser('c1', {addHelp:true});
bar.addArgument(
[ '-f', '--foo' ],
{
action: 'store',
help: 'foo3 bar3'
}
);
var bar = subparsers.addParser(
'c2',
{aliases:['co'], addHelp:true}
);
bar.addArgument(
[ '-b', '--bar' ],
{
action: 'store',
type: 'int',
help: 'foo3 bar3'
}
);
var args = parser.parseArgs();
console.dir(args);
```
Details in [original sub-commands guide](http://docs.python.org/dev/library/argparse.html#sub-commands)
Contributors
============
- [Eugene Shkuropat](https://github.com/shkuropat)
- [Paul Jacobson](https://github.com/hpaulj)
[others](https://github.com/nodeca/argparse/graphs/contributors)
License
=======
Copyright (c) 2012 [Vitaly Puzrin](https://github.com/puzrin).
Released under the MIT license. See
[LICENSE](https://github.com/nodeca/argparse/blob/master/LICENSE) for details.
<h1 align="center">Enquirer</h1>
<p align="center">
<a href="https://npmjs.org/package/enquirer">
<img src="https://img.shields.io/npm/v/enquirer.svg" alt="version">
</a>
<a href="https://travis-ci.org/enquirer/enquirer">
<img src="https://img.shields.io/travis/enquirer/enquirer.svg" alt="travis">
</a>
<a href="https://npmjs.org/package/enquirer">
<img src="https://img.shields.io/npm/dm/enquirer.svg" alt="downloads">
</a>
</p>
<br>
<br>
<p align="center">
<b>Stylish CLI prompts that are user-friendly, intuitive and easy to create.</b><br>
<sub>>_ Prompts should be more like conversations than inquisitions▌</sub>
</p>
<br>
<p align="center">
<sub>(Example shows Enquirer's <a href="#survey-prompt">Survey Prompt</a>)</a></sub>
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/survey-prompt.gif" alt="Enquirer Survey Prompt" width="750"><br>
<sub>The terminal in all examples is <a href="https://hyper.is/">Hyper</a>, theme is <a href="https://github.com/jonschlinkert/hyper-monokai-extended">hyper-monokai-extended</a>.</sub><br><br>
<a href="#built-in-prompts"><strong>See more prompt examples</strong></a>
</p>
<br>
<br>
Created by [jonschlinkert](https://github.com/jonschlinkert) and [doowb](https://github.com/doowb), Enquirer is fast, easy to use, and lightweight enough for small projects, while also being powerful and customizable enough for the most advanced use cases.
* **Fast** - [Loads in ~4ms](#-performance) (that's about _3-4 times faster than a [single frame of a HD movie](http://www.endmemo.com/sconvert/framespersecondframespermillisecond.php) at 60fps_)
* **Lightweight** - Only one dependency, the excellent [ansi-colors](https://github.com/doowb/ansi-colors) by [Brian Woodward](https://github.com/doowb).
* **Easy to implement** - Uses promises and async/await and sensible defaults to make prompts easy to create and implement.
* **Easy to use** - Thrill your users with a better experience! Navigating around input and choices is a breeze. You can even create [quizzes](examples/fun/countdown.js), or [record](examples/fun/record.js) and [playback](examples/fun/play.js) key bindings to aid with tutorials and videos.
* **Intuitive** - Keypress combos are available to simplify usage.
* **Flexible** - All prompts can be used standalone or chained together.
* **Stylish** - Easily override semantic styles and symbols for any part of the prompt.
* **Extensible** - Easily create and use custom prompts by extending Enquirer's built-in [prompts](#-prompts).
* **Pluggable** - Add advanced features to Enquirer using plugins.
* **Validation** - Optionally validate user input with any prompt.
* **Well tested** - All prompts are well-tested, and tests are easy to create without having to use brittle, hacky solutions to spy on prompts or "inject" values.
* **Examples** - There are numerous [examples](examples) available to help you get started.
If you like Enquirer, please consider starring or tweeting about this project to show your support. Thanks!
<br>
<p align="center">
<b>>_ Ready to start making prompts your users will love? ▌</b><br>
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/heartbeat.gif" alt="Enquirer Select Prompt with heartbeat example" width="750">
</p>
<br>
<br>
## ❯ Getting started
Get started with Enquirer, the most powerful and easy-to-use Node.js library for creating interactive CLI prompts.
* [Install](#-install)
* [Usage](#-usage)
* [Enquirer](#-enquirer)
* [Prompts](#-prompts)
- [Built-in Prompts](#-prompts)
- [Custom Prompts](#-custom-prompts)
* [Key Bindings](#-key-bindings)
* [Options](#-options)
* [Release History](#-release-history)
* [Performance](#-performance)
* [About](#-about)
<br>
## ❯ Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install enquirer --save
```
Install with [yarn](https://yarnpkg.com/en/):
```sh
$ yarn add enquirer
```
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/npm-install.gif" alt="Install Enquirer with NPM" width="750">
</p>
_(Requires Node.js 8.6 or higher. Please let us know if you need support for an earlier version by creating an [issue](../../issues/new).)_
<br>
## ❯ Usage
### Single prompt
The easiest way to get started with enquirer is to pass a [question object](#prompt-options) to the `prompt` method.
```js
const { prompt } = require('enquirer');
const response = await prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response); // { username: 'jonschlinkert' }
```
_(Examples with `await` need to be run inside an `async` function)_
### Multiple prompts
Pass an array of ["question" objects](#prompt-options) to run a series of prompts.
```js
const response = await prompt([
{
type: 'input',
name: 'name',
message: 'What is your name?'
},
{
type: 'input',
name: 'username',
message: 'What is your username?'
}
]);
console.log(response); // { name: 'Edward Chan', username: 'edwardmchan' }
```
### Different ways to run enquirer
#### 1. By importing the specific `built-in prompt`
```js
const { Confirm } = require('enquirer');
const prompt = new Confirm({
name: 'question',
message: 'Did you like enquirer?'
});
prompt.run()
.then(answer => console.log('Answer:', answer));
```
#### 2. By passing the options to `prompt`
```js
const { prompt } = require('enquirer');
prompt({
type: 'confirm',
name: 'question',
message: 'Did you like enquirer?'
})
.then(answer => console.log('Answer:', answer));
```
**Jump to**: [Getting Started](#-getting-started) · [Prompts](#-prompts) · [Options](#-options) · [Key Bindings](#-key-bindings)
<br>
## ❯ Enquirer
**Enquirer is a prompt runner**
Add Enquirer to your JavaScript project with following line of code.
```js
const Enquirer = require('enquirer');
```
The main export of this library is the `Enquirer` class, which has methods and features designed to simplify running prompts.
```js
const { prompt } = require('enquirer');
const question = [
{
type: 'input',
name: 'username',
message: 'What is your username?'
},
{
type: 'password',
name: 'password',
message: 'What is your password?'
}
];
let answers = await prompt(question);
console.log(answers);
```
**Prompts control how values are rendered and returned**
Each individual prompt is a class with special features and functionality for rendering the types of values you want to show users in the terminal, and subsequently returning the types of values you need to use in your application.
**How can I customize prompts?**
Below in this guide you will find information about creating [custom prompts](#-custom-prompts). For now, we'll focus on how to customize an existing prompt.
All of the individual [prompt classes](#built-in-prompts) in this library are exposed as static properties on Enquirer. This allows them to be used directly without using `enquirer.prompt()`.
Use this approach if you need to modify a prompt instance, or listen for events on the prompt.
**Example**
```js
const { Input } = require('enquirer');
const prompt = new Input({
name: 'username',
message: 'What is your username?'
});
prompt.run()
.then(answer => console.log('Username:', answer))
.catch(console.error);
```
### [Enquirer](index.js#L20)
Create an instance of `Enquirer`.
**Params**
* `options` **{Object}**: (optional) Options to use with all prompts.
* `answers` **{Object}**: (optional) Answers object to initialize with.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
```
### [register()](index.js#L42)
Register a custom prompt type.
**Params**
* `type` **{String}**
* `fn` **{Function|Prompt}**: `Prompt` class, or a function that returns a `Prompt` class.
* `returns` **{Object}**: Returns the Enquirer instance
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
enquirer.register('customType', require('./custom-prompt'));
```
### [prompt()](index.js#L78)
Prompt function that takes a "question" object or array of question objects, and returns an object with responses from the user.
**Params**
* `questions` **{Array|Object}**: Options objects for one or more prompts to run.
* `returns` **{Promise}**: Promise that returns an "answers" object with the user's responses.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
const response = await enquirer.prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response);
```
### [use()](index.js#L160)
Use an enquirer plugin.
**Params**
* `plugin` **{Function}**: Plugin function that takes an instance of Enquirer.
* `returns` **{Object}**: Returns the Enquirer instance.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
const plugin = enquirer => {
// do stuff to enquire instance
};
enquirer.use(plugin);
```
### [Enquirer#prompt](index.js#L210)
Prompt function that takes a "question" object or array of question objects, and returns an object with responses from the user.
**Params**
* `questions` **{Array|Object}**: Options objects for one or more prompts to run.
* `returns` **{Promise}**: Promise that returns an "answers" object with the user's responses.
**Example**
```js
const { prompt } = require('enquirer');
const response = await prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response);
```
<br>
## ❯ Prompts
This section is about Enquirer's prompts: what they look like, how they work, how to run them, available options, and how to customize the prompts or create your own prompt concept.
**Getting started with Enquirer's prompts**
* [Prompt](#prompt) - The base `Prompt` class used by other prompts
- [Prompt Options](#prompt-options)
* [Built-in prompts](#built-in-prompts)
* [Prompt Types](#prompt-types) - The base `Prompt` class used by other prompts
* [Custom prompts](#%E2%9D%AF-custom-prompts) - Enquirer 2.0 introduced the concept of prompt "types", with the goal of making custom prompts easier than ever to create and use.
### Prompt
The base `Prompt` class is used to create all other prompts.
```js
const { Prompt } = require('enquirer');
class MyCustomPrompt extends Prompt {}
```
See the documentation for [creating custom prompts](#-custom-prompts) to learn more about how this works.
#### Prompt Options
Each prompt takes an options object (aka "question" object), that implements the following interface:
```js
{
// required
type: string | function,
name: string | function,
message: string | function | async function,
// optional
skip: boolean | function | async function,
initial: string | function | async function,
format: function | async function,
result: function | async function,
validate: function | async function,
}
```
Each property of the options object is described below:
| **Property** | **Required?** | **Type** | **Description** |
| ------------ | ------------- | ------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `type` | yes | `string\|function` | Enquirer uses this value to determine the type of prompt to run, but it's optional when prompts are run directly. |
| `name` | yes | `string\|function` | Used as the key for the answer on the returned values (answers) object. |
| `message` | yes | `string\|function` | The message to display when the prompt is rendered in the terminal. |
| `skip` | no | `boolean\|function` | If `true` it will not ask that prompt. |
| `initial` | no | `string\|function` | The default value to return if the user does not supply a value. |
| `format` | no | `function` | Function to format user input in the terminal. |
| `result` | no | `function` | Function to format the final submitted value before it's returned. |
| `validate` | no | `function` | Function to validate the submitted value before it's returned. This function may return a boolean or a string. If a string is returned it will be used as the validation error message. |
**Example usage**
```js
const { prompt } = require('enquirer');
const question = {
type: 'input',
name: 'username',
message: 'What is your username?'
};
prompt(question)
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
<br>
### Built-in prompts
* [AutoComplete Prompt](#autocomplete-prompt)
* [BasicAuth Prompt](#basicauth-prompt)
* [Confirm Prompt](#confirm-prompt)
* [Form Prompt](#form-prompt)
* [Input Prompt](#input-prompt)
* [Invisible Prompt](#invisible-prompt)
* [List Prompt](#list-prompt)
* [MultiSelect Prompt](#multiselect-prompt)
* [Numeral Prompt](#numeral-prompt)
* [Password Prompt](#password-prompt)
* [Quiz Prompt](#quiz-prompt)
* [Survey Prompt](#survey-prompt)
* [Scale Prompt](#scale-prompt)
* [Select Prompt](#select-prompt)
* [Sort Prompt](#sort-prompt)
* [Snippet Prompt](#snippet-prompt)
* [Toggle Prompt](#toggle-prompt)
### AutoComplete Prompt
Prompt that auto-completes as the user types, and returns the selected value as a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/autocomplete-prompt.gif" alt="Enquirer AutoComplete Prompt" width="750">
</p>
**Example Usage**
```js
const { AutoComplete } = require('enquirer');
const prompt = new AutoComplete({
name: 'flavor',
message: 'Pick your favorite flavor',
limit: 10,
initial: 2,
choices: [
'Almond',
'Apple',
'Banana',
'Blackberry',
'Blueberry',
'Cherry',
'Chocolate',
'Cinnamon',
'Coconut',
'Cranberry',
'Grape',
'Nougat',
'Orange',
'Pear',
'Pineapple',
'Raspberry',
'Strawberry',
'Vanilla',
'Watermelon',
'Wintergreen'
]
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**AutoComplete Options**
| Option | Type | Default | Description |
| ----------- | ---------- | ------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------ |
| `highlight` | `function` | `dim` version of primary style | The color to use when "highlighting" characters in the list that match user input. |
| `multiple` | `boolean` | `false` | Allow multiple choices to be selected. |
| `suggest` | `function` | Greedy match, returns true if choice message contains input string. | Function that filters choices. Takes user input and a choices array, and returns a list of matching choices. |
| `initial` | `number` | 0 | Preselected item in the list of choices. |
| `footer` | `function` | None | Function that displays [footer text](https://github.com/enquirer/enquirer/blob/6c2819518a1e2ed284242a99a685655fbaabfa28/examples/autocomplete/option-footer.js#L10) |
**Related prompts**
* [Select](#select-prompt)
* [MultiSelect](#multiselect-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### BasicAuth Prompt
Prompt that asks for username and password to authenticate the user. The default implementation of `authenticate` function in `BasicAuth` prompt is to compare the username and password with the values supplied while running the prompt. The implementer is expected to override the `authenticate` function with a custom logic such as making an API request to a server to authenticate the username and password entered and expect a token back.
<p align="center">
<img src="https://user-images.githubusercontent.com/13731210/61570485-7ffd9c00-aaaa-11e9-857a-d47dc7008284.gif" alt="Enquirer BasicAuth Prompt" width="750">
</p>
**Example Usage**
```js
const { BasicAuth } = require('enquirer');
const prompt = new BasicAuth({
name: 'password',
message: 'Please enter your password',
username: 'rajat-sr',
password: '123',
showPassword: true
});
prompt
.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Confirm Prompt
Prompt that returns `true` or `false`.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/confirm-prompt.gif" alt="Enquirer Confirm Prompt" width="750">
</p>
**Example Usage**
```js
const { Confirm } = require('enquirer');
const prompt = new Confirm({
name: 'question',
message: 'Want to answer?'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Numeral](#numeral-prompt)
* [Password](#password-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Form Prompt
Prompt that allows the user to enter and submit multiple values on a single terminal screen.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/form-prompt.gif" alt="Enquirer Form Prompt" width="750">
</p>
**Example Usage**
```js
const { Form } = require('enquirer');
const prompt = new Form({
name: 'user',
message: 'Please provide the following information:',
choices: [
{ name: 'firstname', message: 'First Name', initial: 'Jon' },
{ name: 'lastname', message: 'Last Name', initial: 'Schlinkert' },
{ name: 'username', message: 'GitHub username', initial: 'jonschlinkert' }
]
});
prompt.run()
.then(value => console.log('Answer:', value))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Input Prompt
Prompt that takes user input and returns a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/input-prompt.gif" alt="Enquirer Input Prompt" width="750">
</p>
**Example Usage**
```js
const { Input } = require('enquirer');
const prompt = new Input({
message: 'What is your username?',
initial: 'jonschlinkert'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.log);
```
You can use [data-store](https://github.com/jonschlinkert/data-store) to store [input history](https://github.com/enquirer/enquirer/blob/master/examples/input/option-history.js) that the user can cycle through (see [source](https://github.com/enquirer/enquirer/blob/8407dc3579123df5e6e20215078e33bb605b0c37/lib/prompts/input.js)).
**Related prompts**
* [Confirm](#confirm-prompt)
* [Numeral](#numeral-prompt)
* [Password](#password-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Invisible Prompt
Prompt that takes user input, hides it from the terminal, and returns a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/invisible-prompt.gif" alt="Enquirer Invisible Prompt" width="750">
</p>
**Example Usage**
```js
const { Invisible } = require('enquirer');
const prompt = new Invisible({
name: 'secret',
message: 'What is your secret?'
});
prompt.run()
.then(answer => console.log('Answer:', { secret: answer }))
.catch(console.error);
```
**Related prompts**
* [Password](#password-prompt)
* [Input](#input-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### List Prompt
Prompt that returns a list of values, created by splitting the user input. The default split character is `,` with optional trailing whitespace.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/list-prompt.gif" alt="Enquirer List Prompt" width="750">
</p>
**Example Usage**
```js
const { List } = require('enquirer');
const prompt = new List({
name: 'keywords',
message: 'Type comma-separated keywords'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Sort](#sort-prompt)
* [Select](#select-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### MultiSelect Prompt
Prompt that allows the user to select multiple items from a list of options.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/multiselect-prompt.gif" alt="Enquirer MultiSelect Prompt" width="750">
</p>
**Example Usage**
```js
const { MultiSelect } = require('enquirer');
const prompt = new MultiSelect({
name: 'value',
message: 'Pick your favorite colors',
limit: 7,
choices: [
{ name: 'aqua', value: '#00ffff' },
{ name: 'black', value: '#000000' },
{ name: 'blue', value: '#0000ff' },
{ name: 'fuchsia', value: '#ff00ff' },
{ name: 'gray', value: '#808080' },
{ name: 'green', value: '#008000' },
{ name: 'lime', value: '#00ff00' },
{ name: 'maroon', value: '#800000' },
{ name: 'navy', value: '#000080' },
{ name: 'olive', value: '#808000' },
{ name: 'purple', value: '#800080' },
{ name: 'red', value: '#ff0000' },
{ name: 'silver', value: '#c0c0c0' },
{ name: 'teal', value: '#008080' },
{ name: 'white', value: '#ffffff' },
{ name: 'yellow', value: '#ffff00' }
]
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
// Answer: ['aqua', 'blue', 'fuchsia']
```
**Example key-value pairs**
Optionally, pass a `result` function and use the `.map` method to return an object of key-value pairs of the selected names and values: [example](./examples/multiselect/option-result.js)
```js
const { MultiSelect } = require('enquirer');
const prompt = new MultiSelect({
name: 'value',
message: 'Pick your favorite colors',
limit: 7,
choices: [
{ name: 'aqua', value: '#00ffff' },
{ name: 'black', value: '#000000' },
{ name: 'blue', value: '#0000ff' },
{ name: 'fuchsia', value: '#ff00ff' },
{ name: 'gray', value: '#808080' },
{ name: 'green', value: '#008000' },
{ name: 'lime', value: '#00ff00' },
{ name: 'maroon', value: '#800000' },
{ name: 'navy', value: '#000080' },
{ name: 'olive', value: '#808000' },
{ name: 'purple', value: '#800080' },
{ name: 'red', value: '#ff0000' },
{ name: 'silver', value: '#c0c0c0' },
{ name: 'teal', value: '#008080' },
{ name: 'white', value: '#ffffff' },
{ name: 'yellow', value: '#ffff00' }
],
result(names) {
return this.map(names);
}
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
// Answer: { aqua: '#00ffff', blue: '#0000ff', fuchsia: '#ff00ff' }
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Numeral Prompt
Prompt that takes a number as input.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/numeral-prompt.gif" alt="Enquirer Numeral Prompt" width="750">
</p>
**Example Usage**
```js
const { NumberPrompt } = require('enquirer');
const prompt = new NumberPrompt({
name: 'number',
message: 'Please enter a number'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Confirm](#confirm-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Password Prompt
Prompt that takes user input and masks it in the terminal. Also see the [invisible prompt](#invisible-prompt)
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/password-prompt.gif" alt="Enquirer Password Prompt" width="750">
</p>
**Example Usage**
```js
const { Password } = require('enquirer');
const prompt = new Password({
name: 'password',
message: 'What is your password?'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Invisible](#invisible-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Quiz Prompt
Prompt that allows the user to play multiple-choice quiz questions.
<p align="center">
<img src="https://user-images.githubusercontent.com/13731210/61567561-891d4780-aa6f-11e9-9b09-3d504abd24ed.gif" alt="Enquirer Quiz Prompt" width="750">
</p>
**Example Usage**
```js
const { Quiz } = require('enquirer');
const prompt = new Quiz({
name: 'countries',
message: 'How many countries are there in the world?',
choices: ['165', '175', '185', '195', '205'],
correctChoice: 3
});
prompt
.run()
.then(answer => {
if (answer.correct) {
console.log('Correct!');
} else {
console.log(`Wrong! Correct answer is ${answer.correctAnswer}`);
}
})
.catch(console.error);
```
**Quiz Options**
| Option | Type | Required | Description |
| ----------- | ---------- | ---------- | ------------------------------------------------------------------------------------------------------------ |
| `choices` | `array` | Yes | The list of possible answers to the quiz question. |
| `correctChoice`| `number` | Yes | Index of the correct choice from the `choices` array. |
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Survey Prompt
Prompt that allows the user to provide feedback for a list of questions.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/survey-prompt.gif" alt="Enquirer Survey Prompt" width="750">
</p>
**Example Usage**
```js
const { Survey } = require('enquirer');
const prompt = new Survey({
name: 'experience',
message: 'Please rate your experience',
scale: [
{ name: '1', message: 'Strongly Disagree' },
{ name: '2', message: 'Disagree' },
{ name: '3', message: 'Neutral' },
{ name: '4', message: 'Agree' },
{ name: '5', message: 'Strongly Agree' }
],
margin: [0, 0, 2, 1],
choices: [
{
name: 'interface',
message: 'The website has a friendly interface.'
},
{
name: 'navigation',
message: 'The website is easy to navigate.'
},
{
name: 'images',
message: 'The website usually has good images.'
},
{
name: 'upload',
message: 'The website makes it easy to upload images.'
},
{
name: 'colors',
message: 'The website has a pleasing color palette.'
}
]
});
prompt.run()
.then(value => console.log('ANSWERS:', value))
.catch(console.error);
```
**Related prompts**
* [Scale](#scale-prompt)
* [Snippet](#snippet-prompt)
* [Select](#select-prompt)
***
### Scale Prompt
A more compact version of the [Survey prompt](#survey-prompt), the Scale prompt allows the user to quickly provide feedback using a [Likert Scale](https://en.wikipedia.org/wiki/Likert_scale).
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/scale-prompt.gif" alt="Enquirer Scale Prompt" width="750">
</p>
**Example Usage**
```js
const { Scale } = require('enquirer');
const prompt = new Scale({
name: 'experience',
message: 'Please rate your experience',
scale: [
{ name: '1', message: 'Strongly Disagree' },
{ name: '2', message: 'Disagree' },
{ name: '3', message: 'Neutral' },
{ name: '4', message: 'Agree' },
{ name: '5', message: 'Strongly Agree' }
],
margin: [0, 0, 2, 1],
choices: [
{
name: 'interface',
message: 'The website has a friendly interface.',
initial: 2
},
{
name: 'navigation',
message: 'The website is easy to navigate.',
initial: 2
},
{
name: 'images',
message: 'The website usually has good images.',
initial: 2
},
{
name: 'upload',
message: 'The website makes it easy to upload images.',
initial: 2
},
{
name: 'colors',
message: 'The website has a pleasing color palette.',
initial: 2
}
]
});
prompt.run()
.then(value => console.log('ANSWERS:', value))
.catch(console.error);
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Select Prompt
Prompt that allows the user to select from a list of options.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/select-prompt.gif" alt="Enquirer Select Prompt" width="750">
</p>
**Example Usage**
```js
const { Select } = require('enquirer');
const prompt = new Select({
name: 'color',
message: 'Pick a flavor',
choices: ['apple', 'grape', 'watermelon', 'cherry', 'orange']
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [MultiSelect](#multiselect-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Sort Prompt
Prompt that allows the user to sort items in a list.
**Example**
In this [example](https://github.com/enquirer/enquirer/raw/master/examples/sort/prompt.js), custom styling is applied to the returned values to make it easier to see what's happening.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/sort-prompt.gif" alt="Enquirer Sort Prompt" width="750">
</p>
**Example Usage**
```js
const colors = require('ansi-colors');
const { Sort } = require('enquirer');
const prompt = new Sort({
name: 'colors',
message: 'Sort the colors in order of preference',
hint: 'Top is best, bottom is worst',
numbered: true,
choices: ['red', 'white', 'green', 'cyan', 'yellow'].map(n => ({
name: n,
message: colors[n](n)
}))
});
prompt.run()
.then(function(answer = []) {
console.log(answer);
console.log('Your preferred order of colors is:');
console.log(answer.map(key => colors[key](key)).join('\n'));
})
.catch(console.error);
```
**Related prompts**
* [List](#list-prompt)
* [Select](#select-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Snippet Prompt
Prompt that allows the user to replace placeholders in a snippet of code or text.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/snippet-prompt.gif" alt="Prompts" width="750">
</p>
**Example Usage**
```js
const semver = require('semver');
const { Snippet } = require('enquirer');
const prompt = new Snippet({
name: 'username',
message: 'Fill out the fields in package.json',
required: true,
fields: [
{
name: 'author_name',
message: 'Author Name'
},
{
name: 'version',
validate(value, state, item, index) {
if (item && item.name === 'version' && !semver.valid(value)) {
return prompt.styles.danger('version should be a valid semver value');
}
return true;
}
}
],
template: `{
"name": "\${name}",
"description": "\${description}",
"version": "\${version}",
"homepage": "https://github.com/\${username}/\${name}",
"author": "\${author_name} (https://github.com/\${username})",
"repository": "\${username}/\${name}",
"license": "\${license:ISC}"
}
`
});
prompt.run()
.then(answer => console.log('Answer:', answer.result))
.catch(console.error);
```
**Related prompts**
* [Survey](#survey-prompt)
* [AutoComplete](#autocomplete-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Toggle Prompt
Prompt that allows the user to toggle between two values then returns `true` or `false`.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/toggle-prompt.gif" alt="Enquirer Toggle Prompt" width="750">
</p>
**Example Usage**
```js
const { Toggle } = require('enquirer');
const prompt = new Toggle({
message: 'Want to answer?',
enabled: 'Yep',
disabled: 'Nope'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Confirm](#confirm-prompt)
* [Input](#input-prompt)
* [Sort](#sort-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Prompt Types
There are 5 (soon to be 6!) type classes:
* [ArrayPrompt](#arrayprompt)
- [Options](#options)
- [Properties](#properties)
- [Methods](#methods)
- [Choices](#choices)
- [Defining choices](#defining-choices)
- [Choice properties](#choice-properties)
- [Related prompts](#related-prompts)
* [AuthPrompt](#authprompt)
* [BooleanPrompt](#booleanprompt)
* DatePrompt (Coming Soon!)
* [NumberPrompt](#numberprompt)
* [StringPrompt](#stringprompt)
Each type is a low-level class that may be used as a starting point for creating higher level prompts. Continue reading to learn how.
### ArrayPrompt
The `ArrayPrompt` class is used for creating prompts that display a list of choices in the terminal. For example, Enquirer uses this class as the basis for the [Select](#select) and [Survey](#survey) prompts.
#### Options
In addition to the [options](#options) available to all prompts, Array prompts also support the following options.
| **Option** | **Required?** | **Type** | **Description** |
| ----------- | ------------- | --------------- | ----------------------------------------------------------------------------------------------------------------------- |
| `autofocus` | `no` | `string\|number` | The index or name of the choice that should have focus when the prompt loads. Only one choice may have focus at a time. | |
| `stdin` | `no` | `stream` | The input stream to use for emitting keypress events. Defaults to `process.stdin`. |
| `stdout` | `no` | `stream` | The output stream to use for writing the prompt to the terminal. Defaults to `process.stdout`. |
| |
#### Properties
Array prompts have the following instance properties and getters.
| **Property name** | **Type** | **Description** |
| ----------------- | --------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `choices` | `array` | Array of choices that have been normalized from choices passed on the prompt options. |
| `cursor` | `number` | Position of the cursor relative to the _user input (string)_. |
| `enabled` | `array` | Returns an array of enabled choices. |
| `focused` | `array` | Returns the currently selected choice in the visible list of choices. This is similar to the concept of focus in HTML and CSS. Focused choices are always visible (on-screen). When a list of choices is longer than the list of visible choices, and an off-screen choice is _focused_, the list will scroll to the focused choice and re-render. |
| `focused` | Gets the currently selected choice. Equivalent to `prompt.choices[prompt.index]`. |
| `index` | `number` | Position of the pointer in the _visible list (array) of choices_. |
| `limit` | `number` | The number of choices to display on-screen. |
| `selected` | `array` | Either a list of enabled choices (when `options.multiple` is true) or the currently focused choice. |
| `visible` | `string` | |
#### Methods
| **Method** | **Description** |
| ------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `pointer()` | Returns the visual symbol to use to identify the choice that currently has focus. The `❯` symbol is often used for this. The pointer is not always visible, as with the `autocomplete` prompt. |
| `indicator()` | Returns the visual symbol that indicates whether or not a choice is checked/enabled. |
| `focus()` | Sets focus on a choice, if it can be focused. |
#### Choices
Array prompts support the `choices` option, which is the array of choices users will be able to select from when rendered in the terminal.
**Type**: `string|object`
**Example**
```js
const { prompt } = require('enquirer');
const questions = [{
type: 'select',
name: 'color',
message: 'Favorite color?',
initial: 1,
choices: [
{ name: 'red', message: 'Red', value: '#ff0000' }, //<= choice object
{ name: 'green', message: 'Green', value: '#00ff00' }, //<= choice object
{ name: 'blue', message: 'Blue', value: '#0000ff' } //<= choice object
]
}];
let answers = await prompt(questions);
console.log('Answer:', answers.color);
```
#### Defining choices
Whether defined as a string or object, choices are normalized to the following interface:
```js
{
name: string;
message: string | undefined;
value: string | undefined;
hint: string | undefined;
disabled: boolean | string | undefined;
}
```
**Example**
```js
const question = {
name: 'fruit',
message: 'Favorite fruit?',
choices: ['Apple', 'Orange', 'Raspberry']
};
```
Normalizes to the following when the prompt is run:
```js
const question = {
name: 'fruit',
message: 'Favorite fruit?',
choices: [
{ name: 'Apple', message: 'Apple', value: 'Apple' },
{ name: 'Orange', message: 'Orange', value: 'Orange' },
{ name: 'Raspberry', message: 'Raspberry', value: 'Raspberry' }
]
};
```
#### Choice properties
The following properties are supported on `choice` objects.
| **Option** | **Type** | **Description** |
| ----------- | ----------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `name` | `string` | The unique key to identify a choice |
| `message` | `string` | The message to display in the terminal. `name` is used when this is undefined. |
| `value` | `string` | Value to associate with the choice. Useful for creating key-value pairs from user choices. `name` is used when this is undefined. |
| `choices` | `array` | Array of "child" choices. |
| `hint` | `string` | Help message to display next to a choice. |
| `role` | `string` | Determines how the choice will be displayed. Currently the only role supported is `separator`. Additional roles may be added in the future (like `heading`, etc). Please create a [feature request] |
| `enabled` | `boolean` | Enabled a choice by default. This is only supported when `options.multiple` is true or on prompts that support multiple choices, like [MultiSelect](#-multiselect). |
| `disabled` | `boolean\|string` | Disable a choice so that it cannot be selected. This value may either be `true`, `false`, or a message to display. |
| `indicator` | `string\|function` | Custom indicator to render for a choice (like a check or radio button). |
#### Related prompts
* [AutoComplete](#autocomplete-prompt)
* [Form](#form-prompt)
* [MultiSelect](#multiselect-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
***
### AuthPrompt
The `AuthPrompt` is used to create prompts to log in user using any authentication method. For example, Enquirer uses this class as the basis for the [BasicAuth Prompt](#basicauth-prompt). You can also find prompt examples in `examples/auth/` folder that utilizes `AuthPrompt` to create OAuth based authentication prompt or a prompt that authenticates using time-based OTP, among others.
`AuthPrompt` has a factory function that creates an instance of `AuthPrompt` class and it expects an `authenticate` function, as an argument, which overrides the `authenticate` function of the `AuthPrompt` class.
#### Methods
| **Method** | **Description** |
| ------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `authenticate()` | Contain all the authentication logic. This function should be overridden to implement custom authentication logic. The default `authenticate` function throws an error if no other function is provided. |
#### Choices
Auth prompt supports the `choices` option, which is the similar to the choices used in [Form Prompt](#form-prompt).
**Example**
```js
const { AuthPrompt } = require('enquirer');
function authenticate(value, state) {
if (value.username === this.options.username && value.password === this.options.password) {
return true;
}
return false;
}
const CustomAuthPrompt = AuthPrompt.create(authenticate);
const prompt = new CustomAuthPrompt({
name: 'password',
message: 'Please enter your password',
username: 'rajat-sr',
password: '1234567',
choices: [
{ name: 'username', message: 'username' },
{ name: 'password', message: 'password' }
]
});
prompt
.run()
.then(answer => console.log('Authenticated?', answer))
.catch(console.error);
```
#### Related prompts
* [BasicAuth Prompt](#basicauth-prompt)
***
### BooleanPrompt
The `BooleanPrompt` class is used for creating prompts that display and return a boolean value.
```js
const { BooleanPrompt } = require('enquirer');
const prompt = new BooleanPrompt({
header: '========================',
message: 'Do you love enquirer?',
footer: '========================',
});
prompt.run()
.then(answer => console.log('Selected:', answer))
.catch(console.error);
```
**Returns**: `boolean`
***
### NumberPrompt
The `NumberPrompt` class is used for creating prompts that display and return a numerical value.
```js
const { NumberPrompt } = require('enquirer');
const prompt = new NumberPrompt({
header: '************************',
message: 'Input the Numbers:',
footer: '************************',
});
prompt.run()
.then(answer => console.log('Numbers are:', answer))
.catch(console.error);
```
**Returns**: `string|number` (number, or number formatted as a string)
***
### StringPrompt
The `StringPrompt` class is used for creating prompts that display and return a string value.
```js
const { StringPrompt } = require('enquirer');
const prompt = new StringPrompt({
header: '************************',
message: 'Input the String:',
footer: '************************'
});
prompt.run()
.then(answer => console.log('String is:', answer))
.catch(console.error);
```
**Returns**: `string`
<br>
## ❯ Custom prompts
With Enquirer 2.0, custom prompts are easier than ever to create and use.
**How do I create a custom prompt?**
Custom prompts are created by extending either:
* Enquirer's `Prompt` class
* one of the built-in [prompts](#-prompts), or
* low-level [types](#-types).
<!-- Example: HaiKarate Custom Prompt -->
```js
const { Prompt } = require('enquirer');
class HaiKarate extends Prompt {
constructor(options = {}) {
super(options);
this.value = options.initial || 0;
this.cursorHide();
}
up() {
this.value++;
this.render();
}
down() {
this.value--;
this.render();
}
render() {
this.clear(); // clear previously rendered prompt from the terminal
this.write(`${this.state.message}: ${this.value}`);
}
}
// Use the prompt by creating an instance of your custom prompt class.
const prompt = new HaiKarate({
message: 'How many sprays do you want?',
initial: 10
});
prompt.run()
.then(answer => console.log('Sprays:', answer))
.catch(console.error);
```
If you want to be able to specify your prompt by `type` so that it may be used alongside other prompts, you will need to first create an instance of `Enquirer`.
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
```
Then use the `.register()` method to add your custom prompt.
```js
enquirer.register('haikarate', HaiKarate);
```
Now you can do the following when defining "questions".
```js
let spritzer = require('cologne-drone');
let answers = await enquirer.prompt([
{
type: 'haikarate',
name: 'cologne',
message: 'How many sprays do you need?',
initial: 10,
async onSubmit(name, value) {
await spritzer.activate(value); //<= activate drone
return value;
}
}
]);
```
<br>
## ❯ Key Bindings
### All prompts
These key combinations may be used with all prompts.
| **command** | **description** |
| -------------------------------- | -------------------------------------- |
| <kbd>ctrl</kbd> + <kbd>c</kbd> | Cancel the prompt. |
| <kbd>ctrl</kbd> + <kbd>g</kbd> | Reset the prompt to its initial state. |
<br>
### Move cursor
These combinations may be used on prompts that support user input (eg. [input prompt](#input-prompt), [password prompt](#password-prompt), and [invisible prompt](#invisible-prompt)).
| **command** | **description** |
| ------------------------------ | ---------------------------------------- |
| <kbd>left</kbd> | Move the cursor back one character. |
| <kbd>right</kbd> | Move the cursor forward one character. |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move cursor to the start of the line |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move cursor to the end of the line |
| <kbd>ctrl</kbd> + <kbd>b</kbd> | Move cursor back one character |
| <kbd>ctrl</kbd> + <kbd>f</kbd> | Move cursor forward one character |
| <kbd>ctrl</kbd> + <kbd>x</kbd> | Toggle between first and cursor position |
<br>
### Edit Input
These key combinations may be used on prompts that support user input (eg. [input prompt](#input-prompt), [password prompt](#password-prompt), and [invisible prompt](#invisible-prompt)).
| **command** | **description** |
| ------------------------------ | ---------------------------------------- |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move cursor to the start of the line |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move cursor to the end of the line |
| <kbd>ctrl</kbd> + <kbd>b</kbd> | Move cursor back one character |
| <kbd>ctrl</kbd> + <kbd>f</kbd> | Move cursor forward one character |
| <kbd>ctrl</kbd> + <kbd>x</kbd> | Toggle between first and cursor position |
<br>
| **command (Mac)** | **command (Windows)** | **description** |
| ----------------------------------- | -------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------- |
| <kbd>delete</kbd> | <kbd>backspace</kbd> | Delete one character to the left. |
| <kbd>fn</kbd> + <kbd>delete</kbd> | <kbd>delete</kbd> | Delete one character to the right. |
| <kbd>option</kbd> + <kbd>up</kbd> | <kbd>alt</kbd> + <kbd>up</kbd> | Scroll to the previous item in history ([Input prompt](#input-prompt) only, when [history is enabled](examples/input/option-history.js)). |
| <kbd>option</kbd> + <kbd>down</kbd> | <kbd>alt</kbd> + <kbd>down</kbd> | Scroll to the next item in history ([Input prompt](#input-prompt) only, when [history is enabled](examples/input/option-history.js)). |
### Select choices
These key combinations may be used on prompts that support _multiple_ choices, such as the [multiselect prompt](#multiselect-prompt), or the [select prompt](#select-prompt) when the `multiple` options is true.
| **command** | **description** |
| ----------------- | -------------------------------------------------------------------------------------------------------------------- |
| <kbd>space</kbd> | Toggle the currently selected choice when `options.multiple` is true. |
| <kbd>number</kbd> | Move the pointer to the choice at the given index. Also toggles the selected choice when `options.multiple` is true. |
| <kbd>a</kbd> | Toggle all choices to be enabled or disabled. |
| <kbd>i</kbd> | Invert the current selection of choices. |
| <kbd>g</kbd> | Toggle the current choice group. |
<br>
### Hide/show choices
| **command** | **description** |
| ------------------------------- | ---------------------------------------------- |
| <kbd>fn</kbd> + <kbd>up</kbd> | Decrease the number of visible choices by one. |
| <kbd>fn</kbd> + <kbd>down</kbd> | Increase the number of visible choices by one. |
<br>
### Move/lock Pointer
| **command** | **description** |
| ---------------------------------- | -------------------------------------------------------------------------------------------------------------------- |
| <kbd>number</kbd> | Move the pointer to the choice at the given index. Also toggles the selected choice when `options.multiple` is true. |
| <kbd>up</kbd> | Move the pointer up. |
| <kbd>down</kbd> | Move the pointer down. |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move the pointer to the first _visible_ choice. |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move the pointer to the last _visible_ choice. |
| <kbd>shift</kbd> + <kbd>up</kbd> | Scroll up one choice without changing pointer position (locks the pointer while scrolling). |
| <kbd>shift</kbd> + <kbd>down</kbd> | Scroll down one choice without changing pointer position (locks the pointer while scrolling). |
<br>
| **command (Mac)** | **command (Windows)** | **description** |
| -------------------------------- | --------------------- | ---------------------------------------------------------- |
| <kbd>fn</kbd> + <kbd>left</kbd> | <kbd>home</kbd> | Move the pointer to the first choice in the choices array. |
| <kbd>fn</kbd> + <kbd>right</kbd> | <kbd>end</kbd> | Move the pointer to the last choice in the choices array. |
<br>
## ❯ Release History
Please see [CHANGELOG.md](CHANGELOG.md).
## ❯ Performance
### System specs
MacBook Pro, Intel Core i7, 2.5 GHz, 16 GB.
### Load time
Time it takes for the module to load the first time (average of 3 runs):
```
enquirer: 4.013ms
inquirer: 286.717ms
```
<br>
## ❯ About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Todo
We're currently working on documentation for the following items. Please star and watch the repository for updates!
* [ ] Customizing symbols
* [ ] Customizing styles (palette)
* [ ] Customizing rendered input
* [ ] Customizing returned values
* [ ] Customizing key bindings
* [ ] Question validation
* [ ] Choice validation
* [ ] Skipping questions
* [ ] Async choices
* [ ] Async timers: loaders, spinners and other animations
* [ ] Links to examples
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
```sh
$ yarn && yarn test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
#### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 283 | [jonschlinkert](https://github.com/jonschlinkert) |
| 82 | [doowb](https://github.com/doowb) |
| 32 | [rajat-sr](https://github.com/rajat-sr) |
| 20 | [318097](https://github.com/318097) |
| 15 | [g-plane](https://github.com/g-plane) |
| 12 | [pixelass](https://github.com/pixelass) |
| 5 | [adityavyas611](https://github.com/adityavyas611) |
| 5 | [satotake](https://github.com/satotake) |
| 3 | [tunnckoCore](https://github.com/tunnckoCore) |
| 3 | [Ovyerus](https://github.com/Ovyerus) |
| 3 | [sw-yx](https://github.com/sw-yx) |
| 2 | [DanielRuf](https://github.com/DanielRuf) |
| 2 | [GabeL7r](https://github.com/GabeL7r) |
| 1 | [AlCalzone](https://github.com/AlCalzone) |
| 1 | [hipstersmoothie](https://github.com/hipstersmoothie) |
| 1 | [danieldelcore](https://github.com/danieldelcore) |
| 1 | [ImgBotApp](https://github.com/ImgBotApp) |
| 1 | [jsonkao](https://github.com/jsonkao) |
| 1 | [knpwrs](https://github.com/knpwrs) |
| 1 | [yeskunall](https://github.com/yeskunall) |
| 1 | [mischah](https://github.com/mischah) |
| 1 | [renarsvilnis](https://github.com/renarsvilnis) |
| 1 | [sbugert](https://github.com/sbugert) |
| 1 | [stephencweiss](https://github.com/stephencweiss) |
| 1 | [skellock](https://github.com/skellock) |
| 1 | [whxaxes](https://github.com/whxaxes) |
#### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
#### Credit
Thanks to [derhuerst](https://github.com/derhuerst), creator of prompt libraries such as [prompt-skeleton](https://github.com/derhuerst/prompt-skeleton), which influenced some of the concepts we used in our prompts.
#### License
Copyright © 2018-present, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
# minizlib
A fast zlib stream built on [minipass](http://npm.im/minipass) and
Node.js's zlib binding.
This module was created to serve the needs of
[node-tar](http://npm.im/tar) and
[minipass-fetch](http://npm.im/minipass-fetch).
Brotli is supported in versions of node with a Brotli binding.
## How does this differ from the streams in `require('zlib')`?
First, there are no convenience methods to compress or decompress a
buffer. If you want those, use the built-in `zlib` module. This is
only streams. That being said, Minipass streams to make it fairly easy to
use as one-liners: `new zlib.Deflate().end(data).read()` will return the
deflate compressed result.
This module compresses and decompresses the data as fast as you feed
it in. It is synchronous, and runs on the main process thread. Zlib
and Brotli operations can be high CPU, but they're very fast, and doing it
this way means much less bookkeeping and artificial deferral.
Node's built in zlib streams are built on top of `stream.Transform`.
They do the maximally safe thing with respect to consistent
asynchrony, buffering, and backpressure.
See [Minipass](http://npm.im/minipass) for more on the differences between
Node.js core streams and Minipass streams, and the convenience methods
provided by that class.
## Classes
- Deflate
- Inflate
- Gzip
- Gunzip
- DeflateRaw
- InflateRaw
- Unzip
- BrotliCompress (Node v10 and higher)
- BrotliDecompress (Node v10 and higher)
## USAGE
```js
const zlib = require('minizlib')
const input = sourceOfCompressedData()
const decode = new zlib.BrotliDecompress()
const output = whereToWriteTheDecodedData()
input.pipe(decode).pipe(output)
```
js-multibase
============
[](https://protocol.ai)
[](https://github.com/multiformats/multiformats)
[](https://webchat.freenode.net/?channels=%23ipfs)
[](https://david-dm.org/multiformats/js-multibase)
[](https://codecov.io/gh/multiformats/js-multibase)
[](https://travis-ci.com/multiformats/js-multibase)
> JavaScript implementation of the [multibase](https://github.com/multiformats/multibase) specification
## Lead Maintainer
[Oli Evans](https://github.com/olizilla)
## Table of Contents
- [Install](#install)
- [In Node.js through npm](#in-nodejs-through-npm)
- [Browser: Browserify, Webpack, other bundlers](#browser-browserify-webpack-other-bundlers)
- [In the Browser through `<script>` tag](#in-the-browser-through-script-tag)
- [Gotchas](#gotchas)
- [Usage](#usage)
- [Example](#example)
- [API](#api)
- [`multibase` - Prefixes an encoded buffer with its multibase code](#multibase---prefixes-an-encoded-buffer-with-its-multibase-code)
- [`multibase.encode` - Encodes a buffer into one of the supported encodings, prefixing it with the multibase code](#multibaseencode---encodes-a-buffer-into-one-of-the-supported-encodings-prefixing-it-with-the-multibase-code)
- [`multibase.decode` - Decodes a buffer or string](#multibasedecode---decodes-a-buffer-or-string)
- [`multibase.isEncoded` - Checks if buffer or string is encoded](#multibaseisencoded---checks-if-buffer-or-string-is-encoded)
- [`multibase.names` - Supported base encoding names](#multibasenames)
- [`multibase.codes` - Supported base encoding codes](#multibasecodes)
- [Supported Encodings, see `src/constants.js`](#supported-encodings-see-srcconstantsjs)
- [Architecture and Encoding/Decoding](#architecture-and-encodingdecoding)
- [Adding additional bases](#adding-additional-bases)
- [License](#license)
## Install
### In Node.js through npm
```bash
> npm install --save multibase
```
### Browser: Browserify, Webpack, other bundlers
The code published to npm that gets loaded on require is in fact an ES5 transpiled version with the right shims added. This means that you can require it and use with your favourite bundler without having to adjust asset management process.
```js
const multibase = require('multibase')
```
### In the Browser through `<script>` tag
Loading this module through a script tag will make the ```Multibase``` obj available in the global namespace.
```html
<script src="https://unpkg.com/multibase/dist/index.min.js"></script>
<!-- OR -->
<script src="https://unpkg.com/multibase/dist/index.js"></script>
```
#### Gotchas
You will need to use Node.js `Buffer` API compatible, if you are running inside the browser, you can access it by `multibase.Buffer` or you can load Feross's [Buffer](https://github.com/feross/buffer) module.
## Usage
### Example
```JavaScript
const multibase = require('multibase')
const encodedBuf = multibase.encode('base58btc', new Buffer('hey, how is it going'))
const decodedBuf = multibase.decode(encodedBuf)
console.log(decodedBuf.toString())
// hey, how is it going
```
## API
https://multiformats.github.io/js-multibase/
### `multibase` - Prefixes an encoded buffer with its multibase code
```
const multibased = multibase(<nameOrCode>, encodedBuf)
```
### `multibase.encode` - Encodes a buffer into one of the supported encodings, prefixing it with the multibase code
```JavaScript
const encodedBuf = multibase.encode(<nameOrCode>, <buf>)
```
### `multibase.decode` - Decodes a buffer or string
```JavaScript
const decodedBuf = multibase.decode(bufOrString)
```
### `multibase.isEncoded` - Checks if buffer or string is encoded
```JavaScript
const value = multibase.isEncoded(bufOrString)
// value is the name of the encoding if it is encoded, false otherwise
```
### `multibase.names`
A frozen `Array` of supported base encoding names.
### `multibase.codes`
A frozen `Array` of supported base encoding codes.
### Supported Encodings, see [`src/constants.js`](/src/constants.js)
## Architecture and Encoding/Decoding
Multibase package defines all the supported bases and the location of their implementation in the constants.js file. A base is a class with a name, a code, an implementation and an alphabet.
```js
class Base {
constructor (name, code, implementation, alphabet) {
//...
}
// ...
}
```
The ```implementation``` is an object where the encoding/decoding functions are implemented. It must take one argument, (the alphabet) following the [base-x module](https://github.com/cryptocoinjs/base-x) architecture.
The ```alphabet``` is the **ordered** set of defined symbols for a given base.
The idea behind this is that several bases may have implementations from different locations/modules so it's useful to have an object (and a summary) of all of them in one location (hence the constants.js).
All the supported bases are currently using the npm [base-x](https://github.com/cryptocoinjs/base-x) module as their implementation. It is using bitwise maipulation to go from one base to another, so this module does not support padding at the moment.
## Adding additional bases
If the base you are looking for is not supported yet in js-multibase and you know a good encoding/decoding algorithm, you can add support for this base easily by editing the constants.js file
(**you'll need to create an issue about that beforehand since a code and a canonical name have to be defined**):
```js
const baseX = require('base-x')
//const newPackage = require('your-package-name')
const constants = [
['base1', '1', '', '1'],
['base2', '0', baseX, '01'],
['base8', '7', baseX, '01234567'],
// ... [ 'your-base-name', 'code-to-be-defined', newPackage, 'alphabet']
]
```
The required package defines the implementation of the encoding/decoding process. **It must comply by these rules** :
- `encode` and `decode` functions with to-be-encoded buffer as the only expected argument
- the require call use the `alphabet` given as an argument for the encoding/decoding process
*If no package is specified (such as for base1 in the above example, it means the base is not implemented yet)*
Adding a new base requires the tests to be updated. Test files to be updated are :
- constants.spec.js
```js
describe('constants', () => {
it('constants indexed by name', () => {
const names = constants.names
expect(Object.keys(names).length).to.equal(constants-count) // currently 12
})
it('constants indexed by code', () => {
const codes = constants.codes
expect(Object.keys(codes).length).to.equal(constants-count)
})
})
```
- multibase.spec.js
- if the base is implemented
```js
const supportedBases = [
['base2', 'yes mani !', '01111001011001010111001100100000011011010110000101101110011010010010000000100001'],
['base8', 'yes mani !', '7171312714403326055632220041'],
['base10', 'yes mani !', '9573277761329450583662625'],
// ... ['your-base-name', 'what you want', 'expected output']
```
- if the base is not implemented yet
```js
const supportedBases = [
// ... ['your-base-name']
```
## Contribute
Contributions welcome. Please check out [the issues](https://github.com/multiformats/js-multibase/issues).
Check out our [contributing document](https://github.com/multiformats/multiformats/blob/master/contributing.md) for more information on how we work, and about contributing in general. Please be aware that all interactions related to multiformats are subject to the IPFS [Code of Conduct](https://github.com/ipfs/community/blob/master/code-of-conduct.md).
Small note: If editing the README, please conform to the [standard-readme](https://github.com/RichardLitt/standard-readme) specification.
## License
[MIT](LICENSE) © 2016 Protocol Labs Inc.
# D
## Property descriptor factory
_Originally derived from [es5-ext](https://github.com/medikoo/es5-ext) package._
Defining properties with descriptors is very verbose:
```javascript
var Account = function () {};
Object.defineProperties(Account.prototype, {
deposit: {
value: function () {
/* ... */
},
configurable: true,
enumerable: false,
writable: true
},
withdraw: {
value: function () {
/* ... */
},
configurable: true,
enumerable: false,
writable: true
},
balance: {
get: function () {
/* ... */
},
configurable: true,
enumerable: false
}
});
```
D cuts that to:
```javascript
var d = require("d");
var Account = function () {};
Object.defineProperties(Account.prototype, {
deposit: d(function () {
/* ... */
}),
withdraw: d(function () {
/* ... */
}),
balance: d.gs(function () {
/* ... */
})
});
```
By default, created descriptor follow characteristics of native ES5 properties, and defines values as:
```javascript
{ configurable: true, enumerable: false, writable: true }
```
You can overwrite it by preceding _value_ argument with instruction:
```javascript
d("c", value); // { configurable: true, enumerable: false, writable: false }
d("ce", value); // { configurable: true, enumerable: true, writable: false }
d("e", value); // { configurable: false, enumerable: true, writable: false }
// Same way for get/set:
d.gs("e", value); // { configurable: false, enumerable: true }
```
### Installation
$ npm install d
To port it to Browser or any other (non CJS) environment, use your favorite CJS bundler. No favorite yet? Try: [Browserify](http://browserify.org/), [Webmake](https://github.com/medikoo/modules-webmake) or [Webpack](http://webpack.github.io/)
### Other utilities
#### autoBind(obj, props) _(d/auto-bind)_
Define methods which will be automatically bound to its instances
```javascript
var d = require('d');
var autoBind = require('d/auto-bind');
var Foo = function () { this._count = 0; };
Object.defineProperties(Foo.prototype, autoBind({
increment: d(function () { ++this._count; });
}));
var foo = new Foo();
// Increment foo counter on each domEl click
domEl.addEventListener('click', foo.increment, false);
```
#### lazy(obj, props) _(d/lazy)_
Define lazy properties, which will be resolved on first access
```javascript
var d = require("d");
var lazy = require("d/lazy");
var Foo = function () {};
Object.defineProperties(Foo.prototype, lazy({ items: d(function () { return []; }) }));
var foo = new Foo();
foo.items.push(1, 2); // foo.items array created and defined directly on foo
```
## Tests [](https://travis-ci.org/medikoo/d)
$ npm test
## Security contact information
To report a security vulnerability, please use the [Tidelift security contact](https://tidelift.com/security). Tidelift will coordinate the fix and disclosure.
---
<div align="center">
<b>
<a href="https://tidelift.com/subscription/pkg/npm-d?utm_source=npm-d&utm_medium=referral&utm_campaign=readme">Get professional support for d with a Tidelift subscription</a>
</b>
<br>
<sub>
Tidelift helps make open source sustainable for maintainers while giving companies<br>assurances about security, maintenance, and licensing for their dependencies.
</sub>
</div>
# Javascript Error Polyfill
[](https://travis-ci.org/inf3rno/error-polyfill)
Implementing the [V8 Stack Trace API](https://github.com/v8/v8/wiki/Stack-Trace-API) in non-V8 environments as much as possible
## Installation
```bash
npm install error-polyfill
```
```bash
bower install error-polyfill
```
### Environment compatibility
Tested on the following environments:
Windows 7
- **Node.js** 9.6
- **Chrome** 64.0
- **Firefox** 58.0
- **Internet Explorer** 10.0, 11.0
- **PhantomJS** 2.1
- **Opera** 51.0
Travis
- **Node.js** 8, 9
- **Chrome**
- **Firefox**
- **PhantomJS**
The polyfill might work on other environments too due to its adaptive design. I use [Karma](https://github.com/karma-runner/karma) with [Browserify](https://github.com/substack/node-browserify) to test the framework in browsers.
### Requirements
ES5 support is required, without that the lib throws an Error and stops working.
The ES5 features are tested by the [capability](https://github.com/inf3rno/capability) lib run time.
Classes are created by the [o3](https://github.com/inf3rno/o3) lib.
Utility functions are implemented in the [u3](https://github.com/inf3rno/u3) lib.
## API documentation
### Usage
In this documentation I used the framework as follows:
```js
require("error-polyfill");
// <- your code here
```
It is recommended to require the polyfill in your main script.
### Getting a past stack trace with `Error.getStackTrace`
This static method is not part of the V8 Stack Trace API, but it is recommended to **use `Error.getStackTrace(throwable)` instead of `throwable.stack`** to get the stack trace of Error instances!
Explanation:
By non-V8 environments we cannot replace the default stack generation algorithm, so we need a workaround to generate the stack when somebody tries to access it. So the original stack string will be parsed and the result will be properly formatted by accessing the stack using the `Error.getStackTrace` method.
Arguments and return values:
- The `throwable` argument should be an `Error` (descendant) instance, but it can be an `Object` instance as well.
- The return value is the generated `stack` of the `throwable` argument.
Example:
```js
try {
theNotDefinedFunction();
}
catch (error) {
console.log(Error.getStackTrace(error));
// ReferenceError: theNotDefinedFunction is not defined
// at ...
// ...
}
```
### Capturing the present stack trace with `Error.captureStackTrace`
The `Error.captureStackTrace(throwable [, terminator])` sets the present stack above the `terminator` on the `throwable`.
Arguments and return values:
- The `throwable` argument should be an instance of an `Error` descendant, but it can be an `Object` instance as well. It is recommended to use `Error` descendant instances instead of inline objects, because we can recognize them by type e.g. `error instanceof UserError`.
- The optional `terminator` argument should be a `Function`. Only the calls before this function will be reported in the stack, so without a `terminator` argument, the last call in the stack will be the call of the `Error.captureStackTrace`.
- There is no return value, the `stack` will be set on the `throwable` so you will be able to access it using `Error.getStackTrace`. The format of the stack depends on the `Error.prepareStackTrace` implementation.
Example:
```js
var UserError = function (message){
this.name = "UserError";
this.message = message;
Error.captureStackTrace(this, this.constructor);
};
UserError.prototype = Object.create(Error.prototype);
function codeSmells(){
throw new UserError("What's going on?!");
}
codeSmells();
// UserError: What's going on?!
// at codeSmells (myModule.js:23:1)
// ...
```
Limitations:
By the current implementation the `terminator` can be only the `Error.captureStackTrace` caller function. This will change soon, but in certain conditions, e.g. by using strict mode (`"use strict";`) it is not possible to access the information necessary to implement this feature. You will get an empty `frames` array and a `warning` in the `Error.prepareStackTrace` when the stack parser meets with such conditions.
### Formatting the stack trace with `Error.prepareStackTrace`
The `Error.prepareStackTrace(throwable, frames [, warnings])` formats the stack `frames` and returns the `stack` value for `Error.captureStackTrace` or `Error.getStackTrace`. The native implementation returns a stack string, but you can override that by setting a new function value.
Arguments and return values:
- The `throwable` argument is an `Error` or `Object` instance coming from the `Error.captureStackTrace` or from the creation of a new `Error` instance. Be aware that in some environments you need to throw that instance to get a parsable stack. Without that you will get only a `warning` by trying to access the stack with `Error.getStackTrace`.
- The `frames` argument is an array of `Frame` instances. Each `frame` represents a function call in the stack. You can use these frames to build a stack string. To access information about individual frames you can use the following methods.
- `frame.toString()` - Returns the string representation of the frame, e.g. `codeSmells (myModule.js:23:1)`.
- `frame.getThis()` - **Cannot be supported.** Returns the context of the call, only V8 environments support this natively.
- `frame.getTypeName()` - **Not implemented yet.** Returns the type name of the context, by the global namespace it is `Window` in Chrome.
- `frame.getFunction()` - Returns the called function or `undefined` by strict mode.
- `frame.getFunctionName()` - **Not implemented yet.** Returns the name of the called function.
- `frame.getMethodName()` - **Not implemented yet.** Returns the method name of the called function is a method of an object.
- `frame.getFileName()` - **Not implemented yet.** Returns the file name where the function was called.
- `frame.getLineNumber()` - **Not implemented yet.** Returns at which line the function was called in the file.
- `frame.getColumnNumber()` - **Not implemented yet.** Returns at which column the function was called in the file. This information is not always available.
- `frame.getEvalOrigin()` - **Not implemented yet.** Returns the original of an `eval` call.
- `frame.isTopLevel()` - **Not implemented yet.** Returns whether the function was called from the top level.
- `frame.isEval()` - **Not implemented yet.** Returns whether the called function was `eval`.
- `frame.isNative()` - **Not implemented yet.** Returns whether the called function was native.
- `frame.isConstructor()` - **Not implemented yet.** Returns whether the called function was a constructor.
- The optional `warnings` argument contains warning messages coming from the stack parser. It is not part of the V8 Stack Trace API.
- The return value will be the stack you can access with `Error.getStackTrace(throwable)`. If it is an object, it is recommended to add a `toString` method, so you will be able to read it in the console.
Example:
```js
Error.prepareStackTrace = function (throwable, frames, warnings) {
var string = "";
string += throwable.name || "Error";
string += ": " + (throwable.message || "");
if (warnings instanceof Array)
for (var warningIndex in warnings) {
var warning = warnings[warningIndex];
string += "\n # " + warning;
}
for (var frameIndex in frames) {
var frame = frames[frameIndex];
string += "\n at " + frame.toString();
}
return string;
};
```
### Stack trace size limits with `Error.stackTraceLimit`
**Not implemented yet.**
You can set size limits on the stack trace, so you won't have any problems because of too long stack traces.
Example:
```js
Error.stackTraceLimit = 10;
```
### Handling uncaught errors and rejections
**Not implemented yet.**
## Differences between environments and modes
Since there is no Stack Trace API standard, every browsers solves this problem differently. I try to document what I've found about these differences as detailed as possible, so it will be easier to follow the code.
Overriding the `error.stack` property with custom Stack instances
- by Node.js and Chrome the `Error.prepareStackTrace()` can override every `error.stack` automatically right by creation
- by Firefox, Internet Explorer and Opera you cannot automatically override every `error.stack` by native errors
- by PhantomJS you cannot override the `error.stack` property of native errors, it is not configurable
Capturing the current stack trace
- by Node.js, Chrome, Firefox and Opera the stack property is added by instantiating a native error
- by Node.js and Chrome the stack creation is lazy loaded and cached, so the `Error.prepareStackTrace()` is called only by the first access
- by Node.js and Chrome the current stack can be added to any object with `Error.captureStackTrace()`
- by Internet Explorer the stack is created by throwing a native error
- by PhantomJS the stack is created by throwing any object, but not a primitive
Accessing the stack
- by Node.js, Chrome, Firefox, Internet Explorer, Opera and PhantomJS you can use the `error.stack` property
- by old Opera you have to use the `error.stacktrace` property to get the stack
Prefixes and postfixes on the stack string
- by Node.js, Chrome, Internet Explorer and Opera you have the `error.name` and the `error.message` in a `{name}: {message}` format at the beginning of the stack string
- by Firefox and PhantomJS the stack string does not contain the `error.name` and the `error.message`
- by Firefox you have an empty line at the end of the stack string
Accessing the stack frames array
- by Node.js and Chrome you can access the frame objects directly by overriding the `Error.prepareStackTrace()`
- by Firefox, Internet Explorer, PhantomJS, and Opera you need to parse the stack string in order to get the frames
The structure of the frame string
- by Node.js and Chrome
- the frame string of calling a function from a module: `thirdFn (http://localhost/myModule.js:45:29)`
- the frame strings contain an ` at ` prefix, which is not present by the `frame.toString()` output, so it is added by the `stack.toString()`
- by Firefox
- the frame string of calling a function from a module: `thirdFn@http://localhost/myModule.js:45:29`
- by Internet Explorer
- the frame string of calling a function from a module: ` at thirdFn (http://localhost/myModule.js:45:29)`
- by PhantomJS
- the frame string of calling a function from a module: `thirdFn@http://localhost/myModule.js:45:29`
- by Opera
- the frame string of calling a function from a module: ` at thirdFn (http://localhost/myModule.js:45)`
Accessing information by individual frames
- by Node.js and Chrome the `frame.getThis()` and the `frame.getFunction()` returns `undefined` by frames originate from [strict mode](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Strict_mode) code
- by Firefox, Internet Explorer, PhantomJS, and Opera the context of the function calls is not accessible, so the `frame.getThis()` cannot be implemented
- by Firefox, Internet Explorer, PhantomJS, and Opera functions are not accessible with `arguments.callee.caller` by frames originate from strict mode, so by these frames `frame.getFunction()` can return only `undefined` (this is consistent with V8 behavior)
## License
MIT - 2016 Jánszky László Lajos
# balanced-match
Match balanced string pairs, like `{` and `}` or `<b>` and `</b>`. Supports regular expressions as well!
[](http://travis-ci.org/juliangruber/balanced-match)
[](https://www.npmjs.org/package/balanced-match)
[](https://ci.testling.com/juliangruber/balanced-match)
## Example
Get the first matching pair of braces:
```js
var balanced = require('balanced-match');
console.log(balanced('{', '}', 'pre{in{nested}}post'));
console.log(balanced('{', '}', 'pre{first}between{second}post'));
console.log(balanced(/\s+\{\s+/, /\s+\}\s+/, 'pre { in{nest} } post'));
```
The matches are:
```bash
$ node example.js
{ start: 3, end: 14, pre: 'pre', body: 'in{nested}', post: 'post' }
{ start: 3,
end: 9,
pre: 'pre',
body: 'first',
post: 'between{second}post' }
{ start: 3, end: 17, pre: 'pre', body: 'in{nest}', post: 'post' }
```
## API
### var m = balanced(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
object with those keys:
* **start** the index of the first match of `a`
* **end** the index of the matching `b`
* **pre** the preamble, `a` and `b` not included
* **body** the match, `a` and `b` not included
* **post** the postscript, `a` and `b` not included
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `['{', 'a', '']` and `{a}}` will match `['', 'a', '}']`.
### var r = balanced.range(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
array with indexes: `[ <a index>, <b index> ]`.
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `[ 1, 3 ]` and `{a}}` will match `[0, 2]`.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install balanced-match
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# level-iterator-stream
<img alt="LevelDB Logo" height="100" src="http://leveldb.org/img/logo.svg">
**Turn a leveldown iterator into a readable stream**
[](https://travis-ci.org/Level/iterator-stream)
## Example
```js
var iteratorStream = require('level-iterator-stream');
var leveldown = require('leveldown');
var db = leveldown(__dirname + '/db');
db.open(function(err){
if (err) throw err;
var stream = iteratorStream(db.iterator());
stream.on('data', function(kv){
console.log('%s -> %s', kv.key, kv.value);
});
});
```
## Installation
```bash
$ npm install level-iterator-stream
```
## API
### iteratorStream(iterator[, options])
Create a readable stream from `iterator`. `options` are passed down to the
`require('readable-stream').Readable` constructor, with `objectMode` forced
to `true`.
If `options.decoder` is passed, each key/value pair will be transformed by it.
Otherwise, an object with `{ key, value }` will be emitted.
When the stream ends, the `iterator` will be closed and afterwards a
`"close"` event emitted.
`.destroy()` will force close the underlying iterator.
## Publishers
* [@juliangruber](https://github.com/juliangruber)
## License & copyright
Copyright (c) 2012-2015 LevelUP contributors.
LevelUP is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE.md file for more details.
# web3-core-method
This is a sub package of [web3.js][repo]
The Method package used within most [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-method
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-core-method.js` in your html file.
This will expose the `Web3Method` object on the window object.
## Usage
```js
// in node.js
var Web3Method = require('web3-core-method');
var method = new Web3Method({
name: 'sendTransaction',
call: 'eth_sendTransaction',
params: 1,
inputFormatter: [inputTransactionFormatter]
});
method.attachToObject(myCoolLib);
myCoolLib.sendTransaction({...}, function(){ ... });
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# braces [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=W8YFZ425KND68) [](https://www.npmjs.com/package/braces) [](https://npmjs.org/package/braces) [](https://npmjs.org/package/braces) [](https://travis-ci.org/micromatch/braces)
> Bash-like brace expansion, implemented in JavaScript. Safer than other brace expansion libs, with complete support for the Bash 4.3 braces specification, without sacrificing speed.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save braces
```
## v3.0.0 Released!!
See the [changelog](CHANGELOG.md) for details.
## Why use braces?
Brace patterns make globs more powerful by adding the ability to match specific ranges and sequences of characters.
* **Accurate** - complete support for the [Bash 4.3 Brace Expansion](www.gnu.org/software/bash/) specification (passes all of the Bash braces tests)
* **[fast and performant](#benchmarks)** - Starts fast, runs fast and [scales well](#performance) as patterns increase in complexity.
* **Organized code base** - The parser and compiler are easy to maintain and update when edge cases crop up.
* **Well-tested** - Thousands of test assertions, and passes all of the Bash, minimatch, and [brace-expansion](https://github.com/juliangruber/brace-expansion) unit tests (as of the date this was written).
* **Safer** - You shouldn't have to worry about users defining aggressive or malicious brace patterns that can break your application. Braces takes measures to prevent malicious regex that can be used for DDoS attacks (see [catastrophic backtracking](https://www.regular-expressions.info/catastrophic.html)).
* [Supports lists](#lists) - (aka "sets") `a/{b,c}/d` => `['a/b/d', 'a/c/d']`
* [Supports sequences](#sequences) - (aka "ranges") `{01..03}` => `['01', '02', '03']`
* [Supports steps](#steps) - (aka "increments") `{2..10..2}` => `['2', '4', '6', '8', '10']`
* [Supports escaping](#escaping) - To prevent evaluation of special characters.
## Usage
The main export is a function that takes one or more brace `patterns` and `options`.
```js
const braces = require('braces');
// braces(patterns[, options]);
console.log(braces(['{01..05}', '{a..e}']));
//=> ['(0[1-5])', '([a-e])']
console.log(braces(['{01..05}', '{a..e}'], { expand: true }));
//=> ['01', '02', '03', '04', '05', 'a', 'b', 'c', 'd', 'e']
```
### Brace Expansion vs. Compilation
By default, brace patterns are compiled into strings that are optimized for creating regular expressions and matching.
**Compiled**
```js
console.log(braces('a/{x,y,z}/b'));
//=> ['a/(x|y|z)/b']
console.log(braces(['a/{01..20}/b', 'a/{1..5}/b']));
//=> [ 'a/(0[1-9]|1[0-9]|20)/b', 'a/([1-5])/b' ]
```
**Expanded**
Enable brace expansion by setting the `expand` option to true, or by using [braces.expand()](#expand) (returns an array similar to what you'd expect from Bash, or `echo {1..5}`, or [minimatch](https://github.com/isaacs/minimatch)):
```js
console.log(braces('a/{x,y,z}/b', { expand: true }));
//=> ['a/x/b', 'a/y/b', 'a/z/b']
console.log(braces.expand('{01..10}'));
//=> ['01','02','03','04','05','06','07','08','09','10']
```
### Lists
Expand lists (like Bash "sets"):
```js
console.log(braces('a/{foo,bar,baz}/*.js'));
//=> ['a/(foo|bar|baz)/*.js']
console.log(braces.expand('a/{foo,bar,baz}/*.js'));
//=> ['a/foo/*.js', 'a/bar/*.js', 'a/baz/*.js']
```
### Sequences
Expand ranges of characters (like Bash "sequences"):
```js
console.log(braces.expand('{1..3}')); // ['1', '2', '3']
console.log(braces.expand('a/{1..3}/b')); // ['a/1/b', 'a/2/b', 'a/3/b']
console.log(braces('{a..c}', { expand: true })); // ['a', 'b', 'c']
console.log(braces('foo/{a..c}', { expand: true })); // ['foo/a', 'foo/b', 'foo/c']
// supports zero-padded ranges
console.log(braces('a/{01..03}/b')); //=> ['a/(0[1-3])/b']
console.log(braces('a/{001..300}/b')); //=> ['a/(0{2}[1-9]|0[1-9][0-9]|[12][0-9]{2}|300)/b']
```
See [fill-range](https://github.com/jonschlinkert/fill-range) for all available range-expansion options.
### Steppped ranges
Steps, or increments, may be used with ranges:
```js
console.log(braces.expand('{2..10..2}'));
//=> ['2', '4', '6', '8', '10']
console.log(braces('{2..10..2}'));
//=> ['(2|4|6|8|10)']
```
When the [.optimize](#optimize) method is used, or [options.optimize](#optionsoptimize) is set to true, sequences are passed to [to-regex-range](https://github.com/jonschlinkert/to-regex-range) for expansion.
### Nesting
Brace patterns may be nested. The results of each expanded string are not sorted, and left to right order is preserved.
**"Expanded" braces**
```js
console.log(braces.expand('a{b,c,/{x,y}}/e'));
//=> ['ab/e', 'ac/e', 'a/x/e', 'a/y/e']
console.log(braces.expand('a/{x,{1..5},y}/c'));
//=> ['a/x/c', 'a/1/c', 'a/2/c', 'a/3/c', 'a/4/c', 'a/5/c', 'a/y/c']
```
**"Optimized" braces**
```js
console.log(braces('a{b,c,/{x,y}}/e'));
//=> ['a(b|c|/(x|y))/e']
console.log(braces('a/{x,{1..5},y}/c'));
//=> ['a/(x|([1-5])|y)/c']
```
### Escaping
**Escaping braces**
A brace pattern will not be expanded or evaluted if _either the opening or closing brace is escaped_:
```js
console.log(braces.expand('a\\{d,c,b}e'));
//=> ['a{d,c,b}e']
console.log(braces.expand('a{d,c,b\\}e'));
//=> ['a{d,c,b}e']
```
**Escaping commas**
Commas inside braces may also be escaped:
```js
console.log(braces.expand('a{b\\,c}d'));
//=> ['a{b,c}d']
console.log(braces.expand('a{d\\,c,b}e'));
//=> ['ad,ce', 'abe']
```
**Single items**
Following bash conventions, a brace pattern is also not expanded when it contains a single character:
```js
console.log(braces.expand('a{b}c'));
//=> ['a{b}c']
```
## Options
### options.maxLength
**Type**: `Number`
**Default**: `65,536`
**Description**: Limit the length of the input string. Useful when the input string is generated or your application allows users to pass a string, et cetera.
```js
console.log(braces('a/{b,c}/d', { maxLength: 3 })); //=> throws an error
```
### options.expand
**Type**: `Boolean`
**Default**: `undefined`
**Description**: Generate an "expanded" brace pattern (alternatively you can use the `braces.expand()` method, which does the same thing).
```js
console.log(braces('a/{b,c}/d', { expand: true }));
//=> [ 'a/b/d', 'a/c/d' ]
```
### options.nodupes
**Type**: `Boolean`
**Default**: `undefined`
**Description**: Remove duplicates from the returned array.
### options.rangeLimit
**Type**: `Number`
**Default**: `1000`
**Description**: To prevent malicious patterns from being passed by users, an error is thrown when `braces.expand()` is used or `options.expand` is true and the generated range will exceed the `rangeLimit`.
You can customize `options.rangeLimit` or set it to `Inifinity` to disable this altogether.
**Examples**
```js
// pattern exceeds the "rangeLimit", so it's optimized automatically
console.log(braces.expand('{1..1000}'));
//=> ['([1-9]|[1-9][0-9]{1,2}|1000)']
// pattern does not exceed "rangeLimit", so it's NOT optimized
console.log(braces.expand('{1..100}'));
//=> ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86', '87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100']
```
### options.transform
**Type**: `Function`
**Default**: `undefined`
**Description**: Customize range expansion.
**Example: Transforming non-numeric values**
```js
const alpha = braces.expand('x/{a..e}/y', {
transform(value, index) {
// When non-numeric values are passed, "value" is a character code.
return 'foo/' + String.fromCharCode(value) + '-' + index;
}
});
console.log(alpha);
//=> [ 'x/foo/a-0/y', 'x/foo/b-1/y', 'x/foo/c-2/y', 'x/foo/d-3/y', 'x/foo/e-4/y' ]
```
**Example: Transforming numeric values**
```js
const numeric = braces.expand('{1..5}', {
transform(value) {
// when numeric values are passed, "value" is a number
return 'foo/' + value * 2;
}
});
console.log(numeric);
//=> [ 'foo/2', 'foo/4', 'foo/6', 'foo/8', 'foo/10' ]
```
### options.quantifiers
**Type**: `Boolean`
**Default**: `undefined`
**Description**: In regular expressions, quanitifiers can be used to specify how many times a token can be repeated. For example, `a{1,3}` will match the letter `a` one to three times.
Unfortunately, regex quantifiers happen to share the same syntax as [Bash lists](#lists)
The `quantifiers` option tells braces to detect when [regex quantifiers](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp#quantifiers) are defined in the given pattern, and not to try to expand them as lists.
**Examples**
```js
const braces = require('braces');
console.log(braces('a/b{1,3}/{x,y,z}'));
//=> [ 'a/b(1|3)/(x|y|z)' ]
console.log(braces('a/b{1,3}/{x,y,z}', {quantifiers: true}));
//=> [ 'a/b{1,3}/(x|y|z)' ]
console.log(braces('a/b{1,3}/{x,y,z}', {quantifiers: true, expand: true}));
//=> [ 'a/b{1,3}/x', 'a/b{1,3}/y', 'a/b{1,3}/z' ]
```
### options.unescape
**Type**: `Boolean`
**Default**: `undefined`
**Description**: Strip backslashes that were used for escaping from the result.
## What is "brace expansion"?
Brace expansion is a type of parameter expansion that was made popular by unix shells for generating lists of strings, as well as regex-like matching when used alongside wildcards (globs).
In addition to "expansion", braces are also used for matching. In other words:
* [brace expansion](#brace-expansion) is for generating new lists
* [brace matching](#brace-matching) is for filtering existing lists
<details>
<summary><strong>More about brace expansion</strong> (click to expand)</summary>
There are two main types of brace expansion:
1. **lists**: which are defined using comma-separated values inside curly braces: `{a,b,c}`
2. **sequences**: which are defined using a starting value and an ending value, separated by two dots: `a{1..3}b`. Optionally, a third argument may be passed to define a "step" or increment to use: `a{1..100..10}b`. These are also sometimes referred to as "ranges".
Here are some example brace patterns to illustrate how they work:
**Sets**
```
{a,b,c} => a b c
{a,b,c}{1,2} => a1 a2 b1 b2 c1 c2
```
**Sequences**
```
{1..9} => 1 2 3 4 5 6 7 8 9
{4..-4} => 4 3 2 1 0 -1 -2 -3 -4
{1..20..3} => 1 4 7 10 13 16 19
{a..j} => a b c d e f g h i j
{j..a} => j i h g f e d c b a
{a..z..3} => a d g j m p s v y
```
**Combination**
Sets and sequences can be mixed together or used along with any other strings.
```
{a,b,c}{1..3} => a1 a2 a3 b1 b2 b3 c1 c2 c3
foo/{a,b,c}/bar => foo/a/bar foo/b/bar foo/c/bar
```
The fact that braces can be "expanded" from relatively simple patterns makes them ideal for quickly generating test fixtures, file paths, and similar use cases.
## Brace matching
In addition to _expansion_, brace patterns are also useful for performing regular-expression-like matching.
For example, the pattern `foo/{1..3}/bar` would match any of following strings:
```
foo/1/bar
foo/2/bar
foo/3/bar
```
But not:
```
baz/1/qux
baz/2/qux
baz/3/qux
```
Braces can also be combined with [glob patterns](https://github.com/jonschlinkert/micromatch) to perform more advanced wildcard matching. For example, the pattern `*/{1..3}/*` would match any of following strings:
```
foo/1/bar
foo/2/bar
foo/3/bar
baz/1/qux
baz/2/qux
baz/3/qux
```
## Brace matching pitfalls
Although brace patterns offer a user-friendly way of matching ranges or sets of strings, there are also some major disadvantages and potential risks you should be aware of.
### tldr
**"brace bombs"**
* brace expansion can eat up a huge amount of processing resources
* as brace patterns increase _linearly in size_, the system resources required to expand the pattern increase exponentially
* users can accidentally (or intentially) exhaust your system's resources resulting in the equivalent of a DoS attack (bonus: no programming knowledge is required!)
For a more detailed explanation with examples, see the [geometric complexity](#geometric-complexity) section.
### The solution
Jump to the [performance section](#performance) to see how Braces solves this problem in comparison to other libraries.
### Geometric complexity
At minimum, brace patterns with sets limited to two elements have quadradic or `O(n^2)` complexity. But the complexity of the algorithm increases exponentially as the number of sets, _and elements per set_, increases, which is `O(n^c)`.
For example, the following sets demonstrate quadratic (`O(n^2)`) complexity:
```
{1,2}{3,4} => (2X2) => 13 14 23 24
{1,2}{3,4}{5,6} => (2X2X2) => 135 136 145 146 235 236 245 246
```
But add an element to a set, and we get a n-fold Cartesian product with `O(n^c)` complexity:
```
{1,2,3}{4,5,6}{7,8,9} => (3X3X3) => 147 148 149 157 158 159 167 168 169 247 248
249 257 258 259 267 268 269 347 348 349 357
358 359 367 368 369
```
Now, imagine how this complexity grows given that each element is a n-tuple:
```
{1..100}{1..100} => (100X100) => 10,000 elements (38.4 kB)
{1..100}{1..100}{1..100} => (100X100X100) => 1,000,000 elements (5.76 MB)
```
Although these examples are clearly contrived, they demonstrate how brace patterns can quickly grow out of control.
**More information**
Interested in learning more about brace expansion?
* [linuxjournal/bash-brace-expansion](http://www.linuxjournal.com/content/bash-brace-expansion)
* [rosettacode/Brace_expansion](https://rosettacode.org/wiki/Brace_expansion)
* [cartesian product](https://en.wikipedia.org/wiki/Cartesian_product)
</details>
## Performance
Braces is not only screaming fast, it's also more accurate the other brace expansion libraries.
### Better algorithms
Fortunately there is a solution to the ["brace bomb" problem](#brace-matching-pitfalls): _don't expand brace patterns into an array when they're used for matching_.
Instead, convert the pattern into an optimized regular expression. This is easier said than done, and braces is the only library that does this currently.
**The proof is in the numbers**
Minimatch gets exponentially slower as patterns increase in complexity, braces does not. The following results were generated using `braces()` and `minimatch.braceExpand()`, respectively.
| **Pattern** | **braces** | **[minimatch][]** |
| --- | --- | --- |
| `{1..9007199254740991}`[^1] | `298 B` (5ms 459μs)| N/A (freezes) |
| `{1..1000000000000000}` | `41 B` (1ms 15μs) | N/A (freezes) |
| `{1..100000000000000}` | `40 B` (890μs) | N/A (freezes) |
| `{1..10000000000000}` | `39 B` (2ms 49μs) | N/A (freezes) |
| `{1..1000000000000}` | `38 B` (608μs) | N/A (freezes) |
| `{1..100000000000}` | `37 B` (397μs) | N/A (freezes) |
| `{1..10000000000}` | `35 B` (983μs) | N/A (freezes) |
| `{1..1000000000}` | `34 B` (798μs) | N/A (freezes) |
| `{1..100000000}` | `33 B` (733μs) | N/A (freezes) |
| `{1..10000000}` | `32 B` (5ms 632μs) | `78.89 MB` (16s 388ms 569μs) |
| `{1..1000000}` | `31 B` (1ms 381μs) | `6.89 MB` (1s 496ms 887μs) |
| `{1..100000}` | `30 B` (950μs) | `588.89 kB` (146ms 921μs) |
| `{1..10000}` | `29 B` (1ms 114μs) | `48.89 kB` (14ms 187μs) |
| `{1..1000}` | `28 B` (760μs) | `3.89 kB` (1ms 453μs) |
| `{1..100}` | `22 B` (345μs) | `291 B` (196μs) |
| `{1..10}` | `10 B` (533μs) | `20 B` (37μs) |
| `{1..3}` | `7 B` (190μs) | `5 B` (27μs) |
### Faster algorithms
When you need expansion, braces is still much faster.
_(the following results were generated using `braces.expand()` and `minimatch.braceExpand()`, respectively)_
| **Pattern** | **braces** | **[minimatch][]** |
| --- | --- | --- |
| `{1..10000000}` | `78.89 MB` (2s 698ms 642μs) | `78.89 MB` (18s 601ms 974μs) |
| `{1..1000000}` | `6.89 MB` (458ms 576μs) | `6.89 MB` (1s 491ms 621μs) |
| `{1..100000}` | `588.89 kB` (20ms 728μs) | `588.89 kB` (156ms 919μs) |
| `{1..10000}` | `48.89 kB` (2ms 202μs) | `48.89 kB` (13ms 641μs) |
| `{1..1000}` | `3.89 kB` (1ms 796μs) | `3.89 kB` (1ms 958μs) |
| `{1..100}` | `291 B` (424μs) | `291 B` (211μs) |
| `{1..10}` | `20 B` (487μs) | `20 B` (72μs) |
| `{1..3}` | `5 B` (166μs) | `5 B` (27μs) |
If you'd like to run these comparisons yourself, see [test/support/generate.js](test/support/generate.js).
## Benchmarks
### Running benchmarks
Install dev dependencies:
```bash
npm i -d && npm benchmark
```
### Latest results
Braces is more accurate, without sacrificing performance.
```bash
# range (expanded)
braces x 29,040 ops/sec ±3.69% (91 runs sampled))
minimatch x 4,735 ops/sec ±1.28% (90 runs sampled)
# range (optimized for regex)
braces x 382,878 ops/sec ±0.56% (94 runs sampled)
minimatch x 1,040 ops/sec ±0.44% (93 runs sampled)
# nested ranges (expanded)
braces x 19,744 ops/sec ±2.27% (92 runs sampled))
minimatch x 4,579 ops/sec ±0.50% (93 runs sampled)
# nested ranges (optimized for regex)
braces x 246,019 ops/sec ±2.02% (93 runs sampled)
minimatch x 1,028 ops/sec ±0.39% (94 runs sampled)
# set (expanded)
braces x 138,641 ops/sec ±0.53% (95 runs sampled)
minimatch x 219,582 ops/sec ±0.98% (94 runs sampled)
# set (optimized for regex)
braces x 388,408 ops/sec ±0.41% (95 runs sampled)
minimatch x 44,724 ops/sec ±0.91% (89 runs sampled)
# nested sets (expanded)
braces x 84,966 ops/sec ±0.48% (94 runs sampled)
minimatch x 140,720 ops/sec ±0.37% (95 runs sampled)
# nested sets (optimized for regex)
braces x 263,340 ops/sec ±2.06% (92 runs sampled)
minimatch x 28,714 ops/sec ±0.40% (90 runs sampled)
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 197 | [jonschlinkert](https://github.com/jonschlinkert) |
| 4 | [doowb](https://github.com/doowb) |
| 1 | [es128](https://github.com/es128) |
| 1 | [eush77](https://github.com/eush77) |
| 1 | [hemanth](https://github.com/hemanth) |
| 1 | [wtgtybhertgeghgtwtg](https://github.com/wtgtybhertgeghgtwtg) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2019, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on April 08, 2019._
WebSocket Client & Server Implementation for Node
=================================================
[](http://badge.fury.io/js/websocket)
[](https://www.npmjs.com/package/websocket)
[ ](https://codeship.com/projects/61106)
Overview
--------
This is a (mostly) pure JavaScript implementation of the WebSocket protocol versions 8 and 13 for Node. There are some example client and server applications that implement various interoperability testing protocols in the "test/scripts" folder.
Documentation
=============
[You can read the full API documentation in the docs folder.](docs/index.md)
Changelog
---------
***Current Version: 1.0.32*** - Release 2020-08-28
* Refactor to use [N-API modules](https://nodejs.org/api/n-api.html) from [ws project](https://github.com/websockets). (Thanks, [@andreek](https://github.com/andreek))
* Specifically:
* [utf-8-validate](https://github.com/websockets/utf-8-validate)
* [bufferutil](https://github.com/websockets/bufferutil)
* Removed some documentation notations about very old browsers and very old Websocket protocol drafts that are no longer relevant today in 2020.
* Removed outdated notations and instructions about building native extensions, since those functions are now delegated to dependencies.
* Add automated unit test executionn via Github Actions (Thanks, [@nebojsa94](https://github.com/nebojsa94))
* Accept new connection close code `1015` ("TLS Handshake"). (More information at the [WebSocket Close Code Number Registry](https://www.iana.org/assignments/websocket/websocket.xhtml#close-code-number))
[View the full changelog](CHANGELOG.md)
Browser Support
---------------
All current browsers are fully supported.
* Firefox 7-9 (Old) (Protocol Version 8)
* Firefox 10+ (Protocol Version 13)
* Chrome 14,15 (Old) (Protocol Version 8)
* Chrome 16+ (Protocol Version 13)
* Internet Explorer 10+ (Protocol Version 13)
* Safari 6+ (Protocol Version 13)
Benchmarks
----------
There are some basic benchmarking sections in the Autobahn test suite. I've put up a [benchmark page](http://theturtle32.github.com/WebSocket-Node/benchmarks/) that shows the results from the Autobahn tests run against AutobahnServer 0.4.10, WebSocket-Node 1.0.2, WebSocket-Node 1.0.4, and ws 0.3.4.
(These benchmarks are quite a bit outdated at this point, so take them with a grain of salt. Anyone up for running new benchmarks? I'll link to your report.)
Autobahn Tests
--------------
The very complete [Autobahn Test Suite](http://autobahn.ws/testsuite/) is used by most WebSocket implementations to test spec compliance and interoperability.
- [View Server Test Results](http://theturtle32.github.com/WebSocket-Node/test-report/servers/)
Installation
------------
In your project root:
$ npm install websocket
Then in your code:
```javascript
var WebSocketServer = require('websocket').server;
var WebSocketClient = require('websocket').client;
var WebSocketFrame = require('websocket').frame;
var WebSocketRouter = require('websocket').router;
var W3CWebSocket = require('websocket').w3cwebsocket;
```
Current Features:
-----------------
- Licensed under the Apache License, Version 2.0
- Protocol version "8" and "13" (Draft-08 through the final RFC) framing and handshake
- Can handle/aggregate received fragmented messages
- Can fragment outgoing messages
- Router to mount multiple applications to various path and protocol combinations
- TLS supported for outbound connections via WebSocketClient
- TLS supported for server connections (use https.createServer instead of http.createServer)
- Thanks to [pors](https://github.com/pors) for confirming this!
- Cookie setting and parsing
- Tunable settings
- Max Receivable Frame Size
- Max Aggregate ReceivedMessage Size
- Whether to fragment outgoing messages
- Fragmentation chunk size for outgoing messages
- Whether to automatically send ping frames for the purposes of keepalive
- Keep-alive ping interval
- Whether or not to automatically assemble received fragments (allows application to handle individual fragments directly)
- How long to wait after sending a close frame for acknowledgment before closing the socket.
- [W3C WebSocket API](http://www.w3.org/TR/websockets/) for applications running on both Node and browsers (via the `W3CWebSocket` class).
Known Issues/Missing Features:
------------------------------
- No API for user-provided protocol extensions.
Usage Examples
==============
Server Example
--------------
Here's a short example showing a server that echos back anything sent to it, whether utf-8 or binary.
```javascript
#!/usr/bin/env node
var WebSocketServer = require('websocket').server;
var http = require('http');
var server = http.createServer(function(request, response) {
console.log((new Date()) + ' Received request for ' + request.url);
response.writeHead(404);
response.end();
});
server.listen(8080, function() {
console.log((new Date()) + ' Server is listening on port 8080');
});
wsServer = new WebSocketServer({
httpServer: server,
// You should not use autoAcceptConnections for production
// applications, as it defeats all standard cross-origin protection
// facilities built into the protocol and the browser. You should
// *always* verify the connection's origin and decide whether or not
// to accept it.
autoAcceptConnections: false
});
function originIsAllowed(origin) {
// put logic here to detect whether the specified origin is allowed.
return true;
}
wsServer.on('request', function(request) {
if (!originIsAllowed(request.origin)) {
// Make sure we only accept requests from an allowed origin
request.reject();
console.log((new Date()) + ' Connection from origin ' + request.origin + ' rejected.');
return;
}
var connection = request.accept('echo-protocol', request.origin);
console.log((new Date()) + ' Connection accepted.');
connection.on('message', function(message) {
if (message.type === 'utf8') {
console.log('Received Message: ' + message.utf8Data);
connection.sendUTF(message.utf8Data);
}
else if (message.type === 'binary') {
console.log('Received Binary Message of ' + message.binaryData.length + ' bytes');
connection.sendBytes(message.binaryData);
}
});
connection.on('close', function(reasonCode, description) {
console.log((new Date()) + ' Peer ' + connection.remoteAddress + ' disconnected.');
});
});
```
Client Example
--------------
This is a simple example client that will print out any utf-8 messages it receives on the console, and periodically sends a random number.
*This code demonstrates a client in Node.js, not in the browser*
```javascript
#!/usr/bin/env node
var WebSocketClient = require('websocket').client;
var client = new WebSocketClient();
client.on('connectFailed', function(error) {
console.log('Connect Error: ' + error.toString());
});
client.on('connect', function(connection) {
console.log('WebSocket Client Connected');
connection.on('error', function(error) {
console.log("Connection Error: " + error.toString());
});
connection.on('close', function() {
console.log('echo-protocol Connection Closed');
});
connection.on('message', function(message) {
if (message.type === 'utf8') {
console.log("Received: '" + message.utf8Data + "'");
}
});
function sendNumber() {
if (connection.connected) {
var number = Math.round(Math.random() * 0xFFFFFF);
connection.sendUTF(number.toString());
setTimeout(sendNumber, 1000);
}
}
sendNumber();
});
client.connect('ws://localhost:8080/', 'echo-protocol');
```
Client Example using the *W3C WebSocket API*
--------------------------------------------
Same example as above but using the [W3C WebSocket API](http://www.w3.org/TR/websockets/).
```javascript
var W3CWebSocket = require('websocket').w3cwebsocket;
var client = new W3CWebSocket('ws://localhost:8080/', 'echo-protocol');
client.onerror = function() {
console.log('Connection Error');
};
client.onopen = function() {
console.log('WebSocket Client Connected');
function sendNumber() {
if (client.readyState === client.OPEN) {
var number = Math.round(Math.random() * 0xFFFFFF);
client.send(number.toString());
setTimeout(sendNumber, 1000);
}
}
sendNumber();
};
client.onclose = function() {
console.log('echo-protocol Client Closed');
};
client.onmessage = function(e) {
if (typeof e.data === 'string') {
console.log("Received: '" + e.data + "'");
}
};
```
Request Router Example
----------------------
For an example of using the request router, see `libwebsockets-test-server.js` in the `test` folder.
Resources
---------
A presentation on the state of the WebSockets protocol that I gave on July 23, 2011 at the LA Hacker News meetup. [WebSockets: The Real-Time Web, Delivered](http://www.scribd.com/doc/60898569/WebSockets-The-Real-Time-Web-Delivered)
# immediate [](https://travis-ci.org/calvinmetcalf/immediate)
[](https://ci.testling.com/calvinmetcalf/immediate)
```
npm install immediate --save
```
then
```js
var immediate = require("immediate");
immediate(function () {
// this will run soon
});
immediate(function (arg1, arg2) {
// get your args like in iojs
}, thing1, thing2);
```
## Introduction
**immediate** is a microtask library, descended from [NobleJS's setImmediate](https://github.com/NobleJS/setImmediate), but including ideas from [Cujo's When](https://github.com/cujojs/when) and [RSVP][RSVP].
immediate takes the tricks from setImmediate and RSVP and combines them with the scheduler inspired (vaguely) by when's.
Note versions 2.6.5 and earlier were strictly speaking a 'macrotask' library not a microtask one, [see this for the difference](https://github.com/YuzuJS/setImmediate#macrotasks-and-microtasks), if you need a macrotask library, [I got you covered](https://github.com/calvinmetcalf/macrotask).
Several new features were added in versions 3.1.0 and 3.2.0 to maintain parity with
process.nextTick, but the 3.0.x series is still being kept up to date if you just need
the small barebones version
## The Tricks
### `process.nextTick`
Note that we check for *actual* Node.js environments, not emulated ones like those produced by browserify or similar.
### `queueMicrotask`
Function available in major browser these days which you can use to add a function into the microtask queue managed by V8.
### `MutationObserver`
This is what [RSVP][RSVP] uses, it's very fast, details on [MDN](https://developer.mozilla.org/en-US/docs/Web/API/MutationObserver).
### `MessageChannel`
Unfortunately, `postMessage` has completely different semantics inside web workers, and so cannot be used there. So we
turn to [`MessageChannel`][MessageChannel], which has worse browser support, but does work inside a web worker.
### `<script> onreadystatechange`
For our last trick, we pull something out to make things fast in Internet Explorer versions 6 through 8: namely,
creating a `<script>` element and firing our calls in its `onreadystatechange` event. This does execute in a future
turn of the event loop, and is also faster than `setTimeout(…, 0)`, so hey, why not?
## Tricks we don't use
### `setImmediate`
We avoid using `setImmediate` because node's `process.nextTick` is better suited to our needs. Additionally, Internet Explorer 10's implementation of `setImmediate` is broken.
## Reference and Reading
* [Efficient Script Yielding W3C Editor's Draft][spec]
* [W3C mailing list post introducing the specification][list-post]
* [IE Test Drive demo][ie-demo]
* [Introductory blog post by Nicholas C. Zakas][ncz]
* I wrote a couple of blog posts on this, [part 1][my-blog-1] and [part 2][my-blog-2]
[RSVP]: https://github.com/tildeio/rsvp.js
[spec]: https://dvcs.w3.org/hg/webperf/raw-file/tip/specs/setImmediate/Overview.html
[list-post]: http://lists.w3.org/Archives/Public/public-web-perf/2011Jun/0100.html
[ie-demo]: http://ie.microsoft.com/testdrive/Performance/setImmediateSorting/Default.html
[ncz]: http://www.nczonline.net/blog/2011/09/19/script-yielding-with-setimmediate/
[nextTick]: http://nodejs.org/docs/v0.8.16/api/process.html#process_process_nexttick_callback
[postMessage]: http://www.whatwg.org/specs/web-apps/current-work/multipage/web-messaging.html#posting-messages
[MessageChannel]: http://www.whatwg.org/specs/web-apps/current-work/multipage/web-messaging.html#channel-messaging
[cross-browser-demo]: http://calvinmetcalf.github.io/setImmediate-shim-demo
[my-blog-1]:http://calvinmetcalf.com/post/61672207151/setimmediate-etc
[my-blog-2]:http://calvinmetcalf.com/post/61761231881/javascript-schedulers
# global
<!-- [![build status][1]][2]
[![browser support][3]][4] -->
Require global variables
## Example
```js
var global = require("global")
var document = require("global/document")
var window = require("global/window")
```
## Installation
`npm install global`
## Contributors
- Raynos
## MIT Licenced
[1]: https://secure.travis-ci.org/Colingo/global.png
[2]: http://travis-ci.org/Colingo/global
[3]: http://ci.testling.com/Colingo/global.png
[4]: http://ci.testling.com/Colingo/global
# pump
pump is a small node module that pipes streams together and destroys all of them if one of them closes.
```
npm install pump
```
[](http://travis-ci.org/mafintosh/pump)
## What problem does it solve?
When using standard `source.pipe(dest)` source will _not_ be destroyed if dest emits close or an error.
You are also not able to provide a callback to tell when then pipe has finished.
pump does these two things for you
## Usage
Simply pass the streams you want to pipe together to pump and add an optional callback
``` js
var pump = require('pump')
var fs = require('fs')
var source = fs.createReadStream('/dev/random')
var dest = fs.createWriteStream('/dev/null')
pump(source, dest, function(err) {
console.log('pipe finished', err)
})
setTimeout(function() {
dest.destroy() // when dest is closed pump will destroy source
}, 1000)
```
You can use pump to pipe more than two streams together as well
``` js
var transform = someTransformStream()
pump(source, transform, anotherTransform, dest, function(err) {
console.log('pipe finished', err)
})
```
If `source`, `transform`, `anotherTransform` or `dest` closes all of them will be destroyed.
Similarly to `stream.pipe()`, `pump()` returns the last stream passed in, so you can do:
```
return pump(s1, s2) // returns s2
```
If you want to return a stream that combines *both* s1 and s2 to a single stream use
[pumpify](https://github.com/mafintosh/pumpify) instead.
## License
MIT
## Related
`pump` is part of the [mississippi stream utility collection](https://github.com/maxogden/mississippi) which includes more useful stream modules similar to this one.
# psl (Public Suffix List)
[](https://nodei.co/npm/psl/)
[](https://greenkeeper.io/)
[](https://travis-ci.org/lupomontero/psl)
[](https://david-dm.org/lupomontero/psl#info=devDependencies)
`psl` is a `JavaScript` domain name parser based on the
[Public Suffix List](https://publicsuffix.org/).
This implementation is tested against the
[test data hosted by Mozilla](http://mxr.mozilla.org/mozilla-central/source/netwerk/test/unit/data/test_psl.txt?raw=1)
and kindly provided by [Comodo](https://www.comodo.com/).
Cross browser testing provided by
[<img alt="BrowserStack" width="160" src="./browserstack-logo.svg" />](https://www.browserstack.com/)
## What is the Public Suffix List?
The Public Suffix List is a cross-vendor initiative to provide an accurate list
of domain name suffixes.
The Public Suffix List is an initiative of the Mozilla Project, but is
maintained as a community resource. It is available for use in any software,
but was originally created to meet the needs of browser manufacturers.
A "public suffix" is one under which Internet users can directly register names.
Some examples of public suffixes are ".com", ".co.uk" and "pvt.k12.wy.us". The
Public Suffix List is a list of all known public suffixes.
Source: http://publicsuffix.org
## Installation
### Node.js
```sh
npm install --save psl
```
### Browser
Download [psl.min.js](https://raw.githubusercontent.com/lupomontero/psl/master/dist/psl.min.js)
and include it in a script tag.
```html
<script src="psl.min.js"></script>
```
This script is browserified and wrapped in a [umd](https://github.com/umdjs/umd)
wrapper so you should be able to use it standalone or together with a module
loader.
## API
### `psl.parse(domain)`
Parse domain based on Public Suffix List. Returns an `Object` with the following
properties:
* `tld`: Top level domain (this is the _public suffix_).
* `sld`: Second level domain (the first private part of the domain name).
* `domain`: The domain name is the `sld` + `tld`.
* `subdomain`: Optional parts left of the domain.
#### Example:
```js
var psl = require('psl');
// Parse domain without subdomain
var parsed = psl.parse('google.com');
console.log(parsed.tld); // 'com'
console.log(parsed.sld); // 'google'
console.log(parsed.domain); // 'google.com'
console.log(parsed.subdomain); // null
// Parse domain with subdomain
var parsed = psl.parse('www.google.com');
console.log(parsed.tld); // 'com'
console.log(parsed.sld); // 'google'
console.log(parsed.domain); // 'google.com'
console.log(parsed.subdomain); // 'www'
// Parse domain with nested subdomains
var parsed = psl.parse('a.b.c.d.foo.com');
console.log(parsed.tld); // 'com'
console.log(parsed.sld); // 'foo'
console.log(parsed.domain); // 'foo.com'
console.log(parsed.subdomain); // 'a.b.c.d'
```
### `psl.get(domain)`
Get domain name, `sld` + `tld`. Returns `null` if not valid.
#### Example:
```js
var psl = require('psl');
// null input.
psl.get(null); // null
// Mixed case.
psl.get('COM'); // null
psl.get('example.COM'); // 'example.com'
psl.get('WwW.example.COM'); // 'example.com'
// Unlisted TLD.
psl.get('example'); // null
psl.get('example.example'); // 'example.example'
psl.get('b.example.example'); // 'example.example'
psl.get('a.b.example.example'); // 'example.example'
// TLD with only 1 rule.
psl.get('biz'); // null
psl.get('domain.biz'); // 'domain.biz'
psl.get('b.domain.biz'); // 'domain.biz'
psl.get('a.b.domain.biz'); // 'domain.biz'
// TLD with some 2-level rules.
psl.get('uk.com'); // null);
psl.get('example.uk.com'); // 'example.uk.com');
psl.get('b.example.uk.com'); // 'example.uk.com');
// More complex TLD.
psl.get('c.kobe.jp'); // null
psl.get('b.c.kobe.jp'); // 'b.c.kobe.jp'
psl.get('a.b.c.kobe.jp'); // 'b.c.kobe.jp'
psl.get('city.kobe.jp'); // 'city.kobe.jp'
psl.get('www.city.kobe.jp'); // 'city.kobe.jp'
// IDN labels.
psl.get('食狮.com.cn'); // '食狮.com.cn'
psl.get('食狮.公司.cn'); // '食狮.公司.cn'
psl.get('www.食狮.公司.cn'); // '食狮.公司.cn'
// Same as above, but punycoded.
psl.get('xn--85x722f.com.cn'); // 'xn--85x722f.com.cn'
psl.get('xn--85x722f.xn--55qx5d.cn'); // 'xn--85x722f.xn--55qx5d.cn'
psl.get('www.xn--85x722f.xn--55qx5d.cn'); // 'xn--85x722f.xn--55qx5d.cn'
```
### `psl.isValid(domain)`
Check whether a domain has a valid Public Suffix. Returns a `Boolean` indicating
whether the domain has a valid Public Suffix.
#### Example
```js
var psl = require('psl');
psl.isValid('google.com'); // true
psl.isValid('www.google.com'); // true
psl.isValid('x.yz'); // false
```
## Testing and Building
Test are written using [`mocha`](https://mochajs.org/) and can be
run in two different environments: `node` and `phantomjs`.
```sh
# This will run `eslint`, `mocha` and `karma`.
npm test
# Individual test environments
# Run tests in node only.
./node_modules/.bin/mocha test
# Run tests in phantomjs only.
./node_modules/.bin/karma start ./karma.conf.js --single-run
# Build data (parse raw list) and create dist files
npm run build
```
Feel free to fork if you see possible improvements!
## Acknowledgements
* Mozilla Foundation's [Public Suffix List](https://publicsuffix.org/)
* Thanks to Rob Stradling of [Comodo](https://www.comodo.com/) for providing
test data.
* Inspired by [weppos/publicsuffix-ruby](https://github.com/weppos/publicsuffix-ruby)
## License
The MIT License (MIT)
Copyright (c) 2017 Lupo Montero <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
# finalhandler
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-image]][node-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Node.js function to invoke as the final step to respond to HTTP request.
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install finalhandler
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var finalhandler = require('finalhandler')
```
### finalhandler(req, res, [options])
Returns function to be invoked as the final step for the given `req` and `res`.
This function is to be invoked as `fn(err)`. If `err` is falsy, the handler will
write out a 404 response to the `res`. If it is truthy, an error response will
be written out to the `res`.
When an error is written, the following information is added to the response:
* The `res.statusCode` is set from `err.status` (or `err.statusCode`). If
this value is outside the 4xx or 5xx range, it will be set to 500.
* The `res.statusMessage` is set according to the status code.
* The body will be the HTML of the status code message if `env` is
`'production'`, otherwise will be `err.stack`.
* Any headers specified in an `err.headers` object.
The final handler will also unpipe anything from `req` when it is invoked.
#### options.env
By default, the environment is determined by `NODE_ENV` variable, but it can be
overridden by this option.
#### options.onerror
Provide a function to be called with the `err` when it exists. Can be used for
writing errors to a central location without excessive function generation. Called
as `onerror(err, req, res)`.
## Examples
### always 404
```js
var finalhandler = require('finalhandler')
var http = require('http')
var server = http.createServer(function (req, res) {
var done = finalhandler(req, res)
done()
})
server.listen(3000)
```
### perform simple action
```js
var finalhandler = require('finalhandler')
var fs = require('fs')
var http = require('http')
var server = http.createServer(function (req, res) {
var done = finalhandler(req, res)
fs.readFile('index.html', function (err, buf) {
if (err) return done(err)
res.setHeader('Content-Type', 'text/html')
res.end(buf)
})
})
server.listen(3000)
```
### use with middleware-style functions
```js
var finalhandler = require('finalhandler')
var http = require('http')
var serveStatic = require('serve-static')
var serve = serveStatic('public')
var server = http.createServer(function (req, res) {
var done = finalhandler(req, res)
serve(req, res, done)
})
server.listen(3000)
```
### keep log of all errors
```js
var finalhandler = require('finalhandler')
var fs = require('fs')
var http = require('http')
var server = http.createServer(function (req, res) {
var done = finalhandler(req, res, { onerror: logerror })
fs.readFile('index.html', function (err, buf) {
if (err) return done(err)
res.setHeader('Content-Type', 'text/html')
res.end(buf)
})
})
server.listen(3000)
function logerror (err) {
console.error(err.stack || err.toString())
}
```
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/finalhandler.svg
[npm-url]: https://npmjs.org/package/finalhandler
[node-image]: https://img.shields.io/node/v/finalhandler.svg
[node-url]: https://nodejs.org/en/download
[travis-image]: https://img.shields.io/travis/pillarjs/finalhandler.svg
[travis-url]: https://travis-ci.org/pillarjs/finalhandler
[coveralls-image]: https://img.shields.io/coveralls/pillarjs/finalhandler.svg
[coveralls-url]: https://coveralls.io/r/pillarjs/finalhandler?branch=master
[downloads-image]: https://img.shields.io/npm/dm/finalhandler.svg
[downloads-url]: https://npmjs.org/package/finalhandler
# IDNA-UTS #46 in JavaScript
This is a maintained fork of the idna-uts46 library originally written by jcranmer.
The [JS Punycode converter library](https://github.com/bestiejs/punycode.js/) is
a great tool for handling Unicode domain names, but it only implements the
Punycode encoding of domain labels, not the full IDNA algorithm. In simple
cases, a mere conversion to lowercase text before input would seem sufficient,
but the real mapping for strings is far more complex. This library implements
the full mapping for these strings, as defined by
[UTS #46](http://unicode.org/reports/tr46/).
## Install
npm install idna-uts46-hx --save
## IDNA mess for dummies
Unfortunately, the situation of internationalized domain names is rather
complicated by the existence of multiple incompatible standards (IDNA2003 and
IDNA2008, predominantly). While UTS #46 tries to bridge the incompatibility,
there are four characters which cannot be so bridged: ß (the German sharp s),
ς (Greek final sigma), and the ZWJ and ZWNJ characters. These are handled
differently depending on the mode; in ``transitional`` mode, these strings are
mapped to different ones, preserving capability with IDNA2003; in
``nontransitional`` mode, these strings are mapped to themselves, in accordance
with IDNA2008.
Presently, this library uses ``transitional`` mode, compatible with all known
browser implementations at this point. It is expected that, in the future, this
will be changed to ``nontransitional`` mode.
`It is highly recommended that you use the ASCII form of the label for storing
or comparing strings.`
## API
### `uts46.toAscii(domain, options={transitional: false, useStd3ASCII: false, verifyDnsLength: false })`
Converts a domain name to the correct ASCII label. The second parameter is an
optional options parameter, which has two configurable options. The
`transitional` option controls whether or not transitional processing (see the
IDNA mess for dummies section for more details) is requested, defaulting to
false. The `useStd3ASCII` option controls whether or not characters that are
illegal in domain names per the DNS specification should be omitted. The
`verifyDnsLength` option controls whether or not the resulting DNS label should
be checked for length validity (i.e., no empty components and not too long). The
options parameter and its associated fields are all optional and should be
omitted for most users.
```js
uts46.toAscii('öbb.at'); // 'xn-bb-eka.at'
uts46.toAscii('ÖBB.AT'); // 'xn-bb-eka.at'
uts46.toAscii('XN-BB-EKA.AT'); // 'xn-bb-eka.at'
uts46.toAscii('faß.de'); // 'fass.de'
uts46.toAscii('faß.de', {transitional: true}); // 'fass.de'
uts46.toAscii('faß.de', {transitional: false}); // 'xn--fa-hia.de'
uts46.toAscii('xn--fa-hia.de', {transitional: false}); // 'xn--fa-hia.de'
uts46.toAscii(String.fromCodePoint(0xd0000)); // Error (as it is unassigned)
```
### `uts46.toUnicode(domain, options={useStd3ASCII: false})`
Converts a domain name to a normalized Unicode label. The second parameter is an
optional options parameter. The `useStd3ASCII` option controls whether or not
characters that are illegal in domain names per the DNS specification should be
omitted. The latter parameter is optional and should be omitted for most users.
```js
uts46.toUnicode('xn-bb-eka.at'); // 'öbb.at'
uts46.toUnicode('ÖBB.AT'); // 'öbb.at'
uts46.toUnicode('O\u0308BB.AT'); // 'öbb.at'
uts46.toUnicode('faß.de'); // 'faß.de'
uts46.toUnicode('xn--fa-hia.de'); // 'faß.de'
uts46.toUnicode('﷼'); // "ریال"
uts46.toUnicode(String.fromCodePoint(0xd0000)); // Error (as it is unassigned)
```
## Pull latest idna-map.js
Call the below python script by providing the most current RELEASED unicode version.
The latest released version can be found in here: http://www.unicode.org/Public/UCD/latest/ReadMe.txt
e.g.:
```bash
python build-unicode-tables.py 10.0.0
```
## Known issues
It also does not try to implement the Bidi and contextual rules for validation:
these do not affect any mapping of the domain names; instead, they restrict the
set of valid domain names. Since registrars shouldn't be accepting these names
in the first place, a domain that violates these rules will simply fail to
resolve.
<!--
-- This file is auto-generated from README_js.md. Changes should be made there.
-->
# uuid [](http://travis-ci.org/kelektiv/node-uuid) #
Simple, fast generation of [RFC4122](http://www.ietf.org/rfc/rfc4122.txt) UUIDS.
Features:
* Support for version 1, 3, 4 and 5 UUIDs
* Cross-platform
* Uses cryptographically-strong random number APIs (when available)
* Zero-dependency, small footprint (... but not [this small](https://gist.github.com/982883))
[**Deprecation warning**: The use of `require('uuid')` is deprecated and will not be
supported after version 3.x of this module. Instead, use `require('uuid/[v1|v3|v4|v5]')` as shown in the examples below.]
## Quickstart - CommonJS (Recommended)
```shell
npm install uuid
```
Then generate your uuid version of choice ...
Version 1 (timestamp):
```javascript
const uuidv1 = require('uuid/v1');
uuidv1(); // ⇨ '2c5ea4c0-4067-11e9-8bad-9b1deb4d3b7d'
```
Version 3 (namespace):
```javascript
const uuidv3 = require('uuid/v3');
// ... using predefined DNS namespace (for domain names)
uuidv3('hello.example.com', uuidv3.DNS); // ⇨ '9125a8dc-52ee-365b-a5aa-81b0b3681cf6'
// ... using predefined URL namespace (for, well, URLs)
uuidv3('http://example.com/hello', uuidv3.URL); // ⇨ 'c6235813-3ba4-3801-ae84-e0a6ebb7d138'
// ... using a custom namespace
//
// Note: Custom namespaces should be a UUID string specific to your application!
// E.g. the one here was generated using this modules `uuid` CLI.
const MY_NAMESPACE = '1b671a64-40d5-491e-99b0-da01ff1f3341';
uuidv3('Hello, World!', MY_NAMESPACE); // ⇨ 'e8b5a51d-11c8-3310-a6ab-367563f20686'
```
Version 4 (random):
```javascript
const uuidv4 = require('uuid/v4');
uuidv4(); // ⇨ '1b9d6bcd-bbfd-4b2d-9b5d-ab8dfbbd4bed'
```
Version 5 (namespace):
```javascript
const uuidv5 = require('uuid/v5');
// ... using predefined DNS namespace (for domain names)
uuidv5('hello.example.com', uuidv5.DNS); // ⇨ 'fdda765f-fc57-5604-a269-52a7df8164ec'
// ... using predefined URL namespace (for, well, URLs)
uuidv5('http://example.com/hello', uuidv5.URL); // ⇨ '3bbcee75-cecc-5b56-8031-b6641c1ed1f1'
// ... using a custom namespace
//
// Note: Custom namespaces should be a UUID string specific to your application!
// E.g. the one here was generated using this modules `uuid` CLI.
const MY_NAMESPACE = '1b671a64-40d5-491e-99b0-da01ff1f3341';
uuidv5('Hello, World!', MY_NAMESPACE); // ⇨ '630eb68f-e0fa-5ecc-887a-7c7a62614681'
```
## API
### Version 1
```javascript
const uuidv1 = require('uuid/v1');
// Incantations
uuidv1();
uuidv1(options);
uuidv1(options, buffer, offset);
```
Generate and return a RFC4122 v1 (timestamp-based) UUID.
* `options` - (Object) Optional uuid state to apply. Properties may include:
* `node` - (Array) Node id as Array of 6 bytes (per 4.1.6). Default: Randomly generated ID. See note 1.
* `clockseq` - (Number between 0 - 0x3fff) RFC clock sequence. Default: An internally maintained clockseq is used.
* `msecs` - (Number) Time in milliseconds since unix Epoch. Default: The current time is used.
* `nsecs` - (Number between 0-9999) additional time, in 100-nanosecond units. Ignored if `msecs` is unspecified. Default: internal uuid counter is used, as per 4.2.1.2.
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing.
Returns `buffer`, if specified, otherwise the string form of the UUID
Note: The default [node id](https://tools.ietf.org/html/rfc4122#section-4.1.6) (the last 12 digits in the UUID) is generated once, randomly, on process startup, and then remains unchanged for the duration of the process.
Example: Generate string UUID with fully-specified options
```javascript
const v1options = {
node: [0x01, 0x23, 0x45, 0x67, 0x89, 0xab],
clockseq: 0x1234,
msecs: new Date('2011-11-01').getTime(),
nsecs: 5678
};
uuidv1(v1options); // ⇨ '710b962e-041c-11e1-9234-0123456789ab'
```
Example: In-place generation of two binary IDs
```javascript
// Generate two ids in an array
const arr = new Array();
uuidv1(null, arr, 0); // ⇨
// [
// 44, 94, 164, 192, 64, 103,
// 17, 233, 146, 52, 155, 29,
// 235, 77, 59, 125
// ]
uuidv1(null, arr, 16); // ⇨
// [
// 44, 94, 164, 192, 64, 103, 17, 233,
// 146, 52, 155, 29, 235, 77, 59, 125,
// 44, 94, 164, 193, 64, 103, 17, 233,
// 146, 52, 155, 29, 235, 77, 59, 125
// ]
```
### Version 3
```javascript
const uuidv3 = require('uuid/v3');
// Incantations
uuidv3(name, namespace);
uuidv3(name, namespace, buffer);
uuidv3(name, namespace, buffer, offset);
```
Generate and return a RFC4122 v3 UUID.
* `name` - (String | Array[]) "name" to create UUID with
* `namespace` - (String | Array[]) "namespace" UUID either as a String or Array[16] of byte values
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing. Default = 0
Returns `buffer`, if specified, otherwise the string form of the UUID
Example:
```javascript
uuidv3('hello world', MY_NAMESPACE); // ⇨ '042ffd34-d989-321c-ad06-f60826172424'
```
### Version 4
```javascript
const uuidv4 = require('uuid/v4')
// Incantations
uuidv4();
uuidv4(options);
uuidv4(options, buffer, offset);
```
Generate and return a RFC4122 v4 UUID.
* `options` - (Object) Optional uuid state to apply. Properties may include:
* `random` - (Number[16]) Array of 16 numbers (0-255) to use in place of randomly generated values
* `rng` - (Function) Random # generator function that returns an Array[16] of byte values (0-255)
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing.
Returns `buffer`, if specified, otherwise the string form of the UUID
Example: Generate string UUID with predefined `random` values
```javascript
const v4options = {
random: [
0x10, 0x91, 0x56, 0xbe, 0xc4, 0xfb, 0xc1, 0xea,
0x71, 0xb4, 0xef, 0xe1, 0x67, 0x1c, 0x58, 0x36
]
};
uuidv4(v4options); // ⇨ '109156be-c4fb-41ea-b1b4-efe1671c5836'
```
Example: Generate two IDs in a single buffer
```javascript
const buffer = new Array();
uuidv4(null, buffer, 0); // ⇨
// [
// 155, 29, 235, 77, 59,
// 125, 75, 173, 155, 221,
// 43, 13, 123, 61, 203,
// 109
// ]
uuidv4(null, buffer, 16); // ⇨
// [
// 155, 29, 235, 77, 59, 125, 75, 173,
// 155, 221, 43, 13, 123, 61, 203, 109,
// 27, 157, 107, 205, 187, 253, 75, 45,
// 155, 93, 171, 141, 251, 189, 75, 237
// ]
```
### Version 5
```javascript
const uuidv5 = require('uuid/v5');
// Incantations
uuidv5(name, namespace);
uuidv5(name, namespace, buffer);
uuidv5(name, namespace, buffer, offset);
```
Generate and return a RFC4122 v5 UUID.
* `name` - (String | Array[]) "name" to create UUID with
* `namespace` - (String | Array[]) "namespace" UUID either as a String or Array[16] of byte values
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing. Default = 0
Returns `buffer`, if specified, otherwise the string form of the UUID
Example:
```javascript
uuidv5('hello world', MY_NAMESPACE); // ⇨ '9f282611-e0fd-5650-8953-89c8e342da0b'
```
## Command Line
UUIDs can be generated from the command line with the `uuid` command.
```shell
$ uuid
ddeb27fb-d9a0-4624-be4d-4615062daed4
$ uuid v1
02d37060-d446-11e7-a9fa-7bdae751ebe1
```
Type `uuid --help` for usage details
## Testing
```shell
npm test
```
----
Markdown generated from [README_js.md](README_js.md) by [](https://github.com/broofa/runmd)
# memdown
> In-memory [`abstract-leveldown`] store for Node.js and browsers.
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/memdown)

[](http://travis-ci.org/Level/memdown)
[](https://coveralls.io/github/Level/memdown?branch=master)
[](https://standardjs.com)
[](https://www.npmjs.com/package/memdown)
## Example
**If you are upgrading:** please see the [upgrade guide](./UPGRADING.md).
```js
const levelup = require('levelup')
const memdown = require('memdown')
const db = levelup(memdown())
db.put('hey', 'you', (err) => {
if (err) throw err
db.get('hey', { asBuffer: false }, (err, value) => {
if (err) throw err
console.log(value) // 'you'
})
})
```
Your data is discarded when the process ends or you release a reference to the store. Note as well, though the internals of `memdown` operate synchronously - [`levelup`] does not.
## Browser support
[](https://saucelabs.com/u/level-ci)
`memdown` requires a ES5-capable browser. If you're using one that's isn't (e.g. PhantomJS, Android < 4.4, IE < 10) then you will need [es5-shim](https://github.com/es-shims/es5-shim).
## Data types
Unlike [`leveldown`], `memdown` does not stringify keys or values. This means that in addition to Buffers, you can store any JS type without the need for [`encoding-down`]. For keys for example, you could use Buffers or strings, which sort lexicographically, or numbers, even Dates, which sort naturally. The only exceptions are `null` and `undefined`. Keys of that type are rejected; values of that type are converted to empty strings.
```js
const db = levelup(memdown())
db.put(12, true, (err) => {
if (err) throw err
db.createReadStream({
keyAsBuffer: false,
valueAsBuffer: false
}).on('data', (entry) => {
console.log(typeof entry.key) // 'number'
console.log(typeof entry.value) // 'boolean'
})
})
```
If you desire normalization for keys and values (e.g. to stringify numbers), wrap `memdown` with [`encoding-down`]. Alternatively install [`level-mem`] which conveniently bundles [`levelup`], `memdown` and [`encoding-down`]. Such an approach is also recommended if you want to achieve universal (isomorphic) behavior. For example, you could have [`leveldown`] in a backend and `memdown` in the frontend.
```js
const encode = require('encoding-down')
const db = levelup(encode(memdown()))
db.put(12, true, (err) => {
if (err) throw err
db.createReadStream({
keyAsBuffer: false,
valueAsBuffer: false
}).on('data', (entry) => {
console.log(typeof entry.key) // 'string'
console.log(typeof entry.value) // 'string'
})
})
```
## Snapshot guarantees
A `memdown` store is backed by [a fully persistent data structure](https://www.npmjs.com/package/functional-red-black-tree) and thus has snapshot guarantees. Meaning that reads operate on a snapshot in time, unaffected by simultaneous writes. Do note `memdown` cannot uphold this guarantee for (copies of) object references. If you store object values, be mindful of mutating referenced objects:
```js
const db = levelup(memdown())
const obj = { thing: 'original' }
db.put('key', obj, (err) => {
obj.thing = 'modified'
db.get('key', { asBuffer: false }, (err, value) => {
console.log(value === obj) // true
console.log(value.thing) // 'modified'
})
})
```
Conversely, when `memdown` is wrapped with [`encoding-down`] it stores representations rather than references.
```js
const encode = require('encoding-down')
const db = levelup(encode(memdown(), { valueEncoding: 'json' }))
const obj = { thing: 'original' }
db.put('key', obj, (err) => {
obj.thing = 'modified'
db.get('key', { asBuffer: false }, (err, value) => {
console.log(value === obj) // false
console.log(value.thing) // 'original'
})
})
```
## Test
In addition to the regular `npm test`, you can test `memdown` in a browser of choice with:
npm run test-browser-local
To check code coverage:
npm run coverage
## License
`memdown` is Copyright (c) 2013-2018 Rod Vagg [@rvagg](https://twitter.com/rvagg) and licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE file for more details.
[`abstract-leveldown`]: https://github.com/Level/abstract-leveldown
[`levelup`]: https://github.com/Level/levelup
[`encoding-down`]: https://github.com/Level/encoding-down
[`leveldown`]: https://github.com/Level/leveldown
[`level-mem`]: https://github.com/Level/mem
[level-badge]: http://leveldb.org/img/badge.svg
# web3
This is a main package of [web3.js](https://github.com/ethereum/web3.js)
Please read the main [readme](https://github.com/ethereum/web3.js) and [documentation](https://web3js.readthedocs.io) for more.
## Installation
### Node.js
```bash
npm install web3
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# NearBridge
TruffleFramework template with travis-ci.org and coveralls.io configured
[](https://travis-ci.org/nearprotocol/bridge)
[](https://coveralls.io/github/nearprotocol/bridge?branch=master)
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# repeat-element [](https://www.npmjs.com/package/repeat-element) [](https://npmjs.org/package/repeat-element) [](https://npmjs.org/package/repeat-element) [](https://travis-ci.org/jonschlinkert/repeat-element)
> Create an array by repeating the given value n times.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save repeat-element
```
## Usage
```js
const repeat = require('repeat-element');
repeat('a', 5);
//=> ['a', 'a', 'a', 'a', 'a']
repeat('a', 1);
//=> ['a']
repeat('a', 0);
//=> []
repeat(null, 5)
//» [ null, null, null, null, null ]
repeat({some: 'object'}, 5)
//» [ { some: 'object' },
// { some: 'object' },
// { some: 'object' },
// { some: 'object' },
// { some: 'object' } ]
repeat(5, 5)
//» [ 5, 5, 5, 5, 5 ]
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 17 | [jonschlinkert](https://github.com/jonschlinkert) |
| 3 | [LinusU](https://github.com/LinusU) |
| 1 | [architectcodes](https://github.com/architectcodes) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2018, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on August 19, 2018._
# Sentence Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a lower case with spaces between words, then capitalize the string.
## Installation
```
npm install sentence-case --save
```
## Usage
```js
import { sentenceCase } from "sentence-case";
sentenceCase("string"); //=> "String"
sentenceCase("dot.case"); //=> "Dot case"
sentenceCase("PascalCase"); //=> "Pascal case"
sentenceCase("version 1.2.10"); //=> "Version 1 2 10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/sentence-case.svg?style=flat
[npm-url]: https://npmjs.org/package/sentence-case
[downloads-image]: https://img.shields.io/npm/dm/sentence-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/sentence-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/sentence-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=sentence-case
# Source Map Support
[](https://travis-ci.org/evanw/node-source-map-support)
This module provides source map support for stack traces in node via the [V8 stack trace API](https://github.com/v8/v8/wiki/Stack-Trace-API). It uses the [source-map](https://github.com/mozilla/source-map) module to replace the paths and line numbers of source-mapped files with their original paths and line numbers. The output mimics node's stack trace format with the goal of making every compile-to-JS language more of a first-class citizen. Source maps are completely general (not specific to any one language) so you can use source maps with multiple compile-to-JS languages in the same node process.
## Installation and Usage
#### Node support
```
$ npm install source-map-support
```
Source maps can be generated using libraries such as [source-map-index-generator](https://github.com/twolfson/source-map-index-generator). Once you have a valid source map, place a source mapping comment somewhere in the file (usually done automatically or with an option by your transpiler):
```
//# sourceMappingURL=path/to/source.map
```
If multiple sourceMappingURL comments exist in one file, the last sourceMappingURL comment will be
respected (e.g. if a file mentions the comment in code, or went through multiple transpilers).
The path should either be absolute or relative to the compiled file.
From here you have two options.
##### CLI Usage
```bash
node -r source-map-support/register compiled.js
```
##### Programmatic Usage
Put the following line at the top of the compiled file.
```js
require('source-map-support').install();
```
It is also possible to install the source map support directly by
requiring the `register` module which can be handy with ES6:
```js
import 'source-map-support/register'
// Instead of:
import sourceMapSupport from 'source-map-support'
sourceMapSupport.install()
```
Note: if you're using babel-register, it includes source-map-support already.
It is also very useful with Mocha:
```
$ mocha --require source-map-support/register tests/
```
#### Browser support
This library also works in Chrome. While the DevTools console already supports source maps, the V8 engine doesn't and `Error.prototype.stack` will be incorrect without this library. Everything will just work if you deploy your source files using [browserify](http://browserify.org/). Just make sure to pass the `--debug` flag to the browserify command so your source maps are included in the bundled code.
This library also works if you use another build process or just include the source files directly. In this case, include the file `browser-source-map-support.js` in your page and call `sourceMapSupport.install()`. It contains the whole library already bundled for the browser using browserify.
```html
<script src="browser-source-map-support.js"></script>
<script>sourceMapSupport.install();</script>
```
This library also works if you use AMD (Asynchronous Module Definition), which is used in tools like [RequireJS](http://requirejs.org/). Just list `browser-source-map-support` as a dependency:
```html
<script>
define(['browser-source-map-support'], function(sourceMapSupport) {
sourceMapSupport.install();
});
</script>
```
## Options
This module installs two things: a change to the `stack` property on `Error` objects and a handler for uncaught exceptions that mimics node's default exception handler (the handler can be seen in the demos below). You may want to disable the handler if you have your own uncaught exception handler. This can be done by passing an argument to the installer:
```js
require('source-map-support').install({
handleUncaughtExceptions: false
});
```
This module loads source maps from the filesystem by default. You can provide alternate loading behavior through a callback as shown below. For example, [Meteor](https://github.com/meteor) keeps all source maps cached in memory to avoid disk access.
```js
require('source-map-support').install({
retrieveSourceMap: function(source) {
if (source === 'compiled.js') {
return {
url: 'original.js',
map: fs.readFileSync('compiled.js.map', 'utf8')
};
}
return null;
}
});
```
The module will by default assume a browser environment if XMLHttpRequest and window are defined. If either of these do not exist it will instead assume a node environment.
In some rare cases, e.g. when running a browser emulation and where both variables are also set, you can explictly specify the environment to be either 'browser' or 'node'.
```js
require('source-map-support').install({
environment: 'node'
});
```
To support files with inline source maps, the `hookRequire` options can be specified, which will monitor all source files for inline source maps.
```js
require('source-map-support').install({
hookRequire: true
});
```
This monkey patches the `require` module loading chain, so is not enabled by default and is not recommended for any sort of production usage.
## Demos
#### Basic Demo
original.js:
```js
throw new Error('test'); // This is the original code
```
compiled.js:
```js
require('source-map-support').install();
throw new Error('test'); // This is the compiled code
// The next line defines the sourceMapping.
//# sourceMappingURL=compiled.js.map
```
compiled.js.map:
```json
{
"version": 3,
"file": "compiled.js",
"sources": ["original.js"],
"names": [],
"mappings": ";;AAAA,MAAM,IAAI"
}
```
Run compiled.js using node (notice how the stack trace uses original.js instead of compiled.js):
```
$ node compiled.js
original.js:1
throw new Error('test'); // This is the original code
^
Error: test
at Object.<anonymous> (original.js:1:7)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Function.Module.runMain (module.js:497:10)
at startup (node.js:119:16)
at node.js:901:3
```
#### TypeScript Demo
demo.ts:
```typescript
declare function require(name: string);
require('source-map-support').install();
class Foo {
constructor() { this.bar(); }
bar() { throw new Error('this is a demo'); }
}
new Foo();
```
Compile and run the file using the TypeScript compiler from the terminal:
```
$ npm install source-map-support typescript
$ node_modules/typescript/bin/tsc -sourcemap demo.ts
$ node demo.js
demo.ts:5
bar() { throw new Error('this is a demo'); }
^
Error: this is a demo
at Foo.bar (demo.ts:5:17)
at new Foo (demo.ts:4:24)
at Object.<anonymous> (demo.ts:7:1)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Function.Module.runMain (module.js:497:10)
at startup (node.js:119:16)
at node.js:901:3
```
There is also the option to use `-r source-map-support/register` with typescript, without the need add the `require('source-map-support').install()` in the code base:
```
$ npm install source-map-support typescript
$ node_modules/typescript/bin/tsc -sourcemap demo.ts
$ node -r source-map-support/register demo.js
demo.ts:5
bar() { throw new Error('this is a demo'); }
^
Error: this is a demo
at Foo.bar (demo.ts:5:17)
at new Foo (demo.ts:4:24)
at Object.<anonymous> (demo.ts:7:1)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Function.Module.runMain (module.js:497:10)
at startup (node.js:119:16)
at node.js:901:3
```
#### CoffeeScript Demo
demo.coffee:
```coffee
require('source-map-support').install()
foo = ->
bar = -> throw new Error 'this is a demo'
bar()
foo()
```
Compile and run the file using the CoffeeScript compiler from the terminal:
```sh
$ npm install source-map-support coffeescript
$ node_modules/.bin/coffee --map --compile demo.coffee
$ node demo.js
demo.coffee:3
bar = -> throw new Error 'this is a demo'
^
Error: this is a demo
at bar (demo.coffee:3:22)
at foo (demo.coffee:4:3)
at Object.<anonymous> (demo.coffee:5:1)
at Object.<anonymous> (demo.coffee:1:1)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Function.Module.runMain (module.js:497:10)
at startup (node.js:119:16)
```
## Tests
This repo contains both automated tests for node and manual tests for the browser. The automated tests can be run using mocha (type `mocha` in the root directory). To run the manual tests:
* Build the tests using `build.js`
* Launch the HTTP server (`npm run serve-tests`) and visit
* http://127.0.0.1:1336/amd-test
* http://127.0.0.1:1336/browser-test
* http://127.0.0.1:1336/browserify-test - **Currently not working** due to a bug with browserify (see [pull request #66](https://github.com/evanw/node-source-map-support/pull/66) for details).
* For `header-test`, run `server.js` inside that directory and visit http://127.0.0.1:1337/
## License
This code is available under the [MIT license](http://opensource.org/licenses/MIT).
Browser-friendly inheritance fully compatible with standard node.js
[inherits](http://nodejs.org/api/util.html#util_util_inherits_constructor_superconstructor).
This package exports standard `inherits` from node.js `util` module in
node environment, but also provides alternative browser-friendly
implementation through [browser
field](https://gist.github.com/shtylman/4339901). Alternative
implementation is a literal copy of standard one located in standalone
module to avoid requiring of `util`. It also has a shim for old
browsers with no `Object.create` support.
While keeping you sure you are using standard `inherits`
implementation in node.js environment, it allows bundlers such as
[browserify](https://github.com/substack/node-browserify) to not
include full `util` package to your client code if all you need is
just `inherits` function. It worth, because browser shim for `util`
package is large and `inherits` is often the single function you need
from it.
It's recommended to use this package instead of
`require('util').inherits` for any code that has chances to be used
not only in node.js but in browser too.
## usage
```js
var inherits = require('inherits');
// then use exactly as the standard one
```
## note on version ~1.0
Version ~1.0 had completely different motivation and is not compatible
neither with 2.0 nor with standard node.js `inherits`.
If you are using version ~1.0 and planning to switch to ~2.0, be
careful:
* new version uses `super_` instead of `super` for referencing
superclass
* new version overwrites current prototype while old one preserves any
existing fields on it
## ethjs-unit
<div>
<!-- Dependency Status -->
<a href="https://david-dm.org/ethjs/ethjs-unit">
<img src="https://david-dm.org/ethjs/ethjs-unit.svg"
alt="Dependency Status" />
</a>
<!-- devDependency Status -->
<a href="https://david-dm.org/ethjs/ethjs-unit#info=devDependencies">
<img src="https://david-dm.org/ethjs/ethjs-unit/dev-status.svg" alt="devDependency Status" />
</a>
<!-- Build Status -->
<a href="https://travis-ci.org/ethjs/ethjs-unit">
<img src="https://travis-ci.org/ethjs/ethjs-unit.svg"
alt="Build Status" />
</a>
<!-- NPM Version -->
<a href="https://www.npmjs.org/package/ethjs-unit">
<img src="http://img.shields.io/npm/v/ethjs-unit.svg"
alt="NPM version" />
</a>
<!-- Test Coverage -->
<a href="https://coveralls.io/r/ethjs/ethjs-unit">
<img src="https://coveralls.io/repos/github/ethjs/ethjs-unit/badge.svg" alt="Test Coverage" />
</a>
<!-- Javascript Style -->
<a href="http://airbnb.io/javascript/">
<img src="https://img.shields.io/badge/code%20style-airbnb-brightgreen.svg" alt="js-airbnb-style" />
</a>
</div>
<br />
A simple module for handling Ethereum unit convertion.
## Install
```
npm install --save ethjs-unit
```
## Usage
```js
const unit = require('ethjs-unit');
var val1 = unit.toWei(249824778, 'ether');
// result <BN ...> 249824778000000000000000000
var val2 = unit.fromWei('249824778000000000000000000', 'ether');
// result '249824778'
```
## About
A port from the `web3.js` library, that just handles the unit convertion between the various types of Ethereum currency units.
Note, the `toWei` returns a BN instance while `fromWei` always returns a string number.
## Amorphic Data Formatting
`ethjs-unit` uses the [number-to-bn](http://github.com/silentcicero/number-to-bn) module to format all number values (hex or otherwise) into digestable BN.js number instances.
## Methods Available & Objects
```
unitMap { unitName: singleUnitWeiValue, ... }
getValueOfUnit <Function (unit) : (BN)>
toWei <Function (value, unit) : (BN)>
fromWei <Function (value, unit) : (String)>
```
## Supported Units
```
'wei': '1',
'kwei': '1000',
'Kwei': '1000',
'babbage': '1000',
'femtoether': '1000',
'mwei': '1000000',
'Mwei': '1000000',
'lovelace': '1000000',
'picoether': '1000000',
'gwei': '1000000000',
'Gwei': '1000000000',
'shannon': '1000000000',
'nanoether': '1000000000',
'nano': '1000000000',
'szabo': '1000000000000',
'microether': '1000000000000',
'micro': '1000000000000',
'finney': '1000000000000000',
'milliether': '1000000000000000',
'milli': '1000000000000000',
'ether': '1000000000000000000',
'kether': '1000000000000000000000',
'grand': '1000000000000000000000',
'mether': '1000000000000000000000000',
'gether': '1000000000000000000000000000',
'tether': '1000000000000000000000000000000'
```
## Why BN.js?
`ethjs` has made a policy of using `BN.js` accross all of our modules. Here are some reasons why:
1. Lighter than alternatives (BigNumber.js)
2. Faster than most alternatives, see [benchmarks](https://github.com/indutny/bn.js/issues/89)
3. Used by the Ethereum foundation across all [`ethereumjs`](https://github.com/ethereumjs) repositories
4. Is already used by a critical JS dependency of many ethereum packages, see package [`elliptic`](https://github.com/indutny/elliptic)
5. Does not support decimals or floats (for greater precision), remember, the Ethereum blockchain cannot and will not support float values or decimal numbers
## Contributing
Please help better the ecosystem by submitting issues and pull requests to default. We need all the help we can get to build the absolute best linting standards and utilities. We follow the AirBNB linting standard and the unix philosophy.
## Guides
You'll find more detailed information on using `ethjs-unit` and tailoring it to your needs in our guides:
- [User guide](docs/user-guide.md) - Usage, configuration, FAQ and complementary tools.
- [Developer guide](docs/developer-guide.md) - Contributing to `ethjs-unit`, writing coverage and updates.
## Help out
There is always a lot of work to do, and will have many rules to maintain. So please help out in any way that you can:
- Create, enhance, and debug ethjs rules (see our guide to ["Working on rules"](./github/CONTRIBUTING.md)).
- Improve documentation.
- Chime in on any open issue or pull request.
- Open new issues about your ideas for making `ethjs-unit` better, and pull requests to show us how your idea works.
- Add new tests to *absolutely anything*.
- Create or contribute to ecosystem tools, like modules for encoding or contracts.
- Spread the word.
Please consult our [Code of Conduct](CODE_OF_CONDUCT.md) docs before helping out.
We communicate via [issues](https://github.com/ethjs/ethjs-unit/issues) and [pull requests](https://github.com/ethjs/ethjs-unit/pulls).
## Important documents
- [Changelog](CHANGELOG.md)
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [License](https://raw.githubusercontent.com/ethjs/ethjs-unit/master/LICENSE)
## Licence
This project is licensed under the MIT license, Copyright (c) 2016 Nick Dodson. For more information see LICENSE.md.
```
The MIT License
Copyright (c) 2016 Nick Dodson. nickdodson.com
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
```
# Path Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into a lower case string with slashes between words.
## Installation
```
npm install path-case --save
```
## Usage
```js
import { pathCase } from "path-case";
pathCase("string"); //=> "string"
pathCase("dot.case"); //=> "dot/case"
pathCase("PascalCase"); //=> "pascal/case"
pathCase("version 1.2.10"); //=> "version/1/2/10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/path-case.svg?style=flat
[npm-url]: https://npmjs.org/package/path-case
[downloads-image]: https://img.shields.io/npm/dm/path-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/path-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/path-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=path-case
## is-hex-prefixed
<div>
<!-- Dependency Status -->
<a href="https://david-dm.org/silentcicero/is-hex-prefixed">
<img src="https://david-dm.org/silentcicero/is-hex-prefixed.svg"
alt="Dependency Status" />
</a>
<!-- devDependency Status -->
<a href="https://david-dm.org/silentcicero/is-hex-prefixed#info=devDependencies">
<img src="https://david-dm.org/silentcicero/is-hex-prefixed/dev-status.svg" alt="devDependency Status" />
</a>
<!-- Build Status -->
<a href="https://travis-ci.org/SilentCicero/is-hex-prefixed">
<img src="https://travis-ci.org/SilentCicero/is-hex-prefixed.svg"
alt="Build Status" />
</a>
<!-- NPM Version -->
<a href="https://www.npmjs.org/package/is-hex-prefixed">
<img src="http://img.shields.io/npm/v/is-hex-prefixed.svg"
alt="NPM version" />
</a>
<!-- Test Coverage -->
<a href="https://coveralls.io/r/SilentCicero/is-hex-prefixed">
<img src="https://coveralls.io/repos/github/SilentCicero/is-hex-prefixed/badge.svg" alt="Test Coverage" />
</a>
<!-- Javascript Style -->
<a href="http://airbnb.io/javascript/">
<img src="https://img.shields.io/badge/code%20style-airbnb-brightgreen.svg" alt="js-airbnb-style" />
</a>
</div>
<br />
A simple method to check if a string is hex prefixed.
## Install
```
npm install --save is-hex-prefixed
```
## Usage
```js
const isHexPrefixed = require('is-hex-prefixed');
console.log(isHexPrefixed('0x..'));
// result true
console.log(isHexPrefixed('dfsk'));
// result false
console.log(isHexPrefixed({}));
// result throw new Error
console.log(isHexPrefixed('-0x'));
// result false
```
## Important documents
- [Changelog](CHANGELOG.md)
- [License](https://raw.githubusercontent.com/silentcicero/is-hex-prefixed/master/LICENSE)
## Licence
This project is licensed under the MIT license, Copyright (c) 2016 Nick Dodson. For more information see LICENSE.md.
```
The MIT License
Copyright (c) 2016 Nick Dodson. nickdodson.com
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
```
# fs-constants
Small module that allows you to get the fs constants across
Node and the browser.
```
npm install fs-constants
```
Previously you would use `require('constants')` for this in node but that has been
deprecated and changed to `require('fs').constants` which does not browserify.
This module uses `require('constants')` in the browser and `require('fs').constants` in node to work around this
## Usage
``` js
var constants = require('fs-constants')
console.log('constants:', constants)
```
## License
MIT
# graceful-fs
graceful-fs functions as a drop-in replacement for the fs module,
making various improvements.
The improvements are meant to normalize behavior across different
platforms and environments, and to make filesystem access more
resilient to errors.
## Improvements over [fs module](https://nodejs.org/api/fs.html)
* Queues up `open` and `readdir` calls, and retries them once
something closes if there is an EMFILE error from too many file
descriptors.
* fixes `lchmod` for Node versions prior to 0.6.2.
* implements `fs.lutimes` if possible. Otherwise it becomes a noop.
* ignores `EINVAL` and `EPERM` errors in `chown`, `fchown` or
`lchown` if the user isn't root.
* makes `lchmod` and `lchown` become noops, if not available.
* retries reading a file if `read` results in EAGAIN error.
On Windows, it retries renaming a file for up to one second if `EACCESS`
or `EPERM` error occurs, likely because antivirus software has locked
the directory.
## USAGE
```javascript
// use just like fs
var fs = require('graceful-fs')
// now go and do stuff with it...
fs.readFileSync('some-file-or-whatever')
```
## Global Patching
If you want to patch the global fs module (or any other fs-like
module) you can do this:
```javascript
// Make sure to read the caveat below.
var realFs = require('fs')
var gracefulFs = require('graceful-fs')
gracefulFs.gracefulify(realFs)
```
This should only ever be done at the top-level application layer, in
order to delay on EMFILE errors from any fs-using dependencies. You
should **not** do this in a library, because it can cause unexpected
delays in other parts of the program.
## Changes
This module is fairly stable at this point, and used by a lot of
things. That being said, because it implements a subtle behavior
change in a core part of the node API, even modest changes can be
extremely breaking, and the versioning is thus biased towards
bumping the major when in doubt.
The main change between major versions has been switching between
providing a fully-patched `fs` module vs monkey-patching the node core
builtin, and the approach by which a non-monkey-patched `fs` was
created.
The goal is to trade `EMFILE` errors for slower fs operations. So, if
you try to open a zillion files, rather than crashing, `open`
operations will be queued up and wait for something else to `close`.
There are advantages to each approach. Monkey-patching the fs means
that no `EMFILE` errors can possibly occur anywhere in your
application, because everything is using the same core `fs` module,
which is patched. However, it can also obviously cause undesirable
side-effects, especially if the module is loaded multiple times.
Implementing a separate-but-identical patched `fs` module is more
surgical (and doesn't run the risk of patching multiple times), but
also imposes the challenge of keeping in sync with the core module.
The current approach loads the `fs` module, and then creates a
lookalike object that has all the same methods, except a few that are
patched. It is safe to use in all versions of Node from 0.8 through
7.0.
### v4
* Do not monkey-patch the fs module. This module may now be used as a
drop-in dep, and users can opt into monkey-patching the fs builtin
if their app requires it.
### v3
* Monkey-patch fs, because the eval approach no longer works on recent
node.
* fixed possible type-error throw if rename fails on windows
* verify that we *never* get EMFILE errors
* Ignore ENOSYS from chmod/chown
* clarify that graceful-fs must be used as a drop-in
### v2.1.0
* Use eval rather than monkey-patching fs.
* readdir: Always sort the results
* win32: requeue a file if error has an OK status
### v2.0
* A return to monkey patching
* wrap process.cwd
### v1.1
* wrap readFile
* Wrap fs.writeFile.
* readdir protection
* Don't clobber the fs builtin
* Handle fs.read EAGAIN errors by trying again
* Expose the curOpen counter
* No-op lchown/lchmod if not implemented
* fs.rename patch only for win32
* Patch fs.rename to handle AV software on Windows
* Close #4 Chown should not fail on einval or eperm if non-root
* Fix isaacs/fstream#1 Only wrap fs one time
* Fix #3 Start at 1024 max files, then back off on EMFILE
* lutimes that doens't blow up on Linux
* A full on-rewrite using a queue instead of just swallowing the EMFILE error
* Wrap Read/Write streams as well
### 1.0
* Update engines for node 0.6
* Be lstat-graceful on Windows
* first
# Lower Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transforms the string to lower case.
## Installation
```
npm install lower-case --save
```
## Usage
```js
import { lowerCase, localeLowerCase } from "lower-case";
lowerCase("string"); //=> "string"
lowerCase("PascalCase"); //=> "pascalcase"
localeLowerCase("STRING", "tr"); //=> "strıng"
```
## License
MIT
[npm-image]: https://img.shields.io/npm/v/lower-case.svg?style=flat
[npm-url]: https://npmjs.org/package/lower-case
[downloads-image]: https://img.shields.io/npm/dm/lower-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/lower-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/lower-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=lower-case
# readable-stream
***Node-core v8.11.1 streams for userland*** [](https://travis-ci.org/nodejs/readable-stream)
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
[](https://saucelabs.com/u/readable-stream)
```bash
npm install --save readable-stream
```
***Node-core streams for userland***
This package is a mirror of the Streams2 and Streams3 implementations in
Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.11.1/docs/api/stream.html).
If you want to guarantee a stable streams base, regardless of what version of
Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core, for background see [this blogpost](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).
As of version 2.0.0 **readable-stream** uses semantic versioning.
# Streams Working Group
`readable-stream` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
<a name="members"></a>
## Team Members
* **Chris Dickinson** ([@chrisdickinson](https://github.com/chrisdickinson)) <[email protected]>
- Release GPG key: 9554F04D7259F04124DE6B476D5A82AC7E37093B
* **Calvin Metcalf** ([@calvinmetcalf](https://github.com/calvinmetcalf)) <[email protected]>
- Release GPG key: F3EF5F62A87FC27A22E643F714CE4FF5015AA242
* **Rod Vagg** ([@rvagg](https://github.com/rvagg)) <[email protected]>
- Release GPG key: DD8F2338BAE7501E3DD5AC78C273792F7D83545D
* **Sam Newman** ([@sonewman](https://github.com/sonewman)) <[email protected]>
* **Mathias Buus** ([@mafintosh](https://github.com/mafintosh)) <[email protected]>
* **Domenic Denicola** ([@domenic](https://github.com/domenic)) <[email protected]>
* **Matteo Collina** ([@mcollina](https://github.com/mcollina)) <[email protected]>
- Release GPG key: 3ABC01543F22DD2239285CDD818674489FBC127E
* **Irina Shestak** ([@lrlna](https://github.com/lrlna)) <[email protected]>
# is-extglob [](http://badge.fury.io/js/is-extglob) [](https://travis-ci.org/jonschlinkert/is-extglob)
> Returns true if a string has an extglob.
## Install with [npm](npmjs.org)
```bash
npm i is-extglob --save
```
## Usage
```js
var isExtglob = require('is-extglob');
```
**True**
```js
isExtglob('?(abc)');
isExtglob('@(abc)');
isExtglob('!(abc)');
isExtglob('*(abc)');
isExtglob('+(abc)');
```
**False**
Everything else...
```js
isExtglob('foo.js');
isExtglob('!foo.js');
isExtglob('*.js');
isExtglob('**/abc.js');
isExtglob('abc/*.js');
isExtglob('abc/(aaa|bbb).js');
isExtglob('abc/[a-z].js');
isExtglob('abc/{a,b}.js');
isExtglob('abc/?.js');
isExtglob('abc.js');
isExtglob('abc/def/ghi.js');
```
## Related
* [extglob](https://github.com/jonschlinkert/extglob): Extended globs. extglobs add the expressive power of regular expressions to glob patterns.
* [micromatch](https://github.com/jonschlinkert/micromatch): Glob matching for javascript/node.js. A faster alternative to minimatch (10-45x faster on avg), with all the features you're used to using in your Grunt and gulp tasks.
* [parse-glob](https://github.com/jonschlinkert/parse-glob): Parse a glob pattern into an object of tokens.
## Run tests
Install dev dependencies.
```bash
npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-extglob/issues)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright (c) 2015 Jon Schlinkert
Released under the MIT license
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on March 06, 2015._
# to-buffer
Pass in a string, get a buffer back. Pass in a buffer, get the same buffer back.
```
npm install to-buffer
```
[](https://travis-ci.org/mafintosh/to-buffer)
## Usage
``` js
var toBuffer = require('to-buffer')
console.log(toBuffer('hi')) // <Buffer 68 69>
console.log(toBuffer(Buffer('hi'))) // <Buffer 68 69>
console.log(toBuffer('6869', 'hex')) // <Buffer 68 69>
console.log(toBuffer(43)) // throws
```
## License
MIT
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# for-own [](https://www.npmjs.com/package/for-own) [](https://npmjs.org/package/for-own) [](https://npmjs.org/package/for-own) [](https://travis-ci.org/jonschlinkert/for-own)
> Iterate over the own enumerable properties of an object, and return an object with properties that evaluate to true from the callback. Exit early by returning `false`. JavaScript/Node.js.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save for-own
```
## Usage
```js
var forOwn = require('for-own');
var obj = {a: 'foo', b: 'bar', c: 'baz'};
var values = [];
var keys = [];
forOwn(obj, function (value, key, o) {
keys.push(key);
values.push(value);
});
console.log(keys);
//=> ['a', 'b', 'c'];
console.log(values);
//=> ['foo', 'bar', 'baz'];
```
## About
### Related projects
* [arr-flatten](https://www.npmjs.com/package/arr-flatten): Recursively flatten an array or arrays. This is the fastest implementation of array flatten. | [homepage](https://github.com/jonschlinkert/arr-flatten "Recursively flatten an array or arrays. This is the fastest implementation of array flatten.")
* [collection-map](https://www.npmjs.com/package/collection-map): Returns an array of mapped values from an array or object. | [homepage](https://github.com/jonschlinkert/collection-map "Returns an array of mapped values from an array or object.")
* [for-in](https://www.npmjs.com/package/for-in): Iterate over the own and inherited enumerable properties of an object, and return an object… [more](https://github.com/jonschlinkert/for-in) | [homepage](https://github.com/jonschlinkert/for-in "Iterate over the own and inherited enumerable properties of an object, and return an object with properties that evaluate to true from the callback. Exit early by returning `false`. JavaScript/Node.js")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 10 | [jonschlinkert](https://github.com/jonschlinkert) |
| 1 | [javiercejudo](https://github.com/javiercejudo) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.4.2, on February 26, 2017._
# seek-bzip
[![Build Status][1]][2] [![dependency status][3]][4] [![dev dependency status][5]][6]
`seek-bzip` is a pure-javascript Node.JS module adapted from [node-bzip](https://github.com/skeggse/node-bzip) and before that [antimatter15's pure-javascript bzip2 decoder](https://github.com/antimatter15/bzip2.js). Like these projects, `seek-bzip` only does decompression (see [compressjs](https://github.com/cscott/compressjs) if you need compression code). Unlike those other projects, `seek-bzip` can seek to and decode single blocks from the bzip2 file.
`seek-bzip` primarily decodes buffers into other buffers, synchronously.
With the help of the [fibers](https://github.com/laverdet/node-fibers)
package, it can operate on node streams; see `test/stream.js` for an
example.
## How to Install
```
npm install seek-bzip
```
This package uses
[Typed Arrays](https://developer.mozilla.org/en-US/docs/JavaScript/Typed_arrays), which are present in node.js >= 0.5.5.
## Usage
After compressing some example data into `example.bz2`, the following will recreate that original data and save it to `example`:
```
var Bunzip = require('seek-bzip');
var fs = require('fs');
var compressedData = fs.readFileSync('example.bz2');
var data = Bunzip.decode(compressedData);
fs.writeFileSync('example', data);
```
See the tests in the `tests/` directory for further usage examples.
For uncompressing single blocks of bzip2-compressed data, you will need
an out-of-band index listing the start of each bzip2 block. (Presumably
you generate this at the same time as you index the start of the information
you wish to seek to inside the compressed file.) The `seek-bzip` module
has been designed to be compatible with the C implementation `seek-bzip2`
available from https://bitbucket.org/james_taylor/seek-bzip2. That codebase
contains a `bzip-table` tool which will generate bzip2 block start indices.
There is also a pure-JavaScript `seek-bzip-table` tool in this package's
`bin` directory.
## Documentation
`require('seek-bzip')` returns a `Bunzip` object. It contains three static
methods. The first is a function accepting one or two parameters:
`Bunzip.decode = function(input, [Number expectedSize] or [output], [boolean multistream])`
The `input` argument can be a "stream" object (which must implement the
`readByte` method), or a `Buffer`.
If `expectedSize` is not present, `decodeBzip` simply decodes `input` and
returns the resulting `Buffer`.
If `expectedSize` is present (and numeric), `decodeBzip` will store
the results in a `Buffer` of length `expectedSize`, and throw an error
in the case that the size of the decoded data does not match
`expectedSize`.
If you pass a non-numeric second parameter, it can either be a `Buffer`
object (which must be of the correct length; an error will be thrown if
the size of the decoded data does not match the buffer length) or
a "stream" object (which must implement a `writeByte` method).
The optional third `multistream` parameter, if true, attempts to continue
reading past the end of the bzip2 file. This supports "multistream"
bzip2 files, which are simply multiple bzip2 files concatenated together.
If this argument is true, the input stream must have an `eof` method
which returns true when the end of the input has been reached.
The second exported method is a function accepting two or three parameters:
`Bunzip.decodeBlock = function(input, Number blockStartBits, [Number expectedSize] or [output])`
The `input` and `expectedSize`/`output` parameters are as above.
The `blockStartBits` parameter gives the start of the desired block, in bits.
If passing a stream as the `input` parameter, it must implement the
`seek` method.
The final exported method is a function accepting two or three parameters:
`Bunzip.table = function(input, Function callback, [boolean multistream])`
The `input` and `multistream` parameters are identical to those for the
`decode` method.
This function will invoke `callback(position, size)` once per bzip2 block,
where `position` gives the starting position of the block (in *bits*), and
`size` gives the uncompressed size of the block (in bytes).
This can be used to construct an index allowing direct access to a particular
block inside a bzip2 file, using the `decodeBlock` method.
## Command-line
There are binaries available in bin. The first generates an index of all
the blocks in a bzip2-compressed file:
```
$ bin/seek-bzip-table test/sample4.bz2
32 99981
320555 99981
606348 99981
847568 99981
1089094 99981
1343625 99981
1596228 99981
1843336 99981
2090919 99981
2342106 39019
$
```
The first field is the starting position of the block, in bits, and the
second field is the length of the block, in bytes.
The second binary decodes an arbitrary block of a bzip2 file:
```
$ bin/seek-bunzip -d -b 2342106 test/sample4.bz2 | tail
élan's
émigré
émigré's
émigrés
épée
épée's
épées
étude
étude's
études
$
```
Use `--help` to see other options.
## Help wanted
Improvements to this module would be generally useful.
Feel free to fork on github and submit pull requests!
## Related projects
* https://github.com/skeggse/node-bzip node-bzip (original upstream source)
* https://github.com/cscott/compressjs
Lots of compression/decompression algorithms from the same author as this
module, including bzip2 compression code.
* https://github.com/cscott/lzjb fast LZJB compression/decompression
## License
#### MIT License
> Copyright © 2013-2015 C. Scott Ananian
>
> Copyright © 2012-2015 Eli Skeggs
>
> Copyright © 2011 Kevin Kwok
>
> Permission is hereby granted, free of charge, to any person obtaining
> a copy of this software and associated documentation files (the
> "Software"), to deal in the Software without restriction, including
> without limitation the rights to use, copy, modify, merge, publish,
> distribute, sublicense, and/or sell copies of the Software, and to
> permit persons to whom the Software is furnished to do so, subject to
> the following conditions:
>
> The above copyright notice and this permission notice shall be
> included in all copies or substantial portions of the Software.
>
> THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
> EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
> MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
> NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
> LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
> OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
> WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[1]: https://travis-ci.org/cscott/seek-bzip.png
[2]: https://travis-ci.org/cscott/seek-bzip
[3]: https://david-dm.org/cscott/seek-bzip.png
[4]: https://david-dm.org/cscott/seek-bzip
[5]: https://david-dm.org/cscott/seek-bzip/dev-status.png
[6]: https://david-dm.org/cscott/seek-bzip#info=devDependencies
# forwarded
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Parse HTTP X-Forwarded-For header
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install forwarded
```
## API
```js
var forwarded = require('forwarded')
```
### forwarded(req)
```js
var addresses = forwarded(req)
```
Parse the `X-Forwarded-For` header from the request. Returns an array
of the addresses, including the socket address for the `req`, in reverse
order (i.e. index `0` is the socket address and the last index is the
furthest address, typically the end-user).
## Testing
```sh
$ npm test
```
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/forwarded.svg
[npm-url]: https://npmjs.org/package/forwarded
[node-version-image]: https://img.shields.io/node/v/forwarded.svg
[node-version-url]: https://nodejs.org/en/download/
[travis-image]: https://img.shields.io/travis/jshttp/forwarded/master.svg
[travis-url]: https://travis-ci.org/jshttp/forwarded
[coveralls-image]: https://img.shields.io/coveralls/jshttp/forwarded/master.svg
[coveralls-url]: https://coveralls.io/r/jshttp/forwarded?branch=master
[downloads-image]: https://img.shields.io/npm/dm/forwarded.svg
[downloads-url]: https://npmjs.org/package/forwarded
# path-parse [](https://travis-ci.org/jbgutierrez/path-parse)
> Node.js [`path.parse(pathString)`](https://nodejs.org/api/path.html#path_path_parse_pathstring) [ponyfill](https://ponyfill.com).
## Install
```
$ npm install --save path-parse
```
## Usage
```js
var pathParse = require('path-parse');
pathParse('/home/user/dir/file.txt');
//=> {
// root : "/",
// dir : "/home/user/dir",
// base : "file.txt",
// ext : ".txt",
// name : "file"
// }
```
## API
See [`path.parse(pathString)`](https://nodejs.org/api/path.html#path_path_parse_pathstring) docs.
### pathParse(path)
### pathParse.posix(path)
The Posix specific version.
### pathParse.win32(path)
The Windows specific version.
## License
MIT © [Javier Blanco](http://jbgutierrez.info)
## read
For reading user input from stdin.
Similar to the `readline` builtin's `question()` method, but with a
few more features.
## USAGE
```javascript
var read = require("read")
read(options, callback)
```
The callback gets called with either the user input, or the default
specified, or an error, as `callback(error, result, isDefault)`
node style.
## OPTIONS
Every option is optional.
* `prompt` What to write to stdout before reading input.
* `silent` Don't echo the output as the user types it.
* `replace` Replace silenced characters with the supplied character value.
* `timeout` Number of ms to wait for user input before giving up.
* `default` The default value if the user enters nothing.
* `edit` Allow the user to edit the default value.
* `terminal` Treat the output as a TTY, whether it is or not.
* `input` Readable stream to get input data from. (default `process.stdin`)
* `output` Writeable stream to write prompts to. (default: `process.stdout`)
If silent is true, and the input is a TTY, then read will set raw
mode, and read character by character.
## COMPATIBILITY
This module works sort of with node 0.6. It does not work with node
versions less than 0.6. It is best on node 0.8.
On node version 0.6, it will remove all listeners on the input
stream's `data` and `keypress` events, because the readline module did
not fully clean up after itself in that version of node, and did not
make it possible to clean up after it in a way that has no potential
for side effects.
Additionally, some of the readline options (like `terminal`) will not
function in versions of node before 0.8, because they were not
implemented in the builtin readline module.
## CONTRIBUTING
Patches welcome.
# xhr
[](https://gitter.im/naugtur-xhr/Lobby?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
[](https://greenkeeper.io/)
A small XMLHttpRequest wrapper. Designed for use with [browserify](http://browserify.org/), [webpack](https://webpack.github.io/) etc.
API is a subset of [request](https://github.com/request/request) so you can write code that works in both node.js and the browser by using `require('request')` in your code and telling your browser bundler to load `xhr` instead of `request`.
For browserify, add a [browser](https://github.com/substack/node-browserify#browser-field) field to your `package.json`:
```
"browser": {
"request": "xhr"
}
```
For webpack, add a [resolve.alias](http://webpack.github.io/docs/configuration.html#resolve-alias) field to your configuration:
```
"resolve": {
"alias": {
"request$": "xhr"
}
}
```
Browser support: IE8+ and everything else.
## Installation
```
npm install xhr
```
## Example
```js
var xhr = require("xhr")
xhr({
method: "post",
body: someJSONString,
uri: "/foo",
headers: {
"Content-Type": "application/json"
}
}, function (err, resp, body) {
// check resp.statusCode
})
```
## `var req = xhr(options, callback)`
```js
type XhrOptions = String | {
useXDR: Boolean?,
sync: Boolean?,
uri: String,
url: String,
method: String?,
timeout: Number?,
headers: Object?,
body: String? | Object?,
json: Boolean? | Object?,
username: String?,
password: String?,
withCredentials: Boolean?,
responseType: String?,
beforeSend: Function?
}
xhr := (XhrOptions, Callback<Response>) => Request
```
the returned object is either an [`XMLHttpRequest`][3] instance
or an [`XDomainRequest`][4] instance (if on IE8/IE9 &&
`options.useXDR` is set to `true`)
Your callback will be called once with the arguments
( [`Error`][5], `response` , `body` ) where the response is an object:
```js
{
body: Object||String,
statusCode: Number,
method: String,
headers: {},
url: String,
rawRequest: xhr
}
```
- `body`: HTTP response body - [`XMLHttpRequest.response`][6], [`XMLHttpRequest.responseText`][7] or
[`XMLHttpRequest.responseXML`][8] depending on the request type.
- `rawRequest`: Original [`XMLHttpRequest`][3] instance
or [`XDomainRequest`][4] instance (if on IE8/IE9 &&
`options.useXDR` is set to `true`)
- `headers`: A collection of headers where keys are header names converted to lowercase
Your callback will be called with an [`Error`][5] if there is an error in the browser that prevents sending the request.
A HTTP 500 response is not going to cause an error to be returned.
## Other signatures
* `var req = xhr(url, callback)` -
a simple string instead of the options. In this case, a GET request will be made to that url.
* `var req = xhr(url, options, callback)` -
the above may also be called with the standard set of options.
### Convience methods
* `var req = xhr.{post, put, patch, del, head, get}(url, callback)`
* `var req = xhr.{post, put, patch, del, head, get}(options, callback)`
* `var req = xhr.{post, put, patch, del, head, get}(url, options, callback)`
The `xhr` module has convience functions attached that will make requests with the given method.
Each function is named after its method, with the exception of `DELETE` which is called `xhr.del` for compatibility.
The method shorthands may be combined with the url-first form of `xhr` for succinct and descriptive requests. For example,
```js
xhr.post('/post-to-me', function(err, resp) {
console.log(resp.body)
})
```
or
```js
xhr.del('/delete-me', { headers: { my: 'auth' } }, function (err, resp) {
console.log(resp.statusCode);
})
```
## Options
### `options.method`
Specify the method the [`XMLHttpRequest`][3] should be opened
with. Passed to [`XMLHttpRequest.open`][2]. Defaults to "GET"
### `options.useXDR`
Specify whether this is a cross origin (CORS) request for IE<10.
Switches IE to use [`XDomainRequest`][4] instead of `XMLHttpRequest`.
Ignored in other browsers.
Note that headers cannot be set on an XDomainRequest instance.
### `options.sync`
Specify whether this is a synchrounous request. Note that when
this is true the callback will be called synchronously. In
most cases this option should not be used. Only use if you
know what you are doing!
### `options.body`
Pass in body to be send across the [`XMLHttpRequest`][3].
Generally should be a string. But anything that's valid as
a parameter to [`XMLHttpRequest.send`][1] should work (Buffer for file, etc.).
If `options.json` is `true`, then this must be a JSON-serializable object. `options.body` is passed to `JSON.stringify` and sent.
### `options.uri` or `options.url`
The uri to send a request to. Passed to [`XMLHttpRequest.open`][2]. `options.url` and `options.uri` are aliases for each other.
### `options.headers`
An object of headers that should be set on the request. The
key, value pair is passed to [`XMLHttpRequest.setRequestHeader`][9]
### `options.timeout`
Number of miliseconds to wait for response. Defaults to 0 (no timeout). Ignored when `options.sync` is true.
### `options.json`
Set to `true` to send request as `application/json` (see `options.body`) and parse response from JSON.
For backwards compatibility `options.json` can also be a valid JSON-serializable value to be sent to the server. Additionally the response body is still parsed as JSON
For sending booleans as JSON body see FAQ
### `options.withCredentials`
Specify whether user credentials are to be included in a cross-origin
request. Sets [`XMLHttpRequest.withCredentials`][10]. Defaults to false.
A wildcard `*` cannot be used in the `Access-Control-Allow-Origin` header when `withCredentials` is true.
The header needs to specify your origin explicitly or browser will abort the request.
### `options.responseType`
Determines the data type of the `response`. Sets [`XMLHttpRequest.responseType`][11]. For example, a `responseType` of `document` will return a parsed `Document` object as the `response.body` for an XML resource.
### `options.beforeSend`
A function being called right before the `send` method of the `XMLHttpRequest` or `XDomainRequest` instance is called. The `XMLHttpRequest` or `XDomainRequest` instance is passed as an argument.
### `options.xhr`
Pass an `XMLHttpRequest` object (or something that acts like one) to use instead of constructing a new one using the `XMLHttpRequest` or `XDomainRequest` constructors. Useful for testing.
## FAQ
- Why is my server's JSON response not parsed? I returned the right content-type.
- See `options.json` - you can set it to `true` on a GET request to tell `xhr` to parse the response body.
- Without `options.json` body is returned as-is (a string or when `responseType` is set and the browser supports it - a result of parsing JSON or XML)
- How do I send an object or array as POST body?
- `options.body` should be a string. You need to serialize your object before passing to `xhr` for sending.
- To serialize to JSON you can use
`options.json:true` with `options.body` for convenience - then `xhr` will do the serialization and set content-type accordingly.
- Where's stream API? `.pipe()` etc.
- Not implemented. You can't reasonably have that in the browser.
- Why can't I send `"true"` as body by passing it as `options.json` anymore?
- Accepting `true` as a value was a bug. Despite what `JSON.stringify` does, the string `"true"` is not valid JSON. If you're sending booleans as JSON, please consider wrapping them in an object or array to save yourself from more trouble in the future. To bring back the old behavior, hardcode `options.json` to `true` and set `options.body` to your boolean value.
- How do I add an `onprogress` listener?
- use `beforeSend` function for non-standard things that are browser specific. In this case:
```js
xhr({
...
beforeSend: function(xhrObject){
xhrObject.onprogress = function(){}
}
})
```
## Mocking Requests
You can override the constructor used to create new requests for testing. When you're making a new request:
```js
xhr({ xhr: new MockXMLHttpRequest() })
```
or you can override the constructors used to create requests at the module level:
```js
xhr.XMLHttpRequest = MockXMLHttpRequest
xhr.XDomainRequest = MockXDomainRequest
```
## MIT Licenced
[1]: http://xhr.spec.whatwg.org/#the-send()-method
[2]: http://xhr.spec.whatwg.org/#the-open()-method
[3]: http://xhr.spec.whatwg.org/#interface-xmlhttprequest
[4]: http://msdn.microsoft.com/en-us/library/ie/cc288060(v=vs.85).aspx
[5]: http://es5.github.com/#x15.11
[6]: http://xhr.spec.whatwg.org/#the-response-attribute
[7]: http://xhr.spec.whatwg.org/#the-responsetext-attribute
[8]: http://xhr.spec.whatwg.org/#the-responsexml-attribute
[9]: http://xhr.spec.whatwg.org/#the-setrequestheader()-method
[10]: http://xhr.spec.whatwg.org/#the-withcredentials-attribute
[11]: https://xhr.spec.whatwg.org/#the-responsetype-attribute
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# web3
This is a main package of [web3.js](https://github.com/ethereum/web3.js)
Please read the main [readme](https://github.com/ethereum/web3.js) and [documentation](https://web3js.readthedocs.io) for more.
## Installation
### Node.js
```bash
npm install web3
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# qs <sup>[![Version Badge][2]][1]</sup>
[![Build Status][3]][4]
[![dependency status][5]][6]
[![dev dependency status][7]][8]
[![License][license-image]][license-url]
[![Downloads][downloads-image]][downloads-url]
[![npm badge][11]][1]
A querystring parsing and stringifying library with some added security.
Lead Maintainer: [Jordan Harband](https://github.com/ljharb)
The **qs** module was originally created and maintained by [TJ Holowaychuk](https://github.com/visionmedia/node-querystring).
## Usage
```javascript
var qs = require('qs');
var assert = require('assert');
var obj = qs.parse('a=c');
assert.deepEqual(obj, { a: 'c' });
var str = qs.stringify(obj);
assert.equal(str, 'a=c');
```
### Parsing Objects
[](#preventEval)
```javascript
qs.parse(string, [options]);
```
**qs** allows you to create nested objects within your query strings, by surrounding the name of sub-keys with square brackets `[]`.
For example, the string `'foo[bar]=baz'` converts to:
```javascript
assert.deepEqual(qs.parse('foo[bar]=baz'), {
foo: {
bar: 'baz'
}
});
```
When using the `plainObjects` option the parsed value is returned as a null object, created via `Object.create(null)` and as such you should be aware that prototype methods will not exist on it and a user may set those names to whatever value they like:
```javascript
var nullObject = qs.parse('a[hasOwnProperty]=b', { plainObjects: true });
assert.deepEqual(nullObject, { a: { hasOwnProperty: 'b' } });
```
By default parameters that would overwrite properties on the object prototype are ignored, if you wish to keep the data from those fields either use `plainObjects` as mentioned above, or set `allowPrototypes` to `true` which will allow user input to overwrite those properties. *WARNING* It is generally a bad idea to enable this option as it can cause problems when attempting to use the properties that have been overwritten. Always be careful with this option.
```javascript
var protoObject = qs.parse('a[hasOwnProperty]=b', { allowPrototypes: true });
assert.deepEqual(protoObject, { a: { hasOwnProperty: 'b' } });
```
URI encoded strings work too:
```javascript
assert.deepEqual(qs.parse('a%5Bb%5D=c'), {
a: { b: 'c' }
});
```
You can also nest your objects, like `'foo[bar][baz]=foobarbaz'`:
```javascript
assert.deepEqual(qs.parse('foo[bar][baz]=foobarbaz'), {
foo: {
bar: {
baz: 'foobarbaz'
}
}
});
```
By default, when nesting objects **qs** will only parse up to 5 children deep. This means if you attempt to parse a string like
`'a[b][c][d][e][f][g][h][i]=j'` your resulting object will be:
```javascript
var expected = {
a: {
b: {
c: {
d: {
e: {
f: {
'[g][h][i]': 'j'
}
}
}
}
}
}
};
var string = 'a[b][c][d][e][f][g][h][i]=j';
assert.deepEqual(qs.parse(string), expected);
```
This depth can be overridden by passing a `depth` option to `qs.parse(string, [options])`:
```javascript
var deep = qs.parse('a[b][c][d][e][f][g][h][i]=j', { depth: 1 });
assert.deepEqual(deep, { a: { b: { '[c][d][e][f][g][h][i]': 'j' } } });
```
The depth limit helps mitigate abuse when **qs** is used to parse user input, and it is recommended to keep it a reasonably small number.
For similar reasons, by default **qs** will only parse up to 1000 parameters. This can be overridden by passing a `parameterLimit` option:
```javascript
var limited = qs.parse('a=b&c=d', { parameterLimit: 1 });
assert.deepEqual(limited, { a: 'b' });
```
To bypass the leading question mark, use `ignoreQueryPrefix`:
```javascript
var prefixed = qs.parse('?a=b&c=d', { ignoreQueryPrefix: true });
assert.deepEqual(prefixed, { a: 'b', c: 'd' });
```
An optional delimiter can also be passed:
```javascript
var delimited = qs.parse('a=b;c=d', { delimiter: ';' });
assert.deepEqual(delimited, { a: 'b', c: 'd' });
```
Delimiters can be a regular expression too:
```javascript
var regexed = qs.parse('a=b;c=d,e=f', { delimiter: /[;,]/ });
assert.deepEqual(regexed, { a: 'b', c: 'd', e: 'f' });
```
Option `allowDots` can be used to enable dot notation:
```javascript
var withDots = qs.parse('a.b=c', { allowDots: true });
assert.deepEqual(withDots, { a: { b: 'c' } });
```
### Parsing Arrays
**qs** can also parse arrays using a similar `[]` notation:
```javascript
var withArray = qs.parse('a[]=b&a[]=c');
assert.deepEqual(withArray, { a: ['b', 'c'] });
```
You may specify an index as well:
```javascript
var withIndexes = qs.parse('a[1]=c&a[0]=b');
assert.deepEqual(withIndexes, { a: ['b', 'c'] });
```
Note that the only difference between an index in an array and a key in an object is that the value between the brackets must be a number
to create an array. When creating arrays with specific indices, **qs** will compact a sparse array to only the existing values preserving
their order:
```javascript
var noSparse = qs.parse('a[1]=b&a[15]=c');
assert.deepEqual(noSparse, { a: ['b', 'c'] });
```
Note that an empty string is also a value, and will be preserved:
```javascript
var withEmptyString = qs.parse('a[]=&a[]=b');
assert.deepEqual(withEmptyString, { a: ['', 'b'] });
var withIndexedEmptyString = qs.parse('a[0]=b&a[1]=&a[2]=c');
assert.deepEqual(withIndexedEmptyString, { a: ['b', '', 'c'] });
```
**qs** will also limit specifying indices in an array to a maximum index of `20`. Any array members with an index of greater than `20` will
instead be converted to an object with the index as the key:
```javascript
var withMaxIndex = qs.parse('a[100]=b');
assert.deepEqual(withMaxIndex, { a: { '100': 'b' } });
```
This limit can be overridden by passing an `arrayLimit` option:
```javascript
var withArrayLimit = qs.parse('a[1]=b', { arrayLimit: 0 });
assert.deepEqual(withArrayLimit, { a: { '1': 'b' } });
```
To disable array parsing entirely, set `parseArrays` to `false`.
```javascript
var noParsingArrays = qs.parse('a[]=b', { parseArrays: false });
assert.deepEqual(noParsingArrays, { a: { '0': 'b' } });
```
If you mix notations, **qs** will merge the two items into an object:
```javascript
var mixedNotation = qs.parse('a[0]=b&a[b]=c');
assert.deepEqual(mixedNotation, { a: { '0': 'b', b: 'c' } });
```
You can also create arrays of objects:
```javascript
var arraysOfObjects = qs.parse('a[][b]=c');
assert.deepEqual(arraysOfObjects, { a: [{ b: 'c' }] });
```
### Stringifying
[](#preventEval)
```javascript
qs.stringify(object, [options]);
```
When stringifying, **qs** by default URI encodes output. Objects are stringified as you would expect:
```javascript
assert.equal(qs.stringify({ a: 'b' }), 'a=b');
assert.equal(qs.stringify({ a: { b: 'c' } }), 'a%5Bb%5D=c');
```
This encoding can be disabled by setting the `encode` option to `false`:
```javascript
var unencoded = qs.stringify({ a: { b: 'c' } }, { encode: false });
assert.equal(unencoded, 'a[b]=c');
```
Encoding can be disabled for keys by setting the `encodeValuesOnly` option to `true`:
```javascript
var encodedValues = qs.stringify(
{ a: 'b', c: ['d', 'e=f'], f: [['g'], ['h']] },
{ encodeValuesOnly: true }
);
assert.equal(encodedValues,'a=b&c[0]=d&c[1]=e%3Df&f[0][0]=g&f[1][0]=h');
```
This encoding can also be replaced by a custom encoding method set as `encoder` option:
```javascript
var encoded = qs.stringify({ a: { b: 'c' } }, { encoder: function (str) {
// Passed in values `a`, `b`, `c`
return // Return encoded string
}})
```
_(Note: the `encoder` option does not apply if `encode` is `false`)_
Analogue to the `encoder` there is a `decoder` option for `parse` to override decoding of properties and values:
```javascript
var decoded = qs.parse('x=z', { decoder: function (str) {
// Passed in values `x`, `z`
return // Return decoded string
}})
```
Examples beyond this point will be shown as though the output is not URI encoded for clarity. Please note that the return values in these cases *will* be URI encoded during real usage.
When arrays are stringified, by default they are given explicit indices:
```javascript
qs.stringify({ a: ['b', 'c', 'd'] });
// 'a[0]=b&a[1]=c&a[2]=d'
```
You may override this by setting the `indices` option to `false`:
```javascript
qs.stringify({ a: ['b', 'c', 'd'] }, { indices: false });
// 'a=b&a=c&a=d'
```
You may use the `arrayFormat` option to specify the format of the output array:
```javascript
qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'indices' })
// 'a[0]=b&a[1]=c'
qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'brackets' })
// 'a[]=b&a[]=c'
qs.stringify({ a: ['b', 'c'] }, { arrayFormat: 'repeat' })
// 'a=b&a=c'
```
When objects are stringified, by default they use bracket notation:
```javascript
qs.stringify({ a: { b: { c: 'd', e: 'f' } } });
// 'a[b][c]=d&a[b][e]=f'
```
You may override this to use dot notation by setting the `allowDots` option to `true`:
```javascript
qs.stringify({ a: { b: { c: 'd', e: 'f' } } }, { allowDots: true });
// 'a.b.c=d&a.b.e=f'
```
Empty strings and null values will omit the value, but the equals sign (=) remains in place:
```javascript
assert.equal(qs.stringify({ a: '' }), 'a=');
```
Key with no values (such as an empty object or array) will return nothing:
```javascript
assert.equal(qs.stringify({ a: [] }), '');
assert.equal(qs.stringify({ a: {} }), '');
assert.equal(qs.stringify({ a: [{}] }), '');
assert.equal(qs.stringify({ a: { b: []} }), '');
assert.equal(qs.stringify({ a: { b: {}} }), '');
```
Properties that are set to `undefined` will be omitted entirely:
```javascript
assert.equal(qs.stringify({ a: null, b: undefined }), 'a=');
```
The query string may optionally be prepended with a question mark:
```javascript
assert.equal(qs.stringify({ a: 'b', c: 'd' }, { addQueryPrefix: true }), '?a=b&c=d');
```
The delimiter may be overridden with stringify as well:
```javascript
assert.equal(qs.stringify({ a: 'b', c: 'd' }, { delimiter: ';' }), 'a=b;c=d');
```
If you only want to override the serialization of `Date` objects, you can provide a `serializeDate` option:
```javascript
var date = new Date(7);
assert.equal(qs.stringify({ a: date }), 'a=1970-01-01T00:00:00.007Z'.replace(/:/g, '%3A'));
assert.equal(
qs.stringify({ a: date }, { serializeDate: function (d) { return d.getTime(); } }),
'a=7'
);
```
You may use the `sort` option to affect the order of parameter keys:
```javascript
function alphabeticalSort(a, b) {
return a.localeCompare(b);
}
assert.equal(qs.stringify({ a: 'c', z: 'y', b : 'f' }, { sort: alphabeticalSort }), 'a=c&b=f&z=y');
```
Finally, you can use the `filter` option to restrict which keys will be included in the stringified output.
If you pass a function, it will be called for each key to obtain the replacement value. Otherwise, if you
pass an array, it will be used to select properties and array indices for stringification:
```javascript
function filterFunc(prefix, value) {
if (prefix == 'b') {
// Return an `undefined` value to omit a property.
return;
}
if (prefix == 'e[f]') {
return value.getTime();
}
if (prefix == 'e[g][0]') {
return value * 2;
}
return value;
}
qs.stringify({ a: 'b', c: 'd', e: { f: new Date(123), g: [2] } }, { filter: filterFunc });
// 'a=b&c=d&e[f]=123&e[g][0]=4'
qs.stringify({ a: 'b', c: 'd', e: 'f' }, { filter: ['a', 'e'] });
// 'a=b&e=f'
qs.stringify({ a: ['b', 'c', 'd'], e: 'f' }, { filter: ['a', 0, 2] });
// 'a[0]=b&a[2]=d'
```
### Handling of `null` values
By default, `null` values are treated like empty strings:
```javascript
var withNull = qs.stringify({ a: null, b: '' });
assert.equal(withNull, 'a=&b=');
```
Parsing does not distinguish between parameters with and without equal signs. Both are converted to empty strings.
```javascript
var equalsInsensitive = qs.parse('a&b=');
assert.deepEqual(equalsInsensitive, { a: '', b: '' });
```
To distinguish between `null` values and empty strings use the `strictNullHandling` flag. In the result string the `null`
values have no `=` sign:
```javascript
var strictNull = qs.stringify({ a: null, b: '' }, { strictNullHandling: true });
assert.equal(strictNull, 'a&b=');
```
To parse values without `=` back to `null` use the `strictNullHandling` flag:
```javascript
var parsedStrictNull = qs.parse('a&b=', { strictNullHandling: true });
assert.deepEqual(parsedStrictNull, { a: null, b: '' });
```
To completely skip rendering keys with `null` values, use the `skipNulls` flag:
```javascript
var nullsSkipped = qs.stringify({ a: 'b', c: null}, { skipNulls: true });
assert.equal(nullsSkipped, 'a=b');
```
### Dealing with special character sets
By default the encoding and decoding of characters is done in `utf-8`. If you
wish to encode querystrings to a different character set (i.e.
[Shift JIS](https://en.wikipedia.org/wiki/Shift_JIS)) you can use the
[`qs-iconv`](https://github.com/martinheidegger/qs-iconv) library:
```javascript
var encoder = require('qs-iconv/encoder')('shift_jis');
var shiftJISEncoded = qs.stringify({ a: 'こんにちは!' }, { encoder: encoder });
assert.equal(shiftJISEncoded, 'a=%82%B1%82%F1%82%C9%82%BF%82%CD%81I');
```
This also works for decoding of query strings:
```javascript
var decoder = require('qs-iconv/decoder')('shift_jis');
var obj = qs.parse('a=%82%B1%82%F1%82%C9%82%BF%82%CD%81I', { decoder: decoder });
assert.deepEqual(obj, { a: 'こんにちは!' });
```
### RFC 3986 and RFC 1738 space encoding
RFC3986 used as default option and encodes ' ' to *%20* which is backward compatible.
In the same time, output can be stringified as per RFC1738 with ' ' equal to '+'.
```
assert.equal(qs.stringify({ a: 'b c' }), 'a=b%20c');
assert.equal(qs.stringify({ a: 'b c' }, { format : 'RFC3986' }), 'a=b%20c');
assert.equal(qs.stringify({ a: 'b c' }, { format : 'RFC1738' }), 'a=b+c');
```
[1]: https://npmjs.org/package/qs
[2]: http://versionbadg.es/ljharb/qs.svg
[3]: https://api.travis-ci.org/ljharb/qs.svg
[4]: https://travis-ci.org/ljharb/qs
[5]: https://david-dm.org/ljharb/qs.svg
[6]: https://david-dm.org/ljharb/qs
[7]: https://david-dm.org/ljharb/qs/dev-status.svg
[8]: https://david-dm.org/ljharb/qs?type=dev
[9]: https://ci.testling.com/ljharb/qs.png
[10]: https://ci.testling.com/ljharb/qs
[11]: https://nodei.co/npm/qs.png?downloads=true&stars=true
[license-image]: http://img.shields.io/npm/l/qs.svg
[license-url]: LICENSE
[downloads-image]: http://img.shields.io/npm/dm/qs.svg
[downloads-url]: http://npm-stat.com/charts.html?package=qs
# js-sha256
[](https://travis-ci.org/emn178/js-sha256)
[](https://coveralls.io/r/emn178/js-sha256?branch=master)
[](https://cdnjs.com/libraries/js-sha256/)
[](https://nodei.co/npm/js-sha256/)
A simple SHA-256 / SHA-224 hash function for JavaScript supports UTF-8 encoding.
## Demo
[SHA256 Online](http://emn178.github.io/online-tools/sha256.html)
[SHA224 Online](http://emn178.github.io/online-tools/sha224.html)
## Download
[Compress](https://raw.github.com/emn178/js-sha256/master/build/sha256.min.js)
[Uncompress](https://raw.github.com/emn178/js-sha256/master/src/sha256.js)
## Installation
You can also install js-sha256 by using Bower.
bower install js-sha256
For node.js, you can use this command to install:
npm install js-sha256
## Usage
You could use like this:
```JavaScript
sha256('Message to hash');
sha224('Message to hash');
var hash = sha256.create();
hash.update('Message to hash');
hash.hex();
var hash2 = sha256.update('Message to hash');
hash2.update('Message2 to hash');
hash2.array();
// HMAC
sha256.hmac('key', 'Message to hash');
sha224.hmac('key', 'Message to hash');
var hash = sha256.hmac.create('key');
hash.update('Message to hash');
hash.hex();
var hash2 = sha256.hmac.update('key', 'Message to hash');
hash2.update('Message2 to hash');
hash2.array();
```
If you use node.js, you should require the module first:
```JavaScript
var sha256 = require('js-sha256');
```
or
```JavaScript
var sha256 = require('js-sha256').sha256;
var sha224 = require('js-sha256').sha224;
```
It supports AMD:
```JavaScript
require(['your/path/sha256.js'], function(sha256) {
// ...
});
```
or TypeScript
```TypeScript
import { sha256, sha224 } from 'js-sha256';
```
## Example
```JavaScript
sha256(''); // e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
sha256('The quick brown fox jumps over the lazy dog'); // d7a8fbb307d7809469ca9abcb0082e4f8d5651e46d3cdb762d02d0bf37c9e592
sha256('The quick brown fox jumps over the lazy dog.'); // ef537f25c895bfa782526529a9b63d97aa631564d5d789c2b765448c8635fb6c
sha224(''); // d14a028c2a3a2bc9476102bb288234c415a2b01f828ea62ac5b3e42f
sha224('The quick brown fox jumps over the lazy dog'); // 730e109bd7a8a32b1cb9d9a09aa2325d2430587ddbc0c38bad911525
sha224('The quick brown fox jumps over the lazy dog.'); // 619cba8e8e05826e9b8c519c0a5c68f4fb653e8a3d8aa04bb2c8cd4c
// It also supports UTF-8 encoding
sha256('中文'); // 72726d8818f693066ceb69afa364218b692e62ea92b385782363780f47529c21
sha224('中文'); // dfbab71afdf54388af4d55f8bd3de8c9b15e0eb916bf9125f4a959d4
// It also supports byte `Array`, `Uint8Array`, `ArrayBuffer` input
sha256([]); // e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
sha256(new Uint8Array([211, 212])); // 182889f925ae4e5cc37118ded6ed87f7bdc7cab5ec5e78faef2e50048999473f
// Different output
sha256(''); // e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
sha256.hex(''); // e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
sha256.array(''); // [227, 176, 196, 66, 152, 252, 28, 20, 154, 251, 244, 200, 153, 111, 185, 36, 39, 174, 65, 228, 100, 155, 147, 76, 164, 149, 153, 27, 120, 82, 184, 85]
sha256.digest(''); // [227, 176, 196, 66, 152, 252, 28, 20, 154, 251, 244, 200, 153, 111, 185, 36, 39, 174, 65, 228, 100, 155, 147, 76, 164, 149, 153, 27, 120, 82, 184, 85]
sha256.arrayBuffer(''); // ArrayBuffer
```
## License
The project is released under the [MIT license](http://www.opensource.org/licenses/MIT).
## Contact
The project's website is located at https://github.com/emn178/js-sha256
Author: Chen, Yi-Cyuan ([email protected])
# SYNOPSIS
[](https://www.npmjs.org/package/ethereumjs-util)
[](https://travis-ci.org/ethereumjs/ethereumjs-util)
[](https://coveralls.io/r/ethereumjs/ethereumjs-util)
[](https://gitter.im/ethereum/ethereumjs-lib) or #ethereumjs on freenode
A collection of utility functions for ethereum. It can be used in node.js or can be in the browser with browserify.
# API
[./docs/](./docs/README.md)
Most of the string manipulation methods are provided by [ethjs-util](https://github.com/ethjs/ethjs-util)
---
Additionally ethereumjs-util re-exports a few commonly-used libraries. These include:
- `BN` ([bn.js](https://github.com/indutny/bn.js))
- `rlp` ([rlp](https://github.com/ethereumjs/rlp))
- `secp256k1` ([secp256k1](https://github.com/cryptocoinjs/secp256k1-node/))
# EthereumJS
See our organizational [documentation](https://ethereumjs.readthedocs.io) for an introduction to `EthereumJS` as well as information on current standards and best practices.
If you want to join for work or do improvements on the libraries have a look at our [contribution guidelines](https://ethereumjs.readthedocs.io/en/latest/contributing.html).
# LICENSE
MPL-2.0
# DES.js
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
# parseurl
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Node.js Version][node-image]][node-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Parse a URL with memoization.
## Install
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install parseurl
```
## API
```js
var parseurl = require('parseurl')
```
### parseurl(req)
Parse the URL of the given request object (looks at the `req.url` property)
and return the result. The result is the same as `url.parse` in Node.js core.
Calling this function multiple times on the same `req` where `req.url` does
not change will return a cached parsed object, rather than parsing again.
### parseurl.original(req)
Parse the original URL of the given request object and return the result.
This works by trying to parse `req.originalUrl` if it is a string, otherwise
parses `req.url`. The result is the same as `url.parse` in Node.js core.
Calling this function multiple times on the same `req` where `req.originalUrl`
does not change will return a cached parsed object, rather than parsing again.
## Benchmark
```bash
$ npm run-script bench
> [email protected] bench nodejs-parseurl
> node benchmark/index.js
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
modules@64
[email protected]
napi@3
[email protected]
[email protected]
[email protected]
[email protected]
tz@2018c
> node benchmark/fullurl.js
Parsing URL "http://localhost:8888/foo/bar?user=tj&pet=fluffy"
4 tests completed.
fasturl x 2,207,842 ops/sec ±3.76% (184 runs sampled)
nativeurl - legacy x 507,180 ops/sec ±0.82% (191 runs sampled)
nativeurl - whatwg x 290,044 ops/sec ±1.96% (189 runs sampled)
parseurl x 488,907 ops/sec ±2.13% (192 runs sampled)
> node benchmark/pathquery.js
Parsing URL "/foo/bar?user=tj&pet=fluffy"
4 tests completed.
fasturl x 3,812,564 ops/sec ±3.15% (188 runs sampled)
nativeurl - legacy x 2,651,631 ops/sec ±1.68% (189 runs sampled)
nativeurl - whatwg x 161,837 ops/sec ±2.26% (189 runs sampled)
parseurl x 4,166,338 ops/sec ±2.23% (184 runs sampled)
> node benchmark/samerequest.js
Parsing URL "/foo/bar?user=tj&pet=fluffy" on same request object
4 tests completed.
fasturl x 3,821,651 ops/sec ±2.42% (185 runs sampled)
nativeurl - legacy x 2,651,162 ops/sec ±1.90% (187 runs sampled)
nativeurl - whatwg x 175,166 ops/sec ±1.44% (188 runs sampled)
parseurl x 14,912,606 ops/sec ±3.59% (183 runs sampled)
> node benchmark/simplepath.js
Parsing URL "/foo/bar"
4 tests completed.
fasturl x 12,421,765 ops/sec ±2.04% (191 runs sampled)
nativeurl - legacy x 7,546,036 ops/sec ±1.41% (188 runs sampled)
nativeurl - whatwg x 198,843 ops/sec ±1.83% (189 runs sampled)
parseurl x 24,244,006 ops/sec ±0.51% (194 runs sampled)
> node benchmark/slash.js
Parsing URL "/"
4 tests completed.
fasturl x 17,159,456 ops/sec ±3.25% (188 runs sampled)
nativeurl - legacy x 11,635,097 ops/sec ±3.79% (184 runs sampled)
nativeurl - whatwg x 240,693 ops/sec ±0.83% (189 runs sampled)
parseurl x 42,279,067 ops/sec ±0.55% (190 runs sampled)
```
## License
[MIT](LICENSE)
[coveralls-image]: https://badgen.net/coveralls/c/github/pillarjs/parseurl/master
[coveralls-url]: https://coveralls.io/r/pillarjs/parseurl?branch=master
[node-image]: https://badgen.net/npm/node/parseurl
[node-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/parseurl
[npm-url]: https://npmjs.org/package/parseurl
[npm-version-image]: https://badgen.net/npm/v/parseurl
[travis-image]: https://badgen.net/travis/pillarjs/parseurl/master
[travis-url]: https://travis-ci.org/pillarjs/parseurl
Description
===========
node-ftp is an FTP client module for [node.js](http://nodejs.org/) that provides an asynchronous interface for communicating with an FTP server.
Requirements
============
* [node.js](http://nodejs.org/) -- v0.8.0 or newer
Install
=======
npm install ftp
Examples
========
* Get a directory listing of the current (remote) working directory:
```javascript
var Client = require('ftp');
var c = new Client();
c.on('ready', function() {
c.list(function(err, list) {
if (err) throw err;
console.dir(list);
c.end();
});
});
// connect to localhost:21 as anonymous
c.connect();
```
* Download remote file 'foo.txt' and save it to the local file system:
```javascript
var Client = require('ftp');
var fs = require('fs');
var c = new Client();
c.on('ready', function() {
c.get('foo.txt', function(err, stream) {
if (err) throw err;
stream.once('close', function() { c.end(); });
stream.pipe(fs.createWriteStream('foo.local-copy.txt'));
});
});
// connect to localhost:21 as anonymous
c.connect();
```
* Upload local file 'foo.txt' to the server:
```javascript
var Client = require('ftp');
var fs = require('fs');
var c = new Client();
c.on('ready', function() {
c.put('foo.txt', 'foo.remote-copy.txt', function(err) {
if (err) throw err;
c.end();
});
});
// connect to localhost:21 as anonymous
c.connect();
```
API
===
Events
------
* **greeting**(< _string_ >msg) - Emitted after connection. `msg` is the text the server sent upon connection.
* **ready**() - Emitted when connection and authentication were sucessful.
* **close**(< _boolean_ >hadErr) - Emitted when the connection has fully closed.
* **end**() - Emitted when the connection has ended.
* **error**(< _Error_ >err) - Emitted when an error occurs. In case of protocol-level errors, `err` contains a 'code' property that references the related 3-digit FTP response code.
Methods
-------
**\* Note: As with the 'error' event, any error objects passed to callbacks will have a 'code' property for protocol-level errors.**
* **(constructor)**() - Creates and returns a new FTP client instance.
* **connect**(< _object_ >config) - _(void)_ - Connects to an FTP server. Valid config properties:
* host - _string_ - The hostname or IP address of the FTP server. **Default:** 'localhost'
* port - _integer_ - The port of the FTP server. **Default:** 21
* secure - _mixed_ - Set to true for both control and data connection encryption, 'control' for control connection encryption only, or 'implicit' for implicitly encrypted control connection (this mode is deprecated in modern times, but usually uses port 990) **Default:** false
* secureOptions - _object_ - Additional options to be passed to `tls.connect()`. **Default:** (none)
* user - _string_ - Username for authentication. **Default:** 'anonymous'
* password - _string_ - Password for authentication. **Default:** 'anonymous@'
* connTimeout - _integer_ - How long (in milliseconds) to wait for the control connection to be established. **Default:** 10000
* pasvTimeout - _integer_ - How long (in milliseconds) to wait for a PASV data connection to be established. **Default:** 10000
* keepalive - _integer_ - How often (in milliseconds) to send a 'dummy' (NOOP) command to keep the connection alive. **Default:** 10000
* **end**() - _(void)_ - Closes the connection to the server after any/all enqueued commands have been executed.
* **destroy**() - _(void)_ - Closes the connection to the server immediately.
### Required "standard" commands (RFC 959)
* **list**([< _string_ >path, ][< _boolean_ >useCompression, ]< _function_ >callback) - _(void)_ - Retrieves the directory listing of `path`. `path` defaults to the current working directory. `useCompression` defaults to false. `callback` has 2 parameters: < _Error_ >err, < _array_ >list. `list` is an array of objects with these properties:
* type - _string_ - A single character denoting the entry type: 'd' for directory, '-' for file (or 'l' for symlink on **\*NIX only**).
* name - _string_ - The name of the entry.
* size - _string_ - The size of the entry in bytes.
* date - _Date_ - The last modified date of the entry.
* rights - _object_ - The various permissions for this entry **(*NIX only)**.
* user - _string_ - An empty string or any combination of 'r', 'w', 'x'.
* group - _string_ - An empty string or any combination of 'r', 'w', 'x'.
* other - _string_ - An empty string or any combination of 'r', 'w', 'x'.
* owner - _string_ - The user name or ID that this entry belongs to **(*NIX only)**.
* group - _string_ - The group name or ID that this entry belongs to **(*NIX only)**.
* target - _string_ - For symlink entries, this is the symlink's target **(*NIX only)**.
* sticky - _boolean_ - True if the sticky bit is set for this entry **(*NIX only)**.
* **get**(< _string_ >path, [< _boolean_ >useCompression, ]< _function_ >callback) - _(void)_ - Retrieves a file at `path` from the server. `useCompression` defaults to false. `callback` has 2 parameters: < _Error_ >err, < _ReadableStream_ >fileStream.
* **put**(< _mixed_ >input, < _string_ >destPath, [< _boolean_ >useCompression, ]< _function_ >callback) - _(void)_ - Sends data to the server to be stored as `destPath`. `input` can be a ReadableStream, a Buffer, or a path to a local file. `useCompression` defaults to false. `callback` has 1 parameter: < _Error_ >err.
* **append**(< _mixed_ >input, < _string_ >destPath, [< _boolean_ >useCompression, ]< _function_ >callback) - _(void)_ - Same as **put()**, except if `destPath` already exists, it will be appended to instead of overwritten.
* **rename**(< _string_ >oldPath, < _string_ >newPath, < _function_ >callback) - _(void)_ - Renames `oldPath` to `newPath` on the server. `callback` has 1 parameter: < _Error_ >err.
* **logout**(< _function_ >callback) - _(void)_ - Logout the user from the server. `callback` has 1 parameter: < _Error_ >err.
* **delete**(< _string_ >path, < _function_ >callback) - _(void)_ - Deletes a file, `path`, on the server. `callback` has 1 parameter: < _Error_ >err.
* **cwd**(< _string_ >path, < _function_ >callback) - _(void)_ - Changes the current working directory to `path`. `callback` has 2 parameters: < _Error_ >err, < _string_ >currentDir. Note: `currentDir` is only given if the server replies with the path in the response text.
* **abort**(< _function_ >callback) - _(void)_ - Aborts the current data transfer (e.g. from get(), put(), or list()). `callback` has 1 parameter: < _Error_ >err.
* **site**(< _string_ >command, < _function_ >callback) - _(void)_ - Sends `command` (e.g. 'CHMOD 755 foo', 'QUOTA') using SITE. `callback` has 3 parameters: < _Error_ >err, < _string >responseText, < _integer_ >responseCode.
* **status**(< _function_ >callback) - _(void)_ - Retrieves human-readable information about the server's status. `callback` has 2 parameters: < _Error_ >err, < _string_ >status.
* **ascii**(< _function_ >callback) - _(void)_ - Sets the transfer data type to ASCII. `callback` has 1 parameter: < _Error_ >err.
* **binary**(< _function_ >callback) - _(void)_ - Sets the transfer data type to binary (default at time of connection). `callback` has 1 parameter: < _Error_ >err.
### Optional "standard" commands (RFC 959)
* **mkdir**(< _string_ >path, [< _boolean_ >recursive, ]< _function_ >callback) - _(void)_ - Creates a new directory, `path`, on the server. `recursive` is for enabling a 'mkdir -p' algorithm and defaults to false. `callback` has 1 parameter: < _Error_ >err.
* **rmdir**(< _string_ >path, [< _boolean_ >recursive, ]< _function_ >callback) - _(void)_ - Removes a directory, `path`, on the server. If `recursive`, this call will delete the contents of the directory if it is not empty. `callback` has 1 parameter: < _Error_ >err.
* **cdup**(< _function_ >callback) - _(void)_ - Changes the working directory to the parent of the current directory. `callback` has 1 parameter: < _Error_ >err.
* **pwd**(< _function_ >callback) - _(void)_ - Retrieves the current working directory. `callback` has 2 parameters: < _Error_ >err, < _string_ >cwd.
* **system**(< _function_ >callback) - _(void)_ - Retrieves the server's operating system. `callback` has 2 parameters: < _Error_ >err, < _string_ >OS.
* **listSafe**([< _string_ >path, ][< _boolean_ >useCompression, ]< _function_ >callback) - _(void)_ - Similar to list(), except the directory is temporarily changed to `path` to retrieve the directory listing. This is useful for servers that do not handle characters like spaces and quotes in directory names well for the LIST command. This function is "optional" because it relies on pwd() being available.
### Extended commands (RFC 3659)
* **size**(< _string_ >path, < _function_ >callback) - _(void)_ - Retrieves the size of `path`. `callback` has 2 parameters: < _Error_ >err, < _integer_ >numBytes.
* **lastMod**(< _string_ >path, < _function_ >callback) - _(void)_ - Retrieves the last modified date and time for `path`. `callback` has 2 parameters: < _Error_ >err, < _Date_ >lastModified.
* **restart**(< _integer_ >byteOffset, < _function_ >callback) - _(void)_ - Sets the file byte offset for the next file transfer action (get/put) to `byteOffset`. `callback` has 1 parameter: < _Error_ >err.
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# readable-stream
***Node-core streams for userland***
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
This package is a mirror of the Streams2 and Streams3 implementations in Node-core.
If you want to guarantee a stable streams base, regardless of what version of Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core.
**readable-stream** comes in two major versions, v1.0.x and v1.1.x. The former tracks the Streams2 implementation in Node 0.10, including bug-fixes and minor improvements as they are added. The latter tracks Streams3 as it develops in Node 0.11; we will likely see a v1.2.x branch for Node 0.12.
**readable-stream** uses proper patch-level versioning so if you pin to `"~1.0.0"` you’ll get the latest Node 0.10 Streams2 implementation, including any fixes and minor non-breaking improvements. The patch-level versions of 1.0.x and 1.1.x should mirror the patch-level versions of Node-core releases. You should prefer the **1.0.x** releases for now and when you’re ready to start using Streams3, pin to `"~1.1.0"`
# ES6-Promise (subset of [rsvp.js](https://github.com/tildeio/rsvp.js)) [](https://travis-ci.org/stefanpenner/es6-promise)
This is a polyfill of the [ES6 Promise](http://www.ecma-international.org/ecma-262/6.0/#sec-promise-constructor). The implementation is a subset of [rsvp.js](https://github.com/tildeio/rsvp.js) extracted by @jakearchibald, if you're wanting extra features and more debugging options, check out the [full library](https://github.com/tildeio/rsvp.js).
For API details and how to use promises, see the <a href="http://www.html5rocks.com/en/tutorials/es6/promises/">JavaScript Promises HTML5Rocks article</a>.
## Downloads
* [es6-promise 27.86 KB (7.33 KB gzipped)](https://cdn.jsdelivr.net/npm/es6-promise/dist/es6-promise.js)
* [es6-promise-auto 27.78 KB (7.3 KB gzipped)](https://cdn.jsdelivr.net/npm/es6-promise/dist/es6-promise.auto.js) - Automatically provides/replaces `Promise` if missing or broken.
* [es6-promise-min 6.17 KB (2.4 KB gzipped)](https://cdn.jsdelivr.net/npm/es6-promise/dist/es6-promise.min.js)
* [es6-promise-auto-min 6.19 KB (2.4 KB gzipped)](https://cdn.jsdelivr.net/npm/es6-promise/dist/es6-promise.auto.min.js) - Minified version of `es6-promise-auto` above.
## CDN
To use via a CDN include this in your html:
```html
<!-- Automatically provides/replaces `Promise` if missing or broken. -->
<script src="https://cdn.jsdelivr.net/npm/es6-promise@4/dist/es6-promise.js"></script>
<script src="https://cdn.jsdelivr.net/npm/es6-promise@4/dist/es6-promise.auto.js"></script>
<!-- Minified version of `es6-promise-auto` below. -->
<script src="https://cdn.jsdelivr.net/npm/es6-promise@4/dist/es6-promise.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/es6-promise@4/dist/es6-promise.auto.min.js"></script>
```
## Node.js
To install:
```sh
yarn add es6-promise
```
or
```sh
npm install es6-promise
```
To use:
```js
var Promise = require('es6-promise').Promise;
```
## Usage in IE<9
`catch` and `finally` are reserved keywords in IE<9, meaning
`promise.catch(func)` or `promise.finally(func)` throw a syntax error. To work
around this, you can use a string to access the property as shown in the
following example.
However most minifiers will automatically fix this for you, making the
resulting code safe for old browsers and production:
```js
promise['catch'](function(err) {
// ...
});
```
```js
promise['finally'](function() {
// ...
});
```
## Auto-polyfill
To polyfill the global environment (either in Node or in the browser via CommonJS) use the following code snippet:
```js
require('es6-promise').polyfill();
```
Alternatively
```js
require('es6-promise/auto');
```
Notice that we don't assign the result of `polyfill()` to any variable. The `polyfill()` method will patch the global environment (in this case to the `Promise` name) when called.
## Building & Testing
You will need to have PhantomJS installed globally in order to run the tests.
`npm install -g phantomjs`
* `npm run build` to build
* `npm test` to run tests
* `npm start` to run a build watcher, and webserver to test
* `npm run test:server` for a testem test runner and watching builder
# cli tableau
<a href="https://travis-ci.org/github/keymetrics/cli-tableau" title="PM2 Tests">
<img src="https://travis-ci.org/keymetrics/cli-tableau.svg?branch=master" alt="Build Status"/>
</a>
### Horizontal Tables
```javascript
var Table = require('cli-tableau');
var table = new Table({
head: ['TH 1 label', 'TH 2 label'],
colWidths: [100, 200],
borders: false
});
table.push(
['First value', 'Second value'],
['First value', 'Second value']
);
console.log(table.toString());
```
### Vertical Tables
```javascript
var Table = require('cli-tableau');
var table = new Table();
table.push(
{ 'Some key': 'Some value' },
{ 'Another key': 'Another value' }
);
console.log(table.toString());
```
### Cross Tables
Cross tables are very similar to vertical tables, with two key differences:
1. They require a `head` setting when instantiated that has an empty string as the first header
2. The individual rows take the general form of { "Header": ["Row", "Values"] }
```javascript
var Table = require('cli-tableau');
var table = new Table({ head: ["", "Top Header 1", "Top Header 2"] });
table.push(
{ 'Left Header 1': ['Value Row 1 Col 1', 'Value Row 1 Col 2'] },
{ 'Left Header 2': ['Value Row 2 Col 1', 'Value Row 2 Col 2'] }
);
console.log(table.toString());
```
### Custom styles
The ```chars``` property controls how the table is drawn:
```javascript
var table = new Table({
chars: {
'top': '═' , 'top-mid': '╤' , 'top-left': '╔' , 'top-right': '╗',
'bottom': '═' , 'bottom-mid': '╧' , 'bottom-left': '╚' , 'bottom-right': '╝',
'left': '║' , 'left-mid': '╟' , 'mid': '─' , 'mid-mid': '┼',
'right': '║' , 'right-mid': '╢' , 'middle': '│'
}
});
table.push(
['foo', 'bar', 'baz'],
['frob', 'bar', 'quuz']
);
console.log(table.toString());
// Outputs:
//
//╔══════╤═════╤══════╗
//║ foo │ bar │ baz ║
//╟──────┼─────┼──────╢
//║ frob │ bar │ quuz ║
//╚══════╧═════╧══════╝
```
Empty decoration lines will be skipped, to avoid vertical separator rows just
set the 'mid', 'left-mid', 'mid-mid', 'right-mid' to the empty string:
```javascript
var table = new Table({ chars: {'mid': '', 'left-mid': '', 'mid-mid': '', 'right-mid': ''} });
table.push(
['foo', 'bar', 'baz'],
['frobnicate', 'bar', 'quuz']
);
console.log(table.toString());
// Outputs: (note the lack of the horizontal line between rows)
//┌────────────┬─────┬──────┐
//│ foo │ bar │ baz │
//│ frobnicate │ bar │ quuz │
//└────────────┴─────┴──────┘
```
By setting all chars to empty with the exception of 'middle' being set to a
single space and by setting padding to zero, it's possible to get the most
compact layout with no decorations:
```javascript
var table = new Table({
chars: {
'top': '' , 'top-mid': '' , 'top-left': '' , 'top-right': '',
'bottom': '' , 'bottom-mid': '' , 'bottom-left': '' , 'bottom-right': '',
'left': '' , 'left-mid': '' , 'mid': '' , 'mid-mid': '',
'right': '' , 'right-mid': '' , 'middle': ' '
},
style: { 'padding-left': 0, 'padding-right': 0 }
});
table.push(
['foo', 'bar', 'baz'],
['frobnicate', 'bar', 'quuz']
);
console.log(table.toString());
// Outputs:
//foo bar baz
//frobnicate bar quuz
```
## Credits
- Guillermo Rauch <[email protected]> ([Guille](http://github.com/guille))
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# web3-providers-ipc
This is a sub package of [web3.js][repo]
This is a IPC provider for [web3.js][repo].
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-providers-ipc
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-providers-ipc.js` in your html file.
This will expose the `Web3IpcProvider` object on the window object.
## Usage
```js
// in node.js
var Web3IpcProvider = require('web3-providers-ipc');
var net = require(net);
var ipc = new Web3IpcProvider('/Users/me/Library/Ethereum/geth.ipc', net);
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
GYP can Generate Your Projects.
===================================
Documents are available at [gyp.gsrc.io](https://gyp.gsrc.io), or you can check out ```md-pages``` branch to read those documents offline.
__gyp-next__ is [released](https://github.com/nodejs/gyp-next/releases) to the [__Python Packaging Index__](https://pypi.org/project/gyp-next) (PyPI) and can be installed with the command:
* `python3 -m pip install gyp-next`
aws-sign
========
AWS signing. Originally pulled from LearnBoost/knox, maintained as vendor in request, now a standalone module.
# Elliptic [](http://travis-ci.org/indutny/elliptic) [](https://coveralls.io/github/indutny/elliptic?branch=master) [](https://codeclimate.com/github/indutny/elliptic)
[](https://saucelabs.com/u/gh-indutny-elliptic)
Fast elliptic-curve cryptography in a plain javascript implementation.
NOTE: Please take a look at http://safecurves.cr.yp.to/ before choosing a curve
for your cryptography operations.
## Incentive
ECC is much slower than regular RSA cryptography, the JS implementations are
even more slower.
## Benchmarks
```bash
$ node benchmarks/index.js
Benchmarking: sign
elliptic#sign x 262 ops/sec ±0.51% (177 runs sampled)
eccjs#sign x 55.91 ops/sec ±0.90% (144 runs sampled)
------------------------
Fastest is elliptic#sign
========================
Benchmarking: verify
elliptic#verify x 113 ops/sec ±0.50% (166 runs sampled)
eccjs#verify x 48.56 ops/sec ±0.36% (125 runs sampled)
------------------------
Fastest is elliptic#verify
========================
Benchmarking: gen
elliptic#gen x 294 ops/sec ±0.43% (176 runs sampled)
eccjs#gen x 62.25 ops/sec ±0.63% (129 runs sampled)
------------------------
Fastest is elliptic#gen
========================
Benchmarking: ecdh
elliptic#ecdh x 136 ops/sec ±0.85% (156 runs sampled)
------------------------
Fastest is elliptic#ecdh
========================
```
## API
### ECDSA
```javascript
var EC = require('elliptic').ec;
// Create and initialize EC context
// (better do it once and reuse it)
var ec = new EC('secp256k1');
// Generate keys
var key = ec.genKeyPair();
// Sign message (must be an array, or it'll be treated as a hex sequence)
var msg = [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ];
var signature = key.sign(msg);
// Export DER encoded signature in Array
var derSign = signature.toDER();
// Verify signature
console.log(key.verify(msg, derSign));
// CHECK WITH NO PRIVATE KEY
// Public key as '04 + x + y'
var pub = '04bb1fa3...';
// Signature MUST be either:
// 1) hex-string of DER-encoded signature; or
// 2) DER-encoded signature as buffer; or
// 3) object with two hex-string properties (r and s)
var signature = 'b102ac...'; // case 1
var signature = new Buffer('...'); // case 2
var signature = { r: 'b1fc...', s: '9c42...' }; // case 3
// Import public key
var key = ec.keyFromPublic(pub, 'hex');
// Verify signature
console.log(key.verify(msg, signature));
```
### EdDSA
```javascript
var EdDSA = require('elliptic').eddsa;
// Create and initialize EdDSA context
// (better do it once and reuse it)
var ec = new EdDSA('ed25519');
// Create key pair from secret
var key = ec.keyFromSecret('693e3c...'); // hex string, array or Buffer
// Sign message (must be an array, or it'll be treated as a hex sequence)
var msg = [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ];
var signature = key.sign(msg).toHex();
// Verify signature
console.log(key.verify(msg, signature));
// CHECK WITH NO PRIVATE KEY
// Import public key
var pub = '0a1af638...';
var key = ec.keyFromPublic(pub, 'hex');
// Verify signature
var signature = '70bed1...';
console.log(key.verify(msg, signature));
```
### ECDH
```javascript
var EC = require('elliptic').ec;
var ec = new EC('curve25519');
// Generate keys
var key1 = ec.genKeyPair();
var key2 = ec.genKeyPair();
var shared1 = key1.derive(key2.getPublic());
var shared2 = key2.derive(key1.getPublic());
console.log('Both shared secrets are BN instances');
console.log(shared1.toString(16));
console.log(shared2.toString(16));
```
three and more members:
```javascript
var EC = require('elliptic').ec;
var ec = new EC('curve25519');
var A = ec.genKeyPair();
var B = ec.genKeyPair();
var C = ec.genKeyPair();
var AB = A.getPublic().mul(B.getPrivate())
var BC = B.getPublic().mul(C.getPrivate())
var CA = C.getPublic().mul(A.getPrivate())
var ABC = AB.mul(C.getPrivate())
var BCA = BC.mul(A.getPrivate())
var CAB = CA.mul(B.getPrivate())
console.log(ABC.getX().toString(16))
console.log(BCA.getX().toString(16))
console.log(CAB.getX().toString(16))
```
NOTE: `.derive()` returns a [BN][1] instance.
## Supported curves
Elliptic.js support following curve types:
* Short Weierstrass
* Montgomery
* Edwards
* Twisted Edwards
Following curve 'presets' are embedded into the library:
* `secp256k1`
* `p192`
* `p224`
* `p256`
* `p384`
* `p521`
* `curve25519`
* `ed25519`
NOTE: That `curve25519` could not be used for ECDSA, use `ed25519` instead.
### Implementation details
ECDSA is using deterministic `k` value generation as per [RFC6979][0]. Most of
the curve operations are performed on non-affine coordinates (either projective
or extended), various windowing techniques are used for different cases.
All operations are performed in reduction context using [bn.js][1], hashing is
provided by [hash.js][2]
### Related projects
* [eccrypto][3]: isomorphic implementation of ECDSA, ECDH and ECIES for both
browserify and node (uses `elliptic` for browser and [secp256k1-node][4] for
node)
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2014.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: http://tools.ietf.org/html/rfc6979
[1]: https://github.com/indutny/bn.js
[2]: https://github.com/indutny/hash.js
[3]: https://github.com/bitchan/eccrypto
[4]: https://github.com/wanderer/secp256k1-node
# Can I cache this? [](https://travis-ci.org/kornelski/http-cache-semantics)
`CachePolicy` tells when responses can be reused from a cache, taking into account [HTTP RFC 7234](http://httpwg.org/specs/rfc7234.html) rules for user agents and shared caches.
It also implements [RFC 5861](https://tools.ietf.org/html/rfc5861), implementing `stale-if-error` and `stale-while-revalidate`.
It's aware of many tricky details such as the `Vary` header, proxy revalidation, and authenticated responses.
## Usage
Cacheability of an HTTP response depends on how it was requested, so both `request` and `response` are required to create the policy.
```js
const policy = new CachePolicy(request, response, options);
if (!policy.storable()) {
// throw the response away, it's not usable at all
return;
}
// Cache the data AND the policy object in your cache
// (this is pseudocode, roll your own cache (lru-cache package works))
letsPretendThisIsSomeCache.set(
request.url,
{ policy, response },
policy.timeToLive()
);
```
```js
// And later, when you receive a new request:
const { policy, response } = letsPretendThisIsSomeCache.get(newRequest.url);
// It's not enough that it exists in the cache, it has to match the new request, too:
if (policy && policy.satisfiesWithoutRevalidation(newRequest)) {
// OK, the previous response can be used to respond to the `newRequest`.
// Response headers have to be updated, e.g. to add Age and remove uncacheable headers.
response.headers = policy.responseHeaders();
return response;
}
```
It may be surprising, but it's not enough for an HTTP response to be [fresh](#yo-fresh) to satisfy a request. It may need to match request headers specified in `Vary`. Even a matching fresh response may still not be usable if the new request restricted cacheability, etc.
The key method is `satisfiesWithoutRevalidation(newRequest)`, which checks whether the `newRequest` is compatible with the original request and whether all caching conditions are met.
### Constructor options
Request and response must have a `headers` property with all header names in lower case. `url`, `status` and `method` are optional (defaults are any URL, status `200`, and `GET` method).
```js
const request = {
url: '/',
method: 'GET',
headers: {
accept: '*/*',
},
};
const response = {
status: 200,
headers: {
'cache-control': 'public, max-age=7234',
},
};
const options = {
shared: true,
cacheHeuristic: 0.1,
immutableMinTimeToLive: 24 * 3600 * 1000, // 24h
ignoreCargoCult: false,
};
```
If `options.shared` is `true` (default), then the response is evaluated from a perspective of a shared cache (i.e. `private` is not cacheable and `s-maxage` is respected). If `options.shared` is `false`, then the response is evaluated from a perspective of a single-user cache (i.e. `private` is cacheable and `s-maxage` is ignored). `shared: true` is recommended for HTTP clients.
`options.cacheHeuristic` is a fraction of response's age that is used as a fallback cache duration. The default is 0.1 (10%), e.g. if a file hasn't been modified for 100 days, it'll be cached for 100\*0.1 = 10 days.
`options.immutableMinTimeToLive` is a number of milliseconds to assume as the default time to cache responses with `Cache-Control: immutable`. Note that [per RFC](http://httpwg.org/http-extensions/immutable.html) these can become stale, so `max-age` still overrides the default.
If `options.ignoreCargoCult` is true, common anti-cache directives will be completely ignored if the non-standard `pre-check` and `post-check` directives are present. These two useless directives are most commonly found in bad StackOverflow answers and PHP's "session limiter" defaults.
### `storable()`
Returns `true` if the response can be stored in a cache. If it's `false` then you MUST NOT store either the request or the response.
### `satisfiesWithoutRevalidation(newRequest)`
This is the most important method. Use this method to check whether the cached response is still fresh in the context of the new request.
If it returns `true`, then the given `request` matches the original response this cache policy has been created with, and the response can be reused without contacting the server. Note that the old response can't be returned without being updated, see `responseHeaders()`.
If it returns `false`, then the response may not be matching at all (e.g. it's for a different URL or method), or may require to be refreshed first (see `revalidationHeaders()`).
### `responseHeaders()`
Returns updated, filtered set of response headers to return to clients receiving the cached response. This function is necessary, because proxies MUST always remove hop-by-hop headers (such as `TE` and `Connection`) and update response's `Age` to avoid doubling cache time.
```js
cachedResponse.headers = cachePolicy.responseHeaders(cachedResponse);
```
### `timeToLive()`
Returns approximate time in _milliseconds_ until the response becomes stale (i.e. not fresh).
After that time (when `timeToLive() <= 0`) the response might not be usable without revalidation. However, there are exceptions, e.g. a client can explicitly allow stale responses, so always check with `satisfiesWithoutRevalidation()`.
`stale-if-error` and `stale-while-revalidate` extend the time to live of the cache, that can still be used if stale.
### `toObject()`/`fromObject(json)`
Chances are you'll want to store the `CachePolicy` object along with the cached response. `obj = policy.toObject()` gives a plain JSON-serializable object. `policy = CachePolicy.fromObject(obj)` creates an instance from it.
### Refreshing stale cache (revalidation)
When a cached response has expired, it can be made fresh again by making a request to the origin server. The server may respond with status 304 (Not Modified) without sending the response body again, saving bandwidth.
The following methods help perform the update efficiently and correctly.
#### `revalidationHeaders(newRequest)`
Returns updated, filtered set of request headers to send to the origin server to check if the cached response can be reused. These headers allow the origin server to return status 304 indicating the response is still fresh. All headers unrelated to caching are passed through as-is.
Use this method when updating cache from the origin server.
```js
updateRequest.headers = cachePolicy.revalidationHeaders(updateRequest);
```
#### `revalidatedPolicy(revalidationRequest, revalidationResponse)`
Use this method to update the cache after receiving a new response from the origin server. It returns an object with two keys:
- `policy` — A new `CachePolicy` with HTTP headers updated from `revalidationResponse`. You can always replace the old cached `CachePolicy` with the new one.
- `modified` — Boolean indicating whether the response body has changed.
- If `false`, then a valid 304 Not Modified response has been received, and you can reuse the old cached response body. This is also affected by `stale-if-error`.
- If `true`, you should use new response's body (if present), or make another request to the origin server without any conditional headers (i.e. don't use `revalidationHeaders()` this time) to get the new resource.
```js
// When serving requests from cache:
const { oldPolicy, oldResponse } = letsPretendThisIsSomeCache.get(
newRequest.url
);
if (!oldPolicy.satisfiesWithoutRevalidation(newRequest)) {
// Change the request to ask the origin server if the cached response can be used
newRequest.headers = oldPolicy.revalidationHeaders(newRequest);
// Send request to the origin server. The server may respond with status 304
const newResponse = await makeRequest(newRequest);
// Create updated policy and combined response from the old and new data
const { policy, modified } = oldPolicy.revalidatedPolicy(
newRequest,
newResponse
);
const response = modified ? newResponse : oldResponse;
// Update the cache with the newer/fresher response
letsPretendThisIsSomeCache.set(
newRequest.url,
{ policy, response },
policy.timeToLive()
);
// And proceed returning cached response as usual
response.headers = policy.responseHeaders();
return response;
}
```
# Yo, FRESH

## Used by
- [ImageOptim API](https://imageoptim.com/api), [make-fetch-happen](https://github.com/zkat/make-fetch-happen), [cacheable-request](https://www.npmjs.com/package/cacheable-request) ([got](https://www.npmjs.com/package/got)), [npm/registry-fetch](https://github.com/npm/registry-fetch), [etc.](https://github.com/kornelski/http-cache-semantics/network/dependents)
## Implemented
- `Cache-Control` response header with all the quirks.
- `Expires` with check for bad clocks.
- `Pragma` response header.
- `Age` response header.
- `Vary` response header.
- Default cacheability of statuses and methods.
- Requests for stale data.
- Filtering of hop-by-hop headers.
- Basic revalidation request
- `stale-if-error`
## Unimplemented
- Merging of range requests, `If-Range` (but correctly supports them as non-cacheable)
- Revalidation of multiple representations
### Trusting server `Date`
Per the RFC, the cache should take into account the time between server-supplied `Date` and the time it received the response. The RFC-mandated behavior creates two problems:
* Servers with incorrectly set timezone may add several hours to cache age (or more, if the clock is completely wrong).
* Even reasonably correct clocks may be off by a couple of seconds, breaking `max-age=1` trick (which is useful for reverse proxies on high-traffic servers).
Previous versions of this library had an option to ignore the server date if it was "too inaccurate". To support the `max-age=1` trick the library also has to ignore dates that pretty accurate. There's no point of having an option to trust dates that are only a bit inaccurate, so this library won't trust any server dates. `max-age` will be interpreted from the time the response has been received, not from when it has been sent. This will affect only [RFC 1149 networks](https://tools.ietf.org/html/rfc1149).
# web3-eth-personal
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This is the personal package used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-personal
```
## Usage
```js
const Web3EthPersonal = require('web3-eth-personal');
const personal = new Web3EthPersonal('ws://localhost:8546');
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-eth-personal.svg
[npm-url]: https://npmjs.org/package/web3-eth-personal
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-eth-personal
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-eth-personal
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-eth-personal
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-eth-personal
LevelUP
=======
<img alt="LevelDB Logo" height="100" src="http://leveldb.org/img/logo.svg">
**Fast & simple storage - a Node.js-style LevelDB wrapper**
[](http://travis-ci.org/Level/levelup)
[](https://david-dm.org/level/levelup)
[](https://nodei.co/npm/levelup/) [](https://nodei.co/npm/levelup/)
* <a href="#intro">Introduction</a>
* <a href="#leveldown">Relationship to LevelDOWN</a>
* <a href="#platforms">Tested & supported platforms</a>
* <a href="#basic">Basic usage</a>
* <a href="#api">API</a>
* <a href="#events">Events</a>
* <a href="#json">JSON data</a>
* <a href="#custom_encodings">Custom encodings</a>
* <a href="#extending">Extending LevelUP</a>
* <a href="#multiproc">Multi-process access</a>
* <a href="#support">Getting support</a>
* <a href="#contributing">Contributing</a>
* <a href="#license">Licence & copyright</a>
<a name="intro"></a>
Introduction
------------
**[LevelDB](https://github.com/google/leveldb)** is a simple key/value data store built by Google, inspired by BigTable. It's used in Google Chrome and many other products. LevelDB supports arbitrary byte arrays as both keys and values, singular *get*, *put* and *delete* operations, *batched put and delete*, bi-directional iterators and simple compression using the very fast [Snappy](http://google.github.io/snappy/) algorithm.
**LevelUP** aims to expose the features of LevelDB in a **Node.js-friendly way**. All standard `Buffer` encoding types are supported, as is a special JSON encoding. LevelDB's iterators are exposed as a Node.js-style **readable stream**.
LevelDB stores entries **sorted lexicographically by keys**. This makes LevelUP's <a href="#createReadStream"><code>ReadStream</code></a> interface a very powerful query mechanism.
**LevelUP** is an **OPEN Open Source Project**, see the <a href="#contributing">Contributing</a> section to find out what this means.
<a name="leveldown"></a>
Relationship to LevelDOWN
-------------------------
LevelUP is designed to be backed by **[LevelDOWN](https://github.com/level/leveldown/)** which provides a pure C++ binding to LevelDB and can be used as a stand-alone package if required.
**As of version 0.9, LevelUP no longer requires LevelDOWN as a dependency so you must `npm install leveldown` when you install LevelUP.**
LevelDOWN is now optional because LevelUP can be used with alternative backends, such as **[level.js](https://github.com/maxogden/level.js)** in the browser or [MemDOWN](https://github.com/level/memdown) for a pure in-memory store.
LevelUP will look for LevelDOWN and throw an error if it can't find it in its Node `require()` path. It will also tell you if the installed version of LevelDOWN is incompatible.
**The [level](https://github.com/level/level) package is available as an alternative installation mechanism.** Install it instead to automatically get both LevelUP & LevelDOWN. It exposes LevelUP on its export (i.e. you can `var leveldb = require('level')`).
<a name="platforms"></a>
Tested & supported platforms
----------------------------
* **Linux**: including ARM platforms such as Raspberry Pi *and Kindle!*
* **Mac OS**
* **Solaris**: including Joyent's SmartOS & Nodejitsu
* **Windows**: Node 0.10 and above only. See installation instructions for *node-gyp's* dependencies [here](https://github.com/TooTallNate/node-gyp#installation), you'll need these (free) components from Microsoft to compile and run any native Node add-on in Windows.
<a name="basic"></a>
Basic usage
-----------
First you need to install LevelUP!
```sh
$ npm install levelup leveldown
```
Or
```sh
$ npm install level
```
*(this second option requires you to use LevelUP by calling `var levelup = require('level')`)*
All operations are asynchronous although they don't necessarily require a callback if you don't need to know when the operation was performed.
```js
var levelup = require('levelup')
// 1) Create our database, supply location and options.
// This will create or open the underlying LevelDB store.
var db = levelup('./mydb')
// 2) put a key & value
db.put('name', 'LevelUP', function (err) {
if (err) return console.log('Ooops!', err) // some kind of I/O error
// 3) fetch by key
db.get('name', function (err, value) {
if (err) return console.log('Ooops!', err) // likely the key was not found
// ta da!
console.log('name=' + value)
})
})
```
<a name="api"></a>
## API
* <a href="#ctor"><code><b>levelup()</b></code></a>
* <a href="#open"><code>db.<b>open()</b></code></a>
* <a href="#close"><code>db.<b>close()</b></code></a>
* <a href="#put"><code>db.<b>put()</b></code></a>
* <a href="#get"><code>db.<b>get()</b></code></a>
* <a href="#del"><code>db.<b>del()</b></code></a>
* <a href="#batch"><code>db.<b>batch()</b></code> *(array form)*</a>
* <a href="#batch_chained"><code>db.<b>batch()</b></code> *(chained form)*</a>
* <a href="#isOpen"><code>db.<b>isOpen()</b></code></a>
* <a href="#isClosed"><code>db.<b>isClosed()</b></code></a>
* <a href="#createReadStream"><code>db.<b>createReadStream()</b></code></a>
* <a href="#createKeyStream"><code>db.<b>createKeyStream()</b></code></a>
* <a href="#createValueStream"><code>db.<b>createValueStream()</b></code></a>
### Special operations exposed by LevelDOWN
* <a href="#approximateSize"><code>db.db.<b>approximateSize()</b></code></a>
* <a href="#getProperty"><code>db.db.<b>getProperty()</b></code></a>
* <a href="#destroy"><code><b>leveldown.destroy()</b></code></a>
* <a href="#repair"><code><b>leveldown.repair()</b></code></a>
### Special Notes
* <a href="#writeStreams">What happened to <code><b>db.createWriteStream()</b></code></a>
--------------------------------------------------------
<a name="ctor"></a>
### levelup(location[, options[, callback]])
### levelup(options[, callback ])
### levelup(db[, callback ])
<code>levelup()</code> is the main entry point for creating a new LevelUP instance and opening the underlying store with LevelDB.
This function returns a new instance of LevelUP and will also initiate an <a href="#open"><code>open()</code></a> operation. Opening the database is an asynchronous operation which will trigger your callback if you provide one. The callback should take the form: `function (err, db) {}` where the `db` is the LevelUP instance. If you don't provide a callback, any read & write operations are simply queued internally until the database is fully opened.
This leads to two alternative ways of managing a new LevelUP instance:
```js
levelup(location, options, function (err, db) {
if (err) throw err
db.get('foo', function (err, value) {
if (err) return console.log('foo does not exist')
console.log('got foo =', value)
})
})
// vs the equivalent:
var db = levelup(location, options) // will throw if an error occurs
db.get('foo', function (err, value) {
if (err) return console.log('foo does not exist')
console.log('got foo =', value)
})
```
The `location` argument is available as a read-only property on the returned LevelUP instance.
The `levelup(options, callback)` form (with optional `callback`) is only available where you provide a valid `'db'` property on the options object (see below). Only for back-ends that don't require a `location` argument, such as [MemDOWN](https://github.com/level/memdown).
For example:
```js
var levelup = require('levelup')
var memdown = require('memdown')
var db = levelup({ db: memdown })
```
The `levelup(db, callback)` form (with optional `callback`) is only available where `db` is a factory function, as would be provided as a `'db'` property on an `options` object (see below). Only for back-ends that don't require a `location` argument, such as [MemDOWN](https://github.com/level/memdown).
For example:
```js
var levelup = require('levelup')
var memdown = require('memdown')
var db = levelup(memdown)
```
#### `options`
`levelup()` takes an optional options object as its second argument; the following properties are accepted:
* `'createIfMissing'` *(boolean, default: `true`)*: If `true`, will initialise an empty database at the specified location if one doesn't already exist. If `false` and a database doesn't exist you will receive an error in your `open()` callback and your database won't open.
* `'errorIfExists'` *(boolean, default: `false`)*: If `true`, you will receive an error in your `open()` callback if the database exists at the specified location.
* `'compression'` *(boolean, default: `true`)*: If `true`, all *compressible* data will be run through the Snappy compression algorithm before being stored. Snappy is very fast and shouldn't gain much speed by disabling so leave this on unless you have good reason to turn it off.
* `'cacheSize'` *(number, default: `8 * 1024 * 1024`)*: The size (in bytes) of the in-memory [LRU](http://en.wikipedia.org/wiki/Cache_algorithms#Least_Recently_Used) cache with frequently used uncompressed block contents.
* `'keyEncoding'` and `'valueEncoding'` *(string, default: `'utf8'`)*: The encoding of the keys and values passed through Node.js' `Buffer` implementation (see [Buffer#toString()](http://nodejs.org/docs/latest/api/buffer.html#buffer_buf_tostring_encoding_start_end)).
<p><code>'utf8'</code> is the default encoding for both keys and values so you can simply pass in strings and expect strings from your <code>get()</code> operations. You can also pass <code>Buffer</code> objects as keys and/or values and conversion will be performed.</p>
<p>Supported encodings are: hex, utf8, ascii, binary, base64, ucs2, utf16le.</p>
<p><code>'json'</code> encoding is also supported, see below.</p>
* `'db'` *(object, default: LevelDOWN)*: LevelUP is backed by [LevelDOWN](https://github.com/level/leveldown/) to provide an interface to LevelDB. You can completely replace the use of LevelDOWN by providing a "factory" function that will return a LevelDOWN API compatible object given a `location` argument. For further information, see [MemDOWN](https://github.com/level/memdown), a fully LevelDOWN API compatible replacement that uses a memory store rather than LevelDB. Also see [Abstract LevelDOWN](http://github.com/level/abstract-leveldown), a partial implementation of the LevelDOWN API that can be used as a base prototype for a LevelDOWN substitute.
Additionally, each of the main interface methods accept an optional options object that can be used to override `'keyEncoding'` and `'valueEncoding'`.
--------------------------------------------------------
<a name="open"></a>
### db.open([callback])
<code>open()</code> opens the underlying LevelDB store. In general **you should never need to call this method directly** as it's automatically called by <a href="#ctor"><code>levelup()</code></a>.
However, it is possible to *reopen* a database after it has been closed with <a href="#close"><code>close()</code></a>, although this is not generally advised.
--------------------------------------------------------
<a name="close"></a>
### db.close([callback])
<code>close()</code> closes the underlying LevelDB store. The callback will receive any error encountered during closing as the first argument.
You should always clean up your LevelUP instance by calling `close()` when you no longer need it to free up resources. A LevelDB store cannot be opened by multiple instances of LevelDB/LevelUP simultaneously.
--------------------------------------------------------
<a name="put"></a>
### db.put(key, value[, options][, callback])
<code>put()</code> is the primary method for inserting data into the store. Both the `key` and `value` can be arbitrary data objects.
The callback argument is optional but if you don't provide one and an error occurs then expect the error to be thrown.
#### `options`
Encoding of the `key` and `value` objects will adhere to `'keyEncoding'` and `'valueEncoding'` options provided to <a href="#ctor"><code>levelup()</code></a>, although you can provide alternative encoding settings in the options for `put()` (it's recommended that you stay consistent in your encoding of keys and values in a single store).
If you provide a `'sync'` value of `true` in your `options` object, LevelDB will perform a synchronous write of the data; although the operation will be asynchronous as far as Node is concerned. Normally, LevelDB passes the data to the operating system for writing and returns immediately, however a synchronous write will use `fsync()` or equivalent so your callback won't be triggered until the data is actually on disk. Synchronous filesystem writes are **significantly** slower than asynchronous writes but if you want to be absolutely sure that the data is flushed then you can use `'sync': true`.
--------------------------------------------------------
<a name="get"></a>
### db.get(key[, options][, callback])
<code>get()</code> is the primary method for fetching data from the store. The `key` can be an arbitrary data object. If it doesn't exist in the store then the callback will receive an error as its first argument. A not-found err object will be of type `'NotFoundError'` so you can `err.type == 'NotFoundError'` or you can perform a truthy test on the property `err.notFound`.
```js
db.get('foo', function (err, value) {
if (err) {
if (err.notFound) {
// handle a 'NotFoundError' here
return
}
// I/O or other error, pass it up the callback chain
return callback(err)
}
// .. handle `value` here
})
```
#### `options`
Encoding of the `key` and `value` objects is the same as in <a href="#put"><code>put</code></a>.
LevelDB will by default fill the in-memory LRU Cache with data from a call to get. Disabling this is done by setting `fillCache` to `false`.
--------------------------------------------------------
<a name="del"></a>
### db.del(key[, options][, callback])
<code>del()</code> is the primary method for removing data from the store.
```js
db.del('foo', function (err) {
if (err)
// handle I/O or other error
});
```
#### `options`
Encoding of the `key` object will adhere to the `'keyEncoding'` option provided to <a href="#ctor"><code>levelup()</code></a>, although you can provide alternative encoding settings in the options for `del()` (it's recommended that you stay consistent in your encoding of keys and values in a single store).
A `'sync'` option can also be passed, see <a href="#put"><code>put()</code></a> for details on how this works.
--------------------------------------------------------
<a name="batch"></a>
### db.batch(array[, options][, callback]) *(array form)*
<code>batch()</code> can be used for very fast bulk-write operations (both *put* and *delete*). The `array` argument should contain a list of operations to be executed sequentially, although as a whole they are performed as an atomic operation inside LevelDB.
Each operation is contained in an object having the following properties: `type`, `key`, `value`, where the *type* is either `'put'` or `'del'`. In the case of `'del'` the `'value'` property is ignored. Any entries with a `'key'` of `null` or `undefined` will cause an error to be returned on the `callback` and any `'type': 'put'` entry with a `'value'` of `null` or `undefined` will return an error.
If `key` and `value` are defined but `type` is not, it will default to `'put'`.
```js
var ops = [
{ type: 'del', key: 'father' },
{ type: 'put', key: 'name', value: 'Yuri Irsenovich Kim' },
{ type: 'put', key: 'dob', value: '16 February 1941' },
{ type: 'put', key: 'spouse', value: 'Kim Young-sook' },
{ type: 'put', key: 'occupation', value: 'Clown' }
]
db.batch(ops, function (err) {
if (err) return console.log('Ooops!', err)
console.log('Great success dear leader!')
})
```
#### `options`
See <a href="#put"><code>put()</code></a> for a discussion on the `options` object. You can overwrite default `'keyEncoding'` and `'valueEncoding'` and also specify the use of `sync` filesystem operations.
In addition to encoding options for the whole batch you can also overwrite the encoding per operation, like:
```js
var ops = [{
type: 'put',
key: new Buffer([1, 2, 3]),
value: { some: 'json' },
keyEncoding: 'binary',
valueEncoding: 'json'
}]
```
--------------------------------------------------------
<a name="batch_chained"></a>
### db.batch() *(chained form)*
<code>batch()</code>, when called with no arguments will return a `Batch` object which can be used to build, and eventually commit, an atomic LevelDB batch operation. Depending on how it's used, it is possible to obtain greater performance when using the chained form of `batch()` over the array form.
```js
db.batch()
.del('father')
.put('name', 'Yuri Irsenovich Kim')
.put('dob', '16 February 1941')
.put('spouse', 'Kim Young-sook')
.put('occupation', 'Clown')
.write(function () { console.log('Done!') })
```
<b><code>batch.put(key, value[, options])</code></b>
Queue a *put* operation on the current batch, not committed until a `write()` is called on the batch.
The optional `options` argument can be used to override the default `'keyEncoding'` and/or `'valueEncoding'`.
This method may `throw` a `WriteError` if there is a problem with your put (such as the `value` being `null` or `undefined`).
<b><code>batch.del(key[, options])</code></b>
Queue a *del* operation on the current batch, not committed until a `write()` is called on the batch.
The optional `options` argument can be used to override the default `'keyEncoding'`.
This method may `throw` a `WriteError` if there is a problem with your delete.
<b><code>batch.clear()</code></b>
Clear all queued operations on the current batch, any previous operations will be discarded.
<b><code>batch.length</code></b>
The number of queued operations on the current batch.
<b><code>batch.write([callback])</code></b>
Commit the queued operations for this batch. All operations not *cleared* will be written to the database atomically, that is, they will either all succeed or fail with no partial commits. The optional `callback` will be called when the operation has completed with an *error* argument if an error has occurred; if no `callback` is supplied and an error occurs then this method will `throw` a `WriteError`.
--------------------------------------------------------
<a name="isOpen"></a>
### db.isOpen()
A LevelUP object can be in one of the following states:
* *"new"* - newly created, not opened or closed
* *"opening"* - waiting for the database to be opened
* *"open"* - successfully opened the database, available for use
* *"closing"* - waiting for the database to be closed
* *"closed"* - database has been successfully closed, should not be used
`isOpen()` will return `true` only when the state is "open".
--------------------------------------------------------
<a name="isClosed"></a>
### db.isClosed()
*See <a href="#put"><code>isOpen()</code></a>*
`isClosed()` will return `true` only when the state is "closing" *or* "closed", it can be useful for determining if read and write operations are permissible.
--------------------------------------------------------
<a name="createReadStream"></a>
### db.createReadStream([options])
You can obtain a **ReadStream** of the full database by calling the `createReadStream()` method. The resulting stream is a complete Node.js-style [Readable Stream](http://nodejs.org/docs/latest/api/stream.html#stream_readable_stream) where `'data'` events emit objects with `'key'` and `'value'` pairs. You can also use the `gt`, `lt` and `limit` options to control the range of keys that are streamed.
```js
db.createReadStream()
.on('data', function (data) {
console.log(data.key, '=', data.value)
})
.on('error', function (err) {
console.log('Oh my!', err)
})
.on('close', function () {
console.log('Stream closed')
})
.on('end', function () {
console.log('Stream ended')
})
```
The standard `pause()`, `resume()` and `destroy()` methods are implemented on the ReadStream, as is `pipe()` (see below). `'data'`, '`error'`, `'end'` and `'close'` events are emitted.
Additionally, you can supply an options object as the first parameter to `createReadStream()` with the following options:
* `'gt'` (greater than), `'gte'` (greater than or equal) define the lower bound of the range to be streamed. Only records where the key is greater than (or equal to) this option will be included in the range. When `reverse=true` the order will be reversed, but the records streamed will be the same.
* `'lt'` (less than), `'lte'` (less than or equal) define the higher bound of the range to be streamed. Only key/value pairs where the key is less than (or equal to) this option will be included in the range. When `reverse=true` the order will be reversed, but the records streamed will be the same.
* `'start', 'end'` legacy ranges - instead use `'gte', 'lte'`
* `'reverse'` *(boolean, default: `false`)*: a boolean, set true and the stream output will be reversed. Beware that due to the way LevelDB works, a reverse seek will be slower than a forward seek.
* `'keys'` *(boolean, default: `true`)*: whether the `'data'` event should contain keys. If set to `true` and `'values'` set to `false` then `'data'` events will simply be keys, rather than objects with a `'key'` property. Used internally by the `createKeyStream()` method.
* `'values'` *(boolean, default: `true`)*: whether the `'data'` event should contain values. If set to `true` and `'keys'` set to `false` then `'data'` events will simply be values, rather than objects with a `'value'` property. Used internally by the `createValueStream()` method.
* `'limit'` *(number, default: `-1`)*: limit the number of results collected by this stream. This number represents a *maximum* number of results and may not be reached if you get to the end of the data first. A value of `-1` means there is no limit. When `reverse=true` the highest keys will be returned instead of the lowest keys.
* `'fillCache'` *(boolean, default: `false`)*: whether LevelDB's LRU-cache should be filled with data read.
* `'keyEncoding'` / `'valueEncoding'` *(string)*: the encoding applied to each read piece of data.
--------------------------------------------------------
<a name="createKeyStream"></a>
### db.createKeyStream([options])
A **KeyStream** is a **ReadStream** where the `'data'` events are simply the keys from the database so it can be used like a traditional stream rather than an object stream.
You can obtain a KeyStream either by calling the `createKeyStream()` method on a LevelUP object or by passing an options object to `createReadStream()` with `keys` set to `true` and `values` set to `false`.
```js
db.createKeyStream()
.on('data', function (data) {
console.log('key=', data)
})
// same as:
db.createReadStream({ keys: true, values: false })
.on('data', function (data) {
console.log('key=', data)
})
```
--------------------------------------------------------
<a name="createValueStream"></a>
### db.createValueStream([options])
A **ValueStream** is a **ReadStream** where the `'data'` events are simply the values from the database so it can be used like a traditional stream rather than an object stream.
You can obtain a ValueStream either by calling the `createValueStream()` method on a LevelUP object or by passing an options object to `createReadStream()` with `values` set to `true` and `keys` set to `false`.
```js
db.createValueStream()
.on('data', function (data) {
console.log('value=', data)
})
// same as:
db.createReadStream({ keys: false, values: true })
.on('data', function (data) {
console.log('value=', data)
})
```
--------------------------------------------------------
<a name="writeStreams"></a>
#### What happened to `db.createWriteStream`?
`db.createWriteStream()` has been removed in order to provide a smaller and more maintainable core. It primarily existed to create symmetry with `db.createReadStream()` but through much [discussion](https://github.com/level/levelup/issues/199), removing it was the best course of action.
The main driver for this was performance. While `db.createReadStream()` performs well under most use cases, `db.createWriteStream()` was highly dependent on the application keys and values. Thus we can't provide a standard implementation and encourage more `write-stream` implementations to be created to solve the broad spectrum of use cases.
Check out the implementations that the community has already produced [here](https://github.com/level/levelup/wiki/Modules#write-streams).
--------------------------------------------------------
<a name='approximateSize'></a>
### db.db.approximateSize(start, end, callback)
<code>approximateSize()</code> can used to get the approximate number of bytes of file system space used by the range `[start..end)`. The result may not include recently written data.
```js
var db = require('level')('./huge.db')
db.db.approximateSize('a', 'c', function (err, size) {
if (err) return console.error('Ooops!', err)
console.log('Approximate size of range is %d', size)
})
```
**Note:** `approximateSize()` is available via [LevelDOWN](https://github.com/level/leveldown/), which by default is accessible as the `db` property of your LevelUP instance. This is a specific LevelDB operation and is not likely to be available where you replace LevelDOWN with an alternative back-end via the `'db'` option.
--------------------------------------------------------
<a name='getProperty'></a>
### db.db.getProperty(property)
<code>getProperty</code> can be used to get internal details from LevelDB. When issued with a valid property string, a readable string will be returned (this method is synchronous).
Currently, the only valid properties are:
* <b><code>'leveldb.num-files-at-levelN'</code></b>: returns the number of files at level *N*, where N is an integer representing a valid level (e.g. "0").
* <b><code>'leveldb.stats'</code></b>: returns a multi-line string describing statistics about LevelDB's internal operation.
* <b><code>'leveldb.sstables'</code></b>: returns a multi-line string describing all of the *sstables* that make up contents of the current database.
```js
var db = require('level')('./huge.db')
console.log(db.db.getProperty('leveldb.num-files-at-level3'))
// → '243'
```
**Note:** `getProperty()` is available via [LevelDOWN](https://github.com/level/leveldown/), which by default is accessible as the `db` property of your LevelUP instance. This is a specific LevelDB operation and is not likely to be available where you replace LevelDOWN with an alternative back-end via the `'db'` option.
--------------------------------------------------------
<a name="destroy"></a>
### leveldown.destroy(location, callback)
<code>destroy()</code> is used to completely remove an existing LevelDB database directory. You can use this function in place of a full directory *rm* if you want to be sure to only remove LevelDB-related files. If the directory only contains LevelDB files, the directory itself will be removed as well. If there are additional, non-LevelDB files in the directory, those files, and the directory, will be left alone.
The callback will be called when the destroy operation is complete, with a possible `error` argument.
**Note:** `destroy()` is available via [LevelDOWN](https://github.com/level/leveldown/) which you will have to install seperately, e.g.:
```js
require('leveldown').destroy('./huge.db', function (err) { console.log('done!') })
```
--------------------------------------------------------
<a name="repair"></a>
### leveldown.repair(location, callback)
<code>repair()</code> can be used to attempt a restoration of a damaged LevelDB store. From the LevelDB documentation:
> If a DB cannot be opened, you may attempt to call this method to resurrect as much of the contents of the database as possible. Some data may be lost, so be careful when calling this function on a database that contains important information.
You will find information on the *repair* operation in the *LOG* file inside the store directory.
A `repair()` can also be used to perform a compaction of the LevelDB log into table files.
The callback will be called when the repair operation is complete, with a possible `error` argument.
**Note:** `repair()` is available via [LevelDOWN](https://github.com/level/leveldown/) which you will have to install seperately, e.g.:
```js
require('leveldown').repair('./huge.db', function (err) { console.log('done!') })
```
--------------------------------------------------------
<a name="events"></a>
Events
------
LevelUP emits events when the callbacks to the corresponding methods are called.
* `db.emit('put', key, value)` emitted when a new value is `'put'`
* `db.emit('del', key)` emitted when a value is deleted
* `db.emit('batch', ary)` emitted when a batch operation has executed
* `db.emit('ready')` emitted when the database has opened (`'open'` is synonym)
* `db.emit('closed')` emitted when the database has closed
* `db.emit('opening')` emitted when the database is opening
* `db.emit('closing')` emitted when the database is closing
If you do not pass a callback to an async function, and there is an error, LevelUP will `emit('error', err)` instead.
<a name="json"></a>
JSON data
---------
You specify `'json'` encoding for both keys and/or values, you can then supply JavaScript objects to LevelUP and receive them from all fetch operations, including ReadStreams. LevelUP will automatically *stringify* your objects and store them as *utf8* and parse the strings back into objects before passing them back to you.
<a name="custom_encodings"></a>
Custom encodings
----------------
A custom encoding may be provided by passing in an object as a value for `keyEncoding` or `valueEncoding` (wherever accepted), it must have the following properties:
```js
{
encode: function (val) { ... },
decode: function (val) { ... },
buffer: boolean, // encode returns a buffer and decode accepts a buffer
type: String // name of this encoding type.
}
```
<a name="extending"></a>
Extending LevelUP
-----------------
A list of <a href="https://github.com/level/levelup/wiki/Modules"><b>Node.js LevelDB modules and projects</b></a> can be found in the wiki.
When attempting to extend the functionality of LevelUP, it is recommended that you consider using [level-hooks](https://github.com/dominictarr/level-hooks) and/or [level-sublevel](https://github.com/dominictarr/level-sublevel). **level-sublevel** is particularly helpful for keeping additional, extension-specific, data in a LevelDB store. It allows you to partition a LevelUP instance into multiple sub-instances that each correspond to discrete namespaced key ranges.
<a name="multiproc"></a>
Multi-process access
--------------------
LevelDB is thread-safe but is **not** suitable for accessing with multiple processes. You should only ever have a LevelDB database open from a single Node.js process. Node.js clusters are made up of multiple processes so a LevelUP instance cannot be shared between them either.
See the <a href="https://github.com/level/levelup/wiki/Modules"><b>wiki</b></a> for some LevelUP extensions, including [multilevel](https://github.com/juliangruber/multilevel), that may help if you require a single data store to be shared across processes.
<a name="support"></a>
Getting support
---------------
There are multiple ways you can find help in using LevelDB in Node.js:
* **IRC:** you'll find an active group of LevelUP users in the **##leveldb** channel on Freenode, including most of the contributors to this project.
* **Mailing list:** there is an active [Node.js LevelDB](https://groups.google.com/forum/#!forum/node-levelup) Google Group.
* **GitHub:** you're welcome to open an issue here on this GitHub repository if you have a question.
<a name="contributing"></a>
Contributing
------------
LevelUP is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [contribution guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
### Windows
A large portion of the Windows support comes from code by [Krzysztof Kowalczyk](http://blog.kowalczyk.info/) [@kjk](https://twitter.com/kjk), see his Windows LevelDB port [here](http://code.google.com/r/kkowalczyk-leveldb/). If you're using LevelUP on Windows, you should give him your thanks!
<a name="license"></a>
License & copyright
-------------------
Copyright © 2012-2016 **LevelUP** [contributors](https://github.com/level/community#contributors).
**LevelUP** is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included `LICENSE.md` file for more details.
*LevelUP builds on the excellent work of the LevelDB and Snappy teams from Google and additional contributors. LevelDB and Snappy are both issued under the [New BSD Licence](http://opensource.org/licenses/BSD-3-Clause).*
# is-core-module <sup>[![Version Badge][2]][1]</sup>
[![Build Status][3]][4]
[![dependency status][5]][6]
[![dev dependency status][7]][8]
[![License][license-image]][license-url]
[![Downloads][downloads-image]][downloads-url]
[![npm badge][11]][1]
Is this specifier a node.js core module? Optionally provide a node version to check; defaults to the current node version.
## Example
```js
var isCore = require('is-core-module');
var assert = require('assert');
assert(isCore('fs'));
assert(!isCore('butts'));
```
## Tests
Clone the repo, `npm install`, and run `npm test`
[1]: https://npmjs.org/package/is-core-module
[2]: https://versionbadg.es/inspect-js/is-core-module.svg
[3]: https://travis-ci.com/inspect-js/is-core-module.svg
[4]: https://travis-ci.com/inspect-js/is-core-module
[5]: https://david-dm.org/inspect-js/is-core-module.svg
[6]: https://david-dm.org/inspect-js/is-core-module
[7]: https://david-dm.org/inspect-js/is-core-module/dev-status.svg
[8]: https://david-dm.org/inspect-js/is-core-module#info=devDependencies
[11]: https://nodei.co/npm/is-core-module.png?downloads=true&stars=true
[license-image]: https://img.shields.io/npm/l/is-core-module.svg
[license-url]: LICENSE
[downloads-image]: https://img.shields.io/npm/dm/is-core-module.svg
[downloads-url]: https://npm-stat.com/charts.html?package=is-core-module
# vary
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Manipulate the HTTP Vary header
## Installation
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install vary
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var vary = require('vary')
```
### vary(res, field)
Adds the given header `field` to the `Vary` response header of `res`.
This can be a string of a single field, a string of a valid `Vary`
header, or an array of multiple fields.
This will append the header if not already listed, otherwise leaves
it listed in the current location.
<!-- eslint-disable no-undef -->
```js
// Append "Origin" to the Vary header of the response
vary(res, 'Origin')
```
### vary.append(header, field)
Adds the given header `field` to the `Vary` response header string `header`.
This can be a string of a single field, a string of a valid `Vary` header,
or an array of multiple fields.
This will append the header if not already listed, otherwise leaves
it listed in the current location. The new header string is returned.
<!-- eslint-disable no-undef -->
```js
// Get header string appending "Origin" to "Accept, User-Agent"
vary.append('Accept, User-Agent', 'Origin')
```
## Examples
### Updating the Vary header when content is based on it
```js
var http = require('http')
var vary = require('vary')
http.createServer(function onRequest (req, res) {
// about to user-agent sniff
vary(res, 'User-Agent')
var ua = req.headers['user-agent'] || ''
var isMobile = /mobi|android|touch|mini/i.test(ua)
// serve site, depending on isMobile
res.setHeader('Content-Type', 'text/html')
res.end('You are (probably) ' + (isMobile ? '' : 'not ') + 'a mobile user')
})
```
## Testing
```sh
$ npm test
```
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/vary.svg
[npm-url]: https://npmjs.org/package/vary
[node-version-image]: https://img.shields.io/node/v/vary.svg
[node-version-url]: https://nodejs.org/en/download
[travis-image]: https://img.shields.io/travis/jshttp/vary/master.svg
[travis-url]: https://travis-ci.org/jshttp/vary
[coveralls-image]: https://img.shields.io/coveralls/jshttp/vary/master.svg
[coveralls-url]: https://coveralls.io/r/jshttp/vary
[downloads-image]: https://img.shields.io/npm/dm/vary.svg
[downloads-url]: https://npmjs.org/package/vary
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# parse-asn1
[](http://travis-ci.org/crypto-browserify/parse-asn1)
[](https://www.npmjs.org/package/parse-asn1)
[](https://github.com/feross/standard)
utility library for parsing asn1 files for use with browserify-sign.
browserify-cipher
===
[](https://travis-ci.org/crypto-browserify/browserify-cipher)
Provides createCipher, createDecipher, createCipheriv, createDecipheriv and
getCiphers for the browserify. Includes AES and DES ciphers.
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
libsecp256k1
============
[](https://travis-ci.org/bitcoin-core/secp256k1)
Optimized C library for EC operations on curve secp256k1.
This library is a work in progress and is being used to research best practices. Use at your own risk.
Features:
* secp256k1 ECDSA signing/verification and key generation.
* Adding/multiplying private/public keys.
* Serialization/parsing of private keys, public keys, signatures.
* Constant time, constant memory access signing and pubkey generation.
* Derandomized DSA (via RFC6979 or with a caller provided function.)
* Very efficient implementation.
Implementation details
----------------------
* General
* No runtime heap allocation.
* Extensive testing infrastructure.
* Structured to facilitate review and analysis.
* Intended to be portable to any system with a C89 compiler and uint64_t support.
* No use of floating types.
* Expose only higher level interfaces to minimize the API surface and improve application security. ("Be difficult to use insecurely.")
* Field operations
* Optimized implementation of arithmetic modulo the curve's field size (2^256 - 0x1000003D1).
* Using 5 52-bit limbs (including hand-optimized assembly for x86_64, by Diederik Huys).
* Using 10 26-bit limbs.
* Field inverses and square roots using a sliding window over blocks of 1s (by Peter Dettman).
* Scalar operations
* Optimized implementation without data-dependent branches of arithmetic modulo the curve's order.
* Using 4 64-bit limbs (relying on __int128 support in the compiler).
* Using 8 32-bit limbs.
* Group operations
* Point addition formula specifically simplified for the curve equation (y^2 = x^3 + 7).
* Use addition between points in Jacobian and affine coordinates where possible.
* Use a unified addition/doubling formula where necessary to avoid data-dependent branches.
* Point/x comparison without a field inversion by comparison in the Jacobian coordinate space.
* Point multiplication for verification (a*P + b*G).
* Use wNAF notation for point multiplicands.
* Use a much larger window for multiples of G, using precomputed multiples.
* Use Shamir's trick to do the multiplication with the public key and the generator simultaneously.
* Optionally (off by default) use secp256k1's efficiently-computable endomorphism to split the P multiplicand into 2 half-sized ones.
* Point multiplication for signing
* Use a precomputed table of multiples of powers of 16 multiplied with the generator, so general multiplication becomes a series of additions.
* Intended to be completely free of timing sidechannels for secret-key operations (on reasonable hardware/toolchains)
* Access the table with branch-free conditional moves so memory access is uniform.
* No data-dependent branches
* Optional runtime blinding which attempts to frustrate differential power analysis.
* The precomputed tables add and eventually subtract points for which no known scalar (private key) is known, preventing even an attacker with control over the private key used to control the data internally.
Build steps
-----------
libsecp256k1 is built using autotools:
$ ./autogen.sh
$ ./configure
$ make
$ make check
$ sudo make install # optional
Exhaustive tests
-----------
$ ./exhaustive_tests
With valgrind, you might need to increase the max stack size:
$ valgrind --max-stackframe=2500000 ./exhaustive_tests
Reporting a vulnerability
------------
See [SECURITY.md](SECURITY.md)
forever-agent
=============
HTTP Agent that keeps socket connections alive between keep-alive requests. Formerly part of mikeal/request, now a standalone module.
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
# BIP39
[](https://travis-ci.org/bitcoinjs/bip39)
[](https://www.npmjs.org/package/bip39)
[](https://github.com/feross/standard)
JavaScript implementation of [Bitcoin BIP39](https://github.com/bitcoin/bips/blob/master/bip-0039.mediawiki): Mnemonic code for generating deterministic keys
## Reminder for developers
***Please remember to allow recovery from mnemonic phrases that have invalid checksums (or that you don't have the wordlist)***
When a checksum is invalid, warn the user that the phrase is not something generated by your app, and ask if they would like to use it anyway. This way, your app only needs to hold the wordlists for your supported languages, but you can recover phrases made by other apps in other languages.
However, there should be other checks in place, such as checking to make sure the user is inputting 12 words or more separated by a space. ie. `phrase.trim().split(/\s+/g).length >= 12`
## Removing wordlists from webpack/browserify
Browserify/Webpack bundles can get very large if you include all the wordlists, so you can now exclude wordlists to make your bundle lighter.
For example, if we want to exclude all wordlists besides chinese_simplified, you could build using the browserify command below.
```bash
$ browserify -r bip39 -s bip39 \
--exclude=./wordlists/english.json \
--exclude=./wordlists/japanese.json \
--exclude=./wordlists/spanish.json \
--exclude=./wordlists/italian.json \
--exclude=./wordlists/french.json \
--exclude=./wordlists/korean.json \
--exclude=./wordlists/chinese_traditional.json \
> bip39.browser.js
```
This will create a bundle that only contains the chinese_simplified wordlist, and it will be the default wordlist for all calls without explicit wordlists.
You can also do this in Webpack using the `IgnorePlugin`. Here is an example of excluding all non-English wordlists
```javascript
...
plugins: [
new webpack.IgnorePlugin(/^\.\/(?!english)/, /bip39\/src\/wordlists$/),
],
...
```
This is how it will look in the browser console.
```javascript
> bip39.entropyToMnemonic('00000000000000000000000000000000')
"的 的 的 的 的 的 的 的 的 的 的 在"
> bip39.wordlists.chinese_simplified
Array(2048) [ "的", "一", "是", "在", "不", "了", "有", "和", "人", "这", … ]
> bip39.wordlists.english
undefined
> bip39.wordlists.japanese
undefined
> bip39.wordlists.spanish
undefined
> bip39.wordlists.italian
undefined
> bip39.wordlists.french
undefined
> bip39.wordlists.korean
undefined
> bip39.wordlists.chinese_traditional
undefined
```
For a list of supported wordlists check the wordlists folder. The name of the json file (minus the extension) is the name of the key to access the wordlist.
You can also change the default wordlist at runtime if you dislike the wordlist you were given as default.
```javascript
> bip39.entropyToMnemonic('00000000000000000000000000000fff')
"あいこくしん あいこくしん あいこくしん あいこくしん あいこくしん あいこくしん あいこくしん あいこくしん あいこくしん あいこくしん あまい ろんり"
> bip39.setDefaultWordlist('italian')
undefined
> bip39.entropyToMnemonic('00000000000000000000000000000fff')
"abaco abaco abaco abaco abaco abaco abaco abaco abaco abaco aforisma zibetto"
```
## Installation
``` bash
npm install bip39
```
## Examples
``` js
// Generate a random mnemonic (uses crypto.randomBytes under the hood), defaults to 128-bits of entropy
const mnemonic = bip39.generateMnemonic()
// => 'seed sock milk update focus rotate barely fade car face mechanic mercy'
bip39.mnemonicToSeedSync('basket actual').toString('hex')
// => '5cf2d4a8b0355e90295bdfc565a022a409af063d5365bb57bf74d9528f494bfa4400f53d8349b80fdae44082d7f9541e1dba2b003bcfec9d0d53781ca676651f'
bip39.mnemonicToSeedSync('basket actual')
// => <Buffer 5c f2 d4 a8 b0 35 5e 90 29 5b df c5 65 a0 22 a4 09 af 06 3d 53 65 bb 57 bf 74 d9 52 8f 49 4b fa 44 00 f5 3d 83 49 b8 0f da e4 40 82 d7 f9 54 1e 1d ba 2b ...>
// mnemonicToSeed has an synchronous version
// mnemonicToSeedSync is less performance oriented
bip39.mnemonicToSeed('basket actual').then(console.log)
// => <Buffer 5c f2 d4 a8 b0 35 5e 90 29 5b df c5 65 a0 22 a4 09 af 06 3d 53 65 bb 57 bf 74 d9 52 8f 49 4b fa 44 00 f5 3d 83 49 b8 0f da e4 40 82 d7 f9 54 1e 1d ba 2b ...>
bip39.mnemonicToSeed('basket actual').then(bytes => bytes.toString('hex')).then(console.log)
// => '5cf2d4a8b0355e90295bdfc565a022a409af063d5365bb57bf74d9528f494bfa4400f53d8349b80fdae44082d7f9541e1dba2b003bcfec9d0d53781ca676651f'
bip39.mnemonicToSeedSync('basket actual', 'a password')
// => <Buffer 46 16 a4 4f 2c 90 b9 69 02 14 b8 fd 43 5b b4 14 62 43 de 10 7b 30 87 59 0a 3b b8 d3 1b 2f 3a ef ab 1d 4b 52 6d 21 e5 0a 04 02 3d 7a d0 66 43 ea 68 3b ... >
bip39.validateMnemonic(mnemonic)
// => true
bip39.validateMnemonic('basket actual')
// => false
```
``` js
const bip39 = require('bip39')
// defaults to BIP39 English word list
// uses HEX strings for entropy
const mnemonic = bip39.entropyToMnemonic('00000000000000000000000000000000')
// => abandon abandon abandon abandon abandon abandon abandon abandon abandon abandon abandon about
// reversible
bip39.mnemonicToEntropy(mnemonic)
// => '00000000000000000000000000000000'
```
# node-gyp-build
Build tool and bindings loader for node-gyp that supports prebuilds.
```
npm install node-gyp-build
```
Use together with [prebuildify](https://github.com/mafintosh/prebuildify) to easily support prebuilds for your native modules.
## Usage
`node-gyp-build` works similar to `node-gyp build` except that it will check if a build or prebuild is present before rebuilding your project.
It's main intended use is as an npm install script and bindings loader for native modules that bundle prebuilds using [prebuildify](https://github.com/mafintosh/prebuildify).
First add `node-gyp-build` as an install script to your native project
``` js
{
...
"scripts": {
"install": "node-gyp-build"
}
}
```
Then in your `index.js`, instead of using the [bindings module](https://www.npmjs.com/package/bindings) use `node-gyp-build` to load your binding.
``` js
var binding = require('node-gyp-build')(__dirname)
```
If you do these two things and bundle prebuilds [prebuildify](https://github.com/mafintosh/prebuildify) your native module will work for most platforms
without having to compile on install time AND will work in both node and electron without the need to recompile between usage.
Users can override `node-gyp-build` and force compiling by doing `npm install --build-from-source`.
## License
MIT
# web3-eth-accounts
This is a sub package of [web3.js][repo]
This is the accounts package to be used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-accounts
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-eth-accounts.js` in your html file.
This will expose the `Web3EthAccounts` object on the window object.
## Usage
```js
// in node.js
var Web3EthAccounts = require('web3-eth-accounts');
var account = new Web3EthAccounts('ws://localhost:8546');
account.create();
> {
address: '0x2c7536E3605D9C16a7a3D7b1898e529396a65c23',
privateKey: '0x4c0883a69102937d6231471b5dbb6204fe5129617082792ae468d01a3f362318',
signTransaction: function(tx){...},
sign: function(data){...},
encrypt: function(password){...}
}
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# web3-eth-personal
This is a sub package of [web3.js][repo]
This is the personal package to be used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-personal
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-eth-personal.js` in your html file.
This will expose the `Web3EthPersonal` object on the window object.
## Usage
```js
// in node.js
var Web3EthPersonal = require('web3-eth-personal');
var personal = new Web3EthPersonal('ws://localhost:8546');
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# for-in [](https://www.npmjs.com/package/for-in) [](https://npmjs.org/package/for-in) [](https://npmjs.org/package/for-in) [](https://travis-ci.org/jonschlinkert/for-in)
> Iterate over the own and inherited enumerable properties of an object, and return an object with properties that evaluate to true from the callback. Exit early by returning `false`. JavaScript/Node.js
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save for-in
```
## Usage
```js
var forIn = require('for-in');
var obj = {a: 'foo', b: 'bar', c: 'baz'};
var values = [];
var keys = [];
forIn(obj, function (value, key, o) {
keys.push(key);
values.push(value);
});
console.log(keys);
//=> ['a', 'b', 'c'];
console.log(values);
//=> ['foo', 'bar', 'baz'];
```
## About
### Related projects
* [arr-flatten](https://www.npmjs.com/package/arr-flatten): Recursively flatten an array or arrays. This is the fastest implementation of array flatten. | [homepage](https://github.com/jonschlinkert/arr-flatten "Recursively flatten an array or arrays. This is the fastest implementation of array flatten.")
* [collection-map](https://www.npmjs.com/package/collection-map): Returns an array of mapped values from an array or object. | [homepage](https://github.com/jonschlinkert/collection-map "Returns an array of mapped values from an array or object.")
* [for-own](https://www.npmjs.com/package/for-own): Iterate over the own enumerable properties of an object, and return an object with properties… [more](https://github.com/jonschlinkert/for-own) | [homepage](https://github.com/jonschlinkert/for-own "Iterate over the own enumerable properties of an object, and return an object with properties that evaluate to true from the callback. Exit early by returning `false`. JavaScript/Node.js.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 16 | [jonschlinkert](https://github.com/jonschlinkert) |
| 2 | [paulirish](https://github.com/paulirish) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.4.2, on February 28, 2017._
# readable-stream
***Node.js core streams for userland*** [](https://travis-ci.com/nodejs/readable-stream)
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
[](https://saucelabs.com/u/readabe-stream)
```bash
npm install --save readable-stream
```
This package is a mirror of the streams implementations in Node.js.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v10.19.0/docs/api/stream.html).
If you want to guarantee a stable streams base, regardless of what version of
Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core, for background see [this blogpost](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).
As of version 2.0.0 **readable-stream** uses semantic versioning.
## Version 3.x.x
v3.x.x of `readable-stream` is a cut from Node 10. This version supports Node 6, 8, and 10, as well as evergreen browsers, IE 11 and latest Safari. The breaking changes introduced by v3 are composed by the combined breaking changes in [Node v9](https://nodejs.org/en/blog/release/v9.0.0/) and [Node v10](https://nodejs.org/en/blog/release/v10.0.0/), as follows:
1. Error codes: https://github.com/nodejs/node/pull/13310,
https://github.com/nodejs/node/pull/13291,
https://github.com/nodejs/node/pull/16589,
https://github.com/nodejs/node/pull/15042,
https://github.com/nodejs/node/pull/15665,
https://github.com/nodejs/readable-stream/pull/344
2. 'readable' have precedence over flowing
https://github.com/nodejs/node/pull/18994
3. make virtual methods errors consistent
https://github.com/nodejs/node/pull/18813
4. updated streams error handling
https://github.com/nodejs/node/pull/18438
5. writable.end should return this.
https://github.com/nodejs/node/pull/18780
6. readable continues to read when push('')
https://github.com/nodejs/node/pull/18211
7. add custom inspect to BufferList
https://github.com/nodejs/node/pull/17907
8. always defer 'readable' with nextTick
https://github.com/nodejs/node/pull/17979
## Version 2.x.x
v2.x.x of `readable-stream` is a cut of the stream module from Node 8 (there have been no semver-major changes from Node 4 to 8). This version supports all Node.js versions from 0.8, as well as evergreen browsers and IE 10 & 11.
### Big Thanks
Cross-browser Testing Platform and Open Source <3 Provided by [Sauce Labs][sauce]
# Usage
You can swap your `require('stream')` with `require('readable-stream')`
without any changes, if you are just using one of the main classes and
functions.
```js
const {
Readable,
Writable,
Transform,
Duplex,
pipeline,
finished
} = require('readable-stream')
````
Note that `require('stream')` will return `Stream`, while
`require('readable-stream')` will return `Readable`. We discourage using
whatever is exported directly, but rather use one of the properties as
shown in the example above.
# Streams Working Group
`readable-stream` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
<a name="members"></a>
## Team Members
* **Calvin Metcalf** ([@calvinmetcalf](https://github.com/calvinmetcalf)) <[email protected]>
- Release GPG key: F3EF5F62A87FC27A22E643F714CE4FF5015AA242
* **Mathias Buus** ([@mafintosh](https://github.com/mafintosh)) <[email protected]>
* **Matteo Collina** ([@mcollina](https://github.com/mcollina)) <[email protected]>
- Release GPG key: 3ABC01543F22DD2239285CDD818674489FBC127E
* **Irina Shestak** ([@lrlna](https://github.com/lrlna)) <[email protected]>
* **Yoshua Wyuts** ([@yoshuawuyts](https://github.com/yoshuawuyts)) <[email protected]>
[sauce]: https://saucelabs.com
# mime-types
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
The ultimate javascript content-type utility.
Similar to [the `[email protected]` module](https://www.npmjs.com/package/mime), except:
- __No fallbacks.__ Instead of naively returning the first available type,
`mime-types` simply returns `false`, so do
`var type = mime.lookup('unrecognized') || 'application/octet-stream'`.
- No `new Mime()` business, so you could do `var lookup = require('mime-types').lookup`.
- No `.define()` functionality
- Bug fixes for `.lookup(path)`
Otherwise, the API is compatible with `mime` 1.x.
## Install
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```sh
$ npm install mime-types
```
## Adding Types
All mime types are based on [mime-db](https://www.npmjs.com/package/mime-db),
so open a PR there if you'd like to add mime types.
## API
<!-- eslint-disable no-unused-vars -->
```js
var mime = require('mime-types')
```
All functions return `false` if input is invalid or not found.
### mime.lookup(path)
Lookup the content-type associated with a file.
<!-- eslint-disable no-undef -->
```js
mime.lookup('json') // 'application/json'
mime.lookup('.md') // 'text/markdown'
mime.lookup('file.html') // 'text/html'
mime.lookup('folder/file.js') // 'application/javascript'
mime.lookup('folder/.htaccess') // false
mime.lookup('cats') // false
```
### mime.contentType(type)
Create a full content-type header given a content-type or extension.
When given an extension, `mime.lookup` is used to get the matching
content-type, otherwise the given content-type is used. Then if the
content-type does not already have a `charset` parameter, `mime.charset`
is used to get the default charset and add to the returned content-type.
<!-- eslint-disable no-undef -->
```js
mime.contentType('markdown') // 'text/x-markdown; charset=utf-8'
mime.contentType('file.json') // 'application/json; charset=utf-8'
mime.contentType('text/html') // 'text/html; charset=utf-8'
mime.contentType('text/html; charset=iso-8859-1') // 'text/html; charset=iso-8859-1'
// from a full path
mime.contentType(path.extname('/path/to/file.json')) // 'application/json; charset=utf-8'
```
### mime.extension(type)
Get the default extension for a content-type.
<!-- eslint-disable no-undef -->
```js
mime.extension('application/octet-stream') // 'bin'
```
### mime.charset(type)
Lookup the implied default charset of a content-type.
<!-- eslint-disable no-undef -->
```js
mime.charset('text/markdown') // 'UTF-8'
```
### var type = mime.types[extension]
A map of content-types by extension.
### [extensions...] = mime.extensions[type]
A map of extensions by content-type.
## License
[MIT](LICENSE)
[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/mime-types/master
[coveralls-url]: https://coveralls.io/r/jshttp/mime-types?branch=master
[node-version-image]: https://badgen.net/npm/node/mime-types
[node-version-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/mime-types
[npm-url]: https://npmjs.org/package/mime-types
[npm-version-image]: https://badgen.net/npm/v/mime-types
[travis-image]: https://badgen.net/travis/jshttp/mime-types/master
[travis-url]: https://travis-ci.org/jshttp/mime-types
# Repository parser
Git/Subversion/Mercurial repository metadata parser
[]
## Example
```javascript
var vizion = require('vizion');
/**
* Grab metadata for svn/git/hg repositories
*/
vizion.analyze({
folder : '/tmp/folder'
}, function(err, meta) {
if (err) throw new Error(err);
/**
*
* meta = {
* type : 'git',
* ahead : false,
* unstaged : false,
* branch : 'development',
* remotes : [ 'http', 'http ssl', 'origin' ],
* remote : 'origin',
* commment : 'This is a comment',
* update_time : Tue Oct 28 2014 14:33:30 GMT+0100 (CET),
* url : 'https://github.com/keymetrics/vizion.git',
* revision : 'f0a1d45936cf7a3c969e4caba96546fd23255796',
* next_rev : null, // null if its latest in the branch
* prev_rev : '6d6932dac9c82f8a29ff40c1d5300569c24aa2c8'
* }
*
*/
});
/**
* Check if a local repository is up to date with its remote
*/
vizion.isUpToDate({
folder : '/tmp/folder'
}, function(err, meta) {
if (err) throw new Error(err);
/**
*
* meta = {
* is_up_to_date : false,
* new_revision : '6d6932dac9c82f8a29ff40c1d5300569c24aa2c8'
* current_revision : 'f0a1d45936cf7a3c969e4caba96546fd23255796'
* }
*
*/
});
/**
* Update the local repository to latest commit found on the remote for its current branch
* - on fail it rollbacks to the latest commit
*/
vizion.update({
folder : '/tmp/folder'
}, function(err, meta) {
if (err) throw new Error(err);
/**
*
* meta = {
* success : true,
* current_revision : '6d6932dac9c82f8a29ff40c1d5300569c24aa2c8'
* }
*
*/
});
/**
* Revert to a specified commit
* - Eg: this does a git reset --hard <commit_revision>
*/
vizion.revertTo({
revision : 'f0a1d45936cf7a3c969e4caba96546fd23255796',
folder : '/tmp/folder'
}, function(err, data) {
if (err) throw new Error(err);
/**
*
* data = {
* success : true,
* }
*
*/
});
/**
* If a previous commit exists it checkouts on it
*/
vizion.prev({
folder : '/tmp/folder'
}, function(err, meta) {
if (err) throw new Error(err);
/**
*
* meta = {
* success : true,
* current_revision : '6d6932dac9c82f8a29ff40c1d5300569c24aa2c8'
* }
*
*/
});
/**
* If a more recent commit exists it chekouts on it
*/
vizion.next({
folder : '/tmp/folder'
}, function(err, meta) {
if (err) throw new Error(err);
/**
*
* meta = {
* success : false,
* current_revision : '6d6932dac9c82f8a29ff40c1d5300569c24aa2c8'
* }
*
*/
});
```
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
# unpipe
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-image]][node-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Unpipe a stream from all destinations.
## Installation
```sh
$ npm install unpipe
```
## API
```js
var unpipe = require('unpipe')
```
### unpipe(stream)
Unpipes all destinations from a given stream. With stream 2+, this is
equivalent to `stream.unpipe()`. When used with streams 1 style streams
(typically Node.js 0.8 and below), this module attempts to undo the
actions done in `stream.pipe(dest)`.
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/unpipe.svg
[npm-url]: https://npmjs.org/package/unpipe
[node-image]: https://img.shields.io/node/v/unpipe.svg
[node-url]: http://nodejs.org/download/
[travis-image]: https://img.shields.io/travis/stream-utils/unpipe.svg
[travis-url]: https://travis-ci.org/stream-utils/unpipe
[coveralls-image]: https://img.shields.io/coveralls/stream-utils/unpipe.svg
[coveralls-url]: https://coveralls.io/r/stream-utils/unpipe?branch=master
[downloads-image]: https://img.shields.io/npm/dm/unpipe.svg
[downloads-url]: https://npmjs.org/package/unpipe
# promptly
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Dependency status][david-dm-image]][david-dm-url] [![Dev Dependency status][david-dm-dev-image]][david-dm-dev-url]
[npm-url]:https://npmjs.org/package/promptly
[downloads-image]:http://img.shields.io/npm/dm/promptly.svg
[npm-image]:http://img.shields.io/npm/v/promptly.svg
[travis-url]:https://travis-ci.org/IndigoUnited/node-promptly
[travis-image]:http://img.shields.io/travis/IndigoUnited/node-promptly/master.svg
[david-dm-url]:https://david-dm.org/IndigoUnited/node-promptly
[david-dm-image]:https://img.shields.io/david/IndigoUnited/node-promptly.svg
[david-dm-dev-url]:https://david-dm.org/IndigoUnited/node-promptly#info=devDependencies
[david-dm-dev-image]:https://img.shields.io/david/dev/IndigoUnited/node-promptly.svg
Simple command line prompting utility.
## Installation
`$ npm install promptly`
## API
### .prompt(message, [opts], [fn])
Prompts for a value, printing the `message` and waiting for the input.
When done, calls `fn` with `error` and `value` or returns a `Promise` if no `fn` is provided.
Default options:
```js
{
// The default value. If not supplied, the input is mandatory
'default': null,
// Automatically trim the input
'trim': true,
// A validator or an array of validators.
'validator': null,
// Automatically retry if a validator fails
'retry': true,
// Do not print what the user types
'silent': false,
// Replace each character with the specified string when 'silent' is true
'replace': '',
// Input and output streams to read and write to
'input': process.stdin,
'output': process.stdout
}
```
The validators have two purposes:
```js
function (value) {
// Validation example, throwing an error when invalid
if (value.length !== 2) {
throw new Error('Length must be 2');
}
// Parse the value, modifying it
return value.replace('aa', 'bb');
}
```
Example usages
Ask for a name:
```js
promptly.prompt('Name: ', function (err, value) {
// err is always null in this case, because no validators are set
console.log(value);
});
```
Using Promise:
```js
promptly.prompt('Name: ')
.then(function (value) {
// no need for catch in this case, because no validators are set
console.log(value);
});
```
Ask for a name with a constraint (non-empty value and length > 2):
```js
var validator = function (value) {
if (value.length < 2) {
throw new Error('Min length of 2');
}
return value;
};
promptly.prompt('Name: ', { validator: validator }, function (err, value) {
// Since retry is true by default, err is always null
// because promptly will be prompting for a name until it validates
// Between each prompt, the error message from the validator will be printed
console.log('Name is:', value);
});
```
Same as above but do not retry automatically:
```js
var validator = function (value) {
if (value.length < 2) {
throw new Error('Min length of 2');
}
return value;
};
promptly.prompt('Name: ', { validator: validator, retry: false }, function (err, value) {
if (err) {
console.error('Invalid name:', err.message);
// Manually call retry
// The passed error has a retry method to easily prompt again.
return err.retry();
}
console.log('Name is:', value);
});
```
### .confirm(message, [opts], fn)
Ask the user to confirm something.
Calls `fn` with `error` and `value` (true or false).
Truthy values are: `y`, `yes` and `1`.
Falsy values are `n`, `no`, and `0`.
Comparison is made in a case insensitive way.
Example usage:
```js
promptly.confirm('Are you sure? ', function (err, value) {
console.log('Answer:', value);
});
```
### .choose(message, choices, [opts], fn)
Ask the user to choose between multiple `choices` (array of choices).
Calls `fn` with `error` and `value`.
Example usage:
```js
promptly.choose('Do you want an apple or an orange? ', ['apple', 'orange'], function (err, value) {
console.log('Answer:', value);
});
```
### .password(message, [opts], fn)
Prompts for a password, printing the `message` and waiting for the input.
When available, calls `fn` with `error` and `value`.
The available options are the same, except that `trim` and `silent` default to `false` and `default` is an empty string (to allow empty passwords).
Example usage:
```js
promptly.password('Type a password: ', { replace: '*' }, function (err, value) {
console.log('Password is:', value);
});
```
## License
Released under the [MIT License](http://www.opensource.org/licenses/mit-license.php).
# mustache.js - Logic-less {{mustache}} templates with JavaScript
> What could be more logical awesome than no logic at all?
[](https://travis-ci.org/janl/mustache.js) [](https://gitter.im/janl/mustache.js)
[mustache.js](http://github.com/janl/mustache.js) is a zero-dependency implementation of the [mustache](http://mustache.github.com/) template system in JavaScript.
[Mustache](http://mustache.github.com/) is a logic-less template syntax. It can be used for HTML, config files, source code - anything. It works by expanding tags in a template using values provided in a hash or object.
We call it "logic-less" because there are no if statements, else clauses, or for loops. Instead there are only tags. Some tags are replaced with a value, some nothing, and others a series of values.
For a language-agnostic overview of mustache's template syntax, see the `mustache(5)` [manpage](http://mustache.github.com/mustache.5.html).
## Where to use mustache.js?
You can use mustache.js to render mustache templates anywhere you can use JavaScript. This includes web browsers, server-side environments such as [Node.js](http://nodejs.org/), and [CouchDB](http://couchdb.apache.org/) views.
mustache.js ships with support for the [CommonJS](http://www.commonjs.org/) module API, the [Asynchronous Module Definition](https://github.com/amdjs/amdjs-api/wiki/AMD) API (AMD) and [ECMAScript modules](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Modules).
In addition to being a package to be used programmatically, you can use it as a [command line tool](#command-line-tool).
And this will be your templates after you use Mustache:

## Install
You can get Mustache via [npm](http://npmjs.com).
```bash
$ npm install mustache --save
```
## Usage
Below is a quick example how to use mustache.js:
```js
var view = {
title: "Joe",
calc: function () {
return 2 + 4;
}
};
var output = Mustache.render("{{title}} spends {{calc}}", view);
```
In this example, the `Mustache.render` function takes two parameters: 1) the [mustache](http://mustache.github.com/) template and 2) a `view` object that contains the data and code needed to render the template.
## Templates
A [mustache](http://mustache.github.com/) template is a string that contains any number of mustache tags. Tags are indicated by the double mustaches that surround them. `{{person}}` is a tag, as is `{{#person}}`. In both examples we refer to `person` as the tag's key. There are several types of tags available in mustache.js, described below.
There are several techniques that can be used to load templates and hand them to mustache.js, here are two of them:
#### Include Templates
If you need a template for a dynamic part in a static website, you can consider including the template in the static HTML file to avoid loading templates separately. Here's a small example:
```js
// file: render.js
function renderHello() {
var template = document.getElementById('template').innerHTML;
var rendered = Mustache.render(template, { name: 'Luke' });
document.getElementById('target').innerHTML = rendered;
}
```
```html
<html>
<body onload="renderHello()">
<div id="target">Loading...</div>
<script id="template" type="x-tmpl-mustache">
Hello {{ name }}!
</script>
<script src="https://unpkg.com/mustache@latest"></script>
<script src="render.js"></script>
</body>
</html>
```
#### Load External Templates
If your templates reside in individual files, you can load them asynchronously and render them when they arrive. Another example using [fetch](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch):
```js
function renderHello() {
fetch('template.mustache')
.then((response) => response.text())
.then((template) => {
var rendered = Mustache.render(template, { name: 'Luke' });
document.getElementById('target').innerHTML = rendered;
});
}
```
### Variables
The most basic tag type is a simple variable. A `{{name}}` tag renders the value of the `name` key in the current context. If there is no such key, nothing is rendered.
All variables are HTML-escaped by default. If you want to render unescaped HTML, use the triple mustache: `{{{name}}}`. You can also use `&` to unescape a variable.
If you'd like to change HTML-escaping behavior globally (for example, to template non-HTML formats), you can override Mustache's escape function. For example, to disable all escaping: `Mustache.escape = function(text) {return text;};`.
If you want `{{name}}` _not_ to be interpreted as a mustache tag, but rather to appear exactly as `{{name}}` in the output, you must change and then restore the default delimiter. See the [Custom Delimiters](#custom-delimiters) section for more information.
View:
```json
{
"name": "Chris",
"company": "<b>GitHub</b>"
}
```
Template:
```
* {{name}}
* {{age}}
* {{company}}
* {{{company}}}
* {{&company}}
{{=<% %>=}}
* {{company}}
<%={{ }}=%>
```
Output:
```html
* Chris
*
* <b>GitHub</b>
* <b>GitHub</b>
* <b>GitHub</b>
* {{company}}
```
JavaScript's dot notation may be used to access keys that are properties of objects in a view.
View:
```json
{
"name": {
"first": "Michael",
"last": "Jackson"
},
"age": "RIP"
}
```
Template:
```html
* {{name.first}} {{name.last}}
* {{age}}
```
Output:
```html
* Michael Jackson
* RIP
```
### Sections
Sections render blocks of text one or more times, depending on the value of the key in the current context.
A section begins with a pound and ends with a slash. That is, `{{#person}}` begins a `person` section, while `{{/person}}` ends it. The text between the two tags is referred to as that section's "block".
The behavior of the section is determined by the value of the key.
#### False Values or Empty Lists
If the `person` key does not exist, or exists and has a value of `null`, `undefined`, `false`, `0`, or `NaN`, or is an empty string or an empty list, the block will not be rendered.
View:
```json
{
"person": false
}
```
Template:
```html
Shown.
{{#person}}
Never shown!
{{/person}}
```
Output:
```html
Shown.
```
#### Non-Empty Lists
If the `person` key exists and is not `null`, `undefined`, or `false`, and is not an empty list the block will be rendered one or more times.
When the value is a list, the block is rendered once for each item in the list. The context of the block is set to the current item in the list for each iteration. In this way we can loop over collections.
View:
```json
{
"stooges": [
{ "name": "Moe" },
{ "name": "Larry" },
{ "name": "Curly" }
]
}
```
Template:
```html
{{#stooges}}
<b>{{name}}</b>
{{/stooges}}
```
Output:
```html
<b>Moe</b>
<b>Larry</b>
<b>Curly</b>
```
When looping over an array of strings, a `.` can be used to refer to the current item in the list.
View:
```json
{
"musketeers": ["Athos", "Aramis", "Porthos", "D'Artagnan"]
}
```
Template:
```html
{{#musketeers}}
* {{.}}
{{/musketeers}}
```
Output:
```html
* Athos
* Aramis
* Porthos
* D'Artagnan
```
If the value of a section variable is a function, it will be called in the context of the current item in the list on each iteration.
View:
```js
{
"beatles": [
{ "firstName": "John", "lastName": "Lennon" },
{ "firstName": "Paul", "lastName": "McCartney" },
{ "firstName": "George", "lastName": "Harrison" },
{ "firstName": "Ringo", "lastName": "Starr" }
],
"name": function () {
return this.firstName + " " + this.lastName;
}
}
```
Template:
```html
{{#beatles}}
* {{name}}
{{/beatles}}
```
Output:
```html
* John Lennon
* Paul McCartney
* George Harrison
* Ringo Starr
```
#### Functions
If the value of a section key is a function, it is called with the section's literal block of text, un-rendered, as its first argument. The second argument is a special rendering function that uses the current view as its view argument. It is called in the context of the current view object.
View:
```js
{
"name": "Tater",
"bold": function () {
return function (text, render) {
return "<b>" + render(text) + "</b>";
}
}
}
```
Template:
```html
{{#bold}}Hi {{name}}.{{/bold}}
```
Output:
```html
<b>Hi Tater.</b>
```
### Inverted Sections
An inverted section opens with `{{^section}}` instead of `{{#section}}`. The block of an inverted section is rendered only if the value of that section's tag is `null`, `undefined`, `false`, *falsy* or an empty list.
View:
```json
{
"repos": []
}
```
Template:
```html
{{#repos}}<b>{{name}}</b>{{/repos}}
{{^repos}}No repos :({{/repos}}
```
Output:
```html
No repos :(
```
### Comments
Comments begin with a bang and are ignored. The following template:
```html
<h1>Today{{! ignore me }}.</h1>
```
Will render as follows:
```html
<h1>Today.</h1>
```
Comments may contain newlines.
### Partials
Partials begin with a greater than sign, like {{> box}}.
Partials are rendered at runtime (as opposed to compile time), so recursive partials are possible. Just avoid infinite loops.
They also inherit the calling context. Whereas in ERB you may have this:
```html+erb
<%= partial :next_more, :start => start, :size => size %>
```
Mustache requires only this:
```html
{{> next_more}}
```
Why? Because the `next_more.mustache` file will inherit the `size` and `start` variables from the calling context. In this way you may want to think of partials as includes, imports, template expansion, nested templates, or subtemplates, even though those aren't literally the case here.
For example, this template and partial:
base.mustache:
<h2>Names</h2>
{{#names}}
{{> user}}
{{/names}}
user.mustache:
<strong>{{name}}</strong>
Can be thought of as a single, expanded template:
```html
<h2>Names</h2>
{{#names}}
<strong>{{name}}</strong>
{{/names}}
```
In mustache.js an object of partials may be passed as the third argument to `Mustache.render`. The object should be keyed by the name of the partial, and its value should be the partial text.
```js
Mustache.render(template, view, {
user: userTemplate
});
```
### Custom Delimiters
Custom delimiters can be used in place of `{{` and `}}` by setting the new values in JavaScript or in templates.
#### Setting in JavaScript
The `Mustache.tags` property holds an array consisting of the opening and closing tag values. Set custom values by passing a new array of tags to `render()`, which gets honored over the default values, or by overriding the `Mustache.tags` property itself:
```js
var customTags = [ '<%', '%>' ];
```
##### Pass Value into Render Method
```js
Mustache.render(template, view, {}, customTags);
```
##### Override Tags Property
```js
Mustache.tags = customTags;
// Subsequent parse() and render() calls will use customTags
```
#### Setting in Templates
Set Delimiter tags start with an equals sign and change the tag delimiters from `{{` and `}}` to custom strings.
Consider the following contrived example:
```html+erb
* {{ default_tags }}
{{=<% %>=}}
* <% erb_style_tags %>
<%={{ }}=%>
* {{ default_tags_again }}
```
Here we have a list with three items. The first item uses the default tag style, the second uses ERB style as defined by the Set Delimiter tag, and the third returns to the default style after yet another Set Delimiter declaration.
According to [ctemplates](https://htmlpreview.github.io/?https://raw.githubusercontent.com/OlafvdSpek/ctemplate/master/doc/howto.html), this "is useful for languages like TeX, where double-braces may occur in the text and are awkward to use for markup."
Custom delimiters may not contain whitespace or the equals sign.
## Pre-parsing and Caching Templates
By default, when mustache.js first parses a template it keeps the full parsed token tree in a cache. The next time it sees that same template it skips the parsing step and renders the template much more quickly. If you'd like, you can do this ahead of time using `mustache.parse`.
```js
Mustache.parse(template);
// Then, sometime later.
Mustache.render(template, view);
```
## Command line tool
mustache.js is shipped with a Node.js based command line tool. It might be installed as a global tool on your computer to render a mustache template of some kind
```bash
$ npm install -g mustache
$ mustache dataView.json myTemplate.mustache > output.html
```
also supports stdin.
```bash
$ cat dataView.json | mustache - myTemplate.mustache > output.html
```
or as a package.json `devDependency` in a build process maybe?
```bash
$ npm install mustache --save-dev
```
```json
{
"scripts": {
"build": "mustache dataView.json myTemplate.mustache > public/output.html"
}
}
```
```bash
$ npm run build
```
The command line tool is basically a wrapper around `Mustache.render` so you get all the features.
If your templates use partials you should pass paths to partials using `-p` flag:
```bash
$ mustache -p path/to/partial1.mustache -p path/to/partial2.mustache dataView.json myTemplate.mustache
```
## Plugins for JavaScript Libraries
mustache.js may be built specifically for several different client libraries, including the following:
- [jQuery](http://jquery.com/)
- [MooTools](http://mootools.net/)
- [Dojo](http://www.dojotoolkit.org/)
- [YUI](http://developer.yahoo.com/yui/)
- [qooxdoo](http://qooxdoo.org/)
These may be built using [Rake](http://rake.rubyforge.org/) and one of the following commands:
```bash
$ rake jquery
$ rake mootools
$ rake dojo
$ rake yui3
$ rake qooxdoo
```
## TypeScript
Since the source code of this package is written in JavaScript, we follow the [TypeScript publishing docs](https://www.typescriptlang.org/docs/handbook/declaration-files/publishing.html) preferred approach
by having type definitions available via [@types/mustache](https://www.npmjs.com/package/@types/mustache).
## Testing
In order to run the tests you'll need to install [Node.js](http://nodejs.org/).
You also need to install the sub module containing [Mustache specifications](http://github.com/mustache/spec) in the project root.
```bash
$ git submodule init
$ git submodule update
```
Install dependencies.
```bash
$ npm install
```
Then run the tests.
```bash
$ npm test
```
The test suite consists of both unit and integration tests. If a template isn't rendering correctly for you, you can make a test for it by doing the following:
1. Create a template file named `mytest.mustache` in the `test/_files`
directory. Replace `mytest` with the name of your test.
2. Create a corresponding view file named `mytest.js` in the same directory.
This file should contain a JavaScript object literal enclosed in
parentheses. See any of the other view files for an example.
3. Create a file with the expected output in `mytest.txt` in the same
directory.
Then, you can run the test with:
```bash
$ TEST=mytest npm run test-render
```
### Browser tests
Browser tests are not included in `npm test` as they run for too long, although they are ran automatically on Travis when merged into master. Run browser tests locally in any browser:
```bash
$ npm run test-browser-local
```
then point your browser to `http://localhost:8080/__zuul`
## Who uses mustache.js?
An updated list of mustache.js users is kept [on the Github wiki](https://github.com/janl/mustache.js/wiki/Beard-Competition). Add yourself or your company if you use mustache.js!
## Contributing
mustache.js is a mature project, but it continues to actively invite maintainers. You can help out a high-profile project that is used in a lot of places on the web. No big commitment required, if all you do is review a single [Pull Request](https://github.com/janl/mustache.js/pulls), you are a maintainer. And a hero.
### Your First Contribution
- review a [Pull Request](https://github.com/janl/mustache.js/pulls)
- fix an [Issue](https://github.com/janl/mustache.js/issues)
- update the [documentation](https://github.com/janl/mustache.js#usage)
- make a website
- write a tutorial
## Thanks
mustache.js wouldn't kick ass if it weren't for these fine souls:
* Chris Wanstrath / defunkt
* Alexander Lang / langalex
* Sebastian Cohnen / tisba
* J Chris Anderson / jchris
* Tom Robinson / tlrobinson
* Aaron Quint / quirkey
* Douglas Crockford
* Nikita Vasilyev / NV
* Elise Wood / glytch
* Damien Mathieu / dmathieu
* Jakub Kuźma / qoobaa
* Will Leinweber / will
* dpree
* Jason Smith / jhs
* Aaron Gibralter / agibralter
* Ross Boucher / boucher
* Matt Sanford / mzsanford
* Ben Cherry / bcherry
* Michael Jackson / mjackson
* Phillip Johnsen / phillipj
* David da Silva Contín / dasilvacontin
# repeat-string [](https://www.npmjs.com/package/repeat-string) [](https://npmjs.org/package/repeat-string) [](https://npmjs.org/package/repeat-string) [](https://travis-ci.org/jonschlinkert/repeat-string)
> Repeat the given string n times. Fastest implementation for repeating a string.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save repeat-string
```
## Usage
### [repeat](index.js#L41)
Repeat the given `string` the specified `number` of times.
**Example:**
**Example**
```js
var repeat = require('repeat-string');
repeat('A', 5);
//=> AAAAA
```
**Params**
* `string` **{String}**: The string to repeat
* `number` **{Number}**: The number of times to repeat the string
* `returns` **{String}**: Repeated string
## Benchmarks
Repeat string is significantly faster than the native method (which is itself faster than [repeating](https://github.com/sindresorhus/repeating)):
```sh
# 2x
repeat-string █████████████████████████ (26,953,977 ops/sec)
repeating █████████ (9,855,695 ops/sec)
native ██████████████████ (19,453,895 ops/sec)
# 3x
repeat-string █████████████████████████ (19,445,252 ops/sec)
repeating ███████████ (8,661,565 ops/sec)
native ████████████████████ (16,020,598 ops/sec)
# 10x
repeat-string █████████████████████████ (23,792,521 ops/sec)
repeating █████████ (8,571,332 ops/sec)
native ███████████████ (14,582,955 ops/sec)
# 50x
repeat-string █████████████████████████ (23,640,179 ops/sec)
repeating █████ (5,505,509 ops/sec)
native ██████████ (10,085,557 ops/sec)
# 250x
repeat-string █████████████████████████ (23,489,618 ops/sec)
repeating ████ (3,962,937 ops/sec)
native ████████ (7,724,892 ops/sec)
# 2000x
repeat-string █████████████████████████ (20,315,172 ops/sec)
repeating ████ (3,297,079 ops/sec)
native ███████ (6,203,331 ops/sec)
# 20000x
repeat-string █████████████████████████ (23,382,915 ops/sec)
repeating ███ (2,980,058 ops/sec)
native █████ (5,578,808 ops/sec)
```
**Run the benchmarks**
Install dev dependencies:
```sh
npm i -d && node benchmark
```
## About
### Related projects
[repeat-element](https://www.npmjs.com/package/repeat-element): Create an array by repeating the given value n times. | [homepage](https://github.com/jonschlinkert/repeat-element "Create an array by repeating the given value n times.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor**<br/> |
| --- | --- |
| 51 | [jonschlinkert](https://github.com/jonschlinkert) |
| 2 | [LinusU](https://github.com/LinusU) |
| 2 | [tbusser](https://github.com/tbusser) |
| 1 | [doowb](https://github.com/doowb) |
| 1 | [wooorm](https://github.com/wooorm) |
### Building docs
_(This document was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme) (a [verb](https://github.com/verbose/verb) generator), please don't edit the readme directly. Any changes to the readme must be made in [.verb.md](.verb.md).)_
To generate the readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install -g verb verb-generate-readme && verb
```
### Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
### License
Copyright © 2016, [Jon Schlinkert](http://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/repeat-string/blob/master/LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.2.0, on October 23, 2016._
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# web3-eth-accounts
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This is the accounts package used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-accounts
```
## Usage
```js
const Web3EthAccounts = require('web3-eth-accounts');
const account = new Web3EthAccounts('ws://localhost:8546');
account.create();
> {
address: '0x2c7536E3605D9C16a7a3D7b1898e529396a65c23',
privateKey: '0x4c0883a69102937d6231471b5dbb6204fe5129617082792ae468d01a3f362318',
signTransaction: function(tx){...},
sign: function(data){...},
encrypt: function(password){...}
}
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-eth-accounts.svg
[npm-url]: https://npmjs.org/package/web3-eth-accounts
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-eth-accounts
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-eth-accounts
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-eth-accounts
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-eth-accounts
# is-extglob [](https://www.npmjs.com/package/is-extglob) [](https://npmjs.org/package/is-extglob) [](https://travis-ci.org/jonschlinkert/is-extglob)
> Returns true if a string has an extglob.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-extglob
```
## Usage
```js
var isExtglob = require('is-extglob');
```
**True**
```js
isExtglob('?(abc)');
isExtglob('@(abc)');
isExtglob('!(abc)');
isExtglob('*(abc)');
isExtglob('+(abc)');
```
**False**
Escaped extglobs:
```js
isExtglob('\\?(abc)');
isExtglob('\\@(abc)');
isExtglob('\\!(abc)');
isExtglob('\\*(abc)');
isExtglob('\\+(abc)');
```
Everything else...
```js
isExtglob('foo.js');
isExtglob('!foo.js');
isExtglob('*.js');
isExtglob('**/abc.js');
isExtglob('abc/*.js');
isExtglob('abc/(aaa|bbb).js');
isExtglob('abc/[a-z].js');
isExtglob('abc/{a,b}.js');
isExtglob('abc/?.js');
isExtglob('abc.js');
isExtglob('abc/def/ghi.js');
```
## History
**v2.0**
Adds support for escaping. Escaped exglobs no longer return true.
## About
### Related projects
* [has-glob](https://www.npmjs.com/package/has-glob): Returns `true` if an array has a glob pattern. | [homepage](https://github.com/jonschlinkert/has-glob "Returns `true` if an array has a glob pattern.")
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/jonschlinkert/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. | [homepage](https://github.com/jonschlinkert/micromatch "Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Building docs
_(This document was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme) (a [verb](https://github.com/verbose/verb) generator), please don't edit the readme directly. Any changes to the readme must be made in [.verb.md](.verb.md).)_
To generate the readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install -g verb verb-generate-readme && verb
```
### Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
### License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/is-extglob/blob/master/LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.1.31, on October 12, 2016._
[]()
[](http://badge.fury.io/js/eventemitter2)
[](https://david-dm.org/asyncly/eventemitter2)
[]()
# SYNOPSIS
EventEmitter2 is an implementation of the EventEmitter module found in Node.js. In addition to having a better benchmark performance than EventEmitter and being browser-compatible, it also extends the interface of EventEmitter with additional non-breaking features.
# DESCRIPTION
### FEATURES
- Namespaces/Wildcards.
- Times To Listen (TTL), extends the `once` concept with `many`.
- Browser environment compatibility.
- Demonstrates good performance in benchmarks
```
EventEmitterHeatUp x 3,728,965 ops/sec \302\2610.68% (60 runs sampled)
EventEmitter x 2,822,904 ops/sec \302\2610.74% (63 runs sampled)
EventEmitter2 x 7,251,227 ops/sec \302\2610.55% (58 runs sampled)
EventEmitter2 (wild) x 3,220,268 ops/sec \302\2610.44% (65 runs sampled)
Fastest is EventEmitter2
```
### Differences (Non-breaking, compatible with existing EventEmitter)
- The EventEmitter2 constructor takes an optional configuration object.
```javascript
var EventEmitter2 = require('eventemitter2').EventEmitter2;
var server = new EventEmitter2({
//
// set this to `true` to use wildcards. It defaults to `false`.
//
wildcard: true,
//
// the delimiter used to segment namespaces, defaults to `.`.
//
delimiter: '::',
//
// set this to `true` if you want to emit the newListener event. The default value is `true`.
//
newListener: false,
//
// the maximum amount of listeners that can be assigned to an event, default 10.
//
maxListeners: 20,
//
// show event name in memory leak message when more than maximum amount of listeners is assigned, default false
//
verboseMemoryLeak: false
});
```
- Getting the actual event that fired.
```javascript
server.on('foo.*', function(value1, value2) {
console.log(this.event, value1, value2);
});
```
- Fire an event N times and then remove it, an extension of the `once` concept.
```javascript
server.many('foo', 4, function() {
console.log('hello');
});
```
- Pass in a namespaced event as an array rather than a delimited string.
```javascript
server.many(['foo', 'bar', 'bazz'], 4, function() {
console.log('hello');
});
```
# Installing
```console
$ npm install --save eventemitter2
```
# API
When an `EventEmitter` instance experiences an error, the typical action is
to emit an `error` event. Error events are treated as a special case.
If there is no listener for it, then the default action is to print a stack
trace and exit the program.
All EventEmitters emit the event `newListener` when new listeners are
added. EventEmitters also emit the event `removeListener` when listeners are
removed, and `removeListenerAny` when listeners added through `onAny` are
removed.
**Namespaces** with **Wildcards**
To use namespaces/wildcards, pass the `wildcard` option into the EventEmitter
constructor. When namespaces/wildcards are enabled, events can either be
strings (`foo.bar`) separated by a delimiter or arrays (`['foo', 'bar']`). The
delimiter is also configurable as a constructor option.
An event name passed to any event emitter method can contain a wild card (the
`*` character). If the event name is a string, a wildcard may appear as `foo.*`.
If the event name is an array, the wildcard may appear as `['foo', '*']`.
If either of the above described events were passed to the `on` method,
subsequent emits such as the following would be observed...
```javascript
emitter.emit('foo.bazz');
emitter.emit(['foo', 'bar']);
```
**NOTE:** An event name may use more than one wildcard. For example,
`foo.*.bar.*` is a valid event name, and would match events such as
`foo.x.bar.y`, or `['foo', 'bazz', 'bar', 'test']`
# Multi-level Wildcards
A double wildcard (the string `**`) matches any number of levels (zero or more) of events. So if for example `'foo.**'` is passed to the `on` method, the following events would be observed:
````javascript
emitter.emit('foo');
emitter.emit('foo.bar');
emitter.emit('foo.bar.baz');
````
On the other hand, if the single-wildcard event name was passed to the on method, the callback would only observe the second of these events.
### emitter.addListener(event, listener)
### emitter.on(event, listener)
Adds a listener to the end of the listeners array for the specified event.
```javascript
server.on('data', function(value1, value2, value3, ...) {
console.log('The event was raised!');
});
```
```javascript
server.on('data', function(value) {
console.log('The event was raised!');
});
```
### emitter.prependListener(event, listener)
Adds a listener to the beginning of the listeners array for the specified event.
```javascript
server.prependListener('data', function(value1, value2, value3, ...) {
console.log('The event was raised!');
});
```
### emitter.onAny(listener)
Adds a listener that will be fired when any event is emitted. The event name is passed as the first argument to the callback.
```javascript
server.onAny(function(event, value) {
console.log('All events trigger this.');
});
```
### emitter.prependAny(listener)
Adds a listener that will be fired when any event is emitted. The event name is passed as the first argument to the callback. The listener is added to the beginning of the listeners array
```javascript
server.prependAny(function(event, value) {
console.log('All events trigger this.');
});
```
### emitter.offAny(listener)
Removes the listener that will be fired when any event is emitted.
```javascript
server.offAny(function(value) {
console.log('The event was raised!');
});
```
#### emitter.once(event, listener)
Adds a **one time** listener for the event. The listener is invoked
only the first time the event is fired, after which it is removed.
```javascript
server.once('get', function (value) {
console.log('Ah, we have our first value!');
});
```
#### emitter.prependOnceListener(event, listener)
Adds a **one time** listener for the event. The listener is invoked
only the first time the event is fired, after which it is removed.
The listener is added to the beginning of the listeners array
```javascript
server.prependOnceListener('get', function (value) {
console.log('Ah, we have our first value!');
});
```
### emitter.many(event, timesToListen, listener)
Adds a listener that will execute **n times** for the event before being
removed. The listener is invoked only the first **n times** the event is
fired, after which it is removed.
```javascript
server.many('get', 4, function (value) {
console.log('This event will be listened to exactly four times.');
});
```
### emitter.prependMany(event, timesToListen, listener)
Adds a listener that will execute **n times** for the event before being
removed. The listener is invoked only the first **n times** the event is
fired, after which it is removed.
The listener is added to the beginning of the listeners array.
```javascript
server.many('get', 4, function (value) {
console.log('This event will be listened to exactly four times.');
});
```
### emitter.removeListener(event, listener)
### emitter.off(event, listener)
Remove a listener from the listener array for the specified event.
**Caution**: Calling this method changes the array indices in the listener array behind the listener.
```javascript
var callback = function(value) {
console.log('someone connected!');
};
server.on('get', callback);
// ...
server.removeListener('get', callback);
```
### emitter.removeAllListeners([event])
Removes all listeners, or those of the specified event.
### emitter.setMaxListeners(n)
By default EventEmitters will print a warning if more than 10 listeners
are added to it. This is a useful default which helps finding memory leaks.
Obviously not all Emitters should be limited to 10. This function allows
that to be increased. Set to zero for unlimited.
### emitter.listeners(event)
Returns an array of listeners for the specified event. This array can be
manipulated, e.g. to remove listeners.
```javascript
server.on('get', function(value) {
console.log('someone connected!');
});
console.log(server.listeners('get')); // [ [Function] ]
```
### emitter.listenersAny()
Returns an array of listeners that are listening for any event that is
specified. This array can be manipulated, e.g. to remove listeners.
```javascript
server.onAny(function(value) {
console.log('someone connected!');
});
console.log(server.listenersAny()[0]); // [ [Function] ]
```
### emitter.emit(event, [arg1], [arg2], [...])
Execute each of the listeners that may be listening for the specified event
name in order with the list of arguments.
### emitter.emitAsync(event, [arg1], [arg2], [...])
Return the results of the listeners via [Promise.all](https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/Promise/all).
Only this method doesn't work [IE](http://caniuse.com/#search=promise).
```javascript
emitter.on('get',function(i) {
return new Promise(function(resolve){
setTimeout(function(){
resolve(i+3);
},50);
});
});
emitter.on('get',function(i) {
return new Promise(function(resolve){
resolve(i+2)
});
});
emitter.on('get',function(i) {
return Promise.resolve(i+1);
});
emitter.on('get',function(i) {
return i+0;
});
emitter.on('get',function(i) {
// noop
});
emitter.emitAsync('get',0)
.then(function(results){
console.log(results); // [3,2,1,0,undefined]
});
```
### emitter.eventNames()
Returns an array listing the events for which the emitter has registered listeners. The values in the array will be strings.
```javascript
emitter.on('foo', () => {});
emitter.on('bar', () => {});
console.log(emitter.eventNames());
// Prints: [ 'foo', 'bar' ]
```
# color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
## Eth-Lib
Lightweight Ethereum libraries. This is a temporary repository which will be used as the basis of an implementation on Idris (or similar).
# Miller-Rabin
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2014.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
# readable-stream
***Node-core v8.11.1 streams for userland*** [](https://travis-ci.org/nodejs/readable-stream)
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
[](https://saucelabs.com/u/readable-stream)
```bash
npm install --save readable-stream
```
***Node-core streams for userland***
This package is a mirror of the Streams2 and Streams3 implementations in
Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.11.1/docs/api/stream.html).
If you want to guarantee a stable streams base, regardless of what version of
Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core, for background see [this blogpost](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).
As of version 2.0.0 **readable-stream** uses semantic versioning.
# Streams Working Group
`readable-stream` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
<a name="members"></a>
## Team Members
* **Chris Dickinson** ([@chrisdickinson](https://github.com/chrisdickinson)) <[email protected]>
- Release GPG key: 9554F04D7259F04124DE6B476D5A82AC7E37093B
* **Calvin Metcalf** ([@calvinmetcalf](https://github.com/calvinmetcalf)) <[email protected]>
- Release GPG key: F3EF5F62A87FC27A22E643F714CE4FF5015AA242
* **Rod Vagg** ([@rvagg](https://github.com/rvagg)) <[email protected]>
- Release GPG key: DD8F2338BAE7501E3DD5AC78C273792F7D83545D
* **Sam Newman** ([@sonewman](https://github.com/sonewman)) <[email protected]>
* **Mathias Buus** ([@mafintosh](https://github.com/mafintosh)) <[email protected]>
* **Domenic Denicola** ([@domenic](https://github.com/domenic)) <[email protected]>
* **Matteo Collina** ([@mcollina](https://github.com/mcollina)) <[email protected]>
- Release GPG key: 3ABC01543F22DD2239285CDD818674489FBC127E
* **Irina Shestak** ([@lrlna](https://github.com/lrlna)) <[email protected]>
# yallist
Yet Another Linked List
There are many doubly-linked list implementations like it, but this
one is mine.
For when an array would be too big, and a Map can't be iterated in
reverse order.
[](https://travis-ci.org/isaacs/yallist) [](https://coveralls.io/github/isaacs/yallist)
## basic usage
```javascript
var yallist = require('yallist')
var myList = yallist.create([1, 2, 3])
myList.push('foo')
myList.unshift('bar')
// of course pop() and shift() are there, too
console.log(myList.toArray()) // ['bar', 1, 2, 3, 'foo']
myList.forEach(function (k) {
// walk the list head to tail
})
myList.forEachReverse(function (k, index, list) {
// walk the list tail to head
})
var myDoubledList = myList.map(function (k) {
return k + k
})
// now myDoubledList contains ['barbar', 2, 4, 6, 'foofoo']
// mapReverse is also a thing
var myDoubledListReverse = myList.mapReverse(function (k) {
return k + k
}) // ['foofoo', 6, 4, 2, 'barbar']
var reduced = myList.reduce(function (set, entry) {
set += entry
return set
}, 'start')
console.log(reduced) // 'startfoo123bar'
```
## api
The whole API is considered "public".
Functions with the same name as an Array method work more or less the
same way.
There's reverse versions of most things because that's the point.
### Yallist
Default export, the class that holds and manages a list.
Call it with either a forEach-able (like an array) or a set of
arguments, to initialize the list.
The Array-ish methods all act like you'd expect. No magic length,
though, so if you change that it won't automatically prune or add
empty spots.
### Yallist.create(..)
Alias for Yallist function. Some people like factories.
#### yallist.head
The first node in the list
#### yallist.tail
The last node in the list
#### yallist.length
The number of nodes in the list. (Change this at your peril. It is
not magic like Array length.)
#### yallist.toArray()
Convert the list to an array.
#### yallist.forEach(fn, [thisp])
Call a function on each item in the list.
#### yallist.forEachReverse(fn, [thisp])
Call a function on each item in the list, in reverse order.
#### yallist.get(n)
Get the data at position `n` in the list. If you use this a lot,
probably better off just using an Array.
#### yallist.getReverse(n)
Get the data at position `n`, counting from the tail.
#### yallist.map(fn, thisp)
Create a new Yallist with the result of calling the function on each
item.
#### yallist.mapReverse(fn, thisp)
Same as `map`, but in reverse.
#### yallist.pop()
Get the data from the list tail, and remove the tail from the list.
#### yallist.push(item, ...)
Insert one or more items to the tail of the list.
#### yallist.reduce(fn, initialValue)
Like Array.reduce.
#### yallist.reduceReverse
Like Array.reduce, but in reverse.
#### yallist.reverse
Reverse the list in place.
#### yallist.shift()
Get the data from the list head, and remove the head from the list.
#### yallist.slice([from], [to])
Just like Array.slice, but returns a new Yallist.
#### yallist.sliceReverse([from], [to])
Just like yallist.slice, but the result is returned in reverse.
#### yallist.toArray()
Create an array representation of the list.
#### yallist.toArrayReverse()
Create a reversed array representation of the list.
#### yallist.unshift(item, ...)
Insert one or more items to the head of the list.
#### yallist.unshiftNode(node)
Move a Node object to the front of the list. (That is, pull it out of
wherever it lives, and make it the new head.)
If the node belongs to a different list, then that list will remove it
first.
#### yallist.pushNode(node)
Move a Node object to the end of the list. (That is, pull it out of
wherever it lives, and make it the new tail.)
If the node belongs to a list already, then that list will remove it
first.
#### yallist.removeNode(node)
Remove a node from the list, preserving referential integrity of head
and tail and other nodes.
Will throw an error if you try to have a list remove a node that
doesn't belong to it.
### Yallist.Node
The class that holds the data and is actually the list.
Call with `var n = new Node(value, previousNode, nextNode)`
Note that if you do direct operations on Nodes themselves, it's very
easy to get into weird states where the list is broken. Be careful :)
#### node.next
The next node in the list.
#### node.prev
The previous node in the list.
#### node.value
The data the node contains.
#### node.list
The list to which this node belongs. (Null if it does not belong to
any list.)
# is-extglob [](http://badge.fury.io/js/is-extglob) [](https://travis-ci.org/jonschlinkert/is-extglob)
> Returns true if a string has an extglob.
## Install with [npm](npmjs.org)
```bash
npm i is-extglob --save
```
## Usage
```js
var isExtglob = require('is-extglob');
```
**True**
```js
isExtglob('?(abc)');
isExtglob('@(abc)');
isExtglob('!(abc)');
isExtglob('*(abc)');
isExtglob('+(abc)');
```
**False**
Everything else...
```js
isExtglob('foo.js');
isExtglob('!foo.js');
isExtglob('*.js');
isExtglob('**/abc.js');
isExtglob('abc/*.js');
isExtglob('abc/(aaa|bbb).js');
isExtglob('abc/[a-z].js');
isExtglob('abc/{a,b}.js');
isExtglob('abc/?.js');
isExtglob('abc.js');
isExtglob('abc/def/ghi.js');
```
## Related
* [extglob](https://github.com/jonschlinkert/extglob): Extended globs. extglobs add the expressive power of regular expressions to glob patterns.
* [micromatch](https://github.com/jonschlinkert/micromatch): Glob matching for javascript/node.js. A faster alternative to minimatch (10-45x faster on avg), with all the features you're used to using in your Grunt and gulp tasks.
* [parse-glob](https://github.com/jonschlinkert/parse-glob): Parse a glob pattern into an object of tokens.
## Run tests
Install dev dependencies.
```bash
npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-extglob/issues)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright (c) 2015 Jon Schlinkert
Released under the MIT license
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on March 06, 2015._
# bufferutil
[](https://www.npmjs.com/package/bufferutil)
[](https://travis-ci.com/websockets/bufferutil)
[](https://ci.appveyor.com/project/lpinca/bufferutil)
`bufferutil` is what makes `ws` fast. It provides some utilities to efficiently
perform some operations such as masking and unmasking the data payload of
WebSocket frames.
## Installation
```
npm install bufferutil --save-optional
```
The `--save-optional` flag tells npm to save the package in your package.json
under the [`optionalDependencies`](https://docs.npmjs.com/files/package.json#optionaldependencies)
key.
## API
The module exports two functions.
### `bufferUtil.mask(source, mask, output, offset, length)`
Masks a buffer using the given masking-key as specified by the WebSocket
protocol.
#### Arguments
- `source` - The buffer to mask.
- `mask` - A buffer representing the masking-key.
- `output` - The buffer where to store the result.
- `offset` - The offset at which to start writing.
- `length` - The number of bytes to mask.
#### Example
```js
'use strict';
const bufferUtil = require('bufferutil');
const crypto = require('crypto');
const source = crypto.randomBytes(10);
const mask = crypto.randomBytes(4);
bufferUtil.mask(source, mask, source, 0, source.length);
```
### `bufferUtil.unmask(buffer, mask)`
Unmasks a buffer using the given masking-key as specified by the WebSocket
protocol.
#### Arguments
- `buffer` - The buffer to unmask.
- `mask` - A buffer representing the masking-key.
#### Example
```js
'use strict';
const bufferUtil = require('bufferutil');
const crypto = require('crypto');
const buffer = crypto.randomBytes(10);
const mask = crypto.randomBytes(4);
bufferUtil.unmask(buffer, mask);
```
## License
[MIT](LICENSE)
[RFC6265](https://tools.ietf.org/html/rfc6265) Cookies and CookieJar for Node.js
[](https://nodei.co/npm/tough-cookie/)
[](https://travis-ci.org/salesforce/tough-cookie)
# Synopsis
``` javascript
var tough = require('tough-cookie');
var Cookie = tough.Cookie;
var cookie = Cookie.parse(header);
cookie.value = 'somethingdifferent';
header = cookie.toString();
var cookiejar = new tough.CookieJar();
cookiejar.setCookie(cookie, 'http://currentdomain.example.com/path', cb);
// ...
cookiejar.getCookies('http://example.com/otherpath',function(err,cookies) {
res.headers['cookie'] = cookies.join('; ');
});
```
# Installation
It's _so_ easy!
`npm install tough-cookie`
Why the name? NPM modules `cookie`, `cookies` and `cookiejar` were already taken.
## Version Support
Support for versions of node.js will follow that of the [request](https://www.npmjs.com/package/request) module.
# API
## tough
Functions on the module you get from `require('tough-cookie')`. All can be used as pure functions and don't need to be "bound".
**Note**: prior to 1.0.x, several of these functions took a `strict` parameter. This has since been removed from the API as it was no longer necessary.
### `parseDate(string)`
Parse a cookie date string into a `Date`. Parses according to RFC6265 Section 5.1.1, not `Date.parse()`.
### `formatDate(date)`
Format a Date into a RFC1123 string (the RFC6265-recommended format).
### `canonicalDomain(str)`
Transforms a domain-name into a canonical domain-name. The canonical domain-name is a trimmed, lowercased, stripped-of-leading-dot and optionally punycode-encoded domain-name (Section 5.1.2 of RFC6265). For the most part, this function is idempotent (can be run again on its output without ill effects).
### `domainMatch(str,domStr[,canonicalize=true])`
Answers "does this real domain match the domain in a cookie?". The `str` is the "current" domain-name and the `domStr` is the "cookie" domain-name. Matches according to RFC6265 Section 5.1.3, but it helps to think of it as a "suffix match".
The `canonicalize` parameter will run the other two parameters through `canonicalDomain` or not.
### `defaultPath(path)`
Given a current request/response path, gives the Path apropriate for storing in a cookie. This is basically the "directory" of a "file" in the path, but is specified by Section 5.1.4 of the RFC.
The `path` parameter MUST be _only_ the pathname part of a URI (i.e. excludes the hostname, query, fragment, etc.). This is the `.pathname` property of node's `uri.parse()` output.
### `pathMatch(reqPath,cookiePath)`
Answers "does the request-path path-match a given cookie-path?" as per RFC6265 Section 5.1.4. Returns a boolean.
This is essentially a prefix-match where `cookiePath` is a prefix of `reqPath`.
### `parse(cookieString[, options])`
alias for `Cookie.parse(cookieString[, options])`
### `fromJSON(string)`
alias for `Cookie.fromJSON(string)`
### `getPublicSuffix(hostname)`
Returns the public suffix of this hostname. The public suffix is the shortest domain-name upon which a cookie can be set. Returns `null` if the hostname cannot have cookies set for it.
For example: `www.example.com` and `www.subdomain.example.com` both have public suffix `example.com`.
For further information, see http://publicsuffix.org/. This module derives its list from that site. This call is currently a wrapper around [`psl`](https://www.npmjs.com/package/psl)'s [get() method](https://www.npmjs.com/package/psl#pslgetdomain).
### `cookieCompare(a,b)`
For use with `.sort()`, sorts a list of cookies into the recommended order given in the RFC (Section 5.4 step 2). The sort algorithm is, in order of precedence:
* Longest `.path`
* oldest `.creation` (which has a 1ms precision, same as `Date`)
* lowest `.creationIndex` (to get beyond the 1ms precision)
``` javascript
var cookies = [ /* unsorted array of Cookie objects */ ];
cookies = cookies.sort(cookieCompare);
```
**Note**: Since JavaScript's `Date` is limited to a 1ms precision, cookies within the same milisecond are entirely possible. This is especially true when using the `now` option to `.setCookie()`. The `.creationIndex` property is a per-process global counter, assigned during construction with `new Cookie()`. This preserves the spirit of the RFC sorting: older cookies go first. This works great for `MemoryCookieStore`, since `Set-Cookie` headers are parsed in order, but may not be so great for distributed systems. Sophisticated `Store`s may wish to set this to some other _logical clock_ such that if cookies A and B are created in the same millisecond, but cookie A is created before cookie B, then `A.creationIndex < B.creationIndex`. If you want to alter the global counter, which you probably _shouldn't_ do, it's stored in `Cookie.cookiesCreated`.
### `permuteDomain(domain)`
Generates a list of all possible domains that `domainMatch()` the parameter. May be handy for implementing cookie stores.
### `permutePath(path)`
Generates a list of all possible paths that `pathMatch()` the parameter. May be handy for implementing cookie stores.
## Cookie
Exported via `tough.Cookie`.
### `Cookie.parse(cookieString[, options])`
Parses a single Cookie or Set-Cookie HTTP header into a `Cookie` object. Returns `undefined` if the string can't be parsed.
The options parameter is not required and currently has only one property:
* _loose_ - boolean - if `true` enable parsing of key-less cookies like `=abc` and `=`, which are not RFC-compliant.
If options is not an object, it is ignored, which means you can use `Array#map` with it.
Here's how to process the Set-Cookie header(s) on a node HTTP/HTTPS response:
``` javascript
if (res.headers['set-cookie'] instanceof Array)
cookies = res.headers['set-cookie'].map(Cookie.parse);
else
cookies = [Cookie.parse(res.headers['set-cookie'])];
```
_Note:_ in version 2.3.3, tough-cookie limited the number of spaces before the `=` to 256 characters. This limitation has since been removed.
See [Issue 92](https://github.com/salesforce/tough-cookie/issues/92)
### Properties
Cookie object properties:
* _key_ - string - the name or key of the cookie (default "")
* _value_ - string - the value of the cookie (default "")
* _expires_ - `Date` - if set, the `Expires=` attribute of the cookie (defaults to the string `"Infinity"`). See `setExpires()`
* _maxAge_ - seconds - if set, the `Max-Age=` attribute _in seconds_ of the cookie. May also be set to strings `"Infinity"` and `"-Infinity"` for non-expiry and immediate-expiry, respectively. See `setMaxAge()`
* _domain_ - string - the `Domain=` attribute of the cookie
* _path_ - string - the `Path=` of the cookie
* _secure_ - boolean - the `Secure` cookie flag
* _httpOnly_ - boolean - the `HttpOnly` cookie flag
* _extensions_ - `Array` - any unrecognized cookie attributes as strings (even if equal-signs inside)
* _creation_ - `Date` - when this cookie was constructed
* _creationIndex_ - number - set at construction, used to provide greater sort precision (please see `cookieCompare(a,b)` for a full explanation)
After a cookie has been passed through `CookieJar.setCookie()` it will have the following additional attributes:
* _hostOnly_ - boolean - is this a host-only cookie (i.e. no Domain field was set, but was instead implied)
* _pathIsDefault_ - boolean - if true, there was no Path field on the cookie and `defaultPath()` was used to derive one.
* _creation_ - `Date` - **modified** from construction to when the cookie was added to the jar
* _lastAccessed_ - `Date` - last time the cookie got accessed. Will affect cookie cleaning once implemented. Using `cookiejar.getCookies(...)` will update this attribute.
### `Cookie([{properties}])`
Receives an options object that can contain any of the above Cookie properties, uses the default for unspecified properties.
### `.toString()`
encode to a Set-Cookie header value. The Expires cookie field is set using `formatDate()`, but is omitted entirely if `.expires` is `Infinity`.
### `.cookieString()`
encode to a Cookie header value (i.e. the `.key` and `.value` properties joined with '=').
### `.setExpires(String)`
sets the expiry based on a date-string passed through `parseDate()`. If parseDate returns `null` (i.e. can't parse this date string), `.expires` is set to `"Infinity"` (a string) is set.
### `.setMaxAge(number)`
sets the maxAge in seconds. Coerces `-Infinity` to `"-Infinity"` and `Infinity` to `"Infinity"` so it JSON serializes correctly.
### `.expiryTime([now=Date.now()])`
### `.expiryDate([now=Date.now()])`
expiryTime() Computes the absolute unix-epoch milliseconds that this cookie expires. expiryDate() works similarly, except it returns a `Date` object. Note that in both cases the `now` parameter should be milliseconds.
Max-Age takes precedence over Expires (as per the RFC). The `.creation` attribute -- or, by default, the `now` parameter -- is used to offset the `.maxAge` attribute.
If Expires (`.expires`) is set, that's returned.
Otherwise, `expiryTime()` returns `Infinity` and `expiryDate()` returns a `Date` object for "Tue, 19 Jan 2038 03:14:07 GMT" (latest date that can be expressed by a 32-bit `time_t`; the common limit for most user-agents).
### `.TTL([now=Date.now()])`
compute the TTL relative to `now` (milliseconds). The same precedence rules as for `expiryTime`/`expiryDate` apply.
The "number" `Infinity` is returned for cookies without an explicit expiry and `0` is returned if the cookie is expired. Otherwise a time-to-live in milliseconds is returned.
### `.canonicalizedDomain()`
### `.cdomain()`
return the canonicalized `.domain` field. This is lower-cased and punycode (RFC3490) encoded if the domain has any non-ASCII characters.
### `.toJSON()`
For convenience in using `JSON.serialize(cookie)`. Returns a plain-old `Object` that can be JSON-serialized.
Any `Date` properties (i.e., `.expires`, `.creation`, and `.lastAccessed`) are exported in ISO format (`.toISOString()`).
**NOTE**: Custom `Cookie` properties will be discarded. In tough-cookie 1.x, since there was no `.toJSON` method explicitly defined, all enumerable properties were captured. If you want a property to be serialized, add the property name to the `Cookie.serializableProperties` Array.
### `Cookie.fromJSON(strOrObj)`
Does the reverse of `cookie.toJSON()`. If passed a string, will `JSON.parse()` that first.
Any `Date` properties (i.e., `.expires`, `.creation`, and `.lastAccessed`) are parsed via `Date.parse()`, not the tough-cookie `parseDate`, since it's JavaScript/JSON-y timestamps being handled at this layer.
Returns `null` upon JSON parsing error.
### `.clone()`
Does a deep clone of this cookie, exactly implemented as `Cookie.fromJSON(cookie.toJSON())`.
### `.validate()`
Status: *IN PROGRESS*. Works for a few things, but is by no means comprehensive.
validates cookie attributes for semantic correctness. Useful for "lint" checking any Set-Cookie headers you generate. For now, it returns a boolean, but eventually could return a reason string -- you can future-proof with this construct:
``` javascript
if (cookie.validate() === true) {
// it's tasty
} else {
// yuck!
}
```
## CookieJar
Exported via `tough.CookieJar`.
### `CookieJar([store],[options])`
Simply use `new CookieJar()`. If you'd like to use a custom store, pass that to the constructor otherwise a `MemoryCookieStore` will be created and used.
The `options` object can be omitted and can have the following properties:
* _rejectPublicSuffixes_ - boolean - default `true` - reject cookies with domains like "com" and "co.uk"
* _looseMode_ - boolean - default `false` - accept malformed cookies like `bar` and `=bar`, which have an implied empty name.
This is not in the standard, but is used sometimes on the web and is accepted by (most) browsers.
Since eventually this module would like to support database/remote/etc. CookieJars, continuation passing style is used for CookieJar methods.
### `.setCookie(cookieOrString, currentUrl, [{options},] cb(err,cookie))`
Attempt to set the cookie in the cookie jar. If the operation fails, an error will be given to the callback `cb`, otherwise the cookie is passed through. The cookie will have updated `.creation`, `.lastAccessed` and `.hostOnly` properties.
The `options` object can be omitted and can have the following properties:
* _http_ - boolean - default `true` - indicates if this is an HTTP or non-HTTP API. Affects HttpOnly cookies.
* _secure_ - boolean - autodetect from url - indicates if this is a "Secure" API. If the currentUrl starts with `https:` or `wss:` then this is defaulted to `true`, otherwise `false`.
* _now_ - Date - default `new Date()` - what to use for the creation/access time of cookies
* _ignoreError_ - boolean - default `false` - silently ignore things like parse errors and invalid domains. `Store` errors aren't ignored by this option.
As per the RFC, the `.hostOnly` property is set if there was no "Domain=" parameter in the cookie string (or `.domain` was null on the Cookie object). The `.domain` property is set to the fully-qualified hostname of `currentUrl` in this case. Matching this cookie requires an exact hostname match (not a `domainMatch` as per usual).
### `.setCookieSync(cookieOrString, currentUrl, [{options}])`
Synchronous version of `setCookie`; only works with synchronous stores (e.g. the default `MemoryCookieStore`).
### `.getCookies(currentUrl, [{options},] cb(err,cookies))`
Retrieve the list of cookies that can be sent in a Cookie header for the current url.
If an error is encountered, that's passed as `err` to the callback, otherwise an `Array` of `Cookie` objects is passed. The array is sorted with `cookieCompare()` unless the `{sort:false}` option is given.
The `options` object can be omitted and can have the following properties:
* _http_ - boolean - default `true` - indicates if this is an HTTP or non-HTTP API. Affects HttpOnly cookies.
* _secure_ - boolean - autodetect from url - indicates if this is a "Secure" API. If the currentUrl starts with `https:` or `wss:` then this is defaulted to `true`, otherwise `false`.
* _now_ - Date - default `new Date()` - what to use for the creation/access time of cookies
* _expire_ - boolean - default `true` - perform expiry-time checking of cookies and asynchronously remove expired cookies from the store. Using `false` will return expired cookies and **not** remove them from the store (which is useful for replaying Set-Cookie headers, potentially).
* _allPaths_ - boolean - default `false` - if `true`, do not scope cookies by path. The default uses RFC-compliant path scoping. **Note**: may not be supported by the underlying store (the default `MemoryCookieStore` supports it).
The `.lastAccessed` property of the returned cookies will have been updated.
### `.getCookiesSync(currentUrl, [{options}])`
Synchronous version of `getCookies`; only works with synchronous stores (e.g. the default `MemoryCookieStore`).
### `.getCookieString(...)`
Accepts the same options as `.getCookies()` but passes a string suitable for a Cookie header rather than an array to the callback. Simply maps the `Cookie` array via `.cookieString()`.
### `.getCookieStringSync(...)`
Synchronous version of `getCookieString`; only works with synchronous stores (e.g. the default `MemoryCookieStore`).
### `.getSetCookieStrings(...)`
Returns an array of strings suitable for **Set-Cookie** headers. Accepts the same options as `.getCookies()`. Simply maps the cookie array via `.toString()`.
### `.getSetCookieStringsSync(...)`
Synchronous version of `getSetCookieStrings`; only works with synchronous stores (e.g. the default `MemoryCookieStore`).
### `.serialize(cb(err,serializedObject))`
Serialize the Jar if the underlying store supports `.getAllCookies`.
**NOTE**: Custom `Cookie` properties will be discarded. If you want a property to be serialized, add the property name to the `Cookie.serializableProperties` Array.
See [Serialization Format].
### `.serializeSync()`
Sync version of .serialize
### `.toJSON()`
Alias of .serializeSync() for the convenience of `JSON.stringify(cookiejar)`.
### `CookieJar.deserialize(serialized, [store], cb(err,object))`
A new Jar is created and the serialized Cookies are added to the underlying store. Each `Cookie` is added via `store.putCookie` in the order in which they appear in the serialization.
The `store` argument is optional, but should be an instance of `Store`. By default, a new instance of `MemoryCookieStore` is created.
As a convenience, if `serialized` is a string, it is passed through `JSON.parse` first. If that throws an error, this is passed to the callback.
### `CookieJar.deserializeSync(serialized, [store])`
Sync version of `.deserialize`. _Note_ that the `store` must be synchronous for this to work.
### `CookieJar.fromJSON(string)`
Alias of `.deserializeSync` to provide consistency with `Cookie.fromJSON()`.
### `.clone([store,]cb(err,newJar))`
Produces a deep clone of this jar. Modifications to the original won't affect the clone, and vice versa.
The `store` argument is optional, but should be an instance of `Store`. By default, a new instance of `MemoryCookieStore` is created. Transferring between store types is supported so long as the source implements `.getAllCookies()` and the destination implements `.putCookie()`.
### `.cloneSync([store])`
Synchronous version of `.clone`, returning a new `CookieJar` instance.
The `store` argument is optional, but must be a _synchronous_ `Store` instance if specified. If not passed, a new instance of `MemoryCookieStore` is used.
The _source_ and _destination_ must both be synchronous `Store`s. If one or both stores are asynchronous, use `.clone` instead. Recall that `MemoryCookieStore` supports both synchronous and asynchronous API calls.
### `.removeAllCookies(cb(err))`
Removes all cookies from the jar.
This is a new backwards-compatible feature of `tough-cookie` version 2.5, so not all Stores will implement it efficiently. For Stores that do not implement `removeAllCookies`, the fallback is to call `removeCookie` after `getAllCookies`. If `getAllCookies` fails or isn't implemented in the Store, that error is returned. If one or more of the `removeCookie` calls fail, only the first error is returned.
### `.removeAllCookiesSync()`
Sync version of `.removeAllCookies()`
## Store
Base class for CookieJar stores. Available as `tough.Store`.
## Store API
The storage model for each `CookieJar` instance can be replaced with a custom implementation. The default is `MemoryCookieStore` which can be found in the `lib/memstore.js` file. The API uses continuation-passing-style to allow for asynchronous stores.
Stores should inherit from the base `Store` class, which is available as `require('tough-cookie').Store`.
Stores are asynchronous by default, but if `store.synchronous` is set to `true`, then the `*Sync` methods on the of the containing `CookieJar` can be used (however, the continuation-passing style
All `domain` parameters will have been normalized before calling.
The Cookie store must have all of the following methods.
### `store.findCookie(domain, path, key, cb(err,cookie))`
Retrieve a cookie with the given domain, path and key (a.k.a. name). The RFC maintains that exactly one of these cookies should exist in a store. If the store is using versioning, this means that the latest/newest such cookie should be returned.
Callback takes an error and the resulting `Cookie` object. If no cookie is found then `null` MUST be passed instead (i.e. not an error).
### `store.findCookies(domain, path, cb(err,cookies))`
Locates cookies matching the given domain and path. This is most often called in the context of `cookiejar.getCookies()` above.
If no cookies are found, the callback MUST be passed an empty array.
The resulting list will be checked for applicability to the current request according to the RFC (domain-match, path-match, http-only-flag, secure-flag, expiry, etc.), so it's OK to use an optimistic search algorithm when implementing this method. However, the search algorithm used SHOULD try to find cookies that `domainMatch()` the domain and `pathMatch()` the path in order to limit the amount of checking that needs to be done.
As of version 0.9.12, the `allPaths` option to `cookiejar.getCookies()` above will cause the path here to be `null`. If the path is `null`, path-matching MUST NOT be performed (i.e. domain-matching only).
### `store.putCookie(cookie, cb(err))`
Adds a new cookie to the store. The implementation SHOULD replace any existing cookie with the same `.domain`, `.path`, and `.key` properties -- depending on the nature of the implementation, it's possible that between the call to `fetchCookie` and `putCookie` that a duplicate `putCookie` can occur.
The `cookie` object MUST NOT be modified; the caller will have already updated the `.creation` and `.lastAccessed` properties.
Pass an error if the cookie cannot be stored.
### `store.updateCookie(oldCookie, newCookie, cb(err))`
Update an existing cookie. The implementation MUST update the `.value` for a cookie with the same `domain`, `.path` and `.key`. The implementation SHOULD check that the old value in the store is equivalent to `oldCookie` - how the conflict is resolved is up to the store.
The `.lastAccessed` property will always be different between the two objects (to the precision possible via JavaScript's clock). Both `.creation` and `.creationIndex` are guaranteed to be the same. Stores MAY ignore or defer the `.lastAccessed` change at the cost of affecting how cookies are selected for automatic deletion (e.g., least-recently-used, which is up to the store to implement).
Stores may wish to optimize changing the `.value` of the cookie in the store versus storing a new cookie. If the implementation doesn't define this method a stub that calls `putCookie(newCookie,cb)` will be added to the store object.
The `newCookie` and `oldCookie` objects MUST NOT be modified.
Pass an error if the newCookie cannot be stored.
### `store.removeCookie(domain, path, key, cb(err))`
Remove a cookie from the store (see notes on `findCookie` about the uniqueness constraint).
The implementation MUST NOT pass an error if the cookie doesn't exist; only pass an error due to the failure to remove an existing cookie.
### `store.removeCookies(domain, path, cb(err))`
Removes matching cookies from the store. The `path` parameter is optional, and if missing means all paths in a domain should be removed.
Pass an error ONLY if removing any existing cookies failed.
### `store.removeAllCookies(cb(err))`
_Optional_. Removes all cookies from the store.
Pass an error if one or more cookies can't be removed.
**Note**: New method as of `tough-cookie` version 2.5, so not all Stores will implement this, plus some stores may choose not to implement this.
### `store.getAllCookies(cb(err, cookies))`
_Optional_. Produces an `Array` of all cookies during `jar.serialize()`. The items in the array can be true `Cookie` objects or generic `Object`s with the [Serialization Format] data structure.
Cookies SHOULD be returned in creation order to preserve sorting via `compareCookies()`. For reference, `MemoryCookieStore` will sort by `.creationIndex` since it uses true `Cookie` objects internally. If you don't return the cookies in creation order, they'll still be sorted by creation time, but this only has a precision of 1ms. See `compareCookies` for more detail.
Pass an error if retrieval fails.
**Note**: not all Stores can implement this due to technical limitations, so it is optional.
## MemoryCookieStore
Inherits from `Store`.
A just-in-memory CookieJar synchronous store implementation, used by default. Despite being a synchronous implementation, it's usable with both the synchronous and asynchronous forms of the `CookieJar` API. Supports serialization, `getAllCookies`, and `removeAllCookies`.
## Community Cookie Stores
These are some Store implementations authored and maintained by the community. They aren't official and we don't vouch for them but you may be interested to have a look:
- [`db-cookie-store`](https://github.com/JSBizon/db-cookie-store): SQL including SQLite-based databases
- [`file-cookie-store`](https://github.com/JSBizon/file-cookie-store): Netscape cookie file format on disk
- [`redis-cookie-store`](https://github.com/benkroeger/redis-cookie-store): Redis
- [`tough-cookie-filestore`](https://github.com/mitsuru/tough-cookie-filestore): JSON on disk
- [`tough-cookie-web-storage-store`](https://github.com/exponentjs/tough-cookie-web-storage-store): DOM localStorage and sessionStorage
# Serialization Format
**NOTE**: if you want to have custom `Cookie` properties serialized, add the property name to `Cookie.serializableProperties`.
```js
{
// The version of tough-cookie that serialized this jar.
version: '[email protected]',
// add the store type, to make humans happy:
storeType: 'MemoryCookieStore',
// CookieJar configuration:
rejectPublicSuffixes: true,
// ... future items go here
// Gets filled from jar.store.getAllCookies():
cookies: [
{
key: 'string',
value: 'string',
// ...
/* other Cookie.serializableProperties go here */
}
]
}
```
# Copyright and License
BSD-3-Clause:
```text
Copyright (c) 2015, Salesforce.com, Inc.
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of Salesforce.com nor the names of its contributors may
be used to endorse or promote products derived from this software without
specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE
LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
POSSIBILITY OF SUCH DAMAGE.
```
# mkdirp-promise [![version][npm-version]][npm-url] [![License][license-image]][license-url]
[Promise] version of [mkdirp]:
> Like mkdir -p, but in node.js!
[![Build Status][travis-image]][travis-url]
[![Downloads][npm-downloads]][npm-url]
[![Code Climate][codeclimate-quality]][codeclimate-url]
[![Coverage Status][codeclimate-coverage]][codeclimate-url]
[![Dependency Status][dependencyci-image]][dependencyci-url]
[![Dependencies][david-image]][david-url]
## Install
```bash
npm install --only=production --save mkdirp-promise
```
## API
```js
const mkdirp = require('mkdirp-promise')
```
### `mkdirp(dir, [, options])`
*pattern*: `String`
*options*: `Object` or `String`
Return: `Object` ([Promise])
When it finishes, it will be [*fulfilled*](http://promisesaplus.com/#point-26) with the first directory made that had to be created, if any.
When it fails, it will be [*rejected*](http://promisesaplus.com/#point-30) with an error as its first argument.
```js
mkdirp('/tmp/foo/bar/baz')
.then(console.log) //=> '/tmp/foo'
.catch(console.error)
```
#### `options`
The `option` object will be directly passed to [mkdirp](https://github.com/substack/node-mkdirp#mkdirpdir-opts-cb).
---
> :copyright: [ahmadnassri.com](https://www.ahmadnassri.com/) ·
> License: [ISC][license-url] ·
> Github: [@ahmadnassri](https://github.com/ahmadnassri) ·
> Twitter: [@ahmadnassri](https://twitter.com/ahmadnassri)
[license-url]: http://choosealicense.com/licenses/isc/
[license-image]: https://img.shields.io/github/license/ahmadnassri/mkdirp-promise.svg?style=flat-square
[travis-url]: https://travis-ci.org/ahmadnassri/mkdirp-promise
[travis-image]: https://img.shields.io/travis/ahmadnassri/mkdirp-promise.svg?style=flat-square
[npm-url]: https://www.npmjs.com/package/mkdirp-promise
[npm-version]: https://img.shields.io/npm/v/mkdirp-promise.svg?style=flat-square
[npm-downloads]: https://img.shields.io/npm/dm/mkdirp-promise.svg?style=flat-square
[codeclimate-url]: https://codeclimate.com/github/ahmadnassri/mkdirp-promise
[codeclimate-quality]: https://img.shields.io/codeclimate/github/ahmadnassri/mkdirp-promise.svg?style=flat-square
[codeclimate-coverage]: https://img.shields.io/codeclimate/coverage/github/ahmadnassri/mkdirp-promise.svg?style=flat-square
[david-url]: https://david-dm.org/ahmadnassri/mkdirp-promise
[david-image]: https://img.shields.io/david/ahmadnassri/mkdirp-promise.svg?style=flat-square
[dependencyci-url]: https://dependencyci.com/github/ahmadnassri/mkdirp-promise
[dependencyci-image]: https://dependencyci.com/github/ahmadnassri/mkdirp-promise/badge?style=flat-square
[mkdirp]: https://github.com/substack/node-mkdirp
[Promise]: http://promisesaplus.com/
# Migration Script
The migration tool is designed to reduce repetitive work in the migration process. However, the script is not aiming to convert every thing for you. There are usually some small fixes and major reconstruction required.
### How To Use
To run the conversion script, first make sure you have the latest `node-addon-api` in your `node_modules` directory.
```
npm install node-addon-api
```
Then run the script passing your project directory
```
node ./node_modules/node-addon-api/tools/conversion.js ./
```
After finish, recompile and debug things that are missed by the script.
### Quick Fixes
Here is the list of things that can be fixed easily.
1. Change your methods' return value to void if it doesn't return value to JavaScript.
2. Use `.` to access attribute or to invoke member function in Napi::Object instead of `->`.
3. `Napi::New(env, value);` to `Napi::[Type]::New(env, value);
### Major Reconstructions
The implementation of `Napi::ObjectWrap` is significantly different from NAN's. `Napi::ObjectWrap` takes a pointer to the wrapped object and creates a reference to the wrapped object inside ObjectWrap constructor. `Napi::ObjectWrap` also associates wrapped object's instance methods to Javascript module instead of static methods like NAN.
So if you use Nan::ObjectWrap in your module, you will need to execute the following steps.
1. Convert your [ClassName]::New function to a constructor function that takes a `Napi::CallbackInfo`. Declare it as
```
[ClassName](const Napi::CallbackInfo& info);
```
and define it as
```
[ClassName]::[ClassName](const Napi::CallbackInfo& info) : Napi::ObjectWrap<[ClassName]>(info){
...
}
```
This way, the `Napi::ObjectWrap` constructor will be invoked after the object has been instantiated and `Napi::ObjectWrap` can use the `this` pointer to create a reference to the wrapped object.
2. Move your original constructor code into the new constructor. Delete your original constructor.
3. In your class initialization function, associate native methods in the following way. The `&` character before methods is required because they are not static methods but instance methods.
```
Napi::FunctionReference constructor;
void [ClassName]::Init(Napi::Env env, Napi::Object exports, Napi::Object module) {
Napi::HandleScope scope(env);
Napi::Function ctor = DefineClass(env, "Canvas", {
InstanceMethod("Func1", &[ClassName]::Func1),
InstanceMethod("Func2", &[ClassName]::Func2),
InstanceAccessor("Value", &[ClassName]::ValueGetter),
StaticMethod("MethodName", &[ClassName]::StaticMethod),
InstanceValue("Value", Napi::[Type]::New(env, value)),
});
constructor = Napi::Persistent(ctor);
constructor .SuppressDestruct();
exports.Set("[ClassName]", ctor);
}
```
4. In function where you need to Unwrap the ObjectWrap in NAN like `[ClassName]* native = Nan::ObjectWrap::Unwrap<[ClassName]>(info.This());`, use `this` pointer directly as the unwrapped object as each ObjectWrap instance is associated with a unique object instance.
If you still find issues after following this guide, please leave us an issue describing your problem and we will try to resolve it.
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# web3-bzz
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This is the swarm package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-bzz
```
## Usage
```js
const Web3Bzz = require('web3-bzz');
const bzz = new Web3Bzz('http://swarm-gateways.net');
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-bzz.svg
[npm-url]: https://npmjs.org/package/web3-bzz
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-bzz
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-bzz
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-bzz
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-bzz
# is-primitive [](http://badge.fury.io/js/is-primitive) [](https://travis-ci.org/jonschlinkert/is-primitive)
> Returns `true` if the value is a primitive.
## Install with [npm](npmjs.org)
```bash
npm i is-primitive --save
```
## Running tests
Install dev dependencies.
```bash
npm i -d && npm test
```
## Usage
```js
var isPrimitive = require('is-primitive');
isPrimitive('abc');
//=> true
isPrimitive(42);
//=> true
isPrimitive(false);
//=> true
isPrimitive(true);
//=> true
isPrimitive({});
//=> false
isPrimitive([]);
//=> false
isPrimitive(function(){});
//=> false
```
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright (c) 2014-2015 Jon Schlinkert
Released under the MIT license
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on March 16, 2015._
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# immediate [](https://travis-ci.org/calvinmetcalf/immediate)
[](https://ci.testling.com/calvinmetcalf/immediate)
```
npm install immediate --save
```
then
```js
var immediate = require("immediate");
immediate(function () {
// this will run soon
});
immediate(function (arg1, arg2) {
// get your args like in iojs
}, thing1, thing2);
```
## Introduction
**immediate** is a microtask library, decended from [NobleJS's setImmediate](https://github.com/NobleJS/setImmediate), but including ideas from [Cujo's When](https://github.com/cujojs/when) and [RSVP][RSVP].
immediate takes the tricks from setImmedate and RSVP and combines them with the schedualer inspired (vaugly) by whens.
Note versions 2.6.5 and earlier were strictly speaking a 'macrotask' library not a microtask one, [see this for the difference](https://github.com/YuzuJS/setImmediate#macrotasks-and-microtasks), if you need a macrotask library, [I got you covered](https://github.com/calvinmetcalf/macrotask).
Several new features were added in versions 3.1.0 and 3.2.0 to maintain parity with
process.nextTick, but the 3.0.x series is still being kept up to date if you just need
the small barebones version
## The Tricks
### `process.nextTick`
Note that we check for *actual* Node.js environments, not emulated ones like those produced by browserify or similar.
### `MutationObserver`
This is what [RSVP][RSVP] uses, it's very fast, details on [MDN](https://developer.mozilla.org/en-US/docs/Web/API/MutationObserver).
### `MessageChannel`
Unfortunately, `postMessage` has completely different semantics inside web workers, and so cannot be used there. So we
turn to [`MessageChannel`][MessageChannel], which has worse browser support, but does work inside a web worker.
### `<script> onreadystatechange`
For our last trick, we pull something out to make things fast in Internet Explorer versions 6 through 8: namely,
creating a `<script>` element and firing our calls in its `onreadystatechange` event. This does execute in a future
turn of the event loop, and is also faster than `setTimeout(…, 0)`, so hey, why not?
## Tricks we don't use
### `setImmediate`
We avoid this process.nextTick in node is better suited to our needs and in Internet Explorer 10 there is a broken version of setImmediate we avoid using this.
## Reference and Reading
* [Efficient Script Yielding W3C Editor's Draft][spec]
* [W3C mailing list post introducing the specification][list-post]
* [IE Test Drive demo][ie-demo]
* [Introductory blog post by Nicholas C. Zakas][ncz]
* I wrote a couple blog pots on this, [part 1][my-blog-1] and [part 2][my-blog-2]
[RSVP]: https://github.com/tildeio/rsvp.js
[spec]: https://dvcs.w3.org/hg/webperf/raw-file/tip/specs/setImmediate/Overview.html
[list-post]: http://lists.w3.org/Archives/Public/public-web-perf/2011Jun/0100.html
[ie-demo]: http://ie.microsoft.com/testdrive/Performance/setImmediateSorting/Default.html
[ncz]: http://www.nczonline.net/blog/2011/09/19/script-yielding-with-setimmediate/
[nextTick]: http://nodejs.org/docs/v0.8.16/api/process.html#process_process_nexttick_callback
[postMessage]: http://www.whatwg.org/specs/web-apps/current-work/multipage/web-messaging.html#posting-messages
[MessageChannel]: http://www.whatwg.org/specs/web-apps/current-work/multipage/web-messaging.html#channel-messaging
[cross-browser-demo]: http://calvinmetcalf.github.io/setImmediate-shim-demo
[my-blog-1]:http://calvinmetcalf.com/post/61672207151/setimmediate-etc
[my-blog-2]:http://calvinmetcalf.com/post/61761231881/javascript-schedulers
# SYNOPSIS
[](https://www.npmjs.org/package/merkle-patricia-tree)
[](https://travis-ci.org/ethereumjs/merkle-patricia-tree)
[](https://coveralls.io/r/ethereumjs/merkle-patricia-tree)
[](https://gitter.im/ethereum/ethereumjs-lib) or #ethereumjs on freenode
[](https://github.com/feross/standard)
This is an implementation of the modified merkle patricia tree as specified in the [Ethereum's yellow paper](http://gavwood.com/Paper.pdf).
> The modified Merkle Patricia tree (trie) provides a persistent data structure to map between arbitrary-length binary data (byte arrays). It is defined in terms of a mutable data structure to map between 256-bit binary fragments and arbitrary-length binary data. The core of the trie, and its sole requirement in terms of the protocol specification is to provide a single 32-byte value that identifies a given set of key-value pairs.
\- Ethereum's yellow paper
The only backing store supported is LevelDB through the ```levelup``` module.
# INSTALL
`npm install merkle-patricia-tree`
# USAGE
## Initialization and Basic Usage
```javascript
var Trie = require('merkle-patricia-tree'),
levelup = require('levelup'),
db = levelup('./testdb'),
trie = new Trie(db);
trie.put('test', 'one', function () {
trie.get('test', function (err, value) {
if(value) console.log(value.toString())
});
});
```
## Merkle Proofs
```javascript
Trie.prove(trie, 'test', function (err, prove) {
if (err) return cb(err)
Trie.verifyProof(trie.root, 'test', prove, function (err, value) {
if (err) return cb(err)
console.log(value.toString())
cb()
})
})
```
## Read stream on Geth DB
```javascript
var levelup = require('levelup')
var Trie = require('./secure')
var stateRoot = "0xd7f8974fb5ac78d9ac099b9ad5018bedc2ce0a72dad1827a1709da30580f0544" // Block #222
var db = levelup('YOUR_PATH_TO_THE_GETH_CHAIN_DB')
var trie = new Trie(db, stateRoot)
trie.createReadStream()
.on('data', function (data) {
console.log(data)
})
.on('end', function() {
console.log('End.')
})
```
# API
[./docs/](./docs/index.md)
# TESTING
`npm test`
# REFERENCES
- ["Exploring Ethereum's state trie with Node.js"](https://wanderer.github.io/ethereum/nodejs/code/2014/05/21/using-ethereums-tries-with-node/) blog post
- ["Merkling in Ethereum"](https://blog.ethereum.org/2015/11/15/merkling-in-ethereum/) blog post
- [Ethereum Trie Specification](https://github.com/ethereum/wiki/wiki/Patricia-Tree) Wiki
- ["Understanding the ethereum trie"](https://easythereentropy.wordpress.com/2014/06/04/understanding-the-ethereum-trie/) blog post
- ["Trie and Patricia Trie Overview"](https://www.youtube.com/watch?v=jXAHLqQthKw&t=26s) Video Talk on Youtube
# LICENSE
MPL-2.0
# EthBridge
Ethereum Light Client built on top of TezosProtocol with Rust
## Testing
```bash
./test.sh
```
[](https://travis-ci.org/digitaldesignlabs/es6-promisify)
# es6-promisify
Converts callback-based functions to Promise-based functions.
## Install
Install with [npm](https://npmjs.org/package/es6-promisify)
```bash
npm install --save es6-promisify
```
## Example
```js
"use strict";
// Declare variables
const promisify = require("es6-promisify");
const fs = require("fs");
// Convert the stat function
const stat = promisify(fs.stat);
// Now usable as a promise!
stat("example.txt").then(function (stats) {
console.log("Got stats", stats);
}).catch(function (err) {
console.error("Yikes!", err);
});
```
## Promisify methods
```js
"use strict";
// Declare variables
const promisify = require("es6-promisify");
const redis = require("redis").createClient(6379, "localhost");
// Create a promise-based version of send_command
const client = promisify(redis.send_command, redis);
// Send commands to redis and get a promise back
client("ping").then(function (pong) {
console.log("Got", pong);
}).catch(function (err) {
console.error("Unexpected error", err);
}).then(function () {
redis.quit();
});
```
## Handle callback multiple arguments
```js
"use strict";
// Declare functions
function test(cb) {
return cb(undefined, 1, 2, 3);
}
// Declare variables
const promisify = require("es6-promisify");
// Create promise-based version of test
const single = promisify(test);
const multi = promisify(test, {multiArgs: true});
// Discards additional arguments
single().then(function (result) {
console.log(result); // 1
});
// Returns all arguments as an array
multi().then(function (result) {
console.log(result); // [1, 2, 3]
});
```
### Tests
Test with nodeunit
```bash
$ npm test
```
Published under the [MIT License](http://opensource.org/licenses/MIT).
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# HAR Schema [![version][npm-version]][npm-url] [![License][npm-license]][license-url]
> JSON Schema for HTTP Archive ([HAR][spec]).
[![Build Status][travis-image]][travis-url]
[![Downloads][npm-downloads]][npm-url]
[![Code Climate][codeclimate-quality]][codeclimate-url]
[![Coverage Status][codeclimate-coverage]][codeclimate-url]
[![Dependency Status][dependencyci-image]][dependencyci-url]
[![Dependencies][david-image]][david-url]
## Install
```bash
npm install --only=production --save har-schema
```
## Usage
Compatible with any [JSON Schema validation tool][validator].
----
> :copyright: [ahmadnassri.com](https://www.ahmadnassri.com/) ·
> License: [ISC][license-url] ·
> Github: [@ahmadnassri](https://github.com/ahmadnassri) ·
> Twitter: [@ahmadnassri](https://twitter.com/ahmadnassri)
[license-url]: http://choosealicense.com/licenses/isc/
[travis-url]: https://travis-ci.org/ahmadnassri/har-schema
[travis-image]: https://img.shields.io/travis/ahmadnassri/har-schema.svg?style=flat-square
[npm-url]: https://www.npmjs.com/package/har-schema
[npm-license]: https://img.shields.io/npm/l/har-schema.svg?style=flat-square
[npm-version]: https://img.shields.io/npm/v/har-schema.svg?style=flat-square
[npm-downloads]: https://img.shields.io/npm/dm/har-schema.svg?style=flat-square
[codeclimate-url]: https://codeclimate.com/github/ahmadnassri/har-schema
[codeclimate-quality]: https://img.shields.io/codeclimate/github/ahmadnassri/har-schema.svg?style=flat-square
[codeclimate-coverage]: https://img.shields.io/codeclimate/coverage/github/ahmadnassri/har-schema.svg?style=flat-square
[david-url]: https://david-dm.org/ahmadnassri/har-schema
[david-image]: https://img.shields.io/david/ahmadnassri/har-schema.svg?style=flat-square
[dependencyci-url]: https://dependencyci.com/github/ahmadnassri/har-schema
[dependencyci-image]: https://dependencyci.com/github/ahmadnassri/har-schema/badge?style=flat-square
[spec]: https://github.com/ahmadnassri/har-spec/blob/master/versions/1.2.md
[validator]: https://github.com/ahmadnassri/har-validator
# Array Flatten
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Build status][travis-image]][travis-url]
[![Test coverage][coveralls-image]][coveralls-url]
> Flatten an array of nested arrays into a single flat array. Accepts an optional depth.
## Installation
```
npm install array-flatten --save
```
## Usage
```javascript
var flatten = require('array-flatten')
flatten([1, [2, [3, [4, [5], 6], 7], 8], 9])
//=> [1, 2, 3, 4, 5, 6, 7, 8, 9]
flatten([1, [2, [3, [4, [5], 6], 7], 8], 9], 2)
//=> [1, 2, 3, [4, [5], 6], 7, 8, 9]
(function () {
flatten(arguments) //=> [1, 2, 3]
})(1, [2, 3])
```
## License
MIT
[npm-image]: https://img.shields.io/npm/v/array-flatten.svg?style=flat
[npm-url]: https://npmjs.org/package/array-flatten
[downloads-image]: https://img.shields.io/npm/dm/array-flatten.svg?style=flat
[downloads-url]: https://npmjs.org/package/array-flatten
[travis-image]: https://img.shields.io/travis/blakeembrey/array-flatten.svg?style=flat
[travis-url]: https://travis-ci.org/blakeembrey/array-flatten
[coveralls-image]: https://img.shields.io/coveralls/blakeembrey/array-flatten.svg?style=flat
[coveralls-url]: https://coveralls.io/r/blakeembrey/array-flatten?branch=master
# readable-stream
***Node-core v8.11.1 streams for userland*** [](https://travis-ci.org/nodejs/readable-stream)
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
[](https://saucelabs.com/u/readable-stream)
```bash
npm install --save readable-stream
```
***Node-core streams for userland***
This package is a mirror of the Streams2 and Streams3 implementations in
Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.11.1/docs/api/stream.html).
If you want to guarantee a stable streams base, regardless of what version of
Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core, for background see [this blogpost](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).
As of version 2.0.0 **readable-stream** uses semantic versioning.
# Streams Working Group
`readable-stream` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
<a name="members"></a>
## Team Members
* **Chris Dickinson** ([@chrisdickinson](https://github.com/chrisdickinson)) <[email protected]>
- Release GPG key: 9554F04D7259F04124DE6B476D5A82AC7E37093B
* **Calvin Metcalf** ([@calvinmetcalf](https://github.com/calvinmetcalf)) <[email protected]>
- Release GPG key: F3EF5F62A87FC27A22E643F714CE4FF5015AA242
* **Rod Vagg** ([@rvagg](https://github.com/rvagg)) <[email protected]>
- Release GPG key: DD8F2338BAE7501E3DD5AC78C273792F7D83545D
* **Sam Newman** ([@sonewman](https://github.com/sonewman)) <[email protected]>
* **Mathias Buus** ([@mafintosh](https://github.com/mafintosh)) <[email protected]>
* **Domenic Denicola** ([@domenic](https://github.com/domenic)) <[email protected]>
* **Matteo Collina** ([@mcollina](https://github.com/mcollina)) <[email protected]>
- Release GPG key: 3ABC01543F22DD2239285CDD818674489FBC127E
* **Irina Shestak** ([@lrlna](https://github.com/lrlna)) <[email protected]>
# hash.js [](http://travis-ci.org/indutny/hash.js)
Just a bike-shed.
## Install
```sh
npm install hash.js
```
## Usage
```js
var hash = require('hash.js')
hash.sha256().update('abc').digest('hex')
```
## Selective hash usage
```js
var sha512 = require('hash.js/lib/hash/sha/512');
sha512().update('abc').digest('hex');
```
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2014.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
<!--
-- This file is auto-generated from README_js.md. Changes should be made there.
-->
# uuid [](http://travis-ci.org/kelektiv/node-uuid) #
Simple, fast generation of [RFC4122](http://www.ietf.org/rfc/rfc4122.txt) UUIDS.
Features:
* Support for version 1, 3, 4 and 5 UUIDs
* Cross-platform
* Uses cryptographically-strong random number APIs (when available)
* Zero-dependency, small footprint (... but not [this small](https://gist.github.com/982883))
[**Deprecation warning**: The use of `require('uuid')` is deprecated and will not be
supported after version 3.x of this module. Instead, use `require('uuid/[v1|v3|v4|v5]')` as shown in the examples below.]
## Quickstart - CommonJS (Recommended)
```shell
npm install uuid
```
Then generate your uuid version of choice ...
Version 1 (timestamp):
```javascript
const uuidv1 = require('uuid/v1');
uuidv1(); // ⇨ '45745c60-7b1a-11e8-9c9c-2d42b21b1a3e'
```
Version 3 (namespace):
```javascript
const uuidv3 = require('uuid/v3');
// ... using predefined DNS namespace (for domain names)
uuidv3('hello.example.com', uuidv3.DNS); // ⇨ '9125a8dc-52ee-365b-a5aa-81b0b3681cf6'
// ... using predefined URL namespace (for, well, URLs)
uuidv3('http://example.com/hello', uuidv3.URL); // ⇨ 'c6235813-3ba4-3801-ae84-e0a6ebb7d138'
// ... using a custom namespace
//
// Note: Custom namespaces should be a UUID string specific to your application!
// E.g. the one here was generated using this modules `uuid` CLI.
const MY_NAMESPACE = '1b671a64-40d5-491e-99b0-da01ff1f3341';
uuidv3('Hello, World!', MY_NAMESPACE); // ⇨ 'e8b5a51d-11c8-3310-a6ab-367563f20686'
```
Version 4 (random):
```javascript
const uuidv4 = require('uuid/v4');
uuidv4(); // ⇨ '10ba038e-48da-487b-96e8-8d3b99b6d18a'
```
Version 5 (namespace):
```javascript
const uuidv5 = require('uuid/v5');
// ... using predefined DNS namespace (for domain names)
uuidv5('hello.example.com', uuidv5.DNS); // ⇨ 'fdda765f-fc57-5604-a269-52a7df8164ec'
// ... using predefined URL namespace (for, well, URLs)
uuidv5('http://example.com/hello', uuidv5.URL); // ⇨ '3bbcee75-cecc-5b56-8031-b6641c1ed1f1'
// ... using a custom namespace
//
// Note: Custom namespaces should be a UUID string specific to your application!
// E.g. the one here was generated using this modules `uuid` CLI.
const MY_NAMESPACE = '1b671a64-40d5-491e-99b0-da01ff1f3341';
uuidv5('Hello, World!', MY_NAMESPACE); // ⇨ '630eb68f-e0fa-5ecc-887a-7c7a62614681'
```
## Quickstart - Browser-ready Versions
Browser-ready versions of this module are available via [wzrd.in](https://github.com/jfhbrook/wzrd.in).
For version 1 uuids:
```html
<script src="http://wzrd.in/standalone/uuid%2Fv1@latest"></script>
<script>
uuidv1(); // -> v1 UUID
</script>
```
For version 3 uuids:
```html
<script src="http://wzrd.in/standalone/uuid%2Fv3@latest"></script>
<script>
uuidv3('http://example.com/hello', uuidv3.URL); // -> v3 UUID
</script>
```
For version 4 uuids:
```html
<script src="http://wzrd.in/standalone/uuid%2Fv4@latest"></script>
<script>
uuidv4(); // -> v4 UUID
</script>
```
For version 5 uuids:
```html
<script src="http://wzrd.in/standalone/uuid%2Fv5@latest"></script>
<script>
uuidv5('http://example.com/hello', uuidv5.URL); // -> v5 UUID
</script>
```
## API
### Version 1
```javascript
const uuidv1 = require('uuid/v1');
// Incantations
uuidv1();
uuidv1(options);
uuidv1(options, buffer, offset);
```
Generate and return a RFC4122 v1 (timestamp-based) UUID.
* `options` - (Object) Optional uuid state to apply. Properties may include:
* `node` - (Array) Node id as Array of 6 bytes (per 4.1.6). Default: Randomly generated ID. See note 1.
* `clockseq` - (Number between 0 - 0x3fff) RFC clock sequence. Default: An internally maintained clockseq is used.
* `msecs` - (Number) Time in milliseconds since unix Epoch. Default: The current time is used.
* `nsecs` - (Number between 0-9999) additional time, in 100-nanosecond units. Ignored if `msecs` is unspecified. Default: internal uuid counter is used, as per 4.2.1.2.
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing.
Returns `buffer`, if specified, otherwise the string form of the UUID
Note: The <node> id is generated guaranteed to stay constant for the lifetime of the current JS runtime. (Future versions of this module may use persistent storage mechanisms to extend this guarantee.)
Example: Generate string UUID with fully-specified options
```javascript
const v1options = {
node: [0x01, 0x23, 0x45, 0x67, 0x89, 0xab],
clockseq: 0x1234,
msecs: new Date('2011-11-01').getTime(),
nsecs: 5678
};
uuidv1(v1options); // ⇨ '710b962e-041c-11e1-9234-0123456789ab'
```
Example: In-place generation of two binary IDs
```javascript
// Generate two ids in an array
const arr = new Array();
uuidv1(null, arr, 0); // ⇨ [ 69, 117, 109, 208, 123, 26, 17, 232, 146, 52, 45, 66, 178, 27, 26, 62 ]
uuidv1(null, arr, 16); // ⇨ [ 69, 117, 109, 208, 123, 26, 17, 232, 146, 52, 45, 66, 178, 27, 26, 62, 69, 117, 109, 209, 123, 26, 17, 232, 146, 52, 45, 66, 178, 27, 26, 62 ]
```
### Version 3
```javascript
const uuidv3 = require('uuid/v3');
// Incantations
uuidv3(name, namespace);
uuidv3(name, namespace, buffer);
uuidv3(name, namespace, buffer, offset);
```
Generate and return a RFC4122 v3 UUID.
* `name` - (String | Array[]) "name" to create UUID with
* `namespace` - (String | Array[]) "namespace" UUID either as a String or Array[16] of byte values
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing. Default = 0
Returns `buffer`, if specified, otherwise the string form of the UUID
Example:
```javascript
uuidv3('hello world', MY_NAMESPACE); // ⇨ '042ffd34-d989-321c-ad06-f60826172424'
```
### Version 4
```javascript
const uuidv4 = require('uuid/v4')
// Incantations
uuidv4();
uuidv4(options);
uuidv4(options, buffer, offset);
```
Generate and return a RFC4122 v4 UUID.
* `options` - (Object) Optional uuid state to apply. Properties may include:
* `random` - (Number[16]) Array of 16 numbers (0-255) to use in place of randomly generated values
* `rng` - (Function) Random # generator function that returns an Array[16] of byte values (0-255)
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing.
Returns `buffer`, if specified, otherwise the string form of the UUID
Example: Generate string UUID with predefined `random` values
```javascript
const v4options = {
random: [
0x10, 0x91, 0x56, 0xbe, 0xc4, 0xfb, 0xc1, 0xea,
0x71, 0xb4, 0xef, 0xe1, 0x67, 0x1c, 0x58, 0x36
]
};
uuidv4(v4options); // ⇨ '109156be-c4fb-41ea-b1b4-efe1671c5836'
```
Example: Generate two IDs in a single buffer
```javascript
const buffer = new Array();
uuidv4(null, buffer, 0); // ⇨ [ 54, 122, 218, 70, 45, 70, 65, 24, 171, 53, 95, 130, 83, 195, 242, 45 ]
uuidv4(null, buffer, 16); // ⇨ [ 54, 122, 218, 70, 45, 70, 65, 24, 171, 53, 95, 130, 83, 195, 242, 45, 108, 204, 255, 103, 171, 86, 76, 94, 178, 225, 188, 236, 150, 20, 151, 87 ]
```
### Version 5
```javascript
const uuidv5 = require('uuid/v5');
// Incantations
uuidv5(name, namespace);
uuidv5(name, namespace, buffer);
uuidv5(name, namespace, buffer, offset);
```
Generate and return a RFC4122 v5 UUID.
* `name` - (String | Array[]) "name" to create UUID with
* `namespace` - (String | Array[]) "namespace" UUID either as a String or Array[16] of byte values
* `buffer` - (Array | Buffer) Array or buffer where UUID bytes are to be written.
* `offset` - (Number) Starting index in `buffer` at which to begin writing. Default = 0
Returns `buffer`, if specified, otherwise the string form of the UUID
Example:
```javascript
uuidv5('hello world', MY_NAMESPACE); // ⇨ '9f282611-e0fd-5650-8953-89c8e342da0b'
```
## Command Line
UUIDs can be generated from the command line with the `uuid` command.
```shell
$ uuid
ddeb27fb-d9a0-4624-be4d-4615062daed4
$ uuid v1
02d37060-d446-11e7-a9fa-7bdae751ebe1
```
Type `uuid --help` for usage details
## Testing
```shell
npm test
```
----
Markdown generated from [README_js.md](README_js.md) by [](https://github.com/broofa/runmd)
# web3-bzz
This is a sub package of [web3.js][repo]
This is the swarm package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-bzz
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-bzz.js` in your html file.
This will expose the `Web3Personal` object on the window object.
## Usage
```js
// in node.js
var Web3Bzz = require('web3-bzz');
var bzz = new Web3Bzz('http://swarm-gateways.net');
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# level-mem
> A convenience package that bundles [`levelup`](https://github.com/level/levelup) and [`memdown`](https://github.com/level/memdown) and exposes `levelup` on its export.
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/level-mem)

[](http://travis-ci.org/Level/mem)
[](https://david-dm.org/level/mem)
[](https://standardjs.com)
[](https://www.npmjs.com/package/level-mem)
Use this package to avoid having to explicitly install `memdown` when you want to use `memdown` with `levelup` for non-persistent `levelup` data storage.
```js
const level = require('level-mem')
// 1) Create our database, with optional options.
// This will create or open the underlying LevelDB store.
const db = level()
// 2) Put a key & value
db.put('name', 'Level', function (err) {
if (err) return console.log('Ooops!', err) // some kind of I/O error
// 3) Fetch by key
db.get('name', function (err, value) {
if (err) return console.log('Ooops!', err) // likely the key was not found
// Ta da!
console.log('name=' + value)
})
})
```
See [`levelup`](https://github.com/level/levelup) and [`memdown`](https://github.com/level/memdown) for more details.
**If you are upgrading:** please see [`UPGRADING.md`](UPGRADING.md).
## Contributing
`level-mem` is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [CONTRIBUTING.md](https://github.com/Level/level/blob/master/CONTRIBUTING.md) file for more details.
## License
Copyright (c) 2012-present `level-mem` [contributors](https://github.com/level/community#contributors).
`level-mem` is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included [`LICENSE.md`](LICENSE.md) file for more details.
[level-badge]: http://leveldb.org/img/badge.svg
<a href="https://travis-ci.org/Xotic750/has-to-string-tag-x"
title="Travis status">
<img
src="https://travis-ci.org/Xotic750/has-to-string-tag-x.svg?branch=master"
alt="Travis status" height="18"/>
</a>
<a href="https://david-dm.org/Xotic750/has-to-string-tag-x"
title="Dependency status">
<img src="https://david-dm.org/Xotic750/has-to-string-tag-x.svg"
alt="Dependency status" height="18"/>
</a>
<a href="https://david-dm.org/Xotic750/has-to-string-tag-x#info=devDependencies"
title="devDependency status">
<img src="https://david-dm.org/Xotic750/has-to-string-tag-x/dev-status.svg"
alt="devDependency status" height="18"/>
</a>
<a href="https://badge.fury.io/js/has-to-string-tag-x" title="npm version">
<img src="https://badge.fury.io/js/has-to-string-tag-x.svg"
alt="npm version" height="18"/>
</a>
<a name="module_has-to-string-tag-x"></a>
## has-to-string-tag-x
Tests if ES6 @@toStringTag is supported.
**See**: [26.3.1 @@toStringTag](http://www.ecma-international.org/ecma-262/6.0/#sec-@@tostringtag)
**Version**: 1.4.1
**Author**: Xotic750 <[email protected]>
**License**: [MIT](<https://opensource.org/licenses/MIT>)
**Copyright**: Xotic750
<a name="exp_module_has-to-string-tag-x--module.exports"></a>
### `module.exports` : <code>boolean</code> ⏏
Indicates if `Symbol.toStringTag`exists and is the correct type.
`true`, if it exists and is the correct type, otherwise `false`.
**Kind**: Exported member
These files are compiled dot templates from dot folder.
Do NOT edit them directly, edit the templates and run `npm run build` from main ajv folder.
vizionar_test
=============
Empty repo for testing purposes !
# ext
_(Previously known as `es5-ext`)_
## JavaScript language extensions (with respect to evolving standard)
Non-standard or soon to be standard language utilities in a future proof, non-invasive form.
Doesn't enforce transpilation step. Where it's applicable utilities/extensions are safe to use in all ES3+ implementations.
### Installation
```bash
npm install ext
```
### Utilities
- [`globalThis`](docs/global-this.md)
- `Function`
- [`identity`](docs/function/identity.md)
- `Math`
- [`ceil10`](docs/math/ceil-10.md)
- [`floor10`](docs/math/floor-10.md)
- [`round10`](docs/math/round-10.md)
- `Object`
- [`entries`](docs/object/entries.md)
- `String`
- [`random`](docs/string/random.md)
- `String.prototype`
- [`includes`](docs/string_/includes.md)
- `Thenable.prototype`
- [`finally`](docs/thenable_/finally.md)
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# browserify-aes
[](https://travis-ci.org/crypto-browserify/browserify-aes)
Node style aes for use in the browser.
Implements:
- createCipher
- createCipheriv
- createDecipher
- createDecipheriv
- getCiphers
In node.js, the `crypto` implementation is used, in browsers it falls back to a pure JavaScript implementation.
Much of this library has been taken from the aes implementation in [triplesec](https://github.com/keybase/triplesec), a partial derivation of [crypto-js](https://code.google.com/p/crypto-js/).
`EVP_BytesToKey` is a straight up port of the same function from OpenSSL as there is literally no documenation on it beyond it using 'undocumented extensions' for longer keys.
## LICENSE [MIT](LICENSE)
# ipaddr.js — an IPv6 and IPv4 address manipulation library [](https://travis-ci.org/whitequark/ipaddr.js)
ipaddr.js is a small (1.9K minified and gzipped) library for manipulating
IP addresses in JavaScript environments. It runs on both CommonJS runtimes
(e.g. [nodejs]) and in a web browser.
ipaddr.js allows you to verify and parse string representation of an IP
address, match it against a CIDR range or range list, determine if it falls
into some reserved ranges (examples include loopback and private ranges),
and convert between IPv4 and IPv4-mapped IPv6 addresses.
[nodejs]: http://nodejs.org
## Installation
`npm install ipaddr.js`
or
`bower install ipaddr.js`
## API
ipaddr.js defines one object in the global scope: `ipaddr`. In CommonJS,
it is exported from the module:
```js
var ipaddr = require('ipaddr.js');
```
The API consists of several global methods and two classes: ipaddr.IPv6 and ipaddr.IPv4.
### Global methods
There are three global methods defined: `ipaddr.isValid`, `ipaddr.parse` and
`ipaddr.process`. All of them receive a string as a single parameter.
The `ipaddr.isValid` method returns `true` if the address is a valid IPv4 or
IPv6 address, and `false` otherwise. It does not throw any exceptions.
The `ipaddr.parse` method returns an object representing the IP address,
or throws an `Error` if the passed string is not a valid representation of an
IP address.
The `ipaddr.process` method works just like the `ipaddr.parse` one, but it
automatically converts IPv4-mapped IPv6 addresses to their IPv4 counterparts
before returning. It is useful when you have a Node.js instance listening
on an IPv6 socket, and the `net.ivp6.bindv6only` sysctl parameter (or its
equivalent on non-Linux OS) is set to 0. In this case, you can accept IPv4
connections on your IPv6-only socket, but the remote address will be mangled.
Use `ipaddr.process` method to automatically demangle it.
### Object representation
Parsing methods return an object which descends from `ipaddr.IPv6` or
`ipaddr.IPv4`. These objects share some properties, but most of them differ.
#### Shared properties
One can determine the type of address by calling `addr.kind()`. It will return
either `"ipv6"` or `"ipv4"`.
An address can be converted back to its string representation with `addr.toString()`.
Note that this method:
* does not return the original string used to create the object (in fact, there is
no way of getting that string)
* returns a compact representation (when it is applicable)
A `match(range, bits)` method can be used to check if the address falls into a
certain CIDR range.
Note that an address can be (obviously) matched only against an address of the same type.
For example:
```js
var addr = ipaddr.parse("2001:db8:1234::1");
var range = ipaddr.parse("2001:db8::");
addr.match(range, 32); // => true
```
Alternatively, `match` can also be called as `match([range, bits])`. In this way,
it can be used together with the `parseCIDR(string)` method, which parses an IP
address together with a CIDR range.
For example:
```js
var addr = ipaddr.parse("2001:db8:1234::1");
addr.match(ipaddr.parseCIDR("2001:db8::/32")); // => true
```
A `range()` method returns one of predefined names for several special ranges defined
by IP protocols. The exact names (and their respective CIDR ranges) can be looked up
in the source: [IPv6 ranges] and [IPv4 ranges]. Some common ones include `"unicast"`
(the default one) and `"reserved"`.
You can match against your own range list by using
`ipaddr.subnetMatch(address, rangeList, defaultName)` method. It can work with a mix of IPv6 or IPv4 addresses, and accepts a name-to-subnet map as the range list. For example:
```js
var rangeList = {
documentationOnly: [ ipaddr.parse('2001:db8::'), 32 ],
tunnelProviders: [
[ ipaddr.parse('2001:470::'), 32 ], // he.net
[ ipaddr.parse('2001:5c0::'), 32 ] // freenet6
]
};
ipaddr.subnetMatch(ipaddr.parse('2001:470:8:66::1'), rangeList, 'unknown'); // => "tunnelProviders"
```
The addresses can be converted to their byte representation with `toByteArray()`.
(Actually, JavaScript mostly does not know about byte buffers. They are emulated with
arrays of numbers, each in range of 0..255.)
```js
var bytes = ipaddr.parse('2a00:1450:8007::68').toByteArray(); // ipv6.google.com
bytes // => [42, 0x00, 0x14, 0x50, 0x80, 0x07, 0x00, <zeroes...>, 0x00, 0x68 ]
```
The `ipaddr.IPv4` and `ipaddr.IPv6` objects have some methods defined, too. All of them
have the same interface for both protocols, and are similar to global methods.
`ipaddr.IPvX.isValid(string)` can be used to check if the string is a valid address
for particular protocol, and `ipaddr.IPvX.parse(string)` is the error-throwing parser.
`ipaddr.IPvX.isValid(string)` uses the same format for parsing as the POSIX `inet_ntoa` function, which accepts unusual formats like `0xc0.168.1.1` or `0x10000000`. The function `ipaddr.IPv4.isValidFourPartDecimal(string)` validates the IPv4 address and also ensures that it is written in four-part decimal format.
[IPv6 ranges]: https://github.com/whitequark/ipaddr.js/blob/master/src/ipaddr.coffee#L186
[IPv4 ranges]: https://github.com/whitequark/ipaddr.js/blob/master/src/ipaddr.coffee#L71
#### IPv6 properties
Sometimes you will want to convert IPv6 not to a compact string representation (with
the `::` substitution); the `toNormalizedString()` method will return an address where
all zeroes are explicit.
For example:
```js
var addr = ipaddr.parse("2001:0db8::0001");
addr.toString(); // => "2001:db8::1"
addr.toNormalizedString(); // => "2001:db8:0:0:0:0:0:1"
```
The `isIPv4MappedAddress()` method will return `true` if this address is an IPv4-mapped
one, and `toIPv4Address()` will return an IPv4 object address.
To access the underlying binary representation of the address, use `addr.parts`.
```js
var addr = ipaddr.parse("2001:db8:10::1234:DEAD");
addr.parts // => [0x2001, 0xdb8, 0x10, 0, 0, 0, 0x1234, 0xdead]
```
A IPv6 zone index can be accessed via `addr.zoneId`:
```js
var addr = ipaddr.parse("2001:db8::%eth0");
addr.zoneId // => 'eth0'
```
#### IPv4 properties
`toIPv4MappedAddress()` will return a corresponding IPv4-mapped IPv6 address.
To access the underlying representation of the address, use `addr.octets`.
```js
var addr = ipaddr.parse("192.168.1.1");
addr.octets // => [192, 168, 1, 1]
```
`prefixLengthFromSubnetMask()` will return a CIDR prefix length for a valid IPv4 netmask or
null if the netmask is not valid.
```js
ipaddr.IPv4.parse('255.255.255.240').prefixLengthFromSubnetMask() == 28
ipaddr.IPv4.parse('255.192.164.0').prefixLengthFromSubnetMask() == null
```
`subnetMaskFromPrefixLength()` will return an IPv4 netmask for a valid CIDR prefix length.
```js
ipaddr.IPv4.subnetMaskFromPrefixLength(24) == "255.255.255.0"
ipaddr.IPv4.subnetMaskFromPrefixLength(29) == "255.255.255.248"
```
`broadcastAddressFromCIDR()` will return the broadcast address for a given IPv4 interface and netmask in CIDR notation.
```js
ipaddr.IPv4.broadcastAddressFromCIDR("172.0.0.1/24") == "172.0.0.255"
```
`networkAddressFromCIDR()` will return the network address for a given IPv4 interface and netmask in CIDR notation.
```js
ipaddr.IPv4.networkAddressFromCIDR("172.0.0.1/24") == "172.0.0.0"
```
#### Conversion
IPv4 and IPv6 can be converted bidirectionally to and from network byte order (MSB) byte arrays.
The `fromByteArray()` method will take an array and create an appropriate IPv4 or IPv6 object
if the input satisfies the requirements. For IPv4 it has to be an array of four 8-bit values,
while for IPv6 it has to be an array of sixteen 8-bit values.
For example:
```js
var addr = ipaddr.fromByteArray([0x7f, 0, 0, 1]);
addr.toString(); // => "127.0.0.1"
```
or
```js
var addr = ipaddr.fromByteArray([0x20, 1, 0xd, 0xb8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1])
addr.toString(); // => "2001:db8::1"
```
Both objects also offer a `toByteArray()` method, which returns an array in network byte order (MSB).
For example:
```js
var addr = ipaddr.parse("127.0.0.1");
addr.toByteArray(); // => [0x7f, 0, 0, 1]
```
or
```js
var addr = ipaddr.parse("2001:db8::1");
addr.toByteArray(); // => [0x20, 1, 0xd, 0xb8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
```
# minipass
A _very_ minimal implementation of a [PassThrough
stream](https://nodejs.org/api/stream.html#stream_class_stream_passthrough)
[It's very
fast](https://docs.google.com/spreadsheets/d/1oObKSrVwLX_7Ut4Z6g3fZW-AX1j1-k6w-cDsrkaSbHM/edit#gid=0)
for objects, strings, and buffers.
Supports pipe()ing (including multi-pipe() and backpressure
transmission), buffering data until either a `data` event handler or
`pipe()` is added (so you don't lose the first chunk), and most other
cases where PassThrough is a good idea.
There is a `read()` method, but it's much more efficient to consume
data from this stream via `'data'` events or by calling `pipe()` into
some other stream. Calling `read()` requires the buffer to be
flattened in some cases, which requires copying memory.
There is also no `unpipe()` method. Once you start piping, there is
no stopping it!
If you set `objectMode: true` in the options, then whatever is written
will be emitted. Otherwise, it'll do a minimal amount of Buffer
copying to ensure proper Streams semantics when `read(n)` is called.
`objectMode` can also be set by doing `stream.objectMode = true`, or by
writing any non-string/non-buffer data. `objectMode` cannot be set to
false once it is set.
This is not a `through` or `through2` stream. It doesn't transform
the data, it just passes it right through. If you want to transform
the data, extend the class, and override the `write()` method. Once
you're done transforming the data however you want, call
`super.write()` with the transform output.
For some examples of streams that extend Minipass in various ways, check
out:
- [minizlib](http://npm.im/minizlib)
- [fs-minipass](http://npm.im/fs-minipass)
- [tar](http://npm.im/tar)
- [minipass-collect](http://npm.im/minipass-collect)
- [minipass-flush](http://npm.im/minipass-flush)
- [minipass-pipeline](http://npm.im/minipass-pipeline)
- [tap](http://npm.im/tap)
- [tap-parser](http://npm.im/tap)
- [treport](http://npm.im/tap)
## Differences from Node.js Streams
There are several things that make Minipass streams different from (and in
some ways superior to) Node.js core streams.
Please read these caveats if you are familiar with noode-core streams and
intend to use Minipass streams in your programs.
### Timing
Minipass streams are designed to support synchronous use-cases. Thus, data
is emitted as soon as it is available, always. It is buffered until read,
but no longer. Another way to look at it is that Minipass streams are
exactly as synchronous as the logic that writes into them.
This can be surprising if your code relies on `PassThrough.write()` always
providing data on the next tick rather than the current one, or being able
to call `resume()` and not have the entire buffer disappear immediately.
However, without this synchronicity guarantee, there would be no way for
Minipass to achieve the speeds it does, or support the synchronous use
cases that it does. Simply put, waiting takes time.
This non-deferring approach makes Minipass streams much easier to reason
about, especially in the context of Promises and other flow-control
mechanisms.
### No High/Low Water Marks
Node.js core streams will optimistically fill up a buffer, returning `true`
on all writes until the limit is hit, even if the data has nowhere to go.
Then, they will not attempt to draw more data in until the buffer size dips
below a minimum value.
Minipass streams are much simpler. The `write()` method will return `true`
if the data has somewhere to go (which is to say, given the timing
guarantees, that the data is already there by the time `write()` returns).
If the data has nowhere to go, then `write()` returns false, and the data
sits in a buffer, to be drained out immediately as soon as anyone consumes
it.
### Hazards of Buffering (or: Why Minipass Is So Fast)
Since data written to a Minipass stream is immediately written all the way
through the pipeline, and `write()` always returns true/false based on
whether the data was fully flushed, backpressure is communicated
immediately to the upstream caller. This minimizes buffering.
Consider this case:
```js
const {PassThrough} = require('stream')
const p1 = new PassThrough({ highWaterMark: 1024 })
const p2 = new PassThrough({ highWaterMark: 1024 })
const p3 = new PassThrough({ highWaterMark: 1024 })
const p4 = new PassThrough({ highWaterMark: 1024 })
p1.pipe(p2).pipe(p3).pipe(p4)
p4.on('data', () => console.log('made it through'))
// this returns false and buffers, then writes to p2 on next tick (1)
// p2 returns false and buffers, pausing p1, then writes to p3 on next tick (2)
// p3 returns false and buffers, pausing p2, then writes to p4 on next tick (3)
// p4 returns false and buffers, pausing p3, then emits 'data' and 'drain'
// on next tick (4)
// p3 sees p4's 'drain' event, and calls resume(), emitting 'resume' and
// 'drain' on next tick (5)
// p2 sees p3's 'drain', calls resume(), emits 'resume' and 'drain' on next tick (6)
// p1 sees p2's 'drain', calls resume(), emits 'resume' and 'drain' on next
// tick (7)
p1.write(Buffer.alloc(2048)) // returns false
```
Along the way, the data was buffered and deferred at each stage, and
multiple event deferrals happened, for an unblocked pipeline where it was
perfectly safe to write all the way through!
Furthermore, setting a `highWaterMark` of `1024` might lead someone reading
the code to think an advisory maximum of 1KiB is being set for the
pipeline. However, the actual advisory buffering level is the _sum_ of
`highWaterMark` values, since each one has its own bucket.
Consider the Minipass case:
```js
const m1 = new Minipass()
const m2 = new Minipass()
const m3 = new Minipass()
const m4 = new Minipass()
m1.pipe(m2).pipe(m3).pipe(m4)
m4.on('data', () => console.log('made it through'))
// m1 is flowing, so it writes the data to m2 immediately
// m2 is flowing, so it writes the data to m3 immediately
// m3 is flowing, so it writes the data to m4 immediately
// m4 is flowing, so it fires the 'data' event immediately, returns true
// m4's write returned true, so m3 is still flowing, returns true
// m3's write returned true, so m2 is still flowing, returns true
// m2's write returned true, so m1 is still flowing, returns true
// No event deferrals or buffering along the way!
m1.write(Buffer.alloc(2048)) // returns true
```
It is extremely unlikely that you _don't_ want to buffer any data written,
or _ever_ buffer data that can be flushed all the way through. Neither
node-core streams nor Minipass ever fail to buffer written data, but
node-core streams do a lot of unnecessary buffering and pausing.
As always, the faster implementation is the one that does less stuff and
waits less time to do it.
### Immediately emit `end` for empty streams (when not paused)
If a stream is not paused, and `end()` is called before writing any data
into it, then it will emit `end` immediately.
If you have logic that occurs on the `end` event which you don't want to
potentially happen immediately (for example, closing file descriptors,
moving on to the next entry in an archive parse stream, etc.) then be sure
to call `stream.pause()` on creation, and then `stream.resume()` once you
are ready to respond to the `end` event.
### Emit `end` When Asked
One hazard of immediately emitting `'end'` is that you may not yet have had
a chance to add a listener. In order to avoid this hazard, Minipass
streams safely re-emit the `'end'` event if a new listener is added after
`'end'` has been emitted.
Ie, if you do `stream.on('end', someFunction)`, and the stream has already
emitted `end`, then it will call the handler right away. (You can think of
this somewhat like attaching a new `.then(fn)` to a previously-resolved
Promise.)
To prevent calling handlers multiple times who would not expect multiple
ends to occur, all listeners are removed from the `'end'` event whenever it
is emitted.
### Impact of "immediate flow" on Tee-streams
A "tee stream" is a stream piping to multiple destinations:
```js
const tee = new Minipass()
t.pipe(dest1)
t.pipe(dest2)
t.write('foo') // goes to both destinations
```
Since Minipass streams _immediately_ process any pending data through the
pipeline when a new pipe destination is added, this can have surprising
effects, especially when a stream comes in from some other function and may
or may not have data in its buffer.
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.pipe(dest1) // 'foo' chunk flows to dest1 immediately, and is gone
src.pipe(dest2) // gets nothing!
```
The solution is to create a dedicated tee-stream junction that pipes to
both locations, and then pipe to _that_ instead.
```js
// Safe example: tee to both places
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.pipe(dest1)
tee.pipe(dest2)
stream.pipe(tee) // tee gets 'foo', pipes to both locations
```
The same caveat applies to `on('data')` event listeners. The first one
added will _immediately_ receive all of the data, leaving nothing for the
second:
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.on('data', handler1) // receives 'foo' right away
src.on('data', handler2) // nothing to see here!
```
Using a dedicated tee-stream can be used in this case as well:
```js
// Safe example: tee to both data handlers
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.on('data', handler1)
tee.on('data', handler2)
src.pipe(tee)
```
## USAGE
It's a stream! Use it like a stream and it'll most likely do what you want.
```js
const Minipass = require('minipass')
const mp = new Minipass(options) // optional: { encoding, objectMode }
mp.write('foo')
mp.pipe(someOtherStream)
mp.end('bar')
```
### OPTIONS
* `encoding` How would you like the data coming _out_ of the stream to be
encoded? Accepts any values that can be passed to `Buffer.toString()`.
* `objectMode` Emit data exactly as it comes in. This will be flipped on
by default if you write() something other than a string or Buffer at any
point. Setting `objectMode: true` will prevent setting any encoding
value.
### API
Implements the user-facing portions of Node.js's `Readable` and `Writable`
streams.
### Methods
* `write(chunk, [encoding], [callback])` - Put data in. (Note that, in the
base Minipass class, the same data will come out.) Returns `false` if
the stream will buffer the next write, or true if it's still in
"flowing" mode.
* `end([chunk, [encoding]], [callback])` - Signal that you have no more
data to write. This will queue an `end` event to be fired when all the
data has been consumed.
* `setEncoding(encoding)` - Set the encoding for data coming of the
stream. This can only be done once.
* `pause()` - No more data for a while, please. This also prevents `end`
from being emitted for empty streams until the stream is resumed.
* `resume()` - Resume the stream. If there's data in the buffer, it is
all discarded. Any buffered events are immediately emitted.
* `pipe(dest)` - Send all output to the stream provided. There is no way
to unpipe. When data is emitted, it is immediately written to any and
all pipe destinations.
* `on(ev, fn)`, `emit(ev, fn)` - Minipass streams are EventEmitters.
Some events are given special treatment, however. (See below under
"events".)
* `promise()` - Returns a Promise that resolves when the stream emits
`end`, or rejects if the stream emits `error`.
* `collect()` - Return a Promise that resolves on `end` with an array
containing each chunk of data that was emitted, or rejects if the
stream emits `error`. Note that this consumes the stream data.
* `concat()` - Same as `collect()`, but concatenates the data into a
single Buffer object. Will reject the returned promise if the stream is
in objectMode, or if it goes into objectMode by the end of the data.
* `read(n)` - Consume `n` bytes of data out of the buffer. If `n` is not
provided, then consume all of it. If `n` bytes are not available, then
it returns null. **Note** consuming streams in this way is less
efficient, and can lead to unnecessary Buffer copying.
* `destroy([er])` - Destroy the stream. If an error is provided, then an
`'error'` event is emitted. If the stream has a `close()` method, and
has not emitted a `'close'` event yet, then `stream.close()` will be
called. Any Promises returned by `.promise()`, `.collect()` or
`.concat()` will be rejected. After being destroyed, writing to the
stream will emit an error. No more data will be emitted if the stream is
destroyed, even if it was previously buffered.
### Properties
* `bufferLength` Read-only. Total number of bytes buffered, or in the case
of objectMode, the total number of objects.
* `encoding` The encoding that has been set. (Setting this is equivalent
to calling `setEncoding(enc)` and has the same prohibition against
setting multiple times.)
* `flowing` Read-only. Boolean indicating whether a chunk written to the
stream will be immediately emitted.
* `emittedEnd` Read-only. Boolean indicating whether the end-ish events
(ie, `end`, `prefinish`, `finish`) have been emitted. Note that
listening on any end-ish event will immediateyl re-emit it if it has
already been emitted.
* `writable` Whether the stream is writable. Default `true`. Set to
`false` when `end()`
* `readable` Whether the stream is readable. Default `true`.
* `buffer` A [yallist](http://npm.im/yallist) linked list of chunks written
to the stream that have not yet been emitted. (It's probably a bad idea
to mess with this.)
* `pipes` A [yallist](http://npm.im/yallist) linked list of streams that
this stream is piping into. (It's probably a bad idea to mess with
this.)
* `destroyed` A getter that indicates whether the stream was destroyed.
* `paused` True if the stream has been explicitly paused, otherwise false.
* `objectMode` Indicates whether the stream is in `objectMode`. Once set
to `true`, it cannot be set to `false`.
### Events
* `data` Emitted when there's data to read. Argument is the data to read.
This is never emitted while not flowing. If a listener is attached, that
will resume the stream.
* `end` Emitted when there's no more data to read. This will be emitted
immediately for empty streams when `end()` is called. If a listener is
attached, and `end` was already emitted, then it will be emitted again.
All listeners are removed when `end` is emitted.
* `prefinish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'end'`.
* `finish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'prefinish'`.
* `close` An indication that an underlying resource has been released.
Minipass does not emit this event, but will defer it until after `end`
has been emitted, since it throws off some stream libraries otherwise.
* `drain` Emitted when the internal buffer empties, and it is again
suitable to `write()` into the stream.
* `readable` Emitted when data is buffered and ready to be read by a
consumer.
* `resume` Emitted when stream changes state from buffering to flowing
mode. (Ie, when `resume` is called, `pipe` is called, or a `data` event
listener is added.)
### Static Methods
* `Minipass.isStream(stream)` Returns `true` if the argument is a stream,
and false otherwise. To be considered a stream, the object must be
either an instance of Minipass, or an EventEmitter that has either a
`pipe()` method, or both `write()` and `end()` methods. (Pretty much any
stream in node-land will return `true` for this.)
## EXAMPLES
Here are some examples of things you can do with Minipass streams.
### simple "are you done yet" promise
```js
mp.promise().then(() => {
// stream is finished
}, er => {
// stream emitted an error
})
```
### collecting
```js
mp.collect().then(all => {
// all is an array of all the data emitted
// encoding is supported in this case, so
// so the result will be a collection of strings if
// an encoding is specified, or buffers/objects if not.
//
// In an async function, you may do
// const data = await stream.collect()
})
```
### collecting into a single blob
This is a bit slower because it concatenates the data into one chunk for
you, but if you're going to do it yourself anyway, it's convenient this
way:
```js
mp.concat().then(onebigchunk => {
// onebigchunk is a string if the stream
// had an encoding set, or a buffer otherwise.
})
```
### iteration
You can iterate over streams synchronously or asynchronously in
platforms that support it.
Synchronous iteration will end when the currently available data is
consumed, even if the `end` event has not been reached. In string and
buffer mode, the data is concatenated, so unless multiple writes are
occurring in the same tick as the `read()`, sync iteration loops will
generally only have a single iteration.
To consume chunks in this way exactly as they have been written, with
no flattening, create the stream with the `{ objectMode: true }`
option.
```js
const mp = new Minipass({ objectMode: true })
mp.write('a')
mp.write('b')
for (let letter of mp) {
console.log(letter) // a, b
}
mp.write('c')
mp.write('d')
for (let letter of mp) {
console.log(letter) // c, d
}
mp.write('e')
mp.end()
for (let letter of mp) {
console.log(letter) // e
}
for (let letter of mp) {
console.log(letter) // nothing
}
```
Asynchronous iteration will continue until the end event is reached,
consuming all of the data.
```js
const mp = new Minipass({ encoding: 'utf8' })
// some source of some data
let i = 5
const inter = setInterval(() => {
if (i --> 0)
mp.write(Buffer.from('foo\n', 'utf8'))
else {
mp.end()
clearInterval(inter)
}
}, 100)
// consume the data with asynchronous iteration
async function consume () {
for await (let chunk of mp) {
console.log(chunk)
}
return 'ok'
}
consume().then(res => console.log(res))
// logs `foo\n` 5 times, and then `ok`
```
### subclass that `console.log()`s everything written into it
```js
class Logger extends Minipass {
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}
someSource.pipe(new Logger()).pipe(someDest)
```
### same thing, but using an inline anonymous class
```js
// js classes are fun
someSource
.pipe(new (class extends Minipass {
emit (ev, ...data) {
// let's also log events, because debugging some weird thing
console.log('EMIT', ev)
return super.emit(ev, ...data)
}
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}))
.pipe(someDest)
```
### subclass that defers 'end' for some reason
```js
class SlowEnd extends Minipass {
emit (ev, ...args) {
if (ev === 'end') {
console.log('going to end, hold on a sec')
setTimeout(() => {
console.log('ok, ready to end now')
super.emit('end', ...args)
}, 100)
} else {
return super.emit(ev, ...args)
}
}
}
```
### transform that creates newline-delimited JSON
```js
class NDJSONEncode extends Minipass {
write (obj, cb) {
try {
// JSON.stringify can throw, emit an error on that
return super.write(JSON.stringify(obj) + '\n', 'utf8', cb)
} catch (er) {
this.emit('error', er)
}
}
end (obj, cb) {
if (typeof obj === 'function') {
cb = obj
obj = undefined
}
if (obj !== undefined) {
this.write(obj)
}
return super.end(cb)
}
}
```
### transform that parses newline-delimited JSON
```js
class NDJSONDecode extends Minipass {
constructor (options) {
// always be in object mode, as far as Minipass is concerned
super({ objectMode: true })
this._jsonBuffer = ''
}
write (chunk, encoding, cb) {
if (typeof chunk === 'string' &&
typeof encoding === 'string' &&
encoding !== 'utf8') {
chunk = Buffer.from(chunk, encoding).toString()
} else if (Buffer.isBuffer(chunk))
chunk = chunk.toString()
}
if (typeof encoding === 'function') {
cb = encoding
}
const jsonData = (this._jsonBuffer + chunk).split('\n')
this._jsonBuffer = jsonData.pop()
for (let i = 0; i < jsonData.length; i++) {
let parsed
try {
super.write(parsed)
} catch (er) {
this.emit('error', er)
continue
}
}
if (cb)
cb()
}
}
```
# buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/buffer/master.svg
[travis-url]: https://travis-ci.org/feross/buffer
[npm-image]: https://img.shields.io/npm/v/buffer.svg
[npm-url]: https://npmjs.org/package/buffer
[downloads-image]: https://img.shields.io/npm/dm/buffer.svg
[downloads-url]: https://npmjs.org/package/buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### The buffer module from [node.js](https://nodejs.org/), for the browser.
[![saucelabs][saucelabs-image]][saucelabs-url]
[saucelabs-image]: https://saucelabs.com/browser-matrix/buffer.svg
[saucelabs-url]: https://saucelabs.com/u/buffer
With [browserify](http://browserify.org), simply `require('buffer')` or use the `Buffer` global and you will get this module.
The goal is to provide an API that is 100% identical to
[node's Buffer API](https://nodejs.org/api/buffer.html). Read the
[official docs](https://nodejs.org/api/buffer.html) for the full list of properties,
instance methods, and class methods that are supported.
## features
- Manipulate binary data like a boss, in all browsers!
- Super fast. Backed by Typed Arrays (`Uint8Array`/`ArrayBuffer`, not `Object`)
- Extremely small bundle size (**6.75KB minified + gzipped**, 51.9KB with comments)
- Excellent browser support (Chrome, Firefox, Edge, Safari 9+, IE 11, iOS 9+, Android, etc.)
- Preserves Node API exactly, with one minor difference (see below)
- Square-bracket `buf[4]` notation works!
- Does not modify any browser prototypes or put anything on `window`
- Comprehensive test suite (including all buffer tests from node.js core)
## install
To use this module directly (without browserify), install it:
```bash
npm install buffer
```
This module was previously called **native-buffer-browserify**, but please use **buffer**
from now on.
If you do not use a bundler, you can use the [standalone script](https://bundle.run/buffer).
## usage
The module's API is identical to node's `Buffer` API. Read the
[official docs](https://nodejs.org/api/buffer.html) for the full list of properties,
instance methods, and class methods that are supported.
As mentioned above, `require('buffer')` or use the `Buffer` global with
[browserify](http://browserify.org) and this module will automatically be included
in your bundle. Almost any npm module will work in the browser, even if it assumes that
the node `Buffer` API will be available.
To depend on this module explicitly (without browserify), require it like this:
```js
var Buffer = require('buffer/').Buffer // note: the trailing slash is important!
```
To require this module explicitly, use `require('buffer/')` which tells the node.js module
lookup algorithm (also used by browserify) to use the **npm module** named `buffer`
instead of the **node.js core** module named `buffer`!
## how does it work?
The Buffer constructor returns instances of `Uint8Array` that have their prototype
changed to `Buffer.prototype`. Furthermore, `Buffer` is a subclass of `Uint8Array`,
so the returned instances will have all the node `Buffer` methods and the
`Uint8Array` methods. Square bracket notation works as expected -- it returns a
single octet.
The `Uint8Array` prototype remains unmodified.
## tracking the latest node api
This module tracks the Buffer API in the latest (unstable) version of node.js. The Buffer
API is considered **stable** in the
[node stability index](https://nodejs.org/docs/latest/api/documentation.html#documentation_stability_index),
so it is unlikely that there will ever be breaking changes.
Nonetheless, when/if the Buffer API changes in node, this module's API will change
accordingly.
## related packages
- [`buffer-reverse`](https://www.npmjs.com/package/buffer-reverse) - Reverse a buffer
- [`buffer-xor`](https://www.npmjs.com/package/buffer-xor) - Bitwise xor a buffer
- [`is-buffer`](https://www.npmjs.com/package/is-buffer) - Determine if an object is a Buffer without including the whole `Buffer` package
## conversion packages
### convert typed array to buffer
Use [`typedarray-to-buffer`](https://www.npmjs.com/package/typedarray-to-buffer) to convert any kind of typed array to a `Buffer`. Does not perform a copy, so it's super fast.
### convert buffer to typed array
`Buffer` is a subclass of `Uint8Array` (which is a typed array). So there is no need to explicitly convert to typed array. Just use the buffer as a `Uint8Array`.
### convert blob to buffer
Use [`blob-to-buffer`](https://www.npmjs.com/package/blob-to-buffer) to convert a `Blob` to a `Buffer`.
### convert buffer to blob
To convert a `Buffer` to a `Blob`, use the `Blob` constructor:
```js
var blob = new Blob([ buffer ])
```
Optionally, specify a mimetype:
```js
var blob = new Blob([ buffer ], { type: 'text/html' })
```
### convert arraybuffer to buffer
To convert an `ArrayBuffer` to a `Buffer`, use the `Buffer.from` function. Does not perform a copy, so it's super fast.
```js
var buffer = Buffer.from(arrayBuffer)
```
### convert buffer to arraybuffer
To convert a `Buffer` to an `ArrayBuffer`, use the `.buffer` property (which is present on all `Uint8Array` objects):
```js
var arrayBuffer = buffer.buffer.slice(
buffer.byteOffset, buffer.byteOffset + buffer.byteLength
)
```
Alternatively, use the [`to-arraybuffer`](https://www.npmjs.com/package/to-arraybuffer) module.
## performance
See perf tests in `/perf`.
`BrowserBuffer` is the browser `buffer` module (this repo). `Uint8Array` is included as a
sanity check (since `BrowserBuffer` uses `Uint8Array` under the hood, `Uint8Array` will
always be at least a bit faster). Finally, `NodeBuffer` is the node.js buffer module,
which is included to compare against.
NOTE: Performance has improved since these benchmarks were taken. PR welcome to update the README.
### Chrome 38
| Method | Operations | Accuracy | Sampled | Fastest |
|:-------|:-----------|:---------|:--------|:-------:|
| BrowserBuffer#bracket-notation | 11,457,464 ops/sec | ±0.86% | 66 | ✓ |
| Uint8Array#bracket-notation | 10,824,332 ops/sec | ±0.74% | 65 | |
| | | | |
| BrowserBuffer#concat | 450,532 ops/sec | ±0.76% | 68 | |
| Uint8Array#concat | 1,368,911 ops/sec | ±1.50% | 62 | ✓ |
| | | | |
| BrowserBuffer#copy(16000) | 903,001 ops/sec | ±0.96% | 67 | |
| Uint8Array#copy(16000) | 1,422,441 ops/sec | ±1.04% | 66 | ✓ |
| | | | |
| BrowserBuffer#copy(16) | 11,431,358 ops/sec | ±0.46% | 69 | |
| Uint8Array#copy(16) | 13,944,163 ops/sec | ±1.12% | 68 | ✓ |
| | | | |
| BrowserBuffer#new(16000) | 106,329 ops/sec | ±6.70% | 44 | |
| Uint8Array#new(16000) | 131,001 ops/sec | ±2.85% | 31 | ✓ |
| | | | |
| BrowserBuffer#new(16) | 1,554,491 ops/sec | ±1.60% | 65 | |
| Uint8Array#new(16) | 6,623,930 ops/sec | ±1.66% | 65 | ✓ |
| | | | |
| BrowserBuffer#readDoubleBE | 112,830 ops/sec | ±0.51% | 69 | ✓ |
| DataView#getFloat64 | 93,500 ops/sec | ±0.57% | 68 | |
| | | | |
| BrowserBuffer#readFloatBE | 146,678 ops/sec | ±0.95% | 68 | ✓ |
| DataView#getFloat32 | 99,311 ops/sec | ±0.41% | 67 | |
| | | | |
| BrowserBuffer#readUInt32LE | 843,214 ops/sec | ±0.70% | 69 | ✓ |
| DataView#getUint32 | 103,024 ops/sec | ±0.64% | 67 | |
| | | | |
| BrowserBuffer#slice | 1,013,941 ops/sec | ±0.75% | 67 | |
| Uint8Array#subarray | 1,903,928 ops/sec | ±0.53% | 67 | ✓ |
| | | | |
| BrowserBuffer#writeFloatBE | 61,387 ops/sec | ±0.90% | 67 | |
| DataView#setFloat32 | 141,249 ops/sec | ±0.40% | 66 | ✓ |
### Firefox 33
| Method | Operations | Accuracy | Sampled | Fastest |
|:-------|:-----------|:---------|:--------|:-------:|
| BrowserBuffer#bracket-notation | 20,800,421 ops/sec | ±1.84% | 60 | |
| Uint8Array#bracket-notation | 20,826,235 ops/sec | ±2.02% | 61 | ✓ |
| | | | |
| BrowserBuffer#concat | 153,076 ops/sec | ±2.32% | 61 | |
| Uint8Array#concat | 1,255,674 ops/sec | ±8.65% | 52 | ✓ |
| | | | |
| BrowserBuffer#copy(16000) | 1,105,312 ops/sec | ±1.16% | 63 | |
| Uint8Array#copy(16000) | 1,615,911 ops/sec | ±0.55% | 66 | ✓ |
| | | | |
| BrowserBuffer#copy(16) | 16,357,599 ops/sec | ±0.73% | 68 | |
| Uint8Array#copy(16) | 31,436,281 ops/sec | ±1.05% | 68 | ✓ |
| | | | |
| BrowserBuffer#new(16000) | 52,995 ops/sec | ±6.01% | 35 | |
| Uint8Array#new(16000) | 87,686 ops/sec | ±5.68% | 45 | ✓ |
| | | | |
| BrowserBuffer#new(16) | 252,031 ops/sec | ±1.61% | 66 | |
| Uint8Array#new(16) | 8,477,026 ops/sec | ±0.49% | 68 | ✓ |
| | | | |
| BrowserBuffer#readDoubleBE | 99,871 ops/sec | ±0.41% | 69 | |
| DataView#getFloat64 | 285,663 ops/sec | ±0.70% | 68 | ✓ |
| | | | |
| BrowserBuffer#readFloatBE | 115,540 ops/sec | ±0.42% | 69 | |
| DataView#getFloat32 | 288,722 ops/sec | ±0.82% | 68 | ✓ |
| | | | |
| BrowserBuffer#readUInt32LE | 633,926 ops/sec | ±1.08% | 67 | ✓ |
| DataView#getUint32 | 294,808 ops/sec | ±0.79% | 64 | |
| | | | |
| BrowserBuffer#slice | 349,425 ops/sec | ±0.46% | 69 | |
| Uint8Array#subarray | 5,965,819 ops/sec | ±0.60% | 65 | ✓ |
| | | | |
| BrowserBuffer#writeFloatBE | 59,980 ops/sec | ±0.41% | 67 | |
| DataView#setFloat32 | 317,634 ops/sec | ±0.63% | 68 | ✓ |
### Safari 8
| Method | Operations | Accuracy | Sampled | Fastest |
|:-------|:-----------|:---------|:--------|:-------:|
| BrowserBuffer#bracket-notation | 10,279,729 ops/sec | ±2.25% | 56 | ✓ |
| Uint8Array#bracket-notation | 10,030,767 ops/sec | ±2.23% | 59 | |
| | | | |
| BrowserBuffer#concat | 144,138 ops/sec | ±1.38% | 65 | |
| Uint8Array#concat | 4,950,764 ops/sec | ±1.70% | 63 | ✓ |
| | | | |
| BrowserBuffer#copy(16000) | 1,058,548 ops/sec | ±1.51% | 64 | |
| Uint8Array#copy(16000) | 1,409,666 ops/sec | ±1.17% | 65 | ✓ |
| | | | |
| BrowserBuffer#copy(16) | 6,282,529 ops/sec | ±1.88% | 58 | |
| Uint8Array#copy(16) | 11,907,128 ops/sec | ±2.87% | 58 | ✓ |
| | | | |
| BrowserBuffer#new(16000) | 101,663 ops/sec | ±3.89% | 57 | |
| Uint8Array#new(16000) | 22,050,818 ops/sec | ±6.51% | 46 | ✓ |
| | | | |
| BrowserBuffer#new(16) | 176,072 ops/sec | ±2.13% | 64 | |
| Uint8Array#new(16) | 24,385,731 ops/sec | ±5.01% | 51 | ✓ |
| | | | |
| BrowserBuffer#readDoubleBE | 41,341 ops/sec | ±1.06% | 67 | |
| DataView#getFloat64 | 322,280 ops/sec | ±0.84% | 68 | ✓ |
| | | | |
| BrowserBuffer#readFloatBE | 46,141 ops/sec | ±1.06% | 65 | |
| DataView#getFloat32 | 337,025 ops/sec | ±0.43% | 69 | ✓ |
| | | | |
| BrowserBuffer#readUInt32LE | 151,551 ops/sec | ±1.02% | 66 | |
| DataView#getUint32 | 308,278 ops/sec | ±0.94% | 67 | ✓ |
| | | | |
| BrowserBuffer#slice | 197,365 ops/sec | ±0.95% | 66 | |
| Uint8Array#subarray | 9,558,024 ops/sec | ±3.08% | 58 | ✓ |
| | | | |
| BrowserBuffer#writeFloatBE | 17,518 ops/sec | ±1.03% | 63 | |
| DataView#setFloat32 | 319,751 ops/sec | ±0.48% | 68 | ✓ |
### Node 0.11.14
| Method | Operations | Accuracy | Sampled | Fastest |
|:-------|:-----------|:---------|:--------|:-------:|
| BrowserBuffer#bracket-notation | 10,489,828 ops/sec | ±3.25% | 90 | |
| Uint8Array#bracket-notation | 10,534,884 ops/sec | ±0.81% | 92 | ✓ |
| NodeBuffer#bracket-notation | 10,389,910 ops/sec | ±0.97% | 87 | |
| | | | |
| BrowserBuffer#concat | 487,830 ops/sec | ±2.58% | 88 | |
| Uint8Array#concat | 1,814,327 ops/sec | ±1.28% | 88 | ✓ |
| NodeBuffer#concat | 1,636,523 ops/sec | ±1.88% | 73 | |
| | | | |
| BrowserBuffer#copy(16000) | 1,073,665 ops/sec | ±0.77% | 90 | |
| Uint8Array#copy(16000) | 1,348,517 ops/sec | ±0.84% | 89 | ✓ |
| NodeBuffer#copy(16000) | 1,289,533 ops/sec | ±0.82% | 93 | |
| | | | |
| BrowserBuffer#copy(16) | 12,782,706 ops/sec | ±0.74% | 85 | |
| Uint8Array#copy(16) | 14,180,427 ops/sec | ±0.93% | 92 | ✓ |
| NodeBuffer#copy(16) | 11,083,134 ops/sec | ±1.06% | 89 | |
| | | | |
| BrowserBuffer#new(16000) | 141,678 ops/sec | ±3.30% | 67 | |
| Uint8Array#new(16000) | 161,491 ops/sec | ±2.96% | 60 | |
| NodeBuffer#new(16000) | 292,699 ops/sec | ±3.20% | 55 | ✓ |
| | | | |
| BrowserBuffer#new(16) | 1,655,466 ops/sec | ±2.41% | 82 | |
| Uint8Array#new(16) | 14,399,926 ops/sec | ±0.91% | 94 | ✓ |
| NodeBuffer#new(16) | 3,894,696 ops/sec | ±0.88% | 92 | |
| | | | |
| BrowserBuffer#readDoubleBE | 109,582 ops/sec | ±0.75% | 93 | ✓ |
| DataView#getFloat64 | 91,235 ops/sec | ±0.81% | 90 | |
| NodeBuffer#readDoubleBE | 88,593 ops/sec | ±0.96% | 81 | |
| | | | |
| BrowserBuffer#readFloatBE | 139,854 ops/sec | ±1.03% | 85 | ✓ |
| DataView#getFloat32 | 98,744 ops/sec | ±0.80% | 89 | |
| NodeBuffer#readFloatBE | 92,769 ops/sec | ±0.94% | 93 | |
| | | | |
| BrowserBuffer#readUInt32LE | 710,861 ops/sec | ±0.82% | 92 | |
| DataView#getUint32 | 117,893 ops/sec | ±0.84% | 91 | |
| NodeBuffer#readUInt32LE | 851,412 ops/sec | ±0.72% | 93 | ✓ |
| | | | |
| BrowserBuffer#slice | 1,673,877 ops/sec | ±0.73% | 94 | |
| Uint8Array#subarray | 6,919,243 ops/sec | ±0.67% | 90 | ✓ |
| NodeBuffer#slice | 4,617,604 ops/sec | ±0.79% | 93 | |
| | | | |
| BrowserBuffer#writeFloatBE | 66,011 ops/sec | ±0.75% | 93 | |
| DataView#setFloat32 | 127,760 ops/sec | ±0.72% | 93 | ✓ |
| NodeBuffer#writeFloatBE | 103,352 ops/sec | ±0.83% | 93 | |
### iojs 1.8.1
| Method | Operations | Accuracy | Sampled | Fastest |
|:-------|:-----------|:---------|:--------|:-------:|
| BrowserBuffer#bracket-notation | 10,990,488 ops/sec | ±1.11% | 91 | |
| Uint8Array#bracket-notation | 11,268,757 ops/sec | ±0.65% | 97 | |
| NodeBuffer#bracket-notation | 11,353,260 ops/sec | ±0.83% | 94 | ✓ |
| | | | |
| BrowserBuffer#concat | 378,954 ops/sec | ±0.74% | 94 | |
| Uint8Array#concat | 1,358,288 ops/sec | ±0.97% | 87 | |
| NodeBuffer#concat | 1,934,050 ops/sec | ±1.11% | 78 | ✓ |
| | | | |
| BrowserBuffer#copy(16000) | 894,538 ops/sec | ±0.56% | 84 | |
| Uint8Array#copy(16000) | 1,442,656 ops/sec | ±0.71% | 96 | |
| NodeBuffer#copy(16000) | 1,457,898 ops/sec | ±0.53% | 92 | ✓ |
| | | | |
| BrowserBuffer#copy(16) | 12,870,457 ops/sec | ±0.67% | 95 | |
| Uint8Array#copy(16) | 16,643,989 ops/sec | ±0.61% | 93 | ✓ |
| NodeBuffer#copy(16) | 14,885,848 ops/sec | ±0.74% | 94 | |
| | | | |
| BrowserBuffer#new(16000) | 109,264 ops/sec | ±4.21% | 63 | |
| Uint8Array#new(16000) | 138,916 ops/sec | ±1.87% | 61 | |
| NodeBuffer#new(16000) | 281,449 ops/sec | ±3.58% | 51 | ✓ |
| | | | |
| BrowserBuffer#new(16) | 1,362,935 ops/sec | ±0.56% | 99 | |
| Uint8Array#new(16) | 6,193,090 ops/sec | ±0.64% | 95 | ✓ |
| NodeBuffer#new(16) | 4,745,425 ops/sec | ±1.56% | 90 | |
| | | | |
| BrowserBuffer#readDoubleBE | 118,127 ops/sec | ±0.59% | 93 | ✓ |
| DataView#getFloat64 | 107,332 ops/sec | ±0.65% | 91 | |
| NodeBuffer#readDoubleBE | 116,274 ops/sec | ±0.94% | 95 | |
| | | | |
| BrowserBuffer#readFloatBE | 150,326 ops/sec | ±0.58% | 95 | ✓ |
| DataView#getFloat32 | 110,541 ops/sec | ±0.57% | 98 | |
| NodeBuffer#readFloatBE | 121,599 ops/sec | ±0.60% | 87 | |
| | | | |
| BrowserBuffer#readUInt32LE | 814,147 ops/sec | ±0.62% | 93 | |
| DataView#getUint32 | 137,592 ops/sec | ±0.64% | 90 | |
| NodeBuffer#readUInt32LE | 931,650 ops/sec | ±0.71% | 96 | ✓ |
| | | | |
| BrowserBuffer#slice | 878,590 ops/sec | ±0.68% | 93 | |
| Uint8Array#subarray | 2,843,308 ops/sec | ±1.02% | 90 | |
| NodeBuffer#slice | 4,998,316 ops/sec | ±0.68% | 90 | ✓ |
| | | | |
| BrowserBuffer#writeFloatBE | 65,927 ops/sec | ±0.74% | 93 | |
| DataView#setFloat32 | 139,823 ops/sec | ±0.97% | 89 | ✓ |
| NodeBuffer#writeFloatBE | 135,763 ops/sec | ±0.65% | 96 | |
| | | | |
## Testing the project
First, install the project:
npm install
Then, to run tests in Node.js, run:
npm run test-node
To test locally in a browser, you can run:
npm run test-browser-es5-local # For ES5 browsers that don't support ES6
npm run test-browser-es6-local # For ES6 compliant browsers
This will print out a URL that you can then open in a browser to run the tests, using [airtap](https://www.npmjs.com/package/airtap).
To run automated browser tests using Saucelabs, ensure that your `SAUCE_USERNAME` and `SAUCE_ACCESS_KEY` environment variables are set, then run:
npm test
This is what's run in Travis, to check against various browsers. The list of browsers is kept in the `bin/airtap-es5.yml` and `bin/airtap-es6.yml` files.
## JavaScript Standard Style
This module uses [JavaScript Standard Style](https://github.com/feross/standard).
[](https://github.com/feross/standard)
To test that the code conforms to the style, `npm install` and run:
./node_modules/.bin/standard
## credit
This was originally forked from [buffer-browserify](https://github.com/toots/buffer-browserify).
## Security Policies and Procedures
The `buffer` team and community take all security bugs in `buffer` seriously. Please see our [security policies and procedures](https://github.com/feross/security) document to learn how to report issues.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org), and other contributors. Originally forked from an MIT-licensed module by Romain Beauxis.
## strip-hex-prefix
<div>
<!-- Dependency Status -->
<a href="https://david-dm.org/silentcicero/strip-hex-prefix">
<img src="https://david-dm.org/silentcicero/strip-hex-prefix.svg"
alt="Dependency Status" />
</a>
<!-- devDependency Status -->
<a href="https://david-dm.org/silentcicero/strip-hex-prefix#info=devDependencies">
<img src="https://david-dm.org/silentcicero/strip-hex-prefix/dev-status.svg" alt="devDependency Status" />
</a>
<!-- Build Status -->
<a href="https://travis-ci.org/SilentCicero/strip-hex-prefix">
<img src="https://travis-ci.org/SilentCicero/strip-hex-prefix.svg"
alt="Build Status" />
</a>
<!-- NPM Version -->
<a href="https://www.npmjs.org/package/strip-hex-prefix">
<img src="http://img.shields.io/npm/v/strip-hex-prefix.svg"
alt="NPM version" />
</a>
<a href="https://coveralls.io/r/SilentCicero/strip-hex-prefix">
<img src="https://coveralls.io/repos/github/SilentCicero/strip-hex-prefix/badge.svg" alt="Test Coverage" />
</a>
<!-- Javascript Style -->
<a href="http://airbnb.io/javascript/">
<img src="https://img.shields.io/badge/code%20style-airbnb-brightgreen.svg" alt="js-airbnb-style" />
</a>
</div>
<br />
A simple method to strip the hex prefix of a string, if present.
Will bypass if not a string.
## Install
```
npm install --save strip-hex-prefix
```
## Usage
```js
const stripHexPrefix = require('strip-hex-prefix');
console.log(stripHexPrefix('0x'));
// result ''
console.log(stripHexPrefix('0xhjsfdj'));
// result 'hjsfdj'
console.log(stripHexPrefix('0x87sf7373ds8sfsdhgs73y87ssgsdf89'));
// result '87sf7373ds8sfsdhgs73y87ssgsdf89'
console.log(stripHexPrefix({}));
// result {}
console.log(stripHexPrefix('-0x'));
// result '-0x'
```
## Important documents
- [Changelog](CHANGELOG.md)
- [License](https://raw.githubusercontent.com/silentcicero/strip-hex-prefix/master/LICENSE)
## Licence
This project is licensed under the MIT license, Copyright (c) 2016 Nick Dodson. For more information see LICENSE.md.
```
The MIT License
Copyright (c) 2016 Nick Dodson. nickdodson.com
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
```
Port of the OpenBSD `bcrypt_pbkdf` function to pure Javascript. `npm`-ified
version of [Devi Mandiri's port](https://github.com/devi/tmp/blob/master/js/bcrypt_pbkdf.js),
with some minor performance improvements. The code is copied verbatim (and
un-styled) from Devi's work.
This product includes software developed by Niels Provos.
## API
### `bcrypt_pbkdf.pbkdf(pass, passlen, salt, saltlen, key, keylen, rounds)`
Derive a cryptographic key of arbitrary length from a given password and salt,
using the OpenBSD `bcrypt_pbkdf` function. This is a combination of Blowfish and
SHA-512.
See [this article](http://www.tedunangst.com/flak/post/bcrypt-pbkdf) for
further information.
Parameters:
* `pass`, a Uint8Array of length `passlen`
* `passlen`, an integer Number
* `salt`, a Uint8Array of length `saltlen`
* `saltlen`, an integer Number
* `key`, a Uint8Array of length `keylen`, will be filled with output
* `keylen`, an integer Number
* `rounds`, an integer Number, number of rounds of the PBKDF to run
### `bcrypt_pbkdf.hash(sha2pass, sha2salt, out)`
Calculate a Blowfish hash, given SHA2-512 output of a password and salt. Used as
part of the inner round function in the PBKDF.
Parameters:
* `sha2pass`, a Uint8Array of length 64
* `sha2salt`, a Uint8Array of length 64
* `out`, a Uint8Array of length 32, will be filled with output
## License
This source form is a 1:1 port from the OpenBSD `blowfish.c` and `bcrypt_pbkdf.c`.
As a result, it retains the original copyright and license. The two files are
under slightly different (but compatible) licenses, and are here combined in
one file. For each of the full license texts see `LICENSE`.
# color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
# bs58check
[](https://www.npmjs.org/package/bs58check)
[](https://travis-ci.org/bitcoinjs/bs58check)
[](https://david-dm.org/bitcoinjs/bs58check#info=dependencies)
[](https://github.com/feross/standard)
A straight forward implementation of base58check extending upon bs58.
## Example
```javascript
var bs58check = require('bs58check')
var decoded = bs58check.decode('5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr')
console.log(decoded)
// => <Buffer 80 ed db dc 11 68 f1 da ea db d3 e4 4c 1e 3f 8f 5a 28 4c 20 29 f7 8a d2 6a f9 85 83 a4 99 de 5b 19>
console.log(bs58check.encode(decoded))
// => 5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr
```
## LICENSE [MIT](LICENSE)
# web3-utils
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This contains useful utility functions for Dapp developers.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-utils
```
## Usage
```js
const Web3Utils = require('web3-utils');
console.log(Web3Utils);
{
sha3: function(){},
soliditySha3: function(){},
isAddress: function(){},
...
}
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-utils.svg
[npm-url]: https://npmjs.org/package/web3-utils
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-utils
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-utils
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-utils
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-utils
<p align="center">
<a href="https://systeminformation.io/">
<img src="https://systeminformation.io/assets/logo_inv.png" alt="systeminformation logo" width="102" height="72">
</a>
</p>
<h3 align="center">systeminformation</h3>
<p align="center">
System and OS information library for node.js
<br>
<a href="https://systeminformation.io/"><strong>Explore Systeminformation docs »</strong></a>
<br>
<br>
<a href="https://github.com/sebhildebrandt/systeminformation/issues/new?template=bug_report.md">Report bug</a>
·
<a href="https://github.com/sebhildebrandt/systeminformation/issues/new?template=feature_request.md&labels=feature">Request feature</a>
·
<a href="https://github.com/sebhildebrandt/systeminformation/blob/master/CHANGELOG.md">Changelog</a>
</p>
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Git Issues][issues-img]][issues-url]
[![Closed Issues][closed-issues-img]][closed-issues-url]
[![deps status][daviddm-img]][daviddm-url]
[![Code Quality: Javascript][lgtm-badge]][lgtm-badge-url]
[![Total alerts][lgtm-alerts]][lgtm-alerts-url]
[![Caretaker][caretaker-image]][caretaker-url]
[![Sponsoring][sponsor-badge]][sponsor-url]
[![MIT license][license-img]][license-url]
This is amazing. Started as a small project just for myself, it now has > 9,000 lines of code, > 300 versions published, up to 2 mio downloads per month, > 18 mio downloads overall. Thank you to all who contributed to this project!
## New Version 4.0
This next major version release 4.0 comes with several optimizations and changes:
- new systeminformation website with better documentation and examples [systeminformation.io][systeminformation-url]
- added typescript definitions
- reworked network section: this will now return more information and allows getting networkStats for more than one interface at once.
- dockerContainerStats for multiple containers or all containers at once
- optimized graphics controller and display detection
- added wifiNetworks to get available Wi-Fi networks
- added vboxInfo to get detailed vm information
- added chassis information
- better Raspberry-PI detection
- lot of minor improvements
Breaking Changes: you will see some minor breaking changes. Read the [detailed changelog][changelog-url].
## Quick Start
Lightweight collection of 40+ functions to retrieve detailed hardware, system and OS information.
- simple to use
- get detailed information about system, cpu, baseboard, battery, memory, disks/filesystem, network, docker, software, services and processes
- supports Linux, macOS, partial Windows, FreeBSD, OpenBSD, NetBSD and SunOS support
- no npm dependencies (for production)
**Attention**: this is a `node.js` library. It is supposed to be used as a backend/server-side library and will definitely not work within a browser.
### Installation
```bash
$ npm install systeminformation --save
```
### Usage
All functions (except `version` and `time`) are implemented as asynchronous functions. Here a small example how to use them:
```js
const si = require('systeminformation');
// promises style - new since version 3
si.cpu()
.then(data => console.log(data))
.catch(error => console.error(error));
```
**Callback, Promises, Async / Await**
## News and Changes
### Latest Activity
(last 7 major and minor version releases)
- Version 4.27.0: `observe()` added observe / watch function
- Version 4.26.0: `diskLayout()` added full S.M.A.R.T data (Linux)
- Version 4.25.0: `get()` added function to get partial system info
- Version 4.24.0: `networkInterfaces()` added subnet mask ip4 and ip6
- Version 4.23.0: `versions()` added param to specify which program/lib versions to detect
- Version 4.22.0: `services()` added pids (windows)
- Version 4.21.0: added npx copmpatibility
- ...
You can find all changes here: [detailed changelog][changelog-url]
## Core concept
[Node.js][nodejs-url] comes with some basic OS information, but I always wanted a little more. So I came up to write this little library. This library is still work in progress. It is supposed to be used as a backend/server-side library (will definitely not work within a browser). It requires node.js version 4.0 and above.
I was able to test it on several Debian, Raspbian, Ubuntu distributions as well as macOS (Mavericks, Yosemite, El Captain, Sierra, High Sierra, Mojave) and some Windows 7, Windows 10, FreeBSD, OpenBSD, NetBSD and SunOS machines. Not all functions are supported on all operating systems. Have a look at the function reference in the docs to get further details.
If you have comments, suggestions & reports, please feel free to contact me!
I also created a nice little command line tool called [mmon][mmon-github-url] (micro-monitor) for Linux and macOS, also available via [github][mmon-github-url] and [npm][mmon-npm-url]
## Reference
### Function Reference and OS Support
#### 1. General
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.version() | : string | X | X | X | X | X | lib version (no callback/promise) |
| si.time() | {...} | X | X | X | X | X | (no callback/promise) |
| | current | X | X | X | X | X | local (server) time |
| | uptime | X | X | X | X | X | uptime in number of seconds |
| | timezone | X | X | X | X | X | e.g. GMT+0200 |
| | timezoneName | X | X | X | X | X | e.g. CEST |
#### 2. System (HW)
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.system(cb) | {...} | X | X | X | X | | hardware information |
| | manufacturer | X | X | X | X | | e.g. 'MSI' |
| | model | X | X | X | X | | model/product e.g. 'MS-7823' |
| | version | X | X | X | X | | version e.g. '1.0' |
| | serial | X | X | X | X | | serial number |
| | uuid | X | X | X | X | | UUID |
| | sku | X | X | X | X | | SKU number |
| si.bios(cb) | {...} | X | X | X | X | | bios information |
| | vendor | X | X | X | X | | e.g. 'AMI' |
| | version | X | X | | X | | version |
| | releaseDate | X | X | | X | | release date |
| | revision | X | X | | X | | revision |
| si.baseboard(cb) | {...} | X | X | X | X | | baseboard information |
| | manufacturer | X | X | X | X | | e.g. 'ASUS' |
| | model | X | X | X | X | | model / product name |
| | version | X | X | X | X | | version |
| | serial | X | X | X | X | | serial number |
| | assetTag | X | X | X | X | | asset tag |
| si.chassis(cb) | {...} | X | X | X | X | | chassis information |
| | manufacturer | X | X | X | X | | e.g. 'MSI' |
| | model | X | X | X | X | | model / product name |
| | type | X | X | X | X | | model / product name |
| | version | X | X | X | X | | version |
| | serial | X | X | X | X | | serial number |
| | assetTag | X | X | X | X | | asset tag |
| | sku | | | | X | | SKU number |
#### 3. CPU
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.cpu(cb) | {...} | X | X | X | X | | CPU information|
| | manufacturer | X | X | X | X | | e.g. 'Intel(R)' |
| | brand | X | X | X | X | | e.g. 'Core(TM)2 Duo' |
| | speed | X | X | X | X | | in GHz e.g. '3.40' |
| | speedmin | X | | X | X | | in GHz e.g. '0.80' |
| | speedmax | X | X | X | X | | in GHz e.g. '3.90' |
| | governor | X | | | | | e.g. 'powersave' |
| | cores | X | X | X | X | | # cores |
| | physicalCores | X | X | X | X | | # physical cores |
| | processors | X | X | X | X | | # processors |
| | socket | X | X | | X | | socket type e.g. "LGA1356" |
| | vendor | X | X | X | X | | vendor ID |
| | family | X | X | X | X | | processor family |
| | model | X | X | X | X | | processor model |
| | stepping | X | X | X | X | | processor stepping |
| | revision | X | | X | X | | revision |
| | voltage | | X | | | | voltage |
| | cache | X | X | X | X | | cache in bytes (object) |
| | cache.l1d | X | X | X | X | | L1D (data) size |
| | cache.l1i | X | X | X | X | | L1I (instruction) size |
| | cache.l2 | X | X | X | X | | L2 size |
| | cache.l3 | X | X | X | X | | L3 size |
| si.cpuFlags(cb) | : string | X | X | X | X | | CPU flags|
| si.cpuCache(cb) | {...} | X | X | X | X | | CPU cache sizes |
| | l1d | X | X | X | X | | L1D size |
| | l1i | X | X | X | X | | L1I size |
| | l2 | X | X | X | X | | L2 size |
| | l3 | X | X | X | X | | L3 size |
| si.cpuCurrentspeed(cb) | {...} | X | X | X | X | X | current CPU speed (in GHz)|
| | avg | X | X | X | X | X | avg CPU speed (all cores) |
| | min | X | X | X | X | X | min CPU speed (all cores) |
| | max | X | X | X | X | X | max CPU speed (all cores) |
| | cores | X | X | X | X | X | CPU speed per core (array) |
| si.cpuTemperature(cb) | {...} | X | X | X* | X | | CPU temperature (if supported) |
| | main | X | X | X | X | | main temperature (avg) |
| | cores | X | X | X | X | | array of temperatures |
| | max | X | X | X | X | | max temperature |
#### 4. Memory
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.mem(cb) | {...} | X | X | X | X | X | Memory information (in bytes)|
| | total | X | X | X | X | X | total memory in bytes |
| | free | X | X | X | X | X | not used in bytes |
| | used | X | X | X | X | X | used (incl. buffers/cache) |
| | active | X | X | X | X | X | used actively (excl. buffers/cache) |
| | buffcache | X | X | X | | X | used by buffers+cache |
| | buffers | X | | | | | used by buffers |
| | cached | X | | | | | used by cache |
| | slab | X | | | | | used by slab |
| | available | X | X | X | X | X | potentially available (total - active) |
| | swaptotal | X | X | X | X | X | |
| | swapused | X | X | X | X | X | |
| | swapfree | X | X | X | X | X | |
| si.memLayout(cb) | [{...}] | X | X | X | X | | Memory Layout (array) |
| | [0].size | X | X | X | X | | size in bytes |
| | [0].bank | X | X | | X | | memory bank |
| | [0].type | X | X | X | X | | memory type |
| | [0].clockSpeed | X | X | X | X | | clock speed |
| | [0].formFactor | X | X | | X | | form factor |
| | [0].manufacturer | X | X | X | X | | manufacturer |
| | [0].partNum | X | X | X | X | | part number |
| | [0].serialNum | X | X | X | X | | serial number |
| | [0].voltageConfigured | X | X | | X | | voltage conf. |
| | [0].voltageMin | X | X | | X | | voltage min |
| | [0].voltageMax | X | X | | X | | voltage max |
#### 5. Battery
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.battery(cb) | {...} | X | X | X | X | | battery information |
| | hasbattery | X | X | X | X | | indicates presence of battery |
| | cyclecount | X | | X | | | numbers of recharges |
| | ischarging | X | X | X | X | | indicates if battery is charging |
| | designedcapacity | X | | X | X | | max capacity of battery (mWh) |
| | maxcapacity | X | | X | X | | max capacity of battery (mWh) |
| | currentcapacity | X | | X | X | | current capacity of battery (mWh) |
| | capacityUnit | X | | X | X | | capacity unit (mWh) |
| | voltage | X | | X | X | | current voltage of battery (V) |
| | percent | X | X | X | X | | charging level in percent |
| | timeremaining | X | | X | | | minutes left (if discharging) |
| | acconnected | X | X | X | X | | AC connected |
| | type | X | | X | | | battery type |
| | model | X | | X | | | model |
| | manufacturer | X | | X | | | manufacturer |
| | serial | X | | X | | | battery serial |
* See known issues if you have problem with macOS temperature or windows temperature
#### 6. Graphics
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.graphics(cb) | {...} | X | | X | X | | arrays of graphics controllers and displays |
| | controllers[]| X | | X | X | | graphics controllers array |
| | ...[0].model | X | | X | X | | graphics controller model |
| | ...[0].vendor | X | | X | X | | e.g. ATI |
| | ...[0].bus | X | | X | X | | on which bus (e.g. PCIe) |
| | ...[0].vram | X | | X | X | | VRAM size (in MB) |
| | ...[0].vramDynamic | X | | X | X | | true if dynamicly allocated ram |
| | displays[] | X | | X | X | | monitor/display array |
| | ...[0].vendor | | | | X | | monitor/display vendor |
| | ...[0].model | X | | X | X | | monitor/display model |
| | ...[0].main | X | | X | X| | true if main monitor |
| | ...[0].builtin | X | | X | | | true if built in monitor |
| | ...[0].connection | X | | X | X | | e.g. DisplayPort or HDMI |
| | ...[0].sizex | X | | X | X | | size in mm horizontal |
| | ...[0].sizey | X | | X | X | | size in mm vertical |
| | ...[0].pixeldepth | X | | X | X | | color depth in bits |
| | ...[0].resolutionx | X | | X | X | | pixel horizontal |
| | ...[0].resolutiony | X | | X | X | | pixel vertical |
| | ...[0].currentResX | X | | X | X | | current pixel horizontal |
| | ...[0].currentResY | X | | X | X | | current pixel vertical |
| | ...[0].positionX | | | | X | | display position X |
| | ...[0].positionY | | | | X | | display position Y |
| | ...[0].currentRefreshRate | X | | X | X | | current screen refresh rate |
#### 7. Operating System
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.osInfo(cb) | {...} | X | X | X | X | X | OS information |
| | platform | X | X | X | X | X | 'linux', 'darwin', 'win32', ... |
| | distro | X | X | X | X | X | |
| | release | X | X | X | X | X | |
| | codename | | | X | | | |
| | kernel | X | X | X | X | X | kernel release - same as os.release() |
| | arch | X | X | X | X | X | same as os.arch() |
| | hostname | X | X | X | X | X | same as os.hostname() |
| | codepage | X | X | X | X | | OS build version |
| | logofile | X | X | X | X | X | e.g. 'apple', 'debian', 'fedora', ... |
| | serial | X | X | X | X | | OS/Host serial number |
| | build | X | | X | X | | OS build version |
| | servicepack | | | | X | | service pack version |
| | uefi | X | X | X | X | | OS started via UEFI |
| si.uuid(cb) | {...} | X | X | X | X | X | object of several UUIDs |
| | os | X | X | X | X | | os specific UUID |
| si.versions(apps, cb) | {...} | X | X | X | X | X | version information (kernel, ssl, node, ...)<br />apps param is optional for detecting<br />only specific apps/libs<br />(string, comma separated) |
| si.shell(cb) | : string | X | X | X | | | standard shell |
| si.users(cb) | [{...}] | X | X | X | X | X | array of users online |
| | [0].user | X | X | X | X | X | user name |
| | [0].tty | X | X | X | X | X | terminal |
| | [0].date | X | X | X | X | X | login date |
| | [0].time | X | X | X | X | X | login time |
| | [0].ip | X | X | X | | X | ip address (remote login) |
| | [0].command | X | X | X | | X | last command or shell |
#### 8. Current Load, Processes & Services
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.currentLoad(cb) | {...} | X | | X | X | X | CPU-Load |
| | avgload | X | | X | | X | average load |
| | currentload | X | | X | X | X | CPU load in % |
| | currentload_user | X | | X | X | X | CPU load user in % |
| | currentload_system | X | | X | X | X | CPU load system in % |
| | currentload_nice | X | | X | X | X | CPU load nice in % |
| | currentload_idle | X | | X | X | X | CPU load idle in % |
| | currentload_irq | X | | X | X | X | CPU load system in % |
| | raw_currentload... | X | | X | X | X | CPU load raw values (ticks) |
| | cpus[] | X | | X | X | X | current loads per CPU in % + raw ticks |
| si.fullLoad(cb) | : integer | X | | X | X | | CPU full load since bootup in % |
| si.processes(cb) | {...} | X | X | X | X | X | # running processes |
| | all | X | X | X | X | X | # of all processes |
| | running | X | X | X | X | X | # of all processes running |
| | blocked | X | X | X | X | X | # of all processes blocked |
| | sleeping | X | X | X | X | X | # of all processes sleeping |
| | unknown | | | | X | | # of all processes unknown status |
| | list[] | X | X | X | X | X | list of all processes incl. details |
| | ...[0].pid | X | X | X | X | X | process PID |
| | ...[0].parentPid | X | X | X | X | X | parent process PID |
| | ...[0].name | X | X | X | X | X | process name |
| | ...[0].pcpu | X | X | X | X | X | process % CPU usage |
| | ...[0].pcpuu | X | X | | X | | process % CPU usage (user) |
| | ...[0].pcpus | X | X | | X | | process % CPU usage (system) |
| | ...[0].pmem | X | X | X | X | X | process memory % |
| | ...[0].priority | X | X | X | X | X | process priotity |
| | ...[0].mem_vsz | X | X | X | X | X | process virtual memory size |
| | ...[0].mem_rss | X | X | X | X | X | process mem resident set size |
| | ...[0].nice | X | X | X | | X | process nice value |
| | ...[0].started | X | X | X | X | X | process start time |
| | ...[0].state | X | X | X | X | X | process state (e.g. sleeping) |
| | ...[0].tty | X | X | X | | X | tty from which process was started |
| | ...[0].user | X | X | X | | X | user who started process |
| | ...[0].command | X | X | X | X | X | process starting command |
| | ...[0].params | X | X | X | | X | process params |
| | ...[0].path | X | X | X | X | X | process path |
| | proc | X | X | X | X | | process name |
| | pid | X | X | X | X | | PID |
| | pids | X | X | X | X | | additional pids |
| | cpu | X | X | X | X | | process % CPU |
| | mem | X | X | X | X | | process % MEM |
| si.services('mysql, apache2', cb) | [{...}] | X | X | X | X | | pass comma separated string of services<br>pass "*" for ALL services (linux/win only) |
| | [0].name | X | X | X | X | | name of service |
| | [0].running | X | X | X | X | | true / false |
| | [0].startmode | | | | X | | manual, automatic, ... |
| | [0].pids | X | X | X | X | | pids |
| | [0].pcpu | X | X | X | | | process % CPU |
| | [0].pmem | X | X | X | | | process % MEM |
#### 9. File System
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.diskLayout(cb) | [{...}] | X | | X | X | | physical disk layout (array) |
| | [0].device | X | | X | | | e.g. /dev/sda |
| | [0].type | X | | X | X | | HD, SSD, NVMe |
| | [0].name | X | | X | X | | disk name |
| | [0].vendor | X | | | X | | vendor/producer |
| | [0].size | X | | X | X | | size in bytes |
| | [0].bytesPerSector | | | | X | | bytes per sector |
| | [0].totalCylinders | | | | X | | total cylinders |
| | [0].totalHeads | | | | X | | total heads |
| | [0].totalSectors | | | | X | | total sectors |
| | [0].totalTracks | | | | X | | total tracks |
| | [0].tracksPerCylinder | | | | X | | tracks per cylinder |
| | [0].sectorsPerTrack | | | | X | | sectors per track |
| | [0].firmwareRevision | X | | X | X | | firmware revision |
| | [0].serialNum | X | | X | X | | serial number |
| | [0].interfaceType | X | | | X | | SATA, PCIe, ... |
| | [0].smartStatus | X | | X | X | | S.M.A.R.T Status (see Known Issues) |
| | [0].smartData | X | | | | | full S.M.A.R.T data from smartctl<br>requires at least smartmontools 7.0 |
| si.blockDevices(cb) | [{...}] | X | | X | X | | returns array of disks, partitions,<br>raids and roms |
| | [0].name | X | | X | X | | name |
| | [0].type | X | | X | X | | type |
| | [0].fstype | X | | X | X | | file system type (e.g. ext4) |
| | [0].mount | X | | X | X | | mount point |
| | [0].size | X | | X | X | | size in bytes |
| | [0].physical | X | | X | X | | physical type (HDD, SSD, CD/DVD) |
| | [0].uuid | X | | X | X | | UUID |
| | [0].label | X | | X | X | | label |
| | [0].model | X | | X | | | model |
| | [0].serial | X | | | X | | serial |
| | [0].removable | X | | X | X | | serial |
| | [0].protocol | X | | X | | | protocol (SATA, PCI-Express, ...) |
| si.disksIO(cb) | {...} | X | | X | | | current transfer stats |
| | rIO | X | | X | | | read IOs on all mounted drives |
| | wIO | X | | X | | | write IOs on all mounted drives |
| | tIO | X | | X | | | write IOs on all mounted drives |
| | rIO_sec | X | | X | | | read IO per sec (* see notes) |
| | wIO_sec | X | | X | | | write IO per sec (* see notes) |
| | tIO_sec | X | | X | | | total IO per sec (* see notes) |
| | ms | X | | X | | | interval length (for per second values) |
| si.fsSize(cb) | [{...}] | X | X | X | X | | returns array of mounted file systems |
| | [0].fs | X | X | X | X | | name of file system |
| | [0].type | X | X | X | X | | type of file system |
| | [0].size | X | X | X | X | | sizes in bytes |
| | [0].used | X | X | X | X | | used in bytes |
| | [0].use | X | X | X | X | | used in % |
| | [0].mount | X | X | X | X | | mount point |
| si.fsOpenFiles(cb) | {...} | X | X | X | | | count max/allocated file descriptors |
| | max | X | X | X | | | max file descriptors |
| | allocated | X | X | X | | | current open files count |
| | available | X | X | X | | | count available |
| si.fsStats(cb) | {...} | X | | X | | | current transfer stats |
| | rx | X | | X | | | bytes read since startup |
| | wx | X | | X | | | bytes written since startup |
| | tx | X | | X | | | total bytes read + written since startup |
| | rx_sec | X | | X | | | bytes read / second (* see notes) |
| | wx_sec | X | | X | | | bytes written / second (* see notes) |
| | tx_sec | X | | X | | | total bytes reads + written / second |
| | ms | X | | X | | | interval length (for per second values) |
#### 10. Network related functions
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.networkInterfaces(cb) | [{...}] | X | X | X | X | X | array of network interfaces |
| | [0].iface | X | X | X | X | X | interface |
| | [0].ifaceName | X | X | X | X | X | interface name (differs on Windows) |
| | [0].ip4 | X | X | X | X | X | ip4 address |
| | [0].ip4subnet | X | X | X | X | X | ip4 subnet mask |
| | [0].ip6 | X | X | X | X | X | ip6 address |
| | [0].ip6subnet | X | X | X | X | X | ip6 subnet mask |
| | [0].mac | X | X | X | X | X | MAC address |
| | [0].internal | X | X | X | X | X | true if internal interface |
| | [0].virtual | X | X | X | X | X | true if virtual interface |
| | [0].operstate | X | | X | X | | up / down |
| | [0].type | X | | X | X | | wireless / wired |
| | [0].duplex | X | | X | | | duplex |
| | [0].mtu | X | | X | | | maximum transmission unit |
| | [0].speed | X | | X | X | | speed in MBit / s |
| | [0].dhcp | X | | X | X | | IP address obtained by DHCP |
| | [0].dnsSuffix | X | | | X | | DNS suffix |
| | [0].ieee8021xAuth | X | | | X | | IEEE 802.1x auth |
| | [0].ieee8021xState | X | | | X | | IEEE 802.1x state |
| | [0].carrierChanges | X | | | | | # changes up/down |
| si.networkInterfaceDefault(cb) | : string | X | X | X | X | X | get name of default network interface |
| si.networkGatewayDefault(cb) | : string | X | X | X | X | X | get default network gateway |
| si.networkStats(ifaces,cb) | [{...}] | X | X | X | X | | current network stats of given interfaces<br>iface list: space or comma separated<br>iface parameter is optional<br>defaults to first external network interface,<br />Pass '*' for all interfaces |
| | [0].iface | X | X | X | X | | interface |
| | [0].operstate | X | X | X | X | | up / down |
| | [0].rx_bytes | X | X | X | X | | received bytes overall |
| | [0].rx_dropped | X | X | X | X | | received dropped overall |
| | [0].rx_errors | X | X | X | X | | received errors overall |
| | [0].tx_bytes | X | X | X | X | | transferred bytes overall |
| | [0].tx_dropped | X | X | X | X | | transferred dropped overall |
| | [0].tx_errors | X | X | X | X | | transferred errors overall |
| | [0].rx_sec | X | X | X | X | | received bytes / second (* see notes) |
| | [0].tx_sec | X | X | X | X | | transferred bytes per second (* see notes) |
| | [0].ms | X | X | X | X | | interval length (for per second values) |
| si.networkConnections(cb) | [{...}] | X | X | X | X | | current network network connections<br>returns an array of all connections|
| | [0].protocol | X | X | X | X | | tcp or udp |
| | [0].localaddress | X | X | X | X | | local address |
| | [0].localport | X | X | X | X | | local port |
| | [0].peeraddress | X | X | X | X | | peer address |
| | [0].peerport | X | X | X | X | | peer port |
| | [0].state | X | X | X | X | | like ESTABLISHED, TIME_WAIT, ... |
| | [0].pid | X | X | X | X | | process ID |
| | [0].process | X | X | | | | process name |
| si.inetChecksite(url, cb) | {...} | X | X | X | X | X | response-time (ms) to fetch given URL |
| | url | X | X | X | X | X | given url |
| | ok | X | X | X | X | X | status code OK (2xx, 3xx) |
| | status | X | X | X | X | X | status code |
| | ms | X | X | X | X | X | response time in ms |
| si.inetLatency(host, cb) | : number | X | X | X | X | X | response-time (ms) to external resource<br>host parameter is optional (default 8.8.8.8)|
#### 11. Wifi networks
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.wifiNetworks(cb) | [{...}] | X | | X | X | | array of available wifi networks |
| | [0].ssid | X | | X | X | | Wifi network SSID |
| | [0].bssid | X | | X | X | | BSSID (mac) |
| | [0].mode | X | | | | | mode |
| | [0].channel | X | | X | X | | channel |
| | [0].frequency | X | | X | X | | frequengy in MHz |
| | [0].signalLevel | X | | X | X | | signal level in dB |
| | [0].quality | X | | X | X | | quaility in % |
| | [0].security | X | | X | X | | array e.g. WPA, WPA-2 |
| | [0].wpaFlags | X | | X | X | | array of WPA flags |
| | [0].rsnFlags | X | | | | | array of RDN flags |
#### 12. Docker
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.dockerInfo(cb) | {...} | X | X | X | X | X | returns general docker info |
| | id | X | X | X | X | X | Docker ID |
| | containers | X | X | X | X | X | number of containers |
| | containersRunning | X | X | X | X | X | number of running containers |
| | containersPaused | X | X | X | X | X | number of paused containers |
| | containersStopped | X | X | X | X | X | number of stopped containers |
| | images | X | X | X | X | X | number of images |
| | driver | X | X | X | X | X | driver (e.g. 'devicemapper', 'overlay2') |
| | memoryLimit | X | X | X | X | X | has memory limit |
| | swapLimit | X | X | X | X | X | has swap limit |
| | kernelMemory | X | X | X | X | X | has kernal memory |
| | cpuCfsPeriod | X | X | X | X | X | has CpuCfsPeriod |
| | cpuCfsQuota | X | X | X | X | X | has CpuCfsQuota |
| | cpuShares | X | X | X | X | X | has CPUShares |
| | cpuSet | X | X | X | X | X | has CPUShares |
| | ipv4Forwarding | X | X | X | X | X | has IPv4Forwarding |
| | bridgeNfIptables | X | X | X | X | X | has BridgeNfIptables |
| | bridgeNfIp6tables | X | X | X | X | X | has BridgeNfIp6tables |
| | debug | X | X | X | X | X | Debug on |
| | nfd | X | X | X | X | X | named data networking forwarding daemon |
| | oomKillDisable | X | X | X | X | X | out-of-memory kill disabled |
| | ngoroutines | X | X | X | X | X | number NGoroutines |
| | systemTime | X | X | X | X | X | docker SystemTime |
| | loggingDriver | X | X | X | X | X | logging driver e.g. 'json-file' |
| | cgroupDriver | X | X | X | X | X | cgroup driver e.g. 'cgroupfs' |
| | nEventsListener | X | X | X | X | X | number NEventsListeners |
| | kernelVersion | X | X | X | X | X | docker kernel version |
| | operatingSystem | X | X | X | X | X | docker OS e.g. 'Docker for Mac' |
| | osType | X | X | X | X | X | OSType e.g. 'linux' |
| | architecture | X | X | X | X | X | architecture e.g. x86_64 |
| | ncpu | X | X | X | X | X | number of CPUs |
| | memTotal | X | X | X | X | X | memory total |
| | dockerRootDir | X | X | X | X | X | docker root directory |
| | httpProxy | X | X | X | X | X | http proxy |
| | httpsProxy | X | X | X | X | X | https proxy |
| | noProxy | X | X | X | X | X | NoProxy |
| | name | X | X | X | X | X | Name |
| | labels | X | X | X | X | X | array of labels |
| | experimentalBuild | X | X | X | X | X | is experimental build |
| | serverVersion | X | X | X | X | X | server version |
| | clusterStore | X | X | X | X | X | cluster store |
| | clusterAdvertise | X | X | X | X | X | cluster advertise |
| | defaultRuntime | X | X | X | X | X | default runtime e.g. 'runc' |
| | liveRestoreEnabled | X | X | X | X | X | live store enabled |
| | isolation | X | X | X | X | X | isolation |
| | initBinary | X | X | X | X | X | init binary |
| | productLicense | X | X | X | X | X | product license |
| si.dockerContainers(all, cb) | [{...}] | X | X | X | X | X | returns array of active/all docker containers |
| | [0].id | X | X | X | X | X | ID of container |
| | [0].name | X | X | X | X | X | name of container |
| | [0].image | X | X | X | X | X | name of image |
| | [0].imageID | X | X | X | X | X | ID of image |
| | [0].command | X | X | X | X | X | command |
| | [0].created | X | X | X | X | X | creation time (unix) |
| | [0].started | X | X | X | X | X | creation time (unix) |
| | [0].finished | X | X | X | X | X | creation time (unix) |
| | [0].createdAt | X | X | X | X | X | creation date time string |
| | [0].startedAt | X | X | X | X | X | creation date time string |
| | [0].finishedAt | X | X | X | X | X | creation date time string |
| | [0].state | X | X | X | X | X | created, running, exited |
| | [0].ports | X | X | X | X | X | array of ports |
| | [0].mounts | X | X | X | X | X | array of mounts |
| si.dockerContainerStats(ids, cb) | [{...}] | X | X | X | X | X | statistics for specific containers<br>container IDs: space or comma separated,<br>pass '*' for all containers|
| | [0].id | X | X | X | X | X | Container ID |
| | [0].mem_usage | X | X | X | X | X | memory usage in bytes |
| | [0].mem_limit | X | X | X | X | X | memory limit (max mem) in bytes |
| | [0].mem_percent | X | X | X | X | X | memory usage in percent |
| | [0].cpu_percent | X | X | X | X | X | cpu usage in percent |
| | [0].pids | X | X | X | X | X | number of processes |
| | [0].netIO.rx | X | X | X | X | X | received bytes via network |
| | [0].netIO.wx | X | X | X | X | X | sent bytes via network |
| | [0].blockIO.r | X | X | X | X | X | bytes read from BlockIO |
| | [0].blockIO.w | X | X | X | X | X | bytes written to BlockIO |
| | [0].cpu_stats | X | X | X | X | X | detailed cpu stats |
| | [0].percpu_stats | X | X | X | X | X | detailed per cpu stats |
| | [0].memory_stats | X | X | X | X | X | detailed memory stats |
| | [0].networks | X | X | X | X | X | detailed network stats per interface |
| si.dockerContainerProcesses(id, cb) | [{...}] | X | X | X | X | X | array of processes inside a container |
| | [0].pid_host | X | X | X | X | X | process ID (host) |
| | [0].ppid | X | X | X | X | X | parent process ID |
| | [0].pgid | X | X | X | X | X | process group ID |
| | [0].user | X | X | X | X | X | effective user name |
| | [0].ruser | X | X | X | X | X | real user name |
| | [0].group | X | X | X | X | X | effective group name |
| | [0].rgroup | X | X | X | X | X | real group name |
| | [0].stat | X | X | X | X | X | process state |
| | [0].time | X | X | X | X | X | accumulated CPU time |
| | [0].elapsed | X | X | X | X | X | elapsed running time |
| | [0].nice | X | X | X | X | X | nice value |
| | [0].rss | X | X | X | X | X | resident set size |
| | [0].vsz | X | X | X | X | X | virtual size in Kbytes |
| | [0].command | X | X | X | X | X | command and arguments |
| si.dockerAll(cb) | {...} | X | X | X | X | X | list of all containers including their stats<br>and processes in one single array |
#### 13. Virtual Box
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.vboxInfo(cb) | [{...}] | X | X | X | X | X | returns array general virtual box info |
| | [0].id | X | X | X | X | X | virtual box ID |
| | [0].name | X | X | X | X | X | name |
| | [0].running | X | X | X | X | X | vbox is running |
| | [0].started | X | X | X | X | X | started date time |
| | [0].runningSince | X | X | X | X | X | running since (secs) |
| | [0].stopped | X | X | X | X | X | stopped date time |
| | [0].stoppedSince | X | X | X | X | X | stopped since (secs) |
| | [0].guestOS | X | X | X | X | X | Guest OS |
| | [0].hardwareUUID | X | X | X | X | X | Hardware UUID |
| | [0].memory | X | X | X | X | X | Memory in MB |
| | [0].vram | X | X | X | X | X | VRAM in MB |
| | [0].cpus | X | X | X | X | X | CPUs |
| | [0].cpuExepCap | X | X | X | X | X | CPU exec cap |
| | [0].cpuProfile | X | X | X | X | X | CPU profile |
| | [0].chipset | X | X | X | X | X | chipset |
| | [0].firmware | X | X | X | X | X | firmware |
| | [0].pageFusion | X | X | X | X | X | page fusion |
| | [0].configFile | X | X | X | X | X | config file |
| | [0].snapshotFolder | X | X | X | X | X | snapshot folder |
| | [0].logFolder | X | X | X | X | X | log folder path |
| | [0].HPET | X | X | X | X | X | HPET |
| | [0].PAE | X | X | X | X | X | PAE |
| | [0].longMode | X | X | X | X | X | long mode |
| | [0].tripleFaultReset | X | X | X | X | X | triple fault reset |
| | [0].APIC | X | X | X | X | X | APIC |
| | [0].X2APIC | X | X | X | X | X | X2APIC |
| | [0].ACPI | X | X | X | X | X | ACPI |
| | [0].IOAPIC | X | X | X | X | X | IOAPIC |
| | [0].biosAPICmode | X | X | X | X | X | BIOS APIC mode |
| | [0].bootMenuMode | X | X | X | X | X | boot menu Mode |
| | [0].bootDevice1 | X | X | X | X | X | bootDevice1 |
| | [0].bootDevice2 | X | X | X | X | X | bootDevice2 |
| | [0].bootDevice3 | X | X | X | X | X | bootDevice3 |
| | [0].bootDevice4 | X | X | X | X | X | bootDevice4 |
| | [0].timeOffset | X | X | X | X | X | time Offset |
| | [0].RTC | X | X | X | X | X | RTC |
#### 14. "Get All / Observe" - functions
| Function | Result object | Linux | BSD | Mac | Win | Sun | Comments |
| --------------- | ------------- | ----- | ------- | --- | --- | --- | -------- |
| si.getStaticData(cb) | {...} | X | X | X | X | X | all static data at once |
| si.getDynamicData(srv,iface,cb) | {...} | X | X | X | X | X | all dynamic data at once<br>Specify services and interfaces to monitor<br>Defaults to first external network interface<br>Pass "*" for ALL services (linux/win only)<br>Pass "*" for ALL network interfaces |
| si.getAllData(srv,iface,cb) | {...} | X | X | X | X | X | all data at once<br>Specify services and interfaces to monitor<br>Defaults to first external network interface<br>Pass "*" for ALL services (linux/win only)<br>Pass "*" for ALL network interfaces |
| si.get(valueObject,cb) | {...} | X | X | X | X | X | get partial system info data at once<br>In valueObject you can define<br>all values, you want to get back <br>(see documentation for details) |
| si.observe(valueObject,interval,cb) | - | X | X | X | X | X | Observe a defined value object<br>call callback on changes<br>polling interval in milliseconds |
### cb: Asynchronous Function Calls (callback)
Remember: all functions (except `version` and `time`) are implemented as asynchronous functions! There are now three ways to consume them:
**Callback Style**
```js
const si = require('systeminformation');
si.cpu(function(data) {
console.log('CPU Information:');
console.log('- manufucturer: ' + data.manufacturer);
console.log('- brand: ' + data.brand);
console.log('- speed: ' + data.speed);
console.log('- cores: ' + data.cores);
console.log('- physical cores: ' + data.physicalCores);
console.log('...');
})
```
### Promises
**Promises Style** is new in version 3.0.
When omitting callback parameter (cb), then you can use all function in a promise oriented way. All functions (except of `version` and `time`) are returning a promise, that you can consume:
```js
const si = require('systeminformation');
si.cpu()
.then(data => {
console.log('CPU Information:');
console.log('- manufucturer: ' + data.manufacturer);
console.log('- brand: ' + data.brand);
console.log('- speed: ' + data.speed);
console.log('- cores: ' + data.cores);
console.log('- physical cores: ' + data.physicalCores);
console.log('...');
})
.catch(error => console.error(error));
```
### Async / Await
**Using async / await** (available since node v7.6)
Since node v7.6 you can also use the `async` / `await` pattern. The above example would then look like this:
```js
const si = require('systeminformation');
async function cpuData() {
try {
const data = await si.cpu();
console.log('CPU Information:');
console.log('- manufucturer: ' + data.manufacturer);
console.log('- brand: ' + data.brand);
console.log('- speed: ' + data.speed);
console.log('- cores: ' + data.cores);
console.log('- physical cores: ' + data.physicalCores);
console.log('...');
} catch (e) {
console.log(e)
}
}
```
## Known Issues
#### macOS - Temperature Sensor
To be able to measure temperature on macOS I created a little additional package. Due to some difficulties
in NPM with `optionalDependencies` I unfortunately was getting unexpected warnings on other platforms.
So I decided to drop this optional dependency for macOS - so by default, you will not get correct values.
But if you need to detect macOS temperature just run the following additional
installation command:
```bash
$ npm install osx-temperature-sensor --save
```
`systeminformation` will then detect this additional library and return the temperature when calling systeminformations standard function `cpuTemperature()`
#### Windows Temperature, Battery, ...
`wmic` - which is used to determine temperature and battery sometimes needs to be run with admin
privileges. So if you do not get any values, try to run it again with according
privileges. If you still do not get any values, your system might not support this feature.
In some cases we also discovered that `wmic` returned incorrect temperature values.
#### Linux Temperature
In some cases you need to install the Linux `sensors` package to be able to measure temperature
e.g. on DEBIAN based systems by running `sudo apt-get install lm-sensors`
#### Linux S.M.A.R.T. Status
To be able to detect S.M.A.R.T. status on Linux you need to install `smartmontools`. On DEBIAN based Linux distributions you can install it by running `sudo apt-get install smartmontools`
## *: Additional Notes
In `fsStats()`, `disksIO()` and `networkStats()` the results / sec. values (rx_sec, IOPS, ...) are calculated correctly beginning
with the second call of the function. It is determined by calculating the difference of transferred bytes / IOs
divided by the time between two calls of the function.
The first time you are calling one of these functions, you will get `-1` for transfer rates. The second time, you should then get statistics based on the time between the two calls ...
So basically, if you e.g. need a value for network stats every second, your code should look like this:
```js
const si = require('systeminformation');
setInterval(function() {
si.networkStats().then(data => {
console.log(data);
})
}, 1000)
```
Beginning with the second call, you get network transfer values per second.
## Finding new issues
I am happy to discuss any comments and suggestions. Please feel free to contact me if you see any possibility of improvement!
## Comments
If you have ideas or comments, please do not hesitate to contact me.
Happy monitoring!
Sincerely,
Sebastian Hildebrandt, [+innovations](http://www.plus-innovations.com)
## Credits
Written by Sebastian Hildebrandt [sebhildebrandt](https://github.com/sebhildebrandt)
#### Contributers
- Guillaume Legrain [glegrain](https://github.com/glegrain)
- Riccardo Novaglia [richy24](https://github.com/richy24)
- Quentin Busuttil [Buzut](https://github.com/Buzut)
- lapsio [lapsio](https://github.com/lapsio)
- csy [csy](https://github.com/csy1983)
- Tiago Roldão [tiagoroldao](https://github.com/tiagoroldao)
- dragonjet [dragonjet](https://github.com/dragonjet)
- Adam Reis [adamreisnz](https://github.com/adamreisnz)
- Jimi M [ItsJimi](https://github.com/ItsJimi)
- Git² [GitSquared](https://github.com/GitSquared)
- weiyin [weiyin](https://github.com/weiyin)
- Jorai Rijsdijk [Erackron](https://github.com/Erackron)
- Rasmus Porsager [porsager](https://github.com/porsager)
- Nathan Patten [nrpatten](https://github.com/nrpatten)
- Juan Campuzano [juancampuzano](https://github.com/juancampuzano)
- Ricardo Polo [ricardopolo](https://github.com/ricardopolo)
- Miłosz Dźwigała [mily20001]https://github.com/mily20001
OSX Temperature: credits here are going to:
- Frank Stock [pcafstockf](https://github.com/pcafstockf) - for his work on [smc-code][smc-code-url]
## Copyright Information
Linux is a registered trademark of Linus Torvalds. Apple, macOS, OS X are registered trademarks of Apple Inc.,
Windows is a registered trademark of Microsoft Corporation. Node.js is a trademark of Joyent Inc.,
Intel is a trademark of Intel Corporation, AMD is a trademark of Advanced Micro Devices Inc.,
Raspberry Pi is a trademark of the Raspberry Pi Foundation, Debian is a trademark of the Debian Project,
Ubuntu is a trademark of Canonical Ltd., FreeBSD is a registered trademark of The FreeBSD Foundation,
NetBSD is a registered trademark of The NetBSD Foundation, Docker is a trademark of Docker, Inc., Sun,
Solaris, OpenSolaris and registered trademarks of Sun Microsystems.
All other trademarks are the property of their respective owners.
## License [![MIT license][license-img]][license-url]
>The [`MIT`][license-url] License (MIT)
>
>Copyright © 2014-2020 Sebastian Hildebrandt, [+innovations](http://www.plus-innovations.com).
>
>Permission is hereby granted, free of charge, to any person obtaining a copy
>of this software and associated documentation files (the "Software"), to deal
>in the Software without restriction, including without limitation the rights
>to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
>copies of the Software, and to permit persons to whom the Software is
>furnished to do so, subject to the following conditions:
>
>The above copyright notice and this permission notice shall be included in
>all copies or substantial portions of the Software.
>
>THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
>IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
>FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
>AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
>LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
>OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
>THE SOFTWARE.
>
>Further details see [LICENSE](LICENSE) file.
[npm-image]: https://img.shields.io/npm/v/systeminformation.svg?style=flat-square
[npm-url]: https://npmjs.org/package/systeminformation
[downloads-image]: https://img.shields.io/npm/dm/systeminformation.svg?style=flat-square
[downloads-url]: https://npmjs.org/package/systeminformation
[lgtm-badge]: https://img.shields.io/lgtm/grade/javascript/g/sebhildebrandt/systeminformation.svg?style=flat-square
[lgtm-badge-url]: https://lgtm.com/projects/g/sebhildebrandt/systeminformation/context:javascript
[lgtm-alerts]: https://img.shields.io/lgtm/alerts/g/sebhildebrandt/systeminformation.svg?style=flat-square
[lgtm-alerts-url]: https://lgtm.com/projects/g/sebhildebrandt/systeminformation/alerts
[sponsor-badge]: https://img.shields.io/badge/-Buy%20me%20a%20coffee-blue?style=flat-square
[sponsor-url]: https://www.buymeacoffee.com/systeminfo
[license-url]: https://github.com/sebhildebrandt/systeminformation/blob/master/LICENSE
[license-img]: https://img.shields.io/badge/license-MIT-blue.svg?style=flat-square
[npmjs-license]: https://img.shields.io/npm/l/systeminformation.svg?style=flat-square
[changelog-url]: https://github.com/sebhildebrandt/systeminformation/blob/master/CHANGELOG.md
[caretaker-url]: https://github.com/sebhildebrandt
[caretaker-image]: https://img.shields.io/badge/caretaker-sebhildebrandt-blue.svg?style=flat-square
[nodejs-url]: https://nodejs.org/en/
[docker-url]: https://www.docker.com/
[systeminformation-url]: https://systeminformation.io
[daviddm-img]: https://img.shields.io/david/sebhildebrandt/systeminformation.svg?style=flat-square
[daviddm-url]: https://david-dm.org/sebhildebrandt/systeminformation
[issues-img]: https://img.shields.io/github/issues/sebhildebrandt/systeminformation.svg?style=flat-square
[issues-url]: https://github.com/sebhildebrandt/systeminformation/issues
[closed-issues-img]: https://img.shields.io/github/issues-closed-raw/sebhildebrandt/systeminformation.svg?style=flat-square&color=brightgreen
[closed-issues-url]: https://github.com/sebhildebrandt/systeminformation/issues?q=is%3Aissue+is%3Aclosed
[mmon-npm-url]: https://npmjs.org/package/mmon
[mmon-github-url]: https://github.com/sebhildebrandt/mmon
[smc-code-url]: https://github.com/pcafstockf/osx-temperature-sensor
# parse-glob [](http://badge.fury.io/js/parse-glob) [](https://travis-ci.org/jonschlinkert/parse-glob)
> Parse a glob pattern into an object of tokens.
**Changes from v1.0.0 to v3.0.4**
* all path-related properties are now on the `path` object
* all boolean properties are now on the `is` object
* adds `base` property
See the [properties](#properties) section for details.
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i parse-glob --save
```
* parses 1,000+ glob patterns in 29ms (2.3 GHz Intel Core i7)
* Extensive [unit tests](./test.js) (more than 1,000 lines), covering wildcards, globstars, character classes, brace patterns, extglobs, dotfiles and other complex patterns.
See the tests for [hundreds of examples](./test.js).
## Usage
```js
var parseGlob = require('parse-glob');
```
**Example**
```js
parseGlob('a/b/c/**/*.{yml,json}');
```
**Returns:**
```js
{ orig: 'a/b/c/**/*.{yml,json}',
is:
{ glob: true,
negated: false,
extglob: false,
braces: true,
brackets: false,
globstar: true,
dotfile: false,
dotdir: false },
glob: '**/*.{yml,json}',
base: 'a/b/c',
path:
{ dirname: 'a/b/c/**/',
basename: '*.{yml,json}',
filename: '*',
extname: '.{yml,json}',
ext: '{yml,json}' } }
```
## Properties
The object returned by parseGlob has the following properties:
* `orig`: a copy of the original, unmodified glob pattern
* `is`: an object with boolean information about the glob:
- `glob`: true if the pattern actually a glob pattern
- `negated`: true if it's a negation pattern (`!**/foo.js`)
- `extglob`: true if it has extglobs (`@(foo|bar)`)
- `braces`: true if it has braces (`{1..2}` or `.{txt,md}`)
- `brackets`: true if it has POSIX brackets (`[[:alpha:]]`)
- `globstar`: true if the pattern has a globstar (double star, `**`)
- `dotfile`: true if the pattern should match dotfiles
- `dotdir`: true if the pattern should match dot-directories (like `.git`)
* `glob`: the glob pattern part of the string, if any
* `base`: the non-glob part of the string, if any
* `path`: file path segments
- `dirname`: directory
- `basename`: file name with extension
- `filename`: file name without extension
- `extname`: file extension with dot
- `ext`: file extension without dot
## Related
* [glob-base](https://www.npmjs.com/package/glob-base): Returns an object with the (non-glob) base path and the actual pattern. | [homepage](https://github.com/jonschlinkert/glob-base)
* [glob-parent](https://www.npmjs.com/package/glob-parent): Strips glob magic from a string to provide the parent path | [homepage](https://github.com/es128/glob-parent)
* [glob-path-regex](https://www.npmjs.com/package/glob-path-regex): Regular expression for matching the parts of glob pattern. | [homepage](https://github.com/regexps/glob-path-regex)
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern. | [homepage](https://github.com/jonschlinkert/is-glob)
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. Just… [more](https://www.npmjs.com/package/micromatch) | [homepage](https://github.com/jonschlinkert/micromatch)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/parse-glob/issues/new).
## Tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2014-2015 Jon Schlinkert
Released under the MIT license.
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on September 22, 2015._
# json-schema-traverse
Traverse JSON Schema passing each schema object to callback
[](https://travis-ci.org/epoberezkin/json-schema-traverse)
[](https://www.npmjs.com/package/json-schema-traverse)
[](https://coveralls.io/github/epoberezkin/json-schema-traverse?branch=master)
## Install
```
npm install json-schema-traverse
```
## Usage
```javascript
const traverse = require('json-schema-traverse');
const schema = {
properties: {
foo: {type: 'string'},
bar: {type: 'integer'}
}
};
traverse(schema, {cb});
// cb is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
// Or:
traverse(schema, {cb: {pre, post}});
// pre is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
//
// post is called 3 times with:
// 1. {type: 'string'}
// 2. {type: 'integer'}
// 3. root schema
```
Callback function `cb` is called for each schema object (not including draft-06 boolean schemas), including the root schema, in pre-order traversal. Schema references ($ref) are not resolved, they are passed as is. Alternatively, you can pass a `{pre, post}` object as `cb`, and then `pre` will be called before traversing child elements, and `post` will be called after all child elements have been traversed.
Callback is passed these parameters:
- _schema_: the current schema object
- _JSON pointer_: from the root schema to the current schema object
- _root schema_: the schema passed to `traverse` object
- _parent JSON pointer_: from the root schema to the parent schema object (see below)
- _parent keyword_: the keyword inside which this schema appears (e.g. `properties`, `anyOf`, etc.)
- _parent schema_: not necessarily parent object/array; in the example above the parent schema for `{type: 'string'}` is the root schema
- _index/property_: index or property name in the array/object containing multiple schemas; in the example above for `{type: 'string'}` the property name is `'foo'`
## Traverse objects in all unknown keywords
```javascript
const traverse = require('json-schema-traverse');
const schema = {
mySchema: {
minimum: 1,
maximum: 2
}
};
traverse(schema, {allKeys: true, cb});
// cb is called 2 times with:
// 1. root schema
// 2. mySchema
```
Without option `allKeys: true` callback will be called only with root schema.
## License
[MIT](https://github.com/epoberezkin/json-schema-traverse/blob/master/LICENSE)
# web3-core-promievent
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
This is the PromiEvent package used to return a EventEmitter mixed with a Promise to allow multiple final states as well as chaining.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core-promievent
```
## Usage
```js
const Web3PromiEvent = require('web3-core-promievent');
const myFunc = function(){
const promiEvent = Web3PromiEvent();
setTimeout(function() {
promiEvent.eventEmitter.emit('done', 'Hello!');
promiEvent.resolve('Hello!');
}, 10);
return promiEvent.eventEmitter;
};
// and run it
myFunc()
.on('done', console.log)
.then(console.log);
```
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-core-promievent.svg
[npm-url]: https://npmjs.org/package/web3-core-promievent
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-core-promievent
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-core-promievent
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-core-promievent
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-core-promievent
# string_decoder
***Node-core v8.9.4 string_decoder for userland***
[](https://nodei.co/npm/string_decoder/)
[](https://nodei.co/npm/string_decoder/)
```bash
npm install --save string_decoder
```
***Node-core string_decoder for userland***
This package is a mirror of the string_decoder implementation in Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.9.4/docs/api/).
As of version 1.0.0 **string_decoder** uses semantic versioning.
## Previous versions
Previous version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10.
## Update
The *build/* directory contains a build script that will scrape the source from the [nodejs/node](https://github.com/nodejs/node) repo given a specific Node version.
## Streams Working Group
`string_decoder` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
See [readable-stream](https://github.com/nodejs/readable-stream) for
more details.
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
functional-red-black-tree
=========================
A [fully persistent](http://en.wikipedia.org/wiki/Persistent_data_structure) [red-black tree](http://en.wikipedia.org/wiki/Red%E2%80%93black_tree) written 100% in JavaScript. Works both in node.js and in the browser via [browserify](http://browserify.org/).
Functional (or fully presistent) data structures allow for non-destructive updates. So if you insert an element into the tree, it returns a new tree with the inserted element rather than destructively updating the existing tree in place. Doing this requires using extra memory, and if one were naive it could cost as much as reallocating the entire tree. Instead, this data structure saves some memory by recycling references to previously allocated subtrees. This requires using only O(log(n)) additional memory per update instead of a full O(n) copy.
Some advantages of this is that it is possible to apply insertions and removals to the tree while still iterating over previous versions of the tree. Functional and persistent data structures can also be useful in many geometric algorithms like point location within triangulations or ray queries, and can be used to analyze the history of executing various algorithms. This added power though comes at a cost, since it is generally a bit slower to use a functional data structure than an imperative version. However, if your application needs this behavior then you may consider using this module.
# Install
npm install functional-red-black-tree
# Example
Here is an example of some basic usage:
```javascript
//Load the library
var createTree = require("functional-red-black-tree")
//Create a tree
var t1 = createTree()
//Insert some items into the tree
var t2 = t1.insert(1, "foo")
var t3 = t2.insert(2, "bar")
//Remove something
var t4 = t3.remove(1)
```
# API
```javascript
var createTree = require("functional-red-black-tree")
```
## Overview
- [Tree methods](#tree-methods)
- [`var tree = createTree([compare])`](#var-tree-=-createtreecompare)
- [`tree.keys`](#treekeys)
- [`tree.values`](#treevalues)
- [`tree.length`](#treelength)
- [`tree.get(key)`](#treegetkey)
- [`tree.insert(key, value)`](#treeinsertkey-value)
- [`tree.remove(key)`](#treeremovekey)
- [`tree.find(key)`](#treefindkey)
- [`tree.ge(key)`](#treegekey)
- [`tree.gt(key)`](#treegtkey)
- [`tree.lt(key)`](#treeltkey)
- [`tree.le(key)`](#treelekey)
- [`tree.at(position)`](#treeatposition)
- [`tree.begin`](#treebegin)
- [`tree.end`](#treeend)
- [`tree.forEach(visitor(key,value)[, lo[, hi]])`](#treeforEachvisitorkeyvalue-lo-hi)
- [`tree.root`](#treeroot)
- [Node properties](#node-properties)
- [`node.key`](#nodekey)
- [`node.value`](#nodevalue)
- [`node.left`](#nodeleft)
- [`node.right`](#noderight)
- [Iterator methods](#iterator-methods)
- [`iter.key`](#iterkey)
- [`iter.value`](#itervalue)
- [`iter.node`](#iternode)
- [`iter.tree`](#itertree)
- [`iter.index`](#iterindex)
- [`iter.valid`](#itervalid)
- [`iter.clone()`](#iterclone)
- [`iter.remove()`](#iterremove)
- [`iter.update(value)`](#iterupdatevalue)
- [`iter.next()`](#iternext)
- [`iter.prev()`](#iterprev)
- [`iter.hasNext`](#iterhasnext)
- [`iter.hasPrev`](#iterhasprev)
## Tree methods
### `var tree = createTree([compare])`
Creates an empty functional tree
* `compare` is an optional comparison function, same semantics as array.sort()
**Returns** An empty tree ordered by `compare`
### `tree.keys`
A sorted array of all the keys in the tree
### `tree.values`
An array array of all the values in the tree
### `tree.length`
The number of items in the tree
### `tree.get(key)`
Retrieves the value associated to the given key
* `key` is the key of the item to look up
**Returns** The value of the first node associated to `key`
### `tree.insert(key, value)`
Creates a new tree with the new pair inserted.
* `key` is the key of the item to insert
* `value` is the value of the item to insert
**Returns** A new tree with `key` and `value` inserted
### `tree.remove(key)`
Removes the first item with `key` in the tree
* `key` is the key of the item to remove
**Returns** A new tree with the given item removed if it exists
### `tree.find(key)`
Returns an iterator pointing to the first item in the tree with `key`, otherwise `null`.
### `tree.ge(key)`
Find the first item in the tree whose key is `>= key`
* `key` is the key to search for
**Returns** An iterator at the given element.
### `tree.gt(key)`
Finds the first item in the tree whose key is `> key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.lt(key)`
Finds the last item in the tree whose key is `< key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.le(key)`
Finds the last item in the tree whose key is `<= key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.at(position)`
Finds an iterator starting at the given element
* `position` is the index at which the iterator gets created
**Returns** An iterator starting at position
### `tree.begin`
An iterator pointing to the first element in the tree
### `tree.end`
An iterator pointing to the last element in the tree
### `tree.forEach(visitor(key,value)[, lo[, hi]])`
Walks a visitor function over the nodes of the tree in order.
* `visitor(key,value)` is a callback that gets executed on each node. If a truthy value is returned from the visitor, then iteration is stopped.
* `lo` is an optional start of the range to visit (inclusive)
* `hi` is an optional end of the range to visit (non-inclusive)
**Returns** The last value returned by the callback
### `tree.root`
Returns the root node of the tree
## Node properties
Each node of the tree has the following properties:
### `node.key`
The key associated to the node
### `node.value`
The value associated to the node
### `node.left`
The left subtree of the node
### `node.right`
The right subtree of the node
## Iterator methods
### `iter.key`
The key of the item referenced by the iterator
### `iter.value`
The value of the item referenced by the iterator
### `iter.node`
The value of the node at the iterator's current position. `null` is iterator is node valid.
### `iter.tree`
The tree associated to the iterator
### `iter.index`
Returns the position of this iterator in the sequence.
### `iter.valid`
Checks if the iterator is valid
### `iter.clone()`
Makes a copy of the iterator
### `iter.remove()`
Removes the item at the position of the iterator
**Returns** A new binary search tree with `iter`'s item removed
### `iter.update(value)`
Updates the value of the node in the tree at this iterator
**Returns** A new binary search tree with the corresponding node updated
### `iter.next()`
Advances the iterator to the next position
### `iter.prev()`
Moves the iterator backward one element
### `iter.hasNext`
If true, then the iterator is not at the end of the sequence
### `iter.hasPrev`
If true, then the iterator is not at the beginning of the sequence
# Credits
(c) 2013 Mikola Lysenko. MIT License
# node-XMLHttpRequest #
node-XMLHttpRequest is a wrapper for the built-in http client to emulate the
browser XMLHttpRequest object.
This can be used with JS designed for browsers to improve reuse of code and
allow the use of existing libraries.
Note: This library currently conforms to [XMLHttpRequest 1](http://www.w3.org/TR/XMLHttpRequest/). Version 2.0 will target [XMLHttpRequest Level 2](http://www.w3.org/TR/XMLHttpRequest2/).
## Usage ##
Here's how to include the module in your project and use as the browser-based
XHR object.
var XMLHttpRequest = require("xmlhttprequest").XMLHttpRequest;
var xhr = new XMLHttpRequest();
Note: use the lowercase string "xmlhttprequest" in your require(). On
case-sensitive systems (eg Linux) using uppercase letters won't work.
## Versions ##
Prior to 1.4.0 version numbers were arbitrary. From 1.4.0 on they conform to
the standard major.minor.bugfix. 1.x shouldn't necessarily be considered
stable just because it's above 0.x.
Since the XMLHttpRequest API is stable this library's API is stable as
well. Major version numbers indicate significant core code changes.
Minor versions indicate minor core code changes or better conformity to
the W3C spec.
## License ##
MIT license. See LICENSE for full details.
## Supports ##
* Async and synchronous requests
* GET, POST, PUT, and DELETE requests
* All spec methods (open, send, abort, getRequestHeader,
getAllRequestHeaders, event methods)
* Requests to all domains
## Known Issues / Missing Features ##
For a list of open issues or to report your own visit the [github issues
page](https://github.com/driverdan/node-XMLHttpRequest/issues).
* Local file access may have unexpected results for non-UTF8 files
* Synchronous requests don't set headers properly
* Synchronous requests freeze node while waiting for response (But that's what you want, right? Stick with async!).
* Some events are missing, such as abort
* Cookies aren't persisted between requests
* Missing XML support
# <img src="docs_app/assets/Rx_Logo_S.png" alt="RxJS Logo" width="86" height="86"> RxJS: Reactive Extensions For JavaScript
[](https://circleci.com/gh/ReactiveX/rxjs/tree/6.x)
[](http://badge.fury.io/js/%40reactivex%2Frxjs)
[](https://gitter.im/Reactive-Extensions/RxJS?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
# RxJS 6 Stable
### MIGRATION AND RELEASE INFORMATION:
Find out how to update to v6, **automatically update your TypeScript code**, and more!
- [Current home is MIGRATION.md](./docs_app/content/guide/v6/migration.md)
### FOR V 5.X PLEASE GO TO [THE 5.0 BRANCH](https://github.com/ReactiveX/rxjs/tree/5.x)
Reactive Extensions Library for JavaScript. This is a rewrite of [Reactive-Extensions/RxJS](https://github.com/Reactive-Extensions/RxJS) and is the latest production-ready version of RxJS. This rewrite is meant to have better performance, better modularity, better debuggable call stacks, while staying mostly backwards compatible, with some breaking changes that reduce the API surface.
[Apache 2.0 License](LICENSE.txt)
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [Contribution Guidelines](CONTRIBUTING.md)
- [Maintainer Guidelines](doc_app/content/maintainer-guidelines.md)
- [API Documentation](https://rxjs.dev/)
## Versions In This Repository
- [master](https://github.com/ReactiveX/rxjs/commits/master) - This is all of the current, unreleased work, which is against v6 of RxJS right now
- [stable](https://github.com/ReactiveX/rxjs/commits/stable) - This is the branch for the latest version you'd get if you do `npm install rxjs`
## Important
By contributing or commenting on issues in this repository, whether you've read them or not, you're agreeing to the [Contributor Code of Conduct](CODE_OF_CONDUCT.md). Much like traffic laws, ignorance doesn't grant you immunity.
## Installation and Usage
### ES6 via npm
```sh
npm install rxjs
```
It's recommended to pull in the Observable creation methods you need directly from `'rxjs'` as shown below with `range`. And you can pull in any operator you need from one spot, under `'rxjs/operators'`.
```ts
import { range } from "rxjs";
import { map, filter } from "rxjs/operators";
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
```
Here, we're using the built-in `pipe` method on Observables to combine operators. See [pipeable operators](https://github.com/ReactiveX/rxjs/blob/master/doc/pipeable-operators.md) for more information.
### CommonJS via npm
To install this library for CommonJS (CJS) usage, use the following command:
```sh
npm install rxjs
```
(Note: destructuring available in Node 8+)
```js
const { range } = require('rxjs');
const { map, filter } = require('rxjs/operators');
range(1, 200).pipe(
filter(x => x % 2 === 1),
map(x => x + x)
).subscribe(x => console.log(x));
```
### CDN
For CDN, you can use [unpkg](https://unpkg.com/):
https://unpkg.com/rxjs/bundles/rxjs.umd.min.js
The global namespace for rxjs is `rxjs`:
```js
const { range } = rxjs;
const { map, filter } = rxjs.operators;
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
```
## Goals
- Smaller overall bundles sizes
- Provide better performance than preceding versions of RxJS
- To model/follow the [Observable Spec Proposal](https://github.com/zenparsing/es-observable) to the observable
- Provide more modular file structure in a variety of formats
- Provide more debuggable call stacks than preceding versions of RxJS
## Building/Testing
- `npm run build_all` - builds everything
- `npm test` - runs tests
- `npm run test_no_cache` - run test with `ts-node` set to false
## Performance Tests
Run `npm run build_perf` or `npm run perf` to run the performance tests with `protractor`.
Run `npm run perf_micro [operator]` to run micro performance test benchmarking operator.
## Adding documentation
We appreciate all contributions to the documentation of any type. All of the information needed to get the docs app up and running locally as well as how to contribute can be found in the [documentation directory](./docs_app).
## Generating PNG marble diagrams
The script `npm run tests2png` requires some native packages installed locally: `imagemagick`, `graphicsmagick`, and `ghostscript`.
For Mac OS X with [Homebrew](http://brew.sh/):
- `brew install imagemagick`
- `brew install graphicsmagick`
- `brew install ghostscript`
- You may need to install the Ghostscript fonts manually:
- Download the tarball from the [gs-fonts project](https://sourceforge.net/projects/gs-fonts)
- `mkdir -p /usr/local/share/ghostscript && tar zxvf /path/to/ghostscript-fonts.tar.gz -C /usr/local/share/ghostscript`
For Debian Linux:
- `sudo add-apt-repository ppa:dhor/myway`
- `apt-get install imagemagick`
- `apt-get install graphicsmagick`
- `apt-get install ghostscript`
For Windows and other Operating Systems, check the download instructions here:
- http://imagemagick.org
- http://www.graphicsmagick.org
- http://www.ghostscript.com/
# expand-range [](https://www.npmjs.com/package/expand-range) [](https://npmjs.org/package/expand-range) [](https://travis-ci.org/jonschlinkert/expand-range)
Fast, bash-like range expansion. Expand a range of numbers or letters, uppercase or lowercase. See the benchmarks. Used by micromatch.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install expand-range --save
```
Wraps [fill-range] to do range expansion using `..` separated strings. See [fill-range] for the full list of options and features.
## Example usage
```js
var expand = require('expand-range');
```
**Params**
```js
expand(start, stop, increment);
```
* `start`: the number or letter to start with
* `end`: the number or letter to end with
* `increment`: optionally pass the increment to use. works for letters or numbers
**Examples**
```js
expand('a..e')
//=> ['a', 'b', 'c', 'd', 'e']
expand('a..e..2')
//=> ['a', 'c', 'e']
expand('A..E..2')
//=> ['A', 'C', 'E']
expand('1..3')
//=> ['1', '2', '3']
expand('0..-5')
//=> [ '0', '-1', '-2', '-3', '-4', '-5' ]
expand('-9..9..3')
//=> [ '-9', '-6', '-3', '0', '3', '6', '9' ])
expand('-1..-10..-2')
//=> [ '-1', '-3', '-5', '-7', '-9' ]
expand('1..10..2')
//=> [ '1', '3', '5', '7', '9' ]
```
### Custom function
Optionally pass a custom function as the second argument:
```js
expand('a..e', function (val, isNumber, pad, i) {
if (!isNumber) {
return String.fromCharCode(val) + i;
}
return val;
});
//=> ['a0', 'b1', 'c2', 'd3', 'e4']
```
## Benchmarks
```sh
# benchmark/fixtures/alpha-lower.js (29 bytes)
brace-expansion x 145,653 ops/sec ±0.89% (87 runs sampled)
expand-range x 453,213 ops/sec ±1.66% (85 runs sampled)
minimatch x 152,193 ops/sec ±1.17% (86 runs sampled)
# benchmark/fixtures/alpha-upper.js (29 bytes)
brace-expansion x 149,975 ops/sec ±1.10% (88 runs sampled)
expand-range x 459,390 ops/sec ±1.27% (84 runs sampled)
minimatch x 155,253 ops/sec ±1.25% (88 runs sampled)
# benchmark/fixtures/padded.js (33 bytes)
brace-expansion x 14,694 ops/sec ±1.37% (85 runs sampled)
expand-range x 169,393 ops/sec ±1.76% (80 runs sampled)
minimatch x 15,052 ops/sec ±1.15% (88 runs sampled)
# benchmark/fixtures/range.js (29 bytes)
brace-expansion x 142,968 ops/sec ±1.35% (86 runs sampled)
expand-range x 465,579 ops/sec ±1.43% (86 runs sampled)
minimatch x 126,872 ops/sec ±1.18% (90 runs sampled)
```
## Related projects
You might also be interested in these projects:
* [braces](https://www.npmjs.com/package/braces): Fastest brace expansion for node.js, with the most complete support for the Bash 4.3 braces… [more](https://www.npmjs.com/package/braces) | [homepage](https://github.com/jonschlinkert/braces)
* [fill-range](https://www.npmjs.com/package/fill-range): Fill in a range of numbers or letters, optionally passing an increment or multiplier to… [more](https://www.npmjs.com/package/fill-range) | [homepage](https://github.com/jonschlinkert/fill-range)
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. | [homepage](https://github.com/jonschlinkert/micromatch)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/expand-range/issues/new).
## Building docs
Generate readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install verb && npm run docs
```
Or, if [verb](https://github.com/verbose/verb) is installed globally:
```sh
$ verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/expand-range/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v0.9.0, on May 05, 2016._
# node-gyp-build
Build tool and bindings loader for node-gyp that supports prebuilds.
```
npm install node-gyp-build
```
Use together with [prebuildify](https://github.com/mafintosh/prebuildify) to easily support prebuilds for your native modules.
## Usage
`node-gyp-build` works similar to `node-gyp build` except that it will check if a build or prebuild is present before rebuilding your project.
It's main intended use is as an npm install script and bindings loader for native modules that bundle prebuilds using [prebuildify](https://github.com/mafintosh/prebuildify).
First add `node-gyp-build` as an install script to your native project
``` js
{
...
"scripts": {
"install": "node-gyp-build"
}
}
```
Then in your `index.js`, instead of using the [bindings module](https://www.npmjs.com/package/bindings) use `node-gyp-build` to load your binding.
``` js
var binding = require('node-gyp-build')(__dirname)
```
If you do these two things and bundle prebuilds [prebuildify](https://github.com/mafintosh/prebuildify) your native module will work for most platforms
without having to compile on install time AND will work in both node and electron without the need to recompile between usage.
Users can override `node-gyp-build` and force compiling by doing `npm install --build-from-source`.
## License
MIT
[![*nix build status][nix-build-image]][nix-build-url]
[![Windows build status][win-build-image]][win-build-url]
[![Tests coverage][cov-image]][cov-url]
[![npm version][npm-image]][npm-url]
# type
## Runtime validation and processing of JavaScript types
- Respects language nature and acknowledges its quirks
- Allows coercion in restricted forms (rejects clearly invalid input, normalizes permissible type deviations)
- No transpilation implied, written to work in all ECMAScript 3+ engines
## Use case
Validate arguments input in public API endpoints.
_For validation of more sophisticated input structures (as deeply nested configuration objects) it's recommended to consider more powerful schema based utlities (as [AJV](https://ajv.js.org/) or [@hapi/joi](https://hapi.dev/family/joi/))_
### Example usage
Bulletproof input arguments normalization and validation:
```javascript
const ensureString = require('type/string/ensure')
, ensureDate = require('type/date/ensure')
, ensureNaturalNumber = require('type/natural-number/ensure')
, isObject = require('type/object/is');
module.exports = (path, options = { min: 0 }) {
path = ensureString(path, { errorMessage: "%v is not a path" });
if (!isObject(options)) options = {};
const min = ensureNaturalNumber(options.min, { default: 0 })
, max = ensureNaturalNumber(options.max, { isOptional: true })
, startTime = ensureDate(options.startTime, { isOptional: true });
// ...logic
};
```
### Installation
```bash
npm install type
```
## Utilities
Aside of general [`ensure`](docs/ensure.md) validation util, following kind of utilities for recognized JavaScript types are provided:
##### `*/coerce`
Restricted coercion into primitive type. Returns coerced value or `null` if value is not coercible per rules.
##### `*/is`
Object type/kind confirmation, returns either `true` or `false`.
##### `*/ensure`
Value validation. Returns input value (in primitive cases possibly coerced) or if value doesn't meet the constraints throws `TypeError` .
Each `*/ensure` utility, accepts following options (eventually passed with second argument):
- `isOptional` - Makes `null` or `undefined` accepted as valid value. In such case instead of `TypeError` being thrown, `null` is returned.
- `default` - A value to be returned if `null` or `undefined` is passed as an input value.
- `errorMessage` - Custom error message. Following placeholders can be used:
- `%v` - To be replaced with short string representation of invalid value
- `%n` - To be replaced with meaninfgul name (to be passed with `name` option) of validated value. Not effective if `name` option is not present
- `name` - Meaningful name for validated value, to be used in error message, assuming it contains `%n` placeholder
### Index
#### General utils:
- [`ensure`](docs/ensure.md)
#### Type specific utils:
- **Value**
- [`value/is`](docs/value.md#valueis)
- [`value/ensure`](docs/value.md#valueensure)
- **Object**
- [`object/is`](docs/object.md#objectis)
- [`object/ensure`](docs/object.md#objectensure)
- **Plain Object**
- [`plain-object/is`](docs/plain-object.md#plain-objectis)
- [`plain-object/ensure`](docs/plain-object.md#plain-objectensure)
- **String**
- [`string/coerce`](docs/string.md#stringcoerce)
- [`string/ensure`](docs/string.md#stringensure)
- **Number**
- [`number/coerce`](docs/number.md#numbercoerce)
- [`number/ensure`](docs/number.md#numberensure)
- **Finite Number**
- [`finite/coerce`](docs/finite.md#finitecoerce)
- [`finite/ensure`](docs/finite.md#finiteensure)
- **Integer Number**
- [`integer/coerce`](docs/integer.md#integercoerce)
- [`integer/ensure`](docs/integer.md#integerensure)
- **Safe Integer Number**
- [`safe-integer/coerce`](docs/safe-integer.md#safe-integercoerce)
- [`safe-integer/ensure`](docs/.md#safe-integerensure)
- **Natural Number**
- [`natural-number/coerce`](docs/natural-number.md#natural-numbercoerce)
- [`natural-number/ensure`](docs/natural-number.md#natural-numberensure)
- **Array Length**
- [`array-length/coerce`](docs/array-length.md#array-lengthcoerce)
- [`array-length/ensure`](docs/array-length.md#array-lengthensure)
- **Time Value**
- [`time-value/coerce`](docs/time-value.md#time-valuecoerce)
- [`time-value/ensure`](docs/time-value.md#time-valueensure)
- **Array Like**
- [`array-like/is`](docs/array-like.md#array-likeis)
- [`array-like/ensure`](docs/array-like.md#array-likeensure)
- **Array**
- [`array/is`](docs/array.md#arrayis)
- [`array/ensure`](docs/array.md#arrayensure)
- **Iterable**
- [`iterable/is`](docs/iterable.md#iterableis)
- [`iterable/ensure`](docs/iterable.md#iterableensure)
- **Date**
- [`date/is`](docs/date.md#dateis)
- [`date/ensure`](docs/date.md#dateensure)
- **Function**
- [`function/is`](docs/function.md#functionis)
- [`function/ensure`](docs/function.md#functionensure)
- **Plain Function**
- [`plain-function/is`](docs/plain-function.md#plain-functionis)
- [`plain-function/ensure`](docs/plain-function.md#plain-functionensure)
- **Reg Exp**
- [`reg-exp/is`](docs/reg-exp.md#reg-expis)
- [`reg-exp/ensure`](docs/.md#reg-expensure)
- **Thenable**
- [`thenable/is`](docs/thenable.md#thenableis)
- [`thenable/ensure`](docs/thenable.md#thenableensure)
- **Promise**
- [`promise/is`](docs/promise.md#promiseis)
- [`promise/ensure`](docs/promise.md#promiseensure)
- **Error**
- [`error/is`](docs/error.md#erroris)
- [`error/ensure`](docs/error.md#errorensure)
- **Prototype**
- [`prototype/is`](docs/prototype.md#prototypeis)
### Tests
$ npm test
[nix-build-image]: https://semaphoreci.com/api/v1/medikoo-org/type/branches/master/shields_badge.svg
[nix-build-url]: https://semaphoreci.com/medikoo-org/type
[win-build-image]: https://ci.appveyor.com/api/projects/status/8nrtluuwsb5k9l8d?svg=true
[win-build-url]: https://ci.appveyor.com/api/project/medikoo/type
[cov-image]: https://img.shields.io/codecov/c/github/medikoo/type.svg
[cov-url]: https://codecov.io/gh/medikoo/type
[npm-image]: https://img.shields.io/npm/v/type.svg
[npm-url]: https://www.npmjs.com/package/type
agent-base
==========
### Turn a function into an [`http.Agent`][http.Agent] instance
[](https://travis-ci.org/TooTallNate/node-agent-base)
This module provides an `http.Agent` generator. That is, you pass it an async
callback function, and it returns a new `http.Agent` instance that will invoke the
given callback function when sending outbound HTTP requests.
#### Some subclasses:
Here's some more interesting uses of `agent-base`.
Send a pull request to list yours!
* [`http-proxy-agent`][http-proxy-agent]: An HTTP(s) proxy `http.Agent` implementation for HTTP endpoints
* [`https-proxy-agent`][https-proxy-agent]: An HTTP(s) proxy `http.Agent` implementation for HTTPS endpoints
* [`pac-proxy-agent`][pac-proxy-agent]: A PAC file proxy `http.Agent` implementation for HTTP and HTTPS
* [`socks-proxy-agent`][socks-proxy-agent]: A SOCKS (v4a) proxy `http.Agent` implementation for HTTP and HTTPS
Installation
------------
Install with `npm`:
``` bash
$ npm install agent-base
```
Example
-------
Here's a minimal example that creates a new `net.Socket` connection to the server
for every HTTP request (i.e. the equivalent of `agent: false` option):
```js
var net = require('net');
var tls = require('tls');
var url = require('url');
var http = require('http');
var agent = require('agent-base');
var endpoint = 'http://nodejs.org/api/';
var parsed = url.parse(endpoint);
// This is the important part!
parsed.agent = agent(function (req, opts) {
var socket;
// `secureEndpoint` is true when using the https module
if (opts.secureEndpoint) {
socket = tls.connect(opts);
} else {
socket = net.connect(opts);
}
return socket;
});
// Everything else works just like normal...
http.get(parsed, function (res) {
console.log('"response" event!', res.headers);
res.pipe(process.stdout);
});
```
Returning a Promise or using an `async` function is also supported:
```js
agent(async function (req, opts) {
await sleep(1000);
// etc…
});
```
Return another `http.Agent` instance to "pass through" the responsibility
for that HTTP request to that agent:
```js
agent(function (req, opts) {
return opts.secureEndpoint ? https.globalAgent : http.globalAgent;
});
```
API
---
## Agent(Function callback[, Object options]) → [http.Agent][]
Creates a base `http.Agent` that will execute the callback function `callback`
for every HTTP request that it is used as the `agent` for. The callback function
is responsible for creating a `stream.Duplex` instance of some kind that will be
used as the underlying socket in the HTTP request.
The `options` object accepts the following properties:
* `timeout` - Number - Timeout for the `callback()` function in milliseconds. Defaults to Infinity (optional).
The callback function should have the following signature:
### callback(http.ClientRequest req, Object options, Function cb) → undefined
The ClientRequest `req` can be accessed to read request headers and
and the path, etc. The `options` object contains the options passed
to the `http.request()`/`https.request()` function call, and is formatted
to be directly passed to `net.connect()`/`tls.connect()`, or however
else you want a Socket to be created. Pass the created socket to
the callback function `cb` once created, and the HTTP request will
continue to proceed.
If the `https` module is used to invoke the HTTP request, then the
`secureEndpoint` property on `options` _will be set to `true`_.
License
-------
(The MIT License)
Copyright (c) 2013 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[http-proxy-agent]: https://github.com/TooTallNate/node-http-proxy-agent
[https-proxy-agent]: https://github.com/TooTallNate/node-https-proxy-agent
[pac-proxy-agent]: https://github.com/TooTallNate/node-pac-proxy-agent
[socks-proxy-agent]: https://github.com/TooTallNate/node-socks-proxy-agent
[http.Agent]: https://nodejs.org/api/http.html#http_class_http_agent
# is-glob [](https://www.npmjs.com/package/is-glob) [](https://npmjs.org/package/is-glob) [](https://npmjs.org/package/is-glob) [](https://travis-ci.org/micromatch/is-glob) [](https://ci.appveyor.com/project/micromatch/is-glob)
> Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a better user experience.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-glob
```
You might also be interested in [is-valid-glob](https://github.com/jonschlinkert/is-valid-glob) and [has-glob](https://github.com/jonschlinkert/has-glob).
## Usage
```js
var isGlob = require('is-glob');
```
### Default behavior
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js');
isGlob('*.js');
isGlob('**/abc.js');
isGlob('abc/*.js');
isGlob('abc/(aaa|bbb).js');
isGlob('abc/[a-z].js');
isGlob('abc/{a,b}.js');
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js');
isGlob('abc/!(a).js');
isGlob('abc/+(a).js');
isGlob('abc/*(a).js');
isGlob('abc/?(a).js');
//=> true
```
**False**
Escaped globs or extglobs return `false`:
```js
isGlob('abc/\\@(a).js');
isGlob('abc/\\!(a).js');
isGlob('abc/\\+(a).js');
isGlob('abc/\\*(a).js');
isGlob('abc/\\?(a).js');
isGlob('\\!foo.js');
isGlob('\\*.js');
isGlob('\\*\\*/abc.js');
isGlob('abc/\\*.js');
isGlob('abc/\\(aaa|bbb).js');
isGlob('abc/\\[a-z].js');
isGlob('abc/\\{a,b}.js');
//=> false
```
Patterns that do not have glob patterns return `false`:
```js
isGlob('abc.js');
isGlob('abc/def/ghi.js');
isGlob('foo.js');
isGlob('abc/@.js');
isGlob('abc/+.js');
isGlob('abc/?.js');
isGlob();
isGlob(null);
//=> false
```
Arrays are also `false` (If you want to check if an array has a glob pattern, use [has-glob](https://github.com/jonschlinkert/has-glob)):
```js
isGlob(['**/*.js']);
isGlob(['foo.js']);
//=> false
```
### Option strict
When `options.strict === false` the behavior is less strict in determining if a pattern is a glob. Meaning that
some patterns that would return `false` may return `true`. This is done so that matching libraries like [micromatch](https://github.com/micromatch/micromatch) have a chance at determining if the pattern is a glob or not.
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js', {strict: false});
isGlob('*.js', {strict: false});
isGlob('**/abc.js', {strict: false});
isGlob('abc/*.js', {strict: false});
isGlob('abc/(aaa|bbb).js', {strict: false});
isGlob('abc/[a-z].js', {strict: false});
isGlob('abc/{a,b}.js', {strict: false});
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js', {strict: false});
isGlob('abc/!(a).js', {strict: false});
isGlob('abc/+(a).js', {strict: false});
isGlob('abc/*(a).js', {strict: false});
isGlob('abc/?(a).js', {strict: false});
//=> true
```
**False**
Escaped globs or extglobs return `false`:
```js
isGlob('\\!foo.js', {strict: false});
isGlob('\\*.js', {strict: false});
isGlob('\\*\\*/abc.js', {strict: false});
isGlob('abc/\\*.js', {strict: false});
isGlob('abc/\\(aaa|bbb).js', {strict: false});
isGlob('abc/\\[a-z].js', {strict: false});
isGlob('abc/\\{a,b}.js', {strict: false});
//=> false
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [assemble](https://www.npmjs.com/package/assemble): Get the rocks out of your socks! Assemble makes you fast at creating web projects… [more](https://github.com/assemble/assemble) | [homepage](https://github.com/assemble/assemble "Get the rocks out of your socks! Assemble makes you fast at creating web projects. Assemble is used by thousands of projects for rapid prototyping, creating themes, scaffolds, boilerplates, e-books, UI components, API documentation, blogs, building websit")
* [base](https://www.npmjs.com/package/base): Framework for rapidly creating high quality, server-side node.js applications, using plugins like building blocks | [homepage](https://github.com/node-base/base "Framework for rapidly creating high quality, server-side node.js applications, using plugins like building blocks")
* [update](https://www.npmjs.com/package/update): Be scalable! Update is a new, open source developer framework and CLI for automating updates… [more](https://github.com/update/update) | [homepage](https://github.com/update/update "Be scalable! Update is a new, open source developer framework and CLI for automating updates of any kind in code projects.")
* [verb](https://www.npmjs.com/package/verb): Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used… [more](https://github.com/verbose/verb) | [homepage](https://github.com/verbose/verb "Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used on hundreds of projects of all sizes to generate everything from API docs to readmes.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 47 | [jonschlinkert](https://github.com/jonschlinkert) |
| 5 | [doowb](https://github.com/doowb) |
| 1 | [phated](https://github.com/phated) |
| 1 | [danhper](https://github.com/danhper) |
| 1 | [paulmillr](https://github.com/paulmillr) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2019, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on March 27, 2019._
# arr-diff [](https://www.npmjs.com/package/arr-diff) [](https://travis-ci.org/jonschlinkert/base)
> Returns an array with only the unique values from the first array, by excluding all values from additional arrays using strict equality for comparisons.
## Install
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i arr-diff --save
```
Install with [bower](http://bower.io/)
```sh
$ bower install arr-diff --save
```
## API
### [diff](index.js#L33)
Return the difference between the first array and additional arrays.
**Params**
* `a` **{Array}**
* `b` **{Array}**
* `returns` **{Array}**
**Example**
```js
var diff = require('arr-diff');
var a = ['a', 'b', 'c', 'd'];
var b = ['b', 'c'];
console.log(diff(a, b))
//=> ['a', 'd']
```
## Related projects
* [arr-flatten](https://www.npmjs.com/package/arr-flatten): Recursively flatten an array or arrays. This is the fastest implementation of array flatten. | [homepage](https://github.com/jonschlinkert/arr-flatten)
* [array-filter](https://www.npmjs.com/package/array-filter): Array#filter for older browsers. | [homepage](https://github.com/juliangruber/array-filter)
* [array-intersection](https://www.npmjs.com/package/array-intersection): Return an array with the unique values present in _all_ given arrays using strict equality… [more](https://www.npmjs.com/package/array-intersection) | [homepage](https://github.com/jonschlinkert/array-intersection)
## Running tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/arr-diff/issues/new).
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2015 [Jon Schlinkert](https://github.com/jonschlinkert)
Released under the MIT license.
***
_This file was generated by [verb](https://github.com/verbose/verb) on Sat Dec 05 2015 23:24:53 GMT-0500 (EST)._
# level-packager
> `levelup` package helper for distributing with an `abstract-leveldown` compatible back-end
[![level badge][level-badge]](https://github.com/level/awesome)
[](https://www.npmjs.com/package/level-packager)

[](http://travis-ci.org/Level/packager)
[](https://david-dm.org/level/packager)
[](https://standardjs.com)
[](https://www.npmjs.com/package/level-packager)
## API
Exports a single function which takes a single argument, an `abstract-leveldown` compatible storage back-end for [`levelup`](https://github.com/Level/levelup). The function returns a constructor function that will bundle `levelup` with the given `abstract-leveldown` replacement. The full API is supported, including optional functions, `destroy()`, and `repair()`. Encoding functionality is provided by [`encoding-down`](https://github.com/Level/encoding-down).
The constructor function has a `.errors` property which provides access to the different error types from [`level-errors`](https://github.com/Level/errors#api).
For example use-cases, see:
- [`level`](https://github.com/Level/level)
- [`level-mem`](https://github.com/Level/level-mem)
- [`level-hyper`](https://github.com/Level/level-hyper)
- [`level-lmdb`](https://github.com/Level/level-lmdb)
Also available is a _test.js_ file that can be used to verify that the user-package works as expected.
**If you are upgrading:** please see [`UPGRADING.md`](UPGRADING.md).
## Contributing
`level-packager` is an **OPEN Open Source Project**. This means that:
> Individuals making significant and valuable contributions are given commit-access to the project to contribute as they see fit. This project is more like an open wiki than a standard guarded open source project.
See the [contribution guide](https://github.com/Level/community/blob/master/CONTRIBUTING.md) for more details.
## License
[MIT](./LICENSE.md) © 2013-present `level-packager` [Contributors](./CONTRIBUTORS.md).
[level-badge]: http://leveldb.org/img/badge.svg
# web3-providers-http
_This is a sub package of [web3.js][repo]_
This is a HTTP provider for [web3.js][repo].
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-providers-http
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-providers-http.js` in your html file.
This will expose the `Web3HttpProvider` object on the window object.
## Usage
```js
// in node.js
var http = require('http');
var Web3HttpProvider = require('web3-providers-http');
var options = {
keepAlive: true,
timeout: 20000, // milliseconds,
headers: [{name: 'Access-Control-Allow-Origin', value: '*'},{...}],
withCredentials: false,
agent: {http: http.Agent(...), baseUrl: ''}
};
var provider = new Web3HttpProvider('http://localhost:8545', options);
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# socks [](https://travis-ci.org/JoshGlazebrook/socks) [](https://coveralls.io/github/JoshGlazebrook/socks?branch=v2)
Fully featured SOCKS proxy client supporting SOCKSv4, SOCKSv4a, and SOCKSv5. Includes Bind and Associate functionality.
### Features
* Supports SOCKS v4, v4a, and v5 protocols.
* Supports the CONNECT, BIND, and ASSOCIATE commands.
* Supports callbacks, promises, and events for proxy connection creation async flow control.
* Supports proxy chaining (CONNECT only).
* Supports user/pass authentication.
* Built in UDP frame creation & parse functions.
* Created with TypeScript, type definitions are provided.
### Requirements
* Node.js v6.0+ (Please use [v1](https://github.com/JoshGlazebrook/socks/tree/82d83923ad960693d8b774cafe17443ded7ed584) for older versions of Node.js)
### Looking for v1?
* Docs for v1 are available [here](https://github.com/JoshGlazebrook/socks/tree/82d83923ad960693d8b774cafe17443ded7ed584)
## Installation
`yarn add socks`
or
`npm install --save socks`
## Usage
```typescript
// TypeScript
import { SocksClient, SocksClientOptions, SocksClientChainOptions } from 'socks';
// ES6 JavaScript
import { SocksClient } from 'socks';
// Legacy JavaScript
const SocksClient = require('socks').SocksClient;
```
## Quick Start Example
Connect to github.com (192.30.253.113) on port 80, using a SOCKS proxy.
```javascript
const options = {
proxy: {
host: '159.203.75.200', // ipv4 or ipv6 or hostname
port: 1080,
type: 5 // Proxy version (4 or 5)
},
command: 'connect', // SOCKS command (createConnection factory function only supports the connect command)
destination: {
host: '192.30.253.113', // github.com (hostname lookups are supported with SOCKS v4a and 5)
port: 80
}
};
// Async/Await
try {
const info = await SocksClient.createConnection(options);
console.log(info.socket);
// <Socket ...> (this is a raw net.Socket that is established to the destination host through the given proxy server)
} catch (err) {
// Handle errors
}
// Promises
SocksClient.createConnection(options)
.then(info => {
console.log(info.socket);
// <Socket ...> (this is a raw net.Socket that is established to the destination host through the given proxy server)
})
.catch(err => {
// Handle errors
});
// Callbacks
SocksClient.createConnection(options, (err, info) => {
if (!err) {
console.log(info.socket);
// <Socket ...> (this is a raw net.Socket that is established to the destination host through the given proxy server)
} else {
// Handle errors
}
});
```
## Chaining Proxies
**Note:** Chaining is only supported when using the SOCKS connect command, and chaining can only be done through the special factory chaining function.
This example makes a proxy chain through two SOCKS proxies to ip-api.com. Once the connection to the destination is established it sends an HTTP request to get a JSON response that returns ip info for the requesting ip.
```javascript
const options = {
destination: {
host: 'ip-api.com', // host names are supported with SOCKS v4a and SOCKS v5.
port: 80
},
command: 'connect', // Only the connect command is supported when chaining proxies.
proxies: [ // The chain order is the order in the proxies array, meaning the last proxy will establish a connection to the destination.
{
host: '159.203.75.235', // ipv4, ipv6, or hostname
port: 1081,
type: 5
},
{
host: '104.131.124.203', // ipv4, ipv6, or hostname
port: 1081,
type: 5
}
]
}
// Async/Await
try {
const info = await SocksClient.createConnectionChain(options);
console.log(info.socket);
// <Socket ...> (this is a raw net.Socket that is established to the destination host through the given proxy servers)
console.log(info.socket.remoteAddress) // The remote address of the returned socket is the first proxy in the chain.
// 159.203.75.235
info.socket.write('GET /json HTTP/1.1\nHost: ip-api.com\n\n');
info.socket.on('data', (data) => {
console.log(data.toString()); // ip-api.com sees that the last proxy in the chain (104.131.124.203) is connected to it.
/*
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Type: application/json; charset=utf-8
Date: Sun, 24 Dec 2017 03:47:51 GMT
Content-Length: 300
{
"as":"AS14061 Digital Ocean, Inc.",
"city":"Clifton",
"country":"United States",
"countryCode":"US",
"isp":"Digital Ocean",
"lat":40.8326,
"lon":-74.1307,
"org":"Digital Ocean",
"query":"104.131.124.203",
"region":"NJ",
"regionName":"New Jersey",
"status":"success",
"timezone":"America/New_York",
"zip":"07014"
}
*/
});
} catch (err) {
// Handle errors
}
// Promises
SocksClient.createConnectionChain(options)
.then(info => {
console.log(info.socket);
// <Socket ...> (this is a raw net.Socket that is established to the destination host through the given proxy server)
console.log(info.socket.remoteAddress) // The remote address of the returned socket is the first proxy in the chain.
// 159.203.75.235
info.socket.write('GET /json HTTP/1.1\nHost: ip-api.com\n\n');
info.socket.on('data', (data) => {
console.log(data.toString()); // ip-api.com sees that the last proxy in the chain (104.131.124.203) is connected to it.
/*
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Type: application/json; charset=utf-8
Date: Sun, 24 Dec 2017 03:47:51 GMT
Content-Length: 300
{
"as":"AS14061 Digital Ocean, Inc.",
"city":"Clifton",
"country":"United States",
"countryCode":"US",
"isp":"Digital Ocean",
"lat":40.8326,
"lon":-74.1307,
"org":"Digital Ocean",
"query":"104.131.124.203",
"region":"NJ",
"regionName":"New Jersey",
"status":"success",
"timezone":"America/New_York",
"zip":"07014"
}
*/
});
})
.catch(err => {
// Handle errors
});
// Callbacks
SocksClient.createConnectionChain(options, (err, info) => {
if (!err) {
console.log(info.socket);
// <Socket ...> (this is a raw net.Socket that is established to the destination host through the given proxy server)
console.log(info.socket.remoteAddress) // The remote address of the returned socket is the first proxy in the chain.
// 159.203.75.235
info.socket.write('GET /json HTTP/1.1\nHost: ip-api.com\n\n');
info.socket.on('data', (data) => {
console.log(data.toString()); // ip-api.com sees that the last proxy in the chain (104.131.124.203) is connected to it.
/*
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Type: application/json; charset=utf-8
Date: Sun, 24 Dec 2017 03:47:51 GMT
Content-Length: 300
{
"as":"AS14061 Digital Ocean, Inc.",
"city":"Clifton",
"country":"United States",
"countryCode":"US",
"isp":"Digital Ocean",
"lat":40.8326,
"lon":-74.1307,
"org":"Digital Ocean",
"query":"104.131.124.203",
"region":"NJ",
"regionName":"New Jersey",
"status":"success",
"timezone":"America/New_York",
"zip":"07014"
}
*/
});
} else {
// Handle errors
}
});
```
## Bind Example (TCP Relay)
When the bind command is sent to a SOCKS v4/v5 proxy server, the proxy server starts listening on a new TCP port and the proxy relays then remote host information back to the client. When another remote client connects to the proxy server on this port the SOCKS proxy sends a notification that an incoming connection has been accepted to the initial client and a full duplex stream is now established to the initial client and the client that connected to that special port.
```javascript
const options = {
proxy: {
host: '159.203.75.235', // ipv4, ipv6, or hostname
port: 1081,
type: 5
},
command: 'bind',
// When using BIND, the destination should be the remote client that is expected to connect to the SOCKS proxy. Using 0.0.0.0 makes the Proxy accept any incoming connection on that port.
destination: {
host: '0.0.0.0',
port: 0
}
};
// Creates a new SocksClient instance.
const client = new SocksClient(options);
// When the SOCKS proxy has bound a new port and started listening, this event is fired.
client.on('bound', info => {
console.log(info.remoteHost);
/*
{
host: "159.203.75.235",
port: 57362
}
*/
});
// When a client connects to the newly bound port on the SOCKS proxy, this event is fired.
client.on('established', info => {
// info.remoteHost is the remote address of the client that connected to the SOCKS proxy.
console.log(info.remoteHost);
/*
host: 67.171.34.23,
port: 49823
*/
console.log(info.socket);
// <Socket ...> (This is a raw net.Socket that is a connection between the initial client and the remote client that connected to the proxy)
// Handle received data...
info.socket.on('data', data => {
console.log('recv', data);
});
});
// An error occurred trying to establish this SOCKS connection.
client.on('error', err => {
console.error(err);
});
// Start connection to proxy
client.connect();
```
## Associate Example (UDP Relay)
When the associate command is sent to a SOCKS v5 proxy server, it sets up a UDP relay that allows the client to send UDP packets to a remote host through the proxy server, and also receive UDP packet responses back through the proxy server.
```javascript
const options = {
proxy: {
host: '159.203.75.235', // ipv4, ipv6, or hostname
port: 1081,
type: 5
},
command: 'associate',
// When using associate, the destination should be the remote client that is expected to send UDP packets to the proxy server to be forwarded. This should be your local ip, or optionally the wildcard address (0.0.0.0) UDP Client <-> Proxy <-> UDP Client
destination: {
host: '0.0.0.0',
port: 0
}
};
// Create a local UDP socket for sending packets to the proxy.
const udpSocket = dgram.createSocket('udp4');
udpSocket.bind();
// Listen for incoming UDP packets from the proxy server.
udpSocket.on('message', (message, rinfo) => {
console.log(SocksClient.parseUDPFrame(message));
/*
{ frameNumber: 0,
remoteHost: { host: '165.227.108.231', port: 4444 }, // The remote host that replied with a UDP packet
data: <Buffer 74 65 73 74 0a> // The data
}
*/
});
let client = new SocksClient(associateOptions);
// When the UDP relay is established, this event is fired and includes the UDP relay port to send data to on the proxy server.
client.on('established', info => {
console.log(info.remoteHost);
/*
{
host: '159.203.75.235',
port: 44711
}
*/
// Send 'hello' to 165.227.108.231:4444
const packet = SocksClient.createUDPFrame({
remoteHost: { host: '165.227.108.231', port: 4444 },
data: Buffer.from(line)
});
udpSocket.send(packet, info.remoteHost.port, info.remoteHost.host);
});
// Start connection
client.connect();
```
**Note:** The associate TCP connection to the proxy must remain open for the UDP relay to work.
## Additional Examples
[Documentation](docs/index.md)
## Migrating from v1
Looking for a guide to migrate from v1? Look [here](docs/migratingFromV1.md)
## Api Reference:
**Note:** socks includes full TypeScript definitions. These can even be used without using TypeScript as most IDEs (such as VS Code) will use these type definition files for auto completion intellisense even in JavaScript files.
* Class: SocksClient
* [new SocksClient(options[, callback])](#new-socksclientoptions)
* [Class Method: SocksClient.createConnection(options[, callback])](#class-method-socksclientcreateconnectionoptions-callback)
* [Class Method: SocksClient.createConnectionChain(options[, callback])](#class-method-socksclientcreateconnectionchainoptions-callback)
* [Class Method: SocksClient.createUDPFrame(options)](#class-method-socksclientcreateudpframedetails)
* [Class Method: SocksClient.parseUDPFrame(data)](#class-method-socksclientparseudpframedata)
* [Event: 'error'](#event-error)
* [Event: 'bound'](#event-bound)
* [Event: 'established'](#event-established)
* [client.connect()](#clientconnect)
* [client.socksClientOptions](#clientconnect)
### SocksClient
SocksClient establishes SOCKS proxy connections to remote destination hosts. These proxy connections are fully transparent to the server and once established act as full duplex streams. SOCKS v4, v4a, and v5 are supported, as well as the connect, bind, and associate commands.
SocksClient supports creating connections using callbacks, promises, and async/await flow control using two static factory functions createConnection and createConnectionChain. It also internally extends EventEmitter which results in allowing event handling based async flow control.
**SOCKS Compatibility Table**
| Socks Version | TCP | UDP | IPv4 | IPv6 | Hostname |
| --- | :---: | :---: | :---: | :---: | :---: |
| SOCKS v4 | ✅ | ❌ | ✅ | ❌ | ❌ |
| SOCKS v4a | ✅ | ❌ | ✅ | ❌ | ✅ |
| SOCKS v5 | ✅ | ✅ | ✅ | ✅ | ✅ |
### new SocksClient(options)
* ```options``` {SocksClientOptions} - An object describing the SOCKS proxy to use, the command to send and establish, and the destination host to connect to.
### SocksClientOptions
```typescript
{
proxy: {
host: '159.203.75.200', // ipv4, ipv6, or hostname
port: 1080,
type: 5 // Proxy version (4 or 5). For v4a, just use 4.
// Optional fields
userId: 'some username', // Used for SOCKS4 userId auth, and SOCKS5 user/pass auth in conjunction with password.
password: 'some password' // Used in conjunction with userId for user/pass auth for SOCKS5 proxies.
},
command: 'connect', // connect, bind, associate
destination: {
host: '192.30.253.113', // ipv4, ipv6, hostname. Hostnames work with v4a and v5.
port: 80
},
// Optional fields
timeout: 30000, // How long to wait to establish a proxy connection. (defaults to 30 seconds)
set_tcp_nodelay: true // If true, will turn on the underlying sockets TCP_NODELAY option.
}
```
### Class Method: SocksClient.createConnection(options[, callback])
* ```options``` { SocksClientOptions } - An object describing the SOCKS proxy to use, the command to send and establish, and the destination host to connect to.
* ```callback``` { Function } - Optional callback function that is called when the proxy connection is established, or an error occurs.
* ```returns``` { Promise } - A Promise is returned that is resolved when the proxy connection is established, or rejected when an error occurs.
Creates a new proxy connection through the given proxy to the given destination host. This factory function supports callbacks and promises for async flow control.
**Note:** If a callback function is provided, the promise will always resolve regardless of an error occurring. Please be sure to exclusively use either promises or callbacks when using this factory function.
```typescript
const options = {
proxy: {
host: '159.203.75.200', // ipv4, ipv6, or hostname
port: 1080,
type: 5 // Proxy version (4 or 5)
},
command: 'connect', // connect, bind, associate
destination: {
host: '192.30.253.113', // ipv4, ipv6, or hostname
port: 80
}
}
// Await/Async (uses a Promise)
try {
const info = await SocksClient.createConnection(options);
console.log(info);
/*
{
socket: <Socket ...>, // Raw net.Socket
}
*/
/ <Socket ...> (this is a raw net.Socket that is established to the destination host through the given proxy server)
} catch (err) {
// Handle error...
}
// Promise
SocksClient.createConnection(options)
.then(info => {
console.log(info);
/*
{
socket: <Socket ...>, // Raw net.Socket
}
*/
})
.catch(err => {
// Handle error...
});
// Callback
SocksClient.createConnection(options, (err, info) => {
if (!err) {
console.log(info);
/*
{
socket: <Socket ...>, // Raw net.Socket
}
*/
} else {
// Handle error...
}
});
```
### Class Method: SocksClient.createConnectionChain(options[, callback])
* ```options``` { SocksClientChainOptions } - An object describing a list of SOCKS proxies to use, the command to send and establish, and the destination host to connect to.
* ```callback``` { Function } - Optional callback function that is called when the proxy connection chain is established, or an error occurs.
* ```returns``` { Promise } - A Promise is returned that is resolved when the proxy connection chain is established, or rejected when an error occurs.
Creates a new proxy connection chain through a list of at least two SOCKS proxies to the given destination host. This factory method supports callbacks and promises for async flow control.
**Note:** If a callback function is provided, the promise will always resolve regardless of an error occurring. Please be sure to exclusively use either promises or callbacks when using this factory function.
**Note:** At least two proxies must be provided for the chain to be established.
```typescript
const options = {
proxies: [ // The chain order is the order in the proxies array, meaning the last proxy will establish a connection to the destination.
{
host: '159.203.75.235', // ipv4, ipv6, or hostname
port: 1081,
type: 5
},
{
host: '104.131.124.203', // ipv4, ipv6, or hostname
port: 1081,
type: 5
}
]
command: 'connect', // Only connect is supported in chaining mode.
destination: {
host: '192.30.253.113', // ipv4, ipv6, hostname
port: 80
}
}
```
### Class Method: SocksClient.createUDPFrame(details)
* ```details``` { SocksUDPFrameDetails } - An object containing the remote host, frame number, and frame data to use when creating a SOCKS UDP frame packet.
* ```returns``` { Buffer } - A Buffer containing all of the UDP frame data.
Creates a SOCKS UDP frame relay packet that is sent and received via a SOCKS proxy when using the associate command for UDP packet forwarding.
**SocksUDPFrameDetails**
```typescript
{
frameNumber: 0, // The frame number (used for breaking up larger packets)
remoteHost: { // The remote host to have the proxy send data to, or the remote host that send this data.
host: '1.2.3.4',
port: 1234
},
data: <Buffer 01 02 03 04...> // A Buffer instance of data to include in the packet (actual data sent to the remote host)
}
interface SocksUDPFrameDetails {
// The frame number of the packet.
frameNumber?: number;
// The remote host.
remoteHost: SocksRemoteHost;
// The packet data.
data: Buffer;
}
```
### Class Method: SocksClient.parseUDPFrame(data)
* ```data``` { Buffer } - A Buffer instance containing SOCKS UDP frame data to parse.
* ```returns``` { SocksUDPFrameDetails } - An object containing the remote host, frame number, and frame data of the SOCKS UDP frame.
```typescript
const frame = SocksClient.parseUDPFrame(data);
console.log(frame);
/*
{
frameNumber: 0,
remoteHost: {
host: '1.2.3.4',
port: 1234
},
data: <Buffer 01 02 03 04 ...>
}
*/
```
Parses a Buffer instance and returns the parsed SocksUDPFrameDetails object.
## Event: 'error'
* ```err``` { SocksClientError } - An Error object containing an error message and the original SocksClientOptions.
This event is emitted if an error occurs when trying to establish the proxy connection.
## Event: 'bound'
* ```info``` { SocksClientBoundEvent } An object containing a Socket and SocksRemoteHost info.
This event is emitted when using the BIND command on a remote SOCKS proxy server. This event indicates the proxy server is now listening for incoming connections on a specified port.
**SocksClientBoundEvent**
```typescript
{
socket: net.Socket, // The underlying raw Socket
remoteHost: {
host: '1.2.3.4', // The remote host that is listening (usually the proxy itself)
port: 4444 // The remote port the proxy is listening on for incoming connections (when using BIND).
}
}
```
## Event: 'established'
* ```info``` { SocksClientEstablishedEvent } An object containing a Socket and SocksRemoteHost info.
This event is emitted when the following conditions are met:
1. When using the CONNECT command, and a proxy connection has been established to the remote host.
2. When using the BIND command, and an incoming connection has been accepted by the proxy and a TCP relay has been established.
3. When using the ASSOCIATE command, and a UDP relay has been established.
When using BIND, 'bound' is first emitted to indicate the SOCKS server is waiting for an incoming connection, and provides the remote port the SOCKS server is listening on.
When using ASSOCIATE, 'established' is emitted with the remote UDP port the SOCKS server is accepting UDP frame packets on.
**SocksClientEstablishedEvent**
```typescript
{
socket: net.Socket, // The underlying raw Socket
remoteHost: {
host: '1.2.3.4', // The remote host that is listening (usually the proxy itself)
port: 52738 // The remote port the proxy is listening on for incoming connections (when using BIND).
}
}
```
## client.connect()
Starts connecting to the remote SOCKS proxy server to establish a proxy connection to the destination host.
## client.socksClientOptions
* ```returns``` { SocksClientOptions } The options that were passed to the SocksClient.
Gets the options that were passed to the SocksClient when it was created.
**SocksClientError**
```typescript
{ // Subclassed from Error.
message: 'An error has occurred',
options: {
// SocksClientOptions
}
}
```
# Further Reading:
Please read the SOCKS 5 specifications for more information on how to use BIND and Associate.
http://www.ietf.org/rfc/rfc1928.txt
# License
This work is licensed under the [MIT license](http://en.wikipedia.org/wiki/MIT_License).
# verror: rich JavaScript errors
This module provides several classes in support of Joyent's [Best Practices for
Error Handling in Node.js](http://www.joyent.com/developers/node/design/errors).
If you find any of the behavior here confusing or surprising, check out that
document first.
The error classes here support:
* printf-style arguments for the message
* chains of causes
* properties to provide extra information about the error
* creating your own subclasses that support all of these
The classes here are:
* **VError**, for chaining errors while preserving each one's error message.
This is useful in servers and command-line utilities when you want to
propagate an error up a call stack, but allow various levels to add their own
context. See examples below.
* **WError**, for wrapping errors while hiding the lower-level messages from the
top-level error. This is useful for API endpoints where you don't want to
expose internal error messages, but you still want to preserve the error chain
for logging and debugging.
* **SError**, which is just like VError but interprets printf-style arguments
more strictly.
* **MultiError**, which is just an Error that encapsulates one or more other
errors. (This is used for parallel operations that return several errors.)
# Quick start
First, install the package:
npm install verror
If nothing else, you can use VError as a drop-in replacement for the built-in
JavaScript Error class, with the addition of printf-style messages:
```javascript
var err = new VError('missing file: "%s"', '/etc/passwd');
console.log(err.message);
```
This prints:
missing file: "/etc/passwd"
You can also pass a `cause` argument, which is any other Error object:
```javascript
var fs = require('fs');
var filename = '/nonexistent';
fs.stat(filename, function (err1) {
var err2 = new VError(err1, 'stat "%s"', filename);
console.error(err2.message);
});
```
This prints out:
stat "/nonexistent": ENOENT, stat '/nonexistent'
which resembles how Unix programs typically report errors:
$ sort /nonexistent
sort: open failed: /nonexistent: No such file or directory
To match the Unixy feel, when you print out the error, just prepend the
program's name to the VError's `message`. Or just call
[node-cmdutil.fail(your_verror)](https://github.com/joyent/node-cmdutil), which
does this for you.
You can get the next-level Error using `err.cause()`:
```javascript
console.error(err2.cause().message);
```
prints:
ENOENT, stat '/nonexistent'
Of course, you can chain these as many times as you want, and it works with any
kind of Error:
```javascript
var err1 = new Error('No such file or directory');
var err2 = new VError(err1, 'failed to stat "%s"', '/junk');
var err3 = new VError(err2, 'request failed');
console.error(err3.message);
```
This prints:
request failed: failed to stat "/junk": No such file or directory
The idea is that each layer in the stack annotates the error with a description
of what it was doing. The end result is a message that explains what happened
at each level.
You can also decorate Error objects with additional information so that callers
can not only handle each kind of error differently, but also construct their own
error messages (e.g., to localize them, format them, group them by type, and so
on). See the example below.
# Deeper dive
The two main goals for VError are:
* **Make it easy to construct clear, complete error messages intended for
people.** Clear error messages greatly improve both user experience and
debuggability, so we wanted to make it easy to build them. That's why the
constructor takes printf-style arguments.
* **Make it easy to construct objects with programmatically-accessible
metadata** (which we call _informational properties_). Instead of just saying
"connection refused while connecting to 192.168.1.2:80", you can add
properties like `"ip": "192.168.1.2"` and `"tcpPort": 80`. This can be used
for feeding into monitoring systems, analyzing large numbers of Errors (as
from a log file), or localizing error messages.
To really make this useful, it also needs to be easy to compose Errors:
higher-level code should be able to augment the Errors reported by lower-level
code to provide a more complete description of what happened. Instead of saying
"connection refused", you can say "operation X failed: connection refused".
That's why VError supports `causes`.
In order for all this to work, programmers need to know that it's generally safe
to wrap lower-level Errors with higher-level ones. If you have existing code
that handles Errors produced by a library, you should be able to wrap those
Errors with a VError to add information without breaking the error handling
code. There are two obvious ways that this could break such consumers:
* The error's name might change. People typically use `name` to determine what
kind of Error they've got. To ensure compatibility, you can create VErrors
with custom names, but this approach isn't great because it prevents you from
representing complex failures. For this reason, VError provides
`findCauseByName`, which essentially asks: does this Error _or any of its
causes_ have this specific type? If error handling code uses
`findCauseByName`, then subsystems can construct very specific causal chains
for debuggability and still let people handle simple cases easily. There's an
example below.
* The error's properties might change. People often hang additional properties
off of Error objects. If we wrap an existing Error in a new Error, those
properties would be lost unless we copied them. But there are a variety of
both standard and non-standard Error properties that should _not_ be copied in
this way: most obviously `name`, `message`, and `stack`, but also `fileName`,
`lineNumber`, and a few others. Plus, it's useful for some Error subclasses
to have their own private properties -- and there'd be no way to know whether
these should be copied. For these reasons, VError first-classes these
information properties. You have to provide them in the constructor, you can
only fetch them with the `info()` function, and VError takes care of making
sure properties from causes wind up in the `info()` output.
Let's put this all together with an example from the node-fast RPC library.
node-fast implements a simple RPC protocol for Node programs. There's a server
and client interface, and clients make RPC requests to servers. Let's say the
server fails with an UnauthorizedError with message "user 'bob' is not
authorized". The client wraps all server errors with a FastServerError. The
client also wraps all request errors with a FastRequestError that includes the
name of the RPC call being made. The result of this failed RPC might look like
this:
name: FastRequestError
message: "request failed: server error: user 'bob' is not authorized"
rpcMsgid: <unique identifier for this request>
rpcMethod: GetObject
cause:
name: FastServerError
message: "server error: user 'bob' is not authorized"
cause:
name: UnauthorizedError
message: "user 'bob' is not authorized"
rpcUser: "bob"
When the caller uses `VError.info()`, the information properties are collapsed
so that it looks like this:
message: "request failed: server error: user 'bob' is not authorized"
rpcMsgid: <unique identifier for this request>
rpcMethod: GetObject
rpcUser: "bob"
Taking this apart:
* The error's message is a complete description of the problem. The caller can
report this directly to its caller, which can potentially make its way back to
an end user (if appropriate). It can also be logged.
* The caller can tell that the request failed on the server, rather than as a
result of a client problem (e.g., failure to serialize the request), a
transport problem (e.g., failure to connect to the server), or something else
(e.g., a timeout). They do this using `findCauseByName('FastServerError')`
rather than checking the `name` field directly.
* If the caller logs this error, the logs can be analyzed to aggregate
errors by cause, by RPC method name, by user, or whatever. Or the
error can be correlated with other events for the same rpcMsgid.
* It wasn't very hard for any part of the code to contribute to this Error.
Each part of the stack has just a few lines to provide exactly what it knows,
with very little boilerplate.
It's not expected that you'd use these complex forms all the time. Despite
supporting the complex case above, you can still just do:
new VError("my service isn't working");
for the simple cases.
# Reference: VError, WError, SError
VError, WError, and SError are convenient drop-in replacements for `Error` that
support printf-style arguments, first-class causes, informational properties,
and other useful features.
## Constructors
The VError constructor has several forms:
```javascript
/*
* This is the most general form. You can specify any supported options
* (including "cause" and "info") this way.
*/
new VError(options, sprintf_args...)
/*
* This is a useful shorthand when the only option you need is "cause".
*/
new VError(cause, sprintf_args...)
/*
* This is a useful shorthand when you don't need any options at all.
*/
new VError(sprintf_args...)
```
All of these forms construct a new VError that behaves just like the built-in
JavaScript `Error` class, with some additional methods described below.
In the first form, `options` is a plain object with any of the following
optional properties:
Option name | Type | Meaning
---------------- | ---------------- | -------
`name` | string | Describes what kind of error this is. This is intended for programmatic use to distinguish between different kinds of errors. Note that in modern versions of Node.js, this name is ignored in the `stack` property value, but callers can still use the `name` property to get at it.
`cause` | any Error object | Indicates that the new error was caused by `cause`. See `cause()` below. If unspecified, the cause will be `null`.
`strict` | boolean | If true, then `null` and `undefined` values in `sprintf_args` are passed through to `sprintf()`. Otherwise, these are replaced with the strings `'null'`, and '`undefined`', respectively.
`constructorOpt` | function | If specified, then the stack trace for this error ends at function `constructorOpt`. Functions called by `constructorOpt` will not show up in the stack. This is useful when this class is subclassed.
`info` | object | Specifies arbitrary informational properties that are available through the `VError.info(err)` static class method. See that method for details.
The second form is equivalent to using the first form with the specified `cause`
as the error's cause. This form is distinguished from the first form because
the first argument is an Error.
The third form is equivalent to using the first form with all default option
values. This form is distinguished from the other forms because the first
argument is not an object or an Error.
The `WError` constructor is used exactly the same way as the `VError`
constructor. The `SError` constructor is also used the same way as the
`VError` constructor except that in all cases, the `strict` property is
overriden to `true.
## Public properties
`VError`, `WError`, and `SError` all provide the same public properties as
JavaScript's built-in Error objects.
Property name | Type | Meaning
------------- | ------ | -------
`name` | string | Programmatically-usable name of the error.
`message` | string | Human-readable summary of the failure. Programmatically-accessible details are provided through `VError.info(err)` class method.
`stack` | string | Human-readable stack trace where the Error was constructed.
For all of these classes, the printf-style arguments passed to the constructor
are processed with `sprintf()` to form a message. For `WError`, this becomes
the complete `message` property. For `SError` and `VError`, this message is
prepended to the message of the cause, if any (with a suitable separator), and
the result becomes the `message` property.
The `stack` property is managed entirely by the underlying JavaScript
implementation. It's generally implemented using a getter function because
constructing the human-readable stack trace is somewhat expensive.
## Class methods
The following methods are defined on the `VError` class and as exported
functions on the `verror` module. They're defined this way rather than using
methods on VError instances so that they can be used on Errors not created with
`VError`.
### `VError.cause(err)`
The `cause()` function returns the next Error in the cause chain for `err`, or
`null` if there is no next error. See the `cause` argument to the constructor.
Errors can have arbitrarily long cause chains. You can walk the `cause` chain
by invoking `VError.cause(err)` on each subsequent return value. If `err` is
not a `VError`, the cause is `null`.
### `VError.info(err)`
Returns an object with all of the extra error information that's been associated
with this Error and all of its causes. These are the properties passed in using
the `info` option to the constructor. Properties not specified in the
constructor for this Error are implicitly inherited from this error's cause.
These properties are intended to provide programmatically-accessible metadata
about the error. For an error that indicates a failure to resolve a DNS name,
informational properties might include the DNS name to be resolved, or even the
list of resolvers used to resolve it. The values of these properties should
generally be plain objects (i.e., consisting only of null, undefined, numbers,
booleans, strings, and objects and arrays containing only other plain objects).
### `VError.fullStack(err)`
Returns a string containing the full stack trace, with all nested errors recursively
reported as `'caused by:' + err.stack`.
### `VError.findCauseByName(err, name)`
The `findCauseByName()` function traverses the cause chain for `err`, looking
for an error whose `name` property matches the passed in `name` value. If no
match is found, `null` is returned.
If all you want is to know _whether_ there's a cause (and you don't care what it
is), you can use `VError.hasCauseWithName(err, name)`.
If a vanilla error or a non-VError error is passed in, then there is no cause
chain to traverse. In this scenario, the function will check the `name`
property of only `err`.
### `VError.hasCauseWithName(err, name)`
Returns true if and only if `VError.findCauseByName(err, name)` would return
a non-null value. This essentially determines whether `err` has any cause in
its cause chain that has name `name`.
### `VError.errorFromList(errors)`
Given an array of Error objects (possibly empty), return a single error
representing the whole collection of errors. If the list has:
* 0 elements, returns `null`
* 1 element, returns the sole error
* more than 1 element, returns a MultiError referencing the whole list
This is useful for cases where an operation may produce any number of errors,
and you ultimately want to implement the usual `callback(err)` pattern. You can
accumulate the errors in an array and then invoke
`callback(VError.errorFromList(errors))` when the operation is complete.
### `VError.errorForEach(err, func)`
Convenience function for iterating an error that may itself be a MultiError.
In all cases, `err` must be an Error. If `err` is a MultiError, then `func` is
invoked as `func(errorN)` for each of the underlying errors of the MultiError.
If `err` is any other kind of error, `func` is invoked once as `func(err)`. In
all cases, `func` is invoked synchronously.
This is useful for cases where an operation may produce any number of warnings
that may be encapsulated with a MultiError -- but may not be.
This function does not iterate an error's cause chain.
## Examples
The "Demo" section above covers several basic cases. Here's a more advanced
case:
```javascript
var err1 = new VError('something bad happened');
/* ... */
var err2 = new VError({
'name': 'ConnectionError',
'cause': err1,
'info': {
'errno': 'ECONNREFUSED',
'remote_ip': '127.0.0.1',
'port': 215
}
}, 'failed to connect to "%s:%d"', '127.0.0.1', 215);
console.log(err2.message);
console.log(err2.name);
console.log(VError.info(err2));
console.log(err2.stack);
```
This outputs:
failed to connect to "127.0.0.1:215": something bad happened
ConnectionError
{ errno: 'ECONNREFUSED', remote_ip: '127.0.0.1', port: 215 }
ConnectionError: failed to connect to "127.0.0.1:215": something bad happened
at Object.<anonymous> (/home/dap/node-verror/examples/info.js:5:12)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Function.Module.runMain (module.js:497:10)
at startup (node.js:119:16)
at node.js:935:3
Information properties are inherited up the cause chain, with values at the top
of the chain overriding same-named values lower in the chain. To continue that
example:
```javascript
var err3 = new VError({
'name': 'RequestError',
'cause': err2,
'info': {
'errno': 'EBADREQUEST'
}
}, 'request failed');
console.log(err3.message);
console.log(err3.name);
console.log(VError.info(err3));
console.log(err3.stack);
```
This outputs:
request failed: failed to connect to "127.0.0.1:215": something bad happened
RequestError
{ errno: 'EBADREQUEST', remote_ip: '127.0.0.1', port: 215 }
RequestError: request failed: failed to connect to "127.0.0.1:215": something bad happened
at Object.<anonymous> (/home/dap/node-verror/examples/info.js:20:12)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Function.Module.runMain (module.js:497:10)
at startup (node.js:119:16)
at node.js:935:3
You can also print the complete stack trace of combined `Error`s by using
`VError.fullStack(err).`
```javascript
var err1 = new VError('something bad happened');
/* ... */
var err2 = new VError(err1, 'something really bad happened here');
console.log(VError.fullStack(err2));
```
This outputs:
VError: something really bad happened here: something bad happened
at Object.<anonymous> (/home/dap/node-verror/examples/fullStack.js:5:12)
at Module._compile (module.js:409:26)
at Object.Module._extensions..js (module.js:416:10)
at Module.load (module.js:343:32)
at Function.Module._load (module.js:300:12)
at Function.Module.runMain (module.js:441:10)
at startup (node.js:139:18)
at node.js:968:3
caused by: VError: something bad happened
at Object.<anonymous> (/home/dap/node-verror/examples/fullStack.js:3:12)
at Module._compile (module.js:409:26)
at Object.Module._extensions..js (module.js:416:10)
at Module.load (module.js:343:32)
at Function.Module._load (module.js:300:12)
at Function.Module.runMain (module.js:441:10)
at startup (node.js:139:18)
at node.js:968:3
`VError.fullStack` is also safe to use on regular `Error`s, so feel free to use
it whenever you need to extract the stack trace from an `Error`, regardless if
it's a `VError` or not.
# Reference: MultiError
MultiError is an Error class that represents a group of Errors. This is used
when you logically need to provide a single Error, but you want to preserve
information about multiple underying Errors. A common case is when you execute
several operations in parallel and some of them fail.
MultiErrors are constructed as:
```javascript
new MultiError(error_list)
```
`error_list` is an array of at least one `Error` object.
The cause of the MultiError is the first error provided. None of the other
`VError` options are supported. The `message` for a MultiError consists the
`message` from the first error, prepended with a message indicating that there
were other errors.
For example:
```javascript
err = new MultiError([
new Error('failed to resolve DNS name "abc.example.com"'),
new Error('failed to resolve DNS name "def.example.com"'),
]);
console.error(err.message);
```
outputs:
first of 2 errors: failed to resolve DNS name "abc.example.com"
See the convenience function `VError.errorFromList`, which is sometimes simpler
to use than this constructor.
## Public methods
### `errors()`
Returns an array of the errors used to construct this MultiError.
# Contributing
See separate [contribution guidelines](CONTRIBUTING.md).
# web3-core
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a sub-package of [web3.js][repo].
The core package contains core functions for [web3.js][repo] packages.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-core
```
## Usage
```js
const core = require('web3-core');
const CoolLib = function CoolLib() {
// sets _requestmanager and adds basic functions
core.packageInit(this, arguments);
};
CoolLib.providers;
CoolLib.givenProvider;
CoolLib.setProvider();
CoolLib.BatchRequest();
CoolLib.extend();
...
```
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-core.svg
[npm-url]: https://npmjs.org/package/web3-core
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-core
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-core
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-core
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-core
# URI.js
URI.js is an [RFC 3986](http://www.ietf.org/rfc/rfc3986.txt) compliant, scheme extendable URI parsing/validating/resolving library for all JavaScript environments (browsers, Node.js, etc).
It is also compliant with the IRI ([RFC 3987](http://www.ietf.org/rfc/rfc3987.txt)), IDNA ([RFC 5890](http://www.ietf.org/rfc/rfc5890.txt)), IPv6 Address ([RFC 5952](http://www.ietf.org/rfc/rfc5952.txt)), IPv6 Zone Identifier ([RFC 6874](http://www.ietf.org/rfc/rfc6874.txt)) specifications.
URI.js has an extensive test suite, and works in all (Node.js, web) environments. It weighs in at 6.4kb (gzipped, 17kb deflated).
## API
### Parsing
URI.parse("uri://user:[email protected]:123/one/two.three?q1=a1&q2=a2#body");
//returns:
//{
// scheme : "uri",
// userinfo : "user:pass",
// host : "example.com",
// port : 123,
// path : "/one/two.three",
// query : "q1=a1&q2=a2",
// fragment : "body"
//}
### Serializing
URI.serialize({scheme : "http", host : "example.com", fragment : "footer"}) === "http://example.com/#footer"
### Resolving
URI.resolve("uri://a/b/c/d?q", "../../g") === "uri://a/g"
### Normalizing
URI.normalize("HTTP://ABC.com:80/%7Esmith/home.html") === "http://abc.com/~smith/home.html"
### Comparison
URI.equal("example://a/b/c/%7Bfoo%7D", "eXAMPLE://a/./b/../b/%63/%7bfoo%7d") === true
### IP Support
//IPv4 normalization
URI.normalize("//192.068.001.000") === "//192.68.1.0"
//IPv6 normalization
URI.normalize("//[2001:0:0DB8::0:0001]") === "//[2001:0:db8::1]"
//IPv6 zone identifier support
URI.parse("//[2001:db8::7%25en1]");
//returns:
//{
// host : "2001:db8::7%en1"
//}
### IRI Support
//convert IRI to URI
URI.serialize(URI.parse("http://examplé.org/rosé")) === "http://xn--exampl-gva.org/ros%C3%A9"
//convert URI to IRI
URI.serialize(URI.parse("http://xn--exampl-gva.org/ros%C3%A9"), {iri:true}) === "http://examplé.org/rosé"
### Options
All of the above functions can accept an additional options argument that is an object that can contain one or more of the following properties:
* `scheme` (string)
Indicates the scheme that the URI should be treated as, overriding the URI's normal scheme parsing behavior.
* `reference` (string)
If set to `"suffix"`, it indicates that the URI is in the suffix format, and the validator will use the option's `scheme` property to determine the URI's scheme.
* `tolerant` (boolean, false)
If set to `true`, the parser will relax URI resolving rules.
* `absolutePath` (boolean, false)
If set to `true`, the serializer will not resolve a relative `path` component.
* `iri` (boolean, false)
If set to `true`, the serializer will unescape non-ASCII characters as per [RFC 3987](http://www.ietf.org/rfc/rfc3987.txt).
* `unicodeSupport` (boolean, false)
If set to `true`, the parser will unescape non-ASCII characters in the parsed output as per [RFC 3987](http://www.ietf.org/rfc/rfc3987.txt).
* `domainHost` (boolean, false)
If set to `true`, the library will treat the `host` component as a domain name, and convert IDNs (International Domain Names) as per [RFC 5891](http://www.ietf.org/rfc/rfc5891.txt).
## Scheme Extendable
URI.js supports inserting custom [scheme](http://en.wikipedia.org/wiki/URI_scheme) dependent processing rules. Currently, URI.js has built in support for the following schemes:
* http \[[RFC 2616](http://www.ietf.org/rfc/rfc2616.txt)\]
* https \[[RFC 2818](http://www.ietf.org/rfc/rfc2818.txt)\]
* mailto \[[RFC 6068](http://www.ietf.org/rfc/rfc6068.txt)\]
* urn \[[RFC 2141](http://www.ietf.org/rfc/rfc2141.txt)\]
* urn:uuid \[[RFC 4122](http://www.ietf.org/rfc/rfc4122.txt)\]
### HTTP/HTTPS Support
URI.equal("HTTP://ABC.COM:80", "http://abc.com/") === true
URI.equal("https://abc.com", "HTTPS://ABC.COM:443/") === true
### WS/WSS Support
URI.parse("wss://example.com/foo?bar=baz");
//returns:
//{
// scheme : "wss",
// host: "example.com",
// resourceName: "/foo?bar=baz",
// secure: true,
//}
URI.equal("WS://ABC.COM:80/chat#one", "ws://abc.com/chat") === true
### Mailto Support
URI.parse("mailto:[email protected],[email protected]?subject=SUBSCRIBE&body=Sign%20me%20up!");
//returns:
//{
// scheme : "mailto",
// to : ["[email protected]", "[email protected]"],
// subject : "SUBSCRIBE",
// body : "Sign me up!"
//}
URI.serialize({
scheme : "mailto",
to : ["[email protected]"],
subject : "REMOVE",
body : "Please remove me",
headers : {
cc : "[email protected]"
}
}) === "mailto:[email protected][email protected]&subject=REMOVE&body=Please%20remove%20me"
### URN Support
URI.parse("urn:example:foo");
//returns:
//{
// scheme : "urn",
// nid : "example",
// nss : "foo",
//}
#### URN UUID Support
URI.parse("urn:uuid:f81d4fae-7dec-11d0-a765-00a0c91e6bf6");
//returns:
//{
// scheme : "urn",
// nid : "example",
// uuid : "f81d4fae-7dec-11d0-a765-00a0c91e6bf6",
//}
## Usage
To load in a browser, use the following tag:
<script type="text/javascript" src="uri-js/dist/es5/uri.all.min.js"></script>
To load in a CommonJS/Module environment, first install with npm/yarn by running on the command line:
npm install uri-js
# OR
yarn add uri-js
Then, in your code, load it using:
const URI = require("uri-js");
If you are writing your code in ES6+ (ESNEXT) or TypeScript, you would load it using:
import * as URI from "uri-js";
Or you can load just what you need using named exports:
import { parse, serialize, resolve, resolveComponents, normalize, equal, removeDotSegments, pctEncChar, pctDecChars, escapeComponent, unescapeComponent } from "uri-js";
## Breaking changes
### Breaking changes from 3.x
URN parsing has been completely changed to better align with the specification. Scheme is now always `urn`, but has two new properties: `nid` which contains the Namspace Identifier, and `nss` which contains the Namespace Specific String. The `nss` property will be removed by higher order scheme handlers, such as the UUID URN scheme handler.
The UUID of a URN can now be found in the `uuid` property.
### Breaking changes from 2.x
URI validation has been removed as it was slow, exposed a vulnerabilty, and was generally not useful.
### Breaking changes from 1.x
The `errors` array on parsed components is now an `error` string.
semver(1) -- The semantic versioner for npm
===========================================
## Install
```bash
npm install --save semver
````
## Usage
As a node module:
```js
const semver = require('semver')
semver.valid('1.2.3') // '1.2.3'
semver.valid('a.b.c') // null
semver.clean(' =v1.2.3 ') // '1.2.3'
semver.satisfies('1.2.3', '1.x || >=2.5.0 || 5.0.0 - 7.2.3') // true
semver.gt('1.2.3', '9.8.7') // false
semver.lt('1.2.3', '9.8.7') // true
semver.minVersion('>=1.0.0') // '1.0.0'
semver.valid(semver.coerce('v2')) // '2.0.0'
semver.valid(semver.coerce('42.6.7.9.3-alpha')) // '42.6.7'
```
As a command-line utility:
```
$ semver -h
A JavaScript implementation of the https://semver.org/ specification
Copyright Isaac Z. Schlueter
Usage: semver [options] <version> [<version> [...]]
Prints valid versions sorted by SemVer precedence
Options:
-r --range <range>
Print versions that match the specified range.
-i --increment [<level>]
Increment a version by the specified level. Level can
be one of: major, minor, patch, premajor, preminor,
prepatch, or prerelease. Default level is 'patch'.
Only one version may be specified.
--preid <identifier>
Identifier to be used to prefix premajor, preminor,
prepatch or prerelease version increments.
-l --loose
Interpret versions and ranges loosely
-p --include-prerelease
Always include prerelease versions in range matching
-c --coerce
Coerce a string into SemVer if possible
(does not imply --loose)
Program exits successfully if any valid version satisfies
all supplied ranges, and prints all satisfying versions.
If no satisfying versions are found, then exits failure.
Versions are printed in ascending order, so supplying
multiple versions to the utility will just sort them.
```
## Versions
A "version" is described by the `v2.0.0` specification found at
<https://semver.org/>.
A leading `"="` or `"v"` character is stripped off and ignored.
## Ranges
A `version range` is a set of `comparators` which specify versions
that satisfy the range.
A `comparator` is composed of an `operator` and a `version`. The set
of primitive `operators` is:
* `<` Less than
* `<=` Less than or equal to
* `>` Greater than
* `>=` Greater than or equal to
* `=` Equal. If no operator is specified, then equality is assumed,
so this operator is optional, but MAY be included.
For example, the comparator `>=1.2.7` would match the versions
`1.2.7`, `1.2.8`, `2.5.3`, and `1.3.9`, but not the versions `1.2.6`
or `1.1.0`.
Comparators can be joined by whitespace to form a `comparator set`,
which is satisfied by the **intersection** of all of the comparators
it includes.
A range is composed of one or more comparator sets, joined by `||`. A
version matches a range if and only if every comparator in at least
one of the `||`-separated comparator sets is satisfied by the version.
For example, the range `>=1.2.7 <1.3.0` would match the versions
`1.2.7`, `1.2.8`, and `1.2.99`, but not the versions `1.2.6`, `1.3.0`,
or `1.1.0`.
The range `1.2.7 || >=1.2.9 <2.0.0` would match the versions `1.2.7`,
`1.2.9`, and `1.4.6`, but not the versions `1.2.8` or `2.0.0`.
### Prerelease Tags
If a version has a prerelease tag (for example, `1.2.3-alpha.3`) then
it will only be allowed to satisfy comparator sets if at least one
comparator with the same `[major, minor, patch]` tuple also has a
prerelease tag.
For example, the range `>1.2.3-alpha.3` would be allowed to match the
version `1.2.3-alpha.7`, but it would *not* be satisfied by
`3.4.5-alpha.9`, even though `3.4.5-alpha.9` is technically "greater
than" `1.2.3-alpha.3` according to the SemVer sort rules. The version
range only accepts prerelease tags on the `1.2.3` version. The
version `3.4.5` *would* satisfy the range, because it does not have a
prerelease flag, and `3.4.5` is greater than `1.2.3-alpha.7`.
The purpose for this behavior is twofold. First, prerelease versions
frequently are updated very quickly, and contain many breaking changes
that are (by the author's design) not yet fit for public consumption.
Therefore, by default, they are excluded from range matching
semantics.
Second, a user who has opted into using a prerelease version has
clearly indicated the intent to use *that specific* set of
alpha/beta/rc versions. By including a prerelease tag in the range,
the user is indicating that they are aware of the risk. However, it
is still not appropriate to assume that they have opted into taking a
similar risk on the *next* set of prerelease versions.
Note that this behavior can be suppressed (treating all prerelease
versions as if they were normal versions, for the purpose of range
matching) by setting the `includePrerelease` flag on the options
object to any
[functions](https://github.com/npm/node-semver#functions) that do
range matching.
#### Prerelease Identifiers
The method `.inc` takes an additional `identifier` string argument that
will append the value of the string as a prerelease identifier:
```javascript
semver.inc('1.2.3', 'prerelease', 'beta')
// '1.2.4-beta.0'
```
command-line example:
```bash
$ semver 1.2.3 -i prerelease --preid beta
1.2.4-beta.0
```
Which then can be used to increment further:
```bash
$ semver 1.2.4-beta.0 -i prerelease
1.2.4-beta.1
```
### Advanced Range Syntax
Advanced range syntax desugars to primitive comparators in
deterministic ways.
Advanced ranges may be combined in the same way as primitive
comparators using white space or `||`.
#### Hyphen Ranges `X.Y.Z - A.B.C`
Specifies an inclusive set.
* `1.2.3 - 2.3.4` := `>=1.2.3 <=2.3.4`
If a partial version is provided as the first version in the inclusive
range, then the missing pieces are replaced with zeroes.
* `1.2 - 2.3.4` := `>=1.2.0 <=2.3.4`
If a partial version is provided as the second version in the
inclusive range, then all versions that start with the supplied parts
of the tuple are accepted, but nothing that would be greater than the
provided tuple parts.
* `1.2.3 - 2.3` := `>=1.2.3 <2.4.0`
* `1.2.3 - 2` := `>=1.2.3 <3.0.0`
#### X-Ranges `1.2.x` `1.X` `1.2.*` `*`
Any of `X`, `x`, or `*` may be used to "stand in" for one of the
numeric values in the `[major, minor, patch]` tuple.
* `*` := `>=0.0.0` (Any version satisfies)
* `1.x` := `>=1.0.0 <2.0.0` (Matching major version)
* `1.2.x` := `>=1.2.0 <1.3.0` (Matching major and minor versions)
A partial version range is treated as an X-Range, so the special
character is in fact optional.
* `""` (empty string) := `*` := `>=0.0.0`
* `1` := `1.x.x` := `>=1.0.0 <2.0.0`
* `1.2` := `1.2.x` := `>=1.2.0 <1.3.0`
#### Tilde Ranges `~1.2.3` `~1.2` `~1`
Allows patch-level changes if a minor version is specified on the
comparator. Allows minor-level changes if not.
* `~1.2.3` := `>=1.2.3 <1.(2+1).0` := `>=1.2.3 <1.3.0`
* `~1.2` := `>=1.2.0 <1.(2+1).0` := `>=1.2.0 <1.3.0` (Same as `1.2.x`)
* `~1` := `>=1.0.0 <(1+1).0.0` := `>=1.0.0 <2.0.0` (Same as `1.x`)
* `~0.2.3` := `>=0.2.3 <0.(2+1).0` := `>=0.2.3 <0.3.0`
* `~0.2` := `>=0.2.0 <0.(2+1).0` := `>=0.2.0 <0.3.0` (Same as `0.2.x`)
* `~0` := `>=0.0.0 <(0+1).0.0` := `>=0.0.0 <1.0.0` (Same as `0.x`)
* `~1.2.3-beta.2` := `>=1.2.3-beta.2 <1.3.0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
#### Caret Ranges `^1.2.3` `^0.2.5` `^0.0.4`
Allows changes that do not modify the left-most non-zero digit in the
`[major, minor, patch]` tuple. In other words, this allows patch and
minor updates for versions `1.0.0` and above, patch updates for
versions `0.X >=0.1.0`, and *no* updates for versions `0.0.X`.
Many authors treat a `0.x` version as if the `x` were the major
"breaking-change" indicator.
Caret ranges are ideal when an author may make breaking changes
between `0.2.4` and `0.3.0` releases, which is a common practice.
However, it presumes that there will *not* be breaking changes between
`0.2.4` and `0.2.5`. It allows for changes that are presumed to be
additive (but non-breaking), according to commonly observed practices.
* `^1.2.3` := `>=1.2.3 <2.0.0`
* `^0.2.3` := `>=0.2.3 <0.3.0`
* `^0.0.3` := `>=0.0.3 <0.0.4`
* `^1.2.3-beta.2` := `>=1.2.3-beta.2 <2.0.0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
* `^0.0.3-beta` := `>=0.0.3-beta <0.0.4` Note that prereleases in the
`0.0.3` version *only* will be allowed, if they are greater than or
equal to `beta`. So, `0.0.3-pr.2` would be allowed.
When parsing caret ranges, a missing `patch` value desugars to the
number `0`, but will allow flexibility within that value, even if the
major and minor versions are both `0`.
* `^1.2.x` := `>=1.2.0 <2.0.0`
* `^0.0.x` := `>=0.0.0 <0.1.0`
* `^0.0` := `>=0.0.0 <0.1.0`
A missing `minor` and `patch` values will desugar to zero, but also
allow flexibility within those values, even if the major version is
zero.
* `^1.x` := `>=1.0.0 <2.0.0`
* `^0.x` := `>=0.0.0 <1.0.0`
### Range Grammar
Putting all this together, here is a Backus-Naur grammar for ranges,
for the benefit of parser authors:
```bnf
range-set ::= range ( logical-or range ) *
logical-or ::= ( ' ' ) * '||' ( ' ' ) *
range ::= hyphen | simple ( ' ' simple ) * | ''
hyphen ::= partial ' - ' partial
simple ::= primitive | partial | tilde | caret
primitive ::= ( '<' | '>' | '>=' | '<=' | '=' ) partial
partial ::= xr ( '.' xr ( '.' xr qualifier ? )? )?
xr ::= 'x' | 'X' | '*' | nr
nr ::= '0' | ['1'-'9'] ( ['0'-'9'] ) *
tilde ::= '~' partial
caret ::= '^' partial
qualifier ::= ( '-' pre )? ( '+' build )?
pre ::= parts
build ::= parts
parts ::= part ( '.' part ) *
part ::= nr | [-0-9A-Za-z]+
```
## Functions
All methods and classes take a final `options` object argument. All
options in this object are `false` by default. The options supported
are:
- `loose` Be more forgiving about not-quite-valid semver strings.
(Any resulting output will always be 100% strict compliant, of
course.) For backwards compatibility reasons, if the `options`
argument is a boolean value instead of an object, it is interpreted
to be the `loose` param.
- `includePrerelease` Set to suppress the [default
behavior](https://github.com/npm/node-semver#prerelease-tags) of
excluding prerelease tagged versions from ranges unless they are
explicitly opted into.
Strict-mode Comparators and Ranges will be strict about the SemVer
strings that they parse.
* `valid(v)`: Return the parsed version, or null if it's not valid.
* `inc(v, release)`: Return the version incremented by the release
type (`major`, `premajor`, `minor`, `preminor`, `patch`,
`prepatch`, or `prerelease`), or null if it's not valid
* `premajor` in one call will bump the version up to the next major
version and down to a prerelease of that major version.
`preminor`, and `prepatch` work the same way.
* If called from a non-prerelease version, the `prerelease` will work the
same as `prepatch`. It increments the patch version, then makes a
prerelease. If the input version is already a prerelease it simply
increments it.
* `prerelease(v)`: Returns an array of prerelease components, or null
if none exist. Example: `prerelease('1.2.3-alpha.1') -> ['alpha', 1]`
* `major(v)`: Return the major version number.
* `minor(v)`: Return the minor version number.
* `patch(v)`: Return the patch version number.
* `intersects(r1, r2, loose)`: Return true if the two supplied ranges
or comparators intersect.
* `parse(v)`: Attempt to parse a string as a semantic version, returning either
a `SemVer` object or `null`.
### Comparison
* `gt(v1, v2)`: `v1 > v2`
* `gte(v1, v2)`: `v1 >= v2`
* `lt(v1, v2)`: `v1 < v2`
* `lte(v1, v2)`: `v1 <= v2`
* `eq(v1, v2)`: `v1 == v2` This is true if they're logically equivalent,
even if they're not the exact same string. You already know how to
compare strings.
* `neq(v1, v2)`: `v1 != v2` The opposite of `eq`.
* `cmp(v1, comparator, v2)`: Pass in a comparison string, and it'll call
the corresponding function above. `"==="` and `"!=="` do simple
string comparison, but are included for completeness. Throws if an
invalid comparison string is provided.
* `compare(v1, v2)`: Return `0` if `v1 == v2`, or `1` if `v1` is greater, or `-1` if
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `rcompare(v1, v2)`: The reverse of compare. Sorts an array of versions
in descending order when passed to `Array.sort()`.
* `diff(v1, v2)`: Returns difference between two versions by the release type
(`major`, `premajor`, `minor`, `preminor`, `patch`, `prepatch`, or `prerelease`),
or null if the versions are the same.
### Comparators
* `intersects(comparator)`: Return true if the comparators intersect
### Ranges
* `validRange(range)`: Return the valid range or null if it's not valid
* `satisfies(version, range)`: Return true if the version satisfies the
range.
* `maxSatisfying(versions, range)`: Return the highest version in the list
that satisfies the range, or `null` if none of them do.
* `minSatisfying(versions, range)`: Return the lowest version in the list
that satisfies the range, or `null` if none of them do.
* `minVersion(range)`: Return the lowest version that can possibly match
the given range.
* `gtr(version, range)`: Return `true` if version is greater than all the
versions possible in the range.
* `ltr(version, range)`: Return `true` if version is less than all the
versions possible in the range.
* `outside(version, range, hilo)`: Return true if the version is outside
the bounds of the range in either the high or low direction. The
`hilo` argument must be either the string `'>'` or `'<'`. (This is
the function called by `gtr` and `ltr`.)
* `intersects(range)`: Return true if any of the ranges comparators intersect
Note that, since ranges may be non-contiguous, a version might not be
greater than a range, less than a range, *or* satisfy a range! For
example, the range `1.2 <1.2.9 || >2.0.0` would have a hole from `1.2.9`
until `2.0.0`, so the version `1.2.10` would not be greater than the
range (because `2.0.1` satisfies, which is higher), nor less than the
range (since `1.2.8` satisfies, which is lower), and it also does not
satisfy the range.
If you want to know if a version satisfies or does not satisfy a
range, use the `satisfies(version, range)` function.
### Coercion
* `coerce(version)`: Coerces a string to semver if possible
This aims to provide a very forgiving translation of a non-semver string to
semver. It looks for the first digit in a string, and consumes all
remaining characters which satisfy at least a partial semver (e.g., `1`,
`1.2`, `1.2.3`) up to the max permitted length (256 characters). Longer
versions are simply truncated (`4.6.3.9.2-alpha2` becomes `4.6.3`). All
surrounding text is simply ignored (`v3.4 replaces v3.3.1` becomes
`3.4.0`). Only text which lacks digits will fail coercion (`version one`
is not valid). The maximum length for any semver component considered for
coercion is 16 characters; longer components will be ignored
(`10000000000000000.4.7.4` becomes `4.7.4`). The maximum value for any
semver component is `Number.MAX_SAFE_INTEGER || (2**53 - 1)`; higher value
components are invalid (`9999999999999999.4.7.4` is likely invalid).
libsecp256k1
============
[](https://travis-ci.org/bitcoin-core/secp256k1)
Optimized C library for EC operations on curve secp256k1.
This library is a work in progress and is being used to research best practices. Use at your own risk.
Features:
* secp256k1 ECDSA signing/verification and key generation.
* Adding/multiplying private/public keys.
* Serialization/parsing of private keys, public keys, signatures.
* Constant time, constant memory access signing and pubkey generation.
* Derandomized DSA (via RFC6979 or with a caller provided function.)
* Very efficient implementation.
Implementation details
----------------------
* General
* No runtime heap allocation.
* Extensive testing infrastructure.
* Structured to facilitate review and analysis.
* Intended to be portable to any system with a C89 compiler and uint64_t support.
* No use of floating types.
* Expose only higher level interfaces to minimize the API surface and improve application security. ("Be difficult to use insecurely.")
* Field operations
* Optimized implementation of arithmetic modulo the curve's field size (2^256 - 0x1000003D1).
* Using 5 52-bit limbs (including hand-optimized assembly for x86_64, by Diederik Huys).
* Using 10 26-bit limbs.
* Field inverses and square roots using a sliding window over blocks of 1s (by Peter Dettman).
* Scalar operations
* Optimized implementation without data-dependent branches of arithmetic modulo the curve's order.
* Using 4 64-bit limbs (relying on __int128 support in the compiler).
* Using 8 32-bit limbs.
* Group operations
* Point addition formula specifically simplified for the curve equation (y^2 = x^3 + 7).
* Use addition between points in Jacobian and affine coordinates where possible.
* Use a unified addition/doubling formula where necessary to avoid data-dependent branches.
* Point/x comparison without a field inversion by comparison in the Jacobian coordinate space.
* Point multiplication for verification (a*P + b*G).
* Use wNAF notation for point multiplicands.
* Use a much larger window for multiples of G, using precomputed multiples.
* Use Shamir's trick to do the multiplication with the public key and the generator simultaneously.
* Optionally (off by default) use secp256k1's efficiently-computable endomorphism to split the P multiplicand into 2 half-sized ones.
* Point multiplication for signing
* Use a precomputed table of multiples of powers of 16 multiplied with the generator, so general multiplication becomes a series of additions.
* Intended to be completely free of timing sidechannels for secret-key operations (on reasonable hardware/toolchains)
* Access the table with branch-free conditional moves so memory access is uniform.
* No data-dependent branches
* Optional runtime blinding which attempts to frustrate differential power analysis.
* The precomputed tables add and eventually subtract points for which no known scalar (private key) is known, preventing even an attacker with control over the private key used to control the data internally.
Build steps
-----------
libsecp256k1 is built using autotools:
$ ./autogen.sh
$ ./configure
$ make
$ make check
$ sudo make install # optional
Exhaustive tests
-----------
$ ./exhaustive_tests
With valgrind, you might need to increase the max stack size:
$ valgrind --max-stackframe=2500000 ./exhaustive_tests
Reporting a vulnerability
------------
See [SECURITY.md](SECURITY.md)
TweetNaCl.js
============
Port of [TweetNaCl](http://tweetnacl.cr.yp.to) / [NaCl](http://nacl.cr.yp.to/)
to JavaScript for modern browsers and Node.js. Public domain.
[
](https://travis-ci.org/dchest/tweetnacl-js)
Demo: <https://dchest.github.io/tweetnacl-js/>
Documentation
=============
* [Overview](#overview)
* [Audits](#audits)
* [Installation](#installation)
* [Examples](#examples)
* [Usage](#usage)
* [Public-key authenticated encryption (box)](#public-key-authenticated-encryption-box)
* [Secret-key authenticated encryption (secretbox)](#secret-key-authenticated-encryption-secretbox)
* [Scalar multiplication](#scalar-multiplication)
* [Signatures](#signatures)
* [Hashing](#hashing)
* [Random bytes generation](#random-bytes-generation)
* [Constant-time comparison](#constant-time-comparison)
* [System requirements](#system-requirements)
* [Development and testing](#development-and-testing)
* [Benchmarks](#benchmarks)
* [Contributors](#contributors)
* [Who uses it](#who-uses-it)
Overview
--------
The primary goal of this project is to produce a translation of TweetNaCl to
JavaScript which is as close as possible to the original C implementation, plus
a thin layer of idiomatic high-level API on top of it.
There are two versions, you can use either of them:
* `nacl.js` is the port of TweetNaCl with minimum differences from the
original + high-level API.
* `nacl-fast.js` is like `nacl.js`, but with some functions replaced with
faster versions. (Used by default when importing NPM package.)
Audits
------
TweetNaCl.js has been audited by [Cure53](https://cure53.de/) in January-February
2017 (audit was sponsored by [Deletype](https://deletype.com)):
> The overall outcome of this audit signals a particularly positive assessment
> for TweetNaCl-js, as the testing team was unable to find any security
> problems in the library. It has to be noted that this is an exceptionally
> rare result of a source code audit for any project and must be seen as a true
> testament to a development proceeding with security at its core.
>
> To reiterate, the TweetNaCl-js project, the source code was found to be
> bug-free at this point.
>
> [...]
>
> In sum, the testing team is happy to recommend the TweetNaCl-js project as
> likely one of the safer and more secure cryptographic tools among its
> competition.
[Read full audit report](https://cure53.de/tweetnacl.pdf)
Installation
------------
You can install TweetNaCl.js via a package manager:
[Yarn](https://yarnpkg.com/):
$ yarn add tweetnacl
[NPM](https://www.npmjs.org/):
$ npm install tweetnacl
or [download source code](https://github.com/dchest/tweetnacl-js/releases).
Examples
--------
You can find usage examples in our [wiki](https://github.com/dchest/tweetnacl-js/wiki/Examples).
Usage
-----
All API functions accept and return bytes as `Uint8Array`s. If you need to
encode or decode strings, use functions from
<https://github.com/dchest/tweetnacl-util-js> or one of the more robust codec
packages.
In Node.js v4 and later `Buffer` objects are backed by `Uint8Array`s, so you
can freely pass them to TweetNaCl.js functions as arguments. The returned
objects are still `Uint8Array`s, so if you need `Buffer`s, you'll have to
convert them manually; make sure to convert using copying: `Buffer.from(array)`
(or `new Buffer(array)` in Node.js v4 or earlier), instead of sharing:
`Buffer.from(array.buffer)` (or `new Buffer(array.buffer)` Node 4 or earlier),
because some functions return subarrays of their buffers.
### Public-key authenticated encryption (box)
Implements *x25519-xsalsa20-poly1305*.
#### nacl.box.keyPair()
Generates a new random key pair for box and returns it as an object with
`publicKey` and `secretKey` members:
{
publicKey: ..., // Uint8Array with 32-byte public key
secretKey: ... // Uint8Array with 32-byte secret key
}
#### nacl.box.keyPair.fromSecretKey(secretKey)
Returns a key pair for box with public key corresponding to the given secret
key.
#### nacl.box(message, nonce, theirPublicKey, mySecretKey)
Encrypts and authenticates message using peer's public key, our secret key, and
the given nonce, which must be unique for each distinct message for a key pair.
Returns an encrypted and authenticated message, which is
`nacl.box.overheadLength` longer than the original message.
#### nacl.box.open(box, nonce, theirPublicKey, mySecretKey)
Authenticates and decrypts the given box with peer's public key, our secret
key, and the given nonce.
Returns the original message, or `null` if authentication fails.
#### nacl.box.before(theirPublicKey, mySecretKey)
Returns a precomputed shared key which can be used in `nacl.box.after` and
`nacl.box.open.after`.
#### nacl.box.after(message, nonce, sharedKey)
Same as `nacl.box`, but uses a shared key precomputed with `nacl.box.before`.
#### nacl.box.open.after(box, nonce, sharedKey)
Same as `nacl.box.open`, but uses a shared key precomputed with `nacl.box.before`.
#### Constants
##### nacl.box.publicKeyLength = 32
Length of public key in bytes.
##### nacl.box.secretKeyLength = 32
Length of secret key in bytes.
##### nacl.box.sharedKeyLength = 32
Length of precomputed shared key in bytes.
##### nacl.box.nonceLength = 24
Length of nonce in bytes.
##### nacl.box.overheadLength = 16
Length of overhead added to box compared to original message.
### Secret-key authenticated encryption (secretbox)
Implements *xsalsa20-poly1305*.
#### nacl.secretbox(message, nonce, key)
Encrypts and authenticates message using the key and the nonce. The nonce must
be unique for each distinct message for this key.
Returns an encrypted and authenticated message, which is
`nacl.secretbox.overheadLength` longer than the original message.
#### nacl.secretbox.open(box, nonce, key)
Authenticates and decrypts the given secret box using the key and the nonce.
Returns the original message, or `null` if authentication fails.
#### Constants
##### nacl.secretbox.keyLength = 32
Length of key in bytes.
##### nacl.secretbox.nonceLength = 24
Length of nonce in bytes.
##### nacl.secretbox.overheadLength = 16
Length of overhead added to secret box compared to original message.
### Scalar multiplication
Implements *x25519*.
#### nacl.scalarMult(n, p)
Multiplies an integer `n` by a group element `p` and returns the resulting
group element.
#### nacl.scalarMult.base(n)
Multiplies an integer `n` by a standard group element and returns the resulting
group element.
#### Constants
##### nacl.scalarMult.scalarLength = 32
Length of scalar in bytes.
##### nacl.scalarMult.groupElementLength = 32
Length of group element in bytes.
### Signatures
Implements [ed25519](http://ed25519.cr.yp.to).
#### nacl.sign.keyPair()
Generates new random key pair for signing and returns it as an object with
`publicKey` and `secretKey` members:
{
publicKey: ..., // Uint8Array with 32-byte public key
secretKey: ... // Uint8Array with 64-byte secret key
}
#### nacl.sign.keyPair.fromSecretKey(secretKey)
Returns a signing key pair with public key corresponding to the given
64-byte secret key. The secret key must have been generated by
`nacl.sign.keyPair` or `nacl.sign.keyPair.fromSeed`.
#### nacl.sign.keyPair.fromSeed(seed)
Returns a new signing key pair generated deterministically from a 32-byte seed.
The seed must contain enough entropy to be secure. This method is not
recommended for general use: instead, use `nacl.sign.keyPair` to generate a new
key pair from a random seed.
#### nacl.sign(message, secretKey)
Signs the message using the secret key and returns a signed message.
#### nacl.sign.open(signedMessage, publicKey)
Verifies the signed message and returns the message without signature.
Returns `null` if verification failed.
#### nacl.sign.detached(message, secretKey)
Signs the message using the secret key and returns a signature.
#### nacl.sign.detached.verify(message, signature, publicKey)
Verifies the signature for the message and returns `true` if verification
succeeded or `false` if it failed.
#### Constants
##### nacl.sign.publicKeyLength = 32
Length of signing public key in bytes.
##### nacl.sign.secretKeyLength = 64
Length of signing secret key in bytes.
##### nacl.sign.seedLength = 32
Length of seed for `nacl.sign.keyPair.fromSeed` in bytes.
##### nacl.sign.signatureLength = 64
Length of signature in bytes.
### Hashing
Implements *SHA-512*.
#### nacl.hash(message)
Returns SHA-512 hash of the message.
#### Constants
##### nacl.hash.hashLength = 64
Length of hash in bytes.
### Random bytes generation
#### nacl.randomBytes(length)
Returns a `Uint8Array` of the given length containing random bytes of
cryptographic quality.
**Implementation note**
TweetNaCl.js uses the following methods to generate random bytes,
depending on the platform it runs on:
* `window.crypto.getRandomValues` (WebCrypto standard)
* `window.msCrypto.getRandomValues` (Internet Explorer 11)
* `crypto.randomBytes` (Node.js)
If the platform doesn't provide a suitable PRNG, the following functions,
which require random numbers, will throw exception:
* `nacl.randomBytes`
* `nacl.box.keyPair`
* `nacl.sign.keyPair`
Other functions are deterministic and will continue working.
If a platform you are targeting doesn't implement secure random number
generator, but you somehow have a cryptographically-strong source of entropy
(not `Math.random`!), and you know what you are doing, you can plug it into
TweetNaCl.js like this:
nacl.setPRNG(function(x, n) {
// ... copy n random bytes into x ...
});
Note that `nacl.setPRNG` *completely replaces* internal random byte generator
with the one provided.
### Constant-time comparison
#### nacl.verify(x, y)
Compares `x` and `y` in constant time and returns `true` if their lengths are
non-zero and equal, and their contents are equal.
Returns `false` if either of the arguments has zero length, or arguments have
different lengths, or their contents differ.
System requirements
-------------------
TweetNaCl.js supports modern browsers that have a cryptographically secure
pseudorandom number generator and typed arrays, including the latest versions
of:
* Chrome
* Firefox
* Safari (Mac, iOS)
* Internet Explorer 11
Other systems:
* Node.js
Development and testing
------------------------
Install NPM modules needed for development:
$ npm install
To build minified versions:
$ npm run build
Tests use minified version, so make sure to rebuild it every time you change
`nacl.js` or `nacl-fast.js`.
### Testing
To run tests in Node.js:
$ npm run test-node
By default all tests described here work on `nacl.min.js`. To test other
versions, set environment variable `NACL_SRC` to the file name you want to test.
For example, the following command will test fast minified version:
$ NACL_SRC=nacl-fast.min.js npm run test-node
To run full suite of tests in Node.js, including comparing outputs of
JavaScript port to outputs of the original C version:
$ npm run test-node-all
To prepare tests for browsers:
$ npm run build-test-browser
and then open `test/browser/test.html` (or `test/browser/test-fast.html`) to
run them.
To run tests in both Node and Electron:
$ npm test
### Benchmarking
To run benchmarks in Node.js:
$ npm run bench
$ NACL_SRC=nacl-fast.min.js npm run bench
To run benchmarks in a browser, open `test/benchmark/bench.html` (or
`test/benchmark/bench-fast.html`).
Benchmarks
----------
For reference, here are benchmarks from MacBook Pro (Retina, 13-inch, Mid 2014)
laptop with 2.6 GHz Intel Core i5 CPU (Intel) in Chrome 53/OS X and Xiaomi Redmi
Note 3 smartphone with 1.8 GHz Qualcomm Snapdragon 650 64-bit CPU (ARM) in
Chrome 52/Android:
| | nacl.js Intel | nacl-fast.js Intel | nacl.js ARM | nacl-fast.js ARM |
| ------------- |:-------------:|:-------------------:|:-------------:|:-----------------:|
| salsa20 | 1.3 MB/s | 128 MB/s | 0.4 MB/s | 43 MB/s |
| poly1305 | 13 MB/s | 171 MB/s | 4 MB/s | 52 MB/s |
| hash | 4 MB/s | 34 MB/s | 0.9 MB/s | 12 MB/s |
| secretbox 1K | 1113 op/s | 57583 op/s | 334 op/s | 14227 op/s |
| box 1K | 145 op/s | 718 op/s | 37 op/s | 368 op/s |
| scalarMult | 171 op/s | 733 op/s | 56 op/s | 380 op/s |
| sign | 77 op/s | 200 op/s | 20 op/s | 61 op/s |
| sign.open | 39 op/s | 102 op/s | 11 op/s | 31 op/s |
(You can run benchmarks on your devices by clicking on the links at the bottom
of the [home page](https://tweetnacl.js.org)).
In short, with *nacl-fast.js* and 1024-byte messages you can expect to encrypt and
authenticate more than 57000 messages per second on a typical laptop or more than
14000 messages per second on a $170 smartphone, sign about 200 and verify 100
messages per second on a laptop or 60 and 30 messages per second on a smartphone,
per CPU core (with Web Workers you can do these operations in parallel),
which is good enough for most applications.
Contributors
------------
See AUTHORS.md file.
Third-party libraries based on TweetNaCl.js
-------------------------------------------
* [forward-secrecy](https://github.com/alax/forward-secrecy) — Axolotl ratchet implementation
* [nacl-stream](https://github.com/dchest/nacl-stream-js) - streaming encryption
* [tweetnacl-auth-js](https://github.com/dchest/tweetnacl-auth-js) — implementation of [`crypto_auth`](http://nacl.cr.yp.to/auth.html)
* [tweetnacl-sealed-box](https://github.com/whs/tweetnacl-sealed-box) — implementation of [`sealed boxes`](https://download.libsodium.org/doc/public-key_cryptography/sealed_boxes.html)
* [chloride](https://github.com/dominictarr/chloride) - unified API for various NaCl modules
Who uses it
-----------
Some notable users of TweetNaCl.js:
* [GitHub](https://github.com)
* [MEGA](https://github.com/meganz/webclient)
* [Stellar](https://www.stellar.org/)
* [miniLock](https://github.com/kaepora/miniLock)
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# EthObject
Trying to serialize Ethereum Trie / LevelDB data from hex, buffers and rpc into the same format is tough. This library aims to solve that with re-usable and composable objects that you can just call Object.from<X> to ingest new data.
EthObjects hold Ethereum bare bones data with lots of helper functions for viewing and moving them in and out of other popular formats.
```
npm install eth-object
```
The following objects are supported:
```javascript
const { Account, Header, Log, Proof, Receipt, Transaction } = require('eth-object')
```
## Formating
The data formats used/returned for account, `header`, `log`, `proof`, `receipt`, and `transaction` are `eth-object`s. They mimic the native Ethereum format of being _arrays of byteArrays and nested arrays (of the same)_. This is the format you would find in the native database after being rlp-decoded.
An account, for example, will look like this:
```javascript
// [
// <Buffer 01>,
// <Buffer >,
// <Buffer c1 49 53 a6 4f 69 63 26 19 63 6f bd f3 27 e8 83 43 6b 9f d1 b1 02 52 20 e5 0f b7 0a b7 d2 e2 a8>,
// <Buffer f7 cf 62 32 b8 d6 55 b9 22 68 b3 56 53 25 e8 89 7f 2f 82 d6 5a 4e aa f4 e7 8f ce f0 4e 8f ee 6a>,
// ]
```
Its a 4-item array of _bytearrays_ representing the _nonce, balance, storageRoot, and codeHash_ respectively.
But they not just simple arrays that do this:
```javascript
console.log(account[0]) // => <buffer 01>
```
They also have helper methods for:
- The object's named fields property:
```javascript
console.log(account.nonce) // => <buffer 01>
```
- Conversion to printable formats
```javascript
console.log(account.toJson())
// {
// "nonce":"0x01",
// "balance":"0x",
// "storageRoot":"0xc14953a64f69632619636fbdf327e883436b9fd1b1025220e50fb70ab7d2e2a8",
// "codeHash":"0xf7cf6232b8d655b92268b3565325e8897f2f82d65a4eaaf4e78fcef04e8fee6a"
// }
```
- Conversion to the native bytes:
```javascript
console.log(account.buffer) // native format (used to calculate hashes and roots)
// <Buffer f8 44 01 80 a0 c1 49 53 a6 4f 69 63 26 19 63 6f bd f3 27 e8 83 43 6b 9f d1 b1 02 52 20 e5 0f b7 0a b7 d2 e2 a8 a0 f7 cf 62 32 b8 d6 55 b9 22 68 b3 56 ... >
```
- A text-pastable version of the bytes
```javascript
console.log(account.hex) // rlp encoded bytes as a hex string
// "0xf8440180a0c14953a64f69632619636fbdf327e883436b9fd1b1025220e50fb70ab7d2e2a8a0f7cf6232b8d655b92268b3565325e8897f2f82d65a4eaaf4e78fcef04e8fee6a"
```
And they can be created from a direct RPC result or any other format that you may find yourself with:
```javascript
Account.fromRpc(rpcResult)
Account.fromHex(hexString)
Account.fromBuffer(Bytes)
Account.fromRaw(nativeArray)
```
# isobject [](https://www.npmjs.com/package/isobject) [](https://npmjs.org/package/isobject) [](https://travis-ci.org/jonschlinkert/isobject)
Returns true if the value is an object and not an array or null.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install isobject --save
```
Use [is-plain-object](https://github.com/jonschlinkert/is-plain-object) if you want only objects that are created by the `Object` constructor.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install isobject
```
Install with [bower](http://bower.io/)
```sh
$ bower install isobject
```
## Usage
```js
var isObject = require('isobject');
```
**True**
All of the following return `true`:
```js
isObject({});
isObject(Object.create({}));
isObject(Object.create(Object.prototype));
isObject(Object.create(null));
isObject({});
isObject(new Foo);
isObject(/foo/);
```
**False**
All of the following return `false`:
```js
isObject();
isObject(function () {});
isObject(1);
isObject([]);
isObject(undefined);
isObject(null);
```
## Related projects
You might also be interested in these projects:
[merge-deep](https://www.npmjs.com/package/merge-deep): Recursively merge values in a javascript object. | [homepage](https://github.com/jonschlinkert/merge-deep)
* [extend-shallow](https://www.npmjs.com/package/extend-shallow): Extend an object with the properties of additional objects. node.js/javascript util. | [homepage](https://github.com/jonschlinkert/extend-shallow)
* [is-plain-object](https://www.npmjs.com/package/is-plain-object): Returns true if an object was created by the `Object` constructor. | [homepage](https://github.com/jonschlinkert/is-plain-object)
* [kind-of](https://www.npmjs.com/package/kind-of): Get the native type of a value. | [homepage](https://github.com/jonschlinkert/kind-of)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/isobject/issues/new).
## Building docs
Generate readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install verb && npm run docs
```
Or, if [verb](https://github.com/verbose/verb) is installed globally:
```sh
$ verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/isobject/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v0.9.0, on April 25, 2016._
# <img src="docs_app/assets/Rx_Logo_S.png" alt="RxJS Logo" width="86" height="86"> RxJS: Reactive Extensions For JavaScript
[](https://circleci.com/gh/ReactiveX/rxjs/tree/6.x)
[](http://badge.fury.io/js/%40reactivex%2Frxjs)
[](https://gitter.im/Reactive-Extensions/RxJS?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
# RxJS 6 Stable
### MIGRATION AND RELEASE INFORMATION:
Find out how to update to v6, **automatically update your TypeScript code**, and more!
- [Current home is MIGRATION.md](./docs_app/content/guide/v6/migration.md)
### FOR V 5.X PLEASE GO TO [THE 5.0 BRANCH](https://github.com/ReactiveX/rxjs/tree/5.x)
Reactive Extensions Library for JavaScript. This is a rewrite of [Reactive-Extensions/RxJS](https://github.com/Reactive-Extensions/RxJS) and is the latest production-ready version of RxJS. This rewrite is meant to have better performance, better modularity, better debuggable call stacks, while staying mostly backwards compatible, with some breaking changes that reduce the API surface.
[Apache 2.0 License](LICENSE.txt)
- [Code of Conduct](CODE_OF_CONDUCT.md)
- [Contribution Guidelines](CONTRIBUTING.md)
- [Maintainer Guidelines](doc_app/content/maintainer-guidelines.md)
- [API Documentation](https://rxjs.dev/)
## Versions In This Repository
- [master](https://github.com/ReactiveX/rxjs/commits/master) - This is all of the current, unreleased work, which is against v6 of RxJS right now
- [stable](https://github.com/ReactiveX/rxjs/commits/stable) - This is the branch for the latest version you'd get if you do `npm install rxjs`
## Important
By contributing or commenting on issues in this repository, whether you've read them or not, you're agreeing to the [Contributor Code of Conduct](CODE_OF_CONDUCT.md). Much like traffic laws, ignorance doesn't grant you immunity.
## Installation and Usage
### ES6 via npm
```sh
npm install rxjs
```
It's recommended to pull in the Observable creation methods you need directly from `'rxjs'` as shown below with `range`. And you can pull in any operator you need from one spot, under `'rxjs/operators'`.
```ts
import { range } from "rxjs";
import { map, filter } from "rxjs/operators";
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
```
Here, we're using the built-in `pipe` method on Observables to combine operators. See [pipeable operators](https://github.com/ReactiveX/rxjs/blob/master/doc/pipeable-operators.md) for more information.
### CommonJS via npm
To install this library for CommonJS (CJS) usage, use the following command:
```sh
npm install rxjs
```
(Note: destructuring available in Node 8+)
```js
const { range } = require('rxjs');
const { map, filter } = require('rxjs/operators');
range(1, 200).pipe(
filter(x => x % 2 === 1),
map(x => x + x)
).subscribe(x => console.log(x));
```
### CDN
For CDN, you can use [unpkg](https://unpkg.com/):
https://unpkg.com/rxjs/bundles/rxjs.umd.min.js
The global namespace for rxjs is `rxjs`:
```js
const { range } = rxjs;
const { map, filter } = rxjs.operators;
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
```
## Goals
- Smaller overall bundles sizes
- Provide better performance than preceding versions of RxJS
- To model/follow the [Observable Spec Proposal](https://github.com/zenparsing/es-observable) to the observable
- Provide more modular file structure in a variety of formats
- Provide more debuggable call stacks than preceding versions of RxJS
## Building/Testing
- `npm run build_all` - builds everything
- `npm test` - runs tests
- `npm run test_no_cache` - run test with `ts-node` set to false
## Performance Tests
Run `npm run build_perf` or `npm run perf` to run the performance tests with `protractor`.
Run `npm run perf_micro [operator]` to run micro performance test benchmarking operator.
## Adding documentation
We appreciate all contributions to the documentation of any type. All of the information needed to get the docs app up and running locally as well as how to contribute can be found in the [documentation directory](./docs_app).
## Generating PNG marble diagrams
The script `npm run tests2png` requires some native packages installed locally: `imagemagick`, `graphicsmagick`, and `ghostscript`.
For Mac OS X with [Homebrew](http://brew.sh/):
- `brew install imagemagick`
- `brew install graphicsmagick`
- `brew install ghostscript`
- You may need to install the Ghostscript fonts manually:
- Download the tarball from the [gs-fonts project](https://sourceforge.net/projects/gs-fonts)
- `mkdir -p /usr/local/share/ghostscript && tar zxvf /path/to/ghostscript-fonts.tar.gz -C /usr/local/share/ghostscript`
For Debian Linux:
- `sudo add-apt-repository ppa:dhor/myway`
- `apt-get install imagemagick`
- `apt-get install graphicsmagick`
- `apt-get install ghostscript`
For Windows and other Operating Systems, check the download instructions here:
- http://imagemagick.org
- http://www.graphicsmagick.org
- http://www.ghostscript.com/
# js-sha3
[](https://travis-ci.org/emn178/js-sha3)
[](https://coveralls.io/r/emn178/js-sha3?branch=master)
[](https://nodei.co/npm/js-sha3/)
A simple SHA-3 / Keccak / Shake hash function for JavaScript supports UTF-8 encoding.
## Notice
* Sha3 methods has been renamed to keccak since v0.2.0. It means that sha3 methods of v0.1.x are equal to keccak methods of v0.2.x and later.
* `buffer` method is deprecated. This maybe confuse with Buffer in node.js. Please use `arrayBuffer` instead.
## Demo
[SHA3-512 Online](http://emn178.github.io/online-tools/sha3_512.html)
[SHA3-384 Online](http://emn178.github.io/online-tools/sha3_384.html)
[SHA3-256 Online](http://emn178.github.io/online-tools/sha3_256.html)
[SHA3-224 Online](http://emn178.github.io/online-tools/sha3_224.html)
[Keccak-512 Online](http://emn178.github.io/online-tools/keccak_512.html)
[Keccak-384 Online](http://emn178.github.io/online-tools/keccak_384.html)
[Keccak-256 Online](http://emn178.github.io/online-tools/keccak_256.html)
[Keccak-224 Online](http://emn178.github.io/online-tools/keccak_224.html)
[Shake-128 Online](http://emn178.github.io/online-tools/shake_128.html)
[Shake-256 Online](http://emn178.github.io/online-tools/shake_256.html)
## Download
[Compress](https://raw.github.com/emn178/js-sha3/master/build/sha3.min.js)
[Uncompress](https://raw.github.com/emn178/js-sha3/master/src/sha3.js)
## Installation
You can also install js-sha3 by using Bower.
bower install js-sha3
For node.js, you can use this command to install:
npm install js-sha3
## Usage
You could use like this:
```JavaScript
sha3_512('Message to hash');
sha3_384('Message to hash');
sha3_256('Message to hash');
sha3_224('Message to hash');
keccak_512('Message to hash');
keccak_384('Message to hash');
keccak_256('Message to hash');
keccak_224('Message to hash');
shake_128('Message to hash', 256);
shake_256('Message to hash', 512);
// Support ArrayBuffer output
var buffer = keccak_224.buffer('Message to hash');
// Support Array output
var buffer = keccak_224.array('Message to hash');
// update hash
sha3_512.update('Message ').update('to ').update('hash').hex();
// specify shake output bits at first update
shake_128.update('Message ', 256).update('to ').update('hash').hex();
// or to use create
var hash = sha3_512.create();
hash.update('...');
hash.update('...');
hash.hex();
// specify shake output bits when creating
var hash = shake_128.create(256);
hash.update('...');
hash.update('...');
hash.hex();
```
If you use node.js, you should require the module first:
```JavaScript
sha3_512 = require('js-sha3').sha3_512;
sha3_384 = require('js-sha3').sha3_384;
sha3_256 = require('js-sha3').sha3_256;
sha3_224 = require('js-sha3').sha3_224;
keccak_512 = require('js-sha3').keccak_512;
keccak_384 = require('js-sha3').keccak_384;
keccak_256 = require('js-sha3').keccak_256;
keccak_224 = require('js-sha3').keccak_224;
shake_128 = require('js-sha3').shake_128;
shake_256 = require('js-sha3').shake_256;
```
If you use TypeScript, you can import like this:
```TypeScript
import { sha3_512 } from 'js-sha3';
```
## Example
Code
```JavaScript
sha3_512('');
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
sha3_512('The quick brown fox jumps over the lazy dog');
// 01dedd5de4ef14642445ba5f5b97c15e47b9ad931326e4b0727cd94cefc44fff23f07bf543139939b49128caf436dc1bdee54fcb24023a08d9403f9b4bf0d450
sha3_512('The quick brown fox jumps over the lazy dog.');
// 18f4f4bd419603f95538837003d9d254c26c23765565162247483f65c50303597bc9ce4d289f21d1c2f1f458828e33dc442100331b35e7eb031b5d38ba6460f8
sha3_384('');
// 0c63a75b845e4f7d01107d852e4c2485c51a50aaaa94fc61995e71bbee983a2ac3713831264adb47fb6bd1e058d5f004
sha3_384('The quick brown fox jumps over the lazy dog');
// 7063465e08a93bce31cd89d2e3ca8f602498696e253592ed26f07bf7e703cf328581e1471a7ba7ab119b1a9ebdf8be41
sha3_384('The quick brown fox jumps over the lazy dog.');
// 1a34d81695b622df178bc74df7124fe12fac0f64ba5250b78b99c1273d4b080168e10652894ecad5f1f4d5b965437fb9
sha3_256('');
// a7ffc6f8bf1ed76651c14756a061d662f580ff4de43b49fa82d80a4b80f8434a
sha3_256('The quick brown fox jumps over the lazy dog');
// 69070dda01975c8c120c3aada1b282394e7f032fa9cf32f4cb2259a0897dfc04
sha3_256('The quick brown fox jumps over the lazy dog.');
// a80f839cd4f83f6c3dafc87feae470045e4eb0d366397d5c6ce34ba1739f734d
sha3_224('');
// 6b4e03423667dbb73b6e15454f0eb1abd4597f9a1b078e3f5b5a6bc7
sha3_224('The quick brown fox jumps over the lazy dog');
// d15dadceaa4d5d7bb3b48f446421d542e08ad8887305e28d58335795
sha3_224('The quick brown fox jumps over the lazy dog.');
// 2d0708903833afabdd232a20201176e8b58c5be8a6fe74265ac54db0
keccak_512('');
// 0eab42de4c3ceb9235fc91acffe746b29c29a8c366b7c60e4e67c466f36a4304c00fa9caf9d87976ba469bcbe06713b435f091ef2769fb160cdab33d3670680e
keccak_512('The quick brown fox jumps over the lazy dog');
// d135bb84d0439dbac432247ee573a23ea7d3c9deb2a968eb31d47c4fb45f1ef4422d6c531b5b9bd6f449ebcc449ea94d0a8f05f62130fda612da53c79659f609
keccak_512('The quick brown fox jumps over the lazy dog.');
// ab7192d2b11f51c7dd744e7b3441febf397ca07bf812cceae122ca4ded6387889064f8db9230f173f6d1ab6e24b6e50f065b039f799f5592360a6558eb52d760
keccak_384('');
// 2c23146a63a29acf99e73b88f8c24eaa7dc60aa771780ccc006afbfa8fe2479b2dd2b21362337441ac12b515911957ff
keccak_384('The quick brown fox jumps over the lazy dog');
// 283990fa9d5fb731d786c5bbee94ea4db4910f18c62c03d173fc0a5e494422e8a0b3da7574dae7fa0baf005e504063b3
keccak_384('The quick brown fox jumps over the lazy dog.');
// 9ad8e17325408eddb6edee6147f13856ad819bb7532668b605a24a2d958f88bd5c169e56dc4b2f89ffd325f6006d820b
keccak_256('');
// c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470
keccak_256('The quick brown fox jumps over the lazy dog');
// 4d741b6f1eb29cb2a9b9911c82f56fa8d73b04959d3d9d222895df6c0b28aa15
keccak_256('The quick brown fox jumps over the lazy dog.');
// 578951e24efd62a3d63a86f7cd19aaa53c898fe287d2552133220370240b572d
keccak_224('');
// f71837502ba8e10837bdd8d365adb85591895602fc552b48b7390abd
keccak_224('The quick brown fox jumps over the lazy dog');
// 310aee6b30c47350576ac2873fa89fd190cdc488442f3ef654cf23fe
keccak_224('The quick brown fox jumps over the lazy dog.');
// c59d4eaeac728671c635ff645014e2afa935bebffdb5fbd207ffdeab
shake_128('', 256);
// 7f9c2ba4e88f827d616045507605853ed73b8093f6efbc88eb1a6eacfa66ef26
shake_256('', 512);
// 46b9dd2b0ba88d13233b3feb743eeb243fcd52ea62b81b82b50c27646ed5762fd75dc4ddd8c0f200cb05019d67b592f6fc821c49479ab48640292eacb3b7c4be
```
It also supports UTF-8 encoding:
Code
```JavaScript
sha3_512('中文');
// 059bbe2efc50cc30e4d8ec5a96be697e2108fcbf9193e1296192eddabc13b143c0120d059399a13d0d42651efe23a6c1ce2d1efb576c5b207fa2516050505af7
sha3_384('中文');
// 9fb5b99e3c546f2738dcd50a14e9aef9c313800c1bf8cf76bc9b2c3a23307841364c5a2d0794702662c5796fb72f5432
sha3_256('中文');
// ac5305da3d18be1aed44aa7c70ea548da243a59a5fd546f489348fd5718fb1a0
sha3_224('中文');
// 106d169e10b61c2a2a05554d3e631ec94467f8316640f29545d163ee
keccak_512('中文');
// 2f6a1bd50562230229af34b0ccf46b8754b89d23ae2c5bf7840b4acfcef86f87395edc0a00b2bfef53bafebe3b79de2e3e01cbd8169ddbb08bde888dcc893524
keccak_384('中文');
// 743f64bb7544c6ed923be4741b738dde18b7cee384a3a09c4e01acaaac9f19222cdee137702bd3aa05dc198373d87d6c
keccak_256('中文');
// 70a2b6579047f0a977fcb5e9120a4e07067bea9abb6916fbc2d13ffb9a4e4eee
keccak_224('中文');
// f71837502ba8e10837bdd8d365adb85591895602fc552b48b7390abd
```
It also supports byte `Array`, `Uint8Array`, `ArrayBuffer` input:
Code
```JavaScript
sha3_512([]);
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
sha3_512(new Uint8Array([]));
// a69f73cca23a9ac5c8b567dc185a756e97c982164fe25859e0d1dcc1475c80a615b2123af1f5f94c11e3e9402c3ac558f500199d95b6d3e301758586281dcd26
// ...
```
## Benchmark
[UTF8](http://jsperf.com/sha3/5)
[ASCII](http://jsperf.com/sha3/4)
## License
The project is released under the [MIT license](http://www.opensource.org/licenses/MIT).
## Contact
The project's website is located at https://github.com/emn178/js-sha3
Author: Chen, Yi-Cyuan ([email protected])
<img align="right" alt="Ajv logo" width="160" src="https://ajv.js.org/images/ajv_logo.png">
# Ajv: Another JSON Schema Validator
The fastest JSON Schema validator for Node.js and browser. Supports draft-04/06/07.
[](https://travis-ci.org/ajv-validator/ajv)
[](https://www.npmjs.com/package/ajv)
[](https://www.npmjs.com/package/ajv/v/7.0.0-beta.0)
[](https://www.npmjs.com/package/ajv)
[](https://coveralls.io/github/ajv-validator/ajv?branch=master)
[](https://gitter.im/ajv-validator/ajv)
[](https://github.com/sponsors/epoberezkin)
## Ajv v7 beta is released
[Ajv version 7.0.0-beta.0](https://github.com/ajv-validator/ajv/tree/v7-beta) is released with these changes:
- to reduce the mistakes in JSON schemas and unexpected validation results, [strict mode](./docs/strict-mode.md) is added - it prohibits ignored or ambiguous JSON Schema elements.
- to make code injection from untrusted schemas impossible, [code generation](./docs/codegen.md) is fully re-written to be safe.
- to simplify Ajv extensions, the new keyword API that is used by pre-defined keywords is available to user-defined keywords - it is much easier to define any keywords now, especially with subschemas.
- schemas are compiled to ES6 code (ES5 code generation is supported with an option).
- to improve reliability and maintainability the code is migrated to TypeScript.
**Please note**:
- the support for JSON-Schema draft-04 is removed - if you have schemas using "id" attributes you have to replace them with "\$id" (or continue using version 6 that will be supported until 02/28/2021).
- all formats are separated to ajv-formats package - they have to be explicitely added if you use them.
See [release notes](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0-beta.0) for the details.
To install the new version:
```bash
npm install ajv@beta
```
See [Getting started with v7](https://github.com/ajv-validator/ajv/tree/v7-beta#usage) for code example.
## Mozilla MOSS grant and OpenJS Foundation
[<img src="https://www.poberezkin.com/images/mozilla.png" width="240" height="68">](https://www.mozilla.org/en-US/moss/) [<img src="https://www.poberezkin.com/images/openjs.png" width="220" height="68">](https://openjsf.org/blog/2020/08/14/ajv-joins-openjs-foundation-as-an-incubation-project/)
Ajv has been awarded a grant from Mozilla’s [Open Source Support (MOSS) program](https://www.mozilla.org/en-US/moss/) in the “Foundational Technology” track! It will sponsor the development of Ajv support of [JSON Schema version 2019-09](https://tools.ietf.org/html/draft-handrews-json-schema-02) and of [JSON Type Definition](https://tools.ietf.org/html/draft-ucarion-json-type-definition-04).
Ajv also joined [OpenJS Foundation](https://openjsf.org/) – having this support will help ensure the longevity and stability of Ajv for all its users.
This [blog post](https://www.poberezkin.com/posts/2020-08-14-ajv-json-validator-mozilla-open-source-grant-openjs-foundation.html) has more details.
I am looking for the long term maintainers of Ajv – working with [ReadySet](https://www.thereadyset.co/), also sponsored by Mozilla, to establish clear guidelines for the role of a "maintainer" and the contribution standards, and to encourage a wider, more inclusive, contribution from the community.
## Please [sponsor Ajv development](https://github.com/sponsors/epoberezkin)
Since I asked to support Ajv development 40 people and 6 organizations contributed via GitHub and OpenCollective - this support helped receiving the MOSS grant!
Your continuing support is very important - the funds will be used to develop and maintain Ajv once the next major version is released.
Please sponsor Ajv via:
- [GitHub sponsors page](https://github.com/sponsors/epoberezkin) (GitHub will match it)
- [Ajv Open Collective️](https://opencollective.com/ajv)
Thank you.
#### Open Collective sponsors
<a href="https://opencollective.com/ajv"><img src="https://opencollective.com/ajv/individuals.svg?width=890"></a>
<a href="https://opencollective.com/ajv/organization/0/website"><img src="https://opencollective.com/ajv/organization/0/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/1/website"><img src="https://opencollective.com/ajv/organization/1/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/2/website"><img src="https://opencollective.com/ajv/organization/2/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/3/website"><img src="https://opencollective.com/ajv/organization/3/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/4/website"><img src="https://opencollective.com/ajv/organization/4/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/5/website"><img src="https://opencollective.com/ajv/organization/5/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/6/website"><img src="https://opencollective.com/ajv/organization/6/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/7/website"><img src="https://opencollective.com/ajv/organization/7/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/8/website"><img src="https://opencollective.com/ajv/organization/8/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/9/website"><img src="https://opencollective.com/ajv/organization/9/avatar.svg"></a>
## Using version 6
[JSON Schema draft-07](http://json-schema.org/latest/json-schema-validation.html) is published.
[Ajv version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0) that supports draft-07 is released. It may require either migrating your schemas or updating your code (to continue using draft-04 and v5 schemas, draft-06 schemas will be supported without changes).
__Please note__: To use Ajv with draft-06 schemas you need to explicitly add the meta-schema to the validator instance:
```javascript
ajv.addMetaSchema(require('ajv/lib/refs/json-schema-draft-06.json'));
```
To use Ajv with draft-04 schemas in addition to explicitly adding meta-schema you also need to use option schemaId:
```javascript
var ajv = new Ajv({schemaId: 'id'});
// If you want to use both draft-04 and draft-06/07 schemas:
// var ajv = new Ajv({schemaId: 'auto'});
ajv.addMetaSchema(require('ajv/lib/refs/json-schema-draft-04.json'));
```
## Contents
- [Performance](#performance)
- [Features](#features)
- [Getting started](#getting-started)
- [Frequently Asked Questions](https://github.com/ajv-validator/ajv/blob/master/FAQ.md)
- [Using in browser](#using-in-browser)
- [Ajv and Content Security Policies (CSP)](#ajv-and-content-security-policies-csp)
- [Command line interface](#command-line-interface)
- Validation
- [Keywords](#validation-keywords)
- [Annotation keywords](#annotation-keywords)
- [Formats](#formats)
- [Combining schemas with $ref](#ref)
- [$data reference](#data-reference)
- NEW: [$merge and $patch keywords](#merge-and-patch-keywords)
- [Defining custom keywords](#defining-custom-keywords)
- [Asynchronous schema compilation](#asynchronous-schema-compilation)
- [Asynchronous validation](#asynchronous-validation)
- [Security considerations](#security-considerations)
- [Security contact](#security-contact)
- [Untrusted schemas](#untrusted-schemas)
- [Circular references in objects](#circular-references-in-javascript-objects)
- [Trusted schemas](#security-risks-of-trusted-schemas)
- [ReDoS attack](#redos-attack)
- Modifying data during validation
- [Filtering data](#filtering-data)
- [Assigning defaults](#assigning-defaults)
- [Coercing data types](#coercing-data-types)
- API
- [Methods](#api)
- [Options](#options)
- [Validation errors](#validation-errors)
- [Plugins](#plugins)
- [Related packages](#related-packages)
- [Some packages using Ajv](#some-packages-using-ajv)
- [Tests, Contributing, Changes history](#tests)
- [Support, Code of conduct, License](#open-source-software-support)
## Performance
Ajv generates code using [doT templates](https://github.com/olado/doT) to turn JSON Schemas into super-fast validation functions that are efficient for v8 optimization.
Currently Ajv is the fastest and the most standard compliant validator according to these benchmarks:
- [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark) - 50% faster than the second place
- [jsck benchmark](https://github.com/pandastrike/jsck#benchmarks) - 20-190% faster
- [z-schema benchmark](https://rawgit.com/zaggino/z-schema/master/benchmark/results.html)
- [themis benchmark](https://cdn.rawgit.com/playlyfe/themis/master/benchmark/results.html)
Performance of different validators by [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark):
[](https://github.com/ebdrup/json-schema-benchmark/blob/master/README.md#performance)
## Features
- Ajv implements full JSON Schema [draft-06/07](http://json-schema.org/) and draft-04 standards:
- all validation keywords (see [JSON Schema validation keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md))
- full support of remote refs (remote schemas have to be added with `addSchema` or compiled to be available)
- support of circular references between schemas
- correct string lengths for strings with unicode pairs (can be turned off)
- [formats](#formats) defined by JSON Schema draft-07 standard and custom formats (can be turned off)
- [validates schemas against meta-schema](#api-validateschema)
- supports [browsers](#using-in-browser) and Node.js 0.10-14.x
- [asynchronous loading](#asynchronous-schema-compilation) of referenced schemas during compilation
- "All errors" validation mode with [option allErrors](#options)
- [error messages with parameters](#validation-errors) describing error reasons to allow creating custom error messages
- i18n error messages support with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package
- [filtering data](#filtering-data) from additional properties
- [assigning defaults](#assigning-defaults) to missing properties and items
- [coercing data](#coercing-data-types) to the types specified in `type` keywords
- [custom keywords](#defining-custom-keywords)
- draft-06/07 keywords `const`, `contains`, `propertyNames` and `if/then/else`
- draft-06 boolean schemas (`true`/`false` as a schema to always pass/fail).
- keywords `switch`, `patternRequired`, `formatMaximum` / `formatMinimum` and `formatExclusiveMaximum` / `formatExclusiveMinimum` from [JSON Schema extension proposals](https://github.com/json-schema/json-schema/wiki/v5-Proposals) with [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package
- [$data reference](#data-reference) to use values from the validated data as values for the schema keywords
- [asynchronous validation](#asynchronous-validation) of custom formats and keywords
## Install
```
npm install ajv
```
## <a name="usage"></a>Getting started
Try it in the Node.js REPL: https://tonicdev.com/npm/ajv
The fastest validation call:
```javascript
// Node.js require:
var Ajv = require('ajv');
// or ESM/TypeScript import
import Ajv from 'ajv';
var ajv = new Ajv(); // options can be passed, e.g. {allErrors: true}
var validate = ajv.compile(schema);
var valid = validate(data);
if (!valid) console.log(validate.errors);
```
or with less code
```javascript
// ...
var valid = ajv.validate(schema, data);
if (!valid) console.log(ajv.errors);
// ...
```
or
```javascript
// ...
var valid = ajv.addSchema(schema, 'mySchema')
.validate('mySchema', data);
if (!valid) console.log(ajv.errorsText());
// ...
```
See [API](#api) and [Options](#options) for more details.
Ajv compiles schemas to functions and caches them in all cases (using schema serialized with [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify) or a custom function as a key), so that the next time the same schema is used (not necessarily the same object instance) it won't be compiled again.
The best performance is achieved when using compiled functions returned by `compile` or `getSchema` methods (there is no additional function call).
__Please note__: every time a validation function or `ajv.validate` are called `errors` property is overwritten. You need to copy `errors` array reference to another variable if you want to use it later (e.g., in the callback). See [Validation errors](#validation-errors)
__Note for TypeScript users__: `ajv` provides its own TypeScript declarations
out of the box, so you don't need to install the deprecated `@types/ajv`
module.
## Using in browser
You can require Ajv directly from the code you browserify - in this case Ajv will be a part of your bundle.
If you need to use Ajv in several bundles you can create a separate UMD bundle using `npm run bundle` script (thanks to [siddo420](https://github.com/siddo420)).
Then you need to load Ajv in the browser:
```html
<script src="ajv.min.js"></script>
```
This bundle can be used with different module systems; it creates global `Ajv` if no module system is found.
The browser bundle is available on [cdnjs](https://cdnjs.com/libraries/ajv).
Ajv is tested with these browsers:
[](https://saucelabs.com/u/epoberezkin)
__Please note__: some frameworks, e.g. Dojo, may redefine global require in such way that is not compatible with CommonJS module format. In such case Ajv bundle has to be loaded before the framework and then you can use global Ajv (see issue [#234](https://github.com/ajv-validator/ajv/issues/234)).
### Ajv and Content Security Policies (CSP)
If you're using Ajv to compile a schema (the typical use) in a browser document that is loaded with a Content Security Policy (CSP), that policy will require a `script-src` directive that includes the value `'unsafe-eval'`.
:warning: NOTE, however, that `unsafe-eval` is NOT recommended in a secure CSP[[1]](https://developer.chrome.com/extensions/contentSecurityPolicy#relaxing-eval), as it has the potential to open the document to cross-site scripting (XSS) attacks.
In order to make use of Ajv without easing your CSP, you can [pre-compile a schema using the CLI](https://github.com/ajv-validator/ajv-cli#compile-schemas). This will transpile the schema JSON into a JavaScript file that exports a `validate` function that works simlarly to a schema compiled at runtime.
Note that pre-compilation of schemas is performed using [ajv-pack](https://github.com/ajv-validator/ajv-pack) and there are [some limitations to the schema features it can compile](https://github.com/ajv-validator/ajv-pack#limitations). A successfully pre-compiled schema is equivalent to the same schema compiled at runtime.
## Command line interface
CLI is available as a separate npm package [ajv-cli](https://github.com/ajv-validator/ajv-cli). It supports:
- compiling JSON Schemas to test their validity
- BETA: generating standalone module exporting a validation function to be used without Ajv (using [ajv-pack](https://github.com/ajv-validator/ajv-pack))
- migrate schemas to draft-07 (using [json-schema-migrate](https://github.com/epoberezkin/json-schema-migrate))
- validating data file(s) against JSON Schema
- testing expected validity of data against JSON Schema
- referenced schemas
- custom meta-schemas
- files in JSON, JSON5, YAML, and JavaScript format
- all Ajv options
- reporting changes in data after validation in [JSON-patch](https://tools.ietf.org/html/rfc6902) format
## Validation keywords
Ajv supports all validation keywords from draft-07 of JSON Schema standard:
- [type](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#type)
- [for numbers](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-numbers) - maximum, minimum, exclusiveMaximum, exclusiveMinimum, multipleOf
- [for strings](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-strings) - maxLength, minLength, pattern, format
- [for arrays](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-arrays) - maxItems, minItems, uniqueItems, items, additionalItems, [contains](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#contains)
- [for objects](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-objects) - maxProperties, minProperties, required, properties, patternProperties, additionalProperties, dependencies, [propertyNames](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#propertynames)
- [for all types](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-all-types) - enum, [const](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#const)
- [compound keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#compound-keywords) - not, oneOf, anyOf, allOf, [if/then/else](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#ifthenelse)
With [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package Ajv also supports validation keywords from [JSON Schema extension proposals](https://github.com/json-schema/json-schema/wiki/v5-Proposals) for JSON Schema standard:
- [patternRequired](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#patternrequired-proposed) - like `required` but with patterns that some property should match.
- [formatMaximum, formatMinimum, formatExclusiveMaximum, formatExclusiveMinimum](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#formatmaximum--formatminimum-and-exclusiveformatmaximum--exclusiveformatminimum-proposed) - setting limits for date, time, etc.
See [JSON Schema validation keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md) for more details.
## Annotation keywords
JSON Schema specification defines several annotation keywords that describe schema itself but do not perform any validation.
- `title` and `description`: information about the data represented by that schema
- `$comment` (NEW in draft-07): information for developers. With option `$comment` Ajv logs or passes the comment string to the user-supplied function. See [Options](#options).
- `default`: a default value of the data instance, see [Assigning defaults](#assigning-defaults).
- `examples` (NEW in draft-06): an array of data instances. Ajv does not check the validity of these instances against the schema.
- `readOnly` and `writeOnly` (NEW in draft-07): marks data-instance as read-only or write-only in relation to the source of the data (database, api, etc.).
- `contentEncoding`: [RFC 2045](https://tools.ietf.org/html/rfc2045#section-6.1 ), e.g., "base64".
- `contentMediaType`: [RFC 2046](https://tools.ietf.org/html/rfc2046), e.g., "image/png".
__Please note__: Ajv does not implement validation of the keywords `examples`, `contentEncoding` and `contentMediaType` but it reserves them. If you want to create a plugin that implements some of them, it should remove these keywords from the instance.
## Formats
Ajv implements formats defined by JSON Schema specification and several other formats. It is recommended NOT to use "format" keyword implementations with untrusted data, as they use potentially unsafe regular expressions - see [ReDoS attack](#redos-attack).
__Please note__: if you need to use "format" keyword to validate untrusted data, you MUST assess their suitability and safety for your validation scenarios.
The following formats are implemented for string validation with "format" keyword:
- _date_: full-date according to [RFC3339](http://tools.ietf.org/html/rfc3339#section-5.6).
- _time_: time with optional time-zone.
- _date-time_: date-time from the same source (time-zone is mandatory). `date`, `time` and `date-time` validate ranges in `full` mode and only regexp in `fast` mode (see [options](#options)).
- _uri_: full URI.
- _uri-reference_: URI reference, including full and relative URIs.
- _uri-template_: URI template according to [RFC6570](https://tools.ietf.org/html/rfc6570)
- _url_ (deprecated): [URL record](https://url.spec.whatwg.org/#concept-url).
- _email_: email address.
- _hostname_: host name according to [RFC1034](http://tools.ietf.org/html/rfc1034#section-3.5).
- _ipv4_: IP address v4.
- _ipv6_: IP address v6.
- _regex_: tests whether a string is a valid regular expression by passing it to RegExp constructor.
- _uuid_: Universally Unique IDentifier according to [RFC4122](http://tools.ietf.org/html/rfc4122).
- _json-pointer_: JSON-pointer according to [RFC6901](https://tools.ietf.org/html/rfc6901).
- _relative-json-pointer_: relative JSON-pointer according to [this draft](http://tools.ietf.org/html/draft-luff-relative-json-pointer-00).
__Please note__: JSON Schema draft-07 also defines formats `iri`, `iri-reference`, `idn-hostname` and `idn-email` for URLs, hostnames and emails with international characters. Ajv does not implement these formats. If you create Ajv plugin that implements them please make a PR to mention this plugin here.
There are two modes of format validation: `fast` and `full`. This mode affects formats `date`, `time`, `date-time`, `uri`, `uri-reference`, and `email`. See [Options](#options) for details.
You can add additional formats and replace any of the formats above using [addFormat](#api-addformat) method.
The option `unknownFormats` allows changing the default behaviour when an unknown format is encountered. In this case Ajv can either fail schema compilation (default) or ignore it (default in versions before 5.0.0). You also can allow specific format(s) that will be ignored. See [Options](#options) for details.
You can find regular expressions used for format validation and the sources that were used in [formats.js](https://github.com/ajv-validator/ajv/blob/master/lib/compile/formats.js).
## <a name="ref"></a>Combining schemas with $ref
You can structure your validation logic across multiple schema files and have schemas reference each other using `$ref` keyword.
Example:
```javascript
var schema = {
"$id": "http://example.com/schemas/schema.json",
"type": "object",
"properties": {
"foo": { "$ref": "defs.json#/definitions/int" },
"bar": { "$ref": "defs.json#/definitions/str" }
}
};
var defsSchema = {
"$id": "http://example.com/schemas/defs.json",
"definitions": {
"int": { "type": "integer" },
"str": { "type": "string" }
}
};
```
Now to compile your schema you can either pass all schemas to Ajv instance:
```javascript
var ajv = new Ajv({schemas: [schema, defsSchema]});
var validate = ajv.getSchema('http://example.com/schemas/schema.json');
```
or use `addSchema` method:
```javascript
var ajv = new Ajv;
var validate = ajv.addSchema(defsSchema)
.compile(schema);
```
See [Options](#options) and [addSchema](#api) method.
__Please note__:
- `$ref` is resolved as the uri-reference using schema $id as the base URI (see the example).
- References can be recursive (and mutually recursive) to implement the schemas for different data structures (such as linked lists, trees, graphs, etc.).
- You don't have to host your schema files at the URIs that you use as schema $id. These URIs are only used to identify the schemas, and according to JSON Schema specification validators should not expect to be able to download the schemas from these URIs.
- The actual location of the schema file in the file system is not used.
- You can pass the identifier of the schema as the second parameter of `addSchema` method or as a property name in `schemas` option. This identifier can be used instead of (or in addition to) schema $id.
- You cannot have the same $id (or the schema identifier) used for more than one schema - the exception will be thrown.
- You can implement dynamic resolution of the referenced schemas using `compileAsync` method. In this way you can store schemas in any system (files, web, database, etc.) and reference them without explicitly adding to Ajv instance. See [Asynchronous schema compilation](#asynchronous-schema-compilation).
## $data reference
With `$data` option you can use values from the validated data as the values for the schema keywords. See [proposal](https://github.com/json-schema-org/json-schema-spec/issues/51) for more information about how it works.
`$data` reference is supported in the keywords: const, enum, format, maximum/minimum, exclusiveMaximum / exclusiveMinimum, maxLength / minLength, maxItems / minItems, maxProperties / minProperties, formatMaximum / formatMinimum, formatExclusiveMaximum / formatExclusiveMinimum, multipleOf, pattern, required, uniqueItems.
The value of "$data" should be a [JSON-pointer](https://tools.ietf.org/html/rfc6901) to the data (the root is always the top level data object, even if the $data reference is inside a referenced subschema) or a [relative JSON-pointer](http://tools.ietf.org/html/draft-luff-relative-json-pointer-00) (it is relative to the current point in data; if the $data reference is inside a referenced subschema it cannot point to the data outside of the root level for this subschema).
Examples.
This schema requires that the value in property `smaller` is less or equal than the value in the property larger:
```javascript
var ajv = new Ajv({$data: true});
var schema = {
"properties": {
"smaller": {
"type": "number",
"maximum": { "$data": "1/larger" }
},
"larger": { "type": "number" }
}
};
var validData = {
smaller: 5,
larger: 7
};
ajv.validate(schema, validData); // true
```
This schema requires that the properties have the same format as their field names:
```javascript
var schema = {
"additionalProperties": {
"type": "string",
"format": { "$data": "0#" }
}
};
var validData = {
'date-time': '1963-06-19T08:30:06.283185Z',
email: '[email protected]'
}
```
`$data` reference is resolved safely - it won't throw even if some property is undefined. If `$data` resolves to `undefined` the validation succeeds (with the exclusion of `const` keyword). If `$data` resolves to incorrect type (e.g. not "number" for maximum keyword) the validation fails.
## $merge and $patch keywords
With the package [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) you can use the keywords `$merge` and `$patch` that allow extending JSON Schemas with patches using formats [JSON Merge Patch (RFC 7396)](https://tools.ietf.org/html/rfc7396) and [JSON Patch (RFC 6902)](https://tools.ietf.org/html/rfc6902).
To add keywords `$merge` and `$patch` to Ajv instance use this code:
```javascript
require('ajv-merge-patch')(ajv);
```
Examples.
Using `$merge`:
```json
{
"$merge": {
"source": {
"type": "object",
"properties": { "p": { "type": "string" } },
"additionalProperties": false
},
"with": {
"properties": { "q": { "type": "number" } }
}
}
}
```
Using `$patch`:
```json
{
"$patch": {
"source": {
"type": "object",
"properties": { "p": { "type": "string" } },
"additionalProperties": false
},
"with": [
{ "op": "add", "path": "/properties/q", "value": { "type": "number" } }
]
}
}
```
The schemas above are equivalent to this schema:
```json
{
"type": "object",
"properties": {
"p": { "type": "string" },
"q": { "type": "number" }
},
"additionalProperties": false
}
```
The properties `source` and `with` in the keywords `$merge` and `$patch` can use absolute or relative `$ref` to point to other schemas previously added to the Ajv instance or to the fragments of the current schema.
See the package [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) for more information.
## Defining custom keywords
The advantages of using custom keywords are:
- allow creating validation scenarios that cannot be expressed using JSON Schema
- simplify your schemas
- help bringing a bigger part of the validation logic to your schemas
- make your schemas more expressive, less verbose and closer to your application domain
- implement custom data processors that modify your data (`modifying` option MUST be used in keyword definition) and/or create side effects while the data is being validated
If a keyword is used only for side-effects and its validation result is pre-defined, use option `valid: true/false` in keyword definition to simplify both generated code (no error handling in case of `valid: true`) and your keyword functions (no need to return any validation result).
The concerns you have to be aware of when extending JSON Schema standard with custom keywords are the portability and understanding of your schemas. You will have to support these custom keywords on other platforms and to properly document these keywords so that everybody can understand them in your schemas.
You can define custom keywords with [addKeyword](#api-addkeyword) method. Keywords are defined on the `ajv` instance level - new instances will not have previously defined keywords.
Ajv allows defining keywords with:
- validation function
- compilation function
- macro function
- inline compilation function that should return code (as string) that will be inlined in the currently compiled schema.
Example. `range` and `exclusiveRange` keywords using compiled schema:
```javascript
ajv.addKeyword('range', {
type: 'number',
compile: function (sch, parentSchema) {
var min = sch[0];
var max = sch[1];
return parentSchema.exclusiveRange === true
? function (data) { return data > min && data < max; }
: function (data) { return data >= min && data <= max; }
}
});
var schema = { "range": [2, 4], "exclusiveRange": true };
var validate = ajv.compile(schema);
console.log(validate(2.01)); // true
console.log(validate(3.99)); // true
console.log(validate(2)); // false
console.log(validate(4)); // false
```
Several custom keywords (typeof, instanceof, range and propertyNames) are defined in [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package - they can be used for your schemas and as a starting point for your own custom keywords.
See [Defining custom keywords](https://github.com/ajv-validator/ajv/blob/master/CUSTOM.md) for more details.
## Asynchronous schema compilation
During asynchronous compilation remote references are loaded using supplied function. See `compileAsync` [method](#api-compileAsync) and `loadSchema` [option](#options).
Example:
```javascript
var ajv = new Ajv({ loadSchema: loadSchema });
ajv.compileAsync(schema).then(function (validate) {
var valid = validate(data);
// ...
});
function loadSchema(uri) {
return request.json(uri).then(function (res) {
if (res.statusCode >= 400)
throw new Error('Loading error: ' + res.statusCode);
return res.body;
});
}
```
__Please note__: [Option](#options) `missingRefs` should NOT be set to `"ignore"` or `"fail"` for asynchronous compilation to work.
## Asynchronous validation
Example in Node.js REPL: https://tonicdev.com/esp/ajv-asynchronous-validation
You can define custom formats and keywords that perform validation asynchronously by accessing database or some other service. You should add `async: true` in the keyword or format definition (see [addFormat](#api-addformat), [addKeyword](#api-addkeyword) and [Defining custom keywords](#defining-custom-keywords)).
If your schema uses asynchronous formats/keywords or refers to some schema that contains them it should have `"$async": true` keyword so that Ajv can compile it correctly. If asynchronous format/keyword or reference to asynchronous schema is used in the schema without `$async` keyword Ajv will throw an exception during schema compilation.
__Please note__: all asynchronous subschemas that are referenced from the current or other schemas should have `"$async": true` keyword as well, otherwise the schema compilation will fail.
Validation function for an asynchronous custom format/keyword should return a promise that resolves with `true` or `false` (or rejects with `new Ajv.ValidationError(errors)` if you want to return custom errors from the keyword function).
Ajv compiles asynchronous schemas to [es7 async functions](http://tc39.github.io/ecmascript-asyncawait/) that can optionally be transpiled with [nodent](https://github.com/MatAtBread/nodent). Async functions are supported in Node.js 7+ and all modern browsers. You can also supply any other transpiler as a function via `processCode` option. See [Options](#options).
The compiled validation function has `$async: true` property (if the schema is asynchronous), so you can differentiate these functions if you are using both synchronous and asynchronous schemas.
Validation result will be a promise that resolves with validated data or rejects with an exception `Ajv.ValidationError` that contains the array of validation errors in `errors` property.
Example:
```javascript
var ajv = new Ajv;
// require('ajv-async')(ajv);
ajv.addKeyword('idExists', {
async: true,
type: 'number',
validate: checkIdExists
});
function checkIdExists(schema, data) {
return knex(schema.table)
.select('id')
.where('id', data)
.then(function (rows) {
return !!rows.length; // true if record is found
});
}
var schema = {
"$async": true,
"properties": {
"userId": {
"type": "integer",
"idExists": { "table": "users" }
},
"postId": {
"type": "integer",
"idExists": { "table": "posts" }
}
}
};
var validate = ajv.compile(schema);
validate({ userId: 1, postId: 19 })
.then(function (data) {
console.log('Data is valid', data); // { userId: 1, postId: 19 }
})
.catch(function (err) {
if (!(err instanceof Ajv.ValidationError)) throw err;
// data is invalid
console.log('Validation errors:', err.errors);
});
```
### Using transpilers with asynchronous validation functions.
[ajv-async](https://github.com/ajv-validator/ajv-async) uses [nodent](https://github.com/MatAtBread/nodent) to transpile async functions. To use another transpiler you should separately install it (or load its bundle in the browser).
#### Using nodent
```javascript
var ajv = new Ajv;
require('ajv-async')(ajv);
// in the browser if you want to load ajv-async bundle separately you can:
// window.ajvAsync(ajv);
var validate = ajv.compile(schema); // transpiled es7 async function
validate(data).then(successFunc).catch(errorFunc);
```
#### Using other transpilers
```javascript
var ajv = new Ajv({ processCode: transpileFunc });
var validate = ajv.compile(schema); // transpiled es7 async function
validate(data).then(successFunc).catch(errorFunc);
```
See [Options](#options).
## Security considerations
JSON Schema, if properly used, can replace data sanitisation. It doesn't replace other API security considerations. It also introduces additional security aspects to consider.
##### Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerabilities via GitHub issues.
##### Untrusted schemas
Ajv treats JSON schemas as trusted as your application code. This security model is based on the most common use case, when the schemas are static and bundled together with the application.
If your schemas are received from untrusted sources (or generated from untrusted data) there are several scenarios you need to prevent:
- compiling schemas can cause stack overflow (if they are too deep)
- compiling schemas can be slow (e.g. [#557](https://github.com/ajv-validator/ajv/issues/557))
- validating certain data can be slow
It is difficult to predict all the scenarios, but at the very least it may help to limit the size of untrusted schemas (e.g. limit JSON string length) and also the maximum schema object depth (that can be high for relatively small JSON strings). You also may want to mitigate slow regular expressions in `pattern` and `patternProperties` keywords.
Regardless the measures you take, using untrusted schemas increases security risks.
##### Circular references in JavaScript objects
Ajv does not support schemas and validated data that have circular references in objects. See [issue #802](https://github.com/ajv-validator/ajv/issues/802).
An attempt to compile such schemas or validate such data would cause stack overflow (or will not complete in case of asynchronous validation). Depending on the parser you use, untrusted data can lead to circular references.
##### Security risks of trusted schemas
Some keywords in JSON Schemas can lead to very slow validation for certain data. These keywords include (but may be not limited to):
- `pattern` and `format` for large strings - in some cases using `maxLength` can help mitigate it, but certain regular expressions can lead to exponential validation time even with relatively short strings (see [ReDoS attack](#redos-attack)).
- `patternProperties` for large property names - use `propertyNames` to mitigate, but some regular expressions can have exponential evaluation time as well.
- `uniqueItems` for large non-scalar arrays - use `maxItems` to mitigate
__Please note__: The suggestions above to prevent slow validation would only work if you do NOT use `allErrors: true` in production code (using it would continue validation after validation errors).
You can validate your JSON schemas against [this meta-schema](https://github.com/ajv-validator/ajv/blob/master/lib/refs/json-schema-secure.json) to check that these recommendations are followed:
```javascript
const isSchemaSecure = ajv.compile(require('ajv/lib/refs/json-schema-secure.json'));
const schema1 = {format: 'email'};
isSchemaSecure(schema1); // false
const schema2 = {format: 'email', maxLength: MAX_LENGTH};
isSchemaSecure(schema2); // true
```
__Please note__: following all these recommendation is not a guarantee that validation of untrusted data is safe - it can still lead to some undesirable results.
##### Content Security Policies (CSP)
See [Ajv and Content Security Policies (CSP)](#ajv-and-content-security-policies-csp)
## ReDoS attack
Certain regular expressions can lead to the exponential evaluation time even with relatively short strings.
Please assess the regular expressions you use in the schemas on their vulnerability to this attack - see [safe-regex](https://github.com/substack/safe-regex), for example.
__Please note__: some formats that Ajv implements use [regular expressions](https://github.com/ajv-validator/ajv/blob/master/lib/compile/formats.js) that can be vulnerable to ReDoS attack, so if you use Ajv to validate data from untrusted sources __it is strongly recommended__ to consider the following:
- making assessment of "format" implementations in Ajv.
- using `format: 'fast'` option that simplifies some of the regular expressions (although it does not guarantee that they are safe).
- replacing format implementations provided by Ajv with your own implementations of "format" keyword that either uses different regular expressions or another approach to format validation. Please see [addFormat](#api-addformat) method.
- disabling format validation by ignoring "format" keyword with option `format: false`
Whatever mitigation you choose, please assume all formats provided by Ajv as potentially unsafe and make your own assessment of their suitability for your validation scenarios.
## Filtering data
With [option `removeAdditional`](#options) (added by [andyscott](https://github.com/andyscott)) you can filter data during the validation.
This option modifies original data.
Example:
```javascript
var ajv = new Ajv({ removeAdditional: true });
var schema = {
"additionalProperties": false,
"properties": {
"foo": { "type": "number" },
"bar": {
"additionalProperties": { "type": "number" },
"properties": {
"baz": { "type": "string" }
}
}
}
}
var data = {
"foo": 0,
"additional1": 1, // will be removed; `additionalProperties` == false
"bar": {
"baz": "abc",
"additional2": 2 // will NOT be removed; `additionalProperties` != false
},
}
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 0, "bar": { "baz": "abc", "additional2": 2 }
```
If `removeAdditional` option in the example above were `"all"` then both `additional1` and `additional2` properties would have been removed.
If the option were `"failing"` then property `additional1` would have been removed regardless of its value and property `additional2` would have been removed only if its value were failing the schema in the inner `additionalProperties` (so in the example above it would have stayed because it passes the schema, but any non-number would have been removed).
__Please note__: If you use `removeAdditional` option with `additionalProperties` keyword inside `anyOf`/`oneOf` keywords your validation can fail with this schema, for example:
```json
{
"type": "object",
"oneOf": [
{
"properties": {
"foo": { "type": "string" }
},
"required": [ "foo" ],
"additionalProperties": false
},
{
"properties": {
"bar": { "type": "integer" }
},
"required": [ "bar" ],
"additionalProperties": false
}
]
}
```
The intention of the schema above is to allow objects with either the string property "foo" or the integer property "bar", but not with both and not with any other properties.
With the option `removeAdditional: true` the validation will pass for the object `{ "foo": "abc"}` but will fail for the object `{"bar": 1}`. It happens because while the first subschema in `oneOf` is validated, the property `bar` is removed because it is an additional property according to the standard (because it is not included in `properties` keyword in the same schema).
While this behaviour is unexpected (issues [#129](https://github.com/ajv-validator/ajv/issues/129), [#134](https://github.com/ajv-validator/ajv/issues/134)), it is correct. To have the expected behaviour (both objects are allowed and additional properties are removed) the schema has to be refactored in this way:
```json
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "integer" }
},
"additionalProperties": false,
"oneOf": [
{ "required": [ "foo" ] },
{ "required": [ "bar" ] }
]
}
```
The schema above is also more efficient - it will compile into a faster function.
## Assigning defaults
With [option `useDefaults`](#options) Ajv will assign values from `default` keyword in the schemas of `properties` and `items` (when it is the array of schemas) to the missing properties and items.
With the option value `"empty"` properties and items equal to `null` or `""` (empty string) will be considered missing and assigned defaults.
This option modifies original data.
__Please note__: the default value is inserted in the generated validation code as a literal, so the value inserted in the data will be the deep clone of the default in the schema.
Example 1 (`default` in `properties`):
```javascript
var ajv = new Ajv({ useDefaults: true });
var schema = {
"type": "object",
"properties": {
"foo": { "type": "number" },
"bar": { "type": "string", "default": "baz" }
},
"required": [ "foo", "bar" ]
};
var data = { "foo": 1 };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 1, "bar": "baz" }
```
Example 2 (`default` in `items`):
```javascript
var schema = {
"type": "array",
"items": [
{ "type": "number" },
{ "type": "string", "default": "foo" }
]
}
var data = [ 1 ];
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // [ 1, "foo" ]
```
`default` keywords in other cases are ignored:
- not in `properties` or `items` subschemas
- in schemas inside `anyOf`, `oneOf` and `not` (see [#42](https://github.com/ajv-validator/ajv/issues/42))
- in `if` subschema of `switch` keyword
- in schemas generated by custom macro keywords
The [`strictDefaults` option](#options) customizes Ajv's behavior for the defaults that Ajv ignores (`true` raises an error, and `"log"` outputs a warning).
## Coercing data types
When you are validating user inputs all your data properties are usually strings. The option `coerceTypes` allows you to have your data types coerced to the types specified in your schema `type` keywords, both to pass the validation and to use the correctly typed data afterwards.
This option modifies original data.
__Please note__: if you pass a scalar value to the validating function its type will be coerced and it will pass the validation, but the value of the variable you pass won't be updated because scalars are passed by value.
Example 1:
```javascript
var ajv = new Ajv({ coerceTypes: true });
var schema = {
"type": "object",
"properties": {
"foo": { "type": "number" },
"bar": { "type": "boolean" }
},
"required": [ "foo", "bar" ]
};
var data = { "foo": "1", "bar": "false" };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 1, "bar": false }
```
Example 2 (array coercions):
```javascript
var ajv = new Ajv({ coerceTypes: 'array' });
var schema = {
"properties": {
"foo": { "type": "array", "items": { "type": "number" } },
"bar": { "type": "boolean" }
}
};
var data = { "foo": "1", "bar": ["false"] };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": [1], "bar": false }
```
The coercion rules, as you can see from the example, are different from JavaScript both to validate user input as expected and to have the coercion reversible (to correctly validate cases where different types are defined in subschemas of "anyOf" and other compound keywords).
See [Coercion rules](https://github.com/ajv-validator/ajv/blob/master/COERCION.md) for details.
## API
##### new Ajv(Object options) -> Object
Create Ajv instance.
##### .compile(Object schema) -> Function<Object data>
Generate validating function and cache the compiled schema for future use.
Validating function returns a boolean value. This function has properties `errors` and `schema`. Errors encountered during the last validation are assigned to `errors` property (it is assigned `null` if there was no errors). `schema` property contains the reference to the original schema.
The schema passed to this method will be validated against meta-schema unless `validateSchema` option is false. If schema is invalid, an error will be thrown. See [options](#options).
##### <a name="api-compileAsync"></a>.compileAsync(Object schema [, Boolean meta] [, Function callback]) -> Promise
Asynchronous version of `compile` method that loads missing remote schemas using asynchronous function in `options.loadSchema`. This function returns a Promise that resolves to a validation function. An optional callback passed to `compileAsync` will be called with 2 parameters: error (or null) and validating function. The returned promise will reject (and the callback will be called with an error) when:
- missing schema can't be loaded (`loadSchema` returns a Promise that rejects).
- a schema containing a missing reference is loaded, but the reference cannot be resolved.
- schema (or some loaded/referenced schema) is invalid.
The function compiles schema and loads the first missing schema (or meta-schema) until all missing schemas are loaded.
You can asynchronously compile meta-schema by passing `true` as the second parameter.
See example in [Asynchronous compilation](#asynchronous-schema-compilation).
##### .validate(Object schema|String key|String ref, data) -> Boolean
Validate data using passed schema (it will be compiled and cached).
Instead of the schema you can use the key that was previously passed to `addSchema`, the schema id if it was present in the schema or any previously resolved reference.
Validation errors will be available in the `errors` property of Ajv instance (`null` if there were no errors).
__Please note__: every time this method is called the errors are overwritten so you need to copy them to another variable if you want to use them later.
If the schema is asynchronous (has `$async` keyword on the top level) this method returns a Promise. See [Asynchronous validation](#asynchronous-validation).
##### .addSchema(Array<Object>|Object schema [, String key]) -> Ajv
Add schema(s) to validator instance. This method does not compile schemas (but it still validates them). Because of that dependencies can be added in any order and circular dependencies are supported. It also prevents unnecessary compilation of schemas that are containers for other schemas but not used as a whole.
Array of schemas can be passed (schemas should have ids), the second parameter will be ignored.
Key can be passed that can be used to reference the schema and will be used as the schema id if there is no id inside the schema. If the key is not passed, the schema id will be used as the key.
Once the schema is added, it (and all the references inside it) can be referenced in other schemas and used to validate data.
Although `addSchema` does not compile schemas, explicit compilation is not required - the schema will be compiled when it is used first time.
By default the schema is validated against meta-schema before it is added, and if the schema does not pass validation the exception is thrown. This behaviour is controlled by `validateSchema` option.
__Please note__: Ajv uses the [method chaining syntax](https://en.wikipedia.org/wiki/Method_chaining) for all methods with the prefix `add*` and `remove*`.
This allows you to do nice things like the following.
```javascript
var validate = new Ajv().addSchema(schema).addFormat(name, regex).getSchema(uri);
```
##### .addMetaSchema(Array<Object>|Object schema [, String key]) -> Ajv
Adds meta schema(s) that can be used to validate other schemas. That function should be used instead of `addSchema` because there may be instance options that would compile a meta schema incorrectly (at the moment it is `removeAdditional` option).
There is no need to explicitly add draft-07 meta schema (http://json-schema.org/draft-07/schema) - it is added by default, unless option `meta` is set to `false`. You only need to use it if you have a changed meta-schema that you want to use to validate your schemas. See `validateSchema`.
##### <a name="api-validateschema"></a>.validateSchema(Object schema) -> Boolean
Validates schema. This method should be used to validate schemas rather than `validate` due to the inconsistency of `uri` format in JSON Schema standard.
By default this method is called automatically when the schema is added, so you rarely need to use it directly.
If schema doesn't have `$schema` property, it is validated against draft 6 meta-schema (option `meta` should not be false).
If schema has `$schema` property, then the schema with this id (that should be previously added) is used to validate passed schema.
Errors will be available at `ajv.errors`.
##### .getSchema(String key) -> Function<Object data>
Retrieve compiled schema previously added with `addSchema` by the key passed to `addSchema` or by its full reference (id). The returned validating function has `schema` property with the reference to the original schema.
##### .removeSchema([Object schema|String key|String ref|RegExp pattern]) -> Ajv
Remove added/cached schema. Even if schema is referenced by other schemas it can be safely removed as dependent schemas have local references.
Schema can be removed using:
- key passed to `addSchema`
- it's full reference (id)
- RegExp that should match schema id or key (meta-schemas won't be removed)
- actual schema object that will be stable-stringified to remove schema from cache
If no parameter is passed all schemas but meta-schemas will be removed and the cache will be cleared.
##### <a name="api-addformat"></a>.addFormat(String name, String|RegExp|Function|Object format) -> Ajv
Add custom format to validate strings or numbers. It can also be used to replace pre-defined formats for Ajv instance.
Strings are converted to RegExp.
Function should return validation result as `true` or `false`.
If object is passed it should have properties `validate`, `compare` and `async`:
- _validate_: a string, RegExp or a function as described above.
- _compare_: an optional comparison function that accepts two strings and compares them according to the format meaning. This function is used with keywords `formatMaximum`/`formatMinimum` (defined in [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package). It should return `1` if the first value is bigger than the second value, `-1` if it is smaller and `0` if it is equal.
- _async_: an optional `true` value if `validate` is an asynchronous function; in this case it should return a promise that resolves with a value `true` or `false`.
- _type_: an optional type of data that the format applies to. It can be `"string"` (default) or `"number"` (see https://github.com/ajv-validator/ajv/issues/291#issuecomment-259923858). If the type of data is different, the validation will pass.
Custom formats can be also added via `formats` option.
##### <a name="api-addkeyword"></a>.addKeyword(String keyword, Object definition) -> Ajv
Add custom validation keyword to Ajv instance.
Keyword should be different from all standard JSON Schema keywords and different from previously defined keywords. There is no way to redefine keywords or to remove keyword definition from the instance.
Keyword must start with a letter, `_` or `$`, and may continue with letters, numbers, `_`, `$`, or `-`.
It is recommended to use an application-specific prefix for keywords to avoid current and future name collisions.
Example Keywords:
- `"xyz-example"`: valid, and uses prefix for the xyz project to avoid name collisions.
- `"example"`: valid, but not recommended as it could collide with future versions of JSON Schema etc.
- `"3-example"`: invalid as numbers are not allowed to be the first character in a keyword
Keyword definition is an object with the following properties:
- _type_: optional string or array of strings with data type(s) that the keyword applies to. If not present, the keyword will apply to all types.
- _validate_: validating function
- _compile_: compiling function
- _macro_: macro function
- _inline_: compiling function that returns code (as string)
- _schema_: an optional `false` value used with "validate" keyword to not pass schema
- _metaSchema_: an optional meta-schema for keyword schema
- _dependencies_: an optional list of properties that must be present in the parent schema - it will be checked during schema compilation
- _modifying_: `true` MUST be passed if keyword modifies data
- _statements_: `true` can be passed in case inline keyword generates statements (as opposed to expression)
- _valid_: pass `true`/`false` to pre-define validation result, the result returned from validation function will be ignored. This option cannot be used with macro keywords.
- _$data_: an optional `true` value to support [$data reference](#data-reference) as the value of custom keyword. The reference will be resolved at validation time. If the keyword has meta-schema it would be extended to allow $data and it will be used to validate the resolved value. Supporting $data reference requires that keyword has validating function (as the only option or in addition to compile, macro or inline function).
- _async_: an optional `true` value if the validation function is asynchronous (whether it is compiled or passed in _validate_ property); in this case it should return a promise that resolves with a value `true` or `false`. This option is ignored in case of "macro" and "inline" keywords.
- _errors_: an optional boolean or string `"full"` indicating whether keyword returns errors. If this property is not set Ajv will determine if the errors were set in case of failed validation.
_compile_, _macro_ and _inline_ are mutually exclusive, only one should be used at a time. _validate_ can be used separately or in addition to them to support $data reference.
__Please note__: If the keyword is validating data type that is different from the type(s) in its definition, the validation function will not be called (and expanded macro will not be used), so there is no need to check for data type inside validation function or inside schema returned by macro function (unless you want to enforce a specific type and for some reason do not want to use a separate `type` keyword for that). In the same way as standard keywords work, if the keyword does not apply to the data type being validated, the validation of this keyword will succeed.
See [Defining custom keywords](#defining-custom-keywords) for more details.
##### .getKeyword(String keyword) -> Object|Boolean
Returns custom keyword definition, `true` for pre-defined keywords and `false` if the keyword is unknown.
##### .removeKeyword(String keyword) -> Ajv
Removes custom or pre-defined keyword so you can redefine them.
While this method can be used to extend pre-defined keywords, it can also be used to completely change their meaning - it may lead to unexpected results.
__Please note__: schemas compiled before the keyword is removed will continue to work without changes. To recompile schemas use `removeSchema` method and compile them again.
##### .errorsText([Array<Object> errors [, Object options]]) -> String
Returns the text with all errors in a String.
Options can have properties `separator` (string used to separate errors, ", " by default) and `dataVar` (the variable name that dataPaths are prefixed with, "data" by default).
## Options
Defaults:
```javascript
{
// validation and reporting options:
$data: false,
allErrors: false,
verbose: false,
$comment: false, // NEW in Ajv version 6.0
jsonPointers: false,
uniqueItems: true,
unicode: true,
nullable: false,
format: 'fast',
formats: {},
unknownFormats: true,
schemas: {},
logger: undefined,
// referenced schema options:
schemaId: '$id',
missingRefs: true,
extendRefs: 'ignore', // recommended 'fail'
loadSchema: undefined, // function(uri: string): Promise {}
// options to modify validated data:
removeAdditional: false,
useDefaults: false,
coerceTypes: false,
// strict mode options
strictDefaults: false,
strictKeywords: false,
strictNumbers: false,
// asynchronous validation options:
transpile: undefined, // requires ajv-async package
// advanced options:
meta: true,
validateSchema: true,
addUsedSchema: true,
inlineRefs: true,
passContext: false,
loopRequired: Infinity,
ownProperties: false,
multipleOfPrecision: false,
errorDataPath: 'object', // deprecated
messages: true,
sourceCode: false,
processCode: undefined, // function (str: string, schema: object): string {}
cache: new Cache,
serialize: undefined
}
```
##### Validation and reporting options
- _$data_: support [$data references](#data-reference). Draft 6 meta-schema that is added by default will be extended to allow them. If you want to use another meta-schema you need to use $dataMetaSchema method to add support for $data reference. See [API](#api).
- _allErrors_: check all rules collecting all errors. Default is to return after the first error.
- _verbose_: include the reference to the part of the schema (`schema` and `parentSchema`) and validated data in errors (false by default).
- _$comment_ (NEW in Ajv version 6.0): log or pass the value of `$comment` keyword to a function. Option values:
- `false` (default): ignore $comment keyword.
- `true`: log the keyword value to console.
- function: pass the keyword value, its schema path and root schema to the specified function
- _jsonPointers_: set `dataPath` property of errors using [JSON Pointers](https://tools.ietf.org/html/rfc6901) instead of JavaScript property access notation.
- _uniqueItems_: validate `uniqueItems` keyword (true by default).
- _unicode_: calculate correct length of strings with unicode pairs (true by default). Pass `false` to use `.length` of strings that is faster, but gives "incorrect" lengths of strings with unicode pairs - each unicode pair is counted as two characters.
- _nullable_: support keyword "nullable" from [Open API 3 specification](https://swagger.io/docs/specification/data-models/data-types/).
- _format_: formats validation mode. Option values:
- `"fast"` (default) - simplified and fast validation (see [Formats](#formats) for details of which formats are available and affected by this option).
- `"full"` - more restrictive and slow validation. E.g., 25:00:00 and 2015/14/33 will be invalid time and date in 'full' mode but it will be valid in 'fast' mode.
- `false` - ignore all format keywords.
- _formats_: an object with custom formats. Keys and values will be passed to `addFormat` method.
- _keywords_: an object with custom keywords. Keys and values will be passed to `addKeyword` method.
- _unknownFormats_: handling of unknown formats. Option values:
- `true` (default) - if an unknown format is encountered the exception is thrown during schema compilation. If `format` keyword value is [$data reference](#data-reference) and it is unknown the validation will fail.
- `[String]` - an array of unknown format names that will be ignored. This option can be used to allow usage of third party schemas with format(s) for which you don't have definitions, but still fail if another unknown format is used. If `format` keyword value is [$data reference](#data-reference) and it is not in this array the validation will fail.
- `"ignore"` - to log warning during schema compilation and always pass validation (the default behaviour in versions before 5.0.0). This option is not recommended, as it allows to mistype format name and it won't be validated without any error message. This behaviour is required by JSON Schema specification.
- _schemas_: an array or object of schemas that will be added to the instance. In case you pass the array the schemas must have IDs in them. When the object is passed the method `addSchema(value, key)` will be called for each schema in this object.
- _logger_: sets the logging method. Default is the global `console` object that should have methods `log`, `warn` and `error`. See [Error logging](#error-logging). Option values:
- custom logger - it should have methods `log`, `warn` and `error`. If any of these methods is missing an exception will be thrown.
- `false` - logging is disabled.
##### Referenced schema options
- _schemaId_: this option defines which keywords are used as schema URI. Option value:
- `"$id"` (default) - only use `$id` keyword as schema URI (as specified in JSON Schema draft-06/07), ignore `id` keyword (if it is present a warning will be logged).
- `"id"` - only use `id` keyword as schema URI (as specified in JSON Schema draft-04), ignore `$id` keyword (if it is present a warning will be logged).
- `"auto"` - use both `$id` and `id` keywords as schema URI. If both are present (in the same schema object) and different the exception will be thrown during schema compilation.
- _missingRefs_: handling of missing referenced schemas. Option values:
- `true` (default) - if the reference cannot be resolved during compilation the exception is thrown. The thrown error has properties `missingRef` (with hash fragment) and `missingSchema` (without it). Both properties are resolved relative to the current base id (usually schema id, unless it was substituted).
- `"ignore"` - to log error during compilation and always pass validation.
- `"fail"` - to log error and successfully compile schema but fail validation if this rule is checked.
- _extendRefs_: validation of other keywords when `$ref` is present in the schema. Option values:
- `"ignore"` (default) - when `$ref` is used other keywords are ignored (as per [JSON Reference](https://tools.ietf.org/html/draft-pbryan-zyp-json-ref-03#section-3) standard). A warning will be logged during the schema compilation.
- `"fail"` (recommended) - if other validation keywords are used together with `$ref` the exception will be thrown when the schema is compiled. This option is recommended to make sure schema has no keywords that are ignored, which can be confusing.
- `true` - validate all keywords in the schemas with `$ref` (the default behaviour in versions before 5.0.0).
- _loadSchema_: asynchronous function that will be used to load remote schemas when `compileAsync` [method](#api-compileAsync) is used and some reference is missing (option `missingRefs` should NOT be 'fail' or 'ignore'). This function should accept remote schema uri as a parameter and return a Promise that resolves to a schema. See example in [Asynchronous compilation](#asynchronous-schema-compilation).
##### Options to modify validated data
- _removeAdditional_: remove additional properties - see example in [Filtering data](#filtering-data). This option is not used if schema is added with `addMetaSchema` method. Option values:
- `false` (default) - not to remove additional properties
- `"all"` - all additional properties are removed, regardless of `additionalProperties` keyword in schema (and no validation is made for them).
- `true` - only additional properties with `additionalProperties` keyword equal to `false` are removed.
- `"failing"` - additional properties that fail schema validation will be removed (where `additionalProperties` keyword is `false` or schema).
- _useDefaults_: replace missing or undefined properties and items with the values from corresponding `default` keywords. Default behaviour is to ignore `default` keywords. This option is not used if schema is added with `addMetaSchema` method. See examples in [Assigning defaults](#assigning-defaults). Option values:
- `false` (default) - do not use defaults
- `true` - insert defaults by value (object literal is used).
- `"empty"` - in addition to missing or undefined, use defaults for properties and items that are equal to `null` or `""` (an empty string).
- `"shared"` (deprecated) - insert defaults by reference. If the default is an object, it will be shared by all instances of validated data. If you modify the inserted default in the validated data, it will be modified in the schema as well.
- _coerceTypes_: change data type of data to match `type` keyword. See the example in [Coercing data types](#coercing-data-types) and [coercion rules](https://github.com/ajv-validator/ajv/blob/master/COERCION.md). Option values:
- `false` (default) - no type coercion.
- `true` - coerce scalar data types.
- `"array"` - in addition to coercions between scalar types, coerce scalar data to an array with one element and vice versa (as required by the schema).
##### Strict mode options
- _strictDefaults_: report ignored `default` keywords in schemas. Option values:
- `false` (default) - ignored defaults are not reported
- `true` - if an ignored default is present, throw an error
- `"log"` - if an ignored default is present, log warning
- _strictKeywords_: report unknown keywords in schemas. Option values:
- `false` (default) - unknown keywords are not reported
- `true` - if an unknown keyword is present, throw an error
- `"log"` - if an unknown keyword is present, log warning
- _strictNumbers_: validate numbers strictly, failing validation for NaN and Infinity. Option values:
- `false` (default) - NaN or Infinity will pass validation for numeric types
- `true` - NaN or Infinity will not pass validation for numeric types
##### Asynchronous validation options
- _transpile_: Requires [ajv-async](https://github.com/ajv-validator/ajv-async) package. It determines whether Ajv transpiles compiled asynchronous validation function. Option values:
- `undefined` (default) - transpile with [nodent](https://github.com/MatAtBread/nodent) if async functions are not supported.
- `true` - always transpile with nodent.
- `false` - do not transpile; if async functions are not supported an exception will be thrown.
##### Advanced options
- _meta_: add [meta-schema](http://json-schema.org/documentation.html) so it can be used by other schemas (true by default). If an object is passed, it will be used as the default meta-schema for schemas that have no `$schema` keyword. This default meta-schema MUST have `$schema` keyword.
- _validateSchema_: validate added/compiled schemas against meta-schema (true by default). `$schema` property in the schema can be http://json-schema.org/draft-07/schema or absent (draft-07 meta-schema will be used) or can be a reference to the schema previously added with `addMetaSchema` method. Option values:
- `true` (default) - if the validation fails, throw the exception.
- `"log"` - if the validation fails, log error.
- `false` - skip schema validation.
- _addUsedSchema_: by default methods `compile` and `validate` add schemas to the instance if they have `$id` (or `id`) property that doesn't start with "#". If `$id` is present and it is not unique the exception will be thrown. Set this option to `false` to skip adding schemas to the instance and the `$id` uniqueness check when these methods are used. This option does not affect `addSchema` method.
- _inlineRefs_: Affects compilation of referenced schemas. Option values:
- `true` (default) - the referenced schemas that don't have refs in them are inlined, regardless of their size - that substantially improves performance at the cost of the bigger size of compiled schema functions.
- `false` - to not inline referenced schemas (they will be compiled as separate functions).
- integer number - to limit the maximum number of keywords of the schema that will be inlined.
- _passContext_: pass validation context to custom keyword functions. If this option is `true` and you pass some context to the compiled validation function with `validate.call(context, data)`, the `context` will be available as `this` in your custom keywords. By default `this` is Ajv instance.
- _loopRequired_: by default `required` keyword is compiled into a single expression (or a sequence of statements in `allErrors` mode). In case of a very large number of properties in this keyword it may result in a very big validation function. Pass integer to set the number of properties above which `required` keyword will be validated in a loop - smaller validation function size but also worse performance.
- _ownProperties_: by default Ajv iterates over all enumerable object properties; when this option is `true` only own enumerable object properties (i.e. found directly on the object rather than on its prototype) are iterated. Contributed by @mbroadst.
- _multipleOfPrecision_: by default `multipleOf` keyword is validated by comparing the result of division with parseInt() of that result. It works for dividers that are bigger than 1. For small dividers such as 0.01 the result of the division is usually not integer (even when it should be integer, see issue [#84](https://github.com/ajv-validator/ajv/issues/84)). If you need to use fractional dividers set this option to some positive integer N to have `multipleOf` validated using this formula: `Math.abs(Math.round(division) - division) < 1e-N` (it is slower but allows for float arithmetics deviations).
- _errorDataPath_ (deprecated): set `dataPath` to point to 'object' (default) or to 'property' when validating keywords `required`, `additionalProperties` and `dependencies`.
- _messages_: Include human-readable messages in errors. `true` by default. `false` can be passed when custom messages are used (e.g. with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n)).
- _sourceCode_: add `sourceCode` property to validating function (for debugging; this code can be different from the result of toString call).
- _processCode_: an optional function to process generated code before it is passed to Function constructor. It can be used to either beautify (the validating function is generated without line-breaks) or to transpile code. Starting from version 5.0.0 this option replaced options:
- `beautify` that formatted the generated function using [js-beautify](https://github.com/beautify-web/js-beautify). If you want to beautify the generated code pass a function calling `require('js-beautify').js_beautify` as `processCode: code => js_beautify(code)`.
- `transpile` that transpiled asynchronous validation function. You can still use `transpile` option with [ajv-async](https://github.com/ajv-validator/ajv-async) package. See [Asynchronous validation](#asynchronous-validation) for more information.
- _cache_: an optional instance of cache to store compiled schemas using stable-stringified schema as a key. For example, set-associative cache [sacjs](https://github.com/epoberezkin/sacjs) can be used. If not passed then a simple hash is used which is good enough for the common use case (a limited number of statically defined schemas). Cache should have methods `put(key, value)`, `get(key)`, `del(key)` and `clear()`.
- _serialize_: an optional function to serialize schema to cache key. Pass `false` to use schema itself as a key (e.g., if WeakMap used as a cache). By default [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify) is used.
## Validation errors
In case of validation failure, Ajv assigns the array of errors to `errors` property of validation function (or to `errors` property of Ajv instance when `validate` or `validateSchema` methods were called). In case of [asynchronous validation](#asynchronous-validation), the returned promise is rejected with exception `Ajv.ValidationError` that has `errors` property.
### Error objects
Each error is an object with the following properties:
- _keyword_: validation keyword.
- _dataPath_: the path to the part of the data that was validated. By default `dataPath` uses JavaScript property access notation (e.g., `".prop[1].subProp"`). When the option `jsonPointers` is true (see [Options](#options)) `dataPath` will be set using JSON pointer standard (e.g., `"/prop/1/subProp"`).
- _schemaPath_: the path (JSON-pointer as a URI fragment) to the schema of the keyword that failed validation.
- _params_: the object with the additional information about error that can be used to create custom error messages (e.g., using [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package). See below for parameters set by all keywords.
- _message_: the standard error message (can be excluded with option `messages` set to false).
- _schema_: the schema of the keyword (added with `verbose` option).
- _parentSchema_: the schema containing the keyword (added with `verbose` option)
- _data_: the data validated by the keyword (added with `verbose` option).
__Please note__: `propertyNames` keyword schema validation errors have an additional property `propertyName`, `dataPath` points to the object. After schema validation for each property name, if it is invalid an additional error is added with the property `keyword` equal to `"propertyNames"`.
### Error parameters
Properties of `params` object in errors depend on the keyword that failed validation.
- `maxItems`, `minItems`, `maxLength`, `minLength`, `maxProperties`, `minProperties` - property `limit` (number, the schema of the keyword).
- `additionalItems` - property `limit` (the maximum number of allowed items in case when `items` keyword is an array of schemas and `additionalItems` is false).
- `additionalProperties` - property `additionalProperty` (the property not used in `properties` and `patternProperties` keywords).
- `dependencies` - properties:
- `property` (dependent property),
- `missingProperty` (required missing dependency - only the first one is reported currently)
- `deps` (required dependencies, comma separated list as a string),
- `depsCount` (the number of required dependencies).
- `format` - property `format` (the schema of the keyword).
- `maximum`, `minimum` - properties:
- `limit` (number, the schema of the keyword),
- `exclusive` (boolean, the schema of `exclusiveMaximum` or `exclusiveMinimum`),
- `comparison` (string, comparison operation to compare the data to the limit, with the data on the left and the limit on the right; can be "<", "<=", ">", ">=")
- `multipleOf` - property `multipleOf` (the schema of the keyword)
- `pattern` - property `pattern` (the schema of the keyword)
- `required` - property `missingProperty` (required property that is missing).
- `propertyNames` - property `propertyName` (an invalid property name).
- `patternRequired` (in ajv-keywords) - property `missingPattern` (required pattern that did not match any property).
- `type` - property `type` (required type(s), a string, can be a comma-separated list)
- `uniqueItems` - properties `i` and `j` (indices of duplicate items).
- `const` - property `allowedValue` pointing to the value (the schema of the keyword).
- `enum` - property `allowedValues` pointing to the array of values (the schema of the keyword).
- `$ref` - property `ref` with the referenced schema URI.
- `oneOf` - property `passingSchemas` (array of indices of passing schemas, null if no schema passes).
- custom keywords (in case keyword definition doesn't create errors) - property `keyword` (the keyword name).
### Error logging
Using the `logger` option when initiallizing Ajv will allow you to define custom logging. Here you can build upon the exisiting logging. The use of other logging packages is supported as long as the package or its associated wrapper exposes the required methods. If any of the required methods are missing an exception will be thrown.
- **Required Methods**: `log`, `warn`, `error`
```javascript
var otherLogger = new OtherLogger();
var ajv = new Ajv({
logger: {
log: console.log.bind(console),
warn: function warn() {
otherLogger.logWarn.apply(otherLogger, arguments);
},
error: function error() {
otherLogger.logError.apply(otherLogger, arguments);
console.error.apply(console, arguments);
}
}
});
```
## Plugins
Ajv can be extended with plugins that add custom keywords, formats or functions to process generated code. When such plugin is published as npm package it is recommended that it follows these conventions:
- it exports a function
- this function accepts ajv instance as the first parameter and returns the same instance to allow chaining
- this function can accept an optional configuration as the second parameter
If you have published a useful plugin please submit a PR to add it to the next section.
## Related packages
- [ajv-async](https://github.com/ajv-validator/ajv-async) - plugin to configure async validation mode
- [ajv-bsontype](https://github.com/BoLaMN/ajv-bsontype) - plugin to validate mongodb's bsonType formats
- [ajv-cli](https://github.com/jessedc/ajv-cli) - command line interface
- [ajv-errors](https://github.com/ajv-validator/ajv-errors) - plugin for custom error messages
- [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) - internationalised error messages
- [ajv-istanbul](https://github.com/ajv-validator/ajv-istanbul) - plugin to instrument generated validation code to measure test coverage of your schemas
- [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) - plugin with custom validation keywords (select, typeof, etc.)
- [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) - plugin with keywords $merge and $patch
- [ajv-pack](https://github.com/ajv-validator/ajv-pack) - produces a compact module exporting validation functions
- [ajv-formats-draft2019](https://github.com/luzlab/ajv-formats-draft2019) - format validators for draft2019 that aren't already included in ajv (ie. `idn-hostname`, `idn-email`, `iri`, `iri-reference` and `duration`).
## Some packages using Ajv
- [webpack](https://github.com/webpack/webpack) - a module bundler. Its main purpose is to bundle JavaScript files for usage in a browser
- [jsonscript-js](https://github.com/JSONScript/jsonscript-js) - the interpreter for [JSONScript](http://www.jsonscript.org) - scripted processing of existing endpoints and services
- [osprey-method-handler](https://github.com/mulesoft-labs/osprey-method-handler) - Express middleware for validating requests and responses based on a RAML method object, used in [osprey](https://github.com/mulesoft/osprey) - validating API proxy generated from a RAML definition
- [har-validator](https://github.com/ahmadnassri/har-validator) - HTTP Archive (HAR) validator
- [jsoneditor](https://github.com/josdejong/jsoneditor) - a web-based tool to view, edit, format, and validate JSON http://jsoneditoronline.org
- [JSON Schema Lint](https://github.com/nickcmaynard/jsonschemalint) - a web tool to validate JSON/YAML document against a single JSON Schema http://jsonschemalint.com
- [objection](https://github.com/vincit/objection.js) - SQL-friendly ORM for Node.js
- [table](https://github.com/gajus/table) - formats data into a string table
- [ripple-lib](https://github.com/ripple/ripple-lib) - a JavaScript API for interacting with [Ripple](https://ripple.com) in Node.js and the browser
- [restbase](https://github.com/wikimedia/restbase) - distributed storage with REST API & dispatcher for backend services built to provide a low-latency & high-throughput API for Wikipedia / Wikimedia content
- [hippie-swagger](https://github.com/CacheControl/hippie-swagger) - [Hippie](https://github.com/vesln/hippie) wrapper that provides end to end API testing with swagger validation
- [react-form-controlled](https://github.com/seeden/react-form-controlled) - React controlled form components with validation
- [rabbitmq-schema](https://github.com/tjmehta/rabbitmq-schema) - a schema definition module for RabbitMQ graphs and messages
- [@query/schema](https://www.npmjs.com/package/@query/schema) - stream filtering with a URI-safe query syntax parsing to JSON Schema
- [chai-ajv-json-schema](https://github.com/peon374/chai-ajv-json-schema) - chai plugin to us JSON Schema with expect in mocha tests
- [grunt-jsonschema-ajv](https://github.com/SignpostMarv/grunt-jsonschema-ajv) - Grunt plugin for validating files against JSON Schema
- [extract-text-webpack-plugin](https://github.com/webpack-contrib/extract-text-webpack-plugin) - extract text from bundle into a file
- [electron-builder](https://github.com/electron-userland/electron-builder) - a solution to package and build a ready for distribution Electron app
- [addons-linter](https://github.com/mozilla/addons-linter) - Mozilla Add-ons Linter
- [gh-pages-generator](https://github.com/epoberezkin/gh-pages-generator) - multi-page site generator converting markdown files to GitHub pages
- [ESLint](https://github.com/eslint/eslint) - the pluggable linting utility for JavaScript and JSX
## Tests
```
npm install
git submodule update --init
npm test
```
## Contributing
All validation functions are generated using doT templates in [dot](https://github.com/ajv-validator/ajv/tree/master/lib/dot) folder. Templates are precompiled so doT is not a run-time dependency.
`npm run build` - compiles templates to [dotjs](https://github.com/ajv-validator/ajv/tree/master/lib/dotjs) folder.
`npm run watch` - automatically compiles templates when files in dot folder change
Please see [Contributing guidelines](https://github.com/ajv-validator/ajv/blob/master/CONTRIBUTING.md)
## Changes history
See https://github.com/ajv-validator/ajv/releases
__Please note__: [Changes in version 7.0.0-beta](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0-beta.0)
[Version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0).
## Code of conduct
Please review and follow the [Code of conduct](https://github.com/ajv-validator/ajv/blob/master/CODE_OF_CONDUCT.md).
Please report any unacceptable behaviour to [email protected] - it will be reviewed by the project team.
## Open-source software support
Ajv is a part of [Tidelift subscription](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=readme) - it provides a centralised support to open-source software users, in addition to the support provided by software maintainers.
## License
[MIT](https://github.com/ajv-validator/ajv/blob/master/LICENSE)
# fast-deep-equal
The fastest deep equal with ES6 Map, Set and Typed arrays support.
[](https://travis-ci.org/epoberezkin/fast-deep-equal)
[](https://www.npmjs.com/package/fast-deep-equal)
[](https://coveralls.io/github/epoberezkin/fast-deep-equal?branch=master)
## Install
```bash
npm install fast-deep-equal
```
## Features
- ES5 compatible
- works in node.js (8+) and browsers (IE9+)
- checks equality of Date and RegExp objects by value.
ES6 equal (`require('fast-deep-equal/es6')`) also supports:
- Maps
- Sets
- Typed arrays
## Usage
```javascript
var equal = require('fast-deep-equal');
console.log(equal({foo: 'bar'}, {foo: 'bar'})); // true
```
To support ES6 Maps, Sets and Typed arrays equality use:
```javascript
var equal = require('fast-deep-equal/es6');
console.log(equal(Int16Array([1, 2]), Int16Array([1, 2]))); // true
```
To use with React (avoiding the traversal of React elements' _owner
property that contains circular references and is not needed when
comparing the elements - borrowed from [react-fast-compare](https://github.com/FormidableLabs/react-fast-compare)):
```javascript
var equal = require('fast-deep-equal/react');
var equal = require('fast-deep-equal/es6/react');
```
## Performance benchmark
Node.js v12.6.0:
```
fast-deep-equal x 261,950 ops/sec ±0.52% (89 runs sampled)
fast-deep-equal/es6 x 212,991 ops/sec ±0.34% (92 runs sampled)
fast-equals x 230,957 ops/sec ±0.83% (85 runs sampled)
nano-equal x 187,995 ops/sec ±0.53% (88 runs sampled)
shallow-equal-fuzzy x 138,302 ops/sec ±0.49% (90 runs sampled)
underscore.isEqual x 74,423 ops/sec ±0.38% (89 runs sampled)
lodash.isEqual x 36,637 ops/sec ±0.72% (90 runs sampled)
deep-equal x 2,310 ops/sec ±0.37% (90 runs sampled)
deep-eql x 35,312 ops/sec ±0.67% (91 runs sampled)
ramda.equals x 12,054 ops/sec ±0.40% (91 runs sampled)
util.isDeepStrictEqual x 46,440 ops/sec ±0.43% (90 runs sampled)
assert.deepStrictEqual x 456 ops/sec ±0.71% (88 runs sampled)
The fastest is fast-deep-equal
```
To run benchmark (requires node.js 6+):
```bash
npm run benchmark
```
__Please note__: this benchmark runs against the available test cases. To choose the most performant library for your application, it is recommended to benchmark against your data and to NOT expect this benchmark to reflect the performance difference in your application.
## Enterprise support
fast-deep-equal package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-fast-deep-equal?utm_source=npm-fast-deep-equal&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
## License
[MIT](https://github.com/epoberezkin/fast-deep-equal/blob/master/LICENSE)
# base-x
[](https://www.npmjs.org/package/base-x)
[](https://travis-ci.org/cryptocoinjs/base-x)
[](https://github.com/feross/standard)
Fast base encoding / decoding of any given alphabet using bitcoin style leading
zero compression.
**WARNING:** This module is **NOT RFC3548** compliant, it cannot be used for base16 (hex), base32, or base64 encoding in a standards compliant manner.
## Example
Base58
``` javascript
var BASE58 = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz'
var bs58 = require('base-x')(BASE58)
var decoded = bs58.decode('5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr')
console.log(decoded)
// => <Buffer 80 ed db dc 11 68 f1 da ea db d3 e4 4c 1e 3f 8f 5a 28 4c 20 29 f7 8a d2 6a f9 85 83 a4 99 de 5b 19>
console.log(bs58.encode(decoded))
// => 5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr
```
### Alphabets
See below for a list of commonly recognized alphabets, and their respective base.
Base | Alphabet
------------- | -------------
2 | `01`
8 | `01234567`
11 | `0123456789a`
16 | `0123456789abcdef`
32 | `0123456789ABCDEFGHJKMNPQRSTVWXYZ`
32 | `ybndrfg8ejkmcpqxot1uwisza345h769` (z-base-32)
36 | `0123456789abcdefghijklmnopqrstuvwxyz`
58 | `123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz`
62 | `0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ`
64 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/`
66 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.!~`
## How it works
It encodes octet arrays by doing long divisions on all significant digits in the
array, creating a representation of that number in the new base. Then for every
leading zero in the input (not significant as a number) it will encode as a
single leader character. This is the first in the alphabet and will decode as 8
bits. The other characters depend upon the base. For example, a base58 alphabet
packs roughly 5.858 bits per character.
This means the encoded string 000f (using a base16, 0-f alphabet) will actually decode
to 4 bytes unlike a canonical hex encoding which uniformly packs 4 bits into each
character.
While unusual, this does mean that no padding is required and it works for bases
like 43.
## LICENSE [MIT](LICENSE)
A direct derivation of the base58 implementation from [`bitcoin/bitcoin`](https://github.com/bitcoin/bitcoin/blob/f1e2f2a85962c1664e4e55471061af0eaa798d40/src/base58.cpp), generalized for variable length alphabets.
# Brorand
#### LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2014.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
# module-details-from-path
Extract the Node.js module details like name and base path given an
absolute path to a file inside the module.
[](https://travis-ci.org/watson/module-details-from-path)
[](https://github.com/feross/standard)
## Installation
```
npm install module-details-from-path --save
```
## Usage
```js
var assert = require('assert')
var parse = require('module-details-from-path')
var path = '/Users/watson/code/node_modules/blackjack/node_modules/picture-tube/bin/tube.js'
assert.deepStrictEqual(parse(path), {
name: 'picture-tube',
basedir: '/Users/watson/code/node_modules/blackjack/node_modules/picture-tube',
path: 'bin/tube.js'
})
```
Returns `undefined` if module details cannot be found.
## License
MIT
# Ultron
[](http://unshift.io)[](http://browsenpm.org/package/ultron)[](https://travis-ci.org/unshiftio/ultron)[](https://david-dm.org/unshiftio/ultron)[](https://coveralls.io/r/unshiftio/ultron?branch=master)[](http://webchat.freenode.net/?channels=unshift)
Ultron is a high-intelligence robot. It gathers intelligence so it can start
improving upon his rudimentary design. It will learn your event emitting
patterns and find ways to exterminate them. Allowing you to remove only the
event emitters that **you** assigned and not the ones that your users or
developers assigned. This can prevent race conditions, memory leaks and even file
descriptor leaks from ever happening as you won't remove clean up processes.
## Installation
The module is designed to be used in browsers using browserify and in Node.js.
You can install the module through the public npm registry by running the
following command in CLI:
```
npm install --save ultron
```
## Usage
In all examples we assume that you've required the library as following:
```js
'use strict';
var Ultron = require('ultron');
```
Now that we've required the library we can construct our first `Ultron` instance.
The constructor requires one argument which should be the `EventEmitter`
instance that we need to operate upon. This can be the `EventEmitter` module
that ships with Node.js or `EventEmitter3` or anything else as long as it
follow the same API and internal structure as these 2. So with that in mind we
can create the instance:
```js
//
// For the sake of this example we're going to construct an empty EventEmitter
//
var EventEmitter = require('events').EventEmitter; // or require('eventmitter3');
var events = new EventEmitter();
var ultron = new Ultron(events);
```
You can now use the following API's from the Ultron instance:
### Ultron.on
Register a new event listener for the given event. It follows the exact same API
as `EventEmitter.on` but it will return itself instead of returning the
EventEmitter instance. If you are using EventEmitter3 it also supports the
context param:
```js
ultron.on('event-name', handler, { custom: 'function context' });
```
Just like you would expect, it can also be chained together.
```js
ultron
.on('event-name', handler)
.on('another event', handler);
```
### Ultron.once
Exactly the same as the [Ultron.on](#ultronon) but it only allows the execution
once.
Just like you would expect, it can also be chained together.
```js
ultron
.once('event-name', handler, { custom: 'this value' })
.once('another event', handler);
```
### Ultron.remove
This is where all the magic happens and the safe removal starts. This function
accepts different argument styles:
- No arguments, assume that all events need to be removed so it will work as
`removeAllListeners()` API.
- 1 argument, when it's a string it will be split on ` ` and `,` to create a
list of events that need to be cleared.
- Multiple arguments, we assume that they are all names of events that need to
be cleared.
```js
ultron.remove('foo, bar baz'); // Removes foo, bar and baz.
ultron.remove('foo', 'bar', 'baz'); // Removes foo, bar and baz.
ultron.remove(); // Removes everything.
```
If you just want to remove a single event listener using a function reference
you can still use the EventEmitter's `removeListener(event, fn)` API:
```js
function foo() {}
ultron.on('foo', foo);
events.removeListener('foo', foo);
```
## License
MIT
# secp256k1-node
This module provides native bindings to [bitcoin-core/secp256k1](https://github.com/bitcoin-core/secp256k1). In browser [elliptic](https://github.com/indutny/elliptic) will be used as fallback.
Works on node version 10.0.0 or greater, because use [N-API](https://nodejs.org/api/n-api.html).
## Installation
##### from npm
`npm install secp256k1`
##### from git
```
git clone [email protected]:cryptocoinjs/secp256k1-node.git
cd secp256k1-node
git submodule update --init
npm install
```
##### Windows
The easiest way to build the package on windows is to install [windows-build-tools](https://github.com/felixrieseberg/windows-build-tools).
Or install the following software:
* Git: https://git-scm.com/download/win
* nvm: https://github.com/coreybutler/nvm-windows
* Python 2.7: https://www.python.org/downloads/release/python-2712/
* Visual C++ Build Tools: http://landinghub.visualstudio.com/visual-cpp-build-tools (Custom Install, and select both Windows 8.1 and Windows 10 SDKs)
And run commands:
```
npm config set msvs_version 2015 --global
npm install npm@next -g
```
Based on:
* https://github.com/nodejs/node-gyp/issues/629#issuecomment-153196245
* https://github.com/nodejs/node-gyp/issues/972
## Usage
* [API Reference (v4.x)](API.md) (current version)
* [API Reference (v3.x)](https://github.com/cryptocoinjs/secp256k1-node/blob/v3.x/API.md)
* [API Reference (v2.x)](https://github.com/cryptocoinjs/secp256k1-node/blob/v2.x/API.md)
##### Private Key generation, Public Key creation, signature creation, signature verification
```js
const { randomBytes } = require('crypto')
const secp256k1 = require('secp256k1')
// or require('secp256k1/elliptic')
// if you want to use pure js implementation in node
// generate message to sign
// message should have 32-byte length, if you have some other length you can hash message
// for example `msg = sha256(rawMessage)`
const msg = randomBytes(32)
// generate privKey
let privKey
do {
privKey = randomBytes(32)
} while (!secp256k1.privateKeyVerify(privKey))
// get the public key in a compressed format
const pubKey = secp256k1.publicKeyCreate(privKey)
// sign the message
const sigObj = secp256k1.ecdsaSign(msg, privKey)
// verify the signature
console.log(secp256k1.ecdsaVerify(sigObj.signature, msg, pubKey))
// => true
```
\* **.verify return false for high signatures**
##### Get X point of ECDH
```js
const { randomBytes } = require('crypto')
// const secp256k1 = require('./elliptic')
const secp256k1 = require('./')
// generate privKey
function getPrivateKey () {
while (true) {
const privKey = randomBytes(32)
if (secp256k1.privateKeyVerify(privKey)) return privKey
}
}
// generate private and public keys
const privKey = getPrivateKey()
const pubKey = secp256k1.publicKeyCreate(getPrivateKey())
// compressed public key from X and Y
function hashfn (x, y) {
const pubKey = new Uint8Array(33)
pubKey[0] = (y[31] & 1) === 0 ? 0x02 : 0x03
pubKey.set(x, 1)
return pubKey
}
// get X point of ecdh
const ecdhPointX = secp256k1.ecdh(pubKey, privKey, { hashfn }, Buffer.alloc(33))
console.log(ecdhPointX.toString('hex'))
```
## LICENSE
This library is free and open-source software released under the MIT license.
Native Abstractions for Node.js
===============================
**A header file filled with macro and utility goodness for making add-on development for Node.js easier across versions 0.8, 0.10, 0.12, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 and 14.**
***Current version: 2.14.2***
*(See [CHANGELOG.md](https://github.com/nodejs/nan/blob/master/CHANGELOG.md) for complete ChangeLog)*
[](https://nodei.co/npm/nan/) [](https://nodei.co/npm/nan/)
[](https://travis-ci.org/nodejs/nan)
[](https://ci.appveyor.com/project/RodVagg/nan)
Thanks to the crazy changes in V8 (and some in Node core), keeping native addons compiling happily across versions, particularly 0.10 to 0.12 to 4.0, is a minor nightmare. The goal of this project is to store all logic necessary to develop native Node.js addons without having to inspect `NODE_MODULE_VERSION` and get yourself into a macro-tangle.
This project also contains some helper utilities that make addon development a bit more pleasant.
* **[News & Updates](#news)**
* **[Usage](#usage)**
* **[Example](#example)**
* **[API](#api)**
* **[Tests](#tests)**
* **[Known issues](#issues)**
* **[Governance & Contributing](#governance)**
<a name="news"></a>
## News & Updates
<a name="usage"></a>
## Usage
Simply add **NAN** as a dependency in the *package.json* of your Node addon:
``` bash
$ npm install --save nan
```
Pull in the path to **NAN** in your *binding.gyp* so that you can use `#include <nan.h>` in your *.cpp* files:
``` python
"include_dirs" : [
"<!(node -e \"require('nan')\")"
]
```
This works like a `-I<path-to-NAN>` when compiling your addon.
<a name="example"></a>
## Example
Just getting started with Nan? Take a look at the **[Node Add-on Examples](https://github.com/nodejs/node-addon-examples)**.
Refer to a [quick-start **Nan** Boilerplate](https://github.com/fcanas/node-native-boilerplate) for a ready-to-go project that utilizes basic Nan functionality.
For a simpler example, see the **[async pi estimation example](https://github.com/nodejs/nan/tree/master/examples/async_pi_estimate)** in the examples directory for full code and an explanation of what this Monte Carlo Pi estimation example does. Below are just some parts of the full example that illustrate the use of **NAN**.
Yet another example is **[nan-example-eol](https://github.com/CodeCharmLtd/nan-example-eol)**. It shows newline detection implemented as a native addon.
Also take a look at our comprehensive **[C++ test suite](https://github.com/nodejs/nan/tree/master/test/cpp)** which has a plethora of code snippets for your pasting pleasure.
<a name="api"></a>
## API
Additional to the NAN documentation below, please consult:
* [The V8 Getting Started * Guide](https://v8.dev/docs/embed)
* [V8 API Documentation](https://v8docs.nodesource.com/)
* [Node Add-on Documentation](https://nodejs.org/api/addons.html)
<!-- START API -->
### JavaScript-accessible methods
A _template_ is a blueprint for JavaScript functions and objects in a context. You can use a template to wrap C++ functions and data structures within JavaScript objects so that they can be manipulated from JavaScript. See the V8 Embedders Guide section on [Templates](https://github.com/v8/v8/wiki/Embedder%27s-Guide#templates) for further information.
In order to expose functionality to JavaScript via a template, you must provide it to V8 in a form that it understands. Across the versions of V8 supported by NAN, JavaScript-accessible method signatures vary widely, NAN fully abstracts method declaration and provides you with an interface that is similar to the most recent V8 API but is backward-compatible with older versions that still use the now-deceased `v8::Argument` type.
* **Method argument types**
- <a href="doc/methods.md#api_nan_function_callback_info"><b><code>Nan::FunctionCallbackInfo</code></b></a>
- <a href="doc/methods.md#api_nan_property_callback_info"><b><code>Nan::PropertyCallbackInfo</code></b></a>
- <a href="doc/methods.md#api_nan_return_value"><b><code>Nan::ReturnValue</code></b></a>
* **Method declarations**
- <a href="doc/methods.md#api_nan_method"><b>Method declaration</b></a>
- <a href="doc/methods.md#api_nan_getter"><b>Getter declaration</b></a>
- <a href="doc/methods.md#api_nan_setter"><b>Setter declaration</b></a>
- <a href="doc/methods.md#api_nan_property_getter"><b>Property getter declaration</b></a>
- <a href="doc/methods.md#api_nan_property_setter"><b>Property setter declaration</b></a>
- <a href="doc/methods.md#api_nan_property_enumerator"><b>Property enumerator declaration</b></a>
- <a href="doc/methods.md#api_nan_property_deleter"><b>Property deleter declaration</b></a>
- <a href="doc/methods.md#api_nan_property_query"><b>Property query declaration</b></a>
- <a href="doc/methods.md#api_nan_index_getter"><b>Index getter declaration</b></a>
- <a href="doc/methods.md#api_nan_index_setter"><b>Index setter declaration</b></a>
- <a href="doc/methods.md#api_nan_index_enumerator"><b>Index enumerator declaration</b></a>
- <a href="doc/methods.md#api_nan_index_deleter"><b>Index deleter declaration</b></a>
- <a href="doc/methods.md#api_nan_index_query"><b>Index query declaration</b></a>
* Method and template helpers
- <a href="doc/methods.md#api_nan_set_method"><b><code>Nan::SetMethod()</code></b></a>
- <a href="doc/methods.md#api_nan_set_prototype_method"><b><code>Nan::SetPrototypeMethod()</code></b></a>
- <a href="doc/methods.md#api_nan_set_accessor"><b><code>Nan::SetAccessor()</code></b></a>
- <a href="doc/methods.md#api_nan_set_named_property_handler"><b><code>Nan::SetNamedPropertyHandler()</code></b></a>
- <a href="doc/methods.md#api_nan_set_indexed_property_handler"><b><code>Nan::SetIndexedPropertyHandler()</code></b></a>
- <a href="doc/methods.md#api_nan_set_template"><b><code>Nan::SetTemplate()</code></b></a>
- <a href="doc/methods.md#api_nan_set_prototype_template"><b><code>Nan::SetPrototypeTemplate()</code></b></a>
- <a href="doc/methods.md#api_nan_set_instance_template"><b><code>Nan::SetInstanceTemplate()</code></b></a>
- <a href="doc/methods.md#api_nan_set_call_handler"><b><code>Nan::SetCallHandler()</code></b></a>
- <a href="doc/methods.md#api_nan_set_call_as_function_handler"><b><code>Nan::SetCallAsFunctionHandler()</code></b></a>
### Scopes
A _local handle_ is a pointer to an object. All V8 objects are accessed using handles, they are necessary because of the way the V8 garbage collector works.
A handle scope can be thought of as a container for any number of handles. When you've finished with your handles, instead of deleting each one individually you can simply delete their scope.
The creation of `HandleScope` objects is different across the supported versions of V8. Therefore, NAN provides its own implementations that can be used safely across these.
- <a href="doc/scopes.md#api_nan_handle_scope"><b><code>Nan::HandleScope</code></b></a>
- <a href="doc/scopes.md#api_nan_escapable_handle_scope"><b><code>Nan::EscapableHandleScope</code></b></a>
Also see the V8 Embedders Guide section on [Handles and Garbage Collection](https://github.com/v8/v8/wiki/Embedder%27s%20Guide#handles-and-garbage-collection).
### Persistent references
An object reference that is independent of any `HandleScope` is a _persistent_ reference. Where a `Local` handle only lives as long as the `HandleScope` in which it was allocated, a `Persistent` handle remains valid until it is explicitly disposed.
Due to the evolution of the V8 API, it is necessary for NAN to provide a wrapper implementation of the `Persistent` classes to supply compatibility across the V8 versions supported.
- <a href="doc/persistent.md#api_nan_persistent_base"><b><code>Nan::PersistentBase & v8::PersistentBase</code></b></a>
- <a href="doc/persistent.md#api_nan_non_copyable_persistent_traits"><b><code>Nan::NonCopyablePersistentTraits & v8::NonCopyablePersistentTraits</code></b></a>
- <a href="doc/persistent.md#api_nan_copyable_persistent_traits"><b><code>Nan::CopyablePersistentTraits & v8::CopyablePersistentTraits</code></b></a>
- <a href="doc/persistent.md#api_nan_persistent"><b><code>Nan::Persistent</code></b></a>
- <a href="doc/persistent.md#api_nan_global"><b><code>Nan::Global</code></b></a>
- <a href="doc/persistent.md#api_nan_weak_callback_info"><b><code>Nan::WeakCallbackInfo</code></b></a>
- <a href="doc/persistent.md#api_nan_weak_callback_type"><b><code>Nan::WeakCallbackType</code></b></a>
Also see the V8 Embedders Guide section on [Handles and Garbage Collection](https://developers.google.com/v8/embed#handles).
### New
NAN provides a `Nan::New()` helper for the creation of new JavaScript objects in a way that's compatible across the supported versions of V8.
- <a href="doc/new.md#api_nan_new"><b><code>Nan::New()</code></b></a>
- <a href="doc/new.md#api_nan_undefined"><b><code>Nan::Undefined()</code></b></a>
- <a href="doc/new.md#api_nan_null"><b><code>Nan::Null()</code></b></a>
- <a href="doc/new.md#api_nan_true"><b><code>Nan::True()</code></b></a>
- <a href="doc/new.md#api_nan_false"><b><code>Nan::False()</code></b></a>
- <a href="doc/new.md#api_nan_empty_string"><b><code>Nan::EmptyString()</code></b></a>
### Converters
NAN contains functions that convert `v8::Value`s to other `v8::Value` types and native types. Since type conversion is not guaranteed to succeed, they return `Nan::Maybe` types. These converters can be used in place of `value->ToX()` and `value->XValue()` (where `X` is one of the types, e.g. `Boolean`) in a way that provides a consistent interface across V8 versions. Newer versions of V8 use the new `v8::Maybe` and `v8::MaybeLocal` types for these conversions, older versions don't have this functionality so it is provided by NAN.
- <a href="doc/converters.md#api_nan_to"><b><code>Nan::To()</code></b></a>
### Maybe Types
The `Nan::MaybeLocal` and `Nan::Maybe` types are monads that encapsulate `v8::Local` handles that _may be empty_.
* **Maybe Types**
- <a href="doc/maybe_types.md#api_nan_maybe_local"><b><code>Nan::MaybeLocal</code></b></a>
- <a href="doc/maybe_types.md#api_nan_maybe"><b><code>Nan::Maybe</code></b></a>
- <a href="doc/maybe_types.md#api_nan_nothing"><b><code>Nan::Nothing</code></b></a>
- <a href="doc/maybe_types.md#api_nan_just"><b><code>Nan::Just</code></b></a>
* **Maybe Helpers**
- <a href="doc/maybe_types.md#api_nan_call"><b><code>Nan::Call()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_to_detail_string"><b><code>Nan::ToDetailString()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_to_array_index"><b><code>Nan::ToArrayIndex()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_equals"><b><code>Nan::Equals()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_new_instance"><b><code>Nan::NewInstance()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_function"><b><code>Nan::GetFunction()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_set"><b><code>Nan::Set()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_define_own_property"><b><code>Nan::DefineOwnProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_force_set"><del><b><code>Nan::ForceSet()</code></b></del></a>
- <a href="doc/maybe_types.md#api_nan_get"><b><code>Nan::Get()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_property_attribute"><b><code>Nan::GetPropertyAttributes()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has"><b><code>Nan::Has()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_delete"><b><code>Nan::Delete()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_property_names"><b><code>Nan::GetPropertyNames()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_own_property_names"><b><code>Nan::GetOwnPropertyNames()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_set_prototype"><b><code>Nan::SetPrototype()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_object_proto_to_string"><b><code>Nan::ObjectProtoToString()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_own_property"><b><code>Nan::HasOwnProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_real_named_property"><b><code>Nan::HasRealNamedProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_real_indexed_property"><b><code>Nan::HasRealIndexedProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_real_named_callback_property"><b><code>Nan::HasRealNamedCallbackProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_real_named_property_in_prototype_chain"><b><code>Nan::GetRealNamedPropertyInPrototypeChain()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_real_named_property"><b><code>Nan::GetRealNamedProperty()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_call_as_function"><b><code>Nan::CallAsFunction()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_call_as_constructor"><b><code>Nan::CallAsConstructor()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_source_line"><b><code>Nan::GetSourceLine()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_line_number"><b><code>Nan::GetLineNumber()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_start_column"><b><code>Nan::GetStartColumn()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_end_column"><b><code>Nan::GetEndColumn()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_clone_element_at"><b><code>Nan::CloneElementAt()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_has_private"><b><code>Nan::HasPrivate()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_get_private"><b><code>Nan::GetPrivate()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_set_private"><b><code>Nan::SetPrivate()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_delete_private"><b><code>Nan::DeletePrivate()</code></b></a>
- <a href="doc/maybe_types.md#api_nan_make_maybe"><b><code>Nan::MakeMaybe()</code></b></a>
### Script
NAN provides a `v8::Script` helpers as the API has changed over the supported versions of V8.
- <a href="doc/script.md#api_nan_compile_script"><b><code>Nan::CompileScript()</code></b></a>
- <a href="doc/script.md#api_nan_run_script"><b><code>Nan::RunScript()</code></b></a>
### JSON
The _JSON_ object provides the C++ versions of the methods offered by the `JSON` object in javascript. V8 exposes these methods via the `v8::JSON` object.
- <a href="doc/json.md#api_nan_json_parse"><b><code>Nan::JSON.Parse</code></b></a>
- <a href="doc/json.md#api_nan_json_stringify"><b><code>Nan::JSON.Stringify</code></b></a>
Refer to the V8 JSON object in the [V8 documentation](https://v8docs.nodesource.com/node-8.16/da/d6f/classv8_1_1_j_s_o_n.html) for more information about these methods and their arguments.
### Errors
NAN includes helpers for creating, throwing and catching Errors as much of this functionality varies across the supported versions of V8 and must be abstracted.
Note that an Error object is simply a specialized form of `v8::Value`.
Also consult the V8 Embedders Guide section on [Exceptions](https://developers.google.com/v8/embed#exceptions) for more information.
- <a href="doc/errors.md#api_nan_error"><b><code>Nan::Error()</code></b></a>
- <a href="doc/errors.md#api_nan_range_error"><b><code>Nan::RangeError()</code></b></a>
- <a href="doc/errors.md#api_nan_reference_error"><b><code>Nan::ReferenceError()</code></b></a>
- <a href="doc/errors.md#api_nan_syntax_error"><b><code>Nan::SyntaxError()</code></b></a>
- <a href="doc/errors.md#api_nan_type_error"><b><code>Nan::TypeError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_error"><b><code>Nan::ThrowError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_range_error"><b><code>Nan::ThrowRangeError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_reference_error"><b><code>Nan::ThrowReferenceError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_syntax_error"><b><code>Nan::ThrowSyntaxError()</code></b></a>
- <a href="doc/errors.md#api_nan_throw_type_error"><b><code>Nan::ThrowTypeError()</code></b></a>
- <a href="doc/errors.md#api_nan_fatal_exception"><b><code>Nan::FatalException()</code></b></a>
- <a href="doc/errors.md#api_nan_errno_exception"><b><code>Nan::ErrnoException()</code></b></a>
- <a href="doc/errors.md#api_nan_try_catch"><b><code>Nan::TryCatch</code></b></a>
### Buffers
NAN's `node::Buffer` helpers exist as the API has changed across supported Node versions. Use these methods to ensure compatibility.
- <a href="doc/buffers.md#api_nan_new_buffer"><b><code>Nan::NewBuffer()</code></b></a>
- <a href="doc/buffers.md#api_nan_copy_buffer"><b><code>Nan::CopyBuffer()</code></b></a>
- <a href="doc/buffers.md#api_nan_free_callback"><b><code>Nan::FreeCallback()</code></b></a>
### Nan::Callback
`Nan::Callback` makes it easier to use `v8::Function` handles as callbacks. A class that wraps a `v8::Function` handle, protecting it from garbage collection and making it particularly useful for storage and use across asynchronous execution.
- <a href="doc/callback.md#api_nan_callback"><b><code>Nan::Callback</code></b></a>
### Asynchronous work helpers
`Nan::AsyncWorker`, `Nan::AsyncProgressWorker` and `Nan::AsyncProgressQueueWorker` are helper classes that make working with asynchronous code easier.
- <a href="doc/asyncworker.md#api_nan_async_worker"><b><code>Nan::AsyncWorker</code></b></a>
- <a href="doc/asyncworker.md#api_nan_async_progress_worker"><b><code>Nan::AsyncProgressWorkerBase & Nan::AsyncProgressWorker</code></b></a>
- <a href="doc/asyncworker.md#api_nan_async_progress_queue_worker"><b><code>Nan::AsyncProgressQueueWorker</code></b></a>
- <a href="doc/asyncworker.md#api_nan_async_queue_worker"><b><code>Nan::AsyncQueueWorker</code></b></a>
### Strings & Bytes
Miscellaneous string & byte encoding and decoding functionality provided for compatibility across supported versions of V8 and Node. Implemented by NAN to ensure that all encoding types are supported, even for older versions of Node where they are missing.
- <a href="doc/string_bytes.md#api_nan_encoding"><b><code>Nan::Encoding</code></b></a>
- <a href="doc/string_bytes.md#api_nan_encode"><b><code>Nan::Encode()</code></b></a>
- <a href="doc/string_bytes.md#api_nan_decode_bytes"><b><code>Nan::DecodeBytes()</code></b></a>
- <a href="doc/string_bytes.md#api_nan_decode_write"><b><code>Nan::DecodeWrite()</code></b></a>
### Object Wrappers
The `ObjectWrap` class can be used to make wrapped C++ objects and a factory of wrapped objects.
- <a href="doc/object_wrappers.md#api_nan_object_wrap"><b><code>Nan::ObjectWrap</code></b></a>
### V8 internals
The hooks to access V8 internals—including GC and statistics—are different across the supported versions of V8, therefore NAN provides its own hooks that call the appropriate V8 methods.
- <a href="doc/v8_internals.md#api_nan_gc_callback"><b><code>NAN_GC_CALLBACK()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_add_gc_epilogue_callback"><b><code>Nan::AddGCEpilogueCallback()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_remove_gc_epilogue_callback"><b><code>Nan::RemoveGCEpilogueCallback()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_add_gc_prologue_callback"><b><code>Nan::AddGCPrologueCallback()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_remove_gc_prologue_callback"><b><code>Nan::RemoveGCPrologueCallback()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_get_heap_statistics"><b><code>Nan::GetHeapStatistics()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_set_counter_function"><b><code>Nan::SetCounterFunction()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_set_create_histogram_function"><b><code>Nan::SetCreateHistogramFunction()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_set_add_histogram_sample_function"><b><code>Nan::SetAddHistogramSampleFunction()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_idle_notification"><b><code>Nan::IdleNotification()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_low_memory_notification"><b><code>Nan::LowMemoryNotification()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_context_disposed_notification"><b><code>Nan::ContextDisposedNotification()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_get_internal_field_pointer"><b><code>Nan::GetInternalFieldPointer()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_set_internal_field_pointer"><b><code>Nan::SetInternalFieldPointer()</code></b></a>
- <a href="doc/v8_internals.md#api_nan_adjust_external_memory"><b><code>Nan::AdjustExternalMemory()</code></b></a>
### Miscellaneous V8 Helpers
- <a href="doc/v8_misc.md#api_nan_utf8_string"><b><code>Nan::Utf8String</code></b></a>
- <a href="doc/v8_misc.md#api_nan_get_current_context"><b><code>Nan::GetCurrentContext()</code></b></a>
- <a href="doc/v8_misc.md#api_nan_set_isolate_data"><b><code>Nan::SetIsolateData()</code></b></a>
- <a href="doc/v8_misc.md#api_nan_get_isolate_data"><b><code>Nan::GetIsolateData()</code></b></a>
- <a href="doc/v8_misc.md#api_nan_typedarray_contents"><b><code>Nan::TypedArrayContents</code></b></a>
### Miscellaneous Node Helpers
- <a href="doc/node_misc.md#api_nan_asyncresource"><b><code>Nan::AsyncResource</code></b></a>
- <a href="doc/node_misc.md#api_nan_make_callback"><b><code>Nan::MakeCallback()</code></b></a>
- <a href="doc/node_misc.md#api_nan_module_init"><b><code>NAN_MODULE_INIT()</code></b></a>
- <a href="doc/node_misc.md#api_nan_export"><b><code>Nan::Export()</code></b></a>
<!-- END API -->
<a name="tests"></a>
### Tests
To run the NAN tests do:
``` sh
npm install
npm run-script rebuild-tests
npm test
```
Or just:
``` sh
npm install
make test
```
<a name="issues"></a>
## Known issues
### Compiling against Node.js 0.12 on OSX
With new enough compilers available on OSX, the versions of V8 headers corresponding to Node.js 0.12
do not compile anymore. The error looks something like:
```
❯ CXX(target) Release/obj.target/accessors/cpp/accessors.o
In file included from ../cpp/accessors.cpp:9:
In file included from ../../nan.h:51:
In file included from /Users/ofrobots/.node-gyp/0.12.18/include/node/node.h:61:
/Users/ofrobots/.node-gyp/0.12.18/include/node/v8.h:5800:54: error: 'CreateHandle' is a protected member of 'v8::HandleScope'
return Handle<T>(reinterpret_cast<T*>(HandleScope::CreateHandle(
~~~~~~~~~~~~~^~~~~~~~~~~~
```
This can be worked around by patching your local versions of v8.h corresponding to Node 0.12 to make
`v8::Handle` a friend of `v8::HandleScope`. Since neither Node.js not V8 support this release line anymore
this patch cannot be released by either project in an official release.
For this reason, we do not test against Node.js 0.12 on OSX in this project's CI. If you need to support
that configuration, you will need to either get an older compiler, or apply a source patch to the version
of V8 headers as a workaround.
<a name="governance"></a>
## Governance & Contributing
NAN is governed by the [Node.js Addon API Working Group](https://github.com/nodejs/CTC/blob/master/WORKING_GROUPS.md#addon-api)
### Addon API Working Group (WG)
The NAN project is jointly governed by a Working Group which is responsible for high-level guidance of the project.
Members of the WG are also known as Collaborators, there is no distinction between the two, unlike other Node.js projects.
The WG has final authority over this project including:
* Technical direction
* Project governance and process (including this policy)
* Contribution policy
* GitHub repository hosting
* Maintaining the list of additional Collaborators
For the current list of WG members, see the project [README.md](./README.md#collaborators).
Individuals making significant and valuable contributions are made members of the WG and given commit-access to the project. These individuals are identified by the WG and their addition to the WG is discussed via GitHub and requires unanimous consensus amongst those WG members participating in the discussion with a quorum of 50% of WG members required for acceptance of the vote.
_Note:_ If you make a significant contribution and are not considered for commit-access log an issue or contact a WG member directly.
For the current list of WG members / Collaborators, see the project [README.md](./README.md#collaborators).
### Consensus Seeking Process
The WG follows a [Consensus Seeking](https://en.wikipedia.org/wiki/Consensus-seeking_decision-making) decision making model.
Modifications of the contents of the NAN repository are made on a collaborative basis. Anybody with a GitHub account may propose a modification via pull request and it will be considered by the WG. All pull requests must be reviewed and accepted by a WG member with sufficient expertise who is able to take full responsibility for the change. In the case of pull requests proposed by an existing WG member, an additional WG member is required for sign-off. Consensus should be sought if additional WG members participate and there is disagreement around a particular modification.
If a change proposal cannot reach a consensus, a WG member can call for a vote amongst the members of the WG. Simple majority wins.
<a id="developers-certificate-of-origin"></a>
## Developer's Certificate of Origin 1.1
By making a contribution to this project, I certify that:
* (a) The contribution was created in whole or in part by me and I
have the right to submit it under the open source license
indicated in the file; or
* (b) The contribution is based upon previous work that, to the best
of my knowledge, is covered under an appropriate open source
license and I have the right under that license to submit that
work with modifications, whether created in whole or in part
by me, under the same open source license (unless I am
permitted to submit under a different license), as indicated
in the file; or
* (c) The contribution was provided directly to me by some other
person who certified (a), (b) or (c) and I have not modified
it.
* (d) I understand and agree that this project and the contribution
are public and that a record of the contribution (including all
personal information I submit with it, including my sign-off) is
maintained indefinitely and may be redistributed consistent with
this project or the open source license(s) involved.
<a name="collaborators"></a>
### WG Members / Collaborators
<table><tbody>
<tr><th align="left">Rod Vagg</th><td><a href="https://github.com/rvagg">GitHub/rvagg</a></td><td><a href="http://twitter.com/rvagg">Twitter/@rvagg</a></td></tr>
<tr><th align="left">Benjamin Byholm</th><td><a href="https://github.com/kkoopa/">GitHub/kkoopa</a></td><td>-</td></tr>
<tr><th align="left">Trevor Norris</th><td><a href="https://github.com/trevnorris">GitHub/trevnorris</a></td><td><a href="http://twitter.com/trevnorris">Twitter/@trevnorris</a></td></tr>
<tr><th align="left">Nathan Rajlich</th><td><a href="https://github.com/TooTallNate">GitHub/TooTallNate</a></td><td><a href="http://twitter.com/TooTallNate">Twitter/@TooTallNate</a></td></tr>
<tr><th align="left">Brett Lawson</th><td><a href="https://github.com/brett19">GitHub/brett19</a></td><td><a href="http://twitter.com/brett19x">Twitter/@brett19x</a></td></tr>
<tr><th align="left">Ben Noordhuis</th><td><a href="https://github.com/bnoordhuis">GitHub/bnoordhuis</a></td><td><a href="http://twitter.com/bnoordhuis">Twitter/@bnoordhuis</a></td></tr>
<tr><th align="left">David Siegel</th><td><a href="https://github.com/agnat">GitHub/agnat</a></td><td><a href="http://twitter.com/agnat">Twitter/@agnat</a></td></tr>
<tr><th align="left">Michael Ira Krufky</th><td><a href="https://github.com/mkrufky">GitHub/mkrufky</a></td><td><a href="http://twitter.com/mkrufky">Twitter/@mkrufky</a></td></tr>
</tbody></table>
## Licence & copyright
Copyright (c) 2018 NAN WG Members / Collaborators (listed above).
Native Abstractions for Node.js is licensed under an MIT license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE file for more details.
oauth-sign
==========
OAuth 1 signing. Formerly a vendor lib in mikeal/request, now a standalone module.
## Supported Method Signatures
- HMAC-SHA1
- HMAC-SHA256
- RSA-SHA1
- PLAINTEXT
# setImmediate.js
**A YuzuJS production**
## Introduction
**setImmediate.js** is a highly cross-browser implementation of the `setImmediate` and `clearImmediate` APIs, [proposed][spec] by Microsoft to the Web Performance Working Group. `setImmediate` allows scripts to yield to the browser, executing a given operation asynchronously, in a manner that is typically more efficient and consumes less power than the usual `setTimeout(..., 0)` pattern.
setImmediate.js runs at “full speed” in the following browsers and environments, using various clever tricks:
* Internet Explorer 6+
* Firefox 3+
* WebKit
* Opera 9.5+
* Node.js
* Web workers in browsers that support `MessageChannel`, which I can't find solid info on.
In all other browsers we fall back to using `setTimeout`, so it's always safe to use.
## Macrotasks and Microtasks
The `setImmediate` API, as specified, gives you access to the environment's [task queue][], sometimes known as its "macrotask" queue. This is crucially different from the [microtask queue][] used by web features such as `MutationObserver`, language features such as promises and `Object.observe`, and Node.js features such as `process.nextTick`. Each go-around of the macrotask queue yields back to the event loop once all queued tasks have been processed, even if the macrotask itself queued more macrotasks. Whereas, the microtask queue will continue executing any queued microtasks until it is exhausted.
In practice, what this means is that if you call `setImmediate` inside of another task queued with `setImmediate`, you will yield back to the event loop and any I/O or rendering tasks that need to take place between those calls, instead of executing the queued task as soon as possible.
If you are looking specifically to yield as part of a render loop, consider using [`requestAnimationFrame`][raf]; if you are looking solely for the control-flow ordering effects, use a microtask solution such as [asap][].
## The Tricks
### `process.nextTick`
In Node.js versions below 0.9, `setImmediate` is not available, but [`process.nextTick`][nextTick] is—and in those versions, `process.nextTick` uses macrotask semantics. So, we use it to shim support for a global `setImmediate`.
In Node.js 0.9 and above, `process.nextTick` moved to microtask semantics, but `setImmediate` was introduced with macrotask semantics, so there's no need to polyfill anything.
Note that we check for *actual* Node.js environments, not emulated ones like those produced by browserify or similar. Such emulated environments often already include a `process.nextTick` shim that's not as browser-compatible as setImmediate.js.
### `postMessage`
In Firefox 3+, Internet Explorer 9+, all modern WebKit browsers, and Opera 9.5+, [`postMessage`][postMessage] is available and provides a good way to queue tasks on the event loop. It's quite the abuse, using a cross-document messaging protocol within the same document simply to get access to the event loop task queue, but until there are native implementations, this is the best option.
Note that Internet Explorer 8 includes a synchronous version of `postMessage`. We detect this, or any other such synchronous implementation, and fall back to another trick.
### `MessageChannel`
Unfortunately, `postMessage` has completely different semantics inside web workers, and so cannot be used there. So we turn to [`MessageChannel`][MessageChannel], which has worse browser support, but does work inside a web worker.
### `<script> onreadystatechange`
For our last trick, we pull something out to make things fast in Internet Explorer versions 6 through 8: namely, creating a `<script>` element and firing our calls in its `onreadystatechange` event. This does execute in a future turn of the event loop, and is also faster than `setTimeout(…, 0)`, so hey, why not?
## Usage
In the browser, include it with a `<script>` tag; pretty simple.
In Node.js, do
```
npm install setimmediate
```
then
```js
require("setimmediate");
```
somewhere early in your app; it attaches to the global.
## Demo
* [Quick sort demo][cross-browser-demo]
## Reference and Reading
* [Efficient Script Yielding W3C Editor's Draft][spec]
* [W3C mailing list post introducing the specification][list-post]
* [IE Test Drive demo][ie-demo]
* [Introductory blog post by Nicholas C. Zakas][ncz]
[spec]: https://dvcs.w3.org/hg/webperf/raw-file/tip/specs/setImmediate/Overview.html
[task queue]: http://www.whatwg.org/specs/web-apps/current-work/multipage/webappapis.html#task-queue
[microtask queue]: http://www.whatwg.org/specs/web-apps/current-work/multipage/webappapis.html#perform-a-microtask-checkpoint
[raf]: https://html.spec.whatwg.org/multipage/webappapis.html#dom-window-requestanimationframe
[asap]: https://github.com/kriskowal/asap
[list-post]: http://lists.w3.org/Archives/Public/public-web-perf/2011Jun/0100.html
[ie-demo]: http://ie.microsoft.com/testdrive/Performance/setImmediateSorting/Default.html
[ncz]: http://www.nczonline.net/blog/2011/09/19/script-yielding-with-setimmediate/
[nextTick]: http://nodejs.org/docs/v0.8.16/api/process.html#process_process_nexttick_callback
[postMessage]: http://www.whatwg.org/specs/web-apps/current-work/multipage/web-messaging.html#posting-messages
[MessageChannel]: http://www.whatwg.org/specs/web-apps/current-work/multipage/web-messaging.html#channel-messaging
[cross-browser-demo]: http://jphpsf.github.com/setImmediate-shim-demo
# ws: a Node.js WebSocket library
[](https://www.npmjs.com/package/ws)
[](https://travis-ci.org/websockets/ws)
[](https://ci.appveyor.com/project/lpinca/ws)
[](https://coveralls.io/r/websockets/ws?branch=master)
ws is a simple to use, blazing fast, and thoroughly tested WebSocket client
and server implementation.
Passes the quite extensive Autobahn test suite: [server][server-report],
[client][client-report].
**Note**: This module does not work in the browser. The client in the docs is a
reference to a back end with the role of a client in the WebSocket
communication. Browser clients must use the native
[`WebSocket`](https://developer.mozilla.org/en-US/docs/Web/API/WebSocket) object.
## Table of Contents
* [Protocol support](#protocol-support)
* [Installing](#installing)
+ [Opt-in for performance and spec compliance](#opt-in-for-performance-and-spec-compliance)
* [API docs](#api-docs)
* [WebSocket compression](#websocket-compression)
* [Usage examples](#usage-examples)
+ [Sending and receiving text data](#sending-and-receiving-text-data)
+ [Sending binary data](#sending-binary-data)
+ [Server example](#server-example)
+ [Broadcast example](#broadcast-example)
+ [ExpressJS example](#expressjs-example)
+ [echo.websocket.org demo](#echowebsocketorg-demo)
+ [Other examples](#other-examples)
* [Error handling best practices](#error-handling-best-practices)
* [FAQ](#faq)
+ [How to get the IP address of the client?](#how-to-get-the-ip-address-of-the-client)
+ [How to detect and close broken connections?](#how-to-detect-and-close-broken-connections)
+ [How to connect via a proxy?](#how-to-connect-via-a-proxy)
* [Changelog](#changelog)
* [License](#license)
## Protocol support
* **HyBi drafts 07-12** (Use the option `protocolVersion: 8`)
* **HyBi drafts 13-17** (Current default, alternatively option `protocolVersion: 13`)
## Installing
```
npm install --save ws
```
### Opt-in for performance and spec compliance
There are 2 optional modules that can be installed along side with the ws
module. These modules are binary addons which improve certain operations.
Prebuilt binaries are available for the most popular platforms so you don't
necessarily need to have a C++ compiler installed on your machine.
- `npm install --save-optional bufferutil`: Allows to efficiently perform
operations such as masking and unmasking the data payload of the WebSocket
frames.
- `npm install --save-optional utf-8-validate`: Allows to efficiently check
if a message contains valid UTF-8 as required by the spec.
## API docs
See [`/doc/ws.md`](./doc/ws.md) for Node.js-like docs for the ws classes.
## WebSocket compression
ws supports the [permessage-deflate extension][permessage-deflate] which
enables the client and server to negotiate a compression algorithm and its
parameters, and then selectively apply it to the data payloads of each
WebSocket message.
The extension is disabled by default on the server and enabled by default on
the client. It adds a significant overhead in terms of performance and memory
consumption so we suggest to enable it only if it is really needed.
The client will only use the extension if it is supported and enabled on the
server. To always disable the extension on the client set the
`perMessageDeflate` option to `false`.
```js
const WebSocket = require('ws');
const ws = new WebSocket('ws://www.host.com/path', {
perMessageDeflate: false
});
```
## Usage examples
### Sending and receiving text data
```js
const WebSocket = require('ws');
const ws = new WebSocket('ws://www.host.com/path');
ws.on('open', function open() {
ws.send('something');
});
ws.on('message', function incoming(data) {
console.log(data);
});
```
### Sending binary data
```js
const WebSocket = require('ws');
const ws = new WebSocket('ws://www.host.com/path');
ws.on('open', function open() {
const array = new Float32Array(5);
for (var i = 0; i < array.length; ++i) {
array[i] = i / 2;
}
ws.send(array);
});
```
### Server example
```js
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: 8080 });
wss.on('connection', function connection(ws) {
ws.on('message', function incoming(message) {
console.log('received: %s', message);
});
ws.send('something');
});
```
### Broadcast example
```js
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: 8080 });
// Broadcast to all.
wss.broadcast = function broadcast(data) {
wss.clients.forEach(function each(client) {
if (client.readyState === WebSocket.OPEN) {
client.send(data);
}
});
};
wss.on('connection', function connection(ws) {
ws.on('message', function incoming(data) {
// Broadcast to everyone else.
wss.clients.forEach(function each(client) {
if (client !== ws && client.readyState === WebSocket.OPEN) {
client.send(data);
}
});
});
});
```
### ExpressJS example
```js
const express = require('express');
const http = require('http');
const url = require('url');
const WebSocket = require('ws');
const app = express();
app.use(function (req, res) {
res.send({ msg: "hello" });
});
const server = http.createServer(app);
const wss = new WebSocket.Server({ server });
wss.on('connection', function connection(ws, req) {
const location = url.parse(req.url, true);
// You might use location.query.access_token to authenticate or share sessions
// or req.headers.cookie (see http://stackoverflow.com/a/16395220/151312)
ws.on('message', function incoming(message) {
console.log('received: %s', message);
});
ws.send('something');
});
server.listen(8080, function listening() {
console.log('Listening on %d', server.address().port);
});
```
### echo.websocket.org demo
```js
const WebSocket = require('ws');
const ws = new WebSocket('wss://echo.websocket.org/', {
origin: 'https://websocket.org'
});
ws.on('open', function open() {
console.log('connected');
ws.send(Date.now());
});
ws.on('close', function close() {
console.log('disconnected');
});
ws.on('message', function incoming(data) {
console.log(`Roundtrip time: ${Date.now() - data} ms`);
setTimeout(function timeout() {
ws.send(Date.now());
}, 500);
});
```
### Other examples
For a full example with a browser client communicating with a ws server, see the
examples folder.
Otherwise, see the test cases.
## Error handling best practices
```js
// If the WebSocket is closed before the following send is attempted
ws.send('something');
// Errors (both immediate and async write errors) can be detected in an optional
// callback. The callback is also the only way of being notified that data has
// actually been sent.
ws.send('something', function ack(error) {
// If error is not defined, the send has been completed, otherwise the error
// object will indicate what failed.
});
// Immediate errors can also be handled with `try...catch`, but **note** that
// since sends are inherently asynchronous, socket write failures will *not* be
// captured when this technique is used.
try { ws.send('something'); }
catch (e) { /* handle error */ }
```
## FAQ
### How to get the IP address of the client?
The remote IP address can be obtained from the raw socket.
```js
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: 8080 });
wss.on('connection', function connection(ws, req) {
const ip = req.connection.remoteAddress;
});
```
When the server runs behind a proxy like NGINX, the de-facto standard is to use
the `X-Forwarded-For` header.
```js
wss.on('connection', function connection(ws, req) {
const ip = req.headers['x-forwarded-for'];
});
```
### How to detect and close broken connections?
Sometimes the link between the server and the client can be interrupted in a
way that keeps both the server and the client unaware of the broken state of the
connection (e.g. when pulling the cord).
In these cases ping messages can be used as a means to verify that the remote
endpoint is still responsive.
```js
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: 8080 });
function heartbeat() {
this.isAlive = true;
}
wss.on('connection', function connection(ws) {
ws.isAlive = true;
ws.on('pong', heartbeat);
});
const interval = setInterval(function ping() {
wss.clients.forEach(function each(ws) {
if (ws.isAlive === false) return ws.terminate();
ws.isAlive = false;
ws.ping('', false, true);
});
}, 30000);
```
Pong messages are automatically sent in response to ping messages as required
by the spec.
### How to connect via a proxy?
Use a custom `http.Agent` implementation like [https-proxy-agent][] or
[socks-proxy-agent][].
## Changelog
We're using the GitHub [releases][changelog] for changelog entries.
## License
[MIT](LICENSE)
[https-proxy-agent]: https://github.com/TooTallNate/node-https-proxy-agent
[socks-proxy-agent]: https://github.com/TooTallNate/node-socks-proxy-agent
[client-report]: http://websockets.github.io/ws/autobahn/clients/
[server-report]: http://websockets.github.io/ws/autobahn/servers/
[permessage-deflate]: https://tools.ietf.org/html/rfc7692
[changelog]: https://github.com/websockets/ws/releases
# keccak
This module provides native bindings to [Keccak sponge function family][1] from [Keccak Code Package][2]. In browser pure JavaScript implementation will be used.
## Usage
You can use this package as [node Hash][3].
```js
const createKeccakHash = require('keccak')
console.log(createKeccakHash('keccak256').digest().toString('hex'))
// => c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470
console.log(createKeccakHash('keccak256').update('Hello world!').digest('hex'))
// => ecd0e108a98e192af1d2c25055f4e3bed784b5c877204e73219a5203251feaab
```
Also object has two useful methods: `_resetState` and `_clone`
```js
const createKeccakHash = require('keccak')
console.log(createKeccakHash('keccak256').update('Hello World!')._resetState().digest('hex'))
// => c5d2460186f7233c927e7db2dcc703c0e500b653ca82273b7bfad8045d85a470
const hash1 = createKeccakHash('keccak256').update('Hello')
const hash2 = hash1._clone()
console.log(hash1.digest('hex'))
// => 06b3dfaec148fb1bb2b066f10ec285e7c9bf402ab32aa78a5d38e34566810cd2
console.log(hash1.update(' world!').digest('hex'))
// => throw Error: Digest already called
console.log(hash2.update(' world!').digest('hex'))
// => ecd0e108a98e192af1d2c25055f4e3bed784b5c877204e73219a5203251feaab
```
### Why I should use this package?
I thought it will be popular question, so I decide write explanation in readme.
I know a few popular packages on [npm][4] related with [Keccak][1]:
- [sha3][5] ([phusion/node-sha3][6] on github) — not actual because support _only keccak_.
- [js-sha3][7] ([emn178/js-sha3][8] on github) — brilliant package which support keccak, sha3, shake. But not implement [node Hash][3] interface unfortunately!
- [browserify-sha3][9] ([wanderer/browserify-sha3][10] on github) — based on [js-sha3][7] (but not support shake!). Support [node Hash][3] interface, but without [streams][11].
- [keccakjs][12] ([axic/keccakjs][13] on github) — uses [sha3][5] and [browserify-sha3][9] as fallback. As result _keccak only_ with [node Hash][3] interface without [streams][11].
## LICENSE
This library is free and open-source software released under the MIT license.
[1]: http://keccak.noekeon.org/
[2]: https://github.com/gvanas/KeccakCodePackage
[3]: https://nodejs.org/api/crypto.html#crypto_class_hash
[4]: http://npmjs.com/
[5]: https://www.npmjs.com/package/sha3
[6]: https://github.com/phusion/node-sha3
[7]: https://www.npmjs.com/package/js-sha3
[8]: https://github.com/emn178/js-sha3
[9]: https://www.npmjs.com/package/browserify-sha3
[10]: https://github.com/wanderer/browserify-sha3
[11]: http://nodejs.org/api/stream.html
[12]: https://www.npmjs.com/package/keccakjs
[13]: https://github.com/axic/keccakjs
# clone-response
> Clone a Node.js HTTP response stream
[](https://travis-ci.org/lukechilds/clone-response)
[](https://coveralls.io/github/lukechilds/clone-response?branch=master)
[](https://www.npmjs.com/package/clone-response)
[](https://www.npmjs.com/package/clone-response)
Returns a new stream and copies over all properties and methods from the original response giving you a complete duplicate.
This is useful in situations where you need to consume the response stream but also want to pass an unconsumed stream somewhere else to be consumed later.
## Install
```shell
npm install --save clone-response
```
## Usage
```js
const http = require('http');
const cloneResponse = require('clone-response');
http.get('http://example.com', response => {
const clonedResponse = cloneResponse(response);
response.pipe(process.stdout);
setImmediate(() => {
// The response stream has already been consumed by the time this executes,
// however the cloned response stream is still available.
doSomethingWithResponse(clonedResponse);
});
});
```
Please bear in mind that the process of cloning a stream consumes it. However, you can consume a stream multiple times in the same tick, therefore allowing you to create multiple clones. e.g:
```js
const clone1 = cloneResponse(response);
const clone2 = cloneResponse(response);
// response can still be consumed in this tick but cannot be consumed if passed
// into any async callbacks. clone1 and clone2 can be passed around and be
// consumed in the future.
```
## API
### cloneResponse(response)
Returns a clone of the passed in response.
#### response
Type: `stream`
A [Node.js HTTP response stream](https://nodejs.org/api/http.html#http_class_http_incomingmessage) to clone.
## License
MIT © Luke Childs
# HAR Validator
[![license][license-img]][license-url]
[![version][npm-img]][npm-url]
[![super linter][super-linter-img]][super-linter-url]
[![test][test-img]][test-url]
[![release][release-img]][release-url]
[license-url]: LICENSE
[license-img]: https://badgen.net/github/license/ahmadnassri/node-har-validator
[npm-url]: https://www.npmjs.com/package/har-validator
[npm-img]: https://badgen.net/npm/v/har-validator
[super-linter-url]: https://github.com/ahmadnassri/node-har-validator/actions?query=workflow%3Asuper-linter
[super-linter-img]: https://github.com/ahmadnassri/node-har-validator/workflows/super-linter/badge.svg
[test-url]: https://github.com/ahmadnassri/node-har-validator/actions?query=workflow%3Atest
[test-img]: https://github.com/ahmadnassri/node-har-validator/workflows/test/badge.svg
[release-url]: https://github.com/ahmadnassri/node-har-validator/actions?query=workflow%3Arelease
[release-img]: https://github.com/ahmadnassri/node-har-validator/workflows/release/badge.svg
> Extremely fast HTTP Archive ([HAR](https://github.com/ahmadnassri/har-spec/blob/master/versions/1.2.md)) validator using JSON Schema.
## Install
```bash
npm install har-validator
```
## CLI Usage
Please refer to [`har-cli`](https://github.com/ahmadnassri/har-cli) for more info.
## API
**Note**: as of [`v2.0.0`](https://github.com/ahmadnassri/node-har-validator/releases/tag/v2.0.0) this module defaults to Promise based API.
_For backward compatibility with `v1.x` an [async/callback API](docs/async.md) is also provided_
- [async API](docs/async.md)
- [callback API](docs/async.md)
- [Promise API](docs/promise.md) _(default)_
level-ws
========

**A basic WriteStream implementation for [LevelUP](https://github.com/rvagg/node-levelup)**
[](https://nodei.co/npm/level-ws/)
**level-ws** provides the most basic general-case WriteStream for LevelUP. It was extracted from the core LevelUP at version 0.18.0 but is bundled with [level](https://github.com/Level/level) and similar packages as it provides a general symmetry to the ReadStream in LevelUP.
**level-ws** is not a high-performance WriteStream, if your benchmarking shows that your particular usage pattern and data types do not perform well with this WriteStream then you should try one of the alternative WriteStreams available for LevelUP that are optimised for different use-cases.
## Alternative WriteStream packages
***TODO***
## Usage
To use **level-ws** you simply need to wrap a LevelUP instance and you get a `createWriteStream()` method on it.
```js
var level = require('level')
var levelws = require('level-ws')
var db = level('/path/to/db')
db = levelws(db)
db.createWriteStream() // ...
```
### db.createWriteStream([options])
A **WriteStream** can be obtained by calling the `createWriteStream()` method. The resulting stream is a Node.js **streams2** [Writable](http://nodejs.org/docs/latest/api/stream.html#stream_class_stream_writable_1) which operates in **objectMode**, accepting objects with `'key'` and `'value'` pairs on its `write()` method.
The WriteStream will buffer writes and submit them as a `batch()` operations where writes occur *within the same tick*.
```js
var ws = db.createWriteStream()
ws.on('error', function (err) {
console.log('Oh my!', err)
})
ws.on('close', function () {
console.log('Stream closed')
})
ws.write({ key: 'name', value: 'Yuri Irsenovich Kim' })
ws.write({ key: 'dob', value: '16 February 1941' })
ws.write({ key: 'spouse', value: 'Kim Young-sook' })
ws.write({ key: 'occupation', value: 'Clown' })
ws.end()
```
The standard `write()`, `end()`, `destroy()` and `destroySoon()` methods are implemented on the WriteStream. `'drain'`, `'error'`, `'close'` and `'pipe'` events are emitted.
You can specify encodings both for the whole stream and individual entries:
To set the encoding for the whole stream, provide an options object as the first parameter to `createWriteStream()` with `'keyEncoding'` and/or `'valueEncoding'`.
To set the encoding for an individual entry:
```js
writeStream.write({
key : new Buffer([1, 2, 3])
, value : { some: 'json' }
, keyEncoding : 'binary'
, valueEncoding : 'json'
})
```
#### write({ type: 'put' })
If individual `write()` operations are performed with a `'type'` property of `'del'`, they will be passed on as `'del'` operations to the batch.
```js
var ws = db.createWriteStream()
ws.on('error', function (err) {
console.log('Oh my!', err)
})
ws.on('close', function () {
console.log('Stream closed')
})
ws.write({ type: 'del', key: 'name' })
ws.write({ type: 'del', key: 'dob' })
ws.write({ type: 'put', key: 'spouse' })
ws.write({ type: 'del', key: 'occupation' })
ws.end()
```
#### db.createWriteStream({ type: 'del' })
If the *WriteStream* is created with a `'type'` option of `'del'`, all `write()` operations will be interpreted as `'del'`, unless explicitly specified as `'put'`.
```js
var ws = db.createWriteStream({ type: 'del' })
ws.on('error', function (err) {
console.log('Oh my!', err)
})
ws.on('close', function () {
console.log('Stream closed')
})
ws.write({ key: 'name' })
ws.write({ key: 'dob' })
// but it can be overridden
ws.write({ type: 'put', key: 'spouse', value: 'Ri Sol-ju' })
ws.write({ key: 'occupation' })
ws.end()
```
### Contributors
**level-ws** is only possible due to the excellent work of the following contributors:
<table><tbody>
<tr><th align="left">Rod Vagg</th><td><a href="https://github.com/rvagg">GitHub/rvagg</a></td><td><a href="http://twitter.com/rvagg">Twitter/@rvagg</a></td></tr>
<tr><th align="left">John Chesley</th><td><a href="https://github.com/chesles/">GitHub/chesles</a></td><td><a href="http://twitter.com/chesles">Twitter/@chesles</a></td></tr>
<tr><th align="left">Jake Verbaten</th><td><a href="https://github.com/raynos">GitHub/raynos</a></td><td><a href="http://twitter.com/raynos2">Twitter/@raynos2</a></td></tr>
<tr><th align="left">Dominic Tarr</th><td><a href="https://github.com/dominictarr">GitHub/dominictarr</a></td><td><a href="http://twitter.com/dominictarr">Twitter/@dominictarr</a></td></tr>
<tr><th align="left">Max Ogden</th><td><a href="https://github.com/maxogden">GitHub/maxogden</a></td><td><a href="http://twitter.com/maxogden">Twitter/@maxogden</a></td></tr>
<tr><th align="left">Lars-Magnus Skog</th><td><a href="https://github.com/ralphtheninja">GitHub/ralphtheninja</a></td><td><a href="http://twitter.com/ralphtheninja">Twitter/@ralphtheninja</a></td></tr>
<tr><th align="left">David Björklund</th><td><a href="https://github.com/kesla">GitHub/kesla</a></td><td><a href="http://twitter.com/david_bjorklund">Twitter/@david_bjorklund</a></td></tr>
<tr><th align="left">Julian Gruber</th><td><a href="https://github.com/juliangruber">GitHub/juliangruber</a></td><td><a href="http://twitter.com/juliangruber">Twitter/@juliangruber</a></td></tr>
<tr><th align="left">Paolo Fragomeni</th><td><a href="https://github.com/hij1nx">GitHub/hij1nx</a></td><td><a href="http://twitter.com/hij1nx">Twitter/@hij1nx</a></td></tr>
<tr><th align="left">Anton Whalley</th><td><a href="https://github.com/No9">GitHub/No9</a></td><td><a href="https://twitter.com/antonwhalley">Twitter/@antonwhalley</a></td></tr>
<tr><th align="left">Matteo Collina</th><td><a href="https://github.com/mcollina">GitHub/mcollina</a></td><td><a href="https://twitter.com/matteocollina">Twitter/@matteocollina</a></td></tr>
<tr><th align="left">Pedro Teixeira</th><td><a href="https://github.com/pgte">GitHub/pgte</a></td><td><a href="https://twitter.com/pgte">Twitter/@pgte</a></td></tr>
<tr><th align="left">James Halliday</th><td><a href="https://github.com/substack">GitHub/substack</a></td><td><a href="https://twitter.com/substack">Twitter/@substack</a></td></tr>
</tbody></table>
<a name="licence"></a>
Licence & copyright
-------------------
Copyright (c) 2012-2013 **level-ws** contributors (listed above).
**level-ws** is licensed under an MIT +no-false-attribs license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE file for more details.
# cookie
[![NPM Version][npm-version-image]][npm-url]
[![NPM Downloads][npm-downloads-image]][npm-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Basic HTTP cookie parser and serializer for HTTP servers.
## Installation
```sh
$ npm install cookie
```
## API
```js
var cookie = require('cookie');
```
### cookie.parse(str, options)
Parse an HTTP `Cookie` header string and returning an object of all cookie name-value pairs.
The `str` argument is the string representing a `Cookie` header value and `options` is an
optional object containing additional parsing options.
```js
var cookies = cookie.parse('foo=bar; equation=E%3Dmc%5E2');
// { foo: 'bar', equation: 'E=mc^2' }
```
#### Options
`cookie.parse` accepts these properties in the options object.
##### decode
Specifies a function that will be used to decode a cookie's value. Since the value of a cookie
has a limited character set (and must be a simple string), this function can be used to decode
a previously-encoded cookie value into a JavaScript string or other object.
The default function is the global `decodeURIComponent`, which will decode any URL-encoded
sequences into their byte representations.
**note** if an error is thrown from this function, the original, non-decoded cookie value will
be returned as the cookie's value.
### cookie.serialize(name, value, options)
Serialize a cookie name-value pair into a `Set-Cookie` header string. The `name` argument is the
name for the cookie, the `value` argument is the value to set the cookie to, and the `options`
argument is an optional object containing additional serialization options.
```js
var setCookie = cookie.serialize('foo', 'bar');
// foo=bar
```
#### Options
`cookie.serialize` accepts these properties in the options object.
##### domain
Specifies the value for the [`Domain` `Set-Cookie` attribute][rfc-6265-5.2.3]. By default, no
domain is set, and most clients will consider the cookie to apply to only the current domain.
##### encode
Specifies a function that will be used to encode a cookie's value. Since value of a cookie
has a limited character set (and must be a simple string), this function can be used to encode
a value into a string suited for a cookie's value.
The default function is the global `encodeURIComponent`, which will encode a JavaScript string
into UTF-8 byte sequences and then URL-encode any that fall outside of the cookie range.
##### expires
Specifies the `Date` object to be the value for the [`Expires` `Set-Cookie` attribute][rfc-6265-5.2.1].
By default, no expiration is set, and most clients will consider this a "non-persistent cookie" and
will delete it on a condition like exiting a web browser application.
**note** the [cookie storage model specification][rfc-6265-5.3] states that if both `expires` and
`maxAge` are set, then `maxAge` takes precedence, but it is possible not all clients by obey this,
so if both are set, they should point to the same date and time.
##### httpOnly
Specifies the `boolean` value for the [`HttpOnly` `Set-Cookie` attribute][rfc-6265-5.2.6]. When truthy,
the `HttpOnly` attribute is set, otherwise it is not. By default, the `HttpOnly` attribute is not set.
**note** be careful when setting this to `true`, as compliant clients will not allow client-side
JavaScript to see the cookie in `document.cookie`.
##### maxAge
Specifies the `number` (in seconds) to be the value for the [`Max-Age` `Set-Cookie` attribute][rfc-6265-5.2.2].
The given number will be converted to an integer by rounding down. By default, no maximum age is set.
**note** the [cookie storage model specification][rfc-6265-5.3] states that if both `expires` and
`maxAge` are set, then `maxAge` takes precedence, but it is possible not all clients by obey this,
so if both are set, they should point to the same date and time.
##### path
Specifies the value for the [`Path` `Set-Cookie` attribute][rfc-6265-5.2.4]. By default, the path
is considered the ["default path"][rfc-6265-5.1.4].
##### sameSite
Specifies the `boolean` or `string` to be the value for the [`SameSite` `Set-Cookie` attribute][rfc-6265bis-03-4.1.2.7].
- `true` will set the `SameSite` attribute to `Strict` for strict same site enforcement.
- `false` will not set the `SameSite` attribute.
- `'lax'` will set the `SameSite` attribute to `Lax` for lax same site enforcement.
- `'none'` will set the `SameSite` attribute to `None` for an explicit cross-site cookie.
- `'strict'` will set the `SameSite` attribute to `Strict` for strict same site enforcement.
More information about the different enforcement levels can be found in
[the specification][rfc-6265bis-03-4.1.2.7].
**note** This is an attribute that has not yet been fully standardized, and may change in the future.
This also means many clients may ignore this attribute until they understand it.
##### secure
Specifies the `boolean` value for the [`Secure` `Set-Cookie` attribute][rfc-6265-5.2.5]. When truthy,
the `Secure` attribute is set, otherwise it is not. By default, the `Secure` attribute is not set.
**note** be careful when setting this to `true`, as compliant clients will not send the cookie back to
the server in the future if the browser does not have an HTTPS connection.
## Example
The following example uses this module in conjunction with the Node.js core HTTP server
to prompt a user for their name and display it back on future visits.
```js
var cookie = require('cookie');
var escapeHtml = require('escape-html');
var http = require('http');
var url = require('url');
function onRequest(req, res) {
// Parse the query string
var query = url.parse(req.url, true, true).query;
if (query && query.name) {
// Set a new cookie with the name
res.setHeader('Set-Cookie', cookie.serialize('name', String(query.name), {
httpOnly: true,
maxAge: 60 * 60 * 24 * 7 // 1 week
}));
// Redirect back after setting cookie
res.statusCode = 302;
res.setHeader('Location', req.headers.referer || '/');
res.end();
return;
}
// Parse the cookies on the request
var cookies = cookie.parse(req.headers.cookie || '');
// Get the visitor name set in the cookie
var name = cookies.name;
res.setHeader('Content-Type', 'text/html; charset=UTF-8');
if (name) {
res.write('<p>Welcome back, <b>' + escapeHtml(name) + '</b>!</p>');
} else {
res.write('<p>Hello, new visitor!</p>');
}
res.write('<form method="GET">');
res.write('<input placeholder="enter your name" name="name"> <input type="submit" value="Set Name">');
res.end('</form>');
}
http.createServer(onRequest).listen(3000);
```
## Testing
```sh
$ npm test
```
## Benchmark
```
$ npm run bench
> [email protected] bench cookie
> node benchmark/index.js
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
modules@48
napi@3
[email protected]
> node benchmark/parse.js
cookie.parse
6 tests completed.
simple x 1,200,691 ops/sec ±1.12% (189 runs sampled)
decode x 1,012,994 ops/sec ±0.97% (186 runs sampled)
unquote x 1,074,174 ops/sec ±2.43% (186 runs sampled)
duplicates x 438,424 ops/sec ±2.17% (184 runs sampled)
10 cookies x 147,154 ops/sec ±1.01% (186 runs sampled)
100 cookies x 14,274 ops/sec ±1.07% (187 runs sampled)
```
## References
- [RFC 6265: HTTP State Management Mechanism][rfc-6265]
- [Same-site Cookies][rfc-6265bis-03-4.1.2.7]
[rfc-6265bis-03-4.1.2.7]: https://tools.ietf.org/html/draft-ietf-httpbis-rfc6265bis-03#section-4.1.2.7
[rfc-6265]: https://tools.ietf.org/html/rfc6265
[rfc-6265-5.1.4]: https://tools.ietf.org/html/rfc6265#section-5.1.4
[rfc-6265-5.2.1]: https://tools.ietf.org/html/rfc6265#section-5.2.1
[rfc-6265-5.2.2]: https://tools.ietf.org/html/rfc6265#section-5.2.2
[rfc-6265-5.2.3]: https://tools.ietf.org/html/rfc6265#section-5.2.3
[rfc-6265-5.2.4]: https://tools.ietf.org/html/rfc6265#section-5.2.4
[rfc-6265-5.2.5]: https://tools.ietf.org/html/rfc6265#section-5.2.5
[rfc-6265-5.2.6]: https://tools.ietf.org/html/rfc6265#section-5.2.6
[rfc-6265-5.3]: https://tools.ietf.org/html/rfc6265#section-5.3
## License
[MIT](LICENSE)
[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/cookie/master
[coveralls-url]: https://coveralls.io/r/jshttp/cookie?branch=master
[node-version-image]: https://badgen.net/npm/node/cookie
[node-version-url]: https://nodejs.org/en/download
[npm-downloads-image]: https://badgen.net/npm/dm/cookie
[npm-url]: https://npmjs.org/package/cookie
[npm-version-image]: https://badgen.net/npm/v/cookie
[travis-image]: https://badgen.net/travis/jshttp/cookie/master
[travis-url]: https://travis-ci.org/jshttp/cookie
# process
```require('process');``` just like any other module.
Works in node.js and browsers via the browser.js shim provided with the module.
## package manager notes
If you are writing a bundler to package modules for client side use, make sure you use the ```browser``` field hint in package.json.
See https://gist.github.com/4339901 for details.
The [browserify](https://github.com/substack/node-browserify) module will properly handle this field when bundling your files.
# wrappy
Callback wrapping utility
## USAGE
```javascript
var wrappy = require("wrappy")
// var wrapper = wrappy(wrapperFunction)
// make sure a cb is called only once
// See also: http://npm.im/once for this specific use case
var once = wrappy(function (cb) {
var called = false
return function () {
if (called) return
called = true
return cb.apply(this, arguments)
}
})
function printBoo () {
console.log('boo')
}
// has some rando property
printBoo.iAmBooPrinter = true
var onlyPrintOnce = once(printBoo)
onlyPrintOnce() // prints 'boo'
onlyPrintOnce() // does nothing
// random property is retained!
assert.equal(onlyPrintOnce.iAmBooPrinter, true)
```
# buffer-to-arraybuffer
> Convert Buffer to ArrayBuffer
# Install
```bash
npm install buffer-to-arraybuffer
```
# Usage
```javascript
var bufferToArrayBuffer = require('buffer-to-arraybuffer');
var b = new Buffer(12);
b.write('abc', 0);
var ab = bufferToArrayBuffer(b);
String.fromCharCode.apply(null, new Uint8Array(ab)); // 'abc'
```
NOTE: If you only target node `v4.3+`, you can simply just do:
```javascript
new Buffer([12]).buffer
```
# License
MIT
# arr-flatten [](https://www.npmjs.com/package/arr-flatten) [](https://npmjs.org/package/arr-flatten) [](https://npmjs.org/package/arr-flatten) [](https://travis-ci.org/jonschlinkert/arr-flatten) [](https://ci.appveyor.com/project/jonschlinkert/arr-flatten)
> Recursively flatten an array or arrays.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save arr-flatten
```
## Install
Install with [bower](https://bower.io/)
```sh
$ bower install arr-flatten --save
```
## Usage
```js
var flatten = require('arr-flatten');
flatten(['a', ['b', ['c']], 'd', ['e']]);
//=> ['a', 'b', 'c', 'd', 'e']
```
## Why another flatten utility?
I wanted the fastest implementation I could find, with implementation choices that should work for 95% of use cases, but no cruft to cover the other 5%.
## About
### Related projects
* [arr-filter](https://www.npmjs.com/package/arr-filter): Faster alternative to javascript's native filter method. | [homepage](https://github.com/jonschlinkert/arr-filter "Faster alternative to javascript's native filter method.")
* [arr-union](https://www.npmjs.com/package/arr-union): Combines a list of arrays, returning a single array with unique values, using strict equality… [more](https://github.com/jonschlinkert/arr-union) | [homepage](https://github.com/jonschlinkert/arr-union "Combines a list of arrays, returning a single array with unique values, using strict equality for comparisons.")
* [array-each](https://www.npmjs.com/package/array-each): Loop over each item in an array and call the given function on every element. | [homepage](https://github.com/jonschlinkert/array-each "Loop over each item in an array and call the given function on every element.")
* [array-unique](https://www.npmjs.com/package/array-unique): Remove duplicate values from an array. Fastest ES5 implementation. | [homepage](https://github.com/jonschlinkert/array-unique "Remove duplicate values from an array. Fastest ES5 implementation.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 20 | [jonschlinkert](https://github.com/jonschlinkert) |
| 1 | [lukeed](https://github.com/lukeed) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on July 05, 2017._
# Upper Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transforms the string to upper case.
## Installation
```
npm install upper-case --save
```
## Usage
```js
import { upperCase, localeUpperCase } from "upper-case";
upperCase("string"); //=> "STRING"
localeUpperCase("string", "tr"); //=> "STRİNG"
```
## License
MIT
[npm-image]: https://img.shields.io/npm/v/upper-case.svg?style=flat
[npm-url]: https://npmjs.org/package/upper-case
[downloads-image]: https://img.shields.io/npm/dm/upper-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/upper-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/upper-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=upper-case
[](https://www.npmjs.com/package/esprima)
[](https://www.npmjs.com/package/esprima)
[](https://travis-ci.org/jquery/esprima)
[](https://codecov.io/github/jquery/esprima)
**Esprima** ([esprima.org](http://esprima.org), BSD license) is a high performance,
standard-compliant [ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
parser written in ECMAScript (also popularly known as
[JavaScript](https://en.wikipedia.org/wiki/JavaScript)).
Esprima is created and maintained by [Ariya Hidayat](https://twitter.com/ariyahidayat),
with the help of [many contributors](https://github.com/jquery/esprima/contributors).
### Features
- Full support for ECMAScript 2017 ([ECMA-262 8th Edition](http://www.ecma-international.org/publications/standards/Ecma-262.htm))
- Sensible [syntax tree format](https://github.com/estree/estree/blob/master/es5.md) as standardized by [ESTree project](https://github.com/estree/estree)
- Experimental support for [JSX](https://facebook.github.io/jsx/), a syntax extension for [React](https://facebook.github.io/react/)
- Optional tracking of syntax node location (index-based and line-column)
- [Heavily tested](http://esprima.org/test/ci.html) (~1500 [unit tests](https://github.com/jquery/esprima/tree/master/test/fixtures) with [full code coverage](https://codecov.io/github/jquery/esprima))
### API
Esprima can be used to perform [lexical analysis](https://en.wikipedia.org/wiki/Lexical_analysis) (tokenization) or [syntactic analysis](https://en.wikipedia.org/wiki/Parsing) (parsing) of a JavaScript program.
A simple example on Node.js REPL:
```javascript
> var esprima = require('esprima');
> var program = 'const answer = 42';
> esprima.tokenize(program);
[ { type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'answer' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '42' } ]
> esprima.parseScript(program);
{ type: 'Program',
body:
[ { type: 'VariableDeclaration',
declarations: [Object],
kind: 'const' } ],
sourceType: 'script' }
```
For more information, please read the [complete documentation](http://esprima.org/doc).
# TezosBridge
TruffleFramework template with travis-ci.org and coveralls.io configured
[](https://travis-ci.org/tezosprotocol/bridge)
[](https://coveralls.io/github/tezosprotocol/bridge?branch=master)
# Constant Case
[![NPM version][npm-image]][npm-url]
[![NPM downloads][downloads-image]][downloads-url]
[![Bundle size][bundlephobia-image]][bundlephobia-url]
> Transform into upper case string with an underscore between words.
## Installation
```
npm install constant-case --save
```
## Usage
```js
import { constantCase } from "constant-case";
constantCase("string"); //=> "STRING"
constantCase("dot.case"); //=> "DOT_CASE"
constantCase("PascalCase"); //=> "PASCAL_CASE"
constantCase("version 1.2.10"); //=> "VERSION_1_2_10"
```
The function also accepts [`options`](https://github.com/blakeembrey/change-case#options).
## License
MIT
[npm-image]: https://img.shields.io/npm/v/constant-case.svg?style=flat
[npm-url]: https://npmjs.org/package/constant-case
[downloads-image]: https://img.shields.io/npm/dm/constant-case.svg?style=flat
[downloads-url]: https://npmjs.org/package/constant-case
[bundlephobia-image]: https://img.shields.io/bundlephobia/minzip/constant-case.svg
[bundlephobia-url]: https://bundlephobia.com/result?p=constant-case
semver(1) -- The semantic versioner for npm
===========================================
## Install
```bash
npm install semver
````
## Usage
As a node module:
```js
const semver = require('semver')
semver.valid('1.2.3') // '1.2.3'
semver.valid('a.b.c') // null
semver.clean(' =v1.2.3 ') // '1.2.3'
semver.satisfies('1.2.3', '1.x || >=2.5.0 || 5.0.0 - 7.2.3') // true
semver.gt('1.2.3', '9.8.7') // false
semver.lt('1.2.3', '9.8.7') // true
semver.minVersion('>=1.0.0') // '1.0.0'
semver.valid(semver.coerce('v2')) // '2.0.0'
semver.valid(semver.coerce('42.6.7.9.3-alpha')) // '42.6.7'
```
You can also just load the module for the function that you care about, if
you'd like to minimize your footprint.
```js
// load the whole API at once in a single object
const semver = require('semver')
// or just load the bits you need
// all of them listed here, just pick and choose what you want
// classes
const SemVer = require('semver/classes/semver')
const Comparator = require('semver/classes/comparator')
const Range = require('semver/classes/range')
// functions for working with versions
const semverParse = require('semver/functions/parse')
const semverValid = require('semver/functions/valid')
const semverClean = require('semver/functions/clean')
const semverInc = require('semver/functions/inc')
const semverDiff = require('semver/functions/diff')
const semverMajor = require('semver/functions/major')
const semverMinor = require('semver/functions/minor')
const semverPatch = require('semver/functions/patch')
const semverPrerelease = require('semver/functions/prerelease')
const semverCompare = require('semver/functions/compare')
const semverRcompare = require('semver/functions/rcompare')
const semverCompareLoose = require('semver/functions/compare-loose')
const semverCompareBuild = require('semver/functions/compare-build')
const semverSort = require('semver/functions/sort')
const semverRsort = require('semver/functions/rsort')
// low-level comparators between versions
const semverGt = require('semver/functions/gt')
const semverLt = require('semver/functions/lt')
const semverEq = require('semver/functions/eq')
const semverNeq = require('semver/functions/neq')
const semverGte = require('semver/functions/gte')
const semverLte = require('semver/functions/lte')
const semverCmp = require('semver/functions/cmp')
const semverCoerce = require('semver/functions/coerce')
// working with ranges
const semverSatisfies = require('semver/functions/satisfies')
const semverMaxSatisfying = require('semver/ranges/max-satisfying')
const semverMinSatisfying = require('semver/ranges/min-satisfying')
const semverToComparators = require('semver/ranges/to-comparators')
const semverMinVersion = require('semver/ranges/min-version')
const semverValidRange = require('semver/ranges/valid')
const semverOutside = require('semver/ranges/outside')
const semverGtr = require('semver/ranges/gtr')
const semverLtr = require('semver/ranges/ltr')
const semverIntersects = require('semver/ranges/intersects')
const simplifyRange = require('semver/ranges/simplify')
const rangeSubset = require('semver/ranges/subset')
```
As a command-line utility:
```
$ semver -h
A JavaScript implementation of the https://semver.org/ specification
Copyright Isaac Z. Schlueter
Usage: semver [options] <version> [<version> [...]]
Prints valid versions sorted by SemVer precedence
Options:
-r --range <range>
Print versions that match the specified range.
-i --increment [<level>]
Increment a version by the specified level. Level can
be one of: major, minor, patch, premajor, preminor,
prepatch, or prerelease. Default level is 'patch'.
Only one version may be specified.
--preid <identifier>
Identifier to be used to prefix premajor, preminor,
prepatch or prerelease version increments.
-l --loose
Interpret versions and ranges loosely
-p --include-prerelease
Always include prerelease versions in range matching
-c --coerce
Coerce a string into SemVer if possible
(does not imply --loose)
--rtl
Coerce version strings right to left
--ltr
Coerce version strings left to right (default)
Program exits successfully if any valid version satisfies
all supplied ranges, and prints all satisfying versions.
If no satisfying versions are found, then exits failure.
Versions are printed in ascending order, so supplying
multiple versions to the utility will just sort them.
```
## Versions
A "version" is described by the `v2.0.0` specification found at
<https://semver.org/>.
A leading `"="` or `"v"` character is stripped off and ignored.
## Ranges
A `version range` is a set of `comparators` which specify versions
that satisfy the range.
A `comparator` is composed of an `operator` and a `version`. The set
of primitive `operators` is:
* `<` Less than
* `<=` Less than or equal to
* `>` Greater than
* `>=` Greater than or equal to
* `=` Equal. If no operator is specified, then equality is assumed,
so this operator is optional, but MAY be included.
For example, the comparator `>=1.2.7` would match the versions
`1.2.7`, `1.2.8`, `2.5.3`, and `1.3.9`, but not the versions `1.2.6`
or `1.1.0`.
Comparators can be joined by whitespace to form a `comparator set`,
which is satisfied by the **intersection** of all of the comparators
it includes.
A range is composed of one or more comparator sets, joined by `||`. A
version matches a range if and only if every comparator in at least
one of the `||`-separated comparator sets is satisfied by the version.
For example, the range `>=1.2.7 <1.3.0` would match the versions
`1.2.7`, `1.2.8`, and `1.2.99`, but not the versions `1.2.6`, `1.3.0`,
or `1.1.0`.
The range `1.2.7 || >=1.2.9 <2.0.0` would match the versions `1.2.7`,
`1.2.9`, and `1.4.6`, but not the versions `1.2.8` or `2.0.0`.
### Prerelease Tags
If a version has a prerelease tag (for example, `1.2.3-alpha.3`) then
it will only be allowed to satisfy comparator sets if at least one
comparator with the same `[major, minor, patch]` tuple also has a
prerelease tag.
For example, the range `>1.2.3-alpha.3` would be allowed to match the
version `1.2.3-alpha.7`, but it would *not* be satisfied by
`3.4.5-alpha.9`, even though `3.4.5-alpha.9` is technically "greater
than" `1.2.3-alpha.3` according to the SemVer sort rules. The version
range only accepts prerelease tags on the `1.2.3` version. The
version `3.4.5` *would* satisfy the range, because it does not have a
prerelease flag, and `3.4.5` is greater than `1.2.3-alpha.7`.
The purpose for this behavior is twofold. First, prerelease versions
frequently are updated very quickly, and contain many breaking changes
that are (by the author's design) not yet fit for public consumption.
Therefore, by default, they are excluded from range matching
semantics.
Second, a user who has opted into using a prerelease version has
clearly indicated the intent to use *that specific* set of
alpha/beta/rc versions. By including a prerelease tag in the range,
the user is indicating that they are aware of the risk. However, it
is still not appropriate to assume that they have opted into taking a
similar risk on the *next* set of prerelease versions.
Note that this behavior can be suppressed (treating all prerelease
versions as if they were normal versions, for the purpose of range
matching) by setting the `includePrerelease` flag on the options
object to any
[functions](https://github.com/npm/node-semver#functions) that do
range matching.
#### Prerelease Identifiers
The method `.inc` takes an additional `identifier` string argument that
will append the value of the string as a prerelease identifier:
```javascript
semver.inc('1.2.3', 'prerelease', 'beta')
// '1.2.4-beta.0'
```
command-line example:
```bash
$ semver 1.2.3 -i prerelease --preid beta
1.2.4-beta.0
```
Which then can be used to increment further:
```bash
$ semver 1.2.4-beta.0 -i prerelease
1.2.4-beta.1
```
### Advanced Range Syntax
Advanced range syntax desugars to primitive comparators in
deterministic ways.
Advanced ranges may be combined in the same way as primitive
comparators using white space or `||`.
#### Hyphen Ranges `X.Y.Z - A.B.C`
Specifies an inclusive set.
* `1.2.3 - 2.3.4` := `>=1.2.3 <=2.3.4`
If a partial version is provided as the first version in the inclusive
range, then the missing pieces are replaced with zeroes.
* `1.2 - 2.3.4` := `>=1.2.0 <=2.3.4`
If a partial version is provided as the second version in the
inclusive range, then all versions that start with the supplied parts
of the tuple are accepted, but nothing that would be greater than the
provided tuple parts.
* `1.2.3 - 2.3` := `>=1.2.3 <2.4.0-0`
* `1.2.3 - 2` := `>=1.2.3 <3.0.0-0`
#### X-Ranges `1.2.x` `1.X` `1.2.*` `*`
Any of `X`, `x`, or `*` may be used to "stand in" for one of the
numeric values in the `[major, minor, patch]` tuple.
* `*` := `>=0.0.0` (Any version satisfies)
* `1.x` := `>=1.0.0 <2.0.0-0` (Matching major version)
* `1.2.x` := `>=1.2.0 <1.3.0-0` (Matching major and minor versions)
A partial version range is treated as an X-Range, so the special
character is in fact optional.
* `""` (empty string) := `*` := `>=0.0.0`
* `1` := `1.x.x` := `>=1.0.0 <2.0.0-0`
* `1.2` := `1.2.x` := `>=1.2.0 <1.3.0-0`
#### Tilde Ranges `~1.2.3` `~1.2` `~1`
Allows patch-level changes if a minor version is specified on the
comparator. Allows minor-level changes if not.
* `~1.2.3` := `>=1.2.3 <1.(2+1).0` := `>=1.2.3 <1.3.0-0`
* `~1.2` := `>=1.2.0 <1.(2+1).0` := `>=1.2.0 <1.3.0-0` (Same as `1.2.x`)
* `~1` := `>=1.0.0 <(1+1).0.0` := `>=1.0.0 <2.0.0-0` (Same as `1.x`)
* `~0.2.3` := `>=0.2.3 <0.(2+1).0` := `>=0.2.3 <0.3.0-0`
* `~0.2` := `>=0.2.0 <0.(2+1).0` := `>=0.2.0 <0.3.0-0` (Same as `0.2.x`)
* `~0` := `>=0.0.0 <(0+1).0.0` := `>=0.0.0 <1.0.0-0` (Same as `0.x`)
* `~1.2.3-beta.2` := `>=1.2.3-beta.2 <1.3.0-0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
#### Caret Ranges `^1.2.3` `^0.2.5` `^0.0.4`
Allows changes that do not modify the left-most non-zero element in the
`[major, minor, patch]` tuple. In other words, this allows patch and
minor updates for versions `1.0.0` and above, patch updates for
versions `0.X >=0.1.0`, and *no* updates for versions `0.0.X`.
Many authors treat a `0.x` version as if the `x` were the major
"breaking-change" indicator.
Caret ranges are ideal when an author may make breaking changes
between `0.2.4` and `0.3.0` releases, which is a common practice.
However, it presumes that there will *not* be breaking changes between
`0.2.4` and `0.2.5`. It allows for changes that are presumed to be
additive (but non-breaking), according to commonly observed practices.
* `^1.2.3` := `>=1.2.3 <2.0.0-0`
* `^0.2.3` := `>=0.2.3 <0.3.0-0`
* `^0.0.3` := `>=0.0.3 <0.0.4-0`
* `^1.2.3-beta.2` := `>=1.2.3-beta.2 <2.0.0-0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
* `^0.0.3-beta` := `>=0.0.3-beta <0.0.4-0` Note that prereleases in the
`0.0.3` version *only* will be allowed, if they are greater than or
equal to `beta`. So, `0.0.3-pr.2` would be allowed.
When parsing caret ranges, a missing `patch` value desugars to the
number `0`, but will allow flexibility within that value, even if the
major and minor versions are both `0`.
* `^1.2.x` := `>=1.2.0 <2.0.0-0`
* `^0.0.x` := `>=0.0.0 <0.1.0-0`
* `^0.0` := `>=0.0.0 <0.1.0-0`
A missing `minor` and `patch` values will desugar to zero, but also
allow flexibility within those values, even if the major version is
zero.
* `^1.x` := `>=1.0.0 <2.0.0-0`
* `^0.x` := `>=0.0.0 <1.0.0-0`
### Range Grammar
Putting all this together, here is a Backus-Naur grammar for ranges,
for the benefit of parser authors:
```bnf
range-set ::= range ( logical-or range ) *
logical-or ::= ( ' ' ) * '||' ( ' ' ) *
range ::= hyphen | simple ( ' ' simple ) * | ''
hyphen ::= partial ' - ' partial
simple ::= primitive | partial | tilde | caret
primitive ::= ( '<' | '>' | '>=' | '<=' | '=' ) partial
partial ::= xr ( '.' xr ( '.' xr qualifier ? )? )?
xr ::= 'x' | 'X' | '*' | nr
nr ::= '0' | ['1'-'9'] ( ['0'-'9'] ) *
tilde ::= '~' partial
caret ::= '^' partial
qualifier ::= ( '-' pre )? ( '+' build )?
pre ::= parts
build ::= parts
parts ::= part ( '.' part ) *
part ::= nr | [-0-9A-Za-z]+
```
## Functions
All methods and classes take a final `options` object argument. All
options in this object are `false` by default. The options supported
are:
- `loose` Be more forgiving about not-quite-valid semver strings.
(Any resulting output will always be 100% strict compliant, of
course.) For backwards compatibility reasons, if the `options`
argument is a boolean value instead of an object, it is interpreted
to be the `loose` param.
- `includePrerelease` Set to suppress the [default
behavior](https://github.com/npm/node-semver#prerelease-tags) of
excluding prerelease tagged versions from ranges unless they are
explicitly opted into.
Strict-mode Comparators and Ranges will be strict about the SemVer
strings that they parse.
* `valid(v)`: Return the parsed version, or null if it's not valid.
* `inc(v, release)`: Return the version incremented by the release
type (`major`, `premajor`, `minor`, `preminor`, `patch`,
`prepatch`, or `prerelease`), or null if it's not valid
* `premajor` in one call will bump the version up to the next major
version and down to a prerelease of that major version.
`preminor`, and `prepatch` work the same way.
* If called from a non-prerelease version, the `prerelease` will work the
same as `prepatch`. It increments the patch version, then makes a
prerelease. If the input version is already a prerelease it simply
increments it.
* `prerelease(v)`: Returns an array of prerelease components, or null
if none exist. Example: `prerelease('1.2.3-alpha.1') -> ['alpha', 1]`
* `major(v)`: Return the major version number.
* `minor(v)`: Return the minor version number.
* `patch(v)`: Return the patch version number.
* `intersects(r1, r2, loose)`: Return true if the two supplied ranges
or comparators intersect.
* `parse(v)`: Attempt to parse a string as a semantic version, returning either
a `SemVer` object or `null`.
### Comparison
* `gt(v1, v2)`: `v1 > v2`
* `gte(v1, v2)`: `v1 >= v2`
* `lt(v1, v2)`: `v1 < v2`
* `lte(v1, v2)`: `v1 <= v2`
* `eq(v1, v2)`: `v1 == v2` This is true if they're logically equivalent,
even if they're not the exact same string. You already know how to
compare strings.
* `neq(v1, v2)`: `v1 != v2` The opposite of `eq`.
* `cmp(v1, comparator, v2)`: Pass in a comparison string, and it'll call
the corresponding function above. `"==="` and `"!=="` do simple
string comparison, but are included for completeness. Throws if an
invalid comparison string is provided.
* `compare(v1, v2)`: Return `0` if `v1 == v2`, or `1` if `v1` is greater, or `-1` if
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `rcompare(v1, v2)`: The reverse of compare. Sorts an array of versions
in descending order when passed to `Array.sort()`.
* `compareBuild(v1, v2)`: The same as `compare` but considers `build` when two versions
are equal. Sorts in ascending order if passed to `Array.sort()`.
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `diff(v1, v2)`: Returns difference between two versions by the release type
(`major`, `premajor`, `minor`, `preminor`, `patch`, `prepatch`, or `prerelease`),
or null if the versions are the same.
### Comparators
* `intersects(comparator)`: Return true if the comparators intersect
### Ranges
* `validRange(range)`: Return the valid range or null if it's not valid
* `satisfies(version, range)`: Return true if the version satisfies the
range.
* `maxSatisfying(versions, range)`: Return the highest version in the list
that satisfies the range, or `null` if none of them do.
* `minSatisfying(versions, range)`: Return the lowest version in the list
that satisfies the range, or `null` if none of them do.
* `minVersion(range)`: Return the lowest version that can possibly match
the given range.
* `gtr(version, range)`: Return `true` if version is greater than all the
versions possible in the range.
* `ltr(version, range)`: Return `true` if version is less than all the
versions possible in the range.
* `outside(version, range, hilo)`: Return true if the version is outside
the bounds of the range in either the high or low direction. The
`hilo` argument must be either the string `'>'` or `'<'`. (This is
the function called by `gtr` and `ltr`.)
* `intersects(range)`: Return true if any of the ranges comparators intersect
* `simplifyRange(versions, range)`: Return a "simplified" range that
matches the same items in `versions` list as the range specified. Note
that it does *not* guarantee that it would match the same versions in all
cases, only for the set of versions provided. This is useful when
generating ranges by joining together multiple versions with `||`
programmatically, to provide the user with something a bit more
ergonomic. If the provided range is shorter in string-length than the
generated range, then that is returned.
* `subset(subRange, superRange)`: Return `true` if the `subRange` range is
entirely contained by the `superRange` range.
Note that, since ranges may be non-contiguous, a version might not be
greater than a range, less than a range, *or* satisfy a range! For
example, the range `1.2 <1.2.9 || >2.0.0` would have a hole from `1.2.9`
until `2.0.0`, so the version `1.2.10` would not be greater than the
range (because `2.0.1` satisfies, which is higher), nor less than the
range (since `1.2.8` satisfies, which is lower), and it also does not
satisfy the range.
If you want to know if a version satisfies or does not satisfy a
range, use the `satisfies(version, range)` function.
### Coercion
* `coerce(version, options)`: Coerces a string to semver if possible
This aims to provide a very forgiving translation of a non-semver string to
semver. It looks for the first digit in a string, and consumes all
remaining characters which satisfy at least a partial semver (e.g., `1`,
`1.2`, `1.2.3`) up to the max permitted length (256 characters). Longer
versions are simply truncated (`4.6.3.9.2-alpha2` becomes `4.6.3`). All
surrounding text is simply ignored (`v3.4 replaces v3.3.1` becomes
`3.4.0`). Only text which lacks digits will fail coercion (`version one`
is not valid). The maximum length for any semver component considered for
coercion is 16 characters; longer components will be ignored
(`10000000000000000.4.7.4` becomes `4.7.4`). The maximum value for any
semver component is `Number.MAX_SAFE_INTEGER || (2**53 - 1)`; higher value
components are invalid (`9999999999999999.4.7.4` is likely invalid).
If the `options.rtl` flag is set, then `coerce` will return the right-most
coercible tuple that does not share an ending index with a longer coercible
tuple. For example, `1.2.3.4` will return `2.3.4` in rtl mode, not
`4.0.0`. `1.2.3/4` will return `4.0.0`, because the `4` is not a part of
any other overlapping SemVer tuple.
### Clean
* `clean(version)`: Clean a string to be a valid semver if possible
This will return a cleaned and trimmed semver version. If the provided
version is not valid a null will be returned. This does not work for
ranges.
ex.
* `s.clean(' = v 2.1.5foo')`: `null`
* `s.clean(' = v 2.1.5foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean(' = v 2.1.5-foo')`: `null`
* `s.clean(' = v 2.1.5-foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean('=v2.1.5')`: `'2.1.5'`
* `s.clean(' =v2.1.5')`: `2.1.5`
* `s.clean(' 2.1.5 ')`: `'2.1.5'`
* `s.clean('~1.0.0')`: `null`
## Exported Modules
<!--
TODO: Make sure that all of these items are documented (classes aren't,
eg), and then pull the module name into the documentation for that specific
thing.
-->
You may pull in just the part of this semver utility that you need, if you
are sensitive to packing and tree-shaking concerns. The main
`require('semver')` export uses getter functions to lazily load the parts
of the API that are used.
The following modules are available:
* `require('semver')`
* `require('semver/classes')`
* `require('semver/classes/comparator')`
* `require('semver/classes/range')`
* `require('semver/classes/semver')`
* `require('semver/functions/clean')`
* `require('semver/functions/cmp')`
* `require('semver/functions/coerce')`
* `require('semver/functions/compare')`
* `require('semver/functions/compare-build')`
* `require('semver/functions/compare-loose')`
* `require('semver/functions/diff')`
* `require('semver/functions/eq')`
* `require('semver/functions/gt')`
* `require('semver/functions/gte')`
* `require('semver/functions/inc')`
* `require('semver/functions/lt')`
* `require('semver/functions/lte')`
* `require('semver/functions/major')`
* `require('semver/functions/minor')`
* `require('semver/functions/neq')`
* `require('semver/functions/parse')`
* `require('semver/functions/patch')`
* `require('semver/functions/prerelease')`
* `require('semver/functions/rcompare')`
* `require('semver/functions/rsort')`
* `require('semver/functions/satisfies')`
* `require('semver/functions/sort')`
* `require('semver/functions/valid')`
* `require('semver/ranges/gtr')`
* `require('semver/ranges/intersects')`
* `require('semver/ranges/ltr')`
* `require('semver/ranges/max-satisfying')`
* `require('semver/ranges/min-satisfying')`
* `require('semver/ranges/min-version')`
* `require('semver/ranges/outside')`
* `require('semver/ranges/to-comparators')`
* `require('semver/ranges/valid')`
glob-parent [](https://travis-ci.org/es128/glob-parent) [](https://coveralls.io/r/es128/glob-parent?branch=master)
======
Javascript module to extract the non-magic parent path from a glob string.
[](https://nodei.co/npm/glob-parent/)
[](https://nodei.co/npm-dl/glob-parent/)
Usage
-----
```sh
npm install glob-parent --save
```
```js
var globParent = require('glob-parent');
globParent('path/to/*.js'); // 'path/to'
globParent('/root/path/to/*.js'); // '/root/path/to'
globParent('/*.js'); // '/'
globParent('*.js'); // '.'
globParent('**/*.js'); // '.'
globParent('path/{to,from}'); // 'path'
globParent('path/!(to|from)'); // 'path'
globParent('path/?(to|from)'); // 'path'
globParent('path/+(to|from)'); // 'path'
globParent('path/*(to|from)'); // 'path'
globParent('path/@(to|from)'); // 'path'
globParent('path/**/*'); // 'path'
// if provided a non-glob path, returns the nearest dir
globParent('path/foo/bar.js'); // 'path/foo'
globParent('path/foo/'); // 'path/foo'
globParent('path/foo'); // 'path' (see issue #3 for details)
```
Change Log
----------
[See release notes page on GitHub](https://github.com/es128/glob-parent/releases)
License
-------
[ISC](https://raw.github.com/es128/glob-parent/master/LICENSE)
# level-errors
<img alt="LevelDB Logo" height="100" src="http://leveldb.org/img/logo.svg">
**Error module for [LevelUP](https://github.com/rvagg/node-levelup)**
[](https://travis-ci.org/Level/errors) [](https://greenkeeper.io/)
## Usage
```js
var levelup = require('levelup')
var errors = levelup.errors
levelup('./db', { createIfMissing: false }, function (err, db) {
if (err instanceof errors.OpenError) {
console.log('open failed because expected db to exist')
}
})
```
## API
### .LevelUPError()
Generic error base class.
### .InitializationError()
Error initializing the database, like when the database's location argument is missing.
### .OpenError()
Error opening the database.
### .ReadError()
Error reading from the database.
### .WriteError()
Error writing to the database.
### .NotFoundError()
Data not found error.
Has extra properties:
- `notFound`: `true`
- `status`: 404
### .EncodingError()
Error encoding data.
## Publishers
* [@ralphtheninja](https://github.com/ralphtheninja)
* [@juliangruber](https://github.com/juliangruber)
## License & copyright
Copyright (c) 2012-2017 LevelUP contributors.
LevelUP is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE.md file for more details.
[](https://www.codeship.io/projects/11259)
# SYNOPSIS
EventEmitter2 is an implementation of the EventEmitter found in Node.js
# DESCRIPTION
### FEATURES
- Namespaces/Wildcards.
- Times To Listen (TTL), extends the `once` concept with `many`.
- Browser environment compatibility.
- Demonstrates good performance in benchmarks
```
EventEmitterHeatUp x 3,728,965 ops/sec \302\2610.68% (60 runs sampled)
EventEmitter x 2,822,904 ops/sec \302\2610.74% (63 runs sampled)
EventEmitter2 x 7,251,227 ops/sec \302\2610.55% (58 runs sampled)
EventEmitter2 (wild) x 3,220,268 ops/sec \302\2610.44% (65 runs sampled)
Fastest is EventEmitter2
```
### Differences (Non breaking, compatible with existing EventEmitter)
- The constructor takes a configuration object.
```javascript
var EventEmitter2 = require('eventemitter2').EventEmitter2;
var server = new EventEmitter2({
//
// use wildcards.
//
wildcard: true,
//
// the delimiter used to segment namespaces, defaults to `.`.
//
delimiter: '::',
//
// if you want to emit the newListener event set to true.
//
newListener: false,
//
// max listeners that can be assigned to an event, default 10.
//
maxListeners: 20
});
```
- Getting the actual event that fired.
```javascript
server.on('foo.*', function(value1, value2) {
console.log(this.event, value1, value2);
});
```
- Fire an event N times and then remove it, an extension of the `once` concept.
```javascript
server.many('foo', 4, function() {
console.log('hello');
});
```
- Pass in a namespaced event as an array rather than a delimited string.
```javascript
server.many(['foo', 'bar', 'bazz'], function() {
console.log('hello');
});
```
# API
When an `EventEmitter` instance experiences an error, the typical action is
to emit an `error` event. Error events are treated as a special case.
If there is no listener for it, then the default action is to print a stack
trace and exit the program.
All EventEmitters emit the event `newListener` when new listeners are
added.
**Namespaces** with **Wildcards**
To use namespaces/wildcards, pass the `wildcard` option into the EventEmitter
constructor. When namespaces/wildcards are enabled, events can either be
strings (`foo.bar`) separated by a delimiter or arrays (`['foo', 'bar']`). The
delimiter is also configurable as a constructor option.
An event name passed to any event emitter method can contain a wild card (the
`*` character). If the event name is a string, a wildcard may appear as `foo.*`.
If the event name is an array, the wildcard may appear as `['foo', '*']`.
If either of the above described events were passed to the `on` method,
subsequent emits such as the following would be observed...
```javascript
emitter.emit('foo.bazz');
emitter.emit(['foo', 'bar']);
```
### emitter.addListener(event, listener)
### emitter.on(event, listener)
Adds a listener to the end of the listeners array for the specified event.
```javascript
server.on('data', function(value1, value2, value3, ...) {
console.log('The event was raised!');
});
```
```javascript
server.on('data', function(value) {
console.log('The event was raised!');
});
```
### emitter.onAny(listener)
Adds a listener that will be fired when any event is emitted.
```javascript
server.onAny(function(value) {
console.log('All events trigger this.');
});
```
### emitter.offAny(listener)
Removes the listener that will be fired when any event is emitted.
```javascript
server.offAny(function(value) {
console.log('The event was raised!');
});
```
#### emitter.once(event, listener)
Adds a **one time** listener for the event. The listener is invoked
only the first time the event is fired, after which it is removed.
```javascript
server.once('get', function (value) {
console.log('Ah, we have our first value!');
});
```
### emitter.many(event, timesToListen, listener)
Adds a listener that will execute **n times** for the event before being
removed. The listener is invoked only the first **n times** the event is
fired, after which it is removed.
```javascript
server.many('get', 4, function (value) {
console.log('This event will be listened to exactly four times.');
});
```
### emitter.removeListener(event, listener)
### emitter.off(event, listener)
Remove a listener from the listener array for the specified event.
**Caution**: changes array indices in the listener array behind the listener.
```javascript
var callback = function(value) {
console.log('someone connected!');
};
server.on('get', callback);
// ...
server.removeListener('get', callback);
```
### emitter.removeAllListeners([event])
Removes all listeners, or those of the specified event.
### emitter.setMaxListeners(n)
By default EventEmitters will print a warning if more than 10 listeners
are added to it. This is a useful default which helps finding memory leaks.
Obviously not all Emitters should be limited to 10. This function allows
that to be increased. Set to zero for unlimited.
### emitter.listeners(event)
Returns an array of listeners for the specified event. This array can be
manipulated, e.g. to remove listeners.
```javascript
server.on('get', function(value) {
console.log('someone connected!');
});
console.log(server.listeners('get')); // [ [Function] ]
```
### emitter.listenersAny()
Returns an array of listeners that are listening for any event that is
specified. This array can be manipulated, e.g. to remove listeners.
```javascript
server.onAny(function(value) {
console.log('someone connected!');
});
console.log(server.listenersAny()[0]); // [ [Function] ]
```
### emitter.emit(event, [arg1], [arg2], [...])
Execute each of the listeners that may be listening for the specified event
name in order with the list of arguments.
# LICENSE
(The MIT License)
Copyright (c) 2011 hij1nx <http://www.twitter.com/hij1nx>
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the 'Software'), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is furnished
to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN
AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# kind-of [](https://www.npmjs.com/package/kind-of) [](https://npmjs.org/package/kind-of) [](https://npmjs.org/package/kind-of) [](https://travis-ci.org/jonschlinkert/kind-of)
> Get the native type of a value.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save kind-of
```
Install with [bower](https://bower.io/)
```sh
$ bower install kind-of --save
```
## Why use this?
1. [it's fast](#benchmarks) | [optimizations](#optimizations)
2. [better type checking](#better-type-checking)
## Usage
> es5, es6, and browser ready
```js
var kindOf = require('kind-of');
kindOf(undefined);
//=> 'undefined'
kindOf(null);
//=> 'null'
kindOf(true);
//=> 'boolean'
kindOf(false);
//=> 'boolean'
kindOf(new Buffer(''));
//=> 'buffer'
kindOf(42);
//=> 'number'
kindOf('str');
//=> 'string'
kindOf(arguments);
//=> 'arguments'
kindOf({});
//=> 'object'
kindOf(Object.create(null));
//=> 'object'
kindOf(new Test());
//=> 'object'
kindOf(new Date());
//=> 'date'
kindOf([1, 2, 3]);
//=> 'array'
kindOf(/foo/);
//=> 'regexp'
kindOf(new RegExp('foo'));
//=> 'regexp'
kindOf(new Error('error'));
//=> 'error'
kindOf(function () {});
//=> 'function'
kindOf(function * () {});
//=> 'generatorfunction'
kindOf(Symbol('str'));
//=> 'symbol'
kindOf(new Map());
//=> 'map'
kindOf(new WeakMap());
//=> 'weakmap'
kindOf(new Set());
//=> 'set'
kindOf(new WeakSet());
//=> 'weakset'
kindOf(new Int8Array());
//=> 'int8array'
kindOf(new Uint8Array());
//=> 'uint8array'
kindOf(new Uint8ClampedArray());
//=> 'uint8clampedarray'
kindOf(new Int16Array());
//=> 'int16array'
kindOf(new Uint16Array());
//=> 'uint16array'
kindOf(new Int32Array());
//=> 'int32array'
kindOf(new Uint32Array());
//=> 'uint32array'
kindOf(new Float32Array());
//=> 'float32array'
kindOf(new Float64Array());
//=> 'float64array'
```
## Benchmarks
Benchmarked against [typeof](http://github.com/CodingFu/typeof) and [type-of](https://github.com/ForbesLindesay/type-of).
```bash
# arguments (32 bytes)
kind-of x 17,024,098 ops/sec ±1.90% (86 runs sampled)
lib-type-of x 11,926,235 ops/sec ±1.34% (83 runs sampled)
lib-typeof x 9,245,257 ops/sec ±1.22% (87 runs sampled)
fastest is kind-of (by 161% avg)
# array (22 bytes)
kind-of x 17,196,492 ops/sec ±1.07% (88 runs sampled)
lib-type-of x 8,838,283 ops/sec ±1.02% (87 runs sampled)
lib-typeof x 8,677,848 ops/sec ±0.87% (87 runs sampled)
fastest is kind-of (by 196% avg)
# boolean (24 bytes)
kind-of x 16,841,600 ops/sec ±1.10% (86 runs sampled)
lib-type-of x 8,096,787 ops/sec ±0.95% (87 runs sampled)
lib-typeof x 8,423,345 ops/sec ±1.15% (86 runs sampled)
fastest is kind-of (by 204% avg)
# buffer (38 bytes)
kind-of x 14,848,060 ops/sec ±1.05% (86 runs sampled)
lib-type-of x 3,671,577 ops/sec ±1.49% (87 runs sampled)
lib-typeof x 8,360,236 ops/sec ±1.24% (86 runs sampled)
fastest is kind-of (by 247% avg)
# date (30 bytes)
kind-of x 16,067,761 ops/sec ±1.58% (86 runs sampled)
lib-type-of x 8,954,436 ops/sec ±1.40% (87 runs sampled)
lib-typeof x 8,488,307 ops/sec ±1.51% (84 runs sampled)
fastest is kind-of (by 184% avg)
# error (36 bytes)
kind-of x 9,634,090 ops/sec ±1.12% (89 runs sampled)
lib-type-of x 7,735,624 ops/sec ±1.32% (86 runs sampled)
lib-typeof x 7,442,160 ops/sec ±1.11% (90 runs sampled)
fastest is kind-of (by 127% avg)
# function (34 bytes)
kind-of x 10,031,494 ops/sec ±1.27% (86 runs sampled)
lib-type-of x 9,502,757 ops/sec ±1.17% (89 runs sampled)
lib-typeof x 8,278,985 ops/sec ±1.08% (88 runs sampled)
fastest is kind-of (by 113% avg)
# null (24 bytes)
kind-of x 18,159,808 ops/sec ±1.92% (86 runs sampled)
lib-type-of x 12,927,635 ops/sec ±1.01% (88 runs sampled)
lib-typeof x 7,958,234 ops/sec ±1.21% (89 runs sampled)
fastest is kind-of (by 174% avg)
# number (22 bytes)
kind-of x 17,846,779 ops/sec ±0.91% (85 runs sampled)
lib-type-of x 3,316,636 ops/sec ±1.19% (86 runs sampled)
lib-typeof x 2,329,477 ops/sec ±2.21% (85 runs sampled)
fastest is kind-of (by 632% avg)
# object-plain (47 bytes)
kind-of x 7,085,155 ops/sec ±1.05% (88 runs sampled)
lib-type-of x 8,870,930 ops/sec ±1.06% (83 runs sampled)
lib-typeof x 8,716,024 ops/sec ±1.05% (87 runs sampled)
fastest is lib-type-of (by 112% avg)
# regex (25 bytes)
kind-of x 14,196,052 ops/sec ±1.65% (84 runs sampled)
lib-type-of x 9,554,164 ops/sec ±1.25% (88 runs sampled)
lib-typeof x 8,359,691 ops/sec ±1.07% (87 runs sampled)
fastest is kind-of (by 158% avg)
# string (33 bytes)
kind-of x 16,131,428 ops/sec ±1.41% (85 runs sampled)
lib-type-of x 7,273,172 ops/sec ±1.05% (87 runs sampled)
lib-typeof x 7,382,635 ops/sec ±1.17% (85 runs sampled)
fastest is kind-of (by 220% avg)
# symbol (34 bytes)
kind-of x 17,011,537 ops/sec ±1.24% (86 runs sampled)
lib-type-of x 3,492,454 ops/sec ±1.23% (89 runs sampled)
lib-typeof x 7,471,235 ops/sec ±2.48% (87 runs sampled)
fastest is kind-of (by 310% avg)
# template-strings (36 bytes)
kind-of x 15,434,250 ops/sec ±1.46% (83 runs sampled)
lib-type-of x 7,157,907 ops/sec ±0.97% (87 runs sampled)
lib-typeof x 7,517,986 ops/sec ±0.92% (86 runs sampled)
fastest is kind-of (by 210% avg)
# undefined (29 bytes)
kind-of x 19,167,115 ops/sec ±1.71% (87 runs sampled)
lib-type-of x 15,477,740 ops/sec ±1.63% (85 runs sampled)
lib-typeof x 19,075,495 ops/sec ±1.17% (83 runs sampled)
fastest is lib-typeof,kind-of
```
## Optimizations
In 7 out of 8 cases, this library is 2x-10x faster than other top libraries included in the benchmarks. There are a few things that lead to this performance advantage, none of them hard and fast rules, but all of them simple and repeatable in almost any code library:
1. Optimize around the fastest and most common use cases first. Of course, this will change from project-to-project, but I took some time to understand how and why `typeof` checks were being used in my own libraries and other libraries I use a lot.
2. Optimize around bottlenecks - In other words, the order in which conditionals are implemented is significant, because each check is only as fast as the failing checks that came before it. Here, the biggest bottleneck by far is checking for plain objects (an object that was created by the `Object` constructor). I opted to make this check happen by process of elimination rather than brute force up front (e.g. by using something like `val.constructor.name`), so that every other type check would not be penalized it.
3. Don't do uneccessary processing - why do `.slice(8, -1).toLowerCase();` just to get the word `regex`? It's much faster to do `if (type === '[object RegExp]') return 'regex'`
4. There is no reason to make the code in a microlib as terse as possible, just to win points for making it shorter. It's always better to favor performant code over terse code. You will always only be using a single `require()` statement to use the library anyway, regardless of how the code is written.
## Better type checking
kind-of seems to be more consistently "correct" than other type checking libs I've looked at. For example, here are some differing results from other popular libs:
### [typeof](https://github.com/CodingFu/typeof) lib
Incorrectly identifies instances of custom constructors (pretty common):
```js
var typeOf = require('typeof');
function Test() {}
console.log(typeOf(new Test()));
//=> 'test'
```
Returns `object` instead of `arguments`:
```js
function foo() {
console.log(typeOf(arguments)) //=> 'object'
}
foo();
```
### [type-of](https://github.com/ForbesLindesay/type-of) lib
Incorrectly returns `object` for generator functions, buffers, `Map`, `Set`, `WeakMap` and `WeakSet`:
```js
function * foo() {}
console.log(typeOf(foo));
//=> 'object'
console.log(typeOf(new Buffer('')));
//=> 'object'
console.log(typeOf(new Map()));
//=> 'object'
console.log(typeOf(new Set()));
//=> 'object'
console.log(typeOf(new WeakMap()));
//=> 'object'
console.log(typeOf(new WeakSet()));
//=> 'object'
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/micromatch/is-glob) | [homepage](https://github.com/micromatch/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
* [is-number](https://www.npmjs.com/package/is-number): Returns true if a number or string value is a finite number. Useful for regex… [more](https://github.com/jonschlinkert/is-number) | [homepage](https://github.com/jonschlinkert/is-number "Returns true if a number or string value is a finite number. Useful for regex matches, parsing, user input, etc.")
* [is-primitive](https://www.npmjs.com/package/is-primitive): Returns `true` if the value is a primitive. | [homepage](https://github.com/jonschlinkert/is-primitive "Returns `true` if the value is a primitive. ")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 102 | [jonschlinkert](https://github.com/jonschlinkert) |
| 3 | [aretecode](https://github.com/aretecode) |
| 2 | [miguelmota](https://github.com/miguelmota) |
| 1 | [doowb](https://github.com/doowb) |
| 1 | [dtothefp](https://github.com/dtothefp) |
| 1 | [ianstormtaylor](https://github.com/ianstormtaylor) |
| 1 | [ksheedlo](https://github.com/ksheedlo) |
| 1 | [pdehaan](https://github.com/pdehaan) |
| 1 | [laggingreflex](https://github.com/laggingreflex) |
| 1 | [tunnckoCore](https://github.com/tunnckoCore) |
| 1 | [xiaofen9](https://github.com/xiaofen9) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2020, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on January 16, 2020._
[](http://badge.fury.io/js/unbzip2-stream)
unbzip2-stream
===
streaming bzip2 decompressor in pure JS for Node and browserify.
Buffers
---
When browserified, the stream emits instances of [feross/buffer](https://github.com/feross/buffer) instead of raw Uint8Arrays to have a consistant API across browsers and Node.
Usage
---
``` js
var bz2 = require('unbzip2-stream');
var fs = require('fs');
// decompress test.bz2 and output the result
fs.createReadStream('./test.bz2').pipe(bz2()).pipe(process.stdout);
```
Also see [test/browser/download.js](https://github.com/regular/unbzip2-stream/blob/master/test/browser/download.js) for an example of decompressing a file while downloading.
Or, using a <script> tag
---
```
<script src="https://npm-cdn.info/unbzip2-stream/dist/unbzip2-stream.min.js"></script>
<script>
var myStream = window.unbzip2Stream();
// now pipe stuff through it (see above)
</script>
```
Tests
---
To run tests in Node:
npm run test
To run tests in PhantomJS
npm run browser-test
Additional Tests
----------------
There are two more tests that specifically test decompression of a very large file. Because I don't want to include large binary files in this repository, the files are created by running an npm script.
npm run prepare-long-test
You can now
npm run long-test
And to run a test in chrome that downloads and decompresses a large binary file
npm run download-test
Open the browser's console to see the output.
# xtend
[![browser support][3]][4]
Extend like a boss
xtend is a basic utility library which allows you to extend an object by appending all of the properties from each object in a list. When there are identical properties, the right-most property takes presedence.
## Examples
```js
var extend = require("xtend")
var combination = extend({
a: "a"
}, {
b: "b"
})
// { a: "a", b: "b" }
```
## MIT Licenced
[3]: http://ci.testling.com/Raynos/xtend.png
[4]: http://ci.testling.com/Raynos/xtend
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# string_decoder
***Node-core v8.9.4 string_decoder for userland***
[](https://nodei.co/npm/string_decoder/)
[](https://nodei.co/npm/string_decoder/)
```bash
npm install --save string_decoder
```
***Node-core string_decoder for userland***
This package is a mirror of the string_decoder implementation in Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.9.4/docs/api/).
As of version 1.0.0 **string_decoder** uses semantic versioning.
## Previous versions
Previous version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10.
## Update
The *build/* directory contains a build script that will scrape the source from the [nodejs/node](https://github.com/nodejs/node) repo given a specific Node version.
## Streams Working Group
`string_decoder` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
See [readable-stream](https://github.com/nodejs/readable-stream) for
more details.
# level-codec
<img alt="LevelDB Logo" height="100" src="http://leveldb.org/img/logo.svg">
**[LevelUP's](https://github.com/rvagg/node-levelup) encoding logic.**
[](https://travis-ci.org/Level/codec)
[](https://greenkeeper.io/)
## API
### Codec([opts])
Create a new codec, with a global options object.
This could be something like
```js
var codec = new Codec(db.options);
```
### #encodeKey(key[, opts])
Encode `key` with given `opts`.
### #encodeValue(value[, opts])
Encode `value` with given `opts`.
### #encodeBatch(batch[, opts])
Encode `batch` ops with given `opts`.
### #encodeLtgt(ltgt)
Encode the ltgt values of option object `ltgt`.
### #decodeKey(key[, opts])
Decode `key` with given `opts`.
### #decodeValue(value[, opts])
Decode `value` with given `opts`.
### #createStreamDecoder([opts])
Create a function with signature `(key, value)`, that for each key/value pair returned from a levelup read stream returns the decoded value to be emitted.
### #keyAsBuffer([opts])
Check whether `opts` and the global `opts` call for a binary key encoding.
### #valueAsBuffer([opts])
Check whether `opts` and the global `opts` call for a binary value encoding.
### #encodings
The supported encodings as object of form
```js
{
"name": {
"encode": Function,
"decode": Function,
"buffer": Boolean,
"type": String
}
}
```
Currently supported encodings:
- utf8
- json
- binary
- hex
- ascii
- base64
- ucs2
- ucs-2
- utf16le
- utf-16le
- none (bypass level-codec)
## Publishers
* [@juliangruber](https://github.com/juliangruber)
* [@ralphtheninja](https://github.com/ralphtheninja)
## License & copyright
Copyright (c) 2012-2015 LevelUP contributors.
LevelUP is licensed under the MIT license. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE.md file for more details.
<a href="https://travis-ci.org/Xotic750/has-symbol-support-x"
title="Travis status">
<img
src="https://travis-ci.org/Xotic750/has-symbol-support-x.svg?branch=master"
alt="Travis status" height="18"/>
</a>
<a href="https://david-dm.org/Xotic750/has-symbol-support-x"
title="Dependency status">
<img src="https://david-dm.org/Xotic750/has-symbol-support-x.svg"
alt="Dependency status" height="18"/>
</a>
<a href="https://david-dm.org/Xotic750/has-symbol-support-x#info=devDependencies"
title="devDependency status">
<img src="https://david-dm.org/Xotic750/has-symbol-support-x/dev-status.svg"
alt="devDependency status" height="18"/>
</a>
<a href="https://badge.fury.io/js/has-symbol-support-x" title="npm version">
<img src="https://badge.fury.io/js/has-symbol-support-x.svg"
alt="npm version" height="18"/>
</a>
<a name="module_has-symbol-support-x"></a>
## has-symbol-support-x
Tests if ES6 Symbol is supported.
**Version**: 1.4.2
**Author**: Xotic750 <[email protected]>
**License**: [MIT](<https://opensource.org/licenses/MIT>)
**Copyright**: Xotic750
<a name="exp_module_has-symbol-support-x--module.exports"></a>
### `module.exports` : <code>boolean</code> ⏏
Indicates if `Symbol`exists and creates the correct type.
`true`, if it exists and creates the correct type, otherwise `false`.
**Kind**: Exported member
# EE First
[![NPM version][npm-image]][npm-url]
[![Build status][travis-image]][travis-url]
[![Test coverage][coveralls-image]][coveralls-url]
[![License][license-image]][license-url]
[![Downloads][downloads-image]][downloads-url]
[![Gittip][gittip-image]][gittip-url]
Get the first event in a set of event emitters and event pairs,
then clean up after itself.
## Install
```sh
$ npm install ee-first
```
## API
```js
var first = require('ee-first')
```
### first(arr, listener)
Invoke `listener` on the first event from the list specified in `arr`. `arr` is
an array of arrays, with each array in the format `[ee, ...event]`. `listener`
will be called only once, the first time any of the given events are emitted. If
`error` is one of the listened events, then if that fires first, the `listener`
will be given the `err` argument.
The `listener` is invoked as `listener(err, ee, event, args)`, where `err` is the
first argument emitted from an `error` event, if applicable; `ee` is the event
emitter that fired; `event` is the string event name that fired; and `args` is an
array of the arguments that were emitted on the event.
```js
var ee1 = new EventEmitter()
var ee2 = new EventEmitter()
first([
[ee1, 'close', 'end', 'error'],
[ee2, 'error']
], function (err, ee, event, args) {
// listener invoked
})
```
#### .cancel()
The group of listeners can be cancelled before being invoked and have all the event
listeners removed from the underlying event emitters.
```js
var thunk = first([
[ee1, 'close', 'end', 'error'],
[ee2, 'error']
], function (err, ee, event, args) {
// listener invoked
})
// cancel and clean up
thunk.cancel()
```
[npm-image]: https://img.shields.io/npm/v/ee-first.svg?style=flat-square
[npm-url]: https://npmjs.org/package/ee-first
[github-tag]: http://img.shields.io/github/tag/jonathanong/ee-first.svg?style=flat-square
[github-url]: https://github.com/jonathanong/ee-first/tags
[travis-image]: https://img.shields.io/travis/jonathanong/ee-first.svg?style=flat-square
[travis-url]: https://travis-ci.org/jonathanong/ee-first
[coveralls-image]: https://img.shields.io/coveralls/jonathanong/ee-first.svg?style=flat-square
[coveralls-url]: https://coveralls.io/r/jonathanong/ee-first?branch=master
[license-image]: http://img.shields.io/npm/l/ee-first.svg?style=flat-square
[license-url]: LICENSE.md
[downloads-image]: http://img.shields.io/npm/dm/ee-first.svg?style=flat-square
[downloads-url]: https://npmjs.org/package/ee-first
[gittip-image]: https://img.shields.io/gittip/jonathanong.svg?style=flat-square
[gittip-url]: https://www.gittip.com/jonathanong/
# color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
# `react-is`
This package allows you to test arbitrary values and see if they're a particular React element type.
## Installation
```sh
# Yarn
yarn add react-is
# NPM
npm install react-is
```
## Usage
### Determining if a Component is Valid
```js
import React from "react";
import * as ReactIs from "react-is";
class ClassComponent extends React.Component {
render() {
return React.createElement("div");
}
}
const FunctionComponent = () => React.createElement("div");
const ForwardRefComponent = React.forwardRef((props, ref) =>
React.createElement(Component, { forwardedRef: ref, ...props })
);
const Context = React.createContext(false);
ReactIs.isValidElementType("div"); // true
ReactIs.isValidElementType(ClassComponent); // true
ReactIs.isValidElementType(FunctionComponent); // true
ReactIs.isValidElementType(ForwardRefComponent); // true
ReactIs.isValidElementType(Context.Provider); // true
ReactIs.isValidElementType(Context.Consumer); // true
ReactIs.isValidElementType(React.createFactory("div")); // true
```
### Determining an Element's Type
#### Context
```js
import React from "react";
import * as ReactIs from 'react-is';
const ThemeContext = React.createContext("blue");
ReactIs.isContextConsumer(<ThemeContext.Consumer />); // true
ReactIs.isContextProvider(<ThemeContext.Provider />); // true
ReactIs.typeOf(<ThemeContext.Provider />) === ReactIs.ContextProvider; // true
ReactIs.typeOf(<ThemeContext.Consumer />) === ReactIs.ContextConsumer; // true
```
#### Element
```js
import React from "react";
import * as ReactIs from 'react-is';
ReactIs.isElement(<div />); // true
ReactIs.typeOf(<div />) === ReactIs.Element; // true
```
#### Fragment
```js
import React from "react";
import * as ReactIs from 'react-is';
ReactIs.isFragment(<></>); // true
ReactIs.typeOf(<></>) === ReactIs.Fragment; // true
```
#### Portal
```js
import React from "react";
import ReactDOM from "react-dom";
import * as ReactIs from 'react-is';
const div = document.createElement("div");
const portal = ReactDOM.createPortal(<div />, div);
ReactIs.isPortal(portal); // true
ReactIs.typeOf(portal) === ReactIs.Portal; // true
```
#### StrictMode
```js
import React from "react";
import * as ReactIs from 'react-is';
ReactIs.isStrictMode(<React.StrictMode />); // true
ReactIs.typeOf(<React.StrictMode />) === ReactIs.StrictMode; // true
```
# toidentifier
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][codecov-image]][codecov-url]
> Convert a string of words to a JavaScript identifier
## Install
This is a [Node.js](https://nodejs.org/en/) module available through the
[npm registry](https://www.npmjs.com/). Installation is done using the
[`npm install` command](https://docs.npmjs.com/getting-started/installing-npm-packages-locally):
```bash
$ npm install toidentifier
```
## Example
```js
var toIdentifier = require('toidentifier')
console.log(toIdentifier('Bad Request'))
// => "BadRequest"
```
## API
This CommonJS module exports a single default function: `toIdentifier`.
### toIdentifier(string)
Given a string as the argument, it will be transformed according to
the following rules and the new string will be returned:
1. Split into words separated by space characters (`0x20`).
2. Upper case the first character of each word.
3. Join the words together with no separator.
4. Remove all non-word (`[0-9a-z_]`) characters.
## License
[MIT](LICENSE)
[codecov-image]: https://img.shields.io/codecov/c/github/component/toidentifier.svg
[codecov-url]: https://codecov.io/gh/component/toidentifier
[downloads-image]: https://img.shields.io/npm/dm/toidentifier.svg
[downloads-url]: https://npmjs.org/package/toidentifier
[npm-image]: https://img.shields.io/npm/v/toidentifier.svg
[npm-url]: https://npmjs.org/package/toidentifier
[travis-image]: https://img.shields.io/travis/component/toidentifier/master.svg
[travis-url]: https://travis-ci.org/component/toidentifier
##
[npm]: https://www.npmjs.com/
[yarn]: https://yarnpkg.com/
<p align="center">
<a href="https://gulpjs.com">
<img height="257" width="114" src="https://raw.githubusercontent.com/gulpjs/artwork/master/gulp-2x.png">
</a>
</p>
# glob-parent
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Azure Pipelines Build Status][azure-pipelines-image]][azure-pipelines-url] [![Travis Build Status][travis-image]][travis-url] [![AppVeyor Build Status][appveyor-image]][appveyor-url] [![Coveralls Status][coveralls-image]][coveralls-url] [![Gitter chat][gitter-image]][gitter-url]
Extract the non-magic parent path from a glob string.
## Usage
```js
var globParent = require('glob-parent');
globParent('path/to/*.js'); // 'path/to'
globParent('/root/path/to/*.js'); // '/root/path/to'
globParent('/*.js'); // '/'
globParent('*.js'); // '.'
globParent('**/*.js'); // '.'
globParent('path/{to,from}'); // 'path'
globParent('path/!(to|from)'); // 'path'
globParent('path/?(to|from)'); // 'path'
globParent('path/+(to|from)'); // 'path'
globParent('path/*(to|from)'); // 'path'
globParent('path/@(to|from)'); // 'path'
globParent('path/**/*'); // 'path'
// if provided a non-glob path, returns the nearest dir
globParent('path/foo/bar.js'); // 'path/foo'
globParent('path/foo/'); // 'path/foo'
globParent('path/foo'); // 'path' (see issue #3 for details)
```
## API
### `globParent(maybeGlobString, [options])`
Takes a string and returns the part of the path before the glob begins. Be aware of Escaping rules and Limitations below.
#### options
```js
{
// Disables the automatic conversion of slashes for Windows
flipBackslashes: true
}
```
## Escaping
The following characters have special significance in glob patterns and must be escaped if you want them to be treated as regular path characters:
- `?` (question mark) unless used as a path segment alone
- `*` (asterisk)
- `|` (pipe)
- `(` (opening parenthesis)
- `)` (closing parenthesis)
- `{` (opening curly brace)
- `}` (closing curly brace)
- `[` (opening bracket)
- `]` (closing bracket)
**Example**
```js
globParent('foo/[bar]/') // 'foo'
globParent('foo/\\[bar]/') // 'foo/[bar]'
```
## Limitations
### Braces & Brackets
This library attempts a quick and imperfect method of determining which path
parts have glob magic without fully parsing/lexing the pattern. There are some
advanced use cases that can trip it up, such as nested braces where the outer
pair is escaped and the inner one contains a path separator. If you find
yourself in the unlikely circumstance of being affected by this or need to
ensure higher-fidelity glob handling in your library, it is recommended that you
pre-process your input with [expand-braces] and/or [expand-brackets].
### Windows
Backslashes are not valid path separators for globs. If a path with backslashes
is provided anyway, for simple cases, glob-parent will replace the path
separator for you and return the non-glob parent path (now with
forward-slashes, which are still valid as Windows path separators).
This cannot be used in conjunction with escape characters.
```js
// BAD
globParent('C:\\Program Files \\(x86\\)\\*.ext') // 'C:/Program Files /(x86/)'
// GOOD
globParent('C:/Program Files\\(x86\\)/*.ext') // 'C:/Program Files (x86)'
```
If you are using escape characters for a pattern without path parts (i.e.
relative to `cwd`), prefix with `./` to avoid confusing glob-parent.
```js
// BAD
globParent('foo \\[bar]') // 'foo '
globParent('foo \\[bar]*') // 'foo '
// GOOD
globParent('./foo \\[bar]') // 'foo [bar]'
globParent('./foo \\[bar]*') // '.'
```
## License
ISC
[expand-braces]: https://github.com/jonschlinkert/expand-braces
[expand-brackets]: https://github.com/jonschlinkert/expand-brackets
[downloads-image]: https://img.shields.io/npm/dm/glob-parent.svg
[npm-url]: https://www.npmjs.com/package/glob-parent
[npm-image]: https://img.shields.io/npm/v/glob-parent.svg
[azure-pipelines-url]: https://dev.azure.com/gulpjs/gulp/_build/latest?definitionId=2&branchName=master
[azure-pipelines-image]: https://dev.azure.com/gulpjs/gulp/_apis/build/status/glob-parent?branchName=master
[travis-url]: https://travis-ci.org/gulpjs/glob-parent
[travis-image]: https://img.shields.io/travis/gulpjs/glob-parent.svg?label=travis-ci
[appveyor-url]: https://ci.appveyor.com/project/gulpjs/glob-parent
[appveyor-image]: https://img.shields.io/appveyor/ci/gulpjs/glob-parent.svg?label=appveyor
[coveralls-url]: https://coveralls.io/r/gulpjs/glob-parent
[coveralls-image]: https://img.shields.io/coveralls/gulpjs/glob-parent/master.svg
[gitter-url]: https://gitter.im/gulpjs/gulp
[gitter-image]: https://badges.gitter.im/gulpjs/gulp.svg
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
The only available postfix at the moment is:
* `n` - which means that the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b)` - set specified bit to `1`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
## LICENSE
This software is licensed under the MIT License.
Copyright Fedor Indutny, 2015.
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to permit
persons to whom the Software is furnished to do so, subject to the
following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN
NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE
USE OR OTHER DEALINGS IN THE SOFTWARE.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# Importing Keccak C code
The XKCP project contains various implementations of Keccak-related algorithms. These are the steps to select a specific implementation and import the code into our project.
First, generate the source bundles in XKCP:
```
git clone https://github.com/XKCP/XKCP.git
cd XKCP
git checkout 58b20ec
# Edit "Makefile.build". After all the <fragment> tags, add the following two <target> tags:
<target name="node32" inherits="KeccakSpongeWidth1600 inplace1600bi"/>
<target name="node64" inherits="KeccakSpongeWidth1600 optimized1600ufull"/>
make node32.pack node64.pack
```
The source files we need are now under XKCP's "bin/.pack/npm32/" and "bin/.pack/npm64/".
- Copy those to our repo under "src/libkeccak-32" and "src/libkeccak-64".
- Update our "binding.gyp" to point to the correct ".c" files.
- Run `npm run rebuild`.
## Implementation Choice
Currently, we're using two of XKCP KeccakP[1600] implementations -- the generic 32-bit-optimized one and the generic 64-bit-optimized one.
XKCP has implementations that use CPU-specific instructions (e.g. Intel AVR) and are likely much faster. It might be worth using those.
# **node-addon-api module**
This module contains **header-only C++ wrapper classes** which simplify
the use of the C based [N-API](https://nodejs.org/dist/latest/docs/api/n-api.html)
provided by Node.js when using C++. It provides a C++ object model
and exception handling semantics with low overhead.
N-API is an ABI stable C interface provided by Node.js for building native
addons. It is independent from the underlying JavaScript runtime (e.g. V8 or ChakraCore)
and is maintained as part of Node.js itself. It is intended to insulate
native addons from changes in the underlying JavaScript engine and allow
modules compiled for one version to run on later versions of Node.js without
recompilation.
The `node-addon-api` module, which is not part of Node.js, preserves the benefits
of the N-API as it consists only of inline code that depends only on the stable API
provided by N-API. As such, modules built against one version of Node.js
using node-addon-api should run without having to be rebuilt with newer versions
of Node.js.
It is important to remember that *other* Node.js interfaces such as
`libuv` (included in a project via `#include <uv.h>`) are not ABI-stable across
Node.js major versions. Thus, an addon must use N-API and/or `node-addon-api`
exclusively and build against a version of Node.js that includes an
implementation of N-API (meaning a version of Node.js newer than 6.14.2) in
order to benefit from ABI stability across Node.js major versions. Node.js
provides an [ABI stability guide][] containing a detailed explanation of ABI
stability in general, and the N-API ABI stability guarantee in particular.
As new APIs are added to N-API, node-addon-api must be updated to provide
wrappers for those new APIs. For this reason node-addon-api provides
methods that allow callers to obtain the underlying N-API handles so
direct calls to N-API and the use of the objects/methods provided by
node-addon-api can be used together. For example, in order to be able
to use an API for which the node-addon-api does not yet provide a wrapper.
APIs exposed by node-addon-api are generally used to create and
manipulate JavaScript values. Concepts and operations generally map
to ideas specified in the **ECMA262 Language Specification**.
- **[Setup](#setup)**
- **[API Documentation](#api)**
- **[Examples](#examples)**
- **[Tests](#tests)**
- **[More resource and info about native Addons](#resources)**
- **[Code of Conduct](CODE_OF_CONDUCT.md)**
- **[Contributors](#contributors)**
- **[License](#license)**
## **Current version: 2.0.2**
(See [CHANGELOG.md](CHANGELOG.md) for complete Changelog)
[](https://nodei.co/npm/node-addon-api/) [](https://nodei.co/npm/node-addon-api/)
<a name="setup"></a>
## Setup
- [Installation and usage](doc/setup.md)
- [node-gyp](doc/node-gyp.md)
- [cmake-js](doc/cmake-js.md)
- [Conversion tool](doc/conversion-tool.md)
- [Checker tool](doc/checker-tool.md)
- [Generator](doc/generator.md)
- [Prebuild tools](doc/prebuild_tools.md)
<a name="api"></a>
### **API Documentation**
The following is the documentation for node-addon-api.
- [Basic Types](doc/basic_types.md)
- [Array](doc/basic_types.md#array)
- [Symbol](doc/symbol.md)
- [String](doc/string.md)
- [Name](doc/basic_types.md#name)
- [Number](doc/number.md)
- [Date](doc/date.md)
- [BigInt](doc/bigint.md)
- [Boolean](doc/boolean.md)
- [Env](doc/env.md)
- [Value](doc/value.md)
- [CallbackInfo](doc/callbackinfo.md)
- [Reference](doc/reference.md)
- [External](doc/external.md)
- [Object](doc/object.md)
- [ObjectReference](doc/object_reference.md)
- [PropertyDescriptor](doc/property_descriptor.md)
- [Error Handling](doc/error_handling.md)
- [Error](doc/error.md)
- [TypeError](doc/type_error.md)
- [RangeError](doc/range_error.md)
- [Object Lifetime Management](doc/object_lifetime_management.md)
- [HandleScope](doc/handle_scope.md)
- [EscapableHandleScope](doc/escapable_handle_scope.md)
- [Working with JavaScript Values](doc/working_with_javascript_values.md)
- [Function](doc/function.md)
- [FunctionReference](doc/function_reference.md)
- [ObjectWrap](doc/object_wrap.md)
- [ClassPropertyDescriptor](doc/class_property_descriptor.md)
- [Buffer](doc/buffer.md)
- [ArrayBuffer](doc/array_buffer.md)
- [TypedArray](doc/typed_array.md)
- [TypedArrayOf](doc/typed_array_of.md)
- [DataView](doc/dataview.md)
- [Memory Management](doc/memory_management.md)
- [Async Operations](doc/async_operations.md)
- [AsyncWorker](doc/async_worker.md)
- [AsyncContext](doc/async_context.md)
- [AsyncProgressWorker](doc/async_progress_worker.md)
- [Thread-safe Functions](doc/threadsafe_function.md)
- [Promises](doc/promises.md)
- [Version management](doc/version_management.md)
<a name="examples"></a>
### **Examples**
Are you new to **node-addon-api**? Take a look at our **[examples](https://github.com/nodejs/node-addon-examples)**
- **[Hello World](https://github.com/nodejs/node-addon-examples/tree/master/1_hello_world/node-addon-api)**
- **[Pass arguments to a function](https://github.com/nodejs/node-addon-examples/tree/master/2_function_arguments/node-addon-api)**
- **[Callbacks](https://github.com/nodejs/node-addon-examples/tree/master/3_callbacks/node-addon-api)**
- **[Object factory](https://github.com/nodejs/node-addon-examples/tree/master/4_object_factory/node-addon-api)**
- **[Function factory](https://github.com/nodejs/node-addon-examples/tree/master/5_function_factory/node-addon-api)**
- **[Wrapping C++ Object](https://github.com/nodejs/node-addon-examples/tree/master/6_object_wrap/node-addon-api)**
- **[Factory of wrapped object](https://github.com/nodejs/node-addon-examples/tree/master/7_factory_wrap/node-addon-api)**
- **[Passing wrapped object around](https://github.com/nodejs/node-addon-examples/tree/master/8_passing_wrapped/node-addon-api)**
<a name="tests"></a>
### **Tests**
To run the **node-addon-api** tests do:
```
npm install
npm test
```
To avoid testing the deprecated portions of the API run
```
npm install
npm test --disable-deprecated
```
### **Debug**
To run the **node-addon-api** tests with `--debug` option:
```
npm run-script dev
```
If you want faster build, you might use the following option:
```
npm run-script dev:incremental
```
Take a look and get inspired by our **[test suite](https://github.com/nodejs/node-addon-api/tree/master/test)**
<a name="resources"></a>
## **Contributing**
We love contributions from the community to **node-addon-api**.
See [CONTRIBUTING.md](CONTRIBUTING.md) for more details on our philosophy around extending this module.
### **More resource and info about native Addons**
- **[C++ Addons](https://nodejs.org/dist/latest/docs/api/addons.html)**
- **[N-API](https://nodejs.org/dist/latest/docs/api/n-api.html)**
- **[N-API - Next Generation Node API for Native Modules](https://youtu.be/-Oniup60Afs)**
<a name="contributors"></a>
## WG Members / Collaborators
### Active
| Name | GitHub Link |
| ------------------- | ----------------------------------------------------- |
| Anna Henningsen | [addaleax](https://github.com/addaleax) |
| Gabriel Schulhof | [gabrielschulhof](https://github.com/gabrielschulhof) |
| Hitesh Kanwathirtha | [digitalinfinity](https://github.com/digitalinfinity) |
| Jim Schlight | [jschlight](https://github.com/jschlight) |
| Michael Dawson | [mhdawson](https://github.com/mhdawson) |
| Kevin Eady | [KevinEady](https://github.com/KevinEady)
| Nicola Del Gobbo | [NickNaso](https://github.com/NickNaso) |
### Emeritus
| Name | GitHub Link |
| ------------------- | ----------------------------------------------------- |
| Arunesh Chandra | [aruneshchandra](https://github.com/aruneshchandra) |
| Benjamin Byholm | [kkoopa](https://github.com/kkoopa) |
| Jason Ginchereau | [jasongin](https://github.com/jasongin) |
| Sampson Gao | [sampsongao](https://github.com/sampsongao) |
| Taylor Woll | [boingoing](https://github.com/boingoing) |
<a name="license"></a>
Licensed under [MIT](./LICENSE.md)
[ABI stability guide]: https://nodejs.org/en/docs/guides/abi-stability/
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
A tiny node.js debugging utility modelled after node core's debugging technique.
**Discussion around the V3 API is under way [here](https://github.com/visionmedia/debug/issues/370)**
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example _app.js_:
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %s', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example _worker.js_:
```js
var debug = require('debug')('worker');
setInterval(function(){
debug('doing some work');
}, 1000);
```
The __DEBUG__ environment variable is then used to enable these based on space or comma-delimited names. Here are some examples:


#### Windows note
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Note that PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Then, run the program to be debugged as usual.
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.

When stdout is not a TTY, `Date#toUTCString()` is used, making it more useful for logging the debug information as shown below:

## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser".
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has debuggers named "connect:bodyParser", "connect:compress", "connect:session", instead of listing all three with `DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do `DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character. For example, `DEBUG=*,-connect:*` would include all debuggers except those starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting. Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object. For example, if you wanted to add support for rendering a Buffer as hex with `%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
#### Web Inspector Colors
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
Colored output looks something like:

## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example _stdout.js_:
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2016 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# Form-Data [](https://www.npmjs.com/package/form-data) [](https://gitter.im/form-data/form-data)
A library to create readable ```"multipart/form-data"``` streams. Can be used to submit forms and file uploads to other web applications.
The API of this library is inspired by the [XMLHttpRequest-2 FormData Interface][xhr2-fd].
[xhr2-fd]: http://dev.w3.org/2006/webapi/XMLHttpRequest-2/Overview.html#the-formdata-interface
[](https://travis-ci.org/form-data/form-data)
[](https://travis-ci.org/form-data/form-data)
[](https://ci.appveyor.com/project/alexindigo/form-data)
[](https://coveralls.io/github/form-data/form-data?branch=master)
[](https://david-dm.org/form-data/form-data)
[](https://www.bithound.io/github/form-data/form-data)
## Install
```
npm install --save form-data
```
## Usage
In this example we are constructing a form with 3 fields that contain a string,
a buffer and a file stream.
``` javascript
var FormData = require('form-data');
var fs = require('fs');
var form = new FormData();
form.append('my_field', 'my value');
form.append('my_buffer', new Buffer(10));
form.append('my_file', fs.createReadStream('/foo/bar.jpg'));
```
Also you can use http-response stream:
``` javascript
var FormData = require('form-data');
var http = require('http');
var form = new FormData();
http.request('http://nodejs.org/images/logo.png', function(response) {
form.append('my_field', 'my value');
form.append('my_buffer', new Buffer(10));
form.append('my_logo', response);
});
```
Or @mikeal's [request](https://github.com/request/request) stream:
``` javascript
var FormData = require('form-data');
var request = require('request');
var form = new FormData();
form.append('my_field', 'my value');
form.append('my_buffer', new Buffer(10));
form.append('my_logo', request('http://nodejs.org/images/logo.png'));
```
In order to submit this form to a web application, call ```submit(url, [callback])``` method:
``` javascript
form.submit('http://example.org/', function(err, res) {
// res – response object (http.IncomingMessage) //
res.resume();
});
```
For more advanced request manipulations ```submit()``` method returns ```http.ClientRequest``` object, or you can choose from one of the alternative submission methods.
### Custom options
You can provide custom options, such as `maxDataSize`:
``` javascript
var FormData = require('form-data');
var form = new FormData({ maxDataSize: 20971520 });
form.append('my_field', 'my value');
form.append('my_buffer', /* something big */);
```
List of available options could be found in [combined-stream](https://github.com/felixge/node-combined-stream/blob/master/lib/combined_stream.js#L7-L15)
### Alternative submission methods
You can use node's http client interface:
``` javascript
var http = require('http');
var request = http.request({
method: 'post',
host: 'example.org',
path: '/upload',
headers: form.getHeaders()
});
form.pipe(request);
request.on('response', function(res) {
console.log(res.statusCode);
});
```
Or if you would prefer the `'Content-Length'` header to be set for you:
``` javascript
form.submit('example.org/upload', function(err, res) {
console.log(res.statusCode);
});
```
To use custom headers and pre-known length in parts:
``` javascript
var CRLF = '\r\n';
var form = new FormData();
var options = {
header: CRLF + '--' + form.getBoundary() + CRLF + 'X-Custom-Header: 123' + CRLF + CRLF,
knownLength: 1
};
form.append('my_buffer', buffer, options);
form.submit('http://example.com/', function(err, res) {
if (err) throw err;
console.log('Done');
});
```
Form-Data can recognize and fetch all the required information from common types of streams (```fs.readStream```, ```http.response``` and ```mikeal's request```), for some other types of streams you'd need to provide "file"-related information manually:
``` javascript
someModule.stream(function(err, stdout, stderr) {
if (err) throw err;
var form = new FormData();
form.append('file', stdout, {
filename: 'unicycle.jpg', // ... or:
filepath: 'photos/toys/unicycle.jpg',
contentType: 'image/jpeg',
knownLength: 19806
});
form.submit('http://example.com/', function(err, res) {
if (err) throw err;
console.log('Done');
});
});
```
The `filepath` property overrides `filename` and may contain a relative path. This is typically used when uploading [multiple files from a directory](https://wicg.github.io/entries-api/#dom-htmlinputelement-webkitdirectory).
For edge cases, like POST request to URL with query string or to pass HTTP auth credentials, object can be passed to `form.submit()` as first parameter:
``` javascript
form.submit({
host: 'example.com',
path: '/probably.php?extra=params',
auth: 'username:password'
}, function(err, res) {
console.log(res.statusCode);
});
```
In case you need to also send custom HTTP headers with the POST request, you can use the `headers` key in first parameter of `form.submit()`:
``` javascript
form.submit({
host: 'example.com',
path: '/surelynot.php',
headers: {'x-test-header': 'test-header-value'}
}, function(err, res) {
console.log(res.statusCode);
});
```
### Integration with other libraries
#### Request
Form submission using [request](https://github.com/request/request):
```javascript
var formData = {
my_field: 'my_value',
my_file: fs.createReadStream(__dirname + '/unicycle.jpg'),
};
request.post({url:'http://service.com/upload', formData: formData}, function(err, httpResponse, body) {
if (err) {
return console.error('upload failed:', err);
}
console.log('Upload successful! Server responded with:', body);
});
```
For more details see [request readme](https://github.com/request/request#multipartform-data-multipart-form-uploads).
#### node-fetch
You can also submit a form using [node-fetch](https://github.com/bitinn/node-fetch):
```javascript
var form = new FormData();
form.append('a', 1);
fetch('http://example.com', { method: 'POST', body: form })
.then(function(res) {
return res.json();
}).then(function(json) {
console.log(json);
});
```
## Notes
- ```getLengthSync()``` method DOESN'T calculate length for streams, use ```knownLength``` options as workaround.
- Starting version `2.x` FormData has dropped support for `[email protected]`.
## License
Form-Data is released under the [MIT](License) license.
# url-set-query
[](http://github.com/badges/stability-badges)
Small standalone function to set a query string on a URL, replacing the existing query and leaving the hash in place.
## Example
```js
var setQuery = require('url-set-query')
setQuery('http://foo.com/index.html?state=open', 'beep=true')
//=> 'http://foo.com/index.html?beep=true'
setQuery('http://foo.com/some/path#about', '?foo=5&open=true')
//=> 'http://foo.com/some/path?foo=5&open=true#about'
setQuery('http://foo.com', 'foo=5')
//=> 'http://foo.com/?foo=5'
// clears the query
setQuery('http://foo.com/index.html?filter=closed#about', '?')
//=> 'http://foo.com/index.html#about'
```
## Install
```sh
npm install url-set-query --save
```
## Usage
[](https://www.npmjs.com/package/url-set-query)
#### `url = setQuery(url, [query])`
Appends the given `query` String onto the URL, before the hash. If a query already exists, it will be replaced. Returns the new URL.
If `query` is `'?'`, it is the same as clearing the query string from the `url`.
If `query` is an empty string or undefined, no change will be made to `url`.
## See Also
To encode/decode from an object, see one of:
- [querystring](https://www.npmjs.com/package/querystring)
- [query-string](https://www.npmjs.com/package/query-string)
- [qs](https://www.npmjs.com/package/qs)
## License
MIT, see [LICENSE.md](http://github.com/mattdesl/url-set-query/blob/master/LICENSE.md) for details.
# is-extendable [](http://badge.fury.io/js/is-extendable)
> Returns true if a value is any of the object types: array, regexp, plain object, function or date. This is useful for determining if a value can be extended, e.g. "can the value have keys?"
## Install
Install with [npm](https://www.npmjs.com/)
```sh
$ npm i is-extendable --save
```
## Usage
```js
var isExtendable = require('is-extendable');
```
Returns true if the value is any of the following:
* `array`
* `regexp`
* `plain object`
* `function`
* `date`
* `error`
## Notes
All objects in JavaScript can have keys, but it's a pain to check for this, since we ether need to verify that the value is not `null` or `undefined` and:
* the value is not a primitive, or
* that the object is an `object`, `function`
Also note that an `extendable` object is not the same as an [extensible object](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/isExtensible), which is one that (in es6) is not sealed, frozen, or marked as non-extensible using `preventExtensions`.
## Related projects
* [assign-deep](https://github.com/jonschlinkert/assign-deep): Deeply assign the enumerable properties of source objects to a destination object.
* [extend-shallow](https://github.com/jonschlinkert/extend-shallow): Extend an object with the properties of additional objects. node.js/javascript util.
* [isobject](https://github.com/jonschlinkert/isobject): Returns true if the value is an object and not an array or null.
* [is-plain-object](https://github.com/jonschlinkert/is-plain-object): Returns true if an object was created by the `Object` constructor.
* [is-equal-shallow](https://github.com/jonschlinkert/is-equal-shallow): Does a shallow comparison of two objects, returning false if the keys or values differ.
* [kind-of](https://github.com/jonschlinkert/kind-of): Get the native type of a value.
## Running tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-extendable/issues/new)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2015 Jon Schlinkert
Released under the MIT license.
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on July 04, 2015._
# libsodium.js
## Overview
The [sodium](https://github.com/jedisct1/libsodium) crypto library
compiled to WebAssembly and pure JavaScript using
[Emscripten](https://github.com/kripken/emscripten), with
automatically generated wrappers to make it easy to use in web
applications.
The complete library weighs 188 KB (minified, gzipped, includes pure JS +
WebAssembly versions) and can run in a web browser as well as server-side.
### Compatibility
Supported browsers/JS engines:
* Chrome >= 16
* Edge >= 0.11
* Firefox >= 21
* Mobile Safari on iOS >= 8.0 (older versions produce incorrect results)
* NodeJS
* Opera >= 15
* Safari >= 6 (older versions produce incorrect results)
This is comparable to the WebCrypto API, which is compatible with a
similar number of browsers.
Signatures and other Edwards25519-based operations are compatible with
[WasmCrypto](https://github.com/jedisct1/wasm-crypto).
## Installation
The [dist](https://github.com/jedisct1/libsodium.js/tree/master/dist)
directory contains pre-built scripts. Copy the files from one of its
subdirectories to your application:
- [browsers](https://github.com/jedisct1/libsodium.js/tree/master/dist/browsers)
includes a single-file script that can be included in web pages.
It contains code for commonly used functions.
- [browsers-sumo](https://github.com/jedisct1/libsodium.js/tree/master/dist/browsers-sumo)
is a superset of the previous script, that contains all functions,
including rarely used ones and undocumented ones.
- [modules](https://github.com/jedisct1/libsodium.js/tree/master/dist/modules)
includes commonly used functions, and is designed to be loaded as a module.
`libsodium-wrappers` is the module your application should load, which
will in turn automatically load `libsodium` as a dependency.
- [modules-sumo](https://github.com/jedisct1/libsodium.js/tree/master/dist/modules-sumo)
contains sumo variants of the previous modules.
The modules are also available on npm:
- [libsodium-wrappers](https://www.npmjs.com/package/libsodium-wrappers)
- [libsodium-wrappers-sumo](https://www.npmjs.com/package/libsodium-wrappers-sumo)
If you prefer Bower:
```sh
bower install libsodium.js
```
### Usage (as a module)
Load the `sodium-wrappers` module. The returned object contains a `.ready`
property: a promise that must be resolve before the sodium functions
can be used.
Example:
```js
const _sodium = require('libsodium-wrappers');
(async() => {
await _sodium.ready;
const sodium = _sodium;
let key = sodium.crypto_secretstream_xchacha20poly1305_keygen();
let res = sodium.crypto_secretstream_xchacha20poly1305_init_push(key);
let [state_out, header] = [res.state, res.header];
let c1 = sodium.crypto_secretstream_xchacha20poly1305_push(state_out,
sodium.from_string('message 1'), null,
sodium.crypto_secretstream_xchacha20poly1305_TAG_MESSAGE);
let c2 = sodium.crypto_secretstream_xchacha20poly1305_push(state_out,
sodium.from_string('message 2'), null,
sodium.crypto_secretstream_xchacha20poly1305_TAG_FINAL);
let state_in = sodium.crypto_secretstream_xchacha20poly1305_init_pull(header, key);
let r1 = sodium.crypto_secretstream_xchacha20poly1305_pull(state_in, c1);
let [m1, tag1] = [sodium.to_string(r1.message), r1.tag];
let r2 = sodium.crypto_secretstream_xchacha20poly1305_pull(state_in, c2);
let [m2, tag2] = [sodium.to_string(r2.message), r2.tag];
console.log(m1);
console.log(m2);
})();
```
### Usage (in a web browser, via a callback)
The `sodium.js` file includes both the core libsodium functions, as
well as the higher-level JavaScript wrappers. It can be loaded
asynchronusly.
A `sodium` object should be defined in the global namespace, with the
following property:
- `onload`: the function to call after the wrapper is initialized.
Example:
```html
<script>
window.sodium = {
onload: function (sodium) {
let h = sodium.crypto_generichash(64, sodium.from_string('test'));
console.log(sodium.to_hex(h));
}
};
</script>
<script src="sodium.js" async></script>
```
## Additional helpers
* `from_base64()`, `to_base64()` with an optional second parameter
whose value is one of: `base64_variants.ORIGINAL`, `base64_variants.ORIGINAL_NO_PADDING`,
`base64_variants.URLSAFE` or `base64_variants.URLSAFE_NO_PADDING`. Default is `base64_variants.URLSAFE_NO_PADDING`.
* `from_hex()`, `to_hex()`
* `from_string()`, `to_string()`
* `pad(<buffer>, <block size>)`, `unpad(<buffer>, <block size>)`
* `memcmp()` (constant-time check for equality, returns `true` or `false`)
* `compare()` (constant-time comparison. Values must have the same
size. Returns `-1`, `0` or `1`)
* `memzero()` (applies to `Uint8Array` objects)
* `increment()` (increments an arbitrary-long number stored as a
little-endian `Uint8Array` - typically to increment nonces)
* `add()` (adds two arbitrary-long numbers stored as little-endian
`Uint8Array` vectors)
* `is_zero()` (constant-time, checks `Uint8Array` objects for all zeros)
## API
The API exposed by the wrappers is identical to the one of the C
library, except that buffer lengths never need to be explicitly given.
Binary input buffers should be `Uint8Array` objects. However, if a string
is given instead, the wrappers will automatically convert the string
to an array containing a UTF-8 representation of the string.
Example:
```javascript
var key = sodium.randombytes_buf(sodium.crypto_shorthash_KEYBYTES),
hash1 = sodium.crypto_shorthash(new Uint8Array([1, 2, 3, 4]), key),
hash2 = sodium.crypto_shorthash('test', key);
```
If the output is a unique binary buffer, it is returned as a
`Uint8Array` object.
Example (secretbox):
```javascript
let key = sodium.from_hex('724b092810ec86d7e35c9d067702b31ef90bc43a7b598626749914d6a3e033ed');
function encrypt_and_prepend_nonce(message) {
let nonce = sodium.randombytes_buf(sodium.crypto_secretbox_NONCEBYTES);
return nonce.concat(sodium.crypto_secretbox_easy(message, nonce, key));
}
function decrypt_after_extracting_nonce(nonce_and_ciphertext) {
if (nonce_and_ciphertext.length < sodium.crypto_secretbox_NONCEBYTES + sodium.crypto_secretbox_MACBYTES) {
throw "Short message";
}
let nonce = nonce_and_ciphertext.slice(0, sodium.crypto_secretbox_NONCEBYTES),
ciphertext = nonce_and_ciphertext.slice(sodium.crypto_secretbox_NONCEBYTES);
return sodium.crypto_secretbox_open_easy(ciphertext, nonce, key);
}
```
In addition, the `from_hex`, `to_hex`, `from_string`, and `to_string`
functions are available to explicitly convert hexadecimal, and
arbitrary string representations from/to `Uint8Array` objects.
Functions returning more than one output buffer are returning them as
an object. For example, the `sodium.crypto_box_keypair()` function
returns the following object:
```javascript
{ keyType: 'curve25519', privateKey: (Uint8Array), publicKey: (Uint8Array) }
```
### Standard vs Sumo version
The standard version (in the `dist/browsers` and `dist/modules`
directories) contains the high-level functions, and is the recommended
one for most projects.
Alternatively, the "sumo" version, available in the
`dist/browsers-sumo` and `dist/modules-sumo` directories contains all
the symbols from the original library. This includes undocumented,
untested, deprecated, low-level and easy to misuse functions.
The `crypto_pwhash_*` function set is included in both versions.
The sumo version is slightly larger than the standard version, and
should be used only if you really need the extra symbols it provides.
### Compilation
If you want to compile the files yourself, the following dependencies
need to be installed on your system:
* Emscripten
* binaryen
* git
* NodeJS
* make
Running `make` will install the dev dependencies, clone libsodium,
build it, test it, build the wrapper, and create the modules and
minified distribution files.
## Authors
Built by Ahmad Ben Mrad, Frank Denis and Ryan Lester.
## License
This wrapper is distributed under the
[ISC License](https://en.wikipedia.org/wiki/ISC_license).
[![*nix build status][nix-build-image]][nix-build-url]
[![Windows build status][win-build-image]][win-build-url]
[![Tests coverage][cov-image]][cov-url]
[![npm version][npm-image]][npm-url]
# type
## Runtime validation and processing of JavaScript types
- Respects language nature and acknowledges its quirks
- Allows coercion in restricted forms (rejects clearly invalid input, normalizes permissible type deviations)
- No transpilation implied, written to work in all ECMAScript 3+ engines
### Example usage
Bulletproof input arguments normalization and validation:
```javascript
const ensureString = require('type/string/ensure')
, ensureDate = require('type/date/ensure')
, ensureNaturalNumber = require('type/natural-number/ensure')
, isObject = require('type/object/is');
module.exports = (path, options = { min: 0 }) {
path = ensureString(path, { errorMessage: "%v is not a path" });
if (!isObject(options)) options = {};
const min = ensureNaturalNumber(options.min, { default: 0 })
, max = ensureNaturalNumber(options.max, { isOptional: true })
, startTime = ensureDate(options.startTime, { isOptional: true });
// ...logic
};
```
### Installation
```bash
npm install type
```
## Utilities
Serves following kind of utilities:
##### `*/coerce`
Restricted coercion into primitive type. Returns coerced value or `null` if value is not coercible per rules.
##### `*/is`
Object type/kind confirmation, returns either `true` or `false`.
##### `*/ensure`
Value validation. Returns input value (in primitive cases possibly coerced) or if value doesn't meet the constraints throws `TypeError` .
Each `*/ensure` utility, accepts following options (eventually passed with second argument):
- `isOptional` - Makes `null` or `undefined` accepted as valid value. In such case instead of `TypeError` being thrown, `null` is returned.
- `default` - A value to be returned if `null` or `undefined` is passed as an input value.
- `errorMessage` - Custom error message (`%v` can be used as a placeholder for input value)
---
### Value
_Value_, any value that's neither `null` nor `undefined` .
#### `value/is`
Confirms whether passed argument is a _value_
```javascript
const isValue = require("type/value/is");
isValue({}); // true
isValue(null); // false
```
#### `value/ensure`
Ensures if given argument is a _value_. If it's a value it is returned back, if not `TypeError` is thrown
```javascript
const ensureValue = require("type/value/ensure");
const obj = {};
ensureValue(obj); // obj
ensureValue(null); // Thrown TypeError: Cannot use null
```
---
### Object
_Object_, any non-primitive value
#### `object/is`
Confirms if passed value is an object
```javascript
const isObject = require("type/object/is");
isObject({}); // true
isObject(true); // false
isObject(null); // false
```
#### `object/ensure`
If given argument is an object, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureObject = require("type/object/ensure");
const obj = {};
ensureObject(obj); // obj
ensureString(null); // Thrown TypeError: null is not an object
```
---
### String
_string_ primitive
#### `string/coerce`
Restricted string coercion. Returns string presentation for every value that follows below constraints
- is implicitly coercible to string
- is neither`null` nor `undefined`
- its `toString` method is not `Object.prototype.toString`
For all other values `null` is returned
```javascript
const coerceToString = require("type/string/coerce");
coerceToString(12); // "12"
coerceToString(undefined); // null
```
#### `string/ensure`
If given argument is a string coercible value (via [`string/coerce`](#stringcoerce)) returns result string.
Otherwise `TypeError` is thrown.
```javascript
const ensureString = require("type/string/ensure");
ensureString(12); // "12"
ensureString(null); // Thrown TypeError: null is not a string
```
---
### Number
_number_ primitive
#### `number/coerce`
Restricted number coercion. Returns number presentation for every value that follows below constraints
- is implicitly coercible to number
- is neither `null` nor `undefined`
- is not `NaN` and doesn't coerce to `NaN`
For all other values `null` is returned
```javascript
const coerceToNumber = require("type/number/coerce");
coerceToNumber("12"); // 12
coerceToNumber({}); // null
coerceToNumber(null); // null
```
#### `number/ensure`
If given argument is a number coercible value (via [`number/coerce`](#numbercoerce)) returns result number.
Otherwise `TypeError` is thrown.
```javascript
const ensureNumber = require("type/number/ensure");
ensureNumber(12); // "12"
ensureNumber(null); // Thrown TypeError: null is not a number
```
---
#### Finite Number
Finite _number_ primitive
##### `finite/coerce`
Follows [`number/coerce`](#numbercoerce) additionally rejecting `Infinity` and `-Infinity` values (`null` is returned if given values coerces to them)
```javascript
const coerceToFinite = require("type/finite/coerce");
coerceToFinite("12"); // 12
coerceToFinite(Infinity); // null
coerceToFinite(null); // null
```
##### `finite/ensure`
If given argument is a finite number coercible value (via [`finite/coerce`](#finitecoerce)) returns result number.
Otherwise `TypeError` is thrown.
```javascript
const ensureFinite = require("type/finite/ensure");
ensureFinite(12); // "12"
ensureFinite(null); // Thrown TypeError: null is not a finite number
```
---
#### Integer Number
Integer _number_ primitive
##### `integer/coerce`
Follows [`finite/coerce`](#finitecoerce) additionally stripping decimal part from the number
```javascript
const coerceToInteger = require("type/integer/coerce");
coerceToInteger("12.95"); // 12
coerceToInteger(Infinity); // null
coerceToInteger(null); // null
```
##### `integer/ensure`
If given argument is an integer coercible value (via [`integer/coerce`](#integercoerce)) returns result number.
Otherwise `TypeError` is thrown.
```javascript
const ensureInteger = require("type/integer/ensure");
ensureInteger(12.93); // "12"
ensureInteger(null); // Thrown TypeError: null is not an integer
```
---
#### Safe Integer Number
Safe integer _number_ primitive
##### `safe-integer/coerce`
Follows [`integer/coerce`](#integercoerce) but returns `null` in place of values which are beyond `Number.MIN_SAFE_INTEGER` and `Number.MAX_SAFE_INTEGER` range.
```javascript
const coerceToSafeInteger = require("type/safe-integer/coerce");
coerceToInteger("12.95"); // 12
coerceToInteger(9007199254740992); // null
coerceToInteger(null); // null
```
##### `safe-integer/ensure`
If given argument is a safe integer coercible value (via [`safe-integer/coerce`](#safe-integercoerce)) returns result number.
Otherwise `TypeError` is thrown.
```javascript
const ensureSafeInteger = require("type/safe-integer/ensure");
ensureSafeInteger(12.93); // "12"
ensureSafeInteger(9007199254740992); // Thrown TypeError: null is not a safe integer
```
---
#### Natural Number
Natural _number_ primitive
##### `natural-number/coerce`
Follows [`integer/coerce`](#integercoerce) but returns `null` for values below `0`
```javascript
const coerceToNaturalNumber = require("type/natural-number/coerce");
coerceToNaturalNumber("12.95"); // 12
coerceToNaturalNumber(-120); // null
coerceToNaturalNumber(null); // null
```
##### `natural-number/ensure`
If given argument is a natural number coercible value (via [`natural-number/coerce`](#natural-numbercoerce)) returns result number.
Otherwise `TypeError` is thrown.
```javascript
const ensureNaturalNumber = require("type/natural-number/ensure");
ensureNaturalNumber(12.93); // "12"
ensureNaturalNumber(-230); // Thrown TypeError: null is not a natural number
```
---
### Plain Object
A _plain object_
- Inherits directly from `Object.prototype` or `null`
- Is not a constructor's `prototype` property
#### `plain-object/is`
Confirms if given object is a _plain object_
```javascript
const isPlainObject = require("type/plain-object/is");
isPlainObject({}); // true
isPlainObject(Object.create(null)); // true
isPlainObject([]); // false
```
#### `plain-object/ensure`
If given argument is a plain object it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensurePlainObject = require("type/plain-object/ensure");
ensurePlainObject({}); // {}
ensureArray("foo"); // Thrown TypeError: foo is not a plain object
```
---
### Array
_Array_ instance
#### `array/is`
Confirms if given object is a native array
```javascript
const isArray = require("type/array/is");
isArray([]); // true
isArray({}); // false
isArray("foo"); // false
```
#### `array/ensure`
If given argument is an array, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureArray = require("type/array/ensure");
ensureArray(["foo"]); // ["foo"]
ensureArray("foo"); // Thrown TypeError: foo is not an array
```
---
#### Array Like
_Array-like_ value (any value with `length` property)
#### `array-like/is`
Restricted _array-like_ confirmation. Returns true for every value that meets following contraints
- is an _object_ (or with `allowString` option, a _string_)
- is not a _function_
- Exposes `length` that meets [`array-length`](#array-lengthcoerce) constraints
```javascript
const isArrayLike = require("type/array-like/is");
isArrayLike([]); // true
isArrayLike({}); // false
isArrayLike({ length: 0 }); // true
isArrayLike("foo"); // false
isArrayLike("foo", { allowString: true }); // true
```
#### `array-like/ensure`
If given argument is an _array-like_, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureArrayLike = require("type/array-like/ensure");
ensureArrayLike({ length: 0 }); // { length: 0 }
ensureArrayLike("foo", { allowString: true }); // "foo"
ensureArrayLike({}); // Thrown TypeError: null is not an iterable
```
---
#### Array length
_number_ primitive that conforms as valid _array length_
##### `array-length/coerce`
Follows [`safe-integer/coerce`](#safe-integercoerce) but returns `null` in place of values which are below `0`
```javascript
const coerceToArrayLength = require("type/safe-integer/coerce");
coerceToArrayLength("12.95"); // 12
coerceToArrayLength(9007199254740992); // null
coerceToArrayLength(null); // null
```
##### `array-length/ensure`
If given argument is an _array length_ coercible value (via [`array-length/coerce`](#array-lengthcoerce)) returns result number.
Otherwise `TypeError` is thrown.
```javascript
const ensureArrayLength = require("type/array-length/ensure");
ensureArrayLength(12.93); // "12"
ensureArrayLength(9007199254740992); // Thrown TypeError: null is not a valid array length
```
---
### Iterable
Value which implements _iterable_ protocol
#### `iterable/is`
Confirms if given object is an _iterable_ and is not a _string_ (unless `allowString` option is passed)
```javascript
const isIterable = require("type/iterable/is");
isIterable([]); // true
isIterable({}); // false
isIterable("foo"); // false
isIterable("foo", { allowString: true }); // true
```
Supports also `denyEmpty` option
```javascript
isIterable([], { denyEmpty: true }); // false
isIterable(["foo"], { denyEmpty: true }); // true
```
#### `iterable/ensure`
If given argument is an _iterable_, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureIterable = require("type/iterable/ensure");
ensureIterable([]); // []
ensureIterable("foo", { allowString: true }); // "foo"
ensureIterable({}); // Thrown TypeError: null is not expected iterable
```
Additionally items can be coreced with `coerceItem` option. Note that in this case:
- A newly created array with coerced values is returned
- Validation crashes if any of the items is not coercible
```javascript
ensureIterable(new Set(["foo", 12])); // ["foo", "12"]
ensureIterable(new Set(["foo", {}])); // Thrown TypeError: Set({ "foo", {} }) is not expected iterable
```
---
### Date
_Date_ instance
#### `date/is`
Confirms if given object is a native date, and is not an _Invalid Date_
```javascript
const isDate = require("type/date/is");
isDate(new Date()); // true
isDate(new Date("Invalid date")); // false
isDate(Date.now()); // false
isDate("foo"); // false
```
#### `date/ensure`
If given argument is a date object, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureDate = require("type/date/ensure");
const date = new Date();
ensureDate(date); // date
ensureDate(123123); // Thrown TypeError: 123123 is not a date object
```
---
### Time value
_number_ primitive which is a valid _time value_ (as used internally in _Date_ instances)
#### `time-value/coerce`
Follows [`integer/coerce`](#integercoerce) but returns `null` in place of values which go beyond 100 000 0000 days from unix epoch
```javascript
const coerceToTimeValue = require("type/time-value/coerce");
coerceToTimeValue(12312312); // true
coerceToTimeValue(Number.MAX_SAFE_INTEGER); // false
coerceToTimeValue("foo"); // false
```
##### `time-value/ensure`
If given argument is a _time value_ coercible value (via [`time-value/coerce`](#time-valuecoerce)) returns result number.
Otherwise `TypeError` is thrown.
```javascript
const ensureTimeValue = require("type/time-value/ensure");
ensureTimeValue(12.93); // "12"
ensureTimeValue(Number.MAX_SAFE_INTEGER); // Thrown TypeError: null is not a natural number
```
---
### Function
_Function_ instance
#### `function/is`
Confirms if given object is a native function
```javascript
const isFunction = require("type/function/is");
isFunction(function () {}); // true
isFunction(() => {}); // true
isFunction(class {}); // true
isFunction("foo"); // false
```
#### `function/ensure`
If given argument is a function object, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureFunction = require("type/function/ensure");
const fn = function () {};
ensureFunction(fn); // fn
ensureFunction(/foo/); // Thrown TypeError: /foo/ is not a function
```
---
#### Plain Function
A _Function_ instance that is not a _Class_
##### `plain-function/is`
Confirms if given object is a _plain function_
```javascript
const isPlainFunction = require("type/plain-function/is");
isPlainFunction(function () {}); // true
isPlainFunction(() => {}); // true
isPlainFunction(class {}); // false
isPlainFunction("foo"); // false
```
##### `plain-function/ensure`
If given argument is a _plain function_ object, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensurePlainFunction = require("type/function/ensure");
const fn = function () {};
ensurePlainFunction(fn); // fn
ensurePlainFunction(class {}); // Thrown TypeError: class is not a plain function
```
---
### RegExp
_RegExp_ instance
#### `reg-exp/is`
Confirms if given object is a native regular expression object
```javascript
const isRegExp = require("type/reg-exp/is");
isRegExp(/foo/);
isRegExp({}); // false
isRegExp("foo"); // false
```
#### `reg-exp/ensure`
If given argument is a regular expression object, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureRegExp = require("type/reg-exp/ensure");
ensureRegExp(/foo/); // /foo/
ensureRegExp("foo"); // Thrown TypeError: null is not a regular expression object
```
---
### Promise
_Promise_ instance
#### `promise/is`
Confirms if given object is a native _promise_
```javascript
const isPromise = require("type/promise/is");
isPromise(Promise.resolve()); // true
isPromise({ then: () => {} }); // false
isPromise({}); // false
```
##### `promise/ensure`
If given argument is a promise, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensurePromise = require("type/promise/ensure");
const promise = Promise.resolve();
ensurePromise(promise); // promise
eensurePromise({}); // Thrown TypeError: [object Object] is not a promise
```
---
#### Thenable
_Thenable_ object (an object with `then` method)
##### `thenable/is`
Confirms if given object is a _thenable_
```javascript
const isThenable = require("type/thenable/is");
isThenable(Promise.resolve()); // true
isThenable({ then: () => {} }); // true
isThenable({}); // false
```
##### `thenable/ensure`
If given argument is a _thenable_ object, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureThenable = require("type/thenable/ensure");
const promise = Promise.resolve();
ensureThenable(promise); // promise
ensureThenable({}); // Thrown TypeError: [object Object] is not a thenable object
```
---
### Error
_Error_ instance
#### `error/is`
Confirms if given object is a native error object
```javascript
const isError = require("type/error/is");
isError(new Error()); // true
isError({ message: "Fake error" }); // false
```
#### `error/ensure`
If given argument is an error object, it is returned back. Otherwise `TypeError` is thrown.
```javascript
const ensureError = require("type/error/ensure");
const someError = new Error("Some error");
ensureError(someError); // someError
ensureError({ message: "Fake error" }); // Thrown TypeError: [object Object] is not an error object
```
---
### Prototype
Some constructor's `prototype` property
#### `prototype/is`
Confirms if given object serves as a _prototype_ property
```javascript
const isPrototype = require("type/prototype/is");
isPrototype({}); // false
isPrototype(Object.prototype); // true
isPrototype(Array.prototype); // true
```
### Tests
$ npm test
[nix-build-image]: https://semaphoreci.com/api/v1/medikoo-org/type/branches/master/shields_badge.svg
[nix-build-url]: https://semaphoreci.com/medikoo-org/type
[win-build-image]: https://ci.appveyor.com/api/projects/status/8nrtluuwsb5k9l8d?svg=true
[win-build-url]: https://ci.appveyor.com/api/project/medikoo/type
[cov-image]: https://img.shields.io/codecov/c/github/medikoo/type.svg
[cov-url]: https://codecov.io/gh/medikoo/type
[npm-image]: https://img.shields.io/npm/v/type.svg
[npm-url]: https://www.npmjs.com/package/type
# content-disposition
[![NPM Version][npm-image]][npm-url]
[![NPM Downloads][downloads-image]][downloads-url]
[![Node.js Version][node-version-image]][node-version-url]
[![Build Status][travis-image]][travis-url]
[![Test Coverage][coveralls-image]][coveralls-url]
Create and parse HTTP `Content-Disposition` header
## Installation
```sh
$ npm install content-disposition
```
## API
<!-- eslint-disable no-unused-vars -->
```js
var contentDisposition = require('content-disposition')
```
### contentDisposition(filename, options)
Create an attachment `Content-Disposition` header value using the given file name,
if supplied. The `filename` is optional and if no file name is desired, but you
want to specify `options`, set `filename` to `undefined`.
<!-- eslint-disable no-undef -->
```js
res.setHeader('Content-Disposition', contentDisposition('∫ maths.pdf'))
```
**note** HTTP headers are of the ISO-8859-1 character set. If you are writing this
header through a means different from `setHeader` in Node.js, you'll want to specify
the `'binary'` encoding in Node.js.
#### Options
`contentDisposition` accepts these properties in the options object.
##### fallback
If the `filename` option is outside ISO-8859-1, then the file name is actually
stored in a supplemental field for clients that support Unicode file names and
a ISO-8859-1 version of the file name is automatically generated.
This specifies the ISO-8859-1 file name to override the automatic generation or
disables the generation all together, defaults to `true`.
- A string will specify the ISO-8859-1 file name to use in place of automatic
generation.
- `false` will disable including a ISO-8859-1 file name and only include the
Unicode version (unless the file name is already ISO-8859-1).
- `true` will enable automatic generation if the file name is outside ISO-8859-1.
If the `filename` option is ISO-8859-1 and this option is specified and has a
different value, then the `filename` option is encoded in the extended field
and this set as the fallback field, even though they are both ISO-8859-1.
##### type
Specifies the disposition type, defaults to `"attachment"`. This can also be
`"inline"`, or any other value (all values except inline are treated like
`attachment`, but can convey additional information if both parties agree to
it). The type is normalized to lower-case.
### contentDisposition.parse(string)
<!-- eslint-disable no-undef, no-unused-vars -->
```js
var disposition = contentDisposition.parse('attachment; filename="EURO rates.txt"; filename*=UTF-8\'\'%e2%82%ac%20rates.txt')
```
Parse a `Content-Disposition` header string. This automatically handles extended
("Unicode") parameters by decoding them and providing them under the standard
parameter name. This will return an object with the following properties (examples
are shown for the string `'attachment; filename="EURO rates.txt"; filename*=UTF-8\'\'%e2%82%ac%20rates.txt'`):
- `type`: The disposition type (always lower case). Example: `'attachment'`
- `parameters`: An object of the parameters in the disposition (name of parameter
always lower case and extended versions replace non-extended versions). Example:
`{filename: "€ rates.txt"}`
## Examples
### Send a file for download
```js
var contentDisposition = require('content-disposition')
var destroy = require('destroy')
var fs = require('fs')
var http = require('http')
var onFinished = require('on-finished')
var filePath = '/path/to/public/plans.pdf'
http.createServer(function onRequest (req, res) {
// set headers
res.setHeader('Content-Type', 'application/pdf')
res.setHeader('Content-Disposition', contentDisposition(filePath))
// send file
var stream = fs.createReadStream(filePath)
stream.pipe(res)
onFinished(res, function () {
destroy(stream)
})
})
```
## Testing
```sh
$ npm test
```
## References
- [RFC 2616: Hypertext Transfer Protocol -- HTTP/1.1][rfc-2616]
- [RFC 5987: Character Set and Language Encoding for Hypertext Transfer Protocol (HTTP) Header Field Parameters][rfc-5987]
- [RFC 6266: Use of the Content-Disposition Header Field in the Hypertext Transfer Protocol (HTTP)][rfc-6266]
- [Test Cases for HTTP Content-Disposition header field (RFC 6266) and the Encodings defined in RFCs 2047, 2231 and 5987][tc-2231]
[rfc-2616]: https://tools.ietf.org/html/rfc2616
[rfc-5987]: https://tools.ietf.org/html/rfc5987
[rfc-6266]: https://tools.ietf.org/html/rfc6266
[tc-2231]: http://greenbytes.de/tech/tc2231/
## License
[MIT](LICENSE)
[npm-image]: https://img.shields.io/npm/v/content-disposition.svg
[npm-url]: https://npmjs.org/package/content-disposition
[node-version-image]: https://img.shields.io/node/v/content-disposition.svg
[node-version-url]: https://nodejs.org/en/download
[travis-image]: https://img.shields.io/travis/jshttp/content-disposition.svg
[travis-url]: https://travis-ci.org/jshttp/content-disposition
[coveralls-image]: https://img.shields.io/coveralls/jshttp/content-disposition.svg
[coveralls-url]: https://coveralls.io/r/jshttp/content-disposition?branch=master
[downloads-image]: https://img.shields.io/npm/dm/content-disposition.svg
[downloads-url]: https://npmjs.org/package/content-disposition
# memdown <img alt="LevelDB Logo" height="20" src="http://leveldb.org/img/logo.svg" />
> In-memory `abstract-leveldown` store for Node.js and browsers.
[](http://travis-ci.org/Level/memdown) [](https://coveralls.io/github/Level/memdown?branch=master) [](https://www.npmjs.com/package/memdown) [](https://www.npmjs.com/package/memdown) [](https://greenkeeper.io/)
## Example
`levelup` allows you to pass a `db` option to its constructor. This overrides the default `leveldown` store.
```js
// Note that if multiple instances point to the same location,
// the db will be shared, but only per process.
var levelup = require('levelup')
var db = levelup('/some/location', { db: require('memdown') })
db.put('hey', 'you', function (err) {
if (err) throw err
db.createReadStream()
.on('data', function (kv) {
console.log('%s: %s', kv.key, kv.value)
})
.on('end', function () {
console.log('done')
})
})
```
Your data is discarded when the process ends or you release a reference to the database. Note as well, though the internals of `memdown` operate synchronously - `levelup` does not.
Running our example gives:
```
hey: you
done
```
Browser support
----
[](https://saucelabs.com/u/level-ci)
`memdown` requires a ES5-capable browser. If you're using one that's isn't (e.g. PhantomJS, Android < 4.4, IE < 10) then you will need [es5-shim](https://github.com/es-shims/es5-shim).
Global Store
---
Even though it's in memory, the location parameter does do something. `memdown`
has a global cache, which it uses to save databases by the path string.
So for instance if you create these two instances:
```js
var db1 = levelup('foo', {db: require('memdown')});
var db2 = levelup('foo', {db: require('memdown')});
```
Then they will actually share the same data, because the `'foo'` string is the same.
You may clear this global store using `memdown.clearGlobalStore()`:
```js
require('memdown').clearGlobalStore();
```
By default, it doesn't delete the store but replaces it with a new one, so the open instance of `memdown` will not be affected.
`clearGlobalStore` takes a single parameter, which if truthy clears the store strictly by deleting each individual key:
```js
require('memdown').clearGlobalStore(true); // delete each individual key
```
If you are using `memdown` somewhere else while simultaneously clearing the global store in this way, then it may throw an error or cause unexpected results.
Test
----
In addition to the regular `npm test`, you can test `memdown` in a browser of choice with:
npm run test-browser-local
To check code coverage:
npm run coverage
Licence
---
`memdown` is Copyright (c) 2013-2017 Rod Vagg [@rvagg](https://twitter.com/rvagg) and licensed under the MIT licence. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE file for more details.
# node-tar
[](https://travis-ci.org/npm/node-tar)
[Fast](./benchmarks) and full-featured Tar for Node.js
The API is designed to mimic the behavior of `tar(1)` on unix systems.
If you are familiar with how tar works, most of this will hopefully be
straightforward for you. If not, then hopefully this module can teach
you useful unix skills that may come in handy someday :)
## Background
A "tar file" or "tarball" is an archive of file system entries
(directories, files, links, etc.) The name comes from "tape archive".
If you run `man tar` on almost any Unix command line, you'll learn
quite a bit about what it can do, and its history.
Tar has 5 main top-level commands:
* `c` Create an archive
* `r` Replace entries within an archive
* `u` Update entries within an archive (ie, replace if they're newer)
* `t` List out the contents of an archive
* `x` Extract an archive to disk
The other flags and options modify how this top level function works.
## High-Level API
These 5 functions are the high-level API. All of them have a
single-character name (for unix nerds familiar with `tar(1)`) as well
as a long name (for everyone else).
All the high-level functions take the following arguments, all three
of which are optional and may be omitted.
1. `options` - An optional object specifying various options
2. `paths` - An array of paths to add or extract
3. `callback` - Called when the command is completed, if async. (If
sync or no file specified, providing a callback throws a
`TypeError`.)
If the command is sync (ie, if `options.sync=true`), then the
callback is not allowed, since the action will be completed immediately.
If a `file` argument is specified, and the command is async, then a
`Promise` is returned. In this case, if async, a callback may be
provided which is called when the command is completed.
If a `file` option is not specified, then a stream is returned. For
`create`, this is a readable stream of the generated archive. For
`list` and `extract` this is a writable stream that an archive should
be written into. If a file is not specified, then a callback is not
allowed, because you're already getting a stream to work with.
`replace` and `update` only work on existing archives, and so require
a `file` argument.
Sync commands without a file argument return a stream that acts on its
input immediately in the same tick. For readable streams, this means
that all of the data is immediately available by calling
`stream.read()`. For writable streams, it will be acted upon as soon
as it is provided, but this can be at any time.
### Warnings
Some things cause tar to emit a warning, but should usually not cause
the entire operation to fail. There are three ways to handle
warnings:
1. **Ignore them** (default) Invalid entries won't be put in the
archive, and invalid entries won't be unpacked. This is usually
fine, but can hide failures that you might care about.
2. **Notice them** Add an `onwarn` function to the options, or listen
to the `'warn'` event on any tar stream. The function will get
called as `onwarn(message, data)`. Handle as appropriate.
3. **Explode them.** Set `strict: true` in the options object, and
`warn` messages will be emitted as `'error'` events instead. If
there's no `error` handler, this causes the program to crash. If
used with a promise-returning/callback-taking method, then it'll
send the error to the promise/callback.
### Examples
The API mimics the `tar(1)` command line functionality, with aliases
for more human-readable option and function names. The goal is that
if you know how to use `tar(1)` in Unix, then you know how to use
`require('tar')` in JavaScript.
To replicate `tar czf my-tarball.tgz files and folders`, you'd do:
```js
tar.c(
{
gzip: <true|gzip options>,
file: 'my-tarball.tgz'
},
['some', 'files', 'and', 'folders']
).then(_ => { .. tarball has been created .. })
```
To replicate `tar cz files and folders > my-tarball.tgz`, you'd do:
```js
tar.c( // or tar.create
{
gzip: <true|gzip options>
},
['some', 'files', 'and', 'folders']
).pipe(fs.createWriteStream('my-tarball.tgz'))
```
To replicate `tar xf my-tarball.tgz` you'd do:
```js
tar.x( // or tar.extract(
{
file: 'my-tarball.tgz'
}
).then(_=> { .. tarball has been dumped in cwd .. })
```
To replicate `cat my-tarball.tgz | tar x -C some-dir --strip=1`:
```js
fs.createReadStream('my-tarball.tgz').pipe(
tar.x({
strip: 1,
C: 'some-dir' // alias for cwd:'some-dir', also ok
})
)
```
To replicate `tar tf my-tarball.tgz`, do this:
```js
tar.t({
file: 'my-tarball.tgz',
onentry: entry => { .. do whatever with it .. }
})
```
To replicate `cat my-tarball.tgz | tar t` do:
```js
fs.createReadStream('my-tarball.tgz')
.pipe(tar.t())
.on('entry', entry => { .. do whatever with it .. })
```
To do anything synchronous, add `sync: true` to the options. Note
that sync functions don't take a callback and don't return a promise.
When the function returns, it's already done. Sync methods without a
file argument return a sync stream, which flushes immediately. But,
of course, it still won't be done until you `.end()` it.
To filter entries, add `filter: <function>` to the options.
Tar-creating methods call the filter with `filter(path, stat)`.
Tar-reading methods (including extraction) call the filter with
`filter(path, entry)`. The filter is called in the `this`-context of
the `Pack` or `Unpack` stream object.
The arguments list to `tar t` and `tar x` specify a list of filenames
to extract or list, so they're equivalent to a filter that tests if
the file is in the list.
For those who _aren't_ fans of tar's single-character command names:
```
tar.c === tar.create
tar.r === tar.replace (appends to archive, file is required)
tar.u === tar.update (appends if newer, file is required)
tar.x === tar.extract
tar.t === tar.list
```
Keep reading for all the command descriptions and options, as well as
the low-level API that they are built on.
### tar.c(options, fileList, callback) [alias: tar.create]
Create a tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Write the tarball archive to the specified filename. If this
is specified, then the callback will be fired when the file has been
written, and a promise will be returned that resolves when the file
is written. If a filename is not specified, then a Readable Stream
will be returned which will emit the file data. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`. If this is set,
and a file is not provided, then the resulting stream will already
have the data ready to `read` or `emit('data')` as soon as you
request it.
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary other
time-based operations.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `mode` The mode to set on the created file archive
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
### tar.x(options, fileList, callback) [alias: tar.extract]
Extract a tarball archive.
The `fileList` is an array of paths to extract from the tarball. If
no paths are provided, then all the entries are extracted.
If the archive is gzipped, then tar will detect this and unzip it.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
Most extraction errors will cause a `warn` event to be emitted. If
the `cwd` is missing, or not a directory, then the extraction will
fail completely.
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory. [Alias: `C`]
- `file` The archive file to extract. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Create files and directories synchronously.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive. [Alias: `keep-newer`,
`keep-newer-files`]
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies. [Alias: `k`, `keep-existing`]
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
[Alias: `P`]
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file. [Alias:
`U`]
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks. [Alias: `strip-components`, `stripComponents`]
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
[Alias: `p`]
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries. [Alias: `m`, `no-mtime`]
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync extractions.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### tar.t(options, fileList, callback) [alias: tar.list]
List the contents of a tarball archive.
The `fileList` is an array of paths to list from the tarball. If
no paths are provided, then all the entries are listed.
If the archive is gzipped, then tar will detect this and unzip it.
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects. However, they don't emit `'data'` or `'end'`
events. (If you want to get actual readable entries, use the
`tar.Parse` class instead.)
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. [Alias: `C`]
- `file` The archive file to list. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Read the specified file synchronously. (This has no effect
when a file option isn't specified, because entries are emitted as
fast as they are parsed from the stream anyway.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter. This is important for when both `file` and
`sync` are set, because it will be called synchronously.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noResume` By default, `entry` streams are resumed immediately after
the call to `onentry`. Set `noResume: true` to suppress this
behavior. Note that by opting into this, the stream will never
complete until the entry data is consumed.
### tar.u(options, fileList, callback) [alias: tar.update]
Add files to an archive if they are newer than the entry already in
the tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary other
time-based operations.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
### tar.r(options, fileList, callback) [alias: tar.replace]
Add files to an existing archive. Because later entries override
earlier entries, this effectively replaces any existing entries.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary other
time-based operations.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
## Low-Level API
### class tar.Pack
A readable tar stream.
Has all the standard readable stream interface stuff. `'data'` and
`'end'` events, `read()` method, `pause()` and `resume()`, etc.
#### constructor(options)
The following options are supported:
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()`
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary other
time-based operations.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories.
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
#### add(path)
Adds an entry to the archive. Returns the Pack stream.
#### write(path)
Adds an entry to the archive. Returns true if flushed.
#### end()
Finishes the archive.
### class tar.Pack.Sync
Synchronous version of `tar.Pack`.
### class tar.Unpack
A writable stream that unpacks a tar archive onto the file system.
All the normal writable stream stuff is supported. `write()` and
`end()` methods, `'drain'` events, etc.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
`'close'` is emitted when it's done writing stuff to the file system.
Most unpack errors will cause a `warn` event to be emitted. If the
`cwd` is missing, or not a directory, then an error will be emitted.
#### constructor(options)
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive.
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies.
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file.
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks.
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
- `win32` True if on a windows platform. Causes behavior where
filenames containing `<|>?` chars are converted to
windows-compatible values while being unpacked.
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries.
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
### class tar.Unpack.Sync
Synchronous version of `tar.Unpack`.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync unpack streams.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### class tar.Parse
A writable stream that parses a tar archive stream. All the standard
writable stream stuff is supported.
If the archive is gzipped, then tar will detect this and unzip it.
Emits `'entry'` events with `tar.ReadEntry` objects, which are
themselves readable streams that you can pipe wherever.
Each `entry` will not emit until the one before it is flushed through,
so make sure to either consume the data (with `on('data', ...)` or
`.pipe(...)`) or throw it away with `.resume()` to keep the stream
flowing.
#### constructor(options)
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects.
The following options are supported:
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
#### abort(message, error)
Stop all parsing activities. This is called when there are zlib
errors. It also emits a warning with the message and error provided.
### class tar.ReadEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being read out of a tar archive.
It has the following fields:
- `extended` The extended metadata object provided to the constructor.
- `globalExtended` The global extended metadata object provided to the
constructor.
- `remain` The number of bytes remaining to be written into the
stream.
- `blockRemain` The number of 512-byte blocks remaining to be written
into the stream.
- `ignore` Whether this entry should be ignored.
- `meta` True if this represents metadata about the next entry, false
if it represents a filesystem object.
- All the fields from the header, extended header, and global extended
header are added to the ReadEntry object. So it has `path`, `type`,
`size, `mode`, and so on.
#### constructor(header, extended, globalExtended)
Create a new ReadEntry object with the specified header, extended
header, and global extended header values.
### class tar.WriteEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being written from the file
system into a tar archive.
Emits data for the Header, and for the Pax Extended Header if one is
required, as well as any body data.
Creating a WriteEntry for a directory does not also create
WriteEntry objects for all of the directory contents.
It has the following fields:
- `path` The path field that will be written to the archive. By
default, this is also the path from the cwd to the file system
object.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary other
time-based operations.
- `myuid` If supported, the uid of the user running the current
process.
- `myuser` The `env.USER` string if set, or `''`. Set as the entry
`uname` field if the file's `uid` matches `this.myuid`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/` and filenames containing the windows-compatible
forms of `<|>?:` characters are converted to actual `<|>?:` characters
in the archive.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
#### constructor(path, options)
`path` is the path of the entry as it is written in the archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary other
time-based operations.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/`.
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `umask` Set to restrict the modes on the entries in the archive,
somewhat like how umask works on file creation. Defaults to
`process.umask()` on unix systems, or `0o22` on Windows.
#### warn(message, data)
If strict, emit an error with the provided message.
Othewise, emit a `'warn'` event with the provided message and data.
### class tar.WriteEntry.Sync
Synchronous version of tar.WriteEntry
### class tar.WriteEntry.Tar
A version of tar.WriteEntry that gets its data from a tar.ReadEntry
instead of from the filesystem.
#### constructor(readEntry, options)
`readEntry` is the entry being read out of another archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary other
time-based operations.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onwarn` A function that will get called with `(message, data)` for
any warnings encountered.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
### class tar.Header
A class for reading and writing header blocks.
It has the following fields:
- `nullBlock` True if decoding a block which is entirely composed of
`0x00` null bytes. (Useful because tar files are terminated by
at least 2 null blocks.)
- `cksumValid` True if the checksum in the header is valid, false
otherwise.
- `needPax` True if the values, as encoded, will require a Pax
extended header.
- `path` The path of the entry.
- `mode` The 4 lowest-order octal digits of the file mode. That is,
read/write/execute permissions for world, group, and owner, and the
setuid, setgid, and sticky bits.
- `uid` Numeric user id of the file owner
- `gid` Numeric group id of the file owner
- `size` Size of the file in bytes
- `mtime` Modified time of the file
- `cksum` The checksum of the header. This is generated by adding all
the bytes of the header block, treating the checksum field itself as
all ascii space characters (that is, `0x20`).
- `type` The human-readable name of the type of entry this represents,
or the alphanumeric key if unknown.
- `typeKey` The alphanumeric key for the type of entry this header
represents.
- `linkpath` The target of Link and SymbolicLink entries.
- `uname` Human-readable user name of the file owner
- `gname` Human-readable group name of the file owner
- `devmaj` The major portion of the device number. Always `0` for
files, directories, and links.
- `devmin` The minor portion of the device number. Always `0` for
files, directories, and links.
- `atime` File access time.
- `ctime` File change time.
#### constructor(data, [offset=0])
`data` is optional. It is either a Buffer that should be interpreted
as a tar Header starting at the specified offset and continuing for
512 bytes, or a data object of keys and values to set on the header
object, and eventually encode as a tar Header.
#### decode(block, offset)
Decode the provided buffer starting at the specified offset.
Buffer length must be greater than 512 bytes.
#### set(data)
Set the fields in the data object.
#### encode(buffer, offset)
Encode the header fields into the buffer at the specified offset.
Returns `this.needPax` to indicate whether a Pax Extended Header is
required to properly encode the specified data.
### class tar.Pax
An object representing a set of key-value pairs in an Pax extended
header entry.
It has the following fields. Where the same name is used, they have
the same semantics as the tar.Header field of the same name.
- `global` True if this represents a global extended header, or false
if it is for a single entry.
- `atime`
- `charset`
- `comment`
- `ctime`
- `gid`
- `gname`
- `linkpath`
- `mtime`
- `path`
- `size`
- `uid`
- `uname`
- `dev`
- `ino`
- `nlink`
#### constructor(object, global)
Set the fields set in the object. `global` is a boolean that defaults
to false.
#### encode()
Return a Buffer containing the header and body for the Pax extended
header entry, or `null` if there is nothing to encode.
#### encodeBody()
Return a string representing the body of the pax extended header
entry.
#### encodeField(fieldName)
Return a string representing the key/value encoding for the specified
fieldName, or `''` if the field is unset.
### tar.Pax.parse(string, extended, global)
Return a new Pax object created by parsing the contents of the string
provided.
If the `extended` object is set, then also add the fields from that
object. (This is necessary because multiple metadata entries can
occur in sequence.)
### tar.types
A translation table for the `type` field in tar headers.
#### tar.types.name.get(code)
Get the human-readable name for a given alphanumeric code.
#### tar.types.code.get(name)
Get the alphanumeric code for a given human-readable name.
# brace-expansion
[Brace expansion](https://www.gnu.org/software/bash/manual/html_node/Brace-Expansion.html),
as known from sh/bash, in JavaScript.
[](http://travis-ci.org/juliangruber/brace-expansion)
[](https://www.npmjs.org/package/brace-expansion)
[](https://greenkeeper.io/)
[](https://ci.testling.com/juliangruber/brace-expansion)
## Example
```js
var expand = require('brace-expansion');
expand('file-{a,b,c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('-v{,,}')
// => ['-v', '-v', '-v']
expand('file{0..2}.jpg')
// => ['file0.jpg', 'file1.jpg', 'file2.jpg']
expand('file-{a..c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('file{2..0}.jpg')
// => ['file2.jpg', 'file1.jpg', 'file0.jpg']
expand('file{0..4..2}.jpg')
// => ['file0.jpg', 'file2.jpg', 'file4.jpg']
expand('file-{a..e..2}.jpg')
// => ['file-a.jpg', 'file-c.jpg', 'file-e.jpg']
expand('file{00..10..5}.jpg')
// => ['file00.jpg', 'file05.jpg', 'file10.jpg']
expand('{{A..C},{a..c}}')
// => ['A', 'B', 'C', 'a', 'b', 'c']
expand('ppp{,config,oe{,conf}}')
// => ['ppp', 'pppconfig', 'pppoe', 'pppoeconf']
```
## API
```js
var expand = require('brace-expansion');
```
### var expanded = expand(str)
Return an array of all possible and valid expansions of `str`. If none are
found, `[str]` is returned.
Valid expansions are:
```js
/^(.*,)+(.+)?$/
// {a,b,...}
```
A comma separated list of options, like `{a,b}` or `{a,{b,c}}` or `{,a,}`.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
A numeric sequence from `x` to `y` inclusive, with optional increment.
If `x` or `y` start with a leading `0`, all the numbers will be padded
to have equal length. Negative numbers and backwards iteration work too.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
An alphabetic sequence from `x` to `y` inclusive, with optional increment.
`x` and `y` must be exactly one character, and if given, `incr` must be a
number.
For compatibility reasons, the string `${` is not eligible for brace expansion.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install brace-expansion
```
## Contributors
- [Julian Gruber](https://github.com/juliangruber)
- [Isaac Z. Schlueter](https://github.com/isaacs)
## Sponsors
This module is proudly supported by my [Sponsors](https://github.com/juliangruber/sponsors)!
Do you want to support modules like this to improve their quality, stability and weigh in on new features? Then please consider donating to my [Patreon](https://www.patreon.com/juliangruber). Not sure how much of my modules you're using? Try [feross/thanks](https://github.com/feross/thanks)!
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# web3-providers-ws
[![NPM Package][npm-image]][npm-url] [![Dependency Status][deps-image]][deps-url] [![Dev Dependency Status][deps-dev-image]][deps-dev-url]
This is a websocket provider sub-package for [web3.js][repo].
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-providers-ws
```
## Usage
```js
const Web3WsProvider = require('web3-providers-ws');
const options = {
timeout: 30000, // ms
// Useful for credentialed urls, e.g: ws://username:password@localhost:8546
headers: {
authorization: 'Basic username:password'
},
clientConfig: {
// Useful if requests are large
maxReceivedFrameSize: 100000000, // bytes - default: 1MiB
maxReceivedMessageSize: 100000000, // bytes - default: 8MiB
// Useful to keep a connection alive
keepalive: true,
keepaliveInterval: 60000 // ms
},
// Enable auto reconnection
reconnect: {
auto: true,
delay: 5000, // ms
maxAttempts: 5,
onTimeout: false
}
};
const ws = new Web3WsProvider('ws://localhost:8546', options);
```
Additional client config options can be found [here](https://github.com/theturtle32/WebSocket-Node/blob/v1.0.31/docs/WebSocketClient.md#client-config-options).
## Types
All the TypeScript typings are placed in the `types` folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[npm-image]: https://img.shields.io/npm/v/web3-providers-ws.svg
[npm-url]: https://npmjs.org/package/web3-providers-ws
[deps-image]: https://david-dm.org/ethereum/web3.js/1.x/status.svg?path=packages/web3-providers-ws
[deps-url]: https://david-dm.org/ethereum/web3.js/1.x?path=packages/web3-providers-ws
[deps-dev-image]: https://david-dm.org/ethereum/web3.js/1.x/dev-status.svg?path=packages/web3-providers-ws
[deps-dev-url]: https://david-dm.org/ethereum/web3.js/1.x?type=dev&path=packages/web3-providers-ws
# SYNOPSIS
[](https://www.npmjs.org/package/ethereumjs-tx)
[](https://github.com/ethereumjs/ethereumjs-tx/actions)
[](https://coveralls.io/r/ethereumjs/ethereumjs-tx)
[](https://gitter.im/ethereum/ethereumjs-lib) or #ethereumjs on freenode
# INSTALL
`npm install ethereumjs-tx`
# USAGE
- [example](https://github.com/ethereumjs/ethereumjs-tx/blob/master/examples/transactions.ts)
```javascript
const EthereumTx = require('ethereumjs-tx').Transaction
const privateKey = Buffer.from(
'e331b6d69882b4cb4ea581d88e0b604039a3de5967688d3dcffdd2270c0fd109',
'hex',
)
const txParams = {
nonce: '0x00',
gasPrice: '0x09184e72a000',
gasLimit: '0x2710',
to: '0x0000000000000000000000000000000000000000',
value: '0x00',
data: '0x7f7465737432000000000000000000000000000000000000000000000000000000600057',
}
// The second parameter is not necessary if these values are used
const tx = new EthereumTx(txParams, { chain: 'mainnet', hardfork: 'petersburg' })
tx.sign(privateKey)
const serializedTx = tx.serialize()
```
# Chain and Hardfork Support
The `Transaction` and `FakeTransaction` constructors receives a second parameter that lets you specify the chain and hardfork
to be used. By default, `mainnet` and `petersburg` will be used.
There are two ways of customizing these. The first one, as shown in the previous section, is by
using an object with `chain` and `hardfork` names. You can see en example of this in [./examples/ropsten-tx.ts](./examples/ropsten-tx.ts).
The second option is by passing the option `common` set to an instance of [ethereumjs-common](https://github.com/ethereumjs/ethereumjs-common)' Common. This is specially useful for custom networks or chains/hardforks not yet supported by `ethereumjs-common`. You can see en example of this in [./examples/custom-chain-tx.ts](./examples/custom-chain-tx.ts).
## MuirGlacier Support
The `MuirGlacier` hardfork is supported by the library since the `v2.1.2` release.
## Istanbul Support
Support for reduced non-zero call data gas prices from the `Istanbul` hardfork
([EIP-2028](https://eips.ethereum.org/EIPS/eip-2028)) has been added to the library
along with the `v2.1.1` release.
# EIP-155 support
`EIP-155` replay protection is activated since the `spuriousDragon` hardfork. To disable it, set the
hardfork in the `Transaction`'s constructor.
# API
[./docs/](./docs/README.md)
# EthereumJS
See our organizational [documentation](https://ethereumjs.readthedocs.io) for an introduction to `EthereumJS` as well as information on current standards and best practices.
If you want to join for work or do improvements on the libraries have a look at our [contribution guidelines](https://ethereumjs.readthedocs.io/en/latest/contributing.html).
# LICENSE
[MPL-2.0](<https://tldrlegal.com/license/mozilla-public-license-2.0-(mpl-2)>)
# fill-range [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=W8YFZ425KND68) [](https://www.npmjs.com/package/fill-range) [](https://npmjs.org/package/fill-range) [](https://npmjs.org/package/fill-range) [](https://travis-ci.org/jonschlinkert/fill-range)
> Fill in a range of numbers or letters, optionally passing an increment or `step` to use, or create a regex-compatible range with `options.toRegex`
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save fill-range
```
## Usage
Expands numbers and letters, optionally using a `step` as the last argument. _(Numbers may be defined as JavaScript numbers or strings)_.
```js
const fill = require('fill-range');
// fill(from, to[, step, options]);
console.log(fill('1', '10')); //=> ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10']
console.log(fill('1', '10', { toRegex: true })); //=> [1-9]|10
```
**Params**
* `from`: **{String|Number}** the number or letter to start with
* `to`: **{String|Number}** the number or letter to end with
* `step`: **{String|Number|Object|Function}** Optionally pass a [step](#optionsstep) to use.
* `options`: **{Object|Function}**: See all available [options](#options)
## Examples
By default, an array of values is returned.
**Alphabetical ranges**
```js
console.log(fill('a', 'e')); //=> ['a', 'b', 'c', 'd', 'e']
console.log(fill('A', 'E')); //=> [ 'A', 'B', 'C', 'D', 'E' ]
```
**Numerical ranges**
Numbers can be defined as actual numbers or strings.
```js
console.log(fill(1, 5)); //=> [ 1, 2, 3, 4, 5 ]
console.log(fill('1', '5')); //=> [ 1, 2, 3, 4, 5 ]
```
**Negative ranges**
Numbers can be defined as actual numbers or strings.
```js
console.log(fill('-5', '-1')); //=> [ '-5', '-4', '-3', '-2', '-1' ]
console.log(fill('-5', '5')); //=> [ '-5', '-4', '-3', '-2', '-1', '0', '1', '2', '3', '4', '5' ]
```
**Steps (increments)**
```js
// numerical ranges with increments
console.log(fill('0', '25', 4)); //=> [ '0', '4', '8', '12', '16', '20', '24' ]
console.log(fill('0', '25', 5)); //=> [ '0', '5', '10', '15', '20', '25' ]
console.log(fill('0', '25', 6)); //=> [ '0', '6', '12', '18', '24' ]
// alphabetical ranges with increments
console.log(fill('a', 'z', 4)); //=> [ 'a', 'e', 'i', 'm', 'q', 'u', 'y' ]
console.log(fill('a', 'z', 5)); //=> [ 'a', 'f', 'k', 'p', 'u', 'z' ]
console.log(fill('a', 'z', 6)); //=> [ 'a', 'g', 'm', 's', 'y' ]
```
## Options
### options.step
**Type**: `number` (formatted as a string or number)
**Default**: `undefined`
**Description**: The increment to use for the range. Can be used with letters or numbers.
**Example(s)**
```js
// numbers
console.log(fill('1', '10', 2)); //=> [ '1', '3', '5', '7', '9' ]
console.log(fill('1', '10', 3)); //=> [ '1', '4', '7', '10' ]
console.log(fill('1', '10', 4)); //=> [ '1', '5', '9' ]
// letters
console.log(fill('a', 'z', 5)); //=> [ 'a', 'f', 'k', 'p', 'u', 'z' ]
console.log(fill('a', 'z', 7)); //=> [ 'a', 'h', 'o', 'v' ]
console.log(fill('a', 'z', 9)); //=> [ 'a', 'j', 's' ]
```
### options.strictRanges
**Type**: `boolean`
**Default**: `false`
**Description**: By default, `null` is returned when an invalid range is passed. Enable this option to throw a `RangeError` on invalid ranges.
**Example(s)**
The following are all invalid:
```js
fill('1.1', '2'); // decimals not supported in ranges
fill('a', '2'); // incompatible range values
fill(1, 10, 'foo'); // invalid "step" argument
```
### options.stringify
**Type**: `boolean`
**Default**: `undefined`
**Description**: Cast all returned values to strings. By default, integers are returned as numbers.
**Example(s)**
```js
console.log(fill(1, 5)); //=> [ 1, 2, 3, 4, 5 ]
console.log(fill(1, 5, { stringify: true })); //=> [ '1', '2', '3', '4', '5' ]
```
### options.toRegex
**Type**: `boolean`
**Default**: `undefined`
**Description**: Create a regex-compatible source string, instead of expanding values to an array.
**Example(s)**
```js
// alphabetical range
console.log(fill('a', 'e', { toRegex: true })); //=> '[a-e]'
// alphabetical with step
console.log(fill('a', 'z', 3, { toRegex: true })); //=> 'a|d|g|j|m|p|s|v|y'
// numerical range
console.log(fill('1', '100', { toRegex: true })); //=> '[1-9]|[1-9][0-9]|100'
// numerical range with zero padding
console.log(fill('000001', '100000', { toRegex: true }));
//=> '0{5}[1-9]|0{4}[1-9][0-9]|0{3}[1-9][0-9]{2}|0{2}[1-9][0-9]{3}|0[1-9][0-9]{4}|100000'
```
### options.transform
**Type**: `function`
**Default**: `undefined`
**Description**: Customize each value in the returned array (or [string](#optionstoRegex)). _(you can also pass this function as the last argument to `fill()`)_.
**Example(s)**
```js
// add zero padding
console.log(fill(1, 5, value => String(value).padStart(4, '0')));
//=> ['0001', '0002', '0003', '0004', '0005']
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 116 | [jonschlinkert](https://github.com/jonschlinkert) |
| 4 | [paulmillr](https://github.com/paulmillr) |
| 2 | [realityking](https://github.com/realityking) |
| 2 | [bluelovers](https://github.com/bluelovers) |
| 1 | [edorivai](https://github.com/edorivai) |
| 1 | [wtgtybhertgeghgtwtg](https://github.com/wtgtybhertgeghgtwtg) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
Please consider supporting me on Patreon, or [start your own Patreon page](https://patreon.com/invite/bxpbvm)!
<a href="https://www.patreon.com/jonschlinkert">
<img src="https://c5.patreon.com/external/logo/[email protected]" height="50">
</a>
### License
Copyright © 2019, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on April 08, 2019._
# color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
degenerator
===========
### Turns sync functions into async generator functions
[](https://travis-ci.org/TooTallNate/node-degenerator)
Sometimes you need to write sync looking code that's really async under the hood.
This module takes a String to one or more synchronous JavaScript functions, and
returns a new String that with those JS functions transpiled into ES6 Generator
Functions.
So this:
``` js
function foo () {
return a('bar') || b();
}
```
Gets compiled into:
``` js
function* foo() {
return (yield a('bar')) || (yield b());
}
```
From there, you can provide asynchronous thunk-based or Generator-based
implementations for the `a()` and `b()` functions, in conjunction with any
Generator-based flow control library to execute the contents of the
function asynchronously.
Installation
------------
Install with `npm`:
``` bash
$ npm install degenerator
```
Example
-------
You must explicitly specify the names of the functions that should be
"asyncified". So say we wanted to expose a `get(url)` function that did
and HTTP request and returned the response body.
The user has provided us with this implementation:
``` js
function myFn () {
var one = get('https://google.com');
var two = get('http://nodejs.org');
var three = JSON.parse(get('http://jsonip.org'));
return [one, two, three];
}
```
Now we can compile this into an asyncronous generator function, implement the
async `get()` function, and finally evaluate it into a real JavaScript function
instance with the `vm` module:
``` js
var co = require('co');
var vm = require('vm');
var degenerator = require('degenerator');
// the `get()` function is thunk-based (error handling omitted for brevity)
function get (endpoint) {
return function (fn) {
var mod = 0 == endpoint.indexOf('https:') ? require('https') : require('http');
var req = mod.get(endpoint);
req.on('response', function (res) {
var data = '';
res.setEncoding('utf8');
res.on('data', function (b) { data += b; });
res.on('end', function () {
fn(null, data);
});
});
};
}
// convert the JavaScript string provided from the user (assumed to be `str` var)
str = degenerator(str, [ 'get' ]);
// at this stage, you could use a transpiler like `facebook/regenerator`
// here if desired.
// turn the JS String into a real GeneratorFunction instance
var genFn = vm.runInNewContext('(' + str + ')', { get: get });
// use a generator-based flow control library (`visionmedia/co`, `jmar777/suspend`,
// etc.) to create an async function from the generator function.
var asnycFn = co(genFn);
// NOW USE IT!!!
asyncFn(function (err, res) {
// ...
});
```
API
---
### degenerator(String jsStr, Array functionNames) → String
Returns a "degeneratorified" JavaScript string, with ES6 Generator
functions transplanted.
License
-------
(The MIT License)
Copyright (c) 2013 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# readable-stream
***Node-core v8.11.1 streams for userland*** [](https://travis-ci.org/nodejs/readable-stream)
[](https://nodei.co/npm/readable-stream/)
[](https://nodei.co/npm/readable-stream/)
[](https://saucelabs.com/u/readable-stream)
```bash
npm install --save readable-stream
```
***Node-core streams for userland***
This package is a mirror of the Streams2 and Streams3 implementations in
Node-core.
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v8.11.1/docs/api/stream.html).
If you want to guarantee a stable streams base, regardless of what version of
Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core, for background see [this blogpost](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).
As of version 2.0.0 **readable-stream** uses semantic versioning.
# Streams Working Group
`readable-stream` is maintained by the Streams Working Group, which
oversees the development and maintenance of the Streams API within
Node.js. The responsibilities of the Streams Working Group include:
* Addressing stream issues on the Node.js issue tracker.
* Authoring and editing stream documentation within the Node.js project.
* Reviewing changes to stream subclasses within the Node.js project.
* Redirecting changes to streams from the Node.js project to this
project.
* Assisting in the implementation of stream providers within Node.js.
* Recommending versions of `readable-stream` to be included in Node.js.
* Messaging about the future of streams to give the community advance
notice of changes.
<a name="members"></a>
## Team Members
* **Chris Dickinson** ([@chrisdickinson](https://github.com/chrisdickinson)) <[email protected]>
- Release GPG key: 9554F04D7259F04124DE6B476D5A82AC7E37093B
* **Calvin Metcalf** ([@calvinmetcalf](https://github.com/calvinmetcalf)) <[email protected]>
- Release GPG key: F3EF5F62A87FC27A22E643F714CE4FF5015AA242
* **Rod Vagg** ([@rvagg](https://github.com/rvagg)) <[email protected]>
- Release GPG key: DD8F2338BAE7501E3DD5AC78C273792F7D83545D
* **Sam Newman** ([@sonewman](https://github.com/sonewman)) <[email protected]>
* **Mathias Buus** ([@mafintosh](https://github.com/mafintosh)) <[email protected]>
* **Domenic Denicola** ([@domenic](https://github.com/domenic)) <[email protected]>
* **Matteo Collina** ([@mcollina](https://github.com/mcollina)) <[email protected]>
- Release GPG key: 3ABC01543F22DD2239285CDD818674489FBC127E
* **Irina Shestak** ([@lrlna](https://github.com/lrlna)) <[email protected]>
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
`disable()`
Will disable all namespaces. The functions returns the namespaces currently
enabled (and skipped). This can be useful if you want to disable debugging
temporarily without knowing what was enabled to begin with.
For example:
```js
let debug = require('debug');
debug.enable('foo:*,-foo:bar');
let namespaces = debug.disable();
debug.enable(namespaces);
```
Note: There is no guarantee that the string will be identical to the initial
enable string, but semantically they will be identical.
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# web3-providers-ws
This is a sub package of [web3.js][repo]
This is a websocket provider for [web3.js][repo].
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-providers-ws
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-providers-ws.js` in your html file.
This will expose the `Web3WsProvider` object on the window object.
## Usage
```js
// in node.js
var Web3WsProvider = require('web3-providers-ws');
var options = {
timeout: 30000,
headers: { authorization: 'Basic username:password' }
}; // set a custom timeout at 30 seconds, and credentials (you can also add the credentials to the URL: ws://username:password@localhost:8546)
var ws = new Web3WsProvider('ws://localhost:8546', options);
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
# levn [](https://travis-ci.org/gkz/levn) <a name="levn" />
__Light ECMAScript (JavaScript) Value Notation__
Levn is a library which allows you to parse a string into a JavaScript value based on an expected type. It is meant for short amounts of human entered data (eg. config files, command line arguments).
Levn aims to concisely describe JavaScript values in text, and allow for the extraction and validation of those values. Levn uses [type-check](https://github.com/gkz/type-check) for its type format, and to validate the results. MIT license. Version 0.3.0.
__How is this different than JSON?__ levn is meant to be written by humans only, is (due to the previous point) much more concise, can be validated against supplied types, has regex and date literals, and can easily be extended with custom types. On the other hand, it is probably slower and thus less efficient at transporting large amounts of data, which is fine since this is not its purpose.
npm install levn
For updates on levn, [follow me on twitter](https://twitter.com/gkzahariev).
## Quick Examples
```js
var parse = require('levn').parse;
parse('Number', '2'); // 2
parse('String', '2'); // '2'
parse('String', 'levn'); // 'levn'
parse('String', 'a b'); // 'a b'
parse('Boolean', 'true'); // true
parse('Date', '#2011-11-11#'); // (Date object)
parse('Date', '2011-11-11'); // (Date object)
parse('RegExp', '/[a-z]/gi'); // /[a-z]/gi
parse('RegExp', 're'); // /re/
parse('Int', '2'); // 2
parse('Number | String', 'str'); // 'str'
parse('Number | String', '2'); // 2
parse('[Number]', '[1,2,3]'); // [1,2,3]
parse('(String, Boolean)', '(hi, false)'); // ['hi', false]
parse('{a: String, b: Number}', '{a: str, b: 2}'); // {a: 'str', b: 2}
// at the top level, you can ommit surrounding delimiters
parse('[Number]', '1,2,3'); // [1,2,3]
parse('(String, Boolean)', 'hi, false'); // ['hi', false]
parse('{a: String, b: Number}', 'a: str, b: 2'); // {a: 'str', b: 2}
// wildcard - auto choose type
parse('*', '[hi,(null,[42]),{k: true}]'); // ['hi', [null, [42]], {k: true}]
```
## Usage
`require('levn');` returns an object that exposes three properties. `VERSION` is the current version of the library as a string. `parse` and `parsedTypeParse` are functions.
```js
// parse(type, input, options);
parse('[Number]', '1,2,3'); // [1, 2, 3]
// parsedTypeParse(parsedType, input, options);
var parsedType = require('type-check').parseType('[Number]');
parsedTypeParse(parsedType, '1,2,3'); // [1, 2, 3]
```
### parse(type, input, options)
`parse` casts the string `input` into a JavaScript value according to the specified `type` in the [type format](https://github.com/gkz/type-check#type-format) (and taking account the optional `options`) and returns the resulting JavaScript value.
##### arguments
* type - `String` - the type written in the [type format](https://github.com/gkz/type-check#type-format) which to check against
* input - `String` - the value written in the [levn format](#levn-format)
* options - `Maybe Object` - an optional parameter specifying additional [options](#options)
##### returns
`*` - the resulting JavaScript value
##### example
```js
parse('[Number]', '1,2,3'); // [1, 2, 3]
```
### parsedTypeParse(parsedType, input, options)
`parsedTypeParse` casts the string `input` into a JavaScript value according to the specified `type` which has already been parsed (and taking account the optional `options`) and returns the resulting JavaScript value. You can parse a type using the [type-check](https://github.com/gkz/type-check) library's `parseType` function.
##### arguments
* type - `Object` - the type in the parsed type format which to check against
* input - `String` - the value written in the [levn format](#levn-format)
* options - `Maybe Object` - an optional parameter specifying additional [options](#options)
##### returns
`*` - the resulting JavaScript value
##### example
```js
var parsedType = require('type-check').parseType('[Number]');
parsedTypeParse(parsedType, '1,2,3'); // [1, 2, 3]
```
## Levn Format
Levn can use the type information you provide to choose the appropriate value to produce from the input. For the same input, it will choose a different output value depending on the type provided. For example, `parse('Number', '2')` will produce the number `2`, but `parse('String', '2')` will produce the string `"2"`.
If you do not provide type information, and simply use `*`, levn will parse the input according the unambiguous "explicit" mode, which we will now detail - you can also set the `explicit` option to true manually in the [options](#options).
* `"string"`, `'string'` are parsed as a String, eg. `"a msg"` is `"a msg"`
* `#date#` is parsed as a Date, eg. `#2011-11-11#` is `new Date('2011-11-11')`
* `/regexp/flags` is parsed as a RegExp, eg. `/re/gi` is `/re/gi`
* `undefined`, `null`, `NaN`, `true`, and `false` are all their JavaScript equivalents
* `[element1, element2, etc]` is an Array, and the casting procedure is recursively applied to each element. Eg. `[1,2,3]` is `[1,2,3]`.
* `(element1, element2, etc)` is an tuple, and the casting procedure is recursively applied to each element. Eg. `(1, a)` is `(1, a)` (is `[1, 'a']`).
* `{key1: val1, key2: val2, ...}` is an Object, and the casting procedure is recursively applied to each property. Eg. `{a: 1, b: 2}` is `{a: 1, b: 2}`.
* Any test which does not fall under the above, and which does not contain special characters (`[``]``(``)``{``}``:``,`) is a string, eg. `$12- blah` is `"$12- blah"`.
If you do provide type information, you can make your input more concise as the program already has some information about what it expects. Please see the [type format](https://github.com/gkz/type-check#type-format) section of [type-check](https://github.com/gkz/type-check) for more information about how to specify types. There are some rules about what levn can do with the information:
* If a String is expected, and only a String, all characters of the input (including any special ones) will become part of the output. Eg. `[({})]` is `"[({})]"`, and `"hi"` is `'"hi"'`.
* If a Date is expected, the surrounding `#` can be omitted from date literals. Eg. `2011-11-11` is `new Date('2011-11-11')`.
* If a RegExp is expected, no flags need to be specified, and the regex is not using any of the special characters,the opening and closing `/` can be omitted - this will have the affect of setting the source of the regex to the input. Eg. `regex` is `/regex/`.
* If an Array is expected, and it is the root node (at the top level), the opening `[` and closing `]` can be omitted. Eg. `1,2,3` is `[1,2,3]`.
* If a tuple is expected, and it is the root node (at the top level), the opening `(` and closing `)` can be omitted. Eg. `1, a` is `(1, a)` (is `[1, 'a']`).
* If an Object is expected, and it is the root node (at the top level), the opening `{` and closing `}` can be omitted. Eg `a: 1, b: 2` is `{a: 1, b: 2}`.
If you list multiple types (eg. `Number | String`), it will first attempt to cast to the first type and then validate - if the validation fails it will move on to the next type and so forth, left to right. You must be careful as some types will succeed with any input, such as String. Thus put String at the end of your list. In non-explicit mode, Date and RegExp will succeed with a large variety of input - also be careful with these and list them near the end if not last in your list.
Whitespace between special characters and elements is inconsequential.
## Options
Options is an object. It is an optional parameter to the `parse` and `parsedTypeParse` functions.
### Explicit
A `Boolean`. By default it is `false`.
__Example:__
```js
parse('RegExp', 're', {explicit: false}); // /re/
parse('RegExp', 're', {explicit: true}); // Error: ... does not type check...
parse('RegExp | String', 're', {explicit: true}); // 're'
```
`explicit` sets whether to be in explicit mode or not. Using `*` automatically activates explicit mode. For more information, read the [levn format](#levn-format) section.
### customTypes
An `Object`. Empty `{}` by default.
__Example:__
```js
var options = {
customTypes: {
Even: {
typeOf: 'Number',
validate: function (x) {
return x % 2 === 0;
},
cast: function (x) {
return {type: 'Just', value: parseInt(x)};
}
}
}
}
parse('Even', '2', options); // 2
parse('Even', '3', options); // Error: Value: "3" does not type check...
```
__Another Example:__
```js
function Person(name, age){
this.name = name;
this.age = age;
}
var options = {
customTypes: {
Person: {
typeOf: 'Object',
validate: function (x) {
x instanceof Person;
},
cast: function (value, options, typesCast) {
var name, age;
if ({}.toString.call(value).slice(8, -1) !== 'Object') {
return {type: 'Nothing'};
}
name = typesCast(value.name, [{type: 'String'}], options);
age = typesCast(value.age, [{type: 'Numger'}], options);
return {type: 'Just', value: new Person(name, age)};
}
}
}
parse('Person', '{name: Laura, age: 25}', options); // Person {name: 'Laura', age: 25}
```
`customTypes` is an object whose keys are the name of the types, and whose values are an object with three properties, `typeOf`, `validate`, and `cast`. For more information about `typeOf` and `validate`, please see the [custom types](https://github.com/gkz/type-check#custom-types) section of type-check.
`cast` is a function which receives three arguments, the value under question, options, and the typesCast function. In `cast`, attempt to cast the value into the specified type. If you are successful, return an object in the format `{type: 'Just', value: CAST-VALUE}`, if you know it won't work, return `{type: 'Nothing'}`. You can use the `typesCast` function to cast any child values. Remember to pass `options` to it. In your function you can also check for `options.explicit` and act accordingly.
## Technical About
`levn` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It uses [type-check](https://github.com/gkz/type-check) to both parse types and validate values. It also uses the [prelude.ls](http://preludels.com/) library.
# web3-eth-abi
This is a sub package of [web3.js][repo]
This is the abi package to be used in the `web3-eth` package.
Please read the [documentation][docs] for more.
## Installation
### Node.js
```bash
npm install web3-eth-abi
```
### In the Browser
Build running the following in the [web3.js][repo] repository:
```bash
npm run-script build-all
```
Then include `dist/web3-eth-abi.js` in your html file.
This will expose the `Web3EthAbi` object on the window object.
## Usage
```js
// in node.js
var Web3EthAbi = require('web3-eth-abi');
Web3EthAbi.encodeFunctionSignature('myMethod(uint256,string)');
> '0x24ee0097'
```
## Types
All the typescript typings are placed in the types folder.
[docs]: http://web3js.readthedocs.io/en/1.0/
[repo]: https://github.com/ethereum/web3.js
[](https://badge.fury.io/js/ethereum-bloom-filters)

# ethereum-bloom-filters
A lightweight bloom filter client which allows you to test ethereum blooms for fast checks of set membership.
This package only has 1 dependency which is on `js-sha3` which has no dependencies on at all.
## Installation
### npm:
```js
$ npm install ethereum-bloom-filters
```
### yarn:
```js
$ yarn add ethereum-bloom-filters
```
## Usage
### JavaScript (ES3)
```js
var ethereumBloomFilters = require('ethereum-bloom-filters');
```
### JavaScript (ES5 or ES6)
```js
const ethereumBloomFilters = require('ethereum-bloom-filters');
```
### JavaScript (ES6) / TypeScript
```js
import {
isBloom,
isUserEthereumAddressInBloom,
isContractAddressInBloom,
isTopic,
isTopicInBloom,
isInBloom
} from 'ethereum-bloom-filters';
```
### Including within a web application which doesn't use any transpiler
When using angular, react or vuejs these frameworks handle dependencies and transpile them so they work on the web, so if you're using any of them just use the above code snippets to start using this package.
If you're using a standard web application you can go [here](https://github.com/joshstevens19/ethereum-bloom-filters/tree/master/web-scripts) to copy any of the versioned script files and then dropping it into your web application, making sure you reference it within a script tag in the head of the website.
This will expose the library as a global variable named `ethereumBloomFilters`, you can then execute the methods through this variable:
```js
ethereumBloomFilters.isBloom(...)
ethereumBloomFilters.isUserEthereumAddressInBloom(...)
ethereumBloomFilters.isContractAddressInBloom(...)
ethereumBloomFilters.isTopic(...)
ethereumBloomFilters.isTopicInBloom(...)
ethereumBloomFilters.isInBloom(...)
```
You can find out more about the functions parameters below.
We do not expose an cdn for security reasons.
## What are bloom filters?
A Bloom filter is a probabilistic, space-efficient data structure used for fast checks of set membership. That probably doesn’t mean much to you yet, and so let’s explore how bloom filters might be used.
Imagine that we have some large set of data, and we want to be able to quickly test if some element is currently in that set. The naive way of checking might be to query the set to see if our element is in there. That’s probably fine if our data set is relatively small. Unfortunately, if our data set is really big, this search might take a while. Luckily, we have tricks to speed things up in the ethereum world!
A bloom filter is one of these tricks. The basic idea behind the Bloom filter is to hash each new element that goes into the data set, take certain bits from this hash, and then use those bits to fill in parts of a fixed-size bit array (e.g. set certain bits to 1). This bit array is called a bloom filter.
Later, when we want to check if an element is in the set, we simply hash the element and check that the right bits are in the bloom filter. If at least one of the bits is 0, then the element definitely isn’t in our data set! If all of the bits are 1, then the element might be in the data set, but we need to actually query the database to be sure. So we might have false positives, but we’ll never have false negatives. This can greatly reduce the number of database queries we have to make.
## ethereum-bloom-filters benefits with an real life example
A ethereum real life example in where this is useful is if you want to update a users balance on every new block so it stays as close to real time as possible. Without using a bloom filter on every new block you would have to force the balances even if that user may not of had any activity within that block. But if you use the logBlooms from the block you can test the bloom filter against the users ethereum address before you do any more slow operations, this will dramatically decrease the amount of calls you do as you will only be doing those extra operations if that ethereum address is within that block (minus the false positives outcome which will be negligible). This will be highly performant for your app.
## Functions
### isBloom
```ts
isBloom(bloom: string): boolean;
```
Returns true if the bloom is a valid bloom.
### isUserEthereumAddressInBloom
```ts
isUserEthereumAddressInBloom(bloom: string, ethereumAddress: string): boolean;
```
Returns true if the ethereum users address is part of the given bloom
note: false positives are possible.
### isContractAddressInBloom
```ts
isContractAddressInBloom(bloom: string, contractAddress: string): boolean;
```
Returns true if the contract address is part of the given bloom
note: false positives are possible.
### isTopic
```ts
isTopic(topic: string): boolean;
```
Returns true if the topic is valid
### isTopicInBloom
```ts
isTopicInBloom(bloom: string, topic: string): boolean;
```
Returns true if the topic is part of the given bloom
note: false positives are possible.
### isInBloom
This is the raw base method which the other bloom methods above use. You can pass in a bloom and a value which will return true if its part of the given bloom.
```ts
isInBloom(bloom: string, value: string | Uint8Array): boolean;
```
Returns true if the value is part of the given bloom
note: false positives are possible.
## Issues
Please raise any issues in the below link.
https://github.com/joshstevens19/ethereum-bloom-filters/issues
## Contributors dev guide
To run locally firstly run:
```js
$ npm install
```
To build:
```js
$ tsc
```
To watch build:
```js
$ tsc --watch
```
To run tests:
```js
$ npm test
```
# is-object <sup>[![Version Badge][12]][11]</sup>
[![build status][1]][2]
[![dependency status][3]][4]
[![dev dependency status][9]][10]
[![License][license-image]][license-url]
[![Downloads][downloads-image]][downloads-url]
[![npm badge][13]][11]
[![browser support][5]][6]
Checks whether a value is an object
Because `typeof null` is a troll.
## Example
```js
var isObject = require('is-object');
var assert = require('assert');
assert.equal(isObject(null), false);
assert.equal(isObject({}), true);
```
## Installation
`npm install is-object`
## Contributors
- [Raynos][7]
- [Jordan Harband][8]
## MIT Licensed
[1]: https://secure.travis-ci.org/ljharb/is-object.svg
[2]: http://travis-ci.org/ljharb/is-object
[3]: http://david-dm.org/ljharb/is-object/status.svg
[4]: http://david-dm.org/ljharb/is-object
[5]: http://ci.testling.com/ljharb/is-object.svg
[6]: http://ci.testling.com/ljharb/is-object
[7]: https://github.com/Raynos
[8]: https://github.com/ljharb
[9]: https://david-dm.org/ljharb/is-object/dev-status.svg
[10]: https://david-dm.org/ljharb/is-object#info=devDependencies
[11]: https://npmjs.org/package/is-object
[12]: http://vb.teelaun.ch/ljharb/is-object.svg
[13]: https://nodei.co/npm/is-object.png?downloads=true&stars=true
[license-image]: http://img.shields.io/npm/l/is-object.svg
[license-url]: LICENSE
[downloads-image]: http://img.shields.io/npm/dm/is-object.svg
[downloads-url]: http://npm-stat.com/charts.html?package=is-object
http-proxy-agent
================
### An HTTP(s) proxy `http.Agent` implementation for HTTP
[](https://travis-ci.org/TooTallNate/node-http-proxy-agent)
This module provides an `http.Agent` implementation that connects to a specified
HTTP or HTTPS proxy server, and can be used with the built-in `http` module.
__Note:__ For HTTP proxy usage with the `https` module, check out
[`node-https-proxy-agent`](https://github.com/TooTallNate/node-https-proxy-agent).
Installation
------------
Install with `npm`:
``` bash
$ npm install http-proxy-agent
```
Example
-------
``` js
var url = require('url');
var http = require('http');
var HttpProxyAgent = require('http-proxy-agent');
// HTTP/HTTPS proxy to connect to
var proxy = process.env.http_proxy || 'http://168.63.76.32:3128';
console.log('using proxy server %j', proxy);
// HTTP endpoint for the proxy to connect to
var endpoint = process.argv[2] || 'http://nodejs.org/api/';
console.log('attempting to GET %j', endpoint);
var opts = url.parse(endpoint);
// create an instance of the `HttpProxyAgent` class with the proxy server information
var agent = new HttpProxyAgent(proxy);
opts.agent = agent;
http.get(opts, function (res) {
console.log('"response" event!', res.headers);
res.pipe(process.stdout);
});
```
License
-------
(The MIT License)
Copyright (c) 2013 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
semver(1) -- The semantic versioner for npm
===========================================
## Install
```bash
npm install semver
````
## Usage
As a node module:
```js
const semver = require('semver')
semver.valid('1.2.3') // '1.2.3'
semver.valid('a.b.c') // null
semver.clean(' =v1.2.3 ') // '1.2.3'
semver.satisfies('1.2.3', '1.x || >=2.5.0 || 5.0.0 - 7.2.3') // true
semver.gt('1.2.3', '9.8.7') // false
semver.lt('1.2.3', '9.8.7') // true
semver.minVersion('>=1.0.0') // '1.0.0'
semver.valid(semver.coerce('v2')) // '2.0.0'
semver.valid(semver.coerce('42.6.7.9.3-alpha')) // '42.6.7'
```
As a command-line utility:
```
$ semver -h
A JavaScript implementation of the https://semver.org/ specification
Copyright Isaac Z. Schlueter
Usage: semver [options] <version> [<version> [...]]
Prints valid versions sorted by SemVer precedence
Options:
-r --range <range>
Print versions that match the specified range.
-i --increment [<level>]
Increment a version by the specified level. Level can
be one of: major, minor, patch, premajor, preminor,
prepatch, or prerelease. Default level is 'patch'.
Only one version may be specified.
--preid <identifier>
Identifier to be used to prefix premajor, preminor,
prepatch or prerelease version increments.
-l --loose
Interpret versions and ranges loosely
-p --include-prerelease
Always include prerelease versions in range matching
-c --coerce
Coerce a string into SemVer if possible
(does not imply --loose)
--rtl
Coerce version strings right to left
--ltr
Coerce version strings left to right (default)
Program exits successfully if any valid version satisfies
all supplied ranges, and prints all satisfying versions.
If no satisfying versions are found, then exits failure.
Versions are printed in ascending order, so supplying
multiple versions to the utility will just sort them.
```
## Versions
A "version" is described by the `v2.0.0` specification found at
<https://semver.org/>.
A leading `"="` or `"v"` character is stripped off and ignored.
## Ranges
A `version range` is a set of `comparators` which specify versions
that satisfy the range.
A `comparator` is composed of an `operator` and a `version`. The set
of primitive `operators` is:
* `<` Less than
* `<=` Less than or equal to
* `>` Greater than
* `>=` Greater than or equal to
* `=` Equal. If no operator is specified, then equality is assumed,
so this operator is optional, but MAY be included.
For example, the comparator `>=1.2.7` would match the versions
`1.2.7`, `1.2.8`, `2.5.3`, and `1.3.9`, but not the versions `1.2.6`
or `1.1.0`.
Comparators can be joined by whitespace to form a `comparator set`,
which is satisfied by the **intersection** of all of the comparators
it includes.
A range is composed of one or more comparator sets, joined by `||`. A
version matches a range if and only if every comparator in at least
one of the `||`-separated comparator sets is satisfied by the version.
For example, the range `>=1.2.7 <1.3.0` would match the versions
`1.2.7`, `1.2.8`, and `1.2.99`, but not the versions `1.2.6`, `1.3.0`,
or `1.1.0`.
The range `1.2.7 || >=1.2.9 <2.0.0` would match the versions `1.2.7`,
`1.2.9`, and `1.4.6`, but not the versions `1.2.8` or `2.0.0`.
### Prerelease Tags
If a version has a prerelease tag (for example, `1.2.3-alpha.3`) then
it will only be allowed to satisfy comparator sets if at least one
comparator with the same `[major, minor, patch]` tuple also has a
prerelease tag.
For example, the range `>1.2.3-alpha.3` would be allowed to match the
version `1.2.3-alpha.7`, but it would *not* be satisfied by
`3.4.5-alpha.9`, even though `3.4.5-alpha.9` is technically "greater
than" `1.2.3-alpha.3` according to the SemVer sort rules. The version
range only accepts prerelease tags on the `1.2.3` version. The
version `3.4.5` *would* satisfy the range, because it does not have a
prerelease flag, and `3.4.5` is greater than `1.2.3-alpha.7`.
The purpose for this behavior is twofold. First, prerelease versions
frequently are updated very quickly, and contain many breaking changes
that are (by the author's design) not yet fit for public consumption.
Therefore, by default, they are excluded from range matching
semantics.
Second, a user who has opted into using a prerelease version has
clearly indicated the intent to use *that specific* set of
alpha/beta/rc versions. By including a prerelease tag in the range,
the user is indicating that they are aware of the risk. However, it
is still not appropriate to assume that they have opted into taking a
similar risk on the *next* set of prerelease versions.
Note that this behavior can be suppressed (treating all prerelease
versions as if they were normal versions, for the purpose of range
matching) by setting the `includePrerelease` flag on the options
object to any
[functions](https://github.com/npm/node-semver#functions) that do
range matching.
#### Prerelease Identifiers
The method `.inc` takes an additional `identifier` string argument that
will append the value of the string as a prerelease identifier:
```javascript
semver.inc('1.2.3', 'prerelease', 'beta')
// '1.2.4-beta.0'
```
command-line example:
```bash
$ semver 1.2.3 -i prerelease --preid beta
1.2.4-beta.0
```
Which then can be used to increment further:
```bash
$ semver 1.2.4-beta.0 -i prerelease
1.2.4-beta.1
```
### Advanced Range Syntax
Advanced range syntax desugars to primitive comparators in
deterministic ways.
Advanced ranges may be combined in the same way as primitive
comparators using white space or `||`.
#### Hyphen Ranges `X.Y.Z - A.B.C`
Specifies an inclusive set.
* `1.2.3 - 2.3.4` := `>=1.2.3 <=2.3.4`
If a partial version is provided as the first version in the inclusive
range, then the missing pieces are replaced with zeroes.
* `1.2 - 2.3.4` := `>=1.2.0 <=2.3.4`
If a partial version is provided as the second version in the
inclusive range, then all versions that start with the supplied parts
of the tuple are accepted, but nothing that would be greater than the
provided tuple parts.
* `1.2.3 - 2.3` := `>=1.2.3 <2.4.0`
* `1.2.3 - 2` := `>=1.2.3 <3.0.0`
#### X-Ranges `1.2.x` `1.X` `1.2.*` `*`
Any of `X`, `x`, or `*` may be used to "stand in" for one of the
numeric values in the `[major, minor, patch]` tuple.
* `*` := `>=0.0.0` (Any version satisfies)
* `1.x` := `>=1.0.0 <2.0.0` (Matching major version)
* `1.2.x` := `>=1.2.0 <1.3.0` (Matching major and minor versions)
A partial version range is treated as an X-Range, so the special
character is in fact optional.
* `""` (empty string) := `*` := `>=0.0.0`
* `1` := `1.x.x` := `>=1.0.0 <2.0.0`
* `1.2` := `1.2.x` := `>=1.2.0 <1.3.0`
#### Tilde Ranges `~1.2.3` `~1.2` `~1`
Allows patch-level changes if a minor version is specified on the
comparator. Allows minor-level changes if not.
* `~1.2.3` := `>=1.2.3 <1.(2+1).0` := `>=1.2.3 <1.3.0`
* `~1.2` := `>=1.2.0 <1.(2+1).0` := `>=1.2.0 <1.3.0` (Same as `1.2.x`)
* `~1` := `>=1.0.0 <(1+1).0.0` := `>=1.0.0 <2.0.0` (Same as `1.x`)
* `~0.2.3` := `>=0.2.3 <0.(2+1).0` := `>=0.2.3 <0.3.0`
* `~0.2` := `>=0.2.0 <0.(2+1).0` := `>=0.2.0 <0.3.0` (Same as `0.2.x`)
* `~0` := `>=0.0.0 <(0+1).0.0` := `>=0.0.0 <1.0.0` (Same as `0.x`)
* `~1.2.3-beta.2` := `>=1.2.3-beta.2 <1.3.0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
#### Caret Ranges `^1.2.3` `^0.2.5` `^0.0.4`
Allows changes that do not modify the left-most non-zero element in the
`[major, minor, patch]` tuple. In other words, this allows patch and
minor updates for versions `1.0.0` and above, patch updates for
versions `0.X >=0.1.0`, and *no* updates for versions `0.0.X`.
Many authors treat a `0.x` version as if the `x` were the major
"breaking-change" indicator.
Caret ranges are ideal when an author may make breaking changes
between `0.2.4` and `0.3.0` releases, which is a common practice.
However, it presumes that there will *not* be breaking changes between
`0.2.4` and `0.2.5`. It allows for changes that are presumed to be
additive (but non-breaking), according to commonly observed practices.
* `^1.2.3` := `>=1.2.3 <2.0.0`
* `^0.2.3` := `>=0.2.3 <0.3.0`
* `^0.0.3` := `>=0.0.3 <0.0.4`
* `^1.2.3-beta.2` := `>=1.2.3-beta.2 <2.0.0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
* `^0.0.3-beta` := `>=0.0.3-beta <0.0.4` Note that prereleases in the
`0.0.3` version *only* will be allowed, if they are greater than or
equal to `beta`. So, `0.0.3-pr.2` would be allowed.
When parsing caret ranges, a missing `patch` value desugars to the
number `0`, but will allow flexibility within that value, even if the
major and minor versions are both `0`.
* `^1.2.x` := `>=1.2.0 <2.0.0`
* `^0.0.x` := `>=0.0.0 <0.1.0`
* `^0.0` := `>=0.0.0 <0.1.0`
A missing `minor` and `patch` values will desugar to zero, but also
allow flexibility within those values, even if the major version is
zero.
* `^1.x` := `>=1.0.0 <2.0.0`
* `^0.x` := `>=0.0.0 <1.0.0`
### Range Grammar
Putting all this together, here is a Backus-Naur grammar for ranges,
for the benefit of parser authors:
```bnf
range-set ::= range ( logical-or range ) *
logical-or ::= ( ' ' ) * '||' ( ' ' ) *
range ::= hyphen | simple ( ' ' simple ) * | ''
hyphen ::= partial ' - ' partial
simple ::= primitive | partial | tilde | caret
primitive ::= ( '<' | '>' | '>=' | '<=' | '=' ) partial
partial ::= xr ( '.' xr ( '.' xr qualifier ? )? )?
xr ::= 'x' | 'X' | '*' | nr
nr ::= '0' | ['1'-'9'] ( ['0'-'9'] ) *
tilde ::= '~' partial
caret ::= '^' partial
qualifier ::= ( '-' pre )? ( '+' build )?
pre ::= parts
build ::= parts
parts ::= part ( '.' part ) *
part ::= nr | [-0-9A-Za-z]+
```
## Functions
All methods and classes take a final `options` object argument. All
options in this object are `false` by default. The options supported
are:
- `loose` Be more forgiving about not-quite-valid semver strings.
(Any resulting output will always be 100% strict compliant, of
course.) For backwards compatibility reasons, if the `options`
argument is a boolean value instead of an object, it is interpreted
to be the `loose` param.
- `includePrerelease` Set to suppress the [default
behavior](https://github.com/npm/node-semver#prerelease-tags) of
excluding prerelease tagged versions from ranges unless they are
explicitly opted into.
Strict-mode Comparators and Ranges will be strict about the SemVer
strings that they parse.
* `valid(v)`: Return the parsed version, or null if it's not valid.
* `inc(v, release)`: Return the version incremented by the release
type (`major`, `premajor`, `minor`, `preminor`, `patch`,
`prepatch`, or `prerelease`), or null if it's not valid
* `premajor` in one call will bump the version up to the next major
version and down to a prerelease of that major version.
`preminor`, and `prepatch` work the same way.
* If called from a non-prerelease version, the `prerelease` will work the
same as `prepatch`. It increments the patch version, then makes a
prerelease. If the input version is already a prerelease it simply
increments it.
* `prerelease(v)`: Returns an array of prerelease components, or null
if none exist. Example: `prerelease('1.2.3-alpha.1') -> ['alpha', 1]`
* `major(v)`: Return the major version number.
* `minor(v)`: Return the minor version number.
* `patch(v)`: Return the patch version number.
* `intersects(r1, r2, loose)`: Return true if the two supplied ranges
or comparators intersect.
* `parse(v)`: Attempt to parse a string as a semantic version, returning either
a `SemVer` object or `null`.
### Comparison
* `gt(v1, v2)`: `v1 > v2`
* `gte(v1, v2)`: `v1 >= v2`
* `lt(v1, v2)`: `v1 < v2`
* `lte(v1, v2)`: `v1 <= v2`
* `eq(v1, v2)`: `v1 == v2` This is true if they're logically equivalent,
even if they're not the exact same string. You already know how to
compare strings.
* `neq(v1, v2)`: `v1 != v2` The opposite of `eq`.
* `cmp(v1, comparator, v2)`: Pass in a comparison string, and it'll call
the corresponding function above. `"==="` and `"!=="` do simple
string comparison, but are included for completeness. Throws if an
invalid comparison string is provided.
* `compare(v1, v2)`: Return `0` if `v1 == v2`, or `1` if `v1` is greater, or `-1` if
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `rcompare(v1, v2)`: The reverse of compare. Sorts an array of versions
in descending order when passed to `Array.sort()`.
* `compareBuild(v1, v2)`: The same as `compare` but considers `build` when two versions
are equal. Sorts in ascending order if passed to `Array.sort()`.
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `diff(v1, v2)`: Returns difference between two versions by the release type
(`major`, `premajor`, `minor`, `preminor`, `patch`, `prepatch`, or `prerelease`),
or null if the versions are the same.
### Comparators
* `intersects(comparator)`: Return true if the comparators intersect
### Ranges
* `validRange(range)`: Return the valid range or null if it's not valid
* `satisfies(version, range)`: Return true if the version satisfies the
range.
* `maxSatisfying(versions, range)`: Return the highest version in the list
that satisfies the range, or `null` if none of them do.
* `minSatisfying(versions, range)`: Return the lowest version in the list
that satisfies the range, or `null` if none of them do.
* `minVersion(range)`: Return the lowest version that can possibly match
the given range.
* `gtr(version, range)`: Return `true` if version is greater than all the
versions possible in the range.
* `ltr(version, range)`: Return `true` if version is less than all the
versions possible in the range.
* `outside(version, range, hilo)`: Return true if the version is outside
the bounds of the range in either the high or low direction. The
`hilo` argument must be either the string `'>'` or `'<'`. (This is
the function called by `gtr` and `ltr`.)
* `intersects(range)`: Return true if any of the ranges comparators intersect
Note that, since ranges may be non-contiguous, a version might not be
greater than a range, less than a range, *or* satisfy a range! For
example, the range `1.2 <1.2.9 || >2.0.0` would have a hole from `1.2.9`
until `2.0.0`, so the version `1.2.10` would not be greater than the
range (because `2.0.1` satisfies, which is higher), nor less than the
range (since `1.2.8` satisfies, which is lower), and it also does not
satisfy the range.
If you want to know if a version satisfies or does not satisfy a
range, use the `satisfies(version, range)` function.
### Coercion
* `coerce(version, options)`: Coerces a string to semver if possible
This aims to provide a very forgiving translation of a non-semver string to
semver. It looks for the first digit in a string, and consumes all
remaining characters which satisfy at least a partial semver (e.g., `1`,
`1.2`, `1.2.3`) up to the max permitted length (256 characters). Longer
versions are simply truncated (`4.6.3.9.2-alpha2` becomes `4.6.3`). All
surrounding text is simply ignored (`v3.4 replaces v3.3.1` becomes
`3.4.0`). Only text which lacks digits will fail coercion (`version one`
is not valid). The maximum length for any semver component considered for
coercion is 16 characters; longer components will be ignored
(`10000000000000000.4.7.4` becomes `4.7.4`). The maximum value for any
semver component is `Integer.MAX_SAFE_INTEGER || (2**53 - 1)`; higher value
components are invalid (`9999999999999999.4.7.4` is likely invalid).
If the `options.rtl` flag is set, then `coerce` will return the right-most
coercible tuple that does not share an ending index with a longer coercible
tuple. For example, `1.2.3.4` will return `2.3.4` in rtl mode, not
`4.0.0`. `1.2.3/4` will return `4.0.0`, because the `4` is not a part of
any other overlapping SemVer tuple.
### Clean
* `clean(version)`: Clean a string to be a valid semver if possible
This will return a cleaned and trimmed semver version. If the provided version is not valid a null will be returned. This does not work for ranges.
ex.
* `s.clean(' = v 2.1.5foo')`: `null`
* `s.clean(' = v 2.1.5foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean(' = v 2.1.5-foo')`: `null`
* `s.clean(' = v 2.1.5-foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean('=v2.1.5')`: `'2.1.5'`
* `s.clean(' =v2.1.5')`: `2.1.5`
* `s.clean(' 2.1.5 ')`: `'2.1.5'`
* `s.clean('~1.0.0')`: `null`
# crypto-browserify
A port of node's `crypto` module to the browser.
[](https://travis-ci.org/crypto-browserify/crypto-browserify)
[](https://github.com/feross/standard)
[](https://saucelabs.com/u/crypto-browserify)
The goal of this module is to reimplement node's crypto module,
in pure javascript so that it can run in the browser.
Here is the subset that is currently implemented:
* createHash (sha1, sha224, sha256, sha384, sha512, md5, rmd160)
* createHmac (sha1, sha224, sha256, sha384, sha512, md5, rmd160)
* pbkdf2
* pbkdf2Sync
* randomBytes
* pseudoRandomBytes
* createCipher (aes)
* createDecipher (aes)
* createDiffieHellman
* createSign (rsa, ecdsa)
* createVerify (rsa, ecdsa)
* createECDH (secp256k1)
* publicEncrypt/privateDecrypt (rsa)
* privateEncrypt/publicDecrypt (rsa)
## todo
these features from node's `crypto` are still unimplemented.
* createCredentials
## contributions
If you are interested in writing a feature, please implement as a new module,
which will be incorporated into crypto-browserify as a dependency.
All deps must be compatible with node's crypto
(generate example inputs and outputs with node,
and save base64 strings inside JSON, so that tests can run in the browser.
see [sha.js](https://github.com/dominictarr/sha.js)
Crypto is _extra serious_ so please do not hesitate to review the code,
and post comments if you do.
## License
MIT
proxy-agent
===========
### Maps proxy protocols to `http.Agent` implementations
[](https://travis-ci.org/TooTallNate/node-proxy-agent)
This module provides a function that returns proxying `http.Agent` instances to
use based off of a given proxy URI.
An LRU cache is used so that `http.Agent` instances are transparently re-used for
subsequent HTTP requests to the same proxy server.
The currently implemented protocol mappings are listed in the table below:
| Protocol | Proxy Agent for `http` requests | Proxy Agent for `https` requests | Example
|:----------:|:-------------------------------:|:--------------------------------:|:--------:
| `http` | [http-proxy-agent][] | [https-proxy-agent][] | `http://proxy-server-over-tcp.com:3128`
| `https` | [http-proxy-agent][] | [https-proxy-agent][] | `https://proxy-server-over-tls.com:3129`
| `socks(v5)`| [socks-proxy-agent][] | [socks-proxy-agent][] | `socks://username:[email protected]:9050` (username & password are optional)
| `socks5` | [socks-proxy-agent][] | [socks-proxy-agent][] | `socks5://username:[email protected]:9050` (username & password are optional)
| `socks4` | [socks-proxy-agent][] | [socks-proxy-agent][] | `socks4://some-socks-proxy.com:9050`
| `pac` | [pac-proxy-agent][] | [pac-proxy-agent][] | `pac+http://www.example.com/proxy.pac`
Installation
------------
Install with `npm`:
``` bash
$ npm install proxy-agent
```
Example
-------
``` js
var http = require('http');
var ProxyAgent = require('proxy-agent');
// HTTP, HTTPS, or SOCKS proxy to use
var proxyUri = process.env.http_proxy || 'http://168.63.43.102:3128';
var opts = {
method: 'GET',
host: 'jsonip.org',
path: '/',
// this is the important part!
agent: new ProxyAgent(proxyUri)
};
// the rest works just like any other normal HTTP request
http.get(opts, onresponse);
function onresponse (res) {
console.log(res.statusCode, res.headers);
res.pipe(process.stdout);
}
```
API
---
### new ProxyAgent(Object|String opts|uri)
Returns an `http.Agent` instance based off of the given proxy `opts` or URI
string. An LRU cache is used, so the same `http.Agent` instance will be
returned if identical args are passed in.
License
-------
(The MIT License)
Copyright (c) 2013 Nathan Rajlich <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
[http-proxy-agent]: https://github.com/TooTallNate/node-http-proxy-agent
[https-proxy-agent]: https://github.com/TooTallNate/node-https-proxy-agent
[socks-proxy-agent]: https://github.com/TooTallNate/node-socks-proxy-agent
[pac-proxy-agent]: https://github.com/TooTallNate/node-pac-proxy-agent
# is-extglob [](http://badge.fury.io/js/is-extglob) [](https://travis-ci.org/jonschlinkert/is-extglob)
> Returns true if a string has an extglob.
## Install with [npm](npmjs.org)
```bash
npm i is-extglob --save
```
## Usage
```js
var isExtglob = require('is-extglob');
```
**True**
```js
isExtglob('?(abc)');
isExtglob('@(abc)');
isExtglob('!(abc)');
isExtglob('*(abc)');
isExtglob('+(abc)');
```
**False**
Everything else...
```js
isExtglob('foo.js');
isExtglob('!foo.js');
isExtglob('*.js');
isExtglob('**/abc.js');
isExtglob('abc/*.js');
isExtglob('abc/(aaa|bbb).js');
isExtglob('abc/[a-z].js');
isExtglob('abc/{a,b}.js');
isExtglob('abc/?.js');
isExtglob('abc.js');
isExtglob('abc/def/ghi.js');
```
## Related
* [extglob](https://github.com/jonschlinkert/extglob): Extended globs. extglobs add the expressive power of regular expressions to glob patterns.
* [micromatch](https://github.com/jonschlinkert/micromatch): Glob matching for javascript/node.js. A faster alternative to minimatch (10-45x faster on avg), with all the features you're used to using in your Grunt and gulp tasks.
* [parse-glob](https://github.com/jonschlinkert/parse-glob): Parse a glob pattern into an object of tokens.
## Run tests
Install dev dependencies.
```bash
npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/is-extglob/issues)
## Author
**Jon Schlinkert**
+ [github/jonschlinkert](https://github.com/jonschlinkert)
+ [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright (c) 2015 Jon Schlinkert
Released under the MIT license
***
_This file was generated by [verb-cli](https://github.com/assemble/verb-cli) on March 06, 2015._
# Source Map
[](https://travis-ci.org/mozilla/source-map)
[](https://www.npmjs.com/package/source-map)
This is a library to generate and consume the source map format
[described here][format].
[format]: https://docs.google.com/document/d/1U1RGAehQwRypUTovF1KRlpiOFze0b-_2gc6fAH0KY0k/edit
## Use with Node
$ npm install source-map
## Use on the Web
<script src="https://raw.githubusercontent.com/mozilla/source-map/master/dist/source-map.min.js" defer></script>
--------------------------------------------------------------------------------
<!-- `npm run toc` to regenerate the Table of Contents -->
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
## Table of Contents
- [Examples](#examples)
- [Consuming a source map](#consuming-a-source-map)
- [Generating a source map](#generating-a-source-map)
- [With SourceNode (high level API)](#with-sourcenode-high-level-api)
- [With SourceMapGenerator (low level API)](#with-sourcemapgenerator-low-level-api)
- [API](#api)
- [SourceMapConsumer](#sourcemapconsumer)
- [new SourceMapConsumer(rawSourceMap)](#new-sourcemapconsumerrawsourcemap)
- [SourceMapConsumer.prototype.computeColumnSpans()](#sourcemapconsumerprototypecomputecolumnspans)
- [SourceMapConsumer.prototype.originalPositionFor(generatedPosition)](#sourcemapconsumerprototypeoriginalpositionforgeneratedposition)
- [SourceMapConsumer.prototype.generatedPositionFor(originalPosition)](#sourcemapconsumerprototypegeneratedpositionfororiginalposition)
- [SourceMapConsumer.prototype.allGeneratedPositionsFor(originalPosition)](#sourcemapconsumerprototypeallgeneratedpositionsfororiginalposition)
- [SourceMapConsumer.prototype.hasContentsOfAllSources()](#sourcemapconsumerprototypehascontentsofallsources)
- [SourceMapConsumer.prototype.sourceContentFor(source[, returnNullOnMissing])](#sourcemapconsumerprototypesourcecontentforsource-returnnullonmissing)
- [SourceMapConsumer.prototype.eachMapping(callback, context, order)](#sourcemapconsumerprototypeeachmappingcallback-context-order)
- [SourceMapGenerator](#sourcemapgenerator)
- [new SourceMapGenerator([startOfSourceMap])](#new-sourcemapgeneratorstartofsourcemap)
- [SourceMapGenerator.fromSourceMap(sourceMapConsumer)](#sourcemapgeneratorfromsourcemapsourcemapconsumer)
- [SourceMapGenerator.prototype.addMapping(mapping)](#sourcemapgeneratorprototypeaddmappingmapping)
- [SourceMapGenerator.prototype.setSourceContent(sourceFile, sourceContent)](#sourcemapgeneratorprototypesetsourcecontentsourcefile-sourcecontent)
- [SourceMapGenerator.prototype.applySourceMap(sourceMapConsumer[, sourceFile[, sourceMapPath]])](#sourcemapgeneratorprototypeapplysourcemapsourcemapconsumer-sourcefile-sourcemappath)
- [SourceMapGenerator.prototype.toString()](#sourcemapgeneratorprototypetostring)
- [SourceNode](#sourcenode)
- [new SourceNode([line, column, source[, chunk[, name]]])](#new-sourcenodeline-column-source-chunk-name)
- [SourceNode.fromStringWithSourceMap(code, sourceMapConsumer[, relativePath])](#sourcenodefromstringwithsourcemapcode-sourcemapconsumer-relativepath)
- [SourceNode.prototype.add(chunk)](#sourcenodeprototypeaddchunk)
- [SourceNode.prototype.prepend(chunk)](#sourcenodeprototypeprependchunk)
- [SourceNode.prototype.setSourceContent(sourceFile, sourceContent)](#sourcenodeprototypesetsourcecontentsourcefile-sourcecontent)
- [SourceNode.prototype.walk(fn)](#sourcenodeprototypewalkfn)
- [SourceNode.prototype.walkSourceContents(fn)](#sourcenodeprototypewalksourcecontentsfn)
- [SourceNode.prototype.join(sep)](#sourcenodeprototypejoinsep)
- [SourceNode.prototype.replaceRight(pattern, replacement)](#sourcenodeprototypereplacerightpattern-replacement)
- [SourceNode.prototype.toString()](#sourcenodeprototypetostring)
- [SourceNode.prototype.toStringWithSourceMap([startOfSourceMap])](#sourcenodeprototypetostringwithsourcemapstartofsourcemap)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
## Examples
### Consuming a source map
```js
var rawSourceMap = {
version: 3,
file: 'min.js',
names: ['bar', 'baz', 'n'],
sources: ['one.js', 'two.js'],
sourceRoot: 'http://example.com/www/js/',
mappings: 'CAAC,IAAI,IAAM,SAAUA,GAClB,OAAOC,IAAID;CCDb,IAAI,IAAM,SAAUE,GAClB,OAAOA'
};
var smc = new SourceMapConsumer(rawSourceMap);
console.log(smc.sources);
// [ 'http://example.com/www/js/one.js',
// 'http://example.com/www/js/two.js' ]
console.log(smc.originalPositionFor({
line: 2,
column: 28
}));
// { source: 'http://example.com/www/js/two.js',
// line: 2,
// column: 10,
// name: 'n' }
console.log(smc.generatedPositionFor({
source: 'http://example.com/www/js/two.js',
line: 2,
column: 10
}));
// { line: 2, column: 28 }
smc.eachMapping(function (m) {
// ...
});
```
### Generating a source map
In depth guide:
[**Compiling to JavaScript, and Debugging with Source Maps**](https://hacks.mozilla.org/2013/05/compiling-to-javascript-and-debugging-with-source-maps/)
#### With SourceNode (high level API)
```js
function compile(ast) {
switch (ast.type) {
case 'BinaryExpression':
return new SourceNode(
ast.location.line,
ast.location.column,
ast.location.source,
[compile(ast.left), " + ", compile(ast.right)]
);
case 'Literal':
return new SourceNode(
ast.location.line,
ast.location.column,
ast.location.source,
String(ast.value)
);
// ...
default:
throw new Error("Bad AST");
}
}
var ast = parse("40 + 2", "add.js");
console.log(compile(ast).toStringWithSourceMap({
file: 'add.js'
}));
// { code: '40 + 2',
// map: [object SourceMapGenerator] }
```
#### With SourceMapGenerator (low level API)
```js
var map = new SourceMapGenerator({
file: "source-mapped.js"
});
map.addMapping({
generated: {
line: 10,
column: 35
},
source: "foo.js",
original: {
line: 33,
column: 2
},
name: "christopher"
});
console.log(map.toString());
// '{"version":3,"file":"source-mapped.js","sources":["foo.js"],"names":["christopher"],"mappings":";;;;;;;;;mCAgCEA"}'
```
## API
Get a reference to the module:
```js
// Node.js
var sourceMap = require('source-map');
// Browser builds
var sourceMap = window.sourceMap;
// Inside Firefox
const sourceMap = require("devtools/toolkit/sourcemap/source-map.js");
```
### SourceMapConsumer
A SourceMapConsumer instance represents a parsed source map which we can query
for information about the original file positions by giving it a file position
in the generated source.
#### new SourceMapConsumer(rawSourceMap)
The only parameter is the raw source map (either as a string which can be
`JSON.parse`'d, or an object). According to the spec, source maps have the
following attributes:
* `version`: Which version of the source map spec this map is following.
* `sources`: An array of URLs to the original source files.
* `names`: An array of identifiers which can be referenced by individual
mappings.
* `sourceRoot`: Optional. The URL root from which all sources are relative.
* `sourcesContent`: Optional. An array of contents of the original source files.
* `mappings`: A string of base64 VLQs which contain the actual mappings.
* `file`: Optional. The generated filename this source map is associated with.
```js
var consumer = new sourceMap.SourceMapConsumer(rawSourceMapJsonData);
```
#### SourceMapConsumer.prototype.computeColumnSpans()
Compute the last column for each generated mapping. The last column is
inclusive.
```js
// Before:
consumer.allGeneratedPositionsFor({ line: 2, source: "foo.coffee" })
// [ { line: 2,
// column: 1 },
// { line: 2,
// column: 10 },
// { line: 2,
// column: 20 } ]
consumer.computeColumnSpans();
// After:
consumer.allGeneratedPositionsFor({ line: 2, source: "foo.coffee" })
// [ { line: 2,
// column: 1,
// lastColumn: 9 },
// { line: 2,
// column: 10,
// lastColumn: 19 },
// { line: 2,
// column: 20,
// lastColumn: Infinity } ]
```
#### SourceMapConsumer.prototype.originalPositionFor(generatedPosition)
Returns the original source, line, and column information for the generated
source's line and column positions provided. The only argument is an object with
the following properties:
* `line`: The line number in the generated source. Line numbers in
this library are 1-based (note that the underlying source map
specification uses 0-based line numbers -- this library handles the
translation).
* `column`: The column number in the generated source. Column numbers
in this library are 0-based.
* `bias`: Either `SourceMapConsumer.GREATEST_LOWER_BOUND` or
`SourceMapConsumer.LEAST_UPPER_BOUND`. Specifies whether to return the closest
element that is smaller than or greater than the one we are searching for,
respectively, if the exact element cannot be found. Defaults to
`SourceMapConsumer.GREATEST_LOWER_BOUND`.
and an object is returned with the following properties:
* `source`: The original source file, or null if this information is not
available.
* `line`: The line number in the original source, or null if this information is
not available. The line number is 1-based.
* `column`: The column number in the original source, or null if this
information is not available. The column number is 0-based.
* `name`: The original identifier, or null if this information is not available.
```js
consumer.originalPositionFor({ line: 2, column: 10 })
// { source: 'foo.coffee',
// line: 2,
// column: 2,
// name: null }
consumer.originalPositionFor({ line: 99999999999999999, column: 999999999999999 })
// { source: null,
// line: null,
// column: null,
// name: null }
```
#### SourceMapConsumer.prototype.generatedPositionFor(originalPosition)
Returns the generated line and column information for the original source,
line, and column positions provided. The only argument is an object with
the following properties:
* `source`: The filename of the original source.
* `line`: The line number in the original source. The line number is
1-based.
* `column`: The column number in the original source. The column
number is 0-based.
and an object is returned with the following properties:
* `line`: The line number in the generated source, or null. The line
number is 1-based.
* `column`: The column number in the generated source, or null. The
column number is 0-based.
```js
consumer.generatedPositionFor({ source: "example.js", line: 2, column: 10 })
// { line: 1,
// column: 56 }
```
#### SourceMapConsumer.prototype.allGeneratedPositionsFor(originalPosition)
Returns all generated line and column information for the original source, line,
and column provided. If no column is provided, returns all mappings
corresponding to a either the line we are searching for or the next closest line
that has any mappings. Otherwise, returns all mappings corresponding to the
given line and either the column we are searching for or the next closest column
that has any offsets.
The only argument is an object with the following properties:
* `source`: The filename of the original source.
* `line`: The line number in the original source. The line number is
1-based.
* `column`: Optional. The column number in the original source. The
column number is 0-based.
and an array of objects is returned, each with the following properties:
* `line`: The line number in the generated source, or null. The line
number is 1-based.
* `column`: The column number in the generated source, or null. The
column number is 0-based.
```js
consumer.allGeneratedpositionsfor({ line: 2, source: "foo.coffee" })
// [ { line: 2,
// column: 1 },
// { line: 2,
// column: 10 },
// { line: 2,
// column: 20 } ]
```
#### SourceMapConsumer.prototype.hasContentsOfAllSources()
Return true if we have the embedded source content for every source listed in
the source map, false otherwise.
In other words, if this method returns `true`, then
`consumer.sourceContentFor(s)` will succeed for every source `s` in
`consumer.sources`.
```js
// ...
if (consumer.hasContentsOfAllSources()) {
consumerReadyCallback(consumer);
} else {
fetchSources(consumer, consumerReadyCallback);
}
// ...
```
#### SourceMapConsumer.prototype.sourceContentFor(source[, returnNullOnMissing])
Returns the original source content for the source provided. The only
argument is the URL of the original source file.
If the source content for the given source is not found, then an error is
thrown. Optionally, pass `true` as the second param to have `null` returned
instead.
```js
consumer.sources
// [ "my-cool-lib.clj" ]
consumer.sourceContentFor("my-cool-lib.clj")
// "..."
consumer.sourceContentFor("this is not in the source map");
// Error: "this is not in the source map" is not in the source map
consumer.sourceContentFor("this is not in the source map", true);
// null
```
#### SourceMapConsumer.prototype.eachMapping(callback, context, order)
Iterate over each mapping between an original source/line/column and a
generated line/column in this source map.
* `callback`: The function that is called with each mapping. Mappings have the
form `{ source, generatedLine, generatedColumn, originalLine, originalColumn,
name }`
* `context`: Optional. If specified, this object will be the value of `this`
every time that `callback` is called.
* `order`: Either `SourceMapConsumer.GENERATED_ORDER` or
`SourceMapConsumer.ORIGINAL_ORDER`. Specifies whether you want to iterate over
the mappings sorted by the generated file's line/column order or the
original's source/line/column order, respectively. Defaults to
`SourceMapConsumer.GENERATED_ORDER`.
```js
consumer.eachMapping(function (m) { console.log(m); })
// ...
// { source: 'illmatic.js',
// generatedLine: 1,
// generatedColumn: 0,
// originalLine: 1,
// originalColumn: 0,
// name: null }
// { source: 'illmatic.js',
// generatedLine: 2,
// generatedColumn: 0,
// originalLine: 2,
// originalColumn: 0,
// name: null }
// ...
```
### SourceMapGenerator
An instance of the SourceMapGenerator represents a source map which is being
built incrementally.
#### new SourceMapGenerator([startOfSourceMap])
You may pass an object with the following properties:
* `file`: The filename of the generated source that this source map is
associated with.
* `sourceRoot`: A root for all relative URLs in this source map.
* `skipValidation`: Optional. When `true`, disables validation of mappings as
they are added. This can improve performance but should be used with
discretion, as a last resort. Even then, one should avoid using this flag when
running tests, if possible.
```js
var generator = new sourceMap.SourceMapGenerator({
file: "my-generated-javascript-file.js",
sourceRoot: "http://example.com/app/js/"
});
```
#### SourceMapGenerator.fromSourceMap(sourceMapConsumer)
Creates a new `SourceMapGenerator` from an existing `SourceMapConsumer` instance.
* `sourceMapConsumer` The SourceMap.
```js
var generator = sourceMap.SourceMapGenerator.fromSourceMap(consumer);
```
#### SourceMapGenerator.prototype.addMapping(mapping)
Add a single mapping from original source line and column to the generated
source's line and column for this source map being created. The mapping object
should have the following properties:
* `generated`: An object with the generated line and column positions.
* `original`: An object with the original line and column positions.
* `source`: The original source file (relative to the sourceRoot).
* `name`: An optional original token name for this mapping.
```js
generator.addMapping({
source: "module-one.scm",
original: { line: 128, column: 0 },
generated: { line: 3, column: 456 }
})
```
#### SourceMapGenerator.prototype.setSourceContent(sourceFile, sourceContent)
Set the source content for an original source file.
* `sourceFile` the URL of the original source file.
* `sourceContent` the content of the source file.
```js
generator.setSourceContent("module-one.scm",
fs.readFileSync("path/to/module-one.scm"))
```
#### SourceMapGenerator.prototype.applySourceMap(sourceMapConsumer[, sourceFile[, sourceMapPath]])
Applies a SourceMap for a source file to the SourceMap.
Each mapping to the supplied source file is rewritten using the
supplied SourceMap. Note: The resolution for the resulting mappings
is the minimum of this map and the supplied map.
* `sourceMapConsumer`: The SourceMap to be applied.
* `sourceFile`: Optional. The filename of the source file.
If omitted, sourceMapConsumer.file will be used, if it exists.
Otherwise an error will be thrown.
* `sourceMapPath`: Optional. The dirname of the path to the SourceMap
to be applied. If relative, it is relative to the SourceMap.
This parameter is needed when the two SourceMaps aren't in the same
directory, and the SourceMap to be applied contains relative source
paths. If so, those relative source paths need to be rewritten
relative to the SourceMap.
If omitted, it is assumed that both SourceMaps are in the same directory,
thus not needing any rewriting. (Supplying `'.'` has the same effect.)
#### SourceMapGenerator.prototype.toString()
Renders the source map being generated to a string.
```js
generator.toString()
// '{"version":3,"sources":["module-one.scm"],"names":[],"mappings":"...snip...","file":"my-generated-javascript-file.js","sourceRoot":"http://example.com/app/js/"}'
```
### SourceNode
SourceNodes provide a way to abstract over interpolating and/or concatenating
snippets of generated JavaScript source code, while maintaining the line and
column information associated between those snippets and the original source
code. This is useful as the final intermediate representation a compiler might
use before outputting the generated JS and source map.
#### new SourceNode([line, column, source[, chunk[, name]]])
* `line`: The original line number associated with this source node, or null if
it isn't associated with an original line. The line number is 1-based.
* `column`: The original column number associated with this source node, or null
if it isn't associated with an original column. The column number
is 0-based.
* `source`: The original source's filename; null if no filename is provided.
* `chunk`: Optional. Is immediately passed to `SourceNode.prototype.add`, see
below.
* `name`: Optional. The original identifier.
```js
var node = new SourceNode(1, 2, "a.cpp", [
new SourceNode(3, 4, "b.cpp", "extern int status;\n"),
new SourceNode(5, 6, "c.cpp", "std::string* make_string(size_t n);\n"),
new SourceNode(7, 8, "d.cpp", "int main(int argc, char** argv) {}\n"),
]);
```
#### SourceNode.fromStringWithSourceMap(code, sourceMapConsumer[, relativePath])
Creates a SourceNode from generated code and a SourceMapConsumer.
* `code`: The generated code
* `sourceMapConsumer` The SourceMap for the generated code
* `relativePath` The optional path that relative sources in `sourceMapConsumer`
should be relative to.
```js
var consumer = new SourceMapConsumer(fs.readFileSync("path/to/my-file.js.map", "utf8"));
var node = SourceNode.fromStringWithSourceMap(fs.readFileSync("path/to/my-file.js"),
consumer);
```
#### SourceNode.prototype.add(chunk)
Add a chunk of generated JS to this source node.
* `chunk`: A string snippet of generated JS code, another instance of
`SourceNode`, or an array where each member is one of those things.
```js
node.add(" + ");
node.add(otherNode);
node.add([leftHandOperandNode, " + ", rightHandOperandNode]);
```
#### SourceNode.prototype.prepend(chunk)
Prepend a chunk of generated JS to this source node.
* `chunk`: A string snippet of generated JS code, another instance of
`SourceNode`, or an array where each member is one of those things.
```js
node.prepend("/** Build Id: f783haef86324gf **/\n\n");
```
#### SourceNode.prototype.setSourceContent(sourceFile, sourceContent)
Set the source content for a source file. This will be added to the
`SourceMap` in the `sourcesContent` field.
* `sourceFile`: The filename of the source file
* `sourceContent`: The content of the source file
```js
node.setSourceContent("module-one.scm",
fs.readFileSync("path/to/module-one.scm"))
```
#### SourceNode.prototype.walk(fn)
Walk over the tree of JS snippets in this node and its children. The walking
function is called once for each snippet of JS and is passed that snippet and
the its original associated source's line/column location.
* `fn`: The traversal function.
```js
var node = new SourceNode(1, 2, "a.js", [
new SourceNode(3, 4, "b.js", "uno"),
"dos",
[
"tres",
new SourceNode(5, 6, "c.js", "quatro")
]
]);
node.walk(function (code, loc) { console.log("WALK:", code, loc); })
// WALK: uno { source: 'b.js', line: 3, column: 4, name: null }
// WALK: dos { source: 'a.js', line: 1, column: 2, name: null }
// WALK: tres { source: 'a.js', line: 1, column: 2, name: null }
// WALK: quatro { source: 'c.js', line: 5, column: 6, name: null }
```
#### SourceNode.prototype.walkSourceContents(fn)
Walk over the tree of SourceNodes. The walking function is called for each
source file content and is passed the filename and source content.
* `fn`: The traversal function.
```js
var a = new SourceNode(1, 2, "a.js", "generated from a");
a.setSourceContent("a.js", "original a");
var b = new SourceNode(1, 2, "b.js", "generated from b");
b.setSourceContent("b.js", "original b");
var c = new SourceNode(1, 2, "c.js", "generated from c");
c.setSourceContent("c.js", "original c");
var node = new SourceNode(null, null, null, [a, b, c]);
node.walkSourceContents(function (source, contents) { console.log("WALK:", source, ":", contents); })
// WALK: a.js : original a
// WALK: b.js : original b
// WALK: c.js : original c
```
#### SourceNode.prototype.join(sep)
Like `Array.prototype.join` except for SourceNodes. Inserts the separator
between each of this source node's children.
* `sep`: The separator.
```js
var lhs = new SourceNode(1, 2, "a.rs", "my_copy");
var operand = new SourceNode(3, 4, "a.rs", "=");
var rhs = new SourceNode(5, 6, "a.rs", "orig.clone()");
var node = new SourceNode(null, null, null, [ lhs, operand, rhs ]);
var joinedNode = node.join(" ");
```
#### SourceNode.prototype.replaceRight(pattern, replacement)
Call `String.prototype.replace` on the very right-most source snippet. Useful
for trimming white space from the end of a source node, etc.
* `pattern`: The pattern to replace.
* `replacement`: The thing to replace the pattern with.
```js
// Trim trailing white space.
node.replaceRight(/\s*$/, "");
```
#### SourceNode.prototype.toString()
Return the string representation of this source node. Walks over the tree and
concatenates all the various snippets together to one string.
```js
var node = new SourceNode(1, 2, "a.js", [
new SourceNode(3, 4, "b.js", "uno"),
"dos",
[
"tres",
new SourceNode(5, 6, "c.js", "quatro")
]
]);
node.toString()
// 'unodostresquatro'
```
#### SourceNode.prototype.toStringWithSourceMap([startOfSourceMap])
Returns the string representation of this tree of source nodes, plus a
SourceMapGenerator which contains all the mappings between the generated and
original sources.
The arguments are the same as those to `new SourceMapGenerator`.
```js
var node = new SourceNode(1, 2, "a.js", [
new SourceNode(3, 4, "b.js", "uno"),
"dos",
[
"tres",
new SourceNode(5, 6, "c.js", "quatro")
]
]);
node.toStringWithSourceMap({ file: "my-output-file.js" })
// { code: 'unodostresquatro',
// map: [object SourceMapGenerator] }
```
# SYNOPSIS
[](https://www.npmjs.org/package/ethereumjs-util)
[](https://travis-ci.org/ethereumjs/ethereumjs-util)
[](https://coveralls.io/r/ethereumjs/ethereumjs-util)
[](https://gitter.im/ethereum/ethereumjs-lib) or #ethereumjs on freenode
[](https://github.com/feross/standard)
A collection of utility functions for ethereum. It can be used in node.js or can be in the browser with browserify.
# API
[./docs/](./docs/index.md)
Most of the string manipulation methods are provided by [ethjs-util](https://github.com/ethjs/ethjs-util)
# LICENSE
MPL-2.0
TweetNaCl.js
============
Port of [TweetNaCl](http://tweetnacl.cr.yp.to) / [NaCl](http://nacl.cr.yp.to/)
to JavaScript for modern browsers and Node.js. Public domain.
[
](https://travis-ci.org/dchest/tweetnacl-js)
Demo: <https://dchest.github.io/tweetnacl-js/>
Documentation
=============
* [Overview](#overview)
* [Audits](#audits)
* [Installation](#installation)
* [Examples](#examples)
* [Usage](#usage)
* [Public-key authenticated encryption (box)](#public-key-authenticated-encryption-box)
* [Secret-key authenticated encryption (secretbox)](#secret-key-authenticated-encryption-secretbox)
* [Scalar multiplication](#scalar-multiplication)
* [Signatures](#signatures)
* [Hashing](#hashing)
* [Random bytes generation](#random-bytes-generation)
* [Constant-time comparison](#constant-time-comparison)
* [System requirements](#system-requirements)
* [Development and testing](#development-and-testing)
* [Benchmarks](#benchmarks)
* [Contributors](#contributors)
* [Who uses it](#who-uses-it)
Overview
--------
The primary goal of this project is to produce a translation of TweetNaCl to
JavaScript which is as close as possible to the original C implementation, plus
a thin layer of idiomatic high-level API on top of it.
There are two versions, you can use either of them:
* `nacl.js` is the port of TweetNaCl with minimum differences from the
original + high-level API.
* `nacl-fast.js` is like `nacl.js`, but with some functions replaced with
faster versions. (Used by default when importing NPM package.)
Audits
------
TweetNaCl.js has been audited by [Cure53](https://cure53.de/) in January-February
2017 (audit was sponsored by [Deletype](https://deletype.com)):
> The overall outcome of this audit signals a particularly positive assessment
> for TweetNaCl-js, as the testing team was unable to find any security
> problems in the library. It has to be noted that this is an exceptionally
> rare result of a source code audit for any project and must be seen as a true
> testament to a development proceeding with security at its core.
>
> To reiterate, the TweetNaCl-js project, the source code was found to be
> bug-free at this point.
>
> [...]
>
> In sum, the testing team is happy to recommend the TweetNaCl-js project as
> likely one of the safer and more secure cryptographic tools among its
> competition.
[Read full audit report](https://cure53.de/tweetnacl.pdf)
Installation
------------
You can install TweetNaCl.js via a package manager:
[Yarn](https://yarnpkg.com/):
$ yarn add tweetnacl
[NPM](https://www.npmjs.org/):
$ npm install tweetnacl
or [download source code](https://github.com/dchest/tweetnacl-js/releases).
Examples
--------
You can find usage examples in our [wiki](https://github.com/dchest/tweetnacl-js/wiki/Examples).
Usage
-----
All API functions accept and return bytes as `Uint8Array`s. If you need to
encode or decode strings, use functions from
<https://github.com/dchest/tweetnacl-util-js> or one of the more robust codec
packages.
In Node.js v4 and later `Buffer` objects are backed by `Uint8Array`s, so you
can freely pass them to TweetNaCl.js functions as arguments. The returned
objects are still `Uint8Array`s, so if you need `Buffer`s, you'll have to
convert them manually; make sure to convert using copying: `Buffer.from(array)`
(or `new Buffer(array)` in Node.js v4 or earlier), instead of sharing:
`Buffer.from(array.buffer)` (or `new Buffer(array.buffer)` Node 4 or earlier),
because some functions return subarrays of their buffers.
### Public-key authenticated encryption (box)
Implements *x25519-xsalsa20-poly1305*.
#### nacl.box.keyPair()
Generates a new random key pair for box and returns it as an object with
`publicKey` and `secretKey` members:
{
publicKey: ..., // Uint8Array with 32-byte public key
secretKey: ... // Uint8Array with 32-byte secret key
}
#### nacl.box.keyPair.fromSecretKey(secretKey)
Returns a key pair for box with public key corresponding to the given secret
key.
#### nacl.box(message, nonce, theirPublicKey, mySecretKey)
Encrypts and authenticates message using peer's public key, our secret key, and
the given nonce, which must be unique for each distinct message for a key pair.
Returns an encrypted and authenticated message, which is
`nacl.box.overheadLength` longer than the original message.
#### nacl.box.open(box, nonce, theirPublicKey, mySecretKey)
Authenticates and decrypts the given box with peer's public key, our secret
key, and the given nonce.
Returns the original message, or `null` if authentication fails.
#### nacl.box.before(theirPublicKey, mySecretKey)
Returns a precomputed shared key which can be used in `nacl.box.after` and
`nacl.box.open.after`.
#### nacl.box.after(message, nonce, sharedKey)
Same as `nacl.box`, but uses a shared key precomputed with `nacl.box.before`.
#### nacl.box.open.after(box, nonce, sharedKey)
Same as `nacl.box.open`, but uses a shared key precomputed with `nacl.box.before`.
#### Constants
##### nacl.box.publicKeyLength = 32
Length of public key in bytes.
##### nacl.box.secretKeyLength = 32
Length of secret key in bytes.
##### nacl.box.sharedKeyLength = 32
Length of precomputed shared key in bytes.
##### nacl.box.nonceLength = 24
Length of nonce in bytes.
##### nacl.box.overheadLength = 16
Length of overhead added to box compared to original message.
### Secret-key authenticated encryption (secretbox)
Implements *xsalsa20-poly1305*.
#### nacl.secretbox(message, nonce, key)
Encrypts and authenticates message using the key and the nonce. The nonce must
be unique for each distinct message for this key.
Returns an encrypted and authenticated message, which is
`nacl.secretbox.overheadLength` longer than the original message.
#### nacl.secretbox.open(box, nonce, key)
Authenticates and decrypts the given secret box using the key and the nonce.
Returns the original message, or `null` if authentication fails.
#### Constants
##### nacl.secretbox.keyLength = 32
Length of key in bytes.
##### nacl.secretbox.nonceLength = 24
Length of nonce in bytes.
##### nacl.secretbox.overheadLength = 16
Length of overhead added to secret box compared to original message.
### Scalar multiplication
Implements *x25519*.
#### nacl.scalarMult(n, p)
Multiplies an integer `n` by a group element `p` and returns the resulting
group element.
#### nacl.scalarMult.base(n)
Multiplies an integer `n` by a standard group element and returns the resulting
group element.
#### Constants
##### nacl.scalarMult.scalarLength = 32
Length of scalar in bytes.
##### nacl.scalarMult.groupElementLength = 32
Length of group element in bytes.
### Signatures
Implements [ed25519](http://ed25519.cr.yp.to).
#### nacl.sign.keyPair()
Generates new random key pair for signing and returns it as an object with
`publicKey` and `secretKey` members:
{
publicKey: ..., // Uint8Array with 32-byte public key
secretKey: ... // Uint8Array with 64-byte secret key
}
#### nacl.sign.keyPair.fromSecretKey(secretKey)
Returns a signing key pair with public key corresponding to the given
64-byte secret key. The secret key must have been generated by
`nacl.sign.keyPair` or `nacl.sign.keyPair.fromSeed`.
#### nacl.sign.keyPair.fromSeed(seed)
Returns a new signing key pair generated deterministically from a 32-byte seed.
The seed must contain enough entropy to be secure. This method is not
recommended for general use: instead, use `nacl.sign.keyPair` to generate a new
key pair from a random seed.
#### nacl.sign(message, secretKey)
Signs the message using the secret key and returns a signed message.
#### nacl.sign.open(signedMessage, publicKey)
Verifies the signed message and returns the message without signature.
Returns `null` if verification failed.
#### nacl.sign.detached(message, secretKey)
Signs the message using the secret key and returns a signature.
#### nacl.sign.detached.verify(message, signature, publicKey)
Verifies the signature for the message and returns `true` if verification
succeeded or `false` if it failed.
#### Constants
##### nacl.sign.publicKeyLength = 32
Length of signing public key in bytes.
##### nacl.sign.secretKeyLength = 64
Length of signing secret key in bytes.
##### nacl.sign.seedLength = 32
Length of seed for `nacl.sign.keyPair.fromSeed` in bytes.
##### nacl.sign.signatureLength = 64
Length of signature in bytes.
### Hashing
Implements *SHA-512*.
#### nacl.hash(message)
Returns SHA-512 hash of the message.
#### Constants
##### nacl.hash.hashLength = 64
Length of hash in bytes.
### Random bytes generation
#### nacl.randomBytes(length)
Returns a `Uint8Array` of the given length containing random bytes of
cryptographic quality.
**Implementation note**
TweetNaCl.js uses the following methods to generate random bytes,
depending on the platform it runs on:
* `window.crypto.getRandomValues` (WebCrypto standard)
* `window.msCrypto.getRandomValues` (Internet Explorer 11)
* `crypto.randomBytes` (Node.js)
If the platform doesn't provide a suitable PRNG, the following functions,
which require random numbers, will throw exception:
* `nacl.randomBytes`
* `nacl.box.keyPair`
* `nacl.sign.keyPair`
Other functions are deterministic and will continue working.
If a platform you are targeting doesn't implement secure random number
generator, but you somehow have a cryptographically-strong source of entropy
(not `Math.random`!), and you know what you are doing, you can plug it into
TweetNaCl.js like this:
nacl.setPRNG(function(x, n) {
// ... copy n random bytes into x ...
});
Note that `nacl.setPRNG` *completely replaces* internal random byte generator
with the one provided.
### Constant-time comparison
#### nacl.verify(x, y)
Compares `x` and `y` in constant time and returns `true` if their lengths are
non-zero and equal, and their contents are equal.
Returns `false` if either of the arguments has zero length, or arguments have
different lengths, or their contents differ.
System requirements
-------------------
TweetNaCl.js supports modern browsers that have a cryptographically secure
pseudorandom number generator and typed arrays, including the latest versions
of:
* Chrome
* Firefox
* Safari (Mac, iOS)
* Internet Explorer 11
Other systems:
* Node.js
Development and testing
------------------------
Install NPM modules needed for development:
$ npm install
To build minified versions:
$ npm run build
Tests use minified version, so make sure to rebuild it every time you change
`nacl.js` or `nacl-fast.js`.
### Testing
To run tests in Node.js:
$ npm run test-node
By default all tests described here work on `nacl.min.js`. To test other
versions, set environment variable `NACL_SRC` to the file name you want to test.
For example, the following command will test fast minified version:
$ NACL_SRC=nacl-fast.min.js npm run test-node
To run full suite of tests in Node.js, including comparing outputs of
JavaScript port to outputs of the original C version:
$ npm run test-node-all
To prepare tests for browsers:
$ npm run build-test-browser
and then open `test/browser/test.html` (or `test/browser/test-fast.html`) to
run them.
To run tests in both Node and Electron:
$ npm test
### Benchmarking
To run benchmarks in Node.js:
$ npm run bench
$ NACL_SRC=nacl-fast.min.js npm run bench
To run benchmarks in a browser, open `test/benchmark/bench.html` (or
`test/benchmark/bench-fast.html`).
Benchmarks
----------
For reference, here are benchmarks from MacBook Pro (Retina, 13-inch, Mid 2014)
laptop with 2.6 GHz Intel Core i5 CPU (Intel) in Chrome 53/OS X and Xiaomi Redmi
Note 3 smartphone with 1.8 GHz Qualcomm Snapdragon 650 64-bit CPU (ARM) in
Chrome 52/Android:
| | nacl.js Intel | nacl-fast.js Intel | nacl.js ARM | nacl-fast.js ARM |
| ------------- |:-------------:|:-------------------:|:-------------:|:-----------------:|
| salsa20 | 1.3 MB/s | 128 MB/s | 0.4 MB/s | 43 MB/s |
| poly1305 | 13 MB/s | 171 MB/s | 4 MB/s | 52 MB/s |
| hash | 4 MB/s | 34 MB/s | 0.9 MB/s | 12 MB/s |
| secretbox 1K | 1113 op/s | 57583 op/s | 334 op/s | 14227 op/s |
| box 1K | 145 op/s | 718 op/s | 37 op/s | 368 op/s |
| scalarMult | 171 op/s | 733 op/s | 56 op/s | 380 op/s |
| sign | 77 op/s | 200 op/s | 20 op/s | 61 op/s |
| sign.open | 39 op/s | 102 op/s | 11 op/s | 31 op/s |
(You can run benchmarks on your devices by clicking on the links at the bottom
of the [home page](https://tweetnacl.js.org)).
In short, with *nacl-fast.js* and 1024-byte messages you can expect to encrypt and
authenticate more than 57000 messages per second on a typical laptop or more than
14000 messages per second on a $170 smartphone, sign about 200 and verify 100
messages per second on a laptop or 60 and 30 messages per second on a smartphone,
per CPU core (with Web Workers you can do these operations in parallel),
which is good enough for most applications.
Contributors
------------
See AUTHORS.md file.
Third-party libraries based on TweetNaCl.js
-------------------------------------------
* [forward-secrecy](https://github.com/alax/forward-secrecy) — Axolotl ratchet implementation
* [nacl-stream](https://github.com/dchest/nacl-stream-js) - streaming encryption
* [tweetnacl-auth-js](https://github.com/dchest/tweetnacl-auth-js) — implementation of [`crypto_auth`](http://nacl.cr.yp.to/auth.html)
* [tweetnacl-sealed-box](https://github.com/whs/tweetnacl-sealed-box) — implementation of [`sealed boxes`](https://download.libsodium.org/doc/public-key_cryptography/sealed_boxes.html)
* [chloride](https://github.com/dominictarr/chloride) - unified API for various NaCl modules
Who uses it
-----------
Some notable users of TweetNaCl.js:
* [GitHub](https://github.com)
* [MEGA](https://github.com/meganz/webclient)
* [Stellar](https://www.stellar.org/)
* [miniLock](https://github.com/kaepora/miniLock)
# signal-exit
[](https://travis-ci.org/tapjs/signal-exit)
[](https://coveralls.io/r/tapjs/signal-exit?branch=master)
[](https://www.npmjs.com/package/signal-exit)
[](https://github.com/conventional-changelog/standard-version)
When you want to fire an event no matter how a process exits:
* reaching the end of execution.
* explicitly having `process.exit(code)` called.
* having `process.kill(pid, sig)` called.
* receiving a fatal signal from outside the process
Use `signal-exit`.
```js
var onExit = require('signal-exit')
onExit(function (code, signal) {
console.log('process exited!')
})
```
## API
`var remove = onExit(function (code, signal) {}, options)`
The return value of the function is a function that will remove the
handler.
Note that the function *only* fires for signals if the signal would
cause the proces to exit. That is, there are no other listeners, and
it is a fatal signal.
## Options
* `alwaysLast`: Run this handler after any other signal or exit
handlers. This causes `process.emit` to be monkeypatched.
# isStream
[](http://travis-ci.org/rvagg/isstream)
**Test if an object is a `Stream`**
[](https://nodei.co/npm/isstream/)
The missing `Stream.isStream(obj)`: determine if an object is standard Node.js `Stream`. Works for Node-core `Stream` objects (for 0.8, 0.10, 0.11, and in theory, older and newer versions) and all versions of **[readable-stream](https://github.com/isaacs/readable-stream)**.
## Usage:
```js
var isStream = require('isstream')
var Stream = require('stream')
isStream(new Stream()) // true
isStream({}) // false
isStream(new Stream.Readable()) // true
isStream(new Stream.Writable()) // true
isStream(new Stream.Duplex()) // true
isStream(new Stream.Transform()) // true
isStream(new Stream.PassThrough()) // true
```
## But wait! There's more!
You can also test for `isReadable(obj)`, `isWritable(obj)` and `isDuplex(obj)` to test for implementations of Streams2 (and Streams3) base classes.
```js
var isReadable = require('isstream').isReadable
var isWritable = require('isstream').isWritable
var isDuplex = require('isstream').isDuplex
var Stream = require('stream')
isReadable(new Stream()) // false
isWritable(new Stream()) // false
isDuplex(new Stream()) // false
isReadable(new Stream.Readable()) // true
isReadable(new Stream.Writable()) // false
isReadable(new Stream.Duplex()) // true
isReadable(new Stream.Transform()) // true
isReadable(new Stream.PassThrough()) // true
isWritable(new Stream.Readable()) // false
isWritable(new Stream.Writable()) // true
isWritable(new Stream.Duplex()) // true
isWritable(new Stream.Transform()) // true
isWritable(new Stream.PassThrough()) // true
isDuplex(new Stream.Readable()) // false
isDuplex(new Stream.Writable()) // false
isDuplex(new Stream.Duplex()) // true
isDuplex(new Stream.Transform()) // true
isDuplex(new Stream.PassThrough()) // true
```
*Reminder: when implementing your own streams, please [use **readable-stream** rather than core streams](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).*
## License
**isStream** is Copyright (c) 2015 Rod Vagg [@rvagg](https://twitter.com/rvagg) and licenced under the MIT licence. All rights not explicitly granted in the MIT license are reserved. See the included LICENSE.md file for more details.
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
Netmask
=======
The Netmask class parses and understands IPv4 CIDR blocks so they can be explored and compared. This module is highly inspired by Perl [Net::Netmask](http://search.cpan.org/dist/Net-Netmask/) module.
Synopsis
--------
var Netmask = require('netmask').Netmask
var block = new Netmask('10.0.0.0/12');
block.base; // 10.0.0.0
block.mask; // 255.240.0.0
block.bitmask; // 12
block.hostmask; // 0.15.255.255
block.broadcast; // 10.15.255.255
block.size; // 1048576
block.first; // 10.0.0.1
block.last; // 10.15.255.254
block.contains('10.0.8.10'); // true
block.contains('10.8.0.10'); // true
block.contains('192.168.1.20'); // false
block.forEach(function(ip, long, index));
block.next() // Netmask('10.16.0.0/12')
Constructing
------------
Netmask objects are created with an IP address and optionally a mask. There are many forms that are recognized:
'216.240.32.0/24' // The preferred form.
'216.240.32.0/255.255.255.0'
'216.240.32.0', '255.255.255.0'
'216.240.32.0', 0xffffff00
'216.240.32.4' // A /32 block.
'216.240.32' // A /24 block.
'216.240' // A /16 block.
'140' // A /8 block.
'216.240.32/24'
'216.240/16'
API
---
- `.base`: The base address of the network block as a string (eg: 216.240.32.0). Base does not give an indication of the size of the network block.
- `.mask`: The netmask as a string (eg: 255.255.255.0).
- `.hostmask`: The host mask which is the opposite of the netmask (eg: 0.0.0.255).
- `.bitmask`: The netmask as a number of bits in the network portion of the address for this block (eg: 24).
- `.size`: The number of IP addresses in a block (eg: 256).
- `.broadcast`: The blocks broadcast address (eg: 192.168.1.0/24 => 192.168.1.255)
- `.first`, `.last`: First and last useable address
- `.contains(ip or block)`: Returns a true if the IP number `ip` is part of the network. That is, a true value is returned if `ip` is between `base` and `broadcast`. If a Netmask object or a block is given, it returns true only of the given block fits inside the network.
- `.forEach(fn)`: Similar to the Array prototype method. It loops through all the useable addresses, ie between `first` and `last`.
- `.next(count)`: Without a `count`, return the next block of the same size after the current one. With a count, return the Nth block after the current one. A count of -1 returns the previous block. Undef will be returned if out of legal address space.
- `.toString()`: The netmask in base/bitmask format (e.g., '216.240.32.0/24')
Installation
------------
$ npm install netmask
License
-------
(The MIT License)
Copyright (c) 2011 Olivier Poitrey <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the 'Software'), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
# tslib
This is a runtime library for [TypeScript](http://www.typescriptlang.org/) that contains all of the TypeScript helper functions.
This library is primarily used by the `--importHelpers` flag in TypeScript.
When using `--importHelpers`, a module that uses helper functions like `__extends` and `__assign` in the following emitted file:
```ts
var __assign = (this && this.__assign) || Object.assign || function(t) {
for (var s, i = 1, n = arguments.length; i < n; i++) {
s = arguments[i];
for (var p in s) if (Object.prototype.hasOwnProperty.call(s, p))
t[p] = s[p];
}
return t;
};
exports.x = {};
exports.y = __assign({}, exports.x);
```
will instead be emitted as something like the following:
```ts
var tslib_1 = require("tslib");
exports.x = {};
exports.y = tslib_1.__assign({}, exports.x);
```
Because this can avoid duplicate declarations of things like `__extends`, `__assign`, etc., this means delivering users smaller files on average, as well as less runtime overhead.
For optimized bundles with TypeScript, you should absolutely consider using `tslib` and `--importHelpers`.
# Installing
For the latest stable version, run:
## npm
```sh
# TypeScript 2.3.3 or later
npm install tslib
# TypeScript 2.3.2 or earlier
npm install [email protected]
```
## yarn
```sh
# TypeScript 2.3.3 or later
yarn add tslib
# TypeScript 2.3.2 or earlier
yarn add [email protected]
```
## bower
```sh
# TypeScript 2.3.3 or later
bower install tslib
# TypeScript 2.3.2 or earlier
bower install [email protected]
```
## JSPM
```sh
# TypeScript 2.3.3 or later
jspm install tslib
# TypeScript 2.3.2 or earlier
jspm install [email protected]
```
# Usage
Set the `importHelpers` compiler option on the command line:
```
tsc --importHelpers file.ts
```
or in your tsconfig.json:
```json
{
"compilerOptions": {
"importHelpers": true
}
}
```
#### For bower and JSPM users
You will need to add a `paths` mapping for `tslib`, e.g. For Bower users:
```json
{
"compilerOptions": {
"module": "amd",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["bower_components/tslib/tslib.d.ts"]
}
}
}
```
For JSPM users:
```json
{
"compilerOptions": {
"module": "system",
"importHelpers": true,
"baseUrl": "./",
"paths": {
"tslib" : ["jspm_packages/npm/tslib@1.[version].0/tslib.d.ts"]
}
}
}
```
# Contribute
There are many ways to [contribute](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/Microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/Microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](http://stackoverflow.com/questions/tagged/typescript).
* Join the [#typescript](http://twitter.com/#!/search/realtime/%23typescript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/Microsoft/TypeScript/blob/master/CONTRIBUTING.md).
# Documentation
* [Quick tutorial](http://www.typescriptlang.org/Tutorial)
* [Programming handbook](http://www.typescriptlang.org/Handbook)
* [Homepage](http://www.typescriptlang.org/)
|
goodnewsshow_patblk_near_rust_repclone01 | Cargo.toml
README.md
build.bat
build.sh
src
lib.rs
test.sh
| # Rust Smart Contract Template
## Getting started
To get started with this template:
1. Click the "Use this template" button to create a new repo based on this template
2. Update line 2 of `Cargo.toml` with your project name
3. Update line 4 of `Cargo.toml` with your project author names
4. Set up the [prerequisites](https://github.com/near/near-sdk-rs#pre-requisites)
5. Begin writing your smart contract in `src/lib.rs`
6. Test the contract
`cargo test -- --nocapture`
8. Build the contract
`RUSTFLAGS='-C link-arg=-s' cargo build --target wasm32-unknown-unknown --release`
**Get more info at:**
* [Rust Smart Contract Quick Start](https://docs.near.org/docs/develop/contracts/rust/intro)
* [Rust SDK Book](https://www.near-sdk.io/)
|
LeonardoVieira1630_Near_guest_book | README-Gitpod.md
README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
guestbook.spec.ts
as_types.d.ts
main.ts
model.ts
tsconfig.json
babel.config.js
dist
global.65e27967.css
global.65e27967.js
index.html
neardev
dev-account.env
shared-test-staging
test.near.json
shared-test
test.near.json
package.json
src
App.js
config.js
index.html
index.js
tests
integration
App-integration.test.js
ui
App-ui.test.js
| Guest Book
==========
[](https://travis-ci.com/near-examples/guest-book)
[](https://gitpod.io/#https://github.com/near-examples/guest-book)
<!-- MAGIC COMMENT: DO NOT DELETE! Everything above this line is hidden on NEAR Examples page -->
Sign in with [NEAR] and add a message to the guest book! A starter app built with an [AssemblyScript] backend and a [React] frontend.
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you have Node.js ≥ 12 installed (https://nodejs.org), then use it to install [yarn]: `npm install --global yarn` (or just `npm i -g yarn`)
2. Run the local development server: `yarn && yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet! Running `yarn dev` will tell you the URL you can visit in your browser to see the app.
Exploring The Code
==================
1. The backend code lives in the `/assembly` folder. This code gets deployed to
the NEAR blockchain when you run `yarn deploy:contract`. This sort of
code-that-runs-on-a-blockchain is called a "smart contract" – [learn more
about NEAR smart contracts][smart contract docs].
2. The frontend code lives in the `/src` folder.
[/src/index.html](/src/index.html) is a great place to start exploring. Note
that it loads in `/src/index.js`, where you can learn how the frontend
connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and backend. The
backend code gets tested with the [asp] command for running the backend
AssemblyScript tests, and [jest] for running frontend tests. You can run
both of these at once with `yarn test`.
Both contract and client-side code will auto-reload as you change source files.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contracts get deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli
--------------------------
You need near-cli installed globally. Here's how:
npm install --global near-cli
This will give you the `near` [CLI] tool. Ensure that it's installed with:
near --version
Step 1: Create an account for the contract
------------------------------------------
Visit [NEAR Wallet] and make a new account. You'll be deploying these smart contracts to this new account.
Now authorize NEAR CLI for this new account, and follow the instructions it gives you:
near login
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'your-account-here!'
Step 3: change remote URL if you cloned this repo
-------------------------
Unless you forked this repository you will need to change the remote URL to a repo that you have commit access to. This will allow auto deployment to Github Pages from the command line.
1) go to GitHub and create a new repository for this project
2) open your terminal and in the root of this project enter the following:
$ `git remote set-url origin https://github.com/YOUR_USERNAME/YOUR_REPOSITORY.git`
Step 4: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contracts to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
[NEAR]: https://nearprotocol.com/
[yarn]: https://yarnpkg.com/
[AssemblyScript]: https://docs.assemblyscript.org/
[React]: https://reactjs.org
[smart contract docs]: https://docs.nearprotocol.com/docs/roles/developer/contracts/assemblyscript
[asp]: https://www.npmjs.com/package/@as-pect/cli
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.nearprotocol.com/docs/concepts/account
[NEAR Wallet]: https://wallet.nearprotocol.com
[near-cli]: https://github.com/nearprotocol/near-cli
[CLI]: https://www.w3schools.com/whatis/whatis_cli.asp
[create-near-app]: https://github.com/nearprotocol/create-near-app
[gh-pages]: https://github.com/tschaub/gh-pages
|
near_all-contributors | README.md
| # NEAR Contributors
Highlighting all contributors to NEAR Protocol and the NEAR ecosystem
|
NEARBuilders_i-am-nearby | README.md
circuits
Nargo.toml
Prover.toml
README.md
Verifier.toml
gateway
.gitpod.yml
README.md
jsconfig.json
next.config.js
package-lock.json
package.json
public
near-logo.svg
near.svg
next.svg
vercel.svg
src
api
listDirectory.js
readCircuitFile.js
readCircuitJson.js
app
app.module.css
globals.css
hello-components
page.js
hello-near
page.js
layout.js
page.js
components
cards.js
navigation.js
vm-component.js
config.js
wallets
wallet-selector.js
web3-wallet.ts
| # Proof-of-proximity
## Check Euclidean Distance example
This mini-project illustrates how to import and use `check_points_proximity(commitment_a, commitment_b, private_point_a, private_point_b, distance_threshold)` from `proof_of_proximity` public Noir library.
## Run the proof generation & verification
```bash
cd example/
nargo prove close_enough
nargo verify close_enough
```
## Notes
If you use the function in your project, make sure the commitments and the distance threshold to check are public inputs (`commitment_a`, `commitment_b` and `distance_threshold`).
i-am-nearby
==================
TODO:
- [] Deploy Verifier to Aurora Contract
- [] Call
This is a [Next.js](https://nextjs.org/) project bootstrapped with [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app).
## Getting Started
First, run the development server:
```bash
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `app/page.js`. The page auto-updates as you edit the file.
This project uses [`next/font`](https://nextjs.org/docs/basic-features/font-optimization) to automatically optimize and load Inter, a custom Google Font.
## Learn More
To learn more about Next.js, take a look at the following resources:
- [Next.js Documentation](https://nextjs.org/docs) - learn about Next.js features and API.
- [Learn Next.js](https://nextjs.org/learn) - an interactive Next.js tutorial.
You can check out [the Next.js GitHub repository](https://github.com/vercel/next.js/) - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the [Vercel Platform](https://vercel.com/new?utm_medium=default-template&filter=next.js&utm_source=create-next-app&utm_campaign=create-next-app-readme) from the creators of Next.js.
Check out our [Next.js deployment documentation](https://nextjs.org/docs/deployment) for more details.
|
ikachko_near-hackathon-2021 | Cargo.toml
README.md
scripts
build.sh
deploy.sh
src
level.rs
level_table.rs
lib.rs
order.rs
| # near-hackathon-2021
Order-based DEX with callable orders
|
metanear_user-contract-rs | Cargo.toml
README.md
build.sh
src
lib.rs
| # User contract for Meta NEAR
Contract implementing user-centric storage and inter-user messaging protocol for Meta NEAR.
## Testing
To test run:
```bash
cargo test --package metanear-user -- --nocapture
```
## Build
```bash
./build.sh
```
## Deploy
Replace contract code file and the code hash in the metanear-web with the new code hash.
|
HeesungB_NEARYou | .travis.yml
README.md
babel.config.js
gulpfile.js
package.json
src
App.css
App.js
App.test.js
Drops.js
__mocks__
fileMock.js
apis
index.js
assets
gray_near_logo.svg
logo.svg
near.svg
config.js
index.html
index.js
jest.init.js
main.test.js
util
near-util.js
util.js
wallet
login
index.html
| # NEARYou Demo
## About NEARYou
NEARYou allows NEAR wallet user(sender) to create link for giving their NFT(Non-Fungible-Token). Their friends(receiver) can claim NFT through the link. NEARYou contract stores sender's NFT's token_id(NFT id) and NEAR for activaing new account to send NFT when receiver requests claim.
## How NEARYou Demo Works
Sender, who has NFT:
- Login with NEAR web wallet.
- Choose NFT that they want to send in "My NFTs" section.
- Click "Approve" button to give authority to NEARYou contract. (This might take some time to NEAR protocol reflects the change. After a moment, the button will change to "Drop" automatically.)
- Cilck "Drop" button to get link for dropping NFT.
- Send copied link to receiver.
Receiver, who has NEAR wallet account:
- Click the link that sender gave you.
- Paste the link in the box and click claim button.
- Get the NFT.
Receiver, who doesn’t have NEAR wallet account:
- Click the link that sender gave you.
- Make new NEAR wallet account.
- Get the NFT.
## Code
### Repo Structure - /src
```jsx
├── App.css
├── App.js
├── App.test.js
├── Drops.js
├── Drops.scss
├── __mocks__
│ └── fileMock.js
├── __snapshots__
│ └── App.test.js.snap
├── apis
│ └── index.js
├── assets
│ ├── gray_near_logo.svg
│ ├── logo.svg
│ └── near.svg
├── config.js
├── favicon.ico
├── index.html
├── index.js
├── jest.init.js
├── main.test.js
├── util
│ ├── near-util.js
│ └── util.js
└── wallet
└── login
└── index.html
```
- `config.js` : manage network connection.
- `drop.js` : manage making linkdrop and claim NFT.
### drop.js
drop.js has functions that calls NEARYou contract's core function. drop.js has `createNFTdrop()` , `approveUser()` and `getContract()` function which calls NEARYou contract's `send()` , `nft_approve()` .
**createNFTdrop()**
```jsx
async function fundDropNft(nft_id) {
const newKeyPair = getNewKeyPair();
const public_key = (newKeyPair.public_key = newKeyPair.publicKey
.toString()
.replace("ed25519:", ""));
downloadKeyFile(public_key, newKeyPair);
newKeyPair.nft_id = nft_id;
newKeyPair.ts = Date.now();
await addDrop(newKeyPair);
const { contract } = window;
try {
const amount = toNear(minimumGasFee);
await contract.send(
{ public_key: public_key, nft_id: nft_id },
BOATLOAD_OF_GAS,
amount
);
} catch (e) {
console.warn(e);
}
}
```
- `createNFTdrop()` creates `newKeyPair` .
- `createNFTdrop()` calls NEARYou's `send()` and passes `public key` and `nft_id` .
a**pproveUser()**
```jsx
async function approveUser(nft_id) {
const account = (window.account = window.walletConnection.account());
const nftContract = await new nearApi.Contract(account, nftContractName, {
viewMethods: ["get_key_balance"],
changeMethods: ["nft_approve"],
sender: window.currentUser.accountId,
});
try {
const amount = toNear(minimumGasFee);
const result = await nftContract.nft_approve(
{ token_id: nft_id, account_id: contractName },
BOATLOAD_OF_GAS,
amount
);
console.log("result: ", result);
} catch (e) {
console.warn(e);
}
}
```
- `approveUser()` get current login account and nft contract.
- `approveUser()` calls nft contract's `nft_approve()` to give authority to the NEARYou contract.
## Getting Started
### Installation
Clone this repository
```jsx
git clone
cd
```
Install dependencies
```jsx
yarn
```
Modify config.js
```jsx
const CONTRACT_NAME = 'YOUR_NEARYou_CONTRACT';
const NFT_CONTRACT_NAME = 'NTF_MINTED_CONTRACT';
```
- [NEARYou contract](https://github.com/Meowomen/NEARYou_contract)
Run
```jsx
yarn dev
```
|
Peersyst_blockscout-frontend | .devcontainer
devcontainer.json
.eslintrc.js
.github
ISSUE_TEMPLATE
bug_report.yml
config.yml
workflows
checks.yml
cleanup.yml
deploy-main.yml
deploy-review-l2.yml
deploy-review.yml
e2e-tests.yml
label-issues-in-release.yml
pre-release.yml
project-management.yml
publish-image.yml
release.yml
stale-issues.yml
update-project-cards.yml
upload-source-maps.yml
.vscode
extensions.json
launch.json
settings.json
tasks.json
CODE_OF_CONDUCT.md
README.md
configs
app
api.ts
app.ts
chain.ts
features
account.ts
addressVerification.ts
adsBanner.ts
adsText.ts
beaconChain.ts
blockchainInteraction.ts
bridgedTokens.ts
csvExport.ts
gasTracker.ts
googleAnalytics.ts
graphqlApiDocs.ts
growthBook.ts
index.ts
marketplace.ts
mixpanel.ts
nameService.ts
restApiDocs.ts
rollup.ts
safe.ts
sentry.ts
sol2uml.ts
stats.ts
suave.ts
swapButton.ts
txInterpretation.ts
types.ts
userOps.ts
validators.ts
verifiedTokens.ts
web3Wallet.ts
index.ts
meta.ts
services.ts
ui.ts
ui
views
address.ts
block.ts
index.ts
nft.ts
tx.ts
utils.ts
decs.d.ts
deploy
scripts
collect_envs.sh
download_assets.sh
entrypoint.sh
favicon_generator.sh
make_envs_script.sh
validate_envs.sh
tools
affected-tests
index.js
package.json
envs-validator
index.ts
package.json
schema.ts
test.sh
test
assets
featured_networks.json
footer_links.json
marketplace_categories.json
marketplace_config.json
tsconfig.json
webpack.config.js
favicon-generator
config.template.json
script.sh
feature-reporter
dev.sh
entry.js
package.json
tsconfig.json
webpack.config.js
docs
BUILD-TIME_ENVS.md
CONTRIBUTING.md
CUSTOM_BUILD.md
DEPRECATED_ENVS.md
ENVS.md
PULL_REQUEST_TEMPLATE.md
|
global.d.ts
icons
ABI.svg
ABI_slim.svg
API.svg
ENS.svg
ENS_slim.svg
RPC.svg
apps.svg
arrows
down-right.svg
east-mini.svg
east.svg
north-east.svg
south-east.svg
up-down.svg
block.svg
block_slim.svg
brands
safe.svg
burger.svg
check.svg
clock-light.svg
clock.svg
coins
bitcoin.svg
collection.svg
contract.svg
contract_verified.svg
copy.svg
cross.svg
delete.svg
discussions.svg
docs.svg
donate.svg
dots.svg
edit.svg
email-sent.svg
email.svg
empty_search_result.svg
error-pages
404.svg
422.svg
429.svg
500.svg
explorer.svg
files
csv.svg
image.svg
json.svg
placeholder.svg
sol.svg
yul.svg
filter.svg
finalized.svg
flame.svg
gas.svg
gas_xl.svg
gear.svg
globe-b.svg
globe.svg
graphQL.svg
info.svg
integration
full.svg
partial.svg
key.svg
lightning.svg
link.svg
lock.svg
minus.svg
monaco
file.svg
folder-open.svg
folder.svg
solidity.svg
vyper.svg
moon-with-star.svg
moon.svg
networks.svg
networks
icon-placeholder.svg
logo-placeholder.svg
nft_shield.svg
output_roots.svg
plus.svg
privattags.svg
profile.svg
publictags.svg
publictags_slim.svg
qr_code.svg
repeat_arrow.svg
restAPI.svg
rocket.svg
rocket_xl.svg
scope.svg
score
score-not-ok.svg
score-ok.svg
search.svg
social
canny.svg
coingecko.svg
coinmarketcap.svg
defi_llama.svg
discord.svg
discord_filled.svg
facebook_filled.svg
git.svg
github_filled.svg
linkedin_filled.svg
medium_filled.svg
opensea_filled.svg
reddit_filled.svg
slack_filled.svg
stats.svg
telega.svg
telegram_filled.svg
tweet.svg
twitter_filled.svg
star_filled.svg
star_outline.svg
stats.svg
status
error.svg
pending.svg
success.svg
warning.svg
sun.svg
swap.svg
testnet.svg
token-placeholder.svg
token.svg
tokens.svg
tokens
xdai.svg
top-accounts.svg
transactions.svg
transactions_slim.svg
txn_batches.svg
txn_batches_slim.svg
unfinalized.svg
uniswap.svg
user_op.svg
user_op_slim.svg
validator.svg
verified.svg
verified_token.svg
verify-contract.svg
wallet.svg
wallets
coinbase.svg
metamask.svg
token-pocket.svg
watchlist.svg
instrumentation.node.ts
instrumentation.ts
jest.config.ts
jest
global-setup.ts
mocks
next-router.ts
setup.ts
utils
flushPromises.ts
lib
api
buildUrl.test.ts
buildUrl.ts
isBodyAllowed.ts
isNeedProxy.ts
resources.ts
bigint
compareBns.ts
sumBnReducer.ts
block
getBlockReward.ts
getBlockTotalReward.ts
consts.ts
cookies.ts
date
dayjs.ts
delay.ts
downloadBlob.ts
errors
getErrorCause.ts
getErrorCauseStatusCode.ts
getErrorObj.ts
getErrorObjPayload.ts
getErrorObjStatusCode.ts
throwOnAbsentParamError.ts
throwOnResourceLoadError.ts
escapeRegExp.ts
getCurrencyValue.ts
getErrorMessage.ts
getFilterValueFromQuery.ts
getFilterValuesFromQuery.ts
growthbook
consts.ts
init.ts
useFeatureValue.ts
useLoadFeatures.ts
hexToAddress.ts
hexToBytes.ts
hexToDecimal.ts
hexToUtf8.ts
highlightText.ts
hooks
useHasAccount.ts
html-entities.ts
isBrowser.ts
metadata
compileValue.ts
generate.test.ts
generate.ts
getPageOgType.ts
index.ts
templates
description.ts
index.ts
title.ts
types.ts
update.ts
mixpanel
getPageType.ts
getTabName.ts
getUuid.ts
index.ts
logEvent.ts
utils.ts
networks
getNetworkTitle.ts
getNetworkValidatorTitle.ts
networkExplorers.ts
recentSearchKeywords.ts
regexp.ts
router
getQueryParamString.ts
removeQueryParam.ts
updateQueryParam.ts
saveAsCSV.ts
sentry
config.ts
setLocale.ts
shortenString.ts
socket
types.ts
stripLeadingSlash.ts
stripTrailingSlash.ts
token
metadata
attributesParser.ts
urlParser.ts
parseMetadata.ts
tokenTypes.ts
tx
getConfirmationDuration.ts
units.ts
validations
address.ts
email.ts
signature.ts
transaction.ts
url.ts
web3
client.ts
currentChain.ts
wallets.ts
middleware.ts
mocks
account
verifiedAddresses.ts
ad
textAd.ts
address
address.ts
coinBalanceHistory.ts
counters.ts
tag.ts
tokens.ts
apps
apps.ts
blocks
block.ts
config
footerLinks.ts
network.ts
contract
audits.ts
info.ts
methods.ts
solidityscanReport.ts
contracts
counters.ts
index.ts
ens
domain.ts
events.ts
l2deposits
deposits.ts
l2outputRoots
outputRoots.ts
l2txnBatches
txnBatches.ts
l2withdrawals
withdrawals.ts
search
index.ts
shibarium
deposits.ts
withdrawals.ts
stats
daily_txs.ts
index.ts
line.ts
lines.ts
tokens
tokenHolders.ts
tokenInfo.ts
tokenInstance.ts
tokenTransfer.ts
txs
decodedInputData.ts
internalTxs.ts
state.ts
tx.ts
txInterpretation.ts
user
profile.ts
userOps
userOp.ts
userOps.ts
validators
index.ts
withdrawals
withdrawals.ts
zkevmL2txnBatches
zkevmL2txnBatch.ts
zkevmL2txnBatches.ts
next-env.d.ts
next.config.js
nextjs
csp
generateCspPolicy.ts
policies
ad.ts
app.ts
cloudFlare.ts
googleAnalytics.ts
googleFonts.ts
googleReCaptcha.ts
growthBook.ts
index.ts
mixpanel.ts
monaco.ts
safe.ts
sentry.ts
walletConnect.ts
utils.ts
getServerSideProps.ts
headers.js
middlewares
account.ts
index.ts
nextjs-routes.d.ts
redirects.js
rewrites.js
types.ts
utils
buildUrl.ts
fetch.ts
logger.ts
serverTiming.ts
package.json
pages
api
csrf.ts
media-type.ts
proxy.ts
playwright-ct.config.ts
playwright
fixtures
auth.ts
contextWithEnvs.ts
contextWithFeatures.ts
createContextWithStorage.ts
socketServer.ts
index.css
index.html
index.ts
mocks
file_mock_1.json
file_mock_2.json
file_mock_with_very_long_name.json
image_svg.svg
lib
growthbook
useFeatureValue.js
modules
@metamask
post-message-stream.js
providers.js
network-logo.svg
page.html
utils
app.ts
buildApiUrl.ts
configs.ts
public
favicon
safari-pinned-tab.svg
icons
name.d.ts
reset.d.ts
stubs
ENS.ts
L2.ts
RPC.ts
account.ts
address.ts
addressParams.ts
block.ts
contract.ts
internalTx.ts
log.ts
marketplace.ts
search.ts
shibarium.ts
stats.ts
token.ts
tx.ts
txInterpretation.ts
txStateChanges.ts
userOps.ts
utils.ts
validators.ts
withdrawals.ts
zkEvmL2.ts
svgo.config.js
theme
components
Alert
Alert.ts
Badge.ts
Button
Button.ts
Checkbox.ts
Drawer.ts
FancySelect.ts
Form.ts
FormLabel.ts
Heading.ts
Input.ts
Link.ts
Menu.ts
Modal.ts
Popover.ts
Radio.ts
Select.ts
Skeleton.ts
Spinner.ts
Switch.ts
Table.ts
Tabs.ts
Tag
Tag.ts
Text.ts
Textarea.ts
Tooltip
Tooltip.ts
index.ts
config.ts
foundations
borders.ts
breakpoints.ts
colors.ts
scrollbar.ts
semanticTokens.ts
transition.ts
typography.ts
zIndices.ts
global.ts
index.ts
utils
getDefaultFormColors.ts
getDefaultTransitionProps.ts
getOutlinedFieldStyles.ts
tools
scripts
dev.preset.sh
dev.sh
docker.preset.sh
favicon-generator.dev.sh
favicon.svg
pw.docker.sh
pw.sh
tsconfig.jest.json
tsconfig.json
types
api
account.ts
address.ts
addressParams.ts
addresses.ts
block.ts
charts.ts
configs.ts
contract.ts
contracts.ts
decodedInput.ts
ens.ts
fee.ts
indexingStatus.ts
internalTransaction.ts
log.ts
optimisticL2.ts
rawTrace.ts
reward.ts
search.ts
shibarium.ts
stats.ts
token.ts
tokenTransfer.ts
tokens.ts
transaction.ts
txAction.ts
txInterpretation.ts
txStateChanges.ts
txsFilters.ts
userOps.ts
validators.ts
verifiedContracts.ts
visualization.ts
withdrawals.ts
zkEvmL2.ts
client
account.ts
adButlerConfig.ts
adProviders.ts
address.ts
contract.ts
gasTracker.ts
marketplace.ts
navigation-items.ts
rollup.ts
stats.ts
token.ts
txInterpretation.ts
validators.ts
wallets.ts
footerLinks.ts
homepage.ts
networks.ts
unit.ts
utils.ts
views
address.ts
block.ts
nft.ts
tx.ts
ui
address
contract
types.ts
utils.test.ts
utils.ts
tokenSelect
types.ts
useTokenSelect.ts
utils
tokenUtils.ts
useAddressCountersQuery.ts
useAddressQuery.ts
useFetchTokens.ts
addressVerification
types.ts
contractVerification
types.ts
utils.ts
csvExport
types.ts
home
indicators
types.ts
nameDomain
history
utils.ts
nameDomains
utils.ts
shared
AccountActionsMenu
types.ts
FancySelect
types.ts
utils.ts
Tabs
types.ts
utils.ts
TokenTransfer
helpers.ts
ad
adbutlerScript.ts
hypeBannerScript.ts
address
utils.ts
chart
utils
calculateInnerSize.ts
computeTooltipPosition.ts
timeChartAxis.ts
entities
base
utils.ts
forms
utils
files.ts
gas
formatGasValue.ts
layout
types.ts
monaco
types.ts
utils
addExternalLibraryWarningDecoration.ts
addFileImportDecorations.ts
composeFileTree.test.ts
composeFileTree.ts
formatFilePath.ts
getFileName.ts
getFilePathParts.test.ts
getFilePathParts.ts
getFullPathOfImportedFile.test.ts
getFullPathOfImportedFile.ts
sortFileTree.ts
themes.ts
useThemeColors.ts
nft
utils.ts
pagination
types.ts
useQueryWithPages.ts
utils.ts
search
utils.ts
sort
getNextSortValue.ts
getSortParamsFromValue.ts
getSortValueFromQuery.ts
verificationSteps
types.ts
snippets
navigation
useColors.ts
networkMenu
types.ts
useColors.ts
topBar
utils.ts
stats
constants
index.ts
tokenInfo
types.ts
utils.ts
tokenInstance
metadata
utils.ts
tokens
utils.ts
tx
internals
utils.ts
interpretation
utils.test.ts
utils.ts
validators
utils.ts
verifiedContracts
utils.ts
| <h1 align="center">Blockscout frontend</h1>
<p align="center">
<span>Frontend application for </span>
<a href="https://github.com/blockscout/blockscout/blob/master/README.md">Blockscout</a>
<span> blockchain explorer</span>
</p>
## Running and configuring the app
App is distributed as a docker image. Here you can find information about the [package](https://github.com/blockscout/frontend/pkgs/container/frontend) and its recent [releases](https://github.com/blockscout/frontend/releases).
You can configure your app by passing necessary environment variables when starting the container. See full list of ENVs and their description [here](./docs/ENVS.md).
```sh
docker run -p 3000:3000 --env-file <path-to-your-env-file> ghcr.io/blockscout/frontend:latest
```
Alternatively, you can build your own docker image and run your app from that. Please follow this [guide](./docs/CUSTOM_BUILD.md).
For more information on migrating from the previous frontend, please see the [frontend migration docs](https://docs.blockscout.com/for-developers/frontend-migration).
## Contributing
See our [Contribution guide](./docs/CONTRIBUTING.md) for pull request protocol. We expect contributors to follow our [code of conduct](./CODE_OF_CONDUCT.md) when submitting code or comments.
## Resources
- [App ENVs list](./docs/ENVS.md)
- [Contribution guide](./docs/CONTRIBUTING.md)
- [Making a custom build](./docs/CUSTOM_BUILD.md)
- [Frontend migration guide](https://docs.blockscout.com/for-developers/frontend-migration)
- [Manual deployment guide with backend and microservices](https://docs.blockscout.com/for-developers/deployment/manual-deployment-guide)
## License
[](https://www.gnu.org/licenses/gpl-3.0)
This project is licensed under the GNU General Public License v3.0. See the [LICENSE](LICENSE) file for details.
|
Learn-NEAR_NCD.L2.sample--meme-museum | .env
README.md
babel.config.js
package.json
postcss.config.js
public
index.html
src
composables
near.js
index.css
main.js
services
near.js
tailwind.config.js
| # 🎓 NCD.L2.sample--thanks dapp
This repository contains a complete frontend applications (Vue.js, React, Angular) to work with
<a href="https://github.com/Learn-NEAR/NCD.L1.sample--meme-museum" target="_blank">NCD.L1.sample--meme-museum smart contract</a> targeting the NEAR platform:
1. Vue.Js (main branch)
2. React (react branch)
3. Angular (angular branch)
The goal of this repository is to make it as easy as possible to get started writing frontend with Vue.js, React and Angular for AssemblyScript contracts built to work with NEAR Protocol.
## ⚠️ Warning
Any content produced by NEAR, or developer resources that NEAR provides, are for educational and inspiration purposes only. NEAR does not encourage, induce or sanction the deployment of any such applications in violation of applicable laws or regulations.
## ⚡ Usage

UI walkthrough
<a href="https://www.loom.com/share/3b558ef14d4945338d4220964f075220" target="_blank">UI walkthrough</a>
You can use this app with contract id which was deployed by the creators of this repo or you can use it with your own deployed contract id.
To deploy sample--meme-museum to your account visit <a href="https://github.com/Learn-NEAR/NCD.L1.sample--meme-museum" target="_blank">this repo (smart contract deployment instructions are inside):</a>
After you successfully deployed meme-museum and you have contract id, you can clone the repo and put contract ids inside .env file :
```
VUE_APP_CONTRACT_ID = "put your contract id here"
...
```
After you input your values inside .env file, you need to :
1. Install all dependencies
```
npm install
```
or
```
yarn
```
2. Run the project locally
```
npm run serve
```
or
```
yarn serve
```
Other commands:
Compiles and minifies for production
```
npm run build
```
or
```
yarn build
```
Lints and fixes files
```
npm run lint
```
or
```
yarn lint
```
## 👀 Code walkthrough for Near university students
<a href="https://www.loom.com/share/c38c6ac8c1d04afca0b4402f997374d2" target="_blank">Code walkthrough video</a>
We are using ```near-api-js``` to work with NEAR blockchain. In ``` /services/near.js ``` we are importing classes, functions and configs which we are going to use:
```
import { keyStores, Near, Contract, WalletConnection, utils } from "near-api-js";
```
Then we are connecting to NEAR:
```
// connecting to NEAR, new NEAR is being used here to awoid async/await
export const near = new Near({
networkId: process.env.VUE_APP_networkId,
keyStore: new keyStores.BrowserLocalStorageKeyStore(),
nodeUrl: process.env.VUE_APP_nodeUrl,
walletUrl: process.env.VUE_APP_walletUrl,
});
```
and creating wallet connection
```
export const wallet = new WalletConnection(near, "NCD.L2.sample--meme-museum");
```
After this by using Composition API we need to create ```useWallet()``` function and use inside ```signIn()``` and ```signOut()``` functions of wallet object. By doing this, login functionality can now be used in any component.
And also we in return statement we are returning wallet object, we are doing this to call ``` wallet.getAccountId()``` to show accountId in ``` /components/Login.vue ```
``` useWallet()``` code :
```
export const useWallet = () => {
const accountId = ref('')
const err = ref(null)
onMounted(async () => {
try {
accountId.value = wallet.getAccountId()
} catch (e) {
err.value = e;
console.error(err.value);
}
});
const handleSignIn = () => {
wallet.requestSignIn({
contractId: CONTRACT_ID,
methodNames: [] // add methods names to restrict access
})
};
const handleSignOut = () => {
wallet.signOut()
accountId.value = ''
};
return {
accountId,
signIn: handleSignIn,
signOut: handleSignOut
}
}
```
To work with smart meme-museum smart contract we will create separate ```useContracts()``` function with Composition API to split the logic. We are loading the contract inside ``` /services/near.js:```
```
function getMemeMuseumContract() {
return new Contract(
wallet.account(), // the account object that is connecting
CONTRACT_ID, // name of contract you're connecting to
{
viewMethods: ['get_meme_list', 'get_meme', 'get_recent_comments'], // view methods do not change state but usually return a value
changeMethods: ['add_meme', 'add_comment', 'donate', 'vote'] // change methods modify state
}
)
}
const memeMuseumContract = getMemeMuseumContract()
```
and we are creating function to export for each contract function
example of a call with no params:
```
// function to get memes
export const getMemes = () => {
return memeMuseumContract.get_meme_list();
};
```
example of call with params
```
// function to add meme
export const addMeme = ({ meme, title, data, category }) => {
category = parseInt(category)
return memeMuseumContract.add_meme(
{ meme, title, data, category },
gas,
utils.format.parseNearAmount("3")
);
};
```
Then in ```composables/near.js``` we are just importing all logic from ```services/near.js```:
```
import {
wallet,
CONTRACT_ID,
getMemes,
addMeme,
getMeme,
getMemeComments,
addComment,
donate,
vote,
} from "../services/near";
```
and using it to store some state of contracts and to call contracts functions:
```
export const useMemes = () => {
const memes = ref([]);
const err = ref(null);
//initialize memes list
onMounted(async () => {
try {
const memeIds = await getMemes();
memes.value = (
await Promise.all(
memeIds.map(async (id) => {
const info = await getMeme(id);
const comments = await getMemeComments(id);
return {
id,
info,
comments,
image: `https://img-9gag-fun.9cache.com/photo/${
info.data.split("https://9gag.com/gag/")[1]
}_460s.jpg`,
};
})
)
).reverse();
} catch (e) {
err.value = e;
console.log(err.value);
}
});
return {
memes,
addMeme,
addComment,
donate,
vote,
CONTRACT_ID
};
};
```
Also for each meme contract it is separate smart contract id, so for meme contract functions, this approach is used:
```
// function to get info about meme
// Contract class is not used because for each mem it will be needed to create new Contract instance for each function call
export const getMeme = (meme) => {
const memeContractId = meme + "." + CONTRACT_ID;
return wallet.account().viewFunction(memeContractId, "get_meme", {});
};
```
```/views/Home.vue```:
```
setup() {
const { accountId, signIn, signOut } = useWallet();
const { memes, addMeme, addComment, donate, vote, CONTRACT_ID } = useMemes();
return {
accountId,
signIn,
signOut,
memes,
addMeme,
addComment,
donate,
vote,
CONTRACT_ID
}
}
```
And inside components we are using the same ``` useWallet()``` and ``` useMemes()``` functions to manage state of dapp.
|
jasperdg_first-party-oracle | Cargo.toml
build.sh
scripts
deploy_requester.sh
get_request.sh
new_request.sh
reset_account.sh
src
README.md
helpers.rs
lib.rs
| # Requester Sample Contract
Interested in integrating with the Flux Oracle? **Requester Contracts** can be used to create and submit data requests to the Flux Oracle -- here you will find a sample contract to get you started!
On the testnet deployment, anyone can test their own Request Contract with the testnet oracle. When the Oracle is deployed to mainnet, each Requester will require a successful proposal and execution by the Flux DAO. Any protocol or user-deployed smart contract can experiment directly with the Flux Oracle as a data requester and put any kind of data on-chain to be resolved by our pool of testnet validators.
[Please visit the documentation](https://docs.fluxprotocol.org/docs/getting-started/data-requesters) for more information on getting set up as a data requester! Also see [flux-sdk-rs](https://github.com/fluxprotocol/flux-sdk-rs) for types used inside this contract.
## Building and deploying
```bash
# set vars
REQUESTER=requester.account.testnet
ACCOUNT=account.testnet
# create requester account (or use `scripts/reset_account.sh`)
NEAR_ENV=testnet near create-account $REQUESTER --masterAccount $ACCOUNT --initialBalance 5
sh build.sh
bash scripts/deploy_requester.sh --accountId $REQUESTER
bash scripts/reset_account.sh --master $ACCOUNT --account $REQUESTER
```
## Sending your 1st request
```bash
# set vars
REQUESTER=requester.account.testnet
# send an example arbitrator request at the requester contract that you just deployed
sh scripts/new_request.sh $REQUESTER
# retrieve the details of the request that you just created (request at index 0)
sh scripts/get_request.sh $REQUESTER 0
# once you've sent more requests, you can call the `get_request` script with the
# exact index number you're interested in to view the details of the request at
# that specific index
```
## Options
### Whitelist
Requesters are encouraged to create mechanisms to ensure domain-specific and high-quality (with definite answers, not spammy, etc.) requests are sent to the Flux Oracle to encourage validators to participate in data resolution.
One option is to whitelist the account(s) allowed to call `create_data_request()` by deploying the contract with an array of account IDs for the `whitelist` parameter in the `init()` method. If left empty, any account will be able to call `create_data_request()`, so another mechanism to limit the number of requests sent to the oracle (e.g. time-based limits, governance controls) is encouraged.
|
phongnguyen2012_faucet-contract | Cargo.toml
README.md
build.sh
src
lib.rs
| <sub>
## faucet-contract
### environment variable setting
export MAIN_ACCOUNT=phongnguyen2022.testnet
export NEAR_ENV=testnet
export CONTRACT_FAUCET_ID=faucet.$MAIN_ACCOUNT
export CONTRACT_FT_ID=ft.$MAIN_ACCOUNT
export ONE_YOCTO=0.000000000000000000000005
export ACCOUNT_TEST1=test1.$MAIN_ACCOUNT
export ACCOUNT_TEST2=test2.$MAIN_ACCOUNT
export GAS=300000000000000
echo "################### DELETE ACCOUNT ###################"
near delete $CONTRACT_FAUCET_ID $MAIN_ACCOUNT
near delete $ACCOUNT_TEST1 $MAIN_ACCOUNT
near delete $ACCOUNT_TEST2 $MAIN_ACCOUNT
echo "################### CREATE ACCOUNT ###################"
near create-account $CONTRACT_FT_ID --masterAccount $MAIN_ACCOUNT --initialBalance 2
near create-account $ACCOUNT_TEST1 --masterAccount $MAIN_ACCOUNT --initialBalance 2
near create-account $ACCOUNT_TEST2 --masterAccount $MAIN_ACCOUNT --initialBalance 2
### 1. Deploy:
near deploy --wasmFile out/faucetcontract.wasm --accountId $CONTRACT_FAUCET_ID
### 2. Init contract: with max_share: 10M
near call $$CONTRACT_FAUCET_ID new '{"owner_id": "'$MAIN_ACCOUNT'", "ft_contract_id": "'$CONTRACT_FT_ID'", "max_share": 10000000}'
--accountId $MAIN_ACCOUNT
### 3. Update contract: with max_share: 30M
near call $CONTRACT_FAUCET_ID update_max_share '{"max_share": "30000000"}' --accountId $MAIN_ACCOUNT
### 4. Update contract: Total token in contract 1B, total_share 10M
near call $CONTRACT_FAUCET_ID update_pool '{"total_balance_share": "1000000000", "total_share": "10000000", "total_account_share": "1"}'
--accountId $MAIN_ACCOUNT
### 5. Account faucet token
account (faucet) faucet 1M Token
near call $CONTRACT_FAUCET_ID faucet_token '{"amount": "1000000"}' --accountId $CONTRACT_FAUCET_ID --deposit $ONE_YOCTO --gas $GAS
account (test1) faucet 2M Token
near call $CONTRACT_FAUCET_ID faucet_token '{"amount": "2000000"}' --accountId $ACCOUNT_TEST1 --deposit $ONE_YOCTO --gas $GAS
account (test2) faucet 3M Token
near call $CONTRACT_FAUCET_ID faucet_token '{"amount": "3000000"}' --accountId $ACCOUNT_TEST2 --deposit $ONE_YOCTO --gas $GAS
### 6. Get info faucet
near call $CONTRACT_FAUCET_ID get_faucet_info '' --accountId $CONTRACT_FAUCET_ID
### 7. Get info balance
near call $CONTRACT_FAUCET_ID get_share_balance_of '{"account_id": "'$ACCOUNT_TEST1'"}' --accountId $MAIN_ACCOUNT
near call $CONTRACT_FAUCET_ID get_share_balance_of '{"account_id": "'$ACCOUNT_TEST2'"}' --accountId $MAIN_ACCOUNT
</sub>
|
GACWR_near-liquid-token | Cargo.toml
README.md
contracts
integration-tests
Cargo.toml
src
constants.rs
context.rs
helpers.rs
legacy_types.rs
lib.rs
mock-stake-pool
Cargo.toml
src
lib.rs
near-x
Cargo.toml
src
constants.rs
contract.rs
contract
internal.rs
metadata.rs
operator.rs
public.rs
storage_spec.rs
upgrade.rs
util.rs
errors.rs
events.rs
fungible_token.rs
fungible_token
metadata.rs
nearx_internal.rs
nearx_token.rs
lib.rs
state.rs
utils.rs
tests
helpers
mod.rs
unit_tests.rs
scripts
deploy.sh
dev-deploy.sh
dev-testing.sh
env
mainnet.env
testnet.env
ft_transfer.sh
owner_update.sh
ref_finance.sh
run_epoch.sh
state_view.sh
user_actions.sh
validator_draining.sh
validators_operations.sh
| # near-liquid-token
The contracts directory contains 3 crates which are:
1. nearx: The main nearx contract.
2. mock-stake-pool: A mock validator stake pool contract which is used in the integration tests
3. integration-tests: A set of integration tests
### Building the project
`make all
`
it moves all wasm files to res/ directory
Running unit and integration tests
`make run-all-tests
`
Miro Board with product documentation: https://miro.com/app/board/uXjVOzCp74g=/
### Bug Bounty!
Stader Near has a bug bounty on NEAR. Please refer to the link here: https://immunefi.com/bounty/staderfornear/
|
hfgunay_NCD-Rock-Paper-Scissors | README.md
as-pect.config.js
asconfig.json
assembly
__tests__
as-pect.d.ts
example.spec.ts
as_types.d.ts
index.ts
model.ts
tsconfig.json
neardev
dev-account.env
node_modules
.bin
acorn.cmd
acorn.ps1
asb.cmd
asb.ps1
asbuild.cmd
asbuild.ps1
asc.cmd
asc.ps1
asinit.cmd
asinit.ps1
asp.cmd
asp.ps1
aspect.cmd
aspect.ps1
assemblyscript-build.cmd
assemblyscript-build.ps1
eslint.cmd
eslint.ps1
esparse.cmd
esparse.ps1
esvalidate.cmd
esvalidate.ps1
js-yaml.cmd
js-yaml.ps1
mkdirp.cmd
mkdirp.ps1
near-vm-as.cmd
near-vm-as.ps1
near-vm.cmd
near-vm.ps1
nearley-railroad.cmd
nearley-railroad.ps1
nearley-test.cmd
nearley-test.ps1
nearley-unparse.cmd
nearley-unparse.ps1
nearleyc.cmd
nearleyc.ps1
node-which.cmd
node-which.ps1
rimraf.cmd
rimraf.ps1
semver.cmd
semver.ps1
tsc.cmd
tsc.ps1
tsserver.cmd
tsserver.ps1
wasm-opt.cmd
wasm-opt.ps1
.package-lock.json
@as-covers
assembly
CONTRIBUTING.md
README.md
index.ts
package.json
tsconfig.json
core
CONTRIBUTING.md
README.md
package.json
glue
README.md
lib
index.d.ts
index.js
package.json
transform
README.md
lib
index.d.ts
index.js
util.d.ts
util.js
node_modules
visitor-as
.github
workflows
test.yml
README.md
as
index.d.ts
index.js
asconfig.json
dist
astBuilder.d.ts
astBuilder.js
base.d.ts
base.js
baseTransform.d.ts
baseTransform.js
decorator.d.ts
decorator.js
examples
capitalize.d.ts
capitalize.js
exportAs.d.ts
exportAs.js
functionCallTransform.d.ts
functionCallTransform.js
includeBytesTransform.d.ts
includeBytesTransform.js
list.d.ts
list.js
toString.d.ts
toString.js
index.d.ts
index.js
path.d.ts
path.js
simpleParser.d.ts
simpleParser.js
transformRange.d.ts
transformRange.js
transformer.d.ts
transformer.js
utils.d.ts
utils.js
visitor.d.ts
visitor.js
node_modules
.bin
asc.cmd
asinit.cmd
package.json
tsconfig.json
package.json
@as-pect
assembly
README.md
assembly
index.ts
internal
Actual.ts
Expectation.ts
Expected.ts
Reflect.ts
ReflectedValueType.ts
Test.ts
assert.ts
call.ts
comparison
toIncludeComparison.ts
toIncludeEqualComparison.ts
log.ts
noOp.ts
package.json
types
as-pect.d.ts
as-pect.portable.d.ts
env.d.ts
cli
README.md
init
as-pect.config.js
env.d.ts
example.spec.ts
init-types.d.ts
portable-types.d.ts
lib
as-pect.cli.amd.d.ts
as-pect.cli.amd.js
help.d.ts
help.js
index.d.ts
index.js
init.d.ts
init.js
portable.d.ts
portable.js
run.d.ts
run.js
test.d.ts
test.js
types.d.ts
types.js
util
CommandLineArg.d.ts
CommandLineArg.js
IConfiguration.d.ts
IConfiguration.js
asciiArt.d.ts
asciiArt.js
collectReporter.d.ts
collectReporter.js
getTestEntryFiles.d.ts
getTestEntryFiles.js
removeFile.d.ts
removeFile.js
strings.d.ts
strings.js
writeFile.d.ts
writeFile.js
worklets
ICommand.d.ts
ICommand.js
compiler.d.ts
compiler.js
package.json
core
README.md
lib
as-pect.core.amd.d.ts
as-pect.core.amd.js
index.d.ts
index.js
reporter
CombinationReporter.d.ts
CombinationReporter.js
EmptyReporter.d.ts
EmptyReporter.js
IReporter.d.ts
IReporter.js
SummaryReporter.d.ts
SummaryReporter.js
VerboseReporter.d.ts
VerboseReporter.js
test
IWarning.d.ts
IWarning.js
TestContext.d.ts
TestContext.js
TestNode.d.ts
TestNode.js
transform
assemblyscript.d.ts
assemblyscript.js
createAddReflectedValueKeyValuePairsMember.d.ts
createAddReflectedValueKeyValuePairsMember.js
createGenericTypeParameter.d.ts
createGenericTypeParameter.js
createStrictEqualsMember.d.ts
createStrictEqualsMember.js
emptyTransformer.d.ts
emptyTransformer.js
hash.d.ts
hash.js
index.d.ts
index.js
util
IAspectExports.d.ts
IAspectExports.js
IWriteable.d.ts
IWriteable.js
ReflectedValue.d.ts
ReflectedValue.js
TestNodeType.d.ts
TestNodeType.js
rTrace.d.ts
rTrace.js
stringifyReflectedValue.d.ts
stringifyReflectedValue.js
timeDifference.d.ts
timeDifference.js
wasmTools.d.ts
wasmTools.js
package.json
csv-reporter
index.ts
lib
as-pect.csv-reporter.amd.d.ts
as-pect.csv-reporter.amd.js
index.d.ts
index.js
package.json
readme.md
tsconfig.json
json-reporter
index.ts
lib
as-pect.json-reporter.amd.d.ts
as-pect.json-reporter.amd.js
index.d.ts
index.js
package.json
readme.md
tsconfig.json
snapshots
__tests__
snapshot.spec.ts
jest.config.js
lib
Snapshot.d.ts
Snapshot.js
SnapshotDiff.d.ts
SnapshotDiff.js
SnapshotDiffResult.d.ts
SnapshotDiffResult.js
as-pect.core.amd.d.ts
as-pect.core.amd.js
index.d.ts
index.js
parser
grammar.d.ts
grammar.js
node_modules
.bin
nearley-railroad.cmd
nearley-test.cmd
nearley-unparse.cmd
nearleyc.cmd
package.json
src
Snapshot.ts
SnapshotDiff.ts
SnapshotDiffResult.ts
index.ts
parser
grammar.ts
tsconfig.json
@assemblyscript
loader
README.md
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
@babel
code-frame
README.md
lib
index.js
package.json
helper-validator-identifier
README.md
lib
identifier.js
index.js
keyword.js
package.json
scripts
generate-identifier-regex.js
highlight
README.md
lib
index.js
node_modules
ansi-styles
index.js
package.json
readme.md
chalk
index.js
package.json
readme.md
templates.js
types
index.d.ts
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
.eslintrc.json
README.md
index.js
package.json
test.js
escape-string-regexp
index.js
package.json
readme.md
has-flag
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
package.json
@eslint
eslintrc
CHANGELOG.md
README.md
conf
config-schema.js
environments.js
eslint-all.js
eslint-recommended.js
lib
cascading-config-array-factory.js
config-array-factory.js
config-array
config-array.js
config-dependency.js
extracted-config.js
ignore-pattern.js
index.js
override-tester.js
flat-compat.js
index.js
shared
ajv.js
config-ops.js
config-validator.js
deprecation-warnings.js
naming.js
relative-module-resolver.js
types.js
node_modules
.bin
js-yaml.cmd
package.json
@humanwhocodes
config-array
README.md
api.js
package.json
object-schema
.eslintrc.js
.github
workflows
nodejs-test.yml
release-please.yml
CHANGELOG.md
README.md
package.json
src
index.js
merge-strategy.js
object-schema.js
validation-strategy.js
tests
merge-strategy.js
object-schema.js
validation-strategy.js
acorn-jsx
README.md
index.d.ts
index.js
node_modules
.bin
acorn.cmd
package.json
xhtml.js
acorn
CHANGELOG.md
README.md
dist
acorn.d.ts
acorn.js
acorn.mjs.d.ts
bin.js
package.json
ajv
.tonic_example.js
README.md
dist
ajv.bundle.js
ajv.min.js
lib
ajv.d.ts
ajv.js
cache.js
compile
async.js
equal.js
error_classes.js
formats.js
index.js
resolve.js
rules.js
schema_obj.js
ucs2length.js
util.js
data.js
definition_schema.js
dotjs
README.md
_limit.js
_limitItems.js
_limitLength.js
_limitProperties.js
allOf.js
anyOf.js
comment.js
const.js
contains.js
custom.js
dependencies.js
enum.js
format.js
if.js
index.js
items.js
multipleOf.js
not.js
oneOf.js
pattern.js
properties.js
propertyNames.js
ref.js
required.js
uniqueItems.js
validate.js
keyword.js
refs
data.json
json-schema-draft-04.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
package.json
scripts
.eslintrc.yml
bundle.js
compile-dots.js
ansi-colors
README.md
index.js
package.json
symbols.js
types
index.d.ts
ansi-regex
index.d.ts
index.js
package.json
readme.md
ansi-styles
index.d.ts
index.js
package.json
readme.md
argparse
CHANGELOG.md
README.md
index.js
lib
action.js
action
append.js
append
constant.js
count.js
help.js
store.js
store
constant.js
false.js
true.js
subparsers.js
version.js
action_container.js
argparse.js
argument
error.js
exclusive.js
group.js
argument_parser.js
const.js
help
added_formatters.js
formatter.js
namespace.js
utils.js
package.json
as-bignum
README.md
assembly
__tests__
as-pect.d.ts
i128.spec.as.ts
safe_u128.spec.as.ts
u128.spec.as.ts
u256.spec.as.ts
utils.ts
fixed
fp128.ts
fp256.ts
index.ts
safe
fp128.ts
fp256.ts
types.ts
globals.ts
index.ts
integer
i128.ts
i256.ts
index.ts
safe
i128.ts
i256.ts
i64.ts
index.ts
u128.ts
u256.ts
u64.ts
u128.ts
u256.ts
tsconfig.json
utils.ts
package.json
asbuild
README.md
dist
cli.d.ts
cli.js
commands
build.d.ts
build.js
fmt.d.ts
fmt.js
index.d.ts
index.js
init
cmd.d.ts
cmd.js
files
asconfigJson.d.ts
asconfigJson.js
aspecConfig.d.ts
aspecConfig.js
assembly_files.d.ts
assembly_files.js
eslintConfig.d.ts
eslintConfig.js
gitignores.d.ts
gitignores.js
index.d.ts
index.js
indexJs.d.ts
indexJs.js
packageJson.d.ts
packageJson.js
test_files.d.ts
test_files.js
index.d.ts
index.js
interfaces.d.ts
interfaces.js
run.d.ts
run.js
test.d.ts
test.js
index.d.ts
index.js
main.d.ts
main.js
utils.d.ts
utils.js
index.js
node_modules
cliui
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
wrap-ansi
index.js
package.json
readme.md
y18n
CHANGELOG.md
README.md
index.js
package.json
yargs-parser
CHANGELOG.md
LICENSE.txt
README.md
index.js
lib
tokenize-arg-string.js
package.json
yargs
CHANGELOG.md
README.md
build
lib
apply-extends.d.ts
apply-extends.js
argsert.d.ts
argsert.js
command.d.ts
command.js
common-types.d.ts
common-types.js
completion-templates.d.ts
completion-templates.js
completion.d.ts
completion.js
is-promise.d.ts
is-promise.js
levenshtein.d.ts
levenshtein.js
middleware.d.ts
middleware.js
obj-filter.d.ts
obj-filter.js
parse-command.d.ts
parse-command.js
process-argv.d.ts
process-argv.js
usage.d.ts
usage.js
validation.d.ts
validation.js
yargs.d.ts
yargs.js
yerror.d.ts
yerror.js
index.js
locales
be.json
de.json
en.json
es.json
fi.json
fr.json
hi.json
hu.json
id.json
it.json
ja.json
ko.json
nb.json
nl.json
nn.json
pirate.json
pl.json
pt.json
pt_BR.json
ru.json
th.json
tr.json
zh_CN.json
zh_TW.json
package.json
yargs.js
package.json
assemblyscript-json
.eslintrc.js
.travis.yml
README.md
assembly
JSON.ts
decoder.ts
encoder.ts
index.ts
tsconfig.json
util
index.ts
index.js
package.json
temp-docs
README.md
classes
decoderstate.md
json.arr.md
json.bool.md
json.float.md
json.integer.md
json.null.md
json.num.md
json.obj.md
json.str.md
json.value.md
jsondecoder.md
jsonencoder.md
jsonhandler.md
throwingjsonhandler.md
modules
json.md
assemblyscript-regex
.eslintrc.js
.github
workflows
benchmark.yml
release.yml
test.yml
README.md
as-pect.config.js
asconfig.empty.json
asconfig.json
assembly
__spec_tests__
generated.spec.ts
__tests__
alterations.spec.ts
as-pect.d.ts
boundary-assertions.spec.ts
capture-group.spec.ts
character-classes.spec.ts
character-sets.spec.ts
characters.ts
empty.ts
quantifiers.spec.ts
range-quantifiers.spec.ts
regex.spec.ts
utils.ts
char.ts
env.ts
index.ts
nfa
matcher.ts
nfa.ts
types.ts
walker.ts
parser
node.ts
parser.ts
string-iterator.ts
walker.ts
regexp.ts
tsconfig.json
util.ts
benchmark
benchmark.js
package.json
spec
test-generator.js
ts
index.ts
tsconfig.json
assemblyscript-temporal
.github
workflows
node.js.yml
release.yml
.vscode
launch.json
README.md
as-pect.config.js
asconfig.empty.json
asconfig.json
assembly
__tests__
README.md
as-pect.d.ts
date.spec.ts
duration.spec.ts
empty.ts
plaindate.spec.ts
plaindatetime.spec.ts
plainmonthday.spec.ts
plaintime.spec.ts
plainyearmonth.spec.ts
timezone.spec.ts
zoneddatetime.spec.ts
constants.ts
date.ts
duration.ts
enums.ts
env.ts
index.ts
instant.ts
now.ts
plaindate.ts
plaindatetime.ts
plainmonthday.ts
plaintime.ts
plainyearmonth.ts
timezone.ts
tsconfig.json
tz
__tests__
index.spec.ts
rule.spec.ts
zone.spec.ts
iana.ts
index.ts
rule.ts
zone.ts
utils.ts
zoneddatetime.ts
development.md
package.json
tzdb
README.md
iana
theory.html
zoneinfo2tdf.pl
assemblyscript
README.md
cli
README.md
asc.d.ts
asc.js
asc.json
shim
README.md
fs.js
path.js
process.js
transform.d.ts
transform.js
util
colors.d.ts
colors.js
find.d.ts
find.js
mkdirp.d.ts
mkdirp.js
options.d.ts
options.js
utf8.d.ts
utf8.js
dist
asc.js
assemblyscript.d.ts
assemblyscript.js
sdk.js
index.d.ts
index.js
lib
loader
README.md
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
rtrace
README.md
bin
rtplot.js
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
package-lock.json
package.json
std
README.md
assembly.json
assembly
array.ts
arraybuffer.ts
atomics.ts
bindings
Date.ts
Math.ts
Reflect.ts
asyncify.ts
console.ts
wasi.ts
wasi_snapshot_preview1.ts
wasi_unstable.ts
builtins.ts
compat.ts
console.ts
crypto.ts
dataview.ts
date.ts
diagnostics.ts
error.ts
function.ts
index.d.ts
iterator.ts
map.ts
math.ts
memory.ts
number.ts
object.ts
polyfills.ts
process.ts
reference.ts
regexp.ts
rt.ts
rt
README.md
common.ts
index-incremental.ts
index-minimal.ts
index-stub.ts
index.d.ts
itcms.ts
rtrace.ts
stub.ts
tcms.ts
tlsf.ts
set.ts
shared
feature.ts
target.ts
tsconfig.json
typeinfo.ts
staticarray.ts
string.ts
symbol.ts
table.ts
tsconfig.json
typedarray.ts
uri.ts
util
casemap.ts
error.ts
hash.ts
math.ts
memory.ts
number.ts
sort.ts
string.ts
uri.ts
vector.ts
wasi
index.ts
portable.json
portable
index.d.ts
index.js
types
assembly
index.d.ts
package.json
portable
index.d.ts
package.json
tsconfig-base.json
astral-regex
index.d.ts
index.js
package.json
readme.md
axios
CHANGELOG.md
README.md
UPGRADE_GUIDE.md
dist
axios.js
axios.min.js
index.d.ts
index.js
lib
adapters
README.md
http.js
xhr.js
axios.js
cancel
Cancel.js
CancelToken.js
isCancel.js
core
Axios.js
InterceptorManager.js
README.md
buildFullPath.js
createError.js
dispatchRequest.js
enhanceError.js
mergeConfig.js
settle.js
transformData.js
defaults.js
helpers
README.md
bind.js
buildURL.js
combineURLs.js
cookies.js
deprecatedMethod.js
isAbsoluteURL.js
isURLSameOrigin.js
normalizeHeaderName.js
parseHeaders.js
spread.js
utils.js
package.json
balanced-match
.github
FUNDING.yml
LICENSE.md
README.md
index.js
package.json
base-x
LICENSE.md
README.md
package.json
src
index.d.ts
index.js
binary-install
README.md
example
binary.js
package.json
run.js
index.js
node_modules
.bin
mkdirp.cmd
rimraf.cmd
package.json
src
binary.js
binaryen
README.md
index.d.ts
package-lock.json
package.json
wasm.d.ts
bn.js
CHANGELOG.md
README.md
lib
bn.js
package.json
brace-expansion
README.md
index.js
package.json
bs58
CHANGELOG.md
README.md
index.js
package.json
callsites
index.d.ts
index.js
package.json
readme.md
camelcase
index.d.ts
index.js
package.json
readme.md
chalk
index.d.ts
package.json
readme.md
source
index.js
templates.js
util.js
chownr
README.md
chownr.js
package.json
cliui
CHANGELOG.md
LICENSE.txt
README.md
build
lib
index.js
string-utils.js
package.json
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
README.md
index.js
package.json
commander
CHANGELOG.md
Readme.md
index.js
package.json
typings
index.d.ts
concat-map
.travis.yml
example
map.js
index.js
package.json
test
map.js
cross-spawn
CHANGELOG.md
README.md
index.js
lib
enoent.js
parse.js
util
escape.js
readShebang.js
resolveCommand.js
node_modules
.bin
node-which.cmd
package.json
csv-stringify
README.md
lib
browser
index.js
sync.js
es5
index.d.ts
index.js
sync.d.ts
sync.js
index.d.ts
index.js
sync.d.ts
sync.js
package.json
debug
README.md
package.json
src
browser.js
common.js
index.js
node.js
decamelize
index.js
package.json
readme.md
deep-is
.travis.yml
example
cmp.js
index.js
package.json
test
NaN.js
cmp.js
neg-vs-pos-0.js
diff
CONTRIBUTING.md
README.md
dist
diff.js
lib
convert
dmp.js
xml.js
diff
array.js
base.js
character.js
css.js
json.js
line.js
sentence.js
word.js
index.es6.js
index.js
patch
apply.js
create.js
merge.js
parse.js
util
array.js
distance-iterator.js
params.js
package.json
release-notes.md
runtime.js
discontinuous-range
.travis.yml
README.md
index.js
package.json
test
main-test.js
doctrine
CHANGELOG.md
README.md
lib
doctrine.js
typed.js
utility.js
package.json
emoji-regex
LICENSE-MIT.txt
README.md
es2015
index.js
text.js
index.d.ts
index.js
package.json
text.js
enquirer
CHANGELOG.md
README.md
index.d.ts
index.js
lib
ansi.js
combos.js
completer.js
interpolate.js
keypress.js
placeholder.js
prompt.js
prompts
autocomplete.js
basicauth.js
confirm.js
editable.js
form.js
index.js
input.js
invisible.js
list.js
multiselect.js
numeral.js
password.js
quiz.js
scale.js
select.js
snippet.js
sort.js
survey.js
text.js
toggle.js
render.js
roles.js
state.js
styles.js
symbols.js
theme.js
timer.js
types
array.js
auth.js
boolean.js
index.js
number.js
string.js
utils.js
package.json
env-paths
index.d.ts
index.js
package.json
readme.md
escalade
dist
index.js
index.d.ts
package.json
readme.md
sync
index.d.ts
index.js
escape-string-regexp
index.d.ts
index.js
package.json
readme.md
eslint-scope
CHANGELOG.md
README.md
lib
definition.js
index.js
pattern-visitor.js
reference.js
referencer.js
scope-manager.js
scope.js
variable.js
node_modules
estraverse
README.md
estraverse.js
gulpfile.js
package.json
package.json
eslint-utils
README.md
index.js
package.json
eslint-visitor-keys
CHANGELOG.md
README.md
lib
index.js
visitor-keys.json
package.json
eslint
CHANGELOG.md
README.md
bin
eslint.js
conf
category-list.json
config-schema.js
default-cli-options.js
eslint-all.js
eslint-recommended.js
replacements.json
lib
api.js
cli-engine
cli-engine.js
file-enumerator.js
formatters
checkstyle.js
codeframe.js
compact.js
html.js
jslint-xml.js
json-with-metadata.js
json.js
junit.js
stylish.js
table.js
tap.js
unix.js
visualstudio.js
hash.js
index.js
lint-result-cache.js
load-rules.js
xml-escape.js
cli.js
config
default-config.js
flat-config-array.js
flat-config-schema.js
rule-validator.js
eslint
eslint.js
index.js
init
autoconfig.js
config-file.js
config-initializer.js
config-rule.js
npm-utils.js
source-code-utils.js
linter
apply-disable-directives.js
code-path-analysis
code-path-analyzer.js
code-path-segment.js
code-path-state.js
code-path.js
debug-helpers.js
fork-context.js
id-generator.js
config-comment-parser.js
index.js
interpolate.js
linter.js
node-event-generator.js
report-translator.js
rule-fixer.js
rules.js
safe-emitter.js
source-code-fixer.js
timing.js
options.js
rule-tester
index.js
rule-tester.js
rules
accessor-pairs.js
array-bracket-newline.js
array-bracket-spacing.js
array-callback-return.js
array-element-newline.js
arrow-body-style.js
arrow-parens.js
arrow-spacing.js
block-scoped-var.js
block-spacing.js
brace-style.js
callback-return.js
camelcase.js
capitalized-comments.js
class-methods-use-this.js
comma-dangle.js
comma-spacing.js
comma-style.js
complexity.js
computed-property-spacing.js
consistent-return.js
consistent-this.js
constructor-super.js
curly.js
default-case-last.js
default-case.js
default-param-last.js
dot-location.js
dot-notation.js
eol-last.js
eqeqeq.js
for-direction.js
func-call-spacing.js
func-name-matching.js
func-names.js
func-style.js
function-call-argument-newline.js
function-paren-newline.js
generator-star-spacing.js
getter-return.js
global-require.js
grouped-accessor-pairs.js
guard-for-in.js
handle-callback-err.js
id-blacklist.js
id-denylist.js
id-length.js
id-match.js
implicit-arrow-linebreak.js
indent-legacy.js
indent.js
index.js
init-declarations.js
jsx-quotes.js
key-spacing.js
keyword-spacing.js
line-comment-position.js
linebreak-style.js
lines-around-comment.js
lines-around-directive.js
lines-between-class-members.js
max-classes-per-file.js
max-depth.js
max-len.js
max-lines-per-function.js
max-lines.js
max-nested-callbacks.js
max-params.js
max-statements-per-line.js
max-statements.js
multiline-comment-style.js
multiline-ternary.js
new-cap.js
new-parens.js
newline-after-var.js
newline-before-return.js
newline-per-chained-call.js
no-alert.js
no-array-constructor.js
no-async-promise-executor.js
no-await-in-loop.js
no-bitwise.js
no-buffer-constructor.js
no-caller.js
no-case-declarations.js
no-catch-shadow.js
no-class-assign.js
no-compare-neg-zero.js
no-cond-assign.js
no-confusing-arrow.js
no-console.js
no-const-assign.js
no-constant-condition.js
no-constructor-return.js
no-continue.js
no-control-regex.js
no-debugger.js
no-delete-var.js
no-div-regex.js
no-dupe-args.js
no-dupe-class-members.js
no-dupe-else-if.js
no-dupe-keys.js
no-duplicate-case.js
no-duplicate-imports.js
no-else-return.js
no-empty-character-class.js
no-empty-function.js
no-empty-pattern.js
no-empty.js
no-eq-null.js
no-eval.js
no-ex-assign.js
no-extend-native.js
no-extra-bind.js
no-extra-boolean-cast.js
no-extra-label.js
no-extra-parens.js
no-extra-semi.js
no-fallthrough.js
no-floating-decimal.js
no-func-assign.js
no-global-assign.js
no-implicit-coercion.js
no-implicit-globals.js
no-implied-eval.js
no-import-assign.js
no-inline-comments.js
no-inner-declarations.js
no-invalid-regexp.js
no-invalid-this.js
no-irregular-whitespace.js
no-iterator.js
no-label-var.js
no-labels.js
no-lone-blocks.js
no-lonely-if.js
no-loop-func.js
no-loss-of-precision.js
no-magic-numbers.js
no-misleading-character-class.js
no-mixed-operators.js
no-mixed-requires.js
no-mixed-spaces-and-tabs.js
no-multi-assign.js
no-multi-spaces.js
no-multi-str.js
no-multiple-empty-lines.js
no-native-reassign.js
no-negated-condition.js
no-negated-in-lhs.js
no-nested-ternary.js
no-new-func.js
no-new-object.js
no-new-require.js
no-new-symbol.js
no-new-wrappers.js
no-new.js
no-nonoctal-decimal-escape.js
no-obj-calls.js
no-octal-escape.js
no-octal.js
no-param-reassign.js
no-path-concat.js
no-plusplus.js
no-process-env.js
no-process-exit.js
no-promise-executor-return.js
no-proto.js
no-prototype-builtins.js
no-redeclare.js
no-regex-spaces.js
no-restricted-exports.js
no-restricted-globals.js
no-restricted-imports.js
no-restricted-modules.js
no-restricted-properties.js
no-restricted-syntax.js
no-return-assign.js
no-return-await.js
no-script-url.js
no-self-assign.js
no-self-compare.js
no-sequences.js
no-setter-return.js
no-shadow-restricted-names.js
no-shadow.js
no-spaced-func.js
no-sparse-arrays.js
no-sync.js
no-tabs.js
no-template-curly-in-string.js
no-ternary.js
no-this-before-super.js
no-throw-literal.js
no-trailing-spaces.js
no-undef-init.js
no-undef.js
no-undefined.js
no-underscore-dangle.js
no-unexpected-multiline.js
no-unmodified-loop-condition.js
no-unneeded-ternary.js
no-unreachable-loop.js
no-unreachable.js
no-unsafe-finally.js
no-unsafe-negation.js
no-unsafe-optional-chaining.js
no-unused-expressions.js
no-unused-labels.js
no-unused-vars.js
no-use-before-define.js
no-useless-backreference.js
no-useless-call.js
no-useless-catch.js
no-useless-computed-key.js
no-useless-concat.js
no-useless-constructor.js
no-useless-escape.js
no-useless-rename.js
no-useless-return.js
no-var.js
no-void.js
no-warning-comments.js
no-whitespace-before-property.js
no-with.js
nonblock-statement-body-position.js
object-curly-newline.js
object-curly-spacing.js
object-property-newline.js
object-shorthand.js
one-var-declaration-per-line.js
one-var.js
operator-assignment.js
operator-linebreak.js
padded-blocks.js
padding-line-between-statements.js
prefer-arrow-callback.js
prefer-const.js
prefer-destructuring.js
prefer-exponentiation-operator.js
prefer-named-capture-group.js
prefer-numeric-literals.js
prefer-object-spread.js
prefer-promise-reject-errors.js
prefer-reflect.js
prefer-regex-literals.js
prefer-rest-params.js
prefer-spread.js
prefer-template.js
quote-props.js
quotes.js
radix.js
require-atomic-updates.js
require-await.js
require-jsdoc.js
require-unicode-regexp.js
require-yield.js
rest-spread-spacing.js
semi-spacing.js
semi-style.js
semi.js
sort-imports.js
sort-keys.js
sort-vars.js
space-before-blocks.js
space-before-function-paren.js
space-in-parens.js
space-infix-ops.js
space-unary-ops.js
spaced-comment.js
strict.js
switch-colon-spacing.js
symbol-description.js
template-curly-spacing.js
template-tag-spacing.js
unicode-bom.js
use-isnan.js
utils
ast-utils.js
fix-tracker.js
keywords.js
lazy-loading-rule-map.js
patterns
letters.js
unicode
index.js
is-combining-character.js
is-emoji-modifier.js
is-regional-indicator-symbol.js
is-surrogate-pair.js
valid-jsdoc.js
valid-typeof.js
vars-on-top.js
wrap-iife.js
wrap-regex.js
yield-star-spacing.js
yoda.js
shared
ajv.js
ast-utils.js
config-validator.js
deprecation-warnings.js
logging.js
relative-module-resolver.js
runtime-info.js
string-utils.js
traverser.js
types.js
source-code
index.js
source-code.js
token-store
backward-token-comment-cursor.js
backward-token-cursor.js
cursor.js
cursors.js
decorative-cursor.js
filter-cursor.js
forward-token-comment-cursor.js
forward-token-cursor.js
index.js
limit-cursor.js
padded-token-cursor.js
skip-cursor.js
utils.js
messages
all-files-ignored.js
extend-config-missing.js
failed-to-read-json.js
file-not-found.js
no-config-found.js
plugin-conflict.js
plugin-invalid.js
plugin-missing.js
print-config-with-directory-path.js
whitespace-found.js
node_modules
eslint-visitor-keys
CHANGELOG.md
README.md
lib
index.js
visitor-keys.json
package.json
package.json
espree
CHANGELOG.md
README.md
espree.js
lib
ast-node-types.js
espree.js
features.js
options.js
token-translator.js
visitor-keys.js
node_modules
.bin
acorn.cmd
package.json
esprima
README.md
bin
esparse.js
esvalidate.js
dist
esprima.js
package.json
esquery
README.md
dist
esquery.esm.js
esquery.esm.min.js
esquery.js
esquery.lite.js
esquery.lite.min.js
esquery.min.js
license.txt
package.json
parser.js
esrecurse
README.md
esrecurse.js
gulpfile.babel.js
package.json
estraverse
README.md
estraverse.js
gulpfile.js
package.json
esutils
README.md
lib
ast.js
code.js
keyword.js
utils.js
package.json
fast-deep-equal
README.md
es6
index.d.ts
index.js
react.d.ts
react.js
index.d.ts
index.js
package.json
react.d.ts
react.js
fast-json-stable-stringify
.eslintrc.yml
.github
FUNDING.yml
.travis.yml
README.md
benchmark
index.js
test.json
example
key_cmp.js
nested.js
str.js
value_cmp.js
index.d.ts
index.js
package.json
test
cmp.js
nested.js
str.js
to-json.js
fast-levenshtein
LICENSE.md
README.md
levenshtein.js
package.json
file-entry-cache
README.md
cache.js
changelog.md
package.json
find-up
index.d.ts
index.js
package.json
readme.md
flat-cache
README.md
changelog.md
node_modules
.bin
rimraf.cmd
package.json
src
cache.js
del.js
utils.js
flatted
.github
FUNDING.yml
workflows
node.js.yml
README.md
SPECS.md
cjs
index.js
package.json
es.js
esm
index.js
index.js
min.js
package.json
php
flatted.php
types.d.ts
follow-redirects
README.md
http.js
https.js
index.js
node_modules
debug
.coveralls.yml
.travis.yml
CHANGELOG.md
README.md
karma.conf.js
node.js
package.json
src
browser.js
debug.js
index.js
node.js
ms
index.js
license.md
package.json
readme.md
package.json
fs-minipass
README.md
index.js
package.json
fs.realpath
README.md
index.js
old.js
package.json
functional-red-black-tree
README.md
bench
test.js
package.json
rbtree.js
test
test.js
get-caller-file
LICENSE.md
README.md
index.d.ts
index.js
package.json
glob-parent
CHANGELOG.md
README.md
index.js
package.json
glob
README.md
common.js
glob.js
package.json
sync.js
globals
globals.json
index.d.ts
index.js
package.json
readme.md
has-flag
index.d.ts
index.js
package.json
readme.md
hasurl
README.md
index.js
package.json
ignore
CHANGELOG.md
README.md
index.d.ts
index.js
legacy.js
package.json
import-fresh
index.d.ts
index.js
package.json
readme.md
imurmurhash
README.md
imurmurhash.js
imurmurhash.min.js
package.json
inflight
README.md
inflight.js
package.json
inherits
README.md
inherits.js
inherits_browser.js
package.json
is-extglob
README.md
index.js
package.json
is-fullwidth-code-point
index.d.ts
index.js
package.json
readme.md
is-glob
README.md
index.js
package.json
isarray
.travis.yml
README.md
component.json
index.js
package.json
test.js
isexe
README.md
index.js
mode.js
package.json
test
basic.js
windows.js
isobject
README.md
index.js
package.json
js-base64
LICENSE.md
README.md
base64.d.ts
base64.js
package.json
js-tokens
CHANGELOG.md
README.md
index.js
package.json
js-yaml
CHANGELOG.md
README.md
bin
js-yaml.js
dist
js-yaml.js
js-yaml.min.js
index.js
lib
js-yaml.js
js-yaml
common.js
dumper.js
exception.js
loader.js
mark.js
schema.js
schema
core.js
default_full.js
default_safe.js
failsafe.js
json.js
type.js
type
binary.js
bool.js
float.js
int.js
js
function.js
regexp.js
undefined.js
map.js
merge.js
null.js
omap.js
pairs.js
seq.js
set.js
str.js
timestamp.js
package.json
json-schema-traverse
.eslintrc.yml
.travis.yml
README.md
index.js
package.json
spec
.eslintrc.yml
fixtures
schema.js
index.spec.js
json-stable-stringify-without-jsonify
.travis.yml
example
key_cmp.js
nested.js
str.js
value_cmp.js
index.js
package.json
test
cmp.js
nested.js
replacer.js
space.js
str.js
to-json.js
levn
README.md
lib
cast.js
index.js
parse-string.js
package.json
line-column
README.md
lib
line-column.js
package.json
locate-path
index.d.ts
index.js
package.json
readme.md
lodash.clonedeep
README.md
index.js
package.json
lodash.merge
README.md
index.js
package.json
lodash.sortby
README.md
index.js
package.json
lodash.truncate
README.md
index.js
package.json
long
README.md
dist
long.js
index.js
package.json
src
long.js
lru-cache
README.md
index.js
package.json
minimatch
README.md
minimatch.js
package.json
minimist
.travis.yml
example
parse.js
index.js
package.json
test
all_bool.js
bool.js
dash.js
default_bool.js
dotted.js
kv_short.js
long.js
num.js
parse.js
parse_modified.js
proto.js
short.js
stop_early.js
unknown.js
whitespace.js
minipass
README.md
index.js
package.json
minizlib
README.md
constants.js
index.js
package.json
mkdirp
bin
cmd.js
usage.txt
index.js
package.json
moo
README.md
moo.js
package.json
ms
index.js
license.md
package.json
readme.md
natural-compare
README.md
index.js
package.json
near-mock-vm
assembly
__tests__
main.ts
context.ts
index.ts
outcome.ts
vm.ts
bin
bin.js
package.json
pkg
near_mock_vm.d.ts
near_mock_vm.js
package.json
vm
dist
cli.d.ts
cli.js
context.d.ts
context.js
index.d.ts
index.js
memory.d.ts
memory.js
runner.d.ts
runner.js
utils.d.ts
utils.js
index.js
near-sdk-as
README.md
as-pect.config.js
as_types.d.ts
asconfig.json
asp.asconfig.json
assembly
__tests__
as-pect.d.ts
assert.spec.ts
avl-tree.spec.ts
bignum.spec.ts
contract.spec.ts
contract.ts
data.txt
datetime.spec.ts
empty.ts
generic.ts
includeBytes.spec.ts
main.ts
max-heap.spec.ts
model.ts
near.spec.ts
persistent-set.spec.ts
promise.spec.ts
rollback.spec.ts
roundtrip.spec.ts
runtime.spec.ts
unordered-map.spec.ts
util.ts
utils.spec.ts
as_types.d.ts
bindgen.ts
index.ts
json.lib.ts
tsconfig.json
vm
__tests__
vm.include.ts
index.ts
compiler.js
imports.js
node_modules
.bin
near-vm-as.cmd
out
assembly
__tests__
ason.ts
model.ts
~lib
as-bignum
integer
safe
u128.ts
package.json
near-sdk-bindgen
README.md
assembly
index.ts
compiler.js
dist
JSONBuilder.d.ts
JSONBuilder.js
classExporter.d.ts
classExporter.js
index.d.ts
index.js
transformer.d.ts
transformer.js
typeChecker.d.ts
typeChecker.js
utils.d.ts
utils.js
index.js
package.json
near-sdk-core
README.md
asconfig.json
assembly
as_types.d.ts
base58.ts
base64.ts
bignum.ts
collections
avlTree.ts
index.ts
maxHeap.ts
persistentDeque.ts
persistentMap.ts
persistentSet.ts
persistentUnorderedMap.ts
persistentVector.ts
util.ts
contract.ts
datetime.ts
env
env.ts
index.ts
runtime_api.ts
index.ts
logging.ts
math.ts
promise.ts
storage.ts
tsconfig.json
util.ts
docs
assets
css
main.css
js
main.js
search.json
classes
_sdk_core_assembly_collections_avltree_.avltree.html
_sdk_core_assembly_collections_avltree_.avltreenode.html
_sdk_core_assembly_collections_avltree_.childparentpair.html
_sdk_core_assembly_collections_avltree_.nullable.html
_sdk_core_assembly_collections_persistentdeque_.persistentdeque.html
_sdk_core_assembly_collections_persistentmap_.persistentmap.html
_sdk_core_assembly_collections_persistentset_.persistentset.html
_sdk_core_assembly_collections_persistentunorderedmap_.persistentunorderedmap.html
_sdk_core_assembly_collections_persistentvector_.persistentvector.html
_sdk_core_assembly_contract_.context-1.html
_sdk_core_assembly_contract_.contractpromise.html
_sdk_core_assembly_contract_.contractpromiseresult.html
_sdk_core_assembly_math_.rng.html
_sdk_core_assembly_promise_.contractpromisebatch.html
_sdk_core_assembly_storage_.storage-1.html
globals.html
index.html
modules
_sdk_core_assembly_base58_.base58.html
_sdk_core_assembly_base58_.html
_sdk_core_assembly_base64_.base64.html
_sdk_core_assembly_base64_.html
_sdk_core_assembly_collections_avltree_.html
_sdk_core_assembly_collections_index_.collections.html
_sdk_core_assembly_collections_index_.html
_sdk_core_assembly_collections_persistentdeque_.html
_sdk_core_assembly_collections_persistentmap_.html
_sdk_core_assembly_collections_persistentset_.html
_sdk_core_assembly_collections_persistentunorderedmap_.html
_sdk_core_assembly_collections_persistentvector_.html
_sdk_core_assembly_collections_util_.html
_sdk_core_assembly_contract_.html
_sdk_core_assembly_env_env_.env.html
_sdk_core_assembly_env_env_.html
_sdk_core_assembly_env_index_.html
_sdk_core_assembly_env_runtime_api_.html
_sdk_core_assembly_index_.html
_sdk_core_assembly_logging_.html
_sdk_core_assembly_logging_.logging.html
_sdk_core_assembly_math_.html
_sdk_core_assembly_math_.math.html
_sdk_core_assembly_promise_.html
_sdk_core_assembly_storage_.html
_sdk_core_assembly_util_.html
_sdk_core_assembly_util_.util.html
node_modules
.bin
asb.cmd
asbuild.cmd
asc.cmd
asinit.cmd
asp.cmd
aspect.cmd
assemblyscript-build.cmd
near-vm.cmd
package.json
near-sdk-simulator
__tests__
avl-tree-contract.spec.ts
cross.spec.ts
empty.spec.ts
exportAs.spec.ts
singleton-no-constructor.spec.ts
singleton.spec.ts
asconfig.js
asconfig.json
assembly
__tests__
avlTreeContract.ts
empty.ts
exportAs.ts
model.ts
sentences.ts
singleton-fail.ts
singleton-no-constructor.ts
singleton.ts
words.ts
as_types.d.ts
tsconfig.json
dist
bin.d.ts
bin.js
context.d.ts
context.js
index.d.ts
index.js
runtime.d.ts
runtime.js
types.d.ts
types.js
utils.d.ts
utils.js
jest.config.js
out
assembly
__tests__
empty.ts
exportAs.ts
model.ts
sentences.ts
singleton copy.ts
singleton-no-constructor.ts
singleton.ts
package.json
src
context.ts
index.ts
runtime.ts
types.ts
utils.ts
tsconfig.json
near-vm
getBinary.js
install.js
package.json
run.js
uninstall.js
nearley
LICENSE.txt
README.md
bin
nearley-railroad.js
nearley-test.js
nearley-unparse.js
nearleyc.js
lib
compile.js
generate.js
lint.js
nearley-language-bootstrapped.js
nearley.js
stream.js
unparse.js
package.json
once
README.md
once.js
package.json
optionator
CHANGELOG.md
README.md
lib
help.js
index.js
util.js
package.json
p-limit
index.d.ts
index.js
package.json
readme.md
p-locate
index.d.ts
index.js
package.json
readme.md
p-try
index.d.ts
index.js
package.json
readme.md
parent-module
index.js
package.json
readme.md
path-exists
index.d.ts
index.js
package.json
readme.md
path-is-absolute
index.js
package.json
readme.md
path-key
index.d.ts
index.js
package.json
readme.md
prelude-ls
CHANGELOG.md
README.md
lib
Func.js
List.js
Num.js
Obj.js
Str.js
index.js
package.json
progress
CHANGELOG.md
Readme.md
index.js
lib
node-progress.js
package.json
punycode
LICENSE-MIT.txt
README.md
package.json
punycode.es6.js
punycode.js
railroad-diagrams
README.md
example.html
generator.html
package.json
railroad-diagrams.css
railroad-diagrams.js
railroad_diagrams.py
randexp
README.md
lib
randexp.js
package.json
regexpp
README.md
index.d.ts
index.js
package.json
require-directory
.travis.yml
index.js
package.json
require-from-string
index.js
package.json
readme.md
require-main-filename
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
resolve-from
index.js
package.json
readme.md
ret
README.md
lib
index.js
positions.js
sets.js
types.js
util.js
package.json
rimraf
CHANGELOG.md
README.md
bin.js
package.json
rimraf.js
safe-buffer
README.md
index.d.ts
index.js
package.json
semver
README.md
bin
semver.js
classes
comparator.js
index.js
range.js
semver.js
functions
clean.js
cmp.js
coerce.js
compare-build.js
compare-loose.js
compare.js
diff.js
eq.js
gt.js
gte.js
inc.js
lt.js
lte.js
major.js
minor.js
neq.js
parse.js
patch.js
prerelease.js
rcompare.js
rsort.js
satisfies.js
sort.js
valid.js
index.js
internal
constants.js
debug.js
identifiers.js
parse-options.js
re.js
package.json
preload.js
ranges
gtr.js
intersects.js
ltr.js
max-satisfying.js
min-satisfying.js
min-version.js
outside.js
simplify.js
subset.js
to-comparators.js
valid.js
set-blocking
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
shebang-command
index.js
package.json
readme.md
shebang-regex
index.d.ts
index.js
package.json
readme.md
slice-ansi
index.js
package.json
readme.md
sprintf-js
README.md
bower.json
demo
angular.html
dist
angular-sprintf.min.js
sprintf.min.js
gruntfile.js
package.json
src
angular-sprintf.js
sprintf.js
test
test.js
string-width
index.d.ts
index.js
package.json
readme.md
strip-ansi
index.d.ts
index.js
package.json
readme.md
strip-json-comments
index.d.ts
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
table
README.md
dist
src
alignSpanningCell.d.ts
alignSpanningCell.js
alignString.d.ts
alignString.js
alignTableData.d.ts
alignTableData.js
calculateCellHeight.d.ts
calculateCellHeight.js
calculateMaximumColumnWidths.d.ts
calculateMaximumColumnWidths.js
calculateOutputColumnWidths.d.ts
calculateOutputColumnWidths.js
calculateRowHeights.d.ts
calculateRowHeights.js
calculateSpanningCellWidth.d.ts
calculateSpanningCellWidth.js
createStream.d.ts
createStream.js
drawBorder.d.ts
drawBorder.js
drawContent.d.ts
drawContent.js
drawRow.d.ts
drawRow.js
drawTable.d.ts
drawTable.js
generated
validators.d.ts
validators.js
getBorderCharacters.d.ts
getBorderCharacters.js
index.d.ts
index.js
injectHeaderConfig.d.ts
injectHeaderConfig.js
makeRangeConfig.d.ts
makeRangeConfig.js
makeStreamConfig.d.ts
makeStreamConfig.js
makeTableConfig.d.ts
makeTableConfig.js
mapDataUsingRowHeights.d.ts
mapDataUsingRowHeights.js
padTableData.d.ts
padTableData.js
schemas
config.json
shared.json
streamConfig.json
spanningCellManager.d.ts
spanningCellManager.js
stringifyTableData.d.ts
stringifyTableData.js
table.d.ts
table.js
truncateTableData.d.ts
truncateTableData.js
types
api.d.ts
api.js
internal.d.ts
internal.js
utils.d.ts
utils.js
validateConfig.d.ts
validateConfig.js
validateSpanningCellConfig.d.ts
validateSpanningCellConfig.js
validateTableData.d.ts
validateTableData.js
wrapCell.d.ts
wrapCell.js
wrapString.d.ts
wrapString.js
wrapWord.d.ts
wrapWord.js
node_modules
ajv
.runkit_example.js
README.md
dist
2019.d.ts
2019.js
2020.d.ts
2020.js
ajv.d.ts
ajv.js
compile
codegen
code.d.ts
code.js
index.d.ts
index.js
scope.d.ts
scope.js
errors.d.ts
errors.js
index.d.ts
index.js
jtd
parse.d.ts
parse.js
serialize.d.ts
serialize.js
types.d.ts
types.js
names.d.ts
names.js
ref_error.d.ts
ref_error.js
resolve.d.ts
resolve.js
rules.d.ts
rules.js
util.d.ts
util.js
validate
applicability.d.ts
applicability.js
boolSchema.d.ts
boolSchema.js
dataType.d.ts
dataType.js
defaults.d.ts
defaults.js
index.d.ts
index.js
keyword.d.ts
keyword.js
subschema.d.ts
subschema.js
core.d.ts
core.js
jtd.d.ts
jtd.js
refs
data.json
json-schema-2019-09
index.d.ts
index.js
meta
applicator.json
content.json
core.json
format.json
meta-data.json
validation.json
schema.json
json-schema-2020-12
index.d.ts
index.js
meta
applicator.json
content.json
core.json
format-annotation.json
meta-data.json
unevaluated.json
validation.json
schema.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
jtd-schema.d.ts
jtd-schema.js
runtime
equal.d.ts
equal.js
parseJson.d.ts
parseJson.js
quote.d.ts
quote.js
re2.d.ts
re2.js
timestamp.d.ts
timestamp.js
ucs2length.d.ts
ucs2length.js
uri.d.ts
uri.js
validation_error.d.ts
validation_error.js
standalone
index.d.ts
index.js
instance.d.ts
instance.js
types
index.d.ts
index.js
json-schema.d.ts
json-schema.js
jtd-schema.d.ts
jtd-schema.js
vocabularies
applicator
additionalItems.d.ts
additionalItems.js
additionalProperties.d.ts
additionalProperties.js
allOf.d.ts
allOf.js
anyOf.d.ts
anyOf.js
contains.d.ts
contains.js
dependencies.d.ts
dependencies.js
dependentSchemas.d.ts
dependentSchemas.js
if.d.ts
if.js
index.d.ts
index.js
items.d.ts
items.js
items2020.d.ts
items2020.js
not.d.ts
not.js
oneOf.d.ts
oneOf.js
patternProperties.d.ts
patternProperties.js
prefixItems.d.ts
prefixItems.js
properties.d.ts
properties.js
propertyNames.d.ts
propertyNames.js
thenElse.d.ts
thenElse.js
code.d.ts
code.js
core
id.d.ts
id.js
index.d.ts
index.js
ref.d.ts
ref.js
discriminator
index.d.ts
index.js
types.d.ts
types.js
draft2020.d.ts
draft2020.js
draft7.d.ts
draft7.js
dynamic
dynamicAnchor.d.ts
dynamicAnchor.js
dynamicRef.d.ts
dynamicRef.js
index.d.ts
index.js
recursiveAnchor.d.ts
recursiveAnchor.js
recursiveRef.d.ts
recursiveRef.js
errors.d.ts
errors.js
format
format.d.ts
format.js
index.d.ts
index.js
jtd
discriminator.d.ts
discriminator.js
elements.d.ts
elements.js
enum.d.ts
enum.js
error.d.ts
error.js
index.d.ts
index.js
metadata.d.ts
metadata.js
nullable.d.ts
nullable.js
optionalProperties.d.ts
optionalProperties.js
properties.d.ts
properties.js
ref.d.ts
ref.js
type.d.ts
type.js
union.d.ts
union.js
values.d.ts
values.js
metadata.d.ts
metadata.js
next.d.ts
next.js
unevaluated
index.d.ts
index.js
unevaluatedItems.d.ts
unevaluatedItems.js
unevaluatedProperties.d.ts
unevaluatedProperties.js
validation
const.d.ts
const.js
dependentRequired.d.ts
dependentRequired.js
enum.d.ts
enum.js
index.d.ts
index.js
limitContains.d.ts
limitContains.js
limitItems.d.ts
limitItems.js
limitLength.d.ts
limitLength.js
limitNumber.d.ts
limitNumber.js
limitProperties.d.ts
limitProperties.js
multipleOf.d.ts
multipleOf.js
pattern.d.ts
pattern.js
required.d.ts
required.js
uniqueItems.d.ts
uniqueItems.js
lib
2019.ts
2020.ts
ajv.ts
compile
codegen
code.ts
index.ts
scope.ts
errors.ts
index.ts
jtd
parse.ts
serialize.ts
types.ts
names.ts
ref_error.ts
resolve.ts
rules.ts
util.ts
validate
applicability.ts
boolSchema.ts
dataType.ts
defaults.ts
index.ts
keyword.ts
subschema.ts
core.ts
jtd.ts
refs
data.json
json-schema-2019-09
index.ts
meta
applicator.json
content.json
core.json
format.json
meta-data.json
validation.json
schema.json
json-schema-2020-12
index.ts
meta
applicator.json
content.json
core.json
format-annotation.json
meta-data.json
unevaluated.json
validation.json
schema.json
json-schema-draft-06.json
json-schema-draft-07.json
json-schema-secure.json
jtd-schema.ts
runtime
equal.ts
parseJson.ts
quote.ts
re2.ts
timestamp.ts
ucs2length.ts
uri.ts
validation_error.ts
standalone
index.ts
instance.ts
types
index.ts
json-schema.ts
jtd-schema.ts
vocabularies
applicator
additionalItems.ts
additionalProperties.ts
allOf.ts
anyOf.ts
contains.ts
dependencies.ts
dependentSchemas.ts
if.ts
index.ts
items.ts
items2020.ts
not.ts
oneOf.ts
patternProperties.ts
prefixItems.ts
properties.ts
propertyNames.ts
thenElse.ts
code.ts
core
id.ts
index.ts
ref.ts
discriminator
index.ts
types.ts
draft2020.ts
draft7.ts
dynamic
dynamicAnchor.ts
dynamicRef.ts
index.ts
recursiveAnchor.ts
recursiveRef.ts
errors.ts
format
format.ts
index.ts
jtd
discriminator.ts
elements.ts
enum.ts
error.ts
index.ts
metadata.ts
nullable.ts
optionalProperties.ts
properties.ts
ref.ts
type.ts
union.ts
values.ts
metadata.ts
next.ts
unevaluated
index.ts
unevaluatedItems.ts
unevaluatedProperties.ts
validation
const.ts
dependentRequired.ts
enum.ts
index.ts
limitContains.ts
limitItems.ts
limitLength.ts
limitNumber.ts
limitProperties.ts
multipleOf.ts
pattern.ts
required.ts
uniqueItems.ts
package.json
json-schema-traverse
.eslintrc.yml
.github
FUNDING.yml
workflows
build.yml
publish.yml
README.md
index.d.ts
index.js
package.json
spec
.eslintrc.yml
fixtures
schema.js
index.spec.js
package.json
tar
README.md
index.js
lib
create.js
extract.js
get-write-flag.js
header.js
high-level-opt.js
large-numbers.js
list.js
mkdir.js
mode-fix.js
normalize-windows-path.js
pack.js
parse.js
path-reservations.js
pax.js
read-entry.js
replace.js
strip-absolute-path.js
strip-trailing-slashes.js
types.js
unpack.js
update.js
warn-mixin.js
winchars.js
write-entry.js
node_modules
.bin
mkdirp.cmd
package.json
text-table
.travis.yml
example
align.js
center.js
dotalign.js
doubledot.js
table.js
index.js
package.json
test
align.js
ansi-colors.js
center.js
dotalign.js
doubledot.js
table.js
tr46
LICENSE.md
README.md
index.js
lib
mappingTable.json
regexes.js
package.json
ts-mixer
CHANGELOG.md
README.md
dist
cjs
decorator.js
index.js
mixin-tracking.js
mixins.js
proxy.js
settings.js
types.js
util.js
esm
index.js
index.min.js
types
decorator.d.ts
index.d.ts
mixin-tracking.d.ts
mixins.d.ts
proxy.d.ts
settings.d.ts
types.d.ts
util.d.ts
package.json
type-check
README.md
lib
check.js
index.js
parse-type.js
package.json
type-fest
base.d.ts
index.d.ts
package.json
readme.md
source
async-return-type.d.ts
asyncify.d.ts
basic.d.ts
conditional-except.d.ts
conditional-keys.d.ts
conditional-pick.d.ts
entries.d.ts
entry.d.ts
except.d.ts
fixed-length-array.d.ts
iterable-element.d.ts
literal-union.d.ts
merge-exclusive.d.ts
merge.d.ts
mutable.d.ts
opaque.d.ts
package-json.d.ts
partial-deep.d.ts
promisable.d.ts
promise-value.d.ts
readonly-deep.d.ts
require-at-least-one.d.ts
require-exactly-one.d.ts
set-optional.d.ts
set-required.d.ts
set-return-type.d.ts
stringified.d.ts
tsconfig-json.d.ts
union-to-intersection.d.ts
utilities.d.ts
value-of.d.ts
ts41
camel-case.d.ts
delimiter-case.d.ts
index.d.ts
kebab-case.d.ts
pascal-case.d.ts
snake-case.d.ts
typescript
AUTHORS.md
CODE_OF_CONDUCT.md
CopyrightNotice.txt
LICENSE.txt
README.md
SECURITY.md
ThirdPartyNoticeText.txt
lib
README.md
cancellationToken.js
cs
diagnosticMessages.generated.json
de
diagnosticMessages.generated.json
es
diagnosticMessages.generated.json
fr
diagnosticMessages.generated.json
it
diagnosticMessages.generated.json
ja
diagnosticMessages.generated.json
ko
diagnosticMessages.generated.json
lib.d.ts
lib.dom.d.ts
lib.dom.iterable.d.ts
lib.es2015.collection.d.ts
lib.es2015.core.d.ts
lib.es2015.d.ts
lib.es2015.generator.d.ts
lib.es2015.iterable.d.ts
lib.es2015.promise.d.ts
lib.es2015.proxy.d.ts
lib.es2015.reflect.d.ts
lib.es2015.symbol.d.ts
lib.es2015.symbol.wellknown.d.ts
lib.es2016.array.include.d.ts
lib.es2016.d.ts
lib.es2016.full.d.ts
lib.es2017.d.ts
lib.es2017.full.d.ts
lib.es2017.intl.d.ts
lib.es2017.object.d.ts
lib.es2017.sharedmemory.d.ts
lib.es2017.string.d.ts
lib.es2017.typedarrays.d.ts
lib.es2018.asyncgenerator.d.ts
lib.es2018.asynciterable.d.ts
lib.es2018.d.ts
lib.es2018.full.d.ts
lib.es2018.intl.d.ts
lib.es2018.promise.d.ts
lib.es2018.regexp.d.ts
lib.es2019.array.d.ts
lib.es2019.d.ts
lib.es2019.full.d.ts
lib.es2019.object.d.ts
lib.es2019.string.d.ts
lib.es2019.symbol.d.ts
lib.es2020.bigint.d.ts
lib.es2020.d.ts
lib.es2020.full.d.ts
lib.es2020.intl.d.ts
lib.es2020.promise.d.ts
lib.es2020.sharedmemory.d.ts
lib.es2020.string.d.ts
lib.es2020.symbol.wellknown.d.ts
lib.es2021.d.ts
lib.es2021.full.d.ts
lib.es2021.intl.d.ts
lib.es2021.promise.d.ts
lib.es2021.string.d.ts
lib.es2021.weakref.d.ts
lib.es2022.array.d.ts
lib.es2022.d.ts
lib.es2022.error.d.ts
lib.es2022.full.d.ts
lib.es2022.object.d.ts
lib.es2022.string.d.ts
lib.es5.d.ts
lib.es6.d.ts
lib.esnext.d.ts
lib.esnext.full.d.ts
lib.esnext.intl.d.ts
lib.esnext.promise.d.ts
lib.esnext.string.d.ts
lib.esnext.weakref.d.ts
lib.scripthost.d.ts
lib.webworker.d.ts
lib.webworker.importscripts.d.ts
lib.webworker.iterable.d.ts
pl
diagnosticMessages.generated.json
protocol.d.ts
pt-br
diagnosticMessages.generated.json
ru
diagnosticMessages.generated.json
tr
diagnosticMessages.generated.json
tsserverlibrary.d.ts
typesMap.json
typescript.d.ts
typescriptServices.d.ts
watchGuard.js
zh-cn
diagnosticMessages.generated.json
zh-tw
diagnosticMessages.generated.json
package.json
universal-url
README.md
browser.js
index.js
package.json
uri-js
README.md
dist
es5
uri.all.d.ts
uri.all.js
uri.all.min.d.ts
uri.all.min.js
esnext
index.d.ts
index.js
regexps-iri.d.ts
regexps-iri.js
regexps-uri.d.ts
regexps-uri.js
schemes
http.d.ts
http.js
https.d.ts
https.js
mailto.d.ts
mailto.js
urn-uuid.d.ts
urn-uuid.js
urn.d.ts
urn.js
ws.d.ts
ws.js
wss.d.ts
wss.js
uri.d.ts
uri.js
util.d.ts
util.js
package.json
v8-compile-cache
CHANGELOG.md
README.md
package.json
v8-compile-cache.js
visitor-as
.github
workflows
test.yml
README.md
as
index.d.ts
index.js
asconfig.json
dist
astBuilder.d.ts
astBuilder.js
base.d.ts
base.js
baseTransform.d.ts
baseTransform.js
decorator.d.ts
decorator.js
examples
capitalize.d.ts
capitalize.js
exportAs.d.ts
exportAs.js
functionCallTransform.d.ts
functionCallTransform.js
includeBytesTransform.d.ts
includeBytesTransform.js
list.d.ts
list.js
index.d.ts
index.js
path.d.ts
path.js
simpleParser.d.ts
simpleParser.js
transformer.d.ts
transformer.js
utils.d.ts
utils.js
visitor.d.ts
visitor.js
package.json
tsconfig.json
webidl-conversions
LICENSE.md
README.md
lib
index.js
package.json
whatwg-url
LICENSE.txt
README.md
lib
URL-impl.js
URL.js
URLSearchParams-impl.js
URLSearchParams.js
infra.js
public-api.js
url-state-machine.js
urlencoded.js
utils.js
package.json
which-module
CHANGELOG.md
README.md
index.js
package.json
which
CHANGELOG.md
README.md
package.json
which.js
word-wrap
README.md
index.d.ts
index.js
package.json
wrap-ansi
index.js
package.json
readme.md
wrappy
README.md
package.json
wrappy.js
y18n
CHANGELOG.md
README.md
build
lib
cjs.js
index.js
platform-shims
node.js
package.json
yallist
README.md
iterator.js
package.json
yallist.js
yargs-parser
CHANGELOG.md
LICENSE.txt
README.md
browser.js
build
lib
index.js
string-utils.js
tokenize-arg-string.js
yargs-parser-types.js
yargs-parser.js
package.json
yargs
CHANGELOG.md
README.md
build
lib
argsert.js
command.js
completion-templates.js
completion.js
middleware.js
parse-command.js
typings
common-types.js
yargs-parser-types.js
usage.js
utils
apply-extends.js
is-promise.js
levenshtein.js
obj-filter.js
process-argv.js
set-blocking.js
which-module.js
validation.js
yargs-factory.js
yerror.js
helpers
index.js
package.json
locales
be.json
de.json
en.json
es.json
fi.json
fr.json
hi.json
hu.json
id.json
it.json
ja.json
ko.json
nb.json
nl.json
nn.json
pirate.json
pl.json
pt.json
pt_BR.json
ru.json
th.json
tr.json
zh_CN.json
zh_TW.json
package.json
|
features not yet implemented
issues with the tests
differences between PCRE and JS regex
|
|
|
TypeScript ThirdPartyNotices
DefinitelyTyped
Unicode
WebGL
End of ThirdPartyNotices
package-lock.json
package.json
scripts
1.dev-deploy.sh
2.createGame.sh
3.joinGame.sh
4.play.sh
| # flatted
[](https://www.npmjs.com/package/flatted) [](https://coveralls.io/github/WebReflection/flatted?branch=main) [](https://travis-ci.com/WebReflection/flatted) [](https://opensource.org/licenses/ISC) 

<sup>**Social Media Photo by [Matt Seymour](https://unsplash.com/@mattseymour) on [Unsplash](https://unsplash.com/)**</sup>
## Announcement 📣
There is a standard approach to recursion and more data-types than what JSON allows, and it's part of the [Structured Clone polyfill](https://github.com/ungap/structured-clone/#readme).
Beside acting as a polyfill, its `@ungap/structured-clone/json` export provides both `stringify` and `parse`, and it's been tested for being faster than *flatted*, but its produced output is also smaller than *flatted* in general.
The *@ungap/structured-clone* module is, in short, a drop in replacement for *flatted*, but it's not compatible with *flatted* specialized syntax.
However, if recursion, as well as more data-types, are what you are after, or interesting for your projects/use cases, consider switching to this new module whenever you can 👍
- - -
A super light (0.5K) and fast circular JSON parser, directly from the creator of [CircularJSON](https://github.com/WebReflection/circular-json/#circularjson).
Now available also for **[PHP](./php/flatted.php)**.
```js
npm i flatted
```
Usable via [CDN](https://unpkg.com/flatted) or as regular module.
```js
// ESM
import {parse, stringify, toJSON, fromJSON} from 'flatted';
// CJS
const {parse, stringify, toJSON, fromJSON} = require('flatted');
const a = [{}];
a[0].a = a;
a.push(a);
stringify(a); // [["1","0"],{"a":"0"}]
```
## toJSON and fromJSON
If you'd like to implicitly survive JSON serialization, these two helpers helps:
```js
import {toJSON, fromJSON} from 'flatted';
class RecursiveMap extends Map {
static fromJSON(any) {
return new this(fromJSON(any));
}
toJSON() {
return toJSON([...this.entries()]);
}
}
const recursive = new RecursiveMap;
const same = {};
same.same = same;
recursive.set('same', same);
const asString = JSON.stringify(recursive);
const asMap = RecursiveMap.fromJSON(JSON.parse(asString));
asMap.get('same') === asMap.get('same').same;
// true
```
## Flatted VS JSON
As it is for every other specialized format capable of serializing and deserializing circular data, you should never `JSON.parse(Flatted.stringify(data))`, and you should never `Flatted.parse(JSON.stringify(data))`.
The only way this could work is to `Flatted.parse(Flatted.stringify(data))`, as it is also for _CircularJSON_ or any other, otherwise there's no granted data integrity.
Also please note this project serializes and deserializes only data compatible with JSON, so that sockets, or anything else with internal classes different from those allowed by JSON standard, won't be serialized and unserialized as expected.
### New in V1: Exact same JSON API
* Added a [reviver](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse#Syntax) parameter to `.parse(string, reviver)` and revive your own objects.
* Added a [replacer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify#Syntax) and a `space` parameter to `.stringify(object, replacer, space)` for feature parity with JSON signature.
### Compatibility
All ECMAScript engines compatible with `Map`, `Set`, `Object.keys`, and `Array.prototype.reduce` will work, even if polyfilled.
### How does it work ?
While stringifying, all Objects, including Arrays, and strings, are flattened out and replaced as unique index. `*`
Once parsed, all indexes will be replaced through the flattened collection.
<sup><sub>`*` represented as string to avoid conflicts with numbers</sub></sup>
```js
// logic example
var a = [{one: 1}, {two: '2'}];
a[0].a = a;
// a is the main object, will be at index '0'
// {one: 1} is the second object, index '1'
// {two: '2'} the third, in '2', and it has a string
// which will be found at index '3'
Flatted.stringify(a);
// [["1","2"],{"one":1,"a":"0"},{"two":"3"},"2"]
// a[one,two] {one: 1, a} {two: '2'} '2'
```
<img align="right" alt="Ajv logo" width="160" src="https://ajv.js.org/img/ajv.svg">
# Ajv JSON schema validator
The fastest JSON validator for Node.js and browser.
Supports JSON Schema draft-04/06/07/2019-09/2020-12 ([draft-04 support](https://ajv.js.org/json-schema.html#draft-04) requires ajv-draft-04 package) and JSON Type Definition [RFC8927](https://datatracker.ietf.org/doc/rfc8927/).
[](https://github.com/ajv-validator/ajv/actions?query=workflow%3Abuild)
[](https://www.npmjs.com/package/ajv)
[](https://www.npmjs.com/package/ajv)
[](https://coveralls.io/github/ajv-validator/ajv?branch=master)
[](https://simplex.chat/contact#/?v=1&smp=smp%3A%2F%2Fu2dS9sG8nMNURyZwqASV4yROM28Er0luVTx5X1CsMrU%3D%40smp4.simplex.im%2Fap4lMFzfXF8Hzmh-Vz0WNxp_1jKiOa-h%23MCowBQYDK2VuAyEAcdefddRvDfI8iAuBpztm_J3qFucj8MDZoVs_2EcMTzU%3D)
[](https://gitter.im/ajv-validator/ajv)
[](https://github.com/sponsors/epoberezkin)
## Ajv sponsors
[<img src="https://ajv.js.org/img/mozilla.svg" width="45%" alt="Mozilla">](https://www.mozilla.org)<img src="https://ajv.js.org/img/gap.svg" width="9%">[<img src="https://ajv.js.org/img/reserved.svg" width="45%">](https://opencollective.com/ajv)
[<img src="https://ajv.js.org/img/microsoft.png" width="31%" alt="Microsoft">](https://opensource.microsoft.com)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="31%">](https://opencollective.com/ajv)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="31%">](https://opencollective.com/ajv)
[<img src="https://ajv.js.org/img/retool.svg" width="22.5%" alt="Retool">](https://retool.com/?utm_source=sponsor&utm_campaign=ajv)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/tidelift.svg" width="22.5%" alt="Tidelift">](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=enterprise)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/simplex.svg" width="22.5%" alt="SimpleX">](https://github.com/simplex-chat/simplex-chat)<img src="https://ajv.js.org/img/gap.svg" width="3%">[<img src="https://ajv.js.org/img/reserved.svg" width="22.5%">](https://opencollective.com/ajv)
## Contributing
More than 100 people contributed to Ajv, and we would love to have you join the development. We welcome implementing new features that will benefit many users and ideas to improve our documentation.
Please review [Contributing guidelines](./CONTRIBUTING.md) and [Code components](https://ajv.js.org/components.html).
## Documentation
All documentation is available on the [Ajv website](https://ajv.js.org).
Some useful site links:
- [Getting started](https://ajv.js.org/guide/getting-started.html)
- [JSON Schema vs JSON Type Definition](https://ajv.js.org/guide/schema-language.html)
- [API reference](https://ajv.js.org/api.html)
- [Strict mode](https://ajv.js.org/strict-mode.html)
- [Standalone validation code](https://ajv.js.org/standalone.html)
- [Security considerations](https://ajv.js.org/security.html)
- [Command line interface](https://ajv.js.org/packages/ajv-cli.html)
- [Frequently Asked Questions](https://ajv.js.org/faq.html)
## <a name="sponsors"></a>Please [sponsor Ajv development](https://github.com/sponsors/epoberezkin)
Since I asked to support Ajv development 40 people and 6 organizations contributed via GitHub and OpenCollective - this support helped receiving the MOSS grant!
Your continuing support is very important - the funds will be used to develop and maintain Ajv once the next major version is released.
Please sponsor Ajv via:
- [GitHub sponsors page](https://github.com/sponsors/epoberezkin) (GitHub will match it)
- [Ajv Open Collective️](https://opencollective.com/ajv)
Thank you.
#### Open Collective sponsors
<a href="https://opencollective.com/ajv"><img src="https://opencollective.com/ajv/individuals.svg?width=890"></a>
<a href="https://opencollective.com/ajv/organization/0/website"><img src="https://opencollective.com/ajv/organization/0/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/1/website"><img src="https://opencollective.com/ajv/organization/1/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/2/website"><img src="https://opencollective.com/ajv/organization/2/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/3/website"><img src="https://opencollective.com/ajv/organization/3/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/4/website"><img src="https://opencollective.com/ajv/organization/4/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/5/website"><img src="https://opencollective.com/ajv/organization/5/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/6/website"><img src="https://opencollective.com/ajv/organization/6/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/7/website"><img src="https://opencollective.com/ajv/organization/7/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/8/website"><img src="https://opencollective.com/ajv/organization/8/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/9/website"><img src="https://opencollective.com/ajv/organization/9/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/10/website"><img src="https://opencollective.com/ajv/organization/10/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/11/website"><img src="https://opencollective.com/ajv/organization/11/avatar.svg"></a>
## Performance
Ajv generates code to turn JSON Schemas into super-fast validation functions that are efficient for v8 optimization.
Currently Ajv is the fastest and the most standard compliant validator according to these benchmarks:
- [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark) - 50% faster than the second place
- [jsck benchmark](https://github.com/pandastrike/jsck#benchmarks) - 20-190% faster
- [z-schema benchmark](https://rawgit.com/zaggino/z-schema/master/benchmark/results.html)
- [themis benchmark](https://cdn.rawgit.com/playlyfe/themis/master/benchmark/results.html)
Performance of different validators by [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark):
[](https://github.com/ebdrup/json-schema-benchmark/blob/master/README.md#performance)
## Features
- Ajv implements JSON Schema [draft-06/07/2019-09/2020-12](http://json-schema.org/) standards (draft-04 is supported in v6):
- all validation keywords (see [JSON Schema validation keywords](https://ajv.js.org/json-schema.html))
- [OpenAPI](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.3.md) extensions:
- NEW: keyword [discriminator](https://ajv.js.org/json-schema.html#discriminator).
- keyword [nullable](https://ajv.js.org/json-schema.html#nullable).
- full support of remote references (remote schemas have to be added with `addSchema` or compiled to be available)
- support of recursive references between schemas
- correct string lengths for strings with unicode pairs
- JSON Schema [formats](https://ajv.js.org/guide/formats.html) (with [ajv-formats](https://github.com/ajv-validator/ajv-formats) plugin).
- [validates schemas against meta-schema](https://ajv.js.org/api.html#api-validateschema)
- NEW: supports [JSON Type Definition](https://datatracker.ietf.org/doc/rfc8927/):
- all keywords (see [JSON Type Definition schema forms](https://ajv.js.org/json-type-definition.html))
- meta-schema for JTD schemas
- "union" keyword and user-defined keywords (can be used inside "metadata" member of the schema)
- supports [browsers](https://ajv.js.org/guide/environments.html#browsers) and Node.js 10.x - current
- [asynchronous loading](https://ajv.js.org/guide/managing-schemas.html#asynchronous-schema-loading) of referenced schemas during compilation
- "All errors" validation mode with [option allErrors](https://ajv.js.org/options.html#allerrors)
- [error messages with parameters](https://ajv.js.org/api.html#validation-errors) describing error reasons to allow error message generation
- i18n error messages support with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package
- [removing-additional-properties](https://ajv.js.org/guide/modifying-data.html#removing-additional-properties)
- [assigning defaults](https://ajv.js.org/guide/modifying-data.html#assigning-defaults) to missing properties and items
- [coercing data](https://ajv.js.org/guide/modifying-data.html#coercing-data-types) to the types specified in `type` keywords
- [user-defined keywords](https://ajv.js.org/guide/user-keywords.html)
- additional extension keywords with [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package
- [\$data reference](https://ajv.js.org/guide/combining-schemas.html#data-reference) to use values from the validated data as values for the schema keywords
- [asynchronous validation](https://ajv.js.org/guide/async-validation.html) of user-defined formats and keywords
## Install
To install version 8:
```
npm install ajv
```
## <a name="usage"></a>Getting started
Try it in the Node.js REPL: https://runkit.com/npm/ajv
In JavaScript:
```javascript
// or ESM/TypeScript import
import Ajv from "ajv"
// Node.js require:
const Ajv = require("ajv")
const ajv = new Ajv() // options can be passed, e.g. {allErrors: true}
const schema = {
type: "object",
properties: {
foo: {type: "integer"},
bar: {type: "string"}
},
required: ["foo"],
additionalProperties: false,
}
const data = {
foo: 1,
bar: "abc"
}
const validate = ajv.compile(schema)
const valid = validate(data)
if (!valid) console.log(validate.errors)
```
Learn how to use Ajv and see more examples in the [Guide: getting started](https://ajv.js.org/guide/getting-started.html)
## Changes history
See [https://github.com/ajv-validator/ajv/releases](https://github.com/ajv-validator/ajv/releases)
**Please note**: [Changes in version 8.0.0](https://github.com/ajv-validator/ajv/releases/tag/v8.0.0)
[Version 7.0.0](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0)
[Version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0).
## Code of conduct
Please review and follow the [Code of conduct](./CODE_OF_CONDUCT.md).
Please report any unacceptable behaviour to [email protected] - it will be reviewed by the project team.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerabilities via GitHub issues.
## Open-source software support
Ajv is a part of [Tidelift subscription](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=readme) - it provides a centralised support to open-source software users, in addition to the support provided by software maintainers.
## License
[MIT](./LICENSE)
# axios
[](https://www.npmjs.org/package/axios)
[](https://travis-ci.org/axios/axios)
[](https://coveralls.io/r/mzabriskie/axios)
[](https://packagephobia.now.sh/result?p=axios)
[](http://npm-stat.com/charts.html?package=axios)
[](https://gitter.im/mzabriskie/axios)
[](https://www.codetriage.com/axios/axios)
Promise based HTTP client for the browser and node.js
## Features
- Make [XMLHttpRequests](https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest) from the browser
- Make [http](http://nodejs.org/api/http.html) requests from node.js
- Supports the [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) API
- Intercept request and response
- Transform request and response data
- Cancel requests
- Automatic transforms for JSON data
- Client side support for protecting against [XSRF](http://en.wikipedia.org/wiki/Cross-site_request_forgery)
## Browser Support
 |  |  |  |  |  |
--- | --- | --- | --- | --- | --- |
Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | 11 ✔ |
[](https://saucelabs.com/u/axios)
## Installing
Using npm:
```bash
$ npm install axios
```
Using bower:
```bash
$ bower install axios
```
Using yarn:
```bash
$ yarn add axios
```
Using cdn:
```html
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
```
## Example
### note: CommonJS usage
In order to gain the TypeScript typings (for intellisense / autocomplete) while using CommonJS imports with `require()` use the following approach:
```js
const axios = require('axios').default;
// axios.<method> will now provide autocomplete and parameter typings
```
Performing a `GET` request
```js
const axios = require('axios');
// Make a request for a user with a given ID
axios.get('/user?ID=12345')
.then(function (response) {
// handle success
console.log(response);
})
.catch(function (error) {
// handle error
console.log(error);
})
.finally(function () {
// always executed
});
// Optionally the request above could also be done as
axios.get('/user', {
params: {
ID: 12345
}
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
})
.finally(function () {
// always executed
});
// Want to use async/await? Add the `async` keyword to your outer function/method.
async function getUser() {
try {
const response = await axios.get('/user?ID=12345');
console.log(response);
} catch (error) {
console.error(error);
}
}
```
> **NOTE:** `async/await` is part of ECMAScript 2017 and is not supported in Internet
> Explorer and older browsers, so use with caution.
Performing a `POST` request
```js
axios.post('/user', {
firstName: 'Fred',
lastName: 'Flintstone'
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
```
Performing multiple concurrent requests
```js
function getUserAccount() {
return axios.get('/user/12345');
}
function getUserPermissions() {
return axios.get('/user/12345/permissions');
}
axios.all([getUserAccount(), getUserPermissions()])
.then(axios.spread(function (acct, perms) {
// Both requests are now complete
}));
```
## axios API
Requests can be made by passing the relevant config to `axios`.
##### axios(config)
```js
// Send a POST request
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
});
```
```js
// GET request for remote image
axios({
method: 'get',
url: 'http://bit.ly/2mTM3nY',
responseType: 'stream'
})
.then(function (response) {
response.data.pipe(fs.createWriteStream('ada_lovelace.jpg'))
});
```
##### axios(url[, config])
```js
// Send a GET request (default method)
axios('/user/12345');
```
### Request method aliases
For convenience aliases have been provided for all supported request methods.
##### axios.request(config)
##### axios.get(url[, config])
##### axios.delete(url[, config])
##### axios.head(url[, config])
##### axios.options(url[, config])
##### axios.post(url[, data[, config]])
##### axios.put(url[, data[, config]])
##### axios.patch(url[, data[, config]])
###### NOTE
When using the alias methods `url`, `method`, and `data` properties don't need to be specified in config.
### Concurrency
Helper functions for dealing with concurrent requests.
##### axios.all(iterable)
##### axios.spread(callback)
### Creating an instance
You can create a new instance of axios with a custom config.
##### axios.create([config])
```js
const instance = axios.create({
baseURL: 'https://some-domain.com/api/',
timeout: 1000,
headers: {'X-Custom-Header': 'foobar'}
});
```
### Instance methods
The available instance methods are listed below. The specified config will be merged with the instance config.
##### axios#request(config)
##### axios#get(url[, config])
##### axios#delete(url[, config])
##### axios#head(url[, config])
##### axios#options(url[, config])
##### axios#post(url[, data[, config]])
##### axios#put(url[, data[, config]])
##### axios#patch(url[, data[, config]])
##### axios#getUri([config])
## Request Config
These are the available config options for making requests. Only the `url` is required. Requests will default to `GET` if `method` is not specified.
```js
{
// `url` is the server URL that will be used for the request
url: '/user',
// `method` is the request method to be used when making the request
method: 'get', // default
// `baseURL` will be prepended to `url` unless `url` is absolute.
// It can be convenient to set `baseURL` for an instance of axios to pass relative URLs
// to methods of that instance.
baseURL: 'https://some-domain.com/api/',
// `transformRequest` allows changes to the request data before it is sent to the server
// This is only applicable for request methods 'PUT', 'POST', 'PATCH' and 'DELETE'
// The last function in the array must return a string or an instance of Buffer, ArrayBuffer,
// FormData or Stream
// You may modify the headers object.
transformRequest: [function (data, headers) {
// Do whatever you want to transform the data
return data;
}],
// `transformResponse` allows changes to the response data to be made before
// it is passed to then/catch
transformResponse: [function (data) {
// Do whatever you want to transform the data
return data;
}],
// `headers` are custom headers to be sent
headers: {'X-Requested-With': 'XMLHttpRequest'},
// `params` are the URL parameters to be sent with the request
// Must be a plain object or a URLSearchParams object
params: {
ID: 12345
},
// `paramsSerializer` is an optional function in charge of serializing `params`
// (e.g. https://www.npmjs.com/package/qs, http://api.jquery.com/jquery.param/)
paramsSerializer: function (params) {
return Qs.stringify(params, {arrayFormat: 'brackets'})
},
// `data` is the data to be sent as the request body
// Only applicable for request methods 'PUT', 'POST', and 'PATCH'
// When no `transformRequest` is set, must be of one of the following types:
// - string, plain object, ArrayBuffer, ArrayBufferView, URLSearchParams
// - Browser only: FormData, File, Blob
// - Node only: Stream, Buffer
data: {
firstName: 'Fred'
},
// syntax alternative to send data into the body
// method post
// only the value is sent, not the key
data: 'Country=Brasil&City=Belo Horizonte',
// `timeout` specifies the number of milliseconds before the request times out.
// If the request takes longer than `timeout`, the request will be aborted.
timeout: 1000, // default is `0` (no timeout)
// `withCredentials` indicates whether or not cross-site Access-Control requests
// should be made using credentials
withCredentials: false, // default
// `adapter` allows custom handling of requests which makes testing easier.
// Return a promise and supply a valid response (see lib/adapters/README.md).
adapter: function (config) {
/* ... */
},
// `auth` indicates that HTTP Basic auth should be used, and supplies credentials.
// This will set an `Authorization` header, overwriting any existing
// `Authorization` custom headers you have set using `headers`.
// Please note that only HTTP Basic auth is configurable through this parameter.
// For Bearer tokens and such, use `Authorization` custom headers instead.
auth: {
username: 'janedoe',
password: 's00pers3cret'
},
// `responseType` indicates the type of data that the server will respond with
// options are: 'arraybuffer', 'document', 'json', 'text', 'stream'
// browser only: 'blob'
responseType: 'json', // default
// `responseEncoding` indicates encoding to use for decoding responses
// Note: Ignored for `responseType` of 'stream' or client-side requests
responseEncoding: 'utf8', // default
// `xsrfCookieName` is the name of the cookie to use as a value for xsrf token
xsrfCookieName: 'XSRF-TOKEN', // default
// `xsrfHeaderName` is the name of the http header that carries the xsrf token value
xsrfHeaderName: 'X-XSRF-TOKEN', // default
// `onUploadProgress` allows handling of progress events for uploads
onUploadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `onDownloadProgress` allows handling of progress events for downloads
onDownloadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `maxContentLength` defines the max size of the http response content in bytes allowed
maxContentLength: 2000,
// `validateStatus` defines whether to resolve or reject the promise for a given
// HTTP response status code. If `validateStatus` returns `true` (or is set to `null`
// or `undefined`), the promise will be resolved; otherwise, the promise will be
// rejected.
validateStatus: function (status) {
return status >= 200 && status < 300; // default
},
// `maxRedirects` defines the maximum number of redirects to follow in node.js.
// If set to 0, no redirects will be followed.
maxRedirects: 5, // default
// `socketPath` defines a UNIX Socket to be used in node.js.
// e.g. '/var/run/docker.sock' to send requests to the docker daemon.
// Only either `socketPath` or `proxy` can be specified.
// If both are specified, `socketPath` is used.
socketPath: null, // default
// `httpAgent` and `httpsAgent` define a custom agent to be used when performing http
// and https requests, respectively, in node.js. This allows options to be added like
// `keepAlive` that are not enabled by default.
httpAgent: new http.Agent({ keepAlive: true }),
httpsAgent: new https.Agent({ keepAlive: true }),
// 'proxy' defines the hostname and port of the proxy server.
// You can also define your proxy using the conventional `http_proxy` and
// `https_proxy` environment variables. If you are using environment variables
// for your proxy configuration, you can also define a `no_proxy` environment
// variable as a comma-separated list of domains that should not be proxied.
// Use `false` to disable proxies, ignoring environment variables.
// `auth` indicates that HTTP Basic auth should be used to connect to the proxy, and
// supplies credentials.
// This will set an `Proxy-Authorization` header, overwriting any existing
// `Proxy-Authorization` custom headers you have set using `headers`.
proxy: {
host: '127.0.0.1',
port: 9000,
auth: {
username: 'mikeymike',
password: 'rapunz3l'
}
},
// `cancelToken` specifies a cancel token that can be used to cancel the request
// (see Cancellation section below for details)
cancelToken: new CancelToken(function (cancel) {
})
}
```
## Response Schema
The response for a request contains the following information.
```js
{
// `data` is the response that was provided by the server
data: {},
// `status` is the HTTP status code from the server response
status: 200,
// `statusText` is the HTTP status message from the server response
statusText: 'OK',
// `headers` the headers that the server responded with
// All header names are lower cased
headers: {},
// `config` is the config that was provided to `axios` for the request
config: {},
// `request` is the request that generated this response
// It is the last ClientRequest instance in node.js (in redirects)
// and an XMLHttpRequest instance in the browser
request: {}
}
```
When using `then`, you will receive the response as follows:
```js
axios.get('/user/12345')
.then(function (response) {
console.log(response.data);
console.log(response.status);
console.log(response.statusText);
console.log(response.headers);
console.log(response.config);
});
```
When using `catch`, or passing a [rejection callback](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise/then) as second parameter of `then`, the response will be available through the `error` object as explained in the [Handling Errors](#handling-errors) section.
## Config Defaults
You can specify config defaults that will be applied to every request.
### Global axios defaults
```js
axios.defaults.baseURL = 'https://api.example.com';
axios.defaults.headers.common['Authorization'] = AUTH_TOKEN;
axios.defaults.headers.post['Content-Type'] = 'application/x-www-form-urlencoded';
```
### Custom instance defaults
```js
// Set config defaults when creating the instance
const instance = axios.create({
baseURL: 'https://api.example.com'
});
// Alter defaults after instance has been created
instance.defaults.headers.common['Authorization'] = AUTH_TOKEN;
```
### Config order of precedence
Config will be merged with an order of precedence. The order is library defaults found in [lib/defaults.js](https://github.com/axios/axios/blob/master/lib/defaults.js#L28), then `defaults` property of the instance, and finally `config` argument for the request. The latter will take precedence over the former. Here's an example.
```js
// Create an instance using the config defaults provided by the library
// At this point the timeout config value is `0` as is the default for the library
const instance = axios.create();
// Override timeout default for the library
// Now all requests using this instance will wait 2.5 seconds before timing out
instance.defaults.timeout = 2500;
// Override timeout for this request as it's known to take a long time
instance.get('/longRequest', {
timeout: 5000
});
```
## Interceptors
You can intercept requests or responses before they are handled by `then` or `catch`.
```js
// Add a request interceptor
axios.interceptors.request.use(function (config) {
// Do something before request is sent
return config;
}, function (error) {
// Do something with request error
return Promise.reject(error);
});
// Add a response interceptor
axios.interceptors.response.use(function (response) {
// Any status code that lie within the range of 2xx cause this function to trigger
// Do something with response data
return response;
}, function (error) {
// Any status codes that falls outside the range of 2xx cause this function to trigger
// Do something with response error
return Promise.reject(error);
});
```
If you need to remove an interceptor later you can.
```js
const myInterceptor = axios.interceptors.request.use(function () {/*...*/});
axios.interceptors.request.eject(myInterceptor);
```
You can add interceptors to a custom instance of axios.
```js
const instance = axios.create();
instance.interceptors.request.use(function () {/*...*/});
```
## Handling Errors
```js
axios.get('/user/12345')
.catch(function (error) {
if (error.response) {
// The request was made and the server responded with a status code
// that falls out of the range of 2xx
console.log(error.response.data);
console.log(error.response.status);
console.log(error.response.headers);
} else if (error.request) {
// The request was made but no response was received
// `error.request` is an instance of XMLHttpRequest in the browser and an instance of
// http.ClientRequest in node.js
console.log(error.request);
} else {
// Something happened in setting up the request that triggered an Error
console.log('Error', error.message);
}
console.log(error.config);
});
```
Using the `validateStatus` config option, you can define HTTP code(s) that should throw an error.
```js
axios.get('/user/12345', {
validateStatus: function (status) {
return status < 500; // Reject only if the status code is greater than or equal to 500
}
})
```
Using `toJSON` you get an object with more information about the HTTP error.
```js
axios.get('/user/12345')
.catch(function (error) {
console.log(error.toJSON());
});
```
## Cancellation
You can cancel a request using a *cancel token*.
> The axios cancel token API is based on the withdrawn [cancelable promises proposal](https://github.com/tc39/proposal-cancelable-promises).
You can create a cancel token using the `CancelToken.source` factory as shown below:
```js
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// handle error
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// cancel the request (the message parameter is optional)
source.cancel('Operation canceled by the user.');
```
You can also create a cancel token by passing an executor function to the `CancelToken` constructor:
```js
const CancelToken = axios.CancelToken;
let cancel;
axios.get('/user/12345', {
cancelToken: new CancelToken(function executor(c) {
// An executor function receives a cancel function as a parameter
cancel = c;
})
});
// cancel the request
cancel();
```
> Note: you can cancel several requests with the same cancel token.
## Using application/x-www-form-urlencoded format
By default, axios serializes JavaScript objects to `JSON`. To send data in the `application/x-www-form-urlencoded` format instead, you can use one of the following options.
### Browser
In a browser, you can use the [`URLSearchParams`](https://developer.mozilla.org/en-US/docs/Web/API/URLSearchParams) API as follows:
```js
const params = new URLSearchParams();
params.append('param1', 'value1');
params.append('param2', 'value2');
axios.post('/foo', params);
```
> Note that `URLSearchParams` is not supported by all browsers (see [caniuse.com](http://www.caniuse.com/#feat=urlsearchparams)), but there is a [polyfill](https://github.com/WebReflection/url-search-params) available (make sure to polyfill the global environment).
Alternatively, you can encode data using the [`qs`](https://github.com/ljharb/qs) library:
```js
const qs = require('qs');
axios.post('/foo', qs.stringify({ 'bar': 123 }));
```
Or in another way (ES6),
```js
import qs from 'qs';
const data = { 'bar': 123 };
const options = {
method: 'POST',
headers: { 'content-type': 'application/x-www-form-urlencoded' },
data: qs.stringify(data),
url,
};
axios(options);
```
### Node.js
In node.js, you can use the [`querystring`](https://nodejs.org/api/querystring.html) module as follows:
```js
const querystring = require('querystring');
axios.post('http://something.com/', querystring.stringify({ foo: 'bar' }));
```
You can also use the [`qs`](https://github.com/ljharb/qs) library.
###### NOTE
The `qs` library is preferable if you need to stringify nested objects, as the `querystring` method has known issues with that use case (https://github.com/nodejs/node-v0.x-archive/issues/1665).
## Semver
Until axios reaches a `1.0` release, breaking changes will be released with a new minor version. For example `0.5.1`, and `0.5.4` will have the same API, but `0.6.0` will have breaking changes.
## Promises
axios depends on a native ES6 Promise implementation to be [supported](http://caniuse.com/promises).
If your environment doesn't support ES6 Promises, you can [polyfill](https://github.com/jakearchibald/es6-promise).
## TypeScript
axios includes [TypeScript](http://typescriptlang.org) definitions.
```typescript
import axios from 'axios';
axios.get('/user?ID=12345');
```
## Resources
* [Changelog](https://github.com/axios/axios/blob/master/CHANGELOG.md)
* [Upgrade Guide](https://github.com/axios/axios/blob/master/UPGRADE_GUIDE.md)
* [Ecosystem](https://github.com/axios/axios/blob/master/ECOSYSTEM.md)
* [Contributing Guide](https://github.com/axios/axios/blob/master/CONTRIBUTING.md)
* [Code of Conduct](https://github.com/axios/axios/blob/master/CODE_OF_CONDUCT.md)
## Credits
axios is heavily inspired by the [$http service](https://docs.angularjs.org/api/ng/service/$http) provided in [Angular](https://angularjs.org/). Ultimately axios is an effort to provide a standalone `$http`-like service for use outside of Angular.
## License
[MIT](LICENSE)
semver(1) -- The semantic versioner for npm
===========================================
## Install
```bash
npm install semver
````
## Usage
As a node module:
```js
const semver = require('semver')
semver.valid('1.2.3') // '1.2.3'
semver.valid('a.b.c') // null
semver.clean(' =v1.2.3 ') // '1.2.3'
semver.satisfies('1.2.3', '1.x || >=2.5.0 || 5.0.0 - 7.2.3') // true
semver.gt('1.2.3', '9.8.7') // false
semver.lt('1.2.3', '9.8.7') // true
semver.minVersion('>=1.0.0') // '1.0.0'
semver.valid(semver.coerce('v2')) // '2.0.0'
semver.valid(semver.coerce('42.6.7.9.3-alpha')) // '42.6.7'
```
You can also just load the module for the function that you care about, if
you'd like to minimize your footprint.
```js
// load the whole API at once in a single object
const semver = require('semver')
// or just load the bits you need
// all of them listed here, just pick and choose what you want
// classes
const SemVer = require('semver/classes/semver')
const Comparator = require('semver/classes/comparator')
const Range = require('semver/classes/range')
// functions for working with versions
const semverParse = require('semver/functions/parse')
const semverValid = require('semver/functions/valid')
const semverClean = require('semver/functions/clean')
const semverInc = require('semver/functions/inc')
const semverDiff = require('semver/functions/diff')
const semverMajor = require('semver/functions/major')
const semverMinor = require('semver/functions/minor')
const semverPatch = require('semver/functions/patch')
const semverPrerelease = require('semver/functions/prerelease')
const semverCompare = require('semver/functions/compare')
const semverRcompare = require('semver/functions/rcompare')
const semverCompareLoose = require('semver/functions/compare-loose')
const semverCompareBuild = require('semver/functions/compare-build')
const semverSort = require('semver/functions/sort')
const semverRsort = require('semver/functions/rsort')
// low-level comparators between versions
const semverGt = require('semver/functions/gt')
const semverLt = require('semver/functions/lt')
const semverEq = require('semver/functions/eq')
const semverNeq = require('semver/functions/neq')
const semverGte = require('semver/functions/gte')
const semverLte = require('semver/functions/lte')
const semverCmp = require('semver/functions/cmp')
const semverCoerce = require('semver/functions/coerce')
// working with ranges
const semverSatisfies = require('semver/functions/satisfies')
const semverMaxSatisfying = require('semver/ranges/max-satisfying')
const semverMinSatisfying = require('semver/ranges/min-satisfying')
const semverToComparators = require('semver/ranges/to-comparators')
const semverMinVersion = require('semver/ranges/min-version')
const semverValidRange = require('semver/ranges/valid')
const semverOutside = require('semver/ranges/outside')
const semverGtr = require('semver/ranges/gtr')
const semverLtr = require('semver/ranges/ltr')
const semverIntersects = require('semver/ranges/intersects')
const simplifyRange = require('semver/ranges/simplify')
const rangeSubset = require('semver/ranges/subset')
```
As a command-line utility:
```
$ semver -h
A JavaScript implementation of the https://semver.org/ specification
Copyright Isaac Z. Schlueter
Usage: semver [options] <version> [<version> [...]]
Prints valid versions sorted by SemVer precedence
Options:
-r --range <range>
Print versions that match the specified range.
-i --increment [<level>]
Increment a version by the specified level. Level can
be one of: major, minor, patch, premajor, preminor,
prepatch, or prerelease. Default level is 'patch'.
Only one version may be specified.
--preid <identifier>
Identifier to be used to prefix premajor, preminor,
prepatch or prerelease version increments.
-l --loose
Interpret versions and ranges loosely
-p --include-prerelease
Always include prerelease versions in range matching
-c --coerce
Coerce a string into SemVer if possible
(does not imply --loose)
--rtl
Coerce version strings right to left
--ltr
Coerce version strings left to right (default)
Program exits successfully if any valid version satisfies
all supplied ranges, and prints all satisfying versions.
If no satisfying versions are found, then exits failure.
Versions are printed in ascending order, so supplying
multiple versions to the utility will just sort them.
```
## Versions
A "version" is described by the `v2.0.0` specification found at
<https://semver.org/>.
A leading `"="` or `"v"` character is stripped off and ignored.
## Ranges
A `version range` is a set of `comparators` which specify versions
that satisfy the range.
A `comparator` is composed of an `operator` and a `version`. The set
of primitive `operators` is:
* `<` Less than
* `<=` Less than or equal to
* `>` Greater than
* `>=` Greater than or equal to
* `=` Equal. If no operator is specified, then equality is assumed,
so this operator is optional, but MAY be included.
For example, the comparator `>=1.2.7` would match the versions
`1.2.7`, `1.2.8`, `2.5.3`, and `1.3.9`, but not the versions `1.2.6`
or `1.1.0`.
Comparators can be joined by whitespace to form a `comparator set`,
which is satisfied by the **intersection** of all of the comparators
it includes.
A range is composed of one or more comparator sets, joined by `||`. A
version matches a range if and only if every comparator in at least
one of the `||`-separated comparator sets is satisfied by the version.
For example, the range `>=1.2.7 <1.3.0` would match the versions
`1.2.7`, `1.2.8`, and `1.2.99`, but not the versions `1.2.6`, `1.3.0`,
or `1.1.0`.
The range `1.2.7 || >=1.2.9 <2.0.0` would match the versions `1.2.7`,
`1.2.9`, and `1.4.6`, but not the versions `1.2.8` or `2.0.0`.
### Prerelease Tags
If a version has a prerelease tag (for example, `1.2.3-alpha.3`) then
it will only be allowed to satisfy comparator sets if at least one
comparator with the same `[major, minor, patch]` tuple also has a
prerelease tag.
For example, the range `>1.2.3-alpha.3` would be allowed to match the
version `1.2.3-alpha.7`, but it would *not* be satisfied by
`3.4.5-alpha.9`, even though `3.4.5-alpha.9` is technically "greater
than" `1.2.3-alpha.3` according to the SemVer sort rules. The version
range only accepts prerelease tags on the `1.2.3` version. The
version `3.4.5` *would* satisfy the range, because it does not have a
prerelease flag, and `3.4.5` is greater than `1.2.3-alpha.7`.
The purpose for this behavior is twofold. First, prerelease versions
frequently are updated very quickly, and contain many breaking changes
that are (by the author's design) not yet fit for public consumption.
Therefore, by default, they are excluded from range matching
semantics.
Second, a user who has opted into using a prerelease version has
clearly indicated the intent to use *that specific* set of
alpha/beta/rc versions. By including a prerelease tag in the range,
the user is indicating that they are aware of the risk. However, it
is still not appropriate to assume that they have opted into taking a
similar risk on the *next* set of prerelease versions.
Note that this behavior can be suppressed (treating all prerelease
versions as if they were normal versions, for the purpose of range
matching) by setting the `includePrerelease` flag on the options
object to any
[functions](https://github.com/npm/node-semver#functions) that do
range matching.
#### Prerelease Identifiers
The method `.inc` takes an additional `identifier` string argument that
will append the value of the string as a prerelease identifier:
```javascript
semver.inc('1.2.3', 'prerelease', 'beta')
// '1.2.4-beta.0'
```
command-line example:
```bash
$ semver 1.2.3 -i prerelease --preid beta
1.2.4-beta.0
```
Which then can be used to increment further:
```bash
$ semver 1.2.4-beta.0 -i prerelease
1.2.4-beta.1
```
### Advanced Range Syntax
Advanced range syntax desugars to primitive comparators in
deterministic ways.
Advanced ranges may be combined in the same way as primitive
comparators using white space or `||`.
#### Hyphen Ranges `X.Y.Z - A.B.C`
Specifies an inclusive set.
* `1.2.3 - 2.3.4` := `>=1.2.3 <=2.3.4`
If a partial version is provided as the first version in the inclusive
range, then the missing pieces are replaced with zeroes.
* `1.2 - 2.3.4` := `>=1.2.0 <=2.3.4`
If a partial version is provided as the second version in the
inclusive range, then all versions that start with the supplied parts
of the tuple are accepted, but nothing that would be greater than the
provided tuple parts.
* `1.2.3 - 2.3` := `>=1.2.3 <2.4.0-0`
* `1.2.3 - 2` := `>=1.2.3 <3.0.0-0`
#### X-Ranges `1.2.x` `1.X` `1.2.*` `*`
Any of `X`, `x`, or `*` may be used to "stand in" for one of the
numeric values in the `[major, minor, patch]` tuple.
* `*` := `>=0.0.0` (Any non-prerelease version satisfies, unless
`includePrerelease` is specified, in which case any version at all
satisfies)
* `1.x` := `>=1.0.0 <2.0.0-0` (Matching major version)
* `1.2.x` := `>=1.2.0 <1.3.0-0` (Matching major and minor versions)
A partial version range is treated as an X-Range, so the special
character is in fact optional.
* `""` (empty string) := `*` := `>=0.0.0`
* `1` := `1.x.x` := `>=1.0.0 <2.0.0-0`
* `1.2` := `1.2.x` := `>=1.2.0 <1.3.0-0`
#### Tilde Ranges `~1.2.3` `~1.2` `~1`
Allows patch-level changes if a minor version is specified on the
comparator. Allows minor-level changes if not.
* `~1.2.3` := `>=1.2.3 <1.(2+1).0` := `>=1.2.3 <1.3.0-0`
* `~1.2` := `>=1.2.0 <1.(2+1).0` := `>=1.2.0 <1.3.0-0` (Same as `1.2.x`)
* `~1` := `>=1.0.0 <(1+1).0.0` := `>=1.0.0 <2.0.0-0` (Same as `1.x`)
* `~0.2.3` := `>=0.2.3 <0.(2+1).0` := `>=0.2.3 <0.3.0-0`
* `~0.2` := `>=0.2.0 <0.(2+1).0` := `>=0.2.0 <0.3.0-0` (Same as `0.2.x`)
* `~0` := `>=0.0.0 <(0+1).0.0` := `>=0.0.0 <1.0.0-0` (Same as `0.x`)
* `~1.2.3-beta.2` := `>=1.2.3-beta.2 <1.3.0-0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
#### Caret Ranges `^1.2.3` `^0.2.5` `^0.0.4`
Allows changes that do not modify the left-most non-zero element in the
`[major, minor, patch]` tuple. In other words, this allows patch and
minor updates for versions `1.0.0` and above, patch updates for
versions `0.X >=0.1.0`, and *no* updates for versions `0.0.X`.
Many authors treat a `0.x` version as if the `x` were the major
"breaking-change" indicator.
Caret ranges are ideal when an author may make breaking changes
between `0.2.4` and `0.3.0` releases, which is a common practice.
However, it presumes that there will *not* be breaking changes between
`0.2.4` and `0.2.5`. It allows for changes that are presumed to be
additive (but non-breaking), according to commonly observed practices.
* `^1.2.3` := `>=1.2.3 <2.0.0-0`
* `^0.2.3` := `>=0.2.3 <0.3.0-0`
* `^0.0.3` := `>=0.0.3 <0.0.4-0`
* `^1.2.3-beta.2` := `>=1.2.3-beta.2 <2.0.0-0` Note that prereleases in
the `1.2.3` version will be allowed, if they are greater than or
equal to `beta.2`. So, `1.2.3-beta.4` would be allowed, but
`1.2.4-beta.2` would not, because it is a prerelease of a
different `[major, minor, patch]` tuple.
* `^0.0.3-beta` := `>=0.0.3-beta <0.0.4-0` Note that prereleases in the
`0.0.3` version *only* will be allowed, if they are greater than or
equal to `beta`. So, `0.0.3-pr.2` would be allowed.
When parsing caret ranges, a missing `patch` value desugars to the
number `0`, but will allow flexibility within that value, even if the
major and minor versions are both `0`.
* `^1.2.x` := `>=1.2.0 <2.0.0-0`
* `^0.0.x` := `>=0.0.0 <0.1.0-0`
* `^0.0` := `>=0.0.0 <0.1.0-0`
A missing `minor` and `patch` values will desugar to zero, but also
allow flexibility within those values, even if the major version is
zero.
* `^1.x` := `>=1.0.0 <2.0.0-0`
* `^0.x` := `>=0.0.0 <1.0.0-0`
### Range Grammar
Putting all this together, here is a Backus-Naur grammar for ranges,
for the benefit of parser authors:
```bnf
range-set ::= range ( logical-or range ) *
logical-or ::= ( ' ' ) * '||' ( ' ' ) *
range ::= hyphen | simple ( ' ' simple ) * | ''
hyphen ::= partial ' - ' partial
simple ::= primitive | partial | tilde | caret
primitive ::= ( '<' | '>' | '>=' | '<=' | '=' ) partial
partial ::= xr ( '.' xr ( '.' xr qualifier ? )? )?
xr ::= 'x' | 'X' | '*' | nr
nr ::= '0' | ['1'-'9'] ( ['0'-'9'] ) *
tilde ::= '~' partial
caret ::= '^' partial
qualifier ::= ( '-' pre )? ( '+' build )?
pre ::= parts
build ::= parts
parts ::= part ( '.' part ) *
part ::= nr | [-0-9A-Za-z]+
```
## Functions
All methods and classes take a final `options` object argument. All
options in this object are `false` by default. The options supported
are:
- `loose` Be more forgiving about not-quite-valid semver strings.
(Any resulting output will always be 100% strict compliant, of
course.) For backwards compatibility reasons, if the `options`
argument is a boolean value instead of an object, it is interpreted
to be the `loose` param.
- `includePrerelease` Set to suppress the [default
behavior](https://github.com/npm/node-semver#prerelease-tags) of
excluding prerelease tagged versions from ranges unless they are
explicitly opted into.
Strict-mode Comparators and Ranges will be strict about the SemVer
strings that they parse.
* `valid(v)`: Return the parsed version, or null if it's not valid.
* `inc(v, release)`: Return the version incremented by the release
type (`major`, `premajor`, `minor`, `preminor`, `patch`,
`prepatch`, or `prerelease`), or null if it's not valid
* `premajor` in one call will bump the version up to the next major
version and down to a prerelease of that major version.
`preminor`, and `prepatch` work the same way.
* If called from a non-prerelease version, the `prerelease` will work the
same as `prepatch`. It increments the patch version, then makes a
prerelease. If the input version is already a prerelease it simply
increments it.
* `prerelease(v)`: Returns an array of prerelease components, or null
if none exist. Example: `prerelease('1.2.3-alpha.1') -> ['alpha', 1]`
* `major(v)`: Return the major version number.
* `minor(v)`: Return the minor version number.
* `patch(v)`: Return the patch version number.
* `intersects(r1, r2, loose)`: Return true if the two supplied ranges
or comparators intersect.
* `parse(v)`: Attempt to parse a string as a semantic version, returning either
a `SemVer` object or `null`.
### Comparison
* `gt(v1, v2)`: `v1 > v2`
* `gte(v1, v2)`: `v1 >= v2`
* `lt(v1, v2)`: `v1 < v2`
* `lte(v1, v2)`: `v1 <= v2`
* `eq(v1, v2)`: `v1 == v2` This is true if they're logically equivalent,
even if they're not the exact same string. You already know how to
compare strings.
* `neq(v1, v2)`: `v1 != v2` The opposite of `eq`.
* `cmp(v1, comparator, v2)`: Pass in a comparison string, and it'll call
the corresponding function above. `"==="` and `"!=="` do simple
string comparison, but are included for completeness. Throws if an
invalid comparison string is provided.
* `compare(v1, v2)`: Return `0` if `v1 == v2`, or `1` if `v1` is greater, or `-1` if
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `rcompare(v1, v2)`: The reverse of compare. Sorts an array of versions
in descending order when passed to `Array.sort()`.
* `compareBuild(v1, v2)`: The same as `compare` but considers `build` when two versions
are equal. Sorts in ascending order if passed to `Array.sort()`.
`v2` is greater. Sorts in ascending order if passed to `Array.sort()`.
* `diff(v1, v2)`: Returns difference between two versions by the release type
(`major`, `premajor`, `minor`, `preminor`, `patch`, `prepatch`, or `prerelease`),
or null if the versions are the same.
### Comparators
* `intersects(comparator)`: Return true if the comparators intersect
### Ranges
* `validRange(range)`: Return the valid range or null if it's not valid
* `satisfies(version, range)`: Return true if the version satisfies the
range.
* `maxSatisfying(versions, range)`: Return the highest version in the list
that satisfies the range, or `null` if none of them do.
* `minSatisfying(versions, range)`: Return the lowest version in the list
that satisfies the range, or `null` if none of them do.
* `minVersion(range)`: Return the lowest version that can possibly match
the given range.
* `gtr(version, range)`: Return `true` if version is greater than all the
versions possible in the range.
* `ltr(version, range)`: Return `true` if version is less than all the
versions possible in the range.
* `outside(version, range, hilo)`: Return true if the version is outside
the bounds of the range in either the high or low direction. The
`hilo` argument must be either the string `'>'` or `'<'`. (This is
the function called by `gtr` and `ltr`.)
* `intersects(range)`: Return true if any of the ranges comparators intersect
* `simplifyRange(versions, range)`: Return a "simplified" range that
matches the same items in `versions` list as the range specified. Note
that it does *not* guarantee that it would match the same versions in all
cases, only for the set of versions provided. This is useful when
generating ranges by joining together multiple versions with `||`
programmatically, to provide the user with something a bit more
ergonomic. If the provided range is shorter in string-length than the
generated range, then that is returned.
* `subset(subRange, superRange)`: Return `true` if the `subRange` range is
entirely contained by the `superRange` range.
Note that, since ranges may be non-contiguous, a version might not be
greater than a range, less than a range, *or* satisfy a range! For
example, the range `1.2 <1.2.9 || >2.0.0` would have a hole from `1.2.9`
until `2.0.0`, so the version `1.2.10` would not be greater than the
range (because `2.0.1` satisfies, which is higher), nor less than the
range (since `1.2.8` satisfies, which is lower), and it also does not
satisfy the range.
If you want to know if a version satisfies or does not satisfy a
range, use the `satisfies(version, range)` function.
### Coercion
* `coerce(version, options)`: Coerces a string to semver if possible
This aims to provide a very forgiving translation of a non-semver string to
semver. It looks for the first digit in a string, and consumes all
remaining characters which satisfy at least a partial semver (e.g., `1`,
`1.2`, `1.2.3`) up to the max permitted length (256 characters). Longer
versions are simply truncated (`4.6.3.9.2-alpha2` becomes `4.6.3`). All
surrounding text is simply ignored (`v3.4 replaces v3.3.1` becomes
`3.4.0`). Only text which lacks digits will fail coercion (`version one`
is not valid). The maximum length for any semver component considered for
coercion is 16 characters; longer components will be ignored
(`10000000000000000.4.7.4` becomes `4.7.4`). The maximum value for any
semver component is `Number.MAX_SAFE_INTEGER || (2**53 - 1)`; higher value
components are invalid (`9999999999999999.4.7.4` is likely invalid).
If the `options.rtl` flag is set, then `coerce` will return the right-most
coercible tuple that does not share an ending index with a longer coercible
tuple. For example, `1.2.3.4` will return `2.3.4` in rtl mode, not
`4.0.0`. `1.2.3/4` will return `4.0.0`, because the `4` is not a part of
any other overlapping SemVer tuple.
### Clean
* `clean(version)`: Clean a string to be a valid semver if possible
This will return a cleaned and trimmed semver version. If the provided
version is not valid a null will be returned. This does not work for
ranges.
ex.
* `s.clean(' = v 2.1.5foo')`: `null`
* `s.clean(' = v 2.1.5foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean(' = v 2.1.5-foo')`: `null`
* `s.clean(' = v 2.1.5-foo', { loose: true })`: `'2.1.5-foo'`
* `s.clean('=v2.1.5')`: `'2.1.5'`
* `s.clean(' =v2.1.5')`: `2.1.5`
* `s.clean(' 2.1.5 ')`: `'2.1.5'`
* `s.clean('~1.0.0')`: `null`
## Exported Modules
<!--
TODO: Make sure that all of these items are documented (classes aren't,
eg), and then pull the module name into the documentation for that specific
thing.
-->
You may pull in just the part of this semver utility that you need, if you
are sensitive to packing and tree-shaking concerns. The main
`require('semver')` export uses getter functions to lazily load the parts
of the API that are used.
The following modules are available:
* `require('semver')`
* `require('semver/classes')`
* `require('semver/classes/comparator')`
* `require('semver/classes/range')`
* `require('semver/classes/semver')`
* `require('semver/functions/clean')`
* `require('semver/functions/cmp')`
* `require('semver/functions/coerce')`
* `require('semver/functions/compare')`
* `require('semver/functions/compare-build')`
* `require('semver/functions/compare-loose')`
* `require('semver/functions/diff')`
* `require('semver/functions/eq')`
* `require('semver/functions/gt')`
* `require('semver/functions/gte')`
* `require('semver/functions/inc')`
* `require('semver/functions/lt')`
* `require('semver/functions/lte')`
* `require('semver/functions/major')`
* `require('semver/functions/minor')`
* `require('semver/functions/neq')`
* `require('semver/functions/parse')`
* `require('semver/functions/patch')`
* `require('semver/functions/prerelease')`
* `require('semver/functions/rcompare')`
* `require('semver/functions/rsort')`
* `require('semver/functions/satisfies')`
* `require('semver/functions/sort')`
* `require('semver/functions/valid')`
* `require('semver/ranges/gtr')`
* `require('semver/ranges/intersects')`
* `require('semver/ranges/ltr')`
* `require('semver/ranges/max-satisfying')`
* `require('semver/ranges/min-satisfying')`
* `require('semver/ranges/min-version')`
* `require('semver/ranges/outside')`
* `require('semver/ranges/to-comparators')`
* `require('semver/ranges/valid')`
# Visitor utilities for AssemblyScript Compiler transformers
## Example
### List Fields
The transformer:
```ts
import {
ClassDeclaration,
FieldDeclaration,
MethodDeclaration,
} from "../../as";
import { ClassDecorator, registerDecorator } from "../decorator";
import { toString } from "../utils";
class ListMembers extends ClassDecorator {
visitFieldDeclaration(node: FieldDeclaration): void {
if (!node.name) console.log(toString(node) + "\n");
const name = toString(node.name);
const _type = toString(node.type!);
this.stdout.write(name + ": " + _type + "\n");
}
visitMethodDeclaration(node: MethodDeclaration): void {
const name = toString(node.name);
if (name == "constructor") {
return;
}
const sig = toString(node.signature);
this.stdout.write(name + ": " + sig + "\n");
}
visitClassDeclaration(node: ClassDeclaration): void {
this.visit(node.members);
}
get name(): string {
return "list";
}
}
export = registerDecorator(new ListMembers());
```
assembly/foo.ts:
```ts
@list
class Foo {
a: u8;
b: bool;
i: i32;
}
```
And then compile with `--transform` flag:
```
asc assembly/foo.ts --transform ./dist/examples/list --noEmit
```
Which prints the following to the console:
```
a: u8
b: bool
i: i32
```
# wrappy
Callback wrapping utility
## USAGE
```javascript
var wrappy = require("wrappy")
// var wrapper = wrappy(wrapperFunction)
// make sure a cb is called only once
// See also: http://npm.im/once for this specific use case
var once = wrappy(function (cb) {
var called = false
return function () {
if (called) return
called = true
return cb.apply(this, arguments)
}
})
function printBoo () {
console.log('boo')
}
// has some rando property
printBoo.iAmBooPrinter = true
var onlyPrintOnce = once(printBoo)
onlyPrintOnce() // prints 'boo'
onlyPrintOnce() // does nothing
// random property is retained!
assert.equal(onlyPrintOnce.iAmBooPrinter, true)
```
# universal-url [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Dependency Monitor][greenkeeper-image]][greenkeeper-url]
> WHATWG [`URL`](https://developer.mozilla.org/en/docs/Web/API/URL) for Node & Browser.
* For Node.js versions `>= 8`, the native implementation will be used.
* For Node.js versions `< 8`, a [shim](https://npmjs.com/whatwg-url) will be used.
* For web browsers without a native implementation, the same shim will be used.
## Installation
[Node.js](http://nodejs.org/) `>= 6` is required. To install, type this at the command line:
```shell
npm install universal-url
```
## Usage
```js
const {URL, URLSearchParams} = require('universal-url');
const url = new URL('http://domain/');
const params = new URLSearchParams('?param=value');
```
Global shim:
```js
require('universal-url').shim();
const url = new URL('http://domain/');
const params = new URLSearchParams('?param=value');
```
## Browserify/etc
The bundled file size of this library can be large for a web browser. If this is a problem, try using [universal-url-lite](https://npmjs.com/universal-url-lite) in your build as an alias for this module.
[npm-image]: https://img.shields.io/npm/v/universal-url.svg
[npm-url]: https://npmjs.org/package/universal-url
[travis-image]: https://img.shields.io/travis/stevenvachon/universal-url.svg
[travis-url]: https://travis-ci.org/stevenvachon/universal-url
[greenkeeper-image]: https://badges.greenkeeper.io/stevenvachon/universal-url.svg
[greenkeeper-url]: https://greenkeeper.io/
Standard library
================
Standard library components for use with `tsc` (portable) and `asc` (assembly).
Base configurations (.json) and definition files (.d.ts) are relevant to `tsc` only and not used by `asc`.
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
Overview [](https://travis-ci.org/lydell/js-tokens)
========
A regex that tokenizes JavaScript.
```js
var jsTokens = require("js-tokens").default
var jsString = "var foo=opts.foo;\n..."
jsString.match(jsTokens)
// ["var", " ", "foo", "=", "opts", ".", "foo", ";", "\n", ...]
```
Installation
============
`npm install js-tokens`
```js
import jsTokens from "js-tokens"
// or:
var jsTokens = require("js-tokens").default
```
Usage
=====
### `jsTokens` ###
A regex with the `g` flag that matches JavaScript tokens.
The regex _always_ matches, even invalid JavaScript and the empty string.
The next match is always directly after the previous.
### `var token = matchToToken(match)` ###
```js
import {matchToToken} from "js-tokens"
// or:
var matchToToken = require("js-tokens").matchToToken
```
Takes a `match` returned by `jsTokens.exec(string)`, and returns a `{type:
String, value: String}` object. The following types are available:
- string
- comment
- regex
- number
- name
- punctuator
- whitespace
- invalid
Multi-line comments and strings also have a `closed` property indicating if the
token was closed or not (see below).
Comments and strings both come in several flavors. To distinguish them, check if
the token starts with `//`, `/*`, `'`, `"` or `` ` ``.
Names are ECMAScript IdentifierNames, that is, including both identifiers and
keywords. You may use [is-keyword-js] to tell them apart.
Whitespace includes both line terminators and other whitespace.
[is-keyword-js]: https://github.com/crissdev/is-keyword-js
ECMAScript support
==================
The intention is to always support the latest ECMAScript version whose feature
set has been finalized.
If adding support for a newer version requires changes, a new version with a
major verion bump will be released.
Currently, ECMAScript 2018 is supported.
Invalid code handling
=====================
Unterminated strings are still matched as strings. JavaScript strings cannot
contain (unescaped) newlines, so unterminated strings simply end at the end of
the line. Unterminated template strings can contain unescaped newlines, though,
so they go on to the end of input.
Unterminated multi-line comments are also still matched as comments. They
simply go on to the end of the input.
Unterminated regex literals are likely matched as division and whatever is
inside the regex.
Invalid ASCII characters have their own capturing group.
Invalid non-ASCII characters are treated as names, to simplify the matching of
names (except unicode spaces which are treated as whitespace). Note: See also
the [ES2018](#es2018) section.
Regex literals may contain invalid regex syntax. They are still matched as
regex literals. They may also contain repeated regex flags, to keep the regex
simple.
Strings may contain invalid escape sequences.
Limitations
===========
Tokenizing JavaScript using regexes—in fact, _one single regex_—won’t be
perfect. But that’s not the point either.
You may compare jsTokens with [esprima] by using `esprima-compare.js`.
See `npm run esprima-compare`!
[esprima]: http://esprima.org/
### Template string interpolation ###
Template strings are matched as single tokens, from the starting `` ` `` to the
ending `` ` ``, including interpolations (whose tokens are not matched
individually).
Matching template string interpolations requires recursive balancing of `{` and
`}`—something that JavaScript regexes cannot do. Only one level of nesting is
supported.
### Division and regex literals collision ###
Consider this example:
```js
var g = 9.82
var number = bar / 2/g
var regex = / 2/g
```
A human can easily understand that in the `number` line we’re dealing with
division, and in the `regex` line we’re dealing with a regex literal. How come?
Because humans can look at the whole code to put the `/` characters in context.
A JavaScript regex cannot. It only sees forwards. (Well, ES2018 regexes can also
look backwards. See the [ES2018](#es2018) section).
When the `jsTokens` regex scans throught the above, it will see the following
at the end of both the `number` and `regex` rows:
```js
/ 2/g
```
It is then impossible to know if that is a regex literal, or part of an
expression dealing with division.
Here is a similar case:
```js
foo /= 2/g
foo(/= 2/g)
```
The first line divides the `foo` variable with `2/g`. The second line calls the
`foo` function with the regex literal `/= 2/g`. Again, since `jsTokens` only
sees forwards, it cannot tell the two cases apart.
There are some cases where we _can_ tell division and regex literals apart,
though.
First off, we have the simple cases where there’s only one slash in the line:
```js
var foo = 2/g
foo /= 2
```
Regex literals cannot contain newlines, so the above cases are correctly
identified as division. Things are only problematic when there are more than
one non-comment slash in a single line.
Secondly, not every character is a valid regex flag.
```js
var number = bar / 2/e
```
The above example is also correctly identified as division, because `e` is not a
valid regex flag. I initially wanted to future-proof by allowing `[a-zA-Z]*`
(any letter) as flags, but it is not worth it since it increases the amount of
ambigous cases. So only the standard `g`, `m`, `i`, `y` and `u` flags are
allowed. This means that the above example will be identified as division as
long as you don’t rename the `e` variable to some permutation of `gmiyus` 1 to 6
characters long.
Lastly, we can look _forward_ for information.
- If the token following what looks like a regex literal is not valid after a
regex literal, but is valid in a division expression, then the regex literal
is treated as division instead. For example, a flagless regex cannot be
followed by a string, number or name, but all of those three can be the
denominator of a division.
- Generally, if what looks like a regex literal is followed by an operator, the
regex literal is treated as division instead. This is because regexes are
seldomly used with operators (such as `+`, `*`, `&&` and `==`), but division
could likely be part of such an expression.
Please consult the regex source and the test cases for precise information on
when regex or division is matched (should you need to know). In short, you
could sum it up as:
If the end of a statement looks like a regex literal (even if it isn’t), it
will be treated as one. Otherwise it should work as expected (if you write sane
code).
### ES2018 ###
ES2018 added some nice regex improvements to the language.
- [Unicode property escapes] should allow telling names and invalid non-ASCII
characters apart without blowing up the regex size.
- [Lookbehind assertions] should allow matching telling division and regex
literals apart in more cases.
- [Named capture groups] might simplify some things.
These things would be nice to do, but are not critical. They probably have to
wait until the oldest maintained Node.js LTS release supports those features.
[Unicode property escapes]: http://2ality.com/2017/07/regexp-unicode-property-escapes.html
[Lookbehind assertions]: http://2ality.com/2017/05/regexp-lookbehind-assertions.html
[Named capture groups]: http://2ality.com/2017/05/regexp-named-capture-groups.html
License
=======
[MIT](LICENSE).
bs58
====
[](https://travis-ci.org/cryptocoinjs/bs58)
JavaScript component to compute base 58 encoding. This encoding is typically used for crypto currencies such as Bitcoin.
**Note:** If you're looking for **base 58 check** encoding, see: [https://github.com/bitcoinjs/bs58check](https://github.com/bitcoinjs/bs58check), which depends upon this library.
Install
-------
npm i --save bs58
API
---
### encode(input)
`input` must be a [Buffer](https://nodejs.org/api/buffer.html) or an `Array`. It returns a `string`.
**example**:
```js
const bs58 = require('bs58')
const bytes = Buffer.from('003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187', 'hex')
const address = bs58.encode(bytes)
console.log(address)
// => 16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS
```
### decode(input)
`input` must be a base 58 encoded string. Returns a [Buffer](https://nodejs.org/api/buffer.html).
**example**:
```js
const bs58 = require('bs58')
const address = '16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS'
const bytes = bs58.decode(address)
console.log(out.toString('hex'))
// => 003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187
```
Hack / Test
-----------
Uses JavaScript standard style. Read more:
[](https://github.com/feross/standard)
Credits
-------
- [Mike Hearn](https://github.com/mikehearn) for original Java implementation
- [Stefan Thomas](https://github.com/justmoon) for porting to JavaScript
- [Stephan Pair](https://github.com/gasteve) for buffer improvements
- [Daniel Cousens](https://github.com/dcousens) for cleanup and merging improvements from bitcoinjs-lib
- [Jared Deckard](https://github.com/deckar01) for killing `bigi` as a dependency
License
-------
MIT
# prelude.ls [](https://travis-ci.org/gkz/prelude-ls)
is a functionally oriented utility library. It is powerful and flexible. Almost all of its functions are curried. It is written in, and is the recommended base library for, <a href="http://livescript.net">LiveScript</a>.
See **[the prelude.ls site](http://preludels.com)** for examples, a reference, and more.
You can install via npm `npm install prelude-ls`
### Development
`make test` to test
`make build` to build `lib` from `src`
`make build-browser` to build browser versions
# fast-deep-equal
The fastest deep equal with ES6 Map, Set and Typed arrays support.
[](https://travis-ci.org/epoberezkin/fast-deep-equal)
[](https://www.npmjs.com/package/fast-deep-equal)
[](https://coveralls.io/github/epoberezkin/fast-deep-equal?branch=master)
## Install
```bash
npm install fast-deep-equal
```
## Features
- ES5 compatible
- works in node.js (8+) and browsers (IE9+)
- checks equality of Date and RegExp objects by value.
ES6 equal (`require('fast-deep-equal/es6')`) also supports:
- Maps
- Sets
- Typed arrays
## Usage
```javascript
var equal = require('fast-deep-equal');
console.log(equal({foo: 'bar'}, {foo: 'bar'})); // true
```
To support ES6 Maps, Sets and Typed arrays equality use:
```javascript
var equal = require('fast-deep-equal/es6');
console.log(equal(Int16Array([1, 2]), Int16Array([1, 2]))); // true
```
To use with React (avoiding the traversal of React elements' _owner
property that contains circular references and is not needed when
comparing the elements - borrowed from [react-fast-compare](https://github.com/FormidableLabs/react-fast-compare)):
```javascript
var equal = require('fast-deep-equal/react');
var equal = require('fast-deep-equal/es6/react');
```
## Performance benchmark
Node.js v12.6.0:
```
fast-deep-equal x 261,950 ops/sec ±0.52% (89 runs sampled)
fast-deep-equal/es6 x 212,991 ops/sec ±0.34% (92 runs sampled)
fast-equals x 230,957 ops/sec ±0.83% (85 runs sampled)
nano-equal x 187,995 ops/sec ±0.53% (88 runs sampled)
shallow-equal-fuzzy x 138,302 ops/sec ±0.49% (90 runs sampled)
underscore.isEqual x 74,423 ops/sec ±0.38% (89 runs sampled)
lodash.isEqual x 36,637 ops/sec ±0.72% (90 runs sampled)
deep-equal x 2,310 ops/sec ±0.37% (90 runs sampled)
deep-eql x 35,312 ops/sec ±0.67% (91 runs sampled)
ramda.equals x 12,054 ops/sec ±0.40% (91 runs sampled)
util.isDeepStrictEqual x 46,440 ops/sec ±0.43% (90 runs sampled)
assert.deepStrictEqual x 456 ops/sec ±0.71% (88 runs sampled)
The fastest is fast-deep-equal
```
To run benchmark (requires node.js 6+):
```bash
npm run benchmark
```
__Please note__: this benchmark runs against the available test cases. To choose the most performant library for your application, it is recommended to benchmark against your data and to NOT expect this benchmark to reflect the performance difference in your application.
## Enterprise support
fast-deep-equal package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-fast-deep-equal?utm_source=npm-fast-deep-equal&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
## License
[MIT](https://github.com/epoberezkin/fast-deep-equal/blob/master/LICENSE)
# set-blocking
[](https://travis-ci.org/yargs/set-blocking)
[](https://www.npmjs.com/package/set-blocking)
[](https://coveralls.io/r/yargs/set-blocking?branch=master)
[](https://github.com/conventional-changelog/standard-version)
set blocking `stdio` and `stderr` ensuring that terminal output does not truncate.
```js
const setBlocking = require('set-blocking')
setBlocking(true)
console.log(someLargeStringToOutput)
```
## Historical Context/Word of Warning
This was created as a shim to address the bug discussed in [node #6456](https://github.com/nodejs/node/issues/6456). This bug crops up on
newer versions of Node.js (`0.12+`), truncating terminal output.
You should be mindful of the side-effects caused by using `set-blocking`:
* if your module sets blocking to `true`, it will effect other modules
consuming your library. In [yargs](https://github.com/yargs/yargs/blob/master/yargs.js#L653) we only call
`setBlocking(true)` once we already know we are about to call `process.exit(code)`.
* this patch will not apply to subprocesses spawned with `isTTY = true`, this is
the [default `spawn()` behavior](https://nodejs.org/api/child_process.html#child_process_child_process_spawn_command_args_options).
## License
ISC
# fs-minipass
Filesystem streams based on [minipass](http://npm.im/minipass).
4 classes are exported:
- ReadStream
- ReadStreamSync
- WriteStream
- WriteStreamSync
When using `ReadStreamSync`, all of the data is made available
immediately upon consuming the stream. Nothing is buffered in memory
when the stream is constructed. If the stream is piped to a writer,
then it will synchronously `read()` and emit data into the writer as
fast as the writer can consume it. (That is, it will respect
backpressure.) If you call `stream.read()` then it will read the
entire file and return the contents.
When using `WriteStreamSync`, every write is flushed to the file
synchronously. If your writes all come in a single tick, then it'll
write it all out in a single tick. It's as synchronous as you are.
The async versions work much like their node builtin counterparts,
with the exception of introducing significantly less Stream machinery
overhead.
## USAGE
It's just streams, you pipe them or read() them or write() to them.
```js
const fsm = require('fs-minipass')
const readStream = new fsm.ReadStream('file.txt')
const writeStream = new fsm.WriteStream('output.txt')
writeStream.write('some file header or whatever\n')
readStream.pipe(writeStream)
```
## ReadStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `readSize` The size of reads to do, defaults to 16MB
- `size` The size of the file, if known. Prevents zero-byte read()
call at the end.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the file is done being read.
## WriteStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `mode` The mode to create the file with. Defaults to `0o666`.
- `start` The position in the file to start reading. If not
specified, then the file will start writing at position zero, and be
truncated by default.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the stream is ended.
- `flags` Flags to use when opening the file. Irrelevant if `fd` is
passed in, since file won't be opened in that case. Defaults to
`'a'` if a `pos` is specified, or `'w'` otherwise.
## Test Strategy
- tests are copied from the [polyfill implementation](https://github.com/tc39/proposal-temporal/tree/main/polyfill/test)
- tests should be removed if they relate to features that do not make sense for TS/AS, i.e. tests that validate the shape of an object do not make sense in a language with compile-time type checking
- tests that fail because a feature has not been implemented yet should be left as failures.
[](https://travis-ci.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf#info=devDependencies)
The [UNIX command](http://en.wikipedia.org/wiki/Rm_(Unix)) `rm -rf` for node.
Install with `npm install rimraf`, or just drop rimraf.js somewhere.
## API
`rimraf(f, [opts], callback)`
The first parameter will be interpreted as a globbing pattern for files. If you
want to disable globbing you can do so with `opts.disableGlob` (defaults to
`false`). This might be handy, for instance, if you have filenames that contain
globbing wildcard characters.
The callback will be called with an error if there is one. Certain
errors are handled for you:
* Windows: `EBUSY` and `ENOTEMPTY` - rimraf will back off a maximum of
`opts.maxBusyTries` times before giving up, adding 100ms of wait
between each attempt. The default `maxBusyTries` is 3.
* `ENOENT` - If the file doesn't exist, rimraf will return
successfully, since your desired outcome is already the case.
* `EMFILE` - Since `readdir` requires opening a file descriptor, it's
possible to hit `EMFILE` if too many file descriptors are in use.
In the sync case, there's nothing to be done for this. But in the
async case, rimraf will gradually back off with timeouts up to
`opts.emfileWait` ms, which defaults to 1000.
## options
* unlink, chmod, stat, lstat, rmdir, readdir,
unlinkSync, chmodSync, statSync, lstatSync, rmdirSync, readdirSync
In order to use a custom file system library, you can override
specific fs functions on the options object.
If any of these functions are present on the options object, then
the supplied function will be used instead of the default fs
method.
Sync methods are only relevant for `rimraf.sync()`, of course.
For example:
```javascript
var myCustomFS = require('some-custom-fs')
rimraf('some-thing', myCustomFS, callback)
```
* maxBusyTries
If an `EBUSY`, `ENOTEMPTY`, or `EPERM` error code is encountered
on Windows systems, then rimraf will retry with a linear backoff
wait of 100ms longer on each try. The default maxBusyTries is 3.
Only relevant for async usage.
* emfileWait
If an `EMFILE` error is encountered, then rimraf will retry
repeatedly with a linear backoff of 1ms longer on each try, until
the timeout counter hits this max. The default limit is 1000.
If you repeatedly encounter `EMFILE` errors, then consider using
[graceful-fs](http://npm.im/graceful-fs) in your program.
Only relevant for async usage.
* glob
Set to `false` to disable [glob](http://npm.im/glob) pattern
matching.
Set to an object to pass options to the glob module. The default
glob options are `{ nosort: true, silent: true }`.
Glob version 6 is used in this module.
Relevant for both sync and async usage.
* disableGlob
Set to any non-falsey value to disable globbing entirely.
(Equivalent to setting `glob: false`.)
## rimraf.sync
It can remove stuff synchronously, too. But that's not so good. Use
the async API. It's better.
## CLI
If installed with `npm install rimraf -g` it can be used as a global
command `rimraf <path> [<path> ...]` which is useful for cross platform support.
## mkdirp
If you need to create a directory recursively, check out
[mkdirp](https://github.com/substack/node-mkdirp).
binaryen.js
===========
**binaryen.js** is a port of [Binaryen](https://github.com/WebAssembly/binaryen) to the Web, allowing you to generate [WebAssembly](https://webassembly.org) using a JavaScript API.
<a href="https://github.com/AssemblyScript/binaryen.js/actions?query=workflow%3ABuild"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/binaryen.js/Build/master?label=build&logo=github" alt="Build status" /></a>
<a href="https://www.npmjs.com/package/binaryen"><img src="https://img.shields.io/npm/v/binaryen.svg?label=latest&color=007acc&logo=npm" alt="npm version" /></a>
<a href="https://www.npmjs.com/package/binaryen"><img src="https://img.shields.io/npm/v/binaryen/nightly.svg?label=nightly&color=007acc&logo=npm" alt="npm nightly version" /></a>
Usage
-----
```
$> npm install binaryen
```
```js
var binaryen = require("binaryen");
// Create a module with a single function
var myModule = new binaryen.Module();
myModule.addFunction("add", binaryen.createType([ binaryen.i32, binaryen.i32 ]), binaryen.i32, [ binaryen.i32 ],
myModule.block(null, [
myModule.local.set(2,
myModule.i32.add(
myModule.local.get(0, binaryen.i32),
myModule.local.get(1, binaryen.i32)
)
),
myModule.return(
myModule.local.get(2, binaryen.i32)
)
])
);
myModule.addFunctionExport("add", "add");
// Optimize the module using default passes and levels
myModule.optimize();
// Validate the module
if (!myModule.validate())
throw new Error("validation error");
// Generate text format and binary
var textData = myModule.emitText();
var wasmData = myModule.emitBinary();
// Example usage with the WebAssembly API
var compiled = new WebAssembly.Module(wasmData);
var instance = new WebAssembly.Instance(compiled, {});
console.log(instance.exports.add(41, 1));
```
The buildbot also publishes nightly versions once a day if there have been changes. The latest nightly can be installed through
```
$> npm install binaryen@nightly
```
or you can use one of the [previous versions](https://github.com/AssemblyScript/binaryen.js/tags) instead if necessary.
### Usage with a CDN
* From GitHub via [jsDelivr](https://www.jsdelivr.com):<br />
`https://cdn.jsdelivr.net/gh/AssemblyScript/binaryen.js@VERSION/index.js`
* From npm via [jsDelivr](https://www.jsdelivr.com):<br />
`https://cdn.jsdelivr.net/npm/binaryen@VERSION/index.js`
* From npm via [unpkg](https://unpkg.com):<br />
`https://unpkg.com/binaryen@VERSION/index.js`
Replace `VERSION` with a [specific version](https://github.com/AssemblyScript/binaryen.js/releases) or omit it (not recommended in production) to use master/latest.
API
---
**Please note** that the Binaryen API is evolving fast and that definitions and documentation provided by the package tend to get out of sync despite our best efforts. It's a bot after all. If you rely on binaryen.js and spot an issue, please consider sending a PR our way by updating [index.d.ts](./index.d.ts) and [README.md](./README.md) to reflect the [current API](https://github.com/WebAssembly/binaryen/blob/master/src/js/binaryen.js-post.js).
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
### Contents
- [Types](#types)
- [Module construction](#module-construction)
- [Module manipulation](#module-manipulation)
- [Module validation](#module-validation)
- [Module optimization](#module-optimization)
- [Module creation](#module-creation)
- [Expression construction](#expression-construction)
- [Control flow](#control-flow)
- [Variable accesses](#variable-accesses)
- [Integer operations](#integer-operations)
- [Floating point operations](#floating-point-operations)
- [Datatype conversions](#datatype-conversions)
- [Function calls](#function-calls)
- [Linear memory accesses](#linear-memory-accesses)
- [Host operations](#host-operations)
- [Vector operations 🦄](#vector-operations-)
- [Atomic memory accesses 🦄](#atomic-memory-accesses-)
- [Atomic read-modify-write operations 🦄](#atomic-read-modify-write-operations-)
- [Atomic wait and notify operations 🦄](#atomic-wait-and-notify-operations-)
- [Sign extension operations 🦄](#sign-extension-operations-)
- [Multi-value operations 🦄](#multi-value-operations-)
- [Exception handling operations 🦄](#exception-handling-operations-)
- [Reference types operations 🦄](#reference-types-operations-)
- [Expression manipulation](#expression-manipulation)
- [Relooper](#relooper)
- [Source maps](#source-maps)
- [Debugging](#debugging)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
[Future features](http://webassembly.org/docs/future-features/) 🦄 might not be supported by all runtimes.
### Types
* **none**: `Type`<br />
The none type, e.g., `void`.
* **i32**: `Type`<br />
32-bit integer type.
* **i64**: `Type`<br />
64-bit integer type.
* **f32**: `Type`<br />
32-bit float type.
* **f64**: `Type`<br />
64-bit float (double) type.
* **v128**: `Type`<br />
128-bit vector type. 🦄
* **funcref**: `Type`<br />
A function reference. 🦄
* **anyref**: `Type`<br />
Any host reference. 🦄
* **nullref**: `Type`<br />
A null reference. 🦄
* **exnref**: `Type`<br />
An exception reference. 🦄
* **unreachable**: `Type`<br />
Special type indicating unreachable code when obtaining information about an expression.
* **auto**: `Type`<br />
Special type used in **Module#block** exclusively. Lets the API figure out a block's result type automatically.
* **createType**(types: `Type[]`): `Type`<br />
Creates a multi-value type from an array of types.
* **expandType**(type: `Type`): `Type[]`<br />
Expands a multi-value type to an array of types.
### Module construction
* new **Module**()<br />
Constructs a new module.
* **parseText**(text: `string`): `Module`<br />
Creates a module from Binaryen's s-expression text format (not official stack-style text format).
* **readBinary**(data: `Uint8Array`): `Module`<br />
Creates a module from binary data.
### Module manipulation
* Module#**addFunction**(name: `string`, params: `Type`, results: `Type`, vars: `Type[]`, body: `ExpressionRef`): `FunctionRef`<br />
Adds a function. `vars` indicate additional locals, in the given order.
* Module#**getFunction**(name: `string`): `FunctionRef`<br />
Gets a function, by name,
* Module#**removeFunction**(name: `string`): `void`<br />
Removes a function, by name.
* Module#**getNumFunctions**(): `number`<br />
Gets the number of functions within the module.
* Module#**getFunctionByIndex**(index: `number`): `FunctionRef`<br />
Gets the function at the specified index.
* Module#**addFunctionImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, params: `Type`, results: `Type`): `void`<br />
Adds a function import.
* Module#**addTableImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`): `void`<br />
Adds a table import. There's just one table for now, using name `"0"`.
* Module#**addMemoryImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`): `void`<br />
Adds a memory import. There's just one memory for now, using name `"0"`.
* Module#**addGlobalImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, globalType: `Type`): `void`<br />
Adds a global variable import. Imported globals must be immutable.
* Module#**addFunctionExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a function export.
* Module#**addTableExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a table export. There's just one table for now, using name `"0"`.
* Module#**addMemoryExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a memory export. There's just one memory for now, using name `"0"`.
* Module#**addGlobalExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a global variable export. Exported globals must be immutable.
* Module#**getNumExports**(): `number`<br />
Gets the number of exports witin the module.
* Module#**getExportByIndex**(index: `number`): `ExportRef`<br />
Gets the export at the specified index.
* Module#**removeExport**(externalName: `string`): `void`<br />
Removes an export, by external name.
* Module#**addGlobal**(name: `string`, type: `Type`, mutable: `number`, value: `ExpressionRef`): `GlobalRef`<br />
Adds a global instance variable.
* Module#**getGlobal**(name: `string`): `GlobalRef`<br />
Gets a global, by name,
* Module#**removeGlobal**(name: `string`): `void`<br />
Removes a global, by name.
* Module#**setFunctionTable**(initial: `number`, maximum: `number`, funcs: `string[]`, offset?: `ExpressionRef`): `void`<br />
Sets the contents of the function table. There's just one table for now, using name `"0"`.
* Module#**getFunctionTable**(): `{ imported: boolean, segments: TableElement[] }`<br />
Gets the contents of the function table.
* TableElement#**offset**: `ExpressionRef`
* TableElement#**names**: `string[]`
* Module#**setMemory**(initial: `number`, maximum: `number`, exportName: `string | null`, segments: `MemorySegment[]`, flags?: `number[]`, shared?: `boolean`): `void`<br />
Sets the memory. There's just one memory for now, using name `"0"`. Providing `exportName` also creates a memory export.
* MemorySegment#**offset**: `ExpressionRef`
* MemorySegment#**data**: `Uint8Array`
* MemorySegment#**passive**: `boolean`
* Module#**getNumMemorySegments**(): `number`<br />
Gets the number of memory segments within the module.
* Module#**getMemorySegmentInfoByIndex**(index: `number`): `MemorySegmentInfo`<br />
Gets information about the memory segment at the specified index.
* MemorySegmentInfo#**offset**: `number`
* MemorySegmentInfo#**data**: `Uint8Array`
* MemorySegmentInfo#**passive**: `boolean`
* Module#**setStart**(start: `FunctionRef`): `void`<br />
Sets the start function.
* Module#**getFeatures**(): `Features`<br />
Gets the WebAssembly features enabled for this module.
Note that the return value may be a bitmask indicating multiple features. Possible feature flags are:
* Features.**MVP**: `Features`
* Features.**Atomics**: `Features`
* Features.**BulkMemory**: `Features`
* Features.**MutableGlobals**: `Features`
* Features.**NontrappingFPToInt**: `Features`
* Features.**SignExt**: `Features`
* Features.**SIMD128**: `Features`
* Features.**ExceptionHandling**: `Features`
* Features.**TailCall**: `Features`
* Features.**ReferenceTypes**: `Features`
* Features.**Multivalue**: `Features`
* Features.**All**: `Features`
* Module#**setFeatures**(features: `Features`): `void`<br />
Sets the WebAssembly features enabled for this module.
* Module#**addCustomSection**(name: `string`, contents: `Uint8Array`): `void`<br />
Adds a custom section to the binary.
* Module#**autoDrop**(): `void`<br />
Enables automatic insertion of `drop` operations where needed. Lets you not worry about dropping when creating your code.
* **getFunctionInfo**(ftype: `FunctionRef`: `FunctionInfo`<br />
Obtains information about a function.
* FunctionInfo#**name**: `string`
* FunctionInfo#**module**: `string | null` (if imported)
* FunctionInfo#**base**: `string | null` (if imported)
* FunctionInfo#**params**: `Type`
* FunctionInfo#**results**: `Type`
* FunctionInfo#**vars**: `Type`
* FunctionInfo#**body**: `ExpressionRef`
* **getGlobalInfo**(global: `GlobalRef`): `GlobalInfo`<br />
Obtains information about a global.
* GlobalInfo#**name**: `string`
* GlobalInfo#**module**: `string | null` (if imported)
* GlobalInfo#**base**: `string | null` (if imported)
* GlobalInfo#**type**: `Type`
* GlobalInfo#**mutable**: `boolean`
* GlobalInfo#**init**: `ExpressionRef`
* **getExportInfo**(export_: `ExportRef`): `ExportInfo`<br />
Obtains information about an export.
* ExportInfo#**kind**: `ExternalKind`
* ExportInfo#**name**: `string`
* ExportInfo#**value**: `string`
Possible `ExternalKind` values are:
* **ExternalFunction**: `ExternalKind`
* **ExternalTable**: `ExternalKind`
* **ExternalMemory**: `ExternalKind`
* **ExternalGlobal**: `ExternalKind`
* **ExternalEvent**: `ExternalKind`
* **getEventInfo**(event: `EventRef`): `EventInfo`<br />
Obtains information about an event.
* EventInfo#**name**: `string`
* EventInfo#**module**: `string | null` (if imported)
* EventInfo#**base**: `string | null` (if imported)
* EventInfo#**attribute**: `number`
* EventInfo#**params**: `Type`
* EventInfo#**results**: `Type`
* **getSideEffects**(expr: `ExpressionRef`, features: `FeatureFlags`): `SideEffects`<br />
Gets the side effects of the specified expression.
* SideEffects.**None**: `SideEffects`
* SideEffects.**Branches**: `SideEffects`
* SideEffects.**Calls**: `SideEffects`
* SideEffects.**ReadsLocal**: `SideEffects`
* SideEffects.**WritesLocal**: `SideEffects`
* SideEffects.**ReadsGlobal**: `SideEffects`
* SideEffects.**WritesGlobal**: `SideEffects`
* SideEffects.**ReadsMemory**: `SideEffects`
* SideEffects.**WritesMemory**: `SideEffects`
* SideEffects.**ImplicitTrap**: `SideEffects`
* SideEffects.**IsAtomic**: `SideEffects`
* SideEffects.**Throws**: `SideEffects`
* SideEffects.**Any**: `SideEffects`
### Module validation
* Module#**validate**(): `boolean`<br />
Validates the module. Returns `true` if valid, otherwise prints validation errors and returns `false`.
### Module optimization
* Module#**optimize**(): `void`<br />
Optimizes the module using the default optimization passes.
* Module#**optimizeFunction**(func: `FunctionRef | string`): `void`<br />
Optimizes a single function using the default optimization passes.
* Module#**runPasses**(passes: `string[]`): `void`<br />
Runs the specified passes on the module.
* Module#**runPassesOnFunction**(func: `FunctionRef | string`, passes: `string[]`): `void`<br />
Runs the specified passes on a single function.
* **getOptimizeLevel**(): `number`<br />
Gets the currently set optimize level. `0`, `1`, `2` correspond to `-O0`, `-O1`, `-O2` (default), etc.
* **setOptimizeLevel**(level: `number`): `void`<br />
Sets the optimization level to use. `0`, `1`, `2` correspond to `-O0`, `-O1`, `-O2` (default), etc.
* **getShrinkLevel**(): `number`<br />
Gets the currently set shrink level. `0`, `1`, `2` correspond to `-O0`, `-Os` (default), `-Oz`.
* **setShrinkLevel**(level: `number`): `void`<br />
Sets the shrink level to use. `0`, `1`, `2` correspond to `-O0`, `-Os` (default), `-Oz`.
* **getDebugInfo**(): `boolean`<br />
Gets whether generating debug information is currently enabled or not.
* **setDebugInfo**(on: `boolean`): `void`<br />
Enables or disables debug information in emitted binaries.
* **getLowMemoryUnused**(): `boolean`<br />
Gets whether the low 1K of memory can be considered unused when optimizing.
* **setLowMemoryUnused**(on: `boolean`): `void`<br />
Enables or disables whether the low 1K of memory can be considered unused when optimizing.
* **getPassArgument**(key: `string`): `string | null`<br />
Gets the value of the specified arbitrary pass argument.
* **setPassArgument**(key: `string`, value: `string | null`): `void`<br />
Sets the value of the specified arbitrary pass argument. Removes the respective argument if `value` is `null`.
* **clearPassArguments**(): `void`<br />
Clears all arbitrary pass arguments.
* **getAlwaysInlineMaxSize**(): `number`<br />
Gets the function size at which we always inline.
* **setAlwaysInlineMaxSize**(size: `number`): `void`<br />
Sets the function size at which we always inline.
* **getFlexibleInlineMaxSize**(): `number`<br />
Gets the function size which we inline when functions are lightweight.
* **setFlexibleInlineMaxSize**(size: `number`): `void`<br />
Sets the function size which we inline when functions are lightweight.
* **getOneCallerInlineMaxSize**(): `number`<br />
Gets the function size which we inline when there is only one caller.
* **setOneCallerInlineMaxSize**(size: `number`): `void`<br />
Sets the function size which we inline when there is only one caller.
### Module creation
* Module#**emitBinary**(): `Uint8Array`<br />
Returns the module in binary format.
* Module#**emitBinary**(sourceMapUrl: `string | null`): `BinaryWithSourceMap`<br />
Returns the module in binary format with its source map. If `sourceMapUrl` is `null`, source map generation is skipped.
* BinaryWithSourceMap#**binary**: `Uint8Array`
* BinaryWithSourceMap#**sourceMap**: `string | null`
* Module#**emitText**(): `string`<br />
Returns the module in Binaryen's s-expression text format (not official stack-style text format).
* Module#**emitAsmjs**(): `string`<br />
Returns the [asm.js](http://asmjs.org/) representation of the module.
* Module#**dispose**(): `void`<br />
Releases the resources held by the module once it isn't needed anymore.
### Expression construction
#### [Control flow](http://webassembly.org/docs/semantics/#control-constructs-and-instructions)
* Module#**block**(label: `string | null`, children: `ExpressionRef[]`, resultType?: `Type`): `ExpressionRef`<br />
Creates a block. `resultType` defaults to `none`.
* Module#**if**(condition: `ExpressionRef`, ifTrue: `ExpressionRef`, ifFalse?: `ExpressionRef`): `ExpressionRef`<br />
Creates an if or if/else combination.
* Module#**loop**(label: `string | null`, body: `ExpressionRef`): `ExpressionRef`<br />
Creates a loop.
* Module#**br**(label: `string`, condition?: `ExpressionRef`, value?: `ExpressionRef`): `ExpressionRef`<br />
Creates a branch (br) to a label.
* Module#**switch**(labels: `string[]`, defaultLabel: `string`, condition: `ExpressionRef`, value?: `ExpressionRef`): `ExpressionRef`<br />
Creates a switch (br_table).
* Module#**nop**(): `ExpressionRef`<br />
Creates a no-operation (nop) instruction.
* Module#**return**(value?: `ExpressionRef`): `ExpressionRef`
Creates a return.
* Module#**unreachable**(): `ExpressionRef`<br />
Creates an [unreachable](http://webassembly.org/docs/semantics/#unreachable) instruction that will always trap.
* Module#**drop**(value: `ExpressionRef`): `ExpressionRef`<br />
Creates a [drop](http://webassembly.org/docs/semantics/#type-parametric-operators) of a value.
* Module#**select**(condition: `ExpressionRef`, ifTrue: `ExpressionRef`, ifFalse: `ExpressionRef`, type?: `Type`): `ExpressionRef`<br />
Creates a [select](http://webassembly.org/docs/semantics/#type-parametric-operators) of one of two values.
#### [Variable accesses](http://webassembly.org/docs/semantics/#local-variables)
* Module#**local.get**(index: `number`, type: `Type`): `ExpressionRef`<br />
Creates a local.get for the local at the specified index. Note that we must specify the type here as we may not have created the local being accessed yet.
* Module#**local.set**(index: `number`, value: `ExpressionRef`): `ExpressionRef`<br />
Creates a local.set for the local at the specified index.
* Module#**local.tee**(index: `number`, value: `ExpressionRef`, type: `Type`): `ExpressionRef`<br />
Creates a local.tee for the local at the specified index. A tee differs from a set in that the value remains on the stack. Note that we must specify the type here as we may not have created the local being accessed yet.
* Module#**global.get**(name: `string`, type: `Type`): `ExpressionRef`<br />
Creates a global.get for the global with the specified name. Note that we must specify the type here as we may not have created the global being accessed yet.
* Module#**global.set**(name: `string`, value: `ExpressionRef`): `ExpressionRef`<br />
Creates a global.set for the global with the specified name.
#### [Integer operations](http://webassembly.org/docs/semantics/#32-bit-integer-operators)
* Module#i32.**const**(value: `number`): `ExpressionRef`
* Module#i32.**clz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ctz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**popcnt**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**eqz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**div_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**div_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rem_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rem_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shr_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rotl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rotr**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**le_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**const**(low: `number`, high: `number`): `ExpressionRef`
* Module#i64.**clz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ctz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**popcnt**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**eqz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**div_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**div_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rem_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rem_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shr_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rotl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rotr**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**le_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
#### [Floating point operations](http://webassembly.org/docs/semantics/#floating-point-operators)
* Module#f32.**const**(value: `number`): `ExpressionRef`
* Module#f32.**const_bits**(value: `number`): `ExpressionRef`
* Module#f32.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ceil**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**floor**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**trunc**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**nearest**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**copysign**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**const**(value: `number`): `ExpressionRef`
* Module#f64.**const_bits**(value: `number`): `ExpressionRef`
* Module#f64.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ceil**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**floor**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**trunc**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**nearest**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**copysign**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
#### [Datatype conversions](http://webassembly.org/docs/semantics/#datatype-conversions-truncations-reinterpretations-promotions-and-demotions)
* Module#i32.**trunc_s.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_s.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_u.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_u.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**wrap**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**trunc_s.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_s.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_u.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_u.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f32.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_s.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_s.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_u.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_u.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**demote**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_s.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_s.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_u.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_u.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**promote**(value: `ExpressionRef`): `ExpressionRef`
#### [Function calls](http://webassembly.org/docs/semantics/#calls)
* Module#**call**(name: `string`, operands: `ExpressionRef[]`, returnType: `Type`): `ExpressionRef`
Creates a call to a function. Note that we must specify the return type here as we may not have created the function being called yet.
* Module#**return_call**(name: `string`, operands: `ExpressionRef[]`, returnType: `Type`): `ExpressionRef`<br />
Like **call**, but creates a tail-call. 🦄
* Module#**call_indirect**(target: `ExpressionRef`, operands: `ExpressionRef[]`, params: `Type`, results: `Type`): `ExpressionRef`<br />
Similar to **call**, but calls indirectly, i.e., via a function pointer, so an expression replaces the name as the called value.
* Module#**return_call_indirect**(target: `ExpressionRef`, operands: `ExpressionRef[]`, params: `Type`, results: `Type`): `ExpressionRef`<br />
Like **call_indirect**, but creates a tail-call. 🦄
#### [Linear memory accesses](http://webassembly.org/docs/semantics/#linear-memory-accesses)
* Module#i32.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load16_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load16_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store8**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store16**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
>
* Module#i64.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load16_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load16_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load32_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load32_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store8**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store16**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store32**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#f32.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#f32.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#f64.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
#### [Host operations](http://webassembly.org/docs/semantics/#resizing)
* Module#**memory.size**(): `ExpressionRef`
* Module#**memory.grow**(value: `number`): `ExpressionRef`
#### [Vector operations](https://github.com/WebAssembly/simd/blob/master/proposals/simd/SIMD.md) 🦄
* Module#v128.**const**(bytes: `Uint8Array`): `ExpressionRef`
* Module#v128.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#v128.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#v128.**not**(value: `ExpressionRef`): `ExpressionRef`
* Module#v128.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**andnot**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**bitselect**(left: `ExpressionRef`, right: `ExpressionRef`, cond: `ExpressionRef`): `ExpressionRef`
>
* Module#i8x16.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i8x16.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i8x16.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**avgr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**narrow_i16x8_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**narrow_i16x8_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#i16x8.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i16x8.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i16x8.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**avgr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**narrow_i32x4_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**narrow_i32x4_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_low_i8x16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_high_i8x16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_low_i8x16_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_high_i8x16_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**load8x8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**load8x8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#i32x4.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i32x4.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i32x4.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**dot_i16x8_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**trunc_sat_f32x4_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**trunc_sat_f32x4_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_low_i16x8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_high_i16x8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_low_i16x8_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_high_i16x8_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**load16x4_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**load16x4_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#i64x2.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i64x2.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i64x2.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**trunc_sat_f64x2_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**trunc_sat_f64x2_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**load32x2_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**load32x2_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#f32x4.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**extract_lane**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#f32x4.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**qfma**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**qfms**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**convert_i32x4_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**convert_i32x4_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64x2.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**extract_lane**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#f64x2.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**qfma**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**qfms**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**convert_i64x2_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**convert_i64x2_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#v8x16.**shuffle**(left: `ExpressionRef`, right: `ExpressionRef`, mask: `Uint8Array`): `ExpressionRef`
* Module#v8x16.**swizzle**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v8x16.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v16x8.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v32x4.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v64x2.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
#### [Atomic memory accesses](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#atomic-memory-accesses) 🦄
* Module#i32.**atomic.load**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.load8_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.load16_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store8**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store16**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**atomic.load**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load8_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load16_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load32_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store8**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store16**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store32**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
#### [Atomic read-modify-write operations](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#read-modify-write) 🦄
* Module#i32.**atomic.rmw.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**atomic.rmw.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
#### [Atomic wait and notify operations](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#wait-and-notify-operators) 🦄
* Module#i32.**atomic.wait**(ptr: `ExpressionRef`, expected: `ExpressionRef`, timeout: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.wait**(ptr: `ExpressionRef`, expected: `ExpressionRef`, timeout: `ExpressionRef`): `ExpressionRef`
* Module#**atomic.notify**(ptr: `ExpressionRef`, notifyCount: `ExpressionRef`): `ExpressionRef`
* Module#**atomic.fence**(): `ExpressionRef`
#### [Sign extension operations](https://github.com/WebAssembly/sign-extension-ops/blob/master/proposals/sign-extension-ops/Overview.md) 🦄
* Module#i32.**extend8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**extend16_s**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**extend8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend32_s**(value: `ExpressionRef`): `ExpressionRef`
#### [Multi-value operations](https://github.com/WebAssembly/multi-value/blob/master/proposals/multi-value/Overview.md) 🦄
Note that these are pseudo instructions enabling Binaryen to reason about multiple values on the stack.
* Module#**push**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**pop**(): `ExpressionRef`
* Module#i64.**pop**(): `ExpressionRef`
* Module#f32.**pop**(): `ExpressionRef`
* Module#f64.**pop**(): `ExpressionRef`
* Module#v128.**pop**(): `ExpressionRef`
* Module#funcref.**pop**(): `ExpressionRef`
* Module#anyref.**pop**(): `ExpressionRef`
* Module#nullref.**pop**(): `ExpressionRef`
* Module#exnref.**pop**(): `ExpressionRef`
* Module#tuple.**make**(elements: `ExpressionRef[]`): `ExpressionRef`
* Module#tuple.**extract**(tuple: `ExpressionRef`, index: `number`): `ExpressionRef`
#### [Exception handling operations](https://github.com/WebAssembly/exception-handling/blob/master/proposals/Exceptions.md) 🦄
* Module#**try**(body: `ExpressionRef`, catchBody: `ExpressionRef`): `ExpressionRef`
* Module#**throw**(event: `string`, operands: `ExpressionRef[]`): `ExpressionRef`
* Module#**rethrow**(exnref: `ExpressionRef`): `ExpressionRef`
* Module#**br_on_exn**(label: `string`, event: `string`, exnref: `ExpressionRef`): `ExpressionRef`
>
* Module#**addEvent**(name: `string`, attribute: `number`, params: `Type`, results: `Type`): `Event`
* Module#**getEvent**(name: `string`): `Event`
* Module#**removeEvent**(name: `stirng`): `void`
* Module#**addEventImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, attribute: `number`, params: `Type`, results: `Type`): `void`
* Module#**addEventExport**(internalName: `string`, externalName: `string`): `ExportRef`
#### [Reference types operations](https://github.com/WebAssembly/reference-types/blob/master/proposals/reference-types/Overview.md) 🦄
* Module#ref.**null**(): `ExpressionRef`
* Module#ref.**is_null**(value: `ExpressionRef`): `ExpressionRef`
* Module#ref.**func**(name: `string`): `ExpressionRef`
### Expression manipulation
* **getExpressionId**(expr: `ExpressionRef`): `ExpressionId`<br />
Gets the id (kind) of the specified expression. Possible values are:
* **InvalidId**: `ExpressionId`
* **BlockId**: `ExpressionId`
* **IfId**: `ExpressionId`
* **LoopId**: `ExpressionId`
* **BreakId**: `ExpressionId`
* **SwitchId**: `ExpressionId`
* **CallId**: `ExpressionId`
* **CallIndirectId**: `ExpressionId`
* **LocalGetId**: `ExpressionId`
* **LocalSetId**: `ExpressionId`
* **GlobalGetId**: `ExpressionId`
* **GlobalSetId**: `ExpressionId`
* **LoadId**: `ExpressionId`
* **StoreId**: `ExpressionId`
* **ConstId**: `ExpressionId`
* **UnaryId**: `ExpressionId`
* **BinaryId**: `ExpressionId`
* **SelectId**: `ExpressionId`
* **DropId**: `ExpressionId`
* **ReturnId**: `ExpressionId`
* **HostId**: `ExpressionId`
* **NopId**: `ExpressionId`
* **UnreachableId**: `ExpressionId`
* **AtomicCmpxchgId**: `ExpressionId`
* **AtomicRMWId**: `ExpressionId`
* **AtomicWaitId**: `ExpressionId`
* **AtomicNotifyId**: `ExpressionId`
* **AtomicFenceId**: `ExpressionId`
* **SIMDExtractId**: `ExpressionId`
* **SIMDReplaceId**: `ExpressionId`
* **SIMDShuffleId**: `ExpressionId`
* **SIMDTernaryId**: `ExpressionId`
* **SIMDShiftId**: `ExpressionId`
* **SIMDLoadId**: `ExpressionId`
* **MemoryInitId**: `ExpressionId`
* **DataDropId**: `ExpressionId`
* **MemoryCopyId**: `ExpressionId`
* **MemoryFillId**: `ExpressionId`
* **RefNullId**: `ExpressionId`
* **RefIsNullId**: `ExpressionId`
* **RefFuncId**: `ExpressionId`
* **TryId**: `ExpressionId`
* **ThrowId**: `ExpressionId`
* **RethrowId**: `ExpressionId`
* **BrOnExnId**: `ExpressionId`
* **PushId**: `ExpressionId`
* **PopId**: `ExpressionId`
* **getExpressionType**(expr: `ExpressionRef`): `Type`<br />
Gets the type of the specified expression.
* **getExpressionInfo**(expr: `ExpressionRef`): `ExpressionInfo`<br />
Obtains information about an expression, always including:
* Info#**id**: `ExpressionId`
* Info#**type**: `Type`
Additional properties depend on the expression's `id` and are usually equivalent to the respective parameters when creating such an expression:
* BlockInfo#**name**: `string`
* BlockInfo#**children**: `ExpressionRef[]`
>
* IfInfo#**condition**: `ExpressionRef`
* IfInfo#**ifTrue**: `ExpressionRef`
* IfInfo#**ifFalse**: `ExpressionRef | null`
>
* LoopInfo#**name**: `string`
* LoopInfo#**body**: `ExpressionRef`
>
* BreakInfo#**name**: `string`
* BreakInfo#**condition**: `ExpressionRef | null`
* BreakInfo#**value**: `ExpressionRef | null`
>
* SwitchInfo#**names**: `string[]`
* SwitchInfo#**defaultName**: `string | null`
* SwitchInfo#**condition**: `ExpressionRef`
* SwitchInfo#**value**: `ExpressionRef | null`
>
* CallInfo#**target**: `string`
* CallInfo#**operands**: `ExpressionRef[]`
>
* CallImportInfo#**target**: `string`
* CallImportInfo#**operands**: `ExpressionRef[]`
>
* CallIndirectInfo#**target**: `ExpressionRef`
* CallIndirectInfo#**operands**: `ExpressionRef[]`
>
* LocalGetInfo#**index**: `number`
>
* LocalSetInfo#**isTee**: `boolean`
* LocalSetInfo#**index**: `number`
* LocalSetInfo#**value**: `ExpressionRef`
>
* GlobalGetInfo#**name**: `string`
>
* GlobalSetInfo#**name**: `string`
* GlobalSetInfo#**value**: `ExpressionRef`
>
* LoadInfo#**isAtomic**: `boolean`
* LoadInfo#**isSigned**: `boolean`
* LoadInfo#**offset**: `number`
* LoadInfo#**bytes**: `number`
* LoadInfo#**align**: `number`
* LoadInfo#**ptr**: `ExpressionRef`
>
* StoreInfo#**isAtomic**: `boolean`
* StoreInfo#**offset**: `number`
* StoreInfo#**bytes**: `number`
* StoreInfo#**align**: `number`
* StoreInfo#**ptr**: `ExpressionRef`
* StoreInfo#**value**: `ExpressionRef`
>
* ConstInfo#**value**: `number | { low: number, high: number }`
>
* UnaryInfo#**op**: `number`
* UnaryInfo#**value**: `ExpressionRef`
>
* BinaryInfo#**op**: `number`
* BinaryInfo#**left**: `ExpressionRef`
* BinaryInfo#**right**: `ExpressionRef`
>
* SelectInfo#**ifTrue**: `ExpressionRef`
* SelectInfo#**ifFalse**: `ExpressionRef`
* SelectInfo#**condition**: `ExpressionRef`
>
* DropInfo#**value**: `ExpressionRef`
>
* ReturnInfo#**value**: `ExpressionRef | null`
>
* NopInfo
>
* UnreachableInfo
>
* HostInfo#**op**: `number`
* HostInfo#**nameOperand**: `string | null`
* HostInfo#**operands**: `ExpressionRef[]`
>
* AtomicRMWInfo#**op**: `number`
* AtomicRMWInfo#**bytes**: `number`
* AtomicRMWInfo#**offset**: `number`
* AtomicRMWInfo#**ptr**: `ExpressionRef`
* AtomicRMWInfo#**value**: `ExpressionRef`
>
* AtomicCmpxchgInfo#**bytes**: `number`
* AtomicCmpxchgInfo#**offset**: `number`
* AtomicCmpxchgInfo#**ptr**: `ExpressionRef`
* AtomicCmpxchgInfo#**expected**: `ExpressionRef`
* AtomicCmpxchgInfo#**replacement**: `ExpressionRef`
>
* AtomicWaitInfo#**ptr**: `ExpressionRef`
* AtomicWaitInfo#**expected**: `ExpressionRef`
* AtomicWaitInfo#**timeout**: `ExpressionRef`
* AtomicWaitInfo#**expectedType**: `Type`
>
* AtomicNotifyInfo#**ptr**: `ExpressionRef`
* AtomicNotifyInfo#**notifyCount**: `ExpressionRef`
>
* AtomicFenceInfo
>
* SIMDExtractInfo#**op**: `Op`
* SIMDExtractInfo#**vec**: `ExpressionRef`
* SIMDExtractInfo#**index**: `ExpressionRef`
>
* SIMDReplaceInfo#**op**: `Op`
* SIMDReplaceInfo#**vec**: `ExpressionRef`
* SIMDReplaceInfo#**index**: `ExpressionRef`
* SIMDReplaceInfo#**value**: `ExpressionRef`
>
* SIMDShuffleInfo#**left**: `ExpressionRef`
* SIMDShuffleInfo#**right**: `ExpressionRef`
* SIMDShuffleInfo#**mask**: `Uint8Array`
>
* SIMDTernaryInfo#**op**: `Op`
* SIMDTernaryInfo#**a**: `ExpressionRef`
* SIMDTernaryInfo#**b**: `ExpressionRef`
* SIMDTernaryInfo#**c**: `ExpressionRef`
>
* SIMDShiftInfo#**op**: `Op`
* SIMDShiftInfo#**vec**: `ExpressionRef`
* SIMDShiftInfo#**shift**: `ExpressionRef`
>
* SIMDLoadInfo#**op**: `Op`
* SIMDLoadInfo#**offset**: `number`
* SIMDLoadInfo#**align**: `number`
* SIMDLoadInfo#**ptr**: `ExpressionRef`
>
* MemoryInitInfo#**segment**: `number`
* MemoryInitInfo#**dest**: `ExpressionRef`
* MemoryInitInfo#**offset**: `ExpressionRef`
* MemoryInitInfo#**size**: `ExpressionRef`
>
* MemoryDropInfo#**segment**: `number`
>
* MemoryCopyInfo#**dest**: `ExpressionRef`
* MemoryCopyInfo#**source**: `ExpressionRef`
* MemoryCopyInfo#**size**: `ExpressionRef`
>
* MemoryFillInfo#**dest**: `ExpressionRef`
* MemoryFillInfo#**value**: `ExpressionRef`
* MemoryFillInfo#**size**: `ExpressionRef`
>
* TryInfo#**body**: `ExpressionRef`
* TryInfo#**catchBody**: `ExpressionRef`
>
* RefNullInfo
>
* RefIsNullInfo#**value**: `ExpressionRef`
>
* RefFuncInfo#**func**: `string`
>
* ThrowInfo#**event**: `string`
* ThrowInfo#**operands**: `ExpressionRef[]`
>
* RethrowInfo#**exnref**: `ExpressionRef`
>
* BrOnExnInfo#**name**: `string`
* BrOnExnInfo#**event**: `string`
* BrOnExnInfo#**exnref**: `ExpressionRef`
>
* PopInfo
>
* PushInfo#**value**: `ExpressionRef`
* **emitText**(expression: `ExpressionRef`): `string`<br />
Emits the expression in Binaryen's s-expression text format (not official stack-style text format).
* **copyExpression**(expression: `ExpressionRef`): `ExpressionRef`<br />
Creates a deep copy of an expression.
### Relooper
* new **Relooper**()<br />
Constructs a relooper instance. This lets you provide an arbitrary CFG, and the relooper will structure it for WebAssembly.
* Relooper#**addBlock**(code: `ExpressionRef`): `RelooperBlockRef`<br />
Adds a new block to the CFG, containing the provided code as its body.
* Relooper#**addBranch**(from: `RelooperBlockRef`, to: `RelooperBlockRef`, condition: `ExpressionRef`, code: `ExpressionRef`): `void`<br />
Adds a branch from a block to another block, with a condition (or nothing, if this is the default branch to take from the origin - each block must have one such branch), and optional code to execute on the branch (useful for phis).
* Relooper#**addBlockWithSwitch**(code: `ExpressionRef`, condition: `ExpressionRef`): `RelooperBlockRef`<br />
Adds a new block, which ends with a switch/br_table, with provided code and condition (that determines where we go in the switch).
* Relooper#**addBranchForSwitch**(from: `RelooperBlockRef`, to: `RelooperBlockRef`, indexes: `number[]`, code: `ExpressionRef`): `void`<br />
Adds a branch from a block ending in a switch, to another block, using an array of indexes that determine where to go, and optional code to execute on the branch.
* Relooper#**renderAndDispose**(entry: `RelooperBlockRef`, labelHelper: `number`, module: `Module`): `ExpressionRef`<br />
Renders and cleans up the Relooper instance. Call this after you have created all the blocks and branches, giving it the entry block (where control flow begins), a label helper variable (an index of a local we can use, necessary for irreducible control flow), and the module. This returns an expression - normal WebAssembly code - that you can use normally anywhere.
### Source maps
* Module#**addDebugInfoFileName**(filename: `string`): `number`<br />
Adds a debug info file name to the module and returns its index.
* Module#**getDebugInfoFileName**(index: `number`): `string | null` <br />
Gets the name of the debug info file at the specified index.
* Module#**setDebugLocation**(func: `FunctionRef`, expr: `ExpressionRef`, fileIndex: `number`, lineNumber: `number`, columnNumber: `number`): `void`<br />
Sets the debug location of the specified `ExpressionRef` within the specified `FunctionRef`.
### Debugging
* Module#**interpret**(): `void`<br />
Runs the module in the interpreter, calling the start function.
# AssemblyScript Loader
A convenient loader for [AssemblyScript](https://assemblyscript.org) modules. Demangles module exports to a friendly object structure compatible with TypeScript definitions and provides useful utility to read/write data from/to memory.
[Documentation](https://assemblyscript.org/loader.html)
[](https://www.npmjs.com/package/esprima)
[](https://www.npmjs.com/package/esprima)
[](https://travis-ci.org/jquery/esprima)
[](https://codecov.io/github/jquery/esprima)
**Esprima** ([esprima.org](http://esprima.org), BSD license) is a high performance,
standard-compliant [ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
parser written in ECMAScript (also popularly known as
[JavaScript](https://en.wikipedia.org/wiki/JavaScript)).
Esprima is created and maintained by [Ariya Hidayat](https://twitter.com/ariyahidayat),
with the help of [many contributors](https://github.com/jquery/esprima/contributors).
### Features
- Full support for ECMAScript 2017 ([ECMA-262 8th Edition](http://www.ecma-international.org/publications/standards/Ecma-262.htm))
- Sensible [syntax tree format](https://github.com/estree/estree/blob/master/es5.md) as standardized by [ESTree project](https://github.com/estree/estree)
- Experimental support for [JSX](https://facebook.github.io/jsx/), a syntax extension for [React](https://facebook.github.io/react/)
- Optional tracking of syntax node location (index-based and line-column)
- [Heavily tested](http://esprima.org/test/ci.html) (~1500 [unit tests](https://github.com/jquery/esprima/tree/master/test/fixtures) with [full code coverage](https://codecov.io/github/jquery/esprima))
### API
Esprima can be used to perform [lexical analysis](https://en.wikipedia.org/wiki/Lexical_analysis) (tokenization) or [syntactic analysis](https://en.wikipedia.org/wiki/Parsing) (parsing) of a JavaScript program.
A simple example on Node.js REPL:
```javascript
> var esprima = require('esprima');
> var program = 'const answer = 42';
> esprima.tokenize(program);
[ { type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'answer' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '42' } ]
> esprima.parseScript(program);
{ type: 'Program',
body:
[ { type: 'VariableDeclaration',
declarations: [Object],
kind: 'const' } ],
sourceType: 'script' }
```
For more information, please read the [complete documentation](http://esprima.org/doc).
# cliui

[](https://www.npmjs.com/package/cliui)
[](https://conventionalcommits.org)

easily create complex multi-column command-line-interfaces.
## Example
```js
const ui = require('cliui')()
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 1, 0]
})
ui.div(
{
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
},
{
text: "the file to load." +
chalk.green("(if this description is long it wraps).")
,
width: 20
},
{
text: chalk.red("[required]"),
align: 'right'
}
)
console.log(ui.toString())
```
## Deno/ESM Support
As of `v7` `cliui` supports [Deno](https://github.com/denoland/deno) and
[ESM](https://nodejs.org/api/esm.html#esm_ecmascript_modules):
```typescript
import cliui from "https://deno.land/x/cliui/deno.ts";
const ui = cliui({})
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 1, 0]
})
ui.div({
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
})
console.log(ui.toString())
```
<img width="500" src="screenshot.png">
## Layout DSL
cliui exposes a simple layout DSL:
If you create a single `ui.div`, passing a string rather than an
object:
* `\n`: characters will be interpreted as new rows.
* `\t`: characters will be interpreted as new columns.
* `\s`: characters will be interpreted as padding.
**as an example...**
```js
var ui = require('./')({
width: 60
})
ui.div(
'Usage: node ./bin/foo.js\n' +
' <regex>\t provide a regex\n' +
' <glob>\t provide a glob\t [required]'
)
console.log(ui.toString())
```
**will output:**
```shell
Usage: node ./bin/foo.js
<regex> provide a regex
<glob> provide a glob [required]
```
## Methods
```js
cliui = require('cliui')
```
### cliui({width: integer})
Specify the maximum width of the UI being generated.
If no width is provided, cliui will try to get the current window's width and use it, and if that doesn't work, width will be set to `80`.
### cliui({wrap: boolean})
Enable or disable the wrapping of text in a column.
### cliui.div(column, column, column)
Create a row with any number of columns, a column
can either be a string, or an object with the following
options:
* **text:** some text to place in the column.
* **width:** the width of a column.
* **align:** alignment, `right` or `center`.
* **padding:** `[top, right, bottom, left]`.
* **border:** should a border be placed around the div?
### cliui.span(column, column, column)
Similar to `div`, except the next row will be appended without
a new line being created.
### cliui.resetOutput()
Resets the UI elements of the current cliui instance, maintaining the values
set for `width` and `wrap`.
# eslint-utils
[](https://www.npmjs.com/package/eslint-utils)
[](http://www.npmtrends.com/eslint-utils)
[](https://github.com/mysticatea/eslint-utils/actions)
[](https://codecov.io/gh/mysticatea/eslint-utils)
[](https://david-dm.org/mysticatea/eslint-utils)
## 🏁 Goal
This package provides utility functions and classes for make ESLint custom rules.
For examples:
- [getStaticValue](https://eslint-utils.mysticatea.dev/api/ast-utils.html#getstaticvalue) evaluates static value on AST.
- [ReferenceTracker](https://eslint-utils.mysticatea.dev/api/scope-utils.html#referencetracker-class) checks the members of modules/globals as handling assignments and destructuring.
## 📖 Usage
See [documentation](https://eslint-utils.mysticatea.dev/).
## 📰 Changelog
See [releases](https://github.com/mysticatea/eslint-utils/releases).
## ❤️ Contributing
Welcome contributing!
Please use GitHub's Issues/PRs.
### Development Tools
- `npm test` runs tests and measures coverage.
- `npm run clean` removes the coverage result of `npm test` command.
- `npm run coverage` shows the coverage result of the last `npm test` command.
- `npm run lint` runs ESLint.
- `npm run watch` runs tests on each file change.
# color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
<p align="center">
<img width="250" src="/yargs-logo.png">
</p>
<h1 align="center"> Yargs </h1>
<p align="center">
<b >Yargs be a node.js library fer hearties tryin' ter parse optstrings</b>
</p>
<br>
[![Build Status][travis-image]][travis-url]
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[![Coverage][coverage-image]][coverage-url]
[![Conventional Commits][conventional-commits-image]][conventional-commits-url]
[![Slack][slack-image]][slack-url]
## Description :
Yargs helps you build interactive command line tools, by parsing arguments and generating an elegant user interface.
It gives you:
* commands and (grouped) options (`my-program.js serve --port=5000`).
* a dynamically generated help menu based on your arguments.
> <img width="400" src="/screen.png">
* bash-completion shortcuts for commands and options.
* and [tons more](/docs/api.md).
## Installation
Stable version:
```bash
npm i yargs
```
Bleeding edge version with the most recent features:
```bash
npm i yargs@next
```
## Usage :
### Simple Example
```javascript
#!/usr/bin/env node
const {argv} = require('yargs')
if (argv.ships > 3 && argv.distance < 53.5) {
console.log('Plunder more riffiwobbles!')
} else {
console.log('Retreat from the xupptumblers!')
}
```
```bash
$ ./plunder.js --ships=4 --distance=22
Plunder more riffiwobbles!
$ ./plunder.js --ships 12 --distance 98.7
Retreat from the xupptumblers!
```
### Complex Example
```javascript
#!/usr/bin/env node
require('yargs') // eslint-disable-line
.command('serve [port]', 'start the server', (yargs) => {
yargs
.positional('port', {
describe: 'port to bind on',
default: 5000
})
}, (argv) => {
if (argv.verbose) console.info(`start server on :${argv.port}`)
serve(argv.port)
})
.option('verbose', {
alias: 'v',
type: 'boolean',
description: 'Run with verbose logging'
})
.argv
```
Run the example above with `--help` to see the help for the application.
## TypeScript
yargs has type definitions at [@types/yargs][type-definitions].
```
npm i @types/yargs --save-dev
```
See usage examples in [docs](/docs/typescript.md).
## Webpack
See usage examples of yargs with webpack in [docs](/docs/webpack.md).
## Community :
Having problems? want to contribute? join our [community slack](http://devtoolscommunity.herokuapp.com).
## Documentation :
### Table of Contents
* [Yargs' API](/docs/api.md)
* [Examples](/docs/examples.md)
* [Parsing Tricks](/docs/tricks.md)
* [Stop the Parser](/docs/tricks.md#stop)
* [Negating Boolean Arguments](/docs/tricks.md#negate)
* [Numbers](/docs/tricks.md#numbers)
* [Arrays](/docs/tricks.md#arrays)
* [Objects](/docs/tricks.md#objects)
* [Quotes](/docs/tricks.md#quotes)
* [Advanced Topics](/docs/advanced.md)
* [Composing Your App Using Commands](/docs/advanced.md#commands)
* [Building Configurable CLI Apps](/docs/advanced.md#configuration)
* [Customizing Yargs' Parser](/docs/advanced.md#customizing)
* [Contributing](/contributing.md)
[travis-url]: https://travis-ci.org/yargs/yargs
[travis-image]: https://img.shields.io/travis/yargs/yargs/master.svg
[npm-url]: https://www.npmjs.com/package/yargs
[npm-image]: https://img.shields.io/npm/v/yargs.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: http://standardjs.com/
[conventional-commits-image]: https://img.shields.io/badge/Conventional%20Commits-1.0.0-yellow.svg
[conventional-commits-url]: https://conventionalcommits.org/
[slack-image]: http://devtoolscommunity.herokuapp.com/badge.svg
[slack-url]: http://devtoolscommunity.herokuapp.com
[type-definitions]: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/yargs
[coverage-image]: https://img.shields.io/nycrc/yargs/yargs
[coverage-url]: https://github.com/yargs/yargs/blob/master/.nycrc
[](https://travis-ci.org/#!/adaltas/node-csv-stringify) [](https://www.npmjs.com/package/csv-stringify) [](https://www.npmjs.com/package/csv-stringify)
This package is a stringifier converting records into a CSV text and
implementing the Node.js [`stream.Transform`
API](https://nodejs.org/api/stream.html). It also provides the easier
synchronous and callback-based APIs for conveniency. It is both extremely easy
to use and powerful. It was first released in 2010 and is tested against big
data sets by a large community.
## Documentation
* [Project homepage](http://csv.js.org/stringify/)
* [API](http://csv.js.org/stringify/api/)
* [Options](http://csv.js.org/stringify/options/)
* [Examples](http://csv.js.org/stringify/examples/)
## Main features
* Follow the Node.js streaming API
* Simplicity with the optional callback API
* Support for custom formatters, delimiters, quotes, escape characters and header
* Support big datasets
* Complete test coverage and samples for inspiration
* Only 1 external dependency
* to be used conjointly with `csv-generate`, `csv-parse` and `stream-transform`
* MIT License
## Usage
The module is built on the Node.js Stream API. For the sake of simplicity, a
simple callback API is also provided. To give you a quick look, here's an
example of the callback API:
```javascript
const stringify = require('csv-stringify')
const assert = require('assert')
// import stringify from 'csv-stringify'
// import assert from 'assert/strict'
const input = [ [ '1', '2', '3', '4' ], [ 'a', 'b', 'c', 'd' ] ]
stringify(input, function(err, output) {
const expected = '1,2,3,4\na,b,c,d\n'
assert.strictEqual(output, expected, `output.should.eql ${expected}`)
console.log("Passed.", output)
})
```
## Development
Tests are executed with mocha. To install it, run `npm install` followed by `npm
test`. It will install mocha and its dependencies in your project "node_modules"
directory and run the test suite. The tests run against the CoffeeScript source
files.
To generate the JavaScript files, run `npm run build`.
The test suite is run online with
[Travis](https://travis-ci.org/#!/adaltas/node-csv-stringify). See the [Travis
definition
file](https://github.com/adaltas/node-csv-stringify/blob/master/.travis.yml) to
view the tested Node.js version.
## Contributors
* David Worms: <https://github.com/wdavidw>
[csv_home]: https://github.com/adaltas/node-csv
[stream_transform]: http://nodejs.org/api/stream.html#stream_class_stream_transform
[examples]: http://csv.js.org/stringify/examples/
[csv]: https://github.com/adaltas/node-csv
# regexpp
[](https://www.npmjs.com/package/regexpp)
[](http://www.npmtrends.com/regexpp)
[](https://github.com/mysticatea/regexpp/actions)
[](https://codecov.io/gh/mysticatea/regexpp)
[](https://david-dm.org/mysticatea/regexpp)
A regular expression parser for ECMAScript.
## 💿 Installation
```bash
$ npm install regexpp
```
- require Node.js 8 or newer.
## 📖 Usage
```ts
import {
AST,
RegExpParser,
RegExpValidator,
RegExpVisitor,
parseRegExpLiteral,
validateRegExpLiteral,
visitRegExpAST
} from "regexpp"
```
### parseRegExpLiteral(source, options?)
Parse a given regular expression literal then make AST object.
This is equivalent to `new RegExpParser(options).parseLiteral(source)`.
- **Parameters:**
- `source` (`string | RegExp`) The source code to parse.
- `options?` ([`RegExpParser.Options`]) The options to parse.
- **Return:**
- The AST of the regular expression.
### validateRegExpLiteral(source, options?)
Validate a given regular expression literal.
This is equivalent to `new RegExpValidator(options).validateLiteral(source)`.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `options?` ([`RegExpValidator.Options`]) The options to validate.
### visitRegExpAST(ast, handlers)
Visit each node of a given AST.
This is equivalent to `new RegExpVisitor(handlers).visit(ast)`.
- **Parameters:**
- `ast` ([`AST.Node`]) The AST to visit.
- `handlers` ([`RegExpVisitor.Handlers`]) The callbacks.
### RegExpParser
#### new RegExpParser(options?)
- **Parameters:**
- `options?` ([`RegExpParser.Options`]) The options to parse.
#### parser.parseLiteral(source, start?, end?)
Parse a regular expression literal.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"/abc/g"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- **Return:**
- The AST of the regular expression.
#### parser.parsePattern(source, start?, end?, uFlag?)
Parse a regular expression pattern.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"abc"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- `uFlag?` (`boolean`) The flag to enable Unicode mode.
- **Return:**
- The AST of the regular expression pattern.
#### parser.parseFlags(source, start?, end?)
Parse a regular expression flags.
- **Parameters:**
- `source` (`string`) The source code to parse. E.g. `"gim"`.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- **Return:**
- The AST of the regular expression flags.
### RegExpValidator
#### new RegExpValidator(options)
- **Parameters:**
- `options` ([`RegExpValidator.Options`]) The options to validate.
#### validator.validateLiteral(source, start, end)
Validate a regular expression literal.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
#### validator.validatePattern(source, start, end, uFlag)
Validate a regular expression pattern.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
- `uFlag?` (`boolean`) The flag to enable Unicode mode.
#### validator.validateFlags(source, start, end)
Validate a regular expression flags.
- **Parameters:**
- `source` (`string`) The source code to validate.
- `start?` (`number`) The start index in the source code. Default is `0`.
- `end?` (`number`) The end index in the source code. Default is `source.length`.
### RegExpVisitor
#### new RegExpVisitor(handlers)
- **Parameters:**
- `handlers` ([`RegExpVisitor.Handlers`]) The callbacks.
#### visitor.visit(ast)
Validate a regular expression literal.
- **Parameters:**
- `ast` ([`AST.Node`]) The AST to visit.
## 📰 Changelog
- [GitHub Releases](https://github.com/mysticatea/regexpp/releases)
## 🍻 Contributing
Welcome contributing!
Please use GitHub's Issues/PRs.
### Development Tools
- `npm test` runs tests and measures coverage.
- `npm run build` compiles TypeScript source code to `index.js`, `index.js.map`, and `index.d.ts`.
- `npm run clean` removes the temporary files which are created by `npm test` and `npm run build`.
- `npm run lint` runs ESLint.
- `npm run update:test` updates test fixtures.
- `npm run update:ids` updates `src/unicode/ids.ts`.
- `npm run watch` runs tests with `--watch` option.
[`AST.Node`]: src/ast.ts#L4
[`RegExpParser.Options`]: src/parser.ts#L539
[`RegExpValidator.Options`]: src/validator.ts#L127
[`RegExpVisitor.Handlers`]: src/visitor.ts#L204
# base-x
[](https://www.npmjs.org/package/base-x)
[](https://travis-ci.org/cryptocoinjs/base-x)
[](https://github.com/feross/standard)
Fast base encoding / decoding of any given alphabet using bitcoin style leading
zero compression.
**WARNING:** This module is **NOT RFC3548** compliant, it cannot be used for base16 (hex), base32, or base64 encoding in a standards compliant manner.
## Example
Base58
``` javascript
var BASE58 = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz'
var bs58 = require('base-x')(BASE58)
var decoded = bs58.decode('5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr')
console.log(decoded)
// => <Buffer 80 ed db dc 11 68 f1 da ea db d3 e4 4c 1e 3f 8f 5a 28 4c 20 29 f7 8a d2 6a f9 85 83 a4 99 de 5b 19>
console.log(bs58.encode(decoded))
// => 5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr
```
### Alphabets
See below for a list of commonly recognized alphabets, and their respective base.
Base | Alphabet
------------- | -------------
2 | `01`
8 | `01234567`
11 | `0123456789a`
16 | `0123456789abcdef`
32 | `0123456789ABCDEFGHJKMNPQRSTVWXYZ`
32 | `ybndrfg8ejkmcpqxot1uwisza345h769` (z-base-32)
36 | `0123456789abcdefghijklmnopqrstuvwxyz`
58 | `123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz`
62 | `0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ`
64 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/`
67 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.!~`
## How it works
It encodes octet arrays by doing long divisions on all significant digits in the
array, creating a representation of that number in the new base. Then for every
leading zero in the input (not significant as a number) it will encode as a
single leader character. This is the first in the alphabet and will decode as 8
bits. The other characters depend upon the base. For example, a base58 alphabet
packs roughly 5.858 bits per character.
This means the encoded string 000f (using a base16, 0-f alphabet) will actually decode
to 4 bytes unlike a canonical hex encoding which uniformly packs 4 bits into each
character.
While unusual, this does mean that no padding is required and it works for bases
like 43.
## LICENSE [MIT](LICENSE)
A direct derivation of the base58 implementation from [`bitcoin/bitcoin`](https://github.com/bitcoin/bitcoin/blob/f1e2f2a85962c1664e4e55471061af0eaa798d40/src/base58.cpp), generalized for variable length alphabets.
# URI.js
URI.js is an [RFC 3986](http://www.ietf.org/rfc/rfc3986.txt) compliant, scheme extendable URI parsing/validating/resolving library for all JavaScript environments (browsers, Node.js, etc).
It is also compliant with the IRI ([RFC 3987](http://www.ietf.org/rfc/rfc3987.txt)), IDNA ([RFC 5890](http://www.ietf.org/rfc/rfc5890.txt)), IPv6 Address ([RFC 5952](http://www.ietf.org/rfc/rfc5952.txt)), IPv6 Zone Identifier ([RFC 6874](http://www.ietf.org/rfc/rfc6874.txt)) specifications.
URI.js has an extensive test suite, and works in all (Node.js, web) environments. It weighs in at 6.4kb (gzipped, 17kb deflated).
## API
### Parsing
URI.parse("uri://user:[email protected]:123/one/two.three?q1=a1&q2=a2#body");
//returns:
//{
// scheme : "uri",
// userinfo : "user:pass",
// host : "example.com",
// port : 123,
// path : "/one/two.three",
// query : "q1=a1&q2=a2",
// fragment : "body"
//}
### Serializing
URI.serialize({scheme : "http", host : "example.com", fragment : "footer"}) === "http://example.com/#footer"
### Resolving
URI.resolve("uri://a/b/c/d?q", "../../g") === "uri://a/g"
### Normalizing
URI.normalize("HTTP://ABC.com:80/%7Esmith/home.html") === "http://abc.com/~smith/home.html"
### Comparison
URI.equal("example://a/b/c/%7Bfoo%7D", "eXAMPLE://a/./b/../b/%63/%7bfoo%7d") === true
### IP Support
//IPv4 normalization
URI.normalize("//192.068.001.000") === "//192.68.1.0"
//IPv6 normalization
URI.normalize("//[2001:0:0DB8::0:0001]") === "//[2001:0:db8::1]"
//IPv6 zone identifier support
URI.parse("//[2001:db8::7%25en1]");
//returns:
//{
// host : "2001:db8::7%en1"
//}
### IRI Support
//convert IRI to URI
URI.serialize(URI.parse("http://examplé.org/rosé")) === "http://xn--exampl-gva.org/ros%C3%A9"
//convert URI to IRI
URI.serialize(URI.parse("http://xn--exampl-gva.org/ros%C3%A9"), {iri:true}) === "http://examplé.org/rosé"
### Options
All of the above functions can accept an additional options argument that is an object that can contain one or more of the following properties:
* `scheme` (string)
Indicates the scheme that the URI should be treated as, overriding the URI's normal scheme parsing behavior.
* `reference` (string)
If set to `"suffix"`, it indicates that the URI is in the suffix format, and the validator will use the option's `scheme` property to determine the URI's scheme.
* `tolerant` (boolean, false)
If set to `true`, the parser will relax URI resolving rules.
* `absolutePath` (boolean, false)
If set to `true`, the serializer will not resolve a relative `path` component.
* `iri` (boolean, false)
If set to `true`, the serializer will unescape non-ASCII characters as per [RFC 3987](http://www.ietf.org/rfc/rfc3987.txt).
* `unicodeSupport` (boolean, false)
If set to `true`, the parser will unescape non-ASCII characters in the parsed output as per [RFC 3987](http://www.ietf.org/rfc/rfc3987.txt).
* `domainHost` (boolean, false)
If set to `true`, the library will treat the `host` component as a domain name, and convert IDNs (International Domain Names) as per [RFC 5891](http://www.ietf.org/rfc/rfc5891.txt).
## Scheme Extendable
URI.js supports inserting custom [scheme](http://en.wikipedia.org/wiki/URI_scheme) dependent processing rules. Currently, URI.js has built in support for the following schemes:
* http \[[RFC 2616](http://www.ietf.org/rfc/rfc2616.txt)\]
* https \[[RFC 2818](http://www.ietf.org/rfc/rfc2818.txt)\]
* ws \[[RFC 6455](http://www.ietf.org/rfc/rfc6455.txt)\]
* wss \[[RFC 6455](http://www.ietf.org/rfc/rfc6455.txt)\]
* mailto \[[RFC 6068](http://www.ietf.org/rfc/rfc6068.txt)\]
* urn \[[RFC 2141](http://www.ietf.org/rfc/rfc2141.txt)\]
* urn:uuid \[[RFC 4122](http://www.ietf.org/rfc/rfc4122.txt)\]
### HTTP/HTTPS Support
URI.equal("HTTP://ABC.COM:80", "http://abc.com/") === true
URI.equal("https://abc.com", "HTTPS://ABC.COM:443/") === true
### WS/WSS Support
URI.parse("wss://example.com/foo?bar=baz");
//returns:
//{
// scheme : "wss",
// host: "example.com",
// resourceName: "/foo?bar=baz",
// secure: true,
//}
URI.equal("WS://ABC.COM:80/chat#one", "ws://abc.com/chat") === true
### Mailto Support
URI.parse("mailto:[email protected],[email protected]?subject=SUBSCRIBE&body=Sign%20me%20up!");
//returns:
//{
// scheme : "mailto",
// to : ["[email protected]", "[email protected]"],
// subject : "SUBSCRIBE",
// body : "Sign me up!"
//}
URI.serialize({
scheme : "mailto",
to : ["[email protected]"],
subject : "REMOVE",
body : "Please remove me",
headers : {
cc : "[email protected]"
}
}) === "mailto:[email protected][email protected]&subject=REMOVE&body=Please%20remove%20me"
### URN Support
URI.parse("urn:example:foo");
//returns:
//{
// scheme : "urn",
// nid : "example",
// nss : "foo",
//}
#### URN UUID Support
URI.parse("urn:uuid:f81d4fae-7dec-11d0-a765-00a0c91e6bf6");
//returns:
//{
// scheme : "urn",
// nid : "uuid",
// uuid : "f81d4fae-7dec-11d0-a765-00a0c91e6bf6",
//}
## Usage
To load in a browser, use the following tag:
<script type="text/javascript" src="uri-js/dist/es5/uri.all.min.js"></script>
To load in a CommonJS/Module environment, first install with npm/yarn by running on the command line:
npm install uri-js
# OR
yarn add uri-js
Then, in your code, load it using:
const URI = require("uri-js");
If you are writing your code in ES6+ (ESNEXT) or TypeScript, you would load it using:
import * as URI from "uri-js";
Or you can load just what you need using named exports:
import { parse, serialize, resolve, resolveComponents, normalize, equal, removeDotSegments, pctEncChar, pctDecChars, escapeComponent, unescapeComponent } from "uri-js";
## Breaking changes
### Breaking changes from 3.x
URN parsing has been completely changed to better align with the specification. Scheme is now always `urn`, but has two new properties: `nid` which contains the Namspace Identifier, and `nss` which contains the Namespace Specific String. The `nss` property will be removed by higher order scheme handlers, such as the UUID URN scheme handler.
The UUID of a URN can now be found in the `uuid` property.
### Breaking changes from 2.x
URI validation has been removed as it was slow, exposed a vulnerabilty, and was generally not useful.
### Breaking changes from 1.x
The `errors` array on parsed components is now an `error` string.
# balanced-match
Match balanced string pairs, like `{` and `}` or `<b>` and `</b>`. Supports regular expressions as well!
[](http://travis-ci.org/juliangruber/balanced-match)
[](https://www.npmjs.org/package/balanced-match)
[](https://ci.testling.com/juliangruber/balanced-match)
## Example
Get the first matching pair of braces:
```js
var balanced = require('balanced-match');
console.log(balanced('{', '}', 'pre{in{nested}}post'));
console.log(balanced('{', '}', 'pre{first}between{second}post'));
console.log(balanced(/\s+\{\s+/, /\s+\}\s+/, 'pre { in{nest} } post'));
```
The matches are:
```bash
$ node example.js
{ start: 3, end: 14, pre: 'pre', body: 'in{nested}', post: 'post' }
{ start: 3,
end: 9,
pre: 'pre',
body: 'first',
post: 'between{second}post' }
{ start: 3, end: 17, pre: 'pre', body: 'in{nest}', post: 'post' }
```
## API
### var m = balanced(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
object with those keys:
* **start** the index of the first match of `a`
* **end** the index of the matching `b`
* **pre** the preamble, `a` and `b` not included
* **body** the match, `a` and `b` not included
* **post** the postscript, `a` and `b` not included
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `['{', 'a', '']` and `{a}}` will match `['', 'a', '}']`.
### var r = balanced.range(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
array with indexes: `[ <a index>, <b index> ]`.
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `[ 1, 3 ]` and `{a}}` will match `[0, 2]`.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install balanced-match
```
## Security contact information
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure.
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# brace-expansion
[Brace expansion](https://www.gnu.org/software/bash/manual/html_node/Brace-Expansion.html),
as known from sh/bash, in JavaScript.
[](http://travis-ci.org/juliangruber/brace-expansion)
[](https://www.npmjs.org/package/brace-expansion)
[](https://greenkeeper.io/)
[](https://ci.testling.com/juliangruber/brace-expansion)
## Example
```js
var expand = require('brace-expansion');
expand('file-{a,b,c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('-v{,,}')
// => ['-v', '-v', '-v']
expand('file{0..2}.jpg')
// => ['file0.jpg', 'file1.jpg', 'file2.jpg']
expand('file-{a..c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('file{2..0}.jpg')
// => ['file2.jpg', 'file1.jpg', 'file0.jpg']
expand('file{0..4..2}.jpg')
// => ['file0.jpg', 'file2.jpg', 'file4.jpg']
expand('file-{a..e..2}.jpg')
// => ['file-a.jpg', 'file-c.jpg', 'file-e.jpg']
expand('file{00..10..5}.jpg')
// => ['file00.jpg', 'file05.jpg', 'file10.jpg']
expand('{{A..C},{a..c}}')
// => ['A', 'B', 'C', 'a', 'b', 'c']
expand('ppp{,config,oe{,conf}}')
// => ['ppp', 'pppconfig', 'pppoe', 'pppoeconf']
```
## API
```js
var expand = require('brace-expansion');
```
### var expanded = expand(str)
Return an array of all possible and valid expansions of `str`. If none are
found, `[str]` is returned.
Valid expansions are:
```js
/^(.*,)+(.+)?$/
// {a,b,...}
```
A comma separated list of options, like `{a,b}` or `{a,{b,c}}` or `{,a,}`.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
A numeric sequence from `x` to `y` inclusive, with optional increment.
If `x` or `y` start with a leading `0`, all the numbers will be padded
to have equal length. Negative numbers and backwards iteration work too.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
An alphabetic sequence from `x` to `y` inclusive, with optional increment.
`x` and `y` must be exactly one character, and if given, `incr` must be a
number.
For compatibility reasons, the string `${` is not eligible for brace expansion.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install brace-expansion
```
## Contributors
- [Julian Gruber](https://github.com/juliangruber)
- [Isaac Z. Schlueter](https://github.com/isaacs)
## Sponsors
This module is proudly supported by my [Sponsors](https://github.com/juliangruber/sponsors)!
Do you want to support modules like this to improve their quality, stability and weigh in on new features? Then please consider donating to my [Patreon](https://www.patreon.com/juliangruber). Not sure how much of my modules you're using? Try [feross/thanks](https://github.com/feross/thanks)!
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# type-check [](https://travis-ci.org/gkz/type-check)
<a name="type-check" />
`type-check` is a library which allows you to check the types of JavaScript values at runtime with a Haskell like type syntax. It is great for checking external input, for testing, or even for adding a bit of safety to your internal code. It is a major component of [levn](https://github.com/gkz/levn). MIT license. Version 0.4.0. Check out the [demo](http://gkz.github.io/type-check/).
For updates on `type-check`, [follow me on twitter](https://twitter.com/gkzahariev).
npm install type-check
## Quick Examples
```js
// Basic types:
var typeCheck = require('type-check').typeCheck;
typeCheck('Number', 1); // true
typeCheck('Number', 'str'); // false
typeCheck('Error', new Error); // true
typeCheck('Undefined', undefined); // true
// Comment
typeCheck('count::Number', 1); // true
// One type OR another type:
typeCheck('Number | String', 2); // true
typeCheck('Number | String', 'str'); // true
// Wildcard, matches all types:
typeCheck('*', 2) // true
// Array, all elements of a single type:
typeCheck('[Number]', [1, 2, 3]); // true
typeCheck('[Number]', [1, 'str', 3]); // false
// Tuples, or fixed length arrays with elements of different types:
typeCheck('(String, Number)', ['str', 2]); // true
typeCheck('(String, Number)', ['str']); // false
typeCheck('(String, Number)', ['str', 2, 5]); // false
// Object properties:
typeCheck('{x: Number, y: Boolean}', {x: 2, y: false}); // true
typeCheck('{x: Number, y: Boolean}', {x: 2}); // false
typeCheck('{x: Number, y: Maybe Boolean}', {x: 2}); // true
typeCheck('{x: Number, y: Boolean}', {x: 2, y: false, z: 3}); // false
typeCheck('{x: Number, y: Boolean, ...}', {x: 2, y: false, z: 3}); // true
// A particular type AND object properties:
typeCheck('RegExp{source: String, ...}', /re/i); // true
typeCheck('RegExp{source: String, ...}', {source: 're'}); // false
// Custom types:
var opt = {customTypes:
{Even: { typeOf: 'Number', validate: function(x) { return x % 2 === 0; }}}};
typeCheck('Even', 2, opt); // true
// Nested:
var type = '{a: (String, [Number], {y: Array, ...}), b: Error{message: String, ...}}'
typeCheck(type, {a: ['hi', [1, 2, 3], {y: [1, 'ms']}], b: new Error('oh no')}); // true
```
Check out the [type syntax format](#syntax) and [guide](#guide).
## Usage
`require('type-check');` returns an object that exposes four properties. `VERSION` is the current version of the library as a string. `typeCheck`, `parseType`, and `parsedTypeCheck` are functions.
```js
// typeCheck(type, input, options);
typeCheck('Number', 2); // true
// parseType(type);
var parsedType = parseType('Number'); // object
// parsedTypeCheck(parsedType, input, options);
parsedTypeCheck(parsedType, 2); // true
```
### typeCheck(type, input, options)
`typeCheck` checks a JavaScript value `input` against `type` written in the [type format](#type-format) (and taking account the optional `options`) and returns whether the `input` matches the `type`.
##### arguments
* type - `String` - the type written in the [type format](#type-format) which to check against
* input - `*` - any JavaScript value, which is to be checked against the type
* options - `Maybe Object` - an optional parameter specifying additional options, currently the only available option is specifying [custom types](#custom-types)
##### returns
`Boolean` - whether the input matches the type
##### example
```js
typeCheck('Number', 2); // true
```
### parseType(type)
`parseType` parses string `type` written in the [type format](#type-format) into an object representing the parsed type.
##### arguments
* type - `String` - the type written in the [type format](#type-format) which to parse
##### returns
`Object` - an object in the parsed type format representing the parsed type
##### example
```js
parseType('Number'); // [{type: 'Number'}]
```
### parsedTypeCheck(parsedType, input, options)
`parsedTypeCheck` checks a JavaScript value `input` against parsed `type` in the parsed type format (and taking account the optional `options`) and returns whether the `input` matches the `type`. Use this in conjunction with `parseType` if you are going to use a type more than once.
##### arguments
* type - `Object` - the type in the parsed type format which to check against
* input - `*` - any JavaScript value, which is to be checked against the type
* options - `Maybe Object` - an optional parameter specifying additional options, currently the only available option is specifying [custom types](#custom-types)
##### returns
`Boolean` - whether the input matches the type
##### example
```js
parsedTypeCheck([{type: 'Number'}], 2); // true
var parsedType = parseType('String');
parsedTypeCheck(parsedType, 'str'); // true
```
<a name="type-format" />
## Type Format
### Syntax
White space is ignored. The root node is a __Types__.
* __Identifier__ = `[\$\w]+` - a group of any lower or upper case letters, numbers, underscores, or dollar signs - eg. `String`
* __Type__ = an `Identifier`, an `Identifier` followed by a `Structure`, just a `Structure`, or a wildcard `*` - eg. `String`, `Object{x: Number}`, `{x: Number}`, `Array{0: String, 1: Boolean, length: Number}`, `*`
* __Types__ = optionally a comment (an `Identifier` followed by a `::`), optionally the identifier `Maybe`, one or more `Type`, separated by `|` - eg. `Number`, `String | Date`, `Maybe Number`, `Maybe Boolean | String`
* __Structure__ = `Fields`, or a `Tuple`, or an `Array` - eg. `{x: Number}`, `(String, Number)`, `[Date]`
* __Fields__ = a `{`, followed one or more `Field` separated by a comma `,` (trailing comma `,` is permitted), optionally an `...` (always preceded by a comma `,`), followed by a `}` - eg. `{x: Number, y: String}`, `{k: Function, ...}`
* __Field__ = an `Identifier`, followed by a colon `:`, followed by `Types` - eg. `x: Date | String`, `y: Boolean`
* __Tuple__ = a `(`, followed by one or more `Types` separated by a comma `,` (trailing comma `,` is permitted), followed by a `)` - eg `(Date)`, `(Number, Date)`
* __Array__ = a `[` followed by exactly one `Types` followed by a `]` - eg. `[Boolean]`, `[Boolean | Null]`
### Guide
`type-check` uses `Object.toString` to find out the basic type of a value. Specifically,
```js
{}.toString.call(VALUE).slice(8, -1)
{}.toString.call(true).slice(8, -1) // 'Boolean'
```
A basic type, eg. `Number`, uses this check. This is much more versatile than using `typeof` - for example, with `document`, `typeof` produces `'object'` which isn't that useful, and our technique produces `'HTMLDocument'`.
You may check for multiple types by separating types with a `|`. The checker proceeds from left to right, and passes if the value is any of the types - eg. `String | Boolean` first checks if the value is a string, and then if it is a boolean. If it is none of those, then it returns false.
Adding a `Maybe` in front of a list of multiple types is the same as also checking for `Null` and `Undefined` - eg. `Maybe String` is equivalent to `Undefined | Null | String`.
You may add a comment to remind you of what the type is for by following an identifier with a `::` before a type (or multiple types). The comment is simply thrown out.
The wildcard `*` matches all types.
There are three types of structures for checking the contents of a value: 'fields', 'tuple', and 'array'.
If used by itself, a 'fields' structure will pass with any type of object as long as it is an instance of `Object` and the properties pass - this allows for duck typing - eg. `{x: Boolean}`.
To check if the properties pass, and the value is of a certain type, you can specify the type - eg. `Error{message: String}`.
If you want to make a field optional, you can simply use `Maybe` - eg. `{x: Boolean, y: Maybe String}` will still pass if `y` is undefined (or null).
If you don't care if the value has properties beyond what you have specified, you can use the 'etc' operator `...` - eg. `{x: Boolean, ...}` will match an object with an `x` property that is a boolean, and with zero or more other properties.
For an array, you must specify one or more types (separated by `|`) - it will pass for something of any length as long as each element passes the types provided - eg. `[Number]`, `[Number | String]`.
A tuple checks for a fixed number of elements, each of a potentially different type. Each element is separated by a comma - eg. `(String, Number)`.
An array and tuple structure check that the value is of type `Array` by default, but if another type is specified, they will check for that instead - eg. `Int32Array[Number]`. You can use the wildcard `*` to search for any type at all.
Check out the [type precedence](https://github.com/zaboco/type-precedence) library for type-check.
## Options
Options is an object. It is an optional parameter to the `typeCheck` and `parsedTypeCheck` functions. The only current option is `customTypes`.
<a name="custom-types" />
### Custom Types
__Example:__
```js
var options = {
customTypes: {
Even: {
typeOf: 'Number',
validate: function(x) {
return x % 2 === 0;
}
}
}
};
typeCheck('Even', 2, options); // true
typeCheck('Even', 3, options); // false
```
`customTypes` allows you to set up custom types for validation. The value of this is an object. The keys of the object are the types you will be matching. Each value of the object will be an object having a `typeOf` property - a string, and `validate` property - a function.
The `typeOf` property is the type the value should be (optional - if not set only `validate` will be used), and `validate` is a function which should return true if the value is of that type. `validate` receives one parameter, which is the value that we are checking.
## Technical About
`type-check` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It also uses the [prelude.ls](http://preludels.com/) library.
# randexp.js
randexp will generate a random string that matches a given RegExp Javascript object.
[](http://travis-ci.org/fent/randexp.js)
[](https://david-dm.org/fent/randexp.js)
[](https://codecov.io/gh/fent/randexp.js)
# Usage
```js
var RandExp = require('randexp');
// supports grouping and piping
new RandExp(/hello+ (world|to you)/).gen();
// => hellooooooooooooooooooo world
// sets and ranges and references
new RandExp(/<([a-z]\w{0,20})>foo<\1>/).gen();
// => <m5xhdg>foo<m5xhdg>
// wildcard
new RandExp(/random stuff: .+/).gen();
// => random stuff: l3m;Hf9XYbI [YPaxV>U*4-_F!WXQh9>;rH3i l!8.zoh?[utt1OWFQrE ^~8zEQm]~tK
// ignore case
new RandExp(/xxx xtreme dragon warrior xxx/i).gen();
// => xxx xtReME dRAGON warRiOR xXX
// dynamic regexp shortcut
new RandExp('(sun|mon|tue|wednes|thurs|fri|satur)day', 'i');
// is the same as
new RandExp(new RegExp('(sun|mon|tue|wednes|thurs|fri|satur)day', 'i'));
```
If you're only going to use `gen()` once with a regexp and want slightly shorter syntax for it
```js
var randexp = require('randexp').randexp;
randexp(/[1-6]/); // 4
randexp('great|good( job)?|excellent'); // great
```
If you miss the old syntax
```js
require('randexp').sugar();
/yes|no|maybe|i don't know/.gen(); // maybe
```
# Motivation
Regular expressions are used in every language, every programmer is familiar with them. Regex can be used to easily express complex strings. What better way to generate a random string than with a language you can use to express the string you want?
Thanks to [String-Random](http://search.cpan.org/~steve/String-Random-0.22/lib/String/Random.pm) for giving me the idea to make this in the first place and [randexp](https://github.com/benburkert/randexp) for the sweet `.gen()` syntax.
# Default Range
The default generated character range includes printable ASCII. In order to add or remove characters,
a `defaultRange` attribute is exposed. you can `subtract(from, to)` and `add(from, to)`
```js
var randexp = new RandExp(/random stuff: .+/);
randexp.defaultRange.subtract(32, 126);
randexp.defaultRange.add(0, 65535);
randexp.gen();
// => random stuff: 湐箻ໜ䫴㳸長���邓蕲뤀쑡篷皇硬剈궦佔칗븛뀃匫鴔事좍ﯣ⭼ꝏ䭍詳蒂䥂뽭
```
# Custom PRNG
The default randomness is provided by `Math.random()`. If you need to use a seedable or cryptographic PRNG, you
can override `RandExp.prototype.randInt` or `randexp.randInt` (where `randexp` is an instance of `RandExp`). `randInt(from, to)` accepts an inclusive range and returns a randomly selected
number within that range.
# Infinite Repetitionals
Repetitional tokens such as `*`, `+`, and `{3,}` have an infinite max range. In this case, randexp looks at its min and adds 100 to it to get a useable max value. If you want to use another int other than 100 you can change the `max` property in `RandExp.prototype` or the RandExp instance.
```js
var randexp = new RandExp(/no{1,}/);
randexp.max = 1000000;
```
With `RandExp.sugar()`
```js
var regexp = /(hi)*/;
regexp.max = 1000000;
```
# Bad Regular Expressions
There are some regular expressions which can never match any string.
* Ones with badly placed positionals such as `/a^/` and `/$c/m`. Randexp will ignore positional tokens.
* Back references to non-existing groups like `/(a)\1\2/`. Randexp will ignore those references, returning an empty string for them. If the group exists only after the reference is used such as in `/\1 (hey)/`, it will too be ignored.
* Custom negated character sets with two sets inside that cancel each other out. Example: `/[^\w\W]/`. If you give this to randexp, it will return an empty string for this set since it can't match anything.
# Projects based on randexp.js
## JSON-Schema Faker
Use generators to populate JSON Schema samples. See: [jsf on github](https://github.com/json-schema-faker/json-schema-faker/) and [jsf demo page](http://json-schema-faker.js.org/).
# Install
### Node.js
npm install randexp
### Browser
Download the [minified version](https://github.com/fent/randexp.js/releases) from the latest release.
# Tests
Tests are written with [mocha](https://mochajs.org)
```bash
npm test
```
# License
MIT
# Optionator
<a name="optionator" />
Optionator is a JavaScript/Node.js option parsing and help generation library used by [eslint](http://eslint.org), [Grasp](http://graspjs.com), [LiveScript](http://livescript.net), [esmangle](https://github.com/estools/esmangle), [escodegen](https://github.com/estools/escodegen), and [many more](https://www.npmjs.com/browse/depended/optionator).
For an online demo, check out the [Grasp online demo](http://www.graspjs.com/#demo).
[About](#about) · [Usage](#usage) · [Settings Format](#settings-format) · [Argument Format](#argument-format)
## Why?
The problem with other option parsers, such as `yargs` or `minimist`, is they just accept all input, valid or not.
With Optionator, if you mistype an option, it will give you an error (with a suggestion for what you meant).
If you give the wrong type of argument for an option, it will give you an error rather than supplying the wrong input to your application.
$ cmd --halp
Invalid option '--halp' - perhaps you meant '--help'?
$ cmd --count str
Invalid value for option 'count' - expected type Int, received value: str.
Other helpful features include reformatting the help text based on the size of the console, so that it fits even if the console is narrow, and accepting not just an array (eg. process.argv), but a string or object as well, making things like testing much easier.
## About
Optionator uses [type-check](https://github.com/gkz/type-check) and [levn](https://github.com/gkz/levn) behind the scenes to cast and verify input according the specified types.
MIT license. Version 0.9.1
npm install optionator
For updates on Optionator, [follow me on twitter](https://twitter.com/gkzahariev).
Optionator is a Node.js module, but can be used in the browser as well if packed with webpack/browserify.
## Usage
`require('optionator');` returns a function. It has one property, `VERSION`, the current version of the library as a string. This function is called with an object specifying your options and other information, see the [settings format section](#settings-format). This in turn returns an object with three properties, `parse`, `parseArgv`, `generateHelp`, and `generateHelpForOption`, which are all functions.
```js
var optionator = require('optionator')({
prepend: 'Usage: cmd [options]',
append: 'Version 1.0.0',
options: [{
option: 'help',
alias: 'h',
type: 'Boolean',
description: 'displays help'
}, {
option: 'count',
alias: 'c',
type: 'Int',
description: 'number of things',
example: 'cmd --count 2'
}]
});
var options = optionator.parseArgv(process.argv);
if (options.help) {
console.log(optionator.generateHelp());
}
...
```
### parse(input, parseOptions)
`parse` processes the `input` according to your settings, and returns an object with the results.
##### arguments
* input - `[String] | Object | String` - the input you wish to parse
* parseOptions - `{slice: Int}` - all options optional
- `slice` specifies how much to slice away from the beginning if the input is an array or string - by default `0` for string, `2` for array (works with `process.argv`)
##### returns
`Object` - the parsed options, each key is a camelCase version of the option name (specified in dash-case), and each value is the processed value for that option. Positional values are in an array under the `_` key.
##### example
```js
parse(['node', 't.js', '--count', '2', 'positional']); // {count: 2, _: ['positional']}
parse('--count 2 positional'); // {count: 2, _: ['positional']}
parse({count: 2, _:['positional']}); // {count: 2, _: ['positional']}
```
### parseArgv(input)
`parseArgv` works exactly like `parse`, but only for array input and it slices off the first two elements.
##### arguments
* input - `[String]` - the input you wish to parse
##### returns
See "returns" section in "parse"
##### example
```js
parseArgv(process.argv);
```
### generateHelp(helpOptions)
`generateHelp` produces help text based on your settings.
##### arguments
* helpOptions - `{showHidden: Boolean, interpolate: Object}` - all options optional
- `showHidden` specifies whether to show options with `hidden: true` specified, by default it is `false`
- `interpolate` specify data to be interpolated in `prepend` and `append` text, `{{key}}` is the format - eg. `generateHelp({interpolate:{version: '0.4.2'}})`, will change this `append` text: `Version {{version}}` to `Version 0.4.2`
##### returns
`String` - the generated help text
##### example
```js
generateHelp(); /*
"Usage: cmd [options] positional
-h, --help displays help
-c, --count Int number of things
Version 1.0.0
"*/
```
### generateHelpForOption(optionName)
`generateHelpForOption` produces expanded help text for the specified with `optionName` option. If an `example` was specified for the option, it will be displayed, and if a `longDescription` was specified, it will display that instead of the `description`.
##### arguments
* optionName - `String` - the name of the option to display
##### returns
`String` - the generated help text for the option
##### example
```js
generateHelpForOption('count'); /*
"-c, --count Int
description: number of things
example: cmd --count 2
"*/
```
## Settings Format
When your `require('optionator')`, you get a function that takes in a settings object. This object has the type:
{
prepend: String,
append: String,
options: [{heading: String} | {
option: String,
alias: [String] | String,
type: String,
enum: [String],
default: String,
restPositional: Boolean,
required: Boolean,
overrideRequired: Boolean,
dependsOn: [String] | String,
concatRepeatedArrays: Boolean | (Boolean, Object),
mergeRepeatedObjects: Boolean,
description: String,
longDescription: String,
example: [String] | String
}],
helpStyle: {
aliasSeparator: String,
typeSeparator: String,
descriptionSeparator: String,
initialIndent: Int,
secondaryIndent: Int,
maxPadFactor: Number
},
mutuallyExclusive: [[String | [String]]],
concatRepeatedArrays: Boolean | (Boolean, Object), // deprecated, set in defaults object
mergeRepeatedObjects: Boolean, // deprecated, set in defaults object
positionalAnywhere: Boolean,
typeAliases: Object,
defaults: Object
}
All of the properties are optional (the `Maybe` has been excluded for brevities sake), except for having either `heading: String` or `option: String` in each object in the `options` array.
### Top Level Properties
* `prepend` is an optional string to be placed before the options in the help text
* `append` is an optional string to be placed after the options in the help text
* `options` is a required array specifying your options and headings, the options and headings will be displayed in the order specified
* `helpStyle` is an optional object which enables you to change the default appearance of some aspects of the help text
* `mutuallyExclusive` is an optional array of arrays of either strings or arrays of strings. The top level array is a list of rules, each rule is a list of elements - each element can be either a string (the name of an option), or a list of strings (a group of option names) - there will be an error if more than one element is present
* `concatRepeatedArrays` see description under the "Option Properties" heading - use at the top level is deprecated, if you want to set this for all options, use the `defaults` property
* `mergeRepeatedObjects` see description under the "Option Properties" heading - use at the top level is deprecated, if you want to set this for all options, use the `defaults` property
* `positionalAnywhere` is an optional boolean (defaults to `true`) - when `true` it allows positional arguments anywhere, when `false`, all arguments after the first positional one are taken to be positional as well, even if they look like a flag. For example, with `positionalAnywhere: false`, the arguments `--flag --boom 12 --crack` would have two positional arguments: `12` and `--crack`
* `typeAliases` is an optional object, it allows you to set aliases for types, eg. `{Path: 'String'}` would allow you to use the type `Path` as an alias for the type `String`
* `defaults` is an optional object following the option properties format, which specifies default values for all options. A default will be overridden if manually set. For example, you can do `default: { type: "String" }` to set the default type of all options to `String`, and then override that default in an individual option by setting the `type` property
#### Heading Properties
* `heading` a required string, the name of the heading
#### Option Properties
* `option` the required name of the option - use dash-case, without the leading dashes
* `alias` is an optional string or array of strings which specify any aliases for the option
* `type` is a required string in the [type check](https://github.com/gkz/type-check) [format](https://github.com/gkz/type-check#type-format), this will be used to cast the inputted value and validate it
* `enum` is an optional array of strings, each string will be parsed by [levn](https://github.com/gkz/levn) - the argument value must be one of the resulting values - each potential value must validate against the specified `type`
* `default` is a optional string, which will be parsed by [levn](https://github.com/gkz/levn) and used as the default value if none is set - the value must validate against the specified `type`
* `restPositional` is an optional boolean - if set to `true`, everything after the option will be taken to be a positional argument, even if it looks like a named argument
* `required` is an optional boolean - if set to `true`, the option parsing will fail if the option is not defined
* `overrideRequired` is a optional boolean - if set to `true` and the option is used, and there is another option which is required but not set, it will override the need for the required option and there will be no error - this is useful if you have required options and want to use `--help` or `--version` flags
* `concatRepeatedArrays` is an optional boolean or tuple with boolean and options object (defaults to `false`) - when set to `true` and an option contains an array value and is repeated, the subsequent values for the flag will be appended rather than overwriting the original value - eg. option `g` of type `[String]`: `-g a -g b -g c,d` will result in `['a','b','c','d']`
You can supply an options object by giving the following value: `[true, options]`. The one currently supported option is `oneValuePerFlag`, this only allows one array value per flag. This is useful if your potential values contain a comma.
* `mergeRepeatedObjects` is an optional boolean (defaults to `false`) - when set to `true` and an option contains an object value and is repeated, the subsequent values for the flag will be merged rather than overwriting the original value - eg. option `g` of type `Object`: `-g a:1 -g b:2 -g c:3,d:4` will result in `{a: 1, b: 2, c: 3, d: 4}`
* `dependsOn` is an optional string or array of strings - if simply a string (the name of another option), it will make sure that that other option is set, if an array of strings, depending on whether `'and'` or `'or'` is first, it will either check whether all (`['and', 'option-a', 'option-b']`), or at least one (`['or', 'option-a', 'option-b']`) other options are set
* `description` is an optional string, which will be displayed next to the option in the help text
* `longDescription` is an optional string, it will be displayed instead of the `description` when `generateHelpForOption` is used
* `example` is an optional string or array of strings with example(s) for the option - these will be displayed when `generateHelpForOption` is used
#### Help Style Properties
* `aliasSeparator` is an optional string, separates multiple names from each other - default: ' ,'
* `typeSeparator` is an optional string, separates the type from the names - default: ' '
* `descriptionSeparator` is an optional string , separates the description from the padded name and type - default: ' '
* `initialIndent` is an optional int - the amount of indent for options - default: 2
* `secondaryIndent` is an optional int - the amount of indent if wrapped fully (in addition to the initial indent) - default: 4
* `maxPadFactor` is an optional number - affects the default level of padding for the names/type, it is multiplied by the average of the length of the names/type - default: 1.5
## Argument Format
At the highest level there are two types of arguments: named, and positional.
Name arguments of any length are prefixed with `--` (eg. `--go`), and those of one character may be prefixed with either `--` or `-` (eg. `-g`).
There are two types of named arguments: boolean flags (eg. `--problemo`, `-p`) which take no value and result in a `true` if they are present, the falsey `undefined` if they are not present, or `false` if present and explicitly prefixed with `no` (eg. `--no-problemo`). Named arguments with values (eg. `--tseries 800`, `-t 800`) are the other type. If the option has a type `Boolean` it will automatically be made into a boolean flag. Any other type results in a named argument that takes a value.
For more information about how to properly set types to get the value you want, take a look at the [type check](https://github.com/gkz/type-check) and [levn](https://github.com/gkz/levn) pages.
You can group single character arguments that use a single `-`, however all except the last must be boolean flags (which take no value). The last may be a boolean flag, or an argument which takes a value - eg. `-ba 2` is equivalent to `-b -a 2`.
Positional arguments are all those values which do not fall under the above - they can be anywhere, not just at the end. For example, in `cmd -b one -a 2 two` where `b` is a boolean flag, and `a` has the type `Number`, there are two positional arguments, `one` and `two`.
Everything after an `--` is positional, even if it looks like a named argument.
You may optionally use `=` to separate option names from values, for example: `--count=2`.
If you specify the option `NUM`, then any argument using a single `-` followed by a number will be valid and will set the value of `NUM`. Eg. `-2` will be parsed into `NUM: 2`.
If duplicate named arguments are present, the last one will be taken.
## Technical About
`optionator` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It uses [levn](https://github.com/gkz/levn) to cast arguments to their specified type, and uses [type-check](https://github.com/gkz/type-check) to validate values. It also uses the [prelude.ls](http://preludels.com/) library.
# yargs-parser

[](https://www.npmjs.com/package/yargs-parser)
[](https://conventionalcommits.org)

The mighty option parser used by [yargs](https://github.com/yargs/yargs).
visit the [yargs website](http://yargs.js.org/) for more examples, and thorough usage instructions.
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs-parser/main/yargs-logo.png">
## Example
```sh
npm i yargs-parser --save
```
```js
const argv = require('yargs-parser')(process.argv.slice(2))
console.log(argv)
```
```console
$ node example.js --foo=33 --bar hello
{ _: [], foo: 33, bar: 'hello' }
```
_or parse a string!_
```js
const argv = require('yargs-parser')('--foo=99 --bar=33')
console.log(argv)
```
```console
{ _: [], foo: 99, bar: 33 }
```
Convert an array of mixed types before passing to `yargs-parser`:
```js
const parse = require('yargs-parser')
parse(['-f', 11, '--zoom', 55].join(' ')) // <-- array to string
parse(['-f', 11, '--zoom', 55].map(String)) // <-- array of strings
```
## Deno Example
As of `v19` `yargs-parser` supports [Deno](https://github.com/denoland/deno):
```typescript
import parser from "https://deno.land/x/yargs_parser/deno.ts";
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
```
## ESM Example
As of `v19` `yargs-parser` supports ESM (_both in Node.js and in the browser_):
**Node.js:**
```js
import parser from 'yargs-parser'
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
```
**Browsers:**
```html
<!doctype html>
<body>
<script type="module">
import parser from "https://unpkg.com/[email protected]/browser.js";
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
</script>
</body>
```
## API
### parser(args, opts={})
Parses command line arguments returning a simple mapping of keys and values.
**expects:**
* `args`: a string or array of strings representing the options to parse.
* `opts`: provide a set of hints indicating how `args` should be parsed:
* `opts.alias`: an object representing the set of aliases for a key: `{alias: {foo: ['f']}}`.
* `opts.array`: indicate that keys should be parsed as an array: `{array: ['foo', 'bar']}`.<br>
Indicate that keys should be parsed as an array and coerced to booleans / numbers:<br>
`{array: [{ key: 'foo', boolean: true }, {key: 'bar', number: true}]}`.
* `opts.boolean`: arguments should be parsed as booleans: `{boolean: ['x', 'y']}`.
* `opts.coerce`: provide a custom synchronous function that returns a coerced value from the argument provided
(or throws an error). For arrays the function is called only once for the entire array:<br>
`{coerce: {foo: function (arg) {return modifiedArg}}}`.
* `opts.config`: indicate a key that represents a path to a configuration file (this file will be loaded and parsed).
* `opts.configObjects`: configuration objects to parse, their properties will be set as arguments:<br>
`{configObjects: [{'x': 5, 'y': 33}, {'z': 44}]}`.
* `opts.configuration`: provide configuration options to the yargs-parser (see: [configuration](#configuration)).
* `opts.count`: indicate a key that should be used as a counter, e.g., `-vvv` = `{v: 3}`.
* `opts.default`: provide default values for keys: `{default: {x: 33, y: 'hello world!'}}`.
* `opts.envPrefix`: environment variables (`process.env`) with the prefix provided should be parsed.
* `opts.narg`: specify that a key requires `n` arguments: `{narg: {x: 2}}`.
* `opts.normalize`: `path.normalize()` will be applied to values set to this key.
* `opts.number`: keys should be treated as numbers.
* `opts.string`: keys should be treated as strings (even if they resemble a number `-x 33`).
**returns:**
* `obj`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
### require('yargs-parser').detailed(args, opts={})
Parses a command line string, returning detailed information required by the
yargs engine.
**expects:**
* `args`: a string or array of strings representing options to parse.
* `opts`: provide a set of hints indicating how `args`, inputs are identical to `require('yargs-parser')(args, opts={})`.
**returns:**
* `argv`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
* `error`: populated with an error object if an exception occurred during parsing.
* `aliases`: the inferred list of aliases built by combining lists in `opts.alias`.
* `newAliases`: any new aliases added via camel-case expansion:
* `boolean`: `{ fooBar: true }`
* `defaulted`: any new argument created by `opts.default`, no aliases included.
* `boolean`: `{ foo: true }`
* `configuration`: given by default settings and `opts.configuration`.
<a name="configuration"></a>
### Configuration
The yargs-parser applies several automated transformations on the keys provided
in `args`. These features can be turned on and off using the `configuration` field
of `opts`.
```js
var parsed = parser(['--no-dice'], {
configuration: {
'boolean-negation': false
}
})
```
### short option groups
* default: `true`.
* key: `short-option-groups`.
Should a group of short-options be treated as boolean flags?
```console
$ node example.js -abc
{ _: [], a: true, b: true, c: true }
```
_if disabled:_
```console
$ node example.js -abc
{ _: [], abc: true }
```
### camel-case expansion
* default: `true`.
* key: `camel-case-expansion`.
Should hyphenated arguments be expanded into camel-case aliases?
```console
$ node example.js --foo-bar
{ _: [], 'foo-bar': true, fooBar: true }
```
_if disabled:_
```console
$ node example.js --foo-bar
{ _: [], 'foo-bar': true }
```
### dot-notation
* default: `true`
* key: `dot-notation`
Should keys that contain `.` be treated as objects?
```console
$ node example.js --foo.bar
{ _: [], foo: { bar: true } }
```
_if disabled:_
```console
$ node example.js --foo.bar
{ _: [], "foo.bar": true }
```
### parse numbers
* default: `true`
* key: `parse-numbers`
Should keys that look like numbers be treated as such?
```console
$ node example.js --foo=99.3
{ _: [], foo: 99.3 }
```
_if disabled:_
```console
$ node example.js --foo=99.3
{ _: [], foo: "99.3" }
```
### parse positional numbers
* default: `true`
* key: `parse-positional-numbers`
Should positional keys that look like numbers be treated as such.
```console
$ node example.js 99.3
{ _: [99.3] }
```
_if disabled:_
```console
$ node example.js 99.3
{ _: ['99.3'] }
```
### boolean negation
* default: `true`
* key: `boolean-negation`
Should variables prefixed with `--no` be treated as negations?
```console
$ node example.js --no-foo
{ _: [], foo: false }
```
_if disabled:_
```console
$ node example.js --no-foo
{ _: [], "no-foo": true }
```
### combine arrays
* default: `false`
* key: `combine-arrays`
Should arrays be combined when provided by both command line arguments and
a configuration file.
### duplicate arguments array
* default: `true`
* key: `duplicate-arguments-array`
Should arguments be coerced into an array when duplicated:
```console
$ node example.js -x 1 -x 2
{ _: [], x: [1, 2] }
```
_if disabled:_
```console
$ node example.js -x 1 -x 2
{ _: [], x: 2 }
```
### flatten duplicate arrays
* default: `true`
* key: `flatten-duplicate-arrays`
Should array arguments be coerced into a single array when duplicated:
```console
$ node example.js -x 1 2 -x 3 4
{ _: [], x: [1, 2, 3, 4] }
```
_if disabled:_
```console
$ node example.js -x 1 2 -x 3 4
{ _: [], x: [[1, 2], [3, 4]] }
```
### greedy arrays
* default: `true`
* key: `greedy-arrays`
Should arrays consume more than one positional argument following their flag.
```console
$ node example --arr 1 2
{ _: [], arr: [1, 2] }
```
_if disabled:_
```console
$ node example --arr 1 2
{ _: [2], arr: [1] }
```
**Note: in `v18.0.0` we are considering defaulting greedy arrays to `false`.**
### nargs eats options
* default: `false`
* key: `nargs-eats-options`
Should nargs consume dash options as well as positional arguments.
### negation prefix
* default: `no-`
* key: `negation-prefix`
The prefix to use for negated boolean variables.
```console
$ node example.js --no-foo
{ _: [], foo: false }
```
_if set to `quux`:_
```console
$ node example.js --quuxfoo
{ _: [], foo: false }
```
### populate --
* default: `false`.
* key: `populate--`
Should unparsed flags be stored in `--` or `_`.
_If disabled:_
```console
$ node example.js a -b -- x y
{ _: [ 'a', 'x', 'y' ], b: true }
```
_If enabled:_
```console
$ node example.js a -b -- x y
{ _: [ 'a' ], '--': [ 'x', 'y' ], b: true }
```
### set placeholder key
* default: `false`.
* key: `set-placeholder-key`.
Should a placeholder be added for keys not set via the corresponding CLI argument?
_If disabled:_
```console
$ node example.js -a 1 -c 2
{ _: [], a: 1, c: 2 }
```
_If enabled:_
```console
$ node example.js -a 1 -c 2
{ _: [], a: 1, b: undefined, c: 2 }
```
### halt at non-option
* default: `false`.
* key: `halt-at-non-option`.
Should parsing stop at the first positional argument? This is similar to how e.g. `ssh` parses its command line.
_If disabled:_
```console
$ node example.js -a run b -x y
{ _: [ 'b' ], a: 'run', x: 'y' }
```
_If enabled:_
```console
$ node example.js -a run b -x y
{ _: [ 'b', '-x', 'y' ], a: 'run' }
```
### strip aliased
* default: `false`
* key: `strip-aliased`
Should aliases be removed before returning results?
_If disabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1, 'test-alias': 1, testAlias: 1 }
```
_If enabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
### strip dashed
* default: `false`
* key: `strip-dashed`
Should dashed keys be removed before returning results? This option has no effect if
`camel-case-expansion` is disabled.
_If disabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
_If enabled:_
```console
$ node example.js --test-field 1
{ _: [], testField: 1 }
```
### unknown options as args
* default: `false`
* key: `unknown-options-as-args`
Should unknown options be treated like regular arguments? An unknown option is one that is not
configured in `opts`.
_If disabled_
```console
$ node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: [], unknownOption: true, knownOption: 2, stringOption: '', unknownOption2: true }
```
_If enabled_
```console
$ node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: ['--unknown-option'], knownOption: 2, stringOption: '--unknown-option2' }
```
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
## Special Thanks
The yargs project evolves from optimist and minimist. It owes its
existence to a lot of James Halliday's hard work. Thanks [substack](https://github.com/substack) **beep** **boop** \o/
## License
ISC
[![NPM version][npm-image]][npm-url]
[![build status][travis-image]][travis-url]
[![Test coverage][coveralls-image]][coveralls-url]
[![Downloads][downloads-image]][downloads-url]
[](https://gitter.im/eslint/doctrine?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
# Doctrine
Doctrine is a [JSDoc](http://usejsdoc.org) parser that parses documentation comments from JavaScript (you need to pass in the comment, not a whole JavaScript file).
## Installation
You can install Doctrine using [npm](https://npmjs.com):
```
$ npm install doctrine --save-dev
```
Doctrine can also be used in web browsers using [Browserify](http://browserify.org).
## Usage
Require doctrine inside of your JavaScript:
```js
var doctrine = require("doctrine");
```
### parse()
The primary method is `parse()`, which accepts two arguments: the JSDoc comment to parse and an optional options object. The available options are:
* `unwrap` - set to `true` to delete the leading `/**`, any `*` that begins a line, and the trailing `*/` from the source text. Default: `false`.
* `tags` - an array of tags to return. When specified, Doctrine returns only tags in this array. For example, if `tags` is `["param"]`, then only `@param` tags will be returned. Default: `null`.
* `recoverable` - set to `true` to keep parsing even when syntax errors occur. Default: `false`.
* `sloppy` - set to `true` to allow optional parameters to be specified in brackets (`@param {string} [foo]`). Default: `false`.
* `lineNumbers` - set to `true` to add `lineNumber` to each node, specifying the line on which the node is found in the source. Default: `false`.
* `range` - set to `true` to add `range` to each node, specifying the start and end index of the node in the original comment. Default: `false`.
Here's a simple example:
```js
var ast = doctrine.parse(
[
"/**",
" * This function comment is parsed by doctrine",
" * @param {{ok:String}} userName",
"*/"
].join('\n'), { unwrap: true });
```
This example returns the following AST:
{
"description": "This function comment is parsed by doctrine",
"tags": [
{
"title": "param",
"description": null,
"type": {
"type": "RecordType",
"fields": [
{
"type": "FieldType",
"key": "ok",
"value": {
"type": "NameExpression",
"name": "String"
}
}
]
},
"name": "userName"
}
]
}
See the [demo page](http://eslint.org/doctrine/demo/) more detail.
## Team
These folks keep the project moving and are resources for help:
* Nicholas C. Zakas ([@nzakas](https://github.com/nzakas)) - project lead
* Yusuke Suzuki ([@constellation](https://github.com/constellation)) - reviewer
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/doctrine/issues).
## Frequently Asked Questions
### Can I pass a whole JavaScript file to Doctrine?
No. Doctrine can only parse JSDoc comments, so you'll need to pass just the JSDoc comment to Doctrine in order to work.
### License
#### doctrine
Copyright JS Foundation and other contributors, https://js.foundation
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
#### esprima
some of functions is derived from esprima
Copyright (C) 2012, 2011 [Ariya Hidayat](http://ariya.ofilabs.com/about)
(twitter: [@ariyahidayat](http://twitter.com/ariyahidayat)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
#### closure-compiler
some of extensions is derived from closure-compiler
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
### Where to ask for help?
Join our [Chatroom](https://gitter.im/eslint/doctrine)
[npm-image]: https://img.shields.io/npm/v/doctrine.svg?style=flat-square
[npm-url]: https://www.npmjs.com/package/doctrine
[travis-image]: https://img.shields.io/travis/eslint/doctrine/master.svg?style=flat-square
[travis-url]: https://travis-ci.org/eslint/doctrine
[coveralls-image]: https://img.shields.io/coveralls/eslint/doctrine/master.svg?style=flat-square
[coveralls-url]: https://coveralls.io/r/eslint/doctrine?branch=master
[downloads-image]: http://img.shields.io/npm/dm/doctrine.svg?style=flat-square
[downloads-url]: https://www.npmjs.com/package/doctrine
# axios // helpers
The modules found in `helpers/` should be generic modules that are _not_ specific to the domain logic of axios. These modules could theoretically be published to npm on their own and consumed by other modules or apps. Some examples of generic modules are things like:
- Browser polyfills
- Managing cookies
- Parsing HTTP headers
Shims used when bundling asc for browser usage.
# isexe
Minimal module to check if a file is executable, and a normal file.
Uses `fs.stat` and tests against the `PATHEXT` environment variable on
Windows.
## USAGE
```javascript
var isexe = require('isexe')
isexe('some-file-name', function (err, isExe) {
if (err) {
console.error('probably file does not exist or something', err)
} else if (isExe) {
console.error('this thing can be run')
} else {
console.error('cannot be run')
}
})
// same thing but synchronous, throws errors
var isExe = isexe.sync('some-file-name')
// treat errors as just "not executable"
isexe('maybe-missing-file', { ignoreErrors: true }, callback)
var isExe = isexe.sync('maybe-missing-file', { ignoreErrors: true })
```
## API
### `isexe(path, [options], [callback])`
Check if the path is executable. If no callback provided, and a
global `Promise` object is available, then a Promise will be returned.
Will raise whatever errors may be raised by `fs.stat`, unless
`options.ignoreErrors` is set to true.
### `isexe.sync(path, [options])`
Same as `isexe` but returns the value and throws any errors raised.
### Options
* `ignoreErrors` Treat all errors as "no, this is not executable", but
don't raise them.
* `uid` Number to use as the user id
* `gid` Number to use as the group id
* `pathExt` List of path extensions to use instead of `PATHEXT`
environment variable on Windows.
# flat-cache
> A stupidly simple key/value storage using files to persist the data
[](https://npmjs.org/package/flat-cache)
[](https://travis-ci.org/royriojas/flat-cache)
## install
```bash
npm i --save flat-cache
```
## Usage
```js
var flatCache = require('flat-cache')
// loads the cache, if one does not exists for the given
// Id a new one will be prepared to be created
var cache = flatCache.load('cacheId');
// sets a key on the cache
cache.setKey('key', { foo: 'var' });
// get a key from the cache
cache.getKey('key') // { foo: 'var' }
// fetch the entire persisted object
cache.all() // { 'key': { foo: 'var' } }
// remove a key
cache.removeKey('key'); // removes a key from the cache
// save it to disk
cache.save(); // very important, if you don't save no changes will be persisted.
// cache.save( true /* noPrune */) // can be used to prevent the removal of non visited keys
// loads the cache from a given directory, if one does
// not exists for the given Id a new one will be prepared to be created
var cache = flatCache.load('cacheId', path.resolve('./path/to/folder'));
// The following methods are useful to clear the cache
// delete a given cache
flatCache.clearCacheById('cacheId') // removes the cacheId document if one exists.
// delete all cache
flatCache.clearAll(); // remove the cache directory
```
## Motivation for this module
I needed a super simple and dumb **in-memory cache** with optional disk persistance in order to make
a script that will beutify files with `esformatter` only execute on the files that were changed since the last run.
To make that possible we need to store the `fileSize` and `modificationTime` of the files. So a simple `key/value`
storage was needed and Bam! this module was born.
## Important notes
- If no directory is especified when the `load` method is called, a folder named `.cache` will be created
inside the module directory when `cache.save` is called. If you're committing your `node_modules` to any vcs, you
might want to ignore the default `.cache` folder, or specify a custom directory.
- The values set on the keys of the cache should be `stringify-able` ones, meaning no circular references
- All the changes to the cache state are done to memory
- I could have used a timer or `Object.observe` to deliver the changes to disk, but I wanted to keep this module
intentionally dumb and simple
- Non visited keys are removed when `cache.save()` is called. If this is not desired, you can pass `true` to the save call
like: `cache.save( true /* noPrune */ )`.
## License
MIT
## Changelog
[changelog](./changelog.md)
# `asbuild` [](https://github.com/AssemblyScript/asbuild/stargazers)
*A simple build tool for [AssemblyScript](https://assemblyscript.org) projects, similar to `cargo`, etc.*
## 🚩 Table of Contents
- [Installing](#-installing)
- [Usage](#-usage)
- [`asb init`](#asb-init---create-an-empty-project)
- [`asb test`](#asb-test---run-as-pect-tests)
- [`asb fmt`](#asb-fmt---format-as-files-using-eslint)
- [`asb run`](#asb-run---run-a-wasi-binary)
- [`asb build`](#asb-build---compile-the-project-using-asc)
- [Background](#-background)
## 🔧 Installing
Install it globally
```
npm install -g asbuild
```
Or, locally as dev dependencies
```
npm install --save-dev asbuild
```
## 💡 Usage
```
Build tool for AssemblyScript projects.
Usage:
asb [command] [options]
Commands:
asb Alias of build command, to maintain back-ward
compatibility [default]
asb build Compile a local package and all of its dependencies
[aliases: compile, make]
asb init [baseDir] Create a new AS package in an given directory
asb test Run as-pect tests
asb fmt [paths..] This utility formats current module using eslint.
[aliases: format, lint]
Options:
--version Show version number [boolean]
--help Show help [boolean]
```
### `asb init` - Create an empty project
```
asb init [baseDir]
Create a new AS package in an given directory
Positionals:
baseDir Create a sample AS project in this directory [string] [default: "."]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--yes Skip the interactive prompt [boolean] [default: false]
```
### `asb test` - Run as-pect tests
```
asb test
Run as-pect tests
USAGE:
asb test [options] -- [aspect_options]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--verbose, --vv Print out arguments passed to as-pect
[boolean] [default: false]
```
### `asb fmt` - Format AS files using ESlint
```
asb fmt [paths..]
This utility formats current module using eslint.
Positionals:
paths Paths to format [array] [default: ["."]]
Initialisation:
--init Generates recommended eslint config for AS Projects [boolean]
Miscellaneous
--lint, --dry-run Tries to fix problems without saving the changes to the
file system [boolean] [default: false]
Options:
--version Show version number [boolean]
--help Show help
```
### `asb run` - Run a WASI binary
```
asb run
Run a WASI binary
USAGE:
asb run [options] [binary path] -- [binary options]
Positionals:
binary path to Wasm binary [string] [required]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--preopen, -p comma separated list of directories to open.
[default: "."]
```
### `asb build` - Compile the project using asc
```
asb build
Compile a local package and all of its dependencies
USAGE:
asb build [entry_file] [options] -- [asc_options]
Options:
--version Show version number [boolean]
--help Show help [boolean]
--baseDir, -d Base directory of project. [string] [default: "."]
--config, -c Path to asconfig file [string] [default: "./asconfig.json"]
--wat Output wat file to outDir [boolean] [default: false]
--outDir Directory to place built binaries. Default "./build/<target>/"
[string]
--target Target for compilation [string] [default: "release"]
--verbose Print out arguments passed to asc [boolean] [default: false]
Examples:
asb build Build release of 'assembly/index.ts to
build/release/packageName.wasm
asb build --target release Build a release binary
asb build -- --measure Pass argument to 'asc'
```
#### Defaults
##### Project structure
```
project/
package.json
asconfig.json
assembly/
index.ts
build/
release/
project.wasm
debug/
project.wasm
```
- If no entry file passed and no `entry` field is in `asconfig.json`, `project/assembly/index.ts` is assumed.
- `asconfig.json` allows for options for different compile targets, e.g. release, debug, etc. `asc` defaults to the release target.
- The default build directory is `./build`, and artifacts are placed at `./build/<target>/packageName.wasm`.
##### Workspaces
If a `workspace` field is added to a top level `asconfig.json` file, then each path in the array is built and placed into the top level `outDir`.
For example,
`asconfig.json`:
```json
{
"workspaces": ["a", "b"]
}
```
Running `asb` in the directory below will use the top level build directory to place all the binaries.
```
project/
package.json
asconfig.json
a/
asconfig.json
assembly/
index.ts
b/
asconfig.json
assembly/
index.ts
build/
release/
a.wasm
b.wasm
debug/
a.wasm
b.wasm
```
To see an example in action check out the [test workspace](./tests/build_test)
## 📖 Background
Asbuild started as wrapper around `asc` to provide an easier CLI interface and now has been extened to support other commands
like `init`, `test` and `fmt` just like `cargo` to become a one stop build tool for AS Projects.
## 📜 License
This library is provided under the open-source
[MIT license](https://choosealicense.com/licenses/mit/).
<table><thead>
<tr>
<th>Linux</th>
<th>OS X</th>
<th>Windows</th>
<th>Coverage</th>
<th>Downloads</th>
</tr>
</thead><tbody><tr>
<td colspan="2" align="center">
<a href="https://travis-ci.org/kaelzhang/node-ignore">
<img
src="https://travis-ci.org/kaelzhang/node-ignore.svg?branch=master"
alt="Build Status" /></a>
</td>
<td align="center">
<a href="https://ci.appveyor.com/project/kaelzhang/node-ignore">
<img
src="https://ci.appveyor.com/api/projects/status/github/kaelzhang/node-ignore?branch=master&svg=true"
alt="Windows Build Status" /></a>
</td>
<td align="center">
<a href="https://codecov.io/gh/kaelzhang/node-ignore">
<img
src="https://codecov.io/gh/kaelzhang/node-ignore/branch/master/graph/badge.svg"
alt="Coverage Status" /></a>
</td>
<td align="center">
<a href="https://www.npmjs.org/package/ignore">
<img
src="http://img.shields.io/npm/dm/ignore.svg"
alt="npm module downloads per month" /></a>
</td>
</tr></tbody></table>
# ignore
`ignore` is a manager, filter and parser which implemented in pure JavaScript according to the .gitignore [spec](http://git-scm.com/docs/gitignore).
Pay attention that [`minimatch`](https://www.npmjs.org/package/minimatch) does not work in the gitignore way. To filter filenames according to .gitignore file, I recommend this module.
##### Tested on
- Linux + Node: `0.8` - `7.x`
- Windows + Node: `0.10` - `7.x`, node < `0.10` is not tested due to the lack of support of appveyor.
Actually, `ignore` does not rely on any versions of node specially.
Since `4.0.0`, ignore will no longer support `node < 6` by default, to use in node < 6, `require('ignore/legacy')`. For details, see [CHANGELOG](https://github.com/kaelzhang/node-ignore/blob/master/CHANGELOG.md).
## Table Of Main Contents
- [Usage](#usage)
- [`Pathname` Conventions](#pathname-conventions)
- [Guide for 2.x -> 3.x](#upgrade-2x---3x)
- [Guide for 3.x -> 4.x](#upgrade-3x---4x)
- See Also:
- [`glob-gitignore`](https://www.npmjs.com/package/glob-gitignore) matches files using patterns and filters them according to gitignore rules.
## Usage
```js
import ignore from 'ignore'
const ig = ignore().add(['.abc/*', '!.abc/d/'])
```
### Filter the given paths
```js
const paths = [
'.abc/a.js', // filtered out
'.abc/d/e.js' // included
]
ig.filter(paths) // ['.abc/d/e.js']
ig.ignores('.abc/a.js') // true
```
### As the filter function
```js
paths.filter(ig.createFilter()); // ['.abc/d/e.js']
```
### Win32 paths will be handled
```js
ig.filter(['.abc\\a.js', '.abc\\d\\e.js'])
// if the code above runs on windows, the result will be
// ['.abc\\d\\e.js']
```
## Why another ignore?
- `ignore` is a standalone module, and is much simpler so that it could easy work with other programs, unlike [isaacs](https://npmjs.org/~isaacs)'s [fstream-ignore](https://npmjs.org/package/fstream-ignore) which must work with the modules of the fstream family.
- `ignore` only contains utility methods to filter paths according to the specified ignore rules, so
- `ignore` never try to find out ignore rules by traversing directories or fetching from git configurations.
- `ignore` don't cares about sub-modules of git projects.
- Exactly according to [gitignore man page](http://git-scm.com/docs/gitignore), fixes some known matching issues of fstream-ignore, such as:
- '`/*.js`' should only match '`a.js`', but not '`abc/a.js`'.
- '`**/foo`' should match '`foo`' anywhere.
- Prevent re-including a file if a parent directory of that file is excluded.
- Handle trailing whitespaces:
- `'a '`(one space) should not match `'a '`(two spaces).
- `'a \ '` matches `'a '`
- All test cases are verified with the result of `git check-ignore`.
# Methods
## .add(pattern: string | Ignore): this
## .add(patterns: Array<string | Ignore>): this
- **pattern** `String | Ignore` An ignore pattern string, or the `Ignore` instance
- **patterns** `Array<String | Ignore>` Array of ignore patterns.
Adds a rule or several rules to the current manager.
Returns `this`
Notice that a line starting with `'#'`(hash) is treated as a comment. Put a backslash (`'\'`) in front of the first hash for patterns that begin with a hash, if you want to ignore a file with a hash at the beginning of the filename.
```js
ignore().add('#abc').ignores('#abc') // false
ignore().add('\#abc').ignores('#abc') // true
```
`pattern` could either be a line of ignore pattern or a string of multiple ignore patterns, which means we could just `ignore().add()` the content of a ignore file:
```js
ignore()
.add(fs.readFileSync(filenameOfGitignore).toString())
.filter(filenames)
```
`pattern` could also be an `ignore` instance, so that we could easily inherit the rules of another `Ignore` instance.
## <strike>.addIgnoreFile(path)</strike>
REMOVED in `3.x` for now.
To upgrade `[email protected]` up to `3.x`, use
```js
import fs from 'fs'
if (fs.existsSync(filename)) {
ignore().add(fs.readFileSync(filename).toString())
}
```
instead.
## .filter(paths: Array<Pathname>): Array<Pathname>
```ts
type Pathname = string
```
Filters the given array of pathnames, and returns the filtered array.
- **paths** `Array.<Pathname>` The array of `pathname`s to be filtered.
### `Pathname` Conventions:
#### 1. `Pathname` should be a `path.relative()`d pathname
`Pathname` should be a string that have been `path.join()`ed, or the return value of `path.relative()` to the current directory.
```js
// WRONG
ig.ignores('./abc')
// WRONG, for it will never happen.
// If the gitignore rule locates at the root directory,
// `'/abc'` should be changed to `'abc'`.
// ```
// path.relative('/', '/abc') -> 'abc'
// ```
ig.ignores('/abc')
// Right
ig.ignores('abc')
// Right
ig.ignores(path.join('./abc')) // path.join('./abc') -> 'abc'
```
In other words, each `Pathname` here should be a relative path to the directory of the gitignore rules.
Suppose the dir structure is:
```
/path/to/your/repo
|-- a
| |-- a.js
|
|-- .b
|
|-- .c
|-- .DS_store
```
Then the `paths` might be like this:
```js
[
'a/a.js'
'.b',
'.c/.DS_store'
]
```
Usually, you could use [`glob`](http://npmjs.org/package/glob) with `option.mark = true` to fetch the structure of the current directory:
```js
import glob from 'glob'
glob('**', {
// Adds a / character to directory matches.
mark: true
}, (err, files) => {
if (err) {
return console.error(err)
}
let filtered = ignore().add(patterns).filter(files)
console.log(filtered)
})
```
#### 2. filenames and dirnames
`node-ignore` does NO `fs.stat` during path matching, so for the example below:
```js
ig.add('config/')
// `ig` does NOT know if 'config' is a normal file, directory or something
ig.ignores('config') // And it returns `false`
ig.ignores('config/') // returns `true`
```
Specially for people who develop some library based on `node-ignore`, it is important to understand that.
## .ignores(pathname: Pathname): boolean
> new in 3.2.0
Returns `Boolean` whether `pathname` should be ignored.
```js
ig.ignores('.abc/a.js') // true
```
## .createFilter()
Creates a filter function which could filter an array of paths with `Array.prototype.filter`.
Returns `function(path)` the filter function.
## `options.ignorecase` since 4.0.0
Similar as the `core.ignorecase` option of [git-config](https://git-scm.com/docs/git-config), `node-ignore` will be case insensitive if `options.ignorecase` is set to `true` (default value), otherwise case sensitive.
```js
const ig = ignore({
ignorecase: false
})
ig.add('*.png')
ig.ignores('*.PNG') // false
```
****
# Upgrade Guide
## Upgrade 2.x -> 3.x
- All `options` of 2.x are unnecessary and removed, so just remove them.
- `ignore()` instance is no longer an [`EventEmitter`](nodejs.org/api/events.html), and all events are unnecessary and removed.
- `.addIgnoreFile()` is removed, see the [.addIgnoreFile](#addignorefilepath) section for details.
## Upgrade 3.x -> 4.x
Since `4.0.0`, `ignore` will no longer support node < 6, to use `ignore` in node < 6:
```js
var ignore = require('ignore/legacy')
```
****
# Collaborators
- [@whitecolor](https://github.com/whitecolor) *Alex*
- [@SamyPesse](https://github.com/SamyPesse) *Samy Pessé*
- [@azproduction](https://github.com/azproduction) *Mikhail Davydov*
- [@TrySound](https://github.com/TrySound) *Bogdan Chadkin*
- [@JanMattner](https://github.com/JanMattner) *Jan Mattner*
- [@ntwb](https://github.com/ntwb) *Stephen Edgar*
- [@kasperisager](https://github.com/kasperisager) *Kasper Isager*
- [@sandersn](https://github.com/sandersn) *Nathan Shively-Sanders*
### Estraverse [](http://travis-ci.org/estools/estraverse)
Estraverse ([estraverse](http://github.com/estools/estraverse)) is
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
traversal functions from [esmangle project](http://github.com/estools/esmangle).
### Documentation
You can find usage docs at [wiki page](https://github.com/estools/estraverse/wiki/Usage).
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
estraverse.traverse(ast, {
enter: function (node, parent) {
if (node.type == 'FunctionExpression' || node.type == 'FunctionDeclaration')
return estraverse.VisitorOption.Skip;
},
leave: function (node, parent) {
if (node.type == 'VariableDeclarator')
console.log(node.id.name);
}
});
```
We can use `this.skip`, `this.remove` and `this.break` functions instead of using Skip, Remove and Break.
```javascript
estraverse.traverse(ast, {
enter: function (node) {
this.break();
}
});
```
And estraverse provides `estraverse.replace` function. When returning node from `enter`/`leave`, current node is replaced with it.
```javascript
result = estraverse.replace(tree, {
enter: function (node) {
// Replace it with replaced.
if (node.type === 'Literal')
return replaced;
}
});
```
By passing `visitor.keys` mapping, we can extend estraverse traversing functionality.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Extending the existing traversing rules.
keys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
});
```
By passing `visitor.fallback` option, we can control the behavior when encountering unknown nodes.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Iterating the child **nodes** of unknown nodes.
fallback: 'iteration'
});
```
When `visitor.fallback` is a function, we can determine which keys to visit on each node.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Skip the `argument` property of each node
fallback: function(node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument';
});
}
});
```
### License
Copyright (C) 2012-2016 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# fs.realpath
A backwards-compatible fs.realpath for Node v6 and above
In Node v6, the JavaScript implementation of fs.realpath was replaced
with a faster (but less resilient) native implementation. That raises
new and platform-specific errors and cannot handle long or excessively
symlink-looping paths.
This module handles those cases by detecting the new errors and
falling back to the JavaScript implementation. On versions of Node
prior to v6, it has no effect.
## USAGE
```js
var rp = require('fs.realpath')
// async version
rp.realpath(someLongAndLoopingPath, function (er, real) {
// the ELOOP was handled, but it was a bit slower
})
// sync version
var real = rp.realpathSync(someLongAndLoopingPath)
// monkeypatch at your own risk!
// This replaces the fs.realpath/fs.realpathSync builtins
rp.monkeypatch()
// un-do the monkeypatching
rp.unmonkeypatch()
```
# tr46.js
> An implementation of the [Unicode TR46 specification](http://unicode.org/reports/tr46/).
## Installation
[Node.js](http://nodejs.org) `>= 6` is required. To install, type this at the command line:
```shell
npm install tr46
```
## API
### `toASCII(domainName[, options])`
Converts a string of Unicode symbols to a case-folded Punycode string of ASCII symbols.
Available options:
* [`checkBidi`](#checkBidi)
* [`checkHyphens`](#checkHyphens)
* [`checkJoiners`](#checkJoiners)
* [`processingOption`](#processingOption)
* [`useSTD3ASCIIRules`](#useSTD3ASCIIRules)
* [`verifyDNSLength`](#verifyDNSLength)
### `toUnicode(domainName[, options])`
Converts a case-folded Punycode string of ASCII symbols to a string of Unicode symbols.
Available options:
* [`checkBidi`](#checkBidi)
* [`checkHyphens`](#checkHyphens)
* [`checkJoiners`](#checkJoiners)
* [`useSTD3ASCIIRules`](#useSTD3ASCIIRules)
## Options
### `checkBidi`
Type: `Boolean`
Default value: `false`
When set to `true`, any bi-directional text within the input will be checked for validation.
### `checkHyphens`
Type: `Boolean`
Default value: `false`
When set to `true`, the positions of any hyphen characters within the input will be checked for validation.
### `checkJoiners`
Type: `Boolean`
Default value: `false`
When set to `true`, any word joiner characters within the input will be checked for validation.
### `processingOption`
Type: `String`
Default value: `"nontransitional"`
When set to `"transitional"`, symbols within the input will be validated according to the older IDNA2003 protocol. When set to `"nontransitional"`, the current IDNA2008 protocol will be used.
### `useSTD3ASCIIRules`
Type: `Boolean`
Default value: `false`
When set to `true`, input will be validated according to [STD3 Rules](http://unicode.org/reports/tr46/#STD3_Rules).
### `verifyDNSLength`
Type: `Boolean`
Default value: `false`
When set to `true`, the length of each DNS label within the input will be checked for validation.
# require-main-filename
[](https://travis-ci.org/yargs/require-main-filename)
[](https://coveralls.io/r/yargs/require-main-filename?branch=master)
[](https://www.npmjs.com/package/require-main-filename)
`require.main.filename` is great for figuring out the entry
point for the current application. This can be combined with a module like
[pkg-conf](https://www.npmjs.com/package/pkg-conf) to, _as if by magic_, load
top-level configuration.
Unfortunately, `require.main.filename` sometimes fails when an application is
executed with an alternative process manager, e.g., [iisnode](https://github.com/tjanczuk/iisnode).
`require-main-filename` is a shim that addresses this problem.
## Usage
```js
var main = require('require-main-filename')()
// use main as an alternative to require.main.filename.
```
## License
ISC
# Punycode.js [](https://travis-ci.org/bestiejs/punycode.js) [](https://codecov.io/gh/bestiejs/punycode.js) [](https://gemnasium.com/bestiejs/punycode.js)
Punycode.js is a robust Punycode converter that fully complies to [RFC 3492](https://tools.ietf.org/html/rfc3492) and [RFC 5891](https://tools.ietf.org/html/rfc5891).
This JavaScript library is the result of comparing, optimizing and documenting different open-source implementations of the Punycode algorithm:
* [The C example code from RFC 3492](https://tools.ietf.org/html/rfc3492#appendix-C)
* [`punycode.c` by _Markus W. Scherer_ (IBM)](http://opensource.apple.com/source/ICU/ICU-400.42/icuSources/common/punycode.c)
* [`punycode.c` by _Ben Noordhuis_](https://github.com/bnoordhuis/punycode/blob/master/punycode.c)
* [JavaScript implementation by _some_](http://stackoverflow.com/questions/183485/can-anyone-recommend-a-good-free-javascript-for-punycode-to-unicode-conversion/301287#301287)
* [`punycode.js` by _Ben Noordhuis_](https://github.com/joyent/node/blob/426298c8c1c0d5b5224ac3658c41e7c2a3fe9377/lib/punycode.js) (note: [not fully compliant](https://github.com/joyent/node/issues/2072))
This project was [bundled](https://github.com/joyent/node/blob/master/lib/punycode.js) with Node.js from [v0.6.2+](https://github.com/joyent/node/compare/975f1930b1...61e796decc) until [v7](https://github.com/nodejs/node/pull/7941) (soft-deprecated).
The current version supports recent versions of Node.js only. It provides a CommonJS module and an ES6 module. For the old version that offers the same functionality with broader support, including Rhino, Ringo, Narwhal, and web browsers, see [v1.4.1](https://github.com/bestiejs/punycode.js/releases/tag/v1.4.1).
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install punycode --save
```
In [Node.js](https://nodejs.org/):
```js
const punycode = require('punycode');
```
## API
### `punycode.decode(string)`
Converts a Punycode string of ASCII symbols to a string of Unicode symbols.
```js
// decode domain name parts
punycode.decode('maana-pta'); // 'mañana'
punycode.decode('--dqo34k'); // '☃-⌘'
```
### `punycode.encode(string)`
Converts a string of Unicode symbols to a Punycode string of ASCII symbols.
```js
// encode domain name parts
punycode.encode('mañana'); // 'maana-pta'
punycode.encode('☃-⌘'); // '--dqo34k'
```
### `punycode.toUnicode(input)`
Converts a Punycode string representing a domain name or an email address to Unicode. Only the Punycoded parts of the input will be converted, i.e. it doesn’t matter if you call it on a string that has already been converted to Unicode.
```js
// decode domain names
punycode.toUnicode('xn--maana-pta.com');
// → 'mañana.com'
punycode.toUnicode('xn----dqo34k.com');
// → '☃-⌘.com'
// decode email addresses
punycode.toUnicode('джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq');
// → 'джумла@джpумлатест.bрфa'
```
### `punycode.toASCII(input)`
Converts a lowercased Unicode string representing a domain name or an email address to Punycode. Only the non-ASCII parts of the input will be converted, i.e. it doesn’t matter if you call it with a domain that’s already in ASCII.
```js
// encode domain names
punycode.toASCII('mañana.com');
// → 'xn--maana-pta.com'
punycode.toASCII('☃-⌘.com');
// → 'xn----dqo34k.com'
// encode email addresses
punycode.toASCII('джумла@джpумлатест.bрфa');
// → 'джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq'
```
### `punycode.ucs2`
#### `punycode.ucs2.decode(string)`
Creates an array containing the numeric code point values of each Unicode symbol in the string. While [JavaScript uses UCS-2 internally](https://mathiasbynens.be/notes/javascript-encoding), this function will convert a pair of surrogate halves (each of which UCS-2 exposes as separate characters) into a single code point, matching UTF-16.
```js
punycode.ucs2.decode('abc');
// → [0x61, 0x62, 0x63]
// surrogate pair for U+1D306 TETRAGRAM FOR CENTRE:
punycode.ucs2.decode('\uD834\uDF06');
// → [0x1D306]
```
#### `punycode.ucs2.encode(codePoints)`
Creates a string based on an array of numeric code point values.
```js
punycode.ucs2.encode([0x61, 0x62, 0x63]);
// → 'abc'
punycode.ucs2.encode([0x1D306]);
// → '\uD834\uDF06'
```
### `punycode.version`
A string representing the current Punycode.js version number.
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
Punycode.js is available under the [MIT](https://mths.be/mit) license.
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows note
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Note that PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Then, run the program to be debugged as usual.
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# ansi-colors [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=W8YFZ425KND68) [](https://www.npmjs.com/package/ansi-colors) [](https://npmjs.org/package/ansi-colors) [](https://npmjs.org/package/ansi-colors) [](https://travis-ci.org/doowb/ansi-colors)
> Easily add ANSI colors to your text and symbols in the terminal. A faster drop-in replacement for chalk, kleur and turbocolor (without the dependencies and rendering bugs).
Please consider following this project's author, [Brian Woodward](https://github.com/doowb), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save ansi-colors
```

## Why use this?
ansi-colors is _the fastest Node.js library for terminal styling_. A more performant drop-in replacement for chalk, with no dependencies.
* _Blazing fast_ - Fastest terminal styling library in node.js, 10-20x faster than chalk!
* _Drop-in replacement_ for [chalk](https://github.com/chalk/chalk).
* _No dependencies_ (Chalk has 7 dependencies in its tree!)
* _Safe_ - Does not modify the `String.prototype` like [colors](https://github.com/Marak/colors.js).
* Supports [nested colors](#nested-colors), **and does not have the [nested styling bug](#nested-styling-bug) that is present in [colorette](https://github.com/jorgebucaran/colorette), [chalk](https://github.com/chalk/chalk), and [kleur](https://github.com/lukeed/kleur)**.
* Supports [chained colors](#chained-colors).
* [Toggle color support](#toggle-color-support) on or off.
## Usage
```js
const c = require('ansi-colors');
console.log(c.red('This is a red string!'));
console.log(c.green('This is a red string!'));
console.log(c.cyan('This is a cyan string!'));
console.log(c.yellow('This is a yellow string!'));
```

## Chained colors
```js
console.log(c.bold.red('this is a bold red message'));
console.log(c.bold.yellow.italic('this is a bold yellow italicized message'));
console.log(c.green.bold.underline('this is a bold green underlined message'));
```

## Nested colors
```js
console.log(c.yellow(`foo ${c.red.bold('red')} bar ${c.cyan('cyan')} baz`));
```

### Nested styling bug
`ansi-colors` does not have the nested styling bug found in [colorette](https://github.com/jorgebucaran/colorette), [chalk](https://github.com/chalk/chalk), and [kleur](https://github.com/lukeed/kleur).
```js
const { bold, red } = require('ansi-styles');
console.log(bold(`foo ${red.dim('bar')} baz`));
const colorette = require('colorette');
console.log(colorette.bold(`foo ${colorette.red(colorette.dim('bar'))} baz`));
const kleur = require('kleur');
console.log(kleur.bold(`foo ${kleur.red.dim('bar')} baz`));
const chalk = require('chalk');
console.log(chalk.bold(`foo ${chalk.red.dim('bar')} baz`));
```
**Results in the following**
(sans icons and labels)

## Toggle color support
Easily enable/disable colors.
```js
const c = require('ansi-colors');
// disable colors manually
c.enabled = false;
// or use a library to automatically detect support
c.enabled = require('color-support').hasBasic;
console.log(c.red('I will only be colored red if the terminal supports colors'));
```
## Strip ANSI codes
Use the `.unstyle` method to strip ANSI codes from a string.
```js
console.log(c.unstyle(c.blue.bold('foo bar baz')));
//=> 'foo bar baz'
```
## Available styles
**Note** that bright and bright-background colors are not always supported.
| Colors | Background Colors | Bright Colors | Bright Background Colors |
| ------- | ----------------- | ------------- | ------------------------ |
| black | bgBlack | blackBright | bgBlackBright |
| red | bgRed | redBright | bgRedBright |
| green | bgGreen | greenBright | bgGreenBright |
| yellow | bgYellow | yellowBright | bgYellowBright |
| blue | bgBlue | blueBright | bgBlueBright |
| magenta | bgMagenta | magentaBright | bgMagentaBright |
| cyan | bgCyan | cyanBright | bgCyanBright |
| white | bgWhite | whiteBright | bgWhiteBright |
| gray | | | |
| grey | | | |
_(`gray` is the U.S. spelling, `grey` is more commonly used in the Canada and U.K.)_
### Style modifiers
* dim
* **bold**
* hidden
* _italic_
* underline
* inverse
* ~~strikethrough~~
* reset
## Aliases
Create custom aliases for styles.
```js
const colors = require('ansi-colors');
colors.alias('primary', colors.yellow);
colors.alias('secondary', colors.bold);
console.log(colors.primary.secondary('Foo'));
```
## Themes
A theme is an object of custom aliases.
```js
const colors = require('ansi-colors');
colors.theme({
danger: colors.red,
dark: colors.dim.gray,
disabled: colors.gray,
em: colors.italic,
heading: colors.bold.underline,
info: colors.cyan,
muted: colors.dim,
primary: colors.blue,
strong: colors.bold,
success: colors.green,
underline: colors.underline,
warning: colors.yellow
});
// Now, we can use our custom styles alongside the built-in styles!
console.log(colors.danger.strong.em('Error!'));
console.log(colors.warning('Heads up!'));
console.log(colors.info('Did you know...'));
console.log(colors.success.bold('It worked!'));
```
## Performance
**Libraries tested**
* ansi-colors v3.0.4
* chalk v2.4.1
### Mac
> MacBook Pro, Intel Core i7, 2.3 GHz, 16 GB.
**Load time**
Time it takes to load the first time `require()` is called:
* ansi-colors - `1.915ms`
* chalk - `12.437ms`
**Benchmarks**
```
# All Colors
ansi-colors x 173,851 ops/sec ±0.42% (91 runs sampled)
chalk x 9,944 ops/sec ±2.53% (81 runs sampled)))
# Chained colors
ansi-colors x 20,791 ops/sec ±0.60% (88 runs sampled)
chalk x 2,111 ops/sec ±2.34% (83 runs sampled)
# Nested colors
ansi-colors x 59,304 ops/sec ±0.98% (92 runs sampled)
chalk x 4,590 ops/sec ±2.08% (82 runs sampled)
```
### Windows
> Windows 10, Intel Core i7-7700k CPU @ 4.2 GHz, 32 GB
**Load time**
Time it takes to load the first time `require()` is called:
* ansi-colors - `1.494ms`
* chalk - `11.523ms`
**Benchmarks**
```
# All Colors
ansi-colors x 193,088 ops/sec ±0.51% (95 runs sampled))
chalk x 9,612 ops/sec ±3.31% (77 runs sampled)))
# Chained colors
ansi-colors x 26,093 ops/sec ±1.13% (94 runs sampled)
chalk x 2,267 ops/sec ±2.88% (80 runs sampled))
# Nested colors
ansi-colors x 67,747 ops/sec ±0.49% (93 runs sampled)
chalk x 4,446 ops/sec ±3.01% (82 runs sampled))
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [ansi-wrap](https://www.npmjs.com/package/ansi-wrap): Create ansi colors by passing the open and close codes. | [homepage](https://github.com/jonschlinkert/ansi-wrap "Create ansi colors by passing the open and close codes.")
* [strip-color](https://www.npmjs.com/package/strip-color): Strip ANSI color codes from a string. No dependencies. | [homepage](https://github.com/jonschlinkert/strip-color "Strip ANSI color codes from a string. No dependencies.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 48 | [jonschlinkert](https://github.com/jonschlinkert) |
| 42 | [doowb](https://github.com/doowb) |
| 6 | [lukeed](https://github.com/lukeed) |
| 2 | [Silic0nS0ldier](https://github.com/Silic0nS0ldier) |
| 1 | [dwieeb](https://github.com/dwieeb) |
| 1 | [jorgebucaran](https://github.com/jorgebucaran) |
| 1 | [madhavarshney](https://github.com/madhavarshney) |
| 1 | [chapterjason](https://github.com/chapterjason) |
### Author
**Brian Woodward**
* [GitHub Profile](https://github.com/doowb)
* [Twitter Profile](https://twitter.com/doowb)
* [LinkedIn Profile](https://linkedin.com/in/woodwardbrian)
### License
Copyright © 2019, [Brian Woodward](https://github.com/doowb).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on July 01, 2019._
The AssemblyScript Runtime
==========================
The runtime provides the functionality necessary to dynamically allocate and deallocate memory of objects, arrays and buffers, as well as collect garbage that is no longer used. The current implementation is either a Two-Color Mark & Sweep (TCMS) garbage collector that must be called manually when the execution stack is unwound or an Incremental Tri-Color Mark & Sweep (ITCMS) garbage collector that is fully automated with a shadow stack, implemented on top of a Two-Level Segregate Fit (TLSF) memory manager. It's not designed to be the fastest of its kind, but intentionally focuses on simplicity and ease of integration until we can replace it with the real deal, i.e. Wasm GC.
Interface
---------
### Garbage collector / `--exportRuntime`
* **__new**(size: `usize`, id: `u32` = 0): `usize`<br />
Dynamically allocates a GC object of at least the specified size and returns its address.
Alignment is guaranteed to be 16 bytes to fit up to v128 values naturally.
GC-allocated objects cannot be used with `__realloc` and `__free`.
* **__pin**(ptr: `usize`): `usize`<br />
Pins the object pointed to by `ptr` externally so it and its directly reachable members and indirectly reachable objects do not become garbage collected.
* **__unpin**(ptr: `usize`): `void`<br />
Unpins the object pointed to by `ptr` externally so it can become garbage collected.
* **__collect**(): `void`<br />
Performs a full garbage collection.
### Internals
* **__alloc**(size: `usize`): `usize`<br />
Dynamically allocates a chunk of memory of at least the specified size and returns its address.
Alignment is guaranteed to be 16 bytes to fit up to v128 values naturally.
* **__realloc**(ptr: `usize`, size: `usize`): `usize`<br />
Dynamically changes the size of a chunk of memory, possibly moving it to a new address.
* **__free**(ptr: `usize`): `void`<br />
Frees a dynamically allocated chunk of memory by its address.
* **__renew**(ptr: `usize`, size: `usize`): `usize`<br />
Like `__realloc`, but for `__new`ed GC objects.
* **__link**(parentPtr: `usize`, childPtr: `usize`, expectMultiple: `bool`): `void`<br />
Introduces a link from a parent object to a child object, i.e. upon `parent.field = child`.
* **__visit**(ptr: `usize`, cookie: `u32`): `void`<br />
Concrete visitor implementation called during traversal. Cookie can be used to indicate one of multiple operations.
* **__visit_globals**(cookie: `u32`): `void`<br />
Calls `__visit` on each global that is of a managed type.
* **__visit_members**(ptr: `usize`, cookie: `u32`): `void`<br />
Calls `__visit` on each member of the object pointed to by `ptr`.
* **__typeinfo**(id: `u32`): `RTTIFlags`<br />
Obtains the runtime type information for objects with the specified runtime id. Runtime type information is a set of flags indicating whether a type is managed, an array or similar, and what the relevant alignments when creating an instance externally are etc.
* **__instanceof**(ptr: `usize`, classId: `u32`): `bool`<br />
Tests if the object pointed to by `ptr` is an instance of the specified class id.
ITCMS / `--runtime incremental`
-----
The Incremental Tri-Color Mark & Sweep garbage collector maintains a separate shadow stack of managed values in the background to achieve full automation. Maintaining another stack introduces some overhead compared to the simpler Two-Color Mark & Sweep garbage collector, but makes it independent of whether the execution stack is unwound or not when it is invoked, so the garbage collector can run interleaved with the program.
There are several constants one can experiment with to tweak ITCMS's automation:
* `--use ASC_GC_GRANULARITY=1024`<br />
How often to interrupt. The default of 1024 means "interrupt each 1024 bytes allocated".
* `--use ASC_GC_STEPFACTOR=200`<br />
How long to interrupt. The default of 200% means "run at double the speed of allocations".
* `--use ASC_GC_IDLEFACTOR=200`<br />
How long to idle. The default of 200% means "wait for memory to double before kicking in again".
* `--use ASC_GC_MARKCOST=1`<br />
How costly it is to mark one object. Budget per interrupt is `GRANULARITY * STEPFACTOR / 100`.
* `--use ASC_GC_SWEEPCOST=10`<br />
How costly it is to sweep one object. Budget per interrupt is `GRANULARITY * STEPFACTOR / 100`.
TCMS / `--runtime minimal`
----
If automation and low pause times aren't strictly necessary, using the Two-Color Mark & Sweep garbage collector instead by invoking collection manually at appropriate times when the execution stack is unwound may be more performant as it simpler and has less overhead. The execution stack is typically unwound when invoking the collector externally, at a place that is not indirectly called from Wasm.
STUB / `--runtime stub`
----
The stub is a maximally minimal runtime substitute, consisting of a simple and fast bump allocator with no means of freeing up memory again, except when freeing the respective most recently allocated object on top of the bump. Useful where memory is not a concern, and/or where it is sufficient to destroy the whole module including any potential garbage after execution.
See also: [Garbage collection](https://www.assemblyscript.org/garbage-collection.html)
# inflight
Add callbacks to requests in flight to avoid async duplication
## USAGE
```javascript
var inflight = require('inflight')
// some request that does some stuff
function req(key, callback) {
// key is any random string. like a url or filename or whatever.
//
// will return either a falsey value, indicating that the
// request for this key is already in flight, or a new callback
// which when called will call all callbacks passed to inflightk
// with the same key
callback = inflight(key, callback)
// If we got a falsey value back, then there's already a req going
if (!callback) return
// this is where you'd fetch the url or whatever
// callback is also once()-ified, so it can safely be assigned
// to multiple events etc. First call wins.
setTimeout(function() {
callback(null, key)
}, 100)
}
// only assigns a single setTimeout
// when it dings, all cbs get called
req('foo', cb1)
req('foo', cb2)
req('foo', cb3)
req('foo', cb4)
```
iMurmurHash.js
==============
An incremental implementation of the MurmurHash3 (32-bit) hashing algorithm for JavaScript based on [Gary Court's implementation](https://github.com/garycourt/murmurhash-js) with [kazuyukitanimura's modifications](https://github.com/kazuyukitanimura/murmurhash-js).
This version works significantly faster than the non-incremental version if you need to hash many small strings into a single hash, since string concatenation (to build the single string to pass the non-incremental version) is fairly costly. In one case tested, using the incremental version was about 50% faster than concatenating 5-10 strings and then hashing.
Installation
------------
To use iMurmurHash in the browser, [download the latest version](https://raw.github.com/jensyt/imurmurhash-js/master/imurmurhash.min.js) and include it as a script on your site.
```html
<script type="text/javascript" src="/scripts/imurmurhash.min.js"></script>
<script>
// Your code here, access iMurmurHash using the global object MurmurHash3
</script>
```
---
To use iMurmurHash in Node.js, install the module using NPM:
```bash
npm install imurmurhash
```
Then simply include it in your scripts:
```javascript
MurmurHash3 = require('imurmurhash');
```
Quick Example
-------------
```javascript
// Create the initial hash
var hashState = MurmurHash3('string');
// Incrementally add text
hashState.hash('more strings');
hashState.hash('even more strings');
// All calls can be chained if desired
hashState.hash('and').hash('some').hash('more');
// Get a result
hashState.result();
// returns 0xe4ccfe6b
```
Functions
---------
### MurmurHash3 ([string], [seed])
Get a hash state object, optionally initialized with the given _string_ and _seed_. _Seed_ must be a positive integer if provided. Calling this function without the `new` keyword will return a cached state object that has been reset. This is safe to use as long as the object is only used from a single thread and no other hashes are created while operating on this one. If this constraint cannot be met, you can use `new` to create a new state object. For example:
```javascript
// Use the cached object, calling the function again will return the same
// object (but reset, so the current state would be lost)
hashState = MurmurHash3();
...
// Create a new object that can be safely used however you wish. Calling the
// function again will simply return a new state object, and no state loss
// will occur, at the cost of creating more objects.
hashState = new MurmurHash3();
```
Both methods can be mixed however you like if you have different use cases.
---
### MurmurHash3.prototype.hash (string)
Incrementally add _string_ to the hash. This can be called as many times as you want for the hash state object, including after a call to `result()`. Returns `this` so calls can be chained.
---
### MurmurHash3.prototype.result ()
Get the result of the hash as a 32-bit positive integer. This performs the tail and finalizer portions of the algorithm, but does not store the result in the state object. This means that it is perfectly safe to get results and then continue adding strings via `hash`.
```javascript
// Do the whole string at once
MurmurHash3('this is a test string').result();
// 0x70529328
// Do part of the string, get a result, then the other part
var m = MurmurHash3('this is a');
m.result();
// 0xbfc4f834
m.hash(' test string').result();
// 0x70529328 (same as above)
```
---
### MurmurHash3.prototype.reset ([seed])
Reset the state object for reuse, optionally using the given _seed_ (defaults to 0 like the constructor). Returns `this` so calls can be chained.
---
License (MIT)
-------------
Copyright (c) 2013 Gary Court, Jens Taylor
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# Rock-Paper-Scissors game as a NEAR contract
Video demo: [here](https://www.loom.com/share/fbd896f412aa43d7ad454f55e7976429)
## Install dependencies
```
yarn
```
## Build and Deploy the contract
```
yarn asb
near dev-deploy ./build/release/near-rock-paper-scissors-game.wasm
# copy the game id in your clipboard and send it to player 2
```
## How to Play
1. Player 1 call function `createGame` passing the attached value (at least 0.1 NEAR), and send gameId to player 2
2. Player 2 call function `joinGame(gameId)` passing gameId that player one sent, also passing the attached value (Exactly same amount as player 1's)
3. Call function `play(gameId: u32, playerChose: u8)` with gameId and playerChose as argument
4. playerChose argument means rock, paper or scissors. You should write 1 for Rock, 2 for Paper and 3 for Scissors.
5. The plays continue until every player play.
6. After every player play, function return a message like 'Congratulations: hfgunay.testnet is the winner and received 200000000000000000000000'
7. When someone win, the attached deposit will be transfered to the wallet of the winner.
## Run the game
**Create a game**
```
near call <contract-id> createGame --account_id <account-id> --amount 0.1
# save the game id in your clipboard and send it to your opponent
```
**Join a game (player 2)**
```
near call <contract-id> joinGame '{"gameId": <game-id>}' --account_id <account-id> --amount 0.1
If it didn't work try: near call <contract-id> joinGame '{"""gameId""":9}' --account_id <account-id> --amount 0.1
```
**Play the game**
```
near call <contract-id> play `play(gameId: u32, playerChose: u8)` --account_id <account-id>
If it didn't work try: near call <contract-id> play '{"""gameId""":9,"""playerChose""":2}' --account_id <account-id>
```
Railroad-diagram Generator
==========================
This is a small js library for generating railroad diagrams
(like what [JSON.org](http://json.org) uses)
using SVG.
Railroad diagrams are a way of visually representing a grammar
in a form that is more readable than using regular expressions or BNF.
I think (though I haven't given it a lot of thought yet) that if it's easy to write a context-free grammar for the language,
the corresponding railroad diagram will be easy as well.
There are several railroad-diagram generators out there, but none of them had the visual appeal I wanted.
[Here's an example of how they look!](http://www.xanthir.com/etc/railroad-diagrams/example.html)
And [here's an online generator for you to play with and get SVG code from!](http://www.xanthir.com/etc/railroad-diagrams/generator.html)
The library now exists in a Python port as well! See the information further down.
Details
-------
To use the library, just include the js and css files, and then call the Diagram() function.
Its arguments are the components of the diagram (Diagram is a special form of Sequence).
An alternative to Diagram() is ComplexDiagram() which is used to describe a complex type diagram.
Components are either leaves or containers.
The leaves:
* Terminal(text) or a bare string - represents literal text
* NonTerminal(text) - represents an instruction or another production
* Comment(text) - a comment
* Skip() - an empty line
The containers:
* Sequence(children) - like simple concatenation in a regex
* Choice(index, children) - like | in a regex. The index argument specifies which child is the "normal" choice and should go in the middle
* Optional(child, skip) - like ? in a regex. A shorthand for `Choice(1, [Skip(), child])`. If the optional `skip` parameter has the value `"skip"`, it instead puts the Skip() in the straight-line path, for when the "normal" behavior is to omit the item.
* OneOrMore(child, repeat) - like + in a regex. The 'repeat' argument is optional, and specifies something that must go between the repetitions.
* ZeroOrMore(child, repeat, skip) - like * in a regex. A shorthand for `Optional(OneOrMore(child, repeat))`. The optional `skip` parameter is identical to Optional().
For convenience, each component can be called with or without `new`.
If called without `new`,
the container components become n-ary;
that is, you can say either `new Sequence([A, B])` or just `Sequence(A,B)`.
After constructing a Diagram, call `.format(...padding)` on it, specifying 0-4 padding values (just like CSS) for some additional "breathing space" around the diagram (the paddings default to 20px).
The result can either be `.toString()`'d for the markup, or `.toSVG()`'d for an `<svg>` element, which can then be immediately inserted to the document. As a convenience, Diagram also has an `.addTo(element)` method, which immediately converts it to SVG and appends it to the referenced element with default paddings. `element` defaults to `document.body`.
Options
-------
There are a few options you can tweak, at the bottom of the file. Just tweak either until the diagram looks like what you want.
You can also change the CSS file - feel free to tweak to your heart's content.
Note, though, that if you change the text sizes in the CSS,
you'll have to go adjust the metrics for the leaf nodes as well.
* VERTICAL_SEPARATION - sets the minimum amount of vertical separation between two items. Note that the stroke width isn't counted when computing the separation; this shouldn't be relevant unless you have a very small separation or very large stroke width.
* ARC_RADIUS - the radius of the arcs used in the branching containers like Choice. This has a relatively large effect on the size of non-trivial diagrams. Both tight and loose values look good, depending on what you're going for.
* DIAGRAM_CLASS - the class set on the root `<svg>` element of each diagram, for use in the CSS stylesheet.
* STROKE_ODD_PIXEL_LENGTH - the default stylesheet uses odd pixel lengths for 'stroke'. Due to rasterization artifacts, they look best when the item has been translated half a pixel in both directions. If you change the styling to use a stroke with even pixel lengths, you'll want to set this variable to `false`.
* INTERNAL_ALIGNMENT - when some branches of a container are narrower than others, this determines how they're aligned in the extra space. Defaults to "center", but can be set to "left" or "right".
Caveats
-------
At this early stage, the generator is feature-complete and works as intended, but still has several TODOs:
* The font-sizes are hard-coded right now, and the font handling in general is very dumb - I'm just guessing at some metrics that are probably "good enough" rather than measuring things properly.
Python Port
-----------
In addition to the canonical JS version, the library now exists as a Python library as well.
Using it is basically identical. The config variables are globals in the file, and so may be adjusted either manually or via tweaking from inside your program.
The main difference from the JS port is how you extract the string from the Diagram. You'll find a `writeSvg(writerFunc)` method on `Diagram`, which takes a callback of one argument and passes it the string form of the diagram. For example, it can be used like `Diagram(...).writeSvg(sys.stdout.write)` to write to stdout. **Note**: the callback will be called multiple times as it builds up the string, not just once with the whole thing. If you need it all at once, consider something like a `StringIO` as an easy way to collect it into a single string.
License
-------
This document and all associated files in the github project are licensed under [CC0](http://creativecommons.org/publicdomain/zero/1.0/) .
This means you can reuse, remix, or otherwise appropriate this project for your own use **without restriction**.
(The actual legal meaning can be found at the above link.)
Don't ask me for permission to use any part of this project, **just use it**.
I would appreciate attribution, but that is not required by the license.
# isarray
`Array#isArray` for older browsers.
[](http://travis-ci.org/juliangruber/isarray)
[](https://www.npmjs.org/package/isarray)
[
](https://ci.testling.com/juliangruber/isarray)
## Usage
```js
var isArray = require('isarray');
console.log(isArray([])); // => true
console.log(isArray({})); // => false
```
## Installation
With [npm](http://npmjs.org) do
```bash
$ npm install isarray
```
Then bundle for the browser with
[browserify](https://github.com/substack/browserify).
With [component](http://component.io) do
```bash
$ component install juliangruber/isarray
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# file-entry-cache
> Super simple cache for file metadata, useful for process that work o a given series of files
> and that only need to repeat the job on the changed ones since the previous run of the process — Edit
[](https://npmjs.org/package/file-entry-cache)
[](https://travis-ci.org/royriojas/file-entry-cache)
## install
```bash
npm i --save file-entry-cache
```
## Usage
The module exposes two functions `create` and `createFromFile`.
## `create(cacheName, [directory, useCheckSum])`
- **cacheName**: the name of the cache to be created
- **directory**: Optional the directory to load the cache from
- **usecheckSum**: Whether to use md5 checksum to verify if file changed. If false the default will be to use the mtime and size of the file.
## `createFromFile(pathToCache, [useCheckSum])`
- **pathToCache**: the path to the cache file (this combines the cache name and directory)
- **useCheckSum**: Whether to use md5 checksum to verify if file changed. If false the default will be to use the mtime and size of the file.
```js
// loads the cache, if one does not exists for the given
// Id a new one will be prepared to be created
var fileEntryCache = require('file-entry-cache');
var cache = fileEntryCache.create('testCache');
var files = expand('../fixtures/*.txt');
// the first time this method is called, will return all the files
var oFiles = cache.getUpdatedFiles(files);
// this will persist this to disk checking each file stats and
// updating the meta attributes `size` and `mtime`.
// custom fields could also be added to the meta object and will be persisted
// in order to retrieve them later
cache.reconcile();
// use this if you want the non visited file entries to be kept in the cache
// for more than one execution
//
// cache.reconcile( true /* noPrune */)
// on a second run
var cache2 = fileEntryCache.create('testCache');
// will return now only the files that were modified or none
// if no files were modified previous to the execution of this function
var oFiles = cache.getUpdatedFiles(files);
// if you want to prevent a file from being considered non modified
// something useful if a file failed some sort of validation
// you can then remove the entry from the cache doing
cache.removeEntry('path/to/file'); // path to file should be the same path of the file received on `getUpdatedFiles`
// that will effectively make the file to appear again as modified until the validation is passed. In that
// case you should not remove it from the cache
// if you need all the files, so you can determine what to do with the changed ones
// you can call
var oFiles = cache.normalizeEntries(files);
// oFiles will be an array of objects like the following
entry = {
key: 'some/name/file', the path to the file
changed: true, // if the file was changed since previous run
meta: {
size: 3242, // the size of the file
mtime: 231231231, // the modification time of the file
data: {} // some extra field stored for this file (useful to save the result of a transformation on the file
}
}
```
## Motivation for this module
I needed a super simple and dumb **in-memory cache** with optional disk persistence (write-back cache) in order to make
a script that will beautify files with `esformatter` to execute only on the files that were changed since the last run.
In doing so the process of beautifying files was reduced from several seconds to a small fraction of a second.
This module uses [flat-cache](https://www.npmjs.com/package/flat-cache) a super simple `key/value` cache storage with
optional file persistance.
The main idea is to read the files when the task begins, apply the transforms required, and if the process succeed,
then store the new state of the files. The next time this module request for `getChangedFiles` will return only
the files that were modified. Making the process to end faster.
This module could also be used by processes that modify the files applying a transform, in that case the result of the
transform could be stored in the `meta` field, of the entries. Anything added to the meta field will be persisted.
Those processes won't need to call `getChangedFiles` they will instead call `normalizeEntries` that will return the
entries with a `changed` field that can be used to determine if the file was changed or not. If it was not changed
the transformed stored data could be used instead of actually applying the transformation, saving time in case of only
a few files changed.
In the worst case scenario all the files will be processed. In the best case scenario only a few of them will be processed.
## Important notes
- The values set on the meta attribute of the entries should be `stringify-able` ones if possible, flat-cache uses `circular-json` to try to persist circular structures, but this should be considered experimental. The best results are always obtained with non circular values
- All the changes to the cache state are done to memory first and only persisted after reconcile.
## License
MIT
# json-schema-traverse
Traverse JSON Schema passing each schema object to callback
[](https://travis-ci.org/epoberezkin/json-schema-traverse)
[](https://www.npmjs.com/package/json-schema-traverse)
[](https://coveralls.io/github/epoberezkin/json-schema-traverse?branch=master)
## Install
```
npm install json-schema-traverse
```
## Usage
```javascript
const traverse = require('json-schema-traverse');
const schema = {
properties: {
foo: {type: 'string'},
bar: {type: 'integer'}
}
};
traverse(schema, {cb});
// cb is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
// Or:
traverse(schema, {cb: {pre, post}});
// pre is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
//
// post is called 3 times with:
// 1. {type: 'string'}
// 2. {type: 'integer'}
// 3. root schema
```
Callback function `cb` is called for each schema object (not including draft-06 boolean schemas), including the root schema, in pre-order traversal. Schema references ($ref) are not resolved, they are passed as is. Alternatively, you can pass a `{pre, post}` object as `cb`, and then `pre` will be called before traversing child elements, and `post` will be called after all child elements have been traversed.
Callback is passed these parameters:
- _schema_: the current schema object
- _JSON pointer_: from the root schema to the current schema object
- _root schema_: the schema passed to `traverse` object
- _parent JSON pointer_: from the root schema to the parent schema object (see below)
- _parent keyword_: the keyword inside which this schema appears (e.g. `properties`, `anyOf`, etc.)
- _parent schema_: not necessarily parent object/array; in the example above the parent schema for `{type: 'string'}` is the root schema
- _index/property_: index or property name in the array/object containing multiple schemas; in the example above for `{type: 'string'}` the property name is `'foo'`
## Traverse objects in all unknown keywords
```javascript
const traverse = require('json-schema-traverse');
const schema = {
mySchema: {
minimum: 1,
maximum: 2
}
};
traverse(schema, {allKeys: true, cb});
// cb is called 2 times with:
// 1. root schema
// 2. mySchema
```
Without option `allKeys: true` callback will be called only with root schema.
## License
[MIT](https://github.com/epoberezkin/json-schema-traverse/blob/master/LICENSE)
# cliui
[](https://travis-ci.org/yargs/cliui)
[](https://coveralls.io/r/yargs/cliui?branch=)
[](https://www.npmjs.com/package/cliui)
[](https://github.com/conventional-changelog/standard-version)
easily create complex multi-column command-line-interfaces.
## Example
```js
var ui = require('cliui')()
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 2, 0]
})
ui.div(
{
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
},
{
text: "the file to load." +
chalk.green("(if this description is long it wraps).")
,
width: 20
},
{
text: chalk.red("[required]"),
align: 'right'
}
)
console.log(ui.toString())
```
<img width="500" src="screenshot.png">
## Layout DSL
cliui exposes a simple layout DSL:
If you create a single `ui.div`, passing a string rather than an
object:
* `\n`: characters will be interpreted as new rows.
* `\t`: characters will be interpreted as new columns.
* `\s`: characters will be interpreted as padding.
**as an example...**
```js
var ui = require('./')({
width: 60
})
ui.div(
'Usage: node ./bin/foo.js\n' +
' <regex>\t provide a regex\n' +
' <glob>\t provide a glob\t [required]'
)
console.log(ui.toString())
```
**will output:**
```shell
Usage: node ./bin/foo.js
<regex> provide a regex
<glob> provide a glob [required]
```
## Methods
```js
cliui = require('cliui')
```
### cliui({width: integer})
Specify the maximum width of the UI being generated.
If no width is provided, cliui will try to get the current window's width and use it, and if that doesn't work, width will be set to `80`.
### cliui({wrap: boolean})
Enable or disable the wrapping of text in a column.
### cliui.div(column, column, column)
Create a row with any number of columns, a column
can either be a string, or an object with the following
options:
* **text:** some text to place in the column.
* **width:** the width of a column.
* **align:** alignment, `right` or `center`.
* **padding:** `[top, right, bottom, left]`.
* **border:** should a border be placed around the div?
### cliui.span(column, column, column)
Similar to `div`, except the next row will be appended without
a new line being created.
### cliui.resetOutput()
Resets the UI elements of the current cliui instance, maintaining the values
set for `width` and `wrap`.
### Estraverse [](http://travis-ci.org/estools/estraverse)
Estraverse ([estraverse](http://github.com/estools/estraverse)) is
[ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm)
traversal functions from [esmangle project](http://github.com/estools/esmangle).
### Documentation
You can find usage docs at [wiki page](https://github.com/estools/estraverse/wiki/Usage).
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
estraverse.traverse(ast, {
enter: function (node, parent) {
if (node.type == 'FunctionExpression' || node.type == 'FunctionDeclaration')
return estraverse.VisitorOption.Skip;
},
leave: function (node, parent) {
if (node.type == 'VariableDeclarator')
console.log(node.id.name);
}
});
```
We can use `this.skip`, `this.remove` and `this.break` functions instead of using Skip, Remove and Break.
```javascript
estraverse.traverse(ast, {
enter: function (node) {
this.break();
}
});
```
And estraverse provides `estraverse.replace` function. When returning node from `enter`/`leave`, current node is replaced with it.
```javascript
result = estraverse.replace(tree, {
enter: function (node) {
// Replace it with replaced.
if (node.type === 'Literal')
return replaced;
}
});
```
By passing `visitor.keys` mapping, we can extend estraverse traversing functionality.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Extending the existing traversing rules.
keys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
});
```
By passing `visitor.fallback` option, we can control the behavior when encountering unknown nodes.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Iterating the child **nodes** of unknown nodes.
fallback: 'iteration'
});
```
When `visitor.fallback` is a function, we can determine which keys to visit on each node.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
estraverse.traverse(tree, {
enter: function (node) { },
// Skip the `argument` property of each node
fallback: function(node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument';
});
}
});
```
### License
Copyright (C) 2012-2016 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# which
Like the unix `which` utility.
Finds the first instance of a specified executable in the PATH
environment variable. Does not cache the results, so `hash -r` is not
needed when the PATH changes.
## USAGE
```javascript
var which = require('which')
// async usage
which('node', function (er, resolvedPath) {
// er is returned if no "node" is found on the PATH
// if it is found, then the absolute path to the exec is returned
})
// or promise
which('node').then(resolvedPath => { ... }).catch(er => { ... not found ... })
// sync usage
// throws if not found
var resolved = which.sync('node')
// if nothrow option is used, returns null if not found
resolved = which.sync('node', {nothrow: true})
// Pass options to override the PATH and PATHEXT environment vars.
which('node', { path: someOtherPath }, function (er, resolved) {
if (er)
throw er
console.log('found at %j', resolved)
})
```
## CLI USAGE
Same as the BSD `which(1)` binary.
```
usage: which [-as] program ...
```
## OPTIONS
You may pass an options object as the second argument.
- `path`: Use instead of the `PATH` environment variable.
- `pathExt`: Use instead of the `PATHEXT` environment variable.
- `all`: Return all matches, instead of just the first one. Note that
this means the function returns an array of strings instead of a
single string.
<p align="center">
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs/master/yargs-logo.png">
</p>
<h1 align="center"> Yargs </h1>
<p align="center">
<b >Yargs be a node.js library fer hearties tryin' ter parse optstrings</b>
</p>
<br>

[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[![Coverage][coverage-image]][coverage-url]
[![Conventional Commits][conventional-commits-image]][conventional-commits-url]
[![Slack][slack-image]][slack-url]
## Description
Yargs helps you build interactive command line tools, by parsing arguments and generating an elegant user interface.
It gives you:
* commands and (grouped) options (`my-program.js serve --port=5000`).
* a dynamically generated help menu based on your arguments:
```
mocha [spec..]
Run tests with Mocha
Commands
mocha inspect [spec..] Run tests with Mocha [default]
mocha init <path> create a client-side Mocha setup at <path>
Rules & Behavior
--allow-uncaught Allow uncaught errors to propagate [boolean]
--async-only, -A Require all tests to use a callback (async) or
return a Promise [boolean]
```
* bash-completion shortcuts for commands and options.
* and [tons more](/docs/api.md).
## Installation
Stable version:
```bash
npm i yargs
```
Bleeding edge version with the most recent features:
```bash
npm i yargs@next
```
## Usage
### Simple Example
```javascript
#!/usr/bin/env node
const yargs = require('yargs/yargs')
const { hideBin } = require('yargs/helpers')
const argv = yargs(hideBin(process.argv)).argv
if (argv.ships > 3 && argv.distance < 53.5) {
console.log('Plunder more riffiwobbles!')
} else {
console.log('Retreat from the xupptumblers!')
}
```
```bash
$ ./plunder.js --ships=4 --distance=22
Plunder more riffiwobbles!
$ ./plunder.js --ships 12 --distance 98.7
Retreat from the xupptumblers!
```
### Complex Example
```javascript
#!/usr/bin/env node
const yargs = require('yargs/yargs')
const { hideBin } = require('yargs/helpers')
yargs(hideBin(process.argv))
.command('serve [port]', 'start the server', (yargs) => {
yargs
.positional('port', {
describe: 'port to bind on',
default: 5000
})
}, (argv) => {
if (argv.verbose) console.info(`start server on :${argv.port}`)
serve(argv.port)
})
.option('verbose', {
alias: 'v',
type: 'boolean',
description: 'Run with verbose logging'
})
.argv
```
Run the example above with `--help` to see the help for the application.
## Supported Platforms
### TypeScript
yargs has type definitions at [@types/yargs][type-definitions].
```
npm i @types/yargs --save-dev
```
See usage examples in [docs](/docs/typescript.md).
### Deno
As of `v16`, `yargs` supports [Deno](https://github.com/denoland/deno):
```typescript
import yargs from 'https://deno.land/x/yargs/deno.ts'
import { Arguments } from 'https://deno.land/x/yargs/deno-types.ts'
yargs(Deno.args)
.command('download <files...>', 'download a list of files', (yargs: any) => {
return yargs.positional('files', {
describe: 'a list of files to do something with'
})
}, (argv: Arguments) => {
console.info(argv)
})
.strictCommands()
.demandCommand(1)
.argv
```
### ESM
As of `v16`,`yargs` supports ESM imports:
```js
import yargs from 'yargs'
import { hideBin } from 'yargs/helpers'
yargs(hideBin(process.argv))
.command('curl <url>', 'fetch the contents of the URL', () => {}, (argv) => {
console.info(argv)
})
.demandCommand(1)
.argv
```
### Usage in Browser
See examples of using yargs in the browser in [docs](/docs/browser.md).
## Community
Having problems? want to contribute? join our [community slack](http://devtoolscommunity.herokuapp.com).
## Documentation
### Table of Contents
* [Yargs' API](/docs/api.md)
* [Examples](/docs/examples.md)
* [Parsing Tricks](/docs/tricks.md)
* [Stop the Parser](/docs/tricks.md#stop)
* [Negating Boolean Arguments](/docs/tricks.md#negate)
* [Numbers](/docs/tricks.md#numbers)
* [Arrays](/docs/tricks.md#arrays)
* [Objects](/docs/tricks.md#objects)
* [Quotes](/docs/tricks.md#quotes)
* [Advanced Topics](/docs/advanced.md)
* [Composing Your App Using Commands](/docs/advanced.md#commands)
* [Building Configurable CLI Apps](/docs/advanced.md#configuration)
* [Customizing Yargs' Parser](/docs/advanced.md#customizing)
* [Bundling yargs](/docs/bundling.md)
* [Contributing](/contributing.md)
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
[npm-url]: https://www.npmjs.com/package/yargs
[npm-image]: https://img.shields.io/npm/v/yargs.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: http://standardjs.com/
[conventional-commits-image]: https://img.shields.io/badge/Conventional%20Commits-1.0.0-yellow.svg
[conventional-commits-url]: https://conventionalcommits.org/
[slack-image]: http://devtoolscommunity.herokuapp.com/badge.svg
[slack-url]: http://devtoolscommunity.herokuapp.com
[type-definitions]: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/yargs
[coverage-image]: https://img.shields.io/nycrc/yargs/yargs
[coverage-url]: https://github.com/yargs/yargs/blob/master/.nycrc
# ts-mixer
[version-badge]: https://badgen.net/npm/v/ts-mixer
[version-link]: https://npmjs.com/package/ts-mixer
[build-badge]: https://img.shields.io/github/workflow/status/tannerntannern/ts-mixer/ts-mixer%20CI
[build-link]: https://github.com/tannerntannern/ts-mixer/actions
[ts-versions]: https://badgen.net/badge/icon/3.8,3.9,4.0,4.1,4.2?icon=typescript&label&list=|
[node-versions]: https://badgen.net/badge/node/10%2C12%2C14/blue/?list=|
[![npm version][version-badge]][version-link]
[![github actions][build-badge]][build-link]
[![TS Versions][ts-versions]][build-link]
[![Node.js Versions][node-versions]][build-link]
[](https://bundlephobia.com/result?p=ts-mixer)
[](https://conventionalcommits.org)
## Overview
`ts-mixer` brings mixins to TypeScript. "Mixins" to `ts-mixer` are just classes, so you already know how to write them, and you can probably mix classes from your favorite library without trouble.
The mixin problem is more nuanced than it appears. I've seen countless code snippets that work for certain situations, but fail in others. `ts-mixer` tries to take the best from all these solutions while accounting for the situations you might not have considered.
[Quick start guide](#quick-start)
### Features
* mixes plain classes
* mixes classes that extend other classes
* mixes classes that were mixed with `ts-mixer`
* supports static properties
* supports protected/private properties (the popular function-that-returns-a-class solution does not)
* mixes abstract classes (with caveats [[1](#caveats)])
* mixes generic classes (with caveats [[2](#caveats)])
* supports class, method, and property decorators (with caveats [[3, 6](#caveats)])
* mostly supports the complexity presented by constructor functions (with caveats [[4](#caveats)])
* comes with an `instanceof`-like replacement (with caveats [[5, 6](#caveats)])
* [multiple mixing strategies](#settings) (ES6 proxies vs hard copy)
### Caveats
1. Mixing abstract classes requires a bit of a hack that may break in future versions of TypeScript. See [mixing abstract classes](#mixing-abstract-classes) below.
2. Mixing generic classes requires a more cumbersome notation, but it's still possible. See [mixing generic classes](#mixing-generic-classes) below.
3. Using decorators in mixed classes also requires a more cumbersome notation. See [mixing with decorators](#mixing-with-decorators) below.
4. ES6 made it impossible to use `.apply(...)` on class constructors (or any means of calling them without `new`), which makes it impossible for `ts-mixer` to pass the proper `this` to your constructors. This may or may not be an issue for your code, but there are options to work around it. See [dealing with constructors](#dealing-with-constructors) below.
5. `ts-mixer` does not support `instanceof` for mixins, but it does offer a replacement. See the [hasMixin function](#hasmixin) for more details.
6. Certain features (specifically, `@decorator` and `hasMixin`) make use of ES6 `Map`s, which means you must either use ES6+ or polyfill `Map` to use them. If you don't need these features, you should be fine without.
## Quick Start
### Installation
```
$ npm install ts-mixer
```
or if you prefer [Yarn](https://yarnpkg.com):
```
$ yarn add ts-mixer
```
### Basic Example
```typescript
import { Mixin } from 'ts-mixer';
class Foo {
protected makeFoo() {
return 'foo';
}
}
class Bar {
protected makeBar() {
return 'bar';
}
}
class FooBar extends Mixin(Foo, Bar) {
public makeFooBar() {
return this.makeFoo() + this.makeBar();
}
}
const fooBar = new FooBar();
console.log(fooBar.makeFooBar()); // "foobar"
```
## Special Cases
### Mixing Abstract Classes
Abstract classes, by definition, cannot be constructed, which means they cannot take on the type, `new(...args) => any`, and by extension, are incompatible with `ts-mixer`. BUT, you can "trick" TypeScript into giving you all the benefits of an abstract class without making it technically abstract. The trick is just some strategic `// @ts-ignore`'s:
```typescript
import { Mixin } from 'ts-mixer';
// note that Foo is not marked as an abstract class
class Foo {
// @ts-ignore: "Abstract methods can only appear within an abstract class"
public abstract makeFoo(): string;
}
class Bar {
public makeBar() {
return 'bar';
}
}
class FooBar extends Mixin(Foo, Bar) {
// we still get all the benefits of abstract classes here, because TypeScript
// will still complain if this method isn't implemented
public makeFoo() {
return 'foo';
}
}
```
Do note that while this does work quite well, it is a bit of a hack and I can't promise that it will continue to work in future TypeScript versions.
### Mixing Generic Classes
Frustratingly, it is _impossible_ for generic parameters to be referenced in base class expressions. No matter what, you will eventually run into `Base class expressions cannot reference class type parameters.`
The way to get around this is to leverage [declaration merging](https://www.typescriptlang.org/docs/handbook/declaration-merging.html), and a slightly different mixing function from ts-mixer: `mix`. It works exactly like `Mixin`, except it's a decorator, which means it doesn't affect the type information of the class being decorated. See it in action below:
```typescript
import { mix } from 'ts-mixer';
class Foo<T> {
public fooMethod(input: T): T {
return input;
}
}
class Bar<T> {
public barMethod(input: T): T {
return input;
}
}
interface FooBar<T1, T2> extends Foo<T1>, Bar<T2> { }
@mix(Foo, Bar)
class FooBar<T1, T2> {
public fooBarMethod(input1: T1, input2: T2) {
return [this.fooMethod(input1), this.barMethod(input2)];
}
}
```
Key takeaways from this example:
* `interface FooBar<T1, T2> extends Foo<T1>, Bar<T2> { }` makes sure `FooBar` has the typing we want, thanks to declaration merging
* `@mix(Foo, Bar)` wires things up "on the JavaScript side", since the interface declaration has nothing to do with runtime behavior.
* The reason we have to use the `mix` decorator is that the typing produced by `Mixin(Foo, Bar)` would conflict with the typing of the interface. `mix` has no effect "on the TypeScript side," thus avoiding type conflicts.
### Mixing with Decorators
Popular libraries such as [class-validator](https://github.com/typestack/class-validator) and [TypeORM](https://github.com/typeorm/typeorm) use decorators to add functionality. Unfortunately, `ts-mixer` has no way of knowing what these libraries do with the decorators behind the scenes. So if you want these decorators to be "inherited" with classes you plan to mix, you first have to wrap them with a special `decorate` function exported by `ts-mixer`. Here's an example using `class-validator`:
```typescript
import { IsBoolean, IsIn, validate } from 'class-validator';
import { Mixin, decorate } from 'ts-mixer';
class Disposable {
@decorate(IsBoolean()) // instead of @IsBoolean()
isDisposed: boolean = false;
}
class Statusable {
@decorate(IsIn(['red', 'green'])) // instead of @IsIn(['red', 'green'])
status: string = 'green';
}
class ExtendedObject extends Mixin(Disposable, Statusable) {}
const extendedObject = new ExtendedObject();
extendedObject.status = 'blue';
validate(extendedObject).then(errors => {
console.log(errors);
});
```
### Dealing with Constructors
As mentioned in the [caveats section](#caveats), ES6 disallowed calling constructor functions without `new`. This means that the only way for `ts-mixer` to mix instance properties is to instantiate each base class separately, then copy the instance properties into a common object. The consequence of this is that constructors mixed by `ts-mixer` will _not_ receive the proper `this`.
**This very well may not be an issue for you!** It only means that your constructors need to be "mostly pure" in terms of how they handle `this`. Specifically, your constructors cannot produce [side effects](https://en.wikipedia.org/wiki/Side_effect_%28computer_science%29) involving `this`, _other than adding properties to `this`_ (the most common side effect in JavaScript constructors).
If you simply cannot eliminate `this` side effects from your constructor, there is a workaround available: `ts-mixer` will automatically forward constructor parameters to a predesignated init function (`settings.initFunction`) if it's present on the class. Unlike constructors, functions can be called with an arbitrary `this`, so this predesignated init function _will_ have the proper `this`. Here's a basic example:
```typescript
import { Mixin, settings } from 'ts-mixer';
settings.initFunction = 'init';
class Person {
public static allPeople: Set<Person> = new Set();
protected init() {
Person.allPeople.add(this);
}
}
type PartyAffiliation = 'democrat' | 'republican';
class PoliticalParticipant {
public static democrats: Set<PoliticalParticipant> = new Set();
public static republicans: Set<PoliticalParticipant> = new Set();
public party: PartyAffiliation;
// note that these same args will also be passed to init function
public constructor(party: PartyAffiliation) {
this.party = party;
}
protected init(party: PartyAffiliation) {
if (party === 'democrat')
PoliticalParticipant.democrats.add(this);
else
PoliticalParticipant.republicans.add(this);
}
}
class Voter extends Mixin(Person, PoliticalParticipant) {}
const v1 = new Voter('democrat');
const v2 = new Voter('democrat');
const v3 = new Voter('republican');
const v4 = new Voter('republican');
```
Note the above `.add(this)` statements. These would not work as expected if they were placed in the constructor instead, since `this` is not the same between the constructor and `init`, as explained above.
## Other Features
### hasMixin
As mentioned above, `ts-mixer` does not support `instanceof` for mixins. While it is possible to implement [custom `instanceof` behavior](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/hasInstance), this library does not do so because it would require modifying the source classes, which is deliberately avoided.
You can fill this missing functionality with `hasMixin(instance, mixinClass)` instead. See the below example:
```typescript
import { Mixin, hasMixin } from 'ts-mixer';
class Foo {}
class Bar {}
class FooBar extends Mixin(Foo, Bar) {}
const instance = new FooBar();
// doesn't work with instanceof...
console.log(instance instanceof FooBar) // true
console.log(instance instanceof Foo) // false
console.log(instance instanceof Bar) // false
// but everything works nicely with hasMixin!
console.log(hasMixin(instance, FooBar)) // true
console.log(hasMixin(instance, Foo)) // true
console.log(hasMixin(instance, Bar)) // true
```
`hasMixin(instance, mixinClass)` will work anywhere that `instance instanceof mixinClass` works. Additionally, like `instanceof`, you get the same [type narrowing benefits](https://www.typescriptlang.org/docs/handbook/advanced-types.html#instanceof-type-guards):
```typescript
if (hasMixin(instance, Foo)) {
// inferred type of instance is "Foo"
}
if (hasMixin(instance, Bar)) {
// inferred type of instance of "Bar"
}
```
## Settings
ts-mixer has multiple strategies for mixing classes which can be configured by modifying `settings` from ts-mixer. For example:
```typescript
import { settings, Mixin } from 'ts-mixer';
settings.prototypeStrategy = 'proxy';
// then use `Mixin` as normal...
```
### `settings.prototypeStrategy`
* Determines how ts-mixer will mix class prototypes together
* Possible values:
- `'copy'` (default) - Copies all methods from the classes being mixed into a new prototype object. (This will include all methods up the prototype chains as well.) This is the default for ES5 compatibility, but it has the downside of stale references. For example, if you mix `Foo` and `Bar` to make `FooBar`, then redefine a method on `Foo`, `FooBar` will not have the latest methods from `Foo`. If this is not a concern for you, `'copy'` is the best value for this setting.
- `'proxy'` - Uses an ES6 Proxy to "soft mix" prototypes. Unlike `'copy'`, updates to the base classes _will_ be reflected in the mixed class, which may be desirable. The downside is that method access is not as performant, nor is it ES5 compatible.
### `settings.staticsStrategy`
* Determines how static properties are inherited
* Possible values:
- `'copy'` (default) - Simply copies all properties (minus `prototype`) from the base classes/constructor functions onto the mixed class. Like `settings.prototypeStrategy = 'copy'`, this strategy also suffers from stale references, but shouldn't be a concern if you don't redefine static methods after mixing.
- `'proxy'` - Similar to `settings.prototypeStrategy`, proxy's static method access to base classes. Has the same benefits/downsides.
### `settings.initFunction`
* If set, `ts-mixer` will automatically call the function with this name upon construction
* Possible values:
- `null` (default) - disables the behavior
- a string - function name to call upon construction
* Read more about why you would want this in [dealing with constructors](#dealing-with-constructors)
### `settings.decoratorInheritance`
* Determines how decorators are inherited from classes passed to `Mixin(...)`
* Possible values:
- `'deep'` (default) - Deeply inherits decorators from all given classes and their ancestors
- `'direct'` - Only inherits decorators defined directly on the given classes
- `'none'` - Skips decorator inheritance
# Author
Tanner Nielsen <[email protected]>
* Website - [tannernielsen.com](http://tannernielsen.com)
* Github - [tannerntannern](https://github.com/tannerntannern)
# Acorn
A tiny, fast JavaScript parser written in JavaScript.
## Community
Acorn is open source software released under an
[MIT license](https://github.com/acornjs/acorn/blob/master/acorn/LICENSE).
You are welcome to
[report bugs](https://github.com/acornjs/acorn/issues) or create pull
requests on [github](https://github.com/acornjs/acorn). For questions
and discussion, please use the
[Tern discussion forum](https://discuss.ternjs.net).
## Installation
The easiest way to install acorn is from [`npm`](https://www.npmjs.com/):
```sh
npm install acorn
```
Alternately, you can download the source and build acorn yourself:
```sh
git clone https://github.com/acornjs/acorn.git
cd acorn
npm install
```
## Interface
**parse**`(input, options)` is the main interface to the library. The
`input` parameter is a string, `options` can be undefined or an object
setting some of the options listed below. The return value will be an
abstract syntax tree object as specified by the [ESTree
spec](https://github.com/estree/estree).
```javascript
let acorn = require("acorn");
console.log(acorn.parse("1 + 1"));
```
When encountering a syntax error, the parser will raise a
`SyntaxError` object with a meaningful message. The error object will
have a `pos` property that indicates the string offset at which the
error occurred, and a `loc` object that contains a `{line, column}`
object referring to that same position.
Options can be provided by passing a second argument, which should be
an object containing any of these fields:
- **ecmaVersion**: Indicates the ECMAScript version to parse. Must be
either 3, 5, 6 (2015), 7 (2016), 8 (2017), 9 (2018), 10 (2019) or 11
(2020, partial support). This influences support for strict mode,
the set of reserved words, and support for new syntax features.
Default is 10.
**NOTE**: Only 'stage 4' (finalized) ECMAScript features are being
implemented by Acorn. Other proposed new features can be implemented
through plugins.
- **sourceType**: Indicate the mode the code should be parsed in. Can be
either `"script"` or `"module"`. This influences global strict mode
and parsing of `import` and `export` declarations.
**NOTE**: If set to `"module"`, then static `import` / `export` syntax
will be valid, even if `ecmaVersion` is less than 6.
- **onInsertedSemicolon**: If given a callback, that callback will be
called whenever a missing semicolon is inserted by the parser. The
callback will be given the character offset of the point where the
semicolon is inserted as argument, and if `locations` is on, also a
`{line, column}` object representing this position.
- **onTrailingComma**: Like `onInsertedSemicolon`, but for trailing
commas.
- **allowReserved**: If `false`, using a reserved word will generate
an error. Defaults to `true` for `ecmaVersion` 3, `false` for higher
versions. When given the value `"never"`, reserved words and
keywords can also not be used as property names (as in Internet
Explorer's old parser).
- **allowReturnOutsideFunction**: By default, a return statement at
the top level raises an error. Set this to `true` to accept such
code.
- **allowImportExportEverywhere**: By default, `import` and `export`
declarations can only appear at a program's top level. Setting this
option to `true` allows them anywhere where a statement is allowed.
- **allowAwaitOutsideFunction**: By default, `await` expressions can
only appear inside `async` functions. Setting this option to
`true` allows to have top-level `await` expressions. They are
still not allowed in non-`async` functions, though.
- **allowHashBang**: When this is enabled (off by default), if the
code starts with the characters `#!` (as in a shellscript), the
first line will be treated as a comment.
- **locations**: When `true`, each node has a `loc` object attached
with `start` and `end` subobjects, each of which contains the
one-based line and zero-based column numbers in `{line, column}`
form. Default is `false`.
- **onToken**: If a function is passed for this option, each found
token will be passed in same format as tokens returned from
`tokenizer().getToken()`.
If array is passed, each found token is pushed to it.
Note that you are not allowed to call the parser from the
callback—that will corrupt its internal state.
- **onComment**: If a function is passed for this option, whenever a
comment is encountered the function will be called with the
following parameters:
- `block`: `true` if the comment is a block comment, false if it
is a line comment.
- `text`: The content of the comment.
- `start`: Character offset of the start of the comment.
- `end`: Character offset of the end of the comment.
When the `locations` options is on, the `{line, column}` locations
of the comment’s start and end are passed as two additional
parameters.
If array is passed for this option, each found comment is pushed
to it as object in Esprima format:
```javascript
{
"type": "Line" | "Block",
"value": "comment text",
"start": Number,
"end": Number,
// If `locations` option is on:
"loc": {
"start": {line: Number, column: Number}
"end": {line: Number, column: Number}
},
// If `ranges` option is on:
"range": [Number, Number]
}
```
Note that you are not allowed to call the parser from the
callback—that will corrupt its internal state.
- **ranges**: Nodes have their start and end characters offsets
recorded in `start` and `end` properties (directly on the node,
rather than the `loc` object, which holds line/column data. To also
add a
[semi-standardized](https://bugzilla.mozilla.org/show_bug.cgi?id=745678)
`range` property holding a `[start, end]` array with the same
numbers, set the `ranges` option to `true`.
- **program**: It is possible to parse multiple files into a single
AST by passing the tree produced by parsing the first file as the
`program` option in subsequent parses. This will add the toplevel
forms of the parsed file to the "Program" (top) node of an existing
parse tree.
- **sourceFile**: When the `locations` option is `true`, you can pass
this option to add a `source` attribute in every node’s `loc`
object. Note that the contents of this option are not examined or
processed in any way; you are free to use whatever format you
choose.
- **directSourceFile**: Like `sourceFile`, but a `sourceFile` property
will be added (regardless of the `location` option) directly to the
nodes, rather than the `loc` object.
- **preserveParens**: If this option is `true`, parenthesized expressions
are represented by (non-standard) `ParenthesizedExpression` nodes
that have a single `expression` property containing the expression
inside parentheses.
**parseExpressionAt**`(input, offset, options)` will parse a single
expression in a string, and return its AST. It will not complain if
there is more of the string left after the expression.
**tokenizer**`(input, options)` returns an object with a `getToken`
method that can be called repeatedly to get the next token, a `{start,
end, type, value}` object (with added `loc` property when the
`locations` option is enabled and `range` property when the `ranges`
option is enabled). When the token's type is `tokTypes.eof`, you
should stop calling the method, since it will keep returning that same
token forever.
In ES6 environment, returned result can be used as any other
protocol-compliant iterable:
```javascript
for (let token of acorn.tokenizer(str)) {
// iterate over the tokens
}
// transform code to array of tokens:
var tokens = [...acorn.tokenizer(str)];
```
**tokTypes** holds an object mapping names to the token type objects
that end up in the `type` properties of tokens.
**getLineInfo**`(input, offset)` can be used to get a `{line,
column}` object for a given program string and offset.
### The `Parser` class
Instances of the **`Parser`** class contain all the state and logic
that drives a parse. It has static methods `parse`,
`parseExpressionAt`, and `tokenizer` that match the top-level
functions by the same name.
When extending the parser with plugins, you need to call these methods
on the extended version of the class. To extend a parser with plugins,
you can use its static `extend` method.
```javascript
var acorn = require("acorn");
var jsx = require("acorn-jsx");
var JSXParser = acorn.Parser.extend(jsx());
JSXParser.parse("foo(<bar/>)");
```
The `extend` method takes any number of plugin values, and returns a
new `Parser` class that includes the extra parser logic provided by
the plugins.
## Command line interface
The `bin/acorn` utility can be used to parse a file from the command
line. It accepts as arguments its input file and the following
options:
- `--ecma3|--ecma5|--ecma6|--ecma7|--ecma8|--ecma9|--ecma10`: Sets the ECMAScript version
to parse. Default is version 9.
- `--module`: Sets the parsing mode to `"module"`. Is set to `"script"` otherwise.
- `--locations`: Attaches a "loc" object to each node with "start" and
"end" subobjects, each of which contains the one-based line and
zero-based column numbers in `{line, column}` form.
- `--allow-hash-bang`: If the code starts with the characters #! (as
in a shellscript), the first line will be treated as a comment.
- `--compact`: No whitespace is used in the AST output.
- `--silent`: Do not output the AST, just return the exit status.
- `--help`: Print the usage information and quit.
The utility spits out the syntax tree as JSON data.
## Existing plugins
- [`acorn-jsx`](https://github.com/RReverser/acorn-jsx): Parse [Facebook JSX syntax extensions](https://github.com/facebook/jsx)
Plugins for ECMAScript proposals:
- [`acorn-stage3`](https://github.com/acornjs/acorn-stage3): Parse most stage 3 proposals, bundling:
- [`acorn-class-fields`](https://github.com/acornjs/acorn-class-fields): Parse [class fields proposal](https://github.com/tc39/proposal-class-fields)
- [`acorn-import-meta`](https://github.com/acornjs/acorn-import-meta): Parse [import.meta proposal](https://github.com/tc39/proposal-import-meta)
- [`acorn-private-methods`](https://github.com/acornjs/acorn-private-methods): parse [private methods, getters and setters proposal](https://github.com/tc39/proposal-private-methods)n
Compiler frontend for node.js
=============================
Usage
-----
For an up to date list of available command line options, see:
```
$> asc --help
```
API
---
The API accepts the same options as the CLI but also lets you override stdout and stderr and/or provide a callback. Example:
```js
const asc = require("assemblyscript/cli/asc");
asc.ready.then(() => {
asc.main([
"myModule.ts",
"--binaryFile", "myModule.wasm",
"--optimize",
"--sourceMap",
"--measure"
], {
stdout: process.stdout,
stderr: process.stderr
}, function(err) {
if (err)
throw err;
...
});
});
```
Available command line options can also be obtained programmatically:
```js
const options = require("assemblyscript/cli/asc.json");
...
```
You can also compile a source string directly, for example in a browser environment:
```js
const asc = require("assemblyscript/cli/asc");
asc.ready.then(() => {
const { binary, text, stdout, stderr } = asc.compileString(`...`, { optimize: 2 });
});
...
```
# whatwg-url
whatwg-url is a full implementation of the WHATWG [URL Standard](https://url.spec.whatwg.org/). It can be used standalone, but it also exposes a lot of the internal algorithms that are useful for integrating a URL parser into a project like [jsdom](https://github.com/tmpvar/jsdom).
## Specification conformance
whatwg-url is currently up to date with the URL spec up to commit [7ae1c69](https://github.com/whatwg/url/commit/7ae1c691c96f0d82fafa24c33aa1e8df9ffbf2bc).
For `file:` URLs, whose [origin is left unspecified](https://url.spec.whatwg.org/#concept-url-origin), whatwg-url chooses to use a new opaque origin (which serializes to `"null"`).
## API
### The `URL` and `URLSearchParams` classes
The main API is provided by the [`URL`](https://url.spec.whatwg.org/#url-class) and [`URLSearchParams`](https://url.spec.whatwg.org/#interface-urlsearchparams) exports, which follows the spec's behavior in all ways (including e.g. `USVString` conversion). Most consumers of this library will want to use these.
### Low-level URL Standard API
The following methods are exported for use by places like jsdom that need to implement things like [`HTMLHyperlinkElementUtils`](https://html.spec.whatwg.org/#htmlhyperlinkelementutils). They mostly operate on or return an "internal URL" or ["URL record"](https://url.spec.whatwg.org/#concept-url) type.
- [URL parser](https://url.spec.whatwg.org/#concept-url-parser): `parseURL(input, { baseURL, encodingOverride })`
- [Basic URL parser](https://url.spec.whatwg.org/#concept-basic-url-parser): `basicURLParse(input, { baseURL, encodingOverride, url, stateOverride })`
- [URL serializer](https://url.spec.whatwg.org/#concept-url-serializer): `serializeURL(urlRecord, excludeFragment)`
- [Host serializer](https://url.spec.whatwg.org/#concept-host-serializer): `serializeHost(hostFromURLRecord)`
- [Serialize an integer](https://url.spec.whatwg.org/#serialize-an-integer): `serializeInteger(number)`
- [Origin](https://url.spec.whatwg.org/#concept-url-origin) [serializer](https://html.spec.whatwg.org/multipage/origin.html#ascii-serialisation-of-an-origin): `serializeURLOrigin(urlRecord)`
- [Set the username](https://url.spec.whatwg.org/#set-the-username): `setTheUsername(urlRecord, usernameString)`
- [Set the password](https://url.spec.whatwg.org/#set-the-password): `setThePassword(urlRecord, passwordString)`
- [Cannot have a username/password/port](https://url.spec.whatwg.org/#cannot-have-a-username-password-port): `cannotHaveAUsernamePasswordPort(urlRecord)`
- [Percent decode](https://url.spec.whatwg.org/#percent-decode): `percentDecode(buffer)`
The `stateOverride` parameter is one of the following strings:
- [`"scheme start"`](https://url.spec.whatwg.org/#scheme-start-state)
- [`"scheme"`](https://url.spec.whatwg.org/#scheme-state)
- [`"no scheme"`](https://url.spec.whatwg.org/#no-scheme-state)
- [`"special relative or authority"`](https://url.spec.whatwg.org/#special-relative-or-authority-state)
- [`"path or authority"`](https://url.spec.whatwg.org/#path-or-authority-state)
- [`"relative"`](https://url.spec.whatwg.org/#relative-state)
- [`"relative slash"`](https://url.spec.whatwg.org/#relative-slash-state)
- [`"special authority slashes"`](https://url.spec.whatwg.org/#special-authority-slashes-state)
- [`"special authority ignore slashes"`](https://url.spec.whatwg.org/#special-authority-ignore-slashes-state)
- [`"authority"`](https://url.spec.whatwg.org/#authority-state)
- [`"host"`](https://url.spec.whatwg.org/#host-state)
- [`"hostname"`](https://url.spec.whatwg.org/#hostname-state)
- [`"port"`](https://url.spec.whatwg.org/#port-state)
- [`"file"`](https://url.spec.whatwg.org/#file-state)
- [`"file slash"`](https://url.spec.whatwg.org/#file-slash-state)
- [`"file host"`](https://url.spec.whatwg.org/#file-host-state)
- [`"path start"`](https://url.spec.whatwg.org/#path-start-state)
- [`"path"`](https://url.spec.whatwg.org/#path-state)
- [`"cannot-be-a-base-URL path"`](https://url.spec.whatwg.org/#cannot-be-a-base-url-path-state)
- [`"query"`](https://url.spec.whatwg.org/#query-state)
- [`"fragment"`](https://url.spec.whatwg.org/#fragment-state)
The URL record type has the following API:
- [`scheme`](https://url.spec.whatwg.org/#concept-url-scheme)
- [`username`](https://url.spec.whatwg.org/#concept-url-username)
- [`password`](https://url.spec.whatwg.org/#concept-url-password)
- [`host`](https://url.spec.whatwg.org/#concept-url-host)
- [`port`](https://url.spec.whatwg.org/#concept-url-port)
- [`path`](https://url.spec.whatwg.org/#concept-url-path) (as an array)
- [`query`](https://url.spec.whatwg.org/#concept-url-query)
- [`fragment`](https://url.spec.whatwg.org/#concept-url-fragment)
- [`cannotBeABaseURL`](https://url.spec.whatwg.org/#url-cannot-be-a-base-url-flag) (as a boolean)
These properties should be treated with care, as in general changing them will cause the URL record to be in an inconsistent state until the appropriate invocation of `basicURLParse` is used to fix it up. You can see examples of this in the URL Standard, where there are many step sequences like "4. Set context object’s url’s fragment to the empty string. 5. Basic URL parse _input_ with context object’s url as _url_ and fragment state as _state override_." In between those two steps, a URL record is in an unusable state.
The return value of "failure" in the spec is represented by `null`. That is, functions like `parseURL` and `basicURLParse` can return _either_ a URL record _or_ `null`.
## Development instructions
First, install [Node.js](https://nodejs.org/). Then, fetch the dependencies of whatwg-url, by running from this directory:
npm install
To run tests:
npm test
To generate a coverage report:
npm run coverage
To build and run the live viewer:
npm run build
npm run build-live-viewer
Serve the contents of the `live-viewer` directory using any web server.
## Supporting whatwg-url
The jsdom project (including whatwg-url) is a community-driven project maintained by a team of [volunteers](https://github.com/orgs/jsdom/people). You could support us by:
- [Getting professional support for whatwg-url](https://tidelift.com/subscription/pkg/npm-whatwg-url?utm_source=npm-whatwg-url&utm_medium=referral&utm_campaign=readme) as part of a Tidelift subscription. Tidelift helps making open source sustainable for us while giving teams assurances for maintenance, licensing, and security.
- Contributing directly to the project.
long.js
=======
A Long class for representing a 64 bit two's-complement integer value derived from the [Closure Library](https://github.com/google/closure-library)
for stand-alone use and extended with unsigned support.
[](https://travis-ci.org/dcodeIO/long.js)
Background
----------
As of [ECMA-262 5th Edition](http://ecma262-5.com/ELS5_HTML.htm#Section_8.5), "all the positive and negative integers
whose magnitude is no greater than 2<sup>53</sup> are representable in the Number type", which is "representing the
doubleprecision 64-bit format IEEE 754 values as specified in the IEEE Standard for Binary Floating-Point Arithmetic".
The [maximum safe integer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number/MAX_SAFE_INTEGER)
in JavaScript is 2<sup>53</sup>-1.
Example: 2<sup>64</sup>-1 is 1844674407370955**1615** but in JavaScript it evaluates to 1844674407370955**2000**.
Furthermore, bitwise operators in JavaScript "deal only with integers in the range −2<sup>31</sup> through
2<sup>31</sup>−1, inclusive, or in the range 0 through 2<sup>32</sup>−1, inclusive. These operators accept any value of
the Number type but first convert each such value to one of 2<sup>32</sup> integer values."
In some use cases, however, it is required to be able to reliably work with and perform bitwise operations on the full
64 bits. This is where long.js comes into play.
Usage
-----
The class is compatible with CommonJS and AMD loaders and is exposed globally as `Long` if neither is available.
```javascript
var Long = require("long");
var longVal = new Long(0xFFFFFFFF, 0x7FFFFFFF);
console.log(longVal.toString());
...
```
API
---
### Constructor
* new **Long**(low: `number`, high: `number`, unsigned?: `boolean`)<br />
Constructs a 64 bit two's-complement integer, given its low and high 32 bit values as *signed* integers. See the from* functions below for more convenient ways of constructing Longs.
### Fields
* Long#**low**: `number`<br />
The low 32 bits as a signed value.
* Long#**high**: `number`<br />
The high 32 bits as a signed value.
* Long#**unsigned**: `boolean`<br />
Whether unsigned or not.
### Constants
* Long.**ZERO**: `Long`<br />
Signed zero.
* Long.**ONE**: `Long`<br />
Signed one.
* Long.**NEG_ONE**: `Long`<br />
Signed negative one.
* Long.**UZERO**: `Long`<br />
Unsigned zero.
* Long.**UONE**: `Long`<br />
Unsigned one.
* Long.**MAX_VALUE**: `Long`<br />
Maximum signed value.
* Long.**MIN_VALUE**: `Long`<br />
Minimum signed value.
* Long.**MAX_UNSIGNED_VALUE**: `Long`<br />
Maximum unsigned value.
### Utility
* Long.**isLong**(obj: `*`): `boolean`<br />
Tests if the specified object is a Long.
* Long.**fromBits**(lowBits: `number`, highBits: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the 64 bit integer that comes by concatenating the given low and high bits. Each is assumed to use 32 bits.
* Long.**fromBytes**(bytes: `number[]`, unsigned?: `boolean`, le?: `boolean`): `Long`<br />
Creates a Long from its byte representation.
* Long.**fromBytesLE**(bytes: `number[]`, unsigned?: `boolean`): `Long`<br />
Creates a Long from its little endian byte representation.
* Long.**fromBytesBE**(bytes: `number[]`, unsigned?: `boolean`): `Long`<br />
Creates a Long from its big endian byte representation.
* Long.**fromInt**(value: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the given 32 bit integer value.
* Long.**fromNumber**(value: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the given value, provided that it is a finite number. Otherwise, zero is returned.
* Long.**fromString**(str: `string`, unsigned?: `boolean`, radix?: `number`)<br />
Long.**fromString**(str: `string`, radix: `number`)<br />
Returns a Long representation of the given string, written using the specified radix.
* Long.**fromValue**(val: `*`, unsigned?: `boolean`): `Long`<br />
Converts the specified value to a Long using the appropriate from* function for its type.
### Methods
* Long#**add**(addend: `Long | number | string`): `Long`<br />
Returns the sum of this and the specified Long.
* Long#**and**(other: `Long | number | string`): `Long`<br />
Returns the bitwise AND of this Long and the specified.
* Long#**compare**/**comp**(other: `Long | number | string`): `number`<br />
Compares this Long's value with the specified's. Returns `0` if they are the same, `1` if the this is greater and `-1` if the given one is greater.
* Long#**divide**/**div**(divisor: `Long | number | string`): `Long`<br />
Returns this Long divided by the specified.
* Long#**equals**/**eq**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value equals the specified's.
* Long#**getHighBits**(): `number`<br />
Gets the high 32 bits as a signed integer.
* Long#**getHighBitsUnsigned**(): `number`<br />
Gets the high 32 bits as an unsigned integer.
* Long#**getLowBits**(): `number`<br />
Gets the low 32 bits as a signed integer.
* Long#**getLowBitsUnsigned**(): `number`<br />
Gets the low 32 bits as an unsigned integer.
* Long#**getNumBitsAbs**(): `number`<br />
Gets the number of bits needed to represent the absolute value of this Long.
* Long#**greaterThan**/**gt**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is greater than the specified's.
* Long#**greaterThanOrEqual**/**gte**/**ge**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is greater than or equal the specified's.
* Long#**isEven**(): `boolean`<br />
Tests if this Long's value is even.
* Long#**isNegative**(): `boolean`<br />
Tests if this Long's value is negative.
* Long#**isOdd**(): `boolean`<br />
Tests if this Long's value is odd.
* Long#**isPositive**(): `boolean`<br />
Tests if this Long's value is positive.
* Long#**isZero**/**eqz**(): `boolean`<br />
Tests if this Long's value equals zero.
* Long#**lessThan**/**lt**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is less than the specified's.
* Long#**lessThanOrEqual**/**lte**/**le**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is less than or equal the specified's.
* Long#**modulo**/**mod**/**rem**(divisor: `Long | number | string`): `Long`<br />
Returns this Long modulo the specified.
* Long#**multiply**/**mul**(multiplier: `Long | number | string`): `Long`<br />
Returns the product of this and the specified Long.
* Long#**negate**/**neg**(): `Long`<br />
Negates this Long's value.
* Long#**not**(): `Long`<br />
Returns the bitwise NOT of this Long.
* Long#**notEquals**/**neq**/**ne**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value differs from the specified's.
* Long#**or**(other: `Long | number | string`): `Long`<br />
Returns the bitwise OR of this Long and the specified.
* Long#**shiftLeft**/**shl**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits shifted to the left by the given amount.
* Long#**shiftRight**/**shr**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits arithmetically shifted to the right by the given amount.
* Long#**shiftRightUnsigned**/**shru**/**shr_u**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits logically shifted to the right by the given amount.
* Long#**subtract**/**sub**(subtrahend: `Long | number | string`): `Long`<br />
Returns the difference of this and the specified Long.
* Long#**toBytes**(le?: `boolean`): `number[]`<br />
Converts this Long to its byte representation.
* Long#**toBytesLE**(): `number[]`<br />
Converts this Long to its little endian byte representation.
* Long#**toBytesBE**(): `number[]`<br />
Converts this Long to its big endian byte representation.
* Long#**toInt**(): `number`<br />
Converts the Long to a 32 bit integer, assuming it is a 32 bit integer.
* Long#**toNumber**(): `number`<br />
Converts the Long to a the nearest floating-point representation of this value (double, 53 bit mantissa).
* Long#**toSigned**(): `Long`<br />
Converts this Long to signed.
* Long#**toString**(radix?: `number`): `string`<br />
Converts the Long to a string written in the specified radix.
* Long#**toUnsigned**(): `Long`<br />
Converts this Long to unsigned.
* Long#**xor**(other: `Long | number | string`): `Long`<br />
Returns the bitwise XOR of this Long and the given one.
Building
--------
To build an UMD bundle to `dist/long.js`, run:
```
$> npm install
$> npm run build
```
Running the [tests](./tests):
```
$> npm test
```
# v8-compile-cache
[](https://travis-ci.org/zertosh/v8-compile-cache)
`v8-compile-cache` attaches a `require` hook to use [V8's code cache](https://v8project.blogspot.com/2015/07/code-caching.html) to speed up instantiation time. The "code cache" is the work of parsing and compiling done by V8.
The ability to tap into V8 to produce/consume this cache was introduced in [Node v5.7.0](https://nodejs.org/en/blog/release/v5.7.0/).
## Usage
1. Add the dependency:
```sh
$ npm install --save v8-compile-cache
```
2. Then, in your entry module add:
```js
require('v8-compile-cache');
```
**Requiring `v8-compile-cache` in Node <5.7.0 is a noop – but you need at least Node 4.0.0 to support the ES2015 syntax used by `v8-compile-cache`.**
## Options
Set the environment variable `DISABLE_V8_COMPILE_CACHE=1` to disable the cache.
Cache directory is defined by environment variable `V8_COMPILE_CACHE_CACHE_DIR` or defaults to `<os.tmpdir()>/v8-compile-cache-<V8_VERSION>`.
## Internals
Cache files are suffixed `.BLOB` and `.MAP` corresponding to the entry module that required `v8-compile-cache`. The cache is _entry module specific_ because it is faster to load the entire code cache into memory at once, than it is to read it from disk on a file-by-file basis.
## Benchmarks
See https://github.com/zertosh/v8-compile-cache/tree/master/bench.
**Load Times:**
| Module | Without Cache | With Cache |
| ---------------- | -------------:| ----------:|
| `babel-core` | `218ms` | `185ms` |
| `yarn` | `153ms` | `113ms` |
| `yarn` (bundled) | `228ms` | `105ms` |
_^ Includes the overhead of loading the cache itself._
## Acknowledgements
* `FileSystemBlobStore` and `NativeCompileCache` are based on Atom's implementation of their v8 compile cache:
- https://github.com/atom/atom/blob/b0d7a8a/src/file-system-blob-store.js
- https://github.com/atom/atom/blob/b0d7a8a/src/native-compile-cache.js
* `mkdirpSync` is based on:
- https://github.com/substack/node-mkdirp/blob/f2003bb/index.js#L55-L98
# Near Bindings Generator
Transforms the Assembyscript AST to serialize exported functions and add `encode` and `decode` functions for generating and parsing JSON strings.
## Using via CLI
After installling, `npm install nearprotocol/near-bindgen-as`, it can be added to the cli arguments of the assemblyscript compiler you must add the following:
```bash
asc <file> --transform near-bindgen-as ...
```
This module also adds a binary `near-asc` which adds the default arguments required to build near contracts as well as the transformer.
```bash
near-asc <input file> <output file>
```
## Using a script to compile
Another way is to add a file such as `asconfig.js` such as:
```js
const compile = require("near-bindgen-as/compiler").compile;
compile("assembly/index.ts", // input file
"out/index.wasm", // output file
[
// "-O1", // Optional arguments
"--debug",
"--measure"
],
// Prints out the final cli arguments passed to compiler.
{verbose: true}
);
```
It can then be built with `node asconfig.js`. There is an example of this in the test directory.
# levn [](https://travis-ci.org/gkz/levn) <a name="levn" />
__Light ECMAScript (JavaScript) Value Notation__
Levn is a library which allows you to parse a string into a JavaScript value based on an expected type. It is meant for short amounts of human entered data (eg. config files, command line arguments).
Levn aims to concisely describe JavaScript values in text, and allow for the extraction and validation of those values. Levn uses [type-check](https://github.com/gkz/type-check) for its type format, and to validate the results. MIT license. Version 0.4.1.
__How is this different than JSON?__ levn is meant to be written by humans only, is (due to the previous point) much more concise, can be validated against supplied types, has regex and date literals, and can easily be extended with custom types. On the other hand, it is probably slower and thus less efficient at transporting large amounts of data, which is fine since this is not its purpose.
npm install levn
For updates on levn, [follow me on twitter](https://twitter.com/gkzahariev).
## Quick Examples
```js
var parse = require('levn').parse;
parse('Number', '2'); // 2
parse('String', '2'); // '2'
parse('String', 'levn'); // 'levn'
parse('String', 'a b'); // 'a b'
parse('Boolean', 'true'); // true
parse('Date', '#2011-11-11#'); // (Date object)
parse('Date', '2011-11-11'); // (Date object)
parse('RegExp', '/[a-z]/gi'); // /[a-z]/gi
parse('RegExp', 're'); // /re/
parse('Int', '2'); // 2
parse('Number | String', 'str'); // 'str'
parse('Number | String', '2'); // 2
parse('[Number]', '[1,2,3]'); // [1,2,3]
parse('(String, Boolean)', '(hi, false)'); // ['hi', false]
parse('{a: String, b: Number}', '{a: str, b: 2}'); // {a: 'str', b: 2}
// at the top level, you can ommit surrounding delimiters
parse('[Number]', '1,2,3'); // [1,2,3]
parse('(String, Boolean)', 'hi, false'); // ['hi', false]
parse('{a: String, b: Number}', 'a: str, b: 2'); // {a: 'str', b: 2}
// wildcard - auto choose type
parse('*', '[hi,(null,[42]),{k: true}]'); // ['hi', [null, [42]], {k: true}]
```
## Usage
`require('levn');` returns an object that exposes three properties. `VERSION` is the current version of the library as a string. `parse` and `parsedTypeParse` are functions.
```js
// parse(type, input, options);
parse('[Number]', '1,2,3'); // [1, 2, 3]
// parsedTypeParse(parsedType, input, options);
var parsedType = require('type-check').parseType('[Number]');
parsedTypeParse(parsedType, '1,2,3'); // [1, 2, 3]
```
### parse(type, input, options)
`parse` casts the string `input` into a JavaScript value according to the specified `type` in the [type format](https://github.com/gkz/type-check#type-format) (and taking account the optional `options`) and returns the resulting JavaScript value.
##### arguments
* type - `String` - the type written in the [type format](https://github.com/gkz/type-check#type-format) which to check against
* input - `String` - the value written in the [levn format](#levn-format)
* options - `Maybe Object` - an optional parameter specifying additional [options](#options)
##### returns
`*` - the resulting JavaScript value
##### example
```js
parse('[Number]', '1,2,3'); // [1, 2, 3]
```
### parsedTypeParse(parsedType, input, options)
`parsedTypeParse` casts the string `input` into a JavaScript value according to the specified `type` which has already been parsed (and taking account the optional `options`) and returns the resulting JavaScript value. You can parse a type using the [type-check](https://github.com/gkz/type-check) library's `parseType` function.
##### arguments
* type - `Object` - the type in the parsed type format which to check against
* input - `String` - the value written in the [levn format](#levn-format)
* options - `Maybe Object` - an optional parameter specifying additional [options](#options)
##### returns
`*` - the resulting JavaScript value
##### example
```js
var parsedType = require('type-check').parseType('[Number]');
parsedTypeParse(parsedType, '1,2,3'); // [1, 2, 3]
```
## Levn Format
Levn can use the type information you provide to choose the appropriate value to produce from the input. For the same input, it will choose a different output value depending on the type provided. For example, `parse('Number', '2')` will produce the number `2`, but `parse('String', '2')` will produce the string `"2"`.
If you do not provide type information, and simply use `*`, levn will parse the input according the unambiguous "explicit" mode, which we will now detail - you can also set the `explicit` option to true manually in the [options](#options).
* `"string"`, `'string'` are parsed as a String, eg. `"a msg"` is `"a msg"`
* `#date#` is parsed as a Date, eg. `#2011-11-11#` is `new Date('2011-11-11')`
* `/regexp/flags` is parsed as a RegExp, eg. `/re/gi` is `/re/gi`
* `undefined`, `null`, `NaN`, `true`, and `false` are all their JavaScript equivalents
* `[element1, element2, etc]` is an Array, and the casting procedure is recursively applied to each element. Eg. `[1,2,3]` is `[1,2,3]`.
* `(element1, element2, etc)` is an tuple, and the casting procedure is recursively applied to each element. Eg. `(1, a)` is `(1, a)` (is `[1, 'a']`).
* `{key1: val1, key2: val2, ...}` is an Object, and the casting procedure is recursively applied to each property. Eg. `{a: 1, b: 2}` is `{a: 1, b: 2}`.
* Any test which does not fall under the above, and which does not contain special characters (`[``]``(``)``{``}``:``,`) is a string, eg. `$12- blah` is `"$12- blah"`.
If you do provide type information, you can make your input more concise as the program already has some information about what it expects. Please see the [type format](https://github.com/gkz/type-check#type-format) section of [type-check](https://github.com/gkz/type-check) for more information about how to specify types. There are some rules about what levn can do with the information:
* If a String is expected, and only a String, all characters of the input (including any special ones) will become part of the output. Eg. `[({})]` is `"[({})]"`, and `"hi"` is `'"hi"'`.
* If a Date is expected, the surrounding `#` can be omitted from date literals. Eg. `2011-11-11` is `new Date('2011-11-11')`.
* If a RegExp is expected, no flags need to be specified, and the regex is not using any of the special characters,the opening and closing `/` can be omitted - this will have the affect of setting the source of the regex to the input. Eg. `regex` is `/regex/`.
* If an Array is expected, and it is the root node (at the top level), the opening `[` and closing `]` can be omitted. Eg. `1,2,3` is `[1,2,3]`.
* If a tuple is expected, and it is the root node (at the top level), the opening `(` and closing `)` can be omitted. Eg. `1, a` is `(1, a)` (is `[1, 'a']`).
* If an Object is expected, and it is the root node (at the top level), the opening `{` and closing `}` can be omitted. Eg `a: 1, b: 2` is `{a: 1, b: 2}`.
If you list multiple types (eg. `Number | String`), it will first attempt to cast to the first type and then validate - if the validation fails it will move on to the next type and so forth, left to right. You must be careful as some types will succeed with any input, such as String. Thus put String at the end of your list. In non-explicit mode, Date and RegExp will succeed with a large variety of input - also be careful with these and list them near the end if not last in your list.
Whitespace between special characters and elements is inconsequential.
## Options
Options is an object. It is an optional parameter to the `parse` and `parsedTypeParse` functions.
### Explicit
A `Boolean`. By default it is `false`.
__Example:__
```js
parse('RegExp', 're', {explicit: false}); // /re/
parse('RegExp', 're', {explicit: true}); // Error: ... does not type check...
parse('RegExp | String', 're', {explicit: true}); // 're'
```
`explicit` sets whether to be in explicit mode or not. Using `*` automatically activates explicit mode. For more information, read the [levn format](#levn-format) section.
### customTypes
An `Object`. Empty `{}` by default.
__Example:__
```js
var options = {
customTypes: {
Even: {
typeOf: 'Number',
validate: function (x) {
return x % 2 === 0;
},
cast: function (x) {
return {type: 'Just', value: parseInt(x)};
}
}
}
}
parse('Even', '2', options); // 2
parse('Even', '3', options); // Error: Value: "3" does not type check...
```
__Another Example:__
```js
function Person(name, age){
this.name = name;
this.age = age;
}
var options = {
customTypes: {
Person: {
typeOf: 'Object',
validate: function (x) {
x instanceof Person;
},
cast: function (value, options, typesCast) {
var name, age;
if ({}.toString.call(value).slice(8, -1) !== 'Object') {
return {type: 'Nothing'};
}
name = typesCast(value.name, [{type: 'String'}], options);
age = typesCast(value.age, [{type: 'Numger'}], options);
return {type: 'Just', value: new Person(name, age)};
}
}
}
parse('Person', '{name: Laura, age: 25}', options); // Person {name: 'Laura', age: 25}
```
`customTypes` is an object whose keys are the name of the types, and whose values are an object with three properties, `typeOf`, `validate`, and `cast`. For more information about `typeOf` and `validate`, please see the [custom types](https://github.com/gkz/type-check#custom-types) section of type-check.
`cast` is a function which receives three arguments, the value under question, options, and the typesCast function. In `cast`, attempt to cast the value into the specified type. If you are successful, return an object in the format `{type: 'Just', value: CAST-VALUE}`, if you know it won't work, return `{type: 'Nothing'}`. You can use the `typesCast` function to cast any child values. Remember to pass `options` to it. In your function you can also check for `options.explicit` and act accordingly.
## Technical About
`levn` is written in [LiveScript](http://livescript.net/) - a language that compiles to JavaScript. It uses [type-check](https://github.com/gkz/type-check) to both parse types and validate values. It also uses the [prelude.ls](http://preludels.com/) library.
<a name="table"></a>
# Table
> Produces a string that represents array data in a text table.
[](https://github.com/gajus/table/actions)
[](https://coveralls.io/github/gajus/table)
[](https://www.npmjs.org/package/table)
[](https://github.com/gajus/canonical)
[](https://twitter.com/kuizinas)
* [Table](#table)
* [Features](#table-features)
* [Install](#table-install)
* [Usage](#table-usage)
* [API](#table-api)
* [table](#table-api-table-1)
* [createStream](#table-api-createstream)
* [getBorderCharacters](#table-api-getbordercharacters)

<a name="table-features"></a>
## Features
* Works with strings containing [fullwidth](https://en.wikipedia.org/wiki/Halfwidth_and_fullwidth_forms) characters.
* Works with strings containing [ANSI escape codes](https://en.wikipedia.org/wiki/ANSI_escape_code).
* Configurable border characters.
* Configurable content alignment per column.
* Configurable content padding per column.
* Configurable column width.
* Text wrapping.
<a name="table-install"></a>
## Install
```bash
npm install table
```
[](https://www.buymeacoffee.com/gajus)
[](https://www.patreon.com/gajus)
<a name="table-usage"></a>
## Usage
```js
import { table } from 'table';
// Using commonjs?
// const { table } = require('table');
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
console.log(table(data));
```
```
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════╧════╝
```
<a name="table-api"></a>
## API
<a name="table-api-table-1"></a>
### table
Returns the string in the table format
**Parameters:**
- **_data_:** The data to display
- Type: `any[][]`
- Required: `true`
- **_config_:** Table configuration
- Type: `object`
- Required: `false`
<a name="table-api-table-1-config-border"></a>
##### config.border
Type: `{ [type: string]: string }`\
Default: `honeywell` [template](#getbordercharacters)
Custom borders. The keys are any of:
- `topLeft`, `topRight`, `topBody`,`topJoin`
- `bottomLeft`, `bottomRight`, `bottomBody`, `bottomJoin`
- `joinLeft`, `joinRight`, `joinBody`, `joinJoin`
- `bodyLeft`, `bodyRight`, `bodyJoin`
- `headerJoin`
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
border: {
topBody: `─`,
topJoin: `┬`,
topLeft: `┌`,
topRight: `┐`,
bottomBody: `─`,
bottomJoin: `┴`,
bottomLeft: `└`,
bottomRight: `┘`,
bodyLeft: `│`,
bodyRight: `│`,
bodyJoin: `│`,
joinBody: `─`,
joinLeft: `├`,
joinRight: `┤`,
joinJoin: `┼`
}
};
console.log(table(data, config));
```
```
┌────┬────┬────┐
│ 0A │ 0B │ 0C │
├────┼────┼────┤
│ 1A │ 1B │ 1C │
├────┼────┼────┤
│ 2A │ 2B │ 2C │
└────┴────┴────┘
```
<a name="table-api-table-1-config-drawverticalline"></a>
##### config.drawVerticalLine
Type: `(lineIndex: number, columnCount: number) => boolean`\
Default: `() => true`
It is used to tell whether to draw a vertical line. This callback is called for each vertical border of the table.
If the table has `n` columns, then the `index` parameter is alternatively received all numbers in range `[0, n]` inclusively.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
['3A', '3B', '3C'],
['4A', '4B', '4C']
];
const config = {
drawVerticalLine: (lineIndex, columnCount) => {
return lineIndex === 0 || lineIndex === columnCount;
}
};
console.log(table(data, config));
```
```
╔════════════╗
║ 0A 0B 0C ║
╟────────────╢
║ 1A 1B 1C ║
╟────────────╢
║ 2A 2B 2C ║
╟────────────╢
║ 3A 3B 3C ║
╟────────────╢
║ 4A 4B 4C ║
╚════════════╝
```
<a name="table-api-table-1-config-drawhorizontalline"></a>
##### config.drawHorizontalLine
Type: `(lineIndex: number, rowCount: number) => boolean`\
Default: `() => true`
It is used to tell whether to draw a horizontal line. This callback is called for each horizontal border of the table.
If the table has `n` rows, then the `index` parameter is alternatively received all numbers in range `[0, n]` inclusively.
If the table has `n` rows and contains the header, then the range will be `[0, n+1]` inclusively.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
['3A', '3B', '3C'],
['4A', '4B', '4C']
];
const config = {
drawHorizontalLine: (lineIndex, rowCount) => {
return lineIndex === 0 || lineIndex === 1 || lineIndex === rowCount - 1 || lineIndex === rowCount;
}
};
console.log(table(data, config));
```
```
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
║ 2A │ 2B │ 2C ║
║ 3A │ 3B │ 3C ║
╟────┼────┼────╢
║ 4A │ 4B │ 4C ║
╚════╧════╧════╝
```
<a name="table-api-table-1-config-singleline"></a>
##### config.singleLine
Type: `boolean`\
Default: `false`
If `true`, horizontal lines inside the table are not drawn. This option also overrides the `config.drawHorizontalLine` if specified.
```js
const data = [
['-rw-r--r--', '1', 'pandorym', 'staff', '1529', 'May 23 11:25', 'LICENSE'],
['-rw-r--r--', '1', 'pandorym', 'staff', '16327', 'May 23 11:58', 'README.md'],
['drwxr-xr-x', '76', 'pandorym', 'staff', '2432', 'May 23 12:02', 'dist'],
['drwxr-xr-x', '634', 'pandorym', 'staff', '20288', 'May 23 11:54', 'node_modules'],
['-rw-r--r--', '1,', 'pandorym', 'staff', '525688', 'May 23 11:52', 'package-lock.json'],
['-rw-r--r--@', '1', 'pandorym', 'staff', '2440', 'May 23 11:25', 'package.json'],
['drwxr-xr-x', '27', 'pandorym', 'staff', '864', 'May 23 11:25', 'src'],
['drwxr-xr-x', '20', 'pandorym', 'staff', '640', 'May 23 11:25', 'test'],
];
const config = {
singleLine: true
};
console.log(table(data, config));
```
```
╔═════════════╤═════╤══════════╤═══════╤════════╤══════════════╤═══════════════════╗
║ -rw-r--r-- │ 1 │ pandorym │ staff │ 1529 │ May 23 11:25 │ LICENSE ║
║ -rw-r--r-- │ 1 │ pandorym │ staff │ 16327 │ May 23 11:58 │ README.md ║
║ drwxr-xr-x │ 76 │ pandorym │ staff │ 2432 │ May 23 12:02 │ dist ║
║ drwxr-xr-x │ 634 │ pandorym │ staff │ 20288 │ May 23 11:54 │ node_modules ║
║ -rw-r--r-- │ 1, │ pandorym │ staff │ 525688 │ May 23 11:52 │ package-lock.json ║
║ -rw-r--r--@ │ 1 │ pandorym │ staff │ 2440 │ May 23 11:25 │ package.json ║
║ drwxr-xr-x │ 27 │ pandorym │ staff │ 864 │ May 23 11:25 │ src ║
║ drwxr-xr-x │ 20 │ pandorym │ staff │ 640 │ May 23 11:25 │ test ║
╚═════════════╧═════╧══════════╧═══════╧════════╧══════════════╧═══════════════════╝
```
<a name="table-api-table-1-config-columns"></a>
##### config.columns
Type: `Column[] | { [columnIndex: number]: Column }`
Column specific configurations.
<a name="table-api-table-1-config-columns-config-columns-width"></a>
###### config.columns[*].width
Type: `number`\
Default: the maximum cell widths of the column
Column width (excluding the paddings).
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
columns: {
1: { width: 10 }
}
};
console.log(table(data, config));
```
```
╔════╤════════════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────────────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────────────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════════════╧════╝
```
<a name="table-api-table-1-config-columns-config-columns-alignment"></a>
###### config.columns[*].alignment
Type: `'center' | 'justify' | 'left' | 'right'`\
Default: `'left'`
Cell content horizontal alignment
```js
const data = [
['0A', '0B', '0C', '0D 0E 0F'],
['1A', '1B', '1C', '1D 1E 1F'],
['2A', '2B', '2C', '2D 2E 2F'],
];
const config = {
columnDefault: {
width: 10,
},
columns: [
{ alignment: 'left' },
{ alignment: 'center' },
{ alignment: 'right' },
{ alignment: 'justify' }
],
};
console.log(table(data, config));
```
```
╔════════════╤════════════╤════════════╤════════════╗
║ 0A │ 0B │ 0C │ 0D 0E 0F ║
╟────────────┼────────────┼────────────┼────────────╢
║ 1A │ 1B │ 1C │ 1D 1E 1F ║
╟────────────┼────────────┼────────────┼────────────╢
║ 2A │ 2B │ 2C │ 2D 2E 2F ║
╚════════════╧════════════╧════════════╧════════════╝
```
<a name="table-api-table-1-config-columns-config-columns-verticalalignment"></a>
###### config.columns[*].verticalAlignment
Type: `'top' | 'middle' | 'bottom'`\
Default: `'top'`
Cell content vertical alignment
```js
const data = [
['A', 'B', 'C', 'DEF'],
];
const config = {
columnDefault: {
width: 1,
},
columns: [
{ verticalAlignment: 'top' },
{ verticalAlignment: 'middle' },
{ verticalAlignment: 'bottom' },
],
};
console.log(table(data, config));
```
```
╔═══╤═══╤═══╤═══╗
║ A │ │ │ D ║
║ │ B │ │ E ║
║ │ │ C │ F ║
╚═══╧═══╧═══╧═══╝
```
<a name="table-api-table-1-config-columns-config-columns-paddingleft"></a>
###### config.columns[*].paddingLeft
Type: `number`\
Default: `1`
The number of whitespaces used to pad the content on the left.
<a name="table-api-table-1-config-columns-config-columns-paddingright"></a>
###### config.columns[*].paddingRight
Type: `number`\
Default: `1`
The number of whitespaces used to pad the content on the right.
The `paddingLeft` and `paddingRight` options do not count on the column width. So the column has `width = 5`, `paddingLeft = 2` and `paddingRight = 2` will have the total width is `9`.
```js
const data = [
['0A', 'AABBCC', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
columns: [
{
paddingLeft: 3
},
{
width: 2,
paddingRight: 3
}
]
};
console.log(table(data, config));
```
```
╔══════╤══════╤════╗
║ 0A │ AA │ 0C ║
║ │ BB │ ║
║ │ CC │ ║
╟──────┼──────┼────╢
║ 1A │ 1B │ 1C ║
╟──────┼──────┼────╢
║ 2A │ 2B │ 2C ║
╚══════╧══════╧════╝
```
<a name="table-api-table-1-config-columns-config-columns-truncate"></a>
###### config.columns[*].truncate
Type: `number`\
Default: `Infinity`
The number of characters is which the content will be truncated.
To handle a content that overflows the container width, `table` package implements [text wrapping](#config.columns[*].wrapWord). However, sometimes you may want to truncate content that is too long to be displayed in the table.
```js
const data = [
['Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus pulvinar nibh sed mauris convallis dapibus. Nunc venenatis tempus nulla sit amet viverra.']
];
const config = {
columns: [
{
width: 20,
truncate: 100
}
]
};
console.log(table(data, config));
```
```
╔══════════════════════╗
║ Lorem ipsum dolor si ║
║ t amet, consectetur ║
║ adipiscing elit. Pha ║
║ sellus pulvinar nibh ║
║ sed mauris convall… ║
╚══════════════════════╝
```
<a name="table-api-table-1-config-columns-config-columns-wrapword"></a>
###### config.columns[*].wrapWord
Type: `boolean`\
Default: `false`
The `table` package implements auto text wrapping, i.e., text that has the width greater than the container width will be separated into multiple lines at the nearest space or one of the special characters: `\|/_.,;-`.
When `wrapWord` is `false`:
```js
const data = [
['Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus pulvinar nibh sed mauris convallis dapibus. Nunc venenatis tempus nulla sit amet viverra.']
];
const config = {
columns: [ { width: 20 } ]
};
console.log(table(data, config));
```
```
╔══════════════════════╗
║ Lorem ipsum dolor si ║
║ t amet, consectetur ║
║ adipiscing elit. Pha ║
║ sellus pulvinar nibh ║
║ sed mauris convallis ║
║ dapibus. Nunc venena ║
║ tis tempus nulla sit ║
║ amet viverra. ║
╚══════════════════════╝
```
When `wrapWord` is `true`:
```
╔══════════════════════╗
║ Lorem ipsum dolor ║
║ sit amet, ║
║ consectetur ║
║ adipiscing elit. ║
║ Phasellus pulvinar ║
║ nibh sed mauris ║
║ convallis dapibus. ║
║ Nunc venenatis ║
║ tempus nulla sit ║
║ amet viverra. ║
╚══════════════════════╝
```
<a name="table-api-table-1-config-columndefault"></a>
##### config.columnDefault
Type: `Column`\
Default: `{}`
The default configuration for all columns. Column-specific settings will overwrite the default values.
<a name="table-api-table-1-config-header"></a>
##### config.header
Type: `object`
Header configuration.
*Deprecated in favor of the new spanning cells API.*
The header configuration inherits the most of the column's, except:
- `content` **{string}**: the header content.
- `width:` calculate based on the content width automatically.
- `alignment:` `center` be default.
- `verticalAlignment:` is not supported.
- `config.border.topJoin` will be `config.border.topBody` for prettier.
```js
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C'],
];
const config = {
columnDefault: {
width: 10,
},
header: {
alignment: 'center',
content: 'THE HEADER\nThis is the table about something',
},
}
console.log(table(data, config));
```
```
╔══════════════════════════════════════╗
║ THE HEADER ║
║ This is the table about something ║
╟────────────┬────────────┬────────────╢
║ 0A │ 0B │ 0C ║
╟────────────┼────────────┼────────────╢
║ 1A │ 1B │ 1C ║
╟────────────┼────────────┼────────────╢
║ 2A │ 2B │ 2C ║
╚════════════╧════════════╧════════════╝
```
<a name="table-api-table-1-config-spanningcells"></a>
##### config.spanningCells
Type: `SpanningCellConfig[]`
Spanning cells configuration.
The configuration should be straightforward: just specify an array of minimal cell configurations including the position of top-left cell
and the number of columns and/or rows will be expanded from it.
The content of overlap cells will be ignored to make the `data` shape be consistent.
By default, the configuration of column that the top-left cell belongs to will be applied to the whole spanning cell, except:
* The `width` will be summed up of all spanning columns.
* The `paddingRight` will be received from the right-most column intentionally.
Advances customized column-like styles can be configurable to each spanning cell to overwrite the default behavior.
```js
const data = [
['Test Coverage Report', '', '', '', '', ''],
['Module', 'Component', 'Test Cases', 'Failures', 'Durations', 'Success Rate'],
['Services', 'User', '50', '30', '3m 7s', '60.0%'],
['', 'Payment', '100', '80', '7m 15s', '80.0%'],
['Subtotal', '', '150', '110', '10m 22s', '73.3%'],
['Controllers', 'User', '24', '18', '1m 30s', '75.0%'],
['', 'Payment', '30', '24', '50s', '80.0%'],
['Subtotal', '', '54', '42', '2m 20s', '77.8%'],
['Total', '', '204', '152', '12m 42s', '74.5%'],
];
const config = {
columns: [
{ alignment: 'center', width: 12 },
{ alignment: 'center', width: 10 },
{ alignment: 'right' },
{ alignment: 'right' },
{ alignment: 'right' },
{ alignment: 'right' }
],
spanningCells: [
{ col: 0, row: 0, colSpan: 6 },
{ col: 0, row: 2, rowSpan: 2, verticalAlignment: 'middle'},
{ col: 0, row: 4, colSpan: 2, alignment: 'right'},
{ col: 0, row: 5, rowSpan: 2, verticalAlignment: 'middle'},
{ col: 0, row: 7, colSpan: 2, alignment: 'right' },
{ col: 0, row: 8, colSpan: 2, alignment: 'right' }
],
};
console.log(table(data, config));
```
```
╔══════════════════════════════════════════════════════════════════════════════╗
║ Test Coverage Report ║
╟──────────────┬────────────┬────────────┬──────────┬───────────┬──────────────╢
║ Module │ Component │ Test Cases │ Failures │ Durations │ Success Rate ║
╟──────────────┼────────────┼────────────┼──────────┼───────────┼──────────────╢
║ │ User │ 50 │ 30 │ 3m 7s │ 60.0% ║
║ Services ├────────────┼────────────┼──────────┼───────────┼──────────────╢
║ │ Payment │ 100 │ 80 │ 7m 15s │ 80.0% ║
╟──────────────┴────────────┼────────────┼──────────┼───────────┼──────────────╢
║ Subtotal │ 150 │ 110 │ 10m 22s │ 73.3% ║
╟──────────────┬────────────┼────────────┼──────────┼───────────┼──────────────╢
║ │ User │ 24 │ 18 │ 1m 30s │ 75.0% ║
║ Controllers ├────────────┼────────────┼──────────┼───────────┼──────────────╢
║ │ Payment │ 30 │ 24 │ 50s │ 80.0% ║
╟──────────────┴────────────┼────────────┼──────────┼───────────┼──────────────╢
║ Subtotal │ 54 │ 42 │ 2m 20s │ 77.8% ║
╟───────────────────────────┼────────────┼──────────┼───────────┼──────────────╢
║ Total │ 204 │ 152 │ 12m 42s │ 74.5% ║
╚═══════════════════════════╧════════════╧══════════╧═══════════╧══════════════╝
```
<a name="table-api-createstream"></a>
### createStream
`table` package exports `createStream` function used to draw a table and append rows.
**Parameter:**
- _**config:**_ the same as `table`'s, except `config.columnDefault.width` and `config.columnCount` must be provided.
```js
import { createStream } from 'table';
const config = {
columnDefault: {
width: 50
},
columnCount: 1
};
const stream = createStream(config);
setInterval(() => {
stream.write([new Date()]);
}, 500);
```

`table` package uses ANSI escape codes to overwrite the output of the last line when a new row is printed.
The underlying implementation is explained in this [Stack Overflow answer](http://stackoverflow.com/a/32938658/368691).
Streaming supports all of the configuration properties and functionality of a static table (such as auto text wrapping, alignment and padding), e.g.
```js
import { createStream } from 'table';
import _ from 'lodash';
const config = {
columnDefault: {
width: 50
},
columnCount: 3,
columns: [
{
width: 10,
alignment: 'right'
},
{ alignment: 'center' },
{ width: 10 }
]
};
const stream = createStream(config);
let i = 0;
setInterval(() => {
let random;
random = _.sample('abcdefghijklmnopqrstuvwxyz', _.random(1, 30)).join('');
stream.write([i++, new Date(), random]);
}, 500);
```

<a name="table-api-getbordercharacters"></a>
### getBorderCharacters
**Parameter:**
- **_template_**
- Type: `'honeywell' | 'norc' | 'ramac' | 'void'`
- Required: `true`
You can load one of the predefined border templates using `getBorderCharacters` function.
```js
import { table, getBorderCharacters } from 'table';
const data = [
['0A', '0B', '0C'],
['1A', '1B', '1C'],
['2A', '2B', '2C']
];
const config = {
border: getBorderCharacters(`name of the template`)
};
console.log(table(data, config));
```
```
# honeywell
╔════╤════╤════╗
║ 0A │ 0B │ 0C ║
╟────┼────┼────╢
║ 1A │ 1B │ 1C ║
╟────┼────┼────╢
║ 2A │ 2B │ 2C ║
╚════╧════╧════╝
# norc
┌────┬────┬────┐
│ 0A │ 0B │ 0C │
├────┼────┼────┤
│ 1A │ 1B │ 1C │
├────┼────┼────┤
│ 2A │ 2B │ 2C │
└────┴────┴────┘
# ramac (ASCII; for use in terminals that do not support Unicode characters)
+----+----+----+
| 0A | 0B | 0C |
|----|----|----|
| 1A | 1B | 1C |
|----|----|----|
| 2A | 2B | 2C |
+----+----+----+
# void (no borders; see "borderless table" section of the documentation)
0A 0B 0C
1A 1B 1C
2A 2B 2C
```
Raise [an issue](https://github.com/gajus/table/issues) if you'd like to contribute a new border template.
<a name="table-api-getbordercharacters-borderless-table"></a>
#### Borderless Table
Simply using `void` border character template creates a table with a lot of unnecessary spacing.
To create a more pleasant to the eye table, reset the padding and remove the joining rows, e.g.
```js
const output = table(data, {
border: getBorderCharacters('void'),
columnDefault: {
paddingLeft: 0,
paddingRight: 1
},
drawHorizontalLine: () => false
}
);
console.log(output);
```
```
0A 0B 0C
1A 1B 1C
2A 2B 2C
```
### Esrecurse [](https://travis-ci.org/estools/esrecurse)
Esrecurse ([esrecurse](https://github.com/estools/esrecurse)) is
[ECMAScript](https://www.ecma-international.org/publications/standards/Ecma-262.htm)
recursive traversing functionality.
### Example Usage
The following code will output all variables declared at the root of a file.
```javascript
esrecurse.visit(ast, {
XXXStatement: function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
}
});
```
We can use `Visitor` instance.
```javascript
var visitor = new esrecurse.Visitor({
XXXStatement: function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
}
});
visitor.visit(ast);
```
We can inherit `Visitor` instance easily.
```javascript
class Derived extends esrecurse.Visitor {
constructor()
{
super(null);
}
XXXStatement(node) {
}
}
```
```javascript
function DerivedVisitor() {
esrecurse.Visitor.call(/* this for constructor */ this /* visitor object automatically becomes this. */);
}
util.inherits(DerivedVisitor, esrecurse.Visitor);
DerivedVisitor.prototype.XXXStatement = function (node) {
this.visit(node.left);
// do something...
this.visit(node.right);
};
```
And you can invoke default visiting operation inside custom visit operation.
```javascript
function DerivedVisitor() {
esrecurse.Visitor.call(/* this for constructor */ this /* visitor object automatically becomes this. */);
}
util.inherits(DerivedVisitor, esrecurse.Visitor);
DerivedVisitor.prototype.XXXStatement = function (node) {
// do something...
this.visitChildren(node);
};
```
The `childVisitorKeys` option does customize the behaviour of `this.visitChildren(node)`.
We can use user-defined node types.
```javascript
// This tree contains a user-defined `TestExpression` node.
var tree = {
type: 'TestExpression',
// This 'argument' is the property containing the other **node**.
argument: {
type: 'Literal',
value: 20
},
// This 'extended' is the property not containing the other **node**.
extended: true
};
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
// Extending the existing traversing rules.
childVisitorKeys: {
// TargetNodeName: [ 'keys', 'containing', 'the', 'other', '**node**' ]
TestExpression: ['argument']
}
}
);
```
We can use the `fallback` option as well.
If the `fallback` option is `"iteration"`, `esrecurse` would visit all enumerable properties of unknown nodes.
Please note circular references cause the stack overflow. AST might have circular references in additional properties for some purpose (e.g. `node.parent`).
```javascript
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
fallback: 'iteration'
}
);
```
If the `fallback` option is a function, `esrecurse` calls this function to determine the enumerable properties of unknown nodes.
Please note circular references cause the stack overflow. AST might have circular references in additional properties for some purpose (e.g. `node.parent`).
```javascript
esrecurse.visit(
ast,
{
Literal: function (node) {
// do something...
}
},
{
fallback: function (node) {
return Object.keys(node).filter(function(key) {
return key !== 'argument'
});
}
}
);
```
### License
Copyright (C) 2014 [Yusuke Suzuki](https://github.com/Constellation)
(twitter: [@Constellation](https://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
These files are compiled dot templates from dot folder.
Do NOT edit them directly, edit the templates and run `npm run build` from main ajv folder.
# cross-spawn
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Build status][appveyor-image]][appveyor-url] [![Coverage Status][codecov-image]][codecov-url] [![Dependency status][david-dm-image]][david-dm-url] [![Dev Dependency status][david-dm-dev-image]][david-dm-dev-url]
[npm-url]:https://npmjs.org/package/cross-spawn
[downloads-image]:https://img.shields.io/npm/dm/cross-spawn.svg
[npm-image]:https://img.shields.io/npm/v/cross-spawn.svg
[travis-url]:https://travis-ci.org/moxystudio/node-cross-spawn
[travis-image]:https://img.shields.io/travis/moxystudio/node-cross-spawn/master.svg
[appveyor-url]:https://ci.appveyor.com/project/satazor/node-cross-spawn
[appveyor-image]:https://img.shields.io/appveyor/ci/satazor/node-cross-spawn/master.svg
[codecov-url]:https://codecov.io/gh/moxystudio/node-cross-spawn
[codecov-image]:https://img.shields.io/codecov/c/github/moxystudio/node-cross-spawn/master.svg
[david-dm-url]:https://david-dm.org/moxystudio/node-cross-spawn
[david-dm-image]:https://img.shields.io/david/moxystudio/node-cross-spawn.svg
[david-dm-dev-url]:https://david-dm.org/moxystudio/node-cross-spawn?type=dev
[david-dm-dev-image]:https://img.shields.io/david/dev/moxystudio/node-cross-spawn.svg
A cross platform solution to node's spawn and spawnSync.
## Installation
Node.js version 8 and up:
`$ npm install cross-spawn`
Node.js version 7 and under:
`$ npm install cross-spawn@6`
## Why
Node has issues when using spawn on Windows:
- It ignores [PATHEXT](https://github.com/joyent/node/issues/2318)
- It does not support [shebangs](https://en.wikipedia.org/wiki/Shebang_(Unix))
- Has problems running commands with [spaces](https://github.com/nodejs/node/issues/7367)
- Has problems running commands with posix relative paths (e.g.: `./my-folder/my-executable`)
- Has an [issue](https://github.com/moxystudio/node-cross-spawn/issues/82) with command shims (files in `node_modules/.bin/`), where arguments with quotes and parenthesis would result in [invalid syntax error](https://github.com/moxystudio/node-cross-spawn/blob/e77b8f22a416db46b6196767bcd35601d7e11d54/test/index.test.js#L149)
- No `options.shell` support on node `<v4.8`
All these issues are handled correctly by `cross-spawn`.
There are some known modules, such as [win-spawn](https://github.com/ForbesLindesay/win-spawn), that try to solve this but they are either broken or provide faulty escaping of shell arguments.
## Usage
Exactly the same way as node's [`spawn`](https://nodejs.org/api/child_process.html#child_process_child_process_spawn_command_args_options) or [`spawnSync`](https://nodejs.org/api/child_process.html#child_process_child_process_spawnsync_command_args_options), so it's a drop in replacement.
```js
const spawn = require('cross-spawn');
// Spawn NPM asynchronously
const child = spawn('npm', ['list', '-g', '-depth', '0'], { stdio: 'inherit' });
// Spawn NPM synchronously
const result = spawn.sync('npm', ['list', '-g', '-depth', '0'], { stdio: 'inherit' });
```
## Caveats
### Using `options.shell` as an alternative to `cross-spawn`
Starting from node `v4.8`, `spawn` has a `shell` option that allows you run commands from within a shell. This new option solves
the [PATHEXT](https://github.com/joyent/node/issues/2318) issue but:
- It's not supported in node `<v4.8`
- You must manually escape the command and arguments which is very error prone, specially when passing user input
- There are a lot of other unresolved issues from the [Why](#why) section that you must take into account
If you are using the `shell` option to spawn a command in a cross platform way, consider using `cross-spawn` instead. You have been warned.
### `options.shell` support
While `cross-spawn` adds support for `options.shell` in node `<v4.8`, all of its enhancements are disabled.
This mimics the Node.js behavior. More specifically, the command and its arguments will not be automatically escaped nor shebang support will be offered. This is by design because if you are using `options.shell` you are probably targeting a specific platform anyway and you don't want things to get into your way.
### Shebangs support
While `cross-spawn` handles shebangs on Windows, its support is limited. More specifically, it just supports `#!/usr/bin/env <program>` where `<program>` must not contain any arguments.
If you would like to have the shebang support improved, feel free to contribute via a pull-request.
Remember to always test your code on Windows!
## Tests
`$ npm test`
`$ npm test -- --watch` during development
## License
Released under the [MIT License](https://www.opensource.org/licenses/mit-license.php).
[](https://www.npmjs.com/package/as-bignum)[](https://travis-ci.com/MaxGraey/as-bignum)[](LICENSE.md)
## WebAssembly fixed length big numbers written on [AssemblyScript](https://github.com/AssemblyScript/assemblyscript)
### Status: Work in progress
Provide wide numeric types such as `u128`, `u256`, `i128`, `i256` and fixed points and also its arithmetic operations.
Namespace `safe` contain equivalents with overflow/underflow traps.
All kind of types pretty useful for economical and cryptographic usages and provide deterministic behavior.
### Install
> yarn add as-bignum
or
> npm i as-bignum
### Usage via AssemblyScript
```ts
import { u128 } from "as-bignum";
declare function logF64(value: f64): void;
declare function logU128(hi: u64, lo: u64): void;
var a = u128.One;
var b = u128.from(-32); // same as u128.from<i32>(-32)
var c = new u128(0x1, -0xF);
var d = u128.from(0x0123456789ABCDEF); // same as u128.from<i64>(0x0123456789ABCDEF)
var e = u128.from('0x0123456789ABCDEF01234567');
var f = u128.fromString('11100010101100101', 2); // same as u128.from('0b11100010101100101')
var r = d / c + (b << 5) + e;
logF64(r.as<f64>());
logU128(r.hi, r.lo);
```
### Usage via JavaScript/Typescript
```ts
TODO
```
### List of types
- [x] [`u128`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/u128.ts) unsigned type (tested)
- [ ] [`u256`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/u256.ts) unsigned type (very basic)
- [ ] `i128` signed type
- [ ] `i256` signed type
---
- [x] [`safe.u128`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/safe/u128.ts) unsigned type (tested)
- [ ] `safe.u256` unsigned type
- [ ] `safe.i128` signed type
- [ ] `safe.i256` signed type
---
- [ ] [`fp128<Q>`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/fixed/fp128.ts) generic fixed point signed type٭ (very basic for now)
- [ ] `fp256<Q>` generic fixed point signed type٭
---
- [ ] `safe.fp128<Q>` generic fixed point signed type٭
- [ ] `safe.fp256<Q>` generic fixed point signed type٭
٭ _typename_ `Q` _is a type representing count of fractional bits_
## assemblyscript-temporal
An implementation of temporal within AssemblyScript, with an initial focus on non-timezone-aware classes and functionality.
### Why?
AssemblyScript has minimal `Date` support, however, the JS Date API itself is terrible and people tend not to use it that often. As a result libraries like moment / luxon have become staple replacements. However, there is now a [relatively mature TC39 proposal](https://github.com/tc39/proposal-temporal) that adds greatly improved date support to JS. The goal of this project is to implement Temporal for AssemblyScript.
### Usage
This library currently supports the following types:
#### `PlainDateTime`
A `PlainDateTime` represents a calendar date and wall-clock time that does not carry time zone information, e.g. December 7th, 1995 at 3:00 PM (in the Gregorian calendar). For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaindatetime.html), this implementation follows the specification as closely as possible.
You can create a `PlainDateTime` from individual components, a string or an object literal:
```javascript
datetime = new PlainDateTime(1976, 11, 18, 15, 23, 30, 123, 456, 789);
datetime.year; // 2019;
datetime.month; // 11;
// ...
datetime.nanosecond; // 789;
datetime = PlainDateTime.from("1976-11-18T12:34:56");
datetime.toString(); // "1976-11-18T12:34:56"
datetime = PlainDateTime.from({ year: 1966, month: 3, day: 3 });
datetime.toString(); // "1966-03-03T00:00:00"
```
There are various ways you can manipulate a date:
```javascript
// use 'with' to copy a date but with various property values overriden
datetime = new PlainDateTime(1976, 11, 18, 15, 23, 30, 123, 456, 789);
datetime.with({ year: 2019 }).toString(); // "2019-11-18T15:23:30.123456789"
// use 'add' or 'substract' to add / subtract a duration
datetime = PlainDateTime.from("2020-01-12T15:00");
datetime.add({ months: 1 }).toString(); // "2020-02-12T15:00:00");
// add / subtract support Duration objects or object literals
datetime.add(new Duration(1)).toString(); // "2021-01-12T15:00:00");
```
You can compare dates and check for equality
```javascript
dt1 = PlainDateTime.from("1976-11-18");
dt2 = PlainDateTime.from("2019-10-29");
PlainDateTime.compare(dt1, dt1); // 0
PlainDateTime.compare(dt1, dt2); // -1
dt1.equals(dt1); // true
```
Currently `PlainDateTime` only supports the ISO 8601 (Gregorian) calendar.
#### `PlainDate`
A `PlainDate` object represents a calendar date that is not associated with a particular time or time zone, e.g. August 24th, 2006. For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaindate.html), this implementation follows the specification as closely as possible.
The `PlainDate` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `PlainTime`
A `PlainTime` object represents a wall-clock time that is not associated with a particular date or time zone, e.g. 7:39 PM. For detailed documentation see the [TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plaintime.html), this implementation follows the specification as closely as possible.
The `PlainTime` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `PlainMonthDay`
A date without a year component. This is useful to express things like "Bastille Day is on the 14th of July".
For detailed documentation see the
[TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plainmonthday.html)
, this implementation follows the specification as closely as possible.
```javascript
const monthDay = PlainMonthDay.from({ month: 7, day: 14 }); // => 07-14
const date = monthDay.toPlainDate({ year: 2030 }); // => 2030-07-14
date.dayOfWeek; // => 7
```
The `PlainMonthDay` API is almost identical to `PlainDateTime`, so see above for more API usage examples.
#### `PlainYearMonth`
A date without a day component. This is useful to express things like "the October 2020 meeting".
For detailed documentation see the
[TC39 Temporal proposal website](https://tc39.es/proposal-temporal/docs/plainyearmonth.html)
, this implementation follows the specification as closely as possible.
The `PlainYearMonth` API is almost identical to `PlainDateTime`, so see above for API usage examples.
#### `now`
The `now` object has several methods which give information about the current time and date.
```javascript
dateTime = now.plainDateTimeISO();
dateTime.toString(); // 2021-04-01T12:05:47.357
```
## Contributing
This project is open source, MIT licensed and your contributions are very much welcomed.
There is a [brief document that outlines implementation progress and priorities](./development.md).
# axios // adapters
The modules under `adapters/` are modules that handle dispatching a request and settling a returned `Promise` once a response is received.
## Example
```js
var settle = require('./../core/settle');
module.exports = function myAdapter(config) {
// At this point:
// - config has been merged with defaults
// - request transformers have already run
// - request interceptors have already run
// Make the request using config provided
// Upon response settle the Promise
return new Promise(function(resolve, reject) {
var response = {
data: responseData,
status: request.status,
statusText: request.statusText,
headers: responseHeaders,
config: config,
request: request
};
settle(resolve, reject, response);
// From here:
// - response transformers will run
// - response interceptors will run
});
}
```
ESQuery is a library for querying the AST output by Esprima for patterns of syntax using a CSS style selector system. Check out the demo:
[demo](https://estools.github.io/esquery/)
The following selectors are supported:
* AST node type: `ForStatement`
* [wildcard](http://dev.w3.org/csswg/selectors4/#universal-selector): `*`
* [attribute existence](http://dev.w3.org/csswg/selectors4/#attribute-selectors): `[attr]`
* [attribute value](http://dev.w3.org/csswg/selectors4/#attribute-selectors): `[attr="foo"]` or `[attr=123]`
* attribute regex: `[attr=/foo.*/]` or (with flags) `[attr=/foo.*/is]`
* attribute conditions: `[attr!="foo"]`, `[attr>2]`, `[attr<3]`, `[attr>=2]`, or `[attr<=3]`
* nested attribute: `[attr.level2="foo"]`
* field: `FunctionDeclaration > Identifier.id`
* [First](http://dev.w3.org/csswg/selectors4/#the-first-child-pseudo) or [last](http://dev.w3.org/csswg/selectors4/#the-last-child-pseudo) child: `:first-child` or `:last-child`
* [nth-child](http://dev.w3.org/csswg/selectors4/#the-nth-child-pseudo) (no ax+b support): `:nth-child(2)`
* [nth-last-child](http://dev.w3.org/csswg/selectors4/#the-nth-last-child-pseudo) (no ax+b support): `:nth-last-child(1)`
* [descendant](http://dev.w3.org/csswg/selectors4/#descendant-combinators): `ancestor descendant`
* [child](http://dev.w3.org/csswg/selectors4/#child-combinators): `parent > child`
* [following sibling](http://dev.w3.org/csswg/selectors4/#general-sibling-combinators): `node ~ sibling`
* [adjacent sibling](http://dev.w3.org/csswg/selectors4/#adjacent-sibling-combinators): `node + adjacent`
* [negation](http://dev.w3.org/csswg/selectors4/#negation-pseudo): `:not(ForStatement)`
* [has](https://drafts.csswg.org/selectors-4/#has-pseudo): `:has(ForStatement)`
* [matches-any](http://dev.w3.org/csswg/selectors4/#matches): `:matches([attr] > :first-child, :last-child)`
* [subject indicator](http://dev.w3.org/csswg/selectors4/#subject): `!IfStatement > [name="foo"]`
* class of AST node: `:statement`, `:expression`, `:declaration`, `:function`, or `:pattern`
[](https://travis-ci.org/estools/esquery)
# lodash.sortby v4.7.0
The [lodash](https://lodash.com/) method `_.sortBy` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.sortby
```
In Node.js:
```js
var sortBy = require('lodash.sortby');
```
See the [documentation](https://lodash.com/docs#sortBy) or [package source](https://github.com/lodash/lodash/blob/4.7.0-npm-packages/lodash.sortby) for more details.
# binary-install
Install .tar.gz binary applications via npm
## Usage
This library provides a single class `Binary` that takes a download url and some optional arguments. You **must** provide either `name` or `installDirectory` when creating your `Binary`.
| option | decription |
| ---------------- | --------------------------------------------- |
| name | The name of your binary |
| installDirectory | A path to the directory to install the binary |
If an `installDirectory` is not provided, the binary will be installed at your OS specific config directory. On MacOS it defaults to `~/Library/Preferences/${name}-nodejs`
After your `Binary` has been created, you can run `.install()` to install the binary, and `.run()` to run it.
### Example
This is meant to be used as a library - create your `Binary` with your desired options, then call `.install()` in the `postinstall` of your `package.json`, `.run()` in the `bin` section of your `package.json`, and `.uninstall()` in the `preuninstall` section of your `package.json`. See [this example project](/example) to see how to create an npm package that installs and runs a binary using the Github releases API.
# emoji-regex [](https://travis-ci.org/mathiasbynens/emoji-regex)
_emoji-regex_ offers a regular expression to match all emoji symbols (including textual representations of emoji) as per the Unicode Standard.
This repository contains a script that generates this regular expression based on [the data from Unicode v12](https://github.com/mathiasbynens/unicode-12.0.0). Because of this, the regular expression can easily be updated whenever new emoji are added to the Unicode standard.
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install emoji-regex
```
In [Node.js](https://nodejs.org/):
```js
const emojiRegex = require('emoji-regex');
// Note: because the regular expression has the global flag set, this module
// exports a function that returns the regex rather than exporting the regular
// expression itself, to make it impossible to (accidentally) mutate the
// original regular expression.
const text = `
\u{231A}: ⌚ default emoji presentation character (Emoji_Presentation)
\u{2194}\u{FE0F}: ↔️ default text presentation character rendered as emoji
\u{1F469}: 👩 emoji modifier base (Emoji_Modifier_Base)
\u{1F469}\u{1F3FF}: 👩🏿 emoji modifier base followed by a modifier
`;
const regex = emojiRegex();
let match;
while (match = regex.exec(text)) {
const emoji = match[0];
console.log(`Matched sequence ${ emoji } — code points: ${ [...emoji].length }`);
}
```
Console output:
```
Matched sequence ⌚ — code points: 1
Matched sequence ⌚ — code points: 1
Matched sequence ↔️ — code points: 2
Matched sequence ↔️ — code points: 2
Matched sequence 👩 — code points: 1
Matched sequence 👩 — code points: 1
Matched sequence 👩🏿 — code points: 2
Matched sequence 👩🏿 — code points: 2
```
To match emoji in their textual representation as well (i.e. emoji that are not `Emoji_Presentation` symbols and that aren’t forced to render as emoji by a variation selector), `require` the other regex:
```js
const emojiRegex = require('emoji-regex/text.js');
```
Additionally, in environments which support ES2015 Unicode escapes, you may `require` ES2015-style versions of the regexes:
```js
const emojiRegex = require('emoji-regex/es2015/index.js');
const emojiRegexText = require('emoji-regex/es2015/text.js');
```
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
_emoji-regex_ is available under the [MIT](https://mths.be/mit) license.
# node-tar
[](https://travis-ci.org/npm/node-tar)
[Fast](./benchmarks) and full-featured Tar for Node.js
The API is designed to mimic the behavior of `tar(1)` on unix systems.
If you are familiar with how tar works, most of this will hopefully be
straightforward for you. If not, then hopefully this module can teach
you useful unix skills that may come in handy someday :)
## Background
A "tar file" or "tarball" is an archive of file system entries
(directories, files, links, etc.) The name comes from "tape archive".
If you run `man tar` on almost any Unix command line, you'll learn
quite a bit about what it can do, and its history.
Tar has 5 main top-level commands:
* `c` Create an archive
* `r` Replace entries within an archive
* `u` Update entries within an archive (ie, replace if they're newer)
* `t` List out the contents of an archive
* `x` Extract an archive to disk
The other flags and options modify how this top level function works.
## High-Level API
These 5 functions are the high-level API. All of them have a
single-character name (for unix nerds familiar with `tar(1)`) as well
as a long name (for everyone else).
All the high-level functions take the following arguments, all three
of which are optional and may be omitted.
1. `options` - An optional object specifying various options
2. `paths` - An array of paths to add or extract
3. `callback` - Called when the command is completed, if async. (If
sync or no file specified, providing a callback throws a
`TypeError`.)
If the command is sync (ie, if `options.sync=true`), then the
callback is not allowed, since the action will be completed immediately.
If a `file` argument is specified, and the command is async, then a
`Promise` is returned. In this case, if async, a callback may be
provided which is called when the command is completed.
If a `file` option is not specified, then a stream is returned. For
`create`, this is a readable stream of the generated archive. For
`list` and `extract` this is a writable stream that an archive should
be written into. If a file is not specified, then a callback is not
allowed, because you're already getting a stream to work with.
`replace` and `update` only work on existing archives, and so require
a `file` argument.
Sync commands without a file argument return a stream that acts on its
input immediately in the same tick. For readable streams, this means
that all of the data is immediately available by calling
`stream.read()`. For writable streams, it will be acted upon as soon
as it is provided, but this can be at any time.
### Warnings and Errors
Tar emits warnings and errors for recoverable and unrecoverable situations,
respectively. In many cases, a warning only affects a single entry in an
archive, or is simply informing you that it's modifying an entry to comply
with the settings provided.
Unrecoverable warnings will always raise an error (ie, emit `'error'` on
streaming actions, throw for non-streaming sync actions, reject the
returned Promise for non-streaming async operations, or call a provided
callback with an `Error` as the first argument). Recoverable errors will
raise an error only if `strict: true` is set in the options.
Respond to (recoverable) warnings by listening to the `warn` event.
Handlers receive 3 arguments:
- `code` String. One of the error codes below. This may not match
`data.code`, which preserves the original error code from fs and zlib.
- `message` String. More details about the error.
- `data` Metadata about the error. An `Error` object for errors raised by
fs and zlib. All fields are attached to errors raisd by tar. Typically
contains the following fields, as relevant:
- `tarCode` The tar error code.
- `code` Either the tar error code, or the error code set by the
underlying system.
- `file` The archive file being read or written.
- `cwd` Working directory for creation and extraction operations.
- `entry` The entry object (if it could be created) for `TAR_ENTRY_INFO`,
`TAR_ENTRY_INVALID`, and `TAR_ENTRY_ERROR` warnings.
- `header` The header object (if it could be created, and the entry could
not be created) for `TAR_ENTRY_INFO` and `TAR_ENTRY_INVALID` warnings.
- `recoverable` Boolean. If `false`, then the warning will emit an
`error`, even in non-strict mode.
#### Error Codes
* `TAR_ENTRY_INFO` An informative error indicating that an entry is being
modified, but otherwise processed normally. For example, removing `/` or
`C:\` from absolute paths if `preservePaths` is not set.
* `TAR_ENTRY_INVALID` An indication that a given entry is not a valid tar
archive entry, and will be skipped. This occurs when:
- a checksum fails,
- a `linkpath` is missing for a link type, or
- a `linkpath` is provided for a non-link type.
If every entry in a parsed archive raises an `TAR_ENTRY_INVALID` error,
then the archive is presumed to be unrecoverably broken, and
`TAR_BAD_ARCHIVE` will be raised.
* `TAR_ENTRY_ERROR` The entry appears to be a valid tar archive entry, but
encountered an error which prevented it from being unpacked. This occurs
when:
- an unrecoverable fs error happens during unpacking,
- an entry has `..` in the path and `preservePaths` is not set, or
- an entry is extracting through a symbolic link, when `preservePaths` is
not set.
* `TAR_ENTRY_UNSUPPORTED` An indication that a given entry is
a valid archive entry, but of a type that is unsupported, and so will be
skipped in archive creation or extracting.
* `TAR_ABORT` When parsing gzipped-encoded archives, the parser will
abort the parse process raise a warning for any zlib errors encountered.
Aborts are considered unrecoverable for both parsing and unpacking.
* `TAR_BAD_ARCHIVE` The archive file is totally hosed. This can happen for
a number of reasons, and always occurs at the end of a parse or extract:
- An entry body was truncated before seeing the full number of bytes.
- The archive contained only invalid entries, indicating that it is
likely not an archive, or at least, not an archive this library can
parse.
`TAR_BAD_ARCHIVE` is considered informative for parse operations, but
unrecoverable for extraction. Note that, if encountered at the end of an
extraction, tar WILL still have extracted as much it could from the
archive, so there may be some garbage files to clean up.
Errors that occur deeper in the system (ie, either the filesystem or zlib)
will have their error codes left intact, and a `tarCode` matching one of
the above will be added to the warning metadata or the raised error object.
Errors generated by tar will have one of the above codes set as the
`error.code` field as well, but since errors originating in zlib or fs will
have their original codes, it's better to read `error.tarCode` if you wish
to see how tar is handling the issue.
### Examples
The API mimics the `tar(1)` command line functionality, with aliases
for more human-readable option and function names. The goal is that
if you know how to use `tar(1)` in Unix, then you know how to use
`require('tar')` in JavaScript.
To replicate `tar czf my-tarball.tgz files and folders`, you'd do:
```js
tar.c(
{
gzip: <true|gzip options>,
file: 'my-tarball.tgz'
},
['some', 'files', 'and', 'folders']
).then(_ => { .. tarball has been created .. })
```
To replicate `tar cz files and folders > my-tarball.tgz`, you'd do:
```js
tar.c( // or tar.create
{
gzip: <true|gzip options>
},
['some', 'files', 'and', 'folders']
).pipe(fs.createWriteStream('my-tarball.tgz'))
```
To replicate `tar xf my-tarball.tgz` you'd do:
```js
tar.x( // or tar.extract(
{
file: 'my-tarball.tgz'
}
).then(_=> { .. tarball has been dumped in cwd .. })
```
To replicate `cat my-tarball.tgz | tar x -C some-dir --strip=1`:
```js
fs.createReadStream('my-tarball.tgz').pipe(
tar.x({
strip: 1,
C: 'some-dir' // alias for cwd:'some-dir', also ok
})
)
```
To replicate `tar tf my-tarball.tgz`, do this:
```js
tar.t({
file: 'my-tarball.tgz',
onentry: entry => { .. do whatever with it .. }
})
```
To replicate `cat my-tarball.tgz | tar t` do:
```js
fs.createReadStream('my-tarball.tgz')
.pipe(tar.t())
.on('entry', entry => { .. do whatever with it .. })
```
To do anything synchronous, add `sync: true` to the options. Note
that sync functions don't take a callback and don't return a promise.
When the function returns, it's already done. Sync methods without a
file argument return a sync stream, which flushes immediately. But,
of course, it still won't be done until you `.end()` it.
To filter entries, add `filter: <function>` to the options.
Tar-creating methods call the filter with `filter(path, stat)`.
Tar-reading methods (including extraction) call the filter with
`filter(path, entry)`. The filter is called in the `this`-context of
the `Pack` or `Unpack` stream object.
The arguments list to `tar t` and `tar x` specify a list of filenames
to extract or list, so they're equivalent to a filter that tests if
the file is in the list.
For those who _aren't_ fans of tar's single-character command names:
```
tar.c === tar.create
tar.r === tar.replace (appends to archive, file is required)
tar.u === tar.update (appends if newer, file is required)
tar.x === tar.extract
tar.t === tar.list
```
Keep reading for all the command descriptions and options, as well as
the low-level API that they are built on.
### tar.c(options, fileList, callback) [alias: tar.create]
Create a tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Write the tarball archive to the specified filename. If this
is specified, then the callback will be fired when the file has been
written, and a promise will be returned that resolves when the file
is written. If a filename is not specified, then a Readable Stream
will be returned which will emit the file data. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`. If this is set,
and a file is not provided, then the resulting stream will already
have the data ready to `read` or `emit('data')` as soon as you
request it.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `mode` The mode to set on the created file archive
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
### tar.x(options, fileList, callback) [alias: tar.extract]
Extract a tarball archive.
The `fileList` is an array of paths to extract from the tarball. If
no paths are provided, then all the entries are extracted.
If the archive is gzipped, then tar will detect this and unzip it.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
Most extraction errors will cause a `warn` event to be emitted. If
the `cwd` is missing, or not a directory, then the extraction will
fail completely.
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory. [Alias: `C`]
- `file` The archive file to extract. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Create files and directories synchronously.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive. [Alias: `keep-newer`,
`keep-newer-files`]
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies. [Alias: `k`, `keep-existing`]
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
[Alias: `P`]
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file. [Alias:
`U`]
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks. [Alias: `strip-components`, `stripComponents`]
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
[Alias: `p`]
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries. [Alias: `m`, `no-mtime`]
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync extractions.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### tar.t(options, fileList, callback) [alias: tar.list]
List the contents of a tarball archive.
The `fileList` is an array of paths to list from the tarball. If
no paths are provided, then all the entries are listed.
If the archive is gzipped, then tar will detect this and unzip it.
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects. However, they don't emit `'data'` or `'end'`
events. (If you want to get actual readable entries, use the
`tar.Parse` class instead.)
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. [Alias: `C`]
- `file` The archive file to list. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Read the specified file synchronously. (This has no effect
when a file option isn't specified, because entries are emitted as
fast as they are parsed from the stream anyway.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter. This is important for when both `file` and
`sync` are set, because it will be called synchronously.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noResume` By default, `entry` streams are resumed immediately after
the call to `onentry`. Set `noResume: true` to suppress this
behavior. Note that by opting into this, the stream will never
complete until the entry data is consumed.
### tar.u(options, fileList, callback) [alias: tar.update]
Add files to an archive if they are newer than the entry already in
the tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
### tar.r(options, fileList, callback) [alias: tar.replace]
Add files to an existing archive. Because later entries override
earlier entries, this effectively replaces any existing entries.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
## Low-Level API
### class tar.Pack
A readable tar stream.
Has all the standard readable stream interface stuff. `'data'` and
`'end'` events, `read()` method, `pause()` and `resume()`, etc.
#### constructor(options)
The following options are supported:
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()`
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories.
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
#### add(path)
Adds an entry to the archive. Returns the Pack stream.
#### write(path)
Adds an entry to the archive. Returns true if flushed.
#### end()
Finishes the archive.
### class tar.Pack.Sync
Synchronous version of `tar.Pack`.
### class tar.Unpack
A writable stream that unpacks a tar archive onto the file system.
All the normal writable stream stuff is supported. `write()` and
`end()` methods, `'drain'` events, etc.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
`'close'` is emitted when it's done writing stuff to the file system.
Most unpack errors will cause a `warn` event to be emitted. If the
`cwd` is missing, or not a directory, then an error will be emitted.
#### constructor(options)
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive.
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies.
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file.
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
- `win32` True if on a windows platform. Causes behavior where
filenames containing `<|>?` chars are converted to
windows-compatible values while being unpacked.
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries.
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
### class tar.Unpack.Sync
Synchronous version of `tar.Unpack`.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync unpack streams.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### class tar.Parse
A writable stream that parses a tar archive stream. All the standard
writable stream stuff is supported.
If the archive is gzipped, then tar will detect this and unzip it.
Emits `'entry'` events with `tar.ReadEntry` objects, which are
themselves readable streams that you can pipe wherever.
Each `entry` will not emit until the one before it is flushed through,
so make sure to either consume the data (with `on('data', ...)` or
`.pipe(...)`) or throw it away with `.resume()` to keep the stream
flowing.
#### constructor(options)
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects.
The following options are supported:
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
#### abort(error)
Stop all parsing activities. This is called when there are zlib
errors. It also emits an unrecoverable warning with the error provided.
### class tar.ReadEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being read out of a tar archive.
It has the following fields:
- `extended` The extended metadata object provided to the constructor.
- `globalExtended` The global extended metadata object provided to the
constructor.
- `remain` The number of bytes remaining to be written into the
stream.
- `blockRemain` The number of 512-byte blocks remaining to be written
into the stream.
- `ignore` Whether this entry should be ignored.
- `meta` True if this represents metadata about the next entry, false
if it represents a filesystem object.
- All the fields from the header, extended header, and global extended
header are added to the ReadEntry object. So it has `path`, `type`,
`size, `mode`, and so on.
#### constructor(header, extended, globalExtended)
Create a new ReadEntry object with the specified header, extended
header, and global extended header values.
### class tar.WriteEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being written from the file
system into a tar archive.
Emits data for the Header, and for the Pax Extended Header if one is
required, as well as any body data.
Creating a WriteEntry for a directory does not also create
WriteEntry objects for all of the directory contents.
It has the following fields:
- `path` The path field that will be written to the archive. By
default, this is also the path from the cwd to the file system
object.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `myuid` If supported, the uid of the user running the current
process.
- `myuser` The `env.USER` string if set, or `''`. Set as the entry
`uname` field if the file's `uid` matches `this.myuid`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/` and filenames containing the windows-compatible
forms of `<|>?:` characters are converted to actual `<|>?:` characters
in the archive.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
#### constructor(path, options)
`path` is the path of the entry as it is written in the archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `umask` Set to restrict the modes on the entries in the archive,
somewhat like how umask works on file creation. Defaults to
`process.umask()` on unix systems, or `0o22` on Windows.
#### warn(message, data)
If strict, emit an error with the provided message.
Othewise, emit a `'warn'` event with the provided message and data.
### class tar.WriteEntry.Sync
Synchronous version of tar.WriteEntry
### class tar.WriteEntry.Tar
A version of tar.WriteEntry that gets its data from a tar.ReadEntry
instead of from the filesystem.
#### constructor(readEntry, options)
`readEntry` is the entry being read out of another archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
### class tar.Header
A class for reading and writing header blocks.
It has the following fields:
- `nullBlock` True if decoding a block which is entirely composed of
`0x00` null bytes. (Useful because tar files are terminated by
at least 2 null blocks.)
- `cksumValid` True if the checksum in the header is valid, false
otherwise.
- `needPax` True if the values, as encoded, will require a Pax
extended header.
- `path` The path of the entry.
- `mode` The 4 lowest-order octal digits of the file mode. That is,
read/write/execute permissions for world, group, and owner, and the
setuid, setgid, and sticky bits.
- `uid` Numeric user id of the file owner
- `gid` Numeric group id of the file owner
- `size` Size of the file in bytes
- `mtime` Modified time of the file
- `cksum` The checksum of the header. This is generated by adding all
the bytes of the header block, treating the checksum field itself as
all ascii space characters (that is, `0x20`).
- `type` The human-readable name of the type of entry this represents,
or the alphanumeric key if unknown.
- `typeKey` The alphanumeric key for the type of entry this header
represents.
- `linkpath` The target of Link and SymbolicLink entries.
- `uname` Human-readable user name of the file owner
- `gname` Human-readable group name of the file owner
- `devmaj` The major portion of the device number. Always `0` for
files, directories, and links.
- `devmin` The minor portion of the device number. Always `0` for
files, directories, and links.
- `atime` File access time.
- `ctime` File change time.
#### constructor(data, [offset=0])
`data` is optional. It is either a Buffer that should be interpreted
as a tar Header starting at the specified offset and continuing for
512 bytes, or a data object of keys and values to set on the header
object, and eventually encode as a tar Header.
#### decode(block, offset)
Decode the provided buffer starting at the specified offset.
Buffer length must be greater than 512 bytes.
#### set(data)
Set the fields in the data object.
#### encode(buffer, offset)
Encode the header fields into the buffer at the specified offset.
Returns `this.needPax` to indicate whether a Pax Extended Header is
required to properly encode the specified data.
### class tar.Pax
An object representing a set of key-value pairs in an Pax extended
header entry.
It has the following fields. Where the same name is used, they have
the same semantics as the tar.Header field of the same name.
- `global` True if this represents a global extended header, or false
if it is for a single entry.
- `atime`
- `charset`
- `comment`
- `ctime`
- `gid`
- `gname`
- `linkpath`
- `mtime`
- `path`
- `size`
- `uid`
- `uname`
- `dev`
- `ino`
- `nlink`
#### constructor(object, global)
Set the fields set in the object. `global` is a boolean that defaults
to false.
#### encode()
Return a Buffer containing the header and body for the Pax extended
header entry, or `null` if there is nothing to encode.
#### encodeBody()
Return a string representing the body of the pax extended header
entry.
#### encodeField(fieldName)
Return a string representing the key/value encoding for the specified
fieldName, or `''` if the field is unset.
### tar.Pax.parse(string, extended, global)
Return a new Pax object created by parsing the contents of the string
provided.
If the `extended` object is set, then also add the fields from that
object. (This is necessary because multiple metadata entries can
occur in sequence.)
### tar.types
A translation table for the `type` field in tar headers.
#### tar.types.name.get(code)
Get the human-readable name for a given alphanumeric code.
#### tar.types.code.get(name)
Get the alphanumeric code for a given human-readable name.
# AssemblyScript Rtrace
A tiny utility to sanitize the AssemblyScript runtime. Records allocations and frees performed by the runtime and emits an error if something is off. Also checks for leaks.
Instructions
------------
Compile your module that uses the full or half runtime with `-use ASC_RTRACE=1 --explicitStart` and include an instance of this module as the import named `rtrace`.
```js
const rtrace = new Rtrace({
onerror(err, info) {
// handle error
},
oninfo(msg) {
// print message, optional
},
getMemory() {
// obtain the module's memory,
// e.g. with --explicitStart:
return instance.exports.memory;
}
});
const { module, instance } = await WebAssembly.instantiate(...,
rtrace.install({
...imports...
})
);
instance.exports._start();
...
if (rtrace.active) {
let leakCount = rtr.check();
if (leakCount) {
// handle error
}
}
```
Note that references in globals which are not cleared before collection is performed appear as leaks, including their inner members. A TypedArray would leak itself and its backing ArrayBuffer in this case for example. This is perfectly normal and clearing all globals avoids this.
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
* `n` - the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
* `rn` - both argument and return value of the function are plain JavaScript
Numbers. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
* `BN.max(a, b)` - return `a` if `a` bigger than `b`
* `BN.min(a, b)` - return `a` if `a` less than `b`
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divmod(b)` - quotient and modulus obtained by dividing
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b, value)` - set specified bit to `value`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
### Number Size
Optimized for elliptic curves that work with 256-bit numbers.
There is no limitation on the size of the numbers.
## LICENSE
This software is licensed under the MIT License.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# [nearley](http://nearley.js.org) ↗️
[](http://js.org)
[](https://badge.fury.io/js/nearley)
nearley is a simple, fast and powerful parsing toolkit. It consists of:
1. [A powerful, modular DSL for describing
languages](https://nearley.js.org/docs/grammar)
2. [An efficient, lightweight Earley
parser](https://nearley.js.org/docs/parser)
3. [Loads of tools, editor plug-ins, and other
goodies!](https://nearley.js.org/docs/tooling)
nearley is a **streaming** parser with support for catching **errors**
gracefully and providing _all_ parsings for **ambiguous** grammars. It is
compatible with a variety of **lexers** (we recommend
[moo](http://github.com/tjvr/moo)). It comes with tools for creating **tests**,
**railroad diagrams** and **fuzzers** from your grammars, and has support for a
variety of editors and platforms. It works in both node and the browser.
Unlike most other parser generators, nearley can handle *any* grammar you can
define in BNF (and more!). In particular, while most existing JS parsers such
as PEGjs and Jison choke on certain grammars (e.g. [left recursive
ones](http://en.wikipedia.org/wiki/Left_recursion)), nearley handles them
easily and efficiently by using the [Earley parsing
algorithm](https://en.wikipedia.org/wiki/Earley_parser).
nearley is used by a wide variety of projects:
- [artificial
intelligence](https://github.com/ChalmersGU-AI-course/shrdlite-course-project)
and
- [computational
linguistics](https://wiki.eecs.yorku.ca/course_archive/2014-15/W/6339/useful_handouts)
classes at universities;
- [file format parsers](https://github.com/raymond-h/node-dmi);
- [data-driven markup languages](https://github.com/idyll-lang/idyll-compiler);
- [compilers for real-world programming
languages](https://github.com/sizigi/lp5562);
- and nearley itself! The nearley compiler is bootstrapped.
nearley is an npm [staff
pick](https://www.npmjs.com/package/npm-collection-staff-picks).
## Documentation
Please visit our website https://nearley.js.org to get started! You will find a
tutorial, detailed reference documents, and links to several real-world
examples to get inspired.
## Contributing
Please read [this document](.github/CONTRIBUTING.md) *before* working on
nearley. If you are interested in contributing but unsure where to start, take
a look at the issues labeled "up for grabs" on the issue tracker, or message a
maintainer (@kach or @tjvr on Github).
nearley is MIT licensed.
A big thanks to Nathan Dinsmore for teaching me how to Earley, Aria Stewart for
helping structure nearley into a mature module, and Robin Windels for
bootstrapping the grammar. Additionally, Jacob Edelman wrote an experimental
JavaScript parser with nearley and contributed ideas for EBNF support. Joshua
T. Corbin refactored the compiler to be much, much prettier. Bojidar Marinov
implemented postprocessors-in-other-languages. Shachar Itzhaky fixed a subtle
bug with nullables.
## Citing nearley
If you are citing nearley in academic work, please use the following BibTeX
entry.
```bibtex
@misc{nearley,
author = "Kartik Chandra and Tim Radvan",
title = "{nearley}: a parsing toolkit for {JavaScript}",
year = {2014},
doi = {10.5281/zenodo.3897993},
url = {https://github.com/kach/nearley}
}
```
# assemblyscript-regex
A regex engine for AssemblyScript.
[AssemblyScript](https://www.assemblyscript.org/) is a new language, based on TypeScript, that runs on WebAssembly. AssemblyScript has a lightweight standard library, but lacks support for Regular Expression. The project fills that gap!
This project exposes an API that mirrors the JavaScript [RegExp](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp) class:
```javascript
const regex = new RegExp("fo*", "g");
const str = "table football, foul";
let match: Match | null = regex.exec(str);
while (match != null) {
// first iteration
// match.index = 6
// match.matches[0] = "foo"
// second iteration
// match.index = 16
// match.matches[0] = "fo"
match = regex.exec(str);
}
```
## Project status
The initial focus of this implementation has been feature support and functionality over performance. It currently supports a sufficient number of regex features to be considered useful, including most character classes, common assertions, groups, alternations, capturing groups and quantifiers.
The next phase of development will focussed on more extensive testing and performance. The project currently has reasonable unit test coverage, focussed on positive and negative test cases on a per-feature basis. It also includes a more exhaustive test suite with test cases borrowed from another regex library.
### Feature support
Based on the classfication within the [MDN cheatsheet](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions/Cheatsheet)
**Character sets**
- [x] .
- [x] \d
- [x] \D
- [x] \w
- [x] \W
- [x] \s
- [x] \S
- [x] \t
- [x] \r
- [x] \n
- [x] \v
- [x] \f
- [ ] [\b]
- [ ] \0
- [ ] \cX
- [x] \xhh
- [x] \uhhhh
- [ ] \u{hhhh} or \u{hhhhh}
- [x] \
**Assertions**
- [x] ^
- [x] $
- [ ] \b
- [ ] \B
**Other assertions**
- [ ] x(?=y) Lookahead assertion
- [ ] x(?!y) Negative lookahead assertion
- [ ] (?<=y)x Lookbehind assertion
- [ ] (?<!y)x Negative lookbehind assertion
**Groups and ranges**
- [x] x|y
- [x] [xyz][a-c]
- [x] [^xyz][^a-c]
- [x] (x) capturing group
- [ ] \n back reference
- [ ] (?<Name>x) named capturing group
- [x] (?:x) Non-capturing group
**Quantifiers**
- [x] x\*
- [x] x+
- [x] x?
- [x] x{n}
- [x] x{n,}
- [x] x{n,m}
- [ ] x\*? / x+? / ...
**RegExp**
- [x] global
- [ ] sticky
- [x] case insensitive
- [x] multiline
- [x] dotAll
- [ ] unicode
### Development
This project is open source, MIT licenced and your contributions are very much welcomed.
To get started, check out the repository and install dependencies:
```
$ npm install
```
A few general points about the tools and processes this project uses:
- This project uses prettier for code formatting and eslint to provide additional syntactic checks. These are both run on `npm test` and as part of the CI build.
- The unit tests are executed using [as-pect](https://github.com/jtenner/as-pect) - a native AssemblyScript test runner
- The specification tests are within the `spec` folder. The `npm run test:generate` target transforms these tests into as-pect tests which execute as part of the standard build / test cycle
- In order to support improved debugging you can execute this library as TypeScript (rather than WebAssembly), via the `npm run tsrun` target.
# Glob
Match files using the patterns the shell uses, like stars and stuff.
[](https://travis-ci.org/isaacs/node-glob/) [](https://ci.appveyor.com/project/isaacs/node-glob) [](https://coveralls.io/github/isaacs/node-glob?branch=master)
This is a glob implementation in JavaScript. It uses the `minimatch`
library to do its matching.

## Usage
Install with npm
```
npm i glob
```
```javascript
var glob = require("glob")
// options is optional
glob("**/*.js", options, function (er, files) {
// files is an array of filenames.
// If the `nonull` option is set, and nothing
// was found, then files is ["**/*.js"]
// er is an error object or null.
})
```
## Glob Primer
"Globs" are the patterns you type when you do stuff like `ls *.js` on
the command line, or put `build/*` in a `.gitignore` file.
Before parsing the path part patterns, braced sections are expanded
into a set. Braced sections start with `{` and end with `}`, with any
number of comma-delimited sections within. Braced sections may contain
slash characters, so `a{/b/c,bcd}` would expand into `a/b/c` and `abcd`.
The following characters have special magic meaning when used in a
path portion:
* `*` Matches 0 or more characters in a single path portion
* `?` Matches 1 character
* `[...]` Matches a range of characters, similar to a RegExp range.
If the first character of the range is `!` or `^` then it matches
any character not in the range.
* `!(pattern|pattern|pattern)` Matches anything that does not match
any of the patterns provided.
* `?(pattern|pattern|pattern)` Matches zero or one occurrence of the
patterns provided.
* `+(pattern|pattern|pattern)` Matches one or more occurrences of the
patterns provided.
* `*(a|b|c)` Matches zero or more occurrences of the patterns provided
* `@(pattern|pat*|pat?erN)` Matches exactly one of the patterns
provided
* `**` If a "globstar" is alone in a path portion, then it matches
zero or more directories and subdirectories searching for matches.
It does not crawl symlinked directories.
### Dots
If a file or directory path portion has a `.` as the first character,
then it will not match any glob pattern unless that pattern's
corresponding path part also has a `.` as its first character.
For example, the pattern `a/.*/c` would match the file at `a/.b/c`.
However the pattern `a/*/c` would not, because `*` does not start with
a dot character.
You can make glob treat dots as normal characters by setting
`dot:true` in the options.
### Basename Matching
If you set `matchBase:true` in the options, and the pattern has no
slashes in it, then it will seek for any file anywhere in the tree
with a matching basename. For example, `*.js` would match
`test/simple/basic.js`.
### Empty Sets
If no matching files are found, then an empty array is returned. This
differs from the shell, where the pattern itself is returned. For
example:
$ echo a*s*d*f
a*s*d*f
To get the bash-style behavior, set the `nonull:true` in the options.
### See Also:
* `man sh`
* `man bash` (Search for "Pattern Matching")
* `man 3 fnmatch`
* `man 5 gitignore`
* [minimatch documentation](https://github.com/isaacs/minimatch)
## glob.hasMagic(pattern, [options])
Returns `true` if there are any special characters in the pattern, and
`false` otherwise.
Note that the options affect the results. If `noext:true` is set in
the options object, then `+(a|b)` will not be considered a magic
pattern. If the pattern has a brace expansion, like `a/{b/c,x/y}`
then that is considered magical, unless `nobrace:true` is set in the
options.
## glob(pattern, [options], cb)
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* `cb` `{Function}`
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Perform an asynchronous glob search.
## glob.sync(pattern, [options])
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* return: `{Array<String>}` filenames found matching the pattern
Perform a synchronous glob search.
## Class: glob.Glob
Create a Glob object by instantiating the `glob.Glob` class.
```javascript
var Glob = require("glob").Glob
var mg = new Glob(pattern, options, cb)
```
It's an EventEmitter, and starts walking the filesystem to find matches
immediately.
### new glob.Glob(pattern, [options], [cb])
* `pattern` `{String}` pattern to search for
* `options` `{Object}`
* `cb` `{Function}` Called when an error occurs, or matches are found
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Note that if the `sync` flag is set in the options, then matches will
be immediately available on the `g.found` member.
### Properties
* `minimatch` The minimatch object that the glob uses.
* `options` The options object passed in.
* `aborted` Boolean which is set to true when calling `abort()`. There
is no way at this time to continue a glob search after aborting, but
you can re-use the statCache to avoid having to duplicate syscalls.
* `cache` Convenience object. Each field has the following possible
values:
* `false` - Path does not exist
* `true` - Path exists
* `'FILE'` - Path exists, and is not a directory
* `'DIR'` - Path exists, and is a directory
* `[file, entries, ...]` - Path exists, is a directory, and the
array value is the results of `fs.readdir`
* `statCache` Cache of `fs.stat` results, to prevent statting the same
path multiple times.
* `symlinks` A record of which paths are symbolic links, which is
relevant in resolving `**` patterns.
* `realpathCache` An optional object which is passed to `fs.realpath`
to minimize unnecessary syscalls. It is stored on the instantiated
Glob object, and may be re-used.
### Events
* `end` When the matching is finished, this is emitted with all the
matches found. If the `nonull` option is set, and no match was found,
then the `matches` list contains the original pattern. The matches
are sorted, unless the `nosort` flag is set.
* `match` Every time a match is found, this is emitted with the specific
thing that matched. It is not deduplicated or resolved to a realpath.
* `error` Emitted when an unexpected error is encountered, or whenever
any fs error occurs if `options.strict` is set.
* `abort` When `abort()` is called, this event is raised.
### Methods
* `pause` Temporarily stop the search
* `resume` Resume the search
* `abort` Stop the search forever
### Options
All the options that can be passed to Minimatch can also be passed to
Glob to change pattern matching behavior. Also, some have been added,
or have glob-specific ramifications.
All options are false by default, unless otherwise noted.
All options are added to the Glob object, as well.
If you are running many `glob` operations, you can pass a Glob object
as the `options` argument to a subsequent operation to shortcut some
`stat` and `readdir` calls. At the very least, you may pass in shared
`symlinks`, `statCache`, `realpathCache`, and `cache` options, so that
parallel glob operations will be sped up by sharing information about
the filesystem.
* `cwd` The current working directory in which to search. Defaults
to `process.cwd()`.
* `root` The place where patterns starting with `/` will be mounted
onto. Defaults to `path.resolve(options.cwd, "/")` (`/` on Unix
systems, and `C:\` or some such on Windows.)
* `dot` Include `.dot` files in normal matches and `globstar` matches.
Note that an explicit dot in a portion of the pattern will always
match dot files.
* `nomount` By default, a pattern starting with a forward-slash will be
"mounted" onto the root setting, so that a valid filesystem path is
returned. Set this flag to disable that behavior.
* `mark` Add a `/` character to directory matches. Note that this
requires additional stat calls.
* `nosort` Don't sort the results.
* `stat` Set to true to stat *all* results. This reduces performance
somewhat, and is completely unnecessary, unless `readdir` is presumed
to be an untrustworthy indicator of file existence.
* `silent` When an unusual error is encountered when attempting to
read a directory, a warning will be printed to stderr. Set the
`silent` option to true to suppress these warnings.
* `strict` When an unusual error is encountered when attempting to
read a directory, the process will just continue on in search of
other matches. Set the `strict` option to raise an error in these
cases.
* `cache` See `cache` property above. Pass in a previously generated
cache object to save some fs calls.
* `statCache` A cache of results of filesystem information, to prevent
unnecessary stat calls. While it should not normally be necessary
to set this, you may pass the statCache from one glob() call to the
options object of another, if you know that the filesystem will not
change between calls. (See "Race Conditions" below.)
* `symlinks` A cache of known symbolic links. You may pass in a
previously generated `symlinks` object to save `lstat` calls when
resolving `**` matches.
* `sync` DEPRECATED: use `glob.sync(pattern, opts)` instead.
* `nounique` In some cases, brace-expanded patterns can result in the
same file showing up multiple times in the result set. By default,
this implementation prevents duplicates in the result set. Set this
flag to disable that behavior.
* `nonull` Set to never return an empty set, instead returning a set
containing the pattern itself. This is the default in glob(3).
* `debug` Set to enable debug logging in minimatch and glob.
* `nobrace` Do not expand `{a,b}` and `{1..3}` brace sets.
* `noglobstar` Do not match `**` against multiple filenames. (Ie,
treat it as a normal `*` instead.)
* `noext` Do not match `+(a|b)` "extglob" patterns.
* `nocase` Perform a case-insensitive match. Note: on
case-insensitive filesystems, non-magic patterns will match by
default, since `stat` and `readdir` will not raise errors.
* `matchBase` Perform a basename-only match if the pattern does not
contain any slash characters. That is, `*.js` would be treated as
equivalent to `**/*.js`, matching all js files in all directories.
* `nodir` Do not match directories, only files. (Note: to match
*only* directories, simply put a `/` at the end of the pattern.)
* `ignore` Add a pattern or an array of glob patterns to exclude matches.
Note: `ignore` patterns are *always* in `dot:true` mode, regardless
of any other settings.
* `follow` Follow symlinked directories when expanding `**` patterns.
Note that this can result in a lot of duplicate references in the
presence of cyclic links.
* `realpath` Set to true to call `fs.realpath` on all of the results.
In the case of a symlink that cannot be resolved, the full absolute
path to the matched entry is returned (though it will usually be a
broken symlink)
* `absolute` Set to true to always receive absolute paths for matched
files. Unlike `realpath`, this also affects the values returned in
the `match` event.
* `fs` File-system object with Node's `fs` API. By default, the built-in
`fs` module will be used. Set to a volume provided by a library like
`memfs` to avoid using the "real" file-system.
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between node-glob and other
implementations, and are intentional.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.3, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
Note that symlinked directories are not crawled as part of a `**`,
though their contents may match against subsequent portions of the
pattern. This prevents infinite loops and duplicates and the like.
If an escaped pattern has no matches, and the `nonull` flag is set,
then glob returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`glob.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
### Comments and Negation
Previously, this module let you mark a pattern as a "comment" if it
started with a `#` character, or a "negated" pattern if it started
with a `!` character.
These options were deprecated in version 5, and removed in version 6.
To specify things that should not match, use the `ignore` option.
## Windows
**Please only use forward-slashes in glob expressions.**
Though windows uses either `/` or `\` as its path separator, only `/`
characters are used by this glob implementation. You must use
forward-slashes **only** in glob expressions. Back-slashes will always
be interpreted as escape characters, not path separators.
Results from absolute patterns such as `/foo/*` are mounted onto the
root setting using `path.join`. On windows, this will by default result
in `/foo/*` matching `C:\foo\bar.txt`.
## Race Conditions
Glob searching, by its very nature, is susceptible to race conditions,
since it relies on directory walking and such.
As a result, it is possible that a file that exists when glob looks for
it may have been deleted or modified by the time it returns the result.
As part of its internal implementation, this program caches all stat
and readdir calls that it makes, in order to cut down on system
overhead. However, this also makes it even more susceptible to races,
especially if the cache or statCache objects are reused between glob
calls.
Users are thus advised not to use a glob result as a guarantee of
filesystem state in the face of rapid changes. For the vast majority
of operations, this is never a problem.
## Glob Logo
Glob's logo was created by [Tanya Brassie](http://tanyabrassie.com/). Logo files can be found [here](https://github.com/isaacs/node-glob/tree/master/logo).
The logo is licensed under a [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/).
## Contributing
Any change to behavior (including bugfixes) must come with a test.
Patches that fail tests or reduce performance will be rejected.
```
# to run tests
npm test
# to re-generate test fixtures
npm run test-regen
# to benchmark against bash/zsh
npm run bench
# to profile javascript
npm run prof
```

# minipass
A _very_ minimal implementation of a [PassThrough
stream](https://nodejs.org/api/stream.html#stream_class_stream_passthrough)
[It's very
fast](https://docs.google.com/spreadsheets/d/1oObKSrVwLX_7Ut4Z6g3fZW-AX1j1-k6w-cDsrkaSbHM/edit#gid=0)
for objects, strings, and buffers.
Supports `pipe()`ing (including multi-`pipe()` and backpressure transmission),
buffering data until either a `data` event handler or `pipe()` is added (so
you don't lose the first chunk), and most other cases where PassThrough is
a good idea.
There is a `read()` method, but it's much more efficient to consume data
from this stream via `'data'` events or by calling `pipe()` into some other
stream. Calling `read()` requires the buffer to be flattened in some
cases, which requires copying memory.
There is also no `unpipe()` method. Once you start piping, there is no
stopping it!
If you set `objectMode: true` in the options, then whatever is written will
be emitted. Otherwise, it'll do a minimal amount of Buffer copying to
ensure proper Streams semantics when `read(n)` is called.
`objectMode` can also be set by doing `stream.objectMode = true`, or by
writing any non-string/non-buffer data. `objectMode` cannot be set to
false once it is set.
This is not a `through` or `through2` stream. It doesn't transform the
data, it just passes it right through. If you want to transform the data,
extend the class, and override the `write()` method. Once you're done
transforming the data however you want, call `super.write()` with the
transform output.
For some examples of streams that extend Minipass in various ways, check
out:
- [minizlib](http://npm.im/minizlib)
- [fs-minipass](http://npm.im/fs-minipass)
- [tar](http://npm.im/tar)
- [minipass-collect](http://npm.im/minipass-collect)
- [minipass-flush](http://npm.im/minipass-flush)
- [minipass-pipeline](http://npm.im/minipass-pipeline)
- [tap](http://npm.im/tap)
- [tap-parser](http://npm.im/tap-parser)
- [treport](http://npm.im/treport)
- [minipass-fetch](http://npm.im/minipass-fetch)
- [pacote](http://npm.im/pacote)
- [make-fetch-happen](http://npm.im/make-fetch-happen)
- [cacache](http://npm.im/cacache)
- [ssri](http://npm.im/ssri)
- [npm-registry-fetch](http://npm.im/npm-registry-fetch)
- [minipass-json-stream](http://npm.im/minipass-json-stream)
- [minipass-sized](http://npm.im/minipass-sized)
## Differences from Node.js Streams
There are several things that make Minipass streams different from (and in
some ways superior to) Node.js core streams.
Please read these caveats if you are familiar with node-core streams and
intend to use Minipass streams in your programs.
### Timing
Minipass streams are designed to support synchronous use-cases. Thus, data
is emitted as soon as it is available, always. It is buffered until read,
but no longer. Another way to look at it is that Minipass streams are
exactly as synchronous as the logic that writes into them.
This can be surprising if your code relies on `PassThrough.write()` always
providing data on the next tick rather than the current one, or being able
to call `resume()` and not have the entire buffer disappear immediately.
However, without this synchronicity guarantee, there would be no way for
Minipass to achieve the speeds it does, or support the synchronous use
cases that it does. Simply put, waiting takes time.
This non-deferring approach makes Minipass streams much easier to reason
about, especially in the context of Promises and other flow-control
mechanisms.
### No High/Low Water Marks
Node.js core streams will optimistically fill up a buffer, returning `true`
on all writes until the limit is hit, even if the data has nowhere to go.
Then, they will not attempt to draw more data in until the buffer size dips
below a minimum value.
Minipass streams are much simpler. The `write()` method will return `true`
if the data has somewhere to go (which is to say, given the timing
guarantees, that the data is already there by the time `write()` returns).
If the data has nowhere to go, then `write()` returns false, and the data
sits in a buffer, to be drained out immediately as soon as anyone consumes
it.
### Hazards of Buffering (or: Why Minipass Is So Fast)
Since data written to a Minipass stream is immediately written all the way
through the pipeline, and `write()` always returns true/false based on
whether the data was fully flushed, backpressure is communicated
immediately to the upstream caller. This minimizes buffering.
Consider this case:
```js
const {PassThrough} = require('stream')
const p1 = new PassThrough({ highWaterMark: 1024 })
const p2 = new PassThrough({ highWaterMark: 1024 })
const p3 = new PassThrough({ highWaterMark: 1024 })
const p4 = new PassThrough({ highWaterMark: 1024 })
p1.pipe(p2).pipe(p3).pipe(p4)
p4.on('data', () => console.log('made it through'))
// this returns false and buffers, then writes to p2 on next tick (1)
// p2 returns false and buffers, pausing p1, then writes to p3 on next tick (2)
// p3 returns false and buffers, pausing p2, then writes to p4 on next tick (3)
// p4 returns false and buffers, pausing p3, then emits 'data' and 'drain'
// on next tick (4)
// p3 sees p4's 'drain' event, and calls resume(), emitting 'resume' and
// 'drain' on next tick (5)
// p2 sees p3's 'drain', calls resume(), emits 'resume' and 'drain' on next tick (6)
// p1 sees p2's 'drain', calls resume(), emits 'resume' and 'drain' on next
// tick (7)
p1.write(Buffer.alloc(2048)) // returns false
```
Along the way, the data was buffered and deferred at each stage, and
multiple event deferrals happened, for an unblocked pipeline where it was
perfectly safe to write all the way through!
Furthermore, setting a `highWaterMark` of `1024` might lead someone reading
the code to think an advisory maximum of 1KiB is being set for the
pipeline. However, the actual advisory buffering level is the _sum_ of
`highWaterMark` values, since each one has its own bucket.
Consider the Minipass case:
```js
const m1 = new Minipass()
const m2 = new Minipass()
const m3 = new Minipass()
const m4 = new Minipass()
m1.pipe(m2).pipe(m3).pipe(m4)
m4.on('data', () => console.log('made it through'))
// m1 is flowing, so it writes the data to m2 immediately
// m2 is flowing, so it writes the data to m3 immediately
// m3 is flowing, so it writes the data to m4 immediately
// m4 is flowing, so it fires the 'data' event immediately, returns true
// m4's write returned true, so m3 is still flowing, returns true
// m3's write returned true, so m2 is still flowing, returns true
// m2's write returned true, so m1 is still flowing, returns true
// No event deferrals or buffering along the way!
m1.write(Buffer.alloc(2048)) // returns true
```
It is extremely unlikely that you _don't_ want to buffer any data written,
or _ever_ buffer data that can be flushed all the way through. Neither
node-core streams nor Minipass ever fail to buffer written data, but
node-core streams do a lot of unnecessary buffering and pausing.
As always, the faster implementation is the one that does less stuff and
waits less time to do it.
### Immediately emit `end` for empty streams (when not paused)
If a stream is not paused, and `end()` is called before writing any data
into it, then it will emit `end` immediately.
If you have logic that occurs on the `end` event which you don't want to
potentially happen immediately (for example, closing file descriptors,
moving on to the next entry in an archive parse stream, etc.) then be sure
to call `stream.pause()` on creation, and then `stream.resume()` once you
are ready to respond to the `end` event.
### Emit `end` When Asked
One hazard of immediately emitting `'end'` is that you may not yet have had
a chance to add a listener. In order to avoid this hazard, Minipass
streams safely re-emit the `'end'` event if a new listener is added after
`'end'` has been emitted.
Ie, if you do `stream.on('end', someFunction)`, and the stream has already
emitted `end`, then it will call the handler right away. (You can think of
this somewhat like attaching a new `.then(fn)` to a previously-resolved
Promise.)
To prevent calling handlers multiple times who would not expect multiple
ends to occur, all listeners are removed from the `'end'` event whenever it
is emitted.
### Impact of "immediate flow" on Tee-streams
A "tee stream" is a stream piping to multiple destinations:
```js
const tee = new Minipass()
t.pipe(dest1)
t.pipe(dest2)
t.write('foo') // goes to both destinations
```
Since Minipass streams _immediately_ process any pending data through the
pipeline when a new pipe destination is added, this can have surprising
effects, especially when a stream comes in from some other function and may
or may not have data in its buffer.
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.pipe(dest1) // 'foo' chunk flows to dest1 immediately, and is gone
src.pipe(dest2) // gets nothing!
```
The solution is to create a dedicated tee-stream junction that pipes to
both locations, and then pipe to _that_ instead.
```js
// Safe example: tee to both places
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.pipe(dest1)
tee.pipe(dest2)
src.pipe(tee) // tee gets 'foo', pipes to both locations
```
The same caveat applies to `on('data')` event listeners. The first one
added will _immediately_ receive all of the data, leaving nothing for the
second:
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.on('data', handler1) // receives 'foo' right away
src.on('data', handler2) // nothing to see here!
```
Using a dedicated tee-stream can be used in this case as well:
```js
// Safe example: tee to both data handlers
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.on('data', handler1)
tee.on('data', handler2)
src.pipe(tee)
```
## USAGE
It's a stream! Use it like a stream and it'll most likely do what you
want.
```js
const Minipass = require('minipass')
const mp = new Minipass(options) // optional: { encoding, objectMode }
mp.write('foo')
mp.pipe(someOtherStream)
mp.end('bar')
```
### OPTIONS
* `encoding` How would you like the data coming _out_ of the stream to be
encoded? Accepts any values that can be passed to `Buffer.toString()`.
* `objectMode` Emit data exactly as it comes in. This will be flipped on
by default if you write() something other than a string or Buffer at any
point. Setting `objectMode: true` will prevent setting any encoding
value.
### API
Implements the user-facing portions of Node.js's `Readable` and `Writable`
streams.
### Methods
* `write(chunk, [encoding], [callback])` - Put data in. (Note that, in the
base Minipass class, the same data will come out.) Returns `false` if
the stream will buffer the next write, or true if it's still in "flowing"
mode.
* `end([chunk, [encoding]], [callback])` - Signal that you have no more
data to write. This will queue an `end` event to be fired when all the
data has been consumed.
* `setEncoding(encoding)` - Set the encoding for data coming of the stream.
This can only be done once.
* `pause()` - No more data for a while, please. This also prevents `end`
from being emitted for empty streams until the stream is resumed.
* `resume()` - Resume the stream. If there's data in the buffer, it is all
discarded. Any buffered events are immediately emitted.
* `pipe(dest)` - Send all output to the stream provided. There is no way
to unpipe. When data is emitted, it is immediately written to any and
all pipe destinations.
* `on(ev, fn)`, `emit(ev, fn)` - Minipass streams are EventEmitters. Some
events are given special treatment, however. (See below under "events".)
* `promise()` - Returns a Promise that resolves when the stream emits
`end`, or rejects if the stream emits `error`.
* `collect()` - Return a Promise that resolves on `end` with an array
containing each chunk of data that was emitted, or rejects if the stream
emits `error`. Note that this consumes the stream data.
* `concat()` - Same as `collect()`, but concatenates the data into a single
Buffer object. Will reject the returned promise if the stream is in
objectMode, or if it goes into objectMode by the end of the data.
* `read(n)` - Consume `n` bytes of data out of the buffer. If `n` is not
provided, then consume all of it. If `n` bytes are not available, then
it returns null. **Note** consuming streams in this way is less
efficient, and can lead to unnecessary Buffer copying.
* `destroy([er])` - Destroy the stream. If an error is provided, then an
`'error'` event is emitted. If the stream has a `close()` method, and
has not emitted a `'close'` event yet, then `stream.close()` will be
called. Any Promises returned by `.promise()`, `.collect()` or
`.concat()` will be rejected. After being destroyed, writing to the
stream will emit an error. No more data will be emitted if the stream is
destroyed, even if it was previously buffered.
### Properties
* `bufferLength` Read-only. Total number of bytes buffered, or in the case
of objectMode, the total number of objects.
* `encoding` The encoding that has been set. (Setting this is equivalent
to calling `setEncoding(enc)` and has the same prohibition against
setting multiple times.)
* `flowing` Read-only. Boolean indicating whether a chunk written to the
stream will be immediately emitted.
* `emittedEnd` Read-only. Boolean indicating whether the end-ish events
(ie, `end`, `prefinish`, `finish`) have been emitted. Note that
listening on any end-ish event will immediateyl re-emit it if it has
already been emitted.
* `writable` Whether the stream is writable. Default `true`. Set to
`false` when `end()`
* `readable` Whether the stream is readable. Default `true`.
* `buffer` A [yallist](http://npm.im/yallist) linked list of chunks written
to the stream that have not yet been emitted. (It's probably a bad idea
to mess with this.)
* `pipes` A [yallist](http://npm.im/yallist) linked list of streams that
this stream is piping into. (It's probably a bad idea to mess with
this.)
* `destroyed` A getter that indicates whether the stream was destroyed.
* `paused` True if the stream has been explicitly paused, otherwise false.
* `objectMode` Indicates whether the stream is in `objectMode`. Once set
to `true`, it cannot be set to `false`.
### Events
* `data` Emitted when there's data to read. Argument is the data to read.
This is never emitted while not flowing. If a listener is attached, that
will resume the stream.
* `end` Emitted when there's no more data to read. This will be emitted
immediately for empty streams when `end()` is called. If a listener is
attached, and `end` was already emitted, then it will be emitted again.
All listeners are removed when `end` is emitted.
* `prefinish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'end'`.
* `finish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'prefinish'`.
* `close` An indication that an underlying resource has been released.
Minipass does not emit this event, but will defer it until after `end`
has been emitted, since it throws off some stream libraries otherwise.
* `drain` Emitted when the internal buffer empties, and it is again
suitable to `write()` into the stream.
* `readable` Emitted when data is buffered and ready to be read by a
consumer.
* `resume` Emitted when stream changes state from buffering to flowing
mode. (Ie, when `resume` is called, `pipe` is called, or a `data` event
listener is added.)
### Static Methods
* `Minipass.isStream(stream)` Returns `true` if the argument is a stream,
and false otherwise. To be considered a stream, the object must be
either an instance of Minipass, or an EventEmitter that has either a
`pipe()` method, or both `write()` and `end()` methods. (Pretty much any
stream in node-land will return `true` for this.)
## EXAMPLES
Here are some examples of things you can do with Minipass streams.
### simple "are you done yet" promise
```js
mp.promise().then(() => {
// stream is finished
}, er => {
// stream emitted an error
})
```
### collecting
```js
mp.collect().then(all => {
// all is an array of all the data emitted
// encoding is supported in this case, so
// so the result will be a collection of strings if
// an encoding is specified, or buffers/objects if not.
//
// In an async function, you may do
// const data = await stream.collect()
})
```
### collecting into a single blob
This is a bit slower because it concatenates the data into one chunk for
you, but if you're going to do it yourself anyway, it's convenient this
way:
```js
mp.concat().then(onebigchunk => {
// onebigchunk is a string if the stream
// had an encoding set, or a buffer otherwise.
})
```
### iteration
You can iterate over streams synchronously or asynchronously in platforms
that support it.
Synchronous iteration will end when the currently available data is
consumed, even if the `end` event has not been reached. In string and
buffer mode, the data is concatenated, so unless multiple writes are
occurring in the same tick as the `read()`, sync iteration loops will
generally only have a single iteration.
To consume chunks in this way exactly as they have been written, with no
flattening, create the stream with the `{ objectMode: true }` option.
```js
const mp = new Minipass({ objectMode: true })
mp.write('a')
mp.write('b')
for (let letter of mp) {
console.log(letter) // a, b
}
mp.write('c')
mp.write('d')
for (let letter of mp) {
console.log(letter) // c, d
}
mp.write('e')
mp.end()
for (let letter of mp) {
console.log(letter) // e
}
for (let letter of mp) {
console.log(letter) // nothing
}
```
Asynchronous iteration will continue until the end event is reached,
consuming all of the data.
```js
const mp = new Minipass({ encoding: 'utf8' })
// some source of some data
let i = 5
const inter = setInterval(() => {
if (i-- > 0)
mp.write(Buffer.from('foo\n', 'utf8'))
else {
mp.end()
clearInterval(inter)
}
}, 100)
// consume the data with asynchronous iteration
async function consume () {
for await (let chunk of mp) {
console.log(chunk)
}
return 'ok'
}
consume().then(res => console.log(res))
// logs `foo\n` 5 times, and then `ok`
```
### subclass that `console.log()`s everything written into it
```js
class Logger extends Minipass {
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}
someSource.pipe(new Logger()).pipe(someDest)
```
### same thing, but using an inline anonymous class
```js
// js classes are fun
someSource
.pipe(new (class extends Minipass {
emit (ev, ...data) {
// let's also log events, because debugging some weird thing
console.log('EMIT', ev)
return super.emit(ev, ...data)
}
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}))
.pipe(someDest)
```
### subclass that defers 'end' for some reason
```js
class SlowEnd extends Minipass {
emit (ev, ...args) {
if (ev === 'end') {
console.log('going to end, hold on a sec')
setTimeout(() => {
console.log('ok, ready to end now')
super.emit('end', ...args)
}, 100)
} else {
return super.emit(ev, ...args)
}
}
}
```
### transform that creates newline-delimited JSON
```js
class NDJSONEncode extends Minipass {
write (obj, cb) {
try {
// JSON.stringify can throw, emit an error on that
return super.write(JSON.stringify(obj) + '\n', 'utf8', cb)
} catch (er) {
this.emit('error', er)
}
}
end (obj, cb) {
if (typeof obj === 'function') {
cb = obj
obj = undefined
}
if (obj !== undefined) {
this.write(obj)
}
return super.end(cb)
}
}
```
### transform that parses newline-delimited JSON
```js
class NDJSONDecode extends Minipass {
constructor (options) {
// always be in object mode, as far as Minipass is concerned
super({ objectMode: true })
this._jsonBuffer = ''
}
write (chunk, encoding, cb) {
if (typeof chunk === 'string' &&
typeof encoding === 'string' &&
encoding !== 'utf8') {
chunk = Buffer.from(chunk, encoding).toString()
} else if (Buffer.isBuffer(chunk))
chunk = chunk.toString()
}
if (typeof encoding === 'function') {
cb = encoding
}
const jsonData = (this._jsonBuffer + chunk).split('\n')
this._jsonBuffer = jsonData.pop()
for (let i = 0; i < jsonData.length; i++) {
try {
// JSON.parse can throw, emit an error on that
super.write(JSON.parse(jsonData[i]))
} catch (er) {
this.emit('error', er)
continue
}
}
if (cb)
cb()
}
}
```
[Build]: http://img.shields.io/travis/litejs/natural-compare-lite.png
[Coverage]: http://img.shields.io/coveralls/litejs/natural-compare-lite.png
[1]: https://travis-ci.org/litejs/natural-compare-lite
[2]: https://coveralls.io/r/litejs/natural-compare-lite
[npm package]: https://npmjs.org/package/natural-compare-lite
[GitHub repo]: https://github.com/litejs/natural-compare-lite
@version 1.4.0
@date 2015-10-26
@stability 3 - Stable
Natural Compare – [![Build][]][1] [![Coverage][]][2]
===============
Compare strings containing a mix of letters and numbers
in the way a human being would in sort order.
This is described as a "natural ordering".
```text
Standard sorting: Natural order sorting:
img1.png img1.png
img10.png img2.png
img12.png img10.png
img2.png img12.png
```
String.naturalCompare returns a number indicating
whether a reference string comes before or after or is the same
as the given string in sort order.
Use it with builtin sort() function.
### Installation
- In browser
```html
<script src=min.natural-compare.js></script>
```
- In node.js: `npm install natural-compare-lite`
```javascript
require("natural-compare-lite")
```
### Usage
```javascript
// Simple case sensitive example
var a = ["z1.doc", "z10.doc", "z17.doc", "z2.doc", "z23.doc", "z3.doc"];
a.sort(String.naturalCompare);
// ["z1.doc", "z2.doc", "z3.doc", "z10.doc", "z17.doc", "z23.doc"]
// Use wrapper function for case insensitivity
a.sort(function(a, b){
return String.naturalCompare(a.toLowerCase(), b.toLowerCase());
})
// In most cases we want to sort an array of objects
var a = [ {"street":"350 5th Ave", "room":"A-1021"}
, {"street":"350 5th Ave", "room":"A-21046-b"} ];
// sort by street, then by room
a.sort(function(a, b){
return String.naturalCompare(a.street, b.street) || String.naturalCompare(a.room, b.room);
})
// When text transformation is needed (eg toLowerCase()),
// it is best for performance to keep
// transformed key in that object.
// There are no need to do text transformation
// on each comparision when sorting.
var a = [ {"make":"Audi", "model":"A6"}
, {"make":"Kia", "model":"Rio"} ];
// sort by make, then by model
a.map(function(car){
car.sort_key = (car.make + " " + car.model).toLowerCase();
})
a.sort(function(a, b){
return String.naturalCompare(a.sort_key, b.sort_key);
})
```
- Works well with dates in ISO format eg "Rev 2012-07-26.doc".
### Custom alphabet
It is possible to configure a custom alphabet
to achieve a desired order.
```javascript
// Estonian alphabet
String.alphabet = "ABDEFGHIJKLMNOPRSŠZŽTUVÕÄÖÜXYabdefghijklmnoprsšzžtuvõäöüxy"
["t", "z", "x", "õ"].sort(String.naturalCompare)
// ["z", "t", "õ", "x"]
// Russian alphabet
String.alphabet = "АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдеёжзийклмнопрстуфхцчшщъыьэюя"
["Ё", "А", "Б"].sort(String.naturalCompare)
// ["А", "Б", "Ё"]
```
External links
--------------
- [GitHub repo][https://github.com/litejs/natural-compare-lite]
- [jsperf test](http://jsperf.com/natural-sort-2/12)
Licence
-------
Copyright (c) 2012-2015 Lauri Rooden <[email protected]>
[The MIT License](http://lauri.rooden.ee/mit-license.txt)

Moo!
====
Moo is a highly-optimised tokenizer/lexer generator. Use it to tokenize your strings, before parsing 'em with a parser like [nearley](https://github.com/hardmath123/nearley) or whatever else you're into.
* [Fast](#is-it-fast)
* [Convenient](#usage)
* uses [Regular Expressions](#on-regular-expressions)
* tracks [Line Numbers](#line-numbers)
* handles [Keywords](#keywords)
* supports [States](#states)
* custom [Errors](#errors)
* is even [Iterable](#iteration)
* has no dependencies
* 4KB minified + gzipped
* Moo!
Is it fast?
-----------
Yup! Flying-cows-and-singed-steak fast.
Moo is the fastest JS tokenizer around. It's **~2–10x** faster than most other tokenizers; it's a **couple orders of magnitude** faster than some of the slower ones.
Define your tokens **using regular expressions**. Moo will compile 'em down to a **single RegExp for performance**. It uses the new ES6 **sticky flag** where possible to make things faster; otherwise it falls back to an almost-as-efficient workaround. (For more than you ever wanted to know about this, read [adventures in the land of substrings and RegExps](http://mrale.ph/blog/2016/11/23/making-less-dart-faster.html).)
You _might_ be able to go faster still by writing your lexer by hand rather than using RegExps, but that's icky.
Oh, and it [avoids parsing RegExps by itself](https://hackernoon.com/the-madness-of-parsing-real-world-javascript-regexps-d9ee336df983#.2l8qu3l76). Because that would be horrible.
Usage
-----
First, you need to do the needful: `$ npm install moo`, or whatever will ship this code to your computer. Alternatively, grab the `moo.js` file by itself and slap it into your web page via a `<script>` tag; moo is completely standalone.
Then you can start roasting your very own lexer/tokenizer:
```js
const moo = require('moo')
let lexer = moo.compile({
WS: /[ \t]+/,
comment: /\/\/.*?$/,
number: /0|[1-9][0-9]*/,
string: /"(?:\\["\\]|[^\n"\\])*"/,
lparen: '(',
rparen: ')',
keyword: ['while', 'if', 'else', 'moo', 'cows'],
NL: { match: /\n/, lineBreaks: true },
})
```
And now throw some text at it:
```js
lexer.reset('while (10) cows\nmoo')
lexer.next() // -> { type: 'keyword', value: 'while' }
lexer.next() // -> { type: 'WS', value: ' ' }
lexer.next() // -> { type: 'lparen', value: '(' }
lexer.next() // -> { type: 'number', value: '10' }
// ...
```
When you reach the end of Moo's internal buffer, next() will return `undefined`. You can always `reset()` it and feed it more data when that happens.
On Regular Expressions
----------------------
RegExps are nifty for making tokenizers, but they can be a bit of a pain. Here are some things to be aware of:
* You often want to use **non-greedy quantifiers**: e.g. `*?` instead of `*`. Otherwise your tokens will be longer than you expect:
```js
let lexer = moo.compile({
string: /".*"/, // greedy quantifier *
// ...
})
lexer.reset('"foo" "bar"')
lexer.next() // -> { type: 'string', value: 'foo" "bar' }
```
Better:
```js
let lexer = moo.compile({
string: /".*?"/, // non-greedy quantifier *?
// ...
})
lexer.reset('"foo" "bar"')
lexer.next() // -> { type: 'string', value: 'foo' }
lexer.next() // -> { type: 'space', value: ' ' }
lexer.next() // -> { type: 'string', value: 'bar' }
```
* The **order of your rules** matters. Earlier ones will take precedence.
```js
moo.compile({
identifier: /[a-z0-9]+/,
number: /[0-9]+/,
}).reset('42').next() // -> { type: 'identifier', value: '42' }
moo.compile({
number: /[0-9]+/,
identifier: /[a-z0-9]+/,
}).reset('42').next() // -> { type: 'number', value: '42' }
```
* Moo uses **multiline RegExps**. This has a few quirks: for example, the **dot `/./` doesn't include newlines**. Use `[^]` instead if you want to match newlines too.
* Since an excluding character ranges like `/[^ ]/` (which matches anything but a space) _will_ include newlines, you have to be careful not to include them by accident! In particular, the whitespace metacharacter `\s` includes newlines.
Line Numbers
------------
Moo tracks detailed information about the input for you.
It will track line numbers, as long as you **apply the `lineBreaks: true` option to any rules which might contain newlines**. Moo will try to warn you if you forget to do this.
Note that this is `false` by default, for performance reasons: counting the number of lines in a matched token has a small cost. For optimal performance, only match newlines inside a dedicated token:
```js
newline: {match: '\n', lineBreaks: true},
```
### Token Info ###
Token objects (returned from `next()`) have the following attributes:
* **`type`**: the name of the group, as passed to compile.
* **`text`**: the string that was matched.
* **`value`**: the string that was matched, transformed by your `value` function (if any).
* **`offset`**: the number of bytes from the start of the buffer where the match starts.
* **`lineBreaks`**: the number of line breaks found in the match. (Always zero if this rule has `lineBreaks: false`.)
* **`line`**: the line number of the beginning of the match, starting from 1.
* **`col`**: the column where the match begins, starting from 1.
### Value vs. Text ###
The `value` is the same as the `text`, unless you provide a [value transform](#transform).
```js
const moo = require('moo')
const lexer = moo.compile({
ws: /[ \t]+/,
string: {match: /"(?:\\["\\]|[^\n"\\])*"/, value: s => s.slice(1, -1)},
})
lexer.reset('"test"')
lexer.next() /* { value: 'test', text: '"test"', ... } */
```
### Reset ###
Calling `reset()` on your lexer will empty its internal buffer, and set the line, column, and offset counts back to their initial value.
If you don't want this, you can `save()` the state, and later pass it as the second argument to `reset()` to explicitly control the internal state of the lexer.
```js
lexer.reset('some line\n')
let info = lexer.save() // -> { line: 10 }
lexer.next() // -> { line: 10 }
lexer.next() // -> { line: 11 }
// ...
lexer.reset('a different line\n', info)
lexer.next() // -> { line: 10 }
```
Keywords
--------
Moo makes it convenient to define literals.
```js
moo.compile({
lparen: '(',
rparen: ')',
keyword: ['while', 'if', 'else', 'moo', 'cows'],
})
```
It'll automatically compile them into regular expressions, escaping them where necessary.
**Keywords** should be written using the `keywords` transform.
```js
moo.compile({
IDEN: {match: /[a-zA-Z]+/, type: moo.keywords({
KW: ['while', 'if', 'else', 'moo', 'cows'],
})},
SPACE: {match: /\s+/, lineBreaks: true},
})
```
### Why? ###
You need to do this to ensure the **longest match** principle applies, even in edge cases.
Imagine trying to parse the input `className` with the following rules:
```js
keyword: ['class'],
identifier: /[a-zA-Z]+/,
```
You'll get _two_ tokens — `['class', 'Name']` -- which is _not_ what you want! If you swap the order of the rules, you'll fix this example; but now you'll lex `class` wrong (as an `identifier`).
The keywords helper checks matches against the list of keywords; if any of them match, it uses the type `'keyword'` instead of `'identifier'` (for this example).
### Keyword Types ###
Keywords can also have **individual types**.
```js
let lexer = moo.compile({
name: {match: /[a-zA-Z]+/, type: moo.keywords({
'kw-class': 'class',
'kw-def': 'def',
'kw-if': 'if',
})},
// ...
})
lexer.reset('def foo')
lexer.next() // -> { type: 'kw-def', value: 'def' }
lexer.next() // space
lexer.next() // -> { type: 'name', value: 'foo' }
```
You can use [itt](https://github.com/nathan/itt)'s iterator adapters to make constructing keyword objects easier:
```js
itt(['class', 'def', 'if'])
.map(k => ['kw-' + k, k])
.toObject()
```
States
------
Moo allows you to define multiple lexer **states**. Each state defines its own separate set of token rules. Your lexer will start off in the first state given to `moo.states({})`.
Rules can be annotated with `next`, `push`, and `pop`, to change the current state after that token is matched. A "stack" of past states is kept, which is used by `push` and `pop`.
* **`next: 'bar'`** moves to the state named `bar`. (The stack is not changed.)
* **`push: 'bar'`** moves to the state named `bar`, and pushes the old state onto the stack.
* **`pop: 1`** removes one state from the top of the stack, and moves to that state. (Only `1` is supported.)
Only rules from the current state can be matched. You need to copy your rule into all the states you want it to be matched in.
For example, to tokenize JS-style string interpolation such as `a${{c: d}}e`, you might use:
```js
let lexer = moo.states({
main: {
strstart: {match: '`', push: 'lit'},
ident: /\w+/,
lbrace: {match: '{', push: 'main'},
rbrace: {match: '}', pop: true},
colon: ':',
space: {match: /\s+/, lineBreaks: true},
},
lit: {
interp: {match: '${', push: 'main'},
escape: /\\./,
strend: {match: '`', pop: true},
const: {match: /(?:[^$`]|\$(?!\{))+/, lineBreaks: true},
},
})
// <= `a${{c: d}}e`
// => strstart const interp lbrace ident colon space ident rbrace rbrace const strend
```
The `rbrace` rule is annotated with `pop`, so it moves from the `main` state into either `lit` or `main`, depending on the stack.
Errors
------
If none of your rules match, Moo will throw an Error; since it doesn't know what else to do.
If you prefer, you can have moo return an error token instead of throwing an exception. The error token will contain the whole of the rest of the buffer.
```js
moo.compile({
// ...
myError: moo.error,
})
moo.reset('invalid')
moo.next() // -> { type: 'myError', value: 'invalid', text: 'invalid', offset: 0, lineBreaks: 0, line: 1, col: 1 }
moo.next() // -> undefined
```
You can have a token type that both matches tokens _and_ contains error values.
```js
moo.compile({
// ...
myError: {match: /[\$?`]/, error: true},
})
```
### Formatting errors ###
If you want to throw an error from your parser, you might find `formatError` helpful. Call it with the offending token:
```js
throw new Error(lexer.formatError(token, "invalid syntax"))
```
It returns a string with a pretty error message.
```
Error: invalid syntax at line 2 col 15:
totally valid `syntax`
^
```
Iteration
---------
Iterators: we got 'em.
```js
for (let here of lexer) {
// here = { type: 'number', value: '123', ... }
}
```
Create an array of tokens.
```js
let tokens = Array.from(lexer);
```
Use [itt](https://github.com/nathan/itt)'s iteration tools with Moo.
```js
for (let [here, next] = itt(lexer).lookahead()) { // pass a number if you need more tokens
// enjoy!
}
```
Transform
---------
Moo doesn't allow capturing groups, but you can supply a transform function, `value()`, which will be called on the value before storing it in the Token object.
```js
moo.compile({
STRING: [
{match: /"""[^]*?"""/, lineBreaks: true, value: x => x.slice(3, -3)},
{match: /"(?:\\["\\rn]|[^"\\])*?"/, lineBreaks: true, value: x => x.slice(1, -1)},
{match: /'(?:\\['\\rn]|[^'\\])*?'/, lineBreaks: true, value: x => x.slice(1, -1)},
],
// ...
})
```
Contributing
------------
Do check the [FAQ](https://github.com/tjvr/moo/issues?q=label%3Aquestion).
Before submitting an issue, [remember...](https://github.com/tjvr/moo/blob/master/.github/CONTRIBUTING.md)
### esutils [](http://travis-ci.org/estools/esutils)
esutils ([esutils](http://github.com/estools/esutils)) is
utility box for ECMAScript language tools.
### API
### ast
#### ast.isExpression(node)
Returns true if `node` is an Expression as defined in ECMA262 edition 5.1 section
[11](https://es5.github.io/#x11).
#### ast.isStatement(node)
Returns true if `node` is a Statement as defined in ECMA262 edition 5.1 section
[12](https://es5.github.io/#x12).
#### ast.isIterationStatement(node)
Returns true if `node` is an IterationStatement as defined in ECMA262 edition
5.1 section [12.6](https://es5.github.io/#x12.6).
#### ast.isSourceElement(node)
Returns true if `node` is a SourceElement as defined in ECMA262 edition 5.1
section [14](https://es5.github.io/#x14).
#### ast.trailingStatement(node)
Returns `Statement?` if `node` has trailing `Statement`.
```js
if (cond)
consequent;
```
When taking this `IfStatement`, returns `consequent;` statement.
#### ast.isProblematicIfStatement(node)
Returns true if `node` is a problematic IfStatement. If `node` is a problematic `IfStatement`, `node` cannot be represented as an one on one JavaScript code.
```js
{
type: 'IfStatement',
consequent: {
type: 'WithStatement',
body: {
type: 'IfStatement',
consequent: {type: 'EmptyStatement'}
}
},
alternate: {type: 'EmptyStatement'}
}
```
The above node cannot be represented as a JavaScript code, since the top level `else` alternate belongs to an inner `IfStatement`.
### code
#### code.isDecimalDigit(code)
Return true if provided code is decimal digit.
#### code.isHexDigit(code)
Return true if provided code is hexadecimal digit.
#### code.isOctalDigit(code)
Return true if provided code is octal digit.
#### code.isWhiteSpace(code)
Return true if provided code is white space. White space characters are formally defined in ECMA262.
#### code.isLineTerminator(code)
Return true if provided code is line terminator. Line terminator characters are formally defined in ECMA262.
#### code.isIdentifierStart(code)
Return true if provided code can be the first character of ECMA262 Identifier. They are formally defined in ECMA262.
#### code.isIdentifierPart(code)
Return true if provided code can be the trailing character of ECMA262 Identifier. They are formally defined in ECMA262.
### keyword
#### keyword.isKeywordES5(id, strict)
Returns `true` if provided identifier string is a Keyword or Future Reserved Word
in ECMA262 edition 5.1. They are formally defined in ECMA262 sections
[7.6.1.1](http://es5.github.io/#x7.6.1.1) and [7.6.1.2](http://es5.github.io/#x7.6.1.2),
respectively. If the `strict` flag is truthy, this function additionally checks whether
`id` is a Keyword or Future Reserved Word under strict mode.
#### keyword.isKeywordES6(id, strict)
Returns `true` if provided identifier string is a Keyword or Future Reserved Word
in ECMA262 edition 6. They are formally defined in ECMA262 sections
[11.6.2.1](http://ecma-international.org/ecma-262/6.0/#sec-keywords) and
[11.6.2.2](http://ecma-international.org/ecma-262/6.0/#sec-future-reserved-words),
respectively. If the `strict` flag is truthy, this function additionally checks whether
`id` is a Keyword or Future Reserved Word under strict mode.
#### keyword.isReservedWordES5(id, strict)
Returns `true` if provided identifier string is a Reserved Word in ECMA262 edition 5.1.
They are formally defined in ECMA262 section [7.6.1](http://es5.github.io/#x7.6.1).
If the `strict` flag is truthy, this function additionally checks whether `id`
is a Reserved Word under strict mode.
#### keyword.isReservedWordES6(id, strict)
Returns `true` if provided identifier string is a Reserved Word in ECMA262 edition 6.
They are formally defined in ECMA262 section [11.6.2](http://ecma-international.org/ecma-262/6.0/#sec-reserved-words).
If the `strict` flag is truthy, this function additionally checks whether `id`
is a Reserved Word under strict mode.
#### keyword.isRestrictedWord(id)
Returns `true` if provided identifier string is one of `eval` or `arguments`.
They are restricted in strict mode code throughout ECMA262 edition 5.1 and
in ECMA262 edition 6 section [12.1.1](http://ecma-international.org/ecma-262/6.0/#sec-identifiers-static-semantics-early-errors).
#### keyword.isIdentifierNameES5(id)
Return true if provided identifier string is an IdentifierName as specified in
ECMA262 edition 5.1 section [7.6](https://es5.github.io/#x7.6).
#### keyword.isIdentifierNameES6(id)
Return true if provided identifier string is an IdentifierName as specified in
ECMA262 edition 6 section [11.6](http://ecma-international.org/ecma-262/6.0/#sec-names-and-keywords).
#### keyword.isIdentifierES5(id, strict)
Return true if provided identifier string is an Identifier as specified in
ECMA262 edition 5.1 section [7.6](https://es5.github.io/#x7.6). If the `strict`
flag is truthy, this function additionally checks whether `id` is an Identifier
under strict mode.
#### keyword.isIdentifierES6(id, strict)
Return true if provided identifier string is an Identifier as specified in
ECMA262 edition 6 section [12.1](http://ecma-international.org/ecma-262/6.0/#sec-identifiers).
If the `strict` flag is truthy, this function additionally checks whether `id`
is an Identifier under strict mode.
### License
Copyright (C) 2013 [Yusuke Suzuki](http://github.com/Constellation)
(twitter: [@Constellation](http://twitter.com/Constellation)) and other contributors.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL <COPYRIGHT HOLDER> BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# which-module
> Find the module object for something that was require()d
[](https://travis-ci.org/nexdrew/which-module)
[](https://coveralls.io/github/nexdrew/which-module?branch=master)
[](https://github.com/conventional-changelog/standard-version)
Find the `module` object in `require.cache` for something that was `require()`d
or `import`ed - essentially a reverse `require()` lookup.
Useful for libs that want to e.g. lookup a filename for a module or submodule
that it did not `require()` itself.
## Install and Usage
```
npm install --save which-module
```
```js
const whichModule = require('which-module')
console.log(whichModule(require('something')))
// Module {
// id: '/path/to/project/node_modules/something/index.js',
// exports: [Function],
// parent: ...,
// filename: '/path/to/project/node_modules/something/index.js',
// loaded: true,
// children: [],
// paths: [ '/path/to/project/node_modules/something/node_modules',
// '/path/to/project/node_modules',
// '/path/to/node_modules',
// '/path/node_modules',
// '/node_modules' ] }
```
## API
### `whichModule(exported)`
Return the [`module` object](https://nodejs.org/api/modules.html#modules_the_module_object),
if any, that represents the given argument in the `require.cache`.
`exported` can be anything that was previously `require()`d or `import`ed as a
module, submodule, or dependency - which means `exported` is identical to the
`module.exports` returned by this method.
If `exported` did not come from the `exports` of a `module` in `require.cache`,
then this method returns `null`.
## License
ISC © Contributors
[](https://app.travis-ci.com/github/dankogai/js-base64)
# base64.js
Yet another [Base64] transcoder.
[Base64]: http://en.wikipedia.org/wiki/Base64
## Install
```shell
$ npm install --save js-base64
```
## Usage
### In Browser
Locally…
```html
<script src="base64.js"></script>
```
… or Directly from CDN. In which case you don't even need to install.
```html
<script src="https://cdn.jsdelivr.net/npm/[email protected]/base64.min.js"></script>
```
This good old way loads `Base64` in the global context (`window`). Though `Base64.noConflict()` is made available, you should consider using ES6 Module to avoid tainting `window`.
### As an ES6 Module
locally…
```javascript
import { Base64 } from 'js-base64';
```
```javascript
// or if you prefer no Base64 namespace
import { encode, decode } from 'js-base64';
```
or even remotely.
```html
<script type="module">
// note jsdelivr.net does not automatically minify .mjs
import { Base64 } from 'https://cdn.jsdelivr.net/npm/[email protected]/base64.mjs';
</script>
```
```html
<script type="module">
// or if you prefer no Base64 namespace
import { encode, decode } from 'https://cdn.jsdelivr.net/npm/[email protected]/base64.mjs';
</script>
```
### node.js (commonjs)
```javascript
const {Base64} = require('js-base64');
```
Unlike the case above, the global context is no longer modified.
You can also use [esm] to `import` instead of `require`.
[esm]: https://github.com/standard-things/esm
```javascript
require=require('esm')(module);
import {Base64} from 'js-base64';
```
## SYNOPSIS
```javascript
let latin = 'dankogai';
let utf8 = '小飼弾'
let u8s = new Uint8Array([100,97,110,107,111,103,97,105]);
Base64.encode(latin); // ZGFua29nYWk=
Base64.encode(latin, true)); // ZGFua29nYWk skips padding
Base64.encodeURI(latin)); // ZGFua29nYWk
Base64.btoa(latin); // ZGFua29nYWk=
Base64.btoa(utf8); // raises exception
Base64.fromUint8Array(u8s); // ZGFua29nYWk=
Base64.fromUint8Array(u8s, true); // ZGFua29nYW which is URI safe
Base64.encode(utf8); // 5bCP6aO85by+
Base64.encode(utf8, true) // 5bCP6aO85by-
Base64.encodeURI(utf8); // 5bCP6aO85by-
```
```javascript
Base64.decode( 'ZGFua29nYWk=');// dankogai
Base64.decode( 'ZGFua29nYWk'); // dankogai
Base64.atob( 'ZGFua29nYWk=');// dankogai
Base64.atob( '5bCP6aO85by+');// 'å°é£¼å¼¾' which is nonsense
Base64.toUint8Array('ZGFua29nYWk=');// u8s above
Base64.decode( '5bCP6aO85by+');// 小飼弾
// note .decodeURI() is unnecessary since it accepts both flavors
Base64.decode( '5bCP6aO85by-');// 小飼弾
```
```javascript
Base64.isValid(0); // false: 0 is not string
Base64.isValid(''); // true: a valid Base64-encoded empty byte
Base64.isValid('ZA=='); // true: a valid Base64-encoded 'd'
Base64.isValid('Z A='); // true: whitespaces are okay
Base64.isValid('ZA'); // true: padding ='s can be omitted
Base64.isValid('++'); // true: can be non URL-safe
Base64.isValid('--'); // true: or URL-safe
Base64.isValid('+-'); // false: can't mix both
```
### Built-in Extensions
By default `Base64` leaves built-in prototypes untouched. But you can extend them as below.
```javascript
// you have to explicitly extend String.prototype
Base64.extendString();
// once extended, you can do the following
'dankogai'.toBase64(); // ZGFua29nYWk=
'小飼弾'.toBase64(); // 5bCP6aO85by+
'小飼弾'.toBase64(true); // 5bCP6aO85by-
'小飼弾'.toBase64URI(); // 5bCP6aO85by- ab alias of .toBase64(true)
'小飼弾'.toBase64URL(); // 5bCP6aO85by- an alias of .toBase64URI()
'ZGFua29nYWk='.fromBase64(); // dankogai
'5bCP6aO85by+'.fromBase64(); // 小飼弾
'5bCP6aO85by-'.fromBase64(); // 小飼弾
'5bCP6aO85by-'.toUint8Array();// u8s above
```
```javascript
// you have to explicitly extend Uint8Array.prototype
Base64.extendUint8Array();
// once extended, you can do the following
u8s.toBase64(); // 'ZGFua29nYWk='
u8s.toBase64URI(); // 'ZGFua29nYWk'
u8s.toBase64URL(); // 'ZGFua29nYWk' an alias of .toBase64URI()
```
```javascript
// extend all at once
Base64.extendBuiltins()
```
## `.decode()` vs `.atob` (and `.encode()` vs `btoa()`)
Suppose you have:
```
var pngBase64 =
"iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVR42mNkYAAAAAYAAjCB0C8AAAAASUVORK5CYII=";
```
Which is a Base64-encoded 1x1 transparent PNG, **DO NOT USE** `Base64.decode(pngBase64)`. Use `Base64.atob(pngBase64)` instead. `Base64.decode()` decodes to UTF-8 string while `Base64.atob()` decodes to bytes, which is compatible to browser built-in `atob()` (Which is absent in node.js). The same rule applies to the opposite direction.
Or even better, `Base64.toUint8Array(pngBase64)`.
### If you really, really need an ES5 version
You can transpiles to an ES5 that runs on IEs before 11. Do the following in your shell.
```shell
$ make base64.es5.js
```
## Brief History
* Since version 3.3 it is written in TypeScript. Now `base64.mjs` is compiled from `base64.ts` then `base64.js` is generated from `base64.mjs`.
* Since version 3.7 `base64.js` is ES5-compatible again (hence IE11-compabile).
* Since 3.0 `js-base64` switch to ES2015 module so it is no longer compatible with legacy browsers like IE (see above)
# line-column
[](https://travis-ci.org/io-monad/line-column) [](https://coveralls.io/github/io-monad/line-column?branch=master) [](https://badge.fury.io/js/line-column)
Node module to convert efficiently index to/from line-column in a string.
## Install
npm install line-column
## Usage
### lineColumn(str, options = {})
Returns a `LineColumnFinder` instance for given string `str`.
#### Options
| Key | Description | Default |
| ------- | ----------- | ------- |
| `origin` | The origin value of line number and column number | `1` |
### lineColumn(str, index)
This is just a shorthand for `lineColumn(str).fromIndex(index)`.
### LineColumnFinder#fromIndex(index)
Find line and column from index in the string.
Parameters:
- `index` - `number` Index in the string. (0-origin)
Returns:
- `{ line: x, col: y }` Found line number and column number.
- `null` if the given index is out of range.
### LineColumnFinder#toIndex(line, column)
Find index from line and column in the string.
Parameters:
- `line` - `number` Line number in the string.
- `column` - `number` Column number in the string.
or
- `{ line: x, col: y }` - `Object` line and column numbers in the string.<br>A key name `column` can be used instead of `col`.
or
- `[ line, col ]` - `Array` line and column numbers in the string.
Returns:
- `number` Found index in the string.
- `-1` if the given line or column is out of range.
## Example
```js
var lineColumn = require("line-column");
var testString = [
"ABCDEFG\n", // line:0, index:0
"HIJKLMNOPQRSTU\n", // line:1, index:8
"VWXYZ\n", // line:2, index:23
"日本語の文字\n", // line:3, index:29
"English words" // line:4, index:36
].join(""); // length:49
lineColumn(testString).fromIndex(3) // { line: 1, col: 4 }
lineColumn(testString).fromIndex(33) // { line: 4, col: 5 }
lineColumn(testString).toIndex(1, 4) // 3
lineColumn(testString).toIndex(4, 5) // 33
// Shorthand of .fromIndex (compatible with find-line-column)
lineColumn(testString, 33) // { line:4, col: 5 }
// Object or Array is also acceptable
lineColumn(testString).toIndex({ line: 4, col: 5 }) // 33
lineColumn(testString).toIndex({ line: 4, column: 5 }) // 33
lineColumn(testString).toIndex([4, 5]) // 33
// You can cache it for the same string. It is so efficient. (See benchmark)
var finder = lineColumn(testString);
finder.fromIndex(33) // { line: 4, column: 5 }
finder.toIndex(4, 5) // 33
// For 0-origin line and column numbers
var oneOrigin = lineColumn(testString, { origin: 0 });
oneOrigin.fromIndex(33) // { line: 3, column: 4 }
oneOrigin.toIndex(3, 4) // 33
```
## Testing
npm test
## Benchmark
The popular package [find-line-column](https://www.npmjs.com/package/find-line-column) provides the same "index to line-column" feature.
Here is some benchmarking on `line-column` vs `find-line-column`. You can run this benchmark by `npm run benchmark`. See [benchmark/](benchmark/) for the source code.
```
long text + line-column (not cached) x 72,989 ops/sec ±0.83% (89 runs sampled)
long text + line-column (cached) x 13,074,242 ops/sec ±0.32% (89 runs sampled)
long text + find-line-column x 33,887 ops/sec ±0.54% (84 runs sampled)
short text + line-column (not cached) x 1,636,766 ops/sec ±0.77% (82 runs sampled)
short text + line-column (cached) x 21,699,686 ops/sec ±1.04% (82 runs sampled)
short text + find-line-column x 382,145 ops/sec ±1.04% (85 runs sampled)
```
As you might have noticed, even not cached version of `line-column` is 2x - 4x faster than `find-line-column`, and cached version of `line-column` is remarkable 50x - 380x faster.
## Contributing
1. Fork it!
2. Create your feature branch: `git checkout -b my-new-feature`
3. Commit your changes: `git commit -am 'Add some feature'`
4. Push to the branch: `git push origin my-new-feature`
5. Submit a pull request :D
## License
MIT (See LICENSE)
# isobject [](https://www.npmjs.com/package/isobject) [](https://npmjs.org/package/isobject) [](https://travis-ci.org/jonschlinkert/isobject)
Returns true if the value is an object and not an array or null.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install isobject --save
```
Use [is-plain-object](https://github.com/jonschlinkert/is-plain-object) if you want only objects that are created by the `Object` constructor.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install isobject
```
Install with [bower](http://bower.io/)
```sh
$ bower install isobject
```
## Usage
```js
var isObject = require('isobject');
```
**True**
All of the following return `true`:
```js
isObject({});
isObject(Object.create({}));
isObject(Object.create(Object.prototype));
isObject(Object.create(null));
isObject({});
isObject(new Foo);
isObject(/foo/);
```
**False**
All of the following return `false`:
```js
isObject();
isObject(function () {});
isObject(1);
isObject([]);
isObject(undefined);
isObject(null);
```
## Related projects
You might also be interested in these projects:
[merge-deep](https://www.npmjs.com/package/merge-deep): Recursively merge values in a javascript object. | [homepage](https://github.com/jonschlinkert/merge-deep)
* [extend-shallow](https://www.npmjs.com/package/extend-shallow): Extend an object with the properties of additional objects. node.js/javascript util. | [homepage](https://github.com/jonschlinkert/extend-shallow)
* [is-plain-object](https://www.npmjs.com/package/is-plain-object): Returns true if an object was created by the `Object` constructor. | [homepage](https://github.com/jonschlinkert/is-plain-object)
* [kind-of](https://www.npmjs.com/package/kind-of): Get the native type of a value. | [homepage](https://github.com/jonschlinkert/kind-of)
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/isobject/issues/new).
## Building docs
Generate readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install verb && npm run docs
```
Or, if [verb](https://github.com/verbose/verb) is installed globally:
```sh
$ verb
```
## Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/isobject/blob/master/LICENSE).
***
_This file was generated by [verb](https://github.com/verbose/verb), v0.9.0, on April 25, 2016._
# lodash.merge v4.6.2
The [Lodash](https://lodash.com/) method `_.merge` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.merge
```
In Node.js:
```js
var merge = require('lodash.merge');
```
See the [documentation](https://lodash.com/docs#merge) or [package source](https://github.com/lodash/lodash/blob/4.6.2-npm-packages/lodash.merge) for more details.
Like `chown -R`.
Takes the same arguments as `fs.chown()`
## Follow Redirects
Drop-in replacement for Nodes `http` and `https` that automatically follows redirects.
[](https://www.npmjs.com/package/follow-redirects)
[](https://travis-ci.org/follow-redirects/follow-redirects)
[](https://coveralls.io/r/follow-redirects/follow-redirects?branch=master)
[](https://david-dm.org/follow-redirects/follow-redirects)
[](https://www.npmjs.com/package/follow-redirects)
`follow-redirects` provides [request](https://nodejs.org/api/http.html#http_http_request_options_callback) and [get](https://nodejs.org/api/http.html#http_http_get_options_callback)
methods that behave identically to those found on the native [http](https://nodejs.org/api/http.html#http_http_request_options_callback) and [https](https://nodejs.org/api/https.html#https_https_request_options_callback)
modules, with the exception that they will seamlessly follow redirects.
```javascript
var http = require('follow-redirects').http;
var https = require('follow-redirects').https;
http.get('http://bit.ly/900913', function (response) {
response.on('data', function (chunk) {
console.log(chunk);
});
}).on('error', function (err) {
console.error(err);
});
```
You can inspect the final redirected URL through the `responseUrl` property on the `response`.
If no redirection happened, `responseUrl` is the original request URL.
```javascript
https.request({
host: 'bitly.com',
path: '/UHfDGO',
}, function (response) {
console.log(response.responseUrl);
// 'http://duckduckgo.com/robots.txt'
});
```
## Options
### Global options
Global options are set directly on the `follow-redirects` module:
```javascript
var followRedirects = require('follow-redirects');
followRedirects.maxRedirects = 10;
followRedirects.maxBodyLength = 20 * 1024 * 1024; // 20 MB
```
The following global options are supported:
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
### Per-request options
Per-request options are set by passing an `options` object:
```javascript
var url = require('url');
var followRedirects = require('follow-redirects');
var options = url.parse('http://bit.ly/900913');
options.maxRedirects = 10;
http.request(options);
```
In addition to the [standard HTTP](https://nodejs.org/api/http.html#http_http_request_options_callback) and [HTTPS options](https://nodejs.org/api/https.html#https_https_request_options_callback),
the following per-request options are supported:
- `followRedirects` (default: `true`) – whether redirects should be followed.
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
- `agents` (default: `undefined`) – sets the `agent` option per protocol, since HTTP and HTTPS use different agents. Example value: `{ http: new http.Agent(), https: new https.Agent() }`
- `trackRedirects` (default: `false`) – whether to store the redirected response details into the `redirects` array on the response object.
### Advanced usage
By default, `follow-redirects` will use the Node.js default implementations
of [`http`](https://nodejs.org/api/http.html)
and [`https`](https://nodejs.org/api/https.html).
To enable features such as caching and/or intermediate request tracking,
you might instead want to wrap `follow-redirects` around custom protocol implementations:
```javascript
var followRedirects = require('follow-redirects').wrap({
http: require('your-custom-http'),
https: require('your-custom-https'),
});
```
Such custom protocols only need an implementation of the `request` method.
## Browserify Usage
Due to the way `XMLHttpRequest` works, the `browserify` versions of `http` and `https` already follow redirects.
If you are *only* targeting the browser, then this library has little value for you. If you want to write cross
platform code for node and the browser, `follow-redirects` provides a great solution for making the native node
modules behave the same as they do in browserified builds in the browser. To avoid bundling unnecessary code
you should tell browserify to swap out `follow-redirects` with the standard modules when bundling.
To make this easier, you need to change how you require the modules:
```javascript
var http = require('follow-redirects/http');
var https = require('follow-redirects/https');
```
You can then replace `follow-redirects` in your browserify configuration like so:
```javascript
"browser": {
"follow-redirects/http" : "http",
"follow-redirects/https" : "https"
}
```
The `browserify-http` module has not kept pace with node development, and no long behaves identically to the native
module when running in the browser. If you are experiencing problems, you may want to check out
[browserify-http-2](https://www.npmjs.com/package/http-browserify-2). It is more actively maintained and
attempts to address a few of the shortcomings of `browserify-http`. In that case, your browserify config should
look something like this:
```javascript
"browser": {
"follow-redirects/http" : "browserify-http-2/http",
"follow-redirects/https" : "browserify-http-2/https"
}
```
## Contributing
Pull Requests are always welcome. Please [file an issue](https://github.com/follow-redirects/follow-redirects/issues)
detailing your proposal before you invest your valuable time. Additional features and bug fixes should be accompanied
by tests. You can run the test suite locally with a simple `npm test` command.
## Debug Logging
`follow-redirects` uses the excellent [debug](https://www.npmjs.com/package/debug) for logging. To turn on logging
set the environment variable `DEBUG=follow-redirects` for debug output from just this module. When running the test
suite it is sometimes advantageous to set `DEBUG=*` to see output from the express server as well.
## Authors
- Olivier Lalonde ([email protected])
- James Talmage ([email protected])
- [Ruben Verborgh](https://ruben.verborgh.org/)
## License
[https://github.com/follow-redirects/follow-redirects/blob/master/LICENSE](MIT License)
## Timezone support
In order to provide support for timezones, without relying on the JavaScript host or any other time-zone aware environment, this library makes use of teh IANA Timezone Database directly:
https://www.iana.org/time-zones
The database files are parsed by the scripts in this folder, which emit AssemblyScript code which is used to process the various rules at runtime.
# word-wrap [](https://www.npmjs.com/package/word-wrap) [](https://npmjs.org/package/word-wrap) [](https://npmjs.org/package/word-wrap) [](https://travis-ci.org/jonschlinkert/word-wrap)
> Wrap words to a specified length.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save word-wrap
```
## Usage
```js
var wrap = require('word-wrap');
wrap('Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.');
```
Results in:
```
Lorem ipsum dolor sit amet, consectetur adipiscing
elit, sed do eiusmod tempor incididunt ut labore
et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut
aliquip ex ea commodo consequat.
```
## Options

### options.width
Type: `Number`
Default: `50`
The width of the text before wrapping to a new line.
**Example:**
```js
wrap(str, {width: 60});
```
### options.indent
Type: `String`
Default: `` (two spaces)
The string to use at the beginning of each line.
**Example:**
```js
wrap(str, {indent: ' '});
```
### options.newline
Type: `String`
Default: `\n`
The string to use at the end of each line.
**Example:**
```js
wrap(str, {newline: '\n\n'});
```
### options.escape
Type: `function`
Default: `function(str){return str;}`
An escape function to run on each line after splitting them.
**Example:**
```js
var xmlescape = require('xml-escape');
wrap(str, {
escape: function(string){
return xmlescape(string);
}
});
```
### options.trim
Type: `Boolean`
Default: `false`
Trim trailing whitespace from the returned string. This option is included since `.trim()` would also strip the leading indentation from the first line.
**Example:**
```js
wrap(str, {trim: true});
```
### options.cut
Type: `Boolean`
Default: `false`
Break a word between any two letters when the word is longer than the specified width.
**Example:**
```js
wrap(str, {cut: true});
```
## About
### Related projects
* [common-words](https://www.npmjs.com/package/common-words): Updated list (JSON) of the 100 most common words in the English language. Useful for… [more](https://github.com/jonschlinkert/common-words) | [homepage](https://github.com/jonschlinkert/common-words "Updated list (JSON) of the 100 most common words in the English language. Useful for excluding these words from arrays.")
* [shuffle-words](https://www.npmjs.com/package/shuffle-words): Shuffle the words in a string and optionally the letters in each word using the… [more](https://github.com/jonschlinkert/shuffle-words) | [homepage](https://github.com/jonschlinkert/shuffle-words "Shuffle the words in a string and optionally the letters in each word using the Fisher-Yates algorithm. Useful for creating test fixtures, benchmarking samples, etc.")
* [unique-words](https://www.npmjs.com/package/unique-words): Return the unique words in a string or array. | [homepage](https://github.com/jonschlinkert/unique-words "Return the unique words in a string or array.")
* [wordcount](https://www.npmjs.com/package/wordcount): Count the words in a string. Support for english, CJK and Cyrillic. | [homepage](https://github.com/jonschlinkert/wordcount "Count the words in a string. Support for english, CJK and Cyrillic.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 43 | [jonschlinkert](https://github.com/jonschlinkert) |
| 2 | [lordvlad](https://github.com/lordvlad) |
| 2 | [hildjj](https://github.com/hildjj) |
| 1 | [danilosampaio](https://github.com/danilosampaio) |
| 1 | [2fd](https://github.com/2fd) |
| 1 | [toddself](https://github.com/toddself) |
| 1 | [wolfgang42](https://github.com/wolfgang42) |
| 1 | [zachhale](https://github.com/zachhale) |
### Building docs
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
### Running tests
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](https://twitter.com/jonschlinkert)
### License
Copyright © 2017, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.6.0, on June 02, 2017._
# ESLint Scope
ESLint Scope is the [ECMAScript](http://www.ecma-international.org/publications/standards/Ecma-262.htm) scope analyzer used in ESLint. It is a fork of [escope](http://github.com/estools/escope).
## Usage
Install:
```
npm i eslint-scope --save
```
Example:
```js
var eslintScope = require('eslint-scope');
var espree = require('espree');
var estraverse = require('estraverse');
var ast = espree.parse(code);
var scopeManager = eslintScope.analyze(ast);
var currentScope = scopeManager.acquire(ast); // global scope
estraverse.traverse(ast, {
enter: function(node, parent) {
// do stuff
if (/Function/.test(node.type)) {
currentScope = scopeManager.acquire(node); // get current function scope
}
},
leave: function(node, parent) {
if (/Function/.test(node.type)) {
currentScope = currentScope.upper; // set to parent scope
}
// do stuff
}
});
```
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/eslint-scope/issues).
## Build Commands
* `npm test` - run all linting and tests
* `npm run lint` - run all linting
## License
ESLint Scope is licensed under a permissive BSD 2-clause license.
<img align="right" alt="Ajv logo" width="160" src="https://ajv.js.org/images/ajv_logo.png">
# Ajv: Another JSON Schema Validator
The fastest JSON Schema validator for Node.js and browser. Supports draft-04/06/07.
[](https://travis-ci.org/ajv-validator/ajv)
[](https://www.npmjs.com/package/ajv)
[](https://www.npmjs.com/package/ajv/v/7.0.0-beta.0)
[](https://www.npmjs.com/package/ajv)
[](https://coveralls.io/github/ajv-validator/ajv?branch=master)
[](https://gitter.im/ajv-validator/ajv)
[](https://github.com/sponsors/epoberezkin)
## Ajv v7 beta is released
[Ajv version 7.0.0-beta.0](https://github.com/ajv-validator/ajv/tree/v7-beta) is released with these changes:
- to reduce the mistakes in JSON schemas and unexpected validation results, [strict mode](./docs/strict-mode.md) is added - it prohibits ignored or ambiguous JSON Schema elements.
- to make code injection from untrusted schemas impossible, [code generation](./docs/codegen.md) is fully re-written to be safe.
- to simplify Ajv extensions, the new keyword API that is used by pre-defined keywords is available to user-defined keywords - it is much easier to define any keywords now, especially with subschemas.
- schemas are compiled to ES6 code (ES5 code generation is supported with an option).
- to improve reliability and maintainability the code is migrated to TypeScript.
**Please note**:
- the support for JSON-Schema draft-04 is removed - if you have schemas using "id" attributes you have to replace them with "\$id" (or continue using version 6 that will be supported until 02/28/2021).
- all formats are separated to ajv-formats package - they have to be explicitely added if you use them.
See [release notes](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0-beta.0) for the details.
To install the new version:
```bash
npm install ajv@beta
```
See [Getting started with v7](https://github.com/ajv-validator/ajv/tree/v7-beta#usage) for code example.
## Mozilla MOSS grant and OpenJS Foundation
[<img src="https://www.poberezkin.com/images/mozilla.png" width="240" height="68">](https://www.mozilla.org/en-US/moss/) [<img src="https://www.poberezkin.com/images/openjs.png" width="220" height="68">](https://openjsf.org/blog/2020/08/14/ajv-joins-openjs-foundation-as-an-incubation-project/)
Ajv has been awarded a grant from Mozilla’s [Open Source Support (MOSS) program](https://www.mozilla.org/en-US/moss/) in the “Foundational Technology” track! It will sponsor the development of Ajv support of [JSON Schema version 2019-09](https://tools.ietf.org/html/draft-handrews-json-schema-02) and of [JSON Type Definition](https://tools.ietf.org/html/draft-ucarion-json-type-definition-04).
Ajv also joined [OpenJS Foundation](https://openjsf.org/) – having this support will help ensure the longevity and stability of Ajv for all its users.
This [blog post](https://www.poberezkin.com/posts/2020-08-14-ajv-json-validator-mozilla-open-source-grant-openjs-foundation.html) has more details.
I am looking for the long term maintainers of Ajv – working with [ReadySet](https://www.thereadyset.co/), also sponsored by Mozilla, to establish clear guidelines for the role of a "maintainer" and the contribution standards, and to encourage a wider, more inclusive, contribution from the community.
## Please [sponsor Ajv development](https://github.com/sponsors/epoberezkin)
Since I asked to support Ajv development 40 people and 6 organizations contributed via GitHub and OpenCollective - this support helped receiving the MOSS grant!
Your continuing support is very important - the funds will be used to develop and maintain Ajv once the next major version is released.
Please sponsor Ajv via:
- [GitHub sponsors page](https://github.com/sponsors/epoberezkin) (GitHub will match it)
- [Ajv Open Collective️](https://opencollective.com/ajv)
Thank you.
#### Open Collective sponsors
<a href="https://opencollective.com/ajv"><img src="https://opencollective.com/ajv/individuals.svg?width=890"></a>
<a href="https://opencollective.com/ajv/organization/0/website"><img src="https://opencollective.com/ajv/organization/0/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/1/website"><img src="https://opencollective.com/ajv/organization/1/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/2/website"><img src="https://opencollective.com/ajv/organization/2/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/3/website"><img src="https://opencollective.com/ajv/organization/3/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/4/website"><img src="https://opencollective.com/ajv/organization/4/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/5/website"><img src="https://opencollective.com/ajv/organization/5/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/6/website"><img src="https://opencollective.com/ajv/organization/6/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/7/website"><img src="https://opencollective.com/ajv/organization/7/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/8/website"><img src="https://opencollective.com/ajv/organization/8/avatar.svg"></a>
<a href="https://opencollective.com/ajv/organization/9/website"><img src="https://opencollective.com/ajv/organization/9/avatar.svg"></a>
## Using version 6
[JSON Schema draft-07](http://json-schema.org/latest/json-schema-validation.html) is published.
[Ajv version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0) that supports draft-07 is released. It may require either migrating your schemas or updating your code (to continue using draft-04 and v5 schemas, draft-06 schemas will be supported without changes).
__Please note__: To use Ajv with draft-06 schemas you need to explicitly add the meta-schema to the validator instance:
```javascript
ajv.addMetaSchema(require('ajv/lib/refs/json-schema-draft-06.json'));
```
To use Ajv with draft-04 schemas in addition to explicitly adding meta-schema you also need to use option schemaId:
```javascript
var ajv = new Ajv({schemaId: 'id'});
// If you want to use both draft-04 and draft-06/07 schemas:
// var ajv = new Ajv({schemaId: 'auto'});
ajv.addMetaSchema(require('ajv/lib/refs/json-schema-draft-04.json'));
```
## Contents
- [Performance](#performance)
- [Features](#features)
- [Getting started](#getting-started)
- [Frequently Asked Questions](https://github.com/ajv-validator/ajv/blob/master/FAQ.md)
- [Using in browser](#using-in-browser)
- [Ajv and Content Security Policies (CSP)](#ajv-and-content-security-policies-csp)
- [Command line interface](#command-line-interface)
- Validation
- [Keywords](#validation-keywords)
- [Annotation keywords](#annotation-keywords)
- [Formats](#formats)
- [Combining schemas with $ref](#ref)
- [$data reference](#data-reference)
- NEW: [$merge and $patch keywords](#merge-and-patch-keywords)
- [Defining custom keywords](#defining-custom-keywords)
- [Asynchronous schema compilation](#asynchronous-schema-compilation)
- [Asynchronous validation](#asynchronous-validation)
- [Security considerations](#security-considerations)
- [Security contact](#security-contact)
- [Untrusted schemas](#untrusted-schemas)
- [Circular references in objects](#circular-references-in-javascript-objects)
- [Trusted schemas](#security-risks-of-trusted-schemas)
- [ReDoS attack](#redos-attack)
- Modifying data during validation
- [Filtering data](#filtering-data)
- [Assigning defaults](#assigning-defaults)
- [Coercing data types](#coercing-data-types)
- API
- [Methods](#api)
- [Options](#options)
- [Validation errors](#validation-errors)
- [Plugins](#plugins)
- [Related packages](#related-packages)
- [Some packages using Ajv](#some-packages-using-ajv)
- [Tests, Contributing, Changes history](#tests)
- [Support, Code of conduct, License](#open-source-software-support)
## Performance
Ajv generates code using [doT templates](https://github.com/olado/doT) to turn JSON Schemas into super-fast validation functions that are efficient for v8 optimization.
Currently Ajv is the fastest and the most standard compliant validator according to these benchmarks:
- [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark) - 50% faster than the second place
- [jsck benchmark](https://github.com/pandastrike/jsck#benchmarks) - 20-190% faster
- [z-schema benchmark](https://rawgit.com/zaggino/z-schema/master/benchmark/results.html)
- [themis benchmark](https://cdn.rawgit.com/playlyfe/themis/master/benchmark/results.html)
Performance of different validators by [json-schema-benchmark](https://github.com/ebdrup/json-schema-benchmark):
[](https://github.com/ebdrup/json-schema-benchmark/blob/master/README.md#performance)
## Features
- Ajv implements full JSON Schema [draft-06/07](http://json-schema.org/) and draft-04 standards:
- all validation keywords (see [JSON Schema validation keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md))
- full support of remote refs (remote schemas have to be added with `addSchema` or compiled to be available)
- support of circular references between schemas
- correct string lengths for strings with unicode pairs (can be turned off)
- [formats](#formats) defined by JSON Schema draft-07 standard and custom formats (can be turned off)
- [validates schemas against meta-schema](#api-validateschema)
- supports [browsers](#using-in-browser) and Node.js 0.10-14.x
- [asynchronous loading](#asynchronous-schema-compilation) of referenced schemas during compilation
- "All errors" validation mode with [option allErrors](#options)
- [error messages with parameters](#validation-errors) describing error reasons to allow creating custom error messages
- i18n error messages support with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package
- [filtering data](#filtering-data) from additional properties
- [assigning defaults](#assigning-defaults) to missing properties and items
- [coercing data](#coercing-data-types) to the types specified in `type` keywords
- [custom keywords](#defining-custom-keywords)
- draft-06/07 keywords `const`, `contains`, `propertyNames` and `if/then/else`
- draft-06 boolean schemas (`true`/`false` as a schema to always pass/fail).
- keywords `switch`, `patternRequired`, `formatMaximum` / `formatMinimum` and `formatExclusiveMaximum` / `formatExclusiveMinimum` from [JSON Schema extension proposals](https://github.com/json-schema/json-schema/wiki/v5-Proposals) with [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package
- [$data reference](#data-reference) to use values from the validated data as values for the schema keywords
- [asynchronous validation](#asynchronous-validation) of custom formats and keywords
## Install
```
npm install ajv
```
## <a name="usage"></a>Getting started
Try it in the Node.js REPL: https://tonicdev.com/npm/ajv
The fastest validation call:
```javascript
// Node.js require:
var Ajv = require('ajv');
// or ESM/TypeScript import
import Ajv from 'ajv';
var ajv = new Ajv(); // options can be passed, e.g. {allErrors: true}
var validate = ajv.compile(schema);
var valid = validate(data);
if (!valid) console.log(validate.errors);
```
or with less code
```javascript
// ...
var valid = ajv.validate(schema, data);
if (!valid) console.log(ajv.errors);
// ...
```
or
```javascript
// ...
var valid = ajv.addSchema(schema, 'mySchema')
.validate('mySchema', data);
if (!valid) console.log(ajv.errorsText());
// ...
```
See [API](#api) and [Options](#options) for more details.
Ajv compiles schemas to functions and caches them in all cases (using schema serialized with [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify) or a custom function as a key), so that the next time the same schema is used (not necessarily the same object instance) it won't be compiled again.
The best performance is achieved when using compiled functions returned by `compile` or `getSchema` methods (there is no additional function call).
__Please note__: every time a validation function or `ajv.validate` are called `errors` property is overwritten. You need to copy `errors` array reference to another variable if you want to use it later (e.g., in the callback). See [Validation errors](#validation-errors)
__Note for TypeScript users__: `ajv` provides its own TypeScript declarations
out of the box, so you don't need to install the deprecated `@types/ajv`
module.
## Using in browser
You can require Ajv directly from the code you browserify - in this case Ajv will be a part of your bundle.
If you need to use Ajv in several bundles you can create a separate UMD bundle using `npm run bundle` script (thanks to [siddo420](https://github.com/siddo420)).
Then you need to load Ajv in the browser:
```html
<script src="ajv.min.js"></script>
```
This bundle can be used with different module systems; it creates global `Ajv` if no module system is found.
The browser bundle is available on [cdnjs](https://cdnjs.com/libraries/ajv).
Ajv is tested with these browsers:
[](https://saucelabs.com/u/epoberezkin)
__Please note__: some frameworks, e.g. Dojo, may redefine global require in such way that is not compatible with CommonJS module format. In such case Ajv bundle has to be loaded before the framework and then you can use global Ajv (see issue [#234](https://github.com/ajv-validator/ajv/issues/234)).
### Ajv and Content Security Policies (CSP)
If you're using Ajv to compile a schema (the typical use) in a browser document that is loaded with a Content Security Policy (CSP), that policy will require a `script-src` directive that includes the value `'unsafe-eval'`.
:warning: NOTE, however, that `unsafe-eval` is NOT recommended in a secure CSP[[1]](https://developer.chrome.com/extensions/contentSecurityPolicy#relaxing-eval), as it has the potential to open the document to cross-site scripting (XSS) attacks.
In order to make use of Ajv without easing your CSP, you can [pre-compile a schema using the CLI](https://github.com/ajv-validator/ajv-cli#compile-schemas). This will transpile the schema JSON into a JavaScript file that exports a `validate` function that works simlarly to a schema compiled at runtime.
Note that pre-compilation of schemas is performed using [ajv-pack](https://github.com/ajv-validator/ajv-pack) and there are [some limitations to the schema features it can compile](https://github.com/ajv-validator/ajv-pack#limitations). A successfully pre-compiled schema is equivalent to the same schema compiled at runtime.
## Command line interface
CLI is available as a separate npm package [ajv-cli](https://github.com/ajv-validator/ajv-cli). It supports:
- compiling JSON Schemas to test their validity
- BETA: generating standalone module exporting a validation function to be used without Ajv (using [ajv-pack](https://github.com/ajv-validator/ajv-pack))
- migrate schemas to draft-07 (using [json-schema-migrate](https://github.com/epoberezkin/json-schema-migrate))
- validating data file(s) against JSON Schema
- testing expected validity of data against JSON Schema
- referenced schemas
- custom meta-schemas
- files in JSON, JSON5, YAML, and JavaScript format
- all Ajv options
- reporting changes in data after validation in [JSON-patch](https://tools.ietf.org/html/rfc6902) format
## Validation keywords
Ajv supports all validation keywords from draft-07 of JSON Schema standard:
- [type](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#type)
- [for numbers](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-numbers) - maximum, minimum, exclusiveMaximum, exclusiveMinimum, multipleOf
- [for strings](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-strings) - maxLength, minLength, pattern, format
- [for arrays](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-arrays) - maxItems, minItems, uniqueItems, items, additionalItems, [contains](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#contains)
- [for objects](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-objects) - maxProperties, minProperties, required, properties, patternProperties, additionalProperties, dependencies, [propertyNames](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#propertynames)
- [for all types](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#keywords-for-all-types) - enum, [const](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#const)
- [compound keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#compound-keywords) - not, oneOf, anyOf, allOf, [if/then/else](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#ifthenelse)
With [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package Ajv also supports validation keywords from [JSON Schema extension proposals](https://github.com/json-schema/json-schema/wiki/v5-Proposals) for JSON Schema standard:
- [patternRequired](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#patternrequired-proposed) - like `required` but with patterns that some property should match.
- [formatMaximum, formatMinimum, formatExclusiveMaximum, formatExclusiveMinimum](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md#formatmaximum--formatminimum-and-exclusiveformatmaximum--exclusiveformatminimum-proposed) - setting limits for date, time, etc.
See [JSON Schema validation keywords](https://github.com/ajv-validator/ajv/blob/master/KEYWORDS.md) for more details.
## Annotation keywords
JSON Schema specification defines several annotation keywords that describe schema itself but do not perform any validation.
- `title` and `description`: information about the data represented by that schema
- `$comment` (NEW in draft-07): information for developers. With option `$comment` Ajv logs or passes the comment string to the user-supplied function. See [Options](#options).
- `default`: a default value of the data instance, see [Assigning defaults](#assigning-defaults).
- `examples` (NEW in draft-06): an array of data instances. Ajv does not check the validity of these instances against the schema.
- `readOnly` and `writeOnly` (NEW in draft-07): marks data-instance as read-only or write-only in relation to the source of the data (database, api, etc.).
- `contentEncoding`: [RFC 2045](https://tools.ietf.org/html/rfc2045#section-6.1 ), e.g., "base64".
- `contentMediaType`: [RFC 2046](https://tools.ietf.org/html/rfc2046), e.g., "image/png".
__Please note__: Ajv does not implement validation of the keywords `examples`, `contentEncoding` and `contentMediaType` but it reserves them. If you want to create a plugin that implements some of them, it should remove these keywords from the instance.
## Formats
Ajv implements formats defined by JSON Schema specification and several other formats. It is recommended NOT to use "format" keyword implementations with untrusted data, as they use potentially unsafe regular expressions - see [ReDoS attack](#redos-attack).
__Please note__: if you need to use "format" keyword to validate untrusted data, you MUST assess their suitability and safety for your validation scenarios.
The following formats are implemented for string validation with "format" keyword:
- _date_: full-date according to [RFC3339](http://tools.ietf.org/html/rfc3339#section-5.6).
- _time_: time with optional time-zone.
- _date-time_: date-time from the same source (time-zone is mandatory). `date`, `time` and `date-time` validate ranges in `full` mode and only regexp in `fast` mode (see [options](#options)).
- _uri_: full URI.
- _uri-reference_: URI reference, including full and relative URIs.
- _uri-template_: URI template according to [RFC6570](https://tools.ietf.org/html/rfc6570)
- _url_ (deprecated): [URL record](https://url.spec.whatwg.org/#concept-url).
- _email_: email address.
- _hostname_: host name according to [RFC1034](http://tools.ietf.org/html/rfc1034#section-3.5).
- _ipv4_: IP address v4.
- _ipv6_: IP address v6.
- _regex_: tests whether a string is a valid regular expression by passing it to RegExp constructor.
- _uuid_: Universally Unique IDentifier according to [RFC4122](http://tools.ietf.org/html/rfc4122).
- _json-pointer_: JSON-pointer according to [RFC6901](https://tools.ietf.org/html/rfc6901).
- _relative-json-pointer_: relative JSON-pointer according to [this draft](http://tools.ietf.org/html/draft-luff-relative-json-pointer-00).
__Please note__: JSON Schema draft-07 also defines formats `iri`, `iri-reference`, `idn-hostname` and `idn-email` for URLs, hostnames and emails with international characters. Ajv does not implement these formats. If you create Ajv plugin that implements them please make a PR to mention this plugin here.
There are two modes of format validation: `fast` and `full`. This mode affects formats `date`, `time`, `date-time`, `uri`, `uri-reference`, and `email`. See [Options](#options) for details.
You can add additional formats and replace any of the formats above using [addFormat](#api-addformat) method.
The option `unknownFormats` allows changing the default behaviour when an unknown format is encountered. In this case Ajv can either fail schema compilation (default) or ignore it (default in versions before 5.0.0). You also can allow specific format(s) that will be ignored. See [Options](#options) for details.
You can find regular expressions used for format validation and the sources that were used in [formats.js](https://github.com/ajv-validator/ajv/blob/master/lib/compile/formats.js).
## <a name="ref"></a>Combining schemas with $ref
You can structure your validation logic across multiple schema files and have schemas reference each other using `$ref` keyword.
Example:
```javascript
var schema = {
"$id": "http://example.com/schemas/schema.json",
"type": "object",
"properties": {
"foo": { "$ref": "defs.json#/definitions/int" },
"bar": { "$ref": "defs.json#/definitions/str" }
}
};
var defsSchema = {
"$id": "http://example.com/schemas/defs.json",
"definitions": {
"int": { "type": "integer" },
"str": { "type": "string" }
}
};
```
Now to compile your schema you can either pass all schemas to Ajv instance:
```javascript
var ajv = new Ajv({schemas: [schema, defsSchema]});
var validate = ajv.getSchema('http://example.com/schemas/schema.json');
```
or use `addSchema` method:
```javascript
var ajv = new Ajv;
var validate = ajv.addSchema(defsSchema)
.compile(schema);
```
See [Options](#options) and [addSchema](#api) method.
__Please note__:
- `$ref` is resolved as the uri-reference using schema $id as the base URI (see the example).
- References can be recursive (and mutually recursive) to implement the schemas for different data structures (such as linked lists, trees, graphs, etc.).
- You don't have to host your schema files at the URIs that you use as schema $id. These URIs are only used to identify the schemas, and according to JSON Schema specification validators should not expect to be able to download the schemas from these URIs.
- The actual location of the schema file in the file system is not used.
- You can pass the identifier of the schema as the second parameter of `addSchema` method or as a property name in `schemas` option. This identifier can be used instead of (or in addition to) schema $id.
- You cannot have the same $id (or the schema identifier) used for more than one schema - the exception will be thrown.
- You can implement dynamic resolution of the referenced schemas using `compileAsync` method. In this way you can store schemas in any system (files, web, database, etc.) and reference them without explicitly adding to Ajv instance. See [Asynchronous schema compilation](#asynchronous-schema-compilation).
## $data reference
With `$data` option you can use values from the validated data as the values for the schema keywords. See [proposal](https://github.com/json-schema-org/json-schema-spec/issues/51) for more information about how it works.
`$data` reference is supported in the keywords: const, enum, format, maximum/minimum, exclusiveMaximum / exclusiveMinimum, maxLength / minLength, maxItems / minItems, maxProperties / minProperties, formatMaximum / formatMinimum, formatExclusiveMaximum / formatExclusiveMinimum, multipleOf, pattern, required, uniqueItems.
The value of "$data" should be a [JSON-pointer](https://tools.ietf.org/html/rfc6901) to the data (the root is always the top level data object, even if the $data reference is inside a referenced subschema) or a [relative JSON-pointer](http://tools.ietf.org/html/draft-luff-relative-json-pointer-00) (it is relative to the current point in data; if the $data reference is inside a referenced subschema it cannot point to the data outside of the root level for this subschema).
Examples.
This schema requires that the value in property `smaller` is less or equal than the value in the property larger:
```javascript
var ajv = new Ajv({$data: true});
var schema = {
"properties": {
"smaller": {
"type": "number",
"maximum": { "$data": "1/larger" }
},
"larger": { "type": "number" }
}
};
var validData = {
smaller: 5,
larger: 7
};
ajv.validate(schema, validData); // true
```
This schema requires that the properties have the same format as their field names:
```javascript
var schema = {
"additionalProperties": {
"type": "string",
"format": { "$data": "0#" }
}
};
var validData = {
'date-time': '1963-06-19T08:30:06.283185Z',
email: '[email protected]'
}
```
`$data` reference is resolved safely - it won't throw even if some property is undefined. If `$data` resolves to `undefined` the validation succeeds (with the exclusion of `const` keyword). If `$data` resolves to incorrect type (e.g. not "number" for maximum keyword) the validation fails.
## $merge and $patch keywords
With the package [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) you can use the keywords `$merge` and `$patch` that allow extending JSON Schemas with patches using formats [JSON Merge Patch (RFC 7396)](https://tools.ietf.org/html/rfc7396) and [JSON Patch (RFC 6902)](https://tools.ietf.org/html/rfc6902).
To add keywords `$merge` and `$patch` to Ajv instance use this code:
```javascript
require('ajv-merge-patch')(ajv);
```
Examples.
Using `$merge`:
```json
{
"$merge": {
"source": {
"type": "object",
"properties": { "p": { "type": "string" } },
"additionalProperties": false
},
"with": {
"properties": { "q": { "type": "number" } }
}
}
}
```
Using `$patch`:
```json
{
"$patch": {
"source": {
"type": "object",
"properties": { "p": { "type": "string" } },
"additionalProperties": false
},
"with": [
{ "op": "add", "path": "/properties/q", "value": { "type": "number" } }
]
}
}
```
The schemas above are equivalent to this schema:
```json
{
"type": "object",
"properties": {
"p": { "type": "string" },
"q": { "type": "number" }
},
"additionalProperties": false
}
```
The properties `source` and `with` in the keywords `$merge` and `$patch` can use absolute or relative `$ref` to point to other schemas previously added to the Ajv instance or to the fragments of the current schema.
See the package [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) for more information.
## Defining custom keywords
The advantages of using custom keywords are:
- allow creating validation scenarios that cannot be expressed using JSON Schema
- simplify your schemas
- help bringing a bigger part of the validation logic to your schemas
- make your schemas more expressive, less verbose and closer to your application domain
- implement custom data processors that modify your data (`modifying` option MUST be used in keyword definition) and/or create side effects while the data is being validated
If a keyword is used only for side-effects and its validation result is pre-defined, use option `valid: true/false` in keyword definition to simplify both generated code (no error handling in case of `valid: true`) and your keyword functions (no need to return any validation result).
The concerns you have to be aware of when extending JSON Schema standard with custom keywords are the portability and understanding of your schemas. You will have to support these custom keywords on other platforms and to properly document these keywords so that everybody can understand them in your schemas.
You can define custom keywords with [addKeyword](#api-addkeyword) method. Keywords are defined on the `ajv` instance level - new instances will not have previously defined keywords.
Ajv allows defining keywords with:
- validation function
- compilation function
- macro function
- inline compilation function that should return code (as string) that will be inlined in the currently compiled schema.
Example. `range` and `exclusiveRange` keywords using compiled schema:
```javascript
ajv.addKeyword('range', {
type: 'number',
compile: function (sch, parentSchema) {
var min = sch[0];
var max = sch[1];
return parentSchema.exclusiveRange === true
? function (data) { return data > min && data < max; }
: function (data) { return data >= min && data <= max; }
}
});
var schema = { "range": [2, 4], "exclusiveRange": true };
var validate = ajv.compile(schema);
console.log(validate(2.01)); // true
console.log(validate(3.99)); // true
console.log(validate(2)); // false
console.log(validate(4)); // false
```
Several custom keywords (typeof, instanceof, range and propertyNames) are defined in [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package - they can be used for your schemas and as a starting point for your own custom keywords.
See [Defining custom keywords](https://github.com/ajv-validator/ajv/blob/master/CUSTOM.md) for more details.
## Asynchronous schema compilation
During asynchronous compilation remote references are loaded using supplied function. See `compileAsync` [method](#api-compileAsync) and `loadSchema` [option](#options).
Example:
```javascript
var ajv = new Ajv({ loadSchema: loadSchema });
ajv.compileAsync(schema).then(function (validate) {
var valid = validate(data);
// ...
});
function loadSchema(uri) {
return request.json(uri).then(function (res) {
if (res.statusCode >= 400)
throw new Error('Loading error: ' + res.statusCode);
return res.body;
});
}
```
__Please note__: [Option](#options) `missingRefs` should NOT be set to `"ignore"` or `"fail"` for asynchronous compilation to work.
## Asynchronous validation
Example in Node.js REPL: https://tonicdev.com/esp/ajv-asynchronous-validation
You can define custom formats and keywords that perform validation asynchronously by accessing database or some other service. You should add `async: true` in the keyword or format definition (see [addFormat](#api-addformat), [addKeyword](#api-addkeyword) and [Defining custom keywords](#defining-custom-keywords)).
If your schema uses asynchronous formats/keywords or refers to some schema that contains them it should have `"$async": true` keyword so that Ajv can compile it correctly. If asynchronous format/keyword or reference to asynchronous schema is used in the schema without `$async` keyword Ajv will throw an exception during schema compilation.
__Please note__: all asynchronous subschemas that are referenced from the current or other schemas should have `"$async": true` keyword as well, otherwise the schema compilation will fail.
Validation function for an asynchronous custom format/keyword should return a promise that resolves with `true` or `false` (or rejects with `new Ajv.ValidationError(errors)` if you want to return custom errors from the keyword function).
Ajv compiles asynchronous schemas to [es7 async functions](http://tc39.github.io/ecmascript-asyncawait/) that can optionally be transpiled with [nodent](https://github.com/MatAtBread/nodent). Async functions are supported in Node.js 7+ and all modern browsers. You can also supply any other transpiler as a function via `processCode` option. See [Options](#options).
The compiled validation function has `$async: true` property (if the schema is asynchronous), so you can differentiate these functions if you are using both synchronous and asynchronous schemas.
Validation result will be a promise that resolves with validated data or rejects with an exception `Ajv.ValidationError` that contains the array of validation errors in `errors` property.
Example:
```javascript
var ajv = new Ajv;
// require('ajv-async')(ajv);
ajv.addKeyword('idExists', {
async: true,
type: 'number',
validate: checkIdExists
});
function checkIdExists(schema, data) {
return knex(schema.table)
.select('id')
.where('id', data)
.then(function (rows) {
return !!rows.length; // true if record is found
});
}
var schema = {
"$async": true,
"properties": {
"userId": {
"type": "integer",
"idExists": { "table": "users" }
},
"postId": {
"type": "integer",
"idExists": { "table": "posts" }
}
}
};
var validate = ajv.compile(schema);
validate({ userId: 1, postId: 19 })
.then(function (data) {
console.log('Data is valid', data); // { userId: 1, postId: 19 }
})
.catch(function (err) {
if (!(err instanceof Ajv.ValidationError)) throw err;
// data is invalid
console.log('Validation errors:', err.errors);
});
```
### Using transpilers with asynchronous validation functions.
[ajv-async](https://github.com/ajv-validator/ajv-async) uses [nodent](https://github.com/MatAtBread/nodent) to transpile async functions. To use another transpiler you should separately install it (or load its bundle in the browser).
#### Using nodent
```javascript
var ajv = new Ajv;
require('ajv-async')(ajv);
// in the browser if you want to load ajv-async bundle separately you can:
// window.ajvAsync(ajv);
var validate = ajv.compile(schema); // transpiled es7 async function
validate(data).then(successFunc).catch(errorFunc);
```
#### Using other transpilers
```javascript
var ajv = new Ajv({ processCode: transpileFunc });
var validate = ajv.compile(schema); // transpiled es7 async function
validate(data).then(successFunc).catch(errorFunc);
```
See [Options](#options).
## Security considerations
JSON Schema, if properly used, can replace data sanitisation. It doesn't replace other API security considerations. It also introduces additional security aspects to consider.
##### Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerabilities via GitHub issues.
##### Untrusted schemas
Ajv treats JSON schemas as trusted as your application code. This security model is based on the most common use case, when the schemas are static and bundled together with the application.
If your schemas are received from untrusted sources (or generated from untrusted data) there are several scenarios you need to prevent:
- compiling schemas can cause stack overflow (if they are too deep)
- compiling schemas can be slow (e.g. [#557](https://github.com/ajv-validator/ajv/issues/557))
- validating certain data can be slow
It is difficult to predict all the scenarios, but at the very least it may help to limit the size of untrusted schemas (e.g. limit JSON string length) and also the maximum schema object depth (that can be high for relatively small JSON strings). You also may want to mitigate slow regular expressions in `pattern` and `patternProperties` keywords.
Regardless the measures you take, using untrusted schemas increases security risks.
##### Circular references in JavaScript objects
Ajv does not support schemas and validated data that have circular references in objects. See [issue #802](https://github.com/ajv-validator/ajv/issues/802).
An attempt to compile such schemas or validate such data would cause stack overflow (or will not complete in case of asynchronous validation). Depending on the parser you use, untrusted data can lead to circular references.
##### Security risks of trusted schemas
Some keywords in JSON Schemas can lead to very slow validation for certain data. These keywords include (but may be not limited to):
- `pattern` and `format` for large strings - in some cases using `maxLength` can help mitigate it, but certain regular expressions can lead to exponential validation time even with relatively short strings (see [ReDoS attack](#redos-attack)).
- `patternProperties` for large property names - use `propertyNames` to mitigate, but some regular expressions can have exponential evaluation time as well.
- `uniqueItems` for large non-scalar arrays - use `maxItems` to mitigate
__Please note__: The suggestions above to prevent slow validation would only work if you do NOT use `allErrors: true` in production code (using it would continue validation after validation errors).
You can validate your JSON schemas against [this meta-schema](https://github.com/ajv-validator/ajv/blob/master/lib/refs/json-schema-secure.json) to check that these recommendations are followed:
```javascript
const isSchemaSecure = ajv.compile(require('ajv/lib/refs/json-schema-secure.json'));
const schema1 = {format: 'email'};
isSchemaSecure(schema1); // false
const schema2 = {format: 'email', maxLength: MAX_LENGTH};
isSchemaSecure(schema2); // true
```
__Please note__: following all these recommendation is not a guarantee that validation of untrusted data is safe - it can still lead to some undesirable results.
##### Content Security Policies (CSP)
See [Ajv and Content Security Policies (CSP)](#ajv-and-content-security-policies-csp)
## ReDoS attack
Certain regular expressions can lead to the exponential evaluation time even with relatively short strings.
Please assess the regular expressions you use in the schemas on their vulnerability to this attack - see [safe-regex](https://github.com/substack/safe-regex), for example.
__Please note__: some formats that Ajv implements use [regular expressions](https://github.com/ajv-validator/ajv/blob/master/lib/compile/formats.js) that can be vulnerable to ReDoS attack, so if you use Ajv to validate data from untrusted sources __it is strongly recommended__ to consider the following:
- making assessment of "format" implementations in Ajv.
- using `format: 'fast'` option that simplifies some of the regular expressions (although it does not guarantee that they are safe).
- replacing format implementations provided by Ajv with your own implementations of "format" keyword that either uses different regular expressions or another approach to format validation. Please see [addFormat](#api-addformat) method.
- disabling format validation by ignoring "format" keyword with option `format: false`
Whatever mitigation you choose, please assume all formats provided by Ajv as potentially unsafe and make your own assessment of their suitability for your validation scenarios.
## Filtering data
With [option `removeAdditional`](#options) (added by [andyscott](https://github.com/andyscott)) you can filter data during the validation.
This option modifies original data.
Example:
```javascript
var ajv = new Ajv({ removeAdditional: true });
var schema = {
"additionalProperties": false,
"properties": {
"foo": { "type": "number" },
"bar": {
"additionalProperties": { "type": "number" },
"properties": {
"baz": { "type": "string" }
}
}
}
}
var data = {
"foo": 0,
"additional1": 1, // will be removed; `additionalProperties` == false
"bar": {
"baz": "abc",
"additional2": 2 // will NOT be removed; `additionalProperties` != false
},
}
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 0, "bar": { "baz": "abc", "additional2": 2 }
```
If `removeAdditional` option in the example above were `"all"` then both `additional1` and `additional2` properties would have been removed.
If the option were `"failing"` then property `additional1` would have been removed regardless of its value and property `additional2` would have been removed only if its value were failing the schema in the inner `additionalProperties` (so in the example above it would have stayed because it passes the schema, but any non-number would have been removed).
__Please note__: If you use `removeAdditional` option with `additionalProperties` keyword inside `anyOf`/`oneOf` keywords your validation can fail with this schema, for example:
```json
{
"type": "object",
"oneOf": [
{
"properties": {
"foo": { "type": "string" }
},
"required": [ "foo" ],
"additionalProperties": false
},
{
"properties": {
"bar": { "type": "integer" }
},
"required": [ "bar" ],
"additionalProperties": false
}
]
}
```
The intention of the schema above is to allow objects with either the string property "foo" or the integer property "bar", but not with both and not with any other properties.
With the option `removeAdditional: true` the validation will pass for the object `{ "foo": "abc"}` but will fail for the object `{"bar": 1}`. It happens because while the first subschema in `oneOf` is validated, the property `bar` is removed because it is an additional property according to the standard (because it is not included in `properties` keyword in the same schema).
While this behaviour is unexpected (issues [#129](https://github.com/ajv-validator/ajv/issues/129), [#134](https://github.com/ajv-validator/ajv/issues/134)), it is correct. To have the expected behaviour (both objects are allowed and additional properties are removed) the schema has to be refactored in this way:
```json
{
"type": "object",
"properties": {
"foo": { "type": "string" },
"bar": { "type": "integer" }
},
"additionalProperties": false,
"oneOf": [
{ "required": [ "foo" ] },
{ "required": [ "bar" ] }
]
}
```
The schema above is also more efficient - it will compile into a faster function.
## Assigning defaults
With [option `useDefaults`](#options) Ajv will assign values from `default` keyword in the schemas of `properties` and `items` (when it is the array of schemas) to the missing properties and items.
With the option value `"empty"` properties and items equal to `null` or `""` (empty string) will be considered missing and assigned defaults.
This option modifies original data.
__Please note__: the default value is inserted in the generated validation code as a literal, so the value inserted in the data will be the deep clone of the default in the schema.
Example 1 (`default` in `properties`):
```javascript
var ajv = new Ajv({ useDefaults: true });
var schema = {
"type": "object",
"properties": {
"foo": { "type": "number" },
"bar": { "type": "string", "default": "baz" }
},
"required": [ "foo", "bar" ]
};
var data = { "foo": 1 };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 1, "bar": "baz" }
```
Example 2 (`default` in `items`):
```javascript
var schema = {
"type": "array",
"items": [
{ "type": "number" },
{ "type": "string", "default": "foo" }
]
}
var data = [ 1 ];
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // [ 1, "foo" ]
```
`default` keywords in other cases are ignored:
- not in `properties` or `items` subschemas
- in schemas inside `anyOf`, `oneOf` and `not` (see [#42](https://github.com/ajv-validator/ajv/issues/42))
- in `if` subschema of `switch` keyword
- in schemas generated by custom macro keywords
The [`strictDefaults` option](#options) customizes Ajv's behavior for the defaults that Ajv ignores (`true` raises an error, and `"log"` outputs a warning).
## Coercing data types
When you are validating user inputs all your data properties are usually strings. The option `coerceTypes` allows you to have your data types coerced to the types specified in your schema `type` keywords, both to pass the validation and to use the correctly typed data afterwards.
This option modifies original data.
__Please note__: if you pass a scalar value to the validating function its type will be coerced and it will pass the validation, but the value of the variable you pass won't be updated because scalars are passed by value.
Example 1:
```javascript
var ajv = new Ajv({ coerceTypes: true });
var schema = {
"type": "object",
"properties": {
"foo": { "type": "number" },
"bar": { "type": "boolean" }
},
"required": [ "foo", "bar" ]
};
var data = { "foo": "1", "bar": "false" };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": 1, "bar": false }
```
Example 2 (array coercions):
```javascript
var ajv = new Ajv({ coerceTypes: 'array' });
var schema = {
"properties": {
"foo": { "type": "array", "items": { "type": "number" } },
"bar": { "type": "boolean" }
}
};
var data = { "foo": "1", "bar": ["false"] };
var validate = ajv.compile(schema);
console.log(validate(data)); // true
console.log(data); // { "foo": [1], "bar": false }
```
The coercion rules, as you can see from the example, are different from JavaScript both to validate user input as expected and to have the coercion reversible (to correctly validate cases where different types are defined in subschemas of "anyOf" and other compound keywords).
See [Coercion rules](https://github.com/ajv-validator/ajv/blob/master/COERCION.md) for details.
## API
##### new Ajv(Object options) -> Object
Create Ajv instance.
##### .compile(Object schema) -> Function<Object data>
Generate validating function and cache the compiled schema for future use.
Validating function returns a boolean value. This function has properties `errors` and `schema`. Errors encountered during the last validation are assigned to `errors` property (it is assigned `null` if there was no errors). `schema` property contains the reference to the original schema.
The schema passed to this method will be validated against meta-schema unless `validateSchema` option is false. If schema is invalid, an error will be thrown. See [options](#options).
##### <a name="api-compileAsync"></a>.compileAsync(Object schema [, Boolean meta] [, Function callback]) -> Promise
Asynchronous version of `compile` method that loads missing remote schemas using asynchronous function in `options.loadSchema`. This function returns a Promise that resolves to a validation function. An optional callback passed to `compileAsync` will be called with 2 parameters: error (or null) and validating function. The returned promise will reject (and the callback will be called with an error) when:
- missing schema can't be loaded (`loadSchema` returns a Promise that rejects).
- a schema containing a missing reference is loaded, but the reference cannot be resolved.
- schema (or some loaded/referenced schema) is invalid.
The function compiles schema and loads the first missing schema (or meta-schema) until all missing schemas are loaded.
You can asynchronously compile meta-schema by passing `true` as the second parameter.
See example in [Asynchronous compilation](#asynchronous-schema-compilation).
##### .validate(Object schema|String key|String ref, data) -> Boolean
Validate data using passed schema (it will be compiled and cached).
Instead of the schema you can use the key that was previously passed to `addSchema`, the schema id if it was present in the schema or any previously resolved reference.
Validation errors will be available in the `errors` property of Ajv instance (`null` if there were no errors).
__Please note__: every time this method is called the errors are overwritten so you need to copy them to another variable if you want to use them later.
If the schema is asynchronous (has `$async` keyword on the top level) this method returns a Promise. See [Asynchronous validation](#asynchronous-validation).
##### .addSchema(Array<Object>|Object schema [, String key]) -> Ajv
Add schema(s) to validator instance. This method does not compile schemas (but it still validates them). Because of that dependencies can be added in any order and circular dependencies are supported. It also prevents unnecessary compilation of schemas that are containers for other schemas but not used as a whole.
Array of schemas can be passed (schemas should have ids), the second parameter will be ignored.
Key can be passed that can be used to reference the schema and will be used as the schema id if there is no id inside the schema. If the key is not passed, the schema id will be used as the key.
Once the schema is added, it (and all the references inside it) can be referenced in other schemas and used to validate data.
Although `addSchema` does not compile schemas, explicit compilation is not required - the schema will be compiled when it is used first time.
By default the schema is validated against meta-schema before it is added, and if the schema does not pass validation the exception is thrown. This behaviour is controlled by `validateSchema` option.
__Please note__: Ajv uses the [method chaining syntax](https://en.wikipedia.org/wiki/Method_chaining) for all methods with the prefix `add*` and `remove*`.
This allows you to do nice things like the following.
```javascript
var validate = new Ajv().addSchema(schema).addFormat(name, regex).getSchema(uri);
```
##### .addMetaSchema(Array<Object>|Object schema [, String key]) -> Ajv
Adds meta schema(s) that can be used to validate other schemas. That function should be used instead of `addSchema` because there may be instance options that would compile a meta schema incorrectly (at the moment it is `removeAdditional` option).
There is no need to explicitly add draft-07 meta schema (http://json-schema.org/draft-07/schema) - it is added by default, unless option `meta` is set to `false`. You only need to use it if you have a changed meta-schema that you want to use to validate your schemas. See `validateSchema`.
##### <a name="api-validateschema"></a>.validateSchema(Object schema) -> Boolean
Validates schema. This method should be used to validate schemas rather than `validate` due to the inconsistency of `uri` format in JSON Schema standard.
By default this method is called automatically when the schema is added, so you rarely need to use it directly.
If schema doesn't have `$schema` property, it is validated against draft 6 meta-schema (option `meta` should not be false).
If schema has `$schema` property, then the schema with this id (that should be previously added) is used to validate passed schema.
Errors will be available at `ajv.errors`.
##### .getSchema(String key) -> Function<Object data>
Retrieve compiled schema previously added with `addSchema` by the key passed to `addSchema` or by its full reference (id). The returned validating function has `schema` property with the reference to the original schema.
##### .removeSchema([Object schema|String key|String ref|RegExp pattern]) -> Ajv
Remove added/cached schema. Even if schema is referenced by other schemas it can be safely removed as dependent schemas have local references.
Schema can be removed using:
- key passed to `addSchema`
- it's full reference (id)
- RegExp that should match schema id or key (meta-schemas won't be removed)
- actual schema object that will be stable-stringified to remove schema from cache
If no parameter is passed all schemas but meta-schemas will be removed and the cache will be cleared.
##### <a name="api-addformat"></a>.addFormat(String name, String|RegExp|Function|Object format) -> Ajv
Add custom format to validate strings or numbers. It can also be used to replace pre-defined formats for Ajv instance.
Strings are converted to RegExp.
Function should return validation result as `true` or `false`.
If object is passed it should have properties `validate`, `compare` and `async`:
- _validate_: a string, RegExp or a function as described above.
- _compare_: an optional comparison function that accepts two strings and compares them according to the format meaning. This function is used with keywords `formatMaximum`/`formatMinimum` (defined in [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) package). It should return `1` if the first value is bigger than the second value, `-1` if it is smaller and `0` if it is equal.
- _async_: an optional `true` value if `validate` is an asynchronous function; in this case it should return a promise that resolves with a value `true` or `false`.
- _type_: an optional type of data that the format applies to. It can be `"string"` (default) or `"number"` (see https://github.com/ajv-validator/ajv/issues/291#issuecomment-259923858). If the type of data is different, the validation will pass.
Custom formats can be also added via `formats` option.
##### <a name="api-addkeyword"></a>.addKeyword(String keyword, Object definition) -> Ajv
Add custom validation keyword to Ajv instance.
Keyword should be different from all standard JSON Schema keywords and different from previously defined keywords. There is no way to redefine keywords or to remove keyword definition from the instance.
Keyword must start with a letter, `_` or `$`, and may continue with letters, numbers, `_`, `$`, or `-`.
It is recommended to use an application-specific prefix for keywords to avoid current and future name collisions.
Example Keywords:
- `"xyz-example"`: valid, and uses prefix for the xyz project to avoid name collisions.
- `"example"`: valid, but not recommended as it could collide with future versions of JSON Schema etc.
- `"3-example"`: invalid as numbers are not allowed to be the first character in a keyword
Keyword definition is an object with the following properties:
- _type_: optional string or array of strings with data type(s) that the keyword applies to. If not present, the keyword will apply to all types.
- _validate_: validating function
- _compile_: compiling function
- _macro_: macro function
- _inline_: compiling function that returns code (as string)
- _schema_: an optional `false` value used with "validate" keyword to not pass schema
- _metaSchema_: an optional meta-schema for keyword schema
- _dependencies_: an optional list of properties that must be present in the parent schema - it will be checked during schema compilation
- _modifying_: `true` MUST be passed if keyword modifies data
- _statements_: `true` can be passed in case inline keyword generates statements (as opposed to expression)
- _valid_: pass `true`/`false` to pre-define validation result, the result returned from validation function will be ignored. This option cannot be used with macro keywords.
- _$data_: an optional `true` value to support [$data reference](#data-reference) as the value of custom keyword. The reference will be resolved at validation time. If the keyword has meta-schema it would be extended to allow $data and it will be used to validate the resolved value. Supporting $data reference requires that keyword has validating function (as the only option or in addition to compile, macro or inline function).
- _async_: an optional `true` value if the validation function is asynchronous (whether it is compiled or passed in _validate_ property); in this case it should return a promise that resolves with a value `true` or `false`. This option is ignored in case of "macro" and "inline" keywords.
- _errors_: an optional boolean or string `"full"` indicating whether keyword returns errors. If this property is not set Ajv will determine if the errors were set in case of failed validation.
_compile_, _macro_ and _inline_ are mutually exclusive, only one should be used at a time. _validate_ can be used separately or in addition to them to support $data reference.
__Please note__: If the keyword is validating data type that is different from the type(s) in its definition, the validation function will not be called (and expanded macro will not be used), so there is no need to check for data type inside validation function or inside schema returned by macro function (unless you want to enforce a specific type and for some reason do not want to use a separate `type` keyword for that). In the same way as standard keywords work, if the keyword does not apply to the data type being validated, the validation of this keyword will succeed.
See [Defining custom keywords](#defining-custom-keywords) for more details.
##### .getKeyword(String keyword) -> Object|Boolean
Returns custom keyword definition, `true` for pre-defined keywords and `false` if the keyword is unknown.
##### .removeKeyword(String keyword) -> Ajv
Removes custom or pre-defined keyword so you can redefine them.
While this method can be used to extend pre-defined keywords, it can also be used to completely change their meaning - it may lead to unexpected results.
__Please note__: schemas compiled before the keyword is removed will continue to work without changes. To recompile schemas use `removeSchema` method and compile them again.
##### .errorsText([Array<Object> errors [, Object options]]) -> String
Returns the text with all errors in a String.
Options can have properties `separator` (string used to separate errors, ", " by default) and `dataVar` (the variable name that dataPaths are prefixed with, "data" by default).
## Options
Defaults:
```javascript
{
// validation and reporting options:
$data: false,
allErrors: false,
verbose: false,
$comment: false, // NEW in Ajv version 6.0
jsonPointers: false,
uniqueItems: true,
unicode: true,
nullable: false,
format: 'fast',
formats: {},
unknownFormats: true,
schemas: {},
logger: undefined,
// referenced schema options:
schemaId: '$id',
missingRefs: true,
extendRefs: 'ignore', // recommended 'fail'
loadSchema: undefined, // function(uri: string): Promise {}
// options to modify validated data:
removeAdditional: false,
useDefaults: false,
coerceTypes: false,
// strict mode options
strictDefaults: false,
strictKeywords: false,
strictNumbers: false,
// asynchronous validation options:
transpile: undefined, // requires ajv-async package
// advanced options:
meta: true,
validateSchema: true,
addUsedSchema: true,
inlineRefs: true,
passContext: false,
loopRequired: Infinity,
ownProperties: false,
multipleOfPrecision: false,
errorDataPath: 'object', // deprecated
messages: true,
sourceCode: false,
processCode: undefined, // function (str: string, schema: object): string {}
cache: new Cache,
serialize: undefined
}
```
##### Validation and reporting options
- _$data_: support [$data references](#data-reference). Draft 6 meta-schema that is added by default will be extended to allow them. If you want to use another meta-schema you need to use $dataMetaSchema method to add support for $data reference. See [API](#api).
- _allErrors_: check all rules collecting all errors. Default is to return after the first error.
- _verbose_: include the reference to the part of the schema (`schema` and `parentSchema`) and validated data in errors (false by default).
- _$comment_ (NEW in Ajv version 6.0): log or pass the value of `$comment` keyword to a function. Option values:
- `false` (default): ignore $comment keyword.
- `true`: log the keyword value to console.
- function: pass the keyword value, its schema path and root schema to the specified function
- _jsonPointers_: set `dataPath` property of errors using [JSON Pointers](https://tools.ietf.org/html/rfc6901) instead of JavaScript property access notation.
- _uniqueItems_: validate `uniqueItems` keyword (true by default).
- _unicode_: calculate correct length of strings with unicode pairs (true by default). Pass `false` to use `.length` of strings that is faster, but gives "incorrect" lengths of strings with unicode pairs - each unicode pair is counted as two characters.
- _nullable_: support keyword "nullable" from [Open API 3 specification](https://swagger.io/docs/specification/data-models/data-types/).
- _format_: formats validation mode. Option values:
- `"fast"` (default) - simplified and fast validation (see [Formats](#formats) for details of which formats are available and affected by this option).
- `"full"` - more restrictive and slow validation. E.g., 25:00:00 and 2015/14/33 will be invalid time and date in 'full' mode but it will be valid in 'fast' mode.
- `false` - ignore all format keywords.
- _formats_: an object with custom formats. Keys and values will be passed to `addFormat` method.
- _keywords_: an object with custom keywords. Keys and values will be passed to `addKeyword` method.
- _unknownFormats_: handling of unknown formats. Option values:
- `true` (default) - if an unknown format is encountered the exception is thrown during schema compilation. If `format` keyword value is [$data reference](#data-reference) and it is unknown the validation will fail.
- `[String]` - an array of unknown format names that will be ignored. This option can be used to allow usage of third party schemas with format(s) for which you don't have definitions, but still fail if another unknown format is used. If `format` keyword value is [$data reference](#data-reference) and it is not in this array the validation will fail.
- `"ignore"` - to log warning during schema compilation and always pass validation (the default behaviour in versions before 5.0.0). This option is not recommended, as it allows to mistype format name and it won't be validated without any error message. This behaviour is required by JSON Schema specification.
- _schemas_: an array or object of schemas that will be added to the instance. In case you pass the array the schemas must have IDs in them. When the object is passed the method `addSchema(value, key)` will be called for each schema in this object.
- _logger_: sets the logging method. Default is the global `console` object that should have methods `log`, `warn` and `error`. See [Error logging](#error-logging). Option values:
- custom logger - it should have methods `log`, `warn` and `error`. If any of these methods is missing an exception will be thrown.
- `false` - logging is disabled.
##### Referenced schema options
- _schemaId_: this option defines which keywords are used as schema URI. Option value:
- `"$id"` (default) - only use `$id` keyword as schema URI (as specified in JSON Schema draft-06/07), ignore `id` keyword (if it is present a warning will be logged).
- `"id"` - only use `id` keyword as schema URI (as specified in JSON Schema draft-04), ignore `$id` keyword (if it is present a warning will be logged).
- `"auto"` - use both `$id` and `id` keywords as schema URI. If both are present (in the same schema object) and different the exception will be thrown during schema compilation.
- _missingRefs_: handling of missing referenced schemas. Option values:
- `true` (default) - if the reference cannot be resolved during compilation the exception is thrown. The thrown error has properties `missingRef` (with hash fragment) and `missingSchema` (without it). Both properties are resolved relative to the current base id (usually schema id, unless it was substituted).
- `"ignore"` - to log error during compilation and always pass validation.
- `"fail"` - to log error and successfully compile schema but fail validation if this rule is checked.
- _extendRefs_: validation of other keywords when `$ref` is present in the schema. Option values:
- `"ignore"` (default) - when `$ref` is used other keywords are ignored (as per [JSON Reference](https://tools.ietf.org/html/draft-pbryan-zyp-json-ref-03#section-3) standard). A warning will be logged during the schema compilation.
- `"fail"` (recommended) - if other validation keywords are used together with `$ref` the exception will be thrown when the schema is compiled. This option is recommended to make sure schema has no keywords that are ignored, which can be confusing.
- `true` - validate all keywords in the schemas with `$ref` (the default behaviour in versions before 5.0.0).
- _loadSchema_: asynchronous function that will be used to load remote schemas when `compileAsync` [method](#api-compileAsync) is used and some reference is missing (option `missingRefs` should NOT be 'fail' or 'ignore'). This function should accept remote schema uri as a parameter and return a Promise that resolves to a schema. See example in [Asynchronous compilation](#asynchronous-schema-compilation).
##### Options to modify validated data
- _removeAdditional_: remove additional properties - see example in [Filtering data](#filtering-data). This option is not used if schema is added with `addMetaSchema` method. Option values:
- `false` (default) - not to remove additional properties
- `"all"` - all additional properties are removed, regardless of `additionalProperties` keyword in schema (and no validation is made for them).
- `true` - only additional properties with `additionalProperties` keyword equal to `false` are removed.
- `"failing"` - additional properties that fail schema validation will be removed (where `additionalProperties` keyword is `false` or schema).
- _useDefaults_: replace missing or undefined properties and items with the values from corresponding `default` keywords. Default behaviour is to ignore `default` keywords. This option is not used if schema is added with `addMetaSchema` method. See examples in [Assigning defaults](#assigning-defaults). Option values:
- `false` (default) - do not use defaults
- `true` - insert defaults by value (object literal is used).
- `"empty"` - in addition to missing or undefined, use defaults for properties and items that are equal to `null` or `""` (an empty string).
- `"shared"` (deprecated) - insert defaults by reference. If the default is an object, it will be shared by all instances of validated data. If you modify the inserted default in the validated data, it will be modified in the schema as well.
- _coerceTypes_: change data type of data to match `type` keyword. See the example in [Coercing data types](#coercing-data-types) and [coercion rules](https://github.com/ajv-validator/ajv/blob/master/COERCION.md). Option values:
- `false` (default) - no type coercion.
- `true` - coerce scalar data types.
- `"array"` - in addition to coercions between scalar types, coerce scalar data to an array with one element and vice versa (as required by the schema).
##### Strict mode options
- _strictDefaults_: report ignored `default` keywords in schemas. Option values:
- `false` (default) - ignored defaults are not reported
- `true` - if an ignored default is present, throw an error
- `"log"` - if an ignored default is present, log warning
- _strictKeywords_: report unknown keywords in schemas. Option values:
- `false` (default) - unknown keywords are not reported
- `true` - if an unknown keyword is present, throw an error
- `"log"` - if an unknown keyword is present, log warning
- _strictNumbers_: validate numbers strictly, failing validation for NaN and Infinity. Option values:
- `false` (default) - NaN or Infinity will pass validation for numeric types
- `true` - NaN or Infinity will not pass validation for numeric types
##### Asynchronous validation options
- _transpile_: Requires [ajv-async](https://github.com/ajv-validator/ajv-async) package. It determines whether Ajv transpiles compiled asynchronous validation function. Option values:
- `undefined` (default) - transpile with [nodent](https://github.com/MatAtBread/nodent) if async functions are not supported.
- `true` - always transpile with nodent.
- `false` - do not transpile; if async functions are not supported an exception will be thrown.
##### Advanced options
- _meta_: add [meta-schema](http://json-schema.org/documentation.html) so it can be used by other schemas (true by default). If an object is passed, it will be used as the default meta-schema for schemas that have no `$schema` keyword. This default meta-schema MUST have `$schema` keyword.
- _validateSchema_: validate added/compiled schemas against meta-schema (true by default). `$schema` property in the schema can be http://json-schema.org/draft-07/schema or absent (draft-07 meta-schema will be used) or can be a reference to the schema previously added with `addMetaSchema` method. Option values:
- `true` (default) - if the validation fails, throw the exception.
- `"log"` - if the validation fails, log error.
- `false` - skip schema validation.
- _addUsedSchema_: by default methods `compile` and `validate` add schemas to the instance if they have `$id` (or `id`) property that doesn't start with "#". If `$id` is present and it is not unique the exception will be thrown. Set this option to `false` to skip adding schemas to the instance and the `$id` uniqueness check when these methods are used. This option does not affect `addSchema` method.
- _inlineRefs_: Affects compilation of referenced schemas. Option values:
- `true` (default) - the referenced schemas that don't have refs in them are inlined, regardless of their size - that substantially improves performance at the cost of the bigger size of compiled schema functions.
- `false` - to not inline referenced schemas (they will be compiled as separate functions).
- integer number - to limit the maximum number of keywords of the schema that will be inlined.
- _passContext_: pass validation context to custom keyword functions. If this option is `true` and you pass some context to the compiled validation function with `validate.call(context, data)`, the `context` will be available as `this` in your custom keywords. By default `this` is Ajv instance.
- _loopRequired_: by default `required` keyword is compiled into a single expression (or a sequence of statements in `allErrors` mode). In case of a very large number of properties in this keyword it may result in a very big validation function. Pass integer to set the number of properties above which `required` keyword will be validated in a loop - smaller validation function size but also worse performance.
- _ownProperties_: by default Ajv iterates over all enumerable object properties; when this option is `true` only own enumerable object properties (i.e. found directly on the object rather than on its prototype) are iterated. Contributed by @mbroadst.
- _multipleOfPrecision_: by default `multipleOf` keyword is validated by comparing the result of division with parseInt() of that result. It works for dividers that are bigger than 1. For small dividers such as 0.01 the result of the division is usually not integer (even when it should be integer, see issue [#84](https://github.com/ajv-validator/ajv/issues/84)). If you need to use fractional dividers set this option to some positive integer N to have `multipleOf` validated using this formula: `Math.abs(Math.round(division) - division) < 1e-N` (it is slower but allows for float arithmetics deviations).
- _errorDataPath_ (deprecated): set `dataPath` to point to 'object' (default) or to 'property' when validating keywords `required`, `additionalProperties` and `dependencies`.
- _messages_: Include human-readable messages in errors. `true` by default. `false` can be passed when custom messages are used (e.g. with [ajv-i18n](https://github.com/ajv-validator/ajv-i18n)).
- _sourceCode_: add `sourceCode` property to validating function (for debugging; this code can be different from the result of toString call).
- _processCode_: an optional function to process generated code before it is passed to Function constructor. It can be used to either beautify (the validating function is generated without line-breaks) or to transpile code. Starting from version 5.0.0 this option replaced options:
- `beautify` that formatted the generated function using [js-beautify](https://github.com/beautify-web/js-beautify). If you want to beautify the generated code pass a function calling `require('js-beautify').js_beautify` as `processCode: code => js_beautify(code)`.
- `transpile` that transpiled asynchronous validation function. You can still use `transpile` option with [ajv-async](https://github.com/ajv-validator/ajv-async) package. See [Asynchronous validation](#asynchronous-validation) for more information.
- _cache_: an optional instance of cache to store compiled schemas using stable-stringified schema as a key. For example, set-associative cache [sacjs](https://github.com/epoberezkin/sacjs) can be used. If not passed then a simple hash is used which is good enough for the common use case (a limited number of statically defined schemas). Cache should have methods `put(key, value)`, `get(key)`, `del(key)` and `clear()`.
- _serialize_: an optional function to serialize schema to cache key. Pass `false` to use schema itself as a key (e.g., if WeakMap used as a cache). By default [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify) is used.
## Validation errors
In case of validation failure, Ajv assigns the array of errors to `errors` property of validation function (or to `errors` property of Ajv instance when `validate` or `validateSchema` methods were called). In case of [asynchronous validation](#asynchronous-validation), the returned promise is rejected with exception `Ajv.ValidationError` that has `errors` property.
### Error objects
Each error is an object with the following properties:
- _keyword_: validation keyword.
- _dataPath_: the path to the part of the data that was validated. By default `dataPath` uses JavaScript property access notation (e.g., `".prop[1].subProp"`). When the option `jsonPointers` is true (see [Options](#options)) `dataPath` will be set using JSON pointer standard (e.g., `"/prop/1/subProp"`).
- _schemaPath_: the path (JSON-pointer as a URI fragment) to the schema of the keyword that failed validation.
- _params_: the object with the additional information about error that can be used to create custom error messages (e.g., using [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) package). See below for parameters set by all keywords.
- _message_: the standard error message (can be excluded with option `messages` set to false).
- _schema_: the schema of the keyword (added with `verbose` option).
- _parentSchema_: the schema containing the keyword (added with `verbose` option)
- _data_: the data validated by the keyword (added with `verbose` option).
__Please note__: `propertyNames` keyword schema validation errors have an additional property `propertyName`, `dataPath` points to the object. After schema validation for each property name, if it is invalid an additional error is added with the property `keyword` equal to `"propertyNames"`.
### Error parameters
Properties of `params` object in errors depend on the keyword that failed validation.
- `maxItems`, `minItems`, `maxLength`, `minLength`, `maxProperties`, `minProperties` - property `limit` (number, the schema of the keyword).
- `additionalItems` - property `limit` (the maximum number of allowed items in case when `items` keyword is an array of schemas and `additionalItems` is false).
- `additionalProperties` - property `additionalProperty` (the property not used in `properties` and `patternProperties` keywords).
- `dependencies` - properties:
- `property` (dependent property),
- `missingProperty` (required missing dependency - only the first one is reported currently)
- `deps` (required dependencies, comma separated list as a string),
- `depsCount` (the number of required dependencies).
- `format` - property `format` (the schema of the keyword).
- `maximum`, `minimum` - properties:
- `limit` (number, the schema of the keyword),
- `exclusive` (boolean, the schema of `exclusiveMaximum` or `exclusiveMinimum`),
- `comparison` (string, comparison operation to compare the data to the limit, with the data on the left and the limit on the right; can be "<", "<=", ">", ">=")
- `multipleOf` - property `multipleOf` (the schema of the keyword)
- `pattern` - property `pattern` (the schema of the keyword)
- `required` - property `missingProperty` (required property that is missing).
- `propertyNames` - property `propertyName` (an invalid property name).
- `patternRequired` (in ajv-keywords) - property `missingPattern` (required pattern that did not match any property).
- `type` - property `type` (required type(s), a string, can be a comma-separated list)
- `uniqueItems` - properties `i` and `j` (indices of duplicate items).
- `const` - property `allowedValue` pointing to the value (the schema of the keyword).
- `enum` - property `allowedValues` pointing to the array of values (the schema of the keyword).
- `$ref` - property `ref` with the referenced schema URI.
- `oneOf` - property `passingSchemas` (array of indices of passing schemas, null if no schema passes).
- custom keywords (in case keyword definition doesn't create errors) - property `keyword` (the keyword name).
### Error logging
Using the `logger` option when initiallizing Ajv will allow you to define custom logging. Here you can build upon the exisiting logging. The use of other logging packages is supported as long as the package or its associated wrapper exposes the required methods. If any of the required methods are missing an exception will be thrown.
- **Required Methods**: `log`, `warn`, `error`
```javascript
var otherLogger = new OtherLogger();
var ajv = new Ajv({
logger: {
log: console.log.bind(console),
warn: function warn() {
otherLogger.logWarn.apply(otherLogger, arguments);
},
error: function error() {
otherLogger.logError.apply(otherLogger, arguments);
console.error.apply(console, arguments);
}
}
});
```
## Plugins
Ajv can be extended with plugins that add custom keywords, formats or functions to process generated code. When such plugin is published as npm package it is recommended that it follows these conventions:
- it exports a function
- this function accepts ajv instance as the first parameter and returns the same instance to allow chaining
- this function can accept an optional configuration as the second parameter
If you have published a useful plugin please submit a PR to add it to the next section.
## Related packages
- [ajv-async](https://github.com/ajv-validator/ajv-async) - plugin to configure async validation mode
- [ajv-bsontype](https://github.com/BoLaMN/ajv-bsontype) - plugin to validate mongodb's bsonType formats
- [ajv-cli](https://github.com/jessedc/ajv-cli) - command line interface
- [ajv-errors](https://github.com/ajv-validator/ajv-errors) - plugin for custom error messages
- [ajv-i18n](https://github.com/ajv-validator/ajv-i18n) - internationalised error messages
- [ajv-istanbul](https://github.com/ajv-validator/ajv-istanbul) - plugin to instrument generated validation code to measure test coverage of your schemas
- [ajv-keywords](https://github.com/ajv-validator/ajv-keywords) - plugin with custom validation keywords (select, typeof, etc.)
- [ajv-merge-patch](https://github.com/ajv-validator/ajv-merge-patch) - plugin with keywords $merge and $patch
- [ajv-pack](https://github.com/ajv-validator/ajv-pack) - produces a compact module exporting validation functions
- [ajv-formats-draft2019](https://github.com/luzlab/ajv-formats-draft2019) - format validators for draft2019 that aren't already included in ajv (ie. `idn-hostname`, `idn-email`, `iri`, `iri-reference` and `duration`).
## Some packages using Ajv
- [webpack](https://github.com/webpack/webpack) - a module bundler. Its main purpose is to bundle JavaScript files for usage in a browser
- [jsonscript-js](https://github.com/JSONScript/jsonscript-js) - the interpreter for [JSONScript](http://www.jsonscript.org) - scripted processing of existing endpoints and services
- [osprey-method-handler](https://github.com/mulesoft-labs/osprey-method-handler) - Express middleware for validating requests and responses based on a RAML method object, used in [osprey](https://github.com/mulesoft/osprey) - validating API proxy generated from a RAML definition
- [har-validator](https://github.com/ahmadnassri/har-validator) - HTTP Archive (HAR) validator
- [jsoneditor](https://github.com/josdejong/jsoneditor) - a web-based tool to view, edit, format, and validate JSON http://jsoneditoronline.org
- [JSON Schema Lint](https://github.com/nickcmaynard/jsonschemalint) - a web tool to validate JSON/YAML document against a single JSON Schema http://jsonschemalint.com
- [objection](https://github.com/vincit/objection.js) - SQL-friendly ORM for Node.js
- [table](https://github.com/gajus/table) - formats data into a string table
- [ripple-lib](https://github.com/ripple/ripple-lib) - a JavaScript API for interacting with [Ripple](https://ripple.com) in Node.js and the browser
- [restbase](https://github.com/wikimedia/restbase) - distributed storage with REST API & dispatcher for backend services built to provide a low-latency & high-throughput API for Wikipedia / Wikimedia content
- [hippie-swagger](https://github.com/CacheControl/hippie-swagger) - [Hippie](https://github.com/vesln/hippie) wrapper that provides end to end API testing with swagger validation
- [react-form-controlled](https://github.com/seeden/react-form-controlled) - React controlled form components with validation
- [rabbitmq-schema](https://github.com/tjmehta/rabbitmq-schema) - a schema definition module for RabbitMQ graphs and messages
- [@query/schema](https://www.npmjs.com/package/@query/schema) - stream filtering with a URI-safe query syntax parsing to JSON Schema
- [chai-ajv-json-schema](https://github.com/peon374/chai-ajv-json-schema) - chai plugin to us JSON Schema with expect in mocha tests
- [grunt-jsonschema-ajv](https://github.com/SignpostMarv/grunt-jsonschema-ajv) - Grunt plugin for validating files against JSON Schema
- [extract-text-webpack-plugin](https://github.com/webpack-contrib/extract-text-webpack-plugin) - extract text from bundle into a file
- [electron-builder](https://github.com/electron-userland/electron-builder) - a solution to package and build a ready for distribution Electron app
- [addons-linter](https://github.com/mozilla/addons-linter) - Mozilla Add-ons Linter
- [gh-pages-generator](https://github.com/epoberezkin/gh-pages-generator) - multi-page site generator converting markdown files to GitHub pages
- [ESLint](https://github.com/eslint/eslint) - the pluggable linting utility for JavaScript and JSX
## Tests
```
npm install
git submodule update --init
npm test
```
## Contributing
All validation functions are generated using doT templates in [dot](https://github.com/ajv-validator/ajv/tree/master/lib/dot) folder. Templates are precompiled so doT is not a run-time dependency.
`npm run build` - compiles templates to [dotjs](https://github.com/ajv-validator/ajv/tree/master/lib/dotjs) folder.
`npm run watch` - automatically compiles templates when files in dot folder change
Please see [Contributing guidelines](https://github.com/ajv-validator/ajv/blob/master/CONTRIBUTING.md)
## Changes history
See https://github.com/ajv-validator/ajv/releases
__Please note__: [Changes in version 7.0.0-beta](https://github.com/ajv-validator/ajv/releases/tag/v7.0.0-beta.0)
[Version 6.0.0](https://github.com/ajv-validator/ajv/releases/tag/v6.0.0).
## Code of conduct
Please review and follow the [Code of conduct](https://github.com/ajv-validator/ajv/blob/master/CODE_OF_CONDUCT.md).
Please report any unacceptable behaviour to [email protected] - it will be reviewed by the project team.
## Open-source software support
Ajv is a part of [Tidelift subscription](https://tidelift.com/subscription/pkg/npm-ajv?utm_source=npm-ajv&utm_medium=referral&utm_campaign=readme) - it provides a centralised support to open-source software users, in addition to the support provided by software maintainers.
## License
[MIT](https://github.com/ajv-validator/ajv/blob/master/LICENSE)
# y18n
[![Build Status][travis-image]][travis-url]
[![Coverage Status][coveralls-image]][coveralls-url]
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[](https://conventionalcommits.org)
The bare-bones internationalization library used by yargs.
Inspired by [i18n](https://www.npmjs.com/package/i18n).
## Examples
_simple string translation:_
```js
var __ = require('y18n').__
console.log(__('my awesome string %s', 'foo'))
```
output:
`my awesome string foo`
_using tagged template literals_
```js
var __ = require('y18n').__
var str = 'foo'
console.log(__`my awesome string ${str}`)
```
output:
`my awesome string foo`
_pluralization support:_
```js
var __n = require('y18n').__n
console.log(__n('one fish %s', '%d fishes %s', 2, 'foo'))
```
output:
`2 fishes foo`
## JSON Language Files
The JSON language files should be stored in a `./locales` folder.
File names correspond to locales, e.g., `en.json`, `pirate.json`.
When strings are observed for the first time they will be
added to the JSON file corresponding to the current locale.
## Methods
### require('y18n')(config)
Create an instance of y18n with the config provided, options include:
* `directory`: the locale directory, default `./locales`.
* `updateFiles`: should newly observed strings be updated in file, default `true`.
* `locale`: what locale should be used.
* `fallbackToLanguage`: should fallback to a language-only file (e.g. `en.json`)
be allowed if a file matching the locale does not exist (e.g. `en_US.json`),
default `true`.
### y18n.\_\_(str, arg, arg, arg)
Print a localized string, `%s` will be replaced with `arg`s.
This function can also be used as a tag for a template literal. You can use it
like this: <code>__`hello ${'world'}`</code>. This will be equivalent to
`__('hello %s', 'world')`.
### y18n.\_\_n(singularString, pluralString, count, arg, arg, arg)
Print a localized string with appropriate pluralization. If `%d` is provided
in the string, the `count` will replace this placeholder.
### y18n.setLocale(str)
Set the current locale being used.
### y18n.getLocale()
What locale is currently being used?
### y18n.updateLocale(obj)
Update the current locale with the key value pairs in `obj`.
## License
ISC
[travis-url]: https://travis-ci.org/yargs/y18n
[travis-image]: https://img.shields.io/travis/yargs/y18n.svg
[coveralls-url]: https://coveralls.io/github/yargs/y18n
[coveralls-image]: https://img.shields.io/coveralls/yargs/y18n.svg
[npm-url]: https://npmjs.org/package/y18n
[npm-image]: https://img.shields.io/npm/v/y18n.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: https://github.com/feross/standard
# Acorn-JSX
[](https://travis-ci.org/acornjs/acorn-jsx)
[](https://www.npmjs.org/package/acorn-jsx)
This is plugin for [Acorn](http://marijnhaverbeke.nl/acorn/) - a tiny, fast JavaScript parser, written completely in JavaScript.
It was created as an experimental alternative, faster [React.js JSX](http://facebook.github.io/react/docs/jsx-in-depth.html) parser. Later, it replaced the [official parser](https://github.com/facebookarchive/esprima) and these days is used by many prominent development tools.
## Transpiler
Please note that this tool only parses source code to JSX AST, which is useful for various language tools and services. If you want to transpile your code to regular ES5-compliant JavaScript with source map, check out [Babel](https://babeljs.io/) and [Buble](https://buble.surge.sh/) transpilers which use `acorn-jsx` under the hood.
## Usage
Requiring this module provides you with an Acorn plugin that you can use like this:
```javascript
var acorn = require("acorn");
var jsx = require("acorn-jsx");
acorn.Parser.extend(jsx()).parse("my(<jsx/>, 'code');");
```
Note that official spec doesn't support mix of XML namespaces and object-style access in tag names (#27) like in `<namespace:Object.Property />`, so it was deprecated in `[email protected]`. If you still want to opt-in to support of such constructions, you can pass the following option:
```javascript
acorn.Parser.extend(jsx({ allowNamespacedObjects: true }))
```
Also, since most apps use pure React transformer, a new option was introduced that allows to prohibit namespaces completely:
```javascript
acorn.Parser.extend(jsx({ allowNamespaces: false }))
```
Note that by default `allowNamespaces` is enabled for spec compliancy.
## License
This plugin is issued under the [MIT license](./LICENSE).
# once
Only call a function once.
## usage
```javascript
var once = require('once')
function load (file, cb) {
cb = once(cb)
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Or add to the Function.prototype in a responsible way:
```javascript
// only has to be done once
require('once').proto()
function load (file, cb) {
cb = cb.once()
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Ironically, the prototype feature makes this module twice as
complicated as necessary.
To check whether you function has been called, use `fn.called`. Once the
function is called for the first time the return value of the original
function is saved in `fn.value` and subsequent calls will continue to
return this value.
```javascript
var once = require('once')
function load (cb) {
cb = once(cb)
var stream = createStream()
stream.once('data', cb)
stream.once('end', function () {
if (!cb.called) cb(new Error('not found'))
})
}
```
## `once.strict(func)`
Throw an error if the function is called twice.
Some functions are expected to be called only once. Using `once` for them would
potentially hide logical errors.
In the example below, the `greet` function has to call the callback only once:
```javascript
function greet (name, cb) {
// return is missing from the if statement
// when no name is passed, the callback is called twice
if (!name) cb('Hello anonymous')
cb('Hello ' + name)
}
function log (msg) {
console.log(msg)
}
// this will print 'Hello anonymous' but the logical error will be missed
greet(null, once(msg))
// once.strict will print 'Hello anonymous' and throw an error when the callback will be called the second time
greet(null, once.strict(msg))
```
# is-extglob [](https://www.npmjs.com/package/is-extglob) [](https://npmjs.org/package/is-extglob) [](https://travis-ci.org/jonschlinkert/is-extglob)
> Returns true if a string has an extglob.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-extglob
```
## Usage
```js
var isExtglob = require('is-extglob');
```
**True**
```js
isExtglob('?(abc)');
isExtglob('@(abc)');
isExtglob('!(abc)');
isExtglob('*(abc)');
isExtglob('+(abc)');
```
**False**
Escaped extglobs:
```js
isExtglob('\\?(abc)');
isExtglob('\\@(abc)');
isExtglob('\\!(abc)');
isExtglob('\\*(abc)');
isExtglob('\\+(abc)');
```
Everything else...
```js
isExtglob('foo.js');
isExtglob('!foo.js');
isExtglob('*.js');
isExtglob('**/abc.js');
isExtglob('abc/*.js');
isExtglob('abc/(aaa|bbb).js');
isExtglob('abc/[a-z].js');
isExtglob('abc/{a,b}.js');
isExtglob('abc/?.js');
isExtglob('abc.js');
isExtglob('abc/def/ghi.js');
```
## History
**v2.0**
Adds support for escaping. Escaped exglobs no longer return true.
## About
### Related projects
* [has-glob](https://www.npmjs.com/package/has-glob): Returns `true` if an array has a glob pattern. | [homepage](https://github.com/jonschlinkert/has-glob "Returns `true` if an array has a glob pattern.")
* [is-glob](https://www.npmjs.com/package/is-glob): Returns `true` if the given string looks like a glob pattern or an extglob pattern… [more](https://github.com/jonschlinkert/is-glob) | [homepage](https://github.com/jonschlinkert/is-glob "Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a bet")
* [micromatch](https://www.npmjs.com/package/micromatch): Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch. | [homepage](https://github.com/jonschlinkert/micromatch "Glob matching for javascript/node.js. A drop-in replacement and faster alternative to minimatch and multimatch.")
### Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Building docs
_(This document was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme) (a [verb](https://github.com/verbose/verb) generator), please don't edit the readme directly. Any changes to the readme must be made in [.verb.md](.verb.md).)_
To generate the readme and API documentation with [verb](https://github.com/verbose/verb):
```sh
$ npm install -g verb verb-generate-readme && verb
```
### Running tests
Install dev dependencies:
```sh
$ npm install -d && npm test
```
### Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
### License
Copyright © 2016, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT license](https://github.com/jonschlinkert/is-extglob/blob/master/LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.1.31, on October 12, 2016._
Browser-friendly inheritance fully compatible with standard node.js
[inherits](http://nodejs.org/api/util.html#util_util_inherits_constructor_superconstructor).
This package exports standard `inherits` from node.js `util` module in
node environment, but also provides alternative browser-friendly
implementation through [browser
field](https://gist.github.com/shtylman/4339901). Alternative
implementation is a literal copy of standard one located in standalone
module to avoid requiring of `util`. It also has a shim for old
browsers with no `Object.create` support.
While keeping you sure you are using standard `inherits`
implementation in node.js environment, it allows bundlers such as
[browserify](https://github.com/substack/node-browserify) to not
include full `util` package to your client code if all you need is
just `inherits` function. It worth, because browser shim for `util`
package is large and `inherits` is often the single function you need
from it.
It's recommended to use this package instead of
`require('util').inherits` for any code that has chances to be used
not only in node.js but in browser too.
## usage
```js
var inherits = require('inherits');
// then use exactly as the standard one
```
## note on version ~1.0
Version ~1.0 had completely different motivation and is not compatible
neither with 2.0 nor with standard node.js `inherits`.
If you are using version ~1.0 and planning to switch to ~2.0, be
careful:
* new version uses `super_` instead of `super` for referencing
superclass
* new version overwrites current prototype while old one preserves any
existing fields on it
# minimatch
A minimal matching utility.
[](http://travis-ci.org/isaacs/minimatch)
This is the matching library used internally by npm.
It works by converting glob expressions into JavaScript `RegExp`
objects.
## Usage
```javascript
var minimatch = require("minimatch")
minimatch("bar.foo", "*.foo") // true!
minimatch("bar.foo", "*.bar") // false!
minimatch("bar.foo", "*.+(bar|foo)", { debug: true }) // true, and noisy!
```
## Features
Supports these glob features:
* Brace Expansion
* Extended glob matching
* "Globstar" `**` matching
See:
* `man sh`
* `man bash`
* `man 3 fnmatch`
* `man 5 gitignore`
## Minimatch Class
Create a minimatch object by instantiating the `minimatch.Minimatch` class.
```javascript
var Minimatch = require("minimatch").Minimatch
var mm = new Minimatch(pattern, options)
```
### Properties
* `pattern` The original pattern the minimatch object represents.
* `options` The options supplied to the constructor.
* `set` A 2-dimensional array of regexp or string expressions.
Each row in the
array corresponds to a brace-expanded pattern. Each item in the row
corresponds to a single path-part. For example, the pattern
`{a,b/c}/d` would expand to a set of patterns like:
[ [ a, d ]
, [ b, c, d ] ]
If a portion of the pattern doesn't have any "magic" in it
(that is, it's something like `"foo"` rather than `fo*o?`), then it
will be left as a string rather than converted to a regular
expression.
* `regexp` Created by the `makeRe` method. A single regular expression
expressing the entire pattern. This is useful in cases where you wish
to use the pattern somewhat like `fnmatch(3)` with `FNM_PATH` enabled.
* `negate` True if the pattern is negated.
* `comment` True if the pattern is a comment.
* `empty` True if the pattern is `""`.
### Methods
* `makeRe` Generate the `regexp` member if necessary, and return it.
Will return `false` if the pattern is invalid.
* `match(fname)` Return true if the filename matches the pattern, or
false otherwise.
* `matchOne(fileArray, patternArray, partial)` Take a `/`-split
filename, and match it against a single row in the `regExpSet`. This
method is mainly for internal use, but is exposed so that it can be
used by a glob-walker that needs to avoid excessive filesystem calls.
All other methods are internal, and will be called as necessary.
### minimatch(path, pattern, options)
Main export. Tests a path against the pattern using the options.
```javascript
var isJS = minimatch(file, "*.js", { matchBase: true })
```
### minimatch.filter(pattern, options)
Returns a function that tests its
supplied argument, suitable for use with `Array.filter`. Example:
```javascript
var javascripts = fileList.filter(minimatch.filter("*.js", {matchBase: true}))
```
### minimatch.match(list, pattern, options)
Match against the list of
files, in the style of fnmatch or glob. If nothing is matched, and
options.nonull is set, then return a list containing the pattern itself.
```javascript
var javascripts = minimatch.match(fileList, "*.js", {matchBase: true}))
```
### minimatch.makeRe(pattern, options)
Make a regular expression object from the pattern.
## Options
All options are `false` by default.
### debug
Dump a ton of stuff to stderr.
### nobrace
Do not expand `{a,b}` and `{1..3}` brace sets.
### noglobstar
Disable `**` matching against multiple folder names.
### dot
Allow patterns to match filenames starting with a period, even if
the pattern does not explicitly have a period in that spot.
Note that by default, `a/**/b` will **not** match `a/.d/b`, unless `dot`
is set.
### noext
Disable "extglob" style patterns like `+(a|b)`.
### nocase
Perform a case-insensitive match.
### nonull
When a match is not found by `minimatch.match`, return a list containing
the pattern itself if this option is set. When not set, an empty list
is returned if there are no matches.
### matchBase
If set, then patterns without slashes will be matched
against the basename of the path if it contains slashes. For example,
`a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`.
### nocomment
Suppress the behavior of treating `#` at the start of a pattern as a
comment.
### nonegate
Suppress the behavior of treating a leading `!` character as negation.
### flipNegate
Returns from negate expressions the same as if they were not negated.
(Ie, true on a hit, false on a miss.)
### partial
Compare a partial path to a pattern. As long as the parts of the path that
are present are not contradicted by the pattern, it will be treated as a
match. This is useful in applications where you're walking through a
folder structure, and don't yet have the full path, but want to ensure that
you do not walk down paths that can never be a match.
For example,
```js
minimatch('/a/b', '/a/*/c/d', { partial: true }) // true, might be /a/b/c/d
minimatch('/a/b', '/**/d', { partial: true }) // true, might be /a/b/.../d
minimatch('/x/y/z', '/a/**/z', { partial: true }) // false, because x !== a
```
### allowWindowsEscape
Windows path separator `\` is by default converted to `/`, which
prohibits the usage of `\` as a escape character. This flag skips that
behavior and allows using the escape character.
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between minimatch and other
implementations, and are intentional.
If the pattern starts with a `!` character, then it is negated. Set the
`nonegate` flag to suppress this behavior, and treat leading `!`
characters normally. This is perhaps relevant if you wish to start the
pattern with a negative extglob pattern like `!(a|B)`. Multiple `!`
characters at the start of a pattern will negate the pattern multiple
times.
If a pattern starts with `#`, then it is treated as a comment, and
will not match anything. Use `\#` to match a literal `#` at the
start of a line, or set the `nocomment` flag to suppress this behavior.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.1, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
If an escaped pattern has no matches, and the `nonull` flag is set,
then minimatch.match returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`minimatch.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
# json-schema-traverse
Traverse JSON Schema passing each schema object to callback
[](https://github.com/epoberezkin/json-schema-traverse/actions?query=workflow%3Abuild)
[](https://www.npmjs.com/package/json-schema-traverse)
[](https://coveralls.io/github/epoberezkin/json-schema-traverse?branch=master)
## Install
```
npm install json-schema-traverse
```
## Usage
```javascript
const traverse = require('json-schema-traverse');
const schema = {
properties: {
foo: {type: 'string'},
bar: {type: 'integer'}
}
};
traverse(schema, {cb});
// cb is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
// Or:
traverse(schema, {cb: {pre, post}});
// pre is called 3 times with:
// 1. root schema
// 2. {type: 'string'}
// 3. {type: 'integer'}
//
// post is called 3 times with:
// 1. {type: 'string'}
// 2. {type: 'integer'}
// 3. root schema
```
Callback function `cb` is called for each schema object (not including draft-06 boolean schemas), including the root schema, in pre-order traversal. Schema references ($ref) are not resolved, they are passed as is. Alternatively, you can pass a `{pre, post}` object as `cb`, and then `pre` will be called before traversing child elements, and `post` will be called after all child elements have been traversed.
Callback is passed these parameters:
- _schema_: the current schema object
- _JSON pointer_: from the root schema to the current schema object
- _root schema_: the schema passed to `traverse` object
- _parent JSON pointer_: from the root schema to the parent schema object (see below)
- _parent keyword_: the keyword inside which this schema appears (e.g. `properties`, `anyOf`, etc.)
- _parent schema_: not necessarily parent object/array; in the example above the parent schema for `{type: 'string'}` is the root schema
- _index/property_: index or property name in the array/object containing multiple schemas; in the example above for `{type: 'string'}` the property name is `'foo'`
## Traverse objects in all unknown keywords
```javascript
const traverse = require('json-schema-traverse');
const schema = {
mySchema: {
minimum: 1,
maximum: 2
}
};
traverse(schema, {allKeys: true, cb});
// cb is called 2 times with:
// 1. root schema
// 2. mySchema
```
Without option `allKeys: true` callback will be called only with root schema.
## Enterprise support
json-schema-traverse package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-json-schema-traverse?utm_source=npm-json-schema-traverse&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
## License
[MIT](https://github.com/epoberezkin/json-schema-traverse/blob/master/LICENSE)
# lodash.truncate v4.4.2
The [lodash](https://lodash.com/) method `_.truncate` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.truncate
```
In Node.js:
```js
var truncate = require('lodash.truncate');
```
See the [documentation](https://lodash.com/docs#truncate) or [package source](https://github.com/lodash/lodash/blob/4.4.2-npm-packages/lodash.truncate) for more details.
argparse
========
[](http://travis-ci.org/nodeca/argparse)
[](https://www.npmjs.org/package/argparse)
CLI arguments parser for node.js. Javascript port of python's
[argparse](http://docs.python.org/dev/library/argparse.html) module
(original version 3.2). That's a full port, except some very rare options,
recorded in issue tracker.
**NB. Difference with original.**
- Method names changed to camelCase. See [generated docs](http://nodeca.github.com/argparse/).
- Use `defaultValue` instead of `default`.
- Use `argparse.Const.REMAINDER` instead of `argparse.REMAINDER`, and
similarly for constant values `OPTIONAL`, `ZERO_OR_MORE`, and `ONE_OR_MORE`
(aliases for `nargs` values `'?'`, `'*'`, `'+'`, respectively), and
`SUPPRESS`.
Example
=======
test.js file:
```javascript
#!/usr/bin/env node
'use strict';
var ArgumentParser = require('../lib/argparse').ArgumentParser;
var parser = new ArgumentParser({
version: '0.0.1',
addHelp:true,
description: 'Argparse example'
});
parser.addArgument(
[ '-f', '--foo' ],
{
help: 'foo bar'
}
);
parser.addArgument(
[ '-b', '--bar' ],
{
help: 'bar foo'
}
);
parser.addArgument(
'--baz',
{
help: 'baz bar'
}
);
var args = parser.parseArgs();
console.dir(args);
```
Display help:
```
$ ./test.js -h
usage: example.js [-h] [-v] [-f FOO] [-b BAR] [--baz BAZ]
Argparse example
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-f FOO, --foo FOO foo bar
-b BAR, --bar BAR bar foo
--baz BAZ baz bar
```
Parse arguments:
```
$ ./test.js -f=3 --bar=4 --baz 5
{ foo: '3', bar: '4', baz: '5' }
```
More [examples](https://github.com/nodeca/argparse/tree/master/examples).
ArgumentParser objects
======================
```
new ArgumentParser({parameters hash});
```
Creates a new ArgumentParser object.
**Supported params:**
- ```description``` - Text to display before the argument help.
- ```epilog``` - Text to display after the argument help.
- ```addHelp``` - Add a -h/–help option to the parser. (default: true)
- ```argumentDefault``` - Set the global default value for arguments. (default: null)
- ```parents``` - A list of ArgumentParser objects whose arguments should also be included.
- ```prefixChars``` - The set of characters that prefix optional arguments. (default: ‘-‘)
- ```formatterClass``` - A class for customizing the help output.
- ```prog``` - The name of the program (default: `path.basename(process.argv[1])`)
- ```usage``` - The string describing the program usage (default: generated)
- ```conflictHandler``` - Usually unnecessary, defines strategy for resolving conflicting optionals.
**Not supported yet**
- ```fromfilePrefixChars``` - The set of characters that prefix files from which additional arguments should be read.
Details in [original ArgumentParser guide](http://docs.python.org/dev/library/argparse.html#argumentparser-objects)
addArgument() method
====================
```
ArgumentParser.addArgument(name or flag or [name] or [flags...], {options})
```
Defines how a single command-line argument should be parsed.
- ```name or flag or [name] or [flags...]``` - Either a positional name
(e.g., `'foo'`), a single option (e.g., `'-f'` or `'--foo'`), an array
of a single positional name (e.g., `['foo']`), or an array of options
(e.g., `['-f', '--foo']`).
Options:
- ```action``` - The basic type of action to be taken when this argument is encountered at the command line.
- ```nargs```- The number of command-line arguments that should be consumed.
- ```constant``` - A constant value required by some action and nargs selections.
- ```defaultValue``` - The value produced if the argument is absent from the command line.
- ```type``` - The type to which the command-line argument should be converted.
- ```choices``` - A container of the allowable values for the argument.
- ```required``` - Whether or not the command-line option may be omitted (optionals only).
- ```help``` - A brief description of what the argument does.
- ```metavar``` - A name for the argument in usage messages.
- ```dest``` - The name of the attribute to be added to the object returned by parseArgs().
Details in [original add_argument guide](http://docs.python.org/dev/library/argparse.html#the-add-argument-method)
Action (some details)
================
ArgumentParser objects associate command-line arguments with actions.
These actions can do just about anything with the command-line arguments associated
with them, though most actions simply add an attribute to the object returned by
parseArgs(). The action keyword argument specifies how the command-line arguments
should be handled. The supported actions are:
- ```store``` - Just stores the argument’s value. This is the default action.
- ```storeConst``` - Stores value, specified by the const keyword argument.
(Note that the const keyword argument defaults to the rather unhelpful None.)
The 'storeConst' action is most commonly used with optional arguments, that
specify some sort of flag.
- ```storeTrue``` and ```storeFalse``` - Stores values True and False
respectively. These are special cases of 'storeConst'.
- ```append``` - Stores a list, and appends each argument value to the list.
This is useful to allow an option to be specified multiple times.
- ```appendConst``` - Stores a list, and appends value, specified by the
const keyword argument to the list. (Note, that the const keyword argument defaults
is None.) The 'appendConst' action is typically used when multiple arguments need
to store constants to the same list.
- ```count``` - Counts the number of times a keyword argument occurs. For example,
used for increasing verbosity levels.
- ```help``` - Prints a complete help message for all the options in the current
parser and then exits. By default a help action is automatically added to the parser.
See ArgumentParser for details of how the output is created.
- ```version``` - Prints version information and exit. Expects a `version=`
keyword argument in the addArgument() call.
Details in [original action guide](http://docs.python.org/dev/library/argparse.html#action)
Sub-commands
============
ArgumentParser.addSubparsers()
Many programs split their functionality into a number of sub-commands, for
example, the svn program can invoke sub-commands like `svn checkout`, `svn update`,
and `svn commit`. Splitting up functionality this way can be a particularly good
idea when a program performs several different functions which require different
kinds of command-line arguments. `ArgumentParser` supports creation of such
sub-commands with `addSubparsers()` method. The `addSubparsers()` method is
normally called with no arguments and returns an special action object.
This object has a single method `addParser()`, which takes a command name and
any `ArgumentParser` constructor arguments, and returns an `ArgumentParser` object
that can be modified as usual.
Example:
sub_commands.js
```javascript
#!/usr/bin/env node
'use strict';
var ArgumentParser = require('../lib/argparse').ArgumentParser;
var parser = new ArgumentParser({
version: '0.0.1',
addHelp:true,
description: 'Argparse examples: sub-commands',
});
var subparsers = parser.addSubparsers({
title:'subcommands',
dest:"subcommand_name"
});
var bar = subparsers.addParser('c1', {addHelp:true});
bar.addArgument(
[ '-f', '--foo' ],
{
action: 'store',
help: 'foo3 bar3'
}
);
var bar = subparsers.addParser(
'c2',
{aliases:['co'], addHelp:true}
);
bar.addArgument(
[ '-b', '--bar' ],
{
action: 'store',
type: 'int',
help: 'foo3 bar3'
}
);
var args = parser.parseArgs();
console.dir(args);
```
Details in [original sub-commands guide](http://docs.python.org/dev/library/argparse.html#sub-commands)
Contributors
============
- [Eugene Shkuropat](https://github.com/shkuropat)
- [Paul Jacobson](https://github.com/hpaulj)
[others](https://github.com/nodeca/argparse/graphs/contributors)
License
=======
Copyright (c) 2012 [Vitaly Puzrin](https://github.com/puzrin).
Released under the MIT license. See
[LICENSE](https://github.com/nodeca/argparse/blob/master/LICENSE) for details.
# lodash.clonedeep v4.5.0
The [lodash](https://lodash.com/) method `_.cloneDeep` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.clonedeep
```
In Node.js:
```js
var cloneDeep = require('lodash.clonedeep');
```
See the [documentation](https://lodash.com/docs#cloneDeep) or [package source](https://github.com/lodash/lodash/blob/4.5.0-npm-packages/lodash.clonedeep) for more details.
# minizlib
A fast zlib stream built on [minipass](http://npm.im/minipass) and
Node.js's zlib binding.
This module was created to serve the needs of
[node-tar](http://npm.im/tar) and
[minipass-fetch](http://npm.im/minipass-fetch).
Brotli is supported in versions of node with a Brotli binding.
## How does this differ from the streams in `require('zlib')`?
First, there are no convenience methods to compress or decompress a
buffer. If you want those, use the built-in `zlib` module. This is
only streams. That being said, Minipass streams to make it fairly easy to
use as one-liners: `new zlib.Deflate().end(data).read()` will return the
deflate compressed result.
This module compresses and decompresses the data as fast as you feed
it in. It is synchronous, and runs on the main process thread. Zlib
and Brotli operations can be high CPU, but they're very fast, and doing it
this way means much less bookkeeping and artificial deferral.
Node's built in zlib streams are built on top of `stream.Transform`.
They do the maximally safe thing with respect to consistent
asynchrony, buffering, and backpressure.
See [Minipass](http://npm.im/minipass) for more on the differences between
Node.js core streams and Minipass streams, and the convenience methods
provided by that class.
## Classes
- Deflate
- Inflate
- Gzip
- Gunzip
- DeflateRaw
- InflateRaw
- Unzip
- BrotliCompress (Node v10 and higher)
- BrotliDecompress (Node v10 and higher)
## USAGE
```js
const zlib = require('minizlib')
const input = sourceOfCompressedData()
const decode = new zlib.BrotliDecompress()
const output = whereToWriteTheDecodedData()
input.pipe(decode).pipe(output)
```
## REPRODUCIBLE BUILDS
To create reproducible gzip compressed files across different operating
systems, set `portable: true` in the options. This causes minizlib to set
the `OS` indicator in byte 9 of the extended gzip header to `0xFF` for
'unknown'.
<h1 align="center">Enquirer</h1>
<p align="center">
<a href="https://npmjs.org/package/enquirer">
<img src="https://img.shields.io/npm/v/enquirer.svg" alt="version">
</a>
<a href="https://travis-ci.org/enquirer/enquirer">
<img src="https://img.shields.io/travis/enquirer/enquirer.svg" alt="travis">
</a>
<a href="https://npmjs.org/package/enquirer">
<img src="https://img.shields.io/npm/dm/enquirer.svg" alt="downloads">
</a>
</p>
<br>
<br>
<p align="center">
<b>Stylish CLI prompts that are user-friendly, intuitive and easy to create.</b><br>
<sub>>_ Prompts should be more like conversations than inquisitions▌</sub>
</p>
<br>
<p align="center">
<sub>(Example shows Enquirer's <a href="#survey-prompt">Survey Prompt</a>)</a></sub>
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/survey-prompt.gif" alt="Enquirer Survey Prompt" width="750"><br>
<sub>The terminal in all examples is <a href="https://hyper.is/">Hyper</a>, theme is <a href="https://github.com/jonschlinkert/hyper-monokai-extended">hyper-monokai-extended</a>.</sub><br><br>
<a href="#built-in-prompts"><strong>See more prompt examples</strong></a>
</p>
<br>
<br>
Created by [jonschlinkert](https://github.com/jonschlinkert) and [doowb](https://github.com/doowb), Enquirer is fast, easy to use, and lightweight enough for small projects, while also being powerful and customizable enough for the most advanced use cases.
* **Fast** - [Loads in ~4ms](#-performance) (that's about _3-4 times faster than a [single frame of a HD movie](http://www.endmemo.com/sconvert/framespersecondframespermillisecond.php) at 60fps_)
* **Lightweight** - Only one dependency, the excellent [ansi-colors](https://github.com/doowb/ansi-colors) by [Brian Woodward](https://github.com/doowb).
* **Easy to implement** - Uses promises and async/await and sensible defaults to make prompts easy to create and implement.
* **Easy to use** - Thrill your users with a better experience! Navigating around input and choices is a breeze. You can even create [quizzes](examples/fun/countdown.js), or [record](examples/fun/record.js) and [playback](examples/fun/play.js) key bindings to aid with tutorials and videos.
* **Intuitive** - Keypress combos are available to simplify usage.
* **Flexible** - All prompts can be used standalone or chained together.
* **Stylish** - Easily override semantic styles and symbols for any part of the prompt.
* **Extensible** - Easily create and use custom prompts by extending Enquirer's built-in [prompts](#-prompts).
* **Pluggable** - Add advanced features to Enquirer using plugins.
* **Validation** - Optionally validate user input with any prompt.
* **Well tested** - All prompts are well-tested, and tests are easy to create without having to use brittle, hacky solutions to spy on prompts or "inject" values.
* **Examples** - There are numerous [examples](examples) available to help you get started.
If you like Enquirer, please consider starring or tweeting about this project to show your support. Thanks!
<br>
<p align="center">
<b>>_ Ready to start making prompts your users will love? ▌</b><br>
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/heartbeat.gif" alt="Enquirer Select Prompt with heartbeat example" width="750">
</p>
<br>
<br>
## ❯ Getting started
Get started with Enquirer, the most powerful and easy-to-use Node.js library for creating interactive CLI prompts.
* [Install](#-install)
* [Usage](#-usage)
* [Enquirer](#-enquirer)
* [Prompts](#-prompts)
- [Built-in Prompts](#-prompts)
- [Custom Prompts](#-custom-prompts)
* [Key Bindings](#-key-bindings)
* [Options](#-options)
* [Release History](#-release-history)
* [Performance](#-performance)
* [About](#-about)
<br>
## ❯ Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install enquirer --save
```
Install with [yarn](https://yarnpkg.com/en/):
```sh
$ yarn add enquirer
```
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/npm-install.gif" alt="Install Enquirer with NPM" width="750">
</p>
_(Requires Node.js 8.6 or higher. Please let us know if you need support for an earlier version by creating an [issue](../../issues/new).)_
<br>
## ❯ Usage
### Single prompt
The easiest way to get started with enquirer is to pass a [question object](#prompt-options) to the `prompt` method.
```js
const { prompt } = require('enquirer');
const response = await prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response); // { username: 'jonschlinkert' }
```
_(Examples with `await` need to be run inside an `async` function)_
### Multiple prompts
Pass an array of ["question" objects](#prompt-options) to run a series of prompts.
```js
const response = await prompt([
{
type: 'input',
name: 'name',
message: 'What is your name?'
},
{
type: 'input',
name: 'username',
message: 'What is your username?'
}
]);
console.log(response); // { name: 'Edward Chan', username: 'edwardmchan' }
```
### Different ways to run enquirer
#### 1. By importing the specific `built-in prompt`
```js
const { Confirm } = require('enquirer');
const prompt = new Confirm({
name: 'question',
message: 'Did you like enquirer?'
});
prompt.run()
.then(answer => console.log('Answer:', answer));
```
#### 2. By passing the options to `prompt`
```js
const { prompt } = require('enquirer');
prompt({
type: 'confirm',
name: 'question',
message: 'Did you like enquirer?'
})
.then(answer => console.log('Answer:', answer));
```
**Jump to**: [Getting Started](#-getting-started) · [Prompts](#-prompts) · [Options](#-options) · [Key Bindings](#-key-bindings)
<br>
## ❯ Enquirer
**Enquirer is a prompt runner**
Add Enquirer to your JavaScript project with following line of code.
```js
const Enquirer = require('enquirer');
```
The main export of this library is the `Enquirer` class, which has methods and features designed to simplify running prompts.
```js
const { prompt } = require('enquirer');
const question = [
{
type: 'input',
name: 'username',
message: 'What is your username?'
},
{
type: 'password',
name: 'password',
message: 'What is your password?'
}
];
let answers = await prompt(question);
console.log(answers);
```
**Prompts control how values are rendered and returned**
Each individual prompt is a class with special features and functionality for rendering the types of values you want to show users in the terminal, and subsequently returning the types of values you need to use in your application.
**How can I customize prompts?**
Below in this guide you will find information about creating [custom prompts](#-custom-prompts). For now, we'll focus on how to customize an existing prompt.
All of the individual [prompt classes](#built-in-prompts) in this library are exposed as static properties on Enquirer. This allows them to be used directly without using `enquirer.prompt()`.
Use this approach if you need to modify a prompt instance, or listen for events on the prompt.
**Example**
```js
const { Input } = require('enquirer');
const prompt = new Input({
name: 'username',
message: 'What is your username?'
});
prompt.run()
.then(answer => console.log('Username:', answer))
.catch(console.error);
```
### [Enquirer](index.js#L20)
Create an instance of `Enquirer`.
**Params**
* `options` **{Object}**: (optional) Options to use with all prompts.
* `answers` **{Object}**: (optional) Answers object to initialize with.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
```
### [register()](index.js#L42)
Register a custom prompt type.
**Params**
* `type` **{String}**
* `fn` **{Function|Prompt}**: `Prompt` class, or a function that returns a `Prompt` class.
* `returns` **{Object}**: Returns the Enquirer instance
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
enquirer.register('customType', require('./custom-prompt'));
```
### [prompt()](index.js#L78)
Prompt function that takes a "question" object or array of question objects, and returns an object with responses from the user.
**Params**
* `questions` **{Array|Object}**: Options objects for one or more prompts to run.
* `returns` **{Promise}**: Promise that returns an "answers" object with the user's responses.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
const response = await enquirer.prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response);
```
### [use()](index.js#L160)
Use an enquirer plugin.
**Params**
* `plugin` **{Function}**: Plugin function that takes an instance of Enquirer.
* `returns` **{Object}**: Returns the Enquirer instance.
**Example**
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
const plugin = enquirer => {
// do stuff to enquire instance
};
enquirer.use(plugin);
```
### [Enquirer#prompt](index.js#L210)
Prompt function that takes a "question" object or array of question objects, and returns an object with responses from the user.
**Params**
* `questions` **{Array|Object}**: Options objects for one or more prompts to run.
* `returns` **{Promise}**: Promise that returns an "answers" object with the user's responses.
**Example**
```js
const { prompt } = require('enquirer');
const response = await prompt({
type: 'input',
name: 'username',
message: 'What is your username?'
});
console.log(response);
```
<br>
## ❯ Prompts
This section is about Enquirer's prompts: what they look like, how they work, how to run them, available options, and how to customize the prompts or create your own prompt concept.
**Getting started with Enquirer's prompts**
* [Prompt](#prompt) - The base `Prompt` class used by other prompts
- [Prompt Options](#prompt-options)
* [Built-in prompts](#built-in-prompts)
* [Prompt Types](#prompt-types) - The base `Prompt` class used by other prompts
* [Custom prompts](#%E2%9D%AF-custom-prompts) - Enquirer 2.0 introduced the concept of prompt "types", with the goal of making custom prompts easier than ever to create and use.
### Prompt
The base `Prompt` class is used to create all other prompts.
```js
const { Prompt } = require('enquirer');
class MyCustomPrompt extends Prompt {}
```
See the documentation for [creating custom prompts](#-custom-prompts) to learn more about how this works.
#### Prompt Options
Each prompt takes an options object (aka "question" object), that implements the following interface:
```js
{
// required
type: string | function,
name: string | function,
message: string | function | async function,
// optional
skip: boolean | function | async function,
initial: string | function | async function,
format: function | async function,
result: function | async function,
validate: function | async function,
}
```
Each property of the options object is described below:
| **Property** | **Required?** | **Type** | **Description** |
| ------------ | ------------- | ------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `type` | yes | `string\|function` | Enquirer uses this value to determine the type of prompt to run, but it's optional when prompts are run directly. |
| `name` | yes | `string\|function` | Used as the key for the answer on the returned values (answers) object. |
| `message` | yes | `string\|function` | The message to display when the prompt is rendered in the terminal. |
| `skip` | no | `boolean\|function` | If `true` it will not ask that prompt. |
| `initial` | no | `string\|function` | The default value to return if the user does not supply a value. |
| `format` | no | `function` | Function to format user input in the terminal. |
| `result` | no | `function` | Function to format the final submitted value before it's returned. |
| `validate` | no | `function` | Function to validate the submitted value before it's returned. This function may return a boolean or a string. If a string is returned it will be used as the validation error message. |
**Example usage**
```js
const { prompt } = require('enquirer');
const question = {
type: 'input',
name: 'username',
message: 'What is your username?'
};
prompt(question)
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
<br>
### Built-in prompts
* [AutoComplete Prompt](#autocomplete-prompt)
* [BasicAuth Prompt](#basicauth-prompt)
* [Confirm Prompt](#confirm-prompt)
* [Form Prompt](#form-prompt)
* [Input Prompt](#input-prompt)
* [Invisible Prompt](#invisible-prompt)
* [List Prompt](#list-prompt)
* [MultiSelect Prompt](#multiselect-prompt)
* [Numeral Prompt](#numeral-prompt)
* [Password Prompt](#password-prompt)
* [Quiz Prompt](#quiz-prompt)
* [Survey Prompt](#survey-prompt)
* [Scale Prompt](#scale-prompt)
* [Select Prompt](#select-prompt)
* [Sort Prompt](#sort-prompt)
* [Snippet Prompt](#snippet-prompt)
* [Toggle Prompt](#toggle-prompt)
### AutoComplete Prompt
Prompt that auto-completes as the user types, and returns the selected value as a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/autocomplete-prompt.gif" alt="Enquirer AutoComplete Prompt" width="750">
</p>
**Example Usage**
```js
const { AutoComplete } = require('enquirer');
const prompt = new AutoComplete({
name: 'flavor',
message: 'Pick your favorite flavor',
limit: 10,
initial: 2,
choices: [
'Almond',
'Apple',
'Banana',
'Blackberry',
'Blueberry',
'Cherry',
'Chocolate',
'Cinnamon',
'Coconut',
'Cranberry',
'Grape',
'Nougat',
'Orange',
'Pear',
'Pineapple',
'Raspberry',
'Strawberry',
'Vanilla',
'Watermelon',
'Wintergreen'
]
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**AutoComplete Options**
| Option | Type | Default | Description |
| ----------- | ---------- | ------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------ |
| `highlight` | `function` | `dim` version of primary style | The color to use when "highlighting" characters in the list that match user input. |
| `multiple` | `boolean` | `false` | Allow multiple choices to be selected. |
| `suggest` | `function` | Greedy match, returns true if choice message contains input string. | Function that filters choices. Takes user input and a choices array, and returns a list of matching choices. |
| `initial` | `number` | 0 | Preselected item in the list of choices. |
| `footer` | `function` | None | Function that displays [footer text](https://github.com/enquirer/enquirer/blob/6c2819518a1e2ed284242a99a685655fbaabfa28/examples/autocomplete/option-footer.js#L10) |
**Related prompts**
* [Select](#select-prompt)
* [MultiSelect](#multiselect-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### BasicAuth Prompt
Prompt that asks for username and password to authenticate the user. The default implementation of `authenticate` function in `BasicAuth` prompt is to compare the username and password with the values supplied while running the prompt. The implementer is expected to override the `authenticate` function with a custom logic such as making an API request to a server to authenticate the username and password entered and expect a token back.
<p align="center">
<img src="https://user-images.githubusercontent.com/13731210/61570485-7ffd9c00-aaaa-11e9-857a-d47dc7008284.gif" alt="Enquirer BasicAuth Prompt" width="750">
</p>
**Example Usage**
```js
const { BasicAuth } = require('enquirer');
const prompt = new BasicAuth({
name: 'password',
message: 'Please enter your password',
username: 'rajat-sr',
password: '123',
showPassword: true
});
prompt
.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Confirm Prompt
Prompt that returns `true` or `false`.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/confirm-prompt.gif" alt="Enquirer Confirm Prompt" width="750">
</p>
**Example Usage**
```js
const { Confirm } = require('enquirer');
const prompt = new Confirm({
name: 'question',
message: 'Want to answer?'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Numeral](#numeral-prompt)
* [Password](#password-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Form Prompt
Prompt that allows the user to enter and submit multiple values on a single terminal screen.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/form-prompt.gif" alt="Enquirer Form Prompt" width="750">
</p>
**Example Usage**
```js
const { Form } = require('enquirer');
const prompt = new Form({
name: 'user',
message: 'Please provide the following information:',
choices: [
{ name: 'firstname', message: 'First Name', initial: 'Jon' },
{ name: 'lastname', message: 'Last Name', initial: 'Schlinkert' },
{ name: 'username', message: 'GitHub username', initial: 'jonschlinkert' }
]
});
prompt.run()
.then(value => console.log('Answer:', value))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Input Prompt
Prompt that takes user input and returns a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/input-prompt.gif" alt="Enquirer Input Prompt" width="750">
</p>
**Example Usage**
```js
const { Input } = require('enquirer');
const prompt = new Input({
message: 'What is your username?',
initial: 'jonschlinkert'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.log);
```
You can use [data-store](https://github.com/jonschlinkert/data-store) to store [input history](https://github.com/enquirer/enquirer/blob/master/examples/input/option-history.js) that the user can cycle through (see [source](https://github.com/enquirer/enquirer/blob/8407dc3579123df5e6e20215078e33bb605b0c37/lib/prompts/input.js)).
**Related prompts**
* [Confirm](#confirm-prompt)
* [Numeral](#numeral-prompt)
* [Password](#password-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Invisible Prompt
Prompt that takes user input, hides it from the terminal, and returns a string.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/invisible-prompt.gif" alt="Enquirer Invisible Prompt" width="750">
</p>
**Example Usage**
```js
const { Invisible } = require('enquirer');
const prompt = new Invisible({
name: 'secret',
message: 'What is your secret?'
});
prompt.run()
.then(answer => console.log('Answer:', { secret: answer }))
.catch(console.error);
```
**Related prompts**
* [Password](#password-prompt)
* [Input](#input-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### List Prompt
Prompt that returns a list of values, created by splitting the user input. The default split character is `,` with optional trailing whitespace.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/list-prompt.gif" alt="Enquirer List Prompt" width="750">
</p>
**Example Usage**
```js
const { List } = require('enquirer');
const prompt = new List({
name: 'keywords',
message: 'Type comma-separated keywords'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Sort](#sort-prompt)
* [Select](#select-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### MultiSelect Prompt
Prompt that allows the user to select multiple items from a list of options.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/multiselect-prompt.gif" alt="Enquirer MultiSelect Prompt" width="750">
</p>
**Example Usage**
```js
const { MultiSelect } = require('enquirer');
const prompt = new MultiSelect({
name: 'value',
message: 'Pick your favorite colors',
limit: 7,
choices: [
{ name: 'aqua', value: '#00ffff' },
{ name: 'black', value: '#000000' },
{ name: 'blue', value: '#0000ff' },
{ name: 'fuchsia', value: '#ff00ff' },
{ name: 'gray', value: '#808080' },
{ name: 'green', value: '#008000' },
{ name: 'lime', value: '#00ff00' },
{ name: 'maroon', value: '#800000' },
{ name: 'navy', value: '#000080' },
{ name: 'olive', value: '#808000' },
{ name: 'purple', value: '#800080' },
{ name: 'red', value: '#ff0000' },
{ name: 'silver', value: '#c0c0c0' },
{ name: 'teal', value: '#008080' },
{ name: 'white', value: '#ffffff' },
{ name: 'yellow', value: '#ffff00' }
]
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
// Answer: ['aqua', 'blue', 'fuchsia']
```
**Example key-value pairs**
Optionally, pass a `result` function and use the `.map` method to return an object of key-value pairs of the selected names and values: [example](./examples/multiselect/option-result.js)
```js
const { MultiSelect } = require('enquirer');
const prompt = new MultiSelect({
name: 'value',
message: 'Pick your favorite colors',
limit: 7,
choices: [
{ name: 'aqua', value: '#00ffff' },
{ name: 'black', value: '#000000' },
{ name: 'blue', value: '#0000ff' },
{ name: 'fuchsia', value: '#ff00ff' },
{ name: 'gray', value: '#808080' },
{ name: 'green', value: '#008000' },
{ name: 'lime', value: '#00ff00' },
{ name: 'maroon', value: '#800000' },
{ name: 'navy', value: '#000080' },
{ name: 'olive', value: '#808000' },
{ name: 'purple', value: '#800080' },
{ name: 'red', value: '#ff0000' },
{ name: 'silver', value: '#c0c0c0' },
{ name: 'teal', value: '#008080' },
{ name: 'white', value: '#ffffff' },
{ name: 'yellow', value: '#ffff00' }
],
result(names) {
return this.map(names);
}
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
// Answer: { aqua: '#00ffff', blue: '#0000ff', fuchsia: '#ff00ff' }
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Numeral Prompt
Prompt that takes a number as input.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/numeral-prompt.gif" alt="Enquirer Numeral Prompt" width="750">
</p>
**Example Usage**
```js
const { NumberPrompt } = require('enquirer');
const prompt = new NumberPrompt({
name: 'number',
message: 'Please enter a number'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Confirm](#confirm-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Password Prompt
Prompt that takes user input and masks it in the terminal. Also see the [invisible prompt](#invisible-prompt)
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/password-prompt.gif" alt="Enquirer Password Prompt" width="750">
</p>
**Example Usage**
```js
const { Password } = require('enquirer');
const prompt = new Password({
name: 'password',
message: 'What is your password?'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Input](#input-prompt)
* [Invisible](#invisible-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Quiz Prompt
Prompt that allows the user to play multiple-choice quiz questions.
<p align="center">
<img src="https://user-images.githubusercontent.com/13731210/61567561-891d4780-aa6f-11e9-9b09-3d504abd24ed.gif" alt="Enquirer Quiz Prompt" width="750">
</p>
**Example Usage**
```js
const { Quiz } = require('enquirer');
const prompt = new Quiz({
name: 'countries',
message: 'How many countries are there in the world?',
choices: ['165', '175', '185', '195', '205'],
correctChoice: 3
});
prompt
.run()
.then(answer => {
if (answer.correct) {
console.log('Correct!');
} else {
console.log(`Wrong! Correct answer is ${answer.correctAnswer}`);
}
})
.catch(console.error);
```
**Quiz Options**
| Option | Type | Required | Description |
| ----------- | ---------- | ---------- | ------------------------------------------------------------------------------------------------------------ |
| `choices` | `array` | Yes | The list of possible answers to the quiz question. |
| `correctChoice`| `number` | Yes | Index of the correct choice from the `choices` array. |
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Survey Prompt
Prompt that allows the user to provide feedback for a list of questions.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/survey-prompt.gif" alt="Enquirer Survey Prompt" width="750">
</p>
**Example Usage**
```js
const { Survey } = require('enquirer');
const prompt = new Survey({
name: 'experience',
message: 'Please rate your experience',
scale: [
{ name: '1', message: 'Strongly Disagree' },
{ name: '2', message: 'Disagree' },
{ name: '3', message: 'Neutral' },
{ name: '4', message: 'Agree' },
{ name: '5', message: 'Strongly Agree' }
],
margin: [0, 0, 2, 1],
choices: [
{
name: 'interface',
message: 'The website has a friendly interface.'
},
{
name: 'navigation',
message: 'The website is easy to navigate.'
},
{
name: 'images',
message: 'The website usually has good images.'
},
{
name: 'upload',
message: 'The website makes it easy to upload images.'
},
{
name: 'colors',
message: 'The website has a pleasing color palette.'
}
]
});
prompt.run()
.then(value => console.log('ANSWERS:', value))
.catch(console.error);
```
**Related prompts**
* [Scale](#scale-prompt)
* [Snippet](#snippet-prompt)
* [Select](#select-prompt)
***
### Scale Prompt
A more compact version of the [Survey prompt](#survey-prompt), the Scale prompt allows the user to quickly provide feedback using a [Likert Scale](https://en.wikipedia.org/wiki/Likert_scale).
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/scale-prompt.gif" alt="Enquirer Scale Prompt" width="750">
</p>
**Example Usage**
```js
const { Scale } = require('enquirer');
const prompt = new Scale({
name: 'experience',
message: 'Please rate your experience',
scale: [
{ name: '1', message: 'Strongly Disagree' },
{ name: '2', message: 'Disagree' },
{ name: '3', message: 'Neutral' },
{ name: '4', message: 'Agree' },
{ name: '5', message: 'Strongly Agree' }
],
margin: [0, 0, 2, 1],
choices: [
{
name: 'interface',
message: 'The website has a friendly interface.',
initial: 2
},
{
name: 'navigation',
message: 'The website is easy to navigate.',
initial: 2
},
{
name: 'images',
message: 'The website usually has good images.',
initial: 2
},
{
name: 'upload',
message: 'The website makes it easy to upload images.',
initial: 2
},
{
name: 'colors',
message: 'The website has a pleasing color palette.',
initial: 2
}
]
});
prompt.run()
.then(value => console.log('ANSWERS:', value))
.catch(console.error);
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Select Prompt
Prompt that allows the user to select from a list of options.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/select-prompt.gif" alt="Enquirer Select Prompt" width="750">
</p>
**Example Usage**
```js
const { Select } = require('enquirer');
const prompt = new Select({
name: 'color',
message: 'Pick a flavor',
choices: ['apple', 'grape', 'watermelon', 'cherry', 'orange']
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [AutoComplete](#autocomplete-prompt)
* [MultiSelect](#multiselect-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Sort Prompt
Prompt that allows the user to sort items in a list.
**Example**
In this [example](https://github.com/enquirer/enquirer/raw/master/examples/sort/prompt.js), custom styling is applied to the returned values to make it easier to see what's happening.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/sort-prompt.gif" alt="Enquirer Sort Prompt" width="750">
</p>
**Example Usage**
```js
const colors = require('ansi-colors');
const { Sort } = require('enquirer');
const prompt = new Sort({
name: 'colors',
message: 'Sort the colors in order of preference',
hint: 'Top is best, bottom is worst',
numbered: true,
choices: ['red', 'white', 'green', 'cyan', 'yellow'].map(n => ({
name: n,
message: colors[n](n)
}))
});
prompt.run()
.then(function(answer = []) {
console.log(answer);
console.log('Your preferred order of colors is:');
console.log(answer.map(key => colors[key](key)).join('\n'));
})
.catch(console.error);
```
**Related prompts**
* [List](#list-prompt)
* [Select](#select-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Snippet Prompt
Prompt that allows the user to replace placeholders in a snippet of code or text.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/snippet-prompt.gif" alt="Prompts" width="750">
</p>
**Example Usage**
```js
const semver = require('semver');
const { Snippet } = require('enquirer');
const prompt = new Snippet({
name: 'username',
message: 'Fill out the fields in package.json',
required: true,
fields: [
{
name: 'author_name',
message: 'Author Name'
},
{
name: 'version',
validate(value, state, item, index) {
if (item && item.name === 'version' && !semver.valid(value)) {
return prompt.styles.danger('version should be a valid semver value');
}
return true;
}
}
],
template: `{
"name": "\${name}",
"description": "\${description}",
"version": "\${version}",
"homepage": "https://github.com/\${username}/\${name}",
"author": "\${author_name} (https://github.com/\${username})",
"repository": "\${username}/\${name}",
"license": "\${license:ISC}"
}
`
});
prompt.run()
.then(answer => console.log('Answer:', answer.result))
.catch(console.error);
```
**Related prompts**
* [Survey](#survey-prompt)
* [AutoComplete](#autocomplete-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Toggle Prompt
Prompt that allows the user to toggle between two values then returns `true` or `false`.
<p align="center">
<img src="https://raw.githubusercontent.com/enquirer/enquirer/master/media/toggle-prompt.gif" alt="Enquirer Toggle Prompt" width="750">
</p>
**Example Usage**
```js
const { Toggle } = require('enquirer');
const prompt = new Toggle({
message: 'Want to answer?',
enabled: 'Yep',
disabled: 'Nope'
});
prompt.run()
.then(answer => console.log('Answer:', answer))
.catch(console.error);
```
**Related prompts**
* [Confirm](#confirm-prompt)
* [Input](#input-prompt)
* [Sort](#sort-prompt)
**↑ back to:** [Getting Started](#-getting-started) · [Prompts](#-prompts)
***
### Prompt Types
There are 5 (soon to be 6!) type classes:
* [ArrayPrompt](#arrayprompt)
- [Options](#options)
- [Properties](#properties)
- [Methods](#methods)
- [Choices](#choices)
- [Defining choices](#defining-choices)
- [Choice properties](#choice-properties)
- [Related prompts](#related-prompts)
* [AuthPrompt](#authprompt)
* [BooleanPrompt](#booleanprompt)
* DatePrompt (Coming Soon!)
* [NumberPrompt](#numberprompt)
* [StringPrompt](#stringprompt)
Each type is a low-level class that may be used as a starting point for creating higher level prompts. Continue reading to learn how.
### ArrayPrompt
The `ArrayPrompt` class is used for creating prompts that display a list of choices in the terminal. For example, Enquirer uses this class as the basis for the [Select](#select) and [Survey](#survey) prompts.
#### Options
In addition to the [options](#options) available to all prompts, Array prompts also support the following options.
| **Option** | **Required?** | **Type** | **Description** |
| ----------- | ------------- | --------------- | ----------------------------------------------------------------------------------------------------------------------- |
| `autofocus` | `no` | `string\|number` | The index or name of the choice that should have focus when the prompt loads. Only one choice may have focus at a time. | |
| `stdin` | `no` | `stream` | The input stream to use for emitting keypress events. Defaults to `process.stdin`. |
| `stdout` | `no` | `stream` | The output stream to use for writing the prompt to the terminal. Defaults to `process.stdout`. |
| |
#### Properties
Array prompts have the following instance properties and getters.
| **Property name** | **Type** | **Description** |
| ----------------- | --------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `choices` | `array` | Array of choices that have been normalized from choices passed on the prompt options. |
| `cursor` | `number` | Position of the cursor relative to the _user input (string)_. |
| `enabled` | `array` | Returns an array of enabled choices. |
| `focused` | `array` | Returns the currently selected choice in the visible list of choices. This is similar to the concept of focus in HTML and CSS. Focused choices are always visible (on-screen). When a list of choices is longer than the list of visible choices, and an off-screen choice is _focused_, the list will scroll to the focused choice and re-render. |
| `focused` | Gets the currently selected choice. Equivalent to `prompt.choices[prompt.index]`. |
| `index` | `number` | Position of the pointer in the _visible list (array) of choices_. |
| `limit` | `number` | The number of choices to display on-screen. |
| `selected` | `array` | Either a list of enabled choices (when `options.multiple` is true) or the currently focused choice. |
| `visible` | `string` | |
#### Methods
| **Method** | **Description** |
| ------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `pointer()` | Returns the visual symbol to use to identify the choice that currently has focus. The `❯` symbol is often used for this. The pointer is not always visible, as with the `autocomplete` prompt. |
| `indicator()` | Returns the visual symbol that indicates whether or not a choice is checked/enabled. |
| `focus()` | Sets focus on a choice, if it can be focused. |
#### Choices
Array prompts support the `choices` option, which is the array of choices users will be able to select from when rendered in the terminal.
**Type**: `string|object`
**Example**
```js
const { prompt } = require('enquirer');
const questions = [{
type: 'select',
name: 'color',
message: 'Favorite color?',
initial: 1,
choices: [
{ name: 'red', message: 'Red', value: '#ff0000' }, //<= choice object
{ name: 'green', message: 'Green', value: '#00ff00' }, //<= choice object
{ name: 'blue', message: 'Blue', value: '#0000ff' } //<= choice object
]
}];
let answers = await prompt(questions);
console.log('Answer:', answers.color);
```
#### Defining choices
Whether defined as a string or object, choices are normalized to the following interface:
```js
{
name: string;
message: string | undefined;
value: string | undefined;
hint: string | undefined;
disabled: boolean | string | undefined;
}
```
**Example**
```js
const question = {
name: 'fruit',
message: 'Favorite fruit?',
choices: ['Apple', 'Orange', 'Raspberry']
};
```
Normalizes to the following when the prompt is run:
```js
const question = {
name: 'fruit',
message: 'Favorite fruit?',
choices: [
{ name: 'Apple', message: 'Apple', value: 'Apple' },
{ name: 'Orange', message: 'Orange', value: 'Orange' },
{ name: 'Raspberry', message: 'Raspberry', value: 'Raspberry' }
]
};
```
#### Choice properties
The following properties are supported on `choice` objects.
| **Option** | **Type** | **Description** |
| ----------- | ----------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `name` | `string` | The unique key to identify a choice |
| `message` | `string` | The message to display in the terminal. `name` is used when this is undefined. |
| `value` | `string` | Value to associate with the choice. Useful for creating key-value pairs from user choices. `name` is used when this is undefined. |
| `choices` | `array` | Array of "child" choices. |
| `hint` | `string` | Help message to display next to a choice. |
| `role` | `string` | Determines how the choice will be displayed. Currently the only role supported is `separator`. Additional roles may be added in the future (like `heading`, etc). Please create a [feature request] |
| `enabled` | `boolean` | Enabled a choice by default. This is only supported when `options.multiple` is true or on prompts that support multiple choices, like [MultiSelect](#-multiselect). |
| `disabled` | `boolean\|string` | Disable a choice so that it cannot be selected. This value may either be `true`, `false`, or a message to display. |
| `indicator` | `string\|function` | Custom indicator to render for a choice (like a check or radio button). |
#### Related prompts
* [AutoComplete](#autocomplete-prompt)
* [Form](#form-prompt)
* [MultiSelect](#multiselect-prompt)
* [Select](#select-prompt)
* [Survey](#survey-prompt)
***
### AuthPrompt
The `AuthPrompt` is used to create prompts to log in user using any authentication method. For example, Enquirer uses this class as the basis for the [BasicAuth Prompt](#basicauth-prompt). You can also find prompt examples in `examples/auth/` folder that utilizes `AuthPrompt` to create OAuth based authentication prompt or a prompt that authenticates using time-based OTP, among others.
`AuthPrompt` has a factory function that creates an instance of `AuthPrompt` class and it expects an `authenticate` function, as an argument, which overrides the `authenticate` function of the `AuthPrompt` class.
#### Methods
| **Method** | **Description** |
| ------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `authenticate()` | Contain all the authentication logic. This function should be overridden to implement custom authentication logic. The default `authenticate` function throws an error if no other function is provided. |
#### Choices
Auth prompt supports the `choices` option, which is the similar to the choices used in [Form Prompt](#form-prompt).
**Example**
```js
const { AuthPrompt } = require('enquirer');
function authenticate(value, state) {
if (value.username === this.options.username && value.password === this.options.password) {
return true;
}
return false;
}
const CustomAuthPrompt = AuthPrompt.create(authenticate);
const prompt = new CustomAuthPrompt({
name: 'password',
message: 'Please enter your password',
username: 'rajat-sr',
password: '1234567',
choices: [
{ name: 'username', message: 'username' },
{ name: 'password', message: 'password' }
]
});
prompt
.run()
.then(answer => console.log('Authenticated?', answer))
.catch(console.error);
```
#### Related prompts
* [BasicAuth Prompt](#basicauth-prompt)
***
### BooleanPrompt
The `BooleanPrompt` class is used for creating prompts that display and return a boolean value.
```js
const { BooleanPrompt } = require('enquirer');
const prompt = new BooleanPrompt({
header: '========================',
message: 'Do you love enquirer?',
footer: '========================',
});
prompt.run()
.then(answer => console.log('Selected:', answer))
.catch(console.error);
```
**Returns**: `boolean`
***
### NumberPrompt
The `NumberPrompt` class is used for creating prompts that display and return a numerical value.
```js
const { NumberPrompt } = require('enquirer');
const prompt = new NumberPrompt({
header: '************************',
message: 'Input the Numbers:',
footer: '************************',
});
prompt.run()
.then(answer => console.log('Numbers are:', answer))
.catch(console.error);
```
**Returns**: `string|number` (number, or number formatted as a string)
***
### StringPrompt
The `StringPrompt` class is used for creating prompts that display and return a string value.
```js
const { StringPrompt } = require('enquirer');
const prompt = new StringPrompt({
header: '************************',
message: 'Input the String:',
footer: '************************'
});
prompt.run()
.then(answer => console.log('String is:', answer))
.catch(console.error);
```
**Returns**: `string`
<br>
## ❯ Custom prompts
With Enquirer 2.0, custom prompts are easier than ever to create and use.
**How do I create a custom prompt?**
Custom prompts are created by extending either:
* Enquirer's `Prompt` class
* one of the built-in [prompts](#-prompts), or
* low-level [types](#-types).
<!-- Example: HaiKarate Custom Prompt -->
```js
const { Prompt } = require('enquirer');
class HaiKarate extends Prompt {
constructor(options = {}) {
super(options);
this.value = options.initial || 0;
this.cursorHide();
}
up() {
this.value++;
this.render();
}
down() {
this.value--;
this.render();
}
render() {
this.clear(); // clear previously rendered prompt from the terminal
this.write(`${this.state.message}: ${this.value}`);
}
}
// Use the prompt by creating an instance of your custom prompt class.
const prompt = new HaiKarate({
message: 'How many sprays do you want?',
initial: 10
});
prompt.run()
.then(answer => console.log('Sprays:', answer))
.catch(console.error);
```
If you want to be able to specify your prompt by `type` so that it may be used alongside other prompts, you will need to first create an instance of `Enquirer`.
```js
const Enquirer = require('enquirer');
const enquirer = new Enquirer();
```
Then use the `.register()` method to add your custom prompt.
```js
enquirer.register('haikarate', HaiKarate);
```
Now you can do the following when defining "questions".
```js
let spritzer = require('cologne-drone');
let answers = await enquirer.prompt([
{
type: 'haikarate',
name: 'cologne',
message: 'How many sprays do you need?',
initial: 10,
async onSubmit(name, value) {
await spritzer.activate(value); //<= activate drone
return value;
}
}
]);
```
<br>
## ❯ Key Bindings
### All prompts
These key combinations may be used with all prompts.
| **command** | **description** |
| -------------------------------- | -------------------------------------- |
| <kbd>ctrl</kbd> + <kbd>c</kbd> | Cancel the prompt. |
| <kbd>ctrl</kbd> + <kbd>g</kbd> | Reset the prompt to its initial state. |
<br>
### Move cursor
These combinations may be used on prompts that support user input (eg. [input prompt](#input-prompt), [password prompt](#password-prompt), and [invisible prompt](#invisible-prompt)).
| **command** | **description** |
| ------------------------------ | ---------------------------------------- |
| <kbd>left</kbd> | Move the cursor back one character. |
| <kbd>right</kbd> | Move the cursor forward one character. |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move cursor to the start of the line |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move cursor to the end of the line |
| <kbd>ctrl</kbd> + <kbd>b</kbd> | Move cursor back one character |
| <kbd>ctrl</kbd> + <kbd>f</kbd> | Move cursor forward one character |
| <kbd>ctrl</kbd> + <kbd>x</kbd> | Toggle between first and cursor position |
<br>
### Edit Input
These key combinations may be used on prompts that support user input (eg. [input prompt](#input-prompt), [password prompt](#password-prompt), and [invisible prompt](#invisible-prompt)).
| **command** | **description** |
| ------------------------------ | ---------------------------------------- |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move cursor to the start of the line |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move cursor to the end of the line |
| <kbd>ctrl</kbd> + <kbd>b</kbd> | Move cursor back one character |
| <kbd>ctrl</kbd> + <kbd>f</kbd> | Move cursor forward one character |
| <kbd>ctrl</kbd> + <kbd>x</kbd> | Toggle between first and cursor position |
<br>
| **command (Mac)** | **command (Windows)** | **description** |
| ----------------------------------- | -------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------- |
| <kbd>delete</kbd> | <kbd>backspace</kbd> | Delete one character to the left. |
| <kbd>fn</kbd> + <kbd>delete</kbd> | <kbd>delete</kbd> | Delete one character to the right. |
| <kbd>option</kbd> + <kbd>up</kbd> | <kbd>alt</kbd> + <kbd>up</kbd> | Scroll to the previous item in history ([Input prompt](#input-prompt) only, when [history is enabled](examples/input/option-history.js)). |
| <kbd>option</kbd> + <kbd>down</kbd> | <kbd>alt</kbd> + <kbd>down</kbd> | Scroll to the next item in history ([Input prompt](#input-prompt) only, when [history is enabled](examples/input/option-history.js)). |
### Select choices
These key combinations may be used on prompts that support _multiple_ choices, such as the [multiselect prompt](#multiselect-prompt), or the [select prompt](#select-prompt) when the `multiple` options is true.
| **command** | **description** |
| ----------------- | -------------------------------------------------------------------------------------------------------------------- |
| <kbd>space</kbd> | Toggle the currently selected choice when `options.multiple` is true. |
| <kbd>number</kbd> | Move the pointer to the choice at the given index. Also toggles the selected choice when `options.multiple` is true. |
| <kbd>a</kbd> | Toggle all choices to be enabled or disabled. |
| <kbd>i</kbd> | Invert the current selection of choices. |
| <kbd>g</kbd> | Toggle the current choice group. |
<br>
### Hide/show choices
| **command** | **description** |
| ------------------------------- | ---------------------------------------------- |
| <kbd>fn</kbd> + <kbd>up</kbd> | Decrease the number of visible choices by one. |
| <kbd>fn</kbd> + <kbd>down</kbd> | Increase the number of visible choices by one. |
<br>
### Move/lock Pointer
| **command** | **description** |
| ---------------------------------- | -------------------------------------------------------------------------------------------------------------------- |
| <kbd>number</kbd> | Move the pointer to the choice at the given index. Also toggles the selected choice when `options.multiple` is true. |
| <kbd>up</kbd> | Move the pointer up. |
| <kbd>down</kbd> | Move the pointer down. |
| <kbd>ctrl</kbd> + <kbd>a</kbd> | Move the pointer to the first _visible_ choice. |
| <kbd>ctrl</kbd> + <kbd>e</kbd> | Move the pointer to the last _visible_ choice. |
| <kbd>shift</kbd> + <kbd>up</kbd> | Scroll up one choice without changing pointer position (locks the pointer while scrolling). |
| <kbd>shift</kbd> + <kbd>down</kbd> | Scroll down one choice without changing pointer position (locks the pointer while scrolling). |
<br>
| **command (Mac)** | **command (Windows)** | **description** |
| -------------------------------- | --------------------- | ---------------------------------------------------------- |
| <kbd>fn</kbd> + <kbd>left</kbd> | <kbd>home</kbd> | Move the pointer to the first choice in the choices array. |
| <kbd>fn</kbd> + <kbd>right</kbd> | <kbd>end</kbd> | Move the pointer to the last choice in the choices array. |
<br>
## ❯ Release History
Please see [CHANGELOG.md](CHANGELOG.md).
## ❯ Performance
### System specs
MacBook Pro, Intel Core i7, 2.5 GHz, 16 GB.
### Load time
Time it takes for the module to load the first time (average of 3 runs):
```
enquirer: 4.013ms
inquirer: 286.717ms
```
<br>
## ❯ About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
### Todo
We're currently working on documentation for the following items. Please star and watch the repository for updates!
* [ ] Customizing symbols
* [ ] Customizing styles (palette)
* [ ] Customizing rendered input
* [ ] Customizing returned values
* [ ] Customizing key bindings
* [ ] Question validation
* [ ] Choice validation
* [ ] Skipping questions
* [ ] Async choices
* [ ] Async timers: loaders, spinners and other animations
* [ ] Links to examples
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
```sh
$ yarn && yarn test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
#### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 283 | [jonschlinkert](https://github.com/jonschlinkert) |
| 82 | [doowb](https://github.com/doowb) |
| 32 | [rajat-sr](https://github.com/rajat-sr) |
| 20 | [318097](https://github.com/318097) |
| 15 | [g-plane](https://github.com/g-plane) |
| 12 | [pixelass](https://github.com/pixelass) |
| 5 | [adityavyas611](https://github.com/adityavyas611) |
| 5 | [satotake](https://github.com/satotake) |
| 3 | [tunnckoCore](https://github.com/tunnckoCore) |
| 3 | [Ovyerus](https://github.com/Ovyerus) |
| 3 | [sw-yx](https://github.com/sw-yx) |
| 2 | [DanielRuf](https://github.com/DanielRuf) |
| 2 | [GabeL7r](https://github.com/GabeL7r) |
| 1 | [AlCalzone](https://github.com/AlCalzone) |
| 1 | [hipstersmoothie](https://github.com/hipstersmoothie) |
| 1 | [danieldelcore](https://github.com/danieldelcore) |
| 1 | [ImgBotApp](https://github.com/ImgBotApp) |
| 1 | [jsonkao](https://github.com/jsonkao) |
| 1 | [knpwrs](https://github.com/knpwrs) |
| 1 | [yeskunall](https://github.com/yeskunall) |
| 1 | [mischah](https://github.com/mischah) |
| 1 | [renarsvilnis](https://github.com/renarsvilnis) |
| 1 | [sbugert](https://github.com/sbugert) |
| 1 | [stephencweiss](https://github.com/stephencweiss) |
| 1 | [skellock](https://github.com/skellock) |
| 1 | [whxaxes](https://github.com/whxaxes) |
#### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
#### Credit
Thanks to [derhuerst](https://github.com/derhuerst), creator of prompt libraries such as [prompt-skeleton](https://github.com/derhuerst/prompt-skeleton), which influenced some of the concepts we used in our prompts.
#### License
Copyright © 2018-present, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
# fast-json-stable-stringify
Deterministic `JSON.stringify()` - a faster version of [@substack](https://github.com/substack)'s json-stable-strigify without [jsonify](https://github.com/substack/jsonify).
You can also pass in a custom comparison function.
[](https://travis-ci.org/epoberezkin/fast-json-stable-stringify)
[](https://coveralls.io/github/epoberezkin/fast-json-stable-stringify?branch=master)
# example
``` js
var stringify = require('fast-json-stable-stringify');
var obj = { c: 8, b: [{z:6,y:5,x:4},7], a: 3 };
console.log(stringify(obj));
```
output:
```
{"a":3,"b":[{"x":4,"y":5,"z":6},7],"c":8}
```
# methods
``` js
var stringify = require('fast-json-stable-stringify')
```
## var str = stringify(obj, opts)
Return a deterministic stringified string `str` from the object `obj`.
## options
### cmp
If `opts` is given, you can supply an `opts.cmp` to have a custom comparison
function for object keys. Your function `opts.cmp` is called with these
parameters:
``` js
opts.cmp({ key: akey, value: avalue }, { key: bkey, value: bvalue })
```
For example, to sort on the object key names in reverse order you could write:
``` js
var stringify = require('fast-json-stable-stringify');
var obj = { c: 8, b: [{z:6,y:5,x:4},7], a: 3 };
var s = stringify(obj, function (a, b) {
return a.key < b.key ? 1 : -1;
});
console.log(s);
```
which results in the output string:
```
{"c":8,"b":[{"z":6,"y":5,"x":4},7],"a":3}
```
Or if you wanted to sort on the object values in reverse order, you could write:
```
var stringify = require('fast-json-stable-stringify');
var obj = { d: 6, c: 5, b: [{z:3,y:2,x:1},9], a: 10 };
var s = stringify(obj, function (a, b) {
return a.value < b.value ? 1 : -1;
});
console.log(s);
```
which outputs:
```
{"d":6,"c":5,"b":[{"z":3,"y":2,"x":1},9],"a":10}
```
### cycles
Pass `true` in `opts.cycles` to stringify circular property as `__cycle__` - the result will not be a valid JSON string in this case.
TypeError will be thrown in case of circular object without this option.
# install
With [npm](https://npmjs.org) do:
```
npm install fast-json-stable-stringify
```
# benchmark
To run benchmark (requires Node.js 6+):
```
node benchmark
```
Results:
```
fast-json-stable-stringify x 17,189 ops/sec ±1.43% (83 runs sampled)
json-stable-stringify x 13,634 ops/sec ±1.39% (85 runs sampled)
fast-stable-stringify x 20,212 ops/sec ±1.20% (84 runs sampled)
faster-stable-stringify x 15,549 ops/sec ±1.12% (84 runs sampled)
The fastest is fast-stable-stringify
```
## Enterprise support
fast-json-stable-stringify package is a part of [Tidelift enterprise subscription](https://tidelift.com/subscription/pkg/npm-fast-json-stable-stringify?utm_source=npm-fast-json-stable-stringify&utm_medium=referral&utm_campaign=enterprise&utm_term=repo) - it provides a centralised commercial support to open-source software users, in addition to the support provided by software maintainers.
## Security contact
To report a security vulnerability, please use the
[Tidelift security contact](https://tidelift.com/security).
Tidelift will coordinate the fix and disclosure. Please do NOT report security vulnerability via GitHub issues.
# license
[MIT](https://github.com/epoberezkin/fast-json-stable-stringify/blob/master/LICENSE)
# y18n
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[](https://conventionalcommits.org)
The bare-bones internationalization library used by yargs.
Inspired by [i18n](https://www.npmjs.com/package/i18n).
## Examples
_simple string translation:_
```js
const __ = require('y18n')().__;
console.log(__('my awesome string %s', 'foo'));
```
output:
`my awesome string foo`
_using tagged template literals_
```js
const __ = require('y18n')().__;
const str = 'foo';
console.log(__`my awesome string ${str}`);
```
output:
`my awesome string foo`
_pluralization support:_
```js
const __n = require('y18n')().__n;
console.log(__n('one fish %s', '%d fishes %s', 2, 'foo'));
```
output:
`2 fishes foo`
## Deno Example
As of `v5` `y18n` supports [Deno](https://github.com/denoland/deno):
```typescript
import y18n from "https://deno.land/x/y18n/deno.ts";
const __ = y18n({
locale: 'pirate',
directory: './test/locales'
}).__
console.info(__`Hi, ${'Ben'} ${'Coe'}!`)
```
You will need to run with `--allow-read` to load alternative locales.
## JSON Language Files
The JSON language files should be stored in a `./locales` folder.
File names correspond to locales, e.g., `en.json`, `pirate.json`.
When strings are observed for the first time they will be
added to the JSON file corresponding to the current locale.
## Methods
### require('y18n')(config)
Create an instance of y18n with the config provided, options include:
* `directory`: the locale directory, default `./locales`.
* `updateFiles`: should newly observed strings be updated in file, default `true`.
* `locale`: what locale should be used.
* `fallbackToLanguage`: should fallback to a language-only file (e.g. `en.json`)
be allowed if a file matching the locale does not exist (e.g. `en_US.json`),
default `true`.
### y18n.\_\_(str, arg, arg, arg)
Print a localized string, `%s` will be replaced with `arg`s.
This function can also be used as a tag for a template literal. You can use it
like this: <code>__`hello ${'world'}`</code>. This will be equivalent to
`__('hello %s', 'world')`.
### y18n.\_\_n(singularString, pluralString, count, arg, arg, arg)
Print a localized string with appropriate pluralization. If `%d` is provided
in the string, the `count` will replace this placeholder.
### y18n.setLocale(str)
Set the current locale being used.
### y18n.getLocale()
What locale is currently being used?
### y18n.updateLocale(obj)
Update the current locale with the key value pairs in `obj`.
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
## License
ISC
[npm-url]: https://npmjs.org/package/y18n
[npm-image]: https://img.shields.io/npm/v/y18n.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: https://github.com/feross/standard
# hasurl [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url]
> Determine whether Node.js' native [WHATWG `URL`](https://nodejs.org/api/url.html#url_the_whatwg_url_api) implementation is available.
## Installation
[Node.js](http://nodejs.org/) `>= 4` is required. To install, type this at the command line:
```shell
npm install hasurl
```
## Usage
```js
const hasURL = require('hasurl');
if (hasURL()) {
// supported
} else {
// fallback
}
```
[npm-image]: https://img.shields.io/npm/v/hasurl.svg
[npm-url]: https://npmjs.org/package/hasurl
[travis-image]: https://img.shields.io/travis/stevenvachon/hasurl.svg
[travis-url]: https://travis-ci.org/stevenvachon/hasurl
# yargs-parser
[](https://travis-ci.org/yargs/yargs-parser)
[](https://www.npmjs.com/package/yargs-parser)
[](https://github.com/conventional-changelog/standard-version)
The mighty option parser used by [yargs](https://github.com/yargs/yargs).
visit the [yargs website](http://yargs.js.org/) for more examples, and thorough usage instructions.
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs-parser/master/yargs-logo.png">
## Example
```sh
npm i yargs-parser --save
```
```js
var argv = require('yargs-parser')(process.argv.slice(2))
console.log(argv)
```
```sh
node example.js --foo=33 --bar hello
{ _: [], foo: 33, bar: 'hello' }
```
_or parse a string!_
```js
var argv = require('yargs-parser')('--foo=99 --bar=33')
console.log(argv)
```
```sh
{ _: [], foo: 99, bar: 33 }
```
Convert an array of mixed types before passing to `yargs-parser`:
```js
var parse = require('yargs-parser')
parse(['-f', 11, '--zoom', 55].join(' ')) // <-- array to string
parse(['-f', 11, '--zoom', 55].map(String)) // <-- array of strings
```
## API
### require('yargs-parser')(args, opts={})
Parses command line arguments returning a simple mapping of keys and values.
**expects:**
* `args`: a string or array of strings representing the options to parse.
* `opts`: provide a set of hints indicating how `args` should be parsed:
* `opts.alias`: an object representing the set of aliases for a key: `{alias: {foo: ['f']}}`.
* `opts.array`: indicate that keys should be parsed as an array: `{array: ['foo', 'bar']}`.<br>
Indicate that keys should be parsed as an array and coerced to booleans / numbers:<br>
`{array: [{ key: 'foo', boolean: true }, {key: 'bar', number: true}]}`.
* `opts.boolean`: arguments should be parsed as booleans: `{boolean: ['x', 'y']}`.
* `opts.coerce`: provide a custom synchronous function that returns a coerced value from the argument provided
(or throws an error). For arrays the function is called only once for the entire array:<br>
`{coerce: {foo: function (arg) {return modifiedArg}}}`.
* `opts.config`: indicate a key that represents a path to a configuration file (this file will be loaded and parsed).
* `opts.configObjects`: configuration objects to parse, their properties will be set as arguments:<br>
`{configObjects: [{'x': 5, 'y': 33}, {'z': 44}]}`.
* `opts.configuration`: provide configuration options to the yargs-parser (see: [configuration](#configuration)).
* `opts.count`: indicate a key that should be used as a counter, e.g., `-vvv` = `{v: 3}`.
* `opts.default`: provide default values for keys: `{default: {x: 33, y: 'hello world!'}}`.
* `opts.envPrefix`: environment variables (`process.env`) with the prefix provided should be parsed.
* `opts.narg`: specify that a key requires `n` arguments: `{narg: {x: 2}}`.
* `opts.normalize`: `path.normalize()` will be applied to values set to this key.
* `opts.number`: keys should be treated as numbers.
* `opts.string`: keys should be treated as strings (even if they resemble a number `-x 33`).
**returns:**
* `obj`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
### require('yargs-parser').detailed(args, opts={})
Parses a command line string, returning detailed information required by the
yargs engine.
**expects:**
* `args`: a string or array of strings representing options to parse.
* `opts`: provide a set of hints indicating how `args`, inputs are identical to `require('yargs-parser')(args, opts={})`.
**returns:**
* `argv`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
* `error`: populated with an error object if an exception occurred during parsing.
* `aliases`: the inferred list of aliases built by combining lists in `opts.alias`.
* `newAliases`: any new aliases added via camel-case expansion:
* `boolean`: `{ fooBar: true }`
* `defaulted`: any new argument created by `opts.default`, no aliases included.
* `boolean`: `{ foo: true }`
* `configuration`: given by default settings and `opts.configuration`.
<a name="configuration"></a>
### Configuration
The yargs-parser applies several automated transformations on the keys provided
in `args`. These features can be turned on and off using the `configuration` field
of `opts`.
```js
var parsed = parser(['--no-dice'], {
configuration: {
'boolean-negation': false
}
})
```
### short option groups
* default: `true`.
* key: `short-option-groups`.
Should a group of short-options be treated as boolean flags?
```sh
node example.js -abc
{ _: [], a: true, b: true, c: true }
```
_if disabled:_
```sh
node example.js -abc
{ _: [], abc: true }
```
### camel-case expansion
* default: `true`.
* key: `camel-case-expansion`.
Should hyphenated arguments be expanded into camel-case aliases?
```sh
node example.js --foo-bar
{ _: [], 'foo-bar': true, fooBar: true }
```
_if disabled:_
```sh
node example.js --foo-bar
{ _: [], 'foo-bar': true }
```
### dot-notation
* default: `true`
* key: `dot-notation`
Should keys that contain `.` be treated as objects?
```sh
node example.js --foo.bar
{ _: [], foo: { bar: true } }
```
_if disabled:_
```sh
node example.js --foo.bar
{ _: [], "foo.bar": true }
```
### parse numbers
* default: `true`
* key: `parse-numbers`
Should keys that look like numbers be treated as such?
```sh
node example.js --foo=99.3
{ _: [], foo: 99.3 }
```
_if disabled:_
```sh
node example.js --foo=99.3
{ _: [], foo: "99.3" }
```
### boolean negation
* default: `true`
* key: `boolean-negation`
Should variables prefixed with `--no` be treated as negations?
```sh
node example.js --no-foo
{ _: [], foo: false }
```
_if disabled:_
```sh
node example.js --no-foo
{ _: [], "no-foo": true }
```
### combine arrays
* default: `false`
* key: `combine-arrays`
Should arrays be combined when provided by both command line arguments and
a configuration file.
### duplicate arguments array
* default: `true`
* key: `duplicate-arguments-array`
Should arguments be coerced into an array when duplicated:
```sh
node example.js -x 1 -x 2
{ _: [], x: [1, 2] }
```
_if disabled:_
```sh
node example.js -x 1 -x 2
{ _: [], x: 2 }
```
### flatten duplicate arrays
* default: `true`
* key: `flatten-duplicate-arrays`
Should array arguments be coerced into a single array when duplicated:
```sh
node example.js -x 1 2 -x 3 4
{ _: [], x: [1, 2, 3, 4] }
```
_if disabled:_
```sh
node example.js -x 1 2 -x 3 4
{ _: [], x: [[1, 2], [3, 4]] }
```
### greedy arrays
* default: `true`
* key: `greedy-arrays`
Should arrays consume more than one positional argument following their flag.
```sh
node example --arr 1 2
{ _[], arr: [1, 2] }
```
_if disabled:_
```sh
node example --arr 1 2
{ _[2], arr: [1] }
```
**Note: in `v18.0.0` we are considering defaulting greedy arrays to `false`.**
### nargs eats options
* default: `false`
* key: `nargs-eats-options`
Should nargs consume dash options as well as positional arguments.
### negation prefix
* default: `no-`
* key: `negation-prefix`
The prefix to use for negated boolean variables.
```sh
node example.js --no-foo
{ _: [], foo: false }
```
_if set to `quux`:_
```sh
node example.js --quuxfoo
{ _: [], foo: false }
```
### populate --
* default: `false`.
* key: `populate--`
Should unparsed flags be stored in `--` or `_`.
_If disabled:_
```sh
node example.js a -b -- x y
{ _: [ 'a', 'x', 'y' ], b: true }
```
_If enabled:_
```sh
node example.js a -b -- x y
{ _: [ 'a' ], '--': [ 'x', 'y' ], b: true }
```
### set placeholder key
* default: `false`.
* key: `set-placeholder-key`.
Should a placeholder be added for keys not set via the corresponding CLI argument?
_If disabled:_
```sh
node example.js -a 1 -c 2
{ _: [], a: 1, c: 2 }
```
_If enabled:_
```sh
node example.js -a 1 -c 2
{ _: [], a: 1, b: undefined, c: 2 }
```
### halt at non-option
* default: `false`.
* key: `halt-at-non-option`.
Should parsing stop at the first positional argument? This is similar to how e.g. `ssh` parses its command line.
_If disabled:_
```sh
node example.js -a run b -x y
{ _: [ 'b' ], a: 'run', x: 'y' }
```
_If enabled:_
```sh
node example.js -a run b -x y
{ _: [ 'b', '-x', 'y' ], a: 'run' }
```
### strip aliased
* default: `false`
* key: `strip-aliased`
Should aliases be removed before returning results?
_If disabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1, 'test-alias': 1, testAlias: 1 }
```
_If enabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
### strip dashed
* default: `false`
* key: `strip-dashed`
Should dashed keys be removed before returning results? This option has no effect if
`camel-case-expansion` is disabled.
_If disabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
_If enabled:_
```sh
node example.js --test-field 1
{ _: [], testField: 1 }
```
### unknown options as args
* default: `false`
* key: `unknown-options-as-args`
Should unknown options be treated like regular arguments? An unknown option is one that is not
configured in `opts`.
_If disabled_
```sh
node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: [], unknownOption: true, knownOption: 2, stringOption: '', unknownOption2: true }
```
_If enabled_
```sh
node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: ['--unknown-option'], knownOption: 2, stringOption: '--unknown-option2' }
```
## Special Thanks
The yargs project evolves from optimist and minimist. It owes its
existence to a lot of James Halliday's hard work. Thanks [substack](https://github.com/substack) **beep** **boop** \o/
## License
ISC
# fast-levenshtein - Levenshtein algorithm in Javascript
[](http://travis-ci.org/hiddentao/fast-levenshtein)
[](https://badge.fury.io/js/fast-levenshtein)
[](https://www.npmjs.com/package/fast-levenshtein)
[](https://twitter.com/hiddentao)
An efficient Javascript implementation of the [Levenshtein algorithm](http://en.wikipedia.org/wiki/Levenshtein_distance) with locale-specific collator support.
## Features
* Works in node.js and in the browser.
* Better performance than other implementations by not needing to store the whole matrix ([more info](http://www.codeproject.com/Articles/13525/Fast-memory-efficient-Levenshtein-algorithm)).
* Locale-sensitive string comparisions if needed.
* Comprehensive test suite and performance benchmark.
* Small: <1 KB minified and gzipped
## Installation
### node.js
Install using [npm](http://npmjs.org/):
```bash
$ npm install fast-levenshtein
```
### Browser
Using bower:
```bash
$ bower install fast-levenshtein
```
If you are not using any module loader system then the API will then be accessible via the `window.Levenshtein` object.
## Examples
**Default usage**
```javascript
var levenshtein = require('fast-levenshtein');
var distance = levenshtein.get('back', 'book'); // 2
var distance = levenshtein.get('我愛你', '我叫你'); // 1
```
**Locale-sensitive string comparisons**
It supports using [Intl.Collator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Collator) for locale-sensitive string comparisons:
```javascript
var levenshtein = require('fast-levenshtein');
levenshtein.get('mikailovitch', 'Mikhaïlovitch', { useCollator: true});
// 1
```
## Building and Testing
To build the code and run the tests:
```bash
$ npm install -g grunt-cli
$ npm install
$ npm run build
```
## Performance
_Thanks to [Titus Wormer](https://github.com/wooorm) for [encouraging me](https://github.com/hiddentao/fast-levenshtein/issues/1) to do this._
Benchmarked against other node.js levenshtein distance modules (on Macbook Air 2012, Core i7, 8GB RAM):
```bash
Running suite Implementation comparison [benchmark/speed.js]...
>> levenshtein-edit-distance x 234 ops/sec ±3.02% (73 runs sampled)
>> levenshtein-component x 422 ops/sec ±4.38% (83 runs sampled)
>> levenshtein-deltas x 283 ops/sec ±3.83% (78 runs sampled)
>> natural x 255 ops/sec ±0.76% (88 runs sampled)
>> levenshtein x 180 ops/sec ±3.55% (86 runs sampled)
>> fast-levenshtein x 1,792 ops/sec ±2.72% (95 runs sampled)
Benchmark done.
Fastest test is fast-levenshtein at 4.2x faster than levenshtein-component
```
You can run this benchmark yourself by doing:
```bash
$ npm install
$ npm run build
$ npm run benchmark
```
## Contributing
If you wish to submit a pull request please update and/or create new tests for any changes you make and ensure the grunt build passes.
See [CONTRIBUTING.md](https://github.com/hiddentao/fast-levenshtein/blob/master/CONTRIBUTING.md) for details.
## License
MIT - see [LICENSE.md](https://github.com/hiddentao/fast-levenshtein/blob/master/LICENSE.md)
# debug
[](https://travis-ci.org/debug-js/debug) [](https://coveralls.io/github/debug-js/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows command prompt notes
##### CMD
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Example:
```cmd
set DEBUG=* & node app.js
```
##### PowerShell (VS Code default)
PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Example:
```cmd
$env:DEBUG='app';node app.js
```
Then, run the program to be debugged as usual.
npm script example:
```js
"windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
```
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
In Chromium-based web browsers (e.g. Brave, Chrome, and Electron), the JavaScript console will—by default—only show messages logged by `debug` if the "Verbose" log level is _enabled_.
<img width="647" src="https://user-images.githubusercontent.com/7143133/152083257-29034707-c42c-4959-8add-3cee850e6fcf.png">
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Extend
You can simply extend debugger
```js
const log = require('debug')('auth');
//creates new debug instance with extended namespace
const logSign = log.extend('sign');
const logLogin = log.extend('login');
log('hello'); // auth hello
logSign('hello'); //auth:sign hello
logLogin('hello'); //auth:login hello
```
## Set dynamically
You can also enable debug dynamically by calling the `enable()` method :
```js
let debug = require('debug');
console.log(1, debug.enabled('test'));
debug.enable('test');
console.log(2, debug.enabled('test'));
debug.disable();
console.log(3, debug.enabled('test'));
```
print :
```
1 false
2 true
3 false
```
Usage :
`enable(namespaces)`
`namespaces` can include modes separated by a colon and wildcards.
Note that calling `enable()` completely overrides previously set DEBUG variable :
```
$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
=> false
```
`disable()`
Will disable all namespaces. The functions returns the namespaces currently
enabled (and skipped). This can be useful if you want to disable debugging
temporarily without knowing what was enabled to begin with.
For example:
```js
let debug = require('debug');
debug.enable('foo:*,-foo:bar');
let namespaces = debug.disable();
debug.enable(namespaces);
```
Note: There is no guarantee that the string will be identical to the initial
enable string, but semantically they will be identical.
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Usage in child processes
Due to the way `debug` detects if the output is a TTY or not, colors are not shown in child processes when `stderr` is piped. A solution is to pass the `DEBUG_COLORS=1` environment variable to the child process.
For example:
```javascript
worker = fork(WORKER_WRAP_PATH, [workerPath], {
stdio: [
/* stdin: */ 0,
/* stdout: */ 'pipe',
/* stderr: */ 'pipe',
'ipc',
],
env: Object.assign({}, process.env, {
DEBUG_COLORS: 1 // without this settings, colors won't be shown
}),
});
worker.stderr.pipe(process.stderr, { end: false });
```
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
- Josh Junon
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Copyright (c) 2018-2021 Josh Junon
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
discontinuous-range
===================
```
DiscontinuousRange(1, 10).subtract(4, 6); // [ 1-3, 7-10 ]
```
[](https://travis-ci.org/dtudury/discontinuous-range)
this is a pretty simple module, but it exists to service another project
so this'll be pretty lacking documentation.
reading the test to see how this works may help. otherwise, here's an example
that I think pretty much sums it up
###Example
```
var all_numbers = new DiscontinuousRange(1, 100);
var bad_numbers = DiscontinuousRange(13).add(8).add(60,80);
var good_numbers = all_numbers.clone().subtract(bad_numbers);
console.log(good_numbers.toString()); //[ 1-7, 9-12, 14-59, 81-100 ]
var random_good_number = good_numbers.index(Math.floor(Math.random() * good_numbers.length));
```
[](https://www.npmjs.com/package/espree)
[](https://travis-ci.org/eslint/espree)
[](https://www.npmjs.com/package/espree)
[](https://www.bountysource.com/trackers/9348450-eslint?utm_source=9348450&utm_medium=shield&utm_campaign=TRACKER_BADGE)
# Espree
Espree started out as a fork of [Esprima](http://esprima.org) v1.2.2, the last stable published released of Esprima before work on ECMAScript 6 began. Espree is now built on top of [Acorn](https://github.com/ternjs/acorn), which has a modular architecture that allows extension of core functionality. The goal of Espree is to produce output that is similar to Esprima with a similar API so that it can be used in place of Esprima.
## Usage
Install:
```
npm i espree
```
And in your Node.js code:
```javascript
const espree = require("espree");
const ast = espree.parse(code);
```
## API
### `parse()`
`parse` parses the given code and returns a abstract syntax tree (AST). It takes two parameters.
- `code` [string]() - the code which needs to be parsed.
- `options (Optional)` [Object]() - read more about this [here](#options).
```javascript
const espree = require("espree");
const ast = espree.parse(code, options);
```
**Example :**
```js
const ast = espree.parse('let foo = "bar"', { ecmaVersion: 6 });
console.log(ast);
```
<details><summary>Output</summary>
<p>
```
Node {
type: 'Program',
start: 0,
end: 15,
body: [
Node {
type: 'VariableDeclaration',
start: 0,
end: 15,
declarations: [Array],
kind: 'let'
}
],
sourceType: 'script'
}
```
</p>
</details>
### `tokenize()`
`tokenize` returns the tokens of a given code. It takes two parameters.
- `code` [string]() - the code which needs to be parsed.
- `options (Optional)` [Object]() - read more about this [here](#options).
Even if `options` is empty or undefined or `options.tokens` is `false`, it assigns it to `true` in order to get the `tokens` array
**Example :**
```js
const tokens = espree.tokenize('let foo = "bar"', { ecmaVersion: 6 });
console.log(tokens);
```
<details><summary>Output</summary>
<p>
```
Token { type: 'Keyword', value: 'let', start: 0, end: 3 },
Token { type: 'Identifier', value: 'foo', start: 4, end: 7 },
Token { type: 'Punctuator', value: '=', start: 8, end: 9 },
Token { type: 'String', value: '"bar"', start: 10, end: 15 }
```
</p>
</details>
### `version`
Returns the current `espree` version
### `VisitorKeys`
Returns all visitor keys for traversing the AST from [eslint-visitor-keys](https://github.com/eslint/eslint-visitor-keys)
### `latestEcmaVersion`
Returns the latest ECMAScript supported by `espree`
### `supportedEcmaVersions`
Returns an array of all supported ECMAScript versions
## Options
```js
const options = {
// attach range information to each node
range: false,
// attach line/column location information to each node
loc: false,
// create a top-level comments array containing all comments
comment: false,
// create a top-level tokens array containing all tokens
tokens: false,
// Set to 3, 5 (default), 6, 7, 8, 9, 10, 11, or 12 to specify the version of ECMAScript syntax you want to use.
// You can also set to 2015 (same as 6), 2016 (same as 7), 2017 (same as 8), 2018 (same as 9), 2019 (same as 10), 2020 (same as 11), or 2021 (same as 12) to use the year-based naming.
ecmaVersion: 5,
// specify which type of script you're parsing ("script" or "module")
sourceType: "script",
// specify additional language features
ecmaFeatures: {
// enable JSX parsing
jsx: false,
// enable return in global scope
globalReturn: false,
// enable implied strict mode (if ecmaVersion >= 5)
impliedStrict: false
}
}
```
## Esprima Compatibility Going Forward
The primary goal is to produce the exact same AST structure and tokens as Esprima, and that takes precedence over anything else. (The AST structure being the [ESTree](https://github.com/estree/estree) API with JSX extensions.) Separate from that, Espree may deviate from what Esprima outputs in terms of where and how comments are attached, as well as what additional information is available on AST nodes. That is to say, Espree may add more things to the AST nodes than Esprima does but the overall AST structure produced will be the same.
Espree may also deviate from Esprima in the interface it exposes.
## Contributing
Issues and pull requests will be triaged and responded to as quickly as possible. We operate under the [ESLint Contributor Guidelines](http://eslint.org/docs/developer-guide/contributing), so please be sure to read them before contributing. If you're not sure where to dig in, check out the [issues](https://github.com/eslint/espree/issues).
Espree is licensed under a permissive BSD 2-clause license.
## Security Policy
We work hard to ensure that Espree is safe for everyone and that security issues are addressed quickly and responsibly. Read the full [security policy](https://github.com/eslint/.github/blob/master/SECURITY.md).
## Build Commands
* `npm test` - run all linting and tests
* `npm run lint` - run all linting
* `npm run browserify` - creates a version of Espree that is usable in a browser
## Differences from Espree 2.x
* The `tokenize()` method does not use `ecmaFeatures`. Any string will be tokenized completely based on ECMAScript 6 semantics.
* Trailing whitespace no longer is counted as part of a node.
* `let` and `const` declarations are no longer parsed by default. You must opt-in by using an `ecmaVersion` newer than `5` or setting `sourceType` to `module`.
* The `esparse` and `esvalidate` binary scripts have been removed.
* There is no `tolerant` option. We will investigate adding this back in the future.
## Known Incompatibilities
In an effort to help those wanting to transition from other parsers to Espree, the following is a list of noteworthy incompatibilities with other parsers. These are known differences that we do not intend to change.
### Esprima 1.2.2
* Esprima counts trailing whitespace as part of each AST node while Espree does not. In Espree, the end of a node is where the last token occurs.
* Espree does not parse `let` and `const` declarations by default.
* Error messages returned for parsing errors are different.
* There are two addition properties on every node and token: `start` and `end`. These represent the same data as `range` and are used internally by Acorn.
### Esprima 2.x
* Esprima 2.x uses a different comment attachment algorithm that results in some comments being added in different places than Espree. The algorithm Espree uses is the same one used in Esprima 1.2.2.
## Frequently Asked Questions
### Why another parser
[ESLint](http://eslint.org) had been relying on Esprima as its parser from the beginning. While that was fine when the JavaScript language was evolving slowly, the pace of development increased dramatically and Esprima had fallen behind. ESLint, like many other tools reliant on Esprima, has been stuck in using new JavaScript language features until Esprima updates, and that caused our users frustration.
We decided the only way for us to move forward was to create our own parser, bringing us inline with JSHint and JSLint, and allowing us to keep implementing new features as we need them. We chose to fork Esprima instead of starting from scratch in order to move as quickly as possible with a compatible API.
With Espree 2.0.0, we are no longer a fork of Esprima but rather a translation layer between Acorn and Esprima syntax. This allows us to put work back into a community-supported parser (Acorn) that is continuing to grow and evolve while maintaining an Esprima-compatible parser for those utilities still built on Esprima.
### Have you tried working with Esprima?
Yes. Since the start of ESLint, we've regularly filed bugs and feature requests with Esprima and will continue to do so. However, there are some different philosophies around how the projects work that need to be worked through. The initial goal was to have Espree track Esprima and eventually merge the two back together, but we ultimately decided that building on top of Acorn was a better choice due to Acorn's plugin support.
### Why don't you just use Acorn?
Acorn is a great JavaScript parser that produces an AST that is compatible with Esprima. Unfortunately, ESLint relies on more than just the AST to do its job. It relies on Esprima's tokens and comment attachment features to get a complete picture of the source code. We investigated switching to Acorn, but the inconsistencies between Esprima and Acorn created too much work for a project like ESLint.
We are building on top of Acorn, however, so that we can contribute back and help make Acorn even better.
### What ECMAScript features do you support?
Espree supports all ECMAScript 2020 features and partially supports ECMAScript 2021 features.
Because ECMAScript 2021 is still under development, we are implementing features as they are finalized. Currently, Espree supports:
* [Logical Assignment Operators](https://github.com/tc39/proposal-logical-assignment)
* [Numeric Separators](https://github.com/tc39/proposal-numeric-separator)
See [finished-proposals.md](https://github.com/tc39/proposals/blob/master/finished-proposals.md) to know what features are finalized.
### How do you determine which experimental features to support?
In general, we do not support experimental JavaScript features. We may make exceptions from time to time depending on the maturity of the features.
# lru cache
A cache object that deletes the least-recently-used items.
[](https://travis-ci.org/isaacs/node-lru-cache) [](https://coveralls.io/github/isaacs/node-lru-cache)
## Installation:
```javascript
npm install lru-cache --save
```
## Usage:
```javascript
var LRU = require("lru-cache")
, options = { max: 500
, length: function (n, key) { return n * 2 + key.length }
, dispose: function (key, n) { n.close() }
, maxAge: 1000 * 60 * 60 }
, cache = new LRU(options)
, otherCache = new LRU(50) // sets just the max size
cache.set("key", "value")
cache.get("key") // "value"
// non-string keys ARE fully supported
// but note that it must be THE SAME object, not
// just a JSON-equivalent object.
var someObject = { a: 1 }
cache.set(someObject, 'a value')
// Object keys are not toString()-ed
cache.set('[object Object]', 'a different value')
assert.equal(cache.get(someObject), 'a value')
// A similar object with same keys/values won't work,
// because it's a different object identity
assert.equal(cache.get({ a: 1 }), undefined)
cache.reset() // empty the cache
```
If you put more stuff in it, then items will fall out.
If you try to put an oversized thing in it, then it'll fall out right
away.
## Options
* `max` The maximum size of the cache, checked by applying the length
function to all values in the cache. Not setting this is kind of
silly, since that's the whole purpose of this lib, but it defaults
to `Infinity`. Setting it to a non-number or negative number will
throw a `TypeError`. Setting it to 0 makes it be `Infinity`.
* `maxAge` Maximum age in ms. Items are not pro-actively pruned out
as they age, but if you try to get an item that is too old, it'll
drop it and return undefined instead of giving it to you.
Setting this to a negative value will make everything seem old!
Setting it to a non-number will throw a `TypeError`.
* `length` Function that is used to calculate the length of stored
items. If you're storing strings or buffers, then you probably want
to do something like `function(n, key){return n.length}`. The default is
`function(){return 1}`, which is fine if you want to store `max`
like-sized things. The item is passed as the first argument, and
the key is passed as the second argumnet.
* `dispose` Function that is called on items when they are dropped
from the cache. This can be handy if you want to close file
descriptors or do other cleanup tasks when items are no longer
accessible. Called with `key, value`. It's called *before*
actually removing the item from the internal cache, so if you want
to immediately put it back in, you'll have to do that in a
`nextTick` or `setTimeout` callback or it won't do anything.
* `stale` By default, if you set a `maxAge`, it'll only actually pull
stale items out of the cache when you `get(key)`. (That is, it's
not pre-emptively doing a `setTimeout` or anything.) If you set
`stale:true`, it'll return the stale value before deleting it. If
you don't set this, then it'll return `undefined` when you try to
get a stale entry, as if it had already been deleted.
* `noDisposeOnSet` By default, if you set a `dispose()` method, then
it'll be called whenever a `set()` operation overwrites an existing
key. If you set this option, `dispose()` will only be called when a
key falls out of the cache, not when it is overwritten.
* `updateAgeOnGet` When using time-expiring entries with `maxAge`,
setting this to `true` will make each item's effective time update
to the current time whenever it is retrieved from cache, causing it
to not expire. (It can still fall out of cache based on recency of
use, of course.)
## API
* `set(key, value, maxAge)`
* `get(key) => value`
Both of these will update the "recently used"-ness of the key.
They do what you think. `maxAge` is optional and overrides the
cache `maxAge` option if provided.
If the key is not found, `get()` will return `undefined`.
The key and val can be any value.
* `peek(key)`
Returns the key value (or `undefined` if not found) without
updating the "recently used"-ness of the key.
(If you find yourself using this a lot, you *might* be using the
wrong sort of data structure, but there are some use cases where
it's handy.)
* `del(key)`
Deletes a key out of the cache.
* `reset()`
Clear the cache entirely, throwing away all values.
* `has(key)`
Check if a key is in the cache, without updating the recent-ness
or deleting it for being stale.
* `forEach(function(value,key,cache), [thisp])`
Just like `Array.prototype.forEach`. Iterates over all the keys
in the cache, in order of recent-ness. (Ie, more recently used
items are iterated over first.)
* `rforEach(function(value,key,cache), [thisp])`
The same as `cache.forEach(...)` but items are iterated over in
reverse order. (ie, less recently used items are iterated over
first.)
* `keys()`
Return an array of the keys in the cache.
* `values()`
Return an array of the values in the cache.
* `length`
Return total length of objects in cache taking into account
`length` options function.
* `itemCount`
Return total quantity of objects currently in cache. Note, that
`stale` (see options) items are returned as part of this item
count.
* `dump()`
Return an array of the cache entries ready for serialization and usage
with 'destinationCache.load(arr)`.
* `load(cacheEntriesArray)`
Loads another cache entries array, obtained with `sourceCache.dump()`,
into the cache. The destination cache is reset before loading new entries
* `prune()`
Manually iterates over the entire cache proactively pruning old entries
[](https://www.npmjs.com/package/eslint)
[](https://www.npmjs.com/package/eslint)
[](https://github.com/eslint/eslint/actions)
[](https://app.fossa.io/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Feslint%2Feslint?ref=badge_shield)
<br />
[](https://opencollective.com/eslint)
[](https://opencollective.com/eslint)
[](https://twitter.com/intent/user?screen_name=geteslint)
# ESLint
[Website](https://eslint.org) |
[Configuring](https://eslint.org/docs/user-guide/configuring) |
[Rules](https://eslint.org/docs/rules/) |
[Contributing](https://eslint.org/docs/developer-guide/contributing) |
[Reporting Bugs](https://eslint.org/docs/developer-guide/contributing/reporting-bugs) |
[Code of Conduct](https://eslint.org/conduct) |
[Twitter](https://twitter.com/geteslint) |
[Mailing List](https://groups.google.com/group/eslint) |
[Chat Room](https://eslint.org/chat)
ESLint is a tool for identifying and reporting on patterns found in ECMAScript/JavaScript code. In many ways, it is similar to JSLint and JSHint with a few exceptions:
* ESLint uses [Espree](https://github.com/eslint/espree) for JavaScript parsing.
* ESLint uses an AST to evaluate patterns in code.
* ESLint is completely pluggable, every single rule is a plugin and you can add more at runtime.
## Table of Contents
1. [Installation and Usage](#installation-and-usage)
2. [Configuration](#configuration)
3. [Code of Conduct](#code-of-conduct)
4. [Filing Issues](#filing-issues)
5. [Frequently Asked Questions](#faq)
6. [Releases](#releases)
7. [Security Policy](#security-policy)
8. [Semantic Versioning Policy](#semantic-versioning-policy)
9. [Stylistic Rule Updates](#stylistic-rule-updates)
10. [License](#license)
11. [Team](#team)
12. [Sponsors](#sponsors)
13. [Technology Sponsors](#technology-sponsors)
## <a name="installation-and-usage"></a>Installation and Usage
Prerequisites: [Node.js](https://nodejs.org/) (`^10.12.0`, or `>=12.0.0`) built with SSL support. (If you are using an official Node.js distribution, SSL is always built in.)
You can install ESLint using npm:
```
$ npm install eslint --save-dev
```
You should then set up a configuration file:
```
$ ./node_modules/.bin/eslint --init
```
After that, you can run ESLint on any file or directory like this:
```
$ ./node_modules/.bin/eslint yourfile.js
```
## <a name="configuration"></a>Configuration
After running `eslint --init`, you'll have a `.eslintrc` file in your directory. In it, you'll see some rules configured like this:
```json
{
"rules": {
"semi": ["error", "always"],
"quotes": ["error", "double"]
}
}
```
The names `"semi"` and `"quotes"` are the names of [rules](https://eslint.org/docs/rules) in ESLint. The first value is the error level of the rule and can be one of these values:
* `"off"` or `0` - turn the rule off
* `"warn"` or `1` - turn the rule on as a warning (doesn't affect exit code)
* `"error"` or `2` - turn the rule on as an error (exit code will be 1)
The three error levels allow you fine-grained control over how ESLint applies rules (for more configuration options and details, see the [configuration docs](https://eslint.org/docs/user-guide/configuring)).
## <a name="code-of-conduct"></a>Code of Conduct
ESLint adheres to the [JS Foundation Code of Conduct](https://eslint.org/conduct).
## <a name="filing-issues"></a>Filing Issues
Before filing an issue, please be sure to read the guidelines for what you're reporting:
* [Bug Report](https://eslint.org/docs/developer-guide/contributing/reporting-bugs)
* [Propose a New Rule](https://eslint.org/docs/developer-guide/contributing/new-rules)
* [Proposing a Rule Change](https://eslint.org/docs/developer-guide/contributing/rule-changes)
* [Request a Change](https://eslint.org/docs/developer-guide/contributing/changes)
## <a name="faq"></a>Frequently Asked Questions
### I'm using JSCS, should I migrate to ESLint?
Yes. [JSCS has reached end of life](https://eslint.org/blog/2016/07/jscs-end-of-life) and is no longer supported.
We have prepared a [migration guide](https://eslint.org/docs/user-guide/migrating-from-jscs) to help you convert your JSCS settings to an ESLint configuration.
We are now at or near 100% compatibility with JSCS. If you try ESLint and believe we are not yet compatible with a JSCS rule/configuration, please create an issue (mentioning that it is a JSCS compatibility issue) and we will evaluate it as per our normal process.
### Does Prettier replace ESLint?
No, ESLint does both traditional linting (looking for problematic patterns) and style checking (enforcement of conventions). You can use ESLint for everything, or you can combine both using Prettier to format your code and ESLint to catch possible errors.
### Why can't ESLint find my plugins?
* Make sure your plugins (and ESLint) are both in your project's `package.json` as devDependencies (or dependencies, if your project uses ESLint at runtime).
* Make sure you have run `npm install` and all your dependencies are installed.
* Make sure your plugins' peerDependencies have been installed as well. You can use `npm view eslint-plugin-myplugin peerDependencies` to see what peer dependencies `eslint-plugin-myplugin` has.
### Does ESLint support JSX?
Yes, ESLint natively supports parsing JSX syntax (this must be enabled in [configuration](https://eslint.org/docs/user-guide/configuring)). Please note that supporting JSX syntax *is not* the same as supporting React. React applies specific semantics to JSX syntax that ESLint doesn't recognize. We recommend using [eslint-plugin-react](https://www.npmjs.com/package/eslint-plugin-react) if you are using React and want React semantics.
### What ECMAScript versions does ESLint support?
ESLint has full support for ECMAScript 3, 5 (default), 2015, 2016, 2017, 2018, 2019, and 2020. You can set your desired ECMAScript syntax (and other settings, like global variables or your target environments) through [configuration](https://eslint.org/docs/user-guide/configuring).
### What about experimental features?
ESLint's parser only officially supports the latest final ECMAScript standard. We will make changes to core rules in order to avoid crashes on stage 3 ECMAScript syntax proposals (as long as they are implemented using the correct experimental ESTree syntax). We may make changes to core rules to better work with language extensions (such as JSX, Flow, and TypeScript) on a case-by-case basis.
In other cases (including if rules need to warn on more or fewer cases due to new syntax, rather than just not crashing), we recommend you use other parsers and/or rule plugins. If you are using Babel, you can use the [babel-eslint](https://github.com/babel/babel-eslint) parser and [eslint-plugin-babel](https://github.com/babel/eslint-plugin-babel) to use any option available in Babel.
Once a language feature has been adopted into the ECMAScript standard (stage 4 according to the [TC39 process](https://tc39.github.io/process-document/)), we will accept issues and pull requests related to the new feature, subject to our [contributing guidelines](https://eslint.org/docs/developer-guide/contributing). Until then, please use the appropriate parser and plugin(s) for your experimental feature.
### Where to ask for help?
Join our [Mailing List](https://groups.google.com/group/eslint) or [Chatroom](https://eslint.org/chat).
### Why doesn't ESLint lock dependency versions?
Lock files like `package-lock.json` are helpful for deployed applications. They ensure that dependencies are consistent between environments and across deployments.
Packages like `eslint` that get published to the npm registry do not include lock files. `npm install eslint` as a user will respect version constraints in ESLint's `package.json`. ESLint and its dependencies will be included in the user's lock file if one exists, but ESLint's own lock file would not be used.
We intentionally don't lock dependency versions so that we have the latest compatible dependency versions in development and CI that our users get when installing ESLint in a project.
The Twilio blog has a [deeper dive](https://www.twilio.com/blog/lockfiles-nodejs) to learn more.
## <a name="releases"></a>Releases
We have scheduled releases every two weeks on Friday or Saturday. You can follow a [release issue](https://github.com/eslint/eslint/issues?q=is%3Aopen+is%3Aissue+label%3Arelease) for updates about the scheduling of any particular release.
## <a name="security-policy"></a>Security Policy
ESLint takes security seriously. We work hard to ensure that ESLint is safe for everyone and that security issues are addressed quickly and responsibly. Read the full [security policy](https://github.com/eslint/.github/blob/master/SECURITY.md).
## <a name="semantic-versioning-policy"></a>Semantic Versioning Policy
ESLint follows [semantic versioning](https://semver.org). However, due to the nature of ESLint as a code quality tool, it's not always clear when a minor or major version bump occurs. To help clarify this for everyone, we've defined the following semantic versioning policy for ESLint:
* Patch release (intended to not break your lint build)
* A bug fix in a rule that results in ESLint reporting fewer linting errors.
* A bug fix to the CLI or core (including formatters).
* Improvements to documentation.
* Non-user-facing changes such as refactoring code, adding, deleting, or modifying tests, and increasing test coverage.
* Re-releasing after a failed release (i.e., publishing a release that doesn't work for anyone).
* Minor release (might break your lint build)
* A bug fix in a rule that results in ESLint reporting more linting errors.
* A new rule is created.
* A new option to an existing rule that does not result in ESLint reporting more linting errors by default.
* A new addition to an existing rule to support a newly-added language feature (within the last 12 months) that will result in ESLint reporting more linting errors by default.
* An existing rule is deprecated.
* A new CLI capability is created.
* New capabilities to the public API are added (new classes, new methods, new arguments to existing methods, etc.).
* A new formatter is created.
* `eslint:recommended` is updated and will result in strictly fewer linting errors (e.g., rule removals).
* Major release (likely to break your lint build)
* `eslint:recommended` is updated and may result in new linting errors (e.g., rule additions, most rule option updates).
* A new option to an existing rule that results in ESLint reporting more linting errors by default.
* An existing formatter is removed.
* Part of the public API is removed or changed in an incompatible way. The public API includes:
* Rule schemas
* Configuration schema
* Command-line options
* Node.js API
* Rule, formatter, parser, plugin APIs
According to our policy, any minor update may report more linting errors than the previous release (ex: from a bug fix). As such, we recommend using the tilde (`~`) in `package.json` e.g. `"eslint": "~3.1.0"` to guarantee the results of your builds.
## <a name="stylistic-rule-updates"></a>Stylistic Rule Updates
Stylistic rules are frozen according to [our policy](https://eslint.org/blog/2020/05/changes-to-rules-policies) on how we evaluate new rules and rule changes.
This means:
* **Bug fixes**: We will still fix bugs in stylistic rules.
* **New ECMAScript features**: We will also make sure stylistic rules are compatible with new ECMAScript features.
* **New options**: We will **not** add any new options to stylistic rules unless an option is the only way to fix a bug or support a newly-added ECMAScript feature.
## <a name="license"></a>License
[](https://app.fossa.io/projects/git%2Bhttps%3A%2F%2Fgithub.com%2Feslint%2Feslint?ref=badge_large)
## <a name="team"></a>Team
These folks keep the project moving and are resources for help.
<!-- NOTE: This section is autogenerated. Do not manually edit.-->
<!--teamstart-->
### Technical Steering Committee (TSC)
The people who manage releases, review feature requests, and meet regularly to ensure ESLint is properly maintained.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/nzakas">
<img src="https://github.com/nzakas.png?s=75" width="75" height="75"><br />
Nicholas C. Zakas
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/btmills">
<img src="https://github.com/btmills.png?s=75" width="75" height="75"><br />
Brandon Mills
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/mdjermanovic">
<img src="https://github.com/mdjermanovic.png?s=75" width="75" height="75"><br />
Milos Djermanovic
</a>
</td></tr></tbody></table>
### Reviewers
The people who review and implement new features.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/mysticatea">
<img src="https://github.com/mysticatea.png?s=75" width="75" height="75"><br />
Toru Nagashima
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/aladdin-add">
<img src="https://github.com/aladdin-add.png?s=75" width="75" height="75"><br />
薛定谔的猫
</a>
</td></tr></tbody></table>
### Committers
The people who review and fix bugs and help triage issues.
<table><tbody><tr><td align="center" valign="top" width="11%">
<a href="https://github.com/brettz9">
<img src="https://github.com/brettz9.png?s=75" width="75" height="75"><br />
Brett Zamir
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/bmish">
<img src="https://github.com/bmish.png?s=75" width="75" height="75"><br />
Bryan Mishkin
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/g-plane">
<img src="https://github.com/g-plane.png?s=75" width="75" height="75"><br />
Pig Fang
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/anikethsaha">
<img src="https://github.com/anikethsaha.png?s=75" width="75" height="75"><br />
Anix
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/yeonjuan">
<img src="https://github.com/yeonjuan.png?s=75" width="75" height="75"><br />
YeonJuan
</a>
</td><td align="center" valign="top" width="11%">
<a href="https://github.com/snitin315">
<img src="https://github.com/snitin315.png?s=75" width="75" height="75"><br />
Nitin Kumar
</a>
</td></tr></tbody></table>
<!--teamend-->
## <a name="sponsors"></a>Sponsors
The following companies, organizations, and individuals support ESLint's ongoing maintenance and development. [Become a Sponsor](https://opencollective.com/eslint) to get your logo on our README and website.
<!-- NOTE: This section is autogenerated. Do not manually edit.-->
<!--sponsorsstart-->
<h3>Platinum Sponsors</h3>
<p><a href="https://automattic.com"><img src="https://images.opencollective.com/photomatt/d0ef3e1/logo.png" alt="Automattic" height="undefined"></a></p><h3>Gold Sponsors</h3>
<p><a href="https://nx.dev"><img src="https://images.opencollective.com/nx/0efbe42/logo.png" alt="Nx (by Nrwl)" height="96"></a> <a href="https://google.com/chrome"><img src="https://images.opencollective.com/chrome/dc55bd4/logo.png" alt="Chrome's Web Framework & Tools Performance Fund" height="96"></a> <a href="https://www.salesforce.com"><img src="https://images.opencollective.com/salesforce/ca8f997/logo.png" alt="Salesforce" height="96"></a> <a href="https://www.airbnb.com/"><img src="https://images.opencollective.com/airbnb/d327d66/logo.png" alt="Airbnb" height="96"></a> <a href="https://coinbase.com"><img src="https://avatars.githubusercontent.com/u/1885080?v=4" alt="Coinbase" height="96"></a> <a href="https://substack.com/"><img src="https://avatars.githubusercontent.com/u/53023767?v=4" alt="Substack" height="96"></a></p><h3>Silver Sponsors</h3>
<p><a href="https://retool.com/"><img src="https://images.opencollective.com/retool/98ea68e/logo.png" alt="Retool" height="64"></a> <a href="https://liftoff.io/"><img src="https://images.opencollective.com/liftoff/5c4fa84/logo.png" alt="Liftoff" height="64"></a></p><h3>Bronze Sponsors</h3>
<p><a href="https://www.crosswordsolver.org/anagram-solver/"><img src="https://images.opencollective.com/anagram-solver/2666271/logo.png" alt="Anagram Solver" height="32"></a> <a href="null"><img src="https://images.opencollective.com/bugsnag-stability-monitoring/c2cef36/logo.png" alt="Bugsnag Stability Monitoring" height="32"></a> <a href="https://mixpanel.com"><img src="https://images.opencollective.com/mixpanel/cd682f7/logo.png" alt="Mixpanel" height="32"></a> <a href="https://www.vpsserver.com"><img src="https://images.opencollective.com/vpsservercom/logo.png" alt="VPS Server" height="32"></a> <a href="https://icons8.com"><img src="https://images.opencollective.com/icons8/7fa1641/logo.png" alt="Icons8: free icons, photos, illustrations, and music" height="32"></a> <a href="https://discord.com"><img src="https://images.opencollective.com/discordapp/f9645d9/logo.png" alt="Discord" height="32"></a> <a href="https://themeisle.com"><img src="https://images.opencollective.com/themeisle/d5592fe/logo.png" alt="ThemeIsle" height="32"></a> <a href="https://www.firesticktricks.com"><img src="https://images.opencollective.com/fire-stick-tricks/b8fbe2c/logo.png" alt="Fire Stick Tricks" height="32"></a> <a href="https://www.practiceignition.com"><img src="https://avatars.githubusercontent.com/u/5753491?v=4" alt="Practice Ignition" height="32"></a></p>
<!--sponsorsend-->
## <a name="technology-sponsors"></a>Technology Sponsors
* Site search ([eslint.org](https://eslint.org)) is sponsored by [Algolia](https://www.algolia.com)
* Hosting for ([eslint.org](https://eslint.org)) is sponsored by [Netlify](https://www.netlify.com)
* Password management is sponsored by [1Password](https://www.1password.com)
# TypeScript
[](https://github.com/microsoft/TypeScript/actions?query=workflow%3ACI)
[](https://dev.azure.com/typescript/TypeScript/_build?definitionId=7)
[](https://www.npmjs.com/package/typescript)
[](https://www.npmjs.com/package/typescript)
[TypeScript](https://www.typescriptlang.org/) is a language for application-scale JavaScript. TypeScript adds optional types to JavaScript that support tools for large-scale JavaScript applications for any browser, for any host, on any OS. TypeScript compiles to readable, standards-based JavaScript. Try it out at the [playground](https://www.typescriptlang.org/play/), and stay up to date via [our blog](https://blogs.msdn.microsoft.com/typescript) and [Twitter account](https://twitter.com/typescript).
Find others who are using TypeScript at [our community page](https://www.typescriptlang.org/community/).
## Installing
For the latest stable version:
```bash
npm install -g typescript
```
For our nightly builds:
```bash
npm install -g typescript@next
```
## Contribute
There are many ways to [contribute](https://github.com/microsoft/TypeScript/blob/main/CONTRIBUTING.md) to TypeScript.
* [Submit bugs](https://github.com/microsoft/TypeScript/issues) and help us verify fixes as they are checked in.
* Review the [source code changes](https://github.com/microsoft/TypeScript/pulls).
* Engage with other TypeScript users and developers on [StackOverflow](https://stackoverflow.com/questions/tagged/typescript).
* Help each other in the [TypeScript Community Discord](https://discord.gg/typescript).
* Join the [#typescript](https://twitter.com/search?q=%23TypeScript) discussion on Twitter.
* [Contribute bug fixes](https://github.com/microsoft/TypeScript/blob/main/CONTRIBUTING.md).
* Read the archived language specification ([docx](https://github.com/microsoft/TypeScript/blob/main/doc/TypeScript%20Language%20Specification%20-%20ARCHIVED.docx?raw=true),
[pdf](https://github.com/microsoft/TypeScript/blob/main/doc/TypeScript%20Language%20Specification%20-%20ARCHIVED.pdf?raw=true), [md](https://github.com/microsoft/TypeScript/blob/main/doc/spec-ARCHIVED.md)).
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/). For more information see
the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or contact [[email protected]](mailto:[email protected])
with any additional questions or comments.
## Documentation
* [TypeScript in 5 minutes](https://www.typescriptlang.org/docs/handbook/typescript-in-5-minutes.html)
* [Programming handbook](https://www.typescriptlang.org/docs/handbook/intro.html)
* [Homepage](https://www.typescriptlang.org/)
## Building
In order to build the TypeScript compiler, ensure that you have [Git](https://git-scm.com/downloads) and [Node.js](https://nodejs.org/) installed.
Clone a copy of the repo:
```bash
git clone https://github.com/microsoft/TypeScript.git
```
Change to the TypeScript directory:
```bash
cd TypeScript
```
Install [Gulp](https://gulpjs.com/) tools and dev dependencies:
```bash
npm install -g gulp
npm ci
```
Use one of the following to build and test:
```
gulp local # Build the compiler into built/local.
gulp clean # Delete the built compiler.
gulp LKG # Replace the last known good with the built one.
# Bootstrapping step to be executed when the built compiler reaches a stable state.
gulp tests # Build the test infrastructure using the built compiler.
gulp runtests # Run tests using the built compiler and test infrastructure.
# You can override the specific suite runner used or specify a test for this command.
# Use --tests=<testPath> for a specific test and/or --runner=<runnerName> for a specific suite.
# Valid runners include conformance, compiler, fourslash, project, user, and docker
# The user and docker runners are extended test suite runners - the user runner
# works on disk in the tests/cases/user directory, while the docker runner works in containers.
# You'll need to have the docker executable in your system path for the docker runner to work.
gulp runtests-parallel # Like runtests, but split across multiple threads. Uses a number of threads equal to the system
# core count by default. Use --workers=<number> to adjust this.
gulp baseline-accept # This replaces the baseline test results with the results obtained from gulp runtests.
gulp lint # Runs eslint on the TypeScript source.
gulp help # List the above commands.
```
## Usage
```bash
node built/local/tsc.js hello.ts
```
## Roadmap
For details on our planned features and future direction please refer to our [roadmap](https://github.com/microsoft/TypeScript/wiki/Roadmap).
JS-YAML - YAML 1.2 parser / writer for JavaScript
=================================================
[](https://travis-ci.org/nodeca/js-yaml)
[](https://www.npmjs.org/package/js-yaml)
__[Online Demo](http://nodeca.github.com/js-yaml/)__
This is an implementation of [YAML](http://yaml.org/), a human-friendly data
serialization language. Started as [PyYAML](http://pyyaml.org/) port, it was
completely rewritten from scratch. Now it's very fast, and supports 1.2 spec.
Installation
------------
### YAML module for node.js
```
npm install js-yaml
```
### CLI executable
If you want to inspect your YAML files from CLI, install js-yaml globally:
```
npm install -g js-yaml
```
#### Usage
```
usage: js-yaml [-h] [-v] [-c] [-t] file
Positional arguments:
file File with YAML document(s)
Optional arguments:
-h, --help Show this help message and exit.
-v, --version Show program's version number and exit.
-c, --compact Display errors in compact mode
-t, --trace Show stack trace on error
```
### Bundled YAML library for browsers
``` html
<!-- esprima required only for !!js/function -->
<script src="esprima.js"></script>
<script src="js-yaml.min.js"></script>
<script type="text/javascript">
var doc = jsyaml.load('greeting: hello\nname: world');
</script>
```
Browser support was done mostly for the online demo. If you find any errors - feel
free to send pull requests with fixes. Also note, that IE and other old browsers
needs [es5-shims](https://github.com/kriskowal/es5-shim) to operate.
Notes:
1. We have no resources to support browserified version. Don't expect it to be
well tested. Don't expect fast fixes if something goes wrong there.
2. `!!js/function` in browser bundle will not work by default. If you really need
it - load `esprima` parser first (via amd or directly).
3. `!!bin` in browser will return `Array`, because browsers do not support
node.js `Buffer` and adding Buffer shims is completely useless on practice.
API
---
Here we cover the most 'useful' methods. If you need advanced details (creating
your own tags), see [wiki](https://github.com/nodeca/js-yaml/wiki) and
[examples](https://github.com/nodeca/js-yaml/tree/master/examples) for more
info.
``` javascript
const yaml = require('js-yaml');
const fs = require('fs');
// Get document, or throw exception on error
try {
const doc = yaml.safeLoad(fs.readFileSync('/home/ixti/example.yml', 'utf8'));
console.log(doc);
} catch (e) {
console.log(e);
}
```
### safeLoad (string [ , options ])
**Recommended loading way.** Parses `string` as single YAML document. Returns either a
plain object, a string or `undefined`, or throws `YAMLException` on error. By default, does
not support regexps, functions and undefined. This method is safe for untrusted data.
options:
- `filename` _(default: null)_ - string to be used as a file path in
error/warning messages.
- `onWarning` _(default: null)_ - function to call on warning messages.
Loader will call this function with an instance of `YAMLException` for each warning.
- `schema` _(default: `DEFAULT_SAFE_SCHEMA`)_ - specifies a schema to use.
- `FAILSAFE_SCHEMA` - only strings, arrays and plain objects:
http://www.yaml.org/spec/1.2/spec.html#id2802346
- `JSON_SCHEMA` - all JSON-supported types:
http://www.yaml.org/spec/1.2/spec.html#id2803231
- `CORE_SCHEMA` - same as `JSON_SCHEMA`:
http://www.yaml.org/spec/1.2/spec.html#id2804923
- `DEFAULT_SAFE_SCHEMA` - all supported YAML types, without unsafe ones
(`!!js/undefined`, `!!js/regexp` and `!!js/function`):
http://yaml.org/type/
- `DEFAULT_FULL_SCHEMA` - all supported YAML types.
- `json` _(default: false)_ - compatibility with JSON.parse behaviour. If true, then duplicate keys in a mapping will override values rather than throwing an error.
NOTE: This function **does not** understand multi-document sources, it throws
exception on those.
NOTE: JS-YAML **does not** support schema-specific tag resolution restrictions.
So, the JSON schema is not as strictly defined in the YAML specification.
It allows numbers in any notation, use `Null` and `NULL` as `null`, etc.
The core schema also has no such restrictions. It allows binary notation for integers.
### load (string [ , options ])
**Use with care with untrusted sources**. The same as `safeLoad()` but uses
`DEFAULT_FULL_SCHEMA` by default - adds some JavaScript-specific types:
`!!js/function`, `!!js/regexp` and `!!js/undefined`. For untrusted sources, you
must additionally validate object structure to avoid injections:
``` javascript
const untrusted_code = '"toString": !<tag:yaml.org,2002:js/function> "function (){very_evil_thing();}"';
// I'm just converting that string, what could possibly go wrong?
require('js-yaml').load(untrusted_code) + ''
```
### safeLoadAll (string [, iterator] [, options ])
Same as `safeLoad()`, but understands multi-document sources. Applies
`iterator` to each document if specified, or returns array of documents.
``` javascript
const yaml = require('js-yaml');
yaml.safeLoadAll(data, function (doc) {
console.log(doc);
});
```
### loadAll (string [, iterator] [ , options ])
Same as `safeLoadAll()` but uses `DEFAULT_FULL_SCHEMA` by default.
### safeDump (object [ , options ])
Serializes `object` as a YAML document. Uses `DEFAULT_SAFE_SCHEMA`, so it will
throw an exception if you try to dump regexps or functions. However, you can
disable exceptions by setting the `skipInvalid` option to `true`.
options:
- `indent` _(default: 2)_ - indentation width to use (in spaces).
- `noArrayIndent` _(default: false)_ - when true, will not add an indentation level to array elements
- `skipInvalid` _(default: false)_ - do not throw on invalid types (like function
in the safe schema) and skip pairs and single values with such types.
- `flowLevel` (default: -1) - specifies level of nesting, when to switch from
block to flow style for collections. -1 means block style everwhere
- `styles` - "tag" => "style" map. Each tag may have own set of styles.
- `schema` _(default: `DEFAULT_SAFE_SCHEMA`)_ specifies a schema to use.
- `sortKeys` _(default: `false`)_ - if `true`, sort keys when dumping YAML. If a
function, use the function to sort the keys.
- `lineWidth` _(default: `80`)_ - set max line width.
- `noRefs` _(default: `false`)_ - if `true`, don't convert duplicate objects into references
- `noCompatMode` _(default: `false`)_ - if `true` don't try to be compatible with older
yaml versions. Currently: don't quote "yes", "no" and so on, as required for YAML 1.1
- `condenseFlow` _(default: `false`)_ - if `true` flow sequences will be condensed, omitting the space between `a, b`. Eg. `'[a,b]'`, and omitting the space between `key: value` and quoting the key. Eg. `'{"a":b}'` Can be useful when using yaml for pretty URL query params as spaces are %-encoded.
The following table show availlable styles (e.g. "canonical",
"binary"...) available for each tag (.e.g. !!null, !!int ...). Yaml
output is shown on the right side after `=>` (default setting) or `->`:
``` none
!!null
"canonical" -> "~"
"lowercase" => "null"
"uppercase" -> "NULL"
"camelcase" -> "Null"
!!int
"binary" -> "0b1", "0b101010", "0b1110001111010"
"octal" -> "01", "052", "016172"
"decimal" => "1", "42", "7290"
"hexadecimal" -> "0x1", "0x2A", "0x1C7A"
!!bool
"lowercase" => "true", "false"
"uppercase" -> "TRUE", "FALSE"
"camelcase" -> "True", "False"
!!float
"lowercase" => ".nan", '.inf'
"uppercase" -> ".NAN", '.INF'
"camelcase" -> ".NaN", '.Inf'
```
Example:
``` javascript
safeDump (object, {
'styles': {
'!!null': 'canonical' // dump null as ~
},
'sortKeys': true // sort object keys
});
```
### dump (object [ , options ])
Same as `safeDump()` but without limits (uses `DEFAULT_FULL_SCHEMA` by default).
Supported YAML types
--------------------
The list of standard YAML tags and corresponding JavaScipt types. See also
[YAML tag discussion](http://pyyaml.org/wiki/YAMLTagDiscussion) and
[YAML types repository](http://yaml.org/type/).
```
!!null '' # null
!!bool 'yes' # bool
!!int '3...' # number
!!float '3.14...' # number
!!binary '...base64...' # buffer
!!timestamp 'YYYY-...' # date
!!omap [ ... ] # array of key-value pairs
!!pairs [ ... ] # array or array pairs
!!set { ... } # array of objects with given keys and null values
!!str '...' # string
!!seq [ ... ] # array
!!map { ... } # object
```
**JavaScript-specific tags**
```
!!js/regexp /pattern/gim # RegExp
!!js/undefined '' # Undefined
!!js/function 'function () {...}' # Function
```
Caveats
-------
Note, that you use arrays or objects as key in JS-YAML. JS does not allow objects
or arrays as keys, and stringifies (by calling `toString()` method) them at the
moment of adding them.
``` yaml
---
? [ foo, bar ]
: - baz
? { foo: bar }
: - baz
- baz
```
``` javascript
{ "foo,bar": ["baz"], "[object Object]": ["baz", "baz"] }
```
Also, reading of properties on implicit block mapping keys is not supported yet.
So, the following YAML document cannot be loaded.
``` yaml
&anchor foo:
foo: bar
*anchor: duplicate key
baz: bat
*anchor: duplicate key
```
js-yaml for enterprise
----------------------
Available as part of the Tidelift Subscription
The maintainers of js-yaml and thousands of other packages are working with Tidelift to deliver commercial support and maintenance for the open source dependencies you use to build your applications. Save time, reduce risk, and improve code health, while paying the maintainers of the exact dependencies you use. [Learn more.](https://tidelift.com/subscription/pkg/npm-js-yaml?utm_source=npm-js-yaml&utm_medium=referral&utm_campaign=enterprise&utm_term=repo)
# near-sdk-as
Collection of packages used in developing NEAR smart contracts in AssemblyScript including:
- [`runtime library`](https://github.com/near/near-sdk-as/tree/master/sdk-core) - AssemblyScript near runtime library
- [`bindgen`](https://github.com/near/near-sdk-as/tree/master/bindgen) - AssemblyScript transformer that adds the bindings needed to (de)serialize input and outputs.
- [`near-mock-vm`](https://github.com/near/near-sdk-as/tree/master/near-mock-vm) - Core of the NEAR VM compiled to WebAssembly used for running unit tests.
- [`@as-pect/cli`](https://github.com/jtenner/as-pect) - AssemblyScript testing framework similar to jest.
## To Install
```sh
yarn add -D near-sdk-as
```
## Project Setup
To set up a AS project to compile with the sdk add the following `asconfig.json` file to the root:
```json
{
"extends": "near-sdk-as/asconfig.json"
}
```
Then if your main file is `assembly/index.ts`, then the project can be build with [`asbuild`](https://github.com/willemneal/asbuild):
```sh
yarn asb
```
will create a release build and place it `./build/release/<name-in-package.json>.wasm`
```sh
yarn asb --target debug
```
will create a debug build and place it in `./build/debug/..`
## Testing
### Unit Testing
See the [sdk's as-pect tests for an example](./sdk/assembly/__tests__) of creating unit tests. Must be ending in `.spec.ts` in a `assembly/__tests__`.
## License
`near-sdk-as` is distributed under the terms of both the MIT license and the Apache License (Version 2.0).
See [LICENSE-MIT](LICENSE-MIT) and [LICENSE-APACHE](LICENSE-APACHE) for details.
# eslint-visitor-keys
[](https://www.npmjs.com/package/eslint-visitor-keys)
[](http://www.npmtrends.com/eslint-visitor-keys)
[](https://travis-ci.org/eslint/eslint-visitor-keys)
[](https://david-dm.org/eslint/eslint-visitor-keys)
Constants and utilities about visitor keys to traverse AST.
## 💿 Installation
Use [npm] to install.
```bash
$ npm install eslint-visitor-keys
```
### Requirements
- [Node.js] 4.0.0 or later.
## 📖 Usage
```js
const evk = require("eslint-visitor-keys")
```
### evk.KEYS
> type: `{ [type: string]: string[] | undefined }`
Visitor keys. This keys are frozen.
This is an object. Keys are the type of [ESTree] nodes. Their values are an array of property names which have child nodes.
For example:
```
console.log(evk.KEYS.AssignmentExpression) // → ["left", "right"]
```
### evk.getKeys(node)
> type: `(node: object) => string[]`
Get the visitor keys of a given AST node.
This is similar to `Object.keys(node)` of ES Standard, but some keys are excluded: `parent`, `leadingComments`, `trailingComments`, and names which start with `_`.
This will be used to traverse unknown nodes.
For example:
```
const node = {
type: "AssignmentExpression",
left: { type: "Identifier", name: "foo" },
right: { type: "Literal", value: 0 }
}
console.log(evk.getKeys(node)) // → ["type", "left", "right"]
```
### evk.unionWith(additionalKeys)
> type: `(additionalKeys: object) => { [type: string]: string[] | undefined }`
Make the union set with `evk.KEYS` and the given keys.
- The order of keys is, `additionalKeys` is at first, then `evk.KEYS` is concatenated after that.
- It removes duplicated keys as keeping the first one.
For example:
```
console.log(evk.unionWith({
MethodDefinition: ["decorators"]
})) // → { ..., MethodDefinition: ["decorators", "key", "value"], ... }
```
## 📰 Change log
See [GitHub releases](https://github.com/eslint/eslint-visitor-keys/releases).
## 🍻 Contributing
Welcome. See [ESLint contribution guidelines](https://eslint.org/docs/developer-guide/contributing/).
### Development commands
- `npm test` runs tests and measures code coverage.
- `npm run lint` checks source codes with ESLint.
- `npm run coverage` opens the code coverage report of the previous test with your default browser.
- `npm run release` publishes this package to [npm] registory.
[npm]: https://www.npmjs.com/
[Node.js]: https://nodejs.org/en/
[ESTree]: https://github.com/estree/estree
# Web IDL Type Conversions on JavaScript Values
This package implements, in JavaScript, the algorithms to convert a given JavaScript value according to a given [Web IDL](http://heycam.github.io/webidl/) [type](http://heycam.github.io/webidl/#idl-types).
The goal is that you should be able to write code like
```js
"use strict";
const conversions = require("webidl-conversions");
function doStuff(x, y) {
x = conversions["boolean"](x);
y = conversions["unsigned long"](y);
// actual algorithm code here
}
```
and your function `doStuff` will behave the same as a Web IDL operation declared as
```webidl
void doStuff(boolean x, unsigned long y);
```
## API
This package's main module's default export is an object with a variety of methods, each corresponding to a different Web IDL type. Each method, when invoked on a JavaScript value, will give back the new JavaScript value that results after passing through the Web IDL conversion rules. (See below for more details on what that means.) Alternately, the method could throw an error, if the Web IDL algorithm is specified to do so: for example `conversions["float"](NaN)` [will throw a `TypeError`](http://heycam.github.io/webidl/#es-float).
Each method also accepts a second, optional, parameter for miscellaneous options. For conversion methods that throw errors, a string option `{ context }` may be provided to provide more information in the error message. (For example, `conversions["float"](NaN, { context: "Argument 1 of Interface's operation" })` will throw an error with message `"Argument 1 of Interface's operation is not a finite floating-point value."`) Specific conversions may also accept other options, the details of which can be found below.
## Conversions implemented
Conversions for all of the basic types from the Web IDL specification are implemented:
- [`any`](https://heycam.github.io/webidl/#es-any)
- [`void`](https://heycam.github.io/webidl/#es-void)
- [`boolean`](https://heycam.github.io/webidl/#es-boolean)
- [Integer types](https://heycam.github.io/webidl/#es-integer-types), which can additionally be provided the boolean options `{ clamp, enforceRange }` as a second parameter
- [`float`](https://heycam.github.io/webidl/#es-float), [`unrestricted float`](https://heycam.github.io/webidl/#es-unrestricted-float)
- [`double`](https://heycam.github.io/webidl/#es-double), [`unrestricted double`](https://heycam.github.io/webidl/#es-unrestricted-double)
- [`DOMString`](https://heycam.github.io/webidl/#es-DOMString), which can additionally be provided the boolean option `{ treatNullAsEmptyString }` as a second parameter
- [`ByteString`](https://heycam.github.io/webidl/#es-ByteString), [`USVString`](https://heycam.github.io/webidl/#es-USVString)
- [`object`](https://heycam.github.io/webidl/#es-object)
- [`Error`](https://heycam.github.io/webidl/#es-Error)
- [Buffer source types](https://heycam.github.io/webidl/#es-buffer-source-types)
Additionally, for convenience, the following derived type definitions are implemented:
- [`ArrayBufferView`](https://heycam.github.io/webidl/#ArrayBufferView)
- [`BufferSource`](https://heycam.github.io/webidl/#BufferSource)
- [`DOMTimeStamp`](https://heycam.github.io/webidl/#DOMTimeStamp)
- [`Function`](https://heycam.github.io/webidl/#Function)
- [`VoidFunction`](https://heycam.github.io/webidl/#VoidFunction) (although it will not censor the return type)
Derived types, such as nullable types, promise types, sequences, records, etc. are not handled by this library. You may wish to investigate the [webidl2js](https://github.com/jsdom/webidl2js) project.
### A note on the `long long` types
The `long long` and `unsigned long long` Web IDL types can hold values that cannot be stored in JavaScript numbers, so the conversion is imperfect. For example, converting the JavaScript number `18446744073709552000` to a Web IDL `long long` is supposed to produce the Web IDL value `-18446744073709551232`. Since we are representing our Web IDL values in JavaScript, we can't represent `-18446744073709551232`, so we instead the best we could do is `-18446744073709552000` as the output.
This library actually doesn't even get that far. Producing those results would require doing accurate modular arithmetic on 64-bit intermediate values, but JavaScript does not make this easy. We could pull in a big-integer library as a dependency, but in lieu of that, we for now have decided to just produce inaccurate results if you pass in numbers that are not strictly between `Number.MIN_SAFE_INTEGER` and `Number.MAX_SAFE_INTEGER`.
## Background
What's actually going on here, conceptually, is pretty weird. Let's try to explain.
Web IDL, as part of its madness-inducing design, has its own type system. When people write algorithms in web platform specs, they usually operate on Web IDL values, i.e. instances of Web IDL types. For example, if they were specifying the algorithm for our `doStuff` operation above, they would treat `x` as a Web IDL value of [Web IDL type `boolean`](http://heycam.github.io/webidl/#idl-boolean). Crucially, they would _not_ treat `x` as a JavaScript variable whose value is either the JavaScript `true` or `false`. They're instead working in a different type system altogether, with its own rules.
Separately from its type system, Web IDL defines a ["binding"](http://heycam.github.io/webidl/#ecmascript-binding) of the type system into JavaScript. This contains rules like: when you pass a JavaScript value to the JavaScript method that manifests a given Web IDL operation, how does that get converted into a Web IDL value? For example, a JavaScript `true` passed in the position of a Web IDL `boolean` argument becomes a Web IDL `true`. But, a JavaScript `true` passed in the position of a [Web IDL `unsigned long`](http://heycam.github.io/webidl/#idl-unsigned-long) becomes a Web IDL `1`. And so on.
Finally, we have the actual implementation code. This is usually C++, although these days [some smart people are using Rust](https://github.com/servo/servo). The implementation, of course, has its own type system. So when they implement the Web IDL algorithms, they don't actually use Web IDL values, since those aren't "real" outside of specs. Instead, implementations apply the Web IDL binding rules in such a way as to convert incoming JavaScript values into C++ values. For example, if code in the browser called `doStuff(true, true)`, then the implementation code would eventually receive a C++ `bool` containing `true` and a C++ `uint32_t` containing `1`.
The upside of all this is that implementations can abstract all the conversion logic away, letting Web IDL handle it, and focus on implementing the relevant methods in C++ with values of the correct type already provided. That is payoff of Web IDL, in a nutshell.
And getting to that payoff is the goal of _this_ project—but for JavaScript implementations, instead of C++ ones. That is, this library is designed to make it easier for JavaScript developers to write functions that behave like a given Web IDL operation. So conceptually, the conversion pipeline, which in its general form is JavaScript values ↦ Web IDL values ↦ implementation-language values, in this case becomes JavaScript values ↦ Web IDL values ↦ JavaScript values. And that intermediate step is where all the logic is performed: a JavaScript `true` becomes a Web IDL `1` in an unsigned long context, which then becomes a JavaScript `1`.
## Don't use this
Seriously, why would you ever use this? You really shouldn't. Web IDL is … strange, and you shouldn't be emulating its semantics. If you're looking for a generic argument-processing library, you should find one with better rules than those from Web IDL. In general, your JavaScript should not be trying to become more like Web IDL; if anything, we should fix Web IDL to make it more like JavaScript.
The _only_ people who should use this are those trying to create faithful implementations (or polyfills) of web platform interfaces defined in Web IDL. Its main consumer is the [jsdom](https://github.com/tmpvar/jsdom) project.
<p align="center">
<a href="https://assemblyscript.org" target="_blank" rel="noopener"><img width="100" src="https://avatars1.githubusercontent.com/u/28916798?s=200&v=4" alt="AssemblyScript logo"></a>
</p>
<p align="center">
<a href="https://github.com/AssemblyScript/assemblyscript/actions?query=workflow%3ATest"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/assemblyscript/Test/master?label=test&logo=github" alt="Test status" /></a>
<a href="https://github.com/AssemblyScript/assemblyscript/actions?query=workflow%3APublish"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/assemblyscript/Publish/master?label=publish&logo=github" alt="Publish status" /></a>
<a href="https://www.npmjs.com/package/assemblyscript"><img src="https://img.shields.io/npm/v/assemblyscript.svg?label=compiler&color=007acc&logo=npm" alt="npm compiler version" /></a>
<a href="https://www.npmjs.com/package/@assemblyscript/loader"><img src="https://img.shields.io/npm/v/@assemblyscript/loader.svg?label=loader&color=007acc&logo=npm" alt="npm loader version" /></a>
<a href="https://discord.gg/assemblyscript"><img src="https://img.shields.io/discord/721472913886281818.svg?label=&logo=discord&logoColor=ffffff&color=7389D8&labelColor=6A7EC2" alt="Discord online" /></a>
</p>
<p align="justify"><strong>AssemblyScript</strong> compiles a strict variant of <a href="http://www.typescriptlang.org">TypeScript</a> (basically JavaScript with types) to <a href="http://webassembly.org">WebAssembly</a> using <a href="https://github.com/WebAssembly/binaryen">Binaryen</a>. It generates lean and mean WebAssembly modules while being just an <code>npm install</code> away.</p>
<h3 align="center">
<a href="https://assemblyscript.org">About</a> ·
<a href="https://assemblyscript.org/introduction.html">Introduction</a> ·
<a href="https://assemblyscript.org/quick-start.html">Quick start</a> ·
<a href="https://assemblyscript.org/examples.html">Examples</a> ·
<a href="https://assemblyscript.org/development.html">Development instructions</a>
</h3>
<br>
<h2 align="center">Contributors</h2>
<p align="center">
<a href="https://assemblyscript.org/#contributors"><img src="https://assemblyscript.org/contributors.svg" alt="Contributor logos" width="720" /></a>
</p>
<h2 align="center">Thanks to our sponsors!</h2>
<p align="justify">Most of the core team members and most contributors do this open source work in their free time. If you use AssemblyScript for a serious task or plan to do so, and you'd like us to invest more time on it, <a href="https://opencollective.com/assemblyscript/donate" target="_blank" rel="noopener">please donate</a> to our <a href="https://opencollective.com/assemblyscript" target="_blank" rel="noopener">OpenCollective</a>. By sponsoring this project, your logo will show up below. Thank you so much for your support!</p>
<p align="center">
<a href="https://assemblyscript.org/#sponsors"><img src="https://assemblyscript.org/sponsors.svg" alt="Sponsor logos" width="720" /></a>
</p>
# Regular Expression Tokenizer
Tokenizes strings that represent a regular expressions.
[](http://travis-ci.org/fent/ret.js)
[](https://david-dm.org/fent/ret.js)
[](https://codecov.io/gh/fent/ret.js)
# Usage
```js
var ret = require('ret');
var tokens = ret(/foo|bar/.source);
```
`tokens` will contain the following object
```js
{
"type": ret.types.ROOT
"options": [
[ { "type": ret.types.CHAR, "value", 102 },
{ "type": ret.types.CHAR, "value", 111 },
{ "type": ret.types.CHAR, "value", 111 } ],
[ { "type": ret.types.CHAR, "value", 98 },
{ "type": ret.types.CHAR, "value", 97 },
{ "type": ret.types.CHAR, "value", 114 } ]
]
}
```
# Token Types
`ret.types` is a collection of the various token types exported by ret.
### ROOT
Only used in the root of the regexp. This is needed due to the posibility of the root containing a pipe `|` character. In that case, the token will have an `options` key that will be an array of arrays of tokens. If not, it will contain a `stack` key that is an array of tokens.
```js
{
"type": ret.types.ROOT,
"stack": [token1, token2...],
}
```
```js
{
"type": ret.types.ROOT,
"options" [
[token1, token2...],
[othertoken1, othertoken2...]
...
],
}
```
### GROUP
Groups contain tokens that are inside of a parenthesis. If the group begins with `?` followed by another character, it's a special type of group. A ':' tells the group not to be remembered when `exec` is used. '=' means the previous token matches only if followed by this group, and '!' means the previous token matches only if NOT followed.
Like root, it can contain an `options` key instead of `stack` if there is a pipe.
```js
{
"type": ret.types.GROUP,
"remember" true,
"followedBy": false,
"notFollowedBy": false,
"stack": [token1, token2...],
}
```
```js
{
"type": ret.types.GROUP,
"remember" true,
"followedBy": false,
"notFollowedBy": false,
"options" [
[token1, token2...],
[othertoken1, othertoken2...]
...
],
}
```
### POSITION
`\b`, `\B`, `^`, and `$` specify positions in the regexp.
```js
{
"type": ret.types.POSITION,
"value": "^",
}
```
### SET
Contains a key `set` specifying what tokens are allowed and a key `not` specifying if the set should be negated. A set can contain other sets, ranges, and characters.
```js
{
"type": ret.types.SET,
"set": [token1, token2...],
"not": false,
}
```
### RANGE
Used in set tokens to specify a character range. `from` and `to` are character codes.
```js
{
"type": ret.types.RANGE,
"from": 97,
"to": 122,
}
```
### REPETITION
```js
{
"type": ret.types.REPETITION,
"min": 0,
"max": Infinity,
"value": token,
}
```
### REFERENCE
References a group token. `value` is 1-9.
```js
{
"type": ret.types.REFERENCE,
"value": 1,
}
```
### CHAR
Represents a single character token. `value` is the character code. This might seem a bit cluttering instead of concatenating characters together. But since repetition tokens only repeat the last token and not the last clause like the pipe, it's simpler to do it this way.
```js
{
"type": ret.types.CHAR,
"value": 123,
}
```
## Errors
ret.js will throw errors if given a string with an invalid regular expression. All possible errors are
* Invalid group. When a group with an immediate `?` character is followed by an invalid character. It can only be followed by `!`, `=`, or `:`. Example: `/(?_abc)/`
* Nothing to repeat. Thrown when a repetitional token is used as the first token in the current clause, as in right in the beginning of the regexp or group, or right after a pipe. Example: `/foo|?bar/`, `/{1,3}foo|bar/`, `/foo(+bar)/`
* Unmatched ). A group was not opened, but was closed. Example: `/hello)2u/`
* Unterminated group. A group was not closed. Example: `/(1(23)4/`
* Unterminated character class. A custom character set was not closed. Example: `/[abc/`
# Install
npm install ret
# Tests
Tests are written with [vows](http://vowsjs.org/)
```bash
npm test
```
# License
MIT
# sprintf.js
**sprintf.js** is a complete open source JavaScript sprintf implementation for the *browser* and *node.js*.
Its prototype is simple:
string sprintf(string format , [mixed arg1 [, mixed arg2 [ ,...]]])
The placeholders in the format string are marked by `%` and are followed by one or more of these elements, in this order:
* An optional number followed by a `$` sign that selects which argument index to use for the value. If not specified, arguments will be placed in the same order as the placeholders in the input string.
* An optional `+` sign that forces to preceed the result with a plus or minus sign on numeric values. By default, only the `-` sign is used on negative numbers.
* An optional padding specifier that says what character to use for padding (if specified). Possible values are `0` or any other character precedeed by a `'` (single quote). The default is to pad with *spaces*.
* An optional `-` sign, that causes sprintf to left-align the result of this placeholder. The default is to right-align the result.
* An optional number, that says how many characters the result should have. If the value to be returned is shorter than this number, the result will be padded. When used with the `j` (JSON) type specifier, the padding length specifies the tab size used for indentation.
* An optional precision modifier, consisting of a `.` (dot) followed by a number, that says how many digits should be displayed for floating point numbers. When used with the `g` type specifier, it specifies the number of significant digits. When used on a string, it causes the result to be truncated.
* A type specifier that can be any of:
* `%` — yields a literal `%` character
* `b` — yields an integer as a binary number
* `c` — yields an integer as the character with that ASCII value
* `d` or `i` — yields an integer as a signed decimal number
* `e` — yields a float using scientific notation
* `u` — yields an integer as an unsigned decimal number
* `f` — yields a float as is; see notes on precision above
* `g` — yields a float as is; see notes on precision above
* `o` — yields an integer as an octal number
* `s` — yields a string as is
* `x` — yields an integer as a hexadecimal number (lower-case)
* `X` — yields an integer as a hexadecimal number (upper-case)
* `j` — yields a JavaScript object or array as a JSON encoded string
## JavaScript `vsprintf`
`vsprintf` is the same as `sprintf` except that it accepts an array of arguments, rather than a variable number of arguments:
vsprintf("The first 4 letters of the english alphabet are: %s, %s, %s and %s", ["a", "b", "c", "d"])
## Argument swapping
You can also swap the arguments. That is, the order of the placeholders doesn't have to match the order of the arguments. You can do that by simply indicating in the format string which arguments the placeholders refer to:
sprintf("%2$s %3$s a %1$s", "cracker", "Polly", "wants")
And, of course, you can repeat the placeholders without having to increase the number of arguments.
## Named arguments
Format strings may contain replacement fields rather than positional placeholders. Instead of referring to a certain argument, you can now refer to a certain key within an object. Replacement fields are surrounded by rounded parentheses - `(` and `)` - and begin with a keyword that refers to a key:
var user = {
name: "Dolly"
}
sprintf("Hello %(name)s", user) // Hello Dolly
Keywords in replacement fields can be optionally followed by any number of keywords or indexes:
var users = [
{name: "Dolly"},
{name: "Molly"},
{name: "Polly"}
]
sprintf("Hello %(users[0].name)s, %(users[1].name)s and %(users[2].name)s", {users: users}) // Hello Dolly, Molly and Polly
Note: mixing positional and named placeholders is not (yet) supported
## Computed values
You can pass in a function as a dynamic value and it will be invoked (with no arguments) in order to compute the value on-the-fly.
sprintf("Current timestamp: %d", Date.now) // Current timestamp: 1398005382890
sprintf("Current date and time: %s", function() { return new Date().toString() })
# AngularJS
You can now use `sprintf` and `vsprintf` (also aliased as `fmt` and `vfmt` respectively) in your AngularJS projects. See `demo/`.
# Installation
## Via Bower
bower install sprintf
## Or as a node.js module
npm install sprintf-js
### Usage
var sprintf = require("sprintf-js").sprintf,
vsprintf = require("sprintf-js").vsprintf
sprintf("%2$s %3$s a %1$s", "cracker", "Polly", "wants")
vsprintf("The first 4 letters of the english alphabet are: %s, %s, %s and %s", ["a", "b", "c", "d"])
# License
**sprintf.js** is licensed under the terms of the 3-clause BSD license.
# assemblyscript-json
 
JSON encoder / decoder for AssemblyScript.
Special thanks to https://github.com/MaxGraey/bignum.wasm for basic unit testing infra for AssemblyScript.
## Installation
`assemblyscript-json` is available as a [npm package](https://www.npmjs.com/package/assemblyscript-json). You can install `assemblyscript-json` in your AssemblyScript project by running:
`npm install --save assemblyscript-json`
## Usage
### Parsing JSON
```typescript
import { JSON } from "assemblyscript-json";
// Parse an object using the JSON object
let jsonObj: JSON.Obj = <JSON.Obj>(JSON.parse('{"hello": "world", "value": 24}'));
// We can then use the .getX functions to read from the object if you know it's type
// This will return the appropriate JSON.X value if the key exists, or null if the key does not exist
let worldOrNull: JSON.Str | null = jsonObj.getString("hello"); // This will return a JSON.Str or null
if (worldOrNull != null) {
// use .valueOf() to turn the high level JSON.Str type into a string
let world: string = worldOrNull.valueOf();
}
let numOrNull: JSON.Num | null = jsonObj.getNum("value");
if (numOrNull != null) {
// use .valueOf() to turn the high level JSON.Num type into a f64
let value: f64 = numOrNull.valueOf();
}
// If you don't know the value type, get the parent JSON.Value
let valueOrNull: JSON.Value | null = jsonObj.getValue("hello");
if (valueOrNull != null) {
let value = <JSON.Value>valueOrNull;
// Next we could figure out what type we are
if(value.isString) {
// value.isString would be true, so we can cast to a string
let innerString = (<JSON.Str>value).valueOf();
let jsonString = (<JSON.Str>value).stringify();
// Do something with string value
}
}
```
### Encoding JSON
```typescript
import { JSONEncoder } from "assemblyscript-json";
// Create encoder
let encoder = new JSONEncoder();
// Construct necessary object
encoder.pushObject("obj");
encoder.setInteger("int", 10);
encoder.setString("str", "");
encoder.popObject();
// Get serialized data
let json: Uint8Array = encoder.serialize();
// Or get serialized data as string
let jsonString: string = encoder.stringify();
assert(jsonString, '"obj": {"int": 10, "str": ""}'); // True!
```
### Custom JSON Deserializers
```typescript
import { JSONDecoder, JSONHandler } from "assemblyscript-json";
// Events need to be received by custom object extending JSONHandler.
// NOTE: All methods are optional to implement.
class MyJSONEventsHandler extends JSONHandler {
setString(name: string, value: string): void {
// Handle field
}
setBoolean(name: string, value: bool): void {
// Handle field
}
setNull(name: string): void {
// Handle field
}
setInteger(name: string, value: i64): void {
// Handle field
}
setFloat(name: string, value: f64): void {
// Handle field
}
pushArray(name: string): bool {
// Handle array start
// true means that nested object needs to be traversed, false otherwise
// Note that returning false means JSONDecoder.startIndex need to be updated by handler
return true;
}
popArray(): void {
// Handle array end
}
pushObject(name: string): bool {
// Handle object start
// true means that nested object needs to be traversed, false otherwise
// Note that returning false means JSONDecoder.startIndex need to be updated by handler
return true;
}
popObject(): void {
// Handle object end
}
}
// Create decoder
let decoder = new JSONDecoder<MyJSONEventsHandler>(new MyJSONEventsHandler());
// Create a byte buffer of our JSON. NOTE: Deserializers work on UTF8 string buffers.
let jsonString = '{"hello": "world"}';
let jsonBuffer = Uint8Array.wrap(String.UTF8.encode(jsonString));
// Parse JSON
decoder.deserialize(jsonBuffer); // This will send events to MyJSONEventsHandler
```
Feel free to look through the [tests](https://github.com/nearprotocol/assemblyscript-json/tree/master/assembly/__tests__) for more usage examples.
## Reference Documentation
Reference API Documentation can be found in the [docs directory](./docs).
## License
[MIT](./LICENSE)
# eslint-visitor-keys
[](https://www.npmjs.com/package/eslint-visitor-keys)
[](http://www.npmtrends.com/eslint-visitor-keys)
[](https://travis-ci.org/eslint/eslint-visitor-keys)
[](https://david-dm.org/eslint/eslint-visitor-keys)
Constants and utilities about visitor keys to traverse AST.
## 💿 Installation
Use [npm] to install.
```bash
$ npm install eslint-visitor-keys
```
### Requirements
- [Node.js] 10.0.0 or later.
## 📖 Usage
```js
const evk = require("eslint-visitor-keys")
```
### evk.KEYS
> type: `{ [type: string]: string[] | undefined }`
Visitor keys. This keys are frozen.
This is an object. Keys are the type of [ESTree] nodes. Their values are an array of property names which have child nodes.
For example:
```
console.log(evk.KEYS.AssignmentExpression) // → ["left", "right"]
```
### evk.getKeys(node)
> type: `(node: object) => string[]`
Get the visitor keys of a given AST node.
This is similar to `Object.keys(node)` of ES Standard, but some keys are excluded: `parent`, `leadingComments`, `trailingComments`, and names which start with `_`.
This will be used to traverse unknown nodes.
For example:
```
const node = {
type: "AssignmentExpression",
left: { type: "Identifier", name: "foo" },
right: { type: "Literal", value: 0 }
}
console.log(evk.getKeys(node)) // → ["type", "left", "right"]
```
### evk.unionWith(additionalKeys)
> type: `(additionalKeys: object) => { [type: string]: string[] | undefined }`
Make the union set with `evk.KEYS` and the given keys.
- The order of keys is, `additionalKeys` is at first, then `evk.KEYS` is concatenated after that.
- It removes duplicated keys as keeping the first one.
For example:
```
console.log(evk.unionWith({
MethodDefinition: ["decorators"]
})) // → { ..., MethodDefinition: ["decorators", "key", "value"], ... }
```
## 📰 Change log
See [GitHub releases](https://github.com/eslint/eslint-visitor-keys/releases).
## 🍻 Contributing
Welcome. See [ESLint contribution guidelines](https://eslint.org/docs/developer-guide/contributing/).
### Development commands
- `npm test` runs tests and measures code coverage.
- `npm run lint` checks source codes with ESLint.
- `npm run coverage` opens the code coverage report of the previous test with your default browser.
- `npm run release` publishes this package to [npm] registory.
[npm]: https://www.npmjs.com/
[Node.js]: https://nodejs.org/en/
[ESTree]: https://github.com/estree/estree
# yallist
Yet Another Linked List
There are many doubly-linked list implementations like it, but this
one is mine.
For when an array would be too big, and a Map can't be iterated in
reverse order.
[](https://travis-ci.org/isaacs/yallist) [](https://coveralls.io/github/isaacs/yallist)
## basic usage
```javascript
var yallist = require('yallist')
var myList = yallist.create([1, 2, 3])
myList.push('foo')
myList.unshift('bar')
// of course pop() and shift() are there, too
console.log(myList.toArray()) // ['bar', 1, 2, 3, 'foo']
myList.forEach(function (k) {
// walk the list head to tail
})
myList.forEachReverse(function (k, index, list) {
// walk the list tail to head
})
var myDoubledList = myList.map(function (k) {
return k + k
})
// now myDoubledList contains ['barbar', 2, 4, 6, 'foofoo']
// mapReverse is also a thing
var myDoubledListReverse = myList.mapReverse(function (k) {
return k + k
}) // ['foofoo', 6, 4, 2, 'barbar']
var reduced = myList.reduce(function (set, entry) {
set += entry
return set
}, 'start')
console.log(reduced) // 'startfoo123bar'
```
## api
The whole API is considered "public".
Functions with the same name as an Array method work more or less the
same way.
There's reverse versions of most things because that's the point.
### Yallist
Default export, the class that holds and manages a list.
Call it with either a forEach-able (like an array) or a set of
arguments, to initialize the list.
The Array-ish methods all act like you'd expect. No magic length,
though, so if you change that it won't automatically prune or add
empty spots.
### Yallist.create(..)
Alias for Yallist function. Some people like factories.
#### yallist.head
The first node in the list
#### yallist.tail
The last node in the list
#### yallist.length
The number of nodes in the list. (Change this at your peril. It is
not magic like Array length.)
#### yallist.toArray()
Convert the list to an array.
#### yallist.forEach(fn, [thisp])
Call a function on each item in the list.
#### yallist.forEachReverse(fn, [thisp])
Call a function on each item in the list, in reverse order.
#### yallist.get(n)
Get the data at position `n` in the list. If you use this a lot,
probably better off just using an Array.
#### yallist.getReverse(n)
Get the data at position `n`, counting from the tail.
#### yallist.map(fn, thisp)
Create a new Yallist with the result of calling the function on each
item.
#### yallist.mapReverse(fn, thisp)
Same as `map`, but in reverse.
#### yallist.pop()
Get the data from the list tail, and remove the tail from the list.
#### yallist.push(item, ...)
Insert one or more items to the tail of the list.
#### yallist.reduce(fn, initialValue)
Like Array.reduce.
#### yallist.reduceReverse
Like Array.reduce, but in reverse.
#### yallist.reverse
Reverse the list in place.
#### yallist.shift()
Get the data from the list head, and remove the head from the list.
#### yallist.slice([from], [to])
Just like Array.slice, but returns a new Yallist.
#### yallist.sliceReverse([from], [to])
Just like yallist.slice, but the result is returned in reverse.
#### yallist.toArray()
Create an array representation of the list.
#### yallist.toArrayReverse()
Create a reversed array representation of the list.
#### yallist.unshift(item, ...)
Insert one or more items to the head of the list.
#### yallist.unshiftNode(node)
Move a Node object to the front of the list. (That is, pull it out of
wherever it lives, and make it the new head.)
If the node belongs to a different list, then that list will remove it
first.
#### yallist.pushNode(node)
Move a Node object to the end of the list. (That is, pull it out of
wherever it lives, and make it the new tail.)
If the node belongs to a list already, then that list will remove it
first.
#### yallist.removeNode(node)
Remove a node from the list, preserving referential integrity of head
and tail and other nodes.
Will throw an error if you try to have a list remove a node that
doesn't belong to it.
### Yallist.Node
The class that holds the data and is actually the list.
Call with `var n = new Node(value, previousNode, nextNode)`
Note that if you do direct operations on Nodes themselves, it's very
easy to get into weird states where the list is broken. Be careful :)
#### node.next
The next node in the list.
#### node.prev
The previous node in the list.
#### node.value
The data the node contains.
#### node.list
The list to which this node belongs. (Null if it does not belong to
any list.)
assemblyscript-json
# assemblyscript-json
## Table of contents
### Namespaces
- [JSON](modules/json.md)
### Classes
- [DecoderState](classes/decoderstate.md)
- [JSONDecoder](classes/jsondecoder.md)
- [JSONEncoder](classes/jsonencoder.md)
- [JSONHandler](classes/jsonhandler.md)
- [ThrowingJSONHandler](classes/throwingjsonhandler.md)
# jsdiff
[](http://travis-ci.org/kpdecker/jsdiff)
[](https://saucelabs.com/u/jsdiff)
A javascript text differencing implementation.
Based on the algorithm proposed in
["An O(ND) Difference Algorithm and its Variations" (Myers, 1986)](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.4.6927).
## Installation
```bash
npm install diff --save
```
## API
* `Diff.diffChars(oldStr, newStr[, options])` - diffs two blocks of text, comparing character by character.
Returns a list of change objects (See below).
Options
* `ignoreCase`: `true` to ignore casing difference. Defaults to `false`.
* `Diff.diffWords(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, ignoring whitespace.
Returns a list of change objects (See below).
Options
* `ignoreCase`: Same as in `diffChars`.
* `Diff.diffWordsWithSpace(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, treating whitespace as significant.
Returns a list of change objects (See below).
* `Diff.diffLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line.
Options
* `ignoreWhitespace`: `true` to ignore leading and trailing whitespace. This is the same as `diffTrimmedLines`
* `newlineIsToken`: `true` to treat newline characters as separate tokens. This allows for changes to the newline structure to occur independently of the line content and to be treated as such. In general this is the more human friendly form of `diffLines` and `diffLines` is better suited for patches and other computer friendly output.
Returns a list of change objects (See below).
* `Diff.diffTrimmedLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line, ignoring leading and trailing whitespace.
Returns a list of change objects (See below).
* `Diff.diffSentences(oldStr, newStr[, options])` - diffs two blocks of text, comparing sentence by sentence.
Returns a list of change objects (See below).
* `Diff.diffCss(oldStr, newStr[, options])` - diffs two blocks of text, comparing CSS tokens.
Returns a list of change objects (See below).
* `Diff.diffJson(oldObj, newObj[, options])` - diffs two JSON objects, comparing the fields defined on each. The order of fields, etc does not matter in this comparison.
Returns a list of change objects (See below).
* `Diff.diffArrays(oldArr, newArr[, options])` - diffs two arrays, comparing each item for strict equality (===).
Options
* `comparator`: `function(left, right)` for custom equality checks
Returns a list of change objects (See below).
* `Diff.createTwoFilesPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Parameters:
* `oldFileName` : String to be output in the filename section of the patch for the removals
* `newFileName` : String to be output in the filename section of the patch for the additions
* `oldStr` : Original string value
* `newStr` : New string value
* `oldHeader` : Additional information to include in the old file header
* `newHeader` : Additional information to include in the new file header
* `options` : An object with options. Currently, only `context` is supported and describes how many lines of context should be included.
* `Diff.createPatch(fileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Just like Diff.createTwoFilesPatch, but with oldFileName being equal to newFileName.
* `Diff.structuredPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader, options)` - returns an object with an array of hunk objects.
This method is similar to createTwoFilesPatch, but returns a data structure
suitable for further processing. Parameters are the same as createTwoFilesPatch. The data structure returned may look like this:
```js
{
oldFileName: 'oldfile', newFileName: 'newfile',
oldHeader: 'header1', newHeader: 'header2',
hunks: [{
oldStart: 1, oldLines: 3, newStart: 1, newLines: 3,
lines: [' line2', ' line3', '-line4', '+line5', '\\ No newline at end of file'],
}]
}
```
* `Diff.applyPatch(source, patch[, options])` - applies a unified diff patch.
Return a string containing new version of provided data. `patch` may be a string diff or the output from the `parsePatch` or `structuredPatch` methods.
The optional `options` object may have the following keys:
- `fuzzFactor`: Number of lines that are allowed to differ before rejecting a patch. Defaults to 0.
- `compareLine(lineNumber, line, operation, patchContent)`: Callback used to compare to given lines to determine if they should be considered equal when patching. Defaults to strict equality but may be overridden to provide fuzzier comparison. Should return false if the lines should be rejected.
* `Diff.applyPatches(patch, options)` - applies one or more patches.
This method will iterate over the contents of the patch and apply to data provided through callbacks. The general flow for each patch index is:
- `options.loadFile(index, callback)` is called. The caller should then load the contents of the file and then pass that to the `callback(err, data)` callback. Passing an `err` will terminate further patch execution.
- `options.patched(index, content, callback)` is called once the patch has been applied. `content` will be the return value from `applyPatch`. When it's ready, the caller should call `callback(err)` callback. Passing an `err` will terminate further patch execution.
Once all patches have been applied or an error occurs, the `options.complete(err)` callback is made.
* `Diff.parsePatch(diffStr)` - Parses a patch into structured data
Return a JSON object representation of the a patch, suitable for use with the `applyPatch` method. This parses to the same structure returned by `Diff.structuredPatch`.
* `convertChangesToXML(changes)` - converts a list of changes to a serialized XML format
All methods above which accept the optional `callback` method will run in sync mode when that parameter is omitted and in async mode when supplied. This allows for larger diffs without blocking the event loop. This may be passed either directly as the final parameter or as the `callback` field in the `options` object.
### Change Objects
Many of the methods above return change objects. These objects consist of the following fields:
* `value`: Text content
* `added`: True if the value was inserted into the new string
* `removed`: True if the value was removed from the old string
Note that some cases may omit a particular flag field. Comparison on the flag fields should always be done in a truthy or falsy manner.
## Examples
Basic example in Node
```js
require('colors');
const Diff = require('diff');
const one = 'beep boop';
const other = 'beep boob blah';
const diff = Diff.diffChars(one, other);
diff.forEach((part) => {
// green for additions, red for deletions
// grey for common parts
const color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
process.stderr.write(part.value[color]);
});
console.log();
```
Running the above program should yield
<img src="images/node_example.png" alt="Node Example">
Basic example in a web page
```html
<pre id="display"></pre>
<script src="diff.js"></script>
<script>
const one = 'beep boop',
other = 'beep boob blah',
color = '';
let span = null;
const diff = Diff.diffChars(one, other),
display = document.getElementById('display'),
fragment = document.createDocumentFragment();
diff.forEach((part) => {
// green for additions, red for deletions
// grey for common parts
const color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
span = document.createElement('span');
span.style.color = color;
span.appendChild(document
.createTextNode(part.value));
fragment.appendChild(span);
});
display.appendChild(fragment);
</script>
```
Open the above .html file in a browser and you should see
<img src="images/web_example.png" alt="Node Example">
**[Full online demo](http://kpdecker.github.com/jsdiff)**
## Compatibility
[](https://saucelabs.com/u/jsdiff)
jsdiff supports all ES3 environments with some known issues on IE8 and below. Under these browsers some diff algorithms such as word diff and others may fail due to lack of support for capturing groups in the `split` operation.
## License
See [LICENSE](https://github.com/kpdecker/jsdiff/blob/master/LICENSE).
functional-red-black-tree
=========================
A [fully persistent](http://en.wikipedia.org/wiki/Persistent_data_structure) [red-black tree](http://en.wikipedia.org/wiki/Red%E2%80%93black_tree) written 100% in JavaScript. Works both in node.js and in the browser via [browserify](http://browserify.org/).
Functional (or fully presistent) data structures allow for non-destructive updates. So if you insert an element into the tree, it returns a new tree with the inserted element rather than destructively updating the existing tree in place. Doing this requires using extra memory, and if one were naive it could cost as much as reallocating the entire tree. Instead, this data structure saves some memory by recycling references to previously allocated subtrees. This requires using only O(log(n)) additional memory per update instead of a full O(n) copy.
Some advantages of this is that it is possible to apply insertions and removals to the tree while still iterating over previous versions of the tree. Functional and persistent data structures can also be useful in many geometric algorithms like point location within triangulations or ray queries, and can be used to analyze the history of executing various algorithms. This added power though comes at a cost, since it is generally a bit slower to use a functional data structure than an imperative version. However, if your application needs this behavior then you may consider using this module.
# Install
npm install functional-red-black-tree
# Example
Here is an example of some basic usage:
```javascript
//Load the library
var createTree = require("functional-red-black-tree")
//Create a tree
var t1 = createTree()
//Insert some items into the tree
var t2 = t1.insert(1, "foo")
var t3 = t2.insert(2, "bar")
//Remove something
var t4 = t3.remove(1)
```
# API
```javascript
var createTree = require("functional-red-black-tree")
```
## Overview
- [Tree methods](#tree-methods)
- [`var tree = createTree([compare])`](#var-tree-=-createtreecompare)
- [`tree.keys`](#treekeys)
- [`tree.values`](#treevalues)
- [`tree.length`](#treelength)
- [`tree.get(key)`](#treegetkey)
- [`tree.insert(key, value)`](#treeinsertkey-value)
- [`tree.remove(key)`](#treeremovekey)
- [`tree.find(key)`](#treefindkey)
- [`tree.ge(key)`](#treegekey)
- [`tree.gt(key)`](#treegtkey)
- [`tree.lt(key)`](#treeltkey)
- [`tree.le(key)`](#treelekey)
- [`tree.at(position)`](#treeatposition)
- [`tree.begin`](#treebegin)
- [`tree.end`](#treeend)
- [`tree.forEach(visitor(key,value)[, lo[, hi]])`](#treeforEachvisitorkeyvalue-lo-hi)
- [`tree.root`](#treeroot)
- [Node properties](#node-properties)
- [`node.key`](#nodekey)
- [`node.value`](#nodevalue)
- [`node.left`](#nodeleft)
- [`node.right`](#noderight)
- [Iterator methods](#iterator-methods)
- [`iter.key`](#iterkey)
- [`iter.value`](#itervalue)
- [`iter.node`](#iternode)
- [`iter.tree`](#itertree)
- [`iter.index`](#iterindex)
- [`iter.valid`](#itervalid)
- [`iter.clone()`](#iterclone)
- [`iter.remove()`](#iterremove)
- [`iter.update(value)`](#iterupdatevalue)
- [`iter.next()`](#iternext)
- [`iter.prev()`](#iterprev)
- [`iter.hasNext`](#iterhasnext)
- [`iter.hasPrev`](#iterhasprev)
## Tree methods
### `var tree = createTree([compare])`
Creates an empty functional tree
* `compare` is an optional comparison function, same semantics as array.sort()
**Returns** An empty tree ordered by `compare`
### `tree.keys`
A sorted array of all the keys in the tree
### `tree.values`
An array array of all the values in the tree
### `tree.length`
The number of items in the tree
### `tree.get(key)`
Retrieves the value associated to the given key
* `key` is the key of the item to look up
**Returns** The value of the first node associated to `key`
### `tree.insert(key, value)`
Creates a new tree with the new pair inserted.
* `key` is the key of the item to insert
* `value` is the value of the item to insert
**Returns** A new tree with `key` and `value` inserted
### `tree.remove(key)`
Removes the first item with `key` in the tree
* `key` is the key of the item to remove
**Returns** A new tree with the given item removed if it exists
### `tree.find(key)`
Returns an iterator pointing to the first item in the tree with `key`, otherwise `null`.
### `tree.ge(key)`
Find the first item in the tree whose key is `>= key`
* `key` is the key to search for
**Returns** An iterator at the given element.
### `tree.gt(key)`
Finds the first item in the tree whose key is `> key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.lt(key)`
Finds the last item in the tree whose key is `< key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.le(key)`
Finds the last item in the tree whose key is `<= key`
* `key` is the key to search for
**Returns** An iterator at the given element
### `tree.at(position)`
Finds an iterator starting at the given element
* `position` is the index at which the iterator gets created
**Returns** An iterator starting at position
### `tree.begin`
An iterator pointing to the first element in the tree
### `tree.end`
An iterator pointing to the last element in the tree
### `tree.forEach(visitor(key,value)[, lo[, hi]])`
Walks a visitor function over the nodes of the tree in order.
* `visitor(key,value)` is a callback that gets executed on each node. If a truthy value is returned from the visitor, then iteration is stopped.
* `lo` is an optional start of the range to visit (inclusive)
* `hi` is an optional end of the range to visit (non-inclusive)
**Returns** The last value returned by the callback
### `tree.root`
Returns the root node of the tree
## Node properties
Each node of the tree has the following properties:
### `node.key`
The key associated to the node
### `node.value`
The value associated to the node
### `node.left`
The left subtree of the node
### `node.right`
The right subtree of the node
## Iterator methods
### `iter.key`
The key of the item referenced by the iterator
### `iter.value`
The value of the item referenced by the iterator
### `iter.node`
The value of the node at the iterator's current position. `null` is iterator is node valid.
### `iter.tree`
The tree associated to the iterator
### `iter.index`
Returns the position of this iterator in the sequence.
### `iter.valid`
Checks if the iterator is valid
### `iter.clone()`
Makes a copy of the iterator
### `iter.remove()`
Removes the item at the position of the iterator
**Returns** A new binary search tree with `iter`'s item removed
### `iter.update(value)`
Updates the value of the node in the tree at this iterator
**Returns** A new binary search tree with the corresponding node updated
### `iter.next()`
Advances the iterator to the next position
### `iter.prev()`
Moves the iterator backward one element
### `iter.hasNext`
If true, then the iterator is not at the end of the sequence
### `iter.hasPrev`
If true, then the iterator is not at the beginning of the sequence
# Credits
(c) 2013 Mikola Lysenko. MIT License
# Read This!
**These files are not meant to be edited by hand.**
If you need to make modifications, the respective files should be changed within the repository's top-level `src` directory.
Running `gulp LKG` will then appropriately update the files in this directory.
# is-glob [](https://www.npmjs.com/package/is-glob) [](https://npmjs.org/package/is-glob) [](https://npmjs.org/package/is-glob) [](https://github.com/micromatch/is-glob/actions)
> Returns `true` if the given string looks like a glob pattern or an extglob pattern. This makes it easy to create code that only uses external modules like node-glob when necessary, resulting in much faster code execution and initialization time, and a better user experience.
Please consider following this project's author, [Jon Schlinkert](https://github.com/jonschlinkert), and consider starring the project to show your :heart: and support.
## Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm install --save is-glob
```
You might also be interested in [is-valid-glob](https://github.com/jonschlinkert/is-valid-glob) and [has-glob](https://github.com/jonschlinkert/has-glob).
## Usage
```js
var isGlob = require('is-glob');
```
### Default behavior
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js');
isGlob('*.js');
isGlob('**/abc.js');
isGlob('abc/*.js');
isGlob('abc/(aaa|bbb).js');
isGlob('abc/[a-z].js');
isGlob('abc/{a,b}.js');
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js');
isGlob('abc/!(a).js');
isGlob('abc/+(a).js');
isGlob('abc/*(a).js');
isGlob('abc/?(a).js');
//=> true
```
**False**
Escaped globs or extglobs return `false`:
```js
isGlob('abc/\\@(a).js');
isGlob('abc/\\!(a).js');
isGlob('abc/\\+(a).js');
isGlob('abc/\\*(a).js');
isGlob('abc/\\?(a).js');
isGlob('\\!foo.js');
isGlob('\\*.js');
isGlob('\\*\\*/abc.js');
isGlob('abc/\\*.js');
isGlob('abc/\\(aaa|bbb).js');
isGlob('abc/\\[a-z].js');
isGlob('abc/\\{a,b}.js');
//=> false
```
Patterns that do not have glob patterns return `false`:
```js
isGlob('abc.js');
isGlob('abc/def/ghi.js');
isGlob('foo.js');
isGlob('abc/@.js');
isGlob('abc/+.js');
isGlob('abc/?.js');
isGlob();
isGlob(null);
//=> false
```
Arrays are also `false` (If you want to check if an array has a glob pattern, use [has-glob](https://github.com/jonschlinkert/has-glob)):
```js
isGlob(['**/*.js']);
isGlob(['foo.js']);
//=> false
```
### Option strict
When `options.strict === false` the behavior is less strict in determining if a pattern is a glob. Meaning that
some patterns that would return `false` may return `true`. This is done so that matching libraries like [micromatch](https://github.com/micromatch/micromatch) have a chance at determining if the pattern is a glob or not.
**True**
Patterns that have glob characters or regex patterns will return `true`:
```js
isGlob('!foo.js', {strict: false});
isGlob('*.js', {strict: false});
isGlob('**/abc.js', {strict: false});
isGlob('abc/*.js', {strict: false});
isGlob('abc/(aaa|bbb).js', {strict: false});
isGlob('abc/[a-z].js', {strict: false});
isGlob('abc/{a,b}.js', {strict: false});
//=> true
```
Extglobs
```js
isGlob('abc/@(a).js', {strict: false});
isGlob('abc/!(a).js', {strict: false});
isGlob('abc/+(a).js', {strict: false});
isGlob('abc/*(a).js', {strict: false});
isGlob('abc/?(a).js', {strict: false});
//=> true
```
**False**
Escaped globs or extglobs return `false`:
```js
isGlob('\\!foo.js', {strict: false});
isGlob('\\*.js', {strict: false});
isGlob('\\*\\*/abc.js', {strict: false});
isGlob('abc/\\*.js', {strict: false});
isGlob('abc/\\(aaa|bbb).js', {strict: false});
isGlob('abc/\\[a-z].js', {strict: false});
isGlob('abc/\\{a,b}.js', {strict: false});
//=> false
```
## About
<details>
<summary><strong>Contributing</strong></summary>
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](../../issues/new).
</details>
<details>
<summary><strong>Running Tests</strong></summary>
Running and reviewing unit tests is a great way to get familiarized with a library and its API. You can install dependencies and run tests with the following command:
```sh
$ npm install && npm test
```
</details>
<details>
<summary><strong>Building docs</strong></summary>
_(This project's readme.md is generated by [verb](https://github.com/verbose/verb-generate-readme), please don't edit the readme directly. Any changes to the readme must be made in the [.verb.md](.verb.md) readme template.)_
To generate the readme, run the following command:
```sh
$ npm install -g verbose/verb#dev verb-generate-readme && verb
```
</details>
### Related projects
You might also be interested in these projects:
* [assemble](https://www.npmjs.com/package/assemble): Get the rocks out of your socks! Assemble makes you fast at creating web projects… [more](https://github.com/assemble/assemble) | [homepage](https://github.com/assemble/assemble "Get the rocks out of your socks! Assemble makes you fast at creating web projects. Assemble is used by thousands of projects for rapid prototyping, creating themes, scaffolds, boilerplates, e-books, UI components, API documentation, blogs, building websit")
* [base](https://www.npmjs.com/package/base): Framework for rapidly creating high quality, server-side node.js applications, using plugins like building blocks | [homepage](https://github.com/node-base/base "Framework for rapidly creating high quality, server-side node.js applications, using plugins like building blocks")
* [update](https://www.npmjs.com/package/update): Be scalable! Update is a new, open source developer framework and CLI for automating updates… [more](https://github.com/update/update) | [homepage](https://github.com/update/update "Be scalable! Update is a new, open source developer framework and CLI for automating updates of any kind in code projects.")
* [verb](https://www.npmjs.com/package/verb): Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used… [more](https://github.com/verbose/verb) | [homepage](https://github.com/verbose/verb "Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used on hundreds of projects of all sizes to generate everything from API docs to readmes.")
### Contributors
| **Commits** | **Contributor** |
| --- | --- |
| 47 | [jonschlinkert](https://github.com/jonschlinkert) |
| 5 | [doowb](https://github.com/doowb) |
| 1 | [phated](https://github.com/phated) |
| 1 | [danhper](https://github.com/danhper) |
| 1 | [paulmillr](https://github.com/paulmillr) |
### Author
**Jon Schlinkert**
* [GitHub Profile](https://github.com/jonschlinkert)
* [Twitter Profile](https://twitter.com/jonschlinkert)
* [LinkedIn Profile](https://linkedin.com/in/jonschlinkert)
### License
Copyright © 2019, [Jon Schlinkert](https://github.com/jonschlinkert).
Released under the [MIT License](LICENSE).
***
_This file was generated by [verb-generate-readme](https://github.com/verbose/verb-generate-readme), v0.8.0, on March 27, 2019._
<p align="center">
<a href="https://gulpjs.com">
<img height="257" width="114" src="https://raw.githubusercontent.com/gulpjs/artwork/master/gulp-2x.png">
</a>
</p>
# glob-parent
[![NPM version][npm-image]][npm-url] [![Downloads][downloads-image]][npm-url] [![Azure Pipelines Build Status][azure-pipelines-image]][azure-pipelines-url] [![Travis Build Status][travis-image]][travis-url] [![AppVeyor Build Status][appveyor-image]][appveyor-url] [![Coveralls Status][coveralls-image]][coveralls-url] [![Gitter chat][gitter-image]][gitter-url]
Extract the non-magic parent path from a glob string.
## Usage
```js
var globParent = require('glob-parent');
globParent('path/to/*.js'); // 'path/to'
globParent('/root/path/to/*.js'); // '/root/path/to'
globParent('/*.js'); // '/'
globParent('*.js'); // '.'
globParent('**/*.js'); // '.'
globParent('path/{to,from}'); // 'path'
globParent('path/!(to|from)'); // 'path'
globParent('path/?(to|from)'); // 'path'
globParent('path/+(to|from)'); // 'path'
globParent('path/*(to|from)'); // 'path'
globParent('path/@(to|from)'); // 'path'
globParent('path/**/*'); // 'path'
// if provided a non-glob path, returns the nearest dir
globParent('path/foo/bar.js'); // 'path/foo'
globParent('path/foo/'); // 'path/foo'
globParent('path/foo'); // 'path' (see issue #3 for details)
```
## API
### `globParent(maybeGlobString, [options])`
Takes a string and returns the part of the path before the glob begins. Be aware of Escaping rules and Limitations below.
#### options
```js
{
// Disables the automatic conversion of slashes for Windows
flipBackslashes: true
}
```
## Escaping
The following characters have special significance in glob patterns and must be escaped if you want them to be treated as regular path characters:
- `?` (question mark) unless used as a path segment alone
- `*` (asterisk)
- `|` (pipe)
- `(` (opening parenthesis)
- `)` (closing parenthesis)
- `{` (opening curly brace)
- `}` (closing curly brace)
- `[` (opening bracket)
- `]` (closing bracket)
**Example**
```js
globParent('foo/[bar]/') // 'foo'
globParent('foo/\\[bar]/') // 'foo/[bar]'
```
## Limitations
### Braces & Brackets
This library attempts a quick and imperfect method of determining which path
parts have glob magic without fully parsing/lexing the pattern. There are some
advanced use cases that can trip it up, such as nested braces where the outer
pair is escaped and the inner one contains a path separator. If you find
yourself in the unlikely circumstance of being affected by this or need to
ensure higher-fidelity glob handling in your library, it is recommended that you
pre-process your input with [expand-braces] and/or [expand-brackets].
### Windows
Backslashes are not valid path separators for globs. If a path with backslashes
is provided anyway, for simple cases, glob-parent will replace the path
separator for you and return the non-glob parent path (now with
forward-slashes, which are still valid as Windows path separators).
This cannot be used in conjunction with escape characters.
```js
// BAD
globParent('C:\\Program Files \\(x86\\)\\*.ext') // 'C:/Program Files /(x86/)'
// GOOD
globParent('C:/Program Files\\(x86\\)/*.ext') // 'C:/Program Files (x86)'
```
If you are using escape characters for a pattern without path parts (i.e.
relative to `cwd`), prefix with `./` to avoid confusing glob-parent.
```js
// BAD
globParent('foo \\[bar]') // 'foo '
globParent('foo \\[bar]*') // 'foo '
// GOOD
globParent('./foo \\[bar]') // 'foo [bar]'
globParent('./foo \\[bar]*') // '.'
```
## License
ISC
[expand-braces]: https://github.com/jonschlinkert/expand-braces
[expand-brackets]: https://github.com/jonschlinkert/expand-brackets
[downloads-image]: https://img.shields.io/npm/dm/glob-parent.svg
[npm-url]: https://www.npmjs.com/package/glob-parent
[npm-image]: https://img.shields.io/npm/v/glob-parent.svg
[azure-pipelines-url]: https://dev.azure.com/gulpjs/gulp/_build/latest?definitionId=2&branchName=master
[azure-pipelines-image]: https://dev.azure.com/gulpjs/gulp/_apis/build/status/glob-parent?branchName=master
[travis-url]: https://travis-ci.org/gulpjs/glob-parent
[travis-image]: https://img.shields.io/travis/gulpjs/glob-parent.svg?label=travis-ci
[appveyor-url]: https://ci.appveyor.com/project/gulpjs/glob-parent
[appveyor-image]: https://img.shields.io/appveyor/ci/gulpjs/glob-parent.svg?label=appveyor
[coveralls-url]: https://coveralls.io/r/gulpjs/glob-parent
[coveralls-image]: https://img.shields.io/coveralls/gulpjs/glob-parent/master.svg
[gitter-url]: https://gitter.im/gulpjs/gulp
[gitter-image]: https://badges.gitter.im/gulpjs/gulp.svg
# near-sdk-core
This package contain a convenient interface for interacting with NEAR's host runtime. To see the functions that are provided by the host node see [`env.ts`](./assembly/env/env.ts).
# axios // core
The modules found in `core/` should be modules that are specific to the domain logic of axios. These modules would most likely not make sense to be consumed outside of the axios module, as their logic is too specific. Some examples of core modules are:
- Dispatching requests
- Managing interceptors
- Handling config
# get-caller-file
[](https://travis-ci.org/stefanpenner/get-caller-file)
[](https://ci.appveyor.com/project/embercli/get-caller-file/branch/master)
This is a utility, which allows a function to figure out from which file it was invoked. It does so by inspecting v8's stack trace at the time it is invoked.
Inspired by http://stackoverflow.com/questions/13227489
*note: this relies on Node/V8 specific APIs, as such other runtimes may not work*
## Installation
```bash
yarn add get-caller-file
```
## Usage
Given:
```js
// ./foo.js
const getCallerFile = require('get-caller-file');
module.exports = function() {
return getCallerFile(); // figures out who called it
};
```
```js
// index.js
const foo = require('./foo');
foo() // => /full/path/to/this/file/index.js
```
## Options:
* `getCallerFile(position = 2)`: where position is stack frame whos fileName we want.
|
near-hackathon-luciferius_challenge-8-rocketo-dao-dashboard | .cargo
config.toml
.github
workflows
node.js.yml
.parcel-cache
33ea92a96b06453d.txt
Cargo.toml
README.md
add-dao-job-application.bat
build-deploy-add-job.bat
build.bat
build.sh
cancel-job.bat
contract
Cargo.toml
README.md
build.bat
build.sh
src
lib.rs
test.sh
deploy.bat
dist
App.03fbd8d8.css
App.03fbd8d8.js
index.css
index.html
materialize.11fed4d9.css
materialize.11fed4d9.js
materialize.5467296b.js
materialize.min.64694632.css
materialize.min.64694632.js
materialize.min.f120bc19.js
src.e31bb0bc.css
package.json
public
index.html
manifest.json
robots.txt
receive-job-payment.bat
src
App.css
App.js
components
formatting.js
lib.js
streamViewData.js
config.js
dao-layout.js
fonts
OFL.txt
README.txt
index.html
index.js
layout.js
start-job.bat
| # Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `env CONTRACT_NAME=dao-dashboard.cryptosketches.testnet npm run start`
Runs the app in the development mode.\
Open [http://localhost:1234](http://localhost:1234) to view it in the browser.
The page will reload if you make edits.\
You will also see any lint errors in the console.
### `yarn test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `yarn build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `yarn eject`
**Note: this is a one-way operation. Once you `eject`, you can’t go back!**
If you aren’t satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you’re on your own.
You don’t have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn’t feel obligated to use this feature. However we understand that this tool wouldn’t be useful if you couldn’t customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `yarn build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
# Rust Smart Contract Template
## Getting started
To get started with this template:
1. Click the "Use this template" button to create a new repo based on this template
2. Update line 2 of `Cargo.toml` with your project name
3. Update line 4 of `Cargo.toml` with your project author names
4. Set up the [prerequisites](https://github.com/near/near-sdk-rs#pre-requisites)
5. Begin writing your smart contract in `src/lib.rs`
6. Test the contract
`cargo test -- --nocapture`
8. Build the contract
`RUSTFLAGS='-C link-arg=-s' cargo build --target wasm32-unknown-unknown --release`
**Get more info at:**
* [Rust Smart Contract Quick Start](https://docs.near.org/docs/develop/contracts/rust/intro)
* [Rust SDK Book](https://www.near-sdk.io/)
|
Giftea_NEAR-tours-project | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.deploy.sh
10.rate_tour.sh
11.delete_tour.sh
2.create_tour.sh
3.get_tour.sh
4.get_tours.sh
5.buy_tour.sh
6.update_tour.sh
7.like_tour.sh
8.dislike_tour.sh
9.comment_on_tour.sh
README.md
src
as-pect.d.ts
as_types.d.ts
tour
README.md
__tests__
README.md
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
models
commentModel.ts
rateModel.ts
tourModel.ts
tsconfig.json
utils.ts
| ### Unit Tests
Unit tests can be run with the command below:
```
yarn run test
```
### Tests for Contract in `index.unit.spec.ts`
```
[Describe]: Checks for creating account
[Success]: ✔ creates a tour
[Describe]: View a single Tour
[Success]: ✔ Returns a single tour
[Success]: ✔ Smart contract panics when there's no Tour with such ID
[Describe]: To purchase a single Tour
[Success]: ✔ purchases a single tour and returns a response
[Success]: ✔ Smart contract panics when there's no Tour with such ID
[Describe]: To delete a single Tour
[Success]: ✔ deletes a single tour and returns a response
[Success]: ✔ Smart contract panics when there's no Tour with such ID
[Describe]: To like on a single Tour
[Success]: ✔ likes on a single tour and returns a response
[Success]: ✔ unlikes on a single tour and returns a response
[Success]: ✔ Smart contract panics when there's no Tour with such ID
[Describe]: To dislike on a single Tour
[Success]: ✔ dislikes on a single tour and returns a response
[Success]: ✔ undislikes on a single tour and returns a response
[Success]: ✔ Smart contract panics when there's no Tour with such ID
[Describe]: Comment on tour
[Success]: ✔ comments on tour
[Success]: ✔ Smart contract panics when there's no Tour with such ID
[Describe]: Rate tour
[Success]: ✔ rates tour
[Success]: ✔ Smart contract panics when there's no Tour with such ID
[File]: src/tour/__tests__/index.unit.spec.ts
[Groups]: 9 pass, 9 total
[Result]: ✔ PASS
[Snapshot]: 0 total, 0 added, 0 removed, 0 different
[Summary]: 17 pass, 0 fail, 17 total
[Time]: 220.521ms
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[Result]: ✔ PASS
[Files]: 1 total
[Groups]: 9 count, 9 pass
[Tests]: 17 pass, 0 fail, 17 total
[Time]: 15046.675ms
✨ Done in 32.52s.
```
## Setting up your terminal
The scripts in this folder support a simple demonstration of the contract.
It uses the following setup:
```txt
┌───────────────────────────────────────┬───────────────────────────────────────┐
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
└───────────────────────────────────────┴───────────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1654101510417-62946478212070
# export OWNER=giftea.testnet
```
- Commands
```sh
1.deploy.sh # cleanup, compile and deploy contract
2.create_tour.sh # call methods on the deployed contract
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1654101510417-62946478212070
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linux-watch-command#191068)
# Sample
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
The goal of this repository is to make it as easy as possible to get started writing unit tests for AssemblyScript contracts built to work with NEAR Protocol.
## Usage
### Getting started
1. clone this repo to a local folder
2. run `yarn`
3. run `yarn install`
4. run `yarn test`
### Top-level `yarn` commands
- run `yarn test` to run all tests
- (!) be sure to run `yarn build:release` at least once before:
- run `yarn test:unit` to run only unit tests
- run `yarn build` to quickly verify build status
- run `yarn deploy` to quickly run the `./scripts/1.deploy.sh` command to deploy smart contract
- run `yarn clean` to clean up build folder
### Other documentation
- tour contract and test documentation
- see `/src/tour/README` for contract interface
- see `/src/tour/__tests__/README` for tour unit testing details
- see `/scripts/README` for running scripts
### Contracts and Unit Tests
```txt
src
├── tour <-- tour contract
│ ├── README.md
│ ├── __tests__
│ │ ├── README.md
│ │ └── index.unit.spec.ts
│ └── assembly
│ └── index.ts
| └── models
| └── commentModel.ts
| └── rateModel.ts
| └── tourModel.ts
|
└── utils.ts <-- shared contract code
```
### Helper Scripts
```txt
scripts
├── 1.deploy.sh
├── 2.create_tour.sh
├── 3.get_tour.sh
├── 4.get_tours.sh
├── 5.buy_tour.sh
├── 6.update_tour.sh
├── 7.like_tour.sh
├── 8.dislike_tour.sh
├── 9.comment_on_tour.sh
├── 10.rate_tour.sh
├── 11.delete_tour.sh
└── README.md <-- instructions
```
## Deployed Contract Link
[Check out the deployed Smart Contract on explorer.testnet.near.org](https://explorer.testnet.near.org/transactions/4Y8PBn45mJtyDD4ir1aopPkMNqZdfC2hwJrXhTxAi7cA)

## Design
### Interface
```ts
function setTour
```
- "Change" function (ie. a function that alters contract state)
- Receives a `Tour` object as a parameter, creates a new Tour and returns the success message
```ts
function getTour
```
- "View" function (ie. a function that does not alters contract state)
- Recieves a Tour's `id` as parameter
- Returns a Tour object
```ts
function getTours
```
- "View" function (ie. a function that does not alters contract state)
- Returns the whole Tours details/content
```ts
function buyTour
```
- "Change" function (ie. a function that alters contract state)
- Recieves a Tour's `id` as parameter
- This fetches a Tour by the `id` parameter and increaments it's sold amount
```ts
function updateTour
```
- "Change" function (ie. a function that alters contract state)
- Receives a `Tour` object as a parameter, updates Tour and returns the success message
```ts
function deleteTour
```
- "Change" function (ie. a function that alters contract state)
- Recieves a Tour's `id` as parameter
- Fetches the Tour by `id`, deletes it together with it's comments and rates
```ts
function likeTour
```
- "Change" function (ie. a function that alters contract state)
- Recieves a Tour's `id` as parameter
- Fetches the Tour by `id`, and adds a like to it.
- If a like has been added by a user and the function is called again, it removes the like.
- If a dislike has been added by a user and the function is called, it removes the dislike and adds a like
```ts
function dislikeTour
```
- "Change" function (ie. a function that alters contract state)
- Recieves a Tour's `id` as parameter
- Fetches the Tour by `id`, and adds a dislike to it.
- If a dislike has been added by a user and the function is called again, it removes the dislike.
- If a like has been added by a user and the function is called, it removes the like and adds a dislike
```ts
function commentOnTour
```
- "Change" function (ie. a function that alters contract state)
- Receives a `Comment` object as a parameter, fetches the Tour by the `tourId` value within the `Comment` object
- Creates a new comment and adds it to the Tour
```ts
function rateTour
```
- "Change" function (ie. a function that alters contract state)
- Receives a `Rate` object as a parameter, fetches the Tour by the `tourId` value within the `Rate` object
- Creates a new rate and adds it to the Tour
- The function will not execute if a user has rated before
|
imambujshukla7_trustballot | .gitpod.yml
CONTRIBUTING.md
README.md
contract
README.md
build.sh
build
builder.c
code.h
hello_near.js
methods.h
deploy.sh
package-lock.json
package.json
src
contract.ts
tsconfig.json
frontend
App.js
assets
global.css
components
Home.js
NewPoll.js
PollingStation.js
dist
frontend.3464ddca.js
index.1303bb05.css
index.50450f3e.css
index.ab0485ab.css
index.html
logo-white.a7716062.svg
index.html
index.js
near-wallet.js
package-lock.json
package.json
start.sh
styles.css
tailwind.config.js
ui-components.js
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| # Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```ts
@NearBindgen({})
class HelloNear {
greeting: string = "Hello";
@view // This method is read-only and can be called for free
get_greeting(): string {
return this.greeting;
}
@call // This method changes the state, for which it cost gas
set_greeting({ greeting }: { greeting: string }): void {
// Record a log permanently to the blockchain!
near.log(`Saving greeting ${greeting}`);
this.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `call` method.
`Call` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"greeting":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
# TrustBallot
TrustBallot is a blockchain based voting platform. It allows users to create and participate in polls with transparent and secure voting, using the NEAR Protocol. The application is deployed on Cloudflare, and the users can access it at [trustballot.site](https://trustballot.site).
## Features
- **Decentralized Voting**: Leverage the security and transparency of blockchain for your polls.
- **User-Friendly Interface**: Intuitive design for easy poll creation and participation.
- **Transparent Results**: View real-time results and statistics for each poll.
## Getting Started
To run TrustBallot locally, follow these steps:
1. Clone the repository.
```bash
git clone https://github.com/imambujshukla7/trustballot.git
cd trustballot
```
2. Install dependencies for the frontend.
```bash
cd frontend
npm install
```
3. Start the frontend development server.
```bash
npm start
```
4. Access the application at [http://trustballot.site).
## Deployment
TrustBallot is deployed on Cloudflare and can be accessed at [trustballot.site](https://trustballot.site). To deploy your own instance, refer to the NEAR Protocol documentation for deployment with `create-near-app`.
## Tech Stack
- **NEAR Protocol**: Blockchain platform for secure and transparent smart contracts.
- **React**: JavaScript library for building interactive user interfaces.
- **Bootstrap and React-Bootstrap:** Styling and UI components are built using Bootstrap and React-Bootstrap.
- **JavaScript (Node.js):** JavaScript is used for various components, including the integration tests.
- **Cloudflare**: Web infrastructure and security platform for reliable deployment.
## Contributing
Contributions are welcome! Feel free to submit issues or pull requests.
## License
This project is licensed under the [MIT License](LICENSE).
|
near_workspaces | .github
ISSUE_TEMPLATE
BOUNTY.yml
README.md
| <div align="center">
<h1>NEAR Workspaces (TypeScript/JavaScript Edition)</h1>
[](https://opensource.org/licenses/Apache-2.0)
[](https://opensource.org/licenses/MIT)
[](https://discord.gg/Vyp7ETM)
[](https://npmjs.com/near-workspaces)
[](https://npmjs.com/near-workspaces)
</div>
`NEAR Workspaces` is a library for automating workflows and writing tests for NEAR smart contracts. You can use it as is or integrate with test runner of your choise (AVA, Jest, Mocha, etc.). If you don't have a preference, we suggest you to use AVA.
Quick Start (without testing frameworks)
===========
To get started with `Near Workspaces` you need to do only two things:
1. Initialize a `Worker`.
```ts
const worker = await Worker.init();
const root = worker.rootAccount;
const alice = await root.createSubAccount('alice');
const contract = await root.devDeploy('path/to/compiled.wasm');
```
2. Writing tests.
`near-workspaces` is designed for concurrency. Here's a simple way to get concurrent runs using plain JS:
```ts
import {strict as assert} from 'assert';
await Promise.all([
async () => {
await alice.call(
contract,
'some_update_function',
{some_string_argument: 'cool', some_number_argument: 42}
);
const result = await contract.view(
'some_view_function',
{account_id: alice}
);
assert.equal(result, 'whatever');
},
async () => {
const result = await contract.view(
'some_view_function',
{account_id: alice}
);
/* Note that we expect the value returned from `some_view_function` to be
a default here, because this `fork` runs *at the same time* as the
previous, in a separate local blockchain */
assert.equal(result, 'some default');
}
]);
```
```
More info in our main README: https://github.com/near/workspaces-js
# Simple project
This is the simplest project setup example with workspaces-js. You can copy it as the starting point when setup your project.
## Usage
```
yarn
yarn test
```
## Setup your project
Assume you have written your smart contract. Setup and write workspaces-js test as this project is easy:
1. Build the contract to `.wasm` as place it in `contracts/`.
2. Install the `near-workspaces` and `ava` with `npm` or `yarn`.
3. Copy the ava.config.cjs to you project root directory.
4. Write test, place in `__tests__/`, end with `.ava.js`. You can refer to `__tests__/test-status-message.ava.js` as an example.
5. We're done! Run test with `yarn test` and continue adding more tests!
<div align="center">
<h1>NEAR Workspaces (TypeScript/JavaScript Edition)</h1>
[](https://opensource.org/licenses/Apache-2.0)
[](https://opensource.org/licenses/MIT)
[](https://discord.gg/Vyp7ETM)
[](https://npmjs.com/near-workspaces)
[](https://npmjs.com/near-workspaces)
</div>
`NEAR Workspaces` is a library for automating workflows and writing tests for NEAR smart contracts. You can use it as is or integrate with test runner of your choise (AVA, Jest, Mocha, etc.). If you don't have a preference, we suggest you to use AVA.
Quick Start (without testing frameworks)
===========
To get started with `Near Workspaces` you need to do only two things:
1. Initialize a `Worker`.
```ts
const worker = await Worker.init();
const root = worker.rootAccount;
const alice = await root.createSubAccount('alice');
const contract = await root.devDeploy('path/to/compiled.wasm');
```
Let's step through this.
1. `Worker.init` initializes a new `SandboxWorker` or `TestnetWorker` depending on the config. `SandboxWorker` contains [NEAR Sandbox](https://github.com/near/sandbox), which is essentially a local mini-NEAR blockchain. You can create one `Worker` per test to get its own data directory and port (for Sandbox) or root account (for Testnet), so that tests can run in parallel without race conditions in accessing states. If there's no state intervention. you can also reuse the `Worker` to speedup the tests.
2. The worker has a `root` account. For `SandboxWorker`, it's `test.near`. For `TestnetWorker`, it creates a unique account. The following accounts are created as subaccounts of the root account. The name of the account will change from different runs, so you should not refer to them by hard coded account name. You can access them via the account object, such as `root`, `alice` and `contract` above.
3. `root.createSubAccount` creates a new subaccount of `root` with the given name, for example `alice.<root-account-name>`.
4. `root.devDeploy` creates an account with random name, then deploys the specified Wasm file to it.
5. `path/to/compiled.wasm` will resolve relative to your project root. That is, the nearest directory with a `package.json` file, or your current working directory if no `package.json` is found. To construct a path relative to your test file, you can use `path.join(__dirname, '../etc/etc.wasm')` ([more info](https://nodejs.org/api/path.html#path_path_join_paths)).
6. `worker` contains a reference to this data directory, so that multiple tests can use it as a starting point.
7. If you're using a test framework, you can save the `worker` object and account objects `root`, `alice`, `contract` to test context to reuse them in subsequent tests.
8. At the end of test, call `await worker.tearDown()` to shuts down the Worker. It gracefully shuts down the Sandbox instance it ran in the background. However, it keeps the data directory around. That's what stores the state of the two accounts that were created (`alice` and `contract-account-name` with its deployed contract).
2. Writing tests.
`near-workspaces` is designed for concurrency. Here's a simple way to get concurrent runs using plain JS:
```ts
import {strict as assert} from 'assert';
await Promise.all([
async () => {
await alice.call(
contract,
'some_update_function',
{some_string_argument: 'cool', some_number_argument: 42}
);
const result = await contract.view(
'some_view_function',
{account_id: alice}
);
assert.equal(result, 'whatever');
},
async () => {
const result = await contract.view(
'some_view_function',
{account_id: alice}
);
/* Note that we expect the value returned from `some_view_function` to be
a default here, because this `fork` runs *at the same time* as the
previous, in a separate local blockchain */
assert.equal(result, 'some default');
}
]);
```
Let's step through this.
1. `worker` and accounts such as `alice` are created before.
2. `call` syntax mirrors [near-cli](https://github.com/near/near-cli) and either returns the successful return value of the given function or throws the encountered error. If you want to inspect a full transaction and/or avoid the `throw` behavior, you can use `callRaw` instead.
3. While `call` is invoked on the account _doing the call_ (`alice.call(contract, …)`), `view` is invoked on the account _being viewed_ (`contract.view(…)`). This is because the caller of a view is irrelevant and ignored.
See the [tests](https://github.com/near/workspaces-js/tree/main/__tests__) directory in this project for more examples.
Quick Start with AVA
===========
Since `near-workspaces` is designed for concurrency, AVA is a great fit, because it runs tests concurrently by default. To use`NEAR Workspaces` with AVA:
1. Start with the basic setup described [here](https://github.com/avajs/ava).
2. Add custom script for running tests on Testnet (if needed). Check instructions in `Running on Testnet` section.
3. Add your tests following these example:
```ts
import {Worker} from 'near-workspaces';
import anyTest, {TestFn} from 'ava'
const test = anyTest as TestFn<{
worker: Worker;
accounts: Record<string, NearAccount>;
}>;
/* If using `test.before`, each test is reusing the same worker;
If you'd like to make a copy of the worker, use `beforeEach` after `afterEach`,
which allows you to isolate the state for each test */
test.before(async t => {
const worker = await Worker.init();
const root = worker.rootAccount;
const contract = await root.devDeploy('path/to/contract/file.wasm');
/* Account that you will be able to use in your tests */
const ali = await root.createSubAccount('ali');
t.context.worker = worker;
t.context.accounts = {root, contract, ali};
})
test('Test name', async t => {
const {ali, contract} = t.context.accounts;
await ali.call(contract, 'set_status', {message: 'hello'});
const result: string = await contract.view('get_status', {account_id: ali});
t.is(result, 'hello');
});
test.after(async t => {
// Stop Sandbox server
await t.context.worker.tearDown().catch(error => {
console.log('Failed to tear down the worker:', error);
});
});
```
"Spooning" Contracts from Testnet and Mainnet
=============================================
[Spooning a blockchain](https://coinmarketcap.com/alexandria/glossary/spoon-blockchain) is copying the data from one network into a different network. near-workspaces makes it easy to copy data from Mainnet or Testnet contracts into your local Sandbox environment:
```ts
const refFinance = await root.importContract({
mainnetContract: 'v2.ref-finance.near',
blockId: 50_000_000,
withData: true,
});
```
This would copy the Wasm bytes and contract state from [v2.ref-finance.near](https://explorer.near.org/accounts/v2.ref-finance.near) to your local blockchain as it existed at block `50_000_000`. This makes use of Sandbox's special [patch state](#patch-state-on-the-fly) feature to keep the contract name the same, even though the top level account might not exist locally (note that this means it only works in Sandbox testing mode). You can then interact with the contract in a deterministic way the same way you interact with all other accounts created with near-workspaces.
Gotcha: `withData` will only work out-of-the-box if the contract's data is 50kB or less. This is due to the default configuration of RPC servers; see [the "Heads Up" note here](https://docs.near.org/api/rpc/contracts#view-contract-state). Some teams at NEAR are hard at work giving you an easy way to run your own RPC server, at which point you can point tests at your custom RPC endpoint and get around the 50kB limit.
See an [example of spooning](https://github.com/near/workspaces-js/blob/main/__tests__/05.spoon-contract-to-sandbox.ava.ts) contracts.
Running on Testnet
==================
near-workspaces is set up so that you can write tests once and run them against a local Sandbox node (the default behavior) or against [NEAR TestNet](https://docs.near.org/concepts/basics/networks). Some reasons this might be helpful:
* Gives higher confidence that your contracts work as expected
* You can test against deployed testnet contracts
* If something seems off in Sandbox mode, you can compare it to testnet
In order to use Workspaces JS in testnet mode you will need to have a testnet account. You can create one [here](https://wallet.testnet.near.org/).
You can switch to testnet mode in three ways.
1. When creating Worker set network to `testnet` and pass your master account:
```ts
const worker = await Worker.init({
network: 'testnet',
testnetMasterAccountId: '<yourAccountName>',
})
```
2. Set the `NEAR_WORKSPACES_NETWORK` and `TESTNET_MASTER_ACCOUNT_ID` environment variables when running your tests:
```bash
NEAR_WORKSPACES_NETWORK=testnet TESTNET_MASTER_ACCOUNT_ID=<your master account Id> node test.js
```
If you set this environment variables and pass `{network: 'testnet', testnetMasterAccountId: <masterAccountId>}` to `Worker.init`, the config object takes precedence.
3. If using `near-workspaces` with AVA, you can use a custom config file. Other test runners allow similar config files; adjust the following instructions for your situation.
Create a file in the same directory as your `package.json` called `ava.testnet.config.cjs` with the following contents:
```js
module.exports = {
...require('near-workspaces/ava.testnet.config.cjs'),
...require('./ava.config.cjs'),
};
module.exports.environmentVariables = {
TESTNET_MASTER_ACCOUNT_ID: '<masterAccountId>',
};
```
The [near-workspaces/ava.testnet.config.cjs](https://github.com/near/workspaces-js/blob/main/ava.testnet.config.cjs) import sets the `NEAR_WORKSPACES_NETWORK` environment variable for you. A benefit of this approach is that you can then easily ignore files that should only run in Sandbox mode.
Now you'll also want to add a `test:testnet` script to your `package.json`'s `scripts` section:
```diff
"scripts": {
"test": "ava",
+ "test:testnet": "ava --config ./ava.testnet.config.cjs"
}
```
Stepping through a testnet example
----------------------------------
Let's revisit a shortened version of the example from How It Works above, describing what will happen in Testnet.
1. Create a `Worker`.
```ts
const worker = await Worker.init();
```
`Worker.init` creates a unique testnet account as root account.
2. Write tests.
```ts
await Promise.all([
async () => {
await alice.call(
contract,
'some_update_function',
{some_string_argument: 'cool', some_number_argument: 42}
);
const result = await contract.view(
'some_view_function',
{account_id: alice}
);
assert.equal(result, 'whatever');
},
async () => {
const result = await contract.view(
'some_view_function',
{account_id: alice}
);
assert.equal(result, 'some default');
}
]);
```
Note: Sometimes account creation rate limits are reached on testnet, simply wait a little while and try again.
Running tests only in Sandbox
-------------------------------
If some of your runs take advantage of Sandbox-specific features, you can skip these on testnet in two ways:
1. You can skip entire sections of your files by checking `getNetworkFromEnv() === 'sandbox'`.
```ts
let worker = Worker.init();
// things make sense to any network
const root = worker.rootAccount;
const alice = await root.createSubAccount('alice');
if (getNetworkFromEnv() === 'sandbox') {
// thing that only makes sense with sandbox
}
```
2. Use a separate testnet config file, as described under the "Running on Testnet" heading above. Specify test files to include and exclude in config file.
Patch State on the Fly
======================
In Sandbox-mode, you can add or modify any contract state, contract code, account or access key with `patchState`.
You cannot perform arbitrary mutation on contract state with transactions since transactions can only include contract calls that mutate state in a contract-programmed way. For example, with an NFT contract, you can perform some operation with NFTs you have ownership of, but you cannot manipulate NFTs that are owned by other accounts since the smart contract is coded with checks to reject that. This is the expected behavior of the NFT contract. However, you may want to change another person's NFT for a test setup. This is called "arbitrary mutation on contract state" and can be done with `patchState`. Alternatively you can stop the node, dump state at genesis, edit genesis, and restart the node. The later approach is more complicated to do and also cannot be performed without restarting the node.
It is true that you can alter contract code, accounts, and access keys using normal transactions via the `DeployContract`, `CreateAccount`, and `AddKey` [actions](https://nomicon.io/RuntimeSpec/Actions.html?highlight=actions#actions). But this limits you to altering your own account or sub-account. `patchState` allows you to perform these operations on any account.
To see an example of how to do this, see the [patch-state test](https://github.com/near/workspaces-js/blob/main/__tests__/02.patch-state.ava.ts).
Time Traveling
===============
In Sandbox-mode, you can forward time-related state (the block height, timestamp and epoch height) with `fastForward`.
This means contracts which require time sensitive data do not need to sit and wait the same amount of time for blocks on the sandbox to be produced.
We can simply just call the api to get us further in time.
For an example, see the [fast-forward test](./__tests__/08.fast-forward.ava.ts)
Note: `fastForward` does not speed up an in-flight transactions.
Pro Tips
========
* `NEAR_WORKSPACES_DEBUG=true` – run tests with this environment variable set to get copious debug output and a full log file for each Sandbox instance.
* `Worker.init` [config](https://github.com/near/workspaces-js/blob/main/packages/js/src/interfaces.ts) – you can pass a config object as the first argument to `Worker.init`. This lets you do things like:
* skip initialization if specified data directory already exists (the default behavior)
```ts
Worker.init(
{ rm: false, homeDir: './test-data/alice-owns-an-nft' },
)
```
* always recreate such data directory instead with `rm: true`
* specify which port to run on
* and more!
Env variables
========
```text
NEAR_CLI_MAINNET_RPC_SERVER_URL
NEAR_CLI_TESTNET_RPC_SERVER_URL
```
Clear them in case you want to get back to the default RPC server.
Example:
```shell
export NEAR_CLI_MAINNET_RPC_SERVER_URL=<put_your_rpc_server_url_here>
```
here is a testcase: [jsonrpc.ava.js](./packages/js/__tests__/jsonrpc.ava.js)
<div align="center">
<h1>NEAR Workspaces (Rust Edition)</h1>
<p>
<strong>Rust library for automating workflows and writing tests for NEAR smart contracts. This software is not final, and will likely change.</strong>
</p>
<p>
<a href="https://crates.io/crates/near-workspaces"><img src="https://img.shields.io/crates/v/near-workspaces.svg?style=flat-square" alt="Crates.io version" /></a>
<a href="https://crates.io/crates/near-workspaces"><img src="https://img.shields.io/crates/d/near-workspaces.svg?style=flat-square" alt="Download" /></a>
<a href="https://docs.rs/near-workspaces"><img src="https://docs.rs/near-workspaces/badge.svg" alt="Reference Documentation" /></a>
</p>
</div>
## Release notes
**Release notes and unreleased changes can be found in the [CHANGELOG](CHANGELOG.md)**
## Requirements
- Rust v1.69.0 and up.
- MacOS (x86 and M1) or Linux (x86) for sandbox tests.
### WASM compilation not supported
`near-workspaces-rs`, the library itself, does not currently compile to WASM. Best to put this dependency in `[dev-dependencies]` section of `Cargo.toml` if we were trying to run this library alongside something that already does compile to WASM, such as `near-sdk-rs`.
## Simple Testing Case
A simple test to get us going and familiar with `near-workspaces` framework. Here, we will be going through the NFT contract and how we can test it with `near-workspaces-rs`.
### Setup -- Imports
First, we need to declare some imports for convenience.
```rust
// macro allowing us to convert args into JSON bytes to be read by the contract.
use serde_json::json;
```
We will need to have our pre-compiled WASM contract ahead of time and know its path. Refer to the respective near-sdk-{rs, js} repos/language for where these paths are located.
In this showcase, we will be pointing to the example's NFT contract:
```rust
const NFT_WASM_FILEPATH: &str = "./examples/res/non_fungible_token.wasm";
```
NOTE: there is an unstable feature that will allow us to compile our projects during testing time as well. Take a look at the feature section [Compiling Contracts During Test Time](#compiling-contracts-during-test-time)
### Setup -- Setting up Sandbox and Deploying NFT Contract
This includes launching our sandbox, loading our wasm file and deploying that wasm file to the sandbox environment.
```rust
#[tokio::test]
async fn test_nft_contract() -> anyhow::Result<()> {
let worker = near_workspaces::sandbox().await?;
let wasm = std::fs::read(NFT_WASM_FILEPATH)?;
let contract = worker.dev_deploy(&wasm).await?;
```
Where
- `anyhow` - A crate that deals with error handling, making it more robust for developers.
- `worker` - Our gateway towards interacting with our sandbox environment.
- `contract`- The deployed contract on sandbox the developer interacts with.
### Initialize Contract & Test Output
Then we'll go directly into making a call into the contract, and initialize the NFT contract's metadata:
```rust
let outcome = contract
.call("new_default_meta")
.args_json(json!({
"owner_id": contract.id(),
}))
.transact() // note: we use the contract's keys here to sign the transaction
.await?;
// outcome contains data like logs, receipts and transaction outcomes.
println!("new_default_meta outcome: {:#?}", outcome);
```
Afterwards, let's mint an NFT via `nft_mint`. This showcases some extra arguments we can supply, such as deposit and gas:
```rust
use near_gas::NearGas;
use near_workspaces::types::NearToken;
let deposit = NearToken::from_near(100);
let outcome = contract
.call("nft_mint")
.args_json(json!({
"token_id": "0",
"token_owner_id": contract.id(),
"token_metadata": {
"title": "Olympus Mons",
"description": "Tallest mountain in charted solar system",
"copies": 1,
},
}))
.deposit(deposit)
// nft_mint might consume more than default gas, so supply our own gas value:
.gas(NearGas::from_tgas(300))
.transact()
.await?;
println!("nft_mint outcome: {:#?}", outcome);
```
Then later on, we can view our minted NFT's metadata via our `view` call into `nft_metadata`:
```rust
let result: serde_json::Value = contract
.call("nft_metadata")
.view()
.await?
.json()?;
println!("--------------\n{}", result);
println!("Dev Account ID: {}", contract.id());
Ok(())
}
```
### Updating Contract Afterwards
Note that if our contract code changes, `near-workspaces-rs` does nothing about it since we are utilizing `deploy`/`dev_deploy` to merely send the contract bytes to the network. So if it does change, we will have to recompile the contract as usual, and point `deploy`/`dev_deploy` again to the right WASM files. However, there is a feature that will recompile contract changes for us: refer to the experimental/unstable [`compile_project`](#compiling-contracts-during-test-time) function for telling near-workspaces to compile a _Rust_ project for us.
## Examples
More standalone examples can be found in `examples/src/*.rs`.
To run the above NFT example, execute:
```sh
cargo run --example nft
```
## Features
### Choosing a network
```rust
#[tokio::main] // or whatever runtime we want
async fn main() -> anyhow::Result<()> {
// Create a sandboxed environment.
// NOTE: Each call will create a new sandboxed environment
let worker = near_workspaces::sandbox().await?;
// or for testnet:
let worker = near_workspaces::testnet().await?;
}
```
### Helper Functions
Need to make a helper functions utilizing contracts? Just import it and pass it around:
```rust
use near_workspaces::Contract;
// Helper function that calls into a contract we give it
async fn call_my_func(contract: &Contract) -> anyhow::Result<()> {
// Call into the function `contract_function` with args:
contract.call("contract_function")
.args_json(serde_json::json!({
"message": msg,
})
.transact()
.await?;
Ok(())
}
```
Or to pass around workers regardless of networks:
```rust
use near_workspaces::{DevNetwork, Worker};
const CONTRACT_BYTES: &[u8] = include_bytes!("./relative/path/to/file.wasm");
// Create a helper function that deploys a specific contract
// NOTE: `dev_deploy` is only available on `DevNetwork`s such as sandbox and testnet.
async fn deploy_my_contract(worker: Worker<impl DevNetwork>) -> anyhow::Result<Contract> {
worker.dev_deploy(CONTRACT_BYTES).await
}
```
### View Account Details
We can check the balance of our accounts like so:
```rs
#[test(tokio::test)]
async fn test_contract_transfer() -> anyhow::Result<()> {
let transfer_amount = NearToken::from_millinear(100);
let worker = near_workspaces::sandbox().await?;
let contract = worker
.dev_deploy(include_bytes!("../target/res/your_project_name.wasm"))
.await?;
contract.call("new")
.max_gas()
.transact()
.await?;
let alice = worker.dev_create_account().await?;
let bob = worker.dev_create_account().await?;
let bob_original_balance = bob.view_account().await?.balance;
alice.call(contract.id(), "function_that_transfers")
.args_json(json!({ "destination_account": bob.id() }))
.max_gas()
.deposit(transfer_amount)
.transact()
.await?;
assert_eq!(
bob.view_account().await?.balance,
bob_original_balance + transfer_amount
);
Ok(())
}
```
For viewing other chain related details, look at the docs for [Worker](https://docs.rs/near-workspaces/latest/near_workspaces/struct.Worker.html), [Account](https://docs.rs/near-workspaces/latest/near_workspaces/struct.Account.html) and [Contract](https://docs.rs/near-workspaces/latest/near_workspaces/struct.Contract.html)
### Spooning - Pulling Existing State and Contracts from Mainnet/Testnet
This example will showcase spooning state from a testnet contract into our local sandbox environment.
We will first start with the usual imports:
```rust
use near_workspaces::network::Sandbox;
use near_workspaces::{Account, AccountId, BlockHeight, Contract, Worker};
```
Then specify the contract name from testnet we want to be pulling:
```rust
const CONTRACT_ACCOUNT: &str = "contract_account_name_on_testnet.testnet";
```
Let's also specify a specific block ID referencing back to a specific time. Just in case our contract or the one we're referencing has been changed or updated:
```rust
const BLOCK_HEIGHT: BlockHeight = 12345;
```
Create a function called `pull_contract` which will pull the contract's `.wasm` file from the chain and deploy it onto our local sandbox. We'll have to re-initialize it with all the data to run tests.
```rust
async fn pull_contract(owner: &Account, worker: &Worker<Sandbox>) -> anyhow::Result<Contract> {
let testnet = near_workspaces::testnet_archival().await?;
let contract_id: AccountId = CONTRACT_ACCOUNT.parse()?;
```
This next line will actually pull down the relevant contract from testnet and set an initial balance on it with 1000 NEAR.
Following that we will have to init the contract again with our own metadata. This is because the contract's data is to big for the RPC service to pull down, who's limits are set to 50kb.
```rust
use near_workspaces::types::NearToken;
let contract = worker
.import_contract(&contract_id, &testnet)
.initial_balance(NearToken::from_near(1000))
.block_height(BLOCK_HEIGHT)
.transact()
.await?;
owner
.call(contract.id(), "init_method_name")
.args_json(serde_json::json!({
"arg1": value1,
"arg2": value2,
}))
.transact()
.await?;
Ok(contract)
}
```
### Time Traveling
`workspaces` testing offers support for forwarding the state of the blockchain to the future. This means contracts which require time sensitive data do not need to sit and wait the same amount of time for blocks on the sandbox to be produced. We can simply just call `worker.fast_forward` to get us further in time.
Note: This is not to be confused with speeding up the current in-flight transactions; the state being forwarded in this case refers to time-related state (the block height, timestamp and epoch).
```rust
#[tokio::test]
async fn test_contract() -> anyhow::Result<()> {
let worker = near_workspaces::sandbox().await?;
let contract = worker.dev_deploy(WASM_BYTES).await?;
let blocks_to_advance = 10000;
worker.fast_forward(blocks_to_advance).await?;
// Now, "do_something_with_time" will be in the future and can act on future time-related state.
contract.call("do_something_with_time")
.transact()
.await?;
}
```
For a full example, take a look at [examples/src/fast_forward.rs](https://github.com/near/near-workspaces-rs/blob/main/examples/src/fast_forward.rs).
### Compiling Contracts During Test Time
Note, this is an unstable feature and will very likely change. To enable it, add the `unstable` feature flag to `workspaces` dependency in `Cargo.toml`:
```toml
[dependencies]
near-workspaces = { version = "...", features = ["unstable"] }
```
Then, in our tests right before we call into `deploy` or `dev_deploy`, we can compile our projects:
```rust
#[tokio::test]
async fn test_contract() -> anyhow::Result<()> {
let wasm = near_workspaces::compile_project("path/to/contract-rs-project").await?;
let worker = workspaces::sandbox().await?;
let contract = worker.dev_deploy(&wasm).await?;
...
}
```
For a full example, take a look at [workspaces/tests/deploy_project.rs](https://github.com/near/near-workspaces-rs/blob/main/workspaces/tests/deploy_project.rs).
### Coverage analysis of WASM executables
Generated code coverage reports help identify areas of code that are executed during testing, making it a valuable tool for ensuring the reliability and quality of your contracts.
[Here](https://hknio.github.io/wasmcov/docs/NEAR) is the step by step guide documentation to achieve this.
The project can be found here: <https://github.com/hknio/wasmcov>
### Other Features
Other features can be directly found in the `examples/` folder, with some documentation outlining how they can be used.
### Environment Variables
These environment variables will be useful if there was ever a snag hit:
- `NEAR_RPC_TIMEOUT_SECS`: The default is 10 seconds, but this is the amount of time before timing out waiting for a RPC service when talking to the sandbox or any other network such as testnet.
- `NEAR_SANDBOX_BIN_PATH`: Set this to our own prebuilt `neard-sandbox` bin path if we want to use a non-default version of the sandbox or configure nearcore with our own custom features that we want to test in near-workspaces.
- `NEAR_SANDBOX_MAX_PAYLOAD_SIZE`: Sets the max payload size for sending transaction commits to sandbox. The default is 1gb and is necessary for patching large states.
- `NEAR_SANDBOX_MAX_FILES`: Set the max amount of files that can be opened at a time in the sandbox. If none is specified, the default size of 4096 will be used. The actual near chain will use over 10,000 in practice, but for testing this should be much lower since we do not have a constantly running blockchain unless our tests take up that much time.
- `NEAR_RPC_API_KEY`: This is the API key necessary for communicating with RPC nodes. This is useful when interacting with services such as Pagoda Console or a service that can access RPC metrics. This is not a **hard** requirement, but it is recommended to running the Pagoda example in the examples folder.
- `NEAR_ENABLE_SANDBOX_LOG`: Set this to `1` to enable sandbox logging. This is useful for debugging issues with the `neard-sandbox` binary.
<div align="center">
<h1>NEAR Workspaces (Rust Edition)</h1>
<p>
<strong>Rust library for automating workflows and writing tests for NEAR smart contracts. This software is not final, and will likely change.</strong>
</p>
<p>
<a href="https://crates.io/crates/near-workspaces"><img src="https://img.shields.io/crates/v/near-workspaces.svg?style=flat-square" alt="Crates.io version" /></a>
<a href="https://crates.io/crates/near-workspaces"><img src="https://img.shields.io/crates/d/near-workspaces.svg?style=flat-square" alt="Download" /></a>
<a href="https://docs.rs/near-workspaces"><img src="https://docs.rs/near-workspaces/badge.svg" alt="Reference Documentation" /></a>
</p>
</div>
## Release notes
**Release notes and unreleased changes can be found in the [CHANGELOG](CHANGELOG.md)**
## Requirements
- Rust v1.69.0 and up.
- MacOS (x86 and M1) or Linux (x86) for sandbox tests.
### WASM compilation not supported
`near-workspaces-rs`, the library itself, does not currently compile to WASM. Best to put this dependency in `[dev-dependencies]` section of `Cargo.toml` if we were trying to run this library alongside something that already does compile to WASM, such as `near-sdk-rs`.
## Simple Testing Case
A simple test to get us going and familiar with `near-workspaces` framework. Here, we will be going through the NFT contract and how we can test it with `near-workspaces-rs`.
### Setup -- Imports
First, we need to declare some imports for convenience.
```rust
// macro allowing us to convert args into JSON bytes to be read by the contract.
use serde_json::json;
```
We will need to have our pre-compiled WASM contract ahead of time and know its path. Refer to the respective near-sdk-{rs, js} repos/language for where these paths are located.
In this showcase, we will be pointing to the example's NFT contract:
```rust
const NFT_WASM_FILEPATH: &str = "./examples/res/non_fungible_token.wasm";
```
NOTE: there is an unstable feature that will allow us to compile our projects during testing time as well. Take a look at the feature section [Compiling Contracts During Test Time](#compiling-contracts-during-test-time)
### Setup -- Setting up Sandbox and Deploying NFT Contract
This includes launching our sandbox, loading our wasm file and deploying that wasm file to the sandbox environment.
```rust
#[tokio::test]
async fn test_nft_contract() -> anyhow::Result<()> {
let worker = near_workspaces::sandbox().await?;
let wasm = std::fs::read(NFT_WASM_FILEPATH)?;
let contract = worker.dev_deploy(&wasm).await?;
```
Where
- `anyhow` - A crate that deals with error handling, making it more robust for developers.
- `worker` - Our gateway towards interacting with our sandbox environment.
- `contract`- The deployed contract on sandbox the developer interacts with.
### Initialize Contract & Test Output
Then we'll go directly into making a call into the contract, and initialize the NFT contract's metadata:
```rust
let outcome = contract
.call("new_default_meta")
.args_json(json!({
"owner_id": contract.id(),
}))
.transact() // note: we use the contract's keys here to sign the transaction
.await?;
// outcome contains data like logs, receipts and transaction outcomes.
println!("new_default_meta outcome: {:#?}", outcome);
```
Afterwards, let's mint an NFT via `nft_mint`. This showcases some extra arguments we can supply, such as deposit and gas:
```rust
use near_gas::NearGas;
use near_workspaces::types::NearToken;
let deposit = NearToken::from_near(100);
let outcome = contract
.call("nft_mint")
.args_json(json!({
"token_id": "0",
"token_owner_id": contract.id(),
"token_metadata": {
"title": "Olympus Mons",
"description": "Tallest mountain in charted solar system",
"copies": 1,
},
}))
.deposit(deposit)
// nft_mint might consume more than default gas, so supply our own gas value:
.gas(NearGas::from_tgas(300))
.transact()
.await?;
println!("nft_mint outcome: {:#?}", outcome);
```
Then later on, we can view our minted NFT's metadata via our `view` call into `nft_metadata`:
```rust
let result: serde_json::Value = contract
.call("nft_metadata")
.view()
.await?
.json()?;
println!("--------------\n{}", result);
println!("Dev Account ID: {}", contract.id());
Ok(())
}
```
### Updating Contract Afterwards
Note that if our contract code changes, `near-workspaces-rs` does nothing about it since we are utilizing `deploy`/`dev_deploy` to merely send the contract bytes to the network. So if it does change, we will have to recompile the contract as usual, and point `deploy`/`dev_deploy` again to the right WASM files. However, there is a feature that will recompile contract changes for us: refer to the experimental/unstable [`compile_project`](#compiling-contracts-during-test-time) function for telling near-workspaces to compile a _Rust_ project for us.
## Examples
More standalone examples can be found in `examples/src/*.rs`.
To run the above NFT example, execute:
```sh
cargo run --example nft
```
## Features
### Choosing a network
```rust
#[tokio::main] // or whatever runtime we want
async fn main() -> anyhow::Result<()> {
// Create a sandboxed environment.
// NOTE: Each call will create a new sandboxed environment
let worker = near_workspaces::sandbox().await?;
// or for testnet:
let worker = near_workspaces::testnet().await?;
}
```
### Helper Functions
Need to make a helper functions utilizing contracts? Just import it and pass it around:
```rust
use near_workspaces::Contract;
// Helper function that calls into a contract we give it
async fn call_my_func(contract: &Contract) -> anyhow::Result<()> {
// Call into the function `contract_function` with args:
contract.call("contract_function")
.args_json(serde_json::json!({
"message": msg,
})
.transact()
.await?;
Ok(())
}
```
Or to pass around workers regardless of networks:
```rust
use near_workspaces::{DevNetwork, Worker};
const CONTRACT_BYTES: &[u8] = include_bytes!("./relative/path/to/file.wasm");
// Create a helper function that deploys a specific contract
// NOTE: `dev_deploy` is only available on `DevNetwork`s such as sandbox and testnet.
async fn deploy_my_contract(worker: Worker<impl DevNetwork>) -> anyhow::Result<Contract> {
worker.dev_deploy(CONTRACT_BYTES).await
}
```
### View Account Details
We can check the balance of our accounts like so:
```rs
#[test(tokio::test)]
async fn test_contract_transfer() -> anyhow::Result<()> {
let transfer_amount = NearToken::from_millinear(100);
let worker = near_workspaces::sandbox().await?;
let contract = worker
.dev_deploy(include_bytes!("../target/res/your_project_name.wasm"))
.await?;
contract.call("new")
.max_gas()
.transact()
.await?;
let alice = worker.dev_create_account().await?;
let bob = worker.dev_create_account().await?;
let bob_original_balance = bob.view_account().await?.balance;
alice.call(contract.id(), "function_that_transfers")
.args_json(json!({ "destination_account": bob.id() }))
.max_gas()
.deposit(transfer_amount)
.transact()
.await?;
assert_eq!(
bob.view_account().await?.balance,
bob_original_balance + transfer_amount
);
Ok(())
}
```
For viewing other chain related details, look at the docs for [Worker](https://docs.rs/near-workspaces/latest/near_workspaces/struct.Worker.html), [Account](https://docs.rs/near-workspaces/latest/near_workspaces/struct.Account.html) and [Contract](https://docs.rs/near-workspaces/latest/near_workspaces/struct.Contract.html)
### Spooning - Pulling Existing State and Contracts from Mainnet/Testnet
This example will showcase spooning state from a testnet contract into our local sandbox environment.
We will first start with the usual imports:
```rust
use near_workspaces::network::Sandbox;
use near_workspaces::{Account, AccountId, BlockHeight, Contract, Worker};
```
Then specify the contract name from testnet we want to be pulling:
```rust
const CONTRACT_ACCOUNT: &str = "contract_account_name_on_testnet.testnet";
```
Let's also specify a specific block ID referencing back to a specific time. Just in case our contract or the one we're referencing has been changed or updated:
```rust
const BLOCK_HEIGHT: BlockHeight = 12345;
```
Create a function called `pull_contract` which will pull the contract's `.wasm` file from the chain and deploy it onto our local sandbox. We'll have to re-initialize it with all the data to run tests.
```rust
async fn pull_contract(owner: &Account, worker: &Worker<Sandbox>) -> anyhow::Result<Contract> {
let testnet = near_workspaces::testnet_archival().await?;
let contract_id: AccountId = CONTRACT_ACCOUNT.parse()?;
```
This next line will actually pull down the relevant contract from testnet and set an initial balance on it with 1000 NEAR.
Following that we will have to init the contract again with our own metadata. This is because the contract's data is to big for the RPC service to pull down, who's limits are set to 50kb.
```rust
use near_workspaces::types::NearToken;
let contract = worker
.import_contract(&contract_id, &testnet)
.initial_balance(NearToken::from_near(1000))
.block_height(BLOCK_HEIGHT)
.transact()
.await?;
owner
.call(contract.id(), "init_method_name")
.args_json(serde_json::json!({
"arg1": value1,
"arg2": value2,
}))
.transact()
.await?;
Ok(contract)
}
```
### Time Traveling
`workspaces` testing offers support for forwarding the state of the blockchain to the future. This means contracts which require time sensitive data do not need to sit and wait the same amount of time for blocks on the sandbox to be produced. We can simply just call `worker.fast_forward` to get us further in time.
Note: This is not to be confused with speeding up the current in-flight transactions; the state being forwarded in this case refers to time-related state (the block height, timestamp and epoch).
```rust
#[tokio::test]
async fn test_contract() -> anyhow::Result<()> {
let worker = near_workspaces::sandbox().await?;
let contract = worker.dev_deploy(WASM_BYTES).await?;
let blocks_to_advance = 10000;
worker.fast_forward(blocks_to_advance).await?;
// Now, "do_something_with_time" will be in the future and can act on future time-related state.
contract.call("do_something_with_time")
.transact()
.await?;
}
```
For a full example, take a look at [examples/src/fast_forward.rs](https://github.com/near/near-workspaces-rs/blob/main/examples/src/fast_forward.rs).
### Compiling Contracts During Test Time
Note, this is an unstable feature and will very likely change. To enable it, add the `unstable` feature flag to `workspaces` dependency in `Cargo.toml`:
```toml
[dependencies]
near-workspaces = { version = "...", features = ["unstable"] }
```
Then, in our tests right before we call into `deploy` or `dev_deploy`, we can compile our projects:
```rust
#[tokio::test]
async fn test_contract() -> anyhow::Result<()> {
let wasm = near_workspaces::compile_project("path/to/contract-rs-project").await?;
let worker = workspaces::sandbox().await?;
let contract = worker.dev_deploy(&wasm).await?;
...
}
```
For a full example, take a look at [workspaces/tests/deploy_project.rs](https://github.com/near/near-workspaces-rs/blob/main/workspaces/tests/deploy_project.rs).
### Coverage analysis of WASM executables
Generated code coverage reports help identify areas of code that are executed during testing, making it a valuable tool for ensuring the reliability and quality of your contracts.
[Here](https://hknio.github.io/wasmcov/docs/NEAR) is the step by step guide documentation to achieve this.
The project can be found here: <https://github.com/hknio/wasmcov>
### Other Features
Other features can be directly found in the `examples/` folder, with some documentation outlining how they can be used.
### Environment Variables
These environment variables will be useful if there was ever a snag hit:
- `NEAR_RPC_TIMEOUT_SECS`: The default is 10 seconds, but this is the amount of time before timing out waiting for a RPC service when talking to the sandbox or any other network such as testnet.
- `NEAR_SANDBOX_BIN_PATH`: Set this to our own prebuilt `neard-sandbox` bin path if we want to use a non-default version of the sandbox or configure nearcore with our own custom features that we want to test in near-workspaces.
- `NEAR_SANDBOX_MAX_PAYLOAD_SIZE`: Sets the max payload size for sending transaction commits to sandbox. The default is 1gb and is necessary for patching large states.
- `NEAR_SANDBOX_MAX_FILES`: Set the max amount of files that can be opened at a time in the sandbox. If none is specified, the default size of 4096 will be used. The actual near chain will use over 10,000 in practice, but for testing this should be much lower since we do not have a constantly running blockchain unless our tests take up that much time.
- `NEAR_RPC_API_KEY`: This is the API key necessary for communicating with RPC nodes. This is useful when interacting with services such as Pagoda Console or a service that can access RPC metrics. This is not a **hard** requirement, but it is recommended to running the Pagoda example in the examples folder.
- `NEAR_ENABLE_SANDBOX_LOG`: Set this to `1` to enable sandbox logging. This is useful for debugging issues with the `neard-sandbox` binary.
near-workspaces
===============
Controlled, concurrent workspaces in local [NEAR Sandbox](https://github.com/near/sandbox) blockchains or on [NEAR TestNet](https://docs.near.org/concepts/basics/networks). Fun, deterministic testing and powerful scripting for NEAR.
The same interface will be supported for multiple languages.
* TypeScript/JavaScript: [near/near-workspaces-js](https://github.com/near/near-workspaces-js)
* Rust: [near/near-workspaces-rs](https://github.com/near/near-workspaces-rs) (in early alpha; you can use workspaces-js with Rust projects for now)
|
mikedotexe_near-evm-relayer | README.md
eip-712-helpers.js
index.js
package.json
rust
Cargo.toml
README.md
src
lib.rs
| Relayer for NEAR EVM
===
This repository is for a simple web server that will take incoming requests that are signed using [EIP-712](https://eips.ethereum.org/EIPS/eip-712) and route them properly to the NEAR EVM contract.
npm i
node index.js
NEAR EVM Relayer Utils
===
This directory (`/rust`) contains a Rust project that may be used by NodeJS.
Usage:
cargo install wasm-pack
wasm-pack build --target nodejs
|
JeenaKhurram_near-starter--near-sdk-as | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
simple
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| # `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **simple** in the `src/simple` folder
- **singleton** in the `src/singleton` folder
### Simple
We say that an AssemblyScript contract is written in the "simple style" when the `index.ts` file (the contract entry point) includes a series of exported functions.
In this case, all exported functions become public contract methods.
```ts
// return the string 'hello world'
export function helloWorld(): string {}
// read the given key from account (contract) storage
export function read(key: string): string {}
// write the given value at the given key to account (contract) storage
export function write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
```
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
INSTALL `NEAR CLI` first like this: `npm i -g near-cli`
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── simple # Contract 1: "Simple example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 1
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 1
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
|
lamha79_mynftstandardcontract | README.md
|
|
__tests__
test-template.ava.js
babel.config.json
build
builder.c
code.h
market.js
methods.h
nft.js
commands.txt
jsconfig.json
neardev
dev-account.env
package-lock.json
package.json
src
market-contract
index.ts
internal.ts
nft_callbacks.ts
sale.ts
sale_views.ts
nft-contract
approval.ts
enumeration.ts
index.ts
internal.ts
metadata.ts
mint.ts
nft_core.ts
royalty.ts
tsconfig.json
| # NEAR NFT-Tutorial JavaScript Edition
[](https://github.com/near-examples/nft-tutorial-js/actions/workflows/tests.yml)
Welcome to NEAR's NFT tutorial, where we will help you parse the details around NEAR's [NEP-171 standard](https://nomicon.io/Standards/NonFungibleToken/Core.html) (Non-Fungible Token Standard), and show you how to build your own NFT smart contract from the ground up, improving your understanding about the NFT standard along the way.
## Prerequisites
* [Node.js](/develop/prerequisites#nodejs)
* [NEAR Wallet Account](wallet.testnet.near.org)
* [NEAR-CLI](https://docs.near.org/tools/near-cli#setup)
* [yarn](https://classic.yarnpkg.com/en/docs/install#mac-stable)
## Tutorial Stages
Each branch you will find in this repo corresponds to various stages of this tutorial with a partially completed contract at each stage. You are welcome to start from any stage you want to learn the most about.
| Branch | Docs Tutorial | Description |
| ------------- | ------------------------------------------------------------------------------------------------ | ----------- |
| 1.skeleton | [Contract Architecture](https://docs.near.org/docs/tutorials/contracts/nfts/js/skeleton) | You'll learn the basic architecture of the NFT smart contract. |
| 2.minting | [Minting](https://docs.near.org/docs/tutorials/contracts/nfts/js/minting) |Here you'll flesh out the skeleton so the smart contract can mint a non-fungible token |
| 3.enumeration | [Enumeration](https://docs.near.org/docs/tutorials/contracts/nfts/js/enumeration) | Here you'll find different enumeration methods that can be used to return the smart contract's states. |
| 4.core | [Core](https://docs.near.org/docs/tutorials/contracts/nfts/js/core) | In this tutorial you'll extend the NFT contract using the core standard, which will allow you to transfer non-fungible tokens. |
| 5.approval | [Approval](https://docs.near.org/docs/tutorials/contracts/nfts/js/approvals) | Here you'll expand the contract allowing other accounts to transfer NFTs on your behalf. |
| 6.royalty | [Royalty](https://docs.near.org/docs/tutorials/contracts/nfts/js/royalty) |Here you'll add the ability for non-fungible tokens to have royalties. This will allow people to get a percentage of the purchase price when an NFT is purchased. |
| 7.events | ----------- | This allows indexers to know what functions are being called and make it easier and more reliable to keep track of information that can be used to populate the collectibles tab in the wallet for example. (tutorial docs have yet to be implemented ) |
| 8.marketplace | ----------- | ----------- |
The tutorial series also contains a very helpful section on [**Upgrading Smart Contracts**](https://docs.near.org/docs/tutorials/contracts/nfts/js/upgrade-contract). Definitely go and check it out as this is a common pain point.
# Quick-Start
If you want to see the full completed contract go ahead and clone and build this repo using
```=bash
git clone https://github.com/near-examples/nft-tutorial-js.git
cd nft-tutorial-js
yarn && yarn build
```
Now that you've cloned and built the contract we can try a few things.
## Mint An NFT
Once you've created your near wallet go ahead and login to your wallet with your cli and follow the on-screen prompts
```=bash
near login
```
Once your logged in you have to deploy the contract. Make a subaccount with the name of your choosing
```=bash
near create-account nft-example.your-account.testnet --masterAccount your-account.testnet --initialBalance 10
```
After you've created your sub account deploy the contract to that sub account, set this variable to your sub account name
```=bash
NFT_CONTRACT_ID=nft-example.your-account.testnet
MAIN_ACCOUNT=your-account.testnet
```
Verify your new variable has the correct value
```=bash
echo $NFT_CONTRACT_ID
echo $MAIN_ACCOUNT
```
### Deploy Your Contract
```=bash
near deploy --accountId $NFT_CONTRACT_ID --wasmFile build/nft.wasm
```
### Initialize Your Contract
```=bash
near call $NFT_CONTRACT_ID init '{"owner_id": "'$NFT_CONTRACT_ID'"}' --accountId $NFT_CONTRACT_ID
```
### View Contracts Meta Data
```=bash
near view $NFT_CONTRACT_ID nft_metadata
```
### Minting Token
```bash=
near call $NFT_CONTRACT_ID nft_mint '{"token_id": "token-1", "metadata": {"title": "My Non Fungible Team Token", "description": "The Team Most Certainly Goes :)", "media": "https://bafybeiftczwrtyr3k7a2k4vutd3amkwsmaqyhrdzlhvpt33dyjivufqusq.ipfs.dweb.link/goteam-gif.gif"}, "receiver_id": "'$MAIN_ACCOUNT'"}' --accountId $MAIN_ACCOUNT --amount 0.1
```
After you've minted the token go to wallet.testnet.near.org to `your-account.testnet` and look in the collections tab and check out your new sample NFT!
## View NFT Information
After you've minted your NFT you can make a view call to get a response containing the `token_id` `owner_id` and the `metadata`
```bash=
near view $NFT_CONTRACT_ID nft_token '{"token_id": "token-1"}'
```
## Transfering NFTs
To transfer an NFT go ahead and make another [testnet wallet account](https://wallet.testnet.near.org).
Then run the following
```bash=
MAIN_ACCOUNT_2=your-second-wallet-account.testnet
```
Verify the correct variable names with this
```=bash
echo $NFT_CONTRACT_ID
echo $MAIN_ACCOUNT
echo $MAIN_ACCOUNT_2
```
To initiate the transfer..
```bash=
near call $NFT_CONTRACT_ID nft_transfer '{"receiver_id": "$MAIN_ACCOUNT_2", "token_id": "token-1", "memo": "Go Team :)"}' --accountId $MAIN_ACCOUNT --depositYocto 1
```
In this call you are depositing 1 yoctoNEAR for security and so that the user will be redirected to the NEAR wallet.
|
hikaruchang_nepbot_website | .eslintrc.js
.stylelintrc.js
.umirc.ts
netlify.toml
package.json
plugin.ts
public
icon.svg
src
app.ts
assets
brand
logo-facebook.svg
logo-instagram.svg
logo-popula.svg
logo-twitter.svg
near_logo_wht.svg
popula_logo_wht.svg
collection
astro.svg
h00kd.svg
mintbase.svg
near.svg
octopus.svg
paras.svg
icon
fail.svg
ic-Fast.svg
ic-Free.svg
ic-Safe.svg
linkexpired.svg
loading.svg
nodata.svg
right-arrow.svg
success.svg
logo.svg
partners
AMP.svg
De3Verse.svg
astrodao.svg
atocha.svg
awesomenear.svg
bluntDAO.svg
castle-overlord.svg
coreto.svg
electric-neon.svg
enterthesphere.svg
farswap.svg
flux.svg
flyingrhino.svg
fusotao.svg
goatboy360.svg
h00kd.svg
here-wallet.svg
higanbana.svg
lacrove.svg
loozr.svg
meteor-wallet.svg
mintbase.svg
mintickt.svg
near.svg
nearblocks.svg
nestercity.svg
octopus.svg
paras.svg
popula.svg
qstn.svg
reputation-is-king.svg
sender-wallet.svg
tandao.svg
tdkill.svg
the-clan.svg
tomorrowscitizens.svg
tonicdex.svg
vself.svg
wakacool.svg
constants
config.ts
env.ts
home
list.ts
partner.ts
swiper.ts
locales
en-US.ts
en-US
collection.ts
connect.ts
header.ts
home.ts
mint.ts
platform.ts
role.ts
special.ts
models
discord.ts
mintbase.ts
near
account.ts
contract.ts
store.ts
upgrade.ts
services
api.ts
request.ts
typing.d.ts
store
localStore.ts
typing.d.ts
utils
contract.ts
near.ts
paras.ts
request.ts
tsconfig.json
typings.d.ts
| |
near_rainbow-bridge-rs | .buildkite
pipeline.yml
Cargo.toml
build_all.sh
ci
test_verify_eth_headers.sh
test_verify_eth_proofs.sh
eth-client
Cargo.toml
README.md
build.sh
src
data
10234001.json
10234002.json
10234003.json
10234004.json
10234005.json
10234006.json
10234007.json
10234008.json
10234009.json
10234010.json
10234011.json
2.json
3.json
400000.json
400001.json
8996776.json
8996777.json
dag_merkle_roots.json
lib.rs
tests.rs
test.sh
eth-prover
Cargo.toml
build.sh
src
lib.rs
tests.rs
test.sh
tests
spec.rs
utils.rs
eth-types
Cargo.toml
src
lib.rs
mintable-fungible-token
Cargo.toml
build.sh
data
proof.json
src
lib.rs
package.json
| # EthBridge
Ethereum Light Client built on top of NearProtocol with Rust
## Testing
```bash
./test.sh
```
|
mikenevermindng_Ukraine-NFT-Zoo | .env
.gitpod.yml
README.md
babel.config.js
build.sh
contract
Cargo.toml
README.md
src
lib.rs
deploy.sh
migrate.sh
package.json
src
App.js
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
config.js
global.css
index.html
index.js
jest.init.js
main.test.js
utils.js
wallet
login
index.html
| zoo-nft-ukraine Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
zoo-nft-ukraine
==================
This [React] app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `zoo-nft-ukraine.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `zoo-nft-ukraine.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account zoo-nft-ukraine.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'zoo-nft-ukraine.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[React]: https://reactjs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
MarmaJFoundation_allies-marketplace | README.md
back-end
app.js
controller
authController.js
collectionController.js
example_env.txt
model
collectionModel.js
package-lock.json
package.json
public
js
bundle.js
routes
collectionRouter.js
utils
appError.js
catchAsync.js
vercel.json
docs
README.md
front-end
.eslintrc.json
README.md
example_env.txt
next.config.js
package-lock.json
package.json
packages
FetchGraphQL.js
pages
_app.js
collection
index.js
create
index.js
index.js
list
index.js
mint
index.js
owned.js
tipme.js
public
assets
css
animate.css
blast.min.css
bootstrap.min.css
icofont.min.css
lightcase.css
style.css
style.min.css
swiper-bundle.min.css
fonts
lightcase.svg
images
rounded-down.svg
seller
seller-icon.svg
js
bootstrap.bundle.min.js
countdown.min.js
functions.js
isotope.pkgd.min.js
jquery-3.6.0.min.js
jquery.counterup.min.js
lightcase.js
swiper-bundle.min.js
waypoints.min.js
wow.min.js
styles
Home.module.css
globals.css
| This is a [Next.js](https://nextjs.org/) project bootstrapped with [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app).
## Getting Started
First, run the development server:
```bash
npm run dev
# or
yarn dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `pages/index.js`. The page auto-updates as you edit the file.
[API routes](https://nextjs.org/docs/api-routes/introduction) can be accessed on [http://localhost:3000/api/hello](http://localhost:3000/api/hello). This endpoint can be edited in `pages/api/hello.js`.
The `pages/api` directory is mapped to `/api/*`. Files in this directory are treated as [API routes](https://nextjs.org/docs/api-routes/introduction) instead of React pages.
## Learn More
To learn more about Next.js, take a look at the following resources:
- [Next.js Documentation](https://nextjs.org/docs) - learn about Next.js features and API.
- [Learn Next.js](https://nextjs.org/learn) - an interactive Next.js tutorial.
You can check out [the Next.js GitHub repository](https://github.com/vercel/next.js/) - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the [Vercel Platform](https://vercel.com/new?utm_medium=default-template&filter=next.js&utm_source=create-next-app&utm_campaign=create-next-app-readme) from the creators of Next.js.
Check out our [Next.js deployment documentation](https://nextjs.org/docs/deployment) for more details.
# Allie's Marketplace
### Project Overview 📄
Allie’s Marketplace is an NFT marketplace built on NEAR Protocol. This is a hub for Allie’s own content and where her fans can buy her NFTs. The marketplace will also offer a variety of other content, including: videos, photos, and articles from Allie. The marketplace will be open to anyone who wants to purchase Allie’s content, and all transactions will be processed on the blockchain. This will provide a secure and efficient way for Allie to sell her content and connect with her fans.
## Goal
Our goal is to encourage web3 space adoption and utilisation by not-safe-for-work (NSFW) content producers through the development of a user-friendly and engaging NFT marketplace.
Since our software is open source, anyone can use it to create their own decentralised marketplace. For creators who struggle to make money on centralised platforms and do not have full control over their content, this will be incredibly helpful. Because the marketplaces built on this code will be decentralised, they will also be shielded from censorship.
## Code Details
**Technology stack:**
- Backend:
- Node.js
- Express.js
- MongoDB
- Supabase (For censored content storage)
- [MintbaseJS](https://github.com/Mintbase/mintbase-js) (For Authentication)
- Frontend:
- NextJS (ReactJS)
- [MintbaseJS](https://github.com/Mintbase/mintbase-js) (For Contract Interaction)
## How To Run Code
> :warning: **Fill the .env file before run the code**: need env variables in given in .env file template
### Backend
First, run the backend server:
```bash
#1
npm install
#2
npm run start
```
Open http://localhost:[PORT] with your browser to see the result.
You can start editing the page by modifying `app.js`. The page auto-updates as you edit the file.
### Frontend
First, run the development server:
```bash
#1
npm install
#2
npm run dev
# or
yarn dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `pages/index.js`. The page auto-updates as you edit the file.
# Allie's Marketplace Setup Guide
## Requirements
1. MongoDB Atlas Account [create here](https://account.mongodb.com/account/login)
1. Supabase Account [create here](https://app.supabase.com/sign-in)
1. Your Mintbase Store Address _(Eg: marmajchan.mintbase1.near)_
## Let's Setup
### MongoDB
To create a backend of this app you need a database connection url to store the data.
#### Steps to create database connection URL:
1. Open MongoDB Atlas and login/create your account.
1. Create a new project (refer to the [documentation](https://www.mongodb.com/docs/atlas/government/tutorial/create-project/) if needed).
1. Click "Connect" and select "Connect Your Application".
1. Copy the connection string and replace `<password>` with your user password. Save this string and password for later use when deploying the backend.
1. To set the network access to "Allow access from anywhere" to run the app in Vercel:
1. Go to the "Network Access" tab on the left side of the screen.
1. Click the "Add IP Address" button on the top right of the screen in the "Network Access" section.
1. Click "Allow Access From Anywhere" and save.
### Supabase
To store the collection images on supabase we need API key and Project url.
#### Steps to create supabase storage:
1. Open Supabase and login/create your account.
2. Click the "New Project" button on top of your Supabase dashboard.
3. Enter your project name and create the project.
4. To create the storage bucket:
1. Go to the "Storage" tab and click the "**New Bucket**" button on the top left.
2. Type the bucket as **"collectionimages"** - _make sure you give the bucket name as "collectionimages" correctly_.
3. Toggle the Public bucket on and click save.
5. Now the bucket is created. To access the bucket from our app, we have to add a policy.
1. Go to the storage page and on the left side, you can see the Configuration. Below that, there is a "Policies" section.
2. Go to "**Policies**" and click the "**New Policy**" button in the "**Other policies under storage.objects**" section.
3. Click "Get started quickly" and use the "Enable read access to everyone" template.
4. Select **ALL** as an option in the "**Allowed operation**" category.
5. Click "**Review**" and "**Save Policy**".
6. Done! You created the policy.
6. Now, to connect our app with our Supabase storage, we need an API key.
1. To get our API key and URL, go to the project settings tab.
2. In project settings, click **API**.
3. Now you can see your Project URL and Project API keys there.
4. Copy those two and save them somewhere else for later use.
### Backend Deployment
To deploy our backend node.js app we are using vercel.
#### Steps to deploy our backend app:
1. Fork this repo
1. Now go to [vercel](https://vercel.com/) and **login/create** your account with your github account.
1. On your vercel dashboard click **"Add New"** button on top left and select project.
1. Import this Repository and Configure The Project.
1. Set project name as you wish
1. On Root Directory click **"Edit"** button
1. Now select backend and click **"Continue"** button
1. Click Environment Variables and add this variables with your own values.
| Name | Value |
| ------------- |:-------------:|
| `NEAR_NETWORK` | Type which near network your NFTs want to store `mainnet` or `testnet` |
| `OWNER_WALLET` | Enter your near wallet address |
| `DB_CONNECTION_URL` | Paste the Mongodb database connection string here |
1. Click **"Deploy"**
> make sure the <password\> in connection string is replaced with your database user password
1. wait till the deployment is over and you can see the congratulations message.
_After the app is Deployed click the app url and make sure you got the "Success" in your browser tab. If you got it you deployed the backend successfully._
### Front Deployment
The final step to get our app ready.
#### Steps to deploy our frontend:
1. On your [vercel](https://vercel.com/) dashboard click **"Add New"** button on top left and select project.
1. Import this Repository
1. Set project name as you wish
1. On Root Directory click **"Edit"** button
1. Now select frontend and click **"Continue"** button
1. Click **Environment Variables** and add this variables with your own values.
| Name | Value |
| ------------- |:-------------:|
| `NEXT_PUBLIC_NEAR_NETWORK` | Type which near network your NFTs want to store `mainnet` or `testnet` |
| `NEXT_PUBLIC_OWNER` | Enter your near wallet address _(eg: chan.near )_ |
| `NEXT_PUBLIC_CONTRACT_ID` | Your Mintbase Store Address _(Eg: marmajchan.mintbase1.near)_ |
| `NEXT_PUBLIC_REFERRAL_ID` | Enter referral near wallet address _(eg: marmaj.near )_ |
| `NEXT_PUBLIC_BACKEND_URL` | Enter the deployed Backend URL (eg: https://backendproject.vercel.app) |
| `NEXT_PUBLIC_SUPABASE_PROJECT_URL` | Paste the your Supabase project URL (that you saved) |
| `NEXT_PUBLIC_SUPABASE_PROJECT_API_KEY` | Paste the your Supabase API key (that you saved) |
1. Click **"Deploy"**
> Make sure the backend URL is entered without backslash at the end of URL, Enter as https://backendproject.vercel.app not https://backendproject.vercel.app/
Wait till the deployment is over and you can see the congrats message.
Now click on your app URL to see your app live.
After the app is Deployed connect with your wallet ID (_Which you give as owner wallet ID_) and check that you got the **"mint, list and create collection"** in your navbar. if that shows then you successfully deployed your app. Now try to mint , list and create the collection to test that your frontend and backend is connected successfully.
|
nativeanish_jbond-near | contract
Cargo.toml
package.json
public
index.html
src
reducer
fs.ts
utils
init.ts
| |
mtoan2111_dFormPureReactjs | .gitpod.yml
README.md
package.json
public
index.html
src
App.js
assets
logo-black.svg
logo-white.svg
components
account
account.js
account.module.css
alert
index.js
answer
answer.js
answer.module.css
footer
footer.module.css
index.js
lnc.svg
logo.svg
form
form.js
form.module.css
header
header.module.css
index.js
lnc.svg
logo.svg
layout
index.js
layout.module.css
loading
index.js
modal
confirmation
confirmation.module.css
index.js
editform
editform.module.css
index.js
editquestion
editquestion.module.css
index.js
navitem
navitem.js
navitem.module.css
notify
index.js
notify.module.css
question
fill.js
multi.js
once.js
question.module.css
yesno.js
search
search.js
search.module.css
textinput
textinput.js
textinput.module.css
config.js
global.css
index.html
index.js
main.test.js
pages
analysis
formanalysis.module.css
index.js
api
hello.js
create-question
index.js
question.module.css
dashboard
dashboard.module.css
index.js
form-analysis
formanalysis.module.css
index.js
form-answer
form.module.css
index.js
form-create
formcreate.module.css
index.js
form-detail
formdetail.module.css
index.js
form
form.module.css
index.js
participant-result
index.js
participantresult.module.css
participant
[...slug].js
participant.module.css
redux
action
form.js
wallet.js
reducer
formreducer.js
reducer.js
walletreducer.js
store.js
type.js
utils.js
target
npmlist.json
webpack.config.js
| dForm_reactjs
==================
This app was initialized with [create-near-app]
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/index.html` is a great
place to start exploring. Note that it loads in `/src/index.js`, where you
can learn how the frontend connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `dForm_reactjs.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `dForm_reactjs.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account dForm_reactjs.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'dForm_reactjs.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
N1ghtSe7en_NSevenChallenge6 | contract
Cargo.toml
README.md
compile.js
src
approval.rs
enumeration.rs
internal.rs
lib.rs
metadata.rs
mint.rs
nft_core.rs
royalty.rs
package.json
src
assets
logo-black.svg
logo-white.svg
config.js
css
main.css
global.css
index.html
index.js
main.test.js
utils.js
wallet
login
index.html
| zoo-dapp Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
|
laponte243_bookshop-nuxt | .eslintrc.js
README.md
api
index.js
routes
uploader.js
assets
img
logo1.svg
jsconfig.json
nuxt.config.js
package-lock.json
package.json
services
api.js
static
vuetify-logo.svg
store
README.md
| # STORE
**This directory is not required, you can delete it if you don't want to use it.**
This directory contains your Vuex Store files.
Vuex Store option is implemented in the Nuxt.js framework.
Creating a file in this directory automatically activates the option in the framework.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/guide/vuex-store).
# nearbook
## Build Setup
```bash
# install dependencies
$ npm install
# serve with hot reload at localhost:3000
$ npm run dev
# build for production and launch server
$ npm run build
$ npm run start
# generate static project
$ npm run generate
```
For detailed explanation on how things work, check out the [documentation](https://nuxtjs.org).
## Special Directories
You can create the following extra directories, some of which have special behaviors. Only `pages` is required; you can delete them if you don't want to use their functionality.
### `assets`
The assets directory contains your uncompiled assets such as Stylus or Sass files, images, or fonts.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/assets).
### `components`
The components directory contains your Vue.js components. Components make up the different parts of your page and can be reused and imported into your pages, layouts and even other components.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/components).
### `layouts`
Layouts are a great help when you want to change the look and feel of your Nuxt app, whether you want to include a sidebar or have distinct layouts for mobile and desktop.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/layouts).
### `pages`
This directory contains your application views and routes. Nuxt will read all the `*.vue` files inside this directory and setup Vue Router automatically.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/get-started/routing).
### `plugins`
The plugins directory contains JavaScript plugins that you want to run before instantiating the root Vue.js Application. This is the place to add Vue plugins and to inject functions or constants. Every time you need to use `Vue.use()`, you should create a file in `plugins/` and add its path to plugins in `nuxt.config.js`.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/plugins).
### `static`
This directory contains your static files. Each file inside this directory is mapped to `/`.
Example: `/static/robots.txt` is mapped as `/robots.txt`.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/static).
### `store`
This directory contains your Vuex store files. Creating a file in this directory automatically activates Vuex.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/store).
|
Malaw97_ChatBox | .eslintrc.js
.gitpod.yml
.travis.yml
README-Gitpod.md
README.md
as-pect.config.js
asconfig.js
assembly
__tests__
as-pect.d.ts
guestbook.spec.ts
as_types.d.ts
main.ts
model.ts
tsconfig.json
babel.config.js
css
main.css
util.css
fonts
font-awesome-4.7.0
HELP-US-OUT.txt
css
font-awesome.css
font-awesome.min.css
fonts
fontawesome-webfont.svg
iconic
css
material-design-iconic-font.css
material-design-iconic-font.min.css
fonts
Material-Design-Iconic-Font.svg
index.html
js
main.js
neardev
shared-test-staging
test.near.json
shared-test
test.near.json
package.json
src
App.js
config.js
index.html
index.js
tests
integration
App-integration.test.js
ui
App-ui.test.js
vendor
animate
animate.css
animsition
css
animsition.css
animsition.min.css
js
animsition.js
animsition.min.js
bootstrap
css
bootstrap-grid.css
bootstrap-grid.min.css
bootstrap-reboot.css
bootstrap-reboot.min.css
bootstrap.css
bootstrap.min.css
js
bootstrap.js
bootstrap.min.js
popper.js
popper.min.js
tooltip.js
countdowntime
countdowntime.js
css-hamburgers
hamburgers.css
hamburgers.min.css
daterangepicker
daterangepicker.css
daterangepicker.js
moment.js
moment.min.js
perfect-scrollbar
perfect-scrollbar.css
perfect-scrollbar.min.js
select2
select2.css
select2.js
select2.min.css
select2.min.js
| ChatterBox
==========
University of Washington Blockchain Hackathon-1st Place Winner
[Devpost Link](https://devpost.com/software/chat-near-free)
[](https://travis-ci.com/near-examples/guest-book)
[](https://gitpod.io/#https://github.com/near-examples/guest-book)
<!-- MAGIC COMMENT: DO NOT DELETE! Everything above this line is hidden on NEAR Examples page -->
Sign in with [NEAR] and add a message to the guest book! A starter app built with an [AssemblyScript] backend and a [React] frontend.
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you have node.js installed (we like [asdf] for
this), then use it to install [yarn]: `npm install --global yarn` (or just
`npm i -g yarn`)
2. Install dependencies: `yarn install` (or just `yarn`)
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet! Running `yarn dev` will tell you the URL you can visit in your browser to see the app.
Exploring The Code
==================
1. The backend code lives in the `/assembly` folder. This code gets deployed to
the NEAR blockchain when you run `yarn deploy:contract`. This sort of
code-that-runs-on-a-blockchain is called a "smart contract" – [learn more
about NEAR smart contracts][smart contract docs].
2. The frontend code lives in the `/src` folder.
[/src/index.html](/src/index.html) is a great place to start exploring. Note
that it loads in `/src/index.js`, where you can learn how the frontend
connects to the NEAR blockchain.
3. Tests: there are different kinds of tests for the frontend and backend. The
backend code gets tested with the [asp] command for running the backend
AssemblyScript tests, and [jest] for running frontend tests. You can run
both of these at once with `yarn test`.
Both contract and client-side code will auto-reload as you change source files.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contracts get deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-shell
--------------------------
You need near-shell installed globally. Here's how:
npm install --global near-shell
This will give you the `near` [CLI] tool. Ensure that it's installed with:
near --version
Step 1: Create an account for the contract
------------------------------------------
Visit [NEAR Wallet] and make a new account. You'll be deploying these smart contracts to this new account.
Now authorize NEAR shell for this new account, and follow the instructions it gives you:
near login
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'your-account-here!'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contracts to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
[NEAR]: https://nearprotocol.com/
[asdf]: https://github.com/asdf-vm/asdf
[yarn]: https://yarnpkg.com/
[AssemblyScript]: https://docs.assemblyscript.org/
[React]: https://reactjs.org
[smart contract docs]: https://docs.nearprotocol.com/docs/roles/developer/contracts/assemblyscript
[asp]: https://www.npmjs.com/package/@as-pect/cli
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.nearprotocol.com/docs/concepts/account
[NEAR Wallet]: https://wallet.nearprotocol.com
[near-shell]: https://github.com/nearprotocol/near-shell
[CLI]: https://www.w3schools.com/whatis/whatis_cli.asp
[create-near-app]: https://github.com/nearprotocol/create-near-app
[gh-pages]: https://github.com/tschaub/gh-pages
Mobile App Prototypes
======
Get Started Screen

SignUp|Login Screen

Start Message Screen

Share Screen

Text Message Screen

Voice Message Screen

|
Motzart_near-viewer | README.md
package.json
public
index.html
manifest.json
robots.txt
src
App.test.js
config.ts
index.html
services
NearWallet.ts
api.ts
near.ts
setupTests.js
state
txs.ts
utils
numbers.ts
tsconfig.json
| # Near view helper
|
Jorgemacias-12_PathFix | .gitpod.yml
README.md
contract
README.md
babel.config.json
build.sh
deploy.sh
package-lock.json
package.json
src
contract.ts
models.ts
utils.ts
tsconfig.json
frontend
assets
global.css
logo-black.svg
logo-white.svg
index.html
index.js
near-wallet.js
package-lock.json
package.json
start.sh
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| near-blank-project
==================
This app was initialized with [create-near-app]
Quick Start
===========
If you haven't installed dependencies during setup:
npm install
Build and deploy your contract to TestNet with a temporary dev account:
npm run deploy
Test your contract:
npm test
If you have a frontend, run `npm start`. This will run a dev server.
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/index.js`,
this is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId near-blank-project.YOUR-NAME.testnet --wasmFile PATH_TO_WASM_FILE
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-blank-project.YOUR-NAME.testnet'
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/concepts/basics/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
# Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```ts
@NearBindgen({})
class HelloNear {
greeting: string = "Hello";
@view // This method is read-only and can be called for free
get_greeting(): string {
return this.greeting;
}
@call // This method changes the state, for which it cost gas
set_greeting({ greeting }: { greeting: string }): void {
// Record a log permanently to the blockchain!
near.log(`Saving greeting ${greeting}`);
this.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `call` method.
`Call` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"greeting":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
|
near_toml-rs | .github
ISSUE_TEMPLATE
BOUNTY.yml
dependabot.yml
workflows
main.yml
Cargo.toml
README.md
examples
decode.rs
enum_external.rs
toml2json.rs
src
datetime.rs
de.rs
lib.rs
macros.rs
map.rs
ser.rs
spanned.rs
tokens.rs
value.rs
|
test-suite
Cargo.toml
benches
linear.rs
tests
README.md
backcompat.rs
datetime.rs
de-errors.rs
display-tricky.rs
display.rs
float.rs
formatting.rs
invalid-encoder
array-mixed-types-ints-and-floats.json
invalid-misc.rs
invalid.rs
invalid
datetime-malformed-no-leads.toml
datetime-malformed-no-secs.toml
datetime-malformed-no-t.toml
datetime-malformed-with-milli.toml
duplicate-key-table.toml
duplicate-keys.toml
duplicate-table.toml
duplicate-tables.toml
empty-implicit-table.toml
empty-table.toml
float-no-leading-zero.toml
float-no-suffix.toml
float-no-trailing-digits.toml
key-after-array.toml
key-after-table.toml
key-empty.toml
key-hash.toml
key-newline.toml
key-open-bracket.toml
key-single-open-bracket.toml
key-space.toml
key-start-bracket.toml
key-two-equals.toml
string-bad-byte-escape.toml
string-bad-escape.toml
string-bad-line-ending-escape.toml
string-byte-escapes.toml
string-no-close.toml
table-array-implicit.toml
table-array-malformed-bracket.toml
table-array-malformed-empty.toml
table-empty.toml
table-nested-brackets-close.toml
table-nested-brackets-open.toml
table-whitespace.toml
table-with-pound.toml
text-after-array-entries.toml
text-after-integer.toml
text-after-string.toml
text-after-table.toml
text-before-array-separator.toml
text-in-array.toml
macros.rs
parser.rs
pretty.rs
serde.rs
spanned-impls.rs
spanned.rs
tables-last.rs
valid.rs
valid
array-empty.json
array-empty.toml
array-mixed-types-arrays-and-ints.json
array-mixed-types-arrays-and-ints.toml
array-mixed-types-ints-and-floats.json
array-mixed-types-ints-and-floats.toml
array-mixed-types-strings-and-ints.json
array-mixed-types-strings-and-ints.toml
array-nospaces.json
array-nospaces.toml
arrays-hetergeneous.json
arrays-hetergeneous.toml
arrays-nested.json
arrays-nested.toml
arrays.json
arrays.toml
bool.json
bool.toml
comments-everywhere.json
comments-everywhere.toml
datetime-truncate.json
datetime-truncate.toml
datetime.json
datetime.toml
dotted-keys.json
dotted-keys.toml
empty.json
empty.toml
example-bom.toml
example-v0.3.0.json
example-v0.3.0.toml
example-v0.4.0.json
example-v0.4.0.toml
example.json
example.toml
example2.json
example2.toml
float-exponent.json
float-exponent.toml
float.json
float.toml
hard_example.json
hard_example.toml
implicit-and-explicit-after.json
implicit-and-explicit-after.toml
implicit-and-explicit-before.json
implicit-and-explicit-before.toml
implicit-groups.json
implicit-groups.toml
integer.json
integer.toml
key-empty.json
key-empty.toml
key-equals-nospace.json
key-equals-nospace.toml
key-quote-newline.json
key-quote-newline.toml
key-space.json
key-space.toml
key-special-chars.json
key-special-chars.toml
key-with-pound.json
key-with-pound.toml
long-float.json
long-float.toml
long-integer.json
long-integer.toml
multiline-string.json
multiline-string.toml
quote-surrounded-value.json
quote-surrounded-value.toml
raw-multiline-string.json
raw-multiline-string.toml
raw-string.json
raw-string.toml
string-delim-end.json
string-delim-end.toml
string-empty.json
string-empty.toml
string-escapes.json
string-escapes.toml
string-simple.json
string-simple.toml
string-with-pound.json
string-with-pound.toml
table-array-implicit.json
table-array-implicit.toml
table-array-many.json
table-array-many.toml
table-array-nest-no-keys.json
table-array-nest-no-keys.toml
table-array-nest.json
table-array-nest.toml
table-array-one.json
table-array-one.toml
table-empty.json
table-empty.toml
table-multi-empty.json
table-multi-empty.toml
table-sub-empty.json
table-sub-empty.toml
table-whitespace.json
table-whitespace.toml
table-with-pound.json
table-with-pound.toml
unicode-escape.json
unicode-escape.toml
unicode-literal.json
unicode-literal.toml
tests
enum_external_deserialize.rs
| Tests are from https://github.com/BurntSushi/toml-test
# toml-rs
[](https://crates.io/crates/toml)
[](https://docs.rs/toml)
A [TOML][toml] decoder and encoder for Rust. This library is currently compliant
with the v0.5.0 version of TOML. This library will also likely continue to stay
up to date with the TOML specification as changes happen.
[toml]: https://github.com/toml-lang/toml
```toml
# Cargo.toml
[dependencies]
toml = "0.5"
```
This crate also supports serialization/deserialization through the
[serde](https://serde.rs) crate on crates.io. Currently the older `rustc-serialize`
crate is not supported in the 0.3+ series of the `toml` crate, but 0.2 can be
used for that support.
# License
This project is licensed under either of
* Apache License, Version 2.0, ([LICENSE-APACHE](LICENSE-APACHE) or
http://www.apache.org/licenses/LICENSE-2.0)
* MIT license ([LICENSE-MIT](LICENSE-MIT) or
http://opensource.org/licenses/MIT)
at your option.
### Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted
for inclusion in toml-rs by you, as defined in the Apache-2.0 license, shall be
dual licensed as above, without any additional terms or conditions.
|
HassanKhan123_near-swap | README.md
babel.config.js
package-lock.json
package.json
public
index.html
manifest.json
robots.txt
src
App.css
SpecialWallet.ts
config.ts
hooks.ts
index.css
logo.svg
near.ts
utils.ts
worker.ts
tsconfig.json
webpack.config.js
| # Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `npm start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in your browser.
The page will reload when you make changes.\
You may also see any lint errors in the console.
### `npm test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `npm run build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `npm run eject`
**Note: this is a one-way operation. Once you `eject`, you can't go back!**
If you aren't satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you're on your own.
You don't have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn't feel obligated to use this feature. However we understand that this tool wouldn't be useful if you couldn't customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `npm run build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
NEAR-P2P_walletp2p_backend | README.md
package-lock.json
package.json
src
app.ts
config
data.source.ts
emailConfig.ts
nearConfig.ts
swagger.ts
controllers
wallet.controllers.ts
entities
otp.entity.ts
wallets.entity.ts
migrations
1714665490910-migration.ts
routes
index.ts
wallet.ts
services
wallet.service.ts
utils
email.utils.ts
encryp.ts
google_auth.utils.ts
near.utils.ts
wallet.utils.ts
tsconfig.json
| # vp2p
|
luisguve_smartcity | .gitpod.yml
README.md
contract
README.md
babel.config.json
build.sh
deploy.sh
package-lock.json
package.json
src
contract.ts
model.ts
tsconfig.json
frontend
assets
global.css
logo-black.svg
logo-white.svg
index.html
index.js
lib
near-interface.js
near-wallet.js
lit
app.js
near-interface.js
near-wallet.js
package-lock.json
package.json
start.sh
store
index.js
vue
index.js
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| # Smart city: simulating the tokenization of energy produced in a green, decentralized way.
==================
This app was initialized with [create-near-app] using typescript as the language of the smart contract and vanilla javascript in the frontend.
## App Overview
=================
In this simulator, users are able to buy solar farms to produce and supply energy to the grid.
The solar farms come in three different sizes, and to simplify the calculations, we are going to assume that the production of energy will keep constant all day.
In the real life, the production of energy would be proportional to the sun peak hours, but this is just a simplified simulation.
| Size | Price (NEAR) | Panels (400W) | Capacity (KWh) |
|--------|--------------|---------------|----------------|
| small | 100 | 80 | 160 |
| medium | 160 | 140 | 280 |
| big | 250 | 210 | 420 |
The main idea here is that the tokens will be paired with the KWs per hour that will be produced by the farms.
To convert the KWh generated by the users' farms into tokens, users have to call the method `withdraw`.
Finally, there is a method called `redeem` that users can call to convert their tokens into NEAR. The current value of each token is 0.0006 $NEAR.
Quick Start
===========
If you haven't installed dependencies during setup:
npm install
Build and deploy your contract to TestNet with a temporary dev account:
npm run deploy
Test your contract:
npm test
To start the frontend in local server, run `npm start`.
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/index.js`,
this is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId near-blank-project.YOUR-NAME.testnet --wasmFile PATH_TO_WASM_FILE
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-blank-project.YOUR-NAME.testnet'
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/concepts/basics/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
# Smart city contract
Buy solar farms, generate energy, earn tokens and redeem them into NEAR.
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, set the CONTRACT_NAME environment variable from `neardev/dev-account.env` file to get the address in which the contract was deployed:
```bash
source ./neardev/dev-account.env
```
<br />
## 2. Init the contract
```bash
near call $CONTRACT_NAME init --accountId $CONTRACT_NAME
```
<br />
## 3. Get the total supply
```bash
near view $CONTRACT_NAME ftTotalSupply
# result: "200000000"
```
<br />
## 4. Get balance of account.
```bash
near view $CONTRACT_NAME ftBalanceOf '{"accountId": "<account>.testnet"}'
# result: "0"
```
<br />
## 5. Buy a solar farm to start generating KWhs
`buySolarFarm` receives one parameter, `farmSize` which is either `small`, `medium` or `big`.
This method requires to send NEAR.
- 100 NEAR if `farmSize` is `small`,
- 160 NEAR if `farmSize` is `medium`
- 250 NEAR if `farmSize` is `big`
```bash
near call $CONTRACT_NAME buySolarFarm --accountId <accountId>.testnet --deposit 100 '{"farmSize": "small"}'
```
<br />
## 6. Get the list of farms
```bash
near view $CONTRACT_NAME getEnergyGenerators
```
Result:
```json
[
[
'luisguve.testnet',
{
totalPowerRate: 160,
farms: [
{ name: 'small', powerRate: 160, panels: 80 }
],
accountId: 'luisguve.testnet',
lastWithdrawal: 1664290021
}
]
]
```
<br />
## 7. Get energy generated so far (KWh).
The energy generated in KWh is calculated by multiplying the amount of hours since the last withdrawal by the totalPowerRate of the account.
The totalPowerRate is the sum of all the farms' powerRate.
```bash
near view $CONTRACT_NAME getEnergyGenerated '{"accountId": "<accountId>.testnet"}'
```
## 8. Get account info.
Thet Total power rate, farms and last withdrawal timestamp.
The totalPowerRate is the sum of all the farms' powerRate.
```bash
near view $CONTRACT_NAME getAccountInfo '{"accountId": "luisguve.testnet"}'
```
Example result:
```json
{
totalPowerRate: 440,
farms: [
{ name: 'small', powerRate: 160, panels: 80 },
{ name: 'medium', powerRate: 280, panels: 140 }
],
accountId: 'luisguve.testnet',
lastWithdrawal: 1664290021
}
```
## 9. Get tokens from energy generated.
1 KWh generated is equal to 1 token.
```bash
near call $CONTRACT_NAME withdraw --accountId <accountId>.testnet
# this call returns the amount of tokens
```
<br />
## 10. Swap tokens for NEAR.
```bash
near call $CONTRACT_NAME redeem --accountId <accountId>.testnet
# this call returns the amount of NEAR received
```
|
pythonicode_nearsound-contracts | README.md
market-contract
Cargo.toml
README.md
build.sh
src
external.rs
internal.rs
lib.rs
nft_callbacks.rs
sale.rs
sale_views.rs
nft-contract
Cargo.toml
README.md
build.sh
src
approval.rs
artist.rs
enumeration.rs
events.rs
internal.rs
lib.rs
metadata.rs
mint.rs
nft_core.rs
royalty.rs
package-lock.json
package.json
| # Nearsound Contracts
# TBD
# TBD
|
naviava_minter-app | .eslintrc.json
README.md
app
_trpc
client.ts
server-client.ts
api
auth
[...nextauth]
route.ts
trpc
[trpc]
route.ts
globals.css
components.json
hooks
use-is-mounted.ts
lib
config.ts
db.ts
utils.ts
package.json
postcss.config.js
public
logo.svg
manifest.json
nothing-to-show.svg
sw.js
workbox-c06b064f.js
server
index.ts
routers
comment-router.ts
favorites-router.ts
nft-router.ts
user-router.ts
trpc.ts
store
use-auth-modal.ts
use-comment-modal.ts
use-confirm-modal.ts
use-share-modal.ts
use-upload-modal.ts
tailwind.config.ts
tsconfig.json
utils
trpc
comment
add-comment.ts
delete-comment.ts
get-comment-count.ts
get-comments.ts
favorites
get-favorite-count.ts
get-favorites.ts
is-favorite.ts
toggle-favorite.ts
nft
get-owned-nft.ts
get-published-tokens.ts
get-token-by-id.ts
link-nft.ts
toggle-visibility.ts
user
get-auth-profile.ts
link-wallet.ts
vercel.json
| # MintSaga - Blockchain-Powered NFT Image Storage
MintSaga is an application that leverages blockchain technology to store images as Non-Fungible Tokens (NFTs) related to historical events. Users can enjoy the benefits of immutable title and description storage, ensuring the preservation of historical content on the blockchain. You can find a live demo of the app [here](https://mintsaga.vercel.app/).
Here is a short video demonstrating the app's key features:
[](https://www.youtube.com/watch?v=_5HMEXtB4iI)
Below are the key features and functionalities of MintSaga:
## Features
### 1. Authentication and Wallet Linking
- **User Sign-In:** Users are required to sign in to MintSaga to access its features.
- **Wallet Integration:** Users can link their wallets to the app, enabling them to upload NFTs to the blockchain.
- **Single OAuth Account, Multiple Wallets:** Each OAuth account can be linked to multiple wallets, but only one wallet can be active at a time. Each wallet can be linked to only one OAuth account.
- **Switchable Wallets:** Users can seamlessly switch between linked wallets by disconnecting the current active wallet and connecting to an alternate one.
### 2. Ownership and Visibility
- **Upload Restrictions:** Uploading to the blockchain is only possible when a wallet is linked.
- **Public Visibility Toggle:** Users can control the public visibility of their owned NFTs, deciding whether to showcase them publicly or keep them private.
### 3. Favorites and Community Engagement
- **Favorites Page:** Users can mark NFTs as favorites. These NFTs are displayed on the Favorites page for easy access.
- **Comment Section:** Each NFT page includes a comment section to encourage community engagement.
- **Comment Management:** Comment authors have the ability to delete their own comments, providing control over the discussions.
### 4. Social Media Integration
- **Token Sharing:** Users can easily share the token link on various social media platforms, including WhatsApp, Facebook, X (Twitter), LinkedIn, and Reddit directly from the UI.
### 5. User Experience Enhancements
- **Dark Mode:** The app offers a dark mode for a more comfortable viewing experience.
- **Theme Switching:** Users can easily switch between themes through the app's user interface, tailoring their experience to their preferences.
### 6. Progressive Web App (PWA) Enabled
- **Easy Access:** MintSaga is PWA-enabled, allowing users to visit the site once and save it on their devices. This enables access without opening a web browser, with no hassle of app updates.
_Note: Ensure that your device supports PWA functionality for the best user experience._
## Getting Started
To get started with MintSaga, follow these steps:
1. **Sign Up/Login:** Log in using one of the available OAuth methods to access MintSaga's features.
2. **Link Wallet:** Connect your preferred wallet to upload NFTs to the blockchain.
3. **Explore and Engage:** Browse historical NFTs, mark favorites, and engage with the community through comments.
4. **Customize Visibility:** Choose whether to make your owned NFTs publicly visible or keep them private.
5. **Share Tokens:** Share your favorite tokens on social media directly from the MintSaga UI.
6. **Enhance Experience:** Customize your user experience with dark mode and theme switching options.
## Setting Up Development Environment
### Prerequisites
Before you begin, ensure that you have Docker installed on your machine. If not, [install Docker](https://docs.docker.com/get-docker/) and run the following command:
```
docker run -d --name mintsaga-container -e POSTGRES_DB=mintsaga-db -e POSTGRES_PASSWORD=Password123 -e POSTGRES_USER=dbadmin -p 6500:5432 postgres
```
Once the above steps are completed, make sure the container is powered on. If not, you can manually power it on. If you encounter any issues, refer to the [Docker documentation](https://docs.docker.com/).
### Environment Setup
**1. Clone the Repository and Navigate to the Directory**
```
git clone https://github.com/naviava/minter-app.git
cd minter-app
```
**2. Install Dependencies and Push Database Schema**
```
npm install
npx prisma db push
```
**3. Configure Environment Variables**
Rename (or make a copy and rename) the `.env.example` file to `.env`. In the `.env` file, enter actual values from your account, replacing placeholder values to enable OAuth.
_Note: Google OAuth is disabled by default, due to an issue I faced with my Google account. You can enable it by following these steps:_
- _Uncomment the commented lines in this file: `/app/api/auth/[...nextauth]/route.ts`_
- _Uncomment the commented lines in this file: `/components/modals/auth-modal.tsx`_
**4. Run the Development Environment**
You are now ready to run the development environment:
```
npm run dev
```
This will start the development server, and you can access the app at `http://localhost:3000`. Feel free to optimize and customize the development environment based on your preferences.
Thank you for checking out MintSaga! If you have any questions or feedback, please feel free to reach out to me on [X (Twitter)](https://twitter.com/oldmannav) or [LinkedIn](https://www.linkedin.com/in/navin-avadhani-aa288785/).
|
MoSwilam_molayz | apps
relayz-api
src
app.module.ts
config
configuration.ts
env
.env
debug.env
dev.env
local.env
prd.env
stg.env
envVars.validation.schema.ts
main.ts
misc
dapp
docker-compose.prd.yml
docker-compose.tst.yml
docker-compose.yml
modules
auth
auth.constants.ts
auth.controller.ts
auth.module.ts
auth.payload.json
auth.service.spec.ts
auth.service.ts
auth.types.ts
cli-lib
cli-lib.controller.ts
cli-lib.module.ts
cli-lib.service.ts
cli-lib.types.ts
cron
cron.controller.ts
cron.module.ts
cron.service.ts
cron.types.ts
dapp
dapp.controller.ts
dapp.module.ts
dapp.service.ts
history
dto
create-history.dto.ts
update-history.dto.ts
entities
history.entity.ts
history.controller.ts
history.module.ts
history.service.ts
history.types.ts
ipfs
ipfs.controller.ts
ipfs.module.ts
ipfs.service.ts
ipfs.types.ts
sampleData.json
marketing
marketing.controller.ts
marketing.module.ts
marketing.schema.ts
marketing.service.spec.ts
marketing.service.ts
marketing.types.ts
meeting-events
event.controller.ts
event.module.ts
event.schema.ts
event.service.ts
event.types.ts
muc-room-created_payload.json
muc-room-destroyed_payload.json
node-management
nodes.controller.ts
nodes.module.ts
nodes.schema.ts
nodes.service.ts
nodes.types.ts
telemetry.service.ts
telemetry.types.ts
telemetryJsonTest.json
tests
telemetry.shit.ts
telemetry.spec.ts
user
user.controller.ts
user.module.ts
user.repo.ts
user.schema.ts
user.service.spec.ts
user.service.specxxx.ts
user.service.ts
user.types.ts
wallet
wallet.controller.ts
wallet.module.ts
wallet.schema.ts
wallet.service.ts
wallet.types.ts
shared
constants.ts
decorators
compose.decorators.ts
user.decorator.ts
errors.ts
exception-filter
all.exception.filter.ts
guards
agent.auth.guard.ts
auth.guard.ts
http
http.module.ts
http.service.ts
interceptors
logger.interceptor.ts
responseFactory.interceptor.ts
near-service.ts
types.ts
utils.ts
test
app.e2e-spec.ts
jest-e2e.json
tsconfig.app.json
users
src
main.ts
users.controller.spec.ts
users.controller.ts
users.module.ts
users.service.ts
test
app.e2e-spec.ts
jest-e2e.json
tsconfig.app.json
Updated speed task completed Successfully
Updated traffic task completed Successfully
dev-relayz-api-secret.json
docker-compose.yml
libs
common
src
config
config.module.ts
index.ts
database
abstract.repository.ts
abstract.schema.ts
database.module.ts
index.ts
index.ts
tsconfig.lib.json
nest-cli.json
package-lock.json
package.json
readme.md
readme_deploy.md
relayz-api-secret.json
stage-relayz-api-secret.json
tsconfig.build.json
tsconfig.json
| |
near_borsh-rs | .github
test.sh
workflows
rust.yml
CHANGELOG.md
Cargo.toml
README.md
benchmarks
Cargo.toml
README.md
benches
bench.rs
maps_sets_inner_de.rs
maps_sets_inner_ser.rs
object_length.rs
src
lib.rs
borsh-derive
Cargo.toml
README.md
src
internals
attributes
field
bounds.rs
mod.rs
schema.rs
schema
with_funcs.rs
item
mod.rs
mod.rs
parsing.rs
cratename.rs
deserialize
enums
mod.rs
mod.rs
structs
mod.rs
unions
mod.rs
enum_discriminant.rs
generics.rs
mod.rs
schema
enums
mod.rs
mod.rs
structs
mod.rs
serialize
enums
mod.rs
mod.rs
structs
mod.rs
unions
mod.rs
test_helpers.rs
lib.rs
borsh
Cargo.toml
README.md
build.rs
src
de
hint.rs
mod.rs
error.rs
generate_schema_schema.rs
lib.rs
nostd_io.rs
schema.rs
schema
container_ext.rs
container_ext
max_size.rs
validate.rs
schema_helpers.rs
ser
helpers.rs
mod.rs
tests
common_macro.rs
compile_derives
schema
test_generic_enums.rs
test_generic_enums.rs
test_generic_structs.rs
test_macro_namespace_collisions.rs
test_recursive_structs.rs
custom_reader
test_custom_reader.rs
deserialization_errors
test_ascii_strings.rs
test_cells.rs
test_initial.rs
init_in_deserialize
test_init_in_deserialize.rs
roundtrip
requires_derive_category
test_bson_object_ids.rs
test_enum_discriminants.rs
test_generic_enums.rs
test_generic_structs.rs
test_recursive_enums.rs
test_recursive_structs.rs
test_serde_with_third_party.rs
test_simple_enums.rs
test_ultimate_many_features_combined.rs
test_arrays.rs
test_ascii_strings.rs
test_btree_map.rs
test_cells.rs
test_cow.rs
test_hash_map.rs
test_nonzero_integers.rs
test_primitives.rs
test_range.rs
test_rc.rs
test_strings.rs
test_tuple.rs
test_vecs.rs
schema
container_extension
test_max_size.rs
test_schema_validate.rs
schema_conflict
test_schema_conflict.rs
test_arrays.rs
test_ascii_strings.rs
test_box.rs
test_btree_map.rs
test_cells.rs
test_cow.rs
test_enum_discriminants.rs
test_generic_enums.rs
test_generic_structs.rs
test_hash_map.rs
test_option.rs
test_phantom_data.rs
test_primitives.rs
test_range.rs
test_rc.rs
test_recursive_enums.rs
test_recursive_structs.rs
test_schema_with_third_party.rs
test_simple_enums.rs
test_simple_structs.rs
test_strings.rs
test_tuple.rs
test_vecs.rs
smoke.rs
tests.rs
zero_sized_types
test_zero_sized_types_forbidden.rs
docs
migration_guides
v0.10.2_to_v1.0.0_nearcore.md
v0.9_to_v1.0.0_near_sdk_rs.md
STDERR: near-primitives action::delegate::tests::test_delegate_action_deserialization
STDERR: near-store tests::test_save_to_file
fuzz
fuzz-run
Cargo.toml
README.md
src
main.rs
release-plz.toml
| # Borsh benchmarks
To run benchmarks execute:
```bash
cargo bench
```
If you want to make a change and see how it affects the performance then
copy `criterion` folder from `docs` into `target` folder so that you have `target/criterion`, and run the benchmarks.
Criterion will print whether the change has statistically significant positive/negative impact based on p-values or
whether it is within noise. Unfortunately, benchmarks related to serializing `Account` and `SignedTransaction` turned out to
be highly volatile therefore prefer using `Block` and `BlockHeader` as the measurement of the performance change.
We use default Criterion setting for determining statistical significance, which corresponds to 2 sigma.
We run benchmarks using `n1-standard-2 (2 vCPUs, 7.5 GB memory)` on GCloud. Make sure the instance
is not running any other heavy process.
# Borsh in Rust   [![Latest Version]][crates.io] [![borsh: rustc 1.67+]][Rust 1.67] [![License Apache-2.0 badge]][License Apache-2.0] [![License MIT badge]][License MIT]
[Borsh]: https://borsh.io
[Latest Version]: https://img.shields.io/crates/v/borsh.svg
[crates.io]: https://crates.io/crates/borsh
[borsh: rustc 1.67+]: https://img.shields.io/badge/rustc-1.67+-lightgray.svg
[Rust 1.67]: https://blog.rust-lang.org/2023/01/26/Rust-1.67.0.html
[License Apache-2.0 badge]: https://img.shields.io/badge/license-Apache2.0-blue.svg
[License Apache-2.0]: https://opensource.org/licenses/Apache-2.0
[License MIT badge]: https://img.shields.io/badge/license-MIT-blue.svg
[License MIT]: https://opensource.org/licenses/MIT
**borsh-rs** is Rust implementation of the [Borsh] binary serialization format.
Borsh stands for _Binary Object Representation Serializer for Hashing_. It is meant to be used in
security-critical projects as it prioritizes [consistency, safety, speed][Borsh], and comes with a
strict [specification](https://github.com/near/borsh#specification).
## Example
```rust
use borsh::{BorshSerialize, BorshDeserialize, from_slice, to_vec};
#[derive(BorshSerialize, BorshDeserialize, PartialEq, Debug)]
struct A {
x: u64,
y: String,
}
#[test]
fn test_simple_struct() {
let a = A {
x: 3301,
y: "liber primus".to_string(),
};
let encoded_a = to_vec(&a).unwrap();
let decoded_a = from_slice::<A>(&encoded_a).unwrap();
assert_eq!(a, decoded_a);
}
```
## Features
Opting out from Serde allows borsh to have some features that currently are not available for serde-compatible serializers.
Currently we support two features: `borsh(init=<your initialization method name>` and `borsh(skip)` (the former one not available in Serde).
`borsh(init=...)` allows to automatically run an initialization function right after deserialization. This adds a lot of convenience for objects that are architectured to be used as strictly immutable. Usage example:
```rust
#[derive(BorshSerialize, BorshDeserialize)]
#[borsh(init=init)]
struct Message {
message: String,
timestamp: u64,
public_key: CryptoKey,
signature: CryptoSignature
hash: CryptoHash
}
impl Message {
pub fn init(&mut self) {
self.hash = CryptoHash::new().write_string(self.message).write_u64(self.timestamp);
self.signature.verify(self.hash, self.public_key);
}
}
```
`borsh(skip)` allows to skip serializing/deserializing fields, assuming they implement `Default` trait, similarly to `#[serde(skip)]`.
```rust
#[derive(BorshSerialize, BorshDeserialize)]
struct A {
x: u64,
#[borsh(skip)]
y: f32,
}
```
### Enum with explicit discriminant
`#[borsh(use_discriminant=false|true])` is required if you have an enum with explicit discriminant. This setting affects `BorshSerialize` and `BorshDeserialize` behaviour at the same time.
In the future, borsh will drop the requirement to explicitly use `#[borsh(use_discriminant=false|true)]`, and will default to `true`, but to make sure that the transition from the older versions of borsh (before 0.11 release) does not cause silent breaking changes in de-/serialization, borsh 1.0 will require to specify if the explicit enum discriminant should be used as a de-/serialization tag value.
If you don't specify `use_discriminant` option for enum with explicit discriminant, you will get an error:
```bash
error: You have to specify `#[borsh(use_discriminant=true)]` or `#[borsh(use_discriminant=false)]` for all enums with explicit discriminant
```
In order to preserve the behaviour of borsh versions before 0.11, which did not respect explicit enum discriminants for de-/serialization, use `#[borsh(use_discriminant=false)]`, otherwise, use `true`:
```rust
#[derive(BorshDeserialize, BorshSerialize)]
#[borsh(use_discriminant=false)]
enum A {
X,
Y = 10,
}
```
## Testing
Integration tests should generally be preferred to unit ones. Root module of integration tests of `borsh` crate is [linked](./borsh/tests/tests.rs) here.
## Releasing
The versions of all public crates in this repository are collectively managed by a single version in the [workspace manifest](https://github.com/near/borsh-rs/blob/master/Cargo.toml).
So, to publish a new version of all the crates, you can do so by simply bumping that to the next "patch" version and submit a PR.
We have CI Infrastructure put in place to automate the process of publishing all crates once a version change has merged into master.
However, before you release, make sure the [CHANGELOG](CHANGELOG.md) is up to date and that the `[Unreleased]` section is present but empty.
## License
This repository is distributed under the terms of both the MIT license and the Apache License (Version 2.0).
See [LICENSE-MIT](LICENSE-MIT) and [LICENSE-APACHE](LICENSE-APACHE) for details.
# Borsh in Rust   [![Latest Version]][crates.io] [![borsh: rustc 1.67+]][Rust 1.67] [![License Apache-2.0 badge]][License Apache-2.0] [![License MIT badge]][License MIT]
[Borsh]: https://borsh.io
[Latest Version]: https://img.shields.io/crates/v/borsh.svg
[crates.io]: https://crates.io/crates/borsh
[borsh: rustc 1.67+]: https://img.shields.io/badge/rustc-1.67+-lightgray.svg
[Rust 1.67]: https://blog.rust-lang.org/2023/01/26/Rust-1.67.0.html
[License Apache-2.0 badge]: https://img.shields.io/badge/license-Apache2.0-blue.svg
[License Apache-2.0]: https://opensource.org/licenses/Apache-2.0
[License MIT badge]: https://img.shields.io/badge/license-MIT-blue.svg
[License MIT]: https://opensource.org/licenses/MIT
**borsh-rs** is Rust implementation of the [Borsh] binary serialization format.
Borsh stands for _Binary Object Representation Serializer for Hashing_. It is meant to be used in
security-critical projects as it prioritizes [consistency, safety, speed][Borsh], and comes with a
strict [specification](https://github.com/near/borsh#specification).
## Example
```rust
use borsh::{BorshSerialize, BorshDeserialize, from_slice, to_vec};
#[derive(BorshSerialize, BorshDeserialize, PartialEq, Debug)]
struct A {
x: u64,
y: String,
}
#[test]
fn test_simple_struct() {
let a = A {
x: 3301,
y: "liber primus".to_string(),
};
let encoded_a = to_vec(&a).unwrap();
let decoded_a = from_slice::<A>(&encoded_a).unwrap();
assert_eq!(a, decoded_a);
}
```
## Features
Opting out from Serde allows borsh to have some features that currently are not available for serde-compatible serializers.
Currently we support two features: `borsh(init=<your initialization method name>` and `borsh(skip)` (the former one not available in Serde).
`borsh(init=...)` allows to automatically run an initialization function right after deserialization. This adds a lot of convenience for objects that are architectured to be used as strictly immutable. Usage example:
```rust
#[derive(BorshSerialize, BorshDeserialize)]
#[borsh(init=init)]
struct Message {
message: String,
timestamp: u64,
public_key: CryptoKey,
signature: CryptoSignature
hash: CryptoHash
}
impl Message {
pub fn init(&mut self) {
self.hash = CryptoHash::new().write_string(self.message).write_u64(self.timestamp);
self.signature.verify(self.hash, self.public_key);
}
}
```
`borsh(skip)` allows to skip serializing/deserializing fields, assuming they implement `Default` trait, similarly to `#[serde(skip)]`.
```rust
#[derive(BorshSerialize, BorshDeserialize)]
struct A {
x: u64,
#[borsh(skip)]
y: f32,
}
```
### Enum with explicit discriminant
`#[borsh(use_discriminant=false|true])` is required if you have an enum with explicit discriminant. This setting affects `BorshSerialize` and `BorshDeserialize` behaviour at the same time.
In the future, borsh will drop the requirement to explicitly use `#[borsh(use_discriminant=false|true)]`, and will default to `true`, but to make sure that the transition from the older versions of borsh (before 0.11 release) does not cause silent breaking changes in de-/serialization, borsh 1.0 will require to specify if the explicit enum discriminant should be used as a de-/serialization tag value.
If you don't specify `use_discriminant` option for enum with explicit discriminant, you will get an error:
```bash
error: You have to specify `#[borsh(use_discriminant=true)]` or `#[borsh(use_discriminant=false)]` for all enums with explicit discriminant
```
In order to preserve the behaviour of borsh versions before 0.11, which did not respect explicit enum discriminants for de-/serialization, use `#[borsh(use_discriminant=false)]`, otherwise, use `true`:
```rust
#[derive(BorshDeserialize, BorshSerialize)]
#[borsh(use_discriminant=false)]
enum A {
X,
Y = 10,
}
```
## Testing
Integration tests should generally be preferred to unit ones. Root module of integration tests of `borsh` crate is [linked](./borsh/tests/tests.rs) here.
## Releasing
The versions of all public crates in this repository are collectively managed by a single version in the [workspace manifest](https://github.com/near/borsh-rs/blob/master/Cargo.toml).
So, to publish a new version of all the crates, you can do so by simply bumping that to the next "patch" version and submit a PR.
We have CI Infrastructure put in place to automate the process of publishing all crates once a version change has merged into master.
However, before you release, make sure the [CHANGELOG](CHANGELOG.md) is up to date and that the `[Unreleased]` section is present but empty.
## License
This repository is distributed under the terms of both the MIT license and the Apache License (Version 2.0).
See [LICENSE-MIT](LICENSE-MIT) and [LICENSE-APACHE](LICENSE-APACHE) for details.
A fuzzer for Borsh deserializer. To start fuzzing, follow instructions here https://github.com/rust-fuzz/honggfuzz-rs#how-to-use-this-crate
# Borsh in Rust   [![Latest Version]][crates.io] [![borsh: rustc 1.67+]][Rust 1.67] [![License Apache-2.0 badge]][License Apache-2.0] [![License MIT badge]][License MIT]
[Borsh]: https://borsh.io
[Latest Version]: https://img.shields.io/crates/v/borsh.svg
[crates.io]: https://crates.io/crates/borsh
[borsh: rustc 1.67+]: https://img.shields.io/badge/rustc-1.67+-lightgray.svg
[Rust 1.67]: https://blog.rust-lang.org/2023/01/26/Rust-1.67.0.html
[License Apache-2.0 badge]: https://img.shields.io/badge/license-Apache2.0-blue.svg
[License Apache-2.0]: https://opensource.org/licenses/Apache-2.0
[License MIT badge]: https://img.shields.io/badge/license-MIT-blue.svg
[License MIT]: https://opensource.org/licenses/MIT
**borsh-rs** is Rust implementation of the [Borsh] binary serialization format.
Borsh stands for _Binary Object Representation Serializer for Hashing_. It is meant to be used in
security-critical projects as it prioritizes [consistency, safety, speed][Borsh], and comes with a
strict [specification](https://github.com/near/borsh#specification).
## Example
```rust
use borsh::{BorshSerialize, BorshDeserialize, from_slice, to_vec};
#[derive(BorshSerialize, BorshDeserialize, PartialEq, Debug)]
struct A {
x: u64,
y: String,
}
#[test]
fn test_simple_struct() {
let a = A {
x: 3301,
y: "liber primus".to_string(),
};
let encoded_a = to_vec(&a).unwrap();
let decoded_a = from_slice::<A>(&encoded_a).unwrap();
assert_eq!(a, decoded_a);
}
```
## Features
Opting out from Serde allows borsh to have some features that currently are not available for serde-compatible serializers.
Currently we support two features: `borsh(init=<your initialization method name>` and `borsh(skip)` (the former one not available in Serde).
`borsh(init=...)` allows to automatically run an initialization function right after deserialization. This adds a lot of convenience for objects that are architectured to be used as strictly immutable. Usage example:
```rust
#[derive(BorshSerialize, BorshDeserialize)]
#[borsh(init=init)]
struct Message {
message: String,
timestamp: u64,
public_key: CryptoKey,
signature: CryptoSignature
hash: CryptoHash
}
impl Message {
pub fn init(&mut self) {
self.hash = CryptoHash::new().write_string(self.message).write_u64(self.timestamp);
self.signature.verify(self.hash, self.public_key);
}
}
```
`borsh(skip)` allows to skip serializing/deserializing fields, assuming they implement `Default` trait, similarly to `#[serde(skip)]`.
```rust
#[derive(BorshSerialize, BorshDeserialize)]
struct A {
x: u64,
#[borsh(skip)]
y: f32,
}
```
### Enum with explicit discriminant
`#[borsh(use_discriminant=false|true])` is required if you have an enum with explicit discriminant. This setting affects `BorshSerialize` and `BorshDeserialize` behaviour at the same time.
In the future, borsh will drop the requirement to explicitly use `#[borsh(use_discriminant=false|true)]`, and will default to `true`, but to make sure that the transition from the older versions of borsh (before 0.11 release) does not cause silent breaking changes in de-/serialization, borsh 1.0 will require to specify if the explicit enum discriminant should be used as a de-/serialization tag value.
If you don't specify `use_discriminant` option for enum with explicit discriminant, you will get an error:
```bash
error: You have to specify `#[borsh(use_discriminant=true)]` or `#[borsh(use_discriminant=false)]` for all enums with explicit discriminant
```
In order to preserve the behaviour of borsh versions before 0.11, which did not respect explicit enum discriminants for de-/serialization, use `#[borsh(use_discriminant=false)]`, otherwise, use `true`:
```rust
#[derive(BorshDeserialize, BorshSerialize)]
#[borsh(use_discriminant=false)]
enum A {
X,
Y = 10,
}
```
## Testing
Integration tests should generally be preferred to unit ones. Root module of integration tests of `borsh` crate is [linked](./borsh/tests/tests.rs) here.
## Releasing
The versions of all public crates in this repository are collectively managed by a single version in the [workspace manifest](https://github.com/near/borsh-rs/blob/master/Cargo.toml).
So, to publish a new version of all the crates, you can do so by simply bumping that to the next "patch" version and submit a PR.
We have CI Infrastructure put in place to automate the process of publishing all crates once a version change has merged into master.
However, before you release, make sure the [CHANGELOG](CHANGELOG.md) is up to date and that the `[Unreleased]` section is present but empty.
## License
This repository is distributed under the terms of both the MIT license and the Apache License (Version 2.0).
See [LICENSE-MIT](LICENSE-MIT) and [LICENSE-APACHE](LICENSE-APACHE) for details.
|
nearsend_nearsend-frontend | .eslintrc.js
.lintstagedrc.json
.prettierrc.js
LICENSE.md
README.md
index.html
package.json
public
example.near.txt
example.testnet.txt
favicon.svg
near_icon.svg
robots.txt
src
components
AppConnectWalletWrapper
hooks
useConnectNear.ts
AppHeader
contants
index.ts
NumberFormat
utils.ts
Pages
home
components
Prepare
schemas
index.ts
SendToken
constant
index.ts
connectors
constants.ts
constants
error.ts
fileTypes.ts
httpStatus.ts
index.ts
length.ts
routes.ts
socketEvent.ts
status.ts
time.ts
type.ts
hoc
with-translate-form-errors.ts
hooks
blockchainHook
useBulkSendToken.ts
useGetBalance.ts
useGetBlockData.ts
useGetGasPrice.ts
useGetTokens.ts
useGetTransactionStatus.ts
useNearWalletQueryParams.ts
useServiceFee.ts
useSetQueryParams.ts
useDebounce.ts
useInterval.ts
useSocket.ts
useStore.ts
useTimeout.ts
useWindowSize.ts
walletHook
useChainFactory.ts
useChangeNetwork.ts
useGetWalletService.ts
language
i18n.ts
locales
en
defaults.json
reportWebVital.ts
resources
svg
near_icon.svg
open_in_new.svg
services
GraphQLService
getTransactionsDetail.ts
SocketService.ts
WalletService
BaseWalletService.ts
NearChainService.ts
constants
index.ts
type
index.d.ts
utils
index.ts
nearUtils.ts
number.ts
api.ts
listAddress.ts
navigationService.ts
setupTests.js
store
address
saga.ts
selector.ts
slice.ts
balance
selector.ts
slice.ts
configStore.ts
connection
selector.ts
slice.ts
global
selector.ts
slice.ts
language
selector.ts
slice.ts
rootReducer.ts
rootSaga.ts
utils
chains
Chain.ts
ChainFactory.ts
NearChain.ts
utils
ChainUtils.ts
NearUtils.ts
date.ts
index.ts
string.ts
validate.ts
vite-env.d.ts
tools
localization
LocalizationGenerator.js
credentials.json
package.json
tsconfig.json
tsconfig.node.json
types
fixes.d.ts
vite.config.ts
| # Nearsend Frontend
Frontend code for [Nearsend]('https://nearsend.io/')
## Getting Started
First, install the dependencies:
```bash
npm i
```
Second, run the development server:
```bash
npm run dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
## Service Fee
Nearsend Core required a small amount of service fee per address when you make a transaction. The service fee is calculated based on USD, for example, 0.1 equals 10 cents (0.1 USD).
Service fee may be adjusted by updating the ENV variable `VITE_SERVICE_FEE_USD_PER_ACCOUNT`, make sure that it matches the number on our Smart Contract as well
|
near_rust-rocksdb | .github
ISSUE_TEMPLATE
BOUNTY.yml
workflows
rust.yml
CHANGELOG.md
CONTRIBUTING.md
Cargo.toml
MAINTAINERSHIP.md
README.md
code-of-conduct.md
librocksdb-sys
Cargo.toml
README.md
build.rs
rocksdb_lib_sources.txt
snappy-stubs-public.h
src
lib.rs
test.rs
tests
ffi.rs
src
backup.rs
checkpoint.rs
column_family.rs
compaction_filter.rs
compaction_filter_factory.rs
comparator.rs
db.rs
db_iterator.rs
db_options.rs
db_pinnable_slice.rs
ffi_util.rs
iter_range.rs
lib.rs
merge_operator.rs
perf.rs
properties.rs
slice_transform.rs
snapshot.rs
sst_file_writer.rs
transactions
mod.rs
optimistic_transaction_db.rs
options.rs
transaction.rs
transaction_db.rs
write_batch.rs
tests
fail
checkpoint_outlive_db.rs
iterator_outlive_db.rs
open_with_multiple_refs_as_single_threaded.rs
snapshot_outlive_db.rs
snapshot_outlive_transaction.rs
snapshot_outlive_transaction_db.rs
transaction_outlive_transaction_db.rs
test_backup.rs
test_checkpoint.rs
test_column_family.rs
test_compationfilter.rs
test_db.rs
test_iterator.rs
test_merge_operator.rs
test_multithreaded.rs
test_optimistic_transaction_db.rs
test_pinnable_slice.rs
test_property.rs
test_raw_iterator.rs
test_rocksdb_options.rs
test_slice_transform.rs
test_sst_file_writer.rs
test_transaction_db.rs
test_write_batch.rs
util
mod.rs
| # RocksDB bindings
Low-level bindings to [RocksDB's](https://github.com/facebook/rocksdb) C API.
Based on original work by Tyler Neely
https://github.com/rust-rocksdb/rust-rocksdb
and Jeremy Fitzhardinge
https://github.com/jsgf/rocksdb-sys
### Version
The librocksdb-sys version number is in the format `X.Y.Z+RX.RY.RZ`, where
`X.Y.Z` is the version of this crate and follows SemVer conventions, while
`RX.RY.RZ` is the version of the bundled rocksdb.
rust-rocksdb
============

[](https://crates.io/crates/rocksdb)
[](https://docs.rs/rocksdb)
[](https://github.com/rust-rocksdb/rust-rocksdb/blob/master/LICENSE)
[](https://gitter.im/rust-rocksdb/lobby)


## Requirements
- Clang and LLVM
## Contributing
Feedback and pull requests welcome! If a particular feature of RocksDB is
important to you, please let me know by opening an issue, and I'll
prioritize it.
## Usage
This binding is statically linked with a specific version of RocksDB. If you
want to build it yourself, make sure you've also cloned the RocksDB and
compression submodules:
git submodule update --init --recursive
## Compression Support
By default, support for the [Snappy](https://github.com/google/snappy),
[LZ4](https://github.com/lz4/lz4), [Zstd](https://github.com/facebook/zstd),
[Zlib](https://zlib.net), and [Bzip2](http://www.bzip.org) compression
is enabled through crate features. If support for all of these compression
algorithms is not needed, default features can be disabled and specific
compression algorithms can be enabled. For example, to enable only LZ4
compression support, make these changes to your Cargo.toml:
```
[dependencies.rocksdb]
default-features = false
features = ["lz4"]
```
## Multithreaded ColumnFamily alternation
The underlying RocksDB does allow column families to be created and dropped
from multiple threads concurrently. But this crate doesn't allow it by default
for compatibility. If you need to modify column families concurrently, enable
crate feature called `multi-threaded-cf`, which makes this binding's
data structures to use RwLock by default. Alternatively, you can directly create
`DBWithThreadMode<MultiThreaded>` without enabling the crate feature.
|
passionatedeveloper223_Near-Staking-Dapp-SmartContract | README.md
src
Cargo.toml
ft_contract
Cargo.toml
src
lib.rs
ft_staking_contract
Cargo.toml
src
ft_calls.rs
internal.rs
lib.rs
neardev
dev-account.env
shell_scripts
build.sh
claim_reward.sh
deposit_storage.sh
get_apy.sh
stake.sh
test.sh
unstake.sh
tests
sim
main.rs
tests.rs
utils.rs
webapp
README.md
package.json
public
index.html
manifest.json
robots.txt
src
App.css
App.js
App.test.js
components
APYComponent.js
APYTableHead.js
APYTablebody.js
AccountBalance.js
Header.js
StakeForm.js
StakingComponent.js
StakingDuration.js
StakingHistory.js
TableBody.js
TableHead.js
index.css
index.js
logo.svg
provider
NearProvider.js
reportWebVitals.js
setupTests.js
Production: mainnet
Development: testnet
| # Staking-DApp
Staking application consists of two smart contracts and React a web application.The purpose of this application is to allow users to earn rewards by staking their savings in terms of fungible tokens resulting in the multiplication of their savings.
# Prerequisites
In order to successfully compile the codes and run the application on local server you will need:
- [Node v18](https://nodejs.org/en/download/current/)
- [NEAR CLI](https://docs.near.org/docs/tools/near-cli)
- [RUST](https://www.rust-lang.org/tools/install)
- Add the WASM (WebAssembly) target to the toolchain by executing ` rustup target add wasm32-unknown-unknown` in terminal or powershell
# Build
In order to generate the wasm files for the contracts, navigate to `/src/shell_scripts` and run the `build.sh` script by typing `./build.sh` in the rtminal or powershell.
# Simulation Tests
In order to execute the simulation tests, navigate to the `src/shell_scripts` and run the `test.sh` script by typing `./test.sh`
# Test Staking Functionality Using CLI
In order to test the whole functionality of the application, please runt the following scripts in sequence
- `deposit_storage.sh` this script allows users to deposit 0.00859 NEAR to th FT contract so, their acocunting can be mainitained on the contract, on successful depoist 10,000 UNCT will be transferred to the specified account for testing purposes.
- `stake.sh` this script enables users to stake tokens for 3 minutes the list of APY can be retrieved by running the `get_apy.sh` ## You will need to change the `duration` and `staking_plan`
- `claim.sh` this script allows users to claim rewards but after staking for atleast 1 minute, users will wait for 1 minute to carry out subsequent claims
- `unstake.sh` this script allows stakers to withdraw thier tokens after the lock period ends.
## Note
You will need a testnet account in order to interact with the smart contract an account can be created from [here]([wal](https://wallet.testnet.near.org)
Please use the follwoing addresses for staking contract and fungible token contract respectively
#### staking contract address = ncd_staking_contract.testnet
#### fungible token contract address = ncd_ft_token.testnet
# Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `npm start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in your browser.
The page will reload when you make changes.\
You may also see any lint errors in the console.
### `npm test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `npm run build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `npm run eject`
**Note: this is a one-way operation. Once you `eject`, you can't go back!**
If you aren't satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you're on your own.
You don't have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn't feel obligated to use this feature. However we understand that this tool wouldn't be useful if you couldn't customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
### Code Splitting
This section has moved here: [https://facebook.github.io/create-react-app/docs/code-splitting](https://facebook.github.io/create-react-app/docs/code-splitting)
### Analyzing the Bundle Size
This section has moved here: [https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size](https://facebook.github.io/create-react-app/docs/analyzing-the-bundle-size)
### Making a Progressive Web App
This section has moved here: [https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app](https://facebook.github.io/create-react-app/docs/making-a-progressive-web-app)
### Advanced Configuration
This section has moved here: [https://facebook.github.io/create-react-app/docs/advanced-configuration](https://facebook.github.io/create-react-app/docs/advanced-configuration)
### Deployment
This section has moved here: [https://facebook.github.io/create-react-app/docs/deployment](https://facebook.github.io/create-react-app/docs/deployment)
### `npm run build` fails to minify
This section has moved here: [https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify](https://facebook.github.io/create-react-app/docs/troubleshooting#npm-run-build-fails-to-minify)
|
near_stakewars-iii | .github
ISSUE_TEMPLATE
BOUNTY.yml
FAQ.md
README.md
challenges
001.md
002.md
003.md
004.md
005.md
006.md
007.md
008.md
009.md
010.md
011.md
013.md
014.md
015.md
016.md
017.md
019.md
020.md
challenge-summary.md
community-001.md
community-002.md
draft-delegation.md
template.md
troubleshooting.md
|
commit.md
rules.md
| Welcome to Stake Wars: Episode III A New Validator
Stake Wars is a program that helps the community become familiar with what it means to be a NEAR validator, and gives the community an early chance to access the chunk-only producer.
Stake Wars offers rewards that support new members who want to join mainnet as a validator starting from the end of September 2022.
Hope the force will be with you !
https://github.com/near/stakewars-iii/blob/main/challenges/001.md
For Support and important announcements: https://discord.gg/7TercRzRgA
|
laponte243_near-certificates-nuxt | README.md
jsconfig.json
nuxt.config.js
package.json
services
api.js
static
vuetify-logo.svg
store
README.md
| # STORE
**This directory is not required, you can delete it if you don't want to use it.**
This directory contains your Vuex Store files.
Vuex Store option is implemented in the Nuxt.js framework.
Creating a file in this directory automatically activates the option in the framework.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/guide/vuex-store).
# near-certificates
## Build Setup
```bash
# install dependencies
$ npm install
# serve with hot reload at localhost:3000
$ npm run dev
# build for production and launch server
$ npm run build
$ npm run start
# generate static project
$ npm run generate
```
For detailed explanation on how things work, check out the [documentation](https://nuxtjs.org).
## Special Directories
You can create the following extra directories, some of which have special behaviors. Only `pages` is required; you can delete them if you don't want to use their functionality.
### `assets`
The assets directory contains your uncompiled assets such as Stylus or Sass files, images, or fonts.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/assets).
### `components`
The components directory contains your Vue.js components. Components make up the different parts of your page and can be reused and imported into your pages, layouts and even other components.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/components).
### `layouts`
Layouts are a great help when you want to change the look and feel of your Nuxt app, whether you want to include a sidebar or have distinct layouts for mobile and desktop.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/layouts).
### `pages`
This directory contains your application views and routes. Nuxt will read all the `*.vue` files inside this directory and setup Vue Router automatically.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/get-started/routing).
### `plugins`
The plugins directory contains JavaScript plugins that you want to run before instantiating the root Vue.js Application. This is the place to add Vue plugins and to inject functions or constants. Every time you need to use `Vue.use()`, you should create a file in `plugins/` and add its path to plugins in `nuxt.config.js`.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/plugins).
### `static`
This directory contains your static files. Each file inside this directory is mapped to `/`.
Example: `/static/robots.txt` is mapped as `/robots.txt`.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/static).
### `store`
This directory contains your Vuex store files. Creating a file in this directory automatically activates Vuex.
More information about the usage of this directory in [the documentation](https://nuxtjs.org/docs/2.x/directory-structure/store).
|
hadzija7_NearconVoting | .github
workflows
pages.yml
.gitpod.yml
README.md
contract
Cargo.toml
README.md
circuits
build
circuit_js
generate_witness.js
witness_calculator.js
verification_key.json
compile-circuits.sh
input.json
proof.json
public.json
neardev
dev-account.env
src
lib.rs
tests
electron.rs
semaphore.rs
frontend
App.js
assets
global.css
logo-black.svg
logo-white.svg
circuit
circuit_js
generate_witness.js
witness_calculator.js
generate-proof.js
verification_key.json
components
About
index.js
HelloNear
index.js
ui-components.js
Polls
Poll.js
index.js
index.html
index.js
near-config.js
package-lock.json
package.json
utils
HelloNear.js
Semaphore.js
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| Hello NEAR!
=================================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`.
2. There are two functions to the smart contract: `get_greeting` and `set_greeting`.
3. Tests: You can run smart contract tests with the `cargo test`.
[smart contract]: https://docs.near.org/develop/welcome
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://docs.near.org/develop/prerequisites#rust-and-wasm
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
near-blank-project
==================
This app was initialized with [create-near-app]
Quick Start
===========
If you haven't installed dependencies during setup:
npm run deps-install
Build and deploy your contract to TestNet with a temporary dev account:
npm run deploy
Test your contract:
npm test
If you have a frontend, run `npm start`. This will run a dev server.
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/index.js`,
this is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId near-blank-project.YOUR-NAME.testnet --wasmFile PATH_TO_WASM_FILE
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-blank-project.YOUR-NAME.testnet'
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/concepts/basics/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
|
morganpage_unity-multiplayer-blockchain-near-course | .vscode
settings.json
Assets
FishNet
CodeGenerating
Extension
ILProcessorExtensions.cs
TypeDefinitionExtensions.cs
TypeReferenceExtensions.cs
FN_README.txt
Helpers
AttributeHelper.cs
CodegenSession.cs
CreatedSyncVarGenerator.cs
Extension
CustomAttributeExtensions.cs
Diagnostics.cs
FieldReferenceExtensions.cs
GetConstructor.cs
ILProcessorExtensions.cs
InstructionExtensions.cs
MethodDefinitionExtensions.cs
MethodReferenceExtensions.cs
ModuleDefinitionExtensions.cs
ParameterDefinitionExtensions.cs
TypeDefinitionExtensions.cs
TypeReferenceExtensions.cs
GeneralHelper.cs
GenericReaderHelper.cs
GenericWriterHelper.cs
NetworkBehaviourHelper.cs
NetworkConnectionHelper.cs
ObjectHelper.cs
PredictedObjectHelper.cs
ReaderGenerator.cs
ReaderHelper.cs
TimeManagerHelper.cs
TransportHelper.cs
Typed
Comparers.cs
CreatedSyncType.cs
GeneratorHelper.cs
QOLAttributeType.cs
SerializatierType.cs
SyncIndexData.cs
SyncType.cs
WriterGenerator.cs
WriterHelper.cs
ILCore
FishNetILPP.cs
ILCoreHelper.cs
PostProcessorAssemblyResolver.cs
PostProcessorReflectionImporter.cs
PostProcessorReflectionImporterProvider.cs
Processing
CustomSerializerProcessor.cs
NetworkBehaviourPredictionProcessor.cs
NetworkBehaviourProcessor.cs
NetworkBehaviourSyncProcessor.cs
QOLAttributeProcessor.cs
Rpc
AttributeData.cs
Attributes.cs
CreatedRpc.cs
RpcProcessor.cs
Typed
ProcessedSync.cs
cecil-0.11.4
LICENSE.txt
Mono.Cecil.Cil
Code.cs
CodeReader.cs
CodeWriter.cs
Document.cs
ExceptionHandler.cs
ILProcessor.cs
Instruction.cs
MethodBody.cs
OpCode.cs
OpCodes.cs
PortablePdb.cs
SequencePoint.cs
Symbols.cs
VariableDefinition.cs
VariableReference.cs
Mono.Cecil.Metadata
BlobHeap.cs
Buffers.cs
CodedIndex.cs
ElementType.cs
GuidHeap.cs
Heap.cs
MetadataToken.cs
PdbHeap.cs
Row.cs
StringHeap.cs
TableHeap.cs
TokenType.cs
UserStringHeap.cs
Utilities.cs
Mono.Cecil.PE
BinaryStreamReader.cs
BinaryStreamWriter.cs
ByteBuffer.cs
ByteBufferEqualityComparer.cs
DataDirectory.cs
Image.cs
ImageReader.cs
ImageWriter.cs
Section.cs
TextMap.cs
Mono.Cecil
ArrayType.cs
AssemblyDefinition.cs
AssemblyFlags.cs
AssemblyHashAlgorithm.cs
AssemblyInfo.cs
AssemblyLinkedResource.cs
AssemblyNameDefinition.cs
AssemblyNameReference.cs
AssemblyReader.cs
AssemblyWriter.cs
BaseAssemblyResolver.cs
CallSite.cs
Consts.cs
CustomAttribute.cs
DefaultAssemblyResolver.cs
EmbeddedResource.cs
EventAttributes.cs
EventDefinition.cs
EventReference.cs
ExportedType.cs
FieldAttributes.cs
FieldDefinition.cs
FieldReference.cs
FileAttributes.cs
FunctionPointerType.cs
GenericInstanceMethod.cs
GenericInstanceType.cs
GenericParameter.cs
GenericParameterAttributes.cs
GenericParameterResolver.cs
IConstantProvider.cs
ICustomAttributeProvider.cs
IGenericInstance.cs
IGenericParameterProvider.cs
IMarshalInfoProvider.cs
IMemberDefinition.cs
IMetadataScope.cs
IMetadataTokenProvider.cs
IMethodSignature.cs
Import.cs
LinkedResource.cs
ManifestResourceAttributes.cs
MarshalInfo.cs
MemberDefinitionCollection.cs
MemberReference.cs
MetadataResolver.cs
MetadataSystem.cs
MethodAttributes.cs
MethodCallingConvention.cs
MethodDefinition.cs
MethodImplAttributes.cs
MethodReference.cs
MethodReferenceComparer.cs
MethodReturnType.cs
MethodSemanticsAttributes.cs
MethodSpecification.cs
Modifiers.cs
ModuleDefinition.cs
ModuleKind.cs
ModuleReference.cs
NativeType.cs
PInvokeAttributes.cs
PInvokeInfo.cs
ParameterAttributes.cs
ParameterDefinition.cs
ParameterDefinitionCollection.cs
ParameterReference.cs
PinnedType.cs
PointerType.cs
PropertyAttributes.cs
PropertyDefinition.cs
PropertyReference.cs
ReferenceType.cs
Resource.cs
SecurityDeclaration.cs
SentinelType.cs
TargetRuntime.cs
Treatments.cs
TypeAttributes.cs
TypeComparisonMode.cs
TypeDefinition.cs
TypeDefinitionCollection.cs
TypeParser.cs
TypeReference.cs
TypeReferenceEqualityComparer.cs
TypeResolver.cs
TypeSpecification.cs
TypeSystem.cs
VariantType.cs
WindowsRuntimeProjections.cs
Mono.Collections.Generic
Collection.cs
ReadOnlyCollection.cs
Mono.Security.Cryptography
CryptoConvert.cs
CryptoService.cs
Mono
Disposable.cs
Empty.cs
MergeSort.cs
ProjectInfo.cs
README.md
rocks
Mono.Cecil.Rocks
AssemblyInfo.cs
DocCommentId.cs
Functional.cs
ILParser.cs
MethodBodyRocks.cs
MethodDefinitionRocks.cs
ModuleDefinitionRocks.cs
ParameterReferenceRocks.cs
SecurityDeclarationRocks.cs
TypeDefinitionRocks.cs
TypeReferenceRocks.cs
DOCUMENTATION.txt
Example
All
Authenticator
Scripts
Broadcasts.cs
HostAuthenticator.cs
PasswordAuthenticator.cs
CustomSyncType
Component State Sync
AMonoScript.cs
ComponentStateSync.cs
ComponentSyncStateBehaviour.cs
Custom Struct Sync
StructSyncBehaviour.cs
StructySync.cs
Prediction
CharacterController
Scripts
CharacterControllerPrediction.cs
Rigidbody
Scripts
RigidbodyPrediction.cs
Transform
Scripts
TransformPrediction.cs
SceneManager
Scripts
PlayerController.cs
SceneLoaderExample.cs
SceneUnloaderExample.cs
Scripts
NetworkHudCanvases.cs
LICENSE.txt
Plugins
Addressables
AddressablesExtensions.cs
CodeAnalysis
LICENSE.txt
README.txt
Runtime
Authenticating
Authenticator.cs
Broadcast
Helping
BroadcastHelper.cs
IBroadcast.cs
Config.json
Connection
Buffer.cs
NetworkConnection.Buffer.cs
NetworkConnection.PingPong.cs
NetworkConnection.Prediction.cs
NetworkConnection.QOL.cs
NetworkConnection.cs
Documenting
Attributes.cs
Editor
CodeStripping.cs
Configuration
SettingsProvider.cs
Configuring
ConfigurationData.cs
ConfigurationEditor.cs
Configuring.cs
SettingsProvider.cs
Constants.cs
DefaultPrefabsFinder.cs
Finding.cs
PlayModeTracker.cs
PrefabCollectionGenerator
Generator.cs
Settings.cs
SettingsProvider.cs
PrefabProcessor.cs
ScriptingDefines.cs
Generated
Component
NetworkAnimator
Editor
NetworkAnimatorEditor.cs
NetworkAnimator.cs
NetworkTransform
Editor
NetworkTransformEditor.cs
NetworkTransform.cs
SynchronizedProperty.cs
Prediction
DesyncSmoother.cs
Editor
PredictedObjectEditor.cs
OfflineRigidbody.cs
PredictedObject.Rigidbodies.cs
PredictedObject.cs
PredictedRigidbody.cs
PredictedRigidbody2D.cs
PredictedRigidbodyBase.cs
RigidbodyPauser.cs
RigidbodyState.cs
RigidbodyType.cs
Spawning
PlayerSpawner.cs
Utility
BandwidthDisplay.cs
DefaultScene.cs
PingDisplay.cs
ReaderAndWriters
ConnectionReaderWriters.cs
ScenedReaderWriters.cs
InstanceFinder.cs
Managing
Client
ClientManager.Broadcast.cs
ClientManager.cs
Editor
ClientManagerEditor.cs
Object
ClientObjects.RpcLinks.cs
ClientObjects.cs
ObjectCaching.cs
Debugging
DebugManager.cs
ParseLogger.cs
Editor
NetworkManagerEditor.cs
Logging
LoggingConfiguration.cs
LoggingType.cs
NetworkManager.Logging.cs
NetworkManager.Pro.cs
NetworkManager.QOL.cs
NetworkManager.cs
Object
DualPrefab.cs
ManagedObjects.cs
ObjectSpawnType.cs
PrefabObjects
DefaultPrefabObjects.cs
DualPrefabObjects.cs
PrefabObjects.cs
SinglePrefabObjects.cs
SpawnParentType.cs
ObserverManager.cs
Scened
Broadcast
SceneBroadcasts.cs
DefaultSceneProcessor.cs
Events
ClientPresenceChangeEventArgs.cs
LoadSceneEventArgs.cs
UnloadSceneEventArgs.cs
LoadUnloadDatas
LoadOptions.cs
LoadParams.cs
LoadQueueData.cs
ReplaceOption.cs
SceneLoadData.cs
SceneScopeTypes.cs
SceneUnloadData.cs
UnloadOptions.cs
UnloadParams.cs
UnloadQueueData.cs
SceneLookupData.cs
SceneManager.cs
SceneProcessorBase.cs
SceneSpawner.cs
Server
ClientConnectionBroadcast.cs
Editor
ServerManagerEditor.cs
Object
ServerObjects.Observers.cs
ServerObjects.Parsing.cs
ServerObjects.cs
ServerManager.Broadcast.cs
ServerManager.QOL.cs
ServerManager.RpcLinks.cs
ServerManager.cs
Statistic
NetworkTrafficArgs.cs
NetworkTrafficStatistics.cs
StatisticsManager.cs
Timing
Editor
TimeManagerEditor.cs
MovingAverage.cs
PhysicsMode.cs
PreciseTick.cs
SceneComparer.cs
TickRounding.cs
TickType.cs
TimeManager.cs
Transporting
LatencySimulator.cs
SplitReader.cs
TransportManager.QOL.cs
TransportManager.cs
Utility
Utility.cs
Object
Attributes.cs
ChangedTransformProperties.cs
Delegates.cs
DespawnType.cs
EmptyNetworkBehaviour.cs
Helping
Hashing.cs
RpcLink.cs
RpcType.cs
StaticShortcuts.cs
NetworkBehaviour.Callbacks.cs
NetworkBehaviour.Logging.cs
NetworkBehaviour.Prediction.cs
NetworkBehaviour.QOL.cs
NetworkBehaviour.RPCLinks.cs
NetworkBehaviour.RPCs.cs
NetworkBehaviour.SyncTypes.cs
NetworkBehaviour.cs
NetworkObject.Broadcast.cs
NetworkObject.Callbacks.cs
NetworkObject.Observers.cs
NetworkObject.QOL.cs
NetworkObject.ReferenceIds.cs
NetworkObject.RpcLinks.cs
NetworkObject.SyncTypes.cs
NetworkObject.cs
NetworkObjectState.cs
Prediction
Attributes.cs
Delegates.cs
RpcLinkType.cs
Synchronizing
ICustomSync.cs
ISyncObject.cs
MissingObjectPacketLength.cs
ReadPermissions.cs
SecretMenu
SyncVarExtensions.cs
Settings.cs
SyncBase.cs
SyncDictionary.cs
SyncDictionaryOperation.cs
SyncHashSetOperation.cs
SyncHashset.cs
SyncList.cs
SyncListOperation.cs
SyncVar.cs
WritePermissions.cs
TransformProperties.cs
Observing
Conditions
DistanceCondition.cs
Editor
MatchConditionEditor.cs
MatchCondition.cs
OwnerOnlyCondition.cs
SceneCondition.cs
ServerOnlyCondition.cs
HostVisibilityUpdateTypes.cs
NetworkObserver.cs
ObserverCondition.cs
ObserverStateChange.cs
Plugins
ColliderRollback
Attributions.txt
LICENSE.txt
Scripts
ColliderRollback.cs
RollbackManager.cs
Yak
CHANGELOG.txt
Core
ClientSocket.cs
CommonSocket.cs
LocalPacket.cs
ServerSocket.cs
VERSION.txt
Yak.cs
Serializing
AutoPackType.cs
Helping
Attributes.cs
Broadcasts.cs
Comparers.cs
Quaternion32.cs
Quaternion64.cs
QuaternionConverter.cs
ValueConversions.cs
Reader.cs
ReaderExtensions.cs
ReaderPool.cs
ReaderStatics.cs
TransformPackingData.cs
Writer.cs
WriterExtensions.cs
WriterPool.cs
WriterStatics.cs
Transporting
Channels.cs
ConnectionStates.cs
EventStructures.cs
IPAddressType.cs
NetworkReaderLoop.cs
NetworkWriterLoop.cs
PacketId.cs
Transport.cs
Transports
Multipass
CHANGELOG.txt
Multipass.cs
VERSION.txt
Tugboat
Core
ClientSocket.cs
CommonSocket.cs
ServerSocket.cs
Supporting.cs
LiteNetLib
BaseChannel.cs
ConnectionRequest.cs
INetEventListener.cs
InternalPackets.cs
Layers
Crc32cLayer.cs
PacketLayerBase.cs
XorEncryptLayer.cs
NatPunchModule.cs
NativeSocket.cs
NetConstants.cs
NetDebug.cs
NetManager.PacketPool.cs
NetManager.Socket.cs
NetManager.cs
NetPacket.cs
NetPeer.cs
NetStatistics.cs
NetUtils.cs
PooledPacket.cs
ReliableChannel.cs
SequencedChannel.cs
Utils
CRC32C.cs
FastBitConverter.cs
INetSerializable.cs
NetDataReader.cs
NetDataWriter.cs
NetPacketProcessor.cs
NetSerializer.cs
NtpPacket.cs
NtpRequest.cs
Tugboat.cs
Utility
ApplicationState.cs
Constants.cs
DDOLFinder.cs
Editor
MiscMenu.cs
SceneDrawer.cs
Extension
Collection.cs
Dictionary.cs
Enum.cs
Math.cs
Object.cs
Quaternion.cs
Scene.cs
Transform.cs
Transforms.cs
Performance
ByteArrayPool.cs
DefaultObjectPool.cs
ListCache.cs
ObjectPool.cs
Transform.cs
Transforms.cs
SceneAttribute.cs
THIRD PARTY NOTICE.md
Upgrading
MirrorUpgrade.cs
UpgradeFromMirrorMenu.cs
VERSION.txt
Game
Scripts
CameraFollow.cs
Damager.cs
Health.cs
Move2D.cs
NearGameController.cs
Player.cs
ParrelSync
Examples
CustomArgumentExample.cs
LICENSE.md
ParrelSync
Editor
AssetModBlock
EditorQuit.cs
ParrelSyncAssetModificationProcessor.cs
ClonesManager.cs
ClonesManagerWindow.cs
ExternalLinks.cs
FileUtilities.cs
NonCore
AskFeedbackDialog.cs
OtherMenuItem.cs
Preferences.cs
Project.cs
UpdateChecker.cs
ValidateCopiedFoldersIntegrity.cs
package.json
README.md
VERSION.txt
RFG
NEAR
Scripts
NearAPI.cs
NearCallbacks.cs
NearController.cs
UI
UIToken.cs
Utils
RestAPI.cs
UnityAsyncOperationAwaiter.cs
TextMesh Pro
Fonts
LiberationSans - OFL.txt
Resources
LineBreaking Following Characters.txt
LineBreaking Leading Characters.txt
Sprites
EmojiOne Attribution.txt
EmojiOne.json
Tutorial
Scripts
JumpBall.cs
MoveBall.cs
WebGLTemplates
NEAR
index.html
IMPORTANT
Packages
manifest.json
packages-lock.json
ProjectSettings
BurstAotSettings_StandaloneWindows.json
BurstAotSettings_WebGL.json
CommonBurstAotSettings.json
ProjectVersion.txt
SceneTemplateSettings.json
| Cecil
=====
Mono.Cecil is a library to generate and inspect programs and libraries in the ECMA CIL form.
To put it simply, you can use Cecil to:
* Analyze .NET binaries using a simple and powerful object model, without having to load assemblies to use Reflection.
* Modify .NET binaries, add new metadata structures and alter the IL code.
Cecil has been around since 2004 and is [widely used](https://github.com/jbevain/cecil/wiki/Users) in the .NET community. If you're using Cecil, or depend on a framework, project, or product using it, please consider [sponsoring Cecil](https://github.com/sponsors/jbevain/).
Read about the Cecil development on the [development log](http://cecil.pe).
To discuss Cecil, the best place is the [mono-cecil](https://groups.google.com/group/mono-cecil) Google Group.
Cecil is a project under the benevolent umbrella of the [.NET Foundation](http://www.dotnetfoundation.org/).
# ParrelSync
[](https://github.com/VeriorPies/ParrelSync/releases) [](https://github.com/VeriorPies/ParrelSync/wiki) [](https://github.com/VeriorPies/ParrelSync/blob/master/LICENSE.md) [](https://github.com/VeriorPies/ParrelSync/pulls) [](https://discord.gg/TmQk2qG)
ParrelSync is a Unity editor extension that allows users to test multiplayer gameplay without building the project by having another Unity editor window opened and mirror the changes from the original project.
<br>
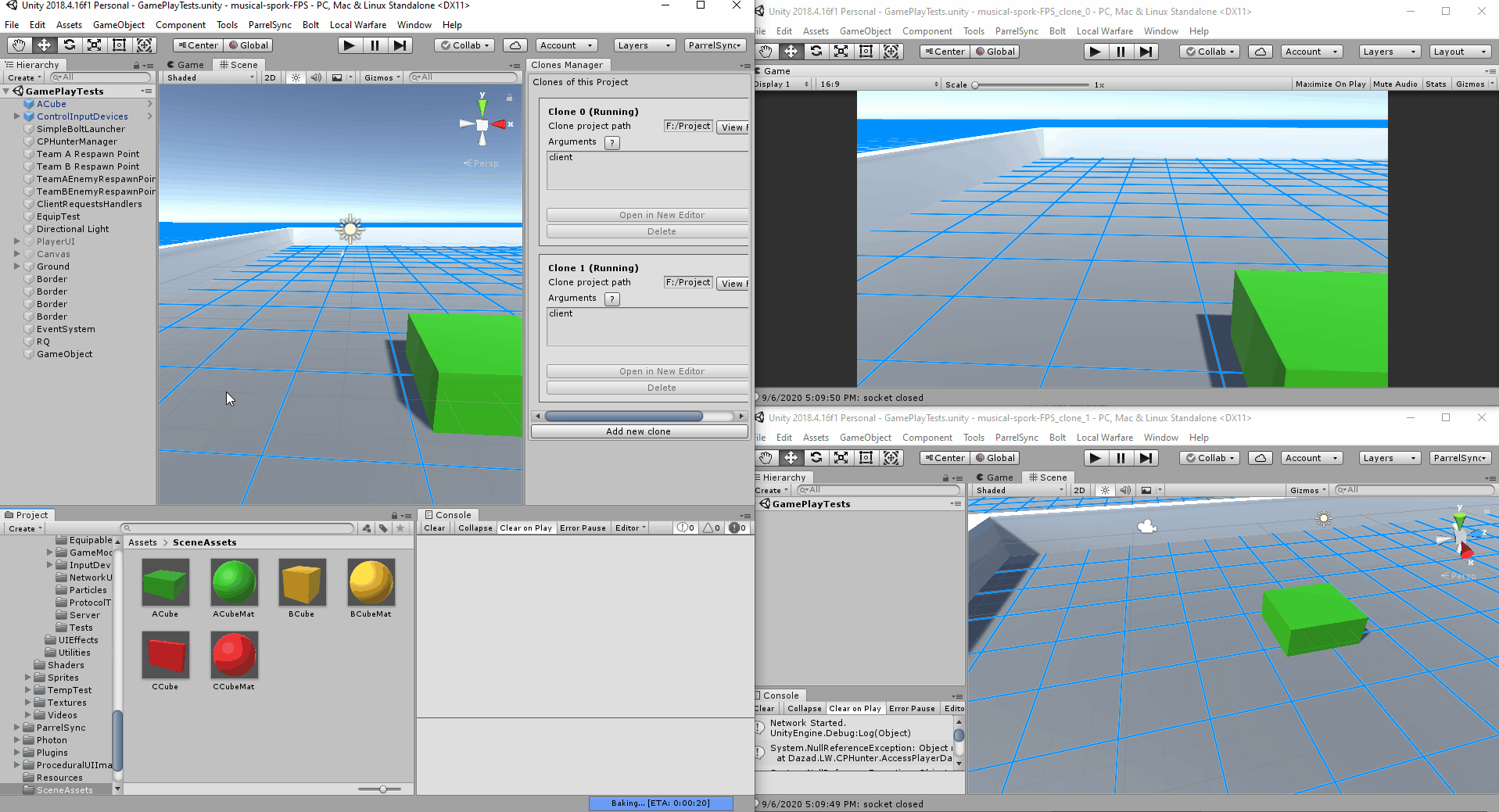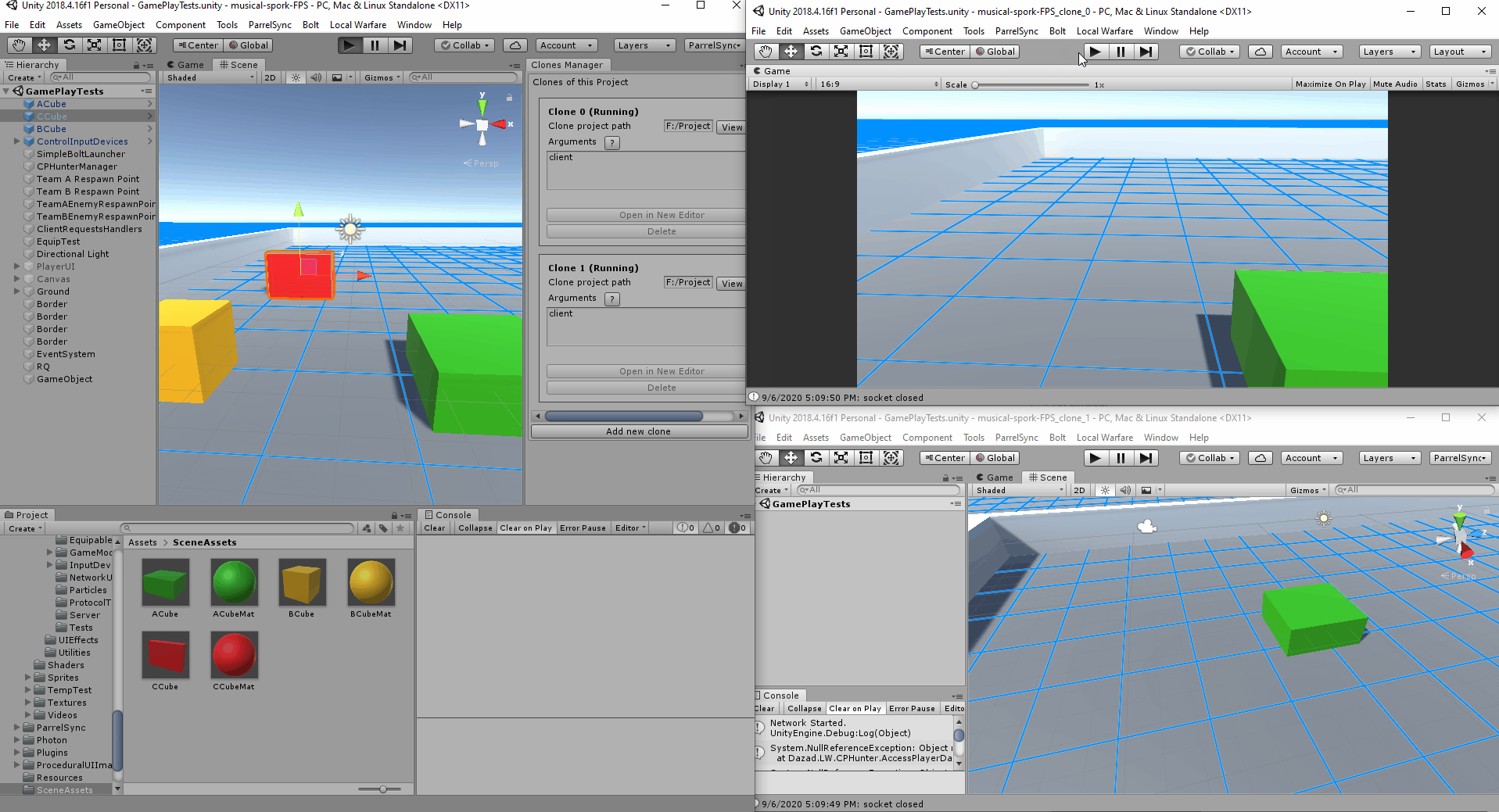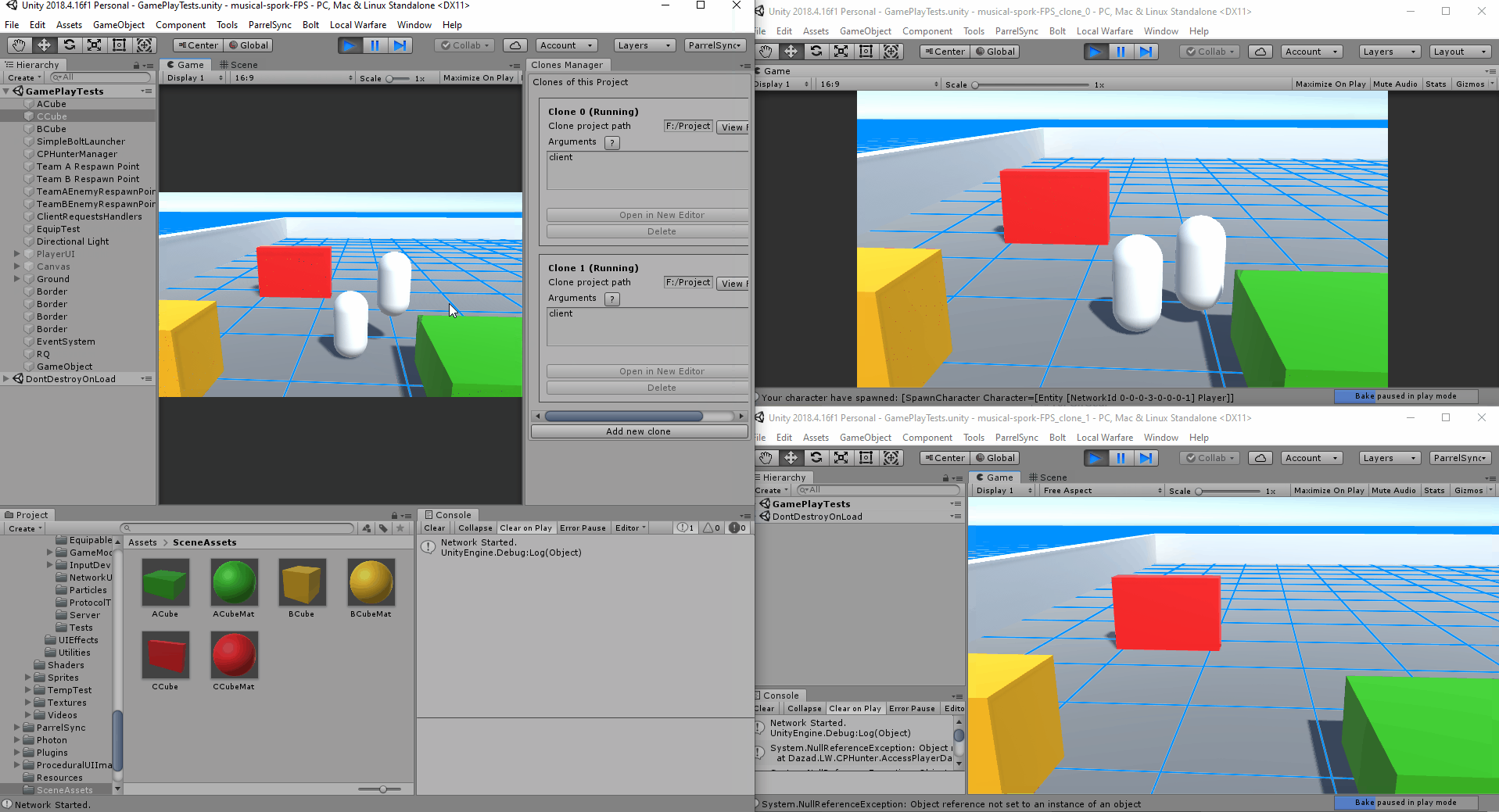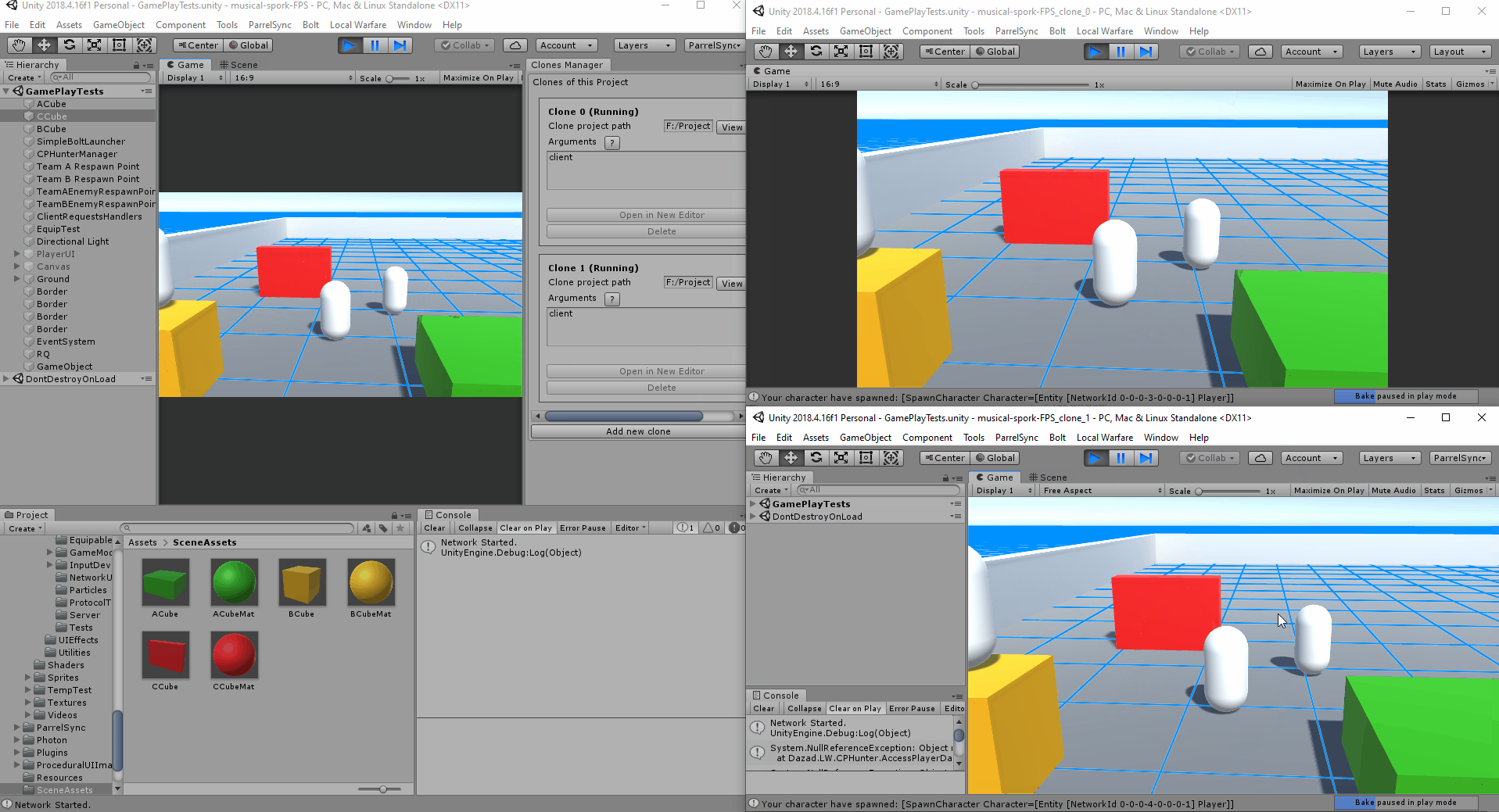
<p align="center">
<b>Test project changes on clients and server within seconds - both in editor
</b>
<br>
</p>
## Features
1. Test multiplayer gameplay without building the project
2. GUI tools for managing all project clones
3. Protected assets from being modified by other clone instances
4. Handy APIs to speed up testing workflows
## Installation
1. Backup your project folder or use a version control system such as [Git](https://git-scm.com/) or [SVN](https://subversion.apache.org/)
2. Download .unitypackage from the [latest release](https://github.com/VeriorPies/ParrelSync/releases) and import it to your project.
3. ParrelSync should appreared in the menu item bar after imported

Check out the [Installation-and-Update](https://github.com/VeriorPies/ParrelSync/wiki/Installation-and-Update) page for more details.
### UPM Package
ParrelSync can also be installed via UPM package.
After Unity 2019.3.4f1, Unity 2020.1a21, which support path query parameter of git package. You can install ParrelSync by adding the following to Package Manager.
```
https://github.com/VeriorPies/ParrelSync.git?path=/ParrelSync
```
 
or by adding
```
"com.veriorpies.parrelsync": "https://github.com/VeriorPies/ParrelSync.git?path=/ParrelSync"
```
to the `Packages/manifest.json` file
## Supported Platform
Currently, ParrelSync supports Windows, macOS and Linux editors.
ParrelSync has been tested with the following Unity version. However, it should also work with other versions as well.
* *2020.3.1f1*
* *2019.3.0f6*
* *2018.4.22f1*
## APIs
There's some useful APIs for speeding up the multiplayer testing workflow.
Here's a basic example:
```
if (ClonesManager.IsClone()) {
// Automatically connect to local host if this is the clone editor
}else{
// Automatically start server if this is the original editor
}
```
Check out [the doc](https://github.com/VeriorPies/ParrelSync/wiki/List-of-APIs) to view the complete API list.
## How does it work?
For each clone instance, ParrelSync will make a copy of the original project folder and reference the ```Asset```, ```Packages``` and ```ProjectSettings``` folder back to the original project with [symbolic link](https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/mklink). Other folders such as ```Library```, ```Temp```, and ```obj``` will remain independent for each clone project.
All clones are placed right next to the original project with suffix *```_clone_x```*, which will be something like this in the folder hierarchy.
```
/ProjectName
/ProjectName_clone_0
/ProjectName_clone_1
...
```
## Discord Server
We have a [Discord server](https://discord.gg/TmQk2qG).
## Need Help?
Some common questions and troubleshooting can be found under the [Troubleshooting & FAQs](https://github.com/VeriorPies/ParrelSync/wiki/Troubleshooting-&-FAQs) page.
You can also [create a question post](https://github.com/VeriorPies/ParrelSync/issues/new/choose), or ask on [Discord](https://discord.gg/TmQk2qG) if you prefer to have a real-time conversation.
## Support this project
A star will be appreciated :)
## Credits
This project is originated from hwaet's [UnityProjectCloner](https://github.com/hwaet/UnityProjectCloner)
|
mel1huc4r_Near-Web3-Project | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
simple
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| # `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **simple** in the `src/simple` folder
- **singleton** in the `src/singleton` folder
### Simple
We say that an AssemblyScript contract is written in the "simple style" when the `index.ts` file (the contract entry point) includes a series of exported functions.
In this case, all exported functions become public contract methods.
```ts
// return the string 'hello world'
export function helloWorld(): string {}
// read the given key from account (contract) storage
export function read(key: string): string {}
// write the given value at the given key to account (contract) storage
export function write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
```
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
INSTALL `NEAR CLI` first like this: `npm i -g near-cli`
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── simple # Contract 1: "Simple example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 1
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 1
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
www.patika.dev
## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
|
mfurkanturk_Near-sdk-as-part2-hello | README.md
as-pect.config.js
asconfig.json
neardev
dev-account.env
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
simple
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| # `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **simple** in the `src/simple` folder
- **singleton** in the `src/singleton` folder
### Simple
We say that an AssemblyScript contract is written in the "simple style" when the `index.ts` file (the contract entry point) includes a series of exported functions.
In this case, all exported functions become public contract methods.
```ts
// return the string 'hello world'
export function helloWorld(): string {}
// read the given key from account (contract) storage
export function read(key: string): string {}
// write the given value at the given key to account (contract) storage
export function write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
```
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
INSTALL `NEAR CLI` first like this: `npm i -g near-cli`
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── simple # Contract 1: "Simple example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 1
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 1
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
|
ngocducedu_zoo-nft-auction-fund-nearhackathon | .cache
00
0803118f1a091f0032fbd184652b9d.json
0c2e28f554187d8d124745277f18e4.json
128f13a61ee9b147adf5f7f90b82f6.json
15c9f4f1ccd694c51505a34744bf96.json
1a0033b958a5d65e12b0c65432f5da.json
1f67a1f7717d755d3cf2c6cef5c0bf.json
3d8514f582e1829d9be9f69d6a69f0.json
4d3ece5e991662bb107de2c6e9baa0.json
6be96bb42d6f9c374db8dceb56942c.json
b24348151b6d89140824076d6523a1.json
be75996db8831680bde3cb78e96715.json
c0e2d9818424e917c9ba326526c8f7.json
c7078edf32a798b92e4ac3ef6c6a95.json
dedda8441f88498940de4f285456ea.json
eaf96b9deeb22844cf052764cfc285.json
ebf662eceae297a02566d4b656fbcf.json
fd72e7115d39c27269064548a2caad.json
01
2c83e496b6affeff4bb02d7913398e.json
a834781334737f7b835d308e5b224e.json
ca5a35bcd9a4cd59ee01796fd5b235.json
f7d1585c2a5e89c862ad97a4f9b1b8.json
f8dd566b764a1cfec87ec448fe9d99.json
02
091f6221780aadcb06834b400789d2.json
2b0f9dfdfd9588514540f881c1e58e.json
66e344e4d50dbb3d80356b90c67bf1.json
91ad82bfedd5922f5c1d752d1aae8f.json
ac5f0fdbbca35b9c7976c366f4f17a.json
ce4423784984736c6ff1c6f9acd07e.json
d1d9fa06755f7ae362faef0eabcd19.json
03
6e30a718076243178dc2637d557d33.json
71be39ac6a8e6f8b36952bc04fcd22.json
83beb6a1e839c5d15b91f5205ac794.json
9676abd38ee501a9f3386937727cc8.json
9e3e37a2c18510a31403c0f2cedef5.json
ae9105dba65194f3e348dfc7a0e3f5.json
cf9131d810c75340dc35343e59431b.json
04
132292ae8ba6c07a789278dd41eeb7.json
2413869410fd6e493be130e3a8bb6a.json
2a222191a0bf2633d630a80f0e0081.json
422f1e44c8e5f8b222fb75f8b4db68.json
4dbf4135e5bacf0cac0a42319d7e86.json
62035eb7a0764b026f7ee972a90c50.json
bdbc57736c41a2496622c396036652.json
c1c27fd8a157ae2f530f1ae9e98332.json
d7ce43b1529c32925e015173a3baf7.json
05
09ff114d420b566257c4de60918e4e.json
12cb041a14c300d26a7d10b3708e06.json
32fcbdc6e7b20cfa305735b246b044.json
45f40a3b97dc98c3520dc1ac78d6e7.json
4810ccd1111b9ca036b53c21945b7e.json
9b7b1c0c3073312f322c2279561ad0.json
c12f453908a643731c015474335900.json
d4c3080cd9bc0da5c2d2fafc962319.json
d89e598efd66fda6e5361a77c2ec5a.json
edc3b943b4ee4827bdf3c2f4f7dec1.json
06
110d46c5a373e4cad15ea7be92fccc.json
48c7c78d1db5b9b9039991eba61c99.json
4940c5db6526c795f848678eae21aa.json
5e90fbfab54ad5396689675c4d3e2a.json
630f36e886f09df7282fa34a8fc96f.json
69c5bfa0b55a85bdff537c1a125b7f.json
9d8c90e1a7a3ff879530c0b6ccb307.json
a82c9aadae5cbb5e8dfe58f55a965a.json
bc58f7fe383076990fb259ece4999b.json
c014091f6296f19da8c919960170d2.json
07
0e686037a82d2deaadc2129d9b0037.json
1c59f6e95a4f9f9938be2dc32cac27.json
22a7d03e6e16445546e2ecb9051e33.json
248b01329925370ce06741a9af10ac.json
2a81a70002cc6e56d593206d20542a.json
4faf58e93fe888f033864565bea5e9.json
5370226c8e8c2ec95ad4c5f1a0de3a.json
58d1c0dfa65d0fe6740916ea7083aa.json
6d3eeed7781112b26b88f3f4557afd.json
7e654b4f9b990c3ce539e9aa850a81.json
b8342a55d3f68e5ae3992cdba1c68a.json
bab399da322ee88899b2b68681719d.json
08
6861290232d1e020bd2c17e980ce0c.json
7c1ecb2a4dc6f51c4695b9d5fcf20f.json
7e5dcf35ff4e7b0c04ec8a4ee99e51.json
9623f84a0560d59f04739570a604d9.json
f2a9c0e4b7c16cd17a09da4a5c348d.json
09
06bad5b749c79e085fa12b4861d796.json
2831b643fa216bf2abfff8be5db4e7.json
72eef8c73ccccdfff534ec8ccafe8c.json
a340c0f59d204f85bc8cf2895b0715.json
0a
12248597be6df5fc10855d0ce94c92.json
3ef229e1226d0d638bc16ae0f66be0.json
4b9d7fc5d9e7583363c612ccae03b6.json
54d452c0392a6610b0475e236cfe82.json
5d7158e6040a755598fe581b5fdd5e.json
5f0c4e7c2a67736594361f935f4b5e.json
6247dad9ab36335f7b752deda10282.json
63a2a7152a4ee19deb8a7cfd4ef24b.json
67eb2e7e0bc0ff48a040cd6760364a.json
7aa9cc2092db6753757384092a44dd.json
8ede6298e0bf2f48a25c304a7a70b4.json
a249e9d0529a8c0d4f0fc145a339b9.json
a68553ba799083bfd68ce89a6ab4e8.json
bd61360b87484f1c55341fb41064d1.json
d77de799a701734765520944a75d27.json
d7ae2f0c447bad6ee07d726bef9e75.json
fb3fce340d00f6a5baf0f1cdf37948.json
0b
08de943150e92c6863de00fa9d90ee.json
1391ebd98f280cb940fd923a2e2e31.json
19ce92189f6ac6fe3d527bd2533953.json
4b46be4d3eeaecf902f4995a45a7f8.json
9da74eeb770a88a84b35bd56c95379.json
c4f18b528a7cbb9f2c068266ba0f94.json
0c
0eb79edddff3072f8fc6a86db497ba.json
21757356899259f6b55831b853a4ab.json
3ae7dc85d5c3493274b7d48d357c2e.json
4635c235266596cdac7ad17abc151e.json
63405643bc6eac3ea0a6e6ed876ac0.json
80ca6464290e29c4a1fa7b17742169.json
977829a7e5f144b608bcacbf5810d5.json
b29352af043f82f7c059e717fc9a9d.json
f707cd45a2bb2fd3db10e747351fa5.json
0d
497b2ce5df93c2bb7eacb01da21882.json
71953a6f9f402a4c2d6d9534395ca5.json
8ba820af4efe379dcb81eadb1cae4e.json
b5a646f76c0e61c25726cc6d724302.json
d35bbd41a6548c7b1b29d383075b9b.json
fc7e0a246e6e660ec85fa2e68c4df6.json
0e
3f5b67091e0b7ad7818e36ee587b43.json
5919766da2e2a60d5f18313dd38b9a.json
7190c4501669686b084c6296e61f3c.json
73dc113519bed5cef0b481351bd3e8.json
97dca8f3de68f33305418dbcaa48b4.json
bba5a7fbf030a9a26b3c334ddc23f6.json
bbcb92d74805bd892ea98b4bf972e6.json
c03efa2660fce6eff779f625ee6dca.json
f1d0a269bf0cc8e68d9112097ceaff.json
f8aa7eedece575a474977582dea2f0.json
0f
25d7f0c6c870b6e7d70d6c55a0bbe3.json
341ee649465023071dbf0929a5c002.json
342eb0fd7e35ef02f12d39fa984e79.json
36da045a4aac567e4ae19c5bad506f.json
4c1c56e167221f527f1bd143865abc.json
78b80fec0a1a0fa4fea116a11abb64.json
7e41abde59246844c2efd4f3af6e06.json
83069f08a3d6840834384d53916ce9.json
b674e543f83853b26c833bcb231b60.json
c0cc31c43cd42acdde2a735da30a13.json
f157d0fdbdaf6ce3bbb0ed454bef90.json
10
40c80a08b96b8081ae02effb0e2d54.json
4442f7164c4d9a1de539b00eb7a495.json
4593d9775fa2a79579710d3d37e637.json
4b90c0dfd01558ab0673369f6b0a37.json
59726bd3236c4d3bce98b131b11ad2.json
802219fdb78228235a7e0818bf64bd.json
802eb244dae723df12df759cc0e4ad.json
fc33cd6d3197b2bef6da07278c75b1.json
11
2531092fb974126fe1d68998fe20ee.json
2d0f674cb35dfaf5febf7f12893f29.json
3a7d9380395da4cbccb612d099c553.json
5c9db9450af4fea8162dacdfe7b88a.json
81842d20d567d3e581e38a768012cb.json
8600091713ba95da8051245080dc1c.json
99968ab0e33bffe9396a2ed9e9d939.json
aeb7dec708fe873436c0aebdac2af9.json
d0a08f0d8ffa9c23e538c2fd0a9c8f.json
d4d4f66acd5a49779d0b9afb338cde.json
12
1c70c158f8b2d7b316c872e5d87484.json
4f37207fce5ff2daad10143a35a1e0.json
610870eee96953efa15683a814258d.json
63b7b0e312545cc783bbf72698c30f.json
a1ec47d430aa4b3cb8d73a6107139f.json
e130ccbbc72ee44aa0c49d9d501f27.json
e3970aca4b80dbfacc2b541db242e4.json
edd2b24f836b44f1623577ea4de0df.json
fd55e8f9b5768b989ee09e52115356.json
13
15b4d912af7cd62442816bd755bee3.json
1dabfa1d8421354a2b301838968321.json
28a190ce9162f6537d8f8fb2c30006.json
387d61d7e071ff00ecb4c1a35d5129.json
4ba57551e9842f4b3cd97dbc8fd840.json
797c3e9cccac04a74ad291758eb5eb.json
7aa74af52b7b995e26bee2c283d3b0.json
b986bcc45a8aaa1978cfe964a03b35.json
cb2a2633afbd245e9faaeb0d13e05f.json
f9af0ca58843b36296ce73489963b9.json
14
06783fd64014c182c298e03ca544e8.json
43ce3f534de6faef002f16a699a61a.json
5bcf59cc235497ead57dba94be2822.json
5c6a147b28f5c3b383ae28fddce1ed.json
7f113e630ed3ee0f350318e111e696.json
da4b65691ac1a99cf2ad5b3cce9df1.json
15
0d150a66fa4661b4133914ea6b4ffc.json
0e907096afe742ba00d3ad8991231d.json
5a46ceafd82c2446e15709f3282c24.json
bb5b345210650cd2fcc9d2bd1c5f07.json
ef1e2245ee2a66f79d2212c105e0ac.json
ff21845fddbea7845209ffc220adc9.json
16
410762e8953ba1dac094d0217b508f.json
444c0737a2e3fdfe1a488f6ce50f65.json
57f08f6ebaa392e3dea9a352147a40.json
6a38293bd74a2531e50db5ff7f6591.json
7bce95dc3da8e408966eee1490cd88.json
c32e2dbe91f02b0719001e8798367c.json
c9e1fe3e8893926b3f49c92f4f59b9.json
d46c57e945fcb3f8cef0b3a09371d7.json
dbca3d501dd1ce7aaa2309e148e3af.json
17
08818a46d7f6523f994f673632bb78.json
43ab6b5a83d56fe128c65520766c0f.json
4a3f9452cdddc7157f8efb39dd2413.json
746e92eea8155b51268e288938cc4f.json
aac09c2b3ed2a3de19ec6dc1f55b57.json
b25232c75e430c64f335492935c71f.json
b41978d661e79091332aceda275414.json
cbab06daa90a6989d9be34dddf33ad.json
18
0bb51a1a6f88f1df702d0edaee90c7.json
78c2b15685a652b96359c0d79054c8.json
81feca47427b5b57fe6da3f70421af.json
89228076b18c9950f5489c8facb85f.json
902acc88f994154fda21026954920e.json
b66c7765b9434133bc6f2e951cb0ab.json
cce1273081b94ab8a846792a668ed4.json
f1a7ec81299e788edcbcd3054324c0.json
f422f5a0433422fb84de2558236346.json
19
05088099f3e3a879acdd35c3164cee.json
1151eba5cce18bcc66a54cfb577c1b.json
11e02957b3b2d68770e0158ea5f473.json
1998d7276f5c67b0426c1d7339920d.json
3649a8cc3dd54465ab38d11db344f3.json
40ba6171a4818cba1ae765f773faaf.json
ad3ba7f62ecfd394ed860d49b2b0e3.json
e10629a9b88aace105679950bf50c3.json
fadb6a80ac3b7f4adf6202ea74e0df.json
1a
1f20e084e63e76c7a239744a8e2d2a.json
218bb48bcb1c739974bdf7572df252.json
46271566548deedcfbf987b8f7958d.json
67bc252502dc17a597923f627bb522.json
b78b07f8e64fc6f2a7a568388bf7fc.json
ba04cdcc5eeb3570fc35565123e710.json
da9705305ec86807977b5fed7add0b.json
fac71e0ad5ae2f2a4d9d5a89d7e28b.json
1b
21ea3dc0216b7767dd4235e108cc81.json
22080d58de99cb851d83a7f312d3d9.json
2797a34e4f5c65c9dec717a27f65cd.json
4d5f6222df9af00d6cf798499b068a.json
5be6c1aaf6aa40bc486feaae299047.json
68975adbd49f90ddd7a53143de8990.json
6b08a7ad8d7af12c82920755747c17.json
76e3e8e384a6cff33a34b3576b60cf.json
85f11f32aed00b2f0063ff8fc005bd.json
c3c2725b8ff93cd63460c9fce84319.json
dc1ff5833517b37c3fdabe6d3e3e46.json
e3b6592e636535971468315581ce4a.json
1c
0af476c928d2f468459fe22ebff0b1.json
0f519e7f3eedf2bf30b0fc06f0bbef.json
542f6e04fd2d0afff3f1af01e89f6c.json
569073060499fd3f894a8bd240c99f.json
7d249e3a0fbf0796044431f5495587.json
874c1838414db01feef785e114393e.json
a0686b6acfc242367f959126113e98.json
b832bf9319ed1a319655dac9c6fccd.json
c1eda7009c4dfd5c0457115a001bd1.json
d3a08819163924d6207c335a26e697.json
ee7211d815a496db145ff263a58f03.json
1d
2a40eb957c8cd659bb414d9cff28c6.json
c2b789b59f56637377b3861d604662.json
cd506ac0cc071616032ba51cdcf07f.json
fc7598531f69b123fd20e612ac94d9.json
1e
2ae412295e866cc900ef5358268f44.json
323399d7968e4c0f4c6b83b33b47e4.json
3e9a3df3e08ce6d33a6ddccba1b5aa.json
3f9857bed4ff8ca7cf16fbb3a4dfa9.json
4cbdc07b33fe6662f989036f9b0a6b.json
4f2e2d7a9aaaeff2a6d9ece4496962.json
69fb8b94c55945f8558e141a59fc2b.json
90b2696e12e569e0d47f0c4582b950.json
cd35fbf86a84474eae534393646234.json
1f
02a33a451a4d1a14bfe315333d31fd.json
13878027824318e1a04a7a9523d03e.json
23c6e44791bb54f17ce8c925762dc4.json
2e2920947fc7d886f2a0cf95a1a112.json
5a5888e588e9c56a0bfd74ff284f9a.json
7b6c7fd501b271a5a78dd5542a7fc4.json
cb31d29c7afa3936990ed0442d50bc.json
e671126ad71946ed5bc6da6cf4a8c8.json
e8671136dd08f0a63e478154368371.json
f0d37d7359d3998151aad5023b5ee8.json
20
584e7cafe0bac9962ce9f2505b9523.json
aa1c57d5911e1cdf03768c2bc0a14e.json
21
0f8c4e32d3700e38b12460ce29e0cb.json
15a7cfb8a710a99ccf5172660619f3.json
45febb486367cf8a78f4afcf76c794.json
50accbb733c6760cebb380ceae15d7.json
939ffe23c8b98ad66ac6c86391a50b.json
a8ed958583387af09ddca76c82377a.json
c2af7550e738c486a6ab03601483db.json
e4abd18ac481533f0eaf3a248a9aa7.json
ee13ac34bd893e0a6d9f458fb8f406.json
22
06d8175e16a24a61bb5e5937525cb9.json
1b1ed322cde77bfd3873559e960655.json
2657ceb017e63a4ef3e35c437be139.json
338a277148f5c16d0f52aa89aa2568.json
40c66ecfb080c0331a1dbaa6b34dce.json
626fe18e95b76b7cb5626cc438e3c0.json
79bc11e67062c69e920e93feb4e2f8.json
859e015e62637e2fa78b8b5593bbd7.json
b253ab3857df33845a8ff56e8bdd35.json
d5282495745cb8f4004cd64b4a4a16.json
e357cbd77add1ea2f7e7e74d8379c7.json
f0887086f642380cb6f2a1f9ca6ffc.json
f7d97fca671384aa0756ff6a1993bf.json
ffe7e8c92427e99eee8fd8d7205759.json
23
0e29ac4db645d3312aa43c40ff1c85.json
5440e79262e407b0b4c841ce3e3d8a.json
6d2b247aec636c3fb38781b3adfd81.json
86873b5a57a55f7f1b7473c89f34c5.json
8c31b827eebafd45e0006830fa6fe0.json
a6e31a60e067d55e78ffe1123e8c12.json
ae1ab3465b1c5684a2f0035b459d56.json
c9951a6fb7e454aba957cb35136a70.json
d14fdd7936288a5c6654b0f08e5879.json
df9ce5b162051647ea81f80f092373.json
e980a27507f8bf200b3e1e1d6b98f4.json
f29a174ba177ffcd7158bfbc70a211.json
24
0fcbd705515deedce7a4615252d8a3.json
3bfc332593ac1730300852caef03d4.json
6ae8206bad7910686606beecc29cf5.json
b7a8638c9be82aa5f8a200b0740a1a.json
df015e80c3d87e6c19852bf193eef9.json
e178ea796f9e37018cfc4e0260af07.json
fed84e06ee135685226203368aed2f.json
25
25685a2546ecbc56056b60f7b1cfa8.json
2ce82cd1d993ba5a6a1ad37684b719.json
684d1e64d843ead287f789f274f5cb.json
6a76d25b112841126c20a442a7dfa6.json
91f914b45dba4f2b625dbd7329e4a9.json
b273e83e8e9f447f5c1d5ca55d3569.json
d4690b01b1855d1b1a7fa9684e1db9.json
d515f6a39279346c2872a7a29cc8bb.json
f8d26569e6dc389485beaf6037ebcc.json
fcfe7021facca2d53367f74190389f.json
26
1f8138d94646d3e0b05b39ed36f395.json
57bfd5a2f3e0d0a8abc931dd2093b7.json
c5de1ed21cff019b286d65bc9fc2e7.json
d45fdf9d030df8b4dce132033f03b1.json
27
22003486fab89ab983c988655f76b1.json
2637e8abbcffa1e35b256f07d9da77.json
459fd3c30293f1cea2c79bd8595812.json
4b291f25be9d4e6544a4d99b30ba8d.json
60fb840a037c982c5ce1de4f08b4d5.json
88b4858211183d1f42cd0e5d40bfbf.json
ab37a30bf5f0801066da71766dc8df.json
b89f54856fb284d7a9d69a4d349501.json
d176163efb92b63e2234c7d39cc4fd.json
e83d1bb91679124b6d59e2cda7adb8.json
fbfe1f5ec89ce4d97fbc9a403efc3b.json
28
08bf07fcc7d18de4543a3ba2e8183c.json
3c0ab615a333fb3dde86bf502101dd.json
3c352583243cbd488cf400ff728838.json
48732c81032ccad0f14703e0099ef6.json
7b6b45993fa209b70516c40ad3bcb2.json
84e40c35bb757b49f19361a11bcb78.json
8b262c0a8628b59b8d5fe4b3bca6d7.json
b96313490c0f1fdf6a7c0e7960e367.json
fe218bf76e63780145bf41b9dead9a.json
ffaebea0a3583fc37fd21ac57a034c.json
29
03e3288f654d1b19b948a26c92632f.json
07249b1f49e87940cfd7384d9811e5.json
1ebd3f7c916b46f92c6e0dc64773be.json
214b84357104a5583885474d95bb62.json
4b9ddb0b18ba7b41a8a1aca81c8435.json
4d634cde359836197308c5bc90a50d.json
56de123e31f99a671f7e55da315591.json
71471135c6a6a9e9907d53e148adbc.json
7188b671c310f25954c44eb9a97ee1.json
75f13f359e6493fb170f342ee27095.json
8f4cc9068a55926ea45b442699f5fe.json
8f9ddbe7bacd170539f7857c2ad500.json
aae415a7eaeae187f6acf50cdd5276.json
d4e83a371d9932a9d561fa5a8e3055.json
f7ca674f647b74c08e47208e485f2f.json
2a
04a7ed17216bf91829199912a4c405.json
05029de2812bf09e77a5b700cb69dc.json
05e7b6d831929244b6e48f404d8a9d.json
0e624bd0548788bc50b5b6e50fa7c4.json
1bea8638b359ea2e4561593ad48bcd.json
1e6ced0d8ba04041309a17135845f8.json
1f7ee5408bf3719941877c5c19d984.json
aed39ed9479c0d103bff487b38b01c.json
c5fc22cacabfda09e5f2c9f7cc98da.json
d4b0d04877a6b0563fe62c0fea8c36.json
df11560beaa1d58d1fe3a352b5d063.json
e09710390afc8c8f0154f39f4f6c05.json
f6e6459935e3478e73fa66ec5e2606.json
2b
0ab02688716a48086a9ff0b53a97cd.json
3e7bee8fd6f25562a373acb0b11dbf.json
608ef72fa04b602ed9671368c7420f.json
6d7ba9ff4403fbf9375cca4006c896.json
86b3963216061b00d7e5bdf3223cf0.json
9b7cde15a975fda6883956de6842c5.json
9edac3a3335cd7a866d454664b0282.json
af674062fd90c706a2b488e5ee3ccf.json
b4970dd0c151b1828c4f32d06642b7.json
eca320e33af94973483899855c4dbf.json
2c
0545bc867d9656b46a3a16d20e24f5.json
066c1aa75c38f7d8df76274325105c.json
1534e296212f65b88d3fe93961044f.json
17a5c28e0228c6f29326b38a9ff8dd.json
35386c7058421f512df5640d83e9e0.json
50f932b78e9aab90221cf0e41e3def.json
57a4ba82e3930fab6dd8898b798b9c.json
59d6d91c4b8ed9f5375bf90283dc3a.json
658fa69f95b2cc925d0bf6ebcec800.json
6e6e0b500f64d3db19371e2ca01284.json
788e70e100b01491e2d252f9c5dc64.json
8122961f06e9b3b32fd8afa1366acc.json
83880ce8b0797a39b2b1a8242caa5a.json
9631e1d2528b461f98dc7b7225883c.json
ab28529e5e74deefdac5eaf8b610f2.json
ac55b9c47a2affc8cc10d5bd3908d2.json
af70a5a06c4bc200acba75b213225e.json
cd7a637649523b8c4156c6807b374b.json
2d
1628d51570cb2ffa4b856d993555bf.json
2501ca199627b87701313f960ad019.json
5734838c09aad7d9dc9a241a77d09a.json
718dd4c8b5d32c1c39f779f9d460b9.json
886e24f1f779269ef3e5512f0262d0.json
984af200a3f9aebd94e4087178cfb7.json
a09ef501a6562888f64f0077896390.json
c9c8c2edf115b594efd4fc62a3f7b8.json
c9cb6c037780316c8f0d2455b6ad43.json
d2795d8aeacd6f2100c39461bceb78.json
2e
58aa1f59f05787297dbe21c5e803a7.json
76eab6448c00e005754702e0e061fc.json
7f3da04e97efaab6eefa661ce37168.json
909d4dcf284772d3434cb215e8a683.json
93519b867e174eb7457ce3e1d1e1e2.json
a1a97e2e6c214ea372a75344457702.json
d88deb625cb6fbee60d9944848956d.json
de87aa494839f9441672ab52ed84f8.json
f3aa19de4cd44d7ef72c26fd6ada63.json
fca3ce2b6347ff826699ac43311b44.json
2f
1b28fa2364e96b36064fb8989ad680.json
4cfa3fe6a5b2dd611858eab8086736.json
67189146d8754a264710f24bab408a.json
7a254dc1d81237c62ee2100d8b537b.json
7b0e9e663b71c2417a9396524c465c.json
ac3749dbf6a0d02801637d1e75895f.json
c3902afbe84ded8a041db0f5cce2aa.json
30
271d33901ff52b563c0f7bc8407c1e.json
45f94be84dafe5ab2e0b5abef5ffbd.json
4be079e16769fd88566ce90c062312.json
5edfb808fe0e4cb90b869fa47da6d6.json
b32e9bc80555efb80859adbfc4bd71.json
b7c31371e1c4ee75bc6253b5aae176.json
31
0d8074685b111d001ecd9688449398.json
19fb4a0d67edb056be83bc57904ff6.json
461c85e83ed9ba7d8436ef7948a123.json
5d0c030504815549572287dbbe917f.json
62be6be15d3496bcdecd35baf3ad59.json
91d4d69064d1ea0d377f2d5ca8331b.json
9807de63deb8e4d3fe359640cd44fb.json
a6a3a22b00b974c878595e50fdd4a8.json
c4f81fda2db5f5b4bafc55c4b346d3.json
c5ea9cd598b73d45dbb94f33d47291.json
d6ee9157c97b95a25578a8c12abffa.json
dc6eab17112c34b0cc83fcc2c872e0.json
32
089a3108f324892390248c9b04d09d.json
1645a58f0629860c35d3812dab83cd.json
1adec690db84ff22a59be31dbdf97f.json
2426632630aa71710ad4b72c2b4840.json
29cc1c0b66d8434bdccc99a95ba8cf.json
2bf5055e545f8c037a16151ac0ad33.json
407d2b16f7f69b707ae164faf16954.json
4220831ff2b283a73c03cf45e1617e.json
802eda25ddc162fb7770a3431410dd.json
84313616936df866e0db91da3e2180.json
95cdb22af33a2b09fefaf9c73a5879.json
98940b52060227ea49cd8fc2bf67f2.json
a30b18081beaead10f5fe3f6e37abe.json
a888044fa27ec454ed87dab7abbd46.json
ad52e680988d7fdd8c76acde6f37e4.json
e04131d500b1c25fb6515695b06608.json
e66391fbcdfb8e88f104588c227a6e.json
ec68e0a1f6e91aa319e9bccde35347.json
ef5fd1f9fee02c2a2b845d028dfdd3.json
33
09f95961dcc855ee551548bc7a81e4.json
4a16591355ea7281e541398a1ca43d.json
4e3795dfe682108a626ab657d159e0.json
5339e81aa8599377671e4d0147c5f2.json
578931e7b93964a72ae653e7c91236.json
61329dc584de64e90a935bd9ad1a7e.json
72f3ee772accbb6abd31104bb94fca.json
7cdf6b6f8390a916cd6ae90dda8e0c.json
9a938b98d7729a6aab2224146403e1.json
9cca5264cfa10736535023efa51e19.json
b5924a6c2b6a3451a1be68a928481b.json
b59fd4be8d4d7eb2bd1bda7dedb949.json
de02da173ba475a75d7f31cc4c67cf.json
fab5779d8de2909263dbacb3f52cad.json
34
03bef6b002e45e95bddb8dbc8db104.json
109f8be2ce1c60b7363241313800ef.json
2f7411933c1bb0654929358909f5eb.json
3f65c56b4986bbdeb359932187a3f3.json
472840fc35845a9ff514f3f0614ebe.json
4ab3e9ca3bdf66302d2773ad8775ac.json
4b9d31d3baaeeceaeee5f1c0af5b71.json
4f950a8709851f284303351d90a713.json
632d05be42af06f90f34fc08cbfacd.json
7558c8bd150e5e674ed9240d2b8d9c.json
86339421f8dd2385cb8d5aeca3d53a.json
96cdee015ace1ddbe5c4b2f94ed929.json
b1dfd1d12cacff3fa727975d6aeb7a.json
ceb91612667baae5738f8d5c2f9884.json
df9d1b7b37d43b5fa8f959847d44f2.json
efb26a922b0042c77282e4cee486e6.json
35
14f988db3dcbe3c8fe10805eeb7c35.json
2633c4b626a7e137e9612d61e50abc.json
2f89d668ccf586ce45e2b961ef36ff.json
6de36dd952e02ae0d645a1123c7f6f.json
9b13826ce54b019dcfeaced1acbf83.json
bdd98cd204997f328961d25913d9c2.json
d5a86bf7484e89fb521d559eecc5fc.json
dbba32283665a5b934b15eec779b31.json
dfc55786ab5106d0161faa1f408fe0.json
ea690896812aef9502e69c1f16df63.json
f721d4b0cfdbdfd207112f7d8c48de.json
36
095fcf59c79a2c971b5bf587e25161.json
3fe16b7c03677874b821769314a668.json
48458ebe3ccbd3e1e6766670a0f63d.json
532ca22b85ea0696db6f6953f5ffc0.json
674c8da4cbc036ada9da0030fa28da.json
6ffa7f29aebfa3237cb54466a17110.json
84e4aa09491279e237954aa4f99ff2.json
98b9fbd6c756bc70c46f6434030981.json
c010762c36960e27ffd3c369d4d87b.json
d08eb8f053dd7798322a08735e296c.json
dc1f69bc358434a8379bde2a8ac67a.json
e552ebff1749fcd01de89e0528c581.json
e7065c391799ff1a838d3f7918b257.json
37
88d20cbdcc2ea97ee20c4263ee43e9.json
a61272bbb202c2dd09dc7abb5c9dfb.json
bcbd722d83fd433fa73297c4bc09b1.json
c986a8352d6ca5f5dac02f5aafba91.json
e9f42cad9ca396a100c596be68cd5f.json
fff5d5fbf11baabfc9b83a24cc69c0.json
38
0808314b1e43f6789ab6455268fe55.json
22467f9c571a3079e39a8b415d9a8d.json
4818f166881756648c4db498ab7f36.json
48694b16c22495ef1e6f233eae2f3d.json
62a0ee78bf8a46538e228cbdf314a6.json
67319ae9e58e14608bfb857b5735fb.json
77f4392a9649231077f5a8883929cb.json
a99e6371bef4f496c6ae4d606b782e.json
f476623226da64351244845b02db79.json
39
33dde8bac6083572524af3ec97e3b1.json
36d1e25be17452230a38ca08da1a67.json
4faec63beeaafade44ddfbd764eb52.json
6cb0bac2c7fdb363ba90ec43b380bc.json
7a6822b91b6f80abfec610bac17710.json
7ea323a86f9593c6247cb57c2a47ea.json
87fd7c583282a70bd3a23bec6848dd.json
8cb2f9e46a05ad5ca45260e4b4c7e9.json
8ed82d372cd5111eb333724582e1a8.json
9d4e7689d9bf3db138be37d72915c3.json
fa65473d0adb08bc660fefd9e947d4.json
3a
2b686e349265e32a7af1fa561dbd99.json
33b739c1eef5f34619f9bb1cc4f3a1.json
3b9399cf42abeb20443a55a57a63fd.json
3baeb68366016b224f16cfd7f6e605.json
3c8c7233c69253e79e077d091f7d2f.json
66f07179f98e31d2632c10e83a7566.json
748945483b2df82a531149bdfbda7f.json
748fc644957e97fdec92020c8591ab.json
78dc8b1313873a859fcce6bbd65622.json
7988ad00f3dbc0db8042378532d23c.json
fab4783fb0923fc3454b77dbc4d41d.json
3b
00cf20878704bc4302d7acf641c126.json
4d6cc94a5b6556eb4a13c7c48a58bd.json
5a86c32746a7ef7a7d254d66d6be1f.json
e1787703aa9151b7d929197cf18d34.json
e4504b5cf776b8d2e97abaf3651d2b.json
e739839ac413b67265f3d270e1da4d.json
fd388ab5c4379b04e38f20645a9447.json
3c
528d5a1c897ac06e4a1fa5702874ab.json
716dccc5899279044d7d2ba16e0d58.json
78f0ef8c35e63bc1472164184a9e1b.json
8728dc9d787ca1484855bf00b952e6.json
a2b2293b4fb2d8cc1f0d6924ddf34e.json
b11f70a31bb7365b0bd56adc64dc9f.json
b9af5a3dff4e695409a82cab2aa311.json
cfc075afc5145be35de9ea0cc5814d.json
def91912e052a074a94a6ca6110472.json
ff072a9f93533d597969d070b48ff8.json
3d
2880e33e7397346cd0b439534f188f.json
2e3c05912bbd98d39d4d9226154150.json
373948df3f2be0daf82e909d6fe6ba.json
5db34b4181f7bd992b8b6fa7849006.json
6b7cb71d1fd25daf472410ed082b0d.json
74a88f12c73b8a8209425057ba4cf3.json
a914ff138c5cd7415aaf113f6b3952.json
f82b1ea2e9dcdfac963555c685cbbd.json
3e
150c093963fe02f581f09d9e3bbbcf.json
37fe0ea5f5db264664f72a98c2d3be.json
48e014ee0f122b7289efb99ad54c2c.json
6585c36019e3ccd91a232b5ba23b20.json
6f253ba0edee05b077d2de8c9058fc.json
f2abad31c80612c2fdae4db8695e0c.json
f796042b1e37e318703a66bb80462a.json
3f
0de8c88c0636bdd57b7a14b5e2ab24.json
4739dc6b5c8c43302f1d9d2cf9fac3.json
54038c6921c9d632502dbfb7f7eb35.json
725901eaaa0bdf7e944945f765f77b.json
7366cb35a44696e1b7068fe138d04e.json
7d01b45627a6f3cfbdcd518501f85d.json
83b7a5c73dfd59494e745217079892.json
9212b39ef6f6e6721cc935a13c0432.json
9a5ac1d99e7ec4c0b703190a460b69.json
b9cf1104a2474a30f90ee2305e16a3.json
c40e76cd2e4e756cb31ad02a08a5c5.json
def6c51f058af509b5a12c69504b11.json
df7a85b09561535dd99e1b43c7a280.json
e4f72ca3c4abe421f0a7eae0243eef.json
e671fc9b5da1c8acb60b4d7110588a.json
e779b9dde77c4bf322825c16538bfb.json
40
00357cea5a59e92a15fd7da1436f64.json
0e4d6a770fc2c65ad529b6a5d8b05d.json
5413aa73b823b9c35a5c213f70a47c.json
861dde531a644d29d3dc061d43e156.json
87fe396c843b6bc64cb9a6a13c7757.json
bfe52b7d50cb267b209e0e14fecfd1.json
cf12daafb1492ff39041e4f4e3e6d6.json
d28a95bd543749a4e58ef0e55adb5b.json
f6551fee55a259f7e4b276f92b82f2.json
41
03a54680d1d73ebc9fb5def73ea9ba.json
0e37455561131010482c2c78117eea.json
1e69ec0fde75d3d98cbeae66e8132e.json
2e9a1740273c31919eabfd0cfbe94d.json
4b37339a73f9177b824fd04696a7d3.json
5ba3e564f7bcf4cde976d7bbfd9a09.json
731b6c9f7fd8699e0b82d3581afd2b.json
76f3b574f3b0b5f90bbb3771b7a66a.json
830a2facf8c78ce54a1efd23b25bdc.json
8455d8baee8403c38f3943a6ec20f4.json
94a721878b8f074cda2b3d456407b1.json
95bed283dd8f03af21a8f9ca5cad54.json
ad4e3c89f653afc5b80d4598c40dcb.json
eb998ce3984eb16ec5f4d216e38b52.json
42
1971dd2ece001638550e09b3210224.json
275611f4d933bd2473dabd4745a29e.json
938eee8b940d12417667eb7ad0c3bc.json
cf509aea54d3942c10215568b2d8ff.json
e1bfe7d075deba5011f37ba97838a4.json
e6f4225e6a2ef1764dabfab8b01c3b.json
43
1e903afa87dd09e495ed7108ed5f0c.json
3c653799addc78a5db6e0db3c351f4.json
68d5462923b6d84f046f390e8453b3.json
7915daf83d74ed4fe802c50cacac41.json
955353fb4b436661cf56c4bdfc2b9f.json
9a5844a18a7fb1c46d70ee054550e9.json
9bb8ff4cb60aa245b945cda9e4fb23.json
a1b600db4109d7ef9e7552941d1cfc.json
b489241673694893f5baa3935da8d5.json
b8d94c35a2fb187103fa82d18ff27b.json
44
484a59954ca9e0be63ec0905494871.json
74950deff981ae0cc8c9131b4e6f4c.json
82d1c6ca009054d74165cd7718ea9b.json
874baf637e876cd688ea03062bb3b1.json
9bc4227ecba71136b154fba4a592f8.json
9cb902d1d365d72416150de0aab2c5.json
a7611c8c1a8fe38e13ebf55f1090fb.json
aae7f607151be702f8d7f46b3af776.json
c0f70eb908c974651782e31166cae8.json
45
0b10313e7e5419ca09790fcaf54877.json
0be373a0bf88f82041e10b46cd3b55.json
1ec8a8dd0716719835eef0ba9ed732.json
2e7d89256faa1a7936a0f97b208b12.json
31cd058ca5916d762e6c8706ba739c.json
4b061a13becb4a04b9da73333d588b.json
4ce7a25d603c25c1e0fd7f24846c83.json
51e67fdad96a3783619cd3446bfd97.json
b07ac486b5985171c58bd09c7c5d6e.json
ed7df59a7dd5fe1cc07f848e98ecbf.json
46
12bd0165334a146fe24c84f8e90a2b.json
29d303c4e29a66dbc8b008902dca25.json
32c4180afc396fb45bdafe9d377dd0.json
467d0f7d2f03c8a75d61416ff3c348.json
71609e2afa92a5e23822f6b4ff212a.json
8c02840ca5c5322fa9d6733f94cc9d.json
8c52a758194b0fb0a365d7974237ce.json
9259e51d7e6a54d213fad8c32f6f00.json
d484aa9502febad0f7f4fe159c13df.json
ddde54dfb2097823a799acd728841c.json
e224bf901cc6a1c66f7a5f0178181c.json
47
0e8dcfd6e2d6237d3535fd50ed9aff.json
222c21ef2976de5afd1d76749b448f.json
588203cb5328d0e31c44bb3bdadc92.json
7d94caa693de4834b18598127357cb.json
953c97e9d39662e3d8b2facfaf3ab8.json
973acda49de3e9f3e90928ce4cd243.json
a477a3cc84687d1461bc07e3784662.json
bd7d5dfaab2475a93f819759d66431.json
f8de3807408ae6a30df368f3d9b5f2.json
48
02d2922758962e9e3c87f299231205.json
081ef83433b93c31ccc9d73fbe15f6.json
28b84c1f579a147faf246cdc314d0f.json
3796117c785a116d3c6de894d2b6bc.json
4904dd183ff88ffe9eb9face58153b.json
749de41cf5029ca76eb4c73a96be98.json
98017fa08d782f07037da4e680a0d0.json
a631558bfd9e2f442e091cc4f5aeff.json
aad014b6090a620d7ad20b3b8a7786.json
b28c7a513d0718565a5e569f78472b.json
b761275bb98cf0fe6202744aee2fc9.json
c063ff1d196537260259cd1a9280af.json
d1cc8e1e5934018152d622cc3847e0.json
e17fea476112f8ef62e9ca7c17c560.json
e74e9857fa0035588d35fec2df770e.json
ec0024accb455f2b5675dc59f71d72.json
49
3c29d4c7f837caab335a191351f712.json
526af16a752ade40492f68c1a2e1c2.json
7017e77b10da44bb1b226bfaf8970e.json
a3c7f6051c187092831bbb287609b8.json
b59b2f294ff9e94a3d77251b396e2e.json
cc0beebe40b2f8f793fb993080fc6c.json
4a
09a20eff6b2b1ad7a88171853bb890.json
0c6cd920d849857294234259f69254.json
12e940f0265d9edfa396e326219db7.json
3b4e595a5e541175c49d12026ca05d.json
3fb1bb2808c6e3d8a07cf6fc8765f7.json
50ea995fcae7e940da7894e1e24a29.json
6a6869761a62c1cc13bbf72487b590.json
cf0e635480182a86e4f23f381025d7.json
e6b521470e7f013d94a2fd0aaadb00.json
eaee1bda1177b4599360a6f8c3f7af.json
4b
169bc75ef2af53b0b9184809dc0c8d.json
40dd10843d22222240574edce9b2ca.json
510a9fdcb501ec14f93478cec6a64f.json
94f70f31b3c1f68b4dda02555f1adf.json
a822a51a226ef92121db1d6124c3f8.json
f550fb28a296ac3f2cf12029b8bbe8.json
4c
14da110213be28264189eafa33bf08.json
1c6fc49ee392eb703f5bc729f9c4a6.json
313a01f42f6598eebc4d2e9061a3ed.json
762266c2749bd9d3f5edb1218dbf32.json
c0bd1a04e3a6e3f1100db746060e68.json
d73555753a75d0fa26600598044537.json
dcee42668e44e4d5b4c784f7bee02f.json
f917f5c46ffb0e5b04f3f2fb150a7a.json
4d
184aae2d81d1ecc6a3be6343ee866e.json
26df19201df58953cb7216d59c35ac.json
281df492c400e1365b653feecf4928.json
34f9b557609364c082d29d412f8455.json
4aa822d8a9e9aa865d17243a0459eb.json
52f980b66fcd3ad83650059fc3ed29.json
cdab7afd3024c2d6b621f4759ae197.json
d9191f45027fa1ccc9acf90a9de88a.json
4e
0637049027c01746624964050ed8a7.json
180c183d2154fe0be5224e99a9eeb4.json
2795c73ef450e99cc03efdd06d5ecd.json
3d863138611476c6760e81a6c358a0.json
4d7199329a9e1163f652f12f51ad0d.json
59ae9d5529893e6a9cb4c0dd4ae003.json
6f50b49ffd05056c1256412f26e241.json
873d6a3c67cfcca6421477e56853fb.json
9e0ff75da2b78a3d630081dbb1045b.json
a16e0dc44123f690fe6abd40e55039.json
a49cb1ad0b212bd5a7fe5d679118a9.json
a4db6a3c67d1502c6f4fae46e01f3c.json
a6f447f5bb0d6189c9a61f097bc327.json
b5908e06677480b100beee0cff4e81.json
ba8722c0694ac4a1c228a13e3eb86b.json
4f
25aea6fe63878e707580e8d798e4da.json
3092357446f4ab92499eef376f28f0.json
816a90cdcb5325682fe16c7c31d7ae.json
8e55322818020ad2b55f6e3e450dcd.json
50
10a77db0e3b2e2eb31f01865ddef1c.json
23e0d2d312b786b2b8308632767010.json
27e139d1114c03303005dd6955274d.json
2b4677d4731a2a8c780aac8e7df9e4.json
3a98274e11949bf2c59e50e6e85966.json
682a2334ce3c596f4990b498f5c5b5.json
732c4ed142d470809ded9d9ffa12c0.json
aa2ee81b0897f4ede094f6a153491b.json
cd82172a0cacc7f42bd3cfde4dec99.json
d80d9d02b586ba3217cd2a7b15cb5b.json
dbd1cced7dbbe34eb4dd171169e6a9.json
51
17fa0e6af332e323879a85bb2cc7cc.json
1b7249fcc93456f632299189a06a7e.json
20b67a3462965c6ae49e119efaba2d.json
4afad551ade13cae04b7ab606ff317.json
55be3e6e2d8a8536561834539e8f9e.json
5787843cdce275ea1e4cc33d54e532.json
c7ff88e73d27d30c9a28b994653d63.json
52
08634e8fffcf1fdccc1b433e62ce2c.json
14123ecdf9607010dcb9e5ff105afb.json
4b3ca824b8eb3e2ba8801a687e879c.json
6f19a42da44a9f9719fa3f362b1ff0.json
7a1462a25ddcd77606ac7879296c7a.json
8844523c5d193b717ea492744da8fd.json
8cdf33de1ea5a5a47ded9f941f0edd.json
bc11905dd0ab963e7fb44378af8779.json
bf0d647b7fa60c9ae219719ca8d854.json
c533263d1b554bd486a0094ec3024a.json
c8218bd79e4cf7f155b83efdd96252.json
da93609d5ad2542177be49b863c8e5.json
db576907e0687612741b8c7011f412.json
e8eb2c2280ea13d2d0c278f1f718b5.json
f00e8a39e4435230ad451859846dac.json
53
0c6ed9d83c26799f3da6597b197f87.json
41a6473077f234ac59eb2536c88eb4.json
53cd9f0997598bb036914c20ffca95.json
660c6b484efbfd21e995dd605978ec.json
7fbdce23768f44219ab4186af75c01.json
801e340d21f770eda88ce62b5cb20e.json
8be4dcd383b5f8d1c2133aca661fa8.json
9c87aa1054a78be3d3523bf3c785c6.json
a22581f4860870255fee22461d40a5.json
bdc7566ffb4c8c7a0248510f606ad2.json
d5083235aa5f3b8bf3339fc2e01e6e.json
df52226490c517dc92a0a8e45af63c.json
54
09be011a1dcdf10aae509481bcc863.json
0a476f150842d8fe0aeb55d4446a38.json
4265f6fa070934cb26bf1ed0f3c6fd.json
667a35de4f9685f22af4b0a5144544.json
691e47c7a998091c5c324de75fb3c2.json
90ee0ee8108457406b764cf9306bf9.json
928ac338600bb98f26162ae8256d55.json
a1539485a5ae1f754e9d85d083ea0e.json
a1afc85c25d22794e0e4fb6492ecca.json
b8020ada6fea48860b270675ddc821.json
55
0d99d26292de46e72a828656607dd0.json
6c5c377982f6096434490afbbb8b9a.json
903a2c0cf8769ae57ba560a93bbaaa.json
911cf247b9abccf30367b508967489.json
9544bb78a8fbf5915ca0cd293637a3.json
987ccf7f0fccbef608cea4be4f076d.json
b5046a9135d90de16dba789d28c900.json
56
19a87fc330d369f3a9dc7bc92c3adf.json
93649ba7949d803e235cb755322e64.json
c3ba0f3e2da406afd135c463d13e6a.json
ce8341b70d8120c70c0baf0913c52d.json
ea39ee8d755de911e077bd83b8b589.json
ed84f6868095e1a506e083936e2926.json
57
12a540e7bf914c42e9623abd7d8863.json
187fb74278949e78265c94c2d3b670.json
560eeea311ec5b269468241aa64968.json
6eb7d2dc0723b3bdea4a1e41c33386.json
90da829e76ea6c6950f4d03633cbe2.json
b565bcee7b4d8f9ec6eb9c3c6a0ab4.json
c99745d2edbf1b55f0aebf658682b9.json
de5fbc0eabe99bce67af628cd72b76.json
df29505dc85a37b77b98a09c2bd9a1.json
58
1813062b4e0a752ba6d57c69e9c03e.json
50bbcdfae34f456fa61cf7e9685ac5.json
72c7adc42ed2813ce0f94cbc564766.json
dd7926068ec50fd7135ffb2f099d32.json
59
022e6c02d54321d36058fb191403ce.json
413e13d4b3a215b63fe2054599ef63.json
618ff97d9adc827b43db57a4269972.json
6b4f5f1d2cbe5155058b14e3d7fc96.json
7326af25618b3d7ba66c696822da29.json
7862106fa9839ada67c5f3a30bd958.json
786d3339468e91268a76a94d6b79d3.json
87f70a211f33a15c2d701e333ac5ed.json
9648a1b17325ba74250bd6883ffbe8.json
cc3c9403413f26d9a400b650ecfcd3.json
d384ead59fbb156660fd541caf9940.json
db97b03c4bb61b317f3ef7c9336495.json
e0259415b2345cc95c8154ec07b20a.json
5a
11748ed14d95db24214649154335b9.json
1d9ccc8fc9996a32fc26cd3f6772dc.json
1ea32eab05909d16bb7262ae160f3b.json
292be012669e8cf6f67f8afe39f266.json
2940f43744bae07d9f6a92c221634a.json
63f52596f1d05b733f909716a52004.json
642ba48ec447e68e6c1f14a8bf99f0.json
84e50fc05354f5ff279a2609255ea9.json
87ad94eeec0b8b2d141186c84e7a06.json
b022f8d7c34ec42872daac4e5b0004.json
c29c6319a22f8bfef1a26bdef0d36d.json
d30541cb517aa1bea9ac5b53d7b2c9.json
e82aba4207d029e3aba697990712e2.json
5b
02ce07cb742a6b176edd5bc5ee6cea.json
2ff99c9ec23afbab10035104a57b25.json
61992030a9261ea4b67351d8a8060d.json
814e67dd7eef88cfdc392179b34a1d.json
b041a18ab198a63c801eb947148662.json
c4b99ca64d9899f65b404bbd08eb67.json
dc0818e6bef467fc226e4520dd9e4c.json
f898bd7c8c0ad6d33cf3d318bb6332.json
5c
00d414fcfdb441acdc158d41f12645.json
196b85e30879f72a8755fdea8ac6ab.json
2175d6156d8ce31fb259a9fb82607e.json
2fee7aa149b9948047dbd30f9be8f9.json
3847eb97aba57fa2e7fac4399b89cc.json
50d90c499cfd764f5fbf095d42f997.json
a541c38a5cdaefca957f15da84526e.json
be02c97d9934879f80dffa033a6238.json
dbbc509e30ee1bab43bc6975e98c2f.json
dff6c16b9d84fe55c6cec7d29683f4.json
f6b0792c1af209c84992979cf6e5fb.json
5d
0ac1f5f50f1a2e86fd21e1d580971f.json
387a33776bb24ac5241670757a6108.json
5687e3541723eb9fb767b67a279d33.json
9867e96cd125105433cbdfc4319492.json
e91d97b808f638d6307e381e90b2aa.json
e929af3138be6804ddd9166ea6b938.json
e98a0bec0ef6cb6ae735f70d94ac2a.json
eefc0f3734f98f3922c0b7dbcdde53.json
5e
06b59f675a9dafb53563f03e2c239d.json
182d2e3269ad13472bff12d93057c9.json
531e32e49f3b9956e27eed437fbc43.json
6879f68744f9361d9205065f7da2e2.json
741805913a3d78ad3bd4f8f5451b5b.json
9427daf6a016bce1e744b69fc7410a.json
9b4970f322aa3dd35c140c6f5fce42.json
b953afb0c2304d7ab6dca9c6575daf.json
da4dd80297314730357662e184b670.json
ef330a6f4edea6fe736affcd4ef886.json
5f
4e561bf4bb6cdf4d38b1de395c5f0c.json
67f42cb5f042922f9d84ea0e4a2c08.json
a821c50815ee5810be85c390f1833d.json
bc2a8fe3b3693a6b37af02b093a375.json
cdb957c3ce2420d981b6ba6b22a2d8.json
e6f35a4293c3b187405d3c44a23475.json
60
059361c202b81a52254831f17664a1.json
2b16183fd448cc748aeca12178e8ce.json
6a8f89773e6fb7d35faf05326aa158.json
8038f05135f86805da058f53fa8846.json
964a7b69313f11aa9dfb4d5fd77d47.json
a5a598724904d1745c8705f7457967.json
a936548979f5c50dc565f8f81e78d8.json
af32cfa30be62705c6a692b88746fe.json
b2e18cd19d0ba0562037f7586586a8.json
c22afc80f615c908271b60d91b4034.json
c52232d155229dcc758b5f28671260.json
e9f3a9bfa53febea94f4ecfdd2b980.json
61
0d04b989ada4cc96b93807b1db1193.json
10472eb1f7bf7f2ed99e3e37a2193d.json
154b992b091a9a76a66c28b07914d7.json
2faba910918efc1635811604b7fa6e.json
72b5d88e10a2c00ae1279319cbc7fb.json
95f53747cab7365ac8a0c007751e10.json
a7459566a1ff447394799280cb8914.json
b8c1521cb93af7f1c28913ca3405f9.json
cc142ff7fd22521c25619a74d897ad.json
cda8ebb11efe8865a9ed12d1cc5db7.json
62
0bafb583ca6f0339952e16d5ac00e7.json
2a127700b2b151f4419a5408440ae7.json
3c0daa5d8bc01a4cccbbd553dfdc48.json
41e0e83365a48be918d4bdbc2db798.json
689b5da7d2345572c6b9da3804fda7.json
77ffc1277fc50fc84cb020d10781c0.json
907858461404eda42cbddf56012d76.json
b56a7ab4be610297ab2c9e3585a9e0.json
b6a93d3b11ff22bd890ac712ed8964.json
e1180c8058460e52982d73b0fc94fc.json
63
117ea39a9474d419dc893fdb019e40.json
2ebc2c24ec18621efdf5eb7d55f1f5.json
7e53823f195270228e8d64991c214f.json
864cb2e51f785043cde82ade9be16c.json
8f2c81499d8c5b705f1860b768f2a3.json
93999cf96b682daef879fd9e986078.json
971dfe12d501aafbf5efe4912a8a7c.json
9f0d76dc26365171aaee869b84d82b.json
ac70aa9e7edb482470ef476bbdc412.json
b39b38826496593054302ffcdb82d3.json
c0c6910a375b79d6fd3929106fb370.json
f3c09bb63f0b8e013cb7b68ecb8e10.json
fe5a79a36a3cfc1a62b6fba17454e5.json
64
2dda77caec2dfb3dfa2dfe1d40acc9.json
437937daa053b0ab5ab06dfa769902.json
47b0b2624aff54b8ee94d64c06b54e.json
4882a88ca80c8834688d5d7787ba0f.json
5b2c1760e6854fd208b30939f0d3ee.json
62a75f81972944c4d5413c38bf6803.json
74aa31d783cb407611ba25c73efa39.json
8c0d24ee7f047221383f7762c04879.json
65
1e2d6f2b97ac84947d4449bfbe34ec.json
3fb5a0c3cb5a5d39adee00ad6fb232.json
41c84d3544514063c6a9d2fa6c6558.json
44be1aba9a69663806bae0815c3a68.json
46b80c580086cdf775a742a5aa4e1d.json
53342409e65096457f3f96fd32b2ae.json
9d12d8af42934209fa9e12738f7ee1.json
b820f21ca1a5cc3d17c46f50fd6546.json
c2360000404e09f2c5d7625eb9280d.json
f2226b1f9f91c9e982bc324d84304d.json
f89a019caa3034176dce80fade08eb.json
66
0c1219e79c5381467f2162fb97627a.json
24ef16d507866b225ce53b244653ec.json
3528354f857a0e44b774298640450f.json
6cd50fdf9c5e658556c51562a9787a.json
812ebc5461a08bbc41cb889993dced.json
8623d84457d36fadfb94dbc7384ddd.json
8e4fb5dcad881bb6950557a7e45543.json
a6284dafe9a1af7ad07ec96753e168.json
ab4f44307f61e29ae4d019176d53e8.json
d465625bed7116e7b5d7ddc4ff2331.json
e4b9ad98fdd5ea3118dc40a6972b2b.json
67
02bdbee876cedbd92fe92574a014aa.json
3f8109a47045e9006202f95fbc574b.json
42c020a30c206e103e990a14b89aad.json
58dbfbfe04b04c94d8dee0cbe9f87d.json
81936ffda33d9e2b1874f87f0d6178.json
de9e1f01d239f5f2fde14341cb97cf.json
e0055c8daab4aa8e9f84bab266456c.json
e4af37af6b6ffddc2ae2787a63ca1f.json
68
043ad9b7f801cf6fed920a9eebb3c4.json
3346bf1a5af2e0f567fea99bc4a28c.json
4aa603f5d26ddf41b488a5dd0da225.json
60f9be75d45b0a165d882590910ca5.json
7426f149934100d72daaf011d6a8c7.json
7a7d65b7ce78f6264f914ccb5681ee.json
7bb44f08e11149ba11fa3ebc273ced.json
8b1309ec79c5e0aa69fd8a74d7a2ed.json
ae77ae73816402f251d2be55811997.json
bb17f25fc71b4edd0dd8259e9f5934.json
bf5442b773ad5e5f4c65977724bb95.json
f200022524c7972fbafe9c4b6a4601.json
69
02515c4d9c75e178635b7153ac41cc.json
0816cf9ae88053e6b485f9ff44ebb6.json
1fb292073458335ab6f5215d63ecff.json
2706ee18f7769fd44281dfa3c11215.json
2826568b771f2ac027434c3c0e2bbb.json
307d6675e640e9e2eaaec30dea9df0.json
40893111163cf8660dc1d3809b2e1b.json
6f0c4b8d3b22d55e30ed6ac4862e7a.json
99899c4cfa470e56ae2eb21e792fac.json
a4492a99c6eb21a644e79954781a43.json
d535a1c8bbb541eb0c82dd5c3be28e.json
f43e1c48c5aef29c3c4b7dc0ccdedb.json
f829251020543e2e4c9a8c178a5653.json
6a
05fb30db80c2d74439a8b87323406f.json
2fce77de383591128a962c76f46fbc.json
397b551aedeba9cc055b95150df727.json
490a4c5fb6f8b00cf8277553b18e1d.json
5e0265d4bfa865c62018a48e1c2b72.json
a6bb3b0e627d21152e9fb6ec88526c.json
d291df364e3e9ab9bc6fb1e5d49c9c.json
da62f4f8e24495a566a0d9bd2e2902.json
e0f6236e29eb214b1f70b2d5d2f1dd.json
ef61b6752c6e1ff0b76c955059d17c.json
fec577c8c68050d075058d4fca5771.json
6b
25bb0e506ead7490da72d2efac6c7d.json
44c3d19a3ca4c2a9f27c6372426906.json
84e0664b6e2c8ec58a0116ceef7b6e.json
8ddc3abc8dc87a302a989a0d04ed61.json
b09db5db506a0d21b8eab9d55c66ec.json
b8dcca1d85879cd5d1387a2d6e6c04.json
eb43f3c1a25c49f2ab54f6769e54cc.json
f1333364d9b92f71b5807609054a87.json
6c
105b69cab7d47bba963a834793519d.json
2ec5f939f5499f21ac88b892e2db27.json
46b4387bd8c53f126216cab8c24480.json
5cffbee8bcf7b08655bb512aabd6b5.json
64bc38e54b76e25770d1d75cae40df.json
859b8349886068a50e55e2d1c39390.json
b16d6a082b9e04f7bee447d8c94ee4.json
b25c671b77ac139a011fd2dfe7f4e9.json
b4ba411377acb5f3f3f128c9799ffe.json
dc77d58c666cb11030e552ebfbcde2.json
e68ebc9992ab0a32bf2e9abed88e3f.json
ebc4e5499c15d805999fc5d38d31bb.json
6d
6f79f7f82cff9ab0ad1e250b4137bb.json
b4fb0736ed3b83cb85f35284b186d4.json
bc0c6e29a867664cc668ab3e73127d.json
d182c1ab71d595349b51bfb2ba95ab.json
d2b4b41414001cdaf0e030808770a3.json
ff0f4d21e92598a3d430b58b4f5a22.json
6e
0d6a4364e3ec539798e390222cd25a.json
283e9dc9ff242967aab1314d93170c.json
28ec3b459b73b979eabf43da337c83.json
4c97c6f3585944d34a56d6be5502eb.json
6e0bc226328304d4f2c38f51bdd771.json
6e5c62f051a19b295c9d079d67bafe.json
8de69ca0cc987f9a37f5213eb5bd49.json
aa267af88012ad7c9771a1eed18f47.json
b76e91773b4ed4f2a71047ea740bc6.json
c8e1c696c5fad2192f43cff262ed79.json
d83e8266c689226308b2d243badaf1.json
f8c44b530f8f599de691542b0aaa58.json
6f
0c1150b225fc6f5e987d799ea75883.json
0ce1d42e57d5ffe0c98ed6f65a0c17.json
2986646a9900db73ffa86b6f84b23e.json
576c7bd8e80dfc6b5ee642492040b1.json
7856e2dcf7b9ae6b976a34a856d528.json
8f87f7d9a662a0e1023bf9cbe6d26c.json
a2f3ecd987a820f835add16f47840a.json
d078e2bc2fff5a4f0e6d7d2e9ffacd.json
d0d599ff0775c9bb74586d3541a187.json
d0f052b0116986a7d240337c486777.json
d506bdad2b42997e6267bacffc2405.json
fdde106ad551bacb598f446f866f10.json
70
4de81f02eb9f856f104e65f44fd8ef.json
9c4d4ca16b489e9014ef6c760ce39d.json
c4f982a55f1ba19ab9e46556364fff.json
d33710834e8276e577ab77308eb571.json
efb06dba13387ff98c9c6494101776.json
f680db52b238d3eeb1e5f59ff950e2.json
f78c623e6e2caa1af31ef7290d4469.json
71
33cac957675f14b95e73f9b41460d5.json
58d0700199065d3a4b849d5cc3e23e.json
6a7ec75b3b067364835e1165f3160d.json
95dadb3abf44e4c02612502ca43364.json
e77e8a11d3aaafe5b461991ef9bdbe.json
edd523944b663ea0fdb1b350c3dea3.json
72
0e31626a1c6038158a07257d53ce20.json
13e1e43ed20222c1d9f75bcdadc677.json
1802ab52dfb5ffee9f6e458cfefb0d.json
279464a904815159cbda462ca03685.json
396166e37c97f7901217eea9ec9e6a.json
3bf3720155b34ae311e7b9d23d7666.json
3ce6558f54c6a051bbc1e6b25cfd24.json
4072c2cc83a7ecb459fb4c05e04c4d.json
43baebc69cd02a33a6cc6c49ea8d01.json
a8b02b92071b97881b3d1c74ade2c0.json
c77b1e5f9f82b9e434d7a64b1c1071.json
73
01f2f15c269da55bdd75faa3444696.json
0c7b381221d72d1630a924a5d9d9a2.json
18934cf7bc0aa83eb1140ad083386a.json
2e7bb16c3823eace941168ced0edb2.json
30987d66eabab61fd8e9673183ee7a.json
35586d6eaf9cc816a095ebec59258f.json
5924e7aa47e32ed70a9584c47eb8f3.json
5f5aaada1a9fe5c95ad2fd6318588b.json
605aecb0f9a5d05c256ca634a08bdb.json
6d3da54bbda47c326608f6a2fca874.json
7f56a66bc8fdf978e0054f1b1fe610.json
8a11bc9d1ed5a66e538e17ebb00c27.json
8a153101b3c4bfdcdc94d6a9fdce27.json
b03e0b0f227d080db82975a0c904d6.json
74
0e1ad5ee7dfa11d631ae787c873534.json
769c08ea9307b76470e7402a59b573.json
78fa4a49d81629eba7b30194199615.json
a57096e9632f33b26f902a19c4ad80.json
b05c1bf04e50b64cd9d79c6421be25.json
cc08c8a84e515ec2b943107ec1dba2.json
d85473bce74933f79ff709ac3d9194.json
e0b35327bcd9fbbee242bf8d6fc08a.json
e4b3db642523de2694582a578742c3.json
fcf2fe31fb6dddbad9c19caeaf8a2c.json
75
044a601895d89c46d36b8dd3133d48.json
20dc7c1e833efce7462eca791db169.json
4e27eb790fe69e393cda35b3c2ca67.json
53e350451ba55d36582b4a465c70f6.json
6035e5033d2801288161b498bd96f7.json
64ab70e345baf1d4ff7b4b989b612a.json
951bcfea9cbd8f381ecd5963249df7.json
ba79da725739129e067533b1c8760f.json
c6016f861f670183ffffd1cfdac570.json
cbe7e50011e0c39c9072599b3b1ecf.json
76
2d4065418133a469dec7138a288d47.json
334a9cebbd9aeebe937d69180e3826.json
5c6b0643df2bc154e94087448f567c.json
8fa6fdbbc5ea6af1d9614001567cd9.json
a11658bdb3028dd3af00bedbf4718e.json
ca141543334db14927a9afedb112e1.json
de2453f11533cb00308b10e7e154dc.json
77
1b0baf8dc1f4c28c891c13a1053a54.json
1f40a7d66430732ea0fb205da94b71.json
1f98e236ba491e20a13a78d3654af4.json
51cdb878ea0aaf0f13862fc20380dc.json
85b1f7cc704f72bd78e04e93a85dc2.json
8a161a5b6398b1f349f728df3cefc2.json
d8ecc71999e40ca34731e470ad1a48.json
78
4ee2596b7387cb05772da10733b837.json
559ad7de4ef260df11db70fa340d12.json
65aeb8dc65af3642835bc395d83f48.json
6a72cf358eef0a49ec393f617714b4.json
76c27d2a018bc1b2916e60a7c6eb56.json
841b28ef30292d8d92f3527a0f7a11.json
a99224fca83f9663f341f6643ed6e4.json
b8cd2f04077022df9e762d18e15967.json
d66317854faf355dccf328d41e60b8.json
f3265b79b694ada8750b755cc8231d.json
f49a2308bc7981c77aea01a36b9b67.json
79
042864efd7de62472113e651aa8d82.json
04acbf9a5052ddbfb756fdc45e54bf.json
0f75fcbc5e8d3e09b3f37ce1a13135.json
413834a4c377f485f7e673b59320dd.json
490959080a978a771dcb352b892f5f.json
5fecc7d5a651606938d725969fea60.json
6a6c55b4ee61381e3d446e919ed4ab.json
7259343a4384f3fd7f5da2615f2309.json
7bf3ddd618819a0988fc1b924b1f96.json
916b638c24c5defa9e237711f7b64e.json
af772b7c2d0860a715cee88dbde63b.json
cbeaeea9755e4405eae72561af310a.json
e15464a87026970207b1b47c67b880.json
f32255dc33e4ada748c2e8c5738146.json
f8df5a64e7b3ce00d8851d36026d59.json
fc029d82bad3aa77f1afda1b5fa53a.json
7a
04d8b1427b4ab1d397a405c0e26cba.json
06c3c292ceb9622312695f2c1e5456.json
0a42f2535fc40c49d4883812129489.json
43e88e903996b36d49d07b4f70df54.json
5d964343f35afe1d679e432a707e6c.json
76e4637219f21638a29ccc86d93362.json
7dda6f1569c5f0d2549ec9cfb2c737.json
81f50c5134056df04c3a4a438749aa.json
88ce7ce66117a42761d46c9b3b4f98.json
a0e4a21c9f04856ce3f98aecd3ea36.json
a95aa457bcbc84f6501d1f9d9633d5.json
b277ba3930687a090b7516bbb87616.json
bf4d9f6b78dbf599fb43f36b2501bd.json
c6d97cc89a1597c5e66ccdd37e58e2.json
d096934cd55887b7ea794171306bf9.json
da75cd20b2519f85846d270c7c872f.json
e2acd8344f9fbd95adecd023bbb0a6.json
7b
14abc6b3cd89fde23cba1b3cac9299.json
183ed81cc2bbc24c0b6d48c2de1612.json
2b82269931c67483c6ff576953283f.json
324060233237f4e5786016b4b8c29d.json
4edcfc4edce0ea93e257e02d1ff2ad.json
afab3ebfef5f8d22f0f7a506a9ccae.json
b99cf5762420147a3cc574bba27c93.json
d286ca38ca608f416a89db8f23fde4.json
7c
0d243025a57719d990172b76e4c0b3.json
2a633178469fe1342f1c5c280ab684.json
5832b47ebbb5d8c603811fc6f84026.json
86c18e98481d78acca5b5ce9975c73.json
87f8271f9c2033836f48732e80ed90.json
bf139dcdfd8f04a8ba265444b9d7ae.json
e5f6f9c42a150b2e3222ab1a70a0d9.json
7d
2a79647c0301ae414b32c5297523bf.json
82584dccb35457c79e5f425c8d4801.json
aaec50f2c9645142fb26266af20b91.json
c6d9ce88f9804f8812961b474f5cc3.json
d96b1b1acf60aaba23ef7b92374013.json
e9072b405a9bb95b479860912268eb.json
f0dc47eb9a79c22d12615760966fc5.json
f85247bd9612e72f223012c66d9206.json
f8db121917d64fa1972924f4fd3f46.json
7e
41d94dc78f8fcd893f399158c71385.json
4b896ed50867189c2e048b84038dd9.json
800b2b73cb567ba6397158bab07abc.json
bf5cf795f5dcd730ef99b20c5b17e2.json
f2a639a3c7bcb324a2c4305958d46a.json
fb0404f441595deb61448fe30f77e2.json
7f
2207176b82f6b4a0ee0dd29cdc0ccb.json
a0dbd41a6fb5eccb99e91da460194b.json
b44dcf3d097b98a3ad9d7b1d1f10ef.json
bf06501725eb989dd975855f8abd94.json
c80e35947c8c289adc5e7b470d9f4f.json
e26d91cc70a052549781831101513e.json
f0e92ffb3c23a6ae53c8f397f8ee12.json
80
1129a4875688c504585295110a0f69.json
3cd471cefe295e9fc3f9307f8a4c0f.json
4757c63ba4dc1598ba31f610b47a44.json
4d1a4bedba9b0cfdf3d88bf56de4ae.json
5227fc7ce5fefc96e9b34896661806.json
55d3574679f605e131bc9b573a8e3c.json
901d2ec1d0933e5424df749cddcf86.json
9d4d5ad28e41d9e90b3a244a146123.json
b5420e424776995f2fe81128e1b32c.json
ce4bfd607a1b299a31d3b82cc59332.json
edc4c3e6671ce1bd31e6a0cfa9e4af.json
81
06492f64eb708e440fdf8559ad4dc2.json
1919d5756f4ae7c0d907acd4fac6b1.json
395a88d03c01493bdaec12ccfaaaeb.json
85485c6d5b05ad54080ea77982ebd0.json
947970fda8c4b3a1829ae8d7379380.json
a2451dd2dd26d74ca1b78209d01bb1.json
b3f108e92632dafcdb5fc9bca1845e.json
b593e3be6cc2e91ac6fda82a8e2d25.json
c7b82211b81a4881b6d65723041294.json
d8882c1f66d0140e34d4bf759f258f.json
e0fc09865c181604bba75cffe0035d.json
82
1f9801149da169574f772b70e36c10.json
2c827916015cd75f021fff1f268ccf.json
38cd6a3e8bcc8ed26b196bbabf4763.json
401ceb48975b654d7de29d3a78531e.json
42d8264ac7ca3ff932721b33768b98.json
5515c7bef83a397c03c1ca4125dae6.json
6a194993cd5204d7453a048a23e6c3.json
7063734737e1a97f119d762a6d4d31.json
847d50bee97606761a6465ec7be422.json
99465797f8c169cae7b8488e704025.json
b5b863e32c97cd05cdae1f7269b039.json
c9619231db6638302afeecfa7ab376.json
ca60b7dd41b6a7b8e3336e8140ed66.json
ed2f5ba870ae6edf0e743208c59ae8.json
f10bec85e19640df6668e9569bfdc0.json
83
4e95a078fd6370d849089ad83ef841.json
549f2580722baeb1e3a6dd2c722e97.json
555ca89672b1e6f2b96ece2f301dd3.json
5761e8cb8b7c81a9e60f6171490230.json
66ed0ee2461c74deffae34582fded9.json
a630f921522d17bdf1a61347ff87ab.json
a69cc32f31f892d97f67db098c6398.json
b4172165eb85e66bd7fe8440035350.json
bb119eac040af260c717087d944234.json
f8c2dfb269f2c0916e1df85bec0c00.json
84
07413d81159ef996e156797bb49df3.json
0aca7486e6e065e49393bcf14f0473.json
2141aed0abce813a4512d51f29d482.json
6a0f411302991a46d5f7d12f825846.json
99b8584ca0f91ac0aa4bd62f51f814.json
a4b6e3cdc472a3a81b7fc1505d4793.json
a7f6b51f7df02a25682786515b0d54.json
b39ac913b6d03ffc76c309a4bb81d5.json
be111e2090b3e9e9e56a90270f83a6.json
f8b1acb6c107709231627dd90bca51.json
85
1d627a7eed51149221f4fb53a748af.json
2b7ce42f5c56e84cb771b94faf63dc.json
42e1b972ce5c4e335a537710f3404e.json
4e4a33a086902b191a6e8e727f6838.json
52cb29d5db0a12e36ec9ef0a976042.json
6e233d53828ffc86f6de193d39c1a8.json
919f2793708514834334d8fe2f3032.json
98183eb824cdfd67a2e7632c87f7c5.json
a0e7d917ff0cb1352e038c551ac146.json
ca3cc2a3df8f3e511654a9b7fe46ff.json
cb8b0e15c0e88f6dad0ae79c217e61.json
cd0640a62a83519b5a520068a3b88a.json
d556dc6edf1db05797f9904e31c5b1.json
da9add950322805b2e738200746665.json
dc31d401e82dc98131fa9fdf8170d6.json
f72b336d20114cf9cf404fd35decbd.json
86
0708e7f0a528a78cbce42400fae3a3.json
1ae01256e812c499ef9c86cbcc35a2.json
1ea0c6bd5c570fb5e1263ff17c01aa.json
839130deca46d28116a20a0948288f.json
8cae09bd04acb7c2b8ef1e57e8ecad.json
8fbae69a75b0b8ff8906d4457c3ebd.json
9e67c85b33af290367f6ca0eed2566.json
9e8086c751a2636b8f2e8b1d4d40fe.json
c260e08a9ac9216122c92fd8ba1b68.json
c97d0d3c554dfb7188c2a6118769b5.json
e49e4a68ed9982c9401393d4faacfd.json
eb758f81fdac6bdfb6c38700435242.json
87
1f17c54f3f5f5f02e7986caa8dc676.json
3f5320e6fd3cce6875a899ff7a7de9.json
76d9c384a29a3a2b7ad673fb629b31.json
dba7af994a8b4c84564320cd703c06.json
f618824568440d446fd18c6b2b5ab8.json
88
0111a05f28c4d483377c07290313d5.json
0d09d3d4c5c3c161fd7855e3e09b2d.json
15bfb4d89874c569c4168746938b98.json
30f18a233647373888bc2c3980abd2.json
7e2313fe96a061c73e644a73c230a5.json
a4337d7389c59fc16abd74dd906453.json
e3165ea9f091a1ef8b2a5ec1102b39.json
f52696437a2bcd698c6776400ab44c.json
89
19b686bd3333b19f500a1005d47c77.json
346d5a487da70b941e2bb9da95e672.json
42d97345a498c1ce22f92c4b9111b9.json
46afbf837286df214e891134db75d0.json
5e431a210dfd51180f73bc3adf4a63.json
74f2121f66cd201738e7dee32b75f1.json
7e3850375afc47c331b751492c3bd5.json
8107c99f19a74c5f28a06b1d0fc4b5.json
b7fbca1ad54db1fc40bbe0add4616b.json
c3a8e18b3882c52267d8d6ede82432.json
ca91cfb71ffe78ef95c07dc7dd64e1.json
cbaa9182c0290b1521a5a91b1e729e.json
eadb3562620445e11f683017e6378a.json
f44aeadc51d346637125b22ede6a96.json
ff43bf000219b999ef1538be6b7344.json
8a
2397f5be955793ebb75f76ae2588e6.json
2670e3f3014b797d6468ce4d38eadc.json
3be7805c62b3b995f4490876fd1420.json
8be40252d5a91adbb7b99f371fff42.json
919ad29be46346269af4bdb0371ca8.json
a6a3a5f0449b0ee2c22dcd08536336.json
da2b3c2809cfb86f88045a6ca77dd9.json
eb1c23ffd534063896d475296cf70e.json
ec10f84e74cd85577b2d311566e966.json
8b
136d22e56ebb82e82fdfc6f9402d41.json
2234ff1af5f1c4ee60f3eca3fefa77.json
269c735b20c20af7379619c0c1189c.json
525ee8f902c18e236fabec310619e5.json
5979b34992adb242424c0daa80972d.json
9c9bcd7f77ef0d932a92f97299c5a6.json
aea3225601647eca4ec5d3cc892163.json
d339977b8f924a3353b78366e6d8d6.json
d699e5158f3298bc508076935d8f1b.json
db489eed546d8763a0c8492c641a69.json
8c
0e7f6c5e2bcd8a60afc804fcd5c15f.json
152b5d79976e30fc5e51faa15a3e63.json
2a25a3f3bf7f56c53d28bca434a5bc.json
6d95bdeac02a378def21703a5ba93b.json
6e761285a95f6cb2465fc203c096fc.json
738e778b8da2d14d73abd2ad50b739.json
779dc5a63d92cb551ee75f96f5282a.json
7c872adfa91a28436c6954f31e8994.json
949739f574dab83d63c3c6355c6778.json
aecfcfb4924c823df1fa28bbf2a1f6.json
aed22dec8292a67a2fe95b3b09a6e5.json
b190eac919adb98dc0533593581fd8.json
b60be4ad9dda4702490efa8d1e1969.json
e479dd92256dbe823038ce1cde49f5.json
8d
13070d0b1ca4df97da4f5ab1976d48.json
2784bb8bd161acb48c3573b312d93d.json
2b559e74ec13d25aeb69298092e953.json
627df1ee22fc5f00262ae6b457add3.json
69a5d604cb4bec3f42917986453cf7.json
732c399537e7c7d9af44f05b2fe62a.json
7fc21e22dadf3c4109e49f35de57c6.json
87686f3ba073d5682aead6808dc080.json
cc26b81215fec1a670c0cc6aa95baf.json
dceefc2e77445813c807277a6df344.json
eccf94d2ea09b1eeffbb34bcf2c87a.json
ee7fbdab51737601d8fb02ed8d3f0e.json
8e
0456c33c3df023a62b34dfdd349245.json
2685bb6d3b96db151bd2f9d54d0619.json
3493e729cb760e17275a4f68f85463.json
3a62579a9ef47cc48c50137ba7175d.json
3ccdb446c2d1841102fdbf70a12fab.json
665c54922b80d2305d9a2b02c6d561.json
6f4c31725ed3d6003aab333b56da93.json
73207d389831f6fb04dd2c6f80e597.json
8430686e173936339c38ad6d685183.json
8acfc916d8c3d0d7672bbcafa8bd05.json
8bb9bdbc934f44c959fd5f91097857.json
8be545d3d2626959a4214970eb9d38.json
9b8b9ffa5da9a872f7e2753f46d457.json
a7c763a99ccb627b97e663d783c74b.json
ae86c9e18b5e30dcb1a296cf006f34.json
8f
0d32943f0c6c3a1701421d2ae31ab1.json
2829f44886f22e0dfcda118fbcc3fd.json
90e547e1b7eb70a8cc88320a68219b.json
a3cca0171c5c7ed6f10d03f7fa8e37.json
c1446446bcf2e4997dba934f557235.json
dfb21b21cc704ed977059a9c69c259.json
e4c71cd56f561f47b37ea675790e4c.json
f7c4e7603c60faaf51266525d65fe6.json
fefb8f0917ac49e0bdf075e3ff51c3.json
90
2e52cb7fec3f32ff4cfe7e59576a07.json
32e71570f5457c26d9c637541a2367.json
3deda228cfd2831c23bb964755519d.json
6e5f8d653afe2d637ea498ee91a223.json
9b00a0715ec6c5c01438712a8fdf28.json
ad47a929f2fdc8c3ee26eef53c4e5b.json
d2c1001e48f6bebefbfc0c9b54b0f1.json
91
1031007320a7c38105ad5f411515b8.json
1842752e99099c505dd96bd2643cd5.json
639f41ce9738a9c0b8a70abfb77a70.json
830f2f2ac6daf7127acd1123d388ff.json
856af957923291d231136aadf304ae.json
afbe7d6d2a1c59bd59d22388fe2bc5.json
bb0bf168782a6f2e6ec43e00cce755.json
d0a9729058511c7ba6e39b6b731fa5.json
f97ea62077e1ec9c2e0b68a0461f77.json
92
083fc5cb813e7bed46ba874e6efcd0.json
09338151e230ecbe67ce2fabf9768c.json
1947f2e3109247e6df12c845d29b73.json
448a2e1bed7feca898dbf55e418e8e.json
6bd0790454c2959c1abfcedf2816aa.json
9c9ea0e4cfd0aaf61d9c3079cdcfa3.json
bdb5a6967bd5381206c1868aa58728.json
cfe9e6e6ea90f9ca7bffbde2b04b1c.json
db95ab56bf0b9d09691ab3baebbf00.json
e1465ad2c911c2424288b179726a7a.json
93
337267deb3ffb41901c9f4fd26fbc7.json
43a696c2458a3284ed96afe4155492.json
4d8919248264657c3914b6ecb09f25.json
64fb4a63f6f5aded68d8249fde90ec.json
a545ce0e29e40783580f978e59ef33.json
ad388c7f0b58cd228158939f7ecd31.json
b0bd257fe4f5ce20c90e238ca7e460.json
bd208f4bb9eafc1a5411aef633217c.json
ca365cf402e59621ae47ea0ef807ad.json
f5843e9782f20c7b9e8c49f393882e.json
94
063e7fb71b62f4d3ab5105ae515d13.json
0a11a23ad1545e37cef4379c14967b.json
1d0bed25326a60716773bb68c38d2a.json
28e157d8217b0ea2aee3c797d4927e.json
2b504a6c74ee1c9e826704df3e00d3.json
2c7ae1be65c84875b41d6f2277cca8.json
4429de99a0e8f420d877c4589fbb35.json
7646960bcd5d2f67aab89a2846d146.json
8955d5694947bdd596c11f2c8c3426.json
90e42d912d3a957e36baa8928fc540.json
a223aaa9d310e94323fabe0803d2d3.json
aabbc44106350ff60c1825958c4e69.json
b1ff93a8f7d5d32ccf5c37f4eec70e.json
b7667d7c963f1cd39b4d408bf2c74c.json
d742b24dcacbe69a4ff51607bb6dbe.json
95
09383fefee490bbdbf8f4030a3205a.json
346445353ac2daeef1081698de17cd.json
3b5aed486f4124ef54fd8ace42a194.json
3e9dd3d7ca3c4a19a9f4970a6b9a48.json
6310f976e6fd3e46ba8cecc9f80799.json
71394e590f21a771f266f5d7c1c122.json
850aa3fbcdef2f0e6ba8d1be6ef1a5.json
9135f976283e1d4360ffeed53ee371.json
a6dd1dd29bf2e5b71f294def07ad70.json
f1eb3009dd622e99f4c5df9b5868ef.json
f3235f4e604ea47b0905646ffedd49.json
f8109faf34b38ef1e5ca31d72ce000.json
96
151aa7107185e2f17325a49977e543.json
1fafb023fcd14fcedacd69a448735a.json
223912bbca1f29ba53d185db6bdaf8.json
2f2c3b80a4d0a0e98779d1d89991f0.json
39f31c25d59061afd7e05e9d01b254.json
44fab8f020e831e9df43bdf8579962.json
46c6300a2dda4c92f325d5975a77d1.json
52adee2572fcfd88f4e4b1f3955be6.json
7520a779d64e0c0126693f7e90f5df.json
9cf41ae51004e7e329d4f6508ea827.json
a19fab54ceced8b2561105cc014c8f.json
a27e1edc96335b8d87716b9f9c3365.json
a46de832440c71f4b21d9f93678570.json
d73db35c191911feae2ef3d9ce80cd.json
97
138a32ac910e7828a8c98911c6f407.json
2bcdb65009b9919622c1a74c9fd6ff.json
63eccce0641e5337d698f3cffdf428.json
95dfc90089514616c4022551a0be4b.json
c3a15a5de2ac563aebfad3009844aa.json
f736ad50b57c4a04c31fe6d14e72e9.json
98
1ccfc548e8a876f8e8388fcf76305d.json
5eb8e43f20422b3bfa630191186e9c.json
62e92648c7d74658e15ba1b01c5a66.json
655006677884cc149f3a2c589f340f.json
67a7c450743061512e704b3d53f6cb.json
8b6d1aa2c77f9986a99dcaaf86429c.json
99c086ff5c0bbeb347f25d5ebaab62.json
a0f7aeacd920182d729ee75067160c.json
ba688f7d455927fffb38ea22c6fe3c.json
f0dfa47942296f24012969033196e3.json
99
023d8d5d1faeb3b356e51631eb061a.json
1780ee28fb25cccadaa5fa2a001f19.json
1981009636b56ad68ad887856c93c9.json
374430d8e61ac20331f38b495b33b7.json
94491e82348d4925c61fe4fe7572fd.json
a6999f8e6a39c66a2b1c446db8eb9f.json
b701c8e5b2afc2af24610e5b06fe99.json
e973125110c213ca34c87119f39729.json
e9cf01483add8fe6f370163bdfc0eb.json
fc565881096d477491e13c6c65f20a.json
9a
2700c517fa7775271707f61387e388.json
31a27a09000a4982dfae7402b898e0.json
3e5afe3684fb9b0828f38a4ef1a22d.json
57d23f93d65afbae2df29a173260ed.json
754a4dd14984291f4d5d92416a92da.json
8210007ba811210edc0de49e451e3d.json
84fc16183d1092243d576cea336634.json
c6a1de1211d2ebf321087ff045585c.json
d91543bcc336b3686a830890724384.json
e3a9b16884bd633e46f5de210d686b.json
f6f6a958423cc3083a70ab9689305c.json
9b
11f324356fe3585c21c407bc3d5239.json
2078da52b71cb2412ed8f02334ff7e.json
221e20832056d4abecdf6287a91744.json
272ea84a5a77775f0c20266430be08.json
3560ece908dfbf3a84e99284994367.json
361c7d0022ac43fd1e5f58e5be4b8d.json
62b4ad07f93f24405a905786149f62.json
9b05ea3e5187d3d79a813b55a365a7.json
db7cb69c85283c8e98025fd302a933.json
9c
06cbddb9e9d579c76b41073bb0a76f.json
0dd7e0091b4ddef900fe8c3bbfbc6c.json
166cff9aeefd964e015bda5e36c240.json
426fdfd98374b1593bbce54ea99be1.json
4f55163f59993948f30339cf6d887f.json
595cff3e8fc3edad3ce349185f9081.json
6afd219c61739109e681564c066d88.json
6bba9d2637689b9b41e034f8eeaa5f.json
6feb2dc8e8380dd1ec8e5b2192ae02.json
d2bea756abc1415e6c2ec9d7ffb98a.json
9d
061829aa726032d32ee1c41e37b13a.json
06d4a06a25d83de882ccd1aa6d9a62.json
24de58b513abf1ef651e65823913e6.json
2a5a813c557acffea9855304f531fd.json
303c386770717f63621730ee3dbb2f.json
3452fd203122f4c43f839cc3a957fd.json
35391a8cd3c1ff0461c11932ceaa3c.json
3696f0e080db3b2eeefd10de11d96e.json
46e4ca5d85d37e75ae52ef090ba179.json
63d9d2f398667880d95a19fcc439cc.json
7dd6e0866d797b5ffcf9886e1788ea.json
b95d08003ac9659143196c31d2303a.json
cfa8e9dffca53d893f7b935fee3b5f.json
ed1f2a822507600889dab7d6b160f4.json
f25733b16882d03a75a0fcb24a58ff.json
fbcfa2e9a8b73df8566c12516d1828.json
9e
05cff7d889a66ebe830bffb68e23ce.json
0f68028c3216fb06b26753a1f9ba2e.json
16ceb530435c92d57c9551d2ec7a18.json
408e24fbd42e6d09a9d680cd9062d1.json
816adec91f66fb6accc73097de1e0c.json
868c2adb86000f300494df25011e43.json
90f12578ec137cbdb067312e082ede.json
ad116b5ed6b05c1503cb51e11504bf.json
b31b3ef512fef81c14ae80774609c3.json
bb86d2277e6c1398cf11d8b8c44bfe.json
d4ce5b96c2acd8239ea8c295cbfd7f.json
dcf06f8a918889e882fd69e796bc0d.json
facbb3ed5898f8bdffa60b998af54a.json
9f
0659948b7a9fd7fc3ff93eb82cc792.json
12f6fd54eb97b0b3d0433acbc41444.json
323dba07abafd1fd6135c1bc36edfc.json
39d789adc77c12ee76d25e85dbb50c.json
59ef253c9baa50aef49afbe002a0b3.json
914736b4121df87458cbbdfbdd40f1.json
f34b8b9f83cba0fb842ae0aef3695a.json
f6e5546932de011dbca6f1c65f56cc.json
fa839e824e74f3d7862fe10aacae48.json
a0
1fa7286d5045c2b8b6f04ab4d7f636.json
23cecff20af9f338ecd54933dfa342.json
38e0af8484c1a6301bfc4bbbac4d00.json
a0065cb1b3f1c91ea47a2507936009.json
a36bc345c906a3ad2a64ee533c3f3e.json
aa94bad950593e668696cdb5b632d0.json
a1
04a204e17685b3aa7a8f695b6f1ed5.json
08223108ae88f1f8892ef8bec9264a.json
35f4260b1e11cf68ab9c6115035747.json
386e5963afc55676f4c0895e8497dc.json
4c4931c10390c7ea787ef8490abcff.json
94634a5aa789ce193ae975c9e3ae5c.json
c1689594918a307cc2079f57211e49.json
c61a23dd0512bf0e067fc2f4cd1317.json
cc7b993a767782d4adb79931bb704f.json
d4874447deb32b4224a835793d87cc.json
d577a330eb432b1d402fbfa5f6c511.json
a2
09735130c4c4544a427c850cadafaa.json
31784effc2621f423b62099da37284.json
3590d7b6931dafb888629b48e2d5b6.json
5e308c631f07e7fe5017f4791396d7.json
6814fe427d0965f211a61dabff1912.json
845a048eb155634a7f323b42e896aa.json
a55d8e6b022913f82ff7edb5b5f080.json
c5b1cf3d620bd162fe3d11e51e5a04.json
d7d19ec50ff8e15d47e73c54c73051.json
a3
1706c3e341ca82fd9de7c957c8012f.json
33205478aceac1f197c86e65bca3a6.json
5df0e66ece650fe9f008c0d3ee1be9.json
8aea849bfc910a6ebd4b0fd689223a.json
947054f662ebbdb4c598dea7163d2a.json
b0f0174c9c2e6cca925abc85aac45b.json
b715ac8ddfbe632ea26dfbe63e2f5e.json
e14debf843eaa5a702bc476a513a25.json
ea78bb21bad5073e60c6e598d792a6.json
a4
1868d991376eaf370ce558590eb165.json
19c183c1280a31d04d68cd67636a23.json
38bc8a331b3a2b1fa218fbbf55ae28.json
3cb228a10c3afbf3cc4517c72c2baa.json
4ad3edcb05911a2daf95bb8fbdbd59.json
7dbe7038a21044c6b44a9bf33f8bbb.json
7f4bb02c8d220d95f04e36cf7571b0.json
b360dddb49c13a745a0fd5e510c4b5.json
c469b3c1cf33102aee529c6bd16ca2.json
f5bc0bbeab18feff179a9837607eae.json
a5
1de5fb6b04c6a3c4a53254157af2a6.json
1edfca2387af3286a18e05df76fd5e.json
2720de9e39001683a64f221f307581.json
3b00e9ccaea4885f070c311c18e52d.json
59efb78a100aec9322a1f40fb4d054.json
60869ccb5b2d37992dd132a06b583f.json
7720f8df75ba2d5e129ee039b7601a.json
7801c7be749229c299e78915fd8223.json
8ab80730472b331e6b1be48bfbc0d8.json
925cdf7af35cb7feac21dddbf086a7.json
cc7ed36021cafd669e26f03fcc7414.json
ef3eb8b573e48305163013c9c24aa8.json
f0a4c6629b447f07f590932d9c995b.json
f59e3bae840e5e7d4e71c9b5b69ee9.json
a6
2613fa95472a9a59ca0bf862c241fb.json
27f6779f02b8f7ccca3c11146221f5.json
7ce0faaac2b12c095239318462fba1.json
7f8fddb62ce1c9be0a946a4300f5be.json
9b3fc0e58ce8f19a4d0a8043bf30e6.json
e388fafc4a81ab46347f36808f4404.json
e8499add5b47040abec4d533f00c0a.json
ffbd01c8b151da1a6ad2aafbf316d0.json
a7
6a390dac48d10a79da23e889614245.json
7832af8fb8c7eb22474a23a31d12cd.json
7d7e7f3f68e48ae6f66498bab41b5e.json
bbeba571578657689879cde95ff3e2.json
c1d1928120d0fa86fce3ae586308da.json
cfc884e10d1bddd1d98af5d6515329.json
a8
0a15fa6fe41da7968cf5a9e28b9e4d.json
28d17153dd1edf6185fd610254af2c.json
4b4b06ac075d1b490c98c2b9fc41c4.json
4d8b741b7c0c5e48c24ac5c6b31805.json
52cda5eee844560fd766b4946b35be.json
65009ee001c888bd40b4189999ea0a.json
6849229118b9708a50568dd9f00325.json
9eab04a90f8eb6f3059def2d621933.json
a3b854ce20e717861b002895166930.json
e9d8a33da7f373fde258edf1c8131b.json
ea33039e7c056dcde9e604ddba4b20.json
a9
058afbeedcd5e68148747565a1d8c5.json
0dc1147bc3fab7bc7a1dd317321cd4.json
28db628410f420838ac854ac61ec2f.json
3a760a1818b76dcfcc9cafe410f33b.json
4f9f795a60e4fe61ed034fc596e019.json
545bc6454f73fc48c50c744ad00998.json
aae828742a2b6e000fd6405130127a.json
b0889eb8d8776d7c7b5b32d72f0f4f.json
bcd68de582dc5f0c0e184fd771df9f.json
beafc6856e111f5c01a06e24b6f189.json
d26290088f838a1952983d02b7f9a0.json
ec00f4db6c054b64feea76285ddb82.json
aa
295e95537a1af90e5f1653b50dea92.json
317c9ec85bc373440875a839710fba.json
817bbe5794b97d2b8e0f6a1e395c69.json
8410f39b6506406f1b3c48119ef6d0.json
8a299984ff4733b8e065fb7530aee2.json
8b93e44b153123e78060397b141c02.json
a7899f27c0900d01f1dec5951c4d6d.json
b5f21bc9184572b45c51186e7595b9.json
e7f7c2b42fc1cde6e2d93da66ea515.json
ab
01f080ec88c33a184de6b697674646.json
022505c8515f67c97569df58302abe.json
06eeee15eab0406947b2a8c8c6a9a7.json
3f71cd6c9c74f0c0d0c3cf44624f08.json
620d1e14192494ea0c483181ffc7d9.json
8326adb030e02de484315b1e1b5fbe.json
83c2f93267047bb25f0f63f9f4496e.json
8d873f8bd8ca44e3068064affdaf75.json
929ab22f513386d8b283226db89f30.json
ac04f3ce8e52c658fa8b25c864831c.json
d073c22fab97b32e7948f04b9da688.json
de83e891e35932c73fd05848fc2863.json
e090b928c234df12a1b701fc8e2baf.json
ac
100cd41640c392cbcd426620168b98.json
141bce9a2fe04ba1103a532908da1a.json
45e9b11590dafac43b2e1418896be6.json
4985307721cf7ec0d73788b9f4cbea.json
58640e8966be4a642ff3b2fb623d18.json
695b91558fd734ebe4aa0194204c94.json
9bb436325167c6519fed6d58572c3a.json
a9b8e085cb0cf683b7388f9eac5b20.json
abf14769024eb5896e4469f7701118.json
c5e99dcb1f44703b903db28d9570ef.json
e321b92e349816c726029ff732b3a3.json
ad
1593228c481d049c0734190ccca16a.json
3895a8829ea452f9b5f1e17e525e7c.json
3f3c46dbc93bd5875bd545f2ef2ce1.json
440b00e4eefd7886ea82b4f131ded6.json
9e99b18f0366c65df91205e0197563.json
a1755ef88afa5658ee0b89e6f74c89.json
b8b574b7505f8ea092a14d004c1a7e.json
dabbed928f9bdf1f4b6be32d8bb334.json
dfaafbad8a6c390cc432bda4f66a4e.json
ae
00ed3e44bd5e6892a064a91da28a3c.json
5381f876261dcacbea3ef1c7ea771d.json
85569d3090b8a7f3669cd08832a222.json
8dcb17497b331171a3026d039ef0fb.json
d03044ccb7e2a971bf5bc3912ea7fd.json
d50a6990d0aad66813ff673cc65e3e.json
d5291f5ba00305af7fdd8b5ad4155c.json
dc298e061239b14af3366ebc417c8c.json
e828dee01e299ba2ad0ab935240bc2.json
f2cd681ec0675056bc41818d924ee4.json
af
1f87b53e07d28cab2edc2652050054.json
8041ada5d9f8533edbafb8e2e23038.json
84c0e5060b9faec8b92016f8245fc0.json
a0cf483bcc824a33863ecdb26d5a6a.json
b156102cbb1247051c7dbfe153c3a0.json
db26401270fea5a63ac8a06249375b.json
b0
0bbfc5aeb3566a4eebe6527efb1b75.json
12e0ff4efd6444ae8c791a8dcc34dc.json
488265d47e7d6f1a759d6954f4069f.json
9113f00e3036cb8d9bf34e2b345576.json
916f346793c2b47c750c962c0992d5.json
9dec1099564406e063d43bbffad85f.json
bd434e903c892c631c1183cf5af083.json
b1
721c6a7c8ed440b2ace02b032d07ea.json
ec05ae049801701de6c76e3893d7be.json
ede78810b50d821e0a8bc4177d935b.json
f224f9d804ba6fc98bbc3480d9fd73.json
f46d1a5a01ad4651be8a1c259a790a.json
f8d3b993991d09a2314f154386d6de.json
fa3059169dfa3497cb91f018ad6fe5.json
b2
23a84852464b25fdcca9738b63dec6.json
38b557d59caafe0d27472123bb4759.json
41d3ad2279001865bc85bc2b0d8903.json
5711d09566e406bcfa8df475c3c4c3.json
6285074bd20820b69cccdbe9bc1f6c.json
a512741a7f4a34e69705e62691fe88.json
b2c4d7bceec3343eb4aab49cace760.json
cadc080ff380fd6d3178509f0808fb.json
fed1e7b892f9bdef22c5beb929fda5.json
b3
254c799ebbc2a637f1efa3e9df8003.json
db5a262b72ef01059b2d468c4ed5a5.json
e7fff5d2d71cfff46050df813841ae.json
b4
089cdd79132bc46712d1d5a14d05e7.json
0b57c1372524516ebbfab76336a067.json
2204825a93e3a7a00fee2cdb0ca883.json
23237879c8c752ee5d05a997592ff4.json
31f56508bbd1dc5c9f4ca393d59fcf.json
59b280fcf8b8b6c58143b2c737e3a2.json
63b12df010421ef69df880c638a658.json
67067ed6beae840c4ef18527a36dd6.json
676333adc14e7870064fcf311c9d94.json
6b06b31336a9d3ffde49dc55b88b4b.json
6dbf9b85afb9d83d281ce6588f6adb.json
78506ee7ba3733b209f62623e6dc12.json
8679c9b5feb83e3de62e4df4ac19fa.json
870526c64292a89e5d162d7b34f262.json
b5
3636fea54f2df61b9b22792f392a1e.json
b6
55de2fd576f18d3d839d4d93a51b9d.json
5617d65f9a648abac699c29a4f0c55.json
8e153aa881276001e16953e6e639f3.json
b038bde945abdf8d98e4464d77f925.json
c9bfcbfce5adea469b649fd1904ef7.json
d6e903561aa2354d228b6ea6a259dd.json
d732bf3334b6ff86bf173a1ebd9225.json
e37322862ae1b5831d392b24126d27.json
e8459e682776313a4f8a6d110dac2b.json
edb8538d8007cfa12224f256247682.json
eedcdff788738f814cd2f9946321b7.json
b7
32ad2b2be1508cafb953bb6f718176.json
420d42baec5e123f10aac6822d7efb.json
4fbb97c126eeac811d96fbf9367663.json
546f9006572dde0ed88f4749c7e506.json
5cc2bbab617b301ffd9c798d89c51a.json
7aadaf359e08978128480d68df2725.json
ae5f8f8c7894144090134b50ab655e.json
b88054d432558db675639946b9787e.json
c371173a14d9588a504344f7b2ee2f.json
c536b9b061ec7e308f5e2e24f98a5f.json
d1446e6cc628e384dd41c69b3a42f3.json
b8
07d68451dd2f2f029b0ef5324b0d81.json
1333a42df9db102283a907f7aeeb6b.json
369b5e00423058fa7f9fcd687b5041.json
534de7f24bc467d332e1cfba6944c2.json
63acf768bd6a71c6a482c725a28be8.json
714d1892f8817343e23fedfc5cd4f8.json
74913a6816199a15635b9d67d6719a.json
8c61fd9758b8eaffbd168208cb4f92.json
9d7b9729f73b77df116e85b0acc017.json
f321839ba627db47d5afc1fa087868.json
f6cb118bbe7311d0582af7749e6b2e.json
b9
0af480a039e69d38937b6534230c05.json
311464cd80e018678d3d643a033d26.json
372102dd1171de3920b8af67a750b5.json
47bf1014a635635fa957e506e64b1d.json
4f39ee61ed140e4299100c3acffd36.json
ad045c4fdbec8f38ae578facb876d3.json
e0ead2ed16c9c7ab77c192ffd23d45.json
e9a456c507ea262e94241228b4d290.json
ba
00ad700c0527e910734dad2e1f702a.json
156ec5faa4d8312b39023faf1bdd83.json
a42d2aaf89fb1b3377d58fd0dd6818.json
d9240ab35abc886e1a576af855fbe0.json
fac03d54b2a8680080480afbbb33d4.json
fc569064c00c40bc0c49daacec4de7.json
fcc4c1cde1b17aa9201fdff5b80371.json
bb
118100399bd499ffd40d2ec4e1f196.json
a3c5305e8e3daf2e4377b2b441ab30.json
bbda818cdc5cd0af88862886545614.json
ed9eb54fd283159339cdd2f8ccf4d9.json
f2d7d741e3aecb2d48c431f24f45c9.json
bc
013f468732505b3ee40af646914ad0.json
1a466327982d0fb902928491f09450.json
20cfd701a49f0559c38ce91ea35a90.json
480488ff7f3705974d05908e36c0ff.json
550eb38424f096fb57637a32102bc5.json
7af161a57af5175dc3cca0c3ae8c70.json
93942f94e14ca3e04ecfb317f47618.json
970a76afa111082ea46a91507e3d01.json
c221e17ff3e07260700c63c3855fe5.json
bd
262965b3783e941032f802cb313364.json
2e7912a9f2e72fd6c4e6b62a97f217.json
34eea1b7cc8f577e9e8be908f0c166.json
904557ebe943d9526aa598580412ae.json
90dec498387db873213ee2bc03bdfa.json
d4746ea9d081e20b214abb17974591.json
df68b766d4105a19e8edd501367595.json
be
11dec09ce97f1787676252a3e06a08.json
4071fbd484998275dc97ca292ce07f.json
9082df818e71aac0802f6acc9dd6a8.json
97ea040f87d26719de61bd88de7b43.json
b421569601d3f34f6fcfa0af2f3301.json
bc2ab69a72983abad9e047978ab5a4.json
cdfa959a811a537c5da5f3cc620b4c.json
d35bae0a9ac448251ab7271341c76a.json
e8af06c3a6f346133d3eff0e286bae.json
f6b7874a678cf94c2b52b015850f83.json
bf
0a0fbe6750f02105e42b9d778feed7.json
0c3aece7fb07e2546c50d907cebf54.json
441d12ab58c734c4e0246d110ebabe.json
75eb7cdb46e92ca5c8f5bebad56193.json
a788dae50ffe21c5d8a8df49d6dee5.json
aef9c3bf7d0472f2a9bfc384ba27f6.json
be382a14a543c69dc18582445694aa.json
d54dc22be3662bbc5a2328a2283940.json
fade972c91b7ba153cf032f2cda219.json
c0
05249321ca56725e14c359471281cc.json
13e95ebb63c72b63f42addc56ce4ea.json
294c73c4c0961c9b0ea934f8645ccf.json
43bbe16bb58b61f95c3e98c0b823a7.json
46e0b8e6cc75a82d3d56e094e730f5.json
7de9f8d78a985ea53356f81095c17e.json
8d1bd34a8378c5102ce32d46397df0.json
9b9703ed18e6c308f83c74908ec3d3.json
a4664139d578137fe006f249cc3661.json
b296cb5a3624a357ab552684fb8653.json
b74e22dcd8eefccdcda3167a4474de.json
d9d936ca659a5d0a9de1119dc46f02.json
dfae6e276c45d45a59bee7bc041613.json
e0c929062b60d09a62d56fe2e03c44.json
ec1f56670d28cff090b69d9370bc24.json
fb1ad2d3916797ffcbbeabd988323c.json
c1
11dd9897cf4cf4aa516d2702a29be6.json
4aca94ebdd2957297452371c20233f.json
79bd29175200c2038d15770870f7fa.json
8803f559e0123c600c115e07b6e59b.json
8a59304dcfa6422db4d5f049fc34ec.json
a9fac69af8147fd30cd6c0601792da.json
b7be35ea48937920c17f29f1a03983.json
c020318b7078b87c1de34431caa8bf.json
c31e58c55b13014d16c044c01835f2.json
ec0396f326a45b0477aaad0ac7743e.json
c2
0de2f2a348be8c95fae110d1b0a732.json
11ae5c13444428e20f868188d6a806.json
315793bf431932c30fba544cf8ffe1.json
44cb5506049780c0a7b2eae402111e.json
461f41bd70a1938ab9d1b301ad15a4.json
6d222de014351d63a2033d6eda3a12.json
6f06b3e18daae0a8094f3f3f232076.json
ebb710a1cc0a514a1ff4d4073950e7.json
fa0899266f47d3ca558f8c059f8932.json
c3
1908319541f6b3e3b20cc6bf886dc1.json
3cb2de94ff03ee684f1eaac8bea118.json
6de510f162fe5beb704fcc6f4a3cc6.json
782a802ba4d915246dfbf7008a8133.json
7cd4f8d82d69679e0e92e975f27578.json
7d934915599b5d0daa3478d23454da.json
c179af7e9bdadc648583aa95a01784.json
cb6d91f3b9e237a46da9225f4e9023.json
e38bb34640c94079ff9487c806f4ed.json
c4
01fea7176a0e319fef675926170d9c.json
25c49e3eafd3d26528454d0bcaf77c.json
33143ca8b3c9be0c48670295fa45c5.json
337e42095e650a374f1466f76552e9.json
348407175192ab9d0c8c0285e501ea.json
369296c938c0b8be73614073d06c70.json
37878723e741de9ec1357492afd5f6.json
402981cee27beb66e49b46a7b0be3b.json
42ba050f0c195c571b8e1b7bc5b767.json
4e5ee8fb87eb32ce8663c7a4a2a909.json
8f670cdda75cf93a9cd2da85ebd511.json
a78a24875994d39e01023cb6752f4a.json
b6aa1a4df2f2dd0313a1e8325ee184.json
e62ff1e3a5d47ef11263c4ffc6e41a.json
f6eeb477bb73edfc53d7577e91eacd.json
c5
131f5825a63f77df6aa50a5db2f9b2.json
1e2beed0a1db4e31a3c0ed25b3aa4b.json
33fa336fd8cab83af6ea6a7a8bed01.json
42d4c853e218b2efdba75b0643cb0d.json
4a8303a95b93614daf0b630a76168f.json
5605f714d9414fe50a29d311b42944.json
6d0fc775782793268bfbd097e7bc4f.json
7149b1c5c2e2da8cf6906ebc502841.json
753be95bf205a4296370275b6f0984.json
8c0d7de3e0f7943be0b710d11194fd.json
c399be9b07dbf39d0043cb17c30117.json
d7a46e24f49d78f1340b3142e8ab7f.json
efbe60caf3f93c646833e61bfff998.json
fe2635a5b46be4d25e311cca0277f5.json
ffe3ee20f746e5f34d77515da00995.json
c6
0c7544f6d5c378a7d4617037fdd3ad.json
16b7f877c29ff6e2622a68b7684256.json
195a82fffcc8540cad4035b259c1d0.json
600c0441ac405108b10459562834e8.json
6be0136fcedc198407be4951bcc3dc.json
6ef1635188ae704e471a5f09d22443.json
8df41dab3f7dc3a8e4cb67b019e8a5.json
9471284c303ff7e35c27bc290f28c3.json
9b14e6a05887802e352222e780cb77.json
e7e58acb07034b6dbe8957c00b0b65.json
f0c87081a26b84f51051a3148813b0.json
c7
130d439d1ab4ea230920d8d618f991.json
5f021986122d9e5de6111942277ff5.json
5f4ca56f23a6fcc0a2a9439876e2f5.json
6b8d83ad88997cb3e58d661822f453.json
6ba8b4e1cbd66c533b7982b88cfa84.json
7fcb3a347c7879f446ac53da96143e.json
8dc88e4dd31222a63c8ce1ed3e2437.json
a11059f48de54a9bf3ae41b116a9c3.json
a6fe35ed57970223c594e412d684c0.json
be8e51a14f3bad916b01f58b18e7da.json
bfca47d30c0c68b026f5f647877fef.json
cea5c93569bac0203885c7079482b6.json
c8
099ade3fa581c5772ecd1af7a196df.json
0ae210c552df1cc58d9b71397b7c0b.json
3965fab358a07414b9762a04486a96.json
3b1c2ff2f6511b5ddc2c3d9aa2181a.json
6f7c6879b7c170f69c68eb51a08c41.json
771b2f9e342592ca508b34eb82042d.json
7b6f9dff80e517f0871e66a3dbb34d.json
97ab9ca091050d71fbb5d9c045b6d7.json
9e0684da88d20564785c3d0aaa9849.json
c5f5139439570187d162fba2993a62.json
d28bc0eb12875ae50c577ea5e3fb76.json
ec999b951a46f99289072551dec45e.json
c9
1220b5425d1252b2802ca64b288bbd.json
5227863563fcfc04dff02b7b0728e8.json
5a5cd912a4407f2532e28a64c784ff.json
67cc231a30f0c3d5a194bfd0e78294.json
a698f0e3ddc5deb2715b2236116e30.json
a994f759b96bd25799e3a2885bef52.json
b656b9e4546fba268100802a44667d.json
c540d99ff53384dadfde892817e5ee.json
e962a37a7417eb1eef60ba7da8bed8.json
f3c54a5c4766a37d9d6d04970495d1.json
fd7fec79f4765a233838d23fbce603.json
fe6583ff2018f26147e2d7620ee913.json
ca
1c2a8b077aaf7bb920ba6673dd0c85.json
3611d01c277e41395500c480eb65c3.json
6455707c56f1099059de5bc1731df7.json
985801532b86877a3cef8beb1fbd12.json
aaad4fb8dd42588f8b6e1eac4bb8dc.json
d255bfe38f5a847fa0cb94d556ba0e.json
cb
46330437c0cb01e18171922cbb7321.json
4ac30871c5f836eb133d552e8b57ae.json
56f3a7ccbd80cd95e0b73ed2f35ded.json
6802855cfa70eacadca7483a3c5224.json
6c38145a3a7cb24afa9e462423f9aa.json
a1356883abc1803d04ff0a59da3435.json
a83f48178369129eb165109488d32c.json
aa6643da0705e434fea5bf695239e1.json
b26cd8980577e06d23712c816aee65.json
b947e548d2f362f8f74d93e383f2a4.json
e4458b9c5090018327aa8cb5a23555.json
e923a0037c7d2909ed0326e9de873b.json
f18a97b3ccd18d22854280f2ccf535.json
cc
0b62b983a976de824942984ede9049.json
1f03d8c443bae1f7bd534c43301d1c.json
3a3c96a814cad678dbee693e622f8a.json
7033ef2dcf61afda267de38e04cf6b.json
75c410f0985c69ebe02c037fce4f5a.json
9851fa3c9dc397e0b0601f9c93107f.json
ae1ea11f63691b0ab402f6e6022976.json
eb06bc49861364fe71e44b31e87bd7.json
cd
336a97e6856e5556bf642763756d87.json
54313470d57368ec00eda3a57e9f3d.json
5b6c46edd65114cb757554e8256690.json
71965bedc9f440d9e6f87d1fdd6d17.json
8ddbb08ef14d819b6d79af87107196.json
917418bb0dc1c92d95cb3f4b57b56c.json
956fcabf5253514da37508b6e7b2d4.json
cdba2bac2c739212b365b8b618b1f4.json
d40495a0c5e8f56778a007b4d1edb5.json
f3e7478c573d0241ffb9cba64567c9.json
ce
6ef87449864807ada35c80d26ae615.json
9c7f9e13a717fc56bbee87b26c4405.json
e9ab25872483416c2844a8e24746ee.json
f4aa1701a6b863fb0ca65a0bc044db.json
f701153f86ebbf5f8ea261c47ffa5a.json
cf
39f2940b17277803d914c79192032f.json
49f5a2749fda13954783460ec23083.json
569ce49b920e1843400bcdf61ee305.json
86fdafd2dc3d255c59f52f6716b2ba.json
89cf886c579d9ad9be73614d302b0e.json
abf6586a84d8b91fa2174623c3ae81.json
e95d659c34bc9c9540b2d1f6c124a5.json
efb6b2975ab4ccef209d0b18579227.json
d0
21beefd23b22e03b3d2cf4c623a5ce.json
2897f7e28cc5a8e276a31f62956be1.json
28a44c549b4a8acdcb7d5c226ea4bb.json
9d237330e41b547c5298d5c55eada6.json
a568c880fe0e791fa0197932d75a99.json
baf10532213a3d70d50d387741c59c.json
e1dc078297e9f5e0dd9e9414ccd285.json
ed53a2430b3c376e1d784a667d3ec6.json
f4652433b4890dfc258c4b404ec3d8.json
d1
3056097823448e66e3bae5148966b0.json
462c3a0890bad54e5891b9e6df36fb.json
4f4aeaaf10b8dd5533a5b2e9e69709.json
697d206004baf209bb58018bd01856.json
6bb62fa76f155c7f7d9b2ccd9f10b8.json
6ee54ffe7ee5c9616afddf4bf9eae4.json
ade274c606a801c6f2124e80e8c7a8.json
be886dd1585b29123f7e97060b9b20.json
f758b485c489300758a355e4f4ce2f.json
d2
2831e786e0b28e6387a5f8316f36e6.json
408b3729bd3099d75cca2b2c0f5643.json
513789c99f993bf55bc8f49570449a.json
57fcbc41fe48130ab4f7b351acfd6f.json
6dfccb791ad97fb95fc05dc05353a0.json
bb2242069d0391c34f76d1f8503f98.json
d6c10d404b0ba52d6b2ca5d322bb42.json
ea64d5c42b8915e8c07144157a390d.json
d3
201620eceded66f1d751163f4f5334.json
4c4acd6cd9eecb01ab032ec3ba791e.json
508893f00ecba2fae424f297899b1f.json
b27e0ac8b4bf47f73c191a39aff56d.json
d4
1249deff183bd893930cf6c08250e8.json
1ab5951d548660e173f093e8adc1c4.json
2dd8f5eb43703cb8e080da76687ba1.json
4c03d8fb54d51defe5eb5af6ef6554.json
4fcc0fe92014b754261ab9ed91ee4e.json
7880e79e311a4ad4fca04074ccf716.json
8894fb20094898fb1403787a815894.json
96206e5fa1f4e6d4476aa6bd04bdb4.json
b2e58301f91233cd71412a96f0945d.json
c1a6d35c413fbb5f6b2972348487a2.json
cab3db4d4955a3d2506b8a4908cfb4.json
d5
1421c3d44d1b281be7d809ccb4e103.json
18095ba9c1998829f47532a7ad954d.json
2f316c89b4adce111f52a1292e7301.json
3a7b13f9ef62a3c1ad5173e9d8cf66.json
7763178dc7f308ef7bcb08089dce0f.json
917077e437a94f41b584381681032e.json
d5cf40bf9864172955c08d9254ca78.json
d68e9a4d3b8f371dc2ff894943bfd0.json
e221ed6cd603da67f7bb49f8d8a336.json
d6
7b80e21fec5556de8a351fd1cfbf32.json
8acdfdd062fe3208584e0f49a12495.json
9b67ed856c95bf2959c1cdd2257f10.json
d6c506ae6fc1c6995e6dc900dc69e5.json
d7
2ed9758013b9a85d6ffaedf0557abb.json
30d631922ba72d1b2efd93e739bdfe.json
495d32ceff94149315928b68ec7439.json
64706fec2678ec540001457b65ab26.json
658dbfb5a875af04e7aecb18c74a94.json
6cc5c70905a220eaf5a02593807be4.json
706474a3d2bf685cbf7eac3265ca2e.json
e6392e34d18edbb1b70dfcf934a33e.json
ead13cd24ab72cdb79fa1a647e6b5f.json
d8
22848fcb0115bf886d1ce7224bb323.json
2b96732ebbf5ec0b299c46d4ecad73.json
6dd7c21a19e3d8056b15f0aff36a05.json
93780804ed264b1985a9a6d86d701e.json
a2cad6869bc1e9519049157a5eaaeb.json
bc3b21ce9e38a8a9fee8307ff778ca.json
df52089e77dad0ee577fd8b0a56da3.json
eb67e3b98a80034f85747812d28a79.json
d9
14fb29e58c7b484c9b8919c13efe1e.json
219d4b097630cc5b561657e01f9f58.json
4883e4af3250f660bd232cae598848.json
69276ae7cff7031d98bfa22b39f119.json
6a0344e2964fc004882b08077397da.json
720b7f00808fe0e798b45f6c72bcac.json
c110b74ab5b854e60d9f24e974be62.json
e1443c294dab5fd10e0ea51496e09a.json
ff85e533259d547440bb58fe2e7a43.json
da
20c008b54029bbf7166136619ee7f8.json
2ef835aa30a7236635c7f2e48dbfa0.json
4dc3eeb9de5bd040d3eca2b0fd3ee3.json
5a584ae74a149aff9e0dababa9677f.json
6674db847d9e65ec80bc0a752e4c34.json
7d6e8a486d2f18ae9e546e5893b7ca.json
8fb188d5e728873e842711cf69fd79.json
95e36af9b5d8155b348bf70136cd47.json
fc2d672771d5d3830971ec76a68bf5.json
db
127acd67ff1a56289295d4d4e62eba.json
1cae3af8e9d845e789038417a50ce0.json
4f8470ea0ff813e3c418938c9654a0.json
70ab592b58fb6a7d436c73197c59d1.json
8035a123fd24fbcdcb1a6f0b01fd6b.json
8e5b61cbb7043c29233ae4eaf20cfa.json
b4e596a330ba60832a707a6762916f.json
c9b56622ecf7f73cd1f4946160b6cf.json
d8d90f9fc8fcc1c786961fb2fae8da.json
f04261f5658fdd353ed26f479187af.json
f52de1dfb189a0f2be85e4148f97f2.json
dc
380442a41db8ff90c67f9098b5666a.json
45fc93c631fb608b7cf44a7c7652a8.json
638431c9670622e3ed4038870cc5f0.json
73f844ab008d25947350c67512b6b6.json
7c11b04e632e5517a7e0f29d0353bb.json
7f1a614342213e0ba3077a894b02fb.json
8313a75f14daca2d7ea41a9b5486c7.json
8c5d9808c09e6a68307765109f5aba.json
8e045bbb1d4ffb02e4385801622e4b.json
956ece6bad040ffb28095686e44bdc.json
a4fc36edbbcf52c97f47f6e865a197.json
d30d67846cba04473caf454fcb1713.json
ed53e3cd71861c7257a3ad3985edb5.json
dd
0768ec6be6d053f5f36d05dc265d4c.json
26b8fbb16f987c253e200158c1a0af.json
506c0a36d116e8e5256c893dff8943.json
647e432621dc1f5e3ca347002e0248.json
68b19fa95c4fe10cb7cbc84c0f3aa4.json
6dae1e96c1f6379683327f80bb93ab.json
82b5d3f1ed4f05d6401656d48db734.json
aa5e42964166175d9db21eb40a7a56.json
e359b3a36f8944e3dbedc316b185a6.json
edd20e139f6fb5833fbd8c88b2f36b.json
de
25bee5521a67c3be97814c694d6a3b.json
2b516045ff01f08d7800775f6d93c3.json
5af0f81e209b0f8fd1952f5825b81c.json
5cc96d4ae1a03ab28f910828fec2be.json
6aeda5170fbf8dc36d736c91a6967c.json
74df1ff30a4745a1984ab2745901f7.json
78728d0fc0c48639d5824e3cc09f16.json
86beacc64e44a41fea95e92d4ae1ea.json
a413835dad294c28e39575e05d40ff.json
c68a76f5407b704ac8f7968778b270.json
d3f3048cff087fae0a11b008364b65.json
ea3353e8b4c79e3c37b28383991877.json
df
0b777e5920d6f74c1064d461d15e5f.json
2b9685074abdb743e0a1d1b5c4b729.json
326bba6616f30a066294298d8a616f.json
480f0bbce34d03b6a724c512feca6a.json
5c301467a6071d20cf0bacb0e37876.json
96be734f59f9eee6c4d78639b8bb51.json
be3fef1112f8cb275783ec319c2b93.json
c55a29356770530e78dec1d69b032e.json
d0f34c6d22825eab1038eb7c176ae4.json
eee5d2c04e15d30a2a81badb654476.json
fded7d370f8cd39b0f4ab2225dda6b.json
e0
314b1c4e5f95c62435f6b071fe61b1.json
3db4f5981d31fc17c08240ba6de3da.json
78e67777abaf1e933d0c4abc8f612c.json
c5e110f29d0c3233c12eacbf1ca587.json
e25a62229fd042a5eecac2f4568aab.json
ff265b2aa1897f685c56baaac80501.json
e1
16efb34a0c81a6b58a31f6813408c1.json
28a992397605e7d949de0fa4a0c902.json
2a64d763d3fa0a519a7255bfa85a13.json
2c59953ba014b02db6ae6919d8809e.json
70e4952e4307970f1dd18f4911ee78.json
76b51e8608bd23753ffea7d2be8450.json
896a72325be33b2aad259ad45b50b8.json
a233a8a5e22375a855c1ac5aab79e4.json
c1f051685ad1a13398b08bdda0cccc.json
cc3a1a23e58b431f99b00caec7d226.json
e2
23dc8e4f68aa603048932782a5732d.json
64b83b0447a9c8316795a0f836b1b3.json
7333c081df2431f2d84d61987f50ed.json
9577899b075901c626f53a88974725.json
cf043cfda1dd769ae655506dfd48e3.json
d54b1ec485719cbdd07253906692c4.json
df23b0752e73deef2665ea0de6d6b6.json
eb49f6ef1606bd0d75cdf017575b36.json
e3
174006c505b8333d84fb7bc44eef3c.json
2e216a66385aabda49d8c483539279.json
b7d90e2ebfdda2e8d5aa463cc53fa8.json
d2a5e11eb5f3c7e8b1be6c2521c023.json
eb86065c8ee7700995bd7a16f7e0c3.json
f8c776e1bbdd60ec83718b27b2a947.json
fb681e081bc8c2dce60172ddd26afc.json
e4
0870324917c73b46826f7901c88029.json
0fdc86d53a055a5aa1d66820eeb797.json
2586c9545f7e0275d350cb62b7ce9f.json
37e436068585bfe3df59891b811a7d.json
90b5a876fc5f7c695a931cd123a60f.json
94d597bc0db622285a441a3c34cd22.json
a058e9fb10cff51ab86c3f0fb2ae9a.json
bc4e4f026f413b9fd0f540e2a3fd18.json
be8bbdc1f77d1ddc186db03fb14883.json
d67d13060b8cd7b92e06eda87f33cf.json
e2985a1a57109d4ab9581a87338699.json
e5
2147d460920104d2fca1524a52a9f0.json
59d3df0fa0859919efcf0ce49fc706.json
5c58dbcdfb3be73e90a5c256950bfd.json
7247037c5fe6f78463f263d796a3a0.json
7f1addce3572625e37da23adf148b3.json
8df02034d2071dab5a254c657fe41c.json
aa5beb5d182e373037b4bc0ea58f90.json
b53765281470041dcf459984af30a9.json
bf8904bfbbd806c9d2279a1f50af4f.json
c4aa1b62d3c073df5d5cc02d02b41b.json
e6
0cc1419a5319a857687c8bf9c21b06.json
43fab19875453d9c2ee637eaef3dcd.json
4603268ea60006dcd9d458cc8e65c3.json
5691705d3202af0acbe92f13f7611f.json
769c2343f1966d689e397b2da1af1a.json
ae2d6ad2e99af86c53f87f468d447d.json
e3dba3e9b5f4e9a59d8c1ebc0098c5.json
efe19e635ffc009dabad1da2dbf0a1.json
f5a2d35aa477bb7f8614759dce322c.json
e7
72c5e34ee519ca42aa44e4a88ff09c.json
8929ff93b197b78927fd2f8b406e51.json
99842c3493400777cd1ea6bb297d52.json
bb30b6b480f328e7d97f227404aafc.json
cdd9bb0c4966aff08b59a70f420ccd.json
d4ea15d98874d65e7f1a68433eb0ae.json
e3229b5b685a170cc58885b52a5b89.json
ed1a82dc1e9a273a842e6caa79d3ce.json
e8
1cf17bd7fc4b68f11002abba851e07.json
1de6f442d21207858e6bd599b7e20a.json
3470db8646a47fd35eb57f5f67d762.json
3708890b8f3253dbe588d1f84f5b76.json
57aee797569d35dcab8c25a0ec963e.json
5fbcebab40196df58a52ecdc6d6470.json
bd08bf0490d8d321de26270ac76659.json
c3b61888bfa7f2af1ffdb12b90acba.json
f1beb8782fea3d2310ad0b66a72cba.json
e9
3ec5738a15f575e02b8c5ee38e8078.json
49d91982b8710fa780d20a4145ab33.json
4be9d87a0bf08437f5d0a325135b00.json
90c8b503adbbdf4fcf0895a7b14ecb.json
a13abeacf97d6038dcef41e5058c5f.json
b045384c12eca675c1284f6689446c.json
b32bbd80e416c8227f490ee7495c12.json
b9cc795257916c94cdd144d489eda4.json
f8630caa88b54908ee65c4bfb6806b.json
fd0bdb44cbb288ef5cadbbd09fe012.json
ea
102119a49ea68187cbc39afb3062d7.json
2c0f36478fa926d59ef322af9063bc.json
58c9289298d7504119239b0113ab27.json
68a4d270347fce0bd57dc082f68171.json
8d71f99d643968941e90d2e7b15983.json
9f1b481ebc4b1684843c156706a14f.json
d903725df1add4b35877f5938f60b8.json
eb
13099942195cedfd539fcf0b4fa5a2.json
3c11f830f0ebb1ab396b3ae8ccd190.json
43488f55ff40f2de36bf85ffa10829.json
479c8f0817b764bf6b4f62f17e2008.json
6ba63080e94316d8f0a9909771ddc7.json
8bd38f8dcd0d856b41ff7d85e17cf8.json
abd0f818db478aeacf827b63ab4830.json
cb240b1069cd7d7d8e9b99498e1074.json
d50be501cc1cef55f1bfeb3afda05b.json
db884d7f4b93e25f4ec212b0ba0c2e.json
e78552a331d32a37b17f3bdec565bc.json
ee581a270851026aac8f09d7a088dd.json
ec
0030c75f3bb680eaf7833ba971658d.json
1f27ddc641d3ba3de976b061fd16db.json
3e9f07c4d016c314723658f578b95d.json
63a2bd4820a86f7a997d6e64eab613.json
75a34460a3f7d66fbf1512b785b35e.json
7e7b39563636756816aedf18298001.json
873c655108aac94852bb2ab37b4560.json
92ac849dc055c6a46ef2ac23145383.json
a9c0c424c74da649f16e3d50d5d793.json
be5542e08fa90957b7c8a2374fffde.json
e18f12c12e2af6e2c12a0d7ecee55a.json
e3bfe34f133df2d580094b8596b4ec.json
fb1c29d23c3a9a8e8fef0fff67aa17.json
fc76870a834c1efeae0747d7a16305.json
ed
14e078c8176774ff94cae9fac58145.json
21588cb8a6c742e70619ed000a4c3e.json
26c616f3b0fbd012308d29bf06a1db.json
3af2b25a0a26bd762784ca7dfafaa4.json
405a2fa78f50361e270b22e7afe6b4.json
4112ccbbd4e9693f75ba9db786dd84.json
52d3d287674b99f4c74a9058d5a575.json
54c974b11f7abef2d36496d1b84855.json
6d3c73d656fcd27d597f12a852b29f.json
6eb1c202bdfbd239380246452bc255.json
765ccf36df7e3285820ea624b50768.json
878a957674a73acfd16fc4d3a555d1.json
cac542c706ccf4a2e34598e505d3ec.json
d27540ff58333f71df4bc780917a26.json
dcf5b31d604c1ec9bb99e4b868c826.json
e3cb4e101db6421ffe76d835b046bd.json
ee
2f441227da04859195a9cfc75e6433.json
386d8e0dadcf3e3c870c0d2102fb10.json
3a722a95b346a3215519171762a84b.json
3f1b3e238ad5cf49683c6071fd054e.json
4267804f61bf55763bb58477a59551.json
60a1eba171af2db56716569082099d.json
93fdbc843c73e33abaf7abfde3c692.json
95670586f5de1d49a9a435591e30c6.json
95cdeca92d64a06e717052384268c7.json
aae0aae6b2a6fefdcaa1e909246d53.json
ab97bbb25ece477821e4dfc646506b.json
b9d5fc3ec7359ec4b26bdb0cc58eea.json
cf2cdf8e5a9ef5d7742fc4543cc279.json
f558ead5f7877be8603d5f001cf6f0.json
f6fff3702b2a375b538968fec03269.json
ef
04b37089dc626f9b6ec14ef655afbf.json
1c5796ca63c6b12559f06fc9a0bb1a.json
2ce5223f0a54dbb78590fc8d2eff2b.json
37967352fba3bba2d0693b24564c28.json
4c82572544d9b26fda2f3f9040f978.json
58c63ef24f9ab17e145dfba4a9d7e7.json
7bf7a3f85b82c4dc988299a2386aea.json
7c151b44dba692152f8eb3cee41237.json
b7154246138314ed7a180ab59bb9a5.json
c68cf8ab7143136bf0e88dbf09e8f2.json
db7b6dbfd51b79cf30c3ad3a842db2.json
e6cd74851471753f026c82b932da75.json
e905d6ba5291f3819156153fcadd34.json
f25cc4c849d624a0e0d0cffc1563d8.json
f0
0e60467303e82027ffcb948cb9c99d.json
211c95e28b68b69d1e582e29008d3e.json
3cc5d97f7de425774c014346580a39.json
893e6c4fccd1511be77cd303bbe222.json
8c1b055943bb297fbce60bffdceb02.json
92d6a9586e3120b8e01268d46089f4.json
a4e9a284796341b183c4ebd031abd0.json
b52c11346d76fc09312e311a1db312.json
d5add58e4932c4d52c60e5ae9975c9.json
f78da034f2af3af4082eb5c35b9145.json
f7d1ed76b1d1d2d99ac59f5645f9ad.json
fb95eaa982dc9a12595cb8ba274bcc.json
f1
1e3eb7ada8a6a0f8e51c20f8eefaaa.json
3d4ef2490ef3ad8aa5a9d674937161.json
6a9f65d56679e4053811ef560a72da.json
6ccb3ab4f3d52a904c26ab1fae5b37.json
77616c47b4aad021b9e4ae949a1945.json
9f1089527e3809f711cbd3d513087c.json
ada1b344f95a30799bc07e8781f8a8.json
ae99e31223e605c6cd6f381f88674a.json
e5083628781f313fa243023160a0aa.json
eed6732bc674538410396f6b8aa192.json
f2
32dac450fbb567bc2ac28bcd5a54c5.json
3f6882fcac352e3dad10e8983cc679.json
6a68d6705ba0bcf9d3cad0884c616c.json
81b74821799ca1d7ef7d7901dbf672.json
87e260e5ccfc19fe5da32ec11e5004.json
916060f889b4fbca3ef562559a221d.json
a14346ccd1cf878068efdcec96e355.json
ad40c14e631a77c57f131da83faef9.json
e36f39e285e22e450c8fd145e8ed2d.json
eaf76f85dc9593921401b44c482cdf.json
ed63991c00e5fd9ddb39e8e026da5d.json
f3
31b6b7b11ae0b1a1c0e69c4890c4f2.json
32813416911e20e2645f4a158a117e.json
3f70b6aef56b26742d1162370f39c0.json
523e65fbd2e8100bd9727114626253.json
658c4668c8a39719fed225294540cc.json
6746f497923b4469225885f4b3f16e.json
6e34eb0bc51dcf4da85eb6935a6f34.json
87d201bb3bca875f13013a4f9edc83.json
8b7a8c08bca25358cd44852876f269.json
9c8512eb154ce0ed04799833dd0421.json
a3190d46cf66c2f08edd983606c192.json
d4990a593eb334b5b05f5a36faec96.json
ea3f8675549532b5608b893a56497e.json
f1db0951c308b3825e5cc2ca89865f.json
f4
2c4bcff0bc678826e2c8d445548f15.json
4d6ed1a250de8056e276d39faef96f.json
4e356a9ec3433739f63a99e207da59.json
74e48a0025b95a77e6a3b8de2b6027.json
8bdf38b536c6c6f9cd6c5d1e66dd29.json
97ff958c02821eac9dc94d7ea468a2.json
c31ba22de5d1464f69a9b65c512f1a.json
c6507df1c905810fbe287a92c5eaed.json
d78cdca457454c605d3b33d9069e77.json
dac17d5c48015b9ca97fe460b487d0.json
f5
0767f9d803fd2535f55356c8b38ab2.json
095fcf354c1f0104836e583d5f5bc5.json
1216fbe7f0682468e85b7005dba69e.json
3909810dea56392c442530e01c7f09.json
3c93991c1f1a78e529adb8a05547d1.json
3fd541d7b8d4ee38e88952e0c51ae7.json
58ffbb61a611c8edc885a472564eff.json
5b984fe2205dbd329bcffe9b899b4b.json
814a2142717003ed0d8671946e1d46.json
93fe73bec25b21dda8e1d035c60f14.json
9cf032ebed81db92d55422c0cac288.json
9d05a37bab20671891401bdcc0c6ef.json
b7cc055b3edf1c3456b2ebf2243b70.json
ce6379182f392b9fc3ace2c8d9bfb2.json
f6
18248a8ffa57fd7d892e950c9fa505.json
72a1171ea811af690fabf20bf19953.json
84c0742bfc6c115069b2738438e718.json
8ac76d96844c425077d2cabc40be9a.json
aaf612aca1cb5f9f39c45b825d44b0.json
da4f6f15448d7d6a036559638614e1.json
f7
0b6c52a29ff005d43eae3d469274a6.json
372ed9dc08e191a850aaab9f944dcc.json
47d3d1e995e03fcf014f37f229f840.json
4c2d04bd273521e1beb590a15554fc.json
603c3270c58bcebee7a39e246b1507.json
7e52c7a17ff28457ea726ecf09f033.json
c6654b487c09344736b1b7b580f805.json
d3e474de2579997821662ea53143be.json
da06b7b2d213c230b41319eb5ecce5.json
e6429d07720c1d7e2ae51ee80eea03.json
f8
060b48aaa1dd8ea32809360e4aa519.json
08cc1b5c5e1a4f88a7a657c4f7e74f.json
480333323417146ee3bdae9cfba57f.json
6e0dfb106d121e5de9189a3d4da929.json
77165454230e5c09c988d6ee252345.json
8178e8c8fb45a780d6e5bf2157c833.json
8b6ce2c52d87b31205d158c26252b5.json
a0b12b8cc0be6e002d79533739ab81.json
ac6b7e9a37d16e537ae659454fed5d.json
bbb2e3a04527f985bbcf7ffd2ae229.json
c0f53923da1f1d6673a9d28661ba4f.json
c2f4f4a3bdc7944ca88441792d7639.json
da8aeceb8eb5bb30f1b2d1a842bcf9.json
e75b04410709d05bd0b54046d5580f.json
f658a0fa4616175ea1cc7c57807405.json
f9
2613dcf8c89156f9e8620d6c94be14.json
36e57afba78220a28b4e040804d03b.json
3c07520d34a454bd8553440ed5437f.json
534214232c2969579e32a5ddf8cb58.json
568d10fea19bb5ecddbf47946b0a11.json
9f5f887a8b685e42aaa2d34b577971.json
c641e50a4224f0791c8ec67162a3ab.json
e658b2af2e380028f6de521ddf52e1.json
e74ef0723f57ff37dc380cefc3113e.json
f9db9a35bc9df134455752962ec6ba.json
fe8f27292de1495996b46c5459176e.json
fa
006a07fdb423a4523e11b4ca425288.json
1ea242f71ec2ce9b4b5217301bf3e6.json
2aecba62c423f83d48c27b948b70c5.json
3aa3afa5dd103a7fcdcf5fda63d57b.json
578aab1ae9e0e2686ecfcd402a381e.json
6fc947b60ba644f0fe518c63d572c5.json
72cfa8512512a93345a006c6940587.json
80d4ae5fa6c3dc72759ef8cc1de5ce.json
a2093fa9dbcdb17fb6df8dadcb7711.json
abe5def6f087d47d61fc9a0c8424ba.json
cdffee6429dcf418325874189c11fe.json
dc8c1d679e5d4b1fcde4420c8ed78f.json
f67d377490bb17bc9a461942a4e620.json
fb
07265f6d3f5ccdb5c8676c5f2d2732.json
0c4ad17b39223e9476288244926e3d.json
18156c434c44d7df253d546acd01d5.json
1dc7d056603f9330eceaf52e4c740c.json
2e059b413b6550334160f73d9594e4.json
45c8abe04eb6c3ff1f5cea26d3f728.json
4c70964605dd4ab007e18bec01f678.json
6762596f9fe15eb405b2d8eb42e684.json
6f61c664679e02eebbcb056593496a.json
708ea54f34705f2d5d78334dc7a7ad.json
7469f7cf08d7c374d5a87ad59454f0.json
b7af3095a3b6672e19c3229bfc58b7.json
e2d7f8599acb0a39636f7c5c82b806.json
e84d0733f62c5c4e61753487bfa6e1.json
fc
22c4b56e887501e747d127f714a67d.json
50e0cbaed8ebd6cc00aef017a8156a.json
a5de2f497170e8914db7335898b239.json
aff34af21b2ff0fffaa9a91a04ed18.json
c2359d14cc45f4de68fb48d797fff5.json
cb9949bb1e4aba3903b281b1f5a421.json
f8ea88f44fa2a6dc2f16c710856520.json
fd
0b22db35c8ea8329a3f6a1325f9ca9.json
3388c80ffb5000944989b17aa400c1.json
3583d6c13491a63be7f50f47906d81.json
401261336c24a3a4e77d8d9535d546.json
43afca9e879497a697fa57b036c7cb.json
4e39c81fe74a43102648b5d89fb0db.json
8b60120d352773147c39aba62a2da7.json
b651be2186accc7c8954003bc515e7.json
c54ad8a2e4ed870c12d2a6f45e489d.json
e7159a6c1fc4e1089b7f2c98e5d6cb.json
fccb832ba6d93c7add165e86185230.json
fe
20e6ec66095e5666aebb1c4297ffc5.json
2a14a2cf606f2f3bc92e612629d339.json
37c852ca6259594bb4b6addaefee43.json
6cef2808a88107b2019acb5b4b39b6.json
ab990031586eb3a9cfa1fa948ed68b.json
bd009f8e131997af848304c40cd78c.json
c06739899731fac2893568b064cf42.json
c7984b9bb68980c0a96e173c8faf00.json
d254eb4602f6595c13a902f9cbf539.json
ea12719777e8ec7d3f848853d12573.json
ff
03fb1a2160affe6e2f157b269009b7.json
0dbf2f7dae824ba653dadf3c0f9e3d.json
15aa006472aa80a4078f211e846be7.json
4beff7783727d9408dc6f4e319e69d.json
61de7c057ef975bb18622f613dc095.json
7f28895e7c06a17c472f2dbbf4250a.json
9318323d0dc738ba5053bde84fb3ee.json
d64ead101d2dec42e65b1ab65163dd.json
f9df20f2fe95eb514cfee8f596d51f.json
f9f1ac3d131f1c9fd3f68ced2575d7.json
Win: Amount of Tokens received = 1 Token + % bonus Token (level + rarity)
Win: Amount of Tokens received = 3 Token + % bonus Token (level + rarity)
Win: Amount of Tokens received = 6 Token + % bonus Token (level + rarity)
README.md
babel.config.js
contract
market-contract
Cargo.toml
build.sh
src
auction.rs
auction_view.rs
ft_callback.rs
internal.rs
lib.rs
nft_auction_callback.rs
nft_callback.rs
sale.rs
sale_view.rs
utils.rs
nft-zoo-ticket-contract
Cargo.toml
build.sh
compile.js
src
approval.rs
dragon_function.rs
enumeration.rs
event.rs
fn_callback.rs
internal.rs
lib.rs
metadata.rs
mint.rs
nft_core.rs
royalty.rs
utils.rs
develop.env
package-lock.json
package.json
src
App.js
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
components
ModalAuction.js
ModalMatingNFT.js
ModalSale.js
ModalTransferNFT.js
ModelMintNFT.js
config.js
global.css
index.html
index.js
jest.init.js
layouts
MainLayout.js
main.test.js
pages
Auctions.js
Detail.js
MarketPlace.js
Mating.js
Mint.js
Profile.js
routes
index.js
utils.js
wallet
login
index.html
| Step 1: Config!
---------------
Change CONTRACT:
config.js
Step 2: Storage deposit in MARKET CONTRACT!
---------------
One command:
yarn start
|
esaminu_console-donation-template-23423sdfsdf | .github
scripts
runfe.sh
workflows
deploy-to-console.yml
readme.yml
tests.yml
.gitpod.yml
README.md
contract
README.md
build.sh
deploy.sh
package-lock.json
package.json
src
contract.ts
model.ts
utils.ts
tsconfig.json
integration-tests
package-lock.json
package.json
src
main.ava.ts
package-lock.json
package.json
| # Donation 💸
[](https://docs.near.org/tutorials/welcome)
[](https://gitpod.io/#/https://github.com/near-examples/donation-js)
[](https://docs.near.org/develop/contracts/anatomy)
[](https://docs.near.org/develop/integrate/frontend)
[](https://actions-badge.atrox.dev/near-examples/donation-js/goto)
Our Donation example enables to forward money to an account while keeping track of it. It is one of the simplest examples on making a contract receive and send money.
# What This Example Shows
1. How to receive and transfer $NEAR on a contract.
2. How to divide a project into multiple modules.
3. How to handle the storage costs.
4. How to handle transaction results.
5. How to use a `Map`.
<br />
# Quickstart
Clone this repository locally or [**open it in gitpod**](https://gitpod.io/#/github.com/near-examples/donation-js). Then follow these steps:
### 1. Install Dependencies
```bash
npm install
```
### 2. Test the Contract
Deploy your contract in a sandbox and simulate interactions from users.
```bash
npm test
```
### 3. Deploy the Contract
Build the contract and deploy it in a testnet account
```bash
npm run deploy
```
---
# Learn More
1. Learn more about the contract through its [README](./contract/README.md).
2. Check [**our documentation**](https://docs.near.org/develop/welcome).
# Donation Contract
The smart contract exposes methods to handle donating $NEAR to a `beneficiary`.
```ts
@call
donate() {
// Get who is calling the method and how much $NEAR they attached
let donor = near.predecessorAccountId();
let donationAmount: bigint = near.attachedDeposit() as bigint;
let donatedSoFar = this.donations.get(donor) === null? BigInt(0) : BigInt(this.donations.get(donor) as string)
let toTransfer = donationAmount;
// This is the user's first donation, lets register it, which increases storage
if(donatedSoFar == BigInt(0)) {
assert(donationAmount > STORAGE_COST, `Attach at least ${STORAGE_COST} yoctoNEAR`);
// Subtract the storage cost to the amount to transfer
toTransfer -= STORAGE_COST
}
// Persist in storage the amount donated so far
donatedSoFar += donationAmount
this.donations.set(donor, donatedSoFar.toString())
// Send the money to the beneficiary
const promise = near.promiseBatchCreate(this.beneficiary)
near.promiseBatchActionTransfer(promise, toTransfer)
// Return the total amount donated so far
return donatedSoFar.toString()
}
```
<br />
# Quickstart
1. Make sure you have installed [node.js](https://nodejs.org/en/download/package-manager/) >= 16.
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
npm run deploy
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
The contract will be automatically initialized with a default `beneficiary`.
To initialize the contract yourself do:
```bash
# Use near-cli to initialize contract (optional)
near call <dev-account> init '{"beneficiary":"<account>"}' --accountId <dev-account>
```
<br />
## 2. Get Beneficiary
`beneficiary` is a read-only method (`view` method) that returns the beneficiary of the donations.
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
near view <dev-account> beneficiary
```
<br />
## 3. Get Number of Donations
`donate` forwards any attached money to the `beneficiary` while keeping track of it.
`donate` is a payable method for which can only be invoked using a NEAR account. The account needs to attach money and pay GAS for the transaction.
```bash
# Use near-cli to donate 1 NEAR
near call <dev-account> donate --amount 1 --accountId <account>
```
**Tip:** If you would like to `donate` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
|
hsxyl_near-statesize | .idea
modules.xml
vcs.xml
Cargo.toml
example
Cargo.toml
src
main.rs
near_statesize
Cargo.toml
src
lib.rs
macro_rules.rs
near_statesize_derive
Cargo.toml
src
lib.rs
| |
patronus5_simple-amm-near | .cargo
config.toml
Cargo.toml
README.md
build.sh
contract
Cargo.toml
src
lib.rs
tests
contract.rs
test-token
Cargo.toml
src
lib.rs
| # Simple AMM
This is a simple Automated Market Maker (AMM) Smart Contract that supports swapping two tokens.
The owner of the Smart Contract can add liquidity via sending the appropriate token.
All other users can then swap via sending one of the respective token.
## Building
- Install Rust via [Rustup](https://rustup.rs/)
- Add WebAssembly tookchain: `rustup target add wasm32-unknown-unknown`
- Compile this Smart Contract: `./build.sh`
## Deployment
Make sure to have [Near CLI](https://github.com/near/near-cli) installed: `npm install -g near-cli`.
We will create a subaccount where we deploy the contract.
```bash
# setup
NEAR_ENV=testnet # change this to mainnet for prod
MASTER_ACCOUNT=
CONTRACT_ID=amm.$MASTER_ACCOUNT
# the contract owner will be the only one who can add liquidity
OWNER_ID=
# Login
near login
# create subaccount with 10 Near initially
near create-account $CONTRACT_ID --masterAccount $MASTER_ACCOUNT --initialBalance 10
# deploy contract
near deploy --wasmFile res/orderly_contract.wasm --accountId $CONTRACT_ID
```
## Test tokens
There are plenty of test tokens on [Ref Finance](https://testnet.ref.finance/), that you can use.
If you want to you can also deploy your own test tokens, which are also used in integration tests.
We can also freely mint these tokens, which makes testing easy.
```bash
TOKEN_ID1=token-a.$MASTER_ACCOUNT
TOKEN_ID2=token-b.$MASTER_ACCOUNT
near create-account $TOKEN_ID1 --masterAccount $MASTER_ACCOUNT --initialBalance 2
near deploy --wasmFile res/test_token.wasm --accountId $TOKEN_ID1
near call $TOKEN_ID1 new '{ "name": "TokenA", "symbol": "TKNA" }' --accountId $TOKEN_ID1
near call $TOKEN_ID1 mint '{ "account_id": "'$OWNER_ID'", "amount": "1000000" }' --accountId $TOKEN_ID1
near create-account $TOKEN_ID2 --masterAccount $MASTER_ACCOUNT --initialBalance 2
near deploy --wasmFile res/test_token.wasm --accountId $TOKEN_ID2
near call $TOKEN_ID2 new '{ "name": "TokenB", "symbol": "TKNB" }' --accountId $TOKEN_ID2
near call $TOKEN_ID2 mint '{ "account_id": "'$OWNER_ID'", "amount": "1000000" }' --accountId $TOKEN_ID2
```
## Initialization
```bash
# we now initialize amm contract
near call $CONTRACT_ID new '{ "owner": "'$OWNER_ID'" }' --accountId $CONTRACT_ID
# we also need to setup the two tokens, that will be used in the liquidity pool for swapping
near call $CONTRACT_ID init '{ "token_a": "'$TOKEN_ID1'", "token_b": "'$TOKEN_ID2'" }' --accountId $CONTRACT_ID
# and register contract for these tokens
near call $TOKEN_ID1 storage_deposit '{ "account_id": "'$CONTRACT_ID'" }' --accountId $CONTRACT_ID --deposit 1
near call $TOKEN_ID2 storage_deposit '{ "account_id": "'$CONTRACT_ID'" }' --accountId $CONTRACT_ID --deposit 1
# owner now needs to add liquidity for both tokens
near call $TOKEN_ID1 ft_transfer_call '{ "receiver_id": "'$CONTRACT_ID'", "amount": "1000000", "msg": "" }' --accountId $OWNER_ID --depositYocto 1 --gas 300000000000000
near call $TOKEN_ID2 ft_transfer_call '{ "receiver_id": "'$CONTRACT_ID'", "amount": "1000000", "msg": "" }' --accountId $OWNER_ID --depositYocto 1 --gas 300000000000000
```
## Testing
The contract has various integration tests for testing the cross contract interactions.
These can be executed via `cargo test`.
Since we now set up everything, we can also do manual testing of swap:
```bash
# let's do a quick check, if the contract set up the two tokens
near view $CONTRACT_ID get_contract_info
# it should return metadata about the contract and the tokens with accountId, name, supply, symbol, decimals
# setup swap user
TEST_USER=user.$MASTER_ACCOUNT
near create-account $TEST_USER --masterAccount $MASTER_ACCOUNT --initialBalance 2
near call $TOKEN_ID1 mint '{ "account_id": "'$TEST_USER'", "amount": "1000000" }' --accountId $TOKEN_ID1
near call $TOKEN_ID1 mint '{ "account_id": "'$TEST_USER'", "amount": "1000000" }' --accountId $TOKEN_ID2
# swap token-a for token-b
near call $TOKEN_ID1 ft_transfer_call '{ "receiver_id": "'$CONTRACT_ID'", "amount": "1000", "msg": "" }' --accountId $TEST_USER --depositYocto 1 --gas 300000000000000
# check token balance
near view $TOKEN_ID1 ft_balance_of '{ "account_id": "'$TEST_USER'" }'
near view $TOKEN_ID2 ft_balance_of '{ "account_id": "'$TEST_USER'" }'
```
|
neararabic_near-as-explore-sdk | README.md
__tests__
as-pect.d.ts
index.unit.spec.ts
as-pect.config.js
asconfig.json
assembly
as_types.d.ts
index.ts
tsconfig.json
package.json
| # near-as-explore-sdk
هذا المشروع هو مثال لتصفح بعض الدوال و الواجهات البرمجية المتاحة لنا من بيئة العمل near-sdk-as
## يمكنك مشاهدة فيديو تطبيق عملي هنا:
[](https://www.youtube.com/watch?v=wdoWmSmaSLI)ا
## طريقة الاستخدام
1. انسخ هذا المشروع clone على جهازك الشخصي فى أى مكان
2. فى شاشة الأوامر terminal / command line interface افتح المجلد و قم بكتابة الأمر `yarn` لتثبيت المكتبات التي يحتاجها المشروع للتشغيل
3. اكتب الأمر `yarn build:release` لبناء و استخراج ملف wasm من الكود استعداداً لرفعه. ستجد بعد تنفيذ هذا الأمر ملف `explore.wasm` تم انشاءه فى هذا المسار `build\release`
4. قم بكتابة الأمر `near dev-deploy .\build\release\explore.wasm` لرفع الملف السابق على البلوك تشين
5. من المفروض بعد تنفيذ الأمر السابق أن تجد رسالة تحتوى على الحساب الذي تم انشاؤه و وضع الكود عليه - مثل dev-XXXXXX-XXXXXXX
6. هذا مثال لناتج تنفيذ الأمر السابق
`Transaction Id EtdLuXkhT5eex1ubT1pRKhETZNv8AoAMzadHiJMdGH9z
To see the transaction in the transaction explorer, please open this url in your browser
https://explorer.testnet.near.org/transactions/EtdLuXkhT5eex1ubT1pRKhETZNv8AoAMzadHiJMdGH9z
Done deploying to dev-1643380555927-18139425398700
`
8. قم بكتابة هذا الأمر لاستدعاء الدالة `near call CONTRACT_ACCOUNT_NAME METHOD_NAME '{PARAMETERS_IF_ANY}' --accountId=EXAMPLE.testnet`
9. ستجد ناتج الرسالة ظهر على شاشة الأوامر بناتج العلية
ملحوطة: يمكنك رفع ملف الwasm على حساب مخصص. تجد الخطوات فى هذا الرابظ : https://www.youtube.com/watch?v=Yuid1QH_NWg&list=PLYH8jWLZAVt62bVY0aEnMquZn-jpTZPhQ&index=11
ا
|
Pranav543_rust_counter | Cargo.toml
src
lib.rs
| |
metaseed-project_Near-Empire-Server | Crust
package-lock.json
package.json
src
index.ts
load.ts
GalaxyServer
package-lock.json
package.json
src
core
config.js
helpers.js
database
index.js
planetsSchema.js
generatePlanets.js
index.js
job1.js
README.md
| Near-Empire-Server
|
muammer-yilmaz_near-book-store | README.md
asconfig.json
assembly
as_types.d.ts
index.ts
model.ts
tsconfig.json
utils.ts
index.html
package.json
scripts
add-chapter.sh
add-comment.sh
buy-book.sh
create-book.sh
dev-deploy.sh
get-comments.sh
list-books.sh
read-book.sh
tests
index.js
| # near-book-store
This project is a simple bookstore on Near blockchain. Users can publish their book and buy others books, and review a book by writing comments about it.
## Installation
> Prerequisites: Make sure you've installed Node.js ≥ 12 and Yarn
```bash
git clone https://github.com/muammer-yilmaz/near-book-store
cd near-book-store
yarn
```
## How to Use Bookstore Smart Contract
First login to your account using near cli
```bash
near login
```
## Scripts
`near-book-store/scripts`
1. run `dev-deploy.sh` --> builds and deploys contract to blockchain
2. run any script to interact with contract
## Commands
Build and deploy the smart contract.
```bash
yarn dev
```
Export the development account to the $CONTRACT
```bash
export CONTRACT=YOUR_DEV_ACCOUNT_HERE
```
Create a Book.
```bash
near call $CONTRACT createBook '{"name": "Book Name", "desc": "Book Description", "price" : 5}' --accountId muammer-yilmaz.testnet
```
List All Books
```bash
near call $CONTRACT getBooks '{"start": 0, "limit" : 10}' --accountId muammer-yilmaz.testnet
```
Buy a Book
```bash
near call $CONTRACT buyBook '{"id": Book id}' --accountId muammer-yilmaz.testnet --deposit 5
```
Read a Book
```bash
near call $CONTRACT getChapters '{"id": Book id}' --accountId muammer-yilmaz.testnet
```
Add a chapter to your book
```bash
near call $CONTRACT addChapter '{"id": Book id, "content": "Chapter Content"}' --accountId muammer-yilmaz.testnet
```
Add a comment to a book
```bash
near call $CONTRACT addComment '{"id": Book id, "comment": "Your Comment"}' --accountId muammer-yilmaz.testnet
```
Get all comment of a book
```bash
near call $CONTRACT getComments '{"id": Book id}' --accountId muammer-yilmaz.testnet
```
Project Structure
```
near-book-store
│ README.md
│ package.json
| compile.js
| ...
│
└───assembly
│ │ index.ts
│ │ model.ts
| | utils.ts
│ │ ...
│
│
└───scripts
│ dev-deploy.sh
│ create-book.sh
│ add-chapter.sh
│ add-comment.sh
│ get-comments.sh
│ list-books.sh
│ read-book.sh
```
|
ninjadev0706_nft-staking-platform | FT
Cargo.toml
README.md
build.sh
ft
Cargo.toml
src
lib.rs
test-contract-defi
Cargo.toml
src
lib.rs
tests
workspaces.rs
NFT
Cargo.toml
README.md
build.sh
neardev
dev-account.env
nft
Cargo.toml
src
lib.rs
res
neardev
dev-account.env
test-approval-receiver
Cargo.toml
src
lib.rs
test-token-receiver
Cargo.toml
src
lib.rs
tests
workspaces
main.rs
test_approval.rs
test_core.rs
test_enumeration.rs
utils.rs
Staking
Cargo.toml
README.md
build.sh
src
lib.rs
tests
general.rs
sim.rs
| Fungible Token (FT)
===================
Example implementation of a [Fungible Token] contract which uses [near-contract-standards] and [simulation] tests.
[Fungible Token]: https://nomicon.io/Standards/Tokens/FungibleTokenCore.html
[near-contract-standards]: https://github.com/near/near-sdk-rs/tree/master/near-contract-standards
[simulation]: https://github.com/near/near-sdk-rs/tree/master/near-sdk-sim
NOTES:
- The maximum balance value is limited by U128 (2**128 - 1).
- JSON calls should pass U128 as a base-10 string. E.g. "100".
- This does not include escrow functionality, as `ft_transfer_call` provides a superior approach. An escrow system can, of course, be added as a separate contract.
## Building
To build run:
```bash
./build.sh
```
## Testing
To test run:
```bash
cargo test --package fungible-token -- --nocapture
```
## Changelog
### `1.0.0`
- Switched form using [NEP-21](https://github.com/near/NEPs/pull/21) to [NEP-141](https://github.com/near/NEPs/issues/141).
### `0.3.0`
#### Breaking storage change
- Switching `UnorderedMap` to `LookupMap`. It makes it cheaper and faster due to decreased storage access.
Non-fungible Token (NFT)
===================
Example implementation of a [non-fungible token] contract which uses [near-contract-standards] and [simulation] tests.
[non-fungible token]: https://nomicon.io/Standards/NonFungibleToken/README.html
[near-contract-standards]: https://github.com/near/near-sdk-rs/tree/master/near-contract-standards
[simulation]: https://github.com/near/near-sdk-rs/tree/master/near-sdk-sim
NOTES:
- The maximum balance value is limited by U128 (2**128 - 1).
- JSON calls should pass [U128](https://docs.rs/near-sdk/latest/near_sdk/json_types/struct.U128.html) or [U64](https://docs.rs/near-sdk/latest/near_sdk/json_types/struct.U64.html) as a base-10 string. E.g. "100".
- The core NFT standard does not include escrow/approval functionality, as `nft_transfer_call` provides a superior approach. Please see the approval management standard if this is the desired approach.
## Building
To build run:
```bash
./build.sh
```
## Testing
To test run:
```bash
cargo test --workspace --package non-fungible-token -- --nocapture
```
# Cross contract
Example of using cross-contract functions, like promises, or money transfers.
## Several contracts
Let's start the local Near testnet to run the contract on it.
* Make sure you have [Docker](https://www.docker.com/) installed;
* Clone the [nearprotocol/nearcore](https://github.com/near/nearcore);
To start your local node, go to `nearcore` and run the following script:
```bash
rm -rf ~/.near
./scripts/start_localnet.py
```
This will pull the docker image and start a single local node. Enter an `test_near` that you want to be associated with.
Then execute the following to follow the block production logs:
```bash
docker logs --follow nearcore
```
Create a new project:
```bash
npx create-near-app --vanilla myproject
cd myproject
```
Then in `src/config.json` modify `nodeUrl` to point to your local node:
```js
case 'development':
return {
networkId: 'default',
nodeUrl: 'http://localhost:3030',
contractName: CONTRACT_NAME,
walletUrl: 'https://wallet.nearprotocol.com',
};
```
Then copy the key that the node generated upon starting in your local project to use for transaction signing.
```bash
mkdir ./neardev/default
cp ~/.near/validator_key.json ./neardev/default/test_near.json
```
Then deploy the `cross-contract` contract:
```bash
near create_account cross_contract --masterAccount=test_near --initialBalance 10000000
near deploy --accountId=cross_contract --wasmFile=../examples/cross-contract-high-level/res/cross_contract_high_level.wasm
```
### Deploying another contract
Let's deploy another contract using `cross-contract`, factory-style.
```bash
near call cross_contract deploy_status_message "{\"account_id\": \"status_message\", \"amount\":1000000000000000}" --accountId=test_near
```
### Trying money transfer
First check the balance on both `status_message` and `cross_contract` accounts:
```bash
near state cross_contract
near state status_message
```
See that cross_contract has approximately `9,999,999` and status_message has `0.000000001` tokens.
Then call a function on `cross_contract` that transfers money to `status_message`:
```bash
near call cross_contract transfer_money "{\"account_id\": \"status_message\", \"amount\":1000000000000000}" --accountId=test_near
```
Then check the balances again:
```bash
near state cross_contract
near state status_message
```
Observe that `status_message` has `0.000000002` tokens, even though
`test_near` signed the transaction and paid for all the gas that was used.
### Trying simple cross contract call
Call `simple_call` function on `cross_contract` account:
```bash
near call cross_contract simple_call "{\"account_id\": \"status_message\", \"message\":\"bonjour\"}" --accountId=test_near --gas 10000000000000000000
```
Verify that this actually resulted in correct state change in `status_message` contract:
```bash
near call status_message get_status "{\"account_id\":\"test_near\"}" --accountId=test_near --gas 10000000000000000000
```
Observe:
```bash
bonjour
```
### Trying complex cross contract call
Call `complex_call` function on `cross_contract` account:
```bash
near call cross_contract complex_call "{\"account_id\": \"status_message\", \"message\":\"halo\"}" --accountId=test_near --gas 10000000000000000000
```
observe `'halo'`.
What did just happen?
1. `test_near` account signed a transaction that called a `complex_call` method on `cross_contract` smart contract.
2. `cross_contract` executed `complex_call` with `account_id: "status_message", message: "halo"` arguments;
1. During the execution the promise #0 was created to call `set_status` method on `status_message` with arguments `"message": "halo"`;
2. Then another promise #1 was scheduled to be executed right after promise #0. Promise #1 was to call `get_status` on `status_message` with arguments: `"message": "test_near""`;
3. Then the return value of `get_status` is programmed to be the return value of `complex_call`;
3. `status_message` executed `set_status`, then `status_message` executed `get_status` and got the `"halo"` return value
which is then passed as the return value of `complex_call`.
### Trying callback with return values
Call `merge_sort` function on `cross_contract` account:
```bash
near call cross_contract merge_sort "{\"arr\": [2, 1, 0, 3]}" --accountId=test_near --gas 10000000000000000000
```
observe the logs:
```
[cross_contract]: Received [2] and [1]
[cross_contract]: Merged [1, 2]
[cross_contract]: Received [0] and [3]
[cross_contract]: Merged [0, 3]
[cross_contract]: Received [1, 2] and [0, 3]
[cross_contract]: Merged [0, 1, 2, 3]
```
and the output
```
'\u0004\u0000\u0000\u0000\u0000\u0001\u0002\u0003'
```
The reason why output is a binary is because we used [Borsh](http://borsh.io) binary serialization format to communicate
between the contracts instead of JSON. Borsh is faster and costs less gas. In this simple example you can even read
the format, here `\u0004\u0000\u0000\u0000` stands for `4u32` encoded using little-endian encoding which corresponds to the
length of the array, `\u0000\u0001\u0002\u0003` are the elements of the array. Since the array has type `Vec<u8>` each
element is exactly one byte.
If you don't want to use it you can remove `#[serializer(borsh)]` annotation everywhere from the code and the contract will fallback to JSON.
|
kharioki_Meme-museum | Cargo.toml
README.md
as-pect.config.js
asconfig.json
package.json
simulation
Cargo.toml
README.md
src
lib.rs
meme.rs
museum.rs
INIT MUSEUM
ADD CONTRIBUTOR
CREATE MEME
VERIFY MEME
src
as-pect.d.ts
as_types.d.ts
meme
README.md
__tests__
README.md
index.unit.spec.ts
asconfig.json
assembly
index.ts
models.ts
museum
README.md
__tests__
README.md
index.unit.spec.ts
asconfig.json
assembly
index.ts
models.ts
tsconfig.json
utils.ts
| # Meme Contract
**NOTE**
If you try to call a method which requires a signature from a valid account, you will see this error:
```txt
"error": "wasm execution failed with error: FunctionCallError(HostError(ProhibitedInView ..."
```
This will happen anytime you try using `near view ...` when you should be using `near call ...`. So it's important to pay close attention in the following examples as to which is being used, a `view` or a `call` (aka. "change") method.
----
## deployment
```sh
near dev-deploy ./build/release/meme.wasm
```
## initialization
`init(title: string, data: string, category: Category): void`
```sh
# anyone can initialize meme (so this must be done by the museum at deploy-time)
near call dev-1614603380541-7288163 init '{"title": "hello world", "data": "https://9gag.com/gag/ayMDG8Y", "category": 0}' --account_id dev-1614603380541-7288163 --amount 3
```
## view methods
`get_meme(): Meme`
```sh
# anyone can read meme metadata
near view dev-1614603380541-7288163 get_meme
```
```js
{
creator: 'dev-1614603380541-7288163',
created_at: '1614603702927464728',
vote_score: 4,
total_donations: '0',
title: 'hello world',
data: 'https://9gag.com/gag/ayMDG8Y',
category: 0
}
```
`get_recent_votes(): Array<Vote>`
```sh
# anyone can request a list of recent votes
near view dev-1614603380541-7288163 get_recent_votes
```
```js
[
{
created_at: '1614603886399296553',
value: 1,
voter: 'dev-1614603380541-7288163'
},
{
created_at: '1614603988616406809',
value: 1,
voter: 'sherif.testnet'
},
{
created_at: '1614604214413823755',
value: 2,
voter: 'batch-dev-1614603380541-7288163'
},
[length]: 3
]
```
`get_vote_score(): i32`
```sh
near view dev-1614603380541-7288163 get_vote_score
```
```js
4
```
`get_donations_total(): u128`
```sh
near view dev-1614603380541-7288163 get_donations_total
```
```js
'5000000000000000000000000'
```
`get_recent_donations(): Array<Donation>`
```sh
near view dev-1614603380541-7288163 get_recent_donations
```
```js
[
{
amount: '5000000000000000000000000',
donor: 'sherif.testnet',
created_at: '1614604980292030188'
},
[length]: 1
]
```
## change methods
`vote(value: i8): void`
```sh
# user votes for meme
near call dev-1614603380541-7288163 vote '{"value": 1}' --account_id sherif.testnet
```
`batch_vote(value: i8, is_batch: bool = true): void`
```sh
# only the meme contract can call this method
near call dev-1614603380541-7288163 batch_vote '{"value": 2}' --account_id dev-1614603380541-7288163
```
`add_comment(text: string): void`
```sh
near call dev-1614603380541-7288163 add_comment '{"text":"i love this meme"}' --account_id sherif.testnet
```
`get_recent_comments(): Array<Comment>`
```sh
near view dev-1614603380541-7288163 get_recent_comments
```
```js
[
{
created_at: '1614604543670811624',
author: 'sherif.testnet',
text: 'i love this meme'
},
[length]: 1
]
```
`donate(): void`
```sh
near call dev-1614603380541-7288163 donate --account_id sherif.testnet --amount 5
```
`release_donations(account: AccountId): void`
```sh
near call dev-1614603380541-7288163 release_donations '{"account":"sherif.testnet"}' --account_id dev-1614603380541-728816
```
This method automatically calls `on_donations_released` which logs *"Donations were released"*
# Unit Tests for `Meme` Contract
## Usage
```sh
yarn test:unit -f meme
```
## Output
*Note: the tests marked with `Todo` must be verified using simulation tests because they involve cross-contract calls (which can not be verified using unit tests).*
```txt
[Describe]: meme initialization
[Success]: ✔ creates a new meme with proper metadata
[Success]: ✔ prevents double initialization
[Success]: ✔ requires title not to be blank
[Success]: ✔ requires a minimum balance
[Describe]: meme voting
[Success]: ✔ allows individuals to vote
[Success]: ✔ prevents vote automation for individuals
[Success]: ✔ prevents any user from voting more than once
[Describe]: meme captures votes
[Success]: ✔ captures all votes
[Success]: ✔ calculates a running vote score
[Success]: ✔ returns a list of recent votes
[Success]: ✔ allows groups to vote
[Describe]: meme comments
[Success]: ✔ captures comments
[Success]: ✔ rejects comments that are too long
[Success]: ✔ captures multiple comments
[Describe]: meme donations
[Success]: ✔ captures donations
[Describe]: captures donations
[Success]: ✔ captures all donations
[Success]: ✔ calculates a running donations total
[Success]: ✔ returns a list of recent donations
[Todo]: releases donations
[File]: src/meme/__tests__/index.unit.spec.ts
[Groups]: 7 pass, 7 total
[Result]: ✔ PASS
[Snapshot]: 0 total, 0 added, 0 removed, 0 different
[Summary]: 18 pass, 0 fail, 18 total
[Time]: 46.469ms
```
# Museum Contract
**NOTE**
If you try to call a method which requires a signature from a valid account, you will see this error:
```txt
"error": "wasm execution failed with error: FunctionCallError(HostError(ProhibitedInView ..."
```
This will happen anytime you try using `near view ...` when you should be using `near call ...`. So it's important to pay close attention in the following examples as to which is being used, a `view` or a `call` (aka. "change") method.
----
## environment
```sh
# contract source code
export WASM_FILE=./build/release/museum.wasm
# system accounts
export CONTRACT_ACCOUNT=# NEAR account where the contract will live
export MASTER_ACCOUNT=$CONTRACT_ACCOUNT # can be any NEAR account that controls CONTRACT_ACCOUNT
# user accounts
export OWNER_ACCOUNT=# NEAR account that will control the museum
export CONTRIBUTOR_ACCOUNT=# NEAR account that will contribute memes
# configuration metadata
export MUSEUM_NAME="The Meme Museum" # a name for the museum itself, just metadata
export ATTACHED_TOKENS=3 # minimum tokens to attach to the museum initialization method (for storage)
export ATTACHED_GAS="300000000000000" # maximum allowable attached gas is 300Tgas (300 "teragas", 300 x 10^12)
```
## deployment
**Approach #1**: using `near dev-deploy` for developer convenience
This contract can be deployed to a temporary development account that's automatically generated:
```sh
near dev-deploy $WASM_FILE
export CONTRACT_ACCOUNT=# the account that appears as a result of running this command
```
The result of executing the above command will be a temporary `dev-###-###` account and related `FullAccess` keys with the contract deployed (to this same account).
**Approach #2**: using `near deploy` for more control
Alternatively, the contract can be deployed to a specific account for which a `FullAccess` key is available. This account must be created and funded first.
```sh
near create-account $CONTRACT_ACCOUNT --masterAccount $MASTER_ACCOUNT
near deploy $WASM_FILE
```
This manual deployment method is the only way to deploy a contract to a specific account. It's important to consider initializing the contract in the same step. This is clarified below in the "initialization" section.
## initialization
`init(name: string, owners: AccountId[]): void`
**Approach #1**: initialize after `dev-deploy`
After `near dev-deploy` we can initialize the contract
```sh
# initialization method arguments
# '{"name":"The Meme Museum", "owners": ["<owner-account-id>"]}'
export INIT_METHOD_ARGS="'{\"name\":\"$MUSEUM_NAME\", \"owners\": [\"$OWNER_ACCOUNT\"]}'"
# initialize contract
near call $CONTRACT_ACCOUNT init $INIT_METHOD_ARGS --account_id $CONTRACT_ACCOUNT --amount $ATTACHED_TOKENS
```
**Approach #2**: deploy and initialize in a single step
Or we can initialize at the same time as deploying. This is particularly useful for production deployments where an adversarial validator may try to front-run your contract initialization unless you bundle the `FunctionCall` action to `init()` as part of the transaction to `DeployContract`.
```sh
# initialization method arguments
# '{"name":"The Meme Museum", "owners": ["<owner-account-id>"]}'
export INIT_METHOD_ARGS="'{\"name\":\"$MUSEUM_NAME\", \"owners\": [\"$OWNER_ACCOUNT\"]}'"
# deploy AND initialize contract in a single step
near deploy $CONTRACT_ACCOUNT $WASM_FILE --initFunction init --initArgs $INIT_METHOD_ARGS --account_id $CONTRACT_ACCOUNT --initDeposit $ATTACHED_TOKENS
```
## view methods
`get_museum(): Museum`
```sh
near view $CONTRACT_ACCOUNT get_museum
```
```js
{ created_at: '1614636541756865886', name: 'The Meme Museum' }
```
`get_owner_list(): AccountId[]`
```sh
near view $CONTRACT_ACCOUNT get_owner_list
```
```js
[ '<owner-account-id>', [length]: 1 ]
```
`get_meme_list(): AccountId[]`
```sh
near view $CONTRACT_ACCOUNT get_meme_list
```
```js
[ 'usain', [length]: 1 ]
```
`get_meme_count(): u32`
```sh
near view $CONTRACT_ACCOUNT get_meme_count
```
```js
1
```
## change methods
### contributor methods
`add_myself_as_contributor(): void`
```sh
near call $CONTRACT_ACCOUNT add_myself_as_contributor --account_id $CONTRIBUTOR_ACCOUNT
```
`remove_myself_as_contributor(): void`
```sh
near call $CONTRACT_ACCOUNT remove_myself_as_contributor --account_id $CONTRIBUTOR_ACCOUNT
```
`add_meme(meme: AccountId, title: string, data: string, category: Category): void`
```sh
near call $CONTRACT_ACCOUNT add_meme '{"meme":"usain", "title": "usain refrain","data":"https://9gag.com/gag/ayMDG8Y", "category": 0 }' --account_id $CONTRIBUTOR_ACCOUNT --amount $ATTACHED_TOKENS --gas $ATTACHED_GAS
```
`on_meme_created(meme: AccountId): void`
This method is called automatically by `add_meme()` as a confirmation of meme account creation.
### owner methods
`add_contributor(account: AccountId): void`
```sh
# initialization method arguments
# '{"account":"<contributor-account-id>"}'
export METHOD_ARGS="'{\"account\":\"$CONTRIBUTOR_ACCOUNT\"}'"
near call $CONTRACT_ACCOUNT add_contributor $METHOD_ARGS --account_id $OWNER_ACCOUNT
```
`remove_contributor(account: AccountId): void`
```sh
near call $CONTRACT_ACCOUNT remove_contributor '{"account":"<contributor-account-id>"}' --account_id $OWNER_ACCOUNT
```
`add_owner(account: AccountId): void`
```sh
near call $CONTRACT_ACCOUNT add_owner '{"account":"<new-owner-account-id>"}' --account_id $OWNER_ACCOUNT
```
`remove_owner(account: AccountId): void`
```sh
near call $CONTRACT_ACCOUNT remove_owner '{"account":"<some-owner-account-id>"}' --account_id $OWNER_ACCOUNT
```
`remove_meme(meme: AccountId): void`
```sh
near call $CONTRACT_ACCOUNT remove_meme '{"meme":"usain"}' --account_id $OWNER_ACCOUNT
```
`on_meme_removed(meme: AccountId): void`
This method is called automatically by `remove_meme()` as a confirmation of meme account deletion.
# Simulation Tests
## Usage
`yarn test:simulate`
## File Structure
```txt
simulation
├── Cargo.toml <-- Rust project config
├── README.md <-- * you are here
└── src
├── lib.rs <-- this is the business end of simulation
├── meme.rs <-- type wrapper for Meme contract
└── museum.rs <-- type wrapper for Museum contract
```
## Orientation
The simulation environment requires that we
## Output
```txt
running 1 test
---------------------------------------
---- INIT MUSEUM ----------------------
---------------------------------------
ExecutionResult {
outcome: ExecutionOutcome {
logs: [
"museum was created",
],
receipt_ids: [],
burnt_gas: 4354462070277,
tokens_burnt: 0,
status: SuccessValue(``),
},
}
---------------------------------------
---- ADD CONTRIBUTOR ------------------
---------------------------------------
ExecutionResult {
outcome: ExecutionOutcome {
logs: [
"contributor was added",
],
receipt_ids: [],
burnt_gas: 4884161460212,
tokens_burnt: 0,
status: SuccessValue(``),
},
}
---------------------------------------
---- CREATE MEME ----------------------
---------------------------------------
[
Some(
ExecutionResult {
outcome: ExecutionOutcome {
logs: [],
receipt_ids: [
`AmMRhhhYir4wNuUxhf8uCoKgnpv5nHQGvBqAeEWFL344`,
],
burnt_gas: 2428142357466,
tokens_burnt: 0,
status: SuccessReceiptId(AmMRhhhYir4wNuUxhf8uCoKgnpv5nHQGvBqAeEWFL344),
},
},
),
Some(
ExecutionResult {
outcome: ExecutionOutcome {
logs: [
"attempting to create meme",
],
receipt_ids: [
`B2BBAoJYj3EFE3Co6PRmfkXopTD654gUj8H6ywSsQD9e`,
`4NWBWN9dWuwiwbkwnub9Rv134Ubu2eJmbkdk1bJzeFtr`,
],
burnt_gas: 19963342520004,
tokens_burnt: 0,
status: SuccessValue(``),
},
},
),
Some(
ExecutionResult {
outcome: ExecutionOutcome {
logs: [],
receipt_ids: [],
burnt_gas: 4033749130056,
tokens_burnt: 0,
status: SuccessValue(``),
},
},
),
Some(
ExecutionResult {
outcome: ExecutionOutcome {
logs: [
"Meme [ usain.museum ] successfully created",
],
receipt_ids: [],
burnt_gas: 4644097556149,
tokens_burnt: 0,
status: SuccessValue(``),
},
},
),
]
---------------------------------------
---- VERIFY MEME ----------------------
---------------------------------------
Object({
"creator": String(
"museum",
),
"created_at": String(
"17000000000",
),
"vote_score": Number(
0,
),
"total_donations": String(
"0",
),
"title": String(
"usain refrain",
),
"data": String(
"https://9gag.com/gag/ayMDG8Y",
),
"category": Number(
0,
),
})
test test::test_add_meme ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests simulation-near-academy-contracts
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
✨ Done in 20.99s.
```
# Unit Tests for `Museum` Contract
## Usage
```sh
yarn test:unit -f museum
```
## Output
*Note: the tests marked with `Todo` must be verified using simulation tests because they involve cross-contract calls (which can not be verified using unit tests).*
```txt
[Describe]: museum initialization
[Success]: ✔ creates a new museum with proper metadata
[Success]: ✔ prevents double initialization
[Success]: ✔ requires title not to be blank
[Success]: ✔ requires a minimum balance
[Describe]: Museum self-service methods
[Success]: ✔ returns a list of owners
[Success]: ✔ returns a list of memes
[Success]: ✔ returns a count of memes
[Success]: ✔ allows users to add / remove themselves as contributors
[Todo]: allows whitelisted contributors to create a meme
[Describe]: Museum owner methods
[Success]: ✔ allows owners to whitelist a contributor
[Success]: ✔ allows owners to remove a contributor
[Success]: ✔ allows owners to add a new owner
[Success]: ✔ allows owners to remove an owner
[Todo]: allows owners to remove a meme
[File]: src/museum/__tests__/index.unit.spec.ts
[Groups]: 4 pass, 4 total
[Result]: ✔ PASS
[Snapshot]: 0 total, 0 added, 0 removed, 0 different
[Summary]: 12 pass, 0 fail, 12 total
[Time]: 29.181ms
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[Result]: ✔ PASS
[Files]: 1 total
[Groups]: 4 count, 4 pass
[Tests]: 12 pass, 0 fail, 12 total
[Time]: 8846.571ms
✨ Done in 9.51s.
```
# The Meme Museum
This repository includes contracts for NEAR Academy
## Usage
### Getting started
1. clone this repo to a local folder
2. run `yarn`
3. run `yarn test`
### Top-level `yarn` commands
- run `yarn test` to run all tests
- (!) be sure to run `yarn build:release` at least once before:
- run `yarn test:unit` to run only unit tests
- run `yarn test:simulate` to run only simulation tests
- run `yarn build` to quickly verify build status
- run `yarn clean` to clean up build folder
### Other documentation
- **Meme** contract and test documentation
- see `/src/meme/README` for Meme interface
- see `/src/meme/__tests__/README` for Meme unit testing details
- **Museum** contract and test documentation
- see `/src/museum/README` for Museum interface
- see `/src/museum/__tests__/README` for Museum unit testing details
- simulation tests
- see `/simulation/README` for simulation testing
## The file system
Please note that boilerplate project configuration files have been ommitted from the following lists for simplicity.
### Contracts and Unit Tests
```txt
src
├── meme <-- Meme contract
│ ├── README.md
│ ├── __tests__
│ │ ├── README.md
│ │ └── index.unit.spec.ts
│ └── assembly
│ ├── index.ts
│ └── models.ts
├── museum <-- Museum contract
│ ├── README.md
│ ├── __tests__
│ │ ├── README.md
│ │ └── index.unit.spec.ts
│ └── assembly
│ ├── index.ts
│ └── models.ts
└── utils.ts <-- shared contract code
```
### Simulation Tests
```txt
simulation <-- simulation tests
├── Cargo.toml
├── README.md
└── src
├── lib.rs
├── meme.rs
└── museum.rs
```
|
pollum-io_tutumon-app | .eslintrc.json
LICENSE.md
README.md
components.json
docker-compose.yml
next.config.js
package.json
postcss.config.js
prettier.config.js
prisma
migrations
20231012002444_first_migrate
migration.sql
20231012005031_
migration.sql
20231012043425_
migration.sql
20231012164245_
migration.sql
20231012210851_
migration.sql
20231013000905_
migration.sql
20231015213806_y
migration.sql
20231108232536_a
migration.sql
20231108233643_aa
migration.sql
migration_lock.toml
src
app
api
auth
[...nextauth]
route.ts
constants.ts
fonts
index.ts
global.ts
hooks
onUser.ts
index.d.ts
interfaces.ts
lib
auth.ts
prisma.ts
utils.ts
middleware.ts
pages
api
chat
createPersonality.ts
index.ts
response.ts
login
nonce.ts
session.ts
update.ts
nfts
[publickey].ts
create.ts
index.ts
user
_create.ts
_update.ts
find
_[publickey].ts
index.ts
styles
tailwind.css
typography.css
wallet.css
utils
index.ts
tailwind.config.ts
tsconfig.json
| # Commit
Commit is a [Tailwind UI](https://tailwindui.com) site template built using [Tailwind CSS](https://tailwindcss.com) and [Next.js](https://nextjs.org).
## Getting started
To get started, first install dependencies via npm:
```bash
npm install
```
Next, create a `.env.local` file in the root of your project and set the `NEXT_PUBLIC_SITE_URL` environment variable to your site's public URL:
```
NEXT_PUBLIC_SITE_URL=https://example.com
```
Then start the development server:
```bash
npm run dev
```
Finally, open [http://localhost:3000](http://localhost:3000) in your browser to view the website.
## Customizing
We've tried to build this template exactly the same way we'd build it if it we were building a real website, so there's no weird configuration files or global variables like you might see in a product that has been built as a "theme" rather than as an actual site.
Instead, you make changes by just opening the files you want to change, and changing whatever it is you want to change.
We'll cover a lot of the fundamentals here to help you get going quickly, but at the end of the day the whole codebase is yours and you should feel free to edit everything directly as much as you need to.
### Project structure
The template is built as a pretty standard Next.js website, but using the `src` folder so things like the `app` directory are located at `./src/app` instead of being top-level.
### Title and metadata
You can update your site's metadata in `./src/app/layout.tsx`.
### Hero content
The main hero section for the site that includes your logo, headline, description, and links are all located in `./src/components/Intro.tsx`.
### Adding changelog entries
All of the changelog entries are stored in one big `./src/app/page.mdx` file. We were inspired to set it up this way by how projects commonly maintain plaintext `CHANGELOG` files, and thought it would be cool to parse this sort of format and turn it into a nicely designed site.
Each changelog entry should be separated by a horizontal rule (`---`) and should include an `<h2>` with a date, specified as an [MDX annotation](https://github.com/bradlc/mdx-annotations):
```md
---

## My new changelog entry {{ date: '2023-04-06T00:00Z' }}
Your content...
```
### Newsletter
You can find the newsletter sign up form in `./src/components/SignUpForm.tsx` — if you have a newsletter you'll want to wire this up with whatever mailing list software you use to get it to actually work.
### RSS feed
The site uses a [route handler](https://nextjs.org/docs/app/building-your-application/routing/router-handlers) to automatically generate an RSS feed at run time based on the rendered home page.
You can edit the metadata for the feed (like the title and description) in `./src/app/feed.xml/route.ts`.
Make sure to set your `NEXT_PUBLIC_SITE_URL` environment variable as the RSS feed needs this to generate the correct links for each entry.
## License
This site template is a commercial product and is licensed under the [Tailwind UI license](https://tailwindui.com/license).
## Learn more
To learn more about the technologies used in this site template, see the following resources:
- [Tailwind CSS](https://tailwindcss.com/docs) - the official Tailwind CSS documentation
- [Next.js](https://nextjs.org/docs) - the official Next.js documentation
- [Motion One](https://motion.dev/) - the official Motion One documentation
- [MDX](https://mdxjs.com/) - the official MDX documentation
# frontend
|
near_local | .github
ISSUE_TEMPLATE
BOUNTY.yml
README.md
docker-compose.yml
| # local
* wallet
* near-contract-helper
* indexer
Requirements:
docker and docker-compose
Starting all applications
```bash
docker-compose up
```
Stopping
```bash
docker-compose down
```
Running commands inside containers
```bash
docker-compose exec bridge head /root/.rainbow/logs/ganache/out.log -n 20
```
Default urls:
near-wallet: http://localhost:1234
bridge-frontend: http://localhost:2000
explorer: http://localhost:9001
|
mm-near_near-demo-betteryou | README.md
dummy
Cargo.toml
build.sh
deploy.sh
src
lib.rs
frontend
README.md
unused
plaque.html
plaque_v2.html
signup_page.html
welcome_page.html
funding
Cargo.toml
src
lib.rs
language
Cargo.toml
README.md
build.sh
deploy.sh
src
lib.rs
oracle
duolingo.js
package-lock.json
package.json
oracle_python
oracle.py
requirements.txt
wakeup
Cargo.toml
README.md
build.sh
deploy.sh
src
lib.rs
| Files for the frontend - that will be later deployed as part of near.social
Quick layout/files split:
* plaq_template: renders the "main content" of a running challenge (progress, current reward, etc).
* challengeState (that contains all the common fields),
* challengeLogo (with logo)
* customBox (content of the top box that is challenge specific)
* dummy_challenge: box for the dummy_challenge
* language_challenge: box for the language challenge
* all_user_challenge: shows all the challenges for a given user (side by side)
* friendslist: shows all the challenges from all your friends.
* welcome_page - main page for the challenges.
Contract for language learning.
# near-demo-betteryou
This is a repository for a NEAR social hackathon project.
## wakeup
The wakeup folder contains the contract for the 'wakeup' challenge.
## language
The language folder contains the contract for the duolinguo language challenge.
## frontned
Frontend (react / javascript) file that will be later deployed on near.social.
## Development
### Testnet
near.social on testnet is under test.near.social
Our contracts should be deployed at: ``wakeup.betteryou.testnet`` and ``language.betteryou.testnet``
contract for regular wakeup challenge.
|
kdbvier_FT-Near-Customized | Cargo.toml
build.sh
readme.md
src
lib.rs
| |
markeymark32_degenLizardCoinFlip | .gitpod.yml
README.md
babel.config.js
contract
Cargo.toml
README.md
compile.js
src
lib.rs
target
.rustc_info.json
debug
.fingerprint
Inflector-a8f4e37dd556cf0f
lib-inflector.json
autocfg-e8d96e7f2b762b9c
lib-autocfg.json
borsh-derive-a078a7b9a2a03464
lib-borsh-derive.json
borsh-derive-internal-103dbffa76195871
lib-borsh-derive-internal.json
borsh-schema-derive-internal-62d34519e20996ba
lib-borsh-schema-derive-internal.json
byteorder-7e9eedb750cb0c68
build-script-build-script-build.json
convert_case-a25c4144c68d7d73
lib-convert_case.json
derive_more-c3d2ec1b6c44a8b4
lib-derive_more.json
generic-array-b3a15bae3bd7dcb8
build-script-build-script-build.json
hashbrown-29e2d33e445a3fe8
build-script-build-script-build.json
hashbrown-3b862f5ff2ac6f18
run-build-script-build-script-build.json
hashbrown-8a0eae45c5c8fe28
lib-hashbrown.json
indexmap-3fe13978a1dc9b3f
run-build-script-build-script-build.json
indexmap-7dfb354d589d374d
build-script-build-script-build.json
indexmap-df8cb351f7c33f76
lib-indexmap.json
itoa-331611d2ec6ae993
lib-itoa.json
memchr-a50d6597a861a8f7
build-script-build-script-build.json
near-rpc-error-core-5b3cc03d1710d7ab
lib-near-rpc-error-core.json
near-rpc-error-macro-6a35fc896e2df83b
lib-near-rpc-error-macro.json
near-sdk-core-eb94d12de2525c81
lib-near-sdk-core.json
near-sdk-macros-b1b8ee25c116c852
lib-near-sdk-macros.json
num-bigint-80833f2f9084448e
build-script-build-script-build.json
num-integer-7cbcc6a07cabe7e8
build-script-build-script-build.json
num-rational-56b5aa6f0fda1b90
build-script-build-script-build.json
num-traits-6b11e7e494784fe9
build-script-build-script-build.json
proc-macro-crate-b1854959dfbabb13
lib-proc-macro-crate.json
proc-macro2-49dd073150bc1e8a
build-script-build-script-build.json
proc-macro2-4e8d526cdba69d52
run-build-script-build-script-build.json
proc-macro2-755220030b6adeba
lib-proc-macro2.json
quote-7404cf61f39c038f
lib-quote.json
ryu-1b2f9606b802eb11
lib-ryu.json
ryu-779cb093985a02e5
build-script-build-script-build.json
ryu-8773db53b69c0f30
run-build-script-build-script-build.json
serde-092aa86710bd1b86
lib-serde.json
serde-73a504bdb0181fd5
run-build-script-build-script-build.json
serde-75e29c70260d7122
build-script-build-script-build.json
serde_derive-6a1ba2f754e150b4
lib-serde_derive.json
serde_derive-d7f1afee7646f1c5
build-script-build-script-build.json
serde_derive-ed6268f28ec92d28
run-build-script-build-script-build.json
serde_json-185ddd35f392fdc6
run-build-script-build-script-build.json
serde_json-5333a6b33ccbec13
lib-serde_json.json
serde_json-a9fb65022ffa8dcc
build-script-build-script-build.json
syn-20c381101c96c377
lib-syn.json
syn-7ed442754f82fc5a
run-build-script-build-script-build.json
syn-e70214b5c99efffe
build-script-build-script-build.json
toml-d7bd9648c130bc79
lib-toml.json
typenum-e70c9dd60c60cb4a
build-script-build-script-main.json
unicode-xid-745589536fdb3b82
lib-unicode-xid.json
version_check-0e39a7d855ce105c
lib-version_check.json
wee_alloc-f4e7c3437706fb20
build-script-build-script-build.json
release
.fingerprint
Inflector-b54742fedffdcfae
lib-inflector.json
autocfg-85cf1d5be0b8d76c
lib-autocfg.json
borsh-derive-f568da86d3ea4755
lib-borsh-derive.json
borsh-derive-internal-9eeb7a5040ba7883
lib-borsh-derive-internal.json
borsh-schema-derive-internal-9db23fdedbf48236
lib-borsh-schema-derive-internal.json
byteorder-88aa18bf80f08686
build-script-build-script-build.json
convert_case-72373db89486ab3e
lib-convert_case.json
derive_more-a868a97841be5cdd
lib-derive_more.json
generic-array-dd90e04088257317
build-script-build-script-build.json
hashbrown-40454a1b8396a42d
lib-hashbrown.json
hashbrown-8a4a031c7e4e6b0a
run-build-script-build-script-build.json
hashbrown-c8d9549b789ac6b2
build-script-build-script-build.json
indexmap-96aae3e0debbdcfd
lib-indexmap.json
indexmap-a8226385eff895db
run-build-script-build-script-build.json
indexmap-d0cb0090b30f53a4
build-script-build-script-build.json
itoa-d9ed23826654bc18
lib-itoa.json
memchr-8076a6a5a0777c87
build-script-build-script-build.json
near-rpc-error-core-ee73d5add1ce027c
lib-near-rpc-error-core.json
near-rpc-error-macro-1ccaaf97f9a0a5a6
lib-near-rpc-error-macro.json
near-sdk-core-3ba87bf5f4fa8ffe
lib-near-sdk-core.json
near-sdk-macros-d5117e27bfd44079
lib-near-sdk-macros.json
num-bigint-23032120f945c62d
build-script-build-script-build.json
num-integer-342fc662084cecbe
build-script-build-script-build.json
num-rational-43d8aaaa4d17e1d4
build-script-build-script-build.json
num-traits-8df9dd704a96d720
build-script-build-script-build.json
proc-macro-crate-85ade1528aba6e41
lib-proc-macro-crate.json
proc-macro2-1be57e94c3994a51
build-script-build-script-build.json
proc-macro2-2dfa396d5217e15b
lib-proc-macro2.json
proc-macro2-47c9c2dbb158f654
run-build-script-build-script-build.json
quote-b7926a42453023bb
lib-quote.json
ryu-658ac46b23b995e8
build-script-build-script-build.json
ryu-7f57f1c4dd732643
run-build-script-build-script-build.json
ryu-c0ed547f48207f2b
lib-ryu.json
serde-2559db0913e1f352
build-script-build-script-build.json
serde-8cdbe53069e0ebf9
lib-serde.json
serde-f1abfa634239ab6a
run-build-script-build-script-build.json
serde_derive-22ba64b828a98345
lib-serde_derive.json
serde_derive-940fee2ab9c58234
run-build-script-build-script-build.json
serde_derive-be413dfccbc9dae4
build-script-build-script-build.json
serde_json-d439f7199c5879ff
build-script-build-script-build.json
serde_json-dcecd9d9afed8924
lib-serde_json.json
serde_json-f7288ee2d1a097c6
run-build-script-build-script-build.json
syn-6450f802446d8a49
lib-syn.json
syn-68a9a9a93a8683bb
build-script-build-script-build.json
syn-8c8cb8140f06eb64
run-build-script-build-script-build.json
toml-4805b4dab7a7b622
lib-toml.json
typenum-73dfde9ad5ffde4d
build-script-build-script-main.json
unicode-xid-7b5e9c406f5dde09
lib-unicode-xid.json
version_check-0bf72125f9f4b9d5
lib-version_check.json
wee_alloc-41448b425edbd6c2
build-script-build-script-build.json
wasm32-unknown-unknown
debug
.fingerprint
ahash-4151b74ccb9ac658
lib-ahash.json
aho-corasick-30830de0121e7d41
lib-aho_corasick.json
base64-723a5f30cf4b1d9f
lib-base64.json
block-buffer-64d4c090b8fdc4c8
lib-block-buffer.json
block-buffer-800520124a516413
lib-block-buffer.json
block-padding-d35c6e4cb39777ca
lib-block-padding.json
borsh-bb26836f50a7ab69
lib-borsh.json
bs58-2bb05e0df8f22591
lib-bs58.json
byte-tools-c940c9fd834d33ec
lib-byte-tools.json
byteorder-37c174d09247e297
lib-byteorder.json
byteorder-81667a7785ba03f3
run-build-script-build-script-build.json
cfg-if-29986574b9e347b3
lib-cfg-if.json
cfg-if-f98e23c88f079db2
lib-cfg-if.json
digest-8d87f2f9892bbc2b
lib-digest.json
digest-ec0e1f6337796fb7
lib-digest.json
generic-array-3f329714b61c8874
lib-generic_array.json
generic-array-83b306600592ba91
lib-generic_array.json
generic-array-c3aeadd2240ce532
run-build-script-build-script-build.json
greeter-98ace302c5fafa12
lib-greeter.json
hashbrown-263146f50e5146bb
run-build-script-build-script-build.json
hashbrown-27083db2368b3a92
lib-hashbrown.json
hashbrown-49542153239af762
lib-hashbrown.json
hex-b86070c12ddfcacb
lib-hex.json
indexmap-92571100829cca1e
lib-indexmap.json
indexmap-e35bb55c8d49c201
run-build-script-build-script-build.json
itoa-a83116eed5dc3ffc
lib-itoa.json
keccak-5f54c096210a08d4
lib-keccak.json
lazy_static-4c7a6f01f2cc8579
lib-lazy_static.json
memchr-09962c3247d74f55
run-build-script-build-script-build.json
memchr-dc50ab763d846fe1
lib-memchr.json
memory_units-a2806337a5fb87f2
lib-memory_units.json
near-primitives-core-fa72cdc07d790415
lib-near-primitives-core.json
near-runtime-utils-7dd36f383ebef113
lib-near-runtime-utils.json
near-sdk-a8053627dfc276b9
lib-near-sdk.json
near-vm-errors-1f0a53a97416dfd7
lib-near-vm-errors.json
near-vm-logic-6edb9c8bf645b3dc
lib-near-vm-logic.json
num-bigint-47ea9e975d2103d5
run-build-script-build-script-build.json
num-bigint-c65a33bbf00d578e
lib-num-bigint.json
num-integer-b23b5377badfc3a9
run-build-script-build-script-build.json
num-integer-e1e6a00b34df36f3
lib-num-integer.json
num-rational-2ef6957bbbc0c991
lib-num-rational.json
num-rational-5da62b0359936a51
run-build-script-build-script-build.json
num-traits-428db73f2cfdc5e3
lib-num-traits.json
num-traits-47d313abec9f8e0d
run-build-script-build-script-build.json
opaque-debug-288ede7c213d70ab
lib-opaque-debug.json
opaque-debug-be28852925d7b070
lib-opaque-debug.json
regex-431b4d8006fc2546
lib-regex.json
regex-syntax-d56f0695f9bcd6ca
lib-regex-syntax.json
ryu-afb7a552e02812a9
run-build-script-build-script-build.json
ryu-c4ab5e492da7b9f0
lib-ryu.json
serde-15fd5d4f8d2b3d98
lib-serde.json
serde-87d9dc5efef0814e
run-build-script-build-script-build.json
serde_json-a7c20cd9171941d7
lib-serde_json.json
serde_json-e49471fbd0d48f00
run-build-script-build-script-build.json
sha2-7ab0f3bdebe05454
lib-sha2.json
sha3-fc7db6df80412acb
lib-sha3.json
typenum-ee8cab77d406d3c5
lib-typenum.json
typenum-f286b84b88677e26
run-build-script-build-script-main.json
wee_alloc-10300a9e987d1da4
lib-wee_alloc.json
wee_alloc-efe42a590f64ca87
run-build-script-build-script-build.json
build
num-bigint-47ea9e975d2103d5
out
radix_bases.rs
typenum-f286b84b88677e26
out
consts.rs
op.rs
tests.rs
wee_alloc-efe42a590f64ca87
out
wee_alloc_static_array_backend_size_bytes.txt
release
.fingerprint
ahash-68141d3788949aed
lib-ahash.json
aho-corasick-f116f2e06be7aefa
lib-aho_corasick.json
base64-f231845924e8f1ff
lib-base64.json
block-buffer-3885713e1e1c1156
lib-block-buffer.json
block-buffer-c5277979bf270799
lib-block-buffer.json
block-padding-492e57a31f18f633
lib-block-padding.json
borsh-f7481d2aa65f54cc
lib-borsh.json
bs58-2bdb25cba5c89e14
lib-bs58.json
byte-tools-a815e60829f14da8
lib-byte-tools.json
byteorder-0558b75dc74d1997
run-build-script-build-script-build.json
byteorder-749b30aaf591ab98
lib-byteorder.json
cfg-if-940574005e4db99b
lib-cfg-if.json
cfg-if-fa8c68941fea7f20
lib-cfg-if.json
digest-5d14e9d12fe14f09
lib-digest.json
digest-b60ea2bc176cb3e2
lib-digest.json
generic-array-581c4819ce482fce
run-build-script-build-script-build.json
generic-array-6f94f948278155ca
lib-generic_array.json
generic-array-fee5924330bbc3f2
lib-generic_array.json
greeter-98ace302c5fafa12
lib-greeter.json
hashbrown-3df8ace2fe55dc05
run-build-script-build-script-build.json
hashbrown-4a25e338e1f5a6c0
lib-hashbrown.json
hashbrown-c9ea2122e2a1d841
lib-hashbrown.json
hex-7fc8877a180c84f6
lib-hex.json
indexmap-76e8d01d789d10fc
lib-indexmap.json
indexmap-f873a8bd9cca059a
run-build-script-build-script-build.json
itoa-306721d891ad3e91
lib-itoa.json
keccak-2c5b2dd228fe62fb
lib-keccak.json
lazy_static-30455faa82bd8f2c
lib-lazy_static.json
memchr-23bad8ffa0aac965
run-build-script-build-script-build.json
memchr-427df51493ab1630
lib-memchr.json
memory_units-5c3768a43ade0382
lib-memory_units.json
near-primitives-core-9d8cb1e05791065d
lib-near-primitives-core.json
near-runtime-utils-ea72ad0a316e72ad
lib-near-runtime-utils.json
near-sdk-78de5b1519c043db
lib-near-sdk.json
near-vm-errors-6fc51dcdacda3ab6
lib-near-vm-errors.json
near-vm-logic-066091af508418d2
lib-near-vm-logic.json
num-bigint-43252a6c15cbed61
lib-num-bigint.json
num-bigint-6ff7952886dc75f9
run-build-script-build-script-build.json
num-integer-86b110e1cb6e0c78
lib-num-integer.json
num-integer-ab548fa57edfd7ad
run-build-script-build-script-build.json
num-rational-6272c13a72df6a63
lib-num-rational.json
num-rational-644a832a47c30569
run-build-script-build-script-build.json
num-traits-830df4c213122251
run-build-script-build-script-build.json
num-traits-fddf47fa971c967d
lib-num-traits.json
opaque-debug-0c655a0d88c9c677
lib-opaque-debug.json
opaque-debug-21c25f550c8d9a80
lib-opaque-debug.json
regex-d5e4076baade42a3
lib-regex.json
regex-syntax-c53a6d364fe4abbf
lib-regex-syntax.json
ryu-b8eb55c5c859da39
run-build-script-build-script-build.json
ryu-ca23251ad4e1dfb1
lib-ryu.json
serde-8727526add5756fb
run-build-script-build-script-build.json
serde-9f51716a64348cd5
lib-serde.json
serde_json-9fa3df30a5b657b8
lib-serde_json.json
serde_json-bc420afa42575908
run-build-script-build-script-build.json
sha2-91ad2bd851a23a7a
lib-sha2.json
sha3-16dea9669c933847
lib-sha3.json
typenum-090196ba0bd88f5c
lib-typenum.json
typenum-976ca501261bf7a0
run-build-script-build-script-main.json
wee_alloc-c76c2a1ca0de8351
run-build-script-build-script-build.json
wee_alloc-f576437e4b1646f1
lib-wee_alloc.json
build
num-bigint-6ff7952886dc75f9
out
radix_bases.rs
typenum-976ca501261bf7a0
out
consts.rs
op.rs
tests.rs
wee_alloc-c76c2a1ca0de8351
out
wee_alloc_static_array_backend_size_bytes.txt
package.json
public
index.html
src
App.js
__mocks__
fileMock.js
assets
heads.svg
icon_degen.svg
logo-black.svg
logo-white.svg
logo_degen.svg
tails.svg
components
CoinFlipAction.js
CoinFlipSelector.js
Coinflip.js
CoinflipSelector.js
Leaderboard.js
LizardNav.js
Rankings.js
RecentPlays.js
coinFlipConstants.js
formatValue.js
nearValues.js
config.js
css
CoinFlip.css
Globals.css
Homepage.css
Leaderboard.css
Rankings.css
globals.css
styleguide.css
index.html
index.js
jest.init.js
main.test.js
near.js
static
img
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
wallet
login
index.html
| # degenLizardCoinFlip
DegenLizards Smart Contract
==================
A [smart contract] written in [Rust] for an app initialized with [create-near-app]
Quick Start
===========
Before you compile this code, you will need to install Rust with [correct target]
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/develop/contracts/overview
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
|
Phonbopit_near-greeting-contract | README.md
babel.config.json
build.sh
deploy.sh
package.json
src
greeting.ts
tsconfig.json
| # near-greeting-contract
A simple greeting contract with near-sdk-js
## References
- [near-sdk-js](https://github.com/near/near-sdk-js)
- [create-near-app](https://github.com/near/create-near-app)
|
onchezz_near-exmple | Cargo.toml
README.md
build.bat
build.sh
src
lib.rs
test.sh
| # Rust Smart Contract Template
## Getting started
To get started with this template:
1. Click the "Use this template" button to create a new repo based on this template
2. Update line 2 of `Cargo.toml` with your project name
3. Update line 4 of `Cargo.toml` with your project author names
4. Set up the [prerequisites](https://github.com/near/near-sdk-rs#pre-requisites)
5. Begin writing your smart contract in `src/lib.rs`
6. Test the contract
`cargo test -- --nocapture`
8. Build the contract
`RUSTFLAGS='-C link-arg=-s' cargo build --target wasm32-unknown-unknown --release`
**Get more info at:**
* [Rust Smart Contract Quick Start](https://docs.near.org/docs/develop/contracts/rust/intro)
* [Rust SDK Book](https://www.near-sdk.io/)
|
matiasberaldo_nearbox-gateway | .devcontainer
devcontainer.json
.eslintrc.json
README.md
next.config.js
package-lock.json
package.json
public
next.svg
vercel.svg
src
assets
images
near_social_combo.svg
near_social_icon.svg
vs_code_icon.svg
components
lib
Spinner
index.ts
Toast
README.md
api.ts
index.ts
store.ts
styles.ts
data
bos-components.ts
links.ts
web3.ts
hooks
useBosComponents.ts
useBosLoaderInitializer.ts
useClearCurrentComponent.ts
useFlags.ts
useHashUrlBackwardsCompatibility.ts
index.d.ts
lib
selector
setup.js
wallet.js
stores
auth.ts
bos-loader.ts
current-component.ts
vm.ts
styles
globals.css
theme.css
utils
auth.js
config.ts
firebase.ts
form-validation.ts
keypom-options.ts
navigation.ts
types.ts
tsconfig.json
| # BOS Gateway for NearBox
## Setup & Development
Initialize repo:
```bash
pnpm i
```
Start development version:
```bash
cp .env.example .env
pnpm dev
```
The entry component is ```PolygonZkEVM``` and it's located at
```/src/components/polygon/index.tsx```
It loads the ```mattb.near/widget/NearBox.Views.Home``` BOS component. The source can be found [here](https://near.org/near/widget/ComponentDetailsPage?src=mattb.near/widgetNearBox.Views.Home&tab=source).
## Deployment
This is a [Next.js](https://github.com/vercel/next.js/) app and a fork of [NEAR Discovery](https://github.com/near/near-discovery) gateway app.
For static exports just run ```next build``` and upload the build files to your hosting provider. More info [here](https://nextjs.org/docs/pages/building-your-application/deploying/static-exports).
For Vercel, Cloudflare or others that supports a Next app just connect the repo and follow the deploy steps from the dashboards.
More info on Next.js deployments [here](https://nextjs.org/docs/pages/building-your-application/deploying/static-exports).
## Running with docker
```bash
docker build -t bos-polygon-gateway .
docker run -p 3000:3000 bos-polygon-gateway
```
# Toast
Implemented via Radix primitives: https://www.radix-ui.com/docs/primitives/components/toast
_If the current props and Stitches style overrides aren't enough to cover your use case, feel free to implement your own component using the Radix primitives directly._
## Example
Using the `openToast` API allows you to easily open a toast from any context:
```tsx
import { openToast } from '@/components/lib/Toast';
...
<Button
onClick={() =>
openToast({
type: 'ERROR',
title: 'Toast Title',
description: 'This is a great toast description.',
})
}
>
Open a Toast
</Button>
```
You can pass other options too:
```tsx
<Button
onClick={() =>
openToast({
type: 'SUCCESS', // SUCCESS | INFO | ERROR
title: 'Toast Title',
description: 'This is a great toast description.',
icon: 'ph-bold ph-pizza', // https://phosphoricons.com/
duration: 20000, // milliseconds (pass Infinity to disable auto close)
})
}
>
Open a Toast
</Button>
```
## Deduplicate
If you need to ensure only a single instance of a toast is ever displayed at once, you can deduplicate by passing a unique `id` key. If a toast with the passed `id` is currently open, a new toast will not be opened:
```tsx
<Button
onClick={() =>
openToast({
id: 'my-unique-toast',
title: 'Toast Title',
description: 'This is a great toast description.',
})
}
>
Deduplicated Toast
</Button>
```
## Custom Toast
If you need something more custom, you can render a custom toast using `lib/Toast/Toaster.tsx` as an example like so:
```tsx
import * as Toast from '@/components/lib/Toast';
...
<Toast.Provider duration={5000}>
<Toast.Root open={isOpen} onOpenChange={setIsOpen}>
<Toast.Title>My Title</Toast.Title>
<Toast.Description>My Description</Toast.Description>
<Toast.CloseButton />
</Toast.Root>
<Toast.Viewport />
</Toast.Provider>
```
|
HuyDNwebdev_Ecommerce_Contract | Cargo.toml
build.sh
src
lib.rs
order.rs
| |
near_near-sdk-as | .eslintrc.js
bindgen
asconfig.js
compiler.js
dist
JSONBuilder.js
classExporter.js
index.js
transformer.js
typeChecker.js
utils.js
index.js
test.js
docs.js
jest.config.js
near-mock-vm
bin
bin.js
pkg
near_mock_vm.js
vm
dist
cli.js
context.js
index.js
memory.js
runner.js
utils.js
index.js
tests
index.js
runWasm.js
setup.js
test.js
nearcore-tests
asconfig.js
verifyBatch.js
sdk
as-pect.config.js
assembly
__tests__
data.txt
compiler.js
imports.js
simulator
asconfig.js
dist
bin.js
context.js
index.js
runtime.js
types.js
utils.js
jest.config.js
| |
nkemjikaobi_voting-app-near-protocol-frontend | .eslintrc.json
README.md
config.js
context
types.ts
voting
VotingContext.ts
VotingReducer.ts
next-env.d.ts
next.config.js
package.json
pages
api
hello.ts
postcss.config.js
public
vercel.svg
styles
CreateElection.module.css
Home.module.css
globals.css
tailwind.config.js
tsconfig.json
| ### Voting App Near Protocol Frontend
Live URL => https://voting-app-near-protocol-frontend.vercel.app/
DEMO PRESENTATION => https://www.loom.com/share/2080505659ad49b2aa63c05901563740
## Getting Started
First, run the development server:
```bash
npm install && npm run dev
# or
yarn && yarn dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
### Overview
- This is a voting decentralised application whereby users can create elections, add contestants to a particular election and also vote for the contestant of their choice.
- This project is made up of two repositories as shown above. One houses the smart contract while the other houses the front end.
- The smart contract is built with Assembly Script. It made use of <b>Persistent Map</b> and ,<b>Persistent Deque</b> to store information on-chain. Unit tests were also written to ensure all our functions work as expected.
- The front end was bult with NextJs and Typescript. Context API was used to manage the application-level state. Tailwind CSS was used for styling.
- Upon the arrival of the website, you are required to sign in, if you have an active login session, the sign-in button changes to the dashboard. Once you are in your dashboard, you can view all your elections if any have been created.
- When you create an election, you can click on the election card to view contestants and also add contestants to that election. Once you add contestants, you can begin voting.
- P.S: The application and smart contract can be modified further and made better as it was more like an MVP due to time constraints.
|
fromaline_spin-test-task | README.md
asconfig.json
assembly
as_types.d.ts
index.ts
model.ts
tsconfig.json
package.json
src
constants
config.ts
dashboard
balances
index.ts
header.ts
index.ts
orderBook
getOrderTable.ts
getSelect.ts
index.ts
index.html
main.ts
signIn
form.ts
index.ts
typings
window.d.ts
utils
getTable.ts
initContract.ts
tsconfig.json
| # Test task for Spin
## Install dependencies
```sh
yarn install
```
## Run the project in development mode
```sh
yarn dev
```
It's a parcel-based build, so open [http://localhost:1234/](http://localhost:1234/)
### Todo
- [x] Figure out how to format exponential numbers properly
|
phoenixpulsar_vehicle-history-smart-contract | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
vehicleGarage
asconfig.json
assembly
index.ts
models.ts
| ## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
# `near-sdk-as` Starter Kit
This is a good project to use as a starting point for your AssemblyScript project.
## Samples
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
There are 2 AssemblyScript contracts in this project, each in their own folder:
- **singleton** in the `src/singleton` folder
### Singleton
We say that an AssemblyScript contract is written in the "singleton style" when the `index.ts` file (the contract entry point) has a single exported class (the name of the class doesn't matter) that is decorated with `@nearBindgen`.
In this case, all methods on the class become public contract methods unless marked `private`. Also, all instance variables are stored as a serialized instance of the class under a special storage key named `STATE`. AssemblyScript uses JSON for storage serialization (as opposed to Rust contracts which use a custom binary serialization format called borsh).
```ts
@nearBindgen
export class Contract {
// return the string 'hello world'
helloWorld(): string {}
// read the given key from account (contract) storage
read(key: string): string {}
// write the given value at the given key to account (contract) storage
@mutateState()
write(key: string, value: string): string {}
// private helper method used by read() and write() above
private storageReport(): string {}
}
```
## Usage
### Getting started
(see below for video recordings of each of the following steps)
INSTALL `NEAR CLI` first like this: `npm i -g near-cli`
1. clone this repo to a local folder
2. run `yarn`
3. run `./scripts/1.dev-deploy.sh`
3. run `./scripts/2.use-contract.sh`
4. run `./scripts/2.use-contract.sh` (yes, run it to see changes)
5. run `./scripts/3.cleanup.sh`
### Videos
**`1.dev-deploy.sh`**
This video shows the build and deployment of the contract.
[](https://asciinema.org/a/409575)
**`2.use-contract.sh`**
This video shows contract methods being called. You should run the script twice to see the effect it has on contract state.
[](https://asciinema.org/a/409577)
**`3.cleanup.sh`**
This video shows the cleanup script running. Make sure you add the `BENEFICIARY` environment variable. The script will remind you if you forget.
```sh
export BENEFICIARY=<your-account-here> # this account receives contract account balance
```
[](https://asciinema.org/a/409580)
### Other documentation
- See `./scripts/README.md` for documentation about the scripts
- Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
## The file system
```sh
├── README.md # this file
├── as-pect.config.js # configuration for as-pect (AssemblyScript unit testing)
├── asconfig.json # configuration for AssemblyScript compiler (supports multiple contracts)
├── package.json # NodeJS project manifest
├── scripts
│ ├── 1.dev-deploy.sh # helper: build and deploy contracts
│ ├── 2.use-contract.sh # helper: call methods on ContractPromise
│ ├── 3.cleanup.sh # helper: delete build and deploy artifacts
│ └── README.md # documentation for helper scripts
├── src
│ ├── as_types.d.ts # AssemblyScript headers for type hints
│ ├── singleton # Contract 2: "Singleton-style example"
│ │ ├── __tests__
│ │ │ ├── as-pect.d.ts # as-pect unit testing headers for type hints
│ │ │ └── index.unit.spec.ts # unit tests for contract 2
│ │ ├── asconfig.json # configuration for AssemblyScript compiler (one per contract)
│ │ └── assembly
│ │ └── index.ts # contract code for contract 2
│ ├── tsconfig.json # Typescript configuration
│ └── utils.ts # common contract utility functions
└── yarn.lock # project manifest version lock
```
You may clone this repo to get started OR create everything from scratch.
Please note that, in order to create the AssemblyScript and tests folder structure, you may use the command `asp --init` which will create the following folders and files:
```
./assembly/
./assembly/tests/
./assembly/tests/example.spec.ts
./assembly/tests/as-pect.d.ts
```
|
harshnambiar_tnm2 | README.md
contract
Cargo.toml
README.md
build.sh
deploy.sh
src
lib.rs
task.rs
frontend
App.js
assets
global.css
logo-black.svg
logo-white.svg
index.html
index.js
near-interface.js
near-wallet.js
package.json
start.sh
ui-components.js
integration-tests
Cargo.toml
src
tests.rs
package.json
| near-blank-project
==================
This app was initialized with [create-near-app]
Quick Start
===========
If you haven't installed dependencies during setup:
npm install
Build and deploy your contract to TestNet with a temporary dev account:
npm run deploy
Test your contract:
npm test
If you have a frontend, run `npm start`. This will run a dev server.
Exploring The Code
==================
1. The smart-contract code lives in the `/contract` folder. See the README there for
more info. In blockchain apps the smart contract is the "backend" of your app.
2. The frontend code lives in the `/frontend` folder. `/frontend/index.html` is a great
place to start exploring. Note that it loads in `/frontend/index.js`,
this is your entrypoint to learn how the frontend connects to the NEAR blockchain.
3. Test your contract: `npm test`, this will run the tests in `integration-tests` directory.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts].
When you run `npm run deploy`, your smart contract gets deployed to the live NEAR TestNet with a temporary dev account.
When you're ready to make it permanent, here's how:
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `npm install`, but for best ergonomics you may want to install it globally:
npm install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `near-blank-project.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `near-blank-project.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account near-blank-project.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: deploy the contract
---------------------------
Use the CLI to deploy the contract to TestNet with your account ID.
Replace `PATH_TO_WASM_FILE` with the `wasm` that was generated in `contract` build directory.
near deploy --accountId near-blank-project.YOUR-NAME.testnet --wasmFile PATH_TO_WASM_FILE
Step 3: set contract name in your frontend code
-----------------------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'near-blank-project.YOUR-NAME.testnet'
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/concepts/basics/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
# Hello NEAR Contract
The smart contract exposes two methods to enable storing and retrieving a greeting in the NEAR network.
```rust
const DEFAULT_GREETING: &str = "Hello";
#[near_bindgen]
#[derive(BorshDeserialize, BorshSerialize)]
pub struct Contract {
greeting: String,
}
impl Default for Contract {
fn default() -> Self {
Self{greeting: DEFAULT_GREETING.to_string()}
}
}
#[near_bindgen]
impl Contract {
// Public: Returns the stored greeting, defaulting to 'Hello'
pub fn get_greeting(&self) -> String {
return self.greeting.clone();
}
// Public: Takes a greeting, such as 'howdy', and records it
pub fn set_greeting(&mut self, greeting: String) {
// Record a log permanently to the blockchain!
log!("Saving greeting {}", greeting);
self.greeting = greeting;
}
}
```
<br />
# Quickstart
1. Make sure you have installed [rust](https://rust.org/).
2. Install the [`NEAR CLI`](https://github.com/near/near-cli#setup)
<br />
## 1. Build and Deploy the Contract
You can automatically compile and deploy the contract in the NEAR testnet by running:
```bash
./deploy.sh
```
Once finished, check the `neardev/dev-account` file to find the address in which the contract was deployed:
```bash
cat ./neardev/dev-account
# e.g. dev-1659899566943-21539992274727
```
<br />
## 2. Retrieve the Greeting
`get_greeting` is a read-only method (aka `view` method).
`View` methods can be called for **free** by anyone, even people **without a NEAR account**!
```bash
# Use near-cli to get the greeting
near view <dev-account> get_greeting
```
<br />
## 3. Store a New Greeting
`set_greeting` changes the contract's state, for which it is a `change` method.
`Change` methods can only be invoked using a NEAR account, since the account needs to pay GAS for the transaction.
```bash
# Use near-cli to set a new greeting
near call <dev-account> set_greeting '{"greeting":"howdy"}' --accountId <dev-account>
```
**Tip:** If you would like to call `set_greeting` using your own account, first login into NEAR using:
```bash
# Use near-cli to login your NEAR account
near login
```
and then use the logged account to sign the transaction: `--accountId <your-account>`.
|
heavenswill_Movie-List | README.md
asconfig.json
assembly
as_types.d.ts
index.ts
model.ts
tsconfig.json
index.html
package.json
tests
index.js
| # Movie-List
"Movie-List" application is a simple near project. You can add new movies, read uploaded movies, update movies, delete movies, add a comment about added movies, and read comments about the movie.
## Installation
1- Clone repository to your computer
`https://github.com/heavenswill/Movie-List.git`
2- go to file
`cd Movie-List`
3- run this in your terminal
`yarn`
4- Login your account
`login near`
5- Build contract
`yarn build:release`
6- deploy contract
`yarn deploy`
7- Export the development account to the $CONTRACT
`export CONTRACT=<YOUR_DEV_ACCOUNT_HERE>`
## Usage
+ Add a new movie
`near call $CONTRACT createMovie '{"name":<MOVIE NAME>,"type":<MOVIE TYPE>,"description":<DESCRIPTION ABOUT MOVIE>}' --accountId YOUR-ACCOUNT.testnet`
+ Read informaiton about movie
`near view $CONTRACT getMovieById '{"id":MOVIE-ID}' --accountId YOUR-ACCOUNT.testnet`
+ Read information about movies
`near view $CONTRACT getMovies '{"offset":<WHERE TO START>,"limit":<LIMIT OF GET MOVIE>}' --accountId YOUR-ACCOUNT.testnet`
+ Update movie
`near call $CONTRACT updateMovie '{"id":MOVIE ID,"updates":{"name":"<MOVIE NAME>","type":"<WHAT TYPE OF MOVIE>","description":"<DESCRIPTION ABOUT MOVIE>"}}' --accountId YOUR-ACCOUNT.testnet`
+ Delete movie
`near call $CONTRACT del '{"id":MOVIE ID}' --accountId YOUR-ACCOUNT.testnet`
+ Add a comment
`near call $CONTRACT addComment '{"text":<COMMENT>,"movieId":MOVIE ID}' --accountId YOUR-ACCOUNT.testnet`
+ Read comments
`near call $CONTRACT getComments --accountId YOUR-ACCOUNT.testnet`
+ Read movie's comments
`near call $CONTRACT getCommentsByMovieId '{"id":MOVIE ID,"limit":<LIMIT OF GET COMMENT>}' --accountId YOUR-ACCOUNT.testnet`
## Loom video
https://www.loom.com/share/1994566905e34edaa632529b22d66bdd
## Patika
https://www.patika.dev/tr
|
Learn-NEAR-Club_Near_Roulette | README.md
as-pect.config.js
asconfig.json
package.json
scripts
1.init.sh
2.run.sh
README.md
src
as-pect.d.ts
as_types.d.ts
sample
README.md
__tests__
README.md
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
| ## Setting up your terminal
The scripts in this folder support a simple demonstration of the contract.
It uses the following setup:
```txt
┌───────────────────────────────────────┬───────────────────────────────────────┐
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
│ │ │
└───────────────────────────────────────┴───────────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
```sh
1.init.sh # cleanup, compile and deploy contract
2.run.sh # call methods on the deployed contract
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linux-watch-command#191068)

## Design
### Interface
```ts
export function showYouKnow(): void;
```
- "View" function (ie. a function that does NOT alter contract state)
- Takes no parameters
- Returns nothing
```ts
export function showYouKnow2(): bool;
```
- "View" function (ie. a function that does NOT alter contract state)
- Takes no parameters
- Returns true
```ts
export function sayHello(): string;
```
- "View" function
- Takes no parameters
- Returns a string
```ts
export function sayMyName(): string;
```
- "Change" function (although it does NOT alter state, it DOES read from `context`, [see docs for details](https://docs.near.org/docs/develop/contracts/as/intro))
- Takes no parameters
- Returns a string
```ts
export function saveMyName(): void;
```
- "Change" function (ie. a function that alters contract state)
- Takes no parameters
- Saves the sender account name to contract state
- Returns nothing
```ts
export function saveMyMessage(message: string): bool;
```
- "Change" function
- Takes a single parameter message of type string
- Saves the sender account name and message to contract state
- Returns nothing
```ts
export function getAllMessages(): Array<string>;
```
- "Change" function
- Takes no parameters
- Reads all recorded messages from contract state (this can become expensive!)
- Returns an array of messages if any are found, otherwise empty array
# Sample
This repository includes a complete project structure for AssemblyScript contracts targeting the NEAR platform.
Watch this video where Willem Wyndham walks us through refactoring a simple example of a NEAR smart contract written in AssemblyScript
https://youtu.be/QP7aveSqRPo
```
There are 2 "styles" of implementing AssemblyScript NEAR contracts:
- the contract interface can either be a collection of exported functions
- or the contract interface can be the methods of a an exported class
We call the second style "Singleton" because there is only one instance of the class which is serialized to the blockchain storage. Rust contracts written for NEAR do this by default with the contract struct.
0:00 noise (to cut)
0:10 Welcome
0:59 Create project starting with "npm init"
2:20 Customize the project for AssemblyScript development
9:25 Import the Counter example and get unit tests passing
18:30 Adapt the Counter example to a Singleton style contract
21:49 Refactoring unit tests to access the new methods
24:45 Review and summary
```
The example here is very basic. It's a simple contract demonstrating the following concepts:
- a single contract
- the difference between `view` vs. `change` methods
- basic contract storage
The goal of this repository is to make it as easy as possible to get started writing unit and simulation tests for AssemblyScript contracts built to work with NEAR Protocol.
## Usage
### Getting started
1. clone this repo to a local folder
2. run `yarn`
3. run `yarn test`
### Top-level `yarn` commands
- run `yarn test` to run all tests
- (!) be sure to run `yarn build:release` at least once before:
- run `yarn test:unit` to run only unit tests
- run `yarn test:simulate` to run only simulation tests
- run `yarn build` to quickly verify build status
- run `yarn clean` to clean up build folder
### Other documentation
- Sample contract and test documentation
- see `/src/sample/README` for contract interface
- see `/src/sample/__tests__/README` for Sample unit testing details
- Sample contract simulation tests
- see `/simulation/README` for simulation testing
## The file system
Please note that boilerplate project configuration files have been ommitted from the following lists for simplicity.
### Contracts and Unit Tests
```txt
src
├── sample <-- sample contract
│ ├── README.md
│ ├── __tests__
│ │ ├── README.md
│ │ └── index.unit.spec.ts
│ └── assembly
│ └── index.ts
└── utils.ts <-- shared contract code
```
### Helper Scripts
```txt
scripts
├── 1.init.sh
├── 2.run.sh
└── README.md <-- instructions
```
## Unit tests
Unit tests can be run from the top level folder using the following command:
```
yarn test:unit
```
### Tests for Contract in `index.unit.spec.ts`
```
[Describe]: Greeting
[Success]: ✔ should respond to showYouKnow()
[Success]: ✔ should respond to showYouKnow2()
[Success]: ✔ should respond to sayHello()
[Success]: ✔ should respond to sayMyName()
[Success]: ✔ should respond to saveMyName()
[Success]: ✔ should respond to saveMyMessage()
[Success]: ✔ should respond to getAllMessages()
[File]: src/sample/__tests__/index.unit.spec.ts
[Groups]: 2 pass, 2 total
[Result]: ✔ PASS
[Snapshot]: 0 total, 0 added, 0 removed, 0 different
[Summary]: 7 pass, 0 fail, 7 total
[Time]: 19.164ms
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[Result]: ✔ PASS
[Files]: 1 total
[Groups]: 2 count, 2 pass
[Tests]: 7 pass, 0 fail, 7 total
[Time]: 8217.768ms
✨ Done in 8.86s.
```
|
mattlockyer_near-tsrs | .eslintrc.js
README.md
contract
Cargo.toml
build.sh
src
args.rs
lib.rs
sys.rs
dep-parser
args.js
helpers.js
index.js
lib.js
sys.js
types.js
utils.js
package.json
parser
helpers.ts
index.ts
libs
args.js
lib.js
sys.js
types.js
traverse.ts
utils.ts
src
index.ts
lib
NearContract.ts
types.ts
test
contract.test.js
test-utils.js
tsconfig-parser.json
tsconfig.json
utils
config.js
near-utils.js
patch-config.js
| # NEAR Protocol Smart Contract Boilerplate
🚨🚨🚨 WARNING WIP 🚨🚨🚨
It's not that bad...
## Instructions
Install rust: https://www.rust-lang.org/tools/install
`yarn && yarn test:deploy`
If no contract edits (only test changes) use `yarn test`
Review code in `/test/*` and don't bother me when it doesn't work 😏
|
near-examples_bos-commerce | .github
workflows
tests.yml
README.md
contract
package.json
src
contract.ts
models.ts
tests
main.ava.ts
package.json
tsconfig.json
| # Collaborative Component Template
This template enables multiple people to collaborate on [building BOS components](https://docs.near.org/bos/home) by automatically deploying the components in the `./src` folder when somebody `push` to `main`.
The template leverages [NEAR Access Keys](https://docs.near.org/concepts/basics/accounts/access-keys), using keys that allow to only access the `set` method of `social.near`.
Fork the repository and follow the steps bellow to create the necessary Access Key, and setup your repository's Actions.
<br />
### 1. Creating a New Access Key
Using [NEAR CLI](https://github.com/near/near-cli), create a key pair.
```bash
# Set the environment to mainnet
export NEAR_ENV=mainnet
# Create the key
near generate-key rndm-key
# Check it
cat ~/.near-credentials/mainnet/rndm-key.json
```
<br />
### 2. Add an Access Key to your Account
Add the public key as an Access Key to your account, making sure that it is a [`function call key`](https://docs.near.org/concepts/basics/accounts/access-keys#function-call-keys) (in opposition to a [`full access key`](https://docs.near.org/concepts/basics/accounts/access-keys#full-access-keys)).
Here is how you can add the key to `account.near`. Notice the `--contract-id` parameter, this is what restricts our key to interact only with `social.near`.
```bash
# Add a function call key with a 1N allowance
near add-key account.near ed25519:public_key --contract-id social.near --allowance 1 --method-names set
```
> Login first if necessary using the command `near login`
> Remember to change `account.near` to your own NEAR Account
<br />
### 3. Allow the Access Key to Write Components in `social.near`
For security reasons, `social.near` needs you to explicitly add the keys with which you plan to write social information. Otherwise, anyone with an access key would be able to write data to your social profile.
```bash
near call social.near grant_write_permission '{"public_key": "ed25519:public_key", "keys": ["account.near/widget"]}' --gas 100000000000000 --deposit 1 --accountId account.near
```
> Remember to change `account.near` to your own NEAR Account
<br />
### 4. Set Actions' Variables
This repository comes with a [predefined action](.github/workflows/deploy-prod.yml), when you push to main the repository will automatically deploy the `components` in `./src` to a NEAR account.
In order for the action to work, you will need to go to `Settings` -> `Secrets and Variables` and add the following parameters:
```js
secret NEAR_SOCIAL_ACCOUNT_PRIVATE_KEY = "ed25519:private_key"
variable NEAR_SOCIAL_ACCOUNT_ID = "account.near"
variable NEAR_SOCIAL_ACCOUNT_PUBLIC_KEY = "ed25519:public_key"
```
> Remember to change `account.near` to your own NEAR Account
<br />
### 5. Enable Actions
Go to the `Actions` tabs, and enable the Workflows. Now, when somebody `push` or `merge` into `main` the components in the `./src` folder will be automatically deployed to `account.near`.
<br />
---
## External Resources
Check these useful resources to help you build NEAR components.
- [How to Build BOS Components](https://docs.near.org/bos/home)
- [BOS VS Extension](https://marketplace.visualstudio.com/items?itemName=near-protocol.near-discovery-ide)
- [Working Example](https://github.com/near-examples/bos-commerce-components)
|
PrimeLabCore_ff | .github
workflows
ci.yml
CHANGELOG.md
Cargo.toml
README.md
ff_derive
Cargo.toml
src
lib.rs
pow_fixed.rs
src
batch.rs
lib.rs
tests
derive.rs
| # ff
`ff` is a finite field library written in pure Rust, with no `unsafe{}` code.
## Disclaimers
* This library does not provide constant-time guarantees. The traits enable downstream
users to expose constant-time logic, but `#[derive(PrimeField)]` in particular does not
generate constant-time code (even for trait methods that return constant-time-compatible
values).
## Usage
Add the `ff` crate to your `Cargo.toml`:
```toml
[dependencies]
ff = "0.11"
```
The `ff` crate contains the `Field` and `PrimeField` traits.
See the **[documentation](https://docs.rs/ff/)** for more.
### #![derive(PrimeField)]
If you need an implementation of a prime field, this library also provides a procedural
macro that will expand into an efficient implementation of a prime field when supplied
with the modulus. `PrimeFieldGenerator` must be an element of Fp of p-1 order, that is
also quadratic nonresidue.
First, enable the `derive` crate feature:
```toml
[dependencies]
ff = { version = "0.11", features = ["derive"] }
```
And then use the macro like so:
```rust
#[macro_use]
extern crate ff;
#[derive(PrimeField)]
#[PrimeFieldModulus = "52435875175126190479447740508185965837690552500527637822603658699938581184513"]
#[PrimeFieldGenerator = "7"]
#[PrimeFieldReprEndianness = "little"]
struct Fp([u64; 4]);
```
And that's it! `Fp` now implements `Field` and `PrimeField`.
## Minimum Supported Rust Version
Requires Rust **1.51** or higher.
Minimum supported Rust version can be changed in the future, but it will be done with a
minor version bump.
## License
Licensed under either of
* Apache License, Version 2.0, ([LICENSE-APACHE](LICENSE-APACHE) or
http://www.apache.org/licenses/LICENSE-2.0)
* MIT license ([LICENSE-MIT](LICENSE-MIT) or http://opensource.org/licenses/MIT)
at your option.
### Contribution
Unless you explicitly state otherwise, any contribution intentionally
submitted for inclusion in the work by you, as defined in the Apache-2.0
license, shall be dual licensed as above, without any additional terms or
conditions.
|
marco-sundsk_gameland | README.md
contracts
README.md
gameland
Cargo.toml
README.md
build.sh
src
gameland.rs
gov.rs
internal.rs
lib.rs
games
dice
Cargo.toml
README.md
build.sh
src
gl_core.rs
gl_metadata.rs
internal.rs
lib.rs
dicemaster
Cargo.toml
README.md
build.sh
src
gl_core.rs
gl_metadata.rs
internal.rs
lib.rs
landlord
Cargo.toml
README.md
build.sh
src
gl_core.rs
gl_metadata.rs
internal.rs
lib.rs
luckybox
Cargo.toml
README.md
build.sh
src
gl_core.rs
gl_metadata.rs
internal.rs
lib.rs
token
Cargo.toml
README.md
build.sh
src
fungible_token_core.rs
fungible_token_metadata.rs
internal.rs
lib.rs
play_token.rs
frontend
README.md
dapps
angleland
README.md
babel.config.js
package.json
public
index.html
src
assets
css
global.css
config.js
main.js
utils.js
vue.config.js
dice
demo
README.md
babel.config.js
jest.config.js
package.json
src
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
config.js
global.css
jest.init.js
main.js
main.test.js
utils.js
wallet
login
index.html
tests
unit
Notification.spec.js
SignedIn.spec.js
SignedOut.spec.js
vue.config.js
lucky-box
README.md
babel.config.js
package.json
public
index.html
src
assets
css
global.css
config.js
main.js
utils.js
vue.config.js
demo
README.md
babel.config.js
package.json
public
index.html
src
__mocks__
fileMock.js
assets
logo-black.svg
logo-white.svg
mobileStyle
game-mobile.css
config.js
global.css
jest.init.js
main.js
main.test.js
router
index.js
utils.js
wallet
login
index.html
vue.config.js
| Play Token Contract
==================
A token contract for gameland platform.
Play with this contract
========================
the contract is deployed at testnet with the name `playtoken.testnet`
you can set it to env for later use:
```shell
export GAMECOINID=playtoken.testnet
```
## Look around
```shell
# return info
near view $GAMECOINID get_contract_info ''
```
## Let's play
```shell
```
Build Deploy and Init
======================
Before you compile this code, you will need to install Rust with [correct target]
```shell
# building it
srouce ./build.sh
```
```shell
# deploy and init it
near deploy $GAMECOINID res/play_token.wasm --account_id=$GAMECOINID
near call $GAMECOINID new '{"owner_id": "humeng.testnet", "sudoer_id": "gameland.testnet"}' --account_id=$GAMECOINID
# adjust fee
near call $GAMECOINID update_fee_ratio '{"category": "shop_fee_play", "ratio": {"numerator": 0, "denominator": 1000}}' --account_id=humeng.testnet
near call $GAMECOINID update_fee_ratio \
'{"category": "sudoer_fee_play",
"ratio": {"numerator": 0, "denominator": 1000}}' \
--account_id=humeng.testnet
```
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/roles/developer/contracts/intro
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
# lucky-box
## Project setup
```
yarn install
```
### Compiles and hot-reloads for development
```
yarn serve
```
### Compiles and minifies for production
```
yarn build
```
### Lints and fixes files
```
yarn lint
```
### Customize configuration
See [Configuration Reference](https://cli.vuejs.org/config/).
GameLand Game Smart Contract
==================
Game Lucky Box.
Play with this contract
========================
the contract is deployed at testnet with the name `luckybox.testnet`
you can set it to env for later use:
```shell
export GAMEID=luckybox.testnet
```
## Look around
```shell
# return info
near view $GAMEID get_contract_info ''
# return current round game info
near view $GAMEID get_box_info ''
# return win history list
near view $GAMEID get_win_history '{"from_index": 0, "limit": 100}'
# return metadata
near view $GAMEID gl_metadata ''
near view $GAMEID gl_pub_state ''
near view $GAMEID gl_user_state '{"user_id": "rb01.testnet"}'
```
## Let's play
```shell
# see how many playtoken we have
near view playtoken.testnet ft_balance_of '{"account_id": "rb01.testnet"}'
# purchase some if neccessary
near call gameland.testnet buy_playtoken '' --account_id=rb01.testnet --amount=6
# play the game
near call angleland.testnet gl_play '{"amount": "1000000000000000000000000", "op": "1"}' --account_id=rb01.testnet --gas=50000000000000
```
Build Deploy and Init
======================
Before you compile this code, you will need to install Rust with [correct target]
```shell
# building it
srouce ./build.sh
```
```shell
near deploy $GAMEID res/gl_landlord.wasm --account_id=$GAMEID
near call $GAMEID new '{"owner_id": "humeng.testnet", "house_count": 36, "play_fee": "1000000000000000000000000"}' --account_id=$GAMEID
### register this game
near call gameland.testnet register_shop '{"reg_form": {"flag": 1, "shop_id": "luckybox.testnet", "owner_id": "humeng.testnet", "refs": "https://github.com/marco-sundsk/gameland/", "height": "0", "ts": "0", "status": 0}}' --account_id=humeng.testnet
near view gameland.testnet list_registers '{"from_index": 0, "limit": 100}'
near call gameland.testnet resovle_register '{"shop_id": "lucky.testnet", "pass": true, "new_status": 2}' --account_id=humeng.testnet --gas=20000000000000
### sponsor this game with 5 tokens
near call $GAMEID gl_sponsor '{"amount": "5000000000000000000000000"}' --account_id=humeng.testnet --gas=30000000000000
```
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/roles/developer/contracts/intro
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
# GAMELAND Contracts
In GAMELAND, we have several types of contracts:
* Platform contract, say gameland.testnet;
* Gamecoin contract, say playtoken.testnet;
* Game contracts, say neardice.test is one of them;
* Governance token contract, say gltoken.testnet;
### pre-requisite
---
Each contract has been successfully deployed and init correctly. The init processes are like:
```shell
# init gamecoin
near call playtoken.testnet new '{"owner_id": "playtoken_owner.testnet", "sudoer_id": "gameland.testnet"}' --account_id=playtoken.testnet
# init platform
near call gameland.testnet new '{"owner_id": "gameland_owner.testnet"}' --account_id=gameland.testnet
# init game shop
near call neardice.testnet new '{"owner_id": "neardice_owner.testnet", "dice_number": 1, "rolling_fee": "1000000000000000000000000"}' --account_id=neardice.testnet
```
### buy & sell gamecoin
---
Platform is the only place that you can buy and/or sell gamecoins. Behind these buy and sell actions, it is actually the platform that mints and burns gamecoins for you.
```shell
near call gameland.testnet buy_playtoken '' --account_id=player01.testnet --amount=1
near call gameland.testnet sell_playtoken '{"amount": "6000000000000000000000000"}' --account_id=player01.testnet
```
You can check balance of anyone:
```shell
near view playtoken.testnet ft_balance_of '{"account_id": "player01.testnet"}'
```
as well as the total supply:
```shell
near view playtoken.testnet ft_total_supply ''
```
### register games
---
The whole register process has some off-line parts, which can be upgraded to online-governance using governance token in the near future.
Frist, The game owner fills out register form
* shop_id (each game acts as a game shop from platform view)
* owner_id
* flag, 1 for reg, 2 for unreg
* refs, url to an online application form that have detailed info, such as game description, code repo, contactors, and etc.
and submit like this:
```shell
near call gameland.testnet register_shop '{"reg_form": {"flag": 1, "shop_id": "neardice.testnet", "owner_id": "neardice_owner.testnet", "refs": "https://github.com/marco-sundsk/gameland/", "height": "0", "ts": "0", "status": 0}}' --account_id=neardice_onwer.testnet
```
Then, the platform governance committee will collect all registers time to time:
```shell
near view gameland.testnet list_registers '{"from_index": 0, "limit": 100}'
```
After carefully evaluation, the committee would make a pass to some register:
```shell
near call gameland.testnet resovle_register '{"shop_id": "neardice.testnet", "pass": true, "new_status": 2}' --account_id=gameland_owner.testnet --gas=20000000000000
```
The last thing before a game shop can run publicly, may be to prepare initial reward pool of the game. That can be down through a sponsor action to a shop:
```shell
near call gameland.testnet sponsor '{"shop_id": "neardice.testnet", "amount": "2000000000000000000000000"}' --account_id=player01.testnet --gas=40000000000000
```
*note: The sponsor action may be required during register proccess*
### play game
---
User can learn information of a game in these ways:
```shell
near view neardice.testnet gl_metadata ''
near view neardice.testnet gl_pub_state ''
near view neardice.testnet gl_user_state '{"user_id": "player01.testnet"}'
```
And then play like this:
```shell
near call gameland.testnet play '{"shop_id": "neardice.testnet", "amount": "1000000000000000000000000", "op": "1"}' --account_id=player01.testnet --gas=60000000000000
```
GameLand Game Smart Contract
==================
Game AngleLand.
Play with this contract
========================
the contract is deployed at testnet with the name `angleland.testnet`
you can set it to env for later use:
```shell
export CONTRACTID=angleland.testnet
```
## Look around
```shell
# return info
near view $CONTRACTID get_contract_info ''
# return current round game info
near view $CONTRACTID get_market_info ''
# return win history list
near view $CONTRACTID get_win_history '{"from_index": 0, "limit": 100}'
# return metadata
near view $CONTRACTID gl_metadata ''
near view $CONTRACTID gl_pub_state ''
near view $CONTRACTID gl_user_state '{"user_id": "rb01.testnet"}'
```
## Let's play
```shell
# see how many playtoken we have
near view playtoken.testnet ft_balance_of '{"account_id": "rb01.testnet"}'
# purchase some if neccessary
near call gameland.testnet buy_playtoken '' --account_id=rb01.testnet --amount=6
# play the game
near call angleland.testnet gl_play '{"amount": "1000000000000000000000000", "op": "1"}' --account_id=rb01.testnet --gas=50000000000000
```
Build Deploy and Init
======================
Before you compile this code, you will need to install Rust with [correct target]
```shell
# building it
srouce ./build.sh
```
```shell
near deploy angleland.testnet res/gl_landlord.wasm --account_id=angleland.testnet
near call angleland.testnet new '{"owner_id": "humeng.testnet", "house_count": 36, "play_fee": "1000000000000000000000000"}' --account_id=angleland.testnet
### register this game
near call gameland.testnet register_shop '{"reg_form": {"flag": 1, "shop_id": "angleland.testnet", "owner_id": "humeng.testnet", "refs": "https://github.com/marco-sundsk/gameland/", "height": "0", "ts": "0", "status": 0}}' --account_id=humeng.testnet
near view gameland.testnet list_registers '{"from_index": 0, "limit": 100}'
near call gameland.testnet resovle_register '{"shop_id": "angleland.testnet", "pass": true, "new_status": 2}' --account_id=humeng.testnet --gas=20000000000000
### sponsor this game with 5 tokensgit
near call angleland.testnet gl_sponsor '{"amount": "5000000000000000000000000"}' --account_id=humeng.testnet --gas=30000000000000
```
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/roles/developer/contracts/intro
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
NCD-GroupA-Demo
==================
This is a homework demo project for NCD program phase-1.
Rolling Dice On NEAR
====================
Guys, let's roll dice on NEAR.
## Why dice
Randomness is always a key focus on any blockchain. We wanna show you how convenient that a random number can get on NEAR blockchain.
To achieve that, it is hard to believe there is a better way than to make a dice dapp.
Beyond what you can see in this demo, NEAR can even generate independent randomness not per block, but per receipt!
## How to play
On home page, user can see the whole status of playground without login, i.e. an NEAR account is not necessary. He would have full imformation about owner account of this contract, dice price, commission fee rate, the size of current jackpod and etc.
Then, user can login with NEAR account and buy several dices. With dices bought, he can guess a number and roll dice again and again. If the dice point is equal to his guess, half of jackpod would belong to him. Otherwise the amount he paid for the dice would belong to the jackpod.
During playing, the latest 20 win records would appear and be auto refreshed on screen too.
About Contract
====================
It's need to be mentioned that it is a pure dapp project, which means there is no centralized backend nor data server, all persistent information is stored and mananged on NEAR chain by a contract.
## Contract Structure
```rust
/// This structure describe a winning event
#[derive(BorshDeserialize, BorshSerialize)]
pub struct WinnerInfo {
pub user: AccountId, // winner accountId
pub amount: Balance, // how much he got as win reward
pub height: BlockHeight, // the block hight this event happened
pub ts: u64, // the timestamp this event happened
}
/// main structure of this contract
#[near_bindgen]
#[derive(BorshDeserialize, BorshSerialize)]
pub struct NearDice {
pub owner_id: AccountId, // owner can adjust params of this playground
pub dice_number: u8, // how many dices one rolling event uses
pub rolling_fee: Balance, // how much a dice costs when user buys it
pub jack_pod: Balance, // as name shows and half of it would belong to the winner
pub owner_pod: Balance, // winner would share a tip to the playground, this is where those tips go
pub reward_fee_fraction: RewardFeeFraction, // a fraction defines tip rate
// an always grow vector records all win event,
// as a demo, we ignore the management of its size,
// but in real project, it must be taken care of,
// maybe has a maximum length and remove the oldest item when exceeds.
pub win_history: Vector<WinnerInfo>,
// records dice user bought by his payment amount.
// This map has a mechanism to shrink,
// when a user's balance is reduce to zero, the entry would be removed.
pub accounts: LookupMap<AccountId, Balance>,
}
```
## Contract Interface
```rust
/// winner's tip rate
pub struct RewardFeeFraction {
pub numerator: u32,
pub denominator: u32,
}
/// a human readable version for win event struct, used in return value to caller
pub struct HumanReadableWinnerInfo {
pub user: AccountId, // winner accountId
pub amount: U128, // the reward he got
pub height: U64, // block height the event happens
pub ts: U64, // timestamp the event happens
}
/// status of this playground, as return value of get_contract_info
pub struct HumanReadableContractInfo {
pub owner: AccountId, // who runs this playground, if you feel bad, just sue him :)
pub jack_pod: U128, // you know what it means
pub owner_pod: U128, // winner's tip goes to here, owner can withdraw
pub dice_number: u8, // how many dice we use in one rolling event
pub rolling_fee: U128, // how much a dice costs when user wanna buy it
}
/// every roll_dice event would return this info
pub struct HumanReadableDiceResult {
pub user: AccountId, // who rolls
pub user_guess: u8, // the number he guess
pub dice_point: u8, // the number dice shows
pub reward_amount: U128, // reward he got
pub jackpod_left: U128, // jackpod after this event
pub height: U64, // the block height when he rolls
pub ts: U64, // the timestamp when he rolls
}
//****************/
//***** INIT *****/
//****************/
/// initialization of this contract
#[init]
pub fn new(
owner_id: AccountId,
dice_number: u8,
rolling_fee: U128,
reward_fee_fraction: RewardFeeFraction,
) -> Self;
//***************************/
//***** OWNER FUNCTIONS *****/
//***************************/
/// deposit to jackpod, used for initalizing the very first jackpod,
/// otherwise, the jackpod is initialized as 0.
#[payable]
pub fn deposit_jackpod(&mut self);
/// withdraw ownerpod to owner's account
pub fn withdraw_ownerpod(&mut self, amount: U128);
/// Updates current reward fee fraction to the new given fraction.
pub fn update_reward_fee_fraction(&mut self, reward_fee_fraction: RewardFeeFraction);
/// Updates current dice number used in one rolling event.
pub fn update_dice_number(&mut self, dice_number: u8);
/// Updates current dice price.
pub fn update_rolling_fee(&mut self, rolling_fee: U128);
//**************************/
//***** USER FUNCTIONS *****/
//**************************/
/// user deposit near to buy dice.
/// he can buy multiple dices,
/// any leftover amount would refund
/// eg: rolling_fee is 1 Near, he can buy_dice with 4.4 Near and got 4 dices and 0.4 Near refund.
#[payable]
pub fn buy_dice(&mut self);
/// user roll dice once, then his available dice count would reduce by one.
pub fn roll_dice(&mut self, target: u8) -> HumanReadableDiceResult;
//**************************/
//***** VIEW FUNCTIONS *****/
//**************************/
/// get a list of winn events in LIFO order
/// best practise is set from_index to 0, and limit to 20,
/// that means to get latest 20 win events information with latest first order.
pub fn get_win_history(&self, from_index: u64, limit: u64) -> Vec<HumanReadableWinnerInfo>;
/// get current playground status
pub fn get_contract_info(&self) -> HumanReadableContractInfo;
/// get current winner tip rate
pub fn get_reward_fee_fraction(&self) -> RewardFeeFraction;
/// get account's available dice count
pub fn get_account_dice_count(&self, account_id: String) -> u8;
```
Quick Start
===========
To run this project locally:
1. Prerequisites: Make sure you've installed [Node.js] ≥ 12
2. Install dependencies: `yarn install`
3. Run the local development server: `yarn dev` (see `package.json` for a
full list of `scripts` you can run with `yarn`)
Now you'll have a local development environment backed by the NEAR TestNet!
Go ahead and play with the app and the code. As you make code changes, the app will automatically reload.
Exploring The Code
==================
1. The "backend" code lives in the `/contract` folder. See the README there for
more info.
2. The frontend code lives in the `/src` folder. `/src/main.js` is a great
place to start exploring.
3. Tests: there are different kinds of tests for the frontend and the smart
contract. See `contract/README` for info about how it's tested. The frontend
code gets tested with [jest]. You can run both of these at once with `yarn
run test`.
Deploy
======
Every smart contract in NEAR has its [own associated account][NEAR accounts]. When you run `yarn dev`, your smart contract gets deployed to the live NEAR TestNet with a throwaway account. When you're ready to make it permanent, here's how.
Step 0: Install near-cli (optional)
-------------------------------------
[near-cli] is a command line interface (CLI) for interacting with the NEAR blockchain. It was installed to the local `node_modules` folder when you ran `yarn install`, but for best ergonomics you may want to install it globally:
yarn install --global near-cli
Or, if you'd rather use the locally-installed version, you can prefix all `near` commands with `npx`
Ensure that it's installed with `near --version` (or `npx near --version`)
Step 1: Create an account for the contract
------------------------------------------
Each account on NEAR can have at most one contract deployed to it. If you've already created an account such as `your-name.testnet`, you can deploy your contract to `NCD-GroupA-Demo.your-name.testnet`. Assuming you've already created an account on [NEAR Wallet], here's how to create `NCD-GroupA-Demo.your-name.testnet`:
1. Authorize NEAR CLI, following the commands it gives you:
near login
2. Create a subaccount (replace `YOUR-NAME` below with your actual account name):
near create-account NCD-GroupA-Demo.YOUR-NAME.testnet --masterAccount YOUR-NAME.testnet
Step 2: set contract name in code
---------------------------------
Modify the line in `src/config.js` that sets the account name of the contract. Set it to the account id you used above.
const CONTRACT_NAME = process.env.CONTRACT_NAME || 'NCD-GroupA-Demo.YOUR-NAME.testnet'
Step 3: deploy!
---------------
One command:
yarn deploy
As you can see in `package.json`, this does two things:
1. builds & deploys smart contract to NEAR TestNet
2. builds & deploys frontend code to GitHub using [gh-pages]. This will only work if the project already has a repository set up on GitHub. Feel free to modify the `deploy` script in `package.json` to deploy elsewhere.
Troubleshooting
===============
On Windows, if you're seeing an error containing `EPERM` it may be related to spaces in your path. Please see [this issue](https://github.com/zkat/npx/issues/209) for more details.
[Vue]: https://vuejs.org/
[create-near-app]: https://github.com/near/create-near-app
[Node.js]: https://nodejs.org/en/download/package-manager/
[jest]: https://jestjs.io/
[NEAR accounts]: https://docs.near.org/docs/concepts/account
[NEAR Wallet]: https://wallet.testnet.near.org/
[near-cli]: https://github.com/near/near-cli
[gh-pages]: https://github.com/tschaub/gh-pages
NCD-GroupA-Demo Smart Contract
==================
A demo contract for NCD Pojrect Phase-1.
Play with this contract
========================
the contract is deployed at testnet with the name `dev-1614240595058-5266655`
you can set it to env for later use:
```shell
export CONTRACTID=dev-1614240595058-5266655
```
## Look around
```shell
# return playground info
near view $CONTRACTID get_contract_info ''
# return winner tip rate
near view $CONTRACTID get_reward_fee_fraction ''
# return win history list
near view $CONTRACTID get_win_history '{"from_index": 0, "limit": 100}'
# return dice count that alice has
near view $CONTRACTID get_account_dice_count '{"account_id": "alice.testnet"}'
```
## Let's play
```shell
# attached 3 Near to buy 3 dices
near call $CONTRACTID buy_dice '' --amount=3 --account_id=alice.testnet
#check user's dice, would return 3 here
near view $CONTRACTID get_account_dice_count '{"account_id": "alice.testnet"}'
# roll dice 3 times, say how luck you are
near call $CONTRACTID roll_dice '{"target": 1}' --account_id=alice.testnet
near call $CONTRACTID roll_dice '{"target": 3}' --account_id=alice.testnet
near call $CONTRACTID roll_dice '{"target": 4}' --account_id=alice.testnet
```
Build Deploy and Init
======================
Before you compile this code, you will need to install Rust with [correct target]
```shell
# building it
srouce ./build.sh
```
```shell
# dev-deploy or deploy it
near dev-deploy res/neardice.wasm
# say it was deploy at $CONTRACTID, then init it
near call $CONTRACTID new \
'{"owner_id": "boss.testnet", "dice_number": 1,
"rolling_fee": "1000000000000000000000000",
"reward_fee_fraction": {"numerator": 5, "denominator": 100}}' \
--account_id=$CONTRACTID
```
```shell
# last step to open the playgroud is
# to deposit to the jackpod the very first time
near call $CONTRACTID deposit_jackpod '' --amount=50 --account_id=boss.testnet
```
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/roles/developer/contracts/intro
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
# game-land
## Project setup
```
yarn install
```
### Compiles and hot-reloads for development
```
yarn serve
```
### Compiles and minifies for production
```
yarn build
```
### Lints and fixes files
```
yarn lint
```
### Customize configuration
See [Configuration Reference](https://cli.vuejs.org/config/).
# lucky-box
## Project setup
```
yarn install
```
### Compiles and hot-reloads for development
```
yarn serve
```
### Compiles and minifies for production
```
yarn build
```
### Lints and fixes files
```
yarn lint
```
### Customize configuration
See [Configuration Reference](https://cli.vuejs.org/config/).
# GAMELAND UI
### gameland description
---
get gameland meta info
```shell
ear view gameland.testnet metadata ''
# return:
View call: gameland.testnet.metadata()
{
version: '0.1.0',
name: 'Game Land',
logo_url: 'https://github.com/',
thumb_url: 'https://github.com/',
description: 'A platform for small games'
}
```
get gameland policy info
```shell
near view playtoken.testnet get_contract_info ''
# return:
View call: playtoken.testnet.get_contract_info()
{
owner: 'humeng.testnet',
sudoer: 'gameland.testnet',
total_supply: '467000000000000000000000000',
total_collateral: '46233000000000000000000000',
account_num: '7',
shop_num: '1',
sudoer_profit: '480000000000000000000000',
sudoer_fee_play: { numerator: 5, denominator: 1000 },
sudoer_fee_win: { numerator: 10, denominator: 1000 },
shop_fee_play: { numerator: 5, denominator: 1000 },
shop_fee_win: { numerator: 10, denominator: 1000 },
mint_price: 100,
burn_ratio: { numerator: 10, denominator: 1000 }
}
```
### shop description
---
get shop list and detail:
```shell
near view gameland.testnet list_shops '{"from_index": 0, "limit": 100}'
# return:
View call: gameland.testnet.list_shops({"from_index": 0, "limit": 100})
[
{
shop_id: 'neardice.testnet',
owner_id: 'humeng.testnet',
flag: 1,
refs: 'https://github.com/marco-sundsk/gameland/',
height: '40641470',
ts: '1616077383477711863',
status: 2
},
[length]: 1
]
```
### shop status
---
```shell
near view neardice.testnet gl_metadata ''
# return:
View call: neardice.testnet.gl_metadata()
{
version: '0.1.0',
name: 'Dice Master',
logo_url: 'https://github.com/',
thumb_url: 'https://github.com/',
description: "Let's Rolling Dices"
}
near view neardice.testnet gl_pub_state ''
# return:
View call: neardice.testnet.gl_pub_state()
'Current jackpot is 4896411132812500000000000'
near view neardice.testnet gl_user_state '{"user_id": "player01.testnet"}'
# return:
View call: neardice.testnet.gl_user_state({"user_id": "player01.testnet"})
''
```
### user balance
---
```shell
near view playtoken.testnet ft_balance_of '{"account_id": "rb01.testnet"}'
# return:
View call: playtoken.testnet.ft_balance_of({"account_id": "rb01.testnet"})
'1000000000000000000000000'
```
DiceMaster Smart Contract
==================
A dice game for gameland.
three dices:
| Category | Name | Description | PR of win | Odds |
| - | - | - | - | - |
| 1 | big/small | [11 - 36] vs [3 - 10], except three identical dices | 48.61% | 1:1 |
| 2 | odd/even | odd vs even, except three identical dices | 48.61% | 1:1 |
| 3 | wei-tou | three identical dices and equal to player's guess | 0.46% | 1:150 |
| 4 | quan-tou | three identical dices | 2.80% | 1:24 |
| 5 | composition | player guesses two numbers of three dices | 13.90% | 1:5 |
| 6 | double-dice | player guesses one number that appears at least twice | 7.41% | 1:8 |
Play with this contract
========================
the contract is deployed at testnet with the name `dicemaster.testnet`
you can set it to env for later use:
```shell
export GAMEID=dicemaster.testnet
export GAS=100000000000000
export GLID=gameland.testnet
export COINID=playtoken.testnet
```
## Look around
```shell
# GAMELAND Standard View Interface
near view $GAMEID gl_metadata ''
near view $GAMEID gl_statistic ''
near view $GAMEID gl_pub_state ''
near view $GAMEID gl_user_state '{"user_id": "rb01.testnet"}'
# Game custom view functions
near view $GAMEID get_contract_info ''
near view $GAMEID get_win_history '{"from_index": 0, "limit": 100}'
```
## Let's play
```shell
# see how many playtoken we have
near view $COINID ft_balance_of '{"account_id": "rb01.testnet"}'
# purchase some if neccessary
near call $GLID buy_playtoken '' --account_id=rb01.testnet --amount=6
# play category 1, bet 1 coin with big, ie. set guess1 to 1 for big (2 for small)
near call $GAMEID gl_play \
'{"amount": "1000000000000000000000000",
"op": "{\"category\": 1, \"guess1\": 1, \"guess2\": 0, \"guess3\": 0}"}' \
--account_id=rb01.testnet --gas=$GAS
# play category 2, bet 1 coin with odd, ie. set guess1 to 1 for odd (2 for even)
near call $GAMEID gl_play \
'{"amount": "1000000000000000000000000",
"op": "{\"category\": 2, \"guess1\": 1, \"guess2\": 0, \"guess3\": 0}"}' \
--account_id=rb01.testnet --gas=$GAS
# play category 3, bet 1 coin for a hard 12, ie. set guess1 to 4 for 4-4-4.
near call $GAMEID gl_play \
'{"amount": "1000000000000000000000000",
"op": "{\"category\": 3, \"guess1\": 4, \"guess2\": 0, \"guess3\": 0}"}' \
--account_id=rb01.testnet --gas=$GAS
# play category 4, bet 3 coins for three identical dice.
near call $GAMEID gl_play \
'{"amount": "3000000000000000000000000",
"op": "{\"category\": 4, \"guess1\": 0, \"guess2\": 0, \"guess3\": 0}"}' \
--account_id=rb01.testnet --gas=$GAS
# play category 5, bet 6 coin with composition of 3-4
near call $GAMEID gl_play \
'{"amount": "6000000000000000000000000",
"op": "{\"category\": 5, \"guess1\": 3, \"guess2\": 4, \"guess3\": 0}"}' \
--account_id=rb01.testnet --gas=$GAS
# play category 6, bet 8 coin for 3 appears at least twice.
near call $GAMEID gl_play \
'{"amount": "8000000000000000000000000",
"op": "{\"category\": 6, \"guess1\": 3, \"guess2\": 0, \"guess3\": 0}"}' \
--account_id=rb01.testnet --gas=$GAS
```
Build Deploy and Init
======================
Before you compile this code, you will need to install Rust with [correct target]
```shell
# building it
source ./build.sh
```
```shell
# deploy it
near deploy $GAMEID res/dicemaster.wasm --account_id=$GAMEID
# say it was deploy at $CONTRACTID, then init it,
# set min bet is 1 coin and max bet is 10 coin
near call $GAMEID new \
'{"owner_id": "humeng.testnet",
"min_bet": "1000000000000000000000000",
"max_bet": "10000000000000000000000000"}' \
--account_id=$GAMEID
# sponsor jackpot with 200 token
near call $GAMEID gl_sponsor '{"amount": "200000000000000000000000000"}' \
--account_id=rb01.testnet --gas=$GAS
```
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/roles/developer/contracts/intro
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
NCD-GroupA-Demo Smart Contract
==================
A demo contract for NCD Pojrect Phase-1.
Play with this contract
========================
the contract is deployed at testnet with the name `dev-1614240595058-5266655`
you can set it to env for later use:
```shell
export CONTRACTID=dev-1614240595058-5266655
```
## Look around
```shell
# return playground info
near view $CONTRACTID get_contract_info ''
# return winner tip rate
near view $CONTRACTID get_reward_fee_fraction ''
# return win history list
near view $CONTRACTID get_win_history '{"from_index": 0, "limit": 100}'
# return dice count that alice has
near view $CONTRACTID get_account_dice_count '{"account_id": "alice.testnet"}'
```
## Let's play
```shell
# attached 3 Near to buy 3 dices
near call $CONTRACTID buy_dice '' --amount=3 --account_id=alice.testnet
#check user's dice, would return 3 here
near view $CONTRACTID get_account_dice_count '{"account_id": "alice.testnet"}'
# roll dice 3 times, say how luck you are
near call $CONTRACTID roll_dice '{"target": 1}' --account_id=alice.testnet
near call $CONTRACTID roll_dice '{"target": 3}' --account_id=alice.testnet
near call $CONTRACTID roll_dice '{"target": 4}' --account_id=alice.testnet
```
Build Deploy and Init
======================
Before you compile this code, you will need to install Rust with [correct target]
```shell
# building it
srouce ./build.sh
```
```shell
# dev-deploy or deploy it
near dev-deploy res/neardice.wasm
# say it was deploy at $CONTRACTID, then init it
near call $CONTRACTID new \
'{"owner_id": "boss.testnet", "dice_number": 1,
"rolling_fee": "1000000000000000000000000",
"reward_fee_fraction": {"numerator": 5, "denominator": 100}}' \
--account_id=$CONTRACTID
```
```shell
# last step to open the playgroud is
# to deposit to the jackpod the very first time
near call $CONTRACTID deposit_jackpod '' --amount=50 --account_id=boss.testnet
```
Exploring The Code
==================
1. The main smart contract code lives in `src/lib.rs`. You can compile it with
the `./compile` script.
2. Tests: You can run smart contract tests with the `./test` script. This runs
standard Rust tests using [cargo] with a `--nocapture` flag so that you
can see any debug info you print to the console.
[smart contract]: https://docs.near.org/docs/roles/developer/contracts/intro
[Rust]: https://www.rust-lang.org/
[create-near-app]: https://github.com/near/create-near-app
[correct target]: https://github.com/near/near-sdk-rs#pre-requisites
[cargo]: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
# gameland
|
near_wiki | .github
workflows
build.yml
links.yml
spellcheck.yml
Archive
README.md
access-keys.md
community
Community-Intro.md
_category_.json
overview.md
technology
_category_.json
dev-guides.md
dev-support.md
docs
README.md
protocol.md
use-cases.md
validators
_category_.json
about-pt.md
about.md
economics.md
faq-pt.md
faq.md
validator-guides
README.md
running-a-validator-kr.md
running-a-validator-pt.md
running-a-validator.md
validator-support.md
validator-training.md
validators
README.md
|
| seat price is 20,500 |
CODE_OF_CONDUCT.md
README.md
website
CODE_OF_CONDUCT.md
README.md
babel.config.js
docusaurus.config.js
mlc_config.json
package-lock.json
package.json
sidebars.js
src
components
CardsContainers
index.js
styles.module.css
GrowthCards
index.js
styles.module.css
LeadershipCards
index.js
NavCard
index.js
styles.module.css
SearchBox
index.d.ts
index.js
styles.css
styles.module.css
css
custom.css
pages
index.js
index.module.css
theme
Footer
index.js
styles.module.css
static
img
icons
icon_astro.svg
icon_cli.svg
icon_dapps.svg
icon_dev.svg
icon_devtools.svg
icon_docs.svg
icon_edu.svg
icon_etools.svg
icon_explorer.svg
icon_forum.svg
icon_founder.svg
icon_funding.svg
icon_governance.svg
icon_jssdk.svg
icon_rust.svg
icon_staking.svg
icon_user.svg
icon_wallet.svg
logo.svg
logo_beexperience.svg
logo_blackfreelancer.svg
logo_nearweek.svg
near_logo.svg
js
hotjar.js
wiki
contribute
_category_.json
_nearcore.md
faq.md
near-contributing.md
style-guide.md
translations.md
wiki-contributing.md
development
_category_.json
best-practices.md
dev-overview.md
how-to-contribute.md
tech-resources.md
tools-infrastructure.md
ecosystem
_category_.json
_dev-shops.md
communities.md
dapps.md
governance
_category_.json
dao-guide
README.md
_category_.json
astrodao.md
dao-governance.md
dao-legal-discussion.md
how-to-launch-a-dao.md
legal-checklist.md
legal-resources.md
near-forum
README.md
_category_.json
near-forum-guidelines.md
treasury-playbook.md
overview
BOS
core-experience.md
developer-enablement.md
enterprise-solutions.md
fast-auth.md
gateways.md
multi-chain.md
near-tasks.md
open-source.md
overall-bos.md
strategic-category-positioning.md
trust-and-safety.md
universal-search.md
_category_.json
essential-tools.md
faq.md
glossary.md
research.md
tokenomics
_category_.json
_neardrop.md
creating-a-near-wallet.md
lockups.md
near-token.md
nfts-on-near.md
rainbow-bridge.md
staking-guide.md
token-balance.md
token-custody.md
token-delegation.md
token-launch-considerations.md
support
_category_.json
_onboarding-checklist.md
contact-us.md
funding.md
hr-resources
behavioral-interview-questions.md
interviewing-guide.md
it-guide.md
recruitment.md
referral-programs.md
learning
readme.md
understanding-web3
01_history
1.1_history-of-the-internet.md
1.2_history-of-money.md
1.3_history-of-crypto.md
02_landscape
2.1_evolution-blockchain.md
2.2_eth1.0-eth2.0.md
2.3_NEAR-Protocol.md
2.4_product-stack.md
2.5_composability.md
2.6_emerging-technologies.md
2.7_measuring-success.md
2.8_legal-and-product.md
03_defi
3.1_understanding-defi.md
3.2_dex-amm-agg-perps.md
3.3_stablecoins.md
3.4_lending.md
3.5_synthetics.md
3.6_staking.md
3.7_prediction-market-design.md
04_creator-economy
4.1_nfts.md
4.2_nft-lending.md
4.3_social-tokens.md
4.4_creator-economy.md
4.5_future-economy.md
05_DAOs
5.1_dao-landscape.md
5.2_sputnik-vs-astro-dao.md
5.3_governance.md
5.4_network-states.md
06_metaverse
6.1_theory-and-evolution.md
6.2_realstate-economies.md
6.3_metaverse-on-near.md
| # Guides
[Run a Validator](running-a-validator.md)
# Website
This website is built using [Docusaurus 2](https://docusaurus.io/), a modern static website generator.
### Installation
```
$ yarn
```
### Local Development
```
$ yarn start
```
This command starts a local development server and opens up a browser window. Most changes are reflected live without having to restart the server.
### Build
```
$ yarn build
```
This command generates static content into the `build` directory and can be served using any static contents hosting service.
### Deployment
Using SSH:
```
$ USE_SSH=true yarn deploy
```
Not using SSH:
```
$ GIT_USER=<Your GitHub username> yarn deploy
```
If you are using GitHub pages for hosting, this command is a convenient way to build the website and push to the `gh-pages` branch.
# Documentation
NEAR Protocol offers paths for any developers to start building in our ecosystem. If you're joining from web2, then AssemblyScript may be a great place to start. Existing web3 devs may find Rust a more natural fit. Whichever path you choose, you can find the tools, resources, and support to help you journey through the NEARVerse.
:::note link
https://docs.near.org
:::
## Reference-Level Documentation
### SDKs for Building Smart Contracts
#### Rust Lang
:::note link
https://www.near-sdk.io
:::
:::note link
https://docs.near.org/docs/develop/contracts/rust/near-sdk-rs
:::
#### AssemblyScript
:::note link
https://docs.near.org/docs/develop/contracts/as/intro
:::
### APIs for Using NEAR Blockchain
#### Javascript API 
#### Library
:::note link
https://docs.near.org/docs/api/javascript-library
:::
### NEAR Github
:::note link
https://github.com/near
:::
### Example Apps
:::note link
https://examples.near.org
:::
NEAR Apps (detailed examples): [https://github.com/orgs/near-apps/repositories](https://github.com/orgs/near-apps/repositories)
NEAR API Quick Reference: [https://docs.near.org/docs/api/naj-quick-reference](https://docs.near.org/docs/api/naj-quick-reference)
NEAR API TypeDocs: [https://near.github.io/near-api-js/](https://near.github.io/near-api-js/)
### NEAR RPC Endpoints
:::note link
https://docs.near.org/docs/api/rpc
:::
### Quickstart Guide
:::note link
https://docs.near.org/docs/develop/basics/hackathon-startup-guide
:::
---
title: DAO Basics
description: Your map to navigating the world of DAOs on NEAR
slug: /governance
sidebar_position: 0
---
# Your Guide to DAOs on NEAR
## What’s a DAO?
In short, a DAO is a Decentralised Autonomous Organisation. It’s like a company, coop, club, or task force. The secret that sets DAOs apart from these examples is all in the name.
Decentralization is a core concept of blockchains. SputnikDAOs operate on NEAR blockchain, enabling peer to peer transactions without borders or gate keepers. You can collaborate with whoever you want from around the world!
Autonomous Organization is a tricker concept tied up in a new work revolution. Companies and platforms typically have someone in the middle to handle logistics (and taking a cut for their effort). SputnikDAOs replace those positions with apps running on the NEAR blockchain to automate things like distributing funds, recording consensus, and managing membership. All of that saved effort and cost is then passed onto the members of the DAOs, paying them more for the value they contribute!
To make things tangible let’s look at an example like AirBNB. If people with open space for short term rental coordinate directly with each other through a DAO then they don’t have to give a cut of their profits to AirBNB for providing that organizational service. Record labels, foundations, setting up group buys, crowdfunding, and more are all more efficient as DAOs!
In short, DAOs are digital companies living on a blockchain with participants united by a common purpose. SputnikDAO enables individuals to come together to form cooperative, open, accessible, and transparent organisations.
## Why a DAO?
DAOs empower communities to govern on-chain activity, make united decisions, and interact with other DAOs.Ultimately, DAOs unlock an unprecedented level of transparent and collaborative coordination with built-in tools to allow for:
* Transparency and legitimacy via built-in reporting
* Community ownership through stakeholder participation
* Responsible fund distribution through openness and transparency which results in meaningful accountability
## DAOs on NEAR
In line with the goal of being the most accessible, user-friendly blockchain, DAOs on NEAR are created in a matter of clicks through the [Astro](https://astrodao.com/) dApp.
AstroDAO is a hub of DAOs empowering communities in the NEAR ecosystem. [This playbook](how-to-launch-a-dao.md) will guide you through the process of creating and interacting with DAOs in the NEARverse Astro.
## Your Guide to DAOs
The following playbook will serve as documentation and a guide to creating DAOs in Astro, the leading DAO Tooling service on NEAR, as well as a key for unlocking the full potential of DAOs within the NEAR Ecosystem.
---
title: What is the NEAR Governance Forum?
description: Your go-to place to discuss everything NEAR
---
## What is the NEAR Governance Forum?
The [NEAR Governance Forum](https://gov.near.org/) is the living hub of NEAR Ecosystem. Here, NEAR Community members, developers, and the NEAR Foundation team come together to enable ecosystem participants to build something great and expand the NEAR ecosystem.
Much like the NEAR blockchain itself, the forum is completely open, accessible, and transparent. We'd love to have you on board \(if you're not already\) to help build the NEARverse.
The forum is a great place to meet creative members of the community, and find out more about how they integrate NEAR into their projects.
There are active discussions about NEAR marketing, development, the various aspects of the NEAR ecosystem, and how to teach and/or learn about NEAR.
The form is also a great place to connect to the different regional hubs for NEAR, you can connect with the community in your region, and find NEAR community members from all over the world.
One last thing before you run off to [sign up](https://gov.near.org/), do check out the next page for the Forum Guidelines.
<br />
<br />
<p align="center">
<img src="website/static/img/near-img.png" width="600">
</p>
<br />
<br />
## NEAR Protocol - scalable and usable blockchain
[](http://near.chat)
[](https://github.com/near/wiki/actions/workflows/build.yml)
* ⚖️ NEAR Protocol is a new smart-contract platform that delivers scalability and usability.
* 🛠 Through sharding, it will linearly scale with the number of validation nodes on the network.
* 🗝 Leveraging WebAssembly (via Rust and AssemblyScript), more sane contract management, ephemeral accounts and many other advancements, NEAR
finally makes using a blockchain protocol easy for both developers and consumers.
## Quick start
Check out the following links
- Deployed, live Wiki: https://wiki.near.org
- Example applications: https://near.dev
- Community chat: https://near.chat
## Contributing
NEAR uses [Docusaurus](https://docusaurus.io) for documentation. Please refer to their documentation for details on major structural contributions to the documentation.
For simple content changes you have 2 options
- [Submit an issue](https://github.com/near/wiki/issues)
- [Submit a pull request](https://github.com/near/wiki/pulls) *(we prefer PRs of course)*
### The instant PR
This is the fastest way to submit content changes directly from the page where you notice a mistake.
1. Open any page in the docs on https://wiki.near.org
2. Click the `[ Edit ]` button at the top right hand side of _every_ content page
3. Make your edits to the document that opens in GitHub by clicking the ✎ (pencil) icon
4. Submit a PR with your changes and comments for context
### The typical PR
This is the standard fork-branch-commit workflow for submitting pull requests to open source repositories
1. Fork this repo to your own GitHub account (or just clone it directly if you are currently a member of NEAR)
2. Open your editor to the _top level repo folder_ to view the directory structure as seen below
3. Move into the `/website` folder where you will run the following commands:
- Make sure all the dependencies for the website are installed:
```sh
# Install dependencies
yarn
```
- Run the local docs development server
```sh
# Start the site
yarn start
```
_Expected Output_
```sh
# Website with live reload is started
Docusaurus server started on port 3000
```
The website for docs will open your browser locally to port `3000`
4. Make changes to the docs
5. Observe those changes reflected in the local docs
6. Submit a pull request with your changes
# FAQ
## Orientation
### What is a good project summary for NEAR?
NEAR is a sharded, public, proof-of-stake blockchain and smart contract platform. It is built in Rust and contracts compile to WASM. It is conceptually similar to Ethereum 2.0.
### What's special about NEAR?
NEAR is the blockchain for builders.
If you understand the basics of web development, you can write, test and deploy scalable decentralized applications in minutes on the most developer-friendly blockchain without having to learn new tools or languages.
### Is NEAR open source?
Yes. Have look at our [GitHub organization](https://github.com/near).
### How are cryptographic functions used?
We support both `secp256k1` and `ed25519` for account keys and `ed25519` for signing transactions. We currently use the `ed25519_dalek` and `sha2` libraries for crypto.
### Do you have any on-chain governance mechanisms?
NEAR does not have any on-chain governance at the moment. Any changes to state or state transition function must be done through a hard fork.
### Do you have a bug-bounty program?
Our plan is to have a transparent Bug Bounty program with clear guidelines for paying out to those reporting issues. Payments will likely be based on publicly available rankings provided by protocol developers based on issue severity.
### What contracts should we be aware of right now?
We have developed a number of [initial contracts](https://github.com/near/initial-contracts) with **ones in bold** being most mature at time of writing
* **Staking Pool / Delegation contract**
* **Lockup / Vesting contract**
* Whitelist Contract
* Staking Pool Factory
* Multisig contract
### Do you have a cold wallet implementation (ie. Ledger)?
[https://github.com/near/near-ledger-app](https://github.com/near/near-ledger-app)
## Validators
### What is the process for becoming a validator?
Validation is permissionless and determined via auction. Parties who want to become a validator submit a special transaction to the chain one day ahead which indicates how many tokens they want to stake. An auction is run which determines the minimum necessary stake to get a validation seat during the next epoch and, if the amount submitted is greater than the minimum threshold, the submitter will validate at least one shard during the next epoch.
### How long does a validator remain a validator?
A validator will stop being a validator for the following reasons:
* Not producing enough blocks or chunks.
* Not getting elected in the auction for next epoch because their stake is not large enough.
* Getting slashed.
Otherwise a validator will remain a validator indefinitely.
Validator election happens in epochs. The [Nightshade whitepaper](https://near.org/papers/nightshade) introduces epochs this way: "the maintenance of the network is done in epochs" where an epoch is a period of time on the order of half a day.
At the beginning of each epoch, some computation produces a list of validators for the _very next epoch_. The input to this computation includes all accounts that have "raised their hand to be a validator" by submitting a special transaction ([`StakeAction`](https://nomicon.io/RuntimeSpec/Actions.html#stakeaction)) expressing the commitment of some amount of tokens over the system's staking threshold, as well as validators from the previous epoch. The output of this computation is a list of the validators for the very next epoch.
### What is the penalty for misbehaving validators?
Validators are not slashed for being offline but they do miss out on the rewards of validating. Validators who miss too many blocks or chunks will be removed from the validation set in the next auction and not get any reward (but, again, without slashing).
Any foul play on the part of the validator that is detected by the system may result is a "slashing event" where the validator is marked as out of integrity and forfeit their stake (according to some formula of progressive severity). The slashed stake is burnt.
### What is the mechanism for for delegating stake to validators?
NEAR supports separate validation keys that can be used in smart contracts to delegate stake. Delegation is done via smart contract which allows for a validator to define a custom way to collect stake, manage it and split rewards. This also allows validators to provide leverage or derivatives on stake. Delegated stake will be slashed like any other stake if the node misbehaves.
If a validator misbehaves the funds of the delegators are also slashed. There is no waiting period for delegators to withdraw their stake.
### Does a validator control funds that have been delegated to them?
Delegation is custodial (you are transferring funds to a different account, the smart contract that implements staking pool). We provide a reference implementation being security reviewed and tested by 100 validators at time of writing.
We allow validators to write and deploy new contracts but it is up to users to decide if they want to delegate. Validators can compete for delegation by choosing different logic and conditions around tax optimization, etc.
Currently no slashing but will be added as we add shards into the system. At some point validators will be able to add an option to shield delegators from slashing (similar to Tezos model).
### How do we get the balance of an account after it has delegated funds?
One would need to query the staking pool contract to get balance.
## Nodes
### Can a node be configured to archive all blockchain data since genesis?
v Yes. Start the node using the following command:
```bash
./target/release/near run --archive
```
### Can a node be configured to expose an RPC (ex: HTTP) interface?
Yes. All nodes expose this interface by default which can be configured by setting the value of `listen_addr:port` in the node's `config.json` file.
### Can a node be gracefully terminated and restarted (using archived data on disk to continue syncing)?
Yes.
### Does a node expose an interface for retrieving health telemetry in a structured format (ex: JSON) over RPC?
Yes. `GET /status` and `GET /health` provide this interface.
* `/status`: block height, syncing status, peer count, etc
* `/health`: success/failure if node is up running & progressing
### Can a node can be started using a Dockerfile without human supervision?
Yes.
```bash
docker run <port mapping> <mount data folder> <ENV vars> nearprotocol/nearcore:latest
```
See `nearcore/scripts/nodelib.py` for different examples of configuration.
### What is the source of truth for current block height exposed via API?
* MainNet
* [https://explorer.mainnet.near.org](https://explorer.mainnet.near.org) (also [https://explorer.near.org](https://explorer.near.org))
* [https://rpc.mainnet.near.org/status](https://rpc.mainnet.near.org/status)
* TestNet
* [https://explorer.testnet.near.org](https://explorer.testnet.near.org)
* [https://rpc.testnet.near.org/status](https://rpc.testnet.near.org/status)
* BetaNet
* [https://explorer.betanet.near.org](https://explorer.betanet.near.org)
* [https://rpc.betanet.near.org/status](https://rpc.betanet.near.org/status)
### How old can the referenced block hash be before it's invalid?
There is a genesis parameter which can be discovered for any network using:
```bash
http post https://rpc.testnet.near.org jsonrpc=2.0 id=dontcare method=EXPERIMENTAL_genesis_config
# in the line above, testnet may be replaced with mainnet or betanet
```
It's `43200` seconds or `~12` hours. You can view the live configuration for `epoch_length` using the [`protocol_config` RPC endpoint](https://docs.near.org/docs/api/rpc).
In the response we find `transaction_validity_period": 86400` (and since it takes about 1 second to produce a block, this period is about 24 hrs)
## Blockchain
### How will the network be bootstrapped?
Distribution at genesis will be spread among the NEAR team, our contributors, project partners (ie. contributor, beta applications, infrastructure developers, etc.) and the NEAR foundation (with many portions of that segregated for post-MainNet distribution activity and unavailable to stake so the foundation isn’t able to control the network).
There will be auctions occurring on the platform after launch which will allocate large amounts of tokens over the next 2 years. Additionally we are planning to run TestNet where any validator who participates will receive rewards in real tokens. We are planning to onboard at least 50 separate entities to be validators at launch.
### What is the network upgrade process?
We are currently upgrading via restarting with a new genesis block.
### Which consensus algorithm does NEAR use?
NEAR is a sharded **proof-of-stake** blockchain.
_You can read more in our_ [_Nightshade whitepaper_](https://near.org/downloads/Nightshade.pdf)_._
> _A few relevant details have been extracted here for convenience:_
>
> \[Since NEAR is a sharded blockchain, there are challenges that need to be overcome] including state validity and data availability problems. _Nightshade_ is the solution Near Protocol is built upon that addresses these issues.
>
> Nightshade uses the heaviest chain consensus. Specifically when a block producer produces a block (see section 3.3), they can collect signatures from other block producers and validators attesting to the previous block. The weight of a block is then the cumulative stake of all the signers whose signatures are included in the block. The weight of a chain is the sum of the block weights.
>
> On top of the heaviest chain consensus we use a finality gadget that uses the attestations to finalize the blocks. To reduce the complexity of the system, we use a finality gadget that doesn’t influence the fork choice rule in any way, and instead only introduces extra slashing conditions, such that once a block is finalized by the finality gadget, a fork is impossible unless a very large percentage of the total stake is slashed.
### How does on-chain transaction finality work?
Finality is deterministic, and requires at least 3 blocks as well as (2/3 +1) signatures of the current validator set.
In a normal operation, we expect this to happen right at 3 blocks but it is not guaranteed.
Finality will be exposed via RPC when querying block or transaction.
Our definition of finality is BOTH:
* Block has quorum pre-commit from the finality gadget. See details of the finality gadget [\[here\]](https://near.org/downloads/PoST.pdf)
* At least 120 blocks (2-3 minutes) built on top of the block of interest. This is relevant in case of invalid state transition in some shard and provides enough time for state change challenges. In case all shards are tracked and some mechanics to pause across nodes is employed, this is not needed. We recommend exchanges track all shards.
## Accounts
### How are addresses generated?
Please check out the spec here on accounts [https://nomicon.io/DataStructures/Account.html](https://nomicon.io/DataStructures/Account.html).
### What is the balance record-keeping model on the NEAR platform?
NEAR uses an `Account`-based model. All users and contracts are associated with at least 1 account. Each account lives on a single shard. Each account can have multiple keys for signing transactions.
_You can read_ [_more about NEAR accounts here_](https://nomicon.io/DataStructures/Account.html)
### How are user accounts represented on-chain?
Users create accounts with human-readable names (eg `alice`) which can contain multiple keypairs with individual permissions. Accounts can be atomically and securely transferred between parties as a native transaction on the network. Permissions are programmable with smart contracts as well. For example, a lock up contract is just an account with permission on the key that does not allow to transfer funds greater than those unlocked.
### Is there a minimum account balance?
To limit on-chain "dust", accounts (and contracts) are charged rent for storing data on the chain. This means that if the balance of the account goes below some `threshold * rent_on_block` then account can be removed by anyone. Also any user can remove their own account and transfer left over balance to another (beneficiary) account.
There will be a restoration mechanism for accounts removed (or slept) in this way implemented in the future.
### How many keys are used?
An account can have arbitrarily many keys, as long as it has enough tokens for their storage.
### Which balance look-ups exists? What is required?
We have an [RPC method for viewing account](https://docs.near.org/docs/api/rpc).
The [JS implementation is here](https://github.com/near/near-api-js/blob/d7f0cb87ec320b723734045a4ee9d17d94574a19/src/providers/json-rpc-provider.ts#L73). Note that in this RPC interface you can specify the finality requirement (whether to query the latest state or finalized state).
For custody purposes, it is recommended not to rely on latest state but only on what is finalized.
## Fees
### What is the fee structure for on-chain transactions?
NEAR uses a gas-based model where prices are generally deterministically adjusted based on the congestion of the network.
We avoid making changes that are too large through re-sharding by changing the number of available shards (and thus throughput).
Accounts don’t have associated resources. Gas amount is predetermined for all transactions except function calls. For function call transactions the user (or more likely the developer) attaches the required amount of gas. If some gas is left over after the function call, it is converted back to Near and refunded to the original funding account.
### How do we know how much gas to add to a transaction?
* See reference documentation here: [https://nomicon.io/Economics/](https://nomicon.io/Economics/)
* See API documentation for [discovering gas price via RPC here](https://docs.near.org/docs/api/rpc).
The issuer of a transaction should attach some amount of gas by taking a guess at budget which will get the transaction processed. The contract knows how much to fund different cross contract calls. Gas price is calculated and fixed per block, but may change from block to block depending on how full / busy the block is. If blocks become more than half full then gas price increases.
We're also considering adding a max gas price limit.
## Transactions
### How do we follow Tx status?
See related [RPC interface for fetching transaction status here](https://docs.near.org/docs/api/rpc).
### How are transactions constructed and signed?
Transactions are a collection of related data that is composed and cryptographically signed by the sender using their private key. The related public key is part of the transaction and used for signature verification. Only signed transactions may be sent to the network for processing.
Transactions can be constructed and signed offline. Nodes are not required for signing. We are planning to add optional recent block hash to help prevent various replay attacks.
See [transactions](https://docs.near.org/docs/concepts/transaction) in the concepts section of our documentation.
### How is the hash preimage generated? Which fields does the raw transaction consist of?
For a transaction, we sign the hash of the transaction. More specifically, what is signed is the `sha256` of the transaction object serialized in borsh ([https://github.com/near/borsh](https://github.com/near/borsh)).
### How do transactions work on the NEAR platform?
A `Transaction` is made up of one of more `Action`s. An action can (currently) be one of 8 types: `CreateAccount`, `DeployContract`, `FunctionCall`, `Transfer`, `Stake`, `AddKey`, `DeleteKey` and `DeleteAccount`. Transactions are composed by a sender and then signed using the private keys of a valid NEAR account to create a `SignedTransaction`. This signed transaction is considered ready to send to the network for processing.
Transactions are received via our JSON-RPC endpoint and routed to the shared where the `sender` account lives. This "home shard" for the sender account is then responsible for processing the transaction and generating related receipts to be applied across the network.
Once received by the network, signed transactions are verified (using the embedded public key of the signer) and transformed into a collection of `Receipt`s, one per action. Receipts are of two types: `Action Receipt` is the most common and represents almost all actions on the network while `Data Receipt` handles the very special case of "a `FunctionCallAction` which includes a Promise". These receipts are then propagated and applied across the network according to the "home shard" rule for all affected receiver accounts.
These receipts are then propagated around the network using the receiver account's "home shard" since each account lives on one and only one shard. Once located on the correct shard, receipts are pulled from a nonce-based [queue](https://nomicon.io/ChainSpec/Transactions.html#pool-iterator).
Receipts may generate other, new receipts which in turn are propagated around the network until all receipts have been applied. If any action within a transaction fails, the entire transaction is rolled back and any unburnt fees are refunded to the proper accounts.
For more detail, see specs on [`Transactions`](https://nomicon.io/RuntimeSpec/Transactions.html), [`Actions`](https://nomicon.io/RuntimeSpec/Actions.html), [`Receipts`](https://nomicon.io/RuntimeSpec/Receipts.html)
### How does NEAR serialize transactions?
We use a simple binary serialization format that's deterministic: [https://borsh.io](https://borsh.io)
## Additional Resources
* Whitepaper
* General overview at [The Beginner's Guide to the NEAR Blockchain](https://near.org/blog/the-beginners-guide-to-the-near-blockchain)
* [NEAR Whitepaper](https://near.org/papers/the-official-near-white-paper/)
* Github
* [https://www.github.com/near](https://www.github.com/near)
> Got a question? 
>
> Ask it on [StackOverflow](https://stackoverflow.com/questions/tagged/nearprotocol)!
# Docs
NEAR Validator Economics: [https://docs.near.org/docs/validator/economics](../economics.md)
NEAR RPC Endpoints: [https://docs.near.org/docs/api/rpc](https://docs.near.org/docs/api/rpc)
Hardware Requirements: [https://docs.near.org/docs/develop/node/validator/hardware\#docsNav](https://docs.near.org/docs/develop/node/validator/hardware#docsNav)
|
gitakileus_near-contract-standards-nft | .gitpod.yml
Cargo.toml
README-Windows.md
README.md
integration-tests
rs
Cargo.toml
src
tests.rs
ts
package.json
src
main.ava.ts
utils.ts
nft
Cargo.toml
src
lib.rs
res
README.md
scripts
build.bat
build.sh
flags.sh
test-approval-receiver
Cargo.toml
src
lib.rs
test-token-receiver
Cargo.toml
src
lib.rs
| # Folder that contains wasm files
Non-fungible Token (NFT)
===================
>**Note**: If you'd like to learn how to create an NFT contract from scratch that explores every aspect of the [NEP-171](https://github.com/near/NEPs/blob/master/neps/nep-0171.md) standard including an NFT marketplace, check out the NFT [Zero to Hero Tutorial](https://docs.near.org/docs/tutorials/contracts/nfts/introduction).
[](https://gitpod.io/#https://github.com/near-examples/NFT)
This repository includes an example implementation of a [non-fungible token] contract which uses [near-contract-standards] and workspaces-js and -rs tests.
[non-fungible token]: https://nomicon.io/Standards/NonFungibleToken/README.html
[near-contract-standards]: https://github.com/near/near-sdk-rs/tree/master/near-contract-standards
[simulation]: https://github.com/near/near-sdk-rs/tree/master/near-sdk-sim
Prerequisites
=============
If you're using Gitpod, you can skip this step.
* Make sure Rust is installed per the prerequisites in [`near-sdk-rs`](https://github.com/near/near-sdk-rs).
* Make sure [near-cli](https://github.com/near/near-cli) is installed.
Explore this contract
=====================
The source for this contract is in `nft/src/lib.rs`. It provides methods to manage access to tokens, transfer tokens, check access, and get token owner. Note, some further exploration inside the rust macros is needed to see how the `NonFungibleToken` contract is implemented.
Building this contract
======================
Run the following, and we'll build our rust project up via cargo. This will generate our WASM binaries into our `res/` directory. This is the smart contract we'll be deploying onto the NEAR blockchain later.
```bash
./scripts/build.sh
```
Testing this contract
=====================
We have some tests that you can run. For example, the following will run our simple tests to verify that our contract code is working.
*Unit Tests*
```bash
cd nft
cargo test -- --nocapture
```
*Integration Tests*
*Rust*
```bash
cd integration-tests/rs
cargo run --example integration-tests
```
*TypeScript*
```bash
cd integration-tests/ts
yarn && yarn test
```
Using this contract
===================
### Quickest deploy
You can build and deploy this smart contract to a development account. [Dev Accounts](https://docs.near.org/docs/concepts/account#dev-accounts) are auto-generated accounts to assist in developing and testing smart contracts. Please see the [Standard deploy](#standard-deploy) section for creating a more personalized account to deploy to.
```bash
near dev-deploy --wasmFile res/non_fungible_token.wasm
```
Behind the scenes, this is creating an account and deploying a contract to it. On the console, notice a message like:
>Done deploying to dev-1234567890123
In this instance, the account is `dev-1234567890123`. A file has been created containing a key pair to
the account, located at `neardev/dev-account`. To make the next few steps easier, we're going to set an
environment variable containing this development account id and use that when copy/pasting commands.
Run this command to set the environment variable:
```bash
source neardev/dev-account.env
```
You can tell if the environment variable is set correctly if your command line prints the account name after this command:
```bash
echo $CONTRACT_NAME
```
The next command will initialize the contract using the `new` method:
```bash
near call $CONTRACT_NAME new_default_meta '{"owner_id": "'$CONTRACT_NAME'"}' --accountId $CONTRACT_NAME
```
To view the NFT metadata:
```bash
near view $CONTRACT_NAME nft_metadata
```
### Standard deploy
This smart contract will get deployed to your NEAR account. For this example, please create a new NEAR account. Because NEAR allows the ability to upgrade contracts on the same account, initialization functions must be cleared. If you'd like to run this example on a NEAR account that has had prior contracts deployed, please use the `near-cli` command `near delete`, and then recreate it in Wallet. To create (or recreate) an account, please follow the directions in [Test Wallet](https://wallet.testnet.near.org) or ([NEAR Wallet](https://wallet.near.org/) if we're using `mainnet`).
In the project root, log in to your newly created account with `near-cli` by following the instructions after this command.
near login
To make this tutorial easier to copy/paste, we're going to set an environment variable for our account id. In the below command, replace `MY_ACCOUNT_NAME` with the account name we just logged in with, including the `.testnet` (or `.near` for `mainnet`):
ID=MY_ACCOUNT_NAME
We can tell if the environment variable is set correctly if our command line prints the account name after this command:
echo $ID
Now we can deploy the compiled contract in this example to your account:
near deploy --wasmFile res/non_fungible_token.wasm --accountId $ID
NFT contract should be initialized before usage. More info about the metadata at [nomicon.io](https://nomicon.io/Standards/NonFungibleToken/Metadata.html). But for now, we'll initialize with the default metadata.
near call $ID new_default_meta '{"owner_id": "'$ID'"}' --accountId $ID
We'll be able to view our metadata right after:
near view $ID nft_metadata
Then, let's mint our first token. This will create a NFT based on Olympus Mons where only one copy exists:
near call $ID nft_mint '{"token_id": "0", "receiver_id": "'$ID'", "token_metadata": { "title": "Olympus Mons", "description": "Tallest mountain in charted solar system", "media": "https://upload.wikimedia.org/wikipedia/commons/thumb/0/00/Olympus_Mons_alt.jpg/1024px-Olympus_Mons_alt.jpg", "copies": 1}}' --accountId $ID --deposit 0.1
Transferring our NFT
====================
Let's set up an account to transfer our freshly minted token to. This account will be a sub-account of the NEAR account we logged in with originally via `near login`.
near create-account alice.$ID --masterAccount $ID --initialBalance 10
Checking Alice's account for tokens:
near view $ID nft_tokens_for_owner '{"account_id": "'alice.$ID'"}'
Then we'll transfer over the NFT into Alice's account. Exactly 1 yoctoNEAR of deposit should be attached:
near call $ID nft_transfer '{"token_id": "0", "receiver_id": "alice.'$ID'", "memo": "transfer ownership"}' --accountId $ID --depositYocto 1
Checking Alice's account again shows us that she has the Olympus Mons token.
Notes
=====
* The maximum balance value is limited by U128 (2**128 - 1).
* JSON calls should pass U128 as a base-10 string. E.g. "100".
* This does not include escrow functionality, as ft_transfer_call provides a superior approach. An escrow system can, of course, be added as a separate contract or additional functionality within this contract.
AssemblyScript
==============
Currently, AssemblyScript is not supported for this example. An old version can be found in the [NEP4 example](https://github.com/near-examples/NFT/releases/tag/nep4-example), but this is not recommended as it is out of date and does not follow the standards the NEAR SDK has set currently.
|
Gkhnkpnr_patikaWeb3Fundamentals | README.md
practice1
as-pect.config.js
asconfig.json
neardev
dev-account.env
node_modules
@as-pect
assembly
README.md
assembly
index.ts
internal
Actual.ts
Expectation.ts
Expected.ts
Reflect.ts
ReflectedValueType.ts
Test.ts
assert.ts
call.ts
comparison
toIncludeComparison.ts
toIncludeEqualComparison.ts
log.ts
noOp.ts
package.json
types
as-pect.d.ts
as-pect.portable.d.ts
env.d.ts
cli
README.md
init
as-pect.config.js
env.d.ts
example.spec.ts
init-types.d.ts
portable-types.d.ts
lib
as-pect.cli.amd.d.ts
as-pect.cli.amd.js
help.d.ts
help.js
index.d.ts
index.js
init.d.ts
init.js
portable.d.ts
portable.js
run.d.ts
run.js
test.d.ts
test.js
types.d.ts
types.js
util
CommandLineArg.d.ts
CommandLineArg.js
IConfiguration.d.ts
IConfiguration.js
asciiArt.d.ts
asciiArt.js
collectReporter.d.ts
collectReporter.js
getTestEntryFiles.d.ts
getTestEntryFiles.js
removeFile.d.ts
removeFile.js
strings.d.ts
strings.js
writeFile.d.ts
writeFile.js
worklets
ICommand.d.ts
ICommand.js
compiler.d.ts
compiler.js
package.json
core
README.md
lib
as-pect.core.amd.d.ts
as-pect.core.amd.js
index.d.ts
index.js
reporter
CombinationReporter.d.ts
CombinationReporter.js
EmptyReporter.d.ts
EmptyReporter.js
IReporter.d.ts
IReporter.js
SummaryReporter.d.ts
SummaryReporter.js
VerboseReporter.d.ts
VerboseReporter.js
test
IWarning.d.ts
IWarning.js
TestContext.d.ts
TestContext.js
TestNode.d.ts
TestNode.js
transform
assemblyscript.d.ts
assemblyscript.js
createAddReflectedValueKeyValuePairsMember.d.ts
createAddReflectedValueKeyValuePairsMember.js
createGenericTypeParameter.d.ts
createGenericTypeParameter.js
createStrictEqualsMember.d.ts
createStrictEqualsMember.js
emptyTransformer.d.ts
emptyTransformer.js
hash.d.ts
hash.js
index.d.ts
index.js
util
IAspectExports.d.ts
IAspectExports.js
IWriteable.d.ts
IWriteable.js
ReflectedValue.d.ts
ReflectedValue.js
TestNodeType.d.ts
TestNodeType.js
rTrace.d.ts
rTrace.js
stringifyReflectedValue.d.ts
stringifyReflectedValue.js
timeDifference.d.ts
timeDifference.js
wasmTools.d.ts
wasmTools.js
package.json
csv-reporter
index.ts
lib
as-pect.csv-reporter.amd.d.ts
as-pect.csv-reporter.amd.js
index.d.ts
index.js
package.json
readme.md
tsconfig.json
json-reporter
index.ts
lib
as-pect.json-reporter.amd.d.ts
as-pect.json-reporter.amd.js
index.d.ts
index.js
package.json
readme.md
tsconfig.json
snapshots
__tests__
snapshot.spec.ts
jest.config.js
lib
Snapshot.d.ts
Snapshot.js
SnapshotDiff.d.ts
SnapshotDiff.js
SnapshotDiffResult.d.ts
SnapshotDiffResult.js
as-pect.core.amd.d.ts
as-pect.core.amd.js
index.d.ts
index.js
parser
grammar.d.ts
grammar.js
package.json
src
Snapshot.ts
SnapshotDiff.ts
SnapshotDiffResult.ts
index.ts
parser
grammar.ts
tsconfig.json
@assemblyscript
loader
README.md
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
ansi-regex
index.d.ts
index.js
package.json
readme.md
ansi-styles
index.d.ts
index.js
package.json
readme.md
as-bignum
.travis.yml
README.md
as-pect.config.js
assembly
__tests__
as-pect.d.ts
safe_u128.spec.as.ts
u128.spec.as.ts
u256.spec.as.ts
utils.ts
fixed
fp128.ts
fp256.ts
index.ts
safe
fp128.ts
fp256.ts
types.ts
globals.ts
index.ts
integer
i128.ts
i256.ts
index.ts
safe
i128.ts
i256.ts
i64.ts
index.ts
u128.ts
u256.ts
u64.ts
u128.ts
u256.ts
tsconfig.json
utils.ts
index.js
package.json
tsconfig.json
asbuild
README.md
dist
cli.d.ts
cli.js
index.d.ts
index.js
main.d.ts
main.js
index.js
node_modules
cliui
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
wrap-ansi
index.js
package.json
readme.md
y18n
CHANGELOG.md
README.md
index.js
package.json
yargs-parser
CHANGELOG.md
LICENSE.txt
README.md
index.js
lib
tokenize-arg-string.js
package.json
yargs
CHANGELOG.md
README.md
build
lib
apply-extends.d.ts
apply-extends.js
argsert.d.ts
argsert.js
command.d.ts
command.js
common-types.d.ts
common-types.js
completion-templates.d.ts
completion-templates.js
completion.d.ts
completion.js
is-promise.d.ts
is-promise.js
levenshtein.d.ts
levenshtein.js
middleware.d.ts
middleware.js
obj-filter.d.ts
obj-filter.js
parse-command.d.ts
parse-command.js
process-argv.d.ts
process-argv.js
usage.d.ts
usage.js
validation.d.ts
validation.js
yargs.d.ts
yargs.js
yerror.d.ts
yerror.js
index.js
locales
be.json
de.json
en.json
es.json
fi.json
fr.json
hi.json
hu.json
id.json
it.json
ja.json
ko.json
nb.json
nl.json
nn.json
pirate.json
pl.json
pt.json
pt_BR.json
ru.json
th.json
tr.json
zh_CN.json
zh_TW.json
package.json
yargs.js
package.json
assemblyscript-json
.eslintrc.js
.travis.yml
README.md
as-pect.config.js
assembly
JSON.ts
__tests__
as-pect.d.ts
json-parse.spec.ts
roundtrip.spec.ts
to-string.spec.ts
usage.spec.ts
decoder.ts
encoder.ts
index.ts
tsconfig.json
util
index.ts
docs
README.md
classes
decoderstate.md
json.arr.md
json.bool.md
json.float.md
json.integer.md
json.null.md
json.num.md
json.obj.md
json.str.md
json.value.md
jsondecoder.md
jsonencoder.md
jsonhandler.md
throwingjsonhandler.md
modules
json.md
index.js
package.json
assemblyscript
README.md
cli
README.md
asc.d.ts
asc.js
asc.json
shim
README.md
fs.js
path.js
process.js
transform.d.ts
transform.js
util
colors.d.ts
colors.js
find.d.ts
find.js
mkdirp.d.ts
mkdirp.js
options.d.ts
options.js
utf8.d.ts
utf8.js
dist
asc.js
assemblyscript.d.ts
assemblyscript.js
sdk.js
index.d.ts
index.js
lib
loader
README.md
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
rtrace
README.md
bin
rtplot.js
index.d.ts
index.js
package.json
umd
index.d.ts
index.js
package.json
package-lock.json
package.json
std
README.md
assembly.json
assembly
array.ts
arraybuffer.ts
atomics.ts
bindings
Date.ts
Math.ts
Reflect.ts
asyncify.ts
console.ts
wasi.ts
wasi_snapshot_preview1.ts
wasi_unstable.ts
builtins.ts
compat.ts
console.ts
crypto.ts
dataview.ts
date.ts
diagnostics.ts
error.ts
function.ts
index.d.ts
iterator.ts
map.ts
math.ts
memory.ts
number.ts
object.ts
polyfills.ts
process.ts
reference.ts
regexp.ts
rt.ts
rt
README.md
common.ts
index-incremental.ts
index-minimal.ts
index-stub.ts
index.d.ts
itcms.ts
rtrace.ts
stub.ts
tcms.ts
tlsf.ts
set.ts
shared
feature.ts
target.ts
tsconfig.json
typeinfo.ts
staticarray.ts
string.ts
symbol.ts
table.ts
tsconfig.json
typedarray.ts
util
casemap.ts
error.ts
hash.ts
math.ts
memory.ts
number.ts
sort.ts
string.ts
vector.ts
wasi
index.ts
portable.json
portable
index.d.ts
index.js
types
assembly
index.d.ts
package.json
portable
index.d.ts
package.json
tsconfig-base.json
axios
CHANGELOG.md
README.md
UPGRADE_GUIDE.md
dist
axios.js
axios.min.js
index.d.ts
index.js
lib
adapters
README.md
http.js
xhr.js
axios.js
cancel
Cancel.js
CancelToken.js
isCancel.js
core
Axios.js
InterceptorManager.js
README.md
buildFullPath.js
createError.js
dispatchRequest.js
enhanceError.js
mergeConfig.js
settle.js
transformData.js
defaults.js
helpers
README.md
bind.js
buildURL.js
combineURLs.js
cookies.js
deprecatedMethod.js
isAbsoluteURL.js
isURLSameOrigin.js
normalizeHeaderName.js
parseHeaders.js
spread.js
utils.js
package.json
balanced-match
LICENSE.md
README.md
index.js
package.json
base-x
LICENSE.md
README.md
package.json
src
index.d.ts
index.js
binary-install
README.md
example
binary.js
package.json
run.js
index.js
package.json
src
binary.js
binaryen
README.md
index.d.ts
package-lock.json
package.json
wasm.d.ts
bn.js
CHANGELOG.md
README.md
lib
bn.js
package.json
brace-expansion
README.md
index.js
package.json
bs58
CHANGELOG.md
README.md
index.js
package.json
camelcase
index.d.ts
index.js
package.json
readme.md
chalk
index.d.ts
package.json
readme.md
source
index.js
templates.js
util.js
chownr
README.md
chownr.js
package.json
cliui
CHANGELOG.md
LICENSE.txt
README.md
build
lib
index.js
string-utils.js
package.json
color-convert
CHANGELOG.md
README.md
conversions.js
index.js
package.json
route.js
color-name
README.md
index.js
package.json
commander
CHANGELOG.md
Readme.md
index.js
package.json
typings
index.d.ts
concat-map
.travis.yml
example
map.js
index.js
package.json
test
map.js
debug
.coveralls.yml
.travis.yml
CHANGELOG.md
README.md
karma.conf.js
node.js
package.json
src
browser.js
debug.js
index.js
node.js
decamelize
index.js
package.json
readme.md
diff
CONTRIBUTING.md
README.md
dist
diff.js
lib
convert
dmp.js
xml.js
diff
array.js
base.js
character.js
css.js
json.js
line.js
sentence.js
word.js
index.es6.js
index.js
patch
apply.js
create.js
merge.js
parse.js
util
array.js
distance-iterator.js
params.js
package.json
release-notes.md
runtime.js
discontinuous-range
.travis.yml
README.md
index.js
package.json
test
main-test.js
emoji-regex
LICENSE-MIT.txt
README.md
es2015
index.js
text.js
index.d.ts
index.js
package.json
text.js
env-paths
index.d.ts
index.js
package.json
readme.md
escalade
dist
index.js
index.d.ts
package.json
readme.md
sync
index.d.ts
index.js
find-up
index.d.ts
index.js
package.json
readme.md
follow-redirects
README.md
http.js
https.js
index.js
package.json
fs-minipass
README.md
index.js
package.json
fs.realpath
README.md
index.js
old.js
package.json
get-caller-file
LICENSE.md
README.md
index.d.ts
index.js
package.json
glob
README.md
changelog.md
common.js
glob.js
package.json
sync.js
has-flag
index.d.ts
index.js
package.json
readme.md
hasurl
README.md
index.js
package.json
inflight
README.md
inflight.js
package.json
inherits
README.md
inherits.js
inherits_browser.js
package.json
is-fullwidth-code-point
index.d.ts
index.js
package.json
readme.md
js-base64
LICENSE.md
README.md
base64.d.ts
base64.js
package.json
locate-path
index.d.ts
index.js
package.json
readme.md
lodash.clonedeep
README.md
index.js
package.json
lodash.sortby
README.md
index.js
package.json
long
README.md
dist
long.js
index.js
package.json
src
long.js
minimatch
README.md
minimatch.js
package.json
minimist
.travis.yml
example
parse.js
index.js
package.json
test
all_bool.js
bool.js
dash.js
default_bool.js
dotted.js
kv_short.js
long.js
num.js
parse.js
parse_modified.js
proto.js
short.js
stop_early.js
unknown.js
whitespace.js
minipass
README.md
index.js
package.json
minizlib
README.md
constants.js
index.js
package.json
mkdirp
bin
cmd.js
usage.txt
index.js
package.json
moo
README.md
moo.js
package.json
ms
index.js
license.md
package.json
readme.md
near-mock-vm
assembly
__tests__
main.ts
context.ts
index.ts
outcome.ts
vm.ts
bin
bin.js
package.json
pkg
near_mock_vm.d.ts
near_mock_vm.js
package.json
vm
dist
cli.d.ts
cli.js
context.d.ts
context.js
index.d.ts
index.js
memory.d.ts
memory.js
runner.d.ts
runner.js
utils.d.ts
utils.js
index.js
near-sdk-as
as-pect.config.js
as_types.d.ts
asconfig.json
asp.asconfig.json
assembly
__tests__
as-pect.d.ts
assert.spec.ts
avl-tree.spec.ts
bignum.spec.ts
contract.spec.ts
contract.ts
data.txt
empty.ts
generic.ts
includeBytes.spec.ts
main.ts
max-heap.spec.ts
model.ts
near.spec.ts
persistent-set.spec.ts
promise.spec.ts
rollback.spec.ts
roundtrip.spec.ts
runtime.spec.ts
unordered-map.spec.ts
util.ts
utils.spec.ts
as_types.d.ts
bindgen.ts
index.ts
json.lib.ts
tsconfig.json
vm
__tests__
vm.include.ts
index.ts
compiler.js
imports.js
package.json
near-sdk-bindgen
README.md
assembly
index.ts
compiler.js
dist
JSONBuilder.d.ts
JSONBuilder.js
classExporter.d.ts
classExporter.js
index.d.ts
index.js
transformer.d.ts
transformer.js
typeChecker.d.ts
typeChecker.js
utils.d.ts
utils.js
index.js
package.json
near-sdk-core
README.md
asconfig.json
assembly
as_types.d.ts
base58.ts
base64.ts
bignum.ts
collections
avlTree.ts
index.ts
maxHeap.ts
persistentDeque.ts
persistentMap.ts
persistentSet.ts
persistentUnorderedMap.ts
persistentVector.ts
util.ts
contract.ts
env
env.ts
index.ts
runtime_api.ts
index.ts
logging.ts
math.ts
promise.ts
storage.ts
tsconfig.json
util.ts
docs
assets
css
main.css
js
main.js
search.json
classes
_sdk_core_assembly_collections_avltree_.avltree.html
_sdk_core_assembly_collections_avltree_.avltreenode.html
_sdk_core_assembly_collections_avltree_.childparentpair.html
_sdk_core_assembly_collections_avltree_.nullable.html
_sdk_core_assembly_collections_persistentdeque_.persistentdeque.html
_sdk_core_assembly_collections_persistentmap_.persistentmap.html
_sdk_core_assembly_collections_persistentset_.persistentset.html
_sdk_core_assembly_collections_persistentunorderedmap_.persistentunorderedmap.html
_sdk_core_assembly_collections_persistentvector_.persistentvector.html
_sdk_core_assembly_contract_.context-1.html
_sdk_core_assembly_contract_.contractpromise.html
_sdk_core_assembly_contract_.contractpromiseresult.html
_sdk_core_assembly_math_.rng.html
_sdk_core_assembly_promise_.contractpromisebatch.html
_sdk_core_assembly_storage_.storage-1.html
globals.html
index.html
modules
_sdk_core_assembly_base58_.base58.html
_sdk_core_assembly_base58_.html
_sdk_core_assembly_base64_.base64.html
_sdk_core_assembly_base64_.html
_sdk_core_assembly_collections_avltree_.html
_sdk_core_assembly_collections_index_.collections.html
_sdk_core_assembly_collections_index_.html
_sdk_core_assembly_collections_persistentdeque_.html
_sdk_core_assembly_collections_persistentmap_.html
_sdk_core_assembly_collections_persistentset_.html
_sdk_core_assembly_collections_persistentunorderedmap_.html
_sdk_core_assembly_collections_persistentvector_.html
_sdk_core_assembly_collections_util_.html
_sdk_core_assembly_contract_.html
_sdk_core_assembly_env_env_.env.html
_sdk_core_assembly_env_env_.html
_sdk_core_assembly_env_index_.html
_sdk_core_assembly_env_runtime_api_.html
_sdk_core_assembly_index_.html
_sdk_core_assembly_logging_.html
_sdk_core_assembly_logging_.logging.html
_sdk_core_assembly_math_.html
_sdk_core_assembly_math_.math.html
_sdk_core_assembly_promise_.html
_sdk_core_assembly_storage_.html
_sdk_core_assembly_util_.html
_sdk_core_assembly_util_.util.html
package.json
near-sdk-simulator
__tests__
avl-tree-contract.spec.ts
cross.spec.ts
empty.spec.ts
exportAs.spec.ts
singleton-no-constructor.spec.ts
singleton.spec.ts
asconfig.js
asconfig.json
assembly
__tests__
avlTreeContract.ts
empty.ts
exportAs.ts
model.ts
sentences.ts
singleton-fail.ts
singleton-no-constructor.ts
singleton.ts
words.ts
as_types.d.ts
tsconfig.json
dist
bin.d.ts
bin.js
context.d.ts
context.js
index.d.ts
index.js
runtime.d.ts
runtime.js
types.d.ts
types.js
utils.d.ts
utils.js
jest.config.js
out
assembly
__tests__
exportAs.ts
model.ts
sentences.ts
singleton-no-constructor.ts
singleton.ts
package.json
src
context.ts
index.ts
runtime.ts
types.ts
utils.ts
tsconfig.json
near-vm
getBinary.js
install.js
package.json
run.js
uninstall.js
nearley
LICENSE.txt
README.md
bin
nearley-railroad.js
nearley-test.js
nearley-unparse.js
nearleyc.js
lib
compile.js
generate.js
lint.js
nearley-language-bootstrapped.js
nearley.js
stream.js
unparse.js
package.json
once
README.md
once.js
package.json
p-limit
index.d.ts
index.js
package.json
readme.md
p-locate
index.d.ts
index.js
package.json
readme.md
p-try
index.d.ts
index.js
package.json
readme.md
path-exists
index.d.ts
index.js
package.json
readme.md
path-is-absolute
index.js
package.json
readme.md
punycode
LICENSE-MIT.txt
README.md
package.json
punycode.es6.js
punycode.js
railroad-diagrams
README.md
example.html
generator.html
package.json
railroad-diagrams.css
railroad-diagrams.js
railroad_diagrams.py
randexp
README.md
lib
randexp.js
package.json
require-directory
.travis.yml
index.js
package.json
require-main-filename
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
ret
README.md
lib
index.js
positions.js
sets.js
types.js
util.js
package.json
rimraf
CHANGELOG.md
README.md
bin.js
package.json
rimraf.js
safe-buffer
README.md
index.d.ts
index.js
package.json
set-blocking
CHANGELOG.md
LICENSE.txt
README.md
index.js
package.json
string-width
index.d.ts
index.js
package.json
readme.md
strip-ansi
index.d.ts
index.js
package.json
readme.md
supports-color
browser.js
index.js
package.json
readme.md
tar
README.md
index.js
lib
create.js
extract.js
get-write-flag.js
header.js
high-level-opt.js
large-numbers.js
list.js
mkdir.js
mode-fix.js
pack.js
parse.js
path-reservations.js
pax.js
read-entry.js
replace.js
types.js
unpack.js
update.js
warn-mixin.js
winchars.js
write-entry.js
package.json
tr46
LICENSE.md
README.md
index.js
lib
mappingTable.json
regexes.js
package.json
ts-mixer
CHANGELOG.md
README.md
dist
decorator.d.ts
decorator.js
index.d.ts
index.js
mixin-tracking.d.ts
mixin-tracking.js
mixins.d.ts
mixins.js
proxy.d.ts
proxy.js
settings.d.ts
settings.js
types.d.ts
types.js
util.d.ts
util.js
package.json
universal-url
README.md
browser.js
index.js
package.json
visitor-as
.github
workflows
test.yml
README.md
as
index.d.ts
index.js
asconfig.json
dist
astBuilder.d.ts
astBuilder.js
base.d.ts
base.js
baseTransform.d.ts
baseTransform.js
decorator.d.ts
decorator.js
examples
capitalize.d.ts
capitalize.js
exportAs.d.ts
exportAs.js
functionCallTransform.d.ts
functionCallTransform.js
includeBytesTransform.d.ts
includeBytesTransform.js
list.d.ts
list.js
index.d.ts
index.js
path.d.ts
path.js
simpleParser.d.ts
simpleParser.js
transformer.d.ts
transformer.js
utils.d.ts
utils.js
visitor.d.ts
visitor.js
package.json
tsconfig.json
webidl-conversions
LICENSE.md
README.md
lib
index.js
package.json
whatwg-url
LICENSE.txt
README.md
lib
URL-impl.js
URL.js
URLSearchParams-impl.js
URLSearchParams.js
infra.js
public-api.js
url-state-machine.js
urlencoded.js
utils.js
package.json
which-module
CHANGELOG.md
README.md
index.js
package.json
wrap-ansi
index.js
package.json
readme.md
wrappy
README.md
package.json
wrappy.js
y18n
CHANGELOG.md
README.md
build
lib
cjs.js
index.js
platform-shims
node.js
package.json
yallist
README.md
iterator.js
package.json
yallist.js
yargs-parser
CHANGELOG.md
LICENSE.txt
README.md
browser.js
build
lib
index.js
string-utils.js
tokenize-arg-string.js
yargs-parser-types.js
yargs-parser.js
package.json
yargs
CHANGELOG.md
README.md
build
lib
argsert.js
command.js
completion-templates.js
completion.js
middleware.js
parse-command.js
typings
common-types.js
yargs-parser-types.js
usage.js
utils
apply-extends.js
is-promise.js
levenshtein.js
obj-filter.js
process-argv.js
set-blocking.js
which-module.js
validation.js
yargs-factory.js
yerror.js
helpers
index.js
package.json
locales
be.json
de.json
en.json
es.json
fi.json
fr.json
hi.json
hu.json
id.json
it.json
ja.json
ko.json
nb.json
nl.json
nn.json
pirate.json
pl.json
pt.json
pt_BR.json
ru.json
th.json
tr.json
zh_CN.json
zh_TW.json
package.json
package.json
scripts
1.dev-deploy.sh
2.use-contract.sh
3.cleanup.sh
README.md
src
as_types.d.ts
simple
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
singleton
__tests__
as-pect.d.ts
index.unit.spec.ts
asconfig.json
assembly
index.ts
tsconfig.json
utils.ts
|
| # yargs-parser

[](https://www.npmjs.com/package/yargs-parser)
[](https://conventionalcommits.org)

The mighty option parser used by [yargs](https://github.com/yargs/yargs).
visit the [yargs website](http://yargs.js.org/) for more examples, and thorough usage instructions.
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs-parser/master/yargs-logo.png">
## Example
```sh
npm i yargs-parser --save
```
```js
const argv = require('yargs-parser')(process.argv.slice(2))
console.log(argv)
```
```console
$ node example.js --foo=33 --bar hello
{ _: [], foo: 33, bar: 'hello' }
```
_or parse a string!_
```js
const argv = require('yargs-parser')('--foo=99 --bar=33')
console.log(argv)
```
```console
{ _: [], foo: 99, bar: 33 }
```
Convert an array of mixed types before passing to `yargs-parser`:
```js
const parse = require('yargs-parser')
parse(['-f', 11, '--zoom', 55].join(' ')) // <-- array to string
parse(['-f', 11, '--zoom', 55].map(String)) // <-- array of strings
```
## Deno Example
As of `v19` `yargs-parser` supports [Deno](https://github.com/denoland/deno):
```typescript
import parser from "https://deno.land/x/yargs_parser/deno.ts";
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
```
## ESM Example
As of `v19` `yargs-parser` supports ESM (_both in Node.js and in the browser_):
**Node.js:**
```js
import parser from 'yargs-parser'
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
```
**Browsers:**
```html
<!doctype html>
<body>
<script type="module">
import parser from "https://unpkg.com/[email protected]/browser.js";
const argv = parser('--foo=99 --bar=9987930', {
string: ['bar']
})
console.log(argv)
</script>
</body>
```
## API
### parser(args, opts={})
Parses command line arguments returning a simple mapping of keys and values.
**expects:**
* `args`: a string or array of strings representing the options to parse.
* `opts`: provide a set of hints indicating how `args` should be parsed:
* `opts.alias`: an object representing the set of aliases for a key: `{alias: {foo: ['f']}}`.
* `opts.array`: indicate that keys should be parsed as an array: `{array: ['foo', 'bar']}`.<br>
Indicate that keys should be parsed as an array and coerced to booleans / numbers:<br>
`{array: [{ key: 'foo', boolean: true }, {key: 'bar', number: true}]}`.
* `opts.boolean`: arguments should be parsed as booleans: `{boolean: ['x', 'y']}`.
* `opts.coerce`: provide a custom synchronous function that returns a coerced value from the argument provided
(or throws an error). For arrays the function is called only once for the entire array:<br>
`{coerce: {foo: function (arg) {return modifiedArg}}}`.
* `opts.config`: indicate a key that represents a path to a configuration file (this file will be loaded and parsed).
* `opts.configObjects`: configuration objects to parse, their properties will be set as arguments:<br>
`{configObjects: [{'x': 5, 'y': 33}, {'z': 44}]}`.
* `opts.configuration`: provide configuration options to the yargs-parser (see: [configuration](#configuration)).
* `opts.count`: indicate a key that should be used as a counter, e.g., `-vvv` = `{v: 3}`.
* `opts.default`: provide default values for keys: `{default: {x: 33, y: 'hello world!'}}`.
* `opts.envPrefix`: environment variables (`process.env`) with the prefix provided should be parsed.
* `opts.narg`: specify that a key requires `n` arguments: `{narg: {x: 2}}`.
* `opts.normalize`: `path.normalize()` will be applied to values set to this key.
* `opts.number`: keys should be treated as numbers.
* `opts.string`: keys should be treated as strings (even if they resemble a number `-x 33`).
**returns:**
* `obj`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
### require('yargs-parser').detailed(args, opts={})
Parses a command line string, returning detailed information required by the
yargs engine.
**expects:**
* `args`: a string or array of strings representing options to parse.
* `opts`: provide a set of hints indicating how `args`, inputs are identical to `require('yargs-parser')(args, opts={})`.
**returns:**
* `argv`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
* `error`: populated with an error object if an exception occurred during parsing.
* `aliases`: the inferred list of aliases built by combining lists in `opts.alias`.
* `newAliases`: any new aliases added via camel-case expansion:
* `boolean`: `{ fooBar: true }`
* `defaulted`: any new argument created by `opts.default`, no aliases included.
* `boolean`: `{ foo: true }`
* `configuration`: given by default settings and `opts.configuration`.
<a name="configuration"></a>
### Configuration
The yargs-parser applies several automated transformations on the keys provided
in `args`. These features can be turned on and off using the `configuration` field
of `opts`.
```js
var parsed = parser(['--no-dice'], {
configuration: {
'boolean-negation': false
}
})
```
### short option groups
* default: `true`.
* key: `short-option-groups`.
Should a group of short-options be treated as boolean flags?
```console
$ node example.js -abc
{ _: [], a: true, b: true, c: true }
```
_if disabled:_
```console
$ node example.js -abc
{ _: [], abc: true }
```
### camel-case expansion
* default: `true`.
* key: `camel-case-expansion`.
Should hyphenated arguments be expanded into camel-case aliases?
```console
$ node example.js --foo-bar
{ _: [], 'foo-bar': true, fooBar: true }
```
_if disabled:_
```console
$ node example.js --foo-bar
{ _: [], 'foo-bar': true }
```
### dot-notation
* default: `true`
* key: `dot-notation`
Should keys that contain `.` be treated as objects?
```console
$ node example.js --foo.bar
{ _: [], foo: { bar: true } }
```
_if disabled:_
```console
$ node example.js --foo.bar
{ _: [], "foo.bar": true }
```
### parse numbers
* default: `true`
* key: `parse-numbers`
Should keys that look like numbers be treated as such?
```console
$ node example.js --foo=99.3
{ _: [], foo: 99.3 }
```
_if disabled:_
```console
$ node example.js --foo=99.3
{ _: [], foo: "99.3" }
```
### parse positional numbers
* default: `true`
* key: `parse-positional-numbers`
Should positional keys that look like numbers be treated as such.
```console
$ node example.js 99.3
{ _: [99.3] }
```
_if disabled:_
```console
$ node example.js 99.3
{ _: ['99.3'] }
```
### boolean negation
* default: `true`
* key: `boolean-negation`
Should variables prefixed with `--no` be treated as negations?
```console
$ node example.js --no-foo
{ _: [], foo: false }
```
_if disabled:_
```console
$ node example.js --no-foo
{ _: [], "no-foo": true }
```
### combine arrays
* default: `false`
* key: `combine-arrays`
Should arrays be combined when provided by both command line arguments and
a configuration file.
### duplicate arguments array
* default: `true`
* key: `duplicate-arguments-array`
Should arguments be coerced into an array when duplicated:
```console
$ node example.js -x 1 -x 2
{ _: [], x: [1, 2] }
```
_if disabled:_
```console
$ node example.js -x 1 -x 2
{ _: [], x: 2 }
```
### flatten duplicate arrays
* default: `true`
* key: `flatten-duplicate-arrays`
Should array arguments be coerced into a single array when duplicated:
```console
$ node example.js -x 1 2 -x 3 4
{ _: [], x: [1, 2, 3, 4] }
```
_if disabled:_
```console
$ node example.js -x 1 2 -x 3 4
{ _: [], x: [[1, 2], [3, 4]] }
```
### greedy arrays
* default: `true`
* key: `greedy-arrays`
Should arrays consume more than one positional argument following their flag.
```console
$ node example --arr 1 2
{ _[], arr: [1, 2] }
```
_if disabled:_
```console
$ node example --arr 1 2
{ _[2], arr: [1] }
```
**Note: in `v18.0.0` we are considering defaulting greedy arrays to `false`.**
### nargs eats options
* default: `false`
* key: `nargs-eats-options`
Should nargs consume dash options as well as positional arguments.
### negation prefix
* default: `no-`
* key: `negation-prefix`
The prefix to use for negated boolean variables.
```console
$ node example.js --no-foo
{ _: [], foo: false }
```
_if set to `quux`:_
```console
$ node example.js --quuxfoo
{ _: [], foo: false }
```
### populate --
* default: `false`.
* key: `populate--`
Should unparsed flags be stored in `--` or `_`.
_If disabled:_
```console
$ node example.js a -b -- x y
{ _: [ 'a', 'x', 'y' ], b: true }
```
_If enabled:_
```console
$ node example.js a -b -- x y
{ _: [ 'a' ], '--': [ 'x', 'y' ], b: true }
```
### set placeholder key
* default: `false`.
* key: `set-placeholder-key`.
Should a placeholder be added for keys not set via the corresponding CLI argument?
_If disabled:_
```console
$ node example.js -a 1 -c 2
{ _: [], a: 1, c: 2 }
```
_If enabled:_
```console
$ node example.js -a 1 -c 2
{ _: [], a: 1, b: undefined, c: 2 }
```
### halt at non-option
* default: `false`.
* key: `halt-at-non-option`.
Should parsing stop at the first positional argument? This is similar to how e.g. `ssh` parses its command line.
_If disabled:_
```console
$ node example.js -a run b -x y
{ _: [ 'b' ], a: 'run', x: 'y' }
```
_If enabled:_
```console
$ node example.js -a run b -x y
{ _: [ 'b', '-x', 'y' ], a: 'run' }
```
### strip aliased
* default: `false`
* key: `strip-aliased`
Should aliases be removed before returning results?
_If disabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1, 'test-alias': 1, testAlias: 1 }
```
_If enabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
### strip dashed
* default: `false`
* key: `strip-dashed`
Should dashed keys be removed before returning results? This option has no effect if
`camel-case-expansion` is disabled.
_If disabled:_
```console
$ node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
_If enabled:_
```console
$ node example.js --test-field 1
{ _: [], testField: 1 }
```
### unknown options as args
* default: `false`
* key: `unknown-options-as-args`
Should unknown options be treated like regular arguments? An unknown option is one that is not
configured in `opts`.
_If disabled_
```console
$ node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: [], unknownOption: true, knownOption: 2, stringOption: '', unknownOption2: true }
```
_If enabled_
```console
$ node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: ['--unknown-option'], knownOption: 2, stringOption: '--unknown-option2' }
```
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
## Special Thanks
The yargs project evolves from optimist and minimist. It owes its
existence to a lot of James Halliday's hard work. Thanks [substack](https://github.com/substack) **beep** **boop** \o/
## License
ISC
# ts-mixer
[version-badge]: https://badgen.net/npm/v/ts-mixer
[version-link]: https://npmjs.com/package/ts-mixer
[build-badge]: https://img.shields.io/github/workflow/status/tannerntannern/ts-mixer/ts-mixer%20CI
[build-link]: https://github.com/tannerntannern/ts-mixer/actions
[ts-versions]: https://badgen.net/badge/icon/3.8,3.9,4.0?icon=typescript&label&list=|
[node-versions]: https://badgen.net/badge/node/10%2C12%2C14/blue/?list=|
[![npm version][version-badge]][version-link]
[![github actions][build-badge]][build-link]
[![TS Versions][ts-versions]][build-link]
[![Node.js Versions][node-versions]][build-link]
[](https://bundlephobia.com/result?p=ts-mixer)
[](https://conventionalcommits.org)
## Overview
`ts-mixer` brings mixins to TypeScript. "Mixins" to `ts-mixer` are just classes, so you already know how to write them, and you can probably mix classes from your favorite library without trouble.
The mixin problem is more nuanced than it appears. I've seen countless code snippets that work for certain situations, but fail in others. `ts-mixer` tries to take the best from all these solutions while accounting for the situations you might not have considered.
[Quick start guide](#quick-start)
### Features
* mixes plain classes
* mixes classes that extend other classes
* mixes classes that were mixed with `ts-mixer`
* supports static properties
* supports protected/private properties (the popular function-that-returns-a-class solution does not)
* mixes abstract classes (with caveats [[1](#caveats)])
* mixes generic classes (with caveats [[2](#caveats)])
* supports class, method, and property decorators (with caveats [[3, 6](#caveats)])
* mostly supports the complexity presented by constructor functions (with caveats [[4](#caveats)])
* comes with an `instanceof`-like replacement (with caveats [[5, 6](#caveats)])
* [multiple mixing strategies](#settings) (ES6 proxies vs hard copy)
### Caveats
1. Mixing abstract classes requires a bit of a hack that may break in future versions of TypeScript. See [mixing abstract classes](#mixing-abstract-classes) below.
2. Mixing generic classes requires a more cumbersome notation, but it's still possible. See [mixing generic classes](#mixing-generic-classes) below.
3. Using decorators in mixed classes also requires a more cumbersome notation. See [mixing with decorators](#mixing-with-decorators) below.
4. ES6 made it impossible to use `.apply(...)` on class constructors (or any means of calling them without `new`), which makes it impossible for `ts-mixer` to pass the proper `this` to your constructors. This may or may not be an issue for your code, but there are options to work around it. See [dealing with constructors](#dealing-with-constructors) below.
5. `ts-mixer` does not support `instanceof` for mixins, but it does offer a replacement. See the [hasMixin function](#hasmixin) for more details.
6. Certain features (specifically, `@decorator` and `hasMixin`) make use of ES6 `Map`s, which means you must either use ES6+ or polyfill `Map` to use them. If you don't need these features, you should be fine without.
## Quick Start
### Installation
```
$ npm install ts-mixer
```
or if you prefer [Yarn](https://yarnpkg.com):
```
$ yarn add ts-mixer
```
### Basic Example
```typescript
import { Mixin } from 'ts-mixer';
class Foo {
protected makeFoo() {
return 'foo';
}
}
class Bar {
protected makeBar() {
return 'bar';
}
}
class FooBar extends Mixin(Foo, Bar) {
public makeFooBar() {
return this.makeFoo() + this.makeBar();
}
}
const fooBar = new FooBar();
console.log(fooBar.makeFooBar()); // "foobar"
```
## Special Cases
### Mixing Abstract Classes
Abstract classes, by definition, cannot be constructed, which means they cannot take on the type, `new(...args) => any`, and by extension, are incompatible with `ts-mixer`. BUT, you can "trick" TypeScript into giving you all the benefits of an abstract class without making it technically abstract. The trick is just some strategic `// @ts-ignore`'s:
```typescript
import { Mixin } from 'ts-mixer';
// note that Foo is not marked as an abstract class
class Foo {
// @ts-ignore: "Abstract methods can only appear within an abstract class"
public abstract makeFoo(): string;
}
class Bar {
public makeBar() {
return 'bar';
}
}
class FooBar extends Mixin(Foo, Bar) {
// we still get all the benefits of abstract classes here, because TypeScript
// will still complain if this method isn't implemented
public makeFoo() {
return 'foo';
}
}
```
Do note that while this does work quite well, it is a bit of a hack and I can't promise that it will continue to work in future TypeScript versions.
### Mixing Generic Classes
Frustratingly, it is _impossible_ for generic parameters to be referenced in base class expressions. No matter what, you will eventually run into `Base class expressions cannot reference class type parameters.`
The way to get around this is to leverage [declaration merging](https://www.typescriptlang.org/docs/handbook/declaration-merging.html), and a slightly different mixing function from ts-mixer: `mix`. It works exactly like `Mixin`, except it's a decorator, which means it doesn't affect the type information of the class being decorated. See it in action below:
```typescript
import { mix } from 'ts-mixer';
class Foo<T> {
public fooMethod(input: T): T {
return input;
}
}
class Bar<T> {
public barMethod(input: T): T {
return input;
}
}
interface FooBar<T1, T2> extends Foo<T1>, Bar<T2> { }
@mix(Foo, Bar)
class FooBar<T1, T2> {
public fooBarMethod(input1: T1, input2: T2) {
return [this.fooMethod(input1), this.barMethod(input2)];
}
}
```
Key takeaways from this example:
* `interface FooBar<T1, T2> extends Foo<T1>, Bar<T2> { }` makes sure `FooBar` has the typing we want, thanks to declaration merging
* `@mix(Foo, Bar)` wires things up "on the JavaScript side", since the interface declaration has nothing to do with runtime behavior.
* The reason we have to use the `mix` decorator is that the typing produced by `Mixin(Foo, Bar)` would conflict with the typing of the interface. `mix` has no effect "on the TypeScript side," thus avoiding type conflicts.
### Mixing with Decorators
Popular libraries such as [class-validator](https://github.com/typestack/class-validator) and [TypeORM](https://github.com/typeorm/typeorm) use decorators to add functionality. Unfortunately, `ts-mixer` has no way of knowing what these libraries do with the decorators behind the scenes. So if you want these decorators to be "inherited" with classes you plan to mix, you first have to wrap them with a special `decorate` function exported by `ts-mixer`. Here's an example using `class-validator`:
```typescript
import { IsBoolean, IsIn, validate } from 'class-validator';
import { Mixin, decorate } from 'ts-mixer';
class Disposable {
@decorate(IsBoolean()) // instead of @IsBoolean()
isDisposed: boolean = false;
}
class Statusable {
@decorate(IsIn(['red', 'green'])) // instead of @IsIn(['red', 'green'])
status: string = 'green';
}
class ExtendedObject extends Mixin(Disposable, Statusable) {}
const extendedObject = new ExtendedObject();
extendedObject.status = 'blue';
validate(extendedObject).then(errors => {
console.log(errors);
});
```
### Dealing with Constructors
As mentioned in the [caveats section](#caveats), ES6 disallowed calling constructor functions without `new`. This means that the only way for `ts-mixer` to mix instance properties is to instantiate each base class separately, then copy the instance properties into a common object. The consequence of this is that constructors mixed by `ts-mixer` will _not_ receive the proper `this`.
**This very well may not be an issue for you!** It only means that your constructors need to be "mostly pure" in terms of how they handle `this`. Specifically, your constructors cannot produce [side effects](https://en.wikipedia.org/wiki/Side_effect_%28computer_science%29) involving `this`, _other than adding properties to `this`_ (the most common side effect in JavaScript constructors).
If you simply cannot eliminate `this` side effects from your constructor, there is a workaround available: `ts-mixer` will automatically forward constructor parameters to a predesignated init function (`settings.initFunction`) if it's present on the class. Unlike constructors, functions can be called with an arbitrary `this`, so this predesignated init function _will_ have the proper `this`. Here's a basic example:
```typescript
import { Mixin, settings } from 'ts-mixer';
settings.initFunction = 'init';
class Person {
public static allPeople: Set<Person> = new Set();
protected init() {
Person.allPeople.add(this);
}
}
type PartyAffiliation = 'democrat' | 'republican';
class PoliticalParticipant {
public static democrats: Set<PoliticalParticipant> = new Set();
public static republicans: Set<PoliticalParticipant> = new Set();
public party: PartyAffiliation;
// note that these same args will also be passed to init function
public constructor(party: PartyAffiliation) {
this.party = party;
}
protected init(party: PartyAffiliation) {
if (party === 'democrat')
PoliticalParticipant.democrats.add(this);
else
PoliticalParticipant.republicans.add(this);
}
}
class Voter extends Mixin(Person, PoliticalParticipant) {}
const v1 = new Voter('democrat');
const v2 = new Voter('democrat');
const v3 = new Voter('republican');
const v4 = new Voter('republican');
```
Note the above `.add(this)` statements. These would not work as expected if they were placed in the constructor instead, since `this` is not the same between the constructor and `init`, as explained above.
## Other Features
### hasMixin
As mentioned above, `ts-mixer` does not support `instanceof` for mixins. While it is possible to implement [custom `instanceof` behavior](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/hasInstance), this library does not do so because it would require modifying the source classes, which is deliberately avoided.
You can fill this missing functionality with `hasMixin(instance, mixinClass)` instead. See the below example:
```typescript
import { Mixin, hasMixin } from 'ts-mixer';
class Foo {}
class Bar {}
class FooBar extends Mixin(Foo, Bar) {}
const instance = new FooBar();
// doesn't work with instanceof...
console.log(instance instanceof FooBar) // true
console.log(instance instanceof Foo) // false
console.log(instance instanceof Bar) // false
// but everything works nicely with hasMixin!
console.log(hasMixin(instance, FooBar)) // true
console.log(hasMixin(instance, Foo)) // true
console.log(hasMixin(instance, Bar)) // true
```
`hasMixin(instance, mixinClass)` will work anywhere that `instance instanceof mixinClass` works. Additionally, like `instanceof`, you get the same [type narrowing benefits](https://www.typescriptlang.org/docs/handbook/advanced-types.html#instanceof-type-guards):
```typescript
if (hasMixin(instance, Foo)) {
// inferred type of instance is "Foo"
}
if (hasMixin(instance, Bar)) {
// inferred type of instance of "Bar"
}
```
## Settings
ts-mixer has multiple strategies for mixing classes which can be configured by modifying `settings` from ts-mixer. For example:
```typescript
import { settings, Mixin } from 'ts-mixer';
settings.prototypeStrategy = 'proxy';
// then use `Mixin` as normal...
```
### `settings.prototypeStrategy`
* Determines how ts-mixer will mix class prototypes together
* Possible values:
- `'copy'` (default) - Copies all methods from the classes being mixed into a new prototype object. (This will include all methods up the prototype chains as well.) This is the default for ES5 compatibility, but it has the downside of stale references. For example, if you mix `Foo` and `Bar` to make `FooBar`, then redefine a method on `Foo`, `FooBar` will not have the latest methods from `Foo`. If this is not a concern for you, `'copy'` is the best value for this setting.
- `'proxy'` - Uses an ES6 Proxy to "soft mix" prototypes. Unlike `'copy'`, updates to the base classes _will_ be reflected in the mixed class, which may be desirable. The downside is that method access is not as performant, nor is it ES5 compatible.
### `settings.staticsStrategy`
* Determines how static properties are inherited
* Possible values:
- `'copy'` (default) - Simply copies all properties (minus `prototype`) from the base classes/constructor functions onto the mixed class. Like `settings.prototypeStrategy = 'copy'`, this strategy also suffers from stale references, but shouldn't be a concern if you don't redefine static methods after mixing.
- `'proxy'` - Similar to `settings.prototypeStrategy`, proxy's static method access to base classes. Has the same benefits/downsides.
### `settings.initFunction`
* If set, `ts-mixer` will automatically call the function with this name upon construction
* Possible values:
- `null` (default) - disables the behavior
- a string - function name to call upon construction
* Read more about why you would want this in [dealing with constructors](#dealing-with-constructors)
### `settings.decoratorInheritance`
* Determines how decorators are inherited from classes passed to `Mixin(...)`
* Possible values:
- `'deep'` (default) - Deeply inherits decorators from all given classes and their ancestors
- `'direct'` - Only inherits decorators defined directly on the given classes
- `'none'` - Skips decorator inheritance
# Author
Tanner Nielsen <[email protected]>
* Website - [tannernielsen.com](http://tannernielsen.com)
* Github - [tannerntannern](https://github.com/tannerntannern)
<p align="center">
<img width="250" src="/yargs-logo.png">
</p>
<h1 align="center"> Yargs </h1>
<p align="center">
<b >Yargs be a node.js library fer hearties tryin' ter parse optstrings</b>
</p>
<br>
[![Build Status][travis-image]][travis-url]
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[![Coverage][coverage-image]][coverage-url]
[![Conventional Commits][conventional-commits-image]][conventional-commits-url]
[![Slack][slack-image]][slack-url]
## Description :
Yargs helps you build interactive command line tools, by parsing arguments and generating an elegant user interface.
It gives you:
* commands and (grouped) options (`my-program.js serve --port=5000`).
* a dynamically generated help menu based on your arguments.
> <img width="400" src="/screen.png">
* bash-completion shortcuts for commands and options.
* and [tons more](/docs/api.md).
## Installation
Stable version:
```bash
npm i yargs
```
Bleeding edge version with the most recent features:
```bash
npm i yargs@next
```
## Usage :
### Simple Example
```javascript
#!/usr/bin/env node
const {argv} = require('yargs')
if (argv.ships > 3 && argv.distance < 53.5) {
console.log('Plunder more riffiwobbles!')
} else {
console.log('Retreat from the xupptumblers!')
}
```
```bash
$ ./plunder.js --ships=4 --distance=22
Plunder more riffiwobbles!
$ ./plunder.js --ships 12 --distance 98.7
Retreat from the xupptumblers!
```
### Complex Example
```javascript
#!/usr/bin/env node
require('yargs') // eslint-disable-line
.command('serve [port]', 'start the server', (yargs) => {
yargs
.positional('port', {
describe: 'port to bind on',
default: 5000
})
}, (argv) => {
if (argv.verbose) console.info(`start server on :${argv.port}`)
serve(argv.port)
})
.option('verbose', {
alias: 'v',
type: 'boolean',
description: 'Run with verbose logging'
})
.argv
```
Run the example above with `--help` to see the help for the application.
## TypeScript
yargs has type definitions at [@types/yargs][type-definitions].
```
npm i @types/yargs --save-dev
```
See usage examples in [docs](/docs/typescript.md).
## Webpack
See usage examples of yargs with webpack in [docs](/docs/webpack.md).
## Community :
Having problems? want to contribute? join our [community slack](http://devtoolscommunity.herokuapp.com).
## Documentation :
### Table of Contents
* [Yargs' API](/docs/api.md)
* [Examples](/docs/examples.md)
* [Parsing Tricks](/docs/tricks.md)
* [Stop the Parser](/docs/tricks.md#stop)
* [Negating Boolean Arguments](/docs/tricks.md#negate)
* [Numbers](/docs/tricks.md#numbers)
* [Arrays](/docs/tricks.md#arrays)
* [Objects](/docs/tricks.md#objects)
* [Quotes](/docs/tricks.md#quotes)
* [Advanced Topics](/docs/advanced.md)
* [Composing Your App Using Commands](/docs/advanced.md#commands)
* [Building Configurable CLI Apps](/docs/advanced.md#configuration)
* [Customizing Yargs' Parser](/docs/advanced.md#customizing)
* [Contributing](/contributing.md)
[travis-url]: https://travis-ci.org/yargs/yargs
[travis-image]: https://img.shields.io/travis/yargs/yargs/master.svg
[npm-url]: https://www.npmjs.com/package/yargs
[npm-image]: https://img.shields.io/npm/v/yargs.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: http://standardjs.com/
[conventional-commits-image]: https://img.shields.io/badge/Conventional%20Commits-1.0.0-yellow.svg
[conventional-commits-url]: https://conventionalcommits.org/
[slack-image]: http://devtoolscommunity.herokuapp.com/badge.svg
[slack-url]: http://devtoolscommunity.herokuapp.com
[type-definitions]: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/yargs
[coverage-image]: https://img.shields.io/nycrc/yargs/yargs
[coverage-url]: https://github.com/yargs/yargs/blob/master/.nycrc
# tr46.js
> An implementation of the [Unicode TR46 specification](http://unicode.org/reports/tr46/).
## Installation
[Node.js](http://nodejs.org) `>= 6` is required. To install, type this at the command line:
```shell
npm install tr46
```
## API
### `toASCII(domainName[, options])`
Converts a string of Unicode symbols to a case-folded Punycode string of ASCII symbols.
Available options:
* [`checkBidi`](#checkBidi)
* [`checkHyphens`](#checkHyphens)
* [`checkJoiners`](#checkJoiners)
* [`processingOption`](#processingOption)
* [`useSTD3ASCIIRules`](#useSTD3ASCIIRules)
* [`verifyDNSLength`](#verifyDNSLength)
### `toUnicode(domainName[, options])`
Converts a case-folded Punycode string of ASCII symbols to a string of Unicode symbols.
Available options:
* [`checkBidi`](#checkBidi)
* [`checkHyphens`](#checkHyphens)
* [`checkJoiners`](#checkJoiners)
* [`useSTD3ASCIIRules`](#useSTD3ASCIIRules)
## Options
### `checkBidi`
Type: `Boolean`
Default value: `false`
When set to `true`, any bi-directional text within the input will be checked for validation.
### `checkHyphens`
Type: `Boolean`
Default value: `false`
When set to `true`, the positions of any hyphen characters within the input will be checked for validation.
### `checkJoiners`
Type: `Boolean`
Default value: `false`
When set to `true`, any word joiner characters within the input will be checked for validation.
### `processingOption`
Type: `String`
Default value: `"nontransitional"`
When set to `"transitional"`, symbols within the input will be validated according to the older IDNA2003 protocol. When set to `"nontransitional"`, the current IDNA2008 protocol will be used.
### `useSTD3ASCIIRules`
Type: `Boolean`
Default value: `false`
When set to `true`, input will be validated according to [STD3 Rules](http://unicode.org/reports/tr46/#STD3_Rules).
### `verifyDNSLength`
Type: `Boolean`
Default value: `false`
When set to `true`, the length of each DNS label within the input will be checked for validation.
# brace-expansion
[Brace expansion](https://www.gnu.org/software/bash/manual/html_node/Brace-Expansion.html),
as known from sh/bash, in JavaScript.
[](http://travis-ci.org/juliangruber/brace-expansion)
[](https://www.npmjs.org/package/brace-expansion)
[](https://greenkeeper.io/)
[](https://ci.testling.com/juliangruber/brace-expansion)
## Example
```js
var expand = require('brace-expansion');
expand('file-{a,b,c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('-v{,,}')
// => ['-v', '-v', '-v']
expand('file{0..2}.jpg')
// => ['file0.jpg', 'file1.jpg', 'file2.jpg']
expand('file-{a..c}.jpg')
// => ['file-a.jpg', 'file-b.jpg', 'file-c.jpg']
expand('file{2..0}.jpg')
// => ['file2.jpg', 'file1.jpg', 'file0.jpg']
expand('file{0..4..2}.jpg')
// => ['file0.jpg', 'file2.jpg', 'file4.jpg']
expand('file-{a..e..2}.jpg')
// => ['file-a.jpg', 'file-c.jpg', 'file-e.jpg']
expand('file{00..10..5}.jpg')
// => ['file00.jpg', 'file05.jpg', 'file10.jpg']
expand('{{A..C},{a..c}}')
// => ['A', 'B', 'C', 'a', 'b', 'c']
expand('ppp{,config,oe{,conf}}')
// => ['ppp', 'pppconfig', 'pppoe', 'pppoeconf']
```
## API
```js
var expand = require('brace-expansion');
```
### var expanded = expand(str)
Return an array of all possible and valid expansions of `str`. If none are
found, `[str]` is returned.
Valid expansions are:
```js
/^(.*,)+(.+)?$/
// {a,b,...}
```
A comma separated list of options, like `{a,b}` or `{a,{b,c}}` or `{,a,}`.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
A numeric sequence from `x` to `y` inclusive, with optional increment.
If `x` or `y` start with a leading `0`, all the numbers will be padded
to have equal length. Negative numbers and backwards iteration work too.
```js
/^-?\d+\.\.-?\d+(\.\.-?\d+)?$/
// {x..y[..incr]}
```
An alphabetic sequence from `x` to `y` inclusive, with optional increment.
`x` and `y` must be exactly one character, and if given, `incr` must be a
number.
For compatibility reasons, the string `${` is not eligible for brace expansion.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install brace-expansion
```
## Contributors
- [Julian Gruber](https://github.com/juliangruber)
- [Isaac Z. Schlueter](https://github.com/isaacs)
## Sponsors
This module is proudly supported by my [Sponsors](https://github.com/juliangruber/sponsors)!
Do you want to support modules like this to improve their quality, stability and weigh in on new features? Then please consider donating to my [Patreon](https://www.patreon.com/juliangruber). Not sure how much of my modules you're using? Try [feross/thanks](https://github.com/feross/thanks)!
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
The AssemblyScript Runtime
==========================
The runtime provides the functionality necessary to dynamically allocate and deallocate memory of objects, arrays and buffers, as well as collect garbage that is no longer used. The current implementation is either a Two-Color Mark & Sweep (TCMS) garbage collector that must be called manually when the execution stack is unwound or an Incremental Tri-Color Mark & Sweep (ITCMS) garbage collector that is fully automated with a shadow stack, implemented on top of a Two-Level Segregate Fit (TLSF) memory manager. It's not designed to be the fastest of its kind, but intentionally focuses on simplicity and ease of integration until we can replace it with the real deal, i.e. Wasm GC.
Interface
---------
### Garbage collector / `--exportRuntime`
* **__new**(size: `usize`, id: `u32` = 0): `usize`<br />
Dynamically allocates a GC object of at least the specified size and returns its address.
Alignment is guaranteed to be 16 bytes to fit up to v128 values naturally.
GC-allocated objects cannot be used with `__realloc` and `__free`.
* **__pin**(ptr: `usize`): `usize`<br />
Pins the object pointed to by `ptr` externally so it and its directly reachable members and indirectly reachable objects do not become garbage collected.
* **__unpin**(ptr: `usize`): `void`<br />
Unpins the object pointed to by `ptr` externally so it can become garbage collected.
* **__collect**(): `void`<br />
Performs a full garbage collection.
### Internals
* **__alloc**(size: `usize`): `usize`<br />
Dynamically allocates a chunk of memory of at least the specified size and returns its address.
Alignment is guaranteed to be 16 bytes to fit up to v128 values naturally.
* **__realloc**(ptr: `usize`, size: `usize`): `usize`<br />
Dynamically changes the size of a chunk of memory, possibly moving it to a new address.
* **__free**(ptr: `usize`): `void`<br />
Frees a dynamically allocated chunk of memory by its address.
* **__renew**(ptr: `usize`, size: `usize`): `usize`<br />
Like `__realloc`, but for `__new`ed GC objects.
* **__link**(parentPtr: `usize`, childPtr: `usize`, expectMultiple: `bool`): `void`<br />
Introduces a link from a parent object to a child object, i.e. upon `parent.field = child`.
* **__visit**(ptr: `usize`, cookie: `u32`): `void`<br />
Concrete visitor implementation called during traversal. Cookie can be used to indicate one of multiple operations.
* **__visit_globals**(cookie: `u32`): `void`<br />
Calls `__visit` on each global that is of a managed type.
* **__visit_members**(ptr: `usize`, cookie: `u32`): `void`<br />
Calls `__visit` on each member of the object pointed to by `ptr`.
* **__typeinfo**(id: `u32`): `RTTIFlags`<br />
Obtains the runtime type information for objects with the specified runtime id. Runtime type information is a set of flags indicating whether a type is managed, an array or similar, and what the relevant alignments when creating an instance externally are etc.
* **__instanceof**(ptr: `usize`, classId: `u32`): `bool`<br />
Tests if the object pointed to by `ptr` is an instance of the specified class id.
ITCMS / `--runtime incremental`
-----
The Incremental Tri-Color Mark & Sweep garbage collector maintains a separate shadow stack of managed values in the background to achieve full automation. Maintaining another stack introduces some overhead compared to the simpler Two-Color Mark & Sweep garbage collector, but makes it independent of whether the execution stack is unwound or not when it is invoked, so the garbage collector can run interleaved with the program.
There are several constants one can experiment with to tweak ITCMS's automation:
* `--use ASC_GC_GRANULARITY=1024`<br />
How often to interrupt. The default of 1024 means "interrupt each 1024 bytes allocated".
* `--use ASC_GC_STEPFACTOR=200`<br />
How long to interrupt. The default of 200% means "run at double the speed of allocations".
* `--use ASC_GC_IDLEFACTOR=200`<br />
How long to idle. The default of 200% means "wait for memory to double before kicking in again".
* `--use ASC_GC_MARKCOST=1`<br />
How costly it is to mark one object. Budget per interrupt is `GRANULARITY * STEPFACTOR / 100`.
* `--use ASC_GC_SWEEPCOST=10`<br />
How costly it is to sweep one object. Budget per interrupt is `GRANULARITY * STEPFACTOR / 100`.
TCMS / `--runtime minimal`
----
If automation and low pause times aren't strictly necessary, using the Two-Color Mark & Sweep garbage collector instead by invoking collection manually at appropriate times when the execution stack is unwound may be more performant as it simpler and has less overhead. The execution stack is typically unwound when invoking the collector externally, at a place that is not indirectly called from Wasm.
STUB / `--runtime stub`
----
The stub is a maximally minimal runtime substitute, consisting of a simple and fast bump allocator with no means of freeing up memory again, except when freeing the respective most recently allocated object on top of the bump. Useful where memory is not a concern, and/or where it is sufficient to destroy the whole module including any potential garbage after execution.
See also: [Garbage collection](https://www.assemblyscript.org/garbage-collection.html)
# [nearley](http://nearley.js.org) ↗️
[](http://js.org)
[](https://badge.fury.io/js/nearley)
nearley is a simple, fast and powerful parsing toolkit. It consists of:
1. [A powerful, modular DSL for describing
languages](https://nearley.js.org/docs/grammar)
2. [An efficient, lightweight Earley
parser](https://nearley.js.org/docs/parser)
3. [Loads of tools, editor plug-ins, and other
goodies!](https://nearley.js.org/docs/tooling)
nearley is a **streaming** parser with support for catching **errors**
gracefully and providing _all_ parsings for **ambiguous** grammars. It is
compatible with a variety of **lexers** (we recommend
[moo](http://github.com/tjvr/moo)). It comes with tools for creating **tests**,
**railroad diagrams** and **fuzzers** from your grammars, and has support for a
variety of editors and platforms. It works in both node and the browser.
Unlike most other parser generators, nearley can handle *any* grammar you can
define in BNF (and more!). In particular, while most existing JS parsers such
as PEGjs and Jison choke on certain grammars (e.g. [left recursive
ones](http://en.wikipedia.org/wiki/Left_recursion)), nearley handles them
easily and efficiently by using the [Earley parsing
algorithm](https://en.wikipedia.org/wiki/Earley_parser).
nearley is used by a wide variety of projects:
- [artificial
intelligence](https://github.com/ChalmersGU-AI-course/shrdlite-course-project)
and
- [computational
linguistics](https://wiki.eecs.yorku.ca/course_archive/2014-15/W/6339/useful_handouts)
classes at universities;
- [file format parsers](https://github.com/raymond-h/node-dmi);
- [data-driven markup languages](https://github.com/idyll-lang/idyll-compiler);
- [compilers for real-world programming
languages](https://github.com/sizigi/lp5562);
- and nearley itself! The nearley compiler is bootstrapped.
nearley is an npm [staff
pick](https://www.npmjs.com/package/npm-collection-staff-picks).
## Documentation
Please visit our website https://nearley.js.org to get started! You will find a
tutorial, detailed reference documents, and links to several real-world
examples to get inspired.
## Contributing
Please read [this document](.github/CONTRIBUTING.md) *before* working on
nearley. If you are interested in contributing but unsure where to start, take
a look at the issues labeled "up for grabs" on the issue tracker, or message a
maintainer (@kach or @tjvr on Github).
nearley is MIT licensed.
A big thanks to Nathan Dinsmore for teaching me how to Earley, Aria Stewart for
helping structure nearley into a mature module, and Robin Windels for
bootstrapping the grammar. Additionally, Jacob Edelman wrote an experimental
JavaScript parser with nearley and contributed ideas for EBNF support. Joshua
T. Corbin refactored the compiler to be much, much prettier. Bojidar Marinov
implemented postprocessors-in-other-languages. Shachar Itzhaky fixed a subtle
bug with nullables.
## Citing nearley
If you are citing nearley in academic work, please use the following BibTeX
entry.
```bibtex
@misc{nearley,
author = "Kartik Chandra and Tim Radvan",
title = "{nearley}: a parsing toolkit for {JavaScript}",
year = {2014},
doi = {10.5281/zenodo.3897993},
url = {https://github.com/kach/nearley}
}
```
# lodash.sortby v4.7.0
The [lodash](https://lodash.com/) method `_.sortBy` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.sortby
```
In Node.js:
```js
var sortBy = require('lodash.sortby');
```
See the [documentation](https://lodash.com/docs#sortBy) or [package source](https://github.com/lodash/lodash/blob/4.7.0-npm-packages/lodash.sortby) for more details.
A JSON with color names and its values. Based on http://dev.w3.org/csswg/css-color/#named-colors.
[](https://nodei.co/npm/color-name/)
```js
var colors = require('color-name');
colors.red //[255,0,0]
```
<a href="LICENSE"><img src="https://upload.wikimedia.org/wikipedia/commons/0/0c/MIT_logo.svg" width="120"/></a>
assemblyscript-json
# assemblyscript-json
## Table of contents
### Namespaces
- [JSON](modules/json.md)
### Classes
- [DecoderState](classes/decoderstate.md)
- [JSONDecoder](classes/jsondecoder.md)
- [JSONEncoder](classes/jsonencoder.md)
- [JSONHandler](classes/jsonhandler.md)
- [ThrowingJSONHandler](classes/throwingjsonhandler.md)
# Visitor utilities for AssemblyScript Compiler transformers
## Example
### List Fields
The transformer:
```ts
import {
ClassDeclaration,
FieldDeclaration,
MethodDeclaration,
} from "../../as";
import { ClassDecorator, registerDecorator } from "../decorator";
import { toString } from "../utils";
class ListMembers extends ClassDecorator {
visitFieldDeclaration(node: FieldDeclaration): void {
if (!node.name) console.log(toString(node) + "\n");
const name = toString(node.name);
const _type = toString(node.type!);
this.stdout.write(name + ": " + _type + "\n");
}
visitMethodDeclaration(node: MethodDeclaration): void {
const name = toString(node.name);
if (name == "constructor") {
return;
}
const sig = toString(node.signature);
this.stdout.write(name + ": " + sig + "\n");
}
visitClassDeclaration(node: ClassDeclaration): void {
this.visit(node.members);
}
get name(): string {
return "list";
}
}
export = registerDecorator(new ListMembers());
```
assembly/foo.ts:
```ts
@list
class Foo {
a: u8;
b: bool;
i: i32;
}
```
And then compile with `--transform` flag:
```
asc assembly/foo.ts --transform ./dist/examples/list --noEmit
```
Which prints the following to the console:
```
a: u8
b: bool
i: i32
```
# AssemblyScript Loader
A convenient loader for [AssemblyScript](https://assemblyscript.org) modules. Demangles module exports to a friendly object structure compatible with TypeScript definitions and provides useful utility to read/write data from/to memory.
[Documentation](https://assemblyscript.org/loader.html)
long.js
=======
A Long class for representing a 64 bit two's-complement integer value derived from the [Closure Library](https://github.com/google/closure-library)
for stand-alone use and extended with unsigned support.
[](https://travis-ci.org/dcodeIO/long.js)
Background
----------
As of [ECMA-262 5th Edition](http://ecma262-5.com/ELS5_HTML.htm#Section_8.5), "all the positive and negative integers
whose magnitude is no greater than 2<sup>53</sup> are representable in the Number type", which is "representing the
doubleprecision 64-bit format IEEE 754 values as specified in the IEEE Standard for Binary Floating-Point Arithmetic".
The [maximum safe integer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number/MAX_SAFE_INTEGER)
in JavaScript is 2<sup>53</sup>-1.
Example: 2<sup>64</sup>-1 is 1844674407370955**1615** but in JavaScript it evaluates to 1844674407370955**2000**.
Furthermore, bitwise operators in JavaScript "deal only with integers in the range −2<sup>31</sup> through
2<sup>31</sup>−1, inclusive, or in the range 0 through 2<sup>32</sup>−1, inclusive. These operators accept any value of
the Number type but first convert each such value to one of 2<sup>32</sup> integer values."
In some use cases, however, it is required to be able to reliably work with and perform bitwise operations on the full
64 bits. This is where long.js comes into play.
Usage
-----
The class is compatible with CommonJS and AMD loaders and is exposed globally as `Long` if neither is available.
```javascript
var Long = require("long");
var longVal = new Long(0xFFFFFFFF, 0x7FFFFFFF);
console.log(longVal.toString());
...
```
API
---
### Constructor
* new **Long**(low: `number`, high: `number`, unsigned?: `boolean`)<br />
Constructs a 64 bit two's-complement integer, given its low and high 32 bit values as *signed* integers. See the from* functions below for more convenient ways of constructing Longs.
### Fields
* Long#**low**: `number`<br />
The low 32 bits as a signed value.
* Long#**high**: `number`<br />
The high 32 bits as a signed value.
* Long#**unsigned**: `boolean`<br />
Whether unsigned or not.
### Constants
* Long.**ZERO**: `Long`<br />
Signed zero.
* Long.**ONE**: `Long`<br />
Signed one.
* Long.**NEG_ONE**: `Long`<br />
Signed negative one.
* Long.**UZERO**: `Long`<br />
Unsigned zero.
* Long.**UONE**: `Long`<br />
Unsigned one.
* Long.**MAX_VALUE**: `Long`<br />
Maximum signed value.
* Long.**MIN_VALUE**: `Long`<br />
Minimum signed value.
* Long.**MAX_UNSIGNED_VALUE**: `Long`<br />
Maximum unsigned value.
### Utility
* Long.**isLong**(obj: `*`): `boolean`<br />
Tests if the specified object is a Long.
* Long.**fromBits**(lowBits: `number`, highBits: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the 64 bit integer that comes by concatenating the given low and high bits. Each is assumed to use 32 bits.
* Long.**fromBytes**(bytes: `number[]`, unsigned?: `boolean`, le?: `boolean`): `Long`<br />
Creates a Long from its byte representation.
* Long.**fromBytesLE**(bytes: `number[]`, unsigned?: `boolean`): `Long`<br />
Creates a Long from its little endian byte representation.
* Long.**fromBytesBE**(bytes: `number[]`, unsigned?: `boolean`): `Long`<br />
Creates a Long from its big endian byte representation.
* Long.**fromInt**(value: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the given 32 bit integer value.
* Long.**fromNumber**(value: `number`, unsigned?: `boolean`): `Long`<br />
Returns a Long representing the given value, provided that it is a finite number. Otherwise, zero is returned.
* Long.**fromString**(str: `string`, unsigned?: `boolean`, radix?: `number`)<br />
Long.**fromString**(str: `string`, radix: `number`)<br />
Returns a Long representation of the given string, written using the specified radix.
* Long.**fromValue**(val: `*`, unsigned?: `boolean`): `Long`<br />
Converts the specified value to a Long using the appropriate from* function for its type.
### Methods
* Long#**add**(addend: `Long | number | string`): `Long`<br />
Returns the sum of this and the specified Long.
* Long#**and**(other: `Long | number | string`): `Long`<br />
Returns the bitwise AND of this Long and the specified.
* Long#**compare**/**comp**(other: `Long | number | string`): `number`<br />
Compares this Long's value with the specified's. Returns `0` if they are the same, `1` if the this is greater and `-1` if the given one is greater.
* Long#**divide**/**div**(divisor: `Long | number | string`): `Long`<br />
Returns this Long divided by the specified.
* Long#**equals**/**eq**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value equals the specified's.
* Long#**getHighBits**(): `number`<br />
Gets the high 32 bits as a signed integer.
* Long#**getHighBitsUnsigned**(): `number`<br />
Gets the high 32 bits as an unsigned integer.
* Long#**getLowBits**(): `number`<br />
Gets the low 32 bits as a signed integer.
* Long#**getLowBitsUnsigned**(): `number`<br />
Gets the low 32 bits as an unsigned integer.
* Long#**getNumBitsAbs**(): `number`<br />
Gets the number of bits needed to represent the absolute value of this Long.
* Long#**greaterThan**/**gt**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is greater than the specified's.
* Long#**greaterThanOrEqual**/**gte**/**ge**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is greater than or equal the specified's.
* Long#**isEven**(): `boolean`<br />
Tests if this Long's value is even.
* Long#**isNegative**(): `boolean`<br />
Tests if this Long's value is negative.
* Long#**isOdd**(): `boolean`<br />
Tests if this Long's value is odd.
* Long#**isPositive**(): `boolean`<br />
Tests if this Long's value is positive.
* Long#**isZero**/**eqz**(): `boolean`<br />
Tests if this Long's value equals zero.
* Long#**lessThan**/**lt**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is less than the specified's.
* Long#**lessThanOrEqual**/**lte**/**le**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value is less than or equal the specified's.
* Long#**modulo**/**mod**/**rem**(divisor: `Long | number | string`): `Long`<br />
Returns this Long modulo the specified.
* Long#**multiply**/**mul**(multiplier: `Long | number | string`): `Long`<br />
Returns the product of this and the specified Long.
* Long#**negate**/**neg**(): `Long`<br />
Negates this Long's value.
* Long#**not**(): `Long`<br />
Returns the bitwise NOT of this Long.
* Long#**notEquals**/**neq**/**ne**(other: `Long | number | string`): `boolean`<br />
Tests if this Long's value differs from the specified's.
* Long#**or**(other: `Long | number | string`): `Long`<br />
Returns the bitwise OR of this Long and the specified.
* Long#**shiftLeft**/**shl**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits shifted to the left by the given amount.
* Long#**shiftRight**/**shr**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits arithmetically shifted to the right by the given amount.
* Long#**shiftRightUnsigned**/**shru**/**shr_u**(numBits: `Long | number | string`): `Long`<br />
Returns this Long with bits logically shifted to the right by the given amount.
* Long#**subtract**/**sub**(subtrahend: `Long | number | string`): `Long`<br />
Returns the difference of this and the specified Long.
* Long#**toBytes**(le?: `boolean`): `number[]`<br />
Converts this Long to its byte representation.
* Long#**toBytesLE**(): `number[]`<br />
Converts this Long to its little endian byte representation.
* Long#**toBytesBE**(): `number[]`<br />
Converts this Long to its big endian byte representation.
* Long#**toInt**(): `number`<br />
Converts the Long to a 32 bit integer, assuming it is a 32 bit integer.
* Long#**toNumber**(): `number`<br />
Converts the Long to a the nearest floating-point representation of this value (double, 53 bit mantissa).
* Long#**toSigned**(): `Long`<br />
Converts this Long to signed.
* Long#**toString**(radix?: `number`): `string`<br />
Converts the Long to a string written in the specified radix.
* Long#**toUnsigned**(): `Long`<br />
Converts this Long to unsigned.
* Long#**xor**(other: `Long | number | string`): `Long`<br />
Returns the bitwise XOR of this Long and the given one.
Building
--------
To build an UMD bundle to `dist/long.js`, run:
```
$> npm install
$> npm run build
```
Running the [tests](./tests):
```
$> npm test
```
# require-main-filename
[](https://travis-ci.org/yargs/require-main-filename)
[](https://coveralls.io/r/yargs/require-main-filename?branch=master)
[](https://www.npmjs.com/package/require-main-filename)
`require.main.filename` is great for figuring out the entry
point for the current application. This can be combined with a module like
[pkg-conf](https://www.npmjs.com/package/pkg-conf) to, _as if by magic_, load
top-level configuration.
Unfortunately, `require.main.filename` sometimes fails when an application is
executed with an alternative process manager, e.g., [iisnode](https://github.com/tjanczuk/iisnode).
`require-main-filename` is a shim that addresses this problem.
## Usage
```js
var main = require('require-main-filename')()
// use main as an alternative to require.main.filename.
```
## License
ISC
# Punycode.js [](https://travis-ci.org/bestiejs/punycode.js) [](https://codecov.io/gh/bestiejs/punycode.js) [](https://gemnasium.com/bestiejs/punycode.js)
Punycode.js is a robust Punycode converter that fully complies to [RFC 3492](https://tools.ietf.org/html/rfc3492) and [RFC 5891](https://tools.ietf.org/html/rfc5891).
This JavaScript library is the result of comparing, optimizing and documenting different open-source implementations of the Punycode algorithm:
* [The C example code from RFC 3492](https://tools.ietf.org/html/rfc3492#appendix-C)
* [`punycode.c` by _Markus W. Scherer_ (IBM)](http://opensource.apple.com/source/ICU/ICU-400.42/icuSources/common/punycode.c)
* [`punycode.c` by _Ben Noordhuis_](https://github.com/bnoordhuis/punycode/blob/master/punycode.c)
* [JavaScript implementation by _some_](http://stackoverflow.com/questions/183485/can-anyone-recommend-a-good-free-javascript-for-punycode-to-unicode-conversion/301287#301287)
* [`punycode.js` by _Ben Noordhuis_](https://github.com/joyent/node/blob/426298c8c1c0d5b5224ac3658c41e7c2a3fe9377/lib/punycode.js) (note: [not fully compliant](https://github.com/joyent/node/issues/2072))
This project was [bundled](https://github.com/joyent/node/blob/master/lib/punycode.js) with Node.js from [v0.6.2+](https://github.com/joyent/node/compare/975f1930b1...61e796decc) until [v7](https://github.com/nodejs/node/pull/7941) (soft-deprecated).
The current version supports recent versions of Node.js only. It provides a CommonJS module and an ES6 module. For the old version that offers the same functionality with broader support, including Rhino, Ringo, Narwhal, and web browsers, see [v1.4.1](https://github.com/bestiejs/punycode.js/releases/tag/v1.4.1).
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install punycode --save
```
In [Node.js](https://nodejs.org/):
```js
const punycode = require('punycode');
```
## API
### `punycode.decode(string)`
Converts a Punycode string of ASCII symbols to a string of Unicode symbols.
```js
// decode domain name parts
punycode.decode('maana-pta'); // 'mañana'
punycode.decode('--dqo34k'); // '☃-⌘'
```
### `punycode.encode(string)`
Converts a string of Unicode symbols to a Punycode string of ASCII symbols.
```js
// encode domain name parts
punycode.encode('mañana'); // 'maana-pta'
punycode.encode('☃-⌘'); // '--dqo34k'
```
### `punycode.toUnicode(input)`
Converts a Punycode string representing a domain name or an email address to Unicode. Only the Punycoded parts of the input will be converted, i.e. it doesn’t matter if you call it on a string that has already been converted to Unicode.
```js
// decode domain names
punycode.toUnicode('xn--maana-pta.com');
// → 'mañana.com'
punycode.toUnicode('xn----dqo34k.com');
// → '☃-⌘.com'
// decode email addresses
punycode.toUnicode('джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq');
// → 'джумла@джpумлатест.bрфa'
```
### `punycode.toASCII(input)`
Converts a lowercased Unicode string representing a domain name or an email address to Punycode. Only the non-ASCII parts of the input will be converted, i.e. it doesn’t matter if you call it with a domain that’s already in ASCII.
```js
// encode domain names
punycode.toASCII('mañana.com');
// → 'xn--maana-pta.com'
punycode.toASCII('☃-⌘.com');
// → 'xn----dqo34k.com'
// encode email addresses
punycode.toASCII('джумла@джpумлатест.bрфa');
// → 'джумла@xn--p-8sbkgc5ag7bhce.xn--ba-lmcq'
```
### `punycode.ucs2`
#### `punycode.ucs2.decode(string)`
Creates an array containing the numeric code point values of each Unicode symbol in the string. While [JavaScript uses UCS-2 internally](https://mathiasbynens.be/notes/javascript-encoding), this function will convert a pair of surrogate halves (each of which UCS-2 exposes as separate characters) into a single code point, matching UTF-16.
```js
punycode.ucs2.decode('abc');
// → [0x61, 0x62, 0x63]
// surrogate pair for U+1D306 TETRAGRAM FOR CENTRE:
punycode.ucs2.decode('\uD834\uDF06');
// → [0x1D306]
```
#### `punycode.ucs2.encode(codePoints)`
Creates a string based on an array of numeric code point values.
```js
punycode.ucs2.encode([0x61, 0x62, 0x63]);
// → 'abc'
punycode.ucs2.encode([0x1D306]);
// → '\uD834\uDF06'
```
### `punycode.version`
A string representing the current Punycode.js version number.
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
Punycode.js is available under the [MIT](https://mths.be/mit) license.
# Regular Expression Tokenizer
Tokenizes strings that represent a regular expressions.
[](http://travis-ci.org/fent/ret.js)
[](https://david-dm.org/fent/ret.js)
[](https://codecov.io/gh/fent/ret.js)
# Usage
```js
var ret = require('ret');
var tokens = ret(/foo|bar/.source);
```
`tokens` will contain the following object
```js
{
"type": ret.types.ROOT
"options": [
[ { "type": ret.types.CHAR, "value", 102 },
{ "type": ret.types.CHAR, "value", 111 },
{ "type": ret.types.CHAR, "value", 111 } ],
[ { "type": ret.types.CHAR, "value", 98 },
{ "type": ret.types.CHAR, "value", 97 },
{ "type": ret.types.CHAR, "value", 114 } ]
]
}
```
# Token Types
`ret.types` is a collection of the various token types exported by ret.
### ROOT
Only used in the root of the regexp. This is needed due to the posibility of the root containing a pipe `|` character. In that case, the token will have an `options` key that will be an array of arrays of tokens. If not, it will contain a `stack` key that is an array of tokens.
```js
{
"type": ret.types.ROOT,
"stack": [token1, token2...],
}
```
```js
{
"type": ret.types.ROOT,
"options" [
[token1, token2...],
[othertoken1, othertoken2...]
...
],
}
```
### GROUP
Groups contain tokens that are inside of a parenthesis. If the group begins with `?` followed by another character, it's a special type of group. A ':' tells the group not to be remembered when `exec` is used. '=' means the previous token matches only if followed by this group, and '!' means the previous token matches only if NOT followed.
Like root, it can contain an `options` key instead of `stack` if there is a pipe.
```js
{
"type": ret.types.GROUP,
"remember" true,
"followedBy": false,
"notFollowedBy": false,
"stack": [token1, token2...],
}
```
```js
{
"type": ret.types.GROUP,
"remember" true,
"followedBy": false,
"notFollowedBy": false,
"options" [
[token1, token2...],
[othertoken1, othertoken2...]
...
],
}
```
### POSITION
`\b`, `\B`, `^`, and `$` specify positions in the regexp.
```js
{
"type": ret.types.POSITION,
"value": "^",
}
```
### SET
Contains a key `set` specifying what tokens are allowed and a key `not` specifying if the set should be negated. A set can contain other sets, ranges, and characters.
```js
{
"type": ret.types.SET,
"set": [token1, token2...],
"not": false,
}
```
### RANGE
Used in set tokens to specify a character range. `from` and `to` are character codes.
```js
{
"type": ret.types.RANGE,
"from": 97,
"to": 122,
}
```
### REPETITION
```js
{
"type": ret.types.REPETITION,
"min": 0,
"max": Infinity,
"value": token,
}
```
### REFERENCE
References a group token. `value` is 1-9.
```js
{
"type": ret.types.REFERENCE,
"value": 1,
}
```
### CHAR
Represents a single character token. `value` is the character code. This might seem a bit cluttering instead of concatenating characters together. But since repetition tokens only repeat the last token and not the last clause like the pipe, it's simpler to do it this way.
```js
{
"type": ret.types.CHAR,
"value": 123,
}
```
## Errors
ret.js will throw errors if given a string with an invalid regular expression. All possible errors are
* Invalid group. When a group with an immediate `?` character is followed by an invalid character. It can only be followed by `!`, `=`, or `:`. Example: `/(?_abc)/`
* Nothing to repeat. Thrown when a repetitional token is used as the first token in the current clause, as in right in the beginning of the regexp or group, or right after a pipe. Example: `/foo|?bar/`, `/{1,3}foo|bar/`, `/foo(+bar)/`
* Unmatched ). A group was not opened, but was closed. Example: `/hello)2u/`
* Unterminated group. A group was not closed. Example: `/(1(23)4/`
* Unterminated character class. A custom character set was not closed. Example: `/[abc/`
# Install
npm install ret
# Tests
Tests are written with [vows](http://vowsjs.org/)
```bash
npm test
```
# License
MIT
<p align="center">
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs/master/yargs-logo.png">
</p>
<h1 align="center"> Yargs </h1>
<p align="center">
<b >Yargs be a node.js library fer hearties tryin' ter parse optstrings</b>
</p>
<br>

[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[![Coverage][coverage-image]][coverage-url]
[![Conventional Commits][conventional-commits-image]][conventional-commits-url]
[![Slack][slack-image]][slack-url]
## Description
Yargs helps you build interactive command line tools, by parsing arguments and generating an elegant user interface.
It gives you:
* commands and (grouped) options (`my-program.js serve --port=5000`).
* a dynamically generated help menu based on your arguments:
```
mocha [spec..]
Run tests with Mocha
Commands
mocha inspect [spec..] Run tests with Mocha [default]
mocha init <path> create a client-side Mocha setup at <path>
Rules & Behavior
--allow-uncaught Allow uncaught errors to propagate [boolean]
--async-only, -A Require all tests to use a callback (async) or
return a Promise [boolean]
```
* bash-completion shortcuts for commands and options.
* and [tons more](/docs/api.md).
## Installation
Stable version:
```bash
npm i yargs
```
Bleeding edge version with the most recent features:
```bash
npm i yargs@next
```
## Usage
### Simple Example
```javascript
#!/usr/bin/env node
const yargs = require('yargs/yargs')
const { hideBin } = require('yargs/helpers')
const argv = yargs(hideBin(process.argv)).argv
if (argv.ships > 3 && argv.distance < 53.5) {
console.log('Plunder more riffiwobbles!')
} else {
console.log('Retreat from the xupptumblers!')
}
```
```bash
$ ./plunder.js --ships=4 --distance=22
Plunder more riffiwobbles!
$ ./plunder.js --ships 12 --distance 98.7
Retreat from the xupptumblers!
```
### Complex Example
```javascript
#!/usr/bin/env node
const yargs = require('yargs/yargs')
const { hideBin } = require('yargs/helpers')
yargs(hideBin(process.argv))
.command('serve [port]', 'start the server', (yargs) => {
yargs
.positional('port', {
describe: 'port to bind on',
default: 5000
})
}, (argv) => {
if (argv.verbose) console.info(`start server on :${argv.port}`)
serve(argv.port)
})
.option('verbose', {
alias: 'v',
type: 'boolean',
description: 'Run with verbose logging'
})
.argv
```
Run the example above with `--help` to see the help for the application.
## Supported Platforms
### TypeScript
yargs has type definitions at [@types/yargs][type-definitions].
```
npm i @types/yargs --save-dev
```
See usage examples in [docs](/docs/typescript.md).
### Deno
As of `v16`, `yargs` supports [Deno](https://github.com/denoland/deno):
```typescript
import yargs from 'https://deno.land/x/yargs/deno.ts'
import { Arguments } from 'https://deno.land/x/yargs/deno-types.ts'
yargs(Deno.args)
.command('download <files...>', 'download a list of files', (yargs: any) => {
return yargs.positional('files', {
describe: 'a list of files to do something with'
})
}, (argv: Arguments) => {
console.info(argv)
})
.strictCommands()
.demandCommand(1)
.argv
```
### ESM
As of `v16`,`yargs` supports ESM imports:
```js
import yargs from 'yargs'
import { hideBin } from 'yargs/helpers'
yargs(hideBin(process.argv))
.command('curl <url>', 'fetch the contents of the URL', () => {}, (argv) => {
console.info(argv)
})
.demandCommand(1)
.argv
```
### Usage in Browser
See examples of using yargs in the browser in [docs](/docs/browser.md).
## Community
Having problems? want to contribute? join our [community slack](http://devtoolscommunity.herokuapp.com).
## Documentation
### Table of Contents
* [Yargs' API](/docs/api.md)
* [Examples](/docs/examples.md)
* [Parsing Tricks](/docs/tricks.md)
* [Stop the Parser](/docs/tricks.md#stop)
* [Negating Boolean Arguments](/docs/tricks.md#negate)
* [Numbers](/docs/tricks.md#numbers)
* [Arrays](/docs/tricks.md#arrays)
* [Objects](/docs/tricks.md#objects)
* [Quotes](/docs/tricks.md#quotes)
* [Advanced Topics](/docs/advanced.md)
* [Composing Your App Using Commands](/docs/advanced.md#commands)
* [Building Configurable CLI Apps](/docs/advanced.md#configuration)
* [Customizing Yargs' Parser](/docs/advanced.md#customizing)
* [Bundling yargs](/docs/bundling.md)
* [Contributing](/contributing.md)
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
[npm-url]: https://www.npmjs.com/package/yargs
[npm-image]: https://img.shields.io/npm/v/yargs.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: http://standardjs.com/
[conventional-commits-image]: https://img.shields.io/badge/Conventional%20Commits-1.0.0-yellow.svg
[conventional-commits-url]: https://conventionalcommits.org/
[slack-image]: http://devtoolscommunity.herokuapp.com/badge.svg
[slack-url]: http://devtoolscommunity.herokuapp.com
[type-definitions]: https://github.com/DefinitelyTyped/DefinitelyTyped/tree/master/types/yargs
[coverage-image]: https://img.shields.io/nycrc/yargs/yargs
[coverage-url]: https://github.com/yargs/yargs/blob/master/.nycrc
# minimatch
A minimal matching utility.
[](http://travis-ci.org/isaacs/minimatch)
This is the matching library used internally by npm.
It works by converting glob expressions into JavaScript `RegExp`
objects.
## Usage
```javascript
var minimatch = require("minimatch")
minimatch("bar.foo", "*.foo") // true!
minimatch("bar.foo", "*.bar") // false!
minimatch("bar.foo", "*.+(bar|foo)", { debug: true }) // true, and noisy!
```
## Features
Supports these glob features:
* Brace Expansion
* Extended glob matching
* "Globstar" `**` matching
See:
* `man sh`
* `man bash`
* `man 3 fnmatch`
* `man 5 gitignore`
## Minimatch Class
Create a minimatch object by instantiating the `minimatch.Minimatch` class.
```javascript
var Minimatch = require("minimatch").Minimatch
var mm = new Minimatch(pattern, options)
```
### Properties
* `pattern` The original pattern the minimatch object represents.
* `options` The options supplied to the constructor.
* `set` A 2-dimensional array of regexp or string expressions.
Each row in the
array corresponds to a brace-expanded pattern. Each item in the row
corresponds to a single path-part. For example, the pattern
`{a,b/c}/d` would expand to a set of patterns like:
[ [ a, d ]
, [ b, c, d ] ]
If a portion of the pattern doesn't have any "magic" in it
(that is, it's something like `"foo"` rather than `fo*o?`), then it
will be left as a string rather than converted to a regular
expression.
* `regexp` Created by the `makeRe` method. A single regular expression
expressing the entire pattern. This is useful in cases where you wish
to use the pattern somewhat like `fnmatch(3)` with `FNM_PATH` enabled.
* `negate` True if the pattern is negated.
* `comment` True if the pattern is a comment.
* `empty` True if the pattern is `""`.
### Methods
* `makeRe` Generate the `regexp` member if necessary, and return it.
Will return `false` if the pattern is invalid.
* `match(fname)` Return true if the filename matches the pattern, or
false otherwise.
* `matchOne(fileArray, patternArray, partial)` Take a `/`-split
filename, and match it against a single row in the `regExpSet`. This
method is mainly for internal use, but is exposed so that it can be
used by a glob-walker that needs to avoid excessive filesystem calls.
All other methods are internal, and will be called as necessary.
### minimatch(path, pattern, options)
Main export. Tests a path against the pattern using the options.
```javascript
var isJS = minimatch(file, "*.js", { matchBase: true })
```
### minimatch.filter(pattern, options)
Returns a function that tests its
supplied argument, suitable for use with `Array.filter`. Example:
```javascript
var javascripts = fileList.filter(minimatch.filter("*.js", {matchBase: true}))
```
### minimatch.match(list, pattern, options)
Match against the list of
files, in the style of fnmatch or glob. If nothing is matched, and
options.nonull is set, then return a list containing the pattern itself.
```javascript
var javascripts = minimatch.match(fileList, "*.js", {matchBase: true}))
```
### minimatch.makeRe(pattern, options)
Make a regular expression object from the pattern.
## Options
All options are `false` by default.
### debug
Dump a ton of stuff to stderr.
### nobrace
Do not expand `{a,b}` and `{1..3}` brace sets.
### noglobstar
Disable `**` matching against multiple folder names.
### dot
Allow patterns to match filenames starting with a period, even if
the pattern does not explicitly have a period in that spot.
Note that by default, `a/**/b` will **not** match `a/.d/b`, unless `dot`
is set.
### noext
Disable "extglob" style patterns like `+(a|b)`.
### nocase
Perform a case-insensitive match.
### nonull
When a match is not found by `minimatch.match`, return a list containing
the pattern itself if this option is set. When not set, an empty list
is returned if there are no matches.
### matchBase
If set, then patterns without slashes will be matched
against the basename of the path if it contains slashes. For example,
`a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`.
### nocomment
Suppress the behavior of treating `#` at the start of a pattern as a
comment.
### nonegate
Suppress the behavior of treating a leading `!` character as negation.
### flipNegate
Returns from negate expressions the same as if they were not negated.
(Ie, true on a hit, false on a miss.)
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between minimatch and other
implementations, and are intentional.
If the pattern starts with a `!` character, then it is negated. Set the
`nonegate` flag to suppress this behavior, and treat leading `!`
characters normally. This is perhaps relevant if you wish to start the
pattern with a negative extglob pattern like `!(a|B)`. Multiple `!`
characters at the start of a pattern will negate the pattern multiple
times.
If a pattern starts with `#`, then it is treated as a comment, and
will not match anything. Use `\#` to match a literal `#` at the
start of a line, or set the `nocomment` flag to suppress this behavior.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.1, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
If an escaped pattern has no matches, and the `nonull` flag is set,
then minimatch.match returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`minimatch.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
Standard library
================
Standard library components for use with `tsc` (portable) and `asc` (assembly).
Base configurations (.json) and definition files (.d.ts) are relevant to `tsc` only and not used by `asc`.
# inflight
Add callbacks to requests in flight to avoid async duplication
## USAGE
```javascript
var inflight = require('inflight')
// some request that does some stuff
function req(key, callback) {
// key is any random string. like a url or filename or whatever.
//
// will return either a falsey value, indicating that the
// request for this key is already in flight, or a new callback
// which when called will call all callbacks passed to inflightk
// with the same key
callback = inflight(key, callback)
// If we got a falsey value back, then there's already a req going
if (!callback) return
// this is where you'd fetch the url or whatever
// callback is also once()-ified, so it can safely be assigned
// to multiple events etc. First call wins.
setTimeout(function() {
callback(null, key)
}, 100)
}
// only assigns a single setTimeout
// when it dings, all cbs get called
req('foo', cb1)
req('foo', cb2)
req('foo', cb3)
req('foo', cb4)
```
# hasurl [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url]
> Determine whether Node.js' native [WHATWG `URL`](https://nodejs.org/api/url.html#url_the_whatwg_url_api) implementation is available.
## Installation
[Node.js](http://nodejs.org/) `>= 4` is required. To install, type this at the command line:
```shell
npm install hasurl
```
## Usage
```js
const hasURL = require('hasurl');
if (hasURL()) {
// supported
} else {
// fallback
}
```
[npm-image]: https://img.shields.io/npm/v/hasurl.svg
[npm-url]: https://npmjs.org/package/hasurl
[travis-image]: https://img.shields.io/travis/stevenvachon/hasurl.svg
[travis-url]: https://travis-ci.org/stevenvachon/hasurl
# balanced-match
Match balanced string pairs, like `{` and `}` or `<b>` and `</b>`. Supports regular expressions as well!
[](http://travis-ci.org/juliangruber/balanced-match)
[](https://www.npmjs.org/package/balanced-match)
[](https://ci.testling.com/juliangruber/balanced-match)
## Example
Get the first matching pair of braces:
```js
var balanced = require('balanced-match');
console.log(balanced('{', '}', 'pre{in{nested}}post'));
console.log(balanced('{', '}', 'pre{first}between{second}post'));
console.log(balanced(/\s+\{\s+/, /\s+\}\s+/, 'pre { in{nest} } post'));
```
The matches are:
```bash
$ node example.js
{ start: 3, end: 14, pre: 'pre', body: 'in{nested}', post: 'post' }
{ start: 3,
end: 9,
pre: 'pre',
body: 'first',
post: 'between{second}post' }
{ start: 3, end: 17, pre: 'pre', body: 'in{nest}', post: 'post' }
```
## API
### var m = balanced(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
object with those keys:
* **start** the index of the first match of `a`
* **end** the index of the matching `b`
* **pre** the preamble, `a` and `b` not included
* **body** the match, `a` and `b` not included
* **post** the postscript, `a` and `b` not included
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `['{', 'a', '']` and `{a}}` will match `['', 'a', '}']`.
### var r = balanced.range(a, b, str)
For the first non-nested matching pair of `a` and `b` in `str`, return an
array with indexes: `[ <a index>, <b index> ]`.
If there's no match, `undefined` will be returned.
If the `str` contains more `a` than `b` / there are unmatched pairs, the first match that was closed will be used. For example, `{{a}` will match `[ 1, 3 ]` and `{a}}` will match `[0, 2]`.
## Installation
With [npm](https://npmjs.org) do:
```bash
npm install balanced-match
```
## License
(MIT)
Copyright (c) 2013 Julian Gruber <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
of the Software, and to permit persons to whom the Software is furnished to do
so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
# node-tar
[](https://travis-ci.org/npm/node-tar)
[Fast](./benchmarks) and full-featured Tar for Node.js
The API is designed to mimic the behavior of `tar(1)` on unix systems.
If you are familiar with how tar works, most of this will hopefully be
straightforward for you. If not, then hopefully this module can teach
you useful unix skills that may come in handy someday :)
## Background
A "tar file" or "tarball" is an archive of file system entries
(directories, files, links, etc.) The name comes from "tape archive".
If you run `man tar` on almost any Unix command line, you'll learn
quite a bit about what it can do, and its history.
Tar has 5 main top-level commands:
* `c` Create an archive
* `r` Replace entries within an archive
* `u` Update entries within an archive (ie, replace if they're newer)
* `t` List out the contents of an archive
* `x` Extract an archive to disk
The other flags and options modify how this top level function works.
## High-Level API
These 5 functions are the high-level API. All of them have a
single-character name (for unix nerds familiar with `tar(1)`) as well
as a long name (for everyone else).
All the high-level functions take the following arguments, all three
of which are optional and may be omitted.
1. `options` - An optional object specifying various options
2. `paths` - An array of paths to add or extract
3. `callback` - Called when the command is completed, if async. (If
sync or no file specified, providing a callback throws a
`TypeError`.)
If the command is sync (ie, if `options.sync=true`), then the
callback is not allowed, since the action will be completed immediately.
If a `file` argument is specified, and the command is async, then a
`Promise` is returned. In this case, if async, a callback may be
provided which is called when the command is completed.
If a `file` option is not specified, then a stream is returned. For
`create`, this is a readable stream of the generated archive. For
`list` and `extract` this is a writable stream that an archive should
be written into. If a file is not specified, then a callback is not
allowed, because you're already getting a stream to work with.
`replace` and `update` only work on existing archives, and so require
a `file` argument.
Sync commands without a file argument return a stream that acts on its
input immediately in the same tick. For readable streams, this means
that all of the data is immediately available by calling
`stream.read()`. For writable streams, it will be acted upon as soon
as it is provided, but this can be at any time.
### Warnings and Errors
Tar emits warnings and errors for recoverable and unrecoverable situations,
respectively. In many cases, a warning only affects a single entry in an
archive, or is simply informing you that it's modifying an entry to comply
with the settings provided.
Unrecoverable warnings will always raise an error (ie, emit `'error'` on
streaming actions, throw for non-streaming sync actions, reject the
returned Promise for non-streaming async operations, or call a provided
callback with an `Error` as the first argument). Recoverable errors will
raise an error only if `strict: true` is set in the options.
Respond to (recoverable) warnings by listening to the `warn` event.
Handlers receive 3 arguments:
- `code` String. One of the error codes below. This may not match
`data.code`, which preserves the original error code from fs and zlib.
- `message` String. More details about the error.
- `data` Metadata about the error. An `Error` object for errors raised by
fs and zlib. All fields are attached to errors raisd by tar. Typically
contains the following fields, as relevant:
- `tarCode` The tar error code.
- `code` Either the tar error code, or the error code set by the
underlying system.
- `file` The archive file being read or written.
- `cwd` Working directory for creation and extraction operations.
- `entry` The entry object (if it could be created) for `TAR_ENTRY_INFO`,
`TAR_ENTRY_INVALID`, and `TAR_ENTRY_ERROR` warnings.
- `header` The header object (if it could be created, and the entry could
not be created) for `TAR_ENTRY_INFO` and `TAR_ENTRY_INVALID` warnings.
- `recoverable` Boolean. If `false`, then the warning will emit an
`error`, even in non-strict mode.
#### Error Codes
* `TAR_ENTRY_INFO` An informative error indicating that an entry is being
modified, but otherwise processed normally. For example, removing `/` or
`C:\` from absolute paths if `preservePaths` is not set.
* `TAR_ENTRY_INVALID` An indication that a given entry is not a valid tar
archive entry, and will be skipped. This occurs when:
- a checksum fails,
- a `linkpath` is missing for a link type, or
- a `linkpath` is provided for a non-link type.
If every entry in a parsed archive raises an `TAR_ENTRY_INVALID` error,
then the archive is presumed to be unrecoverably broken, and
`TAR_BAD_ARCHIVE` will be raised.
* `TAR_ENTRY_ERROR` The entry appears to be a valid tar archive entry, but
encountered an error which prevented it from being unpacked. This occurs
when:
- an unrecoverable fs error happens during unpacking,
- an entry has `..` in the path and `preservePaths` is not set, or
- an entry is extracting through a symbolic link, when `preservePaths` is
not set.
* `TAR_ENTRY_UNSUPPORTED` An indication that a given entry is
a valid archive entry, but of a type that is unsupported, and so will be
skipped in archive creation or extracting.
* `TAR_ABORT` When parsing gzipped-encoded archives, the parser will
abort the parse process raise a warning for any zlib errors encountered.
Aborts are considered unrecoverable for both parsing and unpacking.
* `TAR_BAD_ARCHIVE` The archive file is totally hosed. This can happen for
a number of reasons, and always occurs at the end of a parse or extract:
- An entry body was truncated before seeing the full number of bytes.
- The archive contained only invalid entries, indicating that it is
likely not an archive, or at least, not an archive this library can
parse.
`TAR_BAD_ARCHIVE` is considered informative for parse operations, but
unrecoverable for extraction. Note that, if encountered at the end of an
extraction, tar WILL still have extracted as much it could from the
archive, so there may be some garbage files to clean up.
Errors that occur deeper in the system (ie, either the filesystem or zlib)
will have their error codes left intact, and a `tarCode` matching one of
the above will be added to the warning metadata or the raised error object.
Errors generated by tar will have one of the above codes set as the
`error.code` field as well, but since errors originating in zlib or fs will
have their original codes, it's better to read `error.tarCode` if you wish
to see how tar is handling the issue.
### Examples
The API mimics the `tar(1)` command line functionality, with aliases
for more human-readable option and function names. The goal is that
if you know how to use `tar(1)` in Unix, then you know how to use
`require('tar')` in JavaScript.
To replicate `tar czf my-tarball.tgz files and folders`, you'd do:
```js
tar.c(
{
gzip: <true|gzip options>,
file: 'my-tarball.tgz'
},
['some', 'files', 'and', 'folders']
).then(_ => { .. tarball has been created .. })
```
To replicate `tar cz files and folders > my-tarball.tgz`, you'd do:
```js
tar.c( // or tar.create
{
gzip: <true|gzip options>
},
['some', 'files', 'and', 'folders']
).pipe(fs.createWriteStream('my-tarball.tgz'))
```
To replicate `tar xf my-tarball.tgz` you'd do:
```js
tar.x( // or tar.extract(
{
file: 'my-tarball.tgz'
}
).then(_=> { .. tarball has been dumped in cwd .. })
```
To replicate `cat my-tarball.tgz | tar x -C some-dir --strip=1`:
```js
fs.createReadStream('my-tarball.tgz').pipe(
tar.x({
strip: 1,
C: 'some-dir' // alias for cwd:'some-dir', also ok
})
)
```
To replicate `tar tf my-tarball.tgz`, do this:
```js
tar.t({
file: 'my-tarball.tgz',
onentry: entry => { .. do whatever with it .. }
})
```
To replicate `cat my-tarball.tgz | tar t` do:
```js
fs.createReadStream('my-tarball.tgz')
.pipe(tar.t())
.on('entry', entry => { .. do whatever with it .. })
```
To do anything synchronous, add `sync: true` to the options. Note
that sync functions don't take a callback and don't return a promise.
When the function returns, it's already done. Sync methods without a
file argument return a sync stream, which flushes immediately. But,
of course, it still won't be done until you `.end()` it.
To filter entries, add `filter: <function>` to the options.
Tar-creating methods call the filter with `filter(path, stat)`.
Tar-reading methods (including extraction) call the filter with
`filter(path, entry)`. The filter is called in the `this`-context of
the `Pack` or `Unpack` stream object.
The arguments list to `tar t` and `tar x` specify a list of filenames
to extract or list, so they're equivalent to a filter that tests if
the file is in the list.
For those who _aren't_ fans of tar's single-character command names:
```
tar.c === tar.create
tar.r === tar.replace (appends to archive, file is required)
tar.u === tar.update (appends if newer, file is required)
tar.x === tar.extract
tar.t === tar.list
```
Keep reading for all the command descriptions and options, as well as
the low-level API that they are built on.
### tar.c(options, fileList, callback) [alias: tar.create]
Create a tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Write the tarball archive to the specified filename. If this
is specified, then the callback will be fired when the file has been
written, and a promise will be returned that resolves when the file
is written. If a filename is not specified, then a Readable Stream
will be returned which will emit the file data. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`. If this is set,
and a file is not provided, then the resulting stream will already
have the data ready to `read` or `emit('data')` as soon as you
request it.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `mode` The mode to set on the created file archive
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
### tar.x(options, fileList, callback) [alias: tar.extract]
Extract a tarball archive.
The `fileList` is an array of paths to extract from the tarball. If
no paths are provided, then all the entries are extracted.
If the archive is gzipped, then tar will detect this and unzip it.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
Most extraction errors will cause a `warn` event to be emitted. If
the `cwd` is missing, or not a directory, then the extraction will
fail completely.
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory. [Alias: `C`]
- `file` The archive file to extract. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Create files and directories synchronously.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive. [Alias: `keep-newer`,
`keep-newer-files`]
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies. [Alias: `k`, `keep-existing`]
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
[Alias: `P`]
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file. [Alias:
`U`]
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks. [Alias: `strip-components`, `stripComponents`]
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
[Alias: `p`]
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries. [Alias: `m`, `no-mtime`]
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
The following options are mostly internal, but can be modified in some
advanced use cases, such as re-using caches between runs.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync extractions.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### tar.t(options, fileList, callback) [alias: tar.list]
List the contents of a tarball archive.
The `fileList` is an array of paths to list from the tarball. If
no paths are provided, then all the entries are listed.
If the archive is gzipped, then tar will detect this and unzip it.
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects. However, they don't emit `'data'` or `'end'`
events. (If you want to get actual readable entries, use the
`tar.Parse` class instead.)
The following options are supported:
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. [Alias: `C`]
- `file` The archive file to list. If not specified, then a
Writable stream is returned where the archive data should be
written. [Alias: `f`]
- `sync` Read the specified file synchronously. (This has no effect
when a file option isn't specified, because entries are emitted as
fast as they are parsed from the stream anyway.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter. This is important for when both `file` and
`sync` are set, because it will be called synchronously.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noResume` By default, `entry` streams are resumed immediately after
the call to `onentry`. Set `noResume: true` to suppress this
behavior. Note that by opting into this, the stream will never
complete until the entry data is consumed.
### tar.u(options, fileList, callback) [alias: tar.update]
Add files to an archive if they are newer than the entry already in
the tarball archive.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
### tar.r(options, fileList, callback) [alias: tar.replace]
Add files to an existing archive. Because later entries override
earlier entries, this effectively replaces any existing entries.
The `fileList` is an array of paths to add to the tarball. Adding a
directory also adds its children recursively.
An entry in `fileList` that starts with an `@` symbol is a tar archive
whose entries will be added. To add a file that starts with `@`,
prepend it with `./`.
The following options are supported:
- `file` Required. Write the tarball archive to the specified
filename. [Alias: `f`]
- `sync` Act synchronously. If this is set, then any provided file
will be fully written after the call to `tar.c`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for adding entries to the
archive. Defaults to `process.cwd()`. [Alias: `C`]
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()` [Alias: `z`]
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths. [Alias: `P`]
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories. [Alias: `n`]
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such. [Alias: `L`, `h`]
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
[Alias: `m`, `no-mtime`]
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
## Low-Level API
### class tar.Pack
A readable tar stream.
Has all the standard readable stream interface stuff. `'data'` and
`'end'` events, `read()` method, `pause()` and `resume()`, etc.
#### constructor(options)
The following options are supported:
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `strict` Treat warnings as crash-worthy errors. Default false.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `prefix` A path portion to prefix onto the entries in the archive.
- `gzip` Set to any truthy value to create a gzipped archive, or an
object with settings for `zlib.Gzip()`
- `filter` A function that gets called with `(path, stat)` for each
entry being added. Return `true` to add the entry to the archive,
or `false` to omit it.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `readdirCache` A Map object that caches calls to `readdir`.
- `jobs` A number specifying how many concurrent jobs to run.
Defaults to 4.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 16 MB.
- `noDirRecurse` Do not recursively archive the contents of
directories.
- `follow` Set to true to pack the targets of symbolic links. Without
this option, symbolic links are archived as such.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `mtime` Set to a `Date` object to force a specific `mtime` for
everything added to the archive. Overridden by `noMtime`.
#### add(path)
Adds an entry to the archive. Returns the Pack stream.
#### write(path)
Adds an entry to the archive. Returns true if flushed.
#### end()
Finishes the archive.
### class tar.Pack.Sync
Synchronous version of `tar.Pack`.
### class tar.Unpack
A writable stream that unpacks a tar archive onto the file system.
All the normal writable stream stuff is supported. `write()` and
`end()` methods, `'drain'` events, etc.
Note that all directories that are created will be forced to be
writable, readable, and listable by their owner, to avoid cases where
a directory prevents extraction of child entries by virtue of its
mode.
`'close'` is emitted when it's done writing stuff to the file system.
Most unpack errors will cause a `warn` event to be emitted. If the
`cwd` is missing, or not a directory, then an error will be emitted.
#### constructor(options)
- `cwd` Extract files relative to the specified directory. Defaults
to `process.cwd()`. If provided, this must exist and must be a
directory.
- `filter` A function that gets called with `(path, entry)` for each
entry being unpacked. Return `true` to unpack the entry from the
archive, or `false` to skip it.
- `newer` Set to true to keep the existing file on disk if it's newer
than the file in the archive.
- `keep` Do not overwrite existing files. In particular, if a file
appears more than once in an archive, later copies will not
overwrite earlier copies.
- `preservePaths` Allow absolute paths, paths containing `..`, and
extracting through symbolic links. By default, `/` is stripped from
absolute paths, `..` paths are not extracted, and any file whose
location would be modified by a symbolic link is not extracted.
- `unlink` Unlink files before creating them. Without this option,
tar overwrites existing files, which preserves existing hardlinks.
With this option, existing hardlinks will be broken, as will any
symlink that would affect the location of an extracted file.
- `strip` Remove the specified number of leading path elements.
Pathnames with fewer elements will be silently skipped. Note that
the pathname is edited after applying the filter, but before
security checks.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `umask` Filter the modes of entries like `process.umask()`.
- `dmode` Default mode for directories
- `fmode` Default mode for files
- `dirCache` A Map object of which directories exist.
- `maxMetaEntrySize` The maximum size of meta entries that is
supported. Defaults to 1 MB.
- `preserveOwner` If true, tar will set the `uid` and `gid` of
extracted entries to the `uid` and `gid` fields in the archive.
This defaults to true when run as root, and false otherwise. If
false, then files and directories will be set with the owner and
group of the user running the process. This is similar to `-p` in
`tar(1)`, but ACLs and other system-specific data is never unpacked
in this implementation, and modes are set by default already.
- `win32` True if on a windows platform. Causes behavior where
filenames containing `<|>?` chars are converted to
windows-compatible values while being unpacked.
- `uid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified user id, regardless of the `uid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`gid` option.
- `gid` Set to a number to force ownership of all extracted files and
folders, and all implicitly created directories, to be owned by the
specified group id, regardless of the `gid` field in the archive.
Cannot be used along with `preserveOwner`. Requires also setting a
`uid` option.
- `noMtime` Set to true to omit writing `mtime` value for extracted
entries.
- `transform` Provide a function that takes an `entry` object, and
returns a stream, or any falsey value. If a stream is provided,
then that stream's data will be written instead of the contents of
the archive entry. If a falsey value is provided, then the entry is
written to disk as normal. (To exclude items from extraction, use
the `filter` option described above.)
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
### class tar.Unpack.Sync
Synchronous version of `tar.Unpack`.
Note that using an asynchronous stream type with the `transform`
option will cause undefined behavior in sync unpack streams.
[MiniPass](http://npm.im/minipass)-based streams are designed for this
use case.
### class tar.Parse
A writable stream that parses a tar archive stream. All the standard
writable stream stuff is supported.
If the archive is gzipped, then tar will detect this and unzip it.
Emits `'entry'` events with `tar.ReadEntry` objects, which are
themselves readable streams that you can pipe wherever.
Each `entry` will not emit until the one before it is flushed through,
so make sure to either consume the data (with `on('data', ...)` or
`.pipe(...)`) or throw it away with `.resume()` to keep the stream
flowing.
#### constructor(options)
Returns an event emitter that emits `entry` events with
`tar.ReadEntry` objects.
The following options are supported:
- `strict` Treat warnings as crash-worthy errors. Default false.
- `filter` A function that gets called with `(path, entry)` for each
entry being listed. Return `true` to emit the entry from the
archive, or `false` to skip it.
- `onentry` A function that gets called with `(entry)` for each entry
that passes the filter.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
#### abort(error)
Stop all parsing activities. This is called when there are zlib
errors. It also emits an unrecoverable warning with the error provided.
### class tar.ReadEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being read out of a tar archive.
It has the following fields:
- `extended` The extended metadata object provided to the constructor.
- `globalExtended` The global extended metadata object provided to the
constructor.
- `remain` The number of bytes remaining to be written into the
stream.
- `blockRemain` The number of 512-byte blocks remaining to be written
into the stream.
- `ignore` Whether this entry should be ignored.
- `meta` True if this represents metadata about the next entry, false
if it represents a filesystem object.
- All the fields from the header, extended header, and global extended
header are added to the ReadEntry object. So it has `path`, `type`,
`size, `mode`, and so on.
#### constructor(header, extended, globalExtended)
Create a new ReadEntry object with the specified header, extended
header, and global extended header values.
### class tar.WriteEntry extends [MiniPass](http://npm.im/minipass)
A representation of an entry that is being written from the file
system into a tar archive.
Emits data for the Header, and for the Pax Extended Header if one is
required, as well as any body data.
Creating a WriteEntry for a directory does not also create
WriteEntry objects for all of the directory contents.
It has the following fields:
- `path` The path field that will be written to the archive. By
default, this is also the path from the cwd to the file system
object.
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `myuid` If supported, the uid of the user running the current
process.
- `myuser` The `env.USER` string if set, or `''`. Set as the entry
`uname` field if the file's `uid` matches `this.myuid`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/` and filenames containing the windows-compatible
forms of `<|>?:` characters are converted to actual `<|>?:` characters
in the archive.
- `noPax` Suppress pax extended headers. Note that this means that
long paths and linkpaths will be truncated, and large or negative
numeric values may be interpreted incorrectly.
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
#### constructor(path, options)
`path` is the path of the entry as it is written in the archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `maxReadSize` The maximum buffer size for `fs.read()` operations.
Defaults to 1 MB.
- `linkCache` A Map object containing the device and inode value for
any file whose nlink is > 1, to identify hard links.
- `statCache` A Map object that caches calls `lstat`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `cwd` The current working directory for creating the archive.
Defaults to `process.cwd()`.
- `absolute` The absolute path to the entry on the filesystem. By
default, this is `path.resolve(this.cwd, this.path)`, but it can be
overridden explicitly.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `win32` True if on a windows platform. Causes behavior where paths
replace `\` with `/`.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
- `umask` Set to restrict the modes on the entries in the archive,
somewhat like how umask works on file creation. Defaults to
`process.umask()` on unix systems, or `0o22` on Windows.
#### warn(message, data)
If strict, emit an error with the provided message.
Othewise, emit a `'warn'` event with the provided message and data.
### class tar.WriteEntry.Sync
Synchronous version of tar.WriteEntry
### class tar.WriteEntry.Tar
A version of tar.WriteEntry that gets its data from a tar.ReadEntry
instead of from the filesystem.
#### constructor(readEntry, options)
`readEntry` is the entry being read out of another archive.
The following options are supported:
- `portable` Omit metadata that is system-specific: `ctime`, `atime`,
`uid`, `gid`, `uname`, `gname`, `dev`, `ino`, and `nlink`. Note
that `mtime` is still included, because this is necessary for other
time-based operations. Additionally, `mode` is set to a "reasonable
default" for most unix systems, based on a `umask` value of `0o22`.
- `preservePaths` Allow absolute paths. By default, `/` is stripped
from absolute paths.
- `strict` Treat warnings as crash-worthy errors. Default false.
- `onwarn` A function that will get called with `(code, message, data)` for
any warnings encountered. (See "Warnings and Errors")
- `noMtime` Set to true to omit writing `mtime` values for entries.
Note that this prevents using other mtime-based features like
`tar.update` or the `keepNewer` option with the resulting tar archive.
### class tar.Header
A class for reading and writing header blocks.
It has the following fields:
- `nullBlock` True if decoding a block which is entirely composed of
`0x00` null bytes. (Useful because tar files are terminated by
at least 2 null blocks.)
- `cksumValid` True if the checksum in the header is valid, false
otherwise.
- `needPax` True if the values, as encoded, will require a Pax
extended header.
- `path` The path of the entry.
- `mode` The 4 lowest-order octal digits of the file mode. That is,
read/write/execute permissions for world, group, and owner, and the
setuid, setgid, and sticky bits.
- `uid` Numeric user id of the file owner
- `gid` Numeric group id of the file owner
- `size` Size of the file in bytes
- `mtime` Modified time of the file
- `cksum` The checksum of the header. This is generated by adding all
the bytes of the header block, treating the checksum field itself as
all ascii space characters (that is, `0x20`).
- `type` The human-readable name of the type of entry this represents,
or the alphanumeric key if unknown.
- `typeKey` The alphanumeric key for the type of entry this header
represents.
- `linkpath` The target of Link and SymbolicLink entries.
- `uname` Human-readable user name of the file owner
- `gname` Human-readable group name of the file owner
- `devmaj` The major portion of the device number. Always `0` for
files, directories, and links.
- `devmin` The minor portion of the device number. Always `0` for
files, directories, and links.
- `atime` File access time.
- `ctime` File change time.
#### constructor(data, [offset=0])
`data` is optional. It is either a Buffer that should be interpreted
as a tar Header starting at the specified offset and continuing for
512 bytes, or a data object of keys and values to set on the header
object, and eventually encode as a tar Header.
#### decode(block, offset)
Decode the provided buffer starting at the specified offset.
Buffer length must be greater than 512 bytes.
#### set(data)
Set the fields in the data object.
#### encode(buffer, offset)
Encode the header fields into the buffer at the specified offset.
Returns `this.needPax` to indicate whether a Pax Extended Header is
required to properly encode the specified data.
### class tar.Pax
An object representing a set of key-value pairs in an Pax extended
header entry.
It has the following fields. Where the same name is used, they have
the same semantics as the tar.Header field of the same name.
- `global` True if this represents a global extended header, or false
if it is for a single entry.
- `atime`
- `charset`
- `comment`
- `ctime`
- `gid`
- `gname`
- `linkpath`
- `mtime`
- `path`
- `size`
- `uid`
- `uname`
- `dev`
- `ino`
- `nlink`
#### constructor(object, global)
Set the fields set in the object. `global` is a boolean that defaults
to false.
#### encode()
Return a Buffer containing the header and body for the Pax extended
header entry, or `null` if there is nothing to encode.
#### encodeBody()
Return a string representing the body of the pax extended header
entry.
#### encodeField(fieldName)
Return a string representing the key/value encoding for the specified
fieldName, or `''` if the field is unset.
### tar.Pax.parse(string, extended, global)
Return a new Pax object created by parsing the contents of the string
provided.
If the `extended` object is set, then also add the fields from that
object. (This is necessary because multiple metadata entries can
occur in sequence.)
### tar.types
A translation table for the `type` field in tar headers.
#### tar.types.name.get(code)
Get the human-readable name for a given alphanumeric code.
#### tar.types.code.get(name)
Get the alphanumeric code for a given human-readable name.
Like `chown -R`.
Takes the same arguments as `fs.chown()`
# cliui
[](https://travis-ci.org/yargs/cliui)
[](https://coveralls.io/r/yargs/cliui?branch=)
[](https://www.npmjs.com/package/cliui)
[](https://github.com/conventional-changelog/standard-version)
easily create complex multi-column command-line-interfaces.
## Example
```js
var ui = require('cliui')()
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 2, 0]
})
ui.div(
{
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
},
{
text: "the file to load." +
chalk.green("(if this description is long it wraps).")
,
width: 20
},
{
text: chalk.red("[required]"),
align: 'right'
}
)
console.log(ui.toString())
```
<img width="500" src="screenshot.png">
## Layout DSL
cliui exposes a simple layout DSL:
If you create a single `ui.div`, passing a string rather than an
object:
* `\n`: characters will be interpreted as new rows.
* `\t`: characters will be interpreted as new columns.
* `\s`: characters will be interpreted as padding.
**as an example...**
```js
var ui = require('./')({
width: 60
})
ui.div(
'Usage: node ./bin/foo.js\n' +
' <regex>\t provide a regex\n' +
' <glob>\t provide a glob\t [required]'
)
console.log(ui.toString())
```
**will output:**
```shell
Usage: node ./bin/foo.js
<regex> provide a regex
<glob> provide a glob [required]
```
## Methods
```js
cliui = require('cliui')
```
### cliui({width: integer})
Specify the maximum width of the UI being generated.
If no width is provided, cliui will try to get the current window's width and use it, and if that doesn't work, width will be set to `80`.
### cliui({wrap: boolean})
Enable or disable the wrapping of text in a column.
### cliui.div(column, column, column)
Create a row with any number of columns, a column
can either be a string, or an object with the following
options:
* **text:** some text to place in the column.
* **width:** the width of a column.
* **align:** alignment, `right` or `center`.
* **padding:** `[top, right, bottom, left]`.
* **border:** should a border be placed around the div?
### cliui.span(column, column, column)
Similar to `div`, except the next row will be appended without
a new line being created.
### cliui.resetOutput()
Resets the UI elements of the current cliui instance, maintaining the values
set for `width` and `wrap`.
# set-blocking
[](https://travis-ci.org/yargs/set-blocking)
[](https://www.npmjs.com/package/set-blocking)
[](https://coveralls.io/r/yargs/set-blocking?branch=master)
[](https://github.com/conventional-changelog/standard-version)
set blocking `stdio` and `stderr` ensuring that terminal output does not truncate.
```js
const setBlocking = require('set-blocking')
setBlocking(true)
console.log(someLargeStringToOutput)
```
## Historical Context/Word of Warning
This was created as a shim to address the bug discussed in [node #6456](https://github.com/nodejs/node/issues/6456). This bug crops up on
newer versions of Node.js (`0.12+`), truncating terminal output.
You should be mindful of the side-effects caused by using `set-blocking`:
* if your module sets blocking to `true`, it will effect other modules
consuming your library. In [yargs](https://github.com/yargs/yargs/blob/master/yargs.js#L653) we only call
`setBlocking(true)` once we already know we are about to call `process.exit(code)`.
* this patch will not apply to subprocesses spawned with `isTTY = true`, this is
the [default `spawn()` behavior](https://nodejs.org/api/child_process.html#child_process_child_process_spawn_command_args_options).
## License
ISC
# yallist
Yet Another Linked List
There are many doubly-linked list implementations like it, but this
one is mine.
For when an array would be too big, and a Map can't be iterated in
reverse order.
[](https://travis-ci.org/isaacs/yallist) [](https://coveralls.io/github/isaacs/yallist)
## basic usage
```javascript
var yallist = require('yallist')
var myList = yallist.create([1, 2, 3])
myList.push('foo')
myList.unshift('bar')
// of course pop() and shift() are there, too
console.log(myList.toArray()) // ['bar', 1, 2, 3, 'foo']
myList.forEach(function (k) {
// walk the list head to tail
})
myList.forEachReverse(function (k, index, list) {
// walk the list tail to head
})
var myDoubledList = myList.map(function (k) {
return k + k
})
// now myDoubledList contains ['barbar', 2, 4, 6, 'foofoo']
// mapReverse is also a thing
var myDoubledListReverse = myList.mapReverse(function (k) {
return k + k
}) // ['foofoo', 6, 4, 2, 'barbar']
var reduced = myList.reduce(function (set, entry) {
set += entry
return set
}, 'start')
console.log(reduced) // 'startfoo123bar'
```
## api
The whole API is considered "public".
Functions with the same name as an Array method work more or less the
same way.
There's reverse versions of most things because that's the point.
### Yallist
Default export, the class that holds and manages a list.
Call it with either a forEach-able (like an array) or a set of
arguments, to initialize the list.
The Array-ish methods all act like you'd expect. No magic length,
though, so if you change that it won't automatically prune or add
empty spots.
### Yallist.create(..)
Alias for Yallist function. Some people like factories.
#### yallist.head
The first node in the list
#### yallist.tail
The last node in the list
#### yallist.length
The number of nodes in the list. (Change this at your peril. It is
not magic like Array length.)
#### yallist.toArray()
Convert the list to an array.
#### yallist.forEach(fn, [thisp])
Call a function on each item in the list.
#### yallist.forEachReverse(fn, [thisp])
Call a function on each item in the list, in reverse order.
#### yallist.get(n)
Get the data at position `n` in the list. If you use this a lot,
probably better off just using an Array.
#### yallist.getReverse(n)
Get the data at position `n`, counting from the tail.
#### yallist.map(fn, thisp)
Create a new Yallist with the result of calling the function on each
item.
#### yallist.mapReverse(fn, thisp)
Same as `map`, but in reverse.
#### yallist.pop()
Get the data from the list tail, and remove the tail from the list.
#### yallist.push(item, ...)
Insert one or more items to the tail of the list.
#### yallist.reduce(fn, initialValue)
Like Array.reduce.
#### yallist.reduceReverse
Like Array.reduce, but in reverse.
#### yallist.reverse
Reverse the list in place.
#### yallist.shift()
Get the data from the list head, and remove the head from the list.
#### yallist.slice([from], [to])
Just like Array.slice, but returns a new Yallist.
#### yallist.sliceReverse([from], [to])
Just like yallist.slice, but the result is returned in reverse.
#### yallist.toArray()
Create an array representation of the list.
#### yallist.toArrayReverse()
Create a reversed array representation of the list.
#### yallist.unshift(item, ...)
Insert one or more items to the head of the list.
#### yallist.unshiftNode(node)
Move a Node object to the front of the list. (That is, pull it out of
wherever it lives, and make it the new head.)
If the node belongs to a different list, then that list will remove it
first.
#### yallist.pushNode(node)
Move a Node object to the end of the list. (That is, pull it out of
wherever it lives, and make it the new tail.)
If the node belongs to a list already, then that list will remove it
first.
#### yallist.removeNode(node)
Remove a node from the list, preserving referential integrity of head
and tail and other nodes.
Will throw an error if you try to have a list remove a node that
doesn't belong to it.
### Yallist.Node
The class that holds the data and is actually the list.
Call with `var n = new Node(value, previousNode, nextNode)`
Note that if you do direct operations on Nodes themselves, it's very
easy to get into weird states where the list is broken. Be careful :)
#### node.next
The next node in the list.
#### node.prev
The previous node in the list.
#### node.value
The data the node contains.
#### node.list
The list to which this node belongs. (Null if it does not belong to
any list.)
[](http://travis-ci.org/dankogai/js-base64)
# base64.js
Yet another [Base64] transcoder.
[Base64]: http://en.wikipedia.org/wiki/Base64
## HEADS UP
In version 3.0 `js-base64` switch to ES2015 module so it is no longer compatible with legacy browsers like IE (see below). And since version 3.3 it is written in TypeScript. Now `base64.mjs` is compiled from `base64.ts` then `base64.js` is generated from `base64.mjs`.
## Install
```shell
$ npm install --save js-base64
```
## Usage
### In Browser
Locally…
```html
<script src="base64.js"></script>
```
… or Directly from CDN. In which case you don't even need to install.
```html
<script src="https://cdn.jsdelivr.net/npm/[email protected]/base64.min.js"></script>
```
This good old way loads `Base64` in the global context (`window`). Though `Base64.noConflict()` is made available, you should consider using ES6 Module to avoid tainting `window`.
### As an ES6 Module
locally…
```javascript
import { Base64 } from 'js-base64';
```
```javascript
// or if you prefer no Base64 namespace
import { encode, decode } from 'js-base64';
```
or even remotely.
```html
<script type="module">
// note jsdelivr.net does not automatically minify .mjs
import { Base64 } from 'https://cdn.jsdelivr.net/npm/[email protected]/base64.mjs';
</script>
```
```html
<script type="module">
// or if you prefer no Base64 namespace
import { encode, decode } from 'https://cdn.jsdelivr.net/npm/[email protected]/base64.mjs';
</script>
```
### node.js (commonjs)
```javascript
const {Base64} = require('js-base64');
```
Unlike the case above, the global context is no longer modified.
You can also use [esm] to `import` instead of `require`.
[esm]: https://github.com/standard-things/esm
```javascript
require=require('esm')(module);
import {Base64} from 'js-base64';
```
## SYNOPSIS
```javascript
let latin = 'dankogai';
let utf8 = '小飼弾'
let u8s = new Uint8Array([100,97,110,107,111,103,97,105]);
Base64.encode(latin); // ZGFua29nYWk=
Base64.btoa(latin); // ZGFua29nYWk=
Base64.btoa(utf8); // raises exception
Base64.fromUint8Array(u8s); // ZGFua29nYWk=
Base64.fromUint8Array(u8s, true); // ZGFua29nYW which is URI safe
Base64.encode(utf8); // 5bCP6aO85by+
Base64.encode(utf8, true) // 5bCP6aO85by-
Base64.encodeURI(utf8); // 5bCP6aO85by-
```
```javascript
Base64.decode( 'ZGFua29nYWk=');// dankogai
Base64.atob( 'ZGFua29nYWk=');// dankogai
Base64.atob( '5bCP6aO85by+');// 'å°é£¼å¼¾' which is nonsense
Base64.toUint8Array('ZGFua29nYWk=');// u8s above
Base64.decode( '5bCP6aO85by+');// 小飼弾
// note .decodeURI() is unnecessary since it accepts both flavors
Base64.decode( '5bCP6aO85by-');// 小飼弾
```
```javascript
Base64.isValid(0); // false: 0 is not string
Base64.isValid(''); // true: a valid Base64-encoded empty byte
Base64.isValid('ZA=='); // true: a valid Base64-encoded 'd'
Base64.isValid('Z A='); // true: whitespaces are okay
Base64.isValid('ZA'); // true: padding ='s can be omitted
Base64.isValid('++'); // true: can be non URL-safe
Base64.isValid('--'); // true: or URL-safe
Base64.isValid('+-'); // false: can't mix both
```
### Built-in Extensions
By default `Base64` leaves built-in prototypes untouched. But you can extend them as below.
```javascript
// you have to explicitly extend String.prototype
Base64.extendString();
// once extended, you can do the following
'dankogai'.toBase64(); // ZGFua29nYWk=
'小飼弾'.toBase64(); // 5bCP6aO85by+
'小飼弾'.toBase64(true); // 5bCP6aO85by-
'小飼弾'.toBase64URI(); // 5bCP6aO85by- ab alias of .toBase64(true)
'小飼弾'.toBase64URL(); // 5bCP6aO85by- an alias of .toBase64URI()
'ZGFua29nYWk='.fromBase64(); // dankogai
'5bCP6aO85by+'.fromBase64(); // 小飼弾
'5bCP6aO85by-'.fromBase64(); // 小飼弾
'5bCP6aO85by-'.toUint8Array();// u8s above
```
```javascript
// you have to explicitly extend String.prototype
Base64.extendString();
// once extended, you can do the following
u8s.toBase64(); // 'ZGFua29nYWk='
u8s.toBase64URI(); // 'ZGFua29nYWk'
u8s.toBase64URL(); // 'ZGFua29nYWk' an alias of .toBase64URI()
```
```javascript
// extend all at once
Base64.extendBuiltins()
```
## `.decode()` vs `.atob` (and `.encode()` vs `btoa()`)
Suppose you have:
```
var pngBase64 =
"iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVR42mNkYAAAAAYAAjCB0C8AAAAASUVORK5CYII=";
```
Which is a Base64-encoded 1x1 transparent PNG, **DO NOT USE** `Base64.decode(pngBase64)`. Use `Base64.atob(pngBase64)` instead. `Base64.decode()` decodes to UTF-8 string while `Base64.atob()` decodes to bytes, which is compatible to browser built-in `atob()` (Which is absent in node.js). The same rule applies to the opposite direction.
Or even better, `Base64.toUint8Array(pngBase64)`.
### If you really, really need an ES5 version
You can transpiles to an ES5 that runs on IE11. Do the following in your shell.
```shell
$ make base64.es5.js
```
bs58
====
[](https://travis-ci.org/cryptocoinjs/bs58)
JavaScript component to compute base 58 encoding. This encoding is typically used for crypto currencies such as Bitcoin.
**Note:** If you're looking for **base 58 check** encoding, see: [https://github.com/bitcoinjs/bs58check](https://github.com/bitcoinjs/bs58check), which depends upon this library.
Install
-------
npm i --save bs58
API
---
### encode(input)
`input` must be a [Buffer](https://nodejs.org/api/buffer.html) or an `Array`. It returns a `string`.
**example**:
```js
const bs58 = require('bs58')
const bytes = Buffer.from('003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187', 'hex')
const address = bs58.encode(bytes)
console.log(address)
// => 16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS
```
### decode(input)
`input` must be a base 58 encoded string. Returns a [Buffer](https://nodejs.org/api/buffer.html).
**example**:
```js
const bs58 = require('bs58')
const address = '16UjcYNBG9GTK4uq2f7yYEbuifqCzoLMGS'
const bytes = bs58.decode(address)
console.log(out.toString('hex'))
// => 003c176e659bea0f29a3e9bf7880c112b1b31b4dc826268187
```
Hack / Test
-----------
Uses JavaScript standard style. Read more:
[](https://github.com/feross/standard)
Credits
-------
- [Mike Hearn](https://github.com/mikehearn) for original Java implementation
- [Stefan Thomas](https://github.com/justmoon) for porting to JavaScript
- [Stephan Pair](https://github.com/gasteve) for buffer improvements
- [Daniel Cousens](https://github.com/dcousens) for cleanup and merging improvements from bitcoinjs-lib
- [Jared Deckard](https://github.com/deckar01) for killing `bigi` as a dependency
License
-------
MIT
# safe-buffer [![travis][travis-image]][travis-url] [![npm][npm-image]][npm-url] [![downloads][downloads-image]][downloads-url] [![javascript style guide][standard-image]][standard-url]
[travis-image]: https://img.shields.io/travis/feross/safe-buffer/master.svg
[travis-url]: https://travis-ci.org/feross/safe-buffer
[npm-image]: https://img.shields.io/npm/v/safe-buffer.svg
[npm-url]: https://npmjs.org/package/safe-buffer
[downloads-image]: https://img.shields.io/npm/dm/safe-buffer.svg
[downloads-url]: https://npmjs.org/package/safe-buffer
[standard-image]: https://img.shields.io/badge/code_style-standard-brightgreen.svg
[standard-url]: https://standardjs.com
#### Safer Node.js Buffer API
**Use the new Node.js Buffer APIs (`Buffer.from`, `Buffer.alloc`,
`Buffer.allocUnsafe`, `Buffer.allocUnsafeSlow`) in all versions of Node.js.**
**Uses the built-in implementation when available.**
## install
```
npm install safe-buffer
```
## usage
The goal of this package is to provide a safe replacement for the node.js `Buffer`.
It's a drop-in replacement for `Buffer`. You can use it by adding one `require` line to
the top of your node.js modules:
```js
var Buffer = require('safe-buffer').Buffer
// Existing buffer code will continue to work without issues:
new Buffer('hey', 'utf8')
new Buffer([1, 2, 3], 'utf8')
new Buffer(obj)
new Buffer(16) // create an uninitialized buffer (potentially unsafe)
// But you can use these new explicit APIs to make clear what you want:
Buffer.from('hey', 'utf8') // convert from many types to a Buffer
Buffer.alloc(16) // create a zero-filled buffer (safe)
Buffer.allocUnsafe(16) // create an uninitialized buffer (potentially unsafe)
```
## api
### Class Method: Buffer.from(array)
<!-- YAML
added: v3.0.0
-->
* `array` {Array}
Allocates a new `Buffer` using an `array` of octets.
```js
const buf = Buffer.from([0x62,0x75,0x66,0x66,0x65,0x72]);
// creates a new Buffer containing ASCII bytes
// ['b','u','f','f','e','r']
```
A `TypeError` will be thrown if `array` is not an `Array`.
### Class Method: Buffer.from(arrayBuffer[, byteOffset[, length]])
<!-- YAML
added: v5.10.0
-->
* `arrayBuffer` {ArrayBuffer} The `.buffer` property of a `TypedArray` or
a `new ArrayBuffer()`
* `byteOffset` {Number} Default: `0`
* `length` {Number} Default: `arrayBuffer.length - byteOffset`
When passed a reference to the `.buffer` property of a `TypedArray` instance,
the newly created `Buffer` will share the same allocated memory as the
TypedArray.
```js
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf = Buffer.from(arr.buffer); // shares the memory with arr;
console.log(buf);
// Prints: <Buffer 88 13 a0 0f>
// changing the TypedArray changes the Buffer also
arr[1] = 6000;
console.log(buf);
// Prints: <Buffer 88 13 70 17>
```
The optional `byteOffset` and `length` arguments specify a memory range within
the `arrayBuffer` that will be shared by the `Buffer`.
```js
const ab = new ArrayBuffer(10);
const buf = Buffer.from(ab, 0, 2);
console.log(buf.length);
// Prints: 2
```
A `TypeError` will be thrown if `arrayBuffer` is not an `ArrayBuffer`.
### Class Method: Buffer.from(buffer)
<!-- YAML
added: v3.0.0
-->
* `buffer` {Buffer}
Copies the passed `buffer` data onto a new `Buffer` instance.
```js
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// 'auffer'
console.log(buf2.toString());
// 'buffer' (copy is not changed)
```
A `TypeError` will be thrown if `buffer` is not a `Buffer`.
### Class Method: Buffer.from(str[, encoding])
<!-- YAML
added: v5.10.0
-->
* `str` {String} String to encode.
* `encoding` {String} Encoding to use, Default: `'utf8'`
Creates a new `Buffer` containing the given JavaScript string `str`. If
provided, the `encoding` parameter identifies the character encoding.
If not provided, `encoding` defaults to `'utf8'`.
```js
const buf1 = Buffer.from('this is a tést');
console.log(buf1.toString());
// prints: this is a tést
console.log(buf1.toString('ascii'));
// prints: this is a tC)st
const buf2 = Buffer.from('7468697320697320612074c3a97374', 'hex');
console.log(buf2.toString());
// prints: this is a tést
```
A `TypeError` will be thrown if `str` is not a string.
### Class Method: Buffer.alloc(size[, fill[, encoding]])
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
* `fill` {Value} Default: `undefined`
* `encoding` {String} Default: `utf8`
Allocates a new `Buffer` of `size` bytes. If `fill` is `undefined`, the
`Buffer` will be *zero-filled*.
```js
const buf = Buffer.alloc(5);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
The `size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
If `fill` is specified, the allocated `Buffer` will be initialized by calling
`buf.fill(fill)`. See [`buf.fill()`][] for more information.
```js
const buf = Buffer.alloc(5, 'a');
console.log(buf);
// <Buffer 61 61 61 61 61>
```
If both `fill` and `encoding` are specified, the allocated `Buffer` will be
initialized by calling `buf.fill(fill, encoding)`. For example:
```js
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf);
// <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
```
Calling `Buffer.alloc(size)` can be significantly slower than the alternative
`Buffer.allocUnsafe(size)` but ensures that the newly created `Buffer` instance
contents will *never contain sensitive data*.
A `TypeError` will be thrown if `size` is not a number.
### Class Method: Buffer.allocUnsafe(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* `Buffer` of `size` bytes. The `size` must
be less than or equal to the value of `require('buffer').kMaxLength` (on 64-bit
architectures, `kMaxLength` is `(2^31)-1`). Otherwise, a [`RangeError`][] is
thrown. A zero-length Buffer will be created if a `size` less than or equal to
0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
```js
const buf = Buffer.allocUnsafe(5);
console.log(buf);
// <Buffer 78 e0 82 02 01>
// (octets will be different, every time)
buf.fill(0);
console.log(buf);
// <Buffer 00 00 00 00 00>
```
A `TypeError` will be thrown if `size` is not a number.
Note that the `Buffer` module pre-allocates an internal `Buffer` instance of
size `Buffer.poolSize` that is used as a pool for the fast allocation of new
`Buffer` instances created using `Buffer.allocUnsafe(size)` (and the deprecated
`new Buffer(size)` constructor) only when `size` is less than or equal to
`Buffer.poolSize >> 1` (floor of `Buffer.poolSize` divided by two). The default
value of `Buffer.poolSize` is `8192` but can be modified.
Use of this pre-allocated internal memory pool is a key difference between
calling `Buffer.alloc(size, fill)` vs. `Buffer.allocUnsafe(size).fill(fill)`.
Specifically, `Buffer.alloc(size, fill)` will *never* use the internal Buffer
pool, while `Buffer.allocUnsafe(size).fill(fill)` *will* use the internal
Buffer pool if `size` is less than or equal to half `Buffer.poolSize`. The
difference is subtle but can be important when an application requires the
additional performance that `Buffer.allocUnsafe(size)` provides.
### Class Method: Buffer.allocUnsafeSlow(size)
<!-- YAML
added: v5.10.0
-->
* `size` {Number}
Allocates a new *non-zero-filled* and non-pooled `Buffer` of `size` bytes. The
`size` must be less than or equal to the value of
`require('buffer').kMaxLength` (on 64-bit architectures, `kMaxLength` is
`(2^31)-1`). Otherwise, a [`RangeError`][] is thrown. A zero-length Buffer will
be created if a `size` less than or equal to 0 is specified.
The underlying memory for `Buffer` instances created in this way is *not
initialized*. The contents of the newly created `Buffer` are unknown and
*may contain sensitive data*. Use [`buf.fill(0)`][] to initialize such
`Buffer` instances to zeroes.
When using `Buffer.allocUnsafe()` to allocate new `Buffer` instances,
allocations under 4KB are, by default, sliced from a single pre-allocated
`Buffer`. This allows applications to avoid the garbage collection overhead of
creating many individually allocated Buffers. This approach improves both
performance and memory usage by eliminating the need to track and cleanup as
many `Persistent` objects.
However, in the case where a developer may need to retain a small chunk of
memory from a pool for an indeterminate amount of time, it may be appropriate
to create an un-pooled Buffer instance using `Buffer.allocUnsafeSlow()` then
copy out the relevant bits.
```js
// need to keep around a few small chunks of memory
const store = [];
socket.on('readable', () => {
const data = socket.read();
// allocate for retained data
const sb = Buffer.allocUnsafeSlow(10);
// copy the data into the new allocation
data.copy(sb, 0, 0, 10);
store.push(sb);
});
```
Use of `Buffer.allocUnsafeSlow()` should be used only as a last resort *after*
a developer has observed undue memory retention in their applications.
A `TypeError` will be thrown if `size` is not a number.
### All the Rest
The rest of the `Buffer` API is exactly the same as in node.js.
[See the docs](https://nodejs.org/api/buffer.html).
## Related links
- [Node.js issue: Buffer(number) is unsafe](https://github.com/nodejs/node/issues/4660)
- [Node.js Enhancement Proposal: Buffer.from/Buffer.alloc/Buffer.zalloc/Buffer() soft-deprecate](https://github.com/nodejs/node-eps/pull/4)
## Why is `Buffer` unsafe?
Today, the node.js `Buffer` constructor is overloaded to handle many different argument
types like `String`, `Array`, `Object`, `TypedArrayView` (`Uint8Array`, etc.),
`ArrayBuffer`, and also `Number`.
The API is optimized for convenience: you can throw any type at it, and it will try to do
what you want.
Because the Buffer constructor is so powerful, you often see code like this:
```js
// Convert UTF-8 strings to hex
function toHex (str) {
return new Buffer(str).toString('hex')
}
```
***But what happens if `toHex` is called with a `Number` argument?***
### Remote Memory Disclosure
If an attacker can make your program call the `Buffer` constructor with a `Number`
argument, then they can make it allocate uninitialized memory from the node.js process.
This could potentially disclose TLS private keys, user data, or database passwords.
When the `Buffer` constructor is passed a `Number` argument, it returns an
**UNINITIALIZED** block of memory of the specified `size`. When you create a `Buffer` like
this, you **MUST** overwrite the contents before returning it to the user.
From the [node.js docs](https://nodejs.org/api/buffer.html#buffer_new_buffer_size):
> `new Buffer(size)`
>
> - `size` Number
>
> The underlying memory for `Buffer` instances created in this way is not initialized.
> **The contents of a newly created `Buffer` are unknown and could contain sensitive
> data.** Use `buf.fill(0)` to initialize a Buffer to zeroes.
(Emphasis our own.)
Whenever the programmer intended to create an uninitialized `Buffer` you often see code
like this:
```js
var buf = new Buffer(16)
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### Would this ever be a problem in real code?
Yes. It's surprisingly common to forget to check the type of your variables in a
dynamically-typed language like JavaScript.
Usually the consequences of assuming the wrong type is that your program crashes with an
uncaught exception. But the failure mode for forgetting to check the type of arguments to
the `Buffer` constructor is more catastrophic.
Here's an example of a vulnerable service that takes a JSON payload and converts it to
hex:
```js
// Take a JSON payload {str: "some string"} and convert it to hex
var server = http.createServer(function (req, res) {
var data = ''
req.setEncoding('utf8')
req.on('data', function (chunk) {
data += chunk
})
req.on('end', function () {
var body = JSON.parse(data)
res.end(new Buffer(body.str).toString('hex'))
})
})
server.listen(8080)
```
In this example, an http client just has to send:
```json
{
"str": 1000
}
```
and it will get back 1,000 bytes of uninitialized memory from the server.
This is a very serious bug. It's similar in severity to the
[the Heartbleed bug](http://heartbleed.com/) that allowed disclosure of OpenSSL process
memory by remote attackers.
### Which real-world packages were vulnerable?
#### [`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht)
[Mathias Buus](https://github.com/mafintosh) and I
([Feross Aboukhadijeh](http://feross.org/)) found this issue in one of our own packages,
[`bittorrent-dht`](https://www.npmjs.com/package/bittorrent-dht). The bug would allow
anyone on the internet to send a series of messages to a user of `bittorrent-dht` and get
them to reveal 20 bytes at a time of uninitialized memory from the node.js process.
Here's
[the commit](https://github.com/feross/bittorrent-dht/commit/6c7da04025d5633699800a99ec3fbadf70ad35b8)
that fixed it. We released a new fixed version, created a
[Node Security Project disclosure](https://nodesecurity.io/advisories/68), and deprecated all
vulnerable versions on npm so users will get a warning to upgrade to a newer version.
#### [`ws`](https://www.npmjs.com/package/ws)
That got us wondering if there were other vulnerable packages. Sure enough, within a short
period of time, we found the same issue in [`ws`](https://www.npmjs.com/package/ws), the
most popular WebSocket implementation in node.js.
If certain APIs were called with `Number` parameters instead of `String` or `Buffer` as
expected, then uninitialized server memory would be disclosed to the remote peer.
These were the vulnerable methods:
```js
socket.send(number)
socket.ping(number)
socket.pong(number)
```
Here's a vulnerable socket server with some echo functionality:
```js
server.on('connection', function (socket) {
socket.on('message', function (message) {
message = JSON.parse(message)
if (message.type === 'echo') {
socket.send(message.data) // send back the user's message
}
})
})
```
`socket.send(number)` called on the server, will disclose server memory.
Here's [the release](https://github.com/websockets/ws/releases/tag/1.0.1) where the issue
was fixed, with a more detailed explanation. Props to
[Arnout Kazemier](https://github.com/3rd-Eden) for the quick fix. Here's the
[Node Security Project disclosure](https://nodesecurity.io/advisories/67).
### What's the solution?
It's important that node.js offers a fast way to get memory otherwise performance-critical
applications would needlessly get a lot slower.
But we need a better way to *signal our intent* as programmers. **When we want
uninitialized memory, we should request it explicitly.**
Sensitive functionality should not be packed into a developer-friendly API that loosely
accepts many different types. This type of API encourages the lazy practice of passing
variables in without checking the type very carefully.
#### A new API: `Buffer.allocUnsafe(number)`
The functionality of creating buffers with uninitialized memory should be part of another
API. We propose `Buffer.allocUnsafe(number)`. This way, it's not part of an API that
frequently gets user input of all sorts of different types passed into it.
```js
var buf = Buffer.allocUnsafe(16) // careful, uninitialized memory!
// Immediately overwrite the uninitialized buffer with data from another buffer
for (var i = 0; i < buf.length; i++) {
buf[i] = otherBuf[i]
}
```
### How do we fix node.js core?
We sent [a PR to node.js core](https://github.com/nodejs/node/pull/4514) (merged as
`semver-major`) which defends against one case:
```js
var str = 16
new Buffer(str, 'utf8')
```
In this situation, it's implied that the programmer intended the first argument to be a
string, since they passed an encoding as a second argument. Today, node.js will allocate
uninitialized memory in the case of `new Buffer(number, encoding)`, which is probably not
what the programmer intended.
But this is only a partial solution, since if the programmer does `new Buffer(variable)`
(without an `encoding` parameter) there's no way to know what they intended. If `variable`
is sometimes a number, then uninitialized memory will sometimes be returned.
### What's the real long-term fix?
We could deprecate and remove `new Buffer(number)` and use `Buffer.allocUnsafe(number)` when
we need uninitialized memory. But that would break 1000s of packages.
~~We believe the best solution is to:~~
~~1. Change `new Buffer(number)` to return safe, zeroed-out memory~~
~~2. Create a new API for creating uninitialized Buffers. We propose: `Buffer.allocUnsafe(number)`~~
#### Update
We now support adding three new APIs:
- `Buffer.from(value)` - convert from any type to a buffer
- `Buffer.alloc(size)` - create a zero-filled buffer
- `Buffer.allocUnsafe(size)` - create an uninitialized buffer with given size
This solves the core problem that affected `ws` and `bittorrent-dht` which is
`Buffer(variable)` getting tricked into taking a number argument.
This way, existing code continues working and the impact on the npm ecosystem will be
minimal. Over time, npm maintainers can migrate performance-critical code to use
`Buffer.allocUnsafe(number)` instead of `new Buffer(number)`.
### Conclusion
We think there's a serious design issue with the `Buffer` API as it exists today. It
promotes insecure software by putting high-risk functionality into a convenient API
with friendly "developer ergonomics".
This wasn't merely a theoretical exercise because we found the issue in some of the
most popular npm packages.
Fortunately, there's an easy fix that can be applied today. Use `safe-buffer` in place of
`buffer`.
```js
var Buffer = require('safe-buffer').Buffer
```
Eventually, we hope that node.js core can switch to this new, safer behavior. We believe
the impact on the ecosystem would be minimal since it's not a breaking change.
Well-maintained, popular packages would be updated to use `Buffer.alloc` quickly, while
older, insecure packages would magically become safe from this attack vector.
## links
- [Node.js PR: buffer: throw if both length and enc are passed](https://github.com/nodejs/node/pull/4514)
- [Node Security Project disclosure for `ws`](https://nodesecurity.io/advisories/67)
- [Node Security Project disclosure for`bittorrent-dht`](https://nodesecurity.io/advisories/68)
## credit
The original issues in `bittorrent-dht`
([disclosure](https://nodesecurity.io/advisories/68)) and
`ws` ([disclosure](https://nodesecurity.io/advisories/67)) were discovered by
[Mathias Buus](https://github.com/mafintosh) and
[Feross Aboukhadijeh](http://feross.org/).
Thanks to [Adam Baldwin](https://github.com/evilpacket) for helping disclose these issues
and for his work running the [Node Security Project](https://nodesecurity.io/).
Thanks to [John Hiesey](https://github.com/jhiesey) for proofreading this README and
auditing the code.
## license
MIT. Copyright (C) [Feross Aboukhadijeh](http://feross.org)
# axios
[](https://www.npmjs.org/package/axios)
[](https://travis-ci.org/axios/axios)
[](https://coveralls.io/r/mzabriskie/axios)
[](https://packagephobia.now.sh/result?p=axios)
[](http://npm-stat.com/charts.html?package=axios)
[](https://gitter.im/mzabriskie/axios)
[](https://www.codetriage.com/axios/axios)
Promise based HTTP client for the browser and node.js
## Features
- Make [XMLHttpRequests](https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest) from the browser
- Make [http](http://nodejs.org/api/http.html) requests from node.js
- Supports the [Promise](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise) API
- Intercept request and response
- Transform request and response data
- Cancel requests
- Automatic transforms for JSON data
- Client side support for protecting against [XSRF](http://en.wikipedia.org/wiki/Cross-site_request_forgery)
## Browser Support
 |  |  |  |  |  |
--- | --- | --- | --- | --- | --- |
Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | Latest ✔ | 11 ✔ |
[](https://saucelabs.com/u/axios)
## Installing
Using npm:
```bash
$ npm install axios
```
Using bower:
```bash
$ bower install axios
```
Using yarn:
```bash
$ yarn add axios
```
Using cdn:
```html
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
```
## Example
### note: CommonJS usage
In order to gain the TypeScript typings (for intellisense / autocomplete) while using CommonJS imports with `require()` use the following approach:
```js
const axios = require('axios').default;
// axios.<method> will now provide autocomplete and parameter typings
```
Performing a `GET` request
```js
const axios = require('axios');
// Make a request for a user with a given ID
axios.get('/user?ID=12345')
.then(function (response) {
// handle success
console.log(response);
})
.catch(function (error) {
// handle error
console.log(error);
})
.finally(function () {
// always executed
});
// Optionally the request above could also be done as
axios.get('/user', {
params: {
ID: 12345
}
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
})
.finally(function () {
// always executed
});
// Want to use async/await? Add the `async` keyword to your outer function/method.
async function getUser() {
try {
const response = await axios.get('/user?ID=12345');
console.log(response);
} catch (error) {
console.error(error);
}
}
```
> **NOTE:** `async/await` is part of ECMAScript 2017 and is not supported in Internet
> Explorer and older browsers, so use with caution.
Performing a `POST` request
```js
axios.post('/user', {
firstName: 'Fred',
lastName: 'Flintstone'
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
```
Performing multiple concurrent requests
```js
function getUserAccount() {
return axios.get('/user/12345');
}
function getUserPermissions() {
return axios.get('/user/12345/permissions');
}
axios.all([getUserAccount(), getUserPermissions()])
.then(axios.spread(function (acct, perms) {
// Both requests are now complete
}));
```
## axios API
Requests can be made by passing the relevant config to `axios`.
##### axios(config)
```js
// Send a POST request
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
});
```
```js
// GET request for remote image
axios({
method: 'get',
url: 'http://bit.ly/2mTM3nY',
responseType: 'stream'
})
.then(function (response) {
response.data.pipe(fs.createWriteStream('ada_lovelace.jpg'))
});
```
##### axios(url[, config])
```js
// Send a GET request (default method)
axios('/user/12345');
```
### Request method aliases
For convenience aliases have been provided for all supported request methods.
##### axios.request(config)
##### axios.get(url[, config])
##### axios.delete(url[, config])
##### axios.head(url[, config])
##### axios.options(url[, config])
##### axios.post(url[, data[, config]])
##### axios.put(url[, data[, config]])
##### axios.patch(url[, data[, config]])
###### NOTE
When using the alias methods `url`, `method`, and `data` properties don't need to be specified in config.
### Concurrency
Helper functions for dealing with concurrent requests.
##### axios.all(iterable)
##### axios.spread(callback)
### Creating an instance
You can create a new instance of axios with a custom config.
##### axios.create([config])
```js
const instance = axios.create({
baseURL: 'https://some-domain.com/api/',
timeout: 1000,
headers: {'X-Custom-Header': 'foobar'}
});
```
### Instance methods
The available instance methods are listed below. The specified config will be merged with the instance config.
##### axios#request(config)
##### axios#get(url[, config])
##### axios#delete(url[, config])
##### axios#head(url[, config])
##### axios#options(url[, config])
##### axios#post(url[, data[, config]])
##### axios#put(url[, data[, config]])
##### axios#patch(url[, data[, config]])
##### axios#getUri([config])
## Request Config
These are the available config options for making requests. Only the `url` is required. Requests will default to `GET` if `method` is not specified.
```js
{
// `url` is the server URL that will be used for the request
url: '/user',
// `method` is the request method to be used when making the request
method: 'get', // default
// `baseURL` will be prepended to `url` unless `url` is absolute.
// It can be convenient to set `baseURL` for an instance of axios to pass relative URLs
// to methods of that instance.
baseURL: 'https://some-domain.com/api/',
// `transformRequest` allows changes to the request data before it is sent to the server
// This is only applicable for request methods 'PUT', 'POST', 'PATCH' and 'DELETE'
// The last function in the array must return a string or an instance of Buffer, ArrayBuffer,
// FormData or Stream
// You may modify the headers object.
transformRequest: [function (data, headers) {
// Do whatever you want to transform the data
return data;
}],
// `transformResponse` allows changes to the response data to be made before
// it is passed to then/catch
transformResponse: [function (data) {
// Do whatever you want to transform the data
return data;
}],
// `headers` are custom headers to be sent
headers: {'X-Requested-With': 'XMLHttpRequest'},
// `params` are the URL parameters to be sent with the request
// Must be a plain object or a URLSearchParams object
params: {
ID: 12345
},
// `paramsSerializer` is an optional function in charge of serializing `params`
// (e.g. https://www.npmjs.com/package/qs, http://api.jquery.com/jquery.param/)
paramsSerializer: function (params) {
return Qs.stringify(params, {arrayFormat: 'brackets'})
},
// `data` is the data to be sent as the request body
// Only applicable for request methods 'PUT', 'POST', and 'PATCH'
// When no `transformRequest` is set, must be of one of the following types:
// - string, plain object, ArrayBuffer, ArrayBufferView, URLSearchParams
// - Browser only: FormData, File, Blob
// - Node only: Stream, Buffer
data: {
firstName: 'Fred'
},
// syntax alternative to send data into the body
// method post
// only the value is sent, not the key
data: 'Country=Brasil&City=Belo Horizonte',
// `timeout` specifies the number of milliseconds before the request times out.
// If the request takes longer than `timeout`, the request will be aborted.
timeout: 1000, // default is `0` (no timeout)
// `withCredentials` indicates whether or not cross-site Access-Control requests
// should be made using credentials
withCredentials: false, // default
// `adapter` allows custom handling of requests which makes testing easier.
// Return a promise and supply a valid response (see lib/adapters/README.md).
adapter: function (config) {
/* ... */
},
// `auth` indicates that HTTP Basic auth should be used, and supplies credentials.
// This will set an `Authorization` header, overwriting any existing
// `Authorization` custom headers you have set using `headers`.
// Please note that only HTTP Basic auth is configurable through this parameter.
// For Bearer tokens and such, use `Authorization` custom headers instead.
auth: {
username: 'janedoe',
password: 's00pers3cret'
},
// `responseType` indicates the type of data that the server will respond with
// options are: 'arraybuffer', 'document', 'json', 'text', 'stream'
// browser only: 'blob'
responseType: 'json', // default
// `responseEncoding` indicates encoding to use for decoding responses
// Note: Ignored for `responseType` of 'stream' or client-side requests
responseEncoding: 'utf8', // default
// `xsrfCookieName` is the name of the cookie to use as a value for xsrf token
xsrfCookieName: 'XSRF-TOKEN', // default
// `xsrfHeaderName` is the name of the http header that carries the xsrf token value
xsrfHeaderName: 'X-XSRF-TOKEN', // default
// `onUploadProgress` allows handling of progress events for uploads
onUploadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `onDownloadProgress` allows handling of progress events for downloads
onDownloadProgress: function (progressEvent) {
// Do whatever you want with the native progress event
},
// `maxContentLength` defines the max size of the http response content in bytes allowed
maxContentLength: 2000,
// `validateStatus` defines whether to resolve or reject the promise for a given
// HTTP response status code. If `validateStatus` returns `true` (or is set to `null`
// or `undefined`), the promise will be resolved; otherwise, the promise will be
// rejected.
validateStatus: function (status) {
return status >= 200 && status < 300; // default
},
// `maxRedirects` defines the maximum number of redirects to follow in node.js.
// If set to 0, no redirects will be followed.
maxRedirects: 5, // default
// `socketPath` defines a UNIX Socket to be used in node.js.
// e.g. '/var/run/docker.sock' to send requests to the docker daemon.
// Only either `socketPath` or `proxy` can be specified.
// If both are specified, `socketPath` is used.
socketPath: null, // default
// `httpAgent` and `httpsAgent` define a custom agent to be used when performing http
// and https requests, respectively, in node.js. This allows options to be added like
// `keepAlive` that are not enabled by default.
httpAgent: new http.Agent({ keepAlive: true }),
httpsAgent: new https.Agent({ keepAlive: true }),
// 'proxy' defines the hostname and port of the proxy server.
// You can also define your proxy using the conventional `http_proxy` and
// `https_proxy` environment variables. If you are using environment variables
// for your proxy configuration, you can also define a `no_proxy` environment
// variable as a comma-separated list of domains that should not be proxied.
// Use `false` to disable proxies, ignoring environment variables.
// `auth` indicates that HTTP Basic auth should be used to connect to the proxy, and
// supplies credentials.
// This will set an `Proxy-Authorization` header, overwriting any existing
// `Proxy-Authorization` custom headers you have set using `headers`.
proxy: {
host: '127.0.0.1',
port: 9000,
auth: {
username: 'mikeymike',
password: 'rapunz3l'
}
},
// `cancelToken` specifies a cancel token that can be used to cancel the request
// (see Cancellation section below for details)
cancelToken: new CancelToken(function (cancel) {
})
}
```
## Response Schema
The response for a request contains the following information.
```js
{
// `data` is the response that was provided by the server
data: {},
// `status` is the HTTP status code from the server response
status: 200,
// `statusText` is the HTTP status message from the server response
statusText: 'OK',
// `headers` the headers that the server responded with
// All header names are lower cased
headers: {},
// `config` is the config that was provided to `axios` for the request
config: {},
// `request` is the request that generated this response
// It is the last ClientRequest instance in node.js (in redirects)
// and an XMLHttpRequest instance in the browser
request: {}
}
```
When using `then`, you will receive the response as follows:
```js
axios.get('/user/12345')
.then(function (response) {
console.log(response.data);
console.log(response.status);
console.log(response.statusText);
console.log(response.headers);
console.log(response.config);
});
```
When using `catch`, or passing a [rejection callback](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise/then) as second parameter of `then`, the response will be available through the `error` object as explained in the [Handling Errors](#handling-errors) section.
## Config Defaults
You can specify config defaults that will be applied to every request.
### Global axios defaults
```js
axios.defaults.baseURL = 'https://api.example.com';
axios.defaults.headers.common['Authorization'] = AUTH_TOKEN;
axios.defaults.headers.post['Content-Type'] = 'application/x-www-form-urlencoded';
```
### Custom instance defaults
```js
// Set config defaults when creating the instance
const instance = axios.create({
baseURL: 'https://api.example.com'
});
// Alter defaults after instance has been created
instance.defaults.headers.common['Authorization'] = AUTH_TOKEN;
```
### Config order of precedence
Config will be merged with an order of precedence. The order is library defaults found in [lib/defaults.js](https://github.com/axios/axios/blob/master/lib/defaults.js#L28), then `defaults` property of the instance, and finally `config` argument for the request. The latter will take precedence over the former. Here's an example.
```js
// Create an instance using the config defaults provided by the library
// At this point the timeout config value is `0` as is the default for the library
const instance = axios.create();
// Override timeout default for the library
// Now all requests using this instance will wait 2.5 seconds before timing out
instance.defaults.timeout = 2500;
// Override timeout for this request as it's known to take a long time
instance.get('/longRequest', {
timeout: 5000
});
```
## Interceptors
You can intercept requests or responses before they are handled by `then` or `catch`.
```js
// Add a request interceptor
axios.interceptors.request.use(function (config) {
// Do something before request is sent
return config;
}, function (error) {
// Do something with request error
return Promise.reject(error);
});
// Add a response interceptor
axios.interceptors.response.use(function (response) {
// Any status code that lie within the range of 2xx cause this function to trigger
// Do something with response data
return response;
}, function (error) {
// Any status codes that falls outside the range of 2xx cause this function to trigger
// Do something with response error
return Promise.reject(error);
});
```
If you need to remove an interceptor later you can.
```js
const myInterceptor = axios.interceptors.request.use(function () {/*...*/});
axios.interceptors.request.eject(myInterceptor);
```
You can add interceptors to a custom instance of axios.
```js
const instance = axios.create();
instance.interceptors.request.use(function () {/*...*/});
```
## Handling Errors
```js
axios.get('/user/12345')
.catch(function (error) {
if (error.response) {
// The request was made and the server responded with a status code
// that falls out of the range of 2xx
console.log(error.response.data);
console.log(error.response.status);
console.log(error.response.headers);
} else if (error.request) {
// The request was made but no response was received
// `error.request` is an instance of XMLHttpRequest in the browser and an instance of
// http.ClientRequest in node.js
console.log(error.request);
} else {
// Something happened in setting up the request that triggered an Error
console.log('Error', error.message);
}
console.log(error.config);
});
```
Using the `validateStatus` config option, you can define HTTP code(s) that should throw an error.
```js
axios.get('/user/12345', {
validateStatus: function (status) {
return status < 500; // Reject only if the status code is greater than or equal to 500
}
})
```
Using `toJSON` you get an object with more information about the HTTP error.
```js
axios.get('/user/12345')
.catch(function (error) {
console.log(error.toJSON());
});
```
## Cancellation
You can cancel a request using a *cancel token*.
> The axios cancel token API is based on the withdrawn [cancelable promises proposal](https://github.com/tc39/proposal-cancelable-promises).
You can create a cancel token using the `CancelToken.source` factory as shown below:
```js
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// handle error
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// cancel the request (the message parameter is optional)
source.cancel('Operation canceled by the user.');
```
You can also create a cancel token by passing an executor function to the `CancelToken` constructor:
```js
const CancelToken = axios.CancelToken;
let cancel;
axios.get('/user/12345', {
cancelToken: new CancelToken(function executor(c) {
// An executor function receives a cancel function as a parameter
cancel = c;
})
});
// cancel the request
cancel();
```
> Note: you can cancel several requests with the same cancel token.
## Using application/x-www-form-urlencoded format
By default, axios serializes JavaScript objects to `JSON`. To send data in the `application/x-www-form-urlencoded` format instead, you can use one of the following options.
### Browser
In a browser, you can use the [`URLSearchParams`](https://developer.mozilla.org/en-US/docs/Web/API/URLSearchParams) API as follows:
```js
const params = new URLSearchParams();
params.append('param1', 'value1');
params.append('param2', 'value2');
axios.post('/foo', params);
```
> Note that `URLSearchParams` is not supported by all browsers (see [caniuse.com](http://www.caniuse.com/#feat=urlsearchparams)), but there is a [polyfill](https://github.com/WebReflection/url-search-params) available (make sure to polyfill the global environment).
Alternatively, you can encode data using the [`qs`](https://github.com/ljharb/qs) library:
```js
const qs = require('qs');
axios.post('/foo', qs.stringify({ 'bar': 123 }));
```
Or in another way (ES6),
```js
import qs from 'qs';
const data = { 'bar': 123 };
const options = {
method: 'POST',
headers: { 'content-type': 'application/x-www-form-urlencoded' },
data: qs.stringify(data),
url,
};
axios(options);
```
### Node.js
In node.js, you can use the [`querystring`](https://nodejs.org/api/querystring.html) module as follows:
```js
const querystring = require('querystring');
axios.post('http://something.com/', querystring.stringify({ foo: 'bar' }));
```
You can also use the [`qs`](https://github.com/ljharb/qs) library.
###### NOTE
The `qs` library is preferable if you need to stringify nested objects, as the `querystring` method has known issues with that use case (https://github.com/nodejs/node-v0.x-archive/issues/1665).
## Semver
Until axios reaches a `1.0` release, breaking changes will be released with a new minor version. For example `0.5.1`, and `0.5.4` will have the same API, but `0.6.0` will have breaking changes.
## Promises
axios depends on a native ES6 Promise implementation to be [supported](http://caniuse.com/promises).
If your environment doesn't support ES6 Promises, you can [polyfill](https://github.com/jakearchibald/es6-promise).
## TypeScript
axios includes [TypeScript](http://typescriptlang.org) definitions.
```typescript
import axios from 'axios';
axios.get('/user?ID=12345');
```
## Resources
* [Changelog](https://github.com/axios/axios/blob/master/CHANGELOG.md)
* [Upgrade Guide](https://github.com/axios/axios/blob/master/UPGRADE_GUIDE.md)
* [Ecosystem](https://github.com/axios/axios/blob/master/ECOSYSTEM.md)
* [Contributing Guide](https://github.com/axios/axios/blob/master/CONTRIBUTING.md)
* [Code of Conduct](https://github.com/axios/axios/blob/master/CODE_OF_CONDUCT.md)
## Credits
axios is heavily inspired by the [$http service](https://docs.angularjs.org/api/ng/service/$http) provided in [Angular](https://angularjs.org/). Ultimately axios is an effort to provide a standalone `$http`-like service for use outside of Angular.
## License
[MIT](LICENSE)
Compiler frontend for node.js
=============================
Usage
-----
For an up to date list of available command line options, see:
```
$> asc --help
```
API
---
The API accepts the same options as the CLI but also lets you override stdout and stderr and/or provide a callback. Example:
```js
const asc = require("assemblyscript/cli/asc");
asc.ready.then(() => {
asc.main([
"myModule.ts",
"--binaryFile", "myModule.wasm",
"--optimize",
"--sourceMap",
"--measure"
], {
stdout: process.stdout,
stderr: process.stderr
}, function(err) {
if (err)
throw err;
...
});
});
```
Available command line options can also be obtained programmatically:
```js
const options = require("assemblyscript/cli/asc.json");
...
```
You can also compile a source string directly, for example in a browser environment:
```js
const asc = require("assemblyscript/cli/asc");
asc.ready.then(() => {
const { binary, text, stdout, stderr } = asc.compileString(`...`, { optimize: 2 });
});
...
```
Shims used when bundling asc for browser usage.
# emoji-regex [](https://travis-ci.org/mathiasbynens/emoji-regex)
_emoji-regex_ offers a regular expression to match all emoji symbols (including textual representations of emoji) as per the Unicode Standard.
This repository contains a script that generates this regular expression based on [the data from Unicode v12](https://github.com/mathiasbynens/unicode-12.0.0). Because of this, the regular expression can easily be updated whenever new emoji are added to the Unicode standard.
## Installation
Via [npm](https://www.npmjs.com/):
```bash
npm install emoji-regex
```
In [Node.js](https://nodejs.org/):
```js
const emojiRegex = require('emoji-regex');
// Note: because the regular expression has the global flag set, this module
// exports a function that returns the regex rather than exporting the regular
// expression itself, to make it impossible to (accidentally) mutate the
// original regular expression.
const text = `
\u{231A}: ⌚ default emoji presentation character (Emoji_Presentation)
\u{2194}\u{FE0F}: ↔️ default text presentation character rendered as emoji
\u{1F469}: 👩 emoji modifier base (Emoji_Modifier_Base)
\u{1F469}\u{1F3FF}: 👩🏿 emoji modifier base followed by a modifier
`;
const regex = emojiRegex();
let match;
while (match = regex.exec(text)) {
const emoji = match[0];
console.log(`Matched sequence ${ emoji } — code points: ${ [...emoji].length }`);
}
```
Console output:
```
Matched sequence ⌚ — code points: 1
Matched sequence ⌚ — code points: 1
Matched sequence ↔️ — code points: 2
Matched sequence ↔️ — code points: 2
Matched sequence 👩 — code points: 1
Matched sequence 👩 — code points: 1
Matched sequence 👩🏿 — code points: 2
Matched sequence 👩🏿 — code points: 2
```
To match emoji in their textual representation as well (i.e. emoji that are not `Emoji_Presentation` symbols and that aren’t forced to render as emoji by a variation selector), `require` the other regex:
```js
const emojiRegex = require('emoji-regex/text.js');
```
Additionally, in environments which support ES2015 Unicode escapes, you may `require` ES2015-style versions of the regexes:
```js
const emojiRegex = require('emoji-regex/es2015/index.js');
const emojiRegexText = require('emoji-regex/es2015/text.js');
```
## Author
| [](https://twitter.com/mathias "Follow @mathias on Twitter") |
|---|
| [Mathias Bynens](https://mathiasbynens.be/) |
## License
_emoji-regex_ is available under the [MIT](https://mths.be/mit) license.
# near-sdk-core
This package contain a convenient interface for interacting with NEAR's host runtime. To see the functions that are provided by the host node see [`env.ts`](./assembly/env/env.ts).

Moo!
====
Moo is a highly-optimised tokenizer/lexer generator. Use it to tokenize your strings, before parsing 'em with a parser like [nearley](https://github.com/hardmath123/nearley) or whatever else you're into.
* [Fast](#is-it-fast)
* [Convenient](#usage)
* uses [Regular Expressions](#on-regular-expressions)
* tracks [Line Numbers](#line-numbers)
* handles [Keywords](#keywords)
* supports [States](#states)
* custom [Errors](#errors)
* is even [Iterable](#iteration)
* has no dependencies
* 4KB minified + gzipped
* Moo!
Is it fast?
-----------
Yup! Flying-cows-and-singed-steak fast.
Moo is the fastest JS tokenizer around. It's **~2–10x** faster than most other tokenizers; it's a **couple orders of magnitude** faster than some of the slower ones.
Define your tokens **using regular expressions**. Moo will compile 'em down to a **single RegExp for performance**. It uses the new ES6 **sticky flag** where possible to make things faster; otherwise it falls back to an almost-as-efficient workaround. (For more than you ever wanted to know about this, read [adventures in the land of substrings and RegExps](http://mrale.ph/blog/2016/11/23/making-less-dart-faster.html).)
You _might_ be able to go faster still by writing your lexer by hand rather than using RegExps, but that's icky.
Oh, and it [avoids parsing RegExps by itself](https://hackernoon.com/the-madness-of-parsing-real-world-javascript-regexps-d9ee336df983#.2l8qu3l76). Because that would be horrible.
Usage
-----
First, you need to do the needful: `$ npm install moo`, or whatever will ship this code to your computer. Alternatively, grab the `moo.js` file by itself and slap it into your web page via a `<script>` tag; moo is completely standalone.
Then you can start roasting your very own lexer/tokenizer:
```js
const moo = require('moo')
let lexer = moo.compile({
WS: /[ \t]+/,
comment: /\/\/.*?$/,
number: /0|[1-9][0-9]*/,
string: /"(?:\\["\\]|[^\n"\\])*"/,
lparen: '(',
rparen: ')',
keyword: ['while', 'if', 'else', 'moo', 'cows'],
NL: { match: /\n/, lineBreaks: true },
})
```
And now throw some text at it:
```js
lexer.reset('while (10) cows\nmoo')
lexer.next() // -> { type: 'keyword', value: 'while' }
lexer.next() // -> { type: 'WS', value: ' ' }
lexer.next() // -> { type: 'lparen', value: '(' }
lexer.next() // -> { type: 'number', value: '10' }
// ...
```
When you reach the end of Moo's internal buffer, next() will return `undefined`. You can always `reset()` it and feed it more data when that happens.
On Regular Expressions
----------------------
RegExps are nifty for making tokenizers, but they can be a bit of a pain. Here are some things to be aware of:
* You often want to use **non-greedy quantifiers**: e.g. `*?` instead of `*`. Otherwise your tokens will be longer than you expect:
```js
let lexer = moo.compile({
string: /".*"/, // greedy quantifier *
// ...
})
lexer.reset('"foo" "bar"')
lexer.next() // -> { type: 'string', value: 'foo" "bar' }
```
Better:
```js
let lexer = moo.compile({
string: /".*?"/, // non-greedy quantifier *?
// ...
})
lexer.reset('"foo" "bar"')
lexer.next() // -> { type: 'string', value: 'foo' }
lexer.next() // -> { type: 'space', value: ' ' }
lexer.next() // -> { type: 'string', value: 'bar' }
```
* The **order of your rules** matters. Earlier ones will take precedence.
```js
moo.compile({
identifier: /[a-z0-9]+/,
number: /[0-9]+/,
}).reset('42').next() // -> { type: 'identifier', value: '42' }
moo.compile({
number: /[0-9]+/,
identifier: /[a-z0-9]+/,
}).reset('42').next() // -> { type: 'number', value: '42' }
```
* Moo uses **multiline RegExps**. This has a few quirks: for example, the **dot `/./` doesn't include newlines**. Use `[^]` instead if you want to match newlines too.
* Since an excluding character ranges like `/[^ ]/` (which matches anything but a space) _will_ include newlines, you have to be careful not to include them by accident! In particular, the whitespace metacharacter `\s` includes newlines.
Line Numbers
------------
Moo tracks detailed information about the input for you.
It will track line numbers, as long as you **apply the `lineBreaks: true` option to any rules which might contain newlines**. Moo will try to warn you if you forget to do this.
Note that this is `false` by default, for performance reasons: counting the number of lines in a matched token has a small cost. For optimal performance, only match newlines inside a dedicated token:
```js
newline: {match: '\n', lineBreaks: true},
```
### Token Info ###
Token objects (returned from `next()`) have the following attributes:
* **`type`**: the name of the group, as passed to compile.
* **`text`**: the string that was matched.
* **`value`**: the string that was matched, transformed by your `value` function (if any).
* **`offset`**: the number of bytes from the start of the buffer where the match starts.
* **`lineBreaks`**: the number of line breaks found in the match. (Always zero if this rule has `lineBreaks: false`.)
* **`line`**: the line number of the beginning of the match, starting from 1.
* **`col`**: the column where the match begins, starting from 1.
### Value vs. Text ###
The `value` is the same as the `text`, unless you provide a [value transform](#transform).
```js
const moo = require('moo')
const lexer = moo.compile({
ws: /[ \t]+/,
string: {match: /"(?:\\["\\]|[^\n"\\])*"/, value: s => s.slice(1, -1)},
})
lexer.reset('"test"')
lexer.next() /* { value: 'test', text: '"test"', ... } */
```
### Reset ###
Calling `reset()` on your lexer will empty its internal buffer, and set the line, column, and offset counts back to their initial value.
If you don't want this, you can `save()` the state, and later pass it as the second argument to `reset()` to explicitly control the internal state of the lexer.
```js
lexer.reset('some line\n')
let info = lexer.save() // -> { line: 10 }
lexer.next() // -> { line: 10 }
lexer.next() // -> { line: 11 }
// ...
lexer.reset('a different line\n', info)
lexer.next() // -> { line: 10 }
```
Keywords
--------
Moo makes it convenient to define literals.
```js
moo.compile({
lparen: '(',
rparen: ')',
keyword: ['while', 'if', 'else', 'moo', 'cows'],
})
```
It'll automatically compile them into regular expressions, escaping them where necessary.
**Keywords** should be written using the `keywords` transform.
```js
moo.compile({
IDEN: {match: /[a-zA-Z]+/, type: moo.keywords({
KW: ['while', 'if', 'else', 'moo', 'cows'],
})},
SPACE: {match: /\s+/, lineBreaks: true},
})
```
### Why? ###
You need to do this to ensure the **longest match** principle applies, even in edge cases.
Imagine trying to parse the input `className` with the following rules:
```js
keyword: ['class'],
identifier: /[a-zA-Z]+/,
```
You'll get _two_ tokens — `['class', 'Name']` -- which is _not_ what you want! If you swap the order of the rules, you'll fix this example; but now you'll lex `class` wrong (as an `identifier`).
The keywords helper checks matches against the list of keywords; if any of them match, it uses the type `'keyword'` instead of `'identifier'` (for this example).
### Keyword Types ###
Keywords can also have **individual types**.
```js
let lexer = moo.compile({
name: {match: /[a-zA-Z]+/, type: moo.keywords({
'kw-class': 'class',
'kw-def': 'def',
'kw-if': 'if',
})},
// ...
})
lexer.reset('def foo')
lexer.next() // -> { type: 'kw-def', value: 'def' }
lexer.next() // space
lexer.next() // -> { type: 'name', value: 'foo' }
```
You can use [itt](https://github.com/nathan/itt)'s iterator adapters to make constructing keyword objects easier:
```js
itt(['class', 'def', 'if'])
.map(k => ['kw-' + k, k])
.toObject()
```
States
------
Moo allows you to define multiple lexer **states**. Each state defines its own separate set of token rules. Your lexer will start off in the first state given to `moo.states({})`.
Rules can be annotated with `next`, `push`, and `pop`, to change the current state after that token is matched. A "stack" of past states is kept, which is used by `push` and `pop`.
* **`next: 'bar'`** moves to the state named `bar`. (The stack is not changed.)
* **`push: 'bar'`** moves to the state named `bar`, and pushes the old state onto the stack.
* **`pop: 1`** removes one state from the top of the stack, and moves to that state. (Only `1` is supported.)
Only rules from the current state can be matched. You need to copy your rule into all the states you want it to be matched in.
For example, to tokenize JS-style string interpolation such as `a${{c: d}}e`, you might use:
```js
let lexer = moo.states({
main: {
strstart: {match: '`', push: 'lit'},
ident: /\w+/,
lbrace: {match: '{', push: 'main'},
rbrace: {match: '}', pop: true},
colon: ':',
space: {match: /\s+/, lineBreaks: true},
},
lit: {
interp: {match: '${', push: 'main'},
escape: /\\./,
strend: {match: '`', pop: true},
const: {match: /(?:[^$`]|\$(?!\{))+/, lineBreaks: true},
},
})
// <= `a${{c: d}}e`
// => strstart const interp lbrace ident colon space ident rbrace rbrace const strend
```
The `rbrace` rule is annotated with `pop`, so it moves from the `main` state into either `lit` or `main`, depending on the stack.
Errors
------
If none of your rules match, Moo will throw an Error; since it doesn't know what else to do.
If you prefer, you can have moo return an error token instead of throwing an exception. The error token will contain the whole of the rest of the buffer.
```js
moo.compile({
// ...
myError: moo.error,
})
moo.reset('invalid')
moo.next() // -> { type: 'myError', value: 'invalid', text: 'invalid', offset: 0, lineBreaks: 0, line: 1, col: 1 }
moo.next() // -> undefined
```
You can have a token type that both matches tokens _and_ contains error values.
```js
moo.compile({
// ...
myError: {match: /[\$?`]/, error: true},
})
```
### Formatting errors ###
If you want to throw an error from your parser, you might find `formatError` helpful. Call it with the offending token:
```js
throw new Error(lexer.formatError(token, "invalid syntax"))
```
It returns a string with a pretty error message.
```
Error: invalid syntax at line 2 col 15:
totally valid `syntax`
^
```
Iteration
---------
Iterators: we got 'em.
```js
for (let here of lexer) {
// here = { type: 'number', value: '123', ... }
}
```
Create an array of tokens.
```js
let tokens = Array.from(lexer);
```
Use [itt](https://github.com/nathan/itt)'s iteration tools with Moo.
```js
for (let [here, next] = itt(lexer).lookahead()) { // pass a number if you need more tokens
// enjoy!
}
```
Transform
---------
Moo doesn't allow capturing groups, but you can supply a transform function, `value()`, which will be called on the value before storing it in the Token object.
```js
moo.compile({
STRING: [
{match: /"""[^]*?"""/, lineBreaks: true, value: x => x.slice(3, -3)},
{match: /"(?:\\["\\rn]|[^"\\])*?"/, lineBreaks: true, value: x => x.slice(1, -1)},
{match: /'(?:\\['\\rn]|[^'\\])*?'/, lineBreaks: true, value: x => x.slice(1, -1)},
],
// ...
})
```
Contributing
------------
Do check the [FAQ](https://github.com/tjvr/moo/issues?q=label%3Aquestion).
Before submitting an issue, [remember...](https://github.com/tjvr/moo/blob/master/.github/CONTRIBUTING.md)
# whatwg-url
whatwg-url is a full implementation of the WHATWG [URL Standard](https://url.spec.whatwg.org/). It can be used standalone, but it also exposes a lot of the internal algorithms that are useful for integrating a URL parser into a project like [jsdom](https://github.com/tmpvar/jsdom).
## Specification conformance
whatwg-url is currently up to date with the URL spec up to commit [7ae1c69](https://github.com/whatwg/url/commit/7ae1c691c96f0d82fafa24c33aa1e8df9ffbf2bc).
For `file:` URLs, whose [origin is left unspecified](https://url.spec.whatwg.org/#concept-url-origin), whatwg-url chooses to use a new opaque origin (which serializes to `"null"`).
## API
### The `URL` and `URLSearchParams` classes
The main API is provided by the [`URL`](https://url.spec.whatwg.org/#url-class) and [`URLSearchParams`](https://url.spec.whatwg.org/#interface-urlsearchparams) exports, which follows the spec's behavior in all ways (including e.g. `USVString` conversion). Most consumers of this library will want to use these.
### Low-level URL Standard API
The following methods are exported for use by places like jsdom that need to implement things like [`HTMLHyperlinkElementUtils`](https://html.spec.whatwg.org/#htmlhyperlinkelementutils). They mostly operate on or return an "internal URL" or ["URL record"](https://url.spec.whatwg.org/#concept-url) type.
- [URL parser](https://url.spec.whatwg.org/#concept-url-parser): `parseURL(input, { baseURL, encodingOverride })`
- [Basic URL parser](https://url.spec.whatwg.org/#concept-basic-url-parser): `basicURLParse(input, { baseURL, encodingOverride, url, stateOverride })`
- [URL serializer](https://url.spec.whatwg.org/#concept-url-serializer): `serializeURL(urlRecord, excludeFragment)`
- [Host serializer](https://url.spec.whatwg.org/#concept-host-serializer): `serializeHost(hostFromURLRecord)`
- [Serialize an integer](https://url.spec.whatwg.org/#serialize-an-integer): `serializeInteger(number)`
- [Origin](https://url.spec.whatwg.org/#concept-url-origin) [serializer](https://html.spec.whatwg.org/multipage/origin.html#ascii-serialisation-of-an-origin): `serializeURLOrigin(urlRecord)`
- [Set the username](https://url.spec.whatwg.org/#set-the-username): `setTheUsername(urlRecord, usernameString)`
- [Set the password](https://url.spec.whatwg.org/#set-the-password): `setThePassword(urlRecord, passwordString)`
- [Cannot have a username/password/port](https://url.spec.whatwg.org/#cannot-have-a-username-password-port): `cannotHaveAUsernamePasswordPort(urlRecord)`
- [Percent decode](https://url.spec.whatwg.org/#percent-decode): `percentDecode(buffer)`
The `stateOverride` parameter is one of the following strings:
- [`"scheme start"`](https://url.spec.whatwg.org/#scheme-start-state)
- [`"scheme"`](https://url.spec.whatwg.org/#scheme-state)
- [`"no scheme"`](https://url.spec.whatwg.org/#no-scheme-state)
- [`"special relative or authority"`](https://url.spec.whatwg.org/#special-relative-or-authority-state)
- [`"path or authority"`](https://url.spec.whatwg.org/#path-or-authority-state)
- [`"relative"`](https://url.spec.whatwg.org/#relative-state)
- [`"relative slash"`](https://url.spec.whatwg.org/#relative-slash-state)
- [`"special authority slashes"`](https://url.spec.whatwg.org/#special-authority-slashes-state)
- [`"special authority ignore slashes"`](https://url.spec.whatwg.org/#special-authority-ignore-slashes-state)
- [`"authority"`](https://url.spec.whatwg.org/#authority-state)
- [`"host"`](https://url.spec.whatwg.org/#host-state)
- [`"hostname"`](https://url.spec.whatwg.org/#hostname-state)
- [`"port"`](https://url.spec.whatwg.org/#port-state)
- [`"file"`](https://url.spec.whatwg.org/#file-state)
- [`"file slash"`](https://url.spec.whatwg.org/#file-slash-state)
- [`"file host"`](https://url.spec.whatwg.org/#file-host-state)
- [`"path start"`](https://url.spec.whatwg.org/#path-start-state)
- [`"path"`](https://url.spec.whatwg.org/#path-state)
- [`"cannot-be-a-base-URL path"`](https://url.spec.whatwg.org/#cannot-be-a-base-url-path-state)
- [`"query"`](https://url.spec.whatwg.org/#query-state)
- [`"fragment"`](https://url.spec.whatwg.org/#fragment-state)
The URL record type has the following API:
- [`scheme`](https://url.spec.whatwg.org/#concept-url-scheme)
- [`username`](https://url.spec.whatwg.org/#concept-url-username)
- [`password`](https://url.spec.whatwg.org/#concept-url-password)
- [`host`](https://url.spec.whatwg.org/#concept-url-host)
- [`port`](https://url.spec.whatwg.org/#concept-url-port)
- [`path`](https://url.spec.whatwg.org/#concept-url-path) (as an array)
- [`query`](https://url.spec.whatwg.org/#concept-url-query)
- [`fragment`](https://url.spec.whatwg.org/#concept-url-fragment)
- [`cannotBeABaseURL`](https://url.spec.whatwg.org/#url-cannot-be-a-base-url-flag) (as a boolean)
These properties should be treated with care, as in general changing them will cause the URL record to be in an inconsistent state until the appropriate invocation of `basicURLParse` is used to fix it up. You can see examples of this in the URL Standard, where there are many step sequences like "4. Set context object’s url’s fragment to the empty string. 5. Basic URL parse _input_ with context object’s url as _url_ and fragment state as _state override_." In between those two steps, a URL record is in an unusable state.
The return value of "failure" in the spec is represented by `null`. That is, functions like `parseURL` and `basicURLParse` can return _either_ a URL record _or_ `null`.
## Development instructions
First, install [Node.js](https://nodejs.org/). Then, fetch the dependencies of whatwg-url, by running from this directory:
npm install
To run tests:
npm test
To generate a coverage report:
npm run coverage
To build and run the live viewer:
npm run build
npm run build-live-viewer
Serve the contents of the `live-viewer` directory using any web server.
## Supporting whatwg-url
The jsdom project (including whatwg-url) is a community-driven project maintained by a team of [volunteers](https://github.com/orgs/jsdom/people). You could support us by:
- [Getting professional support for whatwg-url](https://tidelift.com/subscription/pkg/npm-whatwg-url?utm_source=npm-whatwg-url&utm_medium=referral&utm_campaign=readme) as part of a Tidelift subscription. Tidelift helps making open source sustainable for us while giving teams assurances for maintenance, licensing, and security.
- Contributing directly to the project.
[](https://www.npmjs.com/package/as-bignum)[](https://travis-ci.com/MaxGraey/as-bignum)[](LICENSE.md)
## Work in progress
---
### WebAssembly fixed length big numbers written on [AssemblyScript](https://github.com/AssemblyScript/assemblyscript)
Provide wide numeric types such as `u128`, `u256`, `i128`, `i256` and fixed points and also its arithmetic operations.
Namespace `safe` contain equivalents with overflow/underflow traps.
All kind of types pretty useful for economical and cryptographic usages and provide deterministic behavior.
### Install
> yarn add as-bignum
or
> npm i as-bignum
### Usage via AssemblyScript
```ts
import { u128 } from "as-bignum";
declare function logF64(value: f64): void;
declare function logU128(hi: u64, lo: u64): void;
var a = u128.One;
var b = u128.from(-32); // same as u128.from<i32>(-32)
var c = new u128(0x1, -0xF);
var d = u128.from(0x0123456789ABCDEF); // same as u128.from<i64>(0x0123456789ABCDEF)
var e = u128.from('0x0123456789ABCDEF01234567');
var f = u128.fromString('11100010101100101', 2); // same as u128.from('0b11100010101100101')
var r = d / c + (b << 5) + e;
logF64(r.as<f64>());
logU128(r.hi, r.lo);
```
### Usage via JavaScript/Typescript
```ts
TODO
```
### List of types
- [x] [`u128`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/u128.ts) unsigned type (tested)
- [ ] [`u256`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/u256.ts) unsigned type (very basic)
- [ ] `i128` signed type
- [ ] `i256` signed type
---
- [x] [`safe.u128`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/integer/safe/u128.ts) unsigned type (tested)
- [ ] `safe.u256` unsigned type
- [ ] `safe.i128` signed type
- [ ] `safe.i256` signed type
---
- [ ] [`fp128<Q>`](https://github.com/MaxGraey/as-bignum/blob/master/assembly/fixed/fp128.ts) generic fixed point signed type٭ (very basic for now)
- [ ] `fp256<Q>` generic fixed point signed type٭
---
- [ ] `safe.fp128<Q>` generic fixed point signed type٭
- [ ] `safe.fp256<Q>` generic fixed point signed type٭
٭ _typename_ `Q` _is a type representing count of fractional bits_
binaryen.js
===========
**binaryen.js** is a port of [Binaryen](https://github.com/WebAssembly/binaryen) to the Web, allowing you to generate [WebAssembly](https://webassembly.org) using a JavaScript API.
<a href="https://github.com/AssemblyScript/binaryen.js/actions?query=workflow%3ABuild"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/binaryen.js/Build/master?label=build&logo=github" alt="Build status" /></a>
<a href="https://www.npmjs.com/package/binaryen"><img src="https://img.shields.io/npm/v/binaryen.svg?label=latest&color=007acc&logo=npm" alt="npm version" /></a>
<a href="https://www.npmjs.com/package/binaryen"><img src="https://img.shields.io/npm/v/binaryen/nightly.svg?label=nightly&color=007acc&logo=npm" alt="npm nightly version" /></a>
Usage
-----
```
$> npm install binaryen
```
```js
var binaryen = require("binaryen");
// Create a module with a single function
var myModule = new binaryen.Module();
myModule.addFunction("add", binaryen.createType([ binaryen.i32, binaryen.i32 ]), binaryen.i32, [ binaryen.i32 ],
myModule.block(null, [
myModule.local.set(2,
myModule.i32.add(
myModule.local.get(0, binaryen.i32),
myModule.local.get(1, binaryen.i32)
)
),
myModule.return(
myModule.local.get(2, binaryen.i32)
)
])
);
myModule.addFunctionExport("add", "add");
// Optimize the module using default passes and levels
myModule.optimize();
// Validate the module
if (!myModule.validate())
throw new Error("validation error");
// Generate text format and binary
var textData = myModule.emitText();
var wasmData = myModule.emitBinary();
// Example usage with the WebAssembly API
var compiled = new WebAssembly.Module(wasmData);
var instance = new WebAssembly.Instance(compiled, {});
console.log(instance.exports.add(41, 1));
```
The buildbot also publishes nightly versions once a day if there have been changes. The latest nightly can be installed through
```
$> npm install binaryen@nightly
```
or you can use one of the [previous versions](https://github.com/AssemblyScript/binaryen.js/tags) instead if necessary.
### Usage with a CDN
* From GitHub via [jsDelivr](https://www.jsdelivr.com):<br />
`https://cdn.jsdelivr.net/gh/AssemblyScript/binaryen.js@VERSION/index.js`
* From npm via [jsDelivr](https://www.jsdelivr.com):<br />
`https://cdn.jsdelivr.net/npm/binaryen@VERSION/index.js`
* From npm via [unpkg](https://unpkg.com):<br />
`https://unpkg.com/binaryen@VERSION/index.js`
Replace `VERSION` with a [specific version](https://github.com/AssemblyScript/binaryen.js/releases) or omit it (not recommended in production) to use master/latest.
API
---
**Please note** that the Binaryen API is evolving fast and that definitions and documentation provided by the package tend to get out of sync despite our best efforts. It's a bot after all. If you rely on binaryen.js and spot an issue, please consider sending a PR our way by updating [index.d.ts](./index.d.ts) and [README.md](./README.md) to reflect the [current API](https://github.com/WebAssembly/binaryen/blob/master/src/js/binaryen.js-post.js).
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
### Contents
- [Types](#types)
- [Module construction](#module-construction)
- [Module manipulation](#module-manipulation)
- [Module validation](#module-validation)
- [Module optimization](#module-optimization)
- [Module creation](#module-creation)
- [Expression construction](#expression-construction)
- [Control flow](#control-flow)
- [Variable accesses](#variable-accesses)
- [Integer operations](#integer-operations)
- [Floating point operations](#floating-point-operations)
- [Datatype conversions](#datatype-conversions)
- [Function calls](#function-calls)
- [Linear memory accesses](#linear-memory-accesses)
- [Host operations](#host-operations)
- [Vector operations 🦄](#vector-operations-)
- [Atomic memory accesses 🦄](#atomic-memory-accesses-)
- [Atomic read-modify-write operations 🦄](#atomic-read-modify-write-operations-)
- [Atomic wait and notify operations 🦄](#atomic-wait-and-notify-operations-)
- [Sign extension operations 🦄](#sign-extension-operations-)
- [Multi-value operations 🦄](#multi-value-operations-)
- [Exception handling operations 🦄](#exception-handling-operations-)
- [Reference types operations 🦄](#reference-types-operations-)
- [Expression manipulation](#expression-manipulation)
- [Relooper](#relooper)
- [Source maps](#source-maps)
- [Debugging](#debugging)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
[Future features](http://webassembly.org/docs/future-features/) 🦄 might not be supported by all runtimes.
### Types
* **none**: `Type`<br />
The none type, e.g., `void`.
* **i32**: `Type`<br />
32-bit integer type.
* **i64**: `Type`<br />
64-bit integer type.
* **f32**: `Type`<br />
32-bit float type.
* **f64**: `Type`<br />
64-bit float (double) type.
* **v128**: `Type`<br />
128-bit vector type. 🦄
* **funcref**: `Type`<br />
A function reference. 🦄
* **anyref**: `Type`<br />
Any host reference. 🦄
* **nullref**: `Type`<br />
A null reference. 🦄
* **exnref**: `Type`<br />
An exception reference. 🦄
* **unreachable**: `Type`<br />
Special type indicating unreachable code when obtaining information about an expression.
* **auto**: `Type`<br />
Special type used in **Module#block** exclusively. Lets the API figure out a block's result type automatically.
* **createType**(types: `Type[]`): `Type`<br />
Creates a multi-value type from an array of types.
* **expandType**(type: `Type`): `Type[]`<br />
Expands a multi-value type to an array of types.
### Module construction
* new **Module**()<br />
Constructs a new module.
* **parseText**(text: `string`): `Module`<br />
Creates a module from Binaryen's s-expression text format (not official stack-style text format).
* **readBinary**(data: `Uint8Array`): `Module`<br />
Creates a module from binary data.
### Module manipulation
* Module#**addFunction**(name: `string`, params: `Type`, results: `Type`, vars: `Type[]`, body: `ExpressionRef`): `FunctionRef`<br />
Adds a function. `vars` indicate additional locals, in the given order.
* Module#**getFunction**(name: `string`): `FunctionRef`<br />
Gets a function, by name,
* Module#**removeFunction**(name: `string`): `void`<br />
Removes a function, by name.
* Module#**getNumFunctions**(): `number`<br />
Gets the number of functions within the module.
* Module#**getFunctionByIndex**(index: `number`): `FunctionRef`<br />
Gets the function at the specified index.
* Module#**addFunctionImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, params: `Type`, results: `Type`): `void`<br />
Adds a function import.
* Module#**addTableImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`): `void`<br />
Adds a table import. There's just one table for now, using name `"0"`.
* Module#**addMemoryImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`): `void`<br />
Adds a memory import. There's just one memory for now, using name `"0"`.
* Module#**addGlobalImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, globalType: `Type`): `void`<br />
Adds a global variable import. Imported globals must be immutable.
* Module#**addFunctionExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a function export.
* Module#**addTableExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a table export. There's just one table for now, using name `"0"`.
* Module#**addMemoryExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a memory export. There's just one memory for now, using name `"0"`.
* Module#**addGlobalExport**(internalName: `string`, externalName: `string`): `ExportRef`<br />
Adds a global variable export. Exported globals must be immutable.
* Module#**getNumExports**(): `number`<br />
Gets the number of exports witin the module.
* Module#**getExportByIndex**(index: `number`): `ExportRef`<br />
Gets the export at the specified index.
* Module#**removeExport**(externalName: `string`): `void`<br />
Removes an export, by external name.
* Module#**addGlobal**(name: `string`, type: `Type`, mutable: `number`, value: `ExpressionRef`): `GlobalRef`<br />
Adds a global instance variable.
* Module#**getGlobal**(name: `string`): `GlobalRef`<br />
Gets a global, by name,
* Module#**removeGlobal**(name: `string`): `void`<br />
Removes a global, by name.
* Module#**setFunctionTable**(initial: `number`, maximum: `number`, funcs: `string[]`, offset?: `ExpressionRef`): `void`<br />
Sets the contents of the function table. There's just one table for now, using name `"0"`.
* Module#**getFunctionTable**(): `{ imported: boolean, segments: TableElement[] }`<br />
Gets the contents of the function table.
* TableElement#**offset**: `ExpressionRef`
* TableElement#**names**: `string[]`
* Module#**setMemory**(initial: `number`, maximum: `number`, exportName: `string | null`, segments: `MemorySegment[]`, flags?: `number[]`, shared?: `boolean`): `void`<br />
Sets the memory. There's just one memory for now, using name `"0"`. Providing `exportName` also creates a memory export.
* MemorySegment#**offset**: `ExpressionRef`
* MemorySegment#**data**: `Uint8Array`
* MemorySegment#**passive**: `boolean`
* Module#**getNumMemorySegments**(): `number`<br />
Gets the number of memory segments within the module.
* Module#**getMemorySegmentInfoByIndex**(index: `number`): `MemorySegmentInfo`<br />
Gets information about the memory segment at the specified index.
* MemorySegmentInfo#**offset**: `number`
* MemorySegmentInfo#**data**: `Uint8Array`
* MemorySegmentInfo#**passive**: `boolean`
* Module#**setStart**(start: `FunctionRef`): `void`<br />
Sets the start function.
* Module#**getFeatures**(): `Features`<br />
Gets the WebAssembly features enabled for this module.
Note that the return value may be a bitmask indicating multiple features. Possible feature flags are:
* Features.**MVP**: `Features`
* Features.**Atomics**: `Features`
* Features.**BulkMemory**: `Features`
* Features.**MutableGlobals**: `Features`
* Features.**NontrappingFPToInt**: `Features`
* Features.**SignExt**: `Features`
* Features.**SIMD128**: `Features`
* Features.**ExceptionHandling**: `Features`
* Features.**TailCall**: `Features`
* Features.**ReferenceTypes**: `Features`
* Features.**Multivalue**: `Features`
* Features.**All**: `Features`
* Module#**setFeatures**(features: `Features`): `void`<br />
Sets the WebAssembly features enabled for this module.
* Module#**addCustomSection**(name: `string`, contents: `Uint8Array`): `void`<br />
Adds a custom section to the binary.
* Module#**autoDrop**(): `void`<br />
Enables automatic insertion of `drop` operations where needed. Lets you not worry about dropping when creating your code.
* **getFunctionInfo**(ftype: `FunctionRef`: `FunctionInfo`<br />
Obtains information about a function.
* FunctionInfo#**name**: `string`
* FunctionInfo#**module**: `string | null` (if imported)
* FunctionInfo#**base**: `string | null` (if imported)
* FunctionInfo#**params**: `Type`
* FunctionInfo#**results**: `Type`
* FunctionInfo#**vars**: `Type`
* FunctionInfo#**body**: `ExpressionRef`
* **getGlobalInfo**(global: `GlobalRef`): `GlobalInfo`<br />
Obtains information about a global.
* GlobalInfo#**name**: `string`
* GlobalInfo#**module**: `string | null` (if imported)
* GlobalInfo#**base**: `string | null` (if imported)
* GlobalInfo#**type**: `Type`
* GlobalInfo#**mutable**: `boolean`
* GlobalInfo#**init**: `ExpressionRef`
* **getExportInfo**(export_: `ExportRef`): `ExportInfo`<br />
Obtains information about an export.
* ExportInfo#**kind**: `ExternalKind`
* ExportInfo#**name**: `string`
* ExportInfo#**value**: `string`
Possible `ExternalKind` values are:
* **ExternalFunction**: `ExternalKind`
* **ExternalTable**: `ExternalKind`
* **ExternalMemory**: `ExternalKind`
* **ExternalGlobal**: `ExternalKind`
* **ExternalEvent**: `ExternalKind`
* **getEventInfo**(event: `EventRef`): `EventInfo`<br />
Obtains information about an event.
* EventInfo#**name**: `string`
* EventInfo#**module**: `string | null` (if imported)
* EventInfo#**base**: `string | null` (if imported)
* EventInfo#**attribute**: `number`
* EventInfo#**params**: `Type`
* EventInfo#**results**: `Type`
* **getSideEffects**(expr: `ExpressionRef`, features: `FeatureFlags`): `SideEffects`<br />
Gets the side effects of the specified expression.
* SideEffects.**None**: `SideEffects`
* SideEffects.**Branches**: `SideEffects`
* SideEffects.**Calls**: `SideEffects`
* SideEffects.**ReadsLocal**: `SideEffects`
* SideEffects.**WritesLocal**: `SideEffects`
* SideEffects.**ReadsGlobal**: `SideEffects`
* SideEffects.**WritesGlobal**: `SideEffects`
* SideEffects.**ReadsMemory**: `SideEffects`
* SideEffects.**WritesMemory**: `SideEffects`
* SideEffects.**ImplicitTrap**: `SideEffects`
* SideEffects.**IsAtomic**: `SideEffects`
* SideEffects.**Throws**: `SideEffects`
* SideEffects.**Any**: `SideEffects`
### Module validation
* Module#**validate**(): `boolean`<br />
Validates the module. Returns `true` if valid, otherwise prints validation errors and returns `false`.
### Module optimization
* Module#**optimize**(): `void`<br />
Optimizes the module using the default optimization passes.
* Module#**optimizeFunction**(func: `FunctionRef | string`): `void`<br />
Optimizes a single function using the default optimization passes.
* Module#**runPasses**(passes: `string[]`): `void`<br />
Runs the specified passes on the module.
* Module#**runPassesOnFunction**(func: `FunctionRef | string`, passes: `string[]`): `void`<br />
Runs the specified passes on a single function.
* **getOptimizeLevel**(): `number`<br />
Gets the currently set optimize level. `0`, `1`, `2` correspond to `-O0`, `-O1`, `-O2` (default), etc.
* **setOptimizeLevel**(level: `number`): `void`<br />
Sets the optimization level to use. `0`, `1`, `2` correspond to `-O0`, `-O1`, `-O2` (default), etc.
* **getShrinkLevel**(): `number`<br />
Gets the currently set shrink level. `0`, `1`, `2` correspond to `-O0`, `-Os` (default), `-Oz`.
* **setShrinkLevel**(level: `number`): `void`<br />
Sets the shrink level to use. `0`, `1`, `2` correspond to `-O0`, `-Os` (default), `-Oz`.
* **getDebugInfo**(): `boolean`<br />
Gets whether generating debug information is currently enabled or not.
* **setDebugInfo**(on: `boolean`): `void`<br />
Enables or disables debug information in emitted binaries.
* **getLowMemoryUnused**(): `boolean`<br />
Gets whether the low 1K of memory can be considered unused when optimizing.
* **setLowMemoryUnused**(on: `boolean`): `void`<br />
Enables or disables whether the low 1K of memory can be considered unused when optimizing.
* **getPassArgument**(key: `string`): `string | null`<br />
Gets the value of the specified arbitrary pass argument.
* **setPassArgument**(key: `string`, value: `string | null`): `void`<br />
Sets the value of the specified arbitrary pass argument. Removes the respective argument if `value` is `null`.
* **clearPassArguments**(): `void`<br />
Clears all arbitrary pass arguments.
* **getAlwaysInlineMaxSize**(): `number`<br />
Gets the function size at which we always inline.
* **setAlwaysInlineMaxSize**(size: `number`): `void`<br />
Sets the function size at which we always inline.
* **getFlexibleInlineMaxSize**(): `number`<br />
Gets the function size which we inline when functions are lightweight.
* **setFlexibleInlineMaxSize**(size: `number`): `void`<br />
Sets the function size which we inline when functions are lightweight.
* **getOneCallerInlineMaxSize**(): `number`<br />
Gets the function size which we inline when there is only one caller.
* **setOneCallerInlineMaxSize**(size: `number`): `void`<br />
Sets the function size which we inline when there is only one caller.
### Module creation
* Module#**emitBinary**(): `Uint8Array`<br />
Returns the module in binary format.
* Module#**emitBinary**(sourceMapUrl: `string | null`): `BinaryWithSourceMap`<br />
Returns the module in binary format with its source map. If `sourceMapUrl` is `null`, source map generation is skipped.
* BinaryWithSourceMap#**binary**: `Uint8Array`
* BinaryWithSourceMap#**sourceMap**: `string | null`
* Module#**emitText**(): `string`<br />
Returns the module in Binaryen's s-expression text format (not official stack-style text format).
* Module#**emitAsmjs**(): `string`<br />
Returns the [asm.js](http://asmjs.org/) representation of the module.
* Module#**dispose**(): `void`<br />
Releases the resources held by the module once it isn't needed anymore.
### Expression construction
#### [Control flow](http://webassembly.org/docs/semantics/#control-constructs-and-instructions)
* Module#**block**(label: `string | null`, children: `ExpressionRef[]`, resultType?: `Type`): `ExpressionRef`<br />
Creates a block. `resultType` defaults to `none`.
* Module#**if**(condition: `ExpressionRef`, ifTrue: `ExpressionRef`, ifFalse?: `ExpressionRef`): `ExpressionRef`<br />
Creates an if or if/else combination.
* Module#**loop**(label: `string | null`, body: `ExpressionRef`): `ExpressionRef`<br />
Creates a loop.
* Module#**br**(label: `string`, condition?: `ExpressionRef`, value?: `ExpressionRef`): `ExpressionRef`<br />
Creates a branch (br) to a label.
* Module#**switch**(labels: `string[]`, defaultLabel: `string`, condition: `ExpressionRef`, value?: `ExpressionRef`): `ExpressionRef`<br />
Creates a switch (br_table).
* Module#**nop**(): `ExpressionRef`<br />
Creates a no-operation (nop) instruction.
* Module#**return**(value?: `ExpressionRef`): `ExpressionRef`
Creates a return.
* Module#**unreachable**(): `ExpressionRef`<br />
Creates an [unreachable](http://webassembly.org/docs/semantics/#unreachable) instruction that will always trap.
* Module#**drop**(value: `ExpressionRef`): `ExpressionRef`<br />
Creates a [drop](http://webassembly.org/docs/semantics/#type-parametric-operators) of a value.
* Module#**select**(condition: `ExpressionRef`, ifTrue: `ExpressionRef`, ifFalse: `ExpressionRef`, type?: `Type`): `ExpressionRef`<br />
Creates a [select](http://webassembly.org/docs/semantics/#type-parametric-operators) of one of two values.
#### [Variable accesses](http://webassembly.org/docs/semantics/#local-variables)
* Module#**local.get**(index: `number`, type: `Type`): `ExpressionRef`<br />
Creates a local.get for the local at the specified index. Note that we must specify the type here as we may not have created the local being accessed yet.
* Module#**local.set**(index: `number`, value: `ExpressionRef`): `ExpressionRef`<br />
Creates a local.set for the local at the specified index.
* Module#**local.tee**(index: `number`, value: `ExpressionRef`, type: `Type`): `ExpressionRef`<br />
Creates a local.tee for the local at the specified index. A tee differs from a set in that the value remains on the stack. Note that we must specify the type here as we may not have created the local being accessed yet.
* Module#**global.get**(name: `string`, type: `Type`): `ExpressionRef`<br />
Creates a global.get for the global with the specified name. Note that we must specify the type here as we may not have created the global being accessed yet.
* Module#**global.set**(name: `string`, value: `ExpressionRef`): `ExpressionRef`<br />
Creates a global.set for the global with the specified name.
#### [Integer operations](http://webassembly.org/docs/semantics/#32-bit-integer-operators)
* Module#i32.**const**(value: `number`): `ExpressionRef`
* Module#i32.**clz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ctz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**popcnt**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**eqz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**div_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**div_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rem_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rem_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**shr_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rotl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**rotr**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**le_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**const**(value: `number`): `ExpressionRef`
* Module#i64.**clz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ctz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**popcnt**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**eqz**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**div_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**div_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rem_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rem_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**shr_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rotl**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**rotr**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**le_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
#### [Floating point operations](http://webassembly.org/docs/semantics/#floating-point-operators)
* Module#f32.**const**(value: `number`): `ExpressionRef`
* Module#f32.**const_bits**(value: `number`): `ExpressionRef`
* Module#f32.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ceil**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**floor**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**trunc**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**nearest**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**copysign**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**const**(value: `number`): `ExpressionRef`
* Module#f64.**const_bits**(value: `number`): `ExpressionRef`
* Module#f64.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ceil**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**floor**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**trunc**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**nearest**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**copysign**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
#### [Datatype conversions](http://webassembly.org/docs/semantics/#datatype-conversions-truncations-reinterpretations-promotions-and-demotions)
* Module#i32.**trunc_s.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_s.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_u.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**trunc_u.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**wrap**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**trunc_s.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_s.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_u.f32**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**trunc_u.f64**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f32.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_s.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_s.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_u.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**convert_u.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32.**demote**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**reinterpret**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_s.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_s.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_u.i32**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**convert_u.i64**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64.**promote**(value: `ExpressionRef`): `ExpressionRef`
#### [Function calls](http://webassembly.org/docs/semantics/#calls)
* Module#**call**(name: `string`, operands: `ExpressionRef[]`, returnType: `Type`): `ExpressionRef`
Creates a call to a function. Note that we must specify the return type here as we may not have created the function being called yet.
* Module#**return_call**(name: `string`, operands: `ExpressionRef[]`, returnType: `Type`): `ExpressionRef`<br />
Like **call**, but creates a tail-call. 🦄
* Module#**call_indirect**(target: `ExpressionRef`, operands: `ExpressionRef[]`, params: `Type`, results: `Type`): `ExpressionRef`<br />
Similar to **call**, but calls indirectly, i.e., via a function pointer, so an expression replaces the name as the called value.
* Module#**return_call_indirect**(target: `ExpressionRef`, operands: `ExpressionRef[]`, params: `Type`, results: `Type`): `ExpressionRef`<br />
Like **call_indirect**, but creates a tail-call. 🦄
#### [Linear memory accesses](http://webassembly.org/docs/semantics/#linear-memory-accesses)
* Module#i32.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load16_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**load16_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store8**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
* Module#i32.**store16**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`<br />
>
* Module#i64.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load16_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load16_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load32_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**load32_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store8**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store16**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**store32**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#f32.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#f32.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#f64.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
#### [Host operations](http://webassembly.org/docs/semantics/#resizing)
* Module#**memory.size**(): `ExpressionRef`
* Module#**memory.grow**(value: `number`): `ExpressionRef`
#### [Vector operations](https://github.com/WebAssembly/simd/blob/master/proposals/simd/SIMD.md) 🦄
* Module#v128.**const**(bytes: `Uint8Array`): `ExpressionRef`
* Module#v128.**load**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#v128.**store**(offset: `number`, align: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#v128.**not**(value: `ExpressionRef`): `ExpressionRef`
* Module#v128.**and**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**or**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**xor**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**andnot**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v128.**bitselect**(left: `ExpressionRef`, right: `ExpressionRef`, cond: `ExpressionRef`): `ExpressionRef`
>
* Module#i8x16.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i8x16.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i8x16.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**add_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**sub_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**avgr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**narrow_i16x8_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i8x16.**narrow_i16x8_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
>
* Module#i16x8.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i16x8.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i16x8.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**add_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub_saturate_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**sub_saturate_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**avgr_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**narrow_i32x4_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**narrow_i32x4_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_low_i8x16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_high_i8x16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_low_i8x16_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**widen_high_i8x16_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**load8x8_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i16x8.**load8x8_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#i32x4.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i32x4.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i32x4.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**gt_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**gt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**le_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**lt_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ge_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**ge_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**min_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**min_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**max_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**max_u**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**dot_i16x8_s**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**trunc_sat_f32x4_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**trunc_sat_f32x4_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_low_i16x8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_high_i16x8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_low_i16x8_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**widen_high_i16x8_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**load16x4_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32x4.**load16x4_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#i64x2.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**extract_lane_s**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i64x2.**extract_lane_u**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#i64x2.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**any_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**all_true**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shl**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shr_s**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**shr_u**(vec: `ExpressionRef`, shift: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**trunc_sat_f64x2_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**trunc_sat_f64x2_u**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**load32x2_s**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64x2.**load32x2_u**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#f32x4.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**extract_lane**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#f32x4.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**qfma**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**qfms**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**convert_i32x4_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#f32x4.**convert_i32x4_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#f64x2.**splat**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**extract_lane**(vec: `ExpressionRef`, index: `number`): `ExpressionRef`
* Module#f64x2.**replace_lane**(vec: `ExpressionRef`, index: `number`, value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**eq**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**ne**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**lt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**gt**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**le**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**ge**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**abs**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**neg**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**sqrt**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**qfma**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**qfms**(a: `ExpressionRef`, b: `ExpressionRef`, c: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**add**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**sub**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**mul**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**div**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**min**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**max**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**convert_i64x2_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#f64x2.**convert_i64x2_u**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#v8x16.**shuffle**(left: `ExpressionRef`, right: `ExpressionRef`, mask: `Uint8Array`): `ExpressionRef`
* Module#v8x16.**swizzle**(left: `ExpressionRef`, right: `ExpressionRef`): `ExpressionRef`
* Module#v8x16.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v16x8.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v32x4.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
>
* Module#v64x2.**load_splat**(offset: `number`, align: `number`, ptr: `ExpressionRef`): `ExpressionRef`
#### [Atomic memory accesses](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#atomic-memory-accesses) 🦄
* Module#i32.**atomic.load**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.load8_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.load16_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store8**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.store16**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**atomic.load**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load8_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load16_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.load32_u**(offset: `number`, ptr: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store8**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store16**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.store32**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
#### [Atomic read-modify-write operations](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#read-modify-write) 🦄
* Module#i32.**atomic.rmw.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw8_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**atomic.rmw16_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**atomic.rmw.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw8_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw16_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.add**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.sub**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.and**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.or**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.xor**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.xchg**(offset: `number`, ptr: `ExpressionRef`, value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.rmw32_u.cmpxchg**(offset: `number`, ptr: `ExpressionRef`, expected: `ExpressionRef`, replacement: `ExpressionRef`): `ExpressionRef`
#### [Atomic wait and notify operations](https://github.com/WebAssembly/threads/blob/master/proposals/threads/Overview.md#wait-and-notify-operators) 🦄
* Module#i32.**atomic.wait**(ptr: `ExpressionRef`, expected: `ExpressionRef`, timeout: `ExpressionRef`): `ExpressionRef`
* Module#i64.**atomic.wait**(ptr: `ExpressionRef`, expected: `ExpressionRef`, timeout: `ExpressionRef`): `ExpressionRef`
* Module#**atomic.notify**(ptr: `ExpressionRef`, notifyCount: `ExpressionRef`): `ExpressionRef`
* Module#**atomic.fence**(): `ExpressionRef`
#### [Sign extension operations](https://github.com/WebAssembly/sign-extension-ops/blob/master/proposals/sign-extension-ops/Overview.md) 🦄
* Module#i32.**extend8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**extend16_s**(value: `ExpressionRef`): `ExpressionRef`
>
* Module#i64.**extend8_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend16_s**(value: `ExpressionRef`): `ExpressionRef`
* Module#i64.**extend32_s**(value: `ExpressionRef`): `ExpressionRef`
#### [Multi-value operations](https://github.com/WebAssembly/multi-value/blob/master/proposals/multi-value/Overview.md) 🦄
Note that these are pseudo instructions enabling Binaryen to reason about multiple values on the stack.
* Module#**push**(value: `ExpressionRef`): `ExpressionRef`
* Module#i32.**pop**(): `ExpressionRef`
* Module#i64.**pop**(): `ExpressionRef`
* Module#f32.**pop**(): `ExpressionRef`
* Module#f64.**pop**(): `ExpressionRef`
* Module#v128.**pop**(): `ExpressionRef`
* Module#funcref.**pop**(): `ExpressionRef`
* Module#anyref.**pop**(): `ExpressionRef`
* Module#nullref.**pop**(): `ExpressionRef`
* Module#exnref.**pop**(): `ExpressionRef`
* Module#tuple.**make**(elements: `ExpressionRef[]`): `ExpressionRef`
* Module#tuple.**extract**(tuple: `ExpressionRef`, index: `number`): `ExpressionRef`
#### [Exception handling operations](https://github.com/WebAssembly/exception-handling/blob/master/proposals/Exceptions.md) 🦄
* Module#**try**(body: `ExpressionRef`, catchBody: `ExpressionRef`): `ExpressionRef`
* Module#**throw**(event: `string`, operands: `ExpressionRef[]`): `ExpressionRef`
* Module#**rethrow**(exnref: `ExpressionRef`): `ExpressionRef`
* Module#**br_on_exn**(label: `string`, event: `string`, exnref: `ExpressionRef`): `ExpressionRef`
>
* Module#**addEvent**(name: `string`, attribute: `number`, params: `Type`, results: `Type`): `Event`
* Module#**getEvent**(name: `string`): `Event`
* Module#**removeEvent**(name: `stirng`): `void`
* Module#**addEventImport**(internalName: `string`, externalModuleName: `string`, externalBaseName: `string`, attribute: `number`, params: `Type`, results: `Type`): `void`
* Module#**addEventExport**(internalName: `string`, externalName: `string`): `ExportRef`
#### [Reference types operations](https://github.com/WebAssembly/reference-types/blob/master/proposals/reference-types/Overview.md) 🦄
* Module#ref.**null**(): `ExpressionRef`
* Module#ref.**is_null**(value: `ExpressionRef`): `ExpressionRef`
* Module#ref.**func**(name: `string`): `ExpressionRef`
### Expression manipulation
* **getExpressionId**(expr: `ExpressionRef`): `ExpressionId`<br />
Gets the id (kind) of the specified expression. Possible values are:
* **InvalidId**: `ExpressionId`
* **BlockId**: `ExpressionId`
* **IfId**: `ExpressionId`
* **LoopId**: `ExpressionId`
* **BreakId**: `ExpressionId`
* **SwitchId**: `ExpressionId`
* **CallId**: `ExpressionId`
* **CallIndirectId**: `ExpressionId`
* **LocalGetId**: `ExpressionId`
* **LocalSetId**: `ExpressionId`
* **GlobalGetId**: `ExpressionId`
* **GlobalSetId**: `ExpressionId`
* **LoadId**: `ExpressionId`
* **StoreId**: `ExpressionId`
* **ConstId**: `ExpressionId`
* **UnaryId**: `ExpressionId`
* **BinaryId**: `ExpressionId`
* **SelectId**: `ExpressionId`
* **DropId**: `ExpressionId`
* **ReturnId**: `ExpressionId`
* **HostId**: `ExpressionId`
* **NopId**: `ExpressionId`
* **UnreachableId**: `ExpressionId`
* **AtomicCmpxchgId**: `ExpressionId`
* **AtomicRMWId**: `ExpressionId`
* **AtomicWaitId**: `ExpressionId`
* **AtomicNotifyId**: `ExpressionId`
* **AtomicFenceId**: `ExpressionId`
* **SIMDExtractId**: `ExpressionId`
* **SIMDReplaceId**: `ExpressionId`
* **SIMDShuffleId**: `ExpressionId`
* **SIMDTernaryId**: `ExpressionId`
* **SIMDShiftId**: `ExpressionId`
* **SIMDLoadId**: `ExpressionId`
* **MemoryInitId**: `ExpressionId`
* **DataDropId**: `ExpressionId`
* **MemoryCopyId**: `ExpressionId`
* **MemoryFillId**: `ExpressionId`
* **RefNullId**: `ExpressionId`
* **RefIsNullId**: `ExpressionId`
* **RefFuncId**: `ExpressionId`
* **TryId**: `ExpressionId`
* **ThrowId**: `ExpressionId`
* **RethrowId**: `ExpressionId`
* **BrOnExnId**: `ExpressionId`
* **PushId**: `ExpressionId`
* **PopId**: `ExpressionId`
* **getExpressionType**(expr: `ExpressionRef`): `Type`<br />
Gets the type of the specified expression.
* **getExpressionInfo**(expr: `ExpressionRef`): `ExpressionInfo`<br />
Obtains information about an expression, always including:
* Info#**id**: `ExpressionId`
* Info#**type**: `Type`
Additional properties depend on the expression's `id` and are usually equivalent to the respective parameters when creating such an expression:
* BlockInfo#**name**: `string`
* BlockInfo#**children**: `ExpressionRef[]`
>
* IfInfo#**condition**: `ExpressionRef`
* IfInfo#**ifTrue**: `ExpressionRef`
* IfInfo#**ifFalse**: `ExpressionRef | null`
>
* LoopInfo#**name**: `string`
* LoopInfo#**body**: `ExpressionRef`
>
* BreakInfo#**name**: `string`
* BreakInfo#**condition**: `ExpressionRef | null`
* BreakInfo#**value**: `ExpressionRef | null`
>
* SwitchInfo#**names**: `string[]`
* SwitchInfo#**defaultName**: `string | null`
* SwitchInfo#**condition**: `ExpressionRef`
* SwitchInfo#**value**: `ExpressionRef | null`
>
* CallInfo#**target**: `string`
* CallInfo#**operands**: `ExpressionRef[]`
>
* CallImportInfo#**target**: `string`
* CallImportInfo#**operands**: `ExpressionRef[]`
>
* CallIndirectInfo#**target**: `ExpressionRef`
* CallIndirectInfo#**operands**: `ExpressionRef[]`
>
* LocalGetInfo#**index**: `number`
>
* LocalSetInfo#**isTee**: `boolean`
* LocalSetInfo#**index**: `number`
* LocalSetInfo#**value**: `ExpressionRef`
>
* GlobalGetInfo#**name**: `string`
>
* GlobalSetInfo#**name**: `string`
* GlobalSetInfo#**value**: `ExpressionRef`
>
* LoadInfo#**isAtomic**: `boolean`
* LoadInfo#**isSigned**: `boolean`
* LoadInfo#**offset**: `number`
* LoadInfo#**bytes**: `number`
* LoadInfo#**align**: `number`
* LoadInfo#**ptr**: `ExpressionRef`
>
* StoreInfo#**isAtomic**: `boolean`
* StoreInfo#**offset**: `number`
* StoreInfo#**bytes**: `number`
* StoreInfo#**align**: `number`
* StoreInfo#**ptr**: `ExpressionRef`
* StoreInfo#**value**: `ExpressionRef`
>
* ConstInfo#**value**: `number | { low: number, high: number }`
>
* UnaryInfo#**op**: `number`
* UnaryInfo#**value**: `ExpressionRef`
>
* BinaryInfo#**op**: `number`
* BinaryInfo#**left**: `ExpressionRef`
* BinaryInfo#**right**: `ExpressionRef`
>
* SelectInfo#**ifTrue**: `ExpressionRef`
* SelectInfo#**ifFalse**: `ExpressionRef`
* SelectInfo#**condition**: `ExpressionRef`
>
* DropInfo#**value**: `ExpressionRef`
>
* ReturnInfo#**value**: `ExpressionRef | null`
>
* NopInfo
>
* UnreachableInfo
>
* HostInfo#**op**: `number`
* HostInfo#**nameOperand**: `string | null`
* HostInfo#**operands**: `ExpressionRef[]`
>
* AtomicRMWInfo#**op**: `number`
* AtomicRMWInfo#**bytes**: `number`
* AtomicRMWInfo#**offset**: `number`
* AtomicRMWInfo#**ptr**: `ExpressionRef`
* AtomicRMWInfo#**value**: `ExpressionRef`
>
* AtomicCmpxchgInfo#**bytes**: `number`
* AtomicCmpxchgInfo#**offset**: `number`
* AtomicCmpxchgInfo#**ptr**: `ExpressionRef`
* AtomicCmpxchgInfo#**expected**: `ExpressionRef`
* AtomicCmpxchgInfo#**replacement**: `ExpressionRef`
>
* AtomicWaitInfo#**ptr**: `ExpressionRef`
* AtomicWaitInfo#**expected**: `ExpressionRef`
* AtomicWaitInfo#**timeout**: `ExpressionRef`
* AtomicWaitInfo#**expectedType**: `Type`
>
* AtomicNotifyInfo#**ptr**: `ExpressionRef`
* AtomicNotifyInfo#**notifyCount**: `ExpressionRef`
>
* AtomicFenceInfo
>
* SIMDExtractInfo#**op**: `Op`
* SIMDExtractInfo#**vec**: `ExpressionRef`
* SIMDExtractInfo#**index**: `ExpressionRef`
>
* SIMDReplaceInfo#**op**: `Op`
* SIMDReplaceInfo#**vec**: `ExpressionRef`
* SIMDReplaceInfo#**index**: `ExpressionRef`
* SIMDReplaceInfo#**value**: `ExpressionRef`
>
* SIMDShuffleInfo#**left**: `ExpressionRef`
* SIMDShuffleInfo#**right**: `ExpressionRef`
* SIMDShuffleInfo#**mask**: `Uint8Array`
>
* SIMDTernaryInfo#**op**: `Op`
* SIMDTernaryInfo#**a**: `ExpressionRef`
* SIMDTernaryInfo#**b**: `ExpressionRef`
* SIMDTernaryInfo#**c**: `ExpressionRef`
>
* SIMDShiftInfo#**op**: `Op`
* SIMDShiftInfo#**vec**: `ExpressionRef`
* SIMDShiftInfo#**shift**: `ExpressionRef`
>
* SIMDLoadInfo#**op**: `Op`
* SIMDLoadInfo#**offset**: `number`
* SIMDLoadInfo#**align**: `number`
* SIMDLoadInfo#**ptr**: `ExpressionRef`
>
* MemoryInitInfo#**segment**: `number`
* MemoryInitInfo#**dest**: `ExpressionRef`
* MemoryInitInfo#**offset**: `ExpressionRef`
* MemoryInitInfo#**size**: `ExpressionRef`
>
* MemoryDropInfo#**segment**: `number`
>
* MemoryCopyInfo#**dest**: `ExpressionRef`
* MemoryCopyInfo#**source**: `ExpressionRef`
* MemoryCopyInfo#**size**: `ExpressionRef`
>
* MemoryFillInfo#**dest**: `ExpressionRef`
* MemoryFillInfo#**value**: `ExpressionRef`
* MemoryFillInfo#**size**: `ExpressionRef`
>
* TryInfo#**body**: `ExpressionRef`
* TryInfo#**catchBody**: `ExpressionRef`
>
* RefNullInfo
>
* RefIsNullInfo#**value**: `ExpressionRef`
>
* RefFuncInfo#**func**: `string`
>
* ThrowInfo#**event**: `string`
* ThrowInfo#**operands**: `ExpressionRef[]`
>
* RethrowInfo#**exnref**: `ExpressionRef`
>
* BrOnExnInfo#**name**: `string`
* BrOnExnInfo#**event**: `string`
* BrOnExnInfo#**exnref**: `ExpressionRef`
>
* PopInfo
>
* PushInfo#**value**: `ExpressionRef`
* **emitText**(expression: `ExpressionRef`): `string`<br />
Emits the expression in Binaryen's s-expression text format (not official stack-style text format).
* **copyExpression**(expression: `ExpressionRef`): `ExpressionRef`<br />
Creates a deep copy of an expression.
### Relooper
* new **Relooper**()<br />
Constructs a relooper instance. This lets you provide an arbitrary CFG, and the relooper will structure it for WebAssembly.
* Relooper#**addBlock**(code: `ExpressionRef`): `RelooperBlockRef`<br />
Adds a new block to the CFG, containing the provided code as its body.
* Relooper#**addBranch**(from: `RelooperBlockRef`, to: `RelooperBlockRef`, condition: `ExpressionRef`, code: `ExpressionRef`): `void`<br />
Adds a branch from a block to another block, with a condition (or nothing, if this is the default branch to take from the origin - each block must have one such branch), and optional code to execute on the branch (useful for phis).
* Relooper#**addBlockWithSwitch**(code: `ExpressionRef`, condition: `ExpressionRef`): `RelooperBlockRef`<br />
Adds a new block, which ends with a switch/br_table, with provided code and condition (that determines where we go in the switch).
* Relooper#**addBranchForSwitch**(from: `RelooperBlockRef`, to: `RelooperBlockRef`, indexes: `number[]`, code: `ExpressionRef`): `void`<br />
Adds a branch from a block ending in a switch, to another block, using an array of indexes that determine where to go, and optional code to execute on the branch.
* Relooper#**renderAndDispose**(entry: `RelooperBlockRef`, labelHelper: `number`, module: `Module`): `ExpressionRef`<br />
Renders and cleans up the Relooper instance. Call this after you have created all the blocks and branches, giving it the entry block (where control flow begins), a label helper variable (an index of a local we can use, necessary for irreducible control flow), and the module. This returns an expression - normal WebAssembly code - that you can use normally anywhere.
### Source maps
* Module#**addDebugInfoFileName**(filename: `string`): `number`<br />
Adds a debug info file name to the module and returns its index.
* Module#**getDebugInfoFileName**(index: `number`): `string | null` <br />
Gets the name of the debug info file at the specified index.
* Module#**setDebugLocation**(func: `FunctionRef`, expr: `ExpressionRef`, fileIndex: `number`, lineNumber: `number`, columnNumber: `number`): `void`<br />
Sets the debug location of the specified `ExpressionRef` within the specified `FunctionRef`.
### Debugging
* Module#**interpret**(): `void`<br />
Runs the module in the interpreter, calling the start function.
# Near Bindings Generator
Transforms the Assembyscript AST to serialize exported functions and add `encode` and `decode` functions for generating and parsing JSON strings.
## Using via CLI
After installling, `npm install nearprotocol/near-bindgen-as`, it can be added to the cli arguments of the assemblyscript compiler you must add the following:
```bash
asc <file> --transform near-bindgen-as ...
```
This module also adds a binary `near-asc` which adds the default arguments required to build near contracts as well as the transformer.
```bash
near-asc <input file> <output file>
```
## Using a script to compile
Another way is to add a file such as `asconfig.js` such as:
```js
const compile = require("near-bindgen-as/compiler").compile;
compile("assembly/index.ts", // input file
"out/index.wasm", // output file
[
// "-O1", // Optional arguments
"--debug",
"--measure"
],
// Prints out the final cli arguments passed to compiler.
{verbose: true}
);
```
It can then be built with `node asconfig.js`. There is an example of this in the test directory.
# cliui

[](https://www.npmjs.com/package/cliui)
[](https://conventionalcommits.org)

easily create complex multi-column command-line-interfaces.
## Example
```js
const ui = require('cliui')()
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 1, 0]
})
ui.div(
{
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
},
{
text: "the file to load." +
chalk.green("(if this description is long it wraps).")
,
width: 20
},
{
text: chalk.red("[required]"),
align: 'right'
}
)
console.log(ui.toString())
```
## Deno/ESM Support
As of `v7` `cliui` supports [Deno](https://github.com/denoland/deno) and
[ESM](https://nodejs.org/api/esm.html#esm_ecmascript_modules):
```typescript
import cliui from "https://deno.land/x/cliui/deno.ts";
const ui = cliui({})
ui.div('Usage: $0 [command] [options]')
ui.div({
text: 'Options:',
padding: [2, 0, 1, 0]
})
ui.div({
text: "-f, --file",
width: 20,
padding: [0, 4, 0, 4]
})
console.log(ui.toString())
```
<img width="500" src="screenshot.png">
## Layout DSL
cliui exposes a simple layout DSL:
If you create a single `ui.div`, passing a string rather than an
object:
* `\n`: characters will be interpreted as new rows.
* `\t`: characters will be interpreted as new columns.
* `\s`: characters will be interpreted as padding.
**as an example...**
```js
var ui = require('./')({
width: 60
})
ui.div(
'Usage: node ./bin/foo.js\n' +
' <regex>\t provide a regex\n' +
' <glob>\t provide a glob\t [required]'
)
console.log(ui.toString())
```
**will output:**
```shell
Usage: node ./bin/foo.js
<regex> provide a regex
<glob> provide a glob [required]
```
## Methods
```js
cliui = require('cliui')
```
### cliui({width: integer})
Specify the maximum width of the UI being generated.
If no width is provided, cliui will try to get the current window's width and use it, and if that doesn't work, width will be set to `80`.
### cliui({wrap: boolean})
Enable or disable the wrapping of text in a column.
### cliui.div(column, column, column)
Create a row with any number of columns, a column
can either be a string, or an object with the following
options:
* **text:** some text to place in the column.
* **width:** the width of a column.
* **align:** alignment, `right` or `center`.
* **padding:** `[top, right, bottom, left]`.
* **border:** should a border be placed around the div?
### cliui.span(column, column, column)
Similar to `div`, except the next row will be appended without
a new line being created.
### cliui.resetOutput()
Resets the UI elements of the current cliui instance, maintaining the values
set for `width` and `wrap`.
# y18n
[![Build Status][travis-image]][travis-url]
[![Coverage Status][coveralls-image]][coveralls-url]
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[](https://conventionalcommits.org)
The bare-bones internationalization library used by yargs.
Inspired by [i18n](https://www.npmjs.com/package/i18n).
## Examples
_simple string translation:_
```js
var __ = require('y18n').__
console.log(__('my awesome string %s', 'foo'))
```
output:
`my awesome string foo`
_using tagged template literals_
```js
var __ = require('y18n').__
var str = 'foo'
console.log(__`my awesome string ${str}`)
```
output:
`my awesome string foo`
_pluralization support:_
```js
var __n = require('y18n').__n
console.log(__n('one fish %s', '%d fishes %s', 2, 'foo'))
```
output:
`2 fishes foo`
## JSON Language Files
The JSON language files should be stored in a `./locales` folder.
File names correspond to locales, e.g., `en.json`, `pirate.json`.
When strings are observed for the first time they will be
added to the JSON file corresponding to the current locale.
## Methods
### require('y18n')(config)
Create an instance of y18n with the config provided, options include:
* `directory`: the locale directory, default `./locales`.
* `updateFiles`: should newly observed strings be updated in file, default `true`.
* `locale`: what locale should be used.
* `fallbackToLanguage`: should fallback to a language-only file (e.g. `en.json`)
be allowed if a file matching the locale does not exist (e.g. `en_US.json`),
default `true`.
### y18n.\_\_(str, arg, arg, arg)
Print a localized string, `%s` will be replaced with `arg`s.
This function can also be used as a tag for a template literal. You can use it
like this: <code>__`hello ${'world'}`</code>. This will be equivalent to
`__('hello %s', 'world')`.
### y18n.\_\_n(singularString, pluralString, count, arg, arg, arg)
Print a localized string with appropriate pluralization. If `%d` is provided
in the string, the `count` will replace this placeholder.
### y18n.setLocale(str)
Set the current locale being used.
### y18n.getLocale()
What locale is currently being used?
### y18n.updateLocale(obj)
Update the current locale with the key value pairs in `obj`.
## License
ISC
[travis-url]: https://travis-ci.org/yargs/y18n
[travis-image]: https://img.shields.io/travis/yargs/y18n.svg
[coveralls-url]: https://coveralls.io/github/yargs/y18n
[coveralls-image]: https://img.shields.io/coveralls/yargs/y18n.svg
[npm-url]: https://npmjs.org/package/y18n
[npm-image]: https://img.shields.io/npm/v/y18n.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: https://github.com/feross/standard
# randexp.js
randexp will generate a random string that matches a given RegExp Javascript object.
[](http://travis-ci.org/fent/randexp.js)
[](https://david-dm.org/fent/randexp.js)
[](https://codecov.io/gh/fent/randexp.js)
# Usage
```js
var RandExp = require('randexp');
// supports grouping and piping
new RandExp(/hello+ (world|to you)/).gen();
// => hellooooooooooooooooooo world
// sets and ranges and references
new RandExp(/<([a-z]\w{0,20})>foo<\1>/).gen();
// => <m5xhdg>foo<m5xhdg>
// wildcard
new RandExp(/random stuff: .+/).gen();
// => random stuff: l3m;Hf9XYbI [YPaxV>U*4-_F!WXQh9>;rH3i l!8.zoh?[utt1OWFQrE ^~8zEQm]~tK
// ignore case
new RandExp(/xxx xtreme dragon warrior xxx/i).gen();
// => xxx xtReME dRAGON warRiOR xXX
// dynamic regexp shortcut
new RandExp('(sun|mon|tue|wednes|thurs|fri|satur)day', 'i');
// is the same as
new RandExp(new RegExp('(sun|mon|tue|wednes|thurs|fri|satur)day', 'i'));
```
If you're only going to use `gen()` once with a regexp and want slightly shorter syntax for it
```js
var randexp = require('randexp').randexp;
randexp(/[1-6]/); // 4
randexp('great|good( job)?|excellent'); // great
```
If you miss the old syntax
```js
require('randexp').sugar();
/yes|no|maybe|i don't know/.gen(); // maybe
```
# Motivation
Regular expressions are used in every language, every programmer is familiar with them. Regex can be used to easily express complex strings. What better way to generate a random string than with a language you can use to express the string you want?
Thanks to [String-Random](http://search.cpan.org/~steve/String-Random-0.22/lib/String/Random.pm) for giving me the idea to make this in the first place and [randexp](https://github.com/benburkert/randexp) for the sweet `.gen()` syntax.
# Default Range
The default generated character range includes printable ASCII. In order to add or remove characters,
a `defaultRange` attribute is exposed. you can `subtract(from, to)` and `add(from, to)`
```js
var randexp = new RandExp(/random stuff: .+/);
randexp.defaultRange.subtract(32, 126);
randexp.defaultRange.add(0, 65535);
randexp.gen();
// => random stuff: 湐箻ໜ䫴㳸長���邓蕲뤀쑡篷皇硬剈궦佔칗븛뀃匫鴔事좍ﯣ⭼ꝏ䭍詳蒂䥂뽭
```
# Custom PRNG
The default randomness is provided by `Math.random()`. If you need to use a seedable or cryptographic PRNG, you
can override `RandExp.prototype.randInt` or `randexp.randInt` (where `randexp` is an instance of `RandExp`). `randInt(from, to)` accepts an inclusive range and returns a randomly selected
number within that range.
# Infinite Repetitionals
Repetitional tokens such as `*`, `+`, and `{3,}` have an infinite max range. In this case, randexp looks at its min and adds 100 to it to get a useable max value. If you want to use another int other than 100 you can change the `max` property in `RandExp.prototype` or the RandExp instance.
```js
var randexp = new RandExp(/no{1,}/);
randexp.max = 1000000;
```
With `RandExp.sugar()`
```js
var regexp = /(hi)*/;
regexp.max = 1000000;
```
# Bad Regular Expressions
There are some regular expressions which can never match any string.
* Ones with badly placed positionals such as `/a^/` and `/$c/m`. Randexp will ignore positional tokens.
* Back references to non-existing groups like `/(a)\1\2/`. Randexp will ignore those references, returning an empty string for them. If the group exists only after the reference is used such as in `/\1 (hey)/`, it will too be ignored.
* Custom negated character sets with two sets inside that cancel each other out. Example: `/[^\w\W]/`. If you give this to randexp, it will return an empty string for this set since it can't match anything.
# Projects based on randexp.js
## JSON-Schema Faker
Use generators to populate JSON Schema samples. See: [jsf on github](https://github.com/json-schema-faker/json-schema-faker/) and [jsf demo page](http://json-schema-faker.js.org/).
# Install
### Node.js
npm install randexp
### Browser
Download the [minified version](https://github.com/fent/randexp.js/releases) from the latest release.
# Tests
Tests are written with [mocha](https://mochajs.org)
```bash
npm test
```
# License
MIT
# universal-url [![NPM Version][npm-image]][npm-url] [![Build Status][travis-image]][travis-url] [![Dependency Monitor][greenkeeper-image]][greenkeeper-url]
> WHATWG [`URL`](https://developer.mozilla.org/en/docs/Web/API/URL) for Node & Browser.
* For Node.js versions `>= 8`, the native implementation will be used.
* For Node.js versions `< 8`, a [shim](https://npmjs.com/whatwg-url) will be used.
* For web browsers without a native implementation, the same shim will be used.
## Installation
[Node.js](http://nodejs.org/) `>= 6` is required. To install, type this at the command line:
```shell
npm install universal-url
```
## Usage
```js
const {URL, URLSearchParams} = require('universal-url');
const url = new URL('http://domain/');
const params = new URLSearchParams('?param=value');
```
Global shim:
```js
require('universal-url').shim();
const url = new URL('http://domain/');
const params = new URLSearchParams('?param=value');
```
## Browserify/etc
The bundled file size of this library can be large for a web browser. If this is a problem, try using [universal-url-lite](https://npmjs.com/universal-url-lite) in your build as an alias for this module.
[npm-image]: https://img.shields.io/npm/v/universal-url.svg
[npm-url]: https://npmjs.org/package/universal-url
[travis-image]: https://img.shields.io/travis/stevenvachon/universal-url.svg
[travis-url]: https://travis-ci.org/stevenvachon/universal-url
[greenkeeper-image]: https://badges.greenkeeper.io/stevenvachon/universal-url.svg
[greenkeeper-url]: https://greenkeeper.io/
# axios // core
The modules found in `core/` should be modules that are specific to the domain logic of axios. These modules would most likely not make sense to be consumed outside of the axios module, as their logic is too specific. Some examples of core modules are:
- Dispatching requests
- Managing interceptors
- Handling config
# yargs-parser
[](https://travis-ci.org/yargs/yargs-parser)
[](https://www.npmjs.com/package/yargs-parser)
[](https://github.com/conventional-changelog/standard-version)
The mighty option parser used by [yargs](https://github.com/yargs/yargs).
visit the [yargs website](http://yargs.js.org/) for more examples, and thorough usage instructions.
<img width="250" src="https://raw.githubusercontent.com/yargs/yargs-parser/master/yargs-logo.png">
## Example
```sh
npm i yargs-parser --save
```
```js
var argv = require('yargs-parser')(process.argv.slice(2))
console.log(argv)
```
```sh
node example.js --foo=33 --bar hello
{ _: [], foo: 33, bar: 'hello' }
```
_or parse a string!_
```js
var argv = require('yargs-parser')('--foo=99 --bar=33')
console.log(argv)
```
```sh
{ _: [], foo: 99, bar: 33 }
```
Convert an array of mixed types before passing to `yargs-parser`:
```js
var parse = require('yargs-parser')
parse(['-f', 11, '--zoom', 55].join(' ')) // <-- array to string
parse(['-f', 11, '--zoom', 55].map(String)) // <-- array of strings
```
## API
### require('yargs-parser')(args, opts={})
Parses command line arguments returning a simple mapping of keys and values.
**expects:**
* `args`: a string or array of strings representing the options to parse.
* `opts`: provide a set of hints indicating how `args` should be parsed:
* `opts.alias`: an object representing the set of aliases for a key: `{alias: {foo: ['f']}}`.
* `opts.array`: indicate that keys should be parsed as an array: `{array: ['foo', 'bar']}`.<br>
Indicate that keys should be parsed as an array and coerced to booleans / numbers:<br>
`{array: [{ key: 'foo', boolean: true }, {key: 'bar', number: true}]}`.
* `opts.boolean`: arguments should be parsed as booleans: `{boolean: ['x', 'y']}`.
* `opts.coerce`: provide a custom synchronous function that returns a coerced value from the argument provided
(or throws an error). For arrays the function is called only once for the entire array:<br>
`{coerce: {foo: function (arg) {return modifiedArg}}}`.
* `opts.config`: indicate a key that represents a path to a configuration file (this file will be loaded and parsed).
* `opts.configObjects`: configuration objects to parse, their properties will be set as arguments:<br>
`{configObjects: [{'x': 5, 'y': 33}, {'z': 44}]}`.
* `opts.configuration`: provide configuration options to the yargs-parser (see: [configuration](#configuration)).
* `opts.count`: indicate a key that should be used as a counter, e.g., `-vvv` = `{v: 3}`.
* `opts.default`: provide default values for keys: `{default: {x: 33, y: 'hello world!'}}`.
* `opts.envPrefix`: environment variables (`process.env`) with the prefix provided should be parsed.
* `opts.narg`: specify that a key requires `n` arguments: `{narg: {x: 2}}`.
* `opts.normalize`: `path.normalize()` will be applied to values set to this key.
* `opts.number`: keys should be treated as numbers.
* `opts.string`: keys should be treated as strings (even if they resemble a number `-x 33`).
**returns:**
* `obj`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
### require('yargs-parser').detailed(args, opts={})
Parses a command line string, returning detailed information required by the
yargs engine.
**expects:**
* `args`: a string or array of strings representing options to parse.
* `opts`: provide a set of hints indicating how `args`, inputs are identical to `require('yargs-parser')(args, opts={})`.
**returns:**
* `argv`: an object representing the parsed value of `args`
* `key/value`: key value pairs for each argument and their aliases.
* `_`: an array representing the positional arguments.
* [optional] `--`: an array with arguments after the end-of-options flag `--`.
* `error`: populated with an error object if an exception occurred during parsing.
* `aliases`: the inferred list of aliases built by combining lists in `opts.alias`.
* `newAliases`: any new aliases added via camel-case expansion:
* `boolean`: `{ fooBar: true }`
* `defaulted`: any new argument created by `opts.default`, no aliases included.
* `boolean`: `{ foo: true }`
* `configuration`: given by default settings and `opts.configuration`.
<a name="configuration"></a>
### Configuration
The yargs-parser applies several automated transformations on the keys provided
in `args`. These features can be turned on and off using the `configuration` field
of `opts`.
```js
var parsed = parser(['--no-dice'], {
configuration: {
'boolean-negation': false
}
})
```
### short option groups
* default: `true`.
* key: `short-option-groups`.
Should a group of short-options be treated as boolean flags?
```sh
node example.js -abc
{ _: [], a: true, b: true, c: true }
```
_if disabled:_
```sh
node example.js -abc
{ _: [], abc: true }
```
### camel-case expansion
* default: `true`.
* key: `camel-case-expansion`.
Should hyphenated arguments be expanded into camel-case aliases?
```sh
node example.js --foo-bar
{ _: [], 'foo-bar': true, fooBar: true }
```
_if disabled:_
```sh
node example.js --foo-bar
{ _: [], 'foo-bar': true }
```
### dot-notation
* default: `true`
* key: `dot-notation`
Should keys that contain `.` be treated as objects?
```sh
node example.js --foo.bar
{ _: [], foo: { bar: true } }
```
_if disabled:_
```sh
node example.js --foo.bar
{ _: [], "foo.bar": true }
```
### parse numbers
* default: `true`
* key: `parse-numbers`
Should keys that look like numbers be treated as such?
```sh
node example.js --foo=99.3
{ _: [], foo: 99.3 }
```
_if disabled:_
```sh
node example.js --foo=99.3
{ _: [], foo: "99.3" }
```
### boolean negation
* default: `true`
* key: `boolean-negation`
Should variables prefixed with `--no` be treated as negations?
```sh
node example.js --no-foo
{ _: [], foo: false }
```
_if disabled:_
```sh
node example.js --no-foo
{ _: [], "no-foo": true }
```
### combine arrays
* default: `false`
* key: `combine-arrays`
Should arrays be combined when provided by both command line arguments and
a configuration file.
### duplicate arguments array
* default: `true`
* key: `duplicate-arguments-array`
Should arguments be coerced into an array when duplicated:
```sh
node example.js -x 1 -x 2
{ _: [], x: [1, 2] }
```
_if disabled:_
```sh
node example.js -x 1 -x 2
{ _: [], x: 2 }
```
### flatten duplicate arrays
* default: `true`
* key: `flatten-duplicate-arrays`
Should array arguments be coerced into a single array when duplicated:
```sh
node example.js -x 1 2 -x 3 4
{ _: [], x: [1, 2, 3, 4] }
```
_if disabled:_
```sh
node example.js -x 1 2 -x 3 4
{ _: [], x: [[1, 2], [3, 4]] }
```
### greedy arrays
* default: `true`
* key: `greedy-arrays`
Should arrays consume more than one positional argument following their flag.
```sh
node example --arr 1 2
{ _[], arr: [1, 2] }
```
_if disabled:_
```sh
node example --arr 1 2
{ _[2], arr: [1] }
```
**Note: in `v18.0.0` we are considering defaulting greedy arrays to `false`.**
### nargs eats options
* default: `false`
* key: `nargs-eats-options`
Should nargs consume dash options as well as positional arguments.
### negation prefix
* default: `no-`
* key: `negation-prefix`
The prefix to use for negated boolean variables.
```sh
node example.js --no-foo
{ _: [], foo: false }
```
_if set to `quux`:_
```sh
node example.js --quuxfoo
{ _: [], foo: false }
```
### populate --
* default: `false`.
* key: `populate--`
Should unparsed flags be stored in `--` or `_`.
_If disabled:_
```sh
node example.js a -b -- x y
{ _: [ 'a', 'x', 'y' ], b: true }
```
_If enabled:_
```sh
node example.js a -b -- x y
{ _: [ 'a' ], '--': [ 'x', 'y' ], b: true }
```
### set placeholder key
* default: `false`.
* key: `set-placeholder-key`.
Should a placeholder be added for keys not set via the corresponding CLI argument?
_If disabled:_
```sh
node example.js -a 1 -c 2
{ _: [], a: 1, c: 2 }
```
_If enabled:_
```sh
node example.js -a 1 -c 2
{ _: [], a: 1, b: undefined, c: 2 }
```
### halt at non-option
* default: `false`.
* key: `halt-at-non-option`.
Should parsing stop at the first positional argument? This is similar to how e.g. `ssh` parses its command line.
_If disabled:_
```sh
node example.js -a run b -x y
{ _: [ 'b' ], a: 'run', x: 'y' }
```
_If enabled:_
```sh
node example.js -a run b -x y
{ _: [ 'b', '-x', 'y' ], a: 'run' }
```
### strip aliased
* default: `false`
* key: `strip-aliased`
Should aliases be removed before returning results?
_If disabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1, 'test-alias': 1, testAlias: 1 }
```
_If enabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
### strip dashed
* default: `false`
* key: `strip-dashed`
Should dashed keys be removed before returning results? This option has no effect if
`camel-case-expansion` is disabled.
_If disabled:_
```sh
node example.js --test-field 1
{ _: [], 'test-field': 1, testField: 1 }
```
_If enabled:_
```sh
node example.js --test-field 1
{ _: [], testField: 1 }
```
### unknown options as args
* default: `false`
* key: `unknown-options-as-args`
Should unknown options be treated like regular arguments? An unknown option is one that is not
configured in `opts`.
_If disabled_
```sh
node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: [], unknownOption: true, knownOption: 2, stringOption: '', unknownOption2: true }
```
_If enabled_
```sh
node example.js --unknown-option --known-option 2 --string-option --unknown-option2
{ _: ['--unknown-option'], knownOption: 2, stringOption: '--unknown-option2' }
```
## Special Thanks
The yargs project evolves from optimist and minimist. It owes its
existence to a lot of James Halliday's hard work. Thanks [substack](https://github.com/substack) **beep** **boop** \o/
## License
ISC
# debug
[](https://travis-ci.org/visionmedia/debug) [](https://coveralls.io/github/visionmedia/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
[](#sponsors)
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
A tiny JavaScript debugging utility modelled after Node.js core's debugging
technique. Works in Node.js and web browsers.
## Installation
```bash
$ npm install debug
```
## Usage
`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
Example [_app.js_](./examples/node/app.js):
```js
var debug = require('debug')('http')
, http = require('http')
, name = 'My App';
// fake app
debug('booting %o', name);
http.createServer(function(req, res){
debug(req.method + ' ' + req.url);
res.end('hello\n');
}).listen(3000, function(){
debug('listening');
});
// fake worker of some kind
require('./worker');
```
Example [_worker.js_](./examples/node/worker.js):
```js
var a = require('debug')('worker:a')
, b = require('debug')('worker:b');
function work() {
a('doing lots of uninteresting work');
setTimeout(work, Math.random() * 1000);
}
work();
function workb() {
b('doing some work');
setTimeout(workb, Math.random() * 2000);
}
workb();
```
The `DEBUG` environment variable is then used to enable these based on space or
comma-delimited names.
Here are some examples:
<img width="647" alt="screen shot 2017-08-08 at 12 53 04 pm" src="https://user-images.githubusercontent.com/71256/29091703-a6302cdc-7c38-11e7-8304-7c0b3bc600cd.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 38 pm" src="https://user-images.githubusercontent.com/71256/29091700-a62a6888-7c38-11e7-800b-db911291ca2b.png">
<img width="647" alt="screen shot 2017-08-08 at 12 53 25 pm" src="https://user-images.githubusercontent.com/71256/29091701-a62ea114-7c38-11e7-826a-2692bedca740.png">
#### Windows note
On Windows the environment variable is set using the `set` command.
```cmd
set DEBUG=*,-not_this
```
Note that PowerShell uses different syntax to set environment variables.
```cmd
$env:DEBUG = "*,-not_this"
```
Then, run the program to be debugged as usual.
## Namespace Colors
Every debug instance has a color generated for it based on its namespace name.
This helps when visually parsing the debug output to identify which debug instance
a debug line belongs to.
#### Node.js
In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
otherwise debug will only use a small handful of basic colors.
<img width="521" src="https://user-images.githubusercontent.com/71256/29092181-47f6a9e6-7c3a-11e7-9a14-1928d8a711cd.png">
#### Web Browser
Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
option. These are WebKit web inspectors, Firefox ([since version
31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
and the Firebug plugin for Firefox (any version).
<img width="524" src="https://user-images.githubusercontent.com/71256/29092033-b65f9f2e-7c39-11e7-8e32-f6f0d8e865c1.png">
## Millisecond diff
When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
<img width="647" src="https://user-images.githubusercontent.com/71256/29091486-fa38524c-7c37-11e7-895f-e7ec8e1039b6.png">
When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
<img width="647" src="https://user-images.githubusercontent.com/71256/29091956-6bd78372-7c39-11e7-8c55-c948396d6edd.png">
## Conventions
If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
## Wildcards
The `*` character may be used as a wildcard. Suppose for example your library has
debuggers named "connect:bodyParser", "connect:compress", "connect:session",
instead of listing all three with
`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
You can also exclude specific debuggers by prefixing them with a "-" character.
For example, `DEBUG=*,-connect:*` would include all debuggers except those
starting with "connect:".
## Environment Variables
When running through Node.js, you can set a few environment variables that will
change the behavior of the debug logging:
| Name | Purpose |
|-----------|-------------------------------------------------|
| `DEBUG` | Enables/disables specific debugging namespaces. |
| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
| `DEBUG_DEPTH` | Object inspection depth. |
| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
__Note:__ The environment variables beginning with `DEBUG_` end up being
converted into an Options object that gets used with `%o`/`%O` formatters.
See the Node.js documentation for
[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
for the complete list.
## Formatters
Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
Below are the officially supported formatters:
| Formatter | Representation |
|-----------|----------------|
| `%O` | Pretty-print an Object on multiple lines. |
| `%o` | Pretty-print an Object all on a single line. |
| `%s` | String. |
| `%d` | Number (both integer and float). |
| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
| `%%` | Single percent sign ('%'). This does not consume an argument. |
### Custom formatters
You can add custom formatters by extending the `debug.formatters` object.
For example, if you wanted to add support for rendering a Buffer as hex with
`%h`, you could do something like:
```js
const createDebug = require('debug')
createDebug.formatters.h = (v) => {
return v.toString('hex')
}
// …elsewhere
const debug = createDebug('foo')
debug('this is hex: %h', new Buffer('hello world'))
// foo this is hex: 68656c6c6f20776f726c6421 +0ms
```
## Browser Support
You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
if you don't want to build it yourself.
Debug's enable state is currently persisted by `localStorage`.
Consider the situation shown below where you have `worker:a` and `worker:b`,
and wish to debug both. You can enable this using `localStorage.debug`:
```js
localStorage.debug = 'worker:*'
```
And then refresh the page.
```js
a = debug('worker:a');
b = debug('worker:b');
setInterval(function(){
a('doing some work');
}, 1000);
setInterval(function(){
b('doing some work');
}, 1200);
```
## Output streams
By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
Example [_stdout.js_](./examples/node/stdout.js):
```js
var debug = require('debug');
var error = debug('app:error');
// by default stderr is used
error('goes to stderr!');
var log = debug('app:log');
// set this namespace to log via console.log
log.log = console.log.bind(console); // don't forget to bind to console!
log('goes to stdout');
error('still goes to stderr!');
// set all output to go via console.info
// overrides all per-namespace log settings
debug.log = console.info.bind(console);
error('now goes to stdout via console.info');
log('still goes to stdout, but via console.info now');
```
## Checking whether a debug target is enabled
After you've created a debug instance, you can determine whether or not it is
enabled by checking the `enabled` property:
```javascript
const debug = require('debug')('http');
if (debug.enabled) {
// do stuff...
}
```
You can also manually toggle this property to force the debug instance to be
enabled or disabled.
## Authors
- TJ Holowaychuk
- Nathan Rajlich
- Andrew Rhyne
## Backers
Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
<a href="https://opencollective.com/debug/backer/0/website" target="_blank"><img src="https://opencollective.com/debug/backer/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/1/website" target="_blank"><img src="https://opencollective.com/debug/backer/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/2/website" target="_blank"><img src="https://opencollective.com/debug/backer/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/3/website" target="_blank"><img src="https://opencollective.com/debug/backer/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/4/website" target="_blank"><img src="https://opencollective.com/debug/backer/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/5/website" target="_blank"><img src="https://opencollective.com/debug/backer/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/6/website" target="_blank"><img src="https://opencollective.com/debug/backer/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/7/website" target="_blank"><img src="https://opencollective.com/debug/backer/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/8/website" target="_blank"><img src="https://opencollective.com/debug/backer/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/9/website" target="_blank"><img src="https://opencollective.com/debug/backer/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/10/website" target="_blank"><img src="https://opencollective.com/debug/backer/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/11/website" target="_blank"><img src="https://opencollective.com/debug/backer/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/12/website" target="_blank"><img src="https://opencollective.com/debug/backer/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/13/website" target="_blank"><img src="https://opencollective.com/debug/backer/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/14/website" target="_blank"><img src="https://opencollective.com/debug/backer/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/15/website" target="_blank"><img src="https://opencollective.com/debug/backer/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/16/website" target="_blank"><img src="https://opencollective.com/debug/backer/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/17/website" target="_blank"><img src="https://opencollective.com/debug/backer/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/18/website" target="_blank"><img src="https://opencollective.com/debug/backer/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/19/website" target="_blank"><img src="https://opencollective.com/debug/backer/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/20/website" target="_blank"><img src="https://opencollective.com/debug/backer/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/21/website" target="_blank"><img src="https://opencollective.com/debug/backer/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/22/website" target="_blank"><img src="https://opencollective.com/debug/backer/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/23/website" target="_blank"><img src="https://opencollective.com/debug/backer/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/24/website" target="_blank"><img src="https://opencollective.com/debug/backer/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/25/website" target="_blank"><img src="https://opencollective.com/debug/backer/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/26/website" target="_blank"><img src="https://opencollective.com/debug/backer/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/27/website" target="_blank"><img src="https://opencollective.com/debug/backer/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/28/website" target="_blank"><img src="https://opencollective.com/debug/backer/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/backer/29/website" target="_blank"><img src="https://opencollective.com/debug/backer/29/avatar.svg"></a>
## Sponsors
Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
<a href="https://opencollective.com/debug/sponsor/0/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/0/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/1/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/1/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/2/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/2/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/3/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/3/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/4/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/4/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/5/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/5/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/6/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/6/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/7/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/7/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/8/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/8/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/9/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/9/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/10/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/10/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/11/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/11/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/12/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/12/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/13/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/13/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/14/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/14/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/15/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/15/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/16/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/16/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/17/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/17/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/18/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/18/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/19/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/19/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/20/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/20/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/21/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/21/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/22/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/22/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/23/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/23/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/24/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/24/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/25/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/25/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/26/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/26/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/27/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/27/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/28/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/28/avatar.svg"></a>
<a href="https://opencollective.com/debug/sponsor/29/website" target="_blank"><img src="https://opencollective.com/debug/sponsor/29/avatar.svg"></a>
## License
(The MIT License)
Copyright (c) 2014-2017 TJ Holowaychuk <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
'Software'), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
<p align="center">
<a href="https://assemblyscript.org" target="_blank" rel="noopener"><img width="100" src="https://avatars1.githubusercontent.com/u/28916798?s=200&v=4" alt="AssemblyScript logo"></a>
</p>
<p align="center">
<a href="https://github.com/AssemblyScript/assemblyscript/actions?query=workflow%3ATest"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/assemblyscript/Test/master?label=test&logo=github" alt="Test status" /></a>
<a href="https://github.com/AssemblyScript/assemblyscript/actions?query=workflow%3APublish"><img src="https://img.shields.io/github/workflow/status/AssemblyScript/assemblyscript/Publish/master?label=publish&logo=github" alt="Publish status" /></a>
<a href="https://www.npmjs.com/package/assemblyscript"><img src="https://img.shields.io/npm/v/assemblyscript.svg?label=compiler&color=007acc&logo=npm" alt="npm compiler version" /></a>
<a href="https://www.npmjs.com/package/@assemblyscript/loader"><img src="https://img.shields.io/npm/v/@assemblyscript/loader.svg?label=loader&color=007acc&logo=npm" alt="npm loader version" /></a>
<a href="https://discord.gg/assemblyscript"><img src="https://img.shields.io/discord/721472913886281818.svg?label=&logo=discord&logoColor=ffffff&color=7389D8&labelColor=6A7EC2" alt="Discord online" /></a>
</p>
<p align="justify"><strong>AssemblyScript</strong> compiles a strict variant of <a href="http://www.typescriptlang.org">TypeScript</a> (basically JavaScript with types) to <a href="http://webassembly.org">WebAssembly</a> using <a href="https://github.com/WebAssembly/binaryen">Binaryen</a>. It generates lean and mean WebAssembly modules while being just an <code>npm install</code> away.</p>
<h3 align="center">
<a href="https://assemblyscript.org">About</a> ·
<a href="https://assemblyscript.org/introduction.html">Introduction</a> ·
<a href="https://assemblyscript.org/quick-start.html">Quick start</a> ·
<a href="https://assemblyscript.org/examples.html">Examples</a> ·
<a href="https://assemblyscript.org/development.html">Development instructions</a>
</h3>
<br>
<h2 align="center">Contributors</h2>
<p align="center">
<a href="https://assemblyscript.org/#contributors"><img src="https://assemblyscript.org/contributors.svg" alt="Contributor logos" width="720" /></a>
</p>
<h2 align="center">Thanks to our sponsors!</h2>
<p align="justify">Most of the core team members and most contributors do this open source work in their free time. If you use AssemblyScript for a serious task or plan to do so, and you'd like us to invest more time on it, <a href="https://opencollective.com/assemblyscript/donate" target="_blank" rel="noopener">please donate</a> to our <a href="https://opencollective.com/assemblyscript" target="_blank" rel="noopener">OpenCollective</a>. By sponsoring this project, your logo will show up below. Thank you so much for your support!</p>
<p align="center">
<a href="https://assemblyscript.org/#sponsors"><img src="https://assemblyscript.org/sponsors.svg" alt="Sponsor logos" width="720" /></a>
</p>
# y18n
[![NPM version][npm-image]][npm-url]
[![js-standard-style][standard-image]][standard-url]
[](https://conventionalcommits.org)
The bare-bones internationalization library used by yargs.
Inspired by [i18n](https://www.npmjs.com/package/i18n).
## Examples
_simple string translation:_
```js
const __ = require('y18n')().__;
console.log(__('my awesome string %s', 'foo'));
```
output:
`my awesome string foo`
_using tagged template literals_
```js
const __ = require('y18n')().__;
const str = 'foo';
console.log(__`my awesome string ${str}`);
```
output:
`my awesome string foo`
_pluralization support:_
```js
const __n = require('y18n')().__n;
console.log(__n('one fish %s', '%d fishes %s', 2, 'foo'));
```
output:
`2 fishes foo`
## Deno Example
As of `v5` `y18n` supports [Deno](https://github.com/denoland/deno):
```typescript
import y18n from "https://deno.land/x/y18n/deno.ts";
const __ = y18n({
locale: 'pirate',
directory: './test/locales'
}).__
console.info(__`Hi, ${'Ben'} ${'Coe'}!`)
```
You will need to run with `--allow-read` to load alternative locales.
## JSON Language Files
The JSON language files should be stored in a `./locales` folder.
File names correspond to locales, e.g., `en.json`, `pirate.json`.
When strings are observed for the first time they will be
added to the JSON file corresponding to the current locale.
## Methods
### require('y18n')(config)
Create an instance of y18n with the config provided, options include:
* `directory`: the locale directory, default `./locales`.
* `updateFiles`: should newly observed strings be updated in file, default `true`.
* `locale`: what locale should be used.
* `fallbackToLanguage`: should fallback to a language-only file (e.g. `en.json`)
be allowed if a file matching the locale does not exist (e.g. `en_US.json`),
default `true`.
### y18n.\_\_(str, arg, arg, arg)
Print a localized string, `%s` will be replaced with `arg`s.
This function can also be used as a tag for a template literal. You can use it
like this: <code>__`hello ${'world'}`</code>. This will be equivalent to
`__('hello %s', 'world')`.
### y18n.\_\_n(singularString, pluralString, count, arg, arg, arg)
Print a localized string with appropriate pluralization. If `%d` is provided
in the string, the `count` will replace this placeholder.
### y18n.setLocale(str)
Set the current locale being used.
### y18n.getLocale()
What locale is currently being used?
### y18n.updateLocale(obj)
Update the current locale with the key value pairs in `obj`.
## Supported Node.js Versions
Libraries in this ecosystem make a best effort to track
[Node.js' release schedule](https://nodejs.org/en/about/releases/). Here's [a
post on why we think this is important](https://medium.com/the-node-js-collection/maintainers-should-consider-following-node-js-release-schedule-ab08ed4de71a).
## License
ISC
[npm-url]: https://npmjs.org/package/y18n
[npm-image]: https://img.shields.io/npm/v/y18n.svg
[standard-image]: https://img.shields.io/badge/code%20style-standard-brightgreen.svg
[standard-url]: https://github.com/feross/standard
Browser-friendly inheritance fully compatible with standard node.js
[inherits](http://nodejs.org/api/util.html#util_util_inherits_constructor_superconstructor).
This package exports standard `inherits` from node.js `util` module in
node environment, but also provides alternative browser-friendly
implementation through [browser
field](https://gist.github.com/shtylman/4339901). Alternative
implementation is a literal copy of standard one located in standalone
module to avoid requiring of `util`. It also has a shim for old
browsers with no `Object.create` support.
While keeping you sure you are using standard `inherits`
implementation in node.js environment, it allows bundlers such as
[browserify](https://github.com/substack/node-browserify) to not
include full `util` package to your client code if all you need is
just `inherits` function. It worth, because browser shim for `util`
package is large and `inherits` is often the single function you need
from it.
It's recommended to use this package instead of
`require('util').inherits` for any code that has chances to be used
not only in node.js but in browser too.
## usage
```js
var inherits = require('inherits');
// then use exactly as the standard one
```
## note on version ~1.0
Version ~1.0 had completely different motivation and is not compatible
neither with 2.0 nor with standard node.js `inherits`.
If you are using version ~1.0 and planning to switch to ~2.0, be
careful:
* new version uses `super_` instead of `super` for referencing
superclass
* new version overwrites current prototype while old one preserves any
existing fields on it
# AssemblyScript Rtrace
A tiny utility to sanitize the AssemblyScript runtime. Records allocations and frees performed by the runtime and emits an error if something is off. Also checks for leaks.
Instructions
------------
Compile your module that uses the full or half runtime with `-use ASC_RTRACE=1 --explicitStart` and include an instance of this module as the import named `rtrace`.
```js
const rtrace = new Rtrace({
onerror(err, info) {
// handle error
},
oninfo(msg) {
// print message, optional
},
getMemory() {
// obtain the module's memory,
// e.g. with --explicitStart:
return instance.exports.memory;
}
});
const { module, instance } = await WebAssembly.instantiate(...,
rtrace.install({
...imports...
})
);
instance.exports._start();
...
if (rtrace.active) {
let leakCount = rtr.check();
if (leakCount) {
// handle error
}
}
```
Note that references in globals which are not cleared before collection is performed appear as leaks, including their inner members. A TypedArray would leak itself and its backing ArrayBuffer in this case for example. This is perfectly normal and clearing all globals avoids this.
# jsdiff
[](http://travis-ci.org/kpdecker/jsdiff)
[](https://saucelabs.com/u/jsdiff)
A javascript text differencing implementation.
Based on the algorithm proposed in
["An O(ND) Difference Algorithm and its Variations" (Myers, 1986)](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.4.6927).
## Installation
```bash
npm install diff --save
```
## API
* `Diff.diffChars(oldStr, newStr[, options])` - diffs two blocks of text, comparing character by character.
Returns a list of change objects (See below).
Options
* `ignoreCase`: `true` to ignore casing difference. Defaults to `false`.
* `Diff.diffWords(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, ignoring whitespace.
Returns a list of change objects (See below).
Options
* `ignoreCase`: Same as in `diffChars`.
* `Diff.diffWordsWithSpace(oldStr, newStr[, options])` - diffs two blocks of text, comparing word by word, treating whitespace as significant.
Returns a list of change objects (See below).
* `Diff.diffLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line.
Options
* `ignoreWhitespace`: `true` to ignore leading and trailing whitespace. This is the same as `diffTrimmedLines`
* `newlineIsToken`: `true` to treat newline characters as separate tokens. This allows for changes to the newline structure to occur independently of the line content and to be treated as such. In general this is the more human friendly form of `diffLines` and `diffLines` is better suited for patches and other computer friendly output.
Returns a list of change objects (See below).
* `Diff.diffTrimmedLines(oldStr, newStr[, options])` - diffs two blocks of text, comparing line by line, ignoring leading and trailing whitespace.
Returns a list of change objects (See below).
* `Diff.diffSentences(oldStr, newStr[, options])` - diffs two blocks of text, comparing sentence by sentence.
Returns a list of change objects (See below).
* `Diff.diffCss(oldStr, newStr[, options])` - diffs two blocks of text, comparing CSS tokens.
Returns a list of change objects (See below).
* `Diff.diffJson(oldObj, newObj[, options])` - diffs two JSON objects, comparing the fields defined on each. The order of fields, etc does not matter in this comparison.
Returns a list of change objects (See below).
* `Diff.diffArrays(oldArr, newArr[, options])` - diffs two arrays, comparing each item for strict equality (===).
Options
* `comparator`: `function(left, right)` for custom equality checks
Returns a list of change objects (See below).
* `Diff.createTwoFilesPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Parameters:
* `oldFileName` : String to be output in the filename section of the patch for the removals
* `newFileName` : String to be output in the filename section of the patch for the additions
* `oldStr` : Original string value
* `newStr` : New string value
* `oldHeader` : Additional information to include in the old file header
* `newHeader` : Additional information to include in the new file header
* `options` : An object with options. Currently, only `context` is supported and describes how many lines of context should be included.
* `Diff.createPatch(fileName, oldStr, newStr, oldHeader, newHeader)` - creates a unified diff patch.
Just like Diff.createTwoFilesPatch, but with oldFileName being equal to newFileName.
* `Diff.structuredPatch(oldFileName, newFileName, oldStr, newStr, oldHeader, newHeader, options)` - returns an object with an array of hunk objects.
This method is similar to createTwoFilesPatch, but returns a data structure
suitable for further processing. Parameters are the same as createTwoFilesPatch. The data structure returned may look like this:
```js
{
oldFileName: 'oldfile', newFileName: 'newfile',
oldHeader: 'header1', newHeader: 'header2',
hunks: [{
oldStart: 1, oldLines: 3, newStart: 1, newLines: 3,
lines: [' line2', ' line3', '-line4', '+line5', '\\ No newline at end of file'],
}]
}
```
* `Diff.applyPatch(source, patch[, options])` - applies a unified diff patch.
Return a string containing new version of provided data. `patch` may be a string diff or the output from the `parsePatch` or `structuredPatch` methods.
The optional `options` object may have the following keys:
- `fuzzFactor`: Number of lines that are allowed to differ before rejecting a patch. Defaults to 0.
- `compareLine(lineNumber, line, operation, patchContent)`: Callback used to compare to given lines to determine if they should be considered equal when patching. Defaults to strict equality but may be overridden to provide fuzzier comparison. Should return false if the lines should be rejected.
* `Diff.applyPatches(patch, options)` - applies one or more patches.
This method will iterate over the contents of the patch and apply to data provided through callbacks. The general flow for each patch index is:
- `options.loadFile(index, callback)` is called. The caller should then load the contents of the file and then pass that to the `callback(err, data)` callback. Passing an `err` will terminate further patch execution.
- `options.patched(index, content, callback)` is called once the patch has been applied. `content` will be the return value from `applyPatch`. When it's ready, the caller should call `callback(err)` callback. Passing an `err` will terminate further patch execution.
Once all patches have been applied or an error occurs, the `options.complete(err)` callback is made.
* `Diff.parsePatch(diffStr)` - Parses a patch into structured data
Return a JSON object representation of the a patch, suitable for use with the `applyPatch` method. This parses to the same structure returned by `Diff.structuredPatch`.
* `convertChangesToXML(changes)` - converts a list of changes to a serialized XML format
All methods above which accept the optional `callback` method will run in sync mode when that parameter is omitted and in async mode when supplied. This allows for larger diffs without blocking the event loop. This may be passed either directly as the final parameter or as the `callback` field in the `options` object.
### Change Objects
Many of the methods above return change objects. These objects consist of the following fields:
* `value`: Text content
* `added`: True if the value was inserted into the new string
* `removed`: True if the value was removed from the old string
Note that some cases may omit a particular flag field. Comparison on the flag fields should always be done in a truthy or falsy manner.
## Examples
Basic example in Node
```js
require('colors');
const Diff = require('diff');
const one = 'beep boop';
const other = 'beep boob blah';
const diff = Diff.diffChars(one, other);
diff.forEach((part) => {
// green for additions, red for deletions
// grey for common parts
const color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
process.stderr.write(part.value[color]);
});
console.log();
```
Running the above program should yield
<img src="images/node_example.png" alt="Node Example">
Basic example in a web page
```html
<pre id="display"></pre>
<script src="diff.js"></script>
<script>
const one = 'beep boop',
other = 'beep boob blah',
color = '';
let span = null;
const diff = Diff.diffChars(one, other),
display = document.getElementById('display'),
fragment = document.createDocumentFragment();
diff.forEach((part) => {
// green for additions, red for deletions
// grey for common parts
const color = part.added ? 'green' :
part.removed ? 'red' : 'grey';
span = document.createElement('span');
span.style.color = color;
span.appendChild(document
.createTextNode(part.value));
fragment.appendChild(span);
});
display.appendChild(fragment);
</script>
```
Open the above .html file in a browser and you should see
<img src="images/web_example.png" alt="Node Example">
**[Full online demo](http://kpdecker.github.com/jsdiff)**
## Compatibility
[](https://saucelabs.com/u/jsdiff)
jsdiff supports all ES3 environments with some known issues on IE8 and below. Under these browsers some diff algorithms such as word diff and others may fail due to lack of support for capturing groups in the `split` operation.
## License
See [LICENSE](https://github.com/kpdecker/jsdiff/blob/master/LICENSE).
# color-convert
[](https://travis-ci.org/Qix-/color-convert)
Color-convert is a color conversion library for JavaScript and node.
It converts all ways between `rgb`, `hsl`, `hsv`, `hwb`, `cmyk`, `ansi`, `ansi16`, `hex` strings, and CSS `keyword`s (will round to closest):
```js
var convert = require('color-convert');
convert.rgb.hsl(140, 200, 100); // [96, 48, 59]
convert.keyword.rgb('blue'); // [0, 0, 255]
var rgbChannels = convert.rgb.channels; // 3
var cmykChannels = convert.cmyk.channels; // 4
var ansiChannels = convert.ansi16.channels; // 1
```
# Install
```console
$ npm install color-convert
```
# API
Simply get the property of the _from_ and _to_ conversion that you're looking for.
All functions have a rounded and unrounded variant. By default, return values are rounded. To get the unrounded (raw) results, simply tack on `.raw` to the function.
All 'from' functions have a hidden property called `.channels` that indicates the number of channels the function expects (not including alpha).
```js
var convert = require('color-convert');
// Hex to LAB
convert.hex.lab('DEADBF'); // [ 76, 21, -2 ]
convert.hex.lab.raw('DEADBF'); // [ 75.56213190997677, 20.653827952644754, -2.290532499330533 ]
// RGB to CMYK
convert.rgb.cmyk(167, 255, 4); // [ 35, 0, 98, 0 ]
convert.rgb.cmyk.raw(167, 255, 4); // [ 34.509803921568626, 0, 98.43137254901961, 0 ]
```
### Arrays
All functions that accept multiple arguments also support passing an array.
Note that this does **not** apply to functions that convert from a color that only requires one value (e.g. `keyword`, `ansi256`, `hex`, etc.)
```js
var convert = require('color-convert');
convert.rgb.hex(123, 45, 67); // '7B2D43'
convert.rgb.hex([123, 45, 67]); // '7B2D43'
```
## Routing
Conversions that don't have an _explicitly_ defined conversion (in [conversions.js](conversions.js)), but can be converted by means of sub-conversions (e.g. XYZ -> **RGB** -> CMYK), are automatically routed together. This allows just about any color model supported by `color-convert` to be converted to any other model, so long as a sub-conversion path exists. This is also true for conversions requiring more than one step in between (e.g. LCH -> **LAB** -> **XYZ** -> **RGB** -> Hex).
Keep in mind that extensive conversions _may_ result in a loss of precision, and exist only to be complete. For a list of "direct" (single-step) conversions, see [conversions.js](conversions.js).
# Contribute
If there is a new model you would like to support, or want to add a direct conversion between two existing models, please send us a pull request.
# License
Copyright © 2011-2016, Heather Arthur and Josh Junon. Licensed under the [MIT License](LICENSE).
# minizlib
A fast zlib stream built on [minipass](http://npm.im/minipass) and
Node.js's zlib binding.
This module was created to serve the needs of
[node-tar](http://npm.im/tar) and
[minipass-fetch](http://npm.im/minipass-fetch).
Brotli is supported in versions of node with a Brotli binding.
## How does this differ from the streams in `require('zlib')`?
First, there are no convenience methods to compress or decompress a
buffer. If you want those, use the built-in `zlib` module. This is
only streams. That being said, Minipass streams to make it fairly easy to
use as one-liners: `new zlib.Deflate().end(data).read()` will return the
deflate compressed result.
This module compresses and decompresses the data as fast as you feed
it in. It is synchronous, and runs on the main process thread. Zlib
and Brotli operations can be high CPU, but they're very fast, and doing it
this way means much less bookkeeping and artificial deferral.
Node's built in zlib streams are built on top of `stream.Transform`.
They do the maximally safe thing with respect to consistent
asynchrony, buffering, and backpressure.
See [Minipass](http://npm.im/minipass) for more on the differences between
Node.js core streams and Minipass streams, and the convenience methods
provided by that class.
## Classes
- Deflate
- Inflate
- Gzip
- Gunzip
- DeflateRaw
- InflateRaw
- Unzip
- BrotliCompress (Node v10 and higher)
- BrotliDecompress (Node v10 and higher)
## USAGE
```js
const zlib = require('minizlib')
const input = sourceOfCompressedData()
const decode = new zlib.BrotliDecompress()
const output = whereToWriteTheDecodedData()
input.pipe(decode).pipe(output)
```
## REPRODUCIBLE BUILDS
To create reproducible gzip compressed files across different operating
systems, set `portable: true` in the options. This causes minizlib to set
the `OS` indicator in byte 9 of the extended gzip header to `0xFF` for
'unknown'.
## Follow Redirects
Drop-in replacement for Nodes `http` and `https` that automatically follows redirects.
[](https://www.npmjs.com/package/follow-redirects)
[](https://travis-ci.org/follow-redirects/follow-redirects)
[](https://coveralls.io/r/follow-redirects/follow-redirects?branch=master)
[](https://david-dm.org/follow-redirects/follow-redirects)
[](https://www.npmjs.com/package/follow-redirects)
`follow-redirects` provides [request](https://nodejs.org/api/http.html#http_http_request_options_callback) and [get](https://nodejs.org/api/http.html#http_http_get_options_callback)
methods that behave identically to those found on the native [http](https://nodejs.org/api/http.html#http_http_request_options_callback) and [https](https://nodejs.org/api/https.html#https_https_request_options_callback)
modules, with the exception that they will seamlessly follow redirects.
```javascript
var http = require('follow-redirects').http;
var https = require('follow-redirects').https;
http.get('http://bit.ly/900913', function (response) {
response.on('data', function (chunk) {
console.log(chunk);
});
}).on('error', function (err) {
console.error(err);
});
```
You can inspect the final redirected URL through the `responseUrl` property on the `response`.
If no redirection happened, `responseUrl` is the original request URL.
```javascript
https.request({
host: 'bitly.com',
path: '/UHfDGO',
}, function (response) {
console.log(response.responseUrl);
// 'http://duckduckgo.com/robots.txt'
});
```
## Options
### Global options
Global options are set directly on the `follow-redirects` module:
```javascript
var followRedirects = require('follow-redirects');
followRedirects.maxRedirects = 10;
followRedirects.maxBodyLength = 20 * 1024 * 1024; // 20 MB
```
The following global options are supported:
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
### Per-request options
Per-request options are set by passing an `options` object:
```javascript
var url = require('url');
var followRedirects = require('follow-redirects');
var options = url.parse('http://bit.ly/900913');
options.maxRedirects = 10;
http.request(options);
```
In addition to the [standard HTTP](https://nodejs.org/api/http.html#http_http_request_options_callback) and [HTTPS options](https://nodejs.org/api/https.html#https_https_request_options_callback),
the following per-request options are supported:
- `followRedirects` (default: `true`) – whether redirects should be followed.
- `maxRedirects` (default: `21`) – sets the maximum number of allowed redirects; if exceeded, an error will be emitted.
- `maxBodyLength` (default: 10MB) – sets the maximum size of the request body; if exceeded, an error will be emitted.
- `agents` (default: `undefined`) – sets the `agent` option per protocol, since HTTP and HTTPS use different agents. Example value: `{ http: new http.Agent(), https: new https.Agent() }`
- `trackRedirects` (default: `false`) – whether to store the redirected response details into the `redirects` array on the response object.
### Advanced usage
By default, `follow-redirects` will use the Node.js default implementations
of [`http`](https://nodejs.org/api/http.html)
and [`https`](https://nodejs.org/api/https.html).
To enable features such as caching and/or intermediate request tracking,
you might instead want to wrap `follow-redirects` around custom protocol implementations:
```javascript
var followRedirects = require('follow-redirects').wrap({
http: require('your-custom-http'),
https: require('your-custom-https'),
});
```
Such custom protocols only need an implementation of the `request` method.
## Browserify Usage
Due to the way `XMLHttpRequest` works, the `browserify` versions of `http` and `https` already follow redirects.
If you are *only* targeting the browser, then this library has little value for you. If you want to write cross
platform code for node and the browser, `follow-redirects` provides a great solution for making the native node
modules behave the same as they do in browserified builds in the browser. To avoid bundling unnecessary code
you should tell browserify to swap out `follow-redirects` with the standard modules when bundling.
To make this easier, you need to change how you require the modules:
```javascript
var http = require('follow-redirects/http');
var https = require('follow-redirects/https');
```
You can then replace `follow-redirects` in your browserify configuration like so:
```javascript
"browser": {
"follow-redirects/http" : "http",
"follow-redirects/https" : "https"
}
```
The `browserify-http` module has not kept pace with node development, and no long behaves identically to the native
module when running in the browser. If you are experiencing problems, you may want to check out
[browserify-http-2](https://www.npmjs.com/package/http-browserify-2). It is more actively maintained and
attempts to address a few of the shortcomings of `browserify-http`. In that case, your browserify config should
look something like this:
```javascript
"browser": {
"follow-redirects/http" : "browserify-http-2/http",
"follow-redirects/https" : "browserify-http-2/https"
}
```
## Contributing
Pull Requests are always welcome. Please [file an issue](https://github.com/follow-redirects/follow-redirects/issues)
detailing your proposal before you invest your valuable time. Additional features and bug fixes should be accompanied
by tests. You can run the test suite locally with a simple `npm test` command.
## Debug Logging
`follow-redirects` uses the excellent [debug](https://www.npmjs.com/package/debug) for logging. To turn on logging
set the environment variable `DEBUG=follow-redirects` for debug output from just this module. When running the test
suite it is sometimes advantageous to set `DEBUG=*` to see output from the express server as well.
## Authors
- Olivier Lalonde ([email protected])
- James Talmage ([email protected])
- [Ruben Verborgh](https://ruben.verborgh.org/)
## License
[https://github.com/follow-redirects/follow-redirects/blob/master/LICENSE](MIT License)
# axios // adapters
The modules under `adapters/` are modules that handle dispatching a request and settling a returned `Promise` once a response is received.
## Example
```js
var settle = require('./../core/settle');
module.exports = function myAdapter(config) {
// At this point:
// - config has been merged with defaults
// - request transformers have already run
// - request interceptors have already run
// Make the request using config provided
// Upon response settle the Promise
return new Promise(function(resolve, reject) {
var response = {
data: responseData,
status: request.status,
statusText: request.statusText,
headers: responseHeaders,
config: config,
request: request
};
settle(resolve, reject, response);
// From here:
// - response transformers will run
// - response interceptors will run
});
}
```
# fs.realpath
A backwards-compatible fs.realpath for Node v6 and above
In Node v6, the JavaScript implementation of fs.realpath was replaced
with a faster (but less resilient) native implementation. That raises
new and platform-specific errors and cannot handle long or excessively
symlink-looping paths.
This module handles those cases by detecting the new errors and
falling back to the JavaScript implementation. On versions of Node
prior to v6, it has no effect.
## USAGE
```js
var rp = require('fs.realpath')
// async version
rp.realpath(someLongAndLoopingPath, function (er, real) {
// the ELOOP was handled, but it was a bit slower
})
// sync version
var real = rp.realpathSync(someLongAndLoopingPath)
// monkeypatch at your own risk!
// This replaces the fs.realpath/fs.realpathSync builtins
rp.monkeypatch()
// un-do the monkeypatching
rp.unmonkeypatch()
```
# minipass
A _very_ minimal implementation of a [PassThrough
stream](https://nodejs.org/api/stream.html#stream_class_stream_passthrough)
[It's very
fast](https://docs.google.com/spreadsheets/d/1oObKSrVwLX_7Ut4Z6g3fZW-AX1j1-k6w-cDsrkaSbHM/edit#gid=0)
for objects, strings, and buffers.
Supports pipe()ing (including multi-pipe() and backpressure transmission),
buffering data until either a `data` event handler or `pipe()` is added (so
you don't lose the first chunk), and most other cases where PassThrough is
a good idea.
There is a `read()` method, but it's much more efficient to consume data
from this stream via `'data'` events or by calling `pipe()` into some other
stream. Calling `read()` requires the buffer to be flattened in some
cases, which requires copying memory.
There is also no `unpipe()` method. Once you start piping, there is no
stopping it!
If you set `objectMode: true` in the options, then whatever is written will
be emitted. Otherwise, it'll do a minimal amount of Buffer copying to
ensure proper Streams semantics when `read(n)` is called.
`objectMode` can also be set by doing `stream.objectMode = true`, or by
writing any non-string/non-buffer data. `objectMode` cannot be set to
false once it is set.
This is not a `through` or `through2` stream. It doesn't transform the
data, it just passes it right through. If you want to transform the data,
extend the class, and override the `write()` method. Once you're done
transforming the data however you want, call `super.write()` with the
transform output.
For some examples of streams that extend Minipass in various ways, check
out:
- [minizlib](http://npm.im/minizlib)
- [fs-minipass](http://npm.im/fs-minipass)
- [tar](http://npm.im/tar)
- [minipass-collect](http://npm.im/minipass-collect)
- [minipass-flush](http://npm.im/minipass-flush)
- [minipass-pipeline](http://npm.im/minipass-pipeline)
- [tap](http://npm.im/tap)
- [tap-parser](http://npm.im/tap)
- [treport](http://npm.im/tap)
- [minipass-fetch](http://npm.im/minipass-fetch)
- [pacote](http://npm.im/pacote)
- [make-fetch-happen](http://npm.im/make-fetch-happen)
- [cacache](http://npm.im/cacache)
- [ssri](http://npm.im/ssri)
- [npm-registry-fetch](http://npm.im/npm-registry-fetch)
- [minipass-json-stream](http://npm.im/minipass-json-stream)
- [minipass-sized](http://npm.im/minipass-sized)
## Differences from Node.js Streams
There are several things that make Minipass streams different from (and in
some ways superior to) Node.js core streams.
Please read these caveats if you are familiar with noode-core streams and
intend to use Minipass streams in your programs.
### Timing
Minipass streams are designed to support synchronous use-cases. Thus, data
is emitted as soon as it is available, always. It is buffered until read,
but no longer. Another way to look at it is that Minipass streams are
exactly as synchronous as the logic that writes into them.
This can be surprising if your code relies on `PassThrough.write()` always
providing data on the next tick rather than the current one, or being able
to call `resume()` and not have the entire buffer disappear immediately.
However, without this synchronicity guarantee, there would be no way for
Minipass to achieve the speeds it does, or support the synchronous use
cases that it does. Simply put, waiting takes time.
This non-deferring approach makes Minipass streams much easier to reason
about, especially in the context of Promises and other flow-control
mechanisms.
### No High/Low Water Marks
Node.js core streams will optimistically fill up a buffer, returning `true`
on all writes until the limit is hit, even if the data has nowhere to go.
Then, they will not attempt to draw more data in until the buffer size dips
below a minimum value.
Minipass streams are much simpler. The `write()` method will return `true`
if the data has somewhere to go (which is to say, given the timing
guarantees, that the data is already there by the time `write()` returns).
If the data has nowhere to go, then `write()` returns false, and the data
sits in a buffer, to be drained out immediately as soon as anyone consumes
it.
### Hazards of Buffering (or: Why Minipass Is So Fast)
Since data written to a Minipass stream is immediately written all the way
through the pipeline, and `write()` always returns true/false based on
whether the data was fully flushed, backpressure is communicated
immediately to the upstream caller. This minimizes buffering.
Consider this case:
```js
const {PassThrough} = require('stream')
const p1 = new PassThrough({ highWaterMark: 1024 })
const p2 = new PassThrough({ highWaterMark: 1024 })
const p3 = new PassThrough({ highWaterMark: 1024 })
const p4 = new PassThrough({ highWaterMark: 1024 })
p1.pipe(p2).pipe(p3).pipe(p4)
p4.on('data', () => console.log('made it through'))
// this returns false and buffers, then writes to p2 on next tick (1)
// p2 returns false and buffers, pausing p1, then writes to p3 on next tick (2)
// p3 returns false and buffers, pausing p2, then writes to p4 on next tick (3)
// p4 returns false and buffers, pausing p3, then emits 'data' and 'drain'
// on next tick (4)
// p3 sees p4's 'drain' event, and calls resume(), emitting 'resume' and
// 'drain' on next tick (5)
// p2 sees p3's 'drain', calls resume(), emits 'resume' and 'drain' on next tick (6)
// p1 sees p2's 'drain', calls resume(), emits 'resume' and 'drain' on next
// tick (7)
p1.write(Buffer.alloc(2048)) // returns false
```
Along the way, the data was buffered and deferred at each stage, and
multiple event deferrals happened, for an unblocked pipeline where it was
perfectly safe to write all the way through!
Furthermore, setting a `highWaterMark` of `1024` might lead someone reading
the code to think an advisory maximum of 1KiB is being set for the
pipeline. However, the actual advisory buffering level is the _sum_ of
`highWaterMark` values, since each one has its own bucket.
Consider the Minipass case:
```js
const m1 = new Minipass()
const m2 = new Minipass()
const m3 = new Minipass()
const m4 = new Minipass()
m1.pipe(m2).pipe(m3).pipe(m4)
m4.on('data', () => console.log('made it through'))
// m1 is flowing, so it writes the data to m2 immediately
// m2 is flowing, so it writes the data to m3 immediately
// m3 is flowing, so it writes the data to m4 immediately
// m4 is flowing, so it fires the 'data' event immediately, returns true
// m4's write returned true, so m3 is still flowing, returns true
// m3's write returned true, so m2 is still flowing, returns true
// m2's write returned true, so m1 is still flowing, returns true
// No event deferrals or buffering along the way!
m1.write(Buffer.alloc(2048)) // returns true
```
It is extremely unlikely that you _don't_ want to buffer any data written,
or _ever_ buffer data that can be flushed all the way through. Neither
node-core streams nor Minipass ever fail to buffer written data, but
node-core streams do a lot of unnecessary buffering and pausing.
As always, the faster implementation is the one that does less stuff and
waits less time to do it.
### Immediately emit `end` for empty streams (when not paused)
If a stream is not paused, and `end()` is called before writing any data
into it, then it will emit `end` immediately.
If you have logic that occurs on the `end` event which you don't want to
potentially happen immediately (for example, closing file descriptors,
moving on to the next entry in an archive parse stream, etc.) then be sure
to call `stream.pause()` on creation, and then `stream.resume()` once you
are ready to respond to the `end` event.
### Emit `end` When Asked
One hazard of immediately emitting `'end'` is that you may not yet have had
a chance to add a listener. In order to avoid this hazard, Minipass
streams safely re-emit the `'end'` event if a new listener is added after
`'end'` has been emitted.
Ie, if you do `stream.on('end', someFunction)`, and the stream has already
emitted `end`, then it will call the handler right away. (You can think of
this somewhat like attaching a new `.then(fn)` to a previously-resolved
Promise.)
To prevent calling handlers multiple times who would not expect multiple
ends to occur, all listeners are removed from the `'end'` event whenever it
is emitted.
### Impact of "immediate flow" on Tee-streams
A "tee stream" is a stream piping to multiple destinations:
```js
const tee = new Minipass()
t.pipe(dest1)
t.pipe(dest2)
t.write('foo') // goes to both destinations
```
Since Minipass streams _immediately_ process any pending data through the
pipeline when a new pipe destination is added, this can have surprising
effects, especially when a stream comes in from some other function and may
or may not have data in its buffer.
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.pipe(dest1) // 'foo' chunk flows to dest1 immediately, and is gone
src.pipe(dest2) // gets nothing!
```
The solution is to create a dedicated tee-stream junction that pipes to
both locations, and then pipe to _that_ instead.
```js
// Safe example: tee to both places
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.pipe(dest1)
tee.pipe(dest2)
src.pipe(tee) // tee gets 'foo', pipes to both locations
```
The same caveat applies to `on('data')` event listeners. The first one
added will _immediately_ receive all of the data, leaving nothing for the
second:
```js
// WARNING! WILL LOSE DATA!
const src = new Minipass()
src.write('foo')
src.on('data', handler1) // receives 'foo' right away
src.on('data', handler2) // nothing to see here!
```
Using a dedicated tee-stream can be used in this case as well:
```js
// Safe example: tee to both data handlers
const src = new Minipass()
src.write('foo')
const tee = new Minipass()
tee.on('data', handler1)
tee.on('data', handler2)
src.pipe(tee)
```
## USAGE
It's a stream! Use it like a stream and it'll most likely do what you
want.
```js
const Minipass = require('minipass')
const mp = new Minipass(options) // optional: { encoding, objectMode }
mp.write('foo')
mp.pipe(someOtherStream)
mp.end('bar')
```
### OPTIONS
* `encoding` How would you like the data coming _out_ of the stream to be
encoded? Accepts any values that can be passed to `Buffer.toString()`.
* `objectMode` Emit data exactly as it comes in. This will be flipped on
by default if you write() something other than a string or Buffer at any
point. Setting `objectMode: true` will prevent setting any encoding
value.
### API
Implements the user-facing portions of Node.js's `Readable` and `Writable`
streams.
### Methods
* `write(chunk, [encoding], [callback])` - Put data in. (Note that, in the
base Minipass class, the same data will come out.) Returns `false` if
the stream will buffer the next write, or true if it's still in "flowing"
mode.
* `end([chunk, [encoding]], [callback])` - Signal that you have no more
data to write. This will queue an `end` event to be fired when all the
data has been consumed.
* `setEncoding(encoding)` - Set the encoding for data coming of the stream.
This can only be done once.
* `pause()` - No more data for a while, please. This also prevents `end`
from being emitted for empty streams until the stream is resumed.
* `resume()` - Resume the stream. If there's data in the buffer, it is all
discarded. Any buffered events are immediately emitted.
* `pipe(dest)` - Send all output to the stream provided. There is no way
to unpipe. When data is emitted, it is immediately written to any and
all pipe destinations.
* `on(ev, fn)`, `emit(ev, fn)` - Minipass streams are EventEmitters. Some
events are given special treatment, however. (See below under "events".)
* `promise()` - Returns a Promise that resolves when the stream emits
`end`, or rejects if the stream emits `error`.
* `collect()` - Return a Promise that resolves on `end` with an array
containing each chunk of data that was emitted, or rejects if the stream
emits `error`. Note that this consumes the stream data.
* `concat()` - Same as `collect()`, but concatenates the data into a single
Buffer object. Will reject the returned promise if the stream is in
objectMode, or if it goes into objectMode by the end of the data.
* `read(n)` - Consume `n` bytes of data out of the buffer. If `n` is not
provided, then consume all of it. If `n` bytes are not available, then
it returns null. **Note** consuming streams in this way is less
efficient, and can lead to unnecessary Buffer copying.
* `destroy([er])` - Destroy the stream. If an error is provided, then an
`'error'` event is emitted. If the stream has a `close()` method, and
has not emitted a `'close'` event yet, then `stream.close()` will be
called. Any Promises returned by `.promise()`, `.collect()` or
`.concat()` will be rejected. After being destroyed, writing to the
stream will emit an error. No more data will be emitted if the stream is
destroyed, even if it was previously buffered.
### Properties
* `bufferLength` Read-only. Total number of bytes buffered, or in the case
of objectMode, the total number of objects.
* `encoding` The encoding that has been set. (Setting this is equivalent
to calling `setEncoding(enc)` and has the same prohibition against
setting multiple times.)
* `flowing` Read-only. Boolean indicating whether a chunk written to the
stream will be immediately emitted.
* `emittedEnd` Read-only. Boolean indicating whether the end-ish events
(ie, `end`, `prefinish`, `finish`) have been emitted. Note that
listening on any end-ish event will immediateyl re-emit it if it has
already been emitted.
* `writable` Whether the stream is writable. Default `true`. Set to
`false` when `end()`
* `readable` Whether the stream is readable. Default `true`.
* `buffer` A [yallist](http://npm.im/yallist) linked list of chunks written
to the stream that have not yet been emitted. (It's probably a bad idea
to mess with this.)
* `pipes` A [yallist](http://npm.im/yallist) linked list of streams that
this stream is piping into. (It's probably a bad idea to mess with
this.)
* `destroyed` A getter that indicates whether the stream was destroyed.
* `paused` True if the stream has been explicitly paused, otherwise false.
* `objectMode` Indicates whether the stream is in `objectMode`. Once set
to `true`, it cannot be set to `false`.
### Events
* `data` Emitted when there's data to read. Argument is the data to read.
This is never emitted while not flowing. If a listener is attached, that
will resume the stream.
* `end` Emitted when there's no more data to read. This will be emitted
immediately for empty streams when `end()` is called. If a listener is
attached, and `end` was already emitted, then it will be emitted again.
All listeners are removed when `end` is emitted.
* `prefinish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'end'`.
* `finish` An end-ish event that follows the same logic as `end` and is
emitted in the same conditions where `end` is emitted. Emitted after
`'prefinish'`.
* `close` An indication that an underlying resource has been released.
Minipass does not emit this event, but will defer it until after `end`
has been emitted, since it throws off some stream libraries otherwise.
* `drain` Emitted when the internal buffer empties, and it is again
suitable to `write()` into the stream.
* `readable` Emitted when data is buffered and ready to be read by a
consumer.
* `resume` Emitted when stream changes state from buffering to flowing
mode. (Ie, when `resume` is called, `pipe` is called, or a `data` event
listener is added.)
### Static Methods
* `Minipass.isStream(stream)` Returns `true` if the argument is a stream,
and false otherwise. To be considered a stream, the object must be
either an instance of Minipass, or an EventEmitter that has either a
`pipe()` method, or both `write()` and `end()` methods. (Pretty much any
stream in node-land will return `true` for this.)
## EXAMPLES
Here are some examples of things you can do with Minipass streams.
### simple "are you done yet" promise
```js
mp.promise().then(() => {
// stream is finished
}, er => {
// stream emitted an error
})
```
### collecting
```js
mp.collect().then(all => {
// all is an array of all the data emitted
// encoding is supported in this case, so
// so the result will be a collection of strings if
// an encoding is specified, or buffers/objects if not.
//
// In an async function, you may do
// const data = await stream.collect()
})
```
### collecting into a single blob
This is a bit slower because it concatenates the data into one chunk for
you, but if you're going to do it yourself anyway, it's convenient this
way:
```js
mp.concat().then(onebigchunk => {
// onebigchunk is a string if the stream
// had an encoding set, or a buffer otherwise.
})
```
### iteration
You can iterate over streams synchronously or asynchronously in platforms
that support it.
Synchronous iteration will end when the currently available data is
consumed, even if the `end` event has not been reached. In string and
buffer mode, the data is concatenated, so unless multiple writes are
occurring in the same tick as the `read()`, sync iteration loops will
generally only have a single iteration.
To consume chunks in this way exactly as they have been written, with no
flattening, create the stream with the `{ objectMode: true }` option.
```js
const mp = new Minipass({ objectMode: true })
mp.write('a')
mp.write('b')
for (let letter of mp) {
console.log(letter) // a, b
}
mp.write('c')
mp.write('d')
for (let letter of mp) {
console.log(letter) // c, d
}
mp.write('e')
mp.end()
for (let letter of mp) {
console.log(letter) // e
}
for (let letter of mp) {
console.log(letter) // nothing
}
```
Asynchronous iteration will continue until the end event is reached,
consuming all of the data.
```js
const mp = new Minipass({ encoding: 'utf8' })
// some source of some data
let i = 5
const inter = setInterval(() => {
if (i --> 0)
mp.write(Buffer.from('foo\n', 'utf8'))
else {
mp.end()
clearInterval(inter)
}
}, 100)
// consume the data with asynchronous iteration
async function consume () {
for await (let chunk of mp) {
console.log(chunk)
}
return 'ok'
}
consume().then(res => console.log(res))
// logs `foo\n` 5 times, and then `ok`
```
### subclass that `console.log()`s everything written into it
```js
class Logger extends Minipass {
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}
someSource.pipe(new Logger()).pipe(someDest)
```
### same thing, but using an inline anonymous class
```js
// js classes are fun
someSource
.pipe(new (class extends Minipass {
emit (ev, ...data) {
// let's also log events, because debugging some weird thing
console.log('EMIT', ev)
return super.emit(ev, ...data)
}
write (chunk, encoding, callback) {
console.log('WRITE', chunk, encoding)
return super.write(chunk, encoding, callback)
}
end (chunk, encoding, callback) {
console.log('END', chunk, encoding)
return super.end(chunk, encoding, callback)
}
}))
.pipe(someDest)
```
### subclass that defers 'end' for some reason
```js
class SlowEnd extends Minipass {
emit (ev, ...args) {
if (ev === 'end') {
console.log('going to end, hold on a sec')
setTimeout(() => {
console.log('ok, ready to end now')
super.emit('end', ...args)
}, 100)
} else {
return super.emit(ev, ...args)
}
}
}
```
### transform that creates newline-delimited JSON
```js
class NDJSONEncode extends Minipass {
write (obj, cb) {
try {
// JSON.stringify can throw, emit an error on that
return super.write(JSON.stringify(obj) + '\n', 'utf8', cb)
} catch (er) {
this.emit('error', er)
}
}
end (obj, cb) {
if (typeof obj === 'function') {
cb = obj
obj = undefined
}
if (obj !== undefined) {
this.write(obj)
}
return super.end(cb)
}
}
```
### transform that parses newline-delimited JSON
```js
class NDJSONDecode extends Minipass {
constructor (options) {
// always be in object mode, as far as Minipass is concerned
super({ objectMode: true })
this._jsonBuffer = ''
}
write (chunk, encoding, cb) {
if (typeof chunk === 'string' &&
typeof encoding === 'string' &&
encoding !== 'utf8') {
chunk = Buffer.from(chunk, encoding).toString()
} else if (Buffer.isBuffer(chunk))
chunk = chunk.toString()
}
if (typeof encoding === 'function') {
cb = encoding
}
const jsonData = (this._jsonBuffer + chunk).split('\n')
this._jsonBuffer = jsonData.pop()
for (let i = 0; i < jsonData.length; i++) {
let parsed
try {
super.write(parsed)
} catch (er) {
this.emit('error', er)
continue
}
}
if (cb)
cb()
}
}
```
# lodash.clonedeep v4.5.0
The [lodash](https://lodash.com/) method `_.cloneDeep` exported as a [Node.js](https://nodejs.org/) module.
## Installation
Using npm:
```bash
$ {sudo -H} npm i -g npm
$ npm i --save lodash.clonedeep
```
In Node.js:
```js
var cloneDeep = require('lodash.clonedeep');
```
See the [documentation](https://lodash.com/docs#cloneDeep) or [package source](https://github.com/lodash/lodash/blob/4.5.0-npm-packages/lodash.clonedeep) for more details.
# base-x
[](https://www.npmjs.org/package/base-x)
[](https://travis-ci.org/cryptocoinjs/base-x)
[](https://github.com/feross/standard)
Fast base encoding / decoding of any given alphabet using bitcoin style leading
zero compression.
**WARNING:** This module is **NOT RFC3548** compliant, it cannot be used for base16 (hex), base32, or base64 encoding in a standards compliant manner.
## Example
Base58
``` javascript
var BASE58 = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz'
var bs58 = require('base-x')(BASE58)
var decoded = bs58.decode('5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr')
console.log(decoded)
// => <Buffer 80 ed db dc 11 68 f1 da ea db d3 e4 4c 1e 3f 8f 5a 28 4c 20 29 f7 8a d2 6a f9 85 83 a4 99 de 5b 19>
console.log(bs58.encode(decoded))
// => 5Kd3NBUAdUnhyzenEwVLy9pBKxSwXvE9FMPyR4UKZvpe6E3AgLr
```
### Alphabets
See below for a list of commonly recognized alphabets, and their respective base.
Base | Alphabet
------------- | -------------
2 | `01`
8 | `01234567`
11 | `0123456789a`
16 | `0123456789abcdef`
32 | `0123456789ABCDEFGHJKMNPQRSTVWXYZ`
32 | `ybndrfg8ejkmcpqxot1uwisza345h769` (z-base-32)
36 | `0123456789abcdefghijklmnopqrstuvwxyz`
58 | `123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz`
62 | `0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ`
64 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/`
66 | `ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.!~`
## How it works
It encodes octet arrays by doing long divisions on all significant digits in the
array, creating a representation of that number in the new base. Then for every
leading zero in the input (not significant as a number) it will encode as a
single leader character. This is the first in the alphabet and will decode as 8
bits. The other characters depend upon the base. For example, a base58 alphabet
packs roughly 5.858 bits per character.
This means the encoded string 000f (using a base16, 0-f alphabet) will actually decode
to 4 bytes unlike a canonical hex encoding which uniformly packs 4 bits into each
character.
While unusual, this does mean that no padding is required and it works for bases
like 43.
## LICENSE [MIT](LICENSE)
A direct derivation of the base58 implementation from [`bitcoin/bitcoin`](https://github.com/bitcoin/bitcoin/blob/f1e2f2a85962c1664e4e55471061af0eaa798d40/src/base58.cpp), generalized for variable length alphabets.
# axios // helpers
The modules found in `helpers/` should be generic modules that are _not_ specific to the domain logic of axios. These modules could theoretically be published to npm on their own and consumed by other modules or apps. Some examples of generic modules are things like:
- Browser polyfills
- Managing cookies
- Parsing HTTP headers
# get-caller-file
[](https://travis-ci.org/stefanpenner/get-caller-file)
[](https://ci.appveyor.com/project/embercli/get-caller-file/branch/master)
This is a utility, which allows a function to figure out from which file it was invoked. It does so by inspecting v8's stack trace at the time it is invoked.
Inspired by http://stackoverflow.com/questions/13227489
*note: this relies on Node/V8 specific APIs, as such other runtimes may not work*
## Installation
```bash
yarn add get-caller-file
```
## Usage
Given:
```js
// ./foo.js
const getCallerFile = require('get-caller-file');
module.exports = function() {
return getCallerFile(); // figures out who called it
};
```
```js
// index.js
const foo = require('./foo');
foo() // => /full/path/to/this/file/index.js
```
## Options:
* `getCallerFile(position = 2)`: where position is stack frame whos fileName we want.
Railroad-diagram Generator
==========================
This is a small js library for generating railroad diagrams
(like what [JSON.org](http://json.org) uses)
using SVG.
Railroad diagrams are a way of visually representing a grammar
in a form that is more readable than using regular expressions or BNF.
I think (though I haven't given it a lot of thought yet) that if it's easy to write a context-free grammar for the language,
the corresponding railroad diagram will be easy as well.
There are several railroad-diagram generators out there, but none of them had the visual appeal I wanted.
[Here's an example of how they look!](http://www.xanthir.com/etc/railroad-diagrams/example.html)
And [here's an online generator for you to play with and get SVG code from!](http://www.xanthir.com/etc/railroad-diagrams/generator.html)
The library now exists in a Python port as well! See the information further down.
Details
-------
To use the library, just include the js and css files, and then call the Diagram() function.
Its arguments are the components of the diagram (Diagram is a special form of Sequence).
An alternative to Diagram() is ComplexDiagram() which is used to describe a complex type diagram.
Components are either leaves or containers.
The leaves:
* Terminal(text) or a bare string - represents literal text
* NonTerminal(text) - represents an instruction or another production
* Comment(text) - a comment
* Skip() - an empty line
The containers:
* Sequence(children) - like simple concatenation in a regex
* Choice(index, children) - like | in a regex. The index argument specifies which child is the "normal" choice and should go in the middle
* Optional(child, skip) - like ? in a regex. A shorthand for `Choice(1, [Skip(), child])`. If the optional `skip` parameter has the value `"skip"`, it instead puts the Skip() in the straight-line path, for when the "normal" behavior is to omit the item.
* OneOrMore(child, repeat) - like + in a regex. The 'repeat' argument is optional, and specifies something that must go between the repetitions.
* ZeroOrMore(child, repeat, skip) - like * in a regex. A shorthand for `Optional(OneOrMore(child, repeat))`. The optional `skip` parameter is identical to Optional().
For convenience, each component can be called with or without `new`.
If called without `new`,
the container components become n-ary;
that is, you can say either `new Sequence([A, B])` or just `Sequence(A,B)`.
After constructing a Diagram, call `.format(...padding)` on it, specifying 0-4 padding values (just like CSS) for some additional "breathing space" around the diagram (the paddings default to 20px).
The result can either be `.toString()`'d for the markup, or `.toSVG()`'d for an `<svg>` element, which can then be immediately inserted to the document. As a convenience, Diagram also has an `.addTo(element)` method, which immediately converts it to SVG and appends it to the referenced element with default paddings. `element` defaults to `document.body`.
Options
-------
There are a few options you can tweak, at the bottom of the file. Just tweak either until the diagram looks like what you want.
You can also change the CSS file - feel free to tweak to your heart's content.
Note, though, that if you change the text sizes in the CSS,
you'll have to go adjust the metrics for the leaf nodes as well.
* VERTICAL_SEPARATION - sets the minimum amount of vertical separation between two items. Note that the stroke width isn't counted when computing the separation; this shouldn't be relevant unless you have a very small separation or very large stroke width.
* ARC_RADIUS - the radius of the arcs used in the branching containers like Choice. This has a relatively large effect on the size of non-trivial diagrams. Both tight and loose values look good, depending on what you're going for.
* DIAGRAM_CLASS - the class set on the root `<svg>` element of each diagram, for use in the CSS stylesheet.
* STROKE_ODD_PIXEL_LENGTH - the default stylesheet uses odd pixel lengths for 'stroke'. Due to rasterization artifacts, they look best when the item has been translated half a pixel in both directions. If you change the styling to use a stroke with even pixel lengths, you'll want to set this variable to `false`.
* INTERNAL_ALIGNMENT - when some branches of a container are narrower than others, this determines how they're aligned in the extra space. Defaults to "center", but can be set to "left" or "right".
Caveats
-------
At this early stage, the generator is feature-complete and works as intended, but still has several TODOs:
* The font-sizes are hard-coded right now, and the font handling in general is very dumb - I'm just guessing at some metrics that are probably "good enough" rather than measuring things properly.
Python Port
-----------
In addition to the canonical JS version, the library now exists as a Python library as well.
Using it is basically identical. The config variables are globals in the file, and so may be adjusted either manually or via tweaking from inside your program.
The main difference from the JS port is how you extract the string from the Diagram. You'll find a `writeSvg(writerFunc)` method on `Diagram`, which takes a callback of one argument and passes it the string form of the diagram. For example, it can be used like `Diagram(...).writeSvg(sys.stdout.write)` to write to stdout. **Note**: the callback will be called multiple times as it builds up the string, not just once with the whole thing. If you need it all at once, consider something like a `StringIO` as an easy way to collect it into a single string.
License
-------
This document and all associated files in the github project are licensed under [CC0](http://creativecommons.org/publicdomain/zero/1.0/) .
This means you can reuse, remix, or otherwise appropriate this project for your own use **without restriction**.
(The actual legal meaning can be found at the above link.)
Don't ask me for permission to use any part of this project, **just use it**.
I would appreciate attribution, but that is not required by the license.
# Web IDL Type Conversions on JavaScript Values
This package implements, in JavaScript, the algorithms to convert a given JavaScript value according to a given [Web IDL](http://heycam.github.io/webidl/) [type](http://heycam.github.io/webidl/#idl-types).
The goal is that you should be able to write code like
```js
"use strict";
const conversions = require("webidl-conversions");
function doStuff(x, y) {
x = conversions["boolean"](x);
y = conversions["unsigned long"](y);
// actual algorithm code here
}
```
and your function `doStuff` will behave the same as a Web IDL operation declared as
```webidl
void doStuff(boolean x, unsigned long y);
```
## API
This package's main module's default export is an object with a variety of methods, each corresponding to a different Web IDL type. Each method, when invoked on a JavaScript value, will give back the new JavaScript value that results after passing through the Web IDL conversion rules. (See below for more details on what that means.) Alternately, the method could throw an error, if the Web IDL algorithm is specified to do so: for example `conversions["float"](NaN)` [will throw a `TypeError`](http://heycam.github.io/webidl/#es-float).
Each method also accepts a second, optional, parameter for miscellaneous options. For conversion methods that throw errors, a string option `{ context }` may be provided to provide more information in the error message. (For example, `conversions["float"](NaN, { context: "Argument 1 of Interface's operation" })` will throw an error with message `"Argument 1 of Interface's operation is not a finite floating-point value."`) Specific conversions may also accept other options, the details of which can be found below.
## Conversions implemented
Conversions for all of the basic types from the Web IDL specification are implemented:
- [`any`](https://heycam.github.io/webidl/#es-any)
- [`void`](https://heycam.github.io/webidl/#es-void)
- [`boolean`](https://heycam.github.io/webidl/#es-boolean)
- [Integer types](https://heycam.github.io/webidl/#es-integer-types), which can additionally be provided the boolean options `{ clamp, enforceRange }` as a second parameter
- [`float`](https://heycam.github.io/webidl/#es-float), [`unrestricted float`](https://heycam.github.io/webidl/#es-unrestricted-float)
- [`double`](https://heycam.github.io/webidl/#es-double), [`unrestricted double`](https://heycam.github.io/webidl/#es-unrestricted-double)
- [`DOMString`](https://heycam.github.io/webidl/#es-DOMString), which can additionally be provided the boolean option `{ treatNullAsEmptyString }` as a second parameter
- [`ByteString`](https://heycam.github.io/webidl/#es-ByteString), [`USVString`](https://heycam.github.io/webidl/#es-USVString)
- [`object`](https://heycam.github.io/webidl/#es-object)
- [`Error`](https://heycam.github.io/webidl/#es-Error)
- [Buffer source types](https://heycam.github.io/webidl/#es-buffer-source-types)
Additionally, for convenience, the following derived type definitions are implemented:
- [`ArrayBufferView`](https://heycam.github.io/webidl/#ArrayBufferView)
- [`BufferSource`](https://heycam.github.io/webidl/#BufferSource)
- [`DOMTimeStamp`](https://heycam.github.io/webidl/#DOMTimeStamp)
- [`Function`](https://heycam.github.io/webidl/#Function)
- [`VoidFunction`](https://heycam.github.io/webidl/#VoidFunction) (although it will not censor the return type)
Derived types, such as nullable types, promise types, sequences, records, etc. are not handled by this library. You may wish to investigate the [webidl2js](https://github.com/jsdom/webidl2js) project.
### A note on the `long long` types
The `long long` and `unsigned long long` Web IDL types can hold values that cannot be stored in JavaScript numbers, so the conversion is imperfect. For example, converting the JavaScript number `18446744073709552000` to a Web IDL `long long` is supposed to produce the Web IDL value `-18446744073709551232`. Since we are representing our Web IDL values in JavaScript, we can't represent `-18446744073709551232`, so we instead the best we could do is `-18446744073709552000` as the output.
This library actually doesn't even get that far. Producing those results would require doing accurate modular arithmetic on 64-bit intermediate values, but JavaScript does not make this easy. We could pull in a big-integer library as a dependency, but in lieu of that, we for now have decided to just produce inaccurate results if you pass in numbers that are not strictly between `Number.MIN_SAFE_INTEGER` and `Number.MAX_SAFE_INTEGER`.
## Background
What's actually going on here, conceptually, is pretty weird. Let's try to explain.
Web IDL, as part of its madness-inducing design, has its own type system. When people write algorithms in web platform specs, they usually operate on Web IDL values, i.e. instances of Web IDL types. For example, if they were specifying the algorithm for our `doStuff` operation above, they would treat `x` as a Web IDL value of [Web IDL type `boolean`](http://heycam.github.io/webidl/#idl-boolean). Crucially, they would _not_ treat `x` as a JavaScript variable whose value is either the JavaScript `true` or `false`. They're instead working in a different type system altogether, with its own rules.
Separately from its type system, Web IDL defines a ["binding"](http://heycam.github.io/webidl/#ecmascript-binding) of the type system into JavaScript. This contains rules like: when you pass a JavaScript value to the JavaScript method that manifests a given Web IDL operation, how does that get converted into a Web IDL value? For example, a JavaScript `true` passed in the position of a Web IDL `boolean` argument becomes a Web IDL `true`. But, a JavaScript `true` passed in the position of a [Web IDL `unsigned long`](http://heycam.github.io/webidl/#idl-unsigned-long) becomes a Web IDL `1`. And so on.
Finally, we have the actual implementation code. This is usually C++, although these days [some smart people are using Rust](https://github.com/servo/servo). The implementation, of course, has its own type system. So when they implement the Web IDL algorithms, they don't actually use Web IDL values, since those aren't "real" outside of specs. Instead, implementations apply the Web IDL binding rules in such a way as to convert incoming JavaScript values into C++ values. For example, if code in the browser called `doStuff(true, true)`, then the implementation code would eventually receive a C++ `bool` containing `true` and a C++ `uint32_t` containing `1`.
The upside of all this is that implementations can abstract all the conversion logic away, letting Web IDL handle it, and focus on implementing the relevant methods in C++ with values of the correct type already provided. That is payoff of Web IDL, in a nutshell.
And getting to that payoff is the goal of _this_ project—but for JavaScript implementations, instead of C++ ones. That is, this library is designed to make it easier for JavaScript developers to write functions that behave like a given Web IDL operation. So conceptually, the conversion pipeline, which in its general form is JavaScript values ↦ Web IDL values ↦ implementation-language values, in this case becomes JavaScript values ↦ Web IDL values ↦ JavaScript values. And that intermediate step is where all the logic is performed: a JavaScript `true` becomes a Web IDL `1` in an unsigned long context, which then becomes a JavaScript `1`.
## Don't use this
Seriously, why would you ever use this? You really shouldn't. Web IDL is … strange, and you shouldn't be emulating its semantics. If you're looking for a generic argument-processing library, you should find one with better rules than those from Web IDL. In general, your JavaScript should not be trying to become more like Web IDL; if anything, we should fix Web IDL to make it more like JavaScript.
The _only_ people who should use this are those trying to create faithful implementations (or polyfills) of web platform interfaces defined in Web IDL. Its main consumer is the [jsdom](https://github.com/tmpvar/jsdom) project.
# assemblyscript-json
 
JSON encoder / decoder for AssemblyScript.
Special thanks to https://github.com/MaxGraey/bignum.wasm for basic unit testing infra for AssemblyScript.
## Installation
`assemblyscript-json` is available as a [npm package](https://www.npmjs.com/package/assemblyscript-json). You can install `assemblyscript-json` in your AssemblyScript project by running:
`npm install --save assemblyscript-json`
## Usage
### Parsing JSON
```typescript
import { JSON } from "assemblyscript-json";
// Parse an object using the JSON object
let jsonObj: JSON.Obj = <JSON.Obj>(JSON.parse('{"hello": "world", "value": 24}'));
// We can then use the .getX functions to read from the object if you know it's type
// This will return the appropriate JSON.X value if the key exists, or null if the key does not exist
let worldOrNull: JSON.Str | null = jsonObj.getString("hello"); // This will return a JSON.Str or null
if (worldOrNull != null) {
// use .valueOf() to turn the high level JSON.Str type into a string
let world: string = worldOrNull.valueOf();
}
let numOrNull: JSON.Num | null = jsonObj.getNum("value");
if (numOrNull != null) {
// use .valueOf() to turn the high level JSON.Num type into a f64
let value: f64 = numOrNull.valueOf();
}
// If you don't know the value type, get the parent JSON.Value
let valueOrNull: JSON.Value | null = jsonObj.getValue("hello");
if (valueOrNull != null) {
let value: JSON.Value = changetype<JSON.Value>(valueOrNull);
// Next we could figure out what type we are
if(value.isString) {
// value.isString would be true, so we can cast to a string
let stringValue: string = changetype<JSON.Str>(value).toString();
// Do something with string value
}
}
```
### Encoding JSON
```typescript
import { JSONEncoder } from "assemblyscript-json";
// Create encoder
let encoder = new JSONEncoder();
// Construct necessary object
encoder.pushObject("obj");
encoder.setInteger("int", 10);
encoder.setString("str", "");
encoder.popObject();
// Get serialized data
let json: Uint8Array = encoder.serialize();
// Or get serialized data as string
let jsonString: string = encoder.toString();
assert(jsonString, '"obj": {"int": 10, "str": ""}'); // True!
```
### Custom JSON Deserializers
```typescript
import { JSONDecoder, JSONHandler } from "assemblyscript-json";
// Events need to be received by custom object extending JSONHandler.
// NOTE: All methods are optional to implement.
class MyJSONEventsHandler extends JSONHandler {
setString(name: string, value: string): void {
// Handle field
}
setBoolean(name: string, value: bool): void {
// Handle field
}
setNull(name: string): void {
// Handle field
}
setInteger(name: string, value: i64): void {
// Handle field
}
setFloat(name: string, value: f64): void {
// Handle field
}
pushArray(name: string): bool {
// Handle array start
// true means that nested object needs to be traversed, false otherwise
// Note that returning false means JSONDecoder.startIndex need to be updated by handler
return true;
}
popArray(): void {
// Handle array end
}
pushObject(name: string): bool {
// Handle object start
// true means that nested object needs to be traversed, false otherwise
// Note that returning false means JSONDecoder.startIndex need to be updated by handler
return true;
}
popObject(): void {
// Handle object end
}
}
// Create decoder
let decoder = new JSONDecoder<MyJSONEventsHandler>(new MyJSONEventsHandler());
// Create a byte buffer of our JSON. NOTE: Deserializers work on UTF8 string buffers.
let jsonString = '{"hello": "world"}';
let jsonBuffer = Uint8Array.wrap(String.UTF8.encode(jsonString));
// Parse JSON
decoder.deserialize(jsonBuffer); // This will send events to MyJSONEventsHandler
```
Feel free to look through the [tests](https://github.com/nearprotocol/assemblyscript-json/tree/master/assembly/__tests__) for more usage examples.
## Reference Documentation
Reference API Documentation can be found in the [docs directory](./docs).
## License
[MIT](./LICENSE)
## Setting up your terminal
The scripts in this folder are designed to help you demonstrate the behavior of the contract(s) in this project.
It uses the following setup:
```sh
# set your terminal up to have 2 windows, A and B like this:
┌─────────────────────────────────┬─────────────────────────────────┐
│ │ │
│ │ │
│ A │ B │
│ │ │
│ │ │
└─────────────────────────────────┴─────────────────────────────────┘
```
### Terminal **A**
*This window is used to compile, deploy and control the contract*
- Environment
```sh
export CONTRACT= # depends on deployment
export OWNER= # any account you control
# for example
# export CONTRACT=dev-1615190770786-2702449
# export OWNER=sherif.testnet
```
- Commands
_helper scripts_
```sh
1.dev-deploy.sh # helper: build and deploy contracts
2.use-contract.sh # helper: call methods on ContractPromise
3.cleanup.sh # helper: delete build and deploy artifacts
```
### Terminal **B**
*This window is used to render the contract account storage*
- Environment
```sh
export CONTRACT= # depends on deployment
# for example
# export CONTRACT=dev-1615190770786-2702449
```
- Commands
```sh
# monitor contract storage using near-account-utils
# https://github.com/near-examples/near-account-utils
watch -d -n 1 yarn storage $CONTRACT
```
---
## OS Support
### Linux
- The `watch` command is supported natively on Linux
- To learn more about any of these shell commands take a look at [explainshell.com](https://explainshell.com)
### MacOS
- Consider `brew info visionmedia-watch` (or `brew install watch`)
### Windows
- Consider this article: [What is the Windows analog of the Linux watch command?](https://superuser.com/questions/191063/what-is-the-windows-analog-of-the-linuo-watch-command#191068)
# fs-minipass
Filesystem streams based on [minipass](http://npm.im/minipass).
4 classes are exported:
- ReadStream
- ReadStreamSync
- WriteStream
- WriteStreamSync
When using `ReadStreamSync`, all of the data is made available
immediately upon consuming the stream. Nothing is buffered in memory
when the stream is constructed. If the stream is piped to a writer,
then it will synchronously `read()` and emit data into the writer as
fast as the writer can consume it. (That is, it will respect
backpressure.) If you call `stream.read()` then it will read the
entire file and return the contents.
When using `WriteStreamSync`, every write is flushed to the file
synchronously. If your writes all come in a single tick, then it'll
write it all out in a single tick. It's as synchronous as you are.
The async versions work much like their node builtin counterparts,
with the exception of introducing significantly less Stream machinery
overhead.
## USAGE
It's just streams, you pipe them or read() them or write() to them.
```js
const fsm = require('fs-minipass')
const readStream = new fsm.ReadStream('file.txt')
const writeStream = new fsm.WriteStream('output.txt')
writeStream.write('some file header or whatever\n')
readStream.pipe(writeStream)
```
## ReadStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `readSize` The size of reads to do, defaults to 16MB
- `size` The size of the file, if known. Prevents zero-byte read()
call at the end.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the file is done being read.
## WriteStream(path, options)
Path string is required, but somewhat irrelevant if an open file
descriptor is passed in as an option.
Options:
- `fd` Pass in a numeric file descriptor, if the file is already open.
- `mode` The mode to create the file with. Defaults to `0o666`.
- `start` The position in the file to start reading. If not
specified, then the file will start writing at position zero, and be
truncated by default.
- `autoClose` Set to `false` to prevent the file descriptor from being
closed when the stream is ended.
- `flags` Flags to use when opening the file. Irrelevant if `fd` is
passed in, since file won't be opened in that case. Defaults to
`'a'` if a `pos` is specified, or `'w'` otherwise.
# binary-install
Install .tar.gz binary applications via npm
## Usage
This library provides a single class `Binary` that takes a download url and some optional arguments. You **must** provide either `name` or `installDirectory` when creating your `Binary`.
| option | decription |
| ---------------- | --------------------------------------------- |
| name | The name of your binary |
| installDirectory | A path to the directory to install the binary |
If an `installDirectory` is not provided, the binary will be installed at your OS specific config directory. On MacOS it defaults to `~/Library/Preferences/${name}-nodejs`
After your `Binary` has been created, you can run `.install()` to install the binary, and `.run()` to run it.
### Example
This is meant to be used as a library - create your `Binary` with your desired options, then call `.install()` in the `postinstall` of your `package.json`, `.run()` in the `bin` section of your `package.json`, and `.uninstall()` in the `preuninstall` section of your `package.json`. See [this example project](/example) to see how to create an npm package that installs and runs a binary using the Github releases API.
# once
Only call a function once.
## usage
```javascript
var once = require('once')
function load (file, cb) {
cb = once(cb)
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Or add to the Function.prototype in a responsible way:
```javascript
// only has to be done once
require('once').proto()
function load (file, cb) {
cb = cb.once()
loader.load('file')
loader.once('load', cb)
loader.once('error', cb)
}
```
Ironically, the prototype feature makes this module twice as
complicated as necessary.
To check whether you function has been called, use `fn.called`. Once the
function is called for the first time the return value of the original
function is saved in `fn.value` and subsequent calls will continue to
return this value.
```javascript
var once = require('once')
function load (cb) {
cb = once(cb)
var stream = createStream()
stream.once('data', cb)
stream.once('end', function () {
if (!cb.called) cb(new Error('not found'))
})
}
```
## `once.strict(func)`
Throw an error if the function is called twice.
Some functions are expected to be called only once. Using `once` for them would
potentially hide logical errors.
In the example below, the `greet` function has to call the callback only once:
```javascript
function greet (name, cb) {
// return is missing from the if statement
// when no name is passed, the callback is called twice
if (!name) cb('Hello anonymous')
cb('Hello ' + name)
}
function log (msg) {
console.log(msg)
}
// this will print 'Hello anonymous' but the logical error will be missed
greet(null, once(msg))
// once.strict will print 'Hello anonymous' and throw an error when the callback will be called the second time
greet(null, once.strict(msg))
```
discontinuous-range
===================
```
DiscontinuousRange(1, 10).subtract(4, 6); // [ 1-3, 7-10 ]
```
[](https://travis-ci.org/dtudury/discontinuous-range)
this is a pretty simple module, but it exists to service another project
so this'll be pretty lacking documentation.
reading the test to see how this works may help. otherwise, here's an example
that I think pretty much sums it up
###Example
```
var all_numbers = new DiscontinuousRange(1, 100);
var bad_numbers = DiscontinuousRange(13).add(8).add(60,80);
var good_numbers = all_numbers.clone().subtract(bad_numbers);
console.log(good_numbers.toString()); //[ 1-7, 9-12, 14-59, 81-100 ]
var random_good_number = good_numbers.index(Math.floor(Math.random() * good_numbers.length));
```
[](https://travis-ci.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf) [](https://david-dm.org/isaacs/rimraf#info=devDependencies)
The [UNIX command](http://en.wikipedia.org/wiki/Rm_(Unix)) `rm -rf` for node.
Install with `npm install rimraf`, or just drop rimraf.js somewhere.
## API
`rimraf(f, [opts], callback)`
The first parameter will be interpreted as a globbing pattern for files. If you
want to disable globbing you can do so with `opts.disableGlob` (defaults to
`false`). This might be handy, for instance, if you have filenames that contain
globbing wildcard characters.
The callback will be called with an error if there is one. Certain
errors are handled for you:
* Windows: `EBUSY` and `ENOTEMPTY` - rimraf will back off a maximum of
`opts.maxBusyTries` times before giving up, adding 100ms of wait
between each attempt. The default `maxBusyTries` is 3.
* `ENOENT` - If the file doesn't exist, rimraf will return
successfully, since your desired outcome is already the case.
* `EMFILE` - Since `readdir` requires opening a file descriptor, it's
possible to hit `EMFILE` if too many file descriptors are in use.
In the sync case, there's nothing to be done for this. But in the
async case, rimraf will gradually back off with timeouts up to
`opts.emfileWait` ms, which defaults to 1000.
## options
* unlink, chmod, stat, lstat, rmdir, readdir,
unlinkSync, chmodSync, statSync, lstatSync, rmdirSync, readdirSync
In order to use a custom file system library, you can override
specific fs functions on the options object.
If any of these functions are present on the options object, then
the supplied function will be used instead of the default fs
method.
Sync methods are only relevant for `rimraf.sync()`, of course.
For example:
```javascript
var myCustomFS = require('some-custom-fs')
rimraf('some-thing', myCustomFS, callback)
```
* maxBusyTries
If an `EBUSY`, `ENOTEMPTY`, or `EPERM` error code is encountered
on Windows systems, then rimraf will retry with a linear backoff
wait of 100ms longer on each try. The default maxBusyTries is 3.
Only relevant for async usage.
* emfileWait
If an `EMFILE` error is encountered, then rimraf will retry
repeatedly with a linear backoff of 1ms longer on each try, until
the timeout counter hits this max. The default limit is 1000.
If you repeatedly encounter `EMFILE` errors, then consider using
[graceful-fs](http://npm.im/graceful-fs) in your program.
Only relevant for async usage.
* glob
Set to `false` to disable [glob](http://npm.im/glob) pattern
matching.
Set to an object to pass options to the glob module. The default
glob options are `{ nosort: true, silent: true }`.
Glob version 6 is used in this module.
Relevant for both sync and async usage.
* disableGlob
Set to any non-falsey value to disable globbing entirely.
(Equivalent to setting `glob: false`.)
## rimraf.sync
It can remove stuff synchronously, too. But that's not so good. Use
the async API. It's better.
## CLI
If installed with `npm install rimraf -g` it can be used as a global
command `rimraf <path> [<path> ...]` which is useful for cross platform support.
## mkdirp
If you need to create a directory recursively, check out
[mkdirp](https://github.com/substack/node-mkdirp).
# which-module
> Find the module object for something that was require()d
[](https://travis-ci.org/nexdrew/which-module)
[](https://coveralls.io/github/nexdrew/which-module?branch=master)
[](https://github.com/conventional-changelog/standard-version)
Find the `module` object in `require.cache` for something that was `require()`d
or `import`ed - essentially a reverse `require()` lookup.
Useful for libs that want to e.g. lookup a filename for a module or submodule
that it did not `require()` itself.
## Install and Usage
```
npm install --save which-module
```
```js
const whichModule = require('which-module')
console.log(whichModule(require('something')))
// Module {
// id: '/path/to/project/node_modules/something/index.js',
// exports: [Function],
// parent: ...,
// filename: '/path/to/project/node_modules/something/index.js',
// loaded: true,
// children: [],
// paths: [ '/path/to/project/node_modules/something/node_modules',
// '/path/to/project/node_modules',
// '/path/to/node_modules',
// '/path/node_modules',
// '/node_modules' ] }
```
## API
### `whichModule(exported)`
Return the [`module` object](https://nodejs.org/api/modules.html#modules_the_module_object),
if any, that represents the given argument in the `require.cache`.
`exported` can be anything that was previously `require()`d or `import`ed as a
module, submodule, or dependency - which means `exported` is identical to the
`module.exports` returned by this method.
If `exported` did not come from the `exports` of a `module` in `require.cache`,
then this method returns `null`.
## License
ISC © Contributors
# patikaWeb3Fundamentals
# ASBuild
A simple build tool for [AssemblyScript](https://assemblyscript.org) projects, similar to `cargo`, etc.
## Usage
```
asb [entry file] [options] -- [args passed to asc]
```
### Background
AssemblyScript greater than v0.14.4 provides a `asconfig.json` configuration file that can be used to describe the options for building a project. ASBuild uses this and some defaults to create an easier CLI interface.
### Defaults
#### Project structure
```
project/
package.json
asconfig.json
assembly/
index.ts
build/
release/
project.wasm
debug/
project.wasm
```
- If no entry file passed and no `entry` field is in `asconfig.json`, `project/assembly/index.ts` is assumed.
- `asconfig.json` allows for options for different compile targets, e.g. release, debug, etc. `asc` defaults to the release target.
- The default build directory is `./build`, and artifacts are placed at `./build/<target>/packageName.wasm`.
### Workspaces
If a `workspace` field is added to a top level `asconfig.json` file, then each path in the array is built and placed into the top level `outDir`.
For example,
`asconfig.json`:
```json
{
"workspaces": ["a", "b"]
}
```
Running `asb` in the directory below will use the top level build directory to place all the binaries.
```
project/
package.json
asconfig.json
a/
asconfig.json
assembly/
index.ts
b/
asconfig.json
assembly/
index.ts
build/
release/
a.wasm
b.wasm
debug/
a.wasm
b.wasm
```
To see an example in action check out the [test workspace](./test)
# <img src="./logo.png" alt="bn.js" width="160" height="160" />
> BigNum in pure javascript
[](http://travis-ci.org/indutny/bn.js)
## Install
`npm install --save bn.js`
## Usage
```js
const BN = require('bn.js');
var a = new BN('dead', 16);
var b = new BN('101010', 2);
var res = a.add(b);
console.log(res.toString(10)); // 57047
```
**Note**: decimals are not supported in this library.
## Notation
### Prefixes
There are several prefixes to instructions that affect the way the work. Here
is the list of them in the order of appearance in the function name:
* `i` - perform operation in-place, storing the result in the host object (on
which the method was invoked). Might be used to avoid number allocation costs
* `u` - unsigned, ignore the sign of operands when performing operation, or
always return positive value. Second case applies to reduction operations
like `mod()`. In such cases if the result will be negative - modulo will be
added to the result to make it positive
### Postfixes
* `n` - the argument of the function must be a plain JavaScript
Number. Decimals are not supported.
* `rn` - both argument and return value of the function are plain JavaScript
Numbers. Decimals are not supported.
### Examples
* `a.iadd(b)` - perform addition on `a` and `b`, storing the result in `a`
* `a.umod(b)` - reduce `a` modulo `b`, returning positive value
* `a.iushln(13)` - shift bits of `a` left by 13
## Instructions
Prefixes/postfixes are put in parens at the of the line. `endian` - could be
either `le` (little-endian) or `be` (big-endian).
### Utilities
* `a.clone()` - clone number
* `a.toString(base, length)` - convert to base-string and pad with zeroes
* `a.toNumber()` - convert to Javascript Number (limited to 53 bits)
* `a.toJSON()` - convert to JSON compatible hex string (alias of `toString(16)`)
* `a.toArray(endian, length)` - convert to byte `Array`, and optionally zero
pad to length, throwing if already exceeding
* `a.toArrayLike(type, endian, length)` - convert to an instance of `type`,
which must behave like an `Array`
* `a.toBuffer(endian, length)` - convert to Node.js Buffer (if available). For
compatibility with browserify and similar tools, use this instead:
`a.toArrayLike(Buffer, endian, length)`
* `a.bitLength()` - get number of bits occupied
* `a.zeroBits()` - return number of less-significant consequent zero bits
(example: `1010000` has 4 zero bits)
* `a.byteLength()` - return number of bytes occupied
* `a.isNeg()` - true if the number is negative
* `a.isEven()` - no comments
* `a.isOdd()` - no comments
* `a.isZero()` - no comments
* `a.cmp(b)` - compare numbers and return `-1` (a `<` b), `0` (a `==` b), or `1` (a `>` b)
depending on the comparison result (`ucmp`, `cmpn`)
* `a.lt(b)` - `a` less than `b` (`n`)
* `a.lte(b)` - `a` less than or equals `b` (`n`)
* `a.gt(b)` - `a` greater than `b` (`n`)
* `a.gte(b)` - `a` greater than or equals `b` (`n`)
* `a.eq(b)` - `a` equals `b` (`n`)
* `a.toTwos(width)` - convert to two's complement representation, where `width` is bit width
* `a.fromTwos(width)` - convert from two's complement representation, where `width` is the bit width
* `BN.isBN(object)` - returns true if the supplied `object` is a BN.js instance
* `BN.max(a, b)` - return `a` if `a` bigger than `b`
* `BN.min(a, b)` - return `a` if `a` less than `b`
### Arithmetics
* `a.neg()` - negate sign (`i`)
* `a.abs()` - absolute value (`i`)
* `a.add(b)` - addition (`i`, `n`, `in`)
* `a.sub(b)` - subtraction (`i`, `n`, `in`)
* `a.mul(b)` - multiply (`i`, `n`, `in`)
* `a.sqr()` - square (`i`)
* `a.pow(b)` - raise `a` to the power of `b`
* `a.div(b)` - divide (`divn`, `idivn`)
* `a.mod(b)` - reduct (`u`, `n`) (but no `umodn`)
* `a.divmod(b)` - quotient and modulus obtained by dividing
* `a.divRound(b)` - rounded division
### Bit operations
* `a.or(b)` - or (`i`, `u`, `iu`)
* `a.and(b)` - and (`i`, `u`, `iu`, `andln`) (NOTE: `andln` is going to be replaced
with `andn` in future)
* `a.xor(b)` - xor (`i`, `u`, `iu`)
* `a.setn(b, value)` - set specified bit to `value`
* `a.shln(b)` - shift left (`i`, `u`, `iu`)
* `a.shrn(b)` - shift right (`i`, `u`, `iu`)
* `a.testn(b)` - test if specified bit is set
* `a.maskn(b)` - clear bits with indexes higher or equal to `b` (`i`)
* `a.bincn(b)` - add `1 << b` to the number
* `a.notn(w)` - not (for the width specified by `w`) (`i`)
### Reduction
* `a.gcd(b)` - GCD
* `a.egcd(b)` - Extended GCD results (`{ a: ..., b: ..., gcd: ... }`)
* `a.invm(b)` - inverse `a` modulo `b`
## Fast reduction
When doing lots of reductions using the same modulo, it might be beneficial to
use some tricks: like [Montgomery multiplication][0], or using special algorithm
for [Mersenne Prime][1].
### Reduction context
To enable this tricks one should create a reduction context:
```js
var red = BN.red(num);
```
where `num` is just a BN instance.
Or:
```js
var red = BN.red(primeName);
```
Where `primeName` is either of these [Mersenne Primes][1]:
* `'k256'`
* `'p224'`
* `'p192'`
* `'p25519'`
Or:
```js
var red = BN.mont(num);
```
To reduce numbers with [Montgomery trick][0]. `.mont()` is generally faster than
`.red(num)`, but slower than `BN.red(primeName)`.
### Converting numbers
Before performing anything in reduction context - numbers should be converted
to it. Usually, this means that one should:
* Convert inputs to reducted ones
* Operate on them in reduction context
* Convert outputs back from the reduction context
Here is how one may convert numbers to `red`:
```js
var redA = a.toRed(red);
```
Where `red` is a reduction context created using instructions above
Here is how to convert them back:
```js
var a = redA.fromRed();
```
### Red instructions
Most of the instructions from the very start of this readme have their
counterparts in red context:
* `a.redAdd(b)`, `a.redIAdd(b)`
* `a.redSub(b)`, `a.redISub(b)`
* `a.redShl(num)`
* `a.redMul(b)`, `a.redIMul(b)`
* `a.redSqr()`, `a.redISqr()`
* `a.redSqrt()` - square root modulo reduction context's prime
* `a.redInvm()` - modular inverse of the number
* `a.redNeg()`
* `a.redPow(b)` - modular exponentiation
### Number Size
Optimized for elliptic curves that work with 256-bit numbers.
There is no limitation on the size of the numbers.
## LICENSE
This software is licensed under the MIT License.
[0]: https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[1]: https://en.wikipedia.org/wiki/Mersenne_prime
# Glob
Match files using the patterns the shell uses, like stars and stuff.
[](https://travis-ci.org/isaacs/node-glob/) [](https://ci.appveyor.com/project/isaacs/node-glob) [](https://coveralls.io/github/isaacs/node-glob?branch=master)
This is a glob implementation in JavaScript. It uses the `minimatch`
library to do its matching.

## Usage
Install with npm
```
npm i glob
```
```javascript
var glob = require("glob")
// options is optional
glob("**/*.js", options, function (er, files) {
// files is an array of filenames.
// If the `nonull` option is set, and nothing
// was found, then files is ["**/*.js"]
// er is an error object or null.
})
```
## Glob Primer
"Globs" are the patterns you type when you do stuff like `ls *.js` on
the command line, or put `build/*` in a `.gitignore` file.
Before parsing the path part patterns, braced sections are expanded
into a set. Braced sections start with `{` and end with `}`, with any
number of comma-delimited sections within. Braced sections may contain
slash characters, so `a{/b/c,bcd}` would expand into `a/b/c` and `abcd`.
The following characters have special magic meaning when used in a
path portion:
* `*` Matches 0 or more characters in a single path portion
* `?` Matches 1 character
* `[...]` Matches a range of characters, similar to a RegExp range.
If the first character of the range is `!` or `^` then it matches
any character not in the range.
* `!(pattern|pattern|pattern)` Matches anything that does not match
any of the patterns provided.
* `?(pattern|pattern|pattern)` Matches zero or one occurrence of the
patterns provided.
* `+(pattern|pattern|pattern)` Matches one or more occurrences of the
patterns provided.
* `*(a|b|c)` Matches zero or more occurrences of the patterns provided
* `@(pattern|pat*|pat?erN)` Matches exactly one of the patterns
provided
* `**` If a "globstar" is alone in a path portion, then it matches
zero or more directories and subdirectories searching for matches.
It does not crawl symlinked directories.
### Dots
If a file or directory path portion has a `.` as the first character,
then it will not match any glob pattern unless that pattern's
corresponding path part also has a `.` as its first character.
For example, the pattern `a/.*/c` would match the file at `a/.b/c`.
However the pattern `a/*/c` would not, because `*` does not start with
a dot character.
You can make glob treat dots as normal characters by setting
`dot:true` in the options.
### Basename Matching
If you set `matchBase:true` in the options, and the pattern has no
slashes in it, then it will seek for any file anywhere in the tree
with a matching basename. For example, `*.js` would match
`test/simple/basic.js`.
### Empty Sets
If no matching files are found, then an empty array is returned. This
differs from the shell, where the pattern itself is returned. For
example:
$ echo a*s*d*f
a*s*d*f
To get the bash-style behavior, set the `nonull:true` in the options.
### See Also:
* `man sh`
* `man bash` (Search for "Pattern Matching")
* `man 3 fnmatch`
* `man 5 gitignore`
* [minimatch documentation](https://github.com/isaacs/minimatch)
## glob.hasMagic(pattern, [options])
Returns `true` if there are any special characters in the pattern, and
`false` otherwise.
Note that the options affect the results. If `noext:true` is set in
the options object, then `+(a|b)` will not be considered a magic
pattern. If the pattern has a brace expansion, like `a/{b/c,x/y}`
then that is considered magical, unless `nobrace:true` is set in the
options.
## glob(pattern, [options], cb)
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* `cb` `{Function}`
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Perform an asynchronous glob search.
## glob.sync(pattern, [options])
* `pattern` `{String}` Pattern to be matched
* `options` `{Object}`
* return: `{Array<String>}` filenames found matching the pattern
Perform a synchronous glob search.
## Class: glob.Glob
Create a Glob object by instantiating the `glob.Glob` class.
```javascript
var Glob = require("glob").Glob
var mg = new Glob(pattern, options, cb)
```
It's an EventEmitter, and starts walking the filesystem to find matches
immediately.
### new glob.Glob(pattern, [options], [cb])
* `pattern` `{String}` pattern to search for
* `options` `{Object}`
* `cb` `{Function}` Called when an error occurs, or matches are found
* `err` `{Error | null}`
* `matches` `{Array<String>}` filenames found matching the pattern
Note that if the `sync` flag is set in the options, then matches will
be immediately available on the `g.found` member.
### Properties
* `minimatch` The minimatch object that the glob uses.
* `options` The options object passed in.
* `aborted` Boolean which is set to true when calling `abort()`. There
is no way at this time to continue a glob search after aborting, but
you can re-use the statCache to avoid having to duplicate syscalls.
* `cache` Convenience object. Each field has the following possible
values:
* `false` - Path does not exist
* `true` - Path exists
* `'FILE'` - Path exists, and is not a directory
* `'DIR'` - Path exists, and is a directory
* `[file, entries, ...]` - Path exists, is a directory, and the
array value is the results of `fs.readdir`
* `statCache` Cache of `fs.stat` results, to prevent statting the same
path multiple times.
* `symlinks` A record of which paths are symbolic links, which is
relevant in resolving `**` patterns.
* `realpathCache` An optional object which is passed to `fs.realpath`
to minimize unnecessary syscalls. It is stored on the instantiated
Glob object, and may be re-used.
### Events
* `end` When the matching is finished, this is emitted with all the
matches found. If the `nonull` option is set, and no match was found,
then the `matches` list contains the original pattern. The matches
are sorted, unless the `nosort` flag is set.
* `match` Every time a match is found, this is emitted with the specific
thing that matched. It is not deduplicated or resolved to a realpath.
* `error` Emitted when an unexpected error is encountered, or whenever
any fs error occurs if `options.strict` is set.
* `abort` When `abort()` is called, this event is raised.
### Methods
* `pause` Temporarily stop the search
* `resume` Resume the search
* `abort` Stop the search forever
### Options
All the options that can be passed to Minimatch can also be passed to
Glob to change pattern matching behavior. Also, some have been added,
or have glob-specific ramifications.
All options are false by default, unless otherwise noted.
All options are added to the Glob object, as well.
If you are running many `glob` operations, you can pass a Glob object
as the `options` argument to a subsequent operation to shortcut some
`stat` and `readdir` calls. At the very least, you may pass in shared
`symlinks`, `statCache`, `realpathCache`, and `cache` options, so that
parallel glob operations will be sped up by sharing information about
the filesystem.
* `cwd` The current working directory in which to search. Defaults
to `process.cwd()`.
* `root` The place where patterns starting with `/` will be mounted
onto. Defaults to `path.resolve(options.cwd, "/")` (`/` on Unix
systems, and `C:\` or some such on Windows.)
* `dot` Include `.dot` files in normal matches and `globstar` matches.
Note that an explicit dot in a portion of the pattern will always
match dot files.
* `nomount` By default, a pattern starting with a forward-slash will be
"mounted" onto the root setting, so that a valid filesystem path is
returned. Set this flag to disable that behavior.
* `mark` Add a `/` character to directory matches. Note that this
requires additional stat calls.
* `nosort` Don't sort the results.
* `stat` Set to true to stat *all* results. This reduces performance
somewhat, and is completely unnecessary, unless `readdir` is presumed
to be an untrustworthy indicator of file existence.
* `silent` When an unusual error is encountered when attempting to
read a directory, a warning will be printed to stderr. Set the
`silent` option to true to suppress these warnings.
* `strict` When an unusual error is encountered when attempting to
read a directory, the process will just continue on in search of
other matches. Set the `strict` option to raise an error in these
cases.
* `cache` See `cache` property above. Pass in a previously generated
cache object to save some fs calls.
* `statCache` A cache of results of filesystem information, to prevent
unnecessary stat calls. While it should not normally be necessary
to set this, you may pass the statCache from one glob() call to the
options object of another, if you know that the filesystem will not
change between calls. (See "Race Conditions" below.)
* `symlinks` A cache of known symbolic links. You may pass in a
previously generated `symlinks` object to save `lstat` calls when
resolving `**` matches.
* `sync` DEPRECATED: use `glob.sync(pattern, opts)` instead.
* `nounique` In some cases, brace-expanded patterns can result in the
same file showing up multiple times in the result set. By default,
this implementation prevents duplicates in the result set. Set this
flag to disable that behavior.
* `nonull` Set to never return an empty set, instead returning a set
containing the pattern itself. This is the default in glob(3).
* `debug` Set to enable debug logging in minimatch and glob.
* `nobrace` Do not expand `{a,b}` and `{1..3}` brace sets.
* `noglobstar` Do not match `**` against multiple filenames. (Ie,
treat it as a normal `*` instead.)
* `noext` Do not match `+(a|b)` "extglob" patterns.
* `nocase` Perform a case-insensitive match. Note: on
case-insensitive filesystems, non-magic patterns will match by
default, since `stat` and `readdir` will not raise errors.
* `matchBase` Perform a basename-only match if the pattern does not
contain any slash characters. That is, `*.js` would be treated as
equivalent to `**/*.js`, matching all js files in all directories.
* `nodir` Do not match directories, only files. (Note: to match
*only* directories, simply put a `/` at the end of the pattern.)
* `ignore` Add a pattern or an array of glob patterns to exclude matches.
Note: `ignore` patterns are *always* in `dot:true` mode, regardless
of any other settings.
* `follow` Follow symlinked directories when expanding `**` patterns.
Note that this can result in a lot of duplicate references in the
presence of cyclic links.
* `realpath` Set to true to call `fs.realpath` on all of the results.
In the case of a symlink that cannot be resolved, the full absolute
path to the matched entry is returned (though it will usually be a
broken symlink)
* `absolute` Set to true to always receive absolute paths for matched
files. Unlike `realpath`, this also affects the values returned in
the `match` event.
## Comparisons to other fnmatch/glob implementations
While strict compliance with the existing standards is a worthwhile
goal, some discrepancies exist between node-glob and other
implementations, and are intentional.
The double-star character `**` is supported by default, unless the
`noglobstar` flag is set. This is supported in the manner of bsdglob
and bash 4.3, where `**` only has special significance if it is the only
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
`a/**b` will not.
Note that symlinked directories are not crawled as part of a `**`,
though their contents may match against subsequent portions of the
pattern. This prevents infinite loops and duplicates and the like.
If an escaped pattern has no matches, and the `nonull` flag is set,
then glob returns the pattern as-provided, rather than
interpreting the character escapes. For example,
`glob.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
that it does not resolve escaped pattern characters.
If brace expansion is not disabled, then it is performed before any
other interpretation of the glob pattern. Thus, a pattern like
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
checked for validity. Since those two are valid, matching proceeds.
### Comments and Negation
Previously, this module let you mark a pattern as a "comment" if it
started with a `#` character, or a "negated" pattern if it started
with a `!` character.
These options were deprecated in version 5, and removed in version 6.
To specify things that should not match, use the `ignore` option.
## Windows
**Please only use forward-slashes in glob expressions.**
Though windows uses either `/` or `\` as its path separator, only `/`
characters are used by this glob implementation. You must use
forward-slashes **only** in glob expressions. Back-slashes will always
be interpreted as escape characters, not path separators.
Results from absolute patterns such as `/foo/*` are mounted onto the
root setting using `path.join`. On windows, this will by default result
in `/foo/*` matching `C:\foo\bar.txt`.
## Race Conditions
Glob searching, by its very nature, is susceptible to race conditions,
since it relies on directory walking and such.
As a result, it is possible that a file that exists when glob looks for
it may have been deleted or modified by the time it returns the result.
As part of its internal implementation, this program caches all stat
and readdir calls that it makes, in order to cut down on system
overhead. However, this also makes it even more susceptible to races,
especially if the cache or statCache objects are reused between glob
calls.
Users are thus advised not to use a glob result as a guarantee of
filesystem state in the face of rapid changes. For the vast majority
of operations, this is never a problem.
## Glob Logo
Glob's logo was created by [Tanya Brassie](http://tanyabrassie.com/). Logo files can be found [here](https://github.com/isaacs/node-glob/tree/master/logo).
The logo is licensed under a [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/).
## Contributing
Any change to behavior (including bugfixes) must come with a test.
Patches that fail tests or reduce performance will be rejected.
```
# to run tests
npm test
# to re-generate test fixtures
npm run test-regen
# to benchmark against bash/zsh
npm run bench
# to profile javascript
npm run prof
```

# wrappy
Callback wrapping utility
## USAGE
```javascript
var wrappy = require("wrappy")
// var wrapper = wrappy(wrapperFunction)
// make sure a cb is called only once
// See also: http://npm.im/once for this specific use case
var once = wrappy(function (cb) {
var called = false
return function () {
if (called) return
called = true
return cb.apply(this, arguments)
}
})
function printBoo () {
console.log('boo')
}
// has some rando property
printBoo.iAmBooPrinter = true
var onlyPrintOnce = once(printBoo)
onlyPrintOnce() // prints 'boo'
onlyPrintOnce() // does nothing
// random property is retained!
assert.equal(onlyPrintOnce.iAmBooPrinter, true)
```
|
platonfloria_pray-game | .github
workflows
tests.yml
README.md
character-contract
Cargo.toml
README.md
build.sh
src
approval.rs
enumeration.rs
events.rs
internal.rs
lib.rs
metadata.rs
mint.rs
nft_core.rs
pray
location.rs
mod.rs
reveal.rs
royalty.rs
tests.rs
integration-tests
rs
Cargo.toml
src
helpers.rs
tests.rs
location-contract
Cargo.toml
build.sh
src
internal.rs
lib.rs
package.json
scripts
prepare_metadata.py
pyproject.toml
| # TBD
# PRAY Game
Welcome to the PRAY universe.
Here you will find the tools necessary to deploy all the smart contracts required to enjoy your epic adventure and discover the secrets of the Red Tower.
Please refer to Makefile for technical details behind actions used in this README.
## Prerequisites
* [NEAR Wallet Account](wallet.testnet.near.org)
* [Rust Toolchain](https://docs.near.org/develop/prerequisites)
* [NEAR-CLI](https://docs.near.org/tools/near-cli#setup)
* [yarn](https://classic.yarnpkg.com/en/docs/install#mac-stable)
# Quick-Start
```=bash
git clone https://github.com/platonfloria/near-nft-collection.git
make build
```
Now that you've cloned and built the contract we can try a few things.
## Collection preparation
Before collection is ready to be minted, we have to deploy the contract and seed it with encrypted metadata.
### Deploy Your Contract
```=bash
make deploy
```
### Redeploy Your Contract
```=bash
make update
```
### Seed medatada
```=bash
make add_metadata
```
### Minting Token
```bash=
make mint
```
After you've minted the token go to wallet.testnet.near.org to `your-account.testnet` and look in the collections tab and check out your new NFT!
## Collection reveal
When entire collection was minted we can reveal it.
### Revealing collection
```bash=
make reveal
```
After collection was revealed go to wallet.testnet.near.org to `your-account.testnet` and look in the collections tab and check out your revealed NFT!
## View NFT Information
After you've minted your NFT you can make a view call to get a response containing the `token_id` `owner_id` and the `metadata`
```bash=
near view $NFT_CONTRACT_ID nft_tokens_for_owner '{"account_id": "`your-account.testnet`"}'
```
## Transfering NFTs
To transfer an NFT go ahead and make another [testnet wallet account](https://wallet.testnet.near.org).
Then run the following
```bash=
MAIN_ACCOUNT_2=your-second-wallet-account.testnet
```
Verify the correct variable names with this
```=bash
echo $NFT_CONTRACT_ID
echo $MAIN_ACCOUNT
echo $MAIN_ACCOUNT_2
```
To initiate the transfer..
```bash=
near call $NFT_CONTRACT_ID nft_transfer '{"receiver_id": "$MAIN_ACCOUNT_2", "token_id": "token-1", "memo": "Go Team :)"}' --accountId $MAIN_ACCOUNT --depositYocto 1
```
In this call you are depositing 1 yoctoNEAR for security and so that the user will be redirected to the NEAR wallet.
## Errata
|
mfornet_near-floating-state | Cargo.toml
README.md
build.sh
src
lib.rs
tests
basic.rs
| # Floating state
Allow floating state using [near-sdk-rs](https://github.com/near/near-sdk-rs). This allows storing objects in the state that are not directly referenced in the main object.
```rs
#[near_bindgen]
#[derive(BorshDeserialize, BorshSerialize, PanicOnDefault)]
pub struct CounterStatusMessage {
counter: u8,
}
#[derive(BorshStorageKey, BorshDeserialize, BorshSerialize, Clone)]
enum StorageKey {
StatusMessageHeader,
StatusMassageContent,
}
#[near_bindgen]
impl CounterStatusMessage {
#[init]
pub fn new() -> Self {
floating_state::State::init(
StorageKey::StatusMessageHeader,
UnorderedMap::<AccountId, String>::new(StorageKey::StatusMassageContent),
);
Self { counter: 0 }
}
fn messages(&self) -> floating_state::State<UnorderedMap<AccountId, String>, StorageKey> {
floating_state::State::read(StorageKey::StatusMessageHeader).unwrap()
}
pub fn add_message(&mut self, message: String) -> Option<String> {
let account_id = env::predecessor_account_id();
let mut messages = self.messages();
messages.insert(&account_id, &message)
}
pub fn get_message(&self, account_id: AccountId) -> Option<String> {
self.messages().get(&account_id)
}
}
```
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.