
repo
stringlengths 8
116
| tasks
stringlengths 8
117
| titles
stringlengths 17
302
| dependencies
stringlengths 5
372k
| readme
stringlengths 5
4.26k
| __index_level_0__
int64 0
4.36k
|
|---|---|---|---|---|---|
kagaminccino/LAVSE | ['denoising', 'speech enhancement', 'data compression'] | ['Lite Audio-Visual Speech Enhancement'] | main/build_model.py main/scoring.py main/prepare_path_list.py main/data_generator.py main/utils.py main/main.py LAVSE weights_init data_nor stft2spec AV_Dataset prepare_val_path_list prepare_test_path_list prepare_path_list prepare_train_path_list write_score scoring_dir scoring_file scoring_STOI scoring_PESQ prepare_scoring_list val cal_time test collate_fn model_detail_string train xavier_normal_ isinstance named_parameters mean std norm data_nor squeeze log10 permute extend replace extend replace extend replace prepare_val_path_list prepare_test_path_list prepare_train_path_list check_output float replace decode stoi rsplit read scoring_STOI scoring_PESQ sorted replace print glob scoring_file tqdm append extend replace writer time print writerow cal_time len scoring_dir close call open replace list arange min index_select stack zip enumerate column_stack val Visdom time line print cal_time zero_grad localtime av DataLoader asctime save model_detail_string range __name__ len av eval DataLoader train len time print name cal_time len localtime av DataLoader eval asctime __name__ mode | # Lite Audio-Visual Speech Enhancement (Interspeech 2020) ## Introduction This is the PyTorch implementation of [Lite Audio-Visual Speech Enhancement (LAVSE)](https://arxiv.org/abs/2005.11769). We have also put some preprocessed sample data (including enhanced results) in this repository. The dataset of TMSV (Taiwan Mandarin speech with video) used in LAVSE is released [here](https://bio-asplab.citi.sinica.edu.tw/Opensource.html#TMSV). Please cite the following paper if you find the codes useful in your research. ``` @inproceedings{chuang2020lite, title={Lite Audio-Visual Speech Enhancement}, author={Chuang, Shang-Yi and Tsao, Yu and Lo, Chen-Chou and Wang, Hsin-Min}, | 2,600 |
kaichoulyc/tgs-salts | ['semantic segmentation'] | ['TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation'] | lovasz_losses.py lovasz_grad flatten_binary_scores iou binary_xloss xloss lovasz_hinge_flat StableBCELoss lovasz_hinge lovasz_softmax_flat mean flatten_probas lovasz_softmax iou_binary cumsum sum len mean zip append float sum list map zip append float sum range mean lovasz_hinge_flat data lovasz_grad relu Variable sort dot float view Variable float flatten_binary_scores mean lovasz_softmax_flat data lovasz_grad Variable sort size dot append float abs range size view filterfalse isnan iter next enumerate | # AlbuNet for TGS salts Identification Albunet is moification of standart unet [arXiv paper](https://arxiv.org/abs/1801.05746) made by [Vladimir Iglovikov, Alexey Shvets](https://github.com/ternaus/TernausNet) 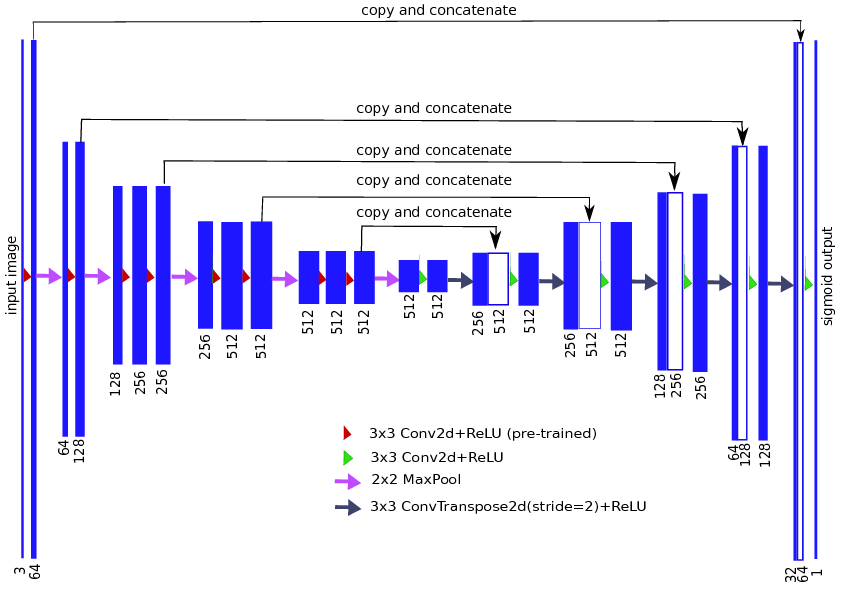 This net was used by me for TGS salts Identification chalange and showed quite good results even without augmentations and long learning. For evaluation was used IoU. [Score](https://www.kaggle.com/c/tgs-salt-identification-challenge/leaderboard): 0.69 on public and 0.72 on private 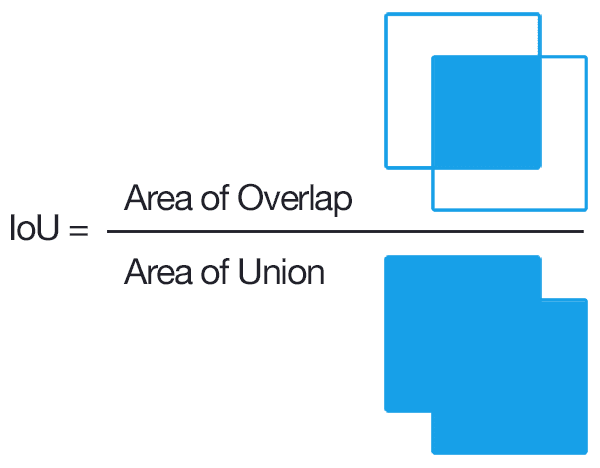 # Reps used for this project: https://github.com/ternaus/TernausNet https://github.com/bermanmaxim/LovaszSoftmax | 2,601 |
kaidi-jin/backdoor_samples_detection | ['adversarial defense'] | ['A Unified Framework for Analyzing and Detecting Malicious Examples of DNN Models'] | utils/model_util.py utils/backdoor_data_util.py attack/generate_backdoor_samples.py model_mutation/SPRT_detector.py injection/injection_utils.py utils/train_data_util.py model_mutation/gaussian_fuzzing.py attack/cw_attack.py injection/injection_model.py main tutorial_cw infect_one_image filter_part generate_backdoor_data infect_by_trigger_img inject_backdoor DataGenerator injection_func mask_pattern_func infect_X BackdoorCall construct_mask_corner construct_mask_box model_structure gaussian_fuzzing get_threshold_relax Trans_csv each_model_predict_result detect calculate_sprt_ratio main Keras_Model load_backdoor_data load_keras_model load_mnist_model load_gtsrb_model load_face_dataset load_mnist_dataset load_gtsrb_dataset load_train_dataset load_h5_dataset CarliniWagnerL2 where set_random_seed save DEBUG argmax KerasModelWrapper GPUOptions Session max str list set_session load_model exit set_log_level shape append sum range predict format close choice mean load_train_dataset generate_np print AccuracyReport min repeat array len tutorial_cw add_argument check_installation ArgumentParser parse_args copy append zeros imread range deepcopy range imread infect_one_image copy list zeros_like print makedirs exit choice infect_by_trigger_img shape load_train_dataset save array range infect_X len copy choice mask_pattern_func injection_func copy remove format evaluate DataGenerator print generate_data fit_generator BackdoorCall load_train_dataset evaluate_generator save load_keras_model exists len append construct_mask_corner zeros clear_session to_categorical save_weights set_weights str exit shape get_weights range normal Dense load_weights time model_structure isinstance evaluate print zfill makedirs print exit writer join time list argmax format clear_session print writerow Keras_Model listdir predict open int time log calculate_sprt_ratio len list map to_csv as_matrix zip DataFrame read_csv values print len exit array Model Input Adam compile compile Sequential Adam add Dense MaxPooling2D Conv2D Flatten Dropout reshape to_categorical astype load_data print exit load_h5_dataset print to_categorical File exit vstack | # BE_detection ## About Code to the paper ["A Unified Framework for Analyzing and Detecting Malicious Examples of DNN Models"](https://arxiv.org/abs/2006.14871). The model mutation method based on the [code](https://github.com/dgl-prc/m_testing_adversatial_sample) for adversarial sample detection. ## Repo Structure - `data:` Training datasets and malicious data. - `model:` Trojaned Backdoor models. - `injecting backdoor:` To train the backdoor model. - `attack:` generate the adversarial example by CW attack and backdoor smaples. | 2,602 |
kaidic/LDAM-DRW | ['long tail learning', 'long tail learning with class descriptors'] | ['Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss'] | losses.py models/resnet_cifar.py imbalance_cifar.py models/__init__.py utils.py cifar_train.py validate adjust_learning_rate main_worker main train IMBALANCECIFAR10 IMBALANCECIFAR100 FocalLoss LDAMLoss focal_loss prepare_folders AverageMeter accuracy ImbalancedDatasetSampler save_checkpoint plot_confusion_matrix calc_confusion_mat resnet110 resnet20 ResNet_s LambdaLayer resnet44 test NormedLinear resnet1202 resnet56 resnet32 _weights_init BasicBlock seed join prepare_folders warn device_count manual_seed main_worker parse_args gpu validate store_name SGD warn DataLoader adjust_learning_rate root_log save_checkpoint arch cuda max open set_device ImbalancedDatasetSampler load_state_dict IMBALANCECIFAR10 to CIFAR100 sum range SummaryWriter format Compose start_epoch lr resume CIFAR10 power IMBALANCECIFAR100 get_cls_num_list flush load join add_scalar print write parameters isfile train epochs array gpu len model zero_grad cuda update format size avg item flush enumerate time criterion backward print add_scalar AverageMeter write accuracy step gpu len eval AverageMeter param_groups lr exp join print store_name astype eval savefig plot_confusion_matrix root_log sum diag format subplots text get_xticklabels confusion_matrix colorbar set tight_layout imshow setp max range print mkdir copyfile replace save weight kaiming_normal_ __name__ print | ## Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, Tengyu Ma _________________ This is the official implementation of LDAM-DRW in the paper [Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss](https://arxiv.org/pdf/1906.07413.pdf) in PyTorch. ### Dependency The code is built with following libraries: - [PyTorch](https://pytorch.org/) 1.2 - [TensorboardX](https://github.com/lanpa/tensorboardX) - [scikit-learn](https://scikit-learn.org/stable/) ### Dataset | 2,603 |
kailigo/SN_loss_for_reID | ['person re identification'] | ['Support Neighbor Loss for Person Re-Identification'] | src/data/dataset/Prefetcher.py src/data/utils/utils.py src/data/utils/dataset_utils.py src/data_preparation/gen_splits.py src/data_preparation/combine_trainval_sets.py src/data_preparation/transform_cuhk03_official_split.py src/data_preparation/reformat_cuhk01_486.py src/data_preparation/transform_cub.py src/model/myModel.py src/data_preparation/transform_cuhk03.py src/data_preparation/reformat_mars.py src/data/utils/visualize_rank_list.py src/data/utils/metric.py src/data/dataset/Dataset.py src/data_preparation/transform_cuhk01.py src/data_preparation/transform_viper.py src/data_preparation/transform_mars.py src/data_preparation/transform_market1501.py src/data_preparation/transform_duke.py src/model/Model.py src/data/utils/visualization.py src/data/dataset/TestSet.py src/data/dataset/__init__.py src/losses/SN_loss.py src/data_preparation/reformat_cuhk01.py src/data/dataset/TrainSet.py src/data/utils/re_ranking.py src/data_preparation/reformat_viper.py src/main.py src/data/utils/distance.py src/data_preparation/reformat_cuhk03_official_split.py src/data_preparation/reformat_cub.py src/data/dataset/PreProcessImage.py src/data_preparation/combine_image_distractor_market.py src/model/resnet.py Config main ExtractFeature Dataset Enqueuer Prefetcher Counter PreProcessIm TestSet TrainSet create_dataset get_im_names parse_im_name move_ims partition_train_val_set normalize compute_dist mean_ap _unique_sample cmc re_ranking load_pickle measure_time tight_float_str may_set_mode save_pickle save_mat find_index adjust_lr_exp set_devices may_transfer_optims set_seed adjust_lr_staircase transfer_optim_state may_transfer_modules_optims load_state_dict is_iterable save_ckpt TransferModulesOptims get_model_wrapper time_str TransferVarTensor to_scalar str2bool may_make_dir set_devices_for_ml load_ckpt RunningAverageMeter AverageMeter ReDirectSTD print_array RecentAverageMeter add_border get_rank_list save_rank_list_to_im read_im make_im_grid save_im Config main ExtractFeature get_im_names combine_trainval_sets move_ims write_json mkdir_if_missing mkdir_if_nonexist read_json move_images_to_dir mkdir_if_nonexist read_json move_images_to_dir main_labeled move_images_to_dir Mars get_names init_dataset mkdir_if_nonexist read_json move_images_to_dir transform parse_original_im_name save_images transform parse_original_im_name save_images old_main transform save_images transform parse_original_im_name save_images transform parse_original_im_name save_images transform parse_original_im_name save_images transform parse_original_im_name save_images transform parse_original_im_name save_images main re_ranking_retrieval euclidean_dist SN_LOSS Model Model ResNet resnet50 Bottleneck resnet152 conv3x3 remove_fc resnet34 resnet18 BasicBlock resnet101 Config staircase_decay_multiply_factor sys_device_ids model_w zero_grad DataParallel exp_decay_at_epoch may_set_mode dataset base_lr cuda seed adjust_lr_exp total_epochs set_devices set_seed adjust_lr_staircase stderr_file Adam log_to_file pprint Model append normalize normalize_feature save_ckpt range update SummaryWriter __dict__ test resume stdout_file float to_scalar long add_scalars ids2labels NLLLoss time load_ckpt criterion backward print Variable AverageMeter test_full staircase_decay_at_epochs dict ReDirectSTD parameters TVT only_test create_dataset next_batch step ckpt_file len update join load_pickle list format print ospeu set dict sum TrainSet TestSet len int glob join array join basename defaultdict format copy append parse_im_name seed int list remove arange setdiff1d sort hstack shuffle set flatten dict unique append array len norm sqrt T normalize matmul zeros list items choice defaultdict cumsum argsort shape _unique_sample zip append zeros range enumerate len format print average_precision_score argsort shape __version__ zeros range minimum exp zeros_like concatenate transpose astype float32 mean int32 unique append zeros sum max range len abspath dirname may_make_dir dict savemat is_tensor isinstance Parameter items list isinstance cpu cuda transfer_optim_state state Optimizer isinstance format Optimizer Module isinstance print state transfer_optim_state cpu cuda __name__ TransferModulesOptims TransferVarTensor find_index list remove TransferModulesOptims sort set TransferVarTensor append load format print load_state_dict zip dict dirname abspath save may_make_dir data items list isinstance print set copy_ keys state_dict eval Module train isinstance makedirs seed format enabled print manual_seed print enumerate param_groups float rstrip print find_index rstrip param_groups print print time format ndarray isinstance copy dtype ndarray isinstance astype enumerate argsort append zip resize transpose asarray open ospdn transpose may_make_dir save add_border read_im zip append save_im make_im_grid len TMO save ExtractFeature str set_trace save_rank_list_to_im load_state_dict rank_list_size format RandomState zip enumerate load get_rank_list compute_dist argsort set_feat_func int basename sort append split list sort set dict zip ospj range len save_pickle load_pickle list format print sort zip ospj range move_ims may_make_dir makedirs dirname mkdir_if_missing makedirs join format copy print range len load join int format str move_images_to_dir glob print len makedirs append range open join join print get_im_names sort cumsum set dict enumerate dirname abspath append save_pickle array move_ims may_make_dir len join list format save_images partition_train_val_set print sort set dict zip range save_pickle len int add_argument zip_file abspath ArgumentParser transform expanduser save_dir parse_args dump format File write zip chain range load_pickle dirname abspath exists may_make_dir minimum exp zeros_like transpose astype float32 mean int32 unique append zeros sum max range len size expand t sqrt addmm_ list rand IntTensor mm deepcopy list items startswith load_url ResNet remove_fc load_state_dict load_url ResNet remove_fc load_state_dict load_url ResNet remove_fc load_state_dict load_url ResNet remove_fc load_state_dict load_url ResNet remove_fc load_state_dict | # Support Neighbor Loss for Person Re-Identification This repository is for the paper introduced in the following paper Kai Li, Zhengming Ding, Kunpeng Li, Yulun Zhang, and Yun Fu, "Support Neighbor Loss for Person Re-Identification", ACM Multimedia (ACM MM) 2018, [[arXiv]](https://arxiv.org/abs/1808.06030) ## Environment Python 3 + PyTorch 3.0 ## Data preparation Please refer [this repo](https://github.com/huanghoujing/person-reid-triplet-loss-baseline) for the data preparation and modify the data locations accordingly in the train.sh and test.sh files. ## Train ``` sh ./train.sh | 2,604 |
kaiolae/UnityMLAgents | ['unity'] | ['Unity: A General Platform for Intelligent Agents'] | ml-agents/mlagents/envs/communicator_objects/environment_parameters_proto_pb2.py ml-agents/tests/trainers/test_trainer_controller.py ml-agents/mlagents/trainers/buffer.py ml-agents/mlagents/trainers/bc/online_trainer.py ml-agents/mlagents/envs/communicator_objects/unity_rl_initialization_input_pb2.py ml-agents/mlagents/envs/communicator_objects/brain_parameters_proto_pb2.py ml-agents/tests/envs/test_envs.py ml-agents/mlagents/envs/communicator_objects/__init__.py ml-agents/mlagents/envs/rpc_communicator.py ml-agents/mlagents/trainers/ppo/__init__.py gym-unity/gym_unity/envs/__init__.py ml-agents/mlagents/trainers/tensorflow_to_barracuda.py ml-agents/mlagents/envs/communicator_objects/agent_action_proto_pb2.py ml-agents/mlagents/trainers/learn.py gym-unity/gym_unity/envs/unity_env.py ml-agents/mlagents/trainers/bc/trainer.py ml-agents/mlagents/trainers/policy.py ml-agents/tests/trainers/test_learn.py ml-agents/mlagents/envs/communicator_objects/unity_rl_initialization_output_pb2.py ml-agents/tests/trainers/test_curriculum.py ml-agents/mlagents/trainers/meta_curriculum.py ml-agents/mlagents/trainers/curriculum.py ml-agents/mlagents/trainers/ppo/models.py ml-agents/mlagents/envs/communicator_objects/space_type_proto_pb2.py ml-agents/mlagents/envs/communicator_objects/unity_output_pb2.py ml-agents/mlagents/envs/communicator_objects/unity_input_pb2.py ml-agents/tests/trainers/test_demo_loader.py gym-unity/gym_unity/__init__.py ml-agents/mlagents/trainers/ppo/policy.py ml-agents/mlagents/envs/communicator_objects/engine_configuration_proto_pb2.py ml-agents/mlagents/envs/socket_communicator.py gym-unity/setup.py ml-agents/mlagents/trainers/trainer_controller.py ml-agents/mlagents/envs/communicator_objects/agent_info_proto_pb2.py ml-agents/mlagents/envs/communicator_objects/unity_to_external_pb2_grpc.py ml-agents/tests/trainers/test_ppo.py ml-agents/mlagents/envs/brain.py ml-agents/mlagents/trainers/bc/policy.py ml-agents/tests/trainers/test_bc.py ml-agents/mlagents/trainers/demo_loader.py ml-agents/tests/mock_communicator.py ml-agents/mlagents/envs/communicator_objects/unity_message_pb2.py ml-agents/mlagents/trainers/models.py ml-agents/mlagents/trainers/__init__.py ml-agents/mlagents/envs/communicator_objects/resolution_proto_pb2.py ml-agents/mlagents/envs/communicator_objects/unity_to_external_pb2.py ml-agents/mlagents/envs/communicator_objects/unity_rl_input_pb2.py ml-agents/mlagents/envs/communicator_objects/demonstration_meta_proto_pb2.py ml-agents/tests/trainers/test_buffer.py ml-agents/mlagents/trainers/trainer.py ml-agents/mlagents/envs/communicator.py ml-agents/tests/envs/test_rpc_communicator.py ml-agents/setup.py ml-agents/mlagents/envs/communicator_objects/unity_rl_output_pb2.py ml-agents/mlagents/envs/__init__.py ml-agents/mlagents/trainers/bc/__init__.py gym-unity/tests/test_gym.py ml-agents/mlagents/envs/exception.py ml-agents/mlagents/envs/environment.py ml-agents/mlagents/trainers/bc/models.py ml-agents/mlagents/trainers/barracuda.py ml-agents/mlagents/envs/communicator_objects/command_proto_pb2.py ml-agents/mlagents/trainers/bc/offline_trainer.py ml-agents/mlagents/trainers/exception.py ml-agents/tests/trainers/test_meta_curriculum.py ml-agents/mlagents/trainers/ppo/trainer.py ml-agents/mlagents/envs/communicator_objects/header_pb2.py ml-agents/tests/trainers/test_barracuda_converter.py UnityGymException ActionFlattener UnityEnv create_mock_vector_braininfo test_gym_wrapper test_multi_agent test_branched_flatten setup_mock_unityenvironment create_mock_brainparams BrainInfo BrainParameters Communicator UnityEnvironment UnityWorkerInUseException UnityException UnityTimeOutException UnityEnvironmentException UnityActionException RpcCommunicator UnityToExternalServicerImplementation SocketCommunicator UnityToExternalServicer UnityToExternalStub add_UnityToExternalServicer_to_server BarracudaWriter compress Build sort lstm write fuse_batchnorm_weights trim gru Model summary Struct parse_args to_json rnn BufferException Buffer Curriculum make_demo_buffer load_demonstration demo_to_buffer CurriculumError MetaCurriculumError TrainerError run_training prepare_for_docker_run init_environment try_create_meta_curriculum main load_config MetaCurriculum LearningModel Policy UnityPolicyException get_layer_shape pool_to_HW flatten process_layer process_model basic_lstm get_attr ModelBuilderContext order_by get_epsilon get_tensor_dtype replace_strings_in_list get_tensor_dims by_op remove_duplicates_from_list by_name convert strides_to_HW get_tensor_data gru UnityTrainerException Trainer TrainerController BehavioralCloningModel OfflineBCTrainer OnlineBCTrainer BCPolicy BCTrainer PPOModel PPOPolicy PPOTrainer get_gae discount_rewards MockCommunicator test_initialization test_reset test_close test_step test_handles_bad_filename test_rpc_communicator_checks_port_on_create test_rpc_communicator_create_multiple_workers test_rpc_communicator_close test_barracuda_converter test_dc_bc_model test_cc_bc_model test_visual_cc_bc_model test_bc_policy_evaluate dummy_config test_visual_dc_bc_model assert_array test_buffer location default_reset_parameters test_init_curriculum_bad_curriculum_raises_error test_init_curriculum_happy_path test_increment_lesson test_get_config test_load_demo basic_options test_docker_target_path test_run_training test_init_meta_curriculum_happy_path test_increment_lessons_with_reward_buff_sizes default_reset_parameters MetaCurriculumTest test_increment_lessons measure_vals reward_buff_sizes test_set_all_curriculums_to_lesson_num test_get_config test_set_lesson_nums test_init_meta_curriculum_bad_curriculum_folder_raises_error more_reset_parameters test_rl_functions test_ppo_model_dc_vector_curio test_ppo_model_dc_vector_rnn test_ppo_model_cc_vector_rnn test_ppo_policy_evaluate test_ppo_model_cc_visual dummy_config test_ppo_model_dc_vector test_ppo_model_dc_visual test_ppo_model_cc_visual_curio test_ppo_model_dc_visual_curio test_ppo_model_cc_vector_curio test_ppo_model_cc_vector test_initialize_online_bc_trainer basic_trainer_controller assert_bc_trainer_constructed test_initialize_trainer_parameters_uses_defaults dummy_bad_config test_take_step_adds_experiences_to_trainer_and_trains test_initialize_trainer_parameters_override_defaults test_initialize_invalid_trainer_raises_exception test_start_learning_trains_until_max_steps_then_saves dummy_config dummy_offline_bc_config_with_override test_initialization_seed test_initialize_ppo_trainer test_start_learning_updates_meta_curriculum_lesson_number assert_ppo_trainer_constructed test_take_step_resets_env_on_global_done test_start_learning_trains_forever_if_no_train_model dummy_offline_bc_config trainer_controller_with_take_step_mocks trainer_controller_with_start_learning_mocks dummy_online_bc_config create_mock_vector_braininfo sample UnityEnv setup_mock_unityenvironment step create_mock_brainparams create_mock_vector_braininfo UnityEnv setup_mock_unityenvironment step create_mock_brainparams setup_mock_unityenvironment create_mock_vector_braininfo create_mock_brainparams UnityEnv Mock list Mock array range method_handlers_generic_handler add_generic_rpc_handlers join isdir print replaceFilenameExtension add_argument exit verbose source_file ArgumentParser target_file sqrt topologicalSort list hasattr layers addEdge Graph print inputs set len list hasattr layers print filter match trim_model compile data layers print tensors float16 replace layers dumps layers isinstance print tensors inputs zip to_json globals Build tanh mad tanh mul Build concat add sigmoid sub mad _ tanh mul Build concat add sigmoid mad Buffer reset_local_buffers number_visual_observations append_update_buffer append range enumerate make_demo_buffer load_demonstration number_steps read suffix BrainParametersProto from_agent_proto DemonstrationMetaProto ParseFromString AgentInfoProto append from_proto _DecodeVarint32 start_learning int str format external_brain_names TrainerController put init_environment try_create_meta_curriculum load_config list MetaCurriculum keys _resetParameters chmod format basename isdir glob copyfile copytree prepare_for_docker_run replace int Process getLogger print run_training start Queue info append randint docopt range endswith len HasField hasattr get_attr tensor_shape ndarray isinstance shape int_val bool_val float_val ListFields name ndarray isinstance str tensor_content ndarray product isinstance get_tensor_dtype print get_tensor_dims unpack int_val bool_val array float_val enter append add set name find_tensor_by_name split name lstm find_tensor_by_name find_forget_bias split get_layer_shape id Struct tensor hasattr name patch_data input_shapes out_shapes input get_attr append replace_strings_in_list tensors astype op zip enumerate print float32 patch_data_fn model_tensors map_ignored_layer_to_its_input co_argcount len items list get_tensors hasattr name print process_layer eval ModelBuilderContext layers verbose Struct process_model open compress node GraphDef Model dims_to_barracuda_shape insert get_tensor_dims inputs ParseFromString cleanup_layers read memories print sort write trim summary list zeros_like size reversed range asarray tolist discount_rewards UnityEnvironment close MockCommunicator UnityEnvironment close MockCommunicator reset str local_done print agents step close reset MockCommunicator UnityEnvironment len UnityEnvironment close MockCommunicator close RpcCommunicator close RpcCommunicator close RpcCommunicator join remove _get_candidate_names convert _get_default_tempdir dirname abspath isfile next BCPolicy evaluate close reset MockCommunicator reset_default_graph UnityEnvironment reset_default_graph reset_default_graph reset_default_graph reset_default_graph flatten list range len get_batch Buffer assert_array append_update_buffer make_mini_batch append reset_agent array range Curriculum Curriculum Curriculum make_demo_buffer load_demonstration dirname abspath MagicMock basic_options MagicMock MetaCurriculum assert_has_calls MetaCurriculumTest increment_lessons assert_called_with MetaCurriculumTest increment_lessons assert_called_with assert_not_called MetaCurriculumTest set_all_curriculums_to_lesson_num MetaCurriculumTest dict update MetaCurriculumTest evaluate close reset MockCommunicator PPOPolicy reset_default_graph UnityEnvironment reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph assert_array_almost_equal array discount_rewards dummy_offline_bc_config TrainerController assert_called_with BrainInfoMock basic_trainer_controller assert_bc_trainer_constructed dummy_offline_bc_config summaries_dir model_path keep_checkpoints BrainInfoMock basic_trainer_controller assert_bc_trainer_constructed summaries_dir model_path keep_checkpoints dummy_offline_bc_config_with_override BrainInfoMock basic_trainer_controller assert_bc_trainer_constructed summaries_dir model_path keep_checkpoints dummy_online_bc_config BrainInfoMock basic_trainer_controller assert_ppo_trainer_constructed summaries_dir dummy_config model_path keep_checkpoints initialize_trainers BrainInfoMock dummy_bad_config basic_trainer_controller MagicMock basic_trainer_controller start_learning assert_called_once MagicMock assert_not_called dummy_config trainer_controller_with_start_learning_mocks assert_called_once_with start_learning assert_called_once MagicMock dummy_config trainer_controller_with_start_learning_mocks assert_called_once_with start_learning MagicMock dummy_config trainer_controller_with_start_learning_mocks assert_called_once_with lesson MagicMock basic_trainer_controller take_step assert_called_once MagicMock trainer_controller_with_take_step_mocks assert_called_once MagicMock take_step assert_not_called trainer_controller_with_take_step_mocks assert_called_once_with | <img src="docs/images/unity-wide.png" align="middle" width="3000"/> <img src="docs/images/image-banner.png" align="middle" width="3000"/> # Unity ML-Agents Toolkit (Beta) **The Unity Machine Learning Agents Toolkit** (ML-Agents) is an open-source Unity plugin that enables games and simulations to serve as environments for training intelligent agents. Agents can be trained using reinforcement learning, imitation learning, neuroevolution, or other machine learning methods through a simple-to-use Python API. We also provide implementations (based on TensorFlow) of state-of-the-art algorithms to enable game developers and hobbyists to easily train intelligent agents for 2D, 3D and VR/AR games. These trained agents can be | 2,605 |
kaiqiangh/extracting-video-features-ResNeXt | ['action recognition'] | ['Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?'] | generate_result_video/generate_result_video.py train.py validation.py models/pre_act_resnet.py models/resnext.py temporal_transforms.py spatial_transforms.py test.py dataset.py models/wide_resnet.py opts.py mean.py models/densenet.py classify.py main.py models/resnet.py model.py classify_video Video get_class_labels load_annotation_data video_loader make_dataset accimage_loader get_default_image_loader get_default_video_loader pil_loader get_video_names_and_annotations get_mean generate_model parse_opts CenterCrop ToTensor Compose Scale Normalize LoopPadding TemporalCenterCrop calculate_video_results test get_fps get_fine_tuning_parameters DenseNet densenet201 densenet169 densenet264 _DenseLayer _DenseBlock _Transition densenet121 conv3x3x3 get_fine_tuning_parameters resnet50 downsample_basic_block resnet152 PreActivationBasicBlock resnet34 resnet200 PreActivationBottleneck resnet18 PreActivationResNet resnet101 conv3x3x3 get_fine_tuning_parameters ResNet downsample_basic_block resnet50 Bottleneck resnet152 resnet34 resnet200 resnet18 resnet10 BasicBlock resnet101 ResNeXtBottleneck conv3x3x3 get_fine_tuning_parameters resnet50 downsample_basic_block ResNeXt resnet152 resnet101 conv3x3x3 get_fine_tuning_parameters WideBottleneck resnet50 downsample_basic_block WideResNet Video Compose DataLoader sample_duration LoopPadding join format image_loader append exists get_default_image_loader append items list format deepcopy list IntTensor append listdir range len densenet169 densenet201 resnet50 densenet264 DataParallel resnet101 resnet34 resnet200 resnet18 resnet152 resnet10 cuda densenet121 parse_args set_defaults add_argument ArgumentParser topk size mean stack append range update time format model print Variable cpu AverageMeter size eval calculate_video_results append range enumerate len decode format communicate len round float listdir Popen find DenseNet DenseNet DenseNet DenseNet append format range named_parameters data isinstance FloatTensor Variable zero_ avg_pool3d cuda cat PreActivationResNet PreActivationResNet PreActivationResNet PreActivationResNet PreActivationResNet PreActivationResNet ResNet ResNet ResNet ResNet ResNet ResNet ResNet ResNeXt ResNeXt ResNeXt WideResNet | # extracting-video-features-ResNeXt Extracting video features from pre-trained ResNeXt model Credit: [repo](https://github.com/kenshohara/video-classification-3d-cnn-pytorch) # Video Classification Using 3D ResNet This is a pytorch code for video (action) classification using 3D ResNet trained by [this code](https://github.com/kenshohara/3D-ResNets-PyTorch). The 3D ResNet is trained on the Kinetics dataset, which includes 400 action classes. This code uses videos as inputs and outputs class names and predicted class scores for each 16 frames in the score mode. In the feature mode, this code outputs features of 512 dims (after global average pooling) for each 16 frames. **Torch (Lua) version of this code is available [here](https://github.com/kenshohara/video-classification-3d-cnn).** ## Requirements | 2,606 |
kaiwang960112/Challenge-condition-FER-dataset | ['facial expression recognition'] | ['Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition'] | AffectNet_dir/simple_sample/part_attention.py AffectNet_dir/simple_sample/train_attention_part_face.py FERplus_dir/part_attention_sample.py FERplus_dir/val_part_attention_sample.py AffectNet_dir/unbalanced_sample_train/part_attentioon_sample_fly.py FERplus_dir/part_attention.py FERplus_dir/train_attention_rank_loss.py AffectNet_dir/unbalanced_sample_train/part_attention.py AffectNet_dir/simple_sample/part_attentioon_sample_fly.py AffectNet_dir/unbalanced_sample_train/sampler.py FERplus_dir/attention_rank_loss.py FERplus_dir/test_rank_loss_attention.py AffectNet_dir/unbalanced_sample_train/train_attention_part_face.py norm_angle ResNet resnet50 Bottleneck resnet152 sigmoid conv3x3 MyLoss resnet34 resnet18 BasicBlock resnet101 load_imgs CaffeCrop MsCelebDataset norm_angle ResNet resnet50 Bottleneck resnet152 sigmoid conv3x3 MyLoss resnet34 resnet18 BasicBlock resnet101 load_imgs CaffeCrop MsCelebDataset norm_angle ResNet resnet50 Bottleneck resnet152 sigmoid conv3x3 MyLoss resnet34 resnet18 BasicBlock resnet101 norm_angle ResNet resnet50 Bottleneck resnet152 sigmoid conv3x3 resnet34 resnet18 BasicBlock resnet101 load_imgs CaffeCrop MsCelebDataset main get_val_data load_imgs CaffeCrop MsCelebDataset sigmoid abs load_url ResNet load_state_dict load_url ResNet load_state_dict ResNet load_url ResNet load_state_dict load_url ResNet load_state_dict list Compose img_dir_val DataLoader CaffeCrop MsCelebDataset model get_val_data resnet34 argmax cuda open str list load_state_dict resnet18 parse_args resnet101 resnet50 eval softmax float enumerate load join int print Variable write split numpy find | ## I have uploaded the occlusion- and pose-RAFDB list, you can see at RAF_DB_dir. Thank you for your kindly waiting. ## Our manuscript has been accepted by Transactions on Image Processing as a REGULAR paper! [link](https://arxiv.org/pdf/1905.04075.pdf) # Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition Kai Wang, Xiaojiang Peng, Jianfei Yang, Debin Meng, and Yu Qiao Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences {kai.wang, xj.peng, db.meng, yu.qiao}@siat.ac.cn  ## Abstract Occlusion and pose variations, which can change facial appearance significantly, are among two major obstacles for automatic Facial Expression Recognition (FER). Though automatic FER has made substantial progresses in the past few decades, occlusion-robust and pose-invariant issues of FER have received relatively less attention, especially in real-world scenarios.Thispaperaddressesthereal-worldposeandocclusionrobust FER problem with three-fold contributions. First, to stimulate the research of FER under real-world occlusions and variant poses, we build several in-the-wild facial expression datasets with manual annotations for the community. Second, we propose a novel Region Attention Network (RAN), to adaptively capture the importance of facial regions for occlusion and pose variant FER. The RAN aggregates and embeds varied number of region features produced by a backbone convolutional neural network into a compact fixed-length representation. Last, inspired by the fact that facial expressions are mainly defined by facial action units, we propose a region biased loss to encourage high attentionweightsforthemostimportantregions.Weexamineour RAN and region biased loss on both our built test datasets and four popular datasets: FERPlus, AffectNet, RAF-DB, and SFEW. Extensive experiments show that our RAN and region biased loss largely improve the performance of FER with occlusion and variant pose. Our methods also achieve state-of-the-art results on FERPlus, AffectNet, RAF-DB, and SFEW.  | 2,607 |
kaiwang960112/Self-Cure-Network | ['facial expression recognition'] | ['Suppressing Uncertainties for Large-Scale Facial Expression Recognition'] | src/train.py src/image_utils.py test.py generate.py Res18Feature color2gray add_gaussian_noise flip_image RafDataSet initialize_weight_goog run_training Res18Feature parse_args normal uint8 astype shape COLOR_RGB2GRAY copy cvtColor add_argument ArgumentParser isinstance fill_ size out_channels Conv2d sqrt normal_ zero_ uniform_ BatchNorm2d Linear zero_grad SGD pretrained DataLoader margin_1 numpy modules raf_path cuda max topk initialize_weight_goog squeeze Adam epochs res18 load_state_dict parse_args margin_2 sum CrossEntropyLoss range state_dict size Compose mean lr softmax Res18Feature float enumerate load int RafDataSet ExponentialLR criterion backward print __len__ parameters beta train step | ## We find that SCN can correct about 50% noisy labels when train two fer datasets (add 10%~30% flip noises) together. We also find that scn can work in Face Recognition!!! ## Thank you for everyone nice and kindly waiting! ## News:My friend [nzhq](https://github.com/nzhq) open the SCN code and reproduce the experiments result!!! Thank you Zhiqing!!! ## For the WebEmotion Dataset, I will open the search and clips generation code, everyone can download the videos from YouTube with my code. ## Our manuscript has been accepted by CVPR2020! [link](https://arxiv.org/pdf/2002.10392.pdf) ## I really appreciate the contribution from my co-authors: Prof. Yu Qiao, Prof. Xiaojiang Peng, Jianfei Yang and Prof. Shijian Lu # Based on our further exploring, SCN can be applied in many other topics. # Suppressing Uncertainties for Large-Scale Facial Expression Recognition Kai Wang, Xiaojiang Peng, Jianfei Yang, Shijian Lu, and Yu Qiao Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences | 2,608 |
kakazxz/myops | ['denoising'] | ['Multi-Modality Pathology Segmentation Framework: Application to Cardiac Magnetic Resonance Images'] | ASSN/cascade_multiseqseg/cascade_network.py ASSN/cascade_multiseqseg/help.py ASSN/config/load_embedding_arg.py ASSN/preprocessor/sitkOPtool.py PRSN/dataset/MDataset.py ASSN/preprocessor/chaos.py ASSN/multiseqseg/convert_to_tfrecord.py PRSN/utils/init_util.py ASSN/dirutil/helper.py ASSN/multiseqseg/utils.py ASSN/cascade_multiseqseg/cascade_prepare.py ASSN/preprocessor/resize_demo.py ASSN/preprocessor/tools.py ASSN/antoencoder.py ASSN/logger/Logger.py PRSN/utils/common.py PRSN/models/gcblock.py PRSN/utils/metrics.py ASSN/reconstrction_seg.py ASSN/multiseqseg/dice_loss.py PRSN/config.py ASSN/multiseqseg/model.py PRSN/inference.py ASSN/preprocessor/prepare_2020_myo.py ASSN/cascade_multiseqseg/reconstruction.py ASSN/multiseqseg/sampler.py ASSN/sitkImageIO/TensorSaver.py ASSN/config/Defines.py ASSN/evaluate/metric.py ASSN/preprocessor/sitkSpatialAugment.py ASSN/cascadeACMyo.py ASSN/multiseqseg/multiseqseg.py ASSN/cascade_multiseqseg/cascade_sampler.py ASSN/multiseqseg/load_data.py ASSN/dirutil/SampleSplitter.py PRSN/models/scmodel.py ASSN/cascade_multiseqseg/restore.py ASSN/sitkImageIO/itkdatawriter.py ASSN/multiseqseg/challenge_sampler.py ASSN/model/base_model.py ASSN/cascade_multiseqseg/tool.py ASSN/multiseqseg/prepare_data.py ASSN/tool/mask.py PRSN/utils/logger.py ASSN/numpyopt/help.py ASSN/preprocessor/Registrator.py ASSN/preprocessor/sitkIntensityAugment.py ASSN/preprocessor/myo_chanlledge.py ASSN/autoencoder/autoencoder.py ASSN/multiseqseg/ops.py PRSN/models/prsn.py ASSN/sitkImageIO/itkdatareader.py PRSN/train.py ASSN/preprocessor/PreProcessor.py ASSN/preprocessor/error_nii_fix.py ASSN/config/configer.py ASSN/preprocessor/Rotater.py ShapeAutoEncode AECNN swap_neighbor_labels_with_prob ACMyoMultiSeq prepare_masked_valid_data prepare_masked_data merge_slice prepare_masked_test_data prepare_slices CascadeMyoSampler CascasedChallengeSample CascasedValidSample CascadeMyoPathologySampler evaluateV2 cal_diceV2 evaluate cal_dice Reconstruction filter_data restore reindex_for_myo_scar_edema_ZHANGZHEN l2_loss reindex_for_myo_scar_edema VoteNetParser RegParser get_reg_config get_vote_config Get_Name_By_Index get_args clear get_name_wo_suffix mkcleardir mkoutputname sort_glob writeListToFile filename listdir mkdir_if_not_exist mk_or_cleardir split_vote remove_file isVoteTestDir split dice_compute dice_and_hd ssd neg_jac computeQualityMeasures ncc mi calculate_binary_dice sad print_mean_and_std getLoggerV3 print_result getLogger BaseModel ChallengeMyoSampler int64_feature bytes_feature write_example soft_dice_loss single_class_dice_coefficient dice_coefficient HDR2LDR LDR2HDR_batch transform_LDR transform_HDR load_data LDR2HDR get_input save_results model tonemap HDR2LDR LDR2HDR tonemap_np Multiseqseg lrelu conv2d_transpose batch_norm binary_cross_entropy linear batch_instance_norm conv2d kl_divergence conv_cond_concat prepare_test_data prepare_data prepare_test_slice prepare_slices Sampler get_image get_image2HDR to_json make_gif radiance_writer save_images transform visualize rgb2gray center_crop merge_images compute_psnr LDR2HDR inverse_transform imread imsave merge zero_padding zero_padding_3d generate_3dMR generate_3dCT fix_image fix_label convert_img convert_lab crop_by_label slice_by_label PostProcessor PreProcessor Registrator Rotater clipScaleImage sigmoid_mapping histogram_equalization mult_and_add_intensity_fields augment_images_intensity resample_segmentations recast_pixel_val paste_roi_image eul2quat augment_img_lab threshold_based_crop augment_multi_imgs_lab parameter_space_regular_grid_sampling parameter_space_random_sampling augment_images_spatial augment_img augment_imgs_labs similarity3D_parameter_space_regular_sampling similarity3D_parameter_space_random_sampling reindex_label_array sitkResize3D simple_random_crop_image sitkResample3DV2 get_bounding_box_by_ids reindex_label get_bounding_box_by_id reverse_one_hot padd binarize_numpy_array get_bounding_box crop_by_bbox resize3DArray zoom3Darray sitkResize3DV2 random_crop_image_and_labels random_crop_for_trainning get_rotate_ref_img convertArrayToImg binarize_img normalize_mask get_bounding_boxV2 convert_img_2_nor_array read_png_seriesV2 convert_lab_2_array FusionSitkDataReader sitk_read_img_lab sitk_read_dico_series LazySitkDataReader VoteDataReader read_png_series convert_p_lab_2_array_batch convert_p_img_2_nor_array_batch RegistorDataReader convert_p_lab_2_array convert_img_2_scale_array convert_p_img_2_nor_array sitk_write_multi_lab sitk_wirte_ori_image write_png_image write_png_lab sitk_write_labs write_images sitk_write_lab sitk_write_image sitk_write_images saveTensor create_mask inference finame val train myops_dataset load_slicer make_one_hot MultiModalityData_load ContextBlock SpatialAttention ChannelAttention MixedFusion_BlockS4 NonLocalBlock MixedFusion_Block3 up maxpool nodo avgpool PRSN4 MixedFusion_Block4 conv_decod_block nonloacl_decod_block scSE cSE sSE random_crop_3d2 finame adjust_learning_rate resize sitk_read_row brats_dataset load_slicer standardization make_one_hot_3d random_crop_3d load_slicer2 normalization norm_img random_gamma random_flip_3d nib_read_row standardization2 load_file_name_list convert random_crop_2d nib_read_row2 weights_init_orthogonal weights_init_normal weights_init_xavier init_weights adjust_learning_rate print_network weights_init_kaiming Logger DiceMeanLoss T P TP SoftDiceLoss DiceMean WeightDiceLoss dice cross_entropy_3D cross_entropy_2D list where copy choice range print sort_glob dataset_dir prepare_slices exists uint16 myo_seg_dir astype ReadImage GetArrayFromImage sort_glob append range sitk_write_image get_bounding_box_by_ids recast_pixel_val sitkLinear crop_by_bbox binarize_img sitkResize3DV2 ReadImage GetArrayFromImage sort_glob range sitk_write_image mk_or_cleardir sitkNearestNeighbor get_name_wo_suffix recast_pixel_val ReadImage sort_glob dataset_dir sitk_write_image get_name_wo_suffix recast_pixel_val ReadImage sort_glob dataset_dir sitk_write_image str print cal_dice mean sort_glob std cal_diceV2 str print mean sort_glob std print dc ReadImage GetArrayFromImage create_mask zip append array print dc ReadImage GetArrayFromImage reindex_for_myo_scar_edema_ZHANGZHEN create_mask zip append array append join walk split zeros_like get_data save abs max str len range replace astype load join filter_data int affine print Nifti1Image split makedirs zeros uint16 where shape zeros uint16 where shape RegParser argv VoteNetParser argv enumerate makedirs join str remove isdir print rmtree isfile listdir clear makedirs clear rmtree makedirs sleep basename split sort remove close writelines exists open glob sort join move print sort len range rmtree listdir exists makedirs join basename isVoteTestDir move mkcleardir listdir mkdir_if_not_exist glob rmtree basename squeeze where print sum sum DisplacementFieldJacobianDeterminant gradient mean GetImageFromArray GetArrayFromImage abs GetHausdorffDistance GetAverageHausdorffDistance dict GetImageFromArray LabelOverlapMeasuresImageFilter HausdorffDistanceImageFilter GetDiceCoefficient Execute hd dc print mean std stdout basicConfig makedirs StreamHandler FileHandler stdout basicConfig getLogger makedirs StreamHandler FileHandler join format concatenate TFRecordWriter close write SerializeToString Example sum mean sum reduce_mean reduce_sum resize_images cast float32 resize_images read TFRecordReader decode_raw uint8 shuffle_batch reshape float32 LDR2HDR_batch transform_LDR cast int32 random_uniform transform_HDR parse_single_example less rot90 cond get_image join sorted glob astype float32 LDR2HDR zeros enumerate len save_images min shape ceil zeros range enumerate len get_shape as_list assert_rank divide reduce_sum assert_equal shape tile expand_dims print sort_glob dataset_dir prepare_slices exists prepare_test_slice sort_glob dataset_dir glob sort sitkLinear sitkResize3DV2 ReadImage range sitk_write_image mk_or_cleardir mean zeros enumerate int round center_crop resize VideoClip write_gif make_gif arange save_images batch_size print sampler strftime uniform gmtime run tile append zeros range enumerate shape zeros shape zeros sitk_read_dico_series where read_png_series zip sitk_write_lab sitk_write_image read_png_seriesV2 sitk_read_dico_series zip sitk_write_lab sitk_write_image load affine dataobj Nifti1Image save load affine print copy Nifti1Image unique save sum glob sitk_wirte_ori_image GetImageFromArray ReadImage GetArrayFromImage glob sitk_wirte_ori_image GetImageFromArray ReadImage GetArrayFromImage sitk_write_image sitkLinear glob crop_by_bbox sitkResize3DV2 ReadImage GetArrayFromImage sitkResample3DV2 mkdir_if_not_exist get_bounding_boxV2 sitkNearestNeighbor sitk_write_image sitkLinear glob crop_by_bbox sitkResize3DV2 ReadImage GetArrayFromImage sitkResample3DV2 mkdir_if_not_exist get_bounding_boxV2 sitkNearestNeighbor SpeckleNoiseImageFilter SmoothingRecursiveGaussianImageFilter SetBeta MedianImageFilter AdaptiveHistogramEqualizationImageFilter SetRadius AdditiveGaussianNoiseImageFilter str BilateralImageFilter ShotNoiseImageFilter append SetAlpha SetRangeSigma GetName WriteImage zip SetVariance enumerate SaltAndPepperNoiseImageFilter SetDomainSigma SetSigma DiscreteGaussianImageFilter GetPixelIDValue GetSpacing GetSize TransformContinuousIndexToPhysicalPoint GetDirection GaussianSource GetOrigin array dtype cumsum min iinfo astype bincount ravel max GetArrayViewFromImage SigmoidImageFilter SetAlpha SetBeta SetOutputMaximum median float SetOutputMinimum GetArrayViewFromImage percentile Threshold RescaleIntensity sitkFloat32 astype ReadImage GetArrayFromImage Execute SetOutputPixelType GetPixelID CastImageFilter GetPixelIDValue recast_pixel_val GetSpacing Image GetSize SetSpacing GetDirection SetOrigin TransformPhysicalPointToIndex Paste GetOrigin SetDirection SetDefaultPixelValue Execute ResampleImageFilter SetInterpolator SetReferenceImage sitkNearestNeighbor list random zip list random zip cos sqrt sin zeros argmax isclose Transform Resample AddTransform append SetParameters GetPixelIDValue Transform Image SetOffset randint pi flatten AffineTransform parameter_space_regular_grid_sampling linspace augment_images_spatial GetSize SetDirection GetDimension GetOrigin similarity3D_parameter_space_random_sampling SetMatrix TransformContinuousIndexToPhysicalPoint SetSpacing TranslationTransform SetTranslation GetDirection TransformPoint zip join SetCenter SetOrigin AddTransform zeros array len GetPixelIDValue Transform Image SetOffset randint pi flatten AffineTransform linspace augment_images_spatial GetSize SetDirection GetDimension GetOrigin similarity3D_parameter_space_random_sampling SetMatrix TransformContinuousIndexToPhysicalPoint SetSpacing TranslationTransform SetTranslation GetDirection TransformPoint zip join SetCenter SetOrigin AddTransform zeros array len GetPixelIDValue Transform Image SetOffset randint pi flatten AffineTransform linspace augment_images_spatial GetSize SetDirection GetDimension append GetOrigin similarity3D_parameter_space_random_sampling SetMatrix TransformContinuousIndexToPhysicalPoint SetSpacing TranslationTransform SetTranslation GetDirection TransformPoint zip join SetCenter SetOrigin AddTransform zeros array len GetPixelIDValue Transform Image SetOffset randint pi flatten AffineTransform parameter_space_regular_grid_sampling linspace augment_images_spatial GetSize SetDirection GetDimension GetOrigin similarity3D_parameter_space_random_sampling SetMatrix TransformContinuousIndexToPhysicalPoint SetSpacing TranslationTransform SetTranslation GetDirection TransformPoint join SetCenter SetOrigin AddTransform zeros array len OtsuThreshold LabelShapeStatisticsImageFilter GetBoundingBox Execute min padd shape nonzero append max range min where padd shape nonzero append max range max isinstance Image min padd shape GetArrayFromImage nonzero append binarize_numpy_array range GetImageFromArray CopyInformation convertArrayToImg where shape GetArrayFromImage zeros zeros where shape all arange slice print len ndim delete append diff seed random_crop concat seed random_crop stack unstack shape GetPixelIDValue Image SetSpacing GetDirection SetOrigin GetOrigin SetDirection int GetPixelIDValue GetSpacing Image GetSize print reshape SetSpacing SetDirection GetDimension matmul flatten GetDirection SetOrigin zeros float abs array SetOutputSpacing list int GetSpacing SetSize Execute SetOutputOrigin SetOutputDirection ResampleImageFilter GetSize astype GetDirection GetOrigin array SetInterpolator SetOutputSpacing list int GetSpacing SetSize Execute SetOutputOrigin SetOutputDirection ResampleImageFilter GetSize astype GetDirection GetOrigin array SetInterpolator CopyInformation to_categorical where GetImageFromArray GetArrayFromImage enumerate to_categorical where enumerate argmax reshape ravel astype float32 where mean GetArrayFromImage std ReadImage GetArrayFromImage zscore RescaleIntensity GetArrayFromImage RescaleIntensity append expand_dims array convert_p_img_2_nor_array GetArrayFromImage ReadImage convert_lab_2_array append expand_dims convert_p_lab_2_array array append ReadImage augment_imgs_labs zip GetGDCMSeriesIDs Execute GetSize print ImageSeriesReader GetGDCMSeriesFileNames SetFileNames len append imread sort_glob stack insert imread sort_glob stack join CopyInformation WriteImage GetImageFromArray range mk_or_cleardir join uint16 CopyInformation astype where WriteImage GetImageFromArray range mk_or_cleardir join WriteImage makedirs join uint16 CopyInformation astype where WriteImage GetImageFromArray mk_or_cleardir join uint16 CopyInformation astype WriteImage GetImageFromArray mk_or_cleardir join CopyInformation WriteImage GetImageFromArray makedirs join uint8 format imwrite Image isinstance astype GetArrayFromImage makedirs join uint8 format imwrite Image isinstance astype where GetArrayFromImage makedirs Nifti1Image range save uint16 where shape zeros enumerate split print eval format array print eval format scalar_summary T format P backward model print TP scalar_summary zero_grad float dice item step enumerate len zeros range append join walk get_data replace split MaxPool2d AvgPool2d BatchNorm2d Sequential ContextBlock Conv2d BatchNorm2d Sequential NonLocalBlock shape array zoom append join walk load ones_like load ones_like replace get_data split mean std where mean std min max ReadImage GetArrayFromImage zoom rint zeros_like shape load_slicer astype resize shape astype load_slicer2 resize zeros range randint randint randint rand flip adjust_gamma rand param_groups lr data normal constant __name__ data normal constant xavier_normal __name__ data normal constant __name__ kaiming_normal data normal constant orthogonal __name__ apply print parameters view log_softmax size nll_loss numel view log_softmax size nll_loss numel sum | # myops2020 Multi-modality Pathology Segmentation Framework: Application to Cardiac Magnetic Resonance Images ``` @inproceedings{zhang2020multi, title={Multi-modality Pathology Segmentation Framework: Application to Cardiac Magnetic Resonance Images}, author={Zhang, Zhen and Liu, Chenyu and Ding, Wangbin and Wang, Sihan and Pei, Chenhao and Yang, Mingjing and Huang, Liqin}, booktitle={Myocardial Pathology Segmentation Combining Multi-Sequence CMR Challenge}, pages={37--48}, year={2020}, organization={Springer} | 2,609 |
kakirastern13/OCR-with-YOLO | ['optical character recognition'] | ['FUNSD: A Dataset for Form Understanding in Noisy Scanned Documents'] | darknet_veztan/scripts/voc_label.py darknet_veztan/python/darknet.py darknet_veztan/python/proverbot.py darknet_veztan/examples/detector.py darknet_veztan/examples/detector-scipy-opencv.py array_to_image detect2 METADATA DETECTION c_array detect IMAGE sample classify BOX predict_tactics predict_tactic convert_annotation convert c_float transpose flatten c_array IMAGE sorted POINTER network_detect make_probs c_void_p make_boxes num_boxes cast classes free_ptrs append range uniform sum range len sorted predict_image classes append range free_detections sorted do_nms_obj c_int pointer h get_network_boxes w predict_image free_image classes append load_image range bbox c_array chr predict sample reset_rnn sorted predict_tactic append range int str parse join text convert write index getroot iter open find | # OCR with YOLO A repository for keep a record of some findings made regarding some OCR project ## Literature & Datasets: Scan and extract text from an image using Python libraries https://developer.ibm.com/tutorials/document-scanner/ Tutorial : Building a custom OCR using YOLO and Tesseract https://medium.com/saarthi-ai/how-to-build-your-own-ocr-a5bb91b622ba Deep Learning Based OCR for Text in the Wild https://nanonets.com/blog/deep-learning-ocr/ ICDAR 2019 Competition on Table Detection and Recognition (cTDaR) | 2,610 |
kaliahinartem/twitter_sentiment_analysis | ['sentiment analysis', 'word embeddings', 'twitter sentiment analysis'] | ['BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs'] | SemEval/dataset_readers/semeval_datareader.py SemEval/dataset_readers/utils.py SemEval/models/semeval_classifier_attention.py SemEval/models/my_bcn.py SemEval/predictors/semeval_predictor.py SemEval/models/semeval_classifier.py SemEvalDatasetReader main preprocess tokenize BiattentiveClassificationNetwork SemEvalClassifier SemEvalClassifierAttention SemEvalPredictor tokenize list punctuation words | # SemEval-2017 Task 4 Sentiment Analysis in Twitter ## Introduction [SemEval-2017 Task 4](http://alt.qcri.org/semeval2017/task4/index.php?id=data-and-tools) is a text sentiment classification task: Given a message, classify whether the message is of positive, negative, or neutral sentiment. ## Run Experiments ```bash # install the environment conda create -n allennlp python=3.6 source activate allennlp pip install -r requirements.txt ``` | 2,611 |
kalyo-zjl/APD | ['pedestrian detection'] | ['Attribute-aware Pedestrian Detection in a Crowd'] | peddla.py demo.py load_model preprocess main parse_args parse_det a_nms peddla_net fill_fc_weights Root Bottleneck get_model_url BasicBlock DLAUp DeformConv DLA BottleneckX Tree IDAUp DLASeg Interpolate conv3x3 Identity fill_up_weights dla34 convolution add_argument ArgumentParser int exp asarray where append numpy range a_nms len minimum ones_like min maximum sqrt append sum max load format print shape load_state_dict state_dict subplots div cuda show sorted load_model imshow parse_args range glob synchronize astype sqrt eval preprocess parse_det sigmoid_ reshape float32 add_patch Rectangle img_list len load_pretrained_model DLA isinstance bias Conv2d modules constant_ data fabs size ceil range DLASeg format | # APD [Attribute-aware Pedestrian Detection in a Crowd](https://arxiv.org/pdf/1910.09188.pdf) ## Installation To run the demo, the following requirements are needed. ``` numpy matplotlib torch >= 0.4.1 glob argparse | 2,612 |
kamata1729/QATM_pytorch | ['template matching'] | ['QATM: Quality-Aware Template Matching For Deep Learning'] | utils.py qatm.py qatm_pytorch.py MyNormLayer nms nms_multi run_one_sample run_multi_sample CreateModel plot_result_multi ImageDataset Featex QATM plot_result all_sample_iou locate_bbox score2curve plot_success_curve evaluate_iou compute_score IoU minimum transpose maximum where append array imwrite tuple copy imshow rectangle minimum int arange concatenate ones reshape transpose astype maximum where array zip append max list imwrite copy imshow color_palette plot_result max range len exp model min log range compute_score resize cpu numpy is_cuda append append run_one_sample min max ones filter2D argmax max int linspace append sum array len locate_bbox append IoU range len show format plot score2curve grid mean ylim title figure linspace xticks yticks | # Pytorch Non-Official Implementation of QATM:Quality-Aware Template Matching For Deep Learning arxiv: https://arxiv.org/abs/1903.07254 original code (tensorflow+keras): https://github.com/cplusx/QATM Qiita(Japanese): https://qiita.com/kamata1729/items/11fd55992c740526f6fc # Dependencies * torch(1.0.0) * torchvision(0.2.1) * cv2 * seaborn * sklearn | 2,613 |
kaminAI/beem | ['iris segmentation'] | ['Boltzmann Exploration Expectation–Maximisation'] | src/plotting.py src/utils.py src/models.py src/evaluation.py compute_purity eval_cluster BeemGMM plot_roc_curve plot_raw_gp_data plot_metrics roc_curve_with_error_bounds plot_purity greedy_sampler boltzmann assign score_mixture_likelihood boltzmann_sampling boltzmann_global_opt make_equal_bin_sizes bincount argmax set homogeneity_score compute_purity adjusted_rand_score normalized_mutual_info_score show subplots set_title plot set_xlabel set_xlim roc_curve trapz now strftime set_ylabel savefig legend set_ylim update show use subplots Patch rc set_xlabel grid now strftime scatter set_style set_ylabel legend color_palette savefig setLevel enumerate subplots arange grid MultipleLocator setLevel show set_major_locator set_xlabel strftime savefig update plot set_xlim mean rc now set_ylabel set_style color_palette fill_between std set_ylim len subplots trapz linspace show set_xlabel strftime savefig legend append update plot set_xlim mean interp minimum rc roc_curve maximum now set_ylabel fill_between std set_ylim len subplots arange grid MultipleLocator setLevel show set_major_locator set_xlabel strftime savefig legend update plot set_xlim mean enumerate rc now set_ylabel set_style color_palette fill_between std set_ylim len divmod len argmax asarray exp reshape sum max exp sum max func mean max argmax | # Boltzmann Exploration Expectation-Maximisation We present a general method for fitting finite mixture models (FMM). Learning in a mixture model consists of finding the most likely cluster assignment for each data-point, as well as finding the parameters of the clusters themselves. In many mixture models this is difficult with current learning methods, where the most common approach is to employ monotone learning algorithms e.g. the conventional expectation-maximisation algorithm. While effective, the success of any monotone algorithm is crucially dependant on good parameter initialisation, where a common choice is _K_-means initialisation, commonly employed for Gaussian mixture models. For other types of mixture models the path to good initialisation parameters is often unclear and may require a problem specific solution. To this end, we propose a general heuristic learning algorithm that utilises Boltzmann exploration to assign each observation to a specific base distribution within the mixture model, which we call Boltzmann exploration expectation-maximisation (BEEM). With BEEM, hard assignments allow straight forward parameter learning for each base distribution by conditioning only on its assigned observations. Consequently it can be applied to mixtures of any base distribution where single component parameter learning is tractable. The stochastic learning procedure is able to escape local optima and is thus insensitive to parameter initialisation. We show competitive performance on a number of synthetic benchmark cases as well as on real-world datasets. [Full paper](https://arxiv.org/abs/1912.08869) **Corresponding authors**: * [Mathias Edman]([email protected]), Kamin AI AB * [Neil Dhir]([email protected]), Kamin AI AB ## Demo There is no specific installation required to use BEEM. This implementation uses only bits and bobs from the standard python SciPy stack and `python 3+`. For an example of how to use it, try the [BEEM_Rainbow_demo.ipynb](BEEM_Rainbow_demo.ipynb) demo, which replicates the results from section **5.1**. <p align="center"> | 2,614 |
kamperh/recipe_semantic_flickraudio | ['word embeddings', 'language acquisition', 'dynamic time warping'] | ['Semantic speech retrieval with a visually grounded model of untranscribed speech', 'Query-by-Example Search with Discriminative Neural Acoustic Word Embeddings'] | kaldi_features/steps/cleanup/internal/get_ctm_edits.py speech_nn/eval_keyword_spotting.py speech_nn/get_unigram_baseline.py speech_nn/tf0_12.py kaldi_features/steps/nnet3/components.py kaldi_features/utils/data/internal/choose_utts_to_combine.py kaldi_features/steps/conf/parse_arpa_unigrams.py speech_nn/train_visionspeech_cnn_custompool.py kaldi_features/steps/cleanup/internal/get_non_scored_words.py kaldi_features/steps/nnet3/tdnn/make_configs.py speech_nn/train_psyc.py kaldi_features/steps/nnet3/chain/nnet3_chain_lib.py kaldi_features/steps/nnet3/chain/gen_topo3.py kaldi_features/utils/reverse_arpa.py kaldi_features/steps/nnet3/chain/gen_topo5.py kaldi_features/steps/nnet3/train_dnn.py vision_nn_1k/train_bow_mlp.py kaldi_features/utils/data/internal/modify_speaker_info.py kaldi_features/flickr8k_data_prep_vad.py kaldi_features/steps/cleanup/internal/modify_ctm_edits.py kaldi_features/steps/nnet2/make_multisplice_configs.py vision_nn_1k/data_prep_mscoco+flickr30k.py kaldi_features/utils/nnet/make_blstm_proto.py kaldi_features/steps/conf/append_eval_to_ctm.py kaldi_features/steps/conf/convert_ctm_to_tra.py speech_nn/apply_psyc_frames.py kaldi_features/utils/nnet/make_lstm_proto.py kaldi_features/steps/diagnostic/analyze_phone_length_stats.py vision_nn_1k/imagenet_classes.py kaldi_features/steps/nnet3/dot/descriptor_parser.py speech_nn/get_vision_tag_prior.py kaldi_features/utils/nnet/gen_splice.py kaldi_features/steps/nnet3/get_successful_models.py kaldi_features/utils/nnet/gen_hamm_mat.py speech_nn/train_bow_cnn_custompool.py kaldi_features/steps/conf/prepare_word_categories.py kaldi_features/steps/conf/prepare_calibration_data.py kaldi_features/steps/nnet3/report/generate_plots.py paths.py vision_nn_1k/data_prep_flickr30k.py kaldi_features/steps/cleanup/internal/segment_ctm_edits.py speech_nn/data_io.py kaldi_features/steps/diagnostic/analyze_lattice_depth_stats.py kaldi_features/utils/nnet/gen_dct_mat.py doc/plotting.py speech_nn/get_queries_search.py kaldi_features/utils/nnet/make_cnn_proto.py speech_nn/get_vision_baseline.py kaldi_features/utils/lang/make_phone_lm.py speech_nn/eval_precision_recall.py kaldi_features/utils/filt.py speech_nn/analyze_embeds.py speech_nn/analyze_captions.py speech_nn/train_bow_cnn.py vision_nn_1k/data_prep_mscoco.py kaldi_features/steps/nnet3/chain/train.py kaldi_features/steps/nnet3/report/summarize_compute_debug_timing.py doc/plot_tsne_embeddings.py speech_nn/keywords_propose_train.py kaldi_features/utils/nnet/make_nnet_proto.py kaldi_features/steps/nnet3/chain/gen_topo4.py speech_nn/keywords_in_set.py vision_nn_1k/get_captions_using_word_ids.py kaldi_features/utils/lang/internal/modify_unk_pron.py vision_nn_1k/eval_precision_recall.py kaldi_features/steps/nnet3/chain/gen_topo2.py kaldi_features/steps/cleanup/combine_short_segments.py kaldi_features/steps/nnet3/nnet3_train_lib.py speech_nn/get_kaldi_mfcc.py kaldi_features/steps/conf/append_prf_to_ctm.py kaldi_features/utils/data/extend_segment_times.py speech_nn/get_kaldi_fbank.py kaldi_features/steps/cleanup/internal/taint_ctm_edits.py kaldi_features/steps/cleanup/make_biased_lms.py speech_nn/train_visionspeech_cnn.py kaldi_features/steps/nnet3/dot/nnet3_to_dot.py speech_nn/train_visionspeech_psyc.py speech_nn/apply_bow_cnn_custompool.py kaldi_features/steps/nnet3/chain/gen_topo.py kaldi_features/steps/data/reverberate_data_dir.py vision_nn_1k/apply_bow_mlp.py kaldi_features/steps/nnet3/make_tdnn_configs.py kaldi_features/steps/nnet3/make_jesus_configs.py speech_nn/apply_bow_cnn.py kaldi_features/steps/cleanup/internal/make_one_biased_lm.py kaldi_features/steps/data/data_dir_manipulation_lib.py kaldi_features/utils/lang/internal/arpa2fst_constrained.py kaldi_features/steps/nnet3/report/nnet3_log_parse_lib.py vision_nn_1k/get_captions_word_ids.py speech_nn/eval_model_semkeyword.py kaldi_features/utils/nnet/make_cnn2d_proto.py kaldi_features/steps/nnet3/lstm/make_configs.py vision_nn_1k/apply_vgg16.py kaldi_features/steps/nnet3/train_rnn.py vision_nn_1k/data_prep_flickr8k.py speech_nn/get_captions.py speech_nn/analyze_speech_data.py vision_nn_1k/vgg16.py make_patch_spines_invisible setup_plot main embeddings_from_pickle plot_labelled_2d_data main ctm_to_dict ParseFileToDict GetArgs MakeDir CheckFiles ParseDataDirInfo CombineSegments GetCombinedUttIndexRange Main WriteCombinedDirFiles WriteDictToFile RunKaldiCommand ProcessGroupOfLines FloatToString OpenFiles ProcessOneUtterance ProcessData PadArrays GetEditType OutputCtm ReadLang NgramCounts ProcessUtterance ProcessUtteranceForRepetitions ReadNonScoredWords PrintRepetitionStats ProcessData PrintNonScoredStats ProcessLineForNonScoredWords AccumulateSegmentStats FloatToString GetSegmentsForUtterance ComputeSegmentCores WriteSegmentsForUtterance PrintDebugInfoForUtterance PrintWordStats PrintSegmentStats ReadNonScoredWords IsTainted ProcessData Segment AccWordStatsForUtterance TimeToString ProcessUtterance ProcessData PrintStats PrintNonScoredStats RunKaldiCommand GetArgs SmoothProbabilityDistribution PickItemWithProbability GenerateReverberatedWavScp CheckArgs AddPrefixToFields ParseNoiseList MakeRoomDict CreateCorruptedUtt2uniq CreateReverberatedCopy ParseSetParameterStrings GenerateReverberationOpts almost_equal Main GetNewId WriteDictToFile ParseFileToDict list_cyclic_iterator AddPointSourceNoise ParseRirList GetPercentile GetMean GetPercentile GetMean create_config_files parse_splice_string get_convolution_index_set AddAffRelNormLayer AddLdaLayer AddSoftmaxLayer AddAffineLayer AddSigmoidLayer AddOutputLayer AddAffPnormLayer AddLstmLayer AddMaxpoolingLayer AddFixedAffineLayer AddFinalLayer AddPermuteLayer AddBlockAffineLayer AddBLstmLayer AddConvolutionLayer GetSumDescriptor AddInputLayer AddNoOpLayer StatisticsConfig SendMail ComputeTrainCvProbabilities GetIvectorDim CleanNnetDir CopyEgsPropertiesToExpDir ComputePreconditioningMatrix RunKaldiCommand RemoveEgs CheckIfCudaCompiled NullstrToNoneAction DoShrinkage ParseModelConfigVarsFile ReadKaldiMatrix StrToBoolAction WriteKaldiMatrix GetNumberOfLeaves ForceSymlink PrepareInitialAcousticModel ComputeAveragePosterior ComputePresoftmaxPriorScale GetNumberOfJobs GetSuccessfulModels CombineModels GetRealignIters ComputeIdctMatrix KaldiCommandException GetFeatDim GenerateEgs GetLearningRate Align ComputeLifterCoeffs VerifyEgsDir WriteIdctMatrix Realign ComputeProgress VerifyIterations AdjustAmPriors SplitData RemoveModel GetArgs TrainNewModels ProcessArgs RunOpts Train Main TrainOneIteration GetArgs TrainNewModels ProcessArgs NullstrToNoneAction RunOpts Train Main TrainOneIteration StrToBoolAction GetNumberOfLeaves GenerateChainEgs ComputeTrainCvProbabilities PrepareInitialAcousticModel ComputeProgress CreatePhoneLm CombineModels CreateDenominatorFst ComputePreconditioningMatrix GetArgs TrainNewModels ProcessArgs RunOpts Train Main CheckForRequiredFiles TrainOneIteration IdentifyNestedSegments ParseSubsegmentsAndArguments ProcessReplaceIndexDescriptor ProcessSumDescriptor ProcessIfDefinedDescriptor ProcessRoundDescriptor ParseNnet3String ProcessAppendDescriptor DescriptorSegmentToDot Nnet3OutputToDot Nnet3DimrangeToDot GetDotNodeName Nnet3DescriptorToDot ProcessOffsetDescriptor Nnet3ComponentToDot Nnet3ComponentNodeToDot ParseConfigLines GroupConfigs Nnet3InputToDot CheckArgs GetArgs ProcessSpliceIndexes Main ParseLstmDelayString PrintConfig ParseSpliceString MakeConfigs GetArgs GenerateClippedProportionPlots GenerateParameterDiffPlots GeneratePlots Main LatexReport GenerateNonlinStatsPlots GenerateAccuracyPlots ParseProgressLogsForParamDiff GenerateAccuracyReport ParseProgressLogsForClippedProportion MalformedClippedProportionLineException ParseProgressLogsForNonlinearityStats ParseProbLogs ParseDifferenceString ParseTrainLogs Main GetArgs FindOpenParanthesisPosition ExtractCommandName CheckArgs GetArgs ParseCnnString Main PrintConfig AddConvMaxpLayer ParseSpliceString AddCnnLayers MakeConfigs FloatToString CombineList SelfTest LessThan GetUtteranceGroups GetFormatString SplitIntoGroups NgramCounts CountsForHistory ReadBigramMap HistoryState ArpaModel fix_filt_step Glorot main check_argv get_embeds_and_labels check_argv plot_embeds_2d plot_data_labelled plot_raw_embeds main main check_argv main build_model apply_model check_argv main build_model apply_model check_argv main build_model apply_model check_argv read_kaldi_ark_from_scp load_flickr8k_padded_bow_labelled load_flickr8k_padded_visionsig pad_sequences main eval_keyword_spotting calculate_eer check_argv get_mean_average_precision get_average_precision eval_semkeyword_exact_sem_counts get_spearmanr check_argv main eval_keyword_spotting calculate_eer eval_precision_recall_fscore analyze_confusions check_argv eval_average_precision main main get_captions_dict get_flickr8k_train_test_dev main main main ctm_to_dict check_argv main check_argv main check_argv main check_argv main check_argv main sequence_mask main build_bow_cnn_from_options_dict train_bow_cnn check_argv main check_argv build_bow_cnn_custompool_from_options_dict train_bow_cnn_custompool main train_psyc build_psyc_from_options_dict check_argv main train_visionspeech_cnn check_argv train_visionspeech_cnn_custompool main check_argv train_visionspeech_psyc main check_argv main apply_model check_argv main images_from_dir check_argv main get_flickr8k_train_test_dev main main main get_captions_urls process_caption eval_precision_recall_fscore main eval_average_precision check_argv main check_argv main check_argv load_bow_labelled build_bow_mlp_from_options_dict check_argv main train_bow_mlp build_conv2d_relu build_linear build_vgg16 main build_maxpool2d set_frame_on set_visible values print array append Counter sorted scatter set join plot_labelled_2d_data TSNE print min embeddings_from_pickle mean shape ylim setup_plot figure legend savefig xlim xticks max fit_transform yticks format ctm_to_dict len now set makedirs join argv print add_argument ArgumentParser parse_args communicate Popen mkdir format open value_processor split join list format sort write close keys open ParseFileToDict data_dir_file exists min max len pop join list remove format out_dir_file sort append WriteDictToFile keys pop deepcopy list format ParseDataDirInfo insert sort GetCombinedUttIndexRange tuple warn WriteCombinedDirFiles append keys range GetArgs output_data_dir MakeDir CheckFiles format minimum_duration CombineSegments print input_data_dir copy exists RunKaldiCommand join format print Popen exit close split lm_opts flush len symbol_table format print readlines close exit set add oov split ctm_edits_out ctm_in edits_in open append len format FloatToString format print exit GetEditType range len list exit PadArrays zip append OutputCtm split readline format print len exit ProcessOneUtterance edits_in append split int str format print readlines exit add set split format readlines exit close add open split append range len append ProcessUtteranceForRepetitions ProcessLineForNonScoredWords ProcessUtterance join close ctm_edits_out ctm_edits_in open sorted format list print sum keys values sorted format list print sum keys values list reversed append range len sorted print keys range len AccumulateSegmentStats MergeWithSegment ContainsAtLeastOneScoredNonOovWord PossiblyAddTaintedLines ComputeSegmentCores PossiblyTruncateBoundaries RelaxBoundaryTruncation PossiblyAddUnkPadding PossiblyTruncateEndForJunkProportion PossiblyTruncateStartForJunkProportion append float range JunkProportion len round str print StartTime Text frame_length range EndTime TimeToString len str sorted list join print DebugInfo frame_length append float range TimeToString len end_index start_index range len items sorted list format print close open GetSegmentsForUtterance segments_out PrintDebugInfoForUtterance WriteSegmentsForUtterance text_out AccWordStatsForUtterance range len join format print sum values CheckArgs warn output_dir makedirs list isinstance set uniform sum values str ParseFileToDict list WriteDictToFile sort GetNewId keys range format rir_list PickItemWithProbability random rir_rspecifier noise_rspecifier next append randint round range format rir_list AddPointSourceNoise PickItemWithProbability noise_rspecifier append next str list list_cyclic_iterator format WriteDictToFile sort floor GetNewId keys range GenerateReverberationOpts join print close open GetNewId range split ParseFileToDict list format AddPrefixToFields print CreateCorruptedUtt2uniq isfile GenerateReverberatedWavScp values RunKaldiCommand sum float probability warn strip append float setattr split format add_argument rir_rspecifier ParseSetParameterStrings ArgumentParser list setattr append sum keys list format SmoothProbabilityDistribution add_argument noise_rspecifier ParseSetParameterStrings ArgumentParser append keys seed sum ParseNoiseList source_sampling_rate MakeRoomDict CreateReverberatedCopy rir_set_para_array ParseRirList random_seed noise_set_para_array rir_smoothing_weight noise_smoothing_weight len items sorted int sum values sum values list sort set append range len int join print min get_convolution_index_set max split splice_indexes join pnorm_input_dim format len write close warn num_hidden_layers sqrt parse_splice_string pnorm_output_dim split append range open pop format append str join format print append append format append format append format append join format append format append format append format append format append format append format append format append format str format AddSoftmaxLayer AddAffineLayer AddSigmoidLayer AddOutputLayer append append abs strip format format AddLstmLayer format Popen communicate Popen str format readlines search index warn sub append float max range compile len int format RunKaldiCommand split int strip int format RunKaldiCommand int format RunKaldiCommand range len join write close open range len copy2 format isfile format RunKaldiCommand strip int split open format RunKaldiCommand int readline remove format ForceSymlink RunKaldiCommand symlink remove format ForceSymlink glob pow WriteKaldiMatrix append sum range RunKaldiCommand len format RunKaldiCommand min max int pow sqrt append float split format RunKaldiCommand info format Align ComputeAveragePosterior AdjustAmPriors info RunKaldiCommand exp log format search split float compile RunKaldiCommand format RunKaldiCommand format RunKaldiCommand int ComputeTrainCvProbabilities format print append range RunKaldiCommand remove format glob sleep RunKaldiCommand format RunKaldiCommand format RunKaldiCommand range RemoveModel RemoveEgs remove format isfile float range pi sin ComputeLifterCoeffs cos pi sqrt float range append ComputeIdctMatrix range WriteKaldiMatrix ProcessArgs use_gpu num_jobs_compute_prior realign_num_jobs RunOpts command ali_dir warning realign_command format communicate print wait close append range RunKaldiCommand ComputeTrainCvProbabilities strip warning exists RunKaldiCommand open str append range format close GetSuccessfulModels sqrt info float int remove ComputeProgress TrainNewModels write SendMail GetIvectorDim CleanNnetDir CopyEgsPropertiesToExpDir ComputePreconditioningMatrix RunKaldiCommand open num_jobs_final str RemoveEgs feat_dir cleanup num_jobs_initial dir ali_dir email ParseModelConfigVarsFile range GetNumberOfLeaves frames_per_eg format lang reporting_interval GenerateAccuracyReport PrepareInitialAcousticModel ComputeAveragePosterior close ComputePresoftmaxPriorScale copy GetNumberOfJobs CombineModels GetRealignIters pformat egs_dir info max_models_combine vars GetFeatDim num_epochs float TrainOneIteration GenerateEgs int preserve_model_interval learning_rate VerifyEgsDir print Realign write add_layers_period prior_subset_size VerifyIterations AdjustAmPriors system online_ivector_dir SplitData realign_times remove_egs RemoveModel Train chunk_width num_bptt_steps chunk_left_context chunk_right_context min format RunKaldiCommand format RunKaldiCommand format RunKaldiCommand exists format deriv_truncate_margin lat_dir GenerateChainEgs shrink_value CreatePhoneLm CheckForRequiredFiles CreateDenominatorFst frame_subsampling_factor deriv_truncate_margin tree_dir lat_dir append strip split pop insert ParseSubsegmentsAndArguments append range len sub join format append range len append format append format join format append range len append format append format append IdentifyNestedSegments format pop strip sub split append range len list keys intersection append format append GetDotNodeName format append GetDotNodeName format append list format ParseNnet3String insert append GroupConfigs keys add_mutually_exclusive_group num_lstm_layers GetNumberOfLeaves feat_dir print num_targets tree_dir exit GetIvectorDim strip ali_dir config_dir ParseLstmDelayString GetFeatDim ivector_dir join close write open print split append max range len append len range split deepcopy AddAffRelNormLayer AddLdaLayer format list insert AddLstmLayer AddFinalLayer AddBLstmLayer PrintConfig AddOutputLayer AddInputLayer keys range str print strip close ParseSpliceString open splice_indexes num_lstm_layers label_delay config_dir MakeConfigs ProcessSpliceIndexes format GenerateAccuracyReport plot suptitle xlabel grid write close ylabel savefig figure legend append AddFigure array open grid clf warning open subplot list set_xlabel savefig legend intersection append format plot close set ParseProgressLogsForNonlinearityStats keys suptitle sort write set_ylabel figure AddFigure array ParseProgressLogsForClippedProportion grid clf warning open subplot list savefig legend intersection append format plot close set keys suptitle sort write set_ylabel figure AddFigure array set_ylim ParseProgressLogsForParamDiff grid clf warning open str list sorted subplot set_xlabel savefig legend intersection append range format plot close set info keys join items suptitle sort write set_ylabel figure AddFigure array len GenerateClippedProportionPlots format GenerateParameterDiffPlots Close LatexReport GenerateNonlinStatsPlots info GenerateAccuracyPlots makedirs GeneratePlots exp_dir output_dir int search groups float compile split float split int list sort search groups set add append float max range compile split max list format sort ParseDifferenceString len search groups set keys warning union range compile split max list values search groups float keys compile split list sort search groups intersection keys compile split str list format keys timedelta append ParseProbLogs ParseTrainLogs split append strip pop len strip join FindOpenParanthesisPosition stdin items sorted list values ExtractCommandName float compile split pnorm_input_dim relu_dim relu_dim_final relu_dim_init pnorm_output_dim pool_z_step num_filters pool_x_step filt_y_dim filt_y_step pool_y_size pool_y_step pool_z_size AddMaxpoolingLayer AddConvolutionLayer pool_x_size filt_x_dim filt_x_step join WriteIdctMatrix format ParseCnnString AddAffineLayer strip AddFixedAffineLayer AddConvMaxpLayer range len add_argument len ArgumentParser append parse_args range split int strip ParseSpliceString open str append close AddCnnLayers print AddAffPnormLayer index len pop list LessThan append range len list append randint sum range CombineList len format values print append sum range CombineList len append readline defaultdict format exit add open split range with_glorot add_argument exit ArgumentParser print_help extend captions_dict_fn check_argv most_common float subplots set_yticklabels set_visible tick_params sorted list make_patch_spines_invisible set_xlabel set_linewidth imshow twinx append range set_position set mean join int get_minorticklines invert_yaxis set_yticks argsort set_ylabel array set_ylim len str TSNE print get_embeds_and_labels plot_data_labelled fit_transform subplot sorted str text set title figure range len set_defaults append array word_type plot_raw_embeds seed show list plot_embeds_tsne plot_embeds_2d imshow append normalize sample keys load plot_all norm plot_rnd split npz_fn sorted xlabel hist sum sigmoid load join sorted build_model print pad_sequences reshape BatchFeedIterator placeholder now shape Saver swapaxes keys int batch_size subset apply_model model_dir ConfigProto layer build_psyc_from_options_dict build_bow_cnn_custompool_from_options_dict dict int min append zeros round enumerate load join sorted print pad_sequences shuffle zeros keys enumerate load join sorted print pad_sequences shuffle zeros keys enumerate roc_curve brentq join sorted format print mean calculate_eer append zeros float sum enumerate analyze Counter dict get_captions_dict keywords_fn eval_keyword_spotting show sorted plot xlabel ylabel average_precision_score precision_recall_curve zeros ravel enumerate normal sorted len average_precision_score mean append zeros enumerate sorted append zeros sum enumerate zeros sorted len get_mean_average_precision get_average_precision eval_semkeyword_exact_sem_counts get_spearmanr sorted format print extend set most_common float sorted plot xlabel extend copy set average_precision_score precision_recall_curve ylabel zeros ravel max values enumerate subplots arange grid most_common xticks tick_params yticks sorted list Counter imshow set_color append range format set enumerate print text set_yticks extend set_xticks zeros array len eval_precision_recall_fscore analyze_confusions plot sigmoid_threshold eval_average_precision print print join format fromarray get_flickr8k_train_test_dev read_kaldi_ark_from_scp array_to_pixels vstack mkdir save savez_compressed std values savez add features round zeros sigmoid_npz word_to_id_pkl arange subplot set_title set_yscale set_xlabel scatter set_xscale set_ylabel flatten build_cnn build_feedforward AdagradOptimizer BatchFeedIterator set_random_seed seed placeholder reduce_sum GradientDescentOptimizer shape cast encode train_fixed_epochs AdadeltaOptimizer format greater_equal MomentumOptimizer swapaxes join sigmoid_cross_entropy_with_logits minimize print md5 load_flickr8k_padded_bow_labelled reshape makedirs now extend dict AdamOptimizer reduce_mean sigmoid isfile len train_bow_cnn copy sequence_mask build_cnn maximum build_feedforward cast ceil range len AdagradOptimizer BatchFeedIterator set_random_seed seed build_bow_cnn_custompool_from_options_dict placeholder reduce_sum GradientDescentOptimizer shape cast encode train_fixed_epochs AdadeltaOptimizer format greater_equal MomentumOptimizer swapaxes join sigmoid_cross_entropy_with_logits minimize print md5 load_flickr8k_padded_bow_labelled reshape makedirs now extend dict AdamOptimizer reduce_mean sigmoid isfile len train_bow_cnn_custompool sequence_mask build_cnn maximum cast ceil range len AdagradOptimizer BatchFeedIterator set_random_seed seed placeholder reduce_sum GradientDescentOptimizer shape cast encode train_fixed_epochs AdadeltaOptimizer format greater_equal MomentumOptimizer swapaxes join sigmoid_cross_entropy_with_logits minimize print md5 load_flickr8k_padded_bow_labelled reshape makedirs now extend dict AdamOptimizer reduce_mean sigmoid isfile build_psyc_from_options_dict len train_psyc eval_precision_recall_fscore AdagradOptimizer BatchFeedIterator set_random_seed apply_model reset_default_graph seed placeholder reduce_sum load_flickr8k_padded_visionsig shape GradientDescentOptimizer cast encode train_fixed_epochs AdadeltaOptimizer format greater_equal MomentumOptimizer swapaxes load join weighted_cross_entropy_with_logits sigmoid_cross_entropy_with_logits minimize print md5 load_flickr8k_padded_bow_labelled reshape now dict AdamOptimizer reduce_mean sigmoid isfile eval_average_precision makedirs train_visionspeech_cnn eval_precision_recall_fscore AdagradOptimizer BatchFeedIterator set_random_seed apply_model reset_default_graph seed build_bow_cnn_custompool_from_options_dict placeholder reduce_sum load_flickr8k_padded_visionsig shape GradientDescentOptimizer cast encode train_fixed_epochs AdadeltaOptimizer format greater_equal MomentumOptimizer swapaxes load join sigmoid_cross_entropy_with_logits minimize print md5 load_flickr8k_padded_bow_labelled reshape now dict AdamOptimizer reduce_mean sigmoid isfile eval_average_precision makedirs train_visionspeech_cnn_custompool eval_precision_recall_fscore AdagradOptimizer BatchFeedIterator set_random_seed apply_model reset_default_graph seed placeholder reduce_sum load_flickr8k_padded_visionsig shape GradientDescentOptimizer cast encode train_fixed_epochs AdadeltaOptimizer format greater_equal MomentumOptimizer swapaxes load join sigmoid_cross_entropy_with_logits minimize print md5 load_flickr8k_padded_bow_labelled reshape now dict AdamOptimizer reduce_mean sigmoid isfile eval_average_precision build_psyc_from_options_dict makedirs train_visionspeech_psyc build_bow_mlp_from_options_dict sigmoid array dataset int sorted join imresize glob min imread BatchFeedIterator input_dir placeholder output_layer build_vgg16 initialize_all_variables images_from_dir output_npz_fn array copyfile str lower sub replace append range process_caption len get_captions_urls range captions_fn word_to_id_fn output_pkl output_dir enumerate join format replace print now shuffle set where zeros float array range enumerate build_feedforward AdagradOptimizer BatchFeedIterator build_bow_mlp_from_options_dict set_random_seed seed sorted load_bow_labelled copyfile placeholder GradientDescentOptimizer shape reduce_sum cast encode train_fixed_epochs AdadeltaOptimizer format greater_equal MomentumOptimizer load join weighted_cross_entropy_with_logits sigmoid_cross_entropy_with_logits minimize print md5 now dict AdamOptimizer reduce_mean sigmoid isfile makedirs train_bow_mlp relu build_conv2d_relu extend flatten softmax build_linear build_maxpool2d imresize imread | kamperh/recipe_semantic_flickraudio | 2,615 |
kamperh/recipe_swbd_wordembeds | ['speech recognition', 'word embeddings'] | ['Deep convolutional acoustic word embeddings using word-pair side information'] | cnn_wordembeds/train_siamese_triplets_cnn.py kaldi_features/utils/nnet/make_lstm_proto.py cnn_wordembeds/train_siamese_triplets_cnn_sweep.py cnn_wordembeds/train_cnn.py cnn_wordembeds/analyze_cnn.py kaldi_features/utils/filt.py kaldi_features/utils/nnet/gen_splice.py cnn_wordembeds/train_cnn_sweep.py kaldi_features/local/make_test_segments.py kaldi_features/utils/nnet/gen_hamm_mat.py cnn_wordembeds/eval_samediff.py cnn_wordembeds/analyze_mlp.py cnn_wordembeds/analyze_sweep.py cnn_wordembeds/data_io.py kaldi_features/utils/reverse_arpa.py cnn_wordembeds/get_swbd_data.py kaldi_features/utils/nnet/make_nnet_proto.py cnn_wordembeds/train_siamese_cnn.py cnn_wordembeds/train_siamese_cnn_sweep.py kaldi_features/utils/nnet/gen_dct_mat.py kaldi_features/local/map_acronyms_transcripts.py kaldi_features/local/map_acronyms_ctm.py cnn_wordembeds/train_mlp_sweep.py cnn_wordembeds/train_mlp.py kaldi_features/local/make_clusters_segments.py kaldi_features/utils/nnet/make_cnn_proto.py kaldi_features/steps/nnet2/make_multisplice_configs.py cnn_wordembeds/apply_layers.py kaldi_features/local/make_dev_segments.py cnn_wordembeds/samediff.py cnn_wordembeds/analyze_embeds.py cnn_wordembeds/sweep_options.py main check_argv get_embeds_and_labels check_argv plot_embeds_2d plot_data_labelled plot_raw_embeds main main check_argv main check_argv main load_model apply_layers check_argv load_swbd_same_diff swbd_utt_to_label swbd_utts_to_labels read_kaldi_ark_from_scp smart_open main load_npz load_swbd_labelled main check_argv main pad_images_width check_argv check_argv average_precision main fixed_dim generate_matches_array main sweep_nn_options load_cnn main train_cnn check_argv main check_argv main train_mlp load_mlp check_argv main check_argv load_siamese_cnn BatchIteratorSameDifferent check_argv main train_siamese_cnn main check_argv load_siamese_triplets_cnn check_argv BatchIteratorTriplets train_siamese_triplets_cnn main main check_argv main check_argv main check_argv main check_argv create_config_files parse_splice_string get_convolution_index_set Glorot add_argument exit ArgumentParser print_help plot_record_dict get_value array_to_pixels model_dir save fromarray str show load_model imshow tile_images close load join print reshape smart_open check_argv figure subplots set_yticklabels set_visible tick_params sorted list make_patch_spines_invisible set_xlabel set_linewidth imshow twinx append range set_position set mean join int get_minorticklines invert_yaxis set_yticks argsort set_ylabel array set_ylim len str TSNE print get_embeds_and_labels plot_data_labelled fit_transform subplot sorted str text set title figure range len set_defaults append swbd_utt_to_label array word_type plot_raw_embeds max seed list plot_embeds_2d append normalize sample keys plot_all norm plot_rnd min split npz_fn len T load_mlp sorted isdir glob model_basedir load_siamese_triplets_cnn load_siamese_cnn load_mlp load_cnn function apply_model vstack lscalar str list sorted load_model shape input shared append range asarray close info keys load join reshape now output smart_open array len basicConfig batch_size set apply_layers info savez_compressed i_layer str get_data_and_labels set add shared_dataset info filter_set load join sorted asarray swbd_utts_to_labels shuffle info append shared keys generate_matches_array load sorted asarray info shared keys append swbd_utt_to_label RandomState entropy metric now pdist average_precision array generate_matches_array int ones round range len pad_images_width data_dir read_kaldi_ark_from_scp mean flatten enumerate makedirs arange plot concatenate cumsum abs xlabel argmin ylabel argsort sum max range len zeros range len shape pdist generate_matches_array distances_fn binary_dists isnan fromfile sum tuple wait Pool str sorted list encode append range get eval_function product keys enumerate deepcopy join map_async md5 print isfile len sweep_nn_options CNN function swbd_utts_to_labels getLogger lscalar errors learning_rule_momentum str basicConfig RandomStreams ivector sorted average_precision pdist apply_layers generate_matches_array dump RandomState l1 close grad dropout_negative_log_likelihood learning_rule_adadelta removeHandler negative_log_likelihood info matrix keys BatchIterator join print reshape l2 makedirs now smart_open parameters train_fixed_epochs_with_validation load_swbd_labelled array len CNN join ivector load RandomState close smart_open info matrix train_cnn copy function swbd_utts_to_labels getLogger lscalar errors learning_rule_momentum str basicConfig RandomStreams ivector sorted average_precision pdist apply_layers generate_matches_array dump RandomState MLP l1 close grad dropout_negative_log_likelihood learning_rule_adadelta removeHandler negative_log_likelihood info matrix keys BatchIterator join print reshape l2 makedirs now smart_open parameters train_fixed_epochs_with_validation load_swbd_labelled array len load join ivector RandomState MLP close smart_open info matrix train_mlp loss_cos_cos cos_same function swbd_utts_to_labels getLogger BatchIteratorSameDifferent load_swbd_same_diff str basicConfig RandomStreams ivector learning_rule_momentum sorted cos_diff loss_cos_cos_margin loss_cos_cos2 average_precision pdist dropout_loss_cos_cos2 apply_layers loss_euclidean_margin SiameseCNN generate_matches_array dropout_loss_euclidean_margin dump Mode RandomState l1 dropout_loss_cos_cos_margin close grad learning_rule_adadelta removeHandler info matrix dropout_loss_cos_cos keys join print reshape l2 now smart_open parameters train_fixed_epochs_with_validation array makedirs load join RandomState close smart_open info matrix SiameseCNN train_siamese_cnn cos_same function swbd_utts_to_labels getLogger BatchIteratorTriplets load_swbd_same_diff str basicConfig RandomStreams ivector learning_rule_momentum sorted cos_diff average_precision pdist apply_layers generate_matches_array Mode dump RandomState l1 close grad loss_hinge_cos learning_rule_adadelta removeHandler info matrix dropout_loss_hinge_cos keys join print reshape l2 now smart_open SiameseTripletCNN parameters train_fixed_epochs_with_validation array makedirs load join RandomState close smart_open SiameseTripletCNN info matrix train_siamese_triplets_cnn clusters_fn int segments_fn tuple write feats_scp_fn open devset_fn n_padding strip testset_fn list sort set append range len int join print min get_convolution_index_set max split splice_indexes join pnorm_input_dim format len write close warn num_hidden_layers sqrt parse_splice_string pnorm_output_dim split append range open with_glorot | kamperh/recipe_swbd_wordembeds | 2,616 |
kanchen-usc/amc_att | ['image retrieval'] | ['AMC: Attention guided Multi-modal Correlation Learning for Image Search'] | clickture/pro_keyword_clickture.py mscoco/pro_keyword_mscoco.py gen_compact_range_by_id gen_count_vector gen_sparse_range_by_id gen_count_vector dump print vocabulary_ open fit_transform len ones astype save enumerate ones astype save enumerate | # AMC: Attention guided Multi-modal Correlation Learning for Image Search This repository includes annotated keyword datasets used by AMC system (CVPR 2017) ## Introduction **AMC System** is initially described in an [arxiv tech report](https://arxiv.org/abs/1704.00763). We leverage visual and textual modalities for image search by learning their correlation with input query. According to the intent of query, attention mechanism can be introduced to adaptively balance the importance of different modalities. ## Framework The framework of AMC is shown below <img src='img/pipeline.png' width='900'> We propose a novel Attention guided Multi-modal Correlation (AMC) learning method which consists of a jointly learned hierarchy of intra and inter-attention networks. Conditioned on query's intent, intra-attention networks (i.e., visual intra-attention network and language intra-attention network) attend on informative parts within each modality; a multi-modal inter-attention network promotes the importance of the most query-relevant modalities. ## Keyword datasets download To validate the effectiveness of AMC System, we annotated a keyword dataset for [Microsoft Clickture dataset](https://www.microsoft.com/en-us/research/project/clickture/) and [MSCOCO Image Caption dataset](http://mscoco.org/dataset/#captions-challenge2015) using an auto-tagging system for each image. Some of the results are shown below (left and right columns are selected samples from Clickture and MSCOCO caption dataset respectively.) | 2,617 |
kanekomasahiro/SLAM18_model | ['language acquisition'] | ['TMU System for SLAM-2018'] | onmt/Dataset.py onmt/modules/__init__.py onmt/Beam.py onmt/Constants.py onmt/Dict.py onmt/modules/GlobalAttention.py test.py Testor.py onmt/__init__.py onmt/Models.py onmt/Optim.py preprocessRNNLM.py BLSTM.py trainRNNLM.py onmt/Translator.py BLSTM makeVocabulary batching saveVocabulary loadData changeStrToFloat initVocabulary make_w2v data_to_batch initFeature feature_to_id changeNumToZero main makeFeature changeStrToFloat reportScore changeNumToZero main feature_to_id Testor measure eval Criterion main trainModel Beam Dataset Dict CNN Decoder NMTModel Encoder StackedLSTM Optim Translator GlobalAttention load_word2vec_format size range load_fasttext_format float items list PAD_WORD UNK_WORD add Dict print makeFeature items list PAD_WORD prune print size UNK_WORD add Dict print makeVocabulary print writeFile pop int list defaultdict items sort changeStrToFloat strip set dict lower open Tensor keys enumerate append split items list defaultdict isinstance dict keys len items list defaultdict fill_ size copy_ PAD dict unsqueeze max range enumerate print range ceil len batch_size make_w2v vocab_size save train_data list sorted minimum_freq initVocabulary initFeature append save_data loadData valid_data keys valid_key remove saveVocabulary print data_to_batch feature_to_id print data Testor strip cuda open defaultdict set_device changeStrToFloat parse_args format set lower detect zip enumerate pop items int sort write output dict Tensor gpu split data ne sum masked_select ones NLLLoss cuda gpus data items sorted view model Variable size measure stack zip append train range cuda CrossEntropyLoss cat len format save_model print start_epoch eval Criterion save preGen train epochs range state_dict Optim copy_ emb_init max_grad_norm BLSTM FloatTensor param_init range stop_lr size zero_ uniform_ optim load learning_rate gpus set_parameters trainModel parameters cpu Dataset | # TMU System for SLAM-2018 This code is [TMU System](http://sharedtask.duolingo.com/papers/kaneko.slam18.pdf) for [SLAM-2018](http://sharedtask.duolingo.com/) ### Requirements - python==3.6.0 - torch==0.4.1 - gensim==3.6.0 ### How to use You need to download data from [this site](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/8SWHNO) and place them to data directory. Preprocessing the data for model training: ```sh | 2,618 |
kanekomasahiro/context-debias | ['word embeddings'] | ['Debiasing Pre-trained Contextualised Embeddings'] | transformers/tests/test_modeling_tf_transfo_xl.py transformers/tests/test_modeling_openai.py transformers/examples/hans/hans_processors.py transformers/docs/source/conf.py transformers/src/transformers/modeling_tf_roberta.py transformers/tests/test_tokenization_bert.py transformers/src/transformers/configuration_electra.py transformers/src/transformers/modeling_electra.py transformers/examples/run_squad.py transformers/src/transformers/tokenization_xlnet.py transformers/src/transformers/modeling_encoder_decoder.py transformers/templates/adding_a_new_model/modeling_xxx.py transformers/tests/test_modeling_tf_camembert.py transformers/src/transformers/utils_encoder_decoder.py transformers/examples/run_aaai.py transformers/tests/test_modeling_tf_albert.py transformers/src/transformers/configuration_transfo_xl.py transformers/src/transformers/modeling_tf_electra.py transformers/templates/adding_a_new_model/tests/test_modeling_tf_xxx.py transformers/tests/test_modeling_auto.py transformers/examples/eval_aaai2019.py transformers/examples/summarization/bertabs/convert_bertabs_original_pytorch_checkpoint.py transformers/src/transformers/modeling_tf_distilbert.py transformers/src/transformers/tokenization_flaubert.py src/run_debias_mlm.py transformers/src/transformers/modeling_tf_xlnet.py transformers/src/transformers/data/processors/squad.py transformers/tests/test_modeling_distilbert.py transformers/examples/distillation/scripts/token_counts.py transformers/tests/test_tokenization_xlm_roberta.py transformers/src/transformers/commands/__init__.py transformers/src/transformers/benchmark_utils.py transformers/src/transformers/convert_bert_pytorch_checkpoint_to_original_tf.py transformers/examples/benchmarks.py transformers/src/transformers/commands/convert.py transformers/src/transformers/modeling_xlm_roberta.py transformers/tests/test_tokenization_fast.py transformers/templates/adding_a_new_model/convert_xxx_original_tf_checkpoint_to_pytorch.py transformers/templates/adding_a_new_model/tests/test_modeling_xxx.py transformers/tests/test_pipelines.py transformers/tests/test_modeling_ctrl.py transformers/src/transformers/modeling_albert.py transformers/utils/download_glue_data.py transformers/src/transformers/modeling_tf_bert.py transformers/src/transformers/tokenization_xlm_roberta.py transformers/tests/test_modeling_bart.py transformers/src/transformers/convert_gpt2_original_tf_checkpoint_to_pytorch.py transformers/src/transformers/modeling_utils.py transformers/tests/test_modeling_tf_bert.py transformers/examples/summarization/bertabs/run_summarization.py transformers/src/transformers/convert_dialogpt_original_pytorch_checkpoint_to_pytorch.py transformers/src/transformers/modeling_roberta.py transformers/src/transformers/modeling_tf_openai.py transformers/src/transformers/data/processors/__init__.py transformers/examples/summarization/t5/test_t5_examples.py transformers/src/transformers/configuration_xlnet.py transformers/examples/summarization/bart/test_bart_examples.py transformers/src/transformers/modeling_tf_auto.py transformers/tests/test_modeling_tf_electra.py transformers/src/transformers/modeling_tf_ctrl.py transformers/examples/summarization/bertabs/modeling_bertabs.py transformers/examples/run_generation.py transformers/src/transformers/modeling_auto.py transformers/examples/glue/run_pl_glue.py transformers/src/transformers/tokenization_bert_japanese.py transformers/tests/test_tokenization_xlnet.py transformers/examples/mm-imdb/utils_mmimdb.py transformers/examples/ner/run_ner.py transformers/src/transformers/convert_albert_original_tf_checkpoint_to_pytorch.py transformers/src/transformers/modeling_tf_gpt2.py transformers/setup.py transformers/src/transformers/configuration_openai.py transformers/src/transformers/tokenization_xlm.py transformers/src/transformers/tokenization_utils.py transformers/src/transformers/modeling_distilbert.py transformers/tests/test_tokenization_ctrl.py transformers/tests/test_modeling_roberta.py transformers/tests/test_modeling_t5.py transformers/examples/eval_aaai.py transformers/examples/run_xnli.py transformers/examples/summarization/bertabs/test_utils_summarization.py transformers/examples/distillation/grouped_batch_sampler.py transformers/src/transformers/configuration_ctrl.py transformers/src/transformers/modeling_gpt2.py transformers/src/transformers/modeling_tf_flaubert.py transformers/examples/hans/test_hans.py transformers/src/transformers/modeling_tf_xlm_roberta.py transformers/tests/test_modeling_flaubert.py transformers/tests/test_modeling_tf_roberta.py transformers/tests/test_modeling_common.py transformers/tests/test_modeling_xlm_roberta.py transformers/utils/link_tester.py transformers/examples/distillation/distiller.py transformers/src/transformers/pipelines.py transformers/src/transformers/tokenization_electra.py transformers/examples/summarization/bart/utils.py transformers/examples/run_language_modeling.py transformers/src/transformers/configuration_xlm.py transformers/src/transformers/file_utils.py transformers/src/transformers/tokenization_transfo_xl.py transformers/examples/run_glue1.py transformers/templates/adding_a_new_model/tests/test_tokenization_xxx.py transformers/src/transformers/optimization.py transformers/src/transformers/commands/train.py transformers/src/transformers/modeling_tf_xlm.py transformers/examples/summarization/bertabs/utils_summarization.py transformers/tests/test_modeling_electra.py transformers/src/transformers/modeling_bart.py transformers/tests/test_tokenization_t5.py transformers/src/transformers/modeling_tf_t5.py transformers/src/transformers/optimization_tf.py transformers/src/transformers/modeling_mmbt.py transformers/tests/test_modeling_tf_gpt2.py transformers/tests/test_tokenization_utils.py transformers/examples/distillation/lm_seqs_dataset.py transformers/src/transformers/hf_api.py transformers/examples/test_examples.py transformers/templates/adding_a_new_model/modeling_tf_xxx.py transformers/examples/summarization/bart/evaluate_cnn.py transformers/src/transformers/modeling_bert.py transformers/src/transformers/configuration_roberta.py transformers/src/transformers/modeling_tf_transfo_xl_utilities.py transformers/src/transformers/modeling_transfo_xl.py transformers/src/transformers/tokenization_bart.py transformers/src/transformers/modelcard.py transformers/src/transformers/tokenization_albert.py transformers/src/transformers/tokenization_t5.py transformers/src/transformers/convert_openai_original_tf_checkpoint_to_pytorch.py transformers/src/transformers/modeling_xlm.py transformers/tests/test_modeling_tf_distilbert.py transformers/src/transformers/configuration_flaubert.py transformers/examples/hans/utils_hans.py transformers/tests/test_modeling_xlnet.py transformers/examples/contrib/run_openai_gpt.py transformers/examples/summarization/bertabs/configuration_bertabs.py transformers/examples/ner/run_pl_ner.py transformers/tests/test_modeling_gpt2.py transformers/tests/test_configuration_auto.py transformers/examples/contrib/run_camembert.py transformers/src/transformers/commands/download.py transformers/tests/test_tokenization_bert_japanese.py transformers/tests/test_tokenization_auto.py transformers/tests/test_modeling_albert.py transformers/tests/test_tokenization_openai.py transformers/tests/test_configuration_common.py transformers/src/transformers/convert_transfo_xl_original_tf_checkpoint_to_pytorch.py transformers/tests/test_doc_samples.py transformers/examples/contrib/run_swag.py transformers/examples/ner/run_tf_ner.py transformers/examples/distillation/scripts/binarized_data.py transformers/tests/test_modeling_tf_t5.py transformers/examples/run_glue.py transformers/src/transformers/configuration_t5.py transformers/examples/summarization/bart/run_bart_sum.py transformers/examples/transformer_base.py transformers/examples/distillation/run_squad_w_distillation.py transformers/examples/run_debias_glue.py transformers/src/transformers/modeling_tf_albert.py transformers/tests/test_tokenization_roberta.py transformers/examples/translation/t5/evaluate_wmt.py transformers/tests/test_modeling_tf_xlnet.py transformers/tests/test_tokenization_distilbert.py transformers/src/transformers/convert_pytorch_checkpoint_to_tf2.py transformers/examples/summarization/t5/download_cnn_daily_mail.py transformers/templates/adding_a_new_example_script/run_xxx.py transformers/tests/test_modeling_transfo_xl.py transformers/tests/test_hf_api.py transformers/examples/contrib/run_transfo_xl.py transformers/src/transformers/configuration_utils.py transformers/hubconf.py transformers/src/transformers/tokenization_gpt2.py transformers/src/transformers/commands/env.py transformers/tests/test_modeling_bert.py transformers/src/transformers/modeling_ctrl.py transformers/src/transformers/tokenization_roberta.py transformers/src/transformers/modeling_tf_utils.py transformers/tests/test_optimization.py transformers/src/transformers/modeling_tf_camembert.py transformers/src/transformers/tokenization_openai.py transformers/tests/test_modeling_camembert.py transformers/src/transformers/commands/serving.py transformers/examples/distillation/utils.py transformers/src/transformers/tokenization_ctrl.py transformers/tests/test_tokenization_gpt2.py transformers/src/transformers/configuration_xlm_roberta.py transformers/tests/test_modeling_tf_xlm.py transformers/templates/adding_a_new_example_script/utils_xxx.py transformers/examples/translation/t5/test_t5_examples.py transformers/src/transformers/configuration_camembert.py transformers/examples/mm-imdb/run_mmimdb.py transformers/examples/run_bertology.py transformers/examples/utils_multiple_choice.py transformers/src/transformers/tokenization_auto.py transformers/tests/test_modeling_tf_auto.py transformers/src/transformers/tokenization_bert.py transformers/src/transformers/configuration_auto.py transformers/src/transformers/data/metrics/squad_metrics.py transformers/examples/distillation/scripts/extract_distilbert.py transformers/src/transformers/data/processors/utils.py transformers/examples/distillation/scripts/extract.py transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py transformers/tests/test_tokenization_albert.py transformers/tests/test_tokenization_transfo_xl.py transformers/src/transformers/modeling_t5.py transformers/src/transformers/convert_roberta_original_pytorch_checkpoint_to_pytorch.py transformers/src/transformers/tokenization_camembert.py transformers/src/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py transformers/tests/utils.py transformers/tests/test_model_card.py transformers/tests/test_modeling_tf_ctrl.py transformers/src/transformers/modeling_camembert.py transformers/tests/test_modeling_xlm.py transformers/examples/run_tf_glue.py transformers/src/transformers/modeling_transfo_xl_utilities.py transformers/src/transformers/convert_xlm_original_pytorch_checkpoint_to_pytorch.py transformers/src/transformers/__init__.py transformers/src/transformers/data/__init__.py transformers/src/transformers/convert_bart_original_pytorch_checkpoint_to_pytorch.py transformers/src/transformers/data/processors/xnli.py src/preprocess.py transformers/examples/summarization/t5/evaluate_cnn.py transformers/src/transformers/activations.py transformers/src/transformers/convert_t5_original_tf_checkpoint_to_pytorch.py transformers/tests/test_activations.py transformers/examples/ner/utils_ner.py transformers/src/transformers/commands/user.py transformers/src/transformers/data/metrics/__init__.py transformers/src/transformers/modeling_flaubert.py transformers/src/transformers/configuration_distilbert.py transformers/examples/distillation/train.py transformers/src/transformers/configuration_bart.py transformers/src/transformers/tokenization_distilbert.py transformers/src/transformers/configuration_bert.py transformers/src/transformers/modeling_openai.py transformers/tests/test_tokenization_xlm.py transformers/src/transformers/convert_xlnet_original_tf_checkpoint_to_pytorch.py transformers/templates/adding_a_new_model/tokenization_xxx.py transformers/templates/adding_a_new_model/configuration_xxx.py transformers/src/transformers/modeling_tf_transfo_xl.py transformers/src/transformers/configuration_gpt2.py transformers/tests/test_optimization_tf.py transformers/src/transformers/configuration_mmbt.py transformers/src/transformers/configuration_albert.py transformers/tests/test_tokenization_common.py transformers/examples/pplm/run_pplm_discrim_train.py transformers/examples/run_multiple_choice.py transformers/tests/test_modeling_tf_openai_gpt.py transformers/src/transformers/modeling_xlnet.py transformers/src/transformers/commands/run.py transformers/src/transformers/data/processors/glue.py transformers/examples/pplm/pplm_classification_head.py transformers/tests/test_modeling_tf_common.py transformers/examples/pplm/run_pplm.py transformers/src/transformers/modeling_tf_pytorch_utils.py split_data main encode_to_is prepare_transformer parse_args TextDataset set_seed LineByLineTextDataset create_dataloader split_data create_dataset main train load_and_cache_examples modelForSequenceClassification config model tokenizer modelForQuestionAnswering modelWithLMHead setup create_setup_and_compute print_summary_statistics _compute_pytorch main _compute_tensorflow set_seed evaluate main train load_and_cache_examples set_seed evaluate main train load_and_cache_examples set_seed evaluate main train load_and_cache_examples entropy print_2d_tensor compute_heads_importance main mask_heads prune_heads set_seed evaluate main train load_and_cache_examples set_seed prepare_xlm_input prepare_transfoxl_input prepare_ctrl_input adjust_length_to_model main prepare_xlnet_input set_seed evaluate main train load_and_cache_examples set_seed evaluate main train load_and_cache_examples TextDataset set_seed evaluate LineByLineTextDataset train _sorted_checkpoints mask_tokens main _rotate_checkpoints load_and_cache_examples simple_accuracy set_seed evaluate select_field main train load_and_cache_examples set_seed evaluate main to_list train load_and_cache_examples set_seed evaluate main train load_and_cache_examples ExamplesTests get_setup_file BaseTransformer set_seed LoggingCallback add_generic_args generic_train ArcProcessor InputFeatures RaceProcessor InputExample convert_examples_to_features SwagProcessor DataProcessor fill_mask load_rocstories_dataset main pre_process_datasets accuracy read_swag_examples set_seed evaluate InputFeatures accuracy _truncate_seq_pair SwagExample convert_examples_to_features select_field main train load_and_cache_examples main Distiller GroupedBatchSampler _quantize create_lengths_groups LmSeqsDataset set_seed evaluate main to_list train load_and_cache_examples main freeze_token_type_embeddings sanity_checks freeze_pos_embeddings set_seed init_gpu_params git_log main GLUETransformer HansProcessor hans_convert_examples_to_features set_seed evaluate main train load_and_cache_examples InputFeatures DataProcessor InputExample load_examples set_seed evaluate main train get_mmimdb_labels collate_fn get_image_transforms ImageEncoder JsonlDataset set_seed evaluate main train load_and_cache_examples NERTransformer load_cache evaluate save_cache main train load_and_cache_examples InputFeatures get_labels InputExample convert_examples_to_features read_examples_from_file ClassificationHead full_text_generation to_var run_pplm_example get_bag_of_words_indices top_k_filter perturb_past set_generic_model_params build_bows_one_hot_vectors generate_text_pplm get_classifier train_discriminator train_epoch cached_collate_fn get_cached_data_loader collate_fn Discriminator Dataset predict evaluate_performance generate_summaries chunks run_generate BartSystem TestBartExamples SummarizationDataset BertAbsConfig convert_bertabs_checkpoints BertAbsPreTrainedModel PositionwiseFeedForward TransformerDecoderLayer build_predictor gelu TransformerDecoder PenaltyBuilder Translator BertAbs Bert TransformerDecoderState BertSumOptimizer tile DecoderState MultiHeadedAttention PositionalEncoding GNMTGlobalScorer format_rouge_scores format_summary evaluate decode_summary save_rouge_scores documents_dir_is_valid main build_data_iterator load_and_cache_examples save_summaries collate SummarizationDataProcessingTest CNNDMDataset encode_for_summarization truncate_or_pad compute_token_type_ids build_mask process_story _add_missing_period main calculate_rouge generate_summaries chunks run_generate TestT5Examples calculate_bleu_score generate_translations chunks run_generate TestT5Examples swish gelu_new _gelu_python get_activation start_memory_tracing MemorySummary bytes_to_human_readable Memory is_memory_tracing_enabled Frame MemoryState UsedMemoryState stop_memory_tracing AlbertConfig AutoConfig BartConfig BertConfig CamembertConfig CTRLConfig DistilBertConfig ElectraConfig FlaubertConfig GPT2Config MMBTConfig RobertaConfig T5Config TransfoXLConfig PretrainedConfig XLMConfig XLMRobertaConfig XLNetConfig convert_tf_checkpoint_to_pytorch convert_bart_checkpoint load_xsum_checkpoint remove_ignore_keys_ rename_key convert_tf_checkpoint_to_pytorch main convert_pytorch_checkpoint_to_tf convert_dialogpt_checkpoint convert_gpt2_checkpoint_to_pytorch convert_openai_checkpoint_to_pytorch convert_all_pt_checkpoints_to_tf convert_pt_checkpoint_to_tf convert_roberta_checkpoint_to_pytorch convert_tf_checkpoint_to_pytorch convert_transfo_xl_checkpoint_to_pytorch convert_xlm_checkpoint_to_pytorch convert_xlnet_checkpoint_to_pytorch is_torch_available cached_path s3_etag http_get hf_bucket_url s3_request s3_get get_from_cache add_start_docstrings add_start_docstrings_to_callable url_to_filename is_remote_url filename_to_url split_s3_path is_tf_available add_end_docstrings S3Object HfApi PresignedUrl ModelInfo S3Obj HfFolder TqdmProgressFileReader ModelCard AlbertForMaskedLM AlbertForQuestionAnswering AlbertTransformer load_tf_weights_in_albert AlbertPreTrainedModel AlbertMLMHead AlbertModel AlbertAttention AlbertLayer AlbertForSequenceClassification AlbertForTokenClassification AlbertEmbeddings AlbertLayerGroup AutoModel AutoModelForQuestionAnswering AutoModelForTokenClassification AutoModelForPreTraining AutoModelWithLMHead AutoModelForSequenceClassification make_padding_mask PretrainedBartModel LayerNorm _get_shape _make_linear_from_emb _check_shapes shift_tokens_right SelfAttention invert_mask _reorder_buffer DecoderLayer _prepare_bart_decoder_inputs LearnedPositionalEmbedding BartModel BartDecoder BartEncoder EncoderLayer BartForConditionalGeneration BartClassificationHead fill_with_neg_inf _filter_out_falsey_values BartForSequenceClassification CamembertForSequenceClassification CamembertModel CamembertForMaskedLM CamembertForQuestionAnswering CamembertForMultipleChoice CamembertForTokenClassification point_wise_feed_forward_network scaled_dot_product_attention CTRLLMHeadModel MultiHeadAttention CTRLModel angle_defn positional_encoding CTRLPreTrainedModel EncoderLayer Transformer DistilBertForSequenceClassification DistilBertForTokenClassification create_sinusoidal_embeddings DistilBertForMaskedLM Embeddings FFN DistilBertPreTrainedModel TransformerBlock DistilBertForQuestionAnswering DistilBertModel MultiHeadSelfAttention load_tf_weights_in_electra ElectraPreTrainedModel ElectraModel ElectraForPreTraining ElectraForMaskedLM ElectraForTokenClassification ElectraGeneratorPredictions ElectraEmbeddings ElectraDiscriminatorPredictions PreTrainedEncoderDecoder FlaubertForSequenceClassification FlaubertWithLMHeadModel FlaubertForQuestionAnswering FlaubertModel FlaubertForQuestionAnsweringSimple GPT2LMHeadModel Block GPT2DoubleHeadsModel load_tf_weights_in_gpt2 MLP GPT2PreTrainedModel GPT2Model Attention ModalEmbeddings MMBTModel MMBTForClassification Block OpenAIGPTPreTrainedModel MLP OpenAIGPTDoubleHeadsModel OpenAIGPTLMHeadModel Attention OpenAIGPTModel load_tf_weights_in_openai_gpt RobertaForSequenceClassification RobertaLMHead RobertaClassificationHead RobertaForTokenClassification RobertaEmbeddings RobertaForQuestionAnswering RobertaForMultipleChoice RobertaForMaskedLM RobertaModel T5LayerSelfAttention T5PreTrainedModel T5Stack load_tf_weights_in_t5 T5Attention T5Model T5LayerCrossAttention T5LayerNorm T5DenseReluDense T5Block T5ForConditionalGeneration T5LayerFF TFAlbertLayerGroup TFAlbertMainLayer TFAlbertSelfAttention TFAlbertTransformer TFAlbertModel TFAlbertForSequenceClassification TFAlbertEmbeddings TFAlbertSelfOutput TFAlbertLayer TFAlbertAttention TFAlbertPreTrainedModel TFAlbertForMaskedLM TFAlbertMLMHead TFAutoModelForSequenceClassification TFAutoModelForQuestionAnswering TFAutoModel TFAutoModelWithLMHead TFAutoModelForTokenClassification TFAutoModelForPreTraining TFBertModel TFBertAttention TFBertPreTrainedModel gelu_new TFBertForPreTraining TFBertIntermediate TFBertNSPHead TFBertForMaskedLM TFBertSelfAttention TFBertLayer TFBertPredictionHeadTransform TFBertEmbeddings TFBertEncoder TFBertPooler TFBertOutput TFBertForSequenceClassification TFBertForTokenClassification gelu TFBertMainLayer TFBertSelfOutput TFBertForNextSentencePrediction TFBertMLMHead swish TFBertForMultipleChoice TFBertForQuestionAnswering TFBertLMPredictionHead TFCamembertForSequenceClassification TFCamembertForMaskedLM TFCamembertModel TFCamembertForTokenClassification OpenAIGPTConfig convert_tf_checkpoint_to_pytorch BertPreTrainingHeads BertForQuestionAnswering BertEncoder BertSelfAttention BertForMaskedLM BertOnlyMLMHead BertOnlyNSPHead BertEmbeddings BertOutput mish BertPredictionHeadTransform BertAttention BertPooler BertPreTrainedModel BertForMultipleChoice BertLayer BertForTokenClassification BertModel BertForNextSentencePrediction BertIntermediate BertForSequenceClassification BertForPreTraining BertLMPredictionHead load_tf_weights_in_bert BertSelfOutput point_wise_feed_forward_network scaled_dot_product_attention TFCTRLLMHeadModel TFEncoderLayer TFMultiHeadAttention TFCTRLPreTrainedModel angle_defn TFCTRLModel TFCTRLMainLayer positional_encoding TFCTRLLMHead ProjectedAdaptiveLogSoftmax TFDistilBertForMaskedLM TFDistilBertPreTrainedModel TFFFN TFDistilBertMainLayer TFDistilBertForQuestionAnswering gelu TFMultiHeadSelfAttention TFDistilBertModel TFTransformerBlock TFTransformer TFDistilBertForSequenceClassification TFDistilBertForTokenClassification TFEmbeddings gelu_new TFDistilBertLMHead TFElectraForMaskedLM TFElectraDiscriminatorPredictions TFElectraEmbeddings TFElectraMainLayer TFElectraForPreTraining TFElectraForTokenClassification TFElectraMaskedLMHead TFElectraPreTrainedModel TFElectraModel TFElectraGeneratorPredictions TFFlaubertWithLMHeadModel TFFlaubertModel TFFlaubertForSequenceClassification TFFlaubertMainLayer TFAttention TFGPT2MainLayer TFMLP TFGPT2LMHeadModel TFGPT2Model gelu TFGPT2PreTrainedModel TFGPT2DoubleHeadsModel TFBlock TFAttention TFMLP gelu swish TFOpenAIGPTModel TFOpenAIGPTMainLayer TFOpenAIGPTPreTrainedModel TFOpenAIGPTLMHeadModel TFOpenAIGPTDoubleHeadsModel TFBlock load_pytorch_model_in_tf2_model load_pytorch_weights_in_tf2_model convert_tf_weight_name_to_pt_weight_name load_pytorch_checkpoint_in_tf2_model load_tf2_checkpoint_in_pytorch_model load_tf2_weights_in_pytorch_model load_tf2_model_in_pytorch_model TFRobertaForTokenClassification TFRobertaForMaskedLM TFRobertaLMHead TFRobertaForSequenceClassification TFRobertaClassificationHead TFRobertaPreTrainedModel TFRobertaMainLayer TFRobertaEmbeddings TFRobertaModel TFT5Block TFT5LayerCrossAttention _NoLayerEmbedTokens TFT5LayerNorm TFT5LayerFF TFT5DenseReluDense TFT5PreTrainedModel TFT5MainLayer TFT5Attention TFT5ForConditionalGeneration TFT5Model TFT5LayerSelfAttention TFPositionalEmbedding TFTransfoXLLMHead TFTransfoXLLMHeadModel TFTransfoXLPreTrainedModel TFRelPartialLearnableDecoderLayer TFPositionwiseFF TFAdaptiveEmbedding TFTransfoXLMainLayer TFRelPartialLearnableMultiHeadAttn TFTransfoXLModel TFAdaptiveSoftmaxMask _create_next_token_logits_penalties TFSequenceSummary TFPreTrainedModel TFSharedEmbeddings set_tensor_by_indices_to_value calc_banned_ngram_tokens BeamHypotheses TFConv1D tf_top_k_top_p_filtering TFModelUtilsMixin keras_serializable calc_banned_bad_words_ids get_initializer shape_list scatter_values_on_batch_indices TFXLMModel get_masks create_sinusoidal_embeddings TFTransformerFFN gelu TFMultiHeadAttention TFXLMPreTrainedModel TFXLMForSequenceClassification TFXLMWithLMHeadModel TFXLMForQuestionAnsweringSimple TFXLMPredLayer TFXLMMainLayer TFXLMRobertaForSequenceClassification TFXLMRobertaForTokenClassification TFXLMRobertaModel TFXLMRobertaForMaskedLM TFXLNetForTokenClassification TFXLNetRelativeAttention TFXLNetPreTrainedModel gelu swish TFXLNetModel TFXLNetForSequenceClassification TFXLNetForQuestionAnsweringSimple TFXLNetLMHead TFXLNetLMHeadModel TFXLNetLayer TFXLNetFeedForward TFXLNetMainLayer TransfoXLModel PositionalEmbedding load_tf_weights_in_transfo_xl AdaptiveEmbedding TransfoXLPreTrainedModel RelPartialLearnableDecoderLayer TransfoXLLMHeadModel PositionwiseFF build_tf_to_pytorch_map RelPartialLearnableMultiHeadAttn prune_layer SQuADHead PoolerAnswerClass SequenceSummary prune_linear_layer calc_banned_ngram_tokens prune_conv1d_layer PoolerEndLogits ModuleUtilsMixin top_k_top_p_filtering calc_banned_bad_words_ids Conv1D PreTrainedModel PoolerStartLogits create_position_ids_from_input_ids BeamHypotheses XLMModel XLMWithLMHeadModel XLMPreTrainedModel XLMPredLayer XLMForSequenceClassification get_masks create_sinusoidal_embeddings MultiHeadAttention XLMForQuestionAnswering TransformerFFN XLMForQuestionAnsweringSimple XLMForTokenClassification XLMRobertaForMultipleChoice XLMRobertaForSequenceClassification XLMRobertaForTokenClassification XLMRobertaModel XLMRobertaForMaskedLM XLNetRelativeAttention XLNetPreTrainedModel XLNetForQuestionAnswering build_tf_xlnet_to_pytorch_map XLNetLMHeadModel XLNetForMultipleChoice XLNetForQuestionAnsweringSimple load_tf_weights_in_xlnet XLNetFeedForward XLNetForSequenceClassification XLNetModel XLNetLayer XLNetForTokenClassification get_constant_schedule_with_warmup AdamW get_linear_schedule_with_warmup get_constant_schedule get_cosine_with_hard_restarts_schedule_with_warmup get_cosine_schedule_with_warmup AdamWeightDecay GradientAccumulator WarmUp create_optimizer TextClassificationPipeline QuestionAnsweringPipeline ArgumentHandler _ScikitCompat JsonPipelineDataFormat TranslationPipeline FeatureExtractionPipeline PipelineDataFormat QuestionAnsweringArgumentHandler PipedPipelineDataFormat FillMaskPipeline NerPipeline SummarizationPipeline get_framework CsvPipelineDataFormat pipeline Pipeline DefaultArgumentHandler AlbertTokenizer AutoTokenizer BartTokenizer BertTokenizerFast BasicTokenizer WordpieceTokenizer load_vocab whitespace_tokenize _is_whitespace _is_control BertTokenizer _is_punctuation BertJapaneseTokenizer MecabTokenizer CharacterTokenizer CamembertTokenizer get_pairs CTRLTokenizer DistilBertTokenizerFast DistilBertTokenizer ElectraTokenizer ElectraTokenizerFast convert_to_unicode FlaubertTokenizer bytes_to_unicode get_pairs GPT2TokenizerFast GPT2Tokenizer get_pairs OpenAIGPTTokenizer _OpenAIGPTCharBPETokenizer text_standardize OpenAIGPTTokenizerFast RobertaTokenizerFast RobertaTokenizer T5Tokenizer LMShuffledIterator LMOrderedIterator TransfoXLCorpus LMMultiFileIterator get_lm_corpus TransfoXLTokenizerFast _TransfoXLDelimiterLookupTokenizer TransfoXLTokenizer PreTrainedTokenizerFast truncate_and_pad PreTrainedTokenizer trim_batch get_pairs replace_unicode_punct remove_non_printing_char romanian_preprocessing XLMTokenizer lowercase_and_remove_accent XLMRobertaTokenizer XLNetTokenizer prepare_encoder_decoder_model_kwargs ConvertCommand convert_command_factory download_command_factory DownloadCommand info_command_factory EnvironmentCommand run_command_factory try_infer_format_from_ext RunCommand ServeForwardResult ServeModelInfoResult serve_command_factory ServeDeTokenizeResult ServeCommand ServeTokenizeResult train_command_factory TrainCommand WhoamiCommand UploadCommand LoginCommand ANSI BaseUserCommand DeleteObjCommand UserCommands LogoutCommand ListObjsCommand BaseTransformersCLICommand compute_f1 find_best_thresh_v2 normalize_answer make_eval_dict _compute_softmax find_all_best_thresh compute_predictions_logits get_final_text find_best_thresh compute_predictions_log_probs compute_exact _get_best_indexes find_all_best_thresh_v2 get_raw_scores get_tokens apply_no_ans_threshold squad_evaluate merge_eval simple_accuracy pearson_and_spearman glue_compute_metrics xnli_compute_metrics is_sklearn_available acc_and_f1 MrpcProcessor ColaProcessor MnliMismatchedProcessor QqpProcessor MnliProcessor StsbProcessor QnliProcessor RteProcessor glue_convert_examples_to_features WnliProcessor Sst2Processor _check_is_max_context SquadProcessor SquadV2Processor squad_convert_examples_to_features _improve_answer_span _is_whitespace SquadV1Processor SquadExample _new_check_is_max_context squad_convert_example_to_features_init squad_convert_example_to_features SquadFeatures SquadResult SingleSentenceClassificationProcessor InputFeatures DataProcessor InputExample XnliProcessor set_seed evaluate main to_list train load_and_cache_examples _check_is_max_context _compute_softmax write_predictions_extended InputFeatures get_final_text _improve_answer_span _get_best_indexes read_squad_examples convert_examples_to_features SquadExample write_predictions XxxConfig convert_tf_checkpoint_to_pytorch TFXxxForTokenClassification TFXxxPreTrainedModel TFXxxForMaskedLM TFXxxForQuestionAnswering TFXxxForSequenceClassification TFXxxModel TFXxxMainLayer TFXxxLayer XxxForTokenClassification XxxPreTrainedModel XxxForSequenceClassification XxxModel XxxForMaskedLM XxxLayer XxxForQuestionAnswering load_tf_weights_in_xxx XxxTokenizer load_vocab TFXxxModelTest XxxModelTest XxxTokenizationTest FlaubertModelTest TFT5ModelIntegrationTests TFT5ModelTest TestActivations AutoConfigTest ConfigTester get_examples_from_file TestCodeExamples HfApiEndpointsTest HfApiPublicTest HfApiLoginTest HfApiCommonTest HfFolderTest AlbertModelTest AutoModelTest _long_tensor BartModelIntegrationTests _assert_tensors_equal prepare_bart_inputs_dict BARTModelTest BartHeadTests ModelTester BertModelTest CamembertModelIntegrationTest ModelUtilsTest _config_zero_init floats_tensor UtilsFunctionsTest ModelTesterMixin ids_tensor CTRLModelLanguageGenerationTest CTRLModelTest DistilBertModelTest ElectraModelTest GPT2ModelTest GPT2ModelLanguageGenerationTest OPENAIGPTModelLanguageGenerationTest OpenAIGPTModelTest RobertaModelTest RobertaModelIntegrationTest T5ModelTest T5ModelIntegrationTests TFAlbertModelTest TFAutoModelTest TFBertModelTest TFCamembertModelIntegrationTest UtilsFunctionsTest _config_zero_init ids_tensor TFModelTesterMixin TFCTRLModelLanguageGenerationTest TFCTRLModelTest TFDistilBertModelTest TFElectraModelTest TFGPT2ModelLanguageGenerationTest TFGPT2ModelTest TFOPENAIGPTModelLanguageGenerationTest TFOpenAIGPTModelTest TFRobertaModelTest TFRobertaModelIntegrationTest TFTransfoXLModelTest TFTransfoXLModelLanguageGenerationTest TFXLMModelTest TFXLMModelLanguageGenerationTest TFXLNetModelLanguageGenerationTest TFXLNetModelTest TransfoXLModelLanguageGenerationTest TransfoXLModelTest XLMModelLanguageGenerationTest XLMModelTest XLMRobertaModelIntegrationTest XLNetModelTest XLNetModelLanguageGenerationTest ModelCardTester ScheduleInitTest unwrap_and_save_reload_schedule OptimizationTest unwrap_schedule OptimizationFTest MonoColumnInputTestCase PipelineCommonTests MultiColumnInputTestCase AlbertTokenizationTest AutoTokenizerTest BertTokenizationTest BertJapaneseTokenizationTest BertJapaneseCharacterTokenizationTest TokenizerTesterMixin CTRLTokenizationTest DistilBertTokenizationTest FastTokenizerMatchingTest GPT2TokenizationTest OpenAIGPTTokenizationTest RobertaTokenizationTest T5TokenizationTest TransfoXLTokenizationTest TokenizerUtilsTest XLMTokenizationTest XLMRobertaTokenizationTest XLNetTokenizationTest require_tf parse_flag_from_env parse_int_from_env custom_tokenizers slow require_torch download_and_extract format_mrpc get_tasks main download_diagnostic find_all_links check_all_links scan_code_for_links list_python_files_in_repository add_argument ArgumentParser from_pretrained tuple strip save prepare_transformer ngrams list len encode append set attributes zip stereotypes encode_to_is compile enumerate print output index split dict dataset keys list create_dataset line_by_line list len shuffle zip range enumerate seed manual_seed_all manual_seed items list min DataLoader iter max gradient_accumulation_steps resize_token_embeddings get_linear_schedule_with_warmup clip_grad_norm_ zero_grad DataParallel DistributedDataParallel max_grad_norm forward max initialize per_gpu_eval_batch_size weighted_loss load_state_dict master_params sum SummaryWriter close create_dataloader shuffle mean eval num_train_epochs info fp16 trange float save_best_model per_gpu_train_batch_size max_steps enumerate load join int n_gpu model_name_or_path AdamW backward tqdm parameters step train_batch_size len enable_attach from_pretrained config_name should_continue resize_token_embeddings block_size data_file warning ArgumentParser device basicConfig add_special_tokens set_seed set_device _sorted_checkpoints parse_args to init_process_group tokenizer_name info fp16 from_config wait_for_attach train load n_gpu model_name_or_path add_argument min barrier max_len split_data bool load_and_cache_examples local_rank add_stylesheet add_js_file isinstance print set_jit _compute_pytorch set_experimental_options _compute_tensorflow print join from_pretrained str start_memory_tracing print float print_summary_statistics half total eval repeat trace encode inference to sum enumerate stop_memory_tracing len from_pretrained str start_memory_tracing print print_summary_statistics total stack repeat encode inference float sum enumerate stop_memory_tracing len is_torch_available create_setup_and_compute tensorflow is_tf_available torch model tuple DataLoader output_dir save exists list set_seed logging_steps state_dict format save_pretrained items evaluate add_scalar print makedirs dumps tuple DataLoader DataParallel argmax max eval_batch_size squeeze per_gpu_eval_batch_size compute_metrics append SequentialSampler cat update format mean eval softmax info item zip load_and_cache_examples join n_gpu makedirs tqdm numpy len pop join str format load get_train_examples max_seq_length data_dir barrier get_labels get_dev_examples TensorDataset convert_examples_to_features save info get_test_examples tensor do_train output_dir eval_all_checkpoints setLevel get_labels WARN update lower save_pretrained task_name join evaluate makedirs dict log join len range info arange model tuple unsqueeze save device output_dir max numel append to sum detach requires_grad_ info view_as enumerate join entropy backward min print_2d_tensor tqdm pow zeros numpy numpy save output_dir max str view tolist numel masking_threshold sum ones_like info float view_as int join clone print_2d_tensor compute_heads_importance masking_amount now dict compute_heads_importance info sum DataParallel DistributedDataParallel DataLoader data_subset prune_heads range format mask_heads Subset compute_heads_importance encode info str list eval input xlm_language keys decode prepare_input squeeze_ length tolist model_type generate get adjust_length_to_model join sorted format glob match output_dir append format save_total_limit rmtree _sorted_checkpoints info max len pad_token_id bool mask_token convert_tokens_to_ids clone randint shape masked_fill_ eq tensor mlm_probability full len device to _rotate_checkpoints output_dir device tensor exp to exit save_vocabulary str do_test simple_accuracy lower select_field len update version_2_with_negative max_answer_length default_timer do_lower_case n_best_size squad_evaluate verbose_logging enumerate int compute_predictions_logits compute_predictions_log_probs version_2_with_negative null_score_diff_threshold unique_id SquadResult squad_convert_examples_to_features warn get_examples_from_dataset version_2_with_negative register_half_function parse_args add_argument ArgumentParser add_argument enable_attach set_seed print fp16_opt_level n_tpu_cores dict Trainer do_train fp16 ModelCheckpoint wait_for_attach fit endings join format replace zip example_id InputFeatures map tqdm question info append contexts encode_plus enumerate len join topk mask_token replace unsqueeze softmax split item append enumerate argmax tuple len append zeros full enumerate gradient_accumulation_steps do_eval model get_linear_schedule_with_warmup n_positions zero_grad add_tokens tokenize_and_encode numpy pre_process_datasets max seed save_vocabulary convert_tokens_to_ids device_count TensorDataset to_json_file eval_dataset SequentialSampler state_dict manual_seed_all lm_coef eval num_train_epochs manual_seed trange max_steps int backward AdamW accuracy train_dataset RandomSampler named_parameters tqdm model_name load_rocstories_dataset step label start_ending convert_tokens_to_ids swag_id _truncate_seq_pair context_sentence tokenize pop len read_swag_examples dirname accuracy batch_size reset_length tgt_len clamp_len mem_len get_iterator same_length ext_len list deepcopy sorted _quantize format info KLDivLoss alpha_squad temperature log_softmax softmax loss_fct alpha_ce end_n_top start_n_top teacher_name_or_path mlm freeze_token_type_embds freeze_pos_embs LmSeqsDataset is_master exists values freeze_pos_embeddings Distiller mlm from_numpy freeze_token_type_embds freeze_token_type_embeddings student_config init_gpu_params sanity_checks dump_path items teacher_name student_pretrained_weights maximum rmtree empty_cache student_model_class git_log Repo int str multi_gpu n_gpu_per_node init_process_group gethostname set_device global_rank n_nodes is_master multi_node info world_size node_id local_rank time shuffle vocab_size str join text_b InputFeatures len get_labels pairID tfds_map guid info label get_example_from_tensor_dict float text_a enumerate append encode_plus criterion load_examples join max_seq_length data_dir get_mmimdb_labels get_image_transforms num_image_embeds JsonlDataset get_label_frequencies tensor BCEWithLogitsLoss MMBTForClassification load_state_dict MMBTConfig ImageEncoder load_examples get_mmimdb_labels zeros stack zip enumerate str sorted range keys read_examples_from_file ignore_index labels progress_bar write now reset_states master_bar summary ceil create_file_writer range list SparseCategoricalCrossentropy progress_bar master_bar experimental_distribute_dataset ceil TFRecordDataset reduce map segment_ids label_ids create_int_feature TFRecordWriter write SerializeToString close OrderedDict Example input_mask info input_ids enumerate load_cache prefetch shuffle save_cache repeat batch TPUClusterResolver experimental_connect_to_cluster initialize_tpu_system experimental_distribute_dataset set_verbosity TPUStrategy set_experimental_options classification_report OneDeviceStrategy INFO flag_values_dict MirroredStrategy join format words extend labels guid num_added_tokens to cuda expand_as data resize_token_embeddings model tuple unsqueeze numpy classifier tensor list ones map matmul shape permute append to sum CrossEntropyLoss range detach softmax zero_ ce_loss backward print t mm cached_path load format isinstance print eval load_state_dict to cached_path append to list append scatter_ get_classifier get_bag_of_words_indices print range append empty_cache numpy generate_text_pplm split decode model top_k_filter unsqueeze classifier tensor topk tolist append sum CrossEntropyLoss set mean multinomial softmax trange ce_loss print perturb_past build_bows_one_hot_vectors from_pretrained decode full_text_generation bos_token seed list set_generic_model_params encode input to append update format set eval manual_seed enumerate get_bag_of_words_indices print parameters split pad_sequences tensor list keys tensor list keys cat format backward print nll_loss zero_grad train_custom discriminator item dataset step enumerate len format print eval dataset len avg_representation print tolist encode tensor DataLoader tqdm enumerate get_cached_data_loader DataLoader save Field tensor sorted splits Adam encode append to range predict state_dict detokenize format set trange evaluate_performance int time random_split print train_epoch parameters Dataset len range len from_pretrained list write batch_encode_plus tqdm chunks generate to flush open generate_summaries add_argument model_name ArgumentParser parse_args output_path from_pretrained generator unsqueeze save device load_state_dict encode state_dict format BertAbsSummarizer eval info item load AbsSummarizer BertAbsConfig print extend allclose len Translator alpha GNMTGlobalScorer list view size contiguous range len from_pretrained format_rouge_scores batch_size min_length summaries_output_dir Rouge dataset from_batch max_length translate_batch alpha compute_rouge get_scores download save_summaries beam_size print build_predictor document_names save_rouge_scores build_data_iterator join zip strip SequentialSampler load_and_cache_examples DataLoader CNNDMDataset documents_dir pad_token_id Batch cls_token_id compute_token_type_ids build_mask tensor decode numpy split summaries_output_dir documents_dir listdir list popleft startswith deque append startswith extend len ones_like append replace as_numpy write flush open update get task_specific_params add_scores format aggregate score RougeScorer BootstrapAggregator write zip open batch_size model_size device score_path calculate_rouge from_pretrained update get list task_specific_params write batch_encode_plus tqdm chunks generate to flush open format corpus_bleu score write open generate_translations calculate_bleu_score nvmlInit nvmlShutdown settrace items sorted defaultdict list Memory MemoryState zip append sum str format AlbertForMaskedLM print load_tf_weights_in_albert save from_json_file state_dict pop load eval load_state_dict from_pretrained hasattr replace remove_ignore_keys_ eval unsqueeze load_xsum_checkpoint upgrade_state_dict load_state_dict _make_linear_from_emb mkdir shared save_pretrained extract_features rename_key predict state_dict pop BertForPreTraining load_tf_weights_in_bert reset_default_graph state_dict makedirs convert_pytorch_checkpoint_to_tf load join pop save makedirs format load_tf_weights_in_gpt2 print GPT2Model save from_json_file GPT2Config state_dict format OpenAIGPTConfig print OpenAIGPTModel save load_tf_weights_in_openai_gpt from_json_file state_dict cached_path str load format model_class from_pretrained print abs load_pytorch_checkpoint_in_tf2_model save_weights dummy_inputs tf_model numpy from_json_file amax cached_path list format remove zip print convert_pt_checkpoint_to_tf isfile keys enumerate len from_pretrained num_classes zeros_like allclose print num_hidden_layers bias extract_features eval BertConfig save_pretrained mkdir item sentence_encoder weight range load_tf_weights_in_t5 T5Model pop str join format __dict__ load_tf_weights_in_transfo_xl print TransfoXLLMHeadModel save abspath TransfoXLConfig from_json_file state_dict load items list format print dict save str join format XLNetForQuestionAnswering print XLNetLMHeadModel XLNetForSequenceClassification load_tf_weights_in_xlnet abspath save from_json_file state_dict urlparse encode endswith hexdigest sha256 str join isinstance str join replace isinstance get_from_cache is_remote_url exists split path netloc urlparse startswith resource split_s3_path Object resource split_s3_path download_fileobj is_torch_available get update format isinstance write close tqdm is_tf_available iter_content len get str s3_etag join isinstance url_to_filename startswith head exists makedirs expanduser load_variable join int format replace info zip print transpose fullmatch from_numpy getattr list_variables abspath append split pad_token_id shift_tokens_right size make_padding_mask invert_mask to data shape Linear squeeze unsqueeze clone eq index_select list items is_available pow cos angle_defn unsqueeze sin cat sqrt softmax permute matmul detach_ FloatTensor cos sin array load_variable int format replace info isinstance endswith print transpose zip fullmatch from_numpy any getattr list_variables abspath append split load_variable int format info zip squeeze fullmatch from_numpy getattr list_variables abspath append split pop int format zip cumsum fullmatch from_numpy getattr dirname info split abspath list transpose from_numpy shape getattr list_variables append format astype info keys load_variable join pop int fullmatch float32 any split count sqrt erf pow tanh sqrt pi load_tf_weights_in_electra ElectraForPreTraining ElectraForMaskedLM load_variable join int format info zip transpose fullmatch from_numpy any getattr list_variables abspath append split power float32 concatenate cast float32 cast pow tanh pi join replace sub bool split load format abspath info sum state_dict base_model_prefix trainable_weights tf_model list discard name transpose squeeze non_trainable_weights append expand_dims format replace convert_tf_weight_name_to_pt_weight_name set dummy_inputs zip info keys batch_set_value pop numpy config format load_weights getattr dummy_inputs info tf_model tf_model_class __name__ weights base_model_prefix list discard name transpose squeeze from_numpy load_state_dict append expand_dims format convert_tf_weight_name_to_pt_weight_name set info keys __name__ items named_parameters dict count hasattr get_config __init__ utils getattr ones put shape zeros shape_list enumerate get tuple tolist zip range append set_tensor_by_indices_to_value cumsum concat min roll argsort softmax gather max shape_list scatter_values_on_batch_indices reshape transpose concat broadcast_to shape_list expand_dims range zeros_like as_list shape constant less_equal assert_equal shape_list cast tile less range count update r_r_bias hasattr tie_weight layers out_layers tie_projs emb_layers r_w_bias transformer emb_projs untie_r zip append out_projs enumerate load_variable pop list format items join transpose from_numpy list_variables info keys build_tf_to_pytorch_map enumerate cumsum sort size min clone scatter softmax max int type_as list size len contiguous copy_ device to detach list size len contiguous copy_ device to detach isinstance Linear size arange count update r_r_bias r_s_bias hasattr r_w_bias bias transformer untie_r seg_embed append weight layer enumerate load_variable pop list format items join isinstance build_tf_xlnet_to_pytorch_map transpose from_numpy list_variables info keys enumerate AdamWeightDecay WarmUp PolynomialDecay from_pretrained warning isinstance OrderedDict rstrip enumerate strip split category category startswith startswith category ord add set append list range ord sub replace load join format TransfoXLCorpus save info exists format enable_truncation enable_padding no_padding no_truncation warning any join category lower append normalize sub replace append category startswith replace pop get update copy endswith SUPPORTED_FORMATS from_str pipeline pipeline Counter get_tokens sum values len print max qas_id list items float len sorted sum enumerate find_best_thresh_v2 sorted sum enumerate find_best_thresh make_eval_dict find_all_best_thresh apply_no_ans_threshold get_raw_scores merge_eval join _strip_spaces list items BasicTokenizer len info tokenize find sorted append range enumerate len append exp strip end_logit _get_best_indexes sorted defaultdict get_final_text _NbestPrediction end_logits OrderedDict append start_logit _compute_softmax insert start_logits info convert_tokens_to_string enumerate join namedtuple text _PrelimPrediction split end_log_prob cls_logits strip sorted defaultdict hasattr do_lowercase_and_remove_accent get_final_text _NbestPrediction do_lower_case OrderedDict append range _compute_softmax info convert_tokens_to_string enumerate join namedtuple text min _PrelimPrediction start_log_prob split simple_accuracy f1_score join text_b float InputFeatures text_a get_labels tfds_map guid info label get_example_from_tensor_dict cardinality encode_plus enumerate append len join tokenize range length start min enumerate min enumerate end_position convert_ids_to_tokens _improve_answer_span warning is_impossible encode_plus cls_token_id tolist encode append range doc_tokens question_text whitespace_tokenize max_len_sentences_pair _new_check_is_max_context answer_text tokenize enumerate minimum join pad_token_id min index max_len start_position SquadFeatures array len arange size min cpu_count tqdm TensorDataset append tensor RawResult write_predictions write_predictions_extended evaluate_on_squad RawResultExtended EVAL_OPTS predict_file arange size read_squad_examples join is_whitespace whitespace_tokenize warning SquadExample append len _DocSpan _improve_answer_span is_impossible orig_answer_text length range doc_tokens question_text start _check_is_max_context namedtuple strip end_logit _get_best_indexes sorted defaultdict get_final_text _NbestPrediction end_logits OrderedDict append start_logit replace _compute_softmax insert start_logits info enumerate join namedtuple text _PrelimPrediction split end_log_prob cls_logits strip find_all_best_thresh_v2 make_qid_to_has_ans sorted defaultdict get_final_text _NbestPrediction do_lower_case OrderedDict append range _compute_softmax info convert_tokens_to_string enumerate join namedtuple text min _PrelimPrediction get_raw_scores start_log_prob split XxxForPreTraining load_tf_weights_in_xxx load_variable join int format info zip transpose fullmatch from_numpy any getattr list_variables abspath append split strip len append enumerate find HfApi ne pad_token_id allclose deepcopy list setattr keys append randint range append random range constant Random append step get_lr range append step get_lr range print remove urlretrieve print join urlretrieve mkdir print join urlretrieve mkdir append split download_and_extract path_to_mrpc data_dir format_mrpc get_tasks tasks mkdir download_diagnostic append join walk append head | # Debiasing Pre-trained Contextualised Embeddings [Masahiro Kaneko](https://sites.google.com/view/masahirokaneko/english?authuser=0), [Danushka Bollegala](http://danushka.net/) Code and debiased word embeddings for the paper: "Debiasing Pre-trained Contextualised Embeddings" (In EACL 2021). If you use any part of this work, make sure you include the following citation: ``` @inproceedings{kaneko-bollegala-2021-context, title={Debiasing Pre-trained Contextualised Embeddings}, author={Masahiro Kaneko and Danushka Bollegala}, booktitle = {Proc. of the 16th European Chapter of the Association for Computational Linguistics (EACL)}, year={2021} } | 2,619 |
kanekomasahiro/dict-debias | ['word embeddings'] | ['Dictionary-based Debiasing of Pre-trained Word Embeddings'] | src/dataset.py src/optim.py src/train.py src/model.py src/trainer.py EmbDataset EmbDictDataset GradReverse Decoder Encoder Optim remove_stop_words save_word2vec_format debiasing_emb preprocess_dictionary retrieve_original_case main parse_args make_optim Trainer add_argument ArgumentParser words set items list defaultdict zip append synsets set_parameters Optim parameters len remove_stop_words set retrieve_original_case tolist zero_grad stack change_model_mode zip ceil encoder to array range len config save_prefix endswith save_word2vec_format EmbDictDataset Trainer DataLoader Path EmbDataset open seed run MSELoss dictionary save_binary preprocess_dictionary load_word2vec_format to manual_seed_all format shuffle Encoder manual_seed info make_optim load embedding debiasing_emb Decoder gpu | # Dictionary-based Debiasing of Pre-trained Word Embeddings [Masahiro Kaneko](https://sites.google.com/view/masahirokaneko/english?authuser=0), [Danushka Bollegala](http://danushka.net/) Code and debiased word embeddings for the paper: "Dictionary-based Debiasing of Pre-trained Word Embeddings" (In EACL 2021). If you use any part of this work, make sure you include the following citation: ``` @inproceedings{kaneko-bollegala-2021-dict, title={Dictionary-based Debiasing of Pre-trained Word Embeddings}, author={Masahiro Kaneko and Danushka Bollegala}, booktitle = {Proc. of the 16th European Chapter of the Association for Computational Linguistics (EACL)}, year={2021} } | 2,620 |
kanekomasahiro/gp_debias | ['word embeddings'] | ['Gender-preserving Debiasing for Pre-trained Word Embeddings'] | src/optim.py hyperparams/hyperparams_gn_glove.py eval_word_embeddings.py src/pre_train_autoencoder.py src/train.py hyperparams/hyperparams_glove.py src/model.py src/eval.py src/pre_train_classifier.py main Hyperparams Hyperparams main de_biassing_emb eval_bias_analogy Decoder Classifier Encoder Optim pre_train_autoencoder pre_train_classifier save_checkpoint remove_words_not_in_word2emb make_no_gender_words create_train_dev remove_pairs_not_in_word2emb make_pair_words shuffle_data main make_optim trainModel input add_argument eval_bias_analogy ArgumentParser load_word2vec_format parse_args norm format print dot open enumerate split format Word2VecKeyedVectors concatenate print add eval stack split load_word2vec_format cuda word_embedding load de_biassing_emb format eval_model print save_word2vec_format Encoder cuda emb_size load_state_dict dropout_rate hidden_size load remove format save_model state_dict FloatTensor shuffle MSELoss run_model save split pta_epochs float range pta_batch_size format save_model save state_dict load remove format save_model MSELoss run_model save cls_epochs float range state_dict randperm len shuffle_data load deepcopy calculate_gender_vektor format save_model state_dict remove print gender_vektor_loss MSELoss gender_no_gender_loss epochs run_model save float BCELoss range len tolist read_csv set_parameters Optim parameters cls_learning_rate zero_grad cls_max_grad_norm cls_lr_decay max_grad_norm open pta_lr_decay stereotype_words pta_max_grad_norm pta_optimizer lr_decay make_pair_words gender_words pre_train_classifier Classifier cls_optimizer pta_learning_rate eval make_optim optimizer word_embedding learning_rate no_gender_words pre_train_autoencoder pta_dropout_rate make_no_gender_words Decoder trainModel create_train_dev | # Gender-preserving Debiasing for Pre-trained Word Embeddings [Masahiro Kaneko](https://sites.google.com/view/masahirokaneko/english?authuser=0), [Danushka Bollegala](http://danushka.net/) Code and debiased word embeddings for the paper: "[Gender-preserving Debiasing for Pre-trained Word Embeddings](https://arxiv.org/abs/1906.00742)" (In ACL 2019). If you use any part of this work, make sure you include the following citation: ``` @inproceedings{Kaneko:ACL:2019, title={Gender-preserving Debiasing for Pre-trained Word Embeddings}, author={Masahiro Kaneko and Danushka Bollegala}, booktitle={Proc. of the 57th Annual Meeting of the Association for Computational Linguistics (ACL)}, year={2019} } | 2,621 |
karins/CoherenceFramework | ['text generation'] | ['Neural Net Models for Open-Domain Discourse Coherence'] | python/corpus/strip_doctags.py python/discourse/syntax_based/compute_syntactic_pairs.py python/discourse/split_docs.py python/setup.py python/discourse/preprocessing/grid.py python/corpus/compare_connectives.py python/corpus/convert_to_mteval.py python/discourse/entity_based/grid_model.py python/discourse/pipeline.py python/discourse/syntax_based/alouis_decoder.py python/corpus/analyse_connectives.py python/discourse/modeleval.py python/discourse/preprocessing/docs.py python/discourse/syntax_based/alouis.py python/corpus/strip_tags.py python/corpus/tokenize_xml_input.py python/corpus/inject_errors.py python/discourse/europarl_filter.py python/discourse/util.py python/discourse/syntax_based/compare.py python/corpus/extract_lexical_cohesion_errors.py python/discourse/entity_based/grid.py python/discourse/preprocessing/ldc.py python/discourse/doctext.py python/discourse/docsgml.py python/discotools.py python/corpus/match_hter_alignments.py python/discourse/preprocessing/parsedoctext.py python/discourse/entity_based/grid_decoder.py python/discourse/syntax_based/dseq.py python/corpus/corpus_pipeline.py python/corpus/process_alignments.py python/discourse/__init__.py python/discourse/preprocessing/sgml2txt.py python/discourse/extract_morphology.py python/discourse/preprocessing/parse.py python/corpus/connective_sense.py python/discourse/wmtgold.py python/discourse/syntax_based/ibm1_decoder.py python/discourse/significance.py python/discourse/extract_scores.py python/corpus/inject_errors_plain.py python/discourse/syntax_based/ibm1.py python/discourse/shuffle.py python/corpus/strip_brackets.py python/corpus/extract_connectives.py python/discourse/rankings.py parse_args configure_commands importall main extract_connectives argparser extract_connectives argparser derive_errors extract_connective_errors main main extract_connectives compare_sense argparser main argparser main make_workspace get_doctext_dir argparser main extract_connectives argparser argparser derive_errors printit extract_nouns main inject_lexical_errors get_tag get_corpora argparser get_alignment is_structural_error_line inject_discourse_errors get_nearest_noun inject_errors get_errors get_corpora_doctext read_alignments tag_error_attributes main inject_clausal_errors print_corpus tag_error inject_lexical_errors get_tag get_corpora argparser get_alignment is_structural_error_line inject_discourse_errors get_nearest_noun inject_errors get_errors get_corpora_doctext read_alignments tag_error_attributes main inject_clausal_errors print_corpus tag_error main argparser extract_docs match_alignments_to_doc get_doc_alignments argparser main read_alignments analyse main argparser main argparser TextFromSGML wmtbadsgml_iterdoc fixwmt_main argparser MakeSGMLDocs fixwmt_argparser badsgml_iterdoc main argparser writedoctext iteraddheader iterdoctext main matches_criteria extract_segment extract_target matches_both_criteria main extract_source parse_args main parse_args output_score get_ref_scores main get_scores parse_args ranks_higher expected_win top1 rho make_namespace extract_dseqs evaluate argparser decode_grid decode_alouis decode_ibm1 train_grid main train_ibm1 file_check wrap_dseqs train_alouis main argparser main parse_args bootstrap_resampling paired_bootstrap_resampling_pairwise assess_first test_ranker argparser assess_comparisons modelcmp test_all_rankers main get_confidence_intervals read_rankings paired_bootstrap_resampling get_refsysid main parse_args partial_ordering _partial_ordering find_least_common ibm_pairwise encode_documents read_documents register_token smart_open bar encode_test_documents pairwise tabulate make_total_ordering command iterclasses itercommands argparser get_number_of_occurrences read_grids get_role_count main train decode_many read_bigrams argparser wrapped_loglikelihood read_unigrams loglikelihood main grid_loglikelihood open_file convert_tree output_grid main extract_grids construct_grid parse_args extract_and_save_txt parse_command_line extract_and_save_sgml main make_workspace grids_from_text parse_command_line make_workspace grids_from_sgml main parse_ldc_name_from_path ldc_name_re get_ldc_name parse_ldc_name parse parse_command_line parse_and_save make_workspace main main parse wrap_parse argparser badsgml2text parse_command_line make_workspace main badsgml2goodsgml minimize argparser loglikelihood main count decode_many decode load_model argparser wrapped_loglikelihood loglikelihood main main parse_args extension read_and_tally get_bigrams get_unigram compute_nonconsecutive_bigrams get_bigram test compute_consecutive_bigrams count_bigrams get_unigrams output_results read_xml dseqs argparser _find_subtrees main find_subtrees ibm1 main loglikelihood argparser decode_many decode load_model argparser wrapped_loglikelihood loglikelihood main parse_args configure_commands importall main extract_connectives argparser extract_connectives argparser derive_errors extract_connective_errors main compare_sense make_workspace get_doctext_dir extract_connectives derive_errors printit extract_nouns inject_lexical_errors get_tag get_corpora get_alignment is_structural_error_line inject_discourse_errors get_nearest_noun inject_errors get_errors get_corpora_doctext read_alignments tag_error_attributes inject_clausal_errors print_corpus tag_error inject_lexical_errors get_tag get_corpora get_alignment is_structural_error_line inject_discourse_errors get_nearest_noun inject_errors get_errors get_corpora_doctext read_alignments tag_error_attributes inject_clausal_errors print_corpus tag_error extract_docs match_alignments_to_doc get_doc_alignments analyse TextFromSGML wmtbadsgml_iterdoc fixwmt_main MakeSGMLDocs fixwmt_argparser badsgml_iterdoc writedoctext iteraddheader iterdoctext matches_criteria extract_segment extract_target matches_both_criteria extract_source parse_args parse_args output_score get_ref_scores get_scores ranks_higher expected_win top1 rho make_namespace extract_dseqs evaluate argparser decode_grid decode_alouis decode_ibm1 train_grid train_ibm1 file_check wrap_dseqs train_alouis main argparser parse_args bootstrap_resampling paired_bootstrap_resampling_pairwise assess_first test_ranker assess_comparisons modelcmp test_all_rankers get_confidence_intervals read_rankings paired_bootstrap_resampling get_refsysid partial_ordering _partial_ordering find_least_common ibm_pairwise encode_documents read_documents register_token smart_open bar encode_test_documents pairwise tabulate make_total_ordering command iterclasses itercommands argparser get_number_of_occurrences read_grids get_role_count main train decode_many read_bigrams argparser wrapped_loglikelihood read_unigrams loglikelihood main grid_loglikelihood open_file convert_tree output_grid extract_grids construct_grid parse_args extract_and_save_txt parse_command_line extract_and_save_sgml make_workspace grids_from_text parse_command_line make_workspace grids_from_sgml parse_ldc_name_from_path ldc_name_re get_ldc_name parse_ldc_name parse parse_and_save main parse wrap_parse argparser badsgml2text badsgml2goodsgml minimize loglikelihood count decode_many decode load_model argparser wrapped_loglikelihood loglikelihood parse_args extension read_and_tally get_bigrams get_unigram compute_nonconsecutive_bigrams get_bigram test compute_consecutive_bigrams count_bigrams get_unigrams output_results read_xml dseqs argparser _find_subtrees find_subtrees ibm1 main loglikelihood argparser decode_many decode load_model wrapped_loglikelihood loglikelihood sorted itercommands add_parser add_subparsers prog_parser sorted add_parser importall func ArgumentParser iterclasses add_subparsers configure_commands extract_connectives info parse_args basicConfig add_argument ArgumentParser defaultdict directory print derive_errors output sep extract_connectives defaultdict derive_errors int list defaultdict items print debug write dumps open append makedirs int list defaultdict items print safe_load split append open mt pe compare_sense int list defaultdict items print debug write dumps append open pop input sep makedirs int str threshold workspace debug error_type corpus get_doctext_dir connective_errors inject_errors extract_nouns read_alignments make_workspace alignments makedirs write dumps sep errorfile get set debug list items defaultdict info items list get_corpora structural connectives errors items list defaultdict inject_lexical_errors debug inject_discourse_errors get_errors get_corpora_doctext inject_clausal_errors tag_error_attributes print_corpus open str list safe_load UNICODE insert debug enumerate int deepcopy remove join items print split findall find print debug defaultdict print defaultdict info load int get rstrip list items print print_corpus tag_error open print pos_tag get_nearest_noun tag_error_attributes print_corpus open str word_tokenize list safe_load UNICODE debug enumerate int deepcopy join remove items print split findall find items list min defaultdict enumerate items list print str defaultdict print debug readlines append DEBUG len extract_docs match_alignments_to_doc open defaultdict debug readlines split find get str list defaultdict rstrip items print debug readlines len write dumps open find append range split basicConfig info analyse len ArgumentDefaultsHelpFormatter set_defaults append strip search group dict iter findall IGNORECASE compile append strip search group dict findall IGNORECASE compile MakeSGMLDocs write add_doc wmtbadsgml_iterdoc writedoctext write output MakeSGMLDocs input attr add_id sgml enumerate split set_defaults add_argument ArgumentParser print join filter append strip replace startswith basename writedoctext iteraddheader iterdoctext extract_target extract_source target output makedirs seek matches_criteria matches_both_criteria startswith append split search startswith search startswith split basicConfig add_argument set_defaults makedirs str list items write info model OrderedDict get_ref_scores get_scores str join debug ceil float len shape range zeros shape range zeros shape range zeros list remove concatenate mean shape range items format Namespace print smoothing unk m1 salience training namespace repr exit insertion info depth alias makedirs format len frozenset info writedoctext smart_open iterdoctext info partial dseqs dry_run map jobs trees info file_check depth Pool len dseq_bigrams communicate unk alouis_config Popen len training append chain format glob alouis_model insertion info join dseq_unigrams dseqs smoothing dry_run split dseq_unigrams alouis_probs dseqs dseq_bigrams smoothing dry_run retest info file_check alouis_decode_many join format t1 dseqs glob communicate dry_run m1 training m1_config split ibm1_model info chain Popen len dseqs t1 dry_run retest ibm1_decode_many ibm1_probs info file_check join format grids glob communicate dry_run Popen salience training grid_model split ibm1_model info chain role_bigrams role_unigrams len grid_probs info dry_run salience retest grid_decode_many grids file_check role_bigrams role_unigrams sorted format debug dry_run makedirs refsys info append array len make_namespace grid train_grid dev ibm1 extract_dseqs ibm1_eval decode_grid decode_alouis training ibm1_probs test alouis train_ibm1 grid_eval alouis_probs evaluate alouis_eval grid_probs decode_ibm1 train_alouis add_argument_group partial_ordering list join append named_system array range strip set make_total_ordering startswith append zeros enumerate len shape combinations list shape zeros range int metric choice shape append range combinations list metric choice shape zeros range combinations pairwise_metric list choice shape zeros range bootstrap_resampling paired_bootstrap_resampling_pairwise assess_first assess_comparisons get_confidence_intervals test_ranker info append read_rankings open join sorted metric index tablefmt refsys rounds info systems array paired_bootstrap_resampling column_stack top1 systems throw column_stack sorted ranker seterr metric refsys rounds ranks_higher partial modelcmp pvalue enumerate index tablefmt test_all_rankers simplefilter ProgressBar next tee list sorted range len get len chain most_common Counter defaultdict register_token array endswith zeros pairwise transpose bar list reduce Counter values size salience read_grids train int strip len startswith zeros split int strip startswith zeros split sum read_bigrams partial zip print size map read_unigrams smart_open read_grids info Pool enumerate len read_bigrams unigrams bigrams format read_unigrams grid_loglikelihood endswith str defaultdict print debug iterdoctext len pos str print get_instance str print zeros keys len print enumerate get_ldc_name info get_ldc_name info basicConfig workspace add_argument ArgumentParser make_workspace parse_args zip map jobs Pool tabulate sgml workspace format info workspace time format info time groups dry_run info split time format parse workspace info join communicate debug Popen time parse info workspace format info workspace format info zeros bar product getpairs bar getpairs stdin unk loglikelihood count boundary mle encode_documents read_documents mean insertion minimize smoothing zeros defaultdict register_token len zeros sum log enumerate len format load_model print read_documents mean encode_test_documents loglikelihood info sum enumerate len load_model read_documents encode_test_documents decode exp args split extension read_and_tally str int print output_results range open print str len split str int print count_bigrams output_results range open print str split print str print str len split print str len split data str getElementsByTagName parse print len print print extend fromstring _find_subtrees isinstance format isinstance is_valid fromstring label get_child find_subtrees append ibm_pairwise list product ibm_pairwise ones bar info append zeros sum array range min_gain max_iterations ll nan_to_num filter progress size | CoherenceFramework ================== This codebase now includes several basic coherence models: ## Entity-based coherence models: Code for: 1. entity grid experiment 2. entity graph experiment Both are multilingual. They currently work for French, German and Spanish. For English, syntactic roles can be derived. This is not the case for French, German and Spanish. | 2,622 |
karlnapf/kernel_goodness_of_fit | ['density estimation'] | ['A Kernel Test of Goodness of Fit'] | density_estimation/increasing_features_fixed_test.py stat_test/unit_tests/test_gaussianQuadraticTest.py sgld_test/mcmc_convergance/generating_mcmc_sample.py stat_test/unit_tests/test.py binomodal/__init__.py tstudent/process_q_st.py density_estimation/increasing_features_fixed_test_plot.py sgld_test/mcmc_convergance/plot_mixing.py sgld_test/sgld_convergance/plot_mixing.py sgld_test/heikos_experiment/__init__.py thinning/plot_thinning.py samplers/__init__.py sgld_test/sgld_convergance/plot_the_sample.py tools/tools.py sgld_test/auxiliary_plots/plotting_gradients.py sgld_test/heikos_experiment/as_likelihood.py goodness_of_fit/test_gaussianQuadraticTest.py binomodal/test.py tstudent/power.py tstudent/quadratic_student.py stat_test/unit_tests/test_SampleSelector.py samplers/austerity.py sgld_test/heikos_experiment/austerity_convergance/generating_aust_sample.py stat_test/unit_tests/__init__.py tstudent/__init__.py sgld_test/mcmc_convergance/cosnt.py sgld_test/mcmc_convergance/__init__.py tstudent/plot_mcmc_student.py sgld_test/unit_tests/__init__.py thinning/what_thinning_does.py goodness_of_fit/test.py thinning/__init__.py tstudent/plot_autocorr.py sgld_test/unit_tests/test_one_sample_SGLD.py sgld_test/sgld_convergance/generate_sgld_sample.py stat_test/quadratic_time.py sgld_test/unit_tests/test_lik_2.py density_estimation/increasing_data_fixed_test.py 2dimNormal/__init__.py samplers/test_austerity.py sgld_test/gradients_of_likelihood.py stat_test/__init__.py stat_test/ar.py sgld_test/auxiliary_plots/__init__.py sgld_test/mcmc_convergance/analyze_acf.py stat_test/unit_tests/test_GaussianSteinTest.py samplers/MetropolisHastings.py sgld_test/heikos_experiment/austerity_convergance/__init__.py sgld_test/mcmc_convergance/plot_the_sample.py sgld_test/sgld_convergance/__init__.py sgld_test/constants.py tools/latex_plot_init.py stat_test/linear_time.py sgld_test/bimodal_SGLD.py 2dimNormal/2dimNormal.py model_criticism/plot_null_vs_alt_gp_regression.py sgld_test/likelihoods.py sgld_test/auxiliary_plots/plotting_posterior.py density_estimation/increasing_data_fixed_test_plot.py tstudent/sgld_student.py grad_log_dens logg grad_log_normal kwargs_gen kwargs_gen GoodnessOfFitTest _GoodnessOfFitTest grad_log_correleted simulatepm TestGaussianQuadraticTest compute_gp_regression_gradients sample_null_simulated_gp prepare_dataset bootstrap_null approximate_MH_accept austerity mh_generator metropolis_hastings TestAusterity SGLD evSGLD lik_2 grad_log_prior manual_grad lik_1 _log_probability _log_lik gen_X log_probability _vector_of_log_likelihoods get_thinning log_density_prior grad_log_lik vectorized_log_lik log_density_prior vectorized_log_lik vectorized_log_density grad_log_pob vectorized_log_density grad_log_pob man_grad_log_prior prior2 scalar_log_lik prior2man TestManualLikelihoods TestOne_sample_SGLD simulate simulatepm mahalanobis_distance GaussianSteinTest SampleSelector grad_log_correleted QuadraticMultiple QuadraticMultiple2 GaussianQuadraticTest grad_log_normal TestGaussianQuadraticTest TestMeanEmbeddingTest TestSelector log_normal store_results log_normal grad_log_normal sample_sgld_t_student grad_log_t_df normal_mild_corr get_thinning grad_log_normal correlatet_t grad_log_normal almost_t_student grad_log_normal log_normal grad_log_normal grad_log_t_df get_thinning get_pair get_pval gen zeros range inv int permutation argsort mean std len randn outer sign mean empty range randn compute_gp_regression_gradients get_statistic_multiple_custom_gradient empty range len log_density_prior hasattr randn rand approximate_MH_accept append range log len min log_lik choice mean sqrt sf abs hasattr randn log_density uniform append array range len permutation randn grad_log_density grad_log_prior choice sqrt zeros array range permutation randn grad_log_density grad_log_prior choice sqrt zeros sum range len lik_2 lik_1 log pdf sum _vector_of_log_likelihoods _log_lik log pdf append rand range randn abs argmin acf sum manual_grad sum grad_log_prior manual_grad append sqrt exp pi zeros sqrt range randn transpose inv solve mean shape dot cov float join to_csv strftime gmtime read_csv append DataFrame exists makedirs grad_log_t_df metropolis_hastings metropolis_hastings rand randn zeros sqrt range randn grad_log_t_df get_statistic_multiple gen get_pval | # Kernel goodness of fit testing Code for the paper "[A Kernel Test of Goodness of Fit](http://arxiv.org/abs/1602.02964)" by Kacper Chwialkowski, Heiko Strathmann, Arthur Gretton Note this code is yet experimental and potentially incomplete. | 2,623 |
karlnapf/nystrom-kexpfam | ['density estimation', 'denoising'] | ['Efficient and principled score estimation with Nyström kernel exponential families'] | nystrom_kexpfam/estimators/SGKEF.py nystrom_kexpfam/density.py nystrom_kexpfam/visualisation.py nystrom_kexpfam/data_generators/Ring.py nystrom_kexpfam/estimators/WrappedEstimatorBase.py nystrom_kexpfam/log.py nystrom_kexpfam/estimators/KMCLite.py scripts/mcmc_glass_ground_truth.py nystrom_kexpfam/estimators/DAE.py nystrom_kexpfam/mathematics.py nystrom_kexpfam/data_generators/Base.py nystrom_kexpfam/data_generators/Dataset.py nystrom_kexpfam/autoencoder.py nystrom_kexpfam/tools.py nystrom_kexpfam/posterior_gp_classification_ard.py nystrom_kexpfam/hamiltonian.py nystrom_kexpfam/data_generators/Gaussian.py DenoisingAutoencoder log_gaussian_pdf rings_sample log_gaussian_pdf_isotropic rings_log_pdf_grad sample_gaussian compute_avg_acceptance leapfrog compute_hamiltonian compute_log_accept_pr Log log_mean_exp avg_prob_of_log_probs score log_sum_exp qmult hypercube GlassPosterior PseudoMarginalHyperparameters log_prior_log_pdf sha1sum pdf_grid visualise_array_2d visualise_fit_2d DataGenerator GlassPosteriorDataset Dataset LogPDFDataset GammaEigenvalueRotatedGaussian Mixture IsotropicGaussian GaussianGrid GaussianGridWrapped GaussianGridWrappedNoGradient Gaussian2Mixture FullGaussian Dataset IsotropicZeroMeanGaussian GaussianBase Ring RingNoGradient DAE KMCLite SGKEFNy SGKEF SGKEFNyD2FixedL2_1e_5 SGKEFNyFixedL2_1e_5 SGKEFNyDFixedL2_1e_5 WrappedEstimatorBase get_am_instance cho_solve pi dot cholesky eye zeros array log len log pi len atleast_1d cholesky len randn reshape rand cos pi choice sin zeros len norm T exp arctan2 logsumexp pi dot shape zeros range array log len add_subplot linspace max log_mean_exp show exp set_title set_xlabel p_sample meshgrid compute_log_accept_pr plot set_xlim grad info leapfrog T norm min set_ylabel figure eye cholesky visualise_array_2d set_ylim len dlogq copy shape zeros array range compute_hamiltonian atleast_2d argmin min delete log_mean_exp exp min isinf float len norm randn copy sign dot outer zeros float range ndim len sha1 nanmax nanmin T set_under set_clim add_subplot colorbar scatter figure pcolor list T log_pdf_multiple product grad_multiple set_data tile sum array len min add_subplot figure linspace pdf_grid visualise_array_2d max AdaptiveMetropolis | Experimental codes for AISTATS 2018 paper "Efficient and principled score estimation with Nyström kernel exponential families" by Dougal Sutherland, Heiko Strathmann, Michael Arbel, and Arthur Gretton, https://arxiv.org/abs/1705.08360. See notebooks/demo.ipynb for how to use the estimator(s), and how to replicate experimental results. Dependencies (some are optional, see demo notebook): * numpy, scipy, matplotlib * Shogun, http://shogun.ml/, more specifically the code in the feature branch https://github.com/karlnapf/shogun/tree/feature/kernel_exp_family, compiled with the Python interface. We are working on pushing this into the main branch of Shogun, so that it can be installed using `conda install -c conda-forge shogun`. * the Python package https://github.com/karlnapf/kernel_exp_family * tensorflow For the Python packages (given that you have downloaded them) and Shogun (given that you have compiled or installed it), this could be achieved with something like ``` export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:path/to/libshogun.so | 2,624 |
karuj/StyleTransfer | ['style transfer'] | ['A Neural Algorithm of Artistic Style'] | StyleTransfer.py get_model load_images gram_matrix get_activation save_image vgg19 isinstance AvgPool2d Sequential Normalization MaxPool2d add_module Conv2d requires_grad_ parameters eval ReLU features cuda requires_grad_ Compose cuda open size view children layer enumerate imwrite ToPILImage tfm squeeze cpu | # Implementing the Gatys et al. paper on Style transfer (https://arxiv.org/abs/1508.06576) Here im using the Adam optimizer instead of the LBFGS optimizer. # Results    | 2,625 |
kashyap7x/QGN | ['scene parsing', 'semantic segmentation'] | ['Quadtree Generating Networks: Efficient Hierarchical Scene Parsing with Sparse Convolutions'] | lib/utils/data/distributed.py lib/nn/modules/tests/test_numeric_batchnorm.py lib/nn/modules/tests/test_sync_batchnorm.py lib/utils/data/sampler.py models/resnext.py lib/utils/th.py lib/nn/__init__.py train.py data_utils/gen_labels.py make_CityScapes.py lib/utils/data/dataloader.py lib/utils/data/__init__.py dataset.py lib/utils/__init__.py models/__init__.py lib/nn/modules/batchnorm.py lib/nn/modules/unittest.py utils.py lib/utils/data/dataset.py models/models.py test.py lib/nn/modules/replicate.py lib/nn/parallel/__init__.py lib/nn/modules/__init__.py lib/nn/parallel/data_parallel.py eval_multipro.py lib/nn/modules/comm.py models/resnet.py make_SUNRGBD.py ValDataset round2nearest_multiple TestDataset TrainDataset eval_train worker evaluate visualize_result main evaluate_simple main make_CityScapes main make_SUNRGBD main test visualize_result adjust_crit_weights adjust_learning_rate checkpoint main train group_weight create_optimizers process_range colorEncode AverageMeter accuracy intersectionAndUnion to_one_hot parse_devices unique NotSupportedCliException gather node_val check_win depth_sub cur_key_to_last_key round2nearest_multiple dense2quad node_val_inter _sum_ft SynchronizedBatchNorm2d _unsqueeze_ft _SynchronizedBatchNorm SynchronizedBatchNorm1d SynchronizedBatchNorm3d SyncMaster FutureResult SlavePipe execute_replication_callbacks CallbackContext DataParallelWithCallback patch_replication_callback TorchTestCase as_numpy handy_var NumericTestCase SyncTestCase handy_var _find_bn mark_volatile as_variable as_numpy DataLoaderIter _set_SIGCHLD_handler default_collate _worker_manager_loop DataLoader _worker_loop ExceptionWrapper pin_memory_batch random_split ConcatDataset Subset TensorDataset Dataset DistributedSampler SubsetRandomSampler WeightedRandomSampler RandomSampler BatchSampler SequentialSampler Sampler PPMBilinear SegmentationModule QuadNet QGN Resnet SegmentationModuleBase conv3x3 conv3x3_bn_relu ModelBuilder ResnetDilated ASPPBilinear C1Bilinear resnet101_transpose_sparse Bottleneck TransBottleneck BasicBlock resnet34_transpose_sparse resnet50_transpose_sparse TransBottleneckSparse resnet101 ResNet resnet50 ResNetTransposeSparse resnet101_transpose load_url resnet34_transpose conv3x3_sparse AddSparseDense TransBasicBlock TransBasicBlockSparse ResNetTranspose conv3x3 resnet50_transpose GroupBottleneck ResNeXt load_url conv3x3 resnext101 join uint8 imwrite replace colorEncode astype result put_nowait num_class visualize_result as_numpy accuracy intersectionAndUnion eval enumerate visualize NLLLoss ValDataset list_val SegmentationModule evaluate set_device DataLoader ModelBuilder build_encoder cuda build_decoder update format num_class visualize_result as_numpy print AverageMeter accuracy intersectionAndUnion strftime mean average eval sum enumerate visualize NLLLoss ValDataset list_val SegmentationModule set_device gpu_id build_encoder ModelBuilder DataLoader cuda build_decoder parse_devices Process devices ceil append sum range get update format mean start Queue empty enumerate join print AverageMeter min average len join listdir make_CityScapes make_SUNRGBD format visualize_result print strftime eval enumerate NLLLoss TestDataset SegmentationModule set_device test gpu_id build_encoder ModelBuilder DataLoader cuda build_decoder zero_grad adjust_learning_rate running_lr_decoder running_lr_encoder append next range update format mean item epoch_iters time backward print AverageMeter average step segmentation_module format ckpt print save state_dict _ConvNd isinstance bias _BatchNorm modules append weight Linear startswith group_weight SGD parameters running_lr_decoder running_lr_encoder param_groups float max_iters lr_encoder lr_pow lr_decoder NLLLoss enhance_weight ones insert prop_weight median adjust_crit_weights ckpt patch_replication_callback num_epoch str UserScatteredDataParallel iter eval_train TrainDataset start_epoch epoch_iters create_optimizers checkpoint deep_sup_scale train list_train concatenate cumsum sort flatten argsort shape nonzero empty zeros astype unique float sum histogram copy list map strip groups match func append split reshape size strides take cuda is_available long ones size scatter_ unsqueeze is_available zeros cuda int min check_win power max int min check_win cur_key_to_last_key power max array resize int node_val power range node_val_inter zeros list hasattr __data_parallel_replicate__ modules enumerate len replicate data isinstance size sum modules isinstance Mapping Sequence isinstance is_tensor Mapping Sequence is_tensor isinstance Sequence Variable Mapping seed init_fn get set_num_threads _set_worker_signal_handlers collate_fn manual_seed get isinstance set_device put pin_memory_batch sum list isinstance Sequence new Mapping type zip _new_shared is_tensor Mapping is_tensor isinstance Sequence SIGCHLD signal getsignal randperm sum load_url ResNet load_state_dict load_url ResNet load_state_dict ResNetTranspose ResNetTranspose ResNetTranspose ResNetTransposeSparse ResNetTransposeSparse ResNetTransposeSparse join format urlretrieve write makedirs load_url load_state_dict ResNeXt | # Quadtree Generating Networks for Scene Parsing
PyTorch implementation of Quadtree Generating Networks, a hierarchical scene parsing architecture based on sparse convolutions.
| 2,626 |
kasungayan/LSTMMSNet | ['time series'] | ['LSTM-MSNet: Leveraging Forecasts on Sets of Related Time Series with Multiple Seasonal Patterns'] | src/LSTM-Models/utility_scripts/invoke_r_energy_DS.py src/LSTM-Models/configs/global_config.py src/LSTM-Models/preprocess_scripts/DS/Prophet-DS/energy_create_tfrecords_mean_hourly_prophet.py src/LSTM-Models/rnn_architectures/stacking_model/energy_stacking_model_DS_trainer.py src/LSTM-Models/rnn_architectures/stacking_model/energy_stacking_model_SE_tester.py src/LSTM-Models/preprocess_scripts/SE/MSTL-7-SE/energy_create_tfrecords_mstl7_feature.py src/LSTM-Models/rnn_architectures/stacking_model/energy_stacking_model_SE_trainer.py src/LSTM-Models/utility_scripts/persist_optimized_config_results.py src/LSTM-Models/utility_scripts/invoke_r_energy_SE.py src/LSTM-Models/external_packages/cocob_optimizer/__init__.py src/LSTM-Models/preprocess_scripts/SE/Fourier-SE-K1/energy_create_tfrecords_fourier.py src/LSTM-Models/preprocess_scripts/SE/TBATS-SE/energy_create_tfrecords_tbats_feature.py src/LSTM-Models/rnn_architectures/stacking_model/energy_stacking_model_DS_tester.py src/LSTM-Models/external_packages/cocob_optimizer/cocob_optimizer.py src/LSTM-Models/tfrecords_handler/moving_window/energy_tfrecord_DS_writer.py src/LSTM-Models/utility_scripts/hyperparameter_scripts/hyperparameter_config_reader.py src/LSTM-Models/tfrecords_handler/moving_window/energy_tfrecord_SE_writer.py src/LSTM-Models/preprocess_scripts/Baseline/energy_create_tfrecords_baseline.py src/LSTM-Models/generic_model_energy_DS_test.py src/LSTM-Models/tfrecords_handler/moving_window/energy_tfrecord_DS_reader.py src/LSTM-Models/preprocess_scripts/DS/MSTL-7-DS/energy_create_tfrecords_mean_hourly_mstl7.py src/LSTM-Models/generic_model_energy_SE_trainer.py src/LSTM-Models/generic_model_energy_SE_test.py src/LSTM-Models/preprocess_scripts/SE/MSTL-SE/energy_create_tfrecords_mstl_feature.py src/LSTM-Models/preprocess_scripts/SE/Fourier-SE/energy_create_tfrecords_fourier.py src/LSTM-Models/preprocess_scripts/DS/MSTL-DS/energy_create_tfrecords_mean_hourly_mstl.py src/LSTM-Models/tfrecords_handler/moving_window/energy_tfrecord_SE_reader.py src/LSTM-Models/utility_scripts/hyperparameter_scripts/hyperparameter_summary_generator.py src/LSTM-Models/preprocess_scripts/DS/TBATS-DS/energy_create_tfrecords_mean_hourly_tbats.py src/LSTM-Models/preprocess_scripts/SE/Prophet-SE/energy_create_tfrecords_prophet_feature.py src/LSTM-Models/generic_model_energy_DS_trainer.py adam_optimizer_fn cocob_optimizer_fn testing adagrad_optimizer_fn read_optimal_hyperparameter_values train_model_smac adagrad_optimizer_fn read_initial_hyperparameter_values smac adam_optimizer_fn cocob_optimizer_fn adam_optimizer_fn cocob_optimizer_fn testing adagrad_optimizer_fn read_optimal_hyperparameter_values train_model_smac adagrad_optimizer_fn read_initial_hyperparameter_values smac adam_optimizer_fn cocob_optimizer_fn training_data_configs model_testing_configs hyperparameter_tuning_configs model_training_configs COCOB StackingModelTester StackingModelTester TFRecordReader TFRecordWriter TFRecordReader TFRecordWriter invoke_r_script invoke_r_script persist_results read_optimal_hyperparameter_values read_initial_hyperparameter_values cell_type input_size Seq2SeqModelTesterWithDenseLayerNonMovingWindow contain_zero_values txt_test_file seed str dataset_name Seq2SeqModelTesterWithNonMovingWindow forecast_horizon test_model actual_results_file model_type Seq2SeqModelTesterWithDenseLayerMovingWindow StackingModelTester invoke_r_script format without_stl_decomposition RNN_FORECASTS_DIRECTORY hyperparameter_tuning binary_train_file_test_mode binary_test_file_test_mode with_truncated_backpropagation optimizer int print AttentionModelTesterWithNonMovingWindowWithSeasonality AttentionModelTesterWithNonMovingWindowWithoutSeasonality input_format bool print train_model optimize format train_model_smac Scenario print ConfigurationSpace SMAC add_hyperparameters UniformFloatHyperparameter UniformIntegerHyperparameter call str list items write close open | LSTM-MSNet: Leveraging Forecasts on Sets of Related Time Series with Multiple Seasonal Patterns =================== This page contains the explanation of our **L**ong **S**hort-**T**erm **M**emory **M**ulti-**S**easonal **Net** (LSTM-MSNet) forecasting framework, which can be used to forecast a sets of time series with multiple seasonal patterns. In the description, we first provide a breif introduction to our methdology, and then explain the steps to be followed to execute our code and use our framework for your research work. # Methodology # <img src ="Images/LSTM-MSNet-Framework.PNG" width="800" align="center"> The above figure gives an overview of the proposed LSTM-MSNet training paradigms. In the DS approach, deseasonalised time series are used to train the LSTM-MSNet. Here, a reseasonalisation phase is required as the target MW patches are seasonally adjusted. Whereas in the SE approach, the seasonal values extracted from the deseasonalisation phase are employed as exogenous variables, along with the original time series to train the LSTM-MSNet. Here a reseasonalisation phase is not required as the target MW patches contain the original distribution of the time series. A more detailed explaination of these training paradigms can be found in our [manuscript](https://arxiv.org/pdf/1909.04293.pdf). We used **DS** and **SE** naming conventions in our code repository to distinguish these training paradigms. Please note that this repo contains seperate preprocessing files for each of these training paradigms. **NOTICE**: You may find duplicated code as a result of these two paradigms. However, we expect to refactor this code, making the type of training paradigm, i.e., DS or SE, as a query parameter in our execution scripts. We also expect to migrate this source code to Tensorflow 2.0 soon. # Usage # | 2,627 |
kata-ai/id-word2vec | ['word embeddings'] | ['KaWAT: A Word Analogy Task Dataset for Indonesian'] | print_analogy_vocab.py run_evaluation.py run_word2vec.py ingredients/corpus.py polyglot2vec.py ingredients/preprocess.py prep_glove_corpus.py print_corpus_stats.py print_vectors_vocab.py make_shared_vocab.py run_glove.py remove_oov_analogy.py get_vocab make_shared default convert default prepare print_vocab get_vocab_from_line default print_stats print_vocab default read_vocab remove_oov default compute_bootstrap_ci evaluate load_word_vectors get_corrects print_corrects is_correct default train shuffle vocab_count cooccur runcmd glove default SentencesCorpus train default read_corpus _read default make_prep_sent default sorted get_vocab intersection_update print split print zip prep_sent join print make_prep_sent from_iterable tqdm append read_corpus add lower split set print sorted set prep_sent update print make_prep_sent from_iterable set tqdm read_corpus info read_vocab info info set split info quantile mean choices append trange defaultdict tuple strip lower startswith append is_correct enumerate split join sorted print load_word_vectors info items list compute_bootstrap_ci log_scalar mean load_word_vectors info system exit mkdir join runcmd Path runcmd join Path runcmd join Path runcmd join Path glove cooccur shuffle vocab_count cls SentencesCorpus save_word2vec_format warn save info Path _read info range compile | kata-ai/id-word2vec | 2,628 |
kata-ai/indosum | ['text summarization', 'extractive summarization'] | ['IndoSum: A New Benchmark Dataset for Indonesian Text Summarization'] | neuralsum/summarize.py run_neuralsum.py ingredients/corpus.py run_lead.py prep_oracle_neuralsum.py run_lexrank.py run_bayes.py create_splits.py serialization.py neuralsum/generate.py ingredients/evaluation.py data.py neuralsum/data_reader.py neuralsum/train.py neuralsum/model_abs.py run_maxent.py run_oracle.py models/oracle.py models/__init__.py run_sumbasic.py run_hmm.py neuralsum/pretrain.py neuralsum/evaluate.py utils.py run_textrank.py connect_mongo.py prep_outliers.py ingredients/summarization.py run_lsa.py neuralsum/model.py make_oracle.py neuralsum/train_abs.py tokenize_jsonl.py attach_gold_labels.py neuralsum/utils.py neuralsum/ranking/lr.py neuralsum/beam_search.py models/supervised.py models/unsupervised.py main read_jsonl main get_filename write_splits report_stats read_jsonl main Document Paragraph Sentence main label_sentences main write_neuralsum_oracle remove_whitespace_only_words truncate_paragraphs create_outlier_detector train_for_summ_length train_for_paras_length read_jsonl main load_model read_idf evaluate summarize train tuned_on_fold2 tuned_on_fold4 tuned_on_fold1 tuned_on_fold5 tuned_on_fold3 default load_model evaluate summarize train tuned_on_fold2 tuned_on_fold4 tuned_on_fold1 tuned_on_fold5 tuned_on_fold3 read_tf default summarize evaluate create_model read_idf evaluate summarize tuned_on_fold2 tuned_on_fold4 tuned_on_fold1 tuned_on_fold5 tuned_on_fold3 default create_model evaluate summarize tuned_on_fold2 tuned_on_fold4 tuned_on_fold1 tuned_on_fold5 tuned_on_fold3 default load_model evaluate summarize train tuned_on_fold2 tuned_on_fold4 tuned_on_fold1 tuned_on_fold5 read_stopwords tuned_on_fold3 default emb300_on_fold5 fasttext_on_fold5 tuned_on_fold2 emb300_on_fold2 default_conf tuned_on_fold4 tuned_on_fold1 tuned_on_fold5 fasttext_on_fold1 tuned_on_fold3 get_model_conf evaluate fasttext_on_fold2 emb300_on_fold3 emb300_on_fold1 emb300_on_fold4 read_jsonl train fasttext_on_fold3 fasttext_on_fold4 summarize evaluate summarize evaluate summarize create_model evaluate default _dump_maxent_clf _load_cpdist _load_fdist _dump_binary_enc _load_lidstone_pdist dump _dump_lidstone_pdist _dump_ele_pdist _dump_hmm _dump_maxent _load_binary_enc _dump_fdist _load_maxent _load_ele_pdist _dump_gaussian_emission _load_hmm load _load_bayes_clf _load_bayes _dump_cpdist _load_gaussian_emission _dump_bayes _dump_bayes_clf _load_cfdist _dump_cfdist _load_maxent_clf main tokenize_text tokenize_obj has_long_summary setup_mongo_observer eval_summaries cfg read_train_jsonl read_test_jsonl read_jsonl read_stopwords read_dev_jsonl cfg run_evaluation cfg run_summarization OracleSummarizer _Gaussian HMMSummarizer NaiveBayesSummarizer _GaussianEmission MaxentSummarizer TextRank LSA SumBasic LexRank Lead AbstractSummarizer BeamSearch Hypothesis load_data_abs Vocab load_data DataReader DataReader_abs main run_test build_model bilstm_doc_enc training_graph linear loss_pretrain loss_extraction lstm_doc_enc lstm_doc_dec model_size conv2d cnn_sen_enc label_prediction highway self_prediction tdnn label_prediction_att bilstm_doc_enc training_graph linear flexible_attention_decoder lstm_doc_enc _extract_argmax_and_embed model_size conv2d cnn_sen_enc loss_generation vanilla_attention_decoder highway tdnn build_model load_wordvec main sparse2dense run_test main run_test build_model main build_model run_test load_wordvec main build_model run_test load_wordvec estimate_lm_score topk random read_ngrams constrained softmax adict open_files argmax Distributional_Extractor load_wordvec load_nn_score train_and_test normalize Sybolic_Extractor print path dumps read_jsonl MongoClient start_ipython url get_filename zip get_filename print Counter zip most_common len seed list write_splits len num_folds shuffle outdir test report_stats dev floor append range enumerate makedirs remove set append max range len remove_whitespace_only_words output_dir split percentile truncate_paragraphs train_path train_for_paras_length train_for_summ_length add_resource info add_resource info add_artifact list info read_train_jsonl run_summarization load_model load_model add_resource info Lead Lead create_model create_model add_resource info realpath add_resource info update join system exit get_model_conf update join list items log_scalar system exit read_jsonl info append eval_summaries get_model_conf OracleSummarizer OracleSummarizer SumBasic SumBasic FreqDist items list items list conditions ConditionalFreqDist items list conditions items list ConditionalFreqDist deepcopy tokenize_text blank append getenv create join zip getLogger Pythonrouge mkdtemp calc_score rmtree info append enumerate items list read_fn log_scalar eval_summaries summarize print paragraphs dumps set read_jsonl to_dict join defaultdict print feed Vocab zeros listdir enumerate join defaultdict print feed Vocab zeros listdir enumerate dataset_iterator enumerate initial_state run update bilstm_doc_enc batch_size dec_outputs loss_extraction lstm_doc_enc lstm_doc_dec final_enc_state logits label_prediction cnn_sen_enc enc_outputs input_cnn label_prediction_att max_doc_length batch_size data_dir max_sen_length load_data DataReader max_doc_length as_list expand_dims highway tdnn int32 placeholder Variable trainable_variables get_shape int32 placeholder int32 placeholder uniform zeros range load_wordvec plogits max_grad_norm loss training_graph loss_pretrain embedding_path self_prediction size learning_rate mkdir train_dir load_model loss_generation vanilla_attention_decoder use_abs DataReader_abs load_data_abs max_output_length ravel ravel ravel sorted ravel enumerate append open items list format debug tuple any append len get tuple len print append sum range load_wordvec output_dir open Distributional_Extractor extract_feature sorted list data_dir load_nn_score embedding_path normalize asarray close nn_score_path predict_proba lr listdir enumerate join items print write extend split Sybolic_Extractor fit | kata-ai/indosum | 2,629 |
kata-ai/kawat | ['word embeddings'] | ['KaWAT: A Word Analogy Task Dataset for Indonesian'] | make_pairs.py print_pairs read_data append enumerate split print range len | # KaWAT: Kata.ai Word Analogy Task KaWAT contains word analogy task for Indonesian. The raw data is stored under `syntax` and `semantic` directory for syntactic and semantic analogy questions respectively. To convert the raw data into Google's Analogy Task format, you must build the dataset by invoking `make` (make sure to have Python 3.6 in your `PATH`). The build results will be stored under `build` directory. Invoke `make help` to see other available commands. ## License This dataset is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License. To view a copy of this license, visit | 2,630 |
kaushalpaneri/ode2scm | ['counterfactual inference'] | ['Integrating Markov processes with structural causal modeling enables counterfactual inference in complex systems'] | inst/python/gf_scm.py inst/python/mapk_scm.py inst/python/mapk_scm_no_double_phos.py inst/python/test.py scm_ras_erk_counterfactual g GF_SCM scm_erk_counterfactual g1 MAPK_SCM g2 scm_erk_counterfactual g1 MAPK_SCM g2 main update_noise_svi model EmpiricalMarginal infer update_noise_importance do GF_SCM update_noise_svi model EmpiricalMarginal infer update_noise_importance do MAPK_SCM print scm_erk_counterfactual | kaushalpaneri/ode2scm | 2,631 |
kckishan/GNE | ['link prediction'] | ['GNE: a deep learning framework for gene network inference by aggregating biological information'] | run_GNE.py evaluation.py LoadData.py GNE.py utils.py convertdata.py create_train_test_split load_data evaluate_ROC_from_matrix load_datafile sigmoid get_edge_embeddings load_embedding GNE LoadData load_network convertAdjMatrixToSortedRankTSV convertSortedRankTSVToAdjMatrix T DataFrame read_csv scale permutation eliminate_zeros DataFrame drop_duplicates round values open str list todense to_scipy_sparse_matrix dia_matrix convertAdjMatrixToSortedRankTSV train_test_split range dump Graph astype close sample print array len roc_auc_score average_precision_score int readline randn load_datafile close hstack open split readline close split open zeros len int multiply append array range len column_stack list reshape astype sort_values nan_to_num tile DataFrame array range len list duplicated print DataFrame astype zeros sort_values drop_duplicates range values len T todense asarray print squeeze coo_matrix diag | # GNE: A deep learning framework for gene network inference by aggregating biological information This is the TensorFlow implementation of the GNE as described in our paper. The code was forked initially from [here](https://github.com/lizi-git/ASNE). WE provide PyTorch implementation for GNE that encodes network struture only in [BionetEmbedding](https://github.com/kckishan/BioNetEmbedding). Note that this is a minimal version of this TensorFlow implementation.  GNE integrates gene interaction network with gene expression data to learn a more informative representations for gene network, which can be plugged into off-the-shelf machine learning methods for diverse functional inference tasks: gene function prediction, gene ontology reconstruction, and genetic interaction prediction. ## Architecture of GNE  Requirements * TensorFlow (1.0 or later) * python3.6 | 2,632 |
kckishan/HOGCN-LP | ['link prediction'] | ['Predicting Biomedical Interactions with Higher-Order Graph Convolutional Networks'] | trainer.py models.py param_parser.py layers.py utils.py main.py DenseNGCNLayer SparseNGCNLayer main MixHopNetwork parameter_parser Trainer features_to_sparse load_data_link_prediction_DTI Data_PPI create_propagator_matrix Data_DDI load_data_link_prediction_PPI normalize_adjacency_matrix tab_printer Data_DTI load_data_link_prediction_DDI load_data normalize Data_GDI load_data_link_prediction_GDI seed parameter_parser Trainer tab_printer device manual_seed fit set_defaults add_argument ArgumentParser sorted print draw add_rows vars Texttable keys diags flatten dot sum array dot power tolist diags concatenate normalize_adjacency_matrix dict coo_matrix eye to concatenate dict shape coo_matrix nonzero to len features_to_sparse create_propagator_matrix setdiff1d set_index arange print reshape multiply tolist shape coo_matrix eye normalize reindex sum array read_csv values features_to_sparse create_propagator_matrix setdiff1d set_index arange print reshape multiply tolist shape coo_matrix eye normalize reindex sum array read_csv values features_to_sparse create_propagator_matrix setdiff1d set_index arange print reshape multiply tolist shape coo_matrix eye normalize reindex sum array read_csv values features_to_sparse arange values multiply tolist apply shape normalize sum create_propagator_matrix setdiff1d coo_matrix reindex set_index print reshape eye array read_csv load_data_link_prediction_DTI load_data_link_prediction_PPI network_type load_data_link_prediction_DDI ratio device input_type load_data_link_prediction_GDI | # Higher-Order Graph Convolutional Networks for Link Prediction A PyTorch implementation of `Predicting Biomedical Interactions with Higher-Order Graph Convolutional Networks (HOGCN)`. ### Block diagram  ### Requirements The codebase is implemented in Python 3.6.9 and the packages used for developments are mentioned below. ``` argparse 1.1 numpy 1.19.1 | 2,633 |
kedz/nnsum | ['text summarization', 'document summarization', 'extractive summarization'] | ['SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents', 'Neural Summarization by Extracting Sentences and Words'] | script_bin/eval_model.py nnsum/module/sentence_encoder/__init__.py nnsum/module/sentence_encoder/rnn_sentence_encoder.py nnsum/model/seq2seq_model.py nnsum/module/sentence_encoder/cnn_sentence_encoder.py nnsum/module/attention/no_attention.py nnsum/data/sample_cache_dataset.py nnsum/module/sentence_extractor/transformer_sentence_extractor.py nnsum/trainer/labels_raml_trainer.py nnsum/trainer/__init__.py tests/test_summarization_dataset.py nnsum/module/attention/bilinear_sigmoid_attention.py nnsum/module/embedding_context.py nnsum/module/attention/scaled_dot_product_attention.py nnsum/model/__init__.py tests/speed_test.py script_bin/train_raml_model.py tests/test_summarization_dataloader.py nnsum/data/summarization_dataloader.py nnsum/module/sentence_extractor/__init__.py tests/test_summarization_model.py nnsum/data/summarization_dataset.py nnsum/trainer_tmp.py nnsum/metrics/__init__.py nnsum/module/sentence_extractor/rnn_sentence_extractor.py nnsum/__init__.py nnsum/module/sentence_extractor/summarunner_sentence_extractor.py nnsum/model/rnn_model.py nnsum/module/attention/multi_head_attention.py nnsum/metrics/perl_rouge.py nnsum/module/attention/bilinear_softmax_attention.py nnsum/util.py tests/test_sentence_encoders.py nnsum/data/__init__.py nnsum/trainer/labels_mle_trainer.py nnsum/io/vocab.py script_bin/embedding_context_tests.py script_bin/train_transformer_model.py nnsum/module/document_rnn_encoder.py nnsum/data_old.py nnsum/data/sample_cache_dataloader.py nnsum/module/__init__.py nnsum/cli.py nnsum/metrics/loss.py nnsum/model/cheng_and_lapata_model.py nnsum/module/attention/__init__.py setup.py nnsum/module/sentence_encoder/averaging_sentence_encoder.py nnsum/io/__init__.py nnsum/model/transformer_model.py nnsum/model/summarization_model.py nnsum/module/sentence_extractor/cheng_and_lapata_sentence_extractor.py nnsum/io/vocab_util.py nnsum/module/sentence_extractor/seq2seq_sentence_extractor.py nnsum/trainer/util.py script_bin/train_model.py ModuleArgumentSelector create_model_from_args training_argparser ModuleArgumentParser MultiModuleParser SingleDocumentDataset create_trainer train_epoch create_evaluator compute_rouge compute_class_weights label_mle_trainer validation_epoch batch_pad_and_stack_vector batch_pad_and_stack_matrix SampleCacheDataLoader SampleCacheDataset SummarizationDataLoader SummarizationDataset Vocab filter_embeddings create_vocab load_pretrained_embeddings initialize_embedding_context _process_file Loss PerlRouge ChengAndLapataModel RNNModel Seq2SeqModel SummarizationModel TransformerModel DocumentRNNEncoder EmbeddingContext BiLinearSigmoidAttention BiLinearSoftmaxAttention MultiHeadAttention NoAttention ScaledDotProductAttention AveragingSentenceEncoder CNNSentenceEncoder RNNSentenceEncoder ChengAndLapataSentenceExtractor RNNSentenceExtractor Seq2SeqSentenceExtractor SummaRunnerSentenceExtractor TransformerSentenceExtractor create_trainer create_checkpoint labels_mle_trainer create_evaluator create_trainer labels_raml_trainer compute_class_weights _class_weights_helper test_fix_all get_loss test_update_all main main main main check_dir main suite TestSentenceEncoder TestSummarizationDataLoader TestSummarizationDataset suite TestSummarizationModel ModuleArgumentSelector add_module_opts argparser add_argument add_module ArgumentParser MultiModuleParser Seq2SeqSentenceExtractor embedding_size SummarizationModel size ChengAndLapataSentenceExtractor CNNSentenceEncoder AveragingSentenceEncoder SummaRunnerSentenceExtractor RNNSentenceExtractor RNNSentenceEncoder format zip unique info numpy array cat run create_trainer attach create_evaluator Engine Engine model zero_grad clamp_ eq binary_cross_entropy_with_logits sum format masked_fill_ float flush enumerate int backward print write parameters train step len int format model print tolist write masked_fill_ eval eq binary_cross_entropy_with_logits compute_rouge float sum enumerate flush len eval fill_ copy_ stack max enumerate len fill_ len copy_ max enumerate get items list sorted format glob extend imap_unordered info append Pool len format FloatTensor Vocab info append len format debug len Vocab info append cat enumerate EmbeddingContext filter_embeddings repr warn create_vocab info load_pretrained_embeddings create_checkpoint PerlRouge EPOCH_COMPLETED add_event_handler create_trainer_fn create_evaluator Loss attach run name str ModelCheckpoint parent labels_mle_trainer sum loads read_text len print imap_unordered Pool enumerate len tokens model Sequential zero_grad abs Adam iter_batch append initialize_embedding_context range vocab get_loss mean Linear backward print clone make_sds_dataset parameters step tokens model Sequential zero_grad abs Adam iter_batch append initialize_embedding_context range vocab get_loss mean Linear backward print clone make_sds_dataset parameters step load vocab model print add_argument cpu_count min SummarizationDataset inputs eval ArgumentParser parse_args cuda gpu SummarizationDataLoader seed manual_seed_all format create_model_from_args compute_class_weights Adam labels_mle_trainer parameters initialize_parameters manual_seed initialize_embedding_context SampleCacheDataLoader SampleCacheDataset labels_raml_trainer dirname makedirs utcnow train_labels save validation_epoch update_command_line_options valid_refs epochs append sum range valid_inputs weighted results_path valid_labels timedelta info model_path model_builder embedding_size train_epoch train_inputs make_sds_dataset check_dir len refs time labels processes dataloader SingleDocumentDataset addTest TestSuite TestSentenceEncoder TestSummarizationModel | # nnsum An extractive neural network text summarization library for the EMNLP 2018 paper *Content Selection in Deep Learning Models of Summarization* (https://arxiv.org/abs/1810.12343). - Data and preprocessing scripts are in a separate library (https://github.com/kedz/summarization-datasets). If a dataset is publicly available the script will download it. The DUC and NYT datasets must be obtained separately before calling the preprocessing script. - To obtain the DUC 2001/2002 datasets: https://duc.nist.gov/data.html - To obtain the NYT dataset: https://catalog.ldc.upenn.edu/ldc2008t19 - Model implementation code is located in `nnsum`. - Training and evaluation scripts are located in `script_bin`. # Installation | 2,634 |
kedz/noiseylg | ['text generation'] | ['A Good Sample is Hard to Find: Noise Injection Sampling and Self-Training for Neural Language Generation Models'] | src/plum/dataio/aggregate_list.py src/d2t/rule_based_classifiers/e2e_v2.py e2e/generate_samples_rule_delex.py src/plum/types/variable.py src/plum/layers/fully_connected.py e2e/eval_model_test.py src/plum/utils.py src/plum/trainer/basic_impl.py src/fg/laptop_metrics.py src/plum/layers/parallel.py src/d2t/rule_based_classifiers/__init__.py src/plum/layers/gru.py src/plum/parser.py src/plum/loggers/classification_logger.py src/plum/dataio/bins_feature.py src/plum/dataio/batch_flat.py src/d2t/postedit/e2e.py src/plum/layers/seq_pool_1d.py src/plum/dataio/__init__.py src/plum/types/property/parameter.py src/plum/layers/zip.py src/plum/models/sequence_classifier.py src/fg/e2e_search_logger.py src/plum/layers/seq_conv_1d.py src/plum/seq2seq/__init__.py src/plum/seq2seq/encoder/__init__.py src/plum/dataio/batch_variables.py src/plum/__init__.py src/plum/dataio/batch_ndtensor.py src/plum/dataio/parallel_datasources.py src/plum/dataio/size.py src/plum/metrics/__init__.py src/plum/layers/attention/feed_forward.py src/plum/dataio/cat.py src/plum/loss_functions/class_cross_entropy.py src/d2t/postedit/__init__.py src/fg/tv_systematic_recommend.py src/fg/tvs_search_logger.py src/plum/dataio/batches.py src/fg/tv_systematic_inform_only_match.py src/plum/types/plum_module.py src/plum/tensor_ops.py src/plum/loggers/search_output_logger.py src/fg/__init__.py src/plum/tasks/predict.py src/plum/checkpoints/__init__.py src/plum/layers/__init__.py src/fg/e2e_predict_nbest.py src/plum/initializers/__init__.py src/plum/layers/linear_predictor.py src/plum/dataio/vocab/__init__.py src/plum/dataio/pad_dim_to_max.py src/d2t/preprocessing/tvs.py src/plum/dataio/vocab_reader.py src/plum/plumr.py src/fg/laptop_systematic_confirm.py src/plum/optimizers/sgd_1cyc.py src/plum/models/encoder_decoder.py src/plum/layers/identity.py src/fg/tv_systematic_select.py src/plum/dataio/vocab_lookup.py src/plum/trainer/__init__.py src/plum/vocab.py src/plum/layers/attention/__init__.py src/fg/laptop_systematic_inform_no_match.py src/plum/seq2seq/decoder/rnn.py src/d2t/preprocessing/laptops.py src/d2t/rule_based_classifiers/laptop.py src/plum/seq2seq/encoder/rnn.py src/plum/types/plum_object.py src/plum/layers/seq_conv_pool_1d.py src/plum/seq2seq/search/beam.py src/plum/dataio/csv.py src/plum/optimizers/sgd.py src/plum/dataio/vocab/pad_index.py src/plum/types/property/plum_property.py src/plum/checkpoints/no_checkpoint.py src/fg/laptop_systematic_recommend.py src/plum/loggers/__init__.py src/fg/sequence_classification.py src/plum/layers/sequential.py src/plum/types/property_types.py src/fg/laptop_systematic_compare.py src/plum/dataio/batch_sequence_ndtensor.py src/setup.py src/plum/types/property/submodule.py src/fg/e2e_eval_script.py src/plum/dataio/pad_list.py src/plum/dataio/vocab/size.py src/d2t/rule_based_classifiers/e2e.py src/fg/laptop_systematic_inform_all.py src/plum/dataio/one_hot.py src/fg/e2e_systematic_generation.py src/fg/tv_predict.py src/fg/tv_systematic_inform_no_match.py src/plum/dataio/long_tensor.py src/plum/types/__init__.py src/fg/tv_systematic_confirm.py src/plum/layers/concat.py src/plum/metrics/classification_metrics.py src/plum/loss_functions/__init__.py e2e/example_generation.py src/plum/types/lazy_dict.py src/plum/models/plum_model.py src/plum/types/property/hyperparameter.py src/plum/seq2seq/search/greedy.py src/fg/laptop_systematic_inform_count.py src/plum/tasks/s2s_evaluator.py src/plum/dataio/mmap_jsonl.py e2e/generate_samples_rule_lex.py src/plum/metrics/metric_dict.py src/fg/tv_systematic_compare.py src/plum/models/__init__.py src/plum/optimizers/__init__.py src/plum/checkpoints/topk_checkpoint.py e2e/generate_samples_clf_delex.py src/fg/tv_metrics.py src/plum/seq2seq/search/ancestral_sampler.py src/fg/laptop_systematic_inform_only_match.py src/d2t/rule_based_classifiers/tv.py src/fg/laptops_search_logger.py src/plum/seq2seq/search/__init__.py src/fg/laptop_systematic_inform.py src/plum/layers/attention/no_attention.py src/plum/layers/activation_function.py src/plum/seq2seq/decoder/__init__.py src/plum/trainer/eval.py src/plum/types/object_registry.py src/plum/metrics/seq2seq_eval_script.py src/fg/e2e_predict.py src/fg/tv_systematic_inform.py src/plum/models/generic_model.py src/fg/laptop_systematic_select.py eval_scripts/eval.py src/fg/tv_systematic_inform_count.py src/fg/laptop_predict.py src/plum/dataio/average.py src/plum/layers/functional.py src/fg/tv_systematic_inform_all.py src/plum/types/property/__init__.py src/plum/tasks/__init__.py src/plum/dataio/stack_ds.py src/plum/dataio/jsonl.py src/plum/dataio/load_vocab.py src/plum/seq2seq/search/greedy_npad.py src/plum/layers/embedding.py src/plum/dataio/select.py main main seq2tsr load_model count_active_fields print_counts load_model make_generator_input count_fields labels2inputs search2inputs rule_classify labels2input main draw_samples filter_candidates check_terminate count_active_fields print_counts load_model make_generator_input count_fields labels2inputs rule_classify labels2input main draw_samples check_terminate count_active_fields print_counts load_model make_generator_input count_fields labels2inputs rule_classify labels2input main draw_samples check_terminate main lexicalize detokenize lexicalize_compare extract_mr_battery extract_mr_warranty lexicalize extract_mr_dimension delexicalize_normal mr2source_inputs_normal lexicalize_request delexicalize_suggest get_field_values extract_mr extract_mr_driverange extract_mr_memory extract_mr_platform delexicalize_compare lexicalize_suggest extract_mr_pricerange extract_mr_count lexicalize_normal delexicalize_request extract_mr_family extract_mr_drive extract_mr_utility extract_mr_price extract_mr_design extract_mr_weight extract_mr_isforbusinesscomputing extract_mr_processor extract_mr_weightrange extract_mr_name delexicalize mr2source_inputs extract_mr_batteryrating mr2source_inputs_compare delexicalize_inform lexicalize_compare lexicalize mr2source_inputs_normal extract_mr_audio delexicalize_suggest lexicalize_request get_field_values extract_mr delexicalize_compare lexicalize_suggest extract_mr_pricerange extract_mr_count lexicalize_normal extract_mr_hasusbport delexicalize_request extract_mr_family extract_mr_price extract_mr_color extract_mr_screensizerange extract_mr_resolution extract_mr_powerconsumption extract_mr_ecorating extract_mr_hdmiport extract_mr_name extract_mr_screensize extract_mr_accessories delexicalize mr2source_inputs mr2source_inputs_compare name area price_range near customer_rating eat_type family_friendly food name area price_range near customer_rating eat_type family_friendly food text2mr_select find_price_range find_battery_rating name text2mr_inform_count find_weight_range find_field no_info is_for_biz text_da2mr text2mr_inform_no_match find_drive_range text2mr_inform find_family classify_da text2mr_compare find_hdmiport text2mr_select find_price_range text2mr_inform_count find_screensizerange find_field has_usb text_da2mr text2mr_inform find_ecorating find_family classify_da text2mr_compare LaptopSystematicInformNoMatch E2EEvalScript E2EPredict LaptopPredictNBEST E2ESearchLogger E2ESystematicGeneration LaptopsSearchLogger LaptopMetrics LaptopPredict LaptopSystematicCompare LaptopSystematicConfirm LaptopSystematicInform LaptopSystematicInformAll LaptopSystematicInformCount LaptopSystematicInformOnlyMatch LaptopSystematicRecommend LaptopSystematicSelect SequenceClassificationError TVsSearchLogger TVMetrics TVPredict TVSystematicCompare TVSystematicConfirm TVSystematicInform TVSystematicInformAll TVSystematicInformCount TVSystematicInformNoMatch TVSystematicInformOnlyMatch TVSystematicRecommend TVSystematicSelect PlumParser pprint_vocab pprint_params pprint_sample_pipeline create_environment pprint_sample_datasource handle_debug_opts import_ext_libs load_plumr_meta find_checkpoints pprint_checkpoints main update_ext_libs get_meta_path pprint_model cat resolve_getters Vocab load NoCheckpoint min_cmp TopKCheckpoint max_cmp AggregateList AverageGetters Batches BatchFlat BatchNDTensor BatchSequenceNDTensor BatchVariables ThresholdFeature Cat CSV JSONL LoadVocab LongTensor MMAPJSONL OneHot PadDimToMax PadList ParallelDatasources Select Len StackDatasource VocabLookup VocabReader pad_index size Normal Constant XavierNormal ActivationFunction Concat Embedding FullyConnected embedding dropout linear seq_conv1d seq_max_pool1d GRU Identity LinearPredictor Parallel Sequential SeqConv1D SeqConvPool1D SeqPool1D Zip FeedForwardAttention _curry_composition NoAttention ClassificationLogger SearchOutputLogger ClassCrossEntropy ClassPRF MetricDict Seq2SeqEvalScript EncoderDecoder GenericModel _curry_forward PlumModel SequenceClassifier SGD SGD_1Cycle RNNDecoder RNNEncoder init_state_dims AncestralSampler BeamSearch GreedySearch GreedyNPAD postprocess Predict S2SEvaluator BasicTrainer BasicEval LazyDict PlumObjectRegistry _to_json_helper PlumModule _to_json_helper PlumObject Boolean Real String Choice NonNegative Interval Positive Integer ExistingPath Variable register Hyperparameter any_type Parameter PlumProperty Submodule decode print check_output add_argument ArgumentParser parse_args t LongTensor loads read_text checkpoint_dir greedy_search beam_search BeamSearch GreedyNPAD npad_search load_model tgt_vocab encode src_vocab GreedySearch load join decoder AncestralSampler output ancestral_sampler items defaultdict print max range values print items list shuffle choice append array append items pop replace stop_token upper append LongTensor Variable size t cuda append upper replace LongTensor Variable t cuda append max len items any item append max enumerate print_counts model count_fields train_mrs size set mkdir cuda gpu values parent dumps float split join sub lower replace append append get_field_values len search split split sub sub sub sub sub sub sub sub sub sub format replace sub range len format replace sub range len sorted sub sorted sub items list sub items list sub sub sub delexicalize_inform delexicalize_suggest delexicalize_compare delexicalize_request escape print escape print sorted sub escape lower lower any any any search search search search search search findall list len findall list len findall list len findall list len findall list len findall list len list format upper findall len findall list sub len findall list len search sort lower findall iterfind append enumerate is_for_biz find_field is_for_biz find_field is_for_biz find_field find_business lower match findall len has_usb findall list len findall list len findall list len findall list sub len has_usb find_usb HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP pprint_vocab pprint_params pprint_sample_pipeline pprint_sample_datasource pprint_pipeline_sample pprint_ds_nsamples pprint_ds_sample pprint_model get str list format items print list format print shuffle pprint range enumerate len print list pprint print list pprint str list format dtype parameter_tags print tuple size named_parameters zip append max print list enumerate write_text format print dumps mkdir get_meta_path pop write_text format print __import__ dumps index append __import__ config P handle_debug_opts import_ext_libs pprint_checkpoints run exit update_ext_libs create_environment pprint_ckpts PlumParser write_text parse_file load_plumr_meta find_checkpoints default_ckpt proj list format name sort read_text warn OrderedDict loads rglob format mkdir lengths field hasattr HP _build_config loads load_state_dict HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP P HP P data isinstance data isinstance transpose permute_as_batch_sequence_features dim data isinstance length_dim size apply_sequence_mask_ data get permute_as_batch_features_sequence size lengths conv1d HP HP P SM SM HP P HP SM HP SM P HP HP HP HP SM HP HP SM HP SM HP HP SM HP HP HP SM out_feats HP SM P HP HP HP HP join sub HP HP HP HP hasattr isinstance | # noiseylg Code repository for INLG 19 paper A Good Sample is Hard to Find: Noise Injection Sampling and Self-Training for Neural Language Generation Models. Please check back closer to the date of the conference (Oct. 29h) for release of the code. # INSTALL First install plum and other libraries: $ cd src; python setup.py install; plumr --add-libs fg ; cd .. Then setup the eval scripts: $ cd eval_scripts; ./install.sh; cd .. # E2E To run E2E experiments/evaluation, please see README in e2e subdirectory. Instructions for downloading models/outputs from paper are in the e2e README. | 2,635 |
kedz/styleeq | ['style transfer', 'text generation'] | ['Low-Level Linguistic Controls for Style Transfer and Content Preservation'] | plum/trainer/basic_impl.py plum/optimizers/sgd.py plum/loggers/classification_logger.py plum/dataio/parallel_datasources.py plum/models/sequence_classifier.py plum/dataio/aggregate_list.py plum/dataio/batches.py plum/dataio/csv.py plum/types/__init__.py plum/dataio/bins_feature.py plum/vocab.py plum/metrics/metric_dict.py plum/loss_functions/__init__.py plum/dataio/jsonl.py plum/types/property/__init__.py plum/dataio/long_tensor.py plum/loss_functions/class_cross_entropy.py plum/types/property/submodule.py plum/checkpoints/__init__.py plum/dataio/batch_flat.py plum/dataio/vocab/size.py plum/layers/fully_connected.py setup.py get_style_json.py plum/seq2seq/search/greedy.py plum/checkpoints/topk_checkpoint.py plum/seq2seq/search/greedy_npad.py plum/models/encoder_decoder.py plum/tasks/s2s_evaluator.py plum/dataio/select.py plum/dataio/stack_ds.py generation_example.py plum/layers/embedding.py plum/types/property/plum_property.py plum/dataio/batch_sequence_ndtensor.py plum/parser.py plum/loggers/search_output_logger.py plum/trainer/__init__.py plum/dataio/one_hot.py plum/layers/functional.py plum/loggers/__init__.py plum/metrics/classification_metrics.py plum/types/plum_module.py plum/layers/parallel.py plum/tasks/__init__.py plum/layers/concat.py plum/types/lazy_dict.py plum/tasks/predict.py plum/types/object_registry.py plum/layers/seq_conv_pool_1d.py plum/layers/__init__.py plum/seq2seq/search/__init__.py plum/__init__.py plum/layers/seq_pool_1d.py plum/dataio/mmap_jsonl.py plum/dataio/cat.py plum/dataio/load_vocab.py plum/types/property_types.py plum/layers/seq_conv_1d.py plum/layers/identity.py plum/dataio/batch_variables.py plum/optimizers/__init__.py plum/dataio/vocab/pad_index.py plum/types/plum_object.py plum/seq2seq/decoder/rnn.py plum/checkpoints/no_checkpoint.py plum/layers/attention/feed_forward.py plum/layers/gru.py plum/dataio/vocab_reader.py plum/layers/sequential.py plum/utils.py plum/plumr.py plum/seq2seq/encoder/rnn.py plum/types/variable.py plum/dataio/vocab_lookup.py plum/metrics/__init__.py plum/layers/attention/no_attention.py plum/dataio/pad_list.py plum/seq2seq/__init__.py plum/seq2seq/search/ancestral_sampler.py plum/trainer/eval.py plum/dataio/batch_ndtensor.py plum/metrics/seq2seq_eval_script.py plum/layers/activation_function.py plum/models/plum_model.py plum/tensor_ops.py eval_scripts/eval.py plum/layers/linear_predictor.py plum/types/property/parameter.py plum/models/generic_model.py plum/seq2seq/search/beam.py plum/initializers/__init__.py plum/dataio/__init__.py plum/optimizers/sgd_1cyc.py plum/seq2seq/decoder/__init__.py plum/dataio/average.py plum/layers/zip.py plum/seq2seq/encoder/__init__.py plum/models/__init__.py plum/dataio/vocab/__init__.py plum/dataio/pad_dim_to_max.py plum/types/property/hyperparameter.py plum/dataio/size.py plum/layers/attention/__init__.py get_close_sent load_model format_output load_database generate_and_print make_transfer_inputs main count_helper_verbs count_conjunction prep_sent count_parse_feats clean_word count_personal_pronouns count_determiner count_punctuation count_prepositions count_length count_negation create_json main PlumParser pprint_vocab pprint_params pprint_sample_pipeline create_environment pprint_sample_datasource handle_debug_opts import_ext_libs load_plumr_meta find_checkpoints pprint_checkpoints main update_ext_libs get_meta_path pprint_model cat resolve_getters Vocab load NoCheckpoint min_cmp TopKCheckpoint max_cmp AggregateList AverageGetters Batches BatchFlat BatchNDTensor BatchSequenceNDTensor BatchVariables ThresholdFeature Cat CSV JSONL LoadVocab LongTensor MMAPJSONL OneHot PadDimToMax PadList ParallelDatasources Select Len StackDatasource VocabLookup VocabReader pad_index size Normal Constant XavierNormal ActivationFunction Concat Embedding FullyConnected embedding dropout linear seq_conv1d seq_max_pool1d GRU Identity LinearPredictor Parallel Sequential SeqConv1D SeqConvPool1D SeqPool1D Zip FeedForwardAttention _curry_composition NoAttention ClassificationLogger SearchOutputLogger ClassCrossEntropy ClassPRF MetricDict Seq2SeqEvalScript EncoderDecoder GenericModel _curry_forward PlumModel SequenceClassifier SGD SGD_1Cycle RNNDecoder RNNEncoder init_state_dims AncestralSampler BeamSearch GreedySearch GreedyNPAD postprocess Predict S2SEvaluator BasicTrainer BasicEval LazyDict PlumObjectRegistry _to_json_helper PlumModule _to_json_helper PlumObject Boolean Real String Choice NonNegative Interval Positive Integer ExistingPath Variable register Hyperparameter any_type Parameter PlumProperty Submodule loads read_text append defaultdict len print slim_down_options len get_close_sent list shuffle append pop list sub list format decoder print fill search _collate_fn extend format_output encode BeamSearch range parse_string PlumParser format kill load_model wait add_argument styleeq_dir strip load_database generate_and_print num_opts ArgumentParser loads parse_args create_json Popen run clean_word split clean_word split clean_word split clean_word split clean_word split lemma_ clean_word tag_ text pos_ lower append annotate print count prep_sent join update function text lower nlp parent print dumps float split pprint_vocab pprint_params pprint_sample_pipeline pprint_sample_datasource pprint_pipeline_sample pprint_ds_nsamples pprint_ds_sample pprint_model get str list format items print list format print shuffle pprint range enumerate len print list pprint print list pprint str list format dtype parameter_tags print tuple size named_parameters zip append max print list enumerate write_text format print dumps mkdir get_meta_path pop write_text format print __import__ dumps index append __import__ config P handle_debug_opts import_ext_libs pprint_checkpoints update_ext_libs create_environment pprint_ckpts write_text parse_file load_plumr_meta find_checkpoints default_ckpt proj gpu list format name sort read_text warn OrderedDict loads rglob format mkdir lengths field hasattr HP _build_config loads load_state_dict HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP HP P HP P data isinstance data isinstance transpose permute_as_batch_sequence_features dim data isinstance length_dim size apply_sequence_mask_ data get permute_as_batch_features_sequence size lengths conv1d HP HP P SM SM HP P HP SM HP SM P HP HP HP HP SM HP HP SM HP SM HP HP SM HP HP HP SM out_feats HP SM P HP HP HP HP join sub HP HP HP HP hasattr isinstance | # styleeq Code for Low-Level Linguistic Controls for Style Transfer and Content Preservation # INSTALL LIBRARY First install plum: `$ python setup.py install` Then download the spacy model data: `$ python -m spacy download en_core_web_sm` Then setup the eval scripts: `$ cd eval_scripts; ./install.sh; cd ..` # DOWNLOAD DATA | 2,636 |
keeganstoner/nn-qft | ['gaussian processes'] | ['Neural Networks and Quantum Field Theory'] | generate_models.py six_pt_prediction.py lam_fit/4pt_exp.py lam_fit/lam_fit_integrals.py lib.py rg.py lam_fit/lam_fit.py free_theory.py six_pt_connected.py lt lm Print K_EFT kernel_tensor intkappa activation K_int_GaussNet Erf_nobackprop K n_point K_int_relu K_relu trim_sym_tensor create_networks partition four_pt_int four_pt_int_infinite local0 K_erf six_pt_tensor four_pt_tensor G_theory nonlocal22 K_product GaussNet init_weights local2 expln K_int intkappa_infinite K_int_erf trim_sym_tensor4 K_GaussNet Print lt lm lt lm lt lm calc_lam MAPE_out converged MAPE print flush normal_ weight bias view d_in model Sequential activation apply GaussNet width n_models d_out range cat Linear list view transpose shape append range sqrt arccos d_in pi dot sqrt sb sw float n_inputs range G_theory n_inputs range G_theory n_inputs range G_theory int list partition append range len enumerate K sqrt arccos d_in pi dot sqrt sb sw float n_inputs range n_inputs range item K_int_erf K_int_relu sb K_int_GaussNet item four_pt_tensor four_pt_int print array range len | # Neural Networks and Quantum Field Theory Implementation of https://arxiv.org/abs/2008.08601 and https://iopscience.iop.org/article/10.1088/2632-2153/abeca3 by James Halverson, Anindita Maiti, and Keegan Stoner ## Abstract We propose a theoretical understanding of neural networks in terms of Wilsonian effective field theory. The correspondence relies on the fact that many asymptotic neural networks are drawn from Gaussian processes (GPs), the analog of non-interacting field theories. Moving away from the asymptotic limit yields a non-Gaussian process (NGP) and corresponds to turning on particle interactions, allowing for the computation of correlation functions of neural network outputs with Feynman diagrams. Minimal NGP likelihoods are determined by the most relevant non-Gaussian terms, according to the flow in their coefficients induced by the Wilsonian renormalization group. This yields a direct connection between overparameterization and simplicity of neural network likelihoods. Whether the coefficients are constants or functions may be understood in terms of GP limit symmetries, as expected from 't Hooft's technical naturalness. General theoretical calculations are matched to neural network experiments in the simplest class of models allowing the correspondence. Our formalism is valid for any of the many architectures that becomes a GP in an asymptotic limit, a property preserved under certain types of training. ## Using this code ```python script.py --activation=ReLU --d-in=1 --n-models=10**6``` | 2,637 |
keevin60907/SpherePHD | ['semantic segmentation'] | ['SpherePHD: Applying CNNs on a Spherical PolyHeDron Representation of 360 degree Images'] | train.py DataLoader.py makedata.py maketable.py layer.py model.py main DataLoader channel_conv maxpool upsample conv2d avgpool construct_triangle get_pixel icosa2pano pano2icosa main make_vertical_edge_link merge_row make_vertical_inner_link make_horizontal_edge_link complete_table connect make_upsample_table make_adjacency_table edge_connect make_conv_table single_connect make_pooling_table main make_horizontal_inner_link auto_encoder MNIST_net main SpherePHD concatenate print make_label DataLoader save asarray asarray gather squeeze reduce_max gather reduce_mean print arange get_pixel zeros max enumerate construct_triangle close save zeros range imwrite readlines open zeros float argmax enumerate split load reshape icosa2pano zeros range append append range single_connect connect list connect range list connect single_connect range range connect enumerate edge_connect range append enumerate make_vertical_edge_link make_vertical_inner_link make_horizontal_edge_link complete_table make_horizontal_inner_link array append list range make_adjacency_table append enumerate list merge_row concatenate astype extend append array range list sorted reshape zip zeros range enumerate make_adjacency_table make_upsample_table make_pooling_table conv2d maxpool T avgpool T channel_conv maxpool upsample conv2d autoencoder train SpherePHD | # SpherePHD Reproduce SpherePHD with python codes (https://arxiv.org/pdf/1811.08196.pdf) # Usage - Using `DataLoader.py` to make `data.npy` and `label.npy` The function will sample the Sphere pixel automatically - Get the reconstruction information from `makedata.py` to get division log. - run `train.py` to train your own data, which includes simpleCNN and autoencoder # Implement Detail - Sampling the pixel from panorama should be different from the original paper. I use direct projection when doing subdivsions. | 2,638 |
keillernogueira/dynamic-rs-segmentation | ['semantic segmentation'] | ['Dynamic Multi-Context Segmentation of Remote Sensing Images based on Convolutional Networks'] | contest_dilated_random.py isprs_dilated_random.py coffee_dilated_random.py _max_pool leaky_relu create_crops dilated_icpr_rate6 dilated_icpr_rate6_SE dynamically_create_patches load_images_torch create_patches_per_map _conv_layer compute_image_mean _avg_pool dilated_icpr_rate6_small dilated_icpr_vary_rate dilated_icpr_rate6_avgpool loss_def create_prediction_map _squeeze_excitation_layer calc_accuracy_by_map define_multinomial_probs _variable_with_weight_decay dilated_grsl_rate8 calc_accuracy_by_crop identity_initializer create_distributions_over_classes dilated_icpr_rate6_nodilation load_imgs_torch _squeeze_conv_layer test normalize_images dilated_grsl softmax dilated_icpr_rate6_densely main _variable_on_cpu dilated_icpr_rate1 select_best_patch_size create_mean_and_std dilated_icpr_rate6_squeeze _fc_layer print_params select_batch _batch_norm save_map BatchColors create_crops_stride dilated_icpr_original _max_pool leaky_relu dilated_icpr_rate6 dilated_icpr_rate6_SE dynamically_create_patches create_patches_per_map _conv_layer compute_image_mean read_pgm loss_def create_prediction_map _squeeze_excitation_layer calc_cccuracy_by_crop define_multinomial_probs _variable_with_weight_decay dilated_grsl_rate8 dilated_grsl_old create_distributions_over_classes dilated_icpr_rate6_nodilation load_imgs_torch class_to_color test_from_model _squeeze_conv_layer test normalize_images dilated_grsl dilated_icpr_rate6_densely main _variable_on_cpu dilated_icpr_old select_best_patch_size create_mean_and_std dilated_icpr_rate6_squeeze _fc_layer print_params select_batch _batch_norm BatchColors train convert_class _max_pool leaky_relu dilated_icpr_rate6 dilated_icpr_rate6_SE dynamically_create_patches create_patches_per_map _conv_layer load_images select_super_batch_instances compute_image_mean _avg_pool dilated_icpr_rate6_small convert_to_class retrieve_class_Using_RGB dilated_icpr_rate6_avgpool loss_def create_prediction_map _squeeze_excitation_layer validate_test dynamically_calculate_mean_and_std calc_accuracy_by_map create_rotation_distribution define_multinomial_probs _variable_with_weight_decay dilated_grsl_rate8 calc_accuracy_by_crop identity_initializer create_distributions_over_classes dilated_icpr_rate6_nodilation _squeeze_conv_layer test normalize_images dilated_grsl softmax dilated_icpr_rate6_densely main _variable_on_cpu validation validate_test_multiscale retrieve_RGB_using_class select_best_patch_size dilated_icpr_rate6_squeeze _fc_layer test_or_validate_whole_images print_params select_batch _batch_norm BatchColors train generate_final_maps dilated_icpr_original print argv range len list asarray concatenate sample range len float full range len subtract divide mean asarray reshape floor swapaxes open empty split append sorted listdir int print size flipud append zeros fliplr range len int print size flipud append zeros fliplr range len print flipud append fliplr len int print shape append zeros range len create_crops_stride squeeze flatten shape bincount range append len fromarray str uint8 save empty range len fromarray str uint8 save reshape shape zeros float range len shape range zeros int print argsort softmax argmax range len add_to_collection mul _variable_on_cpu l2_loss concat _conv_layer Print max_pool avg_pool Print reshape _conv_layer reshape _conv_layer reshape _conv_layer reshape _conv_layer _avg_pool reshape _conv_layer reshape _conv_layer reshape _conv_layer reshape concat _conv_layer reshape _max_pool _conv_layer reshape _max_pool _conv_layer reshape _conv_layer _squeeze_excitation_layer reshape _conv_layer _squeeze_conv_layer reshape sparse_softmax_cross_entropy_with_logits reduce_mean add_to_collection cast int32 create_patches_per_map flatten floor argmax run str shape range format replace astype normalize_images cohen_kappa_score f1_score float int time print reshape save_map zeros len dilated_icpr_rate6_SE dilated_icpr_rate6 load_images_torch Saver ENDC dilated_icpr_vary_rate dilated_icpr_rate6_small exponential_decay argmax dilated_icpr_rate6_avgpool loss_def list exit placeholder FAIL define_multinomial_probs dilated_grsl_rate8 initialize_all_variables range asarray create_distributions_over_classes dilated_icpr_rate6_nodilation dilated_grsl dilated_icpr_rate6_densely sample float dilated_icpr_rate1 join int minimize Variable print create_mean_and_std float32 dilated_icpr_rate6_squeeze print_params dilated_icpr_original int32 zeros bool len print ENDC FAIL str print FAIL ENDC range append len int readline set add convert_class split str print str astype copy FAIL ENDC astype copy shape zeros float range len print str FAIL ENDC load int class_to_color new reshape _conv_layer reshape _max_pool _conv_layer Print boolean_mask int64 bool sum dilated_icpr_rate6_SE dilated_icpr_rate6 Saver ENDC exponential_decay argmax loss_def list placeholder FAIL dilated_grsl_rate8 initialize_all_variables range asarray dilated_grsl_old dilated_icpr_rate6_nodilation dilated_grsl dilated_icpr_rate6_densely sample dilated_icpr_old minimize Variable print float32 dilated_icpr_rate6_squeeze int32 bool len dilated_icpr_rate6_SE dilated_icpr_rate6 dilated_grsl_old dilated_icpr_old print dilated_icpr_rate6_nodilation float32 placeholder dilated_icpr_rate6_squeeze dilated_grsl Saver int32 dilated_icpr_rate6_densely FAIL ENDC bool argmax dilated_grsl_rate8 read_pgm open ones load_imgs_torch test_from_model train exp reshape divide shape sum print str FAIL ENDC print str FAIL ENDC shape empty retrieve_class_Using_RGB range str asarray print compute_image_mean FAIL ENDC range append len OKBLUE str concatenate print reshape img_as_float ReadAsArray RasterCount range Open append ENDC imread empty array zeros normal asarray ones randint rotate flatten shape bincount argmax range int list asarray sample randint range append len OKBLUE FAIL ENDC OKBLUE str print randint range ENDC len retrieve_RGB_using_class dilated_icpr_rate6_SE dilated_icpr_rate6 Saver ENDC dilated_icpr_rate6_small OKGREEN placeholder FAIL dilated_grsl select_best_patch_size float32 dilated_icpr_rate6_squeeze int32 bool dilated_icpr_original create_patches_per_map floor argmax run str shape append sum range format replace astype normalize_images cohen_kappa_score f1_score float int print reshape zeros len create_patches_per_map delete where floor argmax run str shape append sum range format replace astype normalize_images softmax cohen_kappa_score f1_score float load int print select_best_patch_size reshape zeros len dilated_icpr_rate6_SE dilated_icpr_rate6 Saver ENDC dilated_icpr_rate6_small argmax reset_default_graph placeholder FAIL dilated_grsl_rate8 OKBLUE dilated_icpr_rate6_nodilation dilated_grsl dilated_icpr_rate6_densely print float32 dilated_icpr_rate6_squeeze int32 bool dilated_icpr_original arange dynamically_create_patches flatten run str sum range format calc_accuracy_by_crop replace concatenate normalize_images cohen_kappa_score f1_score float time print reshape zeros len select_super_batch_instances save dilated_icpr_rate6_small reset_default_graph OKGREEN getcwd shape load dilated_icpr_original isfile dilated_icpr_rate6 print dilated_icpr_rate6_nodilation float32 placeholder reset_default_graph dilated_grsl Saver int32 dilated_icpr_rate6_densely FAIL ENDC bool argmax dilated_grsl_rate8 dilated_icpr_rate6_small dilated_icpr_original load_images save str OKGREEN getcwd dynamically_calculate_mean_and_std split create_rotation_distribution lower load WARNING test_or_validate_whole_images isfile generate_final_maps | # Dynamic Multi-Context Segmentation of Remote Sensing Images based on Convolutional Networks <p align="center"> <figure> <img src="readme_fig.png" alt="Obtained Results" width="500"> <figcaption>Figure 1. Examples of results obtained in this work.</figcaption> </figure> </p> Semantic segmentation requires methods capable of learning high-level features while dealing with a large volume of data. Towards such goal, Convolutional Networks can learn specific and adaptable features based on the data. However, these networks are not capable of processing a whole remote sensing image, given its huge size. To overcome such limitation, the image is processed using fixed size patches. The definition of the input patch size is usually performed empirically (evaluating several sizes) or imposed (by network constraint). Both strategies suffer from drawbacks and could not lead to the best patch size. To alleviate this problem, several works exploited multi-context information by combining networks or layers. This process increases the number of parameters resulting in a more difficult model to train. In this work, we propose a novel technique to perform semantic segmentation of remote sensing images that exploits a multi-context paradigm without increasing the number of parameters while defining, in training time, the best patch size. The main idea is to train a dilated network with distinct patch sizes, allowing it to capture multi-context characteristics from heterogeneous contexts. While processing these varying patches, the network provides a score for each patch size, helping in the definition of the best size for the current scenario. A systematic evaluation of the proposed algorithm is conducted using four high-resolution remote sensing datasets with very distinct properties. Our results show that the proposed algorithm provides improvements in pixelwise classification accuracy when compared to state-of-the-art methods. ### Usage Each Python code has a usage briefly explaining how to use the code. | 2,639 |
keisks/jfleg | ['grammatical error correction'] | ['JFLEG: A Fluency Corpus and Benchmark for Grammatical Error Correction'] | EACL_exp/m2converter/m2converter.py EACL_exp/m2converter/util/edit_dist.py eval/gleu.py EACL_exp/m2converter/util/assignIOB.py getIOBorg getIOB getEditDist are_synonyms getEditDistWithPOS get_synonyms GLEU append len range enumerate append len range enumerate lemmas name isalpha set append synsets get_synonyms list range len list isinstance lower append range len | # JFLEG (JHU FLuency-Extended GUG) corpus Last updated: December 7th, 2018 (Make sure to download and use the latest version.) [link to the paper](http://aclweb.org/anthology/E17-2037) - - - ## Data . ├── EACL_exp # experiments in the EACL paper │ ├── m2converter # script to create m2 format from plain texts │ ├── mturk # mechanical turk experiments | 2,640 |
keisks/reassess-gec | ['grammatical error correction'] | ['Reassessing the Goals of Grammatical Error Correction: Fluency Instead of Grammaticality'] | trueskill_rankings/cluster.py inter_annotator_agreements/computeIAA.py compute_kappa add_trinary sign check_boundary rank_by_mu sort_by_mu shorten_name get_min_max append combinations print kappa append items list sort append items list sort round | # Reassessing the Goals of Grammatical Error Correction Data and scripts used in 2016 TACL paper, "Reassessing the Goals of Grammatical Error Correction: Fluency Instead of Grammaticality" - Keisuke Sakaguchi - Courtney Napoles - Matt Post - Joel Tetreault Last updated: May 2nd, 2016 - - - This repository contains data and scripts in the following paper: @article{TACL800, | 2,641 |
keithecarlson/StyleTransferBibleData | ['style transfer'] | ['Evaluating prose style transfer with the Bible'] | Code/subword-nmt-master/learn_bpe.py Code/simpleTokenizer.py Code/removeTags.py Code/experiment.py Code/subword-nmt-master/apply_bpe.py Code/deTokenizeFile.py Code/massApplyBPE.py Code/subword-nmt-master/bpe_toy.py Code/subword-nmt-master/chrF.py Code/subword-nmt-master/get_vocab.py Code/subword-nmt-master/segment-char-ngrams.py Experiment tokenizeFile removeTagsFromLines recursiveSimpleTokenize tokenizeFile create_parser BPE get_pairs encode get_stats merge_vocab create_parser get_correct extract_ngrams f1 main create_parser replace_pair get_pair_statistics prune_stats get_vocabulary update_pair_statistics create_parser write readlines close open str word_tokenize join readlines write encode open join replace tokenizeFile mkdir walk add_argument ArgumentParser add set get_pairs endswith tuple min extend index append items list defaultdict split range len join sub escape compile join defaultdict strip len range split range ngram readline format ref get_correct print extract_ngrams precision beta f1 recall int Counter split defaultdict index defaultdict enumerate join list items replace tuple escape sub iter append compile split items list | # StyleTransferBibleData The code and data here are associated with "Evaluating Prose Style Transfer with the Bible" which can be found at https://royalsocietypublishing.org/doi/full/10.1098/rsos.171920 The training, testing, and development data files are provided with the target style tags at the beginning of each source line as they were used by the seq2seq model in our paper. This may be useful information for other systems, but versions of these files without the tags will be created by following the instructions below. All code was run in a linux virtual environment with tensorflow 1.0.1, seq2seq(https://github.com/google/seq2seq), and Moses(http://www.statmt.org/moses/) all installed and working. We also use subword-nmt (https://github.com/rsennrich/subword-nmt), but the code is replicated within this repository. Run all commands from within the Code directory unless otherwise noted. # Preparation We need to do a few things before get into the experiments. First, upload the modified and included experiment.py file into seq2seq/seq2seq/contrib. This will allow us to run evaluation on all checkpoints of a model. Specify the directory that holds your moses installation: MOSES_DIR=~/mosesdecoder/ | 2,642 |
ken90242/js-segment-annotator | ['image retrieval'] | ['Looking at Outfit to Parse Clothing'] | python/annotation_data.py python/generate_coco_json.py read get_metadata AnnotationData main decode read seek loads open format print get_metadata array open open basename create_annotation_info append range walk get format size create_image_info astype enumerate join uint8 get_classes print get_mask get_metadata array AnnotationData | # JS Segment Annotator  Javascript image annotation tool based on image segmentation. * Label image regions with mouse. * Organize labels by class and object * Written in vanilla Javascript, with require.js dependency (packaged). * Pure client-side implementation of image segmentation. A browser must support HTML canvas to use this tool. There is an [online demo](https://uoguelph-ri.github.io/js-segment-annotator/index.html). ## Importing data | 2,643 |
kenichdietrich/LotteryTicketHypothesis | ['network pruning'] | ['The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks'] | lib/layers.py lib/model_base.py lib/pruning.py LotteryLinear LotteryConv2D LotteryModel LotteryRobustExperiment LotterySession random_reset_weights reset_weights reset_masks prune iteration_pruning save_weights pruning_criterion jitter_reset assign numpy quantile pruning_criterion print assign pruning_criterion quantile numpy abs quantile random_normal_initializer shuffle copy where shape assign zip zeros numpy compile enumerate random_normal_initializer shape assign zeros numpy compile k_init random_normal_initializer shape assign zeros compile ones shape assign | # Lottery Ticket Hypothesis API This repository contains an API to perform experiments in the context of the Lottery Ticket Hypothesis [1]. It is integrated in the Keras and Tensorflow (>=2.3.0) framework. ## The API The LTH API consists of three base classes. Each of them must be fed with a Keras sequential model (neither compiled nor built) made up with custom LTH layers (found in layers.py file) which can be combined with original Keras layers such as Flatten, Dropout and BatchNormalization without any problem. The three base classes are, from low to high level, the following: * **LotteryModel**: It allows performing a simple LTH experiment on a model. * **LotterySession**: A session is a set of experiments conducted on the same model. * **LotteryRobust**: This class allows a statistically robust experiment to be carried out by repeating the same experiment by changing initial conditions. These classes follow a hierarchy. LotteryModel constitutes the low-level class which is used by LotterySession in each experiment contained in the session and, in turn, LotteryRobust use a session to conduct the trials of the robust experiment.  Multiple pruning and reinitialisation methods are implemented, many of them inspired by those used in [2]. We are able to prune weights using the following criteria: | 2,644 |
kenjikawaguchi/qSGD | ['stochastic optimization'] | ['Ordered SGD: A New Stochastic Optimization Framework for Empirical Risk Minimization'] | cifar10_WideResNet/utils/progress/progress/helpers.py cifar10_WideResNet/cifar.py cifar10_WideResNet/models/cifar/resnet.py cifar10_WideResNet/models/cifar/__init__.py cifar10_WideResNet/utils/transforms.py cifar10_WideResNet/models/cifar/wrn.py cifar10_WideResNet/utils/progress/progress/counter.py cifar10_WideResNet/utils/eval.py cifar10_WideResNet/utils/logger.py cifar10_WideResNet/utils/visualize.py cifar10_WideResNet/transforms.py plot.py cifar10_WideResNet/utils/progress/progress/spinner.py models/models.py cifar10_WideResNet/utils/__init__.py main.py cifar10_WideResNet/utils/progress/test_progress.py models/preact_resnet.py cifar10_WideResNet/utils/progress/setup.py cifar10_WideResNet/utils/misc.py cifar10_WideResNet/utils/progress/progress/__init__.py cifar10_WideResNet/utils/progress/progress/bar.py lr_scheduler multiClassHingeLoss lr_decay_func output train RandomErasing ResNet Bottleneck conv3x3 resnet BasicBlock wrn BasicBlock NetworkBlock WideResNet accuracy plot_overlap savefig Logger LoggerMonitor init_params AverageMeter mkdir_p get_mean_and_std RandomErasing make_image show_mask_single show_mask gauss colorize show_batch sleep FillingSquaresBar FillingCirclesBar IncrementalBar ChargingBar ShadyBar PixelBar Bar Countdown Stack Counter Pie SigIntMixin WriteMixin WritelnMixin PieSpinner MoonSpinner Spinner PixelSpinner LineSpinner Progress Infinite LeNet Linear PreActBlock PreActResNet50 PreActResNet PreActResNet18 test PreActResNet152 PreActBottleneck PreActResNet101 PreActResNet34 param_groups lr_decay_func lr_scheduler model Variable print lr_decay_func size exit zero_grad backward mean hinge_loss step cuda cross_entropy enumerate format model print train write eval float enumerate WideResNet topk size t eq mul_ expand_as append sum max asarray arange plot numbers enumerate len print DataLoader div_ zeros range len normal constant isinstance kaiming_normal Conv2d bias modules BatchNorm2d weight Linear makedirs numpy range zeros unsqueeze gauss show make_image imshow make_grid make_image subplot make_grid size clone axis upsampling imshow expand_as range make_image subplot make_grid size clone axis upsampling imshow expand_as cpu range len randn print size PreActResNet18 net | # Ordered SGD: a simple modification of SGD to accelerate training and improve test accuracy This repo consists Pytorch code for the AISTATS 2020 paper "[Ordered SGD: A New Stochastic Optimization Framework for Empirical Risk Minimization](http://proceedings.mlr.press/v108/kawaguchi20a.html)". The proposed algorithm, Ordered SGD, **is fast (computationally efficient), is easy to be implemented, and comes with theoretical gurantees in both optimization and generalization**. Implementing Ordered SGD only requires modifications of one line or few lines in any code that uses SGD. The Ordered SGD algorithm accelerates training and improves test accuracy by focusing on the important data samples. The following figure illustrates the advantage of Ordered SGD in that Ordered SGD learns a different type of models than those learned by the standard SGD, which is sometimes beneficial. <p align="center"> <img src="fig/fig1_1.png" height="400" width= "800"> </p> As a result of the above mechanism (and other theoretical facts), Ordered SGD is fast and can improve test errors as shown in the following figure and tables: CIFAR-10 with WideResNet28_10 | Method | test error | | ------------- | ---------- | | 2,645 |
kenkyusha/eyeGazeToScreen | ['gaze estimation'] | ['Appearance-Based Gaze Estimation in the Wild', 'MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation', "It's Written All Over Your Face: Full-Face Appearance-Based Gaze Estimation"] | gaze_estimation/optim.py gaze_estimation/gaze_estimator/head_pose_estimation/head_pose_normalizer.py gaze_estimation/logger.py gaze_estimation/types.py gaze_estimation/gaze_estimator/common/camera.py screenSize.py gaze_estimation/scheduler.py gaze_estimation/utils.py gaze_estimation/gaze_estimator/common/eye.py tools/preprocess_mpiifacegaze.py tools/get_calib_matrix.py gaze_estimation/gaze_estimator/common/face_parts.py gaze_estimation/models/mpiifacegaze/alexnet.py gaze_estimation/__init__.py gaze_estimation/config/__init__.py screen_conf.py train.py point_2_screen.py gaze_estimation/datasets/mpiigaze.py helper_fn.py gaze_estimation/datasets/__init__.py gaze_estimation/gaze_estimator/__init__.py gaze_estimation/gaze_estimator/common/__init__.py gaze_estimation/models/mpiifacegaze/backbones/__init__.py evaluate.py gaze_estimation/gaze_estimator/head_pose_estimation/face_landmark_estimator.py gaze_estimation/config/config_node.py draw_utils.py gaze_estimation/models/mpiigaze/lenet.py gaze_estimation/tensorboard.py gaze_estimation/models/mpiifacegaze/backbones/resnet_simple.py gaze_estimation/transforms.py gaze_estimation/gaze_estimator/common/face.py gaze_estimation/datasets/mpiifacegaze.py gaze_estimation/config/defaults.py gaze_estimation/gaze_estimator/common/face_model.py gaze_estimation/gaze_estimator/common/visualizer.py tools/capture_video.py demo.py gaze_estimation/gaze_estimator/gaze_estimator.py tools/preprocess_mpiigaze.py gaze_estimation/losses.py gaze_estimation/gaze_estimator/head_pose_estimation/__init__.py tools/get_screen_size.py gaze_estimation/models/mpiigaze/resnet_preact.py gaze_estimation/dataloader.py gaze_estimation/models/__init__.py gaze_estimation/models/mpiifacegaze/resnet_simple.py main Demo demo_updown demo_stability color_grid draw_grid plot_eye_XYZ plot_pts demo_sequence random_sequence display_canv accuracy_measure demo_leftright main test round_tup point_to_screen calc_metrics dump_dict main Demo get_screenWH main train validate create_dataloader _create_handlers _create_file_handler create_logger _create_color_formatter _create_plain_formatter _create_stream_handler create_loss get_param_list create_optimizer create_scheduler DummyWriter create_tensorboard_writer _create_mpiifacegaze_transform _create_mpiigaze_transform create_transform LossType GazeEstimationMethod save_config convert_to_unit_vector AverageMeter compute_angle_error setup_cudnn set_seeds create_train_output_dir load_config ConfigNode get_default_config OnePersonDataset OnePersonDataset create_dataset GazeEstimator Camera Eye Face FaceModel FaceParts FacePartsName Visualizer LandmarkEstimator HeadPoseNormalizer _normalize_vector create_model Model Model Model create_backbone initialize_weights Model initialize_weights Model BasicBlock main create_timestamp get_screenWH add_mat_data_to_hdf5 main save_one_person convert_gaze convert_pose main get_eval_info load_config Demo run line rectangle color_grid color_grid color_grid color_grid format plot invert_yaxis grid close title savefig legend array set_trace demo_updown str random_sequence demo_stability color_grid draw_grid imshow moveWindow demo_sequence zeros demo_leftright subplots plot suptitle grid close savefig legend array mean eval device float cat load create_model save_config print stem create_dataloader test mkdir Path output_dir load_state_dict save numpy checkpoint range len pop max int print sort square reversed mean sqrt sum array print round set_trace point_2d_screen str calc_metrics exit width format height reversed plot_pts pop time dump_dict mode pts len Tk withdraw model zero_grad device to update size mean avg info item enumerate add_image time make_grid backward AverageMeter loss_function step add_scalar time info add_histogram AverageMeter named_parameters eval avg device model_params add_scalar validate setup_cudnn create_logger set_seeds val_first seed create_scheduler create_tensorboard_writer epochs range create_optimizer close info create_loss Checkpointer create_train_output_dir train step DataLoader create_dataset _create_handlers getLogger addHandler DEBUG setLevel INFO join _create_file_handler _create_color_formatter _create_plain_formatter append _create_stream_handler split DEBUG setLevel setFormatter StreamHandler setFormatter as_posix DEBUG setLevel FileHandler loss append no_weight_decay_on_bn named_parameters get_param_list Adam SGD MultiStepLR CosineAnnealingLR use_tensorboard Lambda Compose mpiifacegaze_face_size Lambda Compose mpiifacegaze_gray auto auto seed manual_seed benchmark deterministic merge_from_file config options eyes cust_vid save_vid add_argument freeze runtime imgscale merge_from_list get_default_config ArgumentParser demo parse_args printvals mode mkdir Path output_dir exists sqrt cos sin convert_to_unit_vector int OnePersonDataset ConcatDataset len val_ratio Path dataset_dir create_transform auto lower import_module Model device to name import_module isinstance Conv2d xavier_uniform_ zeros_ bias weight Linear ones_ kaiming_normal_ BatchNorm2d now VideoCapture CAP_PROP_FRAME_HEIGHT as_posix ArgumentParser VideoWriter VideoWriter_fourcc release waitKey imshow parse_args set CAP_PROP_FRAME_WIDTH read add_argument write output cap_size uint8 astype list tqdm add_mat_data_to_hdf5 dataset exists arcsin arctan2 arcsin arctan2 drop read_csv apply as_posix pose image sorted iterrows stem append day glob astype convert_pose get_eval_info uint8 convert_gaze float32 dict gaze loadmat array save_one_person | # These are my modifications to the script - functionality to map the predicted gaze vector from webcam image to the computer screen - gridview pointer showing where the gaze is currently pointed at (adjustable pixel size) - added landmark averaging: **AVG_LANDMARKS** over number of frames - added gaze vector averaging: **GAZE_AVG_FLAG** over number of gaze vectors - video playback with different scenarios such as **UPDOWN**, **LEFTRIGHT**, **STABILITY**, **SEQ** - performance evaluation calcuation of **MAE**, **CEP** and **CE95** - drawing functions for the results ## Calibration values Currently it is calibrated to my personal MBP13 so this needs to be adjusted accoring to your computer: | 2,646 |
kenshohara/video-classification-3d-cnn-pytorch | ['action recognition'] | ['Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?'] | generate_result_video/generate_result_video.py train.py validation.py models/pre_act_resnet.py models/resnext.py temporal_transforms.py spatial_transforms.py test.py dataset.py models/wide_resnet.py opts.py mean.py models/densenet.py classify.py main.py models/resnet.py model.py classify_video Video get_class_labels load_annotation_data video_loader make_dataset accimage_loader get_default_image_loader get_default_video_loader pil_loader get_video_names_and_annotations get_mean generate_model parse_opts CenterCrop ToTensor Compose Scale Normalize LoopPadding TemporalCenterCrop calculate_video_results test get_fps get_fine_tuning_parameters DenseNet densenet201 densenet169 densenet264 _DenseLayer _DenseBlock _Transition densenet121 conv3x3x3 get_fine_tuning_parameters resnet50 downsample_basic_block resnet152 PreActivationBasicBlock resnet34 resnet200 PreActivationBottleneck resnet18 PreActivationResNet resnet101 conv3x3x3 get_fine_tuning_parameters ResNet downsample_basic_block resnet50 Bottleneck resnet152 resnet34 resnet200 resnet18 resnet10 BasicBlock resnet101 ResNeXtBottleneck conv3x3x3 get_fine_tuning_parameters resnet50 downsample_basic_block ResNeXt resnet152 resnet101 conv3x3x3 get_fine_tuning_parameters WideBottleneck resnet50 downsample_basic_block WideResNet data Video model Variable size Compose tolist DataLoader sample_duration append LoopPadding max range cat enumerate join format image_loader append exists get_default_image_loader append items list format deepcopy list IntTensor append listdir range len densenet169 densenet201 resnet50 densenet264 DataParallel resnet101 resnet34 resnet200 resnet18 resnet152 resnet10 cuda densenet121 parse_args set_defaults add_argument ArgumentParser topk size mean stack append range update time format model print Variable cpu AverageMeter size eval calculate_video_results append range enumerate len decode format communicate len round float listdir Popen find DenseNet DenseNet DenseNet DenseNet append format range named_parameters data isinstance FloatTensor Variable zero_ avg_pool3d cuda cat PreActivationResNet PreActivationResNet PreActivationResNet PreActivationResNet PreActivationResNet PreActivationResNet ResNet ResNet ResNet ResNet ResNet ResNet ResNet ResNeXt ResNeXt ResNeXt WideResNet | # Video Classification Using 3D ResNet This is a pytorch code for video (action) classification using 3D ResNet trained by [this code](https://github.com/kenshohara/3D-ResNets-PyTorch). The 3D ResNet is trained on the Kinetics dataset, which includes 400 action classes. This code uses videos as inputs and outputs class names and predicted class scores for each 16 frames in the score mode. In the feature mode, this code outputs features of 512 dims (after global average pooling) for each 16 frames. **Torch (Lua) version of this code is available [here](https://github.com/kenshohara/video-classification-3d-cnn).** ## Requirements * [PyTorch](http://pytorch.org/) ``` conda install pytorch torchvision cuda80 -c soumith | 2,647 |
kensun0/Parallel-Wavenet | ['speech synthesis'] | ['ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech'] | masked.py loss.py h512_bo16.py mu_law sample_one_logistic_mix_param linear log_sum_exp inv_mu_law_numpy inv_mu_law log_prob_from_logits causal_linear logistic_likelihood sample_from_discretized_mix_logistic int_shape discretized_mix_logistic_loss temporal_padding shift_right conv1d int8 sign floor cast abs log float32 where sign cast abs equal astype float32 where sign abs equal slice dequeue enqueue_many enqueue matmul FIFOQueue zeros expand_dims bias_add get_variable expand_dims bias_add matmul get_variable get_shape reduce_max len get_shape reduce_max len sigmoid exp exp value softplus reshape maximum where sigmoid log_prob_from_logits tile log exp one_hot maximum reduce_sum random_uniform argmax log argmax maximum one_hot reduce_sum slice reshape shape pad stack as_list temporal_padding reshape bias_add convolution | # Parallel-Wavenet Parallel wavenet has been implemented, partial codes will be placed here soon. # Citings Citing 1: Parallel WaveNet: Fast High-Fidelity Speech Synthesis Citing 2: WAVENET: A GENERATIVE MODEL FOR RAW AUDIO Citing 3: Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders Citing 4: TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS Citing 5: PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications Citing 6: https://github.com/tensorflow/magenta/tree/master/magenta/models/nsynth Citing 7: https://github.com/keras-team/keras/blob/master/keras/backend/tensorflow_backend.py#L3254 | 2,648 |
kentaroy47/BlazeFace_Person.pytorch | ['face detection'] | ['BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs'] | utils/__init__.py utils/focalloss.py train_BlazeFace.py utils/dataset.py utils/ssd_predict_show.py utils/data_augumentation.py utils/ssd.py utils/blazeface.py utils/ssd_model.py utils/match.py train_model adjust_learning_rate weights_init get_current_lr SSD256 BlazeFace initialize nms decode BlazeBlock Detect SSD BlazeFaceExtra2 make_loc_conf256 make_loc_conf DBox BlazeFaceExtra Anno_xml2list make_datapath_list DatasetTransform od_collate_fn VOCDataset SwapChannels ToTensor ToAbsoluteCoords RandomBrightness PhotometricDistort RandomSaturation Resize RandomSampleCrop ToPercentCoords intersect Lambda Compose ConvertColor Expand SubtractMeans jaccard_numpy RandomHue ConvertFromInts RandomMirror RandomContrast ToCV2Image RandomLightingNoise FocalLoss intersect jaccard center_size match point_form encode decode nms Detect SSD2 make_vgg SSD make_extras make_loc_conf DBox L2Norm decode Anno_xml2list Detect make_datapath_list SSD od_collate_fn DataTransform make_vgg make_extras nm_suppression VOCDataset make_loc_conf MultiBoxLoss DBox L2Norm SSDPredictShow data isinstance Conv2d bias kaiming_normal_ constant_ enumerate print param_groups get_current_lr str time format print train zero_grad to_csv eval adjust_learning_rate save device append to DataFrame range state_dict data isinstance Conv2d BatchNorm2d kaiming_normal_ constant_ mul sort new clamp index_select resize_as_ long cat join list strip append open append stack FloatTensor minimum clip maximum intersect clamp size min expand max intersect expand_as squeeze_ size jaccard index_fill_ point_form encode max range log MaxPool2d Conv2d print size mul sort new clamp index_select resize_as_ long |   # BlazeFace_person_pytorch Blazeface trained on pascal_voc person. This repo is an **unofficial** implementation of: `BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs` [Paper](https://arxiv.org/abs/1907.05047) The repo contains.. - [x] SSD-like model - [x] Training script | 2,649 |
kepei1106/SentenceFunction | ['text generation'] | ['Generating Informative Responses with Controlled Sentence Function'] | my_attention_decoder_fn.py output_projection.py my_seq2seq.py utils.py my_loss.py main.py model.py evaluate gen_batched_data load_data inference train build_vocab Seq2SeqModel _create_attention_construct_fn attention_decoder_fn_train _attn_add_fun _attn_mul_fun _init_attention prepare_attention attention_decoder_fn_inference _create_attention_score_fn sequence_loss dynamic_rnn_decoder output_projection_layer sample_gaussian gaussian_kld append zip items sorted list print map index embed_units split append zeros array enumerate append padding max len step_decoder gen_batched_data print zeros step_decoder gen_batched_data append _create_attention_score_fn _create_attention_construct_fn zeros_like LSTMStateTuple h isinstance pow div exp reduce_sum shape exp multiply random_normal | # Generating Informative Responses with Controlled Sentence Function ## Introduction Sentence function is a significant factor to achieve the purpose of the speaker. In this paper, we present a novel model to generate informative responses with controlled sentence function. Given a user post and a sentence function label, our model is to generate a response that is not only coherent with the specified function category, but also informative in content. This project is a tensorflow implementation of our work. ## Dependencies * Python 2.7 * Numpy * Tensorflow 1.3.0 ## Quick Start | 2,650 |
kernsuite-debian/pygsm | ['optical character recognition'] | ['A model of diffuse Galactic Radio Emission from 10 MHz to 100 GHz'] | tests/test_gsm.py tests/test_gsm_observer.py setup.py pygsm/pygsm.py pygsm/__init__.py GlobalSkyModel GSMObserver test_speed compare_to_gsm test_set_methods test_write_fits test_gsm_generate test_observed_mollview test_gsm_observer GlobalSkyModel linspace generate print File average GlobalSkyModel generate abs view set_freq_unit GlobalSkyModel generate set_basemap time print GlobalSkyModel linspace generate remove generated_map_data generate GlobalSkyModel read_map write_fits view GSMObserver view_observed_gsm generate datetime view print close GSMObserver system view_observed_gsm savefig mollview generate range datetime | PyGSM
=====
`PyGSM` is a Python interface for the Global Sky Model (GSM) of [Oliveira-Costa et. al., (2008)](http://onlinelibrary.wiley.com/doi/10.1111/j.1365-2966.2008.13376.x/abstract).
The GSM generates all-sky maps in Healpix format of diffuse Galactic radio emission
from 10 MHz to 94 GHz.
This is *not* a wrapper of the original Fortran code, it is a python-based equivalent
that has some additional features and advantages, such as healpy integration for imaging.
Instead of the original ASCII DAT files that contain the principal component analysis
| 2,651 |
keunwoochoi/kapre | ['data augmentation'] | ['Kapre: On-GPU Audio Preprocessing Layers for a Quick Implementation of Deep Neural Network Models with Keras'] | kapre/backend.py kapre/__init__.py docs/conf.py kapre/composed.py kapre/time_frequency.py tests/test_time_frequency.py setup.py kapre/time_frequency_tflite.py tests/utils.py kapre/tflite_compatible_stft.py kapre/signal.py tests/test_augmentation.py tests/test_backend.py tests/test_signal.py kapre/augmentation.py setup SpecAugment ChannelSwap validate_data_format_str magnitude_to_decibel mu_law_decoding filterbank_log mu_law_encoding filterbank_mel get_window_fn get_stft_mag_phase get_perfectly_reconstructing_stft_istft get_stft_magnitude_layer get_log_frequency_spectrogram_layer get_melspectrogram_layer get_frequency_aware_conv2d MuLawEncoding MuLawDecoding Energy LogmelToMFCC Frame _rdft _rdft_matrix fixed_frame continued_fraction_arctan atan2_tflite stft_tflite _shape_spectrum_output ConcatenateFrequencyMap Magnitude STFT MagnitudeToDecibel Phase InverseSTFT Delta ApplyFilterbank STFTTflite PhaseTflite MagnitudeTflite test_spec_augment_apply_masks_to_axis test_save_load_channel_swap test_channel_swap_correctness test_spec_augment_layer test_spec_augment_depth_exception test_save_load_spec_augment test_filterbank_log test_validate_fail test_mel test_mu_law_correctness test_fb_log_fail test_magnitude_to_decibel test_unsupported_window test_wrong_data_format test_frame_correctness test_mfcc_correctness test_save_load test_energy_correctness test_log_spectrogram_fail test_log_spectrogram_runnable test_spectrogram_correctness_more test_mag_phase _num_frame_valid test_get_frequency_aware_conv2d assert_approx_phase allclose_complex_numbers test_wrong_data_format test_melspectrogram_correctness test_concatenate_frequency_map test_save_load test_perfectly_reconstructing_stft_istft test_spectrogram_correctness test_spectrogram_tflite_correctness test_wrong_input_data_format _num_frame_same test_delta allclose_phase save_load_compare predict_using_tflite get_audio get_spectrogram add_stylesheet hasattr kaiser_window vorbis_window signal kaiser_bessel_derived_window tuple reduce_max _log10 maximum cast floatx astype exp normalize astype log2 floatx zeros float range sign cast int32 log1p abs exp cast_to_floatx sign log1p abs Magnitude validate_data_format_str STFT MagnitudeToDecibel append Magnitude validate_data_format_str STFT MagnitudeToDecibel append ApplyFilterbank Magnitude validate_data_format_str STFT MagnitudeToDecibel filterbank_log append ApplyFilterbank InverseSTFT validate_data_format_str STFT stft_to_stftp concat_layer Magnitude mag_to_decibel validate_data_format_str STFT MagnitudeToDecibel Phase stft_to_stftm Model Input waveform_to_stft Concatenate Conv2D ConcatenateFrequencyMap outer arange pi constant _rdft_matrix concat matmul pad stack real imag list arange slice reshape astype gather shape int32 gcd max len int constant _rdft reshape float32 pad fixed_frame cast ceil window_fn zeros cast range shape logical_and pi where shape cast continued_fraction_arctan zeros equal transpose Sequential add assert_equal get_audio range ChannelSwap predict _apply_masks_to_axis SpecAugment get_spectrogram assert_equal get_spectrogram model Sequential add assert_equal shape SpecAugment assert_allclose save_load_compare ChannelSwap get_audio assert_allclose save_load_compare SpecAugment assert_allclose get_spectrogram magnitude_to_decibel variable stack eval array assert_allclose int T filterbank_mel numpy assert_allclose filterbank_log convert_to_tensor int mu_law_decoding astype float32 assert_equal mu_law_encoding mu_compress numpy filterbank_log get_window_fn validate_data_format_str T Sequential add assert_equal Frame get_audio expand_dims T Sequential Energy add get_audio expand_dims sum assert_allclose power_to_db T assert_allclose squeeze Sequential LogmelToMFCC add sqrt get_audio mfcc melspectrogram expand_dims predict MuLawEncoding power_to_db T save_load_compare MuLawDecoding Energy reshape LogmelToMFCC Frame get_audio expand_dims assert_allclose Frame cos assert_allclose sin sum assert_equal shape real abs imag assert_allclose allclose_complex_numbers T _get_stft_model Magnitude angle transpose Phase get_audio tile allclose_phase expand_dims abs assert_allclose allclose_complex_numbers T _get_stft_model Magnitude angle transpose Phase get_audio tile allclose_phase expand_dims abs assert_allclose power_to_db T transpose _get_melgram_model get_audio tile expand_dims assert_allclose allclose_complex_numbers _get_stft_model predict_using_tflite complex Magnitude assert_allclose Phase PhaseTflite MagnitudeTflite get_audio assert_approx_phase predict get_log_frequency_spectrogram_layer get_audio get_log_frequency_spectrogram_layer get_audio reshape Sequential add Delta array delta_model assert_allclose T get_stft_mag_phase Sequential add assert_equal shape stack take get_audio magphase assert_allclose allclose_complex_numbers int model Sequential get_perfectly_reconstructing_stft_istft astype complex64 assert_equal shape get_audio expand_dims assert_allclose ConcatenateFrequencyMap STFT get_stft_mag_phase astype float32 get_stft_magnitude_layer get_log_frequency_spectrogram_layer get_melspectrogram_layer normal list ConcatenateFrequencyMap tuple assert_equal shape linspace numpy assert_allclose normal freq_aware_conv2d get_frequency_aware_conv2d layer layer transpose copy image_data_format repeat tile expand_dims len transpose uniform image_data_format repeat tile expand_dims join load_model allclose_func model name cleanup Sequential gettempdir add save new_model TemporaryDirectory from_keras_model as_posix get_input_details get_tensor convert write Interpreter get_output_details rmtree invoke set_tensor Path allocate_tensors expand_dims exists append makedirs | # Kapre Keras Audio Preprocessors - compute STFT, ISTFT, Melspectrogram, and others on GPU real-time. Tested on Python 3.6 and 3.7 ## Why Kapre? ### vs. Pre-computation * You can optimize DSP parameters * Your model deployment becomes much simpler and consistent. * Your code and model has less dependencies ### vs. Your own implementation | 2,652 |
kevins99/SegCaps-Keras | ['semantic segmentation'] | ['Capsules for Object Segmentation'] | losses.py train.py post_proc.py metrics.py make_data.py capsnet.py test.py generator.py capsulelayers.py BoxCounting.py generator_objects.py save_rgb.py gen_map.py rgb2gray fractal_dimension CapsNetR1 CapsNetR3 CapsNetBasic Mask ConvCapsuleLayer _squash Length DeconvCapsuleLayer update_routing gray2rgb gen_map loss add_imgs add_masks dice_coef createLargest image_opening crop labelVisualize saveResult print shape int arange boxcount min polyfit shape floor append log get_shape Model Input get_shape Model Input get_shape Model Input get_shape constant while_loop transpose TensorArray fill norm arange gray2rgb fractal_dimension divide isnan pad append zeros expand_dims array atleast_3d amax amax format save open format save open mean sum getStructuringElement morphologyEx MORPH_ELLIPSE MORPH_OPEN shape resize uint8 argmax zeros_like zeros range shape join imsave enumerate | # SegCaps-Keras A simple end to end segmentation pipeline ready to go, easy to tweak and use. The original paper for SegCaps can be found at https://arxiv.org/abs/1804.04241. The original source code can be found at https://github.com/lalonderodney/SegCaps Author's project page for this work can be found at https://rodneylalonde.wixsite.com/personal/research-blog/capsules-for-object-segmentation. | 2,653 |
kevinwss/Deep-SAD-Baseline | ['outlier detection', 'anomaly detection', 'semi supervised anomaly detection'] | ['Deep Semi-Supervised Anomaly Detection'] | src/networks/cifar10_LeNet.py src/baseline_isoforest.py src/datasets/main.py src/base/torchvision_dataset.py src/baselines/kde.py src/baselines/ssad.py src/baseline_ssad.py src/base/base_dataset.py src/baselines/SemiDGM.py src/utils/misc.py src/baselines/shallow_ssad/ssad_convex.py src/datasets/__init__.py src/baselines/shallow_ssad/my_mnist.py src/baseline_SemiDGM.py src/baseline_ocsvm.py src/datasets/mnist0.py src/baseline_kde.py src/utils/__init__.py src/baselines/ocsvm.py src/networks/main.py src/optim/my_mnist.py src/optim/ae_trainer.py src/datasets/odds.py src/base/__init__.py src/base/base_net.py src/datasets/fmnist.py src/utils/visualization/plot_images_grid.py src/optim/variational.py src/datasets/mnist1.py src/DeepSAD.py src/optim/DeepSAD_trainer.py src/base/odds_dataset.py src/base/base_trainer.py src/networks/mnist_LeNet.py src/networks/__init__.py src/networks/layers/standard.py src/datasets/preprocessing.py src/datasets/mnist.py src/optim/__init__.py src/optim/SemiDGM_trainer.py src/networks/layers/stochastic.py src/baselines/__init__.py src/networks/inference/distributions.py src/optim/vae_trainer.py src/main.py src/baselines/isoforest.py src/networks/dgm.py src/networks/fmnist_LeNet.py src/datasets/cifar10.py src/networks/vae.py src/baselines/shallow_ssad/__init__.py src/utils/config.py src/networks/mlp.py main main main main main DeepSAD main BaseADDataset BaseNet BaseTrainer ODDSDataset TorchvisionDataset IsoForest KDE OCSVM SemiDeepGenerativeModel My_dataset mnist SSAD MyData My_dataset mnist MyData ConvexSSAD CIFAR10_Dataset MyCIFAR10 FashionMNIST_Dataset MyFashionMNIST load_dataset MyMNIST MNIST_Dataset MyMNIST MNIST_Dataset mnist MNIST_Dataset MyData ODDSADDataset create_semisupervised_setting CIFAR10_LeNet CIFAR10_LeNet_Decoder CIFAR10_LeNet_Autoencoder DeepGenerativeModel StackedDeepGenerativeModel Classifier FashionMNIST_LeNet_Decoder FashionMNIST_LeNet_Autoencoder FashionMNIST_LeNet build_autoencoder build_network MLP_Decoder MLP_Autoencoder Linear_BN_leakyReLU MLP MNIST_LeNet_Autoencoder MNIST_LeNet MNIST_LeNet_Decoder Decoder VariationalAutoencoder Encoder log_standard_gaussian log_standard_categorical log_gaussian Standardize GaussianSample Stochastic AETrainer DeepSADTrainer My_dataset mnist MyData SemiDeepGenerativeTrainer VAETrainer ImportanceWeightedSampler SVI Config log_sum_exp enumerate_discrete binary_cross_entropy plot_images_grid Config getLogger save_results load_ae IsoForest setLevel load_config seed basicConfig list load_model addHandler set_sharing_strategy load_dataset setFormatter save_config copy test manual_seed info zip INFO FileHandler Formatter train unsqueeze tensor transpose plot_images_grid KDE OCSVM save_model save_vae_results pretrain set_network SemiDeepGenerativeModel set_vae set_num_threads setseed SSAD DeepSAD save_ae_results join urlretrieve print _labels _images expanduser makedirs ODDSADDataset FashionMNIST_Dataset CIFAR10_Dataset MNIST_Dataset int permutation tolist solve flatten array len CIFAR10_LeNet MLP DeepGenerativeModel StackedDeepGenerativeModel MNIST_LeNet FashionMNIST_LeNet VariationalAutoencoder MNIST_LeNet_Autoencoder FashionMNIST_LeNet_Autoencoder CIFAR10_LeNet_Autoencoder MLP_Autoencoder exp log pi ones_like softmax ImportanceWeightedSampler size device to is_cuda cat max make_grid transpose imshow set_visible title savefig clf gca numpy | # Deep SAD: A Method for Deep Semi-Supervised Anomaly Detection This repository provides a [PyTorch](https://pytorch.org/) implementation of the *Deep SAD* method presented in our ICLR 2020 paper ”Deep Semi-Supervised Anomaly Detection”. ## Citation and Contact You find a PDF of the Deep Semi-Supervised Anomaly Detection ICLR 2020 paper on arXiv [https://arxiv.org/abs/1906.02694](https://arxiv.org/abs/1906.02694). If you find our work useful, please also cite the paper: ``` @InProceedings{ruff2020deep, title = {Deep Semi-Supervised Anomaly Detection}, author = {Ruff, Lukas and Vandermeulen, Robert A. and G{\"o}rnitz, Nico and Binder, Alexander and M{\"u}ller, Emmanuel and M{\"u}ller, Klaus-Robert and Kloft, Marius}, | 2,654 |
kevinzakka/one-shot-siamese | ['one shot learning'] | ['Siamese neural networks for one-shot image recognition'] | trainer.py config.py plot.py test_imgs.py utils.py main.py data_loader.py model.py add_argument_group get_config str2bool OmniglotTrain get_train_valid_loader get_test_loader OmniglotTest main SiameseNet main build_parser main load_checkpoint Trainer plot_omniglot_pairs img2array pickle_load prepare_dirs resize_array save_config pickle_dump AverageMeter array2img MacOSFile rolling_window get_num_model load_config append parse_known_args join OmniglotTrain ImageFolder DataLoader OmniglotTest join ImageFolder OmniglotTest DataLoader valid_trials prepare_dirs batch_size Trainer get_test_loader is_train load_config get_train_valid_loader data_dir uniform append range use_gpu num_train save_config shuffle test manual_seed random_seed augment print train way test_trials add_argument ArgumentParser data subplots grid list name model_num ylabel title savefig plot tight_layout mean xlabel rolling_window fill_between std read_csv len load join format print load_state_dict SiameseNet load_checkpoint cuda asarray concatenate array2img resize append expand_dims range show asarray convert resize expand_dims open asarray max show subplots set_title set_yticks add_subplot tight_layout imshow set_xticks set_facecolor savefig tick_params range enumerate strides join rmtree get_num_model flush makedirs update join format __dict__ print ckpt_dir get_num_model load join print dict ckpt_dir get_num_model open num_model | # Siamese Networks for One-Shot Learning <p align="center"> <img src="./plots/loss.png" alt="Drawing", width=80%> </p> ## Paper Modifications I've done some slight modifications to the paper to eliminate variables while I debug my code. Specifically, validation and test accuracy currently suck so I'm checking if there's a bug either in the dataset generation or trainer code. - I'm using `Relu -> Maxpool` rather than `Maxpool - Relu`. - I'm using batch norm between the conv layers. - I'm using He et. al. initialization. - I'm using a global learning rate, l2 reg factor, and momentum rather than per-layer parameters. | 2,655 |
kevtran23/autoregressive_bias_correction | ['data augmentation'] | ['Bias Correction of Learned Generative Models using Likelihood-Free Importance Weighting'] | GRAN/runner/gran_runner.py GRAN/dataset/__init__.py GRAN/run_exp.py GRAN/runner/__init__.py GRAN/dataset/gran_data.py GRAN/runner/classifier.py main GRANData NodeApplyModule Classifier pick_connected_component_new reduce GCN load_graph_list GraphDataSet save_graph_list collate compute_edge_ratio get_graph GranRunner evaluate log_level save_dir seed exit comment pprint parse_arguments run_id manual_seed_all format get_config config_file test info manual_seed setup_logging join print train mean print connected_component_subgraphs list selfloop_edges pick_connected_component_new convert_node_labels_to_integers remove_edges_from max range len connected_component_subgraphs max list sorted subgraph min to_dict_of_lists keys range list map batch zip number_of_nodes from_numpy_matrix asmatrix spectral_stats clustering_stats orbit_stats_all degree_stats | # autoregressive_bias_correction Repository for autoregressive graph generation using Likelihood-Free Importance Weighting Bias Correction technique https://arxiv.org/abs/1906.09531 | 2,656 |
kfiraberman/neural_best_buddies | ['image morphing'] | ['Neural Best-Buddies: Sparse Cross-Domain Correspondence'] | util/util.py models/vgg19_model.py util/draw_correspondence.py algorithms/neural_best_buddies.py util/MLS.py main.py options/options.py algorithms/feature_metric.py normalize_per_pix normalize_tensor response stdv_channels gaussian error_map mean_channels patch_distance stretch_tensor_0_to_1 identity_map sparse_semantic_correspondence vgg19 define_Vgg19 PerceptualLoss Options color_map draw_correspondence draw_dots draw_circle draw_square draw_points MLS read_points batch2im varname save_image read_image get_transform diagnose_network mkdirs tensor2im save_map_image downsample_map read_mask stretch_image feature2images binary2color_image save_tensor_as_mat mkdir map2image info save_final_image grad2image print_numpy upsample_map size sum size sum min max fill_ pow max sum mean_channels size sum copy_ Tensor transpose repeat exp floor identity_map vgg19 cuda pad tile pad floor range tile join color_map draw_dots draw_circle draw_square save_image tensor2im range len join str color_map draw_circle draw_square save_image tensor2im range len append open split get_transform convert append Resize BICUBIC join save_image tensor2im int join binary2color_image pow upsample_map map2image save_image Upsample AvgPool2d zeros transpose numpy tile stretch_image transpose tile zeros numpy range zeros numpy maximum range transpose numpy stretch_image transpose numpy tile transpose numpy array tile amin amax print parameters fromarray save print numpy savemat print join search print float64 astype flatten shape mkdir makedirs print shape array open | # Neural Best-Buddies in PyTorch This is our PyTorch implementation for the Neural-Best Buddies paper. The code was written by [Kfir Aberman](https://kfiraberman.github.io/) and supported by [Mingyi Shi](https://rubbly.cn/). **Neural Best-Buddies: [Project](https://kfiraberman.github.io/neural_best_buddies/) | [Paper](https://arxiv.org/pdf/1805.04140.pdf)** <img src="./images/teaser.jpg" width="800" /> If you use this code for your research, please cite: Neural Best-Buddies: Sparse Cross-Domain Correspondence [Kfir Aberman](https://kfiraberman.github.io/), [Jing Liao](https://liaojing.github.io/html/), [Mingyi Shi](https://rubbly.cn/), [Dani Lischinski](http://danix3d.droppages.com/), [Baoquan Chen](http://www.cs.sdu.edu.cn/~baoquan/), [Daniel Cohen-Or](https://www.cs.tau.ac.il/~dcor/), SIGGRAPH 2018. ## Prerequisites - Linux or macOS | 2,657 |
khalooei/ALOCC-CVPR2018 | ['outlier detection', 'one class classifier', 'anomaly detection'] | ['Adversarially Learned One-Class Classifier for Novelty Detection'] | train.py test.py models.py utils.py ops.py kh_tools.py read_lst_images kh_extractPatches get_image_patches kh_crop get_noisy_data kh_getSliceImages get_patch_video kh_getImages kh_isDirExist read_lst_images_w_noise2 read_image_w_noise kh_extractPatchesOne read_dataset_image_path kh_getSliceImages_simple read_lst_images_w_noise read_dataset_images read_image ALOCC_Model lrelu batch_norm linear concat conv2d deconv2d conv_cond_concat main check_some_assertions process_frame main check_some_assertions save_images montage conv_out_size_same inverse_transform visualize make_gif transform_Slicization center_crop kh_make_patches imread show_all_variables imsave get_image_Slicization get_image merge get_image_SlicizationWithShape merge_images transform to_json append random_noise append join glob random_noise read_image append read_image_w_noise extend get_image_patches read_image_w_noise append extend get_image_patches read_image append join read_image glob read_lst_images get_image_patches format print extend range len append shape array print makedirs basename std kh_crop print min add mean kh_isDirExist dirname resize append zeros range array imsave open basename kh_crop print min kh_isDirExist dirname resize append zeros range array imsave open kh_extractPatchesOne append kh_extractPatches get_shape as_list checkpoint_dir input_height sample_dir output_height makedirs check_some_assertions print pprint __flags ConfigProto GPUOptions patch_step get_image_patches format print patch_size transpose f_test_frozen_model len log_dir dataset trainable_variables analyze_vars imread transform_Slicization astype float32 transform_Slicization astype float32 zeros enumerate squeeze merge int round center_crop imresize VideoClip write_gif make_gif int arange save_images batch_size print sampler strftime choice uniform gmtime run tile ceil zeros range append enumerate list as_strided Number isinstance tuple ndim strides shape array int isinstance imsave ones sqrt ceil array range | # Adversarially Learned One-Class Classifier for Novelty Detection (ALOCC-CVPR2018) [[CVPR Poster]](cvpr18_poster_ALOCC.pdf) [[presentation]](https://github.com/khalooei/ALOCC-CVPR2018/blob/master/presentation/ALOCC-M2LSchool-khalooei.pdf) [[Project]](https://github.com/khalooei/ALOCC-CVPR2018) [[Paper]](http://openaccess.thecvf.com/content_cvpr_2018/papers/Sabokrou_Adversarially_Learned_One-Class_CVPR_2018_paper.pdf) [[tensorflow code]](https://github.com/khalooei/ALOCC-CVPR2018) [[keras code]](https://github.com/Tony607/ALOCC_Keras) This work was inspired by the success of generative adversarial networks (GANs) for training deep models in unsupervised and semi-supervised settings. We proposed an end-to-end architecture for one-class classification. The architecture is composed of two deep networks, each of which trained by competing with each other while collaborating to understand the underlying concept in the target class, and then classify the testing samples. One network works as the novelty detector, while the other supports it by enhancing the inlier samples and distorting the outliers. The intuition is that the separability of the enhanced inliers and distorted outliers is much better than deciding on the original samples. Here is the preliminary version of the code on grayscale databases. Please feel free to contact me if you have any questions. ## overview <p align="center"><img src='imgs/overview.jpg'></p> **Note**: The current software works well with TensorFlow 1.2 ## Prerequisites | 2,658 |
khanhha/crack_segmentation | ['whole slide images', 'anomaly detection'] | ['Manifolds for Unsupervised Visual Anomaly Detection'] | unet/unet_transfer.py evaluate_unet.py train_tiramisu.py data_loader.py densenet/tiramisu.py preprocess/tool_fix_label.py utils.py preprocess/draw_json.py preprocess/tool_split_folder.py train_unet.py preprocess/gen_noncrack_patches.py preprocess/viz_img_label.py plot_training_graph.py inference_unet.py preprocess/label2voc.py train_unet_backup.py densenet/layers.py preprocess/merge_dataset.py preprocess/tool_fix_incorrect_jsonshape.py ImgDataSet ImgDataSetJoint dice general_dice jaccard general_jaccard disable_axis evaluate_img evaluate_img_patch validate error save_weights load_weights adjust_learning_rate weights_init get_predictions save_check_point train validate create_model AverageMeter find_latest_model_path adjust_learning_rate calc_crack_pixel_weight save_check_point train validate create_loader create_model AverageMeter find_latest_model_path adjust_learning_rate calc_crack_pixel_weight main save_check_point train TransitionDown center_crop Bottleneck DenseLayer DenseBlock TransitionUp FCDenseNet57 FCDenseNet103 FCDenseNet FCDenseNet67 main main random_crop copy_Eugen_Muller copy_Rissbilder_for_Florian copy_files copy_CRACK500 copy_GAPS384 copy_Volker copy_CFD copy_forest copy_cracktree200 copy_Nohra copy_Sylvie_Chambon rm_files copy_DeepCrack copy_noncrack UNet16 Interpolate ConvRelu UNetResNet conv3x3 DecoderBlockV2 sum fromarray train_tfms model INTER_AREA resize numpy cuda fromarray int train_tfms model shape cuda append zeros numpy array range enumerate set_visible axis set_ticklabels copyfile join save print format load load_state_dict data size max view size sum model batch_size zero_grad set_description adjust_learning_rate save cuda exists view load_state_dict set_postfix append range update format close lr model_path enumerate load join validation criterion backward print AverageMeter tqdm n_epoch step eval AverageMeter copy save param_groups isinstance kaiming_uniform Conv2d zero_ weight print eval UNet16 UNetResNet int glob append argmax array split find_latest_model_path model_dir glob float imread sum join sorted batch_size Compose ImgDataSet DataLoader zip join create_loader create_model train add_argument SGD model_dir model_type parameters lr ArgumentParser device parse_args to cuda makedirs size draw_label max values open show subplot sorted list shapes_to_label shape imshow dirname img_b64_to_arr load items json_file len fromarray asarray NEAREST print float BILINEAR append resized_crop get_params sum crop range label_colormap print tuple strip readlines tqdm output_dir append enumerate join str uint8 imwrite print glob stem astype set add resize imread loadmat join str uint8 imwrite COLOR_BGR2GRAY print glob stem astype set add resize imread cvtColor join str uint8 imwrite COLOR_BGR2GRAY print glob stem astype set add resize imread cvtColor join str uint8 imwrite COLOR_BGR2GRAY print glob astype resize imread cvtColor join str uint8 imwrite COLOR_BGR2GRAY print glob astype set resize imread cvtColor join str uint8 imwrite COLOR_BGR2GRAY print glob astype set resize imread cvtColor join str uint8 imwrite COLOR_BGR2GRAY print glob astype set resize imread cvtColor join str imwrite COLOR_BGR2GRAY print glob set resize imread cvtColor join list str uint8 imwrite COLOR_BGR2GRAY print glob astype close tqdm dict resize imread cvtColor join list str uint8 imwrite COLOR_BGR2GRAY print glob astype close tqdm dict resize imread cvtColor join list str uint8 imwrite COLOR_BGR2GRAY print glob astype close tqdm dict resize imread cvtColor join list str uint8 imwrite COLOR_BGR2GRAY print glob astype close tqdm dict resize imread cvtColor glob str remove join rm_files copy makedirs | # Crack Segmentation Here I present my solution to the problem crack segmentation for both pavement and concrete meterials. In this article, I describe the approaches, dataset that I exprimented with and desmonstrate the result. My approach is based on the UNet network with transfer learning on the two popular architectures: VGG16 and Resnet101. The result shows that a large crack segmentation dataset helps improve the performance of the model in diverse cases that could happen in practice. # Contents - [Inference Result Preview](#Inference-Result-Preview) - [Overview](#Overview) - [Dataset](#Dataset) | 2,659 |
khornlund/CycleGAN-Music-Style-Transfer-1 | ['style transfer'] | ['Symbolic Music Genre Transfer with CycleGAN'] | style_classifier.py Testfile.py ops.py convert_clean.py module.py utils.py main.py write_midi.py model.py converter get_midi_path midi_filter make_sure_path_exists get_midi_info get_merged main main cyclegan PhraseGenerator generator_midinet discriminator_midinet generator_musegan_bar softmax_criterion PhraseDiscriminator generator_resnet discriminator_classifier abs_criterion generator_unet BarGenerator generator_musegan_phase sce_criterion mae_criterion discriminator_musegan_phase discriminator_musegan_bar discriminator BarDiscriminator lrelu to_chroma_tf batch_norm relu linear to_binary_tf to_binary deconv2d_musegan conv2d_musegan conv2d deconv2d instance_norm Classifer to_binary get_bar_piano_roll get_image load_test_data save_images center_crop load_train_data load_npy_data ImagePool merge_images get_rand_samples save_midis get_now_datetime transform inverse_transform imread load_midi_data imsave get_sample_shape merge set_piano_roll_to_instrument write_piano_rolls_to_midi write_piano_roll_to_midi makedirs endswith join walk append time format time_signature_changes sort denominator estimate_beat_start numerator get_tempo_changes is_drum get_merged_pianoroll tracks Track append enumerate parse_pretty_midi join Multitrack PrettyMIDI make_sure_path_exists get_midi_info save get_merged join get_midi_path format print copyfile midi_filter make_sure_path_exists len checkpoint_dir sample_dir test_dir ConfigProto makedirs as_list slice reduce_max logical_and equal reshape reduce_max float32 reduce_sum stack cast reduce_min reduce_max logical_and equal reshape delete concatenate imread imresize int imresize concatenate uniform ceil imread fliplr PrettyMIDI reshape concatenate load concatenate zeros enumerate int round center_crop concatenate reshape append zeros write_piano_rolls_to_midi range choice strftime pop list concatenate reshape sort len astype index nonzero Note append float range diff set_piano_roll_to_instrument Instrument PrettyMIDI write append set_piano_roll_to_instrument Instrument print PrettyMIDI write append range len | # Symbolic Music Genre Transfer with CycleGAN - Built a CycleGAN-based model to realize music style transfer between different musical domains. - Added extra discriminators to regularize generators to achieve clear style transfer and preserve original melody, which made our model learn more high-level features. - Trained several genre classifiers separately, and combined them with subjective judgement to have more convincing evaluations. ## Paper [Symbolic Music Genre Transfer with CycleGAN](https://www.tik.ee.ethz.ch/file/2e6c8407bf92ce1e47c0faa7e9a3014d/cyclegan-music-style%20(3).pdf) Paper accepted at 30th International Conference on Tools with Artificial Intelligence (ICTAI), Volos, Greece, November 2018. ## Music Samples www.youtube.com/channel/UCs-bI_NP7PrQaMV1AJ4A3HQ ## Model Architecture | 2,660 |
khundman/telemanom | ['anomaly detection'] | ['Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding'] | telemanom/helpers.py telemanom/plotting.py telemanom/modeling.py telemanom/detector.py example.py telemanom/errors.py telemanom/channel.py Channel Detector ErrorWindow Errors Config setup_logging make_dirs Model Plotter Config mkdir stdout getLogger addHandler StreamHandler setLevel INFO | # Telemanom (v2.0) **v2.0** updates: - Vectorized operations via numpy - Object-oriented restructure, improved organization - Merge branches into single branch for both processing modes (with/without labels) - Update requirements.txt and Dockerfile - Updated result output for both modes - PEP8 cleanup ## Anomaly Detection in Time Series Data Using LSTMs and Automatic Thresholding [](https://opensource.org/licenses/Apache-2.0) | 2,661 |
kianoush/Skin_Cancer_CNN | ['lesion segmentation'] | ['Skin Lesion Analysis Toward Melanoma Detection 2018: A Challenge Hosted by the International Skin Imaging Collaboration (ISIC)'] | Skin)cancer CNN.py get_duplicates initialize_model validate set_parameter_requires_grad AverageMeter HAM10000 get_val_rows train compute_img_mean_std list format print astype float32 tqdm mean shape stack reverse resize append imread ravel std range len list list parameters print set_parameter_requires_grad resnet50 exit in_features densenet121 vgg11_bn inception_v3 Linear update criterion model backward print size AverageMeter zero_grad avg item append to step enumerate len print eval AverageMeter | # Skin_Cancer_CNN  Original Data Source Original Challenge: https://challenge2018.isic-archive.com https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/DBW86T [1] Noel Codella, Veronica Rotemberg, Philipp Tschandl, M. Emre Celebi, Stephen Dusza, David Gutman, Brian Helba, Aadi Kalloo, Konstantinos Liopyris,Michael Marchetti, Harald Kittler, Allan Halpern: “Skin Lesion Analysis Toward Melanoma Detection 2018: A Challenge Hosted by the International Skin Imaging Collaboration (ISIC)”, 2018; https://arxiv.org/abs/1902.03368 [2] Tschandl, P., Rosendahl, C. & Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 5, 180161 doi:10.1038/sdata.2018.161 (2018). From Authors | 2,662 |
kibeomKim/House3D_baseline | ['data augmentation'] | ['Building Generalizable Agents with a Realistic and Rich 3D Environment'] | train.py learner.py agent.py actors.py eval.py test.py train_eval.py models.py test_main.py shared_optim.py main.py utils.py get_instruction_idx run_sim preprocess run_agent get_instruction_idx test writeResult getReward learning EnvReset callReset DoneOrNot getState putActions main Params run_test A3C_LSTM_GA get_instruction_idx run_test main Params get_instruction_idx run_sim get_instruction_idx run_sim testing training ensure_shared_grads get_eval_house_id read_config setup_logger get_word_idx weights_init norm_col_init get_house_id get_house_id_length view append get_word_idx array split difficulty join house_id format RenderAPI ptitle clip Environment get_instruction_idx put reset RoomNavTask get_house_id step load_config from_numpy stack array permute RenderAPI Environment RoomNavTask n_test load_config seed basicConfig house_id ptitle max_episode append sum range format weight_dir A3C_LSTM_GA eval action_test mkdir manual_seed info get_house_id run_agent join time get_instruction_idx print n_eval reset step len get range get task_done range FloatTensor task_done range task_done range range callReset getState str join print weight_dir save info float range state_dict n_process EnvReset callReset DoneOrNot basicConfig update_sync range get insert weight_dir action_train action_test mkdir task_done run_agent putActions writeResult time getReward n_eval getState JoinableQueue Process join Array n_process Value SimpleQueue set_start_method start append Params range Lock load Params test RenderAPI n_process Environment RoomNavTask n_test load_config seed basicConfig ptitle append sum range format get_eval_house_id A3C_LSTM_GA action_test manual_seed info get_house_id run_agent join time get_instruction_idx print reset step len basicConfig print weight_dir mkdir info put_reward seed Adam training max_episode range action_train A3C_LSTM_GA manual_seed run_agent parameters basicConfig testing weight_dir mkdir time randint get_instruction_idx action_train reset put_reward step clip sum join get_instruction_idx print n_eval eval reset action_test info append step range len setFormatter getLogger addHandler StreamHandler Formatter setLevel FileHandler load open size randn cpu parameters grad zip list fill_ size sqrt uniform_ prod __name__ | # House3D_RoomNav_baseline This is the baseline model of the RoomNav task using House3D that I implemented. It implements A3C with gated-LSTM policy for discrete actions. In the paper, they used 120 or 200 processes but I only used 20 processes. https://arxiv.org/abs/1801.02209 #### requirements - python 3.6+ - pytorch 0.4.1 ``` pip install -r requirements.txt | 2,663 |
kidach1/NeuralArtisticStyle | ['style transfer'] | ['A Neural Algorithm of Artistic Style'] | run.py deprocess_image Evaluator gram_matrix eval_loss_and_grads content_loss total_variation_loss preprocess_image style_loss expand_dims preprocess_input img_to_array load_img reshape transpose astype dot transpose batch_flatten permute_dimensions gram_matrix square reshape astype f_outputs | ## A Neural Algorithm of Artistic Style https://arxiv.org/pdf/1508.06576.pdf | 2,664 |
kimmo1019/Roundtrip | ['density estimation'] | ['Roundtrip: A Deep Generative Neural Density Estimator'] | model_img.py main_density_est.py util.py main_density_est_img.py evaluate.py model.py load_model odd_evaluate parse_params posterior_bayes find_y_sampler create_2d_grid_data visualize_img precision_at_K visualization_2d RoundtripModel RoundtripModel leaky_relu Generator Encoder Generator_Bayes Discriminator Generator_PCN Generator_res Generator_resnet leaky_relu Encoder_img Discriminator_img Discriminator_img_ucond Generator Generator_img_ucond Encoder Generator_img Discriminator conv_cond_concat GMM_sampler GMM_indep_sampler Mixture_sampler_v2 GMM_Uni_sampler Uniform_sampler cifar10_sampler Swiss_roll_sampler hepmass_sampler Gaussian_sampler Outlier_sampler Mixture_sampler create_2d_grid_data Multi_dis_sampler UCI_sampler mnist_sampler DataPool meshgrid T linspace update rstrip reshape close estimate_py_with_IS colorbar imshow savefig figure create_2d_grid_data X_train print estimate_py_with_IS X_test label_test decision_function IsolationForest precision_at_K fit rankdata sum len load_all concatenate print reshape estimate_py_with_IS eye tile append accuracy_score argmax range show sorted subplots reshape set_yticks tight_layout flatten imshow gray set_xticks savefig startswith zip listdir range int GMM_sampler GMM_indep_sampler print exit cifar10_sampler Swiss_roll_sampler hepmass_sampler array Outlier_sampler UCI_sampler mnist_sampler load RoundtripModel Encoder_img Discriminator_img Generator parse_params find_y_sampler Generator_img Discriminator Gaussian_sampler DataPool get_shape | # Roundtrip [](https://doi.org/10.5281/zenodo.3747161)  Roundtrip is a deep generative neural density estimator which exploits the advantage of GANs for generating samples and estimates density by either importance sampling or Laplace approximation. This repository provides source code and instructions for using Roundtrip on both simulation data and real data. ## Table of Contents - [Requirements](#Requirements) - [Install](#install) - [Reproduction](#reproduction) - [Simulation Data](#simulation-data) - [Real Data](#real-data) | 2,665 |
kiretd/Unsupervised-MIseg | ['medical image segmentation', 'edge detection', 'semantic segmentation'] | ['Unsupervised Medical Image Segmentation with Adversarial Networks: From Edge Diagrams to Segmentation Maps'] | UNet_segmentation.py kidney_workflow.py derm_workflow.py dcrf.py VAE.py MRCNN.py postprocess_dcrf grow_bool_img shrink_bool_img use_mask_rcnn load_images create_synthetic_edge_diagrams preprocess_images convert_to_edge_diagrams Generate_Masks load_all_images print_perf_stats use_Unet plot_mask_overlay plot_synthetic_images convert_to_edge_diagrams train_VAE_and_gen_cones convert_to_png plot_gen_cone test_wnet compute_metrics plot_vae_model segmentation_performance preprocess_images del_all_flags grow_bool_img remove_text_and_resize apply_EAST show_image plot_mask_overlay_ISIC score_model plot_edge_diagram plot_mask_overlay_kidney shrink_bool_img finetune_unet separate_test_data ShapesConfig InferenceConfig MRCNN ISIC_Dataset conv_block decoder_block Unet encoder_block KLDivergenceLayer sampling nll VAE create_pairwise_bilateral imwrite stepInference klDivergence create_pairwise_gaussian DenseCRF unary_from_labels argmax addPairwiseEnergy addPairwiseGaussian addPairwiseBilateral shape uint32 imread inference range DenseCRF2D flat format astype set unique empty startInference int uint8 print reshape setUnaryEnergy len join Path join uint8 basename img_as_float resize imread imsave makedirs zeros any arange empty full arange join uint8 basename shrink_bool_img rgb2gray img_as_float astype skeletonize resize label imread coords imsave regionprops makedirs join grow_bool_img format ellipse line zeros_like arange print uint8 len astype randint where linspace zeros imsave makedirs train create_model MRCNN str list join basename glob makedirs copy append enumerate FILLED cos setInput flatten readNet resize argmax max forward sin bincount append imread range non_max_suppression blobFromImage int min rectangle array show imshow join list glob save makedirs set_size_inches set_axis_off add_axes imshow figure imread Axes show zeros imshow figure COLOR_GRAY2RGB addWeighted uint8 drawContours imwrite fillPoly RETR_EXTERNAL findContours mean shape IMREAD_GRAYSCALE zeros imread CHAIN_APPROX_NONE cvtColor enumerate plot_mask_overlay plot_mask_overlay show str list glob set_axis_off add_axes imshow figure resize sample zeros imread Axes range load_model isinstance print plot_model isfile join Path remove_text_and_resize join imwrite makedirs percentile rescale_intensity gray2rgb rgb2gray equalize_adapthist squeeze zeros_like RETR_TREE convex_hull_image grow_bool_img findContours zip empty drawContours CHAIN_APPROX_SIMPLE opening logical_or join format create_model generate_cones VAE train imsave enumerate makedirs join grow_bool_img basename ellipse zeros_like img_as_float len logical_and where logical_or convex_hull_image linspace skeletonize randint imread imsave makedirs squeeze recall_score flatten shape jaccard_similarity_score resize f1_score accuracy_score img_as_float compute_metrics unique zip append imread enumerate img_as_float compute_metrics unique zip append imread enumerate format std print mean array range len __delattr__ _flags create_model train test Unet segmentation_performance finetune load_model test segmentation_performance train_test_split del_all_flags plot_segmentation_under_test_dir segmentation_performance train_net FLAGS create_BatchDatset reset_default_graph Wnet_bright tf_flags conv_block concatenate sum binary_crossentropy random_normal | # Unsupervised-MIseg This repository contains the code to implement unsupervised medical image segmentation using edge mapping and adversarial learning as described in our paper: [Unsupervised Medical Image Segmentation with Adversarial Networks: From Edge Diagrams to Segmentation Maps](https://arxiv.org/abs/1911.05140). Note that this version was written so that it is easier to follow the logic of the approach. It is therefore meant to be used for scripting. It should be fairly easy to adapt it for different purposes, but we may add other versions for different kinds of users (especially if requested). # Requirements For now, different parts of this project were adapted from different libraries, and so the dependencies vary by which step of the process is being run. The following are needed to run all parts of the code: - Python 3 - [Tensorflow](https://www.tensorflow.org/) - [Keras](https://keras.io/) - [Caffe](https://caffe.berkeleyvision.org/) - [Pytorch](https://pytorch.org/) | 2,666 |
kishansharma3012/HistoNet | ['instance segmentation', 'semantic segmentation'] | ['HistoNet: Predicting size histograms of object instances'] | code/main.py code/train.py code/data_utils.py code/net.py augmentation sample_image1 prepare_dataset data_augmentation random_noise prepare_data sampler sampler_new import_data sample_image_new prepare_redundantCountMap prepare_Label train_val_test import_data_dsn preprocess_data sample_image random_contrast prepare_CountMap_HistLabels HistoNet build_simple_block deep_supervision1 SimpleFactory resnet50 resnet50_DSN build_residual_block deep_supervision2 ConvFactory HistoNet_DSN trainer_histonet visualize_HistoNet_DSN_result evaluate_histonet visualize_HistoNet_result evaluate_histonet_dsn update_loss_history plot_results loss_func_histonet_dsn save_network trainer_histonet_dsn loss_func_histonet load_network str imwrite label range regionprops ceil int sample_image1 range join list print shuffle sample_image_new tqdm mkdir imread listdir range len print join data_augmentation sampler_new join basename arange imwrite print shuffle mkdir imread listdir array range len join int list print tqdm mkdir sample_image imread listdir range len str imwrite label range regionprops print prepare_dataset exists load asarray print transpose shuffle mean exists open load asarray print transpose shuffle mean exists open dump print cpu_count close append listdir open prepare_redundantCountMap pad prepare_CountMap_HistLabels area linspace append label imread range array zeros regionprops len zeros sum range dtype uint8 rand astype float32 dtype uint8 rand astype float32 imwrite random_noise random_contrast imread flip join augmentation list print tqdm mkdir listdir range len ivector print SimpleFactory resnet50 output_shape tensor4 InputLayer ConvFactory ivector print SimpleFactory resnet50_DSN output_shape tensor4 InputLayer ConvFactory update FlattenLayer list build_simple_block DropoutLayer print output_shape DenseLayer PoolLayer build_residual_block ConvFactory update FlattenLayer list build_simple_block DropoutLayer print output_shape DenseLayer PoolLayer build_residual_block deep_supervision2 deep_supervision1 ConvFactory append update int list build_simple_block NonlinearityLayer ElemwiseSumLayer batch_norm Conv2DLayer ConvFactory ConcatLayer FlattenLayer DropoutLayer print output_shape DenseLayer PoolLayer ConvFactory FlattenLayer DropoutLayer print output_shape DenseLayer PoolLayer ConvFactory list visualize_HistoNet_result test_op update_loss_history log append sum range len list visualize_HistoNet_DSN_result test_op update_loss_history log append sum range len savez set_all_param_values append float range len function evaluate_histonet update_loss_history get_value plot_results linspace open str list set_value import_data adam load_network shared sum range inf floatX astype close mean save_network mkdir join train_fn print get_all_params write array len function update_loss_history get_value plot_results linspace open str list set_value evaluate_histonet_dsn adam import_data_dsn load_network shared sum range inf floatX astype close mean save_network mkdir join train_fn print get_all_params write array regularize_network_params get_output function l2 mean abs_ tensor4 matrix sum log regularize_network_params get_output function l2 mean abs_ tensor4 matrix sum log str list plot xlabel len close write ylabel title savefig mkdir figure legend range open arange linspace subplot2grid Figure str list set_title canvas transpose squeeze imshow bar savefig set_canvas range gcf concatenate mkdir set_size_inches set_xticks hist set_ylim arange linspace subplot2grid Figure str list set_title canvas transpose squeeze imshow bar savefig set_canvas range gcf concatenate mkdir set_size_inches set_xticks hist set_ylim | # HistoNet: Predicting size histograms of object instances A new data set of pixel-wise instance labeled soldier fly larvaes. **Dataset**-[Download](https://github.com/kishansharma3012/FlyLarvae_dataset/blob/master/FlyLarvae_dataset.zip) **Paper**-[Link](http://openaccess.thecvf.com/content_WACV_2020/html/Sharma_HistoNet_Predicting_size_histograms_of_object_instances_WACV_2020_paper.html) ## Dataset ### Description This dataset of soldier fly larvae, which are bred in massive quantities for sustainable, environment friendly organic waste decomposition [1,2]. Fly larvae images were collected using a Sony Cyber shot DSC-WX350 camera with image size 1380 X 925 pixels The camera is installed on a professional fixture to guarantee a fixed distance from camera to observation plane for all image acquisitions. This is important to avoid any scale variation between the different image acquisitions. Very large numbers of larvae mingled with a lot of larvae feed lead to high object overlap and occlusions. These similar looking brown colored fly larvaes have variations in their sizes and flexible structure. To simplify our tasks, we choose high contrast black color background. The images were collected by using one spoonful of larvaes weighting approximately 3-6 grams (~700-1900 Larvaes), uniformly scattered over the image area. All larvae instances are labeled pixel-wise. <img src="https://github.com/kishansharma3012/FlyLarvae_dataset/blob/master/fixture_sample.png"> ### Properties This dataset represent crowded scenario of similar looking fly larvaes. The size (pixel area covere) distribution histogram of fly larvae is shown in figure. This dataset consists of 10844 pixel-wise labeled fly larvaes. The average size of fly larvae is 120.2 +- 28.1 px | 2,667 |
kiyukuta/lencon | ['text summarization'] | ['Controlling Output Length in Neural Encoder-Decoders'] | code/beam_search.py code/beam_search_fix_len.py code/greedy_generator.py code/vocabulary.py code/predict.py code/dataset.py code/models/attenders.py code/models/encoder_decoder.py code/models/len_emb.py code/train.py code/models/attention.py code/models/__init__.py code/beam_search_fix_rng.py code/builder.py code/models/len_init.py FixedQueue BeamSearchGenerator main parse_args get_agiga_example FixLen parse_args FixRng GreedyGenerator parse_args get_decoder predict parse_args prepare Trainer AttenderBase DotAttender MlpAttender EncDecEarlyAttn EncDecLateAttn get_attention_components EncoderDecoder LstmEncoder BiLstmEncoder get_lstm_init_bias LenEmbLateAttn LenEmbEarlyAttn LenInitEarlyAttn LenInitLateAttn join reset array enumerate add_argument ArgumentParser join initiate format print generate name length index model_dir BeamSearchGenerator beam_width parse_args revert get_agiga_example array len GreedyGenerator FixLen BeamSearchGenerator FixRng generate strip array split max DotAttender Linear MlpAttender full | # Controlling Output Length in Neural Encoder-Decoders Implementation of "Controlling Output Length in Neural Encoder-Decoders". The purpose of this project is to give the capability of controlling output length to neural encoder-decoder models. It is crucial for applications such as text summarization, in which we have to generate concise summaries with a desired length. There are three models (standard encdec, leninit, and lenemb) and four decoding methods (greedy, standard beamsearch, fixlen beamsearch, and fixrng beamsearch). Although any combination is possible in prediction phase, please see `run_duc04.sh` for the combination we used in the paper. ## Requirements - [Chainer](https://github.com/pfnet/chainer) | 2,668 |
kjetil-lye/ismo_airfoil | ['active learning'] | ['Iterative Surrogate Model Optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks'] | airfoil_chain/optimize_airfoil_traditional.py airfoil_integrated/optimizer_interface.py ensemble_run/run_ensemble_integrated.py plot_info/plot_info.py airfoil_chain/submit_airfoil.py ensemble_run/run_ensemble.py airfoil_chain/run_objective.py airfoil_chain/preprocess.py nuwtun_solver/examples/coupled_with_solver/call_func.py airfoil_chain/plot_compare_renew.py ensemble_run/plot_iterations.py airfoil_chain/simulate_airfoil.py airfoil_chain/plot_tradtional.py airfoil_chain/optimizer_interface.py nuwtun_solver/py-wrap/nuwtun_rae_pywrap.py airfoil_chain/postprocess.py airfoil_integrated/simulate_airfoil.py airfoil_chain/run_simulator.py airfoil_integrated/run_airfoil.py airfoil_integrated/objective.py airfoil_chain/objective.py plot_info/__init__.py Objective create_sample rnd_transform combine_data run_simulator launch_solver WithObjective AirfoilComputer SeveralVariablesCommands Objective RunSimulator create_sample rnd_transform combine_data run_simulator CreateSample launch_solver SimulatorRunner simulate_airfoil ChangeFolder get_competitor_basename run_configuration get_iteration_sizes all_successfully_completed PathForNuwtun get_configuration_name ChangeFolder run_configuration all_successfully_completed PathForNuwtun get_configuration_name find_area init_solver read_parameter extract_data rs mesh_pert clean extract_info add_git_information savePlot get_current_title RedirectStdStreamsToNull get_git_metadata saveData get_plot_metadata get_notebook_name add_additional_plot_parameters get_additional_plot_parameters RedirectStdStreams get_stacktrace_str get_loaded_python_modules get_python_description console_log_show get_environment writeMetadata set_percentage_ticks to_percent showAndSave legendLeft isnotebook set_notebook_name console_log only_alphanum get_loaded_python_modules_formatted str rmtree rnd_transform savetxt copytree str chdir getcwd run split str print loadtxt rmtree zeros range int range len COMM_WORLD create_sample print min barrier Get_size range Get_rank launch_solver system system zeros run_simulator arange glob get_configuration_name mkdir append int strip split split close extract_info open print system print system print rs system print loadtxt reshape close savetxt array exists active_branch hexsha rev_parse url is_dirty sha Repo writeMetadata get_git_metadata deepcopy list str __file__ __version__ append keys __name__ get_loaded_python_modules str list add_text save keys PngInfo open print get_title get_text callback get_current_title text_function get_text get_git_metadata get_plot_metadata title prefix savefig disabled gca gcf text2D lower mkdir writeMetadata deepcopy join text show close savePlot join lower savetxt mkdir gca legend str format print now console_log __name__ print str isnotebook format set_major_formatter FuncFormatter | # Airfoil ISMO run This the the source for the numerical experiments found in the arxiv paper [Iterative Surrogate Model Optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks arXiv:2008.05730 ](https://arxiv.org/abs/2008.05730) Clone with git clone --recursive [email protected]:kjetil-lye/ismo_airfoil.git If you already cloned without the recursive option, do (from ```ismo_airfoil```): git submodule update --init --recursive ## Running in virtualenv To make sure one has all the python packages required (and that one does not mess up ones python directory), one can use virtualenv. [First install it (for python3)](https://virtualenv.pypa.io/en/latest/installation/) : pip3 install --user virtualenv | 2,669 |
kjetil-lye/ismo_heat | ['active learning'] | ['Iterative Surrogate Model Optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks'] | heat_chain/plot_coefficients.py plot_info/plot_info.py test/test_heat_equation.py heat_chain/plot_solution.py heat/__init__.py heat_chain/objective.py heat/solve_heat_equation.py heat_chain/submit_heat.py heat/initial_data.py plot_info/__init__.py heat_chain/simulate_heat.py InitialDataControlSine solve_heat_equation Objective HeatCommands add_git_information savePlot get_current_title RedirectStdStreamsToNull get_git_metadata saveData get_plot_metadata get_notebook_name add_additional_plot_parameters get_additional_plot_parameters RedirectStdStreams get_stacktrace_str get_loaded_python_modules get_python_description console_log_show get_environment writeMetadata set_percentage_ticks to_percent showAndSave legendLeft isnotebook set_notebook_name console_log only_alphanum get_loaded_python_modules_formatted TestHeatEquation arange lil_matrix tocsr min initial_data spsolve zeros range active_branch hexsha rev_parse url is_dirty sha Repo writeMetadata get_git_metadata deepcopy list str __file__ __version__ append keys __name__ get_loaded_python_modules str list add_text save keys PngInfo open print get_title get_text callback get_current_title text_function get_text get_git_metadata get_plot_metadata title prefix savefig disabled gca gcf text2D lower mkdir writeMetadata deepcopy join text show close savePlot join lower savetxt mkdir gca legend str format print now console_log __name__ print str isnotebook format set_major_formatter FuncFormatter | # ismo_heat Experiments for using ISMO on a simple heat equation problem This the the source for the numerical experiments found in the arxiv paper [Iterative Surrogate Model Optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks arXiv:2008.05730 ](https://arxiv.org/abs/2008.05730) | 2,670 |
kjetil-lye/ismo_validation | ['active learning'] | ['Iterative Surrogate Model Optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks'] | validation/examples/sine/submit_sine.py plot_info/plot_info.py validation/examples_integrated/projectile_motion/ball.py validation/examples/sine/objective.py validation/examples_integrated/projectile_motion/projectile_motion.py plot_info/__init__.py validation/examples/projectile_motion/submit_projectile_motion.py validation/bin/run_all_configurations.py validation/examples_integrated/projectile_motion/objective.py validation/examples/sine/evolve_sine.py validation/examples/projectile_motion/ball.py validation/config.py validation/examples/projectile_motion/objective.py validation/examples/projectile_motion/evolve_projectile_motion.py validation/bin/plot_iterations.py validation/examples_integrated/sine/sine.py add_git_information savePlot get_current_title RedirectStdStreamsToNull get_git_metadata saveData get_plot_metadata get_notebook_name add_additional_plot_parameters get_additional_plot_parameters RedirectStdStreams get_stacktrace_str get_loaded_python_modules get_python_description console_log_show get_environment writeMetadata set_percentage_ticks to_percent showAndSave legendLeft isnotebook set_notebook_name console_log only_alphanum get_loaded_python_modules_formatted get_competitor_objective_filename make_prefix_main get_iterations get_objective_filename make_starting_sizes make_prefix_competitor right_hand_side p_alpha_v_0_samples simulate_until_impact p scale Objective ProjectileMotionCommands Objective SineCommands right_hand_side p_alpha_v_0_samples simulate_until_impact p simulate scale Objective Simulator Objective active_branch hexsha rev_parse url is_dirty sha Repo writeMetadata get_git_metadata deepcopy list str __file__ __version__ append keys __name__ get_loaded_python_modules str list add_text save keys PngInfo open print get_title get_text callback get_current_title text_function get_text get_git_metadata get_plot_metadata title prefix savefig disabled gca gcf text2D lower mkdir writeMetadata deepcopy join text show close savePlot join lower savetxt mkdir gca legend str format print now console_log __name__ print str isnotebook format set_major_formatter FuncFormatter append norm pi append right_hand_side array simulate_until_impact zeros float range p print shape pi scale | # ismo_validation This repository contains the numerical experiments for the arxiv paper [Iterative Surrogate Model Optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks arXiv:2008.05730 ](https://arxiv.org/abs/2008.05730) Validation runs for the ismo algorithm Clone with git clone --recursive [email protected]:kjetil-lye/ismo_validation.git ## Running in virtualenv To make sure one has all the python packages required (and that one does not mess up ones python directory), one can use ```virtualenv```. [First install it (for python3)](https://virtualenv.pypa.io/en/latest/installation/) : pip3 install --user virtualenv or you can leave out the ```--user``` option if you want it to be available for all users. | 2,671 |
kjetil-lye/iterative_surrogate_optimization | ['active learning'] | ['Iterative Surrogate Model Optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks'] | examples/runs/sine/sine.py tests/test_trainer_factory.py examples/submission_chain/several_variables/evolve_several_variables.py ismo/submit/chain.py ismo/submit/user_group_id.py ismo/bin/plot_iterations.py ismo/objective_function/__init__.py examples/runs/several_variables/several_variables.py ismo/objective_function/dnn_objective_function.py ismo/train/optimizers/optimizer_factory.py ismo/submit/submission_script.py tests/test_monte_carlo.py ismo/optimizers/optimizer_factory.py ismo/bin/train.py ismo/submit/defaults/commands.py ismo/bin/evaluate_objective.py ismo/optimizers/optimize_samples.py ismo/submit/__init__.py examples/submission_chain/sine/submit_sine.py ismo/bin/generate_samples.py ismo/train/model_skeleton_from_simple_config.py ismo/iterative_surrogate_model_optimization.py ismo/optimizers/numpy_optimizer.py ismo/submit/defaults/__init__.py ismo/submit/submitter_factory.py ismo/submit/command.py examples/submission_chain/several_variables/preprocess.py ismo/gradients/tensor_gradient.py examples/submission_chain/several_variables/objective.py ismo/ensemble/change_folder.py ismo/train/trainer_factory.py ismo/ensemble/__init__.py ismo/samples/__init__.py ismo/train/simple_trainer.py ismo/convergence/convergence_study.py examples/submission_chain/sine/evolve_sine.py ismo/gradients/chain_rule_model.py ismo/train/model_skeleton_from_keras_file.py ismo/samples/sobol.py ismo/convergence/__init__.py examples/submission_chain/sine/objective.py ismo/gradients/__init__.py ismo/submit/bash_submission_script.py ismo/submit/current_repository.py ismo/submit/singularity.py tests/test_gradients.py tests/test_sobol.py examples/submission_chain/several_variables/postprocess.py ismo/optimizers/__init__.py ismo/submit/docker.py ismo/__init__.py ismo/train/multivariate_trainer.py ismo/train/optimizers/__init__.py ismo/objective_function/load_objective_function_from_python_file.py ismo/train/__init__.py ismo/submit/lsf_submission_script.py ismo/train/parameters.py examples/submission_chain/several_variables/submit_several_variables.py ismo/samples/sample_generator_factory.py ismo/bin/run_ensemble.py examples/objective_functions/identity.py ismo/bin/optimize.py ismo/ensemble/run_all_configurations.py ismo/submit/container.py ismo/submit/container_decorator.py ismo/samples/monte_carlo.py Identity evolve Objective Objective Objective SeveralVariablesCommands Objective SineCommands iterative_surrogate_model_optimization LossWriter LossWriter convergence_study ChangeFolder get_competitor_basename run_configuration run_all_configurations get_iteration_sizes all_successfully_completed get_configuration_name ChainRuleModel TensorGradient DNNObjectiveFunction load_objective_function_from_python_file NumpyOptimizer create_optimizer make_bounds optimize_samples MonteCarlo SampleGeneratorFactory create_sample_generator Sobol BashSubmissionScript Chain Command Container ContainerDecorator get_current_repository Docker LsfSubmissionScript Singularity SubmissionScript create_submitter get_group_id get_user_id Commands model_skeleton_from_simple_config_file model_skeleton_from_simple_config MultiVariateTrainer Parameters parameters_from_simple_config_file SimpleTrainer create_trainer_from_simple_file create_optimizer TestTrainerFactory TestMonteCarlo TestSobol TestTrainerFactory tan cos sin zeros range models DNNObjectiveFunction sample_generator extend optimize_samples simulator array enumerate fit arange create_sample_generator LossWriter list defaultdict argmin map MultiVariateTrainer ylabel title savetxt legend append sum range save_plot errorbar create_optimizer close mean enumerate join items print add_loss_history_writer xlabel iterative_surrogate_model_optimization array len glob get_configuration_name mkdir append int set run_configuration get_iteration_sizes sum range append enumerate spec_from_file_location exec_module module_from_spec append array range append optimizer Repo git_dir dirname Docker replace Singularity add_parameter BashSubmissionScript ContainerDecorator LsfSubmissionScript l1 l2 Sequential add Dense model_skeleton_from_simple_config_file parameters_from_simple_config_file | # Iterative Surrogate Model Optimization (ISMO) This repository is the main driver for the experiments found in the arxiv paper [Iterative Surrogate Model Optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks arXiv:2008.05730 ](https://arxiv.org/abs/2008.05730) To get started, it is probably a good idea to checkout the example repositories * https://github.com/kjetil-lye/ismo_validation * https://github.com/kjetil-lye/ismo_airfoil * https://github.com/kjetil-lye/ismo_heat | 2,672 |
kkew3/pytorch-cw2 | ['adversarial attack'] | ['Towards Evaluating the Robustness of Neural Networks'] | cw.py runutils.py _var2numpy L2Adversary from_tanh_space atanh to_tanh_space predict get_cuda_state is_cuda_consistent make_cuda_consistent Module hasattr isinstance dict get get_cuda_state list get_cuda_state Module isinstance move_to_device methodcaller append Variable net | # pytorch-cw2 ## Introduction This is a _rich-documented_ [PyTorch](https://pytorch.org/) implementation of [Carlini-Wanger's L2 attack](https://arxiv.org/abs/1608.04644). The main reason to develop this respository is to make it easier to do research using the attach technique. Another implementation in PyTorch is [rwightman/pytorch-nips2017-attack-example](https://github.com/rwightman/pytorch-nips2017-attack-example.git). However, the author failed to reproduce the result presented in the original paper (by Aug 2, 2018 at least). `cw.py` has been tested under `python 2.7.12` and `torch-0.3.1`. ## References: - [carlini/nn\_robust\_attacks](https://github.com/carlini/nn_robust_attacks.git) - [rwightman/pytorch-nips2017-attack-example](https://github.com/rwightman/pytorch-nips2017-attack-example.git) ## Usage of this library module First of all, make sure the `import runutils` statement in `cw.py` (line 19) is a valid import statement in your development environment. In the following code sample, we assume that `net` is a pretrained network, such that `outputs = net(torch.autograd.Variable(inputs))` returns a `torch.autograd.Variable` of dimension `(batch_size, num_classes)` if `inputs` is of dimension `(batch_size, num_channels, height, width)`. Assume also that when doing normalization to the inputs, the normalization transformation is presented something like: | 2,673 |
kli58/ROIAL | ['active learning'] | ['ROIAL: Region of Interest Active Learning for Characterizing Exoskeleton Gait Preference Landscapes'] | Simulation/evaluate_simulation.py Simulation/plot_ordinal_noise.py Simulation/ROIAL_simulation.py Simulation/plot_3d.py ImportanceTests/KNeighborsRegressor.py Experiment/exo_post_process_all_itera.py Simulation/sample_from_GP_prior.py Experiment/exo_finer_posterior.py Simulation/gp_utility.py Simulation/post_eval_sub_GP.py Simulation/simulate_feedback.py Simulation/plot_individual.py Experiment/utility.py sigmoid_der init_points_to_sample information_gain_acquisition sigmoid_3rd_der preference_GP_objective feedback pref_likelihood tdot kernel sigmoid gp_prior preference_GP_hessian run_individual_GP ord_likelihood sigmoid_2nd_der preference_GP_gradient getPermutationImportance get_ordinal_feedback acc_pref_ord_label evaluate_safe_performance evaluate_acc_labels sigmoid_der information_gain_acquisition sigmoid_3rd_der preference_GP_objective feedback pref_likelihood kernel sigmoid preference_GP_hessian ord_likelihood safe_prob sigmoid_2nd_der preference_GP_gradient plot_3d_function plot_1D_gp plot_add_GP_results plot_results plot_gp_2D norm_objective_data plot_noise_effect eval_posterior init_points_to_sample run_simulation tdot kernel gp_kernel run_GP run_individual_GP sample_GP_prior get_objective_value hartmann_objective_function get_ordinal_feedback determine_ordinal_threshold get_preference T ravel_multi_index linspace meshgrid empty enumerate information_gain_acquisition feedback fill_diagonal inf exp square tdot sum clip kernel shape inv str list pref_likelihood real append sum range normal product mean sqrt info print reshape inv ord_likelihood zeros diag len minimize cumsum astype extend flatten eigh eye preference_GP_hessian append zeros x astype array max range len int sigmoid_der sigmoid array max range len int str fill_diagonal sigmoid_der copy sigmoid shape sigmoid_2nd_der array info zeros max range len print T cumsum sigmoid extend append range len KNeighborsRegressor permutation_importance show inf cumsum print get_ordinal_feedback extend flatten bar item append importances_mean enumerate fit append len get_ordinal_feedback get_preference acc_pref_ord_label arange cumsum flatten accuracy_score abs max str list subplot std shape title ylim append sum range inf plot mean zip sample print min extend figure zeros fill_between array len str list arange plot cumsum flatten mean title fill_between figure zip zeros norm_objective_data std range len dot reshape T inf inf arange add_subplot linspace norm_objective_data show str set_title set_xlabel colorbar savefig meshgrid append range set_xlim set_zticks mean add_axes set_zlim set_zlabel get_cmap suptitle set_yticks set_xticks set_ylabel figure unravel_index zeros plot_surface set_ylim len subplot str set_title suptitle reshape shape scatter contourf figure savefig contour clabel plot ones xlabel ylabel range sqrt title scatter shape figure linspace ylim legend fill_between savefig ravel diag len min max plot_1D_gp str cumsum meshgrid squeeze min inv reshape flatten unravel_index figure linspace plot_gp_2D append norm_objective_data max range len str int min flatten plot_gp_2D figure linspace meshgrid norm_objective_data max range append len show str T format vlines plot xlabel text ylabel sigmoid title ylim figure append sum max range str list zip print init_points_to_sample shape gp_kernel savemat run_individual_GP append zeros array range len reshape kernel shape inv ravel_multi_index getLogger tuple get_ordinal_feedback run_individual_GP setLevel values str list addHandler shape append prod range setFormatter copy set get_preference info sample INFO FileHandler print init_points_to_sample Formatter gp_kernel savemat unravel_index zeros array len str join print now strftime determine_ordinal_threshold run_GP loadmat makedirs exp multivariate_normal plot xlabel ylabel title figure append empty range len array range sigmoid get_objective_value percentile min array zeros max range get_objective_value choice sigmoid sum | # ROIAL: Region of Interest Active Learning for Characterizing Exoskeleton Gait Preference Landscapes The following video gives a quick introduction to the algorithm [](https://vimeo.com/473970586) ## Simulation code A detailed description and specific values of the hyperparameter used in simulation can be found [here](https://github.com/kli58/ROIAL/blob/master/Simulation/ROIAL_hyperparameters.ipynb) Example scripts to run the simulation can be found inside the simulation folder - [2D Simulation](https://github.com/kli58/ROIAL/blob/master/Simulation/run_2D_simulation.ipynb) - [3D Simulation](https://github.com/kli58/ROIAL/blob/master/Simulation/run_3D_simulation.ipynb) ___ ## Experimental Results | 2,674 |
kmike/pymorphy2 | ['morphological analysis'] | ['Morphological Analyzer and Generator for Russian and Ukrainian Languages'] | pymorphy2/shapes.py pymorphy2/version.py benchmarks/__init__.py tests/test_tokenizers.py benchmarks/speed.py pymorphy2/lang/uk/__init__.py tests/test_opencorpora_dict.py tests/test_threading.py pymorphy2/opencorpora_dict/parse.py pymorphy2/lang/uk/_prefixes.py pymorphy2/lang/__init__.py pymorphy2/tokenizers.py pymorphy2/units/by_analogy.py pymorphy2/cache.py tests/test_tagset.py pymorphy2/units/by_lookup.py benchmarks/utils.py docs/conf.py pymorphy2/opencorpora_dict/wrapper.py tests/test_lexemes.py tests/test_prefix_matching.py pymorphy2/utils.py pymorphy2/opencorpora_dict/preprocess.py tests/test_utils.py pymorphy2/__init__.py pymorphy2/lang/uk/config.py pymorphy2/units/unkn.py pymorphy2/lang/ru/config.py tests/test_analyzer.py pymorphy2/opencorpora_dict/compile.py pymorphy2/lang/ru/__init__.py pymorphy2/analyzer.py tests/test_inflection.py pymorphy2/units/by_shape.py pymorphy2/units/utils.py tests/test_result_wrapper.py tests/test_dict_loading.py benchmarks/bench.py pymorphy2/tagset.py pymorphy2/opencorpora_dict/__init__.py pymorphy2/opencorpora_dict/storage.py pymorphy2/units/abbreviations.py pymorphy2/units/by_hyphen.py tests/conftest.py tests/test_numeral_agreement.py pymorphy2/units/base.py pymorphy2/cli.py pymorphy2/dawg.py tests/test_parsing.py setup.py tests/test_cli.py pymorphy2/opencorpora_dict/probability.py tests/utils.py pymorphy2/units/__init__.py get_version main load_words get_total_usages bench_all bench_tag bench_parse measure format_bench bench setup Parse ProbabilityEstimator _iter_entry_points MorphAnalyzer _lang_dict_paths lang_dict_path memoized_with_single_argument parse show_dict_meta show_dict_mem_usage _TokenParserFormatter _open_for_read _iter_tokens_notokenize main _iter_tokens_tokenize PredictionSuffixesDAWG DawgPrefixMatcher WordsDawg assert_can_create ConditionalProbDistDAWG PythonPrefixMatcher restore_word_case _make_the_same_case is_roman_number is_latin is_punctuation is_latin_char restore_capitalization _translate_comma_separated CyrillicOpencorporaTag _translate_tag OpencorporaTag _select_grammeme_from simple_word_tokenize get_mem_usage combinations_of_all_lengths kwargs_repr with_progress longest_common_substring word_splits json_read json_write largest_elements _linearized_paradigm _popular_keys compile_parsed_dict convert_to_pymorphy2 _suffixes_prediction_data _create_out_path _get_suffixes_dawg_data _to_paradigm _join_lexemes _grammemes_from_elem _word_forms_from_xml_elem get_dictionary_info parse_opencorpora_xml xml_clear_elem tag2grammemes _is_ambiguous _split_grammemes _simplify_tag _get_tag_spellings _itertags replace_redundant_grammemes drop_unsupported_parses _get_duplicate_tag_replaces simplify_tags _tag_probabilities add_conditional_tag_probability _all_the_same _parse_probabilities _disambiguated_words build_cpd_dawg estimate_conditional_tag_probability _load_tag_class _load_gramtab _assert_format_is_compatible update_meta load_dict write_meta _load_paradigms load_meta save_compiled_dict Dictionary _InitialsAnalyzer AbbreviatedPatronymicAnalyzer AbbreviatedFirstNameAnalyzer BaseAnalyzerUnit AnalogyAnalizerUnit _PrefixAnalyzer UnknownPrefixAnalyzer KnownSuffixAnalyzer KnownPrefixAnalyzer replace_grammemes HyphenatedWordsAnalyzer HyphenAdverbAnalyzer HyphenSeparatedParticleAnalyzer DictionaryAnalyzer LatinAnalyzer PunctuationAnalyzer NumberAnalyzer _SingleShapeAnalyzer _ShapeAnalyzer RomanNumberAnalyzer UnknAnalyzer without_last_method with_suffix with_prefix replace_methods_stack add_tag_if_not_seen add_parse_if_not_seen without_fixed_prefix without_fixed_suffix append_method morph Tag TestTagAndParse TetsPunctuationPredictor TestNormalForms TestInitials test_iter_known_word_parses TestTagWithPrefix TestUtils with_test_data TestLatinPredictor TestTagMethod TestParseResultClass test_pickling TestHyphen TestParse test_show_memory_usage test_show_dict_meta test_show_usage test_parse_basic run_pymorphy2 test_language_from_dict test_bad_language test_old_dictionaries_not_installed test_nonmatching_language test_old_dictionaries_supported_by_path test_old_dictionaries_supported test_morph_analyzer_bad_path assert_first_inflected_variant test_case_substitution test_second_cases test_first_inflected_value test_not_informal test_best_guess with_test_data test_orel _lexemes_for_word assert_has_full_lexeme parse_full_lexeme test_full_lexemes test_normalized_is_first parse_lexemes test_lexemes_sanity get_lexeme_words test_has_proper_lexemes test_plural_inflected test_plural_num test_plural_forms TestToParadigm TestToyDictionary run_for_all _to_test_data _test_tag _test_has_parse test_prefix_matcher_is_prefixed test_prefix_matcher_prefixes test_normalized test_inflect_invalid test_is_known test_indexing test_inflect_valid test_repr test_len TestContains test_hashing test_pickle test_pickle_custom TestCyrillic test_extra_grammemes TestAttributes TestUpdated test_cls test_threading_single_morph_analyzer _check_analyzer _check_new_analyzer test_threading_multiple_morph_analyzers test_threading_create_analyzer _create_morph_analyzer TestSimpleWordTokenize test_get_mem_usage assert_parse_is_correct docopt bench_all DEBUG setLevel INFO measure len partial info measure show_info partial info load_words get_total_usages debug MorphAnalyzer bench_tag now bench_parse info len time enable disable func append range append timeit range Timer add_stylesheet WorkingSet dict get_path _lang_dict_paths CHAR_SUBSTITUTES DEFAULT_UNITS RLock stdout addHandler debug MorphAnalyzer StreamHandler _open_for_read any get_mem_usage time MorphAnalyzer info items list MorphAnalyzer info int _write iter_tokens write _parse _TokenParserFormatter str str decode isinstance _make_the_same_case lower split append enumerate warn islower istitle isupper defaultdict _select_grammeme_from frozenset set dict str isinstance Process getpid range len setdefault set nlargest map tee list min range len set assert_can_create compile_parsed_dict drop_unsupported_parses simplify_tags parse_opencorpora_xml save_compiled_dict PredictionSuffixesDAWG lexemes tuple links _join_lexemes sorted defaultdict list append chain _to_paradigm update WordsDawg debug set info enumerate dict _suffixes_prediction_data len sorted list move_lexeme set dict keys list longest_common_substring any zip len sorted defaultdict _popular_keys debug with_progress keys _get_suffixes_dawg_data append max range len append largest_elements debug mkdir clear get iterparse enumerate get _word_forms_from_xml_elem text with_progress set _parse info append get_dictionary_info xml_clear_elem get decode list isinstance _grammemes_from_elem lower warning iter append lexemes info debug with_progress _get_tag_spellings _get_duplicate_tag_replaces len lexemes info defaultdict _itertags items sorted list _is_ambiguous keys replace_redundant_grammemes lexemes with_progress int join getLogger update_meta MorphAnalyzer save info build_cpd_dawg estimate_conditional_tag_probability CorpusReader list getLogger with_progress _ConditionalProbDist _disambiguated_words info ConditionalFreqDist parse load _load_gramtab _load_tag_class _assert_format_is_compatible _f json_read load_meta _load_paradigms append range len items list suffixes _dawg_len grammemes prediction_suffixes_dawgs words_dawg debug write_meta _f _init_grammemes json_write save info append enumerate json_read hasattr items list json_write isinstance update write_meta load_meta json_read _init_grammemes get join get str split items list remove add set append add append add loads HIGHEST_PROTOCOL dumps iter_known_word_parses list main importorskip join readouterr run_pymorphy2 join meta readouterr run_pymorphy2 join write_text print readouterr run_pymorphy2 importorskip MorphAnalyzer skip importorskip get_path MorphAnalyzer lang_dict_path MorphAnalyzer lang_dict_path MorphAnalyzer assert_first_inflected_variant assert_first_inflected_variant assert_first_inflected_variant assert_first_inflected_variant assert_first_inflected_variant assert_first_inflected_variant join xfail tuple startswith split splitlines _lexemes_for_word join get_lexeme_words get_lexeme_words parse get_lexeme_words parse assert_has_full_lexeme parse_full_lexeme parse append tuple parse parse zip zip parse join dirname matcher_cls KNOWN_PREFIXES matcher_cls KNOWN_PREFIXES Tag MorphAnalyzer TagClass add loads Tag HIGHEST_PROTOCOL dumps HIGHEST_PROTOCOL MorphAnalyzer dumps add loads TagClass assert_parse_is_correct parse assert_parse_is_correct MorphAnalyzer parse assert_parse_is_correct MorphAnalyzer parse choice importorskip get_mem_usage | kmike/pymorphy2 | 2,675 |
kmswlee/ainized-PointRend | ['instance segmentation', 'semantic segmentation'] | ['PointRend: Image Segmentation as Rendering'] | models/main.py models/pointGenerate.py _if_near getpoint pad int _if_near print uniform append range | # Ainize-run-PointRend example [](https://ainize.web.app/redirect?git_repo=github.com/kmswlee/ainized-PointRend) PointRend is image segmentation as rendering The PointRend neural network module performs point-based segementation predictions at adaptively selected locations based on an iterative subvision algorithm. PointRend achieves higher sharpness on tricky object boundaries such as fingers than Mask R-CNN, and can be added on both semantic and instance segmentation. This module show intermediate results. So if you want to use Point Rend, apply Point Rend to your instance segmentation or semantic segmentation project. Ainize is done in the following steps: 1. click 'default'. | 2,676 |
kodenii/CoSDA-ML | ['data augmentation'] | ['CoSDA-ML: Multi-Lingual Code-Switching Data Augmentation for Zero-Shot Cross-Lingual NLP'] | model/MLDoc/base.py util/dataset/MIXSC/binary_all.py util/dataset/XTDS/all.py util/configue.py model/MLDoc/x.py model/DST/base.py util/data.py start.py model/MLDoc/all.py model/XTDS/all.py util/dataset/WOZ/all.py model/XTDS/base.py util/dataset/WOZ/x.py util/dataset/MLDoc/all.py model/XTDS/all_x.py model/base.py model/DST/x.py util/convert.py util/tool.py model/DST/all.py util/dataset/MIXSC/raw_all.py start Model Model BERTTool Model Model BERTTool Model BERTTool Model Model BERTTool Model BERTTool Model BERTTool Model Configure List Common String Delexicalizer Writer Reader idx_extender Batch in_each Args pad Vocab load_module DatasetTool DatasetTool DatasetTool DatasetTool DatasetTool DatasetTool seed manual_seed_all basicConfig get manual_seed tool name Model load_module Get is_available cuda gpu append range len append len enumerate zip DatasetTool Model | # CoSDA-ML: Multi-Lingual Code-Switching Data Augmentation for Zero-Shot Cross-Lingual NLP [](https://opensource.org/licenses/MIT)<img align="right" src="img/SCIR.jpg" width="12%"><img align="right" src="img/WestLake.jpg" width="15%"> This repository is for the IJCAI-2020 paper: [CoSDA-ML: Multi-Lingual Code-Switching Data Augmentation for Zero-Shot Cross-Lingual NLP](https://arxiv.org/pdf/2006.06402) If you use any source codes or ideas included in this repository for your work, please cite the following paper. <pre> @misc{qin2020cosdaml, title={CoSDA-ML: Multi-Lingual Code-Switching Data Augmentation for Zero-Shot Cross-Lingual NLP}, author={Libo Qin and Minheng Ni and Yue Zhang and Wanxiang Che}, year={2020}, eprint={2006.06402}, | 2,677 |
kolesman/SEC | ['semantic segmentation'] | ['Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation'] | CRF/krahenbuhl2013/__init__.py CRF/krahenbuhl2013/CRF.py deploy/demo.py pylayers/pylayers/__init__.py CRF/setup.py pylayers/setup.py pylayers/pylayers/pylayers.py CRF preprocess write_to_png_file predict_mask ConstrainLossLayer SoftmaxLayer CRFLayer AnnotationLayer ExpandLossLayer SeedLossLayer reshape astype add_pairwise_energy DenseCRF set_unary_energy Writer transpose astype array zoom argmax sum exp zoom transpose CRF preprocess imread forward max log | # Seed, Expand, Constrain: Three Principles for Weakly-Supervised Image Segmentation Created by Alexander Kolesnikov and Christoph Lampert at IST Austria. ## Introduction  We propose a new composite loss function for training convolutional neural networks for the task of weakly-supervised image segmentation. Our approach relies on the following three insights: 1. Image classification neural networks can be used to generate reliable object localization cues (seeds), but fail to predict the exact spatial extent of the objects. We incorporate this aspect | 2,678 |
koncle/TSMLDG | ['domain generalization', 'semantic segmentation'] | ['Generalizable Model-agnostic Semantic Segmentation via Target-specific Normalization'] | network/components/customized_evaluate.py dataset/splitter.py utils/task.py network/nets/__init__.py network/components/evaluate_funcs.py network/components/loss_funs.py network/components/schedulers.py train.py utils/nn_utils.py dataset/natural_datasets.py network/nets/fcn.py paths.py dataset/basedataset.py TSMLDG.py network/nn/seg_modules.py network/inits.py dataset/transforms.py network/nets/psp.py network/components/customized_loss.py predict.py utils/visualize.py network/backbone/__init__.py eval.py network/backbone/resnet.py dataset/dg_dataset.py dataset/__init__.py resnet.py network/nets/SegNet.py do_lots_of_exp_tests parse test_one_run predict Net train MetaFrameWork BaseDataSet CombinedDataSet find_prefix show_dataset get_dataset get_target_loader DGMetaDataSets GTA5 index_class_conversion class_map_2_color_map CityScapesDataSet label_to_citys to_gray dataset_test Synthia get_transform IDD Mapillary GTA5_Multi color_map_2_class_map label_consistency OneLevelKFoldSplitter OneLevelSplitter ZeroLevelKFoldSplitter TrainTestOneLevelKFoldSplitter CSVSplitter MatSplitter TrainTestZeroLevelKFoldSplitter split_trian_dev_test_path BaseSplitter ThreeLevelCaseSplitter TwoLevelSplitter ThreeLevelSplitter RandomFlip CenterCrop RandomRotate random_gaussian_blur random_flip_numpy Compose TargetCrop ToTenser do_nothing Resize natural_image_normalize RandomCrop elastic_transform medical_image_normalize contrast_img_when_neccessary FixScale gamma_correction RandomScale get_dataloader get_loss_func get_eval_func get_logger_manager get_network worker_init_fn get_dataset get_scheduler get_transforms get_solver get_function resnet152_enc ResNet resnet50 resnet50_enc Bottleneck resnet152 resnet18_mit load_url resnet50_mit resnet101_mit resnet34 resnet18 resnet101_enc BasicBlock load_zip resnet101 build_backbone MeterDicts MultiSegMeasure LoggedMeasure NaturalImageMeasure AverageMeter EmptyMeasure SimpleMeasure DiceMeasure SegMeasure ClassificationMeasure Class3SegMeasure AxisMeasureWrapper DirectLoss SegmentationLoss SingleLossWrapper focal_loss SameTargetLossWrapper empty_loss SoftTriple LoggedLoss same_target_loss F_beta dice_loss AreaLoss ohem_crossentropy simplified_dice CenterLoss tensor_to_scala weighted_crossentropy CoverLoss bce_loss dice_bound_loss MultiLossWrapper mse_loss DICE get_inter_union PPV SEN pixel_acc_per_class pixel_acc hausdorff_distance mIoU IOU mean_square_similarity get_confusion_matrix cosine_similarity mean_dice mean_iou get_confusion_matrix_gpu FWIoU GeneralizedDiceLoss SimplifiedDice EmptyLoss OhemCrossEntropy2d WeightedCrossEntropy CrossEntropy BoundedDice DiceLoss WeightedMSE FocalLoss BCELoss StepLR NoneLR CosineLR PolyLR MultiStepLR WarmUpLRScheduler ReduceLROnPlateauLR multi FCN FCN_Vgg multi PSPNet SegNet _ASPPModule PyramidPooling FCNHead ConvNormRelu ASPP Timer make_same_size to_cuda get_img_target all_reduce put_theta mkdir all_gather to_one_hot to_numpy get_prediction get_probability get_logger get_updated_network CfgJob NvidiaSmi Job get_value schedule_tasks change_value Cfg Schedulable SchedulableFunc FunctionJob SchedulableTask save_graphs show_graph_with_col label_overlay_torch show_landmark_2d show_tsne ImageOverlay label_overlay torch_im_show_3d show_landmark_3d show_3d show_segmentation torch_im_show show_graphs load str val format seed update print AverageMeter get_target_loader reset avg Path manual_seed target_specific_val log enumerate test_one_run zip MetaFrameWork parse_args do_lots_of_exp_tests target print parse_args predict_target MetaFrameWork MetaFrameWork print do_train vars parse_args target_dataset partial dataloader get_dataset print get_target_loader zip show_graphs enumerate Compose shape zeros shape range zeros reshape append show_graphs clone range class_map_2_color_map show_graphs print array enumerate CityScapesDataSet print _index_to_class _class_to_index array range train_test_split print format get_src_file in_ch get_function eval Networks nclass net kwargs hasattr get_parameters momentum weight_decay lower base_lr epoch kwargs Schedulers get_function lower eval warmup_epochs iteration_decay len LossFuncs loss_kwargs loss_func eval func nclass get_function update eval_func eval distributed EvalFuncs eval_kwargs get_function random_crop is_3d random_scale random_flip update pred_root kwargs full_dataset name full_kwargs root pred_kwargs eval func full_root Datasets force_cache pred_dataset output_path get_function train_batch_size DistributedSampler shuffle num_workers get_dataset DataLoader dist_ranks drop_last append test_batch_size enumerate loggers update LoggerManager eval loggers_kwargs zip append len join ResNet load_url getenv load_state_dict expanduser join ResNet load_url getenv load_state_dict expanduser join print ResNet load_url getenv load_state_dict expanduser join print ResNet load_url getenv load_state_dict expanduser join ResNet load_url getenv load_state_dict expanduser join format urlretrieve write getenv expanduser makedirs update items list print ResNet index load_url load_state_dict update items list print ResNet index load_url load_state_dict update items list print ResNet index load_url load_state_dict join remove format urlretrieve write getenv expanduser makedirs update print ResNet load_state_dict load_zip update print ResNet load_state_dict load_zip update print ResNet load_state_dict load_zip eval append Tensor isinstance item bincount reshape long bincount to_numpy astype reshape sum diag sum diag sum mIoU transpose astype float32 shape zip append sum list view size to_one_hot type long spacing spacing get_inter_union get_inter_union make_same_size float sum sqrt make_same_size float make_same_size spacing size get_inter_union sum make_same_size spacing sum size get_inter_union get_probability norm_layer Sequential ReLU Conv2d sigmoid size softmax cat list size scatter_ device zeros cuda is_cuda size interpolate items list hasattr Optimizer isinstance append Tensor cuda values append isinstance list argmax_func reshape shape softmax softmax_func to_numpy argmax parent Path append k_param_fn items state_dict grad named_parameters dict put_theta load_state_dict enumerate str setFormatter getLogger addHandler strftime StreamHandler Formatter mkdir Path DEBUG setLevel FileHandler size view isinstance isinstance isinstance zip split split clear print ceil sqrt show_graph_with_col len ceil sqrt show_graph_with_col len set_yticklabels add_subplot axis show ndarray set_title shape imshow savefig ceil range set_xticklabels size astype copy enumerate int isinstance add_patch subplots_adjust figure int32 Rectangle Tensor numpy len torch_im_show range get_prediction numpy show_graphs show add_line Line2D add_subplot imshow figure show plot add_subplot figure range len show add_subplot plot_trisurf figure marching_cubes_lewiner show add_subplot where scatter figure uint8 astype float32 label_overlay interpolate int32 type show uint8 Polygon reshape findContours astype axis copy add_patch add_axes imshow close savefig int32 figure CHAIN_APPROX_NONE Axes RETR_CCOMP show TSNE min scatter max range fit_transform | # TSMLDG This is the source code of paper Generalizable Semantic Segmentation via Model-agnostic Learning and Target-specific Normalization).  ## Environment Pytorch 1.2.0, GPU : 4 * V100, ## DataSets The training procedure needs [gta5(G)](https://download.visinf.tu-darmstadt.de/data/from_games/), [synthia_rand_citys(S)](https://synthia-dataset.net/downloads/), [idd(I)](https://idd.insaan.iiit.ac.in/), [mapillary(M)](https://www.mapillary.com/dataset/vistas?pKey=1GyeWFxH_NPIQwgl0onILw) and [cityscapes(C)](https://www.cityscapes-dataset.com/). Please download them and put to the same folder which can be specified in `paths.py`. The folder tree structure is as follows: ``` ├── GTA5 │ ├── images | 2,679 |
kondratevakate/mri-epilepsy-segmentation | ['data augmentation'] | ['TorchIO: A Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning'] | detection/model_utils.py segmentation/models/unet3d.py segmentation/routine.py segmentation/models/modified_3dunet.py segmentation/metrics.py segmentation/.ipynb_checkpoints/routine-checkpoint.py segmentation/models/.ipynb_checkpoints/unet3d-checkpoint.py utils/.ipynb_checkpoints/viz_tools-checkpoint.py classification/routine.py detection/patch_utils.py segmentation/models/3d_bayes_unet.py segmentation/models/3d_bayes_layers.py detection/preprocessing_utils.py utils/viz_tools.py utils/data.py segmentation/.ipynb_checkpoints/metrics-checkpoint.py classification/models/AE_model.py utils/routine.py classification/models/cnn_model.py run_one_epoch create_model_opt stratified_batch_indices train cross_val_score Classificator Decoder Encoder DownBlock AE Discriminator UpBlock CNN conv3x3x3 DilatedCNN ConvLSTM Flatten BasicBlock VoxResNet get_only_patches get_image_patches get_all_patches_and_labels get_registered_img get_registered_img_and_mask compute_surface_overlap_at_tolerance compute_dice_coefficient compute_average_surface_distance compute_surface_dice_at_tolerance compute_surface_distances compute_robust_hausdorff get_loaders get_dice_score get_model_and_optimizer forward get_torchio_dataset get_dice_loss get_iou_score run_epoch prepare_batch train validate_dsc_asd Action calculate_metrics compute_surface_overlap_at_tolerance compute_dice_coefficient compute_average_surface_distance compute_surface_dice_at_tolerance compute_surface_distances compute_robust_hausdorff get_loaders get_dice_score get_model_and_optimizer forward get_torchio_dataset get_dice_loss get_iou_score run_epoch prepare_batch train validate_dsc_asd Action calculate_metrics BasicDownBlock Up_Conv ConvSample Conv_Transpose_Layer BayesConv2d DeFlatten Down_Conv Init_Conv Final_Conv BasicUpBlock _BayesConvNd BayesConv3d Conv_Layer ConvBlock Flatten UNet3D Modified3DUNet normalization ConvD ConvU Unet normalization ConvD ConvU Unet MriClassification MriSegmentation targets_complete reshape_image load_nii_to_array train stratified_batch_indices run_one_epoch cross_val_score plot_predicted plot_difference plot_central_cuts plot_predicted plot_difference plot_central_cuts log_metric list criterion model backward train zero_grad extend tqdm numpy append to step subplots save show clear_output set_xlabel metric legend append CrossEntropyLoss range state_dict format run_one_epoch plot mean log_metrics __name__ time print set_ylabel figure set_ylim ceil array range append len list create_model_opt stratified_batch_indices len Subset DataLoader append train range CrossEntropyLoss split seed load Sequential Adam parameters ReduceLROnPlateau load_state_dict manual_seed Linear rot90 concatenate ones stack argmax array range rot90 concatenate ones stack argmax range load get_only_patches get_fdata min zeros max get_all_patches_and_labels load join get_filename FLIRT out_file FAST isfile run load join get_filename FLIRT out_file FAST run max norm uint8 sorted ones min astype distance_transform_edt shape int64 any zip correlate zeros array range Inf sum cumsum sum Inf searchsorted sum sum sum append ImagesDataset Subject zip list print get_torchio_dataset DataLoader Queue values to float compute_dice_coefficient compute_average_surface_distance get_iou_score compute_surface_distances uint8 astype tqdm eval prepare_batch append argmax calculate_metrics enumerate sum zero_grad tqdm prepare_batch train array enumerate ylabel run_epoch log_epoch_end TRAIN VALIDATE xlabel step seed AdamW parameters ReduceLROnPlateau manual_seed to len InstanceNorm3d BatchNorm3d GroupNorm print format dataobj asanyarray join list reset_index glob copy tqdm range LabelEncoder startswith dropna DataFrame fit_transform read_csv len metric show subplots isinstance get_fdata Nifti1Image imshow Tensor numpy show uint8 subplots isinstance get_fdata astype Nifti1Image imshow Tensor numpy show uint8 subplots isinstance get_fdata astype Nifti1Image imshow Tensor numpy | # mri-epilepsy-segmentation The current project is devoted to the Focal Cortical Displasia detection on MRI T1w images.  credit: https://doi.org/10.1371/journal.pone.0122252.g002 Focal cortical dysplasia (FCD) is one of the most common epileptogenic lesions associatedwith malformations of cortical development. The findings on magnetic resonance (MR) images areessential for diagnostics and surgical planning in patients with epilepsy. The accurate detection ofthe FCD relies on the radiologist professionalism, and in many cases, the lesion could be missed. Automated detection systems for FCD are now extensively developing, yet it requires large datasetswith annotated data. The aim of this study is to enhance the detection of FCD with the means of transfer learning. ## 1. Detection `baseline` folder contains instructions and tests for medical-detection. Code reproduction for the paper: https://doi.org/10.1016/j.compmedimag.2019.101662 ## 2. Segmentation `segmentation` folder contains segmentation model train and transfer. | 2,680 |
kooBH/VFWS | ['speech recognition', 'speaker recognition', 'speaker separation', 'speech enhancement'] | ['VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking'] | utils/evaluation.py utils/train.py model/model.py pre_data_chime/audio.py pre_data_chime/wav_syncer.py trainer.py utils/audio.py utils/adabound.py utils/hparams.py pre_data_librispeech/utils/audio.py utils/writer.py dataGenerator.py datasets/dataloader.py pre_data_librispeech/utils/mixer.py utils/plotting.py pre_data_librispeech/generator.py pre_data_librispeech/utils/hparams.py VFWSDataset create_dataloader VFWS Audio get_wave_list_recursive cross_correlation_using_fft sync_wav compute_shift vad_merge formatter train_wrapper test_wrapper mix Audio HParam Dotdict merge_dict load_hparam_str load_hparam cal_rms save_waveform cal_amp mix_noise_wav mix_noise cal_adjusted_rms AdaBound Audio validate HParam Dotdict merge_dict load_hparam_str load_hparam fig2np plot_spectrogram_to_numpy train MyWriter ifft fft flipud real int cross_correlation_using_fft argmax len glob readframes str writeframes print fromstring exit getframerate close compute_shift setframerate setnchannels setsampwidth open append list split load join int wav2spec mix_noise formatter sample_rate wav write trim audio_len from_numpy mag save vfws_dir randint mix len randint mix len join items load_all list dict open items list __setitem__ __delitem__ __getitem__ __setitem__ __delitem__ __getitem__ float readframes float64 getnframes astype setparams writeframes close tobytes Wave_write cal_rms cal_amp min cal_adjusted_rms open randint max len cal_rms min cal_adjusted_rms randint max len eval train MSELoss reshape tostring_rgb fromstring subplots xlabel draw close ylabel colorbar tight_layout imshow fig2np L1Loss validate model zero_grad ReduceLROnPlateau warning save cuda set_device Adam MSELoss log10 load_state_dict range epoch Audio info item log_training load join criterion backward error AdaBound isnan parameters pow OneCycleLR step gpu | # VFWS : VoiceFilter Without Speaker Using Voicefilter to noise surppression only without targeted speaker embedding. <img src=https://github.com/kooBH/VFWS/blob/master/resources/VFWS.PNG> # Conclusion Not Good # Result log magnitude, L1 loss, oneCycleLR, step 40k, epoch 3 <img src=https://github.com/kooBH/VFWS/blob/master/resources/VFWS_tensorboard.PNG> <img src=https://github.com/kooBH/VFWS/blob/master/resources/VFWS_v2_step40k.gif> Smudging harmonic components. | 2,681 |
korotulea/Quantifying-Hippocampus-Volume-for-Alzheimers-Progression-AI-Assistant | ['semantic segmentation'] | ['A large annotated medical image dataset for the development and evaluation of segmentation algorithms'] | section2/src/data_prep/HippocampusDatasetLoader.py section2/src/utils/volume_stats.py section3/src/inference/UNetInferenceAgent.py section3/src/networks/RecursiveUNet.py section2/src/networks/RecursiveUNet.py section2/src/run_ml_pipeline.py section2/src/experiments/UNetExperiment.py section3/src/utils/volume_stats.py section2/src/utils/utils.py section2/src/data_prep/SlicesDataset.py section3/src/utils/utils.py section3/src/inference_dcm.py section2/src/inference/UNetInferenceAgent.py Config LoadHippocampusData SlicesDataset UNetExperiment UNetInferenceAgent UnetSkipConnectionBlock UNet med_reshape mpl_image_grid log_to_tensorboard save_numpy_as_image Spec3d Dice3d Sens3d Jaccard3d get_series_for_inference get_predicted_volumes os_command load_dicom_volume_as_numpy_from_list save_report_as_dcm create_report UNetInferenceAgent UnetSkipConnectionBlock UNet med_reshape mpl_image_grid log_to_tensorboard save_numpy_as_image Spec3d Dice3d Sens3d Jaccard3d load join med_reshape print astype single append max subplot int min grid subplots_adjust imshow figure xticks numpy range yticks add_figure mpl_image_grid cpu argmax add_scalar imshow savefig zeros sum sum float sum float sum sum composite truetype uint8 multiline_text Draw text new size astype shape paste array resize argmax flip height dcmwrite ExplicitVRLittleEndian strftime SOPInstanceUID width tobytes generate_uid Dataset SOPClassUID sorted list print walk communicate Popen | # Quantifying Alzheimer's Disease Progression Through Automated Measurement of Hippocampal Volume Alzheimer's disease (AD) is a progressive neurodegenerative disorder that results in impaired neuronal (brain cell) function and eventually, cell death. AD is the most common cause of dementia. Clinically, it is characterized by memory loss, inability to learn new material, loss of language function, and other manifestations. For patients exhibiting early symptoms, quantifying disease progression over time can help direct therapy and disease management. A radiological study via MRI exam is currently one of the most advanced methods to quantify the disease. In particular, the measurement of hippocampal volume has proven useful to diagnose and track progression in several brain disorders, most notably in AD. Studies have shown reduced volume of the hippocampus in patients with AD. The hippocampus is a critical structure of the human brain (and the brain of other vertebrates) that plays important roles in the consolidation of information from short-term memory to long-term memory. In other words, the hippocampus is thought to be responsible for memory and learning (that's why we are all here, after all!)  Humans have two hippocampi, one in each hemishpere of the brain. They are located in the medial temporal lobe of the brain. Fun fact - the word "hippocampus" is roughly translated from Greek as "horselike" because of the similarity to a seahorse, a peculiarity observed by one of the first anatomists to illustrate the structure. <img src="./readme.img/Hippocampus_and_seahorse_cropped.jpg" width=200/> According to [studies](https://www.sciencedirect.com/science/article/pii/S2213158219302542), the volume of the hippocampus varies in a population, depending on various parameters, within certain boundaries, and it is possible to identify a "normal" range when taking into account age, sex and brain hemisphere. <img src="./readme.img/nomogram_fem_right.svg" width=300> | 2,682 |
kramer99/neural-style-transfer | ['style transfer'] | ['A Neural Algorithm of Artistic Style'] | vgg19.py image_utils.py nst.py generate_noise_image reshape_and_normalize_image convert save_image CONFIG cache f get_activations compute_cost_and_gradients df content_cost style_cost_layer style_cost total_cost build_model reshape NOISE_RATIO astype reshape MEANS shape MEANS astype convert imsave function shape dot shape transpose reshape style_cost_layer range len function gradients print f content_cost input style_cost append total_cost reshape compute_cost_and_gradients shape flatten float64 astype grads Sequential loadmat _set_weights_on_layer | # neural-style-transfer This is an implementation of this paper: https://arxiv.org/pdf/1508.06576.pdf It is a method of applying stylistic features learned from one image (the style image) and applying them to "repaint" a content image in that style. Some examples (these images taken from the linked paper above):  ## Setup - The pretrained model is too large to store in this repo (> 500MB), so you need to download it here and place in the repo root directory: [http://www.vlfeat.org/matconvnet/models/imagenet-vgg-verydeep-19.mat](http://www.vlfeat.org/matconvnet/models/imagenet-vgg-verydeep-19.mat) - If you're running the Anaconda distribution, you only need to install Keras: `conda install keras` Otherwise, the following packages should be installed: scipy, numpy, imageio, matplotlib, keras ## Optimizer weirdness Out of nothing more than curiosity, I decided to plot the cost function over iterations and noticed this oddity:  | 2,683 |
krantirk/Wav2letterPlus | ['speech recognition'] | ['wav2letter++: The Fastest Open-source Speech Recognition System'] | recipes/models/seq2seq_tds/librispeech/prepare.py recipes/models/lexicon_free/utilities/compute_upper_ppl_kenlm.py bindings/python/examples/criterion_example.py bindings/python/wav2letter/criterion_torch.py recipes/models/conv_glu/librispeech/prepare.py recipes/models/lexicon_free/utilities/utils.py recipes/timit/data/utils.py recipes/data/wsj/prepare.py recipes/models/utilities/prepare_librispeech_official_lm.py bindings/python/wav2letter/decoder.py recipes/models/lexicon_free/utilities/compute_upper_ppl_convlm.py bindings/python/wav2letter/__init__.py recipes/models/utilities/convlm_serializer/save_pytorch_model.py bindings/python/wav2letter/feature.py bindings/python/examples/feature_example.py recipes/data/librispeech/utils.py recipes/models/conv_glu/wsj/prepare.py recipes/models/lexicon_free/librispeech/prepare.py bindings/python/wav2letter/common.py tutorials/1-librispeech_clean/prepare_data.py recipes/models/lexicon_free/utilities/compute_lower_ppl_kenlm.py recipes/data/wsj/utils.py bindings/python/examples/decoder_example.py bindings/python/setup.py recipes/data/librispeech/prepare.py bindings/python/wav2letter/criterion.py recipes/models/lexicon_free/utilities/compute_lower_ppl_convlm.py tutorials/1-librispeech_clean/prepare_lm.py recipes/models/lexicon_free/utilities/convlm_utils.py recipes/models/lexicon_free/wsj/prepare.py recipes/timit/data/prepare_data.py CMakeExtension CMakeBuild check_negative_env_flag check_env_flag load_emissions load_tn load_transitions assert_near read_struct load_data ASGLoss get_data_ptr_as_bytes run_direction run_backward run_get_workspace_size FCCFunction create_workspace run_forward check_tensor FACFunction get_cuda_stream_as_bytes parse_speakers_gender read_list transcript_to_list find_transcript_files ndx_to_samples convert_to_flac preprocess_word find_transcripts get_spelling compute_word_logprob compute_words_model_pdf_mass compute_ppl_lower_limit compute_denominator compute_word_logprob compute_words_model_pdf_mass compute_ppl_lower_limit compute_denominator compute_ppl_upper_limit_char_convlm compute_ppl_upper_limit_word_convlm compute_upper_limit_ppl_for_kenlm load_char_model_14B compute_new_state load_word_model decodeInputText load_char_model_20B build_token_index_correspondence convert_words_to_letters_asg_rep2 transform_asg_back prepare_vocabs_convlm transform_asg prepare_vocabs compare remap_words_with_same_spelling get_spelling convert save_model copytoflac write_sample findtranscriptfiles join abspath cuda_stream Size fn cpu_impl getattr device run_direction run_direction device run_get_workspace_size endswith join walk append dirname lower sub replace dict join walk setdefault sort join Transformer format remove duration strip system build set_output_format sub replace cuda max argsort sum compute_word_logprob compute_words_model_pdf_mass exp print strip set add append enumerate len list State BaseScore str append power State array BeginSentenceWrite BaseScore transform_asg_back split State exp format print cuda enumerate exp format print cuda enumerate dict items list load compute_new_state eval load_state_dict cuda load compute_new_state eval load_state_dict cuda load compute_new_state eval load_state_dict cuda append dict items list sorted defaultdict dict load Transformer set_output_format build copytoflac join replace endswith join walk append | # wav2letter++ [](https://circleci.com/gh/facebookresearch/wav2letter) wav2letter++ is a fast, open source speech processing toolkit from the Speech team at Facebook AI Research built to facilitate research in end-to-end models for speech recognition. It is written entirely in C++ and uses the [ArrayFire](https://github.com/arrayfire/arrayfire) tensor library and the [flashlight](https://github.com/facebookresearch/flashlight) machine learning library for maximum efficiency. Our approach is detailed in this [arXiv paper](https://arxiv.org/abs/1812.07625). This repository also contains pre-trained models and implementations for various ASR results including: - [Likhomanenko et al. (2019): Who Needs Words? Lexicon-free Speech Recognition](recipes/models/lexicon_free/) - [Hannun et al. (2019): Sequence-to-Sequence Speech Recognition with Time-Depth Separable Convolutions](recipes/models/seq2seq_tds/) The previous iteration of wav2letter (written in Lua) can be found in the [`wav2letter-lua`](https://github.com/facebookresearch/wav2letter/tree/wav2letter-lua) branch. ## Building wav2letter++ and full documentation All details and docs can be found on the [wiki](https://github.com/facebookresearch/wav2letter/wiki): To get started with wav2letter++, checkout the [tutorials](tutorials) section. | 2,684 |
kratzert/ealstm_regional_modeling | ['time series'] | ['Towards Learning Universal, Regional, and Local Hydrological Behaviors via Machine-Learning Applied to Large-Sample Datasets'] | papercode/plotutils.py papercode/nseloss.py papercode/metrics.py papercode/evalutils.py papercode/clusterutils.py papercode/datasets.py papercode/utils.py papercode/lstm.py papercode/morris.py main.py papercode/datautils.py papercode/ealstm.py _setup_run get_args evaluate eval_with_added_noise _store_results evaluate_basin train_epoch _prepare_data Model train eval_robustness get_label_2_color get_variance_reduction get_silhouette_scores get_clusters CamelsH5 CamelsTXT load_forcing load_attributes rescale_features add_camels_attributes normalize_features reshape_data load_discharge EALSTM get_mean_basin_performance get_pvals get_cohens_d get_run_dirs eval_lstm_models eval_benchmark_models LSTM calc_alpha_nse calc_fdc_fhv calc_nse calc_fdc_flv calc_fdc_fms calc_beta_nse get_morris_gradient NSELoss get_shape_collections ecdf get_basin_list create_h5_files update int list items print add_argument uniform Path ArgumentParser vars parse_args parent mkdir now zfill str create_h5_files add_camels_attributes seed str _setup_run NSELoss param_groups get_basin_list Adam MSELoss _prepare_data parameters DataLoader train_epoch save manual_seed CamelsH5 to range state_dict set_postfix_str backward train clip_grad_norm_ zero_grad loss_func tqdm parameters set_description to step load str _store_results evaluate_basin get_basin_list load_attributes CamelsTXT mean tqdm DataLoader date_range load_state_dict to DataFrame std eval eval_with_added_noise load_attributes DataLoader seed str set_postfix_str defaultdict CamelsTXT load_state_dict append to range astype mean mkdir load parent get_basin_list float32 tqdm std eval print KMeans silhouette_samples min mean range fit_predict values fit items list defaultdict intersection append len items list defaultdict var set append values drop str set_index parent glob print concat copy apply Path read_csv drop drop shape range zeros list glob to_datetime map read_csv list glob to_datetime map QObs read_csv glob is_dir list append list defaultdict glob print open_dataset tqdm isnan func keys values items list defaultdict len tqdm func keys values split list get_mean_basin_performance wilcoxon values append items list defaultdict var mean sqrt abs len flatten sum mean flatten flatten flatten log flatten sum flatten sum log min Variable zero_grad grad eval append numpy sort float arange len T list Polygon set_edgecolor set_linewidth set_facecolor append PatchCollection values is_file parent | # Catchment-Aware LSTMs for Regional Rainfall-Runoff Modeling Accompanying code for our HESS paper "Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets" ``` Kratzert, F., Klotz, D., Shalev, G., Klambauer, G., Hochreiter, S., and Nearing, G.: Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets, Hydrol. Earth Syst. Sci., 23, 5089–5110, https://doi.org/10.5194/hess-23-5089-2019, 2019. ``` The manuscript can be found here (publicly available): [Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets](https://www.hydrol-earth-syst-sci.net/23/5089/2019/hess-23-5089-2019.html) The code in this repository was used to produce all results and figures in our manuscript. ## Content of the repository | 2,685 |
kreimanlab/DeepLearning-vs-HighLevelVision | ['action classification'] | ['Can Deep Learning Recognize Subtle Human Activities?'] | computer-vision/detectron/im_detect_features.py computer-vision/detectron/infer_simple_extract_human.py computer-vision/keras/misclassification_rate_list.py human-vision/drinking/custom.py computer-vision/keras/load_inf_numpy_datagen.py human-vision/sitting/parse_trialdata.py computer-vision/keras/gradcam_loop.py human-vision/reading/custom.py computer-vision/detectron/vis_extract_drinking.py computer-vision/keras/misclassification_rate_iterate.py human-vision/sitting/custom.py computer-vision/detectron/vis_extract_reading.py computer-vision/keras/ft_presplit_numpy_datagen.py computer-vision/detectron/infer_simple_extract_reading.py computer-vision/detectron/vis_extract_human.py computer-vision/detectron/infer_simple_extract_drinking.py im_detect_w_features_func box_results_with_nms_and_limit main parse_args main parse_args main parse_args vis_extract_func vis_extract_func vis_extract_func export_csv getLabeledData export_history target_category_loss compile_saliency_function grad_cam deprocess_image load_image grad register_gradient modify_backprop normalize target_category_loss_output_shape export_csv getLabeledData export_csv getLabeledData export_history list_imgs toc segm_results keypoint_results defaultdict im_detect_keypoints MAX_SIZE im_detect_mask box_results_with_nms_and_limit ENABLED im_detect_bbox_aug tic im_detect_mask_aug SCALE RETINANET_ON im_detect_keypoints_aug im_detect_bbox ScopedName nms NUM_CLASSES hstack astype float32 ENABLED FetchBlob vstack NMS VOTE_TH box_voting soft_nms range add_argument exit ArgumentParser print_help getLogger assert_and_infer_cfg output_dir cache_url list basename defaultdict append imread vis_extract_func output_ext format merge_cfg_from_file iglob concatenate average_time im_or_folder cfg info initialize_model_from_cfg enumerate join time items isdir print weights DOWNLOAD_CACHE get_coco_dataset image_ext len decode axis get_class_string CHAIN_APPROX_NONE colormap basename ones len imshow shape savefig setp Axes range get_keypoints format plot concatenate findContours convert_from_cls_format close kp_connections copy add_axes autoscale get_cmap RETR_CCOMP minimum join set_size_inches isinstance Polygon text reshape add_patch argsort figure Rectangle makedirs ones imread ndarray enumerate reshape asarray where concatenate expand_dims img_to_array load_img input max dict output get_default_graph squeeze transpose clip astype minimum uint8 g_func function ones applyColorMap output maximum float32 mean resize normalize COLORMAP_JET max enumerate listdir | This repository contains the code and images used in <i>Jacquot et al., 2020</i> \[[arXiv,](https://arxiv.org/abs/2003.13852) [CVPR](https://openaccess.thecvf.com/content_CVPR_2020/html/Jacquot_Can_Deep_Learning_Recognize_Subtle_Human_Activities_CVPR_2020_paper.html)\]. There is a 1 minute [video presentation](https://www.youtube.com/watch?v=izLNH8WlVF0) of our work on youtube. ## Summary Our work builds on the observation that image datasets used in machine learning contain many biases. Those biases help convolutional neural networks to classify images. For example, in the UCF101 dataset, algorithms can rely on the background color to classify human activities. <div align="center"> <img src="ucf101-example.png" height="110px" /> </div> <br> <br> To address this issue, we followed a rigorous method to build three image datasets corresponding to three human behaviors: drinking, reading, and sitting. Below are some example images from our dataset. The models misclassified the bottom left, middle top, and bottom right pictures, whereas humans correctly classified all six pictures. <div align="center"> | 2,686 |
kridgeway/f-statistic-loss-nips-2018 | ['few shot learning'] | ['Learning Deep Disentangled Embeddings with the F-Statistic Loss'] | models/deep_metric_learning.py data/sprites.py models/cuhk_model.py eval/explicitness.py data/small_norb.py eval/modularity.py loss/triplet_loss.py embedding.py data/google_drive.py eval/estimate_mi_cont_disc.py models/norb_model.py models/cub200.py models/sprite_model.py models/market_model.py batch_gen/batch_pair_generator.py loss/histogram_loss.py data/market1501.py loss/lsss_loss.py data/cuhk03.py loss/binomial_dev_loss.py eval/recall_at_k.py loss/f_statistic_loss.py data/smallnorb_dataset.py generate_batch_pairs do_generate_batch_pairs generate_for_batch download_file_from_google_drive process_dir SmallNORBDataset SmallNORBExample append calculate_mi add_params calculate_explicitness add_params make_mi_csd_plot compute_deviations make_mi_plot compute_mutual_infos max_n_distances p_norm_distances find_l2_distances evaluate find_cos_distances compute_max_n softmax_distances compute_softmax_dist max_distances train_batches create_loss train_batches create_loss getDistributionDensity create_loss train_batches train_batches create_loss train_batches create_loss CUB200Model CUHKModel DMLModel MarketModel NorbModel SpriteModel extend unique append float array range enumerate len do_generate_batch_pairs multi_factor enumerate defaultdict arange batch_size len examples_per_identity delete extend randomize_order unique append generate_for_batch enumerate get get_confirm_token save_response_content Session print glob len groups shape open append zeros array range split lighting pose category image_rt image_lt azimuth elevation instance range len histogram unique zip float sum len len extend LogisticRegression mean predict_proba classes_ append zeros range enumerate roc_auc_score fit add_argument sum print zeros argmax range zeros calculate_mi range show subplot T pcolor use plot suptitle print model_prefix ylabel subplots_adjust argsort mean savefig figure compute_deviations xticks loss show use arange suptitle plot model_prefix ylabel subplots_adjust savefig figure pcolor xticks loss dot T sum exp abs sum float64 astype zeros range len abs zeros range len max_n_distances p_norm_p p_norm_distances find_l2_distances max_n dist manhattan_distances find_cos_distances softmax_distances max_k softmax_l1_beta in1d unique zeros kneighbors max_distances enumerate fit exp reshape multiply reduce_sum placeholder binomial_dev_C reduce_mean int32 gather log generate_batch_pairs params ones_like unique_with_counts batch_ids float32 n_classes map_fn cast scalar arange concat float32 map_fn cast constant ones matmul getDistributionDensity array range len dist_fun margin | # Learning Deep Disentangled Embeddings with the F-Statistic Loss (NIPS 2018) [Read the paper](https://arxiv.org/abs/1802.05312) ## Pre-Reqs 1. Tensorflow (tested on `v1.10.0`) 2. `pip install -r requirements.txt` ## Downloading datasets 1. [CUHK03](http://www.ee.cuhk.edu.hk/~xgwang/CUHK_identification.html) 2. [Market-1501](http://www.liangzheng.org/Project/project_reid.html) 3. Small NORB ( parts [1](https://cs.nyu.edu/~ylclab/data/norb-v1.0-small/smallnorb-5x46789x9x18x6x2x96x96-training-dat.mat.gz), [2](https://cs.nyu.edu/~ylclab/data/norb-v1.0-small/smallnorb-5x01235x9x18x6x2x96x96-testing-dat.mat.gz), [3](https://cs.nyu.edu/~ylclab/data/norb-v1.0-small/smallnorb-5x46789x9x18x6x2x96x96-training-cat.mat.gz), [4](https://cs.nyu.edu/~ylclab/data/norb-v1.0-small/smallnorb-5x01235x9x18x6x2x96x96-testing-cat.mat.gz), [5](https://cs.nyu.edu/~ylclab/data/norb-v1.0-small/smallnorb-5x46789x9x18x6x2x96x96-training-info.mat.gz), [6](https://cs.nyu.edu/~ylclab/data/norb-v1.0-small/smallnorb-5x01235x9x18x6x2x96x96-testing-info.mat.gz) ) 4. [Sprites](http://www-personal.umich.edu/~reedscot/files/nips2015-analogy-data.tar.gz) | 2,687 |
krishnabits001/task_driven_data_augmentation | ['medical image segmentation', 'data augmentation', 'semantic segmentation'] | ['Semi-supervised Task-driven Data Augmentation for Medical Image Segmentation', 'Semi-Supervised and Task-Driven Data Augmentation'] | losses.py experiment_init/init_acdc.py train_model/tr_deformation_cgan_and_unet.py train_model/tr_unet_with_deformation_intensity_cgans_augmentations.py dataloaders.py create_cropped_imgs_acdc.py models.py layers_bn.py train_model/tr_intensity_cgan_and_unet.py utils.py experiment_init/data_cfg_acdc.py f1_utils.py train_model/tr_unet_baseline.py dataloaderObj f1_utilsObj layersObj lossObj modelObj calc_deform isNotEmpty shuffle_minibatch mixup_data_gen get_max_chkpt_file augmentation_function change_axis_img load_val_imgs test_data unlabeled_data val_data train_data get_samples plt_func get_samples plt_func crop_or_pad_slice_to_size asarray squeeze rotate rescale shape uniform crop_or_pad_slice_to_size_1hot append randint round fliplr range normal batch_size reshape resize zeros range reshape concatenate arange choice reshape range concatenate preprocess_data change_axis_img append orig_img_dt join int sort sub findall walk choice range zeros_like beta print exit shuffle_minibatch astype float32 zeros_like write_gif_func range plot_deformed_imgs run plot_intensity_transformed_imgs | **Semi-Supervised and Task-Driven Data Augmentation** <br/> The code is for the article "Semi-Supervised and Task-Driven Data Augmentation" which got accepted as an Oral presentation at IPMI 2019 (26th international conference on Information Processing in Medical Imaging). The method yields competitive segmentation performance with just 1 labelled training volume.<br/> https://arxiv.org/abs/1902.05396 <br/> https://link.springer.com/chapter/10.1007/978-3-030-20351-1_3 <br/> **Authors:** <br/> Krishna Chaitanya ([email](mailto:[email protected])),<br/> Christian F. Baumgartner,<br/> Neerav Karani,<br/> Ender Konukoglu.<br/> | 2,688 |
kroniidvul/mpiigaze_project | ['gaze estimation'] | ['Appearance-Based Gaze Estimation in the Wild', 'MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation'] | eval_model.py edit_dataloader.py main_cyclic.py pretrained_main.py main_attention.py models/vgg16.py models/ens-att.py models/inception.py main_rlrop.py dataloader.py models/en-vgg-res.py models/lenet.py models/attention.py mean_grayscale.py models/ensembledil16.py main_att_msk.py main_hysts.py models/playground.py main_ensemble.py models/alexnet.py models/vgg_att.py models/levgg.py models/izenet.py models/resnet_preact.py models/vgg19_edit.py models/resnet50.py main.py models/ensemble.py models/msk.py main_att.py demo.py models/ensemble-v16.py models/enc_msk.py preprocess_data.py models/vgg_att_prt.py models/vgg19.py main_msk.py figures/vis_vgg19.py models/ensemblev16.py get_loader MPIIGazeDataset parse_args get_loader test MPIIGazeDataset convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error load_images_from_folder convert_gaze get_subject_data convert_pose main get_eval_info convert_to_unit_vector AverageMeter test main parse_args train str2bool compute_angle_error autolabel Model Decoder Encoder ModelB ModelA Ensemble PosNet Upsampling Ensemble ImNet initialize_weights ModelA ModelB VGG_ATT Ensemble initialize_weights ModelB ModelA Ensemble initialize_weights ModelB ModelA Ensemble initialize_weights ModelB ModelA Ensemble initialize_weights ModelB ModelA Ensemble Model initialize_weights Model initialize_weights Model initialize_weights PosNet PosUp Upsampling ImNet Ensemble PosNet PosUp Upsampling ImNet Ensemble Model initialize_weights Model BasicBlock Model Model Model VGG_ATT Model VGG VGG_ATT Model MPIIGazeDataset DataLoader ConcatDataset add_argument ArgumentParser print size make_grid enumerate milestones loads sqrt cos sin convert_to_unit_vector model zero_grad cuda len update val format size mean avg item info test_id add_image enumerate time make_grid criterion backward AverageMeter step add_scalar update time format add_scalar add_histogram AverageMeter named_parameters mean eval test_id avg item info cuda add_image batch_size outdir SGD MultiStepLR arch export_scalars_to_json dataset cuda seed tensorboard MSELoss OrderedDict epochs Model range format test import_module info vgg manual_seed vars test_id join dumps num_workers parameters get_loader train step makedirs flatten VGG_ATT flatten encoder decoder save Encoder Decoder inception CyclicLR ModelB Ensemble ModelA criterion parse_args PosUp ImNet PosNet ReduceLROnPlateau join IMREAD_GRAYSCALE append imread listdir arctan2 astype float32 Rodrigues arcsin arcsin arctan2 join format apply read_csv drop join sorted listdir convert_gaze append iterrows pose astype float32 convert_pose gaze image day loadmat array get_eval_info savez get_subject_data add_argument ArgumentParser Sequential ReLU Linear Conv2d alexnet annotate get_height format isinstance Conv2d xavier_uniform_ bias weight constant_ Linear data kaiming_normal_ BatchNorm2d | # Eye-gaze estimation in PyTorch ## Docker Pull the image from Docker Hub. It contains all the required packages. ``` docker pull kroniidvul/pytorch_mpiigaze:latest ``` Run the container interactively. ``` docker run -it --rm kroniidvul/pytorch_mpiigaze /bin/bash ``` | 2,689 |
ksenia-konyushkova/LAL | ['active learning'] | ['Learning Active Learning from Data'] | LAL dataset generation/Dataset4LAL.py LAL dataset generation/LALmodel.py LAL dataset generation/Tree4LAL.py Classes/experiment.py Classes/lal_model.py Classes/dataset.py Classes/active_learner.py Classes/results.py ActiveLearner ActiveLearnerLAL ActiveLearnerUncertainty ActiveLearnerRandom DatasetStriatumMini DatasetRotatedCheckerboard2x2 DatasetSimulatedUnbalanced DatasetCheckerboard4x4 Dataset DatasetCheckerboard2x2 Experiment LALmodel Results DatasetSimulated LALmodel Tree4LAL | # LAL Code for paper Ksenia Konyushkova, Raphael Sznitman, Pascal Fua 'Learning Active Learning from Data', NIPS 2017 This code can be run with Jupyter notebook 'AL experiments'. You will need the following packages: numpy, sklearn, matplotlib, scipy, time, scipy, math, pickle. 'AL experiment' guides you through the main steps. It uses classes from folder ./Classes, data for the experiments is stored in ./data, data for learning a strategy is stored in ./lal datasets and the results are written into ./exp. Class ActiveLearner implements methods Random, Uncertainty Sampling and LAL. For more details, refer to the paper and comments in the code. | 2,690 |
kskkwn/mppcca | ['time series'] | ['Causal Patterns: Extraction of multiple causal relationships by Mixture of Probabilistic Partial Canonical Correlation Analysis'] | example/toy_scatter_data/toy_scatter_data.py example/time_series_exp/__init__.py example/toy_scatter_data/params/params1.py example/toy_scatter_data/params/params2.py mppcca_from_csv.py example/time_series_exp/time_series_exp.py example/time_series_exp/params/params3.py utils.py mppcca.py example/time_series_exp/params/params2.py example/toy_scatter_data/params/params3.py example/time_series_exp/params/params1.py E_step calc_Wx calc_μ M_step mppcca calc_lpdf_norm calc_π init_params calc_C mppcca_from_csv pca_scatter embed calc_misallocation_rate causal plot generate_data generate_data_exp1 non_causal generate_data_exp2 exp1 exp2 generate_data main items T list randn transpose min zeros matrix einsum einsum inv einsum pi slogdet exp logsumexp calc_Wx calc_π dot calc_C zip calc_μ sum enumerate E_step M_step concatenate print array_equal append init_params argmax len mppcca print reshape exit to_csv read_csv embed append max _calc len show set_title set_xlabel view_init add_subplot PCA scatter set_ylabel figure set_zlabel fit_transform flatten range append len normal T e_Xt e_Yt mean_Xt float normal e_Xt mean_Yt e_Yt mean_Xt float append range zip generate show yticks set_xlabel set_xlim add_subplot subplots_adjust title set_ylabel figure xticks axvspan enumerate len mppcca plot generate_data_exp1 labels_ pca_scatter embed mppcca plot generate_data_exp2 labels_ pca_scatter embed int list extend shuffle generate_data_in_cluster enumerate time mppcca generate_data print calc_misallocation_rate | kskkwn/mppcca | 2,691 |
kspeng/lw-eg-monodepth | ['depth estimation', 'monocular depth estimation'] | ['Edge-Guided Occlusion Fading Reduction for a Light-Weighted Self-Supervised Monocular Depth Estimation'] | monodepth_dataloader.py average_gradients.py utils/evaluation_utils.py utils/evaluate_kitti.py monodepth_main.py monodepth_simple.py bilinear_sampler.py monodepth_model.py utils/npy2image.py average_gradients bilinear_sampler_1d_h string_length_tf MonodepthDataloader count_text_lines test post_process_disparity main train MonodepthModel post_process_disparity main test_simple sub2ind lin_interp convert_disps_to_depths_kitti read_calib_file generate_depth_map compute_errors read_file_data read_text_lines load_gt_disp_kitti load_velodyne_points get_focal_length_baseline concat reduce_mean zip append expand_dims shape linspace meshgrid fliplr clip readlines close open checkpoint_path filenames_file Saver MonodepthDataloader save dataset Session run restore log_directory MonodepthModel dirname sum range start_queue_runners format latest_checkpoint right_image_batch ConfigProto zeros local_variables_initializer time print count_text_lines data_path Coordinator output_directory model_name global_variables_initializer left_image_batch mode test train monodepth_parameters Saver save Session run restore placeholder MonodepthModel image_path shape dirname imread imsave start_queue_runners format imresize astype stack ConfigProto local_variables_initializer join print float32 Coordinator disp_est_ppp global_variables_initializer test_simple maximum mean sqrt abs log astype float32 zfill append imread range shape resize append range len readlines close open format print int32 isfile append split reshape T arange LinearNDInterpolator reshape meshgrid set reshape read_calib_file int T sub2ind lin_interp read_calib_file reshape hstack min dot shape vstack round eye zeros load_velodyne_points | # lw-eg-monodepth This is the implementation of the paper: Light-Weight Edge-Guided Self-supervised Monocular Depth Estimation [[arXiv](https://arxiv.org/abs/1911.11705)]. This work is evolved from the project [Monodepth](https://github.com/mrharicot/monodepth). Please cite our paper if you use our results. Thanks. ``` @article{ kuo2019arXiv, author={Kuo-Shiuan Peng and Gregory Ditzler and Jerzy Rozenblit}, title={ Edge-Guided Occlusion Fading Reduction for a Light-Weighted Self-Supervised Monocular Depth Estimation }, journal={ arXiv }, pages={1911.11705}, year={2019}} ``` | 2,692 |
kstant0725/SpectralNet | ['stochastic optimization'] | ['SpectralNet: Spectral Clustering using Deep Neural Networks'] | src/core/util.py data/reuters/make_reuters.py src/core/train.py src/applications/spectralnet.py src/core/data.py src/applications/plot_2d.py src/applications/run.py src/core/layer.py src/core/costs.py src/core/networks.py src/core/pairs.py make_reuters_data save_hdf5 process run_net full_affinity knn_affinity get_contrastive_loss euclidean_distance eucl_dist_output_shape squared_distance get_triplet_loss generate_cc get_mnist pre_process get_data embed_data split_data load_data predict_with_K_fn stack_layers Orthonorm orthonorm_op SiameseNet SpectralNet get_choices create_pairs_from_labeled_data create_pairs_from_unlabeled_data check_inputs predict_sum train_step predict make_batches get_cluster_labels_from_indices calculate_cost_matrix get_scale print_accuracy grassmann spectral_clustering get_accuracy train_gen LearningHandler make_layer_list get_y_preds get_cluster_sols seed todense asarray permutation save_hdf5 sqrt fit_transform show set_title plot concatenate draw add_subplot get_scale argsort scatter hist figure spectral_clustering fit_predict round get_y_preds str SpectralNet cdist len argmin placeholder predict get concatenate SiameseNet print_accuracy train empty get_cluster_sols toarray print cluster_centers_ float32 nmi fit list ndim square sqrt expand_dims sum range get_median sparse_reorder concat top_k SparseTensor exp transpose cast range tile sparse_tensor_to_dense squared_distance float int isinstance print reshape int32 Print exp variable pow squared_distance expand_dims get concatenate print reshape embed_data split_data create_pairs_from_labeled_data load_data zeros create_pairs_from_unlabeled_data enumerate get get_mnist generate_cc pre_process format function print reshape square mean load_weights prod int outputs append K_fn range len int arange astype append len int permutation randn concatenate reshape expand_dims load_data transform fit matrix_inverse transpose dot sqrt cast cholesky Lambda variable assign add_update zeros orthonorm_op get l l2 dict Dense MaxPooling2D Conv2D Orthonorm BatchNormalization Flatten Dropout int list defaultdict isinstance set get_choice append get_arr array range len list reshape min randrange array range len endswith kneighbors open add_item build get_nns_by_item append range AnnoyIndex format astype empty enumerate load int isinstance print reshape convert_idxs fit min confusion_matrix get_choices int32 install array len as_list empty as_list items list concatenate choice check_inputs zeros empty range len as_list get make_batches list items asarray concatenate min choice check_inputs shape run empty max enumerate append len predict make_batches permutation len update format append enumerate reshape kneighbors fit len zeros sum range zeros range len get_y_preds str format print get_accuracy round ClusterClass range predict fit compute get_cluster_labels_from_indices calculate_cost_matrix confusion_matrix svd transpose square dot sum full_affinity knn_affinity print variable eigh eval sum diag | # SpectralNet  SpectralNet is a python library that performs spectral clustering with deep neural networks. ## requirements To run SpectralNet, you'll need Python 3.x and the following python packages: - scikit-learn - tensorflow==1.15 - keras==2.3 - munkres - annoy | 2,693 |
ksw0306/ClariNet | ['speech synthesis'] | ['ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech'] | preprocessing.py train.py data.py synthesize_student.py wavenet_iaf.py wavenet.py train_student.py synthesize.py modules.py loss.py _pad collate_fn_synthesize _pad_2d collate_fn LJspeechDataset KL_gaussians sample_from_gaussian gaussian_loss GaussianLoss ResBlock stft KL_Loss Conv ExponentialMovingAverage _process_utterance preprocess build_from_path write_metadata load_checkpoint build_model load_checkpoint build_student build_model Wavenet Wavenet_Student Wavenet_Flow pad contiguous array append randint tensor max range len max contiguous append tensor array range len pow clamp transpose exp exp clamp transpose Normal sample pow clamp exp clamp sqrt float sum log ProcessPoolExecutor load join T astype float32 maximum pad log10 save max clip len build_from_path write_metadata makedirs print sum max Wavenet print format load load_state_dict Wavenet_Student | # ClariNet A Pytorch Implementation of ClariNet (Mel Spectrogram --> Waveform) # Requirements PyTorch 0.4.1 & python 3.6 & Librosa # Examples #### Step 1. Download Dataset - LJSpeech : [https://keithito.com/LJ-Speech-Dataset/](https://keithito.com/LJ-Speech-Dataset/) #### Step 2. Preprocessing (Preparing Mel Spectrogram) `python preprocessing.py --in_dir ljspeech --out_dir DATASETS/ljspeech` #### Step 3. Train Gaussian Autoregressive WaveNet (Teacher) | 2,694 |
ktatarnikov/time-series | ['time series', 'dynamic time warping'] | ['SSH (Sketch, Shingle, & Hash) for Indexing Massive-Scale Time Series'] | lsh/cws.py motif/test_sequitur.py preprocessing/feature_engineering.py lsh/minhash.py motif/test_sax.py models/test_lstm.py preprocessing/test_helper.py preprocessing/test_feature_engineering.py preprocessing/test_common.py motif/test_sequitur_anomaly.py lsh/similarity.py motif/sequitur_anomaly.py mf/factor.py models/__init__.py lsh/test_similarity.py lsh/dtw.py models/common.py motif/sequitur.py preprocessing/test_preprocessing.py lsh/test_minhash.py preprocessing/preprocessing.py models/xgboost.py lsh/hashindex.py preprocessing/helper.py models/lstm.py mf/test_factor.py setup.py motif/sax.py models/test_xgboost.py get_script_path get_version get_requirements ConsistentWeightedSamplingError ConsistentWeightedSampling DynamicTimeWarping HashIndex MinhashError Minhash TimeSeriesLSHException TimeSeriesLSH MinhashTest TimeSeriesLSHTest regularization_update TRMF regularization_loss TRMF_AR TestTRMF HyperParams LSTMAutoencoderParams LSTMAutoencoder LSTMAutoencoderTest XGBoostIntegrationTest XGBoostModel SAX Terminal Grammar DigramIndex Rule Sequitur SymbolIndex Sequence SequiturError SequiturAnomaly TestSAX TestSequitur TestSequiturAnomaly TimeSeriesFeatureEngineering TimeseriesHelper TimeSeriesPreprocessor make_series make_multi_series make_labels sinwave TimeSeriesFeatureEngineeringTest TimeseriesHelperTest TimeSeriesPreprocessorTest DataFrame date_range DataFrame date_range Timedelta DataFrame max date_range range pi sin | # TimeSeries tools The tiny collection of algorithms to work with time series. - Preprocessing and Feature Engineering tools -- tsfresh https://tsfresh.readthedocs.io/en/latest/ -- imbalance learn https://imbalanced-learn.readthedocs.io/en/stable/ - Gradient Boosting tree model https://xgboost.readthedocs.io/en/latest/ - LSTM Autoencoder https://blog.keras.io/building-autoencoders-in-keras.html - SAX-PAA and discords | 2,695 |
ktran1/Leant_Laplacian | ['graph learning'] | ['Learning Laplacian Matrix in Smooth Graph Signal Representations'] | Learnt_Laplacian.py prox_negative_and_sum_constraint Construct_leanrt_Laplacian lateral_add_dia_2_matrix FWBW_proximal_gradient_in_sparse_coding float sum len int sum norm prox_negative_and_sum_constraint print copy dot sqrt append zeros float empty array range len zeros range int T dot lateral_add_dia_2_matrix zeros range FWBW_proximal_gradient_in_sparse_coding | # Leant_Laplacian This is an implementation of the paper Learning Laplacian Matrix in Smooth Graph Signal Representations https://arxiv.org/pdf/1406.7842.pdf by [X.Dong et al] min (L) : tr(Y. x L x Y.T) + beta ||L||^2 where L = L.T, tr(L) = number of signals (vertices)., sum(L[i,:]) = 0., L[i,j] <= 0 (i><j) Only require numpy, this implementation can deal in the case of large number of vertices (num_vertices > 1000). Contact : [email protected] | 2,696 |
ku-nlp/bert-based-faqir | ['information retrieval', 'question similarity'] | ['FAQ Retrieval using Query-Question Similarity and BERT-Based Query-Answer Relevance'] | scripts/generate_evaluation_file.py scripts/merge_tsubaki_bert_results.py scripts/calculate_score.py scripts/generate_input.py scripts/generate_test_file.py main format_result get_idmapping print_result main read_question_file main get_negative_samples main read_qaid_file read_question_file read_answer_file main format range enumerate len int isdigit defaultdict format print len format_result group strip search_result dict match split append float testset range open print format array enumerate stdin question_file read_question_file print_result append len sample get_negative_samples n_negative_samples answer_file read_answer_file tsubaki join set add bert | # bert-based-faqir FAQ retrieval system that considers the similarity between a user’s query and a question as well as the relevance between the query and an answer. The detail is on our paper ([`arxiv`](https://arxiv.org/abs/1905.02851)). ## Requirements ``` tensorflow >= 1.11.0 ``` ## Usage ### Data | 2,697 |
ku2482/vae.pytorch | ['style transfer'] | ['Deep Feature Consistent Variational Autoencoder'] | utils/data.py utils/train.py utils/vis.py utils/interpolate.py utils/anno.py models/simple_vae.py utils/loss.py Decoder VAE Encoder parse_annotation gen_images get_df get_celeba_loaders ImageDataset ImgAugTransform FLPLoss KLDLoss _VGG plot_loss Logger imsave_inp imsave to_numeric list columns append dropna DataFrame array split join parse_annotation read_csv to_csv join Compose get_df zip open glob join join plot xlabel makedirs close set_facecolor figure legend savefig array len uint8 imwrite ones hconcat shape dirname vconcat makedirs imwrite dirname vconcat makedirs | # Deep Feature Consistent Variational Autoencoder in PyTorch A PyTorch implementation of Deep Feature Consistent Variational Autoencoder. I implemented DFC-VAE based on [the paper](https://arxiv.org/pdf/1610.00291.pdf) by Xianxu Hou, Linlin Shen, Ke Sun, Guoping Qiu. I trained this model with CelebA dataset. For more details about the dataset, please refer to [the website](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). ## Installation - Clone this repository. - python 3.6 is recommended. - Use command `pip install -r requirements.txt` to install libraries. ## Dataset - You need to download the CelebA dataset from [the website](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) and arrange them like below. ``` . | 2,698 |
kuhnkeF/ABAW2020TNT | ['face alignment'] | ['Two-Stream Aural-Visual Affect Analysis in the Wild'] | aff2compdataset.py write_labelfile.py sort_non_competition_set.py face_alignment.py clip_transforms.py test_val_aff2.py tsav.py utils.py create_database.py video.py Aff2CompDataset AmpToDB NumpyToTensor RandomClipFlip Normalize ComposeWithInvert create_alignments create_database extract_audio draw_mask align_rescale_face render_img_and_mask comp_order sort_videos SubsetSequentialSampler AudioModel VideoModel TwoStreamAuralVisualModel Dummy get_position find_all_files_with_ext_in solve_symlinks get_label_str2 get_filename get_path get_extension split_EX_VA_AU ex_from_one_hot find_all_image_files convert_to_filenames find_all_video_files Video va_to_str ex_to_str au_to_str write_labelfile remove sort_videos get_label_str2 get_filename Video print sort get_extension zfill tqdm symlink write_meta isfile append makedirs join int Transformer remove trim call build pad tqdm dirname find_all_video_files load join uint8 render_img_and_mask Video get_filename print align_rescale_face makedirs copy tqdm open zeros draw_mask enumerate find_all_video_files warpAffine join imwrite COLOR_BGR2RGB COLOR_BGR2GRAY zfill cvtColor polylines LINE_8 append comp_order zeros argmax range basename splitext basename splitext split append sort get_filename append realpath glob join sort sort sort format format format writer int join remove astype write close isfile open range clip makedirs | # TSAV Affect Analysis in the Wild (ABAW2020 submission) **[Two-Stream Aural-Visual Affect Analysis in the Wild](https://arxiv.org/pdf/2002.03399.pdf)** *(Submission to the Affective Behavior Analysis in-the-wild ([ABAW](https://ibug.doc.ic.ac.uk/resources/fg-2020-competition-affective-behavior-analysis/)) 2020 competition)* ## Getting Started Required packages: PyTorch 1.4, Torchaudio 0.4.0, tqdm, Numpy, OpenCV 4.2.0 You also need mkvmerge, mkvextract (from mkvtoolnix) ffmpeg sox | 2,699 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.